
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# Поисковое API для PHP (Flash, Java и других)
**Задача:** организовать поиск по всему сайту затратив как можно меньше усилий и оформить результаты в своем стиле.
**Рассуждение**
Есть различные серверные системы для организации полнотекстового поиска индексируя сайт, индексирую базу данных. Но их надо устанавливать на своем сервере, настраивать, а некоторые из них еще и платные.
В какой-то момент решил воспользоваться Google Ajax Search API через JavaScript, но тут вид результатов менять достаточно сложно, да и еще надо делать запросы в другой домен при помощи javascript.
**Решение**
В итоге набрел на странице [Google AJAX Search API](http://code.google.com/intl/ru-RU/apis/ajaxsearch/documentation/) в раздел [Code Snippets](http://code.google.com/intl/ru-RU/apis/ajaxsearch/documentation/#fonje_snippets) и все стало просто: немного кода на php и полнотекстовый поиск по любому сайту готов.
#### PHP
Приведен слегка упрощенный фрагмент кода. Конечно, хорошо бы сделать проверку на доступность сервера ajax.googleapis.com в данный момент.
> `php<br/
> //Получаем настройки поискового запроса
>
> $data = MyDB::get() -> selectOne('\*',self::TABLE,'`id\_mod` = '.$this->id\_mod);
>
>
>
> //На каком сайте ищем?
>
> $sireUrl = $data['url'];
>
>
>
> //Данные полученные от пользователя
>
> $sigs = array(
>
> 'q' => array('type' => 'string', 'required' => false),
>
> 'start' => array('type' => 'integer', 'required' => false)
>
> );
>
> $reqData = SpeData::sanitize\_vars($this->queryArray, $sigs, 'RequestException');
>
> $q = urlencode($reqData['q'].' site:'.$sireUrl);
>
> $start = empty($reqData['start']) ? 0 : $reqData['start'];
>
>
>
> //Отправляем запрос гуглу, собственно это основаня часть :)
>
> $ch = curl\_init();
>
> curl\_setopt($ch, CURLOPT\_URL, "http://ajax.googleapis.com/ajax/services/search/web?v=1.0&q=$q&rsz=large&hl=ru&start=$start");
>
> curl\_setopt($ch, CURLOPT\_RETURNTRANSFER, 1);
>
> curl\_setopt($ch, CURLOPT\_REFERER, "http://$sireUrl/");
>
> $body = curl\_exec($ch);
>
> curl\_close($ch);
>
>
>
> //Ответ получили, в принципе, зада выполнена :)
>
> $json = json\_decode($body);
>
> //На этом этапе можно сделать print\_r($json) и все станет понятно
>
> //Но что бы в smarty было проще разобрать результаты, можно преобразовать его в следующий вид
>
>
>
> $search = array();
>
>
>
> //Результаты поиска
>
> if (count($json -> responseData -> results) == 0) { //если ничего не найдено
>
> $search['result'] = false;
>
> } else {
>
> foreach ($json -> responseData -> results as $v) {
>
> $search['result'][] = array(
>
> 'GsearchResultClass' => $v -> GsearchResultClass,
>
> 'unescapedUrl' => $v -> unescapedUrl,
>
> 'url' => $v -> url,
>
> 'visibleUrl' => $v -> visibleUrl,
>
> 'cacheUrl' => $v -> cacheUrl,
>
> 'title' => $v -> title, //заголовок найденого документа (индексируется ведь не только html-странички)
>
> 'titleNoFormatting' => $v -> titleNoFormatting,
>
> 'content' => $v -> content //выдержка из текста документа
>
> );
>
> }
>
> }
>
>
>
> //Список ссылок на остальные результаты поиска
>
> if (count($json -> responseData -> results) == 0) { //если ничего не найдено
>
> $search['pages'] = false;
>
> } else {
>
> $url = 'http://'.$\_SERVER['HTTP\_HOST'].$\_SERVER['REDIRECT\_URL'].'?q='.$reqData['q'];
>
> foreach ($json -> responseData -> cursor -> pages as $v) {
>
> $search['pages'][] = array(
>
> 'start' => $v -> start,
>
> 'startUrl' => $url.'&start='.$v -> start,
>
> 'label' => $v -> label
>
> );
>
> }
>
> }
>
>
>
> //Общая информация о результатах поиска
>
> $currentPageIndex = $json -> responseData -> cursor -> currentPageIndex;
>
> $search['info'] = array(
>
> 'q' => $reqData['q'],
>
> 'estimatedResultCount' => $json -> responseData -> cursor -> estimatedResultCount,
>
> 'moreResultsUrl' => $json -> responseData -> cursor -> moreResultsUrl,
>
> 'currentPageIndex' => $currentPageIndex,
>
> 'currentLabel' => $currentPageIndex + 1,
>
> 'startResult' => $currentPageIndex \* 8 + 1,
>
> 'endResult' => ($currentPageIndex \* 8 + 1) + count($search['result']),
>
> 'next' => (count($search['pages']) > $currentPageIndex + 1) ? $search['pages'][$currentPageIndex + 1]['startUrl'] : false,
>
> 'prev' => ($currentPageIndex) ? $search['pages'][$currentPageIndex - 1]['startUrl'] : false
>
> );
>
>
>
>
>
> //Все готово
>
> MySmarty::get() -> assign('search', $search);
>
>
>
> ?>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
#### SMARTY
Использую ограничители «{{» и «}}» что бы отличать smarty от javascript
> `{{if !$search.result}}
>
> По запросу **{{$search.info.q}}** ничего не найдено или в данным момент поисковый сервис недоступен.
>
> {{else}}
>
> Результаты **{{$search.info.startResult}} - {{$search.info.endResult}}** из примерно **{{$search.info.estimatedResultCount}}** для **{{$search.info.q}}**
>
>
>
>
>
>
>
>
>
> {{section name=i loop=$search.result}}
>
> ["{{$search.result[i].url}}"](<font)>{{$search.result[i].title}}
>
>
> {{$search.result[i].content}}
>
>
>
>
>
>
>
>
>
> {{/section}}
>
>
>
>
>
>
>
>
> {{if $search.info.prev}}
>
> ["{{$search.info.prev}}">Предыдущая](<font)
>
> {{/if}}
>
>
>
>
>
> {{section name=i loop=$search.pages}}
>
> {{if $search.info.currentLabel == $search.pages[i].label}}
>
> {{$search.pages[i].label}}
>
> {{else}}
>
> ["{{$search.pages[i].startUrl}}">{{$search.pages[i].label}}](<font)
>
> {{/if}}
>
> {{/section}}
>
>
>
> {{if $search.info.next}}
>
> ["{{$search.info.next}}">Следующая](<font)
>
> {{/if}}
>
>
>
> {{/if}}
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Вот и получили хороший поиск по любого рода данным (html,doc,pdf и остальные документы по которым ищет google).
Так же есть удобный инструмент для тестов [Google Ajax Api Playground](http://code.google.com/apis/ajax/playground/ "Google Ajax Api Playground").
Хабралюди, если вы в курсе, подскажите пожалуйста, как обстоят дела с соглашениями об использовании этого поискового API. Должен ли я на страничке с результатами указывать что пользуюсь поиском google, или делать еще что-либо подобное?
Спасибо за внимание.
P.S. Это мой первый пост на хабре, если что-то сделал не так скажите, исправлю :) | https://habr.com/ru/post/54012/ | null | ru | null |
# Почему маршрутизатор отказывается пустить вас телнетом
**Вступление**
С оборудованием Cisco я работаю уже несколько лет, но с подобной проблемой столкнулся впервые. Хотя может и не впервые :). Точно сказать не могу, так как всякого рода траблов и непоняток было много, из-за того что я настраивал в работу и изучал их одновременно. Но раньше скорее всего все решалось обычным хардрезетом, теперь же я разобрался в чем дело.
**Что было поводом?**
В один прекрасный день мне понадобилось зайти удаленно на один из роутеров Cisco, чтобы посмотреть вывод sh ver. Обычно я захожу со своей машины с OS Windows посредством Putty. Как обычно окно терминала открылось, и…, не выдав никакой текстовой информации с велкомом и приглашением к логину, сразу же закрылось без объяснения причин.
Попробовал с линуксового сервера:
`[valent@linux ~]$ telnet 10.15.xxx.yy
Trying 10.15.xxx.yy...
telnet: connect to address 10.15.xxx.yy: Connection refused
telnet: Unable to connect to remote host: Connection refused`
Попробовав еще несколько раз с тем же результатом с других хостов я решил немного
~~попинать головой стену~~ подумать :)
И вот что обнаружилось и придумалось.
Так как фаервола и ACL от меня в сторону роутера не было, да и я заходил на роутер перед этим много раз на прошлой неделе, настраивая тоннель, то я сделал вывод, что закончились свободные **vty line**. Конечно, дошел к этому выводу я не так быстро и сразу, были разные предположения, но помогло то, что глюков в циске я еще не встречал, роутер по информации маршрутизации и cdp работал, в чудеса особо не верю, заходил на роутер буквально пару дней назад и еще помню примерно конфиг, плюс на днях читал блог одного цисковода, где он как раз тюннинговал эти самые **vty line**.
**Что было сделано?**
На прошлой неделе я настраивал на этом роутере (к слову сказать Cisco 1841) тоннель через партнерские сети к другому такому же роутеру. Что бы окно терминала не закрывалось из-за бездействия при выводе дебага, в настройках **line vty** я установил параметр **exec-timeout 0 0** (время бездействия в 0 минут 0 секунд, то есть сессия будет висеть практически вечно).
В процессе настройки несколько раз выходил нештатно, то есть просто закрывал окно терминала. В итоге все мои telnet-сессии остались открытыми и занятыми и когда я попытался очередной раз зателнетится на роутер — меня не пустило.
Повезло только то, что был еще открыт доступ по http протоколу и это помогло диагностировать и решить проблему.
**Что нужно сделать ?**
Нужно посмотреть сводный статус TCP-соединений:
`cisco#show tcp brief
TCB Local Address Foreign Address (state)
8173B78C 10.15.xxx.yy.23 10.15.aa.bb.2530 ESTAB
...
80CCEB24 10.15.xxx.yy.23 10.15.aa.bb.4427 ESTAB`
Первая колонка — это TCB адрес (Transmission Control Block адрес установленого TCP-соединения). По аналогии с \*nix, можно сказать что это PID процесса, который можно убить:
`router#clear tcp tcb 8173B78C
[confirm]`
для подтверждения нажав «y» мы убиваем данную сессию.
Таким образом, сняв TCP-сессии, я освободил vty линии и смог зайти телнетом на роутер.
Хочу заметить еще, что более подробно о TCP-соединении можно узнать, если ввести команду:
`show tcp tcb [TCB address]`
Например:
`router#show tcp tcb 80CCF254
Connection state is ESTAB, I/O status: 1, unread input bytes: 1
Local host: 10.15.xxx.yy, Local port: 23
Foreign host: 10.15.aa.bb, Foreign port: 1840
Enqueued packets for retransmit: 1, input: 0 mis-ordered: 0 (0 bytes)
Event Timers (current time is 0x374828A8):
Timer Starts Wakeups Next
Retrans 123 7 0x374829CB
TimeWait 0 0 0x0
AckHold 128 11 0x0
SendWnd 0 0 0x0
KeepAlive 0 0 0x0
GiveUp 0 0 0x0
PmtuAger 0 0 0x0
DeadWait 0 0 0x0
iss: 2866020113 snduna: 2866027408 sndnxt: 2866027946 sndwnd: 65097
irs: 672352072 rcvnxt: 672352285 rcvwnd: 3916 delrcvwnd: 212
SRTT: 302 ms, RTTO: 319 ms, RTV: 17 ms, KRTT: 0 ms
minRTT: 156 ms, maxRTT: 564 ms, ACK hold: 200 ms
Flags: passive open, higher precedence, retransmission timeout
Datagrams (max data segment is 536 bytes):
Rcvd: 248 (out of order: 0), with data: 137, total data bytes: 212
Sent: 166 (retransmit: 7, fastretransmit: 0), with data: 154, total data bytes: 8368`
P.S. Хабр читаю уже давно, часто есть желание прокоментировать тот или иной пост. И вот, документируя вышеизложеное в свой вики, я подумал что может быть это будет интересно и еще кому-то.
Пользуясь представленой возможностью, хочу заметить, что это мой первый пост на хабре и, надеюсь, что не последний :)
P.S.S. Сегодня нашел на опеннете то же решение, но опубликованое в 2004 году — <http://www.opennet.ru/tips/info/720.shtml>. Хочу отметить, что мой пост — не плагиат, а 100% самостоятельная работа. | https://habr.com/ru/post/82694/ | null | ru | null |
# Однопоточный JavaScript и многопоточная Java: что быстрее?

Асинхронное выполнение на Java и JavaScript
-------------------------------------------
При необходимости в JavaScript можно запускать дополнительные потоки. Но обычно в Node.js или в браузерах весь код на JavaScript выполняется в одном потоке. В браузерах [один и тот же поток рендерит содержимое веб-страницы на экран](https://medium.com/geekculture/requestanimationframe-not-for-animation-a-key-tool-illustrated-and-explained-7cd987f07697). По сути, один поток выполнения занимается всеми задачами, потому что приложения JavaScript пользуются преимуществами асинхронного выполнения. Для асинхронного выполнения задача помещается в очередь задач. Задачи из очереди одна за другой выполняются единственным потоком. Например, вторая строка кода выполняет планирование асинхронной задачи, которая запускается после завершения текущей задачи:
```
console.log("1");
setTimeout(()=>console.log("2"));
console.log("3");
```
Результатом работы кода будет `1 3 2`.
В Java API под асинхронным выполнением обычно подразумевается, что задача выполняется в новом выделенном потоке. Например, представленный ниже код при помощи метода supplyAsync() планирует асинхронную задачу:
```
System.out.println("current thread: " + Thread.currentThread().getName());
var future = CompletableFuture.supplyAsync(() -> Thread.currentThread().getName());
System.out.println("current thread: " + Thread.currentThread().getName());
System.out.println("task thread: " + future.get());
```
Результат работы программы показывает, что текущий поток создал новый поток для выполнения задачи:
```
current thread: main
current thread: main
task thread: ForkJoinPool.commonPool-worker-1
```
Проблема множественных потоков заключается в том, что Java runtime не может создавать бесконечное их количество. Когда все запущенные потоки ожидают, а новые потоки создать нельзя, приложение тоже ничего не будет делать. Чуть ниже я проиллюстрирую этот случай, но сначала мне бы хотелось упомянуть менее серьёзный, но более распространённый пример.
Сравнение производительности многопоточных и однопоточных приложений
--------------------------------------------------------------------
Теоретически многопоточные приложения должны быть более производительными, чем однопоточные, но на практике это не всегда так. Возьмём в качестве примера основной способ применения Java — серверы приложений Java. В логе видно, что HTTP-запросы обрабатывает множество параллельных потоков с собственными именами. Но если развёрнутое веб-приложение выполняет операции ввода-вывода, то многопоточность по большей мере теряет смысл, поскольку доступ к файловой системе — это узкое «бутылочное горлышко». Десять потоков не могут быть производительнее одного потока, вынужденного ждать содержимого от файловой системы. Например, [Java-сервер Tomcat при передаче статичных файлов проявляет себя не лучше, чем один инстанс Node.js](https://medium.com/codex/what-is-faster-tomcat-or-node-js-with-express-602a829b49b6).
Когда многопоточная Java работает медленнее, чем однопоточный JavaScript
------------------------------------------------------------------------
Давайте попробуем скачать содержимое примерно ста случайных URL. При этом воспользуемся возможностью и сравним производительность древнего `HttpURLConnection` и современного `HttpClient`.
Представленный ниже код извлекает все абсолютные ссылки с <https://www.bbc.com/news/world> (около 100 URL), загружает их содержимое, а затем выводит общее время, потраченное на параллельное получение содержимого:
```
public abstract class Runner {
abstract CompletableFuture> requestManyUrls(List urls) throws Exception;
void run() throws Exception {
var urls = getUrlsFromUrl("https://www.bbc.com/news/world");
var start = System.currentTimeMillis();
var contents = requestManyUrls(urls).get();
var time = System.currentTimeMillis() - start;
var totalLength = contents.stream()
.mapToInt(o -> o.txt().length())
.reduce((a, b) -> a + b).getAsInt();
System.out.println("fetched " + totalLength + " bytes from " + urls.size() + " urls in " + time + " ms");
}
}
```
Также код выводит общий размер загруженного содержимого, чтобы убедиться, что разные способы загружают один и тот же контент. Самое важное для нас в коде — это измерение времени, необходимого для параллельного выполнения множества HTTP-запросов.
`UrlTxt` — это просто запись с двумя полями:
```
public record UrlTxt(String url,String txt) {}
```
Метод `getUrlsFromUrl()` извлекает абсолютные URL из содержимого <https://www.bbc.com/news/world>:
```
public static List getUrlsFromUrl(String url) throws Exception {
return Pattern.compile("href=\"(https:[^\"]+)\"")
.matcher(get(url))
.results()
.map(r -> r.group(1))
.collect(Collectors.toList());
}
```
Параллельные HTTP-запросы при помощи древнего HttpURLConnection
---------------------------------------------------------------
Для получения содержимого URL используется обычный код:
```
public static String get(String url) throws Exception {
var con = (HttpURLConnection) new URL(url).openConnection();
con.setInstanceFollowRedirects(false);
if (con.getResponseCode() == HttpURLConnection.HTTP_NOT_FOUND) {
return ""; // 404 throws FileNotFoundException
}
try ( BufferedReader in = new BufferedReader(new InputStreamReader(con.getInputStream()))) {
var response = new StringBuilder();
String line;
while ((line = in.readLine()) != null) {
response.append(line);
}
return response.toString();
}
}
```
`get()` используется в подклассе общего родителя `Runner`. Чтобы использовать `get()` асинхронным образом, я применяю метод-адаптер `load()`. Кстати, обратите внимание на раздражающее ограничение стандартных функциональных интерфейсов — они не выдают исключений и реализующий их код часто необходимо оборачивать в некрасивые блоки `try catch`.
```
public class URLRequests extends Runner {
CompletableFuture load(String url) {
return CompletableFuture.supplyAsync(() -> {
try {
return new UrlTxt(url, get(url));
} catch (Exception e) {
throw new IllegalStateException(e);
}
});
}
@Override
CompletableFuture> requestManyUrls(List urls) throws InterruptedException, ExecutionException {
CompletableFuture[] requests = urls
.stream().map(url -> load(url)).toArray(i -> new CompletableFuture[i]);
return CompletableFuture.allOf(requests)
.thenApply(v -> {
return Stream.of(requests)
.map(future -> future.join())
.collect(Collectors.toList());
});
}
public static void main(String[] args) Exception {
new URLRequests().run();
}
}
```
Функциональный код в requestManyUrls() адаптирован из самого современного [рецепта по созданию параллельных запросов](https://openjdk.java.net/groups/net/httpclient/recipes.html).
Результат работы кода:
```
fetched 39517285 bytes from 105 urls in 6211 ms
```
Если повторно запустить тот же код, общий размер будет близким, но не точно таким же. Предполагаю, что содержимое некоторых ссылок динамично.
Параллельные HTTP-запросы при помощи современного HttpClient
------------------------------------------------------------
Похоже, в настоящее время `HttpClient` — это лучший класс Java для создания HTTP-запросов. Кажется, он даже поддерживает HTTP/2, потому что иногда выдаёт ошибку HTTP/2 `GOAWAY`.
```
public class HttpClientRequests extends Runner {
@Override
public CompletableFuture> requestManyUrls(List urls) throws InterruptedException, ExecutionException {
HttpClient client = HttpClient.newHttpClient();
CompletableFuture>[] requests = urls.stream()
.map(url -> URI.create(url))
.map(uri -> HttpRequest.newBuilder(uri))
.map(reqBuilder -> reqBuilder.build())
.map(request -> client.sendAsync(request, BodyHandlers.ofString()))
.toArray(i -> new CompletableFuture[i]);
return CompletableFuture.allOf(requests)
.thenApply(v -> {
return Stream.of(requests)
.map(future -> future.join())
.map(response -> new UrlTxt(response.uri().toString(), response.body()))
.collect(Collectors.toList());
});
}
public static void main(String[] args) throws Exception {
new HttpClientRequests().run();
}
}
```
Огромный код с современным `HttpClient` выглядит пугающе, но по сравнению с предыдущим результатом в 6211 мс его работа радует:
```
fetched 39983157 bytes from 105 urls in 4910 ms
```
Параллельные HTTP-запросы на Node.js
------------------------------------
В браузере JavaScript не может скачивать содержимое с других хостов, если целевой хост этого не разрешил. Это мера безопасности. Сайт *bbc.com* не разрешает другим хостам получать его содержимое. Поэтому я использую только Node.js.
Посмотрите, насколько прост полный аналог предыдущего кода на JavaScript:
```
import fetch from 'node-fetch';
const re = /href=\"(https:[^\"]+)\"/g;
function extractLinks(txt) {
return Array.from(txt.matchAll(re), ar => ar[1]);
}
function load(url) {
return fetch(url,{redirect:"manual"})
.then(res => res.text().then(txt => ({ url, txt })));
}
load("https://www.bbc.com/news/world")
.then(({ txt }) => extractLinks(txt))
.then(urls => {
const start = Date.now();
Promise.all(urls.map(url => load(url)))
.then(contents => {
const time= Date.now() - start ;
const totalLength = contents.reduce((total, { url, txt }) => total + txt.length , 0);
console.log("fetched " + totalLength + " bytes from " + urls.length + " urls in " + time + " ms");
});
});
```
Что бы вы ни писали на JavaScript, преимущество очевидно — чем меньше клавиш мы нажимаете, тем меньше тратите времени и тем меньше вероятность внести баги. Однако так думают не все. Многие любят преобразовывать JavaScript в Java-подобный код под названием TypeScript.
Результат работы файла на JavaScript:
```
fetched 39492499 bytes from 105 urls in 1744 ms
```
Почему разница между Java и JavaScript почти трёхкратная?
---------------------------------------------------------
Код на JavaScript сначала выполняет один за другим 105 HTTP-запросов. Когда приходит ответ, движок JavaScript помещает в очередь задач небольшой обратный вызов. После получения всех ответов единственный поток по очереди обрабатывает их.
В Java это работает совершенно иначе. Создаётся множество потоков, каждый из которых отправляет один HTTP-запрос. После создания некого оптимального количества потоков стандартный оптимальный внутренний пул потоков больше не может создавать потоки. Несколько созданных потоков ждут ответов. Код ничего не делает. После поступления ответов создаются новые потоки для отправки новых запросов. И этот процесс повторяется, пока не будут отправлены все запросы. По сути, мой пример кода на Java (4910–1744)/4910=64% от общего времени не делает ничего, кроме как ждёт HTTP-откликов. Ситуация такая же, как и с вводом-выводом в серверах приложений Java, но для Интернет-содержимого время ожидания больше.
Если вы знаете, как реализовать более эффективные параллельные HTTP-запросы на Java, то напишите комментарий.
Исходный код можно скачать с <https://github.com/marianc000/concurrentHTTPRequests>.
[](https://cloud.timeweb.com/?utm_source=habr&utm_medium=banner&utm_campaign=cloud&utm_content=direct&utm_term=low) | https://habr.com/ru/post/592017/ | null | ru | null |
# Linux контейнер для .NET Framework приложения (когда сложно уйти на .Net Core)
Здравствуй, Хабр.
Хочу поделиться с миром достаточно нетипичной, по крайней мере для меня, задачкой и её решением, которое мне кажется вполне приемлемым. Описанное ниже, возможно, не является идеальным выходом из ситуации, но это работает, и работает так, как задумывалось.
#### Завязка и предпосылки
Появилась по работе задача: нужно на сайт вынести 3D-превьюшки BIM-моделей разного оборудования, материалов, объектов. Нужно что-то легковесное, несложное.
На сайте модели этих объектов хранятся и доступны для скачивания в проприетарных форматах различных [САПР](https://ru.wikipedia.org/wiki/%D0%A1%D0%B8%D1%81%D1%82%D0%B5%D0%BC%D0%B0_%D0%B0%D0%B2%D1%82%D0%BE%D0%BC%D0%B0%D1%82%D0%B8%D0%B7%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%BD%D0%BE%D0%B3%D0%BE_%D0%BF%D1%80%D0%BE%D0%B5%D0%BA%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F) и в виде открытых форматов 3D-моделей. Среди них есть и формат [**IFC**](https://ru.wikipedia.org/wiki/Industry_Foundation_Classes). Его-то я и буду использовать, как исходник для решения этого задания.
#### Один из вариантов исполнения и его особенности
Формально можно было бы ограничиться написанием какого-нибудь конвертера \*.ifc во что-то для отображения на web-странице. С этого я и начал.
Для подобного преобразования был избран замечательный тулкит — [**xBIM Toolkit**](https://docs.xbim.net/index.html).
В примерах использования этого инструмента просто и доходчиво [*описано*](https://docs.xbim.net/examples/creating-wexbim-file.html), как работать с IFC и специализированным для web-форматом \*.wexBIM.
**Сначала конвертируем \*.ifc в \*.wexBIM:**
```
using System.IO;
using Xbim.Ifc;
using Xbim.ModelGeometry.Scene;
namespace CreateWexBIM
{
class Program
{
public static void Main()
{
const string fileName = "SampleHouse.ifc";
using (var model = IfcStore.Open(fileName))
{
var context = new Xbim3DModelContext(model);
context.CreateContext();
var wexBimFilename = Path.ChangeExtension(fileName, "wexBIM");
using (var wexBiMfile = File.Create(wexBimFilename))
{
using (var wexBimBinaryWriter = new BinaryWriter(wexBiMfile))
{
model.SaveAsWexBim(wexBimBinaryWriter);
wexBimBinaryWriter.Close();
}
wexBiMfile.Close();
}
}
}
}
}
```
Далее полученный файл используется в «плеере» [**xBIM WeXplorer**](http://docs.xbim.net/XbimWebUI/).
**Пример встраивания \*.wexBIM в страницу:**
```
Hello building!
var viewer = new xViewer('viewer');
viewer.load('data/SampleHouse.wexbim');
viewer.start();
```
Что ж, поехали. Беру [nuget'ы](https://www.nuget.org/packages?q=xbim) от xBIM. Пишу консольное приложение, которое на вход принимает пачку путей к \*.ifc-файлам, рядом с ними складывает пачку \*.wexBIM-файлов. Всё, можно выкладывать на сайт.
Но как-то это простенько… Хочется, чтобы эта программа стала неким сервисом, который по событию загрузки \*.ifc на портал, сразу создаёт необходимый \*.wexBIM, и он сразу отображается в подготовленном контейнере.
Ок, формирую новые требования:
1. пусть задания на конвертацию приходят от нашего [RabbitMQ](https://www.rabbitmq.com/);
2. сами задания хочу видеть в виде бинарного сообщения, которое на самом деле будет готовым для десериализации классом, описанным в [protobuf](https://ru.wikipedia.org/wiki/Protocol_Buffers)-файле;
3. задание будет содержать ссылку для скачивания исходного \*.ifc-файла с нашего [Minio](https://min.io/);
4. задание также будет сообщать мне, в какой bucket в Minio складывать результат;
5. пусть само приложение будет собрано под .net core 3.1 и работет внутри Linux docker-контейнера на нашей «docker-ферме»;
#### Первые сложности и условности
Описывать подробно первые 4 пункта реализации не стану. Возможно позже.
Заставил приложение слушать очередь заданий и отсылать сообщение с результатом в очередь из [CorrelationId](https://www.rabbitmq.com/tutorials/tutorial-six-dotnet.html) сообщения-задания. Прикрутил генерированные классы запрос/ответ из protobuf. Научил скачивать/загружать файлы в [minio](https://docs.min.io/docs/minio-client-complete-guide.html).
Всё это делаю в проекте консольного приложения. В настройках проекта:
```
netcoreapp3.1
```
И на моей машине с Windows 10 всё вполне отлаживается и работает. Но при попытке запустить приложение в [WSL](https://ru.wikipedia.org/wiki/Windows_Subsystem_for_Linux) ловлю ошибку **System.IO.FileLoadException**:
**Полная информация по ошибке:**
```
{
"Type": "System.IO.FileLoadException",
"Message": "Failed to load Xbim.Geometry.Engine64.dll",
"TargetSite": "Void .ctor(Microsoft.Extensions.Logging.ILogger`1[Xbim.Geometry.Engine.Interop.XbimGeometryEngine])",
"StackTrace": " at Xbim.Geometry.Engine.Interop.XbimGeometryEngine..ctor(ILogger`1 logger)\r\n at Xbim.Geometry.Engine.Interop.XbimGeometryEngine..ctor()\r\n at Xbim.ModelGeometry.Scene.Xbim3DModelContext.get_Engine()\r\n at Xbim.ModelGeometry.Scene.Xbim3DModelContext.CreateContext(ReportProgressDelegate progDelegate, Boolean adjustWcs)\r\n at My.Converter.ConvertIfc.CreateWebIfc(String ifcFileFullPath, String wexBIMFolder)",
"Data": {},
"InnerException": {
"Type": "System.IO.FileNotFoundException",
"Message": "Could not load file or assembly 'Xbim.Geometry.Engine.dll, Culture=neutral, PublicKeyToken=null'. The system cannot find the file specified.",
"FileName": "Xbim.Geometry.Engine.dll, Culture=neutral, PublicKeyToken=null",
"FusionLog": "",
"TargetSite": "System.Reflection.RuntimeAssembly nLoad(System.Reflection.AssemblyName, System.String, System.Reflection.RuntimeAssembly, System.Threading.StackCrawlMark ByRef, Boolean, System.Runtime.Loader.AssemblyLoadContext)",
"StackTrace": " at System.Reflection.RuntimeAssembly.nLoad(AssemblyName fileName, String codeBase, RuntimeAssembly assemblyContext, StackCrawlMark& stackMark, Boolean throwOnFileNotFound, AssemblyLoadContext assemblyLoadContext)\r\n at System.Reflection.RuntimeAssembly.InternalLoadAssemblyName(AssemblyName assemblyRef, StackCrawlMark& stackMark, AssemblyLoadContext assemblyLoadContext)\r\n at System.Reflection.Assembly.Load(String assemblyString)\r\n at Xbim.Geometry.Engine.Interop.XbimGeometryEngine..ctor(ILogger`1 logger)",
"Data": {},
"Source": "System.Private.CoreLib",
"HResult": -2147024894
},
"Source": "Xbim.Geometry.Engine.Interop",
"HResult": -2146232799
}
```
Сеанс активного гугления и вдумчивого чтения показал мне, что я крайне невнимателен:
> Recently at work, we were evaluating a few options to render building models in the browser. Building Information Modeling (BIM) in interoperability scenarios is done via Industry Foundation Classes, mostly in the STEP Physical File format. The schema is quite huge and complex with all the things you have to consider, so we were glad to find the xBim open source project on GitHub. They've got both projects to visualize building models in the browser with WebGL as well as conversion tools to create the binary-formatted geometry mesh. To achieve that, native C++ libraries are dynamically loaded (so no .Net Core compatibility) which must be present in the bin folder. The C++ libraries are expected either in the same folder as the application binaries or in a x64 (or x86, respectively) sub folder (See [here](https://github.com/xBimTeam/XbimGeometry/blob/master/Xbim.Geometry.Engine.Interop/XbimCustomAssemblyResolver.cs) for more details). In regular projects, the xBim.Geometry NuGet package adds a build task to copy the dlls into the build output folder, but this doesn't work with the new tooling. You can, however, get it to work in Visual Studio 2015 by taking care of supplying the interop dlls yourself.
И подобные трудности не у одного меня. Многим хочется [xBIM под .Net Core](https://github.com/xBimTeam/XbimEssentials/issues/213).
Не критично, но многое меняет… Всё упирается в невозможность нормально загрузить *Xbim.Geometry.Engine64.dll*. Нужно иметь на машине **[vc\_redist.x64.exe](https://support.microsoft.com/ru-ru/help/2977003/the-latest-supported-visual-c-downloads)**. Какие у меня варианты?
Первое, что подумалось: «А может виндовый контейнер с полным .Net Framework использовать?
Доставить Microsoft Visual C++ Redistributable for Visual Studio 2015, 2017 and 2019 в этот контейнер, и всё будет ок?» Я это попробовал:
**Испытательный Windows-образ для docker:**
Сменил .Net Core на:
```
net47
```
Dockerfile:
```
FROM microsoft/dotnet-framework:4.7
WORKDIR /bimlibconverter
COPY lib/VC_redist.x64.exe /VC_redist.x64.exe
RUN C:\VC_redist.x64.exe /quiet /install
COPY bin/Release .
ENTRYPOINT ["MyConverter.exe"]
```
Что ж, это сработало… It's alive! Но. А как же наша хостовая Linux-машина с docker? Не получится на неё загнать контейнер с образом на [Windows Server Core](https://hub.docker.com/_/microsoft-dotnet-framework-runtime/). Надо выкручиваться…
#### Компромисс и развязка
Очередной поиск в Сети вывел меня на [статью](https://medium.com/better-programming/how-to-run-any-windows-cli-app-in-a-linux-docker-container-318cd49bdd25). В ней автор требует от реализации похожего:
> To make things worse:
>
> All binaries are 32-bits (x86).
>
> Some require visual C++ redistributable runtime components.
>
> Some require the .NET runtime.
>
> Some need a windowing system, even though we only use the command-line interface (CLI).
В посте описывается потенциальная возможность запуска Windows-приложений в wine в Linux-контейнере. Любопытно, решил я.
После некоторых проб, багов и дополнений был получен Dockerfile:
**Docker образ на основе Ubuntu с Wine, .Net Framework и vcredist на борту:**
```
FROM ubuntu:latest
#Добавляем поддержку x86
RUN dpkg --add-architecture i386 \
&& apt-get update \
#Ставим некоторые необходимые пакеты
&& apt-get install -qfy --install-recommends \
software-properties-common \
gnupg2 \
wget \
xvfb \
cabextract \
#Добавляем репозитарий Wine
&& wget -nv https://dl.winehq.org/wine-builds/winehq.key \
&& apt-key add winehq.key \
&& apt-add-repository 'deb https://dl.winehq.org/wine-builds/ubuntu/ bionic main' \
#Дополнительный репозитарий для корректной установки Wine
&& add-apt-repository ppa:cybermax-dexter/sdl2-backport \
#Ставим сам Wine
&& apt-get install -qfy --install-recommends \
winehq-staging \
winbind \
#Подчищаем лишнее
&& apt-get -y clean \
&& rm -rf \
/var/lib/apt/lists/* \
/usr/share/doc \
/usr/share/doc-base \
/usr/share/man \
/usr/share/locale \
/usr/share/zoneinfo
#Переменные окружения для старта Wine
ENV WINEDEBUG=fixme-all
ENV WINEPREFIX=/root/.net
ENV WINEARCH=win64
#Пуск конфигурирования Wine
RUN winecfg \
#Скачиваем winetricks, без них .Net Framework не заведётся
&& wget https://raw.githubusercontent.com/Winetricks/winetricks/master/src/winetricks \
-O /usr/local/bin/winetricks \
&& chmod +x /usr/local/bin/winetricks \
#Подчищаем лишнее
&& apt-get -y clean \
&& rm -rf \
/var/lib/apt/lists/* \
/usr/share/doc \
/usr/share/doc-base \
/usr/share/man \
/usr/share/locale \
/usr/share/zoneinfo \
#Запуск Wine с необходимыми дополнениями
&& wineboot -u && winetricks -q dotnet472 && xvfb-run winetricks -q vcrun2015
WORKDIR /root/.net/drive_c/myconverter/
#Копируем наше приложение
COPY /bin/Release/ /root/.net/drive_c/myconverter/
ENTRYPOINT ["wine", "MyConverter.exe"]
```
UPD: немного изменил файл для сборки более компактного образа. Спасибо комментарию [rueler](https://habr.com/ru/users/rueler/)
Build идёт небыстро, но заканчивается удачно. Пробую, проверяю. Работает!
#### Итоги, выводы, размышления
Это сработало. На выходе получаем Linux-образ для docker-контейнера. Он «пухловат» (~5.2Гб), но вполне быстро стартует и внутри работает консольное Windows-приложени на .Net Framework 4.7, которое слушает RabbitMQ, пишет логи в [Graylog](https://www.graylog.org/), скачивает и загружает файлы на/в Minio. Обновлять само приложение буду по remote docker API.
Решение утилитарной выделенной задачи реализовано. Возможно, и скорее всего, не универсальное. Но меня в принципе устроило. Может быть кому-то тоже пригодится.
Спасибо, что прочли. На Хабр пишу впервые. Увидимся в комментариях. | https://habr.com/ru/post/498396/ | null | ru | null |
# Thymeleaf + Spring WebFlux + Spring Security
Thymeleaf появился довольно давно, как минимум 10 лет назад, но он до сих пор весьма популярен и активно поддерживается. Шаблоны Thymeleaf удобны тем, что при простом открытии в браузере они выглядят как обычные HTML-страницы и их можно использовать как статический прототип приложения.
В этой статье рассмотрим, как создать простое приложение Spring WebFlux с Thymeleaf, аутентификацией Okta OIDC, защитой от CSRF-атак и контролем полномочий.
Будем использовать следующие фреймворки и инструменты:
* [HTTPie 3.0.2](https://httpie.io/)
* [Java 11](https://jdk.java.net/java-se-ri/11)
* [Okta CLI 0.10.0](https://cli.okta.com/)
### Что такое Thymeleaf?
Thymeleaf — это опенсорсный серверный шаблонизатор для различных типов приложений как веб, так и других, созданный Даниэлем Фернандесом (Daniel Fernández). Шаблоны похожи на HTML и могут использоваться со Spring MVC, Spring Security и другими популярными фреймворками. В том числе есть интеграция со Spring WebFlux, но на данный момент об этом довольно мало информации. Thymeleaf-стартер выполняет [автоматическую настройку](https://docs.spring.io/spring-framework/docs/current/reference/html/web-reactive.html#webflux-view-thymeleaf) template engine, template resolver и reactive view resolver.
Возможности Thymeleaf включают в себя:
* Работу с фрагментами: рендеринг только части шаблона. Может использоваться при обновлении части страницы при ответе на AJAX-запросы. Также есть механизм "компонент": фрагменты могут включаться в несколько разных шаблонов.
* Обработку форм с использованием объектов-моделей, содержащих поля формы.
* Рендеринг переменных и внешних текстовых сообщений с помощью языка выражений Thymeleaf [Standard Expression Syntax](https://www.thymeleaf.org/doc/tutorials/3.0/usingthymeleaf.html#standard-expression-syntax).
* Наличие циклов и условных конструкций.
### Spring WebFlux-приложение с Thymeleaf
Мы напишем простое монолитное реактивное приложение на Spring Boot с Thymeleaf. Заготовку приложения можно создать через веб-интерфейс [Spring Initializr](https://start.spring.io/) или с помощью следующей команды HTTPie:
```
https -d start.spring.io/starter.zip bootVersion==2.6.4 \
baseDir==thymeleaf-security \
groupId==com.okta.developer.thymeleaf-security \
artifactId==thymeleaf-security \
name==thymeleaf-security \
packageName==com.okta.developer.demo \
javaVersion==11 \
dependencies==webflux,okta,thymeleaf,devtools
```
У нас будет Maven-проект. Распакуйте его и добавьте пару зависимостей: `thymeleaf-extras-springsecurity5` для поддержки Spring Security в шаблонах и `spring-security-test` для тестов.
```
org.thymeleaf.extras
thymeleaf-extras-springsecurity5
3.0.4.RELEASE
org.springframework.security
spring-security-test
test
```
### Аутентификация с помощью OpenID Connect
Вам понадобится бесплатный аккаунт разработчика Okta. Установите [Okta CLI](https://cli.okta.com/) и запустите `okta register` для создания нового аккаунта. Если у вас уже есть учетная запись, то используйте `okta login`. Для создания нового приложения выполните `okta apps create`.
Имя приложения (Application name) можете оставить по умолчанию или изменить по вашему усмотрению. Тип приложения (Type of Application) выберите **Web**. Framework of Application — **Okta Spring Boot Starter**. Значение Redirect URI оставьте по умолчанию: перенаправление входа (Login Redirect) на `http://localhost:8080/login/oauth2/code/okta` и выхода (Logout Redirect) на `http://localhost:8080`.
Okta CLI создаст OIDC Web App в вашей Okta Org, добавит указанные вами URI перенаправления и предоставит доступ группе Everyone. После завершения должно появиться сообщение, похожее на это:
```
Okta application configuration has been written to:
/path/to/app/src/main/resources/application.properties
```
Реквизиты доступа вашего приложения будут в файле `src/main/resources/application.properties`.
```
okta.oauth2.issuer=https://dev-133337.okta.com/oauth2/default
okta.oauth2.client-id=0oab8eb55Kb9jdMIr5d6
okta.oauth2.client-secret=NEVER-SHOW-SECRETS
```
Для создания приложения вы также можете использовать Okta Admin Console. Подробнее об этом см. раздел [Create a Spring Boot App](https://developer.okta.com/docs/guides/sign-into-web-app/springboot/create-okta-application/) в документации.
Давайте переименуем `application.properties` в `application.yml` и добавим следующие параметры:
```
spring:
thymeleaf:
prefix: file:src/main/resources/templates/
security:
oauth2:
client:
provider:
okta:
user-name-attribute: email
okta:
oauth2:
issuer: https://{yourOktaDomain}/oauth2/default
client-id: {clientId}
client-secret: {clientSecret}
scopes:
- email
- openid
```
Обратите внимание, что нам пока не нужен scope `profile`. Для запросов OpenID Connect [обязателен только openid](https://openid.net/specs/openid-connect-basic-1_0.html#Scopes). Свойство `thymeleaf.prefix` разрешает горячую перезагрузку шаблонов, если в проект подключена зависимость `spring-boot-devtools`.
### Шаблоны Thymeleaf
Для шаблонов создайте папку `src/main/resources/templates` и в ней файл `home.html` со следующим содержимым:
```
User Details
Okta Hosted Login + Spring Boot Example
---------------------------------------
Hello!
If you're viewing this page then you have successfully configured and started this example server.
This example shows you how to use the [Okta Spring Boot
Starter](https://github.com/okta/okta-spring-boot) to add the [Authorization
Code Flow](https://developer.okta.com/docs/guides/implement-grant-type/authcode/main/) to your application.
When you click the login button below, you will be redirected to the login page on your Okta org. After you
authenticate, you will be returned to this application.
Welcome home, Joe Coder!
You have successfully authenticated against your Okta org, and have been redirected back to this
application.
Sign In
```
В приведенном выше шаблоне закомментированный тег позволяет включить фрагменты верхнего и нижнего колонтитулов, определенных в `header.html` и `footer.html`. Они содержат зависимости Bootstrap для оформления шаблонов. Также вместо будет вставлен фрагмент меню.
Условные выражения `th:if` и `th:unless` используются для проверки статуса аутентификации. Если пользователь не аутентифицирован, будет отображаться кнопка "**Sign In**". Иначе — приветствие с именем пользователя.
Далее создайте шаблон head.html:
```
Nothing to see here, move along.
```
И `footer.html`:
```
Nothing to see here, move along.
```
А также шаблон `menu.html` фрагмента меню:
```
* Home
Logout
```
### Контроллер
Для доступа к странице `home` потребуется контроллер. Создайте в пакете `com.okta.developer.demo` класс `HomeController` со следующим содержимым:
```
package com.okta.developer.demo;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.security.core.Authentication;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.reactive.result.view.Rendering;
import reactor.core.publisher.Mono;
import java.util.List;
import java.util.stream.Collectors;
@Controller
public class HomeController {
private static Logger logger = LoggerFactory.getLogger(HomeController.class);
@GetMapping("/")
public Mono home(Authentication authentication) {
List authorities = authentication.getAuthorities()
.stream()
.map(scope -> scope.toString())
.collect(Collectors.toList());
return Mono.just(Rendering.view("home").modelAttribute("authorities", authorities).build());
}
}
```
Этот контроллер отображает представление `home` и заполняет в атрибуте модели полномочия (authorities) для дальнейшей проверки прав доступа.
### Настройка безопасности
Okta-стартер по умолчанию настроен на аутентифицированный доступ ко всем страницам. Нам это нужно немного подправить, поэтому добавьте класс `SecurityConfiguration` в тот же пакет, что и раньше.
```
package com.okta.developer.demo;
import org.springframework.context.annotation.Bean;
import org.springframework.security.config.annotation.method.configuration.EnableReactiveMethodSecurity;
import org.springframework.security.config.annotation.web.reactive.EnableWebFluxSecurity;
import org.springframework.security.config.web.server.ServerHttpSecurity;
import org.springframework.security.web.server.SecurityWebFilterChain;
import org.springframework.security.web.server.authentication.logout.RedirectServerLogoutSuccessHandler;
import org.springframework.security.web.server.authentication.logout.ServerLogoutSuccessHandler;
import java.net.URI;
@EnableWebFluxSecurity
@EnableReactiveMethodSecurity
public class SecurityConfiguration {
@Bean
public ServerLogoutSuccessHandler logoutSuccessHandler(){
RedirectServerLogoutSuccessHandler handler = new RedirectServerLogoutSuccessHandler();
handler.setLogoutSuccessUrl(URI.create("/"));
return handler;
}
@Bean
public SecurityWebFilterChain securityWebFilterChain(ServerHttpSecurity http) {
http
.authorizeExchange().pathMatchers("/").permitAll().and().anonymous()
.and().authorizeExchange().anyExchange().authenticated()
.and().oauth2Client()
.and().oauth2Login()
.and().logout().logoutSuccessHandler(logoutSuccessHandler());
return http.build();
}
}
```
Здесь мы разрешаем анонимный доступ всем пользователям к корневой странице (/), чтобы они могли залогиниться.
### Запуск приложения
Запустите приложение с помощью Maven:
`./mvnw spring-boot:run`
Перейдите по адресу <http://localhost:8080> — вы увидите страницу home и кнопку "**Sign In**". Нажмите кнопку и залогиньтесь, используя учетные данные Okta. После успешного входа вы должны быть перенаправлены на страницу home и увидеть содержимое для аутентифицированных пользователей.
### Защита контента с помощью авторизации
Далее добавим шаблон `userProfile.html`, который будет отображать информацию о `claim`, содержащихся в ID токене, возвращенном Okta, а также полномочия (authorities), полученные Spring Security от токена.
```
User Details
My Profile
----------
Hello, Joe Coder. Below is the
information that was read with your [ID Token](https://developer.okta.com/docs/api/resources/oidc.html#get-user-information).
This route is protected with the annotation `@PreAuthorize("hasAuthority('SCOPE_profile')")`,
which will ensure that this page cannot be accessed until you have authenticated, and have the scope `profile`.
| Claim | Value |
| --- | --- |
| Key | Value |
| Spring Security Authorities |
| --- |
| `Authority` |
```
Настраиваем в `HomeController` маппинг:
```
@GetMapping("/profile")
@PreAuthorize("hasAuthority('SCOPE_profile')")
public Mono userDetails(OAuth2AuthenticationToken authentication) {
return Mono.just(Rendering.view("userProfile")
.modelAttribute("details", authentication.getPrincipal().getAttributes())
.build());
}
```
Аннотация `@PreAuthorize` позволяет определить правила авторизации с помощью SpEL (Spring Expression Language). Правила проверяются перед выполнением метода. В данном случае только пользователи с полномочиями `SCOPE_profile` смогут обратиться к странице `userProfile`. Это защита на стороне сервера.
На клиентской стороне добавьте в шаблоне `home.html` ссылку для доступа к странице `userProfile` после "You successfully …". Ссылка будет отображаться только для пользователей с полномочиями (authority) `SCOPE_profile`.
```
You have successfully authenticated against your Okta org, and have been redirected back to this application.
Visit the My Profile page in this application to view the information retrieved with your OAuth Access Token.
```
Обратите внимание, что условие авторизации реализовано именно таким образом, так как выражения вроде `${#authorization.expression('hasRole(''SCOPE_profile'')')}` не работают в WebFlux из-за отсутствия поддержки в реактивном Spring Security (Spring Security 5.6). Поддерживается только минимальный набор выражений для проверки безопасности: `[isAuthenticated(), isFullyAuthenticated(), isAnonymous(), isRememberMe()]`.
Запустите приложение еще раз. После входа в систему вы не увидите новую ссылку, но если перейдете по адресу `http://localhost:8080/profile`, то получите HTTP ERROR 403 Forbidden — доступ запрещен. Это связано с тем, что в `application.yml` мы настроили только получение scope для `email` и `openid`, а profile не возвращается в токене доступа (access token). Добавьте отсутствующий scope в `application.yml`, перезапустите. Теперь представление `userProfile` должно стать доступно:
Как видите, Spring Security назначает группы, содержащиеся в `claim`, а также запрошенные scope в качестве полномочий (authorities). У scope префикс `SCOPE_`. При создании приложения через Okta CLI по умолчанию создаются группы `ROLE_ADMIN` и `ROLE_USER`, и ваша учетная запись включается в эти группы.
Защита от CSRF-атак
-------------------
Атака CSRF (Cross-site request forgery, межсайтовая подделка запроса) позволяет отправить данные с формы на странице злоумышленника на сайт-жертву, на котором пользователь уже аутентифицирован, и выполнить от лица пользователя вредоносные действия.
Защита от CSRF в Spring Security включена по умолчанию как для сервлет-приложений, так и для WebFlux. Основной способ защиты — [Synchronizer Token Pattern](https://docs.spring.io/spring-security/reference/features/exploits/csrf.html#csrf-protection-stp). В каждый HTTP-запрос помещается случайно сгенерированное значение — CSRF-токен. Токен должен находиться в части запроса, которая не заполняется браузером автоматически. Например, для этого можно использовать HTTP-параметр или заголовок.
Давайте проверим защиту от CSRF, создав простое приложение для проведения опросов. Создайте шаблон `quiz.html` со следующим содержимым:
```
Thymeleaf Quiz
Select the right answer
-----------------------
*
### What is Thymeleaf?
**A.** A server-side Java template engine
**B.** A markup language
**C.** A web framework
Your CSRF token is:
Submit
```
Токен CSRF доступен в качестве атрибута запроса, в учебных целях отобразим его в шаблоне `quiz.html`.
Также добавьте шаблон `result.html` для отображения результата опроса:
```
Thymeleaf Quiz Submission
#### Your selected answer is
Good Job!
It is not the right answer
Try again!
```
Далее класс `QuizSubmission` для хранения ответа:
```
package com.okta.developer.demo;
public class QuizSubmission {
private String answer;
public String getAnswer() {
return answer;
}
public void setAnswer(String answer) {
this.answer = answer;
}
}
```
И контроллер `QuizController` для отображения опроса и обработки данных формы:
```
package com.okta.developer.demo;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.http.MediaType;
import org.springframework.security.access.prepost.PreAuthorize;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.reactive.result.view.Rendering;
import reactor.core.publisher.Mono;
@Controller
public class QuizController {
private static Logger logger = LoggerFactory.getLogger(QuizController.class);
@GetMapping("/quiz")
@PreAuthorize("hasAuthority('SCOPE_quiz')")
public Mono showQuiz() {
return Mono.just(Rendering.view("quiz").modelAttribute("quiz", new QuizSubmission()).build());
}
@PostMapping(path = "/quiz", consumes = {MediaType.APPLICATION\_FORM\_URLENCODED\_VALUE})
@PreAuthorize("hasAuthority('SCOPE\_quiz')")
public Mono saveQuiz(QuizSubmission quizSubmission) {
return Mono.just(Rendering.view("result").modelAttribute("quiz", quizSubmission).build());
}
}
```
В новом контроллере и шаблонах доступ к опросу разрешен только пользователям с полномочиями `SCOPE_quiz`. Добавьте защищенную ссылку в шаблон `home.html` после ссылки на профиль:
```
You have successfully authenticated against your Okta org, and have been redirected back to this application.
Visit the My Profile page in this application to view the information retrieved with your OAuth Access Token.
Visit the Thymeleaf Quiz to test Cross-Site Request Forgery (CSRF) protection.
```
Перед повторным запуском приложения давайте проверим защиту от CSRF с помощью теста. Создайте `QuizControllerTest` в `src/test/java` в пакете `com.okta.developer.demo`:
```
package com.okta.developer.demo;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.autoconfigure.web.reactive.WebFluxTest;
import org.springframework.http.MediaType;
import org.springframework.test.web.reactive.server.WebTestClient;
import static org.springframework.security.test.web.reactive.server.SecurityMockServerConfigurers.csrf;
import static org.springframework.security.test.web.reactive.server.SecurityMockServerConfigurers.mockOidcLogin;
@WebFluxTest
public class QuizControllerTest {
@Autowired
private WebTestClient client;
@Test
void testPostQuiz_noCSRFToken() throws Exception {
QuizSubmission quizSubmission = new QuizSubmission();
this.client.mutateWith(mockOidcLogin())
.post().uri("/quiz")
.exchange()
.expectStatus().isForbidden()
.expectBody().returnResult()
.toString().contains("An expected CSRF token cannot be found");
}
@Test
void testPostQuiz() throws Exception {
this.client.mutateWith(csrf()).mutateWith(mockOidcLogin())
.post().uri("/quiz")
.contentType(MediaType.APPLICATION_FORM_URLENCODED)
.exchange().expectStatus().isOk();
}
@Test
void testGetQuiz_noAuth() throws Exception {
this.client.get().uri("/quiz").exchange().expectStatus().is3xxRedirection();
}
@Test
void testGetQuiz() throws Exception {
this.client.mutateWith(mockOidcLogin())
.get().uri("/quiz").exchange().expectStatus().isOk();
}
}
```
Тест `testPostQuiz_noCSRFToken()` проверяет, что опрос не может быть отправлен без CSRF-токена, даже если пользователь залогинен. Второй тест `testPostQuiz()` — токен CSRF добавляется к фиктивному запросу с помощью `mutateWith(csrf())`. Здесь ожидаемый статус ответа — HTTP 200 OK. Третий тест `testGetQuiz_noAuth()` проверяет, что запрос будет перенаправлен (в форму входа Okta), если пользователь не аутентифицирован. И последний тест `testGetQuiz()` проверяет, что можно получить доступ к опросу, если пользователь аутентифицирован с помощью OIDC.
Поскольку `quiz` не является стандартным scope или scope, определенным в Okta, вам необходимо определить ее для default-сервера авторизации перед запуском приложения. Перейдите в Okta Admin Console в меню **Security > API**, выберите сервер авторизации default. На вкладке **Scopes** нажмите **Add Scope**. Введите имя (Name) quiz и описание (Display phrase). Остальные поля оставьте со значениями по умолчанию и нажмите **Create**. Теперь при логине через OIDC можно требовать scope `quiz`.
Запустите приложение, не добавляя scope `quiz` в `application.yml`, и войдите в систему — вы не должны видеть ссылку на тест. Если выполнить GET-запрос по адресу `http://localhost:8080/quiz`, то ответ будет 403 Forbidden.
Теперь добавьте `quiz` в список scopes в конфигурации Okta в `application.yml`. Окончательная конфигурация должна выглядеть следующим образом:
```
spring:
security:
oauth2:
client:
provider:
okta:
user-name-attribute: email
okta:
oauth2:
issuer: https://{yourOktaDomain}/oauth2/default
client-id: {clientId}
client-secret: {clientSecret}
scopes:
- email
- openid
- profile
- quiz
```
Запустите приложение еще раз. Вы должны увидеть ссылку "Visit the **Thymeleaf Quiz** to test Cross-Site Request Forgery (CSRF) protection". Нажмите на ссылку — вы перейдете на страницу с quiz:
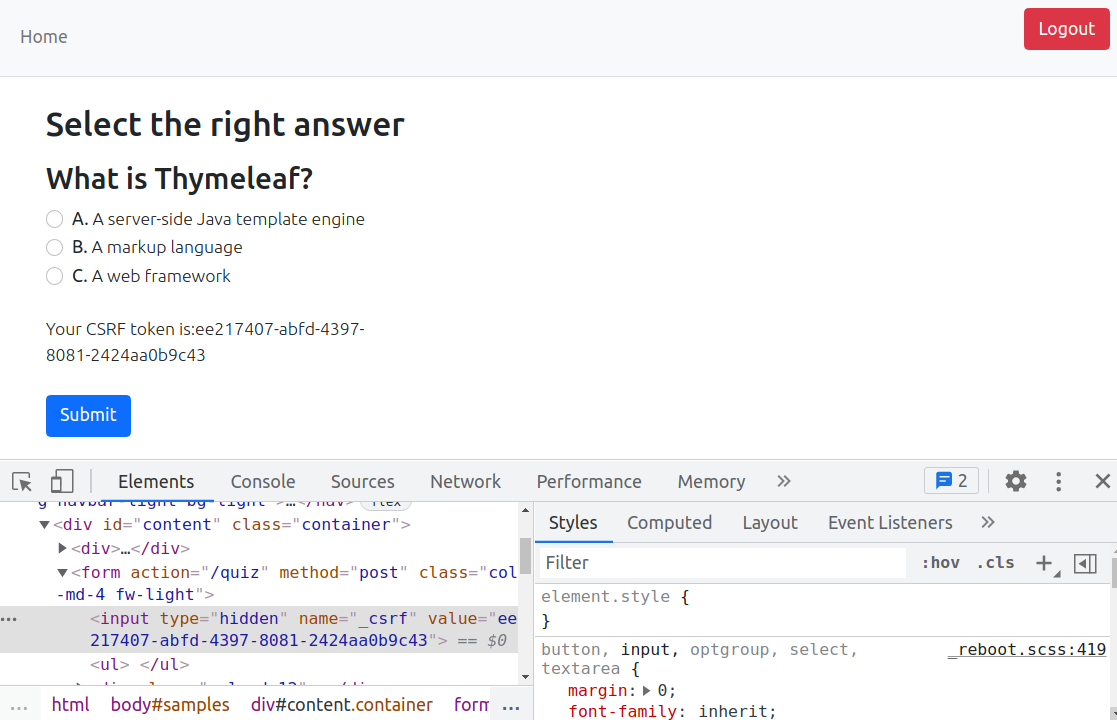Spring Security добавляет CSRF-токен в форму в виде скрытого атрибута .
Можно выполнить POST-запрос с помощью HTTPie и убедиться еще раз, что CSRF-защита работает.
```
$ http POST http://localhost:8080/
HTTP/1.1 403 Forbidden
Cache-Control: no-cache, no-store, max-age=0, must-revalidate
Content-Type: text/plain
Expires: 0
Pragma: no-cache
Referrer-Policy: no-referrer
X-Content-Type-Options: nosniff
X-Frame-Options: DENY
X-XSS-Protection: 1 ; mode=block
content-length: 38
An expected CSRF token cannot be found
```
Интересный факт — CSRF-защита приоритетнее аутентификации в цепочке фильтров Spring Security.
#### Больше о Spring Boot и Spring Security
Надеюсь, вам понравилось это краткое введение в Thymeleaf и вы узнали, как защитить контент и реализовать авторизацию на стороне сервера с помощью Spring Security. Вы также убедились, насколько быстро и легко интегрировать OIDC-аутентификацию с помощью Okta. Узнать больше о Spring Boot Security и OIDC вы можете в следующих статьях:
* [Learn How to Build a Single-Page App with Vue and Spring Boot](https://developer.okta.com/blog/2021/10/04/spring-boot-spa)
* [Kubernetes to the Cloud with Spring Boot and JHipster](https://developer.okta.com/blog/2021/06/01/kubernetes-spring-boot-jhipster)
* [Spring Native in Action with the Okta Spring Boot Starter](https://developer.okta.com/blog/2021/09/16/spring-native-okta-starter)
Исходный код из статьи вы можете найти на [GitHub](https://github.com/oktadev/okta-thymeleaf-security-example).
---
Всех, дочитавших статью до конца, приглашаем на открытое занятие «Validation Framework в Spring». На занятии рассмотрим, как валидировать различные объекты с использованием javax.validation, в Spring проектах с особенностями. Регистрация — [по ссылке](https://otus.pw/0bg6/). | https://habr.com/ru/post/665952/ | null | ru | null |
# Управление распределенной командой в режиме многопроектности (обзор и видео доклада)

23-24 сентября в Санкт-Петербурге проходила конференция [Saint TeamLead Conf 2019](https://teamleadconf.ru/spb/2019). «Флант» принял в ней активное участие: Игорь Цупко (наш директор по неизвестному) провел митап, на котором участники разобрались в способах поиска и выявления тайных знаний внутри организации, а Сергей Гончарук (менеджер проектов) выступил с докладом «Управление распределенной командой в режиме многопроектности». По традиции, мы публикуем обзор доклада и [его видео](https://www.youtube.com/watch?v=iZ4ornp2XwI&list=PL1mJ-PkCYnmB9vljnjxCMP3dlxQY3Dfcq) (~37 минут).
«Распределенная команда» и «многопроектность»
---------------------------------------------
Под распределенной командой разные компании понимают очень разные вещи — например, филиальную сеть или офис и удаленных работников… Но в нашем случае офиса в его «настоящем» понимании вообще нет.

Сейчас у нас работает более 80 сотрудников, которые живут в более чем 20 городах России и не только. Большинство из нас видит друг друга «в живую» только 2 дня в году, на дне рождения «Фланта».
В остальное время мы живем в Москве, Самаре, Тюмени, Нижнем Новгороде или любом другом городе, работаем под пение птиц или запах кофе. Вместо аренды места, инвестируем деньги во что-то действительно полезное. И так как все работают удаленно, у нас нет деления на «филиалы» или «касты».
А главное — мы нанимаем лучших, несмотря ни на какие границы! Вот что значит «распределенность» в нашем понимании.

Давайте теперь разберемся с многопроектностью, но для начала важно немного погрузиться в устройство «Фланта».
Мы инженерная компания, у нас много инженеров. Пять-семь инженеров под управлением тимлида и менеджера составляют команду. Таких команд несколько, и у каждой команды есть свой набор из проектов.

Проект для нас — это инфраструктура клиента для одного продукта либо одной команды разработки. То есть у проекта есть четкие границы, но нет ограничений по росту и развитию!

