
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# Отправка e-mail сообщения в среде разработки 3CX Call Flow Designer
Введение
--------
В этом статье мы расскажем, как отправить e-mail сообщение из [3CX Call Flow Designer](https://www.3cx.com/phone-system/call-flow-designer/), используя компонент Email Sender. Приложение записывает голос позвонившего абонента в WAV файл и отсылает его как e-mail вложение.
Вы можете использовать этот компонент, например, для уведомления о заказе товара через голосовое меню 3CX, и в других ситуациях, когда голосовое взаимодействие пользователя с системой должно сопровождаться отправкой e-mail.
Напомним, что в предыдущих статьях мы рассмотрели создание [CFD приложения для исходящего обзвона](https://habrahabr.ru/company/3cx/blog/336528/) (по завершении обзвона можно отсылать отчет, используя компонент Email Sender), [работу CFD с базами данных](https://habrahabr.ru/company/3cx/blog/334472/) (которые также можно использовать для получения номера абонента) и [маршрутизацию входящих вызовов в зависимости от времени суток](https://habrahabr.ru/company/3cx/blog/333958/) (которую можно комбинировать с исходящим обзвоном)
Обратите внимание — среда разработки 3CX CFD поставляется бесплатно. Но голосовые приложения будут выполняться только на [3CX редакции Pro и Enterprise](https://www.3cx.ru/ip-pbx/edition-comparison/). Скачать CFD можно [отсюда](http://downloads.3cx.com/downloads/3CXCallFlowDesigner.exe).
Демо-проект этого голосового приложения поставляется вместе с дистрибутивом 3CX CFD и находится в папке **Documents\3CX Call Flow Designer Demos**. В демо-приложении для начала работы достаточно указать параметры вашего SMTP сервера.
Создание проекта
----------------
Для создания проекта CFD перейдите в **File → New → Project**, укажите папку размещения проекта и его имя, например, **EMailDemo**.

Запись сообщения пользователя в файл
------------------------------------
Для начала запишем сообщение абонента в файл. Этот файл и будет затем отослан на e-mail. Для этого используется компонент **Record**.

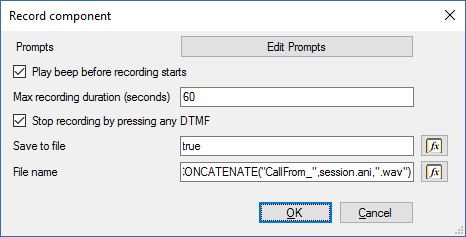
1. Перетащите компонент **Record** в основное окно среды разработки (в голосовое приложение **Main**). Перейдите в окно свойств и переименуйте компонент в **recordYourMessage**.
2. Дважды кликните на компоненте и в открывшимся окне установите следующие параметры:
```
CONCATENATE("CallFrom_",session.ani,".wav")
```
Отправка записанного сообщения на e-mail
----------------------------------------
Теперь отправим записанный аудиофайл в виде e-mail вложения. Для этого добавим компонент **E-Mail Sender** в ветвление **Audio Recorded** компонента **Record** и настроим его как показано ниже:
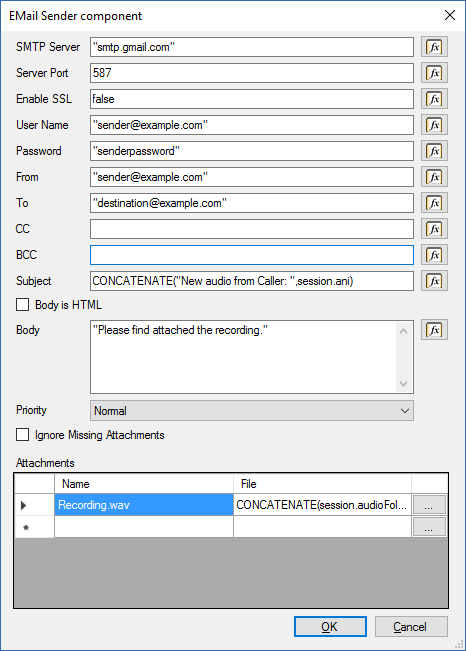
Обратите внимание, что в тех параметрах, где указываются выражения (поля имеют кнопку **Fx** справа), любая указанная константа должна заключаться в кавычки, поскольку в этих полях также могут находится переменные или результаты выражения.
Для параметра **Subject** мы используем выражение, которое добавляет номер позвонившего абонента.
Список вложений **Attachments** содержит описания файлов, состоящие из двух столбцов:
* **Name** — имя файла, которое увидит получатель e-mail сообщения. Укажем здесь **Recording.wav**, чтобы во вложении приходил файл только с этим именем.
* **File** — выражение, которое указывает на физический файл записи, который нужно вложить в письмо. Однако здесь мы должны дополнить выражение, генерирующее имя файла (которое использовалось в предыдущем шаге). В предыдущем шаге в компоненте **Record** использовался относительный путь к файлу — указывалось только имя. Файл создавался в каталоге аудиофайлов данного проекта. Компоненту **Email Sender** следует передать полный путь к файлу, поэтому выражение дополняется переменной **session.audioFolder**:
```
CONCATENATE(session.audioFolder,"/CallFrom_",session.ani,".wav")
```
Теперь голосовое приложение корректно найдет и вложит аудиофайл.
Компиляция и установка приложения на сервер 3CX
-----------------------------------------------
Голосовое приложение готово! Теперь его следует скомпилировать и загрузить на сервер 3CX. Для этого:
* Перейдите в меню **Build → Build All**, и CFD создаст файл **EMailDemo.tcxvoiceapp**.
* Перейдите в интерфейс управления 3CX, в раздел **Очереди вызовов**. Создайте новую Очередь вызовов, укажите название и добавочный номер Очереди, а затем установите опцию **Голосовые приложения** и загрузите скомпилированный файл.
* Сохраните изменения в Очереди вызовов. Голосовое приложение готово к использованию.
 | https://habr.com/ru/post/337096/ | null | ru | null |
# Итерируемый объект, итератор и генератор
Привет, уважаемые читатели Хабрахабра. В этой статье попробуем разобраться что такое итерируемый объект, итератор и генератор. Рассмотрим как они реализованы и используются. Примеры написан на Python, но итераторы и генераторы, на мой взгляд, фундаментальные понятия, которые были актуальны 20 лет назад и еще более актуальны сейчас, при этом за это время фактически не изменились.
Итераторы
---------
Для начала вспомним, что из себя представляет паттерн «Итератор(Iterator)».
Назначение:
* для доступа к содержимому агрегированных объектов без раскрытия их внутреннего представления;
* для поддержки нескольких активных обходов одного и того же агрегированного объекта (желательно, но не обязательно);
* для предоставления единообразного интерфейса с целью обхода различных агрегированных структур.
В итоге мы получаем разделение ответственности: клиенты получают возможность работать с разными коллекциями унифицированным образом, а коллекции становятся проще за счет того, что делегируют перебор своих элементам другой сущности.
Существуют два вида итераторов, *внешний* и *внутренний*.
*Внешний итератор* — это классический (pull-based) итератор, когда процессом обхода явно управляет клиент путем вызова метода Next.
*Внутренний итератор* — это push-based-итератор, которому передается callback функция, и он сам уведомляет клиента о получении следующего элемента.
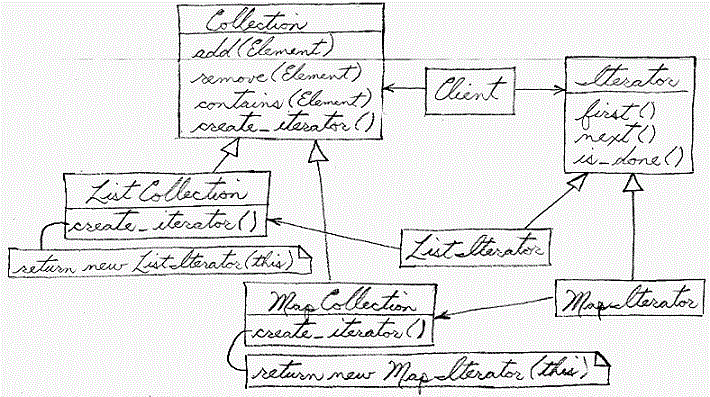
Классическая диаграмма паттерна “Итератор”, как она описана в небезызвестной книги «банды четырех»:
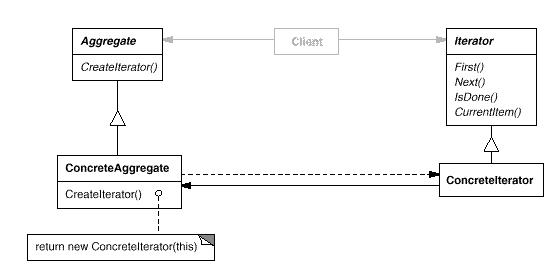
*Aggregate* — составной объект, по которому может перемещаться итератор;
*Iterator* — определяет интерфейс итератора;
*ConcreteAggregate* — конкретная реализация агрегата;
*ConcreteIterator* — конкретная реализация итератора для определенного агрегата;
*Client* — использует объект Aggregate и итератор для его обхода.
### Пробуем реализовать на Python классический итератор
Абстрактные классы:
```
class Aggregate(abc.ABC):
@abc.abstractmethod
def iterator(self):
"""
Возвращает итератор
"""
pass
class Iterator(abc.ABC):
def __init__(self, collection, cursor):
self._collection = collection
self._cursor = cursor
@abc.abstractmethod
def first(self):
"""
Возвращает итератор к началу агрегата.
Так же называют reset
"""
pass
@abc.abstractmethod
def next(self):
"""
Переходит на следующий элемент агрегата.
Вызывает ошибку StopIteration, если достигнут конец последовательности.
"""
pass
@abc.abstractmethod
def current(self):
"""
Возвращает текущий элемент
"""
pass
```
Конкретная реализация итератора для списка:
```
class ListIterator(Iterator):
def __init__(self, collection, cursor):
"""
:param collection: список
:param cursor: индекс с которого начнется перебор коллекции.
так же должна быть проверка -1 >= cursor < len(collection)
"""
super().__init__(collection, cursor)
def first(self):
"""
Начальное значение курсора -1.
Так как в нашей реализации сначала необходимо вызвать next
который сдвинет курсор на 1.
"""
self._cursor = -1
def next(self):
"""
Если курсор указывает на послений элемент, то вызываем StopIteration,
иначе сдвигаем курсор на 1
"""
if self._cursor + 1 >= len(self._collection):
raise StopIteration()
self._cursor += 1
def current(self):
"""
Возвращаяем текущий элемент
"""
return self._collection[self._cursor]
```
Конкретная реализация агрегата:
```
class ListCollection(Aggregate):
def __init__(self, collection):
self._collection = list(collection)
def iterator(self):
return ListIterator(self._collection, -1)
```
Теперь мы можем создать объект коллекции и обойти все ее элементы с помощью итератора:
```
collection = (1, 2, 5, 6, 8)
aggregate = ListCollection(collection)
itr = aggregate.iterator()
# обход коллекции
while True:
try:
itr.next()
except StopIteration:
break
print(itr.current())
```
А так как мы реализовали метод first, который сбрасывает итератор в начальное состояние, то можно воспользоваться этим же итератором еще раз:
```
# возвращаем итератор в исходное состояние
itr.first()
while True:
try:
itr.next()
except StopIteration:
break
print(itr.current())
```
Реализации могут быть разные, но основная идея в том, что итератор может обходить различные структуры, вектора, деревья, хеш-таблицы и много другое, при этом имея снаружи одинаковый интерфейс.
### Протокол итерирования в Python
В книге «банды четырех» о реализации итератора написано:
*Минимальный интерфейс класса Iterator состоит из операций First, Next, IsDone и CurrentItem.* ~~Но если очень хочется, то~~ *этот интерфейс можно упростить, объединив операции Next, IsDone и CurrentItem в одну, которая будет переходить к следующему объекту и возвращать его. Если обход завершен, то эта операция вернет специальное значения(например, 0), обозначающее конец итерации.*
Именно так и реализовано в Python, но вместо специального значения, о конце итерации говорит StopIteration. *Проще просить прощения, чем разрешения.*
Сначала важно определиться с терминами.
Рассмотрим *итерируемый объект* (Iterable). В стандартной библиотеке он объявлен как абстрактный класс collections.abc.Iterable:
```
class Iterable(metaclass=ABCMeta):
__slots__ = ()
@abstractmethod
def __iter__(self):
while False:
yield None
@classmethod
def __subclasshook__(cls, C):
if cls is Iterable:
return _check_methods(C, "__iter__")
return NotImplemented
```
У него есть абстрактный метод \_\_iter\_\_ который должен вернуть объект итератора. И метод \_\_subclasshook\_\_ который проверяет наличие у класса метод \_\_iter\_\_. Таким образом, получается, что *итерируемый объект* это любой объект который реализует метод \_\_iter\_\_
```
class SomeIterable1(collections.abc.Iterable):
def __iter__(self):
pass
class SomeIterable2:
def __iter__(self):
pass
print(isinstance(SomeIterable1(), collections.abc.Iterable))
# True
print(isinstance(SomeIterable2(), collections.abc.Iterable))
# True
```
Но есть один момент, это функция iter(). Именно эту функцией использует например цикл for для получения итератора. Функция iter() в первую очередь для получения итератора из объекта, вызывает его метод \_\_iter\_\_. Если метод не реализован, то она проверяет наличие метода \_\_getitem\_\_ и если он реализован, то на его основе создается итератор. \_\_getitem\_\_ должен принимать индекс с нуля. Если не реализован ни один из этих методов, тогда будет вызвано исключение TypeError.
```
from string import ascii_letters
class SomeIterable3:
def __getitem__(self, key):
return ascii_letters[key]
for item in SomeIterable3():
print(item)
```
Итого, **итерируемый объект** — это любой объект, от которого встроенная функция iter() может получить итератор. Последовательности(abc.Sequence) всегда итерируемые, поскольку они реализуют метод \_\_getitem\_\_
Теперь посмотрим, что с итераторами в Python. Они представлены абстрактным классом collections.abc.Iterator:
```
class Iterator(Iterable):
__slots__ = ()
@abstractmethod
def __next__(self):
'Return the next item from the iterator. When exhausted, raise StopIteration'
raise StopIteration
def __iter__(self):
return self
@classmethod
def __subclasshook__(cls, C):
if cls is Iterator:
return _check_methods(C, '__iter__', '__next__')
return NotImplemented
```
*\_\_next\_\_* Возвращает следующий доступный элемент и вызывает исключение StopIteration, когда элементов не осталось.
*\_\_iter\_\_* Возвращает self. Это позволяет использовать итератор там, где ожидается итерируемых объект, например for.
*\_\_subclasshook\_\_* Проверяет наличие у класса метода \_\_iter\_\_ и \_\_next\_\_
Итого, **итератор в python** — это любой объект, реализующий метод \_\_next\_\_ без аргументов, который должен вернуть следующий элемент или ошибку StopIteration. Также он реализует метод \_\_iter\_\_ и поэтому сам является *итерируемым объектом*.
Таким образом можно реализовать итерируемый объект на основе списка и его итератор:
```
class ListIterator(collections.abc.Iterator):
def __init__(self, collection, cursor):
self._collection = collection
self._cursor = cursor
def __next__(self):
if self._cursor + 1 >= len(self._collection):
raise StopIteration()
self._cursor += 1
return self._collection[self._cursor]
class ListCollection(collections.abc.Iterable):
def __init__(self, collection):
self._collection = collection
def __iter__(self):
return ListIterator(self._collection, -1)
```
Варианты работы:
```
collection = [1, 2, 5, 6, 8]
aggregate = ListCollection(collection)
for item in aggregate:
print(item)
print("*" * 50)
itr = iter(aggregate)
while True:
try:
print(next(itr))
except StopIteration:
break
```
Функция next() вызывает метод \_\_next\_\_. Ей можно передать второй аргумент который она будет возвращать по окончанию итерации вместо ошибки StopIteration.
```
itr = iter(aggregate)
while True:
item = next(itr, None)
if item is None:
break
print(item)
```
Прежде чем переходить к генераторам, рассмотрим еще одну возможность встроенной функции *iter()*. Ее можно вызывать с двумя аргументами, что позволит создать из *вызываемого объекта*(функция или класс с реализованным методом \_\_call\_\_) итератор. Первый аргумент должен быть вызываемым объектом, а второй — неким ограничителем. Вызываемый объект вызывается на каждой итерации и итерирование завершается, когда возбуждается исключение StopIteration или возвращается значения ограничителя.
Например, из функции которая произвольно возвращает 1-6, можно сделать итератор, который будет возвращать значения пока не «выпадет» 6:
```
from random import randint
def d6():
return randint(1, 6)
for roll in iter(d6, 6):
print(roll)
```
**Другие примеры**
Небольшой класс ProgrammingLanguages, у которого есть кортеж c языками программирования, конструктор принимает начальное значения индекса по названию языка и функция \_\_call\_\_ которая перебирает кортеж.
```
class ProgrammingLanguages:
_name = ("Python", "Golang", "C#", "C", "C++", "Java", "SQL", "JS")
def __init__(self, first=None):
self.index = (-1 if first is None else
ProgrammingLanguages._name.index(first) - 1)
def __call__(self):
self.index += 1
if self.index < len(ProgrammingLanguages._name):
return ProgrammingLanguages._name[self.index]
raise StopIteration
```
Можем перебрать все языки начиная с C# и до последнего:
```
for lang in iter(ProgrammingLanguages("C#"), None):
print(lang)
```
C первого до C:
```
pl = ProgrammingLanguages()
for lang in iter(pl, "C"):
print(lang)
```
Еще один пример:
```
# читаем файл до пустой строки
with open('mydata.txt') as fp:
for line in iter(fp.readline, ''):
print(line)
```
Генераторы
----------
С точки зрения реализации, генератор в Python — это языковая конструкция, которую можно реализовать двумя способами: как функция с ключевым словом *yield* или как генераторное выражение. В результате вызова функции или вычисления выражения, получаем объект-генератор типа types.*GeneratorType*.
В объекте-генераторе определены методы \_\_next\_\_ и \_\_iter\_\_, то есть реализован протокол итератора, с этой точки зрения, в Python любой генератор является итератором.
Концептуально, итератор — это механизм поэлементного обхода данных, а генератор позволяет отложено создавать результат при итерации. Генератор может создавать результат на основе какого то алгоритма или брать элементы из источника данных(коллекция, файлы, сетевое подключения и пр) и изменять их.
Ярким пример являются функции range и enumerate:
*range* генерирует ограниченную арифметическую прогрессию целых чисел, не используя никакой источник данных.
*enumerate* генерирует двухэлементные кортежи с индексом и одним элементом из итерируемого объекта.
### Yield
Для начало напишем простой генератор не используя объект-генератор. Это генератор чисел Фибоначчи:
```
class FibonacciGenerator:
def __init__(self):
self.prev = 0
self.cur = 1
def __next__(self):
result = self.prev
self.prev, self.cur = self.cur, self.prev + self.cur
return result
def __iter__(self):
return self
for i in FibonacciGenerator():
print(i)
if i > 100:
break
```
Но используя ключевое слово *yield* можно сильно упростить реализацию:
```
def fibonacci():
prev, cur = 0, 1
while True:
yield prev
prev, cur = cur, prev + cur
for i in fibonacci():
print(i)
if i > 100:
break
```
Любая функция в Python, в теле которой встречается ключевое слово *yield*, называется *генераторной функцией* — при вызове она возвращает *объект-генератор*.
*Объект-генератор* реализует интерфейс итератора, соответственно с этим объектом можно работать, как с любым другим *итерируемым объектом*.
```
fib = fibonacci()
print(next(fib))
# 0
print(next(fib))
# 1
for num, fib in enumerate(fibonacci()):
print('{0}: {1}'.format(num, fib))
if num > 9:
break
# 0: 0
# 1: 1
# 2: 1
...
```
Рассмотрим работу yield:
```
def gen_fun():
print('block 1')
yield 1
print('block 2')
yield 2
print('end')
for i in gen_fun():
print(i)
# block 1
# 1
# block 2
# 2
# end
```
1. при вызове функции gen\_fun создается *объект-генератор*
2. for вызывает iter() с этим объектом и получает итератор этого генератора
3. в цикле вызывает функция next() с этим итератором пока не будет получено исключение StopIteration
4. при каждом вызове next выполнение в функции начинается с того места где было завершено в последний раз и продолжается до следующего *yield*
Происходит приблизительно следующее. Генераторная функция разбивается на части:
```
def gen_fun_1():
print('block 1')
return 1
def gen_fun_2():
print('block 2')
return 2
def gen_fun_3():
print('end')
def gen_fun_end():
raise StopIteration
```
Создается стейт-машина в которой при каждом вызове \_\_next\_\_ меняется состояния и в зависимости от него вызывается тот или иной кусок кода. Если в функции yield в цикле, то соответственно состояние стейт-машины зацикливается пока не будет выполнено условие.
Свой вариант range:
```
def cool_range(start, stop, inc):
x = start
while x < stop:
yield x
x += inc
for n in cool_range(1, 5, 0.5):
print(n)
# 1
# 1.5
# ...
# 4.5
print(list(cool_range(0, 2, 0.5)))
# [0, 0.5, 1.0, 1.5]
```
### Генераторное выражение (generator expression)
Если кратко, то синтаксически более короткий способ создать генератор, не определяя и не вызывая функцию. А так как это выражение, то у него есть и ряд ограничений. В основном удобно использовать для генерации коллекций, их несложных преобразований и применений на них условий.
В языках программирования есть такие понятия, как *ленивые/отложенные вычисления(lazy evaluation)* и *жадные вычисления(eager/greedy evaluation)*. Генераторы можно считать отложенным вычислением, в этом смысле списковое включение(list comprehension) очень похожи на генераторное выражение, но являются разными подходами.
```
(i for i in range(10000000))
[i for i in range(10000000)]
```
Первый вариант работает схожим с нашей функцией cool\_range образом и может генерировать без проблем любой диапазон. А вот второй вариант создаст сразу целый список, со всеми вытекающими от сюда проблемами.
### Yield from
Для обхода ограниченно вложенных структур, традиционный подход использовать вложенные циклы. Тот же подход можно использовать когда генераторная функция должна отдавать значения, порождаемые другим генератором.
Функция похожая на itertools.chain:
```
def chain(*iterables):
for it in iterables:
for i in it:
yield i
g = chain([1, 2, 3], {'A', 'B', 'C'}, '...')
print(list(g))
# [1, 2, 3, 'A', 'B', 'C', '.', '.', '.']
```
Но вложенные циклы можно убрать, добавив конструкцию yield from:
```
def chain(*iterables):
for it in iterables:
yield from it
g = chain([1, 2, 3], {'A', 'B', 'C'}, '...')
print(list(g))
# [1, 2, 3, 'A', 'B', 'C', '.', '.', '.']
```
Основная польза yield from в создании прямого канала между внутренним генератором и клиентом внешнего генератора. Но это уже больше тема про *сопрограммы(coroutines)*, которые заслуживают отдельной статьи. Там же можно обсудить методы генератора: close(), throw() и send().
И в заключении еще один пример. Функция принимающая итерируемый объект, с любым уровнем вложенности другими итерируемыми объектами, и формирующая плоскую последовательность:
```
from collections import Iterable
def flatten(items, ignore_types=(str, bytes)):
"""
str, bytes - являются итерируемыми объектами,
но их хотим возвращать целыми
"""
for x in items:
if isinstance(x, Iterable) and not isinstance(x, ignore_types):
yield from flatten(x)
else:
yield x
items = [1, 2, [3, 4, [5, 6], 7], 8, ('A', {'B', 'C'})]
for x in flatten(items):
print(x)
# 1
# 2
# 3
# 4
# 5
# 6
# 7
# 8
# A
# C
# B
```
На сегодня все. Спасибо! | https://habr.com/ru/post/337314/ | null | ru | null |
# Обзор системы мониторинга приложений Instana
Сегодня я расскажу, что из себя представляет [Instana](https://www.instana.com/), и чем эта система мониторинга (СМ) отличается от других.
Система состоит из **Instana Backend** (сервер с веб-интерфейсом и хранилищем собранных данными) и **Instana Agent** (агент, который устанавливается на целевые хосты для мониторинга приложений). В качестве БД для хранения данных по метрикам используется [Cassandra](http://cassandra.apache.org/). Кроме On-premise установки, есть облачная версия. Обзор посвящен опыту использования первого варианта.
### Установка
Технические детали и ссылки на документацию — под спойлером.
**Подробности установки**### Подготовка
Перед началом установки необходимо убедиться, что у вас открыт доступ к [репозиториям Instana](https://instana.atlassian.net/wiki/display/DOCS/Outbound+Network+Access+Requirements), так как большинство компонентов загружают необходимые пакеты и артефакты при запуске. Это касается и агента Instana. Его дистрибутив содержит только ядро агента: во время установки агент обнаруживает компоненты на целевом сервере и скачивает пакеты, необходимые для мониторинга этих компонентов. Вы можете использовать ваш внутренний репозиторий в режиме прокси (например, [Sonartype Nexus](https://instana.atlassian.net/wiki/display/DOCS/Using+on-premises+agent+repository)).
Выберите операционку — на данный момент для установки бэкенд-сервера поддерживаются:
* SLES: >= 12
* Ubuntu: >= 16.04
* Debian: >= 8
* RedHat Enterprise Linux >= 7.2
* CentOS >= 7
Требования к версиям ОС обусловлены тем, что ПО Instana работает на [Docker](https://www.docker.com/) >= 1.10.
ПО платное, поэтому вам также понадобится [ключ активации для Backend и Agent](https://instana.atlassian.net/wiki/display/DOCS/On+Premises).
### Установка Backend
Мы используем CentOS 7, установка прошла четко по [инструкции](https://instana.atlassian.net/wiki/display/DOCS/Installation).
Добавляем запись о репозитории (используется логин/пароль, выделенный вендором):
```
sudo tee /etc/yum.repos.d/instana.repo <<-EOF
[instanarepo]
name=Instana Repository
baseurl=https://:@package-repository.instana.io/backend/rhel7
enabled=1
gpgcheck=1
gpgkey=https://:@package-repository.instana.io/instana.gpg
EOF
```
После чего запускаем установку пакета через yum:
```
yum install instana-backend
```
После окончания установки не торопитесь запускать, сперва надо скопировать и поправить [конфиг для Instana Backend](https://instana.atlassian.net/wiki/display/DOCS/Installation#Installation-Configuration):
```
cd /etc/instana-backend
cp instana.settings.template instana.settings
```
Нам понадобилось закомментировать строчку в /etc/sudoers с помощью команды visudo, чтобы произвести запуск из под root с помощью sudo:
```
#Defaults requiretty
```
Логинимся в репозиторий Instana:
```
docker login -u ”$INSTANA_REPO_USER” -p “$INSTANA_REPO_PASSWORD” registry-
public.instana.io
```
Добавляем запуск бэкенда в автозагрузку:
```
systemctl enable instana-backend.service
```
Всё, теперь можно запускать:
```
systemctl start instana-backend
```
После этого начнут загружаться необходимые пакеты из репозитория, это займет время. В конце должна появиться радостная надпись:
```
All done :)
```
### Установка агента
На данный момент поддерживаются следующие операционки:
* Linux 32 / 64 bit
* Windows 32 / 64 bit
* Mac OS 64 bit
Для запуска агента необходимо установить [JDK 8](http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html) (не JRE !). Переменная среды JAVA\_HOME должна содержать корректный путь к установленному JDK.
Заходим в веб-интерфейс Instana Backend и скачиваем дистрибутив под нужную операционку:
[](https://habrastorage.org/files/a57/487/dcb/a57487dcbbdb46e596df5ac7d40d4be7.png)
Также можно скачать дистрибутивы напрямую на [сайте вендора](https://instana.atlassian.net/wiki/display/DOCS/Agent+Installation).
Например, на Linux установка агента заключается в копировании и распаковке архива. Перед запуском необходимо поправить [конфиг агента](https://instana.atlassian.net/wiki/display/DOCS/Agent+Proxy+Setup) и указать данные вашего репозитория. Теперь можно запустить агента:
```
/instana-agent/bin/start
```
После запуска можно проверить статус агента командой:
```
/instana-agent/bin/status
```
При необходимости остановить агента можно командой:
```
/instana-agent/bin/stop
```
Текущий лог агента лежит здесь:
```
/instana-agent/data/log/agent.log
```
Чтобы все хосты у вас на карте были разбиты на зоны (как на картинке ниже), искались по тегам, необходимо внести правки в конфиг агента на хосте и перезапустить агента. Всё это подробно описано в [документации](https://instana.atlassian.net/wiki/display/DOCS/Agent+Configuration). Кстати, для начала можно установить агента на сам сервер Backend Instana.
Агента также можно [установить в контейнере](https://instana.atlassian.net/wiki/pages/viewpage.action?pageId=1179728).
### Использование
Несмотря на то, что интерфейс системы очень интуитивный, советую прочитать соответствующую [документацию](https://instana.atlassian.net/wiki/display/DOCS/Getting+Started), встречаются неочевидные моменты.
Например, чтобы посмотреть подробности того или иного параметра необходимо кликнуть на нем (для меня строка таблицы была неочевидным местом клика):
[](https://habrastorage.org/files/fa1/a52/c27/fa1a52c2721d409db155bc17d671c56b.png)
Откроется соответствующий график:
[](https://habrastorage.org/files/cc3/e1b/201/cc3e1b2014824845b3dea5a3960d62ef.png)
Инфраструктурная карта ([Infrastructure Map](https://instana.atlassian.net/wiki/display/DOCS/Infrastructure+View)):
[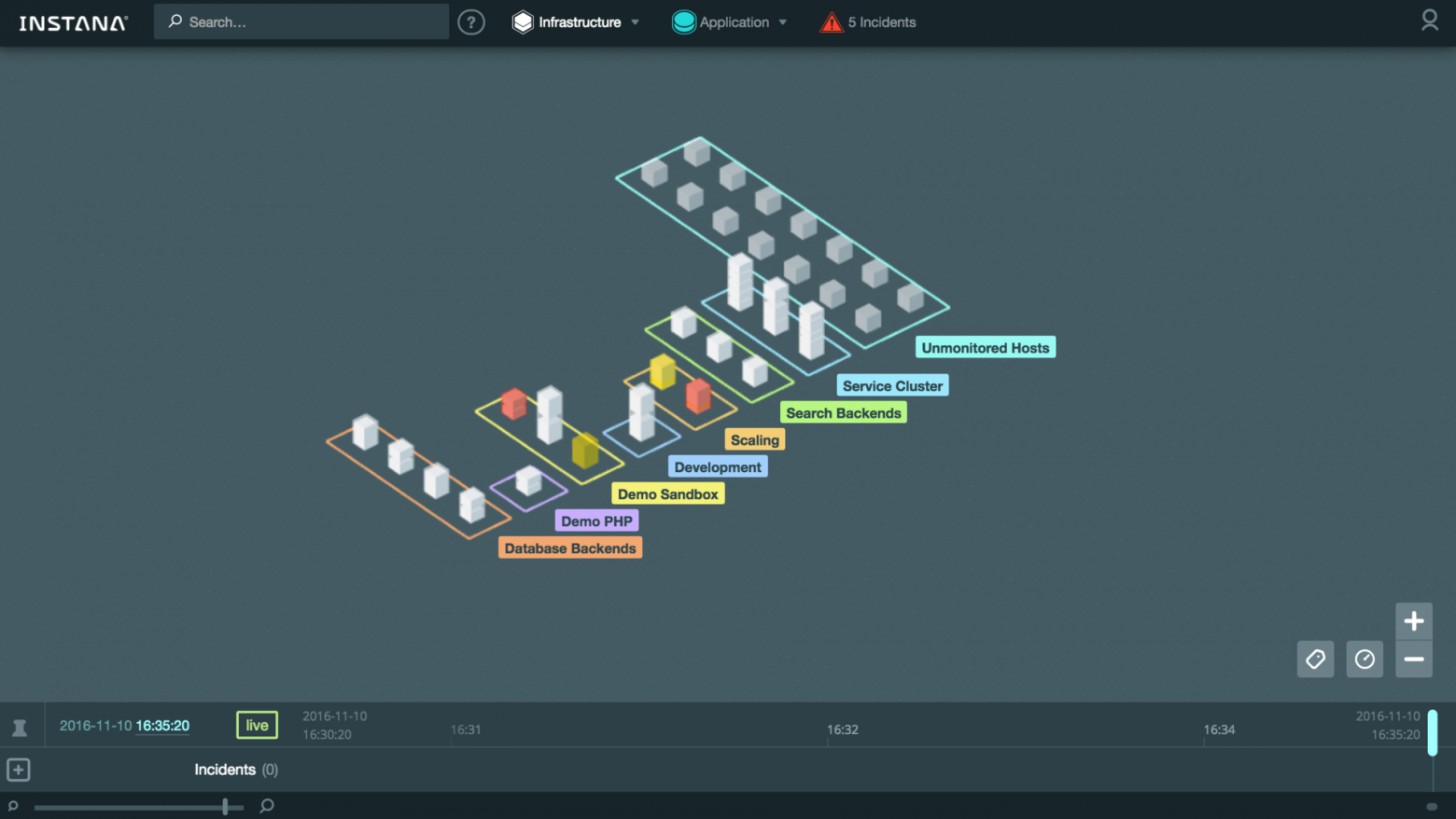](https://habrastorage.org/files/afa/b6a/068/afab6a068bd34f8382506f2c1dc5cde5.png)
Можно включить отображение значений системной метрики (ЦПУ, память) прямо на карте:
[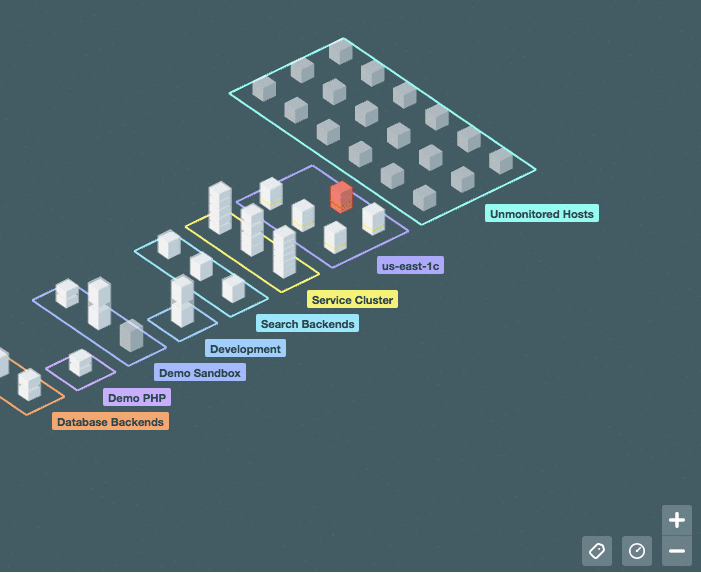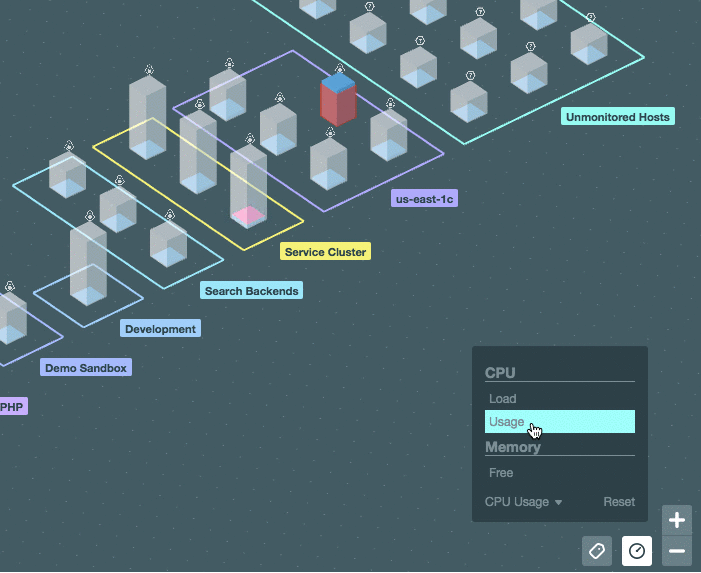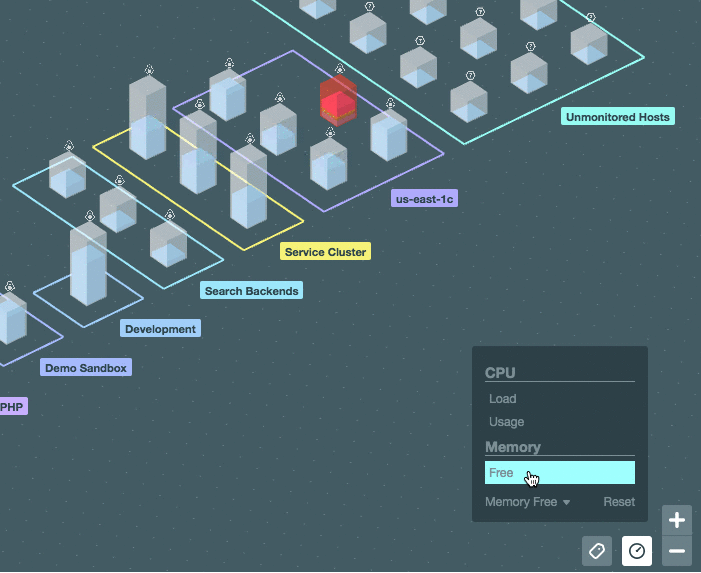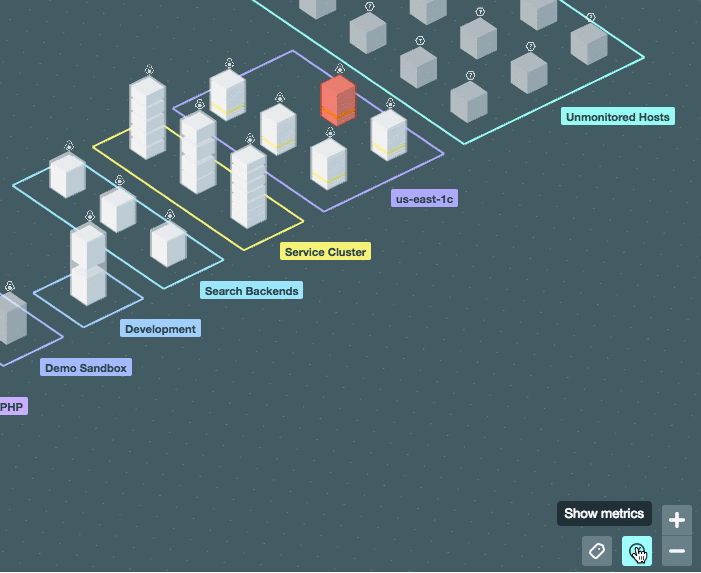](https://habrastorage.org/files/308/341/00c/30834100c8354922b56c0094ab7b5d09.gif)
В новой версии добавилась таблица сравнения. Она позволяет сразу увидеть текущее значение основных системных метрик по всем хостам. К тому же можно быстро выделить нужные хосты и проанализировать произвольную метрику на сводном графике:
[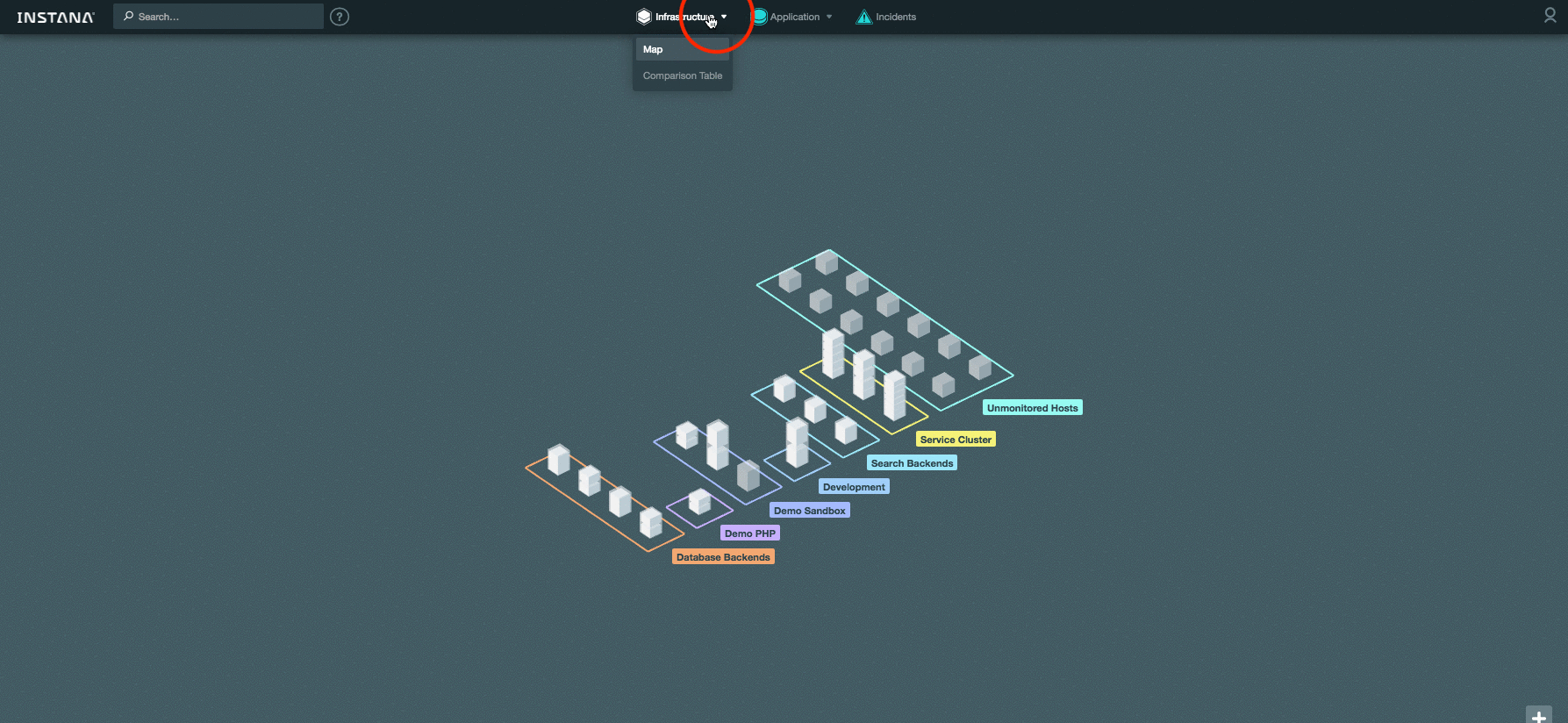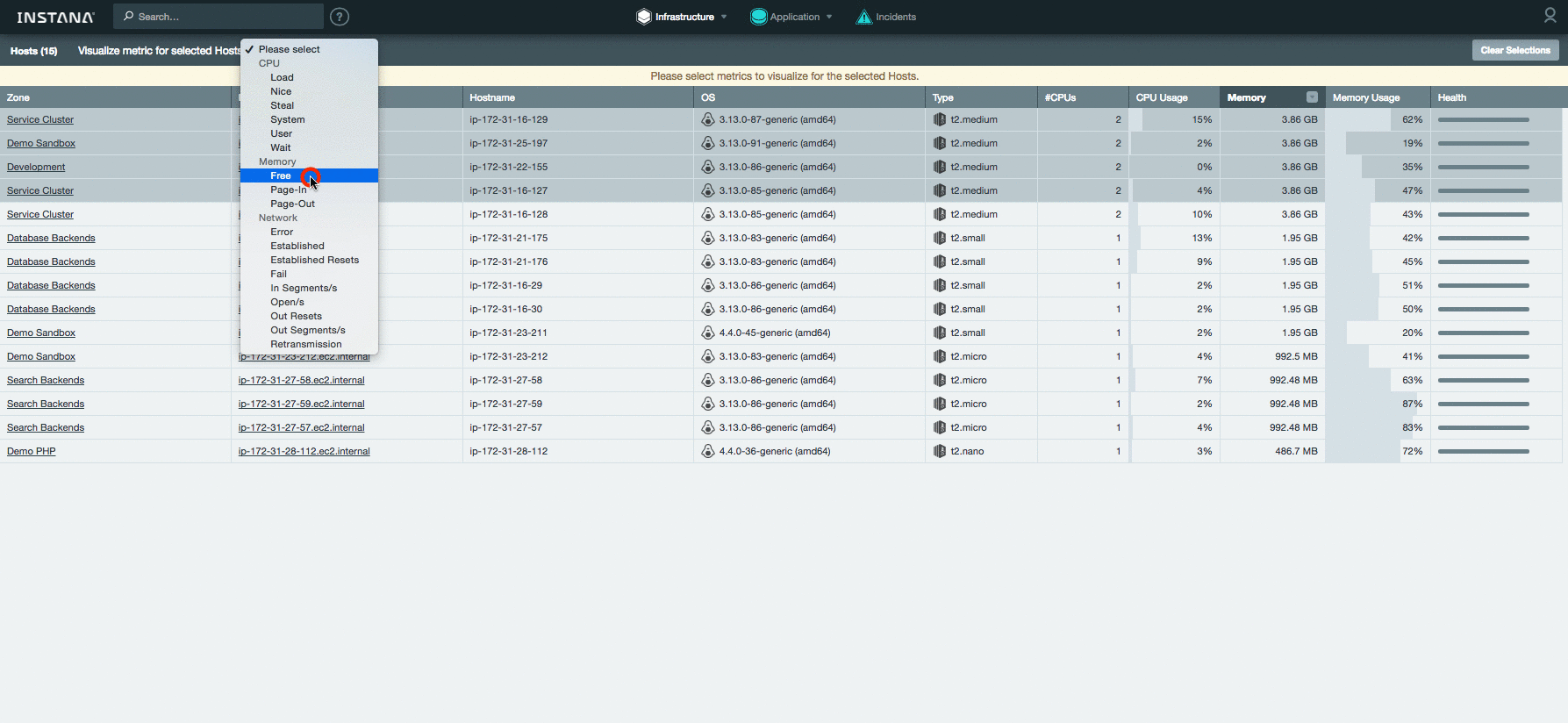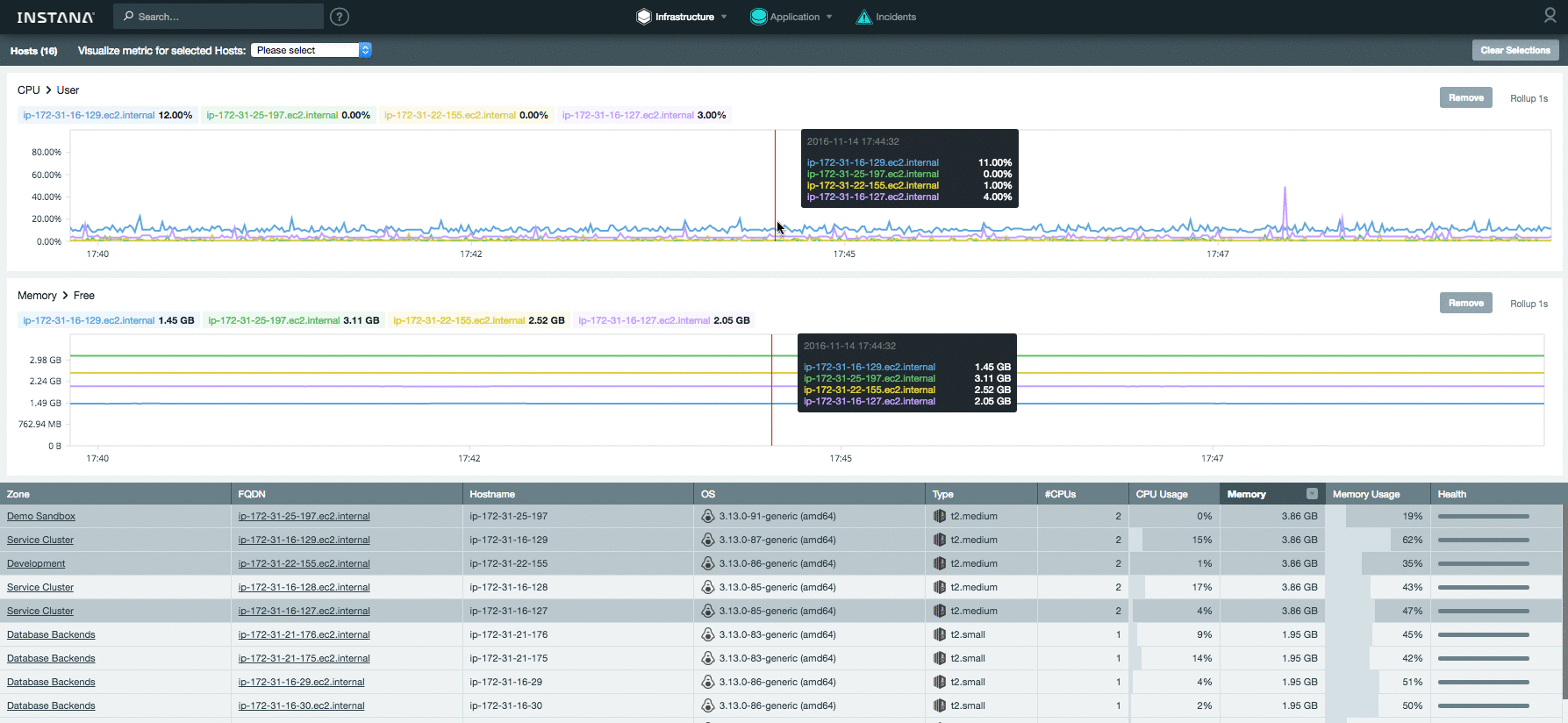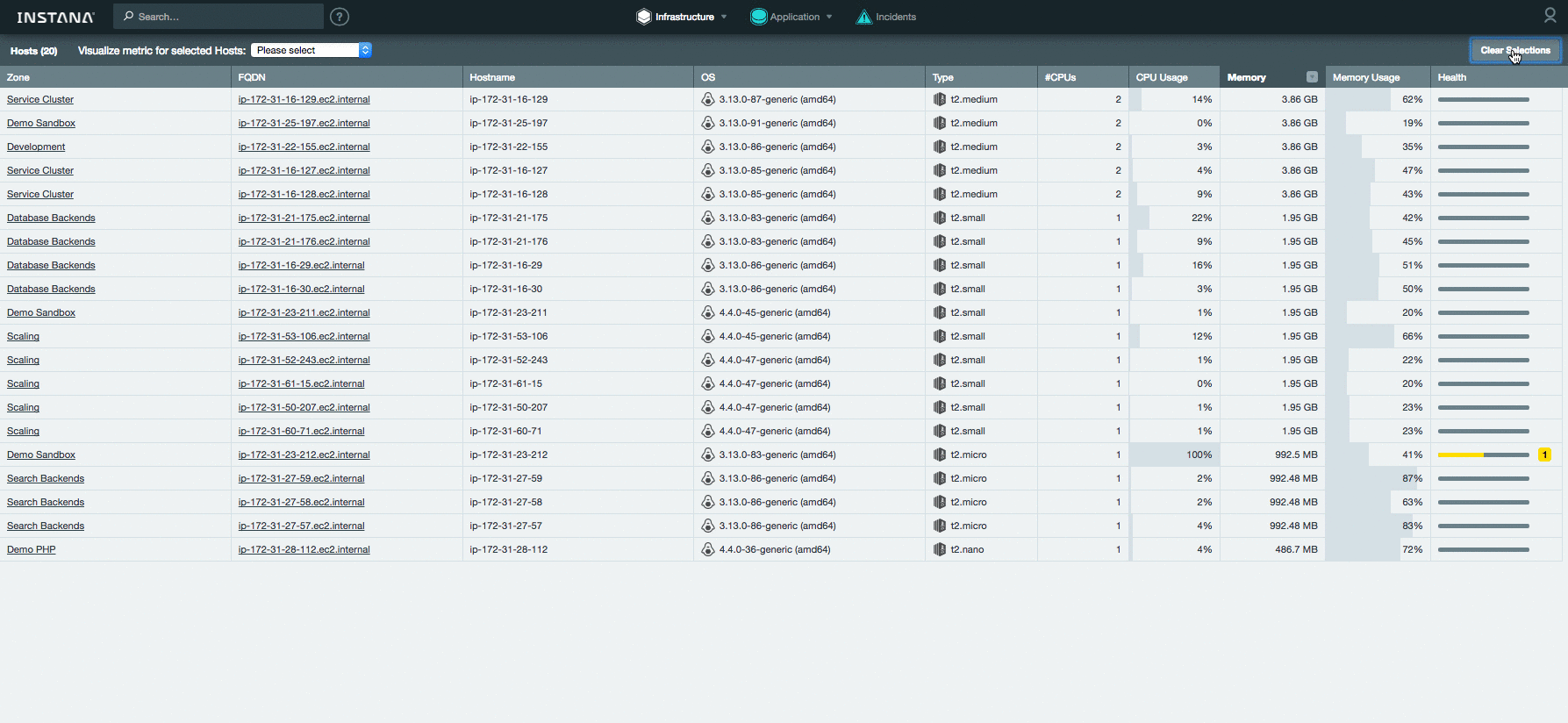](https://habrastorage.org/files/fa0/4f0/c61/fa04f0c613984f59b757e88c9c88ff3c.gif)
Карта приложения ([Application Map](https://instana.atlassian.net/wiki/display/DOCS/Application+Map)):
[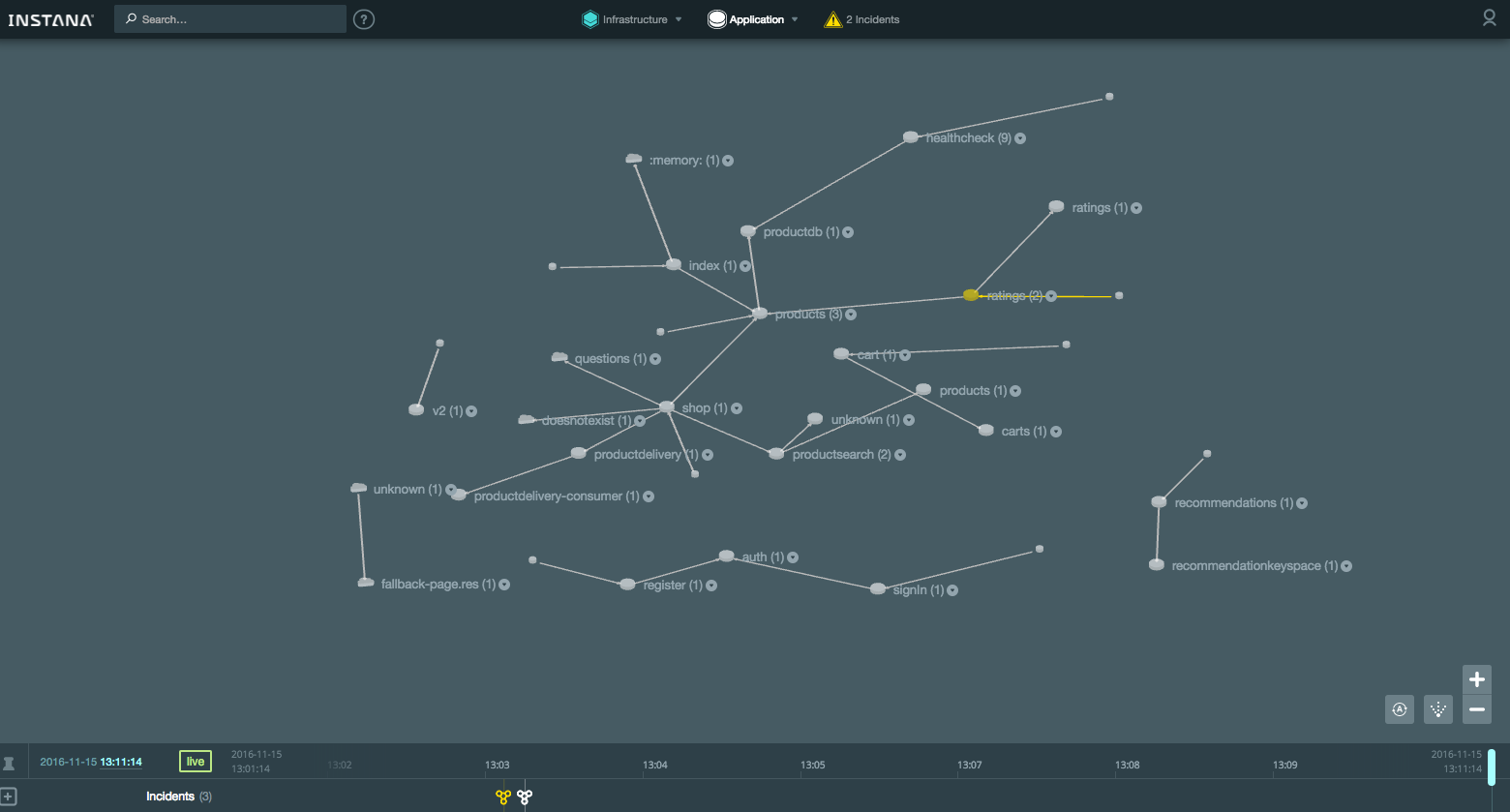](https://habrastorage.org/files/210/c34/082/210c34082aaf4e55a266dc57a31ad981.png)
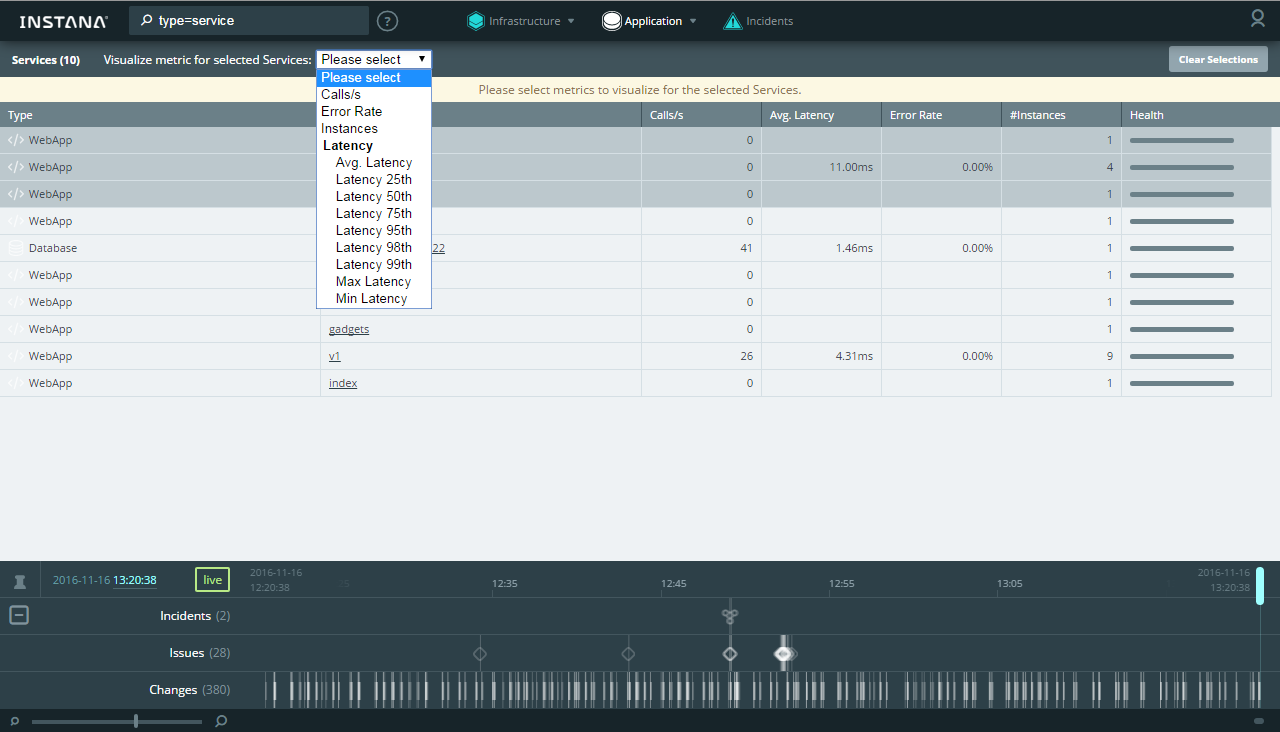
В новой версии добавилась таблица сравнения для компонентов приложения, где также можно выбрать компоненты и проанализировать их на сводном графике:
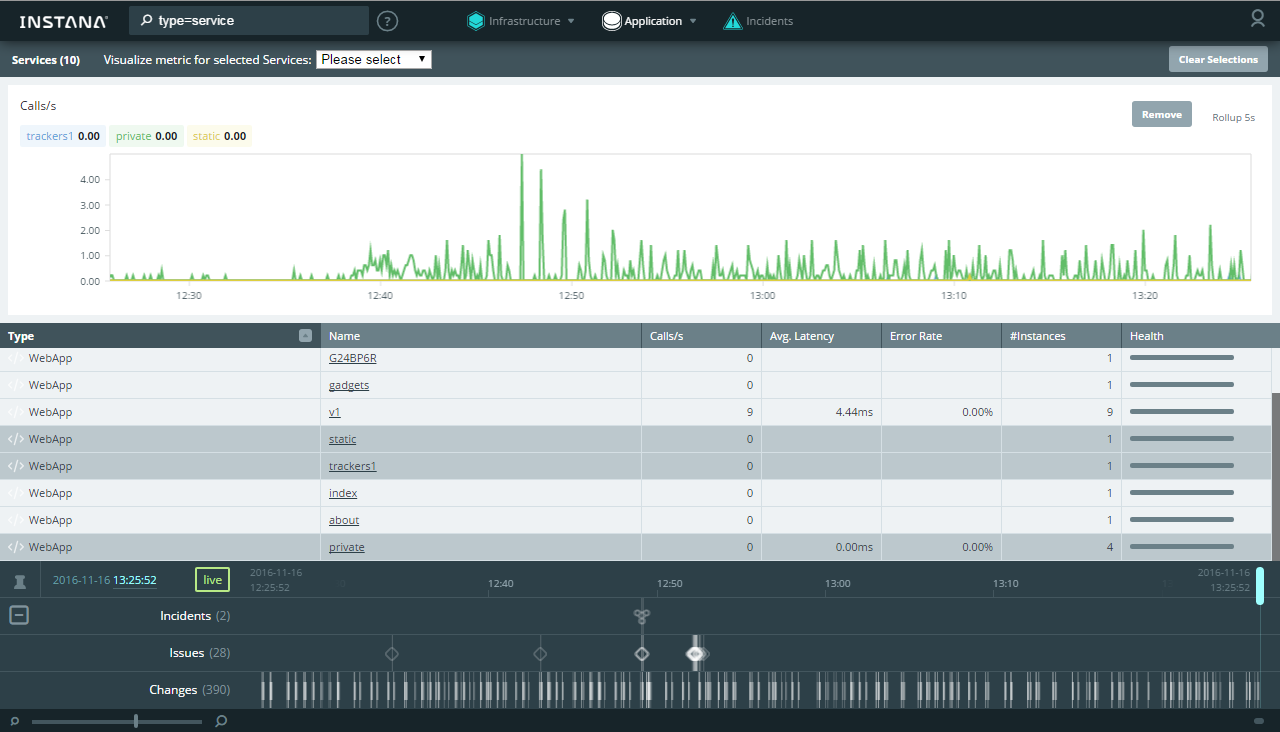
[](https://habrastorage.org/files/95a/59f/183/95a59f183067449fbded1933df05657f.png)
[](https://habrastorage.org/files/1ef/719/1f8/1ef7191f8f7d44ba9a794944c3e4aae1.png)
Все транзакции доступны для анализа в [Trace view](https://instana.atlassian.net/wiki/display/DOCS/Trace+View), где таблица сортируется по любому столбцу (можно, например, быстро найти самую длительную транзакцию):
[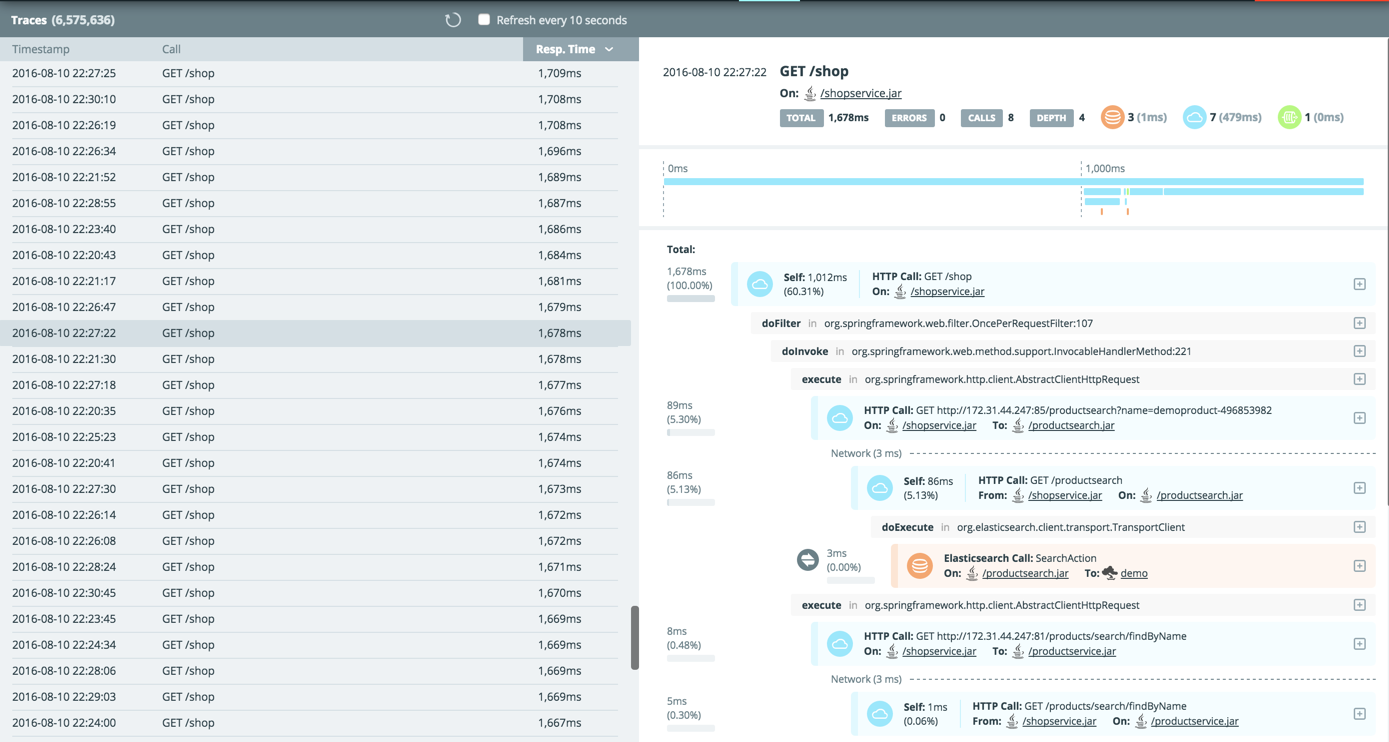](https://habrastorage.org/files/e90/23e/c39/e9023ec3933c4986a23b44c153a11baa.png)
Из любого представления вы можете открыть дашборд, в котором найдете графики и значения метрик по хосту и компонентам на нем:
[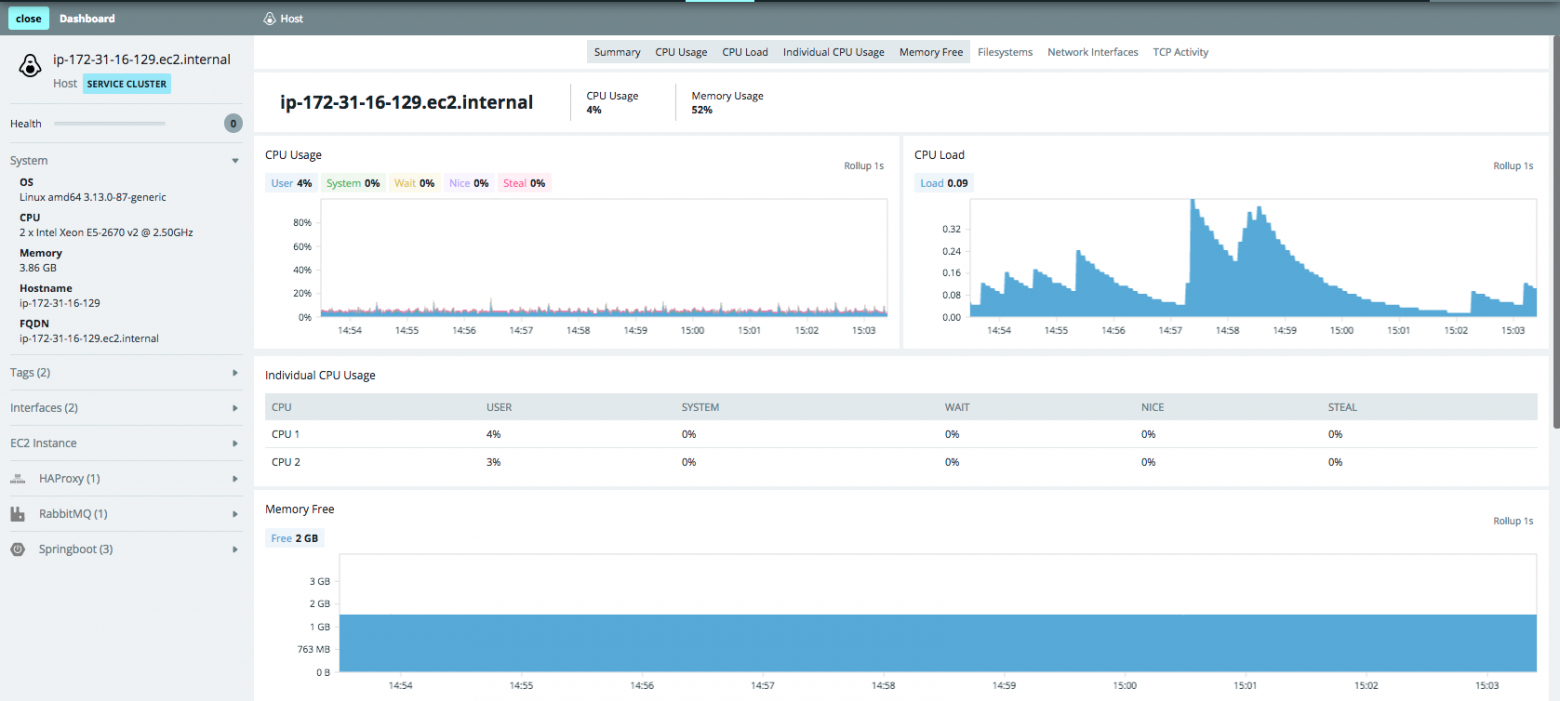](https://habrastorage.org/files/2c3/984/4f2/2c39844f2cb043f7b5d27be9ca8e75f4.png)
Есть поиск по именам хостов, компонентам, трассировке, тегам, зонам — поддерживаются маски (\*) и объединения (AND/OR):
[](https://habrastorage.org/files/271/3cc/62d/2713cc62d9bb4d9a8bea4d0db9c5045b.gif)
Отличительной особенностью, которой на данный момент нет ни у одной другой СМ, является работа с историческими данными в режиме [Timeshift](https://www.instana.com/blog/introducing-timeshift-application-monitoring/). При прокрутке шкалы времени (Timeline) видим не только все события за прошедшее время, но и как выглядела карта (физическая/логическая) в прошлом. Например, видно что на сервере перестал работать Tomcat, как это повлияло на взаимодействия компонентов приложения, как раньше выглядела инфраструктурная карта и карта компонентов приложения. В таком же ключе можно смотреть транзакции (вкладка Application → [Trace](https://instana.atlassian.net/wiki/display/DOCS/Trace+View)).
[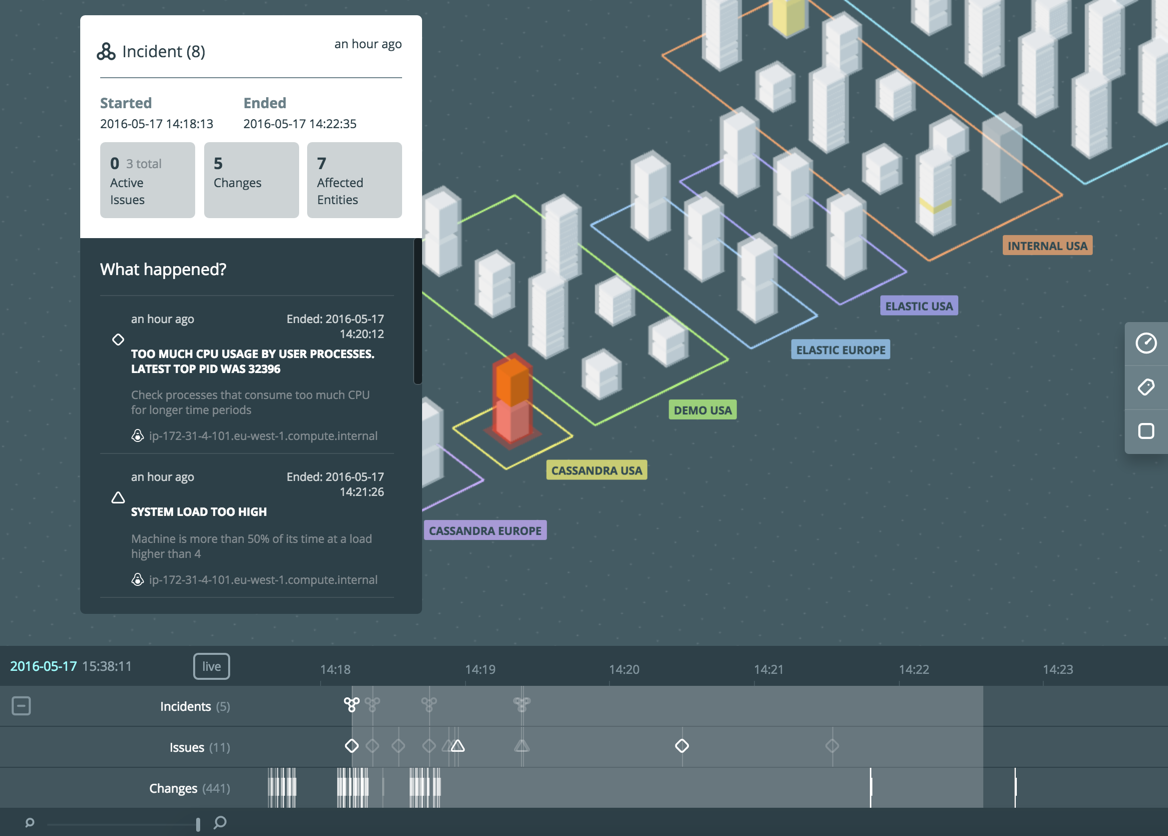](https://habrastorage.org/files/a3d/60a/8ba/a3d60a8ba21343529a7f33b22fbc9ecd.png)
В новой версии бэкенда все события собраны в отдельной вкладке Incidents, где можно отсортировать таблицу по столбцам и анализировать детали:
[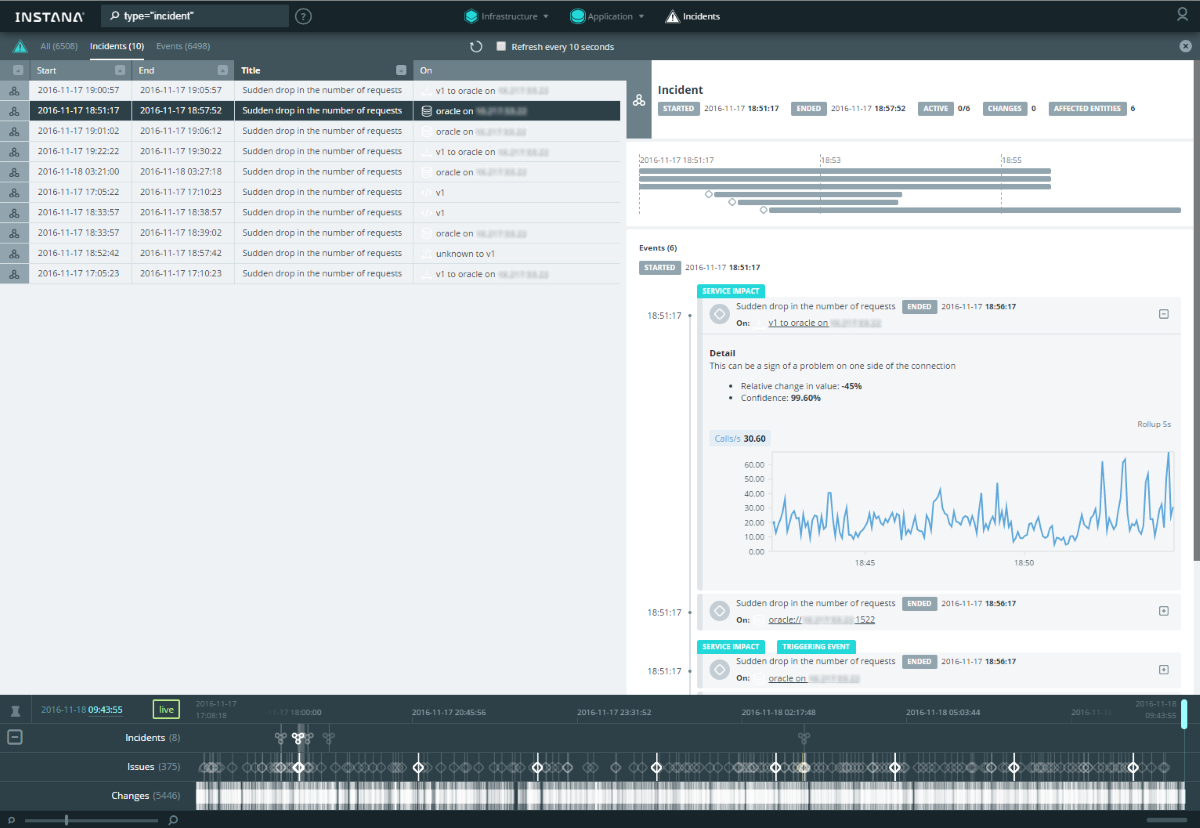](https://habrastorage.org/files/d29/606/ef3/d29606ef3947434f88339aff7e5c36ed.png)
По ссылкам в деталях можно сразу перейти на подробный дашборд соответствующего компонента.
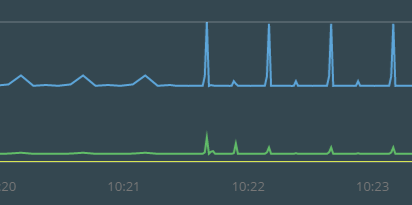
В отличие от классического инфраструктурного мониторинга (доступность хоста, уровень утилизации ЦПУ, доступность HTTP-страницы и т.п.), мониторинг приложений предъявляет более серьезные требования к частоте и детализации (гранулярности) собираемых данных. Чем чаще получаем значение той или иной метрики, тем лучше, особенно это касается транзакционного мониторинга. Это связано с тем, что проблемы при работе приложения могут быть очень непродолжительными, а последствия при этом вполне ощутимыми. Для сравнения графики с различной гранулярностью (1 минута vs 5 секунд):
Сразу понятно, что недостаточно подробные данные в ряде случаев не позволят обнаружить проблему. Данная система позволяет собирать данные с частотой [вплоть до 1 секунды](https://www.instana.com/blog/monitoring-needs-immediate-accurate/). Для уменьшения объема исторических данных они агрегируются относительно давности — чем дальше, тем ниже гранулярность: **1 секунда** (live-данные хранятся 10 минут) → **5 секунд** (хранятся 1 день) → **1 минута** (хранятся 31 день) → **5 минут** (хранятся 3 месяца) → **1 час** (хранятся 1 год, но можно увеличить).
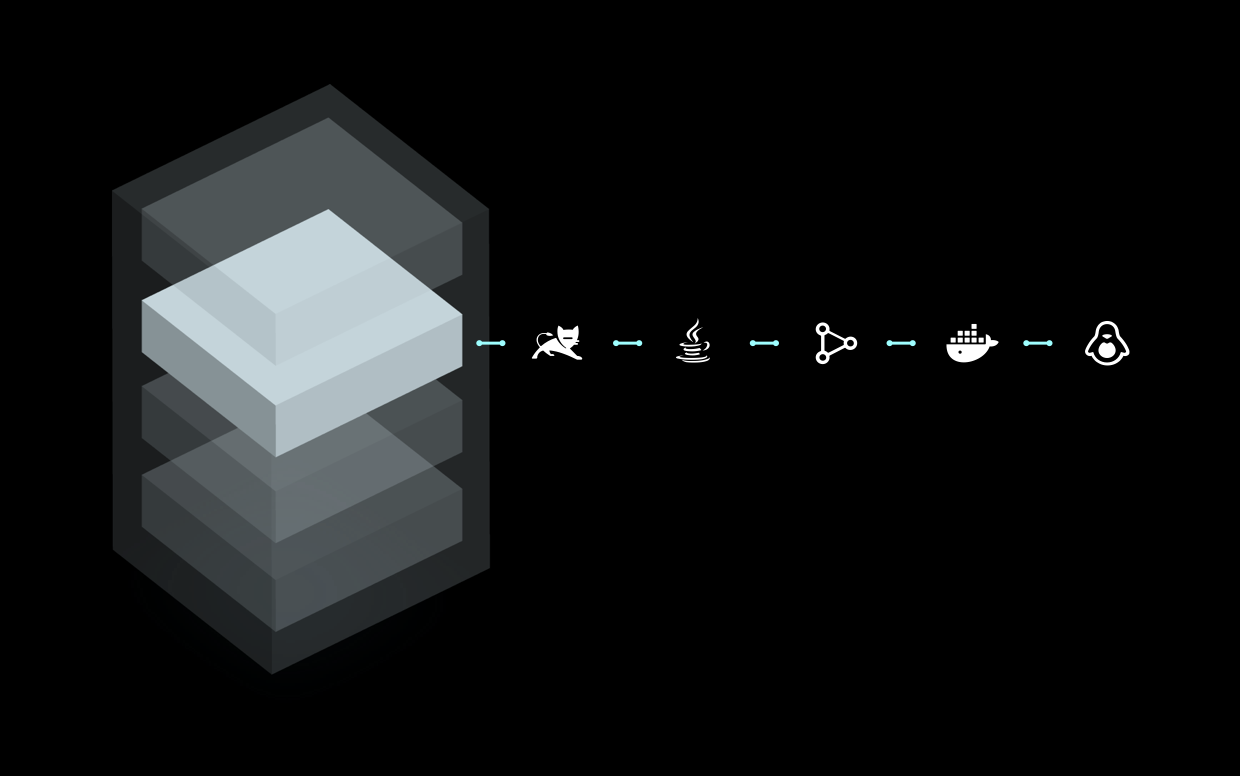
Очень полезен [автоматический поиск (Automatic Discovering) компонентов](https://www.instana.com/blog/auto-change-detection-improves-root-cause-determination/): если на хосте установлен агент Instana, в СМ автоматически появятся все известные ей компоненты и сервисы. Это особенно важно, когда ваше приложение построено на [микросервисах](https://www.instana.com/blog/monitoring-microservices-part-i-discovery-putting-the-puzzle-together/):
[Список поддерживаемых технологий](https://www.instana.com/product/) включает практически всё, что сейчас популярно. Естественно, можно [смотреть транзакции](https://instana.atlassian.net/wiki/display/DOCS/Trace+View) и анализировать работу приложения на уровне вызова метода (в документации есть [подробности механизма трассировки](https://instana.atlassian.net/wiki/display/DOCS/Tracing)).
Важный критерий при выборе СМ для нас — поддержка [Scala](https://ru.wikipedia.org/wiki/Scala_(%D1%8F%D0%B7%D1%8B%D0%BA_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F)), это редкость для СМ приложений. Может показаться, что для СМ достаточно поддержки Java — и глубокий мониторинг приложения ([инструментирование](https://ru.wikipedia.org/wiki/%D0%98%D0%BD%D1%81%D1%82%D1%80%D1%83%D0%BC%D0%B5%D0%BD%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5_(%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5))) в кармане. Но на поверку оказывается, что это не так: без поддержки Scala на мониторинге будет видна трассировка только одного вызова JVM. Поэтому даже [самые известные игроки на рынке APM](https://habrastorage.org/files/13a/05f/dc7/13a05fdc74e7493186f8376736777f0c.png) на сегодняшний день отстают в этом плане.
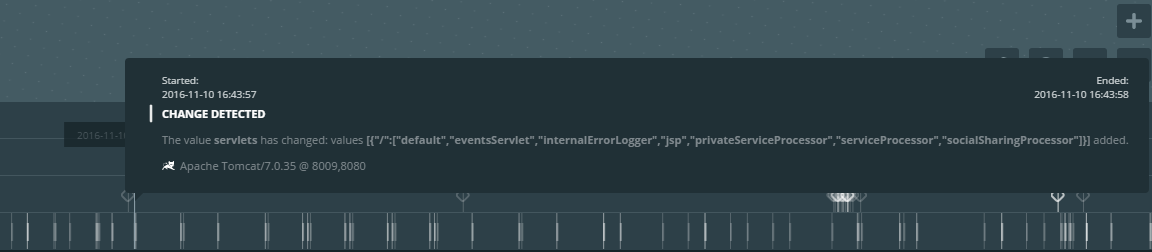
Система видит [изменения компонентов по принципу дельты](https://www.instana.com/blog/auto-change-detection-improves-root-cause-determination/):
[](https://habrastorage.org/files/e02/2f2/8d2/e022f28d297743f9ac04391b859f0f92.png)
Кроме того система способна в онлайн-режиме отображать состояние взаимодействия между компонентами (частота перемещения точек на связях показывает насколько быстро идет обмен данными):
[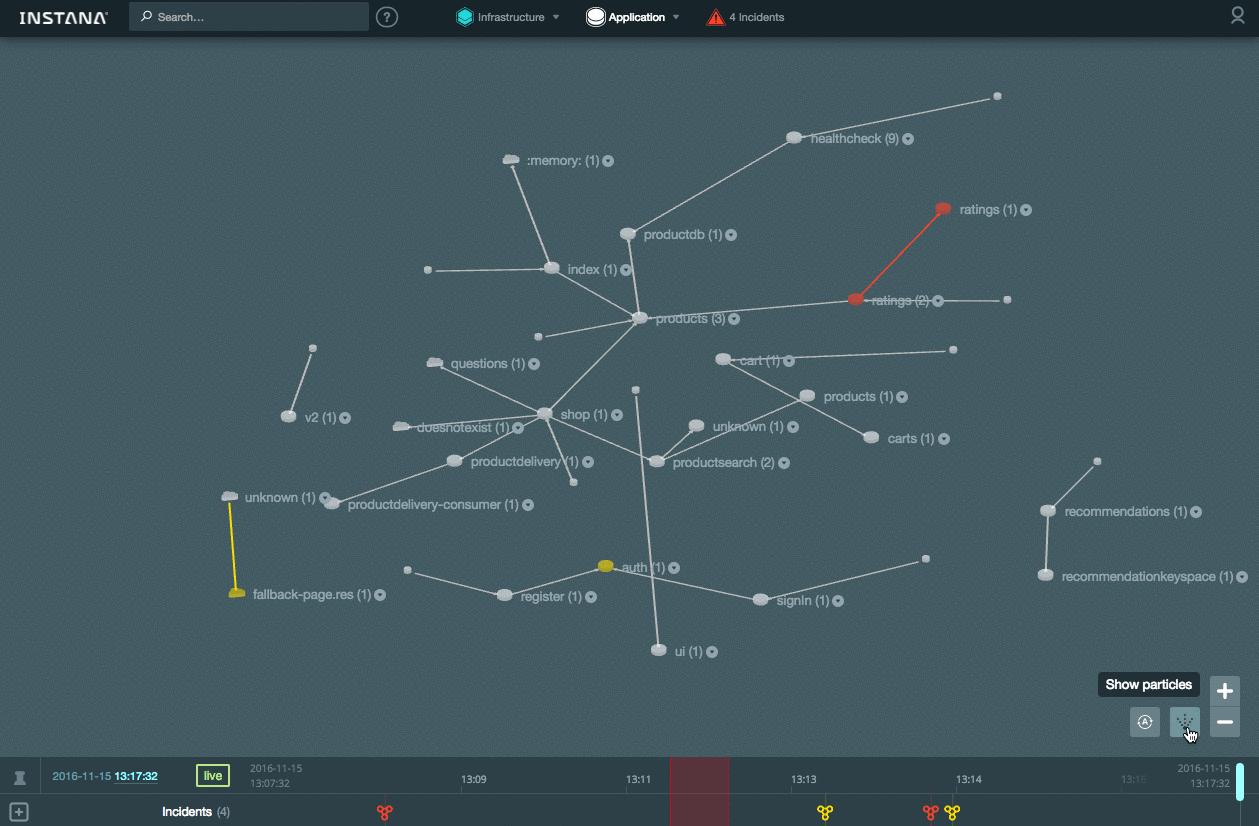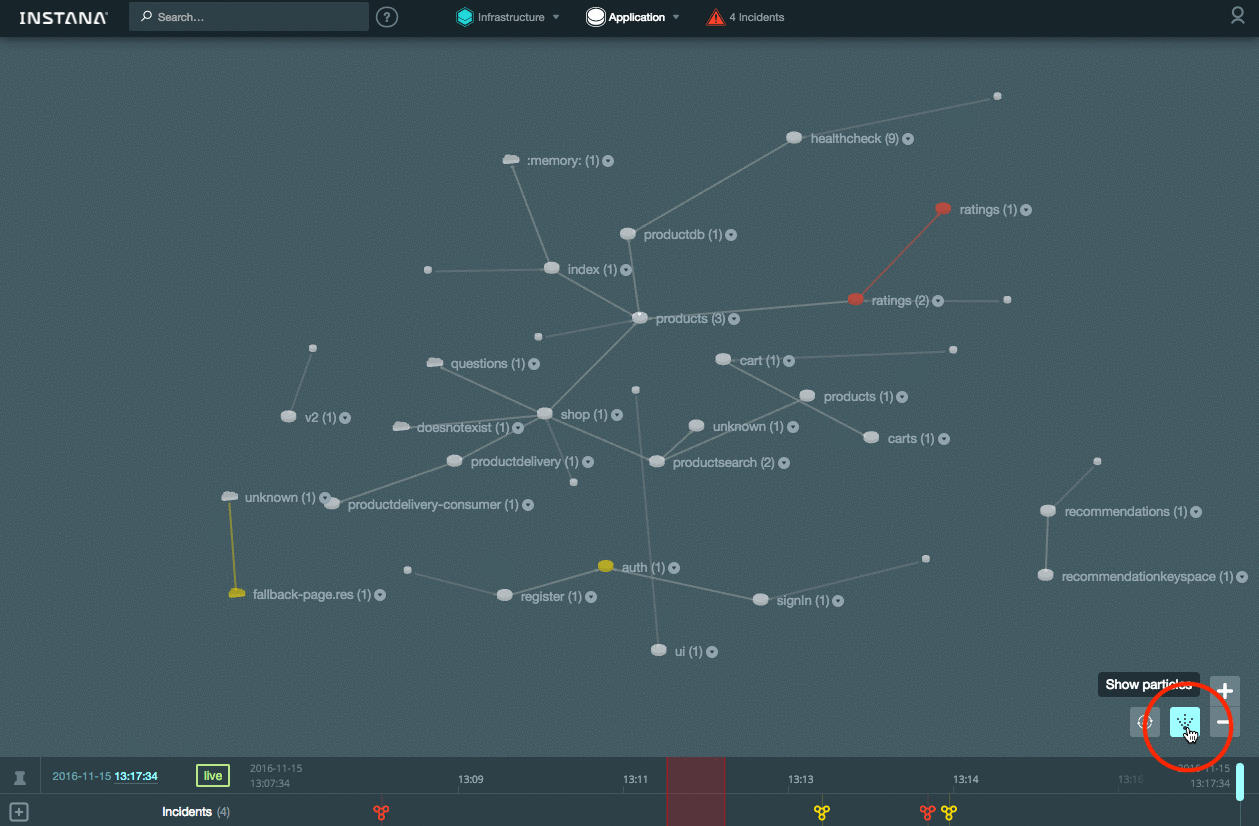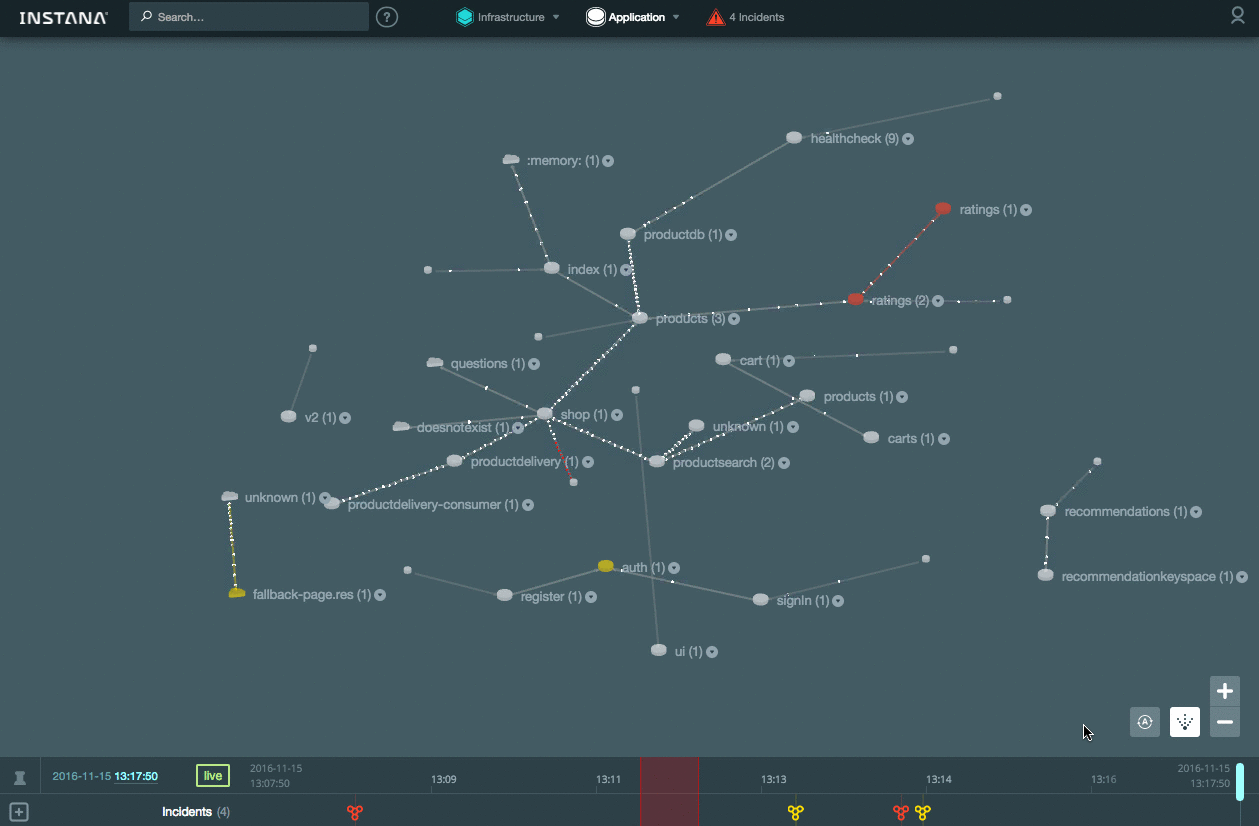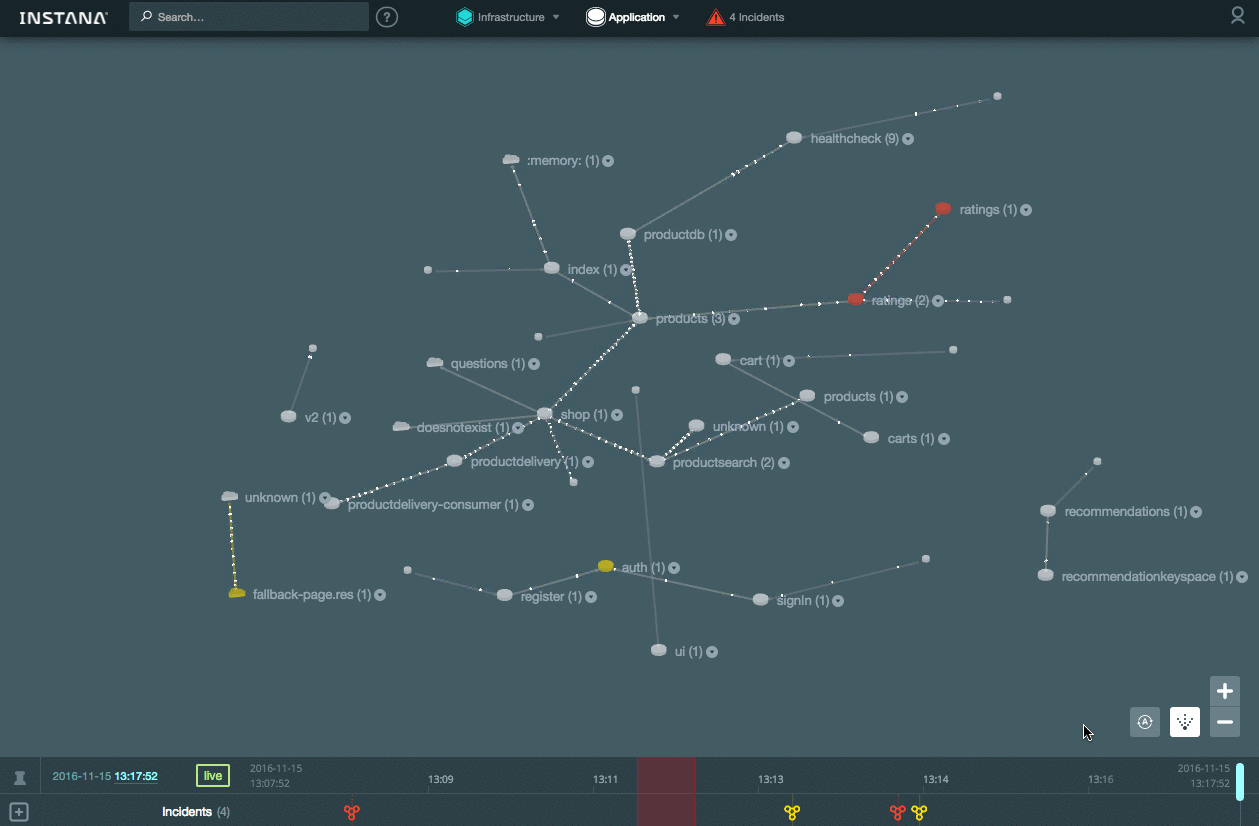](https://habrastorage.org/files/bca/1f1/5e2/bca1f15e23e3482fa217ea3666e04617.gif)
Для оповещения «из коробки» доступны следующие варианты интеграций:
* Email
* OpsGenie
* PagerDuty
* Slack
* Webhook
Продукт [активно развивается](https://instana.atlassian.net/wiki/display/DOCS/Release+Notes), но уже сейчас выглядит удобным инструментом для поиска проблем с приложением как на стадии тестирования/отладки, так и для оперативного мониторинга.
### Ссылки
В статье использованы материалы:
* [Сайт Instana](https://www.instana.com/)
* [Документация Instana](https://instana.atlassian.net/wiki/spaces/DOCS)
* [Канал Instana на Youtube](https://www.youtube.com/channel/UC_AAMzr7IEz8F08qzS9hMwQ) | https://habr.com/ru/post/317254/ | null | ru | null |
# Почему ты не учишь английский язык?
Часто ли вы натыкались в вакансиях на слова "English B2" / "Intermediate English" / "Английский на уровне чтения документации" и задавались ли вы вопросом, почему это резко стало так важно? Сейчас действительно наблюдается тенденция, что больше и больше компаний выделяют английский язык как требуемый навык, несмотря на то что команда полностью русскоговорящая и с иностранными заказчиками не работает.
С учетом того образования, которое есть сейчас в российских школах, на выходе довольно много людей плохо знают английский. И даже видя интерес компаний к знанию английского от соискателя, они откладывают изучение языка в долгий ящик из-за некоторых заблуждений, которые сейчас распространены.
Сегодня я как раз хочу поговорить об этом. Эта статья будет интересна тем людям, кто задумывается, стоит ли сейчас тратить время на изучение английского.
> Это вторая часть из цикла статей об основных проблемах, с которыми могут столкнуться новички на старте карьеры. Первая часть находится [здесь](https://habr.com/ru/sandbox/153134/). Там можно почитать про "ожидание / реальность" работы разработчика.
>
>
---
#### Я смогу выучить, когда он мне понадобится
Если ты, дорогой читатель, узнал в этих словах себя, не совершай ту же ошибку, что многие из нас сделали. Изучение английского требует ежедневного труда, не получится выучить его за неделю и сразу читать техническую документацию.
Да, тебе не нужно знать многие грамматический конструкции, и не так уж надо уметь говорить на языке, но документация написана сложным техническим языком с использованием специфических терминов. Если ты изначально не привыкнешь что массив - это *array*, а переменная - это *variable*, то потом будет тяжело покрывать весь этот объем слов, и ты просто будешь спотыкаться на каждом слове в какой-нибудь статье.
Да и в работе момент, когда "*понадобится*" наступит очень быстро. Когда будут возникать какие-то теоретические вопросы, тебе могут скинуть англоязычную статью или часть документации, который тебе придется как-то читать. Но без знаний и практики конечно это будет медленнее, чем могло бы быть.
#### Большинство вещей, которые мне могут понадобиться, уже переведены на русский язык
Это очень яркое заблуждение, которое рассыпается с началом практики. Начнем с того, что маленькие публичные пакеты предоставляют информацию на английском. Только крупные, популярные библиотеки могут быть переведены на несколько языков.
Часто сервисы прибегают к помощи любительского перевода, то есть сообщество просто из благих побуждений хочет помочь с переводом. Из-за этого он может быть не полный или не актуальный. Приведу несколько примеров из практики, с которыми я сталкивалась.
*MDN - один из самых популярных ресурсов для чтения документации по JavaScript*
Давайте зайдем на [статью](https://developer.mozilla.org/ru/docs/Web/API/Window/scroll) по методу `window.scroll`, она довольно часто используется для прокрутки.
Русская версияОбратите внимание на пераметрыАнглийская версияПараметры уже немного другие или мне кажется?В английской версии мы неожиданно узнаем, что можно передавать не только координаты, но и объект с опциями. Что тоже интересно, но этого нет на скриншотах, что в русской версии нет таблицы с поддержкой от браузеров, а в английской есть, и конкретно для этой функции она весьма важна.
*Nuxt - SSR фреймворк для Vue*
У Vue замечательная документация, которая действительно хорошо переведена. Чего не скажешь о Nuxt. Если сейчас переключить на русский, то вы можете увидеть подобную картину:
Давайте же попробуем почитатьНу в общем-то все понятноЭто на самом деле лучшее, что они могли сделать, потому что до этого был русский перевод, но он был настолько не актуальный, что примеры из него просто не работали, а половины информации там не было вообще.
Английский - это международный язык разработки, самая актуальная и верная информация будет именно на нем.
#### Русских разработчиков так много, что я смогу найти ответ на любой вопрос
Когда что-то не получается, человек идет задавать вопросы гуглу. Кто знает английский язык, тот задаст на английском, а кто не знает - будет задавать на русском. Как вы думаете, кто быстрее найдет ответ?
Большая часть вопросов на том же stackoverflow написана на английском, большая часть issues в пакетах на github написана на английском. Как я уже говорила выше, этот язык - международный в плане разработки, а значит, задавая вопрос на английском, вы получаете доступ к мировой базе информации, большему количеству кейсов и огромному количеству ответов и решений.
#### Я буду работать с русскоговорящими людьми, зачем мне понадобиться английский
Есть стандарты того, что код оформляется на английском языке. То есть названия переменных - это не русская транскрипция, а английские слова. Комментарии к коду часто пишут на английском. Грубо говоря, если ты видишь переменную `width`, ты быстро понимаешь, что это связано с шириной. Человек же не знакомый с этим языком, будет дольше по времени читать программу.
Работа с git тоже часто происходит именно на английском: те же названия веток и коммиты. И даже если ты не используешь иностранный язык, другой человек в команде может, и читая историю коммитов не получится быстро сориентироваться.
---
Надеюсь я убедила вас, что английский надо начинать учить как можно раньше и развеяла ваши заблуждения, если они у вас были. | https://habr.com/ru/post/552276/ | null | ru | null |
# Proof-of-Proof-of-Work на пальцах. На пути к разумному блокчейну
Блокчейн-протоколы должны обеспечивать консенсус среди нод децентрализованной системы. Пожалуй, самым известным алгоритмом консенсуса можно считать «тормозунутый, но надежный, потому что тормознутый» алгоритм Proof-of-Work: каждая нода, имея набор новых транзакций перебирает некоторое число nonce, являющееся полем блока. Блок считается валидным, если валидны все транзакции внутри него и хэш-функция от заголовка блока имеет некоторую общепринятую особенность (например, количество нулей в начале, как в Bitcoin):
**```
Hash( Block{transaction,nonce,…} ) = 000001001...
```**
Как известно, блокчейн — это цепочка блоков. Цепочкой он является потому, что внутри каждого блока записан id (как правило хэш от заголовка) предыдущего блока. Для последующих рассуждений блокчейн в упрощенном виде можно представить так:

В процессе синхронизации ноды с другими нодами, ей необходимо осуществить валидацию всех блоков, которые ей прислали соседи – проверить хэши и транзакции всех новых блоков, а в случае первого подлючения, до самого первого блока (genesis -block). Нетрудно предположить, что это достаточно длительный и затратный процесс…
Есть вариант запросить у соседних нод несколько последних блоков и, доверившись, принять их как валидные. Но этот вариант не соответствует духу безопасности в «среде, где никто никому не доверяет»
### PoPoW-ноды.
Хэш-функция от заголовка блока является его id. Как было сказано ранее, в сети Bitcoin, как и во многих других сетях, особенностью, по которой определяется валидность блока, является число нулей в начале записи id. Это известное и общее для всех майнеров число нулей, называют сложностью майнинга T (mining target). Валидный хэш с T нулями в начале может иметь больше нулей в начале, чем Т. Конкретнее, половина блоков будет иметь только T нулей в начале; половина блоков будет иметь T+1 нуль в начале; четверть блоков T+2 нулей и.т.д. Например так может выглядеть набор валидных блоков для T = 5:
```
000000101… (6 нулей)
000001110… (5 нулей)
000001111… (5 нулей)
000000010… (7 нулей)
000000101… (6 нулей)
000001110… (5 нулей)
000001111… (5 нулей)
```
Количество нулей, превышающее T в id блока назовем уровнем µ, а блоки с уровнем µ будем называть µ — суперблоками. Если блок является µ — суперблоком, то он так же является и
(µ -1)-суперблоком. Таким образом, пока ничего не изменяя, а лишь оперируя введенным параметром µ, можем представить цепочку блоков в следующем µ-уровневом виде:
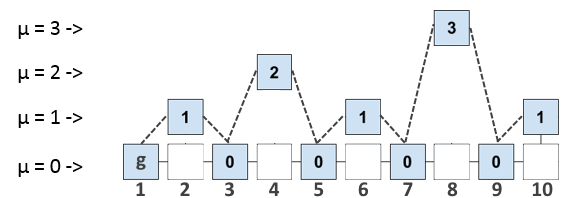
Блоки пронумерованы для простоты описания, нумерация не несет смысловой нагрузки.
Теперь подумаем, как мы можем это использовать. Если в заголовок каждого блока записывать не только id предыдущего блока, но и id всех последних блоков на каждом уровне, то мы позволяем каждому блоку ссылаться на более «древние» блоки, чем предыдущий. Набор всех последних на каждом уровне блоков будем называть interlink (множественная ссылка). Например, Interlink для блока 8 выглядит так:
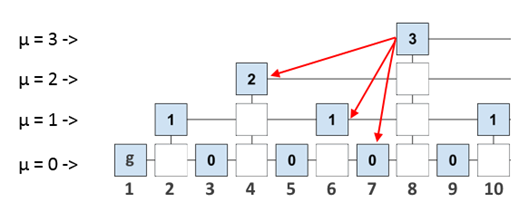
Что нам это дает? Допустим, мы подключили новую ноду и теперь хотим безопасно синхронизировать её. Как мы уже сказали, для полноценной валидации нового блока, ноде нужно «прошагать» до genesis – блока по всему блокчейну. Однако, если мы будем иметь в валидируемом блоке ссылки на некоторые «опорные» блоки, то сможем «прошагать» до genesis – блока, запросив у других нод не весь блокчейн, а лишь некоторое доказательство (proof), которое будет содержать короткий маршрут до самого первого блока. Сам маршрут будет являться валидной подцепочкой самого блокчейна, так как блоки подцепочки последовательно ссылаются друг на друга.

Доказательство – это набор заголовков нескольких предыдущих блоков. Строго говоря, доказательство содержит не только «короткий маршрут», но и ещё несколько заголовков других блоков. Это сделано для верификации доказательства (verify) по задаваемым параметрам безопасности m, k и др. (подробное описание приводится в оригинальной статье, ссылка в конце).
Нода, которая не хранит весь блокчейн, а лишь запрашивает proof у full-нод, хранящих всю историю, называется PoPoW – нодой. Теоретически такую ноду можно развернуть на маломощном компьютере, смартфоне.
Алгорим работы PoPoW-протокола следующий:
1. PoPoW-нода запрашивает доказательство для блока у full – ноды.
2. Full – нода (proover) формирует доказательство и отправляет его.
3. PoPoW-нода (verifier) проверяет доказательство, сопоставляет с доказательствами других нод и делает заключение о валидности блока.
Также стоит отметить, что сложность создания PoPoW доказательства не уступает сложности создания полной цепочки из валидных заголовков (хэш функция заголовка содержит Interlink, поэтому «подделывать» блоки нечестной ноде пришлось бы с учетом µ-уровневой иерархичности). Поэтому использование для валидации блока PoPoW доказательства не влечет потери безопасности.
### NiPoWPoW – алгоритм
Алгорим NiPoPoW – Non-Interactive Proof-of-Proof-of-Work – включает в себя усовершенствованные формирование и проверку доказательств, он устойчив к некоторым атакам, которым подвержен PoPoW. Ссылка на оригинальную статью от авторов так же в конце.
### Для чего все это нужно?
С помощью этих алгоритмов решаются две актуальные проблемы: эффективная верификация транзакции и эффективное доказательство для сайдчейнов (Sidechains).
В первом случае этот алгоритм позволяет подключать к сети «легкие» ноды, которые смогут быстро синхронизироваться с сетью.
Во втором случае алгоритм позволяет хранить и ссылаться на события, произошедшие в других блокчейн-сетях, что полезно для клиентов и кошельков, работающих с несколькими блокчейнами. PoPoW-доказательство достаточно короткое для того, чтобы можно было поместить его в транзакцию. Например, можно писать смарт-контракты в блокчейне A, которые опираются на какие-то события в блокчейне Б.
Данный обзор составлен на свежую голову после участия в хакатоне [Unblock Hackathon](https://binarydistrict.com/ru/courses/blockchain-hackathon/), где одним из заданий было реализовать данный протокол. Авторами задания были партнеры хакатона из [Ergo platform](https://ergoplatform.org/), внутри которой используется этот алгоритм.
Текст подготовлен на основе оригинальных статей
PoPoW: [Proofs of Proofs of Work with Sublinear Complexity. Aggelos Kiayias, Nikolaos Lamprou, and Aikaterini-Panagiota Stouka](http://fc16.ifca.ai/bitcoin/papers/KLS16.pdf)
NiPoPoW: [Non-Interactive Proofs of Proof-of-Work. Aggelos Kiayias, Andrew Miller and Dionysis Zindros](https://eprint.iacr.org/2017/963.pdf) | https://habr.com/ru/post/353160/ | null | ru | null |
# Как запустить несколько пайплайнов с помощью GitLab CI/CD

Запуск и визуализация пайплайнов при настройке GitLab CI/CD для нескольких проектов.
Непрерывная интеграция (CI) — это практика автоматизации сборки и тестирования кода до его слияния с основной веткой. Она позволяет разработчикам вливать код довольно часто и рано, снижая при этом риск внесения новых ошибок в главный репозиторий исходного кода.
Хотя CI проверяет, что новый код не сломается при интеграции с другим кодом в том же репо, прохождение всех тестов на этом репо — это только первый шаг. После запуска CI в коде важно развернуть и запустить тесты в реальной среде. Переход от CI к непрерывной доставке и деплою (CD) является следующим шагом к “взрослому” DevOps. Развертывание и последующее повторное тестирование позволяют тестировать код одного проекта вместе с другими компонентами и сервисами, которые, возможно, управляются другими проектами.
Зачем мне нужно убедиться, что мой код работает с другими компонентами?
-----------------------------------------------------------------------
Хорошим примером может служить архитектура микросервисов. Обычно микросервисы управляются в разных [проектах](https://docs.gitlab.com/ee/user/project/), где каждый микросервис имеет свой собственный репозиторий с пайплайном. Кроме того, очень часто каждая команда разработчиков несёт ответственность за отдельные микросервисы и конфигурации пайплайнов. Как программист, вы возможно захотите убедиться, что изменения в вашем коде не нарушают функциональность зависимых от него микросервисов. Поэтому вы можете запускать тесты на них дополнительно к тестам для вашего проекта.
Пайплайн кросс-проекта
----------------------
При запуске пайплайна проекта, вам также нужно будет запустить кросс-проектные пайплайны, которые в конечном итоге развернут и протестируют последнюю версию всех зависимых микросервисов. Для достижения этой цели вам нужен простой, гибкий и удобный способ запуска других пайплайнов в рамках CI вашего проекта. GitLab CI/CD предлагает легкий путь запуска кросс-проектного пайплайна путем добавления специального задания в файл конфигурации CI.
GitLab CI/CD конфигурационный файл
----------------------------------
В GitLab CI/CD пайплайны, а также задания (jobs) и этапы их компонентов определяются в файле `.gitlab-ci.yml`для каждого проекта. Файл является частью репозитория проекта. Он полностью версионный, и разработчики могут редактировать его с помощью любой IDE по своему выбору. Им не нужно просить системного администратора или команду DevOps вносить изменения в конфигурацию пайплайна, поскольку могут делать это сами. Файл `.gitlab-ci.yml` определяет структуру и порядок пайплайнов, и решает, что надо выполнять с помощью [GitLab Runner](https://docs.gitlab.com/runner/) (агент, который запускает задания), и какие решения следует принимать при возникновении определенных условий, например, когда процесс завершается успешно или выходит из строя.
Добавление job для запуска кросс-проектного пайплайна
-----------------------------------------------------
Начиная с GitLab 11.8, GitLab предоставляет новый синтаксис конфигурации CI/CD для запуска кросс-проектных пайплайнов, его можно найти в [правилах конфигурации пайплайна](https://docs.gitlab.com/ee/ci/yaml/README.html). Следующий код иллюстрирует настройку bridge job для запуска нисходящего пайплайна:
```
// job1 это job в восходящем проекте
deploy:
stage: Deploy
script: this is my script
// job2 это bridge job в восходящем проекте, который запускает кросс-проектный пайплайн
Android:
stage: Trigger-cross-projects
trigger: mobile/android
```
В приведенном выше примере, как только deploy job (задача развертывания) на этапе деплоя выполнится успешно, запустится задание для Android bridge. Его первоначальный статус будет в ожидании. GitLab создаст нисходящий пайплайн в проекте mobile/android, и, как только он будет создан, Android job выполнится успешно. В этом случае mobile/android является полным путем к этому проекту.
Пользователь, создавший вышестоящий пайплайн, должен иметь права доступа к нижестоящему проекту (в данном случае mobile / android). Если нижестоящий проект не может быть найден или у пользователя нет прав доступа для создания там пайплайна, Android job получит статус failed.
Обзор графиков от восходящего до нижестоящего пайплайна
-------------------------------------------------------
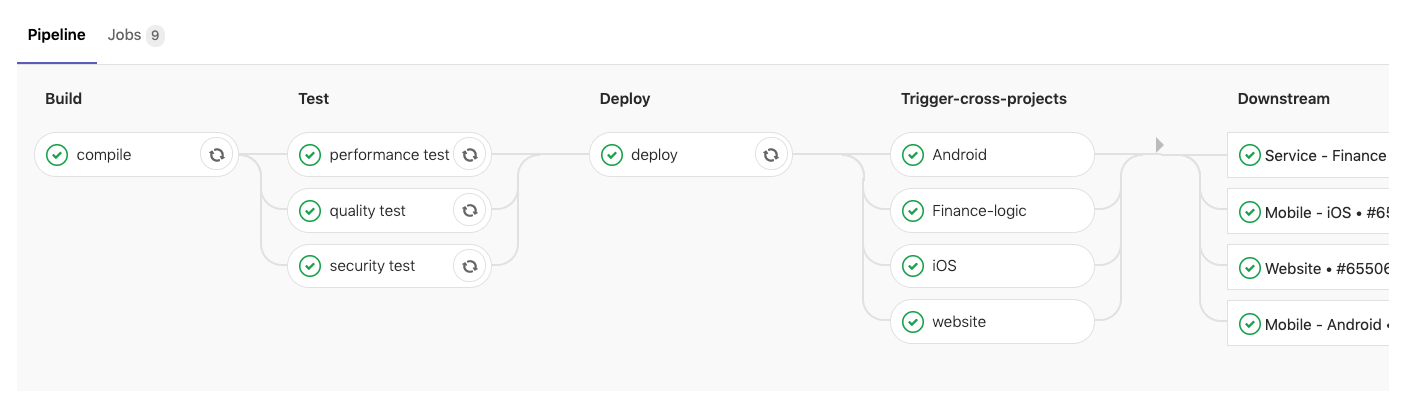
GitLab CI/CD позволяет визуализировать конфигурацию пайплайна. На приведенном ниже рисунке этапы сборки, тестирования и деплоя являются частями восходящего (upstream) проекта. Как только deploy job выполнено успешно, четыре кросс-проекта будут запущены параллельно, и вы сможете перейти к ним, щелкнув на одну из нисходящих (downstream) job.
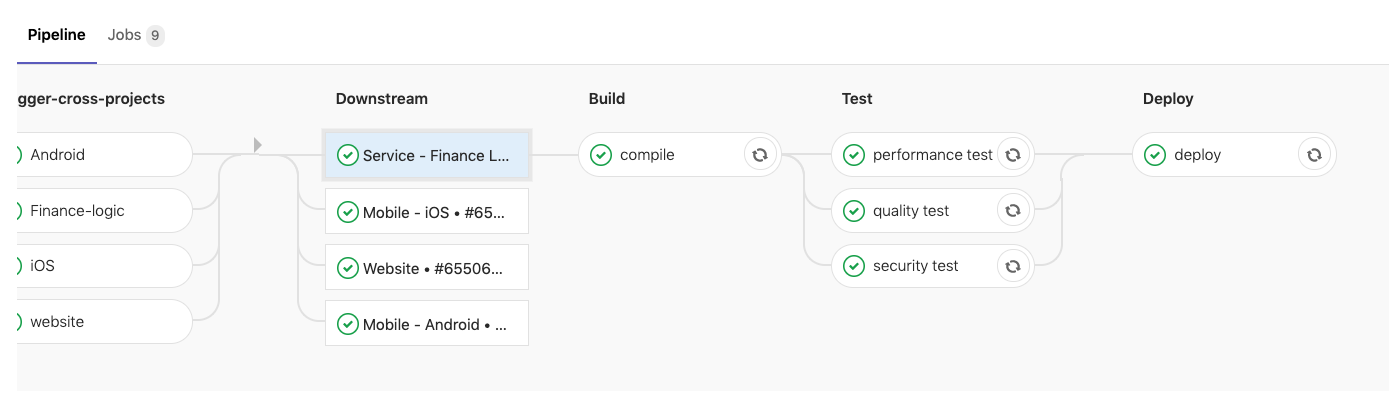
На приведенном ниже рисунке виден нисходящий пайплайн «Сервис — Финансы». Теперь можно прокрутить влево к восходящему пайплайну, прокрутить вправо назад к нисходящему или выбрать другой нисходящий пайплайн.
Определение ветки нижестоящего пайплайна
----------------------------------------
Можно указать имя ветки, которое будет использовать нисходящий пайплайн:
```
trigger:
project: mobile/android
branch: stable-11-2
```
Используйте ключевое слово проекта, чтобы указать полный путь к нисходящему проекту. Используйте ключевое слово branch, чтобы определить имя ветки. GitLab будет использовать коммит, который в данный момент находится в HEAD ветки при создании нисходящего пайплайна.
Передача переменных в нисходящий пайплайн
-----------------------------------------
Когда-нибудь вам возможно захочется передать переменные в нисходящий пайплайн. Вы можете сделать это с помощью ключевых слов для переменных, как и при определении обычной job.
```
Android:
variable:
ENVIRONMENT: ‘This is the variable value for the downstream pipeline’
stage: Trigger-cross-projects
trigger: mobile/android
```
Переменная ENVIRONMENT будет передаваться каждой job, определенной в нисходящем пайплайне. Она будет доступна в качестве переменной среды каждый раз, когда GitLab Runner выбирает job.
Итого о кросс-проектном пайплайне
---------------------------------
Файл `.gitlab-ci.yml`определяет порядок этапов CI/CD, какие задания выполнять и при каких условиях запускать или пропускать выполнение задания. Добавление 'bridge job' с ключевым словом `trigger` в этот файл можно использовать для запуска кросс-проектных пайплайнов. Мы можем передавать параметры заданиям в нисходящих пайплайнах и даже определять ветку, которую будет использовать нисходящий пайплайн.
Пайплайны могут быть сложными структурами с множеством последовательных и параллельных задач, и, как мы только что узнали, иногда они могут запускать нисходящие пайплайны. Чтобы упростить понимание потока пайплайна, включая нисходящие пайплайны, в GitLab есть графики пайплайнов для просмотра пайплайнов и их статусов.

### Также читайте другие статьи в нашем блоге:
* [/etc/resolv.conf для Kubernetes pods, опция ndots:5, как это может негативно сказаться на производительности приложения](https://habr.com/ru/company/nixys/blog/464371/)
* [Разбираемся с пакетом Context в Golang](https://habr.com/ru/company/nixys/blog/461723/)
* [Три простых приема для уменьшения Docker-образов](https://habr.com/ru/company/nixys/blog/437372/)
* [Бэкапы Stateful в Kubernetes](https://habr.com/ru/company/nixys/blog/426543/)
* [Резервное копирование большого количества разнородных web-проектов](https://habr.com/ru/company/nixys/blog/424717/)
* [Telegram-бот для Redmine. Как упростить жизнь себе и людям](https://habr.com/ru/company/nixys/blog/347526/) | https://habr.com/ru/post/467107/ | null | ru | null |
# Как наломать велосипедов поверх костылей при тестировании своего дистрибутива
Диспозиция
==========
Представим на минуту, вы разрабатываете программно-аппаратный комплекс, который базируется на своем дистрибутиве, состоит из множества серверов, обладает кучей логики и в конечном счете это все должно накатываться на вполне реальное железо. Если вы впустите бяку, пользователи вас по головке не погладят. Всплывают три извечных вопроса: что делать? как быть? и кто виноват?
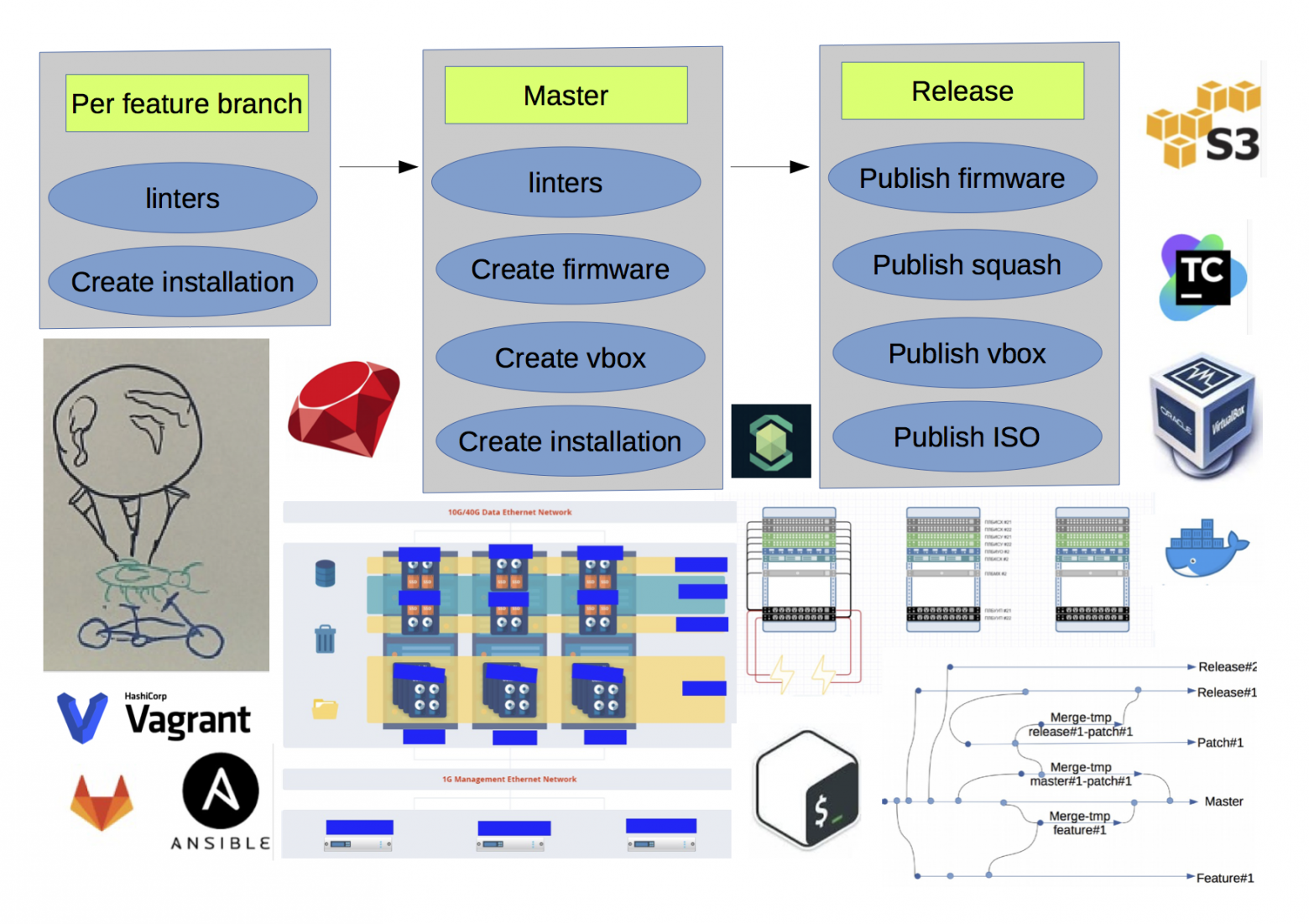
Далее по тексту будет история, как начать стабильно релизиться и как к этому пришли. Чтобы не растягивать статью, не буду говорить про модульное, ручное тестирование и все стадии выкатывания на продуктив.
Сначала было MVP
================
Сложно сделать сразу всё и правильно, особенно, когда конечная цель точно не известна. Первоначальный деплой на стадии MVP выглядел примерно так: никак.
```
make dist
for i in a b c ; do
scp ./result.tar.gz $i:~/
ssh $i "tar -zxvf result.tar.gz"
ssh $i "make -C ~/resutl install"
done
```
Скрипт конечно упрощен донельзя для передачи сути, что CI нет. С машины разработчика на честном слове собрали и залили на тестовую среду для показа. На данном этапе тайное знание настройки серверов сидело в головах разработчиков и немного в документации.
Проблема в том, что есть тайное знание как заливать.
Фигак-Фигак и на staging
========================

Исторически сложилось, что teamcity использовался на множестве проектов, да и gitlab CI еще тогда не было. Teamcity был выбран за основу CI на проекте.
Разово создали виртуальную машину, внутри нее запускались "тесты"
```
make install && ./libs/run_all_tests.sh
make dist
make srpm
rpmbuild -ba SPECS/xxx-base.spec
make publish
```
тесты сводились к следующему:
1. в полуруками предподготовленном окружении установить набор утилит
2. проверить их работу
3. если ок — то опубликовать rpm
4. в полуручном режиме сходить на staging и накатить новую версию
Стало лучше:
* теперь в мастере лежит что-то проверенное
* знаем что в каком-то окружение работает
* отлавливаем детские ошибки
Но чувствуете боль?
* проблемы с зависимостям (часть пакетов пересобрана)
* окружение для разработки каждый разворачивает как умеет
* тесты гоняются в каком-то непонятном окружении
* сборка дистрибутива, настройка инсталляции и тесты — три разные несвязные вещи
Делаем мир чуточку лучше
========================

Такая схема прожила какое-то время, но мы ведь на то и инженеры, чтобы решать проблемы и делать мир лучше.
* Зависимости всего дистрибутива вынесены в метапакет
* Был создан шаблон виртуальной машины используя средства vagrant
* Bash скрипты создания инсталляций переписаны на ansible
* Создана библиотека для интеграционного тестирования, чтобы проверять что система работает в целом правильно
* Часть сценариев покрыта через serverspec
Это позволило:
* Сделать идентичным окружение разработки/тестирования
* Держать код развертывания вместе с кодом приложения
* Ускорить включение в процесс новых разработчиков
Такая схема прожила весьма долго, т.к. за приемлемое время (30-60 минут на билд) позволяла отлавливать множество ошибок, не доводя их до ручного тестирования. Но осадочек был, что при обновление ядра или при откате какого-то пакета всё шло наперекосяк, и где-то начинал грустить щенок.
Становится жарко
================
По ходу пьесы появлялись различные проблемы, которые потянут на отдельную статью:
1. Прогон интеграционных тестов со временем стал затягиваться, т.к. шаблон виртуальной машины стал отставать от актуальных версий пакетов. Пару месяцев пересобирали в полуручном режиме. В итоге сделали, чтобы при выпуске релиза:
* автоматом собирался vmdk
* vmdk прицеплялся к виртуальной машине
* полученная VM паковалась и заливалась в s3 (кстати, кто знает как vagrant подружить с s3?)
2. При одобрении мерджа не виден статус билда — переехали на gitlab ci. Обошлись малой кровью — пришлось отказаться от тригера некоторых билдов по регулярке тэга, в остальном рады.
3. Раз в неделю была рутина по выпуску релиза — автоматизировали:
* Инкремент версии релиза
* Генерация release notes по закрытым задачам
* Обновление changelog
* Создание merge requests
* Создание нового milestone
4. Чтобы ускорить билды — часть шагов была вынесена в docker, как то: линтеры, нотификации, сборка документации, часть тестов итд итп
Несколько упростив, конечная схема получилась такая(красным обозначены неочевидные связи между билдами):
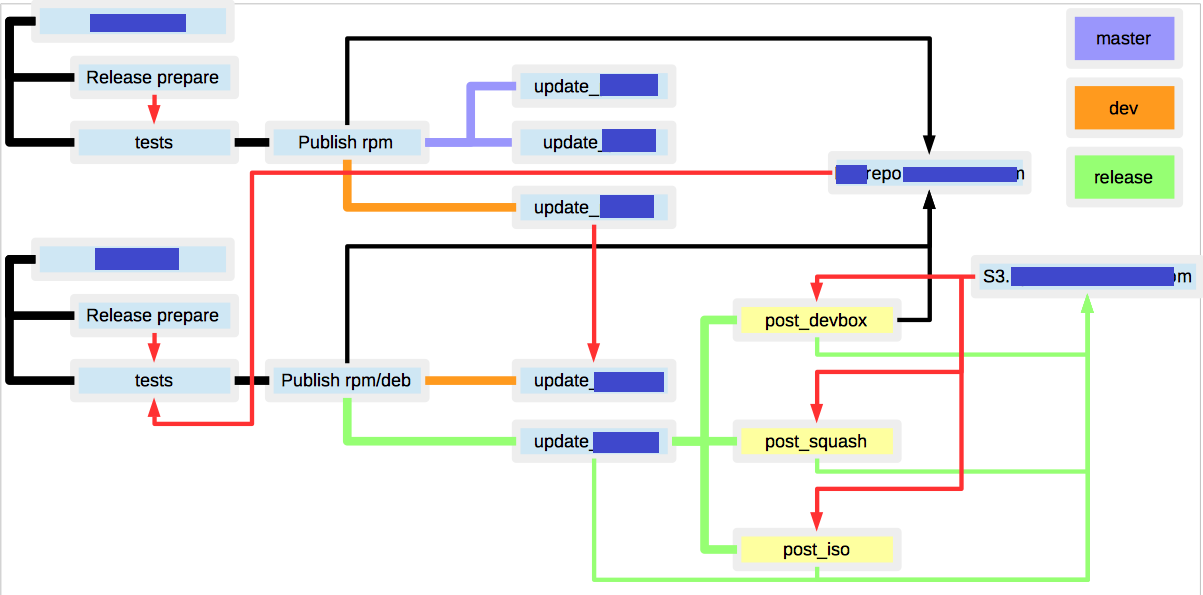
1. множество RPM/DEB репозиториев под разрабатываемые пакеты
2. S3 хранилище для хранения артефактов(firmware, squash, iso, VM templates)
3. если по одному и тому же бранчу запустить сборку дистрибутива, то результат может получится различным, т.к. зависимости между пакетами прописаны не жестко, и состояние репозиториев могло измениться
4. множество неочевидных связей между билдами
Это позволило:
* Выпускать приватный релиз раз в неделю
* Повысить скорость разработки за счет уменьшения кол-ва конфликтов и увеличения прогонов тестов
Заключение
==========

Сложно полученный результат назвать идеальным, но с другой стороны готовых решений для задач такого рода не встречал. Основные посылы из этого опуса:
* дорога в тысячу ли начинается с первого шага (с)
* есть боль — уменьшайте ее.
**UPD:** [English version](http://www.goncharov.xyz/it/how-to-test-custom-os-distr.html) | https://habr.com/ru/post/342216/ | null | ru | null |
# Я бы сделал лучше
Студия Лебедева порадовала нас новым творением — обновился интернет-магазин Техносилы. Все мило и, как обычно в последнее время у Лебедева, лаконично, но…
Что мы видим на первой же странице:

Названия товаров не помещаются и просто обрезаются свойством `overflow: hidden`
Не очень красиво, я бы сказал. Но ведь есть же замечательное, но крайне редко используемое (мне ни разу не попадалось на глаза его использование) свойство `text-overflow: ellipsis`. Что удивительно, его (это свойство) поддерживает дружное семейство браузеров по имени Internet Explorer. Это свойство имеет два (согласно с [сайтом MS](http://msdn.microsoft.com/en-us/library/ms531174%28VS.85%29.aspx)) значения: `clip` (по умолчанию) и `ellipsis`, что в сочетании со свойством `overflow: hidden` дает замечательный результат: текст, который не помещается в каком-либо элементе обрезается с заменой последних символов на многоточие!!! Получается очень аккуратно и симпатично.
[Как это выглядит.](http://starhack.ru/ya-by-sdelal-luchshe/)
Некоторые браузеры, в частности Opera, требуют своего префикса для этого свойства. MSDN рекомендует так же использовать префикс -ms для ИЕ8, но понимает это свойство и без него
Проверил, что Хром 2 и Сафари 4 понимают без префиксов, а ФайрФокс 3 не понимает вовсе
Но если не использовать это свойство, то хотя бы снабдить заголовок соответствующей всплывающей подсказкой, хотя бы в виде title | https://habr.com/ru/post/55587/ | null | ru | null |
# SQL или NoSQL — вот в чём вопрос
Все мы знаем, что в мире технологий баз данных существует два основных направления: SQL и NoSQL, реляционные и нереляционные базы данных. Различия между ними заключаются в том, как они спроектированы, какие типы данных поддерживают, как хранят информацию.
Реляционные БД хранят структурированные данные, которые обычно представляют объекты реального мира. Скажем, это могут быть сведения о человеке, или о содержимом корзины для товаров в магазине, сгруппированные в таблицах, формат которых задан на этапе проектирования хранилища.
Нереляционные БД устроены иначе. Например, документо-ориентированные базы хранят информацию в виде иерархических структур данных. Речь может идти об объектах с произвольным набором атрибутов. То, что в реляционной БД будет разбито на несколько взаимосвязанных таблиц, в нереляционной может храниться в виде целостной сущности.
Внутреннее устройство различных систем управления базами данных влияет на особенности работы с ними. Например, нереляционные базы лучше поддаются масштабированию.
[](https://habrahabr.ru/company/ruvds/blog/324936/)
Какую технологию выбрать? Ответ на этот вопрос зависит от особенностей проекта, о котором идёт речь.
О выборе SQL-баз данных
-----------------------
Не существует баз данных, которые подойдут абсолютно всем. Именно поэтому многие компании используют и реляционные, и нереляционные БД для решения различных задач. Хотя NoSQL-базы стали популярными благодаря быстродействию и хорошей масштабируемости, в некоторых ситуациях предпочтительными могут оказаться структурированные SQL-хранилища. Вот две причины, которые могут послужить поводом для выбора SQL-базы:
1. Необходимость соответствия базы данных требованиям ACID (Atomicity, Consistency, Isolation, Durability — атомарность, непротиворечивость, изолированность, долговечность). Это позволяет уменьшить вероятность неожиданного поведения системы и обеспечить целостность базы данных. Достигается подобное путём жёсткого определения того, как именно транзакции взаимодействуют с базой данных. Это отличается от подхода, используемого в NoSQL-базах, которые ставят во главу угла гибкость и скорость, а не 100% целостность данных.
2. Данные, с которыми вы работаете, структурированы, при этом структура не подвержена частым изменением. Если ваша организация не находится в стадии экспоненциального роста, вероятно, не найдётся убедительных причин использовать БД, которая позволяет достаточно вольно обращаться с типами данных и нацелена на обработку огромных объёмов информации.
О выборе NoSQL-баз данных
-------------------------
Если есть подозрения, что база данных может стать узким местом некоего проекта, основанного на работе с большими объёмами информации, стоит посмотреть в сторону NoSQL-баз, которые позволяют то, чего не умеют реляционные БД.
Вот возможности, которые стали причиной популярности таких NoSQL баз данных, как MongoDB, CouchDB, Cassandra, HBase:
1. Хранение больших объёмов неструктурированной информации. База данных NoSQL не накладывает ограничений на типы хранимых данных. Более того, при необходимости в процессе работы можно добавлять новые типы данных.
2. Использование облачных вычислений и хранилищ. Облачные хранилища — отличное решение, но они требуют, чтобы данные можно было легко распределить между несколькими серверами для обеспечения масштабирования. Использование, для тестирования и разработки, локального оборудования, а затем перенос системы в облако, где она и работает — это именно то, для чего созданы NoSQL базы данных.
3. Быстрая разработка. Если вы разрабатываете систему, используя agile-методы, применение реляционной БД способно замедлить работу. NoSQL базы данных не нуждаются в том же объёме подготовительных действий, которые обычно нужны для реляционных баз.
В следующем разделе рассмотрим некоторые различия между технологиями SQL и NoSQL. А именно, сначала взглянем на простой пример, показывающий фундаментальное различие двух подходов к организации баз данных, потом поговорим о масштабируемости и индексации данных. А в итоге остановимся на примере большой CRM-системы, нуждающейся в высокой производительности хранилища данных.
SQL и NoSQL
-----------
Начнём с некоторых ключевых концепций реляционных и нереляционных баз данных. Ниже показана база данных, содержащая сведения о взаимоотношениях людей. Вариант **a** — это бессхемная структура, построенная в виде графа, характерная для NoSQL-решений. Вариант **b** показывает, как те же данные можно представить в структурированном виде, типичном для SQL.
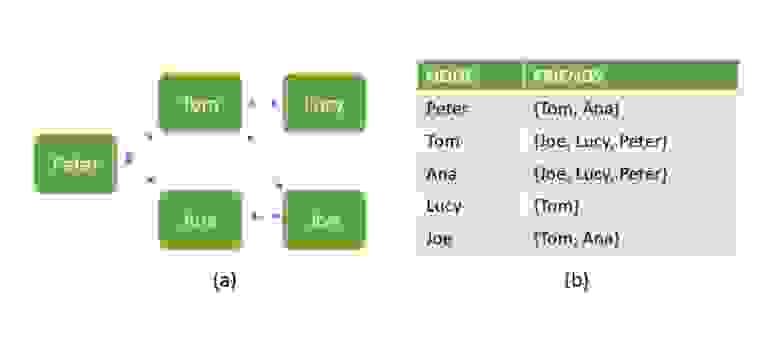
*Два варианта представления данных*
Бессхемность означает, что два документа в структуре данных NoSQL не должны иметь одинаковые поля и могут хранить данные разных типов. Вот, например, массив объектов, набор полей которых не совпадает.
```
var cars = [
{ Model: "BMW", Color: "Red", Manufactured: 2016 },
{ Model: "Mercedes", Type: "Coupe", Color: "Black", Manufactured: "1-1-2017" }
];
```
При реляционном подходе данные надо хранить в заранее спроектированной структуре, из которой эти данные потом можно извлекать. Например, используя оператор `JOIN`при выборке из двух таблиц:
```
SELECT Orders.OrderID, Customers.Name, Orders.Date
FROM Orders
INNER JOIN Customers
ON Orders.CustID = Customers.CustID
```
Как более продвинутый пример, для демонстрации того, когда SQL предпочтительнее NoSQL, рассмотрим особенности применения в NoSQL-базах алгоритмов [уплотнения](http://web.engr.illinois.edu/~sgupta49/papers/compaction.pdf). Проблема заключается в том, что в некоторых NoSQL-базах (например, в CouchDB и HBase) постоянно приходится формировать так называемые `sstables` — строковые таблицы в формате ключ-значение, отсортированные по ключу. В такие таблицы, которые сохраняются на диск, данные попадают из таблиц, хранящихся в памяти, при их переполнении и в других ситуациях. При интенсивной работе с базой создание таблиц, со временем, приводит к тому, что подсистема ввода-вывода устройства хранения данных становится узким местом для операций чтения данных. Как результат, чтение в NoSQL-базе происходит медленнее, чем запись, что сводит на нет одно из главных преимуществ нереляционных баз данных. Именно для того, чтобы уменьшить этот эффект, системы NoSQL используют, в фоновом режиме, алгоритмы уплотнения данных, пытаясь объединить множество таблиц в одну. Но и сама по себе эта операция весьма ресурсоёмка, система работает под повышенной нагрузкой.
### Масштабируемость
Одно из основных различий рассматриваемых технологий заключается в том, что NoSQL-базы лучше поддаются масштабированию. Например, в MongoDB имеется встроенная поддержка репликации и шардинга (горизонтального разделения данных) для обеспечения масштабируемости. Хотя масштабирование поддерживается и в SQL-базах, это требует гораздо больших затрат человеческих и аппаратных ресурсов.
| | | | |
| --- | --- | --- | --- |
| **Тип хранилища данных** | **Сценарий использования** | **Пример** | **Рекомендации** |
| Хранилище типа ключ-значение | Подходит для простых приложений, с одним типом объектов, в ситуациях, когда поиск объектов выполняют лишь по одному атрибуту. | Интерактивное обновление домашней страницы пользователя в Facebook. | Рекомендовано знакомство с технологией memcached.
Если приходится искать объекты по нескольким атрибутам, рассмотрите вариант перехода к хранилищу, ориентированному на документы. |
| Хранилище, ориентированное на документы | Подходит для хранения объектов различных типов. | Транспортное приложение, оперирующее данными о водителях и автомобилях, работая с которым надо искать объекты по разным полям, например — имя или дата рождения водителя, номер прав, транспортное средство, которым он владеет. | Подходит для приложений, в ходе работы с которыми допускается реализация принципа «согласованность в конечном счёте» с ограниченными атомарностью и изоляцией. Рекомендуется применять механизм кворумного чтения для обеспечения своевременной атомарной непротиворечивости. |
| Система хранения данных с расширяемыми записями | Более высокая пропускная способность и лучшие возможности параллельной обработки данных ценой слегка более высокой сложности, нежели у хранилищ, ориентированных на документы. | Приложения, похожие на eBay. Вертикальное и горизонтальное разделение данных для хранения информации клиентов. | Для упрощения разделения данных используются HBase или Hypertable. |
| Масштабируемая RDBMS | Использование семантики ACID освобождает программистов от необходимости работать на достаточно низком уровне, а именно, отвечать за блокировки и непротиворечивость данных, обрабатывать устаревшие данные, коллизии. | Приложения, которым не требуются обновления или слияния данных, охватывающие множество узлов. | Стоит обратить внимание на такие системы, как MySQL Cluster, VoltDB, Clustrix, ориентированные на улучшенное масштабирование. |
Более подробное сравнение SQL и NoSQL можно найти в [этом](http://www.cattell.net/datastores/Datastores.pdf) материале. Вот его основные положения. А именно, были проведены испытания трёх основных характеристик систем: параллельная обработка данных, работа с хранилищами информации, репликация данных. Возможности параллельной обработки оценивались путём анализа механизмов блокировки, управления параллельным доступом на основе многоверсионности, и ACID. Тестирование хранилищ охватывало и физические носители, и хранилища использующие оперативную память. Репликацию испытывали в синхронном и асинхронном режимах.
Используя данные, полученные в ходе испытаний, авторы делают выводы о том, что SQL-базы с возможностью кластеризации показали многообещающие результаты производительности в расчёте на один узел, и, кроме того, обладают способностью масштабируемости, что даёт системам RDBMS преимущество перед NoSQL за счёт полного соответствия принципам ACID.
### Индексация
В системах RDBMS индексация используется для ускорения операций извлечения данных из баз. Отсутствие индекса означает, что таблица должна быть просмотрена целиком для того, чтобы выполнить запрос на чтение.
И в SQL, и в NoSQL-базах индексы служат одной и той же цели — ускорить и оптимизировать извлечение данных. Но то, как именно они работают — различается из-за разных архитектур баз данных и особенностей хранения информации в базе. В то время, как SQL-индексы представлены в виде B-деревьев, которые отражают иерархическую структуру реляционных данных, в NoSQL базах данных они указывают на документы, или на части документов, между которыми, в основном, нет никаких отношений. [Вот](http://sql-vs-nosql.blogspot.co.il/2013/11/indexes-comparison-mongodb-vs-mssqlserver.html) подробный материал на эту тему.
### CRM-системы
CRM-приложения — это один из лучших примеров систем, для которых характерны огромные объёмы ежедневно обрабатываемых данных и очень большое количество транзакций. Все разработчики таких приложений используют и SQL, и NoSQL базы данных. И, хотя большая часть данных транзакций всё ещё хранится в SQL-базах, применение находят общедоступные системы класса DBaaS (data-base-as-a-service, база данных как сервис), наподобие AWS DynamoDB и Azure DocumentDB, в результате, серьёзная нагрузка по обработке данных может быть перенесена в облачные NoSQL-базы.
В то время, как использование подобных служб освобождает разработчика от решения задач по обслуживанию хранилищ, это, кроме того, область, где NoSQL базы применяются для того, для чего они, в основном, и были созданы, например, для глубинного анализа данных. Объёмы информации, хранимой в огромных CRM-системах финансовых и телекоммуникационных компаний, было бы практически невозможно проанализировать, используя инструменты вроде SAS или R. Это потребовало бы огромных аппаратных ресурсов.
Главное преимущество таких систем — использование [неструктурированных](http://panoply.io/blog/how-data-structures-impact-the-data-warehouse/) данных, похожих на документы. Такие данные могут подаваться на вход статистических моделей, которые дают компаниям возможность выполнять различные виды анализа. CRM-приложения, кроме того, являются весьма удачным примером, в котором две системы баз данных выступают не конкурентами, а существуют в гармонии, играя каждая свою роль в большой архитектуре управления данными.
Итоги
-----
Занимаясь поиском системы управления базами данных, можно выбрать одну технологию, а позже, уточнив требования, переключиться на что-то другое. Однако, разумное планирование позволит сэкономить немало времени и средств.
Вот признаки проектов, для которых идеально подойдут SQL-базы:
* Имеются логические требования к данным, которые могут быть определены заранее.
* Очень важна целостность данных.
* Нужна основанная на устоявшихся стандартах, хорошо зарекомендовавшая себя технология, используя которую можно рассчитывать на большой опыт разработчиков и техническую поддержку.
А вот свойства проектов, для которых подойдёт что-то из сферы NoSQL:
* Требования к данным нечёткие, неопределённые, или развивающиеся с развитием проекта.
* Цель проекта может корректироваться со временем, при этом важна возможность немедленного начала разработки.
* Одни из основных требований к базе данных — скорость обработки данных и масштабируемость.
В итоге хочется сказать, что в современном мире нет противостояния между реляционными и нереляционными базами данных. Вместо этого стоит говорить об их совместном использовании для решения задач, на которых та или иная технология показывает себя лучше всего. Кроме того, всё сильнее наблюдается интеграция этих технологий друг в друга. Например, Microsoft, Oracle и Teradata сейчас предлагают некоторые формы интеграции с Hadoop для подключения аналитических инструментов, основанных на SQL, к миру неструктурированных больших данных.
Уважаемые читатели, а вам приходилось выбирать системы управления базами данных для собственных проектов? Если да — поделитесь пожалуйста опытом, расскажите, что и почему вы в итоге выбрали. | https://habr.com/ru/post/324936/ | null | ru | null |
# composer и автодополнение командной строки
Так как я все больше и больше добавляю свои скрипты в файлы `composer.json`, было бы полезно иметь автозаполнение для команды `composer` в `bash`. Мой вопрос в Твиттере не дал немедленного решения, и, поскольку я уже делал нечто подобное для [`Phing`](https://akrabat.com/autocomplete-phing-targets-on-the-command-line/), я закатал рукава и написал своё решение.
Начнем с создания нового файла [bash completion](https://www.gnu.org/software/bash/manual/html_node/Programmable-Completion.html#Programmable-Completion) с именем `composer` в каталоге `bash_completion.d` (файлу необходимы права на выполнение). Этот каталог обычно находится в `/etc/bash_completion.d/`, но в OS X, [использующей Homebrew](https://brew.sh/), он находится в `/usr/local/etc/bash_completion.d/` (при условии, что вы уже установили `brew install bash-complete`).
Вот этот файл:
```
# Store this file in /etc/bash_completion.d/composer
_composer_scripts() {
local cur prev
_get_comp_words_by_ref -n : cur
COMPREPLY=()
prev="${COMP_WORDS[COMP_CWORD-1]}"
#
# Complete the arguments to some of the commands.
#
if [ "$prev" != "composer" ] ; then
local opts=$(composer $prev -h --no-ansi | tr -cs '[=-=][:alpha:]_' '[\n*]' | grep '^-')
COMPREPLY=( $(compgen -W "${opts}" -- ${cur}) )
return 0
fi
if [[ "$cur" == -* ]]; then
COMPREPLY=( $( compgen -W '-h -q -v -V -n -d \
--help --quiet --verbose --version --ansi --no-ansi \
--no-interaction --profile --working-dir' -- "$cur" ) )
else
local scripts=$(composer --no-ansi 2> /dev/null | awk '/^ +[a-z]+/ { print $1 }')
COMPREPLY=( $(compgen -W "${scripts}" -- ${cur}) )
fi
__ltrim_colon_completions "$cur"
return 0
}
complete -F _composer_scripts composer
```
(Обратите внимание, что `__ltrim_colon_completions` поддерживается только в последних версиях `bash-complete`, поэтому вам может потребоваться удалить эту строку.)
Чтобы получить список команд для composer, мы создаем список слов для опции -W для `compgen`, запустив `composer --no-ansi`, а затем с помощью AWK удаляем все, что не является командой. Также мы создаем отдельный список аргументов флага, когда пользователь нажимает клавишу Tab после введенного дефиса.
Запустив `composer {cmd} -h --no-ansi`, мы автоматически заполняем флаги для любой подкоманды и, используя `tr` и `grep`, ограничиваем список только словами, начинающимися с дефиса.
Теперь по нажатию Tab после composer, bash будет автоматически завершать как встроенные команды composer, так и пользовательские сценарии!
Как можете видеть в этом примере, помимо встроенных команд, таких как `dump-autoload` и `show`, отображаются мои собственные сценарии, включая `apiary-fetch` и прочие.
Это очень полезно, когда память меня подводит! | https://habr.com/ru/post/444284/ | null | ru | null |
# Как обмануть Корпорацию Добра или покупаем Nexus 7 в России без гуглолотереи
В [недавней статье](http://habrahabr.ru/post/148463/) на Хабре уже шла речь о том, как закупаться на Google Play в разделе Devices прямо из нашего захолустья. Тема бесспорно интересная: Nexus 7 пока в России и близлежащих странах вообще не водится, а Galaxy Nexus, скорее всего, просто обойдется вам значительно дороже, если, конечно, вы не живете в Москве или Питере. Проблема только в том, что рецепт оказался несколько нестабильный: лично меня Самая Добрая Корпорация небезосновательно заподозрила в подтасовке личных данных, а судя по комментариям – я такой оказался далеко не один.
Неделя мучений и попыток обмануть Google Wallet привела-таки к положительному результату в виде возможности покупать что угодно и где угодно на Google Play, более того, решение, строго говоря, лежало на поверхности и никаких сложных действий не требовало.
Под катом новый рецепт и совсем чуть-чуть скриншотов.
Для начала, будем надеяться, что вы еще не пытались совершить покупку и на вашем ящике еще не лежит письмо от Google Wallet, сообщающее, что ваш аккаунт заблокирован. Если это так – вам придется, как мне, создать новый гуглоаккаунт с нуля специально для покупок. Заблокированные средства вернутся на карту буквально в течение нескольких часов, пока вы будете разбираться с остальным.
##### 1. Shipito.
Первое, что нужно сделать – это создать аккаунт на [shipito](http://www.shipito.com/). В принципе, сейчас есть множество альтернатив, часть из них немного дешевле, но я сторонник проверенных решений. С вас попросят $8,5 предоплаты, которые сразу будут зачислены на ваш счет. Позже ими можно будет расплачиваться за услуги сервиса. Теперь – то, ради чего мы сюда пришли. В вашем аккаунте появится вкладка “Your Shipito and Home Address”, в которой слева можно найти два ваших американских адреса и еще один гонконгский. Выбираем адрес (лично я выбрал адрес в Калифорнии, но мне постфактум посоветовали выбирать второй: он безналоговый и можно сэкономить порядка $30) и записываем его, он нам еще несколько раз пригодится.
##### 2. Qiwi Visa Card.
Следующим сервисом, который нам понадобится, будет [кошелек Qiwi](https://w.qiwi.ru/). Нас он радует тем, что Qiwi не особо ревностно заботится о достоверности указываемых вами личных данных (в отличии от Корпорации Добра). Здесь надо, прежде всего, зарегистрировать собственно кошелек, затем создать виртуальную карту. Лично мне удобнее использовать QVC, поскольку она имеет общий счет с самим аккаунтом Qiwi, который я тоже иногда использую, кроме того – она немного дешевле в использовании, чем QVV. В данных о владельце карты указываем тот самый адрес из shipito. Если QVC у вас уже есть – можно просто создать новую, стоимость карты невелика.
##### 3. Google Wallet.
Осталось подключить свежесозданную карточку к Google Wallet. Заходим, создаем аккаунт, если его нет, указываем все тот же адрес из Shipito, а там, где нужно указать телефон пишем любую абракадабру (Google ее не проверяет), главное – что бы в начале стоял верный телефонный код места, где вы якобы находитесь: я для калифорнии указал код (310). При подключении карты к аккаунту на ней заблокируется $1. Возвращать его Google будет до второго пришествия, так что о нем можно забыть.
##### 4. Tor.
Если сейчас вы попробуете зайти на <https://play.google.com/store/devices> – Google скажет, что вы не там живете и разговаривать, а тем более – торговать он с вами не собирается. Решение этой проблемы простое – браузер [Tor](https://www.torproject.org/). Скачиваем, ставим. Чтобы показать браузеру, что мы хотим оповестить весь мир о том, что находимся в Америке нужно добавить в файл *{Tor}\Data\Tor\torrc* всего две строчки:
`StrictExitNodes 1`
`exitnodes {us}`
Этого достаточно, что бы Google Play любезно открыл перед вами все двери.
##### 5. Покупка, Round 1.
Теперь нам нужно собственно оформить заказ. Идем в [Google Play](https://play.google.com/store/devices), выбираем чего и сколько нам надо, оформляем покупку через созданный аккаунт Google Wallet. Деньги на карте блокируются, Google пишет нам благодарственное письмо, а мы ждем исхода. Существует немалая вероятность, что на этом все кончится, платеж пройдет и вам останется через пару дней перенаправить посылку с shipito себе. Не забываем, что USPS не возит литий и вам нужно выбрать Airmail Priority!
Но может выйти и не так.
Тогда через пару минут Google пришлет вам еще одно письмо с заголовком “Order Canceled”. Текст письма может быть различным, в зависимости от тяжести преступления, в котором вас подозревает Google. Для нас важно, что теперь вместо страницы аккаунта Google Wallet мы увидим заглушку типового обращения в службу поддержки:
**Подтверждение аккаунта**
Но мы же честные люди и все документы об этом у нас на руках! Сканируем любой документ подтверждающий личность (я использовал вообще российский паспорт, можно взять загранпаспорт или права), а затем – главный номер нашей программы: делаем выписку по карте. Для этого возвращаемся в кошелек Qiwi и заходим в раздел “Работа с картами”, там в разделе “Отчеты” выбираем нужную карту, выставляем срок отчета подлиннее и формируем отчет, а затем выписку. Если карта новая, как была у меня у вас должно выйти что-то такое:
**Выписка по карте**
Справа замазаны те самые данные, которых от нас хочет Google. Вам этого делать не нужно, замазываем там только номер своей карты, кроме последних четырех цифр (мало ли что…) и шлем полученное в поддержку Google в качестве Bank Statement.
Google немедленно заверяет вас по почте, что разберется в течение трех рабочих дней. Я получил ответ уже днем первого (с поправкой на разницу в часовых поясах).
##### 6. Покупка, Round 2.
Наконец, Google Wallet снова начинает работать, а у нас в ящике оказывается типовое письмо с извинениями:
`Hello,`
`Thank you for submitting your documents. We have reviewed your verification information and can confirm that your account is fully active. You may now place orders through Google Wallet. We sincerely apologize for any inconvenience this may have caused you.`
`Please keep in mind that your previous order, if any, was cancelled. You may visit the seller's website and place a new order. Please note that you may notice activity on your card statement corresponding to orders cancelled in the last 14 days. This activity is an authorization confirmation with your bank, not an actual charge, and the authorization will be removed from your account within 1-14 business days, depending on your bank.`
`Once again, we apologize for any inconvenience you may have experienced and we thank you for your cooperation during this process. Feel free to reply to this email if you have any additional questions.`
`Sincerely,`
`The Google Wallet Team`
Мы можем со спокойной душой снова пойти в Google Play и оформить новый, уже совершенно легальный, с точки зрения Корпорации Добра, заказ. Уже через полтора-два рабочих дня, если товар в наличии, вы получите его на склад shipito. Снова не забываем про Airmail Priority! Оттуда доставка занимает в среднем от двух до четырех недель.
На этом квест завершен, остается подождать и стать счастливым обладателем вожделенного девайса.
**UPD:** В связи с выходом Nexus 4 появилась новая [инструкция](http://habrahabr.ru/post/161791/) от хабравчанина [andrey\_snegovik](http://habrahabr.ru/users/andrey_snegovik/). | https://habr.com/ru/post/148883/ | null | ru | null |
# TinyMCE 3.x: Подсчет количества слов и символов при редактировании контента
При использовании WYSIWYG редактора TinyMCE 3.x часто возникает потребность отображения статистики редактируемой статьи в реальном времени: отображение количества слов, символов и символов с пробелами.
Для чего это может требоваться?
Самое частое применение: создатели контента (копирайтеры, рерайтеры, контент-редакторы и т.д.) должны иметь возможность оценивать выполненный объем своей работы.
Плагин «из коробки» просто не работает для русского языка (не говоря о парсинге HTML-тегов). Поэтому было принято решение написания своего «велосипеда».
Код функции:
```
$().ready(function() {
/////Инициализация редактора посредством jQuery//////////////////
$('textarea.tinymce').tinymce({
/* .........................................................
..........опции инициализации.........
.........................................................*/
setup : function(ed) {
///////////Функция для подсчета символов и вывода статистики////////////
var wordscount=function () {
content=tinyMCE.activeEditor.getContent({format : 'raw'});
////Вставку кода (pre) - вырезаем///////////
content = content.replace(/(<\s*\/?\s*)pre(\s*([^>]*)?\s*>)*(<\s*\/?\s*)pre(\s*([^>]*)?\s*>)/gi,"");
content=content.replace(/<\/?[^>]+(>|$)/g,' ');
content=content.replace(/&(lt|gt);/g, function (strMatch, p1){
return (p1 == "lt")? "<" : ">";
});
content=content.replace(/ /g,' ');
content=content.replace(/\n/," ");
content=content.replace(/ +/g,' ');
content=content.replace(/\s*((\S+\s*)*)/,'$1');
content=content.replace(/((\s*\S+)*)\s*/,'$1');
words=content.split(" ").length;
charsws=content.length;
chars=content.replace(/ +/g,'').length;
if (content=='') {words=0;chars=0;charsws=0;}
document.getElementById('wordscount').innerHTML=words;
document.getElementById('charscount').innerHTML=chars;
document.getElementById('charswscount').innerHTML=charsws;
//alert(content);
};
/////////////код функции завершился//////////
/////Привязываем функцию к событиям////////
ed.onKeyUp.add(wordscount);
ed.onChange.add(wordscount);
ed.onInit.add(wordscount);
}
```
там, где нам необходимо отображать статистику (ниже, в ````
):
Слов:
Символов:
Симв. с пробелами:
```
Результат работы функции: автоматическое обновление статистики по словам и символам "на лету" при наборе/вставке/загрузке контента статьи.
Код парсинга тэгов - "сыроват", замечания и дополнения - приветствуются.
Пример работы - можно посмотреть по ссылке: [Создание статьи](http://games.shotme.ru/add/article/)
Всем Спасибо!` | https://habr.com/ru/post/162137/ | null | ru | null |
# Диагностика виртуальной сети в Linux. BPFTrace и skbtrace в опенсорсе
Привет! Меня зовут Сергей Кляус, и я как разработчик виртуальной сети сопровождаю создателей приложений, размещённых в Yandex.Cloud. При этом диагностические возможности самого облака ограничены: мы не видим метрики пользовательских виртуальных машин, например количество TCP retransmissions, а записывать и анализировать огромные дампы всего сетевого трафика с помощью tcpdump дорого и трудно из-за ограничений безопасности.
К счастью, динамическая трассировка позволяет получить лучшее от двух миров: исполнять произвольный код в момент увеличения метрики, а в самом коде печатать тело пакета. Например, недавно мы диагностировали проблемы с TCP-соединениями у одного из наших managed-сервисов, и оказалось, что теряются на самом деле UDP-пакеты. Гипотеза требовала уточнения, хотя корреляция между ростом метрики и сбоем была поначалу очевидна. В современном Linux динамическая трассировка реализована через eBPF и утилиту BPFTrace, но постепенно мы накопили набор типовых сценариев их использования и сделали обёртку над BPFTrace. Она называется skbtrace и доступна [на GitHub](https://github.com/yandex-cloud/skbtrace). Про неё я и расскажу под катом.
eBPF и BPFTrace
---------------
Технология eBPF в последнее время активно развивается в ядре Linux. Она берёт свое начало от Berkeley Packet Filter — по сути, небольшой виртуальной машины внутри ядра, которая получала инструкции от `tcpdump`, интерпретировала их перед обработкой ядром пакета, что позволяло фильтровать их чрезвычайно эффективно. Таким образом, в userspace-программу передавались для анализа только отфильтрованные пакеты, а уже она выполняла полный анализ и печатала все распознанные сетевые заголовки и поля в них. Например, поле флагов TCP, в котором злополучный RST (reset) означает аварийное завершение соединения.
Конечно, современный eBPF сильно ушёл вперёд — за это отвечает буква «e» в названии, Extended: JIT-компилятор превращает инструкции BPF-машины в нативные инструкции процессора (например, x86), а за безопасность исполняемого кода отвечает сложный Verifier. Но суть осталась прежней: можно привязаться к определенному месту в ядре через kprobe или XDP-хуки в драйверах сетевой карты, выполнить небольшой код и делать это крайне эффективно.
Однако BPF долгое время страдал из-за сложных инструментов: требовалось писать много кода на языке C и собирать через LLVM с бэкендом BPF, хотя часть boilerplate и управляющих сигналов можно было спрятать за Python/BCC. Наконец, в 2019 году появился BPFTrace, в качестве интерфейса которого используется скриптовый язык, похожий на DTrace (что не удивительно: активное участие в создании обоих принимал Брендан Грегг). BPFTrace гораздо приятнее использовать для задач observability. Достаточно сравнить объём кода на [BCC](https://github.com/iovisor/bcc/blob/master/libbpf-tools/tcpconnect.bpf.c) и [BPFTrace](https://github.com/iovisor/bpftrace/blob/master/tools/tcpconnect.bt) для трассировки TCP-соединений, чтобы понять: BCC ещё более монструозен, чем BPFTrace, пускай и более гибок.
Сегодня для работы с eBPF появилось множество библиотек, а на их базе вышло немало инструментов для мониторинга сети. Например, на прошедшем в 2021 году eBPF summit разработчики из Alibaba [показали](https://www.youtube.com/watch?v=Z4qxd5yYoP4), как с помощью небольшого демона поверх eBPF отлавливать сами TCP Retransmissions. Когда мы начинали работу над skbtrace в 2019 году, эти библиотеки ещё не были развиты, а BPFTrace уже существовал и позволял с помощью небольшого скрипта «проинструментировать» виртуальную сеть.
Но разбор пакета — нетривиальная операция, а у BPFTrace не самый богатый язык. Поэтому каждый раз, когда требовалось получить поле пакета, приходилось вручную преобразовывать порядок байт, а сами скрипты разрастались до монструозных размеров:
**Пример**
```
#include
#include
#include
k:tcp\_gso\_segment {
$orig\_skb = (sk\_buff\*) arg0;
printf("TCP SEGMENT len %d, features %x dev %s\n", $orig\_skb->len, arg1,
$orig\_skb->dev->name);
printf("ORIG SKB len %d hroom %d nhoff %d thoff %d\n", $orig\_skb->len,
$orig\_skb->data - $orig\_skb->head, $orig\_skb->network\_header,
$orig\_skb->inner\_network\_header);
$skbsi = (skb\_shared\_info\*) ($orig\_skb->head + $orig\_skb->end);
printf("SKBSI: nr\_frags %d gso size %d\n",
$skbsi->nr\_frags, $skbsi->gso\_size);
/\* printf("%s", kstack(4)); \*/
}
kretprobe:tcp\_gso\_segment {
$skb = (sk\_buff\*) retval;
$idx = 0;
unroll(2) {
if ($skb) {
$addr = $skb->head + $skb->mac\_header + 14 /\* ETH \*/;
$out\_iph = (xiphdr\*) $addr;
$tot\_len = ($out\_iph->tot\_len >> 8) |
(($out\_iph->tot\_len & 0xff) << 8);
printf("SEG %d len %d hroom %d nhoff %d thoff %d\n", $idx, $skb->len,
$skb->data - $skb->head, $skb->network\_header, $skb->inner\_network\_header);
printf("OUTER: ihl/ver %x proto %x tot len %6d\n",
$out\_iph->ihl\_version, $out\_iph->protocol, $tot\_len);
$skb = $skb->next;
};
$idx = $idx + 1;
};
if ($skb->next) {
printf("... more skbs\n");
}
}
```
Если же надо было добавить вывод какого-нибудь заголовка или поменять режим инкапсуляции пакетов, то скрипт требовал переработки. Так появилась обёртка `yc-bpf-trace` — написанный на Python генератор BPFTrace-скриптов, который позволяет всего одним вызовом командной строки описать выводимые заголовки, используемые пробы и способ агрегации данных. А под флагом избавления от легаси и интеграции с новыми внутренними сервисами, используемыми поддержкой Yandex.Cloud, мы переписали эту утилиту на Go и выложили под названием skbtrace.
Сейчас она поддерживает самый простой сценарий сетевого оверлея: когда пакет пересекает ядро Linux из физического сетевого интерфейса в виртуальный — принадлежащий контейнеру или виртуальной машине, как в нашем случае. К сожалению, она сейчас не поддерживает сценарий «сетевой интерфейс – приложение», но мы думаем, что можно будет трассировать и его, разметив соответствующие пробы и расширив skbtrace.
Ниже я покажу, как добавление ещё одной пробы помогает найти ошибку в конфигурации фаервола, а поле truesize у socket buffer — узнать, что лимит памяти на чтение у сокета `SO_RCVBUF` следует устанавливать со значительным запасом (25-кратным в случае нашего Cloud DNS). Кстати, truesize можно подсмотреть, только если залезть в ядерные структуры данных, что как раз и позволяет BPFTrace.
Ну и честно признаюсь: мы не перенесли некоторые вещи либо из-за их специфики (как в случае со структурами данных и пробами нашего форка TF VRouter), или потому, что немного стыдно публиковать unroll для поиска TCP MSS-опции, реализованный функцией из пяти уровней вложенности.
Примеры использования skbtrace
------------------------------
#### Куда летят пакеты, в какие CloudGate?