У каждого проекта есть свои потребности, которые нужно как-то донести до команды
Это делает менеджер. Таковы основы «многопроектности».
Теперь, когда у нас есть общее понимание терминов из названия доклада, вопрос: что нужно, чтобы в таких условиях всё не просто работало, а работало хорошо?
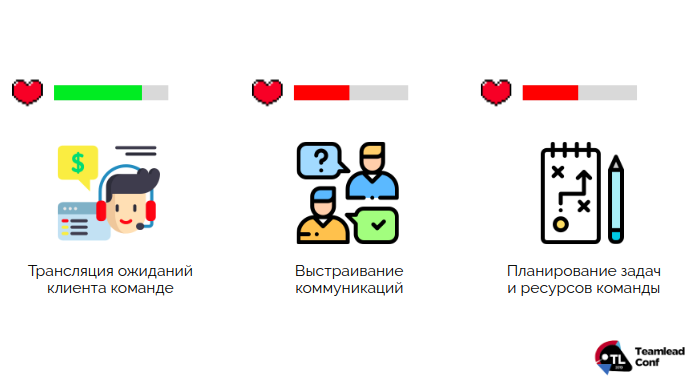
За решение этого вопроса отвечает менеджер команды. Быть «переводчиком» с клиентского на инженерный — это одна из его ключевых компетенций. Вторая — организация конструктивного общения внутри команды и с клиентами. А третья базовая компетенция — нахождение баланса между потоком дел и реальными возможностями инженеров:

Разберем подробнее каждую компетенцию.
1. Трансляция ожиданий
----------------------
Даже у одного и того же клиента могут быть противоречивые ожидания. Например, бизнес клиента требует, чтобы приносящий деньги production был стабилен. И к тому же, постоянно пополнялся новыми функциями, которые помогают увеличить выручку.
Ну, а если уж и случится какая-то авария (бизнес готов к тому, что аварии бывают), то она будет устранена в максимально короткий срок. Звучит очень предсказуемо, не так ли?
Но у этого же клиента есть и разработчики. И их ожидания, оказывается, совсем иные! Для разработчиков dev важнее production’а (ведь на них тоже давит бизнес), а еще они ждут, что любая их просьба будет услышана и сделана прямо сейчас (обычно это описывается фразой «ведь там дел на 5 минут»).
Единственное, что объединяет и бизнес и разработчиков в требованиях, — и те, и другие ожидают, что плановые задачи будут сделаны точно и в обещанные сроки.

Посмотрим на картину в целом… Да тут же полно взаимоисключающих параграфов!
* Добавление новых фич всегда добавляет и новые точки отказа. Бабах! И production работает нестабильно после пятничного релиза.
* Наши инженеры максимально оперативно выполняли в течение дня всё, о чем просят разработчики, а плановые задачи так и остались нетронутыми из-за этого.
* Или вот такая история: стабильности какого окружения уделить больше внимания? Мы стабилизировали dev, выделив на это ресурсы, но у нас после очередного выката начал падать production!
* Частый кейс: сломался production и вся команда ушла его чинить. При этом, конечно, нет продвижения по плановым задачам, и даже разработчики из Индии в чате уже перешли на русский мат, потому что не могут дождаться ответа.

И мы понимаем, что сами требования противоречивы, а значит — напрямую транслировать их невозможно.
2. Коммуникации
---------------
В трансляции ожиданий действительно есть проблемы. Хорошо, может быть, тогда хотя бы с коммуникациями все проще?
Для общения между собой и с клиентами мы используем Slack для текста и Google Meet для митингов и случаев, когда сказать проще, чем написать. Но в чате мы часто получаем сообщения, которые не несут в себе полезного смысла или содержат столько ошибок, что смысл распознать сложно!

Почему мы обращаем на это внимание? Дело в том, что, например, только за июль 2019 года мы получили 1993 обращения от клиентов в Slack, требующих обязательной реакции. И, естественно, с ростом количества клиентов есть и устойчивый тренд по росту количества таких обращений. Около 165 инженеро-часов мы потратили в июле на реакцию на такие обращения. А ведь по каждому обращению требовалось еще и что-то сделать!
Нам очень жаль, когда время инженеров, которое могло бы быть инвестировано в плановые задачи, реакцию на другие обращения или даже на починку аварий, тратится впустую.
Проблема в чатах очевидна, но у видеоконференций наверняка нет проблем?
Мы говорили выше, что используем Google Meet для ежедневных командных митингов, а остальное время делаем задачи, которые разобрали на митинге. Каждый день мы тратим на митинги порядка часа. Мы стараемся тратить на непосредственную работу не менее семи часов в день, то есть на выполнение задач остается 6 часов. Но у нас очень разные по длительности задачи.
Вот и получается, что за час митинга мы могли бы завершить несколько небольших, но, вероятно, важных для наших клиентов задач. И нам надо понять, действительно ли нужны часовые митинги или все же лучше пойти и поработать это время?
Если попробовать собрать проблемы коммуникаций вместе, получаем, что чат генерирует бесполезные прерывания и регулярные митинги «отъедают» рабочее время.

Эффективные коммуникации не выстраиваются сами по себе.
3. Планирование
---------------
Что ж, нам надо решать проблемы в коммуникациях и трансляции ожиданий, но в планировании, наверное, нет никаких подводных камней? Давайте разберемся.
Каждый день создается большое количество новых задач. Хотелось бы, чтобы мы закрывали задачи так же быстро, как они растут. Но в жизни идеал редко бывает достижим. Во-первых, в инфраструктуре иногда что-нибудь да ломается. Во-вторых, всегда есть какие-то мелкие дела, которые проще сделать сразу. В-третьих, есть задачи, о решении которых мы договорились на командном митинге:

А иногда случается так, что из-за аварий и дерганий по мелочам до плановых вообще не удается добраться! При этом новые задачи не перестают прибывать — все обещанные сроки срываются.
Наш рецепт
----------

Но на все проблемы с трансляцией ожиданий, с коммуникациями и планированием, методом набивания шишек удалось получить, как нам кажется, правильный ответ.

Одним из ключевых бизнес-процессов, затрагивающих все три базовые компетенции, является командный митинг. И у нас появилось предположение, что если сделать командный митинг эффективным мы сможем достигнуть 80% результата двадцатью процентами усилий? Мы проверили эту теорию.
Как вы помните, у нас есть команда, обслуживающая свой набор проектов. И у нее есть некий перечень требований от этих проектов. Но каждое требование, как правило, лишь одно в цепочке взаимосвязанных задач. И так в каждом проекте! И прежде, чем взять в работу новую задачу, нам надо понимать, сделали ли мы предыдущий этап?
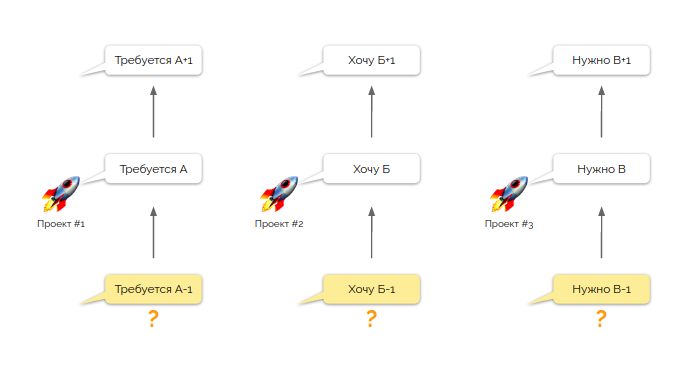
Вчера задачу А-1 выполнял Егор, задачу Б-1 — Семен, а задачу В-1 — Жанна. Но как нам погрузить всех инженеров во все проекты настолько глубоко, чтобы Егору удалось успешно справиться с задачей Б, а Семёну — с двумя небольшими задачами А и В. «Зачем все эти сложности?» — спросите вы. Да дело в том, что Жанна сегодня в отпуске и плановых задач выполнять не будет!

В нашем фокусе внимания много подобных задач. В среднем в каждую команду мы получаем около 25 новых задач каждый рабочий день. И так как задач много, связи между ними запутаны и нет понимания, выполнены ли все задачи предыдущего дня. Для того, чтобы распутывать все это, нужен командный митинг, причем каждый рабочий день, иначе мы не сможем управлять этим потоком.
Учитывая объемы потока, к митингу стоит заранее подготовиться. Мы на подготовке без инженеров не сможем понять, какие именно задачи сделаны полностью, а какие — нет. И, конечно, не сможем передать знания от инженера к инженеру. Но нам однозначно по силам определить приоритеты взятия новых задач в работу.
Приоритезация задач
-------------------
На чем мы основываемся при приоритезации задач? Во-первых, у нас есть стратегические договоренности с клиентом о целях, которые нужно достичь. Во-вторых, раз в неделю мы уточняем тактические планы на online-встрече с заказчиком. Потребности клиента при подготовке как раз отстаивает менеджер, а техническую необходимость и порядок выполнения той или иной задачи — тимлид команды. Именно так, на основании **паритета мнений тимлида и менеджера**, формируется список задач на день.

Культура проведения командных митингов
--------------------------------------
Как только список задач на день определили, чтобы уточнить, что сделано, и погрузить в подробности коллег, начинаем командный митинг, на котором каждый инженер должен подробно рассказать, что он сделал вчера, а вся команда — услышать и, главное, понять произошедшие изменения. Но это проще сказать, чем сделать.
Мы ввели ряд культурных особенностей проведения митинга, которые позволили достигнуть требуемого результата:

В начале митинга, пока все собираются, мы тратим 10-15 минут на разговоры о жизни. О новостях и событиях, не связанных с работой, об увлечениях коллег. Так инженеры, которые находятся в разных городах и почти не видятся, становятся приятелями или даже друзьями. И **эти 10-15 минут в день помогают команде быть более сплоченной**.
После тимбилдинг-беседы приступаем к содержательной части. Вернемся немного назад.

Помните вот эту иллюстрацию? Дело в том, что ни Семен, ни Егор до начала митинга не знают, какие задачи и в каких проектах они будут выполнять сегодня. По целому ряду причин: отпуска, командировки, болезнь, дежурства и т.п. — задача может менять исполнителей изо дня в день, пока не будет полностью решена. И каждый инженер понимает, что сегодня задача может быть назначена и на него, то есть все инженеры уже изначально **заинтересованы вникнуть в подробности каждой задачи**.
Мы разбираем на митинге всей командой возникшие блокировки. Мы настаиваем, чтобы в решении проблемы докладчика приняла участие вся команда. Так мы **мотивируем погружаться в задачи и решать их вместе**.
Если команда работает в офисе, неформальное общение часто происходит «у кулера». Но и в распределенной команде потребность в таком общении существует. Именно поэтому во время обсуждения задач разговор зачастую утекает куда-то не туда. Но мы пресекаем любые отвлечения. Как именно? Нам это удается довольно легко: ведь для отвлеченных разговоров есть специально выделенное время, а сейчас — время работы. Поэтому даже обычного устного «давайте по делу» хватает, чтобы все вернулись к деловой повестке. Пресекая отвлечения в процессе разбора задач, мы **настраиваем команду на рабочий лад**.
Мы стараемся контролировать время доклада каждого инженера. Порой для погружения в детали нам нужен длинный и подробный рассказ о задаче. Тем не менее, в большинстве случаев, мы **стараемся не растянуть митинг**.
Эффективные митинги — серебряная пуля?
--------------------------------------
Благодаря подготовке к митингу на основе паритета мнений тимлида и менеджера и нашим культурным особенностям проведения митинга мы действительно сделали их эффективными. Но получилось ли закрыть 80% по всем компетенциям? Не совсем.
Мы хорошо поработали с трансляцией ожиданий, но в коммуникациях все еще проблемы с неинформативными сообщениями в чатах, а в планировании остались прерывания, которые не дают эффективно делать плановые задачи.
Да, но ведь и неинформативные сообщения в чате — тоже прерывания. И нам необходимо найти механизм, который поможет нам эффективно обрабатывать прерывания всех видов.
Борьба с прерываниями
---------------------
Мы подумали, а что, если у нас будет отдельный человек, который будет «закрывать» собой команду, работающую над плановыми заданиями от потока прерываний?

Идея не новая и в общем хорошая, но кто именно будет это делать? Мы рассматривали два варианта: поиск и найм такой службы или использование уже имеющихся инженеров. Поиск новых людей требовал времени и финансовых ресурсов, а существующие инженеры уже были «проверены в бою» и погружены во все проекты команды. Поэтому вариант с наймом новых людей был отвергнут.
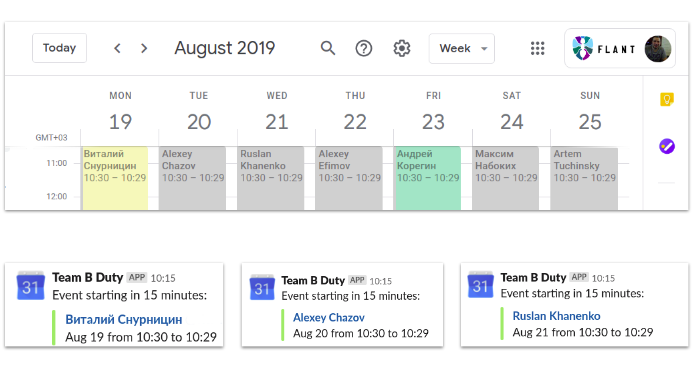
Осталось определиться с вопросом, как организовать такую службу из текущих инженеров. Тут решение было на поверхности: просто применили дежурства по графику, с ротацией инженеров из команды. Само расписание дежурств мы ведем в Google Calendar, плюс настроили уведомления в Slack о том, кто дежурит сегодня.
Казалось бы, все теперь должно быть отлично? Ура? Нет, на самом деле осталась проблема. Помните, чуть раньше мы говорили, что только в Slack получаем почти 2000 обращений в месяц, а это около 16 обращений в день в каждую команду. Но кроме Slack дежурный должен будет обработать сообщения и от систем мониторинга, а в день это:
* 112 — от Prometheus;
* 16 — от okmeter;
* 25 — от систем внешнего blackbox-мониторинга;
* 14 — от различных кастомных скриптов;
* и даже 2 телефонных звонка от клиентов.
Это же 198 прерываний каждый день из разных источников! Но на самом деле источников еще больше:
* Prometheus есть почти у каждого клиента;
* и Okmeter установлен у каждого клиента;
* а вот кастомных скриптов даже у одного клиента может быть сколько угодно…

Чтобы без волшебства и суперспособностей с этим справился любой инженер из команды, мы собрали алерты от всех источников прерываний в одном месте. Этот инструмент мы назвали Madison, а каждое сообщение в него — Инцидентом.
Но Madison лишь собирает инциденты и хранит состояние о них. Нам же нужно понимать, какой инцидент брать в работу первым, то есть произвести триаж, иметь четкий порядок обработки и эскалации, чтобы легко выполнить его в стрессовой ситуации.
Мы создали и такой инструмент — назвали его Polk:

Polk — это рабочее место дежурного инженера. Он позволяет дежурному фокусироваться только на инцидентах, не отвлекаясь на плановые задачи, получать инциденты из всех источников в одном месте, помогает с определением критичности инцидента по заранее определенному Severity, имеет набор четко описанных статусов и алгоритм обработки, определяющий движение по этим статусам.
Технические и культурные особенности общения в чатах
----------------------------------------------------
Отлично: теперь дежурный, снабженный таким мощным инструментом, действительно закрывает команду от прерываний. Но даже с таким инструментарием дежурство выматывает, а бесполезные прерывания только подливают масло в огонь.

Для борьбы с бесполезными прерываниями в чате мы можем применить небольшой набор технических средств, но основное решение этой проблемы точно лежит в культурной плоскости.
С технической точки зрения в Slack мы разделили информацию по проектам, создав раздельно канал для общения с представителями заказчиков, и по каждому проекту — канал для обсуждения инженерами работ по нему. Еще мы написали бота `@flant`, при обращении к которому в Polk автоматически создается инцидент, который обрабатывает дежурный.

Кроме того, мы рекомендовали клиентам использовать `@flant`, а `@channel` (событие, оповещающее всех участников канала) и `@here` (событие, оповещающее всех участников канала, находящихся online) использовать только в тех редких и исключительных случаях, когда без них действительно нельзя обойтись (например, когда бот `@flant` недоступен).
В первый день нашего сотрудничества с клиентом мы размещаем в канале подробную инструкцию по взаимодействию. И на первой же регулярной встрече обязательно обсуждаем взаимодействие, в том числе и разницу между `@channel`, `@here` и `@flant`.
В частности, мы акцентируем внимание на том, что обращение к `@flant` для нас, в первую очередь, это действие с обязательной реакцией, а `@channel` и `@here` для большей части команды — просто прерывание, которое к тому же безадресно и может быть проигнорировано, отвлекая при этом всю команду от решения плановых задач, в том числе по данному проекту.

Но в чат приходят новые коллеги со стороны клиентов, которые не знают о боте. Другие просто забывают. Если так происходит, мы мягко напоминаем о его существовании.

Для общения же между инженерами мы используем те же правила для `@channel`
и `@here`: не использовать их без крайней необходимости. И еще, мы настаиваем на придерживании правила «Не говори просто „привет“ в чате — сразу сформулируй мысль». Это правило обязательно к прочтению всеми новичками. Тем, кто его забыл, об этом обязательно напомнят — если потребуется, развернуто.
Итого: с введением дежурств и исправлением проблем общения в чате мы справились и с большей частью бесполезных прерываний и с влиянием прерываний на выполнение плановых задач.

Прокрастинация и блокировки
---------------------------
Мы проверили, как улучшились наши показатели после этого: действительно, они стали явно лучше, но все еще осталась проблема в планировании.
Когда командный митинг закончился, приходит время поработать. Но зачастую инженеры, особенно работающие удаленно, склонны прокрастинировать. Или, во время работы, упереться в проблему и ходить по кругу в попытке ее решить.

Давайте попробуем разобраться с прокрастинацией. Как ее побороть? Задач в Redmine (нашем трекере задач) слишком много — нужен фокус на тех, что будут в работе именно сегодня. И даже среди них нужно понять, какие задачи сделать в первую очередь, то есть — определить приоритеты. И идеально, если примерно запланировать время, которое мы готовы потратить на каждую задачу…

Мы создали инструмент, который помогает все это решить, и назвали его Ford:

Именно в нем инженер получает задание на рабочий день в виде карточек, расположенных в приоритетном порядке. У всех плановых задач мы проставляем примерное время, которого инженер должен придерживаться при их решении. Инженер учитывает время, которое он потратил на решение задачи. И если время примерно совпало, а задача не решена — это маркер того, что инженер зашел в тупик.

Что с этим можно сделать? Кроме приоритета, в котором расположены карточки,
мы ввели еще и категории приоритетов, выделили их цветами:
* Серое поле используется для обычных, плановых задач;
* Зеленое поле — для задач, которые в текущем дне стоит начинать делать, только если закончатся задачи во всех остальных полях;
* Желтое поле — для задач, которые вдруг внепланово возникли в течение дня;
* Красное поле — для задач, требующих решения до конца текущего рабочего дня.
Если инженер заблокировался по задаче в сером и зеленом полях, то он просто должен начать следующую задачу, а блокировку разобрать на следующем командном митинге.

Но очевидно, что если инженер заблокировался по задачам в желтой или красной зонах, то ждать следующей встречи не стоит: нужно звать на помощь команду в соответствующем канале для общения инженеров по проекту, в котором поставлена задача. И, в соответствии с нашей культурой, инженеры команды или тимлид обязательно придут на помощь.

Стоит оговориться, что возможности Ford значительно шире и мы затронули только «верхушку айсберга», которую вы можете реализовать с помощью других, открытых инструментов.
Итоги
-----
Получается, что для борьбы с прокрастинацией и блокировками мы используем Ford как техническое решение и простые правила в командной культуре.

Помогли ли нам эти инструменты? Да! Но почему-то не на 100%?
Дело в том, что мир меняется и движется вперед. И мы в этих условиях тоже меняемся, стремимся к идеалу, но он, как известно, недостижим.
О достижении идеалов и роли менеджера
-------------------------------------
Всё великое, что создано человечеством за все время его существования, сделали команды профессионалов, у которых были крутые менеджеры.


Мы, «Флант», тоже команда профессионалов. И было бы классно, если бы крутых менеджеров в нашей команде стало больше. Приходите к нам работать и помогать делать наши процессы лучше:
[](https://job.flant.ru/manager)
Видео и слайды
--------------
Видео с выступления (~38 минут):
Презентация доклада:
P.S.
----
Читайте также в нашем блоге:
* «[Работа удалённо: наш опыт](https://habr.com/ru/company/flant/blog/463619/)»;
* «[„Нетипичное отношение к финансам“ — что если сотрудники сами будут управлять доходами. Разговор с Флант](https://habr.com/ru/company/moikrug/blog/444712/)»;
* «[Performance Review и выявление тайного знания (обзор и видео доклада)](https://habr.com/ru/company/flant/blog/455790/)»;
* «[Как „Флант“ помогает новичкам](https://habr.com/ru/company/flant/blog/419051/)»;
* «[Как „Флант“ нанимает сотрудников](https://habr.com/ru/company/flant/blog/417725/)». | https://habr.com/ru/post/469453/ | null | ru | null |
# Секретики Unity3d. Зачем нужен флаг STARTER_ASSETS_PACKAGES_CHECKED в стартовых ассетах
Что за флаг?
------------
Кто устанавливал офицальные ассеты от Unity **"Starter Assets - Third Person Character Controller**" или **"Starter Assets - First Person Character Controller"** возможно замечал что в настройках проета (Project settings -> Player -> Other settings -> Script Compilation) появляется флаг `STARTER_ASSETS_PACKAGES_CHECKED`, но зачем он нужен? Давайте разбираться.
Исследуем скрипты
-----------------
Для иследования был выбран ассет **"Starter Assets - First Person Character Controller".** Открываем скрипт "ThirdPersonController" и что мы видим:
```
...
namespace StarterAssets
{
[RequireComponent(typeof(CharacterController))]
#if ENABLE_INPUT_SYSTEM && STARTER_ASSETS_PACKAGES_CHECKED
[RequireComponent(typeof(PlayerInput))]
#endif
public class ThirdPersonController : MonoBehaviour
{
...
```
```
...
#if ENABLE_INPUT_SYSTEM && STARTER_ASSETS_PACKAGES_CHECKED
private PlayerInput _playerInput;
#endif
...
```
```
...
#if ENABLE_INPUT_SYSTEM && STARTER_ASSETS_PACKAGES_CHECKED
_playerInput = GetComponent();
#else
...
```
По всюду этот флаг используется в паре с флагом `ENABLE_INPUT_SYSTEM`, хм... интересно. Очевидно что флаг `ENABLE_INPUT_SYSTEM` отвечает за новую систему ввода, но вот второй флаг зачем он здесь и кто его устанавливает в настройках проекта? Смотрим дальше. Нашелся еще один флаг в скрипте "StarterAssetsDeployMenu.cs", но уже тут он используется один:
```
...
#if STARTER_ASSETS_PACKAGES_CHECKED
private static void CheckCameras(Transform targetParent, string prefabFolder)
{
CheckMainCamera(prefabFolder);
GameObject vcam = GameObject.Find(CinemachineVirtualCameraName);
...
```
Из кода становиться понятно что он включает работу с кинемашиной. Интересно, значит получается что этот флаг контролирует подключение кода который в свой очередь находиться в двух пакетах "com.unity.inputsystem" и "com.unity.cinemachine". С этим вроде немного разобрались, но всетаки кто устанавливает этот флаг в настройках проекта?
Исследуем файлы проекта
-----------------------
После тщательного обследования файлов ассета, выявлена подозрительная библиотека `Assets\StarterAssets\Editor\PackageChecker\StarterAssetsPackageChecker.dll` давайте ее отрефлектим:
Hidden text
```
// Decompiled with JetBrains decompiler
// Type: StarterAssetsPackageChecker.PackageChecker
// Assembly: StarterAssetsPackageChecker, Version=1.0.0.0, Culture=neutral, PublicKeyToken=null
// MVID: 2A478D25-B4D8-4B2D-BB34-CB7D710194F5
// Assembly location: D:\YandexDisk\Development\Games\secrets-from-unity\Assets\StarterAssets\Editor\PackageChecker\StarterAssetsPackageChecker.dll
using System;
using System.Collections.Generic;
using System.IO;
using UnityEditor;
using UnityEditor.PackageManager;
using UnityEditor.PackageManager.Requests;
using UnityEngine;
namespace StarterAssetsPackageChecker
{
public static class PackageChecker
{
private static ListRequest _clientList;
private static SearchRequest _compatibleList;
private static List \_packagesToAdd;
private static AddRequest[] \_addRequests;
private static bool[] \_installRequired;
private static PackageChecker.Settings \_settings;
[InitializeOnLoadMethod]
private static void CheckPackage()
{
PackageChecker.\_settings = new PackageChecker.Settings();
string[] files = Directory.GetFiles(Application.dataPath, "PackageCheckerSettings.json", SearchOption.AllDirectories);
if (files.Length != 0)
JsonUtility.FromJsonOverwrite(File.ReadAllText(files[0]), (object) PackageChecker.\_settings);
if (PackageChecker.CheckScriptingDefine(PackageChecker.\_settings.PackageCheckerScriptingDefine))
return;
PackageChecker.\_packagesToAdd = new List();
PackageChecker.\_clientList = (ListRequest) null;
PackageChecker.\_compatibleList = (SearchRequest) null;
PackageChecker.\_packagesToAdd = new List();
foreach (string str in PackageChecker.\_settings.PackagesToAdd)
{
char[] chArray = new char[1]{ '@' };
string[] strArray = str.Split(chArray);
PackageChecker.PackageEntry packageEntry = new PackageChecker.PackageEntry()
{
Name = strArray[0],
Version = strArray.Length > 1 ? strArray[1] : (string) null
};
PackageChecker.\_packagesToAdd.Add(packageEntry);
}
PackageChecker.SetScriptingDefine(PackageChecker.\_settings.PackageCheckerScriptingDefine);
PackageChecker.\_compatibleList = Client.SearchAll();
while (!PackageChecker.\_compatibleList.IsCompleted)
{
if ((PackageChecker.\_compatibleList.Status == StatusCode.Failure || PackageChecker.\_compatibleList.Error != null) && PackageChecker.\_compatibleList.Error != null)
{
Debug.LogError((object) PackageChecker.\_compatibleList.Error.message);
break;
}
}
PackageChecker.\_clientList = Client.List();
while (!PackageChecker.\_clientList.IsCompleted)
{
if ((PackageChecker.\_clientList.Status == StatusCode.Failure || PackageChecker.\_clientList.Error != null) && PackageChecker.\_clientList.Error != null)
{
Debug.LogError((object) PackageChecker.\_clientList.Error.message);
break;
}
}
PackageChecker.\_addRequests = new AddRequest[PackageChecker.\_packagesToAdd.Count];
PackageChecker.\_installRequired = new bool[PackageChecker.\_packagesToAdd.Count];
for (int index = 0; index < PackageChecker.\_installRequired.Length; ++index)
PackageChecker.\_installRequired[index] = false;
List packageInfoList1 = new List();
List packageInfoList2 = new List();
foreach (UnityEditor.PackageManager.PackageInfo packageInfo in PackageChecker.\_compatibleList.Result)
packageInfoList1.Add(packageInfo);
foreach (UnityEditor.PackageManager.PackageInfo packageInfo in (IEnumerable) PackageChecker.\_clientList.Result)
packageInfoList2.Add(packageInfo);
for (int index = 0; index < PackageChecker.\_packagesToAdd.Count; ++index)
{
if (PackageChecker.\_packagesToAdd[index].Version == null)
{
foreach (UnityEditor.PackageManager.PackageInfo packageInfo in packageInfoList1)
{
if (PackageChecker.\_packagesToAdd[index].Name == packageInfo.name && packageInfo.versions.verified != string.Empty)
{
PackageChecker.\_packagesToAdd[index].Version = packageInfo.versions.verified;
PackageChecker.\_installRequired[index] = true;
}
}
}
foreach (UnityEditor.PackageManager.PackageInfo packageInfo in packageInfoList2)
{
if (PackageChecker.\_packagesToAdd[index].Name == packageInfo.name)
{
switch (PackageChecker.CompareVersion(PackageChecker.\_packagesToAdd[index].Version, packageInfo.version))
{
case -1:
PackageChecker.\_installRequired[index] = (EditorUtility.DisplayDialog("Confirm Package Downgrade", "The version of \"" + PackageChecker.\_packagesToAdd[index].Name + "\" in this project is " + packageInfo.version + ". The latest verified version is " + PackageChecker.\_packagesToAdd[index].Version + ". " + packageInfo.version + " is unverified. Would you like to downgrade it to the latest verified version? (Recommended)", "Yes", "No") ? 1 : 0) != 0;
Debug.Log((object) ("**Package version ahead**: " + packageInfo.packageId + " is newer than latest verified version " + packageInfo.versions.verified + ", skipped install"));
continue;
case 0:
PackageChecker.\_installRequired[index] = false;
Debug.Log((object) ("**Package version match**: " + packageInfo.packageId + " matches latest verified version " + packageInfo.versions.verified + ". Skipped install"));
continue;
case 1:
PackageChecker.\_installRequired[index] = (EditorUtility.DisplayDialog("Confirm Package Upgrade", "The version of \"" + PackageChecker.\_packagesToAdd[index].Name + "\" in this project is " + packageInfo.version + ". The latest verified version is " + PackageChecker.\_packagesToAdd[index].Version + ". Would you like to upgrade it to the latest version? (Recommended)", "Yes", "No") ? 1 : 0) != 0;
Debug.Log((object) ("**Package version behind**: " + packageInfo.packageId + " is behind latest verified version " + packageInfo.versions.verified + ". prompting user install"));
continue;
default:
continue;
}
}
}
}
for (int index = 0; index < PackageChecker.\_packagesToAdd.Count; ++index)
{
if (PackageChecker.\_installRequired[index])
PackageChecker.\_addRequests[index] = PackageChecker.InstallSelectedPackage(PackageChecker.\_packagesToAdd[index].Name, PackageChecker.\_packagesToAdd[index].Version);
}
PackageChecker.ReimportPackagesByKeyword();
}
private static AddRequest InstallSelectedPackage(
string packageName,
string packageVersion)
{
if (packageVersion != null)
{
packageName = packageName + "@" + packageVersion;
Debug.Log((object) ("**Adding package**: " + packageName));
}
AddRequest addRequest = Client.Add(packageName);
while (!addRequest.IsCompleted)
{
if ((addRequest.Status == StatusCode.Failure || addRequest.Error != null) && addRequest.Error != null)
{
Debug.LogError((object) addRequest.Error.message);
return (AddRequest) null;
}
}
return addRequest;
}
private static void ReimportPackagesByKeyword()
{
AssetDatabase.Refresh();
AssetDatabase.ImportAsset(PackageChecker.\_settings.EditorFolderRoot, ImportAssetOptions.ImportRecursive);
}
public static int CompareVersion(string latestVerifiedVersion, string projectVersion)
{
string[] strArray1 = latestVerifiedVersion.Split('.');
string[] strArray2 = projectVersion.Split('.');
int index1 = 0;
for (int index2 = 0; index1 < strArray1.Length || index2 < strArray2.Length; ++index2)
{
int num1 = 0;
int num2 = 0;
if (index1 < strArray1.Length)
num1 = Convert.ToInt32(strArray1[index1]);
if (index2 < strArray2.Length)
num2 = Convert.ToInt32(strArray2[index2]);
if (num1 > num2)
return 1;
if (num1 < num2)
return -1;
++index1;
}
return 0;
}
private static bool CheckScriptingDefine(string scriptingDefine) => PlayerSettings.GetScriptingDefineSymbolsForGroup(EditorUserBuildSettings.selectedBuildTargetGroup).Contains(scriptingDefine);
private static void SetScriptingDefine(string scriptingDefine)
{
BuildTargetGroup buildTargetGroup = EditorUserBuildSettings.selectedBuildTargetGroup;
string defineSymbolsForGroup = PlayerSettings.GetScriptingDefineSymbolsForGroup(buildTargetGroup);
if (defineSymbolsForGroup.Contains(scriptingDefine))
return;
string defines = defineSymbolsForGroup + ";" + scriptingDefine;
PlayerSettings.SetScriptingDefineSymbolsForGroup(buildTargetGroup, defines);
}
public static void RemovePackageCheckerScriptingDefine()
{
BuildTargetGroup buildTargetGroup = EditorUserBuildSettings.selectedBuildTargetGroup;
string defineSymbolsForGroup = PlayerSettings.GetScriptingDefineSymbolsForGroup(buildTargetGroup);
if (!defineSymbolsForGroup.Contains(PackageChecker.\_settings.PackageCheckerScriptingDefine))
return;
string defines = defineSymbolsForGroup.Replace(PackageChecker.\_settings.PackageCheckerScriptingDefine, "");
PlayerSettings.SetScriptingDefineSymbolsForGroup(buildTargetGroup, defines);
}
private class PackageEntry
{
public string Name;
public string Version;
}
[Serializable]
private class Settings
{
public string EditorFolderRoot = "Assets/StarterAssets/";
public string[] PackagesToAdd = new string[2]
{
"com.unity.cinemachine",
"com.unity.inputsystem"
};
public string PackageCheckerScriptingDefine => "STARTER\_ASSETS\_PACKAGES\_CHECKED";
}
}
}
```
И что мы тут видим? Наш флажочек `STARTER_ASSETS_PACKAGES_CHECKED`)
```
[Serializable]
private class Settings
{
public string EditorFolderRoot = "Assets/StarterAssets/";
public string[] PackagesToAdd = new string[2]
{
"com.unity.cinemachine",
"com.unity.inputsystem"
};
public string PackageCheckerScriptingDefine => "STARTER_ASSETS_PACKAGES_CHECKED";
}
```
Так, я чувствую что мы уже близко к истине.
Разбираем потроха StarterAssetsPackageChecker.dll
-------------------------------------------------
Изучив код этой библиотеки, я пришол к выводу что это - автоматический инсталятор пакетов Unity. Очень интересно! Давайте расскажу как эта штука работает.
Главный метод запускается каждый раз, при "перезагрузки" редактора, о чем говорит аттрибут`[InitializeOnLoadMethod]`в этом методе идет поиск файлов с именем "PackageCheckerSettings.json", а затем настройки из этого файла мапятся на `PackageChecker._settings`.
```
...
[InitializeOnLoadMethod]
private static void CheckPackage()
{
PackageChecker._settings = new PackageChecker.Settings();
string[] files = Directory.GetFiles(Application.dataPath, "PackageCheckerSettings.json", SearchOption.AllDirectories);
if (files.Length != 0)
JsonUtility.FromJsonOverwrite(File.ReadAllText(files[0]), (object) PackageChecker._settings);
...
```
Давайте взглянем что находиться в файле "PackageCheckerSettings.json", и тут мы видим опять наши пакеты, а также какой-то "EditorFolderRoot":
```
{
"EditorFolderRoot": "Assets/StarterAssets/",
"PackagesToAdd": [
"com.unity.cinemachine",
"com.unity.inputsystem"
]
}
```
Вернемся в нашу dll. Далее по коду идет сравнение версий пакетов и их установка с помощью метода `private static AddRequest InstallSelectedPackage`. И тут же видим нашу заветную строчку, которая задает флаг `STARTER_ASSETS_PACKAGES_CHECKED` на уровне проекта:
```
PackageChecker.SetScriptingDefine(PackageChecker._settings.PackageCheckerScriptingDefine);
...
private static void SetScriptingDefine(string scriptingDefine)
{
BuildTargetGroup buildTargetGroup = EditorUserBuildSettings.selectedBuildTargetGroup;
string defineSymbolsForGroup = PlayerSettings.GetScriptingDefineSymbolsForGroup(buildTargetGroup);
if (defineSymbolsForGroup.Contains(scriptingDefine))
return;
string defines = defineSymbolsForGroup + ";" + scriptingDefine;
PlayerSettings.SetScriptingDefineSymbolsForGroup(buildTargetGroup, defines);
}
```
Теперь стало все понятно, этот флаг фиксирует установку пакетов и при дальнейшем вызове метода CheckPackage() идет проверка, что если флаг установлен то установку пакетов уже не производим. Вауля!!!
```
if (PackageChecker.CheckScriptingDefine(PackageChecker._settings.PackageCheckerScriptingDefine))
return;
```
А что насчет строчки `"EditorFolderRoot": "Assets/StarterAssets/"` из конфига? А тут все просто она указывает на папку с ассетами которым нужно сделать реимпорт после установки пакетов
```
private static void ReimportPackagesByKeyword()
{
AssetDatabase.Refresh();
AssetDatabase.ImportAsset(PackageChecker._settings.EditorFolderRoot, ImportAssetOptions.ImportRecursive);
}
```
Что в итоге?
------------
Мы можем использовать библиотеку `StarterAssetsPackageChecker.dll` в паре с файлом `PackageCheckerSettings.json` в своем проекте для автоматической установки пакетов Unity. Просто закидываем их к себе в папку Editor и добавляем необходимые пакеты в файл конфигурации.
Чтобы я улучшил в библиотеке `StarterAssetsPackageChecker.dll` так это сделал бы свойство `public string PackageCheckerScriptingDefine => "STARTER_ASSETS_PACKAGES_CHECKED"` доступным для записи, чтобы можно было задавать произвольное имя флага в своих ассетах. Еще бы добавил итерацию по всем файлам `PackageCheckerSettings.json` находящимся в проекте, чтобы установить все зависимости, а не производить установку только по первому попавшемуся файлу.
Могу предположить что у каманды Unity это своего рода "заготовка" для будущей автоматизации установки пакетов, поэтому будем надеяться и верить что работа с пакетами станет еще проще и удобней. А также пожелаем Unity чтобы она добавила возможность добавлять scope в файлы манифеста с помощью кода.
---
> Присоединяйтесь к моим соц сетям:
>
> YouTube: <https://www.youtube.com/channel/UC8Pm1hZfQMKE8nfSdYqKugg>
>
> VK: <https://vk.com/stupenkovanton>
>
> GitHub: <https://github.com/stupenkov>
>
> Linkedin: <https://www.linkedin.com/in/stupenkov/>
>
> | https://habr.com/ru/post/686526/ | null | ru | null |
# Не только обработка: Как мы сделали из Kafka Streams распределенную базу данных, и что из этого вышло
Привет, Хабр!
Напоминаем, что вслед за книгой о [Kafka](https://www.piter.com/product_by_id/112863410) мы выпустили не менее интересный труд о библиотеке [Kafka Streams API](https://www.piter.com/collection/new/product/kafka-streams-v-deystvii-prilozheniya-i-mikroservisy-dlya-raboty-v-realnom-vremeni).

Пока сообщество только постигает границы возможностей этого мощного инструмента. Так, недавно вышла статья, с переводом которой мы хотим вас познакомить. На собственном опыте автор рассказывает, как сделать из Kafka Streams распределенное хранилище данных. Приятного чтения!
Библиотека Apache [Kafka Streams](https://kafka.apache.org/documentation/streams/) по всему миру используется в энтерпрайзе для распределенной потоковой обработки поверх Apache Kafka. Один из недооцененных аспектов этого фреймворка заключается в том, что он позволяет хранить локальное состояние, производимое на основе потоковой обработки.
В этой статье я расскажу, как в нашей компании удалось выгодно задействовать эту возможность при разработке продукта по безопасности облачных приложений. При помощи Kafka Streams мы создали микросервисы с разделяемым состоянием, каждый из которых служит нам отказоустойчивым и высокодоступным источником достоверной информации о состоянии объектов в системе. Для нас это шаг вперед как в отношении надежности, так и в удобстве поддержки.
Если вас интересует альтернативный подход, позволяющий использовать единую центральную базу данных для поддержки формального состояния ваших объектов – почитайте, будет интересно…
**Почему мы сочли, что пришло время менять наши подходы к работе с разделяемым состоянием**
Нам требовалось поддерживать состояние различных объектов, опираясь на отчеты агентов (например: подвергался ли сайт атаке)? До перехода на Kafka Streams мы зачастую полагались для управления состоянием на единую центральную базу данных (+ сервисный API). У такого подхода есть свои недостатки: в [датаинтенсивных ситуациях](https://www.piter.com/collection/all/product/vysokonagruzhennye-prilozheniya-programmirovanie-masshtabirovanie-podderzhka) поддержка согласованности и синхронизации превращается в настоящий вызов. База данных может стать узким местом, либо оказываться в [состоянии гонки](https://stackoverflow.com/questions/9850336/database-race-conditions) и страдать от непредсказуемости.
*Иллюстрация 1: типичный сценарий с разделением состояния, встречавшийся на до перехода на
Kafka и Kafka Streams: агенты сообщают свои представления через API, обновленное состояние рассчитывается через центральную базу данных*
**Знакомьтесь с Kafka Streams – теперь стало просто создавать микросервисы с разделяемым состоянием**
Примерно год назад мы решили хорошенько пересмотреть наши сценарии работы с разделяемым состоянием, чтобы разобраться с такими проблемами. Сразу же решили попробовать Kafka Streams – известно, насколько она масштабируемая, высокодоступная и отказоустойчивая, какой богатый у нее потоковый функционал (преобразования, в том числе, с сохранением состояния). Как раз то, что нам требовалось, не говоря уже о том, насколько зрелая и надежная система обмена сообщениями сложилась в Kafka.
Каждый из созданных нами микросервисов с сохранением состояния строился на основе инстанса Kafka Streams с довольно простой топологией. Он состоял из 1) источника 2) процессора с постоянным хранилищем ключей и значений 3) стока:

*Иллюстрация 2: задаваемая по умолчанию топология наших потоковых инстансов для микросервисов с сохранением состояния. Обратите внимание: здесь также есть хранилище, в котором находятся метаданные о планировании.*
При таком новом подходе агенты составляют сообщения, подаваемые в исходный топик, а потребители – скажем, сервис почтовых уведомлений – принимают вычисленное разделяемое состояние через сток (выходной топик).

*Иллюстрация 3: новый пример потока задач для сценария с разделяемыми микросервисами: 1) агент порождает сообщение, поступающее в исходный топик Kafka; 2) микросервис с разделяемым состоянием (использующий Kafka Streams) обрабатывает его и записывает вычисленное состояние в конечный топик Kafka; после чего 3) потребители принимают новое состояние*
**Эй, а это встроенное хранилище ключей и значений в самом деле очень полезно!**
Как упоминалось выше, наша топология с разделяемым состоянием содержит хранилище ключей и значений. Мы нашли несколько вариантов его использования, и два из них описаны ниже.
***Вариант #1: использование хранилища ключей и значений при вычислениях***
Наше первое хранилище ключей и значений содержало вспомогательные данные, которые требовались нам для вычислений. Например, в некоторых случаях разделяемое состояние определялось по принципу «большинства голосов». В хранилище можно было держать все последние отчеты агентов о состоянии некоторого объекта. Затем, получая новый отчет от того или иного агента, мы могли сохранить его, извлечь из хранилища отчеты всех остальных агентов о состоянии того же самого объекта и повторить вычисление.
Ниже на иллюстрации 4 показано, как мы открывали доступ к хранилищу ключей и значений обрабатывающему методу процессора, так что затем можно было обработать новое сообщение.
*Иллюстрация 4: открываем доступ к хранилищу ключей и значений для обрабатывающего метода процессора (после этого в каждом сценарии, работающем с разделяемым состоянием, необходимо реализовать метод `doProcess`)*
***Вариант #2: создание CRUD API поверх Kafka Streams***
Наладив наш базовый поток задач, мы стали пробовать написать RESTful CRUD API для наших микросервисов с разделяемым состоянием. Мы хотели, чтобы можно было извлекать состояние некоторых или всех объектов, а также устанавливать или удалять состояние объекта (это полезно при поддержке серверной части).
Для поддержки всех API Get State, всякий раз, когда нам требовалось заново вычислять состояние при обработке, мы надолго укладывали его во встроенное хранилище ключей и значений. В таком случае становится достаточно просто реализовать такой API при помощи единственного экземпляра Kafka Streams, как показано в нижеприведенном листинге:
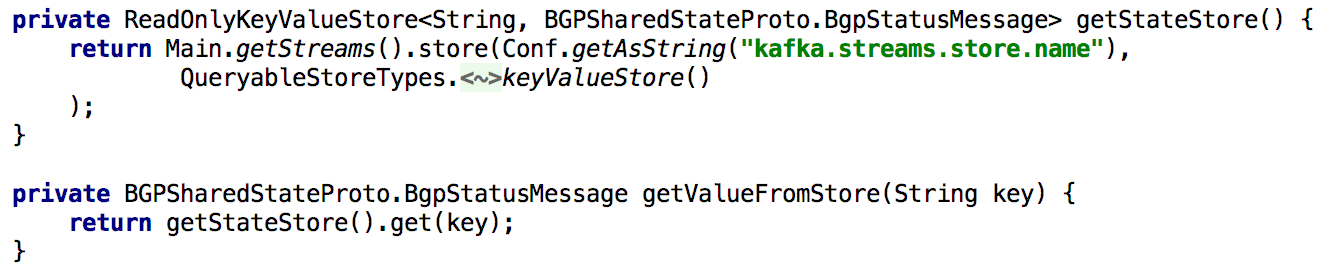
*Иллюстрация 5: использование встроенного хранилища ключей и значений для получения предвычисленного состояния объекта*
Обновление состояния объекта через API также несложно реализовать. В принципе, для этого нужно только создать продьюсер Kafka, а с его помощью сделать запись, в которой заключено новое состояние. Так гарантируется, что все сообщения, сгенерированные через API, будут обрабатываться точно так же, как и поступающие от других продьюсеров (напр. агентов).

*Иллюстрация 6: задать состояние объекта можно при помощи продьюсера Kafka*
**Небольшое осложнение: у Kafka множество партиций**
Далее мы хотели распределить нагрузку, связанную с обработкой, и улучшить доступность, предоставив на каждый сценарий кластер микросервисов с разделяемым состоянием. Настройка далась нам проще простого: после того, как мы сконфигурировали все инстансы так, чтобы они работали с одним и тем же ID приложения (и с теми же серверами начальной загрузки), практически все остальное делалось автоматически. Мы также задали, что каждый исходный топик будет состоять из нескольких партиций, чтобы каждому инстансу можно было присвоить подмножество таких партиций.
Также упомяну, что здесь в порядке вещей делать резервную копию хранилища состояний, чтобы, например, в случае восстановления после отказа переносить эту копию на другой инстанс. На каждое хранилище состояний в Kafka Streams создается реплицируемый топик с журналом изменений (в котором отслеживаются локальные обновления). Таким образом, Kafka постоянно подстраховывает хранилище состояний. Поэтому в случае отказа того или иного инстанса Kafka Streams хранилище состояний может быть быстро восстановлено на другом инстансе, куда перейдут соответствующие партиции. Наш тесты показали, что это делается за считанные секунды даже если в хранилище находятся миллионы записей.
Переходя от одного микросервиса с разделяемым состоянием к кластеру микросервисов, становится не столь тривиально реализовать Get State API. В новой ситуации в хранилище состояний каждого микросервиса содержится только часть общей картины (те объекты, чьи ключи отображались на конкретную партицию). Приходилось определять, на каком инстансе содержалось состояние нужного нам объекта, и мы делали это на основании метаданных потоков, как показано ниже:
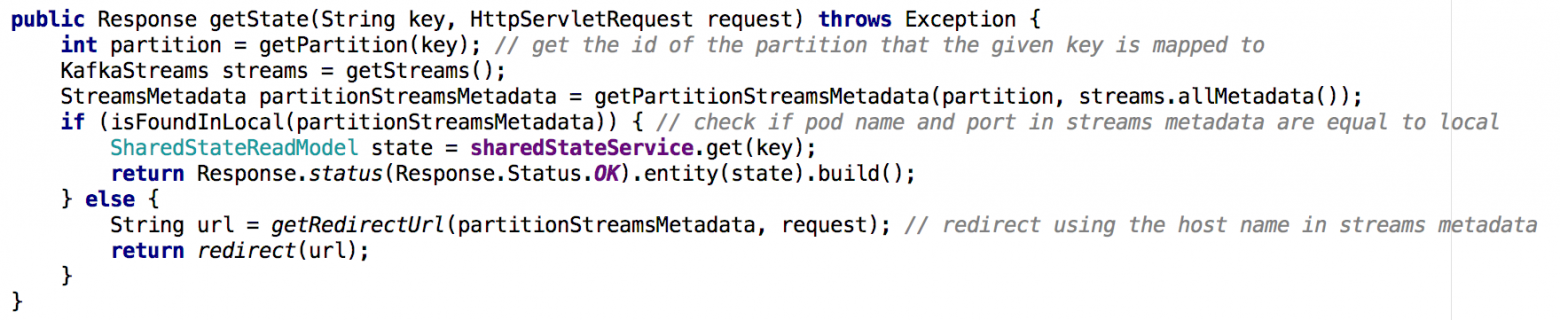
*Иллюстрация 7: при помощи метаданных потоков мы определяем, с какого инстанса запрашивать состояние нужного объекта; подобный подход применялся с GET ALL API*
**Основные выводы**
Хранилища состояний в Kafka Streams де-факто могут служить распределенной базой данных, * постоянно реплицируемой в Kafka
* Поверх такой системы легко выстраивается CRUD API
* Обработка множественных партиций получается немного сложнее
* Также возможно добавить одно или несколько хранилищ состояний в потоковую топологию для хранения вспомогательных данных. Такой вариант может использоваться для:
* Долговременного хранения данных, нужных для вычислений при потоковой обработке
* Долговременного хранения данных, которые могут быть полезны при следующей инициализации потокового инстанса
* многого другого…
Благодаря этим и другим достоинствам Kafka Streams отлично подходит для поддержки глобального состояния в такой распределенной системе как наша. Kafka Streams показала себя весьма надежной в продакшене (с момента ее развертывания мы практически не теряли сообщений), и мы уверены, что этим ее возможности не ограничиваются! | https://habr.com/ru/post/449928/ | null | ru | null |
# Second applet, его закрытие и прозрачные кнопки в Processing 3
Всем КУ. Мой первый пост, прошу не судить строго.
Возникла по работе необходимость считывать визуально состояние оборудования и, при необходимости, производить перезапуск криокомпрессора удаленно. Под рукой была Arduino UNO, к ней приобретены датчик освещенности, пока что 2 реле и 2 соленоида на 12 В(не суть важно). В дальнейшем то дело обрастет датчиками температуры, влажности и давления, но пока того нет в готовом виде.
Причина написания поста — это то, что в интернете нашлось очень мало информации по возможностям Processing 3, особенно в русскоязычной его части. Надеюсь, что таким же чайникам, как я, то когда-то пригодится, чтобы не тупить как я последнюю неделю.
Скетч для Ардуино простой, как три рубля: при получении определенных значений из ком порта дунька устанавливает значение на пинах и пишет об том ответ в ком порт, а так же замеряет освещенность и, так же, отчитывается об том. В дальнейшем он будет расширен.
Скетч Ардуино:
```
#include
#include
int val;
BH1750 lightMeter;
void setup() {
Serial.begin(9600);
lightMeter.begin();
Serial.println("Running...");
pinMode (7, OUTPUT);
pinMode(6, OUTPUT);
digitalWrite(7, HIGH);
digitalWrite(6, HIGH);
}
void loop() {
uint16\_t lux = lightMeter.readLightLevel();
if (Serial.available()) {
val = Serial.read();
if (val == '0') {
digitalWrite(7, HIGH);
digitalWrite(6, HIGH);
Serial.println("Оба реле ВЫКЛЮЧЕНЫ");
}
if (val == '1') {
digitalWrite(7, HIGH);
digitalWrite(6, LOW);
Serial.println("Реле 1 включено");
}
if (val == '2') {
digitalWrite(7, LOW);
digitalWrite(6, HIGH);
Serial.println("Включено реле 2");
}
if (val == '3') {
digitalWrite(7, LOW);
digitalWrite(6, LOW);
Serial.println("ВКЛЮЧЕНЫ оба реле");
}
if (val == '4') {
if (lux >= 800) {
Serial.print("Light: ");
Serial.print(lux);
Serial.println(" lx Все отлично ");
}
else {
Serial.print("Light: ");
Serial.print(lux);
Serial.println(" lx Мне ТЕМНО!!!!!!!");
}
}
}
}
```
Это, думаю, и ежу понятно, но в связи с тем, что функционалом моей приблуды в дальнейшем будут пользоваться другие люди, то захотелось написать простенькое, но понятное GUI. Выбор пал на Processing, так как я был ранее знаком с Arduino IDE, которая, в свою очередь, построена на основе Processing.
В апплете использована библиотека ControlP5 для отрисовки элементов управления.
Лично для меня возникли проблемы с реализацией и поиском информации относительно следующих вещей — 1) запуск второго окна из приложения, 2) закрывание 2-го окна, но чтобы при том основное окно продолжало работать, 3) ради прикола — установка картинок в качестве фона и кнопок, полупрозрачность кнопок.
Итак, скетч Processing:
**Листинг кода**
```
import processing.serial.*;
import controlP5.*;
import java.util.Date;
Serial port;
Textfield recived;
Textfield recived1;
Textfield recived2;
Textfield recived3;
Textfield recived4;
Textfield recived5;
String val;
String data;
String DateTab;
String Dat;
int data2=0;
String time;
Button vyvod;
PrintWriter output;
Table table2;
int i=0;
ControlP5 cp5;
ControlP5 ax;
PFont font;
PFont font2;
String[] args = {"YourSketchNameHere"};
SecondApplet sa;
PImage fon;
PImage fon2;
PImage titlebaricon; // Объявление переменных и классов
void setup() {
titlebaricon = loadImage("data/myicon.png");
surface.setIcon(titlebaricon);
surface.setTitle("Контроль МРТ"); //Установил свою иконку и название приложения)))
printArray(Serial.list());
port = new Serial(this, "/dev/ttyUSB0", 9600); //инициализирую com порт (под Ubuntu, для Windows указываем //com port)
cp5 = new ControlP5(this);
font = createFont("Arial", 20); //устанавливаю шрифт
fon = loadImage("data/phil.bmp"); //моя картинка в качестве фона
fon2 = loadImage("data/fon2.bmp"); /* размер картинки должен соответствовать размерам окна из void settings()*/
PImage img;
img = loadImage("data/image1.bmp"); //кнопки - собранные мной в папку "data" рисунки
image(img, 0, 0);
tint(0, 255, 0, 126); //Прозрачность кнопки - 50% и окрашивает в зеленый цвет
image(img, 50, 0);
PImage img2;
img2 = loadImage("data/image2.bmp");
image(img2, 0, 0);
image(img2, 50, 0); //делаю то же для всех моих кнопок
//только tint() должна вызываться один раз в моем примере.
PImage img3; // цвет и прозрачность всех кнопок будет одинакова.
img3 = loadImage("data/image3.bmp");
image(img3, 0, 0);
image(img3, 50, 0);
PImage img4;
img4 = loadImage("data/image4.bmp");
image(img4, 0, 0);
image(img4, 50, 0);
PImage img5;
img5 = loadImage("data/imagezapros.bmp");
image(img5, 0, 0);
image(img5, 50, 0);
PImage img6;
img6 = loadImage("data/temper.bmp");
image(img6, 0, 0);
image(img6, 50, 0);
cp5.addButton("Relay_1")
.setSize (100, 50)
.setPosition(50, 50)
.setFont(font)
.setImage(img)
.setLabel("Реле 1");
cp5.addButton("Relay_2")
.setSize (100, 50)
.setPosition(250, 50)
.setFont(font)
.setImage(img2)
.setLabel("Реле 2");
cp5.addButton("Relay_ON")
.setSize (300, 50)
.setPosition(50, 120)
.setFont(font)
.setLabel("Реле ВКЛ")
.setImage(img3);
cp5.addButton("Relay_OFF")
.setSize (300, 50)
.setPosition(50, 190)
.setFont(font)
.setLabel("Реле ВЫКЛ")
.setImage(img4);
cp5.addButton("Zapros_sostoyaniya")
.setSize (300, 50)
.setPosition(50, 260)
.setFont(font)
.setLabel("Запрос состояния")
.setImage(img5);
recived=cp5.addTextfield(" ")
.setSize(380,100)
.setPosition(10, 340)
.setColorValueLabel(0)
.setFont(font)
.setColorBackground(color(255, 255, 255));
cp5.addButton("temps")
.setSize (380, 50)
.setPosition(10, 500)
.setColorBackground(color(70, 100, 0))
.setColorForeground(color(0, 0, 0))
.setFont(font)
.setLabel("Температура")
.setImage(img6);
}
void settings(){
size(400, 560);
}
void draw() {
background(fon);
fill(0, 0, 0);
textFont(font);
text("Контроль МРТ", 135, 30);
int s = second();
int m = minute();
int h = hour();
int d = day();
int mo = month();
int y = year();
DateTab = str(d)+ "." + str(mo) + "." + str(y) + (" ") + str(h) + (":") + str(m) + (":") + str(s);
if ( port.available() > 0){
val = port.readString();
if(data2==0){ // до сих пор все должно быть понятно - обрабатываю события кнопок,
recived.setText(val); // пишу-читаю com порт, сохраняю дату-время и значение датчика.
} /* data2 - переменная, чтобы считанные в Second Applet показания не отображались в textfield основного окна программы. */
}
sa = new SecondApplet();
}
void Relay_1(){
port.write("1");
}
void Relay_2(){
port.write("2");
}
void Relay_ON(){
port.write("3");
}
void Relay_OFF(){
port.write("0");
}
void Zapros_sostoyaniya(){
data2=0;
port.write("4");
}
void save123(){ // Веду журнал в виде электронной таблицы
data2=1;
port.write("4");
delay(600);
port.available();
Dat=DateTab + " " + val;
table2 = loadTable("data/Journaltemp.ods"); // открываю файл
table2.setString(0, 0, "t"); //устанавливаю некое значение в ячейку 0.0
table2.removeColumn(0); /*удаляю столбец 0, иначе каждый раз создается новый столбец и таблица растет вширь*/
TableRow newRow = table2.addRow(); //создаю новую строку
newRow.setString(0, Dat); /*пишу в 0 столбец новой строки дату и показания датчика (пока освещенности)*/
saveTable(table2, "data/Journaltemp.ods"); //сохраняю значения в таблице
data2=0;
}
void temps(){
PApplet.runSketch(args, sa); //Запускаю окно Second Applet
}
public class SecondApplet extends PApplet {
public void setup(){
surface.setTitle("Контроль Температуры");
surface.setIcon(titlebaricon);
font2 = createFont("Arial", 20); /*можно установить свой шрифт, кнопки, текстовые поля и т.д.*/
ax = new ControlP5(this);
ax.addButton("test1")
.setSize(159, 70)
.setPosition(1, 300)
.setFont(font2)
.setLabel("Измерить");
ax.addButton("test2")
.setSize(158, 70)
.setPosition(161, 300)
.setFont(font2)
.setLabel("Измерить");
ax.addButton("test3")
.setSize(159, 70)
.setPosition(320, 300)
.setFont(font2)
.setLabel("Измерить");
ax.addButton("test4")
.setSize(159, 70)
.setPosition(480, 300)
.setFont(font2)
.setLabel("Измерить");
ax.addButton("test5")
.setSize(159, 70)
.setPosition(640, 300)
.setFont(font2)
.setLabel("Измерить");
ax.addButton("obj")
.setSize (790, 50)
.setPosition(5, 540)
.setColorBackground(color(70, 100, 0))
.setColorForeground(color(0, 0, 0))
.setFont(font)
.setLabel("Журнал");
recived1 = ax.addTextfield(" ")
.setSize(157, 70)
.setPosition(2, 370)
.setColorValueLabel(0)
.setFont(font)
.setColorBackground(color(255, 255, 255));
recived2=ax.addTextfield(" ")
.setSize(156, 70)
.setPosition(162, 370)
.setColorValueLabel(0)
.setFont(font)
.setColorBackground(color(255, 255, 255));
recived3=ax.addTextfield(" ")
.setSize(157, 70)
.setPosition(321, 370)
.setColorValueLabel(0)
.setFont(font)
.setColorBackground(color(255, 255, 255));
recived4=ax.addTextfield(" ")
.setSize(157, 70)
.setPosition(481, 370)
.setColorValueLabel(0)
.setFont(font)
.setColorBackground(color(255, 255, 255));
recived5=ax.addTextfield(" ")
.setSize(157, 70)
.setPosition(641, 370)
.setColorValueLabel(0)
.setFont(font)
.setColorBackground(color(255, 255, 255));
}
public void settings() {
size(800, 600); // а здесь размер
}
public void draw() {
background(fon2); //а здесь фон))
textFont(font2);
}
public void test1(){
recived1.setText(" 11111");
}
public void test2(){
recived2.setText(" 22222");
}
public void test3(){
recived3.setText(" 33333"); //обрабатываю события кнопок окна Second Applet
}
public void test4(){
recived4.setText(" 44444");
}
public void test5(){
recived5.setText(" 55555");
}
public void obj(){
save123(); /* для ведения журнала в виде электронной таблицы отсылаю к коду в теле основной программы*/
}
public void exitActual(){} //функция выхода из окна по кнопке [X] в верхнем поле окна.
} // при том первое окно продолжит работу, пока в нем не будет нажато [X].
```
Полученная мной программа:
[Раз](https://drive.google.com/open?id=1vscCj4C64BsleMNEF66FGSqkHV6u7jIO)
[Два](https://drive.google.com/open?id=1vok9R9aW2zuoriYn6FOOHeBL9qx3nOEk)
Прошу сильно не пинать — мой первый проект на Processing, надеюсь кому нибудь помоет разобраться с такими простейшими, как оказалось вещами. А если кто подскажет, как оптимизировать мой г… код — буду рад. | https://habr.com/ru/post/478552/ | null | ru | null |
# Безопасный веб-сёрфинг с помощью сервера ReCoBS
Установка удалённо управляемой браузерной системы (ReCoBS) — это один из способов создания безопасной среды веб-сёрфинга для ваших пользователей, использующих Windows Server с бесшовным окном браузера RemoteApp.
> **Содержание:**
>
>
>
> 1. [Недостатки ReCoBS](#1)
> 2. [Настройка безопасного веб-сёрфинга с помощью ReCoBS](#2)
> 3. [Повышенная безопасность ReCoBS](#3)
> 4. [Заключение](#4)
>
На протяжении последних десятилетий разработчики программного обеспечения придерживаются мнения, что клиентские машины постоянно находятся в сети. Пользователи находятся в сети дома и на работе — возможность искать и обмениваться информацией 24 часа в сутки 7 дней в неделю воспринимается как должное. Тот факт, что любое подключение к интернету сопряжено с определёнными рисками, обычно не вызывает беспокойства, поскольку в современном мире, похоже, нет другой альтернативы.
Я работаю в компании, которая всегда требовала отключать компьютеры от интернета по соображениям безопасности. Как можно догадаться, как минимум просмотр веб-страниц всё же должен быть возможен.
Решение заключается в работе с Windows Server со службами удалённых рабочих столов, которым разрешён доступ в интернет. Пользователи могут подключаться к нему и просматривать веб-страницы оттуда, так что они видят только графический вывод браузера в рамках удалённого сеанса, оставляя свою собственную машину отключённой от публичного интернета.
Эта концепция проста, но малоизвестна. Она называется **удалённо управляемой браузерной системой (ReCoBS)**. Наберите в Google термин ReCoBS, и вы обнаружите, что он был описан федеральным агентством по информационной безопасности (BSI) ещё в 2006 году и, вероятно, впервые возник в Германии. Наша компания *(прим. переводчика — компания автора оригинального материала)* использует его уже около 20 лет, начиная с Linux-машины в качестве браузерной системы. Со временем мы перешли на Windows Server и используем бесшовное окно браузера, оно же просмотр через RemoteApp.
Концепция, которую я описываю, подойдёт не каждому, поэтому я начну с определения того, кому стоит её рассматривать.
Недостатки ReCoBS
-----------------
Во-первых, представьте, что вы просто отключили интернет на конечных компьютерах ваших пользователей. Электронная почта будет продолжать поступать и отправляться до тех пор, пока вы используете местный почтовый сервер, на котором всё ещё есть интернет. Во-вторых, то же самое будет относиться и ко всем интернет-сервисам, которые передаются через локальный сервер.
Но как быть с приложениями, которым необходим доступ в интернет для доступа к удалённым службам в облаке? Сюда относятся и облачные хранилища в интернете, и подключение к серверам лицензий для программного обеспечения. Приложения отныне необходимо будет исправлять и обновлять с помощью сервера обновлений в локальной сети, поскольку эти приложения больше не смогут получать обновления из интернета. Кроме того, решения для удалённого управления, такие как Team Viewer, которые вы, возможно, используете для получения помощи по продукту от службы поддержки производителя, больше нельзя будет использовать на ваших конечных точках, по крайней мере, напрямую.
Работа с ReCoBS является решением для вашей корпоративной сети только в том случае, если эти ограничения не оказывают негативного влияния на общую продуктивность вашей рабочей среды.
Настройка безопасного веб-сёрфинга с помощью ReCoBS
---------------------------------------------------
Для создания безопасного веб-сёрфинга с использованием среды ReCoBS необходим сервер Windows Server с удалённым узлом сеанса удалённого рабочего стола (RD Session Host). Я рекомендую работать с Windows Server 2022. Конечно, вам также понадобятся клиентские лицензии удалённого рабочего стола (Remote Desktop CALs).
Роль Remote Desktop Server можно установить двумя разными способами: на основе сеанса или на основе виртуальной машины. Последний способ более безопасен, но требует корпоративного лицензирования Windows по программе обслуживания (software assurance). Если у вас нет корпоративных лицензий, придётся использовать сеансовый способ. В этой статье я подробнее рассмотрю вариант на основе сеансов.
Сервер может быть физическим или виртуальным и должен быть достаточно мощным, поскольку просмотр веб-страниц потребляет значительное количество ресурсов. Чтобы дать вам представление, наше решение (основанное на сеансах) иногда используется 40 пользователями одновременно, поэтому нам нужно 12 ядер процессора и 32 ГБ оперативной памяти. Этого может быть недостаточно для продвинутых пользователей, которые держат открытыми множество вкладок и регулярно просматривают видеоруководства в интернете. Давайте примерно предположим, что для обычного пользователя нам нужно предоставить 1 ГБ оперативной памяти на пользователя и как минимум одно ядро ЦП на каждые три пользователя.
Ваш сервер может быть подключён к домену Active Directory, поэтому вы можете использовать GPO для централизованного управления сервером. Однако, если вы используете RDP, единый вход с использованием доменных учётных записей представляет собой серьёзный риск для безопасности. Если у вас есть машина на основе сеанса, то значит, что все пользователи используют одну и ту же систему. Если эта система скомпрометирована, все учётные записи подвергаются риску стать мишенью для Mimikatz и подобных атак. Поэтому для обеспечения максимальной безопасности я рекомендую не работать с доменными учётными записями, а использовать локальные учётные записи сервера.
Если вы настроите систему таким образом, то у неё будет только один недостаток: лицензирование RDS CAL. Microsoft разрешает использовать RDS CAL только для пользователей домена. Использование локальных пользователей означает, что вам придётся покупать CAL для устройств. Если в вашей среде устройств больше, чем пользователей, это может означать, что ваши расходы в этой сфере немного возрастут.
Остальная часть установки проста: установите ваш любимый браузер на сервер (в этой статье я просто предположу, что вы будете использовать встроенный Microsoft Edge 64 bit) и [разверните его как RemoteApp](https://docs.microsoft.com/en-us/windows-server/remote/remote-desktop-services/rds-create-collection).
 *RemoteApp и Desktop Connection в браузере Edge*
Теперь, когда пользователи перейдут на страницу `https://yourTS.yourdom/rdweb` с помощью (локального) браузера Edge и нажмут на опубликованный значок (удалённого) браузера Edge, им будет предоставлен файл RDP, который они могут сохранить на своём рабочем столе. Затем они могут подключиться к удалённому сеансу и сохранить учётные данные своего личного локального пользователя, после чего откроется удалённый браузер. Он работает и выглядит точно так же, как локальный браузер, но ему не требуется локальное онлайн-соединение на конечной точке. И производительность хорошая, вы можете даже смотреть HD-видео без каких-либо задержек и без необходимости покупать специальные графические адаптеры для сервера.
Повышенная безопасность ReCoBS
------------------------------
Вы не только сделали свои конечные машины более безопасными, отказавшись от локального доступа в интернет, но и повысили безопасность самого веб-сёрфинга.
Наличие выделенного сервера для просмотра позволяет администратору сервера сократить функциональность этого сервера до «только просмотр». Это попросту означает, что администратор сможет без проблем использовать правила белого списка приложений (AppLocker). Вы разрешаете только выполнение браузера, а всё остальное остаётся под запретом. Эта защитная мера, кстати, уже встроена в систему.
Белые списки приложений намного превосходят безопасность, обеспечиваемую антивирусными продуктами, поскольку не требуют никаких определений или анализа поведения. Все drive-by вирусы в какой-то момент попытаются запустить вредоносный процесс, который просто не будет запущен.
Кроме того, представьте, как легко можно изолировать этот сервер с помощью брандмауэра. Входящий сервер должен быть доступен только по RDP, а исходящий сервер должен иметь доступ только к вашему прокси-серверу или маршрутизатору. Таким образом вы можете изолировать сервер от всех ценных данных компании.
Так как RemoteApp по умолчанию позволяет перенаправлять локальные диски на сервер, это, конечно же, будет необходимо отключить. На скриншоте ниже видно, как именно это сделать через опции сбора сеансов (Session Collection):
 *Свойства QuickSessionCollection — Отключить перенаправление дисков (Drives)*
Даже если злоумышленники обойдут AppLocker, им нечего будет атаковать. Рабочие данные не сохраняются локально, и они смогут увидеть только локальные учётные записи. Следовательно, даже учётные данные домена не могут быть перехвачены.
Но, увы, этот идеальный сценарий основан на предположении, что браузер нужен только для просмотра, но не для загрузки. Как только вы захотите перенести свои загрузки с сервера на вашу персональную систему, вам придётся построить некий мост. К счастью, это легко сделать, разрешив SMB-трафик и предоставив общий доступ к папке загрузок сервера в режиме только для чтения. Это означает, что клиенты смогут читать загрузки, но не смогут ничего записать в эту папку, даже случайно; это означает, что утечка данных будет довольно эффективно предотвращена.
Заключение
----------
Как я показал в данной статье, ReCoBS — это эффективный способ развёртывания безопасного просмотра веб-страниц и минимизации поверхности для атаки конечных серверов при минимальных затратах и усилиях. Тестовая установка заняла у меня менее часа, и она не требует никаких лицензий. Если вашим конечным точкам нужен интернет только для просмотра веб-страниц, вам стоит попробовать это решение.
---
НЛО прилетело и оставило здесь промокод для читателей нашего блога:
— [15% на все тарифы VDS](https://firstvds.ru/?utm_source=habr&utm_medium=article&utm_campaign=product&utm_content=vds15exeptprogrev) (кроме тарифа Прогрев) — **HABRFIRSTVDS**. | https://habr.com/ru/post/661525/ | null | ru | null |
# Кому в микроконтроллере жить хорошо?