CloudGate обрабатывает ваш трафик
CloudGate, о которых уже [писал](https://habr.com/ru/company/yandex/blog/487694/) [PurplePowder](https://habr.com/ru/users/purplepowder/), — окно во внешний мир для виртуальной сети. Это отдельные виртуальные машины, к тому же зарезервированные в виде ECMP-группы. При этом пользовательская виртуальная машина может отправить трафик в любую из них. Но недавно мы нашли неприятную ошибку, из-за которой в редких случаях случался сильный дисбаланс в таком выборе и один из CloudGate получал семикратную нагрузку.
Чтобы подтвердить гипотезу со стороны виртуальной сети, нам было достаточно всего лишь построить агрегацию: посчитать количество пакетов, отправленных в каждый из CloudGate. При этом ключом был бы IP-адрес CloudGate, то есть Destination IP Address во внешнем IP-заголовке. Вот так это выглядело в лабе:
```
$ skbtrace aggregate -6 -P xmit -i eth1 -k outer-dst \
-F 'inner-src == 2a02:6b8:c0e:205:0:417a:0:3da' 2s
```
**Смотреть скринкаст**

#### Отслеживание потерянных пакетов
Потерянный или dropped-пакет — регулярное явление в виртуальной сети. Запрещает группа безопасности? Дроп. Погасил виртуальную машину, но продолжил лить на неё нагрузку? Дроп. Куда интереснее ситуация, когда машину подняли обратно, а потери пакетов продолжились. Последней ситуации мы хотим избежать и регулярно проверяем, не всплывает ли она. Для этого снимаем заголовки дропнутых пакетов и убеждаемся, что виртуальная машина с таким IP-адресом и правда не запущена.
Замечу, что BPFTrace не помогает в постмортем-анализе: если потери наблюдались минуту назад, запуск трассировщика уже ничего не покажет. Но и натура дропов такова, что их лучше делать как можно быстрее, а на дропнутые пакеты не тратить дополнительные ресурсы. С этой точки зрения подход с трассировщиком в целом оправдан.
Но в примере ниже мы посмотрим в Linux Netfilter. BPFTrace и, соответственно, skbtrace умеют выводить kernel stack, и по функции `nf_hook_slow` видно, что причина дропов — пакетный фильтр:
```
$ skbtrace dump -6 -P free -F 'dst == 2a02:6b8:c0e:205:0:417a:0:3da' -K -o ipv6
Attaching 2 probes...
01:55:29.118794463 - kprobe:kfree_skb
IPV6: priority_version 66 payload_len 40
IPV6: nexthdr 6 hop_limit 51 src 2a02:6b8:bf00:300:9cbe:4ff:fea9:b3de dst 2a02:6b8:c0e:205:0:417a:0:3da
kfree_skb+1
nf_hook_slow+192
br_nf_forward_ip+1101
nf_hook_slow+95
__br_forward+361
...
```
`kfree_skb` — это освобождение socket buffer. Учитывая, что в большинстве своём диагностика iptables — нетривиальное занятие, гораздо приятнее начинать её с более простого инструмента, подтверждающего, что проблема действительно в фаерволе.
#### Таргеты сетевого балансировщика, отвечающие за сотни миллисекунд
Среди пользователей облака есть те, кто довольно чувствителен к высоким задержкам. В целом, проверки healthchecks позволяют отсекать совсем уж неработоспособные таргеты, но что если задержки возникают на единичных запросах? Такие запросы можно отловить по времени handshake. По сути это время между отправкой первого SYN пакета и последующего (первого в соединении) ACK-пакета, при этом у них совпадает five tuple.
Время между событиями, идентифицируемыми по ключу, можно ловить с помощью команды `skbtrace timeit from ... to ...` (в данном случае есть более удобный алиас: `skbtrace timeit handshake --ingress`). А вот аномальные пакеты лучше ловить через подкоманду `outliers`. `aggregate -f hist` используется без дополнительных подкоманд и выводит гистограмму, по которой видно: один five tuple handshake занял больше 256 мс (по умолчанию skbtrace считает все времена в микросекунднах, то есть 256K = 256 000 мкс = 256 мс):
```
$ skbtrace timeit tcp handshake -i tapa7kkobaif-1 --ingress
Attaching 5 probes...
12:21:54
@:
[512, 1K) 1 |@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[1K, 2K) 0 | |
[2K, 4K) 0 | |
[4K, 8K) 0 | |
[8K, 16K) 0 | |
[16K, 32K) 0 | |
[32K, 64K) 2 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[64K, 128K) 0 | |
[128K, 256K) 0 | |
[256K, 512K) 1 |@@@@@@@@@@@@@@@@@@@@@@@@@@ |
$ skbtrace timeit tcp handshake -i tapa7kkobaif-1 --ingress outliers -o ip -o tcp
Attaching 4 probes...
TIME: 152467 us
12:22:19.670245756 - kprobe:dev_queue_xmit
IP: ihl/ver 45 tot_len 52 frag_off 0 (- DF) check 4643
IP: id 23291 ttl 62 protocol 6 saddr 100.64.117.131 daddr 192.168.1.26
TCP: source 45972 dest 80 check 3a5e
TCP: seq 1558770843 ack_seq 693522456 doff 8 win 229
TCP: flags -A---
```
В этом примере задержка добавлена с помощью `tc qdisc change dev eth1 root netem delay 1ms 100ms distribution paretonormal`. В целом, используя эту же подкоманду, но для `--egress`, можно диагностировать клиента — и искать сервисы, которые отвечают слишком медленно.
#### Охота на ретрансмиты
Наверное, каждый сетевой инженер сталкивался с этой неприятной чёрной полоской в выводе Wireshark и розоватыми буквами: TCP Retransmission. Но tcpdump ещё надо снять, проанализировать, а нам интересно состояние нашего виртуального роутера в момент ретрансмита. В общем случае ретрансмит — это повторный ACK-пакет с таким же sequence number, который мы уже видели в рамках этого соединения, идентифицируемого по five tuple. То есть надо немного изменить поведение команды `timeit`, чтобы она реагировала на повторный пакет с таким же ключом, но не замеряла время, а выходила, а при выходе мы могли бы запустить дополнительные диагностические скрипты.
В этом примере мы будем иногда дропать первый SYN-пакет в TCP-соединении с помощью iptables на стороне виртуальный машины и отслеживать повторную посылку, которая выполняется через секунду:
```
$ skbtrace timeit tcp retransmit -i tapa7kkobaif-1 --ingress -o ip -o tcp
Attaching 3 probes...
DUPLICATE EVENT TIME: 998231 us
10:56:25.222838145 - kprobe:dev_queue_xmit
IP: ihl/ver 45 tot_len 60 frag_off 0 (- DF) check be7e
IP: id 58039 ttl 62 protocol 6 saddr 100.64.117.131 daddr 192.168.1.26
TCP: source 45570 dest 80 check 5449
TCP: seq 850649414 ack_seq 0 doff 10 win 29200
TCP: flags S----
```
Обычно в случае виртуальной сети чуть больший интерес представляют такие ретрансмиты перед нашим виртуальным роутером. Это хороший повод начать искать потери.
#### DNS и UdpInErrors
BPFTrace (и skbtrace) можно использовать не только для анализа сетевых пакетов, но и для получения представления других структур в ядре. Например, наш новый DNS удалось стабилизировать только при значениях Receive Buffer в ~100 МБ. Иначе возникали потери UdpInErrors из-за нехватки места в буфере чтения. Дело не в том, что сервис медленно читает данные или у него такая колоссальная нагрузка. Просто ядро Linux переиспользует сетевые буферы большего размера, чем нужно, иногда даже размером в несколько килобайт для стобайтного пакета. Это видно, если посмотреть значение `truesize`: накладные расходы для 113-байтного пакета составляет почти 700%:
```
$ skbtrace dump -P recv -F 'dport == 53' -p udp -o layout
Attaching 2 probes...
09:24:58.304536041 - kprobe:netif_receive_skb_internal
LAYOUT: hroom 78 hlen 113 mac hoff 64 net hoff 78 trans hoff 98
LAYOUT: len 113 data_len 0 troom -129 truesize 896
```
Таким образом, даже в нашей лаборатории у DNS-сервиса пришлось бы выставлять `SO_RCVBUF` с 8-кратным запасом, а, как я уже говорил, в PROD-инсталляции потребовался 25-кратный запас. Если вы наблюдаете что-то похожее на UdpInErrors, возможно, вам тоже стоит проверить накладные расходы на socket buffers.
#### Вместо ложки дёгтя
Конечно BPFTrace — не серебряная пуля, и нам пришлось столкнуться с многими его ограничениями, а в skbtrace предусмотреть «подпорки» для них. Например, он некорректно взаимодействует с битовыми полями в структурах. Да, мы до сих пор не используем BTF и потому работаем с заголовочными файлами.
Мы не рискнули применять постоянно запущенные мониторы и оформлять skbtrace в виде демона, опасаясь проблем со стабильностью. Но эти страхи не оправдались. Более того, коллеги из команды CloudGate довольно успешно реализовали такой демон. Но запускать одновременно демон и BPFTrace нельзя — по крайней мере, не разрешено в нашей версии ядра.
Cам по себе skbtrace, конечно, примитивен по сравнению с tcpdump, который умеет корректно нарезать пакеты и определять заголовки там, где skbtrace нуждается в подсказках. Зато он чрезвычайно быстр: можно сказать «до свидания» гигабайтным pcap-файлам.
Утилита [выложена на GitHub](https://github.com/yandex-cloud/skbtrace). Приносите свои сценарии в комментарии, а предложения в Issues и Pull Requests. | https://habr.com/ru/post/646297/ | null | ru | null |
# Основы BASH. Часть 1
Безусловно, все те кто общается с ОС Linux хоть раз да имели дело(во всяком случае слышали точно) с командной оболочкой BASH. Но BASH не только командная оболочка, это еще и превосходный скриптовый язык программирования.
Цель этой статьи — познакомить поближе юзеров с bash, рассказать про синтаксис, основные приемы и фишки языка, для того чтобы даже обычный пользователь смог быстренько написать простой скрипт для выполнения ежедневной(-недельной, -месячной) рутинной работы или, скажем, «на коленке» наваять скриптик для бэкапа директории.
### Введение
BASH — Bourne-Again SHell (что может переводится как «перерожденный шел», или «Снова шел Борна(создатель sh)»), самый популярный командный интерпретатор в юниксоподобных системах, в особенности в GNU/Linux. Ниже приведу ряд встроенных команд, которые мы будем использовать для создания своих скриптов.
`break выход из цикла for, while или until
continue выполнение следующей итерации цикла for, while или until
echo вывод аргументов, разделенных пробелами, на стандартное устройство вывода
exit выход из оболочки
export отмечает аргументы как переменные для передачи в дочерние процессы в среде
hash запоминает полные имена путей команд, указанных в качестве аргументов, чтобы не искать их при следующем обращении
kill посылает сигнал завершения процессу
pwd выводит текущий рабочий каталог
read читает строку из ввода оболочки и использует ее для присвоения значений указанным переменным.\
return заставляет функцию оболочки выйти с указанным значением
shift перемещает позиционные параметры налево
test вычисляет условное выражение
times выводит имя пользователя и системное время, использованное оболочкой и ее потомками
trap указывает команды, которые должны выполняться при получении оболочкой сигнала
unset вызывает уничтожение переменных оболочки
wait ждет выхода из дочернего процесса и сообщает выходное состояние.`
И конечно же кроме встроенных команд мы будем использовать целую кучу внешних, отдельных команд-программ, с которыми мы познакомимся уже в процессе
### Что необходимо знать с самого начала
1. Любой bash-скрипт должен начинаться со строки:
`#!/bin/bash`
в этой строке после #! указывается путь к bash-интерпретатору, поэтому если он у вас установлен в другом месте(где, вы можете узнать набрав whereis bash) поменяйте её на ваш путь.
2. Коментарии начинаются с символа # (кроме первой строки).
3. В bash переменные не имеют типа(о них речь пойдет ниже)
### Переменные и параметры скрипта
Приведу как пример небольшой пример, который мы разберем:
`#!/bin/bash
#указываем где у нас хранится bash-интерпретатор
parametr1=$1 #присваиваем переменной parametr1 значение первого параметра скрипта
script_name=$0 #присваиваем переменной script_name значение имени скрипта
echo "Вы запустили скрипт с именем $script_name и параметром $parametr1" # команда echo выводит определенную строку, обращение к переменным осуществляется через $имя_переменной.
echo 'Вы запустили скрипт с именем $script_name и параметром $parametr1' # здесь мы видим другие кавычки, разница в том, что в одинарных кавычках не происходит подстановки переменных.
exit 0 #Выход с кодом 0 (удачное завершение работы скрипта)`
Результат выполнения скрипта:
`ite@ite-desktop:~$ ./test.sh qwerty
Вы запустили скрипт с именем ./test.sh и параметром qwerty
Вы запустили скрипт с именем $script_name и параметром $parametr1`
После того как мы познакомились как использовать переменные и передавать скрипту параметры, время познакомиться с зарезервированными переменными:
``$DIRSTACK - содержимое вершины стека каталогов
$EDITOR - текстовый редактор по умолчанию
$EUID - Эффективный UID. Если вы использовали программу su для выполнения команд от другого пользователя, то эта переменная содержит UID этого пользователя, в то время как...
$UID - ...содержит реальный идентификатор, который устанавливается только при логине.
$FUNCNAME - имя текущей функции в скрипте.
$GROUPS - массив групп к которым принадлежит текущий пользователь
$HOME - домашний каталог пользователя
$HOSTNAME - ваш hostname
$HOSTTYPE - архитектура машины.
$LC_CTYPE - внутренняя переменная, котороя определяет кодировку символов
$OLDPWD - прежний рабочий каталог
$OSTYPE - тип ОС
$PATH - путь поиска программ
$PPID - идентификатор родительского процесса
$SECONDS - время работы скрипта(в сек.)
$# - общее количество параметров переданных скрипту
$* - все аргументы переданыне скрипту(выводятся в строку)
$@ - тоже самое, что и предыдущий, но параметры выводятся в столбик
$! - PID последнего запущенного в фоне процесса
$$ - PID самого скрипта
### Условия
Условные операторы, думаю, знакомы практически каждому, кто хоть раз пытался на чем-то писать программы. В bash условия пишутся след. образом (как обычно на примере):
#!/bin/bash
source=$1 #в переменную source засовываем первый параметр скрипта
dest=$2 #в переменную dest засовываем второй параметр скрипта
if [[ "$source" -eq "$dest" ]] # в ковычках указываем имена переменных для сравнения. -eq - логическое сравнение обозначающие "равны"
then # если они действительно равны, то
echo "Применик $dest и источник $source один и тот же файл!" #выводим сообщение об ошибке, т.к. $source и $dest у нас равны
exit 1 # выходим с ошибкой (1 - код ошибки)
else # если же они не равны
cp $source $dest # то выполняем команду cp: копируем источник в приемник
echo "Удачное копирование!"
fi #обозначаем окончание условия.`
Результат выполнения скрипта:
`ite@ite-desktop:~$ ./primer2.sh 1 1
Применик 1 и источник 1 один и тот же файл!
ite@ite-desktop:~$ ./primer2.sh 1 2
Удачное копирование!`
Структура if-then-else используется следующим образом:
if <команда или набор команд возвращающих код возврата(0 или 1)>
then
<если выражение после if истино, то выполняется этот блок>
else
<если выражение после if ложно, тот этот>
В качестве команд возвращающих код возврата могут выступать структуры [[ , [ , test, (( )) или любая другая(или несколько) linux-команда.
test - используется для логического сравнения. после выражения, неоьбходима закрывающая скобка "]"
[ - синоним команды test
[[ - расширенная версия "[" (начиная с версии 2.02)(как в примере), внутри которой могут быть использованы || (или), & (и). Долна иметь закрывающуб скобку "]]"
(( )) - математическое сравнение.
для построения многоярусных условий вида:
`if ...
then ....
else
if ....
then....
else ....`
для краткости и читаемости кода, можно использовать структуру:
`if ..
then ...
elif ...
then ...
elif ...`
### Условия. Множественный выбор
Если необходимо сравнивать какоую-то одну переменную с большим количеством параметров, то целесообразней использовать оператор case.
`#!/bin/bash
echo "Выберите редатор для запуска:"
echo "1 Запуск программы nano"
echo "2 Запуск программы vi"
echo "3 Запуск программы emacs"
echo "4 Выход"
read doing #здесь мы читаем в переменную $doing со стандартного ввода
case $doing in
1)
/usr/bin/nano # если $doing содержит 1, то запустить nano
;;
2)
/usr/bin/vi # если $doing содержит 2, то запустить vi
;;
3)
/usr/bin/emacs # если $doing содержит 3, то запустить emacs
;;
4)
exit 0
;;
*) #если введено с клавиатуры то, что в case не описывается, выполнять следующее:
echo "Введено неправильное действие"
esac #окончание оператора case.`
Результат работы:
`ite@ite-desktop:~$ ./menu2.sh
Выберите редатор для запуска:
1 Запуск программы nano
2 Запуск программы vi
3 Запуск программы emacs
4 Выход`
После выбор цифры и нажатия Enter запуститься тот редактор, который вы выбрали(если конечно все пути указаны правильно, и у вас установлены эти редакторы :) )
Прведу список логических операторв, которые используются для конструкции if-then-else-fi:
`-z # строка пуста
-n # строка не пуста
=, (==) # строки равны
!= # строки неравны
-eq # равно
-ne # неравно
-lt,(< ) # меньше
-le,(<=) # меньше или равно
-gt,(>) #больше
-ge,(>=) #больше или равно
! #отрицание логического выражения
-a,(&&) #логическое «И»
-o,(||) # логическое «ИЛИ»`
С основами языка и условиями мы разобрались, чтобы не перегружать статью, разобью её на несколько частей(допустим на 3). Во второй части разберем операторы цикла и выполнение математических операций.
**UPD:** Исправил некоторые ошибки
**UPD:** Обновил часть про условия if-then-else
Статьи на [unix-admin.su](http://unix-admin.su)` | https://habr.com/ru/post/47163/ | null | ru | null |
# Wifi-радио с тёплым ламповым дисплеем. Часть 1. Дисплей

Как и многие я любитель слушать музыку с различных интернет радиостанций. И давным-давно задумал себе сделать wifi-радио. Сначала его заменяли смартфоны, планшеты, но хотелось чего-то стационарного, оригинального, своего. Плюс хотелось чего-то лампового и с linux. Такого в продаже, конечно же, нет. Тогда и пришла идея запилить такое радио самому.
*Ремарка. Хочется сразу отметить, что эта серия статей невероятный долгострой. По ряду причин никак не могла выйти в свет в течение двух лет. Поэтому не пугайтесь дат. К счастью я нашёл в себе силы, энергию и энтузиазм таки её выложить. И искренне надеюсь, что это будет не последняя часть.*
После моего поста о написании драйвера для lcd-дисплея на lpt-порт [habrahabr.ru/post/206148](http://habrahabr.ru/post/206148/) я заболел дисплеями. Однако хитачевский дисплей, который я использовал в том посте, совершенно устарел и уже совершенно не интересен. Поэтому изготавливать на нём уникальное устройство было бы глупо. В очередной раз, в поисках вдохновения плутал по ebay, разглядывая конструкции старинных приёмников и дисплеев. И внезапно наткнулся на **VFD** (Vacuum fluorescent display — Вакуумно-люминесцентный индикатор (ВЛИ)), просто за безумные деньги (что-то типа 500 долларов США). Платить такую сумму я был не готов, но уже тогда влюбился данные экранчики. В дальнейшем от goodic я узнал, что данные экраны используются в кассовых аппаратах и называются «Дисплеи покупателя». Стало ясно чего хотеть и искать.
#### Дисплей покупателя
Долго рыская по интернетам, и читая различную документацию, я таки определился, чего же на самом деле хочу. Мой выбор пал на дисплеи компании «Posiflex.». Лично я остановился на двух моделях: **PD-2600** и **PD-2800**. Воспользуюсь случаем и принесу слова благодарности компании «АТОЛ» за данные модели. Главное их отличие между собой в способе подключения к компьютеру и блоке питания. Для работы первого дисплея требуется внешний блок питания, и подключается он через СОМ-порт компьютера. Второй же дисплей подключается по USB и от него же берёт питание. В остальном отличие у них заканчивается. Не смотря на USB-интерфейс – этот дисплей не отличается по принципу работы от PD-2600. USB-интерфейс данного дисплея – это просто обёртка виртуального СОМ-порта и питания.
Следует отметить, что цвет свечения у данных дисплеев разный. У меня один был зелёный, другой голубой. Как оказалось, что цвет дисплея определяется только светофильтром из оргстекла. В нормальном виде (без светофильтра) он светит почти белым (с зеленоватым отливом).

**Слева кусок оранжевого оргстекла, посередине естественный цвет экрана, справа родной синий светофильтр.**
Дисплеи появились у меня под Новый Год (с 2013 на 2014), по этому я не преминул воспользоваться возможностью и вывести поздравление на них :)

**Разница внешнего вида дисплеев PD-2600 и PD-2800. Надпись – это дань традиции, зарождённой во время чтения и работы в журнале “Хакер”. Прошу простить :)**
Разумеется, всё это было мерзким читерством для пробы дисплеев я ничего не особенного не делал. А просто воспользовался готовой операционной системой для касс на базе Линукс, запущенную на виртуальной машине:
**Операционка на виртуалке**
Но, выводить надписи через сторонние приложения, было скучно и я начал разбираться, как же с ним можно дружить.
#### Как же работать с этим зверьком?
Когда готовишь статью, то эпизодически рыскаешь в поисках лучшего описания своей задачи. И на хабре наткнулся на [статью](https://habrahabr.ru/post/235105/), где кратенько рассказывается о том, как автор загружал свои шрифты на дисплей. Однако, совершенно не говорится ни о модели, ни о том, что же эти команды на самом деле делают. Поэтому я постараюсь описать человеческим языком, что и почему мы делаем, но данный пост не является кратким пересказом мануалов (**RTFM**!). Так же отмечу, что тема столь обширная, дабы не разжёвывать каждый шаг, будет формат матана: «очевидно, что...».
Даю сразу ссылку на документацию: **[ДОКУМЕНТАЦИЯ](https://yadi.sk/i/WC1GMCo5oYbsd)** Обращаю внимание, что документацию я искал долго и упорно, нашёл на каком-то американском сайте Posiflex. Сейчас она есть на сайте «АТОЛ» (Российского представительства компании Posiflex). Документация от других дисплеев, увы, не подойдёт или подойдёт, но не во всех вопросах (Не все йогурты одинаково полезны). Ниже объясню почему.
Итак, перейдём к вкусняшкам. После включения любого из дисплеев, он нас будет приветствовать таким образом:

Это сообщение говорит нам о том, что данный дисплей находится в режиме команд, совместимым со стандартом Epson. Этот режим задаётся переключателями на корпусе дисплея, и как правило по умолчанию на всех дисплеях покупателя стоит именно он.
**Задаём режим работы дисплея**
Обращаю внимание, что существует множество режимов работы. Мы будем использовать систему команд, совместимую с дисплеями Epson. В документации это раздел **EPSON EMULATION MODE**. «Дитям мороженое, бабе цветы. Смотри не перепутай»(с)
В данном режиме дисплей управляется ESC-последовательностями почти как vt52-терминал (однако совместимость не полная).
**Пару слов об интерфейсе** Чтобы упростить понимание, что же мы делаем и зачем, я напомню, что это весьма детально описывал в своей статье «[Создание собственных драйверов под Linux](https://habrahabr.ru/post/206148/)». Там есть спойлер FAQ (найдите через поиск), и там красиво в картинках показано что и как работает, и для чего какие команды. Чтобы было понятно в той статье «\033» эквивалентно записи «\x1B» в данной статье (одна в восьмеричной системе, вторая в шестнадцатеричной)
Давайте поиграемся с дисплеем из командной строки. Не будем подключать большого программирования. Для сегодняшней статьи этого будет с головой. Будем считать, что дисплей PD-2600 у нас подключён через USB-переходник и видится системой как /dev/ttyUSB0. То же самое будет работать с дисплеем PD-2800, только он будет у нас определяться как /dev/ttyACM0.
Для начала выставим скорость работы. По умолчанию скорость работы СОМ-порта (на обоих дисплеях) 9600. Эта скорость также задаётся переключателями.
```
stty 9600 < /dev/ttyUSB0
```
И уже после этой «весьма сложной команды» мы можем протестировать.
```
echo -en "Hello world" > /dev/ttyUSB0
```

**Суровый аппаратный привет миру.**
Всё, на этом повествование можно заканчивать. Привет мир удался. Но на самом деле не всё так просто. Данный дисплей поддерживает Великий и Могучий русский язык. Но делает это весьма своеобразно. Для работы с русским языком, согласно документации требуется выбрать кодовую таблицу. Если этого не сделать, то при выводе будет вот такая петрушка.
```
echo -en "Привет Хабру\nот dlinyj" > /dev/ttyUSB0
```

Чтобы включить кодовую страницу с русской кириллицей следует отдать следующую команду:
```
echo -en "\x1B\x74\x06" > /dev/ttyUSB0
```
После чего пробуем вывести снова наш текст
```
echo -en "Привет Хабру\nот dlinyj" > /dev/ttyUSB0
```
И-и-и-и, вновь нас ждёт облом…

Так в чём же дело? Проблема оказалось простой, но мне потребовалось два дня, чтобы до этого дотукать. Всё элементарно — проблема кодировок. Хвала камраду [goodic](https://habrahabr.ru/users/goodic/) за то, что мне подсказал верную кодировку. В результате получаем многострадальную команду, которая нам таки перекодирует наш текст в русский и выведет на экран.
```
echo -en "Привет Хабру\nот dlinyj" | iconv -f UTF-8 -t CP866 > /dev/ttyUSB0
```

На самом деле я опустил деталь, что каждый раз я отсоединял питание дисплея, заново инициализировал СОМ-порт и давал эти команды. Но существует ещё множество вкусных команд. Таких как: сдвиг курсора, очистка экрана, помещение курсора домой и т.п. Часть команд совместимо с vt52. Если привести весь список команд из документации, то он будет выглядеть вот так:

Теперь, по науке, чтобы вывести «Привет хабру», надо сделать следующее. На английском подписи соответствует названию команды в таблице выше, для удобства.
```
stty 9600 < /dev/ttyUSB0 #устанавливаем скорость СОМ-порта
echo -en "\x1B\x74\x06" > /dev/ttyUSB0 # Select character code page table. Включаем кодовую страницу с поддержкой русских шрифтов (страница№6).
echo -en "\x1B\x40" > /dev/ttyUSB0 #Initialize display. Инициализация дисплея. Очищает экран и помещает курсор домой (левый верхний угол).
echo -en "Привет Хабру\nот dlinyj" | iconv -f UTF-8 -t CP866 > /dev/ttyUSB0 #iconv в данном случае осуществляет перекодировку из UTF-8 в CP866.
```
Как мы видим, команды позволяют делать различные очень вкусные вещи. Например, можно с помощью команд включать и выключать запятую (точку) на экране. Например.
```
echo -en "\x1F," > /dev/ttyUSB0 #вывести запятую
echo -en "\x1F." > /dev/ttyUSB0 #вывести точку
```
У неё есть отдельное место. Но я ни разу не видел, чтобы кто-то пользовался этой возможностью. Как правило, все просто используют под точку отдельное знакоместо. Так же есть символ подчёркивания. В общем, дисплей разве что щи не варит. Демонстрировать все возможности дисплея в фотографиях я не буду, тем более что задача эта не благодарная. В посте про драйвера, этот громадный спойлер прочитало лишь несколько человек.
Для меня самое главное в данных дисплеях, это загрузка пользовательских шрифтов. О них и поговорим ниже.
#### Подключаем тяжёлую артиллерию. Пользовательские шрифты.
Самое крутое в данных дисплеях — это поддержка пользовательских шрифтов. Однако, могу разочаровать, что дальнейшее описание подходит только к PD-2600 и PD-2800 моделям дисплея. Даже в рамках одной фирмы отличается синтаксис команд загрузки шрифтов. И лично поимел немало граблей, используя документацию на ранние версии дисплеев данной фирмы. К сожалению, не понимаю, почему в таком простом месте каждый изобретает велосипед, а не примут какой-то единый стандарт, даже хотя бы в рамках одного предприятия.
Проблема поиска документации разработчика на данные дисплеи стояла очень остро. Общей информации очень много, но вот документации разработчика найти было очень сложно (2013-2014 год). Кратко опишу свой тернистый путь, быть может, кто-то по нему пройдёт.
Изначально, документация, программиста, которую удалось найти — это была документация на дисплей PD2100/2200. Особенность загрузки символа заключается в том, что в символе множество точек, и выглядит карта символов следующим образом:

**Карта символов**
Согласно документации загрузка символа осуществляется командой: <1B> <26> ~ (режим Epson и далее говорим только о нём). Где ad — это номер загружаемого символа, а x1 — x5 это пять байт карты символов, согласно таблице:

**Таблица точек в байте, для дисплея PD2100/2200**
Опытным путём было установлено, что загрузка символов идёт (хоть на том спасибо), но данная таблица не соответствует дисплею PD-2600! Разработчики, обратите внимание, что **дисплеи НЕ ВЗАИМОЗАМЕНЯЕМЫ** с точки зрения команд! С большим трудом удалось найти документацию разработчика на дисплей PD-2600. Там таблица точек выглядит следующим образом:

**Таблица точек в байте, для дисплея PD2600/2800**
Перекодирование символа превращается в тот ещё ребус, но вполне решаемый.
Так же, оказалось, что можно загрузить только **два** пользовательских символа, если загружать больше, то предыдущие символы сбрасываются в значение по умолчанию! Единственное, что символ, выведенный на экран уже не меняет своих очертаний, так что можно выводить символы и перезагружать его новым значением (что весьма неудобно).
Перестаём ныть, и давайте рассмотрим пример вывода символа вертикальной черты. Нарисуем его и переведём согласно таблице.

**Перекодировка символа**
Получаем такую картину:
> X1=0001 0000b=0x10
>
> X2=0100 0010b=0x42
>
> X3=0000 1000b=0x08
>
> X4=0010 0001b=0x21
>
> X5=0000 0100b=0x04
>
>
Посылка в СОМ-порт будет выглядеть следующим образом (данные в hex):
**1B 25 01** разрешаем использование пользовательского символа (Set/cancel user-defined characters). 01 – символ 1.
**1B 26 A0 10 42 08 21 04** загрузка пользовательского символа по адресу **A0** (Define user defined characters), последние пять байт — битовая маска символа.
**A0** — печатаем символ
Таким образом в консоли всё будет выглядеть следующим образом.
Для начала проинициализируем дисплей
```
echo -en "\x1B\x40" > /dev/ttyUSB0 #Initialize display.
```
Первое, это надо дать команду, разрешающую пользовательские шрифты
```
echo -en "\x1B\x25\x01" > /dev/ttyUSB0 # Set/cancel user-defined characters.
```
Далее загрузим символ вертикальной черты, следующей командой
```
echo -en "\x1B\x26\ xA0\x10\x42\x08\x21\x04" > /dev/ttyUSB0 # Define user defined characters
```
Символ загружен на позицию A0, выведем его:
```
echo -en "\xA0" > /dev/ttyUSB0
```
В результате получим:

**Отрисованный символ**
Можно даже завалить экран “забором”, для наглядности

**Забор**
Вообще с перезагрузкой символов можно делать весьма крутые штуки. Например, бегущую палочку, которая является перезагрузкой из пяти различных символов.
Для чего это всё нужно, поведаю в других статьях.
#### Заключение к первой части
В данной части мы рассмотрели работу дисплеев Posiflex PD-2600 и PD-2800. Этот пост претендует даже на самостоятельность, т.к. показывает пример работы с дисплеем покупателя. Вы даже можете теперь достать такой дисплей (или подобный), и сделать на нём вывод полезной для вас информации. Хоть сообщения твитера.
В дальнейшем будет ясно, для чего я сделал такой большой упор на дисплей, т.к. это будет ключевым звеном в дальнейшей поделке.

**Один из этапов прототипа.**
В следующих статьях мы рассмотрим программирование данного дисплея на тёплом ламповом си, работа с маршрутизатором, mpd и многие другие вкусности.
З.Ы. Убедительно прошу писать мне обо всех найденных ошибках, неточностях и т.п. личным сообщением. Постараюсь максимально оперативно исправлять все ошибки!!! | https://habr.com/ru/post/276879/ | null | ru | null |
# DataStore — CRUD (Create Read Update Delete)
Прощай Redux, MobX, Apollo! Грань между бэкендом и фронтендом сломана! Инновационый шаг эволюции стейт менеджеров.
------------------------------------------------------------------------------------------------------------------
Одна из самых сложных задачах при разработке веб и мобильных приложений — это синхронизация данных между устройствами и выполнение автономных операции. В идеале, когда устройство находится в автономном режиме, ваши клиенты должны иметь возможность продолжать использовать ваше приложение не только для доступа к данным, но также для их создания и изменения. Когда устройство возвращается в оперативный режим, приложение должно повторно подключиться к бэкэнду, синхронизировать данные и разрешить конфликты, если таковые имеются. Для правильной обработки всех крайних случаев требуется много недифференцированного кода, даже при использовании кэша AWS AppSync SDK на устройстве с автономными мутациями и дельта-синхронизацией.
Amplify DataStore предоставляет постоянное хранилище на устройстве для записи, чтения и наблюдения за изменениями данных, если вы подключены к Интернету или в автономном режиме, а также позволяет легко синхронизировать данные с облаком и между устройствами.
Amplify DataStore позволяет разработчикам писать приложения, используя распределенные данные, без написания дополнительного кода для автономного или онлайн-сценария.
Вы можете использовать Amplify DataStore для автономного использования в режиме «только локальный» без учетной записи AWS или предоставить весь бэкэнд с помощью AWS AppSync и Amazon DynamoDB.
DataStore включает в себя Delta Sync с использованием вашего бэкенда GraphQL и несколько стратегий разрешения конфликтов.
Преимущества DataStore от AWS Amplify над Redux, MobX, Apollo, Relay, селектрорами, деселекторами и прочими флаксами:
---------------------------------------------------------------------------------------------------------------------
Сравнивать AWS Amplify с Redux, MobX не корректно, так как AWS Amplify это не только стейт-менеджер, но и клиент-сервер, поэтому в классе клиент-сервер мы будем сравнивать его с Apollo и Relay.
1. Real time из коробки
-----------------------
Не думаю, что можно считать бизнес серьезным, если у его мобильного приложения отсустствуют события подписок реализованых на технологии web sockets.
А многие ли приложения в наше время работают на web sockets?
Думаю нет, по причине того, что real time это дополнительная работа разработчиков на бэке и фронтенде.
Для нас же, [fullStack serverless](https://react-native-village.github.io/docs/amplify-01) разработчиков на AWS Amplify, real time идет из коробки, как на фронте так и на бэке и нам не надо писать код реализации для интеграции вэбсокетов на каждую модель, так как он генерируется автоматически, также как и написание документации для всего нашего сгенерированого кода, имплементированого в наш проект на основоании инструкции GraphQL схемы. Чтобы не пугать громкими словами, я покажу вам пример, из [прошлого урока](https://react-native-village.github.io/docs/amplify-03), того как в AWS Amplify определяется Store:
```
type Job
@model
@auth(
rules: [
{allow: owner, ownerField: "owner", operations: [create, update, delete]},
])
{
id: ID!
position: String!
rate: String!
description: String!
owner: String
}
```
Так определяется модель в сторе, не только для фронтенда, но и для бэкенда. Один источник правды для фронтенда и для бэкенда. Да да, вижу я, что еще не раз повтою это в своей жизни, так как это киллер фича и панч лайн vs Redux, MobX, Apollo, Relay.
Вот именно эта отличная от Redux, MobX, Apollo архитектура, стерает грань между бэкендом и фронтендом. И ставит AWS Amplify DataStore над всеми
Все!!!
Если вы с бэкенда, то вам больше не нужно писать резолверы к базе данных и тащить подписки на каждую модель данных.
Serverless — это когда разработчикам бэкенда пришла пора учить фронтенд, так как их услуги нужны исключительно легаси проектам, не шагающим в ногу со временем, от чего и не живущими real time.
2. Генерация кода
-----------------
Что такое кодогенерация вы можете прочитать и без меня в википедии, если конечно же не знаете его значения, которое и в этом панче напоминает нам о себе.
Old schoolщик?
Юзаем fetch или axios?
Отправляя запросы в дремучий лес API, который еще и сами пишим в связке с Redux, MobX, Apollo, Relay.
Так вот вам еще одна новость дня!
Вам больше не нужно писать эти запросы к API, вам их нужно только вызвать.
Это значит, что больше не нужно создовать эту немаленькую папочку с кодом запроса к серверу, так как в AWS Amplify DataStore они также генерируются в вашем проекте на основании вашего стора, определенного все той же GraphQL схемы их первого пункта. И выполняется это одной командой:
```
npm run amplify-modelgen
```
В итоге получаем папку models с генерированным кодом.
И папка graphql после пуша на сервер, со всем запросом во Flow, TS или ваниле JavaScript.
3. Offline data & cloud sync
----------------------------
Не нужно писать дополнительный код, для отправки запроса на сервер, после выхода приложения в онлайн.
Иногда вы попадаете в ненадежную ситуацию, но вам лучше подождать дольше, чем явно провалить операцию.
У Apollo есть apollo-link-retry который обеспечивает экспоненциальный откат и запросы на сервер между попытками по умолчанию. Правда он (в настоящее время) не обрабатывает повторы для ошибок GraphQL в ответе, только для сетевых ошибок.
У Redux, MobX понятное дело под капотом этого решения нет так как они не клиенты и приходится задействовать сторонние мидлвари, по причине того, что REST как дедушка на пенсии с поддержкой любимых внуков. Подробный разбор [GraphQL vs REST](https://react-native-village.github.io/docs/amplify-02).
У AWS Amplify DataStore есть не только аналог apollo-link-retry, но и встроенная в него и настраиваемая привычную знакомая модель программирования с автоматическим контролем версий, обнаружением конфликтов и разрешением в облаке.
Из минусов AWS Amplify хочу назвать то, что хуки Apollo c его loading и error из коробки сокращают количество написанного кода на фронте, поэтому написал open source [библиотеку](https://github.com/react-native-village/aws-amplify-react-hooks), которая решает это недоразумение.
[Официальная документация](https://aws-amplify.github.io/docs/js/datastore)
В конце этого урока мы соберем с вами это мобильное приложение c использованием Amplify DataStore:
Поехали!
Данный урок является продолжением урока по [аутентификции](https://react-native-village.github.io/docs/auth1-00), так как работа с DataStore будет выполняться аутентифицированым пользователем. Поэтому, если вы его не прошли, то вернитесь на шаг назад.
Чат поддержки [AWS Amplify](https://teleg.run/awsamplify)
Финальный код этой части можно найти на [Github](https://github.com/fullstackserverless/startup/tree/datastore).
Клонируем репозиторий
---------------------
Если вы продолжаете прошлый урок, то можете сразу перейти к шагу 5
```
git clone https://github.com/fullstackserverless/startup.git
```
Переходим в папку проекта
```
cd startup
```
Install dependencies
```
yarn
```
или
```
npm install
```
Регистрируем свой AWS account
-----------------------------
Шаг для тех, кто еще не зарегистрирован на AWS
Регистрируемся согласно [этой](https://aws-amplify.github.io/docs/) инструкции и по видео учебнику чекаем все 5 шагов.
#### Внимание!!!
Потребуется банковская карта, где должно быть более 1$
Там же смотрим и ставим Amplify Command Line Interface (CLI)
Инициализация AWS Amplify в проект React Native
-----------------------------------------------
В корневой директории проекта React Native инициализируем наш AWS Amplify проект
```
amplify init
```
Отвечаем на вопросы:
Проект инициализацировался
Подключаем плагин аутентификации
--------------------------------
Теперь, когда приложение находится в облаке, вы можете добавить некоторые функции, такие как предоставление пользователям возможности зарегистрироваться в нашем приложении и войти в систему.
Командой
```
amplify add auth
```
подключаем функцию аутентификации. Выбираем конфигурацию по умолчанию. Это добавляет конфигурации ресурсов auth локально в ваш каталог ampify/backend/auth
#### Выбираем профиль, который мы хотим использовать. default. Enter и как пользователи будут входить в систему. Email(За SMS списывают деньги).
Отправляем изменения в облако
```
amplify push
```
All resources are updated in the cloud
Собираем проект и проверяем работоспособность аутентификации.
ampify-app
----------
Самый быстрый способ начать работу c DataStore — использовать npx-скрипт ampify-app.
```
npx amplify-app@latest
```
Установка зависимостей
----------------------
Подробная установка [здесь](https://aws-amplify.github.io/docs/js/datastore#setup)
Если у вас React Native Cli, то
```
yarn add @aws-amplify/datastore @react-native-community/netinfo @react-native-community/async-storage
```
И если вы используете React Native> 0.60, то выполните следующую команду для iOS:
```
cd ios && pod install && cd ..
```
Подключаем плагин API(App Sync)
-------------------------------
Если подключали его в [прошлом уроке](https://react-native-village.github.io/docs/amplify-03), то пропускаем этот шаг.
Если нет то, подключаем плагин API
```
amplify add api
```
После выбранных пунктов откроется схема GraphQL в `amplify/backend/api//schema.graphql` куда вставляем эту модель:
```
type Job
@model
@auth(
rules: [
{allow: owner, ownerField: "owner", operations: [create, update, delete]},
])
{
id: ID!
position: String!
rate: String!
description: String!
owner: String
}
```
Подробней о ней [здесь](https://react-native-village.github.io/docs/amplify-03#schemagraphql)
Генерация моделей
-----------------
Моделирование ваших данных и создание моделей, используемых DataStore, — это первый шаг к началу работы. GraphQL используется в качестве общего языка для JavaScript, iOS и Android для этого процесса, а также используется в качестве сетевого протокола при синхронизации с облаком. GraphQL также поддерживает некоторые функции, такие как Automerge в AppSync. Генерация модели может быть выполнена с помощью сценария NPX или из командной строки с помощью Amplify CLI.
> Вам не нужна учетная запись AWS для ее запуска и локального использования DataStore, однако, если вы хотите синхронизироваться с облаком, рекомендуется установить и настроить Amplify CLI как в прошлом уроке.
Так как схему мы описали в прошлом уроке, то сейчас нам достаточно запустить команду
```
npm run amplify-modelgen
```
и получить сгенерированную модель в папке src/models
Обновляем API
-------------
Включаем DataStore для всего API
```
amplify update api
```
Отправляем изменения в облако
```
amplify push
```
All resources are updated in the cloud
READ
----
Создаем экран JobsMain src/screens/Jobs/JobsMain.js
На этом экране мы сделаем запрос Query, с опцией пагинации, где число через хук useQuery и он нам вернет массив, который мы отправим в Flatlist.
```
import React, { useEffect, useState } from 'react'
import { FlatList } from 'react-native'
import { Auth } from 'aws-amplify'
import { AppContainer, CardVacancies, Space, Header } from 'react-native-unicorn-uikit'
import { DataStore } from '@aws-amplify/datastore'
import { Job } from '../../models'
import { goBack, onScreen } from '../../constants'
const JobsMain = ({ navigation }) => {
const [data, updateJobs] = useState([])
const fetchJobs = async () => {
const mess = await DataStore.query(Job)
updateJobs(mess)
}
useEffect(() => {
fetchJobs()
const subscription = DataStore.observe(Job).subscribe(() => fetchJobs())
return () => {
subscription.unsubscribe()
}
}, [data])
const _renderItem = ({ item }) => {
const owner = Auth.user.attributes.sub
const check = owner === item.owner
return (
<>
)
}
const _keyExtractor = (obj) => obj.id.toString()
return (
}
stickyHeaderIndices={[0]}
/>
)
}
export { JobsMain }
```
Для раскрытия подробностей вакансии создаем экран JobDetail src/screens/Jobs/JobDetail.js
```
import React from 'react'
import { Platform } from 'react-native'
import { AppContainer, CardVacancies, Space, Header } from 'react-native-unicorn-uikit'
import { goBack } from '../../constants'
const JobDetail = ({ route, navigation }) => {
return (
)
}
export { JobDetail }
```
CREATE UPDATE DELETE
--------------------
Создаем экран JobAdd src/screens/Jobs/JobAdd.js, где мы выполняем функции CREATE UPDATE DELETE
```
import React, { useState, useEffect, useRef } from 'react'
import { AppContainer, Input, Space, Button, Header, ButtonLink } from 'react-native-unicorn-uikit'
import { DataStore } from '@aws-amplify/datastore'
import { Formik } from 'formik'
import * as Yup from 'yup'
import { Job } from '../../models'
import { goBack } from '../../constants'
const JobAdd = ({ route, navigation }) => {
const [loading, setLoading] = useState(false)
const [check, setOwner] = useState(false)
const [error, setError] = useState('')
const [input, setJob] = useState({
id: '',
position: '',
rate: '',
description: ''
})
const formikRef = useRef()
useEffect(() => {
const obj = route.params
if (typeof obj !== 'undefined') {
setOwner(true)
setJob(obj)
const { setFieldValue } = formikRef.current
const { position, rate, description } = obj
setFieldValue('position', position)
setFieldValue('rate', rate)
setFieldValue('description', description)
}
}, [route.params])
const createJob = async (values) => (await DataStore.save(new Job({ ...values }))) && goBack(navigation)()
const updateJob = async ({ position, rate, description }) => {
try {
setLoading(true)
const original = await DataStore.query(Job, input.id)
const update = await DataStore.save(
Job.copyOf(original, (updated) => {
updated.position = position
updated.rate = rate
updated.description = description
})
)
update && goBack(navigation)()
setLoading(false)
} catch (err) {
setError(err)
}
}
const deleteJob = async () => {
try {
setLoading(true)
const job = await DataStore.query(Job, input.id)
const del = await DataStore.delete(job)
del && goBack(navigation)()
setLoading(false)
} catch (err) {
setError(err)
}
}
return (
(check ? updateJob(values) : createJob(values))}
validationSchema={Yup.object().shape({
position: Yup.string().min(3).required(),
rate: Yup.string().min(3).required(),
description: Yup.string().min(3).required()
})}
>
{({ values, handleChange, errors, setFieldTouched, touched, isValid, handleSubmit }) => (
<>
setFieldTouched('position')}
placeholder="Position"
touched={touched}
errors={errors}
/>
setFieldTouched('rate')}
placeholder="Rate"
touched={touched}
errors={errors}
/>
setFieldTouched('description')}
placeholder="Description"
touched={touched}
errors={errors}
multiline
numberOfLines={5}
/>
{check && (
<>
)}
)}
)
}
export { JobAdd }
```
и в screens/Jobs/index.js экспортируем экраны
```
export * from './JobsMain'
export * from './JobDetail'
export * from './JobAdd'
```
Навигация
---------
Добавляем импорт экранов Jobs и подключаем их в StackNavigator
```
import * as React from 'react'
import { createStackNavigator } from '@react-navigation/stack'
import { enableScreens } from 'react-native-screens' // eslint-disable-line
import { Hello, SignUp, SignIn, ConfirmSignUp, User, Forgot, ForgotPassSubmit } from './screens/Authenticator'
import { JobsMain, JobDetail, JobAdd } from './screens/Jobs'
enableScreens()
const Stack = createStackNavigator()
const AppNavigator = () => {
return (
)
}
export default AppNavigator
```
Кнопка Jobs
-----------
Редактируем экран User в screens/Authenticator/User/index.js
```
import React, { useState, useEffect } from 'react'
import { Auth } from 'aws-amplify'
import * as Keychain from 'react-native-keychain'
import { AppContainer, Button } from 'react-native-unicorn-uikit'
import { goHome, onScreen } from '../../../constants'
const User = ({ navigation }) => {
const [loading, setLoading] = useState(false)
const [error, setError] = useState('')
useEffect(() => {
const checkUser = async () => {
await Auth.currentAuthenticatedUser()
}
checkUser()
})
const _onPress = async () => {
setLoading(true)
try {
await Auth.signOut()
await Keychain.resetInternetCredentials('auth')
goHome(navigation)()
} catch (err) {
setError(err.message)
}
}
const _onPressJob = () => onScreen('JOBS_MAIN', navigation)() // переход на экран JOBS_MAIN
return (
)
}
export { User }
```
Собираем приложение и тестируем
Done
----
References
----------
<https://aws-amplify.github.io>
<https://learning.oreilly.com/library/view/full-stack-serverless/9781492059882/>
<https://www.altexsoft.com/blog/engineering/graphql-core-features-architecture-pros-and-cons/>
<https://engineering.fb.com/core-data/graphql-a-data-query-language/>
<https://graphql.org/learn> | https://habr.com/ru/post/503964/ | null | ru | null |
# Что нового в react-router v6
Совсем недавно состоялся релиз 6-ой версии react-router. Вообще создатели react-router часто меняют подходы, используемые в библиотеке, но в этот раз они объединили лучшее, что было в прошлых версиях.
В статье приведу краткий обзор того, что поменялось.
Поиграть с новой версией можно [тут](https://codepen.io/NapalmDeath/pen/oNeOxjq).
* [Switch -> Routes](#1)
* [Относительные пути](#2)
* [Element вместо Component / render](#3)
* [Отказ от withRouter и новые хуки](#4)
* [Вложенные роуты](#5)
* [Индексные роуты](#6)
* [useRoutes вместо react-router-config](#7)
Switch → Routes
---------------
Вместо компонента Switch теперь появился компонент Routes. Но это не просто переименование — Routes более функционален. Основное отличие в том, что Routes не требует жесткого порядка роутов внутри.
Switch обходил роуты в строгом порядке сверху вниз и при первом совпадении пути рендерил заданный компонент. Поэтому важно было определить порядок: например, выносить вниз наиболее общий роут. Рассмотрим пример:
```
const Main = () => (
<- Switch всегда будет попадать в этот роут
)
```
В таком случае по любом URL рендерился бы компонент Home. Чтобы этого избежать, пришлось бы поставить в конец Switch.
В случае с Routes этого делать не нужно. Компонент «более умный» и сматчит наиболее подходящий роут:
```
}/>
}/>
```
Это срабатывает даже с более сложными кейсами, например с именованными параметрами. Пример из документации:
```
} />
} />
```
По урлу teams/new откроется не компонент Team, а NewTeamForm, хотя путь teams/:teamId тоже матчится с урлом teams/new.
Относительные пути
------------------
Следующее важное нововведение — относительные пути. Раньше в пропсе path у компонентов Route нужно было указывать полный путь, например:
И в роутах внутри компонента Courses пришлось бы тоже указывать полные пути:
```
```
Теперь вам достаточно указать относительный путь в пропсе path. Он будет автоматически добавлен к пути родительского роута. Например, компонент Courses теперь можно написать так:
```
} />
} />
```
То же самое правило действует для компонентов Link, которые отвечают за ссылки. В пропсе “to” можно указать относительный путь, который сработает по той же схеме, что и “path” в Route. Например, если в компоненте Courses сделать `id=123`, то ссылка будет вести на /courses/123.
Element вместо Component / render
---------------------------------
Это, пожалуй, одна из самых удобных фичей, которые появились в новом роутере.
Раньше в компоненте Route был выбор: либо указать компонент для рендера, либо передать render-prop функцию. В первом случае код выглядит красиво:
Но у него есть существенный недостаток. Вы не могли прокинуть дополнительные пропсы в компонент из родителя. Проблема решалась использованием render-функции:
```
} />
```
В новой версии роутера даже этого делать не придется. Оба этих пропса заменены на один — element. В него можно передать любой JSX-элемент. Пример выше в таком случае будет выглядеть так:
```
} />
```
Это намного более удобно, сокращает код и делает его визуально более понятным.
Отказ от withRouter и новые хуки
--------------------------------
react-router появился давно, еще когда функциональные компоненты не имели возможности привязаться к жизненному циклу компонентов. Тогда для большинства компонентов (кроме совсем «глупых») использовались классовые компоненты. Единственным способом подмешать какую-то логику / пропсы в них была композиция, а именно использовался паттерн HOC (Higher Order Component).
В react-router был HOC withRouter, которым нужно было обернуть компонент, чтобы у него появились нужные для роутинга пропсы, например, объект истории, location, параметры и тд.
С появлением хуков в функциональных компонентах смысл использования HOC’а, который добавляет лишнюю обертку над компонентом, пропал. React-router добавил поддержку хуков useHistory, useLocation, useParams, которые отвечали за получение объекта истории, локейшна и сматченных параметров.
В 6 версии HOC withRouter вообще не упоминается, а все пропсы роутера рекомендуется получать через хуки useNavigate, useLocation, useParams.
Вложенные роуты
---------------
У этого изменения более глубокие корни. Чтобы понять мотивацию, придется вернуться аж к версии react-router v1.
В первой версии была возможность указать вложенные роуты [прямо в конфиге](https://github.com/remix-run/react-router/blob/v1.0.3/docs/Introduction.md):
```
const routes = {
path: '/',
component: App,
childRoutes: [
{ path: 'about', component: About },
{ path: 'inbox', component: Inbox },
]
}
render(, document.body)
```
Либо в качестве children’ов в [компоненте Route](https://github.com/remix-run/react-router/blob/v1.0.3/docs/Introduction.md#with-react-router):
```
```
В примере выше в обоих случаях в компоненте App нужно рендерить children:
```
App
===
{props.children}
```
Вложенные роуты позволяют перерендеривать только необходимую часть страницы при изменении урла. Например, оставлять шапку страницы с какими-нибудь табами, а перерисовывать только внутреннее содержимое.
В более поздних версиях роутера эту возможность убрали, заменив на возможность вставить Route на любом уровне вложенности в компонентах.
А теперь снова вернули, только в новом обличии. Теперь вы можете сделать ровно такой же «конфиг» роутов, но [использовать компонент Outlet](https://reactrouter.com/docs/en/v6/getting-started/overview#nested-routes) в родительском роуте. Пример из документации:
```
function App() {
return (
} />
}>
} />
} />
);
}
function Users() {
return (
My Profile
← сюда подставится дочерний роут с path=”me” или “:id”
);
}
```
Однако это не единственная возможность сделать вложенные роуты! Возможность использовать Routes на любом уровне вложенности остается:
```
// Main
}/>
// Students
const Students = () => (
Страница студентов
==================
} />
)
```
Обратите внимание на *"\**" в пропсе path роута /students/\**.*
Звездочка означает, что данный роут будет матчиться с урлами вида /students/что-либо. При рендере компонента Students для урлов с параметров после /students/<тут> будет рендериться компонент Student. Основное отличие от того, что было раньше — звездочка.
Кстати, пропс exact исчез. Благодаря звездочке в нем пропала необходимость. Получается, что звездочка в пути отражает, что роут может матчиться с вложенными роутами. Если же звездочки нет — то только при точном совпадении пути. Это одна из важных особенностей при переводе проекта на v6, как и исключение [регулярных выражений из пути](https://reactrouter.com/docs/en/v6/upgrading/v5#note-on-route-path-patterns), и опциональных параметров.
Примеры из документации:
Валидные пути:
```
/groups
/groups/admin
/users/:id
/users/:id/messages
/files/
/files/:id/
```
Невалидные пути:
```
/users/:id?
/tweets/:id(\d+)
/files//cat.jpg
/files-*
```
Индексные роуты
---------------
Индексные роуты также вернулись к нам из v1-v3. В v4 индексные роуты [были заменены на exact](https://github.com/remix-run/react-router/blob/v4.4.0/packages/react-router/docs/guides/migrating.md#switch). Их назначение — отрендерить некоторый компонент [по заданному пути в случае точного совпадения](https://reactrouter.com/docs/en/v6/getting-started/overview#index-routes). Пример из документации:
```
function Layout() {
return (
<- место для вложенных роутов
);
}
function App() {
return (
}>
} /> <- индексный роут
} />
} />
);
}
```
Компонент Activity будет отрендерен на месте внутри компонента Layout.
Таким образом, получается удобная композиция вложенного роута, который нужно отрендерить, если путь полностью соответствует родительскому (path = “/” в примере выше отрендерит Layout c Activity внутри).
useRoutes вместо react-router-config
------------------------------------
Как уже упоминалось выше, в роутере v1 существовала возможность задать конфиг роутера для всего приложения. Это было особенно удобно для [серверного рендеринга](https://habr.com/ru/company/kts/blog/598571/), когда на сервере важно знать структуру роутов приложения.
Затем эта возможность переместилась в отдельный пакет [react-router-config](https://www.npmjs.com/package/react-router-config).
А теперь снова вернулась! [Но уже в основной пакет](https://reactrouter.com/docs/en/v6/getting-started/concepts#defining-routes).
Пример из документации:
```
function App() {
let element = useRoutes([
{
path: "/",
element: ,
children: [
{
path: "messages",
element:
},
{ path: "tasks", element: }
]
},
{ path: "team", element: }
]);
return element;
}
```
Такая конфигурация позволяет декларативно указать структуру роутов приложения.
Заключение
----------
Есть и другие изменения, но я постарался подсветить наиболее интересные — на мой взгляд — и рассмотреть их через призму истории развития библиотеки. Создатели react-router часто меняют парадигмы, требуя от разработчиков изучения новых подходов, но с каждым разом библиотека становится только удобнее и функциональнее. | https://habr.com/ru/post/598835/ | null | ru | null |
# Как Xcode 14 непреднамеренно увеличивает размер приложения
Xcode 14 был выпущен 12 сентября со многими новыми функциями и улучшениями. "Первое, что вы заметите", это то, что Xcode быстрее и на 30% меньше.[1](https://developer.apple.com/videos/play/wwdc2022/110427/) Повышенный параллелизм делает создание проектов на 25% быстрее, а длительные тесты до 30% быстрее.
Вскоре после выпуска Xcode 14 в ряде приложений для iOS был замечен значительный прирост в размере. Сначала мы [написали в Твиттере](https://twitter.com/emergetools/status/1575597900825915393) о наблюдении большого скачка в приложении Zillow для iOS. Zillow не был отдельным примером.
Между серединой сентября и началом октября:
* 8 октября размер установки приложения Nike для iOS составлял 182,2 МБ. Неделю спустя он был равен 322,1 МБ (+77%)
* American Airlines выросла с 182,2 МБ до 389,1 МБ, - Xcode 14 стал причиной увеличения на 76,2 МБ (+113%)
* Chime увеличен с 162,8 МБ до 212,8 МБ (+31%)
Размер установочного файла с течением времени для приложений Nike, American, Chime и Zillow для iOSВ каждом случае скачок размера связан с тем, что эти приложения впервые выпускаются с Xcode 14. В числе прочих функций, Xcode 14 отключил битовый код по умолчанию.
> Xcode больше не создает битовый код по умолчанию... Возможность сборки с помощью битового кода будет удалена в будущем выпуске Xcode. IPA, содержащие битовый код, будут удалены перед отправкой в App Store.
>
> *Примечания к выпуску Xcode 14*
>
>
Что такое битовый код (биткод)? Bitcode - это альтернативный способ упаковки приложения, который оставляет часть процесса сборки для Apple после отправки в App Store. Одна из вещей, которую делает Apple, это удаляет двоичные символы.
А удаление двоичных символов? Удаление двоичных символов - это когда определенные типы метаданных, которые не нужны для запуска приложения в производстве, удаляются из двоичного файла. Это метаданные, которые могут быть полезны до начала производства, например, для создания файлов dSYM, но в производственной сборке только «раздувают» телефон пользователя.
Простыми словами, битовый код оптимизирует производственные сборки, частично удаляя двоичные символы. Без включения битового кода настройки сборки Xcode должны быть изменены, чтобы удалить двоичные символы.
Этот блог не о том, является ли устаревший биткод хорошим или плохим, он про выделение менее известного эффекта выпускаемых с помощью Xcode 14 приложений. Ниже мы:
* Сравним сборки приложения до и после Xcode 14
* Выясним, какие приложения имели регрессию размера из-за Xcode 14
* Покажем как любое приложение может удалять бинарный код
### Сравнение Nike до и после Xcode 14
С Xcode 14 любое приложение, которое полагалось на битовый код, больше не обязательно удаляет двоичные символы из своего приложения. Это означает, что приложение может стать намного больше без добавления какой-либо функциональности.
Вот рентгеновский снимок от Emerge Size Analysis для версии 22.35.0 (в соотношении 10/8) приложения Nike для iOS. В этой версии фреймворки составляют 163,7 МБ от размера установки 191,7 МБ. Если вы находитесь у большого экрана, попробуйте взаимодействовать с древовидной картой, чтобы увидеть детализированные разбивки по размерам.
Рентгеновский снимок Emerge Size AnalysisВ версии 22.36.1 (10/15) фреймворки подскакивают до 293,8 МБ (+127,3 МБ) из общих 322,1 МБ. Обратите внимание на добавление темно-синих “String table", найденных в каждом фреймворке.
Рентгеновский снимок Emerge Size AnalysisКогда мы сравниваем две сборки, мы видим, что практически все увеличение на 130 МБ происходит из-за роста DYLD.String tables. Эти String tables являются ненужными метаданными, которые теперь используются в производстве.
Сравнение размеров между двумя сборками NikeNike вырос с 213,9 КБ двоичных символов (0,11% от общего размера приложения) до 127,5 МБ двоичных символов - почти 40% всего приложения.
")Размер двоичного символа в v22.35.0 (до Xcode 14)")Размер двоичного символа в v22.36.1 (после Xcode 14)В целом, приложение Nike для iOS увеличилось на 130 МБ без каких-либо серьезных изменений.
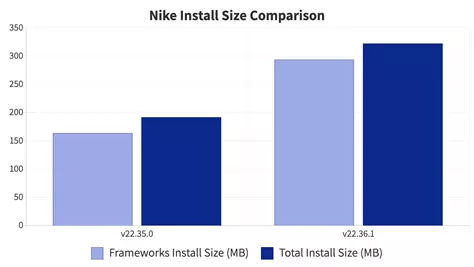### Сколько приложений было затронуто
Emerge Tools регулярно загружает приложения из App Store для анализа, что позволяет нам обнаружить эти регрессии и присмотреться. Приведенные ниже данные представляют все приложения, где:
* Есть более 2 МБ двоичных символов
* Более 5% приложения - это двоичные символы
* Процент приложения, которое является двоичными символами, вырос по крайней мере на 5% между сборками
Все приложения извлекаются непосредственно из App Store. Предоставленный анализ предназначен только для образовательных целей и не представляет клиентов Emerge Tools.
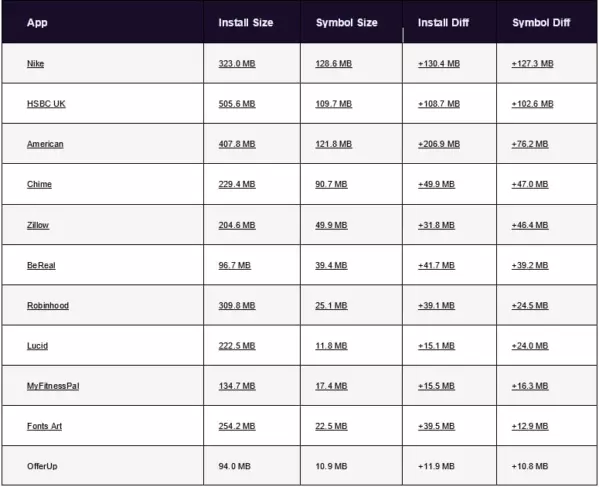Каждое из вышеперечисленных приложений, вероятно, регрессировало из-за выпуска с Xcode 14. Тем не менее, есть много других приложений, которые имеют значительную экономию за счет удаления двоичных символов, которые не могут быть однозначно связаны с Xcode 14.
Приложение Toyota (v2.0.9), о котором мы твитнули в начале блога, имеет установочный размер 550,2 МБ и может сэкономить 109,8 МБ (20% от общего размера приложения) за счет удаления двоичных символов. Это был первый раз, когда Emerge Tools проанализировало приложение Toyota, и мы не смогли сказать, было ли в нем раздувание двоичных символов в предыдущих сборках.
Есть также такие приложения, как TurboTax, которое мы анализируем еженедельно с апреля 2022 года. TurboTax обеспечивает потенциальную экономию более 100 МБ в каждой сборке, которую мы измерили. Три основных приложения Intuit для iOS — [TurboTax](https://www.emergetools.com/app/example/ios/turbotax-xcode14), [Mint](https://www.emergetools.com/app/example/ios/mint-xcode14)и [Quickbooks](https://www.emergetools.com/app/example/ios/quickbooks-xcode14)— имеют общий установочный размер 1,37 ГБ. Они могли бы сэкономить 578 МБ (42% размера), просто удалив двоичные символы.
Ниже приведен список приложений, в которых более 15 МБ двоичных символов, но мы не можем точно сказать, связано ли это с переходом на Xcode 14.
### Как удалить двоичные символы без битового кода
К счастью, удаление двоичных символов из конечного продукта сборки просто. Вот два способа использования настроек сборки Xcode:
Вы можете выполнить автоматическую зачистку сборок во время выполнения Архивной сборки, установив:
* "Deployment Postprocessing" = "Yes"
* "Strip Linked Product" to "Yes"
* "Additional Strip Flags" to `-rSTx`
* Все остальные настройки зачистки на значения по умолчанию
Однако с этим методом вы должны быть осторожны, т.к. настройки одинаковые для всех таргетов. Кроме того, могут быть подводные камни при использовании менеджеров пакетов. Для Cocoapods [здесь обсуждается](https://github.com/CocoaPods/CocoaPods/issues/10277) проблема, которая связана с одним возможным [решением](https://github.com/home-assistant/iOS/pull/2234/files#diff-8f7d6adf31268a2d897ee34bd170592648d6e520aa237104395e4a4438af50cb) (убедитесь, что все удаляемые фреймворки являются динамическими, если вы это делаете).
### Использование сценария оболочки
Вы также можете запустить приведенный ниже скрипт в самом конце процесса сборки, прямо перед подписанием. Обратите внимание, что для некоторых менеджеров пакетов, таких как Cocoapods, может не быть какой-либо промежуточной точки между копированием фреймворков и подписанием, где можно запустить пользовательский скрипт. В этом случае подпись необходимо будет снова выполнить вручную после зачистки, потому что зачистка сделает подпись недействительной.
Ниже приведен пример скрипта, который вы можете использовать для удаления двоичных файлов. Огромное спасибо Филипу Бьюзику из Doordash за помощь!
```
#!/bin/bash
set -e
# if [ "Release" = "${CONFIGURATION}" ]; then # Uncomment and only do this for release builds that you don't need to debug
# Path to the app directory
APP_DIR_PATH="${BUILT_PRODUCTS_DIR}/${EXECUTABLE_FOLDER_PATH}"
# Strip main binary
strip -rSTx "${APP_DIR_PATH}/${EXECUTABLE_NAME}"
# Path to the Frameworks directory
APP_FRAMEWORKS_DIR="${APP_DIR_PATH}/Frameworks"
# Strip symbols from frameworks, if Frameworks/ exists at all
# ... as long as the framework is NOT signed by Apple
if [ -d "$APP_FRAMEWORKS_DIR" ]; then
find "$APP_FRAMEWORKS_DIR" -type f -perm +111 -maxdepth 2 -mindepth 2 -exec bash -c 'codesign -v -R="anchor apple" "{}" &> /dev/null || (printf "%s\\n" "{}" && strip -rSTx "{}")' \;
fi
# Re-sign binaries as necessary
# fi
```
*strip\_binary\_symbols.sh hosted with ❤ by GitHub*
В настройках этапов сборки убедитесь, что флажок «На основе анализа зависимостей» не установлен, чтобы скрипт запускался при каждой сборке. Подробнее об этом методе можно прочитать [в нашей документации](https://docs.emergetools.com/docs/strip-binary-symbols).
**Примечание**: Удаление двоичного кода необходимо выполнить перед кодовой подписью приложения, иначе подпись кода будет признана недействительной.
### Почему это имеет значение
Как Apple сказала в своем видео про Xcode 14, размер приложения - это первое, что заметит ваш пользователь. И пользователи обращают внимание, как выразился недавний рецензент приложения American Airlines для iOS: 372 мб: приложение слишком большое, постоянно падает
Обзор приложения American Airlines для iOS в App StoreДокументация Play Console от Google имеет аналогичную рекомендацию:
> Размер приложения является одним из самых больших факторов, которые могут повлиять на показатели установки и удаления вашего приложения. Важно регулярно отслеживать и понимать, как вы можете уменьшить размеры загрузки и установки вашего приложения.
>
> - Документация Play Console
>
>
Хорошо… размер имеет значение… Если предположить, что это правда, как можно было бы избежать этой регрессии?
Нереально ожидать, что разработчики будут в курсе всех нюансов изменений версии платформы. Именно здесь вступает в действие непрерывный мониторинг. Если измерения выполняются вручную, регрессии не будут обнаруживаться последовательно до того, как они попадут в производство.
*“Привет, ребята из Emerge! Мы только что загрузили нашу первую сборку, сделанную с помощью Xcode 14, и мы видим огромное увеличение в размере, которое в большей степени связано со строковыми таблицами DYLD. Возможно ли, что это артефакт вашего анализа или же это реальное явление? Если да, есть ли у вас какое-либо представление о том, что происходит? Некоторое беглое гугление было не очень полезным.”*
Выше приведен Slack от одного из наших клиентов, который спрашивает об увеличении размера своего приложения после перехода на Xcode 14. Они заметили регрессию перед релизом с помощью инструментов непрерывной интеграции Emerge.
Устаревание битового кода, которое пришло как часть Xcode 14, безусловно, является крайним примером регрессии размера приложения. Однако мы обнаруживаем, что небольшие регрессии происходят все время, будь то обновление SDK или новая функция. Со временем эти изменения накапливаются и приводят к заметному ухудшению опыта взаимодействия пользователя с продуктом, что является еще одной причиной для того, чтобы заранее задуматься о размере вашего приложения.
Авторы статьи: Макс Топольски и Джош Коэнзаде.
Перевод и адаптация: SwiftBook.
[Оригинал статьи](https://www.emergetools.com/blog/posts/how-xcode14-unintentionally-increases-app-size)
Подписывайся на наши соцсети: [Telegram](https://t.me/swiftbook_news) / [VKontakte](https://vk.com/swiftbook)
Вступай в открытый чат для iOS-разработчиков: [t.me/swiftbook\_chat](https://zen.yandex.ru/profile/editor/id/62305a2685b4d86601d09326/630e1238f8df182ac8cc30ab/t.me/swiftbook_chat)
Смотри [бесплатные уроки по iOS-разработке с нуля](https://swiftbook.org/shop) | https://habr.com/ru/post/703362/ | null | ru | null |
# Расширенный поиск Яндекса (и Гугла) с помощью установленного скрипта или в интерфейсе
[](https://greasyfork.org/ru/scripts/16332-yandex-extra-buttons)В яндекс-поисковике, как и в Гугле, есть настройки расширенного поиска (по датам, документам, сайтам, стране, языку, ...) и специальные страницы для [расширенного](https://yandex.ru/search/advanced) [поиска](https://www.google.ru/advanced_search?q=test+site:cc&hl=en&site=webhp). То и другое бывает неудобно из-за интерфейса — большого количества нажимаемых кнопок, кликов и движений. Для некоторых (частоиспользуемых) режимов поиска сделаны юзерскрипты с выбором одной из десятков кнопок в один клик. На экране видны лишь несколько стартовых кнопок, работающих как спадающие списки по наведению мыши.
Такой скрипт, когда-то бывший без спадающих списков, давно [работал на страницах Гугла](https://greasyfork.org/en/scripts/7543-google-search-extra-buttons), и, судя по количеству скачиваний, приобрёл популярность среди англоязычных пользователей (есть выбор 5 языков интерфейса). Однажды подумалось, что его несложно будет [перенести на Яндекс](https://greasyfork.org/ru/scripts/16332-yandex-extra-buttons), и на выходных за пару дней адаптация и перекраска под цвета Яндекса была сделана, и теперь он представляется «целевой аудитории» — людям из IT, которым иногда приходится много искать и которым привычно устанавливать дополнительные скрипты и ходить по [гит](https://github.com/spmbt/googleSearchExtraButtons)ха[бам](https://github.com/spmbt/haPages/tree/gh-pages/userscript/yandex).

Кроме утилитарной пользы, скрипт может быть интересен как полигон для отработки интерфейсных решений. Связка 2-3 скриптов в перспективе может начать работать как мета-поисковик, всё для этого уже есть, кроме последних штрихов — поставить связующие кнопки, портировать на mаilru и другие поисковики.
Сейчас же — рассмотрим, какие особенности Яндекса добавились в ранее существовавшее решение для Гугл.
Первое и единственное ограничение у Яндекса, которое бросается в глаза — это отсутствие поиска за последние часы. Скорее всего, у Яндекса ещё нет такой функциональности, [вопрос на toster.ru](https://toster.ru/q/283388) ответа не принёс, но сейчас, может быть, что-то напишут разработчики из Яндекса в комментариях.
Появилось и расширение функций в поиске по документам — интерфейс запросов к Яндексу позволяет искать по группе типов документов (мультиселект в настройках), а Гугл каждый раз — только по одному типу документов (PDF, DOC, SWF, ...).
В остальном — режим специальных настроек настолько хорошо пересекается, что позволил сделать похожим не только интерфейс, но и хранение параметров настроек. Это — поиск по сайту (домену) и поиск за последний интервал времени (более дня).
Подробности хранения настроек — решение с внешним localStorage
--------------------------------------------------------------
Ранее для Гугла аналогичное расширение приобрело сохранение настроек поиска. Просто потому что список своих доменов или язык интерфейса иногда желательно менять, а изменения прямо в скрипте — мало, что привычно лишь программистам-фронтендщикам, ещё и при довольно частых обновлениях нет возможности сохранить код части исправленного пользователем скрипта от общего обновления. Если появляются хранимые (в localStorage) настройки, то вопрос снимается.
Но тут у Гугла обнаружилась привычка стирать локальную память! С этим сталкивались ранее и пользователи Фейсбука, и для решения этой проблемы была [статья на Хабре](http://habrahabr.ru/post/249949/) и скрипт по другому поводу (букмарклет закладок с прокруткой скролла окна). Здесь — аналогично, требовалось бежать с домена Гугла куда-нибудь на другой домен, куда скрипты-чистильщики не дотянутся. Организовано общение с тихой [скромной страницей](https://spmbt.github.io/googleSearchExtraButtons/saveYourLocalStorage.html) на github.io, где всё надёжно хранилось, почти как в банке. (Ссылка эта пригодится после установки скрипта, чтобы увидеть, куда настройки сохранились.)
Для Яндекса это вылилось в то, что хранение его настроек тоже было сделано на том же домене (github.io). Это немедленно привело к тому, что 2 разных скрипта, разных домена и разные поисковики приобрели общие настройки. Нет, их крайне несложно разделить, но зачем? Список любимых сайтов для поиска, язык интерфейса, и впоследствии — хранение последних интервалов дат — всё это стало появляться одинаково как в Гугле, так и в Яндексе, при условии пользования одним и тем же браузером.
Именно этот механизм сейчас даёт возможность очень просто сделать метапоиск — добавить в сохраняемые настройки поле для команд — просто команду «искать» или «искать с настройками», или «искать в выбранных поисковиках»). В дальнейшем, можно пофантазировать, что появится и синхронное управление картами, и просмотр в разделах, например, новостей, картинок. Согласитесь, удобно ведь ходить по карте в одном окне, а в соседнем — иметь синхронную копию в картах Гугл, чтобы переключаться на то окно, где более полная информация. И выдача картинок будет заметно разная и дополняющая.

Справочник вариантов расширенного поиска в Яндексе и Гугле
----------------------------------------------------------
Этот список, **возможно, дополнят** специалисты-пользователи и разработчики компаний (дополню по комментариям или [ЛС](http://habrahabr.ru/conversations/spmbt/)).
Все способы и виды сведены в список в целях организации небольшого справочника.
Многое в интерфейсе юзерскрипта не реализовано. Что реализовано — указано.
### В Яндексе:
* **по региону**
в интерфейсе — поле с подсказками, где выбирается «регион» — страна, область или город;
в запросе — **&rstr=** c магическим многозначным числом со знаком, совпадающим с другим недокументируемым параметром **lr** для своего региона; не всё работает — например, поиск по Маниле (rstr=-10629, это же Филиппины) не сильно отличается от общего;
* **по сайту или домену**
в интерфейсе — вводим в поле название домена (2 или 3 уровня, без продолжения)
в строке поиска — пишем (без кавычек) " site:3dnews.ru" или подобное;
*Yandex Extra Buttons* — спадающий список заранее прописанных доменов под кнопкой «site». Состав списка можно менять в настройках, через кнопку site--Настройки--форма настроек--перезагрузка страницы. Сохраняется во внешнем localStorage. Свой список доменов полезно скопировать для хранения, переноса на другой браузер и для восстановления.
в запросе — **&site=anysite.ru**;
* **по стране**
в интерфейсе — переключается кнопка со смыслом «своя страна», т.е. на домене .by это — выбор «by» и не более;
в запросе — **&country=by**, при этом можно указать и некоторые другие страны, по которым работает Яндекс, но что из них реально работает — не документировано. Например, *&country=tr* или *com.tr* не работает, как и множество «не близких» стран, не обязательно мелких;
* **точный запрос**
в интерфейсе — отдельная кнопка в подзаголовке или на специальной странице;
в строке поиска — обрамить все слова или часть из них (составляющие точную часть запроса) кавычками;
в запросе — **&wordforms=exact**
* **по языку страницы**
выбор языков небольшой, но он покрывает все страны, где Яндекс присутствует как отдельный конкурирующий поисковик, плюс английский, немецкий, французский; *(этот список может быть кандидатом на ещё одну кнопку в юзерскрипте, но многие ли пользуются этой настройкой? Скорее всего, нет)*;
* **по типам** (множественное число) **документов**
в интерфейсе — выбрать из мультиселектового списка; при каждом клике сменяется выдача по аяксу (без перезагрузки); на странице [advanced](https://yandex.ru/search/advanced) — выбрать типы из 14 (сейчас) чекбоксов;
в строке поиска — дописывают (без кавычек) " mime: pdf" или подобное, поддерживается много типов, но один на запрос; что интересно, такой выбор типов НЕ поддерживается скриптами подзаголовка — очевидно, это — более старый способ выбора параметра;
*Yandex Extra Buttons* — спадающий список заранее прописанных типов документа под кнопкой «PDF», которая сама по себе тоже выбирает указанный тип; по кликам страница подхватывает результаты и изменяет список выбранных типов в подзаголовке; скрипт устраняет баг отображения — подкрашивает кнопку типов, если хотя бы один тип был выбран; таким образом, кнопки юзерскрипта, по сути, инициируют «клики» по типам в подзаголовке, сами не отображают результаты мультивыбора, но работают и без подзаголовка (он появляется сам после первого клика);
в запросе — **&mime=rtf** или **&mime=rtf%2Cdoc**, указывая все выбранные типы; работает и **&mime=rtf&mime=doc** и далее; запросы идут по AJAX, но с главной таким же способом можно отправить и не аяксовый запрос;
* **по последнему интервалу дат**
в интерфейсе — 3 отдельных кнопки в подзаголовке или 5 — на спецстранице;
*Yandex Extra Buttons* — 4 спадающих списка в виде изначально небольших 4 кнопок — выбор за последние несколько: дней, недель, месяцев, лет. Выбранное значение сохраняется в настройках и перемещается в начало списка, чтобы при повторном таком же выборе было достаточно только нажать кнопку. Технически реализуется через запрос по произвольному интервалу дат (раздел ниже), страница запрос выполняет по AJAX, но с главной работает как обычная перезагрузка страницы;
в запросе — магический параметр **&within=число** для некоторых интервалов; например, &within=1 — за 2 недели; 77 — за сутки, 2 — за месяц; 3 — за 3 месяца; 4 — за полгода, 5 — за год, 6 — за 2 года и т.д., 7 — за текущий день, 8 — за 3 суток или 4 дня (неизвестно точно, не проверялось), 9 — за 8 дней; можно попроверять, на результирующей странице интервал указывается с точностью до дня, а результаты — с точностью от часа до дня;
* **по интервалу дат**
в интерфейсе — 2 поля с дейт-пикерами (табличками для выбора дат из календаря);
в запросе — **&from\_date\_full=11.01.2016&to\_date\_full=19.01.2016**
Есть ряд других более специфических параметров, язык запросов (например, минус-слова и упомянутые кавычки), которые не будем рассматривать, но часть их могут оказаться в интерфейсе юзерскрипта расширенного поиска. Кроме того, у Яндекса есть ряд типов страниц (картинки, видео, новости, Маркет, и т.д.), где запросы могут иметь особенности (например, есть поиск по изображениям, поиск географического места на карте). Скрипт же сейчас покрывает основное поле — текстовый поиск.
В разделе Яндекс-новостей расширенный поиск идёт по другим именам параметров, и скрипт на данном этапе в этом разделе не выполняется. У Гугла же в разделе новостей действуют те же правила построения запросов, скрипт для Гугла работает во всех его основных разделах.
### В Гугле:
Что интересно, разные параметры запроса дают те же результаты, но в 2 дизайнах страницы — с чёрным заголовком (более старый) и с белым. Качество выдачи при этом, скорее всего, одно и то же. Страница расширенного поиска выдаёт сейчас ответ с чёрным заголовком, и это не обязательно верно для разных стран. (Извстно также, что [дудлы](http://www.google.com/doodles/) выдаются в разные часы для разных часовых поясов.)
* **по типу** (единственное число) **документа**
в интерфейсе — [advanced\_search](https://www.google.com/advanced_search) — file type:
— один из 10 форматов; текстовым запросом могут искаться и другие типы, кроме названных в списке;
в строке поиска — дописывают (без кавычек) " **filetype: pdf**" или подобное;
*Google Search Extra Buttons* — пока что сделано как 2 отдельных кнопки (без списков) для PDF и DOC (прочие типы в Гугле достаточно удобно задавать в строке поиска, поэтому много типов документов было введено, только начиная со скрипта для Яндекса);
в запросе — **&as\_filetype=xls**
* **по последнему интервалу дат**
в интерфейсе — *Search Tools* — (*Any Time* | *Past* <период>), далее — 5 вариантов выбора, или есть вариант задания любого интервала дат здесь же или на спецстранице;
*Google Search Extra Buttons* — 5 спадающих списков в виде изначально небольших 5 кнопок — выбор за последние несколько: дней, недель, месяцев, лет, **часов** (в дополнение к тому же в Яндексе). Выбранное значение сохраняется в настройках и перемещается в начало списка, чтобы при повторном таком же выборе было достаточно нажать кнопку;
в запросе — 2 вида запросов с теми же результатами, но с разным дизайном страницы выдачи
**&as\_qdr=m2** — вид с чёрным заголовком;
**&tbs=qdr:h1** — более новый вид; вместо «h» ставится h, d, w, m, или y; число — количество размерных единиц или пусто, что будет равносильно 1;
* **по интервалу дат**
в интерфейсе — *Search Tools* — (*Any Time* | *Past* <период>) — *Custom Range...*; на спецстранице — выбор только по нескольким последним интервалам дат (раздел выше);
*Google Search Extra Buttons* — отдельная кнопка, сразу вызывающая форму интерфейса; на главной — нет её поддержки, поэтому кнопка скриптом не отображается;
в запросе — **&tbs=cdr%3A1%2Ccd\_min%3A12%2F29%2F2015%2Ccd\_max%3A1%2F5%2F2016**;
* **по сайту или домену, в том числе верхнего уровня (.com, .cc, ...)**
в интерфейсе — на странице расширенного поиска (значок зубчатки — Advanced Search);
в строке поиска — дописывают (без кавычек) " **site: anysite.com**" или подобное, в том числе домен верхнего уровня без точки;
*Google Search Extra Buttons* — отдельная кнопка со спадающим списком с заранее прописанными доменами, список которых можно менять в настройках. При клике по начальной кнопке она не инициирует поиск, а только выводит текст в строку поиска, что удобно для поправки домена. Поэтому первый домен можно вообще задавать пустой строкой;
в запросе — **&as\_sitesearch=anysite.com**;
Другие параметры — у Гугла есть ряд других параметров для текстового поиска и язык запросов, подробное рассмотрение которых выходит за рамки цели статьи, но они могут оказаться в будущем в интерфейсе юзерскрипта.
* **точное слово или группа**
* **любое из слов**
* **исключая слова**
* **интервал размерностей (кг, денежные единицы, годы)**
* **по языку страницы**
* **в регионе (государства)**
* **по месту на странице**
* **семейный фильтр**
* **по наличию лицензий**
В выдаче возможна сортировка по релевантности или по дате.
Имеется ряд типов поиска (картинки, видео, новости, карты, ...), где параметры поиска будут другие или со спецификой. Скрипт *Google Search Extra Buttons* сохраняет тип страницы поиска, с которой он был начат.
По теме организации метапоиска по обычным запросам
--------------------------------------------------
(Дальше пойдут планы и фантазии, интересные разработчикам интерфейсов.)
В самом простом виде метапоиск — это просмотр результатов в 2 соседних окнах одного браузера. Дополнительно можно поисключать одинаковые ответы из второго окна. Если задаться целью получить выдачу в одно окно, нужно решать, в каком месте списка внедрять элементы списка из второго окна. Скорее всего, удобно внедрять на примерно ту же позицию, которую занимал элемент во 2-м окне. И, конечно, указывать, от какого поисковика пришли ответы, чтобы у пользователя накапливалась в памяти статистика, по каким запросам от какого поисковика он получил себе полезный ответ.
Замечание по политике поисковиков. Делать метапоиск в одном окне технически невозможно, потому что современные крупные поисковики строго следят, чтобы запрос выполнялся не в фрейме, чтобы ответ приходил в настоящую страницу, а не в XMLHTTP-объект. Это связано с доходами от сопутствующей рекламы, составляющих ныне основной хлеб любого поисковика. Для пользователя, наоборот, важен результат и максимум — тот движок, который его даёт.
Метапоиск на скриптах — это вероятность близкого будущего. Для реализации — коды скриптов имеются на Гитхабе ([Yandex](https://github.com/spmbt/haPages/tree/gh-pages/userscript/yandex), [Google](https://github.com/spmbt/googleSearchExtraButtons)), приветствуются новые решения.
**UPD**: Кто поможет сделать белорусскую, казахскую и турецкую локализации?**объём и формат**
```
ru:{
'search in PDF files':'поиск по документам PDF'
,'search in':'искать по'
,'from / to':'за период'
,'last':['за последний','за последние','за последнюю']
,'day':'сутки'
,'days':['дня','дней']
,'week':'неделю'
,'weeks':['недели','недель']
,'month':'месяц'
,'months':['месяца','месяцев']
,'year':'год'
,'years':['года','лет']
,'hour':'час'
,'hours':['часа','часов']
,'Settings':'Настройки'
,'of userscript':'юзерскрипта'
,'reload page for effect':'перезагрузить страницу'
,'Interface language':'Язык интерфейса'
,'Less positions at the end of selects':'Меньше выбора в конце селектов'
,'Sites':'Сайты'
}
```
**UPD2** 2016-01-22: первичные кнопки сделаны как стрелки, по стилю кнопки Яндекса. Скриншоты в статье заменены. | https://habr.com/ru/post/275479/ | null | ru | null |
# Telegram бот для персонализированной подборки статей с Хабра
Для вопросов в стиле "зачем?" есть более старая статья — [Натуральный Geektimes — делаем пространство чище](https://habr.com/ru/post/391233/).
Статей много, по субъективным причинам некоторые не нравятся, а некоторые, наоборот, жалко пропускать. Хочется оптимизировать этот процесс и экономить время.
В вышеупомянутой статье предлагался подход со скриптами в браузере, но он мне не очень понравился (хоть я им и пользовался раньше) по следующим причинам:
* Для разных браузеров на компе/телефоне приходится настраивать заново, если это вообще возможно.
* Жёсткая фильтрация по авторам не всегда удобна.
* Не решена проблема с авторами, чьи статьи не хочется пропускать, даже если они выходят раз в год.
Встроенная в сайт фильтрация по рейтингу статей не всегда удобна, так как узкоспециализированные статьи при всей их ценности могут получать довольно скромный рейтинг.
Изначально я хотел генерировать rss ленту (или даже неколько), оставляя там только интересное. Но в итоге получилось, что чтение rss показалось не очень удобным: в любом случае для комментирования/голосования за статью/добавления её в избранное приходится заходить через браузер. Поэтому я написал бота для телеграмма, которые кидает мне в личку интересные статьи. Телеграм сам по себе делает из них красивые превьюшки, что в сочетнии с информацией об авторе/рейтинге/просмотрах выглядит довольно информативно.
Под катом подробности типа особенностей работы, процесса написания и технических решений.
Кратко о боте
-------------
Репозиторий: <https://github.com/Kright/habrahabr_reader>
Бот в телеграмме: <https://t.me/HabraFilterBot>
Пользователь задаёт добавочный рейтинг для тэгов и авторов. После этого к статьям применяется фильтр — складываются рейтинг статьи на Хабре, пользовательский рейтинг автора и среднее для пользовательских рейтингов по тегам. Если сумма оказывается больше заданного пользователем порогового значения, то статья проходит фильтр.
Побочной целью написания бота было получение фана и опыта. Кроме того, я регулярно напоминал себе, что [я — не гугл](https://habr.com/ru/company/infopulse/blog/330708/), а потому многие вещи сделаны максимально просто и даже примитивно. Впрочем, это не помешало процессу написания бота растянуться на три месяца.
За окном было лето
------------------
Заканчивался июль, а я решил написать бота. И не в одиночку, а со знакомым, который осваивал scala и хотел что-нибудь написать на ней. Начало выглядело многообещающим — код будет пилиться "комадной", задача казалось нетрудной и я думал, что через пару недель или месяц бот будет готов.
Несмотря на то, что я сам последние несколько лет время от времени пишу код на скале, этот код обычно никто не видит и не смотрит: пет проекты, проверка каких-то идей, предобработка данных, освоение каких-то концепций из ФП. Мне было реально интересно, как же выглядит написание кода в команде, потому что код на скале можно писать очень по-разному.
Что же могло пойти **так**? Впрочем, не будем торопить события.
Всё происходящее можно отследить по истории коммитов.
Знакомый создал репозитрий 27 июля, но больше ничего не сделал, а потому я начал писать код.
### 30 июля
Кратко: я написал парсинг rss ленты Хабра.
* `com.github.pureconfig` для чтения typesafe конфигов прямов в case классы (оказалось очень удобно)
* `scala-xml` для чтения xml: поскольку изначально я хотел написать свою реализацию для rss — ленты, а rss лента в формате xml, то для парсинга использовал эту библиотчеку. Собственно, парсинг rss тоже появился.
* `scalatest` для тестов. Даже для крохотных проектов написание тестов экономит время — например, при отладке парсинга xml намного проще скачать его в файлик, написать тесты и поправить ошибки. Когда в дальнейшем появился баг с парсингом каких-то странных html с невалидными utf-8 символами, оказалось опять же удобнее положить его в файлик и добавить тест.
* акторы из Akka. Объективно, они вообще не были нужны, но проект писался for fun, я хотел их попробовать. В результате готов сказать, что мне понравилось. На идею ООП можно взглянуть с другой стороны — есть акторы, которые обмениваются сообщениями. Что интереснее — можно (и нужно) писать код с таким рассчётом, что сообщение может не дойти или не быть обработано (вообще говоря, при работе акки на одном-единственном компе сообщения не должны теряться). Я поначалу ломал голову и в коде происходил треш с подписками акторов друг на друга, но в итоге удалось прийти довольно простой и изящной архитектуре. Код внутри каждого актора можно считать однопоточным, при падениях актора акка перезапускает его — получается довольно отказоустойчивая система.
### 9 августа
Я добавил в проект `scala-scrapper` для парсинга html страничек с хабра (чтобы вытаскивать информацию типа рейтинга статьи, количества добавлений в закладки и т.п.).
И Cats. Те самые, которые в скале.

Я тогда читал одну книжку про распределённые базы данных, мне понравилась идея CRDT (Conflict-free replicated data type, [https://en.wikipedia.org/wiki/Conflict-free\_replicated\_data\_type](http://wiki), [habr](https://habr.com/ru/post/418897/)), поэтому я запилил тайп-класс комутативной полугруппы для информации о статьи на хабре.
На самом деле, идея очень простая — у нас есть счётчики, которые монотонно изменяются. Количество промотров плавно растёт, количество плюсов тоже (впрочем, как и количество минусов). Если у меня есть две версии информации о статье, то можно их "слить в одну" — более акутальной считать то состояние счётчика, которое больше.
Полугруппа обозначает, что два объекта с информацией о статье можно слить в один. Коммутитивная обозначает, что сливать можно и А + B и B + A, результат от порядка не зависит, в итоге останется наиболее новая версия. К слову, ассоциативность тут тоже есть.
Например, по-задумке, rss после парсинга давала чуть ослебленную информацию о статье — без метрик типа количества просмотров. Специальный актор после этого брал информацию о статьях и бегал к html страничкам, чтобы её обновить и слить со старой версией.
Вообще говоря, как и в akka, в этом не было нужды, можно было просто для статьи хранить updateDate и брать более новую без всяких слияний, но меня вела дорога приключений.
12 августа
----------
Я начал свободнее себя чувствовать и ради интереса сделал, чтобы каждый чат был отдельным актором. Теоретически, актор сам по себе весит около 300 байт и их можно хоть миллионами создавать, так что это вполне нормальный подход. Получилось, как мне кажется, довольно интересно решение:
Один актор был мостом между сервером телеграмма и системой сообщений в акке. Он просто получал сообщения и отправлял их нужному актору-чату. Актор-чат в ответ мог послать что-нибудь обратно — и оно отправлялось обратно в телеграм. Что было очень удобно — этот актор получился максимально простым и содержал только логику ответа на сообщения. Кстати, информация о новых статьях приходила в каждый чат, но я опять же не вижу в этом никаких проблем.
В общем, бот уже работал, отвечал на сообщения, хранил список отправленных пользователю статей и я уже думал о том, что бот практически готов. Я потихоньку допиливал маленькие фишки типа нормализации имён авторов и тэгов (заменял "s.d f" на "s\_d\_f").
Оставалось одно *маленькое но* — состояние никуда не сохранялось.
Всё пошло не так
----------------
Возможно, вы заметили, что бота я писал преимущественно один. Так вот, второй участник включился в разработку, и в коде оказались следующие изменения:
* Для хранения состояния появилась mongoDB. Заодно в проекте поломались логи, потому что монга зачем-то начинала в них спамить и кое-кто их просто глобально выключил.
* Актор-мост в телеграм преобразился до неузнаваемости и начал сам парсить сообщения.
* Акторы для чатов были безжалостно выпилены, вместо них появился актор, который прятал в себе всю информацию о всех чатах сразу. На каждый чих этот актор лез в монгу. Ну да, типа при обновлении информации о статье отправить её всем акторам-чатам — тяжело (мы же как гугл, миллионы пользователей так и ждут по миллиону статей в чат для каждого), а вот при каждом обновлении чата лезть в монгу — это нормально. Как я понял сильно позже, работающая логика работы чатов тоже была полностью выпилена и взамен появилось неработающее нечто.
* От тайп-классов не осталось и следа.
* В акторах появилась какая-то нездоровая логика с подписками их друг на друга, ведущая к race condition.
* Структуры данных с полями типа `Option[Int]` превратились в Int с магическими дефолтными значениями типа -1. Позже я понял, что mongoDB хранит json и нет ничего плохого в том, чтобы хранить там `Option` ну или хотя бы парсить -1 как None, но на тот момент я этого не знал и поверил на слово, что "так надо". Тот код писал не я, и я не лез его менять до поры до времени.
* Я узнал, что мой публичный айпи адрес имеет свойство меняться, и каждый раз приходилось добавлять его в whitelist монге. Бота я запускал локально, монга была где-то на серверах монги как компании.
* Внезапно пропала нормализация тегов и форматирование сообщений для телеграмма. (Хм, с чего бы это?)
* Мне понравилось, что состояние бота хранится во внешней БД, и при перезапуске он продолжает работать как ни в чём ни бывало. Впрочем, это был единственный плюс.
Второй человек не особо торопился, и все эти изменения появились одной большой кучей уже в начале сентября. Я не сразу оценил масштаб полученных разрушений и начал разбираться в работе БД, т.к. раньше и с ними не имел дело. Только потом я понял, сколько работающего кода было выпилено и сколько багов добавлено взамен.
Сентябрь
--------
Поначалу я думал, что было бы полезно освоить монгу и сделать всё хорошо. Потом я потихоньку начал понимать, что организовать общение с бд — тоже искусство, в котором можно понаделать гонок и просто ошибок. Например, если от пользователя придут два сообщения типа `/subscribe` — и мы в ответ на каждое создадим по записи в табличке, потому что на момент обработки тех сообщений пользователь не подписан. У меня возникло подозрение, что общение с монгой в существуещем виде написано не лучшим образом. Например, настройки пользователя создавались в тот момент, когда он подписывался. Если он пробовал их поменять до факта подписки… бот ничего не отвечал, потому что код в акторе лез в базу за настройками, не находил и падал. На вопрос — почему бы не создавать настройки по необходимости я узнал, что нечего их менять, если пользователь не подписался… Система фильтрации сообщений была сделана как-то неочевидно, и я даже после пристального взгляда в код не смог понять, было так задумано изначально или там ошибка.
Списка отправленных в чат статей не было, вместо этого было предложено, чтобы я сам их написал. Меня это удивило — я в общем-то был не против втаскивания в проект всяких штук, но было бы логично втащившему эти штуки их и прикрутить. Но нет, второй участник, похоже, подзабил на всё, но сказал, что список внутри чата — якобы плохое решение, и надо сделать табличку с ивентами типа "пользователю x была отправлена статья у". Потом, если пользователь запрашивал прислать новые статьи, надо было отправить запрос к бд, который из ивентов выделил бы ивенты, относящиеся к пользователю, ещё получить список новых статей, отфильтровать их, отправить пользователю и накидать ивентов об этом обратно в бд.
Второго участника куда-то понесло в сторону абстракций, когда боту будут приходить не только статьи с Хабра и отправляться не только в телеграм.
Я как-то реализовал ивенты в виде отдельной таблички ко второй половине сентября. Неоптимально, но бот хотя бы заработал и снова начал присылать мне статьи, а я потихоньку разобрался с происходящим в коде.
Сейчас можно вернуться вначало и вспомнить, что репозиторий изначально создавал не я. Что же могло пойти так? Мой пул-реквест был отклонен. Оказалось, что у меня быдлокод, что я не умею работать в команде и я должен был править баги в текущей кривой реализации, а не дорабатывать её до юзабельного состояния.
Я расстроился, посмотрел историю коммитов, количество написанного кода. Посмотрел на моменты, которые изначально были написаны хорошо, а потом сломаны обратно...
F\*rk it
--------
Я вспомнил статью [Вы — не Google](https://habr.com/ru/company/infopulse/blog/330708/).
Подумал о том, что идея без реализации никому особо не нужна. Подумал о том, что я хочу иметь работающего бота, который будет в одном-единственном экземпляре работать на одном-единственном компе как простая java-программа. Я знаю, что мой бот будет работать месяцами без перезапусков, благо в прошлом я уже писал таких ботов. Если он вдруг всё-таки упадёт и не пришлёт пользователю очередную статью, небо не обрушится на землю и ничего катастрофического не произойдёт.
Зачем мне докер, mongoDB и прочий карго-культ "серьёзного" софта, если код тупо не работает или работает криво?
Я форкнул проект и сделал всё как хотел.
Примерно тогда же я поменял место работы и свободного времени стало катастрофически не хватать. Утром я просыпался ровно на электричку, вечером возвращался поздно и что-либо делать уже не хотелось. Я какое-то время не делал ничего, потом желание дописать бота пересилило, и я стал потихоньку переписывать код, пока ездил на работу утром. Не скажу, что это было продуктивно: сидеть в трясущейся электричке с ноутбуком на коленях и подглядывать на stack overflow с телефона не очень удобно. Впрочем, время за написанием кода пролетало совершенно незаметно, и проект начал потихоньку двигаться к рабочему состоянию.
Где-то в глубине души был червячок сомнения, который хотел использовать mongoDB, но я подумал, что кроме плюсов с "надёжным" хранением состояния есть заметные минусы:
* БД становится ещё одной точкой отказа.
* Код становится сложнее, и писать его я буду дольше.
* Код становится медленным и неэффективным, вместо изменения объекта в памяти изменения отправляются в БД и при необходимости вытаскиваются обратно.
* Появляются ограничения типа хранения ивентов в отдельной табличке, которые связаны с особенностями работы БД.
* В триальной версии монги есть какие-то ограничения, и если в них упереться, придётся на чём-то монгу запускать и настраивать.
Выпилил монгу, теперь состояние бота просто хранится в памяти программы и время от времени сохраняется в файлик в виде json. Возможно, в комментариях напишут, что я не прав, бд именно тут надо использовать и т.п. Но это мой проект, подход с файлом максимально прост и он работает прозрачным образом.
Выкинул магические значения типа -1 и вернул нормальные `Option`, добавил хранение хеш-таблички с отправленными статьями обратно в объект с информацией о чате. Добавил удаление информации о статьях старше пяти дней, чтобы не хранить всё подряд. Привёл логирование к рабочему состоянию — логи в разумных количествах пишутся и в файл и в консоль. Добавил несколько админских команд типа сохранения состояния или получения статистики типа количества пользователей и статей.
Исправил кучу мелочей: например, для статей теперь указывается количество просмотров, лайков-дизлайков и комментариев на момент прохождения фильтра пользователя. Вообще, удивительно, сколько мелочей пришлось поправить. Я вёл списочек, отмечал там все "шероховатости" и по мере возможностей исправлял их.
Например, я добавил возможность прямо в одном сообщении задать все настройки:
```
/subscribe
/rating +20
/author a -30
/author s -20
/author p +9000
/tag scala 20
/tag akka 50
```
И ещё команда `/settings` выводит их именно в таком виде, можно брать текст от неё и отправлять все настройки другу.
Вроде и мелочь, но подобных нюансов — десятки.
Реализовал фильтрацию статей в виде простой линейной модели — пользователь может задать дополнительный рейтинг авторам и тегам, а так же пороговое значение. Если сумма рейтинга автора, среднего рейтинга для тегов и реального рейтинга статьи окажется больше порогового значения, то статья показывается пользователю. Можно либо просить у бота статьи командой /new, либо подписаться на бота и он будет кидать статьи в личку в любое время суток.
Вообще говоря, у меня была идея для каждой статьи вытянуть больше признаков (хабы, количество комментариев, добавлений в закладки, динамику изменения рейтинга, количество текста, картинок и кода в статье, ключевые слова), а пользователю показывать голосовалку ок/не ок под каждой статьей и под каждого пользователя обучать модель, но мне стало лень.
Вдобавок, логика работы станет не такой очевидной. Сейчас я могу вручную поставить для patientZero рейтинг +9000 и при пороговом рейтинге в +20 буду гарантированно получать все его статьи (если, конечно, не поставлю -100500 для каких нибудь тегов).
Итоговая архитектура получилась довольно простой:
1. Актор, который хранит состояние всех чатов и статей. Он грузит своё состояние из файлика на диске и время от времени сохраняет его обратно, каждый раз в новый файлик.
2. Актор, который время от времени набегает в rss-ленту, узнаёт о новых статьях, заглядывает по ссылкам, парсит, и оправляет эти статьи первому актору. Кроме того, он иногда запрашивает у первого актора список статей, выбирает те их них, которые не старше трёх дней, но при этом давно не обновлялись, и обновляет их.
3. Актор, который общается с телеграммом. Я всё-таки вынес парсинг сообщений полностью сюда. По-хорошему хочется разделить его на два — чтобы один парсил входящие сообщения, а второй занимался транспортными проблемами типа переотправки неотправившихся сообщений. Сейчас переотправки нет, и не дошедшее из-за ошибки сообщение просто потеряется (разве что в логах отметится), но пока что это не вызывает проблем. Возможно, проблемы возникнут, если на бота подпишется куча человек и я достигну лимита на отправку сообщений).
Что мне понравилось — благодаря akka падения акторов 2 и 3 в общем-то не влияют на работоспособность бота. Возможно, какие-то статьи не обновляются вовремя или какие-то сообщения не доходят до телеграмма, но акка перезапускает актор и всё продолжает работать дальше. Я сохраняю информацию о том, что статья показана пользователю только тогда, когда телеграм актор ответит, что он успешно доставил сообщение. Самое страшное, что мне грозит — отправить сообщение несколько раз (если оно доставится, но потверждение каким-то неведомым образом потеряется). В принципе, если бы первый актор не хранил состояние в себе, а общался с какой-нибудь бд, то он мог бы тоже незаметно падать и возвращаться к жизни. Ещё я мог бы попробовать akka persistance для восстановления состояния акторов, но текущая реализация меня устраивает своей простотой. Не то чтобы мой код часто падал — наоборот, я приложил довольно много усилий, чтобы это было невозможным. Но shit happens, и возможность разбить программу на изолированные кусочки-акторы показалась мне реально удобной и практичной.
Добавил circle-ci для того, чтобы при поломке кода сразу об этом узнавать. Как минимум, о том, что код перестал компилироваться. Изначально хотел добавить travis, но он показывал только мои проекты без форкнутых. В общем-то обе эти штуки можно свободно использовать на открытых репозиториях.
Итоги
-----
Уже ноябрь. Бот написан, я пользовался им последние две недели и мне понравилось. Если есть идеи по улучшению — пишите. Я не вижу смыла монетизировать его — пускай просто работает и присылает интересные статьи.
Ссылка на бота: <https://t.me/HabraFilterBot>
Гитхаб: <https://github.com/Kright/habrahabr_reader>
Небольшие выводы:
* Даже маленький проект может сильно затянуться по времени.
* Вы — не гугл. Нет смысла стрелять из пушки по воробьям. Простое решение может работать ничуть не хуже.
* Пэт-проекты очень хорошо подходят для экспериментов с новыми технологиями.
* Телеграм боты пишутся довольно просто. Если бы не "командная работа" и эксперименты с технологиями, бот был бы написан за неделю-две.
* Модель акторов — интересная штука, хорошо сочетающаяся с многопоточностью и отказоустойчивостью кода.
* Кажется, я почувствовал на себе, почему open source сообщество любит форки.
* Базы данных хороши тем, что состояние приложения перестаёт зависеть от падений/перезапусков приложения, но работа с БД усложняет код и накладывает ограничения на структуру данных. | https://habr.com/ru/post/475450/ | null | ru | null |
# AStA: собираем APK на самом устройстве
**Что такое AStA?** Это акроним от «Android Studio on Android». Это метод, позволяющий собирать проекты Android Studio на Android устройстве с помощью chroot/Debian, JDK, Android SDK и Gradle.
**Зачем это вообще нужно?** Да мало ли, зачем… Бывает, например, хочется проверить какую-то идею, а декстопа под рукой нет. В общем, пусть на вопрос «зачем» каждый ответит для себя сам.
**Какие существуют альтернативы?** Из существующих решений мне известно только [AIDE](https://play.google.com/store/apps/details?id=com.aide.ui&hl=ru), но у него есть свои минусы. Во-первых, постоянно выскакивает окошко с предложением проапгрейдить версию за 600 рублей, а если этого не сделать, то нельзя сохранять проекты, состоящие из более чем 5 файлов. Во-вторых, AIDE не поддерживает сборку проектов Android Studio, состоящих из более, чем одного модуля.
#### Что нам потребуется?
1. Устройство с ядром Android, совместимым с Debian Stretch.
2. Наличие root-прав на устройстве.
3. 4 ГБ свободного места на карте памяти под образ Debian.
4. Заранее установленный на устройстве [Busybox](https://play.google.com/store/apps/details?id=stericson.busybox).
5. Desktop с Debian на борту + adb (в случае установки через скрипт).
#### Установка через скрипт
Следующий скрипт создает образ Debian с помощью debootstrap, кладет его, а также все прочие необходимые файлы, на карту памяти устройства, а затем запускает скрипт настройки Debian на самом устройстве:
```
#!/bin/sh
# Чтобы не спрашивало пароль в середине скрипта:
sudo echo 'installDebianOnAndroid script started'
# Архитектура устройства
ARCH=armhf
# Версия Debian
DEBIAN_VERSION=stretch
# Путь к карте памяти на устройстве:
STORAGE=/sdcard
# Место, где мы создадим образ на декстопе:
DATA_DRIVE=/Data
# Для совместимости с файловой системой FAT32
# размер файла образа не должен превышать (2^32 - 1) байт
BS=1M
COUNT=4095
# Создаем файл образа:
dd if=/dev/zero of=$DATA_DRIVE/debianOnAndroid.img bs=$BS count=$COUNT
# Создаем точку монтирования на десктопе:
mkdir -p ~/debianOnAndroid
# Создаем на образе файловую систему:
sudo mkfs.ext3 $DATA_DRIVE/debianOnAndroid.img
# Монтируем образ:
sudo mount -o user,loop,exec,dev $DATA_DRIVE/debianOnAndroid.img ~/debianOnAndroid/
# С помощью debootstrap создаем на образе debian:
sudo debootstrap --verbose --arch $ARCH --foreign $DEBIAN_VERSION ~/debianOnAndroid/ http://ftp.se.debian.org/debian
# Размонтируем образ:
sudo umount $DATA_DRIVE/debianOnAndroid.img
# Кладем образ на карту памяти:
adb push $DATA_DRIVE/debianOnAndroid.img $STORAGE
# Busybox лучше заранее установить через приложение:
# https://play.google.com/store/apps/details?id=stericson.busybox
#adb push busybox/busybox-armv6l /sdcard/busybox
#adb shell su -c cp /sdcard/busybox /data/local/busybox
#adb shell su -c chmod 755 /data/local/busybox
# Создаем папки AStA на Android:
adb shell mkdir -p $STORAGE/AStA
adb shell mkdir -p $STORAGE/AStA/Projects
adb shell mkdir -p $STORAGE/AStA/archives
adb shell mkdir -p $STORAGE/AStA/scripts
# Скрипт для первого монтирования и настройки Debian
adb push firstMountAndConfigureDebian.sh $STORAGE/AStA/scripts
# Скрипты для монтирования и размонтирования
adb push mountDebian.sh $STORAGE/AStA/scripts
adb push umountDebian.sh $STORAGE/AStA/scripts
# Заранее приготовленные архивы JDK, Android SDK и gradle
ANDROID_SDK_TAR_GZ=android-sdk-linux.tar.gz
JDK_8_TAR_GZ=jdk-8u144-linux-arm32-vfp-hflt.tar.gz
GRADLE_ZIP=gradle-3.5-bin.zip
# Кладем архивы в папку AStA/archives на карте памяти:
adb push archives/$ANDROID_SDK_TAR_GZ $STORAGE/AStA/archives
adb push archives/$JDK_8_TAR_GZ $STORAGE/AStA/archives
adb push archives/$GRADLE_ZIP $STORAGE/AStA/archives
# Скрипт для запуска команд Gradle:
adb push gradleExec.sh $STORAGE/AStA/scripts
# Запускаем скрипт первоначальной настройки Debian:
adb shell su -c sh $STORAGE/AStA/scripts/firstMountAndConfigureDebian.sh
# Размонтируем образ:
adb shell su -c sh $STORAGE/AStA/scripts/umountDebian.sh
# Имя файла приложения:
ASTA_APP_APK=AStA-app.apk
# Кладем приложение в папку AStA и устанавливаем:
adb push apk/$ASTA_APP_APK $STORAGE/AStA
echo 'installing AStA-app'
adb shell pm install -r $STORAGE/AStA/$ASTA_APP_APK
echo 'installDebianOnAndroid script done'
```
Скрипт настройки Debian на устройстве:
```
echo 'firstMountAndConfigureDebian script started'
# Пароль для доступа по SSH:
PASSWORD=1234567
# Точка монтирования Debian:
MNTPT=/data/local/debianOnAndroid
# Путь к карте памяти:
STORAGE=/sdcard
# Образ Debian:
IMG_FILE=$STORAGE/debianOnAndroid.img
# Версия Debian:
DEBIAN_VERSION=stretch
# Создаем точку монтирования:
mkdir -p $MNTPT
# Монтируем образ:
busybox mount -o loop $IMG_FILE $MNTPT
# Нужно для корректной работы chroot:
export PATH=/sbin:/usr/sbin:/bin:/usr/bin:/system/bin:/system/xbin:/su/bin:/su/xbin
# Второй этап debootstrap:
chroot $MNTPT /debootstrap/debootstrap --second-stage
# Настраиваем apt:
echo "deb http://ftp.se.debian.org/debian $DEBIAN_VERSION main contrib non-free" > $MNTPT/etc/apt/sources.list
# Монтируем:
busybox mount -t proc none $MNTPT/proc
busybox mount -t sysfs none $MNTPT/sys
busybox mount -o bind /dev $MNTPT/dev
busybox mount -t devpts none $MNTPT/dev/pts
export TMPDIR=/tmp
#chroot $MNTPT /bin/bash
# Чтобы apt мог работать с сетью, нужно перевести его в группу Internet (3003)
chroot $MNTPT sed -i 's#_apt:x:104:65534::/nonexistent:/bin/false#_apt:x:104:3003::/nonexistent:/bin/false#' /etc/passwd
# Устанавливаем пакеты, которые нам понадобятся:
chroot $MNTPT apt-get update
chroot $MNTPT apt-get --yes upgrade
chroot $MNTPT apt-get --yes install ne openssh-server unzip \
android-sdk-build-tools android-sdk-platform-tools
# Устанавливаем пароль для доступа по SSH:
echo "echo 'root:$PASSWORD' | chpasswd" > $MNTPT/root/setpasswd.sh
chroot $MNTPT /bin/sh /root/setpasswd.sh
cat $MNTPT/root/setpasswd.sh
# Заменяем строчку в конфиге SSH, чтобы работал доступ под root'ом:
chroot $MNTPT sed -i '/PermitRootLogin without-password/c\PermitRootLogin yes' /etc/ssh/sshd_config
chroot $MNTPT /etc/init.d/ssh restart
# Создаем папку AStA в Debian и монтируем на нее папку Android:
mkdir -p $MNTPT/AStA
busybox mount -o bind $STORAGE/AStA $MNTPT/AStA
# Имена файлов архивов:
ANDROID_SDK_TAR_GZ=android-sdk-linux.tar.gz
JDK_8_TAR_GZ=jdk-8u144-linux-arm32-vfp-hflt.tar.gz
GRADLE_ZIP=gradle-3.5-bin.zip
# Распаковываем архивы:
chroot $MNTPT tar -xzvf /AStA/archives/$ANDROID_SDK_TAR_GZ -C /opt
chroot $MNTPT tar -xzvf /AStA/archives/$JDK_8_TAR_GZ -C /opt
chroot $MNTPT unzip /AStA/archives/$GRADLE_ZIP -d /opt
#
echo 'firstMountAndConfigureDebian script done'
```
#### Запуск установки через скрипт
Чтобы установить на устройство образ Debian, приложение и все необходимые скрипты, нужно выполнить следующую последовательность действий:
```
git clone https://github.com/tabatsky/AStA.git
cd AStA/scripts
# Подправить переменные в скрипте start.sh
sh start.sh
```
Так же можно скачать готовый образ Debian (под armhf) [здесь](https://yadi.sk/d/xvJflNsq3MokRG), либо скачать через [приложение](https://yadi.sk/d/vhQ_VHH23N4oju).
#### Подключение и отключение Debian
Следующий скрипт монтирует Debian и запускает ssh, а также монтирует папку AStA с устройства на Debian:
```
MNTPT=/data/local/debianOnAndroid
STORAGE=/sdcard
IMG_FILE=$STORAGE/debianOnAndroid.img
mkdir -p $MNTPT
busybox mount -o loop $IMG_FILE $MNTPT
export PATH=/sbin:/usr/sbin:/bin:/usr/bin:/system/bin:/system/xbin:/su/bin:/su/xbin
busybox mount -t proc none $MNTPT/proc
busybox mount -t sysfs none $MNTPT/sys
busybox mount -o bind /dev $MNTPT/dev
busybox mount -t devpts none $MNTPT/dev/pts
export TMPDIR=/tmp
#chroot $MNTPT bash
chroot $MNTPT /etc/init.d/ssh start
mkdir -p $STORAGE/AStA
mkdir -p $MNTPT/AStA
busybox mount -o bind $STORAGE/AStA $MNTPT/AStA
```
А этот, соответственно, останавливает ssh и все размонтирует:
```
MNTPT=/data/local/debianOnAndroid
export PATH=/sbin:/usr/sbin:/bin:/usr/bin:/system/bin:/system/xbin:/su/bin:/su/xbin
busybox umount $MNTPT/AStA
chroot $MNTPT /etc/init.d/ssh stop
busybox umount $MNTPT/dev/pts
busybox umount $MNTPT/dev
busybox umount $MNTPT/proc
busybox umount $MNTPT/sys
busybox umount $MNTPT
```
Запустить данные скрипты можно через shell:
```
su -c sh /sdcard/AStA/scripts/mountDebian.sh
su -c sh /sdcard/AStA/scripts/umountDebian.sh
```
Либо можно просто нажать на соответствующую кнопку в приложении.
#### Запуск команд Gradle
Запустить сборку Gradle можно, подключившись по ssh, и запустив следующую команду:
```
sh /AStA/scripts/gradleExec.sh /AStA/Projects/MyProject/myModule/ myCmd
# Например:
sh /AStA/scripts/gradleExec.sh /AStA/Projects/AStA-app/app/ assembleDebug
```
Аналогично, можно просто выбрать нужную команду, проект и модуль и нажать на кнопку в приложении.
#### Ограничения
1. В файле build.gradle проекта должна быть указана версия 'com.android.tools.build:gradle': 2.2.\*;
2. В файлах build.gradle всех модулей должна быть указана buildToolsVersion == 24.0.0;
3. В файлах build.gradle всех модулей должна быть указана compileSdkVersion <= 24.
#### На этом у меня все
Все скрипты, а также исходный код [приложения](https://yadi.sk/d/vhQ_VHH23N4oju), можно найти здесь:
[github.com/tabatsky/AStA](https://github.com/tabatsky/AStA)
В качестве заключения хочу сказать, что этим методом мне удалось успешно собрать само приложение AStA-app. | https://habr.com/ru/post/338216/ | null | ru | null |
# Git: Игнорирование отслеживания файлов, которые уже есть в удаленном репозитории
Если внести файл в **.gitignore**, то он не будет отслеживаться гитом лишь в том случае, если этого файла нет в удаленном репозитории.
Но если в репозитории уже есть (к примеру конфиги сайта), а мы не хотим, чтобы наши локальные конфиги отслеживались, то можно выполнить команду:
`git update-index --assume-unchanged application/config/database.php`
либо всю папку
`git update-index --assume-unchanged application/config/*`
Чтобы перестать игнорировать изменения, нужно использовать параметр **--no-assume-unchanged**.
`git update-index --no-assume-unchanged application/config/*`
#### Update: Если конфиг изменили
Если всё же кто-то изменил структуру файла конфига, то git не даст сделать pull, т.к. все-равно будет считать, что файл конфига с нашими паролями отличается от того, что прийдет с командой pull.
Чтобы все-таки получить новые изменения, но и свои пароли сохранить в конфиге нужно сделать следующее:
1. Сохранить текущие конфиги (с нашими локальными паролями) в отдельную папку например.
2. Отменить игнорирование изменений (параметр `--no-assume-unchanged`).
`git update-index --no-assume-unchanged application/config/database.php`
3. На данном шаге команда `git status` покажет, что файл **application/config/database.php** был изменен, но еще не проиндексирован. Именно эти изменения и мешают нам забрать командой `git pull` новые изменения. Учитывая, что на шаге 1 мы сохранили наши конфиги в отдельную папку — мы можем сейчас отменить эти изменения.
`git checkout application/config/database.php`
4. Сейчас `git status` покажет, что изменений нет (`nothing to commit, working tree clean`). Забираем новые изменения:
`git pull`
5. *Опционально:* Если мы привыкли работать в отдельной ветке (не в **master**), то переходим в эту ветку (например: **dev-branch**) для последующей работы:
`git checkout dev-branch`
и вливаем в ветку dev-branch новые изменения из ветки master (куда мы их уже получили командой `git pull`):
`git merge master`
6. Изменяем теперь наши обновленные конфиги, возвращая туда наши локальные пароли и все то, что мы желаем там видеть, но не хотим это хранить в репозитории (для этого мы сохранили все в шаге 1). После чего команда `git status` естественно покажет, что конфиги изменены, но не проиндексированы.
7. И только теперь мы можем снова включить игнорирование (`--assume-unchanged`):
`git update-index --assume-unchanged application/config/database.php`
После чего `git status` покажет, что все чисто (`nothing to commit, working tree clean`) и мы сможем снова работать, делать коммиты и переключаться между ветками.
**P.S.** *Разумеется автор не рекомендует хранить конфиги с паролями в репозитории. Это лишь наглядный пример.*
***Модератору:** Данный 2do list писал ранее для себя в жж (https://pashakiz.livejournal.com/183468.html)
Если для хабра это важно — могу скрыть свою пост в жж под ключ.* | https://habr.com/ru/post/709246/ | null | ru | null |
# Расшифровка сохранённых паролей в MS SQL Server
Давным-давно, в далёкой галактике, пред-предыдущий администратор вашего SQL Server задал в нём linked server, используя специально для этой цели созданный аккаунт со сгенерированным паролем. Теперь вам с этим линком нужно что-то сделать, например перенести его на другой SQL Server; но просто так это не сделать, потому что никто не знает пароля от того аккаунта. Знакомая ситуация?
Хотя MSSQL не хранит пароли для своих аккаунтов, а хранит только их хэши, — с linked server-ами так не получится, потому что для успешной аутентикации перед внешним сервером нужно обладать паролем в открытом виде. Пароли для linked server-ов хранятся в зашифрованном виде в таблице `master.sys.syslnklgns`:
Но не всё так просто. Во-первых, эта таблица недоступна из обычного SQL-соединения, а доступна только из [Dedicated Administrative Connection](http://technet.microsoft.com/en-us/library/ms178068%28v=sql.105%29.aspx). На DAC накладываются существенные ограничения: открыть DAC может только пользователь с привилегией sysadmin, и одновременно к одному серверу может быть открыто только одно DAC. Если у вас есть права локального администратора на сервере, но вы не можете войти в MSSQL с правами sysadmin, то есть [обходной путь](https://www.netspi.com/blog/entryid/133/sql-server-local-authorization-bypass) — заходить не из-под своего аккаунта, а из-под аккаунта сервиса MSSQL или даже из-под LocalSystem.
Во-вторых, несмотря на то, что поле с зашифрованным паролем называется `pwdhash` — это никакой не хэш, а зашифрованные данные. Ключ для расшифровки хранится в системной таблице `master.sys.key_encryptions`:
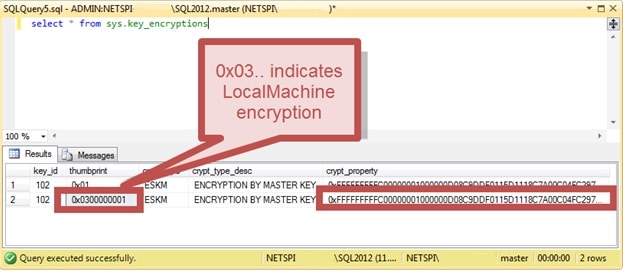
Этот ключ хранится в двух экземплярах: первый (`thumbprint=0x01`) позволяет использование только из-под аккаунта сервиса MSSQL, второй (`thumbprint=0x0300000001`) — из-под любого аккаунта на сервере. Обратите внимание, что ни один из хранящихся ключей не пригоден для «офлайн-расшифровки» паролей вне сервера, так что если злоумышленнику и удастся украсть данные обеих этих системных таблиц, ему это ничего не даст.
В-третьих, ключ для расшифровки сам зашифрован, и «ключ для ключа» хранится в системном реестре в `HKLM:\SOFTWARE\Microsoft\Microsoft SQL Server\$InstanceName\Security\Entropy`:
Чтобы прочитать из реестра это значение, опять же требуются права локального администратора на сервере.
Для получения всех трёх составляющих и расшифровки сохранённых паролей, автор создал [удобный PowerShell-скрипт](https://github.com/NetSPI/Powershell-Modules/blob/master/Get-MSSQLLinkPasswords.psm1).
Если запустить его из-под аккаунта локального администратора на сервере, он порадует вас примерно таким окошком:
Если же вы не хотите запускать на production-сервере непонятно кем написанные скрипты, то саму расшифровку можно выполнить и без прав администратора, если сначала вытащить три составляющих при помощи SQL Studio и regedit, и вставить их в скрипт в явном виде. Первый шаг расшифровки (`$ServiceKey = [System.Security.Cryptography.ProtectedData]::Unprotect($SmkBytes, $Entropy, 'LocalMachine')`) обязан выполняться на сервере, но второй (`$Decrypt = $Decryptor.CreateDecryptor($ServiceKey,$Logins.iv)` и последующая работа с CryptoStream) может выполняться и в офлайне.
[Аналогичным образом](https://blog.netspi.com/decrypting-mssql-credential-passwords/) расшифровываются и credentials, сохранённые в базе для выполнения команд (`xp_cmdshell` и т.п.) от имени менее привилегированных аккаунтов, нежели сервис MSSQL.
С одной стороны, всё это кажется вопиющим примером security through obscurity: если расшифровка паролей для соединения с linked server-ами уже реализована в MSSQL, то почему нет возможности показать эти пароли забывчивому администратору? С другой стороны, с точки зрения безопасности всё весьма неплохо: для расшифровки паролей нужен доступ к серверу с правами локального администратора, а если злоумышленник получил такой доступ, то он уже и так может делать с сервером всё что захочет. Нежелательное повышение привилегий возможно лишь в том случае, если пароль от какого-нибудь linked server-а используется впридачу для чего-нибудь важного, например как пароль администратора того же сервера :^) | https://habr.com/ru/post/351386/ | null | ru | null |
# Правильная адаптивная типографика с FlowType.JS
[](http://simplefocus.com/flowtype/)
Согласно правилам типографики, контент страницы хорошо читается, если в строке от 45 до 75 символов. При разработке адаптивного дизайна это сложно реализовать только лишь с помощью Media Queries. Появился [jQuery плагин FlowType](http://simplefocus.com/flowtype/), который помогает добиться такого соотношения при любом размере экрана и ширине окна.
**FlowType** меняет размер шрифта и междустрочный интервал в соответствии с шириной блока контента. Кроме того можно задавать параметры плагина, например максимальную и минимальную ширину окна, при которой FlowType будет работать.
```
$('body').flowtype({
minimum : 500,
maximum : 1200
});
```
А также пределы размеров шрифта на странице:
```
$('body').flowtype({
minFont : 12,
maxFont : 40
});
```
Из-за того, что все шрифты различаются, иногда целесообразно задать некий коэффициент, который будет масштабировать шрифт и междустрочный интервал на странице для лучшей читабельности:
```
$('body').flowtype({
fontRatio : 30,
lineRatio : 1.45
});
```
**FlowType** — проект с открытым кодом ([страница на GitHub](https://github.com/simplefocus/FlowType.JS)), распространяется под [лицензией MIT](http://choosealicense.com/licenses/mit/). [Демонстрация](http://simplefocus.com/flowtype/demo.html), где весь контент масштабируется плагином. | https://habr.com/ru/post/191106/ | null | ru | null |
# Паттерн проектирования «Адаптер» / «Adapter»
[Почитать](http://spiff.habrahabr.ru/blog/84706/) описание других паттернов.
Пожалуй, начнем.
Для начала, поясню несколько организационных вопросов.
* Описание того или иного паттерна, является моей сугубо личной интерпретацией теоретического и практического материала, собранного из книг и интернет-статей;
* При построении UML-диаграмм, я буду использовать свободный редактор от компании [astah](http://astah.change-vision.com/en/product/astah-community.html), ввиду его простоты и независимости от конкретного языка или среды. При этом, диаграммы не будут отличатся изобилием картинок и цветов, но будут ясно отображать суть паттерна;
* При реализации практических примеров, язык программирования будет выбираться совершенно случайно. Однако, я буду стараться подбирать те языковые средства, на которых данный паттерн реализуется не тривиально;
* Каждый мой пост, будет содержать как минимум 5 секций — Проблема, Описание патерна, Практическая задача, Диаграмма классов и Реализация;
* Если Вы, с чем-то не согласны или у Вас есть дополнения к материалу, изложенному мной — я буду рад их почитать в комментариях. Однако, помните — я тоже изучаю паттерны вместе с Вами :)
#### Интро
Как Вы уже успели заметить, данная секция является не обязательной в моих постах про паттерны. Но я не мог начать писать о конкретном паттерне, не объяснив, зачем они собственно нужны.
Не так давно, когда я был на младших курсах, на мое высказывание «Да мы уже умеем писать программы!», мой коллега сказал — «Максимум, что вы умеет писать — это алгоритмы, но не программы.» Эти его слова я вспоминаю до сих пор с улыбкой на лице. Он был совершенно прав, все чему нас научили за 3 года (я тогда был на третьем курсе) — реализация базовых алгоритмов из Кормена/Кнута. Мы действительно могли писать эти алгоритмы, могли писать функции, процедуры реализующие их. Даже могли написать класс на C++ или Java в котором описать все логику работы с данным классом объектов. Но когда таких классов становилось два или даже три :) начинались проблемы. И при любой попытке написания какой-либо «программы» начиналось изобретение велосипеда (я думаю, что каждый кто читает этот пост, сам изобрел несколько таких велосипедов). Тогда, я начал подозревать, что должно быть что-то, какая теоретическая база, аппарат, механизм, называйте это как хотите, которая в принципе расскажет мне — «как писать программы».
Оказалось, такая база есть — это паттерны проектирования. По большому счету, *паттерн — это типичное решение общих проблем проектирования*. Паттерны решают ряд основных проблем, связанных с программированием/проектированием. Это — изобретение велосипеда, проблема повторного использования кода, проблема сопровождения кода.
Безусловно, шаблоны проектирования если не решают, то упрощают решение данных проблем. Так, разработчик или проектировщик, зная хотя бы базовый набор паттернов, использует их в замену придумываемым велосипедам. Повторное использование кода становится более прозрачное и оправданное. А сопровождать код, написанный с использованием паттернов как минимум понятно и не затруднительно.
Теперь, мне кажется можно перейти к рассмотрению конкретного паттерна — «Адаптера» («Adapter»).
#### Проблема
Обеспечить взаимодействие объектов с различными интерфейсами. Адаптировать, а не переписывать существующий код к требуемому интерфейсу.
#### Описание
Паттерн «Адаптер», на самом деле, является одним из немногих, который программисты применяют на практике, сами того не осознавая. Адаптер можно найти, пожалуй в любой современной программой системе — будь это простое приложение или, например, Java API.
Взглянем более детально на проблему, для понимая того как должен выглядеть Адаптер. Проблема, опять-таки, заключается в повторном использовании кода. Иными словами, есть клиент, который умеет работать с некоторым интерфейсом, назовем его клиентским. Есть класс, который, в принципе, делает то, что нужно клиенту но не реализует клиентский интерфейс. Безусловно, программирование нового класса довольно бессмысленная трата времени и ресурсов. Проще *адаптировать* уже существующий код к виду, пригодному для использования клиентом. Для этого и существует адаптер. Причем, разделяют два вида адаптеров — Object Adapter (адаптер на уровне объекта) и Class Adapter (адаптер на уровне класса). Мы рассмотри оба, но по порядку.
#### Практическая задача
Для примера, рассмотрим простую ситуацию. Есть некоторый класс — SequenceGenerator, генерирующий последовательности целых чисел, по определенному закону — это и есть наш клиент. Есть интерфейс — Generator, который использует клиент непосредственно для генерации каждого отдельного элемента последовательности — это наш клиентский интерфейс. К тому-же, есть класс RandomGenerator, который уже умеет генерировать случайные числа. Конечно, SequenceGenerator не может использовать RandomGenerator для генерации элементов, потому что он не соответствует клиентскому интерфейсу. Наша задача — написать адаптер (двумя способами) RandomGenerator к SequenceGenerator.
#### Диаграммы классов
##### Object Adapter

##### Class Adapter

Итак, имея диаграммы классов давайте поговорим об отличиях между адаптером на уровне объекта и адаптером на уровне класса. На самом деле различия видны уже из названия. В первом случае, адаптируемый объект (RandomGenerator) является полем (ссылкой) в классе адаптера (RandomGeneratorAdapter), во втором же он и является адаптером за счет использования механизма наследования. В реальных проектах, рекомендуется использовать Object Adapter, за счет его меньшей связности с адаптируемым объектом.
#### Реализация
Рассмотрим реализацию поставленной задачи. Object Adapter я реализовывал на С++, Class Adapter на Java.
##### Object Adapter
> `class Generator {
>
> public:
>
> virtual int next() = 0;
>
>
>
> };
>
>
>
> class SequenceGenerator {
>
> private:
>
> Generator \*generator;
>
> protected:
>
> public:
>
> SequenceGenerator(Generator& generator);
>
>
>
> int\* generate(int length);
>
> };
>
>
>
> SequenceGenerator::SequenceGenerator(Generator& generator) {
>
> this->generator = &generator
>
> }
>
>
>
> int\* SequenceGenerator::generate(int length) {
>
> int \*ret = new int[length];
>
>
>
> for (int i=0; i
> ret[i] = this->generator->next();
>
> }
>
>
>
> return ret;
>
> }
>
>
>
> class RandomGenerator {
>
> public:
>
> inline int getRandomNumber() { return 4; }; // It`s really random number.
>
>
>
> };
>
>
>
> class RandomGeneratorAdapter : public Generator {
>
> private:
>
> RandomGenerator \*adaptee;
>
> public:
>
>
>
> RandomGeneratorAdapter(RandomGenerator& adaptee);
>
>
>
> virtual int next();
>
>
>
> };
>
>
>
> RandomGeneratorAdapter::RandomGeneratorAdapter(RandomGenerator& adaptee) {
>
> this->adaptee = &adaptee
>
> }
>
>
>
> int RandomGeneratorAdapter::next() {
>
> return this->adaptee->getRandomNumber();
>
> }
>
>
>
>
>
> // Использование
>
>
>
> int main(int argc, char \*argv[]) {
>
>
>
> RandomGenerator rgenerator;
>
> RandomGeneratorAdapter adapter(rgenerator);
>
> SequenceGenerator sgenerator(adapter);
>
>
>
> const int SIZE = 10;
>
>
>
> int \*seq = sgenerator.generate(SIZE);
>
>
>
> for (int i=0; i
> cout << seq[i] << " ";
>
> }
>
>
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
##### Class Adapter
Классическая реализация паттерна Class Adapter подразумевает использование множественного наследования. В Java, можно воспользоваться имплементацией интерфейсов. На мой взгляд, это даже как-то корректнее.
> `public interface Generator {
>
>
>
> public int next();
>
>
>
> }
>
>
>
> public class SequenceGenerator {
>
>
>
> private Generator generator;
>
>
>
> public SequenceGenerator(Generator generator) {
>
> super();
>
> this.generator = generator;
>
> }
>
>
>
> public int[] generate(int length) {
>
> int ret[] = new int[length];
>
>
>
> for (int i=0; i
> ret[i] = generator.next();
>
> }
>
>
>
> return ret;
>
> }
>
> }
>
>
>
> public class RandomGenerator {
>
>
>
> public int getRandomNumber() {
>
> return 4;
>
> }
>
> }
>
>
>
> public class RandomGeneratorAdapter extends RandomGenerator implements Generator {
>
>
>
> @Override
>
> public int next() {
>
> return getRandomNumber();
>
> }
>
>
>
> }
>
>
>
> // Использование
>
> public class Main {
>
>
>
> public static void main(String[] args) {
>
>
>
> RandomGeneratorAdapter adapter = new RandomGeneratorAdapter();
>
> SequenceGenerator generator = new SequenceGenerator(adapter);
>
>
>
> for (int i: generator.generate(10)) {
>
> System.out.print(i + " ");
>
> }
>
> }
>
> }
>
>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
На этом все. Жду Ваших отзывов в комментариях. | https://habr.com/ru/post/85095/ | null | ru | null |
# Осваиваем Grid в SwiftUI

> Салют, хабр. Прежде, чем мы перейдем к статье, хочу абсолютно бесплатно поделиться с вами записью двух очень полезных уроков которые провели наши преподаватели в преддверии старта базового и продвинутого курсов по iOS-разработке:
>
>
>
> **1. [Быстрый старт в iOS-разработку](https://otus.pw/dLC3/)
> 2. [Делаем многопоточное приложение Kotlin Multiplatform](https://otus.pw/uttH/)**
*А теперь перейдем к статье.*
---
На этой неделе я хочу поговорить с вами о сетках элементов (Grids) — одном из самых ожидаемых нововведений в SwiftUI. Все с нетерпением ждали альтернативы `UICollectionView` в SwiftUI, и, наконец, в этом году она появилась. SwiftUI предоставляет нам представления *LazyVGrid* и *LazyHGrid*, которые мы можем использовать для создания макетов с сетками элементов.
### Основы
*LazyVGrid* и *LazyHGrid* — это два новых типа представления (View), которые SwiftUI предоставляет нам для создания супер настраиваемого макета (Layout) на основе сетки элементов. Единственное различие между ними — ось заполнения. *LazyVGrid* заполняет доступное пространство в вертикальном направлени. *LazyHGrid* же размещает свои дочерние элементы в горизонтальном направлении. Ось — единственное различие между двумя этими представлениями. По этому все, что вы узнаете о *LazyVGrid*, применимо к *LazyHGrid* и наоборот. Давайте посмотрим на первый пример.
```
struct ContentView: View {
private var columns: [GridItem] = [
GridItem(.fixed(100), spacing: 16),
GridItem(.fixed(100), spacing: 16),
GridItem(.fixed(100), spacing: 16)
]
var body: some View {
ScrollView {
LazyVGrid(
columns: columns,
alignment: .center,
spacing: 16,
pinnedViews: [.sectionHeaders, .sectionFooters]
) {
Section(header: Text("Section 1").font(.title)) {
ForEach(0...10, id: \.self) { index in
Color.random
}
}
Section(header: Text("Section 2").font(.title)) {
ForEach(11...20, id: \.self) { index in
Color.random
}
}
}
}
}
}
```
В приведенном выше примере мы создаем сетку из трех столбцов, в которой каждый столбец имеет фиксированный размер в 100pt. Я собираюсь использовать этот пример, чтобы описать все доступные нам варианты конфигурации.
1. Параметр `columns` — это массив, который определяет столбцы в макете сетки (grid layout). Для описания столбца SwiftUI предоставляет нам тип *GridItem*. Мы поговорим о нем немного позже.
2. Параметр `alignment` позволяет нам выровнять содержимое сетки с помощью перечисления `HorizontalAlignment` для *LazyVGrid* и `VerticalAlignment` для *LazyHGrid*. Работает так же, как `stack alignment`.
3. Параметр `spacing` указывает расстояние между каждой строкой внутри *LazyVGrid* или пространство между каждым столбцом внутри *LazyHGrid*.
4. Параметр `pinnedViews` позволяет определять опции для закрепления верхних и нижних колонтитулов секции (headers и footers). По умолчанию он пуст, что означает, что верхние и нижние колонтитулы ведут себя как содержимое и исчезают при прокрутке. Вы можете включить закрепление верхнего и нижнего колонтитулов, в этом случае они будут накладываться на контент и становятся постоянно видимыми.
### GridItem
Каждый столбец в сетке должен быть определен с помощью структуры `GridItem`. Тип `GridItem` позволяет нам указывать размер (size), выравнивание (alignment) и интервал (spacing) для каждого столбца. Давайте посмотрим на небольшой пример.
```
private var columns: [GridItem] = [
GridItem(.fixed(50), spacing: 16, alignment: .leading),
GridItem(.fixed(75)),
GridItem(.fixed(100))
]
```
Как видите, каждый столбец может иметь разные параметры размера, интервала и выравнивания. Самое интересное здесь — размер. Есть три способа определить размер столбца внутри сетки. Он может быть фиксированным (fixed), гибким (flexible) или адаптивным (adaptive).
**Fixed** столбец является самым очевидным. Сетка размещает столбец в соответствии с заданным вами размером. В предыдущем примере мы создали макет с тремя столбцами, в котором столбцы имеют фиксированные размеры 50pt, 75pt и 100pt соответственно.
Опция **flexible** позволяет определить столбец который расширяется или сжимается в зависимости от доступного пространства. Мы также можем предоставить минимальный и максимальный размер гибкого столбца. По умолчанию он использует минимальное значение 10pt и не ограничен по максимуму.
```
private var columns: [GridItem] = [
GridItem(.flexible(minimum: 250)),
GridItem(.flexible())
]
```

Здесь мы создаем макет, который делит доступное пространство между двумя гибкими столбцами. Первый столбец занимает 250pt своего минимального размера, а второму остается все остальное доступное пространство.
Самый интересная опция — **adaptive**. Адаптивный вариант позволяет нам размещать несколько элементов в пространстве одного гибкого столбца. Давайте попробуем разобраться с этим на примере.
```
private var columns: [GridItem] = [
GridItem(.adaptive(minimum: 50, maximum: 100)),
GridItem(.adaptive(minimum: 150))
]
```
Как вы можете видеть, у нас есть два адаптивных столбца. В первом столбце разместилось несколько элементов с минимальным размером 50pt и максимальным 100pt. Адаптивные столбцы удобны, когда количество элементов внутри столбца должно зависеть от доступного пространства.
Настоящая мощь сеток проявляется, когда вы начинаете смешивать типы столбцов. Вы можете создать макет из двух столбцов, где первый фиксированный, а второй адаптивный. Давайте посмотрим как это будет выглядеть.
```
private var columns: [GridItem] = [
GridItem(.fixed(100)),
GridItem(.adaptive(minimum: 50))
]
```

### Заключение
Сетка позволяет создавать очень сложные и интересные макеты путем смешивания различных типов `GridItem`. Следует отметить, что все изменения в сетках можно анимировать. Надеюсь, вам понравилась эта статья. Не стесняйтесь подписываться на меня в [Твиттере](https://twitter.com/mecid) и задавать свои вопросы, связанные с этой темой. Спасибо за внимание, до встречи!
---
Узнать подробнее о наших курсах вы можете по ссылкам ниже:
* [iOS-разработчик. Базовый курс](https://otus.pw/dLC3/)
* [iOS-разработчик. Продвинутый курс](https://otus.pw/uttH/)
--- | https://habr.com/ru/post/516566/ | null | ru | null |
# Prisma-CMS как движок для быстрого создания MVP
Наверняка многие слышали понятие MVP (Минимально жизнеспособный продукт [вики](https://ru.wikipedia.org/wiki/%D0%9C%D0%B8%D0%BD%D0%B8%D0%BC%D0%B0%D0%BB%D1%8C%D0%BD%D0%BE_%D0%B6%D0%B8%D0%B7%D0%BD%D0%B5%D1%81%D0%BF%D0%BE%D1%81%D0%BE%D0%B1%D0%BD%D1%8B%D0%B9_%D0%BF%D1%80%D0%BE%D0%B4%D1%83%D0%BA%D1%82)). На хабре тоже много статей про MVP, но в основном это или просто описание что такое MVP и для чего оно, или различные success и не очень story. Но я не нашел ни одной статьи, где бы описывалось на чем кто свое это MVP делал. Но ведь считается, что блоги личные проще делать на одном движке, интернет-магазины на другом и т.п. (каждый подставит свое название любимого движка для этих целей). Но почему тогда не определен более удобный движок для MVP? Я не дам четкого ответа на этот вопрос, но поделюсь своими мыслями чем именно для создания MVP хороша моя Prisma CMS, о которой я [писал](https://habr.com/ru/post/448982/) здесь пару месяцев назад. Кому интересно, прошу под кат.
Что интересно, по большому счету MVP можно сравнить с более продвинутым прототипированием [вики](https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%BE%D1%82%D0%BE%D1%82%D0%B8%D0%BF%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5). При этом для прототипирования есть специальное ПО, и я когда-то давно даже пользовался тем же самым Axure. Но чего мне не хватило в Axure и из-за чего я практически сразу от него отказался? (Я не знаю, может сейчас он стал более продвинутым и решены эти вопросы, но на тот момент не было).
1. Отсутствует работа с реальными данными. То есть у меня есть в прототипе раздел Пользователи, но я не могу по API получить данные пользователей и вывести их в цикле в своем шаблоне. Да и вообще в принципе нет возможности работать с реальными данными (создавать записи, читать их).
2. Проходя этап прототипирования и переходя непосредственно к разработке, нельзя использовать созданные в прототипе шаблоны. То есть после того, как прототип был создан и согласован с заказчиком и когда перешли к программированию, на прототип мы могли только что смотреть глазами, более ничего с ним сделать нельзя было. А так хотелось накидать прототип и далее уже использовать его в разработке.
Были и еще моменты, но вот эти два самых главных. Получалось, что этапы прототипирования и программирования жили своей самостоятельной жизнью и никак друг на друга не влияли. А хотелось бы, чтобы этап прототипирования плавно переходил непосредственно в программирование. А в рамках текущей статьи можно и вовсе предложить, что прототипирование перетекает в создание MVP, а далее уже, в случае успеха, MVP развивать до конечного полноценного продукта. Ведь если так подумать, то создание MVP не всегда гарантирует то, что в дальнейшем будет более полный продукт. Ведь в чем смысл создания MVP? Во-первых, с минимальными издержками реализовать идею, чтобы можно было попробовать в работе, а во-вторых, чтобы изучить спрос и решить для себя стоит ли дальше вкладываться и развивать это до полноценного продукта. И вот получается, что нужен инструмент, который позволил бы быстро создавать прототипы/MVP, а с другой стороны в случае успеха MVP можно было бы развивать проект далее без особых ограничений.
Собственно говоря, глядя на Prisma CMS, я как раз и вижу такой движок. Здесь многое есть для того, чтобы быстро накидать заготовку проекта:
* Практически вся работа выполняется на фронте через собственный WYSIWYG фронт-редактор.
* УРЛы реализованы на react-router, что позволяет адресность так же прописывать прям во фронте в редакторе, а не на сервере.
* API реализовано на GraphQL, что позволяет и запросы писать во фронте, а не на сервере. При этом встроен Graph*i*QL, что упрощает процесс написания запросов.
* Плюс к этому есть генерируемые фильтры, постраничность и прочие полезные плюшки.
И все это openSource, то есть это не SaaS, за который надо постоянно платить (еще и не имея всего в собственном распоряжении). Это можно разворачивать на своем сервере и кастомизировать под себя.
Прежде чем я опишу процесс установки его на свой сервер и процессы кастомизации, предлагаю посмотреть запись процесса создания отдельного раздела на сайте. Он почти 15 минут, но достаточно посмотреть первые 4 минуты, этого более чем достаточно для того, чтобы получить представление о Prisma CMS, и при наличии интереса перейти к дальнейшему чтению топика, а может и попробовать развернуть движок у себя.
Итак, установка Prisma CMS на сервер (я использую ubuntu, желательно минимум 4Gb ОЗУ и диск SSD).
*Предполагается, что вы уже знакомы с node-js, npm/yarn, react и graphql.*
### 1. Устанавливаем необходимое ПО
*Если в терминале вставлять сразу все, выполнение может оборваться, так что лучше построчно выполнять.*
Это минимальная установка без каких-то настроек уровней доступов и т.п., просто в ознакомительных целях, то есть если вы на новом чистом сервере будете пробовать, то выполнение всего будет от рута (в том числе запуск сайта). Для нашего эксперимента это совсем не важно.
```
sudo apt update
sudo apt install mc
sudo apt install git
curl -sL https://deb.nodesource.com/setup_10.x | sudo -E bash -
sudo apt-get install -y nodejs
sudo npm i -g yarn
sudo apt-get install software-properties-common python-software-properties
sudo apt-key adv --keyserver hkp://p80.pool.sks-keyservers.net:80 --recv-keys 58118E89F3A912897C070ADBF76221572C52609D
sudo apt-add-repository 'deb https://apt.dockerproject.org/repo ubuntu-xenial main'
sudo apt-get update
sudo apt-get install -y docker-engine
sudo curl -L https://github.com/docker/compose/releases/download/1.18.0/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose
sudo chmod +x /usr/local/bin/docker-compose
```
### 2. Клонируем репозиторий
```
mkdir /var/www
cd /var/www
git clone https://github.com/prisma-cms/boilerplate
cd boilerplate
yarn --ignore-engines
```
3. Запускаем докер-контейнеры с MySQL и prisma (prisma — это отдельный продукт, не мой, но с которым сильно связана серверная часть, смотрите [github.com/prisma/prisma](https://github.com/prisma/prisma)).
```
sudo docker-compose -f src/server/scripts/docker/prisma/docker-compose.yml up -d
```
Если вам захочется смотреть в базу данных через phpMyAdmin, установим и его.
```
sudo docker run -d --link prisma_mysql_1:db --network prisma_default -p 8090:80 phpmyadmin/phpmyadmin
```
Будет висеть на порту 8090. По умолчанию логин/пароль root/prisma
### 4. Деплоим схему
```
endpoint=http://localhost:4466/my-project/dev yarn deploy
```
my-project/dev соответственно можно писать свои и на одном сервере создавать много проектов.
*Важно! На продакшене порт 4466 должен быть закрыт фаерволом, к нему не должно быть прямого доступа извне.*
### 5. Запускаем API-сервер
```
APP_SECRET=MyStrongSecret endpoint=http://localhost:4466/my-project/dev yarn start-server
```
После запуска вы можете открыть API-интерфейс [server-ip](http://server-ip):4000.
Как я и писал в предыдущей статье, это промежуточный сервер, реализующий вашу собственную логику поверх сгенерированной (которая крутится на порту 4466).
### 6. Запускаем фронт
Открываем еще один терминал и в той же папке выполняем
```
yarn start
```
Запустится фронт на порту 3000. Теперь можно преступать непосредственно к «программированию» фронта. Открываете [server-ip](http://server-ip):3000. При заходе, пока еще для фронта нет ни одного сохраненного шаблона, для вас будет выведена кнопка авторизации. Логика в том, чтобы зарегистрироваться и начать оформлять сайт. Кто первый — того и ~~тапки~~ сайт. Вот так это примерно выглядит:
### 7. Билдим скрипты и запускаем SSR (Servcer-Side Rendering)
Запуск через yarn start — это dev-режим, подходит для первого запуска (проверки, что все работает) и для программирования непосредственно JS-части. А для боя конечно же нужнен собранный фронт. Прерываем запущенный yarn start через Ctrl+C и билдим скрипты.
```
yarn build
```
Можно сходить покурить и налить кофе, процесс этот небыстрый. В редких случаях билдинг с первого раза разваливается, просто запустите еще раз, в таком случае как правило он завершается успешно и значительно быстрее.
Когда билдинг закончится, запускаем собранный фронт.
```
yarn start-ssr
```
Теперь и запуск значительно быстрее, и скрипты меньше в размерах.
### Заключение
На видео видно, что есть местами весьма большие проблемы с юзабилити, но проект еще развивается, постепенно эти проблемы устраняются. Но зато многое можно сделать прям во фронте. Так же предстоит еще серьезная чистка исходников, так как там накопилось много всего, что уже особо и не нужно, а просто тянется наследием. В результате фронт должен значительно облегчиться. И собираться будет шустрее, и загрузка страницы оперативней.
В любом случае, повторюсь, на мой взгляд, как движок для MVP очень даже может сгодиться — быстро накидать что-то и показать клиенту. При этом если переходить к разработке конечного продукта, даже если фронт не устраивает, можно его полностью выкинуть и переписать по-своему, при этом база данных и серверная логика никуда не денется. Ведь это headless-cms. Но я рассчитываю на то, что со временем фронт будет доведен до вполне приемлемого уровня.
Если у сообщества будет интерес, я тогда еще отдельно напишу топики про то как кастомизировать фронт (добавлять свои блоки для фронт-редактора) и как кастомизировать сервер (расширять схему, добавлять свои сущности, дописывать резолверы и т.п.). Уже наработано довольно много средств для быстрого выполнения подобных задач.
[Исходники проекта](https://github.com/prisma-cms/)
Всем спасибо за внимание! | https://habr.com/ru/post/457270/ | null | ru | null |
# Push уведомления в приложениях для iOS
Добрый день, Хабражитель.
Все наверное в курсе, что в iOS существует такой полезный сервис как Push уведомления. Я тоже был в курсе, но пока не столкнулся с его реальным использованием, даже не знал, что с ним есть так много нюансов. В этом топике вы узнаете два аспекта об этом сервисе: что нужно делать в xCode, и как отсылать сами пуш сообщения через php сервер.
Под катом описано то, как все это работает.
Столкнулся я с Push совсем недавно, когда разрабатывал свое новое приложение — [Family Expenses](http://itunes.apple.com/ru/app/id464151086). Там я собирался применить Push для уведомления пользователя о запросе синхронизации.
Push-уведомления бывают двух видов: локальные и удаленные. Локальные в этой статье рассматривать не будем. У них достаточно простой механизм реализации и детально описан в референсах.
Механизм удаленного Push уведомления выглядит следующим образом.
1. При старте приложения вызывается метод didRegisterForRemoteNotificationsWithDeviceToken который, если есть подключение к интернет возвращает 64 символьную строку Token. С этой стройкой есть нюанс: она почему-то приходит с символами «<» и «>» в начале и конце и пробелами в средине. Поэтому стоит почистить строку от этих символов.
2. Токен необходимо отправить на ваш сервер, который хранит его. По сути он является уникальным адресом приложения и девайса. Через него потом и ведётся отправка Push уведомления. В коде ниже как раз представлен механизм описанный в пунктах 1 и 2.
```
- (void)application:(UIApplication*)application didRegisterForRemoteNotificationsWithDeviceToken:(NSData*)deviceToken
{
NSMutableString *tokenString = [NSMutableString stringWithString:
[[deviceToken description] uppercaseString]];
[tokenString replaceOccurrencesOfString:@"<"
withString:@""
options:0
range:NSMakeRange(0, tokenString.length)];
[tokenString replaceOccurrencesOfString:@">"
withString:@""
options:0
range:NSMakeRange(0, tokenString.length)];
[tokenString replaceOccurrencesOfString:@" "
withString:@""
options:0
range:NSMakeRange(0, tokenString.length)];
NSLog(@"Token: %@", tokenString);
if (tokenString) {
[[NSUserDefaults standardUserDefaults] setObject:tokenString forKey:@"token"];
}
NSString *urlFormat = @"http://your.domain.com/regDevice.php?deviceToken=%@";
NSURL *registrationURL = [NSURL URLWithString:[NSString stringWithFormat:
urlFormat, tokenString];
NSMutableURLRequest *registrationRequest = [[NSMutableURLRequest alloc]
initWithURL:registrationURL];
[registrationRequest setHTTPMethod:@"PUT"];
NSURLConnection *connection = [NSURLConnection connectionWithRequest:registrationRequest
delegate:self];
[connection start];
[registrationRequest release];
}
```
На стороне приложения это практически все, не считая механизма обработки входящего сообщения.
3. По мере необходимости наш сервер инициализирует отправку Push уведомления, адресом получателя в котором является Токен. Для этого на сервере должен быть Push сертификат который можно получить [developer.apple.com](http://developer.apple.com/) в разделе Provisioning Portal -> App IDs -> Configure напротив вашего App ID. Детально описывать этот процесс не буду, потому что там же есть пошаговая инструкция как создать сертификат.
Но тот сертификат для нашего сервера не подходит полностью. Его необходимо ещё обработать и обединить с вашим сертификатом разработчика.
Детальную пошаговую инструкцию можно подсмотреть [здесь](http://blog.boxedice.com/2009/07/10/how-to-build-an-apple-push-notification-provider-server-tutorial/).
Для отправки сообщения на сервере, в нашем случае хостинг с PHP, необходимо установить сертификат, который сгенерирован по инструкции в ссылке выше.
На своем сервере я использовал ApnsPHP — это класс с открытым исходным кодом для взаимодействия с Apple Push Notification service.
Все очень просто и удобно. Самое главное – заводится с пол-пинка. [code.google.com/p/apns-php](http://code.google.com/p/apns-php/)
Там же есть и пример проекта для xCode с механизмом обработки входящих Push сообщений.
Если в общем – то это практически все.
**Теперь нюансы, с которыми я столкнулся.**
Для отправки сообщений в Apple предусмотрели два сервера:
`ssl://gateway.push.apple.com:2195
ssl://gateway.sandbox.push.apple.com:2195`
Первый используется для завершенных продуктов, а второй для тестирования, «песочница».
Если вы тестируете приложение в режиме Debug и с Developer provision profile – тогда при тестировании на сервере используйте sandbox. Если же вы делаете Ad Hoc релиз, то есть подписываете приложение уже сертификатом для дистрибуции – тогда sandbox уже работать не будет. Пишу об этом, потому что сам долго не мог понять, почему не работает.
Ещё есть специальный механизм для чистки базы токенов от адресов, которые уже не действительны. Например, если приложение было удалено с девайса.
Для этого можно использовать ApnsPHP там тоже есть для этого механизмы.
Надеюсь, что достаточно просто описал механизм.
**UPD.**
Только что эксперементировал. Оказалось, что Токен один для конкретного девайса, и или, может быть для одного разработчика. Потому что с разными bundle ID у меня выдает один и тот же токен. А вот какому приложению отсылать — это определяет сертификат, который на сервере. | https://habr.com/ru/post/130365/ | null | ru | null |
# Про NAP, MAB и динамические VLAN-ы
Статья о том, как в нашей небольшой организации используются технологии корпораций Microsoft и Cisco в плане ограничения предоставления доступа к сети различным устройствам. Под катом будет рассказано про NAP, MAB и как все это можно использовать.
Некоторые вещи описаны вскользь, т.к. общеизвестны либо достаточно подробно описаны во многих документах.
**Технология номер один** — NAP (Network Access Protection) от Microsoft — предоставление доступа к сети на основании состояния «здоровья» компьютеров. Другими словами — определяются некоторые политики в которых сказано, что для получения доступа к сети компьютер должен удовлетворять некоторым требованиям — например необходимо наличие антивируса, наличие антивируса с обновленными антивирусными базами, наличие работающего фаервола или службы автоматических обновлений и проч. Если компьютер удовлетворяет требуемым условиям, то доступ к сети предоставляется. Если не удовлетворяет, то доступ не предоставляется, либо предоставляется но ограниченный.
Технологию NAP можно применять в различных сценариях — с [DHCP, IPSec'ом, RD-Gate'ом](http://www.microsoft.com/rus/windows-server/network-access-protection.mspx). В нашей небольшой организации NAP применяется совместно с протоколом 802.1X для проверки и предоставления\не предоставления доступа к сети устройствам подключенным к портам коммутаторов или по Wi-Fi. Т.е. как только компьютер подключается к сетевой розетке происходит аутентификация и проверка его соответствия заданным политикам — на основании результатов данной проверки коммутатору от RADIUS-сервера приходит мессейдж о том пускаем клиента в сеть или не пускаем. Если пускаем, то куда (VLAN).
Если компьютер не удовлетворяет заданным требованиям, то его можно переместить в карантинный VLAN, в котором данному компьютеру будет доступен некий сервер — сервер восстановления. С данного сервера можно скачать и установить например антивирус и попытаться повторно получить доступ к нужной сети.
Данный алгоритм работы предполагает, что все клиенты у нас получают адреса по DHCP — и это очень важный момент.
**Технология номер два** — MAB (MAC Authentication Bypass) от Cisco — аутентификация устройств подключенных к сети по MAC-адресам. Т.е. при подключении устройства к порту правильно-настроенного коммутатора (правильно-настроенный коммутатор в сеть кого попало без предварительной проверки не пропускает) происходит аутентификация подключенного девайса. Правильно-настроенный коммутатор пересылает соответствующий запрос RADIUS-серверу используя MAC-адрес девайса в качестве логина и пароля. Далее коммутатор уже ориентируется на ответ RADIUS-сервера — либо MAB-Success либо банан.
А теперь о том, как мы все это используем.
Как не трудно подметить, технология NAP отлично прилагается к девайсам типа компьютер, т.к. именно здесь реализоваться ее, технологии, потенциал (проверка на установленный антивирус, фаер, обновления...) и не важно под какой ОС работает компьютер — есть, правда платные, реализации под Linux и вроде даже как под Mac. Для Windows многое бесплатно из коробки (коробка правда стоит денег).
С другой стороны MAB отлично прилагается к девайсам не особо сведущим о таких высоких материях как 802.1X или тем более NAP — т.е. принтера (хотя многие принтера и могут работать по 802.1X), сетевые сканеры, видео-регистраторы, холодильники…
Зная какие устройства используются в сети была разработана соответствующая хитрая схема адресации внутри этой самой сети с определением соответствующих VLAN-ов. Т.е. принтерам была выделена отдельная подсеть и назначен VLAN скажем 5. Компьютерам пользователей своя подсеть и VLAN скажем 6. Количество VLAN-ов и подсетей зависит от того, как именно требуется разграничивать доступ и вообще стоит ли это делать.
VLAN-ы, и это немаловажно, назначаются динамически — т.е. в какую бы розетку пользователь не воткнулся он получит доступ именно к своей сети (если конечно у него есть соответствующие “разрешения” и он удовлетворяет заданным политикам). Тоже самое и с другими девайсами. Случайны прохожий всюду получит банан.
Далее были развернуты RADIUS-сервера и нацелены на Active Directory. В свою очередь в AD были созданы спец. группы в которые добавляются учетные записи компьютеров (в зависимости от принадлежности к отделу\департаменту\… или требуемому уровню доступа).
Также в AD заводятся учетные записи пользователей соответствующие устройствам не понимающим NAP и 802.1X, которые будут проходить по MAB-у. Во время тестирования и настройки единственное что удалось найти в интернете про авторизацию по MAC-адресу (в частности на сайте Майкрософт) — [MAC Address Authorization](http://technet.microsoft.com/en-us/library/dd197535(WS.10).aspx) — статья, следуя которой MAB НЕ настроить. А настроить его можно так:
* в настройках NPS добавить к существующей политике протокол аутентификации PAP;
* прочитать указанную выше статью технета, и убедиться что у вас в реестре НЕТ данных ключей (в статье их рекомендуют создать);
* создать в AD учетки пользователей с именами и паролями соответствующими MAC-адресу устройства (маленькими буквами без разделителей);
Созданные учетные записи пользователей для устройств также добавляются в специально заведенные группы — например принтера, сканеры, тонкие клиенты, датчики теплого пола…
Далее на RADIUS-серверах заводятся RADIUS-клиенты, т.е. коммутаторы от которых будут приходить запросы на аутентификацию и авторизацию.
*Во времена, когда NAP только появился мы начали его разворачивать на Windows 2008 Standard и очень быстро уперлись, в нашей небольшой организации, в ограничение данной версии — стандартная версия с ролью NPS (Network Policy Server — он же в нашем случае RADIUS) поддерживает только 50 RADIUS-клиентов. В мануалах об этом конечно же написано, но как-то подзаб~~и~~ылось.*
Помимо RADIUS-клиентов на серверах создаются соответствующие правила как для работы NAP-а, так и MAB-а. Правила примерно следующие — если запрос пришел из подсети *xxx.xxx.xxx.xxx*, и клиент входит в группу в AD *YYY*, да еще и удовлетворяет всем предъявляемым требованиям определенной политики (например имеется рабочий антивирус с актуальными базами и включенным фаерволом для всех сетевых подключений), то предоставляется полный доступ к сети — VLAN *ZZZ*.
Для MAB-а политика такая же, только без проверки состояния здоровья и проверяется уже членство в определенной группе пользователя, а не компьютера.
Как уже было сказано выше, для MAB-а используется протокол аутентификации PAP, для NAP-а, соответственно, PEAP. На PEAP-е стоит заострить внимание иначе в один прекрасный день это сделает сам PEAP. Дело в том, что PEAP завязан на сертификат сервера — в нашем случае это сертификат RAS IAS сервера. У сертификатов есть отличная способность — срок их действия однажды истекает. Поэтому неплохо позаботится заранее о политике autoenroll-а NPS-серверам соответствующих сертификатов, т.к. иначе десятки, сотни или быть может тысячи пользователей рискуют остаться без доступа к сети (в зависимости от размеров организации и степени проникновения NAP-а).
Далее идет настройка сетевого оборудования. Важно, чтобы коммутаторы поддерживали протокол 802.1X иначе фокус не получится. В нашей небольшой организации повсюду используются девайсы производства Cisco, но даже с ними были проблемы — необходимая поддержка появилась в более поздних версиях IOS-а.
Все что необходимо сделать на коммутаторах это:
— указать RADIUS-сервера и shared key;
— настроить необходимые порты.
Пример:
`aaa authentication dot1x default group radius
dot1x system-auth-control
!
interface GigabithtEthernetX/X/X
switchport mode access
authentication order mab dot1x
authentication port-control auto
mab
dot1x guest-vlan XXX
spanning-tree portfast
!
radius-server host XXX.XXX.XXX.XXX auth-port 1812 acct-port 1813 key XXX`
Собственно на этом настройка на сетевом оборудовании заканчивается.
Однако для того чтобы все это заработало необходимо, помимо всего прочего, выполнить некоторые настройки и на клиентских компьютерах. А именно — выставить в autostart службы Network Access Protection и Wired Autoconfig — по дефолту они в состоянии Manual.
*Замечена особенность — при подключении компьютеров к сети через IP-телефоны Cisco совершенно разных моделей периодически возникает ситуация, когда телефон блокирует прохождение через себя EAP-пакетов. На некоторых телефонах это лечится включением в настройках параметра SPAN to PC. На многих телефонах такой настроки нет. Поэтому кому-то приходится подключаться мимо телефонов в сеть, либо перезагружать телефон. Есть ли похожие ништяки у других вендоров не известно — у нас используется только Cisco.*
В результате мы получаем неплохую защиту нашей сети уже на этапе попытки подключения к ней. Уходим от таких вещей как port-security или за-shutdown-енные порты. В качестве бонуса получая динамически-назначаемые VLAN-ы.
В обчем и целом можно сказать, что технологии неплохие и вполне рабочие. | https://habr.com/ru/post/124697/ | null | ru | null |
# TeamCity C# API для сборки приложений
Начиная с первых версий .NET Core для сборки приложений, компания Microsoft предоставляет простой и удобный интерфейс командной строки ([.NET CLI](https://docs.microsoft.com/en-us/dotnet/core/tools/)). Его возможности покрывают большинство потребностей по сборке, упаковке и тестированию приложений. Несмотря на это, по мере роста приложения, увеличения количества его составных частей/сборок/пакетов, усложнения процессов тестирования и развертывания, рядом с проектом часто появляются такие файлы сценариев как *build.ps1*, *build.sh*, *build.cmd* или даже полноценные инфраструктуры автоматизации построения приложений. В статье [TeamCity C# script runner](https://habr.com/ru/company/JetBrains/blog/586906/) была предложена еще одна альтернатива - [сценарии C#](https://docs.microsoft.com/en-us/archive/msdn-magazine/2016/january/essential-net-csharp-scripting), которые особенно полезны, когда необходимо эффективно автоматизировать какой либо аспект сборки силами .NET разработчиков или DevOps, знакомыми с синтаксисом C#. Тогда же была упомянута идея расширить [встроенный API сценариев](https://github.com/JetBrains/teamcity-csharp-interactive#usage-scenarios) для более глубокой интеграции с TeamCity и для поддержки наиболее частых вариантов использования. Предполагая, что API сценариев чаще всего будет задействован при сборке приложений, мы в первую очередь решили расширить именно его. В этой статье будут приведены примеры использования этого API.
Расширение API прежде всего коснулось следующего:
* запуск произвольных процессов синхронно и асинхронно;
* запуск процессов [.NET CLI](https://docs.microsoft.com/en-us/dotnet/core/tools/) и получение детализированных информации об ошибках, предупреждениях и тестах;
* запуск процессов в Docker контейнерах;
* создание сценариев с использованием опыта [ASP.NET Core](https://docs.microsoft.com/en-us/aspnet/core/fundamentals/dependency-injection) в плане композиции и внедрения зависимостей.
Этот API вместе с произвольным набором .NET библиотек позволяет достаточно просто и гибко реализовать сложные сценарии с минимальными усилиями. Очевидно, что сложные сценарии требуют больше затрат на развитие, поддержку и контроль регрессии. Возможность отладки сценариев и модульные тесты уменьшают эти затраты. Для этого, помимо пакета [TeamCity.csi](https://www.nuget.org/packages/TeamCity.csi) с инструментом для запуска сценариев, был добавлен пакет [TeamCity.CSharpInteractive](https://www.nuget.org/packages/TeamCity.CSharpInteractive/). Он позволяет использовать API сценариев из обычных консольных приложений .NET. Ещё один пакет [TeamCity.CSharpInteractive.Templates](https://www.nuget.org/packages/TeamCity.CSharpInteractive.Templates/) с шаблоном проекта поможет с быстрым созданием подобных консольных приложений. Установка шаблона *"build"* выполняется командой .NET CLI:
`dotnet new -i TeamCity.CSharpInteractive.Templates`
Рассмотрим [пример](https://github.com/JetBrains/teamcity-csharp-interactive/tree/master/Samples/DemoProject/MySampleLib), в котором есть некое решение, и его нужно собрать. Воспользуемся сценариями C#. Первым делом создадим директорию, например [Build1](https://github.com/JetBrains/teamcity-csharp-interactive/tree/master/Samples/DemoProject/MySampleLib/Build1), и в ней выполним команду .NET CLI для создания проекта по шаблону *"build"*:
`dotnet new build`
В директории [Build1](https://github.com/JetBrains/teamcity-csharp-interactive/tree/master/Samples/DemoProject/MySampleLib/Build1) появится проект консольного приложения. Это приложение при его выполнении будет собирать решение в родительской директории - [*..\Build1*](https://github.com/JetBrains/teamcity-csharp-interactive/tree/master/Samples/DemoProject/MySampleLib). Новый проект уже содержит ссылку на NuGet пакет [TeamCity.CSharpInteractive](https://www.nuget.org/packages/TeamCity.CSharpInteractive/), и изначально включает два файла.
Файл [Program.cs](https://github.com/JetBrains/teamcity-csharp-interactive/blob/master/Samples/DemoProject/MySampleLib/Build1/Program.cs) содержит код сценария:
```
using HostApi;
return new DotNetBuild().Build().ExitCode ?? 1;
```
и файл [Program.csx](https://github.com/JetBrains/teamcity-csharp-interactive/blob/master/Samples/DemoProject/MySampleLib/Build1/Program.csx) - “точку входа” для запуска этого сценария:
```
#load "Program.cs"
```
*Program.csx*, используя специальный REPL оператор сценариев `#load`, загружает код из файла *Program.cs*. Выражение `using HostApi;` добавляет пространство имен *HostApi* для использования API сценариев. Выражение `new DotNetBuild()` создает экземпляр соответствующей .NET CLI команде `dotnet build`, а метод расширения `Build()` выполняет эту команду, собирает приложение в текущей рабочей директории и возвращает результат выполнения, включая статистику сборки.
Но вместе с этим и *Program.cs* сам по себе является точкой входа консольного .NET приложения, представленного [операторами верхнего уровня](https://docs.microsoft.com/en-us/dotnet/csharp/fundamentals/program-structure/top-level-statements). Для его отладки в среде разработки первым делом необходимо указать рабочую директорию, относительно которой оно будет запущено и, следовательно, какие рабочие директории будут у порожденных им процессов. Например, если вы хотите собрать проект в директории *c:\Projects\MySolution*, эту директорию и нужно указать в качестве рабочей директории для отладки. Запуск "шаблонного" консольного приложения [Build1](https://github.com/JetBrains/teamcity-csharp-interactive/tree/master/Samples/DemoProject/MySampleLib/Build1) выполнит процесс `dotnet build`, результатом его выполнения будет детальная статистика: сообщения от SDK, включая статистику по тестированию, при ее наличии. Если статистика сборки не нужна, то вместо метода расширения `Build()` для запуска процесса `dotnet build` можно воспользоваться методом расширения `Run()`, который просто выполнит процесс и вернет код выхода. Каждый метод расширения `Build()` и `Run()` имеет свой асинхронный аналог с постфиксом *Async* для запуска процессов асинхронно.
Так как проект в директории [Build1](https://github.com/JetBrains/teamcity-csharp-interactive/tree/master/Samples/DemoProject/MySampleLib/Build1) - это обычное консольное .NET приложение, его можно выполнить из командной строки, например так: `dotnet run --project Build1` или, используя [C# Script tool](http://nuget.org/packages/TeamCity.csi), и “точку входа” для запуска C# сценария: `dotnet csi Build1\Program.csx`. За аналогичные действия на TeamCity отвечает команда run в [.NET runner](https://www.jetbrains.com/help/teamcity/net.html#Build+Runner+Options) или [C# Script runner](https://www.jetbrains.com/help/teamcity/c-script.html) для сценария *Build1\Program.csx*. Это позволяет без дополнительных усилий собирать решения локально, и использовать этот же сценарий на TeamCity всего лишь в одном шаге конфигурации сборки. Хочется отметить, что статистика выполнения на рабочей машине и в TeamCity, а именно: список ошибок, предупреждений, тестов - будет совпадать.
Немного модифицируем сценарий [Build1](https://github.com/JetBrains/teamcity-csharp-interactive/tree/master/Samples/DemoProject/MySampleLib/Build1) в следующем примере [Build2](https://github.com/JetBrains/teamcity-csharp-interactive/tree/master/Samples/DemoProject/MySampleLib/Build2). Теперь приложение собирается с определённой версией и конфигурацией, переданными через свойства *“version”* и *"configuration"*. В случае успешной сборки параллельно выполняются два одинаковых набора тестов: на текущей машине и в Linux контейнере *"mcr.microsoft.com/dotnet/sdk:6.0"*. Перед запуском в контейнере текущая директория процесса монтируется в *"/project"*, на нее же будет указывать и рабочая директория для процесса внутри контейнера:
```
using HostApi;
using NuGet.Versioning;
var configuration = Property.Get("configuration", "Release");
var version = NuGetVersion.Parse(Property.Get("version", "1.0.0-dev", true));
var result = new DotNetBuild()
.WithConfiguration(configuration)
.AddProps(("version", version.ToString()))
.Build();
Assertion.Succeed(result);
var test = new DotNetTest()
.WithConfiguration(configuration)
.WithNoBuild(true);
var testInContainer = new DockerRun(
test.WithExecutablePath("dotnet"),
$"mcr.microsoft.com/dotnet/sdk:6.0")
.WithPlatform("linux")
.AddVolumes((Environment.CurrentDirectory, "/project"))
.WithContainerWorkingDirectory("/project");
var results = await Task.WhenAll(
test.BuildAsync(),
testInContainer.BuildAsync()
);
Assertion.Succeed(results);
```
В файл [Tools.cs](https://github.com/JetBrains/teamcity-csharp-interactive/blob/master/Samples/DemoProject/MySampleLib/Build2/Tools.cs) вынесены вспомогательные методы: `Property.Get` для получения параметров и `Assertion.Succeed` для проверки результатов выполнения .NET CLI команд. В последнем анализируется код выхода и статистика тестов, и если код выхода не 0, выполнение сценария прекращается с информацией об ошибке и списком неудачных тестов. `DotNetBuild`, `DotNetTest`, `DockerRun` представляют процессы и их параметры. Этих параметров достаточно много, и в них можно запутаться, но среда разработки подсказывает их назначение.
Для выполнения консольного проекта и его отладки достаточно того, чтобы он просто собирался. Для выполнения REPL (read-evaluate-print-loop) сценария [Program.csx](https://github.com/JetBrains/teamcity-csharp-interactive/blob/master/Samples/DemoProject/MySampleLib/Build2/Program.csx) необходимо загрузить весь исполняемый код в правильной последовательности. Так как код в *Program.cs* зависит от кода в *Tools.cs*, код из *Tools.cs* должен быть загружен до кода из *Program.cs,* используя REPL операторы `#load`:
```
#load "Tools.cs"
#load "Program.cs"
```
Если же проект зависит, например, от пакета *MyPackage* версии 1.2.3, то для корректной работы сценария необходимо добавить REPL оператор `#r "nuget: MyPackage, 1.2.3"` до использования любых его типов. Для загрузки сборки используется похожий оператор вида `#r "MyAssembly.dll”`.
Оба примера выше просты и стоимость их поддержки невелика. Этого нельзя сказать про множество других проектов, со сложной логикой построения, множеством сборок, пакетов, других артефактов, разнообразием тестов, выполняемых при различных условиях. Часто они полагаются на сценарии *PowerShell*, *Bash*, сложные *MSBuild* проекты, [Cake](https://cakebuild.net/), [Nuke](https://nuke.build/) для описания и контроля процесса построения. Поэтому немного усложним [Build2](https://github.com/JetBrains/teamcity-csharp-interactive/tree/master/Samples/DemoProject/MySampleLib/Build2) в следующем примере [Build3](https://github.com/JetBrains/teamcity-csharp-interactive/tree/master/Samples/DemoProject/MySampleLib/Build3). Точка входа в приложение [Program.cs](https://github.com/JetBrains/teamcity-csharp-interactive/blob/master/Samples/DemoProject/MySampleLib/Build3/Program.cs) теперь выглядит так:
```
using Microsoft.Extensions.DependencyInjection;
using NuGet.Versioning;
var configuration = Property.Get("configuration", "Release");
var version = NuGetVersion.Parse(Property.Get("version", "1.0.0-dev", true));
await
GetService()
.AddSingleton(\_ => new Settings(configuration, version))
.AddSingleton()
.AddSingleton()
.AddSingleton()
.BuildServiceProvider()
.GetRequiredService()
.BuildAsync();
```
Для того, чтобы собирать подзадачи в более крупные задачи здесь используется композиция. Для контроля управления зависимостями и создания корня композиции применяется знакомая многим библиотека [Microsoft Dependency Injection](https://docs.microsoft.com/en-us/dotnet/core/extensions/dependency-injection). Вместо того, чтобы придумывать [DSL](https://martinfowler.com/bliki/DomainSpecificLanguage.html) для “оркестрации" задач и процессов, как сделано, например, в [Cake](https://cakebuild.net/docs/writing-builds/tasks/) и [Nuke](https://www.nuke.build/docs/authoring-builds/fundamentals.html), пока предлагается максимально простой API. А как его использовать: запускать процессы/задачи последовательно, асинхронно, параллельно, использовать машину состояний и т. п., полностью зависит от автора проекта, так как:
* любой DSL нужно изучать,
* вероятно у автора есть уже свои предпочтения,
* любой DSL имеет ограничения, и часто приходится с ним бороться, чтобы сделать что-либо выходящее за его возможности.
`GetService` из первой строчки после `await` — это статическая функция для доступа ко всему набору сервисов API сценариев. Выражение `GetService()` получает коллекцию [IServiceCollection](https://docs.microsoft.com/en-us/aspnet/core/fundamentals/dependency-injection#framework-provided-services), она уже содержит весь этот же набор сервисов. Следующие набор выражений [AddSingleton<>()](https://docs.microsoft.com/en-us/dotnet/api/microsoft.extensions.dependencyinjection.servicecollectionserviceextensions.addsingleton#microsoft-extensions-dependencyinjection-servicecollectionserviceextensions-addsingleton-2(microsoft-extensions-dependencyinjection-iservicecollection)) регистрируют несколько реализаций задач в эту коллекцию. Далее вызов функции [BuildServiceProvider()](https://docs.microsoft.com/en-us/dotnet/api/microsoft.extensions.dependencyinjection.servicecollectioncontainerbuilderextensions.buildserviceprovider#microsoft-extensions-dependencyinjection-servicecollectioncontainerbuilderextensions-buildserviceprovider(microsoft-extensions-dependencyinjection-iservicecollection)) cоздает экземпляр [IServiceProvider](https://docs.microsoft.com/en-us/dotnet/api/system.iserviceprovider), содержащий сервисы и задачи из коллекции выше, а вызов [GetRequiredService()](https://docs.microsoft.com/en-us/dotnet/api/microsoft.extensions.dependencyinjection.serviceproviderserviceextensions.getrequiredservice) создает корень композиции `IRoot` - “главную" задачу. И в заключении асинхронно вызывает её единственную функцию `BuildAsync()` из файла [Root.cs](https://github.com/JetBrains/teamcity-csharp-interactive/blob/master/Samples/DemoProject/MySampleLib/Build3/Root.cs), которая играет роль диспетчера и, используя свойство *"target"*, выбирает и выполняет подзадачу:
```
public Task BuildAsync() =>
Property.Get(\_properties, "target", "Build") switch
{
"Build" => \_build.BuildAsync(),
"CreateImage" => \_createImage.BuildAsync(),
\_ => throw new ArgumentOutOfRangeException()
};
```
где:
“[Build](https://github.com/JetBrains/teamcity-csharp-interactive/blob/master/Samples/DemoProject/MySampleLib/Build3/Build.cs)” это, по сути, весь предыдущий сценарий из примера [Build2](https://github.com/JetBrains/teamcity-csharp-interactive/tree/master/Samples/DemoProject/MySampleLib/Build2)
* собирает приложение,
* выполняет тесты параллельно,
* дополнительно публикует бинарные файлы приложения в директорию,
* возвращает путь к этой директории в качестве результата.
“[CreateImage](https://github.com/JetBrains/teamcity-csharp-interactive/blob/master/Samples/DemoProject/MySampleLib/Build3/CreateImage.cs)” используя бинарные файлы приложения, создает Docker образ
* выполняет “[Build](https://github.com/JetBrains/teamcity-csharp-interactive/blob/master/Samples/DemoProject/MySampleLib/Build3/Build.cs)”,
* готовит образ для запуска приложения в Docker контейнере,
* сохраняет его в *.tar* файл,
* публикует его как артефакт TeamCity, если выполняется под TeamCity,
* возвращает путь к файлу с образом в качестве результата.
Этот пример не требует изучения специализированных DSL. Все связи между задачами при передаче параметров и результатов - очевидны. Кроме того, код в этом примере имеет слабую связанность и лоялен к модульному тестированию вследствие того, что все нестабильные зависимости внедряются в экземпляры типов через конструктор. А использование таких статических методов расширения, как `Build()` или `Run()`, из предыдущих примеров заменено на вызовы соответствующих сервисов. Например, вместо кода в примере [Build2](https://github.com/JetBrains/teamcity-csharp-interactive/tree/master/Samples/DemoProject/MySampleLib/Build2):
```
new DotNetBuild()
.WithConfiguration(configuration)
.AddProps(("version", version.ToString()))
.Build();
```
в примере [Build3](https://github.com/JetBrains/teamcity-csharp-interactive/tree/master/Samples/DemoProject/MySampleLib/Build3) используется немного модифицированный аналог:
```
var build = new DotNetBuild()
.WithConfiguration(_settings.Configuration)
.AddProps(("version", _settings.Version.ToString()));
_runner.RunAsync(build);
```
где `_runner` - это экземпляр сервиса `IBuildRunner` из API сценариев, внедренный через конструктор.
Подводя итог, API сценариев C# предоставляет следующие возможности:
* использовать привычный синтаксис языка C#;
* упростить создание нового проекта для построения приложения с помощью шаблона "[build](https://www.nuget.org/packages/TeamCity.CSharpInteractive.Templates/)" и .NET CLI команды `dotnet new build`;
* делать код сценариев простым и с низкой связанностью;
* отлаживать код в среде разработки;
* писать модульные тесты;
* запускать код как кроссплатформенное консольное .NET приложение или как сценарий;
* запускать приложения или сценарии как локально, так и на CI/CD сервере в [одном шаге сборки TeamCity](https://teamcity.jetbrains.com/project/TeamCityPluginsByJetBrains_TeamCityCScript_ApiDemo), при этом статистика сборки (ошибки, предупреждения, тесты) на TeamCity и локально будет совпадать. | https://habr.com/ru/post/651247/ | null | ru | null |
# Удобное создание Composition Root с помощью Autofac
Проекты, разработкой и сопровождением которых я занимаюсь, довольно велики по объему. По этой причине в них активно используется паттерн [Dependency Injection](https://en.wikipedia.org/wiki/Dependency_injection).
Важнейшей частью его реализации является [Composition Root](http://blog.ploeh.dk/2011/07/28/CompositionRoot/) — точка сборки, обычно выполняемая по паттерну [Register-Resolve-Release](http://blog.ploeh.dk/2010/09/29/TheRegisterResolveReleasepattern/). Для хорошо читаемого, компактного и выразительного описания Composition Root обычно используется такой инструмент как [DI-контейнер](https://smarly.net/dependency-injection-in-net/putting-dependency-injection-on-the-map/di-containers/introducing-di-containers), при наличии выбора я предпочитаю использовать [Autofac](https://autofac.org/).
Несмотря на то, что данный контейнер заслуженно считается лидером по удобству, у разработчиков встречается немало вопросов и даже претензий. Для наиболее частых проблем из собственной практики я опишу способы, которые могут помочь смягчить или полностью убрать практически все трудности, связанные с использованием Autofac как инструмента конфигурации Composition Root.
Много ошибок в настройке конфигурации выявляется только во время исполнения
---------------------------------------------------------------------------
### Типобезопасная версия метода [As](https://autofac.org/apidoc/html/88A742DA.htm)
Минимальное средство с максимальным эффектом:
```
public static IRegistrationBuilder AsStrict(
this IRegistrationBuilder registrationBuilder)
{
return registrationBuilder.As();
}
public static IRegistrationBuilder AsStrict(
this IRegistrationBuilder registrationBuilder)
{
return registrationBuilder.As();
}
```
Приходится писать метод-однострочник на каждое употребительное сочетание данных активации и стиля регистрации, так как частичного автовывода типов для обобщений C# не поддерживает.
Но единственный плюс окупает все затраты: теперь несоответствие типов интерфейса и реализации приведет к ошибке компиляции.
### Образцы замены Resharper для облегчения перехода к AsStrict
Если у вас уже есть довольно большой проект, то можно облегчить внедрение типобезопасной версии As с помощью [пользовательских образцов замены Resharper](https://www.jetbrains.com/resharper/help/Reference__Options__Code_Inspection__Custom_Patterns.html).
У меня получилось по одному образцу на каждый однострочник. Выражения поиска и замены у всех одинаковые:
```
// Поиск
$builder$.As<$type$>()
builder - expression placeholder
type - type placeholder
// Замена
$builder$.AsStrict<$type>()
```
А вот ограничение на тип у $builder$ у каждого образца свое:
```
IRegistrationBuilder<$type$, SimpleActivatorData, SingleRegistrationStyle>
IRegistrationBuilder<$type$, ConcreteReflection, SingleRegistrationStyle>
```
### Использование [Register](https://autofac.org/apidoc/html/99787E84.htm) вместо [RegisterType](https://autofac.org/apidoc/html/9C29D49E.htm)
Это также может быть полезно:
1. Можно тоньше настроить создание реализаций
2. По сравнению с регистрацией типа проще и яснее явная передача параметров
3. Выше производительность при разрешении реализаций
… но есть и минусы:
1. Любое изменение сигнатуры конструктора класса потребует исправления кода регистрации
2. Регистрация типа заметно компактнее самой простой регистрации делегата
Сложно понять, какой именно тип регистрируется через делегат
------------------------------------------------------------
Лучше всегда указывать тип интерфейса с помощью AsStrict, за исключением случаев использования RegisterType<>() с идентичными типами интерфейса и реализации. Бонусом пойдет ошибка при компиляции, если типы интерфейса и значения, возвращаемого делегатом, несовместимы
Регистрация реализаций через делегат занимает слишком много места
-----------------------------------------------------------------
Иногда и более одной строки может быть слишком много, особенно если именно из-за нее набор регистраций перестает помещаться в экран.
Проще всего выделить регистрацию через делегат в метод расширения для [ContainerBuilder](https://autofac.org/apidoc/html/717248.htm)
```
public static IRegistrationBuilder RegisterImplementation(
this ContainerBuilder builder)
{
return builder.Register(c =>
{
// Здесь некоторое количество кода
// ...
return implementation;
});
}
```
Использовать лучше в сочетании с предыдущим способом
```
builder.RegisterImplementation().AsStrict();
```
Сложно найти регистрацию именованного делегата
----------------------------------------------
Autofac умеет разрешать значения таких делегатов через [автосвязывание](http://docs.autofac.org/en/latest/resolve/relationships.html#parameterized-instantiation-func-x-y-b), но тут есть нюансы:
1. Если параметрам анонимного делегата(Func) параметры конструктора сопоставляются по типам, то параметрам именованных делегатов — по именам
2. Если тип значения, возвращаемого анонимным делегатом виден сразу, то для именованного надо сначала перейти к его определению
В результате именованные делегаты создают сразу два дополнительных уровня косвенности — один при поиске соответствующей регистрации, второй при сопоставлении параметров конструктора.
### Отказ от использования именованных делегатов
Если в конструкторе нет параметров одинаковых типов, то замена на анонимный делегат элементарна.
В противном случае можно заменить множество параметров на структуру, класс или интерфейс (а-ля EventArgs), которые надо зарегистрировать отдельно.
### Явная регистрация именованных делегатов
Этот вариант более правилен с точки зрения независимости бизнес-сущностей от DI контейнера, успешно устраняет дополнительную косвенность, но требует более многословной регистрации.
Сложно поддерживать необходимый порядок инициализации компонентов
-----------------------------------------------------------------
Казалось бы этой проблемы в проекте, построенном по паттерну DI, быть не должно. Но всегда может оказаться необходимым использовать внешние фреймворки, библиотеки, отдельные классы, которые спроектированы иначе. Также свой вклад нередко вносит унаследованный код.
Традиционно для паттерна Dependency Injection последовательность заменяется зависимостью.
### Устранение RegisterInstance
Любой вызов [RegisterInstance](https://autofac.org/apidoc/html/23FE467C.htm) — это де-факто Resolve, чего при регистрации быть не должно. Даже заранее созданную реализацию лучше регистрировать как SingleInstance.
### Создание специальных классов инициализации
Для любого инициализирующего действия, которое в рамках вашего Composition Root считается атомарным, создается отдельный класс. Само действие выполняется в конструкторе этого класса.
Если нужна финализация — реализуется обычный IDisposable
Каждый такой класс наследуется от маркерного интерфейса IInitializer
В Composition Root в качестве Resolve используется
```
context.Resolve>();
```
### Упорядочение инициализации
Если одни инициализирующие действия требуется выполнять позже других, то в более позднем действии достаточно воспользоваться ссылкой на интерфейс, реализуемый более ранним. Если такой ссылки нет (есть только требование определенного порядка действий), то класс-инициализатор более раннего действия помечается маркерным интерфейсом, а конструкторе "позднего" инициализатора добавляется параметр соответствующего типа.
В результате будут получены следующие плюшки:
1. Сложная процедура инициализации разбивается на маленькие, простые, легко реализуемые, повторно используемые части
2. Autofac сам выстраивает правильный порядок инициализации при добавлении, удалении или изменении инициализаторов
3. Autofac автоматически определяет наличие циклов и разрывов в требованиях такого порядка
4. Собственно реализация паттерна RRR легко выносится в отдельный, не зависящий от конкретного модуля или проекта класс
Единственным минусом является потеря наглядности инициализации в целом, что лично я не считаю проблемой, так как это легко восполняется продуманным логированием.
Composition Root слишком велик
------------------------------
Документация Autofac советует использовать собственных наследников класса [Module](https://autofac.org/apidoc/html/2A2437.htm). Это немного помогает, вернее, помогает немного. Все дело в том, что модули сами по себе никак не разделены друг с другом. Ничто не мешает классу, зарегистрированному в одном модуле, зависеть от класса в другом. И повторная регистрация реализации того же интерфейса в другом модуле никак не исключена.
### Декомпозиция Composition Root
Autofac позволяет разделить один монолитный Composition Root на совокупность корневого и дочерних с помощью весьма скупо описанной в документации возможности [регистрации компонентов при создании LifetimeScope](http://docs.autofac.org/en/latest/lifetime/working-with-scopes.html#adding-registrations-to-a-lifetime-scope).
С дочерними точками сборки можно провести точно такую же операцию и повторять до тех пор, пока описание регистраций для каждой конкретной точки сборки не войдет в разумные с вашей точки зрения рамки (для меня это один экран).
### Устранение InstanceForLifetimeScope
Начав использовать регистрацию компонентов при создании LifetimeScope можно сразу получить еще одну вкусную плюшку: полный отказ от [InstanceForLifetimeScope](https://autofac.org/apidoc/html/8804210E.htm) и [InstancePerMatchedLifetimeScope](https://autofac.org/apidoc/html/49BAD240.htm). Достаточно просто регистрировать эти компоненты как SingleInstance в родном для них LifetimeScope. Попутно исчезает зависимость от тегов LifetimeScope и их становится возможным использовать по своему усмотрению, в моем случае каждый LifetimeScope получает в качестве тега уникальное человекочитаемое имя.
### Удобная регистрация дочерних Composition Root
К сожалению, прямое использование метода [BeginLifetimeScope](https://autofac.org/apidoc/html/7F476CFE.htm) нетривиально. Но этому горю можно помочь, используя следующий метод:
```
///
/// Регистрация типа с использованием внутреннего скоупа
///
/// Регистрируемый интерфейс
/// Параметр для создания реализации (если необходимо)
/// Внешний контейнер
/// Источник тегов для внутренних контейнеров
/// Метод для регистрации зависимостей во внутреннем скоупе - их видно только фабрике
/// Фабрика для создания реализаций с использованием обоих скоупов и параметра
///
public static IRegistrationBuilder, SimpleActivatorData, SingleRegistrationStyle>
RegisterWithInheritedScope(
this ContainerBuilder builder,
Func innerScopeTagResolver,
Action innerScopeBuilder,
Func factory)
{
return builder.Register>(c => p =>
{
var innerScope = c.Resolve().BeginLifetimeScope(innerScopeTagResolver(c, p),
b => innerScopeBuilder(b, c, p));
return factory(c, innerScope, p);
});
}
```
Это наиболее общий вариант использования, позволяющий создать фабрику с передачей параметров и генерацией тегов для дочерних скоупов (отдельный дочерний скоуп создается для каждого объекта, реализующего интерфейс T).
Важный момент: о своевременной очистке внутреннего скоупа вы должны позаботиться сами. В этом вам может помочь идея из [одной из моих предыдущих статей](https://habrahabr.ru/post/272497/)
Плюсы:
1. Внешний скоуп никак не зависит от внутреннего.
2. Все, что зарегистрировано во внешнем скоупе, доступно и во внутреннем.
3. Регистрации во внутреннем скоупе могут спокойно перекрывать внешние.
Минусы:
1. Внутренний скоуп получает в нагрузку все прелести [наследования реализаций](https://habrahabr.ru/post/310314/)
Следующий метод позволяет полностью контролировать зависимость внутреннего скоупа от внешнего (включая вариант с полной изоляцией).
```
public static IRegistrationBuilder, SimpleActivatorData, SingleRegistrationStyle>
RegisterWithIsolatedScope(
this ContainerBuilder builder,
Func innerScopeTagResolver,
Action innerScopeBuilder,
Func factory)
{
return builder.Register>(c => p =>
{
var innerScope = new ContainerBuilder().Build().BeginLifetimeScope(
innerScopeTagResolver(c, p),
b => innerScopeBuilder(b, c, p));
return factory(c, innerScope, p);
});
}
```
Итоги
=====
1. Для полноценного применения внедрения зависимостей в сложных случаях требуется как подходящий инструмент (контейнер), так и отработанные навыки разработчика в его использовании
2. Даже такой гибкий, мощный и прекрасно документированный контейнер как Autofac требует определенной доработки напильником под нужды конкретного проекта и конкретной команды.
3. Декомпозиция точек сборки с помощью Autofac вполне возможна, реализация такой идеи относительно проста, хотя и не описана в официальной документации.
4. Модули Autofac для декомпозиции непригодны, так как не обеспечивают инкапсуляцию.
PS: Дополнения и критика традиционно приветствуются. | https://habr.com/ru/post/269479/ | null | ru | null |
# vCard и упрощение заполнения форм
Регистрация на сайте — процесс довольно долгий и напрягающий пользователя. Все стараются ускорить его и сделать максимально простым. Но вводить в данные в поля все равно приходится, и от этого никуда не денешься.
Раздумывая над этим, в один прекрасный вечер, появилась идея, как, с помощью vCard и пары скриптов, можно упростить эту процедуру.
Описание
--------
Суть идеи заключается в подстановке данных о пользователе из формата vCard в поля регистрационной формы. Откуда мы возьмем данные в vCard-формате не важно — пользователь может указать ссылку на страничку со своим hCard, и мы его преобразуем в vCard, или загрузить VCF файл с локального компьютера. Где будет происходить обработка vCard — на клиентской стороне или на серверной — тоже не важно.
### Пример
Дана форма, в которой нужно указать ФИО, телефон, адрес и место работы. Даны дополнительные поля: загрузить vCard и hCard URL. Пользователь выбирает подходящий способ. Система загружает информацию о пользователе, разбирает ее и подставляет в заданные поля формы.
#### Данные vCard:
`BEGIN:VCARD
PRODID:-//suda.co.uk//X2V 0.11 (BETA)//EN
SOURCE:http://artem.chertov.name/
NAME:Artem Chertov's diary
VERSION:3.0
N;LANGUAGE=en;CHARSET=utf-8:Chertov;Artem;V
FN;LANGUAGE=en;CHARSET=utf-8:Artem.Chertov
URL:http://artem.chertov.name/
END:VCARD`
#### Форма после подстановки данных из файла:

Идея не только для регистрации. Можно применять этот способ для любой формы на сайте. Интересно, будет ли способ востребован, и вообще, стоит ли игра свеч? Интересно услышать ваше мнение по этому поводу.
[Оригинал статьи](http://artem.chertov.name/2009/02/vcard-and-simplify-forms/)
Спасибо. | https://habr.com/ru/post/52956/ | null | ru | null |
# Настройка TeamCity для новичков
Эта статья в первую очередь пригодится тем, кто использует тот же стек технологий, что и наша команда, а именно: ASP.NET, C#, NUnit, Selenium 2, git, MSBuild. Будут рассмотрены такие задачи, как интеграция с git, сборка C#-проектов, NUnit-тесты (как модульные, так и тесты UI), а также деплой на сервер. Впрочем, наверняка найдётся интересное и для других пользователей, кроме разве что съевших на этом вопросе собаку. Но они опять же смогут обратить внимание на ошибки в статье или что-то посоветовать: например, как оптимизировать фазу деплоя.
Что такое «непрерывная интеграция», отлично рассказано [здесь](http://habrahabr.ru/post/82724/) и [вот здесь](http://habrahabr.ru/post/185740/), повторять эту тему в сотый раз вряд ли нужно.
Ну и для начала – что может TeamCity (далее – просто TC)? А может он следующее: при появлении изменений в указанной ветке репозитория (или ином событии) выполнить сценарий, включающий в себя, например, сборку приложения, прогон тестов, выполнение других сценариев, заливку файлов на удаленный сервер и т.п.
Важным моментом является то, что «сервер интеграции» и «машина, на которой будет проходить этот процесс», – обычно (не обязательно) разные серверы. Более того, машинок, на которых запускаются сборки и тесты, может быть несколько, даже много, и все на разных ОС – в общем, есть, где развернуться.
Для запуска процесса сборки используется программа-агент, принимающая команды от TC-сервера, запустить ее можно на любой из основных ОС (слава мультиплатформенности Java). На один компьютер можно установить несколько агентов и запускать их параллельно, но важно помнить, что один агент единовременно может обрабатывать только один проект. При старте задачи TC выбирает первый подходящий незанятый агент, причем можно устанавливать «фильтры», например, выбирать агента только с ОС Windows или только с установленным .NET версии не ниже 4.0 и т.п.
Теперь нужно придумать сценарий работы. Мы используем в работе следующие ветки:
1. **release** – содержит актуальный код, рабочую версию, которая находится на боевом сервере;
2. **dev** – в неё идут все новые фичи, позже вливается в release;
3. **отдельная ветка на каждую фичу**, которая отпочковывается от dev и в неё же возвращается.
В общем, практически стандартный git-flow, о котором более подробно можно прочитать, например, [здесь](http://habrahabr.ru/post/147260/).
В связи с этим наш сценарий будет выглядеть так:
1. забрать свежие изменения из репозитория ветки dev;
2. скомпилировать проект;
3. если всё прошло успешно на предыдущем шаге – прогнать юнит-тесты;
4. если всё прошло успешно на предыдущем шаге – прогнать функциональные тесты;
5. если всё прошло успешно на предыдущем шаге – залить изменения на тестовый сервер.
Для релизной ветки делаем всё то же самое, но на время заливки новых данных приостанавливаем сервер и показываем заглушку.
А теперь вперёд – реализовывать сценарий!
Забрать свежие изменения из репозитория
---------------------------------------
Начинается всё с немудрёного создания проекта.
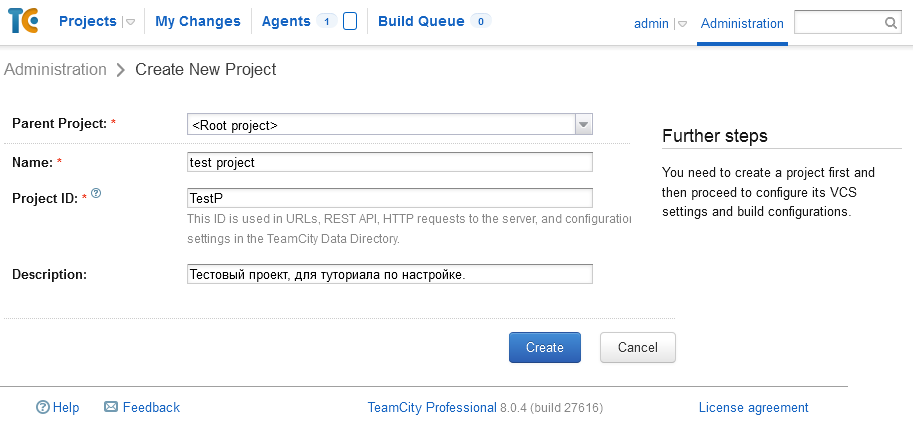
После – создание «**build configuration**» (конфигурации сборки). Конфигурация определяет сценарий сборки.
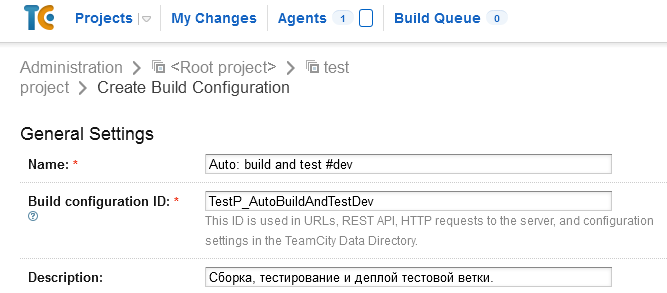
На втором же шаге создания конфигурации нас спросят об использованной VCS, так что отвечаем честно, что у нас тут git. У вас может быть другая VCS – не теряйтесь. Добавление нового репозитория производится кнопкой **Create and attach new VCS root**.
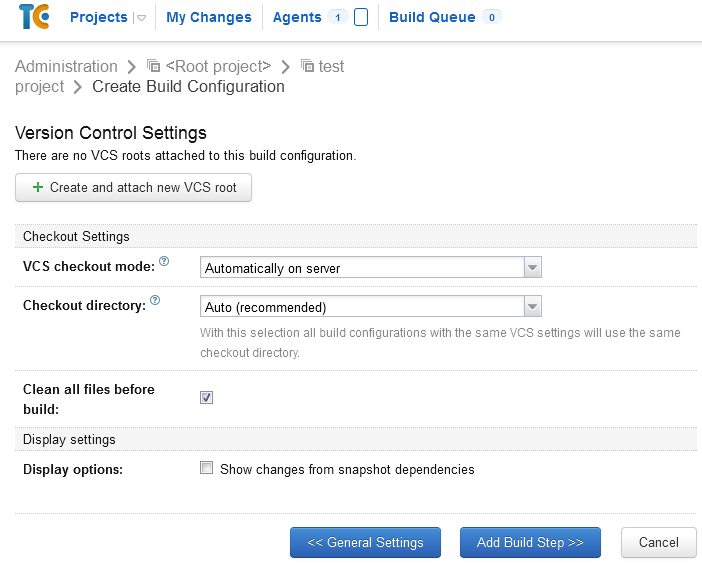
Итак, ключевые настройки:
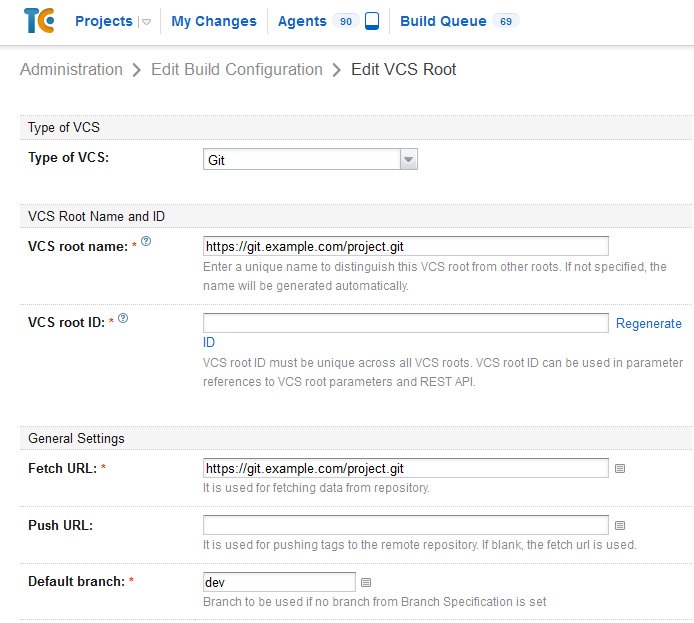
* **VCS root ID** можно не трогать – уникальный код, как ни крути. Если оставить пустым, генерируется автоматически;
* **Fetch URL** – тот адрес, с которого мы будем забирать содержимое репозитория;
* **Default branch** – ветка, с которой будет браться информация;
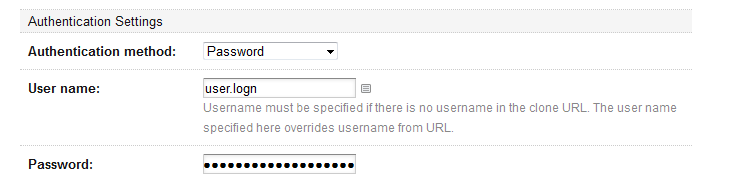
* **Authentication method** – самое интересное – способ аутентификации. Тут может быть и доступ без авторизации (если данные лежат на внутреннем сервере, например), и по ключу, и по паролю. Для каждого варианта дополнительные поля будут свои, сами понимаете.
Остальное многообразие опций – на ваш вкус и цвет.
Далее, нужно настроить автоматический запуск задания. Идём в «**Build Triggers**» (условия сборки) и выбираем условие **VCS Trigger** – при настройках по умолчанию он будет раз в минуту проверять наличие новых коммитов в репозитории, а если таковые найдутся – запустит задание на выполнение.
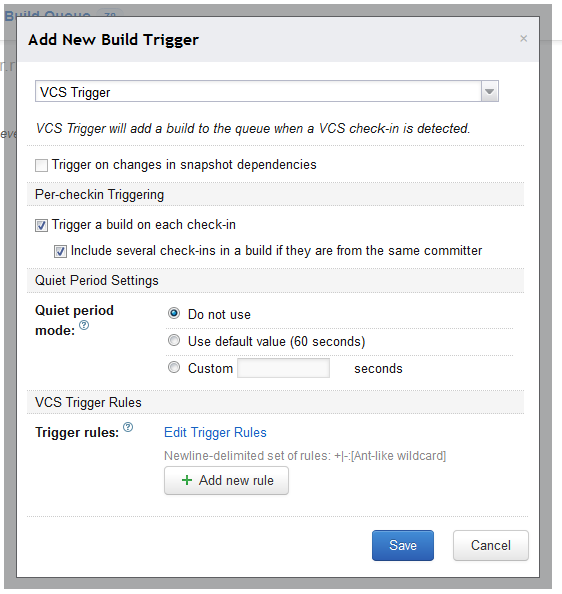
Скомпилировать проект
---------------------
Поскольку у нас проект на ASP.NET в виде Solution’а из Visual Studio – тут тоже было всё просто.
Идём в меню «**Build Steps**» (Шаги сборки), выбираем **runner type** (а их тут действительно много) и останавливаемся на **MSBuild**. Почему именно на нём? Он даёт достаточно простой способ описать процесс сборки, даже достаточно сложный, добавляя или удаляя различные шаги в простом XML-файле.
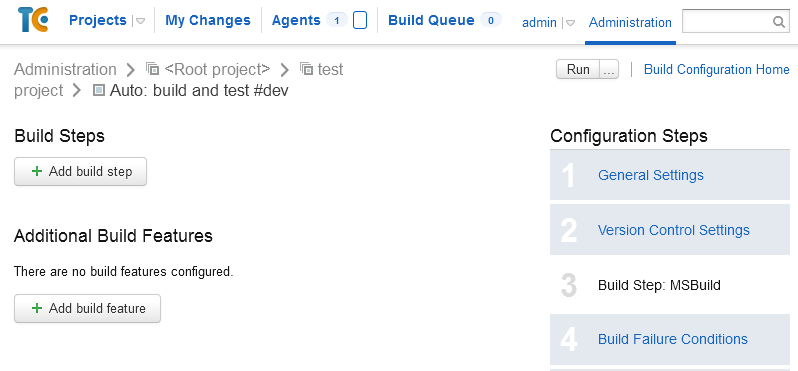
Далее всё элементарно.
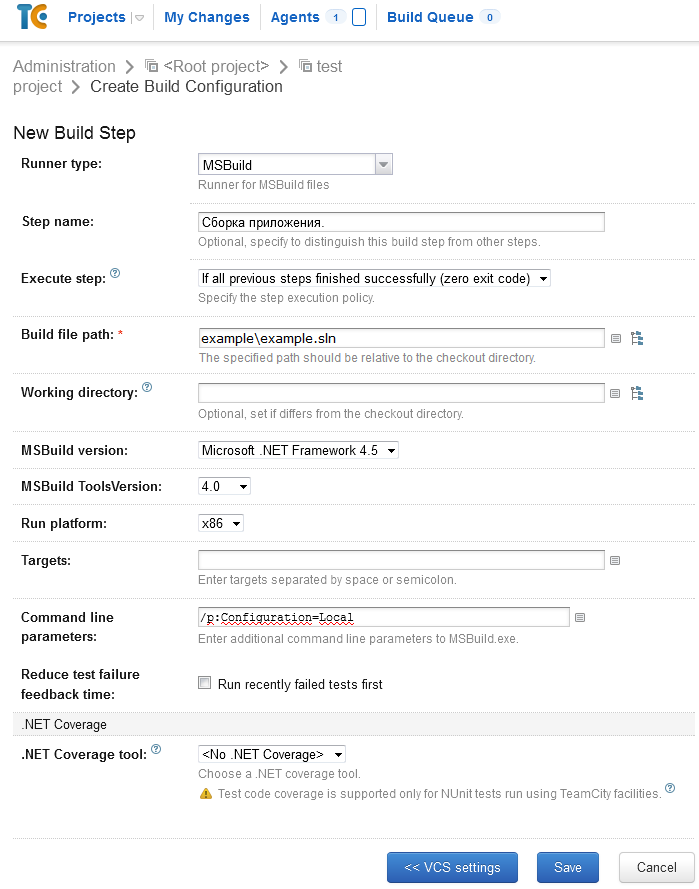
**Build file path** – путь к sln-файлу.
**MSBuild version**, **MSBuild ToolsVersion** и **Run platform** выбираем под требования своего проекта.
Если в проекте несколько конфигураций, то можно использовать опцию **Command line parameters** для ввода примерно такого ключа:
```
/p:Configuration=Production
```
где **Production** заменить на нужный конфиг.
Включить скачивание NuGet-пакетов
---------------------------------
Важный пункт, в случае если вы используете NuGet-пакеты; если нет – можно переходить сразу к следующему пункту.
Поскольку NuGet-пакеты весят немало, да и хранить в репозитории бинарники библиотек без особой необходимости не хочется, можно использовать замечательную опцию **NuGet Package Restore**:
В этой ситуации бинарники библиотек в репозиторий не включаются, а докачиваются по мере необходимости в процессе сборки.
Но **MSBuild** – настоящий джентльмен и не будет без разрешения делать лишних телодвижений, поэтому и докачивать пакеты просто так не будет – ему сей процесс нужно разрешить. Для этого придется либо на клиенте установить переменную окружения **Enable NuGet Package Restore** в значение **true**, либо пойти в меню **Build Parameters** и выставить его там.
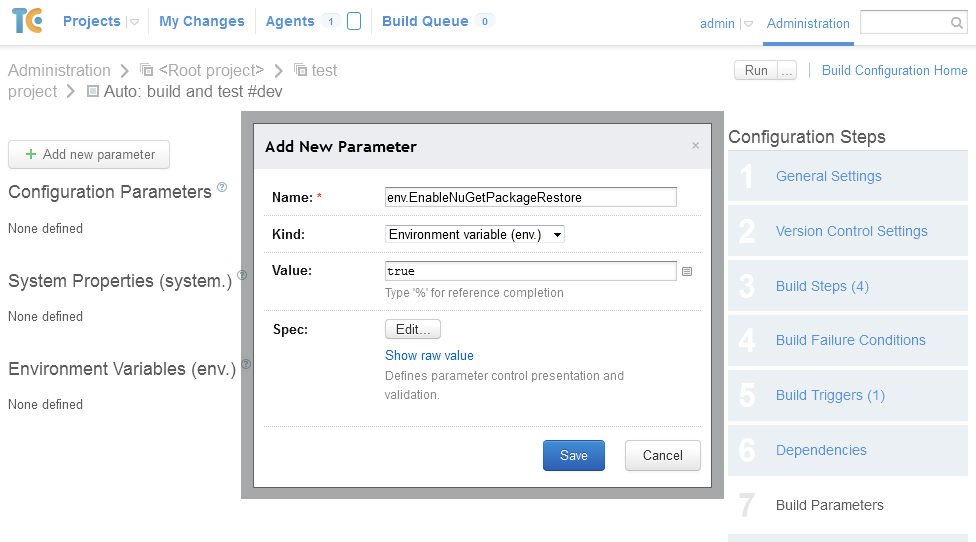
Прогнать юнит-тесты
-------------------
У нас юнит-тесты являются отдельным проектом внутри решения. Так что на предыдущем шаге они уже скомпилированы – осталось их запустить.
Добавляем новый шаг, только теперь **Runner** – это **NUnit**. Обратите внимание на параметр **Execute step**: он указывает, при каких условиях нужно выполнять шаг, и имеет 4 значения:
* **If all previous steps finished successfully (zero exit code)** – если все предыдущие шаги завершились без ошибок. При этом проверка выполняется чисто на агенте;
* **Only if build status is successful** – аналогично предыдущему, но при этом агент ещё и уточняет у сервера TC статус билда. Нужно для более тонкого управления логикой задания, например, если нулевой код возврата конкретного шага для нас является ошибкой;
* **Even if some of the previous steps failed** – даже если какой-то из предыдущих шагов завершился с ошибкой;
* **Always, even if build stop command was issued** – выполнять шаг, даже если подана команда на отмену выполнения сборки.
Здесь самое важное – указать верный путь к сборке с тестами внутри проекта в графе Run tests from. У нас, например, он выглядит вот так:
```
%teamcity.build.checkoutDir%\project\project.FuncTests\bin\Dev\project.FuncTests.dll
```
**%teamcity.build.checkoutDir%** – это переменная, указывающая на папку, в которую скачиваются данные из репозитория. В принципе, она не обязательна для указывания, т.к. по умолчанию путь идёт именно относительно этой директории, поэтому путь можно было бы сократить до:
```
project\project.FuncTests\bin\Dev\project.FuncTests.dll
```
Отдельно отмечу опцию **Run recently failed test first** – если в предыдущем прогоне какие-то тесты упали, то в следующем запуске первыми запустятся именно они, и вы быстро узнаете об успешности последних изменений.
Прогнать тесты интерфейса (функциональные тесты)
------------------------------------------------
Здесь все гораздо интереснее, чем с юнит-тестами. Кэп тут подсказывает, что, чтобы протестировать проект в браузере, его, т.е. проект, необходимо запустить. Но тут мы схитрили, запуская веб-сервер прямо из кода тестов Selenium:
```
[SetUpFixture]
class ServerInit
{
private const string ApplicationName = "justtest";
private Process _iisProcess;
private string GetApplicationPath(string applicationName) {
var tmpDirName=AppDomain.CurrentDomain.BaseDirectory.TrimEnd('\\');
var solutionFolder = Path.GetDirectoryName(Path.GetDirectoryName(Path.GetDirectoryName(tmpDirName)));
string result = Path.Combine(solutionFolder, applicationName);
return result;
}
[SetUp]
public void RunBeforeAnyTests()
{
[…]
var applicationPath = GetApplicationPath(ApplicationName);
var programFiles = Environment.GetFolderPath(Environment.SpecialFolder.ProgramFiles);
_iisProcess = new Process
{
StartInfo =
{
FileName = string.Format("{0}/IIS Express/iisexpress.exe", programFiles),
Arguments = string.Format("/path:\"{0}\" /port:{1}", applicationPath, UrlProvider.Port)
}
};
_iisProcess.Start();
}
[TearDown]
public void RunAfterAnyTests()
{
[…]
if (_iisProcess.HasExited == false)
{
_iisProcess.Kill();
}
}
}]
```
А сам запуск выглядит абсолютно точно так же, как на шаге с юнит-тестами.
Залить изменения на тестовый сервер
-----------------------------------
Сервер, на котором находится агент TC, и сервер, на котором установлен IIS, – разные серверы, причем, более того, находятся они в разных сетях. Поэтому файлы нужно как-то на конечный сервер доставить. И вот тут решение выбрано, может, не очень элегантное, зато крайне простое. Используем заливку через FTP, причем делает сие за нас **MSBuild**.
Схема такая:
1. настраиваем на сервере FTP аккаунт для заливки файлов. Для дополнительной безопасности можно запретить заливку для всех IP, кроме внутреннего, если TC-сервер лежит во внутренней сети, конечно;
2. устанавливаем на агента **MSBuild Community Tasks**, чтобы получить возможность использовать задачу «Залить по FTP». [Качать тут](http://code.google.com/p/msbuildtasks/downloads/list);
3. подготовить файл-сценарий для MSBuild, который будет производить следующие действия:
1. сборка приложения во временной папке;
2. подмена конфигурационного файла;
3. заливка файлов по FTP.
**Вот так будет выглядеть этот файл (deploy.xml)**
```
xml version="1.0" encoding="utf-8"?
bin
../output
Dev
..\project\project\Web.template.config
..\project\project\Web.$(Configuration).config
..\project\output\Web.config
False
WebProjectOutputDir=$(PublishDir);OutputPath=$(OutputDir);Configuration=Dev
dev.example.com
ЛОГИН
ПАРОЛЬ
..\project\output
```
А так – задание по его вызову:
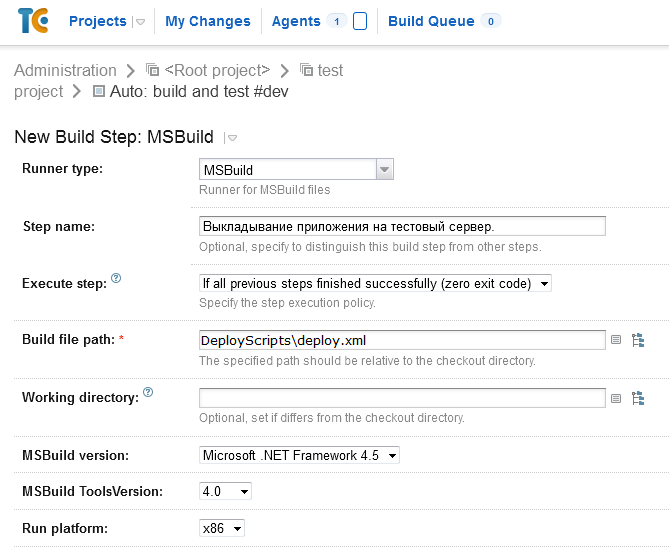
Недостаток решения – заливаются ВСЕ файлы, а не только новые изменившиеся. На проекте с кучей файлов верстки или множеством модулей это может стать проблемой из-за затрачиваемого на заливку времени.
Ещё один замеченный недостаток – при встрече файла с нелатиницей в названии падает с ошибкой. Латиница и буквы/цифры обрабатываются нормально. Ноги этой проблемы, похоже, растут из специфики протокола FTP: тот основан на ASCII, но, как именно кодировать не ASCII-символы, он не описывает, предлагая «делать так, как будет понимать ваш сервер». Соответственно, чтобы вылечить проблему, не меняя схему, нужно пропатчить MSBuild Community Tasks, благо, [исходники открыты](https://github.com/loresoft/msbuildtasks/blob/master/Source/MSBuild.Community.Tasks/Ftp/FtpClientTaskBase.cs). Ну, или воспользоваться альтернативным способом заливки файлов, например через WinSCP.
Остановка и запуск сервера для релизного сценария
-------------------------------------------------
Мы её решаем чуть диким, но симпатичным способом. У IIS’а есть особенность: если в корень сайта положить файл с именем **app\_offline.html**, то сайт отрубается, при обращении ко всем файлам будет выдаваться содержимое этого файла.
Минус – обращение именно что КО ВСЕМ файлам, включая статичные. Так что, если хочется сделать заглушку с оформлением, CSS и картинками, используйте инлайн-стили и data:url, ну, или как вариант – выложите их на отдельном сервере.
Включаем-отключаем мы сервер через WinSCP-сценарий и такие вот файлики:
**server\_off.cmd**
```
winscp.exe /console /script=server_off.txt
```
**server\_on.cmd**
```
winscp.exe /console /script=server_on.txt
```
**server\_off.txt**
```
option batch abort
option confirm off
open ftp://ЛОГИН:ПАРОЛЬ@dev.example.com
mv _app_offline.htm app_offline.htm
close
exit
```
**server\_on.txt**
```
option batch abort
option confirm off
open ftp://ЛОГИН:ПАРОЛЬ@dev.example.com
rm app_offline.htm
close
exit
```
Т.е., изначально файл лежит в корне и называется **\_app\_offline.html**. Когда нужно заблокировать доступ на время апдейта, мы переименовываем его в **app\_offline.html**. При заливке файлов заливается новый файл **\_app\_offline.html**, а после окончания – удаляется файл **app\_offline.html**. И получаем именно то, что было изначально.
В тексте страницы-заглушки крайне рекомендую воспользоваться мета-тегом [refresh](http://en.wikipedia.org/wiki/Meta_refresh), который периодически будет обновлять страницу. Если к этому времени процесс обновления завершился, пользователь вернётся обратно в сервис, чему наверняка будет несказанно рад.
Вызов сценария включения заглушки (отключение заглушки происходит аналогично):
Да, **WinCSP** лежит в результате прямо в репозитории. Да, пароли в открытом виде лежат в файле. Да, не самое элегантное решение, но, поскольку доступ в репозиторий и к виртуальной машине с агентом имеют только разработчики из нашей команды, почему бы и нет? Да, можно было бы хранить файл с паролями, например, непосредственно на агенте, но принципиально безопасность это не повысило бы, а вот развертку нового агента, например, замедлило бы.
Данные настройки используются нами на протяжении где-то полугода, и пока ни единой проблемы не возникло – всё работает как часы, что не может не радовать.
На этом всё. С удовольствием выслушаю комментарии и советы по улучшению этих шагов, а также ваши рассказы о том, какие возможности TC вы используете у себя.
**Update от 3 ноября 2014 года.**
Выбирая Runner Type «Command line» не требуется как-либо экранировать пробелы — Team City озаботится об этом самостоятельно. | https://habr.com/ru/post/205402/ | null | ru | null |
# Отложенная обработка массива
Однажды, при разработке сложного приложения на JavaScript-е возникла непреодолимая проблема — большой массив в Internet Explorer (далее IE). Так как я изначально проверял работу в Chrome, то не замечал каких-либо проблем при использовании массивов. Скажу больше — вложенные массивы не вызывали чувства страха. Chrome легко справлялся с трудными задачами. Однако IE, в очень жёсткой форме, указал на все мои огрехи и недостатки кода, особенно на обработку Больших массивов.
#### В двух словах
Разрабатываемое приложение должно было, в режиме реального времени, реагировать на события приходящие с сервера. Для этих целей воспользовались библиотекой [Socket.IO](http://socket.io/), что позволило легко реализовать двухстороннее общение с сервером. При этом приложение также было завязано на сторонний сервис, к которому я имел доступ только через внешнее REST API.
Слабым звеном оказался большой цикл который должен был обрабатывать массив данных, полученные как раз со стороннего сервиса. При этом приходилось в цикле одновременно изменять DOM модель. В этих случаях IE уходил в состояние глубокой задумчивости и естественно рвал соединение. Чисто внешне это было неприемлемо — блокировка приложения и постоянно крутящийся значок загрузки не могли удовлетворить заказчика. Да, многие могут справедливо указать на большие затраты при изменении DOM модели. И должен вас заверить, что эта часть проблемы была решена выносом всех изменений за пределы цикла. Однако основная проблема — разрыв соединения при обработке массива осталась.
Полный рефакторинг страшно пугал, так как уже были написаны тысячи строк кода. К тому же поджимали сроки. Именно в таких условиях родилась идея “отложенной”, частичной обработки массива.
#### Алгоритм
Массив логически разбивается на несколько диапазонов, обработку каждого из которых производим с задержкой. Суть работы представлена на рисунке:

Таким образом имея единый глобальный массив **Array** функция обрабатывает его по частям, с заранее заданной задержкой. Для асинхронного язык, которым является JavaScript, данная техника позволяет разгрузить основной поток (так же один единственный) при обработки очень больших массивов.
Основное тело обработчика:
```
//Lazy array processing
/**
* Input parameters
* params = {
* outerFuntion : function(array, start, stop),
* mainArray: []
* startIndex: Int,
* stepRange Int,
* timeOut: Int,
* callback: function()
*}
*/
var lazyProcessing = function(params) {
var innerFunction = (function(_) {
return function() {
var arrayLength = _.mainArray.length,
stopIndex = _.startIndex + _.stepRange;
if(arrayLength < stopIndex) {
_.outerFunction(
_.mainArray,
_.startIndex,
arrayLength - _.startIndex);
if(_.callback != undefined) {
_.callback();
}
return;
} else {
_.outerFunction(
_.mainArray,
_.startIndex,
stopIndex);
_.startIndex += _.stepRange;
lazyProcessing(_);
}
}
})(params);
setTimeout(innerFunction, params.timeOut);
};
//Outer function works with mainArray in given range
var func = function(mainArray, start, stop) {
//TODO: this should be everything you want to do with elements of
for (var i = start; i < stop; ++i) {
// do something
}
};
```
В теле функции **lazyProcessing** создается локальная функция **innerFunction**, которая замыкает в себе полученные параметры **params**. Это позволяет каждый раз, при рекурсивном вызове функции **lazyProcessing** из себя, сохранять уникальные параметры.
Функция **innerFunction** возвращает безымянную функция, которая выполняет следующие достаточно простые действия:
1. Проверяет достижение конца глобального массива
2. Вызывает внешнюю функцию **outerFuntion** с различными значениям **stop**
3. В случае достижения конца массива — вызывает **callback** функцию
4. В противном случае рекурсивно вызывает **lazyProcessing**.
Внешней функции **outerFuntion** передается сам массив (по причине его глобальности, этого можно было не делать, однако при этом пострадает наглядность), а так же индексы начала и конца цикла. При этом, результаты обработки можно либо сохранять в массив, либо в другие глобальные переменные. Все зависит от текущей задачи.
При достижении конца массива может быть вызвана callback функция, но это опционально.
#### За и против
Естественно в данном решении есть свои подводные камни и недостатки:
1. Если установить **stepRange** минимальным, при достаточно большом **mainArray** массиве, можно банально «упасть» по переполнению стека
2. Поток все же будет блокироваться при вызове внешней outerFunction. Т.е. быстродействие напрямую будет зависеть от алгоритма обработки элементов массива
3. “Лапша” из вложенных и возвращаемых функций смотрится не очень дружественно
Вместе с тем, частичная обработка массива через равные промежутки времени — не блокирует поток выполнения программы. Что позволяет обрабатывать другие callback функции.
**Полный работающий пример:**
```
//Test array
var test = [];
for(var i = 0; i < 100000; ++i) {
test[i] = i;
}
//Lazy array processing
/*
params = {
outerFuntion : function(array, start, stop),
mainArray: []
startIndex: Int,
stepRange Int,
timeOut: Int,
callback: function()
}
*/
var lazyProcessing = function(params) {
var _params = params;
var innerFunction = (function(_) {
return function() {
var arrayLength = _.mainArray.length,
stopIndex = _.startIndex + _.stepRange;
if(arrayLength < stopIndex) {
_.outerFunction(
.mainArray,
_.startIndex,
arrayLength - _.startIndex);
if(_.callback != undefined) {
_.callback();
}
return;
} else {
_.outerFunction(
_.mainArray,
_.startIndex,
stopIndex);
_.startIndex += _.stepRange;
lazyProcessing(_);
}
}
})(_params);
setTimeout(innerFunction, _params.timeOut);
};
//Test function works with array
var func = function(mainArray, start, stop) {
//TODO: this should be everything
//you want to do with elements of mainArray
var _t = 0;
for (var i = start; i < stop; ++i) {
mainArray[i] = mainArray[i]+2;
_t += mainArray[i];
}
};
lazyProcessing({
outerFunction: func,
mainArray: test,
startIndex: 0,
stepRange: 1000,
timeOut: 100,
callback: function() {
alert("Done");
}
});
```
PS. Пользователь [zimorodok](http://habrahabr.ru/users/zimorodok/) скинул замечательный пример — такой же по духу и по сути. Не могу не добавить его.
Проход по массиву с callback-ом для каждого элемент с возможностью задавать timeOut:
```
/*
example of use
var arr = ['masha','nadya', 'elena'];
iterate_async(arr, function (el, index, arr) {
console.log(el + ' is #' + (index + 1));
}, 99);
*/
function iterate_async (arr, callback, timeout) {
var item_to_proceed;
item_to_proceed = 0;
(function proceed_next () {
if (item_to_proceed < arr.length) {
setTimeout(function () {
callback.call(arr, arr[item_to_proceed], item_to_proceed, arr);
item_to_proceed += 1;
proceed_next();
}, timeout || 50);
}
}());
}
``` | https://habr.com/ru/post/151155/ | null | ru | null |
# JetBrains MPS для интересующихся #1
Введение
--------
Спасибо всем за критику в комменте под [первым постом](https://habrahabr.ru/post/334108/), где я хотел попробовать написать про MPS, не затрагивая важные темы, чтобы можно было потом более качественно начать писать по порядку.
Зачем нам нужен язык Weather?
-----------------------------
В комментариях к 1 посту [было следующее высказывание](https://habrahabr.ru/post/334108/#comment_10328140)
> С этой точки зрения, DSL — это как фреймворк, только с более удобным интерфейсом. Ясное дело, под один проект фреймворк делать никто не будет, за исключением совсем уж монструозных случаев. А сделать его под конкретную предметную область — почему бы и нет?..
В принципе, так оно все и работает. Хорошие языки похожи по сути на хорошие фреймворки: они позволяют писать что-то важное, не заморачиваясь о том, что мы не хотим писать. По ходу повествования я буду периодически обращаться к другим языкам для аналогий и сравнений.
Синтаксис
---------
Язык Weather, который мы хотим реализовать, должен выполнять следующую задачу: мы должны уметь лаконично выражать условия (погода сегодня, например) и следствия (погода завтра, послезавтра...).
В языке Weather мы будем делать наши прогнозы отталкиваясь от 1 фактора: от температуры на сегодняшний день(массив объектов время + погодные условия).
**Пример массива входных данных на JS**
```
const weatherInput = [
{
time: 1501179579253,
temperature: {
unit: "celsius",
value: 23.7
}
},
{
time: 1501185944759,
temperature: {
unit: "fahrenheit",
value: 15.3
}
}
]
```
Думаю сойдет.
**Реализация на Weather**
```
Weather prediction rules for Saint Petersburg
data Today:
[21:23]{
temperature = 23.7 °C
}
[23:06]{
temperature = 15.3 °F
}
```
У нас очень простые данные — время + температура в единицах измерения. Создадим абстрактный концепт *WeatherTimedData* — он нам нужен для хранения времени измерения и самой температуры.
Теперь нужно определить, что такое *Temperature* и *Time*.
*Time* реализован очень просто — у нас есть время в часах и минутах, а отображается оно как `hh : mm`.
Если с *Time* все понятно, то с *Temperature* немного нет. Во-первых — value это какой-то `_FPNumber_String`. На самом деле это MPS'овский double, так что ничего страшного. Но вопрос — как из интерфейса *Temperature* сделать реализации температуры в разных единицах измерения, да так чтобы это еще и красиво было? И вообще, что такое интерфейс концепт?
У таких концептов не может быть реализации в AST. То есть, вообще никакой. Только если другой концепт расширяет его, и никак иначе. Делается это, как и в ООП, для того, чтобы обобщить несколько классов под одно общее начало.
Вот как я реализовал отображение в редакторе для *Temperature*:

Здесь у нас первая ячейка — double значение, величина температуры, а вторая — *Read-Only model access*. Здесь мы немного отдаляемся от практики и переходим к теории.
Теория
------
В MPS все строится на концептах, если проводить прямую параллель с ООП, то концепты — это классы. Они могут расширять другие концепты, реализовывать интерфейсы, но еще они могут иметь какую-то логику. Например, если мы описываем абстрактный класс температуры, то нужно предусмотреть возможность задания собственных единиц измерения.
```
abstract class Temperature{
abstract double value;
public abstract String getUnit();
override String toString(){
return value + this.getUnit();
}
}
```
Можно было бы задать unit как переменную, а не писать абстрактный метод, но…
Есть аспект, называется **Behavior**. Все, что он может делать — добавлять новые методы к концепту. То есть добавить переменную мы не можем, поэтому будем использовать абстрактный метод.
И вот после этого мы можем у каждой реализации концепта *Temperature* вызывать этот метод. Но где же его вызывать? Как вообще кодить в этом MPS?..
Снова практика
--------------
Мы остановились на том, что у нас есть непонятная ячейка в **Editor** аспекте — ReadOnly model access. Все очень просто — если нужно как-то логически обработать proeprty/children/reference перед тем, как его показывать, и на это не хватает встроенных приколов, то мы можем сами получить нужную строку из контекста редактора и реализации концепта. Если просто — нам дают текущий объект концепта, то есть реализованный, и мы можем из него получить все, что мы там понапихали. В данном случае мы хотим получить единицу измерения, поэтому мы нажимаем на ячейку *R/O model access* и пишем

Кстати, в любом месте кода вы можете тыкнуть на штучку, что Вас интересует и нажать *Ctrl + Shift + T* и получить информацию о типе этой штучки. Например, если мы нажмем на **node** в скрине выше и узнаем его тип, то мы получим
`node<Название Концепта>` = какая-то реализация концепта
`concept<Название Концепта>` = класс концепта
Так! Мы уже умеем составлять температуру по значению и единице измерения, но откуда мы возьмем, какая единица измерения нам нужна? Из дочерних реализаций, естественно.
Создаем пустой *CelsiusTemperature* концепт, расширяем Temperature и создаем для него behavior.
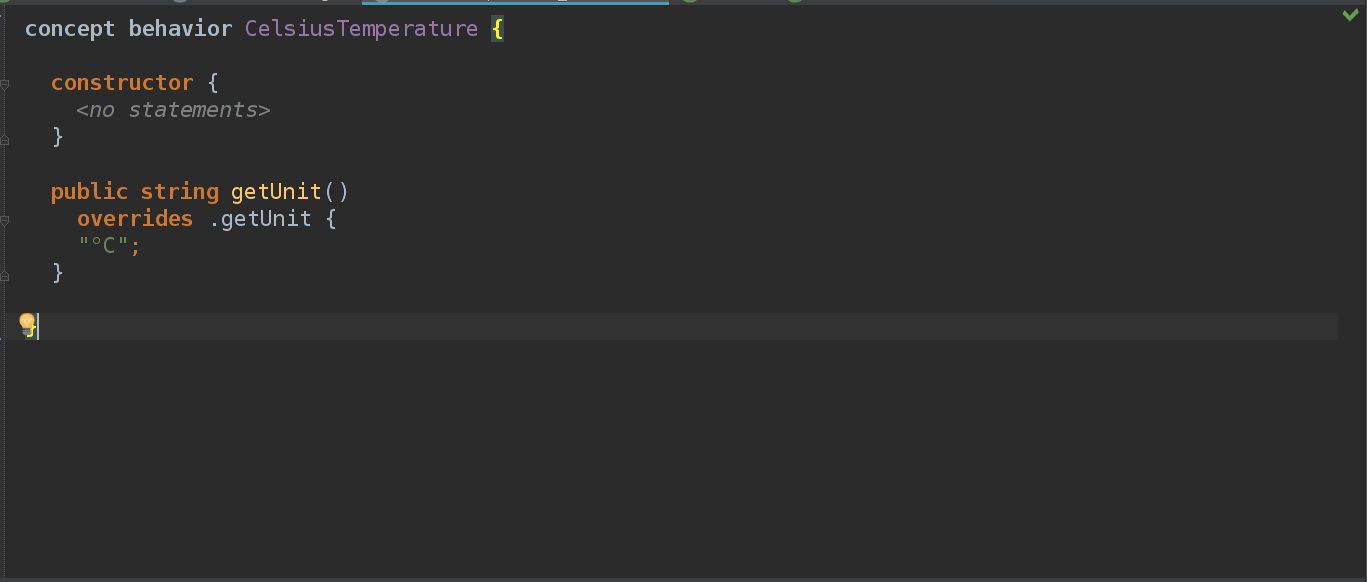
Как видно на последнем скрине, мы переопределяем метод *getUnit*(он имеется в зоне видимости из-за того, что мы наследовали концепт от *Temperature*) и возвраещем `"°C"`. Все просто!
Остается только собрать все вместе в *WeatherTimedData*:
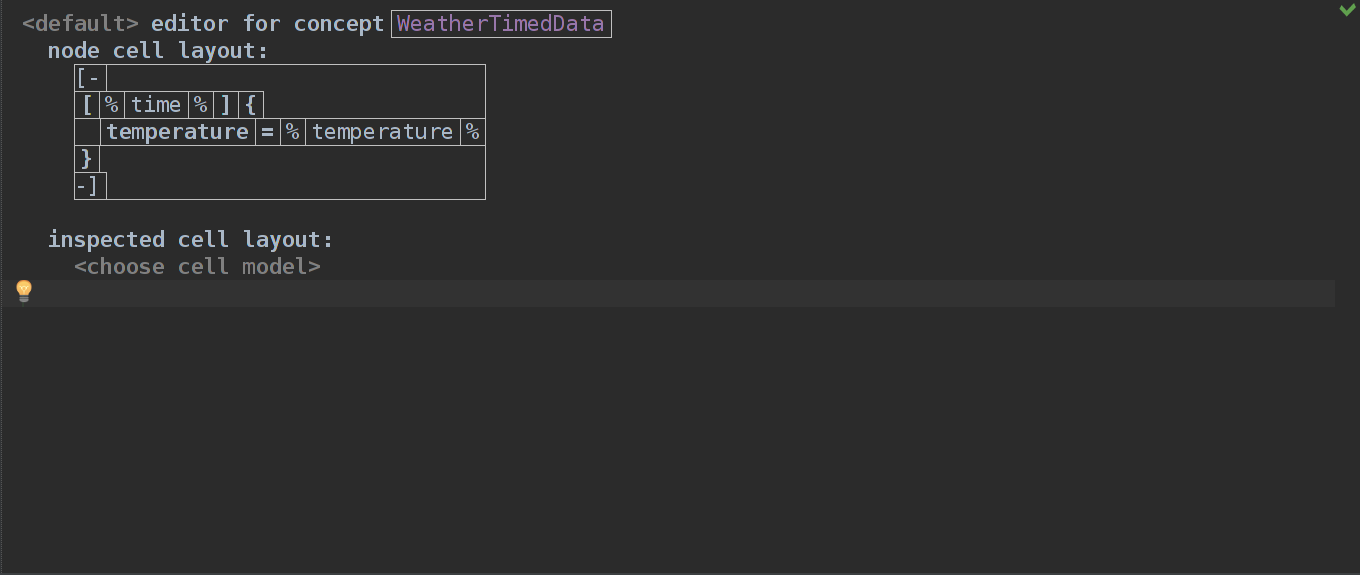
Собираем язык и смотрим на результат:
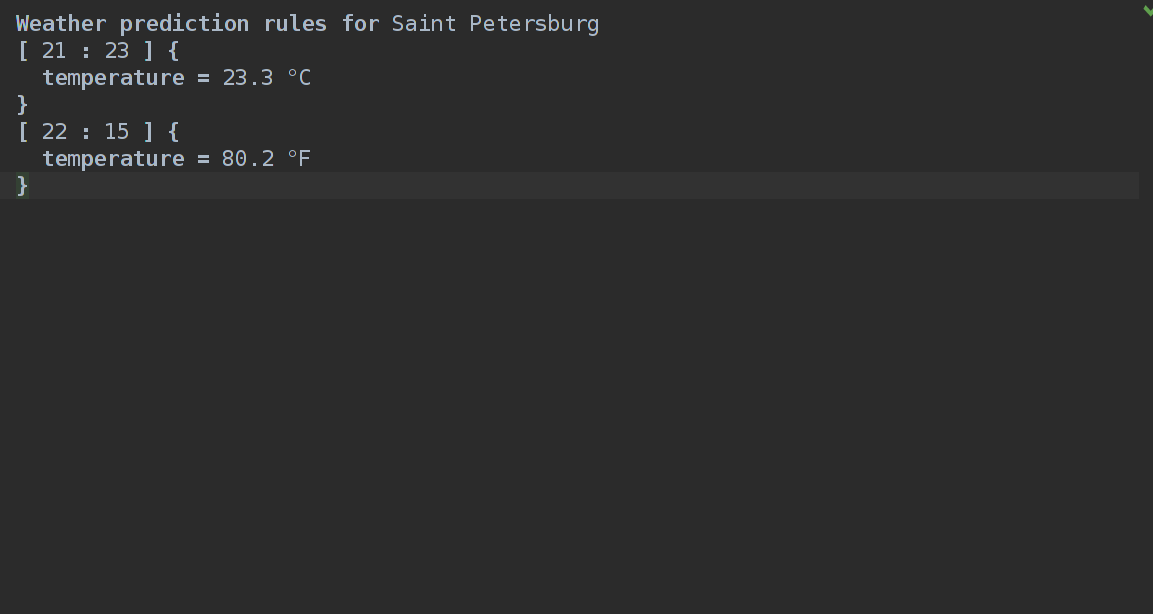
Вроде похоже на правду. Еще, конечно, нет самих предсказаний погоды, нет подсветки, к тому же часы у нас могут быть больше 24 и меньше нуля, минуты тоже не ограничены ничем, кроме размерности integer… В следующем посте ждите разъяснений по новому аспекту — **constraints** и еще чего-нибудь. А пока — пишите фидбек в комментариях, все как всегда, если вопрос простой — отвечаю там же, если он обширен и скорее как пожелание — то я постараюсь с каждым постом писать все качественнее. Спасибо за внимание!
//UPDATE\
Завел кривой репозиторий с проектом, где каждая ветка — новый туториал на Хабре. [Это он!!!](https://github.com/enchanting4/mps_weather) | https://habr.com/ru/post/334308/ | null | ru | null |
# Компиляция контейнеров — Dockerfiles, LLVM и BuildKit
Эта статья конкатенация двух статей Адама Гордона Белла (Adam Gordon Bell) из Earthly. Добавил в основную статью про компиляцию контейнеров BuildKit выдержки из его другой [статьи](https://blog.earthly.dev/what-is-buildkit-and-what-can-i-do-with-it/) про BuildKit для понимания как это работает и как использовать BuildKit напрямую.
Тынис Тийги (Tõnis Tiigi), сотрудник Docker и основной разработчик BuildKit, создал BuildKit, чтобы отделить логику построения образов от основного проекта moby и обеспечить возможность дальнейшего развития. BuildKit поддерживает подключаемые интерфейсы, которые позволяют создавать не только образы docker из Dockerfiles. С помощью BuildKit мы можем заменить синтаксис Dockerfile на hlb и заменить формат образа докера на вывод в виде чистого tar-файла. Это лишь одна из возможных комбинаций, которые открывает BuildKit с его подключаемыми бэкэндами и интерфейсами.
Введение
--------
Как получаются контейнеры? Обычно из серии операторов, таких как `RUN`,`FROM` и `COPY`, которые помещаются в Dockerfile и собираются. Но как эти команды превращаются в образ, а затем в работающий контейнер? Понять это можно если пройти этапы создания образа контейнера самостоятельно. Мы создадим образ программно, а затем разработаем обычный синтаксический интерфейс и будем использовать его для создания образа.
docker build
------------
Мы можем создавать образы контейнеров несколькими способами. Мы можем использовать пакеты сборки, мы можем использовать инструменты сборки, такие как Bazel или sbt, но, безусловно, наиболее распространенным способом создания образов является использование `docker build` с Dockerfile. Таким образом создаются знакомые базовые образы Alpine, Ubuntu и Debian.
Вот пример Dockerfile:
```
FROM alpine
COPY README.md README.md
RUN echo "standard docker build" > /built.txt"
```
В этом руководстве мы будем использовать вариации этого Dockerfile.
Мы можем собрать его так:
```
docker build . -t test
```
Но что происходит, когда вы вызываете docker build? Чтобы понять это, нам понадобится немного предыстории.
Background
----------
Образ докера состоит из слоев. Эти слои образуют неизменную файловую систему. Образ контейнера также содержит некоторые описательные данные, такие как команда запуска, открываемые порты и монтируемые тома. Когда вы делаете`docker run` образа, он запускается внутри среды выполнения контейнера.
Мне нравится рассматривать образы и контейнеры по аналогии. Если образ похож на исполняемый файл, то контейнер похож на процесс. Вы можете запускать несколько контейнеров из одного образа, а работающий образ - это вовсе не образ, а контейнер.
Продолжая нашу аналогию, BuildKit - это компилятор, как например LLVM. Но в то время как компилятор берет исходный код и библиотеки и создает исполняемый файл, BuildKit берет Dockerfile и путь к файлу и создает образ контейнера.
Docker build использует BuildKit, чтобы превратить Dockerfile в образ докера, образ OCI или другой формат образа. Здесь мы в основном будем использовать BuildKit напрямую.
Как работают компиляторы?
-------------------------
Традиционный компилятор берет код на языке высокого уровня и переводит его на язык более низкого уровня. В большинстве обычных компиляторов, конечной целью является машинный код. Машинный код - это язык программирования низкого уровня, который понимает ваш процессор.
Компиляция классического «Hello, World» на С в ассемблерный код x86 с использованием интерфейса Clang для LLVM выглядит так:
Создание образа из файла докеров работает аналогичным образом:
BuildKit передается Dockerfile и контексту сборки, который является текущим рабочим каталогом на приведенной выше схеме. Проще говоря, каждая строка в файле Dockerfile превращается в слой в итоговом изображении. Одним из существенных отличий построения образа от компиляции является контекст сборки. Входные данные компилятора ограничены исходным кодом, тогда как docker build принимает ссылку на файловую систему хоста в качестве входных данных и использует ее для выполнения таких действий, как COPY.
В чем подвох
------------
На предыдущей диаграмме, где компиляции «Hello, World» отображена за один шаг, упущена важная деталь. Если бы каждый компилятор представлял собой вручную закодированный маппинг с языка высокого уровня на машинный код x86, то переход на процессор Apple M1 был бы довольно сложным, поскольку он имеет другой набор инструкций.
Авторы компилятора преодолели эту проблему, разбив компиляцию на фазы. Традиционные фазы - это frontend (интерфейс), backend и middle, которую иногда называют оптимизатором (optimizer), и она имеет дело в основном с внутренним представлением (IR).
Такой поэтапный подход означает, что вам не нужен новый компилятор для каждой новой машинной архитектуры. Вместо этого вам просто нужен новый backend. Вот пример того, как это выглядит в LLVM:
Промежуточные представления
---------------------------
Такой подход с использованием нескольких бэкэндов позволяет LLVM ориентироваться на ARM, X86 и многие другие компьютерные архитектуры, используя промежуточное представление LLVM (IR) в качестве стандартного протокола. LLVM IR - это удобочитаемый язык программирования, который серверная часть должна принимать в качестве входных данных. Чтобы создать новый бэкэнд, вам нужно написать переводчик из LLVM IR в целевой машинный код. Этот перевод - основная задача каждого бэкэнда.
Когда у вас есть этот IR, у вас есть протокол, который различные фазы компилятора могут использовать в качестве интерфейса, и вы можете создавать не только множество бэкэндов, но и множество интерфейсов (frontend). LLVM имеет интерфейсы для множества языков, включая C, Julia, Objective-C, Rust и Swift.
Если вы можете написать перевод со своего языка на LLVM IR, LLVM сможет перевести этот IR в машинный код для всех поддерживаемых им бэкэндов. Эта функция трансляции - основная задача внешнего интерфейса компилятора.
На практике дело не только в этом. Интерфейсы должны токенизировать и анализировать входные файлы, и они должны возвращать нужные ошибки. Бэкенды часто требуют оптимизации для конкретных целей и эвристики. Но для нас сейчас критическим моментом является то, что стандартное представление превращается в мост, соединяющий многие интерфейсы со многими внутренними интерфейсами. Этот общий интерфейс устраняет необходимость в создании компилятора для каждой комбинации языка и машинной архитектуры. Это простой, но очень полезный трюк!
BuildKit
--------
Образы, в отличие от исполняемых файлов, имеют собственную изолированную файловую систему. Тем не менее, задача создания образа очень похожа на компиляцию исполняемого файла. Они могут иметь различный синтаксис (dockerfile1.0, dockerfile1.2), и результат должен быть нацелен на несколько архитектур компьютеров (arm64 против x86\_64).
> *“LLB для Dockerfile так же как LLVM IR для C”* [BuildKit Readme](https://github.com/moby/buildkit/blob/master/README.md)
>
>
Это сходство не ускользнуло от внимания создателей BuildKit. BuildKit имеет собственное промежуточное представление LLB. И там, где LLVM IR имеет такие вещи, как вызовы функций и стратегии сборки мусора, LLB имеет монтируемые файловые системы и выполнение операторов.
LLB определяется как буфер протокола, а это означает, что внешние интерфейсы BuildKit могут делать запросы GRPC к buildkitd для непосредственного создания контейнера.
Программное создание образа
---------------------------
Давайте программно сгенерируем LLB для образа, а затем соберем образ.
*В этом примере мы будем использовать Go, который позволяет нам использовать существующие библиотеки BuildKit, но это можно сделать на любом языке с поддержкой Protocol Buffer.*
Импортирeм LLB:
```
import (
"github.com/moby/buildkit/client/llb"
)
```
Создадим LLB для образа Alpine:
```
func createLLBState() llb.State {
return llb.Image("docker.io/library/alpine").
File(llb.Copy(llb.Local("context"), "README.md", "README.md")).
Run(llb.Args([]string{"/bin/sh", "-c", "echo \"programmatically built\" > /built.txt"})).
Root()
}
```
Мы выполняем эквивалент `FROM`, используя lib.Image. Затем мы копируем файл из локальной файловой системы в образ, используя FILE и COPY. Наконец, мы запускаем RUN для вывода текста в файл. LLB имеет гораздо больше операций, но вы можете воссоздать множество стандартных образов с помощью этих трех блоков.
Последнее, что нам нужно сделать, это превратить это в протокол-буфер и выдать его в стандартный вывод:
```
func main() {
dt, err := createLLBState().Marshal(context.TODO(), llb.LinuxAmd64)
if err != nil {
panic(err)
}
llb.WriteTo(dt, os.Stdout)
}
```
Давайте посмотрим что сгенерируется, используя параметр `dump-llb` в buildctl:
```
go run ./writellb/writellb.go |
buildctl debug dump-llb |
jq .
```
Мы получаем этот LLB в формате JSON:
```
{
"Op": {
"Op": {
"source": {
"identifier": "local://context",
"attrs": {
"local.unique": "s43w96rwjsm9tf1zlxvn6nezg"
}
}
},
"constraints": {}
},
"Digest": "sha256:c3ca71edeaa161bafed7f3dbdeeab9a5ab34587f569fd71c0a89b4d1e40d77f6",
"OpMetadata": {
"caps": {
"source.local": true,
"source.local.unique": true
}
}
}
{
"Op": {
"Op": {
"source": {
"identifier": "docker-image://docker.io/library/alpine:latest"
}
},
"platform": {
"Architecture": "amd64",
"OS": "linux"
},
"constraints": {}
},
"Digest": "sha256:665ba8b2cdc0cb0200e2a42a6b3c0f8f684089f4cd1b81494fbb9805879120f7",
"OpMetadata": {
"caps": {
"source.image": true
}
}
}
{
"Op": {
"inputs": [
{
"digest": "sha256:665ba8b2cdc0cb0200e2a42a6b3c0f8f684089f4cd1b81494fbb9805879120f7",
"index": 0
},
{
"digest": "sha256:c3ca71edeaa161bafed7f3dbdeeab9a5ab34587f569fd71c0a89b4d1e40d77f6",
"index": 0
}
],
"Op": {
"file": {
"actions": [
{
"input": 0,
"secondaryInput": 1,
"output": 0,
"Action": {
"copy": {
"src": "/README.md",
"dest": "/README.md",
"mode": -1,
"timestamp": -1
}
}
}
]
}
},
"platform": {
"Architecture": "amd64",
"OS": "linux"
},
"constraints": {}
},
"Digest": "sha256:ba425dda86f06cf10ee66d85beda9d500adcce2336b047e072c1f0d403334cf6",
"OpMetadata": {
"caps": {
"file.base": true
}
}
}
{
"Op": {
"inputs": [
{
"digest": "sha256:ba425dda86f06cf10ee66d85beda9d500adcce2336b047e072c1f0d403334cf6",
"index": 0
}
],
"Op": {
"exec": {
"meta": {
"args": [
"/bin/sh",
"-c",
"echo "programmatically built" > /built.txt"
],
"cwd": "/"
},
"mounts": [
{
"input": 0,
"dest": "/",
"output": 0
}
]
}
},
"platform": {
"Architecture": "amd64",
"OS": "linux"
},
"constraints": {}
},
"Digest": "sha256:d2d18486652288fdb3516460bd6d1c2a90103d93d507a9b63ddd4a846a0fca2b",
"OpMetadata": {
"caps": {
"exec.meta.base": true,
"exec.mount.bind": true
}
}
}
{
"Op": {
"inputs": [
{
"digest": "sha256:d2d18486652288fdb3516460bd6d1c2a90103d93d507a9b63ddd4a846a0fca2b",
"index": 0
}
],
"Op": null
},
"Digest": "sha256:fda9d405d3c557e2bd79413628a435da0000e75b9305e52789dd71001a91c704",
"OpMetadata": {
"caps": {
"constraints": true,
"platform": true
}
}
}
```
Просматривая вывод, мы видим, как наш код отображается на LLB.
Вот наша COPY как часть FileOp:
```
"Action": {
"copy": {
"src": "/README.md",
"dest": "/README.md",
"mode": -1,
"timestamp": -1
}
```
Вот отображение контекста нашей сборки для использования в нашей команде COPY:
```
"Op": {
"source": {
"identifier": "local://context",
"attrs": {
"local.unique": "s43w96rwjsm9tf1zlxvn6nezg"
}
}
```
Точно так же вывод содержит LLB, который соответствует нашим командам RUN и FROM.
Создание нашего LLB
-------------------
BuildKit состоит из двух основных компонентов: buildctl и buildkitd. buildctl - это контроллер BuildKit, который взаимодействует с buildkitd.
Buildkitd отвечает за создание образа, но фактическое выполнение каждого шага выполняет runc. Runc выполняет каждую команду RUN в вашем файле докеров в отдельном процессе. Runc требует ядра Linux 5.2 или более поздней версии с поддержкой cgroups, поэтому buildkitd не может работать изначально в macOS или Windows.
Как устанавливать описано [тут](https://github.com/moby/buildkit) - не будем останавливаться. В примере ниже описан способ через docker как более универсальный, так как запустить buildcid в macOS или Windows.
```
docker run --rm --privileged -d --name buildkit moby/buildkit
export BUILDKIT_HOST=docker-container://buildkit
go run ./writellb/writellb.go |
buildctl build
--local context=.
--output type=image,name=docker.io/agbell/test,push=true
```
Флаг вывода (output) позволяет нам указать, какой бэкэнд мы хотим использовать в BuildKit. Мы попросим его создать образ OCI и отправить его в docker.io. По умолчанию результат сборки остается внутренним для BuildKit поэтому мы указали тип вывода. BuildKit поддерживает несколько типов вывода. Мы можем вывести tar: `--output type=tar,dest=out.tar` (этот файл не является образом. Нет никаких слоев или манифестов, только полная файловая система, которую будет содержать созданный образ).
*В реальном инструменте мы могли бы захотеть программно убедиться, что buildkitd запущен, и отправить RPC-запрос прямо ему, а также предоставить понятные сообщения об ошибках. Сейчас мы все это пропустим.*
Мы можем запустить с тем же результатом:
```
docker run -it --pull always agbell/test:latest /bin/sh
```
Затем мы можем увидеть результаты наших программных команд COPY и RUN:
```
cat built.txt
programmatically built
ls README.md
README.md
```
Пример полного кода может стать отличной отправной точкой для создания вашего собственного программного образа докера.
frontend для BuildKit
---------------------
Настоящая клиентская часть компилятора делает больше, чем просто выдает жестко запрограммированный IR. Правильный интерфейс принимает файлы, токенизирует их, анализирует их, генерирует синтаксическое дерево, а затем опускает это синтаксическое дерево во внутреннее представление. [Mockerfiles](https://matt-rickard.com/building-a-new-dockerfile-frontend/) - пример такого интерфейса:
```
#syntax=r2d4/mocker
apiVersion: v1alpha1
images:- name: demo
from: ubuntu:16.04
package:
install:
- curl
- git
- gcc
```
А поскольку сборка Docker поддерживает команду `#syntax`, мы даже можем создать Mockerfiles напрямую с помощью `docker build`.
```
docker build -f mockerfile.yaml
```
Для поддержки команды `#syntax` все, что нужно, - это поместить интерфейс в образ докера, который принимает запрос gRPC в правильном формате, опубликовать это изображение где-нибудь. На этом этапе любой может использовать ваш интерфейс `docker build`, просто используя `#syntax = yourimagename`.
Создание собственного примера внешнего интерфейса для docker build
------------------------------------------------------------------
Создание токенизатора и парсера как службы gRPC выходит за рамки этой статьи. Но мы можем научится этому, извлекая и изменяя существующий интерфейс. Стандартный интерфейс Dockerfile легко отделить от проекта moby. Я вытащил соответствующие части в отдельный [репозиторий](https://github.com/agbell/compiling-containers/tree/main/ickfile). Давайте внесем в него несколько изменений и проверим.
До сих пор мы использовали только команды докера FROM, RUN и COPY. Поверхностно синтаксис Dockerfile с его командами, начинающимися с заглавной буквы, очень похож на язык программирования INTERCAL. Давайте изменим эти команды на их эквивалент INTERCAL и разработаем наш собственный формат Ickfile.
| | |
| --- | --- |
| **Dockerfile** | **Ickfile** |
| FROM | COME FROM |
| RUN | PLEASE |
| COPY | STASH |
Модули в интерфейсе dockerfile разделяют синтаксический анализ входного файла на несколько дискретных шагов, выполняемых следующим образом:
В этом руководстве мы собираемся внести только тривиальные изменения во внешний интерфейс. Мы оставим все этапы нетронутыми и сосредоточимся на настройке существующих команд под свой вкус. Для этого все, что нам нужно сделать, это изменить command.go:
```
package command
// Define constants for the command strings
const (
Copy = "stash"
Run = "please"
From = "come_from"
...
)
```
Затем мы можем увидеть результаты наших команд `STASH` и `PLEASE`:
Я отправил этот образ в dockerhub. Любой может начать создавать образы, используя наш формат ickfile, добавив `#syntax = agbell/ick` к существующему Dockerfile. Никакой ручной установки не требуется!
Еще пару примеров использования BuildKit напрямую
-------------------------------------------------
Если у нас есть образ локально на нашей машине, можем ли мы использовать его в FROM для создания чего-либо на его основе? Давайте узнаем, изменив наш FROM для использования локального образа:
```
FROM agbell/test:local
RUN echo "BuildKit built"> file
CMD ["/bin/sh"]
```
```
> docker tag alpine agbell/test:local
> buildctl build \
--frontend=dockerfile.v0 \
--local context=. \
--local dockerfile=. \
------
> [internal] load metadata for docker.io/agbell/test:local:
------
error: failed to solve: rpc error: code = Unknown desc = failed to solve with frontend dockerfile.v0: failed to create LLB definition: docker.io/agbell/test:local: not found
```
Это не работает. Похоже, он пытается получить изображение из docker.io, реестра docker-хаба по умолчанию.
Мы можем проверить это, быстро перехватив запросы от buildkitd:
```
➜ cat ~\Dockerfile
FROM moby/buildkit
RUN apk update && apk add curl
WORKDIR /usr/local/share/ca-certificates
COPY mitmproxy.crt mitmproxy.crt
RUN update-ca-certificates
➜ docker build . -t buildkit:mitm
...
➜ docker run --rm --privileged -d --name buildkit buildkit:mitm
6676dc0109eb3f5f09f7380d697005b6aae401bb72a4ee366f0bb279c0be137b
```
Мы видим ошибку 404, и это подтверждает, что buildkitd ожидает доступа к реестру по сети с помощью docker registry v2 api.
Мы можем наблюдать за выполнением нашей сборки, используя pstree и watch. Откройте два терминала, запустите в одном:
```
docker exec -it buildkit "/bin/watch" "-n1" "pstree -p"
```
В другом:
```
buildctl build ...
```
Вы увидите, что buildkitd запускает процесс buildkit-runc, а затем отдельный процесс для каждой команды RUN.
Заключение
----------
BuildKit используется внутри сборки докеров в современных версиях docker, но его использование напрямую открывает некоторые дополнительные возможности.
Мы рассмотрели одно использование - изменение типа вывода. Мы можем использовать BuildKit для экспорта tar и локальных файловых систем. Мы также используем pstree и mitmProxy, чтобы наблюдать, как buildkitd обрабатывает процессы и делает сетевые запросы.
Мы узнали, что трехэтапная структура, заимствованная у компиляторов, обеспечивает создание образов, что промежуточное представление, называемое LLB, является ключом к этой структуре. Опираясь на эти знания, мы создали два интерфейса для создания образов.
BuildKit стоит за функцией мультиплатформенной сборки docker buildx и поддерживает возможность параллельного выполнения сборок несколькими рабочими процессами. BuildKit также поддерживает кеширование, различные внешние интерфейсы, сборки для создания докеров, более быстрые многоступенчатые сборки и несколько других функций.
Анонсы других публикаций и возможность комментирования (если тут не можете) в [телеге](https://t.me/orangedevops). | https://habr.com/ru/post/550562/ | null | ru | null |
# Интеграция сервиса шаринга AddThis с Google Analytics
В этом году в Google Analytics появился новый отчет **Посетители > Соцфункции**. Он, как можно догадаться, должен показывать взаимодействие с сайтом посредством социальных кнопок (like, share и т.п.)
Но для отслеживания каждой социальной кнопки необходимо было создавать функцию обратного вызова, которая бы посредством вызова метода `_trackSocial` и должна отслеживать нажатие на кнопку.
Об этом можно почитать в справке Google Analytics: <http://code.google.com/intl/ru-RU/apis/analytics/docs/tracking/gaTrackingSocial.html>
И это было не очень удобное решение, т.к. социальных кнопок на сайте может быть много и для каждой придется писать функцию.
Теперь же появилось более изящное и простое решение для отслеживания социального взаимодействия. А именно, интеграция с сервисом социальных кнопок [AddThis](http://www.addthis.com). Этот сервис содержит достаточно большую базу социальных кнопок и широкие возможности по кастомизации своего виджета.

Для интеграции виджета AddThis с Google Analytics необходимо добавить небольшой код в блок вызова виджета:
```
var addthis\_config = {
data\_ga\_property: 'UA-xxxxxx-x',
data\_ga\_social: true
};
```
В итоге весь блок вызова виджета должен выглядеть примерно так:
```
[](http://addthis.com/bookmark.php?v=250)
var addthis\_config = {
data\_ga\_property: 'UA-xxxxxx-x',
data\_ga\_social: true
};
```
Подробнее про интеграцию тут: <http://www.addthis.com/help/google-analytics-integration>
После того, как посетители начнут кликать на социальные кнопки виджета AddThis, взаимодействие можно увидеть в отчетах GA:
* **Посетители > Соцфункции > Взаимодействие** — Позволяет сравнивать основные показатели сайта (количество просмотренных страниц за посещение, среднюю длительность пребывания на сайте, показатель отказов и т.п.), как включавших, так и не включавших социальные действия.
* **Посетители > Соцфункции > Действие** — Позволяет сравнивать количество социальных действий (нажатий Share, Like и т. д.) для каждого источника и различных комбинаций источников и действий.
* **Посетители > Соцфункции > Страницы** — С помощью этого отчета можно сравнивать количество социальных действий на разных страницах сайта. Эти данные можно просматривать как по источникам, так и по комбинациям источников и действий.
В отчетах AddThis есть еще один интересный показатель, которого нет в GA: «Вирусность» — отношение кликов по расшаренной ссылке к общему количеству расшариваний этой ссылки.
**Источник:** [Официальный блог Google Analytics](http://analytics.blogspot.com/2011/10/optimize-engagement-with-addthis-and.html)
p.s. удачного отслеживания социальных взаимодействий на сайте! | https://habr.com/ru/post/132639/ | null | ru | null |
# Почему использование юнит тестов это отличная инвестиция в качественную архитектуру
На понимание факта, что юнит тесты это не только инструмент борьбы с регрессией в коде, но также и отличная инвестиция в качественную архитектуру меня натолкнул топик, посвященный модульному тестированию в одном англоязычном .net сообществе. Автора топика звали Джонни и он описывал свой первый (и последний) день в компании, занимавшейся разработкой программного обеспечения для предприятий финансового сектора. Джонни претендовал на вакансию разработчика модульных тестов и был расстроен низким качеством кода, который ему вменялось тестировать. Он сравнил увиденный им код со свалкой, набитой объектами, бесконтрольно создающими друг друга в любых непригодных для этого местах. Также он писал, что ему так и не удалось найти в репозитории абстрактные типы данных, код состоял исключительно из туго переплетенных в один клубок реализаций, перекрестно вызывающих друг друга. Джонни, понимая всю бесполезность применения практики модульного тестирования в этой компании, обрисовал ситуацию нанявшему его менеджеру и, отказавшись от дальнейшего сотрудничества, дал напоследок ценный, с его точки зрения, совет. Он посоветовал отправить команду разработчиков на курсы, где бы их смогли научить правильно инстанцировать объекты и пользоваться преимуществами абстрактных типов данных. Я не знаю, последовал ли менеджер совету (думаю, что нет), но если вам интересно, что имел в виду Джонни и как использование практик модульного тестирования может повлиять на качество вашей архитектуры, добро пожаловать под кат, будем разбираться вместе.
##### Изоляция зависимостей — основа модульного тестирования
Модульным или юнит тестом называется тест, проверяющий функционал модуля в изоляции от его зависимостей. Под изоляцией зависимостей понимается подмена реальных объектов, с которыми взаимодействует тестируемый модуль, на заглушки, имитирующие корректное поведение своих прототипов. Такая подмена позволяет сосредоточиться на тестировании конкретного модуля, игнорируя возможность некорректного поведения его окружения. Из необходимости в рамках теста подменять зависимости вытекает интересное свойство. Разработчик, понимающий, что его код будет использоваться в том числе и в модульных тестах, вынужден разрабатывать, пользуясь всеми преимуществами абстракций, и рефакторить при первых признаках появления высокой связанности.
##### Пример для наглядности
Давайте попытаемся представить, как мог бы выглядеть модуль отправки личных сообщения в системе, разработанной компанией, из которой сбежал Джонни. И как бы выглядел этот же модуль, если бы разработчики применяли модульное тестирование. Наш модуль должен уметь cохранять сообщение в базе данных и, если пользователь, которому было адресовано сообщение, находится в системе — отображать сообщение на его экране всплывающим уведомлением.
```
//Модуль отправки сообщений на языке C#. Версия 1.
public class MessagingService
{
public void SendMessage(Guid messageAuthorId, Guid messageRecieverId, string message)
{
//объект репозиторий сохраняет текст сообщения в базе данных
new MessagesRepository().SaveMessage(messageAuthorId, messageRecieverId, message);
//проверяем, находится ли пользователь онлайн
if (UsersService.IsUserOnline(messageRecieverId))
{
//отправляем всплывающее уведомление, вызвав метод статического объекта
NotificationsService.SendNotificationToUser(messageAuthorId, messageRecieverId, message);
}
}
}
```
Давайте посмотрим — какие зависимости есть у нашего модуля. В функции SendMessage вызываются статические методы объектов NotificationsService, UsersService и создается объект MessagesRepository, ответственный за работу с базой данных. В том, что наш модуль взаимодействует с другими объектами проблемы нет. Проблема в том, как построено это взаимодействие, а построено оно неудачно. Прямое обращение к методам сторонних объектов сделало наш модуль крепко связанным с конкретными реализациями. У такого взаимодействия есть много минусов, но для нас главное то, что модуль MessagingService потерял возможность быть протестированным в отрыве от реализаций объектов NotificationsService, UsersService и MessagesRepository. Мы действительно не можем в рамках модульного теста, подменить эти объекты на заглушки.
Теперь давайте посмотрим, как выглядел бы этот же модуль, если бы разработчик позаботился о его тестируемости.
```
//Модуль отправки сообщений на языке C#. Версия 2.
public class MessagingService: IMessagingService
{
private readonly IUserService _userService;
private readonly INotificationService _notificationService;
private readonly IMessagesRepository _messagesRepository;
public MessagingService(IUserService userService, INotificationService notificationService, IMessagesRepository messagesRepository)
{
_userService = userService;
_notificationService = notificationService;
_messagesRepository = messagesRepository;
}
public void AddMessage(Guid messageAuthorId, Guid messageRecieverId, string message)
{
//объект репозиторий сохраняет текст сообщения в базе данных
_messagesRepository.SaveMessage(messageAuthorId, messageRecieverId, message);
//проверяем, находится ли пользователь онлайн
if (_userService.IsUserOnline(messageRecieverId))
{
//отправляем всплывающее уведомление
_notificationService.SendNotificationToUser(messageAuthorId, messageRecieverId, message);
}
}
}
```
Эта версия уже намного лучше. Теперь взаимодействие между объектами строится не напрямую, а через интерфейсы. Мы больше не обращаемся к статическим классам и не инстанцируем объекты в методах с бизнес логикой. И, самое главное, все зависимости мы теперь можем подменить, передав в конструктор заглушки для теста. Таким образом, добиваясь тестируемости нашего кода, мы смогли параллельно улучшить архитектуру нашего приложения. Нам пришлось отказаться от прямого использования реализаций в пользу интерфейсов и мы перенесли инстанцирование на слой находящийся уровнем выше. А это именно то, чего хотел Джонни.
##### Пишем тест к модулю отправки сообщений
**Спецификация на тесты**Определим, что именно должен проверять наш тест.
* факт однократного вызова метода IMessageRepository.SaveMessage
* факт однократного вызова метода INotificationsService.SendNotificationToUser(), в случае если метод IsUserOnline() стаба над объектом IUsersService вернул true
* отсутствие вызова метода INotificationsService.SendNotificationToUser(), в случае если метод IsUserOnline() стаба над объектом IUsersService вернул false
Выполнение этих трех условий гарантирует нам, что реализация метода SendMessage корректна и не содержит ошибок.
**Тесты**Тест реализован с помощью изоляционного фреймворка [Moq](https://github.com/Moq)
```
[TestMethod]
public void AddMessage_MessageAdded_SavedOnce()
{
//Arrange
//отправитель
Guid messageAuthorId = Guid.NewGuid();
//получатель, находящийся онлайн
Guid recieverId = Guid.NewGuid();
//сообщение, посылаемое от отправителя получателю
string msg = "message";
// стаб для метода IsUserOnline интерфейса IUserService
Mock userServiceStub = new Mock(new MockBehavior());
userServiceStub.Setup(x => x.IsUserOnline(It.IsAny())).Returns(true);
//моки для INotificationService и IMessagesRepository
Mock notificationsServiceMoq = new Mock();
Mock repositoryMoq = new Mock();
//создаем модуль сообщений, передавая в качестве его зависимостей моки и стабы
var messagingService = new MessagingService(userServiceStub.Object, notificationsServiceMoq.Object,
repositoryMoq.Object);
//Act
messagingService.AddMessage(messageAuthorId, recieverId, msg);
//Assert
repositoryMoq.Verify(x => x.SaveMessage(messageAuthorId, recieverId, msg), Times.Once);
}
[TestMethod]
public void AddMessage\_MessageSendedToOffnlineUser\_NotificationDoesntRecieved()
{
//Arrange
//отправитель
Guid messageAuthorId = Guid.NewGuid();
//получатель находящийся оффлайн
Guid offlineReciever = Guid.NewGuid();
//сообщение, посылаемое от отправителя получателю
string msg = "message";
// стаб для метода IsUserOnline интерфейса IUserService
Mock userServiceStub = new Mock(new MockBehavior());
userServiceStub.Setup(x => x.IsUserOnline(offlineReciever)).Returns(false);
//моки для INotificationService и IMessagesRepository
Mock notificationsServiceMoq = new Mock();
Mock repositoryMoq = new Mock();
//создаем модуль сообщений, передавая в качестве его зависимостей моки и стабы
var messagingService = new MessagingService(userServiceStub.Object, notificationsServiceMoq.Object,
repositoryMoq.Object);
//Act
messagingService.AddMessage(messageAuthorId, offlineReciever, msg);
//Assert
notificationsServiceMoq.Verify(x => x.SendNotificationToUser(messageAuthorId, offlineReciever, msg),
Times.Never);
}
[TestMethod]
public void AddMessage\_MessageSendedToOnlineUser\_NotificationRecieved()
{
//Arrange
//отправитель
Guid messageAuthorId = Guid.NewGuid();
//получатель, находящийся онлайн
Guid onlineRecieverId = Guid.NewGuid();
//сообщение, посылаемое от отправителя получателю
string msg = "message";
// стаб для метода IsUserOnline интерфейса IUserService
Mock userServiceStub = new Mock(new MockBehavior());
userServiceStub.Setup(x => x.IsUserOnline(onlineRecieverId)).Returns(true);
//моки для INotificationService и IMessagesRepository
Mock notificationsServiceMoq = new Mock();
Mock repositoryMoq = new Mock();
//создаем модуль сообщений, передавая в качестве его зависимостей моки и стабы
var messagingService = new MessagingService(userServiceStub.Object, notificationsServiceMoq.Object,
repositoryMoq.Object);
//Act
messagingService.AddMessage(messageAuthorId, onlineRecieverId, msg);
//Assert
notificationsServiceMoq.Verify(x => x.SendNotificationToUser(messageAuthorId, onlineRecieverId, msg),
Times.Once);
}
```
##### Поиск идеальной архитектуры — бесполезное занятие
Юнит тесты — это отличная проверка архитектуры на низкую связанность между модулями. Но следует помнить, что проектирование сложных технических систем — это всегда поиск компромисса. Идеальной архитектуры не бывает, учесть все возможные сценарии развития приложения при проектировании невозможно. Качество архитектуры зависит от множества параметров, часто друг друга взаимоисключающих. Любую проблему дизайна можно решить путём введения дополнительного уровня абстракции, кроме проблемы слишком большого количества уровней абстракций. Не стоит рассматривать как догму, что взаимодействие между объектами должно быть построено только на основе абстракций, главное чтобы выбор, совершенный вами, был осознанным и вы понимали, что код, допускающий взаимодействие между реализациями, становится менее гибким и, как следствие, теряет возможность быть протестированным модульными тестами. | https://habr.com/ru/post/210518/ | null | ru | null |
# VBscript в помощь 1С-программисту
Недавно получил ТЗ на разработку несложного отчета с выводом результатов в файлы. Ничего необычного, кроме нескольких пунктов:
1. Результат работы отчета должен будет отсылаться по расписанию специальной утилитой от стороннего разработчика
2. Все должно работать в полностью автоматическом режиме
3. Изменения в конфигурацию вносить нельзя
Если бы не пункт 3, то наверняка реализовал бы довольно распространенным способом: включил отчет в конфигурацию, в модуль приложения добавил выполнение отчета при входе специального пользователя с определенным именем. Соответственно, перед запуском сторонней утилиты настроил бы запуск 1С из командной строки под учетной записью этого специального пользователя. Но…
Практически вся первоначальная реализация идеи (простенький VBScript, который, используя OLE Automation, подключает COM-объект приложения 1С и инициирует выполнение внешнего отчета) отражена в процедуре *Execute()* представленного ниже кода. Все остальное было написано в порыве «сделать красиво» и облегчить жизнь себе и другим: настройки оформлены отдельным блоком с переменными, ошибки выполнения обрабатываются и записываются в лог-файл с указанием кода, описания и источника ошибки.
> `On Error Resume Next
>
>
>
> Dim ComApp, ExtProc, Path, Dest, LogName, ExtRep, ConnectionString
>
>
>
> 'Строка подключения к ИБ
>
> ConnectionString = "Srvr=APPSERVER;Ref=base"
>
> 'Папка назначения для файлов отчета
>
> Dest = "D:\Out\"
>
> 'Получаем папку скрипта
>
> Path = LEFT(WScript.ScriptFullName, InStrRev(WScript.ScriptFullName,"\"))
>
> 'Полный путь к лог-файлу
>
> LogName = Path & "errors.log"
>
> 'Полный путь к внешнему отчету
>
> ExtRep = Path & "extreport.erf"
>
>
>
> Execute()
>
> CheckErr()
>
> Set ExtProc = Nothing
>
> ComApp.Exit(False)
>
> Set ComApp = Nothing
>
>
>
> Sub Execute()
>
> Set Connector = CreateObject("V81.ComConnector")
>
> Connector.Connect(ConnectionString) 'Будет исключение, если база недоступна
>
> Set ComApp = CreateObject("V81.Application")
>
> ComApp.Connect(ConnectionString)
>
> Set ExtProc = ComApp.ExternalReports.Create(ExtRep)
>
> ExtProc.Path = Dest
>
> ExtProc.Service = Path
>
> ExtProc.Code = "42"
>
> ExtProc.Exec()
>
> End Sub
>
>
>
> Sub CheckErr()
>
> If Err.Number = 0 Then Exit Sub
>
> Set FS = CreateObject("Scripting.FileSystemObject")
>
> Set LogFile = FS.OpenTextFile(LogName, 8, True)
>
> LogFile.WriteLine(Now & " (" & Err.Number & ") " & Err.Description & " - " & Err.Source)
>
> LogFile.Close
>
> Err.Clear
>
> End Sub
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Когда писал скрипт, то столкнулся с двумя неочевидными для меня моментами.
Первый – это обработка исключительных ситуаций без привычных *try … catch*.
Немного «помучив» по этому поводу MSDN обнаружил, что если указать инструкцию *On Error Resume Next* то управление будет передаваться на следующую строку, после той, в которой возникла ошибка. А если ошибка возникает в теле процедуры, то управление передается на строку следующую за вызовом процедуры.
Таким образом, поместил весь основной код в процедуру *Execute()*, а исключения решил отлавливать процедурой *CheckErr()*.
Второе – это «зависание» выполнения скрипта, если информационная база отсутствует.
Точнее при отсутствии базы COM-приложение показывает диалоговое окошко с сообщением об ее отсутствии и ждет реакции пользователя. Но согласно ТЗ пользователь не увидит этого и процесс будет «висеть»… Здесь меня спас COMConnector, который вызывает исключение в случае проблем с соединением, вместо отображения диалоговых окон, и в начале кода процедуры *Execute()* появились еще две строки.
Здесь *Set ExtProc = ComApp.ExternalReports.Create(ExtRep)* создается экземпляр COM-объекта для внешнего отчета с помощью обращения к менеджеру *ВнешниеОтчеты* по его английскому синониму.
Далее инициализация параметров отчета и запуск на исполнение.
Написание внешнего отчета 1С выходит за рамки этого топика, но нужно сделать одно важное замечание: реквизиты отчета, экспортные функции и процедуры, которые вы хотите сделать доступными Automation-клиенту, должны именоваться по-английски, иначе к ним нельзя будет обратиться из VBScript.
Если вы обратили внимание, в строке подключения к базе нет учетных данных пользователя. Для успешного соединения, нужно чтобы в информационной базе был зарегистрирован пользователь с Windows-аутентификацией по windows-пользователю, от имени которого исполняется скрипт. Думаю, плюс этого способа очевиден.
Теперь осталось поместить в cmd-файл вызов скрипта и утилиты отправки, и… цель достигнута – все работает и все согласно ТЗ. | https://habr.com/ru/post/53534/ | null | ru | null |
# Docker: На старт. Внимание. Деплой
Как часто вам приходилось настраивать окружения сервера для деплоя вашего приложения (например веб-сайта)? Наверняка чаще чем хотелось бы.
В лучшем случае, у вас был скрипт, который все это делал автоматически. В худшем случае, это могло выглядеть вот так:
* установить базу данных D версии x.x.x
* установить веб сервер N версии x.x и т.д.
Управление окружением, сконфигурированное подобным образом, со временем становится очень ресурсозатратным. Любое, даже незначительное изменение в конфигурации означает как минимум:
* что каждый разработчик должен быть в курсе данных изменений
* все эти изменения должны быть безболезненно добавлены в продакшн среду
Трудно отслеживать такие изменения и управлять ими без специальных инструментов. Так или иначе, возникают проблемы с конфигурацией зависимостей окружения. Чем дальше движется разработка, тем сложнее становится находить и устранять эти проблемы.
Выше я описал то, что называется vendor lock-in. Для разработки приложений, в частности серверного типа, это явление становится большой проблемой. В данной статье мы рассмотрим одно из возможных решений — [Docker](https://www.docker.com/). Вы узнаете, как создать, задеплоить и запустить приложение на его основе.