В каком году — рассчитывай, в какой земле — угадывай, задачился вопросами. Насколько ARM быстрее AVR? Какая разновидность протокола Modbus более «быстрая»? ASCII или RTU?
Под «быстротой», в данном случае, будем понимать количество машинных циклов процессора необходимых для исполнения всех действий протокола.
Исследование быстродействия будем проводить на, широко известной в узких кругах, библиотеке [**ModBus Slave RTU/ASCII**](https://habr.com/ru/post/526880/), портированной на микроконтроллеры ATMega48 и STM32L052. Вывод информации будем осуществлять по протоколу Modbus в эмулятор панели Weintek. Тестирование будем производить на [**демонстрационном примере**](https://habr.com/ru/post/530144/). Помимо результатов теста на панель выводятся состояния регистров Modbus: дискретных входов, дискретных выходов, регистров для чтения и регистров для чтения/записи. Также средствами панели производится подсчет количества ошибок обмена данными с микроконтроллером. Внешний вид тестового окна приведен на рисунке.
Оценку быстродействия будем проводить измеряя время выполнения функции обработки сообщений протокола. Измерение времени выполнения будем проводить рабоче-крестьянским способом. Перед запуском функции обнуляем аппаратный таймер, частота счета которого равна тактовой частоте микроконтроллера, после выполнения функции считываем значения таймера и проводим обработку результатов измерений. Вычисляем минимальное, максимальное и среднее значение времени выполнения функции обработки сообщений протокола Modbus.
```
while(1)
{
TIM6->CNT=0;
ModBusRTU();
//ModBusASCII();
tcurent=TIM6->CNT;
if(tcurenttmax)tmax=tcurent;
avg32=avg32-(avg32>>16)+tcurent;
tavg=avg32>>alfa;
...
```
Результаты исследований, сведены в таблицу. Исследование проводились при различных опциях библиотеки:
* **ModBusUseTableCRC** — Использовать расчет CRC по таблице;
* **ModBusUseErrMes** — Использовать сообщения о логических ошибках протокола;
А также при различных стратегиях оптимизации компилятора.
Библиотека ModBus Slave RTU/ASCII поддерживает, в некоторых случаях, важную функцию — пауза между получением запроса от Modbus Master и ответом Modbus Slave. Исследование проводились при значениях паузы 2 милисекунды и 0 (то есть без паузы), эти значения указаны в графе таблицы «Пауза П/П». В графе «Размер» указан размер модуля, который включает в себя обе функции обработки сообщений Modbus (ModBusRTU(), ModBusASCII()).
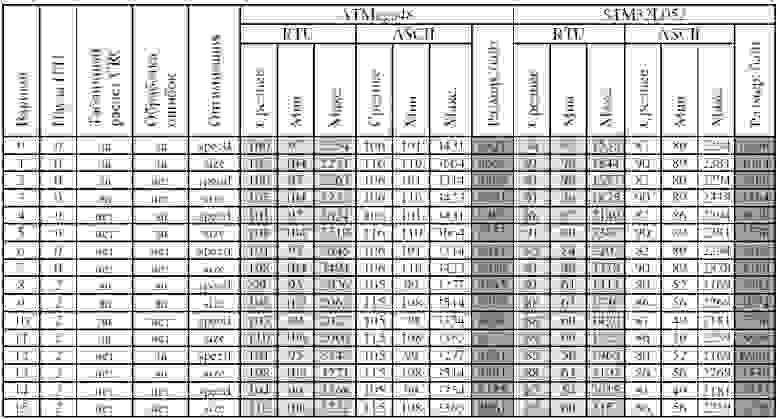
На взгляд автора наиболее целесообразно оценивать быстродействие по наихудшему случаю, то есть, по максимальному времени выполнения функции.
Глубоко задумавшись над результатами исследований, можно сделать следующие выводы:
1. AVR не такой уж медленный!!! В среднем он в полтора раза медленнее ARM при той же тактовой частоте. А в случае оптимизации по размеру (например варианты 13 и 15) практически приближается к ARM.
2. Протокол ASCII, по сравнению c RTU, не только более медленный по скорости передачи, но и занимает гораздо больше ресурсов микроконтроллера.
3. Использование сообщений о логических ошибках протокола, никак не влияет на быстродействие.
4. Табличный метод вычисления CRC позволяет более чем в полтора раза снизить использование вычислительных ресурсов микроконтроллера.
5. Использование паузы между приемом запроса и передачей ответа, позволяет не только избежать конфликтов на шине RS-485, но и уменьшить блокирующие действие функции обработки сообщений протокола Modbus.
Какие выводы еще можно сделать?
[Проект на GitHub
----------------](https://github.com/IBAH-II/modbus-M48)
[### Скачать одним файлом](https://github.com/IBAH-II/modbus-M48/archive/main.zip)
**UPD. Обновил проект на GitHub!**
Переписал функцию вычисления CRC по таблице, время выполнения функции сократилось на 32%
Итоговое быстродействие Modbus RTU для наилучшего случая (вариант 8):
**AVR среднее-105; минимальное-99; максимальное-1924;
STM32 среднее-86; минимальное-59; максимальное-1293;**
Снижение максимального времени выполнения
**STM32L052 — 124 такта
ATMega48 — 102 такта** | https://habr.com/ru/post/530978/ | null | ru | null |
# Пишем продвинутый планировщик с использованием React, Nest и NX. Часть 1: настройка проекта
Друзья, всем привет! Меня зовут Игорь Карелин, я frontend-разработчик в компании Домклик. В серии статей мы поэтапно разработаем продвинутое приложение-планировщик. Сначала создадим и настроим монорепозиторий c помощью NX, разработаем интерфейс с помощью React, добавим backend на основе NestJS, и, наконец, подключим базу данных MongoDB.
Будем использовать такие технологии:
1. NodeJS — программная платформа на движке V8 (компилирующем JavaScript в машинный код), которая превращает JavaScript из узкоспециализированного языка в язык общего назначения.
2. NX — система инструментов, позволяющая создавать монорепозитории для JavaScript-приложений.
3. TypeScript — язык программирования для разработки современных веб-приложений, расширяющий возможности традиционного JavaScript.
4. React — одна из самых популярных JavaScript-библиотек для создания пользовательских интерфейсов.
5. NestJS — фреймворк, который ускоряет и упрощает разработку масштабируемых серверных приложений на основе программной платформы NodeJS.
6. MongoDB — документоориентированная система управления базами данных, не требующая описания схемы таблиц. Считается одним из классических примеров NoSQL-систем, использует JSON-подобные документы и схему базы данных.
7. Docker — контейнеризатор приложений: программное обеспечение для автоматизации развёртывания и управления приложениями в средах с поддержкой контейнеризации.
Сначала установим NodeJs с официального [сайта](https://nodejs.org/en/) и редактор кода, я буду использовать [Visual Studio Code](https://code.visualstudio.com/).
Почему монорепозиторий?
-----------------------
Что такое монорепозиторий и для чего он нужен? Монорепозиторий — это стратегия разработки, при которой код нескольких приложений находится в одном репозитории. Это даёт ряд преимуществ:
* Упрощённое управление зависимостями, в монорепозитории сборку легко оптимизировать, поскольку все зависимые компоненты находятся в одной и той же кодовой базе.
* Сотрудничество между командами.
Я выбрал монорепозиторий, чтобы не усложнять настройку проекта и иметь возможность легко переиспользовать различные компоненты, интерфейсы и типы. Создадим его с помощью NX — эта технология обеспечивает готовую структуру проекта и продвинутую работу с CLI для лёгкого создания и внедрения приложений. Ознакомиться с NX и узнать о нём подробнее вы можете по этой [ссылке](https://nx.dev/).
### Создание и настройка проекта
Для создания проекта нам потребуется терминал, я работаю со штатным инструментом MacOS; в зависимости от операционной системы команды могут отличаться. Установите проект NX, в котором сразу будет присутствовать React, далее выберите директорию и выполните команду `npx create-nx-workspace@latest --preset=react`.
В ходе установки нужно ответить на несколько пунктов:
1. Выберите любые названия проекта, приложений и препроцессор.
2. Название проекта: todo-app.
3. Название React-приложения: frontend.
4. Я выбрал SASS(.scss)
Готово! Мы только что создали проект NX с приложением React. Теперь установим NestJS. Сначала добавьте плагин Nest в существующую рабочую область. Перейдите в папку проекта и выполните команду `npm install -D @nrwl/nest`.
Теперь создадим приложение Nest с помощью команды `nx g @nrwl/nest:app backend --frontendProject frontend`. Мы сгенерировали приложение с названием “backend” и сообщили, что хотим связать его с “frontend”. Благодаря NX нам не нужно вручную настраивать порты, всё будет сделано автоматически.
В файле proxy.conf.json NX сам добавил пути для работы с API. Теперь для получения данных из backend достаточно просто перейти на `/api`:
```
proxy.conf.json
{
"/api": {
"target": "http://localhost:3333",
"secure": false
}
}
```
Давайте коротко обсудим некоторые папки, которые сгенерировал для нас NX:
* `/apps` — папка, в которой хранятся наши сгенерированые приложения frontend и backend;
* `/libs` — здесь будут храниться части приложения, которые мы можем переиспользовать внутри монорепозитория (ведь одно из преимуществ — это упрощённое управление зависимостями и переиспользование кода между приложениями);
* `/tools` — эта папка используется для различных правил или настроек. Например, правил EsLint, работы с автоматизацией и т.д.
Поговорив о создании и структуре проекта, самое время запустить его! И снова идём в терминал: `nx run-many --parallel --target=serve --projects=backend,frontend`. Мы запустили параллельно несколько проектов без дополнительных настроек. Откройте браузер и проверьте, для этого перейдите по адресу `localhost:4200`:
и по адресу `localhost:4200/api`:
Отлично, всё работает!
Установка и подключение к базе данных
-------------------------------------
**Сначала хочу предупредить вас: не стоит хранить в репозиториях файлы \*.env и Docker-файлы с секретами! В статье я так делаю для ознакомительных целей.**
Мы будем использовать MongoDB, её я выбрал исходя из простоты использования. Подробнее ознакомиться с этой базой данных вы можете на официальном сайте.
Использовать MongoDB можно несколькими способами:
* Создать удалённую БД на серверах Mongo.
* Установить MongoDB на свой компьютер.
* Использовать Docker — этот способ мы и рассмотрим.
Для начала установите Docker на свой компьютер, инструкцию можете посмотреть на официальном [сайте](https://www.docker.com/). После этого создайте в корне проекта файл docker-compose.yml с такой структурой:
```
version: '3'
services:
mongo:
image: mongo
container_name: mongo
restart: always
environment:
- MONGO_INITDB_ROOT_USERNAME=admin
- MONGO_INITDB_ROOT_PASSWORD=admin
ports:
- 27017:27017
volumes:
- ./mongo-data:/data/db
```
Подробно не буду останавливаться, про Docker написано множество статей и есть подробная официальная [документация](https://www.docker.com/). Теперь запустите Docker Compose командой `docker-compose up -d`. Docker скачает необходимые файлы для правильной работы и в корне проекта появится папка `mongo-data`, в которой хранятся данные MongoDB, я добавил её в gitignore.
Следующим шагом нужно подключиться к БД из NestJS. Сначала установите необходимые зависимости: библиотеку mongoose для работы с БД и Nest config, который обеспечит работу с файлами \*.env: `npm install --save mongoose @nestjs/mongoose @nestjs/config`.
Я создал папку `envs` и добавил файл `.backend.env`, в котором объявил переменные:
```
DB_LOGIN=admin
DB_PASSWORD=admin
DB_HOST=localhost
DB_PORT=27017
DB_AUTHDATABASE=admin
```
Теперь создайте конфигурационный файл, который поможет генерировать ссылку для подключения к БД:
```
db-connect.config.ts
import { ConfigService } from '@nestjs/config';
import { MongooseModuleOptions } from '@nestjs/mongoose';
const getMongoString = (configService: ConfigService) =>
'mongodb://' +
configService.get('DB_LOGIN') +
':' +
configService.get('DB_PASSWORD') +
'@' +
configService.get('DB_HOST') +
':' +
configService.get('DB_PORT') +
'/' +
configService.get('DB_AUTHDATABASE');
const getMongoOptions = () => ({
useNewUrlParser: true,
useUnifiedTopology: true,
});
export const getMongoConfig = async (
configService: ConfigService
): Promise => {
console.log(getMongoString(configService));
return {
uri: getMongoString(configService),
...getMongoOptions(),
};
};
```
Далее перейдите в app.module.ts и импортируйте в него ConfigModule и MongooseModule. Пара слов о модулях в NestJS: это классы с декоратором `Module()`, предоставляющим метаданные, которые Nest использует для организации структуры приложения.
В конечном счёте файл будет выглядеть так:
```
app.module.ts
import { Module } from '@nestjs/common';
import { ConfigModule, ConfigService } from '@nestjs/config';
import { MongooseModule } from '@nestjs/mongoose';
import { getMongoConfig } from '../config/db-connect.config';
import { AppController } from './app.controller';
import { AppService } from './app.service';
@Module({
imports: [
ConfigModule.forRoot({
isGlobal: true, // Позволяет обратиться к env во всем приложении
envFilePath: 'envs/.backend.env', // Указываем путь до env файла
}),
MongooseModule.forRootAsync({ // Модуль для работы с mongo
imports: [ConfigModule],
inject: [ConfigService],
useFactory: getMongoConfig, // добавляем созданную ранее функцию подключения к БД
}),
],
controllers: [AppController],
providers: [AppService],
})
export class AppModule {}
```
На этом пока остановимся. Мы разобрали настройку проекта и подключение к базе данных для дальнейшей работы. В следующих частях напишем логику работы с базой данных, добавим регистрацию пользователей и т.д. Спасибо за внимание!
Исходный код доступен по [ссылке](https://github.com/Igoryas/nx-react-nest). | https://habr.com/ru/post/672546/ | null | ru | null |
# Самодельный билд-светофор в офис
#### Предыстория
В связи в планируемым переходом на continious integration и прочтением пары статей о светофорах в офисе захотелось и себе заиметь такой теплый ламповый прибор. В результате он получился совсем не теплым и не ламповым, но об этом потом.
Кто интересовался этой темой, уже знает что цена нового светофора колеблется в районе $500. Попытки найти бывший в употреблении списанный прибор так и не увенчались успехом. Оба варианта никак не могли радовать бюджет и душу двух энтузиастов из офиса, поэтому было принято решение сделать светофор самому.
#### Идея
В принципе ничего сложного в конструкции светофора нет, но какой никакой макет все же был сделан. Так было легче представить себе что нужно вырезать и как это лучше сделать.
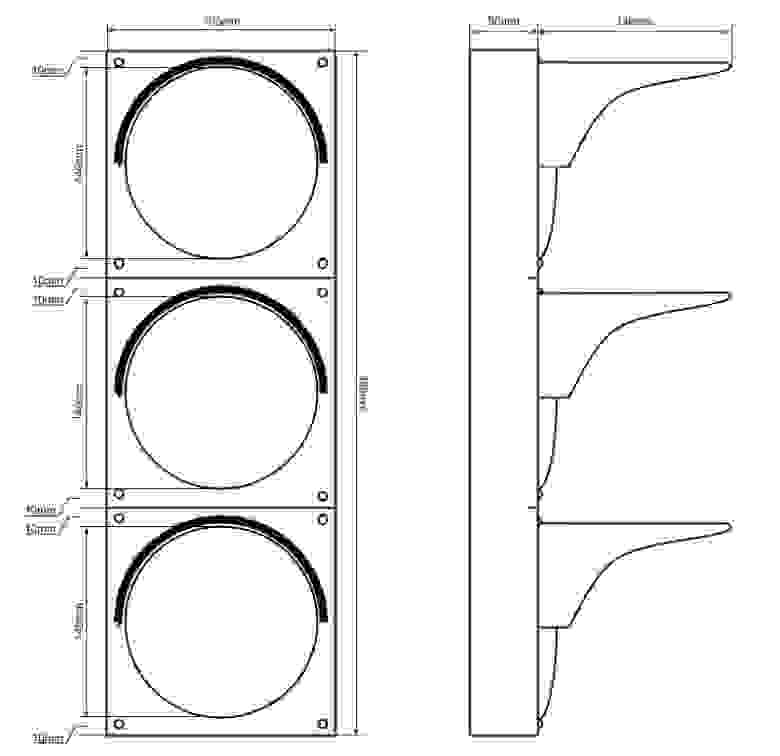
Перед тем как делать макет на одном из сайтов с объявлениями нам повезло найти стекла от советского светофора. Это стало огромным облегчением, так как оригинальные стекла как ничто лучше придают конструкции аутентичности. Соответственно размеры корпуса были продиктованы размером стекол, а также размерами внутренних компонент таких как блоки питания, разводка и т. п.
Главным “мозгом” был назначен raspberry pi по нескольким причинам. Первая єто его наличие после предыдущих экспериментов с “малинкой”, вторая это простота реализации управления светофором извне, установка разного рода софта, wifi и т. д.
#### Корпус
Началось все конечно с корпуса. Для его изготовления был применен ПВХ пластик который используется для изготовления внешней рекламы. Он очень легко поддаётся обработке и в комбинации с супер клеем на выходе дает довольно прочную конструкцию. Пластик с порезкой соответствующих размеров был заказан в рекламном агентстве. Точность порезки вышла немного хуже ожидаемой, поэтому после склейки корпуса пришлось изрядно поработать пластиковой шпатлевкой и наждаком. В итоге получился вот такой вот корпус.

Пластик оказался настолько податливым что изготовить козырьки оказалось проще чем кто либо мог предполагать. Вырезанные детали козырьков были брошены в кипящую воду, а затем изогнуты о двухлитровую банку до остывания. Да да диаметр двухлитровой банки оказался таким же что и стекол. Вот это унификация была в СССР!
Пока просто приложив стекла можно было уже отчетливо видеть будущий светофор, хотя еще на этапе корпуса казалось что ничего хорошего с этой идеи не получится.

После покраски в чёрный “светофорный” цвет все стало выглядеть еще более замечательно. Также были наклеены маскировочные шнуры для прикрытия крепежа стекол и придания конструкции более завершенного вида.

#### Электроника
В угоду безопасности, уменьшения энергопотребления и еще ряда причин в качестве источника света были выбраны светодиоды. Всего 27 штук, по 9 на цвет. Для них в корпусе соответственно было просверлено 27 отверстий.

Для удобства ремонта и установки светодиодов они были размещены на пластиковых матрицах с размещением совпадающим с отверстиями в корпусе.

Они с легкостью устанавливаются и снимаются на случай если сгорит один из светодиодов. Для управления логикой используются выводы GPIO на raspberry pi, соответственно в качестве управляющей логики была изготовлена плата с тремя реле управляемыми напряжением 3В и коммутирующими 12В, которые подаются на светодиодные матрицы.

На этапе тестирования перед окончательной сборкой сборкой все выглядело примерно вот так.

Все “заброшено” в корпус и приделан временный шнур питания на 220В так как под рукой в момент сборки не было шнура достаточной длинны. Внутри также размещено два блока питания. Один 12В для питания светодиодов, второй блок с портом USB для raspberry pi.
#### Программное обеспечение
Для простоты управления извне был установлен lighttpd сервер с mod\_fcgi для python. Таким образом управлять режимом можно просто из браузера. Так было удобно побаловаться самому. Позже для Jenkins был написан код который опрашивает его и соответственно меняет статус светофора. Python же был выбран не случайно, с его помощью довольно легко справиться с управлением выводами GPIO на raspberry при помощи набора библиотек [wiringpi.com](http://wiringpi.com).
Простенький код веб скрипта для управления, который позже был заменен на описанный выше.
```
#!/usr/bin/pythonRoot
# Bring in the libraries
import RPi.GPIO as G
from flup.server.fcgi import WSGIServer
import sys, urlparse, time
# GPIO lights map
light_r = 4
light_y = 17
light_g = 22
# Set up our GPIO pins
G.setmode(G.BCM)
G.setup(light_r, G.OUT)
G.setup(light_y, G.OUT)
G.setup(light_g, G.OUT)
# Offs all lights
def offLights():
G.output(light_r, False)
G.output(light_y, False)
G.output(light_g, False)
# Function which is called for each http request we receive
def app(environ, start_response):
# start our http response
start_response("200 OK", [("Content-Type", "text/html")])
# look for inputs on the URL
i = urlparse.parse_qs(environ["QUERY_STRING"])
yield (' ') # flup expects a string to be returned from this function
# if there's a url variable named 'q'
if "mode" in i:
if i["mode"][0] == "red":
offLights()
G.output(light_r, True)
elif i["mode"][0] == "yellow":
offLights()
G.output(light_y, True)
elif i["mode"][0] == "green":
offLights()
G.output(light_g, True)
elif i["mode"][0] == "off":
offLights()
#Run app
WSGIServer(app).run()
```
#### Затраты
На все ушла примерно неделя работы двух человек, по часу в день после работы. По деньгам же:
| | |
| --- | --- |
| Raspberry Pi model B | $50 |
| Пластик ПВХ для корпуса с порезкой | $15 |
| Краска чёрная матовая | $10 |
| Блоки питания | $10 |
| Реле, светодиоды и прочая мелочь | $10 |
| Wifi свисток для raspberry | $10 |
| Стекла | $7 |
| Шпатлевка | $5 |
| | Итого: $117 |
#### Заключение
Начнем с видео работы в демонстрационном режиме.
Как видно из видео, холодное свечение светодиодов в комбинации з нашим стеклом дало синеватый оттенок. Сейчас обдумываем варианты исправления, благо ремонтопригодность была заложена в нашу конструкцию.
Согласитесь разница в бюджете колоссальная, энтузиазм удовлетворен и результат более чем удовлетворительный. В результате получился хоть и не теплый ламповый а холодный светодиодный, но все же светофор, который в скором будущем надеюсь станет выполнять свое предназначение. Процесс перехода на continious integration еще пока не завершен.
Всем удачи, и поменьше красных на билд-светофорах! | https://habr.com/ru/post/206486/ | null | ru | null |
# «Boost.Asio C++ Network Programming». Глава 2: Основы Boost.Asio. Часть 1
Всем привет!
Продолжаю перевод книги John Torjo «Boost.Asio C++ Network Programming». Вторая глава получилась большая, поэтому разобью ее на две части. В этой части мы поговорим именно про основы Boost.Asio, а во второй части речь пойдет про асинхронное программирование.
Содержание:
* [Глава 1: Приступая к работе с Boost.Asio](http://habrahabr.ru/post/192284/)
* Глава 2: Основы Boost.Asio
+ **Часть 1: Основы Boost.Asio**
+ [Часть 2: Асинхронное программирование](http://habrahabr.ru/post/195006/)
* [Глава 3: Echo Сервер/Клиент](http://habrahabr.ru/post/195386/)
* [Глава 4: Клиент и Сервер](http://habrahabr.ru/post/195794/)
* [Глава 5: Синхронное против асинхронного](http://habrahabr.ru/post/196354/)
* [Глава 6: Boost.Asio – другие особенности](http://habrahabr.ru/post/196888/)
* [Глава 7: Boost.Asio – дополнительные темы](http://habrahabr.ru/post/197392/)
В этой главе мы рассмотрим то, что вам обязательно знать, используя Boost.Asio. Мы углубимся в асинхронное программирование, которое намного сложнее, чем синхронное и гораздо более интересное.
#### Сетевое API
В этом разделе показано, что вам необходимо знать, чтобы написать сетевое приложение с использованием Boost.Asio.
##### Пространства имен Boost.Asio
Все в Boost.Asio находится в пространстве имен `boost::asio` или его подпространстве, рассмотрим их:
* `boost::asio`: Это где находятся все основные классы и функции. Главные классы это `io_service` и `streambuf`. Здесь находятся такие функции как `read, read_at, read_until`, их асинхронные копии, а так же функции записи и их асинхронные копии.
* `boost::asio::ip`: Это место, где находится сетевая часть библиотеки. Основные классы это `address, endpoint, tcp, udp, icmp`, а основные функции это `connect` и `async_connect`. Обратите внимание, что `socket` в `boost::asio::ip::tcp::socket` это просто `typedef` внутри класса `boost::asio::ip::tcp`.
* `boost::asio::error`: Это пространство имен содержит коды ошибок, которые вы можете получить при вызове подпрограммы ввода/вывода
* `boost::asio::ssl`: Это пространство имен содержит классы, имеющие дело с SSL.
* `boost::asio::local`: Это пространство имен содержит POSIX-специфичные классы
* `boost::asio::windows`: Это пространство имен содержит Windows-специфичные классы
##### IP адреса
Для работы с IP адресами Boost.Asio предоставляет классы `ip::address, ip::address_v4` и `ip::address_v6`.
Они предоставляют множество функций. Вот наиболее важные из них:
* `ip::address(v4_or_v6_address)`: Эта функция конвертирует v4 или v6 адрес в `ip::address`
* `ip::address:from_string(str)`: Эта функция создает адрес из IPv4 адреса (разделенных точками) или из IPv6 (шестнадцатиричный формат)
* `ip::address::to_string()`: Эта функция возвращает представление адреса в благоприятном строчном виде
* `ip::address_v4::broadcast([addr, mask])`: Эта функция создает `broadcast` адрес
* `ip::address_v4::any()`: Эта функция возвращает адрес, который олицетворяет любой адрес
* `ip::address_v4::loopback(), ip_address_v6::loopback()`: Эта функция возвращает шлейф адресов (из v4/v6 протокола)
* `ip::host_name()`: Эта функция возвращает имя текущего хоста в виде строчки
Скорее всего чаще всего вы будете использовать функцию `ip::address::from_string`:
```
ip::address addr = ip::address::from_string("127.0.0.1");
```
Если вам необходимо подключиться к имени хоста, читайте дальше. Следующий код не будет работать:
```
// throws an exception
ip::address addr = ip::address::from_string("www.yahoo.com");
```
##### Конечные точки (Endpoints)
Конечная точка это адрес подключения вместе с портом. Каждый тип сокетов имеет свой endpoint класс, например, `ip::tcp::endpoint, ip::udp::endpoint`, и `ip::icmp::endpoint`.
Если вы хотите подключиться к `localhost` по 80 порту, то вам нужно написать следующее:
```
ip::tcp::endpoint ep( ip::address::from_string("127.0.0.1"), 80);
```
Вы можете создать конечную точку тремя способами:
* `endpoint()`: конструктор по умолчанию и он может быть иногда использован для UDP/ICMP сокетов
* `endpoint(protocol, port)`: обычно используется на серверных сокетах для приема новых подключений
* `endpoint(addr, port)`: создание конечной точки по адресу и порту
Вот несколько примеров:
```
ip::tcp::endpoint ep1;
ip::tcp::endpoint ep2(ip::tcp::v4(), 80);
ip::tcp::endpoint ep3( ip::address::from_string("127.0.0.1), 80);
```
Если же вы хотите подключится к хосту (не IP адресу), то вам нужно сделать следующее:
```
// outputs "87.248.122.122"
io_service service;
ip::tcp::resolver resolver(service);
ip::tcp::resolver::query query("www.yahoo.com", "80");
ip::tcp::resolver::iterator iter = resolver.resolve( query);
ip::tcp::endpoint ep = *iter;
std::cout << ep.address().to_string() << std::endl;
```
Можете заменить tcp на нужный вам тип сокета. Во-первых, создайте запрос с именем, к которому хотите подключиться, это можно реализовать с помощью функции `resolve()`. В случае успеха вернется хотя бы одна запись.
Получив конечную точку, вы можете получить из нее адрес, порт и IP протокол (v4 или v6):
```
std::cout << ep.address().to_string() << ":" << ep.port() << "/" << ep.protocol() << std::endl;
```
##### Сокеты
Boost.Asio включает в себя три типа классов сокетов: `ip::tcp, ip::udp`, и `ip::icmp`, ну и, конечно же, расширяется. Вы можете создать свой собственный класс сокета, хотя это довольно сложно. В случае если вы все же решите сделать это посмотрите `boost/ asio/ip/tcp.hpp`, `boost/asio/ip/udp.hpp`, и `boost/asio/ip/icmp.hpp`. Все они это довольно маленькие классы с внутренними `typedef` ключевыми словами.
Вы можете думать о классах `ip::tcp, ip::udp, ip::icmp` как о заполнителях; они дают возможность легко добраться до других классов/функций, которые определяются следующим образом:
* ip::tcp::socket, ip::tcp::acceptor, ip::tcp::endpoint, ip::tcp::resolver, ip::tcp::iostream
* ip::udp::socket, ip::udp::endpoint, ip::udp::resolver
* ip::icmp::socket, ip::icmp::endpoint, ip::icmp::resolver
Класс `socket` создает соответствующий сокет. Вы всегда передаете экземпляр `io_service` в конструктор:
```
io_service service;
ip::udp::socket sock(service)
sock.set_option(ip::udp::socket::reuse_address(true));
```
Каждое имя сокета имеет `typedef`:
* `ip::tcp::socket= basic_stream_socket`
`ip::udp::socket= basic_datagram_socketp>
`ip::icmp::socket= basic_raw_socket`
#### Коды ошибок синхронных функций
Все синхронные функции имеют перегрузки, которые выбрасывают исключения или возвращают код ошибки, как показано ниже:
```
sync_func( arg1, arg2 ... argN); // throws
boost::system::error_code ec;
sync_func( arg1 arg2, ..., argN, ec); // returns error code
```
В оставшейся части главы, Вы увидите много синхронных функций. Чтобы не усложнять, я опустил показ перегрузок, которые возвращают код ошибки, но они существуют.
##### Функции сокетов
Все функции разделены на несколько групп. Не все функции доступны для каждого типа сокета. Список в конце этого раздела покажет вам, какие функции к какому классу сокетов относятся.
Отметим, что все асинхронные функции отвечают мгновенно, в то время как их коллеги синхронные отвечают только после того, как операция была завершена.
###### Соединительно-связывающие функции
Это функции, которые подключаются или соединяются с сокетом, отключают его и делают запрос о подключении, активно оно или нет:
+ `assign(protocol,socket)`: эта функция присваивает сырой(естественный) сокет к экземпляру сокета. Используйте ее при работе с наследуемым кодом (то есть когда сырые сокеты уже созданы).
+ `open(protocol)`: эта функция открывает сокет с заданным IP-протоколом (v4 или v6). Вы будете использовать ее в основном для UDP/ICMP сокетов или серверных сокетов
+ `bind(endpoint)`: эта функция связывается с данным адресом.
+ `connect(endpoint)`: эта функция синхронно подключается по данному адресу.
+ `async_connect(endpoint)`: эта функция асинхронно подключается по данному адресу.
+ `is_open()`: эта функция возвращает true если сокет открыт.
+ `close()`: эта функция закрывает сокет. Любые асинхронные операции на этом сокете немедленно прекращаются и возвращают `error::operation_aborted` код ошибки.
+ `shutdown(type_of_shutdown)`: эта функция отключает операцию `send , receive` или обе сразу же после вызова.
+ `cancel()`: эта функция отменяет все асинхронные операции на этом сокете. Все асинхронные операции на этом сокете будут немедленно завершены и вернут `error::operation_aborted` код ошибки.
Приведем небольшой пример:
```
ip::tcp::endpoint ep( ip::address::from_string("127.0.0.1"), 80);
ip::tcp::socket sock(service);
sock.open(ip::tcp::v4());
sock.connect(ep);
sock.write_some(buffer("GET /index.html\r\n"));
char buff[1024]; sock.read_some(buffer(buff,1024));
sock.shutdown(ip::tcp::socket::shutdown_receive);
sock.close();
```
###### Функции чтения/записи
Это функции, которые выполняют ввод/вывод на сокете.
Для асинхронных функций обработчик имеем следующую сигнатуру `void handler(const boost::system::error_code& e, size_t bytes);`. А вот сами функции:
+ `async_receive(buffer, [flags,] handler)`: эта функция запускает асинхронную операцию получения данных от сокета.
+ `async_read_some(buffer,handler)`: эта функция эквивалента `async_receive(buffer, handler)`.
+ `async_receive_from(buffer, endpoint[, flags], handler)`: эта функция запускает асинхронное получение данных от определенного адреса.
+ `async_send(buffer [, flags], handler)`: эта функция запускает операцию асинхронной передачи данных из буфера
+ `async_write_some(buffer, handler)`: эта функция эквивалентна `async_send(buffer, handler)`.
+ `async_send_to(buffer, endpoint, handler)`: эта функция запускает операцию асинхронной передачи данных из буфера по определенному адресу.
+ `receive(buffer [, flags])`: эта функция синхронно принимает данные в буфер. Функция заблокирована пока не начнут приходить данные или если произошла ошибка.
+ `read_some(buffer)`: эта функция эквивалентна `receive(buffer)`.
+ `receive_from(buffer, endpoint [, flags])`: эта функция синхронно принимает данные от определенного адреса в данный буфер. Функция заблокирована пока не начали приходить данные или если произошла ошибка.
+ `send(buffer [, flags])`: эта функция синхронно отправляет данные из буфера. Функция заблокирована пока идет отправка данных или если произошла ошибка.
+ `write_some(buffer)`: эта функция эквивалентна `send(buffer)`.
+ `send_to(buffer, endpoint [, flags])`: эта функция синхронно передает данные из буфера по данному адресу. Функция заблокирована пока идет отправка данных или если произошла ошибка.
+ `available()`: эта функция возвращает количество байт, которое можно считать синхронно, без блокировки.
Мы будем говорить о буферах в ближайшее время. Давайте рассмотрим флаги. Значение по умолчанию для флагов равно 0, но возможны комбинации:
+ `ip::socket_type::socket::message_peek`: этот флаг только заглядывает в сообщение. Он вернет сообщение, но при следующем вызове, чтобы прочитать сообщение нужно будет его перечитать.
+ `ip::socket_type::socket::message_out_of_band`: этот флаг обрабатывает вне-полосные данные(out-of-band). OOB данные это данные, которые помечены как более важные, по сравнению с обычными данными. Обсуждение OOB данных выходит за рамки данной книги.
+ `ip::socket_type::socket::message_do_not_route`: этот флаг указывает, что сообщение должно быть отправлено без использования таблиц маршрутизации.
+ `ip::socket_type::socket::message_end_of_record:` этот флаг указывает на то, что данные помечены маркером об окончании записи. Это не поддерживается в Windows.
Скорее всего вы использовали `message_peek`, если когда-нибудь писали следующий код:
```
char buff[1024];
sock.receive(buffer(buff), ip::tcp::socket::message_peek );
memset(buff,1024, 0);
// re-reads what was previously read
sock.receive(buffer(buff) );
```
Ниже приведены примеры, которые дают указания читать как синхронно так и асинхронно различным типам сокетов:
+ Пример 1: синхронные чтение и запись в TCP сокет:
```
ip::tcp::endpoint ep( ip::address::from_string("127.0.0.1"), 80);
ip::tcp::socket sock(service);
sock.connect(ep);
sock.write_some(buffer("GET /index.html\r\n"));
std::cout << "bytes available " << sock.available() << std::endl;
char buff[512];
size_t read = sock.read_some(buffer(buff));
```
+ Пример 2: синхронные чтение и запись в UDP сокет:
```
ip::udp::socket sock(service);
sock.open(ip::udp::v4());
ip::udp::endpoint receiver_ep("87.248.112.181", 80);
sock.send_to(buffer("testing\n"), receiver_ep);
char buff[512];
ip::udp::endpoint sender_ep;
sock.receive_from(buffer(buff), sender_ep);
```
Обратите внимание, что читая из UDP сокета с использованием `receive_from`, вам необходимо использовать конструктор по умолчанию конечной точки, как показано в предыдущем примере.
+ Пример 3: асинхронное чтение из UDP серверного сокета:
```
using namespace boost::asio;
io_service service;
ip::udp::socket sock(service);
boost::asio::ip::udp::endpoint sender_ep;
char buff[512];
void on_read(const boost::system::error_code & err, std::size_t
read_bytes)
{
std::cout << "read " << read_bytes << std::endl;
sock.async_receive_from(buffer(buff), sender_ep, on_read);
}
int main(int argc, char* argv[])
{
ip::udp::endpoint ep( ip::address::from_string("127.0.0.1"),
8001);
sock.open(ep.protocol());
sock.set_option(boost::asio::ip::udp::socket::reuse_
address(true));
sock.bind(ep);
sock.async_receive_from(buffer(buff,512), sender_ep, on_read);
service.run();
}
```
##### Управление сокетом
Эти функции работают с дополнительными параметрами сокета:
+ `get_io_service()`: эта функция возвращает экземпляр `io_service`, который был принят в конструкторе.
+ `get_option(option)`: эта функция возвращает параметр сокета
+ `set_option(option)`: эта функция устанавливает параметр сокета
+ `io_control(cmd)`: эта функция приводит в исполнение команды ввода/вывода на сокете.
Следующие параметры вы можете получать/задавать сокету:
| Имя | Определение | Тип |
| --- | --- | --- |
| `broadcast` | Если `true`, то позволяет широковещательные сообщения | bool |
| `debug` | Если `true`, то позволяет отладку на уровне сокетов | bool |
| `do_not_route` | Если `true`, то предотвращает маршрутизацию и использует только локальные интерфейсы | bool |
| `enable_connection_aborted` | Если `true`, то переподключает оборванное соединение | bool |
| `keep_alive` | Если `true`, то посылает `keep-alives` | bool |
| `linger` | Если `true`, то сокет задерживается на `close()`, если есть не сохраненные
данные | bool |
| `receive_buffer_size` | Размер буфера приема | `int` |
| `receive_low_watemark` | Предоставляет минимальное число байт при обработке входного сокета | `int` |
| `reuse_address` | Если `true`, то сокет может быть связан с адресом, который уже используется | bool |
| `send_buffer_size` | Размер буфера отправки | `int` |
| `send_low_watermark` | Предоставляет минимальное число байт для отправки в выходном сокете | `int` |
| `ip::v6_only` | Если `true`, то позволяет использовать только IPv6 связи | `bool` |
Каждое имя представляет собой внутренний `typedef` сокета или класса. Вот как их можно использовать:
```
ip::tcp::endpoint ep( ip::address::from_string("127.0.0.1"), 80);
ip::tcp::socket sock(service);
sock.connect(ep);
// TCP socket can reuse address
ip::tcp::socket::reuse_address ra(true);
sock.set_option(ra);
// get sock receive buffer size
ip::tcp::socket::receive_buffer_size rbs;
sock.get_option(rbs);
std::cout << rbs.value() << std::endl;
// set sock's buffer size to 8192
ip::tcp::socket::send_buffer_size sbs(8192);
sock.set_option(sbs);
```
Сокет должен быть открыт для работы предыдущей функции, иначе вылетит исключение.
##### TCP против UDP и ICMP
Как я уже сказал, не все функции-члены доступны для всех классов сокетов. Я составил список, где функции-члены отличаются. Если функции-члена здесь нет, то это означает, что она присутствует во всех классах сокетов:
| Name | TCP | UDP | ICMP |
| --- | --- | --- | --- |
| `async_read_some` | Yes | - | - |
| `async_write_some` | Yes | - | - |
| `async_send_to` | - | Yes | Yes |
| `read_some` | Yes | - | - |
| `receive_from` | - | Yes | Yes |
| `write_some` | Yes | - | - |
| `send_to` | - | Yes | Yes |
##### Прочие функции
Остальные функции, связанные с соединением или вводом/выводом:
+ `local_endpoint()`: эта функция возвращает адрес, если сокет подключен локально.
+ `remote_endpoint()`: эта функция возвращает удаленные адреса, куда сокет был подключен.
+ `native_handle()`: эта функция возвращает чистый сокет. Ее нужно использовать только тогда, когда вы хотите использовать функции для работы с чистыми сокетами, которые не поддерживаются Boost.Asio.
+ `non_blocking()`: эта функция возвращает `true` если сокет неблокирующий, иначе `false`.
+ `native_non_blocking()`: эта функция возвращает `true` если сокет неблокирующий, иначе `false`. Тем не менее он будет вызывать чистый API для естественного сокета. Как правило вам это не нужно (`non_blocking()` всегда кэширует этот результат); вы должны использовать ее только тогда, когда вы непосредственно имеете дело с `native_handle()`.
+ `at_mark()`: эта функция возвращает `true`, еси вы собираетесь читать в сокете OOB данные. Она нужна очень редко.
##### Другие соображения
И на последок, экземпляр сокета не может быть скопирован, так как конструктор копирования и `operator=` недоступны.
```
ip::tcp::socket s1(service), s2(service);
s1 = s2; // compile time error
ip::tcp::socket s3(s1); // compile time error
```
В этом много смысла, так как каждый экземпляр хранит и управляет ресурсами (сам естественный сокет). Если бы мы использовали копирующий конструктор, то в конечном итоге мы имели два экземпляра одного и того же сокета; они должны были бы как то управлять правом собственности (либо один экземпляр имеет право собственности, или используется подсчет ссылок, или какой-то другой метод). В Boost.Asio было принято запретить копирование (если вы хотите создавать копии, просто используйте общий (`shared`) указатель).
```
typedef boost::shared_ptr socket\_ptr;
socket\_ptr sock1(new ip::tcp::socket(service));
socket\_ptr sock2(sock1); // ok
socket\_ptr sock3;
sock3 = sock1; // ok
```
#### Буферы сокетов
При чтении или записи в сокет, вам понадобиться буфер, который будет содержать входящие или исходящие данные. Память буфера должна пережить операции ввода/вывода; вы должны убедиться, что до тех пор пока она не освобождена, она не выйдет из области видимости пока длятся операции ввода/вывода.
Это очень просто для синхронных операций; конечно, `buff` должен пережить обе операции `receive` и `send`:
```
char buff[512];
...
sock.receive(buffer(buff));
strcpy(buff, "ok\n");
sock.send(buffer(buff));
```
И это не так просто для асинхронных операций, как показано в следующем фрагменте:
```
// very bad code ...
void on_read(const boost::system::error_code & err, std::size_t read_
bytes)
{ ... }
void func()
{
char buff[512];
sock.async_receive(buffer(buff), on_read);
}
```
После вызова `async_receive()`,`buff` выйдет из области видимости, таким образом его память будет освобождена. Когда мы собираемся на самом деле получить некоторые данные на сокете, то надо скопировать их в память больше нам не принадлежащую; она может быть либо освобождена, либо перераспределена по коду для других данных, при этом всем имеет повреждение памяти.
Есть несколько решений поставленной задачи:
+ Использовать глобальный буфер
+ Создать буфер и уничтожить его, когда операция завершится
+ Иметь объект связи для поддержки сокета и дополнительные данные, такие как буфер (ы).
Первое решение не очень удобно, так как мы все знаем, что глобальные переменные это плохо. Кроме того, что произойдет, если два обработчика будут использовать один и тот же буфер?
Вот как вы можете реализовать второе решение:
```
void on_read(char * ptr, const boost::system::error_code & err,
std::size_t read_bytes)
{
delete[] ptr;
}
....
char * buff = new char[512];
sock.async_receive(buffer(buff, 512), boost::bind(on_
read,buff,_1,_2));
```
Если вы хотите, чтобы буфер автоматически выходил из области видимости, когда завершается операция, то используйте общий указатель (`shared pointer`):
```
struct shared_buffer
{
boost::shared_array buff;
int size;
shared\_buffer(size\_t size) : buff(new char[size]), size(size)
{}
mutable\_buffers\_1 asio\_buff() const
{
return buffer(buff.get(), size);
}
};
// when on\_read goes out of scope, the boost::bind object is released,
// and that will release the shared\_buffer as well
void on\_read(shared\_buffer, const boost::system::error\_code & err,
std::size\_t read\_bytes) {}
...
shared\_buffer buff(512);
sock.async\_receive(buff.asio\_buff(), boost::bind(on\_read,buff,\_1,\_2));
```
Класс `shared_buffer` содержит внутри себя `shared_array<>`, который является копией экземпляра `shared_buffer`, так что `shared_array <>` будет оставаться в живых; когда последний выйдет из области видимости, `shared_array <>` автоматически разрушится, как раз то, что мы хотели.
Это работает как и следовало ожидать, так как Boost.Asio будет держать копию завершающего обработчика, который вызывается при завершении операции. Эта копия является функтором `boost::bind`, который внутри хранит копию нашего экземпляра `shared_buffer`. Это очень аккуратно!
Третий вариант состоит в использовании объекта связи, который поддерживает сокет и содержит дополнительные данные, такие как буферы, обычно это правильное решение, но довольно сложное. Оно будет рассмотрено в конце этой главы.
#### Врапер функции буфера
В коде, который мы видели раньше, мы всегда нуждались в буфере для операций чтения/записи, код оборачивался в объект реального буфера, в вызов `buffer()` и передачу его функции:
```
char buff[512];
sock.async_receive(buffer(buff), on_read
```
В основном оборачивается любой буфер, который у нас есть в классе, что позволяет функциям из Boost.Asio итерироваться по буферу. Скажите, вы используете следующий код:
```
sock.async_receive(some_buffer, on_read);
```
Экземпляр `some_buffer` должен удовлетворять некоторым требованиям, а именно `ConstBufferSequence` или `MutableBufferSequence` (вы можете посмотреть о них более подробно в документации по Boost.Asio). Подробности создания своего собственного класса для удовлетворения этих требований являются довольно сложными, но Boost.Asio уже содержит некоторые классы, моделирующие эти требования. Вы не обращаетесь к ним напрямую, вы используете функцию `buffer()`.
Достаточно сказать, что вы можете обернуть все ниже следующее в функцию `buffer()`:
+ константный массив символов
+ `void*` и размер в символах
+ строку `std::string`
+ константный массив POD[] (POD подходит для старых данных, то есть конструктор и деструктор ничего не делают)
+ массив `std::vector` из любых POD
+ массив `boost::array` из любых POD
+ массив `std::array` из любых POD
Следующий код рабочий:
```
struct pod_sample { int i; long l; char c; };
...
char b1[512];
void * b2 = new char[512];
std::string b3; b3.resize(128);
pod_sample b4[16];
std::vector b5; b5.resize(16);
boost::array b6;
std::array b7;
sock.async\_send(buffer(b1), on\_read);
sock.async\_send(buffer(b2,512), on\_read);
sock.async\_send(buffer(b3), on\_read);
sock.async\_send(buffer(b4), on\_read);
sock.async\_send(buffer(b5), on\_read);
sock.async\_send(buffer(b6), on\_read);
sock.async\_send(buffer(b7), on\_read);
```
В общем, вместо того, чтобы создавать свой собственный класс для удовлетворения требований `ConstBufferSequence` или `MutableBufferSequence`, вы можете создать класс, который будет содержать буфер до тех пор, пока это необходимо и возвращать экземпляр `mutable_ buffers_1`, это то же самое, что мы делали в классе `shared_buffer` ранее.
#### Независимые функции чтения/записи/подключения
Boost.Asio дает вам независимые функции для работы с вводом/выводом. Я разделил их на четыре группы.
##### Функции подключения
Эти функции подключают сокет или конечный адрес:
+ `connect(socket, begin [, end] [, condition])`: эта функция пытается синхронно подключить каждый конечный адрес в последовательности, начиная с `begin` и заканчивая `end`. Итератор `begin` является результатом вызова `socket_type::resolver::query` (если хотите, можете посмотреть раздел «Конечные точки» еще раз). Указание конечного итератора не является обязательным, вы можете забыть об этом. Вы можете указать `condition` функции, которое вызывается перед каждой попыткой подключения. Это есть сигнатура `Iterator connect_condition(const boost::system::error_code & err, Iterator next);`. Вы можете выбрать другой итератор для возврата, чем следующий, это позволяет пропускать некоторые конечные адреса.
+ `async_connect(socket, begin [, end] [, condition], handler):` эта функция выполняет асинхронное подключение и в конце вызывает обработчик завершения. Сигнатура обработчика следующая `void handler(const boost::system::error_code & err, Iterator iterator);`. Вторым параметром, передаваемым в обработчик является успешно подключенный конечный адрес (или итератор end в противном случае).
Приведем следующий пример:
```
using namespace boost::asio::ip;
tcp::resolver resolver(service);
tcp::resolver::iterator iter = resolver.resolve(tcp::resolver::query("www.yahoo.com","80"));
tcp::socket sock(service);
connect(sock, iter);
```
Имя хоста может вмещать более одного адреса, таким образом `connect` и `async_connect` освобождают вас от бремени проверять каждый адрес, чтобы понять какой из них доступен; они делают это за вас.
##### Функции чтения/записи
Это функции чтения или записи в поток (который может быть как сокетом так и любым другим классом, который ведет себя как поток):
+ `async_read(stream, buffer [, completion] ,handler)`: эта функция асинхронно читает из потока. По завершении вызывается обработчик. Он имеет следующую сигнатуру `void handler(const boost::system::error_code & err, size_t bytes);`. При необходимости вы сами можете задать completion функцию. `Completion` функция вызывается после каждой успешной операции `read`, и сообщает Boost.Asio если функция `async_read` завершилась (если нет, то функция продолжит чтение). Следующий параметр это `size_t completion (const boost::system::error_code& err, size_t bytes_transfered)`. Когда эта завершающая функция возвращает 0, мы считаем, что операция чтения завершилась; если же вернулось ненулевое значение, то это означает, что максимальное количество байт будет прочитано при следующем вызове операции `async_read_some` в потоке. Далее будет рассмотрен пример для более лучшего понимания.
+ `async_write(stream, buffer [, completion], handler)`: это функция асинхронной записи в поток. Список аргументов схож с `async_read`.
+ `read(stream, buffer [, completion])`: это функция синхронного чтения из потока. Список аргументов схож с `async_read`
+ `write(stream, buffer [, completion])`: это функция синхронной записи в поток. Список аргументов схож с `async_read`.
+ `async_read(stream, stream_buffer [, completion], handler)`
+ `async_write(strean, stream_buffer [, completion], handler)`
+ `write(stream, stream_buffer [, completion])`
+ `read(stream, stream_buffer [, completion])`
Во-первых заметим, что вместо сокета первым аргументом передается поток. Сюда может передаваться сокет, но этим не ограничивается. Например, вместо сокета вы можете использовать файл Windows.
Каждая операция чтения или записи закончится при выполнении одного из следующих условий:
+ Предоставленный буфер заполнится (для чтения) или все данные в буфере будут записаны (для записи).
+ `Completion` функция вернет 0 (если вы предоставили одну из таких функций).
+ Если произошла ошибка.
Следующий код асинхронно читает, пока не встретит '\n':
```
io_service service;
ip::tcp::socket sock(service);
char buff[512];
int offset = 0;
size_t up_to_enter(const boost::system::error_code &, size_t bytes)
{
for ( size_t i = 0; i < bytes; ++i)
if ( buff[i + offset] == '\n')
return 0;
return 1;
}
void on_read(const boost::system::error_code &, size_t) {}
...
async_read(sock, buffer(buff), up_to_enter, on_read);
```
Кроме того, Boost.Asio предоставляет для помощи несколько `completion` функций:
+ transfer\_at\_least(n)
+ transfer\_exactly(n)
+ transfer\_all()
Это иллюстрируется в следующем примере:
```
char buff[512];
void on_read(const boost::system::error_code &, size_t) {}
// read exactly 32 bytes
async_read(sock, buffer(buff), transfer_exactly(32), on_read);
```
Последние четыре функции вместо обычного буфера используют функцию `stream_buffer` из Boost.Asio, это производная от `std::streambuf`. Сами потоки и их буферы из STL являются очень гибкими, вот пример:
```
io_service service;
void on_read(streambuf& buf, const boost::system::error_code &,
size_t)
{
std::istream in(&buf);
std::string line;
std::getline(in, line);
std::cout << "first line: " << line << std::endl;
}
int main(int argc, char* argv[])
{
HANDLE file = ::CreateFile("readme.txt", GENERIC_READ, 0, 0,
OPEN_ALWAYS, FILE_ATTRIBUTE_NORMAL | FILE_FLAG_OVERLAPPED,0);
windows::stream_handle h(service, file);
streambuf buf;
async_read(h, buf, transfer_exactly(256),
boost::bind(on_read,boost::ref(buf),_1,_2));
service.run();
}
```
Здесь я показал вам, что вы можете вызвать `async_read` (или что-то подобное) для файлов Windows. Мы считываем первые 256 символов и сохраняем их в буфер. Когда операция чтения завершится, будет вызвана `on_read`, я создаю `std::istream` буфер, считываю первую строчку (`std::getline`) и вывожу это в консоль.
##### Функции `read_until/async_read_until`
Эти функции производят чтение пока не будет выполнено некоторое условие:
+ `async_read_until(stream, stream_buffer, delim, handler)`: эта функция начинает операцию асинхронного чтения. Операция чтения остановится как только будет прочитан разделитель (`delim`). Разделителем может быть любой символ, `std::string` или `boost::regex`. Сигнатура обработчика следующая `void handler(const boost::system::error_code & err, size_t bytes);`.
+ `async_read_until(stream, stream_buffer, completion, handler)`: эта функция такая же как и предыдущая, но вместо разделителя мы имеем завершающую функцию. Она имеем следующую сигнатуру `pair completion(iterator begin, iterator end);`, когда итератор есть`buffers_iterator`. Вам необходимо помнить, что итератор имеет тип итератора произвольного доступа. Вы смотрите в диапазоне (`begin, end`) и сами решаете должна ли операция чтения завершится или нет. У вас возвращается пара; первый член которой это итератор указывающий на последний символ прочитанный функцией; второй член это `true`, в противном случае, если операция чтения должна прекратиться, то `false`.
+ `read_until(stream, stream_buffer, delim)`: эта функция выполняет операцию синхронного чтения. Значения параметров являются такими же как и у `async_read_until`.
В следующем примере мы будем читать до знаков препинания:
```
typedef buffers_iterator iterator;
std::pair match\_punct(iterator begin, iterator end)
{
while ( begin != end)
if ( std::ispunct(\*begin))
return std::make\_pair(begin,true);
return std::make\_pair(end,false);
}
void on\_read(const boost::system::error\_code &, size\_t) {}
...
streambuf buf;
async\_read\_until(sock, buf, match\_punct, on\_read);
```
Если бы мы хотели читать до пробела, то изменили бы последнюю строчку на:
```
async_read_until(sock, buff, ' ', on_read);
```
##### Функции \*\_at
Это функции случайных операций чтения/записи в поток. Вы указываете, где операции чтения/записи должны начаться (указываете смещение):
+ `async_read_at(stream, offset, buffer [, completion], handler)`: эта функция начинает операцию асинхронного чтения в данном потоке, начиная со смещения `offset`. При завершении операции будет вызван обработчик `handler (const boost::system::error_code& err, size_t bytes);`. Буфер может быть как обычной обвязкой `buffer()` так и функцией `streambuf`. Если задать функцию завершения, то она будет вызываться после каждого успешного чтения и сообщает Boost.Asio если операция `async_read_at operation` завершилась (если нет, то чтение продолжится). Сигнатура завершающей функции следующая `size_t completion(const boost::system::error_code& err, size_t bytes);`. Когда эта функция возвращает 0, то мы считаем, что операция чтения завершилась, если же вернулось ненулевое значение, то это означает, что максимальное число байт будет прочитано при следующем вызове `async_read_some_at` в этом потоке.
+ `async_write_at(stream, offset, buffer [, completion], handler)`: эта функция запускает операцию асинхронной записи. Параметры схожи с `async_read_at`.
+ `read_at(stream, offset, buffer [, completion])`: эта функция читает со смещением в данном потоке. Параметры схожи с `async_read_at`.
+ `read_at(stream, offset, buffer [, completion])`: эта функция читает со смещением в данном потоке. Параметры схожи с `async_read_at`.
Эти функции не имеют дело с сокетами. Они имеют дело с потоками случайного доступа; другими словами, с потоками, которые могут быть доступны в случайном порядке. Сокеты явно не этот случай (сокеты являются `forward-only`).
Вот как вы можете прочитать 128 байт из файла, начиная со смещением в 256:
```
io_service service;
int main(int argc, char* argv[])
{
HANDLE file = ::CreateFile("readme.txt", GENERIC_READ, 0, 0,
OPEN_ALWAYS, FILE_ATTRIBUTE_NORMAL | FILE_FLAG_OVERLAPPED,0);
windows::random_access_handle h(service, file);
streambuf buf;
read_at(h, 256, buf, transfer_exactly(128));
std::istream in(&buf);
std::string line;
std::getline(in, line);
std::cout << "first line: " << line << std::endl;
}
```
Всем большое спасибо за внимание, в следующий раз поговорим про асинхронное программирование. Все замечания пишите в комментариях. обязательно отвечу.
Всем удачи!` | https://habr.com/ru/post/193038/ | null | ru | null |
# Пишем фильтры WASM для Envoy и деплоим их с Istio