**/Disclaimer:/** Это не обзорный доклад о Docker. В конце этой статьи приведен список полезной литературы, которая описывает работу с Docker лучше. Это первая точка вхождения для разработчиков, которые планируют деплоить node.js приложения при помощи Docker контейнеров.
Разрабатывая [один из своих проектов](https://opporty.com/), я столкнулся с отсутствием подробных статей, что породило немалое количество велосипедов. Этот пост с небольшим опозданием пытается исправить недостаток информации по теме.
Что это такое и с чем его едят?
-------------------------------
Простыми словами, Docker — это абстракция над LXC контейнерами. Это значит, что процессы, запущенные при помощи Docker, будут видеть только себя и своих потомков. Такие процессы называются Docker контейнерами.
Для того, чтобы иметь возможность создавать какие-то абстракции на базе таких контейнеров, в Docker существует образ (/docker image/). На базе Docker образа можно конфигурировать и создавать контейнеры.
Существуют тысячи готовых Docker образов с уже предустановленными базами данных, веб серверами и прочими важными элементами. Еще одно преимущество Docker состоит в том, что это очень экономичный по потреблению памяти инструмент, так как он использует только необходимые ему ресурсы.
Знакомимся ближе
----------------
На [установке](https://docs.docker.com/install/) долго останавливаться не будем. Процесс за последние несколько релизов упростили до нескольких кликов/команд.
В этой статье мы разберем деплой Docker приложения на примере серверного Node.js приложения. Вот его примитивный, исходный код:
```
// index
const http = require('http');
const server = http.createServer(function(req, res) {
res.write('hello world from Docker');
res.end();
});
server.listen(3000, function() {
console.log('server in docker container is started on port : 3000');
});
```
У нас есть как минимум два способа упаковки приложения в Docker контейнер:
* создать и запустить контейнер из существующего образа при помощи command-line-interface инструмента;
* создать собственный образ на основе готового образца.
Чаще используется второй способ.
Для начала скачаем официальный node.js образ:
```
docker pull node
```
Команда docker pull скачивает Docker образ. После этого можно выполнить команду docker run. Это создаст и запустит контейнер на базе скачанного образа.
```
docker run -it -d --rm -v "$PWD":/app -w=/app -p 80:3000 node node index.js
```
Эта команда запустит index.js файл, произведет маппинг 3000 порта на 80 и выведет id созданного контейнера. Уже лучше! Но на одном CLI далеко не уедешь. Давайте создадим Dockerfile для нашего сервера.
```
FROM node
WORKDIR /app
RUN cp . /app
CMD ["node", "index.js"]
```
Данный Dockerfile описывает образ, от какого наследуется текущий вариант, а также директорию, в которой начнут выполнятся команды контейнера и команда копирования файлов из директории, в которой запускается сборка образа. Последняя строчка указывает, какая команда запустится в созданном контейнере.
Далее нам потребуется собрать из этого Dockerfile образ, который мы будем деплоить: *docker build -t username/helloworld-with-docker:0.1.0*. Данная команда создает новый образ, помечает его именем *username/helloworld-with-docker* и создает тег 0.1.0.
Наш контейнер готов. Мы можем запускать его при помощи команды docker run. Таким образом, мы решаем vendor lock-in проблему. Запуск приложения уже не зависит от окружения. Код доставляется вместе с Docker образом. Эти два критерия позволяют нам деплоить приложение в любое место, где мы можем запустить Docker.
Деплой
------
Не так страшны первые 99% как оставшиеся 99%.
После того, как мы выполнили все инструкции выше, сам процесс деплоя уже становится делом техники и вашего окружения разработки. Мы рассмотрим 2 варианта деплоя Docker:
* ручной деплой Docker образа;
* деплой при помощи Travis-CI.
В каждом случае, мы рассмотрим доставку образа в независимое окружение, например, staging сервер вашего продукта.
### Ручной деплой
Данный вариант хорош, если у вас нет какой-либо среды непрерывной интеграции. Сперва нужно загрузить Docker образ в место, доступное staging серверу. В нашем случае это будет DockerHub. Каждому пользователю он бесплатно предоставляет один приватный репозиторий образа и неограниченное количество публичных репозиториев.
Авторизуемся для доступа к нашему DockerHub:
```
docker login -e [email protected] -u username -p userpass
```
Загружаем туда наш образ: *docker push username/helloworld-with-docker:0.1.0.*
Далее заходим на staging сервер (напоминаю, на нем уже должен быть предустановлен Docker).
Для деплоя нашего приложения на сервере нам потребуется выполнить всего одну команду:
```
docker run -d --rm -p 80:3000 username/helloworld-with-docker:0.1.0.
```
И все! Проверьте локальный регистр образов. Если не найдете нужный результат, введите *username/helloworld-with-docker* для проверки DockerHub регистра. Образ с таким именем найдется в регистре, так как мы его туда уже загрузили. Docker скачает его, создаст на его основе контейнер и запустит в нем ваше приложение.
Теперь каждый раз, когда вам нужно будет обновить версию вашего приложения, вы можете делать push с новым тегом и просто перезапускать каждый раз контейнер на сервере.
P.S. Данный способ не рекомендуется, если есть возможность воспользоваться Travis-CI.
### Деплой при помощи Travis-CI
Первым делом добавим в Travis-CI данные DockerHub. Они будут хранится в переменных окружения.
```
travis encrypt [email protected]
travis encrypt DOCKER_USER=username
travis encrypt DOCKER_PASS=password
```
Затем добавим полученные ключи в .travis.yml файл. Так же мы добавим комментарий к каждому ключу для того, чтобы различать их в будущем.
```
env:
global:
- secure: "UkF2CHX0lUZ...VI/LE=" # DOCKER_EMAIL
- secure: "Z3fdBNPt5hR...VI/LE=" # DOCKER_USER
- secure: "F4XbD6WybHC...VI/LE=" # DOCKER_PASS
```
Далее нам нужно авторизоваться и загрузить образ:
```
after_success:
- docker login -e $DOCKER_EMAIL -u $DOCKER_USER -p $DOCKER_PASS
- docker build -f Dockerfile -t username/hello-world-with-travis.
- docker tag username/hello-world-with-travis 0.1.0
- docker push username/hello-world-with-travis
```
Также доставка образа может запускаться из Travis-CI различными способами:
* вручную;
* через подключение по ssh;
* онлайн деплой сервисы (Deploy Bot, deployhq);
* AWS CLI;
* Kubernates;
* Инструменты для Docker деплоя.
Итоги
-----
В этой статье мы рассмотрели подготовку и деплой Docker на примере простого node.js сервера двумя способами: автоматическим и автоматизированными при помощи Travis-CI. Надеюсь, эта статья принесла вам пользу. | https://habr.com/ru/post/466493/ | null | ru | null |
# Ваш сайт на Joomla неправильно отдает страницу 404

Известно, что для того, чтобы удержать посетителя на сайте, нужно правильно обрабатывать HTTP/1.0 404 и другие подобные коды. На просторах интернета можно найти массу занимательных примеров страниц 404, а также руководств – что и как сделать, чтобы ошибка 404 правильно обрабатывалась сайтом как для посетителя, так и для поисковых систем.
Хочу с вами обсудить проблему 404 для сайтов Joomla.
#### Общие рекомендации по настройке Joomla для обработки HTTP/1.0 404
Не буду повторять здесь все причины тех или иных шагов и настроек, буду перечислять кратко то, что можно [найти в Интернете](https://yandex.ru/yandsearch?&text=404 joomla).
1. Создаем в нашей Joomla «красивую страничку 404». Можно несколько — при реализации вашей особенной логики и способа их выбора для
посетителя;
2. В свой шаблон, который используется на сайте в качестве основного шаблона frontend, из системного шаблона system переписываем файл error.php;
3. Далее редактируем этот файл для того, чтобы следовать следующей логике – если мы отловили ошибку 404 – то сначала выдать заголовок HTTP/1.0 404, а затем выдать страницу, которую мы ранее подготовили. Предположим, номер (ID) нашей «красивой страницы 404» равен 1001. Файл error.php в вашем шаблоне может выглядеть так:
```
defined('_JEXEC') or die;
if (!isset($this->error))
{
$this->error = JError::raiseWarning(404, JText::_('JERROR_ALERTNOAUTHOR'));
$this->debug = false;
}
// Get language and direction
$doc = JFactory::getDocument();
$app = JFactory::getApplication();
$this->language = $doc->language;
$this->direction = $doc->direction;
if($this->error->getCode()=='404') {
header("HTTP/1.0 404 Not Found");
header('Location: index.php?option=com_content&view=article&id=1001');
}
```
Теперь проверяем. Вводим адрес сайта. Далее – абракадабра после символа /. Работает? Работает, чего и следовало ожидать.
#### В чем подвох?
Открываем отладку страниц в вашем любимом браузере (мой любимый браузер – Fitefox с Firebug-ом), вкладка «Сеть», и смотрим заголовки, которыми общается браузер с сайтом.
Вводим адрес сайта – заголовок HTTP/1.0 200 OK
Теперь абракадабра… Ожидаем HTTP/1.0 400 Not Found — смотрим заголовки:
1. Сначала HTTP/1.0 302 Found
2. Затем наша красивая страница отдается браузеру с кодом HTTP/1.0 200 OK

#### Чем это плохо?
— Но, ведь, работает? — Скажете вы. Да, работает. А как на это смотрит поисковая система?
Был у меня переезд страниц сайта с одного раздела (папки) сайта на другой. Но переехать должны были не все страницы. Страницы старого раздела сайта были в индексе. Те, что переехали – выдавались с кодом HTTP/1.0 301 Moved Permanently (классика жанра) и поисковики их правильно «переехали» на новое место. А те, что должны были «кануть в лету» – так и мелькали в индексе, хотя физически отсутствовали на сайте, а при обращении к ним выдавалась «красивая страничка 404», но не код HTTP/1.0 404 (смотрим выше).
#### Выход из этой ситуации
Для страниц с ошибкой 404 я решил выдавать заголовок HTTP/1.0 404 Not Found и делать не редирект через заголовок Location, а читать поток «красивой страницы 404» и перенаправлять его браузеру. Вот реализация:
```
if($this->error->getCode()=='404') {
header("HTTP/1.0 404 Not Found");
$url=JURI::root()."index.php?option=com_content&view=article&id=1001";
$data = file_get_contents($url) or die("Cannot open URL");
echo $data;
}
```
Теперь, и нужная страница посетителю отдается при ошибке 404, и поисковая машина видет действительно код 404 и считает введенный адрес таковым — Not Found. | https://habr.com/ru/post/271225/ | null | ru | null |
# Обзор шины SPI и разработка драйвера ведомого SPI устройства для embedded Linux (Часть вторая, практическая)
Это вторая часть моей статьи по разработке драйверов для ведомых SPI устройств в Linux. Предыдущая часть находится [здесь](http://habrahabr.ru/blogs/linux/123145/).
#### 3. Разработка userspace протокольного SPI драйвера с использованием spidev
Как уже было сказано выше, для SPI устройств существует ограниченная поддержка userspace API, с поддержкой базовых полудуплексных read() и write() вызовов для доступа к ведомым SPI устройствам. Используя ioctl() вызовы, можно производить полнодуплексный обмен данными с ведомым устройством, а также изменение параметров устройства.
Есть ряд причин, когда может возникнуть желание использовать данный userspace API:
* Прототипирование в окружении не подверженном возникновению неисправимых ошибок. Невалидные указатели в пространстве пользователя обычно не могут привести к краху всей системы.
* Разработка простых протоколов, используемых для обмена данными с микроконтроллерами, работающими в режиме ведомого SPI устройства, которые необходимо часто менять.
Конечно же, существуют драйверы, которые невозможно реализовать средствами userspace API, так как им необходим доступ к другим интерфейсам ядра (например, обработчики прерываний или другие подсистемы стека драйверов), недоступным в пространстве пользователя.
Для включения поддержки spidev необходимо:
1. При настройке ядра в menuconfig активировать пункт:
```
Device Drivers
SPI support
User mode SPI device driver support
```
2. Добавить в массив структур spi\_board\_info, о котором шла речь в предыдущем пункте, в файле платы:
```
{ /* spidev */
.modalias = "spidev",
.chip_select = 2,
.max_speed_hz = 15 * 1000 * 1000,
.mode = SPI_MODE_0,
.bus_num = 1,
},
```
После пересборки и загрузки нового ядра в системе появится соответствующее устройство с именем вида /dev/spidevB.C, где B — номер шины SPI, а C — номер Chip select'а. Данное устройство нельзя создавать вручную через mknod, его должны автоматически создавать такие службы как udev/mdev.
Отлично, устройство у нас есть. Осталось научиться с ним работать. Предположим мы хотим отправить байт 0x8E в устройство висящее на SPI1 с номером CS 2. Наверное, самый простой способ это сделать выглядит так:
```
echo -ne "\x8e">/dev/spidev1.2
```
После чего на моём тестовом устройстве можно было наблюдать такую картину:

Следует сказать пару слов о тестовом устройстве. Наверное, самое главное в том, что оно почти что бесполезно и делалось лишь для изучения работы с SPI в Linux. Оно сделано на одном сдвиговом регистре 74HC164N, а на 3-х элементах 2И-НЕ из 74HC132N сделано некоторое подобие chipselect'а, которое разрешает синхронизирующий сигнал только при низком уровне на входе ~CS (сразу хочу заметить, да, я знаю о существовании 74HC595, но у меня в городе её достать не удалось). У данного устройства лишь одна функция — отображать на светодиодах последний записанный в неё байт. Так как моё устройство не является полностью «честным», при чтении из него мы будем получать не то что записали (как должно было быть), а значение сдвинутое на один бит влево.
Параметры работы с ведомым устройством можно настроить посредством ioctl() вызовов. Они позволяют изменить скорость передачи данных, размер передаваемого слова, порядок байт в передаче, и естественно режим работы SPI.
Следующие ioctl() запросы позволяют управлять параметрами ведомого устройства:
* SPI\_IOC\_RD\_MODE, SPI\_IOC\_WR\_MODE — в случае чтения (RD) байту на который передан указатель, производится присваивание значения текущего SPI режима. В случае записи (WR), для устройства устанавливается режим соответственно значению байта по переданному указателю. Для задания режима используются константы SPI\_MODE\_0… SPI\_MODE\_3, либо же комбинация констант SPI\_CPHA (фаза синхронизации, захват по переднему фронту, если установлено) и SPI\_CPOL (полярность синхронизации, сигнал синхронизации начинается с высокого уровня) через побитовое «или».
* SPI\_IOC\_RD\_LSB\_FIRST, SPI\_IOC\_WR\_LSB\_FIRST — передаёт указатель на байт, который определяет выравнивание битов при передаче SPI слов. Нулевое значение показывает что старший бит является первым (MSB-first), другие значения показывают что используется более редкий вариант, и младший бит является первым (LSB-first). В обоих случаях каждое слово будет выравнено по правому краю, так что неиспользуемые/неопределённые биты будут находится в старших разрядах. RD/WR — чтение/запись параметра, определяющего выравнивание битов в словах, соответственно.
* SPI\_IOC\_RD\_BITS\_PER\_WORD, SPI\_IOC\_WR\_BITS\_PER\_WORD — передаёт указатель на байт, определяющий количество бит на слово при передаче данных по SPI. Нулевое значение соответствует восьми битам. RD/WR — чтение/запись количества бит на слово соответственно.
* SPI\_IOC\_RD\_MAX\_SPEED\_HZ, SPI\_IOC\_WR\_MAX\_SPEED\_HZ — передаёт указатель на переменную u32, которая определяет максимальную скорость передачи данных по SPI в Гц. Как правило, контроллер не может точно установить заданную скорость.
Изменяя частоту, я узнал что моё тестовое устройство может работать на частоте не выше примерно 15 МГц, что не так уж плохо с учётом длины шлейфов около 25 см, сборке на монтажной плате и соединения контактов с помощью МГТФа.
Теперь хочу сделать ещё одно важное замечание, смена порядка следования бит опять таки поддерживается не всеми контроллерами. Для того чтобы узнать какие функции поддерживает контроллер надо смотреть битовую маску spi\_master.mode\_bits. Определить значение битов в маске можно из определения флагов в структуре [spi\_device](http://www.kernel.org/doc/htmldocs/device-drivers/API-struct-spi-device.html). Я не стану здесь приводить полные описания структур spi\_device и [spi\_master](http://www.kernel.org/doc/htmldocs/device-drivers/API-struct-spi-master.html), так как они не являются критически важными для понимания в данном случае. Ссылку на документацию, в которой можно найти описания всех указанных структур, я дам в конце статьи.
Как я упомянул вначале, spidev позволяет производить полудуплексные передачи, с помощью соответсвтующей команды ioctl():
```
int ret;
ret = ioctl(fd, SPI_IOC_MESSAGE(num), tr);
```
где num — количество передач в массиве структур типа spi\_ioc\_transfer;
tr — указатель на массив структур spi\_ioc\_transfer;
В случае неудачи возвращается отрицательное значение, в случае успеха — суммарное количество успешно переданных байт для всех передач.
Сама структура передачи имеет следующий вид:
```
struct spi_ioc_transfer {
__u64 tx_buf;
__u64 rx_buf;
__u32 len;
__u32 speed_hz;
__u16 delay_usecs;
__u8 bits_per_word;
__u8 cs_change;
__u32 pad;
};
```
tx\_buf и rx\_buf — хранят указатели в пространстве пользователя на буфер для передачи/приёма данных соответственно. Если tx\_buf равен NULL, то будут выталкиваться нули. В случае если rx\_buf установлен в NULL, то данные полученные от ведомого игнорируются.
len — длина буферов приёма и передачи (rx и tx) в байтах.
speed\_hz — переопределяет скорость передачи данных для данной передачи.
bits\_per\_word — переопределяет количество бит на слово для данной передачи.
delay\_usecs — задержка в микросекундах перед деактивацией устройства (перед вызовом cs\_deactivate), после передачи последнего бита данных.
Практически все поля структуры spi\_ioc\_transfer соответствуют полям структуры spi\_transfer. Буферы данных предварительно копируются в/из пространства ядра с помощью функций copy\_from\_user()/copy\_to\_user() в недрах драйвера spidev.
Как я уже выше говорил, не все контроллеры поддерживают возможность смены скорости и размера слова для каждой передачи в отдельности, так что лучше ставьте там нули, если хотите получить переносимый код. Именно поэтому стандартный пример для работы с spidev в полнодуплексном режиме, идущий в комплекте с документацией ядра, работать без исправлений в инициализации структуры spi\_ioc\_transfer не станет на чипах семейства at91.
Замечания:
* На данный момент нет возможности получить реальную скорость с которой происходит выталкивание/захват бит данных для данного устройства.
* На данный момент нельзя поменять полярность chip select'а через spidev. Каждое ведомое устройство деактивируется, когда оно не находится в стадии активного использования, позволяя другим драйверам обмениваться данными с соответствующими им устройствами.
* Существует ограничение на количество байт, передаваемых при каждом запросе ввода/вывода. Как правило, ограничение соответствует размеру одной страницы памяти. Это значение может быть изменено с помощью параметра модуля ядра.
* Так как SPI не имеет низкоуровневого способа подтверждения доставки, то не существует способа узнать о наличии каких-либо ошибок при передаче, или, например, при выборе несуществующего устройства.
Теперь я приведу пример, это упрощённый вариант программы для работы с spidev идущей в комплекте с ядром. Хотя в примере это явно не показано, но никто не запрещает использовать системные вызовы read() и write() для полудуплексного обмена данными.
```
#include
#include
#include
#include
#include
#include
#include
#include
#include
static void pabort(const char \*s)
{
perror(s);
abort();
}
static uint8\_t mode = SPI\_MODE\_0;
static uint8\_t bits = 0;
static uint32\_t speed = 500000;
int main(int argc, char \*argv[])
{
int ret = 0;
int fd;
uint8\_t tx[] = { 0x81, 0x18 };
uint8\_t rx[] = {0, 0 };
if(argc!=2) {
fprintf(stderr, "Usage: %s \n", argv[0]);
exit(1);
}
fd = open(argv[1], O\_RDWR);
if (fd < 0)
pabort("can't open device");
/\* spi mode \*/
ret = ioctl(fd, SPI\_IOC\_WR\_MODE, &mode);
if (ret == -1)
pabort("can't set spi mode");
ret = ioctl(fd, SPI\_IOC\_RD\_MODE, &mode);
if (ret == -1)
pabort("can't get spi mode");
/\* bits per word \*/
ret = ioctl(fd, SPI\_IOC\_WR\_BITS\_PER\_WORD, &bits);
if (ret == -1)
pabort("can't set bits per word");
ret = ioctl(fd, SPI\_IOC\_RD\_BITS\_PER\_WORD, &bits);
if (ret == -1)
pabort("can't get bits per word");
/\* max speed hz \*/
ret = ioctl(fd, SPI\_IOC\_WR\_MAX\_SPEED\_HZ, &speed);
if (ret == -1)
pabort("can't set max speed hz");
ret = ioctl(fd, SPI\_IOC\_RD\_MAX\_SPEED\_HZ, &speed);
if (ret == -1)
pabort("can't get max speed hz");
printf("spi mode: %d\n", mode);
printf("bits per word: %d\n", bits);
printf("max speed: %d Hz (%d KHz)\n", speed, speed/1000);
/\* full-duplex transfer \*/
struct spi\_ioc\_transfer tr = {
.tx\_buf = (unsigned long)tx,
.rx\_buf = (unsigned long)rx,
.len = 2,
.delay\_usecs = 0,
.speed\_hz = 0,
.bits\_per\_word = bits,
};
ret = ioctl(fd, SPI\_IOC\_MESSAGE(1), &tr);
if (ret < 1)
pabort("can't send spi message");
for (ret = 0; ret < 2; ret++) {
printf("%.2X ", rx[ret]);
}
puts("");
close(fd);
return ret;
}
```
Думаю здесь всё достаточно очевидно, все запросы передаваемые к устройству через ioctl() мы уже разобрали. Осталось только привести Makefile для сборки:
```
all: spidev_test
CC = /opt/arm-2010q1/bin/arm-none-linux-gnueabi-gcc
INCLUDES = -I.
CCFLAGS = -O2 -Wall
clean:
rm -f spidev_test
spidev_test: spidev_test.c
$(CC) $(INCLUDES) $(CCFLAGS) spidev_test.c -o spidev_test
```
Единственное, понадобится укзать свой путь до кросс-компилятора в переменной CC.
#### 4. Разработка протокольного SPI драйвера уровня ядра
Разработка модуля ядра тема гораздо более объёмная, поэтому в данном случае пойдём другим путём: я приведу вначале пример кода, потом дам краткое описание его работы, объясню как его задействовать. Описывать все подробности я не стану, иначе никакой статьи не хватит, просто укажу наиболее важные моменты, в разделе статьи о документации можно найти ссылки на всю необходимую информацию. В данном примере я покажу как сделать доступными атрибуты устройства через sysfs. Как реализовать драйвер предоставляющий доступ к устройству посредством файла устройства уже обсуждалось ранее: [раз](http://habrahabr.ru/blogs/linux/106702/), [два](http://habrahabr.ru/blogs/personal/100753/).
Мой драйвер будет предоставлять пользователю возможность изменения двух атрибутов:
value — в него можно записать число, которое нужно отобразить в бинарном виде с помощью светодиодов;
mode — переключатель режимов, позволяет выставить один из трёх режимов работы. Поддерживаются следующие режимы: 0 — стандартный режим отображения числа в бинарном виде, 1 — режим прогресс-бара с отображением слева-направо, 2 — режим прогресс-бара с отображением справа-налево;
В режиме прогресс-бара устройство будет отображать неразрывную линию светодиодов, показывающую какой процент значение записанное в value составляет от 256. Например, если записать в mode 1, а в value 128, то засветится 4 светодиода из 8 слева.
Если в номере режима выставить третий бит, то будет использоваться полнодуплексный режим (функция fdx\_transfer()), вместо асинхронных вызовов spi\_write() и spi\_read(). Номера полнодуплексных режимов будут соответственно 4,5,6. Режиму номер 3 соответствует 0.
Ну а теперь сам код:
```
#include
#include
#include
#define SPI\_LED\_DRV\_NAME "spi\_led"
#define DRIVER\_VERSION "1.0"
static unsigned char led\_mode=0;
static unsigned char fduplex\_mode=0;
unsigned char retval=0;
char \*mtx, \*mrx;
static unsigned char stbl\_tmp;
enum led\_mode\_t {LED\_MODE\_DEF, LED\_MODE\_L2R, LED\_MODE\_R2L };
static inline unsigned char led\_progress(unsigned long val) {
unsigned char i, result=0x00;
val++;
val/=32;
for(i = 0; i < val; i++) {
if(led\_mode==LED\_MODE\_R2L)
result|=(0x01<>i);
}
return (unsigned char)result;
}
static int fdx\_transfer(struct spi\_device \*spi, unsigned char \*val) {
int ret;
struct spi\_transfer t = {
.tx\_buf = mtx,
.rx\_buf = mrx,
.len = 1,
};
struct spi\_message m;
mtx[0]=\*val;
mrx[0]=0;
spi\_message\_init(&m);
spi\_message\_add\_tail(&t, &m);
if((ret=spi\_sync(spi, &m))<0)
return ret;
retval=mrx[0];
return ret;
}
static ssize\_t spi\_led\_store\_val(struct device \*dev,
struct device\_attribute \*attr,
const char \*buf, size\_t count)
{
struct spi\_device \*spi = to\_spi\_device(dev);
unsigned char tmp;
unsigned long val;
if (strict\_strtoul(buf, 10, &val) < 0)
return -EINVAL;
if (val > 255)
return -EINVAL;
switch(led\_mode) {
case LED\_MODE\_L2R:
case LED\_MODE\_R2L:
tmp = led\_progress(val);
break;
default:
tmp = (unsigned char)val;
}
stbl\_tmp=tmp;
if(fduplex\_mode)
fdx\_transfer(spi, &tmp);
else
spi\_write(spi, &tmp, sizeof(tmp));
return count;
}
static ssize\_t spi\_led\_show\_val(struct device \*dev,
struct device\_attribute \*attr,
char \*buf)
{
unsigned char val;
struct spi\_device \*spi = to\_spi\_device(dev);
if(!fduplex\_mode)
spi\_read(spi, &val, sizeof(val));
return scnprintf(buf, PAGE\_SIZE, "%d\n", fduplex\_mode ? retval : val);
}
static ssize\_t spi\_led\_store\_mode(struct device \*dev,
struct device\_attribute \*attr,
const char \*buf, size\_t count)
{
unsigned long tmp;
if (strict\_strtoul(buf, 10, &tmp) < 0)
return -EINVAL;
if(tmp>6)
return -EINVAL;
led\_mode = (unsigned char)tmp&0x03;
fduplex\_mode = ((unsigned char)tmp&0x04)>>2;
return count;
}
static ssize\_t spi\_led\_show\_mode(struct device \*dev,
struct device\_attribute \*attr,
char \*buf)
{
return scnprintf(buf, PAGE\_SIZE, "%d\n", led\_mode);
}
static DEVICE\_ATTR(value, S\_IWUSR|S\_IRUSR, spi\_led\_show\_val, spi\_led\_store\_val);
static DEVICE\_ATTR(mode, S\_IWUSR|S\_IRUSR, spi\_led\_show\_mode, spi\_led\_store\_mode);
static struct attribute \*spi\_led\_attributes[] = {
&dev\_attr\_value.attr,
&dev\_attr\_mode.attr,
NULL
};
static const struct attribute\_group spi\_led\_attr\_group = {
.attrs = spi\_led\_attributes,
};
static int \_\_devinit spi\_led\_probe(struct spi\_device \*spi) {
int ret;
spi->bits\_per\_word = 8;
spi->mode = SPI\_MODE\_0;
spi->max\_speed\_hz = 500000;
ret = spi\_setup(spi);
if(ret<0)
return ret;
return sysfs\_create\_group(&spi->dev.kobj, &spi\_led\_attr\_group);
}
static int \_\_devexit spi\_led\_remove(struct spi\_device \*spi) {
sysfs\_remove\_group(&spi->dev.kobj, &spi\_led\_attr\_group);
return 0;
}
static struct spi\_driver spi\_led\_driver = {
.driver = {
.name = SPI\_LED\_DRV\_NAME,
.owner = THIS\_MODULE,
},
.probe = spi\_led\_probe,
.remove = \_\_devexit\_p(spi\_led\_remove),
};
static int \_\_init spi\_led\_init(void) {
mtx=kzalloc(1, GFP\_KERNEL);
mrx=kzalloc(1, GFP\_KERNEL);
return spi\_register\_driver(&spi\_led\_driver);
}
static void \_\_exit spi\_led\_exit(void) {
kfree(mtx);
kfree(mrx);
spi\_unregister\_driver(&spi\_led\_driver);
}
MODULE\_AUTHOR("Lampus");
MODULE\_DESCRIPTION("spi\_led 8-bit");
MODULE\_LICENSE("GPL v2");
MODULE\_VERSION(DRIVER\_VERSION);
module\_init(spi\_led\_init);
module\_exit(spi\_led\_exit);
```
Теперь, нужно добавить наше устройство в список SPI устройств в файле платы. Для моей SK-AT91SAM9260 нужно открыть файл arch/arm/mach-at91/board-sam9260ek.c и в массив структур spi\_board\_info добавить оную для нашего устройства (по аналогии с spidev):
```
{ /* LED SPI */
.modalias = "spi_led",
.chip_select = 1,
.max_speed_hz = 15 * 1000 * 1000,
.mode = SPI_MODE_0,
.bus_num = 1,
},
```
Как видно из кода выше моё устройство работает на частоте 15 Мгц, висит на SPI1 с номером CS 1. Если этого не сделать, то при загрузке модуля не будет происходить связывания драйвера с устройством.
Для сборки модуля я использую следующий Makefile:
```
ifneq ($(KERNELRELEASE),)
obj-m := spi_led.o
else
KDIR := /media/stuff/StarterKit/new_src/linux-2.6.39.1_st3
all:
$(MAKE) -C $(KDIR) M=`pwd` modules
endif
```
Переменная KDIR должна указывать на ваш путь с исходными кодами ядра.
Сборка производится следующим образом:
```
ARCH=arm CROSS_COMPILE=/opt/arm-2010q1/bin/arm-none-linux-gnueabi- make
```
где переменная CROSS\_COMPILE указывает ваш префикс кросс-компилятора.
Теперь пересобираем ядро, перекидываем наш модуль на плату и загружаем его:
```
insmod /path/to/spi_led.ko
```
После чего в системе появятся атрибутами устройства, и в ней мы увидим следующую картину:
```
ls /sys/module/spi_led/drivers/spi:spi_led/spi1.1
driver modalias mode power subsystem uevent value
```
Теперь вернёмся непосредственно к коду. Смотреть надо начинать с конца. Макросы MODULE\_AUTHOR, MODULE\_DESCRIPTION, MODULE\_LICENSE, MODULE\_VERSION определяют информацию которая будет доступна с помощью команды modinfo, соответственно имя автора, описание модуля, лицензия и версия. Наиболее важное значение имеет указание лицензия, ибо при использовании не GPL лицензии вы не сможете дёргать код из модулей, использующих лицензию GPL.
Макросы [module\_init()](http://www.kernel.org/doc/htmldocs/device-drivers/API-module-init.html) и [module\_exit()](http://www.kernel.org/doc/htmldocs/device-drivers/API-module-exit.html) определяют функции инициализации и выгрузки модуля соответственно. В случае если модуль собран статически, функция указанная в макросе module\_exit никогда не будет вызываться.
В структуре [struct spi\_driver](http://www.kernel.org/doc/htmldocs/device-drivers/API-struct-spi-driver.html) spi\_led\_driver устанавливаются ссылки на функции привязки драйвера к устройству (probe), функции отключения устройства(remove), также имя драйвера владелец. Также там могут устанавливаться ссылки на функции перехода в энергосберегающий режи (suspend) и выхода из него (resume). Если драйвер поддерживает несколько различных устройств, одного класса, то их идентификаторы сохраняются в поле id\_table.
Регистрация SPI драйвера в системе производится с помощью функции [spi\_register\_driver(struct spi\_driver \* sdrv)](http://www.kernel.org/doc/htmldocs/device-drivers/API-spi-register-driver.html). Именно после регистрации может быть произведено связывание устройства и драйвера. Если всё пройдёт успешно, то следующей будет вызвана функция определнная в указателе probe. Убрать регистрацию драйвера из системы можно соответственно с помощью функции [spi\_unregister\_driver (struct spi\_driver \* sdrv)](http://www.kernel.org/doc/htmldocs/device-drivers/API-spi-unregister-driver.html)
Функция spi\_led\_probe() выполняет установку параметров контроллера для работы с устройством в структуре spi\_device, определённых ранее в [spi\_board\_info](http://www.kernel.org/doc/htmldocs/device-drivers/API-struct-spi-board-info.html). После переопределения необходимых полей в структуре spi\_device вызывается функция настройки контроллера [spi\_setup()](http://www.kernel.org/doc/htmldocs/device-drivers/API-spi-setup.html).
Теперь обсудим атрибуты. Про работу с атрибутами устройства через sysfs можно почитать в файле Documentation/filesystems/sysfs.txt. Макрос DEVICE\_ATTR предназначен для определения структуры device\_attribute. Например, такое определение
```
static DEVICE_ATTR(foo, S_IWUSR | S_IRUGO, show_foo, store_foo);
```
эквиваленто следующему:
```
static struct device_attribute dev_attr_foo = {
.attr = {
.name = "foo",
.mode = S_IWUSR | S_IRUGO,
.show = show_foo,
.store = store_foo,
},
};
```
где show – указатель на функцию выполянемую при открытии файла атрибута;
store – указатель на функцию выполянемую при запси в файл атрибута;
mode – определяет права доступа к файлу атрибута;
name – имя файла атрибута.
Для примера посмотрите на строку
```
static DEVICE_ATTR(value, S_IWUSR|S_IRUSR, spi_led_show_val, spi_led_store_val);
```
Она определяет аттрибут устройства с названием value, разрешённый на чтение/запись пользователем, функция-обработчик запси атрибута — spi\_led\_store\_val, функция-обработчик чтения атрибута — spi\_led\_show\_val. Один из указателей на функции store/show может быть равен NULL, если запись/чтение данного атрибута не предусмотрены.
Посмотрим как выглядит работа с даным атрибутом:
```
cd /sys/module/spi_led/drivers/spi:spi_led/spi1.1
ls -l value
-rw------- 1 root root 4096 Jun 29 14:10 value
echo "32">value
cat value
64
```
Помните я упомянал что моя железка при чтении сдвигает данные на один бит влево? Вот именно поэтому мы получили 64 вместо записанных 32-х. Что происходит при записи числа в файл атрибута: функция strict\_strtoul() пытается преобразовать полученный строковый буфер в число, потом идёт защита от дурака – проверка того что число не превышает 255. Если всё же оно больше, то возвращаем ошибку. Для пользователя это будет выгялядеть так:
```
# echo "257">value
bash: echo: write error: Invalid argument
```
Дальше идёт проверка текущего режима работы и в зависимости от него устанавливается переменная tmp. В случае режима прогресс-бара будет получено число с «неразрывными» единичными битами, иначе в SPI просто будет выведено байт заданный пользователем без изменений. В завимости от флага fduplex\_mode выбирается способ передачи: полудуплексный или полнодуплексный. В первом случае используется функция [spi\_write()](http://www.kernel.org/doc/htmldocs/device-drivers/API-spi-write.html), во втором самописная fdx\_transfer().
Теперь переходим полнодуплесной передаче данных. Как видите паямть под буферы (указатели mtx, mrx) для передачи у меня выделяются с помощью функции kzmalloc. Как я уже говорил, это вызвано необходимостью расположения буферов в области памяти доступной для DMA. Теперь смотрим на саму функцию fdx\_transfer(). По сути она собирает сообщение spi\_message, и передаёт его с помощью функции [spi\_sync()](http://www.kernel.org/doc/htmldocs/device-drivers/API-spi-sync.html) Байт полученный при отправке сообщения сохраняется в глобальную переменную retval, которая и будет всегда возвращаться функцией чтения атрибута value, в случае выставленного флага fduplex\_mode.
Работа с атрибутом mode заключается лишь в парсинге переданного режима, разбора его на два глобальные переменных led\_mode и fduplex\_mode, определяющие режим отображения и дуплекса соответственно.
Наверняка многие из вас обратили внимание на то, что не понятно что будет происходить при попытке одновременно записать файл атрибута из нескольких приложений. Ничего хорошего не произойдёт точно, здесь мы имеем явный race condition. Я постарался излишне не усложнять код, но для тех кому интересно как поступать в таких случаях рекомендую почитать [Unreliable Guide To Locking](http://kernel.org/doc/htmldocs/kernel-locking/)
Надеюсь с остальным проблем для понимания возникнуть не должно.
#### 5. Документация
[Здесь](http://habrahabr.ru/blogs/personal/26391/) уже обсуждался вопрос поиска документации по ядру.
Исходные коды ядра поставляются с набором документации в каталоге Documentation/. Как правило, с неё и стоит начать.
Ядро работает с собственной системой документирования исходного кода kerneldoc. С помощью неё можно сгенерировать документацию по системам ядра и API с помощью следующих команд из папки исходных текстов ядра:
```
sudo apt-get install xmlto
make htmldocs
```
Документация для последней стабильной версии ядра всегда доступна по адресу: [www.kernel.org/doc](http://www.kernel.org/doc/)
Наверное, первое что оттуда стоит прочесть это Unreliable Guide To Hacking The Linux Kernel: [www.kernel.org/doc/htmldocs/kernel-hacking.html](http://www.kernel.org/doc/htmldocs/kernel-hacking.html)
Изучение работы c SPI в Linux следует начинать с обзорных документов в каталоге Documentation/spi, в частности spi-summary и spidev. Также там есть замечательные примеры для работы через spidev: spidev\_fdx.c и spidev\_test.c; надеюсь вы не забыли что для некоторых контроллеров в них может понадобится внести небольшие исправления.
Про работу с атрибутами устройства через sysfs можно почитать в файле Documentation/filesystems/sysfs.txt.
Весь API используемый для работы с SPI в ядре описан тут: SPI Linux kernel API description [www.kernel.org/doc/htmldocs/device-drivers/spi.html](http://www.kernel.org/doc/htmldocs/device-drivers/spi.html)
Для облегчения поиска чего-либо в кодах ядра стоит использовать Linux Cross Reference: [lxr.linux.no](http://lxr.linux.no/) или [lxr.free-electrons.com](http://lxr.free-electrons.com/)
Также очень рекомендую презентации от Free Electrons: [free-electrons.com/docs](http://free-electrons.com/docs/) Там собран просто замечательный набор презентаций по Embedded Linux, кратко и ясно доносящих суть дела.
На этом всё, всем спасибо за внимание, можете ругать. | https://habr.com/ru/post/123266/ | null | ru | null |
# 9 лучших практик развертывания приложений высокой доступности на платформе OpenShift
OpenShift широко используется в мире в качестве платформы для критически важных корпоративных приложений. От таких приложений ждут, что они будут работать в режиме высокой доступности, выдавая типичные для отрасли «пять девяток» и обеспечивая непрерывное обслуживание конечных пользователей и клиентов. OpenShift предлагает целый ряд технологий развертывания в режиме высокой доступности, помогающих не допускать простоя приложения, даже когда его экземпляры или нижележащая ИТ-инфраструктура деградируют или перезапускаются. Сегодня мы рассмотрим девять лучших практик обеспечения высокой доступности приложений на платформе OpenShift.
1. Множественные реплики
------------------------
Когда приложение развернуто и работает в виде нескольких экземпляров (pod’ов), то при исчезновении одного из них оно будет работать и дальше. Если же pod только один, то после его исчезновения приложение просто станет недоступно (хотя обычно и ненадолго). В целом, когда у вас есть только один экземпляр приложения, то любое его нештатное завершение – это простой. Поэтому у приложения должно быть минимум две одновременно работающие реплики. А встроенный балансировщик нагрузки будет распределять сетевой трафик между pod’ам развертывания.
### Рекомендации
Мы рекомендуем сразу задавать несколько реплик при развертывании:
```
spec:
replicas: 3
```
2. Стратегия обновления приложения
----------------------------------
Есть две стратегии развертывания: «накатом» ([Rolling](https://docs.openshift.com/container-platform/4.9/applications/deployments/deployment-strategies.html#deployments-rolling-strategy_deployment-strategies)) и «с нуля» ([Recreate](https://docs.openshift.com/container-platform/4.9/applications/deployments/deployment-strategies.html#deployments-recreate-strategy_deployment-strategies)).
По умолчанию применяется стратегия Rolling. По ней pod’ы старой версии приложения меняются на pod’ы новой версии последовательно, одним за другим. Причем система следит, чтобы всегда оставался хотя бы один работающий pod.
Что касается стратегии Recreate, то здесь сначала убираются все старые pod’ы, и лишь затем развертываются новые. Понятно, что при обновлении будет иметь место определенный простой. Он может не представлять проблему, если регламент предусматривает окна обслуживания или перебои в работе приложения. Однако для критически важных приложений с высокими уровнями SLA и повышенными требованиями к доступности следует использовать стратегию развертывания Rolling.
### Рекомендации
Мы рекомендуем использовать RollingUpdate везде, где это возможно:
```
strategy
type: RollingUpdate
```
3. Корректная обработка сигнала SIGTERM
---------------------------------------
Когда перезапускает развертывание OpenShift Container Platform или удаляется pod, Kubernetes посылает сигнал [SIGTERM](https://docs.openshift.com/container-platform/4.9/applications/deployments/route-based-deployment-strategies.html#deployments-graceful-termination_route-based-deployment-strategies) всем контейнерам этого pod’а, чтобы они могли корректно завершить свою работу. Обычно корректная отработка SIGTERM сводится к завершению обработки клиентских запросов или к сохранению состояния.
По умолчанию период корректной обработки сигнала SIGTERM составляет 30 секунд. Если вы считает, что на это надо больше времени, то можно подкрутить параметр развертывания terminationGracePeriod.
### Рекомендации
Приложения должны обрабатывать сигнал SIGTERM, чтобы корректно завершать свою работу. При необходимости настройте должным образом параметр terminationGracePeriod:
```
spec:
...
spec:
terminationGracePeriodSeconds: 30
containers:
...
```
4: Зонды (probes)
-----------------
Зонды (проверки health check) играют важную роль в мониторинге исправности приложений. Зонды готовности (readiness probes) определяют, готово ли приложение к приему трафика. Зонды активности (liveness probes) проверяют, отвечает ли приложение, или его пора перезапустить.
### Зонды активности (liveness probes)
Зонды [активности](https://docs.openshift.com/container-platform/4.9/applications/application-health.html#application-health-about_application-health) используются для того, чтобы перезапустить приложение, если оно сломалось. Это функция самовосстановления в Kubernetes/OpenShift, и она важна для того, чтобы приложения имели возможность попробовать восстановиться автоматически.
```
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 15
periodSeconds: 20
```
### Зонды готовности (readiness probe)
Зонды [готовности](https://docs.openshift.com/container-platform/4.9/applications/application-health.html#application-health-about_application-health) используются для того, чтобы вывести приложение из пула балансировки нагрузки, если оно перешло в нежелательное состояние и стало неспособно обслуживать трафик. Эти зонды предотвращают подключение клиентов к приложению, когда его надо временно вывести из пула балансировки для восстановления (но не для перезапуска).
Приложение принимает трафик лишь тогда, когда проверка готовности заканчивается положительно и приложение получает статус Ready. Если проверка еще не закончилась или результат отрицательный, то приложение не принимает трафик и остается вне пула.
```
readinessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
```
### Зонды запуска (startup probe)
Некоторые приложения могут иметь большое время запуска. Например, если в ходе инициализации они должны выполнить много задач, или зависят от внешнего сервиса, который может быть не готов на момент запуска приложения. Это затрудняет настройку зондов liveness и readiness, поскольку сложно определить, сколько времени приложению потребуется для запуска. И здесь помогут зонды запуска (startup probe), которые собственно и детектируют сам момент запуска приложения. После того, как такой зонд рапортует об успешном запуске приложения, в дело вступают зонды активности и готовности:
```
startupProbe:
httpGet:
path: /healthz
port: 8080
failureThreshold: 30
periodSeconds: 10
```
### Рекомендации
Мы рекомендуем использовать зонды Liveness и Readiness, чтобы постоянно контролировать доступность приложения и его способность обрабатывать входящий трафик. Также можно использовать startup-зонды для определения момента запуска приложения.
5. Контроль готовности внешних зависимостей
-------------------------------------------
Когда приложение запускается, оно не должно аварийно завершаться, если вдруг отсутствует какая-то из его зависимостей, например, не отвечает база данных. Кроме того, хотелось бы регулярно контролировать исправность этих зависимостей не только при запуске, но и в ходе работы приложения. Для этого можно использовать initContainers/startupProbe, чтобы проверять внешние зависимости перед запуском основного контейнера. А когда приложение уже запущено и работает, можно использовать readinessProbe для главного контейнера, чтобы он трактовался как Ready, только если успешно подключен к исправным внешним зависимостям.
Зонд readinessProbes мы уже показали выше, а пример с initContainer, который ожидает готовности БД, выглядит так:
```
initContainers:
- name: wait-postgres
image: postgres:12.1-alpine
command:
- sh
- -c
- |
until (pg_isready -h example.org -p 5432 -U postgres); do
sleep 1
Done
```
### Рекомендации
Мы рекомендуем использовать initContainer или startupProbe, чтобы отложить запуск приложения до тех пор, пока не будут исправны его зависимости. Во время работы приложения используйте readinessProbe, чтобы следить за состоянием зависимостей.
6: Квоты PodDisruptionBudget (PDB)
----------------------------------
Квоты [Pod Disruption Budge](https://docs.openshift.com/container-platform/4.9/nodes/pods/nodes-pods-configuring.html#nodes-pods-configuring-pod-distruption-about_nodes-pods-configuring) (PDB) ограничивают кластер в возможности отключать реплики pod’ов при проведении технического обслуживания. Иначе говоря, это минимальное число реплик, которые всегда должны оставаться работающими. При расселении узла командой drain все pod’ы на нем удаляются и затем повторно диспетчеризуются. При высокой нагрузке расселение может негативно влиять на доступность. Для того, чтобы поддерживать доступность во время обслуживания кластера, и служат квоты PDB.
### Рекомендации
PDB рекомендуется применять для критически важных приложений в режиме продакшен. С помощью этих квот можно вводить максимальное ограничение на количество pod’ов приложения, которые разрешено отключать на период его обслуживания.
```
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: my-pdb
spec:
selector:
matchLabels:
foo: bar
minAvailable: 2
```
7. Автомасштабирование
----------------------
В OpenShift есть два инструмента автомасштабирования pod’ов приложений, горизонтальный и вертикальный:
* [Horizontal pod autoscaler](https://docs.openshift.com/container-platform/4.9/nodes/pods/nodes-pods-autoscaling.html) (HPA)
* [Vertical pod autoscaler](https://docs.openshift.com/container-platform/4.9/nodes/pods/nodes-pods-vertical-autoscaler.html) (VPA)
### Horizontal pod autoscaler (HPA)
Функция HPA автоматически увеличивает или уменьшает количество pod’ов на основании собранных данных метрик. С ее помощью можно поддерживать доступность приложения на требуемом уровне и улучшать отклик при внезапном всплеске трафика.
HPA масштабирует число pod’ов по следующей формуле:
```
X = N * (c/t)
```
Здесь X – это желаемое число реплик, N – текущее число реплик, c – текущее значение метрики, t – целевое значение метрики. Подробнее алгоритм описывается в [документации](https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/#algorithm-details).
Для примера рассмотрим HPA по загрузке ЦП, который варьирует число pod’ов в диапазоне от 3 до 10 для поддержания средней загрузки ЦП на уровне 50%:
```
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 3
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
```
Еще пример: здесь HPA по использованию памяти варьирует число pod’ов от 3 до 10, чтобы средний расход памяти составлял 500Mi:
```
metrics:
- type: Resource
resource:
name: memory
target:
type: AverageValue
averageValue: 500Mi
```
**Примечание.** В этих примерах используется API версии autoscaling/v2beta2, последней на момент написания статьи. Для метрик использования ЦП можно использовать либо API версии autoscaling/v1, либо autoscaling/v2beta2. Для метрик использования памяти должна применяться только версия autoscaling/v2beta2.
### Vertical pod autoscaler (VPA)
Если горизонтальный автоскейлер HPA увеличивает-уменьшает количество pod’ов, то его вертикальный собрат VPA варьирует объем ресурсов, выделяемых pod’у. VPA оптимизирует значения запросов на ресурсы процессора и памяти, позволяя максимально повысить эффективность использования вычислительных мощностей кластера.
Как и HPA, VPA автоматически рассчитывает целевые значения путем мониторинга использования ресурсов. Однако, в отличие от HPA, он вначале выселяет pod с узла, чтобы обновить его согласно новым лимитам на ресурсы. **VPA учитывает любые регулирующие политики PDB-квот, чтобы гарантировать отсутствие нарушений в работе приложения при выселении pod’ов**. И наконец, затем, когда выполняется повторное развертывание рабочей нагрузки, VPA’шный веб-хук mutating admission перезаписывает ресурсы pod’а с оптимизированными лимитами на ресурсы и запросы, прежде чем pod’ы пойдут на узлы.
Рассмотрим пример VPA для автоматического режима, который назначает запросы на ресурсы при создании pod’а и обновляет существующие pod’ы. Причем, он вначале завершает их, если запрошенные ресурсы сильно отличаются от новых рекомендаций:
```
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: vpa-recommender
spec:
targetRef:
apiVersion: "apps/v1"
kind: Deployment
name: frontend
updatePolicy:
updateMode: "Auto"
```
Помимо автоматического есть другие режимы VPA, подробнее см. [документацию](https://docs.openshift.com/container-platform/4.9/nodes/pods/nodes-pods-vertical-autoscaler.html#nodes-pods-vertical-autoscaler-using-auto_nodes-pods-vertical-autoscaler).
##### Что важно знать, прежде чем применять VPA:
* Чтобы VPA мог автоматически удалять pod’ы, pod’ов должно быть минимум 2.
* Чтобы VPA мог рекомендовать ресурсы и применять рекомендации к новым pod’ам, pod’ы уже должны быть запущены в проекте.
* VPA реагирует на большинство событий out-of-memory, но не на все.
### Рекомендации
* Избегайте использовать HPA и VPA в тандеме, если только вы не настроите HPA на использование пользовательских или внешних метрик.
* В продакшене используйте VPA в режиме рекомендаций (Recommendation mode). Это поможет выяснить оптимальные значения запросов на ресурсы и как они меняются со временем.
* Для парирования внезапных всплесков нагрузки используйте HPA, а не VPA, поскольку VPA выдает рекомендации на основании более продолжительной выборки данных.
8. Ограничения Pod Topology Spread Constraints
----------------------------------------------
Одна из основных задач OpenShift заключается в том, чтобы автоматически распределять pod’ы по узлам кластера. Однако если все реплики уходят в один и тот же домен отказа (это может быть узел, серверная стойка или зона доступности) и в какой-то момент этом домен становится неисправен, то случится простой приложения. И этот простой устранится только тогда, когда реплики будут повторно развернуты в другом домене. Предотвратить такой вариант событий позволяют ограничения [Pod Topology Spread Constraints](https://docs.openshift.com/container-platform/4.9/nodes/scheduling/nodes-scheduler-pod-topology-spread-constraints.html).
Функция Pod Topology Spread Constraints позволяет равномерно распределять реплики pod’ов по кластеру, вот как она настраивается:
```
kind: Pod
apiVersion: v1
metadata:
name: my-pod
labels:
foo: bar
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: node
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
foo: bar
- maxSkew: 1
topologyKey: zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
foo: bar
containers:
- image: "docker.io/ocpqe/hello-pod"
name: hello-pod
```
В этом примере заданы два ограничения pod topology spread. Первое используется для того, чтобы pod’ы распределялись между узлами путем ссылки на топологическую метку "node" (задается через параметр topologyKey). Чтобы это работало эффективно, каждый узел в кластере должен иметь метку "node" с уникальным значением. Параметр maxSkew задает максимально допустимую разницу в количестве pod’ов между любыми двумя узлами.
Второе ограничение pod topology spread в этом примере используется для равномерного распределения pod’ов между зонами доступности. Чтобы оно работало эффективно, каждый узел в кластере должен иметь метку "zone", в значении которой прописывается зона доступности, к которой отнесен этот узел. Используя два этих ограничения, можно обеспечить равномерное распределение pod’ов как между зонами доступности, так и между узлами в этих зонах.
### Рекомендации
Используйте Pod Topology Spread Constraints, чтобы разносить pod’ы по разным доменам отказа. Для надежного распределения рабочих нагрузок узлы кластера должны иметь правильные метки.
9. Развертывание приложений по сине-зеленому методу и канареечным способом
--------------------------------------------------------------------------
На большинстве предприятий развертывание приложений и функций должно выполняться так, чтобы не прерывать работу пользователей или процессов, которые с ними взаимодействуют. Поэтому в корпоративной ИТ-практике широко применяются сине-зеленая и канареечная схемы развертывания. Рассмотрим, как организовать их в рамках OpenShift.
### Сине-зеленое развертывание (Blue/Green)
Согласно этой стратегии, новая версия приложения («зеленая») развертывается рядом со старой («синяя»), а затем трафик разом переключается с «синей» версии на «зеленую». Если с новой версией возникают проблемы, то трафик легко переключается обратно на старую
Такое переключение трафика можно организовать средствами маршрутов OpenShift Route. Вот как, например, выглядит маршрут на «синюю» версию сервиса:
```
apiVersion: route.openshift.io/v1
kind: Route
metadata:
name: my-app
spec:
port:
targetPort: 8080
to:
kind: Service
name: my-app-blue
```
Чтобы переключить трафик на «зеленую» версию после ее развертывания, в маршруте достаточно изменить секцию "to":
```
kind: Service
name: my-app-green
```
Недостаток сине-зеленой схемы состоит в том, что она полностью переключает весь трафик: запросы идут либо туда, либо туда. А иногда надо, чтобы часть трафика уходила на старую версию, а часть – на новую, и желательно иметь возможность варьировать эти части. Именно эту задачу и решает канареечное развертывание.
### Канареечное развертывание (Canary Deployment)
Канареечное развертывание позволяет перенаправить на новую версию приложения лишь часть трафика, к примеру, 10%. А оставшиеся 90% будут по-прежнему обрабатываться старой версией. Если новая версия работает нормально и в ней не обнаруживаются ошибки, то ее долю в обработке трафика можно постепенно увеличить до 100%.
Вот как выглядит маршрут OpenShift, переводящий 10% трафика на новую («зеленую») версию приложения:
```
apiVersion: route.openshift.io/v1
kind: Route
metadata:
name: my-app
spec:
port:
targetPort: 8080
to:
kind: Service
name: my-app-blue
weight: 90
alternateBackends:
- kind: Service
name: my-app-green
weight: 10
```
Процент трафика, который уходит на заданный сервис, рассчитывается по формуле «weight / сумма всех значений weight». В нашем примере сервис my-app-blue («синяя» версия) будет обрабатывать 90% трафика, так как 90/(90+100) = 0,9. А на долю сервиса my-app-green («зеленая» версия) останется 10%. Таким образом, канареечное развертывание позволяет постепенно наращивать долю новой версии в обработке клиентских или пользовательских запросов, мониторя исправность приложения.
### Рекомендации
Используйте сине-зеленую или канареечную стратегию, чтобы предотвратить нарушения в штатной работе людей и сервисов при развертывании новых версий приложения. Используйте канареечный метод, если хотите гибко и постепенно переводить пользователей на новую версию, не отрубая старую одним махом. | https://habr.com/ru/post/648129/ | null | ru | null |
# Как оптимизировать запоминание иностранных слов

Прежде чем взяться за разработку мобильного приложения для заучивания лексики, мы в школе Skyeng потратили массу времени на изучение алгоритмов работы памяти и запоминания слов. В результате разработка Aword заняла чуть больше времени, но мы более уверены в результате — использование определенных алгоритмов в показе слов помогает эффективнее пополнять словарный запас.
На рынке представлено большое количество приложений для заучивания иностранных слов. Всех их объединяет общая черта — использование зубрежки (дриллинга) в качестве основного инструмента обучения. Чем больше времени ученик проводит за повторением слов, тем выше шанс, что он их запомнит. Например, вполне реально за час выучить сто слов. Однако без повторения уже через 6 часов половина из них будет забыта. Еще через шесть часов в памяти останется не больше 15 слов. Чтобы этого не произошло, необходимо регулярно повторять весь набор (зубрить).
Если ученик делает в повторении списка паузу (на неделю, на месяц, на отпуск, на рабочий аврал, ...) — высока вероятность, что слова забудутся, и зубрежку придется начать с начала. Если он переключился с одного набора слов на следующий и не повторил первый через некоторое время — он его забудет. Для того, чтобы такое запоминание работало эффективно, необходимо самостоятельно или с помощью преподавателя составить четкий план обучения и неукоснительно ему следовать, иначе зубрежка превратится в бессмысленную потерю огромного количества времени без явного, прогнозируемого результата.
Мы задумались: можно ли сделать приложение, которое будет обеспечивать не только процесс «дриллинга», но также составление и поддержание плана занятий и контроль за полученными знаниями? Как максимизировать эффективность обучения и сэкономить время ученика?
Начать придется издалека: с разговора об устройстве нашей памяти, которая бывает краткосрочной и долгосрочной.
### Зубрежка vs запоминание
Краткосрочная хорошо знакома студентам, сдающим какой-нибудь не очень нужный формальный предмет. Если проштудировать учебник ночью накануне экзамена, есть высокая вероятность, что большая часть информации, пусть и в разрозненном виде, останется в памяти достаточно долго, чтобы сдать экзамен или зачет. Однако уже через пару дней она бесследно выветрится (точнее, как показывают исследования, не выветрится, но так надежно скроется в глубинах сознания, что извлечь ее оттуда будет проблематично).
Долгосрочная память – это то, что позволяет нам легко вспомнить полученные сведения и через год, и через пять лет. Но для того, чтобы она заработала, необходимы регулярные тренировки, причем наиболее эффективный формат этих тренировок – не перечитывание учебника, а проверка по контрольным вопросам или постоянное применение полученных знаний на практике.
Например, студент, изучающий новый язык программирования, получает эту тренировку в виде ежедневных сессий кодинга. Постигнув тему объектов в C++, он сможет навсегда ее запомнить, если будет регулярно использовать. Поэтому преподаватели требуют объектного программирования даже тривиальных задач, где разумно было бы без него обойтись.
Долгосрочная память требуется не всегда. Химику совершенно не обязательно знать все формулы; юристу не нужно иметь в голове полные версии уголовного, гражданского и процессуального кодекса. Им на помощь всегда могут прийти справочники; для них важнее понимание принципов работы и знание направления поиска данных.
Но есть сферы, где долгосрочная память необходима. Наиболее очевидные – медицина и лингвистика. Врач должен помнить симптомы любых, даже редких, болезней. Человек, претендующий на свободное владение английским языком, должен знать слово serendipity, даже если он никогда в жизни с ним не столкнется. Разумеется, наиболее эффективный способ развить такую долгосрочную память – практика. Выпускник медицинского вуза на несколько лет отправляется в ординатуру или интернатуру. Профессиональный переводчик обязательно едет на стажировку в среду носителей языка.
Но что делать, если такой возможности нет? И как быть, если врач за время ординатуры так и не столкнулся со случаем синдрома Кавасаки?
Необходимо развивать долгосрочную память как-то иначе. Неудивительно, что основные исследования в этой области проводятся как раз медиками и лингвистами.
### Польский студент и немецкий психолог
Петр Возняк, автор самого известного алгоритма запоминания SuperMemo, задумался об оптимизации этого процесса в 80-е годы, будучи студентом Познаньского Политеха. Одной из задач, которые он ставил перед собой, было полноценное владение английским языком – его не устраивал тот поверхностно-профессиональный уровень, которым вполне довольствовались его сокурсники.
Возняк оказался достаточно упертым парнем. Он создал базу из карточек по английскому языку и биологии, содержащих вопрос и ответ, и занялся ежедневными тренировками, тщательно записывая результаты в дневник. Под конец эксперимента у него образовалось три тысячи карточек по английскому и более полутора тысяч по биологии.
С помощью несложных вычислений, основанных на полученных данных, Возняк установил, что для запоминания небольшого словаря в 15 тысяч английских слов ему потребуется тратить на тренировки ежедневно по два часа. Потраченное время растет пропорционально количеству слов: для запоминания 30 тысяч потребуется четыре часа повторений ежедневно. Не очень удобно.
К счастью, за сто лет до Петра Возняка аналогичной проблемой озаботился немецкий психолог Герман Эббингауз, тоже весьма упертый человек. Эббингауз провел два годичных эксперимента, в ходе которых запоминал бессмысленные наборы слогов. В результате было сделано несколько открытий, самым важным из которых является Кривая забывания.
Эббингауз экспериментальным путем установил, что скорость забывания информации падает после каждого повторения. После первого запоминания данных забывание идет очень быстро: уже через час из головы вылетает примерно половина материала, через десять часов – 65%; впрочем, около 20% остается и через месяц после изучения. Однако, если в течение первого часа повторить весь материал, процесс его забывания значительно замедлится, и новое повторение можно делать уже через сутки. Воспользовавшись Кривой забывания, можно расставить повторения таким образом, чтобы произошло максимальное долговременное усвоение материала за минимальное количество тренировок.
Этот метод называется «интервальные повторения» (Spaced Repitition). В 30-е годы был проведен эксперимент, показавший, что такая техника действительно благотворно влияет на процесс обучения. Однако популярности она в то время не обрела из-за своей чрезмерной сложности: необходимо было готовить тысячи карточек с вопросами-ответами, правильно их тасовать, вовремя повторять… Но потом появились компьютеры.

Вернемся к польскому студенту Петру Возняку, мечтавшему выучить английский, но не горевшему желанием тратить на тренировки по четыре часа в день. Он решил алгоритмизировать технику интервальных повторений, что в конце концов вылилось в программу SuperMemo. Разумеется, все оказалось далеко не так просто, и разработка SuperMemo стала, по сути, делом его жизни.
Алгоритмизация метода интервальных повторений – задача достаточно очевидная. Главная проблема этого метода – необходимость точно рассчитать время, когда повторение будет максимально эффективным – т.е. тот самый момент, когда информация забывается. Если написать программу, которая будет не только проводить тренировки, но и своевременно напоминать пользователю об их необходимости, это теоретически позволит добиться более эффективного обучения.
Здесь есть свои особенности. Сама по себе кривая забывания – явление универсальное, однако у разных людей на нее накладываются разные экспоненты. Кому-то третье повторение требуется через 20 минут, кому-то – через час; аналогичным образом изменяется расстояние и между последующими повторами. Поэтому тренировки должны быть гибкими – в их ходе алгоритм старается понять скорость забывания конкретного ученика и подстроиться под нее.
Важной проблемой на пути к успешному обучению становится человеческий фактор. Для того, чтобы эффективно запомнить максимальный объем информации за минимальный срок, нужно точно следовать графику. В реальности это создает неудобства, и ученики решают отложить на потом. В результате, пропустив нужный момент, они откатываются назад – на шаг, на два, а то и к самому началу обучения. Этот откат также надо правильно просчитать, чтобы минимизировать издержки из-за пропусков.
### Лицензия на слова
В основе нашего мобильного приложения Aword лежит концепция «лицензий на слова» — по аналогии с ограниченными по времени лицензиями ПО. После первого запоминания «лицензия» действует примерно час; если не повторить слово, оно будет забыто. Если повторить слова в конце этого часа, появится новая «лицензия», уже на шесть часов. Следующая «лицензия» будет на сутки, потом на три дня, на неделю, месяц, полгода, два года. Самый эффективный момент для повтора — пограничный, когда предыдущая «лицензия» истекает, и для того, чтобы вспомнить слово, надо приложить определенные усилия. Все «лицензии» для каждого слова хранятся на нашем сервере в учетной записи ученика, и задача мобильного приложения — вовремя напомнить, что настала пора их обновить.
Базовый алгоритм, лежащий в основе Aword, можно описать таким псевдокодом:
```
function makeRepetition( user, word, license ){
var timePassed = (new Date()) - license.startTime;
var answer = showWordCard( word );
user.tuneParameters( license, timePassed, answer.quality );
word.tuneComplexity( license, timePassed, answer.quality );
if(answer.quality > 0) {
license.next( timePassed );
} else {
license.rollback( timePassed );
}
}
```
Основной код этого алгоритма определяет, можно ли дать увеличенную «лицензию» на слово, или же его надо учить снова. tuneParameters и tuneComplexity — условные ссылки на настроечные алгоритмы; качество ответа (answer.quality) представляет собой число от 0 до 1. Это число равно единице, если ученик быстро, с первого раза узнал слово; у него хорошо работает память, задача оказалась для него слишком легкой. В этом случае алгоритм увеличит интервалы повторений. Если качество ответа близко меньше 0,5 — ответ был дан с трудом, после подсказок; стандартный интервал повторов для этого ученика слишком велик, необходимо проводить тренировки чаще.
Оригинальная кривая забывания была построена на основе данных синтетического эксперимента. Эббингауз намеренно использовал ничего не значащие слоги, чтобы в итоге получить максимально чистые результаты.
Современные студенты-медики успешно используют кривую забывания в ее начальном виде, например, для запоминания данных по фармакологии (тоже, в общем, состоящей из наборов букв). Вот, например, [типичная инструкция](http://www.happydoctor.ru/info/92) по повторению материала:
— первый повтор – сразу после прочтения (проверка по контрольным вопросам);
— второй повтор – через 20 минут;
— третий – через сутки;
— четвертый – через 48 часов после третьего;
— пятый – через 72 часа после четвертого.
Существуют универсальные алгоритмы, позволяющие использовать метод интервальных повторений для эффективного запоминания любой информации. Самая известная (и к тому же бесплатная) такая программа — [Anki](http://ankisrs.net/). Она, разумеется, не учитывает особенностей, связанных с изучением иностранных языков, однако может здорово пригодиться, если необходимо надолго запомнить что-то действительно важное.
При изучении же иностранного языка мы имеем дело не с хаотичными наборами букв, а с осмысленными словами. Степень осмысленности и понятности слова ученику напрямую влияет на скорость запоминания. Так, инженер значительно быстрее запомнит слово «шестеренка», чем философ. Привычные, легко представляемые слова («дуб») запоминаются легче, чем экзотические («пихта»). Как следствие, необходимо аккуратно подбирать группы с примерно одинаковой скоростью запоминания. Алгоритм SuperMemo использует для такого подбора субъективную оценку пользователя – насколько ему сложно дается слово; это не очень точный показатель. Еще один фактор – уже имеющаяся у ученика словарная база, которую необходимо оценить для составления программы. Все это тоже должно быть алгоритмизировано. Впрочем, это темы для отдельных статей.
Алгоритмы, используемые в нашем мобильном приложении, в течение полугода тестировались на добровольцах из числа сотрудников и их знакомых. Это позволило нам подобрать некоторые средние параметры (срок «лицензий»), которые в итоге используются для оптимизации процесса долговременного запоминания слов. Сейчас, когда приложение стало доступно всем желающим, мы сможем собрать значительно больше аналитических данных для дальнейшей точной подстройки этих параметров. И все это можно увидеть, [скачав мобильное приложение в App Store](https://app.appsflyer.com/id1112765220?pid=habra&c=review
https://app.apssflyer.com/id1112765220). В конце октября приложение будет выложено в Google Play, а в ноябре — доступно на Web.
А если вы сами хотите поучаствовать в разработке подобных штук — у нас [масса интересных вакансий](https://moikrug.ru/companies/skyeng/vacancies)! | https://habr.com/ru/post/312126/ | null | ru | null |
# Алгоритм поиска пути A* в воксельной 3d игре на Unity
Введение
========
При разработке своей игры, я дошёл до момента создания первых NPC. И появился вопрос как заставить NPC обойти стену а не "идти в неё".
Полазив по интернету я нашёл такие алгоритмы:
* **Поиск в ширину (BFS, Breadth-First Search)**
* **Алгоритм Дейкстры (Dijkstra)**
* **А Star "A со звёздочкой"**
* **Поиск по первому наилучшему совпадению (Best-First Search)**
* **IDA *(A* с итеративным углублением)**
* **Jump Point Search**
И решил попробовать реализовать свой A\* на воксельной 3д сетке.

**Пример карты моей игры**
Описание алгоритма
==================
A\* пошагово просматривает все пути, ведущие от начальной вершины в конечную, пока не найдёт минимальный. Как и все информированные алгоритмы поиска, он просматривает сначала те маршруты, которые «кажутся» ведущими к цели. От жадного алгоритма, который тоже является алгоритмом поиска по первому лучшему совпадению, его отличает то, что при выборе вершины он учитывает, помимо прочего, весь пройденный до неё путь.
**Визуализация работы A\* с википедии**

Реализация
==========
Так как алгоритму нужны "ноды" — точки для определения пути напишем класс структуру нода:
**Код нода:**
```
public enum EMoveAction { walk, jump, fall, swim };
public class PathPoint
{
// текущая точка
public Vector3 point { get; set; }
// расстояние от старта
public float pathLenghtFromStart { get; set; }
// примерное расстояние до цели
public float heuristicEstimatePathLenght { get; set; }
// еврестическое расстояние до цели
public float estimateFullPathLenght
{
get
{
return this.heuristicEstimatePathLenght + this.pathLenghtFromStart;
}
}
// способ движения
public EMoveAction moveAction = EMoveAction.walk;
// точка из которой пришли сюда
public PathPoint cameFrom;
}
```
**Небольшие конструкторы класса:**
```
private PathPoint NewPathPoint(Vector3 point, float pathLenghtFromStart, float heuristicEstimatePathLenght, EMoveAction moveAction)
{
PathPoint a = new PathPoint();
a.point = point;
a.pathLenghtFromStart = pathLenghtFromStart;
a.heuristicEstimatePathLenght = heuristicEstimatePathLenght;
a.moveAction = moveAction;
return a;
}
private PathPoint NewPathPoint(Vector3 point, float pathLenghtFromStart, float heuristicEstimatePathLenght, EMoveAction moveAction, PathPoint ppoint)
{
PathPoint a = new PathPoint();
a.point = point;
a.pathLenghtFromStart = pathLenghtFromStart;
a.heuristicEstimatePathLenght = heuristicEstimatePathLenght;
a.moveAction = moveAction;
a.cameFrom = ppoint;
return a;
}
```
Далее нам пригодится структура настроек поиска пути:
**Код настроек поиска пути:**
```
public struct SPathFinderType
{
// Возможность персонажа ходить, прыгать, падать, и плавать
public bool walk, jump, fall, swim;
// Максимальная высота падения, прыжка
public int maxFallDistance, jumpHeight, jumpDistance;
// Высота персонажа
public int characterHeight;
// Создаём стандартные настройки
public static SPathFinderType normal()
{
SPathFinderType n = new SPathFinderType();
n.walk = true;
n.jump = true;
n.fall = true;
n.swim = false;
n.maxFallDistance = 1;
n.jumpHeight = 1;
n.jumpDistance = 0;
n.characterHeight = 1;
return n;
}
}
```
Далее "World" — класс своебразная БД для хранения информации о блоках карты. У вас может быть реализован по другому.
**Итог поиска пути функция получения маршрута:**
```
public List GetPathToTarget(Vector3 beginPoint, Vector3 targetPoint, World worldData, SPathFinderType pfType)
{
List path = new List();
// Список не проверенных нодов
List openPoints = new List();
// Список проверенных нодов
List closedPoints = new List();
// Добавляем к открытым начальную точку
openPoints.Add(NewPathPoint(beginPoint, 0, GameLogic.Distance(beginPoint, targetPoint), EMoveAction.walk));
// закрываем точку
closedPoints.Add(openPoints[0]);
// открываем новые точки и удаляем закрытую
openPoints = ClosePoint(0, openPoints, closedPoints, worldData, pfType, targetPoint);
// "Стоп сигнал" для нашего поиска
bool stopFlag = true;
// Устанавливаем ограничители чтобы избежать проверки всей карты
float maxEstimatePath = 1500;
int maxNodes = 6000;
while (stopFlag)
{
// Находим индекс точки с минимальным евристическим расстоянием
int minIndex = GetMinEstimate(openPoints);
if (openPoints.Count > 0)
if (openPoints[minIndex].estimateFullPathLenght < maxEstimatePath)
{
// закрываем точку
closedPoints.Add(openPoints[minIndex]);
// добавляем новые если есть и удаляем minIndex
openPoints = ClosePoint(minIndex, openPoints, closedPoints, worldData, pfType, targetPoint);
}
else
{
// если расстояние достигло пределов поиска
// просто закрываем точку без добавления новых
closedPoints.Add(openPoints[minIndex]);
openPoints.RemoveAt(minIndex);
}
// Функция проверяет найден ли финиш
if (FinishFounded(closedPoints))
{
Debug.Log("Финиш найден!");
path = GetPathToTarget(closedPoints);
stopFlag = false; // остановка цикла если найдена цель
}
if (openPoints.Count <= 0)
stopFlag = false; // остановка цикла если открытых точек нет
if ((openPoints.Count>= maxNodes) ||(closedPoints.Count>= maxNodes))
stopFlag = false; // остановка цикла слишком много нодов
}
Debug.Log("Nodes created "+ closedPoints.Count.ToString());
// Рисуем полученные пути
DrawPath(openPoints, Color.green, 6f);
DrawPath(closedPoints, Color.blue, 6f);
DrawPath(path, Color.red, 6f);
return path;
}
```
**GetMinEstimate**
```
// находит индекс точки ближайшей к точке назначения
private int GetMinEstimate(List points)
{
int min = 0;
for (int i = 0; i < points.Count; i++)
{
if (points[i].estimateFullPathLenght < points[min].estimateFullPathLenght)
min = i;
}
return min;
}
```
**DrawPath**
```
// Рисует линии из точек пути
public void DrawPath(List points, Color c, float time)
{
for (int i = 0; i < points.Count; i++)
{
if (points[i].cameFrom != null)
Debug.DrawLine(points[i].point, points[i].cameFrom.point, c, time);
}
}
```
**FinishFounded**
```
// проверяет найдена ли цель
private bool FinishFounded(List points)
{
for (int i = 0; i < points.Count; i++)
{
if (points[i].heuristicEstimatePathLenght <= 0)
return true;
}
return false;
}
```
**GetPathToTarget**
```
// Возвращает список точек от старта до финиша
private List GetPathToTarget(List points)
{
List path = new List();
int targetIndex = 0;
for (int i = 0; i < points.Count; i++)
{
if (points[i].heuristicEstimatePathLenght <= 0)
targetIndex = i;
}
PathPoint ppoint = new PathPoint();
ppoint = points[targetIndex];
while (ppoint.pathLenghtFromStart > 0)
{
path.Add(ppoint);
ppoint = ppoint.cameFrom;
}
path.Reverse();
return path;
}
```
ClosePoint
==========
Функция ClosePoint зависит сугубо от реализации класса World, она добавляет в список открытых точек все возможные пути из неё и удаляёт из этого списка текущую точку (закрывает её). Приведу пример своего "закрытия точки" в первых четырёх направлениях.
**Внимание большое нагромождение кода**
```
private List ClosePoint(int index, List openPoints, List closedPoints, World worldData, SPathFinderType pfType, Vector3 targetPoint)
{
List newOpenPoints = openPoints;
PathPoint lastPoint = openPoints[index];
// если персонаж может идти
if (pfType.walk)
// если персонаж может стоять на текущем блоке
if (CanStand(new Vector3(lastPoint.point.x, lastPoint.point.y, lastPoint.point.z), pfType.characterHeight, worldData))
{
// ---------------------------------------------------------------
//north
// /|\
// |
// если не в списке закрытых
if (!InList(closedPoints, new Vector3(lastPoint.point.x + 1, lastPoint.point.y, lastPoint.point.z)))
// и уже не добавлена
if (!InList(newOpenPoints, new Vector3(lastPoint.point.x + 1, lastPoint.point.y, lastPoint.point.z)))
// если может там стоять
if (CanStand(new Vector3(lastPoint.point.x + 1, lastPoint.point.y, lastPoint.point.z), pfType.characterHeight, worldData))
{
newOpenPoints.Add(NewPathPoint(new Vector3(lastPoint.point.x + 1, lastPoint.point.y, lastPoint.point.z)
, lastPoint.pathLenghtFromStart + GetTravelCost(new Vector3(lastPoint.point.x + 1, lastPoint.point.y, lastPoint.point.z), worldData, pfType.characterHeight)
, GameLogic.Distance(new Vector3(lastPoint.point.x + 1, lastPoint.point.y, lastPoint.point.z), targetPoint)
, EMoveAction.walk
, lastPoint));
}
// south
// |
// \|/
// если не в списке закрытых
if (!InList(closedPoints, new Vector3(lastPoint.point.x - 1, lastPoint.point.y, lastPoint.point.z)))
// и уже не добавлена
if (!InList(newOpenPoints, new Vector3(lastPoint.point.x - 1, lastPoint.point.y, lastPoint.point.z)))
// если может там стоять
if (CanStand(new Vector3(lastPoint.point.x - 1, lastPoint.point.y, lastPoint.point.z), pfType.characterHeight, worldData))
{
newOpenPoints.Add(NewPathPoint(new Vector3(lastPoint.point.x - 1, lastPoint.point.y, lastPoint.point.z)
, lastPoint.pathLenghtFromStart + GetTravelCost(new Vector3(lastPoint.point.x - 1, lastPoint.point.y, lastPoint.point.z), worldData, pfType.characterHeight)
, GameLogic.Distance(new Vector3(lastPoint.point.x - 1, lastPoint.point.y, lastPoint.point.z), targetPoint)
, EMoveAction.walk
, lastPoint));
}
// east
// ---->
//
// если не в списке закрытых
if (!InList(closedPoints, new Vector3(lastPoint.point.x, lastPoint.point.y, lastPoint.point.z + 1)))
// и уже не добавлена
if (!InList(newOpenPoints, new Vector3(lastPoint.point.x, lastPoint.point.y, lastPoint.point.z + 1)))
// если может там стоять
if (CanStand(new Vector3(lastPoint.point.x, lastPoint.point.y, lastPoint.point.z + 1), pfType.characterHeight, worldData))
{
newOpenPoints.Add(NewPathPoint(new Vector3(lastPoint.point.x, lastPoint.point.y, lastPoint.point.z + 1)
, lastPoint.pathLenghtFromStart + GetTravelCost(new Vector3(lastPoint.point.x, lastPoint.point.y, lastPoint.point.z + 1), worldData, pfType.characterHeight)
, GameLogic.Distance(new Vector3(lastPoint.point.x, lastPoint.point.y, lastPoint.point.z + 1), targetPoint)
, EMoveAction.walk
, lastPoint));
}
// west
// <----
//
// если не в списке закрытых
if (!InList(closedPoints, new Vector3(lastPoint.point.x, lastPoint.point.y, lastPoint.point.z - 1)))
// и уже не добавлена
if (!InList(newOpenPoints, new Vector3(lastPoint.point.x, lastPoint.point.y, lastPoint.point.z - 1)))
//если может стоять там
if (CanStand(new Vector3(lastPoint.point.x, lastPoint.point.y, lastPoint.point.z - 1), pfType.characterHeight, worldData))
{
newOpenPoints.Add(NewPathPoint(new Vector3(lastPoint.point.x, lastPoint.point.y, lastPoint.point.z - 1)
, lastPoint.pathLenghtFromStart + GetTravelCost(new Vector3(lastPoint.point.x, lastPoint.point.y, lastPoint.point.z - 1), worldData, pfType.characterHeight)
, GameLogic.Distance(new Vector3(lastPoint.point.x, lastPoint.point.y, lastPoint.point.z - 1), targetPoint)
, EMoveAction.walk
, lastPoint));
}
}
newOpenPoints.RemoveAt(index);
return newOpenPoints;
}
```
Оптимизация
===========
Простым делением пути от старта до текущей точки, мы сокращаем количество нодов во много раз и делаем его более "жадным".
```
return this.heuristicEstimatePathLenght + this.pathLenghtFromStart /2;
```
Итоги
=====
**Плюсы:**
* Быстрый поиск на открытых пространствах.
* Универсальность алгоритма
**Минусы:**
* Требует много памяти для вычисления маршрута.
Зелёным показан открытый список нодов, красным путь до цели, синим закрытые ноды.
**Полученные маршруты до оптимизации:**

**Полученные маршруты после оптимизации:**

Литература
==========
<https://tproger.ru/articles/pathfindings/>
[https://ru.wikipedia.org/wiki/A\*](https://ru.wikipedia.org/wiki/A*) | https://habr.com/ru/post/416737/ | null | ru | null |
# React: основные подходы к управлению состоянием

Доброго времени суток, друзья!
Предлагаю вашему вниманию простое приложение — список задач. Что в нем особенного, спросите вы. Дело в том, что я попытался реализовать одну и ту же «тудушку» с использованием четырех разных подходов к управлению состоянием в React-приложениях: useState, useContext + useReducer, Redux Toolkit и Recoil.
Начнем с того, что такое состояние приложения, и почему так важен выбор правильного инструмента для работы с ним.
Состояние — это собирательное понятие для любой информации, имеющей отношение к приложению. Это могут быть как данные, используемые в приложении, такие как тот же список задач или список пользователей, так и состояние как таковое, например, состояние загрузки или состояние формы.
Условно, состояние можно разделить на локальное и глобальное. Под локальным состоянием, обычно, понимается состояние отдельно взятого компонента, например, состояние формы, как правило, является локальным состоянием соответствующего компонента. В свою очередь, глобальное состояние правильнее именовать распределенным или совместно используемым, подразумевая под этим то, что такое состояние используется более чем одним компонентом. Условность рассматриваемой градации выражается в том, что локальное состояние вполне может использоваться несколькими компонентами (например, состояние, определенное с помощью useState(), может в виде пропов передаваться дочерним компонентам), а глобальное состояние не обязательно используется всеми компонентами приложения (например, в Redux, где имеется одно хранилище для состояния всего приложения, обычно, создается отдельный срез (slice) состояния для каждой части UI, точнее, для логики управления этой частью).
Важность выбора правильного инструмента для управления состоянием приложения обусловлена теми проблемами, которые возникают при несоответствии инструмента размерам приложения или сложности реализуемой в нем логики. Мы убедимся в этом в процессе разработки списка задач.
Я не буду вдаваться в подробности работы каждого инструмента, а ограничусь общим описанием и ссылками на соответствующие материалы. Для прототипирования UI будет использоваться [react-bootstrap](https://react-bootstrap.github.io/).
[Код на GitHub](https://github.com/harryheman/React-Projects/tree/main/client/state-management)
[Песочница на CodeSandbox](https://codesandbox.io/s/react-state-management-ng9l1)
Создаем проект с помощью Create React App:
```
yarn create react-app state-management
# или
npm init react-app state-management
# или
npx create-react-app state-management
```
Устанавливаем зависимости:
```
yarn add bootstrap react-bootstrap nanoid
# или
npm i bootstrap react-bootstrap nanoid
```
* bootstrap, react-bootstrap — стили
* [nanoid](https://www.npmjs.com/package/nanoid) — утилита для генерации уникального ID
В src создаем директорию «use-state» для первого варианта тудушки.
### useState()
[Шпаргалка по хукам](https://github.com/harryheman/React-Total/blob/main/md/hooks.md)
Хук «useState()» предназначен для управления локальным состоянием компонента. Он возвращает массив с двумя элементами: текущим значением состояния и сеттером — функцией для обновления этого значения. Сигнатура данного хука:
```
const [state, setState] = useState(initialValue)
```
* state — текущее значение состояния
* setState — сеттер
* initialValue — начальное или дефолтное значение
Одним из преимуществ деструктуризации массива, в отличие от деструктуризации объекта, является возможность использования произвольных названий переменных. По соглашению, название сеттера должно начинаться с «set» + название первого элемента с большой буквы ([count, setCount], [text, setText] и т.п.).
Пока ограничимся четырьмя базовыми операциями: добавление, переключение (выполнение), обновление и удаление задачи, но усложним себе жизнь тем, что наше начальное состояние будет иметь форму нормализованных данных (это позволит как следует попрактиковаться в иммутабельном обновлении).
Структура проекта:
```
|--use-state
|--components
|--index.js
|--TodoForm.js
|--TodoList.js
|--TodoListItem.js
|--App.js
```
Думаю, тут все понятно.
В App.js мы с помощью useState() определяем начальное состояние приложения, импортируем и рендерим компоненты приложения, передавая им состояние и сеттер в виде пропов:
```
// хук
import { useState } from 'react'
// компоненты
import { TodoForm, TodoList } from './components'
// стили
import { Container } from 'react-bootstrap'
// начальное состояние
// изучите его как следует, чтобы понимать логику обновления
const initialState = {
todos: {
ids: ['1', '2', '3', '4'],
entities: {
1: {
id: '1',
text: 'Eat',
completed: true
},
2: {
id: '2',
text: 'Code',
completed: true
},
3: {
id: '3',
text: 'Sleep',
completed: false
},
4: {
id: '4',
text: 'Repeat',
completed: false
}
}
}
}
export default function App() {
const [state, setState] = useState(initialState)
const { length } = state.todos.ids
return (
useState
========
{length ? : null}
)
}
```
В TodoForm.js мы реализуем добавление новой задачи в список:
```
// хук
import { useState } from 'react'
// утилита для генерации ID
import { nanoid } from 'nanoid'
// стили
import { Container, Form, Button } from 'react-bootstrap'
// функция принимает сеттер
export const TodoForm = ({ setState }) => {
const [text, setText] = useState('')
const updateText = ({ target: { value } }) => {
setText(value)
}
const addTodo = (e) => {
e.preventDefault()
const trimmed = text.trim()
if (trimmed) {
const id = nanoid(5)
const newTodo = { id, text, completed: false }
// обратите внимание, как нам приходится обновлять состояние
setState((state) => ({
...state,
todos: {
...state.todos,
ids: state.todos.ids.concat(id),
entities: {
...state.todos.entities,
[id]: newTodo
}
}
}))
setText('')
}
}
return (
#### Form
Add
)
}
```
В TodoList.js мы просто рендерим список элементов:
```
// компонент
import { TodoListItem } from './TodoListItem'
// стили
import { Container, ListGroup } from 'react-bootstrap'
// функция принимает состояние и сеттер только для того,
// чтобы передать их потомкам
// обратите внимание, как мы передаем отдельную задачу
export const TodoList = ({ state, setState }) => (
#### List
{state.todos.ids.map((id) => (
))}
)
```
Наконец, в TodoListItem.js происходит самое интересное — здесь мы реализуем оставшиеся операции: переключение, обновление и удаление задачи:
```
// стили
import { ListGroup, Form, Button } from 'react-bootstrap'
// функция принимает задачу и сеттер
export const TodoListItem = ({ todo, setState }) => {
const { id, text, completed } = todo
// переключение задачи
const toggleTodo = () => {
setState((state) => {
// небольшая оптимизация
const { todos } = state
return {
...state,
todos: {
...todos,
entities: {
...todos.entities,
[id]: {
...todos.entities[id],
completed: !todos.entities[id].completed
}
}
}
}
})
}
// обновление задачи
const updateTodo = ({ target: { value } }) => {
const trimmed = value.trim()
if (trimmed) {
setState((state) => {
const { todos } = state
return {
...state,
todos: {
...todos,
entities: {
...todos.entities,
[id]: {
...todos.entities[id],
text: trimmed
}
}
}
}
})
}
}
// удаление задачи
const deleteTodo = () => {
setState((state) => {
const { todos } = state
const newIds = todos.ids.filter((_id) => _id !== id)
const newTodos = newIds.reduce((obj, id) => {
if (todos.entities[id]) return { ...obj, [id]: todos.entities[id] }
else return obj
}, {})
return {
...state,
todos: {
...todos,
ids: newIds,
entities: newTodos
}
}
})
}
// небольшой финт для упрощения обновления задачи
const inputStyles = {
outline: 'none',
border: 'none',
background: 'none',
textAlign: 'center',
textDecoration: completed ? 'line-through' : '',
opacity: completed ? '0.8' : '1'
}
return (
Delete
)
}
```
В components/index.js мы выполняем повторный экспорт компонентов:
```
export { TodoForm } from './TodoForm'
export { TodoList } from './TodoList'
```
Файл «scr/index.js» выглядит следующим образом:
```
import React from 'react'
import { render } from 'react-dom'
// стили
import 'bootstrap/dist/css/bootstrap.min.css'
// компонент
import App from './use-state/App'
const root$ = document.getElementById('root')
render(, root$)
```
Основные проблемы данного подхода к управлению состоянием:
* Необходимость передачи состояния и/или сеттера на каждом уровне вложенности, обусловленная локальным характером состояния
* Логика обновления состояния приложения разбросана по компонентам и смешана с логикой самих компонентов
* Сложность обновления состояния, вытекающая из его иммутабельности
* Однонаправленный поток данных, невозможность свободного обмена данными между компонентами, находящимися на одном уровне вложенности, но в разных поддеревьях виртуального DOM
Первые две проблемы можно решить с помощью комбинации useContext()/ useReducer().
### useContext() + useReducer()
[Шпаргалка по хукам](https://github.com/harryheman/React-Total/blob/main/md/hooks.md)
Контекст (context) позволяет передавать значения дочерним компонентам напрямую, минуя их предков. Хук «useContext()» позволяет извлекать значения из контекста в любом компоненте, обернутом в провайдер (provider).
Создание контекста:
```
const TodoContext = createContext()
```
Предоставление контекста с состоянием дочерним компонентам:
```
```
Извлечение значения состония из контекста в компоненте:
```
const state = useContext(TodoContext)
```
Хук «useReducer()» принимает редуктор (reducer) и начальное состояние. Он возвращает значение текущего состояния и функцию для отправки (dispatch) операций (actions), на основе которых осуществляется обновление состояния. Сигнатура данного хука:
```
const [state, dispatch] = useReducer(todoReducer, initialState)
```
Алгоритм обновления состояния выглядит так: компонент отправляет операцию в редуктор, а редуктор на основе типа операции (action.type) и опциональной полезной нагрузки операции (action.payload) определенным образом изменяет состояния.
Результатом комбинации useContext() и useReducer() является возможность передачи состояния и диспетчера, возвращаемых useReducer(), любому компоненту, являющемуся потомком провайдера контекста.
Создаем директорию «use-reducer» для второго варианта тудушки. Структура проекта:
```
|--use-reducer
|--modules
|--components
|--index.js
|--TodoForm.js
|--TodoList.js
|--TodoListItem.js
|--todoReducer
|--actions.js
|--actionTypes.js
|--todoReducer.js
|--todoContext.js
|--App.js
```
Начнем с редуктора. В actionTypes.js мы просто определяем типы (названия, константы) операций:
```
const ADD_TODO = 'ADD_TODO'
const TOGGLE_TODO = 'TOGGLE_TODO'
const UPDATE_TODO = 'UPDATE_TODO'
const DELETE_TODO = 'DELETE_TODO'
export { ADD_TODO, TOGGLE_TODO, UPDATE_TODO, DELETE_TODO }
```
Типы операций определяются в отдельном файле, поскольку используются как при создании объектов операции, так и при выборе редуктора случая (case reducer) в инструкции «switch». Существует другой подход, когда типы, создатели операции и редуктор размещаются в одном файле. Такой подход назвается «утиной» структурой файла.
В actions.js определяются так называемые создатели операций (action creators), возвращающие объекты определенной формы (для редуктора):
```
import { ADD_TODO, TOGGLE_TODO, UPDATE_TODO, DELETE_TODO } from './actionTypes'
const createAction = (type, payload) => ({ type, payload })
const addTodo = (newTodo) => createAction(ADD_TODO, newTodo)
const toggleTodo = (todoId) => createAction(TOGGLE_TODO, todoId)
const updateTodo = (payload) => createAction(UPDATE_TODO, payload)
const deleteTodo = (todoId) => createAction(DELETE_TODO, todoId)
export { addTodo, toggleTodo, updateTodo, deleteTodo }
```
В todoReducer.js определяется сам редуктор. Еще раз: редуктор принимает состояние приложения и операцию, отправленную из компонента, и на основе типа операции (и полезной нагрузки) выполняет определенные действия, приводящие к обновлению состояния. Обновление состояния выполняется точно также, как в предыдущем варианте тудушки, только вместо setState() редуктор возвращает новое состояние.
```
// утилита для генерации ID
import { nanoid } from 'nanoid'
// типы операций
import * as actions from './actionTypes'
export const todoReducer = (state, action) => {
const { todos } = state
switch (action.type) {
case actions.ADD_TODO: {
const { payload: newTodo } = action
const id = nanoid(5)
return {
...state,
todos: {
...todos,
ids: todos.ids.concat(id),
entities: {
...todos.entities,
[id]: { id, ...newTodo }
}
}
}
}
case actions.TOGGLE_TODO: {
const { payload: id } = action
return {
...state,
todos: {
...todos,
entities: {
...todos.entities,
[id]: {
...todos.entities[id],
completed: !todos.entities[id].completed
}
}
}
}
}
case actions.UPDATE_TODO: {
const { payload: id, text } = action
return {
...state,
todos: {
...todos,
entities: {
...todos.entities,
[id]: {
...todos.entities[id],
text
}
}
}
}
}
case actions.DELETE_TODO: {
const { payload: id } = action
const newIds = todos.ids.filter((_id) => _id !== id)
const newTodos = newIds.reduce((obj, id) => {
if (todos.entities[id]) return { ...obj, [id]: todos.entities[id] }
else return obj
}, {})
return {
...state,
todos: {
...todos,
ids: newIds,
entities: newTodos
}
}
}
// по умолчанию (при отсутствии совпадения со всеми case) редуктор возвращает состояние в неизменном виде
default:
return state
}
}
```
В todoContext.js определяется начальное состояние приложения, создается и экспортируется провайдер контекста со значением состояния и диспетчером из useReducer():
```
// react
import { createContext, useReducer, useContext } from 'react'
// редуктор
import { todoReducer } from './todoReducer/todoReducer'
// создаем контекст
const TodoContext = createContext()
// начальное состояние
const initialState = {
todos: {
ids: ['1', '2', '3', '4'],
entities: {
1: {
id: '1',
text: 'Eat',
completed: true
},
2: {
id: '2',
text: 'Code',
completed: true
},
3: {
id: '3',
text: 'Sleep',
completed: false
},
4: {
id: '4',
text: 'Repeat',
completed: false
}
}
}
}
// провайдер
export const TodoProvider = ({ children }) => {
const [state, dispatch] = useReducer(todoReducer, initialState)
return (
{children}
)
}
// утилита для извлечения значений из контекста
export const useTodoContext = () => useContext(TodoContext)
```
В этом случае src/index.js выглядит так:
```
// React, ReactDOM и стили
import { TodoProvider } from './use-reducer/modules/TodoContext'
import App from './use-reducer/App'
const root$ = document.getElementById('root')
render(
,
root$
)
```
Теперь у нас нет необходимости передавать состояние и функцию для его обновления на каждом уровне вложенности компонентов. Компонент извлекает состояние и диспетчера с помощью useTodoContext(), например:
```
import { useTodoContext } from '../TodoContext'
// в компоненте
const { state, dispatch } = useTodoContext()
```
Операции отправляются в редуктор с помощью dispatch(), которому передается создатель операции, которому может передаваться полезная нагрузка:
```
import * as actions from '../todoReducer/actions'
// в компоненте
dispatch(actions.addTodo(newTodo))
```
**Код компонентов**
App.js:
```
// components
import { TodoForm, TodoList } from './modules/components'
// styles
import { Container } from 'react-bootstrap'
// context
import { useTodoContext } from './modules/TodoContext'
export default function App() {
const { state } = useTodoContext()
const { length } = state.todos.ids
return (
useReducer
==========
{length ? : null}
)
}
```
TodoForm.js:
```
// react
import { useState } from 'react'
// styles
import { Container, Form, Button } from 'react-bootstrap'
// context
import { useTodoContext } from '../TodoContext'
// actions
import * as actions from '../todoReducer/actions'
export const TodoForm = () => {
const { dispatch } = useTodoContext()
const [text, setText] = useState('')
const updateText = ({ target: { value } }) => {
setText(value)
}
const handleAddTodo = (e) => {
e.preventDefault()
const trimmed = text.trim()
if (trimmed) {
const newTodo = { text, completed: false }
dispatch(actions.addTodo(newTodo))
setText('')
}
}
return (
#### Form
Add
)
}
```
TodoList.js:
```
// components
import { TodoListItem } from './TodoListItem'
// styles
import { Container, ListGroup } from 'react-bootstrap'
// context
import { useTodoContext } from '../TodoContext'
export const TodoList = () => {
const {
state: { todos }
} = useTodoContext()
return (
#### List
{todos.ids.map((id) => (
))}
)
}
```
TodoListItem.js:
```
// styles
import { ListGroup, Form, Button } from 'react-bootstrap'
// context
import { useTodoContext } from '../TodoContext'
// actions
import * as actions from '../todoReducer/actions'
export const TodoListItem = ({ todo }) => {
const { dispatch } = useTodoContext()
const { id, text, completed } = todo
const handleUpdateTodo = ({ target: { value } }) => {
const trimmed = value.trim()
if (trimmed) {
dispatch(actions.updateTodo({ id, trimmed }))
}
}
const inputStyles = {
outline: 'none',
border: 'none',
background: 'none',
textAlign: 'center',
textDecoration: completed ? 'line-through' : '',
opacity: completed ? '0.8' : '1'
}
return (
dispatch(actions.toggleTodo(id))}
/>
dispatch(actions.deleteTodo(id))}>
Delete
)
}
```
Таким образом, мы решили две первые проблемы, связанные с использованием useState() в качестве инструмента для управления состоянием. На самом деле, прибегнув к помощи одной интересной библиотеки, мы можем решить и третью проблему — сложность обновления состояния. [immer](https://immerjs.github.io/immer/docs/introduction) позволяет безопасно мутировать иммутабельные значения (да, я знаю, как это звучит), для этого достаточно обернуть редуктор в функцию «produce()». Создадим файл «todoReducer/todoProducer.js»:
```
// утилита, предоставляемая immer
import produce from 'immer'
import { nanoid } from 'nanoid'
// типы операций
import * as actions from './actionTypes'
// сравните с "классической" реализацией редуктора
// для обновления состояния используется draft - черновик исходного состояния
export const todoProducer = produce((draft, action) => {
const {
todos: { ids, entities }
} = draft
switch (action.type) {
case actions.ADD_TODO: {
const { payload: newTodo } = action
const id = nanoid(5)
ids.push(id)
entities[id] = { id, ...newTodo }
break
}
case actions.TOGGLE_TODO: {
const { payload: id } = action
entities[id].completed = !entities[id].completed
break
}
case actions.UPDATE_TODO: {
const { payload: id, text } = action
entities[id].text = text
break
}
case actions.DELETE_TODO: {
const { payload: id } = action
ids.splice(ids.indexOf(id), 1)
delete entities[id]
break
}
default:
return draft
}
})
```
Главное ограничение, накладываемое immer, состоит в том, что мы должны либо мутировать состояние напрямую, либо возвращать состояние, обновленное иммутабельно. Нельзя делать и то, и другое одновременно.
Вносим изменения в todoContext.js:
```
// import { todoReducer } from './todoReducer/todoReducer'
import { todoProducer } from './todoReducer/todoProducer'
// в провайдере
// const [state, dispatch] = useReducer(todoReducer, initialState)
const [state, dispatch] = useReducer(todoProducer, initialState)
```
Все работает, как и прежде, но код редуктора стало легче читать и анализировать.
Двигаемся дальше.
### Redux Toolkit
[Руководство по Redux Toolkit](https://github.com/harryheman/React-Total/blob/main/md/redux-toolkit.md)
Redux Toolkit — это набор инструментов, облегчающий работу с Redux. Сам по себе Redux очень похож на то, что мы реализовали с помощью useContext() + useReducer():
* Состояние всего приложения находится в одном хранилище (store)
* Дочерние компоненты оборачиваются в Provider из [react-redux](https://react-redux.js.org/), которому в виде пропа «store» передается хранилище
* Редукторы (reducers) каждой части состояния объединяются с помощью combineReducers() в один корневой редуктор (root reducer), который передается при создании хранилища в createStore()
* Компоненты подключаются к хранилищу с помощью connect() (+ mapStateToProps(), mapDispatchToProps()) и т.д.
Для реализации основных операций мы воспользуемся следующими утилитами из Redux Toolkit:
* configureStore() — для создания и настройки хранилища
* createSlice() — для создания частей состояния
* createEntityAdapter() — для создания адаптера сущностей
Чуть позже мы расширим функционал списка задач с помощью следующих утилит:
* createSelector() — для создания селекторов
* createAsyncThunk() — для создания преобразователей (thunk)
Также в компонентах мы будем использовать следующие хуки из react-redux: «useDispatch()» — для получения доступа к диспетчеру и «useSelector()» — для получения доступа к селекторам.
Создаем директорию «redux-toolkit» для третьего варианта тудушки. Устанавливаем Redux Toolkit:
```
yarn add @reduxjs/toolkit
# или
npm i @reduxjs/toolkit
```
Структура проекта:
```
|--redux-toolkit
|--modules
|--components
|--index.js
|--TodoForm.js
|--TodoList.js
|--TodoListItem.js
|--slices
|--todosSlice.js
|--App.js
|--store.js
```
Начнем с хранилища. store.js:
```
// утилита для создания хранилища
import { configureStore } from '@reduxjs/toolkit'
// редуктор
import todosReducer from './modules/slices/todosSlice'
// начальное состояние
const preloadedState = {
todos: {
ids: ['1', '2', '3', '4'],
entities: {
1: {
id: '1',
text: 'Eat',
completed: true
},
2: {
id: '2',
text: 'Code',
completed: true
},
3: {
id: '3',
text: 'Sleep',
completed: false
},
4: {
id: '4',
text: 'Repeat',
completed: false
}
}
}
}
// хранилище
const store = configureStore({
reducer: {
todos: todosReducer
},
preloadedState
})
export default store
```
В этом случае src/index.js выглядит так:
```
// React, ReactDOM & стили
// провайдер
import { Provider } from 'react-redux'
// основной компонент
import App from './redux-toolkit/App'
// хранилище
import store from './redux-toolkit/store'
const root$ = document.getElementById('root')
render(
,
root$
)
```
Переходим к редуктору. slices/todosSlice.js:
```
// утилиты для создания части состояния и адаптера сущностей
import {
createSlice,
createEntityAdapter
} from '@reduxjs/toolkit'
// создаем адаптер
const todosAdapter = createEntityAdapter()
// инициализируем начальное состояние
// получаем { ids: [], entities: {} }
const initialState = todosAdapter.getInitialState()
// создаем часть состояния
const todosSlice = createSlice({
// уникальный ключ, используемый в качестве префикса при генерации создателей операции
name: 'todos',
// начальное состояние
initialState,
// редукторы
reducers: {
// данный создатель операции отправляет в редуктор операцию { type: 'todos/addTodo', payload: newTodo }
addTodo: todosAdapter.addOne,
// Redux Toolkit использует immer для обновления состояния
toggleTodo(state, action) {
const { payload: id } = action
const todo = state.entities[id]
todo.completed = !todo.completed
},
updateTodo(state, action) {
const { id, text } = action.payload
const todo = state.entities[id]
todo.text = text
},
deleteTodo: todosAdapter.removeOne
}
})
// экспортируем селектор для получения всех entities в виде массива
export const { selectAll: selectAllTodos } = todosAdapter.getSelectors(
(state) => state.todos
)
// экспортируем создателей операции
export const {
addTodo,
toggleTodo,
updateTodo,
deleteTodo
} = todosSlice.actions
// эскпортируем редуктор
export default todosSlice.reducer
```
В компоненте для доступа к диспетчеру используется useDispatch(), а для отправки конкретной операции создатель операции, импортируемый из todosSlice.js:
```
import { useDispatch } from 'react-redux'
import { addTodo } from '../slices/todosSlice'
// в компоненте
const dispatch = useDispatch()
dispatch(addTodo(newTodo))
```
Давайте немного расширим функционал нашей тудушки, а именно: добавим возможность фильтрации задач, кнопки для выполнения всех задач и удаления выполненных задач, а также некоторую полезную статистику. Также давайте реализуем получение списка задач с сервера.
Начнем с сервера.
В качестве «fake API» мы будем использовать [JSON Server](https://github.com/typicode/json-server). Вот [шпаргалка по работе с ним](https://github.com/harryheman/React-Total/blob/main/md/json-server/README.md). Устанавливаем json-server и [concurrently](https://www.npmjs.com/package/concurrently) — утилиту для выполнения двух и более команд:
```
yarn add json-server concurrently
# или
npm i json-server concurrently
```
Вносим изменения в раздел «scripts» package.json:
```
"server": "concurrently \"json-server -w db.json -p 5000 -d 1000\" \"yarn start\""
```
* -w — означает наблюдение за изменениями файла «db.json»
* -p — означает порт, по умолчанию запросы из приложения отправляются на порт 3000
* -d — задержка ответа от сервера
Создаем файл «db.json» в корневой директории проекта (state-management):
```
{
"todos": [
{
"id": "1",
"text": "Eat",
"completed": true,
"visible": true
},
{
"id": "2",
"text": "Code",
"completed": true,
"visible": true
},
{
"id": "3",
"text": "Sleep",
"completed": false,
"visible": true
},
{
"id": "4",
"text": "Repeat",
"completed": false,
"visible": true
}
]
}
```
По умолчанию все запросы из приложения отправляются на порт 3000 (порт, на котором запущен сервер для разработки). Для того, чтобы запросы отправлялись на порт 5000 (порт, на котором будет работать json-server), необходимо их проксировать. Добавляем в package.json следующую строку:
```
"proxy": "http://localhost:5000"
```
Запускаем сервер с помощью команды «yarn server».
Создаем еще одну часть состояния. slices/filterSlice.js:
```
import { createSlice } from '@reduxjs/toolkit'
// фильтры
export const Filters = {
All: 'all',
Active: 'active',
Completed: 'completed'
}
// начальное состояние - отображать все задачи
const initialState = {
status: Filters.All
}
// состояние фильтра
const filterSlice = createSlice({
name: 'filter',
initialState,
reducers: {
setFilter(state, action) {
state.status = action.payload
}
}
})
export const { setFilter } = filterSlice.actions
export default filterSlice.reducer
```
Вносим изменения в store.js:
```
// нам больше не требуется preloadedState
import { configureStore } from '@reduxjs/toolkit'
import todosReducer from './modules/slices/todosSlice'
import filterReducer from './modules/slices/filterSlice'
const store = configureStore({
reducer: {
todos: todosReducer,
filter: filterReducer
}
})
export default store
```
Вносим изменения в todosSlice.js:
```
import {
createSlice,
createEntityAdapter,
// утилита для создания селекторов
createSelector,
// утилита для создания преобразователей
createAsyncThunk
} from '@reduxjs/toolkit'
// утилита для выполнения HTTP-запросов
import axios from 'axios'
// фильтры
import { Filters } from './filterSlice'
const todosAdapter = createEntityAdapter()
const initialState = todosAdapter.getInitialState({
// добавляем в начальное состояние статус загрузки
status: 'idle'
})
// адрес сервера
const SERVER_URL = 'http://localhost:5000/todos'
// преобразователь
export const fetchTodos = createAsyncThunk('todos/fetchTodos', async () => {
try {
const response = await axios(SERVER_URL)
return response.data
} catch (err) {
console.error(err.toJSON())
}
})
const todosSlice = createSlice({
name: 'todos',
initialState,
reducers: {
addTodo: todosAdapter.addOne,
toggleTodo(state, action) {
const { payload: id } = action
const todo = state.entities[id]
todo.completed = !todo.completed
},
updateTodo(state, action) {
const { id, text } = action.payload
const todo = state.entities[id]
todo.text = text
},
deleteTodo: todosAdapter.removeOne,
// создатель операции для выполнения всех задач
completeAllTodos(state) {
Object.values(state.entities).forEach((todo) => {
todo.completed = true
})
},
// создатель операции для очистки выполненных задач
clearCompletedTodos(state) {
const completedIds = Object.values(state.entities)
.filter((todo) => todo.completed)
.map((todo) => todo.id)
todosAdapter.removeMany(state, completedIds)
}
},
// дополнительные редукторы
extraReducers: (builder) => {
builder
// после начала выполнения запроса на получения задач
// меняем значение статуса на loading
// это позволит отображать индикатор загрузки в App.js
.addCase(fetchTodos.pending, (state) => {
state.status = 'loading'
})
// после получения задач от сервера
// записываем их в состояние
// и меняем статус загрузки
.addCase(fetchTodos.fulfilled, (state, action) => {
todosAdapter.setAll(state, action.payload)
state.status = 'idle'
})
}
})
export const { selectAll: selectAllTodos } = todosAdapter.getSelectors(
(state) => state.todos
)
// создаем и экспортируем кастомный селектор для получения отфильтрованных задач
export const selectFilteredTodos = createSelector(
selectAllTodos,
(state) => state.filter,
(todos, filter) => {
const { status } = filter
if (status === Filters.All) return todos
return status === Filters.Active
? todos.filter((todo) => !todo.completed)
: todos.filter((todo) => todo.completed)
}
)
export const {
addTodo,
toggleTodo,
updateTodo,
deleteTodo,
completeAllTodos,
clearCompletedTodos
} = todosSlice.actions
export default todosSlice.reducer
```
Вносим изменения в src/index.js:
```
// после импорта компонента "App"
import { fetchTodos } from './redux-toolkit/modules/slices/todosSlice'
store.dispatch(fetchTodos())
```
App.js выглядит так:
```
// хук для доступа к селекторам
import { useSelector } from 'react-redux'
// индикатор загрузки - спиннер
import Loader from 'react-loader-spinner'
// компоненты
import {
TodoForm,
TodoList,
TodoFilters,
TodoControls,
TodoStats
} from './modules/components'
// стили
import { Container } from 'react-bootstrap'
// селектор для получения всех entitites в виде массива
import { selectAllTodos } from './modules/slices/todosSlice'
export default function App() {
// получаем длину массива сущностей
const { length } = useSelector(selectAllTodos)
// получаем значение статуса
const loadingStatus = useSelector((state) => state.todos.status)
// стили для индикатора загрузки
const loaderStyles = {
position: 'absolute',
top: '50%',
left: '50%',
transform: 'translate(-50%, -50%)'
}
if (loadingStatus === 'loading')
return (
)
return (
Redux Toolkit
=============
{length ? (
<>
) : null}
)
}
```
**Код остальных компонентов**
TodoControls.js:
```
// redux
import { useDispatch } from 'react-redux'
// styles
import { Container, ButtonGroup, Button } from 'react-bootstrap'
// action creators
import { completeAllTodos, clearCompletedTodos } from '../slices/todosSlice'
export const TodoControls = () => {
const dispatch = useDispatch()
return (
#### Controls
dispatch(completeAllTodos())}
>
Complete all
dispatch(clearCompletedTodos())}
>
Clear completed
)
}
```
TodoFilters.js:
```
// redux
import { useDispatch, useSelector } from 'react-redux'
// styles
import { Container, Form } from 'react-bootstrap'
// filters & action creator
import { Filters, setFilter } from '../slices/filterSlice'
export const TodoFilters = () => {
const dispatch = useDispatch()
const { status } = useSelector((state) => state.filter)
const changeFilter = (filter) => {
dispatch(setFilter(filter))
}
return (
#### Filters
{Object.keys(Filters).map((key) => {
const value = Filters[key]
const checked = value === status
return (
changeFilter(value)}
checked={checked}
/>
)
})}
)
}
```
TodoForm.js:
```
// react
import { useState } from 'react'
// redux
import { useDispatch } from 'react-redux'
// libs
import { nanoid } from 'nanoid'
// styles
import { Container, Form, Button } from 'react-bootstrap'
// action creator
import { addTodo } from '../slices/todosSlice'
export const TodoForm = () => {
const dispatch = useDispatch()
const [text, setText] = useState('')
const updateText = ({ target: { value } }) => {
setText(value)
}
const handleAddTodo = (e) => {
e.preventDefault()
const trimmed = text.trim()
if (trimmed) {
const newTodo = { id: nanoid(5), text, completed: false }
dispatch(addTodo(newTodo))
setText('')
}
}
return (
#### Form
Add
)
}
```
TodoList.js:
```
// redux
import { useSelector } from 'react-redux'
// component
import { TodoListItem } from './TodoListItem'
// styles
import { Container, ListGroup } from 'react-bootstrap'
// selector
import { selectFilteredTodos } from '../slices/todosSlice'
export const TodoList = () => {
const filteredTodos = useSelector(selectFilteredTodos)
return (
#### List
{filteredTodos.map((todo) => (
))}
)
}
```
TodoListItem.js:
```
// redux
import { useDispatch } from 'react-redux'
// styles
import { ListGroup, Form, Button } from 'react-bootstrap'
// action creators
import { toggleTodo, updateTodo, deleteTodo } from '../slices/todosSlice'
export const TodoListItem = ({ todo }) => {
const dispatch = useDispatch()
const { id, text, completed } = todo
const handleUpdateTodo = ({ target: { value } }) => {
const trimmed = value.trim()
if (trimmed) {
dispatch(updateTodo({ id, trimmed }))
}
}
const inputStyles = {
outline: 'none',
border: 'none',
background: 'none',
textAlign: 'center',
textDecoration: completed ? 'line-through' : '',
opacity: completed ? '0.8' : '1'
}
return (
dispatch(toggleTodo(id))}
/>
dispatch(deleteTodo(id))}>
Delete
)
}
```
TodoStats.js:
```
// react
import { useState, useEffect } from 'react'
// redux
import { useSelector } from 'react-redux'
// styles
import { Container, ListGroup } from 'react-bootstrap'
// selector
import { selectAllTodos } from '../slices/todosSlice'
export const TodoStats = () => {
const allTodos = useSelector(selectAllTodos)
const [stats, setStats] = useState({
total: 0,
active: 0,
completed: 0,
percent: 0
})
useEffect(() => {
if (allTodos.length) {
const total = allTodos.length
const completed = allTodos.filter((todo) => todo.completed).length
const active = total - completed
const percent = total === 0 ? 0 : Math.round((active / total) * 100) + '%'
setStats({
total,
active,
completed,
percent
})
}
}, [allTodos])
return (
#### Stats
{Object.entries(stats).map(([[first, ...rest], count], index) => (
{first.toUpperCase() + rest.join('')}: {count}
))}
)
}
```
Как мы видим, с появлением Redux Toolkit использовать Redux для управления состоянием приложения стало проще, чем комбинацию useContext() + useReducer() (невероятно, но факт), не считая того, что Redux предоставляет больше возможностей для такого управления. Однако, Redux все-таки рассчитан на большие приложения со сложным состоянием. Существует ли какая-то альтернатива для управления состоянием небольших и средних приложений, кроме useContext()/useReducer(). Ответ: да, существует. Это [Recoil](https://recoiljs.org/).
### Recoil
[Руководство по Recoil](https://github.com/harryheman/React-Total/blob/main/md/recoil.md)
Recoil — это новый инструмент для управления состоянием в React-приложениях. Что значит новый? Это значит, что некоторые его API все еще находятся на стадии разработки и могут измениться в будущем. Однако, те возможности, которые мы будем использовать для создания тудушки, являются стабильными.
В основе Recoil лежат атомы и селекторы. Атом — это часть состояния, а селектор — часть производного состояния. Атомы создаются с помощью функции «atom()», а селекторы — с помощью функции «selector()». Для извлечение значений из атомов и селекторов используются хуки «useRecoilState()» (для чтения и записи), «useRecoilValue()» (только для чтения), «useSetRecoilState()» (только для записи) и др. Компоненты, использующие состояние Recoil, должны быть обернуты в RecoilRoot. По ощущениям, Recoil представляет собой промежуточное звено между useState() и Redux.
Создаем директорию «recoil» для последнего варианта тудушки и устанавливаем Recoil:
```
yarn add recoil
# или
npm i recoil
```
Структура проекта:
```
|--recoil
|--modules
|--atoms
|--filterAtom.js
|--todosAtom.js
|--components
|--index.js
|--TodoControls.js
|--TodoFilters.js
|--TodoForm.js
|--TodoList.js
|--TodoListItem.js
|--TodoStats.js
|--App.js
```
Вот как выглядит атом списка задач:
```
// todosAtom.js
// утилиты для создания атомов и селекторов
import { atom, selector } from 'recoil'
// утилита для выполнения HTTP-запросов
import axios from 'axios'
// адрес сервера
const SERVER_URL = 'http://localhost:5000/todos'
// атом с состоянием для списка задач
export const todosState = atom({
key: 'todosState',
default: selector({
key: 'todosState/default',
get: async () => {
try {
const response = await axios(SERVER_URL)
return response.data
} catch (err) {
console.log(err.toJSON())
}
}
})
})
```
Одной из интересных особенностей Recoil является то, что мы можем смешивать синхронную и асинхронную логику при создании атомов и селекторов. Он спроектирован таким образом, что у нас имеется возможность использовать React Suspense для отображения резервного контента до получения данных. Также у нас имеется возможность использовать предохранитель (ErrorBoundary) для перехвата ошибок, возникающих при создании атомов и селекторов, в том числе асинхронным способом.
В этом случае src/index.js выглядит так:
```
import React, { Component, Suspense } from 'react'
import { render } from 'react-dom'
// recoil
import { RecoilRoot } from 'recoil'
// индикатор загрузки
import Loader from 'react-loader-spinner'
import App from './recoil/App'
// предохранитель с официального сайта React
class ErrorBoundary extends Component {
constructor(props) {
super(props)
this.state = { error: null, errorInfo: null }
}
componentDidCatch(error, errorInfo) {
this.setState({
error: error,
errorInfo: errorInfo
})
}
render() {
if (this.state.errorInfo) {
return (
Something went wrong.
---------------------
{this.state.error && this.state.error.toString()}
{this.state.errorInfo.componentStack}
)
}
return this.props.children
}
}
const loaderStyles = {
position: 'absolute',
top: '50%',
left: '50%',
transform: 'translate(-50%, -50%)'
}
const root$ = document.getElementById('root')
// мы оборачиваем основной компонент приложения сначала в Suspense, затем в ErrorBoundary
render(
}
>
,
root$
)
```
Атом фильтра выглядит следующим образом:
```
// filterAtom.js
// recoil
import { atom, selector } from 'recoil'
// атом
import { todosState } from './todosAtom'
export const Filters = {
All: 'all',
Active: 'active',
Completed: 'completed'
}
export const todoListFilterState = atom({
key: 'todoListFilterState',
default: Filters.All
})
// данный селектор использует два атома: атом фильтра и атом списка задач
export const filteredTodosState = selector({
key: 'filteredTodosState',
get: ({ get }) => {
const filter = get(todoListFilterState)
const todos = get(todosState)
if (filter === Filters.All) return todos
return filter === Filters.Completed
? todos.filter((todo) => todo.completed)
: todos.filter((todo) => !todo.completed)
}
})
```
Компоненты извлекают значения из атомов и селекторов с помощью указанных выше хуков. Например, код компонента «TodoListItem» выглядит так:
```
// хук
import { useRecoilState } from 'recoil'
// стили
import { ListGroup, Form, Button } from 'react-bootstrap'
// атом
import { todosState } from '../atoms/todosAtom'
export const TodoListItem = ({ todo }) => {
// данный хук - это как useState() для состояния Recoil
const [todos, setTodos] = useRecoilState(todosState)
const { id, text, completed } = todo
const toggleTodo = () => {
const newTodos = todos.map((todo) =>
todo.id === id ? { ...todo, completed: !todo.completed } : todo
)
setTodos(newTodos)
}
const updateTodo = ({ target: { value } }) => {
const trimmed = value.trim()
if (!trimmed) return
const newTodos = todos.map((todo) =>
todo.id === id ? { ...todo, text: value } : todo
)
setTodos(newTodos)
}
const deleteTodo = () => {
const newTodos = todos.filter((todo) => todo.id !== id)
setTodos(newTodos)
}
const inputStyles = {
outline: 'none',
border: 'none',
background: 'none',
textAlign: 'center',
textDecoration: completed ? 'line-through' : '',
opacity: completed ? '0.8' : '1'
}
return (
Delete
)
}
```
**Код остальных компонентов**
TodoControls.js:
```
// recoil
import { useRecoilState } from 'recoil'
// styles
import { Container, ButtonGroup, Button } from 'react-bootstrap'
// atom
import { todosState } from '../atoms/todosAtom'
export const TodoControls = () => {
const [todos, setTodos] = useRecoilState(todosState)
const completeAllTodos = () => {
const newTodos = todos.map((todo) => (todo.completed = true))
setTodos(newTodos)
}
const clearCompletedTodos = () => {
const newTodos = todos.filter((todo) => !todo.completed)
setTodos(newTodos)
}
return (
#### Controls
Complete all
Clear completed
)
}
```
TodoFilters.js:
```
// recoil
import { useRecoilState } from 'recoil'
// styles
import { Container, Form } from 'react-bootstrap'
// filters & atom
import { Filters, todoListFilterState } from '../atoms/filterAtom'
export const TodoFilters = () => {
const [filter, setFilter] = useRecoilState(todoListFilterState)
return (
#### Filters
{Object.keys(Filters).map((key) => {
const value = Filters[key]
const checked = value === filter
return (
setFilter(value)}
checked={checked}
/>
)
})}
)
}
```
TodoForm.js:
```
// react
import { useState } from 'react'
// recoil
import { useSetRecoilState } from 'recoil'
// libs
import { nanoid } from 'nanoid'
// styles
import { Container, Form, Button } from 'react-bootstrap'
// atom
import { todosState } from '../atoms/todosAtom'
export const TodoForm = () => {
const [text, setText] = useState('')
const setTodos = useSetRecoilState(todosState)
const updateText = ({ target: { value } }) => {
setText(value)
}
const addTodo = (e) => {
e.preventDefault()
const trimmed = text.trim()
if (trimmed) {
const newTodo = { id: nanoid(5), text, completed: false }
setTodos((oldTodos) => oldTodos.concat(newTodo))
setText('')
}
}
return (
#### Form
Add
)
}
```
TodoList.js:
```
// recoil
import { useRecoilValue } from 'recoil'
// components
import { TodoListItem } from './TodoListItem'
// styles
import { Container, ListGroup } from 'react-bootstrap'
// atom
import { filteredTodosState } from '../atoms/filterAtom'
export const TodoList = () => {
const filteredTodos = useRecoilValue(filteredTodosState)
return (
#### List
{filteredTodos.map((todo) => (
))}
)
}
```
TodoStats.js:
```
// react
import { useState, useEffect } from 'react'
// recoil
import { useRecoilValue } from 'recoil'
// styles
import { Container, ListGroup } from 'react-bootstrap'
// atom
import { todosState } from '../atoms/todosAtom'
export const TodoStats = () => {
const todos = useRecoilValue(todosState)
const [stats, setStats] = useState({
total: 0,
active: 0,
completed: 0,
percent: 0
})
useEffect(() => {
if (todos.length) {
const total = todos.length
const completed = todos.filter((todo) => todo.completed).length
const active = total - completed
const percent = total === 0 ? 0 : Math.round((active / total) * 100) + '%'
setStats({
total,
active,
completed,
percent
})
}
}, [todos])
return (
#### Stats
{Object.entries(stats).map(([[first, ...rest], count], index) => (
{first.toUpperCase() + rest.join('')}: {count}
))}
)
}
```
### Заключение
Итак, мы с вами реализовали список задач с использованием четырех разных подходов к управлению состоянием. Какие выводы можно из всего этого сделать?
Я выскажу свое мнение, оно не претендует на статус истины в последней инстанции. Разумеется, выбор правильного инструмента для управления состоянием зависит от задач, решаемых приложением:
* Для управления локальным состоянием (состоянием одного-двух компонентов; при условии, что эти два компонента тесно связаны между собой) используйте useState()
* Для управления распределенным состоянием (состоянием двух и более автономных компонентов) или состоянием небольших и средних приложений используйте Recoil или сочетание useContext()/useReducer()
* Обратите внимание, что если вам нужно просто передавать значения в глубоко вложенные компоненты, то вам вполне хватит useContext() (useContext() сам по себе не является инструментом для управления состоянием)
* Наконец, для управления глобальным состоянием (состоянием всех или большинства компонентов) или состоянием сложного приложения используйте Redux Toolkit
До MobX, о котором я слышал много хорошего, руки пока не дошли.
Благодарю за внимание и хорошего дня. | https://habr.com/ru/post/546632/ | null | ru | null |
# Случайное распределение урона в RPG

Для вычисления [урона от атаки](http://www.dandwiki.com/wiki/SRD:Attack_Damage) в таких настольных ролевых играх, как Dungeons & Dragons, используются броски урона. Это логично для игры, чей процесс основан на бросках кубиков. Во многих компьютерных RPG урон и другие атрибуты (сила, очки магии, ловкость и т.д.) вычисляются по похожей системе.
Обычно сначала пишется код вызова `random()`, а затем результаты корректируются и подстраиваются под нужное игре поведение. В этой статье будут рассмотрены три темы:
1. Простые корректировки — среднее значение и дисперсия
2. Добавление асимметрии — отбрасывание результатов или добавление критических попаданий
3. Полная свобода в настройке случайных чисел, неограниченная возможностями кубиков
Основы
------
В этой статье предполагается, что у вас есть функция `random(*N*)`, возвращающая случайное целое число в пределах от `0` до `range-1`. В Python можно использовать `random.randrange(*N*)`. В Javascript можно пользоваться `Math.floor(*N* * Math.random())`. В стандартной библиотеке C есть `rand() % *N*`, но она плохо работает, так что используйте другой генератор случайных чисел. В C++ можно подключить `uniform_int_distribution(0,*N*-1)` к [объекту генератора случайных чисел](http://www.cplusplus.com/reference/random/). В Java можно создать объект генератора случайных чисел с помощью `new Random()`, а затем вызывать для него `.nextInt(*N*)`. В стандартных библиотеках многих языков нет хороших генераторов случайных чисел, но существует множество сторонних библиотек, например, [PCG](http://www.pcg-random.org/) для C и C++.
Давайте начнём с одного кубика. На этой гистограмме показаны результаты бросков одной 12-сторонней кости: `1+random(12)`. Поскольку `random(12)` возвращает число от 0 до 11, а нам нужно число от 1 до 12, мы прибавляем к нему 1. На оси X расположен урон, на оси Y — частота получения соответствующего урона. Для одной кости бросок урона 2 или 12 так же вероятен, как и бросок 7.

Для броска нескольких кубиков полезно использовать запись, применяемую в играх с костями: *N*d*S* означает, что нужно бросить *S*-сторонню кость *N* раз. Бросок одной 12-сторонней кости записывается как sided 1d12; [3d4](http://www.wolframalpha.com/input/?i=3d4) означает, что нужно бросить 4-стороннюю кость три раза. В коде это можно записать как `3 + random(4) + random(4) + random(4)`.
Давайте бросим две 6-сторонние кости (2d6) и суммируем результаты:
```
damage = 0
for each 0 ≤ i < 2:
damage += 1+random(6)
```
Результаты могут находиться в пределах от 2 (на обеих костях выпала 1) до 12 (на обеих костях выпала 6). Вероятность получения 7 выше, чем 12.

Что произойдёт, если мы увеличим количество костей, но уменьшим их размер?


Самый важный эффект — распределение станет не *широким*, а *узким*. Есть и второй эффект — пик *смещается* вправо. Давайте для начала исследуем использование смещений.
### Постоянные смещения
Часть оружия в Dungeons & Dragons даёт бонусный урон. Можно записать 2d6+1, чтобы обозначить бонус +1 к урону. В некоторых играх броня или щиты снижают урон. Можно записать 2d6-3, что обозначает снятие 3 очков урона (в этом примере я предположу, что минимальный урон равен 0).
Попробуем смещать урон в отрицательную (для снижения урона) или в положительную (для бонуса урона) стороны:



Прибавляя бонус урона или вычитая заблокированный урон, мы просто смещаем всё распределение влево или вправо.
### Дисперсия распределения
При переходе от 2d6 к 6d2 распределение становится *уже* и *смещается* вправо. Как мы видели в предыдущем разделе, смещение — это простой сдвиг. Давайте рассмотрим дисперсию распределения.
Определим функцию для *N* бросков подряд `random(*S+1*)`, возвращающую число от **0** до *N\*S*:
```
function rollDice(N, S):
# Сумма N костей, каждая из которых имеет значение от 0 до S
value = 0
for 0 ≤ i < N:
value += random(S+1)
return value
```
Генерирование случайных чисел от 0 до 24 с помощью нескольких костей даёт следующее распределение результатов:
При увеличении количества бросков и сохранении постоянного диапазона от 0 до *N\*S* распределение становится *уже* (с меньшей дисперсией). Больше результатов будет рядом с серединой диапазона.
Примечание: при увеличении количества сторон *S* (см. изображения ниже) и делении результата на *S* распределение приближается к [нормальному](https://ru.wikipedia.org/wiki/%D0%9D%D0%BE%D1%80%D0%BC%D0%B0%D0%BB%D1%8C%D0%BD%D0%BE%D0%B5_%D1%80%D0%B0%D1%81%D0%BF%D1%80%D0%B5%D0%B4%D0%B5%D0%BB%D0%B5%D0%BD%D0%B8%D0%B5). Простой способ случайного выбора из нормального распределения — [преобразование Бокса-Мюллера](https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%B5%D0%BE%D0%B1%D1%80%D0%B0%D0%B7%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5_%D0%91%D0%BE%D0%BA%D1%81%D0%B0_%E2%80%94_%D0%9C%D1%8E%D0%BB%D0%BB%D0%B5%D1%80%D0%B0).
Асимметрия
----------
Распределения для `rollDice(*N*, *S*)` *симметричны*. Значения меньше среднего так же вероятны, как и значения выше среднего. Подойдёт ли это для вашей игры? Если нет, то существуют разные техники создания асимметрии.
### Отсечение бросков или перебрасывание
Предположим, нам нужно, чтобы значения больше среднего были более частыми, чем меньше среднего. Такая схема редко используется для урона, но применима для таких атрибутов, как сила, интеллект и т.д. Один из способов её реализации — сделать несколько бросков и выбрать лучший результат.
Давайте попробуем бросить кубики `rollDice(2,20)` дважды и выберем максимальный результат:
```
roll1 = rollDice(2, 20)
roll2 = rollDice(2, 20)
damage = max(roll1, roll2)
```

При выборе максимального из `rollDice(2, 12)` и `rollDice(2, 12)` у нас получится число от 0 до 24. Ещё один способ получения числа от 0 до 24 — использовать `rollDice(1, 12)` трижды и выбрать лучшие два из трёх результатов. Форма будет ещё более ассиметричной, чем при выборе одного из двух `rollDice(2, 12)`:
```
roll1 = rollDice(1, 12)
roll2 = rollDice(1, 12)
roll3 = rollDice(1, 12)
damage = roll1 + roll2 + roll3
# теперь отбрасываем наименьшее:
damage = damage - min(roll1, roll2, roll3)
```
Ещё один способ — перебрасывать наименьший результат. В целом он похож на предыдущие подходы, но немного отличается в реализации:
```
roll1 = rollDice(1, 8)
roll2 = rollDice(1, 8)
roll3 = rollDice(1, 8)
damage = roll1 + roll2 + roll3
# теперь отбрасываем наименьшее и бросаем снова:
damage = damage - min(roll1, roll2, roll3)
+ rollDice(1, 8)
```

Любой из этих подходов можно использовать для обратной асимметрии, сделав более частыми значения меньше среднего. Можно также считать, что распределение создаёт случайные всплески высоких значений. Такое распределение часто используется для урона и редко — для атрибутов. Здесь `max()` мы меняем на `min()`:
```
roll1 = rollDice(2, 12)
roll2 = rollDice(2, 12)
damage = min(roll1, roll2)
```
*Отбрасываем наибольшее из двух бросков*
### Критические удары
Ещё один способ создания случайных всплесков высокого урона — их более непосредственная реализация. В некоторых играх определённый бонус даёт «критический удар». Простейший бонус — это дополнительный урон. В представленном ниже коде урон от критического удара прибавляется в 5% случаев:
```
damage = rollDice(3, 4)
if random(100) < 5:
damage += rollDice(3, 4)
```
*Вероятность критического урона 5%*

*Вероятность критического урона 60%*
В других подходах к добавлению асимметрии используются дополнительные атаки: при критических ударах есть шанс на срабатывание дополнительных критических ударов; при критических ударах срабатывает вторая атака, пробивающая защиту; при критических ударах противник промахивается при атаке. Но в этой статье я не буду рассматривать распределение урона при множественных атаках.
### Попробуем создать собственное распределение
При использовании случайности (урон, атрибуты и т.д.) надо начинать с описания характеристик распределения, которое нам требуется для игрового процесса:
* **Интервал:** какими будут минимальное и максимальное значения (если они есть)? Используйте масштабирование и смещение, чтобы уместить распределение в этом интервале.
* **Дисперсия:** насколько часто значения должны быть близки к среднему? Можно использовать меньшее количество бросков для большей дисперсии или большее количество для меньшей дисперсии.
* **Асимметрия:** нужно ли, чтобы чаще встречались значения больше или меньше среднего? Используйте min, max или критические бонусы для добавления в распределение асимметрии.
Вот пара примеров с некоторыми из параметров:
```
value = 0 + rollDice(3, 8)
# Min с перебрасыванием:
value = min(value, 0 + rollDice(3, 8))
# Max с перебрасыванием:
value = max(value, 0 + rollDice(3, 8))
# Критический бонус:
if random(100) < 15:
value += 0 + rollDice(7, 4)
```
```
value = 0 + rollDice(3, 8)
# Min с перебрасыванием:
value = min(value, 0 + rollDice(3, 8))
```

```
value = 0 + rollDice(3, 8)
# Max с перебрасыванием:
value = max(value, 0 + rollDice(3, 8))
# Критический бонус:
if random(100) < 15:
value += 0 + rollDice(7, 4)
```

Существует множество других способов структурирования случайных чисел, но надеюсь, эти примеры дали понятие о том, насколько уже гибка система. Стоит посмотреть также на [этот калькулятор бросков урона](http://www.avanderw.co.za/dice-distributions/). Однако иногда сочетаний бросков кубиков недостаточно.
Произвольные формы
------------------
Мы начали с *входных* алгоритмов и изучения соответствующих им *выходных* распределений. Нам пришлось перебирать множество входных алгоритмов, чтобы найти нужный нам результат на выходе. Есть ли более прямой способ получения подходящего алгоритма? *Да!*
**Давайте сделаем наоборот** и начнём с нужных нам выходных данных, представленных в виде гистограммы. Попробуем сделать это на простом примере.
Предположим, мне нужно выбирать из 3, 4, 5 и 6 в следующих пропорциях:

Это не соответствует ничему, что можно получить бросками костей.
Как написать код для этих результатов?
```
x = random(30+20+10+40)
if x < 30: value = 3
else if x < 30+20: value = 4
else if x < 30+20+10: value = 5
else: value = 6
```
Изучите этот код и разберитесь, как он работает, прежде чем переходить к следующим шагам. Давайте сделаем код более общим, чтобы его можно было использовать для разных таблиц вероятностей. Первый шаг — это создание таблицы:
```
damage_table = [ # массив (вес, урон)
(30, 3),
(20, 4),
(10, 5),
(40, 6),
];
```
В этом написанном вручную коде каждая конструкция `if` сравнивает `x` с *общей* суммой вероятностей. Вместо того, чтобы писать отдельные конструкции `if` с заданными вручную суммами, мы можем циклически перебирать все записи таблицы:
```
cumulative_weight = 0
for (weight, result) in table:
cumulative_weight += weight
if x < cumulative_weight:
value = result
break
```
Последнее, что нужно обобщить — сумму записей таблицы. Давайте вычислим сумму и используем её для выбора случайного x:
```
sum_of_weights = 0
for (weight, value) in table:
sum_of_weights += weight
x = random(sum_of_weights)
```
Объединив всё вместе, мы можем написать функцию для поиска результатов в таблице и функцию для выбора случайного результата (можно превратить их в методы класса таблицы урона):
```
function lookup_value(table, x):
# считаем, что 0 ≤ x < sum_of_weights
cumulative_weight = 0
for (weight, value) in table:
cumulative_weight += weight
if x < cumulative_weight:
return value
function roll(table):
sum_of_weights = 0
for (weight, value) in table:
sum_of_weights += weight
x = random(sum_of_weights)
return lookup_value(damage_table, x)
```
Код генерирования чисел из таблицы очень прост. Для моих задач он был достаточно быстрым, но если профайлер сообщает, что он слишком медленный, попробуйте ускорить линейный поиск двоичным/интерполяционным поиском, таблицами поиска или [методом псевдонимов](http://www.keithschwarz.com/darts-dice-coins/). См. также [метод обратного преобразования](https://ru.wikipedia.org/wiki/%D0%9C%D0%B5%D1%82%D0%BE%D0%B4_%D0%BE%D0%B1%D1%80%D0%B0%D1%82%D0%BD%D0%BE%D0%B3%D0%BE_%D0%BF%D1%80%D0%B5%D0%BE%D0%B1%D1%80%D0%B0%D0%B7%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F).
### Рисуем собственное распределение
Этот способ удобен тем, что позволяет использовать *любую* форму.
```
damage_table = [(53,1), (63,2), (75,3), (52,4), (47,5), (43,6), (37,7), (38,8), (35,9), (35,10), (33,11), (33,12), (30,13), (29,14), (29,15), (29,16), (28,17), (28,18), (28,19), (28,20), (28,21), (29,22), (31,23), (33,24), (36,25), (40,26), (45,27), (82,28), (81,29), (76,30), (68,31), (60,32), (54,33), (48,34), (44,35), (39,36), (37,37), (34,38), (32,39), (30,40), (29,41), (25,42), (25,43), (21,44), (18,45), (15,46), (14,47), (12,48), (10,49), (10,50)]
```
С помощью этого подхода мы можем выбрать распределение, соответствующее любому игровому процессу, не ограниченное распределениями, создаваемыми бросками костей.
Заключение
----------
Случайные броски урона и случайные атрибуты реализуются просто. Вы, как гейм-дизайнер, должны сами выбирать свойства, которыми будет обладать конечное распределение. Если вы будете использовать броски кубиков:
* Для управления дисперсией используйте *количество* бросков. Малое количество соответствует высокой дисперсии, и наоборот.
* Для управления масштабом используйте *смещение* и *размер кости*. Если вы хотите, чтобы случайные числа находились в интервале от *X* до *Y*, то при каждом из *N* бросков должно получаться случайное число от 0 до *(Y-X)/N*, после чего к нему прибавляется *X*. Положительные смещения можно использовать для бонусов урона или бонусов атрибутов. Отрицательные смещения можно использовать для блокировки урона.
* Для более частых значений больше или меньше среднего используйте *асимметрию*. Для бросков атрибутов чаще требуются значения выше среднего, их можно получить выбором максимального, лучшего из трёх или перебрасыванием минимального значения. Для бросков урона чаще требуются значения ниже среднего, их можно получить выбором минимального или критическими бонусами. Для сложности случайных встреч с врагами тоже часто используются значения ниже среднего.
Подумайте о том, как должно варьироваться распределение в вашей игре. Бонусы атаки, блокировка урона и критические удары можно использовать для варьирования распределения с простыми параметрами. Эти параметры можно связать с предметами в игре. Воспользуйтесь «песочницей» в [оригинале статьи](http://www.redblobgames.com/articles/probability/damage-rolls.html), чтобы понаблюдать, как эти параметры влияют на распределения. Задумайтесь о том, как должно работать распределение при повышении уровня игрока; см. на [этой странице](http://rpg.stackexchange.com/questions/91264/what-dice-mechanic-gives-a-bell-curve-distribution-that-narrows-and-increases-me) информацию об увеличении и уменьшении дисперсии со временем при вычислении распределений с помощью [AnyDice](http://anydice.com/) (о которой есть [отличный блог](http://anydice.com/articles/)).
В отличие от игроков в настольные игры с костями, вы не ограничены распределениями на основе сумм случайных чисел. С помощью кода, написанного в разделе «Попробуем создать собственное распределение», *вы можете использовать любое распределение*. Можете написать визуальный инструмент, позволяющий рисовать гистограммы, сохранять данные в таблицы, а затем отрисовывать случайные числа на основе этого распределения. Можете изменять таблицы в формате JSON или XML. Можно также редактировать таблицы в Excel и экспортировать их в CSV. Распределения без параметров обеспечивают большую гибкость, а использование таблиц данных вместо кода позволяет выполнять быстрые итерации без повторной компиляции кода.
Существует множество способов реализации интересных распределений вероятностей на основе простого кода. Сначала определитесь с теми свойствами, которые вам необходимы, а затем подбирайте под них код. | https://habr.com/ru/post/335840/ | null | ru | null |
# Создание нового модуля для open-source CRM EspoCRM
[](http://beta.hstor.org/files/559/193/389/559193389e7e40778dbd55d9a07c5793.png)В этой статье я хотел бы познакомить читателей с архитектурой весьма интересного open-source (GPL3) проекта EspoCRM на примере создания нового модуля для этой системы.
Что такое CRM-система (Customer relationship management), думаю, многие уже давно знают. Особенность данной CRM-системы в том, что она написана как Single Page Application и поэтому довольно «шустрая».
Простой дизайн и современные технологии программирования многим придутся по вкусу, а быстродействие данной CRM-системы приятно удивит. На сайте доступна демо-версия.
Добиться высокой скорости работы помогло кэширование скриптов и шаблонов в Local Storage. Все view вместе с дочерними собираются в один большой HTML, который отображается на экране у пользователя.
Система имеет мощный API, использующий JSON, а веб-интерфейс по сути является API-клиентом.
Система не перегружена функционалом, но имеет все необходимое, а также неплохо настраивается.
#### Создание нового модуля
Для начала нужно создать рабочую директорию нового модуля (это будет пакет модуля) и поместить её в `application/Espo/Modules`:
```
application/Espo/Modules/PM
```
Структура каталогов нашего модуля должна быть следующая:
```
application/Espo/Modules/PM/Controllers/
application/Espo/Modules/PM/Entities/
application/Espo/Modules/PM/Resources/
```
#### Описание метаданных
При разработке PM мы должны описать две сущности — Project и ProjectTask. Для этого необходимо создать два JSON-файла со следующим содержанием:
**application/Espo/Modules/PM/Resources/metadata/scopes/Project.json**
```
{
"entity": true,
"layouts": true,
"tab": true,
"acl": true,
"module": "PM",
"customizable": true,
"stream": true,
"importable": true
}
```
**application/Espo/Modules/PM/Resources/metadata/scopes/ProjectTask.json**
```
{
"entity": true,
"layouts": true,
"tab": false,
"acl": true,
"module": "PM",
"customizable": true,
"stream": true,
"importable": true
}
```
После этого мы должны описать поля и связи для наших сущностей в метаданных `entityDefs`.
**application/Espo/Modules/PM/Resources/metadata/entityDefs/Project.json**
```
{
"fields": {
"name": {
"type": "varchar",
"required": true
},
"status": {
"type": "enum",
"options": [
"Draft",
"Active",
"Completed",
"On Hold",
"Dropped"
],
"default": "Active"
},
"description": {
"type": "text"
},
"account": {
"type": "link"
},
"createdAt": {
"type": "datetime",
"readOnly": true
},
"modifiedAt": {
"type": "datetime",
"readOnly": true
},
"createdBy": {
"type": "link",
"readOnly": true
},
"modifiedBy": {
"type": "link",
"readOnly": true
},
"assignedUser": {
"type": "link",
"required": true
},
"teams": {
"type": "linkMultiple"
}
},
"links": {
"createdBy": {
"type": "belongsTo",
"entity": "User"
},
"modifiedBy": {
"type": "belongsTo",
"entity": "User"
},
"assignedUser": {
"type": "belongsTo",
"entity": "User"
},
"teams": {
"type": "hasMany",
"entity": "Team",
"relationName": "EntityTeam"
},
"account": {
"type": "belongsTo",
"entity": "Account",
"foreign": "projects"
},
"projectTasks": {
"type": "hasMany",
"entity": "ProjectTask",
"foreign": "project"
}
},
"collection": {
"sortBy": "createdAt",
"asc": false,
"boolFilters": [
"onlyMy"
]
}
}
```
**application/Espo/Modules/PM/Resources/metadata/entityDefs/ProjectTask.json**
```
{
"fields": {
"name": {
"type": "varchar",
"required": true
},
"status": {
"type": "enum",
"options": [
"Not Started",
"Started",
"Completed",
"Canceled"
],
"default": "Not Started"
},
"dateStart": {
"type": "date"
},
"dateEnd": {
"type": "date"
},
"estimatedEffort": {
"type": "float"
},
"actualDuration": {
"type": "float"
},
"description": {
"type": "text"
},
"project": {
"type": "link"
},
"createdAt": {
"type": "datetime",
"readOnly": true
},
"modifiedAt": {
"type": "datetime",
"readOnly": true
},
"createdBy": {
"type": "link",
"readOnly": true
},
"modifiedBy": {
"type": "link",
"readOnly": true
},
"assignedUser": {
"type": "link",
"required": true
},
"teams": {
"type": "linkMultiple"
}
},
"links": {
"createdBy": {
"type": "belongsTo",
"entity": "User"
},
"modifiedBy": {
"type": "belongsTo",
"entity": "User"
},
"assignedUser": {
"type": "belongsTo",
"entity": "User"
},
"teams": {
"type": "hasMany",
"entity": "Team",
"relationName": "EntityTeam"
},
"project": {
"type": "belongsTo",
"entity": "Project",
"foreign": "projectTasks"
}
},
"collection": {
"sortBy": "createdAt",
"asc": false,
"boolFilters": [
"onlyMy"
]
}
}
```
Указываем, что будем использовать контроллер для CRUD. Файл помещаем в директорию `clientDefs`.
**application/Espo/Modules/PM/Resources/metadata/clientDefs/Project.json**
```
{
"controller": "Controllers.Record"
}
```
**application/Espo/Modules/PM/Resources/metadata/clientDefs/ProjectTask.json**
```
{
"controller": "Controllers.Record"
}
```
#### Контроллеры классов
Для работы сущностей необходимо описать их контроллеры.
**application/Espo/Modules/PM/Controllers/Project.php**
```
php
namespace Espo\Modules\PM\Controllers;
class Project extends \Espo\Core\Controllers\Record
{
}
</code
```
**application/Espo/Modules/PM/Controllers/ProjectTask.php**
```
php
namespace Espo\Modules\PM\Controllers;
class ProjectTask extends \Espo\Core\Controllers\Record
{
}
</code
```
#### Классы сущностей
Помимо определения контроллеров, также необходимо определить и классы для сущностей.
**application/Espo/Modules/PM/Entities/Project.php**
```
php
namespace Espo\Modules\PM\Entities;
class Project extends \Espo\Core\ORM\Entity
{
}
</code
```
**application/Espo/Modules/PM/Entities/ProjectTask.php**
```
php
namespace Espo\Modules\PM\Entities;
class ProjectTask extends \Espo\Core\ORM\Entity
{
}
</code
```
#### Локализация (I18n)
Добавляем имена наших сущностей в глобальный файл локализации `Global.json`:
**application/Espo/Modules/PM/Resources/i18n/en\_US/Global.json**
```
{
"scopeNames": {
"Project": "Project",
"ProjectTask": "Project Task"
},
"scopeNamesPlural": {
"Project": "Projects",
"ProjectTask": "Project Tasks"
}
}
```
Для перевода полей, выпадающих списков, связей и т.п. в наших сущностях нужно создать отдельные файлы локализации:
**application/Espo/Modules/PM/Resources/i18n/en\_US/Project.json**
```
{
"labels": {
"Create Project": "Create Project"
},
"fields": {
"name": "Name",
"status": "Status",
"account": "Account"
},
"links": {
"projectTasks": "Project Tasks"
}
}
```
**application/Espo/Modules/PM/Resources/i18n/en\_US/ProjectTask.json**
```
{
"labels": {
"Create ProjectTask": "Create Project Task"
},
"fields": {
"name": "Name",
"status": "Status",
"project": "Project",
"dateStart": "Date Start",
"dateEnd": "Date End",
"estimatedEffort": "Estimated Effort (hrs)",
"actualDuration": "Actual Duration (hrs)"
}
}
```
#### Последний штрих
После осуществления всех вышеописанных действий переходим в панель Администратора и производим восстановление системы (Menu -> Administration -> Rebuild), а затем обновляем страницу.
Теперь наш модуль Projects по умолчанию является скрытым; для отображения переходим в панель Администратора (Administration -> User Interface) и делаем его видимым. При помощи Field Manager и Layout Manager можно легко добавить новые поля и настроить внешний вид отображения данных.
Я по сути не имею отношения к проекту, я лишь довольный пользователь. Процесс создания модуля описан разработчиками и публикуется с их согласия. И разработчики, и я готовы ответить на все интересующие вопросы. | https://habr.com/ru/post/230065/ | null | ru | null |
# интересный баг в ИЕ7 (или фича)
столкнулся с нигде не описанным свойством ИЕ7.
вкратце:
Есть HTML код:
> `<a href="1">ссылкаa>`
Есть конструкция Jquery:
> `$("a").click(function(){
>
> var a = $(this).attr("href");
>
> });
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
В ИЕ 7 в переменной «а» будет находится строка
> `http : // домен/полный/путь/на/сайте/1`
Во всех остальных браузерах ФФ, Опера, хром и даже ИЕ8 будет число «1»
В интернете насколько я понимаю ничего подобного не описано… | https://habr.com/ru/post/72764/ | null | ru | null |
# Сравнение похожих строк
Задача сравнения похожих строк встречается на практике довольно часто: лично я недавно столкнулся с ней при попытке импорта почтовых адресов из одной программы в другую.
Например, один адрес может выглядеть как «Тверская обл., Кашин г, Советская ул, 1, 5», а другой – как «Тверская область; город Кашин; улица Советская; дом 1; квартира 5». Похожи ли эти строки и насколько? Несомненно, похожи. И «невооруженным глазом» видна их структура: область – населенный пункт – улица – дом – квартира. Логично, что для адресов важно такое разбиение строк на группы; то есть сравнивать мы должны не «две каши» из сходных слов (где одна «каша» состоит из слов первой строки, а вторая – из слов второй), а именно осуществлять «погруппное» сравнение слов из первой строки со словами из второй. Просматривается и критерий разбиения на группы: в первой строке разделителем групп является «, », а во второй – «; ».
В то же время есть строки, где никакого явного разбиения на группы не просматривается. Например, возьмем «классику»: «Когда в товарищах согласья нет, на лад их дело не пойдет, и выйдет из него не дело — только мука.» И вторая строка: «Проказница мартышка, Осел, Козел да косолапый Мишка затеяли сыграть квартет.» Явно строки разные (и даже мораль у этих басен разная, хотя параллели и можно найти ).
Рассматриваемая задача не нова. Существуют алгоритмы (порой весьма сложные), которые пытаются решить ее, и даже иногда успешно решают. Я предлагаю в копилку алгоритмов еще один. При его составлении я исходил из следующих принципов:
* простота вызова функции сравнения;
* простота реализации;
* достаточная универсальность.
Кроме того, алгоритм реализован на VBA Excel, поэтому он очень «демократичный», и его можно применять повсеместно: Excel не только существует среди программного обеспечения самых разных компьютеров «сам по себе», но и в него экспортируются данные из всевозможных СУБД и приложений.
Итак, начнем.
Функцию сравнения назовем StrCompare. У нее будет 4 аргумента, два из которых необязательные: первая строка str1, вторая строка str2, разделитель групп первой строки div1 и разделитель групп второй строки div2. Если div1 либо div2 пропущены, то по умолчанию подразумевается разделитель “|”. “|” выбран потому, что он вряд ли встретится в «среднестатистической» строке, и поэтому может использоваться для сравнения монолитных (не разбиваемых на группы) строк. Подобные монолитные строки можно также считать строками, состоящими из одной группы. То есть заголовок функции сравнения выглядит так:
```
Public Function StrCompare(str1 As String, str2 As String, Optional div1 As String = "|", Optional div2 As String = "|") As Single
```
Single – потому что результатом функции будет число, показывающее степень сходства сравниваемых строк.
Все группы строки 1 последовательно сравниваются со всеми группами строки 2 пословно, и считается количество совпадений слов в каждой паре групп. Для каждой группы строки 1 в итоге выбирается «лучшая группа» из строки 2 (то есть группа с наибольшим количеством совпадений). Совпадения для каждой пары слов проверяются по слову с минимальной длиной: то есть «улица = ул», а «г = город». Это правило не относится к числам: то есть 200<>20. При выделении слов все «незначащие символы» внутри групп как раз и являются разделителями слов, но сами они при этом игнорируются, то есть слова могут состоять только из символов WordSymbols = «0123456789АБВГДЕЁЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯABCDEFGHIJKLMNOPQRSTUVWXYZ». Понятно, что регистр символов во внимание не принимается.
Для поиска совпадающего слова в текущей группе второй строки используется быстрый метод половинного деления (но немного модернизированный по сравнению с «классическим», так как совпадения проверяются по вышеописанному способу). А поскольку для работы метода половинного деления требуются отсортированные массивы, то применяется еще и алгоритм быстрой сортировки.
Итогом работы функции StrCompare будет результат деления количества совпадающих слов на общее количество слов в строках 1 и 2:
```
StrCompare = (da * 2) / ((kon1_2 - nach1_2 + 1) * (kon1_1 - nach1_1 + 1) + (kon2_2 - nach2_2 + 1) * (kon2_1 - nach2_1 + 1))
```
Здесь, например, kon1\_2 – конечная граница массива 1 (массив слов, содержащихся в группах первой строки) по 2-му измерению (1-е измерение – это количество групп, а 2-е – количество слов в группе).
Настало время представить код:
```
'Функция "интеллектуального" сравнения двух строк. Аргументы:
'строка1, строка2, разделители1, разделители2
Public Function StrCompare(str1 As String, str2 As String, Optional div1 As String = "|", Optional div2 As String = "|") As Single
WordSymbols = "0123456789АБВГДЕЁЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯABCDEFGHIJKLMNOPQRSTUVWXYZ"
Dim massiv1() As String, massiv2() As String, mass1() As String, mass2() As String, m1() As Variant, m2() As Variant 'одномерные массивы групп и двумерные массивы слов
Dim mm1() As String, mm2() As String
Dim nach1_1 As Integer, kon1_1 As Integer, nach1_2 As Integer, kon1_2 As Integer, nach2_1 As Integer, kon2_1 As Integer, nach2_2 As Integer, kon2_2 As Integer
Dim item As String, itemnumber As Integer
Dim yes As Integer, maxyes As Integer, da As Integer
Dim counter As Integer 'счетчик noname
str1 = UCase(str1): str2 = UCase(str2)
massiv1 = Split(str1, div1)
ReDim mass1(LBound(massiv1) To UBound(massiv1), 0 To 1000)
maxk = 0
counter = 0
For i = LBound(massiv1) To UBound(massiv1)
item = massiv1(i)
dlina = Len(item)
slovo = ""
NewWord = False
k = 0 'второй индекс для массива слов
For j = 1 To dlina
bukva = mid(item, j, 1)
If (InStr(1, WordSymbols, bukva) > 0) And Not NewWord Then
NewWord = True
slovo = slovo + bukva
Else
If InStr(1, WordSymbols, bukva) > 0 Then
slovo = slovo + bukva
Else
If (InStr(1, WordSymbols, bukva) = 0) And NewWord Then
NewWord = False
mass1(i, k) = slovo
If k > maxk Then maxk = k
k = k + 1
slovo = ""
End If
End If
End If
Next j
If NewWord Then
mass1(i, k) = slovo
If k > maxk Then maxk = k
End If
Next i
ReDim Preserve mass1(LBound(massiv1) To UBound(massiv1), 0 To maxk)
'*************************************************************'
massiv2 = Split(str2, div2)
ReDim mass2(LBound(massiv2) To UBound(massiv2), 0 To 1000)
maxk = 0
For i = LBound(massiv2) To UBound(massiv2)
item = massiv2(i)
dlina = Len(item)
slovo = ""
NewWord = False
k = 0 'второй индекс для массива слов
For j = 1 To dlina
bukva = mid(item, j, 1)
If (InStr(1, WordSymbols, bukva) > 0) And Not NewWord Then
NewWord = True
slovo = slovo + bukva
Else
If InStr(1, WordSymbols, bukva) > 0 Then
slovo = slovo + bukva
Else
If (InStr(1, WordSymbols, bukva) = 0) And NewWord Then
NewWord = False
mass2(i, k) = slovo
If k > maxk Then maxk = k
k = k + 1
slovo = ""
End If
End If
End If
Next j
If NewWord Then
mass2(i, k) = slovo
If k > maxk Then maxk = k
End If
Next i
ReDim Preserve mass2(LBound(massiv2) To UBound(massiv2), 0 To maxk)
' а теперь непосредственно "гибкое" сравнение строк; пример: kon1_2 - конечная граница массива 1 по 2-му измерению
nach1_1 = LBound(mass1, 1)
kon1_1 = UBound(mass1, 1)
nach1_2 = LBound(mass1, 2)
kon1_2 = UBound(mass1, 2)
nach2_1 = LBound(mass2, 1)
kon2_1 = UBound(mass2, 1)
nach2_2 = LBound(mass2, 2)
kon2_2 = UBound(mass2, 2)
For i = nach1_1 To kon1_1
For j = nach1_2 To kon1_2
If mass1(i, j) = "" Then
counter = counter + 1
mass1(i, j) = "noname" + Trim(Str(counter))
End If
'MsgBox ("mass1(" + Trim(Str(i)) + "," + Trim(Str(j)) + ")=" + mass1(i, j))
Next j
Next i
For i = nach2_1 To kon2_1
For j = nach2_2 To kon2_2
If mass2(i, j) = "" Then
counter = counter + 1
mass2(i, j) = "noname" + Trim(Str(counter))
End If
'MsgBox ("mass2(" + Trim(Str(i)) + "," + Trim(Str(j)) + ")=" + mass2(i, j))
Next j
Next i
'сортировка "внутренних массивов-групп"
ReDim m2(nach2_2 To kon2_2) As Variant
For i = nach2_1 To kon2_1
For j = nach2_2 To kon2_2
m2(j) = mass2(i, j)
Next j
Call QuickSort(m2, nach2_2, kon2_2)
For j = nach2_2 To kon2_2
mass2(i, j) = m2(j)
Next j
Next i
'а теперь непосредственно само сравнение: каждая группа строки1 сравнивается с каждой группой строки2 почленно
ReDim mm2(nach2_2 To kon2_2)
da = 0
For k = nach1_1 To kon1_1 'цикл по группам строки1
maxyes = 0
For i = nach2_1 To kon2_1 'цикл по группам строки2
yes = 0
For j = nach2_2 To kon2_2: mm2(j) = mass2(i, j): Next j 'цикл по членам конкретной группы строки2
For l = nach1_2 To kon1_2 'цикл по членам конкретной группы строки1
If BinarySearch(mm2, nach2_2, kon2_2, mass1(k, l)) <> -1 Then yes = yes + 1
Next l
If yes > maxyes Then maxyes = yes
Next i
da = da + maxyes
Next k
StrChange = (da * 2) / ((kon1_2 - nach1_2 + 1) * (kon1_1 - nach1_1 + 1) + (kon2_2 - nach2_2 + 1) * (kon2_1 - nach2_1 + 1))
'StrChange = da
End Function
Public Sub QuickSort(ByRef vArray() As Variant, inLow As Integer, inHi As Integer)
Dim pivot As Variant
Dim tmpSwap As Variant
Dim tmpLow As Integer
Dim tmpHi As Integer
tmpLow = inLow
tmpHi = inHi
pivot = vArray((inLow + inHi) \ 2)
While (tmpLow <= tmpHi)
While (vArray(tmpLow) < pivot And tmpLow < inHi)
tmpLow = tmpLow + 1
Wend
While (pivot < vArray(tmpHi) And tmpHi > inLow)
tmpHi = tmpHi - 1
Wend
If (tmpLow <= tmpHi) Then
tmpSwap = vArray(tmpLow)
vArray(tmpLow) = vArray(tmpHi)
vArray(tmpHi) = tmpSwap
tmpLow = tmpLow + 1
tmpHi = tmpHi - 1
End If
Wend
If (inLow < tmpHi) Then QuickSort vArray, inLow, tmpHi
If (tmpLow < inHi) Then QuickSort vArray, tmpLow, inHi
End Sub
Public Function BinarySearch(vArray() As String, inLow As Integer, inHi As Integer, key As String) As Integer
Dim lev As Integer, prav As Integer, mid As Integer
Dim key_ As String, arritem As String, arritem_ As String
Dim minlen As Integer, keylen As Integer, arritemlen As Integer
If key = Trim(Str(Val(key))) Then 'это число
lev = inLow: prav = inHi
While lev <= prav
mid = lev + (prav - lev) \ 2
arritem = vArray(mid)
If key < arritem Then
prav = mid - 1
ElseIf key > arritem Then
lev = mid + 1
Else
BinarySearch = mid
Exit Function
End If
Wend
Else
keylen = Len(key)
lev = inLow
prav = inHi
While lev <= prav
mid = lev + (prav - lev) \ 2
arritem = vArray(mid)
arritemlen = Len(arritem)
minlen = IIf(keylen < arritemlen, keylen, arritemlen)
key_ = left(key, minlen)
arritem_ = left(arritem, minlen)
If key_ < arritem_ Then
prav = mid - 1
ElseIf key_ > arritem_ Then
lev = mid + 1
Else
BinarySearch = mid
Exit Function
End If
Wend
End If
BinarySearch = -1
End Function
```
Комментировать все подряд, я думаю, нет смысла: можно сориентироваться по коду. Просто проанализируем работу функции сравнения на нескольких строках разной природы.
1. str1=”Тверская обл., Кашин г, Советская ул, 1, 5” str2=”Тверская область; город Кашин; улица Советская; дом 1; квартира 5”.
Сначала сравним строки без учета групп:
StrCompare(str1,str2) дает результат 0.8888889.
А теперь с учетом:
StrCompare(str1,str2,”, “,”; “) — результат 0.8.
Как видим, группы более строго относятся к сравнению; в данном случае для них важно, чтобы «дом был домом, а квартира – квартирой». При игнорировании групп это роли не играет.
2. str1=”Жил-был у бабушки серенький козлик” str2=”Жил-был у бабушки серый козел”
StrCompare(str1,str2) -> 0.6666667
3. str1=”Иванов Иван Иванович м.р. Калуга 1950” str2=”Иванов И.И. 20.01.1950”
StrCompare(str1,str2) -> 0.6153846
4. str1=”Когда в товарищах согласья нет, на лад их дело не пойдет, и выйдет из него не дело — только мука.” str2=”Проказница мартышка, Осел, Козел да косолапый Мишка затеяли сыграть квартет.”
StrCompare(str1,str2) -> 0
5. str1=”В соответствии с пунктом 1 ст. 540 ГК РФ в случае, когда абонентом по договору энергоснабжения выступает гражданин, использующий энергию для бытового потребления, договор считается заключенным с момента фактического подключения абонента к сети. |Согласно части 1 статьи 153 Жилищного кодекса РФ граждане обязаны своевременно и полностью вносить плату за жилое помещение и коммунальные услуги. | В период с «\_\_\_\_»\_\_\_\_\_\_\_\_\_2017 по «\_\_\_\_»\_\_\_\_\_\_\_\_\_\_2017 Гарантирующий поставщик поставил Вам электроэнергию на сумму\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_. |В связи с нарушением Вами своих обязательств по оплате электрической энергии, что привело к образованию задолженности потребителя перед гарантирующим поставщиком в размере, более чем за 2 расчетных периода, в отношении жилого помещения Потребителя, за счет средств Гарантирующего поставщика, были произведены действия по ограничению/ возобновлению предоставления коммунальной услуги по электроснабжению.|В соответствии с пунктом 121(1) Правил предоставления коммунальных услуг собственникам и пользователям помещений в многоквартирных домах и жилых домов, утвержденных Постановлением Правительства от 06.05.2011г. №354, расходы исполнителя, связанные с введением ограничения, приостановлением и возобновлением предоставления коммунальной услуги потребителю-должнику, подлежат возмещению за счет потребителя, в отношении которого осуществлялись указанные действия.|Стоимость расходов на оплату действий по введению ограничения и последующему восстановлению электроснабжения составляет для Гарантирующего поставщика сумму \_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_.|На основании вышеизложенного, ОП «ТверьАтомЭнергоСбыт» просит Вас оплатить задолженность за действия по ограничению/возобновлению предоставления коммунальной услуги по электроснабжению в размере \_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_ руб. по следующим реквизитам с указанием номера лицевого счета и назначением платежа:”
str2=”«\_\_\_\_» \_\_\_\_\_\_\_\_\_\_ 2017 г. между АО «АтомЭнергоСбыт» — Гарантирующим поставщиком и \_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_ — Потребителем заключен договор энергоснабжения №\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_, сроком действия с \_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_ года, с условием его дальнейшей пролонгации (пункт 8.1 договора, статья 540 Гражданского кодекса Российской Федерации), согласно пункту 1.1. которого гарантирующий поставщик обязался осуществлять продажу электрической энергии (мощности), а также самостоятельно или через привлеченных третьих лиц оказывать услуги по передаче электрической энергии и услуги, оказание которых является неотъемлемой частью процесса поставки электрической энергии потребителю, а Покупатель обязался оплачивать приобретаемую электрическую энергию (мощность). |В связи с нарушением Потребителем своих обязательств по оплате электрической энергии (п.5.2. договора энергоснабжения №\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_ от \_\_\_\_\_\_\_\_\_\_\_), что привело к образованию задолженности потребителя перед гарантирующим поставщиком в размере, более чем за один расчетный период, в отношении объекта электросетевого хозяйства потребителя -\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_ были произведены действия по ограничению/возобновлению режима потребления энергоснабжения в соответствии с Правилами полного и (или) частичного ограничения режима потребления электрической энергии, утвержденными Постановлением Правительства РФ от 04.05.2012 г. №442 (далее – Правила). |Согласно пункту 24 Правил, потребитель обязан компенсировать исполнителю расходы на оплату действий по введению ограничения и последующему восстановлению режима потребления электрической энергии.|Стоимость расходов Гарантирующего поставщика на оплату действий по введению ограничения и последующему восстановлению режима потребления электрической энергии составляет сумму \_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_.|На основании вышеизложенного, ОП «ТверьАтомЭнергоСбыт» просит Вас оплатить расходы Гарантирующего поставщика за действия по ограничению/возобновлению режима потребления электрической энергии в размере \_\_\_\_\_\_\_\_\_\_\_\_\_\_\_ руб. по следующим реквизитам с указанием номера договора и назначением платежа:|Назначение платежа: оплата ограничения / возобновления режима потребления электрической энергии по договору №\_\_\_\_\_\_\_\_\_\_\_\_”
Здесь str1 и str2 – фрагменты очень схожих документов (Договоров энергоснабжения для физических и юридических лиц соответственно). Для «грубой оценки» сходства документов можно применить сравнение без групп StrCompare(str1,str2,”\*”,”\*”) (символ «|» в данном случае не годится, т.к. в исходных строках именно он применяется для разбиения их на группы), которое обнаруживает приличное сходство 0.75 (т.е. документы явно одной природы!). А для конкретизации сходства применяем разбиение на группы: StrCompare(str1,str2,”|”,”|”) (или просто StrCompare(str1,str2)). Результат: 0.3790227.
И теперь, возможно, самый интересный пример. Сюжет басни про ворону и лисицу был известен еще со времен Эзопа. Сравним с помощью StrCompare две басни: классический вариант от И.А. Крылова и менее известный от А.П. Сумарокова:
str1=”Уж сколько раз твердили миру, Что лесть гнусна, вредна; но только все не впрок, И в сердце льстец всегда отыщет уголок. Вороне где-то бог послал кусочек сыру; На ель Ворона взгромоздясь, Позавтракать было совсем уж собралась, Да призадумалась, а сыр во рту держала. На ту беду Лиса близехонько бежала; Вдруг сырный дух Лису остановил: Лисица видит сыр, Лисицу сыр пленил. Плутовка к дереву на цыпочках подходит; Вертит хвостом, с Вороны глаз не сводит И говорит так сладко, чуть дыша: «Голубушка, как хороша! Ну что за шейка, что за глазки! Рассказывать, так, право, сказки! Какие перушки! какой носок! И, верно, ангельский быть должен голосок! Спой, светик, не стыдись! Что, ежели, сестрица, При красоте такой и петь ты мастерица,- Ведь ты б у нас была царь-птица!» Вещуньина с похвал вскружилась голова, От радости в зобу дыханье сперло,- И на приветливы Лисицыны слова Ворона каркнула во все воронье горло: Сыр выпал — с ним была плутовка такова.”
str2=”И птицы держатся людского ремесла. Ворона сыру кус когда-то унесла И на дуб села. Да только лишь еще ни крошечки не ела. Увидела Лиса во рту у ней кусок И думает она: «Я дам Вороне сок! Хотя туда не вспряну, Кусочек этот я достану, Дуб сколько ни высок». «Здорово, — говорит Лисица, — Дружок, Воронушка, названая сестрица! Прекрасная ты птица! Какие ноженьки, какой носок, И можно то сказать тебе без лицемерья, Что паче всех ты мер, мой светик, хороша! И попугай ничто перед тобой, душа, Прекраснее стократ твои павлиньих перья!» (Нелестны похвалы приятно нам терпеть). «О, если бы еще умела ты и петь, Так не было б тебе подобной птицы в мире!» Ворона горлышко разинула пошире, Чтоб быти соловьем, «А сыру, — думает, — и после я поем. В сию минуту мне здесь дело не о пире!» Разинула уста И дождалась поста. Чуть видит лишь конец Лисицына хвоста. Хотела петь, не пела, Хотела есть, не ела.
Причина та тому, что сыру больше нет. Сыр выпал из роту, — Лисице на обед.”
StrCompare(str1,str2) дает результат 0.5590062 – так что сходство сюжета налицо! | https://habr.com/ru/post/447068/ | null | ru | null |
# Разбор: «Эй, диск-жокей, поставь мой floppy-диск»
Рассказываем, кто записывает и пытается слушать музыку на дискетах, какие технологии применяют для таких проектов и что из этого получается: от сжатия аудио до «музыкальных инструментов».
Фотография: Karim Ghantous. Источник: Unsplash.com3½ дюйма для подкаста
---------------------
Записать 33-минутный выпуск «[Шоу непрошеной точности](https://festivalofthespokennerd.com/podcast/)» на дискету попытался Теренс Иден, энтузиаст и эксперт по технологическим стандартам. В подготовительной части [эксперимента](https://shkspr.mobi/blog/2020/09/podcasts-on-floppy-disk/) он провел форматирование, после чего доступными остались ~11 тыс. килобит [HD-формат, 1440 Кб].
Теренс обработал аудиофайл с помощью [Opus](https://auphonic.com/blog/2012/09/26/opus-revolutionary-open-audio-codec-podcasts-and-internet-audio/) — специального кодека для сжатия с потерями. Его представили [IETF](https://en.wikipedia.org/wiki/Internet_Engineering_Task_Force) в 2012 году как открытый и бесплатный [стандарт](https://tools.ietf.org/html/rfc6716) от разработчиков [CELT](https://en.wikipedia.org/wiki/CELT) и [SILK](https://en.wikipedia.org/wiki/SILK). Opus использует преимущества обоих предшественников: сочетает сильные стороны CELT с точки зрения сжатия музыкального и разговорного контента, плюс — специализацию SILK на работе с речью.
Формат видят практически все популярные плееры и бразуеры, а конвертацию можно осуществлять [с помощью foobar2000](http://www.saunalahti.fi/~cse/Opus/) или [в командной строке](https://www.opus-codec.org/downloads/) [вот компактный [гайд](https://opus-codec.org/docs/opus-tools/opusenc.html#Encoding_options)], что и сделал Теренс:
```
opusenc in.wav --downmix-mono --bitrate 6 --cvbr --framesize 60 out.opus
```
Так он получил выпуск подкаста, который спокойно умещается на дискету: установил фиксированный битрейт в 6 кбит/с и размер аудиофрейма в 60 мс. Звучание выпуска после сжатия можно оценить [здесь](https://shkspr.mobi/blog/2020/09/podcasts-on-floppy-disk/) вместе с версиями для 4 кбит/с (удивительно, но разборчивая) и 2 кбит/с (не очень).
Фотография: Brian Kostiuk. Источник: Unsplash.comЕсть вероятность, что автор эксперимента не знал о более совершенной версии — Codec 2. Она способна выдавать еще более впечатляющие результаты. [На Хабре [есть](https://habr.com/ru/post/415557/) перевод [заметки о кодеке](https://auphonic.com/blog/2018/06/01/codec2-podcast-on-floppy-disk/#wavenet-examples).]
Флоппитроны
-----------
В качестве развития проекта Иден [попробовал](https://shkspr.mobi/blog/2020/09/a-floppy-disk-mp3-player-using-a-raspberry-pi/) записать на дискету альбом «A Hard Day's Night». Пусть звучание и получилось как на старом радиоприемнике с кучей помех, но идея была реализована. Прослушать «гибкую пластинку» на Walkman'е он смог с помощью привода и Raspberry Pi Zero.
С дискетами и сопутствующей «инфраструктурой» чего только не делали. Так, пять лет назад на Хабре [рассказывали](https://habr.com/ru/post/379833/) об «органе» из дисководов. Посмотрите, как он выглядит, и послушайте, как звучит:
Его аналог называется [Floppotron](https://en.wikipedia.org/wiki/Floppotron). Проект существует с 2012 года. За шесть лет с начала разработки количество используемых приводов для него увеличили с 2 до 64, а потом добавили и другое периферийное оборудование. Оцените [кавер](https://youtu.be/ph5OW9p-GHM) для легендарной «Bohemian Rhapsody».
Как думаете, что если такую музыку еще и на дискету записать?
Делайте, что угодно
-------------------
Попытки выпуска настоящих релизов на дискетах действительно предпринимали. Два года назад западные СМИ [рассказывали](https://www.cbc.ca/radio/asithappens/as-it-happens-wednesday-edition-1.4742296/bringing-back-the-floppy-disk-ontario-record-label-promotes-vaporwave-music-1.4742298) о лейбле, который выбрал именно такой способ, чтобы на некоторое время вернуть интерес к [Vaporwavе-музыке](https://ru.wikipedia.org/wiki/Vaporwave). [На Хабре есть [перевод](https://habr.com/ru/post/418687/) статьи об этом из Rolling Stone.]
Фотография: Bob Abednego. Источник: Unsplash.comЧуть более практичный подход к ностальгии по формату можно увидеть в проекте [Diskplayer](https://www.dinofizzotti.com/blog/2020-02-05-diskplayer-using-3.5-floppy-disks-to-play-albums-on-spotify/). Это — бокс с дискетами, которые служат «стартером» для стриминга любимых альбомов. Здесь тоже задействована Raspberry Pi и цифро-аналоговый преобразователь HiFiBerry DAC+ Pro, а для переназначения альбомов — разработан простой и удобный интерфейс. [[Репозиторий](https://github.com/dinofizz/diskplayer) проекта на GitHub и подробный [материал](https://www.dinofizzotti.com/blog/2020-02-05-diskplayer-using-3.5-floppy-disks-to-play-albums-on-spotify/) об этом эксперименте, заслуживающий отдельного перевода.]
P.S. Обсуждение на Хабре: [**зачем искать музыку без помощи стриминговых сервисов**](https://habr.com/ru/company/audiomania/blog/523190/).
---
**Другие материалы в нашем Мире Hi-Fi:**
* [Как энтузиасты скачивали компьютерные программы с помощью радио](https://www.audiomania.ru/content/art-7641.html)
* [От пищалок до «крэйзифрога» — краткая история кастомных рингтонов](https://www.audiomania.ru/content/art-7629.html)
* [История домашнего аудио: золотая эра Hi-Fi](https://www.audiomania.ru/content/art-7517.html)
--- | https://habr.com/ru/post/523894/ | null | ru | null |
# Checking the Roslyn Source Code

Once in a while we go back to the projects that we have previously checked using PVS-Studio, which results in their descriptions in various articles. Two reasons make these comebacks exciting for us. Firstly, the opportunity to assess the progress of our analyzer. Secondly, monitoring the feedback of the project's authors to our article and the report of errors, which we usually provide them with. Of course, errors can be corrected without our participation. However, it is always nice when our efforts help to make a project better. Roslyn was no exception. The previous article about this project check dates back to December 23, 2015. It's quite a long time, in the view of the progress that our analyzer has made since that time. Since the C# core of the PVS-Studio analyzer is based on Roslyn, it gives us additional interest in this project. As a result, we're as keen as mustard about the code quality of this project. Now let's test it once again and find out some new and interesting issues (but let's hope that nothing significant) that PVS-Studio will be able to find.
Many of our readers are likely to be well aware of Roslyn (or .NET Compiler Platform). In short, it is a set of open source compilers and an API for code analysis of C# and Visual Basic .NET languages from Microsoft. The source code of the project is available on [GitHub](https://github.com/dotnet/roslyn).
I won't give a detailed description of this platform and I'll recommend checking out the article by my colleague Sergey Vasiliev "[Introduction to Roslyn and its use in program development](https://www.viva64.com/en/b/0399/)" to all interested readers. From this article, you can find out not only about the features of the Roslyn's architecture, but how exactly we use this platform.
As I mentioned earlier, it has been more than 3 years since my colleague Andrey Karpov wrote the last article about the Roslyn check "[New Year PVS-Studio 6.00 Release: Scanning Roslyn](https://www.viva64.com/en/b/0363/)". Since then the C# PVS-Studio analyzer had got many new features. Actually, Andrey's article was a test case, as at that time the C# analyzer was just added in PVS-Studio. Despite this, we managed to detect errors in the Roslyn project, which was certainly of high-quality. So what has changed in the analyzer for C# code by this moment that will allow us to perform a more in-depth analysis?
Since then, both the core and the infrastructure have been developing. We added support for Visual Studio 2017 and Roslyn 2.0, and a deep integration with MSBuild. The article by my colleague Paul Eremeev "[Support of Visual Studio 2017 and Roslyn 2.0 in PVS-Studio: sometimes it's not that easy to use ready-made solutions as it may seem](https://www.viva64.com/en/b/0503/)" describes our approach to integration with MSBuild and reasons for this decision.
At the moment we are actively working on moving to Roslyn 3.0 in the same way as we initially supported Visual Studio 2017. It requires usage of our own toolset, included in the PVS-Studio distributive as a «stub», which is an empty MSBuild.exe file. Despite the fact that it looks like a «crutch» (MSBuild API is not very friendly for reusing in third-party projects due to low libraries portability), such approach has already helped us to relatively seamlessly overcome multiple Roslyn updates in terms of Visual Studio 2017. Until now it was helping (even with some challenges) to pass through the Visual Studio 2019 update and maintain full backward compatibility and performance for systems with older MSBuild versions.
The analyzer core has also undergone a number of improvements. One of the main features is a complete interprocedural analysis with consideration of input and output methods' values, evaluating (depending on these parameters) reachability of the execution branches and return points.
We are on our way to completing the task of monitoring parameters inside the methods (for example, potentially dangerous dereferences) along with saving their auto-annotations. For a diagnostic that uses data-flow mechanism, this will allow taking into account dangerous situations, occurring when passing a parameter in a method. Before this, when analyzing such dangerous places, a warning wasn't generated, as we couldn't know about all possible input values in such a method. Now we can detect danger, as in all the places of calling this method, these input parameters will be taken into account.
Note: you can read about basic analyzer mechanisms, such as data-flow and others in the article "[Technologies used in the PVS-Studio code analyzer for finding bugs and potential vulnerabilities](https://www.viva64.com/en/b/0592/)".
Interprocedural analysis in PVS-Studio C# is limited neither by input parameters, nor the depth. The only limitation is virtual methods in classes, open for inheritance, as well as getting into recursion (the analysis stops when it stumbles upon a repeated call of the already evaluated method). In doing so, the recursive method itself will be eventually evaluated assuming that the return value of its recursion is unknown.
Another great new feature in the C# analyzer has become taking into account possible dereference of a potentially null pointer. Before that, the analyzer complained of a possible null reference exception, being ensured that in all execution branches the variable value will be null. Of course, it was wrong in some cases, that's why the [V3080](https://www.viva64.com/en/w/v3080/)diagnostic had been previously called potential null reference.
Now the analyzer is aware of the fact that the variable could be null in one of the execution branches (for example, under a certain *if* condition). If it notices access to such a variable without a check, it will issue the V3080 warning, but at a lower level of certainty, than if it sees null in all branches. Along with the improved interprocedural analysis, such a mechanism allows finding errors that are very difficult to detect. Here is an example — imagine a long chain of method calls, the last of which is unfamiliar to you. Under certain circumstances, it returns null in the *catch* block, but you haven't protected from this, as you simple haven't known. In this case, the analyzer only complains, when it exactly sees null assignment. In our view, it qualitatively distinguishes our approach from such feature of C# 8.0 as nullable type reference, which, in fact, confines to setting checks for null for each method. However, we suggest the alternative — to perform checks only in places where null can really occur, and our analyzer can now search for such cases.
So, let's not delay the main point for too long and go to blame-storming — analyzing the results of the Roslyn check. First, let's consider the errors, found due to the features, described above. In sum, there were quite a lot of warnings for the Roslyn code this time. I think it is related to the fact that the platform is very actively evolving (at this point the codebase is about 2 770 000 lines excluding empty), and we haven't analyzed this project for long. Nevertheless, there are not so many critical errors, whereas they are of the most interest for the article. As usual, I excluded tests from the check, there are quite a lot of them in Roslyn.
I will start with V3080 errors of the Medium level of certainty, in which the analyzer has detected a possible access by null reference, but not in all possible cases (code branches).
**Possible null dereference — Medium**
V3080 Possible null dereference. Consider inspecting 'current'. CSharpSyntaxTreeFactoryService.PositionalSyntaxReference.cs 70
```
private SyntaxNode GetNode(SyntaxNode root)
{
var current = root;
....
while (current.FullSpan.Contains(....)) // <=
{
....
var nodeOrToken = current.ChildThatContainsPosition(....);
....
current = nodeOrToken.AsNode(); // <=
}
....
}
public SyntaxNode AsNode()
{
if (_token != null)
{
return null;
}
return _nodeOrParent;
}
```
Let's consider the method *GetNode*. The analyzer suggests the access by null reference is possible in the condition of the *while* block*.* The variable is assigned a value in the body of the *while* block, which is a result of the *AsNode* method. In some cases, this value will be *null*. A good example of interprocedural analysis in action.
Now let's consider a similar case, in which the interprocedural analysis was carried out via two method calls.
V3080 Possible null dereference. Consider inspecting 'directory'. CommonCommandLineParser.cs 911
```
private IEnumerable
ExpandFileNamePattern(string path, string baseDirectory, ....)
{
string directory = PathUtilities.GetDirectoryName(path);
....
var resolvedDirectoryPath = (directory.Length == 0) ? // <=
baseDirectory :
FileUtilities.ResolveRelativePath(directory, baseDirectory);
....
}
public static string GetDirectoryName(string path)
{
return GetDirectoryName(path, IsUnixLikePlatform);
}
internal static string GetDirectoryName(string path, bool isUnixLike)
{
if (path != null)
{
....
}
return null;
}
```
The *directory* variable in the body of the *ExpandFileNamePattern* method gets the value from the method *GetDirectoryName(string)*. That, in turn, returns the result of the overloaded method *GetDirectoryName (string, bool)* whose value can be *null*. Since the variable *directory* is used without a preliminary check for null in the body of the method *ExpandFileNamePattern* — we can proclaim the analyzer correct about issuing the warning. This is a potentially unsafe construction.
Another code fragment with the V3080 error, more precisely, with two errors, issued for a single line of code. The interprocedural analysis wasn't needed here.
V3080 Possible null dereference. Consider inspecting 'spanStartLocation'. TestWorkspace.cs 574
V3080 Possible null dereference. Consider inspecting 'spanEndLocationExclusive'. TestWorkspace.cs 574
```
private void MapMarkupSpans(....)
{
....
foreach (....)
{
....
foreach (....)
{
....
int? spanStartLocation = null;
int? spanEndLocationExclusive = null;
foreach (....)
{
if (....)
{
if (spanStartLocation == null &&
positionInMarkup <= markupSpanStart && ....)
{
....
spanStartLocation = ....;
}
if (spanEndLocationExclusive == null &&
positionInMarkup <= markupSpanEndExclusive && ....)
{
....
spanEndLocationExclusive = ....;
break;
}
....
}
....
}
tempMappedMarkupSpans[key].
Add(new TextSpan(
spanStartLocation.Value, // <=
spanEndLocationExclusive.Value - // <=
spanStartLocation.Value));
}
}
....
}
```
The variables *spanStartLocation* and *spanEndLocationExclusive* are of the *nullable int* type and are initialized by *null*. Further along the code they can be assigned values, but only under certain conditions. In some cases, their value remains *null*. After that, these variables are accessed by reference without preliminary check for null, which the analyzer indicates.
The Roslyn code contains quite a lot of such errors, more than 100. Often the pattern of these errors is the same. There is some kind of a general method, which potentially returns *null*. The result of this method is used in many places, sometimes through dozens of intermediate method calls or additional checks. It is important to understand that these errors are not fatal, but they can potentially lead to access by null reference. While detecting of such errors is quite challenging. That's why in some cases one should consider code refactoring, in which case if *null* returns, the method will throw an exception. Otherwise, you can secure your code only with general checks which is quite tiring and sometimes unreliable. Anyway, it's clear that each specific case requires a solution based on project specifications.
Note. It so happens, that at a given point there are no such cases (input data), when the method returns *null* and there is no actual error. However, such code is still not reliable, because everything can change when introducing some code changes.
In order to drop the [V3080](https://www.viva64.com/en/w/v3080/) subject, let's look at obvious errors of High certainty level, when the access by null reference is the likeliest or even inevitable.
**Possible null dereference — High**
V3080 Possible null dereference. Consider inspecting 'collectionType.Type'. AbstractConvertForToForEachCodeRefactoringProvider.cs 137
```
public override async Task
ComputeRefactoringsAsync(CodeRefactoringContext context)
{
....
var collectionType = semanticModel.GetTypeInfo(....);
if (collectionType.Type == null &&
collectionType.Type.TypeKind == TypeKind.Error)
{
return;
}
....
}
```
Due to the typo in the condition (*&&* is used instead of the operator *||*), the code works differently than intended and the access to the *collectionType.Type* variable will be executed when it is *null*. The condition should be corrected as follows:
```
if (collectionType.Type == null ||
collectionType.Type.TypeKind == TypeKind.Error)
....
```
By the way, things may unfold in another way: in the first part of the condition the operators *==* and *!=* are messed up*.* Then the correct code would look like this:
```
if (collectionType.Type != null &&
collectionType.Type.TypeKind == TypeKind.Error)
....
```
This version of the code is less logical, but also corrects the error. The final solution rests for project's authors to decide.
Another similar error.
V3080 Possible null dereference. Consider inspecting 'action'. TextViewWindow\_InProc.cs 372
```
private Func GetLightBulbApplicationAction(....)
{
....
if (action == null)
{
throw new
InvalidOperationException(
$"Unable to find FixAll in {fixAllScope.ToString()}
code fix for suggested action '{action.DisplayText}'.");
}
....
}
```
The error is made when generating the message for the exception. It is followed by the attempt to access the *action.DisplayText* property via the *action* variable, which is known to be *null*.
Here comes the last V3080 error of the High level.
V3080 Possible null dereference. Consider inspecting 'type'. ObjectFormatterHelpers.cs 91
```
private static bool IsApplicableAttribute(
TypeInfo type,
TypeInfo targetType,
string targetTypeName)
{
return type != null && AreEquivalent(targetType, type)
|| targetTypeName != null && type.FullName == targetTypeName;
}
```
The method is quite small, so I cite it entirely. The condition in the *return* block is incorrect. In some cases, when accessing *type.FullName*, an exception may occur. I'll use parentheses to make it clear (they won't change the behavior):
```
return (type != null && AreEquivalent(targetType, type))
|| (targetTypeName != null && type.FullName == targetTypeName);
```
According to the operations precedence, the code will work exactly like this. In case if the *type* variable is *null*, we'll fall in the else-check, where we'll use the *type* null reference, having checked the variable *targetTypeName* for *null*. Code might be fixed, for example, as follows:
```
return type != null &&
(AreEquivalent(targetType, type) ||
targetTypeName != null && type.FullName == targetTypeName);
```
I think, it's enough for reviewing V3080 errors. Now it's high time to see other interesting stuff that the PVS-Studio analyzer managed to find.
**Typo**
[V3005](https://www.viva64.com/en/w/v3005/) The 'SourceCodeKind' variable is assigned to itself. DynamicFileInfo.cs 17
```
internal sealed class DynamicFileInfo
{
....
public DynamicFileInfo(
string filePath,
SourceCodeKind sourceCodeKind,
TextLoader textLoader,
IDocumentServiceProvider documentServiceProvider)
{
FilePath = filePath;
SourceCodeKind = SourceCodeKind; // <=
TextLoader = textLoader;
DocumentServiceProvider = documentServiceProvider;
}
....
}
```
Due to failing variables naming, a typo was made in the constructor of the *DynamicFileInfo* class. The *SourceCodeKind* field is assigned its own value instead of using the parameter *sourceCodeKind*. To minimize the likelihood of such errors, we recommend that you use the underscore prefix to the parameter names in such cases. Here is an example of a corrected version of the code:
```
public DynamicFileInfo(
string _filePath,
SourceCodeKind _sourceCodeKind,
TextLoader _textLoader,
IDocumentServiceProvider _documentServiceProvider)
{
FilePath = _filePath;
SourceCodeKind = _sourceCodeKind;
TextLoader = _textLoader;
DocumentServiceProvider = _documentServiceProvider;
}
```
**Inadvertence**
[V3006](https://www.viva64.com/en/w/v3006/) The object was created but it is not being used. The 'throw' keyword could be missing: throw new InvalidOperationException(FOO). ProjectBuildManager.cs 61
```
~ProjectBuildManager()
{
if (_batchBuildStarted)
{
new InvalidOperationException("ProjectBuilderManager.Stop()
not called.");
}
}
```
Under a certain condition, the destructor must throw an exception, but it's not happening while the exception object is simply created. The *throw* keyword was missed. Here is the corrected version of the code:
```
~ProjectBuildManager()
{
if (_batchBuildStarted)
{
throw new InvalidOperationException("ProjectBuilderManager.Stop()
not called.");
}
}
```
The issue with destructors in C# and throwing exceptions from them is a topic for another discussion, which is beyond the scope of this article.
**When the result is not important**
Methods, which received the same value in all cases, triggered a certain number of [V3009](https://www.viva64.com/en/w/v3009/) warnings. In some cases it can be not critical or the return value is simply not checked in the calling code. I skipped such warnings. But a few code snippets seemed suspicious. Here is one of them:
V3009 It's odd that this method always returns one and the same value of 'true'. GoToDefinitionCommandHandler.cs 62
```
internal bool TryExecuteCommand(....)
{
....
using (context.OperationContext.AddScope(....))
{
if (....)
{
return true;
}
}
....
return true;
}
```
The method *TryExecuteCommand* returns nothing but *true*. In doing so, in the calling code the returned value is involved in some checks.
```
public bool ExecuteCommand(....)
{
....
if (caretPos.HasValue && TryExecuteCommand(....))
{
....
}
....
}
```
It's hard to say exactly to what extent such behaviour is dangerous. But if the result is not needed, maybe the type of the return value should be changed to void and one should make small edits in the calling method. This will make the code more readable and secure.
Similar analyzer warnings:
* V3009 It's odd that this method always returns one and the same value of 'true'. CommentUncommentSelectionCommandHandler.cs 86
* V3009 It's odd that this method always returns one and the same value of 'true'. RenameTrackingTaggerProvider.RenameTrackingCommitter.cs 99
* V3009 It's odd that this method always returns one and the same value of 'true'. JsonRpcClient.cs 138
* V3009 It's odd that this method always returns one and the same value of 'true'. AbstractFormatEngine.OperationApplier.cs 164
* V3009 It's odd that this method always returns one and the same value of 'false'. TriviaDataFactory.CodeShapeAnalyzer.cs 254
* V3009 It's odd that this method always returns one and the same value of 'true'. ObjectList.cs 173
* V3009 It's odd that this method always returns one and the same value of 'true'. ObjectList.cs 249
**Checked the wrong thing**
[V3019](https://www.viva64.com/en/w/v3019/) Possibly an incorrect variable is compared to null after type conversion using 'as' keyword. Check variables 'value', 'valueToSerialize'. RoamingVisualStudioProfileOptionPersister.cs 277
```
public bool TryPersist(OptionKey optionKey, object value)
{
....
var valueToSerialize = value as NamingStylePreferences;
if (value != null)
{
value = valueToSerialize.CreateXElement().ToString();
}
....
}
```
The *value* variable is cast to the type *NamingStylePreferences*. The problem is in the check that follows this. Even if the *value* variable was non null, it doesn't guarantee that type casting was successful and *valueToSerialize* doesn't contain *null*. Possible throwing of the exception *NullReferenceException*. The code needs to be corrected as follows:
```
var valueToSerialize = value as NamingStylePreferences;
if (valueToSerialize != null)
{
value = valueToSerialize.CreateXElement().ToString();
}
```
Another similar bug:
V3019 Possibly an incorrect variable is compared to null after type conversion using 'as' keyword. Check variables 'columnState', 'columnState2'. StreamingFindUsagesPresenter.cs 181
```
private void SetDefinitionGroupingPriority(....)
{
....
foreach (var columnState in ....)
{
var columnState2 = columnState as ColumnState2;
if (columnState?.Name == // <=
StandardTableColumnDefinitions2.Definition)
{
newColumns.Add(new ColumnState2(
columnState2.Name, // <=
....));
}
....
}
....
}
```
The *columnState* variable is cast to the type *ColumnState2*. However, the operation result, which is the variable *columnState2,* is not checked for *null* further. Instead, the *columnState* variable is checked using the conditional *null* operator. Why is this code dangerous? Just like in the previous example, casting with the *as* operator may fail and the variable will be *null* which will result in an exception. By the way, a typo may be to blame here. Take a look at the condition in the *if* block.
Perhaps, instead of *columnState?.Name* the author wanted to write *columnState2?.Name*. It is very likely, considering rather faulty variable names *columnState* and *columnState2.*
**Redundant checks**
Quite a large number of warnings (more than 100) were issued on noncritical, but potentially unsafe constructions related to redundant checks. For example, this is one of them.
[V3022](https://www.viva64.com/en/w/v3022/) Expression 'navInfo == null' is always false. AbstractSyncClassViewCommandHandler.cs 101
```
public bool ExecuteCommand(....)
{
....
IVsNavInfo navInfo = null;
if (symbol != null)
{
navInfo = libraryService.NavInfoFactory.CreateForSymbol(....);
}
if (navInfo == null)
{
navInfo = libraryService.NavInfoFactory.CreateForProject(....);
}
if (navInfo == null) // <=
{
return true;
}
....
}
public IVsNavInfo CreateForSymbol(....)
{
....
return null;
}
public IVsNavInfo CreateForProject(....)
{
return new NavInfo(....);
}
```
May be there is no actual bug here. It's just a good reason to demonstrate «interprocedural analysis + dataflow analysis» working in a tow. The analyzer suggests the second check *navInfo == null* is redundant. Indeed, before it the value assigned to *navInfo* will be obtained from the method *libraryService.NavInfoFactory.CreateForProject*, which will construct and return a new object of the *NavInfo* class. No way it will return *null*. Here the question arises, why didn't the analyzer issue a warning for the first check *navInfo == null*? There are some reasons. Firstly, if the *symbol* variable is *null*, the *navInfo* value will remain a null reference as well. Secondly, even if *navInfo* gets the value from the method *ibraryService.NavInfoFactory.CreateForSymbol*, this value can also be *null*. Thus, the first check *navInfo == null* is really needed.
**Insufficient checks**
Now the reverse situation from the discussed above. Several [V3042](https://www.viva64.com/en/w/v3042/) warnings were triggered for the code, in which access by null reference is possible. Even one or two small checks could have fixed everything.
Let's consider another interesting code fragment, which has two such errors.
V3042 Possible NullReferenceException. The '?.' and '.' operators are used for accessing members of the 'receiver' object Binder\_Expressions.cs 7770
V3042 Possible NullReferenceException. The '?.' and '.' operators are used for accessing members of the 'receiver' object Binder\_Expressions.cs 7776
```
private BoundExpression GetReceiverForConditionalBinding(
ExpressionSyntax binding,
DiagnosticBag diagnostics)
{
....
BoundExpression receiver = this.ConditionalReceiverExpression;
if (receiver?.Syntax != // <=
GetConditionalReceiverSyntax(conditionalAccessNode))
{
receiver = BindConditionalAccessReceiver(conditionalAccessNode,
diagnostics);
}
var receiverType = receiver.Type; // <=
if (receiverType?.IsNullableType() == true)
{
....
}
receiver = new BoundConditionalReceiver(receiver.Syntax, 0, // <=
receiverType ?? CreateErrorType(),
hasErrors: receiver.HasErrors) // <=
{ WasCompilerGenerated = true };
return receiver;
}
```
The *receiver* variable may be null. The author of the code knows about this, as he uses the conditional *null* operator in the condition of the *if* block to access *receiver?.Syntax*. Further the *receiver* variable is used without any checks to access *receiver.Type*, *receiver.Syntax* and *receiver.HasErrors*. These errors must be corrected:
```
private BoundExpression GetReceiverForConditionalBinding(
ExpressionSyntax binding,
DiagnosticBag diagnostics)
{
....
BoundExpression receiver = this.ConditionalReceiverExpression;
if (receiver?.Syntax !=
GetConditionalReceiverSyntax(conditionalAccessNode))
{
receiver = BindConditionalAccessReceiver(conditionalAccessNode,
diagnostics);
}
var receiverType = receiver?.Type;
if (receiverType?.IsNullableType() == true)
{
....
}
receiver = new BoundConditionalReceiver(receiver?.Syntax, 0,
receiverType ?? CreateErrorType(),
hasErrors: receiver?.HasErrors)
{ WasCompilerGenerated = true };
return receiver;
}
```
We also have to be sure that the constructor supports getting *null* values for its parameters or we need to perform additional refactoring.
Other similar errors:
* V3042 Possible NullReferenceException. The '?.' and '.' operators are used for accessing members of the 'containingType' object SyntaxGeneratorExtensions\_Negate.cs 240
* V3042 Possible NullReferenceException. The '?.' and '.' operators are used for accessing members of the 'expression' object ExpressionSyntaxExtensions.cs 349
* V3042 Possible NullReferenceException. The '?.' and '.' operators are used for accessing members of the 'expression' object ExpressionSyntaxExtensions.cs 349
**Error in the condition**
[V3057](https://www.viva64.com/en/w/v3057/) The 'Substring' function could receive the '-1' value while non-negative value is expected. Inspect the second argument. CommonCommandLineParser.cs 109
```
internal static bool TryParseOption(....)
{
....
if (colon >= 0)
{
name = arg.Substring(1, colon - 1);
value = arg.Substring(colon + 1);
}
....
}
```
In case if the *colon* variable is 0, which is fine according to the condition in the code, the *Substring* method will throw an exception. This has to be fixed:
```
if (colon > 0)
```
**Possible typo**
[V3065](https://www.viva64.com/en/w/v3065/) Parameter 't2' is not utilized inside method's body. CSharpCodeGenerationHelpers.cs 84
```
private static TypeDeclarationSyntax
ReplaceUnterminatedConstructs(....)
{
....
var updatedToken = lastToken.ReplaceTrivia(lastToken.TrailingTrivia,
(t1, t2) =>
{
if (t1.Kind() == SyntaxKind.MultiLineCommentTrivia)
{
var text = t1.ToString();
....
}
else if (t1.Kind() == SyntaxKind.SkippedTokensTrivia)
{
return ReplaceUnterminatedConstructs(t1);
}
return t1;
});
....
}
```
The lambda expression accepts two parameters: t1 and t2. However, only t1 is used. It looks suspicious, taking into account the fact how easy it is to make a mistake when using variables with such names.
**Inadvertence**
[V3083](https://www.viva64.com/en/w/v3083/) Unsafe invocation of event 'TagsChanged', NullReferenceException is possible. Consider assigning event to a local variable before invoking it. PreviewUpdater.Tagger.cs 37
```
public void OnTextBufferChanged()
{
if (PreviewUpdater.SpanToShow != default)
{
if (TagsChanged != null)
{
var span = _textBuffer.CurrentSnapshot.GetFullSpan();
TagsChanged(this, new SnapshotSpanEventArgs(span)); // <=
}
}
}
```
The *TagsChanged* event is invoked in an unsafe way. Between checking for *null* and invoking the event, someone may unsubscribe from it, then an exception will be thrown. Furthermore, other operations are performed in the body of the *if* block right before invoking the event. I called this error «Inadvertence», because this event is handled more carefully in other places, as follows:
```
private void OnTrackingSpansChanged(bool leafChanged)
{
var handler = TagsChanged;
if (handler != null)
{
var snapshot = _buffer.CurrentSnapshot;
handler(this,
new SnapshotSpanEventArgs(snapshot.GetFullSpan()));
}
}
```
Usage of an additional *handler* variable prevents the problem. In the method *OnTextBufferChanged,* one has to make edits in order to safely handle the event.
**Intersecting ranges**
[V3092](https://www.viva64.com/en/w/v3092/) Range intersections are possible within conditional expressions. Example: if (A > 0 && A < 5) {… } else if (A > 3 && A < 9) {… }. ILBuilderEmit.cs 677
```
internal void EmitLongConstant(long value)
{
if (value >= int.MinValue && value <= int.MaxValue)
{
....
}
else if (value >= uint.MinValue && value <= uint.MaxValue)
{
....
}
else
{
....
}
}
```
For better understanding, let me rewrite this code, changing the names of the constants with their actual values:
```
internal void EmitLongConstant(long value)
{
if (value >= -2147483648 && value <= 2147483648)
{
....
}
else if (value >= 0 && value <= 4294967295)
{
....
}
else
{
....
}
}
```
Probably, there is no real error, but the condition looks strange. Its second part (*else if*) will be executed only for the range from 2147483648 + 1 to 4294967295.
Another couple of similar warnings:
* V3092 Range intersections are possible within conditional expressions. Example: if (A > 0 && A < 5) {… } else if (A > 3 && A < 9) {… }. LocalRewriter\_Literal.cs 109
* V3092 Range intersections are possible within conditional expressions. Example: if (A > 0 && A < 5) {… } else if (A > 3 && A < 9) {… }. LocalRewriter\_Literal.cs 66
**More about checks for null (or lack of them)**
A couple of [V3095](https://www.viva64.com/en/w/v3095/) errors on the check of a variable for null right after its usage. The first is ambiguous, let's consider the code.
V3095 The 'displayName' object was used before it was verified against null. Check lines: 498, 503. FusionAssemblyIdentity.cs 498
```
internal static IAssemblyName ToAssemblyNameObject(string displayName)
{
if (displayName.IndexOf('\0') >= 0)
{
return null;
}
Debug.Assert(displayName != null);
....
}
```
It is assumed that the reference *displayName* can be null. For this, the check *Debug.Assert* was performed. It is not clear why it goes after using a string. It also has to be taken into account that for configurations different from Debug, the compiler will remove *Debug.Assert* at all*.* Does it mean that getting a null reference is possible only for Debug? If it is not so, why did the author make the check of *string.IsNullOrEmpty(string)*, for example. It is the question to authors of the code.
The following error is more evident.
V3095 The 'scriptArgsOpt' object was used before it was verified against null. Check lines: 321, 325. CommonCommandLineParser.cs 321
```
internal void FlattenArgs(...., List scriptArgsOpt, ....)
{
....
while (args.Count > 0)
{
....
if (parsingScriptArgs)
{
scriptArgsOpt.Add(arg); // <=
continue;
}
if (scriptArgsOpt != null)
{
....
}
....
}
}
```
I think this code doesn't need any explanations. Let me give you the fixed version:
```
internal void FlattenArgs(...., List scriptArgsOpt, ....)
{
....
while (args.Count > 0)
{
....
if (parsingScriptArgs)
{
scriptArgsOpt?.Add(arg);
continue;
}
if (scriptArgsOpt != null)
{
....
}
....
}
}
```
In Roslyn code, there were 15 more similar errors:
* V3095 The 'LocalFunctions' object was used before it was verified against null. Check lines: 289, 317. ControlFlowGraphBuilder.RegionBuilder.cs 289
* V3095 The 'resolution.OverloadResolutionResult' object was used before it was verified against null. Check lines: 579, 588. Binder\_Invocation.cs 579
* V3095 The 'resolution.MethodGroup' object was used before it was verified against null. Check lines: 592, 621. Binder\_Invocation.cs 592
* V3095 The 'touchedFilesLogger' object was used before it was verified against null. Check lines: 111, 126. CSharpCompiler.cs 111
* V3095 The 'newExceptionRegionsOpt' object was used before it was verified against null. Check lines: 736, 743. AbstractEditAndContinueAnalyzer.cs 736
* V3095 The 'symbol' object was used before it was verified against null. Check lines: 422, 427. AbstractGenerateConstructorService.Editor.cs 422
* V3095 The '\_state.BaseTypeOrInterfaceOpt' object was used before it was verified against null. Check lines: 132, 140. AbstractGenerateTypeService.GenerateNamedType.cs 132
* V3095 The 'element' object was used before it was verified against null. Check lines: 232, 233. ProjectUtil.cs 232
* V3095 The 'languages' object was used before it was verified against null. Check lines: 22, 28. ExportCodeCleanupProvider.cs 22
* V3095 The 'memberType' object was used before it was verified against null. Check lines: 183, 184. SyntaxGeneratorExtensions\_CreateGetHashCodeMethod.cs 183
* V3095 The 'validTypeDeclarations' object was used before it was verified against null. Check lines: 223, 228. SyntaxTreeExtensions.cs 223
* V3095 The 'text' object was used before it was verified against null. Check lines: 376, 385. MSBuildWorkspace.cs 376
* V3095 The 'nameOrMemberAccessExpression' object was used before it was verified against null. Check lines: 206, 223. CSharpGenerateTypeService.cs 206
* V3095 The 'simpleName' object was used before it was verified against null. Check lines: 83, 85. CSharpGenerateMethodService.cs 83
* V3095 The 'option' object was used before it was verified against null. Check lines: 23, 28. OptionKey.cs 23
Let's consider [V3105](https://www.viva64.com/en/w/v3105/) errors. Here the conditional *null* operator is used when initializing the variable, but further the variable is used without checks for *null*.
Two warnings indicate the following error:
V3105 The 'documentId' variable was used after it was assigned through null-conditional operator. NullReferenceException is possible. CodeLensReferencesService.cs 138
V3105 The 'documentId' variable was used after it was assigned through null-conditional operator. NullReferenceException is possible. CodeLensReferencesService.cs 139
```
private static async Task
GetDescriptorOfEnclosingSymbolAsync(....)
{
....
var documentId = solution.GetDocument(location.SourceTree)?.Id;
return new ReferenceLocationDescriptor(
....
documentId.ProjectId.Id,
documentId.Id,
....);
}
```
The *documentId* variable can be initialized by *null*. As a result, creating an object *ReferenceLocationDescriptor* will result in throwing an exception. The code must be fixed:
```
return new ReferenceLocationDescriptor(
....
documentId?.ProjectId.Id,
documentId?.Id,
....);
```
Developers should also cover the possibility of variables, passed to a constructor, to be *null.*
Other similar errors in the code:
* V3105 The 'symbol' variable was used after it was assigned through null-conditional operator. NullReferenceException is possible. SymbolFinder\_Hierarchy.cs 44
* V3105 The 'symbol' variable was used after it was assigned through null-conditional operator. NullReferenceException is possible. SymbolFinder\_Hierarchy.cs 51
**Priorities and parentheses**
[V3123](https://www.viva64.com/en/w/v3123/) Perhaps the '?:' operator works in a different way than it was expected. Its priority is lower than the priority of other operators in its condition. Edit.cs 70
```
public bool Equals(Edit other)
{
return \_kind == other.\_kind
&& (\_oldNode == null) ? other.\_oldNode == null :
\_oldNode.Equals(other.\_oldNode)
&& (\_newNode == null) ? other.\_newNode == null :
\_newNode.Equals(other.\_newNode);
}
```
The condition in the return block is evaluated not as the developer intended. It was assumed that the first condition will be *\_kind == other.\_kin*d, (this is why after this condition there is a line break), and after that the blocks of conditions with the operator "*?*" will be evaluated in sequence. In fact, the first condition is *\_kind == other.\_kind && (\_oldNode == null)*. This is due to the fact that the operator *&&* has a higher priority than operator "*?*". To fix this, a developer should take all expressions of the operator "*?*" in parentheses:
```
return _kind == other._kind
&& ((_oldNode == null) ? other._oldNode == null :
_oldNode.Equals(other._oldNode))
&& ((_newNode == null) ? other._newNode == null :
_newNode.Equals(other._newNode));
```
That concludes my description of the errors found.
**Conclusion**
Despite the large number of errors, which I managed to find, in terms of the size of the Roslyn project code (2 770 000 lines), it is not too much. As Andrey wrote in a previous article, I am also ready to acknowledge the high quality of this project.
I'd like to note that such occasional code checks have nothing to do with the methodology of static analysis and are almost unhelpful. Static analysis should be applied regularly, and not on a case-by-case basis. This way, many errors will be corrected at the earliest stages, and hence the cost of fixing them will be ten times less. This idea is set forth in more detail in this little [note](https://www.viva64.com/en/b/0534/), please, check it out.
You can check yourself some errors both in this project and in another. To do this, you just need to [download](https://www.viva64.com/en/pvs-studio-download/) and try our analyzer. | https://habr.com/ru/post/446588/ | null | en | null |
# Брутальный Protocol Buffers от Google vs статический анализ кода
Protocol Buffers — это очень популярный, крутой и качественный проект, развиваемый в основном компанией Google. Это хороший вызов для статического анализатора кода PVS-Studio. Найти хоть что-то — это уже достижение. Попробуем.

Продолжая наш многолетний [цикл публикаций](https://pvs-studio.com/ru/blog/inspections/) про проверку открытых проектов, я обратил внимание на проект [Protocol Buffers](https://github.com/protocolbuffers/protobuf) (protobuf). Библиотека реализует протокол сериализации (передачи) структурированных данных. Это эффективная бинарная альтернатива текстовому формату XML.
Проект показался мне интересным вызовом для анализатора PVS-Studio, ведь компания Google весьма основательно подходит к качеству разрабатываемого C++ кода. Взять хотя бы документ "[Безопасное использование C++](https://habr.com/ru/company/pvs-studio/blog/580762/)", который недавно активно [обсуждался](https://old.reddit.com/r/cpp/comments/pkru4h/safer_usage_of_c_in_chrome/). Дополнительно protobuf используется большим количеством разработчиков в своих проектах и потому хорошо ими протестирован. Найти хотя бы пару ошибок в этом проекте является достижением, которое будет лестно нашей команде. Так чего мы ждём, вперёд!

Раньше мы никогда специально не проверяли этот проект. Однажды, три года назад, мы заглянули в него, когда писали цикл статей про проверку проекта Chromium. Мы заметили интересную ошибку в функции проверки даты, которую описали в отдельной заметке "[31 февраля](https://habr.com/ru/company/pvs-studio/blog/346128/)".
Признаюсь, у меня была задумка, когда я писал эту статью. Я хотел показать возможности нового [механизма межмодульного анализа С++ проектов](https://pvs-studio.com/ru/blog/posts/cpp/0851/). К сожалению, в этот раз межмодульный анализ ничего нового не привнёс. Что с ним, что без него — находятся одни и те же интересные места. Впрочем, это неудивительно. В этом проекте вообще сложно что-то найти :).
Итак давайте посмотрим, какие ляпы скрылись от внимания разработчиков и других инструментов.
Copy-Paste
----------
```
void SetPrimitiveVariables(....) {
....
if (HasHasbit(descriptor)) {
(*variables)["get_has_field_bit_message"] = ....;
(*variables)["set_has_field_bit_message"] = ....;
(*variables)["clear_has_field_bit_message"] = ....;
....
} else {
(*variables)["set_has_field_bit_message"] = ""; // <=
(*variables)["set_has_field_bit_message"] = ""; // <=
(*variables)["clear_has_field_bit_message"] = "";
....
}
```
Предупреждение PVS-Studio: [V519](https://pvs-studio.com/ru/w/v519/) [CWE-563] The variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 163, 164. java\_primitive\_field\_lite.cc 164
Классическая ошибка, возникшая в процессе копирования строк. Где-то фрагмент строки заменили, где-то нет. В результате ключом два раза является "set\_has\_field\_bit\_message".
Если посмотреть код выше, то становится понятно, что на самом деле в else-ветке планировалось написать:
```
(*variables)["get_has_field_bit_message"] = "";
(*variables)["set_has_field_bit_message"] = "";
(*variables)["clear_has_field_bit_message"] = "";
```
Утечка файлового дескриптора
----------------------------
```
ExpandWildcardsResult ExpandWildcards(
const string& path, std::function consume) {
....
HANDLE handle = ::FindFirstFileW(wpath.c\_str(), &metadata);
....
do {
// Ignore ".", "..", and directories.
if ((metadata.dwFileAttributes & FILE\_ATTRIBUTE\_DIRECTORY) == 0 &&
kDot != metadata.cFileName && kDotDot != metadata.cFileName) {
matched = ExpandWildcardsResult::kSuccess;
string filename;
if (!strings::wcs\_to\_utf8(metadata.cFileName, &filename)) {
return ExpandWildcardsResult::kErrorOutputPathConversion; // <=
}
....
} while (::FindNextFileW(handle, &metadata));
FindClose(handle);
return matched;
}
```
Предупреждение PVS-Studio: [V773](https://pvs-studio.com/ru/w/v773/) [CWE-401] The function was exited without releasing the 'handle' handle. A resource leak is possible. io\_win32.cc 400
Перед выходом из функции файловый дескриптор *handle* должен быть закрыт с помощью вызова *FindClose(handle)*. Однако этого не произойдёт, если не удастся сконвертировать текст из формата UTF-8-encoded в UTF-8. Функция просто завершит работу и вернёт статус ошибки.
Потенциальное переполнение
--------------------------
```
uint32_t GetFieldOffset(const FieldDescriptor* field) const {
if (InRealOneof(field)) {
size_t offset =
static_cast(field->containing\_type()->field\_count() +
field->containing\_oneof()->index());
return OffsetValue(offsets\_[offset], field->type());
} else {
return GetFieldOffsetNonOneof(field);
}
}
```
Предупреждение PVS-Studio: [V1028](https://pvs-studio.com/ru/w/v1028/) [CWE-190] Possible overflow. Consider casting operands, not the result. generated\_message\_reflection.h 140
Складываются два значение типа *int* и помещаются в переменную типа *size\_t*:
```
size_t offset = static_cast(int\_var\_1 + int\_var\_2);
```
Предполагается, что в случае 64-битной сборки сумма значений двух 32-битных переменных может превысить значение *INT\_MAX*. Поэтому результат помещается в переменную типа *size\_t*, которая будет 64-битной в 64-битной программе. Более того, понимая, что при сложении двух *int* может произойти переполнение, программистом используется явное приведение типа.
Вот только используется это явное приведение типа неправильно. Оно ни от чего не защищает. И без него сработало бы неявное расширение типа от *int* к *size\_t*. Так что написанный код ничем не отличается от варианта:
```
size_t offset = int_var_1 + int_var_2;
```
Скорее всего, по невнимательности скобку поставили не там, где нужно. Правильным вариантом является:
```
size_t offset = static_cast(int\_var\_1) + int\_var\_2;
```
Разыменование нулевого указателя
--------------------------------
```
bool KotlinGenerator::Generate(....)
{
....
std::unique_ptr file\_generator;
if (file\_options.generate\_immutable\_code) {
file\_generator.reset(
new FileGenerator(file, file\_options, /\* immutable\_api = \*/ true));
}
if (!file\_generator->Validate(error)) {
return false;
}
....
}
```
Предупреждение PVS-Studio: [V614](https://pvs-studio.com/ru/w/v614/) [CWE-457] Potentially null smart pointer 'file\_generator' used. java\_kotlin\_generator.cc 100
Если переменная *generate\_immutable\_code* вдруг окажется равна *fasle*, то умный указатель *file\_generator* останется равен *nullptr*. Как следствие, произойдёт разыменование нулевого указателя.
Видимо, пока переменная *generate\_immutable\_code* всегда истинна, раз эта ошибка ещё не обнаружена. Её можно счесть несущественной. Как только в процессе редактирования кода логика работы изменится, то произойдёт разыменование нулевого указателя, что будет сразу замечено и исправлено. А с другой стороны, в этом коде находится мина, которую лучше найти и исправить заранее, чем ждать, когда кто-то на ней подорвётся в будущем. Суть статического анализа как раз том, чтобы найти ошибки заранее.
Там ли скобка?
--------------
```
AlphaNum::AlphaNum(strings::Hex hex) {
char *const end = &digits[kFastToBufferSize];
char *writer = end;
uint64 value = hex.value;
uint64 width = hex.spec;
// We accomplish minimum width by OR'ing in 0x10000 to the user's value,
// where 0x10000 is the smallest hex number that is as wide as the user
// asked for.
uint64 mask = ((static_cast(1) << (width - 1) \* 4)) | value;
....
}
```
Нас интересует это подвыражение:
```
((static_cast(1) << (width - 1) \* 4))
```
Код не нравится анализатору сразу по 2 причинам:
* [V634](https://pvs-studio.com/ru/w/v634/) [CWE-783] The priority of the '\*' operation is higher than that of the '<<' operation. It's possible that parentheses should be used in the expression. strutil.cc 1408
* [V592](https://pvs-studio.com/ru/w/v592/) The expression was enclosed by parentheses twice: ((expression)). One pair of parentheses is unnecessary or misprint is present. strutil.cc 1408
Согласитесь, предупреждения дополняют друг друга. Есть совместное использование оператора сдвига и умножения. Легко забыть, какой из этих операторов более приоритетен. А повторяющиеся скобочки намекают на то, что про эту неоднозначность знали и хотели её избежать. Но не получилось.
Есть два варианта. Первый: код корректен. В этом случае дополнительные скобки просто должны упрощать чтение кода, но ни на что не влияют:
```
uint64 mask = (static_cast(1) << ((width - 1) \* 4)) | value;
```
Второй: выражение написано с ошибкой. Тогда дополнительные скобки должны поменять последовательность выполняемых операций:
```
uint64 mask = ((static_cast(1) << (width - 1)) \* 4) | value;
```
Заключение
----------
Приятно, что удалось найти недоработки в таком известном и качественном проекте. С другой стороны, это плохой проект для демонстрации возможностей статических анализаторов кода :). Сложно показать пользу от инструмента, если находится всего пара ошибок :).

Следует помнить, что пользу статический анализатор приносит при [регулярном использовании](https://pvs-studio.com/ru/blog/posts/cpp/0639/) для проверки свежего кода, а не при разовых проверках уже оттестированных проектов.
Тем не менее, нужно с чего-то начать. Поэтому предлагаю [скачать PVS-Studio](https://pvs-studio.com/ru/pvs-studio/try-free/), проверить проект и взглянуть на самые [лучшие предупреждения](https://pvs-studio.com/ru/docs/manual/6532/). Скорее всего, вы увидите много для себя интересного :).
Если же ваш код столь же качественный, как protobuf, то предлагаем сразу перейти к полноценному сценарию использования инструмента. Попробуйте внедрить PVS-Studio в процесс разработки и посмотреть, что интересного будет находиться каждый день. Как это сделать в случае, если у вас большой проект, описано [здесь](https://pvs-studio.com/ru/blog/posts/0743/).
Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Andrey Karpov. [Protocol Buffers, a brutal protocol from Google, vs. PVS-Studio, a static code analyzer](https://habr.com/en/company/pvs-studio/blog/587478/). | https://habr.com/ru/post/587486/ | null | ru | null |
# Под капотом сортировок в STL

Стандарт С++ почти никогда не указывает, как именно должен быть реализован тот или иной std алгоритм. Дается только описание того, что на входе, что на выходе и асимптотические ограничения по времени работы и памяти. В статье я постарался прикинуть, какие математические алгоритмы и структуры данных имели ввиду авторы стандарта, указывая ограничения для той или иной сортировки и для некоторых других алгоритмов. А так же как эти алгоритмы реализованы на практике.
При написании статьи я использовал стандарт C++17. В качестве реализаций рассматривал GCC 10.1.0 (май 2020) и LLVM/Clang 10.0.0 (март 2020). В каждой и них есть своя реализация STL, а значит и std алгоритмов.
1. Однопоточные реализации
--------------------------
### 1.1. Готовые сортировки
* **std::sort()**. Еще в стандарте C++98/C++03 мы видим, что сложность алгоритма примерно n\*log(n) сравнений. А также есть примечание, что если важна сложность в худшем случае, то следует использовать `std::stable_sort()` или `std::partial_sort()`. Похоже, что в качестве реализации `std::sort()` подразумевался [quicksort](https://en.wikipedia.org/wiki/Quicksort) (в худшем случае O(n2) сравнений). Однако, начиная с C++11 мы видим, что сложность `std::sort()` уже O(n\*log(n)) сравнений безо всяких оговорок. GCC реализует предложенную в 1997 году [introsort](https://en.wikipedia.org/wiki/Introsort) (O(n\*log(n)) сравнений, как в среднем, так и в худшем случае). Introsort сначала сортирует как quicksort, но вскоре переключается на [heapsort](https://en.wikipedia.org/wiki/Heapsort) и в самом конце сортировки, когда остаются небольшие интервалы (в случае GCC менее 16 элементов), сортирует их при помощи [insertion sort](https://en.wikipedia.org/wiki/Insertion_sort). А вот LLVM реализует весьма сложный алгоритм с множеством оптимизаций в зависимости от размеров сортируемых интервалов и того, являются ли сортируемые элементы тривиально копируемыми и тривиально конструируемыми.
* **std::partial\_sort()**. Поиск некоторого числа элементов с минимальным значением из множества элементов и их сортировка. Во всех версиях стандарта сложность примерно n\*log(m) сравнений, где n — количество элементов в контейнере, а m — количество минимальных элементов, которое нужно найти. Задача для heapsort. Сложность в точности совпадает с этим алгоритмом. Так и реализовано в LLVM и GCC.
* **std::stable\_sort()**. Тут немного сложнее. Во-первых, в отличии от предыдущих сортировок в стандарте отмечено, что она стабильная. Т.е. не меняет местами эквивалентные элементы при сортировке. Во-вторых, сложность ее в худшем случае n\*(log(n))2 сравнений. Но если достаточно памяти, то должно быть n\*log(n) сравнений. Т.е. имеется ввиду 2 разных алгоритма стабильной сортировки. В варианте, когда памяти много подходит стандартный [merge sort](https://en.wikipedia.org/wiki/Merge_sort). Как раз ему требуется дополнительная память для работы. Сделать merge sort без дополнительной памяти за O(n\*log(n)) сравнений так же возможно. Но это сложный алгоритм и не смотря на асимптотику n\*log(n) сравнений константа у него велика, и в обычных условиях он будет работать не очень быстро. Поэтому обычно используется вариант merge sort без дополнительной памяти, который имеет асимптотику n\*(log(n))2 сравнений. И в GCC и в LLVM реализации в целом похожи. Реализованы оба алгоритма: один работает при наличии памяти, другой — когда памяти не хватает. Обе реализации, когда дело доходит до небольших интервалов, используют insertion sort. Она стабильная и не требует дополнительной памяти. Но ее сложность O (n2) сравнений, что не играет роли на маленьких интервалах.
* **std::list::sort(), std::forward\_list::sort()**. Все перечисленные выше сортировки требуют итераторы произвольного доступа для задания сортируемого интервала. А что если требуется отсортировать контейнер, который не обеспечивает таких итераторов? Например, `std::list` или `std::forward_list`. У этих контейнеров есть специальный метод `sort()`. Согласно стандарту, он должен обеспечить стабильную сортировку за примерно n\*log(n) сравнений, где n число элементов контейнера. В целом вполне подходит merge sort. Ее и реализуют GCC и LLVM и для `std::list::sort()`, и для `std::forward_list::sort()`. Но зачем вообще потребовались частные реализации сортировки для списков? Почему бы для `std::stable_sort()` просто не ослабить итераторы до однонаправленных или хотя бы двунаправленных, чтоб этот алгоритм можно было применять и к спискам? Дело в том, что в `std::stable_sort()` используются оптимизации, которые требуют итераторы произвольного доступа. Например, как я писал выше, когда дело доходит до сортировки небольших интервалов в `std::stable_sort()` разумно переключиться на insertion sort, а эта сортировка требует итераторы произвольного доступа.
* **std::make\_heap(), std::sort\_heap()**. Алгоритмы по работе с кучей (max heap), включая сортировку. `std::sort_heap()` это единственный способ сортировки, алгоритм для которого указан явно. Сортировка должна быть реализована, как heapsort. Так и реализовано в LLVM и GCC.
**Сводная таблица**
| Алгоритм | Сложность согласно стандарту C++17 | Реализация в GCC | Реализация в LLVM/Clang |
| --- | --- | --- | --- |
| std::sort() | O(n\*log(n)) | introsort | - |
| std::partial\_sort() | O(n\*log(m)) | heapsort | heapsort |
| std::stable\_sort() | O(n\*log(n))/O(n\*(log(n))2) | merge sort | merge sort |
| std::list::sort(), std::forward\_list::sort() | O(n\*log(n)) | merge sort | merge sort |
| std::make\_heap(), std::sort\_heap() | O(n\*log(n)) | heapsort | heapsort |
*Примечание. В качестве реализации в GCC и LLVM указан алгоритм, который используется для больших сортируемых интервалов. Для особых случаев (небольшие интервалы и т.п.) часто используются оптимизации.*
### 1.2. Составляющие алгоритмов сортировки
* **std::merge()**. Слияние двух сортированных интервалов. Этот алгоритм не меняет местами эквивалентные элементы, т.е. он стабильный. Количество сравнений не более, чем сумма длин сливаемых интервалов минус 1. На базе данного алгоритма очень просто реализовать merge sort. Однако напрямую этот алгоритм не используется в `std::stable_sort()` ни LLVM, ни в GCC. Для шага слияния в `std::stable_sort()` написаны отдельные реализации.
* **std::inplace\_merge()**. Этот алгоритм также реализует слияние двух сортированных интервалов и он также стабильный. У него есть интерфейсные отличия от `std::merge()`, но кроме них есть еще одно, очень важное. По сути `std::inplace_merge()` это два алгоритма. Один вызывается при наличии достаточного количества дополнительной памяти. Его сложность, как и в случае `std::merge()`, не более чем сумма длин объединяемых интервалов минус 1. А другой, если дополнительной памяти нет и нужно сделать слияние "in place". Сложность этого "in place" алгоритма n\*log(n) сравнений, где n сумма элементов в сливаемых интервалах. Все это очень напоминает `std::stable_sort()`, и это неспроста. Как кажется, авторы стандарта предполагали использование `std::inplace_merge()` или подобных алгоритмов в `std::stable_sort()`. Эту идею отражают реализации. В LLVM для реализации `std::stable_sort()` используется `std::inplace_merge()`, в GCC для реализаций `std::stable_sort()` и `std::inplace_merge()` используются некоторые общие методы.
* **std::partition()/std::stable\_partition()**. Данные алгоритмы также можно использовать для написания сортировок. Например, для quicksort или introsort. Но ни GCC ни LLVM не использует их напрямую для реализации сортировок. Используются аналогичные им, но оптимизированные, для случая конкретной сортировки, варианты реализации.
2. Многопоточные реализации
---------------------------
В C++17 для многих алгоритмов появилась возможность задавать политику исполнения (ExecutionPolicy). Она обычно указывается первым параметром алгоритма. Алгоритмы сортировок не стали исключением. Политику исполнения можно задать для большинства алгоритмов рассмотренных выше. В том числе и указать, что алгоритм может выполняться в несколько потоков (`std::execution::par`, `std::execution::par_unseq`). Это значит, что именно может, а не обязан. А будет вычисляться в несколько потоков или нет зависит от целевой платформы, реализации и варианта сборки компилятора. Асимптотическая сложность также остается неизменной, однако константа может оказаться меньше за счет использования многих потоков.
Тут ключевое слово «может». Дело в том, что однопоточные реализации, описанные выше, подходят для соответствующих алгоритмов, какая бы политика исполнения ни была задана. И однопоточные реализации часто используются на настоящий момент независимо от политики исполнения. Я рассмотрел следующие версии:
* LLVM/Clang (Apple clang version 11.0.3 (clang-1103.0.32.62)) и MacOS 10.15.4. В этом случае заголовочный файл execution не нашелся. Т.е. политику многопоточности задать не получится;
* LLVM/Clang 10.0.0 сборка из brew. Тот же результат, что и в случае Apple clang;
* GCC 10.1.0 — файл execution есть и политику задать можно. Но какая бы политика ни была задана, использоваться будет однопоточная версия. Для вызова многопоточной версии необходимо, чтобы был подключен файл tbb/tbb.h при компиляции на платформе Intel. А для этого должна быть установлена библиотека [Intel Threading Building Blocks](https://en.wikipedia.org/wiki/Threading_Building_Blocks) (TBB) и пути поиска заголовочных файлов были прописаны. Установлен ли TBB проверяется при помощи специальной команды в gcc: `__has_include()` в файле c++config.h. И если данный файл виден, то используется многопоточная версия написанная на базе Threading Building Blocks, а если нет, то последовательная. Про TBB немного подробнее ниже. Дополнительную информацию о поддержке компилятором параллельных вычислений, как впрочем и другой функциональности, можно посмотреть на [cppreference.com](https://en.cppreference.com/w/cpp/compiler_support).
3. Intel Threading Building Blocks
----------------------------------
Чтоб стало возможным использовать многопоточные версии разных алгоритмов, на сегодня нужно использовать дополнительные библиотеку Threading Building Blocks, разрабатываемую Intel. Это несложно:
* Клонируем репозиторий Threading Building Blocks с <https://github.com/oneapi-src/oneTBB>
* Из корня запускаем make и ждем несколько минут пока компилируется TBB или make all и ждем пару часов, чтоб прошли еще и тесты
* Далее при компиляции указываем пути к includes (`-I oneTBB/include`) и к динамической библиотеке (у меня был такой путь `-L tbb/oneTBB/build/macos_intel64_clang_cc11.0.3_os10.15.4_release -ltbb`, т.к. я собирал TBB при помощи Apple clang version 11.0.3 на MacOS)
4. Эпилог
---------
Как кажется, когда комитет C++ описывает те или иные особенности языка в стандарте, он предполагает те или иные сценарии использования и те или иные алгоритмы реализации. Часто все развивается, как предполагалось. Иногда идет своим путем. Иногда не используется вовсе. Какие бы ни были реализации тех или иных алгоритмов или структур данных сегодня, завтра это может измениться. Измениться впрочем может и стандарт. Но меняясь, стандарт почти всегда обеспечивает совместимость с ранее написанным кодом. При выпуске новых версий компиляторов могут меняться и реализации. Но изменяясь они предполагают, что разработчики полагаются на стандарт. На мой взгляд, имеет смысл понимать, как обычно реализуются те или иные части стандартной библиотеки. Но полагаться при разработке нужно именно на ограничения, заданные стандартом.
**Ссылки на упомянутые алгоритмы и библиотеку:**
* [Quicksort](https://en.wikipedia.org/wiki/Quicksort)
* [Introsort](https://en.wikipedia.org/wiki/Introsort)
* [Insertion Sort](https://en.wikipedia.org/wiki/Insertion_sort)
* [Heapsort](https://en.wikipedia.org/wiki/Heapsort)
* [Merge Sort](https://en.wikipedia.org/wiki/Merge_sort)
* [Threading Building Blocks](https://en.wikipedia.org/wiki/Threading_Building_Blocks)
**Благодарности**
Большое спасибо Ольге [Serine](https://habr.com/ru/users/serine/) за замечание по статье и картинку. | https://habr.com/ru/post/518996/ | null | ru | null |
# NetApp ONTAP и антивирусная защита NAS
Системы хранения NetApp с прошивкой ONTAP поддерживают интеграцию NAS с антивирусом, для того чтобы файлы перед чтением/записью сначала проверялись, эта функция называется Off-box Anti-Virus Scanning. Она позволяет повысить уровень защиты корпоративных сред и сгрузить лишнюю нагрузку с рабочих станций. Так как поддержка антивирусных баз всех рабочих станций в актуальном состоянии может быть не выполнимой задачей. Поддерживаются продукты от:
* Kaspersky
* Symantec
* Trend Micro
* Computer Associates
* McAfee
* Sophos
Кроме этого поддерживается расширенный функционал файл-скрининга (FPolicy), позволяющий ограничивать работы с файлами не только на основе их расширения, но и типа файла основываясь на заголовке внутри этого файла.
Сегодня я хотел бы подробнее остановиться на интеграции ONTAP с CIFS(SMB) шарой и антивирусной системой McAfee. Которая в принципе похожим образом устроена и с другими антивирусными системами.
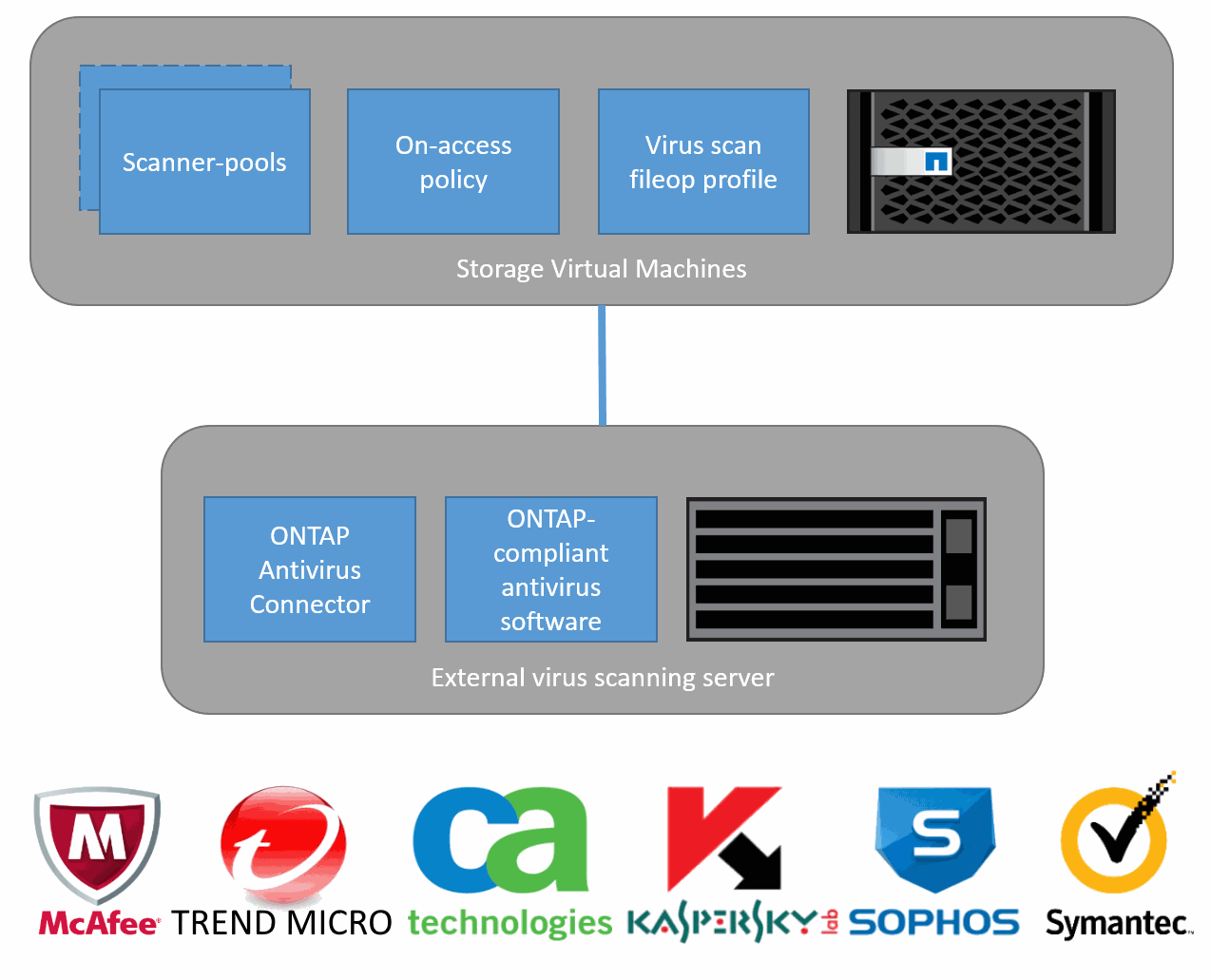
1. Для настройки интеграции нам понадобится несколько компонент:
2. Microsoft Windows Server 2008 и выше
3. СХД с прошивкой ONTAP (на базе аппаратной платформы NetApp FAS или в виде виртуальной машины ONTAP Select или ONTAP Cloud в облаке Amazone/Azure)
4. McAfee VirusScan Enterprise for Storage. Скачать [VSEfS здесь](http://www.mcafee.com/us/downloads/downloads.aspx)
5. Для сканирования используется SMB 2 и старше, версия 1.0 не поддерживается.
6. NetApp ONTAP AV Connector. Скачать [AV Connecor здесь](http://support.netapp.com/NOW/download/software/ontap_av_connector)
Более подробно обращайтесь в [матрицу совместимости](http://mysupport.netapp.com/matrix/).
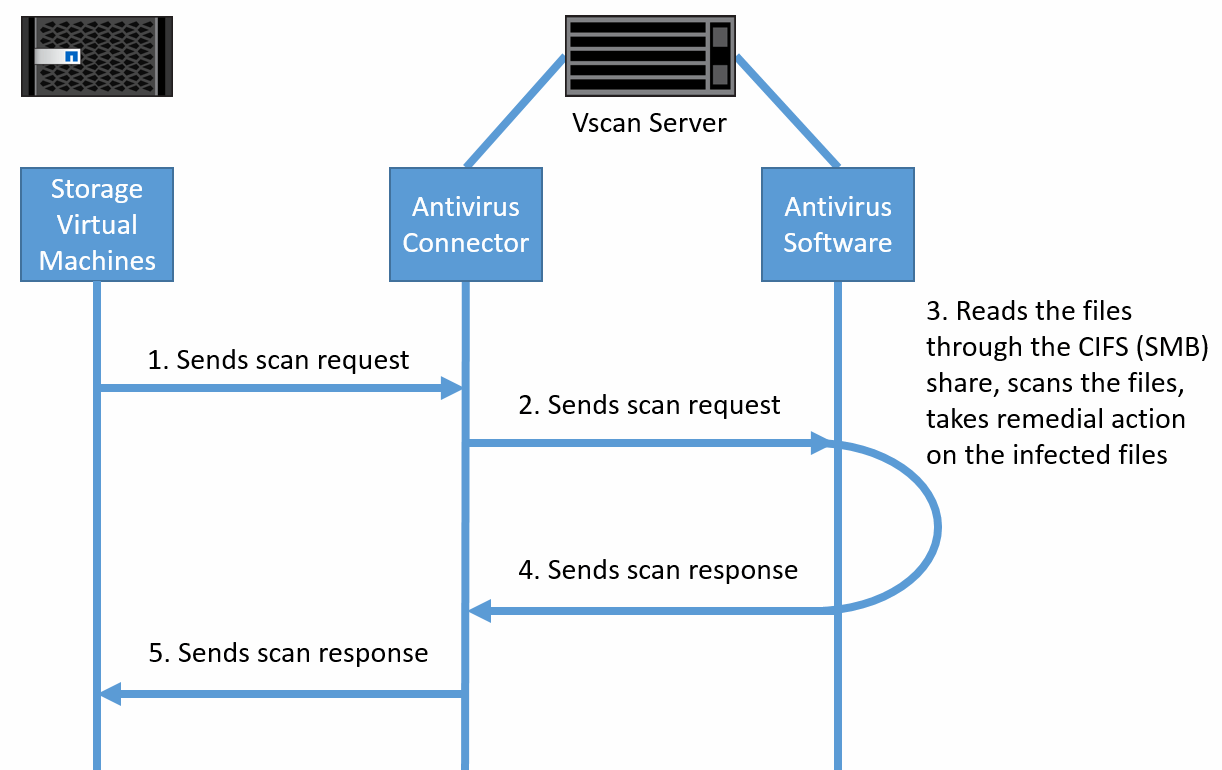
Схема взаимодействия антивируса при запросе от SMB клиента к NAS.
#### Подготовка
В соответствии с нижеприведённой схемой нужно установить и настроить все компоненты ПО, для интеграции с NAS.
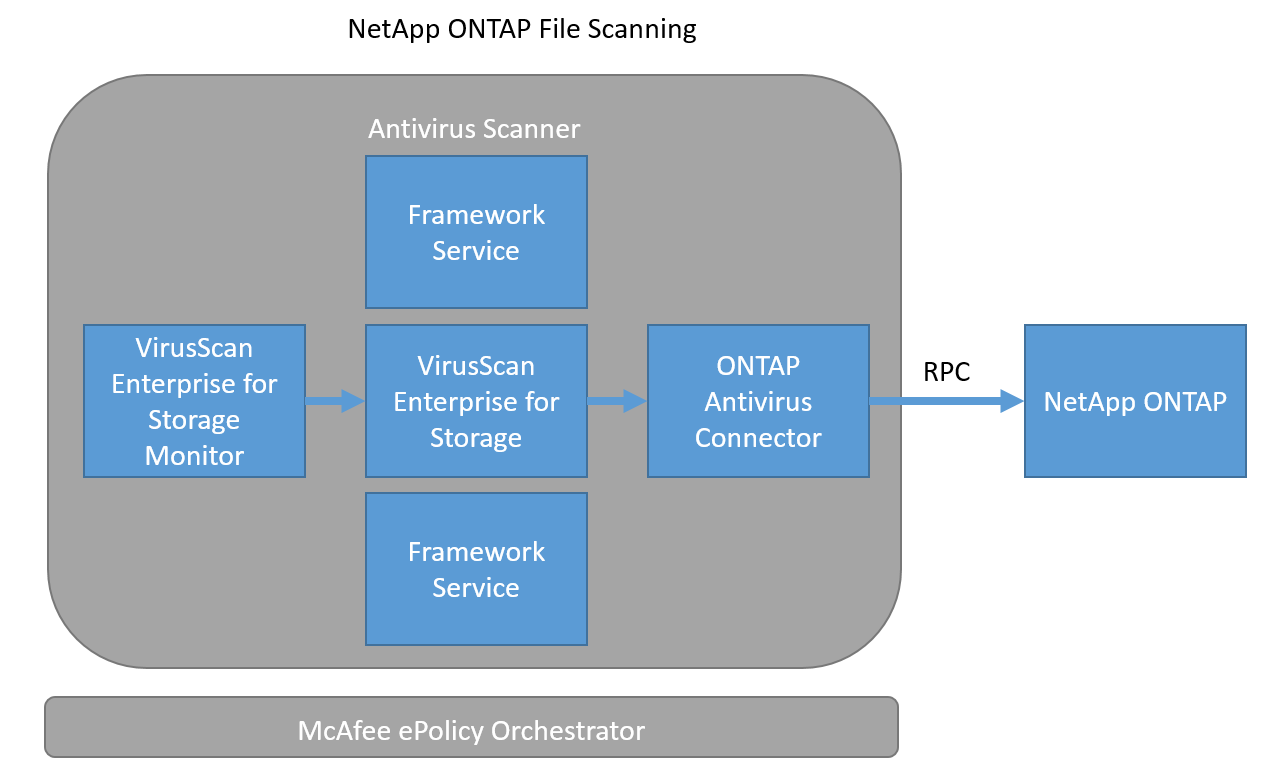
##### VSEfS
Устанавливаем McAfee VSEfS, который может работать в двух режимах: как самостоятельный продукт или как продукт, управляемый McAfee ePolicy Orchestrator (McAfee ePO). В этой статье я рассмотрю режим работы «самостоятельный продукт». Для установки McAfee VSEfS понадобится уже установленные и настроенные:
* McAfee VirusScan Enterprise (VSE). Скачать [VSE здесь](http://www.mcafee.com/us/downloads/downloads.aspx)
* McAfee ePolicy Orchestrator (ePO), не нужен если VirusScan используется как самостоятельный продукт
##### SCAN-сервер
Для начала создадим несколько SCAN серверов, чтобы балансировать нагрузку антивирусной проверки между ними. Каждый SCAN сервер будет установлен на Windows Server и включать следующие компоненты: McAfee VSE, McAfee VSEfS и ONTAP AV Connector. Для примера подготовим три таких сервера: SCAN1, SCAN2, SCAN3.
##### AD
Создаём пользователя scanuser в домене (в нашем примере домен «NetApp») с административными правами на серверах SCAN1, SCAN2, SCAN3.
##### ONTAP
Настроим ONTAP, создадим Cluster Management LIF и один VSM Management LIF. Включаем поддержку CIFS протокола и запускаем интеграцию с AD, создаём data-LIF'ы для доступа конечных пользователей к файловым шарам. Создаём файловую шару. Создадим пользователя scanuser для кластера и VSM, который будет аутентифицироваться в том же самом AD домене, что и SCANx сервера. Пускай Кластер будет доступен по менеджмент IP адресу с именем NCluster-mgmt, а менеджмент VSM IP адрес по имени VSM01-mgmt.
```
NCluster::> network interface create -vserver NCluster -home-node NCluster-01 -home-port e0M -role data -protocols none -lif NCluster-mgmt -address 10.0.0.100 -netmask 255.0.0.0
NCluster::> network interface create -vserver VSM01 -home-node NCluster-01 -home-port e0M -role data -protocols none -lif VSM01-mgmt -address 10.0.0.105 -netmask 255.0.0.0
NCluster::> domain-tunnel create -vserver VSM01
NCluster::> security login create -username netApp\scanuser -application ontapi -authmethod domain -role readonly -vserver NCluster
NCluster::> security login create -username netApp\scanuser -application ontapi -authmethod domain -role readonly -vserver VSM01
```
##### ONTAP AV Connector
на каждом SCAN-сервере устанавливаем ONTAP AV Connector и запускаем настройку, по окончанию установщика вбиваем имя пользователя и пароль:

Если при приложении говорит «Access is denied», проверьте что UAC (Use Account Control) выключен, перезагрузите компьютер.
*Start → All Programs → NetApp → ONTAP AV Connector → Configure ONTAP Management LIFs*
В поле «Management LIF» вбиваем IP или DNS имя VSM или кластера: NCluster-mgmt или VSM01-mgmt.
В поле «Account» Вбиваем имя и пароль пользователя AD домена: NetApp\scanuser. Нажимаем кнопку «Test», затем «Update» и «Save», если тест прошел удачно.
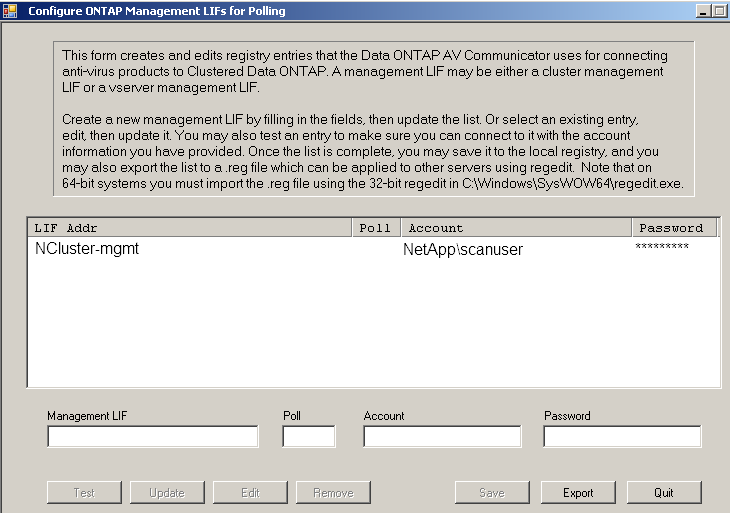
##### McAfee Network Appliance Filer AV Scanner Administrator Account
на каждом SCAN-сервере заходим как Администратора и запускаем: Windows taskbar — правой кнопкой миши на «McAfee menulet → Выбираем VirusScan консоль», в VirusScan консоли — открываем «Network Appliance Filer AV Scanner», далее идём на вкладку «Network Appliance Filer AV Scanner and Network Appliance Filers». В поле «This Server is processing scan request for these filers» создаём сервер при помощи кнопки «Add», в поле «имя сервера» вбиваем Значение «127.0.0.1» (не ONTAP!). Далее заполняем поля «Administrator Account», куда вписываем всё того же пользователя AD «scanuser», а в поле «Domain», отдельно от имени пользователя, вписываем домен, в нашем случае «NetApp».
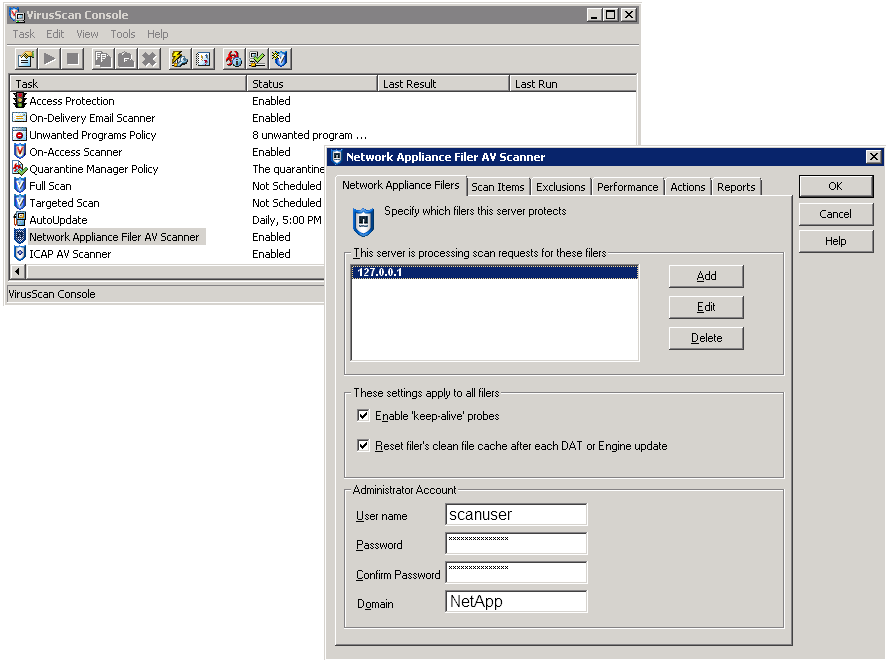
##### Возвращаемся к ONTAP
И конфигурируем интеграцию: настраиваем off-box сканирование, включаем его, создаём и применяем политику сканирования:
```
NCluster::> vserver vscan scanner-pool create -vserver VSM01 -scanner-pool POOL1 -servers SCAN1,SCAN2,SCAN3 -privileged-users NetApp\scanuser
NCluster::> vserver vscan scanner-pool show
Scanner Pool Privileged Scanner
Vserver Pool Owner Servers Users Policy
-------- ---------- ------- ------------ ------------ -------
VSM01 POOL1 vserver SCAN1, NetApp\scanuser idle
SCAN2,SCAN3
NCluster::> vserver vscan scanner-pool show -instance
Vserver: VSM01
Scanner Pool: POOL1
Applied Policy: idle
Current Status: off
Scanner Pool Config Owner: vserver
List of IPs of Allowed Vscan Servers: SCAN1, SCAN2, SCAN3
List of Privileged Users: NetApp\scanuser
NCluster::> vserver vscan scanner-pool apply-policy -vserver VSM01 -scanner-pool POOL1 -scanner-policy primary
NCluster::> vserver vscan enable -vserver VSM01
NCluster::> vserver vscan connection-status show
Connected Connected
Vserver Node Server-Count Servers
--------- -------- ------------ ------------------------
VSM01 NClusterN1 3 SCAN1, SCAN2, SCAN3
NCluster::> vserver vscan on-access-policy show
Policy Policy File-Ext Policy
Vserver Name Owner Protocol Paths Excluded Excluded Status
--------- --------- ------- -------- ---------------- ---------- ------
NCluster default_ cluster CIFS - - off
CIFS
VSM01 default_ cluster CIFS - - on
CIFS
```
#### Лицензии
Для работы FPolicy и Off-box Anti-Virus Scanning, со стороны СХД не требуется каких-либо Дополнительных лицензий, этот функционал присутствует в базовой поставке ONTAP. Со стороны ПО антивирусной защиты и ПО для расширенной работы с FPolicy могут потребоваться дополнительные лицензии, что можно уточнить у соответствующих вендоров и их партнёров-представителей.
#### Выводы
Возможность интеграции NAS с антивирусной системой позволяет с одной стороны сгрузить нагрузку конечных клиентов, но и устраняет потенциальную угрозу заражения из-за невозможности поддерживания антивирусных баз всех клиентов в актуальном состоянии. А FPolicy ограничивает запись файлов, не предназначенных для хранения в корпоративной среде.
PS
Также обратите внимание на документ описывающий [настройки безопасности ONTAP для усиления защиты (Security Hardening Guide for NetApp ONTAP 9)](http://www.netapp.com/us/media/tr-4569.pdf).
Перевод на английский:
**[ONTAP & Antivirus NAS protection](https://wp.me/p9LTcx-2d)**
**Здесь могут содержаться ссылки на Habra-статьи, которые будут опубликованы позже**.
**Сообщения по ошибкам в тексте прошу направлять в ЛС**.
**Замечания, дополнения и вопросы по статье напротив, прошу в комментарии**. | https://habr.com/ru/post/280666/ | null | ru | null |
# UB-2017. Часть 1
**От переводчика:***Переводы статьи про неопределённое поведение в языке C от Криса Латтнера, одного из ведущих разработчиков проекта LLVM, вызвали большой интерес, и даже некоторое непонимание со стороны тех, кто не встречался с описываемыми явлениями на практике. В своей статье Крис даёт ссылку на блог Джона Реджера, и на его статью от 2010 года, посвящённую UB в C и C++. Но в блоге Реджера есть и гораздо более новые статьи на эту тему (что не отменяет ценность старых, однако).
Я хочу предложить вашему вниманию свежую статью «Undefined Behavior in 2017». Статья в оригинале имеет очень большой объём, и я разбил её на части.
В первой части речь пойдёт о разных инструментах поиска UB: ASan, UBSan, TSan и т.д.
**ASan** — Address Sanitizer от компании Google, разработанный на основе LLVM.
**UBSan** — Undefined Behavior Sanitizer, предназначен для обнаружения различных UB в программах на C и C++, доступен для Clang и GCC.
**TSan** — Thread Sanitizer, предназначен для обнаружения UB в многопоточных программах.
Если вам эта тема покажется далёкой от практики, я рекомендую дождаться продолжения, потому что в конце вас ждёт поистине огромный список UB языка С++ (их должно быть около 200!)
И я рекомендую прочитать также старые статьи Реджера, они не утратили актуальности.
Об авторе: Джон Реджер является профессором Computer Science в университете штата Юта в США.*
Мы часто слышим, что некоторые люди утверждают, что проблемы, вытекающие из неопределённого поведения (UB) в C и C++ в основном решены путём широкого распространения инструментов динамической проверки, таких, как ASan, UBSan, MSan и TSan. Мы здесь покажем очевидное: несмотря на то, что в последние годы произошло множество прекрасных улучшений в этих инструментах, проблемы UB далеки от разрешения, и рассмотрим ситуацию в деталях.

Valgrind и большинство санитайзеров предназначены для отладки: они генерируют дружественные диагностические сообщения, относящиеся к случаям неопределённого поведения, произошедшим во время тестирования. Такие инструменты исключительно полезны и помогают нам развиваться от состояния мира, в котором почти каждая нетривиальная программа на C и C++ выполняется как непрерывный поток UB к состоянию мира, в котором существенное количество важных программ в основном свободны от UB в своих самых распространённых конфигурациях и вариантах использования.
Проблема с инструментами динамической отладки заключается в том, что они ничего не делают, чтобы помочь нам справиться с самыми плохими случаями UB: про которые нам неизвестно, как они сработают при тестировании, но кто-то другой может выяснить, как UB будет проявляться в релизе и использовать его как уязвимость. Проблема сводится к качественному тестированию, что сложно. Инструменты, такие, как afl-fuzz хороши, но они вряд ли даже начали затрагивать большие программы. Один из способов для того, чтобы обойти проблему тестирования, заключается в том, чтобы использовать статические инструменты обнаружения UB. Они непрерывно совершенствуются, но уверенный и точный статический анализ не обязательно проще сделать, чем достичь хорошего тестового покрытия. Конечно, две этих техники направлены на решение одной проблемы, идентификации возможных путей исполнения программы, но с разных сторон. Эта проблема всегда была очень сложна, и, возможно, всегда таковой будет. Было написано очень много о нахождении UB путём статического анализа, в этой статье мы сфокусируемся на на динамических инструментах. Другой путь решения проблемы тестирования — это использования инструментов «смягчения» UB: они превращают неопределённое поведение в определённое при использовании C и C++, эффективно достигая некоторых преимуществ использования безопасных языков программирования. Трудности в проектировании инструментов, «смягчающих» UB, следующие:
— не сломать код в «краевых» случаях (corner cases)
— иметь низкие накладные расходы
— не добавлять дополнительных уязвимостей, например, требуя линковки с непроверенной рантайм-библиотекой
— затруднять возможность атаки
— сочетаться друг с другом (в противоположность, некоторые инструменты отладки, такие, как ASan и TSan, не совместимы, и требуют двух запусков тестового набора для проекта, в котором нужны оба инструмента).
Прежде, чем рассматривать отдельные случаи UB, давайте определим наши цели. Они применимы к любому компилятору C и C++.
**Цель 1:** каждый случай UB (да, их около 200, мы приведем полный список в конце) должен либо быть документирован, как имеющий определённое поведение, либо диагностироваться компилятором как фатальная ошибка, либо, как последнее средство, иметь санитайзер, который обнаруживает UB в рантайме. Это не должно вызывать споров, это как бы минимальное требование для разработки на C и C++ в современном мире, где сетевые пакеты и оптимизации компилятора могут быть использованы злоумышленниками.
**Цель 2:** каждый случай UB должен быть либо документирован, либо диагностироваться компилятором как фатальная ошибка, либо иметь опциональный механизм «смягчения», удовлетворяющий предыдущим требованиям. Это сложнее. Мы полагаем, что это может быть достигнуто на многих платформах. Ядра операционных систем и другой код, для которого быстродействие является критически важным, нуждается в использовании других технологий, таких, как формальные методы. В оставшейся части статьи мы рассмотрим текущую ситуацию для различных классов неопределённого поведения.
Начнём с большого класса UB.
#### Нарушения безопасности пространства памяти (Spatial Memory Safety Violations)
**Описание:** Доступ за пределы хранилища и даже создание таких указателей является UB в C и C++. В 1988 году червь Морриса намекнул на то, что нас ожидает в следующие N лет. Как мы знаем, N >= 29, и возможно, значение N достигнет 75.
**Отладка:** Valgrind и ASan являются отличными инструментами отладки. Во многих случаях ASan лучше, потому что вносит меньшие накладные расходы. Оба инструмента представляют адреса как 32- или 64-битные значения, и резервируют запретную красную зону вокруг валидных блоков. Это надёжный подход, он позволяет бесшовно работать с обычными бинарными библиотеками, на использующими данный инструмент, и также поддерживает обычный код, в котором есть операции преобразования указателей в целые.
Valgrind работает из исполняемого кода, не может вставлять красные зоны между стековыми переменными, т.к. размещение объектов на стеке уже закодировано в значениях смещения в инструкциях, обращающихся к стеку, и невозможно поменять адреса обращения к стеку «на лету». В результате, Valgrind имеет ограниченную поддержку в обнаружении ошибок с манипуляцией объектов на стеке. ASan работает во время компиляции и вставляет красные зоны вокруг стековых переменных. Стековые переменные малы и многочисленны, и адресное пространство и соображения локальности предотвращают использование очень больших красных зон. С дефолтными настройками, адреса двух смежных локальных целых переменных x и y будут разделены шестнадцатью байтами. Другими словами, верификации, производимые ASan и Valgrind касаются только размещения объектов в памяти, и размещение объектов при включенной верификации отличается от размещения объектов без применения инструментов верификации.
Некоторый недостаток ASan и Valgrind заключается в том, что они могут пропустить UB, если какой-то код был удалён оптимизатором, и не может быть запущен, как в примере.
**Смягчение**: У нас давно есть механизм смягчения для небезопасных операций с памятью, включая ASLR, «стековые канарейки», «защищённые аллокаторы», и NX-биты.
**ASLR***рандомизация размещения адресного пространства (Address space layout randomization) — технология, применяемая в операционных системах, при использовании которой случайным образом изменяется расположение в адресном пространстве процесса важных структур данных, а именно образов исполняемого файла, подгружаемых библиотек, кучи и стека.
<https://en.wikipedia.org/wiki/Address_space_layout_randomization>
Прим. перев.*
**стековые канарейки***«стековые канарейки» (stack canary) — название происходит от канарейки, которую брали с собой шахтёры, чтобы заметить повышенную концентрацию рудничного газа.
Метод защиты от атаки переполнением буфера, при котором перед адресом возврата в стековом фрейме записывается «канареечное значение». Любая попытка переписать адрес, используя переполнение буфера приведёт к тому, что канареечное значение будет переписано и переполнение буфера будет обнаружено.
Прим. перев.*
**защищённые аллокаторы***«защищённые аллокаторы» (hardened allocators) — аллокаторы памяти в LLVM, предназначенные для дополнительного смягчения уязвимостей, связанных с динамически распределяемой памятью. Подробнее см.: <https://llvm.org/docs/ScudoHardenedAllocator.html>
Прим. перев.*
**NX bit***NX bit — Атрибут (бит) NX-Bit (англ. no execute bit) — бит запрета исполнения, добавленный в страницы для реализации возможности предотвращения выполнения данных как кода. Используется для предотвращения уязвимости типа «переполнение буфера». Подробнее см.: <https://en.wikipedia.org/wiki/NX_bit>
Прим. перев.*
Позднее стали доступны production-grade CFI (контроль целостности потока управления). Другая интересная недавняя разработка — это идентификация указателей в ARMv8.3. В этой статье даётся обзор средств смягчения UB, связанных с безопасностью памяти.
Серьёзный недостаток ASan как средства смягчения UB показан здесь:
```
$ cat asan-defeat.c
#include
#include
#include
char a[128];
char b[128];
int main(int argc, char \*argv[]) {
strcpy(a + atoi(argv[1]), "owned.");
printf("%s\n", b);
return 0;
}
$ clang-4.0 -O asan-defeat.c
$ ./a.out 128
owned.
$ clang-4.0 -O -fsanitize=address -fno-common asan-defeat.c
$ ./a.out 160
owned.
$
```
Другими словами, ASan просто заставит атакующего вычислить другое смещение для того, чтобы испортить нужный регион памяти. (Спасибо Юрию Грибову за то, что подсказал, что нужно использовать -fno-common flag в ASan.)
Для того, чтобы смягчить этот вариант неопределённого поведения, должна производиться реальная проверка выхода за границы, а не простая проверка того, что каждый доступ к памяти происходит в валидном регионе. Безопасность памяти является здесь золотым стандартом. Хотя существует много академических работ по безопасности памяти, и некоторые демонстрируют подходы с приемлемыми накладными расходами и хорошей совместимостью с существующим ПО, они не получили широкого распространения. Checked Cis — очень крутой проект в этой области.
**Заключение:**Инструменты отладки для ошибок такого рода очень хороши. Возможно существенно смягчить этот тип UB, но для того, чтобы полностью его устранить, понадобится полная безопасность типов и памяти.
#### Нарушение безопасности временных объектов памяти (Temporal Memory Safety Violations)
**Описание:** Нарушение безопасности временных объектов памяти — это любое использование локации памяти после истечения её времени жизни. Сюда включается адресация автоматических переменных вне области жизни этих переменных, использование после освобождения, использование «висячего» указателя (dangling pointer) для чтения или записи, двойное освобождение, которое может быть очень опасно на практике, т.к. free() изменяет метаданные, которые обычно принадлежат освобождаемому блоку. Если блок уже освобождён, запись в эти данные может повредить данные, используемые для других целей, и, в принципе, может иметь такие же последствия, как любая другая невалидная запись.
**Отладка:**ASan разработан для обнаружения багов «использование после освобождения», которые часто приводят к трудновоспроизводимому, ошибочному поведению. Он делает такую проверку, помещая освобождённые блоки в «карантин», предотвращая их немедленное переиспользование. Для некоторых программ и входных данных это может увеличить потребление памяти и снизить локальность. Пользователь может сконфигурировать размер карантина, чтобы найти компромисс между ложноположительными срабатываниями и использованием ресурсов.
ASan также может обнаруживать адреса автоматических переменных, переживших область видимости этих переменных. Идея состоит в том, чтобы превратить автоматические переменные в блоки, аллоцируемые в динамической памяти, которые компилятор автоматически аллоцирует, когда исполнение заходит в блок, и освобождает (оставляя при этом в карантине), когда исполнение покидает блок. Эта опция выключена по умолчанию, так как желает программу ещё более прожорливой в смысле памяти.
Нарушение безопасности временных объектов памяти в программе ниже вызывает разницу в поведении при дефолтной оптимизации и при -O2. ASan может обнаружить проблему в программе без оптимизации, но только если установлена опция detect\_stack\_use\_after\_return, и только если не была скомпилирована с оптимизацией.
```
$ cat temporal.c
#include
int \*G;
int f(void) {
int l = 1;
int res = \*G;
G = &l
return res;
}
int main(void) {
int x = 2;
G = &x
f();
printf("%d\n", f());
}
$ clang -Wall -fsanitize=address temporal.c
$ ./a.out
1
$ ASAN\_OPTIONS=detect\_stack\_use\_after\_return=1 ./a.out
=================================================================
==5425==ERROR: AddressSanitizer: stack-use-after-return ...
READ of size 4 at 0x0001035b6060 thread T0
^C
$ clang -Wall -fsanitize=address -O2 temporal.c
$ ./a.out
32767
$ ASAN\_OPTIONS=detect\_stack\_use\_after\_return=1 ./a.out
32767
$ clang -v
Apple LLVM version 8.0.0 (clang-800.0.42.1)
...
```
В некоторых других примерах санитайзер не может обнаружить UB, которое было удалено оптимизатором, и, таким образом, является безопасным, так как удалённый код с UB не может иметь последствий. Но здесь не такой случай! Программа бессмысленна в любом случае, но неоптимизированная программа работает детерминированно, как если бы переменная x была объявлена статической, тогда как оптимизированная программа, в которой ASan не нашёл ничего подозрительного, не ведёт себя детерминированно и раскрывает внутреннее состояние, не предназначенное для того, чтобы его можно было увидеть:
```
$ clang -Wall -O2 temporal.c
$ ./a.out
1620344886
$ ./a.out
1734516790
$ ./a.out
1777709110
```
**Смягчение:** Как обсуждалось выше, ASan не предназначен для защиты от уязвимостей, но различные защищённые аллокаторы доступны, и используют ту же стратегию карантина для того, чтобы закрыть уязвимость «использование после освобождения».
**Заключение:** Использовать ASan (вместе с “ASAN\_OPTIONS=detect\_stack\_use\_after\_return=1” для тестирования в небольших случаях). При разных уровнях оптимизации могут ловится ошибки, которые не будут ловиться при других уровнях.
#### Переполнение целых (Integer Overflow)
**Описание:** не бывает антипереполнения целых, но может быть переполнение в обоих направлениях. Переполнение знаковых целых, это UB, сюда включается INT\_MIN / -1, INT\_MIN % -1, минус INT\_MIN, сдвиги отрицательных чисел, сдвиг влево числа с единицей после знакового бита, а также (иногда), сдвиг влево числа с единицей в знаковом бите.
Деление на ноль и сдвиг на величину, больше разрядности числа, это UB, как для знаковых, так и для беззнаковых чисел. Также см.: [Understanding Integer Overflow in C/C++](http://www.cs.utah.edu/~regehr/papers/tosem15.pdf)
**Отладка:** UBSan — очень хороший инструмент для поиска UB, связанного с целыми числами. Так как UBSan работает на уровне исходников, он очень надёжен. Существуют некоторые странности, относящиеся к вычислениям времени компиляции, например, некоторая программа может ловить исключение, если она скомпилирована как C++11, и не ловить при компиляции в C11, мы думаем, что это соответствует стандартам, но не вдавались в подробности. У GCC есть своя версия UBSan, но ей нельзя доверять на 100%, там константы сворачиваются перед тем, как выполняется проход этого инструмента.
**Смягчение:** UBSan в «trapping mode» (когда ловится UB, процесс прекращается без вывода диагностики) может быть использован для смягчения UB. Это эффективно и не добавляет уязвимостей. Частично Android использует UBSan для смягчения этого типа UB. Хотя переполнение целых, это, в основном, логическая ошибка, в C и C++ такие ошибки особенно опасны, потому что могут привести к нарушениям безопасности памяти. В языках с безопасным доступом к памяти, они гораздо менее опасны.
**Заключение:** Целочисленное UB не очень сложно отловить, UBSan, это всё, что вам для этого нужно. Проблема в том, что смягчение целочисленного UB приводит к появлению избыточности. Например, при этом SPEC CPU 2006 выполняется на 30% медленнее. Здесь много мест для улучшения, и устранение проверок переполнения там, где оно не может повредить, и сделать остальные проверки менее мешающими для оптимизатора циклов. Кто, то, обладающий достаточными ресурсами, должен сделать это.
#### Strict Aliasing Violations
**Описание:** Правила “strict aliasing" в стандартах C и C++ позволяют компилятору позволяют компилятору предполагать, что если два указателя ссылаются на разные типы, они не указывают на один объект. Это позволяет выполнять прекрасные оптимизации, но есть риск поломать программы с более гибким взглядом на вещи (а это, по приблизительным оценкам, 100% больших программ на C и C++). Для более подробного обзора см. раздел 1-3 этой статьи (*будет опубликовано в следующей части. прим. перев.*).
**Отладка:** Текущее состояние инструментов отладки для нарушений «strict aliasing» слабое. Компиляторы выдают предупреждения в некоторых простых случаях, но эти предупреждения очень ненадёжны. libcrunch предупреждает, что указатель преобразован в тип «указатель на что-то», хотя фактически указывает на что-то другое. Это позволяет выполнять преобразования типов через указатель на void, но отлавливает неверные преобразования указателей, которые также являются этим типом UB. благодаря стандарту C и тому, как компиляторы С интерпретируют, что они могут сделать при оптимизации TBAA (type-based alias analysis), libcrunch не является ни надёжным (он не отлавливает некоторые нарушения, которые происходят при выполнении программы), ни полным (он предупреждает о преобразовании указателей, если оно выглядит подозрительно, но не нарушает стандарт).
**Смягчение:** Это просто: передаёте компилятору флаг (-fno-strict-aliasing), и он отключает оптимизацию, основанную на strict aliasing. В результате компилятор опирается на старую добрую модель памяти, где могут выполняться более или менее произвольные преобразования между типами указателей, и результирующий код ведёт себя, как ожидалось. Из «большой тройки», такому UB подвержены только GCC и LLVM, MSVC не реализует такой класс оптимизаций.
**Заключение:** Чувствительный к данному UB код нуждается в тщательной проверке: всегда подозрительно и опасно преобразовывать указатели во что-то, кроме char \*. Как альтернатива, можно просто выключить оптимизацию TBAA, используя флаг, и убедившись, что никто не скомпилирует код без использования этого флага.
#### Нарушение выравнивания (Alignment Violations)
**Описание:** RISC-процессоры имеют тенденцию запрещать доступ к памяти по невыровненным адресам. С другой стороны, программы C и C++, с использованием невыровненного доступа, имеют UB, вне зависимости от целевой архитектуры. Исторически мы смотрели на это сквозь пальцы, вначале потому, что x86/x64 поддерживает невыровненный доступ, во-вторых, потому, что компиляторы до сих пор не использовали это UB для оптимизаций. Но и в этом случае, есть [прекрасная статья](https://pzemtsov.github.io/2016/11/06/bug-story-alignment-on-x86.html), объясняющая, как компилятор может сломать код с невыровненным доступом на x64. Код в статье нарушает strict aliasing, в добавок к нарушению выравнивания, и падает (проверялось на GCC 7.1.0 в OS X), несмотря на флаг -fno-strict-aliasing.
**Отладка:** UBSan может обнаруживать нарушения выравнивания.
**Смягчение:** неизвестно
**Заключение:** используйте UBSan
#### Циклы, не выполняющие операций ввода-вывода и не завершающиеся (Loops that Neither Perform I/O nor Terminate)
**Описание:** Циклы в коде C или C++, не выполняющие операций ввода-вывода и не завершающиеся, являются неопределёнными и могут быть произвольно завершены компилятором. См. [эту статью](https://blog.regehr.org/archives/140) и [эту заметку](http://www.open-std.org/jtc1/sc22/wg14/www/docs/n1528.htm).
**Отладка:** нет инструментальных средств
**Смягчение:** Нет, кроме избегания слишком сильно оптимизирующих компиляторов.
**Заключение:** Это UB не является проблемой практического характера (даже если и неприятно для кого-то из нас).
#### Состязания данных (Data Races)
**Описание:** состязания данных происходят, когда участок памяти доступен более чем одному потоку, и как минимум одному из них — на запись, и доступ не синхронизирован механизмами типа блокировок. Состязания данных приводят к UB в современных версиях C и C++ (они не имеют смысла в старых версиях, так как эти стандарты не описывали многопоточный код).
**Прим. перев.***Здесь я не соглашусь с автором, так как многопоточный код мог быть запущен с помощью API операционной системы, такого, как, например, POSIX Threads, и это можно сделать в любых версиях C и C++, неважно, насколько старых. Также код, обрабатывающий прерывания в микроконтроллере, может приводить к аналогичным эффектам при совместном доступе к данным с основным циклом программы. Это также не зависит от года стандарта C и С++. Прим. перев.*
**Описание:** TSan — прекрасный детектор динамических состязаний памяти. Существуют другие похожие инструменты, такие, как плагин Helgrind для Valgrind, но мы их не использовали в последнее время. Использование детекторов динамических состязаний осложняется фактом, что состязание очень трудно заставить сработать, и хуже всего то, что их срабатывание зависит от количества ядер, алгоритма планировщика потоков, от того, что ещё запущено на тестовой машине, от фаз луны и т.д.
**Смягчение:** не создавайте потоков
**Заключение:** Для этого конкретного UB есть хорошая идея: если вам не нравятся объекты блокировки, то не используйте код, выпоняющийся параллельно, используйте вместо него атомарные действия.
#### Модификации с нарушением точек следования (Unsequenced Modifications)
**Описание:** В С, «точка следования» ограничивает то, насколько рано или поздно выражение с побочным эффектом, такое, как x++, возымеет эффект. C++ имеет другую, но более-менее эквивалентную формулировку этого правила. В обоих языках, модификации с нарушением точек следования приводят к UB.
**Отладка:** некоторые компиляторы генерируют предупреждение при очевидных нарушениях правил следования:
```
$ cat unsequenced2.c
int a;
int foo(void) {
return a++ - a++;
}
$ clang -c unsequenced2.c
unsequenced2.c:4:11: warning: multiple unsequenced modifications to 'a' [-Wunsequenced]
return a++ - a++;
^ ~~
1 warning generated.
$ gcc-7 -c unsequenced2.c -Wall
unsequenced2.c: In function 'foo':
unsequenced2.c:4:11: warning: operation on 'a' may be undefined [-Wsequence-point]
return a++ - a++;
~^~
```
Однако, небольшое косвенное нарушение не вызывает предупреждений:
```
$ cat unsequenced.c
#include
int main(void) {
int z = 0, \*p = &z
\*p += z++;
printf("%d\n", z);
return 0;
}
$ gcc-4.8 -Wall unsequenced.c ; ./a.out
0
$ gcc-7 -Wall unsequenced.c ; ./a.out
1
$ clang -Wall unsequenced.c ; ./a.out
1
```
**Смягчение:** Неизвестно, однако можно почти тривиально определить порядок, в котором будут выполняться побочные эффекты. Язык Java является примером того, как это делается. У нас был трудный период, когда мы верили, что такое ограничение помешает любому современному оптимизирующему компилятору. Если комитет по стандартизации поверит от всего сердца, что это не так, разработчики компиляторов должны будут следовать правилам. В идеале, все основные компиляторы должны в таких случаях поступать одинаково.
**Заключение:** С некоторой практикой, не очень сложно заметить потенциальное нарушение точек следования при кодревью. Мы должны беспокоиться при виде очень сложных выражений с побочными эффектами. Это бывает в легаси-коде, но посмотрите, он же до сих пор работает, значит, возможно, это не проблема. На самом деле, эта проблема должна быть исправлена в компиляторах.
Не-UB, относящееся к нарушениям точек следования является «неопределённой последовательностью» (indeterminately sequenced), в которой операторы могут выполняться в порядке, задаваемом компилятором. Примером служит порядок вызова двух функций при вычислении f(a(), b()). Этот порядок должен быть определён тоже. Слева направо, например. Здесь не будет никаких потерь быстродействия, если не рассматривать совсем безумные ситуации.
*Продолжение следует.* | https://habr.com/ru/post/341694/ | null | ru | null |
# Нативный — не значит быстрый. Обгоняем map, filter и reduce на больших массивах

Несколько дней назад я выкладывал пост [LINQ на JavaScript для самых маленьких](https://habr.com/ru/post/514716/). Но моя библиотека сильно уступала по производительности нативным методам и [Lodash](https://lodash.com/). В общем-то, сейчас мы будем менять ситуацию.
Скажу сразу: в статье не будет каких-либо откровений, мы не будем строить безумные алгоритмы и т. д. Мы просто сравним производительность разных конструкций языка.
Когда я впервые выложил свою библиотеку в публичный доступ, у меня стоял вопрос лишь о том, чтобы удешевить итерацию нативного метода. Я старался облегчить callback, потому что у меня даже не возникало мысли, что map, filter или reduce могут быть даже чуточку медленнее, чем скорость света.
Прежде чем мы приступим
=======================

### Поговорим о статистике
Мы будем проводить замеры следующих методов:
* Нативный метод
* Аналог написанный с помощью for of
* Аналог написанный с помощью for
* Аналогичный метод из библиотеки [Lodash](https://lodash.com/)
* Аналогичный метод из моей собственной библиотеки [ursus-utilus-collections](https://github.com/afferenslucem/ursus-utilus-collections)
> Ахтунг!
>
>
>
> Если вы посмотрите исходники, то увидите, что методы из моей библиотеки основаны сугубо на конструкции for.
>
> Но я привожу здесь код с ними сугубо для того, чтобы ~~похвастаться~~ вы могли оценить как влияют на производительность дополнительные слои абстракции.
За замер производительности у нас будет отвечать [Benchmark.js](https://benchmarkjs.com). Каждый пример проходил замеры 10 раз на массиве размером в 10,000,000 элементов.
Среда выполнения: Node.js.
Так с входными данными разобрались, теперь давайте обсудим то, что будет на выходе.
Я буду приводить пример кода и его **наиболее средний** бенчмарк.
В конце раздела я приведу таблицу с наиболее полной статистикой: с межквартильным средним и с медианным бенчмарками. И приведу весь бенчмарк-лог.
Приступим
=========

Filter
------
Для замера производительности мы будем отфильтровывать все нечетные числа:
```
const filterCondition = (item: number) => !!(item % 2);
```
### Нативная фильтрация
```
array.filter(filterCondition);
```
> Benchmark
>
> native filter x 3.58 ops/sec ±5.48% (13 runs sampled)
---
### For of
```
const result = [];
for(let item of array) {
if(filterCondition(item)) {
result.push(item)
}
}
```
> Benchmark
>
> for… of x 3.48 ops/sec ±3.46% (14 runs sampled)
Внимание, for of почти не уступает про производительности нативной фильтрации, но дальше — больше.
---
### For
```
filterSuite.add('for', () => {
const result = [];
for(let i = 0; i < array.length; i++) {
const item = array[i]
if(filterCondition(item)) {
result.push(item)
}
}
})
```
> Benchmark
>
> for x 6.92 ops/sec ±5.47% (20 runs sampled)
Обычный for обгоняет filter в **2 раза**.
---
### Lodash
**Перейдем к игрокам на поле абстракций:**
```
lodash(array).filter(filterCondition).value();
```
> Benchmark
>
> lodash filter x 3.60 ops/sec ±4.13% (13 runs sampled)
Lodash по производительности не уступает filter.
---
### Моя библиотека
```
ursus(array).where(filterCondition).toArray();
```
> Benchmark
>
> ursus where x 6.87 ops/sec ±4.86% (20 runs sampled)
Моя реализация фильтра ± равна for, но незначительно медленнее.
---
### Итоги
**Benchmark log**
```
lodash filter x 3.75 ops/sec ±4.09% (13 runs sampled)
native filter x 3.35 ops/sec ±7.99% (13 runs sampled)
for ... of x 3.38 ops/sec ±3.88% (13 runs sampled)
for x 6.04 ops/sec ±3.54% (20 runs sampled)
optimized for x 5.82 ops/sec ±3.05% (20 runs sampled)
ursus where x 5.83 ops/sec ±4.62% (21 runs sampled)
lodash filter x 3.37 ops/sec ±3.40% (13 runs sampled)
native filter x 3.33 ops/sec ±4.76% (13 runs sampled)
for ... of x 3.86 ops/sec ±9.36% (14 runs sampled)
for x 6.92 ops/sec ±5.47% (20 runs sampled)
optimized for x 6.96 ops/sec ±4.22% (20 runs sampled)
ursus where x 6.71 ops/sec ±4.75% (19 runs sampled)
lodash filter x 3.51 ops/sec ±4.94% (13 runs sampled)
native filter x 3.72 ops/sec ±0.74% (13 runs sampled)
for ... of x 3.54 ops/sec ±2.14% (14 runs sampled)
for x 6.84 ops/sec ±4.60% (20 runs sampled)
optimized for x 6.85 ops/sec ±3.58% (19 runs sampled)
ursus where x 6.46 ops/sec ±11.83% (20 runs sampled)
lodash filter x 3.55 ops/sec ±6.26% (13 runs sampled)
native filter x 3.66 ops/sec ±3.06% (13 runs sampled)
for ... of x 3.41 ops/sec ±4.28% (14 runs sampled)
for x 6.95 ops/sec ±3.85% (20 runs sampled)
optimized for x 6.79 ops/sec ±4.33% (20 runs sampled)
ursus where x 7.17 ops/sec ±3.29% (21 runs sampled)
lodash filter x 3.63 ops/sec ±3.38% (13 runs sampled)
native filter x 3.63 ops/sec ±3.35% (13 runs sampled)
for ... of x 3.44 ops/sec ±3.99% (14 runs sampled)
for x 6.89 ops/sec ±4.53% (20 runs sampled)
optimized for x 6.95 ops/sec ±3.17% (20 runs sampled)
ursus where x 6.87 ops/sec ±4.86% (20 runs sampled)
lodash filter x 3.60 ops/sec ±4.13% (13 runs sampled)
native filter x 3.58 ops/sec ±5.48% (13 runs sampled)
for ... of x 3.48 ops/sec ±3.46% (14 runs sampled)
for x 6.95 ops/sec ±3.73% (20 runs sampled)
optimized for x 6.78 ops/sec ±5.62% (20 runs sampled)
ursus where x 7.17 ops/sec ±3.79% (21 runs sampled)
lodash filter x 3.64 ops/sec ±4.11% (13 runs sampled)
native filter x 3.63 ops/sec ±3.35% (13 runs sampled)
for ... of x 3.55 ops/sec ±2.36% (14 runs sampled)
for x 6.91 ops/sec ±4.51% (20 runs sampled)
optimized for x 6.89 ops/sec ±3.76% (20 runs sampled)
ursus where x 7.03 ops/sec ±4.84% (21 runs sampled)
lodash filter x 3.59 ops/sec ±4.17% (13 runs sampled)
native filter x 3.60 ops/sec ±3.14% (13 runs sampled)
for ... of x 3.45 ops/sec ±4.69% (14 runs sampled)
for x 7.09 ops/sec ±2.65% (20 runs sampled)
optimized for x 6.81 ops/sec ±2.90% (20 runs sampled)
ursus where x 7.15 ops/sec ±2.60% (21 runs sampled)
lodash filter x 3.60 ops/sec ±5.57% (13 runs sampled)
native filter x 3.60 ops/sec ±4.55% (13 runs sampled)
for ... of x 3.39 ops/sec ±7.33% (13 runs sampled)
for x 5.71 ops/sec ±2.74% (19 runs sampled)
optimized for x 5.85 ops/sec ±2.70% (20 runs sampled)
ursus where x 6.10 ops/sec ±2.43% (21 runs sampled)
lodash filter x 3.18 ops/sec ±5.88% (13 runs sampled)
native filter x 3.34 ops/sec ±4.43% (13 runs sampled)
for ... of x 3.89 ops/sec ±6.84% (14 runs sampled)
for x 7.09 ops/sec ±2.79% (21 runs sampled)
optimized for x 6.70 ops/sec ±3.32% (20 runs sampled)
ursus where x 7.07 ops/sec ±4.02% (20 runs sampled)
```
| | Межкв. Среднее | Медиана |
| --- | --- | --- |
| filter | 3,57 ops/sec | 3,60 ops/sec |
| for | 3,48 ops/sec | 3,47 ops/sec |
| for of | 6,91 ops/sec | 6,92 ops/sec |
| lodash | 3,58 ops/sec | 3,60 ops/sec |
| ursus | 6,88 ops/sec | 6,95 ops/sec |
#### Результаты гонки:
1) For
2) Ursus
3) Lodash
4) Filter
5) For of
Map
---
Для тестирования мы будем прибавлять ко всем числам **+1**
```
const mapCondition = (item: number) => item + 1;
```
### Нативное отображение
```
array.map(mapCondition);
```
> Benchmark
>
> native map x 0.68 ops/sec ±3.60% (6 runs sampled)
---
### For of
```
const result = [];
for(let item of array) {
result.push(mapCondition(item))
}
```
> Benchmark
>
> for… of x 2.19 ops/sec ±3.47% (10 runs sampled)
В случае отображения for of обгоняет нативный метод в **3 раза**.
---
### For
```
const result = [];
for(let i = 0; i < array.length; i++) {
result.push(mapCondition(array[i]))
}
```
> Benchmark
>
> for x 3.49 ops/sec ±6.82% (12 runs sampled)
Классический for обгоняет нативный метод в **5 раз**.
---
### Lodash
```
lodash(array).map(mapCondition).value();
```
> Benchmark
>
> lodash map x 5.78 ops/sec ±9.03% (18 runs sampled)
Lodash обходит всех в **9 раз**!
> Честно, разработчики какие-то волшебники, я не представляю как они такого добились.
---
### Моя библиотека
```
ursus(array).select(mapCondition).toArray();
```
> Benchmark
>
> ursus select x 3.54 ops/sec ±5.71% (13 runs sampled)
Каким-то образом моя реализация чуточку быстрее чем просто for, на котором она основана. ¯\_(ツ)\_/¯
### Итоги
**Benchmark log**
```
lodash map x 6.08 ops/sec ±4.84% (19 runs sampled)
native map x 0.57 ops/sec ±17.60% (6 runs sampled)
for ... of x 1.91 ops/sec ±13.65% (9 runs sampled)
for x 3.51 ops/sec ±5.25% (13 runs sampled)
optimized for x 3.62 ops/sec ±7.49% (13 runs sampled)
ursus select x 3.29 ops/sec ±9.24% (13 runs sampled)
lodash map x 5.59 ops/sec ±10.61% (19 runs sampled)
native map x 0.61 ops/sec ±11.70% (6 runs sampled)
for ... of x 2.30 ops/sec ±2.13% (10 runs sampled)
for x 3.72 ops/sec ±4.39% (13 runs sampled)
optimized for x 3.58 ops/sec ±5.24% (13 runs sampled)
ursus select x 3.58 ops/sec ±5.21% (13 runs sampled)
lodash map x 6.06 ops/sec ±5.23% (19 runs sampled)
native map x 0.68 ops/sec ±3.60% (6 runs sampled)
for ... of x 2.27 ops/sec ±3.49% (10 runs sampled)
for x 3.45 ops/sec ±10.41% (13 runs sampled)
optimized for x 3.59 ops/sec ±4.29% (13 runs sampled)
ursus select x 3.54 ops/sec ±6.08% (12 runs sampled)
lodash map x 5.81 ops/sec ±7.23% (19 runs sampled)
native map x 0.68 ops/sec ±3.63% (6 runs sampled)
for ... of x 2.31 ops/sec ±7.11% (10 runs sampled)
for x 3.62 ops/sec ±4.74% (13 runs sampled)
optimized for x 3.45 ops/sec ±6.67% (13 runs sampled)
ursus select x 3.64 ops/sec ±4.42% (13 runs sampled)
lodash map x 6.03 ops/sec ±5.26% (20 runs sampled)
native map x 0.69 ops/sec ±6.27% (6 runs sampled)
for ... of x 2.12 ops/sec ±8.87% (10 runs sampled)
for x 3.29 ops/sec ±9.33% (13 runs sampled)
optimized for x 3.53 ops/sec ±5.18% (13 runs sampled)
ursus select x 3.66 ops/sec ±4.03% (13 runs sampled)
lodash map x 5.78 ops/sec ±9.03% (18 runs sampled)
native map x 0.65 ops/sec ±6.52% (6 runs sampled)
for ... of x 2.07 ops/sec ±7.41% (10 runs sampled)
for x 3.49 ops/sec ±6.82% (12 runs sampled)
optimized for x 3.50 ops/sec ±5.93% (13 runs sampled)
ursus select x 3.54 ops/sec ±5.71% (13 runs sampled)
lodash map x 5.68 ops/sec ±8.47% (18 runs sampled)
native map x 0.67 ops/sec ±6.40% (6 runs sampled)
for ... of x 2.11 ops/sec ±5.06% (10 runs sampled)
for x 3.52 ops/sec ±5.58% (13 runs sampled)
optimized for x 3.29 ops/sec ±5.51% (13 runs sampled)
ursus select x 3.38 ops/sec ±5.31% (13 runs sampled)
lodash map x 6.37 ops/sec ±3.10% (19 runs sampled)
native map x 0.67 ops/sec ±2.43% (6 runs sampled)
for ... of x 2.19 ops/sec ±3.47% (10 runs sampled)
for x 3.41 ops/sec ±8.13% (13 runs sampled)
optimized for x 3.54 ops/sec ±5.15% (13 runs sampled)
ursus select x 3.53 ops/sec ±6.28% (13 runs sampled)
lodash map x 5.85 ops/sec ±11.04% (19 runs sampled)
native map x 0.66 ops/sec ±4.30% (6 runs sampled)
for ... of x 2.20 ops/sec ±2.97% (10 runs sampled)
for x 3.45 ops/sec ±8.03% (13 runs sampled)
optimized for x 3.48 ops/sec ±5.13% (13 runs sampled)
ursus select x 3.68 ops/sec ±3.33% (13 runs sampled)
lodash map x 5.31 ops/sec ±12.87% (18 runs sampled)
native map x 0.68 ops/sec ±4.26% (6 runs sampled)
for ... of x 2.11 ops/sec ±6.97% (10 runs sampled)
for x 3.35 ops/sec ±6.12% (13 runs sampled)
optimized for x 3.38 ops/sec ±5.55% (13 runs sampled)
ursus select x 3.54 ops/sec ±6.20% (13 runs sampled)
```
| | Межкв. Среднее | Медиана |
| --- | --- | --- |
| map | 0.67 ops/sec | 0.67 ops/sec |
| for | 2.17 ops/sec | 2.16 ops/sec |
| for of | 3.47 ops/sec | 3.47 ops/sec |
| lodash | 5.79 ops/sec | 5.80 ops/sec |
| ursus | 3.56 ops/sec | 3.54 ops/sec |
#### Результаты гонки:
1) Lodash
2) Ursus
3) For
4) For of
5) Map
Reduce
------
Свертку мы будем тестировать на суммировании элементов
```
const sumCondition = (item1: number, item2: number) => item1 + item2;
```
### Нативная свертка
```
array.reduce(sumCondition);
```
> Benchmark
>
> native reduce x 6.09 ops/sec ±9.13% (20 runs sampled)
---
### For of
> Пропускает гонку, так как я не придумал как его можно приладить без операций с массивом. А с ними замеры уже будут не такие объективные.
---
### For
```
let result = array[0];
for(let i = 1; i < array.length; i++) {
result = sumCondition(result, array[i])
}
```
> Benchmark
>
> for x 57.01 ops/sec ±2.53% (59 runs sampled)
For обходит нативный метод почти в **10 раз**!
---
### Lodash
```
lodash(array).sum();
```
> Benchmark
>
> lodash sum x 8.30 ops/sec ±7.79% (25 runs sampled)
А вот lodash подкачал, он почти такой же, как и reduce.
---
### Моя библиотека
```
ursus(array).sum(sumCondition);
```
> Benchmark
>
> ursus sum x 56.12 ops/sec ±2.38% (58 runs sampled)
### Итоги
**Benchmark log**
```
lodash sum x 8.60 ops/sec ±4.35% (25 runs sampled)
native reduce x 6.69 ops/sec ±3.73% (21 runs sampled)
for x 68.67 ops/sec ±3.41% (70 runs sampled)
optimized for x 70.75 ops/sec ±2.63% (72 runs sampled)
ursus sum x 67.78 ops/sec ±3.12% (70 runs sampled)
lodash sum x 9.00 ops/sec ±3.93% (26 runs sampled)
native reduce x 5.47 ops/sec ±21.31% (19 runs sampled)
for x 56.61 ops/sec ±2.70% (59 runs sampled)
optimized for x 56.85 ops/sec ±2.27% (59 runs sampled)
ursus sum x 56.08 ops/sec ±2.40% (59 runs sampled)
lodash sum x 8.69 ops/sec ±3.36% (26 runs sampled)
native reduce x 6.09 ops/sec ±9.13% (20 runs sampled)
for x 57.01 ops/sec ±2.53% (59 runs sampled)
optimized for x 57.38 ops/sec ±2.64% (60 runs sampled)
ursus sum x 56.12 ops/sec ±2.38% (58 runs sampled)
lodash sum x 8.68 ops/sec ±4.11% (26 runs sampled)
native reduce x 6.06 ops/sec ±9.39% (19 runs sampled)
for x 69.97 ops/sec ±2.82% (71 runs sampled)
optimized for x 66.55 ops/sec ±4.16% (68 runs sampled)
ursus sum x 69.29 ops/sec ±2.73% (71 runs sampled)
lodash sum x 7.86 ops/sec ±8.39% (24 runs sampled)
native reduce x 6.35 ops/sec ±4.79% (20 runs sampled)
for x 55.91 ops/sec ±5.01% (58 runs sampled)
optimized for x 56.41 ops/sec ±2.70% (59 runs sampled)
ursus sum x 57.11 ops/sec ±2.16% (58 runs sampled)
lodash sum x 8.11 ops/sec ±4.72% (24 runs sampled)
native reduce x 5.97 ops/sec ±7.80% (20 runs sampled)
for x 56.43 ops/sec ±3.62% (59 runs sampled)
optimized for x 56.87 ops/sec ±3.75% (59 runs sampled)
ursus sum x 55.37 ops/sec ±3.60% (58 runs sampled)
lodash sum x 8.52 ops/sec ±6.70% (25 runs sampled)
native reduce x 6.12 ops/sec ±7.39% (20 runs sampled)
for x 57.96 ops/sec ±3.50% (58 runs sampled)
optimized for x 55.19 ops/sec ±5.32% (59 runs sampled)
ursus sum x 56.75 ops/sec ±3.33% (58 runs sampled)
lodash sum x 8.00 ops/sec ±8.94% (25 runs sampled)
native reduce x 5.75 ops/sec ±6.95% (19 runs sampled)
for x 56.78 ops/sec ±4.21% (57 runs sampled)
optimized for x 56.89 ops/sec ±2.32% (60 runs sampled)
ursus sum x 54.61 ops/sec ±7.04% (57 runs sampled)
lodash sum x 8.11 ops/sec ±8.83% (24 runs sampled)
native reduce x 5.97 ops/sec ±7.84% (19 runs sampled)
for x 57.32 ops/sec ±4.17% (59 runs sampled)
optimized for x 55.97 ops/sec ±4.18% (59 runs sampled)
ursus sum x 55.76 ops/sec ±3.90% (58 runs sampled)
lodash sum x 8.30 ops/sec ±7.79% (25 runs sampled)
native reduce x 6.31 ops/sec ±5.42% (20 runs sampled)
for x 55.45 ops/sec ±5.56% (58 runs sampled)
optimized for x 57.54 ops/sec ±3.52% (59 runs sampled)
ursus sum x 55.22 ops/sec ±4.34% (57 runs sampled)
```
| | Межкв. Среднее | Медиана |
| --- | --- | --- |
| reduce | 6.09 ops/sec | 6.08 ops/sec |
| for | 57.02 ops/sec | 56.90 ops/sec |
| lodash | 8.39 ops/sec | 8.41 ops/sec |
| ursus | 56.20 ops/sec | 56.10 ops/sec |
#### Результаты гонки:
1) For
2) Ursus
3) Lodash
4) Reduce
Заключение
==========
Как вы могли увидеть, на 10 миллионном массиве нативные реализации работают в разы медленнее, чем for и библиотечные реализации.
> В общем-то, нативная реализация начинает обгонять lodash на 50k элементов в массиве и меньше.
>
>
>
> А на 25k начинает обгонять даже for.
На мой взгляд, в целом, получился довольно любопытный эксперимент, но имея теперь такую информацию, на большом количестве элементов я пожалуй буду, как минимум, проверять производительность нативных реализаций.
Спасибо за внимание! | https://habr.com/ru/post/516034/ | null | ru | null |
# Коммуникационный виджет от 3CX для вашего сайта Wordpress
Представляем новый коммуникационный виджет для вашего сайта Wordpress от создателей АТС 3CX!
При входе на сайт, у посетителя появляется небольшой виджет (коммуникационная панель), через который клиент может общаться с сотрудниками вашей компании. Новый плагин [3CX Live Chat and Talk](https://wordpress.org/plugins/3cx-clicktotalk/) работает с [3CX v16](https://www.3cx.ru/blog/pbx-instance-manager-alpha-2/) и выше. Вызовы из плагина направляются в АТС через WebRTC (Web Real-Time Communication) шлюз, интегрированный в АТС, и совершенно бесплатны.
Возможности плагина 3CX Live Chat and Talk для Wordpress
--------------------------------------------------------
* Посетители могут общаться как в чате, так и голосом, и даже подключать видео — в один клик!
* Плагин совершенно бесплатен для вашей компании. Без подписки и каких-либо скрытых платежей. Фактически, для пользователя АТС, — это бесплатная входящая телефонная линия.
* Подключается за пару минут. Установите 3CX > Установите плагин > Общайтесь.
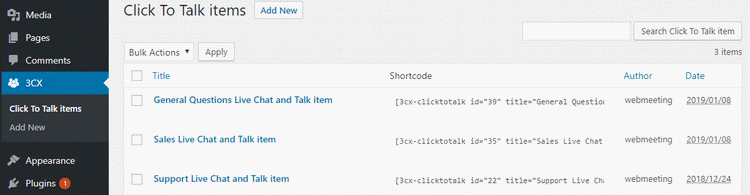
Мы постарались реализовать виджет максимально просто для посетителя — последний просто начинает чат, либо нажимает кнопку Audio или Video — и связывается с вашим сотрудником (или группой сотрудников). Никаких специальных приложений, мессенджеров, подписок на сервисы или «обратных звонков через 30 секунд» (которые часто просто не работают из-за какой-то нестыковки с сотрудником). Ваше собственное решение на вашей корпоративной АТС! И огромная экономия на номере 0800.
Основные преимущества виджета от 3CX для вашей компании:
* Простые коммуникации (консультации) с вашими сотрудниками. Одна кнопка — и сразу к продавцам.
* Быстрая коммуникация, без сбоев и с отличным качеством, не зависящим от оператора связи, делает посетителей сайта лояльнее.
* Большое число запросов теперь поддерживается обновленным сервисом Очередей в 3CX v16.
* Менеджеры по продажам могут ответить на запрос с сайта через веб-клиент 3CX или бесплатные приложения 3CX для iOS и Android.
* Возможность видеосвязи с пользователем лучше подходит для решения некоторых проблем. Особенно это актуально, если проблему проще показать, чем объяснить (медицинские проблемы, неисправности оборудования и т.п.).
* Технологическое преимущество нашего решения позволяет перевести беседу из чата в голосовое общение, а затем в видеоконсультацию.
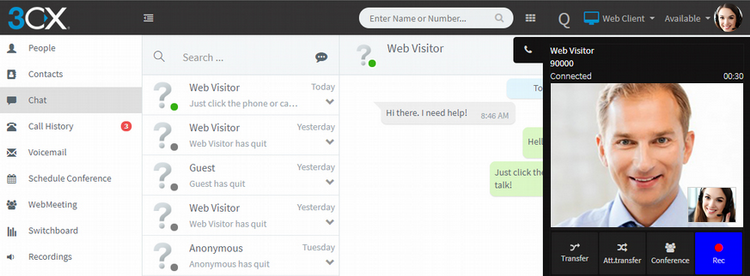
Установка и настройка плагина
-----------------------------
Для установки плагина зайдите в интерфейс управления CMS Wordpress и перейдите в раздел Plugins > Add New. Выполните поиск плагина 3CX Live Chat and Talk и нажмите Install Now. После завершения установки перейдите в интерфейс управления 3CX в раздел Settings > WordPress > Click2Talk и укажите URL вашего сайта Wordpress (например, [my-wordpress.company.com](https://my-wordpress.company.com), без "/") для авторизации коммуникаций.
Безопасность подключения реализуется параметром «Maximum allowed requests per IP Address per period», который ограничивает количество входящих, но неотвеченных чат-запросов к добавочному номеру 3CX. Параметр «Request throttle period length, seconds» указывает период в секундах, в течение которого подсчитывается количество неотвеченных чат-запросов.
### Создание объекта «Click To Talk»
После установки плагина на сайте, создайте объекты Click to Call. Они используются на определенных Страницах и Записях в блоге или на всем сайте для размещения коммуникационного виджета.
Для создания объекта Click To Talk, в панели администратора Wordpress перейдите в раздел 3CX, нажмите Add New и укажите имя объекта.
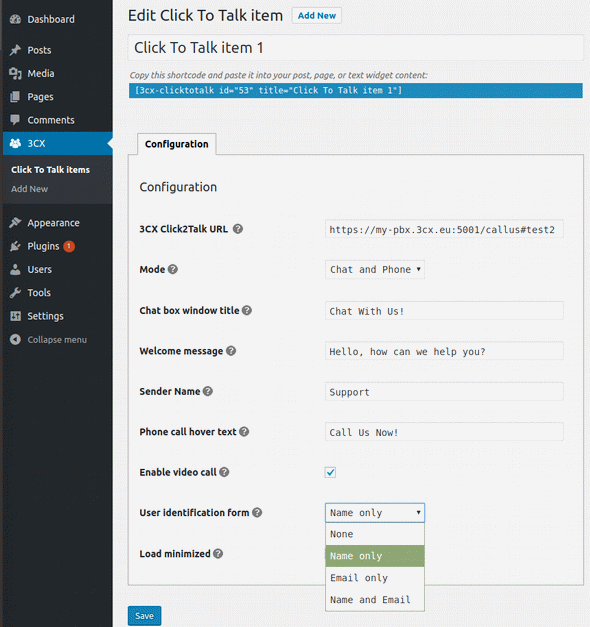
В поле 3CX Click2Talk URL укажите Click2Talk URL из секции Click2Talk/Click2Meet в параметрах добавочного номера (пользователя) 3CX или Очереди вызовов 3CX, которые будут отвечать за коммуникации с посетителями сайта.
Для кастомизации поведения и внешнего вида виджета используются следующие параметры:
* Mode — включить в виджете голосовой вызов, чат или оба способа связи.
* Chat box window title — заголовок виджета.
* Chat welcome message — приветственное сообщение, которое автоматически показывается посетителям сайта в интерфейсе виджета.
* Sender Name — имя сотрудника (пользователя 3CX), которое будет отображаться посетителям сайта при общении.
* Phone call hover text — подсказка, которая показывается посетителю при наведении на иконку телефона, если установлен только голосовой вызов.
* Enable video call — посетили будут сразу начинать видеовызов вместо аудиовызова.
* User identification form — запрос от посетителя имени и/или e-mail адреса для начала коммуникаций.
* Load minimized — показ минимизированной панели коммуникаций (виджета).
Размещение виджета на сайте Wordpress
-------------------------------------
Чтобы разместить панель коммуникаций в нужном месте сайте, скопируйте соответствующий шорткод из списка объектов Click to Talk.
Размещение на всех страницах сайта: перейдите в Appearance > Widgets и перетащите виджет Text в область виджетов, которые отображаются на всем сайте, например, в нижней части (футере) темы Wordpress. Затем добавьте шорткод, например, `[3cx-clicktotalk id="15" title="Кликните для связи"]` в область контента и нажмите Save.
Размещение на выбранных страницах: создайте Запись в блоге или Страницу, а затем добавьте шорткод в область контента. Нажмите Preview Changes, чтобы увидеть страницу со встроенным виджетом.
Текущие ограничения плагина
---------------------------
1. Видеовызовы пока не принимаются на устройствах iOS. Это будет исправлено в следующем релизе.
2. Internet Explorer не поддерживается. | https://habr.com/ru/post/436802/ | null | ru | null |
# Удобное скачивание музыки из vkontakte
**Внимание!** Статья не претендует на научное соискательство. Опубликована исключительно в целях помочь тем, кто не хочет писать код сам. Если Вы не слушаете музыку вконтакте, не пользуетесь соц. сетями и у Вас аллергия на мой говнокод код написанный студентом, Вам будет не интересно.
Примерно год назад я написал скрипт для скачивания музыки из vk, причем в нормальном качестве (хотя бы > 250 кбит/c ). Он будет полезен для тех, кто хочет скачать свой плейлист вконтакте или просто для удобного выкачивания музыки пока не поздно. Под «удобным скачиванием», на тот момент, я понимал скачивание песен являющимися саундтреками к какому-либо сериалу или фильму, скачивание по артисту и скачивание по названию. Например вводим «OST Pulp Fiction» и получаем папку с песнями из кинофильма Криминальное чтиво.
**Как появился скрипт**
Я меломан и всю музыку стараюсь хранить на домашнем компьютере. Но однажды я оказался оторван от своей домашней медиатеки. Поиски способов быстро выкачать всю музыку, которую я обычно слушаю, а также докачивать новую, привели меня к написанию скрипта. Ни о каких онлайн сервисах речи не шло, т.к. я хотел слушать музыку и оффлайн, и на смартфоне. Скрипт писал исключительно для себя, в свете недавних событий решил поделиться.
**Как использовать скрипт**
Для работы скрипта нужен Python 2.7.
Архив со скриптом можно скачать [здесь](https://github.com/c0rp-aubakirov/vkMusicDwn/archive/master.zip). Распаковываем, открываем файл vkMusicDwn.py и корректируем параметры в самом начале файла.
```
# Path to download folder
dpath = '/music/'
### This block uncommented if you want put email and
### password from keyboard
email = raw_input("Email: ")
password = getpass.getpass()
### This block for static email and password
###
#email = 'email'
#password = 'password'
bitrate = 230
```
**dpath** Папка куда будет скачиваться музыка.
**email** Ваш логин
**password** Ваш пароль
**bitrate** Минимальный битрейт
Если не хотите каждый раз вводить логин и пароль можно раскомментировать блок " ### This block for static email and password ", и ввести свой логин и пароль.
Не забудьте закомментировать блок "### This block uncommented if you want put email and". Авторизатор взят [отсюда.](http://habrahabr.ru/post/143972/)
Запускаем скрипт.
```
user@user:$ python vkMusicDwn.py.
```
**Как работает скрипт**
Фильтрация песен.
* Песня должна весить не больше 23 Мегабайт и битрейт должен быть выше 230. Если нет — песня попадает в список плохих песен
* Из названия файла убираются все лишние слова и символы. Скрипт скачивает песни, и сохраняет их в виде «Artist — Title.mp3»
* Для всех песен из плохого списка повторяется операция поиска
У скрипта есть 2 основных режима работы.
* Скачивание плейлиста пользователя
* Скачивание песен по введенной строке
В первом случае все понятно. После запуска и ввода логина\ пароля будет задан вопрос:
```
Download users playlist? ( yes/no ):
```
Отвечаем 'yes' и скрипт будет пытаться выкачать всю музыку из вашего плейлиста.
Во втором случае Вы отвечаете 'no' и вводите что хотите найти, какое количество песен скачать, и какое смещение (offset) сделать относительно поисковой выдачи vkontakte. К примеру захотелось освоить группу Metallica.
```
What do want to find: Metallica
How many songs do want to download: 10
Put offset: 0
```
Скачиваем песни группы Metallica, 10 штук, смещение 0. Позже, если группа понравилась вводим те же параметры, но смещение ставим 10. В результате скрипт докачает следующие 10 песен из поисковой выдачи.
Позже пытался прикрутить какой-нибудь интерефейс, но к сожалению времени не хватает. Как говорят нет ничего более постоянного, чем временное.
[Сслыка](https://github.com/c0rp-aubakirov/vkMusicDwn) на github.com.
Буду рад любой конструктивной критике, особенно относительно кода.
**Update** Спасибо [scorched](http://habrahabr.ru/users/scorched/) за сообщения об ошибках. Исправил проблему с закачиванием своего плейлиста. | https://habr.com/ru/post/183852/ | null | ru | null |
# Муравьиная оптимизация и сетевые алгоритмы
Как вы могли заметить, у нас тут затишье. Но наш творческий поиск не прекращается, и первая октябрьская публикация будет посвящена ACO (Ant Colony Optimization)

Отдавая должное автору, мы не будем публиковать здесь последнюю часть статьи, содержащую пример на JavaScript, а предложим вам опробовать его на сайте оригинала. Под катом же вы найдете перевод теоретической части, доступно рассказывающей о тонкостях муравьиной оптимизации в различных сценариях.
Оптимизация по алгоритму муравьиной колонии (ACO) была впервые предложена Марко Дориго в 1992 году. Эта техника оптимизации строится на основании той стратегии, которой придерживаются муравьи, прокладывая путь в поисках пищи. Кроме того, ACO — это частный случай роевого интеллекта. Роевой интеллект — это разновидность искусственного интеллекта, где для решения задач применяется децентрализованное коллективное поведение. Муравьиные алгоритмы шире всего применяются для комбинаторной оптимизации, например, при решении задачи коммивояжера, хотя они применимы и в качестве разнообразных решений в области планирования и маршрутизации.
Важное преимущество муравьиных алгоритмов по сравнению с другими алгоритмами оптимизации — это присущая им возможность адаптации к динамическим средам. Именно поэтому они столь незаменимы при сетевой маршрутизации, где обычны частые изменения, к которым приходится приспосабливаться.
**Муравьи в природе**
Чтобы полностью понять ACO, важно хорошо представлять себе поведение муравьев в природе, которое и послужило основой для алгоритма.
При поисках пищи муравьи следуют сравнительно простому набору правил. При всей простоте эти правила позволяют муравьям коммуницировать и совместно оптимизировать пути к добыче. Одно из основных свойств всех этих правил — это использование феромонных следов. Именно при помощи феромонов одни муравьи сообщают другим, где найдена пища, и как к ней попасть. Как правило, если муравей набредает на феромонный след, то может рассчитывать, что по нему он найдет пищу. Однако муравьи не бегут по первому попавшемуся феромонному следу. В зависимости от его пахучести муравей может отправиться по другой дорожке или вообще избрать случайный путь, где никакого феромона нет. В среднем же, чем сильнее пахнет феромонный след, тем вероятнее, что муравей решит на него свернуть.
Со временем феромонный след постепенно улетучивается, если другие муравьи не обновляют его. Таким образом, феромонные следы, не ведущие к еде, рано или поздно забрасываются, и муравьям приходится прокладывать новые маршруты к новым источникам пищи.
Чтобы понять, как этот процесс развивается со временем, и как колония оптимизирует собственное поведение, рассмотрим следующий пример:

Это путь, по которому муравей отправился к пище. С нашей точки зрения, этот путь явно не оптимален, хотя и возможен. Но здесь начинается самое интересное. Далее другие муравьи из той же колонии натыкаются на феромонный след первого. Большинство из них следуют по исходному маршруту, но некоторые избирают другой, более прямой путь:

Хотя первый феромонный след в данной точке может быть более пахуч, начинает развиваться и второй след — соответствующий той дорожке, на которую случайно сворачивают некоторые муравьи. В этом сценарии важно, что второй путь предпочтительнее, поскольку избравшие его насекомые добегут до пищи и достанут ее быстрее, чем муравьи, последовавшие по первому пути. Например, один муравей может потратить 3 минуты, чтобы добежать по первой дорожке от муравейника до источника пищи и обратно, но другой муравей за то же время пробежит по другому маршруту вдвое быстрее и, соответственно, успеет оставить там два феромонных следа. По этой причине краткий путь вскоре становится более пахучим, чем первый. Соответственно, первый след используется все реже, пока, наконец, не исчезает, а остается только новый, более короткий путь.