[Envoy](https://www.envoyproxy.io/) — это высокопроизводительный программируемый прокси L3/L4 и L7, на котором основано множество реализаций service mesh, например, [Istio](https://istio.io/). Envoy обрабатывает трафик с помощью сетевых фильтров, которые можно объединять в цепочки, чтобы реализовывать сложные функции для контроля доступа, преобразования, обогащения данных, аудита и так далее. Чтобы расширить функционал Envoy, новые фильтры можно добавить одним из двух способов:
* Интегрируем дополнительные фильтры в исходный код Envoy и компилируем новую версию Envoy. Недостаток такого подхода в том, что придется поддерживать свою версию Envoy и постоянно синхронизировать ее с официальным дистрибутивом. Фильтр, кстати, нужно реализовать на C++, как и сам Envoy.
* Динамически загружаем новые фильтры в Envoy Proxy в рантайме.
Второй вариант гораздо интереснее и проще — мы используем WebAssembly (WASM), эффективный и портативный бинарный формат инструкций со встраиваемой и изолированной средой выполнения.
Расскажу подробнее о фильтрах WASM.
Почему фильтры WASM? ︎
----------------------
Плюсы фильтров WASM:
* Гибкость — фильтры можно динамически загружать в запущенный процесс Envoy без остановки или перекомпиляции.
* Простота использования — мы расширяем функционал Envoy, не меняя кодовую базу.
* Разнообразие — мы можем выбрать язык для реализации фильтров, например C/C++, Rust или golang, и скомпилировать его в WASM.
* Надежность и изоляция — мы деплоим фильтры на виртуальной машине (в песочнице) изолированно от самого процесса Envoy (если что-то пойдет не так, процесс не пострадает).
* Безопасность — фильтры общаются с хостом (Envoy Proxy) через продуманный API, поэтому у них есть доступ к ограниченному числу соединений или свойств запросов.
Минусы, конечно, тоже есть:
* Производительность на уровне 70% от C++.
* Нужно больше памяти, чтобы запускать виртуальные машины для WASM.
Envoy Proxy WASM SDK ︎
----------------------
Envoy Proxy выполняет фильтры WASM внутри виртуальной машины на основе стека, поэтому память фильтра изолирована от хост-среды. Все взаимодействия между хостом (Envoy Proxy) и фильтром WASM реализуются через функции и обратные вызовы, предоставляемые Envoy Proxy WASM SDK. С Envoy Proxy WASM SDK можно выбрать разные языки:
* [C++](https://github.com/proxy-wasm/proxy-wasm-cpp-sdk)
* [Rust](https://github.com/proxy-wasm/proxy-wasm-rust-sdk)
* [AssemblyScript](https://github.com/solo-io/proxy-runtime)
* [Go](https://github.com/mathetake/proxy-wasm-go)
Здесь я расскажу, как писать фильтры WASM для Envoy с помощью C++ Envoy Proxy WASM SDK. Мы не будем подробно останавливаться на API для Envoy Proxy WASM SDK, но постараемся разобраться в основах написания фильтров WASM для Envoy.
Для реализации фильтров нам нужны два класса:
```
class RootContext;
class Context;
```
Когда мы загружаем плагин WASM (бинарный код WASM с фильтром), создается **root context**. Root context существует столько же, сколько инстанс виртуальной машины, который выполняет фильтр. Его задачи:
* взаимодействия между кодом и Envoy Proxy при начальной настройке;
* взаимодействия, которые продолжат существовать после запроса.
`onConfigure(size_t)` вызывается Envoy Proxy в `RootContext` только для передачи конфигураций в виртуальную машину и плагин. Если плагин с одним или несколькими фильтрами ожидает от Envoy Proxy конфигурацию, эту функцию можно отменить и получить конфигурацию с помощью вспомогательной функции `getBufferBytes` через `WasmBufferType::VmConfiguration` и `WasmBufferType::PluginConfiguration` соответственно.
Сетевой трафик, обрабатываемый Envoy Proxy, будет проходить через цепочку фильтров, связанную с [listener](https://www.envoyproxy.io/docs/envoy/latest/intro/arch_overview/listeners/listeners#arch-overview-listeners), который получает этот трафик. Для каждого нового потока через цепочку фильтров Envoy Proxy создает новый **контекст**, который существует до конца потока.
Базовый класс `Context` предоставляет хуки (обратные вызовы) в виде виртуальных функций `onXXXX(...)` для трафика HTTP и TCP, которые вызываются, когда Envoy Proxy проходит по цепочке фильтров. Обратные вызовы в `Context` зависят от уровня цепочки фильтров, в которую входит фильтр (HTTP или TCP). Например, `FilterHeadersStatus onRequestHeaders(uint32_t)` вызывается только для фильтров WASM в цепочке на уровне HTTP, но не для TCP.
Реализация базового класса `Context` используется Envoy Proxy для взаимодействия с кодом на протяжении времени существования потока. В этих функциях обратных вызовов мы можем управлять трафиком. SDK предоставляет функции для управления заголовками HTTP-запросов и ответов (`getRequestHeader`, `addRequestHeader` и т. д.), телом HTTP-запроса, TCP-потоками (например, `getBufferBytes`, `setBufferBytes`) и т. д. Каждая функция обратного вызова возвращает статус, по которому Envoy Proxy узнает, надо или нет передавать обработку потока на следующий фильтр в цепочке.
Следующий шаг — зарегистрировать инстансы `factory`, чтобы создать реализации `RootContext` и `Context` через объявление статической переменной типа
```
class RegisterContextFactory;
```
Переменная будет ждать root context factory и context factory в виде аргументов конструктора.
### Пример фильтра ︎
Вот очень простой пример скелета фильтра WASM, который можно создать с C++ Envoy Proxy WASM SDK: **example-filter.cc:**
```
#include "proxy_wasm_intrinsics.h"
class ExampleRootContext: public RootContext {
public:
explicit ExampleRootContext(uint32_t id, StringView root_id): RootContext(id, root_id) {}
bool onStart(size_t) override;
};
class ExampleContext: public Context {
public:
explicit ExampleContext(uint32_t id, RootContext* root) : Context(id, root) {}
FilterHeadersStatus onResponseHeaders(uint32_t) override;
FilterStatus onDownstreamData(size_t, bool) override;
};
// register factories for ExampleContext and ExampleRootContext
static RegisterContextFactory register_FilterContext(CONTEXT_FACTORY(ExampleContext),
ROOT_FACTORY(ExampleRootContext),
"my_root_id");
// invoked when the plugin initialised and is ready to process streams
bool ExampleRootContext::onStart(size_t n) {
LOG_DEBUG("ready to process streams");
return true;
}
// invoked when HTTP response header is decoded
FilterHeadersStatus ExampleContext::onResponseHeaders(uint32_t) {
addResponseHeader("resp-header-demo", "added by our filter");
return FilterHeadersStatus::Continue;
}
// invoked when downstream TCP data chunk is received
FilterStatus ExampleContext::onDownstreamData(size_t, bool) {
auto res = setBuffer(WasmBufferType::NetworkDownstreamData, 0, 0, "prepend payload to downstream data");
if (res != WasmResult::Ok) {
LOG_ERROR("Modifying downstream data failed: " + toString(res));
return FilterStatus::StopIteration;
}
return FilterStatus::Continue;
}
```
Сборка фильтра
--------------
Самый простой способ собрать фильтр — использовать Docker, потому что так нам не придется хранить на локальном компьютере разные библиотеки.
1. Сначала создаем образ docker с помощью C++ Envoy Proxy WASM SDK, как описано [здесь](https://github.com/proxy-wasm/proxy-wasm-cpp-sdk#docker).
2. Создаем Makefile для фильтра WASM. **Makefile:**
```
.PHONY = all clean
PROXY_WASM_CPP_SDK=/sdk
all: example-filter.wasm
include ${PROXY_WASM_CPP_SDK}/Makefile.base_lite
```
1. Собираем фильтр WASM:
```
docker run -v $PWD:/work -w /work wasmsdk:v2 /build_wasm.sh
```
Деплоим фильтр WASM с Istio ︎
-----------------------------
> Узнать о работе с Istio и внедрении service mesh можно на [интенсиве 19—21 марта](https://slurm.io/intensive-service-mesh?utm_source=habr&utm_medium=post&utm_campaign=service-mesh-intensive&utm_content=post_02-02-2021&utm_term=bartov).
Деплоим наш фильтр Envoy WASM для приложения, запущенного в Istio service mesh в Kubernetes. Можем быстро запустить Istio mesh с демо-приложением в Kubernetes с помощью [Backyards](https://banzaicloud.com/docs/backyards/overview/), дистрибутива Istio от Banzai Cloud. *(**прим. переводчика:** также можно воспользоваться [этой getting started инструкцией](https://istio.io/latest/docs/setup/getting-started/) до шага Deploy the sample application включительно и далее использовать bookinfo приложение в следующих шагах).*
```
backyards install -a --run-demo
```
Всего одна команда — и к нашим услугам production-ready и полностью рабочая Istio service mesh с демо-приложением из нескольких микросервисов внутри.
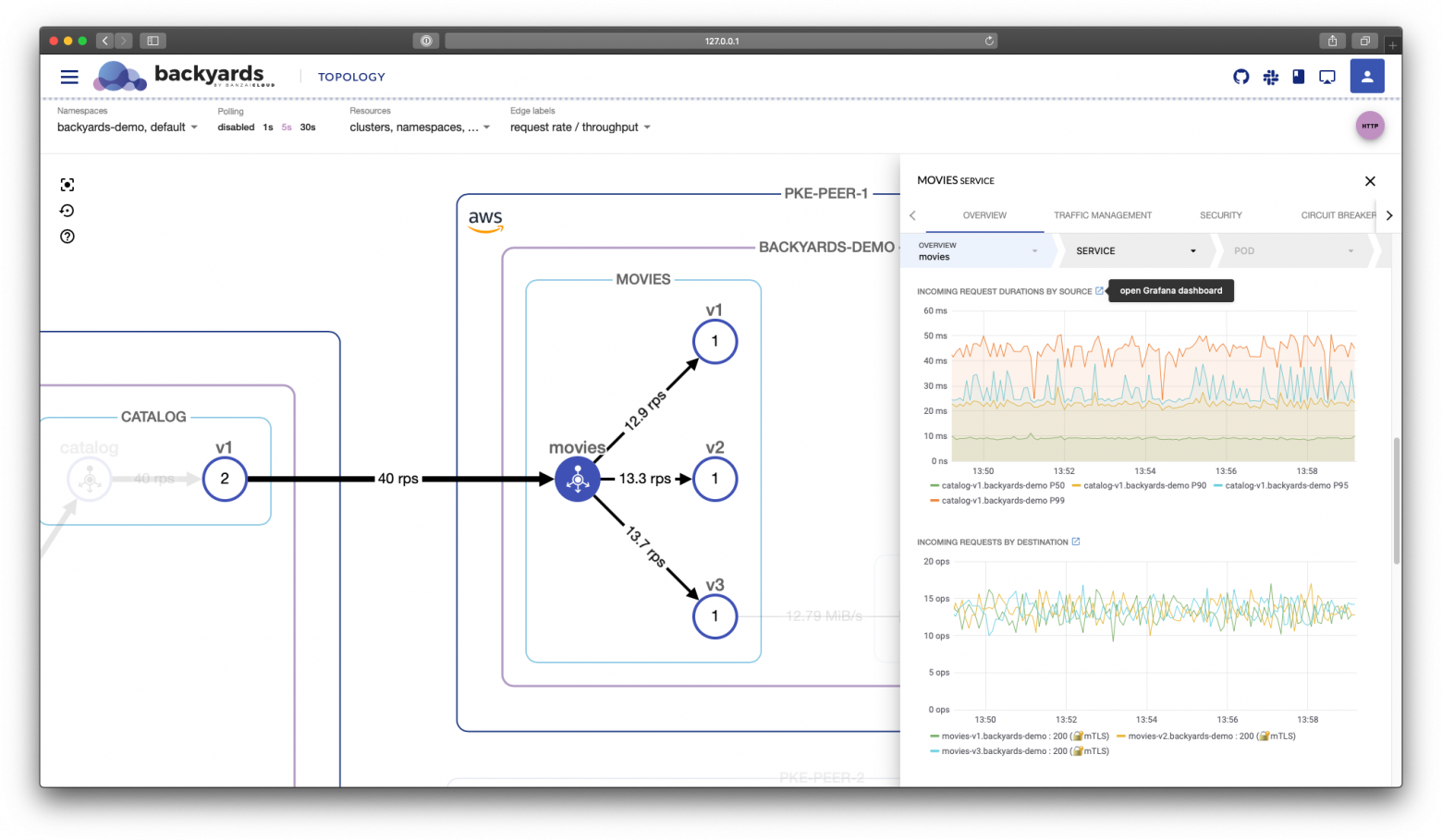
#### Создаем config map для кода wasm
Создаем config map, где будет размещаться код `WASM` для нашего фильтра, в неймспейс `backyards-demo`, где запущено демо *(**прим. переводчика:**либо bookinfo в случае использования чистого Istio)*.
```
kubectl create cm -n backyards-demo example-filter --from-file=example-filter.wasm
```
#### Внедряем код wasm в демо с помощью Istio ︎
1. Внедряем код wasm в сервис `frontpage` нашего демо-приложения с помощью двух аннотаций:
```
sidecar.istio.io/userVolume: '[{"name":"wasmfilters-dir","configMap": {"name": "example-filter"}}]'
sidecar.istio.io/userVolumeMount: '[{"mountPath":"/var/local/lib/wasm-filters","name":"wasmfilters-dir"}]'
```
1. Выполняем
```
kubectl scale deployment -n backyards-demo frontpage-v1 --replicas=1
kubectl patch deployment -n backyards-demo frontpage-v1 -p '{"spec":{"template":{"metadata":{"annotations":{"sidecar.istio.io/userVolume":"[{\"name\":\"wasmfilters-dir\",\"configMap\": {\"name\": \"example-filter\"}}]","sidecar.istio.io/userVolumeMount":"[{\"mountPath\":\"/var/local/lib/wasm-filters\",\"name\":\"wasmfilters-dir\"}]"}}}}}'
```
Теперь код фильтра WASM доступен в `/var/local/lib/wasm-filters` в контейнере istio-proxy:
```
kubectl exec -n backyards-demo -it deployment/frontpage-v1 -c istio-proxy -- ls /var/local/lib/wasm-filters/
example-filter.wasm
```
1. Включаем для фильтров WASM логирование на уровне DEBUG при обработке трафика к сервису `frontpage`:
```
kubectl port-forward -n backyards-demo deployment/frontpage-v1 15000
curl -XPOST "localhost:15000/logging?wasm=debug"
```
1. Вставляем фильтр WASM в цепочку на уровне HTTP, привязанную к порту HTTP 8080:
```
kubectl apply -f-<
```
**Примечание.** При тестировании мы обнаружили, что фильтр `portNumber`, указанный для listener match в кастомном ресурсе `EnvoyFilter`, некорректно обрабатывался в Istio, поэтому хуки для фильтра не вызывались. Мы исправили эту проблему в нашем дистрибутиве Istio — [Backyards](https://banzaicloud.com/products/backyards/).
1. Отправляем трафик через порт HTTP 8080 в сервис `frontpage`:
```
kubectl run curl --image=yauritux/busybox-curl --restart=Never -it --rm sh
/home # curl -L -v http://frontpage.backyards-demo:8080
```
**Мы ожидаем увидеть заголовок фильтра, добавленный к заголовку ответа:**
```
* About to connect() to frontpage.backyards-demo port 8080 (#0)
* Trying 10.10.178.38...
* Adding handle: conn: 0x10eadbd8
* Adding handle: send: 0
* Adding handle: recv: 0
* Curl_addHandleToPipeline: length: 1
* - Conn 0 (0x10eadbd8) send_pipe: 1, recv_pipe: 0
* Connected to frontpage.backyards-demo (10.10.178.38) port 8080 (#0)
> GET / HTTP/1.1
> User-Agent: curl/7.30.0
> Host: frontpage.backyards-demo:8080
> Accept: */*
>
< HTTP/1.1 200 OK
< content-type: text/plain
< date: Thu, 16 Apr 2020 16:32:20 GMT
< content-length: 9
< x-envoy-upstream-service-time: 10
< resp-header-demo: added by our filter
< x-envoy-peer-metadata: CjYKDElOU1RBTkNFX0lQUxImGiQxMC4yMC4xLjU3LGZlODA6OmQwNDM6NDdmZjpmZWYwOmVkMjkK2QEKBkxBQkVMUxLOASrLAQoSCgNhcHASCxoJZnJvbnRwYWdlCiEKEXBvZC10ZW1wbGF0ZS1oYXNoEgwaCjU3OGM2NTU0ZDQKJAoZc2VjdXJpdHkuaXN0aW8uaW8vdGxzTW9k
ZRIHGgVpc3RpbwouCh9zZXJ2aWNlLmlzdGlvLmlvL2Nhbm9uaWNhbC1uYW1lEgsaCWZyb250cGFnZQorCiNzZXJ2aWNlLmlzdGlvLmlvL2Nhbm9uaWNhbC1yZXZpc2lvbhIEGgJ2MQoPCgd2ZXJzaW9uEgQaAnYxChoKB01FU0hfSUQSDxoNY2x1c3Rlci5sb2NhbAonCgROQU1FEh8aHWZyb250cGFnZS12MS01N
zhjNjU1NGQ0LWxidnFrCh0KCU5BTUVTUEFDRRIQGg5iYWNreWFyZHMtZGVtbwpXCgVPV05FUhJOGkxrdWJlcm5ldGVzOi8vYXBpcy9hcHBzL3YxL25hbWVzcGFjZXMvYmFja3lhcmRzLWRlbW8vZGVwbG95bWVudHMvZnJvbnRwYWdlLXYxCi8KEVBMQVRGT1JNX01FVEFEQVRBEhoqGAoWCgpjbHVzdGVyX2lkEg
gaBm1hc3RlcgocCg9TRVJWSUNFX0FDQ09VTlQSCRoHZGVmYXVsdAofCg1XT1JLTE9BRF9OQU1FEg4aDGZyb250cGFnZS12MQ==
< x-envoy-peer-metadata-id: sidecar~10.20.1.57~frontpage-v1-578c6554d4-lbvqk.backyards-demo~backyards-demo.svc.cluster.local
< x-by-metadata: CjYKDElOU1RBTkNFX0lQUxImGiQxMC4yMC4xLjU3LGZlODA6OmQwNDM6NDdmZjpmZWYwOmVkMjkK2QEKBkxBQkVMUxLOASrLAQoSCgNhcHASCxoJZnJvbnRwYWdlCiEKEXBvZC10ZW1wbGF0ZS1oYXNoEgwaCjU3OGM2NTU0ZDQKJAoZc2VjdXJpdHkuaXN0aW8uaW8vdGxzTW9kZRIHGgVp
c3RpbwouCh9zZXJ2aWNlLmlzdGlvLmlvL2Nhbm9uaWNhbC1uYW1lEgsaCWZyb250cGFnZQorCiNzZXJ2aWNlLmlzdGlvLmlvL2Nhbm9uaWNhbC1yZXZpc2lvbhIEGgJ2MQoPCgd2ZXJzaW9uEgQaAnYxChoKB01FU0hfSUQSDxoNY2x1c3Rlci5sb2NhbAonCgROQU1FEh8aHWZyb250cGFnZS12MS01NzhjNjU1N
GQ0LWxidnFrCh0KCU5BTUVTUEFDRRIQGg5iYWNreWFyZHMtZGVtbwpXCgVPV05FUhJOGkxrdWJlcm5ldGVzOi8vYXBpcy9hcHBzL3YxL25hbWVzcGFjZXMvYmFja3lhcmRzLWRlbW8vZGVwbG95bWVudHMvZnJvbnRwYWdlLXYxCi8KEVBMQVRGT1JNX01FVEFEQVRBEhoqGAoWCgpjbHVzdGVyX2lkEggaBm1hc3
RlcgocCg9TRVJWSUNFX0FDQ09VTlQSCRoHZGVmYXVsdAofCg1XT1JLTE9BRF9OQU1FEg4aDGZyb250cGFnZS12MQ==
* Server istio-envoy is not blacklisted
< server: istio-envoy
< x-envoy-decorator-operation: frontpage.backyards-demo.svc.cluster.local:8080/*
<
* Connection #0 to host frontpage.backyards-demo left intact
frontpage
```
1. Если мы хотим зарегистрировать фильтр WASM в цепочке TCP для сервиса `frontpage`, который принимает TCP на порте 8083, кастомный ресурс `EnvoyFilter` будет выглядеть как-то так:
```
kubectl apply -f-<
```
Если мы добавили фильтр в цепочку на уровне TCP, вызываются только хуки для TCP-трафика.
Вот наглядная схема того, как это работает с Istio:
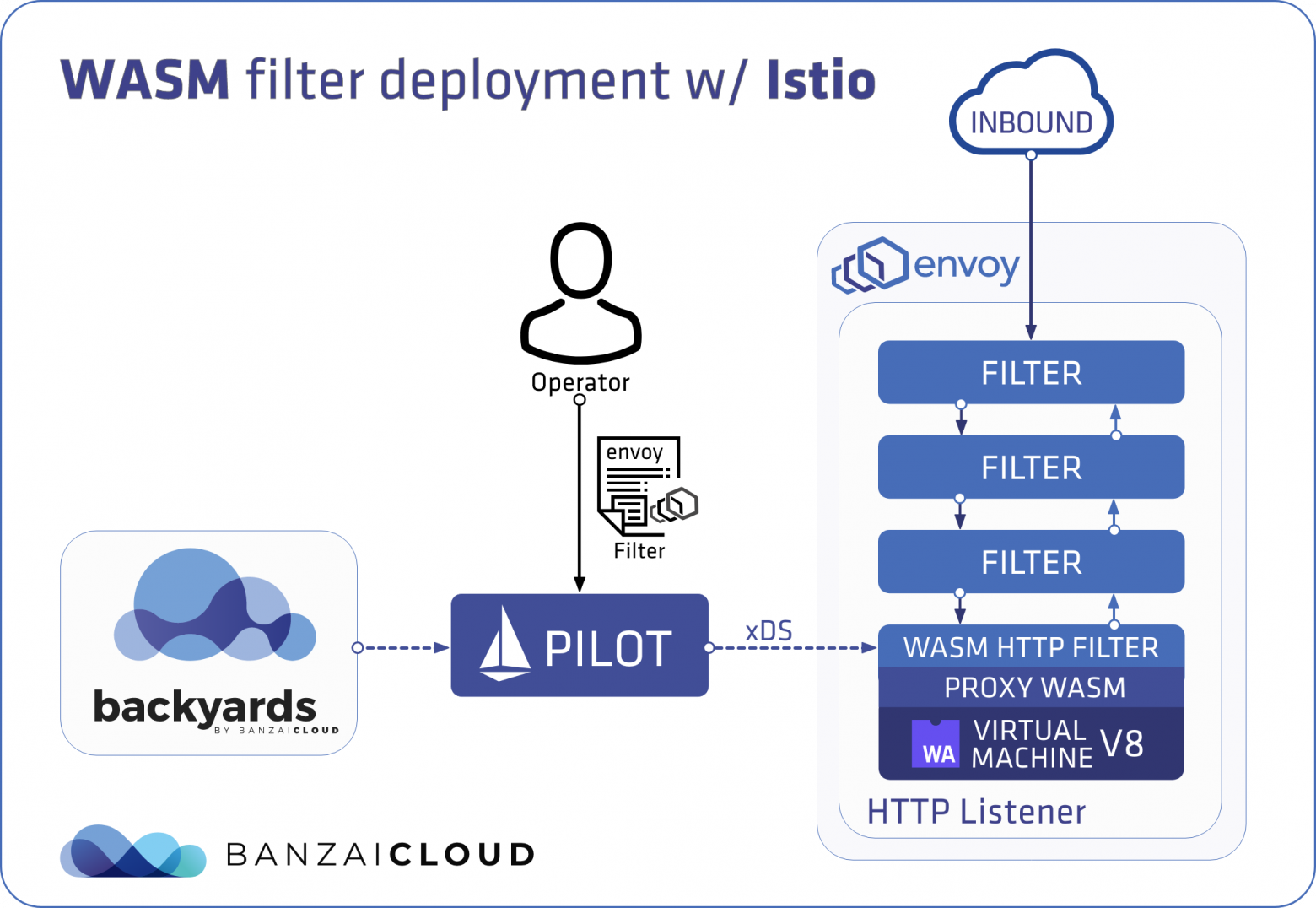
Пишем фильтры WASM для Envoy с WASME ︎
--------------------------------------
[Solo.io](https://docs.solo.io/web-assembly-hub/latest) предложили решение для разработки фильтров WASM для Envoy — WebAssembly Hub, чтобы загружать и выгружать свои коды фильтров WASM. Используйте инструмент [WASME](https://github.com/solo-io/wasme) для скаффолдинга, сборки и отправки фильтров WASM в [WebAssembly Hub](https://webassemblyhub.io/).
При деплое фильтра WASM `wasme` вытаскивает образ с плагином фильтра WASM из WebAssembly Hub, запускает daemonset, чтобы извлечь код плагина WASM из этого образа, и открывает его для Envoy Proxy на каждой ноде через тома `hostPath`.
**Примечание.** Образы из WebAssembly Hub не будут отображаться как стандартные образы Docker.
Правда, тут мы публикуем и храним фильтры WASM в стороннем хранилище (WebAssembly Hub), так что этот вариант вам не подойдет, если из-за строгих политик безопасности или по другой причине вы не хотите обнародовать проприетарный код, даже в бинарном формате, за пределами корпоративной сети.
#### Заключение ︎
С фильтрами WASM для Envoy можно написать свой код, скомпилировать его в плагины WASM и настроить Envoy для его выполнения. Плагины могут содержать произвольную логику, поэтому подходят для любых интеграций и изменений в сообщениях. Так что фильтры WASM для Envoy Proxy — это идеальный способ интегрировать любую логику в сетевое взаимодействие. | https://habr.com/ru/post/539484/ | null | ru | null |
# Слежение за процессами и обработка ошибок, часть 2
#### Преамбула
[В первой части данной статьи](http://habrahabr.ru/blogs/erlang/114620/) мы рассмотрели механизм связей между процессами и процесс распространения ошибок. Сегодя давайте рассмотрим один случай, который не был освещен в предыдущей части – постреляем по процессам сигналом kill.
#### Сигнал kill
Сигнал kill не перехватываемый сигнал, т.е. он всегда убивает процесс, даже, если он системный. Это используется в OTP супервизором для принудительного завершения сбойных процессов. Когда процесс получает сигнал kill, он умирает и сигналы killed рассылаются по всем его связям.
Во всех примерах будет использовать такое дерево процессов.

Рисунок 1
Давайте напишем небольшой модуль.
```
-module(test).
-export([start/1, proc/2]).
start(Sysproc) ->
process_flag(trap_exit, Sysproc),
io:format("Shell Pid: ~p~n", [self()]),
PidA = spawn_link(test, proc, [self(), a]),
PidB = spawn_link(test, proc, [self(), b]),
io:format("ProcA: ~p~nProcB: ~p~n", [PidA, PidB]),
exit(PidB, kill).
proc(Shell, Tag) ->
receive
after 5000 ->
Shell ! {hello_from, Tag, self()}
end.
```
В функции start/1 мы создаем два процесса: A и B, телом процессов служит функция proc/2, первым аргументом которой является Pid оболочки, второй Tag:atom(), который служит для удобства восприятия при анализе от какого процесса пришло сообщение. После создания вызывается функция exit/2, которая процессу B посылает сигнал kill.
Компилируем и запускаем.
```
(emacs@aleksio-mobile)2> test:start(false).
Shell Pid: <0.36.0>
ProcA: <0.43.0>
ProcB: <0.44.0>
** exception exit: killed
(emacs@aleksio-mobile)3> flush().
ok
(emacs@aleksio-mobile)4> self().
<0.45.0>
(emacs@aleksio-mobile)5>
```
Вызываем функцию start/1 (shell в данном примере не системный процесс и сигналы выхода ловить не может). После порождения процессов видим сообщение "\*\* exception exit: killed", которое означает, что shell был убит с причиной killed. То, что shell действительно пал смертью храбрых говорит его новый Pid <0.45.0>. Схематично весь процесс можно изобразить следующим образом.

Рисунок 2
Ошибка распространяется по всем связям и все процессы умирают. Теперь слегка модифицируем код так, чтобы создаваемые процессы можно было сделать системными.
```
-module(test).
-export([start/1, proc/3]).
start(Sysproc) ->
process_flag(trap_exit, Sysproc),
io:format("Shell Pid: ~p~n", [self()]),
PidA = spawn_link(test, proc, [self(), a, false]),
PidB = spawn_link(test, proc, [self(), b, true]),
io:format("ProcA: ~p~nProcB: ~p~n", [PidA, PidB]),
exit(PidB, kill).
proc(Shell, Tag, Sysproc) ->
process_flag(trap_exit, Sysproc),
receive
after 5000 ->
Shell ! {hello_from, Tag, self()}
end.
```
```
(emacs@aleksio-mobile)2> test:start(false).
Shell Pid: <0.36.0>
ProcA: <0.43.0>
ProcB: <0.44.0>
** exception exit: killed
(emacs@aleksio-mobile)3> flush().
ok
(emacs@aleksio-mobile)4> self().
<0.45.0>
(emacs@aleksio-mobile)5>
```
Несмотря на то, что процесс B был сделан системным (двойная окружность на рисунке 3), он все равно умирает получив сигнал kill, после чего сигнал killed распространяется по связям и все процессы умирают.
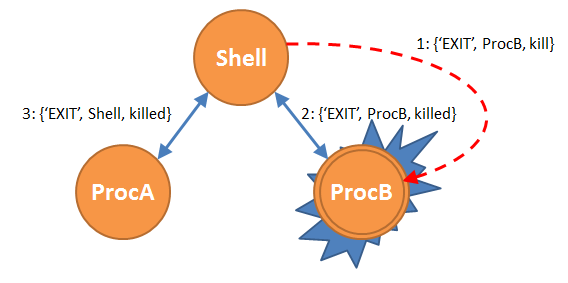
Рисунок 3
Теперь давайте сделаем shell тоже системным.
```
(emacs@aleksio-mobile)2> test:start(true).
Shell Pid: <0.36.0>
ProcA: <0.43.0>
ProcB: <0.44.0>
true
(emacs@aleksio-mobile)3> flush().
Shell got {'EXIT',<0.44.0>,killed}
Shell got {hello_from,a,<0.43.0>}
Shell got {'EXIT',<0.43.0>,normal}
ok
(emacs@aleksio-mobile)4> self().
<0.36.0>
(emacs@aleksio-mobile)5>
```
Видим, что процесс B был убит, shell смог перехватить сигнал выхода от него (Shell got {'EXIT',<0.44.0>,killed}), процесс A послал сообщение и благополучно завершил работу (рисунок 4).

Рисунок 4
Осталось протестировать ещё один случай.
```
-module(test).
-export([start/1, proc/4]).
start(Sysproc) ->
process_flag(trap_exit, Sysproc),
io:format("Shell Pid: ~p~n", [self()]),
PidA = spawn_link(test, proc, [self(), a, true,
fun() -> ok end]),
PidB = spawn_link(test, proc, [self(), b, false,
fun() -> exit(kill) end]),
io:format("ProcA: ~p~nProcB: ~p~n", [PidA, PidB]).
proc(Shell, Tag, Sysproc, F) ->
process_flag(trap_exit, Sysproc),
F(),
receive
Msg ->
io:format("Proc ~p get msg: ~p.~n", [Tag, Msg])
after 5000 ->
Shell ! {hello_from, Tag, self()}
end.
```
В функцию proc был добавлен дополнительный аргумент — функция, которая будет вызываться перед блоком receive. Для процесса A функцию будет возвращать лишь значение ок, для процесса B в ней будет происходить вызов функции exit/1 с параметром kill, т.е. kill мы будем создавать внутри процесса, а не посылать сигнал снаружи. Процесс A в данном эксперименте всегда будет системным. Запускаем проверяем.
```
(emacs@aleksio-mobile)2> test:start(false).
Shell Pid: <0.36.0>
ProcA: <0.43.0>
ProcB: <0.44.0>
Proc a get msg: {'EXIT',<0.36.0>,killed}.
** exception exit: killed
(emacs@aleksio-mobile)3> flush().
ok
(emacs@aleksio-mobile)4> self().
<0.45.0>
(emacs@aleksio-mobile)5>
```
Вызываем нашу функцию start/1 (shell делаем не системным), как и ожидалось shell упал. Процесс B был убит сигналом kill, после чего сигнал был передан shell, оболочка упала, затем сигнал был пойман процессом A (рисунок 5).

Рисунок 5
Внимание вопрос! Какой сигнал был передан процессом B оболочке (на рисунке три знака вопроса). По идее должен быть killed. Давайте это проверим — сделаем shell системным.
```
(emacs@aleksio-mobile)2> test:start(true).
Shell Pid: <0.36.0>
ProcA: <0.43.0>
ProcB: <0.44.0>
ok
(emacs@aleksio-mobile)3> flush().
Shell got {'EXIT',<0.44.0>,kill}
Shell got {hello_from,a,<0.43.0>}
Shell got {'EXIT',<0.43.0>,normal}
ok
(emacs@aleksio-mobile)4> self().
<0.36.0>
(emacs@aleksio-mobile)5>
```
Оболочка получила сигнал {'EXIT',<0.44.0>,kill}, но не завершила свою работу! Готового ответа почему так у меня пока нет. Может быть кто-нибудь из читателей знает?
В следующей части мы рассмотрим механизм мониторов.
#### Список литературы
1. [Отличная интерактивная документация](http://erldocs.com/).
2. ERLANG Programming by Francesco Cesarini and Simon Thompson.
3. Programming Erlang: Software for a Concurrent World by Joe Armstrong. | https://habr.com/ru/post/114753/ | null | ru | null |
# В jQuery 2.0 не будет поддержки IE 6/7/8
Разработчики jQuery опубликовали [план](http://blog.jquery.com/2012/06/28/jquery-core-version-1-9-and-beyond/) выпуска новых версий библиотеки.
* **jQuery 1.8**: выйдет в течение месяца.
* **jQuery 1.9 (начало 2013)**: удаляются многие интерфейсы, устаревшие в версии 1.8; некоторые из них останутся в виде плагинов или альтернативных APIs. Поддержка IE 6/7/8 пока сохраняется.
* **jQuery 1.9.x (в течение 2013 года и далее)**: версия с добавлением патчей, устранением багов, поддержкой новых браузеров и т.д.
* **jQuery 2.0 (начало 2013, вскоре после 1.9)**: поддержка тех же APIs, что и в jQuery 1.9, но удаление «странностей» IE 6/7/8, таких как модель event’ов, “attroperties” в IE7, HTML5shim и проч.
Цель состоит в том, что 1.9 и 2.0 должны быть взаимозаменяемыми в рамках поддерживаемых наборов API. Когда выйдет jQuery 2.0, разработчики получат выбор, какую из версий использовать: нужна ли им поддержка IE 6/7/8. Версия jQuery 2.0 будет меньшего размера и с лучшей производительностью.
Как вариант, можно перейти сразу на jQuery 2.0, но включить загрузку jQuery 1.9 для посетителей со старым IE.
```
<
```
Плагина oldIE для jQuery 2.0 не будет, это слишком усложняет код библиотеки. | https://habr.com/ru/post/146758/ | null | ru | null |
# Шаблоны GRASP: Information Expert (информационный эксперт)
*Привет, хабровчане. На связи Владислав Родин. В настоящее время я преподаю на портале OTUS курсы, посвященные архитектуре ПО и архитектуре ПО, подверженного высокой нагрузке. **В этот раз я решил написать небольшой авторский материал в преддверии старта нового курса [«Архитектура и шаблоны проектирования»](https://otus.pw/02qg/)**. Приятного прочтения.*

---
Введение
--------
Описанные в книге Craig'а Larman'а «Applying UML and patterns, 3rd edition», GRASP'овские паттерны являются обобщением GoF'овских паттернов, а также непосредственным следствием принципов ООП. Они дополняют недостающую ступеньку в логической лестнице, которая позволяет получить GoF'овские паттерны из принципов ООП. Шаблоны GRASP являются скорее не паттернами проектирования (как GoF'овские), а фундаментальными принципами распределения ответственности между классами. Они, как показывает практика, не обладают особой популярностью, однако анализ спроектированных классов с использованием полного набора GRASP'овских паттернов является необходимым условием написания хорошего кода.
Полный список шаблонов GRASP состоит из 9 элементов:
* **Information Expert**
* Creator
* Controller
* Low Coupling
* High Cohesion
* Polymorphism
* Pure Fabrication
* Indirection
* Protected Variations
Предлагаю рассмотреть самый очевидный и самый важный паттерн из списка: Information Expert.
Information Expert
------------------
### Формулировка
Избегая наукообразных формулировок, суть данного паттерна можно выразить следующим образом: **информация должна обрабатываться там, где она содержится.**
### Пример нарушения
Несмотря на кажущуюся простоту и очевидность, я уверен, что в коде любого проекта можно найти множество нарушений данного принципа.
Рассмотрим простейшую систему классов: Order (заказ), содержащий список OrderItem'ов (строчек заказа), элементы которого в свою очередь содержат Good (товар) и его количество, а товар может содержать, например, цену, название и т.д.:
```
@Getter
@AllArgsConstructor
public class Order {
private List orderItems;
private String destinationAddress;
}
@Getter
@AllArgsConstructor
public class OrderItem {
private Good good;
private int amount;
}
@Getter
@AllArgsConstructor
public class Good {
private String name;
private int price;
}
```
Перед нами стоит простая задача: посчитать сумму заказа. Если подойти к решению данной задачи не очень вдумчиво, то можно сходу написать что-нибудь такое в клиентском коде, работающем с объектами класса Order:
```
public class Client {
public void doSmth() {
}
private int getOrderPrice(Order order) {
List orderItems = order.getOrderItems();
int result = 0;
for (OrderItem orderItem : orderItems) {
int amount = orderItem.getAmount();
Good good = orderItem.getGood();
int price = good.getPrice();
result += price \* amount;
}
return result;
}
}
```
Давайте проанализируем такое решение.
Во-первых, если у нас начнет добавляться бизнес-логика, связанная с расчетом цены, код метода Client::getOrderPrice будет не только неминуемо разрастаться, но и обрастать всевозможными if-ами (скидка пенсионерам, скидка по праздничным дням, скидка из-за покупки оптом), что в конце концов приведет к тому, что данный код будет невозможно ни читать, ни тем более менять.
Во-вторых, если построить UML-диаграмму, то можно обнаружить, что имеет место зависимость класса Client аж на 3 класса: Order, OrderItem и Good. В него вытянута вся бизнес-логика по работе с этими классами. Это означает, что если мы захотим переиспользовать OrderItem или Good отдельно от Order (например, для подсчета цены товаров, оставшихся на складах), мы просто не сможем этого сделать, ведь бизнес-логика лежит в клиентском коде, что приведет к неминуемому дублированию кода.
В данном примере, как и практически везде, где есть цепочка из get'ов, нарушен принцип Information Expert, ведь обрабатывает информацию клиентский код, а содержит ее Order.
### Пример применения
Попробуем перераспределить обязанности согласно принципу:
```
@Getter
@AllArgsConstructor
public class Order {
private List orderItems;
private String destinationAddress;
public int getPrice() {
int result = 0;
for(OrderItem orderItem : orderItems) {
result += orderItem.getPrice();
}
return result;
}
}
@Getter
@AllArgsConstructor
public class OrderItem {
private Good good;
private int amount;
public int getPrice() {
return amount \* good.getPrice();
}
}
@Getter
@AllArgsConstructor
public class Good {
private String name;
private int price;
}
public class Client {
public void doSmth() {
Order order = new Order(new ArrayList<>(), "");
order.getPrice();
}
}
```
Теперь информация обрабатывается в содержащем ее классе, клиентский код зависит лишь на Order, ничего не подозревая об его внутреннем устройстве, а классы Order, OrderItem и Good, либо OrderItem и Good могут быть собраны в отдельную библиотеку, которую можно использовать в различных участках проекта.
Вывод
-----
Information Expert, следующий из инкапсуляции, является одним из фундаментальнейших принципов разделения ответственности GRASP. Его нарушение легко как определить, так и устранить, увеличив простоту восприятия кода (принцип наименьшего удивления), добавив возможность переиспользования и уменьшив число связей между классами.
**Приглашаем на [бесплатный вебинар](https://otus.pw/02qg/) в рамках которого можно будет изучить особенности монолитного приложения, многоуровневой и бессерверной архитектур. Подробно рассмотреть систему, управляемую событиями, сервис-ориентированную систему и микросервисную архитектуру.** | https://habr.com/ru/post/491636/ | null | ru | null |
# Первоапрельские CSS-сниппеты
Предлагается вот такой вот комплект CSS снипетов, которыми можно раскарсить первое апреля.
```
/*
Turn every website upside down
*/
body {
/*-webkit-transform: rotate(180deg);
transform: rotate(180deg);*/
}
/*
blur every website for a split second every 30 seconds
*/
body {
/*-webkit-animation: blur 30s infinite;*/
}
/*
Spin every Website
*/
body {
/*-webkit-animation: spin 5s linear infinite;
animation: spin 5s linear infinite;*/
}
```
##### Продолжение...
```
/*
Flip all images upside down
*/
img {
/*-webkit-transform: rotate(180deg);
transform: rotate(180deg);*/
}
/*
COMIC SANS EVERYTHING
*/
body, p, body p, body div p {
/*font-family: 'Comic Sans MS', cursive !important;*/
}
/*
Spin all images
*/
img {
/*-webkit-animation: spin 1s linear infinite;
animation: spin 1s linear infinite;*/
}
/*
Hide every 2nd paragraph element on a page
*/
p:nth-child(2) {
/*display:none !important;*/
}
/*
Permanent cursor wait
*/
html {
/*cursor:wait !important; */
}
/*
hide the cursor all together
*/
html {
/*cursor:none !important;*/
}
/*
slowly grow text
*/
p {
-webkit-animation: grow 120s ease-in;
-moz-animation: grow 120s ease-in;
animation: grow 120s ease-in;
}
/*
Spin dev tools round and round
*/
#-webkit-web-inspector {
/*-webkit-animation: spin 1s linear infinite; */
}
/*
Flip dev tools upside down
*/
#-webkit-web-inspector {
/*-webkit-transform:rotate(180deg);*/
}
/* Hide the close button */
#-webkit-web-inspector .toolbar-item.close-left {
/*display:none !important;*/
}
/* Make console text all blurry */
#-webkit-web-inspector .console-group-messages {
/*text-shadow: 0 0 3px rgba(0,0,0,.5) !important;*/
}
#-webkit-web-inspector .console-error-level .console-message-text,
#-webkit-web-inspector .console-error-level .section .header .title {
/*text-shadow: 0 0 3px rgba(255,0,0,.5) !important;*/
}
#-webkit-web-inspector .console-user-command > .console-message-text {
/*text-shadow: 0 0 3px rgba(0,128,255,.5) !important;*/
}
#-webkit-web-inspector .console-group-messages,
#-webkit-web-inspector .console-user-command > .console-message-text,
#-webkit-web-inspector .console-formatted-null,
#-webkit-web-inspector .console-formatted-undefined,
#-webkit-web-inspector .console-debug-level .console-message-text,
#-webkit-web-inspector .console-error-level .console-message-text,
#-webkit-web-inspector .console-error-level .section .header .title,
#-webkit-web-inspector .console-group-messages .section .header .title,
#-webkit-web-inspector .console-formatted-object,
#-webkit-web-inspector .console-formatted-node,
#-webkit-web-inspector .console-formatted-array,
#-webkit-web-inspector .section .properties .name,
#-webkit-web-inspector .event-properties .name,
#-webkit-web-inspector .console-formatted-object .name,
#-webkit-web-inspector .console-formatted-number,
#-webkit-web-inspector .console-formatted-string,
#-webkit-web-inspector #console-messages a {
/*color: transparent !important;*/
}
/* HTML PRIDE! */
html {
/*-webkit-animation: rainbow 8s infinite;*/
}
/*
Make every website fall over!
*/
/*
html, body {
height: 100%;
}
html {
-webkit-perspective: 1000;
perspective: 1000;
}
body {
-webkit-transform-origin: bottom center;
-webkit-transform: rotateX(-90deg);
-webkit-animation: fall 1.5s ease-in;
}
*/
/*
Insert a phrase every paragraph
*/
/*
p:before {
content: "YOLO ";
}
*/
/* Animations */
@-webkit-keyframes blur {
0% { -webkit-filter: blur(0px); }
49% { -webkit-filter: blur(0px); }
50% { -webkit-filter: blur(1px); }
51% { -webkit-filter: blur(0px); }
100% { -webkit-filter: blur(0px); }
}
@-webkit-keyframes spin {
0% { -webkit-transform: rotate(0deg); }
100% { -webkit-transform: rotate(360deg); }
}
@-webkit-keyframes rainbow {
100% { -webkit-filter: hue-rotate(360deg); }
}
@-webkit-keyframes fall {
0% { -webkit-transform: none; }
100% { -webkit-transform: rotateX(-90deg); }
}
@keyframes spin {
0% { transform: rotate(0deg); }
100% { transform: rotate(360deg); }
}
@keyframes fall {
0% { transform: none; }
100% { transform: rotateX(-90deg); }
}
@-moz-keyframes spin {
0% { transform: rotate(0deg); }
100% { transform: rotate(360deg); }
}
@-moz-keyframes fall {
0% { transform: none; }
100% { transform: rotateX(-90deg); }
}
@-webkit-keyframes grow {
0% { font-size: none; }
100% { font-size: 80pt; }
}
@-moz-keyframes grow {
0% { font-size: none; }
100% { font-size: 80pt; }
}
@keyframes grow {
0% { font-size: none; }
100% { font-size: 80pt; }
}
```
Забрать файл и форкнуться, можно по ссылке [github.com/wesbos/aprilFools.css](https://github.com/wesbos/aprilFools.css) | https://habr.com/ru/post/174935/ | null | ru | null |
# Кросс-доменные Cookie
Рассмотри случай когда у вас есть несколько поддоменов на одном сервере. Нам нужно чтобы сессия хранилась на сервере и читалась всем скриптами на разных поддоменах.Это возможно сделать несколькими путями:
1) Переставить домен куки для сессия перед началом сессии:
`session_set_cookie_params(0 , '/', '.site.ru');
session_start();`2) Переставить куки после создания сесси, и перед каждым началом сессии вызывать её название. | https://habr.com/ru/post/37575/ | null | ru | null |
# Firefox 3.6 и ориентация в пространстве
Разработчики Firefox [анонсировали](http://hacks.mozilla.org/2009/10/orientation-for-firefox/) новую фичу для Firefox 3.6 — поддержка пространственной ориентации в устройствах, оборудованных соответствующими датчиками.
Можно сделать так, что будет поворачиваться веб-страница целиком, или реализовать поддержку для отдельных объектов, так что они будут крутиться независимо друг от друга. Например, таким способом можно реализовать управление в браузерных веб-играх ([пример](http://dougt.org/random/orientationdemo/index.xhtml) такой игры).
Как показано на видео ([ogv](http://videos.mozilla.org/serv/blizzard/orientation-demo/mozOrientation.ogv), [mp4](http://videos.mozilla.org/serv/blizzard/orientation-demo/mozOrientation.mp4)), распознаются координаты в трёх измерениях. При наклоне устройства вперёд/назад картинка в браузере будет приближаться/удаляться.
Поддержка ориентации была изначально разработана для мобильного браузера, но её решили включить и в обычный Firefox, потому что некоторые современные ноутбуки тоже оснащены такими датчиками.
Фича реализована через API, и для её поддержки достаточно добавить такой код.
````
window.addEventListener("MozOrientation", function(e) {
/* 3 values: e.x, e.y, e.z */
}, true);
````
Вот [дополнительная](http://dougt.org/wordpress/2009/08/orientation/) [информация](http://dougt.org/wordpress/2009/08/orientation-update/) и [документация](http://www.bitstampede.com/2009/10/01/device-orientation-documentation/) по теме. | https://habr.com/ru/post/72282/ | null | ru | null |
# Локализация приложений: как мы подружили перевод и разработку

Привет, Хабр! Я ведущий разработчик системы локализации в Badoo. Мы работаем с несколькими большими проектами: Badoo, Bumble, Lumen и Chappy. Сейчас в системе локализации у нас находятся 150 000 фраз и текстов, переведённых на 52 языка. При этом каждое из наших приложений имеет свою аудиторию, свои рынки, свой стиль общения с пользователями, версии для веба и для мобильных платформ.
В этой статье я расскажу, как мы выстроили процесс локализации, как подходим к контролю качества, как релизим переводы в зависимости от платформы, и главное — как мы добились того, что разработчики хорошо отзываются о нашей системе переводов. Это очень важный момент: над проектами трудятся более 300 разработчиков, работа которых должна быть комфортной. Разработчики не переводчики и не должны думать о переводах.
Статья написана по мотивам [моего доклада](https://youtu.be/OJk9wP8jTak) на конференции Highload++ в ноябре.
### Содержание:
[Техническое задание всему голова!](#tehnicheskoe-zadanie)
[Особенности процесса перевода](#perevody)
[Просим пользователей помочь](#pomosch-polzovateley)
[Организация разработки](#razrabotka)
[Контроль качества локализации](#kontrol-kachestva)
[Релизы, версии](#reliz)
[Главное. Итоги](#finalnye-vyvody)
[Дополнительные материалы](#materialy-kotorymi-ya-by-hotel-s-vami-podelitsya)
Для начала давайте посмотрим, как в целом выглядит процесс локализации у нас в компании.
На этой схеме я не стал отражать все нюансы — для общего понимания они не нужны. Суть в том, что мы начинаем с технического задания (ТЗ). Дальше идут клиентская и серверная разработка, а параллельно им — процесс перевода.
ТЗ и финальный этап релиза не зря выделены одним цветом. Это намёк на то, что релиз должен соответствовать ТЗ. Никак иначе. Если ТЗ недостаточно полное, то разработчикам будет непонятно, кто за что отвечает, кто из них должен интегрировать текст: «мобильщики» должны «зашить» его в мобильное приложение или серверные разработчики отдавать с сервера в ответ на запрос.
Давайте со всем этим разбираться. Но сначала я хочу ввести и объяснить один термин.
> Лексема — любой неделимый текст, который надо переводить. Это может быть надпись на кнопке, заголовок или целый параграф.
Вот теперь мы готовы переходить к основному материалу!
Техническое задание
-------------------
Первый этап нашего процесса — это составление правильного технического задания. Главным элементом, относящимся к локализации, в нём является таблица лексем. По сути, это список текстов, которые должны быть использованы в приложении или на сайте.

В таблице лексем указано, отдаётся текст сервером или интегрируется в приложение. Обязательно указывается ключ: если текст раньше использовался, то ключ будет присутствовать в этой таблице; если же текст нигде не использовался, то будет указан порядковый номер текста, а разработчик сможет задать удобный ключ.
Переиспользование текста — очень коварный момент. С одной стороны, процесс локализации при этом ускоряется, а с другой — вы можете попасть в курьёзную ситуацию.
Объясню на примере. Однажды у нас был вопрос “Do you smoke?” c вариантами ответа “Yes” и “No”. Здесь мы видим три лексемы: две для ответов и одну — для вопроса. Вопрос на русский язык перевели как «Вы курите?», варианты ответов — «Курю» и «Не курю». Потом мы решили провести другой опрос и переиспользовать варианты ответа. На английском языке всё выглядело корректно: “Fancy visiting a party?” — “Yes”/“No”. На русском языке из-за переиспользования лексем получился следующий «диалог»: «Пойдёте на вечеринку?» — «Курю»/«Не курю».
Теперь, когда мы составляем ТЗ и решаем вопрос о повторном использовании текста, мы учитываем, в каких контекстах он раньше использовался. Мы также указываем, отдаётся лексема сервером или интегрируется в клиент и доставляется клиентам через App Store или Google Play.
Эти приёмы помогают экономить время, потому что исключают обсуждение на дальнейших этапах.
Переводы
--------
Следующий этап — перевод. И главное здесь — не потерять изначально заложенную мысль. А это часто случается, потому что все языки разные, со своими оттенками и оборотами. Иногда самый точный перевод просто не умещается на экране и переводчикам приходится искать компромисс.
Расскажу по пунктам, с чего мы начинаем переводить, как доносим до переводчиков контекст, поддерживаем единый стиль и проверяем результат.
### Порядок перевода
Порядок есть там, где есть правила (и все им следуют). Поэтому у нас существует регламент очерёдности перевода.
Для начала выбираем язык, который понятен большинству переводчиков. Именно на нём мы будем готовить исходные тексты, чтобы потом они без проблем были переведены на остальные языки. Все языки, на которые мы переводим (а их у нас 52), разделены на основные (родительские) и диалекты. Языком, на котором готовятся тексты, у нас является английский (мы его называем Master). Далее с английского мы переводим на остальные языки: испанский, французский, русский и другие. Иногда перевод требуется уточнить для одного из диалектов — тогда мы переводим на мексиканский испанский или на австралийский английский. Но если нам это не нужно, мы будем использовать перевод на родительский язык: основной испанский или основной английский.
Пример. Допустим, нам нужно приветствие сделать более формальным. Изначально на английском было “Hey”, на испанском — “Hola”, на французском — “Salut”, на русском — «Привет», на австралийском — “G’day mate”, на мексиканском — “Que onda” («Как волна?»; мексиканцы крутые!). Если мы хотим изменить текст, сделав его более официальным, то придётся менять исходный текст на английском. В этот момент переводы на остальные языки становятся некорректными: их необходимо проверить и уточнить. Мы обращаем внимание переводчиков на это.
### Влияние контекста
Важный момент — контекст, в котором существует перевод.
Объясню на примерах.
Сразу отмечу, что некоторые примеры — скриншоты известных ресурсов, но их имена не имеют для нас значения, мы просто рассмотрим наиболее распространённые типы ошибок в локализации.

Это табличка с АЗС: «Перед началом движения убедитесь в отсутствии пистолета в баке». На английский слово «пистолет» перевели дословно: “gun”. Но “gun” для американца — это оружие. В этом контексте просьба «Вытащи пистолет из бака» звучит довольно странно.
В следующем примере создатели приложения решили сделать универсальный вариант текста для мужчин и женщин — видимо, для них есть какая-то выгода в этом. Ощущение такое, что тексты и картинки просто собраны на одном экране: о чём идет речь, непонятно.
Следующий пример — о том, как в результате перевода потерялась изначальная мысль текста. Посмотрите на русский вариант справа: нам предлагают начать общение с самим собой. Хотя подразумевалось, что нам дают возможность привязать к аккаунту свой Instagram.
Такие ошибки случаются, когда перевод происходит в отрыве от контекста. Поэтому для каждой лексемы в нашей системе локализации указывается следующее:
* текстовое описание;
* картинка, на которой видно, какие элементы находятся рядом с текстом на экране;
* отметка о том, мужчинам или женщинам будет показан текст, — чтобы переводчики могли определить, необходимы два разных перевода или достаточно одного;
* типы переменных (это очень важный пункт, и я расскажу о нём подробнее, когда мы будем разбирать процесс разработки);
* максимальная длина текста: она очень важна для пуш-уведомлений, потому что ширина экрана мобильного устройства не безгранична.
Также мы обязательно разбиваем большой текст на части. Это удобно, если потом нужно искать или вносить изменения.
Давайте разберём этот момент более детально. Когда мы разбили текст, мы потеряли связь между отдельными фразами и предложениями. Поэтому мы должны обязательно показать переводчикам, что было до и после этого текста. Это актуально, например, в случае с юридическими документами — чтобы они были переведены корректно.
Также мы обязательно подсвечиваем в лексемах локальные термины, жаргонные слова. Например, в случае с предложением “Unlock your Likes List to see everyone who’s interested at once” переводчику нужно знать, что Likes в данном случае — специальная директория приложения, в которой собраны контакты пользователей, которым понравился профиль. Ещё один аналогичный пример — это термин “Stories” («сторис»). Десять лет назад никто при слове «сторис» не представлял себе Instagram. Сейчас же оно ассоциируется в первую очередь с ним.
Итак, мы убедились, что вариант перевода сильно зависит от контекста, а именно от следующих факторов:
* пола пользователя;
* численной переменной, которая встречается в тексте: «У вас всего лишь один друг» и «У вас уже десять друзей»;
* платформы: Web, Android, iOS;
* проекта, для которого выполняется перевод.
Остановимся подробнее на последнем пункте — зависимости перевода от проекта. Это важно, потому что каждый проект имеет свой стиль.
Это заголовки писем, которые отправляются пользователю, если его аккаунт был заблокирован.
Для Badoo: «Ваш аккаунт заблокирован».
Для Lumen: «Ваш аккаунт заблокирован».
Для Bumble: «Вы были заблокированы».
А для Chappy — «А-оу!».
Чтобы сохранять единый стиль в рамках каждого проекта, нужно дать переводчикам доступ к истории переводов. У нас есть инструмент, который называется «Память переводов» (Translation memory, TM). Переводчику всегда доступна информация о совпадениях и проценте схожести: он может либо использовать старый перевод, либо ввести новый. Мы показываем переводчикам не только 100%-ные совпадения, но и менее схожие варианты, и обязательно подсвечиваем различия.

Помимо того, что «Память переводов» позволяет сохранять стиль в рамках проекта, она ещё и помогает ускорить процесс, потому что переводчику не нужно вводить два раза одно и то же.
### Падежи и числительные
У нас есть инструмент, который называется «Матрица падежных форм». Это как таблица умножения, только для падежей и форм числительных.
Переводчики по мере необходимости заполняют эту матрицу для разных слов в каждом языке. Заполнить её в один приём нереально, поэтому это происходит постепенно: понадобилось слово — внесли.
В результате матрица помогает избежать вот таких ошибок:
Преимущество инструмента в том, что нужная форма выбирается непосредственно перед отрисовкой, перед показом пользователю. Вот как это происходит:

Например, у нас есть перевод на русский язык. “Credits” в центре — это идентификатор, ссылка на матрицу падежных форм. “Credits amount” слева — это число, которое придёт от разработчика. А @3 — это падеж, который указал переводчик (в данном случае винительный).
«Вам нужно 10 кредитов»: словосочетание «10 кредитов» будет подставлено автоматически.
### Проверка переводов
Если умножить 150 000 фраз и текстов на 52 языка, мы получим число в районе 7,5 млн. Конечно, проверить всё это вручную нереально. Поэтому мы сделали автоматическую проверку переводов в момент сохранения.
Мы автоматически проверяем такие особенности, как пропущенные эмоджи или переменные. Если переводчик случайно удалил переменную, фраза теряет структуру и смысл. Сравните: «Вам нужно 10 кредитов» и «Вам нужно кредитов» — вторая фраза испорчена, мысль потеряна.
Также мы проверяем пропущенный HTML, иначе поедет вёрстка.
И мы обязательно предупреждаем переводчика о том, что его перевод длиннее оригинала. В этот момент он должен проверить, подойдёт ли он, уместится ли на экране текст.
#### Выделим основные моменты:
* переводчикам необходимо понимание контекста;
* система переводов должна быть настолько гибкой, чтобы на каждый язык можно было сделать уместный перевод, чтобы переводчик не выбирал универсальные формулировки; необходимо обеспечить поддержку склонений и падежей;
* обязательно нужно автоматически проверять переводы.
Помощь пользователей
--------------------
Кроме труда профессиональных переводчиков, мы используем помощь пользователей. Здесь есть два метода: A/B-тестирование и совместный перевод.
### A/B-тестирование
Итак, вам нужен перевод, например, на русский язык. Переводчик перевёл одну фразу двумя разными способами, и вы не знаете, какой вариант выбрать. В этом случае можно провести A/B-тест: показать пользователям разные варианты и выбрать один в зависимости от их реакции.
У нас был выбор между двумя вариантами: «Готовы к новым знакомствам? Присоединяйтесь!» и «Ещё пара шагов… и вы станете частью Badoo». В результате тестирования мы выяснили, что больше пользователей завершили регистрацию, когда увидели второй вариант пуш-уведомления. Его мы и оставили.
Ниже — полная схема факторов, от которых зависит вариант перевода. Пятый элемент — это как раз A/B тест: если пользователь попадает в какую-то группу, значит, ему будет показан соответствующий вариант текста.
### Совместный перевод
Однажды мы разослали пользователям из Мексики уведомление с просьбой перевести некоторые тексты на их язык за небольшое вознаграждение в виде кредитов — внутренней валюты приложения. И они согласились: всего за два дня перевели для нас 5000 лексем. Это огромная помощь, а мексиканцы — отличные ребята!
Чем интересен и почему важен такой подход? Если у вас нет переводчика на локальный диалект, разрешите пользователям делать эту работу. Как выяснилось, они действительно готовы участвовать в развитии проекта, который им нравится.
У нас есть [платформа для совместных переводов](https://translate.badoo.com/). В систему можно войти с помощью аккаунта Badoo. И проголосовать за лучший перевод.
Это скриншот окна перевода на немецкий язык. Пользователь может добавить свой вариант. Когда один из вариантов набирает пороговое количество голосов, мы показываем его нашему штатному переводчику, и он может быть использован как основной (при условии, что он соответствует стилистике, правилам проекта, никого не оскорбляет и так далее).
Не бойтесь просить пользователей о помощи. Они подскажут и помогут.
Разработка
----------
Переходим к самому интересному — к процессу разработки. Я специально сначала рассказал о процессе перевода, описал распространённые проблемы, чтобы потом показать, как эти проблемы решают разработчики.
Основных сложностей здесь две: как организовать параллельную разработку и как отслеживать ошибки при использовании лексем, чтобы правильные переводы показывались в правильное время.
### Параллельная разработка
Начну с истории. Раньше схема разработки у нас выглядела иначе. Исходные тексты хранились в файле, в репозитории. Два разработчика могли что-то параллельно менять, и потом возникала необходимость объединять эти изменения. Проблема небольшая, но неудобно.

*Старая схема, в которой приходилось объединять изменения*
Теперь мы изменяем и вносим лексемы централизованно в системе локализации. Разработчикам нужно только скачать набор лексем перед началом работы над задачей и использовать их. Ключ указан, написал код, используешь — всё, ни о чём больше не думаешь.
### Ошибки при использовании лексем
В переводах много переменных.

Если вы спешите, то легко можете спутать “credit\_amount” и “credit”. Чтобы избежать этого, мы ввели контроль — текстовый контейнер, некую абстракцию над переводом, которая знает, переменные какого типа используются в этом переводе. Она производит подстановку и контролирует, что переданные типы значений для подстановки соответствуют ожидаемым. Если все подстановки сделаны, то она возвращает строчку, которую уже можно показывать пользователю. Если нет, то возвращается такой же контейнер. Если мы попытаемся показать пользователю перевод раньше, чем успели произвести все подстановки, то в логах мы увидим предупреждение и будем знать, куда идти и как исправлять ситуацию.
#### Основные моменты в разработке:
* разработчики должны заниматься только своей работой — они не должны думать о локализации, изменении текстов и прочем;
* нужно проверять то, что сделали разработчики, и эту проверку тоже лучше автоматизировать — это сохранит нервные клетки всех участников процесса.
Контроль качества
-----------------
Итак, у нас уже есть разработанный продукт, который мы перевели. Осталось проверить, насколько хорошо мы это сделали.
Начнём с примеров. Сколько косяков на данном скриншоте?
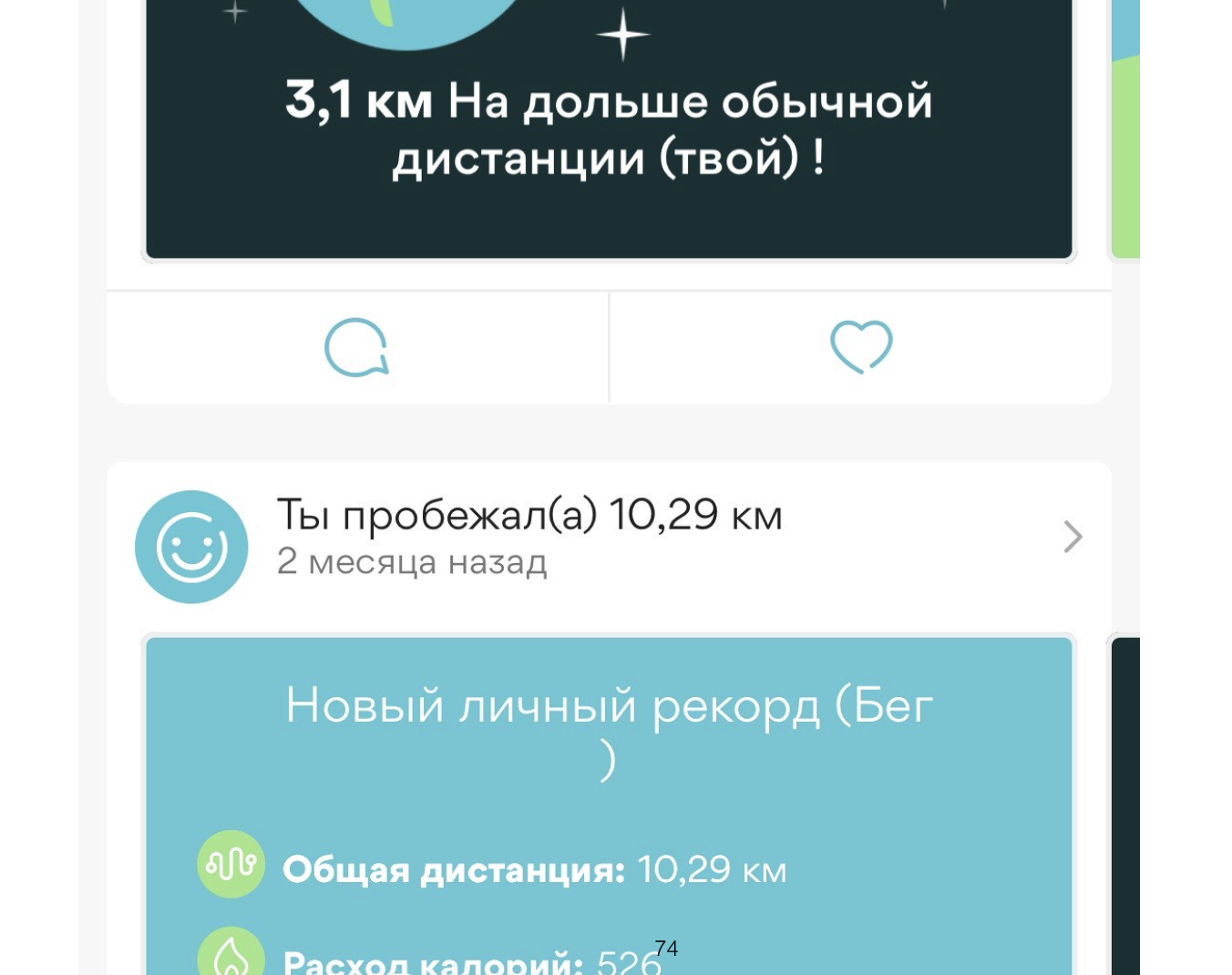
Я выделил два. Сверху — переводчик, видимо, не знал, что перед его фразой будет показываться дистанция. Снизу — не учтена ширина экрана, на котором показывается перевод.
Второй пример тоже касается слишком длинных переводов, не соответствующих ширине экрана, — здесь просто всё обрезано, надпись не умещается на кнопке.

В следующем примере помимо того, что нам показывают текст на разных языках, нам ещё и предлагают узнать боль.
Чтобы подобных ошибок не возникало на проде, контроль качества просто необходим.
### Варианты контроля
Давайте разберёмся, какие варианты контроля существуют.
Первый, который приходит в голову, — это проверить перевод на тестовой версии сайта или приложения. То есть просто запустить и посмотреть, соответствует ли то, что получилось, дизайну, задумке, ТЗ и так далее. С помощью этого способа мы поймали вот такую ошибку в пуш-уведомлении:
#### Скриншоты приложения
Следующий способ контроля качества — по скриншотам приложения.
Мы разработали специальный инструмент, который в тестовом окружении делает скриншоты всех экранов мобильных приложений на всех языках. Посмотреть, как они выглядят, можно через браузер. Также там есть специальный режим, переключившись на который, мы можем видеть идентификаторы текста, который нам показывают. Это очень помогает при отладке: можно быстро узнать, какая это лексема и почему она попала туда, куда попала (может быть, мы унаследовали код, в котором эта лексема подставляется).
Если у вас есть веб-версия и вам нужно лишь получить откуда-то картинки, можно интегрировать маркеры лексем в исходный текст, написать плагин для Google Chrome — и с машин тестировщиков, из их браузеров, этот плагин будет присылать вам в систему локализации скриншоты страниц, на которых он обнаружил лексемы.
```
* ...
* Знакомства
* ...
```
Мы пользовались этим способом довольно долго. Он позволил собрать огромное количество картинок буквально за две недели. Но мы от него отказались, потому что с его помощью можно получать изображения только уже выпущенной версии, а мы научились получать картинки и дизайн на этапе формирования ТЗ.
#### Контроль во время перевода
Как я сказал выше, нам показалось мало делать картинки, когда уже есть готовое приложение. Мы решили делать скриншоты, когда приложение ещё не готово, когда ещё ничего нет и необходимо как-то контролировать качество, понимать, всё ли идёт как надо.
Так у нас появился инструмент контроля во время перевода.

Объясню принцип его работы. Наши дизайнеры используют Sketch — приложение, в котором они создают интерфейсы, в том числе и интерфейсы мобильных приложений. Мы научились заменять тексты в Sketch-файлах и с помощью программного интерфейса Sketch генерировать скриншоты нужного нам экрана. Теперь, в процессе работы переводчика, мы можем ему сразу показывать скриншоты экранов на его языке. И делать это даже до того, как разработчики начали создавать первую версию нового функционала.
Позже мы оформили это решение как open-source ([статья](https://habr.com/ru/company/badoo/blog/338814/), [код](https://github.com/AlexTimin/sketch-modifier)).
#### Аудит перевода
Если нет возможности проверить перевод на каком-то конкретном языке, например на японском, то можно заказать выборочный аудит, то есть сторонней фирме показать перевод каждой сотой лексемы с картинкой и спросить, всё ли корректно.
#### Основные моменты в контроле качества:
визуальная оценка качества перевода необходима;
в процессе тестирования важно понять, какими устройствами пользуется ваша аудитория, и тестировать приложение на всех этих устройствах.
Релиз
-----
Итак, у нас есть протестированная круто написанная функциональность. Осталось доставить её пользователям.
### Версионирование лексем
У нас в приложении Badoo была услуга «Суперсила». В какой-то момент нам потребовалось изменить её название на “Badoo Premium”, причём сразу во всех версиях атомарно, чтобы пользователь не видел на одном экране «Суперсила», а на другом — “Badoo Premium”.
Для этого к каждой ветке задачи в Jira у нас прикреплена версия лексем. Когда мы включаем в новую версию проекта изменения из какой-либо ветки, то сразу подтягивается и новая версия лексем. Если надо что-то откатить, мы изымаем ветку задачи из новой версии и вместе с ней изымаем версию лексем с переводами на все языки.
Когда лексема попала на тестирование или когда её уже видят пользователи, нужно быть очень осторожными: лучше ничего не менять в ней, а создать новую версию, прикрепить её к тикету и с новым релизом задеплоить новую версию лексемы с новыми переводами.
### Версионирование переводов
Однако при переводе можно допустить ошибки. В примере ниже их две.
Неверно: “It's a remath”.
Верно: “It’s a rematch”.
В английском языке нельзя использовать прямой апостроф. Также пропущена буква “с”.
Версионирование лексем и версионирование переводов — это разные вещи. Перевод можно исправить в любой момент: когда задача находится в разработке, когда она на стадии тестирования или даже когда функциональность уже доведена до пользователя (ничего страшного не произойдёт, если в новой версии приложения пользователи увидят исправленный перевод).
### Сервер != смартфон
Доставка обновлений на разные платформы происходит по-разному. Если вы разрабатываете мобильное приложение, то наверняка у вас есть серверная и клиентская части.
То, что вы показываете пользователю, или частично приходит с сервера, или находится у него на смартфоне (например, интегрированный перевод).
Путь, который проходит перевод с сервера до пользователя, лежит через наш продакшен-сервер, куда можно запросто доставить обновлённые версии файлов с переводами.
А вот путь интегрированного перевода длинный: он лежит через App Store или Google Play. Пользователь скачивает обновление и только после этого видит исправления. Нам этот процесс показался слишком медленным, и мы придумали свой механизм обновления “Hot Update”. Он позволяет по нажатию кнопки сгенерировать новую версию переводов и дать понять всем клиентам в мире, что есть что-то новое, что нужно скачать и использовать.
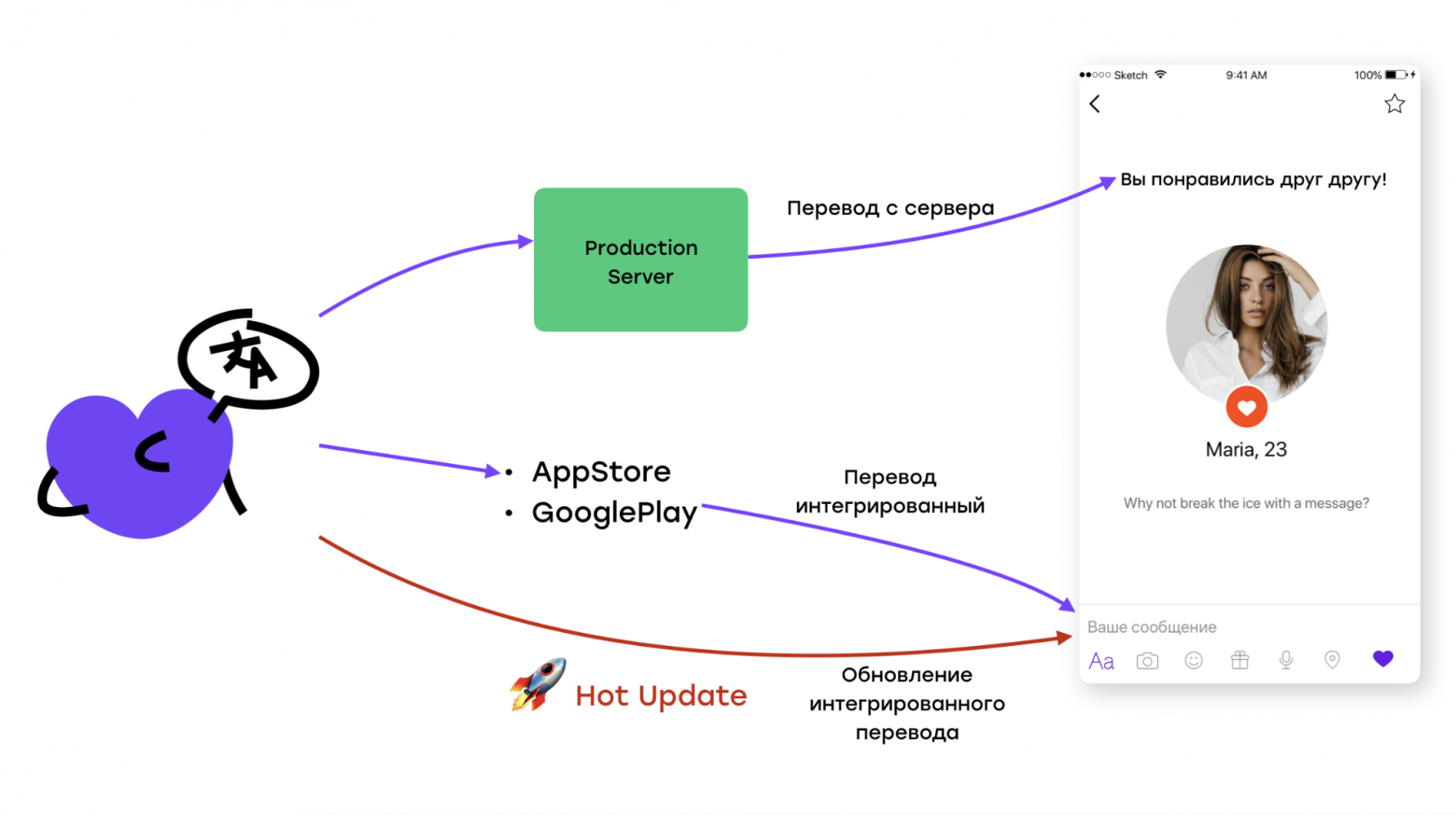
Когда на мобильном устройстве запускают приложение, оно отправляет на сервер уведомление о запуске и сообщает текущую версию переводов. Если у системы локализации есть готовое обновление, то она выдаёт в ответ уведомление об этом. Клиент скачивает обновление, применяет его.
Новые переводы пользователь увидит, когда переключится на следующий экран. Реализации данного решения посвящены две наши статьи: [раз](https://tech.badoo.com/ru/article/403/obnovlenie-strok-na-letu-part-1/) и [два](https://tech.badoo.com/ru/article/419/obnovlenie-strok-na-letu-v/).
#### Релиз: основные моменты
В процессе релиза нужно обязательно учесть, какой путь проходит приложение от вас до ваших клиентов. Вероятно, разные части вашего приложения обновляются по-разному.
Финальные выводы
----------------
Давайте вернёмся к схеме, которую я приводил в начале статьи.

На что стоит обратить внимание, если вы разрабатываете систему переводов:
* писать подробное ТЗ;
* учитывать контекст и предоставить переводчикам доступ к нему;
* вести историю переводов, чтобы поддерживать единый стиль в рамках проекта;
* автоматизировать контроль (иначе любой случайный переводчик, который находится в нескольких часовых поясах от вас, сможет сделать всё по-своему);
* освободить разработчиков от решения непрофильных задач. Именно они создают новые версии вашего продукта, это доставляет радость вашим пользователям и дает удовлетворение от проекта, который вы создаёте.
### Материалы, которыми я бы хотел с вами поделиться
[Обновление строк на лету в мобильных приложениях: часть 1](https://tech.badoo.com/ru/article/403/obnovlenie-strok-na-letu-part-1/)
[Обновление строк на лету в мобильных приложениях: часть 2](https://tech.badoo.com/ru/article/419/obnovlenie-strok-na-letu-v/)
[Как научить веб-приложение говорить на 100 языках: особенности локализации](https://habr.com/ru/company/badoo/blog/317484/)
[Переводим интерфейсы на полсотни языков. Sketch](https://habr.com/ru/company/badoo/blog/338814/)
[GitHub sketch-modifier](https://github.com/AlexTimin/sketch-modifier) | https://habr.com/ru/post/485138/ | null | ru | null |
# Филипп Торчинский из Semonix: установка SmartOS и использование Node.js на ней
29 ноября в офисе Яндекса в Питере я буду проводить [научный семинар](http://events.yandex.ru/events/science-seminars/Torchinskiy-nov-2012/) «DTrace — проверочная работа для вашего кода». Те, кто на YaC 2012 слушал мой [доклад «Инфраструктура облачных вычислений на основе ядра Illumos»](http://events.yandex.ru/talks/301/) — да и многие другие — знают, что в Semonix я занимаюсь облачными технологиями, тесно связанными со SmartOS. На семинаре я расскажу, как с помощью технологии DTrace проводить глубокий анализ производительности и детально изучать работу приложения. Поиск по Хабру находит только [одну статью про SmartOS](http://habrahabr.ru/post/126456/), и чтобы на семинар пришло больше тех, кто уже знаком с ней, я решил заранее написать про установку SmartOS и использование Node.js на ней.
Для начала расскажу, для чего нужна SmartOS. Если коротко, её предназначение – быть хост-системой для виртуальных машин. Она часто используется как основа для публичных и частных облаков, например, облачных служб Joyent и MITAC. Службой Joyent пользуется LinkedIn: вся его мобильная серверная часть сделана на Node.js, который запущен в облаке Joyent. Мы подробно писали об этом в блоге компании Semonix в статьях [о SmartOS](http://semonix.ru/neskolko-slov-o-smartos/) и [об облаках, основанных на illumos](http://semonix.ru/category/blog/cloud-blog/), а я рассказывал в докладе на YaC 2012, который уже упоминал.
Типичные случаи применения SmartOS – системы для ЦОДов, системы для разработки и эксплуатации нагруженного веб-приложения, платформа для создания приватного или публичного облака. При работе над этой статьей я активно использовал [статью Сту Радниджа](http://stu.radnidge.com/post/30612112900), который проделывал примерно такой же путь установки SmartOS, как и я, но с использованием VMware вместо VirtualBox.
#### Планируем тестовую установку
Допустим, вы оказались одним из тех, кому интересно попробовать SmartOS. Как это проще сделать? Я пошел по самому простому пути, который не даст запустить Windows или Linux в вирутальной машине, зато позволит воспользоваться готовым образом SmartOS + Node.js. Запускать буду SmartOS в VirtualBox. Понятно, что KVM в виртуалке под VirtualBox не заработает, а остальное – должно заработать на ура.
SmartOS может быть хост-системой для гостей под управлением Windows, Linux и самой SmartOS. В этой статье я рассматриваю только вариант с гостевыми системами под управлением SmartOS. В них реализуется легковесная виртуализация (то же самое, что зоны в Solaris и нечто похожее на клетки во FreeBSD), и, стало быть, для их работы не требуется KVM, который поддерживается только на физических компьютерах. Вся конфигурация показана на рисунке ниже. SmartOS (host) – это система, которая является гостем по отношению к Windows на моем ноутбуке, и хостом — по отношению к системам SmartOS, запущенным в зонах внутри этой SmartOS.

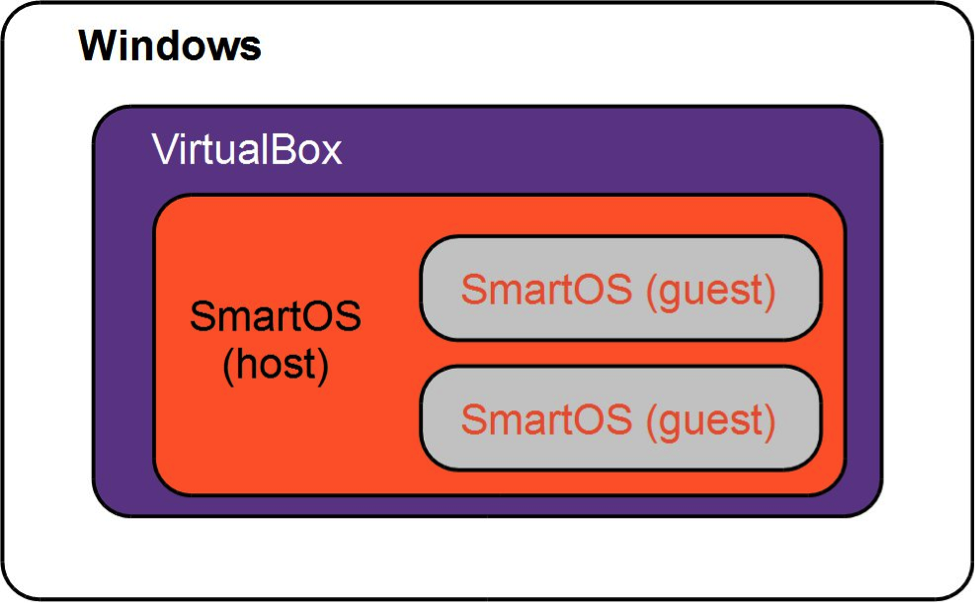
SmartOS будем ставить в виртуальную машину с двумя сетевыми интерфейсами. Зачем? Очень просто: я хочу из своей хост-системы (в данном случае – Windows) подсоединяться обычным ssh к SmartOS, чтобы можно было открыть несколько окон — хотя бы по одной штуке для каждой гостевой системы внутри моей SmartOS.
Почему бы не воспользоваться графическим режимом в консоли и не запустить там нужное количество xterm или gnome-terminal? Дело в том, что графика («иксы» — X) в SmartOS не установлена. Существует проект по переносу поддержки X11 в SmartOS, но пока он не завершен, и Джонатан Перкин (Jonathan Perkin), ведущий этот проект на общественных началах, сообщил мне, что срок окончания работы над ним неизвестен. Поэтому, если я хочу открыть пять окон с ssh к своему SmartOS, то понадобится доступ по TCP с моей хост-системы к SmartOS в VirtualBox.
Кроме этого, в гостевую машину SmartOS нельзя установить VirtualBox Guest Additions, позволяющие выполнять cut-and-paste между гостевой системой и хост-системой, в которой я пишу статью (и хочу в нее копировать тексты из терминала). Теоретически, я думаю, установить Guest Additions можно (там по сути нужно установить модули ядра), но для Solaris-подобных систем Guest Additions поставляется в виде пакета формата .pkg, который в SmartOS не поддерживается. Я решил, что мороки с распаковкой пакета и ручным прикручиванием модуля к ядру будет больше, чем с доступом по ssh из хост-системы.
Зачем же нужен второй интерфейс? Чтобы SmartOS мог через NAT выйти за пакетами в интернет. Это ограничение на условия задачи накладывает VirtualBox – сделать в нем доступную из хост-системы виртуалку с NAT/DHCP иначе можно только через bridged network, а это не всегда удобно. Обсуждение случаев, когда не очень удобно (или не поддерживается в определенных хост-системах или версиях VirtualBox), выходит за рамки этой статьи, но поверьте – такое бывает. Самые простые варианты: кончились DHCP-адреса в той сети, куда у вас подключен физический компьютер, или не хочется каждый раз смотреть, какой адрес в этот раз выдан системе перед тем, как к ней цепляться ssh.
#### Как сделать два сетевых интерфейса в VirtualBox
Настроить виртуальную машину так, чтобы в ней было 2 сетевых адаптера – элементарно: на закладке «Сеть» надо просто указать, что активен не только первый адаптер в режиме host adapter, но и второй — в режиме NAT (см. рисунок ниже). Обратите внимание, что для SmartOS имеет смысл выбрать тип виртуальной машины Solaris 10 10/09 or later (64 bit). Возможно, что вариант Solaris 11 подойдет лучше. У меня без проблем и задержек заработало и так.
#### Что еще надо настроить?
К CD-ROM виртуальной машины надо подсоединить файл latest.iso — из него будет грузиться SmartOS.

После загрузки в первый раз система задаст несколько вопросов про настройки (в частности, пароль root’a), отформатирует диск, создаст пул ZFS на диске и запишет настройки на диск. После перезагрузки вы должны увидеть нечто, подобное рисунку ниже.