Именно по этой причине самые густые феромонные следы обычно откладываются по самым выгодным маршрутам, которые постепенно становятся предпочтительными для всех муравьев из данного муравейника.
Вкратце отметим, что это — упрощенная картина поведения муравьев в природе; кроме того, разные виды муравьев пользуются феромонами немного по-своему.
**Алгоритм**
В этой статье будет рассмотрено применение алгоритма ACO для решения задачи коммивояжера. Если вы пока не знакомы с сутью этой задачи, отсылаем вас к статье [Applying a genetic algorithm to the traveling salesman problem](http://www.theprojectspot.com/tutorial-post/applying-a-genetic-algorithm-to-the-travelling-salesman-problem/5).
Основная часть алгоритма ACO состоит всего из нескольких этапов. Во-первых, каждый муравей из колонии выстраивает решение, исходя из имеющихся феромонных следов. Далее муравьи оставляют следы по отрезкам выбранного маршрута, в зависимости от качества выработанного решения. В примере с задачей коммивояжера это были бы ребра (или отрезки пути между городами). Наконец, когда все муравьи завершат прокладку маршрута и феромонных следов, феромон начинает стабильно испаряться на каждом отрезке. Затем такая последовательность этапов многократно прогоняется до получения адекватного решения.
***Разработка решения***
Как было указано выше, при прокладке маршрута муравей обычно бежит по самому пахучему феромонному следу. Однако если муравей начинает рассматривать иные решения, кроме того, которое в данный момент считается оптимальным, то в процесс принятия решения привносится доля случайности. Вдобавок рассчитывается и учитывается эвристическая ценность решений, благодаря чему поиск развивается в сторону оптимальных вариантов. В примере с задачей коммивояжера эвристика обычно связана с длиной ребра до следующего города, в который планируется попасть. Чем короче ребро, тем вероятнее, что маршрут продолжится по нему.
Рассмотрим, как это реализуется математически:
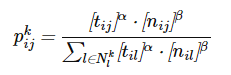
В данном уравнении вычисляется вероятность выбора конкретного компонента решения. Здесь tij означает количество феромона на отрезке между состояниями i и j, а nij — его эвристическую ценность. α и β — параметры, при помощи которых контролируется важность феромонного следа и эвристическая информация при выборе компонента.
В коде эту информацию принято выражать как выбор в стиле рулеточного алгоритма:
```
rouletteWheel = 0
states = ant.getUnvisitedStates()
for newState in states do
rouletteWheel += Math.pow(getPheromone(state, newState), getParam('alpha'))
* Math.pow(calcHeuristicValue(state, newState), getParam('beta'))
end for
randomValue = random()
wheelPosition = 0
for newState in states do
wheelPosition += Math.pow(getPheromone(state, newState), getParam('alpha'))
* Math.pow(calcHeuristicValue(state, newState), getParam('beta'))
if wheelPosition >= randomValue do
return newState
end for
```
В контексте задачи коммивояжера состояние соответствует конкретному городу в графе. В нашем случае муравей будет выбирать следующий пункт в зависимости от расстояния, которое придется преодолеть, и от количества феромона на данном отрезке.
**Локальное обновление феромона**
Процесс локального обновления феромона задействуется всякий раз, когда муравей получает успешное решение. Данный шаг имитирует прокладку феромонных следов, оставляемых муравьями в природе на пути к пище. Как вы помните из вышесказанного, в природе наиболее успешные маршруты получают больше всего феромонов, поскольку преодолеваются муравьями быстрее. В ACO эта характеристика воспроизводится так: количество феромона на отрезке пути будет варьироваться в зависимости от того, насколько успешно то или иное решение. Если взять для примера задачу коммивояжера, то феромон откладывался бы на дорогах между городами в зависимости от общей дистанции.
На схеме показаны феромонные следы, оставляемые на отрезках между точками («городами») в типичной задаче коммивояжера.
Прежде чем рассмотреть реализацию в коде, обратимся к математике:
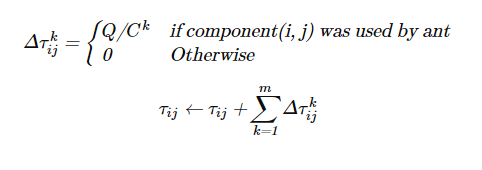
Здесь Ck определяется как общая стоимость решения, в задаче коммивояжера это была бы общая длина пути. Q — просто параметр, помогающий откорректировать количество оставляемого феромона, обычно он задается равным 1. Мы суммируем Q/Ck для каждого решения, использовавшего компонент(i, j), затем это значение принимается за количество феромона, которое будет оставлено на компонент(i, j).
Чтобы прояснить ситуацию, давайте рассмотрим простой пример данного процесса применительно к задаче коммивояжера…

Здесь мы имеем типичный граф из задачи коммивояжера и хотим рассчитать, сколько феромона должно быть на отрезке A. Предположим, что по этому ребру при прокладке маршрутов прошли три муравья. Также допустим, что общие длины трех маршрутов получились такими:
*Tour 1: 450
Tour 2: 380
Tour 1: 460*
Чтобы вычислить, сколько феромона должно быть на каждом из них, просто суммируем:
`componentNewPheromone = (Q / 450) + (Q / 380) + (Q / 460)`
Затем приплюсуем это значение к имеющемуся значению феромона на отрезке:
`componentPheromone = componentPheromone + componentNewPheromone`
Теперь — простой пример с кодом:
```
for ant in colony do
tour = ant.getTour();
pheromoneToAdd = getParam('Q') / tour.distance();
for cityIndex in tour do
if lastCity(cityIndex) do
edge = getEdge(cityIndex, 0)
else do
edge = getEdge(cityIndex, cityIndex+1)
end if
currentPheromone = edge.getPheromone();
edge.setPheromone(currentPheromone + pheromoneToAdd)
end for
end for
```
В данном примере мы просто перебираем маршруты всей колонии, извлекая каждый маршрут и применяя феромонное значение к каждому ребру маршрута.
***Глобальное обновление феромона***
Глобальное обновление феромона — это этап, на котором феромон улетучивается с отрезков пути. Данный этап применяется после каждой итерации алгоритма, когда каждый муравей успешно выстроил маршрут и применил правило локального обновления.
Глобальное обновление феромона математически описывается так:
*τij←(1−ρ)⋅τij*
где τij – это феромон на отрезке, пролегающем между состояниями i и j, а ρ – параметр, при помощи которого корректируется скорость улетучивания.
В коде ситуацию можно представить так:
```
for edge in edges
updatedPheromone = (1 - getParam('rho')) * edge.getPheromone()
edge.setPheromone(updatedPheromone)
end for
```
**Оптимизация**
Алгоритм ACO допускает много вариантов оптимизации, важнейшие из которых — элитарная (elitist) и MaxMin. В зависимости от задачи эти вариации вполне могут оказаться более работоспособными, чем стандартная система ACO, рассмотренная выше. К счастью, нам не составит труда расширить алгоритм так, чтобы он учитывал две эти модификации.
***Элитарная разновидность***
В элитарных ACO-системах наиболее успешная вереница муравьев, а также наиболее результативный муравей из всех на этапе локального обновления оставляют чуть больше феромона, чем все остальные. Поэтому колония адаптирует принимаемые решения по образцу тех, которые обладают наилучшей историей достижений. Если все идет нормально, то качество поиска при этом повышается.
С математической точки зрения элитарная процедура локального обновления практически аналогична обычной, с одним небольшим дополнением:

Где e — параметр, используемый для коррекции дополнительного объема феромона, откладываемого при наилучшем (или «элитарном») решении.
***MaxMin***
Алгоритм MaxMin напоминает элитарный вариант ACO в том, что отдает приоритет «высокорейтинговым» решениям. Однако MaxMin не просто присваивает дополнительный вес элитарным решениям, но разрешает оставлять феромонный след лишь самой работоспособной веренице, соответствующей наилучшему глобальному решению. Кроме того, MaxMin требует, чтобы феромонные следы укладывались в диапазоне между определенным минимальным и максимальным значением. В основе алгоритма лежит идея о том, что если количество феромона на любой конкретной дорожке относится к определенному диапазону, то удастся избежать преждевременного схождения на неоптимальных решениях.
Во многих реализациях MaxMin наиболее успешным считается тот муравей, который оставляет феромонные следы. Затем этот алгоритм видоизменяется таким образом, что возможность оставлять след сохраняется только у «глобально» лучшего муравья. Этот процесс стимулирует такой поиск, который изначально распределен по всему имеющемуся пространству, но впоследствии сосредотачивается на оптимальных маршрутах, допуская, возможно, минимальные поправки.
Наконец, минимальное и максимальное значение можно либо передавать в виде параметров, либо адаптивно устанавливать в коде.
Интересное практическое решение TSP на JavaScript — на [сайте](http://www.theprojectspot.com/tutorial-post/ant-colony-optimization-for-hackers/10) автора | https://habr.com/ru/post/268513/ | null | ru | null |
# Voila: из ноутбука в веб-приложение
Исходники: <https://github.com/voila-dashboards/voila>Документация: <https://voila.readthedocs.io/en/stable/>Галерея: <https://voila-gallery.org/>
Voilà это библиотека, которая позволяет превращать Jupyter Notebook’и в интерактивные веб-приложения и дашборды. В основном это требуется чтобы продемонстрировать вашу работу сторонним людям или предоставить им какой-либо сервис.
Основной конкурент Voilà – Streamlit. Но у них разные подходы. В то время как для стримлита нужно писать отдельное приложение, “вуаля” (так читается Voilà) работает непосредственно с кодом ноутбука и “конвертирует” его в веб-приложение, используя при этом возможности заложенные в них. И хотя в среднем Streamlit выглядит красивее, сила Voilà в простоте и скорости “разработки” (хотя и Voilà можно кастомизировать почти к любому виду).
> В отличие от статичных HTML-страниц, экспортированных из ноутбуков, в Voilà каждый пользователь, получает выделенное ядро Jupyter, которое и позволяет использовать интерактивные элементы.
>
>
Установка и запуск
------------------
Для установки выполните в консоли команду:
```
pip install voila
```
Запустить Voilà можно тремя способами:
#### Как отдельное приложение
Выполните в консоли подобную команду:
```
voila
```
Откроется веб-страница с отрендеренным ноутбуком.
Если просто выполнить в консоли команду `voila`, то отобразится список всех ноутов в текущей (для консоли) папке. Щелкните по какому-либо ноутбуку чтобы отрендерить его.
#### К часть Jupyter-сервера
Запустите/откройте ваш юпитер сервер. Допишите к базовому URL "суффикс" */voila*:
```
/voila
```
Вам отобразится список всех ноутбуков - щелкните по одному из них, чтобы отрендерить.
#### Кнопка
Самый простой запустить Voilà – по кнопке из интерфейса ноутбука.
З.Ы. Для диагностики ошибок Voilà можно запустить в режиме отладки:
```
voila .ipynb --debug
```
Использование
-------------
А теперь посмотрим как работать с Voilà. Тут все подходы можно разделить на три крупных блока…
### Статика
Тут все просто. Все статичные картинки и текст отображаются как есть, ничего изобретать не нужно. Например:
> Везде где текст и заголовки тип ячейки нужно перевести в тип Markdown
>
>
```
> Ячейка_1
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
> Ячейка_2 (Markdown)
Какой-то текст..
> Ячейка_3 (Markdown)
## Таблица
> Ячейка_4
df = load_iris(as_frame=True)['frame']
df
> Ячейка_5 (Markdown)
## График
> Ячейка_6
plt.figure(figsize=(11,6));
sns.scatterplot(
data=df,
x='petal width (cm)',
y='petal length (cm)',
hue='target',
palette='jet_r'
);
```
### Интерактивные интерфейсы
Ряд библиотек и инструментов Python имеют встроенные интерактивные элементы, которые не нужно никак (по умолчанию) настраивать и которые работают как есть в интерфейсе Voilà. Например Plotly, Bokeh, Folium, KeplerGL и многие другие. Задействуем парочку их них...
Интерактивный график на основе Plotly:
```
import plotly.graph_objects as go
import pandas as pd
df = pd.read_csv('biocon.csv')
fig1 = go.Figure(data=[go.Candlestick(
x=df['Date'],
open=df['Open'],
high=df['High'],
low=df['Low'],
close=df['Close'])])
fig1.show()
```
Интерактивная карта на основе Folium:
```
import folium
from branca.element import Figure
fig = Figure(width=800, height=500)
m = folium.Map(location=[55.5236, 52.6750],width=800,height=500)
fig.add_child(m)
```
### Виджеты
Если же вы хотите какой-то кастомный функционал, то вам потребуется виджеты. В частности библиотека ipywidgets, которая входит в экосистему юпитера. В документации ipywidgets довольно подробно описаны все ее виджеты: <https://ipywidgets.readthedocs.io/en/7.x/examples/Widget%20List.html>
Сначала сделаем интерактивный EDA – будем выбирать поля для графика из ниспадающих списков:
```
> Ячейка_1
from ipywidgets import interact, FloatSlider
from sklearn.ensemble import RandomForestClassifier
import numpy as np
import warnings
warnings.filterwarnings('ignore')
> Ячейка_2
df = load_iris(as_frame=True)['frame']
X = df.drop(columns='target')
y = df['target']
> Ячейка_3
def get_graf(select_x, select_y):
df0 = go.Scatter(
x=df.query('target == 0')[select_x],
y=df.query('target == 0')[select_y],
mode='markers',
name='0')
df1= go.Scatter(
x=df.query('target == 1')[select_x],
y=df.query('target == 1')[select_y],
mode='markers',
name='1')
df3 = go.Scatter(
x=df.query('target == 2')[select_x],
y=df.query('target == 2')[select_y],
mode='markers',
name='2')
g = go.FigureWidget(
data=[df0, df1, df3],
layout=go.Layout(
title={
'text': 'Iris Measurements',
'y':0.85,
'x':0.5,
'xanchor': 'center',
'yanchor': 'top'},
xaxis_title=select_x,
yaxis_title=select_y,
legend_title = 'Iris Species'
))
g.show()
select_x = Dropdown(
options=list(X.columns), layout=Layout(width = '160px'))
select_y = Dropdown(
options=list(X.columns[::-1]), layout=Layout(width = '160px'))
ui = HBox([select_x, select_y])
out = interactive_output(
get_graf, {'select_x': select_x, 'select_y': select_y})
display(ui, out)
```
Предположим, мы обучили модель и хотим показать как она делает предсказания:
```
> Ячейка_2
model = RandomForestClassifier()
model.fit(X, y);
> Ячейка_3
def get_pred(sepal_length, sepal_width, petal_length, petal_width):
sample = [sepal_length,sepal_width,petal_length,petal_width]
pred_class = model.predict(np.array([sample]))[0]
out = Output(layout={'border': '1px solid white'})
with out:
display(HTML(value=f'**Класс - {pred\_class}**'))
return out
interact(
get_pred,
sepal_length = FloatSlider(
min = 4.0, max = 8.0, step = 0.1, description = 'Sepal length'),
sepal_width = FloatSlider(
min = 1.8, max = 4.6, step = 0.1, description = 'Sepal width'),
petal_length = FloatSlider(
min = 0.8, max = 7, step = 0.1, description = 'Petal length'),
petal_width = FloatSlider(
min = 0.0, max = 2.8, step = 0.1, description = 'Petal width')
);
```
Кастомизация
------------
Базовая визуализация Voilà выглядит довольно просто. Но Voilà поддерживает несколько методов кастомизации.
**Темы** – позволяют вам вносить простые изменения в отображение, такие как изменение цвета, отступы и прочее. Запускать так:
```
voila .ipynb --theme=dark
```
**Шаблоны** – посредством библиотеки nbconvert и шаблонов Jinja, ноутбуки можно конвертировать в сложные дашборады, с паралельным расположением ячеек и прочим наворотами. Указать шаблон при запуске можно так:
```
voila .ipynb --template=gridstack
```
Более подробно о содании тем и шаблонов (а также про другие настройки) читайте в документации: <https://voila.readthedocs.io/en/stable/customize.html>
> Обратите внимание на функционал горячих ядер, который позволяет ускорить загрузку приложений.
>
>
Публикация приложений
---------------------
В документации Voilà описано развертывание с помощью трех публичных сервисов: Binder, Heroku иr GCP App Engine. Помимо этого вы можете опубликовать Voilà на своем собственном сервер или с помощью утилиты ngrok.
Более подробно читайте в: <https://voila.readthedocs.io/en/stable/deploy.html#cloud-service-providers>
Что дальше…
-----------
Можете ознакомиться с галереей примеров, созданных с помощью виджетов Voilà и Jupyter: <https://voila-gallery.org>. Большинство примеров основаны на библиотеках ipywidgets, ipyleaflet, ipyvolume, bqplot and ipympl и демонстрируют, как создавать сложные веб-приложения, полностью основанные на блокнотах.
На гите также есть папка с примерами (только не забудьте установить необходимые библиотеки из requirements): <https://github.com/voila-dashboards/voila/tree/main/notebooks>
----------------
[Мой телеграм-канал](https://t.me/ds_private_sharing) | https://habr.com/ru/post/698662/ | null | ru | null |
# Номинативная типизация в TypeScript или как защитить свой интерфейс от чужих идентификаторов

Недавно, изучая причины некорректной работы своего домашнего проекта, я в очередной раз заметил за собой ошибку, которая часто повторяется из-за усталости. Суть ошибки сводится к тому, что, имея в одном блоке кода несколько идентификаторов, при вызове некоторой функции я передаю идентификатор объекта другого типа. В данной статья я расскажу о том, как решить эту проблему средствами TypeScript.
Немного теории
--------------
TypeScript основан на структурной типизации, что хорошо ложится на утиную идеологию JavaScript. Об этом написано достаточной статей. Я не буду их повторять, лишь обозначу основное отличие от номинативной типизации, которая более распространена в других языках. Разберем небольшой пример.
```
class Car {
id: number;
numberOfWheels: number;
move (x: number, y: number) {
// некая реализация
}
}
class Boat {
id: number;
move (x: number, y: number) {
// некая реализация
}
}
let car: Car = new Boat(); // здесь TypeScript выдаст ошибку
let boat: Boat = new Car(); // а на этой строчке все в порядке
```
Почему TypeScript поведет себя именно так? Это как раз является проявлением структурной типизации. В отличие от номинативной, которая следит за названиями типов, структурная типизация принимает решение о совместимости типов на основе их содержимого. Класс Car содержит все свойства и методы класса Boat, поэтому Car может использоваться в качестве Boat. Обратное неверно, потому как в Boat отсутствует свойство numberOfWheels.
Типизируем идентификаторы
-------------------------
Первым делом зададим типы для идентификаторов
```
type CarId: number;
type BoatId: number;
```
и перепишем классы и использованием данных типов.
```
class Car {
id: CarId;
numberOfWheels: number;
move (x: number, y: number) {
// некая реализация
}
}
class Boat {
id: BoatId;
move (x: number, y: number) {
// некая реализация
}
}
```
Вы заметите, что ситуация не сильно изменилась, ведь мы по прежнему не имеем контроля над тем, откуда мы взяли идентификатор, и будете правы. Но этот пример уже дает некоторые преимущества.
1. В процессе разработки программы может внезапно поменяться тип идентификатора. Так, например, некоторый числовой номер автомобиля, уникальный для проекта, может быть заменен на строковой VIN номер. Без задания типа идентификатора придется во всех местах, где он встречается, заменить number на string. С заданием типа, изменение нужно будет сделать только в одном месте, где определяется сам тип.
2. При вызове функций мы получаем подсказки от нашего редактора кода, какого типа должны быть идентификаторы. Допустим у нас объявлены следующие функции:
```
function getCarById(id: CarId): Car {
// ...
}
function getBoatById(id: BoatId): Boat {
// ...
}
```
Тогда мы получим от редактора подсказку, что должны передать не просто число, а CarId или BoatId.
Эмулируем самую строгую типизацию
---------------------------------
Номинальной типизации в TypeScript нет, но мы можем сэмулировать его поведение, сделав любой тип уникальным. Для этого в тип необходимо добавить уникальное свойство. Этот прием упоминается в англоязычных статьях под термином Branding, и вот как это выглядит:
```
type BoatId = number & { _type: 'BoatId'};
type CarId = number & { _type: 'CarId'};
```
Указав, что наши типы должны одновременно быть и числом, и объектом со свойством с уникальным значением, мы сделали наши типы несовместимыми в понимании структурной типизации. Посмотрим, как это работает.
```
let carId: CarId;
let boatId: BoatId;
let car: Car;
let boat: Boat;
car = getCarById(carId); // OK
car = getCarById(boatId); // ERROR
boat = getBoatById(boatId); // OK
boat = getBoatById(carId); // ERROR
carId = 1; // ERROR
boatId = 2; // ERROR
car = getCarById(3); // ERROR
boat = getBoatById(4); // ERROR
```
Все выглядит неплохо за исключением четырех последних строчек. Для создания идентификаторов понадобится функция-хелпер:
```
function makeCarIdFromVin(id: number): CarId {
return vin as any;
}
```
Недостатком этого способа является то, что данная функция останется в рантайме.
Делаем строгую типизацию чуть менее строгой
-------------------------------------------
В прошлом примере для создания идентификатора приходилось использовать дополнительную функцию. Избавиться от нее можно с помощью определения интерфейса Flavor:
```
interface Flavoring {
\_type?: FlavorT;
}
export type Flavor = T & Flavoring;
```
Теперь задать типы для идентификаторов можно следующим образом:
```
type CarId = Flavor
type BoatId = Flavor
```
Поскольку свойство \_type является необязательным, можно воспользоваться неявным преобразованием:
```
let boatId: BoatId = 5; // OK
let carId: CarId = 3; // OK
```
И мы по прежнему не можем перепутать идентификаторы:
```
let carId: CarId = boatId; // ERROR
```
Какой вариант выбрать
---------------------
Оба варианта имеют право на существование. Branding имеет преимущество, когда необходимо защитить переменную от прямого присваивания. Это полезно, если переменная хранит строку в некотором формате, например абсолютный путь файла, дата или IP адрес. Функция-хелпер, которая занимается приведением типов в этом случае так же может выполнять проверку и обработку входных данных. В остальных случаях удобнее использовать Flavor.
Источники
---------
1. [Отправная точка stackoverflow.com](https://stackoverflow.com/questions/49260143/how-do-you-emulate-nominal-typing-in-typescript)
2. [Вольная интерпретация статьи](https://spin.atomicobject.com/2018/01/15/typescript-flexible-nominal-typing/) | https://habr.com/ru/post/446768/ | null | ru | null |
# Простейшая реализация кроссплатформенного мультиплеера на примере эволюции одной .NET игры. Часть вторая, более техническая
Итак, обещанное продолжение моей [первой статьи из песочницы](http://habrahabr.ru/post/186486/), в котором будет немного технических деталей по реализации простой многопользовательской игры с возможностью играть с клиентов на разных платформах.
Предыдущую часть я закончил тем, что в последней версии моей игры «Магический Yatzy» в качестве инструмента клиент-серверного взаимодействия я использую WebSocket’ы. Теперь немного технических подробностей.
##### 1. Общее
В общем, все выглядит как показано на этой схеме:

Выше представлена схема взаимодействия между тремя клиентами на различных платформах и сервером. Рассмотрим каждую часть по-подробнее.
##### 2. Сервер
Сервер у меня на базе MVC4, работающего как «Cloud service» в Windows Azure. Почему такой выбор. Все просто:
1) Ничего кроме .NET я не знаю.
2) WebSocket у меня только для взаимодействий, касающихся игры, все остальное, такое как проверка статуса сервера, получение/сохранение очков и прочее – через WebApi – поэтому MVC.
3) У меня есть подписка на сервисы Azure.
Согласно схеме выше – сервер состоит из трех частей:
1) ServerGame – реализация всей логики игры;
2) ServerClient – своего рода посредник между игрой и сетевой частью;
3) WSCommunicator – часть, ответственная за сетевое взаимодействие с клиентом – прием/отправка команд.
Конкретная реализация **ServerGame** и **ServerClient** зависит от конкретной игры, которую вы разрабатываете. В общем случае **ServerClient** получает комманду от клиента, обрабатывает ее и оповещает игру о действии клиента. В тоже время он следит за изменением состояния игры (**ServerGame**) и оповещает (отправляет информацию через **WSCommunicator**) своего клиента о любых изменениях.
Например, касательно моей игры в кости: в свой ход пользователь на Windows 8 клиенте закрепил несколько костей (сделал так, чтобы их значение не изменилось при следующем броске). Эта информация была передана на сервер и **ServerClient** оповестил об этом класс **ServerGame**, который сделал необходимые изменения в состоянии игры. Об этом изменении были оповещены все другие **ServerClient**’ы, подключенные к данной игре (в рассматриваемом случае – WP и Android), а они в свою очередь отправили информацию на устройства для оповещения пользователей через UI.
Следует сказать, что в самом классе **ServerGame** ничего «серверного» нету. Это обычный .NET класс, имеющий общий интерфейс с **ClientGame**. Таким образом мы может подставить его вместо **ClientGame** в клиентской программе и таким образом получить локальную игру. Именно так и работает локальная игра в моем «книффеле»– когда из одной UI странички возможна как локальная так и сетевая игра.
**WSCommunicator** – как я уже сказал, класс ответственный за сетевое взаимодействие. Конкретно этот реализует это взаимодействие посредством WebSocket’ов. В .NET 4.5 появилась собственная реализация вебсокетов. Основным в этой реализации является класс WebSocket, **WSCommunicator** по сути является оберткой над ним, реализующей открытие/закрытие соединения, попытки переподключения, отправки/получения данных в определенном формате.
Теперь немного кода. Для первоначального соединения используется Http Handler. Физическую страницу добавлять не обязательно. Достаточно задать параметры в WebConfig’e:
```
…
…
```
Таким образом, при обращении к страничке (виртуальной) «app.ashx» на сервере будет вызван код из класса «Sanet.Kniffel.Server.ClientRequestHandler». Вот этот код:
```
public class ClientRequestHandler : IHttpHandler
{
public void ProcessRequest(HttpContext context)
{
if (context.IsWebSocketRequest) //обращение через WebSocket
context.AcceptWebSocketRequest(new Func(MyWebSocket));
else //обращение через Http
context.Response.Output.Write("Здесь ничего нет...");
}
public async Task MyWebSocket(AspNetWebSocketContext context)
{
string playerId = context.QueryString["playerId"];
if (playerId == null) playerId = string.Empty;
try
{
WebSocket socket = context.WebSocket;
//новый класс, унаследованный от WSCommunicator'а и имеющий дополнительный функционал по подключению клиента к игре
ServerClientLobby clientLobby = null;
if (!string.IsNullOrEmpty(playerId))
{
//проверяем не подключен ли уже клиент с таким айди
if ( !ServerClientLobby.playerToServerClientLobbyMapping.TryGetValue(playerId, out clientLobby))
{
//если нет - создаем новый
clientLobby = new ServerClientLobby(ServerLobby, playerId);
ServerClientLobby.playerToServerClientLobbyMapping.TryAdd(playerId, clientLobby);
}
}
else
{
//запрос с пустым айди оставляем без внимания
return;
}
//устанавливаем новый вебсокет и запускаем
clientLobby.WebSocket = socket;
await clientLobby.Start();
}
catch (Exception ex)
{
//что-то пошло не так...
}
}
}
```
Думаю, с учетом комментариев все должно быть понятно. Метод WSCommunicator.Start() запускает «режим ожидания» команды от клиента. Вот как это выглядит ():
```
public async Task Start()
{
if (Interlocked.CompareExchange(ref isRunning, 1, 0) == 0)
{
await Run();
}
}
protected virtual async Task Run()
{
while (WebSocket != null && WebSocket.State == WebSocketState.Open)
{
try
{
string result = await Receive();
if (result == null)
{
return;
}
}
catch (OperationCanceledException) //это нормально при отмене операции
{ }
catch (Exception e)
{
//что-то непоправимое
//закрываем соединение
CloseConnections();
//оповещаем всех, что этот клиент отключен от игры
OnReceiveCrashed(e);
}
}
}
```
Это общая часть, дальнейшее описание сервера опускаю, так как оно будет в большей степени зависеть от игры, которую вы делаете. Скажу только, что команды через WebSocket передаются (в том числе) в текстовом формате. Конкретная реализация этих команд опять таки в основном зависит от игры. При получении команды от клиента, она будет обработана методом WSCommunicator.Receive(), для отправки клиенту — WSCommunicator.Send(). Все, что между – опять же зависит от логики игры.
##### 3. Клиент
###### 3.1 WinRT.
Если бы клиент был на полноценной .NET 4.5, то для него можно было бы использовать тот же класс **WSCommunicator**, что и на серевере с небольшими лишь дополнениями – вместо класса WebSocket необходим был бы класс ClientWebSocket, плюс добавить логику по запросу на соединение с сервером. Но в WinRT используется своя реализация вебсокетов с классами StreamWebSocket и MessageWebSocket. Для передачи текстовых сообщений используется второй. Вот код по установлению соединения с сервером с его использованием:
```
public async Task ConnectAsync(string id, bool isreconnect = false)
{
try
{
//работаем с локальной копией вебсокета, чтобы избежать его закрытия из другого потока во время асинхронной операции
//(маловероятно, но возможно)
MessageWebSocket webSocket = ClientWebSocket;
// Проверяем что не подключены
if (!IsConnected)
{
//получаем адрес сервера (ws://myserver/app.ashx")
var uri = ServerUri();
webSocket = new MessageWebSocket();
webSocket.Control.MessageType = SocketMessageType.Utf8;
//устанавливаем обработчики
webSocket.MessageReceived += Receive;
webSocket.Closed += webSocket\_Closed;
await webSocket.ConnectAsync(uri);
ClientWebSocket = webSocket; //устанавливаем в переменную класса только после успешного подключения
if (Connected != null)
Connected(); //сообщаем, что мы подключились
return true;
}
return false;
}
catch (Exception e)
{
//что-то не так
return false;
}
}
```
Далее все как на сервере: WSCommunicator.Receive() получает сообщения с сервера, WSCommunicator.Send() – отправляет. **GameClient** работает в соответствии с данными, получаемыми с сервера и от пользователя.
###### 3.2 Windows Phone, Xamarin и Silverlight (а также .NET 2.0)
Во всех этих платформах нет поддержки вебсокетов «из коробки». К счастью есть отличная опенсорс библиотека [WebSocket4Net](http://websocket4net.codeplex.com/), которую я упоминал в предыдущей статье. Заменив в **WSCommunicatar**e класс вебсокета на реализованный в этой библиотеке, мы получим возможность подключения к серверу с указанных платформ. Вот как изменится код по установке соединения:
```
public async Task ConnectAsync(string id, bool isreconnect = false)
{
try
{
//работаем с локальной копией вебсокета, чтобы избежать его закрытия из другого потока во время асинхронной операции
//(маловероятно, но возможно)
WebSocket webSocket = ClientWebSocket;
// Проверяем что не поделючены
if (!IsConnected)
{
//получаем адресс сервера (ws://myserver/app.ashx")
var uri = ServerUri();
webSocket = new WebSocket(uri.ToString());
//устанавливаем обработчики
webSocket.Error += webSocket\_Error;
webSocket.MessageReceived += Receive;
webSocket.Closed += webSocket\_Closed;
//соединение не асинхронное, поэтому "асинхронизируем" его принудительно
var tcs = new TaskCompletionSource();
webSocket.Opened += (s, e) =>
{
//устанавливаем в переменную класса только после успешного подключения
ClientWebSocket = webSocket;
if (Connected != null)
Connected(); //сообщаем, что мы подключились
else tcs.SetResult(true);
};
webSocket.Open();
return await tcs.Task;
}
return false;
}
catch (Exception ex)
{
//что-то не так
return false;
}
}
```
Как видим отличия есть, но их не так много, основное -это не асинхронное открытие соединения с сервером, но это легко исправить (правда для поддержки async await в старых версиях .NET необходимо установить Microsoft.Bcl пакет с нугета).
##### Вместо заключения
Прочитал, что написал и понимаю, что вопросов, возможно, больше чем ответов. К сожалению описать все в одной статье физически не возможно, а она и так уже получается не самой короткой… но я буду продолжать тренироваться. | https://habr.com/ru/post/187282/ | null | ru | null |
# Unreal Engine 4. Новая сетевая модель: PushModel
В стандартной сетевой архитектуре Unreal Engine, сервер проверяет, изменение значения у реплицированной переменной Actor класса, и в случае отличия, значение синхронизируется между сервером и клиентом. Когда объем данных для синхронизации не больших размеров, особых проблем с производительностью нет.
Однако, игра часто может состоять из огромного множества Актеров и переменных, которые необходимо реплицировать одному или нескольким клиентам, и это уже может стать проблемным местом.
UE уже предоставляет такие функции как: NetUpdateFrequency, NetCullDistanceSquared и т.д. Основная задача которых состоит в том, что бы устранить из общей картины репликации, как можно больше актеров не нуждающихся в постоянно синхронизации данных.
PushModel, пока что экспериментальная фича, которая может позволить разработчикам активно отмечать необходимость синхронизации свойства, для этого предоставляется несколько макросов:
```
#define MARK_PROPERTY_DIRTY(Object, Property)
#define MARK_PROPERTY_DIRTY_STATIC_ARRAY_INDEX(Object, RepIndex, ArrayIndex)
#define MARK_PROPERTY_DIRTY_STATIC_ARRAY(Object, RepIndex, ArrayIndex)
#define MARK_PROPERTY_DIRTY_FROM_NAME(ClassName, PropertyName, Object)
#define MARK_PROPERTY_DIRTY_FROM_NAME_STATIC_ARRAY_INDEX(ClassName, PropertyName, ArrayIndex, Object)
#define MARK_PROPERTY_DIRTY_FROM_NAME_STATIC_ARRAY(ClassName, PropertyName, ArrayIndex, Object)
```
Эти макросы устанавливают определенной переменной метку необходимости синхронизации, а сервер в свою очередь убирает необходимость постоянно проверять изменение значения.
Как настроить PushModel. В первую очередь в Build.cs, необходимо добавить, что б исключить проблемы компиляции
```
PublicDependencyModuleNames.AddRange(new string[] {"NetCore"});
```
Во вторых добавить в DefaultEngine.ini в папке config добавить:
```
[SystemSettings]
net.IsPushModelEnabled=1
```
В третьих отметить необходимые перменные UPROPERTY(Replicated) или (ReplicatedUsing)
В четвертых, в функции GetLifetimeReplicatedProps, нам необходимо использовать DOREPLIFETIME\_WITH\_PARAMS или DOREPLIFETIME\_WITH\_PARAMS\_FAST, вместо DOREPLIFETIME или DOREPLIFETIME\_CONDITION, что бы отметить переменную для репликации. Пример:
```
void ASomeActor::GetLifetimeReplicatedProps(TArray< class FLifetimeProperty > & OutLifetimeProps) const
{
Super::GetLifetimeReplicatedProps(OutLifetimeProps);
FDoRepLifetimeParams SharedParams;
SharedParams.bIsPushBased = true;
SharedParams.Condition = COND_OwnerOnly;
DOREPLIFETIME_WITH_PARAMS_FAST(ASomeActor, SomeVar, SharedParams);
}
```
FDoRepLifetimeParams имеет в себе 3 прекрасный параметра:
```
struct ENGINE_API FDoRepLifetimeParams
{
/** Replication Condition. The property will only be replicated to connections where this condition is met. */
ELifetimeCondition Condition = COND_None;
/** * RepNotify Condition. The property will only trigger a RepNotify if this condition is met, and has been * properly set up to handle RepNotifies. */
ELifetimeRepNotifyCondition RepNotifyCondition = REPNOTIFY_OnChanged;
/** Whether or not this property uses Push Model. See PushModel.h */
bool bIsPushBased = false;
};
```
В данной структуре bIsPushBased указывает, следует ли включать данную переменную в PushModel. В одном и том же Актере, несколько разных переменных, могут использовать данный функционал. Для того что бы оповестить сервер о необходимости репликации, необходимо вызвать макрос:
```
MARK_PROPERTY_DIRTY_FROM_NAME(ASomeActor, SomeVar, this);
SomeVar = SomeValue;
```
Тем самым, сервер синхронизирует значение переменной.
Заключение
----------
Использование PushModel может здорово сократить количество данных, которые постоянно обрабатываются на серверной стороне, тем самым уменьшить количество потребляемых ресурсов.
Подробные примеры использования можно посмотреть в классе APlayerState в движке.
Всем спасибо за внимание и хорошего времяпровождения. | https://habr.com/ru/post/539604/ | null | ru | null |
# Обновляем контент, не проходя повторное ревью в сторах
Схема работы Server driven viewВсем привет, я Дима Авдеев из Туту, наша команда разрабатывает приложения с 20М инсталлов. Расскажу, как можно обновлять приложение без выкатки релиза. Например, когда мы хотим быстро донести до пользователей коронавирусные ограничения.
Ниже реализация на SwiftUI и Kotlin (но вы можете использовать UIkit и серверный язык, принятый в вашей команде), а в GitHub-репозитории в конце статьи вы найдёте код сервера и приложений для детального изучения.
Пост по мотивам [моего доклада](https://www.youtube.com/watch?v=gk0SxLKmpX8&t).
**Оглавление**
* [Зачем вообще Server driven view](https://habr.com/ru/company/tuturu/blog/648849/#why)
* [Заглянем глубже](https://habr.com/ru/company/tuturu/blog/648849/#more)
* [А что на практике](https://habr.com/ru/company/tuturu/blog/648849/#practice)
### Как это работает
С сервера будет приходить JSON в формате дерева. Там мы опишем нашу вёрстку. Потом на SwiftUI нативно отрендерим JSON. Если пользователь взаимодействует с кнопкой, отправится новый HTTP-вызов: в тело этого вызова мы добавим айдишник кнопки, в результате чего вернётся новый JSON с сервера, а мы его отобразим. Сервер также может послать какие-то дополнительные данные, а мы их обработаем. И даже сможем обеспечить логику наподобие диплинков.
Это похоже на MVI ?По сути, это однонаправленная архитектура MVI (Model View Intent). Model — это данные JSON, которые к нам приходят от сервера. View — это наш SwiftUI. Intent — тело нового серверного вызова.
Вот [хорошее видео](https://www.youtube.com/watch?v=y0CHhHBzEkw), если вы хотите больше знать о MVI
Давайте сделаем экран с важной информацией. Вот вёрстка этого экрана. Наша структура Server driven view — это SwiftUI-структура. Туда, в конструктор, мы передаём ID пользователя и серверный путь, по которому будем запрашивать JSON для отображения.
```
ServerDrivenView(
userId: "my_user_id",
networkReducerUrl: "http://localhost:8081/important_reducer",
autoUpdate: true
)
```
Давайте посмотрим, как сервер отвечает на этот вызов. Отдаётся дерево. Например в корне может лежать вертикальный контейнер, в нём первый ребёнок — это картинка, второй — текст.
```
rootContainer {
image("http://localhost:8081/static/covid_test.png", 250, 250)
text("Это ServerDrivenView")
}
```
Чтобы не формировать JSON руками, мы сделали специальную DSL-обёртку — причём её можно изменять, перезапускать сервер и сразу видеть изменения на клиенте.
### Но зачем Server driven view, когда есть…
* Вы cможете обеспечить привычный пользователю нативный интерфейс iOS, в отличие от WebView и Push. При этом подходы не противоречат Server driven view, их можно использовать вместе.
* Вы сможете сами поднять простой сервер, проверить, как отображается вёрстка, отредактировать её и поотлаживать. Можно выделить для этого отдельный микросервис и развернуть в своей инфраструктуре. Логику работы этого сервиса разумнее отдать на реализацию мобильным разработчикам: мы лучше знаем, в каком формате принимать эту вёрстку и сможем заложиться под совместимости и версионирование.
* При этом серверный разработчик может поменять UI и поотлаживать логику своей фичи на сервере, не дожидаясь, когда освободится iOS-команда.
* А/B-тестами можно будет управлять из серверного кода, добавляя варианты эксперимента на лету без feature toggle на клиенте.
* Всё это также применимо для Android-приложения — и один микросервис может обслуживать обе платформы.
Но есть нюансыПравила Apple и Google разрешают использовать такие обновляемые view, но ограниченно: не меняйте основную функциональность приложения.
Время отклика при нажатии на кнопки может возрасти, если у клиента плохой интернет. Может возрасти нагрузка на серверную инфраструктуру, но мы можем оптимизировать это, добавив слой кеширования, поменяв JSON на бинарные данные или поменяв протокол на вебсокет.
Наконец, версионирование. Нужно сделать несколько серверных URL, и клиент в зависимости от версии будет обращаться к ним. А сервер — разруливать всё так, чтобы старым клиентам не дать лишнюю информацию.
### Заглянем глубже
Структура SwiftUI имеет три состояния: состояние загрузки, нормальное состояние и состояние ошибки.
```
public var body: some View {
switch myViewModel.myState.screen {
case let loadingScreen as ServerDrivenViewState.ServerDrivenViewScreenLoading:
Text("Loading...")
case let normalScreen as ServerDrivenViewState.ServerDrivenViewScreenNormal:
RenderNode(normalScreen.node, myViewModel.myState.clientStorage) { (intent: ClientIntent) in
mviStore.sendIntent(intent: intent)
}
case let errorScreen as ServerDrivenViewState.ServerDrivenViewScreenNetworkError:
VStack {
Text("Сетевая ошибка")
Text(errorScreen.exception)
}
default:
Text("wrong ServerDrivenViewState myViewModel.myState.screen: \(myViewModel.myState.screen)")
}
}
```
Нормальное состояние вызывает структуру Render Node:она нужна, чтобы рендерить любые элементы нашего JSON. В списке могут быть все возможные JSON-объекты — вертикальный или горизонтальный контейнер, текст, прямоугольник, кнопка и так далее.
Кнопка принимает в себя Intent, он же айдишник кнопки, которая будет нажата.
```
public struct LeafButton: View {
let nodeButton: ViewTreeNode.Leaf.LeafButton
let sendIntent: (ClientIntent) -> Void
public init(_ nodeButton: ViewTreeNode.LeafButton, _ sendIntent: @escaping (ClientIntent) -> ()) {
self.nodeButton = nodeButton
self.sendIntent = sendIntent
}
public var body: some View {
Button(action: {
sendIntent(SwiftHelperKt.buttonIntent(buttonId: nodeButton.id))
}) {
Text(nodeButton.text)
.font(.system(size: CGFloat(nodeButton.fontSize)))
}
}
}
```
Контейнер перебирает всех своих детей и для каждого ребёнка заново вызывает функцию Render Node. То есть, по сути, получается рекурсия.
```
public struct ContainerHorizontal: View {
let containerHorizontal: ViewTreeNode.Container.ContainerHorizontal
public init(_ containerHorizontal: ViewTreeNode.ContainerHorizontal) {
self.containerHorizontal = containerHorizontal
}
public var body: some View {
HStack(alignment: containerHorizontal.verticalAlignment.toSwiftAlignment()) {
ForEach(containerHorizontal.children) { child in
RenderNode(child, ...)
}
}
}
}
```
Контейнер также может содержать ещё один контейнер внутри себя. Таким образом мы можем отрендерить всё дерево: у нас есть глобальный Render Node, и каждый узел мы отдельно описываем в SwiftUI.
### Насколько удобно изменять и обновлять вьюшку с сервера на практике
Давайте сделаем экран со статистикой заболевших: у нас будет город, картинка для города, статистика за несколько дней в вертикальных прямоугольниках (зелёный — мало заболевших, красный — много), плюс описание, какие ограничения действуют сейчас в этом городе.
Заведём модельку города — название, картинка, статистика заболевших за несколько дней (далее будет идти код сервера на Kotlin).
```
data class City(
val name:String,
val img:String,
val stat:List = List(7) {
Day(
it.toDayOfWeek(),
(100..1000).random()
)
},
val desc:String = createRandomDescription()
)
```
И модельку для дня, это будет текстовая строка «день недели» и количество заболевших в этот день. Данные сгенерируем случайно в диапазоне от 100 до 1000.
```
data class Day(
val dayOfWeek:String,
val infected:Int
)
```
Теперь подставим данные в нашу карточку и сделаем отображение статистики для одного города. Перебираем в цикле дни из модельки города и отображаем количество заболевших.
```
fun NodeDsl.cityCard(city: City) {
horizontalContainer(lightBlue) {
verticalContainer {
text(city.name)
image(city.img, 100, 100)
}
verticalContainer {
text("Статистика коронавируса", 15)
horizontalContainer(contentAlignment = VAlign.Bottom) {
city.stat.forEach {
verticalContainer {
text(it.infected.toString(), 14)
val normalized = it.infected / 1000.0
val red = (255 * normalized).toInt()
val green = 255 - red
val height = (60 * normalized).toInt()
rectangle(20, height, Color(red, green, 0))
text(it.dayOfWeek, 16)
}
}
}
text(city.desc, 16)
}
}
}
```
Далее перебираем в цикле все города cities и отображаем cityCard(city).
```
val cities = listOf(
City("Москва", moscowUrl),
City("Санкт-Петербург", spbUrl),
City("Владивосток", vladivostokUrl),
)
fun serverResponsePlayground(clientStorage: ClientStorage): ViewTreeNode {
return rootContainer() {
cities.forEach { city ->
cityCard(city)
}
}
}
```
Всё, мы сделали экранчик исключительно в серверном коде, можем достаточно быстро вносить изменения и смотреть, как они отображаются на клиенте.
**P.S.** Подробности можно изучить [в этом GitHub-репозитории](https://github.com/tutu-ru-mobile/cocoaheads-2021-kmm): там вы найдёте Android- и iOS-приложения, сервер и инструкцию по сборке и запуску.
Спасибо за внимание! | https://habr.com/ru/post/648849/ | null | ru | null |
# Jii: Полноценное приложение с архитектурой Yii2 в браузере
Привет всем хабровчанам, любителям **Yii** и **Node.js**. Продолжаю серию статей про Jii, на сей раз настала очередь рассказать о том, что Jii можно использовать в браузере.

Представьте, уже сейчас все структуры фреймворка, такие как [приложения](http://www.jiiframework.ru/guide/structure-applications), [компоненты](http://www.jiiframework.ru/guide/concept-components), [контроллеры](http://www.jiiframework.ru/guide/structure-controllers), [модули](http://www.jiiframework.ru/guide/structure-modules), модели, представления доступны в браузере!
Для тех, кто в первый раз слышит об этом фреймворке, рекомендую прочитать [предыдущие статьи](http://habrahabr.ru/search/?q=%5Bjii%5D&target_type=posts) или [посетить сайт](http://jiiframework.ru). Если коротко, то
> Jii — это фреймфорк, архитектура и API которого базируется на PHP фреймворке Yii 2.0, взяв из него лучшие стороны и сохраняя приемущества JavaScript.
Jii на клиенте (в браузере)
---------------------------
Jii изначально пишется так, чтобы его можно было использовать везде, где может выполняться JavaScript код. Если код модуля не завязан на серверной инфраструктуре, то его можно использовать в браузере.
Все это разбито и подключается по частям, в видел npm модулей:
* [jii](https://www.npmjs.com/package/jii) (или *jii/deps*) — базовые классы и основа фреймворка;
* [jii-clientrouter](https://www.npmjs.com/package/jii-clientrouter) — Роутер, запускающий действия при изменении адресной строки; Работает совместно с *jii-urlmanager*;
* [jii-comet](https://www.npmjs.com/package/jii-comet) — Комет клиент;
* [jii-model](https://www.npmjs.com/package/jii-model) — Модель набором валидаторов (которые указываются в rules());
* [jii-urlmanager](https://www.npmjs.com/package/jii-urlmanager) — Разбор url, получение route на основе указанных правил;
* [jii-view](https://www.npmjs.com/package/jii-view) — Рендер представлений.
Создание приложения на клиенте
------------------------------
Создаваться приложение будет почти также как и серверное:
```
// Libs
require('jii/deps'); // included underscore and underscore.string libraries
require('jii-urlmanager');
require('jii-clientrouter');
// Application
require('./controllers/SiteController');
Jii.createWebApplication({
application: {
basePath: location.href,
components: {
urlManager: {
className: 'Jii.urlManager.UrlManager',
rules: {
'': 'site/index'
}
},
router: {
className: 'Jii.clientRouter.Router'
}
}
}
}).start();
console.log('Index page url: ' + Jii.app.urlManager.createUrl('site/index'));
```
Зависимости
-----------

Jii имеет зависимости от библиотек [Underscore](http://underscorejs.org/) и [Underscore.string](http://epeli.github.io/underscore.string/). Если они уже подключены у вас на странице, то нужно подключать Jii как *require('jii')*, если зависимости нужны — *require('jii/deps')*.
Компиляция JavaScript кода
--------------------------
Jii рекомендует использовать CommonJS подход для подгрузки зависимостей. Сборку модулей можно делать любыми средствами, например, используя [Browserify](http://browserify.org/). Рассмотрим простейший пример сборки.
Установка зависимотей:
```
npm install --save-dev gulp gulp-easy
```
Файл gulpfile.js:
```
require('gulp-easy')(require('gulp'))
.js('sources/index.js', 'bundle.js')
```
Роутинг на клиенте
------------------

Когда необходимо следить и обрабатывать состояние адресной строки браузера, в бой вступает модуль [jii-clientrouter](https://www.npmjs.com/package/jii-clientrouter), предназначенный именно для этой цели.
Jii-clientrouter устанавливается как [компонент приложения](http://www.jiiframework.ru/guide/structure-application-components) и подписывается на событие *popstate* (или *hashchange* для браузеров, не поддерживающих HTML5 History API).
При загрузке страницы или изменении адресной строки запускается обработчик, который парсит адресную строку компонентом *Jii.urlManager.UrlManager*, получает route с параметрами запроса и запускает действие (action), эквивалентное найденному route. Поэтому для работы Jii-clientrouter необходимо так же подключить [jii-urlmanager](https://www.npmjs.com/package/jii-urlmanager).
Пример конфигурации приложения:
```
require('jii/deps');
require('jii-urlmanager');
require('jii-clientrouter');
// Application
window.app = Jii.namespace('app');
require('./controllers/SiteController');
Jii.createWebApplication({
application: {
basePath: location.href,
components: {
urlManager: {
className: 'Jii.urlManager.UrlManager',
rules: {
'': 'site/index',
'article/': 'site/article',
}
},
router: {
className: 'Jii.clientRouter.Router'
},
// ...
}
}
}).start();
```
В действии будут доступны компоненты *request (Jii.clientRouter.Request)* и *response (Jii.clientRouter.Response)*, как это было при работе на сервере с HTTP сервером. Используя эти компоненты, можно получить параметры из адресой строки. Рассмотрим небольшой пример такого действия.
Предположим, что у нас адресная строка содержить адрес *[localhost](http://localhost):3000/article/new-features*, тогда при переходе на заданный адрес на клиенте сработает обработчик *Jii.clientRouter.Router.\_onRoute()*, который найдет роутер *site/article* и запустит действие (метод) *actionArticle()* контроллера *app.controllers.SiteController*:
```
/**
* @class app.controllers.SiteController
* @extends Jii.base.Controller
*/
Jii.defineClass('app.controllers.SiteController', /** @lends app.controllers.SiteController.prototype */{
__extends: Jii.base.Controller,
// ...
actionArticle: function(context) {
console.log(context.request.getQueryParams()); // {id: 'new-features'}
}
});
```
Демо
----
Пример использования Jii в браузере можно посмотреть на Github в исходниках примитивного чата — [jiisoft/jii-boilerplate-chat](https://github.com/jiisoft/jii-boilerplate-chat).
Не стоит воспринимать данный пример как «лучшие практики» использования Jii, так как эти практики еще не сформировались. Я буду рад услышать рекомендации по оформлению и структуре кода на клиенте.
В заключении
------------

Напомню, Jii — опенсорсный проект, поэтому я буду очень рад, если кто-то присоединится к его разработке. Пишите на [email protected].
Сайт фреймворка — [jiiframework.ru](http://www.jiiframework.ru/)
GitHub — <https://github.com/jiisoft>
Обсуждение фич проходит на [гитхабе](https://github.com/jiisoft/jii/issues/10)
> Нравится идея фреймворка? Ставь [звезду](https://github.com/jiisoft/jii/stargazers) на [гитхабе](https://github.com/jiisoft/jii)!
> ---------------------------------------------------------------------------------------------------------------------------------
>
>
**Навигация по статьям** * [Jii: конфигурация и масштабирование](http://habrahabr.ru/post/266929/)
* [Jii — JavaScript фреймворк с архитектурой от Yii 2](http://habrahabr.ru/post/260931/)
* [Jii: Active Record для Node.js с API от Yii 2](http://habrahabr.ru/post/260569/)
* [Jii: Полноценный Query Builder для Node.js с API от Yii 2](http://habrahabr.ru/post/260295/) | https://habr.com/ru/post/268361/ | null | ru | null |
# Карринг vs Частичное применение функции

*Перевод статьи Джона Скита, известного гуру языка* C#*, автора книги* C# *In Depth, сотрудника Google, человека* [#1](http://stackoverflow.com/users?tab=reputation&filter=all) *по репутации на stackoverflow.com и наконец героя [Jon Skeet Facts](http://meta.stackoverflow.com/questions/9134/jon-skeet-facts). В этой статье Джон доступно объясняет, что представляют из себя карринг и частичное применение функции, концепции, пришедшие из мира функционального программирования. Кроме того, он подробно поясняет в чём их различие. Признаюсь, что я и сам их путал до прочтения этой статьи, поэтому мне показалось полезным сделать перевод.*
Это немного странный пост, и прежде чем читать его вам, пожалуй, следует отнести себя к одной из этих групп:
* Те, кто не интересуются функциональным программированием и находят функции высшего порядка запутанными: вы можете пропустить эту статью полностью.
* Те, кто знают всё о функциональном программировании и хорошо понимают разницу между каррингом (currying) и частичным применением функции (partial function application): пожалуйста, внимательно прочтите этот пост и отпишитесь в комментариях, если найдете неточности.
* Те, кто *частично* знаком с функциональным программированием, и заинтересован узнать больше: отнеситесь к этому посту скептически и внимательно прочтите комментарии. Прочитайте другие статьи более опытных разработчиков для получения дополнительной информации.
В общем-то, я знаю, что некоторые люди иногда путают термины *карринг* и *частичное применение функции* — используют их взаимозаменяемо, когда этого делать не следует. Это одна из тех тем (как, например, монады), которую я до некоторой степени понимаю, и я решил, что лучшим способом удостовериться в своих знаниях будет написать об этом. Если это сделает эту тему более доступной для других разработчиков, тем лучше.
#### Этот пост не содержит Haskell
Почти во всех разъяснениях на эту тему, что я видел, были даны примеры на «правильных» функциональных языках, обычно на Haskell. Я ничего не имею против Haskell, просто мне обычно легче понять примеры на языке, который я хорошо знаю. Тем более, мне *гораздо* легче *писать* примеры на таком языке, поэтому все примеры в этом посте будут на C#. Собственно, все примеры доступны в [одном файле](http://www.yoda.arachsys.com/csharp/blogfiles/Curry.cs), правда, несколько переменных в нем переименованы. Просто скомпилируйте и запустите.
C# на самом деле не является функциональным языком — я знаю достаточно, чтобы понимать, что делегаты не являются полной заменой для функций высшего порядка. Тем не менее, они достаточно хороши для демонстрации описываемых принципов.
Хотя можно продемонстрировать карринг и частичное применение, используя функцию (метод) с небольшим количеством аргументов, я решил использовать три аргумента для ясности. Хотя мои методы выполнения карринга и частичного применения будут обобщенными (поэтому все типы параметров и возвращаемого значения произвольны), в целях демонстрации я использую простую функцию:
```
static string SampleFunction(int a, int b, int c)
{
return string.Format("a={0}; b={1}; c={2}", a, b, c);
}
```
Пока всё просто. В этом методе *нет ничего хитрого*, не ищите в нем ничего удивительного.
#### О чем вообще речь?
И карринг и частичное применение это способы преобразования одного вида функции в другой. Мы будем использовать делегаты в качестве аппроксимации функций, поэтому для работы с методом SampleFunction как со значением, мы можем написать:
```
Func function = SampleFunction;
```
Эта строчка полезна по двум причинам:
* Присвоение значения переменной внушает идею, что это действительно значение. Экземпляр делегата является объектом, так же, как и экземпляр любого другого типа, а значение функциональной переменной — это просто ссылка.
* Преобразование группы методов (использование имени метода как способа создать делегат) плохо работает с выводом типов, когда вызывается обобщенный метод.
Теперь мы можем вызывать делегат с тремя аргументами:
```
string result = function(1, 2, 3);
```
Или то же самое:
```
string result = function.Invoke(1, 2, 3);
```
(Компилятор C# преобразует первую короткую форму во вторую. Сгенерированный IL будет тем же самым.)
Хорошо, если нам доступны все три аргумента единовременно, но что если нет? Для конкретного (хотя и несколько надуманного) примера, предположим у нас есть функция логирования с тремя параметрами (источник, серьезность, сообщение) и в пределах одного класса (который я буду называть BusinessLogic), мы хотим всегда использовать одно и то же значение для параметра «источник». Мы хотим иметь возможность легко логировать из любой точки класса, указывая только серьезность и сообщение. У нас есть несколько вариантов:
* Создать класс-адаптер, который принимает функцию логирования (или даже объект-логгер) и значение параметра «источник» в свой конструктор, сохраняет их в своих полях и выставляет наружу метод с двумя параметрами. Этот метод просто делегирует вызов сохраненному логгеру, передавая сохраненный «источник» первым параметром функции логгера. В классе BusinessLogic мы создаем экземпляр адаптера и сохраняем ссылку на него в поле, а далее просто вызываем метод с двумя параметрами где хотим. Пожалуй, это оверкилл, если нам нужен только адаптер от BusinessLogic, но его можно переиспользовать… до тех пор, пока мы будем адаптировать ту же логирующую функцию.
* Хранить исходный объект логгера в нашем классе BusinessLogic, но создать вспомогательный метод с двумя параметрами, внутри которого будет захардкожено значение для параметра «источник». Если нам надо сделать так в нескольких местах, это начинает раздражать.
* Использовать более функциональный подход — в данном случае *частичное применение функции*.
Я умышленно игнорирую различие между хранением ссылки на объект-логгер и хранением ссылки на функцию логирования. Очевидно, есть существенное различие, если нам нужно использовать более одной функции класса логгера, но для того, чтобы размышлять о карринге и частичном применении, мы будем думать о «логгере» как о «функции, принимающей три параметра» (как наша функция в примере).
Теперь, когда я дал псевдо-реальный конкретный кейс для мотивации, мы забудем его до конца статьи и будем рассматривать только функцию-пример. Я не хочу писать весь класс BusinessLogic, который будет делать вид, что занимается чем-то полезным; я уверен вы сможете сделать мысленное преобразование из «функции-примера» в «что-то, что вы на самом деле хотели бы сделать».
#### Частичное применение функции
Частичное применение берет функцию с N параметрами и значение для одного из этих параметров и возвращает функцию с N-1 параметрами, такую, что, будучи вызванной, она соберет все необходимые значения (первый аргумент, переданный самой функции частичного применения, и остальные N-1 аргументы переданы возвращаемой функции). Таким образом, эти два вызова должны быть эквивалентны нашему методу с тремя параметрами:
```
// обычный вызов
string result1 = function(1, 2, 3);
// вызов через частичное применение
Func partialFunction = ApplyPartial(function, 1);
string result2 = partialFunction(2, 3);
```
В данном случае, я реализовал частичное применение с единственным параметром, первым по счету — вы *можете* написать ApplyPartial, которая будет принимать большее число аргументов или будет подставлять их в другие позиции в окончательном выполнении функции. По видимому, сбор параметров по одному, начиная с начала — самый обычный подход.
Спасибо анонимным функциям (в данном случае лямбда-выражению, но анонимный метод не был бы сильно многословнее), реализация ApplyPartial проста:
```
static Func ApplyPartial
(Func function, T1 arg1)
{
return (b, c) => function(arg1, b, c);
}
```
Обобщения заставляют этот метод выглядеть сложнее, чем он есть на самом деле. Обратите внимание, что отсутствие типов высшего порядка (higher order types) в C# означает, что вам необходима реализация этого метода для *каждого* делегата, который вы хотите использовать — если вам необходима версия для функции с четырьмя параметрами, вам необходим метод ApplyPartial и т.д. Вам, вероятно, так же понадобиться набор методов для семейства делегатов Action.
Последнее, что необходимо отметить — имея все эти методы, мы можем выполнять частичное применение вновь, даже потенциально до результирующей функции без параметров, если захотим:
```
Func partial1 = ApplyPartial(function, 1);
Func partial2 = ApplyPartial(partial1, 2);
Func partial3 = ApplyPartial(partial2, 3);
string result = partial3();
```
Опять же, только последняя строчка вызовет исходную функцию.
Ок, это и есть частичное применение функции. Оно *относительно* простое. Карринг, на мой взгляд, немного сложнее для понимания.
#### Карринг
В то время как частичное применение преобразует функцию с N параметрами в функцию с N-1 параметрами, применяя один аргумент, карринг декомпозирует функцию на функции от одного аргумента. Мы не передаем никаких дополнительных аргументов в метод Curry, кроме преобразуемой функции:
* Curry(f) возвращает функцию f1, такую что...
* f1(a) возвращает функцию f2, такую что...
* f2(b) возвращает функцию f3, такую что...
* f3(с) вызывает f(a, b, c)
(Опять же, обратите внимание, что это относится только к нашей функции с тремя параметрами — надеюсь, очевидно, как это будет работать с другими сигнатурами.)
Для нашего «эквивалентного» примера, мы можем написать:
```
// обычный вызов
string result1 = function(1, 2, 3);
// вызов через карринг
Func>> f1 = Curry(function);
Func> f2 = f1(1);
Func f3 = f2(2);
string result2 = f3(3);
// или соберем все вызовы вместе...
var curried = Curry(function);
string result3 = curried(1)(2)(3);
```
Различие между последними примерами показывает причину того, почему в функциональных языках зачастую есть хороший вывод типов и компактное представление типов функций: объявление f1 очень страшное.
Теперь, когда мы знаем, что должен делать метод Curry, его реализация удивительно проста. На самом деле, всё, что нам нужно сделать это транслировать пункты выше в лямбда выражения. Красота:
```
static Func>> Curry
(Func function)
{
return a => b => c => function(a, b, c);
}
```
Не стесняйтесь добавлять скобки, если хотите сделать код более понятным для себя, лично я думаю, что они только добавят беспорядка. В любом случае, мы получили то, что хотели. (Стоит подумать о том, как утомительно было бы это написать без лямбда-выражений или анонимных методов. Не *трудно*, просто утомительно.)
Это и есть карринг. Я думаю. Возможно.
#### Заключение
Я не могу сказать, что я когда либо использовал карринг, тогда как некоторые части парсинга текста для [Noda Time](http://noda-time.googlecode.com/) фактически используют частичное применение. (Если кто-то действительно хочет чтобы я это проверил, я сделаю это.)
Я очень надеюсь, что я показал вам разницу между этими двумя связанными между собой, но, тем не менее весьма различными понятиями. Теперь, когда мы подошли к концу, подумайте о том, как различие между ними проявится для функции с двумя параметрами, и, надеюсь, вы поймете, почему я решил использовать три :)
Мое шестое чувство говорит мне, что карринг является полезной концепцией в академическом контексте, в то время как частичное применение более полезно на практике. Однако это шестое чувство человека, который не использовал функциональные языки по полной. Если я когда-либо начну использовать F#, возможно я напишу дополняющий пост. Теперь, я надеюсь, что мои опытные читатели могут дать полезные мысли в комментариях. | https://habr.com/ru/post/143465/ | null | ru | null |
# PostgreSQL Antipatterns: сказ об итеративной доработке поиска по названию, или «Оптимизация туда и обратно»
Тысячи менеджеров из офисов продаж по всей стране фиксируют в [нашей CRM-системе](https://sbis.ru/crm) **ежедневно десятки тысяч контактов** — фактов общения с потенциальными или уже работающими с нами клиентами. А для этого клиента надо сначала найти, и желательно очень быстро. И происходит это чаще всего по названию.
Поэтому неудивительно, что, разбирая в очередной раз «тяжелые» запросы на одной из самых нагруженных баз — нашего собственного [корпоративного аккаунта СБИС](https://sbis.ru/), я обнаружил «в топе» **запрос для «быстрого» поиска по названию** для карточек организаций.
Причем дальнейшее расследование выявило интересный пример ***сначала оптимизации, а затем деградации производительности*** запроса при последовательной его доработке силами нескольких команд, каждая из которых действовала исключительно из лучших побуждений.
0: чего же хотел пользователь
-----------------------------
[КДПВ [отсюда](http://xendz.ru/all/it-proekty-v-kartinkah/)]
Что вообще обычно подразумевает пользователь, когда говорит про «быстрый» поиск по названию? Почти никогда это не оказывается «честный» поиск по подстроке типа `... LIKE '%роза%'` — ведь тогда в результат попадают не только `'Розалия'` и `'Магазин Роза'`, но и `'Гроза'` и даже `'Дом Деда Мороза'`.
Пользователь же подразумевает на бытовом уровне, что вы ему обеспечите **поиск по началу слова** в названии и покажете более релевантным то, что **начинается на** введенное. И сделаете это **практически мгновенно** — при подстрочном вводе.
1: ограничиваем задачу
----------------------
И уж тем более не будет человек специально вводить `'роз магаз'`, чтобы каждое слово вам приходилось искать префиксно. Нет, пользователю отреагировать на быструю подсказку для последнего слова гораздо проще, чем целенаправленно «недовводить» предыдущие — посмотрите, как это отрабатывает любой поисковик.
Вообще, **правильно** сформулировать требования к задаче — больше половины решения. Иногда внимательный анализ use case [может существенно влиять на результат](https://habr.com/post/483176/).
Что же делает абстрактный разработчик?
#### 1.0: внешний поисковый движок
Ой, поиск это сложно, что-то вообще им заниматься не хочется — давайте отдадим это devops! Пусть они нам развернут внешнюю относительно БД поисковую систему: Sphinx, ElasticSearch,…
Рабочий, хоть и трудоемкий в плане синхронизации и оперативности изменений вариант. Но не в нашем случае, поскольку поиск осуществляется для каждого клиента только в рамках данных его аккаунта. А данные имеют достаточно высокую изменчивость — и если сейчас менеджер внес карточку `'Магазин Роза'`, то через 5-10 секунд он уже может вспомнить, что забыл указать там email и захотеть ее найти и поправить.
Поэтому — давайте **искать «прямо по базе»**. К счастью, PostgreSQL позволяет нам это делать, и не одним вариантом — их и рассмотрим.
#### 1.1: «честная» подстрока
Цепляемся за слово «подстрока». А ведь ровно для индексного поиска по подстроке (и даже по регулярным выражениям!) есть отличный [модуль pg\_trgm](https://postgrespro.ru/docs/postgresql/12/pgtrgm)! Только потом надо будет правильно посортировать.
Давайте попробуем взять для простоты модели такую табличку:
```
CREATE TABLE firms(
id
serial
PRIMARY KEY
, name
text
);
```
Заливаем туда 7.8 миллионов записей реальных организаций и индексируем:
```
CREATE EXTENSION pg_trgm;
CREATE INDEX ON firms USING gin(lower(name) gin_trgm_ops);
```
Поищем для подстрочного поиска первые 10 записей:
```
SELECT
*
FROM
firms
WHERE
lower(name) ~ ('(^|\s)' || 'роза')
ORDER BY
lower(name) ~ ('^' || 'роза') DESC -- сначала "начинающиеся на"
, lower(name) -- остальное по алфавиту
LIMIT 10;
```

[[посмотреть на explain.tensor.ru]](https://explain.tensor.ru/archive/explain/fc71844f5d1a31ba814c768d1267b2ed:0:2020-03-05)
Ну, такое… ***26мс, 31MB*** прочитанных данных и больше 1.7K отфильтрованных записей — для 10 искомых. Накладные расходы слишком велики, нельзя ли как-то поэффективнее?
#### 1.2: поиск по тексту? это же FTS!
Действительно, PostgreSQL предоставляет очень мощный [механизм полнотекстового поиска](https://postgrespro.ru/docs/postgresql/12/textsearch-controls#TEXTSEARCH-PARSING-QUERIES) (Full Text Search), в том числе с возможностью префиксного поиска. Отличный вариант, даже расширений устанавливать не нужно! Давайте попробуем:
```
CREATE INDEX ON firms USING gin(to_tsvector('simple'::regconfig, lower(name)));
```
```
SELECT
*
FROM
firms
WHERE
to_tsvector('simple'::regconfig, lower(name)) @@ to_tsquery('simple', 'роза:*')
ORDER BY
lower(name) ~ ('^' || 'роза') DESC
, lower(name)
LIMIT 10;
```
[[посмотреть на explain.tensor.ru]](https://explain.tensor.ru/archive/explain/e24fd4431d07eef55a36d1a990c6bdd1:0:2020-03-05)
Тут нам немного помогла параллелизация исполнения запроса, сократив время вдвое до ***11мс***. Да и прочитать нам пришлось в 1.5 раза меньше — всего ***20MB***. А тут чем меньше — тем лучше, ведь чем больший объем мы вычитываем, тем выше шансы получить cache miss, и каждая лишняя прочитанная с диска страница данных — потенциальные «тормоза» для запроса.
#### 1.3: все-таки LIKE?
Всем предыдущий запрос хорош, да только если его дернуть сотню тысяч раз за сутки, то набежит уже ***2TB*** прочитанных данных. В лучшем случае — из памяти, но если не повезет, то и с диска. Так что давайте попробуем сделать его поменьше.
Вспомним, что пользователь хочет видеть **сначала «которые начинаются на ...»**. Так ведь это же в чистом виде [префиксный поиск](https://postgrespro.ru/docs/postgresql/12/indexes-opclass) с помощью `text_pattern_ops`! И только если нам «не хватит» до 10 искомых записей, то дочитывать их придется с помощью FTS-поиска:
```
CREATE INDEX ON firms(lower(name) text_pattern_ops);
```
```
SELECT
*
FROM
firms
WHERE
lower(name) LIKE ('роза' || '%')
LIMIT 10;
```

[[посмотреть на explain.tensor.ru]](https://explain.tensor.ru/archive/explain/2ed3f58b4dd67a5de9b3e78938cddc8a:0:2020-03-06)
Отличные показатели — всего ***0.05мс и чуть больше 100KB*** прочитано! Только мы же забыли **сортировку по названию**, чтобы пользователь не заблудился в результатах:
```
SELECT
*
FROM
firms
WHERE
lower(name) LIKE ('роза' || '%')
ORDER BY
lower(name)
LIMIT 10;
```
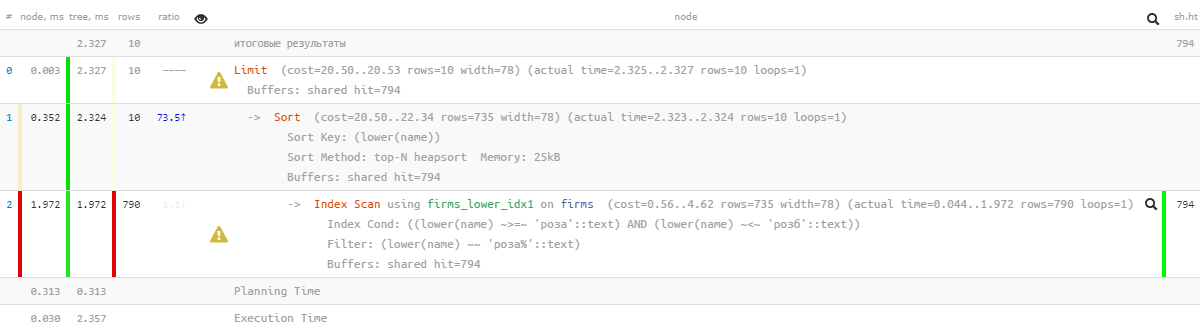
[[посмотреть на explain.tensor.ru]](https://explain.tensor.ru/archive/explain/77c8cde742f642062063242b70513a02:0:2020-03-06)
Ой, что-то уже не так красиво — вроде и индекс есть, но сортировка летит мимо него… Оно, конечно, уже в разы эффективнее, чем предыдущий вариант, но…
#### 1.4: «доработать напильником»
Но есть же индекс, который позволяет и по диапазону искать, и сортировку при этом нормально использовать — **обычный btree**!
```
CREATE INDEX ON firms(lower(name));
```
Только запрос под него придется «собирать вручную»:
```
SELECT
*
FROM
firms
WHERE
lower(name) >= 'роза' AND
lower(name) <= ('роза' || chr(65535)) -- для UTF8, для однобайтовых - chr(255)
ORDER BY
lower(name)
LIMIT 10;
```

[[посмотреть на explain.tensor.ru]](https://explain.tensor.ru/archive/explain/ab750979b310013f4bd046a28e32286f:0:2020-03-06)
Отлично — и сортировка работает, и потребление ресурсов осталось «микроскопическим», **в тысячи раз эффективнее «чистого» FTS**! Осталось собрать в единый запрос:
```
(
SELECT
*
FROM
firms
WHERE
lower(name) >= 'роза' AND
lower(name) <= ('роза' || chr(65535)) -- для UTF8, для однобайтовых кодировок - chr(255)
ORDER BY
lower(name)
LIMIT 10
)
UNION ALL
(
SELECT
*
FROM
firms
WHERE
to_tsvector('simple'::regconfig, lower(name)) @@ to_tsquery('simple', 'роза:*') AND
lower(name) NOT LIKE ('роза' || '%') -- "начинающиеся на" мы уже нашли выше
ORDER BY
lower(name) ~ ('^' || 'роза') DESC -- используем ту же сортировку, чтобы НЕ пойти по btree-индексу
, lower(name)
LIMIT 10
)
LIMIT 10;
```
Замечу, что второй подзапрос выполняется **только если первый вернул меньше ожидаемого** последним `LIMIT` количества строк. Про такой способ оптимизации запросов я [уже писал раньше](https://habr.com/post/479508/).
Таки да, мы теперь имеем на таблице одновременно btree и gin, зато статистически получилось, что **меньше 10% запросов доходят до выполнения второго блока**. То есть при таких известных заранее типичных ограничениях для задачи мы смогли уменьшить суммарное потребление ресурсов сервера практически в тысячи раз!
#### 1.5\*: обойдемся без напильника
Выше `LIKE` нам помешала использовать неправильная сортировка. Но ее можно «наставить на путь истинный» с помощью указания USING-оператора:
> По умолчанию подразумевается `ASC`. Кроме того, можно задать имя специфического оператора сортировки в предложении `USING`. Оператор сортировки должен быть членом «меньше» или «больше» некоторого семейства операторов B-дерева. `ASC` обычно равнозначно `USING <` и `DESC` обычно равнозначно `USING >`.
В нашем случае «меньше» — это `~<~`:
```
SELECT
*
FROM
firms
WHERE
lower(name) LIKE ('роза' || '%')
ORDER BY
lower(name) USING ~<~
LIMIT 10;
```
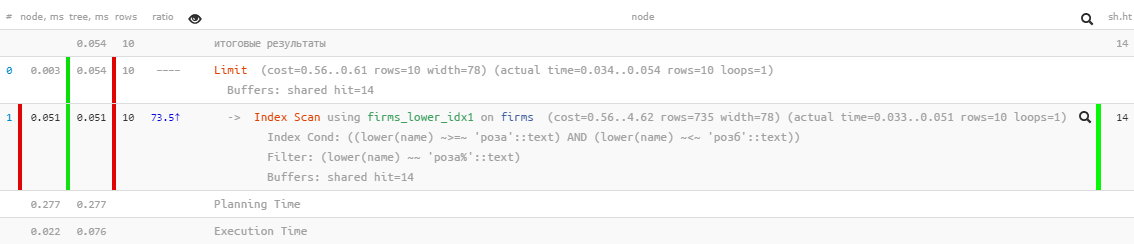
[[посмотреть на explain.tensor.ru]](https://explain.tensor.ru/archive/explain/7e9d596c3d4b40381fd328aa047d510d:0:2020-03-10)
2: как «прокисают» запросы
--------------------------
Теперь оставляем наш запрос «настояться» полгода-год, и с удивлением снова обнаруживаем его «в топе» с показателями суммарного суточного «прокачивания» памяти (*buffers shared hit*) в **5.5TB** — то есть еще больше, чем было исходно.
Нет, конечно, и бизнес у нас вырос, и нагрузка увеличилась, но не настолько же! Значит, что-то тут нечисто — давайте разбираться.
#### 2.1: рождение пейджинга
В какой-то момент другой команде разработчиков захотелось сделать возможность из быстрого подстрочного поиска «прыгнуть» в реестр с теми же, но расширенными результатами. А какой реестр без постраничной навигации? Давайте прикрутим!
```
( ... LIMIT + 10)
UNION ALL
( ... LIMIT + 10)
LIMIT 10 OFFSET ;
```
Теперь можно было без напрягов для разработчика показывать реестр результатов поиска с «типа-постраничной» подгрузкой.
Конечно, на самом-то деле, **для каждой следующей страницы данных читается все больше и больше** (все из предыдущего раза, которые отбросим, плюс нужный «хвостик») — то есть это однозначный антипаттерн. А правильнее было бы — запускать поиск на следующей итерации от запомненного в интерфейсе ключа, но про это — в другой раз.
#### 2.2: хочется экзотики
В какой-то момент разработчику захотелось **разнообразить результирующую выборку данными** из другой таблицы, для чего весь предыдущий запрос был отправлен в CTE:
```
WITH q AS (
...
LIMIT + 10
)
SELECT
\*
, (SELECT ...) sub\_query -- какой-то запрос к связанной таблице
FROM
q
LIMIT 10 OFFSET ;
```
И даже так — неплохо, поскольку вложенный запрос вычисляется только для 10 возвращаемых записей, если бы не…
#### 2.3: DISTINCT бессмысленный и беспощадный
Где-то в процессе такой эволюции из 2-го подзапроса **потерялось `NOT LIKE` условие**. Понятно, что после этого `UNION ALL` начал возвращать **некоторые записи дважды** — сначала найденные по началу строки, а потом еще раз — по началу первого слова этой строки. В пределе, все записи 2го подзапроса могли совпасть с записями первого.
Что делает разработчик вместо поиска причины?.. Не вопрос!
* **расширим вдвое размер** исходных выборок
* **наложим DISTINCT**, чтобы получились только одинарные экземпляры каждой строки
```
WITH q AS (
( ... LIMIT <2 * N> + 10)
UNION ALL
( ... LIMIT <2 * N> + 10)
LIMIT <2 * N> + 10
)
SELECT DISTINCT
*
, (SELECT ...) sub_query
FROM
q
LIMIT 10 OFFSET ;
```
То есть понятно, что результат, в итоге, ровно тот же, но шанс «пролететь» во 2-й подзапрос CTE стал сильно выше, да и без этого, **читается явно больше**.
Но это не самая печаль. Поскольку разработчик попросил отобрать **`DISTINCT` не по конкретным, а сразу по всем полям** записи, то туда автоматом попало и поле sub\_query — результат подзапроса. Теперь, для выполнения `DISTINCT`, базе пришлось выполнить уже **не 10 подзапросов, а все <2 \* N> + 10**!
#### 2.4: кооперация превыше всего!
Вот так вот, разработчики жили — не тужили, потому что в реестре «докрутить» до существенных значений N при хроническом замедлении получения каждой следующей «страницы» у пользователя явно не хватало терпения.
Пока к ним не пришли разработчики из другого отдела, и не захотели воспользоваться таким удобным методом **для итеративного поиска** — то есть берем из какой-то выборки кусочек, фильтруем по дополнительным условиям, рисуем результат, потом следующий кусочек (что в нашем случае достигается за счет увеличения N), и так пока не заполним экран.
В общем, в пойманном экземпляре **N достигло значений почти в 17K**, а всего за сутки было выполнено «по цепочке» не меньше 4K таких запросов. Последние из них смело сканировали уже по **1GB памяти на каждой итерации**…
Итого
-----
 | https://habr.com/ru/post/491162/ | null | ru | null |
# OceanLotus: обновление малвари для macOS
В марте 2019 года в VirusTotal, популярный онлайн-сервис сканирования, был загружен новый образец вредоносного ПО для macOS кибергруппы OceanLotus. Исполняемый файл бэкдора обладает теми же возможностями, что и предыдущая изученная нами версия малвари для macOS, но его структура изменилась и его стало сложнее обнаружить. К сожалению, мы не смогли найти дроппер, связанный с этим образцом, поэтому пока не знаем вектор заражения.
Недавно мы опубликовали [пост про OceanLotus](https://habr.com/post/446604/) и о том, как операторы пытаются обеспечить персистентность, ускорить выполнение кода и свести к минимуму следы присутствия в системах Windows. Известно также, что у этой кибергруппы есть и компонент для macOS. В данном посте подробно описываются изменения в новейшей версии малвари для macOS в сравнении с предыдущим вариантом ([описанным Trend Micro](https://blog.trendmicro.com/trendlabs-security-intelligence/new-macos-backdoor-linked-to-oceanlotus-found/)), а также рассказывается, как при анализе можно автоматизировать расшифровку строк с помощью IDA Hex-Rays API.

Анализ
------
В следующих трех частях описывается анализ образца с хэшем SHA-1 `E615632C9998E4D3E5ACD8851864ED09B02C77D2`. Файл называется **flashlightd**, антивирусные продукты ESET детектируют его как OSX/OceanLotus.D.
#### Антиотладка и защита от песочниц
Как все macOS-бинарники OceanLotus, образец упакован с UPX, но большинство средств идентификации упаковщиков не распознают его как таковой. Вероятно, потому, что они в основном содержат подпись, зависящую от наличия строки “UPX”, кроме того, Mach-O сигнатуры встречаются реже и не так часто обновляются. Эта особенность затрудняет статическое обнаружение. Интересно, что после распаковки точка входа находится в начале раздела `__cfstring` в сегменте `.TEXT`. В этом разделе есть атрибуты flag, как показано на рисунке ниже.
*Рисунок 1. Атрибуты раздела MACH-O \_\_cfstring*
Как показано на рисунке 2, расположения кода в разделе `__cfstring` позволяет обмануть некоторые инструменты дизассемблирования, отображая код в виде строк.

*Рисунок 2. Код бэкдора определяется IDA как данные*
После запуска бинарный файл создает поток в качестве средства защиты от отладки, единственной целью которого является постоянная проверка наличия дебаггера. Для этого поток:
* Пытается отцепить любой дебаггер, вызывая `ptrace` с `PT_DENY_ATTACH` в качестве параметра запроса
* Проверяет, открыты ли некоторые исключительные порты, вызывая функцию `task_get_exception_ports`
* Проверяет, подключен ли дебаггер, как показано на рисунке ниже, путем проверки наличия флага `P_TRACED` в текущем процессе

*Рисунок 3. Проверка подключения дебаггера посредством функции sysctl*
Если сторожевая схема обнаруживает присутствие дебаггера, вызывается функция `exit`. Кроме того, затем образец проверяет среду, выполняя две команды:
`ioreg -l | grep -e "Manufacturer" и sysctl hw.model`
После этого образец проверяет возвращаемое значение по жестко закодированному списку строк известных систем виртуализации: **acle**, **vmware**, **virtualbox** или **parallels**. Наконец, следующая команда проверяет, является ли машина одной из следующих “MBP”, “MBA”, “MB”, “MM”, “IM”, “MP” and “XS”. Это коды модели системы, например, “MBP” означает MacBook Pro, “MBA” – MacBook Air и т. д.
`system_profiler SPHardwareDataType 2>/dev/null | awk '/Boot ROM Version/ {split($0, line, ":");printf("%s", line[2]);}`
#### Основные дополнения
Несмотря на то, что команды бэкдора не изменились со времен исследования Trend Micro, мы заметили несколько других модификаций. C&C-серверы, используемые в этом образце, довольно новые, дата их создания – 22.10.2018.
* **daff.faybilodeau[.]com**
* **sarc.onteagleroad[.]com**
* **au.charlineopkesston[.]com**
Ресурс URL изменился на `/dp/B074WC4NHW/ref=gbps_img_m-9_62c3_750e6b35`.
Первый пакет, отправляемый на C&C-сервер, содержит больше информации о хост-машине, включая все данные, собираемые командами из таблицы ниже.

Помимо этого, изменения конфигурации, образец использует для сетевой фильтрации не библиотеку [libcurl](https://curl.haxx.se/libcurl/), а внешнюю библиотеку. Чтобы найти ее, бэкдор пытается расшифровать каждый файл в текущем каталоге, используя AES-256-CBC с ключом `gFjMXBgyXWULmVVVzyxy`, дополненным нулями. Каждый файл расшифровывается и сохраняется как `/tmp/store`, а попытка его загрузить как библиотеку сделана с использованием функции [dlopen](https://developer.apple.com/library/archive/documentation/System/Conceptual/ManPages_iPhoneOS/man3/dlopen.3.html). Когда попытка расшифровки приводит к успешному вызову `dlopen`, бэкдор извлекает экспортированные функции `Boriry` и `ChadylonV`, которые, по всей видимости, отвечают за сетевое взаимодействие с сервером. У нас нет дроппера или других файлов из исходного местоположения образца, поэтому мы не можем проанализировать эту библиотеку. Более того, поскольку компонент зашифрован, YARA-правило, основанное на этих строках, не будет соответствовать файлу, найденному на диске.
Как описано в вышеупомянутой статье, создается *cliendID*. Этот идентификатор является хешем MD5 возвращаемого значения одной из следующих команд:
— `ioreg -rd1 -c IOPlatformExpertDevice | awk '/IOPlatformSerialNumber/ { split($0, line, "\""); printf("%s", line[4]); }'`
— `ioreg -rd1 -c IOPlatformExpertDevice | awk '/IOPlatformUUID/ { split($0, line, "\""); printf("%s", line[4]); }'`
— `ifconfig en0 | awk \'/ether /{print $2}\'` (получить MAC адрес)
— неизвестная команда ("`\x1e\x72\x0a`"), которая используется в предыдущих образцах
Перед хешированием к возвращаемому значению добавляется символ «0» или «1», указывающий на наличие root привилегий. Этот *clientID* хранится в `/Library/Storage/File System/HFS/25cf5d02-e50b-4288-870a-528d56c3cf6e/pivtoken.appex`, если код запущен от root или в ~/Library/SmartCardsServices/Technology/PlugIns/drivers/snippets.ecgML во всех остальных случаях. Файл обычно скрыт с помощью функции [\_chflags](https://developer.apple.com/library/archive/documentation/System/Conceptual/ManPages_iPhoneOS/man2/chflags.2.html), его временная метка изменяется с помощью команды `touch –t` со случайным значением.
#### Расшифровка строк
Как и в предыдущих вариантах, строки зашифрованы с использованием AES-256-CBC (шестнадцатеричный ключ: `9D7274AD7BCEF0DED29BDBB428C251DF8B350B92` дополнен нулями, а IV заполнен нулями) посредством функции [CCCrypt](https://developer.apple.com/library/archive/documentation/System/Conceptual/ManPages_iPhoneOS/man3/CCCrypt.3cc.html). Ключ изменен в сравнении с предыдущими версиями, но, поскольку группа все еще использует тот же алгоритм шифрования строк, расшифровка может быть автоматизирована. Помимо этого поста мы выпускаем скрипт IDA, использующий API Hex-Rays для расшифровки строк, присутствующих в бинарном файле. Этот скрипт может помочь в будущем анализе OceanLotus и анализе существующих образцов, которые мы пока не смогли получить. В основе сценария – универсальный метод получения аргументов, переданных функции. Кроме того, он ищет назначения параметров. Метод можно использовать повторно, чтобы получить список аргументов функции и затем передать на обратный вызов (callback).
Зная прототип функции *decrypt*, скрипт находит все перекрестные ссылки на эту функцию, все аргументы, затем расшифровывает данные и помещает простой текст внутри комментария по адресу перекрестной ссылки. Чтобы скрипт работал правильно, в нем должен быть установлен пользовательский алфавит, используемый функцией декодирования base64, и должна быть определена глобальная переменная, содержащая длину ключа (в данном случае DWORD, см. рисунок 4).

*Рисунок 4. Определение глобальной переменной key\_len*
В окне Function можно вызвать правой кнопкой мыши функцию расшифровки и кликнуть «Извлечь и расшифровать аргументы». Сценарий должен помещать расшифрованные строки в комментарии, как показано на рисунке 5.

*Рисунок 5. Расшифрованный текст помещен в комментарии*
Таким образом расшифрованные строки удобно размещаются вместе в окне IDA *xrefs* для этой функции, как показано на рисунке 6.
*Рисунок 6. Xrefs to функции f\_decrypt*
Финальный вариант сценария можно найти на [Github repository](https://github.com/eset/malware-research/tree/master/oceanlotus/).
Вывод
-----
Как уже было сказано, OceanLotus постоянно совершенствуют и обновляют свой набор инструментов. На этот раз кибергруппа усовершенствовала вредоносное ПО для работы с Мас-пользователями. Код не сильно изменился, но, поскольку многие Мас-пользователи игнорируют продукты для безопасности, защита малвари от обнаружения имеет второстепенное значение.
Продукты ESET уже детектировали этот файл на момент исследования. Поскольку сетевая библиотека, используемая для C&C-коммуникации, теперь зашифрована на диске, точный сетевой протокол, используемый атакующими, пока неизвестен.
Индикаторы компрометации
------------------------
Индикаторы компрометации, а также атрибуты MITRE ATT&CK также доступны на [GitHub](https://github.com/eset/malware-research/tree/master/oceanlotus/). | https://habr.com/ru/post/447530/ | null | ru | null |
# Подключаем устройства Intel для интернета вещей к Microsoft Azure IoT Suite
Если подключить устройства для IoT, основанные на микроконтроллерах Intel, к PAAS-решению Microsoft Azure IoT Suite, получится среда для реализации бесчисленного множества проектов в области интернета вещей. Сегодня мы расскажем об особенностях Azure IoT Suite и поговорим о том, как связывать с этим набором облачных служб Intel Edison, Intel Curie и шлюзы от Intel.
[](https://habrahabr.ru/company/intel/blog/267815/)
Azure IoT Suite и Microsoft Azure
---------------------------------
Azure – это открытая, гибкая облачная вычислительная платформа корпоративного класса. Она представляет собой постоянно развивающийся комплекс интегрированных сервисов, таких, как службы аналитики, средства для работы с базами данных и сетевые инструменты. Azure поддерживает работу с мобильными системами и хранилищами данных, позволяет создавать сложные веб-проекты. Одна из особенностей Azure – возможность быстрого масштабирования. То есть, если проекту, на некотором этапе его развития, понадобится больше мощности, он её получит.
Microsoft предлагает набор инструментов Azure IoT Suites, который является частью предварительно сконфигурированных IoT-решений компании, построенных на базе Azure. Такой подход упрощает, в частности, безопасное подключение «вещей» к облаку.
Широкий набор протоколов, который поддерживает Azure и набор IoT-сервисов из Azure IoT Suites позволяют быстро создавать приложения для интернета вещей. IoT-сервисы дают разработчику возможность собирать данные с устройств, анализировать потоки информации в реальном времени, хранить большие наборы данных и работать с ними, производить анализ и визуализацию как данных в реальном времени, так и исторических сведений.
Сервисы, о которых мы говорим, включают в себя следующее:
* Azure IoT Hub – точка подключения для IoT-устройств.
* Azure Machine Learning – система машинного обучения.
* Azure Stream Analytics –средство обработки потоковой информации.
* Azure Notification Hubs – концентраторы уведомлений.
* Microsoft Power BI – набор средств бизнес-аналитики.
Их можно комбинировать с другими возможностями Azure, такими, как хранилища BLOB-объектов и когнитивные сервисы, что позволяет, например, строить интеллектуальные IoT-приложения.
**Azure IoT Hub** – это среда для организации двунаправленного обмена данными между устройствами и облаком. Данный сервис предоставляет такие возможности, как управление устройствами и их идентификацию, обеспечение безопасности. Он поддерживает протоколы MQ Telemetry Transport (MQTT), HTTP и Advanced Message Queuing Protocol (AMQP). Azure IoT Hub предоставляет полный доступ к устройству через собственный реестр. Он поддерживает аутентификацию устройств и безопасный двунаправленный обмен данными между ними и облаком. Сервис так же можно интегрировать с собственным реестром устройств с помощью службы удостоверений, можно создавать идентификаторы устройств и организовывать защищённые каналы связи.
Кроме того, Azure IoT Hub предоставляет локальное хранилище сообщений и выделенную очередь сообщений для каждого подключённого устройства, что позволяет безопасно работать с сообщениями. Это избавляет от лишней работы по созданию отдельных очередей отправки сообщений на устройства.
**Azure Machine Learning** даёт разработчику графические инструменты для построения моделей машинного обучения. Система поддерживает специализированные пакеты R и Python. Предварительно подготовленные алгоритмы позволяют добавлять в систему собственный код и строить модели, соответствующие нуждам конкретного проекта.
**Azure Stream Analytics** предоставляет возможности обработки потоков данных в реальном времени. Речь идёт о миллионах событий в секунду. Это позволяет сравнивать и согласовывать множество потоков, работать с данными, используя SQL, создавать информационные панели, настраивать напоминания.
**Azure Notifications Hub** предоставляет универсальный интерфейс для отправки push-уведомлений на мобильные устройства.
**Power BI** – это облачная служба, которая, в тесном взаимодействии с другими инструментами Microsoft, позволяет визуализировать и анализировать данные с помощью мощных и гибких средств. Например, Azure Stream Analytics может поставлять данные Power BI, после чего они, в реальном времени, выводятся на информационную панель, предназначенную для дальнейшей работы с поступившей в систему информацией.
Способы взаимодействия Azure и удалённых устройств
--------------------------------------------------
Как уже было сказано, Azure IoT Hub поддерживает протоколы HTTP, AMQP, и MQTT. Взаимодействие между устройствами Intel (да и любыми другими IoT-устройствами) и Azure должно осуществляться только с использованием этих протоколов.
MQTT это нетребовательный к ресурсам способ обмена сообщениями (Message Oriented Middleware, MOM), основанный на модели издатель – подписчик. Протокол разработан для связи между устройствами в условиях, когда объём передаваемых данных невелик.
Модель издатель – подписчик включает в себя брокера, который служит посредником между клиентами, заинтересованными в обмене сообщениями. Взаимодействие основано на использовании так называемых тем – именованных логических каналов связи.
Клиент может действовать в роли подписчика и получать сообщения, опубликованные в некоторой теме. Если клиент играет роль издателя, он публикует сообщения, так же указывая тему. В контексте IoT, устройства, для приёма или отправки сообщений, подключаются к центральному MQTT-брокеру по TCP.
MQTT широко используется в устройствах, ресурсы которых ограничены, а также в сетях, где необходимо обеспечить как можно меньшую нагрузку на инфраструктуру. [Вот материал](https://habrahabr.ru/company/intel/blog/304228/), из которого можно узнать подробности об этом протоколе.
AMQP – ещё один популярный способ обмена сообщениями. Протокол поддерживает модель, основанную на запросах, а также, как и MQTT, модель издатель – подписчик. Кроме того, сообщения могут обрабатываться в рамках транзакций. AMQP работает поверх TCP и предоставляет средства для надёжной доставки сообщений.
Протокол AMQP, кроме того, благодаря использованию AMQP-серверов, позволяет организовывать связь между самыми разными клиентскими системами, созданными на базе различных аппаратных и программных платформ.
С точки зрения IoT, например, это означает, что некие сенсоры, генерирующие данные, могут отправлять их AMQP-серверу (в необработанном или обработанном виде), а эти данные затем передаются другим системам для мониторинга и анализа.
Azure IoT Hub предоставляет вспомогательные SDK для работы с устройствами, рассчитанные на Linux, Windows, операционные системы реального времени. Это значительно упрощает развёртывание соответствующих клиентов на различных устройствах и подключение их к Azure IoT Hub. Однако, применение SDK необязательно. Производители устройств могут использовать соответствующие API для того, чтобы встраивать в свои изделия программные модули, необходимые для подключения к платформе Azure. Например, это JavaScript-API для платы Intel Edison или оптимизированные C-библиотеки для Linux-устройств. Вышеупомянутые SDK можно найти [здесь](https://github.com/Azure/azure-iot-sdks).
Вот схема взаимодействия IoT-устройств с Azure IoT Hub.

*Подключение IoT-устройств Intel к Azure IoT Hub с использованием протоколов AMQP или MQTT*
Подключение платы Intel Edison к Azure IoT Hub
----------------------------------------------
Для того, чтобы подключить Intel Edison к Microsoft Azure IoT Hub, можно воспользоваться одной из библиотек (на C, на JavaScript для Node.js, или на Java) из Azure IoT SDK. Для целей разработки и отладки нужно будет загрузить подходящую IDE. Например, Intel XDK IoT Edition подойдёт для JavaScript, Intel System Studio IoT Edition можно использовать для разработки на C и C++. Java-программисты могут работать в среде Intel System Studio IoT Edition, которая рассчитана на Java. Если планируется писать для Edison Arduino-скетчи, можно взять Arduino IDE.
После того, как выбор сделан, соответствующие библиотеки из Azure IoT SDK можно интегрировать в собственный код, подключить устройство к облаку и организовать обмен данными. Например – передавать в Azure показатели датчиков.
Ещё одна возможность подключения устройства к облаку – сгенерировать код для вставки в собственные приложения с помощью страницы [Подключение устройства к центру Azure IoT](https://azure.microsoft.com/ru-ru/develop/iot/get-started/). Вот, как ведётся работа с этой страницей:
1. В разделе **Выбор устройства** нужно щёлкнуть по значку **Intel Edison**.
2. В разделе **Выбор платформы** – по значку **Linux**.
3. В разделе **Выбор языка** надо выбрать ту закладку, которая соответствует нужному языку программирования. Здесь доступны C, C#, JavaScript и Java.
Система сгенерирует код для заданного устройства, платформы и языка. В переменной `connectionString` должно находиться значение, соответствующее учётной записи разработчика в Azure IoT Hub. О параметрах, которые должны присутствовать в этой переменной, можно узнать на портале Azure.
Для того, чтобы взаимодействовать с датчиками и актуаторами, подключёнными к Edison, Intel предоставляет библиотеку Libmraa. Эта библиотека создаёт уровень абстракции поверх поддерживаемого аппаратного обеспечения. В результате можно организовать удобную работу с устройствами, подключёнными к плате. Например, читать показания датчиков. Кроме того, библиотека подходит для создания приложений, рассчитанных на разные платформы.
После того, как показания датчиков были прочитаны, их можно передать в Azure IoT Hub с использованием протоколов AMQP или MQTT. Обычно данные конвертируют в некий удобный для работы формат, вроде JSON, и пересылают с использованием клиентской библиотеки Azure IoT Hub. Если у устройства есть такая возможность, оно может подключиться напрямую к интернету и к Azure IoT Hub посредством Wi-Fi или по Ethernet. Ещё один вариант – подключение к шлюзу Intel, который, в свою очередь, связан с Azure.
Подключение вычислительного модуля Intel Curie к Azure IoT Hub
--------------------------------------------------------------
Модуль Intel Curie использует интегральную систему Intel Quark. Это – экономичное решение для создания носимых устройств, потребительской и промышленной электроники. В Intel Curie встроен 6-осевой комбинированный сенсор, объединяющий гироскоп и акселерометр, энергоэффективный Bluetooth-передатчик. Это делает Curie идеальным выбором для создания устройств, которые должны быть постоянно включены, например – приборов для контроля физической формы и показателей жизнедеятельности организма.
Для того, чтобы приступить к прототипированию устройств и созданию приложений, можно использовать соответствующую Arduino-совместимую плату – Genuino 101 (Arduino 101). Такие платы поставляются вместе с Intel Curie. Для разработки Arduino-скетчей используется Arduino IDE. Здесь, в частности, можно создать приложение, которое будет получать сведения с датчиков, подключённых к плате.
Эти сведения можно передать в Azure IoT Hub. Один из вариантов подключения к интернету устройств, основанных на Intel Curie, заключается в следующем. Устройство соединяется по Bluetooth со смартфоном, который, в свою очередь, подключён к интернету через сотовую сеть или по Wi-Fi. В результате данные с устройства можно передать в Azure. Существуют специальные [библиотеки](https://www.arduino.cc/en/Reference/CurieBLE) поддержки Bluetooth для Intel Curie. Они значительно облегчают взаимодействие с другими устройствами, поддерживающими Bluetooth.
Ещё один вариант подключения платы к Azure заключается в работе с облачным сервисом через шлюз Intel для интернета вещей.
Способы взаимодействия Intel Curie с Azure не исчерпываются вышеперечисленными вариантами. Так, например, можно подключить Curie к интернету напрямую, использовав плату расширения Wi-Fi. Способ подключения устройства к интернету зависит от особенностей конкретного проекта.
Программная экосистема Intel Curie постоянно развивается, в частности, ведется работа над ОС реального времени для этого модуля. На [этой странице](https://software.intel.com/en-us/iot/hardware/curie) можно узнать подробности и подписаться на новости проекта.
Подключение шлюзов Intel к Azure IoT Hub
----------------------------------------
Шлюзы Intel для интернета вещей применяются, в основном, в ситуациях, когда устройства не могут напрямую подключиться к Azure IoT Hub. Такое случается при несовместимости поддерживаемых протоколов, или если данные с устройств нужно, перед отправкой в облако, обработать, например – отфильтровать или оперативно проанализировать на месте их сбора. Кроме того, шлюз может использоваться в тех случаях, когда к сетям передачи данных предъявляются особые требования, например, касающиеся безопасности.
Проблема с несовместимыми протоколами встречается особенно часто при подключении к облачным службам устройств, которые уже работают в неких проектах, например – в промышленных системах или в комплексах домашней автоматизации, вроде «умного дома».
Подобные устройства обычно используют узкоспециализированные протоколы, такие, как ZigBee или ZWave. Напрямую к Azure IoT Hub эти устройства не подключить, а вот с помощью шлюза можно собрать с них данные и отправить в облако с использованием подходящего протокола.
Для организации связи шлюзов Intel с Azure IoT Hub можно воспользоваться одной из библиотек Azure IoT SDK. В частности, доступны библиотеки для C, C++, Python, JavaScript, Java. Настройка шлюза на работу с Azure очень похожа на подключение к облаку Intel Edison.
О разработке IoT-приложений с использованием Azure IoT Hub и сервисов Azure
---------------------------------------------------------------------------
Когда данные с устройства оказались в Azure IoT Hub, можно начать работать с ними. Например – визуализировать. Обычно другие сервисы Azure используют данные из Azure IoT Hub для дальнейшей обработки.
Скажем, можно создать сервис Azure Stream Analytics, обращение к которому производится после того, как данные поступили в Azure IoT Hub. Этот сервис будет использовать заданные правила для фильтрации и обработки поступивших от устройства данных, используя SQL-подобные запросы и выводя результаты в хранилище (например, в Azure Blob), передавая их Azure Event Hubs или даже в Power BI для визуализации.
Azure Event Hubs работает как центральный узел обработки данных, где множество обработчиков событий могут получать сообщения от главного сервиса и выполнять требуемые действия. Например, обработчики событий могут вызывать сервис Azure Machine Learning для анализа отфильтрованных данных и прогнозирования на их основе неких будущих показателей, а другой обработчик может обращаться к Azure Notification Hub для отправки уведомлений на мобильные устройства.
Итоги
-----
Мы рассказали о наборе сервисов Microsoft Azure IoT Suite и о том, как подключать к ним устройства Intel для интернета вещей
Когда данные оказываются в облаке, приходит время работать с ними. В частности, благодаря обширной интегрированной инфраструктуре, можно быстро создавать IoT-приложения, комбинируя различные сервисы Azure и реализуя IoT-проекты любой сложности. | https://habr.com/ru/post/267815/ | null | ru | null |
# Программируем Windows 7: Taskbar. Часть 1 — Progress Bar
Новая операционная система Windows 7 содержит большое количество нововведений и улучшений. Эти улучшения касаются безопасности, производительности, надежности и т.д. Серьезное внимание также уделено и пользовательскому интерфейсу. Для разработчиков ПО на платформе Windows новая ОС также представляет интерес, т.к. в ней содержатся элементы, на которые можно воздействовать программно. В течении нескольких постов мы поговорим об основных нововведениях и программной модели для них.

Первое что бросается в глаза при работе с Windows 7 – это, конечно, обновленный task bar. В новом taskbar’е действительно много концептуальных изменений. Одно из таких изменений – возможность отображения прогресса выполнения задачи (progress bar).
На этом рисунке хорошо видно, что прямо на панели задач отображается информация о процессе копирования. Такая функциональность реализована в Windows 7 для копирования файлов на диске, загрузке данных из сети (IE8). Однако, важно, что эту функциональность мы можем использовать и для своих приложений. Сценариев может быть огромное количество – отображение процесса преобразования, копирования, формирования данных, построение отчетов, генерация изображений, и т.д.
С точки зрения разработчика клиентских приложений для Windows, процесс использования данной функциональности представляется достаточно просто. Взаимодействие с ОС происходит на unmanaged уровне, поэтому для .NET приложений необходима реализация управляемых оберток. Всю эту работу уже проделали разработчики из Microsoft и поместили это в библиотеку [.NET Interop Sample Library](http://blogs.gotdotnet.ru/personal/sergun/ct.ashx?id=08a1e197-64b1-477a-8f40-9343c06776e6&url=http%3a%2f%2fcode.msdn.microsoft.com%2fWindows7Taskbar%2fRelease%2fProjectReleases.aspx%3fReleaseId%3d2246).
Библиотека .NET Interop Sample Library состоит из множества компонентов и демонстрационных приложений. Мы не будем подробно останавливаться на каждом из них. Для нас важно, что в ее состав входит Vista Bridge Sample Library, Windows7.DesktopIntegration и Windows7.DesktopIntegration.Registration.
Проект “Windows7.DesktopIntegration” содержит те классы, которые необходимы нам для работы с taskbar’ом. В составе этого проекта есть класс WindowsFormsExtensions, который содержит набор методов расширения (extension methods) для класса Form (Windows Forms). В нашем случае нас интересуют сдледующие методы:
* SetTaskbarProgress(float percent)
* SetTaskbarProgressState(ThumbnailProgressState state)
Вызов первого метода позволяет указать процент выполнения текущей задачи. Т.к. это методы расширения для класса Form, то этот класс передается в метод в качестве параметра. Это необходимо для того, чтобы определить handle окна, для которого выполняются действия.
`// процесс выполнения = 35%
// вызов метода расширения
WindowsFormsExtensions.SetTaskbarProgress(this, 35);
// или так
(this = Form)this.SetTaskbarProgress(35);`
У нас также имеется возможность указать состояние прогресс-бара. Доступные состояния:
* NoProgress – прогресс не отображается
* Indeterminate – прогресс бар постоянно мерцает
* Normal – обычное отображение прогресса
* Error – отображение ошибки
* Paused – отображение паузы
* Задание состояние прогресс-бара осуществляется при помощи второго метода.
`WindowsFormsExtensions.SetTaskbarProgressState(this, Windows7Taskbar.ThumbnailProgressState.Normal);
// или так
this.SetTaskbarProgressState(Windows7Taskbar.ThumbnailProgressState.Normal);`
К сожалению, методы расширения существуют только для WinForms приложений. Однако, несложно построить подобный класс и для WPF приложений (см. демо-приложение).
В итоге я собрал небольшое приложение, которое демонстрирует возможности прогресс-бара в панели задач Windows 7. Выглядит оно следующим образом.

С помощью управляющих кнопок мы можем указать текущее значение прогресс-бара, а также можем выбрать его состояние.
* Режим “Normal”

* Режим “Indeterminate”

* Режим “Error”

* Режим “Paused”

Удачи вам в разработке ваших приложений для Windows 7!
Демонстрационное приложение:
[Taskbar-Progress.zip](http://blogs.gotdotnet.ru/personal/sergun/ct.ashx?id=08a1e197-64b1-477a-8f40-9343c06776e6&url=http%3a%2f%2fblogs.gotdotnet.ru%2fpersonal%2fsergun%2fcontent%2fbinary%2fWindowsLiveWriter%2fWindows7Taskbar.1Progressbar_11A60%2fTaskbar-Progress.zip) | https://habr.com/ru/post/59856/ | null | ru | null |
# IncrediBuild: Как ускорить сборку и анализ вашего проекта
*"Да сколько ты ещё будешь собирать?"* - фраза, которую каждый разработчик произносил хотя бы раз посреди ночи. Да, сборка бывает долгой и от этого никуда не деться. Нельзя же просто так взять и распараллелить всё это дело не на каких-то жалких 8 – 12 ядер, а так, чтобы на 100+. Или всё-таки можно?
Мне нужно больше ядер!
----------------------
Как вы могли заметить, речь сегодня пойдёт как раз о том, как можно ускорить компиляцию. И нет, в этот раз будут рассмотрены не какие-то специфичные механизмы, а самое обычное распараллеливание. Ну, тут всё, казалось бы, просто – выставляем доступное физически количество ядер, нажимаем на build и идём пить условный чай.
Но с ростом кодовой базы время компиляции постепенно растёт и однажды оно станет настолько большим, что полностью проект будет собираться разве что ночью. Поэтому нужно подумать о том, как бы всё это ускорить. Вокруг же сидят довольные коллеги, которые занимаются своими программистскими делами, а их машины тихо и не напрягаясь выводят немного текста на экраны...
*"Взять бы у этих бездельников ядра"* - могли вы подумать. И правильно бы сделали, ведь это вполне себе можно реализовать. Но не нужно, конечно, принимать мои слова близко к сердцу и вооружаться паяльником. Впрочем, это уже на ваше усмотрение :)
Отдай!
------
Так как реквизировать машины коллег нам вряд ли кто-либо даст, будем пользоваться обходными путями. Даже если у вас и получилось убедить своих коллег поделиться железом, всё равно пользы от лишних процессоров у вас не будет, разве что можете выбрать себе тот, который пошустрее. А нам нужно то решение, которое каким-то образом позволит запускать дополнительные потоки сборки на удалённых машинах.
Благо среди тысяч категорий всякого полезного ПО, затесалась и нужная нам - [система распределённой сборки](https://ru.wikipedia.org/wiki/%D0%90%D0%B2%D1%82%D0%BE%D0%BC%D0%B0%D1%82%D0%B8%D0%B7%D0%B0%D1%86%D0%B8%D1%8F_%D1%81%D0%B1%D0%BE%D1%80%D0%BA%D0%B8). Программы этой категории делают именно то, что нам было и нужно: выдают на время простаивающие ядра коллег и при этом делают это ~~без их ведома~~ в автоматическом режиме. Разве что сперва нужно будет поставить всё это на их машины, но об этом немного позже...
На ком будем проверять?
-----------------------
Для того, чтобы убедиться, что всё функционирует действительно хорошо, нужно было найти качественного подопытного. Так как у нас уже не раз были в статьях и [Chromium](https://www.viva64.com/ru/b/0552/) и [Linux](https://www.viva64.com/ru/b/0460/), а выделиться как-то хотелось, нужно было найти что-нибудь новое... Поэтому я пошёл в сторону открытых игр (а где же ещё искать большие проекты?). И как вы увидите ниже, очень пожалел об этом решении.
Впрочем, поиск чего-то объёмного труда не составил, да и мне "повезло" повстречать открытый проект на Unreal Engine. Вдуматься только! Я действительно до момента написания этой статьи и подумать не мог, что на UE бывает Open Source.
Итак, герой этой статьи: [Unreal Tournament](https://github.com/EpicGames/UnrealTournament). Только вы не спешите сразу переходить по ссылке, так как вам может понадобиться пара дополнительных кликов - подробности \*[тут](https://www.unrealengine.com/en-US/ue4-on-github)\*.
Да будет сборка на 100+ ядер!
-----------------------------
В качестве примера [системы распределённой сборки](https://ru.wikipedia.org/wiki/%D0%90%D0%B2%D1%82%D0%BE%D0%BC%D0%B0%D1%82%D0%B8%D0%B7%D0%B0%D1%86%D0%B8%D1%8F_%D1%81%D0%B1%D0%BE%D1%80%D0%BA%D0%B8) я, пожалуй, остановлюсь на [IncrediBuild](https://www.incredibuild.com/). Не то, чтобы у меня был большой выбор - у нас была уже лицензия IncrediBuild на 20 машин. Нет, есть, конечно, открытый [distcc](https://github.com/distcc/distcc), но он не так прост в настройке, да и к тому же практически все машины у нас под Windows.
Итак, первым делом нужно поставить агентов на машины других разработчиков. Есть два способа:
* попросить коллег в местном Slack;
* воззвать к силам сисадмина.
Разумеется, как и любой другой наивный человек, я написал сперва в Slack... Спустя пару дней еле-еле дошло до 12 машин из 20. После этого я воззвал к силам сисадмина и, о чудо, заветная двадцатка была у меня в руке. Так что теперь у меня было около 145 ядер (+/- 10) :)
За исключением необходимости поставить агентов (делается это парой кликов в установщике), нужно было поставить себе координатора. Это делается немного сложнее, поэтому оставлю [ссылку на доки](https://incredibuild.atlassian.net/wiki/spaces/IUM/pages/1498185796/Installing+the+Coordinator+with+an+Agent).
Итак, у нас теперь есть сетка на стероидах, поэтому пришло время добраться до Visual Studio. Выбираем в плагине сборку... А вот и нет :)
Если вдруг вы и сами захотите попробовать, то учтите, что сперва нужно собрать проекты *ShaderCompileWorker* и *UnrealLightmass*. Так как они не большие, я собрал их локально. Вот теперь уже можно нажать на заветную кнопку:
Итак, какая же получилась разница?
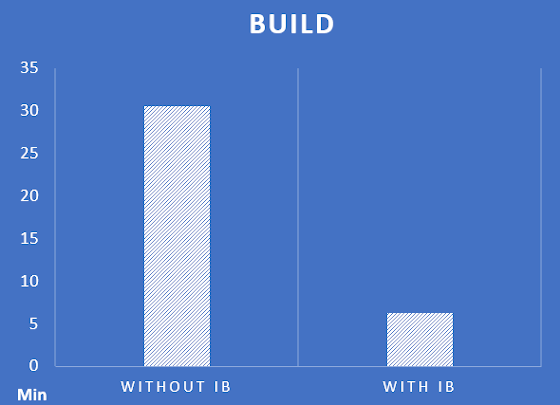Как видите, нам удалось ускорить сборку с 30 минут до почти 6! Очень даже нехило. Кстати, запуск проводился посреди рабочего дня, так что примерно таких цифр можно ожидать и не на синтетическом тесте. Впрочем, от проекта к проекту разница может быть разной.
Что ещё можно ускорить?
-----------------------
Помимо сборки можно натравить IncrediBuild на любую тулзу, которая плодит много подпроцессов. Как вы, может, обратили внимание, я работаю в PVS-Studio. Поэтому конечно же я не могу обойти стороной возможность скормить ему и наш анализатор.
Профит в быстром анализе примерно такой же, как и в быстрой сборке: возможность локальных прогонов перед коммитом. Конечно, всегда есть желание залить всё сразу в мастер; но обычно тимлид бывает не в восторге от подобных действий, особенно когда валятся ночные прогоны на сервере... Поверьте мне – я валил :(
Настраивать особенно анализатор не нужно, разве что нам не повредит указать старые-добрые 145 потоков в настройках:
Ну и стоит указать местной сборочной системе кто тут анализатор:
*Подробности \**[*тут*](https://www.viva64.com/ru/b/0666)*\**
Итак, пришло время нажать на сборку ещё раз и насладиться ускорением:
Вышло около семи минут, что подозрительно похоже на время сборки... Тут я и подумал, что видимо забыл добавить флаг. Зашёл в настройки и увидел, что всё на месте... Такого я не ожидал, поэтому отправился курить мануалы.
Попытка запуска PVS-Studio #2
-----------------------------
Спустя какое-то время я вспомнил про версию Unreal Engine, которая используется в этом проекте:
Не то, чтобы это плохо само по себе, но флаг -StaticAnalyzer появился много позже. Поэтому интегрироваться напрямую не то, чтобы было возможно. Примерно на этом моменте я уже начал задумываться о том, чтобы забить на всё это дело и уйти пить кофе.
После пары кружек бодрящего напитка у меня возникла мысль всё-таки дочитать [туториал по интеграци](https://www.viva64.com/ru/b/0666/)и до конца. Помимо указанного выше способа есть ещё и мониторинг компиляции. Это как раз тот вариант, когда ничего уже не помогает.
Первым делом включим сервер мониторинга:
```
CLMonitor.exe monitor
```
Эта штука будет крутиться на фоне и следить за ~~тобой~~ вызовами компилятора. Но она не может отслеживать происходящее в IncrediBuild, поэтому придётся один раз собрать без него.
На фоне предыдущего запуска локальная пересборка выглядит очень бедно:
```
Total build time: 1710,84 seconds (Local executor: 1526,25 seconds)
```
Теперь сохраним то, что насобирали в отдельный файл:
```
CLMonitor.exe saveDump -d dump.gz
```
Дальше можно будет пользоваться этим дампом, пока вы не добавите новый файл в проект. Да, это не так удобно, как с флагом, но ничего не поделаешь – версия движка слишком старая.
Сам же анализ запускается вот этой командой:
```
CLMonitor.exe analyzeFromDump -l UE.plog -d dump.gz
```
Только не стоит его так запускать, ведь мы же хотим его запустить под IncrediBuild. Так что закинем эту команду в *analyze.bat.* И создадим рядом файл *profile.xml*:
```
xml version="1.0" encoding="UTF-8" standalone="no" ?
```
*Подробности \**[*тут*](https://www.viva64.com/ru/m/0041/)*\**
И теперь мы можем запустить всё с нашими 145-ю ядрами:
```
ibconsole /command=analyze.bat /profile=profile.xml
```
И как это выглядит в Build Monitor:
Что-то много ошибок на этом графике, не так ли? К нам закралась ещё одна проблема. И в этот раз дело не в то, что кто-то что-то не поддерживает. Сборка Unreal Tournament оказалась несколько специфичной.
Попытка запуска PVS-Studio #3
-----------------------------
Если посмотреть внимательно, то это не ошибки анализа, а [неудачи при препроцессировании исходников](https://www.viva64.com/ru/w/v008/). Причём, причина данного фейла была одна и та же:
```
....\Build.h(42): fatal error C1189: #error: Exactly one of [UE_BUILD_DEBUG \
UE_BUILD_DEVELOPMENT UE_BUILD_TEST UE_BUILD_SHIPPING] should be defined to be 1
```
Так в чём проблема? Всё довольно просто – препроцессор требует, чтобы только один из следующих макросов имел значение 1:
* UE\_BUILD\_DEBUG;
* UE\_BUILD\_DEVELOPMENT;
* UE\_BUILD\_TEST;
* UE\_BUILD\_SHIPPING.
Да, вроде как всё собиралось раньше, а теперь что-то страшное вылетело. Пришлось закопаться в логи, а точнее в дамп компиляции. Там-то проблема и нашлась. Дело было в том, что эти макросы объявляются в местном *precompile header*, а мы хотим только препроцессировать. Так что пришлось добавить все эти макросы вручную:
```
#ifdef PVS_STUDIO
#define _DEBUG
#define UE_BUILD_DEVELOPMENT 1
#define WITH_EDITOR 1
#define WITH_ENGINE 1
#define WITH_UNREAL_DEVELOPER_TOOLS 1
#define WITH_PLUGIN_SUPPORT 1
#define UE_BUILD_MINIMAL 1
#define IS_MONOLITHIC 1
#define IS_PROGRAM 1
#define PLATFORM_WINDOWS 1
#endif
```
*Самое начало файла build.h*
И уже с этим небольшим ~~костылём~~ элегантным решением можно запустить анализ. Причём сборка не сломается, так как мы воспользовались макросом PVS\_STUDIO.
Итак, долгожданные результаты анализа:
Согласитесь, почти 15 минут вместо двух с половиной часов – это очень хорошее ускорение. Сложно представить, чтобы вы могли пить кофе 2 часа к ряду и ни у кого не возникло бы сомнений на ваш счёт. А вот 15 минутный перекур вопросов не вызывает. Наверно...
И что у нас в итоге?
--------------------
Разумеется, что в идеальном мире увеличение количества потоков в *N* раз увеличило бы скорость сборки в *N* раз. Но живём мы в совершенно ином мире, поэтому стоит учитывать локальную нагрузку на агентов (удалённые машины), нагрузку на сеть, время на организацию всего этого дела и ещё много деталей, которые скрыты под капотом.
Впрочем, ускорение действительно есть и местами оно позволяет не просто запускать полную сборку или же анализ раз в день, а делать это куда чаще. Например, после каждого фикса или же перед коммитами. А теперь предлагаю посмотреть на то, как это всё выглядит в одной таблице:
 :)")Я запустил по пять раз и посчитал среднее по запускам (эти цифры вы и видели в графиках) :) | https://habr.com/ru/post/557816/ | null | ru | null |
# Kubernetes NodePort vs LoadBalancer vs Ingress? Когда и что использовать?

Недавно меня спросили, в чем разница между NodePorts, LoadBalancers и Ingress. Все это разные способы получить внешний трафик в кластер. Давайте посмотрим, чем они отличаются, и когда использовать каждый из них.
***Примечание:*** *рекомендации рассчитаны на [Google Kubernetes Engine](https://cloud.google.com/kubernetes-engine/). Если вы работаете в другом облаке, на собственном сервере, на миникубе или чем-то еще, будут отличия. Я не углубляюсь в технические детали. Если хотите подробностей, обратитесь к [официальной документации](https://kubernetes.io/docs/concepts/services-networking/service/).*
### ClusterIP
ClusterIP — сервис Kubernetes по умолчанию. Он обеспечивает сервис внутри кластера, к которому могут обращаться другие приложения внутри кластера. Внешнего доступа нет.
YAML для сервиса ClusterIP выглядит следующим образом:
```
apiVersion: v1
kind: Service
metadata:
name: my-internal-service
selector:
app: my-app
spec:
type: ClusterIP
ports:
- name: http
port: 80
targetPort: 80
protocol: TCP
```
С чего я заговорил о сервисе ClusterIP, если к нему нельзя получить доступ из интернета? Способ есть: с помощью прокси-сервера Kubernetes!
Запускаем прокси-сервер Kubernetes:
```
$ kubectl proxy --port=8080
```
Теперь можно выполнять навигацию по API Kubernetes для доступа к этому сервису, используя схему:
<http://localhost:8080/api/v1/proxy/namespaces/>/services/:/
Используем этот адрес для доступа к вышеуказанному сервису:
<http://localhost:8080/api/v1/proxy/namespaces/default/services/my-internal-service:http/>
### Когда использовать?
Существует несколько сценариев использования прокси-сервера Kubernetes для доступа к сервисам.
Отладка сервисов или подключение к ним напрямую с ноутбука с другими целями
Разрешение внутреннего трафика, отображение внутренних панелей и т. д
Поскольку этот метод требует запуска kubectl в качестве аутентифицированного пользователя, не следует использовать его для предоставления доступа к сервису в интернете или для продакшен-сервисов.
### NodePort
Сервис NodePort — самый примитивный способ направить внешний трафик в сервис. NodePort, как следует из названия, открывает указанный порт для всех Nodes (виртуальных машин), и трафик на этот порт перенаправляется сервису.
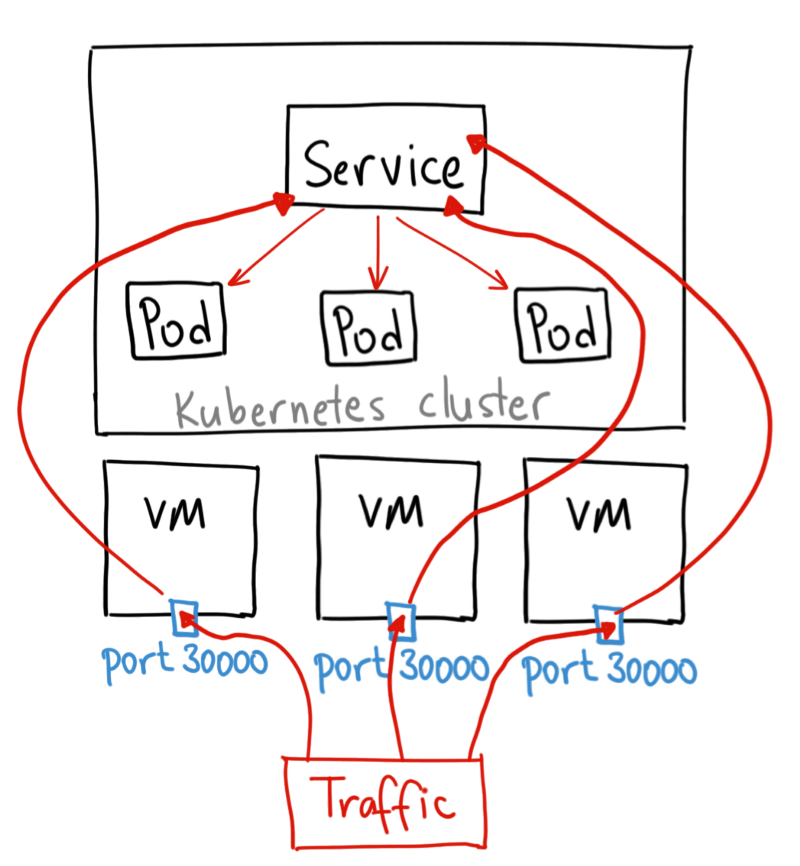
YAML для службы NodePort выглядит так:
```
apiVersion: v1
kind: Service
metadata:
name: my-nodeport-service
selector:
app: my-app
spec:
type: NodePort
ports:
- name: http
port: 80
targetPort: 80
nodePort: 30036
protocol: TCP
```
По сути, сервис NodePort имеет два отличия от обычного сервиса ClusterIP. Во-первых, тип NodePort. Существует дополнительный порт, называемый nodePort, который указывает, какой порт открыть на узлах. Если мы не укажем этот порт, он выберет случайный. В большинстве случаев дайте Kubernetes самому выбрать порт. Как говорит [thockin](https://medium.com/@thockin), с выбором портов все не так просто.
### Когда использовать?
Метод имеет множество недостатков:
На порт садится только один сервис
Доступны только порты 30000–32767
Если IP-адрес узла/виртуальной машины изменяется, придется разбираться
По этим причинам я не рекомендую использовать этот метод в продакшн, чтобы напрямую предоставлять доступ к сервису. Но если постоянная доступность сервиса вам безразлична, а уровень затрат — нет, этот метод для вас. Хороший пример такого приложения — демка или временная затычка.
### LoadBalancer
Сервис LoadBalancer — стандартный способ предоставления сервиса в интернете. На GKE он развернет [Network Load Balancer](https://cloud.google.com/compute/docs/load-balancing/network/), который предоставит IP адрес. Этот IP адрес будет направлять весь трафик на сервис.
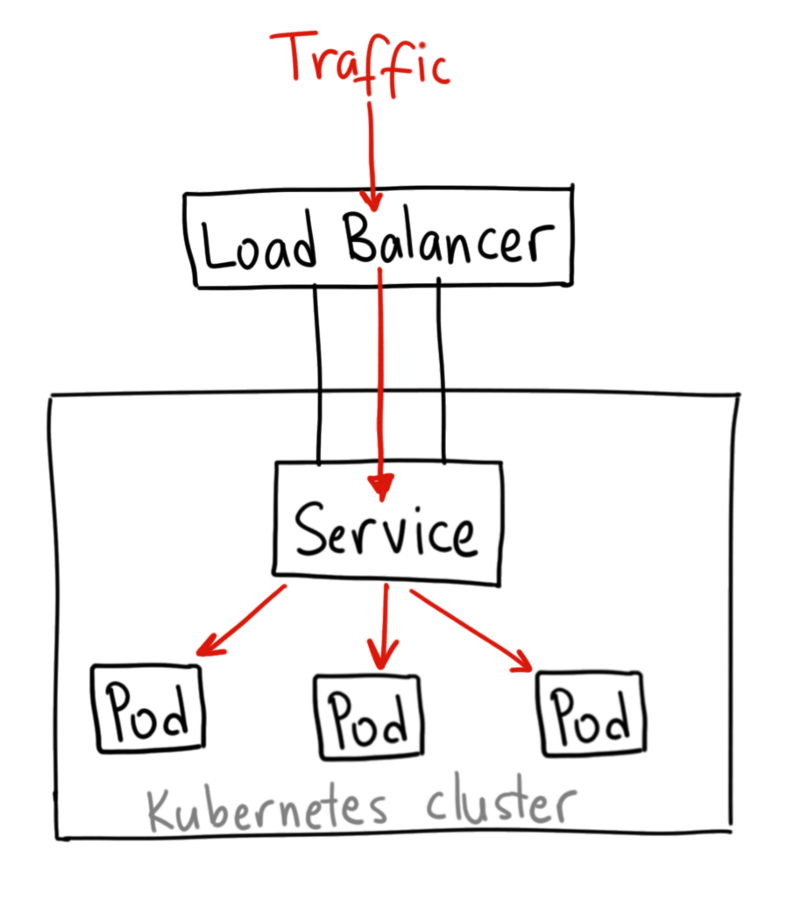
### Когда использовать?
Если вы хотите раскрыть сервис напрямую, это метод по умолчанию. Весь трафик указанного порта будет направлен на сервис. Нет фильтрации, нет маршрутизации и т.д. Это означает, что мы можем направить на сервис такие виды трафика как HTTP, TCP, UDP, Websockets, gRPC и тому подобное.
! Но есть один недостаток. Каждому сервису, который мы раскрываем с помощью LoadBalancer, нужен свой IP-адрес, что может влететь в копеечку.
### Ingress
В отличие от приведенных примеров, Ingress сам по себе не сервис. Он стоит перед несколькими сервисами и действует как «интеллектуальный маршрутизатор» или точка вхождения в кластер.
Есть разные типы контроллеров Ingress с богатыми возможностями.
Контроллер GKE по умолчанию запускает [HTTP(S) Load Balancer](https://cloud.google.com/compute/docs/load-balancing/http/). Вам одновременно будет доступна маршрутизация в бекенд сервисы на основе путей и субдоменов. Например, все на foo.yourdomain.com отправляем в сервис foo, а путь yourdomain.com/bar/ со всеми вложениями — в сервис bar.
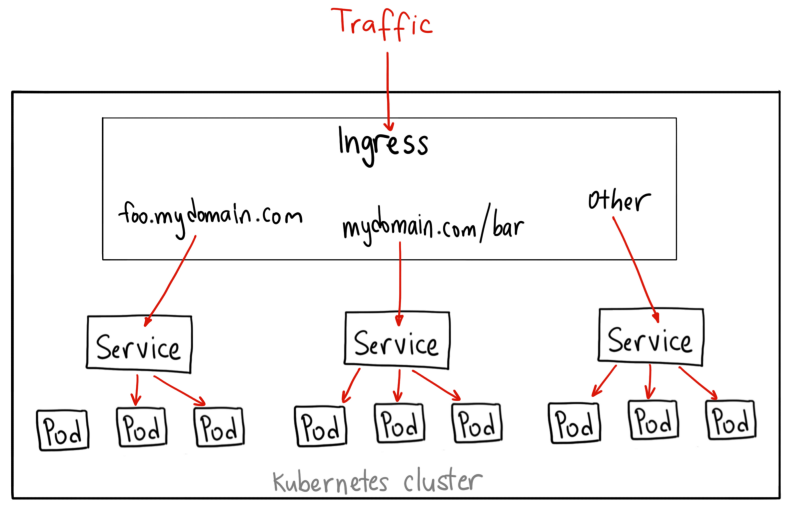
YAML для объекта Ingress на GKE с [L7 HTTP Load Balancer](https://cloud.google.com/compute/docs/load-balancing/http/) выглядит следующим образом:
```
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: my-ingress
spec:
backend:
serviceName: other
servicePort: 8080
rules:
- host: foo.mydomain.com
http:
paths:
- backend:
serviceName: foo
servicePort: 8080
- host: mydomain.com
http:
paths:
- path: /bar/*
backend:
serviceName: bar
servicePort: 8080
```
**Когда использовать?**
С одной стороны, Ingress — один из лучших способов раскрыть сервисы. С другой стороны — один из самых сложных. Существует множество контроллеров Ingress: [Google Cloud Load Balancer](https://cloud.google.com/kubernetes-engine/docs/tutorials/http-balancer), [Nginx](https://github.com/kubernetes/ingress-nginx), [Contour](https://github.com/heptio/contour), [Istio](https://istio.io/docs/tasks/traffic-management/ingress.html) и прочие. Есть и плагины для Ingress-контроллеров, такие как [cert-manager](https://github.com/jetstack/cert-manager), который автоматически предоставляет SSL-сертификаты для сервисов.
Ingress хорош при раскрытии нескольких сервисов на одном IP-адресе, когда все сервисы используют общий протокол L7 (обычно HTTP). Используя встроенную интеграцию GCP, вы платите только за один балансировщик нагрузки. А поскольку Ingress «умный», вы из коробки получаете множество функций (например, SSL, Auth, Routing и т.д.)
За диаграммы спасибо [Ahmet Alp Balkan](https://medium.com/@ahmetb).
Это не самая технически точная диаграмма, но она хорошо иллюстрирует работу NodePort.
Оригинал: [Kubernetes NodePort vs LoadBalancer vs Ingress? When should I use what?](https://medium.com/google-cloud/kubernetes-nodeport-vs-loadbalancer-vs-ingress-when-should-i-use-what-922f010849e0). | https://habr.com/ru/post/358824/ | null | ru | null |
# Functional C#: Non-nullable reference types (ненулевые ссылочные типы)
Третья статья в серии «Функциональный C#».
* [Functional C#: Immutability](http://habrahabr.ru/post/266873/)
* [Functional C#: Primitive obsession](http://habrahabr.ru/post/266937/)
* **Functional C#: Non-nullable reference types**
* [Functional C#: работа с ошибками](http://habrahabr.ru/post/267231/)
Ненулевые ссылочные типы в C# — текущее состояние дел
-----------------------------------------------------
Давайте рассмотрим такой пример:
```
Customer customer = _repository.GetById(id);
Console.WriteLine(customer.Name);
```
Смотрится знакомо, не так ли? Какие проблемы можно найти в этом коде?
Проблема здесь в том, что мы не знаем может или нет метод GetById вернуть null. Если метод возвращает null для каких-то id, мы рискуем получить NullReferenceException в рантайме. Даже хуже, между тем, как customer-у будет присвоен null, и тем, как мы используем этот объект, может пройти значительное количество времени. Такой код сложно отлаживать, т.к. будет непросто узнать где именно объекту был присвоен null.
Чем быстрее мы получаем фидбек, тем меньше времени требуется для фикса проблем в коде. Конечно, наиболее быстрый фидбек мог бы дать компилятор. Как здорово было бы написать следующий код и дать возможность компилятору сделать все проверки за нас?
```
Customer! customer = _repository.GetById(id);
Console.WriteLine(customer.Name);
```
Здесь тип Customer! означает ненулевой тип, т.е. тип, объекты которого не могут быть null ни при каких обстоятельствах. Или еще лучше:
```
Customer customer = _repository.GetById(id);
Console.WriteLine(customer.Name);
```
Т.е. сделать все ссылочные типы ненулевыми по умолчанию (ровно так же как value-типы сейчас) и есть нам нужен именно нулевой тип, то указывать это явно, вот так:
```
Customer? customer = _repository.GetById(id);
Console.WriteLine(customer.Name);
```
К сожалению, ненулевые ссылочные типы не могут быть добавлены в C# на уровне языка. Подобные решения необходимо принимать с самого начала, иначе они ломают почти весь имеющийся код. Ссылки на эту тему: [раз](http://blog.coverity.com/2013/11/20/c-non-nullable-reference-types/), [два](http://twistedoakstudios.com/blog/Post330_non-nullable-types-vs-c-fixing-the-billion-dollar-mistake). В новых версиях C# ненулевые ссылочные типы возможно будут [добавлены на уровне warning-ов](https://github.com/dotnet/roslyn/issues/5032), но с этим нововведением пока тоже не все гладко.
И хотя мы не можем заставить компилятор выявлять ошибки связанные с неверным использованием null, мы можем решить проблему с помощью workaround-а. Давайте посмотрим на код класса Customer, которым мы закончили [предыдущую статью](http://habrahabr.ru/post/266937/):
```
public class Customer
{
public CustomerName Name { get; private set; }
public Email Email { get; private set; }
public Customer(CustomerName name, Email email)
{
if (name == null)
throw new ArgumentNullException(“name”);
if (email == null)
throw new ArgumentNullException(“email”);
Name = name;
Email = email;
}
public void ChangeName(CustomerName name)
{
if (name == null)
throw new ArgumentNullException(“name”);
Name = name;
}
public void ChangeEmail(Email email)
{
if (email == null)
throw new ArgumentNullException(“email”);
Email = email;
}
}
```
Мы переместили всю валидацию, связанную с имейлами и кастомерами в отдельные классы, но мы не смогли ничего сделать с проверками на нал. Как можно видеть, это единственные оставшиеся проверки.
Убираем проверки на null
------------------------
Итак, как мы можем избавиться от них?
С помощью IL rewriter-а. Мы можем использовать NuGet пакет [NullGuard.Fody](https://github.com/Fody/NullGuard), который был создан специально для этой цели: он добавляет проверки на null в ваш код, заставляя ваши классы кидать исключения в случае если null приходит в виде входящего параметра, либо возвращается как результат работы метода.
Для того, чтобы начать использовать его, установите пакет NullGuard.Fody и пометьте свою сборку атрибутом
```
[assembly: NullGuard(ValidationFlags.All)]
```
С этого момент все методы и свойства в пределах сборки автоматически получат валидацию на null для всех входящих и выходящих параметров. Наш класс Customer теперь может быть написан следующим образом:
```
public class Customer
{
public CustomerName Name { get; private set; }
public Email Email { get; private set; }
public Customer(CustomerName name, Email email)
{
Name = name;
Email = email;
}
public void ChangeName(CustomerName name)
{
Name = name;
}
public void ChangeEmail(Email email)
{
Email = email;
}
}
```
И даже еще проще:
```
public class Customer
{
public CustomerName Name { get; set; }
public Email Email { get; set; }
public Customer(CustomerName name, Email email)
{
Name = name;
Email = email;
}
}
```
Вот что у нас получается на выходе благодаря IL rewriter-у:
```
public class Customer
{
private CustomerName _name;
public CustomerName Name
{
get
{
CustomerName customerName = _name;
if (customerName == null)
throw new InvalidOperationException();
return customerName;
}
set
{
if (value == null)
throw new ArgumentNullException();
_name = value;
}
}
private Email _email;
public Email Email
{
get
{
Email email = _email;
if (email == null)
throw new InvalidOperationException();
return email;
}
set
{
if (value == null)
throw new ArgumentNullException();
_email = value;
}
}
public Customer(CustomerName name, Email email)
{
if (name == null)
throw new ArgumentNullException(“name”, “[NullGuard] name is null.”);
if (email == null)
throw new ArgumentNullException(“email”, “[NullGuard] email is null.”);
Name = name;
Email = email;
}
}
```
Как можно видеть, валидации эквивалентны тем, что мы писали вручную, за исключением того, что тут также добавлена валидация для возвращаемых значений, что тоже очень полезно.
Как теперь быть с null?
-----------------------
Как быть если нам необходим null? Мы можем использовать структуру Maybe:
```
public struct Maybe
{
private readonly T \_value;
public T Value
{
get
{
Contracts.Require(HasValue);
return \_value;
}
}
public bool HasValue
{
get { return \_value != null; }
}
public bool HasNoValue
{
get { return !HasValue; }
}
private Maybe([AllowNull] T value)
{
\_value = value;
}
public static implicit operator Maybe([AllowNull] T value)
{
return new Maybe(value);
}
}
```
Входящие значения в Maybe помечены атрибутом AllowNull. Это указывает rewriter-у, что он не должен добавлять проверки на null для этих конкретных параметров.
Используя Maybe, мы можем писать следующий код:
```
Maybe customer = \_repository.GetById(id);
```
И теперь при чтении кода становится очевидно, что метод GetById может вернуть null. Нет необходимости смотреть код метода чтобы понять его семантику.
Более того, теперь мы не можем случайно перепутать нулевой тип с ненулевым, такой код приведет к ошибке компилятора:
```
Maybe customer = \_repository.GetById(id);
ProcessCustomer(customer); // Compiler error
private void ProcessCustomer(Customer customer)
{
// Method body
}
```
Безусловно, не все сборки есть смысл изменять с помощью rewriter-а. К примеру, применять подобные правила в сборке с WFP пожалуй будет не лучшей идеей, так как слишком много системных компонент в ней nullable по своей природе. В подобных условиях, проверки на null не имеют смысл, т.к. вы все равно ничего не сможете поделать с большинством из этих наллов.
Что касается доменных сборок, их определенно стоит усовершенствовать подобным образом. Более того, именно доменные классы получат наибольшую выгоду от этого подхода.
Заключение
----------
Преимущества описанного подхода:
* Он помогает уменьшить количество багов путем обеспечения быстрого фидбека в случае если null неожиданно протиснулся там, где его не ждали.
* Существенно улучшает читаемость кода. Нет необходимости углубляться в метод чтобы понять может ли он вернуть null.
* Теперь проверки на null существуют в коде по умолчанию. Методы и свойства классов защищены от нулевых значений, нет необходимости писать шаблонный код по проверке на нал.
Остальные статьи в цикле
------------------------
* [Functional C#: Immutability](http://habrahabr.ru/post/266873/)
* [Functional C#: Primitive obsession](http://habrahabr.ru/post/266937/)
* **Functional C#: Non-nullable reference types**
* [Functional C#: работа с ошибками](http://habrahabr.ru/post/267231/)
Английская версия статьи: [Functional C#: Non-nullable reference types](http://enterprisecraftsmanship.com/2015/03/13/functional-c-non-nullable-reference-types/) | https://habr.com/ru/post/267063/ | null | ru | null |
# Semantic Web и Linked Data. Исправления и дополнения
Хочу представить публике фрагмент вот этой недавно вышедшей книги:
> Онтологическое моделирование предприятий: методы и технологии [Текст]: монография / [С. В. Горшков, С. С. Кралин, О. И. Муштак и др.; ответственный редактор С. В. Горшков]. — Екатеринбург: Изд-во Уральского ун-та, 2019. — 234 с.: ил., табл.; 20 см. — Авт. указаны на обороте тит. с. — Библиогр. в конце гл. — ISBN 978-5-7996-2580-1: 200 экз.
**Обложка и корешок книги**

Цель выкладки этого фрагмента на Хабре троякая:
* Собрать вопросы и замечания, чтобы учесть их при включении этого текста в переработанном виде в другие издания.
* Внести дополнения, не очень совместимые с форматом печатной монографии: злободневные примечания (ниже они под спойлерами) и гиперссылки; а также внести исправления (ниже они никак не выделены).
* Многие адепты Semantic Web и Linked Data до сих пор считают, что их круг столь узок в основном потому, что широкой публике все еще по-хорошему не объяснили, что же это такое — Semantic Web и Linked Data. Автор фрагмента, хоть к этому кругу и принадлежит, такого мнения не придерживается, но, тем не менее, считает себя обязанным сделать еще одну попытку.
Содержание параграфа
--------------------
[Semantic Web](#semantic-webanchoranchor)
[Linked Data](#linked-dataanchoranchor)
[RDF](#rdfanchoranchor)
[RDFS](#rdfsanchoranchor)
[SPARQL](#sparqlanchoranchor)
[OWL](#owlanchoranchor)
[Linking Enterprise Data](#linking-enterprise-dataanchoranchor)
[Connecting Enterprise Data](#connecting-enterprise-dataanchoranchor)
[Литература](#literaturaanchoranchor)
Semantic Web
------------
Эволюцию Интернета можно представить следующим образом (или говорить о его сегментах, формировавшихся в указанном ниже порядке):
1. *Документы в интернете*. Ключевые технологии — Gopher, FTP и т. п.
Интернет является глобальной сетью для обмена локальными ресурсами.
2. *Интернет документов*. Ключевые технологии — HTML и HTTP.
Характер выставляемых ресурсов учитывает особенности среды их передачи.
3. *Данные в интернете*. Ключевые технологии — REST и SOAP API, XHR и пр.
Можно сказать, что потребителями ресурсов становятся не только люди.
4. *Интернет данных*. Ключевые технологии — технологии Linked Data.
Этот четвертый этап, предсказываемый Бернерсом-Ли, создателем ключевых технологий второго и директором W3C, и называется Semantic Web; технологии Linked Data призваны сделать данные в вебе не только машиночитаемыми, но и «машинопонимаемыми».
**Мертв ли Semantic Web?**
Поисковые системы [довольно успешно](https://w3techs.com/technologies/history_overview/structured_data/all) принуждают веб-сайты к использованию RDFa и JSON-LD и сами используют технологии, родственные описываемым далее (Google Knowledge Graph, Bing Knowledge Graph и пр.).
Что мешает более широкому и глубокому использованию этих технологий на вебе? Ответить на этот вопрос автор не может, но может высказаться на основе личного опыта. Задачи, которые в условиях наступления семантического веба решались бы «из коробки», имеются, но не очень массовые, и те, перед кем эти задачи встают, не имеют средств принуждения в отношении тех, кто способен обеспечить решение. Самостоятельное же обеспечение решения этими последними противоречит их бизнес-моделям.
Однако технологии Linked Data получили распространение и за пределами массового веба; этим их применениям книга, собственно, и посвящена, и в настоящее время сообщество Linked Data надеется, что эти технологии получат большее распространение в корпоративной среде благодаря фиксации (или провозглашению) Gartner таких трендов, как как Knowledge Graphs и Data Fabric.
Приведенная периодизация была впервые предложена, похоже, вот в этой брошюре 2011 года: [F. Bauer, M. Kaltenböck. Linked Open Data: The Essentials. A Quick Start Guide for Decision Makers](https://www.reeep.org/LOD-the-Essentials.pdf).
Semantic Web — скорее системное видение будущего интернета, чем конкретный стихийный или лоббируемый тренд, хотя способен учитывать и эти последние. Например, важной характеристикой того, что называется Web 2.0, считается «создаваемое пользователями содержимое». Принимать её во внимание призваны, в частности, рекомендация W3C «[Web Annotation Ontology](https://www.w3.org/TR/annotation-vocab/)» и такое начинание, как [Solid](https://solid.mit.edu/).
Из дальнейшего читателю станет ясно соответствие ключевых понятий второго и четвертого этапов:
* аналогами URL являются URI,
* аналогом HTML является RDF,
* HTML-гиперссылкам аналогичны вхождения URI в RDF-документы.
Linked Data
-----------
Бернерс-Ли определял Linked Data как «правильно сделанный» семантический веб: cовокупность подходов и технологий, позволяющую достичь его конечных целей. Базовые принципы Linked Data Бернерс-Ли [выделял](https://www.w3.org/DesignIssues/LinkedData.html) следующие.
*Принцип 1*. Использование URI ([Uniform Resource Identifier](https://en.wikipedia.org/wiki/Uniform_Resource_Identifier)) для именования сущностей.
URI являются глобальными идентификаторами сущностей в противоположность локальным строковым идентификаторам записей. Впоследствии лучшее выражение этот принцип нашел в слогане Google Knowledge Graph «[things, not strings](https://www.blog.google/products/search/introducing-knowledge-graph-things-not/)».
*Принцип 2*. Использование URI в схеме HTTP, чтобы их было возможно дереференсировать.
Обратившись к URI, должно быть возможно получить означаемое, стоящее за этим означающим (тут понятна аналогия с названием оператора «`*`» в Си); точнее, получить некоторое представление этого означаемого — в зависимости от значения HTTP-заголовка `Accept:`. Быть может, с наступлением эпохи AR/VR можно будет получить сам ресурс, пока же, скорее всего, это будет RDF-документ, являющийся результатом выполнения SPARQL-запроса `DESCRIBE`.
*Принцип 3*. Использование стандартов W3C — в первую очередь, RDF(S) и SPARQL — в частности, при дереференсировании URI.
Эти отдельные «слои» стека технологий Linked Data, известного также под названием [Semantic Web Layer Cake](https://en.wikipedia.org/wiki/Semantic_Web_Stack), будут описаны нами далее.
*Принцип 4*. Использование при описании сущностей ссылок на другие URI.
RDF позволяет ограничиться словесным описанием ресурса на естественном языке, и четвертый принцип призывает этого не делать. При всеобщем соблюдении первого принципа появляется возможность при описании ресурса ссылаться на другие, в том числе «чужие», отчего данные и называются связанными. На самом деле почти неизбежно использования URI, поименованных в словаре RDFS.
### RDF
[RDF](https://www.w3.org/TR/rdf11-concepts/) (Resource Description Framework) — формализм описания взаимосвязанных сущностей.
О сущностях и их взаимосвязях делаются утверждения вида «субъект-предикат-объект», называемые триплетами. В простейшем случае и субъект, и предикат, и объект — это URI. Один и тот же URI может в различных триплетах находиться в различных позициях: быть и субъектом, и предикатом, и объектом; тем самым триплеты образуют своего рода граф, называемый RDF-графом.
Субъекты и объекты могут быть не только URI, но и так называемыми *пустыми узлами*, а объекты могут быть еще и *литералами*. Литералы — экземпляры примитивных типов, состоящие из строкового представления и указания типа.
Примеры записи литералов (в Turtle-синтаксисе, о нем ниже): `"5.0"^^xsd:float` и `"five"^^xsd:string`. Литералы с типом `rdf:langString` могут быть снабжены еще и языковым тегом, в Turtle это записывается так: `"five"@en` и `"пять"@ru`.
Пустые узлы — «анонимные» ресурсы без глобальных идентификаторов, о которых, однако, могут делаться утверждения; своего рода экзистенциальные переменные.
Итак (в этом, собственно, и заключается вся суть RDF):
* субъект — это URI или пустой узел,
* предикат — это URI,
* объект — это URI, пустой узел или литерал.
**Почему предикаты не могут быть пустыми узлами?**
Вероятная причина — желание неформально понимать и переводить на язык логики предикатов первого порядка триплет `s p o` как нечто наподобие , где  — предикат,  и  — константы. Cледы такого понимания есть в документе «[LBase: Semantics for Languages of the Semantic Web](https://www.w3.org/TR/lbase/)», имеющем статус заметки рабочей группы W3С. При таком понимании триплет `s p []`, где `[]` — пустой узел, будет переведен как , где  — переменная, но как тогда перевести `s [] o`? Имеющий статус рекомендации W3C документ «[RDF 1.1 Semantics](https://www.w3.org/TR/rdf11-mt/)» предлагает другой способ перевода, но возможность предикатов быть пустыми узлами все равно не рассматривает.
Впрочем, Ману Спорни [разрешили](https://www.w3.org/TR/json-ld/#relationship-to-rdf).
RDF — абстрактная модель. RDF может быть записан (сериализован) в различных синтаксисах: [RDF/XML](https://www.w3.org/TR/rdf-syntax-grammar/), [Turtle](https://www.w3.org/TR/turtle/) (наиболее человекочитаемый), [JSON-LD](https://www.w3.org/TR/json-ld/), [HDT](http://www.rdfhdt.org/) (бинарный).
Один и тот же RDF может быть сериализован в RDF/XML различными способами, поэтому, например, получившийся XML бессмысленно валидировать с помощью XSD или пытаться извлекать данные с помощью XPath. Равным образом JSON-LD вряд ли удовлетворит желание рядового Javascript-разработчика работать с RDF с использованием точечной и квадратно-скобочной нотации Javascript (хотя JSON-LD и движется в этом направлении, предлагая механизм [фрейминга](https://w3c.github.io/json-ld-framing/)).
Большинство синтаксисов предлагает способы сокращения длинных URI. Например, объявление `@prefix rdf:` в Turtle позволит потом писать вместо просто`rdf:type`.
### RDFS
[RDFS](https://www.w3.org/TR/rdf-schema/) (RDF Schema) — базовый словарь моделирования, вводит понятия свойства и класса и такие свойства, как `rdf:type`, `rdfs:subClassOf`, `rdfs:domain` и `rdfs:range`. С помощью словаря RDFS могут быть записаны, например, следующие верные выражения:
```
rdf:type rdf:type rdf:Property .
rdf:Property rdf:type rdfs:Class .
rdfs:Class rdfs:subClassOf rdfs:Resource .
rdfs:subClassOf rdfs:domain rdfs:Class .
rdfs:domain rdfs:domain rdf:Property .
rdfs:domain rdfs:range rdfs:Class .
rdfs:label rdfs:range rdfs:Literal .
```
RDFS является словарем описания и моделирования, но не является языком ограничений (хотя официальная спецификация и [оставляет](https://www.w3.org/TR/rdf-schema/#ch_domainrange) возможность подобного употребления). Слово «Schema» не следует понимать в том же смысле, что и в выражении «XML Schema». Например, `:author rdfs:range foaf:Person` означает, что `rdf:type` всех значений свойства `:author` — `foaf:Person`, но не означает, что об этом должно быть сказано заранее.
### SPARQL
[SPARQL](https://www.w3.org/TR/sparql11-overview/) (SPARQL Protocol and RDF Query Language) — язык запросов к RDF-данным. В простом случае SPARQL-запрос представляет собой набор образцов, с которыми сопоставляются триплеты опрашиваемого графа. В образцах в позициях субъектов, предикатов и объектов могут находиться переменные.
Запрос возвратит такие значения переменных, при подстановке которых в образцы может получиться подграф опрашиваемого RDF-графа (подмножество его триплетов). Одноименные переменные в различных образцах триплетов должны иметь при этом одинаковые значения.
Например, на приведенном выше наборе из семи RDFS-аксиом следующий запрос вернет `rdfs:domain` и `rdfs:range` в качестве значений `?s` и `?p` соответственно:
```
SELECT * WHERE {
?s ?p rdfs:Class .
?p ?p rdf:Property .
}
```
Стоит отметить, что SPARQL декларативен и не является языком описания обхода графа (впрочем, некоторые RDF-хранилища предлагают способы корректировки плана выполнения запроса). Поэтому некоторые стандартные графовые задачи, например, поиск кратчайшего пути, не могут быть решены на SPARQL, в том числе и с использованием механизма [property paths](https://www.w3.org/TR/sparql11-query/#propertypaths) (но, опять же, отдельные RDF-хранилища предлагают специальные расширения для решения этих задач).
SPARQL не разделяет презумпцию открытости мира и следует подходу «negation as failure», в нем [возможны](https://www.w3.org/TR/sparql11-query/#negation) такие конструкции, как `FILTER NOT EXISTS {…}`. Распределенность данных учитывается с помощью механизма [федеративных запросов](https://www.w3.org/TR/2013/REC-sparql11-federated-query-20130321/).
Точка доступа SPARQL — RDF-хранилище, способное обрабатывать SPARQL-запросы — не имеет прямых аналогов из второго этапа (см. начало данного параграфа). Её можно уподобить базе данных, на основе содержимого которой генерировались HTML-страницы, но доступной вовне. Точка доступа SPARQL является аналогом скорее точки доступа API из третьего этапа, однако с двумя основными отличиями. Во-первых, есть возможность объединять несколько «атомарных» запросов в один (что считается ключевой характеристикой GraphQL), во-вторых, такой API полностью самодокументирован (чего пытался достичь HATEOAS).
**Полемическое замечание**
RDF — способ публикации данных на вебе, поэтому RDF-хранилища следовало бы считать документными СУБД. Правда, поскольку RDF — граф, а не дерево, они заодно получились и графовыми. Удивительно, что вообще получились. Кто бы мог подумать, что найдутся умники, которые реализуют blank nodes. У Кодда вот [не вышло](https://dl.acm.org/citation.cfm?doid=320107.320109).
Имеются и менее полнофунуциональные способы организации доступа к RDF-данным, например, [Linked Data Fragments](http://linkeddatafragments.org/) (LDF) и [Linked Data Platform](http://linkeddatafragments.org/) (LDP).
### OWL
[OWL](https://www.w3.org/TR/owl2-overview/) (Web Ontology Language) — формализм представления знаний, синтаксический вариант дескрипционной логики  (всюду ниже правильнее говорить OWL 2, первая версия OWL была основана на ).
Концептам дескрипционных логик в OWL соответствуют классы, ролям — свойства, индивиды сохраняют свои прежнее название. Аксиомы также называются аксиомами.
Например, в так называемом [манчестерском синтаксисе](https://www.w3.org/TR/owl2-manchester-syntax/) для записи OWL уже известная нам аксиома  будет записана так:
```
Class: Human
Class: Parent
EquivalentClass: Human and (inverse hasParent) some Human
ObjectProperty: hasParent
```
Имеются и другие синтаксисы для записи OWL, например, [функциональный синтаксис](https://www.w3.org/TR/owl2-syntax/), используемый в официальной спецификации, и [OWL/XML](https://www.w3.org/TR/owl2-xml-serialization/). Кроме того, OWL может быть сериализован [в абстрактный синтаксис RDF](https://www.w3.org/TR/owl-mapping-to-rdf/) и в дальнейшем — в любой из конкретных синтаксисов.
OWL в отношении к RDF выступает в двояком отношении. Его, с одной стороны, можно рассматривать как некий словарь, расширяющий RDFS. С другой стороны, это более мощный формализм, для которого RDF лишь формат сериализации. Не все элементарные конструкции OWL можно записать посредством единственного RDF-триплета.
В зависимости от того, какое подмножество конструкций OWL разрешено использовать, говорят о так называемых [профилях OWL](https://www.w3.org/TR/owl2-profiles/). Стандартизованные и наиболее известные — это OWL EL, OWL RL и OWL QL. Выбор профиля влияет на вычислительную сложность типовых задач. Полный набор конструкций OWL, соответствующий , называется OWL DL. Иногда также говорят об OWL Full, в котором конструкции OWL разрешено использовать с полной свободой, присущей RDF, без семантических и вычислительных ограничений . Например, нечто может быть и классом, и свойством. OWL Full неразрешим.
Ключевые принципы присоединения следствий в OWL — принятие презумпции открытого мира (open world assumption, [OWA](https://en.wikipedia.org/wiki/Open-world_assumption)) и отказ от презумпции уникальности имен (unique name assumption, [UNA](https://en.wikipedia.org/wiki/Unique_name_assumption)). Ниже мы увидим, к чему могут приводить эти принципы, и познакомимся с некоторыми конструкциями OWL.
Пусть онтология содержит следующий фрагмент (в манчестерском синтаксисе):
```
Class: manyChildren
EquivalentTo: Human that hasChild min 3
Individual: John
Types: Human
Facts: hasChild Alice, hasChild Bob, hasChild Carol
```
Будет ли из сказанного следовать, что Джон многодетен? Отказ от UNA заставит движок вывода ответить на этот вопрос отрицательно, ведь Алиса и Боб вполне могут быть одним и тем же человеком. Чтобы следование имело место, потребуется добавить такую аксиому:
```
DifferentIndividuals: Alice, Bob, Carol, John
```
Пусть теперь фрагмент онтологии имеет следующий вид (Джон объявлен многодетным, но у него указано лишь двое детей):
```
Class: manyChildren
EquivalentTo: Human that hasChild min 3
Individual: John
Types: Human, manyChildren
Facts: hasChild Alice, hasChild Bob
DifferentIndividuals: Alice, Bob, Carol, John
```
Будет ли эта онтология противоречивой (что можно интерпретировать как свидетельство невалидности данных)? Принятие OWA заставит движок вывода ответить отрицательно: «где-то» еще (в другой онтологии) вполне может быть сказано, что Кэрол также является ребенком Джона.
Чтобы исключить возможность этого, добавим новый факт о Джоне:
```
Individual: John
Facts: hasChild Alice, hasChild Bob, not hasChild Carol
```
Чтобы исключить появление и других детей, скажем, что все значения свойства «иметь ребенка» — люди, которых у нас всего четверо:
```
ObjectProperty: hasChild
Domain: Human
Сharacteristics: Irreflexive
Class: Human
EquivalentTo: { Alice, Bill, Carol, John }
```
Теперь онтология станет противоречивой, о чем движок вывода не преминет сообщить. Последней из аксиом мы в каком-то смысле «замкнули» мир, и обратите внимание, каким способом исключена возможность того, что Джон является ребенком самому себе.
Linking Enterprise Data
-----------------------
Набор подходов и технологий Linked Data первоначально предназначался для публикации данных в вебе. Использование их во внутрикорпоративной среде сталкивается с рядом затруднений.
Например, в замкнутой корпоративной среде оказывается слишком слабой дедуктивная сила OWL, основанного на принятии OWA и отказе от UNA — решениях, обусловленных открытым и распределенным характером веба. И здесь возможны следующие выходы.
* Наделение OWL семантикой, предполагающий отказ от OWA и принятие UNA, реализация соответствующего движка вывода. — По такому пути [идет](https://www.stardog.com/docs/#_validating_constraints) RDF-хранилище Stardog.
* Отказ от дедуктивных возможностей OWL в пользу движков правил. — Stardog поддерживает [SWRL](https://www.w3.org/Submission/SWRL/); Jena и GraphDB предлагают [собственные](https://jena.apache.org/documentation/inference/#rules) [языки](http://graphdb.ontotext.com/documentation/standard/reasoning.html#rule-format-and-semantics) правил.
* Отказ от дедуктивных возможностей OWL, использование для моделирования того или иного подмножества, близкого к RDFS. — См. об этом далее.
Другая проблема — более существенное внимание, которое в корпоративном мире возможно уделить проблемам качества данных, и отсутствие в стеке Linked Data инструментов валидации данных. Выходы здесь следующие.
* Опять-таки, использование для валидации конструкций OWL с семантикой закрытого мира и уникальности имен при наличии соответствующего движка вывода.
* Использование [SHACL](https://www.w3.org/TR/shacl/), стандартизованного уже после того, как перечень слоев Semantic Web Layer Cake был зафиксирован (впрочем, он может использоваться и в качестве движка правил), или [ShEx](http://shex.io/).
* Осознание того, что все в конечном итоге делается SPARQL-запросами, создание собственного несложного механизма валидации данных с их использованием.
Впрочем, даже полный отказ от дедуктивных возможностей и инструментов валидации оставляет стек Linked Data вне конкуренции в задачах, ландшафтно сходных с открытым и распределенным вебом — в задачах интеграции данных.
**Как насчет обычной корпоративной информационной системы?**
Опишу здесь типичную первоначальную реакцию участников разработки, чтобы показать, как выглядит этот стек с точки зрения традиционного IT (напоминает притчу о слоне):
* *Бизнес-аналитик*: RDF — это что-то типа непосредственно хранимой логической модели.
* *Системный аналитик*: RDF — это [EAV](https://en.wikipedia.org/wiki/Entity%E2%80%93attribute%E2%80%93value_model), только с кучей индексов и удобным языком запросов.
* *Разработчик*: ну, это все в духе концепций rich model и low code, [читал](https://www.stardog.com/blog/where-does-business-logic-go/) недавно об этом.
* *Руководитель проекта*: да это же [collapsing the stack](https://www.slideshare.net/AlanMorrison/collapsing-the-it-stack-clearing-a-path-for-ai-adoption)!
Практика показывает, что стек чаще всего используется в задачах, связанных с распределенностью и гетерогенностью данных, например, при построении систем класса MDM (Master Data Management) или DWH (Data Warehouse). Такие задачи имеются в любой отрасли.
Что до применений с отраслевой спецификой, в настоящее время технологии Linked Data наиболее популярны в следующих отраслях.
* биомедицинские технологии (где их популярность, по-видимому, связана со сложностью предметной области);
**актуальное**
В «Точке кипения» на днях в проходила организованная ассоциацией «Национальная база медицинских знаний» конференция «[Объединение онтологий. От теории к практическому применению](http://nbmz.ru/konferencija-po-ontologij/)».
* изготовление и эксплуатация сложных изделий (крупное машиностроение, добыча нефти и газа; чаще всего речь идет о стандарте [ISO 15926](https://en.wikipedia.org/wiki/ISO_15926));
**актуальное**
Здесь тоже причиной является сложность предметной области, когда, например, на этапе upstream, если говорить о нефтегазовой отрасли, простой учетной нужно иметь некоторые функции САПР.
В 2008 году прошла организованная Chevron представительная установочная [конференция](https://www.w3.org/2008/12/ogws-report.html).
ISO 15926 в конце концов показался нефтегазовой отрасли тяжеловатым (и едва ли не большее применение нашел в машиностроении). Основательно на него подсела разве что Statoil (Equinor), в Норвегии вокруг него сложилась целая [экосистема](https://www.dataversity.net/semantic-data-ecosystem-oil-gas-sector-norway/). Прочие пытаются делать что-то свое. Например, по слухам, отечественный Минэнерго намерен заняться созданием «концептуальной онтологической модели ТЭК», аналогичной, по-видимому, [созданной для электроэнергетики](http://zakupki.gov.ru/epz/order/notice/ok44/view/common-info.html?regNumber=0173100008317000073).
* финансовые организации (даже XBRL можно рассматривать как некий гибрид SDMX и онтологии RDF Data Cube);
**актуальное**
LinkedIn в начале года активно спамил автора вакансиями едва ли не у всех гигантов финансовой индустрии, названия которых он знает: Goldman Sachs, JPMorgan Chase и/или Morgan Stanley, Wells Fargo, SWIFT/Visa/Mastercard, Bank of America, Citigroup, ФРС, Deutsche Bank. К слову, на [Knowledge Graph Conference](http://sps.columbia.edu/executive-education/knowledge-graph-conference) финансовые организации заняли всё [утро первого дня](https://docs.google.com/spreadsheets/u/1/d/e/2PACX-1vShOQ8Cn_l4Ukh87F92o9TtnKbH0z6b2dYYa50d3JIf8qxLrmIZNhEauyXXaTpigBAbNHvzcEvZABHa/pubhtml).
На HeadHunter же что-то интересное попадалось только у Сбербанка, речь шла о «EAV-хранилище с RDF-подобной моделью данных».
Вероятно, различие в степени любви к соответствующим технологиям отечественных и западных финансовых институций обусловлена транснациональным характером деятельности последних. По-видимому, интеграции сквозь государственные границы требуют качественно иных организационных и технических решений.
* вопросно-ответные системы, имеющие коммерческое применение (IBM Watson, Apple Siri, Google Knowledge Graph);
**актуальное**
К слову, создатель Siri Томас Грубер — автор того самого определения онтологии (в ИТ-значении) как «спецификации концептуализации». На мой взгляд, перестановка слов в этом определении не меняет его смысл, что, возможно, свидетельствует о том, что его там и нет.
* публикация структурированных данных (с большим основанием это может быть отнесено уже к Linked Open Data).
**актуальное**
Большие любители Linked Data — так называемые GLAM: Galleries, Libraries, Archives, and Museums. Тут достаточно сказать, что на замену MARC21 Библиотека Конгресса продвигает [BIBFRAME](https://www.loc.gov/bibframe/), который *provides a foundation for the future of bibliographic description* и, разумеется, основан на RDF.
Часто в качестве примера успешного проекта в сфере Linked Open Data приводят Wikidata — своего рода машиночитаемую версию Википедии, содержимое которой, в противоположность DBPedia, не генерируется импортом из инфобоксов статей, а создается более-менее вручную (и в последующем становится источником информации для тех же инфобоксов).
Рекомендуем также для ознакомления [список](https://www.stardog.com/customers/) пользователей RDF-хранилища Stardog на сайте Stardog в разделе «Customers».
Как бы то ни было, в гартнеровском [«Hype Cycle for Emerging Technologies» 2016 года](http://www.gartner.com/document/3383817) «Enterprise Taxonomy and Ontology Management» помещен в середине спуска в долину разочарования с перспективой выхода на «плато продуктивности» не ранее чем через 10 лет.
Connecting Enterprise Data
--------------------------
**Немного истории**
Из исторического интереса свел в таблицу гартнеровские прогнозы различных лет по интересующим нас технологиям.
| Год | Технология | Отчет | Положение | Лет до плато |
| --- | --- | --- | --- | --- |
| 2001 | Semantic Web | Emerging Technologies | Innovation Trigger | 5-10 |
| 2006 | Corporate Semantic Web | Emerging Technologies | Peak of Inflated Expectations | 5-10 |
| 2012 | Semantic Web | Big Data | Peak of Inflated Expectations | >10 |
| 2015 | Linked Data | Advanced Analytics and Data Science | Trough of Disillusionment | 5-10 |
| 2016 | Enterprise Taxonomy and Ontology Management | Emerging Technologies | Trough of Disillusionment | >10 |
| 2017 | Enterprise Taxonomy and Ontology Management | Emerging Technologies | Trough of Disillusionment | 5-10 |
| 2018 | Knowledge Graphs | Emerging Technologies | Innovation Trigger | 5-10 |
Впрочем, уже в [«Hype Cycle…» 2018 года](https://www.gartner.com/document/3885468) появился другой восходящий тренд — Knowledge Graphs. Произошла некая реинкарнация: графовые СУБД, на которые оказалось переключено внимание пользователей и силы разработчиков, под влиянием запросов первых и привычек последних стали обретать контуры и позиционирование своих предшественников-конкурентов.
Практически каждая графовая СУБД теперь объявляет себя подходящей платформой для построения корпоративного «графа знаний» («linked data» иногда заменяется на «connected data»), но насколько оправданы подобные притязания?
Графовые базы данных по-прежнему асемантичны, данные в графовой СУБД — все тот же data silo. Строковые идентификаторы вместо URI делают задачу интеграции двух графовых СУБД все той же задачей интеграции, в то время как интеграция двух RDF-хранилищ зачастую сводится просто к объединению двух RDF-графов. Другой аспект асемантичности — нерефлексивность графовой модели LPG, делающая затруднительным управление метаданными с использованием той же платформы.
Наконец, графовые СУБД не имеют движков вывода и движков правил. Результаты работы таких движков могут быть воспроизведены усложнением запросов, но такое возможно даже в SQL.
Впрочем, ведущие RDF-хранилища не испытывают затруднений с поддержкой модели LPG. Наиболее солидным считается подход, предложенный в свое время в Blazegraph: модель RDF\*, объединяющая RDF и LPG.
**Подробнее**
Подробнее о поддержке RDF-хранилищами модели LPG можно прочитать в предыдущей статье на Хабре: [«Что сейчас происходит с RDF-хранилищами»](https://habr.com/ru/post/451206/). Про Knowledge Graphs и Data Fabric будет, надеюсь, однажды написана отдельная статья. Заключительный раздел, как легко понять, дописывался в спешке, впрочем, и спустя полгода с этими концепциями все не намного яснее. Пока что я бы сказал так: *Data Fabric — это, по сути, NoETL, ну а Knowledge Graph — это, как водится, Data Fabric done right.*
Литература
----------
1. Halpin, H., Monnin, A. (eds.) (2014) Philosophical Engineering: Toward a Philosophy of the Web
2. Allemang, D., Hendler, J. (2011) Semantic Web for the Working Ontologist (2nd ed.)
3. Staab, S., Studer, R. (eds.) (2009) Handbook on Ontologies (2nd ed.)
4. Wood, D. (ed.). (2011) Linking Enterprise Data
5. Uschold M. (2018) Demystifying OWL for the Enterprise
6. Keet, M. (2018) An Introduction to Ontology Engineering | https://habr.com/ru/post/455008/ | null | ru | null |
# Simple XML Framework — пишем API для работы с диаграммами DIA
  **Dia Diagram Editor**
Фреймфорк [Simple XML](http://simple.sourceforge.net/) — известен многим, при своей простоте, он способен потягаться возможностями с большим «интерпрайзным» JAXB, и при этом совместим с Андроид.
Статей по его использованию не «навалом», но хватает. Фреймфорк [упоминался на Хабре](https://habrahabr.ru/post/116830/), есть [статья на ibm developerworks](http://www.ibm.com/developerworks/library/x-simplexobjs/), в конце концов, на официальном сайте есть хорошие [примеры](http://simple.sourceforge.net/download/stream/doc/examples/examples.php) и [руководство](http://simple.sourceforge.net/download/stream/doc/tutorial/tutorial.php).
В общем и целом, как использовать фреймворк ясно. Но бывает, встречаются структуры, для которых уже не хватает методов, описанных в мануалах и туториалах. Именно такую структуру XML я обнаружил, когда начал разбираться с тем, как DIA хранит свои диаграммы.
В данной статье будет рассказано о том, как научить Simple Framework работать в такой ситуации. Мы создадим собственную «стратегию» для Simple Framework; мы отнаследуемся от класса TreeStrategy и опишем «хитрую логику» того, как надо сопоставлять элементы xml-файла DIA к Java классам.
И да, я предполагаю, что читатель знаком с основами использования Simple XML Framework.
Пару слов про DIA и начало истории
----------------------------------
Думаю, редактор диаграмм DIA известен практически всем. В своем роде, это «классика жанра».
Создан он достаточно давно, но более-менее внятного и полного описания формата файла нет. Известно, что файл .dia — это zip-архив xml-файла с расширением .dia (к слову, редактор диаграмм умеет работать с несжатыми файлами, активировать сохранение без сжатия можно в настройках).
А дальше… дальше, мол, «разберётесь сами, там не сложно».
В почтовой рассылке пару лет назад упоминалось ссылки на некие более-менее связанные описания, но ныне они мертвы.
Про наличие какого либо программного интерфейса для генерации или редактирования диаграмм, речи тоже нет. Есть список редакторов диаграмм, способных экспортировать в формат Dia, но ничего пригодного для себя я не нашел.
«Программы — это хорошо», подумал я, «но мне нужен API. Готовый к использованию. Желательно на Java».
В итоге, я решился делать свой *велосипед*. Удобный мне, формой под моё седалище,
с рулем под форму моих рук, с колесами по форме выбоин тропинок, которыми хожу я.
Формат хранения диаграмм в Dia и его особенности
------------------------------------------------
Не будем сейчас разбирать полностью всю структуру, а перейдем сразу к «проблемным особенностям».
В .dia, структура хранения любого элемента диаграммы унифицирована: это тег object, который «обрамляет» перечень тегов attribute, в которых описываются все характеристики объекта.
**Например, вот так описывается элемент 'линия' из базовой палитры DIA**
```
```
Основная проблема тут в том, что все типы элементов описываются одним тегом.
В итоге, не понятно как сказать Simple Framework, что
— надо разбирать в объект класса Line, а
— в объект класса Box. В штатном наборе инструментария Simple Framework я не нашел как решать эту задачу. Именно поэтому была описана «стратегия» DiaTreeStrategy, история создания которой приведена ниже.
**К слову, раз уж мы говорим про минимализм Simple Framework применимо к разбору формата .dia, стоит упомянуть про аннотацию @Xpath и её ограничения.**Проблема кроется в том, что состав атрибутов объекта диаграммы, которые Dia сохраняет в xml — не постоянен и зависит от того, какие свойства вы меняли у данного объекта.
Из-за этого, при разборе xml структур в .dia, нельзя использовать аннотацию @Xpath с указанием индекса для того, что бы сопоставить свойство класса и описываемый в xml атрибут объекта. Если бы в @Xpath можно было указать имя и значения атрибута, как мы это можем сделать в xpath-запросе — то это сделало бы задачу проще, но увы — в @Xpath можно указать только путь и индекс. Эти обстоятельства привели к появлению у меня в коде не самого удобного механизма заполнения свойств класса из массива атрибутов, но об этом в другой раз.
«Cтратегия» в Simple Framework, начинаем писать DiaTreeStrategy
---------------------------------------------------------------
Класс реализующий «стратегию» (реализующий интерфейс Strategy) в Simple Framework занимается тем, что определяет сопоставление между узлами XML и классами в Java.
У этого интерфейса всего 2 метода — read() и write(). Первый занимается тем, что по переданному xml-узлу пытается понять, какой класс мы сейчас будем заполнять, а второй создает xml-узел, в который мы будем заполнять свойства объекта.
Писать стратегию с нуля — «дело не барское», тем более, что обычный TreeStrategy во всем остальном (кроме незнания как правильно сопоставлять классы и узлы типа object) — вполне хорошо работает. Потому мы его просто подправим. Отнаследуем и подправим.
```
public class DiaTreeStrategy extends TreeStrategy
```
Читатель наверняка уже догадался, что «всё», что нам надо — это научить «стратегию» читать свойство type у тега object, и откуда-то понимать что «UML — Class» — соответствует классу diaXML.shapes.uml.UmlClass, а «Standard — Box» — классу diaXML.shapes.standart.StdBox.
Информацию о маппинге (type + version => имя класса) я решил хранить в обычном ArrayList:
```
ArrayList diaObj2ClassMap;
```
**Инициализируем маппинг прямо под объявлением**
```
public ArrayList diaObj2ClassMap
= new ArrayList();
{ //default base mapping - object type name and version mapped to java class name.
//use "\*" for 'any class' or 'any version'
diaObj2ClassMap.add(new DiaObjToClassMapRecord("UML - Class", "0", "diaXML.shapes.uml.UmlClass" ));
diaObj2ClassMap.add(new DiaObjToClassMapRecord("UML - Association", "2", "diaXML.shapes.uml.UmlAssociation" ));
diaObj2ClassMap.add(new DiaObjToClassMapRecord("Standard - Box", "0", "diaXML.shapes.standart.StdBox" ));
diaObj2ClassMap.add(new DiaObjToClassMapRecord("Standard - Text", "1", "diaXML.shapes.standart.StdText" ));
diaObj2ClassMap.add(new DiaObjToClassMapRecord("Standard - ZigZagLine", "1", "diaXML.shapes.standart.StdZigZagLine" ));
diaObj2ClassMap.add(new DiaObjToClassMapRecord("Standard - BezierLine", "\*", "diaXML.shapes.standart.StdBezierLine" ));
//universal
diaObj2ClassMap.add(new DiaObjToClassMapRecord("\*", "\*", "diaXML.shapes.UncknownShapeObject" ));
}
```
Как видите, все достаточно прозрачно. Маппинг можно расширить своими классами (если кто напишет свой класс для ещё одного элемента диаграммы) как только будет создан экземпляр DiaTreeStrategy. Пока описано 5 классов (POJO) которые умеют инициализировать свои свойства из атрибутов объекта диаграммы, и один класс универсальный — UncknownShapeObject — в него попадают всё неизвестные нам объекты; он ничего не инициализирует, и хранит массив атрибутов в неизменном виде.
**Механизм поиска в этом массиве сопоставления я вынес в отдельную функцию**
```
private Class readValueAdv(Type type, NodeMap node) throws Exception
{
// we need here catch only tag
if( !"object".equals(node.getName()) )
return null;
Node entry\_type = node.get("type");
Node entry\_version = node.get("version");
if( entry\_type == null || entry\_version==null)
{ return null;
};
String name\_type = entry\_type.getValue();
String name\_version = entry\_version.getValue();
String className=null;
Class expect=null;
for (DiaObjToClassMapRecord crec: diaObj2ClassMap)
{
if ( ( crec.diaType!=null && (crec.diaType.equals(name\_type) || !crec.diaType.isEmpty() && crec.diaType.equals("\*") )
)
&&
( crec.diaVersion!=null && ( crec.diaVersion.equals(name\_version) || !crec.diaVersion.isEmpty() && crec.diaVersion.equals("\*") )
)
)
{ className = crec.javaClassName;
break;
}
}
if (className !=null)
{ expect = loader.load(className);
Node entry = node.remove(label);
}
return expect;
}
```
Теперь все что осталось — исправить метод read.
```
public class DiaTreeStrategy extends TreeStrategy
...
@Override
public Value read(Type type, NodeMap node, Map map) throws Exception
{
Class actualDeclaredByDia = readValueAdv(type, node);
if (actualDeclaredByDia==null)
return super.read(type, node, map);
return new ObjectValue(actualDeclaredByDia);
}
```
Это, почти всё. Вернее, это был «краеугольный камень преткновения», который не позволял с помощью Simple Framework парсить файлы, которые генерирует DIA.
Естественно, помимо того, что описано в статье, было проведено много другой работы, связанной с аннотированием классов, исследованием того, как в Simple XML работают аннотации-перехватчики событий в процессе сериализации и разбора XML, созданием сервисных классов и тд. и тп., но это уже другой разговор.
Ради чего это всё и как этим пользоваться?
------------------------------------------
В конце хотел бы привести пару примеров того, как использовать «DiaXML API». Без DiaTreeStrategy оно бы не заработало. И не забудьте перед сборкой подключить к проекту diaXmlApi.jar (брать [тут](https://v2.pikacode.com/tachikoma/diaxml_api/src/4608c1ef4696ed8d9990b54a8e3f419c184b2d31/DiaXML_API/jar/diaXmlApi.jar)).
**Как почитать .dia**
```
import java.io.File;
import org.simpleframework.xml.strategy.DiaTreeStrategy;
import diaXML.Diagram;
import diaXML.shapes.standart.StdText;
public void main(String[] args)
{
Strategy strategy = new DiaTreeStrategy();
Serializer serializer = new Persister(strategy);
File source = new File("path/to/dia/file/to/read.dia");
Diagram probeDia=null;
try { probeDia = serializer.read(Diagram.class, source);
} catch (Exception e) { e.printStackTrace(); return ;}
System.out.println(" File readed. Here is list of objects at layer 0 :");
for (IDiaObject cObj: probeDia.layers.get(0).objects )
{ System.out.println(" dia type ["+cObj.getObjectType()+"]ver.["+cObj.getObjectTypeVersion()+"] objId:["+cObj.getId()+"] name:["+cObj.getName()+"]");
if ( StdText.TYPENAME.equals(cObj.getObjectType()) )
{ System.out.println(" text value is:["+((StdText)cObj).textValue+"]");
};
}
}
```
**Как создать .dia**
```
import java.io.File;
import org.simpleframework.xml.strategy.DiaTreeStrategy;
import diaXML.Diagram;
import diaXML.shapes.standart.StdText;
public void main(String[] args)
{
Strategy strategy = new DiaTreeStrategy();
Serializer serializer = new Persister(strategy);
StdText cText= new StdText();
cText.textValue="this is a demo \n of creating DIA-file";
cText.obj_pos.moveTo(15, 5);
Diagram probeDia=new Diagram().initWithDefaults();
probeDia.layers.get(0).objects.add(cText);
File resultFile = new File("path/to/dia/file/to/write.dia");
try { serializer.write(probeDia, resultFile);
} catch (Exception e) { e.printStackTrace(); }
}
```
Ещё пару примеров можно найти в исходниках проекта ([тут](https://v2.pikacode.com/tachikoma/diaxml_api/src/4608c1ef4696ed8d9990b54a8e3f419c184b2d31/DiaXML_API/src/jse_diaxmlapi_examples)).
Заключение
----------
В этой статье я хотел рассказать о том, что такое «стратегия» в Simple XML Framework и как её использовать в ситуации, когда штатных средств уже не хватает и о некоторых ограничениях Simple Framework (например, про то, что в @Xpath-аннотации нельзя использовать выражения для имени и значений атрибутов, как это мы можем делать в @Xpath-запросах).
Решение этих вопросов позволило успешно реализовать ключевые классы проекта «DiaXML API» наименьшими силами. Полный текст исходного кода вы найдете в репозитории проекта.
Cсылки
------
* [DiaXML API project](https://v2.pikacode.com/tachikoma/diaxml_api)
* [Simple XML Framework project](http://simple.sourceforge.net/)
* [Dia Diagram Editor](http://dia-installer.de/)
**PS:** С использованием разработанного API, была разработана утилита, которая отрисовывает в DIA схему базы данных (или обновляет ранее созданную). В качестве источника данных используется схема БД в формате Turbine XML, которую умеет создавать [Apache DDL Utils](http://db.apache.org/ddlutils/). | https://habr.com/ru/post/318898/ | null | ru | null |
# Re: Примитивная защита от фишинга
Пару ночей назад, пытаясь одолеть упущенные 1000+ в Google Reader, я наткунлся на топик «[Примитивная защита от фишинга](http://habrahabr.ru/blogs/infosecurity/47313/)» хабраюзера [hooey](https://geektimes.ru/users/hooey/). И вдохновился.
Захотелось реализовать идею в виде расширения для Firefox, что я и попытался сделать.
Предупрежаю, это моё первое расширение для Firefox, оно было написано за пару вечеров, и я совершенно не пытаюсь сразу выдать какой-либо конечный продукт, а лишь хочу показать некий прототип.
#### Идея
Итак, вкратце:
1. ищем ссылки, текстом которых является URL;
2. проверяем, является ли ссылкой значение href (может оказаться что там якорь);
3. сравнимаем хосты в тексте и в href;
4. если не совпало, громко кричим и не даём пользователю ходить «налево».
#### Код
> `var fishurl = {
>
> onLoad: function() {
>
> var appcontent = document.getElementById("appcontent");
>
> if (appcontent)
>
> appcontent.addEventListener("DOMContentLoaded", this.onDOMLoad, true);
>
> },
>
> onDOMLoad: function(e) {
>
> if (e.originalTarget instanceof HTMLDocument) {
>
> fishurl.\_parseDocument(e.originalTarget);
>
> }
>
> },
>
> \_parseDocument : function(doc) {
>
> // перебираем все ссылочке в документе
>
> for (var i = 0, l = doc.links.length, item, textUrl, hrefUrl; i < l; i++)
>
> {
>
> item = doc.links[i];
>
>
>
> textUrl = this.\_parseUrl(item.text);
>
>
>
> // пропускаем, если текст ссылки не является URL
>
> if (!textUrl)
>
> continue;
>
>
>
> hrefUrl = this.\_parseUrl(item.href);
>
>
>
> // пропускаем, если href не является URL (он, к примеру, может быть якорем)
>
> if (!hrefUrl)
>
> continue;
>
>
>
> // собственно, самая важная проверка
>
> if (textUrl.host != hrefUrl.host)
>
> {
>
> // запоминаем куда ведёт подозрительная ссылка
>
> var \_href = item.href;
>
>
>
> // и вешаемся на click по ней
>
> item.addEventListener(
>
> "click",
>
> function() {
>
> // если всё же пользователю хочется, открываем в новой вкладочке
>
> if (confirm ("Хочешь попробовать фишинг на своей шкуре?\n[" + \_href + "]"))
>
> gBrowser.selectedTab = gBrowser.addTab(\_href);
>
>
>
> return false;
>
> },
>
> false);
>
> // убираем оригинальный URL от греха подальше
>
> item.removeAttribute("href");
>
> item.setAttribute("rel", "nohref");
>
> // курсор на ссылке «говорит» нельзя
>
> item.style.cursor = "not-allowed";
>
> // ну и вообще стоит эту гадость зачеркнуть
>
> item.style.textDecoration = "line-through";
>
> }
>
> }
>
> },
>
> \_parseUrl: function(data) {
>
> // корявый regexp, я знаю!.. если URL «хороший», то вернётся объект, иначе — false
>
> return data.match(/(ftp|http|https):\/\/(\w+:{0,1}\w\*@)?([\w.-]+)(:[0-9]+)?(\/([\w#!:.?+=&%@!\-\/])\*)?/) ?
>
> { url: RegExp['$&'], schema: RegExp.$1, auth: RegExp.$2, host: RegExp.$3, port: RegExp.$4, path: RegExp.$5 } : false;
>
> }
>
> };
>
>
>
> // вешаемся на событие load
>
> window.addEventListener("load", function() { fishurl.onLoad(); }, false);
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
#### Картинка
Вот так (отвратительно) это, пока что, выглядит на деле:
На изображении этого не видно, но при наведении курсора на «плохую» ссылку, он принимает вид перечёркнутого кружочка, намекая что жать сюда не стоит.
Так же, в href кладётся «#» (а начиная с версии svn11 вообще href убирается), дабы пользователь не перешёл по ссылке перетягивая её (с помощью какого-нибудь расширения вроде [QuickDrag](http://mozilla.ktechcomputing.com/quickdrag/)).
Как вариант, ещё можно у ссылки выводить какую-нибудь предупредительную иконку.
#### Что дальше?
Если кого-нибудь заинтересует, я продолжу этим заниматься. Напишите что хочется, что не нравится, и спросите, если что-то не ясно в коде или логике.
Естественно, есть проблема ложных срабатываний, к примеру, при том же скачивании с Народ.Диск.
Поэтому, вероятно, надо будет организовать black- или white- списки.
#### Где взять?
Скачать можно тут: [fishurl-svn12.xpi](http://narod.ru/disk/4812470000/fishurl-svn12.xpi.html)
Раздаю под лицензией BSD, поэтому, если интересно, открываем xpi-файл (это ZIP-архив) и делаем с этим что душе угодно.
Если автору идеи ([hooey](https://geektimes.ru/users/hooey/)) это каким-либо образом не нравится, я конечно же прекращу это дело ;)
И большое-пребольшое ему спасибо, и за идею, и за то что разбудил во мне желание покодить, и даже за увлекательные часы чтения [developer.mozilla.org](https://developer.mozilla.org/)! | https://habr.com/ru/post/48494/ | null | ru | null |
# .Net и Navision 5.0 — Дружба Навек
**### Завязка.**
И так, здравствуйте.
Работая в конторе, которая занимается внедрением такой штуки, как Ms Dynamics Nav пришлось, столкнуться с одной проблемой, решение которой средствами самого Навика (позволю себе столь фамильярное обращение), было невозможным.
Суть проблемы такова:
внедряя систему в предприятие, которое занимается переводом, встала жесткая проблема с названиями файлов, так как требования гласили, что название, которым был наречен исходный файл, должно полностью соответствовать названию, которое получит уже переведенный файл. При всем при этом, заказчик требовал записи файлов в базу данных MS SQL. Так как навик ооочень далек от юникода, то все встроенные функции работы с файлами коверкали название, убирая умляуты, аксанты и прочие элементы европейского алфавита.
Для решения сией проблемы была поставлена задача написать dll-ку, которая будет записывать в базу данных файлы с корректными названиями. А затем, по требованию возвращать эти файлы из базы данных в файловую систему. При всем при этом возникла проблема с загрузкой больших файлов, поэтому, опять-таки, было принято волевое решение об использовании в MS SQL такой вещи, как FILESTREAM.
**### Решение**
**#### Глава I**
Искренне надеюсь, что суть проблемы стала ясна. Теперь же приступим к разрешению.
Так как лучше всего ваш покорный слуга обращается с С#, то решил писать именно на нем. Подобным никогда не занимался, поэтому пришлось перерыть кучу материалов.
Первым делом был написан ряд функция, которые осуществляют выше описанную деятельность, без подключения к навижну.
Следующим шагом нужно сделать нашу библиотеку Com доступной. То бишь прописать [assembly: ComVisible(true)] в файле AssemblyInfo.cs
Далее соответственно зарегистрировать ее в системе regasm — ом.
Regasm d:/Classlibraryfornav.dll /codebase /tlb
**#### Глава II**
Теперь нам необходимо подготовить таблицу куда все это будет записываться.
Сначала мы создаем таблицу в Навижне, а потом редактируем ее в MS SQL, для подключения FILESTREAM.
Поначалу таблица выглядит так:

Но потом, включаем на Эскуэль сервере FILESTREAM:
Для включения FILESTREAM необходимо:
1. Запустить SQL Server Configuration Manager и в свойствах SQL Server’а на вкладке FILESTREAM проставить все три галочки; затем выполнить следующий запрос:
`EXEC sp_configure filestream_access_level, 2
RECONFIGURE`
2. Далее необходимо добавить файловую группу и обозначить хранилище файлов.
`ALTER database currentDb
ADD FILEGROUP Uploads
CONTAINS FILESTREAM
GO
ALTER database currentDb
ADD FILE
(
NAME= 'Upload',
FILENAME = 'C:\Users\Administrator\Upload'
)
TO FILEGROUP Uploads
GO`
Ну и немного подправим саму табличку:
выполняем следующие три команды:
a. ALTER TABLE \*\*\*.dbo.\*\*\* ADD [Id] [uniqueidentifier] ROWGUIDCOL NOT NULL UNIQUE — необходимо для FILESTREAM
b. ALTER TABLE \*\*\*.dbo.\*\*\* ADD UploadFiles VARBINARY(MAX) FILESTREAM — он сам, собственно
c. ALTER TABLE \*\*\*.dbo.\*\*\* ADD FileFullName NVARCHAR(MAX) — поле, плохо воспринимаемое Навиком, но необходимое, для мультиязыкового отображения.
То есть получается, что у нас дублируются два поля:
Id = NavId — одно для навижена, другое для FILESTREAM
FileName != FullFileName — в первом содержится название файла с путем, преобразованное в ASCII, для того, чтобы его возможно было просматривать в навике. И поле FullFileName, недоступное Навижну, но необходимое для сохранения полноценного имени файла.
**#### Глава III**
Следующим этапом, подключаем нашу длл-ку к Навику. То есть в Codeunit создаем переменную типа Automation и в подтипе находим нашу зарегистрированную библиотеку, с определенным, созданным нами, классом. У меня это вышло так: 
Далее уже в коде:
CREATE(«Var»);
«Var».PutToDataBase('Order','Material','Project', TRUE);
P.s.
При использовании арабского, к примеру, языка, в навике по-любому показываются вопросики. Бороться с этим можно только ставя арабский язык, и переключаем программу на этот язык целиком. | https://habr.com/ru/post/90156/ | null | ru | null |
# Пользовательские запросы к БД в MODx Revolution
Данный топик наверняка будет полезен тем, у кого довольно большие проекты на MODx Revolution, так как с обычными сайтами-визитками достаточно и стандартных методов работы а-ля **$modx->getObject()**, **$modx->getCollection()** и т.п. И данные методы по сути своей не просто работа с базой данных, а еще и с объектами MODx.
При работе с большими проектами методы а-ля **$modx->getCollection()** для нас не лучшее решение по двум причинам:
1. Перерасход ресурсов. Данные методы не просто получают данные из БД, но еще и создают инстанции получаемых объектов. В данном случае получая информацию о 10000 документов, мы получаем 10000 объектов modResource, что не очень круто.
2. Осложняется задача подсчета получаемых записей. Помимо прямых сложностей подсчета еще на уровне запроса, даже если вы получите 10 записей одного и того же документа (к примеру), MODx вернет вам как результат только один объект modResource. И хотя часто такое устроит многих программистов (они получили уникальные объекты и рады), кого-то это не устроит, так как опять же происходит перерасход ресурсов, а по конечному результату сразу и не видно, что запрос не оптимизированный.
К тому же при работе на крупных проектах нам чаще всего нужны не сами объекты, а только информация (записи из базы данных).
Описанные здесь методы работы с БД ставят 2 задачи:
1. Дать бОльшую гибкость в написании запросов к БД.
2. Придерживаться стандартных методов xPDO, то есть избежать чистого SQL, так как чистый SQL по некоторым причинам в фреймворках вообще не кашерно (хотя бы с точки зрения возможной миграции на другой тип БД, смены названий таблиц, префиксов или еще чего-нибудь)
Итак, к делу.
Для начала нам необходимо освоить важный метод
```
$modx->newQuery($class);
```
Для построения всех запросов в MODx всегда нужен хотя бы один базовый класс, от которого будет плясать весь запрос.
Вот более развернутый пример:
```
$q = $modx->newQuery('modResource');
$q->where(array(
'context_key' => 'web'
));
$result = $modx->getCollection('modResource', $q);
```
В данном случае **$q** — это часто встречающаяся нам в документации так называемая **criteria**.
Это почти что тоже самое, что и **where**, когда мы передаем его в качестве второго параметра, только более мощный инструмент, так как у него много важных методов типа Sortby, leftJoin, innerJoin, Limit и другие.
Сейчас мы как раз получили то, с чем и собрались бороться, то есть на выходе мы получили несколько объектов modResource. Просто от этого привычного примера нам легче будет двинуться дальше к нашей цели.
Итак, несколько переделаем наш запрос.
```
$q = $modx->newQuery('modResource');
$q->where(array(
'context_key' => 'web'
));
$q->prepare();
$sql = $q->toSQL();
```
Вот здесь мы уже получим чистый SQL, что наверняка много кому понадобится.
В данном примере мы увидели еще один важный метод
```
$q->prepare();
```
Он как раз и готовит конечный SQL.
Теперь же мы можем выполнить этот SQL
```
$q = $modx->newQuery('modResource');
$q->where(array(
'context_key' => 'web'
));
$q->limit(10); // Добавим лимит записей
$q->prepare();
$sql = $q->toSQL();
$query = $modx->prepare($sql);
$query->execute();
$result = $query->fetchAll(PDO::FETCH_ASSOC);
print_r($result);
```
UPD: этот пример оставлю в качестве демонстрашки $modx->prepare($sql);, но сразу за этим смотрите исправленный пример с одним вызовом ->prepare();
```
$q = $modx->newQuery('modResource');
$q->where(array(
'context_key' => 'web'
));
$q->limit(10); // Добавим лимит записей
$q->prepare();
$q->stmt->execute();
$result = $q->stmt->fetchAll(PDO::FETCH_ASSOC);
print_r($result);
```
На выходе мы как раз и получим массив данных.
Но колонки будут иметь не совсем удачные названия а-ля
[modResource\_id] => 0
[modResource\_type] => document
Чтобы было понятней, добавим явный SELECT в запрос.
```
$q = $modx->newQuery('modResource');
$q->where(array(
'context_key' => 'web'
));
$q->select(array(
'modResource.*'
));
$q->limit(10);
$q->prepare();
$q->stmt->execute();
$result = $q->stmt->fetchAll(PDO::FETCH_ASSOC);
print_r($result);
```
Вот теперь все хорошо с именами колонок :-)
А теперь довольно полезный и наглядный пример: Получим 1/10 записей со сдвигом 1/20 и упорядочим по ID.
```
$q = $modx->newQuery('modResource');
$q->where(array(
'context_key' => 'web'
));
$q->select(array(
'modResource.*'
));
// Подсчитываем общее число записей
$total = $modx->getCount('modResource', $q);
// Устанавливаем лимит 1/10 от общего количества записей
// со сдвигом 1/20 (offset)
$q->limit($total / 10, $total / 20);
// И сортируем по ID в обратном порядке
$q->sortby('id', 'DESC');
$q->prepare();
$q->stmt->execute();
$result = $q->stmt->fetchAll(PDO::FETCH_ASSOC);
print_r($result);
```
Кстати, довольно легко эти примеры переделать так, чтобы получить конечные объекты.
```
$q = $modx->newQuery('modResource');
$q->where(array(
'context_key' => 'web'
));
$q->select(array(
'modResource.*'
));
// Подсчитываем общее число записей
$total = $modx->getCount('modResource', $q);
// Устанавливаем лимит 1/10 от общего количества записей
// со сдвигом 1/20 (offset)
$q->limit($total / 10, $total / 20);
// И сортируем по ID в обратном порядке
$q->sortby('id', 'DESC');
$q->prepare();
// Получаем объекты
$docs = $modx->getCollection('modResource', $q);
```
Суть методов $modx->getObject() и $modx->getCollection() заключается в том, чтобы получив данные из БД, инициировать указанный класс и набить в него полученные данные методом $object->fromArray($array());
Кстати, настоятельно не советую играться с print\_r($docs);, так как результат методов а-ля $modx->getCollection() — массив указанных объектов, каждый из которых является расширенным объектом xPDO и MODx вместе взятых, то есть это ооочень много информации.
Потому для вывода информации из объектов используйте метод $object->toArray();
В данном случае примерно так:
```
foreach($docs as $doc){
print_r($doc->toArray());
}
```
Еще на заметку: элементы в массиве объектов MODx перечислены не по порядку, а каждый ключ — ID объекта (записи), потому вы не можете наверняка обратиться к 11-му элементу через $docs[10], так как документ с ID 10 может оказаться 1-ым, или 100-ым, или его может вообще не быть, хотя в массиве будет 100 документов.
Можете сами убедиться, переделав вывод как
```
foreach($docs as $id => $doc){
print "
". $id;
}
```
Для работы с массивами объектов MODx очень полезно изучить методы работы с элементами массивов, описанных [здесь](http://php.net/manual/ru/function.current.php).
end() — Устанавливает внутренний указатель массива на его последний элемент
key() — Выбирает ключ из массива
each() — Возвращает текущую пару ключ/значение из массива и смещает его указатель
prev() — Передвигает внутренний указатель массива на одну позицию назад
reset() — Устанавливает внутренний указатель массива на его первый элемент
next() — Передвигает внутренний указатель массива на одну позицию вперёд
К примеру, если мы хотим получить первый элемент из массива MODx, никак нельзя обращаться $doc = $docs[0]; В 99,9% вы ничего не получите, так как записи с ID = 0 практически никогда не используются.
Правильно обратиться так: $doc = current($doc);
Те, кому этот метод понравится, наверняка построят таким образом и более сложные запросы сразу из нескольких таблиц и т.п.
P.S. Небольшой сборный запрос с парой полезных фильтров.
Получим все настройки из контекстов WEB и MGR, значения которых IS NOT NULL и != ''
```
$q = $modx->newQuery('modContext');
$where = array(
'modContext.key:in' => array('web', 'mgr'),
'cs.value:!=' => NULL,
'cs.value:!=' => '',
);
$q->select(array(
'modContext.key',
'cs.key as setting_key',
'cs.value'
));
$q->innerJoin('modContextSetting', 'cs', 'cs.context_key = modContext.key');
$q->where($where);
$q->prepare();
$q->stmt->execute();
$result = $q->stmt->fetchAll(PDO::FETCH_ASSOC);
print_r($result);
``` | https://habr.com/ru/post/152123/ | null | ru | null |
# Не решают ли программисты противоречащие задачи (архитектура кода)
Допустим, у нас есть сайт с товарами. У нас есть метод `Product::getProducts` — возвращает массив товаров.
Затем к нам пришел менеджер и сказал: хотим сделать акции на сайте (скидки, распродажи). В каждой акции будут прикреплены товары. Мы написали метод `Action::getProductsByActionId(actionId)`
Затем к нам снова пришел менеджер и сказал что нужны еще статьи, к которым прикреплены товары. Добавим метод `Article::getProductsByArticleId(arcticleId)`.
Вы скажите — давайте сделаем 1 метод с параметрами. Ок, мы до этого дойдем.
**И тут внимание:** к нам пришел менеджер и говорит — мы хотим иметь возможность отключать товары на сайте. Т.е. необходимо добавить флаг active для товаров, имеющий значение true/false. Товары с флагом false не должны отображаться на сайте.
Итог: нам надо найти в коде все места, которые достают товары и везде добавить логику, чтобы возвращались только товары с флагом active=true. Т.е. надо поправить 3 метода:
`Product::getProducts,`
`Action::getProductsByActionId(actionId),`
`Article::getProductsByArticleId(arcticleId)`
То, что нам надо поправить код не в 1 месте, порождает ошибки — в каком-то месте забыли поправить.
Что же, давайте сделаем так, чтобы у нас было только 1 место, откуда доставать товары. Тогда такой ошибки не будет.
Опять та же ситуация: достаем товары для основного каталога сайта, акций и статей: пишем метод `Product::getProducts(actionId = null, articleId = null)`. Если не задан ни один параметр, то достаются товары как в `Product::getProducts` раньше, если задан articleId, то достаются товары `Action::getProductsByActionId(actionId)`, и т.д.
Пока остановимся на том моменте, что мы не включали флаг активации товаров, т.е. менеджер с таким требованием не приходил.
Приходит менеджер и говорит: хотим показывать товары в складской программе. Ок. Мы уже поняли, что будет, если мы добавим метод `Store::getProducts` — в какой-то момент доработки программы мы можем просто про него забыть, и не внести в него необходиму логику. По этому переиспользуем метод `Product::getProducts`. На складе должны показываться абсолютно все товары (вообще всегда все, это может быть не складская программа, а какая-нибудь админка или другая бек-система для персонала), по этому мы вызываем этот метод без параметров.
**И тут внимание: приходит менеджер и говорит**: хотим сделать активные и неактивные товары, флаг active. Чтобы на сайте показывались только активные товары. Ок. У нас есть 1 метод — `Product::getProducts` и мы правим его и добавляем чтобы из него возвращались только товары с флагом active=true.
Мы вносим изменения в единственный метод. И опять — нам надо посмотреть везде где этот метод используется. И если в 1 месте мы забыли посмотреть, то это приведет к ошибке — на складе пропадает часть товаров. Хотя там по ТЗ должны отображаться вообще все товары. Мы просто забыли, что наш универсальный метод `Product::getProducts` используется еще и в бек-системах, где флаг active не должен применяться к товарам. Получается при написании 1 метода тоже возникает ошибка.
### Вывод
Получается что написать 1 метод — это приведет в определенной ситуации к ошибке, и написать несколько методов — это приведет в другой ситуации к ошибке. Получается сколько методов не напиши — всегда когда-нибудь, при изменении бизнес-требований будет ошибка. Получается программист решает нерешаемую без ошибок задачу. Тогда становится понятно, почему идеального кода — не бывает.
UPD:
В комментариях указали, что если сделать 1 метод: Product::getProducts, и затем при изменении в нем назвать его например Product::getProductsV2, а Product::getProducts вообще запретить вызывать, то тогда тогда мы точно найдем все места, где этот метод вызывался, и исключим ошибку.
Второй способ: создать специализированный класс, содержащий 1 private функцию Product::getProducts. И в том же классе создать кучу public методов, на каждый функционал свою функцию, т.е. для каталога - Product::getProductsForCatalog, для акций - Product::getProductsForAction, для статей: Product::getProductsForArticles, Product::getProductsForStore и т.д. Главное условие - чтобы вызов каждой функции был только из 1 места, и все функции находились в 1 классе. Тогда просмотрев лишь 1 класс (это сильно упрощает задачу), мы сразу сможем понять где используется наша функция. | https://habr.com/ru/post/531432/ | null | ru | null |
# Качество, что за зверь и как его обнаружить
Не секрет, насколько молоды профессии контроля и особенно обеспечения качества. Их значимость для IT индустрии давно обоснована. Но и сейчас, по мнению многих соискателей, это проходная ступень, которая не требует особых знаний и навыков. В моем багаже опыт работы с ПО из разных областей — ЖКХ, платежные терминалы, интернет-провайдер, retail и наконец игры. Во всех компаниях, на разных позициях, раньше и теперь я ручаюсь за качество продукта. Казус в том, что нигде я не получила убедительного ответа к какому именно «качеству» мы стремимся. Сегодня, на должности руководителя QA, я отвечаю на этот вопрос сама и хочу провести ликбез как можно шире.
Отмечу самые популярные требования к качеству.
— «Функционал должен соответствовать требованиям»
наличие настоящих требований и спецификаций роскошь, доступная не всем компаниям. И если требования есть, они целиком зависят от опыта аналитика, который к тому же может ошибиться в их структурировании и акцентировании из-за сыгравшего человеческого фактора. Не говоря уже о том, насколько шире и многообразней системы по сравнению со своими спецификациями.
— «Не должно быть багов в проде»
я не знаю ничего более относительного, чем «баг». При стремительном развитии рынка через полгода блокером может стать то, что раньше даже дефектом не считалось. Как часто фича в разработке, после выпуска воспринимается пользователем как дефект, заводится и исправляется соответственно.
— «После выпуска должно быть все хорошо/ удовлетворять пользователя»
по моему мнению это требование точнее остальных, проблема только в его неточности. В погоне за симпатией пользователя, тестирование становится необъятным, никогда не достаточно времени, чтобы убедиться в качественности и выпустить достаточно хороший продукт. Приходится выбирать наиболее критичное и смиряться с «кое-какерством». Это довольно грустно. И в этих условиях появляется привычка противопоставлять качество скорости.
```
абсолютное качество/скорость = прибыли
```
Однако, я считаю, что «качество», понятие индивидуальное и не требует абсолютности, конкретное и исчисляемое. А также не существует конфликта между качеством и скоростью, так как индивидуальное качество равнозначно прибыльности и включает в себя скорость.
```
индивидуальное качество = конкурентоспособность = прибыли
```
Качество — старт
----------------
Первым, кто связал качество продукта с прибылями, выявил и описал причинно-следственные связи, стал Эдвардс Деминг, доктор в области физики, статистик и основоположник качества в производстве. Успех его работы на заводах Toyota в 80-х годах, позже был назван Японским чудом.
Основная идея его философии — ублажение потребителя. Непрерывные изменения на всех этапах разработки продукта в пользу улучшения потребительских свойств. Только это гарантирует конкурентоспособность и, как следствие, прибыльность.
Деминг выделяет 2 типа потребителя — промежуточного и конечного. Как вычислить, кто они и чего хотят, отлично сформулировано в его «Вопросах, призванных команде взять старт». Опросник применим к любому уровню организационной структуры:
> Ваша организация:
>
>
>
> 1. Где расположен ваш отдел в общей организационной структуре?
> 2. Какие товары и услуги производит и оказывает ваша организация?
> 3. Как производится этот товар и оказывается услуга, с помощью каких процессов?
> 4. Что случится, если ваша компания (подразделение, отдел, группа) вдруг перестанет производить продукцию и оказывать услуги?
>
>
>
> Вы:
>
>
>
> 1. Какие задачи выполняет ваш отдел, в чем состоит его работа?
> 2. Что вы создаете или производите в отделе, что именно является результатом работы?
> 3. Как вы это делаете (дайте общее описание того, что вы делаете)?
> 4. Откуда вы знаете, получились ли у вас хорошие или плохие результаты (существуют ли стандарты или критерии хорошей работы)?
> 5. Как были установлены стандарты?
>
>
>
> Вопросы, касающиеся ваших потребителей:
>
>
>
> 1. Промежуточный потребитель
>
> * Кто промежуточный потребитель товара или услуги, которые вы производите или оказываете (ваш персональный потребитель)?
> * Как ваш потребитель использует то, что вы производите?
> * Что произойдет, если вы допустите ошибку?
> * Как на ваши ошибки отреагируют потребители?
> * Как вы узнаете о том, удовлетворили ли вы запросы ваших потребителей (от потребителей, от босса из отчетов)?
> 2. Промежуточный и конечный потребитель
>
> * Насколько далеко (от вашего конечного потребителя) вы находитесь, можете проследить эффект от того, что вы сделали?
>
>
>
> Вопросы, касающиеся ваших поставщиков:
>
>
>
> 1. Кем инициируется ваша работа (указание начальника, запрос потребителя, собственная инициатива)?
> 2. Кто поставляет вам материалы, информацию, услуги и другие средства, которые нужны для выполнения вашей работы (начальник, потребитель, коллега — из вашей бригады, люди из других подразделений)?
> 3. Что будет с вами, если ваши поставщики не сделают своей работы?
> 4. Есть ли у них стандарты качества их работы?
> 5. Как их ошибки повлияют на вашу работу?
> 6. Как они обнаруживают, удовлетворили ли они ваши потребности или требования? Вы с ними сотрудничаете? Выполняете ли вы свои обязательства по отношению к ним?
>
>
>
>
Качество — составляющие
-----------------------
Промежуточным потребителям в IT друг от друга, как правило, нужно одно и то же — полная, достоверная, своевременная, понятная информация для выполнения работ, артефакты, которые не нужно уточнять и дорабатывать, чтобы использовать. Все это решается через процессы и призвано экономить время. Так скорость становится частью модели качества.
Конечный потребитель прихотливее, он готов платить только за полученное благо от использования продукта. Международный стандарт ISO-9126 классифицировал продукт по 6 качественным характеристикам, каждая из которых отражает укрупненное потребительское свойство.
Насколько функциональности отвечают потребностям, привлекательны, интуитивны и удобны в использовании. Насколько стабильна работоспособность системы, эффективно потребление физических ресурсов. В каком количестве сред, условий и конфигураций она будет приносить одинаковое количество пользы. И наконец, сколько усилий понадобится команде проекта, чтобы спланировать масштабирование, внести изменения, протестировать и диагностировать состояние системы в работе.
Неконкретные качественные характеристики разбиваются на атрибуты, однозначные и измеримые. Их рекомендуется приоритизировать и сосредотачиваться на наиболее значимых с точки зрения своего личного потребителя — пользователя продукта, заказчика и команды проекта.
Качество — определение
----------------------
**1) Функциональность**
Разумеется наиважнейшая характеристика функциональность. Остальные усиливают ее результативность или наоборот, у кого как с качеством. Одновременно она же самая сложная для формализации, «соответствие требованиям» необходимо, но недостаточно. Потребитель хочет провести время, выполнить свои задачи, получить доход, увеличить экономию и не думать о программном обеспечении, тем более не формулировать требования к нему. А также не нацелен использовать все возможные функции продукта. Качество функциональности определяется количеством бесперебойно работающих сценариев, во всех существенных контекстах потребителя. Это доказывает огромное количество литературы об исследовательском тестировании, появившееся в последние годы. Обеспечить работоспособность всего вообще во всех возможных случаях использования невозможно и не требуется. Жизненно важно выяснить контексты своих потребителей, в том числе с помощью требований к ПО. Приоритизировать их и зорко контролировать, так как любая поломка повлечет потери.
**2) Удобство использования**
Функциональность предоставляется еще задолго до появления первых тестировщиков на проекте, а порой и разработчиков. Один из признанных знатоков приготовления [MVP (Minimum Viable Product)](https://rb.ru/howto/mvp/) Рэнд Фишкин, известный за рубежом SEO-специалист и маркетолог, напоминает, что первое впечатление нельзя произвести дважды, и успешно продвигает концепцию входить на рынок с [EVP (Exceptional, Viable Product)](https://moz.com/rand/7-unlikely-recommendations-for-startups-entrepreneurs/), который не только полезен, но и симпатичен пользователю. Справедливо, что в условиях искушенного потребителя, характеристика удобства использования занимает второе место. Технология usability дизайна непрерывно развивается и обрастает новыми лучшими практиками, которые можно и нужно устанавливать и применять в своем продукте.
**3) Переносимость**
Продукт, привлекший внимание широкого круга, обычно начинает использоваться в различных условиях. Его пользователи ожидают корректной работы во всех из них. Определить стандарты переносимости помогают внутренняя и внешняя статистики, и конечно же здравый смысл. При определенной доле настойчивости, в любой компании можно получить статистику о распространенных условиях активной аудитории. Статистику о популярных трендах можно найти в интернете в свободном доступе, при этом важно учитывать по крайней мере территориальную когорту — данные по России и миру имеют свойство различаться. Здравый смысл нужен, чтобы стандарт к переносимости не включал в себя поддержку +100500 условий использования. С учетом, что у ОС, девайсов, браузеров также существуют стандарты, часть из них гарантированно будет работать одинаково или не хуже предыдущей версии.
**4) Надежность и Эффективность**
Первый настоящий успех продукта, по обыкновению, бьет по нему же проблемами с эффективностью и надежностью. Массовое потребление — мечта и трудность одновременно. Надежность, которая в конечном счете исчисляется временем доступности системы, должна стремиться к 100% не зависимо ни от чего. Эффективность оценивается пользователем через время отклика. Кто-то из Badoo сказал: «Будьте на 20% быстрее своего самого быстрого конкурента» и это хорошее подспорье для нахождения своей персональной нормы эффективности.
**5) Удобство сопровождения**
Проекты долгожители неизбежно усложняются, обрастают противоречиями, архитектурной несогласованностью. Специфика текучести кадров в IT не улучшает положение. Чем старше продукт, тем весомее значение удобства сопровождения. Документация всех уровней, от инструкций к использованию до комментирования кода и логгирования работы функций, значительно ускоряет работу с системой на всех этапах — при постановке требований, разработке, тестировании и поддержке. А в некоторых случая даже защищает от заведомо неверных решений.
Вот, пожалуй, и все. Однако должна сделать несколько оговорок:
* каждая характеристика разбивается на множество атрибутов, которые также имеют различный вес для конечного потребителя. Потому постановка обеспечения качества может вестись параллельно по главным атрибутам нескольких характеристик. Я лишь попыталась отразить условия, влияющие на приоритет каждой из них.
* наиболее сложная характеристика — функциональность. Реалии таковы, что ПО теперь неотделимо от сервиса, предоставляющего ПО, а это выходит за определения стандарта ISO-9126. Только знание ценностей потребителей и ориентир на них позволит выявить, какие именно функциональности важны и что конкретно они в себя включают.
* предложенные приоритеты характеристик подходят не всем системам, я ориентируюсь на коммерческое ПО для внешнего пользователя с относительно небольшой ценой ошибки и высокой конкуренцией. Другие условия, как правило, смягчают требования к качеству, если только цена ошибки не приравнивается к человеческой жизни, огласке государственной тайны, нарушению законодательства. Там приоритеты расставляются иначе и, я надеюсь, работают гуру контроля и обеспечения качества.
* жизнеспособность продукта во времени, определяется спросом (мера интереса) и монетизацией (мера ценности), которые поддерживаются частотой обновлений. Это позволяет приравнять скорость к седьмой характеристике качества и вычислять ее на том же основании, как и все остальные, с оглядкой на конкурента.
По итогу выходит, что качество является неотъемлемой частью успешности продукта. Требования к нему зависят от потребителя, ниши рынка, прямых конкурентов. А также оно не противопоставляется производству в целом, так как потери в индивидуальном качестве приведут к потере успеха всего дела.
```
функциональность + удобство использования + переносимость + надежность+ эффективность + удобство сопровождения + частота обновлений = индивидуальное качество
```
 | https://habr.com/ru/post/333460/ | null | ru | null |
# Scalar type hints в PHP
Johannes Schlüter опубликовал в своем блоге информацию о том что в trunk (PHP) появилась поддержка scalar type hints. Многие из нас очень давно этого ждали.
Выглядит это приблизительно так:
`php <br/
function check_counter( int $counter)
{
return;
}
?>`
Если попытаться передать в такую функцию не int, получим Catchable fatal error. | https://habr.com/ru/post/101229/ | null | ru | null |
# Сенсорные выключатели с Modbus: зачем нужны и как применить в умной квартире

В бюджетных системах умного дома обычно используют стандартные выключатели — их тип выхода также называют [«сухой контакт»](https://ru.wikipedia.org/wiki/%D0%A1%D1%83%D1%85%D0%BE%D0%B9_%D0%BA%D0%BE%D0%BD%D1%82%D0%B0%D0%BA%D1%82). Однако это не единственный вариант: в поисках красивого выключателя я наткнулся на устройства с протоколом Modbus RTU внутри. Кроме красивого внешнего вида, они позволяют настроить режим работы каждой кнопки, детально управлять подсветкой, а для их подключения к центральному контроллеру (я использовал [Wiren Board 5](https://wirenboard.com/ru/product/wiren-board-5/)) достаточно четырёх проводов — питание, земля и две линии для RS-485.
Как подключить такой выключатель и настроить управление светом и вентиляцией с него, смотрите ниже. Также в статье будет подробно описано, как вообще работать с Modbus-устройствами.
*Пояснение от маркетолога Wiren Board: эта статья родилась из темы, созданной [Kallyanbl4](https://habr.com/users/kallyanbl4/) на [нашем форуме](https://forums.contactless.ru/). После нашей просьбы он написал полноценную статью и разрешил опубликовать её в нашем блоге, за что ему большое спасибо. Весь текст написан автором, кроме примечаний в конце.*
### Описание выключателей
Изучив, что сейчас есть на рынке, купил у китайцев [вот такие](https://russian.alibaba.com/product-detail/4-way-12v-dc-rs485-modbus-protocol-smart-hotel-light-touch-switch-60477583851.html) интересные выключатели:

Их преимущества:
* неплохой дизайн;
* выключатели cенсорные, при нажатии мигают, подсвечиваются в темноте приятным белым цветом;
* относительно небольшая цена – 2000 рублей за штуку. В стоимость входит индивидуальная лазерная гравировка;
* выключатель программируемый — можно задать кнопке практически любое действие: включение света, управление светодиодами, поднять/опустить штору, ...
Технические характеристики выключателя:
* напряжение питания – 12 В;
* скорость передачи данных — 19200 бит/с;
* количество передаваемых бит – 8;
* количество стоповых бит – 1;
* контроль чётности – нет проверки.
При работе по Modbus RTU подключаемые устройства имеют так называемые регистры – ячейки, в которых хранится информация. На скриншоте описание регистров для четырёхклавишного выключателя:
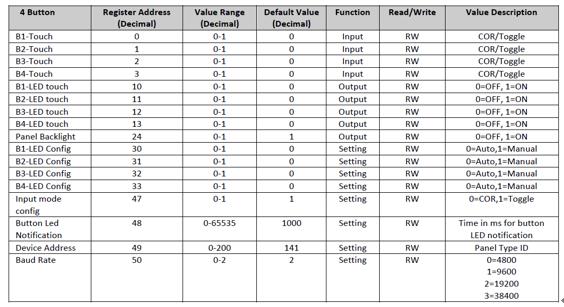
При нажатии на одну из сенсорных кнопок значения в регистрах 0-3 будет меняться с 0 на 1.
### Коммутация выключателей
В контроллере Wiren Board 5 в зависимости от комплектации бывает от двух до четырёх портов RS-485. Выключатели (в моём случае их 27) необходимо присоединить к этим портам.
В данном случае все выключатели могут работать на одной общей шине. Выключатели можно соединить последовательно, ведя кабель от одного выключателя до другого, но я решил скоммутировать все кабели в одном щитке.
Соединяющий кабель — восьмижильный Cat 5e UTP. Можно использовать и четырёхжильный, но я обычно всё делаю по принципу «на всякий случай». Можно рассмотреть и другие четырёхжильные кабели, но важный момент – кабель должен быть экранированным, ибо даже несмотря на достаточно низкие частоты сигнала, потери и наводки не исключены.
В итоге все выключатели у меня соединены между собой как показано на картинке:

Как видно из рисунка, все выключатели соединены между собой с помощью пассивного UTP-коммутатора. По жилам 1 и 2 (оранжевая и бело-оранжевая) передается данные (линии A и B), к жилам 7 и 8 (коричневая и бело-коричневый) подключено питание 12 В. В качестве источника питания использую Mean Well NDR-75-12.
Я не знал, как поведет себя пассивный китайский UTP-коммутатор, поэтому при проектировании щитка предусмотрел место для активного RS-423 коммутатора. Отмечу, что схема работает как через пассивный, так и через активный коммутаторы. И даже при их совместном подключении.

### Управление светом с помощью реле
По моему проекту в квартире запланированы 27 независимых устройств (свет, вентиляторы), питаемые от 220 В. Для управления ими были выбраны три релейных модуля [WBIO-DO-R10A-8](https://wirenboard.com/ru/product/WBIO-DO-R10A-8/) и одно [WBIO-DO-R10R-4](https://wirenboard.com/ru/product/WBIO-DO-R10R-4/). Выбор обусловлен тем, что практически всё освещение в квартире – светодиодное, которое отличается от ламп накаливания высоким пусковым током. Выбранные реле способны обеспечить коммутацию тока до 10 А на канал, что в моём случае излишне — но, как было указано ранее, «на всякий случай с запасом».

Переключение реле происходит через [веб-интерфейс контроллера](https://contactless.ru/wiki/index.php/%D0%92%D0%B5%D0%B1-%D0%B8%D0%BD%D1%82%D0%B5%D1%80%D1%84%D0%B5%D0%B9%D1%81_Wiren_Board). Процедура интуитивно понятная, инструкция или подсказки не требуются.
### Программная часть
**Файл порта**
Из [описания аппаратной части Wiren Board 5](https://wirenboard.com/wiki/index.php/Wiren_Board_5:%D0%90%D0%BF%D0%BF%D0%B0%D1%80%D0%B0%D1%82%D0%BD%D0%B0%D1%8F_%D1%87%D0%B0%D1%81%D1%82%D1%8C) узнаём, что у него двум портам RS-485 соответствуют файлы устройств */dev/ttyAPP1* и */dev/ttyAPP4*. В моём случае выключатель подключен к порту */dev/ttyAPP1*.
**Адрес устройства (выключателя)**
При обмене данными по протоколу Modbus RTU каждое устройство идентифицируется собственным уникальным номером – Modbus-адресом. Как правило, производитель указывает этот адрес в виде трёх цифр на самом устройстве, но если такого номера на устройстве нет, можно [перебрать адреса из командной строки](https://wirenboard.com/wiki/index.php/%D0%9E%D0%BF%D1%80%D0%B5%D0%B4%D0%B5%D0%BB%D0%B5%D0%BD%D0%B8%D0%B5_%D0%B8_%D0%B8%D0%B7%D0%BC%D0%B5%D0%BD%D0%B5%D0%BD%D0%B8%D0%B5_Modbus-%D0%B0%D0%B4%D1%80%D0%B5%D1%81%D0%B0_%D1%83%D1%81%D1%82%D1%80%D0%BE%D0%B9%D1%81%D1%82%D0%B2_Wirenboard) (используется то, что адрес хранится в Modbus-регистре 0x80):
```
root@wirenboard:~# service wb-mqtt-serial stop
root@wirenboard:~# for i in {1..247}; do modbus_client -mrtu /dev/ttyAPP1 --debug -a$i -t3 -r0x80 -s1 -pnone; done 2>/dev/null | grep Data:
```
Результат должен быть в виде:
```
Data: 0x008e
```
Ответ получен в шестнадцатеричном формате и соответствует цифре 142 в десятичном.
Стоит отметить, что при каждом вызове утилиты *modbus\_client* следует останавливать стандартный для контроллера драйвер опроса *[wb-mqtt-serial](https://contactless.ru/wiki/index.php/%D0%94%D1%80%D0%B0%D0%B9%D0%B2%D0%B5%D1%80_wb-mqtt-serial)*; в противном случае утилита *modbus\_client* работать не будет.
**Обмен данными между выключателем и Wiren Board**
Выше написан цикл, который опрашивает все возможные Modbus-адреса и возвращает значение адреса, если устройство найдено. В цикле задействована утилита *[modbus\_client](https://wirenboard.com/wiki/index.php/Modbus-client)*, которая необходима для отладки подключаемых устройств. В этом пункте с помощью неё убедимся, что всё подключено верно, и выключатель взаимодействует с контроллером должным образом. Для этого попробуем прочитать данные в регистре 0х01 выключателя:
```
root@wirenboard:~# service wb-mqtt-serial stop
root@wirenboard:~# modbus_client -mrtu /dev/ttyAPP1 --debug -a142 -s1 -pnone -b19200 -a142 -t0x03
```
(описание утилиты и её ключей есть в документации контроллера).
Результат будет следующего вида:
```
Opening /dev/ttyAPP1 at 19200 bauds (N, 8, 1)
[8E][03][00][64][00][01][DA][EA]
Waiting for a confirmation...
<8E><03><02><00><01><2C><5B>
SUCCESS: read 1 of elements:
Data: 0x0001
```
Такой результат означает, что в регистре записана дискретная величина 1. После нажатия на одну из кнопок выключателя значение регистра изменится на противоположное значение:
```
SUCCESS: read 1 of elements:
Data: 0x0000
```
Если наблюдается результат, как в этом пункте, то значит все подключено верно, выключатель и контроллер понимают друг друга.
**Собственный драйвер для выключателя**
После того как мы убедились, что контроллер и выключатель понимают друг друга, настало время дать описание клавишам выключателя на программном уровне. Разработчики предлагают добавлять описание подключенного устройства в файл /etc/wb-mqtt-serial.conf или создать собственный шаблон в виде файла /usr/share/wb-mqtt-serial/templates/config-\*.json
Я пошел по второму пути, мой шаблон выглядит так:
```
{
"device_type": "4-band-switch",
"device": {
"name": "4-band-switch",
"id": "4bsw",
"enabled": true,
"channels": [{
"name": "All",
"reg_type": "holding",
"address": "0x00",
"type": "switch"
},
{
"name": "Window",
"reg_type": "holding",
"address": "0x01",
"type": "switch"
},
{
"name": "Side",
"reg_type": "holding",
"address": "0x02",
"type": "switch"
},
{
"name": "Diode",
"reg_type": "holding",
"address": "0x03",
"type": "switch"
}
]
}
}
```
Детальное описание написанного выше шаблона есть в [описании драйвера *wb-mqtt-serial*](https://github.com/contactless/wb-mqtt-serial). Кратко разберёмся с полями:
* «name»: «All» – имя кнопки. Если шаблон написан верно, эта кнопка появится во вкладке Settings с адресом */devices/4bsw\_142/controls/All*
* «reg\_type»: «holding» – тип и размер регистра. В выключателе используется «holding» – 16-битный регистр, доступный на чтение и запись.
* «address»: «0x00» – адрес регистра выключателя, из которого контроллер будет читать данные.
* «type»: «switch» – как выключатель будет отображаться в веб-интерфейсе. В случае «switch» — в виде дискретного переключателя.
Сохраняем шаблон на контроллер. После этого в разделе веб-интерфейса (Configs -> /etc/wb-mqtt-serial.conf) можно будет добавить новое устройство с таким шаблоном (4-band-switch). Добавляем наш первый выключатель и нажимаем Save.
#### Правило, включающее реле при нажатии кнопки выключателя
Внутри контроллера состояния всех подключенных устройств описываются [MQTT-сообщениями](https://wirenboard.com/wiki/index.php/MQTT#.D0.9A.D0.BB.D0.B8.D0.B5.D0.BD.D1.82.D1.8B_.D0.BE.D1.87.D0.B5.D1.80.D0.B5.D0.B4.D0.B8_.D1.81.D0.BE.D0.BE.D0.B1.D1.89.D0.B5.D0.BD.D0.B8.D0.B9). Управляются устройства также через отправку MQTT-сообщений. Клиентами очереди MQTT-сообщений (брокера) являются и веб-интерфейс, и [движок правил](https://wirenboard.com/wiki/index.php/%D0%94%D0%B2%D0%B8%D0%B6%D0%BE%D0%BA_%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D0%BB_wb-rules).
Для наглядности посмотрим, как веб-интерфейс обрабатывает пришедшее сообщение. Открываем вкладку Settings веб-интерфейса и наблюдаем, что будет происходить при нажатии кнопки All выключателя: внутри выключателя поменяется значение Modbus-регистра, драйвер *wb-mqtt-serial* опросит выключатель, и в соответствии с шаблоном устройства 4-band-switch отправит MQTT-сообщение в топик */devices/4bsw\_142/controls/All* — и на странице Settings значение в топике */devices/4bsw\_142/controls/All* моментально изменится с 0 на 1.
Рассмотрим второго клиента – движок правил. Движок так же, как и веб-интерфейс, работает с очередью сообщений, и может среагировать на изменения значения — для этого используется функция *whenChanged*. В моём случае правило выглядело так:
```
//Коридор и гостиная
defineRule("switch_all", {
whenChanged: "4bsw_142/All",
then: function(newValue, devName, cellName) {
dev["wb-gpio"]["EXT3_R3A2"] = newValue;
dev["wb-gpio"]["EXT3_R3A5"] = newValue;
dev["wb-gpio"]["EXT1_R3A1"] = newValue;
dev["wb-gpio"]["EXT1_R3A2"] = newValue;
dev["wb-gpio"]["EXT1_R3A5"] = newValue;
dev["wb-gpio"]["EXT2_R3A8"] = newValue;
dev["wb-gpio"]["EXT3_R3A7"] = newValue;
}
});
//маленькая комната
defineRule("switch_window", {
whenChanged: "4bsw_142/Window",
then: function(newValue, devName, cellName) {
dev["wb-gpio"]["EXT4_ON4"] = newValue;
// dev["wb-gpio"]["EXT3_R3A6"] = newValue;
// dev["wb-gpio"]["EXT3_R3A7"] = newValue;
}
});
//Санузлы
defineRule("switch_side", {
whenChanged: "4bsw_142/Side",
then: function(newValue, devName, cellName) {
dev["wb-gpio"]["EXT1_R3A3"] = newValue;
dev["wb-gpio"]["EXT1_R3A4"] = newValue;
dev["wb-gpio"]["EXT2_R3A1"] = newValue;
}
});
//Кухня
defineRule("switch_diode", {
whenChanged: "4bsw_142/Diode",
then: function(newValue, devName, cellName) {
dev["wb-gpio"]["EXT2_R3A2"] = newValue;
dev["wb-gpio"]["EXT2_R3A3"] = newValue;
dev["wb-gpio"]["EXT3_R3A3"] = newValue;
}
});
```
На все вопросы буду рад ответить в комментариях.
### Примечания маркетолога
1. Прокладывать линию RS-485 лучше кабелем КСПЭВГ 2х2х0,35 (стоит всего 30 рублей за метр), причём не звездой, а шиной.
2. Со светодиодными лампами мы советуем быть осторожнее — их пусковой ток может превышать номинальный в 150 (!) раз (про это будет отдельная статья) — присмотритесь к мощным релейным модулям [WB-MR6](https://wirenboard.com/ru/product/WB-MR6/): ток 16 А на канал, в том числе пусковой ток до 800 (!) ампер в модификации S. | https://habr.com/ru/post/417093/ | null | ru | null |
# Анализатор морфологии на автоматах
Периодически на хабре проскакивают статьи о том, как написать программу для анализа морфологии. В основном авторы пользуются базами данных, либо стандартными структурами, такими как словари. Но это не всегда удобно. Во-первых, страдает скорость. Во-вторых, некоторые алгоритмы, такие как предсказание морфологии незнакомых слов, реализуются нетривиально.
Здесь я привожу версию, основанную на конечных автоматах, где попробую избежать данных проблем. Как это работает можно [посмотреть здесь](http://www.delinguis.com/morph).
Итак, чего мы хотим от морфологии. Обычно, от модуля анализа морфологии требуют:
* получение леммы по заданному слову
* получение морфологической информации по заданному слову
* предсказание морфологии
Готовить все это будем из двух ингредиентов: морфологического словаря и библиотеки автоматов. Первый возьмем (как уже принято) из проекта [aot.ru](http://aot.ru), спасибо им за LGPL. А библиотеку автоматов — отсюда: [openfst.org](http://openfst.org). Кода будет по минимуму: все нужные операции уже реализованы в библиотеке.
#### Шаг первый. Парсим морфологический словарь.
В морфологическом словаре находятся строки вида:
`МГЛ А га Ы гб Е гв У гг ОЙ гд ОЮ гд Е ге Ы гж АМ ги Ы гй АМИ гк АХ гл`
Здесь приведен пример для слова 'мгла'. Буквы МГЛ — это корень слова. Остальное — окончания (флексии). Лемму, или нормализованное слово мы можем получить, сложив корень и первую флексию, в данном случае — МГЛА. Малые двухбуквенные сочетания — это анкод. Т.е. это код, однозначно определяющий морфологию словоформы. К примеру для 'га' это — 'существительное, женский род, единственное число, именительный падеж'.
Перейдем к действиям. Для каждой строки словаря строим вот такую структуру.

Это конечный преобразователь. Работает следующим образом. Каждый переход маркируется двумя буквами, где первая — входной символ, вторая — символ на выходе. Если мы «соберем» входящие и исходящие символы вдоль любого из путей из начального состояния в конечное, то получим два слова. Магия в том, что здесь входным словом будет одна из морфологических форм слова, а выходом — лемма + анкод. К примеру, «скормив» в этот автомат слово «МГЛОЮ», мы получим навыходе «МГЛАмг». Стоит отметить, что "-" обозначает пустой символ, и при проходе по графу мы можем его игнорировать.
Вообще, получить выходное слово по входному можно применив стандартную операцию композиции:
если D — словарь, как на картинке выше,
W — слово, где W = <(М, М)(Г, Г)(Л, Л)(О, О)(Ю, Ю),(И, И)>
То M — результат композиции — будет равен (за вычетом пустых символов)
M = W o D = <(М, М)(Г, Г)(Л, Л)(А, А)(а, а)(м, м)
#### Шаг второй. Оптимизация.
У структуры на рисунке выше есть проблема. Она не оптимальна. Первое — много лишних пустых символов, которые бесполезно «раздувают» преобразователь. Второе — этот преобразователь сам по себе не оптимален. Если построить такую конструкцию для полного словаря, последний будет очень большим.
И так, сначала сдвигаем исходящие символы в сторону начального состояния. Этим мы уменьшим количество пустых символов. В библиотеке openfst реализована такая операция. Зовется fstpush.

Как видно на рисунке появились дуги с метками "-:-". Они удалятся в процессе упаковки.
Далее, упаковываем преобразователь. Здесь есть тонкость. В общем случае конечный преобразователь не может быть упакован как обычный конечный автомат. Дело в том, что для минимизации преобразователя, как и автомата, он должен быть детерминирован (каждому входному слову соответствует единственное выходное). Но данный преобразователь таковым не является.
Чтобы решить эту проблему, можно
* привести преобразователь к конечному автомату
* упаковать автомат (по стандартному алгоритму)
* привести получившийся автомат к преобразователю
Все эти операции стандартны, код писать нет нужды. Результат для слова «мгла» на картинке ниже.

Как видно из рисунка, количество состояний и переходов заметно сократилось. А это и есть наша цель.
#### Шаг третий. Предсказание морфологии неизвестного слова.
Здесь все просто. Все что нам нужно — для входящего слова W построить композицию с двумя преобразователями и найти кратчайший путь до конечного состояния:
P = shortest(W o T o D)
где, D — словарь
T — специальный преобразователь с весами, который поглощает префикс слова, при этом штрафуя за каждый «съеденный» символ.

Предсказание я пока не реализовал в примере. Возможно, позже.
#### Выводы
На мой взгляд это довольно интересный способ работать с морфологией. Я могу выделить два существенных плюса:
* скорость и ресурсы
* простота разработки
* универсальность алгоритмов
Относительно скорости в данном примере мне не удалось с наскока добиться хороших результатов. Получилось что-то вроде 2000 слов/сек. Но я использовал стандартную библиотеку и не очень заботился об оптимизации. Возможно, если использовать другие виды трансдьюсеров скорость может возрасти. Словарь весил около 35М (однако, если использовать компактное представление, он сжимается в 3 раза).
На счет простоты: здесь ненужно много кода. Достаточно пользоваться стандартными операциями: композиция, конкатенация, объединение и поиск кратчайшего пути. Конструкция словаря заняло что-то около 50 строк кода. Тарбол примера с исходниками и питоновскими байндингами можно [скачать здесь](http://delinguis.com/static/pymorph-0.1.tar.gz).
Кроме того, у данного подхода есть очень интересная особенность. Он позволяет выстраивать сложные преобразования за счет объединения трансдьюсеров в более сложные схемы. К примеру, добавив в предиктор автомат из моей [прошлой статьи о спелчекере](http://habrahabr.ru/blogs/algorithm/105450/) мы получим логический дивайс, который ответит на вопрос: «а является ли это слово действительно неизвестным, или оно содержит ошибку».
Пожалуй, пока все. Надеюсь, было интересно. | https://habr.com/ru/post/109736/ | null | ru | null |
# Играем в Тетрис на электромеханическом экране

Однажды, просматривая объявления на Avito, я наткнулся на очень любопытную вещь — блинкерное табло или flip-dot display по-английски. Такие табло используются для отображения информации в аэропортах, вокзалах, стадионах или маршрутоуказателях на общественном транспорте.
Я подумал, что с дисплеем такого типа можно сделать много всего интересного.
Где был установлен мой экран, можно только догадываться по остатку надписи (“АГАЗИН”). Возможно, это был информационный стенд на вокзале или остановке ОТ — пишите ваши идеи в комментариях.
Экран представлял собой матрицу ячеек размером 7 строк на 30 столбцов. Каждая ячейка содержала круглую, вращающуюся двухцветную пластину и светодиод зеленого свечения. На плате имелось некоторое количество логических элементов серии 74HCххx и других микросхем, которых, как выяснилось позже, было почти достаточно для управления экраном через нехитрый последовательный интерфейс.
После покупки я потратил немного времени на поиски информации о том, как работать с такими экранами, учитывая, что в моем распоряжении была только часть, непосредственно выводящая изображение, а обычно присутствует еще и контроллер, которым можно управлять клавиатурой либо через порт UART софтом с PC.
По надписям на плате установить принадлежность к производителю не удалось, но, возможно, я не сильно и старался, т. к. интереснее было самому разобраться, как оно работает, нарисовать схему устройства и разработать модуль сопряжения с типовым микроконтроллером.
Но сначала надо было поставить себе конкретную цель, для чего можно применить этот экран в быту. Первой идеей были часы с отображением расширенной информации о погоде на улице и дома, времени, даты, коротких мотивирующих посланий ;) и т. д. Потом я подумал, что, если повернуть экран на 90о, он здорово напоминает стакан для Тетриса, поэтому было решено сделать Тетрис, а дальше будет видно.
Как же работают электромеханические экраны
------------------------------------------
Очень просто: каждая ячейка экрана (флажок) состоит из диска — плоского постоянного магнита, окрашенного с одной стороны в желтый, а с другой — в черный цвет, и электромагнита, расположенного под диском. При подаче электрического импульса на катушку электромагнита флажок переворачивается и, что важно, фиксируется в одном положении. При смене направления тока и подачи повторного импульса флажок поворачивается и фиксируется другой стороной. Для переключения достаточно импульса длительностью в 1 миллисекунду, напряжением 12 вольт.
Сопротивление катушки электромагнита примерно равно 18 Ом.
| | |
| --- | --- |
|
Устройство ячейки, источник: [Eldi](https://www.eldisrl.com/en-gb/magnetic-indicators) datasheet |
Как происходит поворот диска, источник: [Flip-Disc Display](https://breakfastny.com/flip-disc-system) |
Для удобства управления катушки через два диода объединены в матрицу строк и столбцов. Для переключения любой точки экрана нужно активировать источник тока (current source) на строке и сток тока (current sink) на ряду, на пересечении которых находится катушка электромагнита или, наоборот, для переключения в другую сторону. По сути, это аналогично управлению двигателями постоянного тока через Н-мост, только в импульсном режиме.
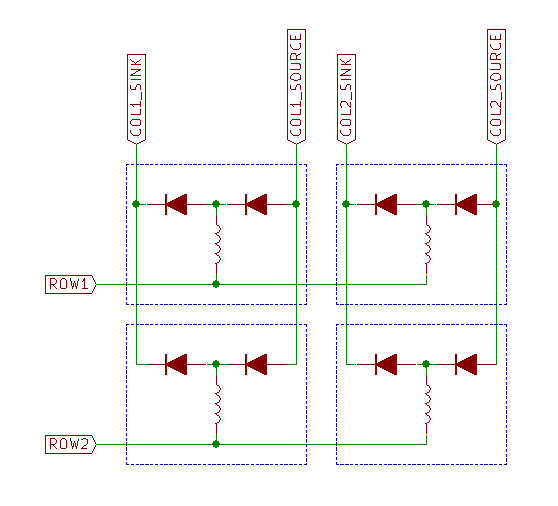
С тем, как управлять флажками в теории, мы разобрались. Пора переходить к практический реализации.
Реверс-инжиниринг экрана
------------------------
Вооружившись мультиметром и Kicad, я стал перерисовывать схему экрана, начав с управления светодиодами. Оказалось, что эта часть самодостаточна, и при подаче питания и управляющих сигналов можно зажечь любой светодиод в любом ряду экрана через довольно простой интерфейс. В каждый момент времени активной может быть только одна строка, поэтому вывод изображения должен быть динамическим.
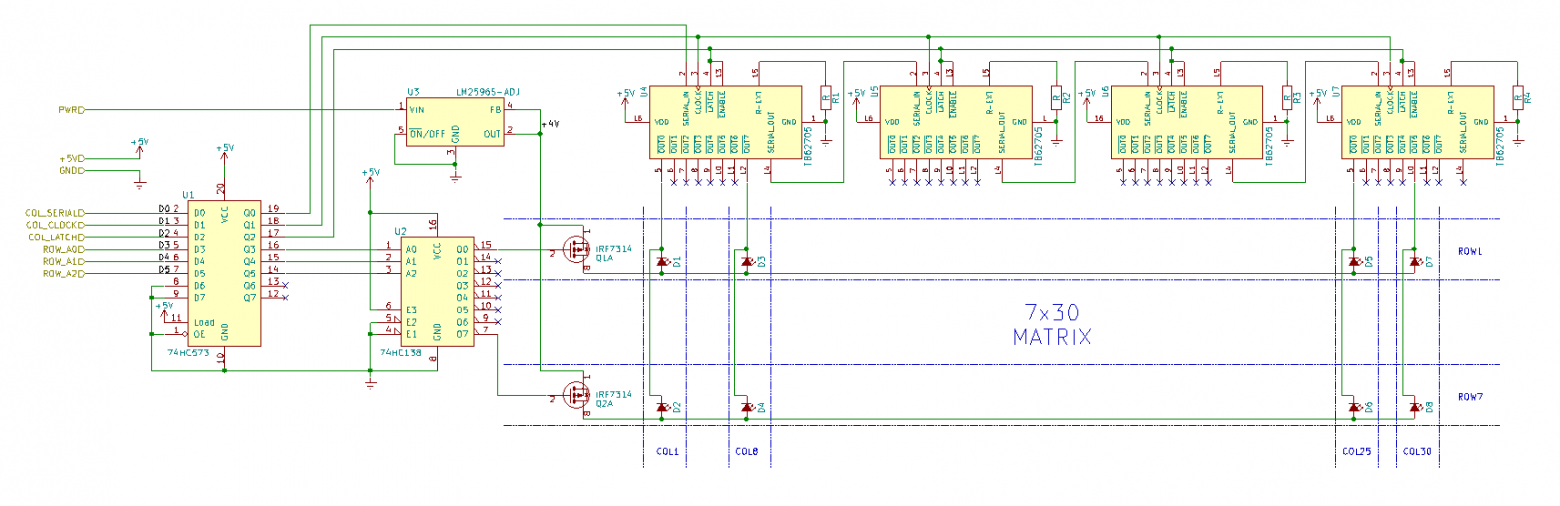
Схема модуля состоит из матрицы светодиодов, катоды которых подключены к LED драйверам Toshiba TB62705. С точки зрения логики управления это обычные 8-битные сдвиговые регистры, соединенные в цепочку. Аноды светодиодов в каждой строке соединены и подключены к стокам MOSFET транзисторов. Истоки подключены к выходу DC-DC преобразователя, а затворы всех 7 транзисторов соединены с выходами дешифратора 3:8 74HC238.
Таким образом, для управления светодиодами нужно выбрать строку экрана, подав ее номер на вход дешифратора, потом загрузить 32 бита данных через SERIAL и CLOCK входы первого LED-драйвера. Затем подать лог. “1” на вход LATCH, и соответствующие светодиоды загорятся на время удержания LATCH в “1”.
Чтобы поморгать светодиодами, я использовал лежащую под рукой arduino-совместимую плату [Teensy 3.5](https://www.pjrc.com/teensy/index.html). Пример кода управления светодиодами можно найти на [GitHub](https://github.com/sintech/Flip-Dot-Display/tree/master/src/led_test)
Вторая часть схемы, ответственная за управление блинкерами, немного сложнее.
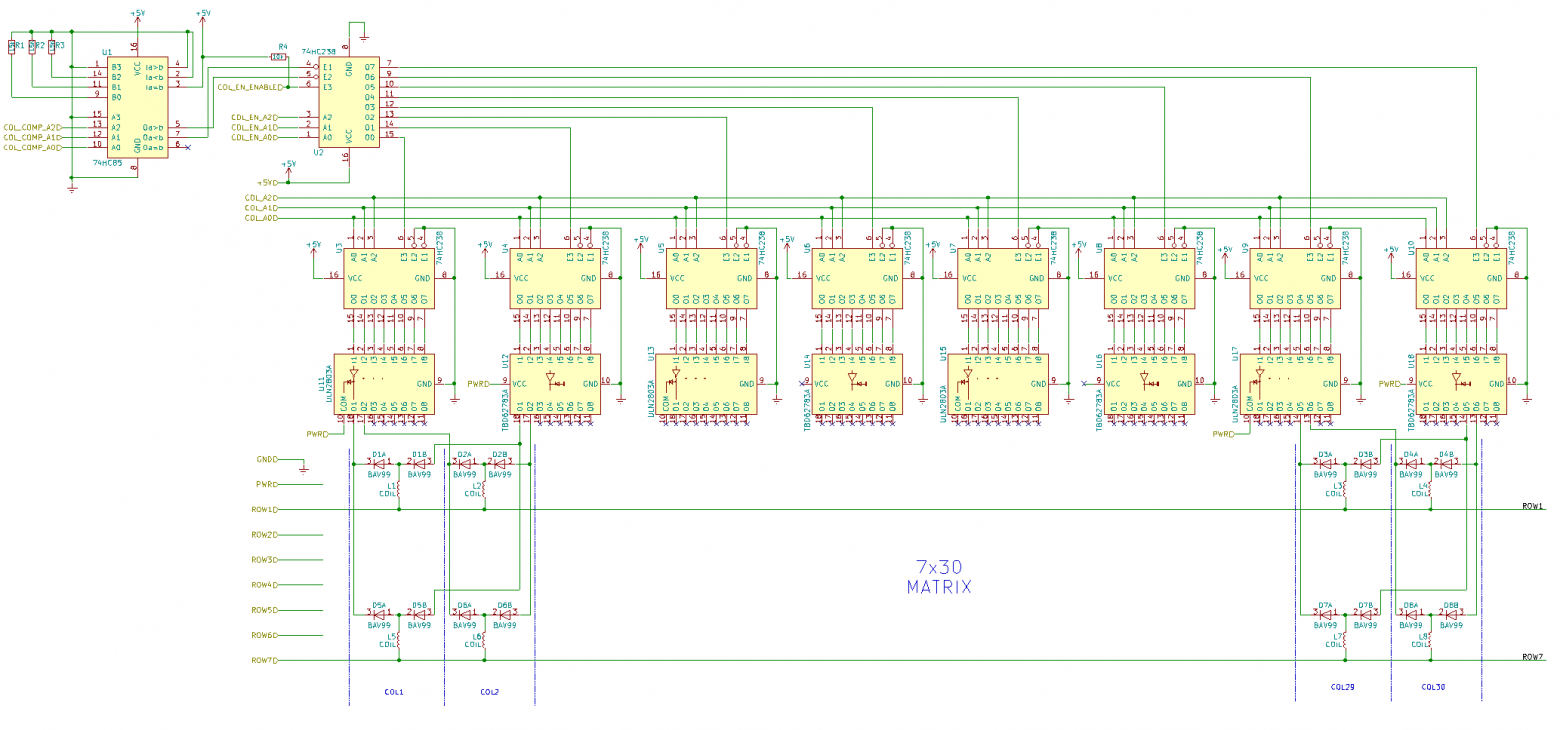
Силовая часть управления колонками состоит из пары микросхем источника/стока тока (current source/sink), выходы которых соединены через защитные диоды с первым выводом каждой катушки в колонке. В качестве источника тока использована микросхема Toshiba TBD62783, а в качестве стока — любимая многими ULN2803 от TI. Вторые выводы катушек объединены в строки и подключены к разъему на плате экрана. По всей видимости, это было сделано для того, чтобы вынести управление строками в отдельный модуль, так как несколько экранов могут объединяться в один длинный экран. Однако немного непонятно, почему для управления светодиодами разработчики разместили все необходимые компоненты на каждой плате экрана.
Логика состоит из восьми 3:8 дешифраторов 74HC238, управляющие входы которых соединены параллельно. Выходы четных дешифраторов подключены к управляющим входам источников тока, а нечетных — к входам стоков. Разрешающие входы 74HC238 подключены к еще одному 3:8 дешифратору, что позволяет полностью исключить ситуацию, когда одновременно активны микросхемы источника и стока тока. Вход разрешения общего дешифратора подключен к микросхеме компаратора и активируется только при совпадении значений на его входе. Эта часть схемы, скорее всего, также отвечает за объединение нескольких модулей в один большой экран.
Таким образом, для выбора конкретной колонки нужно подать ее номер (0-7) в группе на шину COL\_A0-A2, а затем активировать выходы конкретной 74HC238 путем подачи ее номера на входы COL\_EN\_A0-A2 общего дешифратора. Причем вход A0 можно использовать как признак источник/сток, а оставшиеся 2 бита — как номер группы (0-3).
Входы управляющей логики и питания выведены на два 50-контактных IDC разъема. Распайка одного из них показана на схеме.
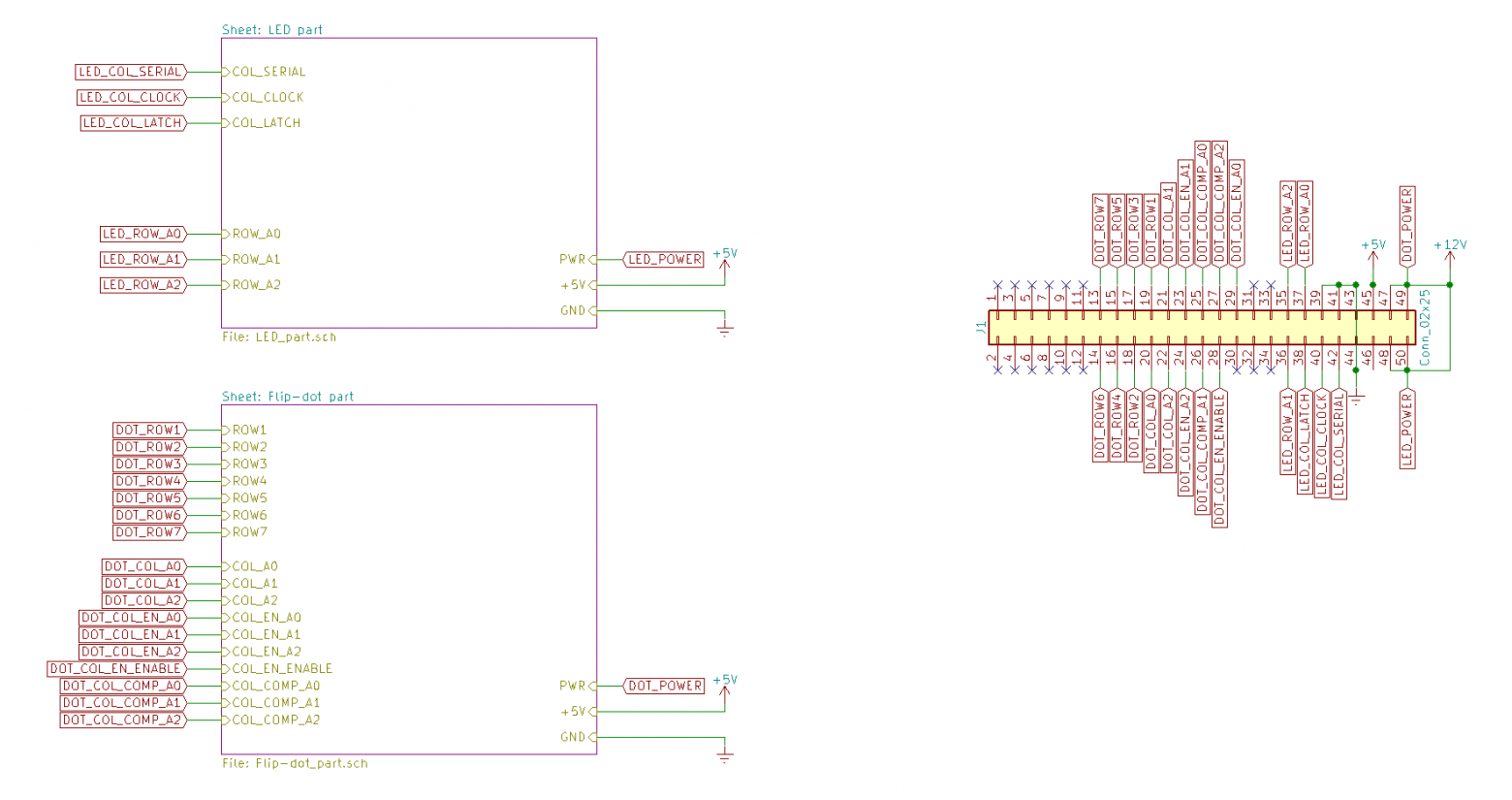
После анализа схемы я понял, что поморгать флажками без помощи Kicad и паяльника, не получится и приступил к созданию модуля выбора строк и сопряжения.
Модуль адаптера и управление строками
-------------------------------------
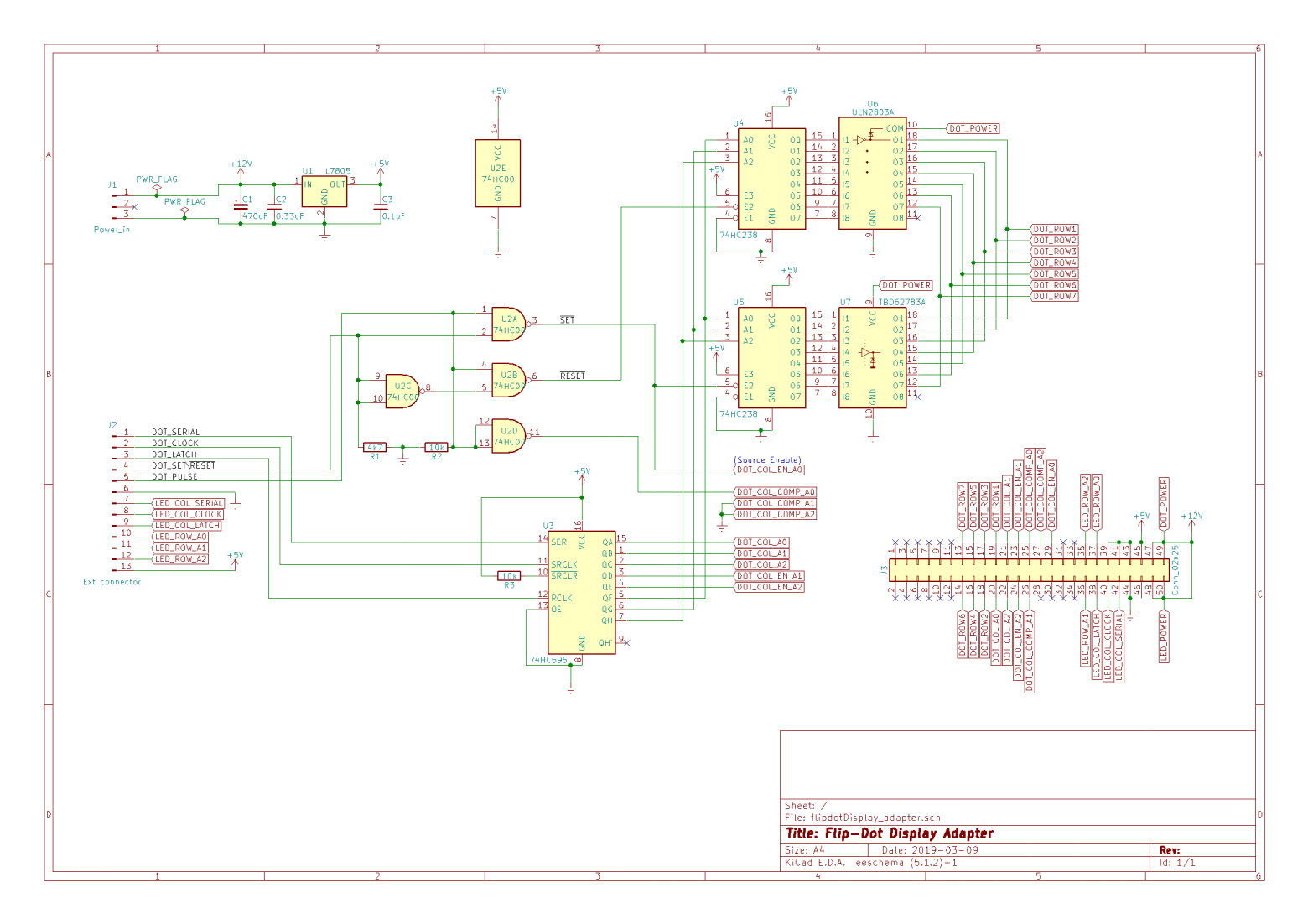
Для упрощения конструкции я решил повторить реализацию выбора колонки и поместил на схему TBD62783 и ULN2803 в паре с дешифраторами 74HC238 для выбора нужной строки, а также одну микросхему логики 74HC00 (4хNAND) для четкого разделения режимов SET, RESET и входа PULSE, непосредственно активирующего подачу напряжения на выбранный электромагнит. Для экономии выводов микроконтроллера было решено подключить сигналы выбора строк и столбцов к выходам одного сдвигового регистра.
В итоге для управления флажком нужно:
1. послать и зафиксировать его координаты в последовательном коде через SERIAL/CLOCK/LATCH
2. выбрать желаемое состояние SET/RESET
3. на короткое время активировать PULSE
Расшифровка байта координат:
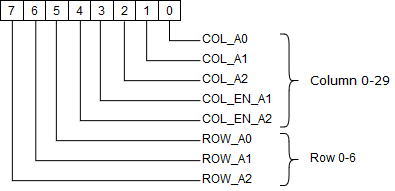
Первая версия схемы без сдвигового регистра была собрана на беспаечной макетной плате. После проверки и небольшого волнения, что все сгорит, я включил питание и подал вручную импульс PULSE быстрым нажатием на кнопку. Ток, протекающий через катушку электромагнита, был на всякий случай ограничен на лабораторном источнике питания. Флажок переключился успешно, и при изменении уровня SET/RESET, переключился обратно. “Это успех”, ‒ подумал я и начал переносить схему на обычную макетную плату, используя любимый МГТФ-0.07 и одножильный kynar-wire для шин питания/земли.
Для подключения к экрану через 50-контактный разъем на плате нужно было задействовать 22 контакта + питание, поэтому возиться с отдельными проводками не хотелось. Напрашивалось использование плоского шлейфа, как для IDE или, скорее, старых SCSI устройств.
Немного гугления навело меня на специальный инструмент для обжима IDC коннекторов, который было решено незамедлительно купить: [Кримпер ProsKit 6PK-214 для IDC коннекторов](https://www.proskit-shop.ru/6pk-214-detail). Потренировавшись на небольших коннекторах, я с первого раза сделал себе 20-сантиметровый шлейф с IDC-50F разъемами на концах.
Пишем управляющую программу
---------------------------
Как я упоминал выше, в качестве управляющего контроллера использовался TEENSY 3.5, средой разработки для которого является Arduino IDE, поэтому программа была написана на arduino диалекте C.
**Основная функция изменения состояния точки экрана**
```
void update_dot(bool state, byte row, byte col) {
byte cmd=0;
// set 7-5 cmd bits to row 2-0 bits
cmd=(row&B111)<<5;
// set 4-0 cmd bits to col 4-0 bits
cmd=cmd|(col&B11111);
// write to Register
digitalWriteFast(DOT_LATCH,LOW);
for (byte i=0;i<8;i++) {
byte onebit=bitRead(cmd,7-i);
digitalWriteFast(DOT_CLOCK,LOW);
digitalWriteFast(DOT_SERIAL_DATA,onebit);
digitalWriteFast(DOT_CLOCK,HIGH);
}
digitalWriteFast(DOT_LATCH,HIGH);
delayMicroseconds(10);
digitalWriteFast(DOT_LATCH,LOW);
// set set/reset pin
if (state) {
digitalWriteFast(DOT_SET_RESET,HIGH);
}
else {
digitalWriteFast(DOT_SET_RESET,LOW);
}
// pulse
digitalWriteFast(DOT_PULSE,HIGH);
delay(1);
digitalWriteFast(DOT_PULSE,LOW);
}
```
Я провел несколько экспериментов, чтобы определить оптимальное напряжение источника питания и время подачи импульса. Получилось, что 12В и 1мс достаточно для стабильной фиксации флажка в одном из положений.
После тестовых заливок одним цветом я заметил, что один «пиксель» битый и не переворачивается. Замер мультиметром сопротивления катушки показал несколько мегаом, а детальный осмотр выявил, что один вывод оторвался. Очень повезло, что нерабочий «пиксель» был с краю экрана, поэтому мне удалось припаять провод. Проблема была решена.
**Фото починенной ячейки**

Вот что получилось после первых экспериментов с заливками и выводом текста:

Тетрис
------
Написать реализацию Тетриса на C оказалось проще, чем я думал. Спасибо Javier López и его руководству [Tetris tutorial in C++ for beginners](http://javilop.com/gamedev/tetris-tutorial-in-c-platform-independent-focused-in-game-logic-for-beginners/). Я переписал основные функции так, как я их понял, и адаптировал код к особенностям моего экрана (отсутствие границ и низкое разрешение). Не буду утомлять подробностями работы, в руководстве все подробно описано.
Для управления использовался модуль аналогового джойстика, поэтому пришлось написать функцию для преобразования значений на выходе АЦП в цифровые константы. Тут возникла сложность с тем, чтобы, с одной стороны, не допустить ложных срабатываний, а с другой — обеспечить правильный геймплей. Если положение джойстика не меняется после очередного считывания состояния, добавляется задержка.
Поиграв минут 10, я понял, что мне скучно, потому что скорость падения фигур не меняется и счет никак не отображается. Отсутствует элемент соревнования.
Выводить счет флажками было некрасиво из-за нехватки места на экране, так что было решено задействовать светодиоды для создания альтернативной плоскости вывода информации. Я нашел в интернете битовое представление шрифта 3x5 для цифр от 0 до 9 и написал функцию отображения счета по количеству убранных линий. Для пущей красоты решил добавить моргание заполненной строки при ее исчезновении.
Динамический характер отображения подтолкнул к идее вызывать функцию обновления LED-части экрана в таймерном прерывании. Частота прерывания и время удержания строки светодиодов в активном состоянии определяют яркость свечения.
Еще я сделал так, что скорость падения фигурок тетрамино увеличивается по мере очищения линий. В первой версии фигурки смещались на одну строку вниз каждые 200 мсек. Если отнимать от этого числа 40 мсек каждые 10 удаленных линий, то темп игры сильно ускоряется, и появляется интерес. Мой рекорд 38 линий!
Тот редкий случай, когда вертикальное видео подходит как нельзя лучше.
[Код проекта](https://github.com/sintech/Flip-Dot-Display/tree/master/src), [схемы экрана и модуля сопряжения](https://github.com/sintech/Flip-Dot-Display/tree/master/schematics) выложены на GitHub.
Если у вас есть идей, что еще можно сделать с таким экраном, пишите, пожалуйста, в комментарии.
Полезные ссылки:
1. [Hackaday: Flip-Dot Display & DIY Controller](https://hackaday.io/project/159415-flip-dot-display-diy-controller).
2. [Tetris tutorial in C++ platform independent focused in game logic for beginners](http://javilop.com/gamedev/tetris-tutorial-in-c-platform-independent-focused-in-game-logic-for-beginners/).
3. [Репозиторий проекта на GitHub](https://github.com/sintech/Flip-Dot-Display). | https://habr.com/ru/post/447472/ | null | ru | null |
# Как я нашёл баг в процессорах Intel Skylake
Инструкторы курсов «Введение в программирование» знают, что студенты находят любые причины для ошибок своих программ. Процедура сортировки отбраковала половину данных? «Это может быть вирус в Windows!» Двоичный поиск ни разу не сработал? «Компилятор Java сегодня странно себя ведёт!» Опытные программисты очень хорошо знают, что баг обычно в их собственном коде, иногда в сторонних библиотеках, очень редко в системных библиотеках, крайне редко в компиляторе и никогда — в процессоре. Я тоже так думал до недавнего времени. Пока не столкнулся с багом в процессорах Intel Skylake, когда занимался отладкой таинственных сбоев OCaml.
Первое проявление
=================
В конце апреля 2016 года вскоре после выпуска OCaml 4.03.0 один Очень Серьёзный Индустриальный Пользователь OCaml (ОСИП) обратился ко мне в частном порядке с плохими новостями: одно из наших приложений, написанное на OCaml и скомпилированное в OCaml 4.03.0, падало случайным образом. Не при каждом запуске, но иногда вылетал segfault, в разных местах кода. Более того, сбои наблюдались только на их самых новых компьютерах, которые работали на процессорах Intel Skylake (Skylake — это кодовое название последнего на тот момент поколения процессоров Intel. Сейчас последним поколением является Kaby Lake).
За последние 25 лет мне сообщали о многих багах OCaml, но это сообщение вызывало особенное беспокойство. Почему только процессоры Skylake? В конце концов, я даже не мог воспроизвести сбои в бинарниках ОСИПа на компьютерах в моей компании Inria, потому что все они работали на более старых процессорах Intel. Почему сбои не воспроизводятся? Однопоточное приложение ОСИПа делает сетевые и дисковые операции I/O, так что его выполнение должно быть строго детерминировано, и любой баг, который вызвал segfault, должен проявлять себя при каждом запуске в том же месте кода.
Моим первым предположением было то, что у ОСИПа глючит железо: плохая микросхема памяти? перегрев? По моему опыту, из-за таких неисправностей компьютер может нормально загружаться и работать в GUI, но падает под нагрузкой. Итак, я посоветовал ОСИПу запустить проверку памяти, снизить тактовую частоту процессора и отключить Hyper-Threading. Предположение насчёт HT появилось в связи с недавним сообщением о баге в Skylake с векторной арифметикой AVX, который проявлялся только при включенном HT ([см. описание](http://arstechnica.com/gadgets/2016/01/intel-skylake-bug-causes-pcs-to-freeze-during-complex-workloads/)).
ОСИПу не понравились мои советы. Он возразил (логично), что они запускали другие требовательные к CPU и памяти задачи/тесты, но падают только программы, написанные на OCaml. Очевидно, они решили, что их железо в порядке, а баг в моей программе. Ну отлично. Я всё-таки уговорил их запустить тест памяти, который не выявил ошибок, но мою просьбу выключить HT они проигнорировали. (Очень плохо, потому что это сэкономило бы нам кучу времени).
Одновременно ОСИП провёл впечатляющее расследование с использованием разных версий OCaml, разных компиляторов C, которые используются для компиляции системы поддержки выполнения OCaml, и разных операционных систем. Вердикт был следующий. Глючит OCaml 4.03, включая ранние беты, но не 4.02.3. Из компиляторов глючит GCC, но не Clang. Из операционных систем — Linux и Windows, но не MacOS. Поскольку в MacOS используется Clang и там работает порт с Windows-версии на GCC, то причиной чётко назвали OCaml 4.03 и GCC.
Конечно, ОСИП рассуждал логично: мол, в системе поддержки выполнения OCaml 4.03 был фрагмент плохого кода С — с [неопределённым поведением](https://blog.regehr.org/archives/213), как мы говорим в бизнесе — из-за которого GCC генерировал сбойный машинный код, поскольку компиляторам C позволено работать при наличии неопределённого поведения. Это не первый раз, когда GCC максимально некорректно обрабатывает неопределённое поведение. Например, см. [эту уязвимость в безопасности](http://www.kb.cert.org/vuls/id/162289) или [этот сломанный бенчмарк](https://blog.regehr.org/archives/918).
Такое объяснение казалось вполне правдоподобным, но оно не объясняло случайный характер сбоев. GCC генерирует причудливый код из-за неопределённого поведения, но это по-прежнему детерминистический код. Единственной причиной случайности, которую я смог придумать, могла быть [Address Space Layout Randomization](https://en.wikipedia.org/wiki/Address_space_layout_randomization) (ASLR) — функция ОС для рандомизации адресного пространства, которая изменяет абсолютные адреса в памяти при каждом запуске. Система поддержки выполнения OCaml кое-где использует абсолютные адреса, в том числе для индексации страниц памяти в хеш-таблицу. Но сбои оставались случайными даже после отключения ASLR, в частности, во время работы отладчика GDB.
Наступил май 2016 года, и пришла моя очередь замарать руки, когда ОСИП прислал тонкий намёк — дал доступ в шелл к своей знаменитой машине Skylake. Первым делом я собрал отладочную версию OCaml 4.03 (к которой позже планировал добавить больше отладочного инструментария) и собрал заново приложение ОСИПа с этой версией OCaml. К сожалению, эта отладочная версия не вызывала сбой. Вместо этого я начал работать с исполняемым файлом от ОСИПа, сначала интерактивно вручную под GDB (но это сводило меня с ума, потому что иногда приходилось ждать сбоя целый час), а затем с небольшим скриптом OCaml, который запускал программу 1000 раз и сохранял дампы памяти на каждом сбое.
Отладка системы поддержки выполнения OCaml — не самое весёлое занятие, но посмертная отладка из дампов памяти вообще ужасна. Анализ 30 дампов памяти показал ошибки segfault в семи разных местах, два места в OCaml GC, а ещё пять в приложении. Самым популярным местом с 50% сбоев была функция `mark_slice` в сборщике мусора OCaml. Во всех случаях у OCaml была повреждена куча: в хорошо сформированной структуре данных находился плохой указатель, то есть указатель, который указывал не на первое поле блока Caml, а на заголовок или на середину блока Caml, или даже на недействительный адрес памяти (уже освобождённой). Все 15 сбоев `mark_slice` были вызваны указателем на два слова впереди блока размером 4.
Все эти симптомы согласовались со знакомыми ошибками, вроде той, что компилятор `mark_slice` забывал зарегистрировать объект памяти в сборщике мусора. Однако такие ошибки привели бы к воспроизводимым сбоям, которые зависят только от распределения памяти и действий сборщика мусора. Я совершенно не понимал, какой тип ошибки управления памятью OCaml мог вызвать *случайные* сбои!
За неимением лучших идей, я опять прислушался к внутреннему голосу, который шептал: «аппаратный баг!». У меня было неясное ощущение, что сбои чаще случаются, если машина находится под большей нагрузкой, как будто это просто перегрев. Для проверки этой теории я изменил свой скрипт OCaml для параллельного запуска N копий программы ОСИПа. Для некоторых прогонов я также отключал уплотнитель памяти OCaml, что вызывало большее потреблением памяти и большую активность сборщика мусора. Результаты оказались не такими, как я ожидал, но всё равно поразительными:
| N | Загрузка системы | С настройками по умолчанию | С отключенным уплотнителем |
| --- | --- | --- | --- |
| 1 | 3+epsilon | 0 сбоев | 0 сбоев |
| 2 | 4+epsilon | 1 сбой | 3 сбоя |
| 4 | 6+epsilon | 12 сбоев | 19 сбоев |
| 8 | 10+epsilon | 17 сбоев | 23 сбоя |
| 16 | 18+epsilon | 16 сбоев | |
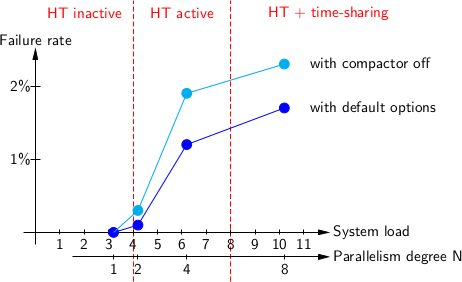
Здесь показано количество сбоев на 1000 запусков тестовой программы. Видите скачок между  и ? И плато между более высокими значениями ? Чтоб объяснить эти цифры, нужно более подробно рассказать о тестовой машине Skylake. У неё 4 физических ядра и 8 логических ядер, поскольку включен HT. Два ядра были заняты в фоне двумя долговременными тестами (не моими), но в остальном машина была свободна. Следовательно, загрузка системы равнялась , где  — это количество тестов, запущенных параллельно.
Когда одновременно работает не более четырёх процессов, планировщик ОС поровну распределяет их между четырьмя ядрами машины и упорно старается не направлять два процесса на два логических ядра одного физического ядра, потому что это приведёт к недостаточному использованию других физических ядер. Такое происходит в случае с , а также большую часть времени в случае с . Если количество активных процессов превышает 4, то ОС начинает применять HT, назначая процессы двум логическим ядрам на одном и том же физическом ядре. Это случай . Только если все 8 логических ядер на машине заняты, ОС осуществляет традиционное разделение времени между процессами. В нашем эксперименте это случаи  и .
Теперь стало видно, что сбои начинаются только при включении Hyper-Threading, точнее, тогда, когда программа OCaml работала рядом с другим потоком (логическим ядром) на том же физическом ядре процессора.
Я отправил ОСИПу результаты экспериментов, умоляя его принять мою теорию о том, что во всём виновата многопоточность. В этот раз он послушал и отключил HT на своей машине. После этого сбои полностью исчезли: двое суток непрерывного тестирования не выявили вообще ни одной проблемы.
Проблема решена? Да! Счастливый конец? Не совсем. Ни я, ни ОСИП не пытались сообщить о проблеме в Intel или кому-то ещё, потому что ОСИП был удовлетворён тем, что можно компилировать OCaml c Clang, а ещё потому что он не хотел неприятной огласки в духе «продукты ОСИПа падают случайным образом!». Я же совсем устал от этой проблемы, да и не знал, как сообщать о таких вещах (в Intel нет публичного баг-трекера, как у обычных людей), а ещё я подозревал, что это баг конкретных машин ОСИПа (например, партия сбойных микросхем, которая случайно попала не в ту корзину на фабрике).
Второе проявление
=================
2016-й год прошёл спокойно, больше никто не сообщал, что небо (sky, точнее, Skylake — каламбур) падает из-за OCaml 4.03, так что я с радостью забыл об этом маленьком эпизоде с ОСИПом (и продолжил сочинять ужасные каламбуры).
Затем, 6 января 2017 года Ангерран Декорн и Джорис Джованнанджели из [Ahrefs](https://ahrefs.com/) (ещё один Очень Серьёзный Индустриальный Пользователь OCaml, член [Консорциума Caml](http://caml.inria.fr/consortium/index.en.html) в придачу) сообщили о загадочных случайных сбоях с OCaml 4.03.0: это [PR#7452](https://caml.inria.fr/mantis/view.php?id=7452) в баг-трекере Caml.
В их примере повторяемого сбоя сам компилятор ocamlopt.opt иногда падал или выдавал бессмысленный результат, когда компилировал большой исходный файл. Это не слишком удивительно, потому что ocamlopt.opt сам по себе является программой OCaml, скомпилированной компилятором ocamlopt.byte, но так было проще обсуждать и воспроизвести проблему.
Публично открытые комментарии к багу PR#7452 довольно хорошо показывают, что произошло дальше, а сотрудники Ahrefs подробно описали свою охоту за багом в [этой статье](https://tech.ahrefs.com/skylake-bug-a-detective-story-ab1ad2beddcd). Так что я выделю только ключевые моменты этой истории.
* Через 12 часов после открытия тикета, когда в обсуждении было уже 19 комментариев, Ангерран Декорн сообщил, что «все машины, которые смогли воспроизвести баг, работают на процессорах семейства Intel Skylake».
* На следующий день я упомянул о случайных сбоях у ОСИПа и предложил отключить многопоточность (Hyper-Threading).
* Ещё через день Джорис Джованнанджели подтвердил, что баг не воспроизводится при отключенном Hyper-Threading.
* Параллельно Джорис обнаружил, что сбой происходит только если система поддержки выполнения OCaml собрана с параметром `gcc -O2`, но не `gcc -O1`. Оглядываясь назад, это объясняет отсутствие сбоев с отладочной версией окружения OCaml и с OCaml 4.02, поскольку они обе по умолчанию собираются с параметром `gcc -O1`.
* Я выхожу на сцену и публикую следующий комментарий:
> Будет ли безумием предположить, что настройка `gcc -O2` на окружении OCaml 4.03 выдаёт специфическую последовательность инструкций, которая вызывает аппаратный сбой (какие-то степпинги) в процессорах Skylake с Hyper-Threading? Возможно, это и безумие. С другой стороны, уже есть одна задокументированная аппаратная проблема с Hyper-Threading и Skylake [(ссылка)](http://arstechnica.com/gadgets/2016/01/intel-skylake-bug-causes-pcs-to-freeze-during-complex-workloads/)
* Марк Шинвелл связался с коллегами в Intel и сумел протолкнуть отчёт через отдел поддержки пользователей.
Затем ничего не происходило 5 месяцев, пока…
Открытие
========
26 мая 2017 года пользователь "ygrek" опубликовал [ссылку](http://metadata.ftp-master.debian.org/changelogs/non-free/i/intel-microcode/intel-microcode_3.20170511.1_changelog) на следующий журнал изменений из пакета с «микрокодом» от Debian:
`* New upstream microcode datafile 20170511 [...]
* Likely fix nightmare-level Skylake erratum SKL150. Fortunately,
either this erratum is very-low-hitting, or gcc/clang/icc/msvc
won't usually issue the affected opcode pattern and it ends up
being rare.
SKL150 - Short loops using both the AH/BH/CH/DH registers and
the corresponding wide register *may* result in unpredictable
system behavior. Requires both logical processors of the same
core (i.e. sibling hyperthreads) to be active to trigger, as
well as a "complex set of micro-architectural conditions"`
Эррата SKL150 была задокументирована компанией Intel в апреле 2017 года и описана на странице 65 в [Обновлении спецификаций семейства процессоров Intel 6-го поколения](http://www.intel.co.uk/content/dam/www/public/us/en/documents/specification-updates/desktop-6th-gen-core-family-spec-update.pdf). Похожая эррата упоминается под номерами SKW144, SKX150, SKZ7 для разновидностей архитектуры Skylake и KBL095, KBW095 для более новой архитектуры Kaby Lake. Слова «полный кошмар» не упоминаются в документации Intel, но приблизительно описывают ситуацию.
Несмотря на довольно расплывчатое описание («сложный набор микроархитектурных условий», и не говорите!) эта эррата бьёт прямо в цель: включенный Hyper-Threading? Есть такое! Проявляется псевдослучайно? Есть! Не имеет отношения ни к плавающей запятой, ни к векторным инструкциям? Есть! К тому же, готово обновление микрокода, которое устраняет эту ошибку, оно мило упаковано в Debian и готово к загрузке в наши тестовые машины. Через несколько часов Джорис Джованнанджели подтвердил, что сбой исчез после обновления микрокода. Я запустил ещё больше тестов на своей новёхонькой рабочей станции с процессором Skylake (спасибо отделу снабжения Inria) и пришёл к тому же выводу, поскольку тест, который обваливался быстрее чем за 10 минут на старом микрокоде, проработал 2,5 суток без проблем на новом микрокоде.
Есть ещё одна причина считать, что SKL150 — виновник наших проблем. Дело в том, что проблемный код, описанный в этой эррате, как раз и генерирует GCC при компиляции системы поддержки выполнения OCaml. Например, в файле `byterun/major_gc.c` для функции `sweep_slice` получается такой код C:
```
hd = Hd_hp (hp);
/*...*/
Hd_hp (hp) = Whitehd_hd (hd);
```
После макрорасширения это выглядит так:
```
hd = *hp;
/*...*/
*hp = hd & ~0x300;
```
Clang компилирует этот код банальным способом, используя только регистры полной ширины:
```
movq (%rbx), %rax
[...]
andq $-769, %rax # imm = 0xFFFFFFFFFFFFFCFF
movq %rax, (%rbx)
```
Однако GCC предпочитает использовать 8-битный регистр `%ah` для работы с битами от 8 до 15 из полного регистра `%rax`, оставляя остальные биты без изменений:
```
movq (%rdi), %rax
[...]
andb $252, %ah
movq %rax, (%rdi)
```
Эти два кода функционально эквиваленты. Одной возможной причиной выбора GCC может быть то, что его код более компактный: 8-битная константа `$252` помещается в один байт кода, в то время как 32-битной, расширенной до 64 бит, константе `$-769` нужно 4 байта. Во всяком случае, сгенерированный GCC код использует и `%rax`, и `%ah` и, в зависимости от уровня оптимизации и неудачного стечения обстоятельств, такой код может окончиться циклом, достаточно маленьким, чтобы вызвать баг SKL150.
Так что, в итоге, это всё-таки аппаратный баг. Говорил же!
Эпилог
======
Intel выпустила обновления микрокода для процессоров Skylake и Kaby Lake, которые исправляют или обходят проблему. Debian опубликовала [подробные инструкции](https://lists.debian.org/debian-devel/2017/06/msg00308.html) для проверки, подвержен ли багу ваш процессор и как получить и применить обновления микрокода.
Публикация о баге и выпуск микрокода оказались очень своевременными, потому что у нескольких проектов на OCaml начали происходить таинственные сбои. Например, у [Lwt](https://github.com/ocsigen/lwt/issues/315), [Coq](https://coq.inria.fr/bugs/show_bug.cgi?id=5517) и [Coccinelle](https://sympa.inria.fr/sympa/arc/caml-list/2017-06/msg00115.html).
Об аппаратном баге написал ряд технических сайтов, например, [Ars Technica](https://arstechnica.com/information-technology/2017/06/skylake-kaby-lake-chips-have-a-crash-bug-with-hyperthreading-enabled/), [HotHardware](https://hothardware.com/news/critical-flaw-in-intel-skylake-and-kaby-lake-hyperthreading-discovered-requiring-bios-microcode-fix), [Tom's Hardware](http://www.tomshardware.com/news/hyperthreading-kaby-lake-skylake-skylake-x,34876.html) и [Hacker's News](https://news.ycombinator.com/item?id=14630183) [и [GeekTimes](https://geektimes.ru/post/290461/) — прим. пер.]. | https://habr.com/ru/post/332552/ | null | ru | null |
# Android-программа для управления «умным» вибратором хранила аудиофайлы без ведома девушек

*Мобильное приложение Lovense Remote для удалённого управления вибратором*
Небольшой скандал разгорелся вокруг гонконгской компании Lovense, которая занимается производством секс-игрушек и распространяет мобильное приложение [Lovense Remote](https://play.google.com/store/apps/details?id=com.lovense.wear&hl=en) для удалённого управления ими. Один из пользователей Reddit [обратил внимание](https://www.reddit.com/r/sex/comments/6nxxou/fyi_if_you_bought_a_wevibe_vibrator_in_the_us_in/?st=J9RFCMLF&sh=78017a64), что программа без ведома девушки сохраняет историю использования вибратора. Более того, в локальной папке программы на смартфоне можно найти шестиминутный аудиофайл, записанный во время последнего сеанса.
Разумеется, такое поведение программы вызвало недоумение у пользователей. В комментариях Reddit. Девушки говорят, что они действительно давали разрешение на использование камеры и микрофона, но подразумевалось, что те будут использоваться только для чата, встроенного в программу, и отправку голосовых команд, а не для постоянной записи всех звуков, которые они издают в процессе… работы с гаджетом. Несанкционированные действия программы подтвердили несколько человек в треде.
Один из пользователей, который [представился как представитель компании Lovense](https://www.reddit.com/r/sex/comments/7bmi3i/psa_lovense_remote_control_vibrator_app_recording/dpm4050/), признал некорректное поведение приложения, которое он назвал «незначительным багом». Он сказал, что баг имеется только в Android-версии приложения, при этом никакие аудиофайлы не отправляются на серверы компании. Временные аудиофайлы записываются и хранятся исключительно локально. В тот же день вышло обновление приложения, в котором устранили баг.
В [комментарии](https://www.theverge.com/2017/11/10/16634442/lovense-sex-toy-spy-surveillance) изданию *The Verge* компания Lovense подтвердила, что человек на форуме действительно является официальным представителем компании и его слова соответствуют действительности: «Как и было сказано, мы не храним аудиофайлов на наших серверах. Чтобы работала функция звука [голосового управления и передачи звуковых клипов], нам нужно создать аудиофайл в локальном кэше. Предполагается, что этот файл должн удаляться после каждой сессии, но из-за бага в последней версии Android-приложения он не удалялся, — сказано в заявлении компании. — Из-за этого бага звуковой файл хранился на устройстве до следующей сессии, когда он перезаписывался новым аудиофайлом в кэше».
Всё выглядит так, что действия компании действительно были непреднамеренными, они похожи на небольшую техническую ошибку. Впрочем, это не отменяет того факта, что парень девушки или другой посторонний человек, который получил доступ к её смартфону, мог легко прослушать или скопировать себе довольно интимные звуки. Сейчас многие компании озабочены распространением интимных фотографий и видео с целью порномести, так вот интимный звук тоже вполне подходит для этих целей. Другими словами, утечка подобного личного контента представляет собой непосредственную угрозу информационной безопасности и конфиденциальности пользовательницы.
Нужно заметить, что это уже не первый случай утечки подобного рода конфиденциальных данных от гаджетов компании Lovesense. Буквально месяц назад стало известно об уязвимости другого гаджета компании под названием Hush (устройство не совсем понятной функциональности, типа butt plug, что-то вроде затычки в ванной). Как и многие другие секс-игрушки, он работает по протоколу Bluetooth Low Energy (BLE). Оказалось, что этот гаджет [можно взломать](https://www.evilsocket.net/2017/09/23/This-is-not-a-post-about-BLE-introducing-BLEAH/).
Хакер по имени Симоне Маргарителли (Simone Margaritelli), известный в сообществе как evilsocket, написал BLE-сканер BLEAH ([исходный код на Github](https://github.com/evilsocket/bleah)) и опубликовал инструкции по взлому BLE-гаджетов.
Сканер исключительно прост в использовании. Достаточно запустить его с флагом `-t0` — и он приступает к непрерывному сканированию всех гаджетов BLE вокруг.