Войдите как root, используя пароль, который вы задали раньше. Уже сейчас можно подсоединиться к SmartOS с помощью ssh, для этого только надо узнать, какой у сервера адрес:
```
ipadm show-addr
```
#### Как сделать два сетевых интерфейса в SmartOS
Конфигурация системы в SmartOS хранится в файле /usbkey/config. Файловая система /usbkey монтируется с диска, в отличие от /etc, которая всегда загружается с LiveCD или LiveUSB и монтируется на RAM-диск. Поэтому изменения, внесенные в файлы из /etc будут потеряны при перезагрузке, а в /usbkey – сохранятся.
Файл /usbkey/config создается при первом запуске SmartOS на компьютере, и по умолчанию он описывает только первый интерфейс в системе. Для того чтобы видел и второй, надо немного изменить файл. Для его модификации нам потребуется узнать MAC-адреса интерфейсов. Для этого можно использовать команду
```
dladm show-phys -m
```
```
LINK SLOT ADDRESS INUSE CLIENT
e1000g0 primary 8:0:27:f7:e9:a3 yes e1000g0
e1000g1 primary 8:0:27:d0:35:3b no --
```
Теперь изменим файл /usbkey/config, чтобы он выглядел вот так:
```
#
# This file was auto-generated and must be source-able by bash.
#
# admin_nic is the nic admin_ip will be connected to for headnode zones.
admin_nic=8:0:27:f7:e9:a3
admin_ip=dhcp
admin_netmask=
admin_network=...
admin_gateway=dhcp
external_nic=8:0:27:d0:35:3b
external_ip=dhcp
external_netmask=255.255.255.0
external_gateway=dhcp
dns_resolvers=8.8.8.8,8.8.4.4
dns_domain=
ntp_hosts=pool.ntp.org
compute_node_ntp_hosts=dhcp
```
#### Создание виртуальной машины внутри SmartOS
Вначале надо скачать образ виртуальной машины. Для этого надо обновить список образов:
```
imgadm update
```
А теперь посмотрим, какие готовые образы есть в репозитории:
```
imgadm avail
```
```
UUID OS PUBLISHED URN
78ab4d60-2610-11e2-b3f7-b3bd2c369427 linux 2012-11-04 sdc:jpc:ubuntu-12.04:2.1.2
6a67c702-2083-11e2-b4fa-03f9d1d64ef0 linux 2012-10-28 sdc:jpc:ubuntu-12.04:2.1.1
b00acc20-14ab-11e2-85ae-4f03a066e93e smartos 2012-10-12 sdc:sdc:mongodb:1.4.0
1fc068b0-13b0-11e2-9f4e-2f3f6a96d9bc smartos 2012-10-11 sdc:sdc:nodejs:1.4.0
8700b668-0da4-11e2-bde4-17221283a2f4 linux 2012-10-03 sdc:jpc:centos-6:1.3.0
55330ab4-066f-11e2-bd0f-434f2462fada smartos 2012-09-25 sdc:sdc:base:1.8.1
60a3b1fa-0674-11e2-abf5-cb82934a8e24 smartos 2012-09-25 sdc:sdc:base64:1.8.1
...
```
Теперь перед нами – список образов, доступных для установки. Здесь приведена только часть списка – он значительно длиннее. На момент написания статьи в репозитории были доступны 96 образов. Нас интересует образ base64 – минимальная система, включающая в себя node.js. В данный момент самая свежая версия этого образа — 1.8.1 (включает node 0.8.9), и его UUID — 60a3b1fa-0674-11e2-abf5-cb82934a8e24.
Скачаем образ виртуальной машины:
```
imgadm import 60a3b1fa-0674-11e2-abf5-cb82934a8e24
```
Теперь сделаем описание виртуальной машины, которую мы создадим на основе только что загруженного образа и запустим ее внутри хоста SmartOS.
Описание делается в виде файла JSON (подробности процесса описаны в документации на smartos.org, я здесь просто положу работающий пример – пусть у нас он лежит в /zones/template.json). Файл должен лежать в файловой системе, которая размещается на диске и сохраняется между перезагрузками, удобнее всего – в /zones.
Обратите внимание на dataset\_uuid – это тот самый UUID, который принадлежит только что полученному из репозитория образу. В зоне тоже будет два сетевых интерфейса — «внутренний» и «внешний». Такая настройка используется в ЦОДах в реальной жизни: к внутреннему интерфейсу подключается внутренняя сеть, в которой работают администраторы ЦОДа, к внешнему — интернет, откуда приходят клиенты.
```
{
"brand": "joyent",
"dataset_uuid": "60a3b1fa-0674-11e2-abf5-cb82934a8e24",
"max_physical_memory": 1024,
"nics": [
{
"nic_tag": "admin",
"ip": "dhcp",
"gateway": "dhcp"
},
{
"nic_tag": "external",
"ip": "dhcp",
"gateway": "10.0.3.2"
}
]
}
```
Теперь создаем новую виртуальную машину SmartOS (для краткости будем дальше ее назвать «зона»):
```
vmadm create -f /zones/ template.json
```
Если все получилось нормально, можно увидеть запущенную новую зону, дав команду
```
vmadm list
UUID TYPE RAM STATE ALIAS
570cccb2-0511-400b-9143-7616b2ca8a3d OS 1024 running -
```
Теперь можно подключиться к новой зоне либо из консоли SmartOS, либо через ssh:
```
zlogin 570cccb2-0511-400b-9143-7616b2ca8a3d
```
Обратите внимание: UUID зоны отличается от UUID образа зоны, потому что из одного и того же образа можно создать много зон. Одновременно в одной хост-системе SmartOS может быть запущено до 8191 виртуальных машин.
Для подключения к зоне через ssh следует уточнить, какой адрес ей выдан, для этого надо вначале к ней присоединиться через zlogin, а затем узнать адрес:
```
zlogin 570cccb2-0511-400b-9143-7616b2ca8a3d
ipadm show-addr
```
#### Управление пакетами
Теперь можно установить любые нужные нам в зоне пакеты. Для этого надо обновить информацию о доступных пакетах с помощью **pkgin update**, получить их список **pkgin list** или искать требуемое с помощью **pkgin search**. Для установки пакета следует использовать **pkgin install**.
#### Как запустить Node.js
Предположим, вы не были знакомы с Node.js ранее. Тогда для начала можно сделать очень простое веб-приложение, выдающее банальное Hello, World! Освоение Node.js можно начать с чтения [широко известного руководства](http://nodebeginner.ru/). Следуя ему, создаем наш Hello, World.
Для этого соединяемся с зоной
```
zlogin 570cccb2-0511-400b-9143-7616b2ca8a3d
```
и создаем, например, в каталоге /home/node файл server.js с таким содержимым:
```
var http = require("http");
http.createServer(function(request, response) {
response.writeHead(200, {"Content-Type": "text/plain"});
response.write("Hello World");
response.end();
}).listen(80);
```
Теперь запускаем **node /home/node/server.js** и обращаемся к нашей зоне из обычного браузера. В моем случае это потребовало настройки маршрутизации между зоной и хост-системой Windows:
В зоне: route add 192.168.56.1 192.168.56.101
В Windows: route add 192.168.56.102 192.168.56.101
Адрес 192.168.56.1 – это интерфейс VirtualBox в Windows, 192.168.56.101 – хост-система SmartOS, 192.168.56.102 – зона в ней.
#### Как использовать DTrace с Node.js?
Провайдер DTrace для node называется (сюрприз!) node. Так как это провайдер типа USDT, то его датчики надо указывать либо в виде **node\*:::<название датчика>**, либо с указанием конкретного PID процесса node, например, **node3297:::<название датчика>**.
Живой пример использования DTrace для наблюдения за работой вашего сервера под Node.js — протоколирование обращений к нему. Чтобы узнать, какие запросы получают серверы из разных зон (типичный случай для хостинг-провайдера), запускаем короткий скрипт:
```
# dtrace -L /var/lib/dtrace -n 'node*:::http-server-request{printf("%s: %s of %s\n",zonename, args[0]->method, args[0]->url)}' -q
570cccb2-0511-400b-9143-7616b2ca8a3d: GET of /
570cccb2-0511-400b-9143-7616b2ca8a3d: GET of /favicon.ico
570cccb2-0511-400b-9143-7616b2ca8a3d: GET of /
570cccb2-0511-400b-9143-7616b2ca8a3d: GET of /favicon.ico
570cccb2-0511-400b-9143-7616b2ca8a3d: GET of /
570cccb2-0511-400b-9143-7616b2ca8a3d: GET of /favicon.ico
```
Чтобы посмотреть, с каких адресов приходят запросы, можно слегка модифицировать скрипт:
```
# dtrace -L /var/lib/dtrace -n 'node*:::http-server-request{printf("%s: %s of %s\n",args[1]->remoteAddress, args[0]->method, args[0]->url)}' -q
192.168.56.1: GET of /
192.168.56.1: GET of /
192.168.56.1: GET of /favicon.ico
192.168.56.1: GET of /
192.168.56.1: GET of /favicon.ico
192.168.56.1: GET of /
192.168.56.1: GET of /
```
Для node в DTrace доступны следующие датчики:
gc-start
gc-done
http-client-request
http-client-response
http-server-request
http-server-response
net-server-connection
net-socket-read
net-socket-write
net-stream-end
Если вы обнаруживаете, что какие-то датчики недоступны, это – верный признак того, что файла /usr/lib/dtrace/node.d у вас нет. Тогда надо создать каталог /var/lib/dtrace/, скачать туда файл (он лежит по адресу <https://raw.github.com/joyent/node/master/src/node.d>) и запускать dtrace с ключом –L /var/lib/dtrace/ (он означает «включить в путь поиска библиотек DTrace указанный после ключа L каталог).
Подробное описание датчиков с примерами кода (на английском) есть на странице [dtrace.org/blogs/rm/2011/03/01/dtrace-probes-for-node-v0-4-x/#httpd](http://dtrace.org/blogs/rm/2011/03/01/dtrace-probes-for-node-v0-4-x/#httpd) (там, правда, речь идет об устаревшей версии Node.js).
#### Заключение
Особая прелесть настроек SmartOS в том, что единожды установив, их не надо повторять после выхода обновления. Можно скачать очередной latest.iso, заменить им прежний и загрузиться с нового. Все настройки, виртуальные машины и файлы внутри них будут подхвачены автоматически, так как в них никто и ничего не меняет — изменяется только загружаемый образ, а настройки существуют отдельно от него.
Тех, кому интересно послушать мой рассказ про DTrace, буду ждать 29 ноября в 19:00 в петербургском офисе Яндекса. Семинар совершенно бесплатный, но количество мест ограничено, поэтому нужно [зарегистрироваться](http://events.yandex.ru/events/science-seminars/Torchinskiy-nov-2012/). Для тех, кто не попадёт на него, организаторы обеспечат [онлайн-трансляцию](http://events.yandex.ru/events/science-seminars/Torchinskiy-nov-2012/). А тем, кто собирается, скажу, что нужно взять с собой ноутбуки с установленной SmartOS под VirtualBox, потому что важной частью семинара будет решение практических задач.
Встреча будет полезна всем, кто интересуется анализом производительности приложений в UNIX-подобных системах, особенно разработчикам ПО под Solaris, разработчикам ПО под Node.js, системным администраторам и другим ответственным за производительность (если они работают с системами FreeBSD, Solaris, QNX, OpenIndiana, SmartOS и другими, поддерживающими DTrace). | https://habr.com/ru/post/159661/ | null | ru | null |
# Учим старый-добрый CRTP новым трюкам
Иногда мы делаем вещи, ценность которых является весьма сомнительной. Это как раз тот самый случай.
#### Код лучше тысячи слов
Не буду тянуть кота за хвост, а перейду сразу к делу. Обычно мы используем [CRTP](http://en.wikipedia.org/wiki/Curiously_recurring_template_pattern "Curiously recurring template pattern") примерно так:
```
template
struct Base
{};
template
void f(const Base&)
{}
struct Foo : Base
{};
int main()
{
Foo foo;
f(foo);
}
```
Функции `f()` на самом деле всё равно, какой тэг у её аргумента, и она принимает объект любого типа, унаследованого от `Base`. Но не будет ли более удобным, если мы просто опустим не интересующий нас тэг? Зацените:
```
template
struct base\_tag { typedef decltype(get\_tag((t\*)42)) type; };
template::type>
struct Base
{
friend tag get\_tag(type\*); //never defined
};
template
void f(const Base&)
{}
struct Foo : Base
{};
int main()
{
Foo foo;
f(foo);
}
```
Теперь, посмотрев на объявление `f()`, мы интуитивно поймём, что функции действительно всё равно, какой тэг у её аргумента.
#### Как это работает
В классе `Base` объявляется функция-друг, возвращающая тэг и принимающая указатель на унаследованный тип. Заметьте, что эта функция не нуждается в определении. Когда мы определяем тип, например, `Foo`, мы фактически объявляем функцию со соответствующим прототипом, в данном случае:
```
void get_tag(Foo*);
```
Когда мы вызываем `f()`, при этом создавая экземпляр шаблона (template instantiation), компилятор пытается определить аргумент шаблона по умолчанию для аргумента функции (который является объектом класса `Foo`):
1. от экземпляра шаблона `base_tag` компилятор получает тип тэга ,
2. который, в свою очередь, определён как тип, возвращаемый функцией `get_tag()`, с указателем `Foo*` в качестве аргумента,
3. что вызывает срабатывание механизма перегрузки функций (overload resolution) и даёт функцию, объявленную в классе `Base` с типом `Foo` и `void` в качестве аргументов шаблона, то есть `Base`
4. ???
5. Profit!
То есть, круг замкнулся!
#### ECRTP
Ничего лучше не придумав, я называю это «excessively-curious’ly recurring template pattern». Так что ещё оно может?
Если мы *действительно хотим* этого, тэг может быть указан явно:
```
template
void g(const Base&)
{}
struct Bar : Base
{};
int main()
{
Foo foo;
Bar bar;
f(foo);
f(bar);
g(foo); //doesn't compile by design
g(bar);
}
```
Заметьте, что `g(foo)` намеренно не позволит скомпилировать код, потому что тэг аргумента должен быть типом `int` (в то время как он является типом `void` для `Foo`). В такой ситуации компилятор выдаёт красивое сообщение об ошибке. Ну, по крайней мере MSVC10 и GCC4.7.
**MSVC10**
```
main.cpp(30): error C2784: 'void g(const Base &)' : could not deduce template argument
for 'const Base &' from 'Foo'
main.cpp(18) : see declaration of 'g'
```
**GCC4.7**
```
source.cpp: In function 'int main()':
source.cpp:30:8: error: no matching function for call to 'g(Foo&)'
source.cpp:30:8: note: candidate is:
source.cpp:18:6: note: template void g(const Base&)
source.cpp:18:6: note: template argument deduction/substitution failed:
source.cpp:30:8: note: mismatched types 'int' and 'void'
source.cpp:30:8: note: 'Foo' is not derived from 'const Base'
```
Даже лучше, чем у MSVC!
Также можно задать тэг по умолчанию:
```
template
void get\_tag(type\*); //default tag is 'void'
template
struct base\_tag { typedef decltype(get\_tag((t\*)42)) type; };
template::type>
struct Base
{
friend tag get\_tag(type\*); //never defined
};
struct Foo : Base //tag defaults to void
{};
```
Определение выше эквивалентно
```
struct Foo : Base
{};
```
Так что теперь мы можем считать, что нет вообще никакого тэга и оставить этот функционал для продвинутого использования.
#### Что насчёт C++98?
Более старые компиляторы не поддерживают ключевое слово `decltype`. Но если у вас конечное число тэгов (или чего бы то ни было), вы можете использовать приём с `sizeof` (`sizeof` trick):
```
struct tag1 {}; //a set of tags
struct tag2 {};
struct tag3 {};
#define REGISTER_TAG(tag, id) char (&get_tag_id(tag))[id];\
template<> struct tag_by_id\
{ typedef tag type; };
template struct tag\_by\_id;
REGISTER\_TAG(tag1, 1) //defines id's
REGISTER\_TAG(tag2, 2)
REGISTER\_TAG(tag3, 42)
template
struct base\_tag
{
enum
{
tag\_id = sizeof(get\_tag\_id(get\_tag((t\*)42)))
};
typedef typename tag\_by\_id::type type;
};
template::type>
struct Base
{
friend tag get\_tag(type\*); //never defined
};
template
void f(const Base&)
{}
struct Foo : Base
{};
int main()
{
Foo foo;
f(foo);
}
```
Немного многословно, но зато работает.
#### Лишние телодвижения?
Так действительно ли всё это лишние телодвижения?
Мы уже видели, что этот приём делает код чуточку красивее. Давайте посмотрим, что будет в случае двух аргументов. Конечно же, мы можем написать код так:
```
template
void h(const Base&, const Base&)
{}
```
Даже более короткое ключевое слово `class` не делает код существенно короче.
Сравните с этим:
```
template
void h(const Base&, const Base&)
{}
```
Тэг? Не, не слышал…
Фантастическую ситуацию с тремя и более аргументами вы можете представить сами.
Мысль такова: если нас не интересует некая вещь, должна ли она обязательно быть явной? Когда кто-то пишет ``std::vector, скорее всего ему на самом деле совершенно не интересен тип аллокатора (и он получает аллокатор по умолчанию), и вряд ли он имеет ввиду "я хочу std::vector` в точности с аллокатором (подразумеваемым) по умолчанию `std::allocator`". Но делая так, вы ограничиваете область применения вашей сущности (например, функции), которая может взаимодействовать только с вектором с аллокатором по умолчанию. С другой стороны, было бы слишком муторно упоминать аллокатор то тут, то там. Возможно, было бы неплохо иметь для вектора механизм определения аллокатора подобным автоматическим способом, описанным выше.
#### Выводы
Ну, в этот раз я предлагаю решать вам, стоит ли этот приём чего-то или это всего лишь очередная бесполезная головоломка.` | https://habr.com/ru/post/152387/ | null | ru | null |
# Xamarin.Forms — простой пример Host-based Card Emulation
В этой статье будем реализовывать так называемую [Host-based Card Emulation](http://www.androiddocs.com/guide/topics/connectivity/nfc/hce.html) (HCE, Эмуляция банковской карты на телефоне). В сети много подробных описаний этой технологии, здесь я сделал акцент именно на получении работающих приложений эмулятора и ридера и решении ряда практических задач. Да, понадобятся 2 устройства с nfc.
Сценариев использования очень много: [система пропусков](https://habr.com/ru/post/347574/), карты лояльности, транспортные карты, получение дополнительной информации об экспонатах в музее, [менеджер паролей](https://www.youtube.com/watch?v=yHrNEJb-zoQ).
При этом приложение на телефоне, эмулирующем карту, может быть запущено или нет и экран вашего телефона может быть заблокирован.
Для Xamarin Android есть готовые примеры [эмулятора карты](https://github.com/xamarin/monodroid-samples/tree/master/CardEmulation) и [ридера](https://github.com/xamarin/monodroid-samples/tree/master/CardReader).
Попробуем с помощью этих примеров сделать 2 приложения Xamarin Forms, эмулятор и ридер, и решить в них следующие задачи:
1. выводить данные от эмулятора на экране ридера
2. выводить данные от ридера на экране эмулятора
3. эмулятор должен работать с незапущенным приложением и заблокированным экраном
4. управление настройками эмулятора
5. запуск приложения эмулятора при обнаружении ридера
6. проверка состояния nfc-адаптера и переход в настройки nfc
Эта статья про андроид, поэтому, если у вас приложение также и под iOS, то там должна быть отдельная реализация.
Минимум теории.
Как написано в [документации android](https://developer.android.com/guide/topics/connectivity/nfc/hce), начиная с версии 4.4 (kitkat) добавлена возможность эмулировать ISO-DEP карты, и обрабатывать APDU-команды.
Эмуляция карт основана на сервисах android, известных как «HCE services».
Когда пользователь прикладывает устройство к NFC-ридеру, андроиду необходимо понять к какому HCE-сервису хочет подключиться ридер. В ISO/IEC 7816-4 описан способ выбора приложения, основанный на Application ID (AID).
Если интересно углубиться в прекрасный мир байтовых массивов, то [здесь](https://habr.com/ru/post/210062/) и [здесь](https://habr.com/ru/post/367241/) подробнее про APDU-команды. В данной статье используется всего пара команд, необходимых для обмена данными.
### Приложение «Ридер»
Начнём с ридера, т.к. он проще.
Создаём в Visual Studio новый проект типа «Mobile App(Xamarin.Forms)» далее выбираем шаблон «Blank» и оставляем только галочку «Android» в разделе «Platforms».
В андроид-проекте надо сделать следующее:
* Класс CardReader — в нём несколько констант и метод OnTagDiscovered
* MainActivity — инициализация класса CardReader, а также методы OnPause и OnResume для включения/выключения ридера при сворачивании приложения
* AndroidManifest.xml — разрешения для nfc
И в кроссплатформенном проекте в файле App.xaml.cs:
* Метод для вывода сообщения пользователю
#### Класс CardReader
```
using Android.Nfc;
using Android.Nfc.Tech;
using System;
using System.Linq;
using System.Text;
namespace ApduServiceReaderApp.Droid.Services
{
public class CardReader : Java.Lang.Object, NfcAdapter.IReaderCallback
{
// ISO-DEP command HEADER for selecting an AID.
// Format: [Class | Instruction | Parameter 1 | Parameter 2]
private static readonly byte[] SELECT_APDU_HEADER = new byte[] { 0x00, 0xA4, 0x04, 0x00 };
// AID for our loyalty card service.
private static readonly string SAMPLE_LOYALTY_CARD_AID = "F123456789";
// "OK" status word sent in response to SELECT AID command (0x9000)
private static readonly byte[] SELECT_OK_SW = new byte[] { 0x90, 0x00 };
public async void OnTagDiscovered(Tag tag)
{
IsoDep isoDep = IsoDep.Get(tag);
if (isoDep != null)
{
try
{
isoDep.Connect();
var aidLength = (byte)(SAMPLE_LOYALTY_CARD_AID.Length / 2);
var aidBytes = StringToByteArray(SAMPLE_LOYALTY_CARD_AID);
var command = SELECT_APDU_HEADER
.Concat(new byte[] { aidLength })
.Concat(aidBytes)
.ToArray();
var result = isoDep.Transceive(command);
var resultLength = result.Length;
byte[] statusWord = { result[resultLength - 2], result[resultLength - 1] };
var payload = new byte[resultLength - 2];
Array.Copy(result, payload, resultLength - 2);
var arrayEquals = SELECT_OK_SW.Length == statusWord.Length;
if (Enumerable.SequenceEqual(SELECT_OK_SW, statusWord))
{
var msg = Encoding.UTF8.GetString(payload);
await App.DisplayAlertAsync(msg);
}
}
catch (Exception e)
{
await App.DisplayAlertAsync("Error communicating with card: " + e.Message);
}
}
}
public static byte[] StringToByteArray(string hex) =>
Enumerable.Range(0, hex.Length)
.Where(x => x % 2 == 0)
.Select(x => Convert.ToByte(hex.Substring(x, 2), 16))
.ToArray();
}
}
```
В режиме чтения nfc-адаптера при обнаружении карты будет вызван метод OnTagDiscovered. В нём IsoDep — это объект с помощью которого мы будем обмениваться с картой командами (isoDep.Transceive(command)). Команды — это массивы байт.
В коде видно, что мы отправляем эмулятору последовательность, состоящую из заголовка SELECT\_APDU\_HEADER, длины нашего AID в байтах и самого AID:
```
0 164 4 0 // SELECT_APDU_HEADER
5 // длина AID в байтах
241 35 69 103 137 // SAMPLE_LOYALTY_CARD_AID (F1 23 45 67 89)
```
#### MainActivity ридера
Здесь надо объявить поле ридера:
```
public CardReader cardReader;
```
и два вспомогательных метода:
```
private void EnableReaderMode()
{
var nfc = NfcAdapter.GetDefaultAdapter(this);
if (nfc != null) nfc.EnableReaderMode(this, cardReader, READER_FLAGS, null);
}
private void DisableReaderMode()
{
var nfc = NfcAdapter.GetDefaultAdapter(this);
if (nfc != null) nfc.DisableReaderMode(this);
}
```
в методе OnCreate() инициализируем ридер и включаем режим чтения:
```
protected override void OnCreate(Bundle savedInstanceState)
{
...
cardReader = new CardReader();
EnableReaderMode();
LoadApplication(new App());
}
```
а также, включаем/выключаем режим чтения при сворачивании/открытии приложения:
```
protected override void OnPause()
{
base.OnPause();
DisableReaderMode();
}
protected override void OnResume()
{
base.OnResume();
EnableReaderMode();
}
```
#### App.xaml.cs
Статический метод для вывода сообщения:
```
public static async Task DisplayAlertAsync(string msg) =>
await Device.InvokeOnMainThreadAsync(async () => await Current.MainPage.DisplayAlert("message from service", msg, "ok"));
```
#### AndroidManifest.xml
В [документации android](https://developer.android.com/guide/topics/connectivity/nfc/nfc) написано, что для использования nfc в своём приложении и правильной с ним работы, надо объявить эти элементы в AndroidManifest.xml:
```
а лучше
```
При этом, если ваше приложение может использовать nfc, но это не обязательная функция, то можете пропустить элемент uses-feature и проверять доступность nfc в процессе работы.
Это всё, что касается ридера.
### Приложение «Эмулятор»
Опять создаём в Visual Studio новый проект типа «Mobile App(Xamarin.Forms)» далее выбираем шаблон «Blank» и оставляем только галочку «Android» в разделе «Platforms».
В Android-проекте надо сделать следующее:
* Класс CardService — здесь нужны константы и метод ProcessCommandApdu(), а также метод SendMessageToActivity()
* Описание сервиса в файле aid\_list.xml
* Механизм отправки сообщений в MainActivity
* Запуск приложения (при необходимости)
* AndroidManifest.xml — разрешения для nfc
И в кроссплатформенном проекте в файле App.xaml.cs:
* Метод для вывода сообщения пользователю
#### Класс CardService
```
using Android.App;
using Android.Content;
using Android.Nfc.CardEmulators;
using Android.OS;
using System;
using System.Linq;
using System.Text;
namespace ApduServiceCardApp.Droid.Services
{
[Service(Exported = true, Enabled = true, Permission = "android.permission.BIND_NFC_SERVICE"),
IntentFilter(new[] { "android.nfc.cardemulation.action.HOST_APDU_SERVICE" }, Categories = new[] { "android.intent.category.DEFAULT" }),
MetaData("android.nfc.cardemulation.host_apdu_service", Resource = "@xml/aid_list")]
public class CardService : HostApduService
{
// ISO-DEP command HEADER for selecting an AID.
// Format: [Class | Instruction | Parameter 1 | Parameter 2]
private static readonly byte[] SELECT_APDU_HEADER = new byte[] { 0x00, 0xA4, 0x04, 0x00 };
// "OK" status word sent in response to SELECT AID command (0x9000)
private static readonly byte[] SELECT_OK_SW = new byte[] { 0x90, 0x00 };
// "UNKNOWN" status word sent in response to invalid APDU command (0x0000)
private static readonly byte[] UNKNOWN_CMD_SW = new byte[] { 0x00, 0x00 };
public override byte[] ProcessCommandApdu(byte[] commandApdu, Bundle extras)
{
if (commandApdu.Length >= SELECT_APDU_HEADER.Length
&& Enumerable.SequenceEqual(commandApdu.Take(SELECT_APDU_HEADER.Length), SELECT_APDU_HEADER))
{
var hexString = string.Join("", Array.ConvertAll(commandApdu, b => b.ToString("X2")));
SendMessageToActivity($"Recieved message from reader: {hexString}");
var messageToReader = "Hello Reader!";
var messageToReaderBytes = Encoding.UTF8.GetBytes(messageToReader);
return messageToReaderBytes.Concat(SELECT_OK_SW).ToArray();
}
return UNKNOWN_CMD_SW;
}
public override void OnDeactivated(DeactivationReason reason) { }
private void SendMessageToActivity(string msg)
{
Intent intent = new Intent("MSG_NAME");
intent.PutExtra("MSG_DATA", msg);
SendBroadcast(intent);
}
}
}
```
При получении APDU-команды от ридера, будет вызван метод ProcessCommandApdu и в него передана команда в виде массива байтов.
Сначала проверяем, что сообщение начинается на SELECT\_APDU\_HEADER и если это так, составляем ответ ридеру. В реальности обмен может проходить в несколько шагов вопрос-ответ вопрос-ответ итд.
Перед классом в атрибуте Service описаны параметры сервиса android. При сборке xamarin преобразует это описание в такой элемент в AndroidManifest.xml:
```
```
#### Описание сервиса в файле aid\_list.xml
В папке xml надо создать файл aid\_list.xml:
```
xml version="1.0" encoding="utf-8"?
```
Ссылка на него есть в атрибуте Service в классе CardService — Resource = "@xml/aid\_list"
Здесь задан AID нашего приложения, по которому ридер будет к нему обращаться и атрибут requireDeviceUnlock=«false» чтобы карта считывалась при неразблокированном экране.
В коде есть 2 константы: `@string/service_name` и `@string/card_title`. Они объявляются в файле values/strings.xml:
```
My Loyalty Card
My Company
```
#### Механизм отправки сообщений:
Сервис не имеет ссылок на MainActivity, которая в момент получения APDU команды может быть и вовсе не запущена. Поэтому отправляем сообщения из CardService в MainActivity с помощью BroadcastReceiver следующим образом:
Метод для отправки сообщения из CardService:
```
private void SendMessageToActivity(string msg)
{
Intent intent = new Intent("MSG_NAME");
intent.PutExtra("MSG_DATA", msg);
SendBroadcast(intent);
}
```
Получение сообщения:
Создаём класс MessageReceiver:
```
using Android.Content;
namespace ApduServiceCardApp.Droid.Services
{
public class MessageReceiver : BroadcastReceiver
{
public override async void OnReceive(Context context, Intent intent)
{
var message = intent.GetStringExtra("MSG_DATA");
await App.DisplayAlertAsync(message);
}
}
}
```
Регистрируем MessageReceiver в MainActivity:
```
protected override void OnCreate(Bundle savedInstanceState)
{
...
var receiver = new MessageReceiver();
RegisterReceiver(receiver, new IntentFilter("MSG_NAME"));
LoadApplication(new App());
}
```
#### App.xaml.cs
Такой же как в ридере метод для вывода сообщения:
```
public static async Task DisplayAlertAsync(string msg) =>
await Device.InvokeOnMainThreadAsync(async () => await Current.MainPage.DisplayAlert("message from service", msg, "ok"));
```
#### AndroidManifest.xml
```
или 14
```
На данный момент у нас уже есть следующие функции:
* выводить данные от эмулятора на экране ридера
* выводить данные от ридера на экране эмулятора
* эмулятор должен работать с незапущенным приложением и с выключенным экраном.
Далее.
#### Управление эмулятором
Настройки буду хранить с помощью Xamarin.Essentials.
Сделаем так: при перезапуске приложения эмулятора будем обновлять настройку:
```
Xamarin.Essentials.Preferences.Set("key1", Guid.NewGuid().ToString());
```
а в методе ProcessCommandApdu будем каждый раз заново брать это значение:
```
var messageToReader = $"Hello Reader! - {Xamarin.Essentials.Preferences.Get("key1", "key1 not found")}";
```
теперь при каждом перезапуске(не сворачивании) приложения эмулятора видим новый guid, например:
```
Hello Reader! - 76324a99-b5c3-46bc-8678-5650dab0529d
```
Так же через настройки включаем/выключаем эмулятор:
```
Xamarin.Essentials.Preferences.Set("IsEnabled", false);
```
а в начало метода ProcessCommandApdu добавляем:
```
var IsEnabled = Xamarin.Essentials.Preferences.Get("IsEnabled", false);
if (!IsEnabled) return UNKNOWN_CMD_SW; // 0x00, 0x00
```
Это простой способ, но есть и [другие](https://stackoverflow.com/questions/25487365/can-i-prevent-host-card-emulation-service-from-being-triggered-by-select-aid).
#### Запуск приложения эмулятора при обнаружении ридера
Если надо просто открыть приложение эмулятора, то в методе ProcessCommandApdu добавьте строку:
```
StartActivity(typeof(MainActivity));
```
Если необходимо передать в приложение параметры, то так:
```
var activity = new Intent(this, typeof(MainActivity));
intent.PutExtra("MSG_DATA", "data for application");
this.StartActivity(activity);
```
Прочитать переданные параметры можно в классе MainActivity в методе OnCreate:
```
...
LoadApplication(new App());
if (Intent.Extras != null)
{
var message = Intent.Extras.GetString("MSG_DATA");
await App.DisplayAlertAsync(message);
}
```
#### Проверка состояния nfc-адаптера и переход в настройки nfc
Этот раздел применим и к ридеру и к эмулятору.
Создадим в андроид-проекте NfcHelper и используем DependencyService для доступа к нему из кода страницы MainPage.
```
using Android.App;
using Android.Content;
using Android.Nfc;
using ApduServiceCardApp.Services;
using Xamarin.Forms;
[assembly: Dependency(typeof(ApduServiceCardApp.Droid.Services.NfcHelper))]
namespace ApduServiceCardApp.Droid.Services
{
public class NfcHelper : INfcHelper
{
public NfcAdapterStatus GetNfcAdapterStatus()
{
var adapter = NfcAdapter.GetDefaultAdapter(Forms.Context as Activity);
return adapter == null ? NfcAdapterStatus.NoAdapter : adapter.IsEnabled ? NfcAdapterStatus.Enabled : NfcAdapterStatus.Disabled;
}
public void GoToNFCSettings()
{
var intent = new Intent(Android.Provider.Settings.ActionNfcSettings);
intent.AddFlags(ActivityFlags.NewTask);
Android.App.Application.Context.StartActivity(intent);
}
}
}
```
Теперь в кроссплатформенном проекте добавим интерфейс INfcHelper:
```
namespace ApduServiceCardApp.Services
{
public interface INfcHelper
{
NfcAdapterStatus GetNfcAdapterStatus();
void GoToNFCSettings();
}
public enum NfcAdapterStatus
{
Enabled,
Disabled,
NoAdapter
}
}
```
и используем всё это в коде MainPage.xaml.cs:
```
protected override async void OnAppearing()
{
base.OnAppearing();
await CheckNfc();
}
private async Task CheckNfc()
{
var nfcHelper = DependencyService.Get();
var status = nfcHelper.GetNfcAdapterStatus();
switch (status)
{
case NfcAdapterStatus.Enabled:
default:
await App.DisplayAlertAsync("nfc enabled!");
break;
case NfcAdapterStatus.Disabled:
nfcHelper.GoToNFCSettings();
break;
case NfcAdapterStatus.NoAdapter:
await App.DisplayAlertAsync("no nfc adapter found!");
break;
}
}
```
#### Ссылки на GitHub
[эмулятор](https://github.com/aleks42/ApduServiceCardApp)
[ридер](https://github.com/aleks42/ApduServiceReaderApp) | https://habr.com/ru/post/471622/ | null | ru | null |
# Grafana как инструмент визуализации потока данных в Kafka
### 1. Введение
Сегодня, в эпоху больших данных, когда компании тонут в информации из самых различных локальных и облачных источников, сотрудникам трудно увидеть общую картину. Анализ информации для отделения зерен от плевел требует все больше усилий. Визуализация данных помогает превратить все данные в понятную, визуально привлекательную и полезную информацию. Хорошо продуманная визуализация данных имеет критическое значение для принятия решений на их основе. Визуализация позволяет не только замечать и интерпретировать связи и взаимоотношения, но и выявлять развивающиеся тенденции, которые не привлекли бы внимания в виде необработанных данных. Большинство средств визуализации данных могут подключаться к источникам данных и таким образом использовать их для анализа. Пользователи могут выбрать наиболее подходящий способ представления данных из нескольких вариантов. В результате информация может быть представлена в графической форме, например, в виде круговой диаграммы, графика или визуального представления другого типа.
Большинство средств визуализации предлагает широкий выбор вариантов отображения данных, от обычных линейных графиков и столбчатых диаграмм до временных шкал, карт, зависимостей, гистограмм и настраиваемых представлений. Для решения задачи визуализации принципиальное значение имеет тип источника данных. И хотя современные средства визуализации проделали в этом вопросе большой путь, и предлагают на сегодняшний день весьма большой выбор, задача визуализации не решена в полной мере. Если для баз данных и целого ряда web сервисов задача визуализации не представляет принципиальной проблемы, то понять, что происходит с информационными потоками внутри некоторых программных продуктов из мира больших данных, не так просто.
Инструмент, на котором хотелось бы остановиться более подробно – Kafka. Он используется многими ведущими ИT-компаниями по всему миру. Это унифицированная платформа для обработки всех потоков данных в реальном времени [1]. Среди важных преимуществ данного инструмента следует выделить такие как: горизонтальная масштабируемость, поддержка доставки сообщений с низкой задержкой и гарантия отказоустойчивости при наличии отказов машины. Она способна обрабатывать большое количество разнообразных потребителей. Kafka очень быстрая – она может выполнять до нескольких миллионов операций записи в секунду и сохранять все данные на диск [2].
Как правило, Kafka является центральным элементом событийно-ориентированной архитектуры (см. рис. 1), что позволяет отцепить приложения друг от друга. Поскольку потоки данных, проходящие через Kafka, весьма велики, то визуализировать их непросто, хотя-бы в силу их объема. Однако если исходить из того что нам интересны не сами данные, а некая статистическая информация на их основе, то задача упрощается. Проще говоря, мы могли бы визуализировать результат работы некоторых агрегатных функций, отражающих основные тенденции в потоках данных. Для этого наши функции должны работать непосредственно с данными, т.е. расчет должен быть выполнен «внутри» самой Kafka. И такая возможность действительно существует: для решения такой задачи можно применить SQL-запросы к данным, которые могут выполнены при помощи плагина – ksqIDB.
Давайте рассмотрим такую задачу более подробно.
### 2. Топология современного ETL-процесса
Рис. 1
Пример схемы потоковой обработки данныхПеред нами (рис. 1) одна из наиболее популярных схем построения потоковой обработки данных, где Kafka расположена в центре схемы и берет на себя роль инструмента для работы с большим количеством быстрых транзакций. Такая архитектура позволяет решить ряд проблем, связанных с работой хранилищ данных. Традиционные хранилища данных, в первую очередь, предназначены для анализа, где требуются длинные транзакции и сложные аналитические запросы, а вот с задачами OLTP (Online Transaction Processing) справляются хуже. Kafka обладает теми качествами которые приписываются OLTP системам, а следовательно если по топологии расположена перед [корпоративных хранилищ данных](https://www.bigdataschool.ru/bigdata/lsa-data-warehouse-architecture.html) (КХД), то такая связка Kafka-КХД является очень выгодным решением. Таким образом, можно объединить преимущества как OLAP (Online analytical processing) так и OLTP подходов. Кафка, которая установлена «перед» КХД позволяет сгладить пиковые нагрузки и даже если КХД работает на пределе своих возможностей по приему данных, это не приводит к информационным потерям. Та часть данных, которую не успевает обрабатывать КХД будет оставаться в Kafka, но лишь до того времени пока нагрузка не уменьшится, после чего данные «догрузятся» в КХД.
Обычно данные в Kafka не рассматриваются как «сырье» для анализа, они лишь ждут своего часа, пока не будут загружены в КХД. То есть через некоторое время, (возможно, речь идет о достаточно большом временном промежутке), когда попадут в нужные таблицы, они будут пригодны для анализа. И это потенциальная проблема, так как при таком подходе теряется возможность оперативно увидеть негативные тенденции в данных. Сложные аналитические расчеты позволяют понять причинно-следственные связи, закономерности, установить причину проблемы и т.д. Но какова оперативность такой информации, насколько быстро может быть получен такого рода ответ. Современные КХД даже в простом варианте предусматривают несколько слоев хранения данных и лишь на последнем будет построена витрина, по которой можно будет понять, что не так с данными. А можно ли понять наличие проблемы с данными оперативно, как только данные поступают в систему. Отчасти, да, потому что Kafka, а точнее надстройка над ней в виде возможности выполнять SQL-запросы, позволяет сделать некоторые выводы о полученных сырых данных.
Ну, а минусом такого подхода можно считать ряд ограничений данной технологии, не позволяющей строить сложные SQL- запросы. Однако для оценки ситуации иногда достаточно и относительно простого анализа данных. В качестве демонстрации данного утверждения можно рассмотреть следующий пример. Допустим мы собираем данные о финансовых транзакциях с нескольких магазинов по продаже канцелярских товаров. Если данные поступают из нескольких магазинов равномерно, т. е. количество транзакций примерно соответствует предыдущим промежуткам времени, то будем считать ситуацию штатной. При этом нам не обязательно знать детали о каждой отдельной транзакции, можно исходить из того, что количество и сумма покупок на определённый промежуток времени примерно соответствует той же величине, что наблюдалась в течении нескольких последних дней за соответствующий временной промежуток. В этом случае сигналом к тому, что что-то пошло не так, может служить значительное отклонение от нормы по одному или нескольким параметрам.
Рассмотрим пример, как мог бы быть организован такой процесс в простейшем случае. И самое первое что нам понадобится – Kafka.
### 3. Загрузка данных в Kafka
Для создания необходимого нам, topic-а kafka, воспользуемся стандартной консольной утилитой kafka\_topics.sh:
```
kafka-topics.sh --create \
--topic tpk_products \
--bootstrap-server localhost:9092 \
--partitions 1 \
--replication-factor 1
```
Теперь, при помощи другого инструмента – `kafka-console-producer` – зальем в только что созданный топик тестовые данные:
```
kafka-console-producer.sh \
--broker-list localhost:9092 \
--topic tpk_products
```
В нашем случае данные будут в JSON формате. JSON сейчас, пожалуй, самый популярный формат обмена данными между приложениями, поэтому логично воспользоваться именно им.
Пример:
```
{"Shop":"Азбука", "name":"Книга записная", "price":"167"}
```
### 4. Преобразования данных с использованием KsqlDB и Schema Registry
Инструмент, который позволит нам выполнять запросы к данным в Kafka – ksqIDB. KsqIDB – это база данных потоковой передачи событий, построенная по архитектуре клиент-сервер.
Конфигурация сервера хранится в соответствующем файле ksql-server.properties, а запуск сервера можно настроить как отдельный сервис. либо запускать его когда вам это нужно. Пример запуска сервера:
```
/usr/bin/ksql-server-start /etc/ksqldb/ksql-server.properties
```
Подобно другим программным продуктам из экосистемы больших данных, ksqIDB можно запустить как в режиме standalone, так и сгруппировать несколько серверов вместе, т.е. здесь также возможно горизонтальное масштабирование. KsqIDB позволяет выполнять различные операции потоковой аналитики больших данных: фильтрация, соединения, агрегация, создание материализованных представлений, преобразования и сопоставления потоков событий с помощью типового инструментария SQL-запросов [3].
Пример запуска клиентской части ksqIDB:
```
/usr/bin/ksql http://0.0.0.0:8088
```
В открывшемся консольном приложении создаем стрим `str_products` на основе topic-а `tpk_products`
```
CREATE OR REPLACE STREAM str_products (
shop VARCHAR
, name VARCHAR
, price DECIMAL(10,2)
) WITH (
KAFKA_TOPIC = 'tpk_products'
, VALUE_FORMAT = 'JSON'
);
```
Как раннее было показано в [4], объекты в ksqlDB можно создать таким образом, что результат работы объекта (в нашем случае это таблица) запишется в другой Kafka topic. Так, к примеру, в приведенном ниже листинге целевой topic – `tpk_shops`. В нашем случае была создана таблица `tbl_agg_products` так, чтобы выполнялось суммирование по полю price, также были добавлены дополнительные поля необходимые нам для сбора статических данных. Сама таблица будет содержать данные в AVRO формате, а вот конвертация данных из JSON в AVRO будет выполнена механизмом schema registry.
То, что ключи в topic могут повторяться (поле `pkey` выполняет роль первичного ключа), не должно вводить в заблуждение. Строго говоря, Kafka позволяет как сохранять всю историю данных, так и только последнее актуальное значение value для каждого key. Более подробно на эту тему можно почитать здесь [5].
`WINDOWSTART` и `WINDOWEND` – временное окно «от и до» (в нашем случае это 10 минут). Нас будет интересовать ситуация, при которой `total_sum` суммируется для каждого магазина за выбранный промежуток времени (внутри выбранного окна).
Чтобы преобразование в формат AVRO было возможным, необходимо установить и настроить такой продукт как schema-registry [4].
Теперь добавим необходимую нам схему для преобразования:
```
curl -X POST -H "Content-Type: application/vnd.schemaregistry.v1+json" \
-d '{"schema": "{\"type\": \"record\", \"name\": \"Shops\", \"fields\": [{\"name\": \"shop\", \"type\": \"string\"}, {\"name\": \"total_sum\", \"type\": \"string\"}, {\"name\": \"ts\", \"type\": \"string\"}, {\"name\": \"window_start\", \"type\": \"string\"}, {\"name\": \"window_end\", \"type\": \"string\"}]}"}' \
http://localhost:8081/subjects/tpk_shops/versions
```
Результат добавления схемы можем просмотреть в браузере по ссылке
```
http://localhost:8081/schemas/
```
Чтобы проверить как это работает добавим в topic `tpk_products` какую-либо строку в формате JSON `{"Shop":"Азбука", "name":"Книга записная", "price":"167"}` можем увидеть результат в формате AVRO в топике `tpk_shops`, а поскольку результатом преобразования будут данные в формате AVRO, то и мы воспользуемся соответствующим AVRO консьюмером:
```
/usr/bin/kafka-avro-console-consumer \
--bootstrap-server localhost:9092 \
--topic tpk_shops \
--property print.key=true --property print.value=true
--from-beginning \
--property schema.registry.url=http://localhost:8081
```
Получим следующий результат:
```
{
"SHOP":{"string":"Азбука"},
"TOTAL_SUM":{"string":"167.00"},
"TS":{"string":"2022-07-21 09:14:59"},
"WINDOW_START":{"string":"2022-07-21 09:10:00"},
"WINDOW_END":{"string":"2022-07-21 09:20:00"}
}
```
Как видно, здесь только value. Если хотите увидеть еще и key, то придётся добавить в листинг соответствующие ключи:
```
--print.key=true \
--key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
```
Минусом такого подходя является то, что работа таблицы `tbl_agg_products` построена так, что при каждом добавлении новой строки во входной topic (`tpk_products`) сразу же добавляется новая строка в выходной (`tpk_shops`). Таким образом, в tpk\_shops мы будем видеть не только актуальный результат суммирования, но и все предыдущие результаты. Ниже, в таблице, приведен результат (`tpk_shops`), добавления трёх одинаковых записей в topic `tpk_products`, причем две из них попали в одно временное окно (первые две), а третья – в другое.
| | | | | |
| --- | --- | --- | --- | --- |
| Азбука | 167.00 | 2022-07-21 09:14:59 | 2022-07-21 09:10:00 | 2022-07-21 09:20:00 |
| Азбука | 334.00 | 2022-07-21 09:18:56 | 2022-07-21 09:10:00 | 2022-07-21 09:20:00 |
| Азбука | 167.00 | 2022-07-21 09:24:50 | 2022-07-21 09:20:00 | 2022-07-21 09:30:00 |
Первая запись в таблице по сути является не нужной для статистики, однако является неизбежным результатом потоковой обработки данных. Проще говоря, было бы хорошо получить результат, при котором записи с одинаковым названием магазина и временным окном являлись бы уникальными. И такое решение есть – достаточно передать полученный результат в какую-либо таблицу базы данных, выстроив правильным образом уникальные ключи, а данные которые сейчас мы получили в topic `tpk_shops`, считать промежуточным результатом. Следовательно, и сам topic можно настроить так, чтобы не хранить в нем записи сколь-нибудь значимый период времени, что сэкономит нам место на диске. Напомним, что параметр, ответственный за временное хранение – `retention.ms`. Осталось решить вопрос – каким образом мы передадим данные в базу. Конечно, вариантов можно предложить достаточно много, но можно не придумывать какие-то сторонние решения, а остаться в рамках экосистемы Kafka. Для решения вопроса воспользуемся `Kafka Sink Connector.`
### 5. Sink Connector – инструмент для передачи данных в BD
Чтобы `Kafka Connect` мог работать с нужными jar-файлами, необходимо развернуть архив в папку, на которую будет указывать параметр `plugin.path` из соответствующего файла настроек (`plugin.path=/usr/local/share/java`, см. пример файла `connect-standalone.properties` ниже по тексту).
Нам также потребуется архив с jar-файлами для коннекта из Kafka к базе, Для этого возьмем архив с сайта Сonfluence [6]. Файл добавим по тому же пути, на который указывает plugin.path.
В качестве базы данных я выбрал MySQL, далее была создана база данных –`STATS`, а ниже приведен листинг по созданию таблицы, в которую из нашего topic tpk\_shops будут поступать данные:
```
CREATE TABLE stats.tbl_shops_stat (
shop VARCHAR(100)
, total_sum DECIMAL
, ts TIMESTAMP
, window_start TIMESTAMP
, window_end TIMESTAMP
, CONSTRAINT tbl_shop_pkey PRIMARY KEY (shop, window_start)
);
```
Для того, чтобы обеспечить подключение к базе MySQL, нам потребуется соответствующий jdbc драйвер, который можно взять с сайта [7]. (при выборе драйвера лучше выбирать вариант Platform Independent – это упростит установку). Скаченный драйвер был добавлен по пути, указанному в plugin.path.
Поскольку мы будем работать в standalone режиме, нам понадобится файл конфигурации рабочего процесса Kafka Connect (connect-standalone.properties) и файл конфигурации коннектора (`jdbc-sink.properties`).
Пример запуска Kafka Connect в режиме Standalone.
```
/usr/local/kafka/bin/connect-standalone.sh /
~/kconf/connect-standalone.properties /
~/kconf/jdbc-sink.properties
```
Теперь давайте подробнее поговорим о самих конфигурационных файлах, так как они должны решать несколько задач.
Во-первых, необходимо объяснить коннектору что value в топике находятся в формате AVRO. Выбор этого формата неслучаен, как следует из документации [8] именно Avro Converter рекомендован для передачи данных в Kafka Connect. AVRO может быть легко использован для общего формата и обмена данными между системами. Это сводит к минимуму необходимость написания пользовательского кода и стандартизирует данные в гибком формате. Кроме того, мы получаем преимущества, которые дает на schema registry при преобразовании данных. А вот key значений мы не приводили к формату AVRO, следовательно, и указывать для него данный формат не нужно.
Итак, как было сказано выше, мы воспользуемся соответствующими ключами для преобразования:
```
key.converter=org.apache.kafka.connect.storage.StringConverter
key.converter.schemas.enable=false
value.converter=io.confluent.connect.avro.AvroConverter
value.converter.schema.registry.url=http://localhost:8081
```
Здесь хорошо видно, что для преобразования пары key-value совсем не обязательно использовать один и тот же сериализатор.
Во-вторых, соединиться с базой.
Данные параметры мы пропишем в файле настройки - `jdbc-sink.properties`
```
Конфигурация MySQL сервера - url=jdbc:mysql://localhost:3306/stats
Логин - user=
Пароль - password=
```
И наконец, в третьих – особенности загрузки данных. Нам необходимо выполнить вставку данных в таблицу `tbl_shops_stat` в режиме `upsert`. Для тех, кто работает с базами данных, хорошо известен SQL оператор `MERGE`. Несколько упрощая, данный оператор устроен следующим образом: если нет записи (нет совпадения по уникальным ключам), то выполняется insert строки, а если соответствующая запись обнаружена, то будет выполнен update для всех полей, которые не являются уникальными ключами. Upsert будет работать именно так, если запись с таким названием магазина и временным окном уже есть в таблице (`SHOP,WINDOW_START`) – обновит поле `total_sum`. Если такой записи нет – добавит новую.
Ниже приведу полный листинг файлов параметров:
`1. connect-standalone.properties`
```
bootstrap.servers=localhost:9092
offset.storage.file.filename=/tmp/connect.offsets
#Для key не было преобразования формата, по сути он остался стрингом
key.converter=org.apache.kafka.connect.storage.StringConverter
key.converter.schemas.enable=false
#А вот value было преобразовано в avro формат по схеме приведенной выше
value.converter=io.confluent.connect.avro.AvroConverter
value.converter.schema.registry.url=http://localhost:8081
value.converter.enhanced.avro.schema.support=true
value.converter.schemas.enable=true
errors.log.enable=true
errors.log.include.messages=true
print.key=true
errors.tolerance=all
topics=tpk_shops
offset.flush.interval.ms=1000
plugin.path=/usr/local/share/java
```
`2. jdbc-sink.properties`
```
name=jdbc-sink-connector
connector.class=io.confluent.connect.jdbc.JdbcSinkConnector
tasks.max=1
# The topics to consume from - required for sink connectors
topics=tpk_shops
connection.url=jdbc:mysql://localhost:3306/stats
connection.user=sky
connection.password=*****
connection.ds.pool.size=2
batch.size=1
table.name.format=stats.tbl_shops_stat
pk.mode=record_value
pk.fields=SHOP,WINDOW_START
insert.mode=upsert
```
### 6. Grafana – инструмент визуализации полученного результата
Данные, которые мы переложили в MySQL, теперь необходимо визуализировать. Для этого воспользуемся Grafana. Это инструмент с открытым исходным кодом, имеющий лицензию Apache 2.0, разработанный шведским разработчиком Torkel Ödegaard в 2014 году. Одна из причин популярности Grafana состоит в том, что разработчики могут создавать собственные информационные панели с панелями для различных источников данных.
Итак, чтобы продемонстрировать – как работает агрегирование данных в отдельный topic – проведем следующий эксперимент. В консольном окне, topic-а tpk\_products введем данные в формате JSON. Причем данные для наглядности разделим на три группы:
Первая группа записей
```
{"Shop":"Азбука", "name":"Книга записная", "price":"165"}
{"Shop":"Азбука", "name":"Блокнот деловой", "price":"251"}
{"Shop":"Клякса", "name":"Бумага цветная", "price":"35"}
{"Shop":"Отличник", "name":"Калькулятор Brilliant", "price":"389"}
{"Shop":"Отличник", "name":"Фломастеры 24 цвета", "price":"206"}
{"Shop":"Перемена", "name":"Ламинатор Camel", "price":"355"}
{"Shop":"Перемена", "name":"Дырокол", "price":"110"}
```
Вторая группа записей (добавим с временной задержкой 10 минут)
```
{"Shop":"Азбука", "name":"Комплект из 2-х ручек", "price":"448"}
{"Shop":"Клякса", "name":"Набор цветной бумаги", "price":"39"}
{"Shop":"Клякса", "name":"Фотобумага глянцевая", "price":"51"}
{"Shop":"Отличник", "name":"Фломастеры 24 цвета", "price":"206"}
{"Shop":"Перемена", "name":"Степлер", "price":"45"}
```
Третья группа записей (добавим с временной задержкой 10 минут)
```
{"Shop":"Азбука", "name":"Ручка роллер", "price":"210"}
{"Shop":"Азбука", "name":"Глобус Bestar GOLD", "price":"290"}
{"Shop":"Клякса", "name":"Набор цветной бумаги", "price":"39"}
{"Shop":"Клякса", "name":"Бумага цветная", "price":"52"}
{"Shop":"Отличник", "name":"Клей-карандаш", "price":"126"}
```
Наши данные можно увидеть простым SQL-запросом к таблице tbl\_agg\_products.
В консоли KsqLDB выполним следующий запрос:
```
SELECT shop, total_sum, window_start, window_end
FROM TBL_AGG_PRODUCTS;
```
```
+--------+---------+-------------------+-------------------+
|SHOP |TOTAL_SUM|WINDOW_START |WINDOW_END |
+--------+---------+-------------------+-------------------+
|Азбука |416.00 |2022-07-26 23:20:00|2022-07-26 23:30:00|
|Азбука |448.00 |2022-07-26 23:30:00|2022-07-26 23:40:00|
|Азбука |500.00 |2022-07-26 23:40:00|2022-07-26 23:50:00|
|Клякса |35.00 |2022-07-26 23:20:00|2022-07-26 23:30:00|
|Клякса |90.00 |2022-07-26 23:30:00|2022-07-26 23:40:00|
|Клякса |91.00 |2022-07-26 23:40:00|2022-07-26 23:50:00|
|Отличник|595.00 |2022-07-26 23:20:00|2022-07-26 23:30:00|
|Отличник|206.00 |2022-07-26 23:30:00|2022-07-26 23:40:00|
|Отличник|126.00 |2022-07-26 23:40:00|2022-07-26 23:50:00|
|Перемена|465.00 |2022-07-26 23:20:00|2022-07-26 23:30:00|
|Перемена|45.00 |2022-07-26 23:30:00|2022-07-26 23:40:00|
```
Полученный результат в полной мере отражает ожидания, т.е. произведено суммирование по каждому магазину внутри каждого временного окна. Теперь посмотрим – что попало в MySQL таблицу:
Рис.2
Результат агрегации данных по каждому магазину внутри десятиминутного окна. Полученный результат представлен на скриншоте: видно, что механизм upsert при добавлении записей в базу затер промежуточные результаты и конечный результат полностью аналогичен тому, что мы видели при запросе к таблице `TBL_AGG_PRODUCTS`.
Теперь отобразим его графически в Grafana. Для этого, настроив datasouce на базу MySQL, можем получить следующий графический результат:
Рис. 3
Распределение выручки по времени для каждого из 4 магазиновЗдесь хорошо видно, что один из магазинов резко уменьшил выручку, а позже и вовсе перестал отображаться на графике, что может свидетельствовать об обрыве связи или других проблемах в его работе. Получая информацию о состоянии продаж, практически в реальном времени мы можем максимально оперативно принимать меры, которые позволяет не допустить негативного развития событий.
### Заключение
Экосистема Kafka на сегодняшний день обладает достаточно большим арсеналом инструментов, позволяющим выполнять широкий спектр задач в области ETL.Что примечательно, решение задач потокового ETL выполняется по сути без написания единой строки программного кода. Такое направление в разработке приято назвать «no coding». Данный подход действительно имеет целый ряд преимуществ [9] и сторонников, а фраза «The future of coding is no coding at all» принадлежит Крису Ванстрату, соучредителю и бывшему генеральному директору GitHub.
В статье были продемонстрированы возможности такого компонента экосистемы Kafka как Kafka Connect. Он обеспечивает быструю интеграцию кластера Kafka с внешними источниками и приемниками данных с минимальными затратами на разработку. Его ключевым преимуществом является возможность повторного использования коннекторов, которые действуют как плагины между Kafka и внешними источниками данных или приемниками.
Рис.4
Блок-схема процесса мониторинга поступающих данных в режиме реального времениПроцесс добавления мониторинга в уже имеющуюся систему не требует хоть сколько ни будь существенного дискового пространства, поскольку сохранять данные в topic-е для агрегации данных можно весьма непродолжительное время, лишь незначительно превосходящее период, указанный при создании таблицы агрегации. Сами же данные в базе могут обновляться не так часто, как показано в примере. К тому же, в потоке для мониторинга нет необходимости хранить большинство полей, которые имеют место при передачи данных в основном потоке. Таким образом, нагрузка на базу (в нашем случае это MySQL) также не должна приводить к существенному росту нагрузки на систему в целом.
Среди положительных сторон такого подхода следует выделить максимальную оперативность получения данных, наглядность и отсутствие необходимости писать программный код.
**Источники**
[1] [Apache Kafka: обзор](https://habr.com/ru/company/piter/blog/352978/)
[2] [Apache Kafka – Краткое руководство](https://coderlessons.com/tutorials/bolshie-dannye-i-analitika/vyuchit-apache-kafka/apache-kafka-kratkoe-rukovodstvo)
[3] [ksqlDB](https://www.bigdataschool.ru/wiki/ksqldb)
[4] [ksqlDb или SQL как инструмент обработки потоков данных](https://habr.com/ru/company/neoflex/blog/593769/)
[5] [PVbase: compacted topic в Apache Kafka](https://habr.com/ru/company/sberbank/blog/590045/)
[6] [JDBC Connector (Source and Sink)](https://confluent.io/hub/confluentinc/kafka-connect-jdbc)
[7] [Connector/J](https://dev.mysql.com/downloads/connector/j/)
[8] [Installing and Configuring Kafka Connect](https://docs.huihoo.com/apache/kafka/confluent/3.1/connect/userguide.html)
[9] [Движение No-code — конец программистов? Разбираем плюсы и минусы](https://vc.ru/services/146312-dvizhenie-no-code-konec-programmistov-razbiraem-plyusy-i-minusy) | https://habr.com/ru/post/682582/ | null | ru | null |
# Закончен предварительный перевод книги «Волшебство Git»
Я, как и многие программисты, после знаменитого [выступления Линуса Торвальдса о Git на Google Talks](http://habrahabr.ru/blogs/development_tools/58766/) заинтересовался распределенными системами управления версиями, а в особенно Git.
Я довольно таки свободно читаю на английском, но мне приятнее читать на русском языке, при условии нормального перевода.
Существует замечательная книга [«Git Magic» Бена Лина](http://www-cs-students.stanford.edu/~blynn/gitmagic/index.html) (Ben Lynn).
Благодаря труду многих людей вышел первый черновой вариант этой книги. Всех желающих улучшить перевод — приглашаю под кат.
Это предварительный, черновой вариант и если у Вас есть желание улучшить его, то необходимо:
`$ git clone git://github.com/mifistor/gitmagic-ru.git # клонировать репозиторий
$ cd gitmagic-ru/ru/ # перейти в директорию с русским переводом
$ выполнить редактирование
$ git diff > fix.patch # создать patch, отражающий внесенные изменения, и выслать его мне на электронную почту [email protected]`
Если Вы желаете посмотреть результат в виде книги, то Вы можете скомпилировать ее в нужном формате:
`$ make book.pdf LANG=ru # создаст pdf-файл на русском языке.
$ make LANG=ru # Создаст книгу в HTML, pdf и xml-формате на русском языке`
Или же скачать уже [скомпилированный файл (PDF, 490 Кб)](http://dl.dropbox.com/u/281916/delete/book.pdf).
Я благодарю за помощь всех участников перевода. Активные будут включены в раздел «благодарности» после окончания работы.
*P.S. Я был бы благодарен за совет, как собрать книгу с правильным оглавлением, т.к. с asciidoc&xmlto не знаком.* | https://habr.com/ru/post/80909/ | null | ru | null |
# Опубликована инструкция по созданию сайтов в даркнете TON
*На самом низком уровне взаимодействие между узлами TON производится по протоколу UDP. Узел зашифровывает пакет открытым ключом получателя и добавляет в начало пакета 256-битный адрес получателя. Источник: [«TON: Telegram Open Network. Часть 1: Вступление, сетевой уровень, ADNL, DHT, оверлейные сети»](https://habr.com/ru/post/354366/)*
На неофициальном сайте Telegram Open Network [опубликована инструкция](https://ru.ton-telegram.net/instructions/kak-sozdat-ton-site/) по настройке прокси для доступа к TON Sites и созданию новых сайтов в сети Telegram Open Network.
В силу особенностей архитектуры пользователей Telegram Open Network значительно сложнее идентифицировать. Эта одноранговая сеть (P2P) защищена встроенным прокси и анонимайзером. По такому же принципу функционируют известные проекты анонимных одноранговых сетей вроде I2P и Tor.
«С технической точки зрения TON Sites похожи на обычные веб-сайты, но доступ к ним осуществляется через сеть Telegram Open Network, которая представляет собой оверлейную сеть внутри Интернета, а не через Интернет, — поясняется в инструкции. — Более конкретно, у сайтов есть адрес ADNL (вместо более привычного адреса IPv4 или IPv6), и TON Sites принимают запросы HTTP через протокол RLDP (который является протоколом RPC более высокого уровня, основанным на ADNL, главном протоколе сети TON) вместо обычного TCP/IP протокола. Всё шифрование обрабатывается ADNL, поэтому нет необходимости использовать HTTPS».
«Для доступа к существующим TON Sites и для создания новых сайтов TON необходимы специальные шлюзы между классическим Интернетом и сетью TON. По сути, доступ к сайтам TON осуществляется с помощью HTTP -> RLDP-прокси, работающего локально на клиентской машине, и они создаются с помощью обратного RLDP -> HTTP-прокси, работающего на удаленном веб-сервере».
В инструкции описывается специальная утилита RLDP-HTTP Proxy, предназначенная для доступа к TON Sites и создания сайтов TON. Текущая альфа-версия утилиты является частью общего исходного кода [TON Blockchain](https://github.com/ton-blockchain/ton).
Чтобы получить доступ к существующим TON-сайтам, нужен работающий экземпляр RLDP-HTTP Proxy на компьютере:
`rldp-http-proxy / rldp-http-proxy -p 8080 -c 3333 -C ton-global.config.json`
Конфигурационный файл ton-global.config.json можно скачать по [этому адресу](https://test.ton.org/ton-global.config.json).
Настроив `localhost:8080` в качестве HTTP-прокси, можно вводить адреса даркнета TON, такие как `http://test.ton`, в адресной строке обычного браузера и взаимодействовать с TON Web так же, как с обычными веб-сайтами.
Для создания сайта в сети TON требуется запустить на сервере RLDP-HTTP Proxy вместе с обычным программным обеспечением веб-сервера, таким как Apache или Nginx. Далее из инструкции:
> После этого выполняете
>
>
>
> `rldp-http-proxy -a <ваш-сервер-ip>: 3333 -L example.ton -C ton-global.config.json`
>
>
>
> в фоновом режиме (можете сначала попробовать это в терминале, но если вы хотите, чтобы ваш сайт TON работал постоянно, придётся также использовать опции -d и -l ).
>
>
>
> Если все работает правильно, RLDP-HTTP прокси будет принимать входящие HTTP-запросы из сети TON через RLDP/ADNL, работающие через UDP-порт 3333 (конечно, вы можете использовать любой другой UDP-порт, если хотите) с IPv4-адресом <ваш- server-ip> (в частности, если вы используете firewall не забудьте разрешить rldp-http-proxy принимать и отправлять UDP-пакеты с этого порта), и он будет перенаправлять эти HTTP-запросы, адресованные хосту example.ton к TCP-порту 80 на 127.0.0.1, т. е. к обычному веб-серверу.
>
>
>
> Вы можете зайти на TON Site [example.ton](http://example.ton) из браузера, запущенного на клиентском компьютере, как описано выше и проверить, действительно ли ваш TON сайт публично доступен.
Концепция Telegram Open Network разработана Павлом и Николаем Дуровыми. Они привлекли под этот проект инвестиции в несколько миллиардов долларов и запланировали перевод на TON популярного мессенджера Telegram. | https://habr.com/ru/post/487760/ | null | ru | null |
# Vivid UI
Первое, что видит пользователь - UI приложения. И в мобильной разработке больше всего вызовов связано именно с его построением, а большую часть времени разработчик тратит на ~~чизкейк~~ верстку и логику презентационного слоя. В мире существует множество подходов к решению этих задач. Часть того, что мы расскажем, скорее всего уже используется в индустрии. Но мы попытались собрать воедино некоторые из них, и уверены, что это станет вам полезно.
На старте проекта мы захотели прийти к такому процессу разработки фич, чтобы вносить как можно меньше изменений в код при максимальном соответствии с пожеланиями дизайнеров, а также иметь под рукой широкий спектр инструментов и абстракций для борьбы с бойлерплейтом.
Эта статья будет полезна тем, кто хочет тратить меньше времени на рутинные процессы верстки и повторяющуюся логику обработки состояний экранов.
Декларативный стиль UI
----------------------
#### View modifiers aka decorator
Начиная разработку, мы решили организовать построение UI компонентов как можно более гибко с возможностью собрать из готовых частей что-то прямо на месте.
Для этого мы решили использовать декораторы: они соответствуют нашему представлению о простоте и переиспользуемости кода.
Декораторы представляют собой структуру с замыканием, которая расширяет функционал вью, без необходимости наследования.
```
public struct ViewDecorator {
let decoration: (View) -> Void
func decorate(\_ view: View) {
decoration(view)
}
}
public protocol DecoratableView: UIView {}
extension DecoratableView {
public init(decorator: ViewDecorator) {
self.init(frame: .zero)
decorate(with: decorator)
}
@discardableResult
public func decorated(with decorator: ViewDecorator) -> Self {
decorate(with: decorator)
return self
}
public func decorate(with decorator: ViewDecorator) {
decorator.decorate(self)
currentDecorators.append(decorator)
}
public func redecorate() {
currentDecorators.forEach {
$0.decorate(self)
}
}
}
```
Почему мы не стали использовать сабклассы:
* Их трудно соединять в цепочки;
* Невозможно отказаться от функциональности родительского класса;
* Нужно описывать отдельно от контекста применения (в отдельном файле)
Декораторы помогли настроить UI компонентов унифицированно и здорово сократили количество кода.
Это также позволило установить связи с дизайн гайдлайнами типовых элементов.
```
static var headline2: ViewDecorator {
ViewDecorator {
$0.decorated(with: .font(.f2))
$0.decorated(with: .textColor(.c1))
}
}
```
В клиентском коде цепочка декораторов выглядит просто и наглядно, позволяя быстро собрать определенную часть интерфейса сразу при объявлении.
```
private let titleLabel = UILabel()
.decorated(with: .headline2)
.decorated(with: .multiline)
.decorated(with: .alignment(.center))
```
Здесь мы, например, расширили декоратор заголовка возможностью занимать произвольное количество строк и равнять текст по центру.
А теперь сравним код с декораторами и без них.
Пример использования декоратора:
```
private let fancyLabel = UILabel(
decorator: .text("?? ???? ???"))
.decorated(with: .cellTitle)
.decorated(with: .alignment(.center))
```
Без декораторов аналогичный код выглядел бы примерно так:
```
private let fancyLabel: UILabel = {
let label = UILabel()
label.text = "???? ? ????"
label.numberOfLines = 0
label.font = .f4
label.textColor = .c1
label.textAlignment = .center
return label
}()
```
Что здесь плохо — 9 строк кода против 4. Внимание рассеивается.
Для navigation bar особенно актуально, так как под строчками вида:
```
navigationController.navigationBar
.decorated(with: .titleColor(.purple))
.decorated(with: .transparent)
```
Скрывается:
```
static func titleColor(_ color: UIColor) -> ViewDecorator {
ViewDecorator {
let titleTextAttributes: [NSAttributedString.Key: Any] = [
.font: UIFont.f3,
.foregroundColor: color
]
let largeTitleTextAttributes: [NSAttributedString.Key: Any] = [
.font: UIFont.f1,
.foregroundColor: color
]
if #available(iOS 13, \*) {
$0.modifyAppearance {
$0.titleTextAttributes = titleTextAttributes
$0.largeTitleTextAttributes = largeTitleTextAttributes
}
} else {
$0.titleTextAttributes = titleTextAttributes
$0.largeTitleTextAttributes = largeTitleTextAttributes
}
}
}
```
```
static var transparent: ViewDecorator {
ViewDecorator {
if #available(iOS 13, \*) {
$0.isTranslucent = true
$0.modifyAppearance {
$0.configureWithTransparentBackground()
$0.backgroundColor = .clear
$0.backgroundImage = UIImage()
}
} else {
$0.setBackgroundImage(UIImage(), for: .default)
$0.shadowImage = UIImage()
$0.isTranslucent = true
$0.backgroundColor = .clear
}
}
}
```
Декораторы показали себя хорошим инструментом и помогли нам:
* Улучшить переиспользование кода
* Сократить время разработки
* Через связанность компонентов легко накатывать изменения в дизайне
* Легко настраивать navigation bar через перегрузку свойства с массивом декораторов базового класса экрана
```
override var navigationBarDecorators: [ViewDecorator] {
[.withoutBottomLine, .fillColor(.c0), .titleColor(.c1)]
}
```
* Сделать код единообразным: не рассеивается внимание, знаешь где что искать.
* Получить контекстно-зависимый код: доступны лишь те декораторы, которые применимы для данного визуального компонента.
#### HStack, VStack
После того, как определились с тем, как будет выглядеть построение отдельных компонентов, мы задумались о том, как сделать удобным расположение компонентов на экране друг относительно друга. Мы также руководствовались тем, чтобы сделать вёрстку простой и декларативной.
Стоит отметить, что история iOS претерпела не одну эволюцию в работе с лейаутом. Чтобы освежить это в памяти ~~и забыть как страшный сон~~, достаточно взглянуть всего на один простенький пример.
На дизайне выше мы выделили область, для которой мы и будем писать верстку.
Сначала используем наиболее актуальную версию констрейнтов - anchors.
```
[expireDateTitleLabel, expireDateLabel, cvcCodeView].forEach {
view.addSubview($0)
$0.translatesAutoresizingMaskIntoConstraints = false
}
NSLayoutConstraint.activate([
expireDateTitleLabel.topAnchor.constraint(equalTo: view.topAnchor),
expireDateTitleLabel.leftAnchor.constraint(equalTo: view.leftAnchor),
expireDateLabel.topAnchor.constraint(equalTo: expireDateTitleLabel.bottomAnchor, constant: 2),
expireDateLabel.leftAnchor.constraint(equalTo: view.leftAnchor),
expireDateLabel.bottomAnchor.constraint(equalTo: view.bottomAnchor),
cvcCodeView.leftAnchor.constraint(equalTo: expireDateTitleLabel.rightAnchor, constant: 44),
cvcCodeView.bottomAnchor.constraint(equalTo: view.bottomAnchor),
cvcCodeView.rightAnchor.constraint(equalTo: view.rightAnchor)
])
```
То же самое можно реализовать на стеках, через нативный UIStackView это будет выглядеть так.
```
let stackView = UIStackView()
stackView.alignment = .bottom
stackView.axis = .horizontal
stackView.layoutMargins = .init(top: 0, left: 16, bottom: 0, right: 16)
stackView.isLayoutMarginsRelativeArrangement = true
let expiryDateStack: UIStackView = {
let stackView = UIStackView(
arrangedSubviews: [expireDateTitleLabel, expireDateLabel]
)
stackView.setCustomSpacing(2, after: expireDateTitleLabel)
stackView.axis = .vertical
stackView.layoutMargins = .init(top: 8, left: 0, bottom: 0, right: 0)
stackView.isLayoutMarginsRelativeArrangement = true
return stackView
}()
let gapView = UIView()
gapView.setContentCompressionResistancePriority(.defaultLow, for: .horizontal)
gapView.setContentHuggingPriority(.defaultLow, for: .horizontal)
stackView.addArrangedSubview(expiryDateStack)
stackView.addArrangedSubview(gapView)
stackView.addArrangedSubview(cvcCodeView)
```
Как видите, в обоих случаях код получился громоздким. Сама идея верстать на стеках имела больше декларативного потенциала. И если быть честными, то этот подход был предложен одним из разработчиков еще до сессии WWDC про SwiftUI. И мы рады, что в данном подразделении Apple работают наши единомышленники! Тут не будет сюрпризов, еще раз взглянем на иллюстрацию, показанную ранее и представим ее в виде стеков.
```
view.layoutUsing.stack {
$0.hStack(
alignedTo: .bottom,
$0.vStack(
expireDateTitleLabel,
$0.vGap(fixed: 2),
expireDateLabel
),
$0.hGap(fixed: 44),
cvcCodeView,
$0.hGap()
)
}
```
А так выглядит тот же код, если написать его на SwiftUI
```
var body: some View {
HStack(alignment: .bottom) {
VStack {
expireDateTitleLabel
Spacer().frame(width: 0, height: 2)
expireDateLabel
}
Spacer().frame(width: 44, height: 0)
cvcCodeView
Spacer()
}
}
```
Коллекции как инструмент построения
-----------------------------------
Каждый iOS-разработчик знает как неудобно использовать коллекции UITableView и UICollectionView. Надо не забыть зарегистрировать все нужные классы ячеек, проставить делегаты и источники данных. Кроме того, однажды вашей команде может прийти озарение поменять таблицу на коллекцию. Причин для этого масса: невероятные лейауты и кастомные анимированные вставки, свопы и удаления элементов. И вот тогда переписывать придется действительно много.
Собрав все эти идеи воедино, мы пришли к реализации адаптера списков. Теперь для создания динамического списка на экране достаточно всего нескольких строк.
```
private let listAdapter = VerticalListAdapter()
private let collectionView = UICollectionView(
frame: .zero,
collectionViewLayout: UICollectionViewFlowLayout()
)
```
И далее настраиваем основные свойства адаптера.
```
func setupCollection() {
listAdapter.heightMode = .fixed(height: 8)
listAdapter.setup(collectionView: collectionView)
listAdapter.spacing = Constants.pocketSpacing
listAdapter.onSelectItem = output.didSelectPocket
}
```
И на этом все. Осталось загрузить модели.
```
listAdapter.reload(items: viewModel.items)
```
Это помогает избавиться от кучи методов, которые дублируются из класса в класс и сосредоточиться на отличиях коллекций друг от друга.
В итоге:
* Абстрагировали от конкретной коллекции (UITableView -> UICollectionView).
* Ускорили время построения экранов со списками
* Обеспечили единообразие архитектуры всех экранов, построенных на коллекциях
* На основе адаптера списка разработали адаптер для смеси динамических и статических ячеек
* Уменьшили количество потенциальных ошибок в рантайме, благодаря компайл тайм проверкам дженерик типов ячеек
Состояния экрана
----------------
Очень скоро разработчик замечает, что каждый экран состоит из таких состояний как: начальное состояние, загрузка данных, отображение загруженных данных, отсутствие данных.
Давайте поговорим более подробно о состоянии загрузки экрана.
### Shimmering Views
Отображение состояний загрузки разных экранов в приложении обычно не сильно отличается и требует одних и тех же инструментов. В нашем проекте таким визуальным инструментом стали шиммеры (shimmering views).
Шиммер - это такой прообраз реального экрана, где на время загрузки данных на месте финального UI отображаются мерцающие блоки соответствующих этим компонентам размеров.
Также есть возможность кастомизировать лэйаут, выбрав родительскую view, относительно которой будем показывать, а также привязать к различным краям.
Трудно представить себе хоть один экран онлайн приложения, который бы не нуждался в таком скелетоне, поэтому логичным шагом стало создание удобной переиспользуемой логики.
Поэтому мы создали SkeletonView, в который добавили анимацию градиента:
```
func makeStripAnimation() -> CAKeyframeAnimation {
let animation = CAKeyframeAnimation(keyPath: "locations")
animation.values = [
Constants.stripGradientStartLocations,
Constants.stripGradientEndLocations
]
animation.repeatCount = .infinity
animation.isRemovedOnCompletion = false
stripAnimationSettings.apply(to: animation)
return animation
}
```
Основными методами для работы со скелетоном являются показ и скрытие его на экране:
```
protocol SkeletonDisplayable {...}
protocol SkeletonAvailableScreenTrait: UIViewController, SkeletonDisplayable {...}
extension SkeletonAvailableScreenTrait {
func showSkeleton(animated: Bool = false) {
addAnimationIfNeeded(isAnimated: animated)
skeletonViewController.view.isHidden = false
skeletonViewController.setLoading(true)
}
func hideSkeleton(animated: Bool = false) {
addAnimationIfNeeded(isAnimated: animated)
skeletonViewController.view.isHidden = true
skeletonViewController.setLoading(false)
}
}
```
Для того, чтобы настроить отображение скелетона на конкретном экране используется расширение к протоколу. Внутри самих экранов достаточно добавить вызов:
```
setupSkeleton()
```
#### Smart skeletons
К сожалению, не всегда удается доставить лучший пользовательский опыт, попросту затерев весь пользовательский интерфейс. На некоторых экранах есть необходимость перезагрузить лишь его часть, оставив полностью функционирующей всю остальную. Этой цели служат так называемые умные скелетоны.
Чтобы построить умный скелетон для какого-либо UI компонента требуется знать: список его дочерних компонентов, загрузки данные, которые мы ожидаем, а так же их скелетон-представления:
```
public protocol SkeletonDrivenLoadableView: UIView {
associatedtype LoadableSubviewID: CaseIterable
typealias SkeletonBone = (view: SkeletonBoneView, excludedPinEdges: [UIRectEdge])
func loadableSubview(for subviewId: LoadableSubviewID) -> UIView
func skeletonBone(for subviewId: LoadableSubviewID) -> SkeletonBone
}
```
Для примера, рассмотрим простенький компонент, состоящий из иконки и лейбла заголовка.
```
extension ActionButton: SkeletonDrivenLoadableView {
public enum LoadableSubviewID: CaseIterable {
case icon
case title
}
public func loadableSubview(for subviewId: LoadableSubviewID) -> UIView {
switch subviewId {
case .icon:
return solidView
case .title:
return titleLabel
}
}
public func skeletonBone(for subviewId: LoadableSubviewID) -> SkeletonBone {
switch subviewId {
case .icon:
return (ActionButton.iconBoneView, excludedPinEdges: [])
case .title:
return (ActionButton.titleBoneView, excludedPinEdges: [])
}
}
}
```
Теперь мы можем запустить загрузку такого UI компонента с возможностью выбора дочерних элементов для шиммеринга:
```
actionButton.setLoading(isLoading, shimmering: [.icon])
// or
actionButton.setLoading(isLoading, shimmering: [.icon, .title])
// which is equal to
actionButton.setLoading(isLoading)
```
Таким образом, пользователь видит актуальную информацию, а для блоков, которые требуют загрузки, мы показываем скелетоны.
### Машина состояний
Кроме загрузки, есть и другие состояния экрана, переходы между которыми сложно держать в голове. Неумелая организация переходов между ними приводит к неконсистентности информации, отображаемой на экране.
Так как у нас есть конечное число состояний, в котором может находиться экран, и мы можем определить переходы между ними, эта задача прекрасно решается с помощью машины состояний.
Для экрана она выглядит следующим образом:
```
final class ScreenStateMachine: StateMachine {
public init() {
super.init(state: .initial,
transitions: [
.loadingStarted: [.initial => .loading, .error => .loading],
.errorReceived: [.loading => .error],
.contentReceived: [.loading => .content, .initial => .content]
])
}
}
```
Ниже мы привели свою реализацию.
```
class StateMachine {
public private(set) var state: State {
didSet {
onChangeState?(state)
}
}
private let initialState: State
private let transitions: [Event: [Transition]]
private var onChangeState: ((State) -> Void)?
public func subscribe(onChangeState: @escaping (State) -> Void) {
self.onChangeState = onChangeState
self.onChangeState?(state)
}
@discardableResult
open func processEvent(\_ event: Event) -> State {
guard let destination = transitions[event]?.first(where: { $0.source == state })?.destination else {
return state
}
state = destination
return state
}
public func reset() {
state = initialState
}
}
```
Остается вызвать нужные события, чтобы запустить переход состояний.
```
func reloadTariffs() {
screenStateMachine.processEvent(.loadingStarted)
interactor.obtainTariffs()
}
```
Если есть состояния, то кто-то должен уметь эти состояния показывать.
```
protocol ScreenInput: ErrorDisplayable,
LoadableView,
SkeletonDisplayable,
PlaceholderDisplayable,
ContentDisplayable
```
Как можно догадаться, конкретный экран реализует каждый из вышеперечисленных аспектов:
* Показ ошибок
* Управление загрузкой
* Показ скелетонов
* Показ заглушек с ошибкой и возможностью попытаться снова
* Показ контента
Также для state machine можно реализовать собственные переходы между состояниями:
```
final class DogStateMachine: StateMachine<ConfirmByCodeResendingState, ConfirmByCodeResendingEvent> {
init() {
super.init(
state: .laying,
transitions: [
.walkCommand: [
.laying => .walking,
.eating => .walking,
],
.seatCommand: [.walking => .sitting],
.bunnyCommand: [
.laying => .sitting,
.sitting => .sittingInBunnyPose
]
]
)
}
}
```
#### Трейт экрана с машиной состояний
Хорошо, а как все это связать воедино? Для этого потребуется еще один протокол оркестратор.
```
public extension ScreenStateMachineTrait {
func setupScreenStateMachine() {
screenStateMachine.subscribe { [weak self] state in
guard let self = self else { return }
switch state {
case .initial:
self.initialStateDisplayableView?.setupInitialState()
self.skeletonDisplayableView?.hideSkeleton(animated: false)
self.placeholderDisplayableView?.setPlaceholderVisible(false)
self.contentDisplayableView?.setContentVisible(false)
case .loading:
self.skeletonDisplayableView?.showSkeleton(animated: true)
self.placeholderDisplayableView?.setPlaceholderVisible(false)
self.contentDisplayableView?.setContentVisible(false)
case .error:
self.skeletonDisplayableView?.hideSkeleton(animated: true)
self.placeholderDisplayableView?.setPlaceholderVisible(true)
self.contentDisplayableView?.setContentVisible(false)
case .content:
self.skeletonDisplayableView?.hideSkeleton(animated: true)
self.placeholderDisplayableView?.setPlaceholderVisible(false)
self.contentDisplayableView?.setContentVisible(true)
}
}
}
private var skeletonDisplayableView: SkeletonDisplayable? {
view as? SkeletonDisplayable
}
// etc.
}
```
А для перехода по триггерам событий на действия с соответствующим аспектом экрана он использует уже описанную ранее машину состояний.
Отображение ошибок
------------------
Еще одной из наиболее часто встречаемых задач является отображение ошибок и обработка реакции пользователя на них.
Для того, чтобы отображение ошибок было одинаковым как для пользователя, так и для разработчиков, мы определились с конечным набором визуального стиля и переиспользуемой логики.
На помощь снова спешат протоколы и трейты.
Для описания представления всех видов ошибок определена единая вьюмодель.
```
struct ErrorViewModel {
let title: String
let message: String?
let presentationStyle: PresentationStyle
}
enum PresentationStyle {
case alert
case banner(
interval: TimeInterval = 3.0,
fillColor: UIColor? = nil,
onHide: (() -> Void)? = nil
)
case placeholder(retryable: Bool = true)
case silent
}
```
Дальше мы передаём её в метод протокола ErrorDisplayable:
```
public protocol ErrorDisplayable: AnyObject {
func showError(_ viewModel: ErrorViewModel)
}
```
```
public protocol ErrorDisplayableViewTrait: UIViewController, ErrorDisplayable, AlertViewTrait {}
```
В зависимости от стиля презентации используем конкретный инструмент отображения.
```
public extension ErrorDisplayableViewTrait {
func showError(_ viewModel: ErrorViewModel) {
switch viewModel.presentationStyle {
case .alert:
// show alert
case let .banner(interval, fillColor, onHide):
// show banner
case let .placeholder(retryable):
// show placeholder
case .silent:
return
}
}
}
```
Помимо отображения ошибок, существуют еще и сущности бизнес слоя. Каждую из таких сущностей можно в любой момент очень легко вывести на экран, используя приведенную выше вью модель. Таким образом, достигается универсальный и легкий в поддержке механизм отображения ошибок из любой части приложения.
```
extension APIError: ErrorViewModelConvertible {
public func viewModel(_ presentationStyle: ErrorViewModel.PresentationStyle) -> ErrorViewModel {
.init(
title: Localisation.network_error_title,
message: message,
presentationStyle: presentationStyle
)
}
}
extension CommonError: ErrorViewModelConvertible {
public func viewModel(_ presentationStyle: ErrorViewModel.PresentationStyle) -> ErrorViewModel {
.init(
title: title,
message: message,
presentationStyle: isSilent ? .silent : presentationStyle
)
}
}
```
К слову, баннер может быть использован не только для отображения ошибок, но и для предоставления информации пользователю.
Занимательные цифры
-------------------
* Средний размер вьюконтроллера - 196,8934010152 строк
* Средний размер компонента - 138,2207792208 строк
* Время написания экрана - 1 день
* Время написания скрипта для подсчёта этих строк кода - 1 час
Выводы
------
Благодаря нашему подходу к построению UI новые разработчики довольно быстро вливаются в процесс разработки. Есть удобные и простые в использовании инструменты, которые позволяют сократить время, обычно съедаемое рутинными процессами.
Более того, UI остаётся расширяемым и максимально гибким, что позволяет без труда реализовать интерфейс любой сложности, в соответствии со смелыми замыслами дизайнеров.
Теперь разработчики больше задумываются о самом приложении, а интерфейс легко дополняет бизнес-логику.
Еще не может не радовать сильно похудевшая кодовая база. Это мы осветили в занимательных цифрах. А ясное разделение на компоненты и их взаимное расположение не дают запутаться в коде даже самого сложного экрана.
В конце концов, все разработчики немного дети и стремятся получать удовольствие от разработки. И, кажется, нашей команде это удается! | https://habr.com/ru/post/538126/ | null | ru | null |
# Применение интегрирования Монте-Карло в рендеринге
Все мы изучали в курсе математики численные методы. Это такие методы, как интегрирование, интерполяция, ряды и так далее. Существует два вида числовых методов: детерминированные и рандомизированные.
Типичный детерминированный метод интегрирования функции  в интервале ![$[a, b]$](https://habrastorage.org/getpro/habr/formulas/58b/7f7/be8/58b7f7be8c846796f6af0f80072b3431.svg) выглядит так: мы берём  равномерно расположенных в интервале точек , вычисляем  в средней точке  каждого из интервалов, определяемых этими точками, суммируем результаты и умножаем на ширину каждого интервала . Для достаточно непрерывных функций  при увеличении  результат будет сходиться к верному значению.
Вероятностный метод, или метод *Монте-Карло* для вычисления, или, если точнее, *приблизительной оценки* интеграла  в интервале ![$[a, b]$](https://habrastorage.org/getpro/habr/formulas/58b/7f7/be8/58b7f7be8c846796f6af0f80072b3431.svg), выглядит так: пусть  — случайно выбранные точки в интервале ![$[a, b]$](https://habrastorage.org/getpro/habr/formulas/58b/7f7/be8/58b7f7be8c846796f6af0f80072b3431.svg). Тогда  — это случайное значение, среднее которого является интегралом ![$\int_{[a,b]}f$](https://habrastorage.org/getpro/habr/formulas/205/dab/c57/205dabc57a31af5d7fa9d131d1f87eed.svg). Для реализации метода мы используем генератор случайных чисел, генерирующий  точек в интервале ![$[a, b]$](https://habrastorage.org/getpro/habr/formulas/58b/7f7/be8/58b7f7be8c846796f6af0f80072b3431.svg), вычисляем в каждой , усредняем результаты и умножаем на . Это даёт нам приблизительное значение интеграла, как показано на рисунке ниже.  с 20 сэмплами аппроксимирует верный результат, равный .
Разумеется, каждый раз, когда мы будем вычислять такое приблизительное значение, то будем получать разный результат. Дисперсия этих значений зависит от формы функции . Если мы генерируем случайные точки  неравномерно, то нам необходимо слегка изменить формулу. Но благодаря использованию неравномерного распределения точек мы получаем огромное преимущество: заставив неравномерное распределение отдавать предпочтение точкам , где  велика, мы можем значительно снизить дисперсию приблизительных значений. Такое принцип неравномерной дискретизации называется *выборкой по значимости*.
Так как за последние десятилетия в методиках рендеринга произошёл масштабный переход от детерминированных к рандомизированным подходам, мы изучим рандомизируемые подходы, применяемые для решения уравнений рендеринга. Для этого мы используем случайные величины, математическое ожидание и дисперсию. Мы имеем дело с дискретными значениями, потому что компьютеры дискретны по своей сути. Непрерывные величины имеют дело с *функцией плотности вероятности*, но в статье мы не будем её рассматривать. Мы поговорим о *функции распределения масс* (probability mass function). PMF обладает двумя свойствами:
1. Для каждого  существует .
2. 
Первое свойство называется «неотрицательностью». Второе называется «нормальностью». Интуитивно понятно, что  представляет собой множество результатов некоторого эксперимента, а  — это результат вероятности , член . *Исход* — это подмножество пространства вероятностей. Вероятность исхода является суммой PMF элементов этого исхода, поскольку

*Случайная переменная* — это функция, обычно обозначаемая заглавной буквой, ставящая в соответствие пространству вероятностей вещественные числа:

Учтите, что функция  — это не переменная, а функция с вещественными значениями. Она также не является *случайной*,  — это отдельное вещественное число для любого результата .
Случайная переменная используется для определения исходов. Например, множество результата , для которого , то есть если ht и th — это множество строк, обозначающих «орлы» или «решки», то

и

это исход с вероятностью . Запишем это как . Мы используем предикат  как укороченную запись для исхода, определяемого предикатом.
Давайте взглянем на фрагмент кода, симулирующий эксперимент, описанный представленными выше формулами:
```
headcount = 0
if (randb()): // first coin flip
headcount++
if (randb()): // second coin flip
headcount++
return headcount
```
Здесь мы обозначаем как `ranb()` булеву функцию, которая возвращает true в половине случаев. Как она связана с нашей абстракцией? Представьте множество  *всех возможных выполнений* программы, объявив два выполнения одинаковыми значениями, возвращаемыми `ranb`, попарно идентичными. Это значит, что существует четыре возможных выполнений программы, в которых два вызова `ranb()` возвращают TT, TF, FT и FF. По своему опыту мы можем сказать, что эти четыре выполнения равновероятны, то есть каждое встречается примерно в четверти случаев.
Теперь аналогия становится понятнее. Множество возможных выполнений программы и связанные с ними вероятности — это пространство вероятностей. Переменные программы, зависящие от вызовов `ranb`, — это случайные переменные. Надеюсь, теперь вам всё понятно.
Давайте обсудим ожидаемое значение, также называемое средним. По сути это сумма произведения PMF и случайной переменной:
![$ E[X] = \sum_{s\in S} p(s)X(s) $](https://habrastorage.org/getpro/habr/formulas/030/3d1/cba/0303d1cba0a941277294c599c24ee4ed.svg)
Представьте, что h — это «орлы», а t — «решки». Мы уже рассмотрели ht и th. Также существуют hh и tt. Поэтому ожидаемое значение будет следующим:
![$ E[X] = p(hh)X(hh) + p(ht)X(ht) + p(th)X(th) + p(tt)X(tt) $](https://habrastorage.org/getpro/habr/formulas/1e3/b98/c94/1e3b98c94f575f829007671ab65130f0.svg)


Вы можете задаться вопросом, откуда взялся . Здесь я имел в виду, что мы должны назначать значение  самостоятельно. В данном случае мы присвоили h значение 1, а t значение 0.  равно 2, потому что в ней содержится 2 .
Давайте поговорим о распределении. Распределение вероятностей — это функция, дающая вероятности различных исходов события.
Когда мы говорим, что случайная переменная  имеет распределение , то должны обозначить .
*Рассеяние* значений, скопившихся вокруг , называется её *дисперсией* и определяется следующим образом:
![$ \boldsymbol{Var}[X] = E[(X - \bar{X})^2] $](https://habrastorage.org/getpro/habr/formulas/75e/e7c/d4e/75ee7cd4e0367584f39db70263232cbb.svg)
Где  — это среднее .
 называется *стандартным отклонением*. Случайные переменные  и  называются *независимыми*, если:

Важные свойства независимых случайных переменных:
1. ![$ E[XY] = E[X]E[Y] $](https://habrastorage.org/getpro/habr/formulas/064/932/6e4/0649326e42e183c8af346419b21e6225.svg)
2. ![$ \boldsymbol{Var}[X + Y] = \boldsymbol{Var}[X] + \boldsymbol{Var}[Y] $](https://habrastorage.org/getpro/habr/formulas/693/7ba/00b/6937ba00b0dc8e0d3902801d3bb8c971.svg)
Когда я начал с рассказа о вероятности, то сравнивал непрерывную и дискретную вероятности. Мы рассмотрели дискретную вероятность. Теперь поговорим о разнице между непрерывной и дискретной вероятностями:
1. Значения непрерывны. То есть числа бесконечны.
2. Некоторые аспекты анализа требуют таких математических тонкостей, как *измеряемость*.
3. Наше пространство вероятностей будет бесконечным. Вместо PMF мы должны использовать функцию *плотности* вероятностей (PDF).
Свойства PDF:
1. Для каждого  у нас есть 
2. 
*Но* если распределение  *равномерно*, то PDF определяется так:

При непрерывной вероятности ![$E[X]$](https://habrastorage.org/getpro/habr/formulas/21b/2bd/703/21b2bd703d762fc0d2466eee0869dd6b.svg) определяется следующим образом:
![$ E[X] := \int_{s\in S} p(s)X(s) $](https://habrastorage.org/getpro/habr/formulas/d94/59d/d4a/d9459dd4ac5f8556eba5fb267afba427.svg)
Теперь сравним определения PMF и PDF:


В случае непрерывной вероятности случайные величины лучше называть *случайными точками*. Потому что если  — пространство вероятностей, а  отображается в другое пространство, отличающееся от , тогда мы должны назвать  *случайной точкой*, а не случайной величиной. Понятие плотности вероятностей применимо здесь, потому что можно сказать, что для любого  мы имеем:

Теперь давайте применим то, что мы узнали, к сфере. Сфера имеет три координаты: широту, долготу и дополнение широты. Долготу и дополнение широты мы используем только в , двухмерные декартовы координаты, применённые к случайной величине , превращают её в . Получаем следующую детализацию:
![$ Y : [0, 1] \times [0, 1] \rightarrow S^2 : (u, v) \rightarrow (\cos(2\pi u)\sin(\pi v), \cos(\pi v) \sin( 2\pi u) sin(\pi v)) $](https://habrastorage.org/getpro/habr/formulas/186/0ad/ec1/1860adec1497af0c233fe810fe8120ae.svg)
Мы начинаем с равномерной плотности вероятностей  при ![$[0, 1] \times [0, 1]$](https://habrastorage.org/getpro/habr/formulas/3e8/8bc/62f/3e88bc62f3ada3352fbf9237a1d5985e.svg), или . Посмотрите выше формулу плотности равномерной вероятности. Для удобства мы запишем .
У нас есть интуитивное понимание, что если выбирать точки равномерно и случайно в единичном квадрате и использовать  для преобразования их в точки на единичной сфере, то они будут скапливаться рядом с полюсом. Это означает, что полученная плотность вероятностей в  не будет равномерной. Это показано на рисунке ниже.
Теперь мы обсудим способы приблизительного определения ожидаемого значения непрерывной случайной величины и его применения для определения интегралов. Это важно, потому что в рендеринге нам нужно определять значение *интеграла отражающей способности*:

для различных значений  и . Значение  — это направление падающего света. Код, генерирующий случайное число, равномерно распределённое в интервале ![$[0, 1]$](https://habrastorage.org/getpro/habr/formulas/a5d/538/f83/a5d538f83bd73f9d1c9e8338db9a398a.svg) и берущий квадратный корень, создаёт значение в интервале от 0 до 1. Если мы используем для него PDF, поскольку это равномерное значение, то ожидаемое значение будет равно . Также это значение является средним значением  в этом интервале. Что это означает?
Рассмотрим теорему 3.48 из книги «Computer Graphics: Principles and Practice». Она гласит, что если ![$f : [a, b] \rightarrow \mathbb{R}$](https://habrastorage.org/getpro/habr/formulas/940/105/624/9401056244e224bbcdb6d3928f64b582.svg) является функцией с вещественными значениями, а  является равномерной случайной величиной в интервале ![$[a, b]$](https://habrastorage.org/getpro/habr/formulas/58b/7f7/be8/58b7f7be8c846796f6af0f80072b3431.svg), то  — это случайная величина, ожидаемое значение которой имеет вид:
![$ E[(b-a)f(x)] = \int_a^b f(x)dx . $](https://habrastorage.org/getpro/habr/formulas/ebb/b5b/ffc/ebbb5bffc933069bc1afc07b76f55a87.svg)
Что это нам говорит? Это значит, что ***можно использовать рандомизированный алгоритм для вычисления значения интеграла, если мы достаточно много раз выполним код и усредним результаты***.
В общем случае мы получим некую величину , как в показанном выше интеграле, которую нужно определить, и некий рандомизированный алгоритм, возвращающий приблизительное значение . Такая случайная переменная для величины называется *эстиматором*. Считается, что эстиматор *без искажений*, если его ожидаемое значение равно . В общем случае эстиматоры без искажений предпочтительнее, чем с искажениями.
Мы уже обсудили дискретные и непрерывные вероятности. Но существует и третий тип, который называется *смешанными вероятностями* и используется в рендеринге. Такие вероятности возникают вследствие импульсов в функциях распределения двунаправленного рассеяния, или импульсов, вызванных точечными источниками освещения. Такие вероятности определены в непрерывном множестве, например, в интервале ![$[0, 1]$](https://habrastorage.org/getpro/habr/formulas/a5d/538/f83/a5d538f83bd73f9d1c9e8338db9a398a.svg), но не определены строго функцией PDF. Рассмотрим такую программу:
```
if uniform(0, 1) > 0.6 :
return 0.3
else :
return uniform(0, 1)
```
В шестидесяти процентах случаев программа будет возвращать 0.3, а в оставшихся 40% она будет возвращать значение, равномерно распределённое в ![$[0, 1]$](https://habrastorage.org/getpro/habr/formulas/a5d/538/f83/a5d538f83bd73f9d1c9e8338db9a398a.svg). Возвращаемое значение — это случайная переменная, имеющая при 0.3 массу вероятности 0.6, а его PDF во всех других точках задаётся как . Мы должны определить PDF как:

В целом, *случайная переменная со смешанной вероятностью* — это такая переменная, для которой существует конечное множество точек в области определения PDF, и наоборот, равномерно распределённые точки, где PMF не определена. | https://habr.com/ru/post/461805/ | null | ru | null |
# Python (+numba) быстрее Си — серьёзно?! Часть 1. Теория
Давно собирался написать статью о numba и о сравнении её быстродействия с си. Статья про хаскелл «[Быстрее, чем C++; медленнее, чем PHP](https://habr.com/ru/post/483864/)» подтолкнула к действию. В комментариях к этой статье упомянули о библиотеке numba и о том, что она магическим образом может приблизить скорость выполнения кода на питоне к скорости на си. В данной статье после небольшого обзора по numba (часть 1) чуть более подробный разбор этой ситуации ([часть 2](https://habr.com/ru/post/484142/)).
Главным недостатком питона принято считать его скорость. Разгонять python с переменным успехом стали чуть ли не с первых дней его существования: [shedskin](https://ru.wikipedia.org/wiki/Shedskin), [psyco](https://en.wikipedia.org/wiki/Psyco), [unladen shallow](https://ru.wikipedia.org/wiki/Unladen_Swallow), [parakeet](https://github.com/iskandr/parakeet), [theano](https://ru.wikipedia.org/wiki/Theano), [nuitka](https://ru.wikipedia.org/wiki/Nuitka), [pythran](https://pythran.readthedocs.io/en/latest/), [cython](https://ru.wikipedia.org/wiki/Cython), [pypy](https://ru.wikipedia.org/wiki/PyPy), [numba](https://en.wikipedia.org/wiki/Numba).