Если среди них вы находите что-то интересное, то можно подключиться к устройству.

После этого на устройство можно отправить произвольные команды, которое оно выполнит. На демонстрационном видео внизу показано, как гаджет получает с ноутбука через сканер BLEAH команду `vibrate:20;`. В данном случае устройство думает, что команда поступает от мобильного приложения Lovense Remote — того же приложения, которое используется для управления вышеупомянутым вибратором и другими секс-игрушками компании Lovense.
Хакеры дизассемблировали это Java-приложение и разобрали команды для управления.
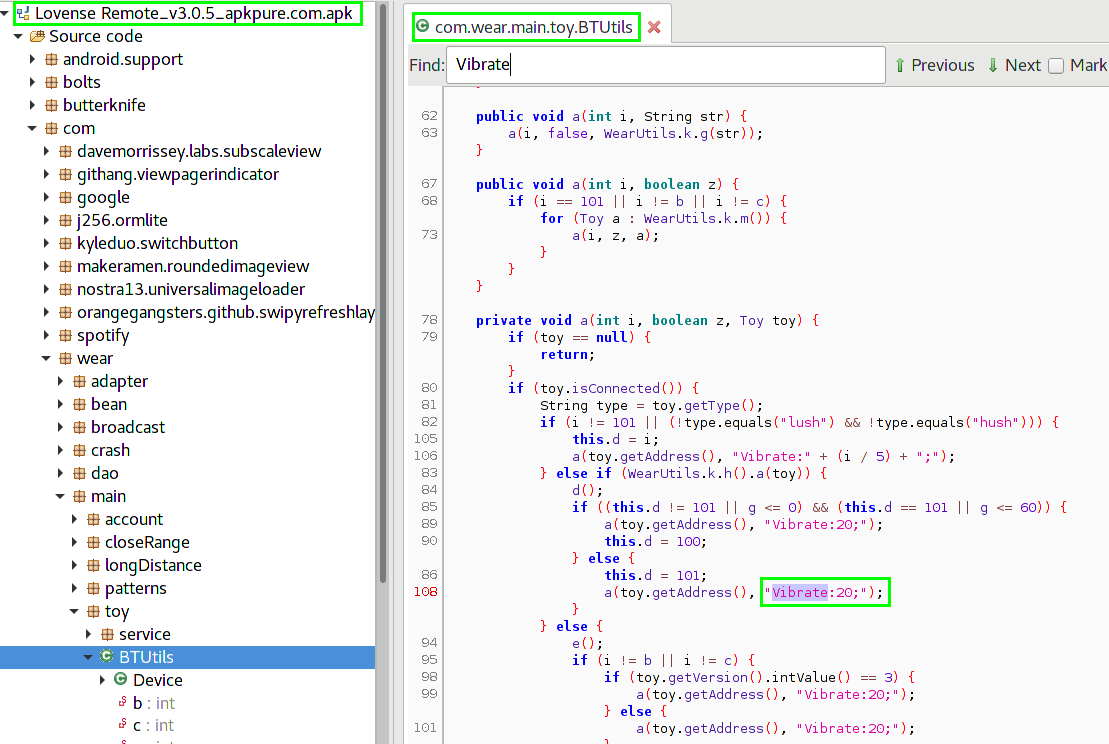
*Исходный код приложения Lovense Remote*
Понятно, что в случае с секс-игрушкой несакнционированное удалённое управление может представлять некоторую опасность: например, злоумышленник может таким образом быстро разрядить батарею гаджета и испортить пользователю всё удовольствие.
В другом случае пользовательницы Bluetooth-вибраторов We-Vibe [подали коллективный иск на $3,75 млн](http://www.sicclassactionsettlement.com/) против канадской компании Standard Innovation, что мобильное приложение для управления гаджетом записывало персональную информацию. Производитель согласился выплатить компенсацию (сумму поделят между всеми, кто заполнит и подаст анкету, максимум $199 на каждую девушку). | https://habr.com/ru/post/408175/ | null | ru | null |
# 22 интересные фичи, которые стоит добавить в Telegram

13 августа 2013 вышел первый официальный клиент Telegram. С тех пор он стремительно развивается и увеличивает аудиторию. На это повлияли отличия от других мессенджеров, а также частые большие нововведения от разработчиков: видеозвонки, групповые голосовые чаты, встроенная система продажи товаров, кастомизация дизайна интерфейса. Но в этой статье мы рассмотрим то, чего пока нет в мессенджере, но, возможно, появится в будущем, так как такие фичи улучшат опыт использования Telegram.
*Многие идеи были подсмотрены в других сервисах, а также на баг-трекере <https://bugs.telegram.org>, где есть раздел с идеями.*
Реакции на сообщения или посты в каналах
----------------------------------------
`Оригинал идеи:` <https://bugs.telegram.org/c/23>
**upd от 31.12.2021** — функция была добавлена в [этой версии](https://telegram.org/blog/reactions-spoilers-translations/ru#reaktsii)
Идея из интерфейса Discord: пользователь может поставить любую реакцию (а не только те, которые выбрал автор поста) на сообщение, чтобы выразить своё отношение. При этом не создавать отдельное сообщение, которое будет являться ответом. Список пользователей, оставивших реакции, может быть анонимным или нет.

Подсветка синтаксиса
--------------------
`Оригинал идеи:` <https://bugs.telegram.org/c/824>
Telegram является очень удобным мессенджером для программистов, так как в нём есть функция выделения текста, внутри которого не заменяются смайлики и другие специальные сочетания символов, а также не изменяются пробелы и отступы. В таком поле можно было бы активировать подсветку кода, если явно указан язык программирования.
Больше ролей в чате
-------------------
`Оригинал идеи: Discord`
На данный момент в чатах есть 3 роли: создатель, админы (с различными полномочиями) и обычные участники. Создателю и админам можно сделать описание, которое будет отображаться напротив ника в списке сообщений (ограничение на длину — 16 символов, которых очень часто не хватает).
Польза от ролей достаточно очевидна: если необходимо, чтобы несколько админов имели одинаковые права, то легко им дать роль и далее редактировать полномочия этой роли. Также так можно обозначать заслуги и категории участников чата.
Пинги
-----
`Оригинал идеи:` <https://bugs.telegram.org/c/11>
Этот пункт служит дополнением к предыдущему, но может быть реализован и отдельно.
Сейчас в Telegram можно упомянуть только одного пользователя за раз. Предлагается ввести такие упоминания как `@all`, `@online`, `@admin` и так далее. При создании дополнительных ролей появляется возможность написать `@` и упомянуть всех пользователей с такой ролью.
Зал ожидания для вступления в чат
---------------------------------
`Оригинал идеи:` <https://bugs.telegram.org/c/504>
**upd от 03.11.2021** — функция была добавлена в [этой версии](https://telegram.org/blog/shared-media-scrolling-calendar-join-requests-and-more/ru#zayavki-na-vstuplenie-v-gruppi-i-kanali)
Этот пункт будет очень удобен для небольших чатов, у которых есть короткая ссылка на вступление. По ссылке заходят новые участники, а также спам-боты, которых никто не хотел видеть в чате. Для решения этой проблемы можно создать зал ожидания, в котором находится пользователь после перехода по ссылке-приглашению или нажатию кнопки `Вступить в чат`. После этого администраторы в ручном режиме принимают или отклоняют заявки на вступление, а до этого желающие могут только читать чат, либо не имеют доступа к истории сообщений.
Спойлеры
--------
`Источник идеи: Discord`
**upd от 31.12.2021** — функция для текста была добавлена в [этой версии](https://telegram.org/blog/reactions-spoilers-translations/ru#skritii-tekst)
Идея опять проста: возможность обозначить часть сообщения или медиафайл как спойлер, для просмотра которого требуется дополнительное действие (например, нажатие). Это позволит участникам отмечать контент, который может быть нежелательным для некоторых участников чата.
Двойное дно
-----------
`Источник идеи и неофициальная реализация фичи:` <https://postufgram.com>
Идея заключается в следующем: для входа в приложение используется графический, или биометрический, или любой другой пароль, но есть несколько верных комбинаций, которые ведут в разные аккаунты. Например, такая система уже используется во "Втором пространстве" на некоторых Android-телефонах.
Это будет полезно в разных ситуациях: если вы хотите сразу входить в нужный аккаунт, а не переключаться между ними в приложении, либо вы хотите показать кому-либо почти пустой аккаунт под видом своего основного. Также несколько человек могут войти в свои аккаунты на одном устройстве, но не иметь доступ к аккаунтам других.
Боты для голосовых чатов
------------------------
`Источник идеи: Discord`
Я бы назвал этот пункт самым сложным для реализации разработчиками. В данный момент в голосовых чатах могут состоять только реальные пользователи, что очень неудобно для создания ботов, так как для юзербота необходимо иметь как минимум дополнительный аккаунт для каждого чата.
Такой функционал позволит создать различных полезных ботов:
* Диджей-бот для проигрывания музыки в голосовом чате. Так у всех участников будет возможность делиться музыкой со всеми. Пример: Rythm Bot в дискорде (<https://rythm.fm/>). Сейчас такой бот в Telegram (@GroupsMusicBot) реализован с помощью юзерботов, а их ограниченное число создаёт очередь.
* Интеграция с голосовыми помощниками ("Алиса", Siri и подобные). Это позволит искать информацию не выходя из чата, а ответ будут слышать все.
* Text-to-speech бот. Он может зачитывать новые сообщения в текстовых чатах, чтобы участникам не приходилось отвлекаться от звонка на их чтение.
Анонимное создание аккаунта
---------------------------
`Оригинал идеи:` <https://bugs.telegram.org/c/65>
Сейчас, если вы создаёте аккаунт, то всем пользователем Telegram, у которых вы есть в контактах, придёт сообщение о том, что вы присоединились к Telegram. Так, если у абстрактного Васи есть ваш номер, то вы не сможете создать аккаунт, не показав его Васе. Решением может быть галочка при создании аккаунта — уведомить о создании аккаунта или нет.
Также этот пункт является не только проблемой приватности, но и бедой обычных пользователей, которым часто приходят сообщения о присоединении человека. В таких случаях была бы очень удобной функция отключения автоматического создания чатов с новыми аккаунтами.
Избранные сообщения
-------------------
`Оригинал идеи:` <https://bugs.telegram.org/c/87>
Часто в чатах бывают сообщения, которые создатели не запинили, но хочется иметь к нему быстрый доступ в этом чате без пересылки его в сохранённые сообщения (чтобы не засорять их). Было бы удобно поставить звёздочку на сообщении и иметь список всех отмеченных сообщений в чате для быстрой навигации.
Чаты с повышенным доверием
--------------------------
`Оригинал идеи:` <https://bugs.telegram.org/c/84>
В чатах друзей, семьи или других, где все участники доверяют друг другу можно добавить возможность просмотреть, когда определённый участник чата прочитал определённое сообщение. Так можно будет понять, собеседник не зашёл в чат, хотя был в сети, или решил не отвечать на это сообщение.
Улучшение поиска
----------------
`Оригинал идеи:` <https://bugs.telegram.org/c/1964>
Сейчас глобальный поиск каналов и чатов работает очень плохо: анализирует только заголовки и показывает максимум 3-5 результатов. Популярные запросы забиты рекламными или просто бесполезными каналами. Есть различные сторонние сайты, но там ситуация похожа, так как без ручной модерации сложно найти хорошие варианты по запросу.
Введение тегов тематики каналов, а также кнопки "Показать больше" в поиске поможет решить проблему, и искать интересные для себя тематические каналы можно будет в обычном поиске.
QR-код инвайта
--------------
**upd от 31.12.2021** — функция была добавлена в [этой версии](https://telegram.org/blog/reactions-spoilers-translations/ru#qr-kodi-s-nastroikami-oformleniya)
При личном общении удобно отсканировать QR-код с телефона друга, а не перепечатывать юзернейм или скидывать в личные сообщения длинную ссылку-приглашение. Можно сделать в интерфейсе рядом со ссылками иконку QR-кода, при нажатии на которую появляется увеличенная версия. Такой QR-код можно быстро отсканировать и перейти по ссылке.
Свои аватарки контактов
-----------------------
`Оригинал идеи:` <https://bugs.telegram.org/c/85>
Многие пользователи не ставят себе аватарки, из-за чего они отображаются в списке чатов как первые буквы имени и фамилии на фоне случайного цвета (причём этот цвет разный на разных устройствах). Если бы для таких пользователей использовались аватарки из списка контактов телефона, то проблема была бы решена.
Также можно пойти дальше и сделать возможность пользователю ставить аватарку другому человеку, чтобы она отображалась на всех устройствах, причём такая аватарка может отличаться от телефонных контактов.
Сообщения с общим доступом
--------------------------
Идея лежит на поверхности: чек-листы, списки покупок, запись в очередь — для всего этого удобно, когда одно сообщение могут редактировать все участники чата. Сейчас такой функционал доступен в каналах, но создание каналов и добавление всех как администраторов — достаточно непростое занятие.
Конфликты одновременного редактирования можно решать двумя методами: кто последний нажал сохранить, тот прав, либо запретить редактирование сообщения, если его уже кто-то редактирует.
Участники-призраки
------------------
В Telegram есть опция импорта чата (например, из WhatsApp). В групповых чатах сообщения отсылаются от имени несуществующих пользователей, у которых вместо имён номера телефона.
С помощью таких пользователей-призраков удобно было бы реализовывать текстовые квесты, где общаются несколько NPC, а их сообщения показываются в чате не от одного бота, а от различных имён, что намного удобнее.
Репорты администраторам чата
----------------------------
`Оригинал идеи:` <https://bugs.telegram.org/c/1937>
Кнопка Report на сообщении отправляет уведомление модераторам Telegram, которые могут долго реагировать или не посчитать, что данное сообщение нарушает какие-то правила, не зная контекста. В публичных чатах с большим количеством участников было бы удобно отправлять репорты администраторам и модераторам чата, которые следят за ним. Такой функционал сейчас присутствует в ботах, но встроенный был бы намного удобнее для всех.
Улучшенные папки
----------------
`Источники:` [1](https://bugs.telegram.org/c/1273), [2](https://bugs.telegram.org/c/5085)
Распределение чатов на папки — очень удобно для организации комфортной работы. Но есть несколько неудобных моментов, которые хотелось бы исправить:
* Папка All Chats. В ней отображаются уведомление со всех чатов, что очень сильно раздражает. Если бы была возможность её спрятать сверху списка (как архивированные чаты, только в списке папок), то это было бы удобнее.
* Добавление чата в папку. Сейчас это можно сделать только через настройки папки, но если бы в списке чатов можно было бы нажать ПКМ и выбрать там опцию "Добавить в папку", то это было бы удобнее, так как список чатов часто намного больше, чем папок.
Цитата
------
`Оригинал идеи:` <https://bugs.telegram.org/c/1050>
В разговорах часто удобно использовать цитирование или ответ на часть сообщения, но такой возможности пока нет. В ответе будет отображаться исходное сообщение и на какую часть ссылается ответ.
Улучшение работы с файлами
--------------------------
`Оригинал первой идеи:` <https://bugs.telegram.org/c/1176>
Несколько полезных улучшений:
* Переименовывание файла после отправки. Сейчас для этого нужно заново загружать файл, что часто бывает неудобно.
* Варианты скачивания при совпадении имён. Если в папке загрузок уже есть файл с таким названием, то можно либо создать файл с `(1)` в названии, либо перезаписать прошлый. Оба варианта имеют право на существование, и иметь возможность выбирать между ними было бы удобно.
Лента сообщений
---------------
**upd от 31.08.2021** — в новой версии телеграма появилась функция [перехода между каналами](https://telegram.org/blog/live-streams-forwarding-next-channel/ru#bistrii-perehod-mezhdu-kanalami)
Основной метод просмотра записей в других социальных сетях можно добавить в Telegram в адаптивном формате, например, возможность создать ленту из всех сообщений в каналах в папке. Так можно будет смотреть все сообщения сразу в хронологическом порядке.
Кнопка "Ответить лично"
-----------------------
`Оригинал идеи:` <https://bugs.telegram.org/c/1168>
Название кнопки полностью описывает то, что она делает: ответить на сообщение в личных сообщениях с автором. Часто бывает полезно в любых чатах, а переслать сообщение кому-либо очень сложно (и почти невозможно, если диалога с этим человеком раньше не существовало).
В завершение
------------
Уже сейчас, по мнению многих пользователей, Telegram является лучшим мессенджером по возможностям и простоте работы с интерфейсом. Конечно, в статье были упомянуты не все идеи. Так что если у вас есть своё предложение, то вы можете поделиться им с комьюнити "Хабра" в комментариях под этим постом, либо на сайте <https://bugs.telegram.org>, где на идею могут обратить внимание разработчики.
 | https://habr.com/ru/post/572648/ | null | ru | null |
# Использование драйверов из Android приложения
Рут даёт практически абсолютную власть над Android устройством. Сегодня я расскажу вам как получить еще больше имея склонность к программированию и желание исследовать систему на своём устройстве. Кто заинтересовался — прошу под кат.
Что же, начнём по порядку.
##### Что необходимо
1. Минимальные знания C.
2. Минимальные знания Java.
3. Некоторое понимание того как взаимодействуют элементы системы Android.
4. Рутованый Android телефон.
5. IDE с поддержкой Android SDK/NDK (в моём случае eclipse, его очень легко настроить для работы с Android и описано это много раз).
6. Тулчейн для кросс компиляции которым было собрано ядро на целевом устройстве.
7. Собранное ядро для нашего устройства с правильной локальной версией.
Стоит сказать что я использовал ОС Linux Ubuntu 11.10 и все примеры буду приводить для неё.
Первые 3 пункта очевидны, как добиться 4 и 5 легко найти в интернете. Последние два рассмотрим подробно.
###### Выбор тулчейна для кросс компиляции модулей ядра (драйверов)
В данной статье мы не рассматриваем возможность прошивки собственноручно собранного ядра на свой телефон поэтому мы должны придерживаться определённых правил.
Для того чтобы узнать каким компилятором собрано ядро на нашем устройстве выполняем команду:
```
cat /proc/version
```
c помощью любого эмулятора терминала или используя утилиту adb:
```
adb shell "cat /proc/version"
```
В результате получаем строку вроде этой:
```
Linux version 3.0.69-g26a847e (blindnumb@iof303) (gcc version 4.7.2 20120701 (prerelease) (Linaro GCC 4.7-2012.07)) #1 PREEMPT Mon Mar 18 12:19:10 MST 2013
```
Видим что у нас установлено ядро версии 3.0.69 локальная версия "-g26a847e" и собрано оно тулчейном Linaro GCC 4.7-2012.07. Зная версию находим необходимый тулчейн и распаковываем в любую папку. У меня путь выглядел так:
```
/home/user/android/android_prebuilt_linux-x86_toolchain_arm-gnueabihf-linaro-4.7
```
###### Сборка ядра
Для начала узнаем какое именно ядро использует наше устройство. Это можно сделать выполнив команду указанную выше или зайдя на устройстве в настройки, раздел «О телефоне».
**Информация о системе**
Как было сказано выше в моём случае это 3.0.69-g26a847e. Немного поковырявшись на гитхабе прошивки (PACman for HTC Desire S) я определил что это ядро AndromadusMod.
Копируем найденные иходники себе на локальную машину (я предварительно форкнул необходимый репозиторий себе в гитхаб и выполнил git clone, производители вроде Google и изготовители кастомных прошивок держат исходники ядра в репозиториях с открытым доступом, некоторые просто позволяют скачать исходники в виде архива). Для меня это выглядело так:
```
/home/user/android/saga-3.0.69
```
Теперь нужно найти конфигурацию с которой собрано ядро нашего устройства. В большинстве случаев конфигурация лежит на самом устройстве и получить её можно с помощью adb, распаковать и скопировать в папку с исходниками ядра:
```
adb pull /proc/config.gz .
gunzip ./config.gz
cp ./config /home/user/android/saga-3.0.69/arch/arm/my_device_defconfig
```
Необходимо также немного изменить конфигурацию — установить локальную версию на идентичную той что мы узнали ранее и выключить автоматическое назначение локальной версии. Сделать это можно с помощью любого текстового редактора:
```
CONFIG_LOCAL_VERSION="-g26a847e"
CONFIG_LOCAL_VESION_AUTO=n
```
После переходим в папку с исходниками, настраиваем переменные окружения для сборки и собственно собираем ядро:
```
cd /home/user/android/saga-3.0.69
export ARCH=arm
export CROSS_COMPILE=/home/user/android/android_prebuilt_linux-x86_toolchain_arm-gnueabihf-linaro-4.7/bin/arm-eabi-
export LOCALVERSION= all
make my_device_defconfig
make
```
Теперь можно перейти к программированию.
##### Написание кода
###### Android приложение
Учитывая огромное количество статей о написании Android приложения я рассмотрю только моменты связанные с задачей.
Наше приложение будет иметь всего 1 Activity:
**activity\_main.xml**
```
```
Выглядит это в итоге вот так:
На кнопку мы назначаем событие которое получит информацию от нашего драйвера и запишет её в текстовое поле:
**MainActivity class**
```
public class MainActivity extends Activity {
private EditText text;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
text = (EditText)findViewById(R.id.editText1);
}
@Override
public boolean onCreateOptionsMenu(Menu menu) {
// Inflate the menu; this adds items to the action bar if it is present.
getMenuInflater().inflate(R.menu.main, menu);
return true;
}
public void onClick(View view) {
switch (view.getId()) {
case R.id.button1:
text.setText(IoctlWrapper.getData());
}
}
}
```
Теперь создадим класс обёртку для нашей jni библиотеки:
```
public class IoctlWrapper {
public static native String getKData(); //Объявление нашего нативного метода, который будет общаться с драйвером
public static String getData() {
return getKData();
}
static {
System.loadLibrary("ioctlwrap");
}
}
```
###### JNI
Создадим папку jni в корне проекта Android приложения.
Далее сгенерируем Си хедер для нашей нативной библиотеки:
```
cd src
javac -d /tmp/ com/propheta13/amoduse/IoctlWrapper.java
cd /tmp
javah -jni com.propheta13.amoduse.IoctlWrapper
```
Получаем хедер и копируем в ранее созданную папку, создадим соответствующий .c и конфигурацию сборки Android.mk:
```
cd [PATH TO ANDROIDPROJ]/jni
cp /tmp/com_propheta13_amoduse_IoctlWrapper.h ./ioctlwrap.h
touch ./ioctlwrap.c
touch ./Android.mk
```
Содержимое Android.mk:
```
LOCAL_PATH := $(call my-dir)
include $(CLEAR_VARS)
LOCAL_MODULE := ioctlwrap
LOCAL_SRC_FILES := ioctlwrap.c
```
Алгоритм работы библиотеки:
1. Открыть ноду драйвера.
2. Выделить буфер под информацию из драйвера
3. Получить информацию с помощью ioctl запроса.
4. Закрыть ноду.
5. Преобразовать информацию в Java строку и передать в обёртку.
Полный код:
**ioctlwrap.c**
```
const char string[] = "Driver open failed.";
#define BUF_SIZE 4096
JNIEXPORT jstring JNICALL Java_com_propheta13_amoduse_IoctlWrapper_getKData
(JNIEnv *env, jclass jcl)
{
char *info_buf = NULL;
int dfd = 0, rc = 0;
dfd = open(TKMOD_DEV_PATH, O_RDONLY);
if(dfd < 0)
{
jstring RetString = (*env)->NewStringUTF(env, string);
goto exit;
}
info_buf = malloc(BUF_SIZE);
rc = ioctl(dfd, TKMOD_IOCTL_GET_DATA, info_buf);
if(rc < 0)
{
strerror_r(rc, info_buf, BUF_SIZE);
}
jstring RetString = (*env)->NewStringUTF(env, info_buf);
free(info_buf);
close(dfd);
exit:
return RetString;
}
```
###### Драйвер ядра
Полностью описывать процесс написания драйвера я не буду, сделаю лишь пару заметок:
1. Драйвер написанный для этой статьи не делает ничего сверхъестественного — только возвращает список имён сетевых интерфейсов.
2. Для общения с драйвером используется механизм ioctl.
3. Makefile для сборки позволяет указывать ядро для которого требуется собрать данный драйвер, для этого нужно правильно указать переменные окружения и использовать команду:
```
make KMODDIR=[path to kernel]
```
##### Запуск
Для начала зальём собранный драйвер на устройство, и установим его в ядро, заодно сделаем ноду драйвера доступной для всех:
```
adb push ./test_kmod.ko /data/local/tmp
root@android:/ # rmmod test_kmod
root@android:/ # insmod /data/local/tmp/test_kmod.ko
root@android:/ # chmod 777 /dev/tkmod_device
```
Если версия ядра модифицирована правильно и ядро совпадает с тем которое было на устройстве ошибок быть не должно.
После можно запускать Android приложение напрямую через eclipse или установить его. Нажимаем единственную кнопку и получаем результат:

Логи ядра можно получить командой:
```
root@android:/ # dmesg | grep [TEST_KMOD] # можно и не фильтровать но так лучше видно.
```
**Лог ядра**
```
<6>[ 8695.448028] [TEST_KMOD] == Module init ==
<7>[ 8775.583587] [TEST_KMOD] tkmod opened. Descriptor: 0xc2e98e00.
<7>[ 8775.583770] [TEST_KMOD] TKMOD_IOCTL_GET_DATA request.
<6>[ 8775.583923] [TEST_KMOD] name = lo
<6>[ 8775.584167] [TEST_KMOD] name = dummy0
<6>[ 8775.584259] [TEST_KMOD] name = rmnet0
<6>[ 8775.584320] [TEST_KMOD] name = rmnet1
<6>[ 8775.584503] [TEST_KMOD] name = rmnet2
<6>[ 8775.584564] [TEST_KMOD] name = rmnet3
<6>[ 8775.584655] [TEST_KMOD] name = rmnet4
<6>[ 8775.584777] [TEST_KMOD] name = rmnet5
<6>[ 8775.584930] [TEST_KMOD] name = rmnet6
<6>[ 8775.585021] [TEST_KMOD] name = rmnet7
<6>[ 8775.585113] [TEST_KMOD] name = gre0
<6>[ 8775.585266] [TEST_KMOD] name = sit0
<6>[ 8775.585357] [TEST_KMOD] name = ip6tnl0
<7>[ 8775.585479] [TEST_KMOD] tkmod_ 0xc2e98e00 closed successfuly.
```
##### Заключение
Показанное применение данной связки не единственное. Использование драйверов ядра позволяет напрямую работать с любыми интерфейсами устройства, влиять на работу любого приложения и системы в целом, также позволяет работать с интерфейсами которые спрятаны глубоко в системе за целой кучей API и фреймворков — например драйвер который будет писать необходимую вам информацию прямо в буфер видеопамяти устройства. Данное решение применимо не только для телефонов но и для любых устройств на базе Android.
Полные исходники лежат на [GitHub](https://github.com/Propheta13/android_mod_use).
На этом заканчиваю, спасибо за внимание. Надеюсь что данный материал окажется для кого-нибудь полезным.
##### Использованные ресурсы:
1. [developer.android.com](http://developer.android.com) — Android SDK/NDK и прочее.
2. [www.vogella.com](http://www.vogella.com) — довольно неплохие и понятные статьи по разработке Android приложений.
3. [blog.edwards-research.com/2012/04/tutorial-android-jni](http://blog.edwards-research.com/2012/04/tutorial-android-jni/) — туториал по использованию JNI.
4. [docs.oracle.com/javase/1.5.0/docs/guide/jni/spec/functions.html](http://docs.oracle.com/javase/1.5.0/docs/guide/jni/spec/functions.html) — справочный материал по интерфейсу JNI.
5. Linux Device Drivers, 3ed — библия программиста Linux Kernel.
##### UPD
Поправил несколько опечаток, ошибок в коде. Спасибо: [bmx666](http://habrahabr.ru/users/bmx666/),[Shirixae](http://habrahabr.ru/users/shirixae/) | https://habr.com/ru/post/174077/ | null | ru | null |
# CometQL — api работы с комет сервером по протоколу MySQL
[](http://habrahabr.ru/company/comet-server/blog/264425/)
**CometQL** — это api для работы с [saas комет сервисом](https://comet-server.ru/%D1%80%D0%B0%D0%B7%D0%B4%D0%B5%D0%BB/15/subject/1) по протоколу MySQL.
#### Почему это круто
* Единый api для более чем [12 языков программирования](https://ru.wikipedia.org/wiki/MySQL#.D0.AF.D0.B7.D1.8B.D0.BA.D0.B8_.D0.BF.D1.80.D0.BE.D0.B3.D1.80.D0.B0.D0.BC.D0.BC.D0.B8.D1.80.D0.BE.D0.B2.D0.B0.D0.BD.D0.B8.D1.8F)
* Простой и понятный вид запросов
* В php есть средства поддержания постоянных соединений с MySQL и теперь их можно так же использовать для работы с comet сервером.
Например для получения информации о том когда пользователь был online достаточно выполнить следующий запрос:
```
select id, time from users_time where id = 2;
```
А вот запрос для отправки сообщения в канал:
```
INSERT INTO pipes_messages (name, event, message)VALUES("pipe_name", "event_in_pipe", "text message");
```
#### Как подключится и попробовать самостоятельно
Вы можете сами подключится с демо данными и попробовать.
```
# Сервер app.comet-server.ru
# Логин 15
# Пароль lPXBFPqNg3f661JcegBY0N0dPXqUBdHXqj2cHf04PZgLHxT6z55e20ozojvMRvB8
# База данных CometQL_v1
# Строка для подключения из консоли
mysql -h app.comet-server.ru -u15 -plPXBFPqNg3f661JcegBY0N0dPXqUBdHXqj2cHf04PZgLHxT6z55e20ozojvMRvB8 -DCometQL_v1
```
**Для тех кто хочет попробовать подключится но нет под рукой консольного mysql клиента**Вы можете опробовать работу CometQL с помощью [online CometQL командной строки](http://comet-server.ru/wiki/doku.php/comet:cometql) (расположена в правом нижнем углу на любой странице)
#### Общие сведения о CometQL
CometQL внешне представляет из себя некое подобие базы данных. При чём когда мы при подключении выбираем базу данных CometQL\_v1 это фактически инструкция указывающая с какой версией api мы хотим взаимодействовать.
Надо понимать что не какого MySQL сервера на бекэнде нет, запросы парсятся и выполняются непосредственно comet сервером. А представление всех возможных действий в виде таблиц и запросов к ним просто удобно и привычно для многих вебмастеров.
#### Таблица pipes\_messages
Таблица pipes\_messages содержит сообщения передаваемые через каналы. Для отправки сообщения в канал надо выполнить запрос вставки ( insert ) в эту таблицу.
```
mysql> insert into pipes_messages (name, event, message)values("pipe_name", "event_in_pipe", "text message");
Query OK, 0 rows affected (0.13 sec)
```
Поля «name» и «event» должны соответствовать следующему регулярному выражению [0-9A-z=+/\_]
Запрос выборки из pipes\_messages вернёт историю сообщений в канале если функция сохранения истории включена для этого канала (о том как эту функцию включить написано ниже).
```
mysql> select * from pipes_messages where name = "p10";
+------+-------+-------+--------------+
| name | index | event | message |
+------+-------+-------+--------------+
| p10 | 0 | event | msgData |
| p10 | 1 | event | msgqqrrata |
| p10 | 2 | evt3 | msgqqrrata |
+------+-------+-------+--------------+
3 rows in set (0.00 sec)
```
Очищает историю сообщений в канале.
```
mysql> delete from pipes_messages where name = 'p10';
Query OK, 0 rows affected (0.13 sec)
```
[Online пример отправки сообщений](http://comet-server.ru/wiki/doku.php/comet:cometql?&#online_пример)
#### Таблица pipes
Таблица pipes содержит информацию о том сколько человек подписались на сообщения из каналов. Таблица доступна только для чтения.
```
mysql> select * from pipes where name in( "web_admins", "web_php_chat");
+--------------+-------+
| name | users |
+--------------+-------+
| web_admins | 3 |
| web_php_chat | 2 |
+--------------+-------+
2 rows in set (0.30 sec)
```
[Online пример подписок на каналы](http://comet-server.ru/wiki/doku.php/comet:cometql?&#online_пример1)
#### Таблица users\_in\_pipes
Таблица users\_in\_pipes содержит данные о том кто из авторизованных пользователей подписался на канал. Таблица доступна только для чтения.
```
mysql> select * from users_in_pipes where name = "web_admins";
+------------+---------+
| name | user_id |
+------------+---------+
| web_admins | 2 |
| web_admins | 4 |
| web_admins | 14 |
| web_admins | 9 |
+------------+---------+
4 row in set (0.32 sec)
```
Примечательно что поле users содержит суммарное количество подписчиков как авторизованных так и не авторизованных в то время как таблица users\_in\_pipes содержит список только авторизованных подписчиков.
#### Таблица pipes\_settings
Таблица pipes\_settings содержит настройки логирования каналов. По умолчанию сообщения проходящие через канал не запоминаются. Но если включить механизм логирования для канала то в комет сервере будет хранится n последних сообщений прошедших через этот канал.
Для включения механизма логирования в канале надо выполнить следующий запрос.
```
mysql> insert into pipes_settings (name, length) values ('p10', 10);
Query OK, 1 row affected (0.00 sec)
```
Здесь параметр length это то сколько последних сообщений будет запомнено. Принимает значения от 0 до 99.
Для того чтобы получить значения настроек канала нужно выполнить запрос выборки из pipes\_settings.
```
mysql> select * from pipes_settings where name = 'p10';
+------+--------+
| name | length |
+------+--------+
| p10 | 10 |
+------+--------+
1 row in set (0.00 sec)
```
Для того чтобы отключить механизм логирования надо удалить из pipes\_settings запись настроек.
```
mysql> delete from pipes_settings where name = 'p10';
Query OK, 0 rows affected (0.00 sec)
```
#### Механизм авторизации пользователей на комет сервере
Помимо каналов где каждый кто знает имя канала может подписаться на него, есть возможность авторизации пользователей на комет сервере и отправки личных сообщений пользователям по их идентификаторам. Авторизация пользователя происходит в 2 этапа. Первый этап это отправка идентификатора пользователя в вашей системе и случайного хеша в комет сервер.
```
mysql> INSERT INTO users_auth (id, hash )VALUES (1, 'auth_hash1');
```
* Здесь строка auth\_hash1 — это текстовый ключ авторизации. Вы его сами генерируете на своём сервере и отправляете сначала в комет по средствам insert запроса в таблицу users\_auth, а затем передаёте в JavaScript для авторизации конкретного пользователя на комет сервере.
* id пользователя на вашем сайте, любое целое положительное число не более чем из 9 цифр.
На втором этапе эти сведения (идентификатор пользователя и хеш) надо передать в JavaScript Api
```
$(document).ready(function()
{
CometServer().start({dev_id:1, user_key:"auth_hash1", user_id:"Числовой_Идентификатор_пользователя" })
});
```
Здесь dev\_id это публичный идентификатор разработчика.
И теперь пользователь будет авторизован на комет сервере.
#### Доставка сообщений для авторизованных пользователей
При отправке сообщений авторизованным пользователям по их идентификатору (insert запрос в таблицу users\_messages) сообщения доставляются пользователю на все устройства (До 16 устройств) на которых он прошёл авторизацию в данный момент. Это очень удобно в том случаи если человек зашёл на ваш сайт и авторизовался на нём более чем с одного устройства (к примеру телефон и компьютер или просто в двух разных браузерах сидит одновременно).
Если человек в данный момент ofline то сообщение помещается в очередь сообщений и будет доставлено когда человек появится online. В данный момент для каждого пользователя максимальный размер очереди ограничен.
Основное назначение очереди сообщений это доставка сообщений после кратковременного перехода человека в ofline. Например в тех случаях когда человек обновляет страницу сайта на которой было открыто соединение он уходит в ofline примерно на 1 секунду.
#### Таблица users\_messages
Таблица users\_messages предназначена для отправки сообщений авторизованным пользователям по их идентификатору.
Например для отправки сообщения пользователю с id = 2 и текстом сообщения 'message' надо выполнить следующий запрос
```
mysql> insert into users_messages (id, event, message)values (2, 'event', 'message');
Query OK, 0 row affected (0.00 sec)
```
Сообщение либо отправлено пользователю сразу либо помещено в очередь для отправки пользователю позже.
Для того чтобы получить все те сообщения которые ещё не доставлены пользователю и находятся в очереди надо выполнить запрос select
```
mysql> select * from users_messages where id = 2;
+----+-------+-------+---------+
| id | index | event | message |
+----+-------+-------+---------+
| 2 | 0 | evnt1 | message |
| 2 | 1 | evnt2 | messag2 |
+----+-------+-------+---------+
2 rows in set (0.00 sec)
```
Здесь видно что отправки ожидает 2 сообщения. Они будут отправлены сразу как пользователь появится online.
Таблица содержит колонки:
* id — Идентификатор пользователя
* index — Номер сообщения в очереди
* event — Имя события
* message — Тело сообщения
Для очистки очереди используйте запрос удаления.
```
mysql> delete from users_messages where id = 2;
Query OK, 0 rows affected (0.08 sec)
```
После того как сообщение будет доставлено пользователю оно автоматически удалится из очереди сообщений.
#### Таблица users\_time
Таблица users\_time содержит данные о том когда были пользователи online. Таблица доступна только для чтения. Данные о времени хранятся в [UNIX-time](https://ru.wikipedia.org/wiki/UNIX-%D0%B2%D1%80%D0%B5%D0%BC%D1%8F)
```
mysql> select * from users_time where id in( 2, 3, 145);
+-----+------------+
| id | time |
+-----+------------+
| 2 | 0 |
| 3 | 1438245468 |
| 145 | -1 |
+-----+------------+
3 rows in set (0.31 sec)
```
Здесь пользователь с id = 2 в данный момент на сайте, пользователь с id = 3 был online 30 июля, а для пользователя с id = 145 нет данных.
#### Таблица users\_auth
Таблица users\_auth содержит данные для авторизации пользователей на комет сервере.
```
mysql> insert into users_auth (id, hash )values (12, 'hash1');
Query OK, 1 row affected (0.13 sec)
```
```
mysql> select * from users_auth where id in(2, 3, 12);
+----+----------------------------+
| id | hash |
+----+----------------------------+
| 2 | bjl6knotdb2t1oov958mhuian7 |
| 12 | hash1 |
+----+----------------------------+
2 rows in set (0.32 sec)
```
Здесь для пользователя с id = 3 нет данных, а для пользователей 2 и 12 данные присутствуют.
Важно отметить что в поле hash можно передавать только строки длиной не более 32 символов и соответствующие регулярному выражению [0-9A-z=+/\_].
Для удаления данных авторизации пользователей используйте запрос delete
```
delete from users_auth where id = 12;
Query OK, 0 rows affected (0.00 sec)
```
#### Советы тем кто делает своё публичное api
Вот, на мой взгляд, 3 наиболее полезные статьи для любого кто собирается делать публичный api интерфейс:
* [habrahabr.ru/post/181988](http://habrahabr.ru/post/181988/)
* [habrahabr.ru/post/224929](http://habrahabr.ru/post/224929/)
* [habrahabr.ru/company/yandex/blog/237459](http://habrahabr.ru/company/yandex/blog/237459/)
#### Ещё примеры использования CometQL в реальных проектах
Примеры использования CometQL есть в статье [как сделать чат на сайте](http://comet-server.ru/wiki/doku.php/comet:chat-with-authorization) и в статье про интеграцию [приватного чат на сайт](http://comet-server.ru/wiki/doku.php/comet:star-comet-chat) | https://habr.com/ru/post/264425/ | null | ru | null |
# Миграция фотографий или ещё одна очередь на MySQL
 Недавно мы [писали о том](http://habrahabr.ru/company/badoo/blog/197456/), как перед нами впервые встала задача крупномасштабной миграции данных пользователей между дата-центрами и о том как мы ее решили.
В этот раз мы подробнее остановимся на том, каким образом осуществлялась миграция фотографий пользователей и какие структуры данных использовались для ограничения создаваемой нагрузки на сервера с фотографиями.
Ежедневно пользователи Badoo загружают примерно 3 миллиона фотографий. Для их хранения мы выделили специальный кластер серверов, занимающихся также изменением размеров, наложением «водяных знаков», импортом фотографий из других социальных сетей и прочими манипуляциями с файлами.
Все машины этого кластера можно условно разделить на три группы. Первая ― это серверы, отвечающие за быструю отдачу фотографий пользователям (можно сказать, собственная реализация CDN). В контексте миграции эти серверы нам не будут интересны. Вторая группа ― это хранилища с дисками, на которых, собственно, и находятся все фотографии. И третья группа ― это серверы, предоставляющие интерфейс ко второй группе, условно назовём их фотосерверами. На них по оптоволокну смонтированы дисковые массивы хранилищ, на эти же машины происходит загрузка фотографий и здесь же работают все скрипты, выполняющие какие-либо операции с файлами.
Таким образом, для PHP-кода совершенно неважно, на каком именно диске какого хранилища находится фотография. Все, что нужно сделать, это перенести фотографии пользователя с одного фотосервера на другой и обновить эту информацию в базе данных и некоторых демонах. Здесь важно отметить, что все фотографии пользователя всегда находятся на одном фотосервере.
#### Постановка задачи
Суммарный объем всех фотографий, когда-либо загруженных нашими пользователями, составляет примерно 600 Тб. В это число входят как оригиналы фотографий, так и набор фотографий с измененными размерами, необходимый для отображения в том или ином случае.
Грубая оценка показывает, что если 190 миллионов пользователей загрузили 600 ТБ данных, то 1,5 миллиона пользователей из Тайланда (самой крупной из перенесённых между дата-центрами стран) загрузили 4,7 ТБ. Пропускная способность канала между нашими дата-центрами на на момент миграции составляла 200 Мбит/с. Путем нехитрых вычислений мы получаем 55 часов на перенесение всех фотографий пользователей из Тайланда. Естественно, этот канал уже частично занят другими данными, постоянно циркулирующими между дата-центрами, и в действительности понадобится больше, чем 55 часов. А наша цель ― успеть за 8 часов.
Можно было бы перенести только оригиналы фотографий и сделать для них «ресайзы» на новом фотосервере, но это привело бы к нежелательному росту нагрузки на процессоры. Поэтому мы решили перенести фотографии заранее, рассчитывая, что пользователи не успеют загрузить много новых фотографий за время, необходимое на перенесение фотографий всей страны.
То есть сначала мы просто копируем уже существующие фотографии, а во время миграции всех данных пользователя (когда сайт для него недоступен и невозможно что-то изменить в своих фотографиях) проверяем, были ли какие-то изменения после переноса фотографий. Если изменения были, то копируем фотографии еще раз (вернее, сделаем rsync), и только после этого обновим данные в базах и демонах, чтобы фотографии пользователя стали показываться и загружаться на новом фотосервере.
Как показала практика, наши ожидания оправдались, и делать rsync второй раз пришлось для очень незначительного процента пользователей.
Еще одним ограничением для нас являлась производительность дисков хранилищ. Мы выяснили, что даже имея канал в сотни терабит, мы не сможем использовать его на полную мощность, поскольку на фотосерверы постоянно загружаются фотографии, с ними производятся различные операции. Кроме того, наш CDN «читает» эти фотографии с дисков, и дополнительная нагрузка на чтение может существенно замедлить повседневные операции. То есть интенсивность миграции фотографий должна быть искусственно ограничена.
#### Реализация
Первое, что пришло нам на ум ― это очередь в базе данных (мы используем MySQL), в которой будут находиться все пользователи, чьи фотографии нужно перенести. Очередь будет обрабатываться в несколько процессов. Ограничивая число процессов на один фотосервер, мы тем самым решим проблему ограничения нагрузки на диски. Ограничение на общее число процессов позволит нам регулировать загруженность канала между дата-центрами.
Допустим, у нас есть таблица MigrationPhoto следующей структуры:
```
CREATE TABLE MigrationPhoto (
user_id INT PRIMARY KEY,
updated TIMESTAMP,
photoserver VARCHAR(255), # фотосервер c фотографиями пользователя
script_name VARCHAR(255), # имя процесса, обрабатывающего пользователя
done TINYINT(1), # 1 если фотографии были перенесены, иначе 0
KEY photoserver (photoserver),
KEY script_name (script_name)
)
```
Сначала добавляем всех пользователей, фотографии которых мы хотим перенести, в нашу таблицу:
```
INSERT INTO MigrationPhoto (user_id,photoserver) VALUES (00000000, 'photoserver1')
```
Ограничение на суммарное число процессов легко достигается с помощью расширения pcntl и не представляет большого интереса, поэтому далее будем рассматривать один процесс, занимающийся переносом.
Нам нужно обеспечить конкретное число процессов на один фотосервер. Сначала разберемся, пользователи с каких фотосерверов вообще есть в очереди. Чтобы не делать каждый раз *SELECT photoserver, COUNT(\*) FROM MigrationPhoto*, заведем отдельную таблицу:
```
CREATE TABLE MigrationPhotoCounters (
photoserver VARCHAR(255) PRIMARY KEY,
users INT
)
```
Мы будем заполнять ее при вставке каждого пользователя в таблицу MigrationPhoto:
```
INSERT INTO MigrationPhotoCounters (photoserver, users) VALUES ('photoserver1', 1) ON DUPLICATE KEY UPDATE users = users + VALUES(users)
```
Либо после заполнения MigrationPhoto сделаем так:
```
INSERT INTO MigrationPhotoCounters (bphotos_server, users) VALUES (SELECT photoserver, COUNT(*) AS users FROM MigrationPhoto)
```
Имея такую таблицу, при запуске каждого процесса будем делать
```
SELECT photoserver FROM MigrationPhotoCounters WHERE users>0 ORDER BY RAND()
```
Получив список всех фотосерверов, определим, для какого из них можно запустить процесс так, чтобы не превысить ограничения. Для этого поставим в базе лок, имя которого состоит из имени фотосервера и порядкового номера процесса в рамках данного сервера:
```
$processNumber = null;
foreach ($photoservers as $serverName) {
for ($i = 1; $i <= PROCESSES_PER_SERVER; $i++) {
$lock = executeQuery("SELECT GET_LOCK('migration" . $serverName . '_' . $processNumber . "', 0)");
if ($lock === '1') {
$processNumber = $i;
break;
}
}
if ($processNumber) {
$serverName = $serverName;
$scriptName = 'migration' . $serverName . '_' . $processNumber;
break;
}
}
```
Таким образом, мы перебираем в двух вложенных циклах все фотосерверы и номера процессов для них. Если выполнены все итерации внутреннего цикла и переменная *$processNumber* не определена, значит, для данного фотосервера достигнут лимит количества процессов. Если выполнены все итерации внешнего цикла, значит, такой лимит достигнут для всех фотосерверов, на которых еще имеются пользователи, подлежащие переносу.
Допустим, мы выбрали фотосервер photoserver1, и это второй процесс для него, то есть идентификатор процесса будет *$scriptName = 'migration\_photoserver1\_2'*.
Перед тем как двигаться дальше, вернем в общую очередь тех пользователей, которые по тем или иным причинам остались помеченными выбранным нами идентификатором процесса *($scriptName)* при предыдущих запусках:
```
UPDATE MIgrationPhoto SET script_name = NULL WHERE done = 0 AND script_name = 'migration_photoserver1_2'
```
Пометим порцию пользователей как обрабатываемую данным процессом:
```
UPDATE SET MigrationPhoto script_name='migration_photoserver1_2' WHERE photoserver='photoserver1' AND done = 0 AND script_name IS NULL LIMIT 100;
```
Теперь возьмем из очереди несколько пользователей, которые соответствуют выбранному нами фотосерверу и еще не обрабатываются другим процессом:
```
SELECT * FROM MigrationPhoto WHERE script_name='migration_photoserver1_2' AND done=0;
```
После этого мы можем быть уверены, что выбранные нами записи не обрабатывает ни один другой процесс.
Запоминаем, когда мы перенесли фотографии пользователя:
```
UPDATE MigrationPhoto SET updated=NOW() WHERE user_id = 00000000
```
Выполняем все необходимые нам операции, упрощенно их можно представить как rsync. После успешного перенесения фотографий нам нужно отметить это в базе (для каждого из выбранных пользователей):
```
BEGIN;
UPDATE MigrationPhotoCounters SET users = users - 1 WHERE photoserver = 'photoserver1';
UPDATE MigrationPhoto SET done = 1 WHERE user_id = 00000000;
COMMIT;
```
Может случиться так, что из 100 взятых на обработку пользователей для некоторых не удастся осуществить перенос по самым разнообразным причинам. Таких пользователей нужно вернуть в очередь, чтобы перенести их позже:
```
UPDATE MigrationPhoto SET script_name = NULL WHERE user_id IN ()
```
Завершаем процесс:
```
SELECT RELEASE_LOCK('migration_photoserver1_2')
```
Казалось бы, на этом можно закончить. Но у нашей схемы есть принципиальный недостаток.
Предположим, что запустился процесс, у которого *$scriptName='migration\_photoserver1\_10'*, при этом *PROCESSES\_PER\_SERVER=10*. И этот процесс упал, не вернув взятых им пользователей в очередь. Для того чтобы эти пользователи снова были выбраны, либо снова должен запуститься процесс с таким же *$scriptName*, либо кто-то должен выставить этим пользователям в базе *script\_name=NULL*. Запуска процесса с таким же *$scriptName* может больше и не случиться.
Например, у нас 100 фотосерверов в MigrationPhotoCounters, ограничение на суммарное число процессов ― 50, ограничение на число процессов на один ― 10, тогда очевидно, что если в какой-то момент на один фотосервер пришлось 10 процессов, то в дальнейшем этот фотосервер может получать только по одному процессу. Поэтому напишем еще один скрипт, который, допустим, один раз в минуту будет устанавливать *script\_name=NULL* для тех пользователей, процессы которых сейчас не запущены:
```
foreach ($photoservers as $serverName) {
for ($i = 1; $i <= PROCESSES_PER_SERVER; $i++) {
$lock = executeQuery("SELECT GET_LOCK('migration" . $serverName . '_' . $processNumber . "', 0)");
if ($lock === '1') {
executeQuery("UPDATE MigrationPhoto SET script_name = NULL WHERE done = 0 AND script_name = 'migration" . $serverName . '_' . $processNumber . "'");
}
}
}
```
Теперь, даже в случае падения процесса, его пользователи станут доступны для обработки другим процессам. Кроме того, это позволит менять ограничение числа процессов на один фотосервер «на лету».
Когда процесс будет завершен и начнется миграция всех остальных данных пользователя, достаточно лишь проверить, что фотографии пользователя не менялись со времени, указанного в поле updated таблицы MigrationPhoto. А если менялись ― то просто повторить rsync. Это не займет много времени, так как практически никто из пользователей не меняет все свои фотографии за 2-3 суток.
В итоге у нас было 63 фотосервера, с которых мы читали фотографии, и 30 серверов, на которые писали. Все это происходило силами 80 процессов, с ограничением не более 3 процессов на один фотосервер. При таких ограничениях трафик составлял 150 Мбит/с. Перенесение фотографий для пользователей из Тайланда заняло чуть менее трех суток. Учитывая объем данных, мы получили отличный результат.
#### Заключение
Конечно, наша схема допускает расширения и улучшения. Например, можно ограничивать количество процессов обработки для каждого фотосервера индивидуально. Можно регулировать это количество в зависимости от того, сколько пользователей конкретного фотосервера находится в очереди. Можно добавить приоритеты, прогрессивный тайм-аут на следующую обработку записи (в случае неудачной текущей), максимальное количество неудачных обработок, логи, графики и еще много чего.
Но нам хотелось донести саму идею параллельной обработки очереди с заданными ограничениями, которая, конечно, может быть использована не только для переноса файлов между серверами.
Сегодня мы не стали описывать процесс обработки разнообразных ошибок и исключительных ситуаций, равно как и механизм создания и поддержания заданного количества процессов, и реализацию переноса файлов. Но если это вам интересно ― спрашивайте, и мы обязательно ответим в комментариях.
**Антон Степаненко, Team Lead, PHP-разработчик** | https://habr.com/ru/post/204028/ | null | ru | null |
# Эмуляция интерфейса iPhone с помощью CSS
 Некоторое время назад мне потребовалось «красиво» оформить логи бесед в жаббире. Поскольку рисовать я не умею вовсе, я обратился за подмогой к мирозданию. Поиск по готовым решениям открыл для меня малоизвестную, но, безусловно, заслуживающую внимания библиотечку. Строго говоря, это не библиотека. Это тщательно написанная и выверенная каскадная таблица стилей, позволяющая имитировать iPhone-интерфейс в браузерах.
Координатные данные проекта UiUiKit (Universal iPhone UI Kit):
* *Сайт автора:*[www.minid.net](http://www.minid.net)
* *SVN URL:*[code.google.com/p/iphone-universal/source/checkout](http://code.google.com/p/iphone-universal/source/checkout)
* *Download:*[code.google.com/p/iphone-universal/downloads/list](http://code.google.com/p/iphone-universal/downloads/list)
Оригинально библиотека заточена под web-приложения именно для iPhone, поэтому всякий CSS3+ ограничивается указанием свойств *только* для `webkit`'а. Я пропатчил [CSS](http://chatter.mudasobwa.ru/stylesheets/iphone.css) директивами для остальных и развернул [демонстрационную страничку](http://chatter.mudasobwa.ru), чтобы можно было сразу потыкать в элементы интерфейса.
Выглядит симпатично (на картинке в начале топика — скриншот моего браузера). Приятного использования! | https://habr.com/ru/post/131935/ | null | ru | null |
# Проектировщики RISC-V из Yadro покажут школьникам как проектировать процессоры
Станислав Жельнио, проектировщик Syntacore, проводит семинар для школьников в Зеленограде в позапрошлом годуЧерез неделю будет выставка ChipEXPO, на которой для будет [школа проектирования железа для начинающих с упражнениями на FPGA платах](http://www.chipexpo.ru/shkola-sinteza-cifrovyh-shem-na-verilog), а для более продвинутых - конференция [Микроархитектура, верификация и физическое проектирование микросхем](http://www.chipexpo.ru/programm).
И на секции для школьников, и на секции для взрослых будут выступать проектировщики RISC-V процессора из Syntacore / Yadro Станислав Жельнио и Никита Поляков. Сегодня [Коммерсантъ сравнил этот проект с полетом на Луну](https://www.kommersant.ru/doc/4975430).
Количество заявок на школу существенно превысило количество посадочных мест, но у нас еще остался небольшой резерв FPGA плат, с бесплатной их раздачей школьникам и преподавателям из далеких от Москвы городов, которые могут принять участие в школе онлайн. В начале этой заметке мы опишем как получить плату и установить софтвер, нужный для упражнений.
Далее мы расскажем про новые упражнения в школе этого года - распознавание и генерацию музыки с помощью FPGA и приведем забавные сведения из советской физматшкольной книжки 1963 года как Бах изменил гаммы.
В конце поста мы покажем, как эта деятельность поможет получить в будущем интересные и высокооплачиваемые работы в Apple, Intel, SpaceX, как и самом в модном в этом сезоне российском микроэлектронном проекте - Syntacore / Yadro (в конце поста скриншоты их объявлений).
Наташа держит Omdazz, одну из плат которая используется на школеПрежде всего, так как количество заявок вдвое (а сейчас уже может и втрое) превысило количество мест офлайн, мы решили отдавать приоритет на посадочные места для тех, кто прошел три небольших онлайн-курса от Роснано [«От транзистора до микросхемы»](https://stemford.org/education/courses/details/6410690722451343819), [«Логическая сторона цифровой схемотехники»](https://stemford.org/education/courses/details/6410690722451344036) и [«Физическая сторона цифровой схемотехники»](https://stemford.org/education/courses/details/6410690722451344042).
Этот курс гарантирует, что человек, который садится за стол с FPGA платой, по крайней мере не впервые в жизни слышит слова D-триггер и неблокирующее присваивание. Без этого человек будет переносить на код на языке описания аппаратуры Verilog свои ассоциации с программированием, и происходящее на плате будет казаться бредом. Также без курса может быть непонятно как упражнения с лампочками и кнопочками приводит к позиции проектирощика на уровне регистровых передач (Register Transfer Level (RTL) Desigfn Engineer) в тоp-20 электронных компаниях или в купленном Ядром стартапе Syntacore, который теоретически может превратить Россию в великую электронную державу лет через 10-20, аккурат к творческим вершинам карьеры современных школьников.
Прохождение этого курса также нужно, если вы не можете приехать в Сколково, но вы хотели бы получить плату, чтобы практиковаться удаленно. Эта опция доступна школьникам и преподавателям школ, вузов и кружков. Помимо платы вы получите микрофон и усилитель для упражнений со звуком. Вам нужно показать серфитикат после прохождения роснановского онлайн-курса и договориться с Михаилом Коробковым (Команда проекта FPGA-Systems.ru, [[email protected]](mailto:[email protected])) чтобы он выслал вам плату.
Если у вас нет платы, вы не школьник и просто хотите посмотреть, вы можете присоединиться к занятиям Школы через интернет, на онлайн платформе [eventwallet](https://eventswallet.com/ru/events/282), на которую будут вестить прямые трансляции всех лекций и практических занятий Школы. Для этого нужно зайти на платформу, зарегистрироваться и перейти на вкладку ПРОГРАММА в левом меню. Там увидите виртуальный конференц-зал, в котором будет идти трансляция.Можно задавать вопросы спикерам в режиме чата.
Студенты Иннополиса во время хакатона по алгоритмам автоматизации проектирования микросхемДеньги на платы, перевод и трансляцию мероприятия дали: [Cadence Design Systems](https://www.cadence.com/), [Siemens EDA](http://mentor.com/) / [МЕГРАТЕК (Megratec - Mentor Graphics Technologies)](https://megratec.ru/), [Наносемантика](http://nanosemantics.ai/), [Alchemical Music Box](http://www.ambox.me/), Максим Маслов (сооснователь Eltechs и автор шумящего сейчас поста ["Легенды и мифы процессора Эльбрус в примерах"](https://habr.com/ru/post/576420/)) и ваш покорный слуга Юрий Панчул.
Примеры которые используются в этой части семинара работают со всеми версиями Quartus начиная с 13.0sp1. Желательно конечно использовать последнюю из бесплатных (Lite) версий, но текущая бесплатная версия Quartus Prime Lite Edition 20.1.1 не работает сразу после скачивания ни на текущей версии Windows 10, ни на текущей версии Linux Ubuntu 20.04 LTS. Для Windows у нее истекла дата сертификата драйвера, а для Linux она использует устаревшую библиотеку.
Обе проблемы можно решить: для Windows - c помощью скачивания [patch](https://www.intel.com/content/altera-www/global/en_us/index/support/support-resources/knowledge-base/tools/2021/why-does-the-intel--fpga-download-cables-drivers-installation-fa.html), а для Linux - с помощью "sudo ln -sf /lib/x86\_64-linux-gnu/libudev.so.1 /lib/x86\_64-linux-gnu/libudev.so.0".
Для проверки, что ваша FPGA плата и установка Quartus работает, вы можете скачать минимальный пакет "before" по следующей ссылке:
ChipEXPO 2021 Digital Design School before package v2.0 <https://bit.ly/chipexpo2021ddsbefore20>
[Прямая ссылка](https://www.dropbox.com/s/c9ybmrxg6vr9i0g/ce2020labs_before_20210905_125508.zip?dl=0)
В качестве инструкций можно использовать видео Сергея Иванца с прошлого года, но применять их для нового пакета, а также использовать новые версии Quartus для Linux и Windows.
Теперь насчет упражнений по распознаванию и генерации звуков на верилоге с помощью FPGA платы. Сначала мы думали использовать синтетический звук из телефона, но потом решили, что это неспортивно - нужен живой звук, на котором можно тренировать техническую смекалку, требуемую для решения задач на распознавание.
Преподавательница флейты Мария Беличенко будет играть мелодии для распознавания FPGA платой Piswords с Intel FPGA Cyclone IVВ процессе подготовки упражнений с музыкой на FPGA я узнал из советской книжки для детей 1963 года удивительный факт:
Оказывается, современные гаммы отличаются по частотам нот от гамм, которые были до Баха. В современных гаммах полутона находятся в геометрической прогрессии, на расстоянии корня 12-той степени из двойки друг от друга. А в 17 веке клавесины и арфы настраивали по другому, так, чтобы частоты образовывали кратные отношения (так называемый "чистый строй"). Из-за этого мелодии нельзя было транспонировать в другие тональности - они начинали звучать криво. Собственно именно Бах пропиарил новую систему в "Хорошо темперированном клавире" и доказал что с корнем 12-й степени из двойки сочинять можно. До этого эстеты лет 20 считали новую систему ("равномерно темперированный строй") немного варварской.
В упрямой России нововведение критиковали даже в 19 веке, согласно википедии: "Русский простолюдин с музыкальным дарованием, у которого ухо ещё не испорчено ни уличными шарманками, ни итальянскою оперою, поет весьма верно; и по собственному чутью берет интервал весьма отчетливо, разумеется, не в нашей уродливой темперированной гамме" Владимир Одоевский
Более реально чем теплый ламповый звук между прочим!
Каким образом FPGA плата может распознать какую-нюбудь простую мелодию, например из фильма "Крестный отец" (эта мелодия также звучит в советском мультфильме "Контакт")?
Если звук достаточно чистый, то можно распознать и без Фурье-преобразования, просто подсчетом тактов (но не музыкальных, а тактового сигнала 50 MHz на FPGA плате) между моментами, когда синусоида уровня сигнала пересекает его среднее значение. Этот метод называется zero crossing, и он вполне работает для звуков флейты. Флейту принесет преподавательница [Мария Беличенко](http://mariaflute.com/) . Вот как zero-crossing выглядит на языке описания аппаратуры Verilog:
<https://github.com/DigitalDesignSchool/ce2020labs/blob/master/day_2/piswords/lab_5_mic/top.v>
```
reg [15:0] prev_value;
reg [19:0] counter;
reg [19:0] distance;
localparam [15:0] threshold = 16'h1000;
always @ (posedge clk or posedge reset)
if (reset)
begin
prev_value <= 16'h0;
counter <= 20'h0;
distance <= 20'h0;
end
else
begin
prev_value <= value;
if ( value > threshold
& prev_value < threshold)
begin
distance <= counter;
counter <= 20'h0;
end
else if (counter != ~ 20'h0) // To prevent overflow
begin
counter <= counter + 20'h1;
end
end
// Теперь в distance у нас лежит период нижней гармоники ноты
// выраженный в тактах 50-мегагерцового тактового сигнала
```
Уровень звукового сигнала снимается вот таким микрофоном, который мы выдадим:
Pmod MIC3: MEMS Microphone with Adjustable GainТакже с помощью вот такого усилителя можно сгенерировать звук. Если все хорошо отладить, то после распознавания мелодии ее можно продолжить из усилителя:
Pmod AMP3: Stereo Power AmplifierМикрофон передает уровень сигнала в FPGA с помощью протокола SPI, а усилитель использует протокол I2S.
Протокол I2S из https://digilent.com/reference/pmod/pmodamp3/reference-manualОба протокола реализуются простым сдвиговым регистром, см. [код для I2S Виктора Прутьянова](https://github.com/DigitalDesignSchool/ce2020labs/blob/master/day_2/piswords/lab_6_i2s/top.v):
```
module i2s
(
input clk, // CLK - 50 MHz
input reset,
input [2:0] octave,
input [3:0] note,
output mclk, // MCLK - 12.5 MHz
output bclk, // BCLK - 3.125 MHz serial clock - for a 48 KHz Sample Rate
output lrclk, // LRCLK - 32-bit L, 32-bit R
output sdata
);
reg [9:0] clk_div;
reg [31:0] shift;
reg [7:0] cnt;
wire [15:0] value;
wire [7:0] cnt_max;
always @ (posedge clk or posedge reset)
if (reset)
clk_div <= 0;
else
clk_div <= clk_div + 10'b1;
assign mclk = clk_div [1];
assign bclk = clk_div [3];
assign lrclk = clk_div [9];
always @ (posedge clk or posedge reset)
if (reset)
cnt <= 0;
else if (clk_div [9:0] == 10'b11_1111_1111)
cnt <= (cnt == cnt_max) ? 8'b0 : cnt + 8'b1;
assign sdata = shift [31];
always @ (posedge clk or posedge reset)
if (reset)
shift <= 0;
else
begin
if (clk_div [8:0] == 9'b1_1111_1111)
shift <= value << 16;
else if (clk_div [3:0] == 4'b1111)
shift <= shift << 1;
end
lut lut
(
.octave ( octave ),
.note ( note ),
.x ( cnt ),
.x_max ( cnt_max ),
.y ( value )
);
endmodule
```
Для усилителя вам нужны будут наушники, а если хотите генерировать стерео звуки, то вот такой кабель:
Monoprice 6inch 3.5mm Stereo Jack/Two 3.5mm Stereo Plug CableМожет вы сможете повторить сцену из мультфильма Контакт с помощью FPGA платы:
Кроме лаб со звуком, лаб с процессором schoolRISCV еще будут лабы с VGA играми. Они были очень популярны на школе в Зеленограде:
Для этих упражнений вам понадобится дополнительный монитор с VGA входом, чтобы воткнуть его в FPGA плату. Этих мониторов у нас дефицит, так как в Сколково будуь стоять только 25 моноблоков, которые нам организовал Евгений Певцов из МИРЭА. Если можете принести свой мониторчик, будет хорошо (если вы делаете упражнения удаленно, у вас наверняка есть старый монитор или вы можете одолжить).
Теперь зачем все это нужно. Упражнения с FPGA - это путь в проектирование на уровне регистровых передач. Он на уровне верилога и микроархитектуры более-менее общий и для FPGA и для ASIC - микросхем которые стоят в сматрфонах и других массовых устройствах. Причем работы в крутых компаниях есть и на FPGA, и для интернов. Это интересно и хорошо оплачивается. Причем и на [школе для начинающих](http://www.chipexpo.ru/shkola-sinteza-cifrovyh-shem-na-verilog), и на [школе для продолжающих (секции 2 и 3)](http://www.chipexpo.ru/programm) у нас будут задачки по мотивам реальных вопросов на собеседованиях :-)
 | https://habr.com/ru/post/576622/ | null | ru | null |
# A minute of Black Magic

В этой статье расскажем, как научиться отлаживать и полюбить маленькую черную плату Black Magic Probe V2.1. Но для начала немного о том, что это такое и зачем она нужна.
Плата Black Magic Probe Mini V2.1 (BMPM2) разработана 1BitSquared в сотрудничестве с Black Sphere Technologies, является адаптером JTAG и SWD, предназначена для программирования и отладки микроконтроллеров ARM Cortex-M и ARM Cortex-A. Можно добавить поддержку других процессоров. Описание процесса добавления можно найти по [ссылке](https://github.com/blacksphere/blackmagic/wiki/Adding-target-drivers). Стоит также отметить, что любой процессор с поддержкой ADIv5 (ARM Debug Interface v5) будет определяться платой.
На рисунках приведены процессоры семейств ARM Cortex-M и ARM Cortex-A, поддерживаемые платой Black Magic Probe Mini V2.1.


В процессе тестирования Black Magic Probe было выявлено, что поддерживаемые процессоры не ограничиваются списком, предоставленным производителем. Официально не поддерживаемые процессоры с ARM Debug Interface v5 определяются, например, как "Cortex-M0" или “Cortex-A7”. При этом, не гарантируется полная функциональность, но все же произвести минимальные действия по отладке получится.
Что можно делать с использованием платы Black Magic Probe:
* прерывать процесс исполнения программы;
* наблюдать за изменениями регистров и переменных;
* устанавливать точки останова (можно установить точку останова в коде, которая заставит программу остановиться, как только эта точка будет достигнута);
* просматривать стек вызовов (список функций и их параметров, которые привели нас к текущей точке и состоянию программы);
* дизассемблирование (возможность просмотреть машинный код и узнать, что именно делает программа);
* дамп памяти (сохранение ОЗУ и/или флэш-контента в файл).
Функции Black Magic Probe, которые могут быть полезны при исследовании информационной безопасности устройств:
* разработка встроенного программного обеспечения и устройств для проведения атак;
* реверс-инжиниринг IoT;
* поиск уязвимостей;
* динамический анализ с помощью IDA и других инструментов, совместимых с серверами gdb.
BMPM2 обладает двумя основными особенностями. Первая заключается в том, что на самом устройстве запускается gdbсервер, открывающий виртуальный порт, к которому можно напрямую подключиться через клиент gdb на своем хост-компьютере (рекомендуется набор инструментов [gcc-arm-embedded](https://launchpad.net/gcc-arm-embedded)), поэтому не нужно настраивать конфигурации [OpenOCD](http://openocd.org/) или [STLink](http://www.st.com/en/development-tools/st-link-v2.html). Сравнение схем подключения отладочного интерфейса при помощи OpenOCD/STLink и BMPM2 можно увидеть ниже. Как видно, вариант с подключением через BMPM2 проще.
Второй является возможность скомпилировать прошивку под другие платы, при этом необходимость в BMPM2 отпадает. Совместимые платы представлены [тут](https://github.com/blacksphere/blackmagic/wiki/Debugger-Hardware).
Для изучения возможностей работы были взяты четыре платы: TM32F103C8, STM32vldiscovery, STM32F429I-disc1 и предлагаемая разработчиками 1Bitsy V1.0.
Более подробно будет рассмотрена работа с 1Bitsy и STM32F429I-disc1. Первая была выбрана по рекомендации самих разработчиков, а у второй есть сенсорный экран, что делает процесс исследования более наглядным.
**Познаем мир отладки с Black Magic Probe**
Изучение работы Black Magic Probe V2.1 удобно начать с отладки 1Bitsy. Эта плата была создана специально для работы с BMPM2, поэтому не должно возникнуть никаких затруднений.
Соединим Black Magic Probe и 1Bitsy между собой кабелем JTAG и подключим их к компьютеру.
Ниже будет описана работа в среде GNU/Linux, руководство по работе в ОС Windows и MacOS легко найти по [ссылке](http://1bitsy.org/overview/quickstart/).
После подключения BMPM2 к ПК и к разъему JTAG, на 1Bitsy выполним три команды в gdb для начала отладки. Важно, чтобы пользователь был добавлен в группу dialout командой "sudo adduser $USER dialout", иначе ничего не заработает. Первой командой “target extended-remote /dev/ttyACMx” подключаемся к BMPM2, где x — номер серийного порта, далее сканируем все подключенные к Black Magic Probe устройства с помощью команды “monitor jtag\_scan”. Если все хорошо, то будет выведен список найденных устройств и командой “attach 1” мы подключимся к 1Bitsy.
```
(gdb) target extended-remote /dev/ttyACM0
Remote debugging using /dev/ttyACM0
(gdb) monitor jtag_scan
Target voltage: 3.3V
Available Targets:
No. Att Driver
1 STM32F4xx
(gdb) attach 1
Attaching to Remote target
warning: No executable has been specified and target does not support
determining executable automatically. Try using the "file" command.
0x0800026c in ?? ()
(gdb)
```
Все, теперь мы можем выполнить отладку прошивки, загруженной в 1Bitsy. С 1Bitsy, и правда, не возникло никаких проблем с подключением, все просто и достаточно удобно. Сохранится ли простота и удобство при работе с другой платой?
В наличии была плата на основе микроконтроллера STM32 — STM32F429I-disc1, ей и воспользуемся, заодно зальем на нее какую-нибудь интересную прошивку. Главным отличием в работе с этой платой от работы с 1Bitsy является соединение по интерфейсу SWD, а не JTAG.
Перед началом работы соединяем платы через JTAG/SWD [адаптер](https://1bitsquared.com/collections/embedded-hardware/products/jtag-swd-100mil-pitch-breakout) по следующей схеме:
на интерфейсе SWD (если считать с крайнего сверху выхода):
1. SWCLK
2. GND
3. SWDIO
4. 3V — tVref.

Для демонстрации работоспособности процесса отладки была использована [прошивка](https://github.com/miehigh/STM32F429I-Discovery_FW_V1.0.1/tree/master/Projects/Demonstration), содержащая несколько программных модулей. Один из них — игра Reversi, её будет отлаживать интереснее всего.
Заливаем прошивку на плату и в gdb вводим почти те же команды, что и для 1Bitsy, с той лишь разницей, что плата подключена по SWD, поэтому потребуется использовать команду swdp\_scan.
```
(gdb) target extended-remote /dev/ttyACM0
Remote debugging using /dev/ttyACM0
(gdb) monitor swdp_scan
Target voltage: 3.3V
Available Targets:
No. Att Driver
1 STM32F4xx
(gdb) attach 1
Attaching to Remote target
warning: No executable has been specified and target does not support
determining executable automatically. Try using the "file" command.
0x0800026c in ?? ()
(gdb)
```
К огромной печали, нам ни разу не удалось выиграть, поэтому захотелось что-нибудь в ней поломать. Для начала, мы посмотрели [исходники](https://github.com/miehigh/STM32F429I-Discovery_FW_V1.0.1/blob/master/Projects/Demonstration/Core/Demo/demo_game.c). В них была найдена переменная Board, предположительно, обозначающая адрес первой ячейки доски. Рядом есть строки "Reversi — Player 1" и "Reversi — Player 2".
```
static void _SetPlayer(int Player) {
int Score, ValidMoves, PossibleMoves;
char ac[256];
_Board.ActPlayer = Player;
if (Player == 1) {
FRAMEWIN_SetText(_hFrame, "Reversi - Player 1");
} else {
FRAMEWIN_SetText(_hFrame, "Reversi - Player 2");
}
FRAMEWIN_SetBarColor(_hFrame, 1, (Player == 1) ? GUI_RED : GUI_BLUE);
PossibleMoves = _CalcValidMoves(&_Board);
GUI_Exec();
if (!PossibleMoves) {
GUI_Exec();
_Board.ActPlayer = 3 - Player;
```
По этим строкам мы осуществили поиск в дизассемблере IDA. Выяснили, что из псевдокода можно узнать адрес, который является начальным адресом ячеек доски.
```
v1 = a1;
v2002CB74 = a1;
if ( a1 == 1 )
{
sub_D8B3C(v2002CB80, "Reversi - Player 1");
v2 = 255;
}
else
{
sub_D8B3C(v2002CB80, "Reversi - Player 2");
v2 = 16711680;
}
sub_E06A8(v2002CB80, 1, v2);
v3 = sub_DEDF8(0x2002CAF4);
result = ((int (*)(void))sub_C91B4)();
if ( v3 )
return result;
sub_C91B4(result);
v2002CB74 = 3 - v1;
v5 = sub_DEDF8(0x2002CAF4);
```
Далее, решили воспользоваться gdb для того, чтобы посмотреть, что находится по этому адресу.


Все верно. Если внимательно изучить данную таблицу и расположение фишек в начале игры, то можно заметить, что 001 означает красную фишку, а 002 — синюю. Можно попробовать изменить значение одной из ячеек. Для этого мы воспользовались командой:
`set *(char *) 0x2002CAF4 = 1`
Результат:


После этого мы решили попробовать значения всех ячеек приравнять единице, и тем самым выиграть игру с первого хода.
Результат выполнения скрипта:


Скрипт успешно отработал, нам удалось победить в игре, а это значит, что с помощью платы Black Magic Probe Mini V2.1 через gdb можно успешно отлаживать и "ломать" прошивки.
А теперь немного скучных примеров с моргающими лампочками.
**STM32F103C8**
Плату STM32F103C8 подсоединим к Black Magic Probe V2.1 через интерфейс JTAG.

Исходники для прошивки платы можно взять [тут](https://github.com/jollheef/stm32f103c8t6_hello).
В исходном коде можно попробовать изменять скорость моргания лампочки, уменьшая или увеличивая интервалы времени, когда она горит и когда гаснет.
**STM32vldiscovery**
Плату STM32vldiscovery подсоединим к Black Magic Probe V2.1 через интерфейс SWD, а именно:
1. 3V3 — tVref
2. PA13 — SWDIO
3. PA14 — SWCLK
4. GND — GND
Исходники для прошивки платы можно взять [тут](https://gitlab.com/sakura.ix86/stmf100rbt6_blink).
Здесь все аналогично предыдущей плате, также меняем интервалы времени в исходниках и смотрим на лампочку.
**Выводы**
Плата Black Magic Probe Mini V2.1 — простая в использовании и имеет набор инструментов и библиотек с открытым исходным кодом, это является ее основными плюсами.
Минусом платы является отсутствие поддержки архитектуры процессоров arm64 и процессоров Texas Instruments.
<http://1bitsy.org/overview/introduction/>
<https://1bitsquared.com/products/black-magic-probe>
<https://github.com/esden/1bitsy-bmpm-exercises/blob/master/embedded_programming_with_black_magic_and_lights_on-workshop_guide.pdf>
<https://github.com/blacksphere/blackmagic/wiki>
**Авторы**
* Евгений Рассказов [Jokiv](https://habrahabr.ru/users/jokiv/)
* Валерия Губарева [veneramuholovka](https://habrahabr.ru/users/veneramuholovka/) | https://habr.com/ru/post/339940/ | null | ru | null |
# ГИС: определение вложенности административных округов
Встала задача организовать административные центры в чёткую иерархию по принципу матрёшки, например, Украина — Крым — ЮБК — Ялта, и исправить имеющиеся ошибки в текущей базе данных.
В этой статье я расскажу, как я решил эту проблему с помощью KML-файлов обрамляющих границ и Postgres+Postgis.
Дело в том, что база, которой мы пользуемся для [нашего проекта](http://zero2hero.org/), не коммерческая (user generated, open source) и в ней есть ошибки. Например, самый частый случай — множесто городов приписаны к стране, но не относятся ни к одному из её регионов и областей, мы называем их *orphaned cities*.
Плюс к этому, бизнес у нас туристический, так что административно-политическое дробление стран не всегда подходит, иногда нет-нет да и приходится добавлять туристические регионы вручную. Например, такого административного региона как «Южный берег Крыма» нет, но есть такой туристический район, по которому туристы выбирают, куда ехать — ищут «дома на ЮБК», а не «дома в ялте, гаспре, гурзуфе и вообще где-то там».
Вопрос в том, как автоматически найти такому административному региону родителя (Крым) и задать всех входящих в него детей (города вроде Ялты и Судака).
К слову: у нас страна состоит из регионов, регионы состоят из областей, области из подобластей. Прямо как смерть Кощеева…
Для решения этой задачи было решено использовать данные с границами регионов, и по ним сопоставить родителей и детей.
#### Готовим данные
Базу данных границ регионов интересующей вас части мира вполне можно найти в интернете. Я использовал файлы для Google Earth — либо KML (XML c координатами), либо KMZ (KML в zip-архиве), их удобно смотреть прямо в Google Earth.
KMZ автоматически превратить в KML не получилось — ломаются Unicode-символы в названиях топонимов, так что я открыл KMZ-файлы в Google Earth и сохранил как KML. Конечно, «недостойно талантливому человеку тратить, подобно рабу, часы на вычисления, которые, безусловно, можно было бы доверить любому лицу, если бы при этом применить машину», но если бы файлов было больше, точно искал бы средство автоматизации.
Второй путь, если нужны кастомные области вроде ЮБК — отрисовать руками в Google Earth и сохранить в KML-файл.
В файлах данных, которые были у меня, были отличные регионы каждой области, но не было взаимосвязей между родителями и детьми. Например, отдельный файл «все регионы страны», а отдельно — «все области страны». В принципе, это и есть задача, которую нам надо решить, но для этого у нас теперь есть все данные.
#### Готовим платформу
Поначалу я хотел использовать MySQL, благо у них есть поддержка spatial-типов данных и операций над ними, но потом оказалось, что эти самые операции реализованы в сильно упрощённом виде и для реальных задач непригодны. Упрощённый вид означает, что MySQL работает только с MBR — прямоугольником, описывающим полигон. Получается, вместо красивых границ Крыма операции будут производиться с тупым прямоугольником вокруг него, а подсчёт реальной площади заменился бы просто площадью этого прямоугольника (что будет использоваться для решения данной задачи). Это делает MySQL непригодным для этой задачи.
Используем Postgres и устанавливаем на него библиотеку PostGis для работы с географическими типами данных.
#### Загружаем данные
Я подготовил несколько таблиц — `country`, `region`, `area`, `subarea`. Для каждой из них также были сделаны таблицы с суффиксом "`_boundary`", поскольку один и тот же регион может иметь больше чем одну границу (например, острова).
Сами данные можно загружать 2 способами:
1. будучи незнакомым с арсеналом PostGis, я написал свой обработчик KML — по сути, XML-ноды с координатами парсились и превращались в SQL-полигоны,
2. альтернатива ручной работе — встроенная в PostGis функция [`ST_GeomFromKML`](http://postgis.org/docs/ST_GeomFromKML.html)
#### Чистим данные
Полученные границы вышли слишком уж детализированными, с большим числом точек. Это означает более долгую обработку, а также больше данных для отправки клиенту в браузер через AJAX, если эти полигоны надо отрисовать на карте. Забегая вперёд, скажу, что таким образом размер данных удалось уменьшить в 10 раз, и ajax-запросы стали «летать».
Поэтому я решил упростить полигоны, благо для этого в PostGis есть функция `ST_Simplify` — ей на вход надо дать полигон и значение сглаживания.
Поигравшись с тестовыми данными, я выбрал параметр сглаживания равным 0.001.
Запрос получился такой:
```
UPDATE "subarea_boundary"
SET "path" = ST_Simplify("path", 0.001);
```
Сравните сами «до» и «после»:


#### Подбираем родителя
В PostGis есть разные функции для выяснения отношений между полигонами, но я пришёл к выводу, что лучше всего использовать следующую идею: *территория считается дочерней в том случае, если дочерняя территория входит в родительскую более, чем наполовину.*
В формульном виде это выглядит так: *[площадь пересечения] / [площадь дочерней территории] > 0.5*
В терминах функций PostGis это выглядит так:
```
ST_Area(ST_Intersection(region_path, area_path)) / ST_Area(area_path) > 0.5
```
Далее, я написал несколько похожих хранимых процедур для нахождения нужного родителя заданной территории.
Вот пример нахождения региона-родителя для области:
```
CREATE OR REPLACE FUNCTION "SuggestRegion" ("area_path" geometry) RETURNS integer AS
'DECLARE
admId integer := 0;
BEGIN
SELECT INTO admId "parent_id"
FROM "region_boundary"
WHERE ST_Area(ST_Intersection(region_path, area_path))/ST_Area(area_path) > 0.5
LIMIT 1;
RETURN admId;
END;'
LANGUAGE "plpgsql" COST 100
VOLATILE
RETURNS NULL ON NULL INPUT
SECURITY INVOKER
```
Чтобы получить ID региона, в который входит данная область, надо прогнать полигоны данной области через эту функцию:
```
SELECT "SuggestRegion" ("path") AS parent_id
FROM area_boundary
WHERE area_id = XXX
LIMIT 1;
```
Если полученное ID больше нуля, то можно сохранить полученный регион как регион-родитель данной области.
Для городов ещё проще, так как город задан только координатой центра — применяем функцию проверки полного вхождения `ST_Within`.
Надеюсь, данная статья окажется полезной для других любителей геодезии. | https://habr.com/ru/post/164997/ | null | ru | null |
# Неизменяемый JavaScript: как это делается с ES6 и выше
Здравствуйте, уважаемые читатели. Сегодня мы хотели бы предложить вам перевод статьи о неизменяемости в современном JavaScript. Подробнее о различных возможностях ES6 [рекомендуем](https://habrahabr.ru/company/piter/blog/309298/) почитать в вышедшей у нас замечательной книге Кайла Симпсона "[ES6 и не только](http://www.piter.com/collection/all/product/es6-i-ne-tolko)".
Писать неизменяемый код Javascript – правильно. Существует ряд потрясающих библиотек, например, [Immutable.js](https://facebook.github.io/immutable-js/), которые могли бы для этого пригодиться. Но можно ли сегодня обойтись без библиотек – писать на «ванильном» JavaScript нового поколения?
Если коротко — да. В ES6 и ES.Next есть ряд потрясающих возможностей, позволяющих добиться неизменяемого поведения без какой-либо возни. В этой статье я расскажу, как ими пользоваться – это интересно!
ES.Next – это следующ(ая/ие) верси(я/и) EcmaScript. [Новые релизы](http://www.2ality.com/2015/11/tc39-process.html) EcmaScript выходят ежегодно и содержат возможности, которыми можно пользоваться уже сегодня при помощи транспилятора, например, [Babel](http://babeljs.io).
### Проблема
Для начала определимся, почему неизменяемость так важна? Ну, если изменять данные, то может получиться сложночитаемый код, подверженный ошибкам. Если речь идет о примитивных значениях (например, числах и строках), писать «неизменяемый» код совсем просто – ведь сами эти значения изменяться не могут. Переменные, содержащие примитивные типы, всегда указывают на конкретное значение. Если передать его другой переменной, то другая переменная получит копию этого значения.
С объектами (и массивами) другая история: они передаются *по ссылке*. Это означает, что, если передать объект другой переменной, то обе они будут ссылаться на один и тот же объект. Если же вы впоследствии измените объект, принадлежащий любой из них, то изменения отразятся на обеих переменных. Пример:
```
const person = {
name: 'John',
age: 28
}
const newPerson = person
newPerson.age = 30
console.log(newPerson === person) // истина
console.log(person) // { name: 'John', age: 30 }
```
Видите, что происходит? Изменив `newObj`, мы автоматически поменяем и старую переменную `obj`. Все потому, что они ссылаются на один и тот же объект. В большинстве случаев такое поведение нежелательно, и писать код таким образом плохо. Посмотрим, как можно решить эту проблему.

### Обеспечиваем неизменяемость
А что если не передавать объект и не изменять его, а вместо этого создавать **совершенно новый** объект:
```
const person = {
name: 'John',
age: 28
}
const newPerson = Object.assign({}, person, {
age: 30
})
console.log(newPerson === person) // ложь
console.log(person) // { name: 'John', age: 28 }
console.log(newPerson) // { name: 'John', age: 30 }
```
`Object.assign` – это возможность ES6, позволяющая принимать объекты в качестве параметров. Она объединяет все передаваемые ей объекты с первым. Возможно, вы удивились: а почему первый параметр – это пустой объект `{}`? Если бы первым шел параметр `‘person’`, то мы по-прежнему изменяли бы `person`. Если бы у нас было написано `{ age: 30 }`, то мы бы опять перезаписали 30 значением 28, так как оно шло бы позже. Наше решение работает — person сохранилось без изменений, так как мы поступили с ним как с неизменяемым!
Хотите без лишних хлопот опробовать эти примеры? Открывайте [JSBin](http://jsbin.com/?js,console). В левой панели щелкните Javascript и замените его на ES6/Babel. Все, уже можете писать на ES6 :).
Однако, на самом деле в EcmaScript есть специальный синтаксис, еще сильнее упрощающий такие задачи. Он называется object spread, использовать его можно при помощи транспилятора Babel. Смотрите:
```
const person = {
name: 'John',
age: 28
}
const newPerson = {
...person,
age: 30
}
console.log(newPerson === person) // ложь
console.log(newPerson) // { name: 'John', age: 30 }
```
Тот же результат, только теперь Код еще чище. Сначала оператор `‘spread’ (...)` копирует все свойства из `person` в новый объект. Затем мы определяем новое свойство `‘age’`, которым перезаписываем старое. Соблюдайте порядок: если бы `age: 30` было определено выше `person`, то затем оно было бы перезаписано `age: 28`.
А если нужно убрать элемент? Нет, удалять мы его не будем, ведь при этом объект вновь бы изменился. Такой прием немного сложнее, и мы могли бы поступить, например, вот так:
```
const person = {
name: 'John',
password: '123',
age: 28
}
const newPerson = Object.keys(person).reduce((obj, key) => {
if (key !== property) {
return { ...obj, [key]: person[key] }
}
return obj
}, {})
```
Как видите, практически всю операцию приходится программировать самостоятельно. Эту функциональность можно было бы поставить во главу угла как универсальный инструмент. Но как изменение и неизменяемость применяются с массивами?
### Массивы
Небольшой пример: как добавить элемент в массив, изменяя его:
```
const characters = [ 'Obi-Wan', 'Vader' ]
const newCharacters = characters
newCharacters.push('Luke')
console.log(characters === newCharacters) // истина :-(
```
Та же проблема, что и с объектами. Нам решительно не удалось создать новый массив, мы просто изменили старый. К счастью, в ES6 есть оператор spread для массива! Вот как его использовать:
```
const characters = [ 'Obi-Wan', 'Vader' ]
const newCharacters = [ ...characters, 'Luke' ]
console.log(characters === newCharacters) // false
console.log(characters) // [ 'Obi-Wan', 'Vader' ]
console.log(newCharacters) // [ 'Obi-Wan', 'Vader', 'Luke' ]
```
Как же просто! Мы создали новый массив, в котором содержатся старые символы плюс ‘Luke’, а старый массив не тронули.
Рассмотрим, как делать с массивами другие операции, не изменяя исходного массива:
```
const characters = [ 'Obi-Wan', 'Vader', 'Luke' ]
// Удаляем Вейдера
const withoutVader = characters.filter(char => char !== 'Vader')
console.log(withoutVader) // [ 'Obi-Wan', 'Luke' ]
// Меняем Вейдера на Энекина
const backInTime = characters.map(char => char === 'Vader' ? 'Anakin' : char)
console.log(backInTime) // [ 'Obi-Wan', 'Anakin', 'Luke' ]
// Все символы в верхнем регистре
const shoutOut = characters.map(char => char.toUpperCase())
console.log(shoutOut) // [ 'OBI-WAN', 'VADER', 'LUKE' ]
// Объединяем два множества символов
const otherCharacters = [ 'Yoda', 'Finn' ]
const moreCharacters = [ ...characters, ...otherCharacters ]
console.log(moreCharacters) // [ 'Obi-Wan', 'Vader', 'Luke', 'Yoda', 'Finn' ]
```
Видите, какие приятные «функциональные» операторы? Действующий в ES6 синтаксис стрелочных функций их только красит. Каждый раз при запуске такой функции такая функция возвращает новый массив, одно исключение – древний метод сортировки:
```
const characters = [ 'Obi-Wan', 'Vader', 'Luke' ]
const sortedCharacters = characters.sort()
console.log(sortedCharacters === characters) // истина :-(
console.log(characters) // [ 'Luke', 'Obi-Wan', 'Vader' ]
```
Да, знаю. Я считаю, что `push` и `sort` должны действовать точно как `map`, `filter` и `concat`, возвращать новые массивы. Но они этого не делают, и если что-то поменять, то, вероятно, можно сломать Интернет. Если вам требуется сортировка, то, пожалуй, можно воспользоваться `slice`, чтобы все получилось:
```
const characters = [ 'Obi-Wan', 'Vader', 'Luke' ]
const sortedCharacters = characters.slice().sort()
console.log(sortedCharacters === characters) // false :-D
console.log(sortedCharacters) // [ 'Luke', 'Obi-Wan', 'Vader' ]
console.log(characters) // [ 'Obi-Wan', 'Vader', 'Luke' ]
```
Остается ощущение, что `slice()` – немного «хак», но он работает.
Как видите, неизменяемость легко достигается при помощи самого обычного современного JavaScript! В конце концов, важнее всего – здравый смысл и понимание, что именно делает ваш код. Если программировать неосторожно, JavaScript может быть непредсказуем.
### Замечание о производительности
Что насчет производительности? Ведь создавать новые объекты – напрасная трата времени и памяти? Да, действительно, возникают лишние издержки. Но этот недостаток с лихвой компенсируют приобретаемые преимущества.
Одна из наиболее сложных операций в JavaScript – это отслеживание изменений объекта. Решения вроде `Object.observe(object, callback)` довольно тяжеловесны. Однако, если держать состояние неизменяемым, то можно обойтись `oldObject === newObject` и таким образом проверять, не изменился ли объект. Такая операция не так сильно нагружает CPU.
Второе важное достоинство – улучшается качество кода. Когда нужно гарантировать неизменяемость состояния, приходится лучше продумывать структуру всего приложения. Вы программируете «функциональнее», весь код проще отслеживать, а гнусные баги в нем заводятся реже. Куда ни кинь – всюду вин, верно?
### Для справки
» [Таблица совместимости ES6:](http://kangax.github.io/compat-table/esnext/)
» [Таблица совместимости ES.Next:](http://kangax.github.io/compat-table/esnext/) | https://habr.com/ru/post/317248/ | null | ru | null |
# Yet another python Chat client
Приветствую, хабраюзер.
Уже была статья про чат-клиент на питоне [на хабре](http://habrahabr.ru/post/151623/). Данная статья и сподвигла написать свой велосипед в академических целях, но повторять чужой код не интересно, поставим задачу поинтереснее: Jabber(Асимитричное шифрование RSA)+PyQt.
Если интересно добро пожаловать под кат.
Конечно, не только это, а например и то, что чаты в соцсетях будут прослушиваться, и просто повысить свой скилл в написании программ на питоне.
Писался данный код под Debian, python 2.7, Qt 4.7, поэтому описывать буду для него, на других системах не проверялось.
### Приступим
Определимся с форматом сообщений.
1. Запрос ключа
#getkey «Если вы видите это сообщение, значит необходимо поставить утилиту ...»
2. Посылку ключа
#sendkey 234234234
3. Сообщение
#mesg 123123123
4. Пересылка последнего сообщения (не реализовано)
#getlastmesg
Я решил, что #<что-то> неплохой выбор для обозначения команд, к тому же все сообщения проходят шифрование и сообщение вида #<что либо> будет отправлено корректно. Думаю, что можно было обойтись и без этого, просто хотелось красивее.
#### Начнем с простого, а именно с жаббир части.
Писать свой движок для жаббер-клиента интересно, но сейчас движемся на результат, поэтому возьмем уже готовый модуль xmpppy. Установим его командой
**sudo easy\_install xmpppy.**
Можно, конечно, использовать сразу же данную библиотеку, но я думаю, лучше использовать нашу обертку, и вынести данный функционал в отдельный файл, который в будущем будет проще рефакторить, если возникнет такая надобность. Для работы данной библиотеки необходимо следующее: наш jid, наш пароль и колбек для пришедших сообещений.
**jabber.py**
```
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import xmpp,sys
#Данный фаил сожердит обертку для xmpp
class sjabber:
def __init__(self,xmpp_jid,xmpp_pwd):
self.xmpp_jid = xmpp_jid
self.xmpp_pwd = xmpp_pwd
self.jid = xmpp.protocol.JID(xmpp_jid)
self.client = xmpp.Client(self.jid.getDomain(),debug=[])
def connect(self):
con=self.client.connect()
if not con:
print 'could not connect!'
sys.exit()
print 'connected with',con
auth = self.client.auth(self.jid.getNode(),str(self.xmpp_pwd),resource='xmpppy')
if not auth:
print 'could not authenticate!'
sys.exit()
print 'authenticated using',auth
#Говорим серверу что мы онлайн!
self.client.sendInitPresence(1)
def Process(self):
a = self.client.Process(1)
def send(self,to,mess):
id = self.client.send(xmpp.protocol.Message(to,mess))
print 'sent message with id',id
def disconnect(self):
self.client.sendInitPresence(1)
self.client.disconnect()
def userList(self):
return self.client.getRoster().keys()
def StepOn(self):
try:
self.Process()
except:
return 0
return 1
def setCB(self, CB):
self.CB = CB
self.client.RegisterHandler('message',self.messageCB)
def messageCB(self,conn,mess):
if ( mess.getBody() == None ):
return
self.CB(self,mess)
```
Данный код при создании инициализирует объекты для подключения. По команде connect подключается к серверу. Также имеет обертку для отправки сообщений. И по сути является только декоратором для кода библиотеки. Наличие большого количества уже готовых библиотек, на мой взгляд, является большим плюсом для питона и позволяет писать код в достаточно сжатые сроки.
#### Прикручиваем шифрование.
В качестве алгоритма шифрования я решил взять RSA, просто потому что он мне нравится. К тому же он асимметричный, т.е. мы можем каждую сессию генерировать новые пары ключей и распространять только публичную часть. Таким образом, вместо сообщений третье лицо увидит только кучу HEX вместо сообщений.
Модуль шифрования я сделал отдельным по тем же самым причинам.
**rsa\_decor.py**
```
# -*- coding: utf-8 -*-
import rsa
class Crypt:
def __init__(self):
#Словарь в котором будут храниться известные нам ключи
self.keys = dict()
#Генерируем и сохраняем наши ключи
(a,b) = self.genKey(1024)
self.privateKey = b
self.pubKey = a
def hasKey(self,id):
#Проверяем на наличие ключа для контакта
if self.keys.has_key(id)==False:
return False
else:
return True
def decodeKey(self,key):
#Создаем публичный ключи и загружаем переданый по сети вариант
return rsa.PublicKey(1,1).load_pkcs1(key,format='DER')
def saveKey(self,id,key):
#Сохраняем ключ
self.keys[id]= key
def genKey(self,size):
#Обертка для рса
return rsa.newkeys(size, poolsize=8)
def cryptMesg(self,to,mesg):
#Шифруем сообщение
getHex =mesg.encode('utf-8').encode('hex')
a = rsa.encrypt(getHex, self.keys[to])
#print len(mesg),len(a)
return a.encode('hex')
def decryptMesg(self,mesg):
#Пытаемся расшифровать сообщение, иначе выдаем ошибку
try:
mess = rsa.decrypt(mesg.decode("hex"),self.privateKey)
except rsa.pkcs1.DecryptionError:
print "cant decrypt"
return "#errorDecrypt"
return mess.decode('hex').decode('utf-8')
```
Тут тоже все просто и логично. Декорируем нужные нам функции, а также храним все что связанно с ключами (а точнее наши приватные и публичные ключи, словарь с известными нам ключами).
#### Приступим к главному
Данная часть была написана достаточно быстро, и было решено ваять главный модуль, собственно ядро приложения, которое бы связывало части.
Изначально было решено писать интерфейс на TK. Но получалось плохо, и я вспомнил, что питон умеет неплохо общаться с Qt.
Поэтому доставляем в систему Qt Designer и сам PyQt, на момент написания была версия 4.7 (к сожалению инсталляцию всего этого под Win подсказать не могу, в линуксе все ставится пакетной системой вашего дистрибутива) установим
**sudo apt-get install pyqt4-dev-tools libqt4-core libqt4-dev libqt4-gui python-qt4 qt4-designer**
Этого набора пакетов должно хватить.
Поэтому начнем с рисования формы.
Запустим Qt Designer
Создадим форму main\_widget.
Организуем следующим образом, центральный виджет
— вертикальный слой.
В нем расположим 2 виджета: горизонтальный слой, в котором будет место для ввода сообщения и кнопка для отправки, сплитеер, в котором будет текстовый браузер для отображения сообщений и лист-виджет, в который мы положим список контактов.
В итоге должно получиться вот так.

Останавливаться на работе QtDesigner не будем, он хорошо описан в документации (у Qt на редкость хорошая документация)
[Готовый ui-файл.](https://raw.github.com/ice2heart/rsaChat/master/main_window.ui)
Однако этот файл не готов для использования нами, необходимо превратить его в питоновский код, для этого нам необходима утилита pyuic4.
Воспользуемся ей.
**pyuic4 main\_window.ui -o gui.py**
Теперь у нас есть файл с графикой, с шифрованием, с жаббером, осталось все вместе объединить.
Для его объединения напишем класс.
```
def __init__(self):
#Первым делом загрузим настройки
self.loadConfig()
#Создадим объект для шифрования
self.crypt = Crypt()
#Создадим и подключимся к жабберу
self.jb = sjabber(self.xmpp_jid,self.xmpp_pwd)
self.jb.connect()
#Зададим колбек для приходящих сообщений
self.jb.setCB(self.messageCB)
#Создадим Qt-обработчик событий для графики
self.app = QApplication(sys.argv)
self.window = QMainWindow()
self.ui = Ui_MainWindow()
self.ui.setupUi(self.window)
```
Тут остановимся подробнее, в Qt существует система сигналов и слотов, для её обработки требуется класс QApplication, а так как графика использует именно их, то добавим его. После чего создадим окно и сами графические элементы (их мы создали выше), после чего разместим их в нашем окне.
```
#Подключим сигналы нажатия на кнопку отправить и нажатие энтер
self.ui.pushButton.clicked.connect(self.sendMsg)
self.ui.lineEdit.returnPressed.connect(self.sendMsg)
self.window.show()
#А теперь заполним юзерлист
userList = self.jb.userList()
for i in userList:
self.ui.listWidget.addItem(i)
#Меняем пользователя для отправки сообщения
self.ui.listWidget.currentRowChanged.connect(self.setToRow)
#Выберем по умолчанию первого пользователя
self.ui.listWidget.setCurrentRow(0)
#Создадим рабочего который будет "дергать" обработчик жаббера
self.workThread = WorkThread()
self.workThread.setWorker(self.jb)
self.workThread.start()
```
Данная реализация жаббер-клиента требует постоянного “подергивания” для обработки входящих сообщений, который к тому же блокирует основной поток, поэтому создадим отдельный класс рабочего, который будет жить в отдельном потоке и обслуживать жаббер-клиент. Что характерно, данный класс очень похож на Си++ код для Qt для работы с потоками.
```
class WorkThread(QThread):
def __init__(self):
QThread.__init__(self)
def setWorker(self,jb):
self.jb = jb
def run(self):
while self.jb.StepOn(): pass
```
Собственно на этом наше приложение почти готово, за исключением колбека, обрабатывающего входящие сообщения (ну и немного другой мелочевки).
**def messageCB(self,conn,mess)**
```
def messageCB(self,conn,mess):
#Данный колбек проверяет регулярное выражение, после чего
#Либо работает с ключами, либо шифрует сообщения
if ( mess.getBody() == None ):
return
msg = mess.getBody()
patern = re.compile('^#(getkey|sendkey|mesg|getlastmesg) ?(.*)')
res = patern.search(msg)
if res:
#Проверка
a = res.groups()[0]
if a == "getkey":
self.sendKey(mess.getFrom())
if self.crypt.hasKey(mess.getFrom())!=False:
conn.send(mess.getFrom(),"#getkey")
elif a == "sendkey":
if res.groups()[1]!='':
a = self.crypt.decodeKey(res.groups()[1].decode("hex"))
self.crypt.saveKey(mess.getFrom().getStripped(),a)
elif a == "mesg":
decryptMess = self.crypt.decryptMesg(res.groups()[1])
if decryptMess=="#errorDecrypt":
self.sendKey(mess.getFrom())
self.print_("Error decrypt sendKey")
else:
self.print_(self.to+"--> "+decryptMess)
elif a == "getlastmesg*":
print a
```
В качестве обработчика Я не стал придумывать ничего нового, поэтому сообщение проверяется регулярным выражением, в случае совпадения с оным, осуществляется переход на реакцию, соответствующего типу сообщения.
Ещё один ужас — это отправка сообщений. Дело в том, что стандартный алгоритм RSA может шифровать строки определенной длины, зависящей от размера ключа, что для 1024 байт составляет примерно 52 символа в юникоде, поэтому процедура делит строку на кусочки, которые шифрует и посылает. На мой взгляд, это ужасный костыль, однако моё знание питона не позволило мне сделать красивее.
Весь код вы можете наблюдать на [гитхабе.](https://github.com/ice2heart/rsaChat)
Собственно результат

Приветствуется конструктивная критика кода. | https://habr.com/ru/post/165243/ | null | ru | null |
# Что именно происходит, когда пользователь набирает в адресной строке google.com? Часть 1
*Перевод первой части [материала с github](https://github.com/alex/what-happens-when), обстоятельно объясняющего работу интернета: что именно происходит, когда пользователь набирает в адресной строке google.com?*
#### Кнопка «ввод» возвращается в исходное положение
Для начала отсчёта выберем момент, когда кнопка «ввод» утоплена. В этот момент замыкается контур, отвечающий за эту кнопку. Небольшой ток проходит по логическим контурам клавиатуры. Они сканируют состояние всех переключателей, гасят паразитные электрические импульсы, и преобразовывают нажатие в код клавиши 13. Контроллер кодирует код для передачи в компьютер. Теперь это почти всегда делается через USB или Bluetooth, а раньше в процессе участвовали PS/2 или ADB.
#### Если это USB
USB в клавиатуре запитано с напряжением в 5В по первому штырьку контроллера хоста USB в компьютере. Код клавиши сохраняется в памяти клавиатуры в регистре «endpoint». Каждые 10 миллисекунд контроллер USB запрашивает данные из этого регистра. Так он получает сохранённые коды. Код передаётся в USB SIE (Serial Interface Engine) и преобразуется в один или несколько пакетов низкоуровневого USB-протокола. Пакеты отправляются посредством дифференциального электрического сигнала по штырькам D+ и D- с максимальной скоростью в 1.5 Мб/с, поскольку HID (Human Interface Device) считается низкоскоростным устройством.
Затем последовательный сигнал декодируется в контроллере и интерпретируется драйвером HID клавиатуры. Значение кода передаётся в слой абстракции железа операционной системы.
#### Если это виртуальная клавиатура (сенсорный экран)
Когда пользователь помещает палец на ёмкостном экране, между ним и пальцем проходит небольшой ток. Это замыкает контур в электростатическом поле проводящего слоя и создаёт падение напряжение в этой точке экрана. Контроллер экрана подымает прерывание, сообщая координаты нажатия.
Мобильная ОС передаёт сообщение в текущее приложение по поводу клика на одном из GUI-элементов (в данном случае это клавиши виртуальной клавиатуры). Клавиатура подымает прерывание для отправки сообщения о нажатии клавиши в ОС.
#### Возникновение прерывания (не на USB-клавиатуре)
Клавиатура отправляет запрос прерывания (IRQ), который контроллер прерываний сопоставляет с вектором прерываний. CPU использует таблицу описаний прерываний IDT, чтобы сопоставить вектора с функциями-обработчиками прерываний, которые предоставляет ядро. По приходу прерывания CPU запускает нужный обработчик. Так мы попадаем в ядро.
#### (Windows) В приложение отправляется сообщение WM\_KEYDOWN
HID передаёт событие нажатия в драйвер KBDHID.sys, который преобразовывает его в сканкод. В нашем случае он равен VK\_RETURN (0x0D). Этот драйвер общается с драйвером KBDCLASS.sys. Последний отвечает за обработку ввода клавиатуры безопасным способом. Он вызывает Win32K.sys (возможно, после передачи сообщения через разные фильтры клавиатуры). Это происходит в режиме ядра.
Win32K.sys узнаёт, какое окно активно, через API GetForegroundWindow(). Это API предоставляет хэндлер для строки ввода браузера. Затем система обработки сообщений Windows вызывает SendMessage(hWnd, WM\_KEYDOWN, VK\_RETURN, lParam). lParam – битовая маска, содержащая дополнительную информацию о нажатии – повторения, сканкод, нажаты ли дополнительные клавиши и др.
SendMessage API добавляет сообщение в очередь для заданного хэндлера окна (hWnd). Позже для обработки очереди вызывается функция обработки сообщений WindowProc.
Активное окно hWnd – окно редактирования, и в этом случае у WindowProc есть обработчик сообщений для WM\_KEYDOWN. Поскольку был передан код VK\_RETURN, он знает, что пользователь нажал Enter.
#### (OS X) В приложение передаётся KeyDown NSEvent
Сигнал прерывания вызывает событие в драйвере I/O Kit. Он преобразовывает сигнал в код клавиши и передаёт его в процесс WindowServer. Тот создаёт событие для активных приложений через их порт Mach. События помещаются в очереди этих приложений. Прочитываются они оттуда тредами, имеющими соответствующий уровень доступа при помощи функции mach\_ipc\_dispatch. Чаще всего это делается через главный цикл NSApplication при помощи NSEvent / NSEventType KeyDown.
#### (GNU/Linux) Сервер Xorg отслеживает коды
При использовании графического сервера X для получения кода будет задействован драйвер evdev. По имеющимся правилам код клавиши будет преобразован в сканкод. После этого символ передаётся в менеджер окон (DWM, metacity, i3, и т.д.), который в свою очередь передаёт символ окну, находящемуся в фокусе. Графический API окна получает символ и выводит соответствующий символ в том окне, в котором находится фокус.
#### Разбор URL
Теперь у браузера есть следующая информация из URL (Uniform Resource Locator):
> Протокол «http» — используем 'Hyper Text Transfer Protocol'
>
> Ресурс "/" – запросить главную страницу
#### Это URL или поисковый запрос?
Если не задан протокол и строка не является допустимым доменным именем, браузер передаёт этот текст поисковой системе по умолчанию.
#### Проверка списка HSTS
Браузер проверяет список HSTS (HTTP Strict Transport Security). Это список сайтов, к которым нужно обращаться только по HTTPS. Если сайт в списке, то браузер отправляет запрос через HTTPS. Иначе – через HTTP.
Преобразуем символы в имени сервера, которые не относятся к таблице ASCII.
Браузер проверяет, есть ли символы не из диапазонов a-z, A-Z, 0-9, -,.
Поскольку у нас google.com, таких символов не будет. Иначе к имени сервера будет применено кодирование по системе Punycode.
#### Запрос DNS
Браузер проверяет, есть ли домен в КЭШе. Если нет, вызывается библиотечная функция gethostbyname (в зависимости от ОС). Она проверяет, можно ли узнать адрес сервера по имени на основании информации из локального файла hosts. Если это не помогает, происходит запрос к DNS-серверу, который указан в настройках сети. Это либо локальный роутер, либо DNS-сервер провайдера. Если DNS-сервер в той же подсети, библиотека работает по протоколу ARP с сервером. Иначе запрос отправляется на IP-адрес стандартного шлюза.
#### Протокол ARP (Address Resolution Protocol)
Для отправки широковещательного запроса ARP, сетевому стеку нужно узнать IP-адрес получателя и MAC-адрес интерфейса, который будет для этого использован.
Сначала проверяется кэш ARP на предмет наличия IP получателя. Если он есть в кэше, возвращается результат «IP получателя = MAC».
Если её нет в кэше, то таблица роутинга просматривается на предмет наличия ip-адреса в какой-либо из локальных подсетей. Если он там есть, используется интерфейс, присвоенный этой подсети. Если нет, библиотека использует интерфейс подсети основного шлюза. Затем ищется MAC-адрес выбранного интерфейса и отправляется Layer 2 ARP запрос:
```
Sender MAC: interface:mac:address:here
Sender IP: interface.ip.goes.here
Target MAC: FF:FF:FF:FF:FF:FF (Broadcast)
Target IP: target.ip.goes.here
```
Если компьютер подключён к роутеру напрямую, роутер даёт ответ ARP Reply. Если подключение идёт через хаб, тот передаёт запрос по всем портам. Если там будет роутер, он даст ответ. Если подключение через свитч, тот определит по своей таблице CAM/MAC, у какого порта есть нужный MAC-адрес. Если не найдёт, то распространит запрос по всем портам. А если найдёт, то отправит запрос по тому порту, где есть нужный MAC.
Ответ ARP Reply:
```
Sender MAC: target:mac:address:here
Sender IP: target.ip.goes.here
Target MAC: interface:mac:address:here
Target IP: interface.ip.goes.here
```
Теперь у библиотеки есть ip-адрес либо DNS-сервера, либо основного шлюза. Можно продолжить процесс распознавания домена. Открывается 53 порт и на сервер отправляется UDP-запрос (в случае больших запросов используется TCP). Если информации у DNS-сервера не оказывается, то запрашивается рекурсивный поиск, который проходит по списку DNS-серверов, пока не доходит до SOA и не находится нужный ответ.
#### Открытие сокета
Когда браузер получает ip-адрес сервера назначения, он вместе с портом (для HTTP порт по умолчанию – 80, для HTTPS – 443) использует их как параметры вызова функции socket и запрашивает поток TCP socket stream — AF\_INET и SOCK\_STREAM.
Сначала этот запрос передаётся в транспортный слой, где создаётся сегмент TCP. Порт назначения добавляется в заголовок, а порт источника выбирается динамически из списка портов ядра (в Linux это ip\_local\_port\_range).
Сегмент отправляется в сетевой слой, где ему добавляют ip-заголовок, в котором содержится ip-адрес сервера назначения и ip-адрес нашего компьютера. Затем пакет попадает в Link Layer. К нему добавляется заголовок фрейма, в котором содержится MAC-адрес компьютера и шлюза (локального роутера). Если ядру неизвестен MAC-адрес шлюза, для его выяснения отправляется ARP-броадкаст. И теперь наш пакет готов к отправке через Ethernet, WiFi или мобильную связь.
В большинстве случаев пакет из компьютера проходит по локальной сети, затем попадает в модем (модулятор/демодулятор), где превращается из цифрового в аналоговый сигнал. Такой сигнал можно передавать по телефону, кабелю или беспроводному соединению. Модем принимающей стороны преобразовывает его обратно в цифровую форму, откуда он поступает на следующий узел сети, где адреса отправителя и получателя подвергаются дальнейшему разбору.
Иногда пакет отправляется сразу через Ethernet или оптику, тогда он остаётся цифровым и доходит до следующего узла сети. В конце концов сигнал доходит до роутера локальной подсети. Оттуда он идёт через пограничные роутеры AS, другие AS, и доходит до сервера назначения. Каждый роутер по пути извлекает ip-адрес назначения и передаёт пакет следующему хопу. При этом TTL в пакете уменьшается на единичку. Пакет отбрасывается, если оно достигает нуля, или если у текущего роутера закончилось место в очереди. Отправка и получение пакетов происходят многократно в рамках соединения по TCP.
Сначала клиент выбирает изначальный номер последовательности (ISN) и отправляет пакет на сервер, установив бит SYN так, чтобы было ясно, что это ISN.
Если сервер получает SYN и находится в благоприятном расположении духа, тогда он выбирает свой ISN, устанавливает SYN для индикации того, что в пакете содержится ISN, копирует в поле ACK клиентский ISN+1 и добавляет флаг ACK, чтобы подтвердить получение первого пакета.
Клиент подтверждает соединение, отправляя пакет, где увеличивается свой ISN, увеличивается ISN отправителя и установлено поле ACK.
Данные передаются так: когда одна сторона отправляет N байт, она увеличивает SEQ на это число. Когда другая сторона подтверждает получение пакета (или их цепочки), она отправляет пакет ACK, где значение ACK равняется последней полученной от другой стороны последовательности.
Для закрытия соединения закрывающая сторона отправляет пакет FIN, другая сторона подтверждает получение пакета и отправляет свой FIN, а первая подтверждает его получение. | https://habr.com/ru/post/251373/ | null | ru | null |
# Связка rvm + Rails + Nginx + Unicorn или деплоим рельсы правильно
Целью данной заметки я ставлю в подробностях описать организацию сервера для Rails приложений в самой популярной на данный момент связке: rvm + Rails + Nginx + Unicorn. К написанию статьи побудило отсутствие полной пошаговой документации по этой связке, понятной не только ядреным профессионалам этой области. Далее я попытаюсь подробно, шаг за шагом, описать идеологически правильный процесс организации сервера для обслуживания нескольких Rails приложений (на примере одного) — если у вас есть **абсолютная** уверенность в том, что на подопытной машине **никогда** не будет работать более одного приложения — настройка может быть существенно короче и проще. Хочу предупредить, что тонкости, касающиеся работы приложения под высокой нагрузкой в статье не описываются, т.к. цель ставилась иная — заставить работать приложение в связке и сократить количество конфликтов с другими приложениями до минимума.
##### SSH ключ
Прежде, чем использовать инструменты, перечисленные в заголовке, необходимо подготовить сервер на котором мы собираемся все организовать. Предположим, вы только что установили свежую Ubuntu 10.04 LTS на сервер (+ завели в процессе первого пользователя), и подняли там OpenSSH daemon. Все! Отныне сервер не должен быть прикасаем для рук, ног и других конечностей — работать с ним мы будем только удаленно, а для этого на своей рабочей машине следует выполнить:
```
ssh-copy-id [email protected]
```
где vasya — это имя пользователя на сервере, от имени и прав которого будет осуществляться деплой, а rails-production.example.com — это адрес или имя только что поднятого вами сервера. После ввода будет необходимо согласиться с добавлением хоста в список known hosts у вас на машине — ничего страшного — это нормально. И ввести Васин пароль. Это будет последним разом, когда вы будете вводить пароль Василия. Теперь доступ к серверу возможен по ssh ключу и ничего вводить не надо.
Казалось бы, это основы о которых и упоминать-то не стоит — но всегда есть определенный процент людей, имеющий альтернативную точку зрения на доступ к машине по ssh ключам. Для них я могу посоветовать мазь от артрита суставов кисти, остальным же предлагаю просто поверить, что ssh ключи — это благо.
##### База данных
Здесь я лишь дам подсказки по установке нужных пакетов для двух самых популярных СУБД:
```
sudo apt-get install mysql-server mysql-client libmysqld-dev # MySQL
sudo apt-get install postgresql postgresql-client postgresql-server-dev #Postgresql
```
Настройка СУБД на сервере — это тема отдельной статьи, поэтому предположим, что с этим вы можете справиться самостоятельно. Поэтому — тадааам! СУБД запущена и работает.
##### Rvm
[Rvm](https://rvm.io/) — это средство управления версиями Ruby в системе, позволяющее создавать отдельные «окружения» из гемов, что в нашем случае не важно. Если рассмотреть концепции [bundler](http://gembundler.com/) и гемсетов Rvm, то может возникнуть чувство, что они созданы для одной и той же цели — изолировать окружение для работы конкретного приложения. Bundler — это замечательное средство разрешения зависимостей гемов, к тому же Rails 3 по умолчанию работает именно с ним. И вообще раз уж об этом зашла речь — я рекомендую использовать bundler для Rails 2.3.x, как это можно сделать описано [здесь](http://gembundler.com/rails23.html).
Rvm нам нужен только для того, чтобы без труда переключаться между разными версиями Ruby, и такая необходимость скорее всего возникнет на сервере, где одновременно будут крутиться приложения, написанные на разных версиях Ruby on Rails. У Rvm есть и свои противники. Нет и на самом деле — если вы **абсолютно точно** уверены, что на этой железке **никогда** не будет работать больше одной версии ruby, то будет правильнее установить какой-нибудь ree как системный интерпретатор ruby и гореть в аду потихонечкурадоваться жизни. Но реальность сурова, поэтому я просто рекомендую использовать rvm — это позволит держать все вещи в порядке.
Если вы уже ознакомились с документацией, то наверное заметили, что существует два способа установки Rvm — от root (так называемая system wide install) и обычная — для простого пользователя. Так вот, опять я хочу испытать вашу веру — не устанавливайте от root. Не зря же мы создавали пользователя, ответственного за деплой. Поэтому зайдя на сервер под нашим Василием выполняем следующую последовательность команд:
```
sudo apt-get install git-core curl #Это для того, чтобы заработала установка Rvm.
curl -L https://get.rvm.io | bash -s stable --ruby
type rvm | head -1
```
Последняя команда должна выдать «rvm is a function» или аналог на русском языке. Если этого не произошло — стоит начать изучение [отсюда](https://rvm.io/rvm/install/) и до момента — «пока оно не заработает».
##### Ruby
Выбор версии руби зависит от того, какая версия рельс используется в приложении: так для 2.3.x предпочтительнее использовать [Ruby Enterprise Edition](http://www.rubyenterpriseedition.com/), для 3.x рекомендуют использовать 1.9.3. В моем случае — это приложение на 2.3.x и ree соответственно. И если для установки ruby 1.9.3 ничего экстраординарного от системы не требуется, то для установки ree необходимо несколько системных пакетов:
```
sudo apt-get install build-essential bison openssl libreadline6 libreadline6-dev curl git-core zlib1g zlib1g-dev libssl-dev libyaml-dev libsqlite3-0 libsqlite3-dev sqlite3 libxml2-dev libxslt-dev autoconf libc6-dev ncurses-dev
rvm install ree-1.8.7-2011.03 # Устанавливаем ree
rvm ree # Указываем, какой интерпретатор Ruby использовать. Если вам так больше нравится - создайте себе гемсет вот так: rvm ree@myapp --create. Но с Bundler он становится попросту ненужным.
gem install bundler # Единственный gem, который мы поставим руками.
sudo mkdir -p /srv/myapp # Создаем директорию, в которой будет находиться наше приложение.
sudo chown -R vasya:vasya /srv/myapp # Передаем права на владение Василию (так как директория пуста, параметр -R можно пропустить).
```
##### Nginx
Раз уж мы будем использовать Unicorn, то без Nginx нам никак не обойтись — есть у Unicorn такая особенность — не может он работать с медленными клиентами. Есть, правда, его аналог, который может — Rainbows, но Nginx сам по себе исключительно полезен, хорош и прост в эксплуатации. Инструкции по установке вы можете найти на [сайте](http://sysoev.ru/nginx/) автора этого замечательного сервера — Игоря Сысоева. Я лишь приведу здесь простой init скрипт для запуска nginx и nginx.conf:
```
#! /bin/sh
EXEC_PATH="/usr/local/nginx/sbin/nginx"
case "$1" in
start)
echo "Starting NginX"
start-stop-daemon --start --exec $EXEC_PATH
;;
stop)
echo "Stopping NginX"
start-stop-daemon --stop --exec $EXEC_PATH
;;
restart)
echo "Stopping NginX"
start-stop-daemon --stop --exec $EXEC_PATH
sleep 1
echo "Starting NginX"
start-stop-daemon --start --exec $EXEC_PATH
;;
*)
echo "Usage: {start|stop|restart}"
exit 1
;;
esac
exit 0
```
```
worker_processes 1; # Более одного рабочего процесса обычно не требуется.
user vasya vasya; # Пользователь с правами которого запускается worker - он же пользователь, от которого осуществляется деплой.
pid /tmp/nginx.pid; # Задаем местоположение файла с идентификатором текущего мастер-процесса Nginx.
error_log /tmp/nginx.error.log;
events {
worker_connections 1024; # Стандартный показатель количества одновременно открытых соединений рабочего процесса.
accept_mutex off; # Ну и раз уж воркер у нас один - отключаем.
}
http {
# Дальше немного стандартных директив - если нет особого желания менять здесь что-то - не меняйте:
include mime.types;
default_type application/octet-stream;
access_log /tmp/nginx.access.log combined;
sendfile on;
tcp_nopush on;
tcp_nodelay off;
gzip on;
# Теперь самая сладкая часть. Далее происходит указание upstream сервера. Так как все происходит в рамках одной машины, слушать апстрим лучше через сокет.
upstream myapp_server {
server unix:/srv/myapp/shared/unicorn.sock fail_timeout=0; # Местоположение сокета должно совпадать с настройками файла config/unicorn.rb от корня вашего приложения.
}
server {
listen 80 default deferred; # Опять же, если на одном и том же ip находится несколько серверов, то эта строка будет выглядеть как-то так myapp.mydomain.ru:80
client_max_body_size 1G; # Максимальный размер тела запроса (а простым языком - ограничение на размер заливаемого на сервер файла).
server_name myapp.mydomain.ru; # Имя сервера
keepalive_timeout 5;
root /srv/myapp/current/public; # Эта строка всегда должна указывать в директорию public Rails приложения. А current там потому что деплой происходит через Capistrano
try_files $uri/index.html $uri.html $uri @myapp; # Имя переменной не важно - главное, чтобы в блоке location ниже было аналогичное
location @myapp {
proxy_pass http://myapp_server; # Часть после http:// должна полностью соответствовать имени в блоке upstream выше.
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $http_host;
proxy_redirect off;
}
error_page 500 502 503 504 /500.html;
location = /500.html {
root /srv/myapp/current/public;
}
}
}
```
Стоит сразу предупредить, что когда Nginx одновременно обслуживает несколько приложений то блоки `server { ... }` стоит выносить в отдельные файлы в директории `/usr/local/nginx/conf/vhosts` а в nginx.conf писать `include /usr/local/nginx/conf/vhosts/*` — в примере этого не сделано для наглядности.
##### Unicorn
Unicorn можно установить для всей системы, но делать этого не следует — гораздо правильнее включить в Gemfile соответствующий гем:
```
gem 'unicorn'
```
и запускать Unicorn командой `bundle exec`. Кстати, рекомендация распространяется не только Unicorn, но и на любые исполняемые файлы, идущие вместе с гемами. Установка Unicorn в рамках конкретного приложения позволит вам без проблем завести сколько угодно приложений на одной машине.
Далее я приведу пример конфигурации сервера, которая обеспечивает так называемый zero downtime deploy. Итак, config/unicorn.rb:
```
deploy_to = "/srv/myapp"
rails_root = "#{deploy_to}/current"
pid_file = "#{deploy_to}/shared/pids/unicorn.pid"
socket_file= "#{deploy_to}/shared/unicorn.sock"
log_file = "#{rails_root}/log/unicorn.log"
err_log = "#{rails_root}/log/unicorn_error.log"
old_pid = pid_file + '.oldbin'
timeout 30
worker_processes 4 # Здесь тоже в зависимости от нагрузки, погодных условий и текущей фазы луны
listen socket_file, :backlog => 1024
pid pid_file
stderr_path err_log
stdout_path log_file
preload_app true # Мастер процесс загружает приложение, перед тем, как плодить рабочие процессы.
GC.copy_on_write_friendly = true if GC.respond_to?(:copy_on_write_friendly=) # Решительно не уверен, что значит эта строка, но я решил ее оставить.
before_exec do |server|
ENV["BUNDLE_GEMFILE"] = "#{rails_root}/Gemfile"
end
before_fork do |server, worker|
# Перед тем, как создать первый рабочий процесс, мастер отсоединяется от базы.
defined?(ActiveRecord::Base) and
ActiveRecord::Base.connection.disconnect!
# Ниже идет магия, связанная с 0 downtime deploy.
if File.exists?(old_pid) && server.pid != old_pid
begin
Process.kill("QUIT", File.read(old_pid).to_i)
rescue Errno::ENOENT, Errno::ESRCH
# someone else did our job for us
end
end
end
after_fork do |server, worker|
# После того как рабочий процесс создан, он устанавливает соединение с базой.
defined?(ActiveRecord::Base) and
ActiveRecord::Base.establish_connection
end
```
##### Capistrano
Ну вот мы уже настроили все, что только можно базовые вещи, поэтому следует разобраться с Capistrano. Для начала стоит поместить гем capistrano в группу :development нашего Gemfile, а также поместить туда же rvm-capistrano для интеграции с rvm (для версий rvm >= 1.1.0):
```
group :development do
gem "capistrano"
gem "rvm-capistrano"
end
```
После установки гема выполняем команду:
```
bundle exec capify .
```
и получаем почти пустой файл config/deploy.rb. Я же приведу пример файла под наши нужды:
```
require 'rvm/capistrano' # Для работы rvm
require 'bundler/capistrano' # Для работы bundler. При изменении гемов bundler автоматически обновит все гемы на сервере, чтобы они в точности соответствовали гемам разработчика.
set :application, "myapp"
set :rails_env, "production"
set :domain, "[email protected]" # Это необходимо для деплоя через ssh. Именно ради этого я настоятельно советовал сразу же залить на сервер свой ключ, чтобы не вводить паролей.
set :deploy_to, "/srv/#{application}"
set :use_sudo, false
set :unicorn_conf, "#{deploy_to}/current/config/unicorn.rb"
set :unicorn_pid, "#{deploy_to}/shared/pids/unicorn.pid"
set :rvm_ruby_string, 'ree' # Это указание на то, какой Ruby интерпретатор мы будем использовать.
set :scm, :git # Используем git. Можно, конечно, использовать что-нибудь другое - svn, например, но общая рекомендация для всех кто не использует git - используйте git.
set :repository, "[email protected]:myprojects/myapp.git" # Путь до вашего репозитария. Кстати, забор кода с него происходит уже не от вас, а от сервера, поэтому стоит создать пару rsa ключей на сервере и добавить их в deployment keys в настройках репозитария.
set :branch, "master" # Ветка из которой будем тянуть код для деплоя.
set :deploy_via, :remote_cache # Указание на то, что стоит хранить кеш репозитария локально и с каждым деплоем лишь подтягивать произведенные изменения. Очень актуально для больших и тяжелых репозитариев.
role :web, domain
role :app, domain
role :db, domain, :primary => true
before 'deploy:setup', 'rvm:install_rvm', 'rvm:install_ruby' # интеграция rvm с capistrano настолько хороша, что при выполнении cap deploy:setup установит себя и указанный в rvm_ruby_string руби.
after 'deploy:update_code', :roles => :app do
# Здесь для примера вставлен только один конфиг с приватными данными - database.yml. Обычно для таких вещей создают папку /srv/myapp/shared/config и кладут файлы туда. При каждом деплое создаются ссылки на них в нужные места приложения.
run "rm -f #{current_release}/config/database.yml"
run "ln -s #{deploy_to}/shared/config/database.yml #{current_release}/config/database.yml"
end
# Далее идут правила для перезапуска unicorn. Их стоит просто принять на веру - они работают.
# В случае с Rails 3 приложениями стоит заменять bundle exec unicorn_rails на bundle exec unicorn
namespace :deploy do
task :restart do
run "if [ -f #{unicorn_pid} ] && [ -e /proc/$(cat #{unicorn_pid}) ]; then kill -USR2 `cat #{unicorn_pid}`; else cd #{deploy_to}/current && bundle exec unicorn_rails -c #{unicorn_conf} -E #{rails_env} -D; fi"
end
task :start do
run "bundle exec unicorn_rails -c #{unicorn_conf} -E #{rails_env} -D"
end
task :stop do
run "if [ -f #{unicorn_pid} ] && [ -e /proc/$(cat #{unicorn_pid}) ]; then kill -QUIT `cat #{unicorn_pid}`; fi"
end
end
```
P.S. Если у кого-то возникнут предложения по улучшению изложенного материала или конструктивные замечания буду рад прочесть и исправить. | https://habr.com/ru/post/120368/ | null | ru | null |
# Книга «Эффективный Spark. Масштабирование и оптимизация»
[](https://habr.com/company/piter/blog/414525/)В этом посте мы рассмотрим доступ к API Spark из различных языков программирования в JVM, а также некоторые вопросы производительности при выходе за пределы языка Scala. Даже если вы работаете вне JVM, данный раздел может оказаться полезен, поскольку не-JVM-языки часто зависят от API Java, а не от API Scala.
Работа на других языках программирования далеко не всегда означает необходимость выхода за пределы JVM, и работа в JVM имеет немало преимуществ с точки зрения производительности — в основном вследствие того, что не требуется копировать данные. Хотя для обращения к Spark не из языка Scala не обязательно нужны специальные библиотеки привязки или адаптеры, вызвать код на языке Scala из других языков программирования может быть непросто. Фреймворк Spark поддерживает использование в преобразованиях лямбда-выражений языка Java 8, а у тех, кто применяет более старые версии JDK, есть возможность реализовать соответствующий интерфейс из пакета org.apache.spark.api.java.function. Даже в случаях, когда не требуется копировать данные, у работы на другом языке программирования могут быть небольшие, но важные нюансы, связанные с производительностью.
Особенно ярко сложности с обращением к различным API Scala проявляют себя при вызове функций с тегами классов или при использовании свойств, предоставляемых с помощью неявных преобразований типов (например, всей относящейся к классам Double и Tuple функциональности наборов RDD). Для механизмов, зависящих от неявных преобразований типов, часто предоставляются эквивалентные конкретные классы наряду с явными преобразованиями к ним. Функциям, зависящим от тегов классов, можно передавать фиктивные теги классов (скажем, AnyRef), причем зачастую адаптеры делают это автоматически. Применение конкретных классов вместо неявного преобразования типов обычно не приводит к дополнительным накладным расходам, но фиктивные теги классов могут накладывать ограничения на некоторые оптимизации компилятора.
API Java не слишком отличается от API Scala в смысле свойств, лишь изредка отсутствуют некоторые функциональные возможности или API разработчика. Поддержка других языков программирования JVM, например языка Clojure с DSL [Flambo](https://github.com/yieldbot/flambo) и библиотеки [sparkling](https://github.com/gorillalabs/sparkling), осуществляется с помощью различных API Java вместо непосредственного вызова API Scala. Поскольку большинство привязок языков, даже таких не-JVM-языков, как Python и R, идет через API [Java](http://spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.api.java.package), то полезно будет разобраться с ним.
API Java очень напоминают API Scala, хотя и не зависят от тегов классов и неявных преобразований. Отсутствие последних означает, что вместо автоматического преобразования наборов RDD объектов Tuple или double в специальные классы с дополнительными функциями приходится использовать функции явного преобразования типа (например, mapToDouble или mapToPair). Указанные функции определены только для наборов RDD языка Java; к счастью для совместимости, эти специальные типы представляют собой просто адаптеры для наборов RDD языка Scala. Кроме того, эти специальные функции возвращают различные типы данных, такие как JavaDoubleRDD и JavaPairRDD, с возможностями, предоставляемыми неявными преобразованиями языка Scala.
Вновь обратимся к каноническому образцу подсчета слов, воспользовавшись API Java (пример 7.1). Поскольку вызов API Scala из Java может иногда оказаться непростым делом, то API Java фреймворка Spark почти все реализованы на языке Scala со спрятанными тегами классов и неявными преобразованиями. Благодаря этому адаптеры Java представляют собой очень тонкий слой, в среднем состоящий лишь из нескольких строк кода, и их переписывание практически не требует усилий.
Пример 7.1. Подсчет слов (Java)
```
import scala.Tuple2;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaPairRDD
import org.apache.spark.api.java.JavaSparkContext;
import java.util.regex.Pattern;
import java.util.Arrays;
public final class WordCount {
private static final Pattern pattern = Pattern.compile(" ");
public static void main(String[] args) throws Exception {
JavaSparkContext jsc = new JavaSparkContext();
JavaRDD lines = jsc.textFile(args[0]);
JavaRDD words = lines.flatMap(e -> Arrays.asList(
pattern.split(e)).iterator());
JavaPairRDD wordsIntial = words.mapToPair(
e -> new Tuple2(e, 1));
}
}
```
Иногда может понадобиться преобразовать наборы RDD Java в наборы RDD Scala или наоборот. Чаще всего это бывает нужно для библиотек, требующих на входе или возвращающих наборы RDD Scala, но иногда базовые свойства Spark могут еще не быть доступны в API Java. Преобразование набора RDD Java в набор RDD Scala — простейший способ использовать эти новые свойства.
При необходимости передать набор RDD Java в библиотеку Scala, ожидающую на входе обычный RDD Spark, получить доступ к находящемуся в его основе RDD Scala можно с помощью метода rdd(). Чаще всего этого оказывается достаточно для передачи итогового RDD в любую нужную библиотеку Scala; в числе заслуживающих упоминания исключений — библиотеки Scala, полагающиеся в своей работе на неявные преобразования типов содержимого наборов или информацию тегов классов. В таком случае простейшим способом обращения к неявным преобразованиям будет написание небольшого адаптера на Scala. Если Scala-оболочки использовать нельзя, то можно вызвать соответствующую функцию класса [JavaConverters](http://www.scala-lang.org/api/2.12.0/scala/collection/JavaConverters%24.html) и сформировать фиктивный тег класса.
Для создания фиктивного тега класса можно использовать метод scala.reflect.ClassTag$.MODULE$.AnyRef() или получить настоящий с помощью scala.reflect.ClassTag$.MODULE$.apply(CLASS), как показано в примерах 7.2 и 7.3.
Для преобразования из RDD Scala в RDD Java информация о теге класса часто важнее, чем для большинства библиотек Spark. Причина в том, что, хотя различные классы JavaRDD предоставляют общедоступные конструкторы, принимающие RDD Scala в качестве аргументов, они предназначены для вызова из кода на языке Scala, а потому требуют информации о теге класса.
Фиктивные теги классов чаще всего используются в обобщенном или шаблонизированном коде, где точные типы неизвестны в момент компиляции. Таких тегов часто бывает достаточно, хотя существует возможность потери некоторых нюансов на стороне Scala-кода; в очень редких случаях для кода на языке Scala необходима точная информация о теге класса. В этом случае придется использовать настоящий тег. В большинстве случаев это требует не намного больших усилий и улучшает производительность, так что старайтесь использовать такие теги везде, где только возможно.
Пример 7.2. Обеспечение совместимости RDD Java/Scala с помощью фиктивного тега класса
```
public static JavaPairRDD wrapPairRDDFakeCt(
RDD> RDD) {
// Формируем теги классов путем приведения типа AnyRef — это чаще
// всего делается в случае обобщенного или шаблонизированного кода,
// когда невозможно явным образом сформировать правильный тег класса,
// поскольку использование фиктивного тега класса может привести
// к снижению производительности
ClassTag fake = ClassTag$.MODULE$.AnyRef();
return new JavaPairRDD(rdd, fake, fake);
}
```
Пример 7.3. Обеспечение совместимости RDD Java/Scala
```
public static JavaPairRDD wrapPairRDD(
RDD> RDD) {
// Формируем теги классов
ClassTag strCt = ClassTag$.MODULE$.apply(String.class);
ClassTag longCt = ClassTag$.MODULE$.apply(scala.Long.class);
return new JavaPairRDD(rdd, strCt, longCt);
}
```
API как Spark SQL, так и конвейера ML были по большей части сделаны единообразно в Java и Scala. Однако существуют предназначенные для Java вспомогательные функции, а функции языка Scala, эквивалентные им, вызвать непросто. Вот их примеры: различные числовые функции, такие как plus, minus и т. д., для класса Column. Вызвать их перегруженные эквиваленты из языка Scala (+, -) сложно. Вместо использования JavaDataFrame и JavaSQLContext необходимые для Java методы сделаны доступными в SQLContext и обычных наборах DataFrame. Это может смутить вас, ведь некоторые упомянутые в документации по Java методы нельзя задействовать из кода на языке Java, но в подобных случаях для вызова из Java предоставляются функции с аналогичными названиями.
Пользовательские функции (UDF) в языке Java, а если уж на то пошло, и в большинстве других языков, кроме Scala, требуют указания типа возвращаемого функцией значения, поскольку его невозможно логически вывести, подобно тому как это выполняется в языке Scala (пример 7.4).
Пример 7.4. Образец UDF для языка Java
```
sqlContext.udf()
.register("strlen",
(String s) -> s.length(), DataTypes.StringType);
```
Хотя необходимые для API Scala и Java типы различаются, обертывание типов-коллекций языка Java не требует дополнительного копирования. В случае итераторов требуемое для адаптера преобразование типа выполняется отложенным образом по мере обращения к элементам, что позволяет фреймворку Spark сбрасывать данные в случае надобности (как обсуждалось в разделе «Выполнение преобразований “итератор — итератор” с помощью функции mapPartitions» на с. 121). Это очень важно, поскольку для многих простых операций стоимость копирования данных может оказаться выше затрат на само вычисление.
### За пределами и Scala, и JVM
Если не ограничивать себя JVM, то количество доступных для работы языков программирования резко возрастает. Однако при текущей архитектуре Spark работа вне JVM — особенно на рабочих узлах — может приводить к существенному росту затрат из-за копирования данных в рабочих узлах между JVM и кодом на целевом языке. При сложных операциях доля затрат на копирование данных относительно невелика, но при простых она легко способна привести к удвоению общих вычислительных затрат.
Первый непосредственно поддерживаемый вне Spark не-JVM-язык программирования — Python, его API и интерфейс стали образцом, на котором основываются реализации для остальных не-JVM-языков программирования.
### Как работает PySpark
PySpark подключается к JVM Spark с помощью смеси каналов на работниках и Py4J — специализированной библиотеки, обеспечивающей взаимодействие Python/Java — на драйвере. Под этой, на первый взгляд, простой архитектурой скрывается немало сложных нюансов, благодаря которым работает PySpark, как показано на рис. 7.1. Одна из основных проблем: даже когда данные скопированы из работника Python в JVM, они находятся не в том виде, который может легко разобрать виртуальная машина. Необходимы специальные усилия на стороне и работника Python, и Java, чтобы гарантировать наличие в JVM достаточного объема информации для таких операций, как секционирование.
### Наборы RDD PySpark
Затраты ресурсов на передачу данных в JVM и из нее, а также на запуск исполнителя Python весьма значительны. Избежать многих проблем с производительностью с API наборов RDD PySpark можно, используя API DataFrame/Dataset, благодаря тому что данные при этом как можно дольше остаются в JVM.
Копирование данных из JVM в Python выполняется с помощью сокетов и сериализованных байтов. Более общая версия для взаимодействия с программами на других языках доступна через интерфейс PipedRDD, применение которого показано в подразделе «Использование pipe».
Организация каналов для обмена данными (в двух направлениях) для каждого преобразования была бы слишком дорогостоящей. Вследствие этого PySpark организует (при возможности) конвейер преобразований Python внутри интерпретатора Python, соединяя в цепочку операцию filter, а после нее — map, на итераторе Python-объектов с помощью специализированного класса PipelinedRDD. Даже когда нужно перетасовать данные и PySpark не способен связать преобразования цепочкой в виртуальной машине отдельного работника, можно повторно использовать интерпретатор Python, так что затраты на запуск интерпретатора не приведут к дальнейшему замедлению работы.
Это только часть головоломки. Обычные PipedRDD работают с типом String, перетасовывать который не так уж просто из-за отсутствия естественного ключа. В PySpark же, а по его образу и подобию в библиотеках привязки ко многим другим языкам программирования, применяется специальный тип PairwiseRDD, где ключ представляет собой длинное целое, а его десериализация выполняется пользовательским кодом на языке Scala, предназначенном для синтаксического разбора Python-значений. Затраты на эту десериализацию не слишком велики, но она демонстрирует, что Scala в фреймворке Spark в основном рассматривает результаты работы кода Python как «непрозрачные» байтовые массивы.
При всей его простоте этот подход к интеграции работает на удивление хорошо, причем в языке Python доступно большинство операций над наборами RDD Scala. В некоторых наиболее сложных местах кода происходит обращение к библиотекам, например MLlib, а также загрузка/сохранение данных из различных источников.
Работа с различными форматами данных тоже накладывает свои ограничения, поскольку значительная часть кода загрузки/сохранения данных фреймворка Spark основана на Java-интерфейсах Hadoop. Это значит, что все загружаемые данные сначала загружаются в JVM, а лишь потом перемещаются в Python.
Для взаимодействия с MLlib обычно применяются два подхода: или в PySpark используется специализированный тип данных с преобразованиями типов Scala, или алгоритм заново реализуется в Python. Этих проблем можно избежать с помощью пакета Spark ML, в котором применяется интерфейс DataFrame/Dataset, обычно хранящий данные в JVM.
### Наборы DataFrame и Dataset пакета PySpark
Наборы DataFrame и Dataset лишены многих проблем с производительностью API наборов RDD Python благодаря тому, что хранят данные в JVM как можно дольше. Тот же тест производительности, который мы провели для иллюстрации превосходства наборов DataFrame над наборами RDD (см. рис. 3.1), показывает значительные различия при запуске в Python (рис. 7.2).
При многих операциях с наборами DataFrame и Dataset, возможно, вообще не потребуется перемещать данные из JVM, хотя использование различных UDF, UDAF и лямбда-выражений языка Python, естественно, требует перемещения части данных в JVM. Это приводит к следующей упрощенной схеме для многих операций, выглядящей так, как показано на рис. 7.3.
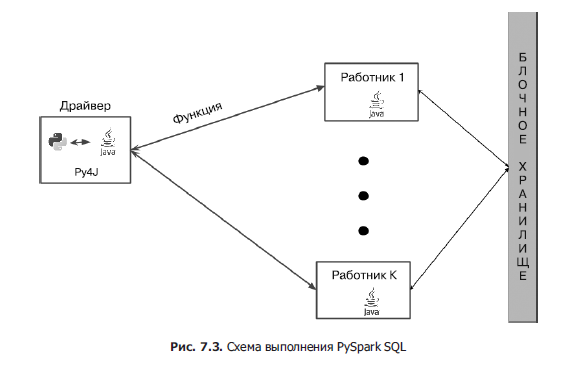
### Доступ к нижележащим Java-объектам и смешанному коду на Scala
Важное следствие архитектуры PySpark состоит в том, что многие из Python-классов фреймворка Spark фактически являются адаптерами, служащими для трансляции вызовов из кода на Python в понятную JVM-форму.
Если вы сотрудничаете с разработчиками на Scala/Java и хотите взаимодействовать с их кодом, то заранее никаких адаптеров для обращения к вашему коду не будет, но вы можете зарегистрировать свои Java/Scala UDF и воспользоваться ими из кода на Python. Начиная со Spark 2.1, это можно сделать с помощью метода registerJavaFunction объекта sqlContext.
Иногда эти адаптеры не имеют всех необходимых механизмов, и, поскольку в языке Python отсутствует жесткая защита от обращения к приватным методам, можно сразу обратиться к JVM. Такая же методика позволит обратиться к собственному коду в JVM и с небольшими усилиями преобразовать результаты обратно в объекты Python.
В подразделе «Большие планы запросов и итеративные алгоритмы» на с. 91 мы отмечали важность использования JVM-версии наборов DataFrame и RDD в целях сокращения плана запроса. Это обходной путь, ведь когда планы запросов становятся слишком большими для обработки оптимизатором Spark SQL, SQL-оптимизатор, из-за помещения набора RDD в середину теряет возможность заглянуть за пределы момента появления данных в RDD. Того же можно добиться с помощью общедоступных API Python, однако при этом потеряются многие преимущества наборов DataFrame, ведь все данные должны будут пройти туда и обратно через рабочие узлы Python. Вместо этого можно сократить граф происхождения, продолжая хранить данные в JVM (как показано в примере 7.5).
Пример 7.5. Усечение большого плана запроса для набора DataFrame с помощью Python
```
def cutLineage(df):
"""
Усечение графа происхождения DataFrame — используется для итеративных алгоритмов
.. Примечание: эта функция использует внутренние члены классов
и может перестать работать в следующих версиях
>>> df = RDD.toDF()
>>> cutDf = cutLineage(df)
>>> cutDf.count()
3
"""
jRDD = df._jdf.toJavaRDD()
jSchema = df._jdf.schema()
jRDD.cache()
sqlCtx = df.sql_ctx
try:
javaSqlCtx = sqlCtx._jsqlContext
except:
javaSqlCtx = sqlCtx._ssql_ctx
newJavaDF = javaSqlCtx.createDataFrame(jRDD, jSchema)
newDF = DataFrame(newJavaDF, sqlCtx)
return newDF
```
Вообще говоря, по соглашению для доступа к внутренним Java-версиям большинства объектов Python используется синтаксис \_j[сокращенное\_наименование]. Так, например, у объекта SparkContext есть \_jsc, который позволяет получить внутренний Java-объект SparkContext. Это возможно только в драйверной программе, так что при отправке PySpark-объектов на рабочие узлы вы не сможете получить доступ к внутреннему Java-компоненту и большая часть API работать не будет.
Для обращения к классу Spark в JVM, у которого нет Python-адаптера, можно воспользоваться шлюзом Py4J на драйвере. Объект SparkContext содержит ссылку на шлюз в свойстве \_gateway. Обратиться к любому Java-объекту позволит синтаксис sc.\_gateway.jvm.[полное\_имя\_класса\_в\_JVM].
Подобная методика сработает и для ваших собственных классов Scala, если они располагаются в соответствии с путем к классам. Добавить файлы JAR в путь к классам можно с помощью команды spark-submit с параметром --jars или задав свойства конфигурации spark.driver.extraClassPath. Пример 7.6, который помог сгенерировать рис. 7.2, умышленно устроен так, что генерирует данные для тестирования производительности с помощью существующего кода на языке Scala.
Пример 7.6. Вызов не-Spark-JVM-классов с помощью Py4J
```
sc = sqlCtx._sc
# Получение SQL Context, синтаксис версий 2.1, 2.0 и более ранних,
# чем 2.0, — ух ты, какие нюансы :p
try:
try:
javaSqlCtx = sqlCtx._jsqlContext
except:
javaSqlCtx = sqlCtx._ssql_ctx
except:
javaSqlCtx = sqlCtx._jwrapped
jsc = sc._jsc
scalasc = jsc.sc()
gateway = sc._gateway
# Вызов java-метода, возвращающего набор RDD JVM-объектов
# Row (Int, Double). Хотя наборы RDD языка Python представляют собой
# обернутые RDD языка Java (даже наборы объектов Row), содержимое их
# различается, так что непосредственное его обертывание невозможно.
# Он возвращает Java-RDD объектов Row — обычно лучше было бы
# вернуть непосредственно набор DataFrame, но для целей иллюстрации
# мы воспользуемся набором RDD объектов Row.
java_rdd = (gateway.jvm.com.highperformancespark.examples.
tools.GenerateScalingData.
generateMiniScaleRows(scalasc, rows, numCols))
# Схемы сериализуются в формат JSON и пересылаются туда и обратно.
# Формируем Python-схему и преобразуем ее в Java-схему.
schema = StructType([
StructField("zip", IntegerType()),
StructField("fuzzyness", DoubleType())])
# Синтаксис версии 2.1 / до 2.1
try:
jschema = javaSqlCtx.parseDataType(schema.json())
except:
jschema = sqlCtx._jsparkSession.parseDataType(schema.json())
# Преобразуем RDD (Java) в DataFrame (Java)
java_dataframe = javaSqlCtx.createDataFrame(java_rdd, jschema)
# Обертываем DataFrame (Java) в DataFrame (Python)
python_dataframe = DataFrame(java_dataframe, sqlCtx)
# Преобразуем DataFrame (Python) в набор RDD
pairRDD = python_dataframe.rdd.map(lambda row: (row[0], row[1]))
return (python_dataframe, pairRDD)
```
Хотя многие классы языка Python представляют собой просто адаптеры Java-объектов, далеко не все Java-объекты можно обернуть в Python-объекты и затем использовать в Spark. Например, объекты в наборах RDD PySpark представлены в виде сериализованных строк, выполнить синтаксический разбор которых с легкостью можно только в коде на языке Python. К счастью, объекты DataFrame стандартизированы между разными языками программирования, так что если вы сумеете преобразовать свои данные в наборы DataFrame, то сможете затем обернуть их в Python-объекты и либо задействовать непосредственно в виде DataFrame языка Python, либо преобразовать DataFrame языка Python в RDD этого же языка.
» Более подробно с книгой можно ознакомиться на [сайте издательства](https://www.piter.com/collection/new/product/effektivnyy-spark-masshtabirovanie-i-optimizatsiya)
» [Оглавление](https://storage.piter.com/upload/contents/978544610705/978544610705_X.pdf)
» [Отрывок](https://storage.piter.com/upload/contents/978544610705/978544610705_p.pdf)
Для Хаброжителей скидка 20% по купону — **Spark** | https://habr.com/ru/post/414525/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.