На сегодняшний день наиболее востребованными являются последние три. `Cython` (не путать с cpython) — довольно сильно отличается семантически от обычного питона. Фактически это отдельный язык — некий гибрид си и python. Что касается `pypy` (альтернативная реализация транслятора python с использованием jit-компиляции) и `numba` (библиотека для транскомпиляции кода в llvm) – они пошли разными путями. В `pypy` изначально была заявлена поддержка всех конструкций python. В numba же исходили из того, что чаще всего требует ускорения (cpu bound) — математические вычисления, соответственно, они выделили часть языка, связанную с вычислениями и начали разгонять её, постепенно увеличивая «охват» (например, до недавнего времени не было поддержки строк, сейчас она появилась). Соответственно, в `numba` разгоняется не вся программа, а *отдельные функции*, это позволяет совместить высокую скорость и обратную совместимость с библиотеками, которые `numba` (пока) не поддерживает. Numpy поддерживается (с незначительными ограничениями) и в `pypy`, и в `numba`.
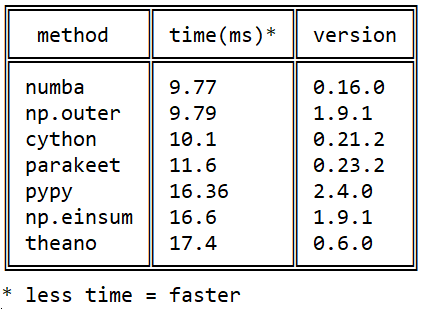 Моё знакомство с Numba началось в 2015 году вот с этого вопроса на stackoverflow про скорость умножения матриц на питоне: [Efficient outer product in python](https://stackoverflow.com/questions/27809511/efficient-outer-product-in-python)
С тех пор произошло много событий в каждой из библиотек, но качественно картина в отношении `numba`/`cython`/`pypy` не изменилась: `numba` обгоняет `cython` за счёт использования нативных процессорных инструкций (`cython` не умеет jit), а `pypy` – за счёт более эффективного выполнения байткода llvm.
Мне numba пригождается по работе (обработка гиперспектральных изображений) и в преподавании (численное интегрирование, решение дифф.уравнений).
#### как установить
Еще пару лет назад были проблемы с установкой, сейчас всё разрешилось: одинаково хорошо устанавливается и через `pip install numba`, и через `conda install numba`. llvm подтягивается и устанавливается при этом автоматически.
#### как ускорять
Чтобы ускорить функцию, надо перед её определением вписать декоратор njit:
```
from numba import njit
@njit
def f(n):
s = 0.
for i in range(n):
s += sqrt(i)
return s
```
Ускорение в **40** раз.
Корень нужен, потому что иначе numba распознает сумму арифметической прогрессии(!) и вычислит её за константное время.
#### jit vs njit
Раньше был актуален режим просто `@jit` (а не `@njit`). Смысл в том, что в этом режиме можно использовать неподдерживаемые нумбой операции: нумба на большой скорости доходит до первой такой операции, затем замедляется, и до конца функции исполнение продолжается с обычной питоновской скоростью, даже если больше в функции ничего «запретного» не встречается (т.н. object mode), что, очевидно, нерационально. Сейчас от `@jit` постепенно отказываются, рекомендуется всегда пользоватся @njit (или в полной форме `@jit(nopython=True)`): в этом режиме нумба ругается исключениями на такие места – всё равно лучше их переписать, чтобы не потерять в скорости.
#### что умеет разгонять
В разогнанных функциях можно использовать только часть функционала питона и нумбы. Все операторы, функции и классы делятся в отношении нумбы на две части: те, которые нумба «понимает» и те, которые она «не понимает».
В документации по numba есть два таких списка (с примерами):
* подмножество функционала [питона](https://numba.pydata.org/numba-doc/dev/reference/pysupported.html), знакомое нумбе и
* подмножество функционала [numpy](https://numba.pydata.org/numba-doc/dev/reference/numpysupported.html), знакомое нумбе.
Из примечательного в этих списках:
* нумба «понимает» питоновские списки с быстрым (амортизированное O(1)) добавлением в конец, которые «не понимает» numpy (правда, только однородные – из элементов одного типа),
* numpy'евские массивы, которые отсутствуют в базовом питоне. Понимает также
* кортежи (tuples): они могут, как и в обычном питоне, содержать элементы разных типов.
* словари (dict): в numba своя реализация типизированного словаря. Все ключи должны быть одного типа, ровно как и значения. Питоновский dict нельзя передать в numba, зато нумбовский `numba.typed.Dict` можно создавать в питоне и передавать в/из нумбы (при этом в питоне он работает чуть медленнее питоновского).
* с недавних пор str и bytes, правда, только в качестве входных параметров, создавать их (пока?) нельзя.
Никакие другие библиотеки (в частности, scipy и pandas) она не понимает совсем.
Но даже того подмножества языка, которое она понимает, достаточно, чтобы разогнать большую часть кода для научных приложений, на которые numba в первую очередь и ориентирована.
#### важно!
Из разогнанных функций можно вызывать только разогнанные, не разогнанные нельзя.
(хотя разогнанные функции можно вызывать и из разогнанных и из не разогнанных).
#### globals
В разогнанных функциях глобальные переменные становятся константами: их значение фиксируется на момент компиляции функции ([пример](https://python-nsu.bitbucket.io/numba/globals.html)). => Не используйте глобальные переменные в разогнанных функциях (кроме констант).
#### сигнатуры
В нумбе каждой функции сопоставляется один или несколько типов входных и выходных аргументов, т.н. сигнатуры. При первом вызове функции сигнатура формируется и автоматически компилируется соответствующий бинарный код функции. При запуске с другими типами аргументов будут создаваться новые сигнатуры и новые бинарники (старые при этом сохраняются). Таким образом, «выход на режим» по скорости исполнения для каждой сигнатуры наступает, начиная со второго запуска с этими типами аргументов. Так что надо либо
* «прогревать кэш», запуская с небольшими размерами входных массивов, либо
* указывать аргумент `@jit(cache=True)` для сохранения скомпилированного кода на диск с автоматической его загрузкой при последующих запусках программы (правда на практике на сегодняшний день этот первый запуск всё равно немного медленнее, чем последующие, но быстрее, чем без `cache=True`).
Есть ещё третий способ. Сигнатуры можно задавать вручную:
```
from numba import int16, int32
@njit(int32(int16, int16))
def f(x, y):
return x + y
>>> f.signatures
[(int16, int16)]
```
При запуске функции с сигнатурой, указанной в декораторе, уже первый запуск будет быстрым: компиляция произойдёт в тот момент, когда питон увидит определение функции, а не при первом запуске. Сигнатур может быть несколько, порядок их следования имеет значение.
Предупреждение: этот последний способ не future-safe. Авторы numba предупреждают о том, что синтаксис указания типов может измениться в будущем, `@jit`/`@njit` без сигнатур – более безопасный в этом плане вариант.
`f.signatures` начинают показывать сигнатуры только тогда, когда питон о них узнает, то есть после первого вызова функции, либо если они заданы вручную.
Кроме `f.signatures` сигнатуры можно посмотреть через `f.inspect_types()` – кроме типов входных параметров эта функция покажет типы выходных параметров, а также типы всех локальных переменных.
Кроме типов входных и выходных параметров, есть возможность вручную указать типы локальных переменных:
```
from numba import int16, int32
@njit(int32(int16, int16), locals={'z': int32})
def f(x, y):
z = y + 10
return x + z
```
#### int
В нумбе у целых чисел нет длинной арифметики как в «просто» питоне, но есть стандартные типы различной ширины от `int8` до `int64` ([таблица типов](https://numba.pydata.org/numba-doc/0.12.2/tutorial_types.html#supported-types-in-numba) в документации). Есть ещё типы `int_` (а также `float_`), используя которые вы предоставляете нумбе возможность выбрать оптимальную (с её точки зрения) ширину поля.
#### классы
Поддержка классов (@jitclass) вообще есть, но пока она экспериментальная, так что лучше пока избегать их использования (на текущий момент, по моему опыту, с ними сильно медленнее, чем без них).
#### custom dtypes
В numba поддерживается некая альтернатива классам из numpy – структурные массивы (structured array), или, иначе говоря, пользовательские dtype'ы. Они работают с той же скоростью, что и обычные массивы numpy, их чуть удобнее индексировать (например, `a['y2']` более читаемо, чем `a[3]`). Интересно, что в numba, в отличие от numpy, наряду с обычным синтаксисом `a['y2']` допускается более лаконичный `a.y2`. Но в целом их поддержка в numba оставляет желать лучшего, и некоторые очевидные даже в numpy операции с ними в нумбе записываются достаточно нетривиально.
#### GPU
Умеет выполнять разогнанный код на GPU, причём в отличие от того же, например, pycuda или pytorch, не только на nvidia, но и на amd'шных карточках. С этим пока разбирался мало. Вот статья на хабре 2016 года [Сравнение производительности GPU-расчетов на Python и C](https://habr.com/ru/post/317328/). Там получилась сопоставимая с С скорость.
#### ahead-of-time компиляция
В нумбе есть режим обычной (то есть не jit) компиляции ([документация](https://numba.pydata.org/numba-doc/dev/user/pycc.html)), но этот режим является не основным, я с ним не разбирался.
#### автоматическое распараллеливание
Некоторые задачи (например, умножение матрицы на число) распараллеливаются естественным образом. Но есть такие задачи, выполнение которых распараллелить не получается. С декоратором `@njit(parallel=True)` нумба анализирует код разгоняемой функции, находит такие участки, каждый из которых самого по себе распараллелить невозможно, и выполняет их одновременно на разных ядрах CPU ([документация](https://numba.pydata.org/numba-doc/dev/user/parallel.html)). Раньше распараллеливать функции можно было только вручную при помощи `@vectorize` ([документация](https://numba.pydata.org/numba-doc/dev/reference/jit-compilation.html#numba.vectorize)), что требовало изменения кода.
На практике это выглядит так: добавляем `parallel=True`, замеряем скорость, если повезло и получилось быстрее – оставляем, медленнее – убираем. (\*\*Update Как отметили в [комментарии](https://habr.com/ru/post/484142/#comment_21141366) ко второй части статьи, по этому флагу много открытых багов)
#### освобождение GIL
Функции, декорированные `@jit(nogil=True)` и запущенные в разных потоках, могут исполняться параллельно. Для избежания race conditions необходимо использовать синхронизацию потоков.
#### документация
Нумбе до сих пор не хватает толковой документации. Она есть, но в ней есть не всё.
#### оптимизация
Есть некоторая непредсказуемость при оптимизации кода вручную: unpythonic код зачастую работает быстрее, чем pythonic.
Заинтересовавшимся темой могу порекомендовать [видео](https://www.youtube.com/watch?v=1AwG0T4gaO0) мастер-класса по numba с конференции scipy 2017 (есть [исходники](https://github.com/gforsyth/numba_tutorial_scipy2017) на гитхабе). Оно правда длинновато и частично устарело (например, строки уже поддерживаются), но общее представление получить помогает: там есть, в частности, про pythonic/unpythonic, [jit](https://habr.com/ru/users/jit/)(parallel=True) и пр.
Во [второй](https://habr.com/ru/post/484142/) части рассмотрим применение numba на примере кода из упомянутой в начале статьи. | https://habr.com/ru/post/484136/ | null | ru | null |
# Эластичное избыточное S3-совместимое хранилище за 15 минут
S3 сегодня не удивишь наверное никого. Его используют и как бэкенд хранилище под веб сервисы, и как хранилище файлов в медиа индустрии, так и как архив для бэкапов.

Рассмотрим небольшой пример развертывания S3-совместимого хранилища на основе объектного хранилища Ceph
##### Краткая справка
[Ceph](http://ceph.com/) — это open source разработка эластичного легко масштабируемого петабайтного хранилища. В основе лежит объединение дисковых пространств нескольких десятков серверов в объектное хранилище, что позволяет реализовать гибкую многократную псевдослучайную избыточность данных. Разработчики Ceph дополняют такое объектное хранилище еще тремя проектами:
* RADOS Gateway — S3- и Swift-совместимый RESTful интерфейс
* RBD — блочное устройство с поддержкой тонкого роста и снапшотами
* Ceph FS — распределенная POSIX-совместимая файловая система
##### Описание примера
В моем примере я [продолжаю](http://habrahabr.ru/post/179823/) использовать 3 сервера по 3 SATA диска в каждом: `/dev/sda` как системный и `/dev/sdb` и `/dev/sdc` под данные объектного хранилища. В качестве клиента могут выступать различные программы, модули, фреймворки для работы с S3 совместимым хранилищем. Я успешно протестировал [DragonDisk](http://www.dragondisk.com), [CrossFTP](http://www.crossftp.com) и [S3Browser](http://s3browser.com/).
Также в этом примере я использую всего один RADOS Gateway на ноде node01. S3 интерфейс будет доступен по адресу `s3.ceph.labspace.studiogrizzly.com`.
Стоит отметить что на данный момент Ceph поддерживает такие S3 операции <http://ceph.com/docs/master/radosgw/s3/>.
#### Приступим
##### Шаг 0. Подготовка Ceph
Так как я продолжаю использовать уже [развернутый кластер Ceph](http://habrahabr.ru/post/179823/), мне необходимо только немного поправить конфигурацию `/etc/ceph/ceph.conf` — дописать определение для RADOS Gateway
```
[client.radosgw.gateway]
host = node01
keyring = /etc/ceph/keyring.radosgw.gateway
rgw socket path = /tmp/radosgw.sock
log file = /var/log/ceph/radosgw.log
rgw dns name = s3.ceph.labspace.studiogrizzly.com
rgw print continue = false
```
и обновить ее на других нодах
```
scp /etc/ceph/ceph.conf node02:/etc/ceph/ceph.conf
scp /etc/ceph/ceph.conf node03:/etc/ceph/ceph.conf
```
##### Шаг 1. Инсталлируем Apache2, FastCGI и RADOS Gateway
```
aptitude install apache2 libapache2-mod-fastcgi radosgw
```
##### Шаг 2. Конфигурация Apache
Включаем необходимы модули
```
a2enmod rewrite
a2enmod fastcgi
```
Создаем VirtualHost для RADOS Gateway `/etc/apache2/sites-available/rgw.conf`
```
FastCgiExternalServer /var/www/s3gw.fcgi -socket /tmp/radosgw.sock
ServerName s3.ceph.labspace.studiogrizzly.com
ServerAdmin [email protected]
DocumentRoot /var/www
RewriteEngine On
RewriteRule ^/([a-zA-Z0-9-\_.]\*)([/]?.\*) /s3gw.fcgi?page=$1¶ms=$2&%{QUERY\_STRING} [E=HTTP\_AUTHORIZATION:%{HTTP:Authorization},L]
Options +ExecCGI
AllowOverride All
SetHandler fastcgi-script
Order allow,deny
Allow from all
AuthBasicAuthoritative Off
AllowEncodedSlashes On
ErrorLog /var/log/apache2/error.log
CustomLog /var/log/apache2/access.log combined
ServerSignature Off
```
Включаем созданный VirtualHost и выключаем дефолтный
```
a2ensite rgw.conf
a2dissite default
```
Создаем FastCGI скрипт `/var/www/s3gw.fcgi`:
```
#!/bin/sh
exec /usr/bin/radosgw -c /etc/ceph/ceph.conf -n client.radosgw.gateway
```
и делаем его исполняемым
```
chmod +x /var/www/s3gw.fcgi
```
##### Шаг 3. Подготавливаем RADOS Gateway
Создаем необходимую директорию
```
mkdir -p /var/lib/ceph/radosgw/ceph-radosgw.gateway
```
Генерируем ключ для нового сервиса RADOS Gateway
```
ceph-authtool --create-keyring /etc/ceph/keyring.radosgw.gateway
chmod +r /etc/ceph/keyring.radosgw.gateway
ceph-authtool /etc/ceph/keyring.radosgw.gateway -n client.radosgw.gateway --gen-key
ceph-authtool -n client.radosgw.gateway --cap osd 'allow rwx' --cap mon 'allow r' /etc/ceph/keyring.radosgw.gateway
```
и добавляем его в кластер
```
ceph -k /etc/ceph/ceph.keyring auth add client.radosgw.gateway -i /etc/ceph/keyring.radosgw.gateway
```
##### Шаг 4. Запуск
Рестартуем Apache2 и RADOS Gateway
```
service apache2 restart
/etc/init.d/radosgw restart
```
##### Шаг 5. Создаем первого пользователя
Что бы использовать S3 клиент нам необходимо получить ключи `access_key` и `secret_key` для нового пользователя
```
radosgw-admin user create --uid=i --display-name="Igor" [email protected]
```
смотрите вывод команды и скопируйте ключи в ваш клиент
##### Шаг 6. DNS
Для того что бы заработали buckets нам необходимо что бы DNS сервер при запросе любого субдомена для `s3.ceph.labspace.studiogrizzly.com` указывал на IP адрес хоста где запущен RADOS Gateway.
Например, при создании bucket с названием `mybackups` — домен `mybackups.s3.ceph.labspace.studiogrizzly.com.` должен указывать на IP адрес node01, что есть — 192.168.2.31.
В моем случае я просто добавлю CNAME запись
```
* IN CNAME node01.ceph.labspace.studiogrizzly.com.
```
##### Послесловие
За 15 минут мы успели развернуть S3-совместимое хранилище. Теперь попробуйте подключить ваш любимый S3 клиент.
---
#### Бонусная часть
Я попросил [sn00p](https://habrahabr.ru/users/sn00p/) рассказать о его опыте использовании RADOS Gateway в продакшн в компании [2GIS](http://habrahabr.ru/company/2gis/). Ниже его отзыв:
##### Общее описание
У нас стоит варниш, варнишу бекендами подцеплены 4 апача радосгейтвеев. Приложение сначала лезет в варниш, если там облом, то раундробином ломится напрямую в апачи. Эта штука жмет 20000 рпс без проблем по синтетическим тестам jmeter c access логом за месяц. Внутри полмиллиона фоточек, рабочая нагрузка на фронтенд около 300 рпс.

Ceph пока что на 5 машинах, там отдельный диск под osd и для журнала отдельный ssd. Репликация дефолтная, ^2. Система без проблем переживает падение двух нод одновременно и там дальше с вариациями. За полгода ни одной ошибки еще клиенту не показали.
Нет проблем с гибкостью — размер хранилища, иноды, раскладка по каталогам — это все в прошлом осталось.
##### Особенности решения
* Пять серверов HP Proliant Gen8 DL360e. Под задачи Ceph на каждом сервере выделены по одному 300 Гб SAS 15krpm. Для существенного повышения производительности журналы демонов osd вынесены на ssd диски Hitachi Ultrastar 400M.
* Две виртуальные машины kvm с apache2 и radosgw внутри. Как nginx работает с FastCGI мне лично не понравилось. Nginx при аплоаде использует буферизацию перед тем, как отдать контент бэкенду. Теоретически, могут возникнуть проблемы при больших файлах или потоках. Но, дело вкуса и ситуации, nginx тоже работает.
* Apache2 используем модифицированный, который позволяет обрабатывать `100-continue HTTP response`. Готовые пакеты можно взять [здесь](http://ceph.com/docs/master/radosgw/manual-install/#continue-support).
* Приложение с varnish смотрит на обе ноды с radosgw. Здесь может быть любой кэш или балансер. Если он падает, приложение умеет опрашивать radosgw напрямую:
**раскрыть**
```
backend radosgw1 {
.host = "radosgw1";
.port = "8080";
.probe = {
.url = "/";
.interval = 2s;
.timeout = 1s;
.window = 5;
.threshold = 3;
}
}
backend radosgw2 {
.host = "radosgw2";
.port = "8080";
.probe = {
.url = "/";
.interval = 2s;
.timeout = 1s;
.window = 5;
.threshold = 3;
}
}
director cephgw round-robin {
{
.backend = radosgw1;
}
{
.backend = radosgw2;
}
}
```
* Каждому приложению выделен свой bucket. Поддерживаются различные acl, можно гибко регулировать права доступа для bucket и для каждого объекта в нем.
* Для работы со всей кухней мы используем `python-boto`. Вот пример скрипта на python (осторожно, отступы), который умеет с файловой системы залить все в bucket. Данный способ удобен для пакетной обработки кучи файлов в автоматическом режиме. Если не нравится python — не проблема, можно использовать другие популярные языки.
**раскрыть**
```
#!/usr/bin/env python
import fnmatch
import os, sys
import boto
import boto.s3.connection
access_key = 'insert_access_key'
secret_key = 'insert_secret_key'
pidfile = "/tmp/copytoceph.pid"
def check_pid(pid):
try:
os.kill(pid, 0)
except OSError:
return False
else:
return True
if os.path.isfile(pidfile):
pid = long(open(pidfile, 'r').read())
if check_pid(pid):
print "%s already exists, doing natting" % pidfile
sys.exit()
pid = str(os.getpid())
file(pidfile, 'w').write(pid)
conn = boto.connect_s3(
aws_access_key_id = access_key,
aws_secret_access_key = secret_key,
host = 'cephgw1',
port = 8080,
is_secure=False,
calling_format = boto.s3.connection.OrdinaryCallingFormat(),
)
mybucket = conn.get_bucket('test')
mylist = mybucket.list()
i = 0
for root, dirnames, filenames in os.walk('/var/storage/photoes', followlinks=True):
for filename in fnmatch.filter(filenames, '*'):
myfile = os.path.join(root,filename)
key = mybucket.get_key(filename)
i += 1
if not key:
key = mybucket.new_key(filename)
key.set_contents_from_filename(myfile)
key.set_canned_acl('public-read')
print key
print i
os.unlink(pidfile)
```
* Из коробки radosgw сильно разговорчивый и при нормальной нагрузке генерит большие файлы с логами. При наших нагрузках обязательно снизили уровень логирования:
**раскрыть**[client.radosgw.gateway]
…
debug rgw = 2
rgw enable ops log = false
log to stderr = false
rgw enable usage log = false
...
* Для мониторинга используем шаблон для Zabbix, исходники можно забрать [тут](https://github.com/thelan/ceph-zabbix).
Все это работает у нас уже полгода и вообще не требует вмешательства администратора ))
##### Планы на будущее
Сейчас я пробую использовать Ceph для хранения и отдачи уже 15 миллионов файлов по ~4-200кб. С S3 это весьма не удобно — там нет операций bulk-copy, нельзя удалить bucket с данными, чтобы первоначально хранилище наполнить — это медленно ппц. Исследуем как это подкрутить.
Но главная задача — геокластер, мы сами в Сибири и хотим отдавать данные из географически близкой точки клиенту. До Москвы у нас контент летит с задержкой уже — до 100мс плюсом, это не годится. Ну у разработчиков Ceph вроде все в [планах такое](http://wiki.ceph.com/01Planning/02Blueprints/Dumpling/RGW_Geo-Replication_and_Disaster_Recovery). | https://habr.com/ru/post/180415/ | null | ru | null |
# классический TCP сервер
мой первый TCP Сервер был создан пару лет назад. Основой создания послужила книга Р.Стивенсона «Unix — Профессиональное программирование.» Есть несколько подходов к созданию TCP-серверов. В данном посте хочется рассказать про классический TCP сервер.
При построение классического TCP Сервера можно выделить три составные части:
* демонизация процесса
* работа с сокетами
* создание дочернего процесса и обработка его завершения
При работе с сокетами необходимо:
* создать дескриптор сокетов
* назначить сокету адрес
* принять запрос на установку соединения
* установить соединение
* принять / отправить данные
рассмотрим код, смотрим комментарии:
`1 struct sockaddr_in addr;
2 struct sockaddr_un local;
3
4 int err,len;
5
6 // создаем дескриптор сокета
7 if( -1 == ( ls = socket( AF_INET, SOCK_STREAM, IPPROTO_TCP ) )) {
8 perror( "Socket can not created!\n");
9 return ;
10 }
11
12 // задаем сокету опцию SO_REUSEADDR
13 // повторное использование локальных адресов для функц. bind()
14 setsockopt( ls, SOL_SOCKET, SO_REUSEADDR, &rc, sizeof(rc) );
15 memset( &addr , 0, sizeof(addr) );
16
17 // задаем адрес прослушивания и порт
18 addr.sin_family = AF_INET;
19 addr.sin_port = htons (port);
20 addr.sin_addr.s_addr = INADDR_ANY ;
21
22 // связываем адрес с дескриптором слушающего сокета
23 if ( err = bind( ls, (struct sockaddr*) &addr, sizeof(addr) ) < 0 ) {
24 close(ls);
25 perror( "bind error!\n%s ", gai_strerror(err) );
26 return ;
27 }
28
29
30 // начинаем слушать сокет
31 if ( listen( ls, 25) < 0) { ;
32 close(ls);
33 perror( "listen error!\n");
34 return ;
35 }
36
37 // демонизируем процесс
38 pid_t pid = Demonize();
39
40 if ( pid==-1 ) {
41 close(ls);
42 perror( "demonize error!\n");
43 return;
44 }
45
46 // бесконечный цикл на прием соединения
47 while (true) {
48 // прием соединения, создание дескриптора
49 rc = accept( ls, NULL, NULL );
50 // пораждаем дочерний процесс
51 pid = fork();
52
53 if ( pid < 0) syslog( LOG_ERR, " fork abort" );
54 if (pid == 0 ) { // дочерний процесс
55 close( ls ); // закрываем дескриптор сдушающего сокетов
56
57 process(rc); // пользовательская функция,
58 // параметром передается дескриптор открытого соединения
59 close(rc);
60 return;
61 } else {
62 // Родительский процесс
63 close( rc ); // закрываем дескриптор соединения
64 }
65
66 } // end while`
А теперь немного пояснений:
Создаем дескриптор слушающего сокета Строки 7-10:
#include
int socket(int domain, int type, int protocol);
константа domain:
AF\_INET — IP сокет
AF\_UNIX — UNIX сокет
константа type:
SOCK\_STREAM — сокет постоянного соединения
SOCK\_DGRAM — сокет датаграм
константа int protocol:
IPPROTO\_TCP — тип протокола
Функция socket возвращает номер дескриптора прослушающего сокета. Если результат меньше 0, то ошибка системы.
Строки 12-28 Назначаем сокету адрес.
#include
int setsockopt(int socket, int level, int option\_name, const void \*option\_value, socklen\_t option\_len);
задает сокету опциии:
SO\_REUSEADDR повторное использование локальных адресов для функции bind()
Если результат выполнение операции меньше 0, то ошибка системы.
Строки 18-20 задаем адрес прослушивания и порт в структуре sockaddr\_in
addr.sin\_family = AF\_INET; // тип домена INET
addr.sin\_port = htons (port); // назначаем порт
addr.sin\_addr.s\_addr = INADDR\_ANY; // любой входящий адрес
Функция bind ассоциирует адрес с безымяннымсокетом:
#include
int bind(int socket, const struct sockaddr \*address, socklen\_t address\_len);
int socket — дескриптор сокета
address — адресс структуры sockaddr с
address\_len — размер структуры sockaddr
Если результат выполнение операции меньше 0, то ошибка системы.
Начинаем прослушивать сокет Строки 31-35. С помощью функции listen сервер заявляет свое желание принимать запросы на установку соединения:
#include
int listen(int socket, int backlog);
int socket — дескриптор сокета
int backlog — максимальная длинна очереди ожидающих запросов на соединение
Если результат выполнение операции меньше 0, то ошибка системы.
Строка 38-44, Демонизируем процесс. Более подробно в сл. статье о процессах-демонах.
Строки 47-66, обработка соединения
Строка 49, Функция accept прием запроса и преобразование его в соединение.
#include
int accept(int socket, struct sockaddr \*restrict address, socklen\_t \*restrict address\_len);
int socket — дескриптор слушающего сокета, он не связан для соединения и остается для прослушивания последующих соединений,
address — указатель на структуру адреса сокета, в которой по окончании будет хранится адрес клиента
address\_len — размер буфера, для размещения структуры адреса, если address и address\_len передать NULL — то нас не интересует адрес клиента.
Функция accept возвращает дескриптор сокета, связанного с соединением или -1 в случае неудачи.
Мы можем обработать соединение и принять следующее, но как правило, соединения обрабатываются какое-то длительное время а сервер ждать не может, по этому, после установки соединения порождается дочерний процесс строка 51, командой fork. Далее, в родительском процессе закрываем дескриптор соединения, а в дочернем процессе закрываем дескриптор слушающего сокета и вызываем пользовательскую функцию, которая обработает наше соединение.
Обработка соединения осуществляется командами read/write:
запись в сокет: write (rc, buff, len )
чтение из сокета: read (rc, buff, len )
rc — дескриптор соединения
buff — буфер чтения/записи
len длинна буфера.
По окончанию обработки соединения, дескриптор сокета rc необходимо закрыть: close(rc).
Что не вошло и будет отдельно изложено другими статьями: описание команды fork, обработка сигналов, демонизация процесса. | https://habr.com/ru/post/70796/ | null | ru | null |
# Унифицированная обработка ошибок (C++ вариант для микроконтроллеров)
При разработке ПО для микроконтроллеров на С++ очень часто можно столкнуться с тем, что использование стандартной библиотеки может привести к нежелательным дополнительным расходам ресурсов, как ОЗУ, так и ПЗУ. Поэтому зачастую классы и методы из библиотеки `std` не совсем подходят для реализации в микроконтроллере. Существуют также некоторые ограничения в использовании динамически выделяемой памяти, RTTI, исключений и так далее. В общем случае, чтобы писать компактный и быстрый код нельзя просто так взять библиотеку `std` и начать пользоваться, скажем операторами типа `typeid`, потому что необходима поддержка RTTI, а это уже накладные расходы, хоть и не очень большие.
Поэтому иногда приходится изобретать велосипеды, чтобы выполнить все эти условия. Таких задач немного, но они есть. В данном посте, хотелось бы рассказать про вроде бы как простую задачку — расширить коды возврата существующих подсистем в ПО для микроконтроллера.
Задача
------
Допустим у вас есть подсистема диагностики CPU и у неё есть перечисляемые коды возврата, скажем такие:
```
enum class Cpu_Error
{
Ok,
Alu,
Rom,
Ram
} ;
```
В случае, если подсистема диагностики CPU обнаружит отказ одного из модуля CPU, (например, ALU или RAM) она должна будет возвратить соответствующий код.
Тоже самое для другой подсистемы, пусть это будет диагностика измерений, проверяющей что измеренное значение находится в диапазоне и оно вообще валидно (не равное NAN или Infinity):
```
enum class Measure_Error
{
OutOfLimits,
Ok,
BadCode
} ;
```
Для каждой подсистемы пусть будет метод `GetLastError()` возвращающий перечисляемый тип ошибки данной подсистемы. Для `CpuDiagnostic` будет возвращен код типа `Cpu_Error`, для `MeasureDiagnostic` код типа `Measure_Error`.
И есть некий журнал, который при возникновении ошибки должен логировать код ошибки.
Для понимания я напишу это в очень упрощенном виде:
```
void Logger::Update()
{
Log(static_cast(cpuDiagnostic.GetLastError()) ;
Log(static\_cast(measureDiagnostic.GetLastError()) ;
}
```
Ясно, что при преобразовании перечисляемых типов в целое, мы можем получить одно и то же значение для разных типов. Как же различить что код первой ошибки это код ошибки подсистемы диагностики Cpu, а второй подсистемы измерения?
### Поиск решений
Логично было бы чтобы метод `GetLastError()` возвращал различный код для различных подсистем. Одним из самых прямых решений в лоб, было бы использование различных диапазонов кодов для каждого перечисляемого типа. Что-то типа такого
```
constexpr tU32 CPU_ERROR_ALU = 0x10000001 ;
constexpr tU32 CPU_ERROR_ROM = 0x10000002 ;
...
constexpr tU32 MEAS_ERROR_OUTOF = 0x01000001 ;
constexpr tU32 MEAS_ERROR_BAD = 0x01000002 ;
...
enum class Cpu_Error
{
Ok,
Alu = CPU_ERROR_ALU,
Rom = CPU_ERROR_ROM,
Ram = CPU_ERROR_RAM
} ;
...
```
Думаю, очевидны недостатки такого подхода. Во-первых, много ручной работы, нужно вручную определять диапазоны и коды возврата, что непременно приведет к человеческой ошибке. Во-вторых, подсистем может быть много, и дописывать для каждой подсистемы перечисления вообще не вариант.
Собственно, было бы замечательно, если бы можно было вообще не трогать перечисления, расширить их коды немного другим способом, например, чтобы имелась возможность сделать так:
```
ResultCode result = Cpu_Error::Ok ;
//GetLastError() возвращает перечисление Cpu_Error
result = cpuDiagnostic.GetLastError() ;
if(result) //проверяем были ли ошибки
{
//логируем сразу и код и категорию кода
Logger::Log(result) ;
}
//GetLastError() возвращает перечисление Measure_Error
result = measureDiagnostic.GetLastError() ;
if(result) //проверяем были ли ошибки
{
//логируем сразу и код и категорию кода
Logger::Log(result) ;
}
```
Или так:
```
ReturnCode result ;
for(auto it: diagnostics)
{
//GetLastError() возвращает перечисление подсистемы диагностики
result = it.GetLastError() ;
if (result) //проверяем были ли ошибки
{
Logger::Log(result) ; //логируем и код и категорию кода
}
}
```
Или так:
```
void CpuDiagnostic::SomeFunction(ReturnCode errocode)
{
Cpu_Error status = errorcode ;
switch (status)
{
case CpuError::Alu:
// do something ;
break;
....
}
}
```
Как видно из кода, здесь используется некий класс `ReturnCode`, который должен содержать и код ошибки и его категорию. В стандартной библиотеке есть такой класс `std::error_code`, который собственно практически все это делает. Очень хорошо его назначение описано здесь:
[Ваши собственные std::code\_error](http://habr.com/ru/post/340604/)
[Поддержка системных ошибок в C++](http://habr.com/ru/post/336012/)
[Детерминированные исключения и обработка ошибок в «C++ будущего»](https://habr.com/ru/post/430690/)
Основная претензия заключается в том, что для использования этого класса, нам необходимо унаследовать `std::error_category`, который явно сильно перегружен для использования во встроенном ПО на небольших микроконтроллерах. Даже хотя бы использованием std::string.
```
class CpuErrorCategory:
public std::error_category
{
public:
virtual const char * name() const;
virtual std::string message(int ev) const;
};
```
Кроме того, придется также описывать категорию(имя и сообщение) для каждого своего перечисляемого типа вручную. А еще код означающий отсутствие ошибки в `std::error_code` равен 0. А возможны варианты когда для разных типов код отсутствия ошибок будет различен.
Хотелось бы, чтобы накладных расходов, кроме как добавление номера категории, вообще не было.
Поэтому было бы логично «изобрести» что-то такое, что позволяло бы разработчику сделать минимум телодвижений в части добавления категории для своего перечисляемого типа.
Для начала нужно сделать класс, похожий на `std::error_code`, умеющий преобразовывать любой перечисляемый тип в целое и обратно из целого в перечисляемый тип. Плюсом к этим возможностям, чтобы была возможность вернуть категорию, собственно значение кода, а также уметь делать проверку:
```
//GetLastError() возвращает перечисление CpuError
ReturnCode result(cpuDiagnostic.GetLastError()) ;
if(result) //проверяем были ли ошибки
{
...
}
```
### Решение
Класс должен хранить в себе код ошибки, код категории и код соответствующий отсутствию ошибок, оператор приведения, и оператор присваивания. Соответствующий класс выглядит следующим образом:
**Код класса**
```
class ReturnCode
{
public:
ReturnCode()
{
}
template
explicit ReturnCode(const T initReturnCode):
errorValue(static\_cast(initReturnCode)),
errorCategory(GetCategory(initReturnCode)),
goodCode(GetOk(initReturnCode))
{
static\_assert(std::is\_enum::value, "Тип должен быть перечисляемым") ;
}
template
operator T() const
{
//Cast to only enum types
static\_assert(std::is\_enum::value, "Тип должен быть перечисляемым") ;
return static\_cast(errorValue) ;
}
tU32 GetValue() const
{
return errorValue;
}
tU32 GetCategoryValue() const
{
return errorCategory;
}
operator bool() const
{
return (GetValue() != goodCode);
}
template
ReturnCode& operator=(const T returnCode)
{
errorValue = static\_cast(returnCode) ;
errorCategory = GetCategory(returnCode) ;
goodCode = GetOk(returnCode) ;
return \*this ;
}
private:
tU32 errorValue = 0U ;
tU32 errorCategory = 0U ;
tU32 goodCode = 0U ;
} ;
```
Нужно немного пояснить, что тут происходит. Для начала шаблонный конструктор
```
template
explicit ReturnCode(const T initReturnCode):
errorValue(static\_cast(initReturnCode)),
errorCategory(GetCategory(initReturnCode)),
goodCode(GetOk(initReturnCode))
{
static\_assert(std::is\_enum::value, "Тип должен быть перечисляемым") ;
}
```
Он позволяет создать объект класс из любого перечисляемого типа:
```
ReturnCode result(Cpu_Error::Ok) ;
ReturnCode result1(My_Error::Error1);
ReturnCode result2(cpuDiagnostic.GetLatestError()) ;
```
Для того, чтобы конструктор мог принимать только перечисляемый тип, в его тело добавлен `static_assert`, который на этапе компиляции проверит передаваемый в конструктор тип с помощью `std::is_enum` и выдаст ошибку с понятным текстом. Реального кода тут не генерится, это все для компилятора. Так что по факту это пустой конструктор.
Также конструктор инициализирует приватные атрибуты, я вернусь к этому позже…
Далее оператор приведения:
```
template
operator T() const
{
//Cast to only enum types
static\_assert(std::is\_enum::value, "Тип должен быть перечисляемым") ;
return static\_cast(errorValue) ;
}
```
Он также может привести только к перечисляемому типу и позволяет делать нам следующее:
```
ReturnCode returnCode(Cpu_Error::Rom) ;
Cpu_Error status = errorCode ;
returnCode = My_Errror::Error2;
My_Errror status1 = returnCode ;
returnCode = myDiagnostic.GetLastError() ;
MyDiagsonticError status2 = returnCode ;
```
Ну и отдельно оператор bool():
```
operator bool() const
{
return (GetValue() != goodCode);
}
```
Позволит нам напрямую проверять есть ли вообще ошибка в коде возврата:
```
//GetLastError() возвращает перечисление Cpu_Error
ReturnCode result(cpuDiagnostic.GetLastError()) ;
if(result) //проверяем были ли ошибки
{
...
}
```
По сути это все. Остается вопрос в функциях `GetCategory()` и `GetOkCode()`. Как нетрудно догадаться, первая предназначена для того, чтобы перечисляемый тип, каким то образом сообщил о своей категории классу `ReturnCode`, а вторая чтобы перечисляемый тип сообщил, что является удачным кодом возврата, так как мы собираемся сравнивать с ним в операторе `bool()`.
Ясно, что эти функции могут быть предоставлены пользователем, и мы честно можем их вызывать в нашем конструкторе через механизм аргумент-зависимого поиска.
Например:
```
enum class CategoryError
{
Nv = 100,
Cpu = 200
};
enum class Cpu_Error
{
Ok,
Alu,
Rom
} ;
inline tU32 GetCategory(Cpu_Error errorNum)
{
return static_cast(CategoryError::Cpu);
}
inline tU32 GetOkCode(Cpu\_Error)
{
return static\_cast(Cpu\_Error::Ok);
}
```
Это требует дополнительных усилий от разработчика. Нужно для каждого перечисляемого типа, который мы хотим категоризировать добавлять эти два метода и обновлять `CategoryError` перечисление.
Однако наше желание это чтобы разработчик вообще практически ничего не добавлял в код и не заморачивался по поводу того, как ему расширить свой перечисляемый тип.
Что же можно сделать.
* Во-первых было замечательно, чтобы категория вычислялась автоматически, и разработчику **не надо** было бы предоставлять реализацию метода `GetCategory()` для каждого перечисления.
* Во-вторых, в 90% случаев в нашем коде, для возврата хорошего кода у нас используется Ok. Поэтому можно написать общую реализацию для этих 90%, а для 10% придется делать специализацию.
Итак, сконцентрируемся на первой задаче — автоматическое вычисление категории. Идея, подсказанная моим коллегой, заключается в том, чтобы разработчик имел возможность зарегистрировать свой перечисляемый тип. Это можно сделать используя шаблон с переменным количеством аргументов. Объявим такую структуру
```
template
struct EnumTypeRegister{}; // структура для регистрации типов
```
Теперь чтобы зарегистрировать новое перечисление, которое должно быть расширено категорией просто зададим новый тип
```
using CategoryErrorsList = EnumTypeRegister;
```
Если вдруг нам надо добавить еще одно перечисление, то просто добавляем его в список параметров шаблона:
```
using CategoryErrorsList = EnumTypeRegister;
```
Очевидно, что категорией для наших перечислений может быть позиция в списке параметров шаблона, т.е. для `Cpu_Error` это **0**, для `Measure_Error`, это **1**, для `My_Error` это **2**. Осталось заставить компилятор вычислить это автоматически. Для С++14 делаем так:
```
template
constexpr tU32 GetEnumPosition(EnumTypeRegister)
{
static\_assert(std::is\_same::value,
"Тип не зарегистрирован в списке EnumTypeRegister");
return tU32(0U) ;
}
template
constexpr std::enable\_if\_t::value, tU32>
GetEnumPosition(EnumTypeRegister)
{
return 0U ;
}
template
constexpr std::enable\_if\_t::value, tU32>
GetEnumPosition(EnumTypeRegister)
{
return 1U + GetEnumPosition(EnumTypeRegister()) ;
}
```
Что тут происходит. В кратце, функция `GetEnumPosition>` , с входным параметром являющимся списком перечисляемых типов `EnumTypeRegister`, в нашем случае `EnumTypeRegister`, и параметром шаблона **T** — являющимся перечисляемым типом, индекс которого мы должны найти в этом списке, пробегается по списку и в случае, если Т совпадает с одним из типов в списке возвращает его индекс, в противном случае выдается сообщение "«Тип не зарегистрирован в списке EnumTypeRegister»"
```
//Т.е. если определен список
constexpr EnumTypeRegister list
//то вызов
GetEnumPosition(list)
// должен вернуть 1 - что является индексом Measure\_Error в данном списке.
```
Разберем подробнее. Самую нижняя функцию
```
template
constexpr std::enable\_if\_t::value, tU32>
GetEnumPosition(TypeRegister)
{
return 1U + GetEnumPosition(TypeRegister()) ;
}
```
Здесь ветка `std::enable_if_t<**!std::is\_same**..` проверяет совпадает ли запрошенный тип с первым типом в списке шаблона, если нет, то возвращаемый тип функции `GetEnumPosition` будет `tU32` и далее выполняется тело функции, а именно рекурсивный вызов опять этой же функции, при этом количество аргументов шаблона уменьшается на **1**, а возвращаемое значение увеличится на **1**. Т.е на каждой итерации будет что-то похожее на это:
```
//Iteration 1, 1+:
tU32 GetEnumPosition(EnumTypeRegister)
//Iteration 2, 1+1+:
tU32 GetEnumPosition(EnumTypeRegister)
//Iteration 3, 1+1+1:
tU32 GetEnumPosition(EnumTypeRegister)
```
Как только все типы в списке закончатся, `std::enable_if_t` не сможет вывести тип возвращаемого значения функции `GetEnumPosition()` и на этом итерации закончатся:
```
//Как только итерации дойдут до последнего типа в списке
GetEnumPosition(TypeRegister<>)
template
constexpr tU32 GetEnumPosition(EnumTypeRegister)
{
static\_assert(std::is\_same::value,
"Тип не зарегистрирован в списке EnumTypeRegister");
return tU32(0U) ;
}
```
Что же произойдет, если тип есть в списке. В этом случае, будет работать другая ветка ветка c `std::enable_if_t<**std::is\_same**..`:
```
template
constexpr std::enable\_if\_t::value, tU32>
GetEnumPosition(TypeRegister)
{
return 0U ;
}
```
Тут идет проверка на совпадение типов `std::enable_if_t<**std::is\_same**...` И если, скажем на входе будет тип `Measure_Error`, то получится следующая последовательность:
```
//Iteration 1,
tU32 GetEnumPosition(EnumTypeRegister)
{
return 1U + GetEnumPosition(EnumTypeRegister)
}
//Iteration 2:
tU32 GetEnumPosition(EnumTypeRegister)
{
return 0 ;
}
```
На второй итерации рекурсионный вызов функции прекратиться и на выходе получим 1(из первой итерации) + 0(из второй) = **1** — это и есть индекс типа Measure\_Error в списке `EnumTypeRegister`
Поскольку это функция `constexpr,` то все вычисления делаются на этапе компиляции и собственно никакого кода не генериться.
Все это можно было не писать, будь в распоряжении С++17. К сожалению мой IAR компилятор не поддерживает в полной мере С++17, а так можно было всю портянку заменить на следующий код:
```
//for C++17
template
constexpr tU32 GetEnumPosition(EnumTypeRegister)
{
// если обнаружил тип в списке заканчиваем рекурсию
if constexpr (std::is\_same::value)
{
return 0U ;
} else
{
return 1U + GetEnumPosition(EnumTypeRegister()) ;
}
}
```
Осталось теперь сделать шаблонные методы `GetCategory()` и `GetOk()`, которые будут вызывать `GetEnumPosition`.
```
template
constexpr tU32 GetCategory(const T)
{
return static\_cast(GetEnumPosition(categoryDictionary));
}
template
constexpr tU32 GetOk(const T)
{
return static\_cast(T::Ok);
}
```
Вот и все. Давайте теперь посмотрим, что происходит при таком конструировании объекта:
```
ReturnCode result(Measure_Error::Ok) ;
```
Вернемся обратно к конструктору класса `ReturnCode`
```
template
explicit ReturnCode(const T initReturnCode):
errorValue(static\_cast(initReturnCode)),
errorCategory(GetCategory(initReturnCode)),
goodCode(GetOk(initReturnCode))
{
static\_assert(std::is\_enum::value, "The type have to be enum") ;
}
```
Он шаблонный, и в случае, если `T` есть `Measure_Error` а значит вызывается инстанциация шаблона метода `GetCategory(Measure_Error)`, для типа `Measure_Error`, который в свою очередь вызывает `GetEnumPosition` с типом `Measure_Error`, `GetEnumPosition(EnumTypeRegister)`, который возвращает позицию `Measure_Error` в списке. Позиция равна **1**. И собственно весь код конструктора при инстанциации типа `Measure_Error` заменяется компилятором на:
```
explicit ReturnCode(const Measure_Error initReturnCode):
errorValue(1),
errorCategory(1),
goodCode(1)
{
}
```
### Итог
Для разработчика, который возжелал пользоваться `ReturnCode` нужно сделать только одну вещь:
Зарегистрировать свой перечисляемый тип в списке.
```
// Add enum in the category
using CategoryErrorsList = EnumTypeRegister;
```
И никаких лишних движений, существующий код не трогается, а для расширения нужно всего лишь зарегистрировать тип в списке. Причем, все это сделается на этапе компиляции, и компилятор не только рассчитает все категории, но и предупредит вас в случае, если вы забыли зарегистрировать тип, или попытались передать тип не являющийся неперечисляемым.
Справедливость ради, стоит отметь, что в тех 10% кода, где у перечислений вместо кода Ок используется другое названия, придется сделать свою специализацию для этого типа.
```
template<>
constexpr tU32 GetOk(const MyError)
{
return static\_cast(MyError::Good) ;
} ;
```
Я выложил небольшой пример здесь: [пример кода](https://onlinegdb.com/rkXtMXH8N)
В общем виде, вот такое приложение:
```
enum class Cpu_Error {
Ok,
Alu,
Rom,
Ram
} ;
enum class Measure_Error {
OutOfLimits,
Ok,
BadCode
} ;
enum class My_Error {
Error1,
Error2,
Error3,
Error4,
Ok
} ;
// Add enum in the category list
using CategoryErrorsList = EnumTypeRegister;
Cpu\_Error CpuCheck() {
return Cpu\_Error::Ram;
}
My\_Error MyCheck() {
return My\_Error::Error4;
}
int main() {
ReturnCode result(CpuCheck());
//cout << " Return code: "<< result.GetValue()
// << " Return category: "<< result.GetCategoryValue() << endl;
if (result) //if something wrong
{
result = MyCheck() ;
// cout << " Return code: "<< result.GetValue()
// << " Return category: "<< result.GetCategoryValue() << endl;
}
result = Measure\_Error::BadCode ;
//cout << " Return code: "<< result.GetValue()
// << " Return category: "<< result.GetCategoryValue() << endl;
result = Measure\_Error::Ok ;
if (!result) //if all is Ok
{
Measure\_Error mError = result ;
if (mError == Measure\_Error::Ok)
{
// cout << "mError: "<< tU32(mError) << endl;
}
}
return 0;
}
```
Выведет следующие строки:
> Return code: 3 Return category: 0
>
> Return code: 3 Return category: 2
>
> Return code: 2 Return category: 1
>
> mError: 1
>
> | https://habr.com/ru/post/441956/ | null | ru | null |
# Linux From Scratch, не вдаваясь в детали
Linux From Scratch, не вдаваясь в детали
========================================
LFS — это книга о том, как собрать работающую операционную систему GNU/Linux из исходных кодов. Конечно, лучше самому собрать систему по этой книжке. Но если тратить несколько дней своего времени жалко, а познакомиться все же охота — попробую рассказать.
На основе Linux From Scratch, Version 7.3, на английском языке.
Мне захотелось собрать LFS чтобы лучше понять устройство линукс, надеюсь вам тоже это интересно. Признаюсь, было еще одно желание — собрать эталонный, «ванильный» линукс. Увы, эталонный линукс существует только в воображении наивных айтишников.
Тем не менее по книжке LFS можно собрать замечательную действующую систему, а по BLFS (это следующая книжка), допилить её до полного соответствия Linux Standard Base. Это, кстати, сообщается в одной из первых глав.
Главы в основном короткие и лаконичные. Язык, простой и ясный. Читать такую книжку одно удовольствие.
Система собирается путем компиляции из исходных кодов всех необходимых программ — ядра, основной библиотеки C, компилятора, оболочки командной строки, и др. Все пакеты с исходными кодами приводятся в файле wget-list. Так что скачать их все очень просто. Также приводится файл md5sum — для проверки целостности файлов после скачивания.
Cначала нужно использовать какой-нибудь другой linux (можно live-cd). Используя его компилятор и другие инструменты, в нём производится сборка окружения необходимого для сборки (компилятор, линковщик). Результаты помещаются в `/mnt/lfs/tools`.
Потом, монтируются служебные файловые системы (`/mnt/lfs/proc -> /proc`, `/mnt/lfs/dev -> /dev`, и др.) и с помощью `chroot` сеанс пользователя переключается на использование `/mnt/lfs` как корневой файловой системы вашего нового линукса. А папка `/tools` дописывается в переменную окружения `$PATH`. Таким образом по мере сборки инструментов они будут подменять свои временные аналоги из `/tools`.
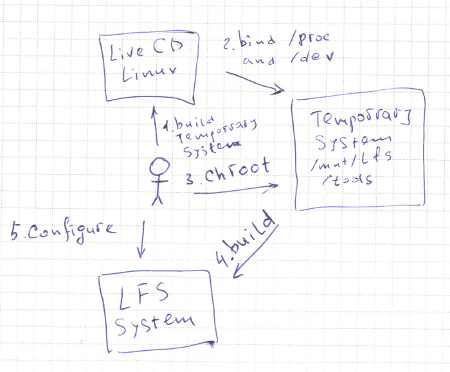
С помощью временной системы заново собираются все инструменты, но на этот раз они размещаются в `/bin`, `/sbin`, `/lib`. После чего устанавливаются скрипты загрузки из одного из скачанных пакетов.
Далее производится минимальная настройка системы (сеть, консоль, устройства). Создается файл `/etc/fstab` (настройка дисков), компилируется и устанавливается ядро (НАКОНЕЦ-ТО!), настраивается GRUB, и выполняется перезагрузка. Всё.
Стоит упомянуть, что в книжке довольно неплохо объясняются некоторые моменты. Например: что за файлы /etc/profile, ~/.bash\_profile, ~/.bashrc и как они взаимодействуют. Или разъясняется как с помощью udev настроить чтобы двум сетевым картам всегда выдавались одни и те же имена eth0, eth1. Для каждого пакета приводится список всех входящих в него программ с кратким описанием каждой. | https://habr.com/ru/post/183714/ | null | ru | null |
# Задачи с доминошками на собеседованиях
По личному опыту, могу сказать, что довольно популярными на собеседованиях являются задачи, так или иначе связанные с покрытиями доминошками каких-либо поверхностей. Условия могут варьироваться, но суть у всех остается одна.
##### Пример 1
Имеется шахматная доска 8 на 8 клеток, левый нижний и правый верхний углы которой отрезаны.

Можно ли полностью покрыть такую доску доминошками размера 2×1 клетку?
На доске остается четное число клеток (62), так что на первый взгляд решение возможно. Однако, давайте сделаем одну очень простую вещь:

Мы раскрасили клетки через одну. Теперь все становится очевидным. Каждая доминошка может занимать строго две клетки: одну белую и одну черную. Других вариантов не дано. Смотрим, какие клетки на доске отрезаны – обе черные, соответственно мы имеем 32 белых и 30 черных клеткок и полностью покрыть такую доску не представляется возможным.
Условия задачи могут варьироваться, но в целом, задачи на возможность-невозможность сразу бросаются в глаза.
##### Пример 2
Имеется большой куб сыра 3x3x3 состоящий из 27 одинаковых кубиков сыра и мышонок, который съедая один кубик принимается за соседний с ним по грани кубик сыра. Сможет ли мышонок полностью съесть весь сыр, если центральный кубик заменить на несъедобный муляж?
Задача та же самая, только в пространстве, а не на плоскости. Считаем клеточки: в изначальном раскладе это 14 на 13, после удаления центрального кубика: 14 на 12 и как следствие, решения нет.
Следующими по популярности идут задачи на подсчет количества вариантов решений.
##### Пример 3
Даны две доски:

На каждой вырезано по 2 клетке. Количество вариантов покрытия доминошками какой из досок больше? В обоих случаях вырезаны клетки разного цвета, так что все познания с раскраской из предыдущих примеров нам здесь не помогут. Времени на собеседованиях на задачи отводится мало, так что нужно искать какую-то зацепку. А она есть. Исключим из первого варианта все покрытия содержащие вырезанные клетки второй доски, а из второго варианта – первой. (Если так проще представить – то можно считать, что вырезанные клетки изначально покрыты доминошкой – которую нельзя двигать, и, очевидно, что таким образом мы приводим доски к идентичному состоянию и количество вариантов покрытий будет тоже идентичным). После этого рассмотрим нижний угол 3 на 2 клетки. Во втором варианте, левая нижняя клетка может быть покрыта только одним способом. Сопоставим этому покрытию вариант для первой доски:
Оставшася часть за исключением этого угла идентична, соответственно и количество покрытий тоже идентично. Таким образом, каждому варианту покрытия второй доски, сопоставлен вариант покрытия первой доски. Однако в первом случае также еще возможен вариант, где все доминошки расположены вертикально, не соответветсвующий ни одному варианту второй доски. Следовательно, число вариантов покрытия доски с клетками, отрезанными в углу больше.
##### Пример 4
Найти количество вариантов покрытия доминошками доски 2хN клеток.
Пусть ее можно покрыть X(N) способов. Рассмотрим вариант покрытия левой верхней клетки:

Оставшуюся часть в первом случае можно покрыть X(N-1) способами, а во втором, очевидно, X(N-2).
Так как перечислены все варианты покрытия и никакие из них не будут совпадать, то получаем уравнение X(N) = X(N-1) + X(N-2)
X(1) = 1, X(2) = 2, а Х(N) будет равно N+1 числу последовательности Фибоначчи.
##### Пример 5
Написать программу, вычисляющую количество способов покрытия доски 3xN клеток доминошками.
Сразу скажу, возможно, для этого примера есть тоже оптимальное решение, но я перейду тут уже от частных решений к общему. По сути, все что стоит за такими задачами можно представить [двудольным графом](http://ru.wikipedia.org/wiki/%D0%91%D0%B8%D0%B3%D1%80%D0%B0%D1%84), одно из множеств вершин которого – черные клетки, а другое – белые. Покрытие доминошками – есть не что иное как максимальное паросочетание такого графа. Для его поиска могут применяться различные алгоритмы (например Куна), с подсчетом количества вариантов все несколько сложнее. В любом случае, это за пределами данной статьи.
В заключение, для демонстрации, реализация алгоритма “в лоб” на питоне:
`from itertools import combinations
# формирование матрици инцидентности опущено для краткости
# оно тривиально
# Например, для доски 2x2 с номерами клеток:
# 1 2
# 3 4
# это:
# mat = [
# [0, 1, 1, 0],
# [0, 0, 0, 1],
# [0, 0, 0, 1],
# [0, 0, 0, 0]
#]
# 1 => 2, 1 => 3, 2 => 4, 3 => 4
# Обратные направления ( напр. 3 => 1 )
# не представляют для нас интереса
N = len(mat)
# создаем итератор со всеми парами вершин
all_edges = combinations(xrange(N), 2)
# фильтруем по матрице инцидентности
edges = [(x,y) for x,y in all_edges if mat[x][y]]
# отфильтровываем все максимальные варианты
matchings = [tuples for tuples in combinations(edges, N/2) \
if len(set(reduce(lambda x, y: x+y, tuples))) == N]
print len(matchings)
# осторожно, сложность O(N!)` | https://habr.com/ru/post/285346/ | null | ru | null |
# Как сделать классическую игру «Жизнь» на хуках React
Задача разработчика — показать пользователю, как живут и умирают цифровые клетки. Автор воспользовался React и её хуками: управление состоянием и возможность абстрагироваться от логики, связанной с состоянием, позволяют легко читать и понимать проект. Подробностями реализации и кодом на Github делимся, пока у нас начинается [курс по Frontend-разработке](https://skillfactory.ru/frontend-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fr_221121&utm_term=lead).
---
Правила игрыВселенная игры — бесконечная двумерная ортогональная сетка квадратных клеток, каждая из которых находится в одном из двух возможных состояний: живая или мёртвая (или заселённая и незаселённая соответственно). Каждая клетка взаимодействует со своими восемью соседями — клетками, которые расположены рядом по горизонтали, по вертикали или по диагонали. На каждом шаге во времени происходят следующие переходы:
* Любая живая клетка с менее чем двумя живыми соседями умирает от недонаселения.
* Любая живая клетка с двумя или тремя живыми соседями переходит в следующее поколение.
* Любая живая клетка с более чем тремя живыми соседями умирает, как при перенаселении.
* Любая мёртвая клетка с тремя живыми соседями становится живой клеткой, как будто размножаясь.
[Попробуйте](https://jordansgameoflife.now.sh/) моё приложение, а затем поговорим о его работе под капотом.
Структура данных, которую я решил использовать для представления ячеек, довольно проста. Вот массив объектов:
Этот массив объектов представляет нашу сетку, а каждый объект представляет отдельную ячейку. Свойство alive — ключевое в игреСоздаём компонент отображения Grid, он накладывается на массив сетки и генерирует индивидуальную ячейку для каждого объекта в массиве сетки:
Grid создаёт для каждого объекта ячейки в массиве сетки ячейку — тег Видно, что и `div` Grid, — контейнер сетки, и div ячеек имеют встроенные стили, смотрите строки 9 и 17. Значение стиля задаётся вспомогательной функцией. Причина такого подхода заключается в том, что он позволяет динамически изменять стили сетки и ячеек на основе передаваемых в функции данных.
`gridSize` хранит размер сетки. У меня есть три размера по умолчанию: 15x15, 30x30 или 50x50. У разных размеров будут разные стили. Посмотрим на вспомогательные функции:
Вспомогательная функция динамически изменяет количество места, отведённого каждому столбцу и строке сеткиФункция в cellSize возвращает ширину и высоту отдельной ячейки на основе gridSize. Функция в cellDisplay создаёт 3 случайных цвета, а затем проверяет, жива или мертва переданная ячейка. Если она живая, то динамически устанавливает размер ячейки и затем даёт ей случайный цвет; если мёртвая, то динамически устанавливает размер ячейки и задаёт чёрный фонТеперь посмотрим на логику изменения ячейки в зависимости от поколения и на то, как подключены элементы управления игры. Вся логика, связанная с состоянием, а также то, как мы управляем внешним видом сетки в отдельном поколении, обрабатывается в пользовательском хуке `useGrid`.
`useGrid` содержит несколько вызовов `useState` для отслеживания информации, которую мы используем и для итерации поколений, и для управления игрой:
Состояние для отслеживания информации, которую мы будем использовать для итерации поколений и для управления игройСначала нужно узнать, есть ли в сетке комбинация ячеек, которые можно изменить. Соответствующая логика располагается во вспомогательной функции `stepThroughAutomata` внутри `useGrid`. Я приступил к составлению плана функции, используя методы решения задач Джорджа Пойа.
План разработки stepThroughAutomataВоплощаем план в жизнь:
")Шаг 1. Задайте переменную, чтобы определить, валидна ли клетка (возможна ли мутация на основе правил)Шаг 2. Примените отображение к текущей сетке, сохранив результат как nextGeneration, и с помощью вспомогательной функции getNeighbors проверьте соседей текущей ячейкиШаг 3. Инициализируйте значение livingNeighbors значением 0, затем проверьте всех соседей текущей клетки, чтобы узнать, есть ли среди них живые. Для каждого живого соседа увеличьте значение livingNeighbors на 1Шаг 4. Исходя из количества живых соседей текущей ячейки, проверьте правила игры и переключите текущую ячейку на живую, если она была мёртвой, на мёртвую, если она была живой, или на неизменную. Установите validGrid в true, если мутация выполнена: если это возможно, то сетка валиднаШаг 5. Если сетка валидная, увеличьте значение счётчика поколений; в противном случае сообщите пользователю, что сетка невалидная. Наконец, установите сетку в качестве следующего поколения. Следующее поколение будет старой сеткой, но с изменениями на основе правилИ это всё! Переходим к управлению.
УправлениеИтак, первая кнопка здесь — «Step 1 Generation».
Реализовать кнопку довольно просто: у нас есть функция `stepThroughAutomata`. А ниже видим компонент `Controls`.
На строке 13 у нас есть первая кнопка. Мы просто добавляем свойство `onClick` к этой кнопке и передаём в него `stepThroughAutomata`:
На строке 22 у нас есть поле ввода, определяющее скорость итераций.
И, наконец, есть третья кнопка, значение которой — «Start» или «Stop» в зависимости от того, кликабельны ли отдельные ячейки. Если клетки кликабельны, то игра запущена. Если нет, игра не запущена.
Вы можете спросить: «Секундочку, когда я нажимаю кнопку запуска, функция `stepThroughAutomata` не запускается?». Да! Метод JS `setInterval` не очень хорошо работает с `onClick`. Поэтому для этой функциональности нужно было создать собственный хук. Посмотрим, как он работает:
GridContainer: чёрный ящик с магиейВыше мы деструктурируем все данные из `useGrid`, но прямо под этим кодом вызываем другой пользовательский хук — `useInterval` с четырьмя параметрами. Это:
1. Функция обратного вызова (здесь — `stepThroughAutomata`).
2. Время между вызовами передаваемой функции в миллисекундах. Значение `speedInput` по умолчанию — 500.
3. Текущая сетка.
4. Булево значение, здесь `clickable`.
useInterval и магия хуков.Мы создали хук `useInterval` потому, что встроенная функция setInterval не всегда хорошо сочетается с тем, как React перерисовывает компоненты.
Нам нужен способ узнать, что сетка меняется, и, следовательно, сетка должна повторно отобразиться, а мы должны быть уверены, что она последовательно изменяется каждые `n` миллисекунд. Узнать это мы можем с помощью встроенного хука `useRef`. Сначала инициализируем `savedCallback` как ссылку.
Теперь воспользуемся `useEffect`, чтобы установить текущий `savedCallback` в качестве переданного обратного вызова. Это связано с тем, как `setInterval` подписывается на объект `window` и отписывается от него.
Будем обновлять `savedCallback.current` каждый раз, когда возвращаемое значение обратного вызова изменяется. Это должно происходить при каждом выполнении функции обратного вызова.
Второй вызов useEffect внутри useInterval.Переходим ко второму вызову `useEffect`. Сначала проверим, истинно ли `clickable`. Если это так, то не хочется запускать функцию внутри: такой запуск означает, что игра идёт прямо сейчас. Если `clickable` — ложно, это означает, что игра запускается впервые. Поэтому быстро инициализируем функцию `tick`, которая вызывает текущий сохранённый обратный вызов.
Сохраняем результат вызова `setInterval`, передавая `tick` и задержку, а затем сразу же отписываемся, используя анонимную функцию и выполняя clearInterval с передачей `id`.
Замечательно, что передаваемый обратный вызов — это та же функция, которую мы используем для перебора по одному поколению за раз, так что алгоритм итерации полностью пригоден для повторного использования.
Резюме:
* Хуки позволяют писать чистый код, который можно использовать повторно.
* Определение соседей путём сплющивания сетки в вектор и выполнение математических операций для поиска соседей дают пространственную сложность `O(n)`.
* Встроенная функция повторного рендеринга в React позволяет создать бесшовное представление UI игры «Жизнь».
[Код на Github](https://github.com/Jordan-Stoddard/Conways-Game-Of-Life).
Продолжить изучение ReactJS вы сможете на наших курсах:
* [Узнать подробности акции](https://skillfactory.ru/catalogue?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=sf_allcourses_221121&utm_term=conc)
* [Профессия Fullstack-разработчик на Python (15 месяцев)](https://skillfactory.ru/python-fullstack-web-developer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fpw_221121&utm_term=conc)
* [Профессия Data Scientist (24 месяца)](https://skillfactory.ru/data-scientist-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dspr_221121&utm_term=conc)
Другие профессии и курсы**Data Science и Machine Learning**
* [Профессия Data Scientist](https://skillfactory.ru/data-scientist-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dspr_221121&utm_term=cat)
* [Профессия Data Analyst](https://skillfactory.ru/data-analyst-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=analytics_dapr_221121&utm_term=cat)
* [Курс «Математика для Data Science»](https://skillfactory.ru/matematika-dlya-data-science#syllabus?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_mat_221121&utm_term=cat)
* [Курс «Математика и Machine Learning для Data Science»](https://skillfactory.ru/matematika-i-machine-learning-dlya-data-science?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_matml_221121&utm_term=cat)
* [Курс по Data Engineering](https://skillfactory.ru/data-engineer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dea_221121&utm_term=cat)
* [Курс «Machine Learning и Deep Learning»](https://skillfactory.ru/machine-learning-i-deep-learning?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_mldl_221121&utm_term=cat)
* [Курс по Machine Learning](https://skillfactory.ru/machine-learning?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_ml_221121&utm_term=cat)
**Python, веб-разработка**
* [Профессия Fullstack-разработчик на Python](https://skillfactory.ru/python-fullstack-web-developer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fpw_221121&utm_term=cat)
* [Курс «Python для веб-разработки»](https://skillfactory.ru/python-for-web-developers?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_pws_221121&utm_term=cat)
* [Профессия Frontend-разработчик](https://skillfactory.ru/frontend-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fr_221121&utm_term=cat)
* [Профессия Веб-разработчик](https://skillfactory.ru/webdev?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_webdev_221121&utm_term=cat)
**Мобильная разработка**
* [Профессия iOS-разработчик](https://skillfactory.ru/ios-razrabotchik-s-nulya?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_ios_221121&utm_term=cat)
* [Профессия Android-разработчик](https://skillfactory.ru/android-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_andr_221121&utm_term=cat)
**Java и C#**
* [Профессия Java-разработчик](https://skillfactory.ru/java-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_java_221121&utm_term=cat)
* [Профессия QA-инженер на JAVA](https://skillfactory.ru/java-qa-engineer-testirovshik-po?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_qaja_221121&utm_term=cat)
* [Профессия C#-разработчик](https://skillfactory.ru/c-sharp-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_cdev_221121&utm_term=cat)
* [Профессия Разработчик игр на Unity](https://skillfactory.ru/game-razrabotchik-na-unity-i-c-sharp?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_gamedev_221121&utm_term=cat)
**От основ — в глубину**
* [Курс «Алгоритмы и структуры данных»](https://skillfactory.ru/algoritmy-i-struktury-dannyh?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_algo_221121&utm_term=cat)
* [Профессия C++ разработчик](https://skillfactory.ru/c-plus-plus-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_cplus_221121&utm_term=cat)
* [Профессия Этичный хакер](https://skillfactory.ru/cyber-security-etichnij-haker?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_hacker_221121&utm_term=cat)
**А также:**
* [Курс по DevOps](https://skillfactory.ru/devops-ingineer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_devops_221121&utm_term=cat)
* [Все курсы](https://skillfactory.ru/catalogue?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=sf_allcourses_221121&utm_term=conc) | https://habr.com/ru/post/590783/ | null | ru | null |
# Колхозинг* Mikrotik RB2011UiAS-2HnD-IN: внешние антенны и другие прибамбасы
\*Здесь *колхозинг* означает DIY или сделай сам. Этимологию слова и связь с земледельческой техникой см. ниже.
**Аннотация**
Подключение внешних антенн Wi-Fi к Mikrotik RB2011UiAS-2HnD-IN: как, зачем и нужно ли? Полезные бюджетные опции для минироутера. Проблемы с USB-модемами, скрытые дефекты активных удлинителей USB, методы выявления и устранения данных неприятностей.
> *Что делает в меру усталый айтишник на даче?
>
> Настраивает он Интернет, не иначе...*
Mikrotik RB2011UiAS-2HnD-IN — на редкость удачный телекомбайн для SOHO, который пользуется популярностью почти пять лет без изменений, эдакая бюджетная красно-чёрная акулка в мини-эволюции телекома. Я настолько влюбился в это устройство, что решил превратить его в легкий сетевой кроссовер, но материала, как это бывает, набралось на небольшую публикацию. DISCLAIMER: усиленные внешние антенны (на фото) далеко не всегда улучшают качество связи по причинам, изложенным далее.

**\*Колхозинг. Этимология слова.***Колхозинг* — изначально автолюбительский слэнг. Глагол *наколхозили* я впервые услышал от своего автомеханика, живописавшего за рюмкой чая состояние Mercedes Benz Coupe 1969 года после любительского ремонта. Вот за что люблю русский язык, так это за оттенки эмоций и феноменальную информационную ёмкость матерных слов. Буквально одно выражение доступно описывает как конечное состояние агрегата, так и квалификацию инженеров, которые пытались его ремонтировать. Но добавим позитива простой заменой приставки: *сколхозить антенну*, это уже созидательно-креативно. А *инговое* окончание у слова *колхоз* не только нейтрализует запах навоза, но и превращает пьяного тракториста с кувалдой в инженера-любителя с напильником. Пользователь **denis-21061** в 2007 году [предложил](http://vaz-2106.ru/forum/index.php?s=3b82afaea86eccca29206e032eddae15&showtopic=2856&view=findpost&p=37888) такое определение (пунктуация сохранена):
> Колхозинг — это болезнь автовлюбителя, которая выражается в безвкусном и бесполезном, с точки зрения практичности, внешнем и внутреннем оформлении своего автомобиля, в результате чего, автомобиль напоминает новогоднюю елку.
Но мой автомеханик считает, что «ёлочный» внешний тюнинг авто — это лишь частный случай, характерный для автолюбителей из южных губерний и Северного Кавказа. В более общем случае *колхозингом* он предлагает обозначать такой авторемонт, когда вместо оригинальной (новой, качественной) детали ставится деталь, например, от трактора или комбайна, обработанная напильником (как в том самом анекдоте), либо кустарно изготовленная (восстановленная) в мастерской.
### Внешние антенны
RB2011UiAS-2HnD-IN укомплектован парой несъёмных антенн Wi-Fi с усилением 4dBi, которых вполне достаточно для большинства задач. Вообще, не стоит терроризировать эфир излишней мощностью, специалисты, наоборот, рекомендуют её [в некоторых случаях уменьшать](https://habrahabr.ru/post/149418). Если «на пальцах»: бесконтрольно увеличивая мощность передатчика на точке доступа, вы ничем не улучшаете ответный сигнал терминала (смартфона, планшета), который и так еле-еле преодолевает пару бетонных стен. В пределе терминал точку «слышит» и думает, что она близко, а она его вообще не слышит. Да ещё и соседям мешает. **Хотя...**Хотя некоторых соседей (которые регулярно выпивают, шумно и вонюче курят вам в окна, перманентно орут матом на своих малолетних детей и воспитывают их тумаками) я бы, наверное, угощал СВЧ-физиотерапией из бортовой РЛС, снятой с боевого самолёта. Например, из старенького РЛПК [Сапфир-29](http://www.airbase.ru/alpha/rus/n/n019/). Но только пока дети учатся в школе, а добрые соседи на десять квартир вокруг — на работе: киловаттный передатчик, параболическая антенна, металлические волноводы в руку толщиной и всё такое. Мухи дохнут, кошки засыпают… Впрочем, бог судья таким родителям, дети подрастут и вернут им всё с процентами.
**Настройка мощности на Mikrotik**Основная настройка в разделе Wireless, опции `Frequency Mode`, `Country` и `Antenna Gain`. Если по-честному, то выставляете `regulatory-domain`, свою страну и КУ антенны. Если хочется вжарить по полной, тогда `Frequency Mode` в `manual-txpower`, мощность можно подрегулировать дополнительно на вкладке Tx Power: `Tx Power Mode` в положение `all rates fixed` и задать мощность в `Tx Power`.
Чувствительность антенны зависит от её коэффициента усиления. Поэтому, установив мощную антенну и даже чуть ослабив передатчик на точке доступа (увеличив значение Antenna Gain), в теории можно лучше принять сигнал от (своих) устройств за стенами, обеспечив более высокую скорость передачи данных по обоим направлениям. Но в реальности сигнал, преодолевая препятствия, многократно отражаясь и интерферируя сам с собой, может слишком деградировать, никакая антенна не поможет. Так что усиленная всенаправленная антенна — это скорее дачно-садовый вариант: ушёл работать в поле, и вдруг захотелось, скажем, в танчики поиграть. Но благодаря двум «хлыстам» по 8dBi даже в поле ломовой сигнал Wi-Fi: достаёшь из карманов здоровенный игровой ноутбук и режешься…
Лично моя мотивация *приколхозить* внешнюю антенну: запереть минироутер в стальной шкафчик подальше от шаловливых ручек пользователей и посетителей объекта, высунув наружу только антенны. Лучше в радиопрозрачном боксе, сделанном из обычного короба. В «стоечных» вариантах типа RB2011UiAS-RM наличие Wi-Fi радиомодуля — это скорее абсурд. Даже если офис небольшой фирмы продвинут настолько, что в нём есть шкаф 19", да ещё и в отдельном помещении, точки доступа мостятся где-нибудь на шкафу или на стене, ну не сажать же их в клетку Фарадея… Иногда к точкам проложен кабель с розеткой 220В, естественно, без ИБП. И вот электричество кончилось, бесперебойники пищат, пора срочно сохранять данные на сервер… ага, только сети нет. Конечно, у читателя данного ресурса такой ситуации не может возникнуть в принципе, тем более на RB2011 есть PoE.
Итак, модифицируем наш минироутер выходами на съёмные антенны, используя 6-дюймовые пигтейлы MMCX на RP-SMA.
**пигтейлы, MMCX, RP-SMA: что это за хрень вообще?**Термин *пигтейл* появился в ВОЛС и обозначает недлинный отрезок волокна с разъёмом только на одном конце (оптический полу-патчкорд), свободный конец которого предназначен для приварки, например, к магистральному кабелю. Именно из-за этого свободного хвоста «колечком» изделие прозвали пигтейлом.
Оптические пигтейлы удобны технологически: одни (суровые) ребята протягивают тугой бронированный кабель через канализационный коллектор на объект, где их радостно встречают другие (весёлые) ребята с варочным оборудованием и комплектом пигтейлов нужного типа. Кабель свежуют, отделяя броню и скелет, очищают нежные жилы в оболочке от вязкого гидрофобного наполнителя. Затем жилы сваривают с пигтейлами, фиксируя разъёмы на *оптическом кроссе*. Эта встреча на Эльбе иногда завершается торжественным подписанием акта о выполненных работах, братанием и совместным распитием чего-нибудь горячительного.
*Пигтейл коаксиальный* (радиочастотный) — по сути, адаптер, обжатый с двух концов разъёмами радиокабель, не защищённый «уличной» оболочкой. Обычно тонкий, иногда розовато-жёлтый из-за медной оплётки, которую хорошо видно через прозрачное FEP-покрытие (см. например, кабель RG316). Радиочастотный пигтейл тоже свёрнут колечком, что ещё более добавляет сходства с хрюшкиным хвостом. Используется как адаптер-переходник внутри корпуса, в длину редко достигает метра. Разъёмы дополнительно прикрываются термоусадкой, чтобы не подпускать кислород к меди.
MMCX (micro-miniature coaxial) — миниатюрный СВЧ-разъём, в Mikrotik RB2011UiAS-2HnD-IN используется на плате. Чтобы не свернуть ему шею, я использовал маленькие «электронные» плоскогубцы. Крутить MMCX бесполезно, резьбы там нет.
SMA (SubMiniature version A) — это среднего размера СВЧ-разъём с дюймовой резьбой 1/4"-36 (ближайший метрический размер — М6).
RP-SMA (Reverse Polarity SMA) — это просто вывернутый наоборот SMA, никакой обратной полярности там нет; RP-SMA почему-то более популярен в отрасли. RP-SMA «мама» имеет внешнюю резьбу.
Серьёзные *антенно-фидерные* системы операторов связи используют толстый «уличный» радиочастотный кабель (например, 5D-FB или 8D-FB), его вместе с разъёмами принято именовать *кабельной сборкой*. Крохотные разъёмчики MMCX такому кабелю можно натянуть разве что на центральную жилу, поэтому в профессиональном оборудовании чаще можно встретить брутальные разъёмы типа N. Впрочем, на 5D-FB налезает и SMA.
Очень важно, что все упомянутые элементы, включая и толстенный 8D-FB, и тонкий RG316, и разъёмы имеют идентичное волновое сопротивление 50 Ом, которое не зависит от длины кабеля. Если читатель не изучал ни радиосвязь, ни даже раздел о *длинных линиях* теории электроцепей, ничего страшного. Представьте себе длинный цилиндрический конденсатор, одна из обкладок которого — это сам цилиндр, а другая — провод строго по оси цилиндра. Теперь мысленно заполните пространство внутри диэлектриком, причём равномерно, без пузырей и комков. Тогда диэлектрическая проницаемость, а также диаметры внешнего цилиндра и центральной жилы будут постоянны вдоль всей длины, а их сочетание, по сути, и характерируется волновым сопротивлением получившегося коаксиального кабеля. Но можно взять тугой цилиндр побольше с жилой потолще и заполнить его вспененным диэлектриком: варьируя несколько параметров, получаем те же 50 Ом волнового сопротивления, но для улицы.
Важно, что любой градиент (изменение, скачок) волнового сопротивления на линии приводит к *рассогласованию* и потерям мощности: бросьте камень в воду рядом с берегом, волны начнут отражаться от берега, сталкиваться со встречными, возникает интерференция, помехи и потеря мощности. Это касается и разъёмов тоже: несмотря на позолоту, даже качественный разъём теряет порядка 0.5дБ мощности, «сломанный» или «перегнутый» коаксимальный кабель требует замены, особенно на сверхвыскоих частотах. Поэтому если читатель никогда раньше не работал с частотами порядка 2ГГц, кабели и пигтейлы для Wi-Fi не надо обжимать самому, это вам не телевизор на даче. Не подойдут и коаксиальные детали для устаревшего оборудования на 450МГц, и уж тем более 75-омные. Если сомневаетесь, закажите в адекватном магазине, можно поискать и на aliexpress по ключевым словам «RP-SMA MMCX RG316 15cm adapter connector», стоит порядка $1 за штуку, качество нормальное, только не перепутайте разъёмы.
Поскольку волновое сопротивление [не зависит](http://www.cqham.ru/forum/showthread.php?11068-%CE%E1%FC%FF%F1%ED%E8%F2%E5-%EF%F0%EE-%E2%EE%EB%ED%EE%E2%EE%E5-%F1%EE%EF%F0%EE%F2%E8%E2%EB%E5%ED%E8%E5&s=8329da283e63c140a12aefdff2a4f84d&p=261163&viewfull=1#post261163) от длины, то лично я вообще не воспринимаю его в качестве погонной характеристики радиочастотного кабеля. Погонная характеристика для меня — это удельный коэффициент затухания мощности, измеряемый в децибеллах на метр. Например, затухание в тонком кабеле пигтейла RG316 на частоте 2.4ГГц составляет около 1.3дБ/м, т.е. 6-дюймов не в счёт, потери только на разъёмах. Но при длине порядка нескольких метров пигтейл будет работать как очень дорогой и неэффективный нагреватель воздуха, зато у 8D-FB на той же частоте затухание 0.25дБ/м, т.е. в пять раз меньше.
Аутопсию минироутера я пропущу, её без меня делали уже не [раз](http://www.lanmart.ru/blogs/review_mikrotik_rb2011uas-2hnd-in), и не [два](http://www.technotrade.com.ua/Articles/mikrotik_rb2011uas-2hnd_review.php). Перед публикацией здесь я решил проверить, кто ещё делал нечто подобное. Оказалось, в 2014 году пользователь SvZol тоже [колхозил](http://forummikrotik.ru/viewtopic.php?t=5430) внешние антенны. Правда, SvZol преследовал несколько иные цели, использовал «родные» пигтейлы [ACMMCXRPSMA](http://routerboard.com/ACMMCXRPSMA) по $8 за штуку, но тем не менее.
Итак, для начала заказываем на aliexpress пару 6-дюймовых пигтейлов MMCX RP-SMA по $1 за штуку, а пока они едут, идём в ближайший хозяйственный магазин и покупаем четыре кузовных шайбы (с широкими полями) под метизы М6. Можно, конечно, напечатать красивые пластиковые держатели на 3D-принтере, но моя сделка на четыре шайбы со слов кассирши оказалась самой маленькой за всю историю наблюдения. Две шайбы чуть-чуть подпиливаем, как показано на фото. Чтобы не было контакта с корпусом, шайбы желательно покрыть автоэмалью (£1 за флакончик) или лаком для ногтей (shareware), можно даже подобрать красный или чёрный, в тон корпуса изделия.

Штатные антенны вынимаем, аккуратно отстегнув СВЧ-разъёмы MMCX от платы. От антенн должны остаться на корпусе пластиковые держатели, прихваченные к металлу чем-то вроде резинового клея. Он довольно легко отделяется маленькой плоскошлицевой отвёрточкой, в итоге остаются два почти круглых отверстия D~8мм.
 
**ВНИМАНИЕ: устройство без антенн не включать!**
Половинки разобранного роутера удобно разложить на столе в виде буквы «Т» или «Г», дабы не порвать связующий их шлейф LCD-экранчика, но при этом иметь жёсткий упор для работы. Вставляем заранее припасённые короткие пигтейлы разъёмами MMCX на плату, а разъёмы RP-SMA зажимаем на корпусе, проложив кузовные шайбы. Для законтривания RP-SMA понадобятся два рожковых ключа на 8, либо ключ и насадка на «трещётку». Хотя мой автомеханик, наверное, смог бы и без ключей закрутить (у парня пальцы киборга с биодинамометром, так что даже резьбу не срывает). При этом очень важно, чтобы подпиленные шайбы оказались внутри корпуса, а не снаружи, и смотрели подпиленными боками в сторону платы. Эти самые бока должны встретиться с нижней частью корпуса минироутера и не мешать закрыть крышку. Хотя крышка гибкая, у SvZol получилось и так.
Есть и нюанс: толщина двух кузовных шайб М6 в сочетании со стенкой корпуса у меня составила примерно 5мм, в то время как вся резьба на RP-SMA 11мм, причём надо оставить 5мм с запасом для накручивания ответного разъёма. Поэтому гроверными шайбами (если пришли с пигтейлами) придётся пожертвовать, но не выбрасывайте их, а рассчитайтесь золочёной СВЧ-бижутерией за использованный ранее лак для ногтей (ВНИМАНИЕ: мелкие детали, не давать маленьким детям). Впрочем, семейные взаиморасчёты читателя — не моё дело;-)
**Что нужно из расходников и инструментов**
| | |
| --- | --- |
| Пигтейл MMCX / RP-SMA 15см | 2 шт |
| Шайба кузовная для метизов М6 | 4 шт |
| Лак для ногтей или автоэмаль | 2 слоя |
| Отвертка крестовая PH1 (для открывания корпуса) | да |
| Мини-плоскогубцы «электронные» (для отделения MMCX от платы) | да |
| Отвертка с плоским шлицем 2-3мм (для удаления клея) | да |
| Ключ рожковый на 8 (для удержания RP-SMA изнутри корпуса) | да |
| Ключ рожковый или накидной на 8 (для законтривания RP-SMA) | да |
| Надфиль по металлу плоский (ну куда же без напильника?) | да |
Вот, что получается:

**ВНИМАНИЕ: устройство без антенн не включать! (на всякий случай)**
Для проверки я таки привинтил к своему колхозу пару «хлыстов» TP-LINK, но напомню, что изначальный план — убрать минироутер в стальной ящик, а антенны закрепить снаружи, подтянув к ним метровые пигтейлы. Возможно, я как-нибудь напишу про свой *ящик конвергентных информационных услуг*: всё *SOHOзяйство* вместе с минироутером, сервером, ИБП и видеонаблюдением зашло в шкафчик ВxШxГ 501x600x350мм, ещё место осталось. Сэкономил денег, что довольно актуально.
Штатные антенны Mikrotik не выбрасывайте, вдруг придётся роутер по гарантии менять;-) Хотя с такой-то ценой проще держать полный комплект ЗИП и докупать новые единицы по мере необходимости. За два года эксплуатации у меня только один раз залип гигабитный порт (после перегрузки всё стало нормально).
### Гигабит, ещё гигабит
Что делать, если большинство проектных файлов хранятся на сервере и достигают (и превышают) десятки мегабайт? Для начала надо подключать все рабочие станции к гигабитным портам, которых, кстати… а сколько у нас гигабитных портов?
Если посмотреть на блок-схему минироутера, то на севере можно увидеть стандартный агрегат AR9344 (мозги + коммутатор 100Мбит + модуль Wi-Fi), усиленный на юге гигабитным коммутатором AR8327, который обслуживает пять медных портов и один трансивер SFP.
**Блок-схема RB2011UiAS-2HnD-IN**
Не открою Америку, если скажу, что гигабитная коммутация без нагрузки на ЦП возможна здесь только тогда, когда пакеты идут внутри AR8327, т.е. без всяких мостов, фаэрволов и маршрутизации. Я попробовал нагрузить роутер, через головной мозг на моей конфигурации больше «сотки» не протягивается, процессор 90%. Мост без маршрутизации протягивает уже 200-300Мбит/с, процессор примерно 60%. Но ведь хочется гигабитов нахаляву! Именно для этого было введено «портовое рабство»: все гигабитные порты в состоянии slave (включая SFP) форвардят пакеты внутри AR8327, не переводя стрелки на центральный процессор. Вот тогда получается субгигабитная скорость, и *sustained* процессор около 10%. Это и есть норма.
Пользователь SvZol привлёк моё внимание ещё и тем, что ухитрился [приколхозить](http://mikrotik.ru/forum/viewtopic.php?f=3&t=5114&start=30) на RB2011 ещё и вентилятор охлаждения, похоже, с целью разгона процессора. Правда, не знаю, зачем: в телекоме процессор на пределе возможностей обычно означает пропущенные пакеты, это не десктоп, его не надо нагружать и разгонять. Вместо этого надо либо менять конфигурацию, либо выбирать другое устройство. Впрочем, никому не навязываю эту точку зрения.
Гигабитных портов всего пять, но если «оптика» не нужна, слот SFP пропадает зря. Шестой гигабитный порт легко получить, установив туда медный трансивер. Я был весьма удивлён, насколько абсурдными могут быть цены на такую простую вещь, как медные SFP-трансиверы. Сам Mikrotik предлагает [S-RJ01](http://routerboard.com/S-RJ01) за $29, поисковик выдал мне массу предложений местных магазинов от $40 и далее. На aliexpress можно найти медный трансивер SFP за $14.99, используя ключевые слова «SFP-T RJ45» или даже «GLC-T RJ45». Я попробовал, после «продувки» гигабитным трафиком через патч-корд 15м ошибок на интерфейсе не увидел. Может, надо было продувать через бухту 100м? Если кто в теме, прокомментируйте, пожалуйста.

**Трансивер сам о себе**По внешним признакам это похоже на попытку клонировать медный трансивер Cisco GLC-T, который стоит чуть дороже нашего минироутера. А может, это и есть GLC-T, только напрямую с завода, без посредников?
| | |
| --- | --- |
| **Параметр** | **Значение** |
| Link length copper | 100 m |
| Vendor Name | CISCO-METHODE |
| Vendor Part Number | SP7041\_Rev\_F |
| Vendor Revision | F |
| Vendor Serial | MTCxxxxxxxM |
| Wavelength | 16653.93 nm |
### Мини-распределитель питания для ИБП
Внешний блок питания минироутера — это элемент, который обычно портит всю инженерную эстетику. Представим себе ухоженный шкаф 19", внизу какой-нибудь роскошный ИБП, аккуратно заправлены в органайзеры кабели [IEC 320 C13/C14](https://en.wikipedia.org/wiki/IEC_60320#C13.2FC14_coupler), тут и там всякие стяжки-хомутики, любо-дорого смотреть. И посреди всего этого великолепия — почти пустой распределитель питания (PDU) на всю ширину 19", из которого торчит единственный внешний блок питания кабельного модема, минироутера или ещё чего-нибудь в таком духе. Причём розетки смотрят из шкафа горизонтально, а блок под действием гравитации только и норовит вывалиться увесистым трансформатором прямо на ногу тому, кто неосторожно откроет дверцу. Заодно и весь офис без связи оставить. Конечно, у читателя данного ресурса такой ситуации не может быть в принципе (я уже это говорил?).
В сегменте SOHO кабельно-розеточная индустрия уже давно поставляет т.н. «сетевой фильтр для UPS» в виде пяти евророзеток на шнуре с вилкой C14 для вставки в ИБП. В положении «на полу» гравитация уже нипочём, но я нашёл ещё более компактный вариант, который внимательный читатель, наверное, приметил на фото в самом начале публикации. Загоняется прямо в ИБП, не люфтит, блок питания держится жёстко.
 
На aliexpress это изделие можно найти за $2 по словам «IEC 320 C14 C13 Adapter PDU UPS». Обратите внимание, как ровно вписался блок питания Mikrotik под сигнальным USB-кабелем в Smart UPS 750, перекрыв всего два разъёма питания и оставив 3+1 (евровилка просто для демонстрации).
### Не очень активные удлинители USB
В большинство крупных городов пришёл (или ещё идёт) стандарт беспроводной связи LTE, который активно используется и бизнесом, и потребителями. Но чтобы получить хороший сигнал и качественную связь, скоростной модем нужно (а) хорошенько запитать электричеством и (б) установить в точке оптимального радиоприёма. Последняя, по всем законам жанра, оказывается слишком далеко от минироутера. Что делать? Можно купить внешнюю антенну, протянуть к ней толстый уличный радиокабель, заодно пробурить стену, получить разрешение собственника объекта на доступ к фасаду и т.д. Можно вместо этого подвесить минироутер в окне и перетянуть к нему всю локальную сеть. Можно вообще ничего не делать и довольствоваться 3G вместо LTE.
Очевидная альтернатива «для бедных» — вместо роутера в окне подвесить модем на USB-удлинителе, что многие и пытаются делать. Но именно здесь обычно и проявляются все пакости: у Mikrotik и так хилое питание USB-порта, которого едва хватает для работы 3G-модема, не говоря уже про *энергоёмкий абонентский терминал LTE*. Вот скажите, пожалуйста, разве бывают радиомодемы, которые имеют в два-три раза большую пропускную способсность, но при этом потребляют меньше энергии (по сравнению с 3G)?
Обычный USB-модем периодически зависает, это его *modus operandi*, но тоненькие жилки кабеля `28AWG/1P 26AWG/2C` доводят его до перманентного энергетического голодания (см. также [про AWG](http://www.rapidtables.com/calc/wire/awg-to-mm.htm)). Несчастное устройство, если даже определяется через три метра удлинителя, то работает нестабильно, зависает. Побороть это отчасти можно, навесив пассивный USB-хаб на дальний конец удлинителя и воткнув в него модем. Некоторые ещё используют Y-кабель для подкачки энергии в порт USB из внешнего источника, но, если не вколхозить в Y-кабель ещё и реле питания, подкачка заблокирует функцию программного перезапуска зависшего модема командой `/system routerboard usb power-reset`. А ведь именно ради таких «фишек» мы и выбираем изделия Mikrotik, не правда ли?
**Чисто модемные подвохи**Серия Mikrotik RB2011 на момент написания публикации из доступных LTE-терминалов адекватно поддерживает только Huawei E3372 и только в режиме HiLink, но см. [документацию](http://wiki.mikrotik.com/wiki/Supported_Hardware). Найденный в загашнике E3272 оказался с «неправильным» VID/PID, поэтому не заработал. Старенький E3276 вообще не поддерживается.
Но суть проблемы в том, что когда Mikrotik работает с LTE-модемом в режиме PPP, то, как [отмечают пользователи](http://forum.mikrotik.com/viewtopic.php?t=89458#p489216), на скоростях порядка 30Мбит/с инкапсуляция HDLC (т.е. компоновка фреймов канального уровня) съедает около 30% процессорного ресурса. Это много, и для разгрузки хоста скоростные модемы эмулируют буферный сегмент Ethernet, в который «смотрят» внутренний интерфейс [192.168.8.1] модема и внешний интерфейс [192.168.8.100] хоста (т.е. нашего минироутера). Это и есть режим HiLink, побочный эффект которого, увы, двойная трансляция сетевого адреса (Double NAT).
Разница между т.н. Stick и HiLink на примере Huawei E3372 лучше всего [поясняется](http://4pda.ru/forum/index.php?showtopic=582284) на сайте 4pda, см. ЧАВО. Вычислительная основа Huawei E3372 — два ядра ARM, на которых параллельно работают две операционки: VxWorks (реального времени) и Android (IP-сервисы, веб-интерфейсы и пр.), эдакие Инь и Ян. Вот, например, то, что говорит андролинуксовая часть при запуске:
`<5>[ 0.000000] Linux version 3.4.5 (b84016561@balongv7r2) (gcc version 4.6.x-google 20120106 (prerelease) (GCC) ) #1 PREEMPT Fri Nov 27 19:19:51 CST 2015
<4>[ 0.000000] CPU: ARMv7 Processor [414fc091] revision 1 (ARMv7), cr=18c53c7d`
Чтобы нивелировать проблему Double NAT, пользователи [рекомендуют](http://forum.mikrotik.com/viewtopic.php?t=89458#p521860) декларировать адрес 192.168.8.100 как DMZ в настройках HiLink-модема, тогда все входящие соединения снаружи будут просто пробрасываться на минироутер. Безусловно, это неудобно, но даже с учётом *андролинукса* пробросить WAN-адрес напрямую в минироутер совсем непросто, см, например, [комментарий](http://4pda.ru/forum/index.php?showtopic=582284&st=4340#entry38368744) пользователя **forth32**. Но функция DMZ наличествует не во всех прошивках модема:)
**О прошивках USB-модемов и относительно халявной связи**Во-первых, снимаю шляпу перед аудиторией портала [4pda.ru](http://4pda.ru): ребята разбирают мобильные терминалы почти на атомы, такого количества информации об их внутренностях вряд ли можно найти где-либо ещё. Видел восторженно-уважительные комментарии на иностранных форумах в стиле «да, есть один сайт [4pda.ru], информации много, но всё на русском, трудно разобраться». Да, братцы, как я вас понимаю. Когда для того же E3372 выложен целый лес прошивок и веб-интерфейсов, а для управления всем этим хозяйством ещё и дюжина утилит, тут и с русским языком непросто.
В итоге для экспериментов я остановился на прошивке `E3372h-153_Update_22.315.01.00.00_M_AT_05` с веб-интерфейсом `Update_WEBUI_17.100.13.01.03_HILINK_Mod1.0`, хотя сейчас уже наверняка вышли ещё несколько версий. ВНИМАНИЕ: прошивка имеет открытый telnet и ADB! Изменить пароль root, закрыть межсетевым экраном!
**UPD:**
Полностью оценить этот швейцарский нож для мобильной связи мне удалось спустя полгода после написания публикации. Известно, что операторы связи особой щедростью не отличаются, а уж в плане беспроводного широкополосного Интернета — тем более. Но нет-нет, да и мелькнёт по-настоящему безлимитный тариф без этих традиционных «только с 03:00 до 06:00 утра». Но есть условия — использовать только в одном смартфоне и не делиться Интернетом с друзьями и сотрудниками. HILINK — это в любом случае роутер, т.е. не то, что небольшую сеть, даже один компьютер не подключить. Но оказалось, что мобильное Интернет-неравенство относительно легко восстановить до безлимитного равенства, поменяв IMEI терминала и манипулируя TTL-полями сетевых пакетов. И соль в том, что «правильно» прошитый E3372 всё это умеет делать, как говорится, «out-of-the-box»! Ну, ещё пара программ-скриптов понадобится, их легко взять с того же 4pda.ru.
Поскольку я стараюсь поддерживать строгую санитарию на рабочем ноутбуке, все эти свистопляски (драйверы, пред-прошивки, прошивки, обновления) пришлось исполнять на *замапленном* USB-устройстве под аккомпанемент виртуального гипервизора, что добавило спецэффектов. Например, если прошивка вылетает с ошибкой X, на ВМ следует немедленно переустановить драйвер Y, а когда появляется сообщение Z, надо виртуально отстегнуть устройство от машины и пристегнуть обратно, чтобы переключилась USB-композиция. А иногда и то, и другое.
Увлекательнейший квест, но он того стоил: я получил функцию DMZ, root-доступ к android и смог читать логи. Оболочка busybox — это наше всё. Заодно можно прикрутить туда же [socat](http://www.dest-unreach.org/socat/doc/socat.html), собранный под архитектуру ARM, и выпустить интерфейс AT-команд через TCP, чтобы в случае чего можно было *буратинить\** устройство прямо с минироутера. Ещё раз напомню: не забывайте ставить пароли и прикрывать межсетевым экраном.
\*Буратинить — здесь: выполнять не до конца обдуманные, рискованные инженерные операции.
К счастью, индустрия USB-кабелей, наконец, откликнулась на требования потребителей и выпустила на рынок т.н. *активные удлинители USB*. Если обычный удлинитель имеет маркировку кабеля `28AWG/1P 26AWG/2C`, то активные удлинители — `28AWG/1P 24AWG/2C` или `28AWG/1P 22AWG/2C`, т.е. сечение питающих жил 0.33мм2 вместо 0.13мм2. Но главное — это повторитель USB на дальнем конце aka «однопортовый хаб». Такие удлинители обычно имеют длину 5м и допускают (по утверждению производителя) каскадное объединение до 5 штук в одну линию, получая тракт общей длиной до 25м. Благодаря повторителям сигнал ретранслируется и не рассыпается в хлам. Оконечное устройство питается лучше, подкачка энергии уже не требуется, любимая функция сброса порта работает, вроде бы всё шоколадно, но…
Очередной подвох ждал меня в самом неожиданном месте. Таков уж закон жанра: если есть способ сэкономить даже в ущерб качеству, но достаточно незаметно, то так и будет. Повторитель — это микроконтроллер с прошивкой, а там, где есть программирование, есть баги, это тоже закон жанра.
**Подвох с активным удлинителем USB**Подключив модем Huawei E3372 через пятиметровый активный удлинитель USB [GEMBIRD UAE016](http://gmb.nl/item.aspx?id=1555), я сперва очень обрадовался, потому что до этого модем не определялся вообще. Но стоило мне приступить к стандартным истязаниям радиоэфира утилитой [speedtest.net](http://speedtest.net), Mikrotik начал спонтанно, но достаточно часто «хлопать» интерфейсом LTE. Отчёт об увлекательном прохождении квеста по материалам проекта [4pda.ru](http://4pda.ru/forum/index.php?showtopic=582284) я поместил в отдельный спойлер выше, но на выходе появилась бесценная возможность заходить внутрь модема и работать в привычном Linux-окружении. Модем чётко рапортует о команде SUSPEND со стороны хоста:
**момент interface flap прямо из бортжурнала устройства**`<7>[011136832ms] **dwc3 dwc3: dwc3\_gadget\_suspend**
<3>[011136832ms] U_PNP:(U_TRACE)composite_suspend():suspend
<3>[011136837ms] U_ECM:(U_TRACE)ecm_suspend():ecm_suspend
<3>[011136842ms] U_NET:(U_TRACE)eth_suspend():eth_suspend
<3>[011136847ms] U_ALL:(U_INFO)usb_notify_syswatch():U_EVENT: usb_notify_syswatch<1,7>
<7>[011136855ms] dwc3 dwc3: Endpoint Command Complete
<4>[011136855ms] dwc3 dwc3: gadget not enabled for remote wakeup
<6>[011136861ms] android_work: sent uevent USB_STATE=SUSPENDED
...
<6>[011136980ms] device eth_x left promiscuous mode
<6>[011136980ms] wan0: port 1(eth_x) entered disabled state
...
<4>[011137070ms] device_event_send: queue is NOT empty
<1>[011137074ms] device_event_send: msg send over
<6>[011137144ms] device eth_v entered promiscuous mode
<6>[011137144ms] wan0: port 1(eth_v) entered forwarding state
<6>[011137144ms] wan0: port 1(eth_v) entered forwarding state`
Что за чертовщина? Но поскольку я уже [разбирал стек USB и собирал обратно](https://habrahabr.ru/post/236401/), то освежить [понятие SUSPEND](http://www.usbmadesimple.co.uk/ums_3.htm) оказалось просто: это всего лишь полное молчание хоста в течение 3 миллисекунд или более. Вывод: раз интерфейс «хлопает» только при работе через повторитель, значит, сам повторитель периодически залипает на время, чуть большее 3мс, модем считает это за команду SUSPEND и останавливается, затем сразу пробуждается. Интерфейс при этом болтает, как трусы на бельевой верёвке в ветреную погоду. Вот и вся история активного удлинителя от GEMBIRD, который я отнёс обратно в магазин. Интересно было наблюдать за лицами продавцов в момент объяснения мною причины возврата *кабеля, который, дескать, работает некорректно, потому что, мол, три миллисекунды — это много*… Но деньги вернули, и на том спасибо. Если берёте этот удлинитель, проверяйте модем на предмет «хлопающего интерфейса» (*interface flapping*) под нагрузкой. Может, мне просто не повезло с партией.
В итоге я решил взять более дорогой активный удлинитель USB производства Z-TEK, на упаковке которого среди иероглифов я с некоторым удивлением обнаружил голограммы (тоже с иероглифами). Голограмма с серийным номером нашлась и на самом изделии. Кисть для голографической каллиграфии в Поднебесной — вот это была бы бомба… Но помимо иероглифов, на упаковке всё-таки можно разобрать надписи **Z-TEK USB 2.0 5m**. Если присмотреться, на обороте можно найти код изделия **ZK010A**. Ну а если совсем постараться, можно даже найти [страничку продукта](http://www.z-tek.com.cn/USB2_0/73.html) (на китайском, причём переключение языка уводит вообще на другой сайт). Во втором магазине было уже не так интересно наблюдать за лицами продавцов, оговаривая условия возврата товара в случае превышения кабелем допустимых 3мс (см. спойлер выше). Но голограммы не соврали, изделие оказалось вполне добротным, модем перестал хлопать интерфейсом. Ну почти перестал, раз в сутки не в счёт. А с помощью прибора Электродиетолог, описанного в одной из прошлых [публикаций](https://geektimes.ru/post/248004/), я попытался сравнить энергопотребление модема Huawei E3372 на приёме и передаче, используя два различных удлинителя. Результаты в спойлере.
 
**Результаты сравнения двух активных удлинителей USB**DISCLAIMER: показания снимались субъективно и без соблюдения метрологических правил, поэтому речь скорее о качественном отличии. Очень надеюсь, что GEMBIRD уже исправили баг в прошивке и затоварили рынок дешёвыми и качественными активными удлинителями, которые потребляют ещё меньше энергии и не залипают больше, чем на 2мс.
| | | |
| --- | --- | --- |
| **Параметр** | **GEMBIRD UAE016** | **Z-TEK ZK010A** |
| Толщина жил питания | 24AWG (0.20мм2) | 22AWG (0.33мм2) |
| Толщина жил дифф. пары (USB DATA) | 28AWG (0.08мм2) | 28AWG (0.08мм2) |
| Uмодема, приём 20Мбит/с | 4.34В | 4.45В (+0.11В) |
| Uмодема, передача 30Мбит/с | 3.98В | 4.26В (+0.27В) |
| Iцепи, приём 20Мбит/с | 250мА | 240мА (-10мА) |
| Iцепи, передача 30Мбит/с | 550мА | 500мА (-50мА) |
### Резюме
* Телекоммуникационные потребности дома и малого офиса до сих пор позволяют использовать достаточно бюджетные изделия серии RB2011, но ценой недоступного диапазона 5ГГц.
* Чтобы спрятать минироутер в закрытый шкаф, требуются внешние антенны, отсутствие которых легко исправить.
* Мощные антенны не всегда означают лучшее качество связи, но попробовать можно.
* Комплектующие для минироутера не должны стоить половину самого минироутера.
* Активные удлинители USB могут иметь скрытые дефекты, которые проявляются в виде учащённого «хлопанья» модемного интерфейса.
### Ссылки
[www.lanmart.ru/blogs/review\_mikrotik\_rb2011uas-2hnd-in](http://www.lanmart.ru/blogs/review_mikrotik_rb2011uas-2hnd-in)
[www.technotrade.com.ua/Articles/mikrotik\_rb2011uas-2hnd\_review.php](http://www.technotrade.com.ua/Articles/mikrotik_rb2011uas-2hnd_review.php)
[forummikrotik.ru/viewtopic.php?t=5430](http://forummikrotik.ru/viewtopic.php?t=5430)
[habrahabr.ru/post/149418](http://habrahabr.ru/post/149418)
[geektimes.ru/post/248004](http://geektimes.ru/post/248004)
[habrahabr.ru/post/236401](http://habrahabr.ru/post/236401)
[www.usbmadesimple.co.uk/ums\_3.htm](http://www.usbmadesimple.co.uk/ums_3.htm)
[gmb.nl/item.aspx?id=1555](http://gmb.nl/item.aspx?id=1555)
[www.z-tek.com.cn/USB2\_0/73.html](http://www.z-tek.com.cn/USB2_0/73.html)
[speedtest.net](http://speedtest.net)
[4pda.ru/forum/index.php?showtopic=582284](http://4pda.ru/forum/index.php?showtopic=582284)
[wiki.mikrotik.com/wiki/Supported\_Hardware](http://wiki.mikrotik.com/wiki/Supported_Hardware)
[www.rapidtables.com/calc/wire/awg-to-mm.htm](http://www.rapidtables.com/calc/wire/awg-to-mm.htm)
[en.wikipedia.org/wiki/IEC\_60320#C13.2FC14\_coupler](https://en.wikipedia.org/wiki/IEC_60320#C13.2FC14_coupler)
[vaz-2106.ru/forum/index.php?s=3b82afaea86eccca29206e032eddae15&showtopic=2856&view=findpost&p=37888](http://vaz-2106.ru/forum/index.php?s=3b82afaea86eccca29206e032eddae15&showtopic=2856&view=findpost&p=37888) | https://habr.com/ru/post/394181/ | null | ru | null |
# Лучшие подходы и решения для уменьшения кода на React. Часть 1
Доброго времени суток! Здесь вы сможете ознакомится с переводом серии статей Rahul Sharma, в которой вы найдете способы, и примеры к ним, уменьшения Вашего кода на React.
Всего в данной серии 3 статьи:
* [Лучшие подходы и решения для уменьшения кода на React. Часть 1](https://habr.com/ru/post/657673/)
* [Лучшие подходы и решения для уменьшения кода на React. Часть 2](https://habr.com/ru/post/657879/)
* [Лучшие подходы и решения для уменьшения кода на React. Часть 3](https://habr.com/ru/post/658079/)
Введение
--------
Я работаю с React последние несколько лет и использовал его в нескольких проектах. При работе на разных проектах я выделил простые паттерны, с которыми и хочу поделиться в данных статьях. Но хватит лишних слов, давайте приступать.
1. Создавайте собственные хуки для Redux
----------------------------------------
Я не фанат использования redux, но использовал библиотеку в нескольких проектов. А redux-thunk и вовсе использовался почти во всех проектах, над которыми работал. Я обнаружил, что использование данного кода довольно-таки универсально.
```
const useUser = () => {
const dispatch = useDispatch();
const state = useSelector(); // получение данных авторизации, как пример
const fetchUser = (id) => {
return fetch(`/api/user/${id}`).then((res) => res.json())
.then((user) => dispatch({type: "FETCH_USER", payload: user}));
};
const fetchUsers = () => {
return fetch('/api/users').then((res) => res.json())
.then((user) => dispatch({type: "FETCH_USERS", payload: user}));
};
return { fetchUser, fetchUsers };
}
```
### Внутри компонента
```
const { fetchUser } = useUser();
useEffect(() => fetchUser(1), []);
```
***Примечание:*** *как вы можете заметить, нет необходимости создавать много функций для обработки всех redux экшенов.
Мы можем также использовать useSelector хук для получения любой информации из redux.*
2. Используйте объект вместо switch внутри reducer
--------------------------------------------------
Плохая идея, если вы хотите использовать много switch ключей для обработки. Вы можете использовать объекты как альтернатива для switch. Это улучшит читаемость и упростит поддержку.
```
const actionMap = {
INCREMENT: (state, act) => ({...state, count: state.count + 1 }),
DECREMENT: (state, act) => ({...state, count: state.count - 1 }),
}
const reducer = (state, action) => {
const handler = actionMap[action.type];
return handler ? handler(state, action) : state;
};
```
***Примечание:*** *переменная с ключами должна быть объявлена отдельно, иначе она будет постоянно перевызываться. Сложность поиска switch O (log n), у map (объект) же O (1).*
3. Создайте хук для REST запросов.
----------------------------------
Вы можете использовать браузерное fetch API и создать собственный хук для избегания повтора кода. К примеру, получение данных из API для обновления состояния приложения и отрисовки.
```
const useFetch = (input, { auto, ...init }) => {
const [result, setResult] = useState([null, null, true]);
const fetcher = useCallback(
(query, config) =>
fetch(query, config)
.then((res) => res.json())
.then((data) => setResult([null, data, false]))
.catch((err) => setResult([err, null, false])),
[input, init]
);
useEffect(() => {
if (auto) fetcher(input, init);
}, []); // Если необходимо получить данные только один раз, делайте так
return [...result, fetcher];
//fetcher(refetch) это либо функция либо может быть использованно для отправки запросов
};
```
### Внутри компонента
```
const Users = () => {
const [err, users, loading, refetch] = useFetch(`/api/users`, {auto:true});
const onClick = () => refetch(...);
return (
{users.map((user) => )}
);
}
```
***Примечание:*** *это похоже на react-query/useSWR, и обе библиотеки могут предложить гораздо больше функционала. Вы можете использовать их, но, если есть ограничения в вашем проекте, вы можете использовать данный код как альтернативу.*
4. Разделение кода
------------------
Используйте React.lazy, это мощный инструмент, который позволяет загружать ваши компоненты, только когда они необходимы. React.lazy функция дает возможность отображать динамически импортированные компоненты, как обычные.
**Хорошее место для начала, это роутер**. При обычном решении, перед тем как отобразить элементы на странице, вам приходится загружать все компоненты сразу, что является не хорошим решением, так как это занимает дополнительное время. Даже, когда у нас нет необходимости показывать часть из компонентов.
Мы можем использовать **react.lazy** для загрузки компонентов асинхронно. Так, когда вы на первой (Home) странице, вы загружаете только домашнюю страницу. А когда переходите на вторую страницу (About), подгружается второй компонент. Это решение позволяет избежать ненужные загрузки.
```
const Home = React.lazy(() => import('./Home'));
const About = React.lazy(() => import('./About'));
function MyComponent() {
return (
Loading...
```
}>
);
}***Примечание:*** *это простой пример, но что будет, когда у вас будут сотни элементов навигации и компонентов? Вы увидите большое различие в производительности.*
Спасибо за прочтение! | https://habr.com/ru/post/657673/ | null | ru | null |
# GTA V подключили к платформе OpenAI Universe для обучения ИИ автопилота

Прошло чуть больше месяца с тех пор, как некоммерческая организация OpenAI Илона Маска [представила](https://geektimes.ru/post/283384/) связующее программное обеспечение [Universe](https://openai.com/blog/universe) для тренировки и обучения сильного ИИ. Теоретически, обучение может происходить на всей информации человечества, доступной через интернет. С помощью программной платформы Universe интеллектуальный агент использует компьютер в точности так же, как это делает человек: он будет смотреть на пиксели компьютерного экрана и взаимодействовать при помощи виртуальных клавиатуры и мыши.
Сейчас к десяткам игр, доступных для тренировки ИИ, [добавилась игра Grand Theft Auto V](https://openai.com/blog/GTA-V-plus-Universe/), которая отличается исключительным реализмом.
Вы можете создать агента ИИ беспилотного автомобиля на любом фреймворке для машинного обучения и относительно легко подключить к игре на компьютере с установленной GTA V.

*Агент ИИ стоит на перекрёстке. В консольной диагностике слева отображается статус нажатия педали тормоза (true) и другие текущие параметры автопилота*
Игра GTA V, пусть даже с отключенным насилием, предоставляет богатые возможности для обучения ИИ для беспилотного автомобиля. Это один из самых больших и насыщенных открытых миров. Игровое действие происходит на территории острова Сан-Андреас площадью почти в 20% настоящего Лос-Анджелеса. Тут можно запускать самые разные сценарии для тестирования ИИ. Агентам доступны 257 различных типов автомобилей, 7 типов велосипедов, 14 типов погоды, а окружающая среда поддаётся изменению прямо во время симуляции.

*Остров Сан-Андреас*
Благодаря [многочисленным модам](https://www.gta5-mods.com/maps/vicecity-in-v), в игру GTA V можно загружать здания из настоящих городов, настоящие автомобили, настоящие дорожные знаки и другие объекты. Соответственно, ваш агент ИИ будет обучаться управлению автомобилем в настоящих дорожных условиях.
Платформа Universe
==================
Открытие всеобщей универсальной платформы Universe — продолжение планомерных действий OpenAI по созданию всемирного открытого универсального ИИ. В апреле текущего года организация [выпустила](https://openai.com/blog/openai-gym-beta/) публичную бета-версию инструментария [OpenAI Gym](https://gym.openai.com/) для разработки и сравнения алгоритмов обучения с подкреплением. «Спортзал» OpenAI Gym состоит из большого количества [окружений](https://gym.openai.com/envs) (от [симулятора гуманоидного робота](https://gym.openai.com/envs/Humanoid-v0) до [игр Atari](https://gym.openai.com/envs/MsPacman-v0)). Есть сайт для [сравнения и воспроизведения результатов](https://gym.openai.com/envs/CartPole-v0#feed).
OpenAI считает, что обучение с подкреплением — важный способ машинного обучения, который позволит в значительной степени усовершенствовать ИИ. В процессе обучения таким методом испытуемая система (агент) обучается, взаимодействуя с некоторой средой. В отличие от традиционного обучения с учителем, откликом на принятые решения ИИ являются сигналы подкрепления, при этом некоторые правила подкрепления формируются динамически и труднодоступны пониманию человека, то есть базируются на одновременной активности формальных нейронов.
Запуск агента ИИ на своём компьютере с GTA V
============================================
Интеграция Universe с [Grand Theft Auto V](http://www.rockstargames.com/V/) создана и поддерживается в рамках проекта [DeepDrive](http://deepdrive.io/), который сейчас перешёл на open source. Проект предусматривает возможность запуска агента Universe на своём собственном компьютере с установленной копией игры.

Посредством Universe агент искусственного интеллекта получает доступ к реалистичному трёхмерному игровому миру GTA V. На следующем видеоролике показаны кадры из игры, которые переданы для обработки агенту ИИ (искусственно замедлены до 8 FPS, слева вверху), диагностическая информация от агента и окружения (слева внизу), а также удобный для просмотра человеком вид с камеры (справа).
Интеграция ИИ в игру запрещает любые насильственные действия в GTA V.
Для начала работы агента на своём компьютере требуется запустить [серверный процесс GTA V](https://github.com/openai/universe-windows-envs/blob/master/vnc-gtav/README.md#using-the-prebuilt-ami). Предварительно следует установить питоновскую библиотеку [universe](https://github.com/openai/universe#install-universe), а затем подключить агента с помощью следующего кода.
```
import gym
import universe # register Universe environments into Gym
from universe.spaces import joystick_event
env = gym.make('gtav.SaneDriving-v0')
env.configure(remotes='vnc://$host:$port') # point to the GTA V Universe server
observation_n = env.reset()
while True:
steer = joystick_event.JoystickAxisXEvent(-1) # turn right
throttle = joystick_event.JoystickAxisZEvent(-1) # go in reverse
# Alternatively, use WASD to steer: ('KeyEvent', 'w', True)
action_n = [[steer, throttle] for _ in observation_n]
observation_n, reward_n, done_n, info = env.step(action_n)
env.render()
```
Как обычно для агентов Universe, ИИ использует виртуальную клавиатуру, но в этом случае ему доступен и виртуальный джойстик. Лучшие результаты ИИ демонстрирует именно с джойстиком.
DeepDrive
=========
DeepDrive — это специализированная платформа для разработки ИИ для беспилотных автомобилей с открытым исходным кодом. В ней используются моддерские фреймворки и специальные техники, чтобы превратить GTA V в нормальный автомобильный симулятор. Доступны предварительно обученные агенты со способностями к управлению транспортом и наборы данных, на которых происходило их обучение.
Хотя платформа DeepDrive появилась раньше, чем Universe, но теперь её разработчик принял решение, что будет разумно перевести свою работу на эту универсальную открытую платформу. Это был правильный шаг. Раньше для запуска агента требовался компьютер под Windows и много часов настройки окружения (там использовался [перехват DirectX](https://github.com/crizCraig/deepdrive-obs) для захвата экрана, а для написания агентов нужно было использовать интерфейс C++ к Caffe под Windows). Теперь DeepDrive устанавливается за 20 минут, работает под Linux и OS X, а писать агентов можно на любом фреймворке для машинного обучения.
В открытом доступе опубликованы [исходный код](https://github.com/openai/universe-windows-envs/tree/master/vnc-gtav) и [AMI](https://github.com/openai/universe-windows-envs/blob/master/vnc-gtav/README.md#using-the-prebuilt-ami) для GTA V, предварительно обученный [агент-водитель](https://github.com/deepdrive/deepdrive-universe). Его обучение продолжалось 21 час (600 тыс. изображений). Агент обладает базовыми навыками вождения и представляет собой хорошее начало для собственных экспериментов.
Совместными усилиями тысяч агентов ИИ можно создать по-настоящему изысканного водителя — программу, которая может управлять настоящим беспилотным автомобилем в реальном мире. | https://habr.com/ru/post/400551/ | null | ru | null |
# Средство малой механизации для Кармаграфа
Думаю, очень многие знают [Кармаграф](http://habrahabr.ru/blogs/ilhh/10994/) и пользуются им. При этом лично для меня самый частый сценарий использования — это, как ни странно, не любоваться на рост своей кармы, а посмотреть недавние изменения кармы *другого* хабрапользователя (типичный пример — в каком-нибудь посте написан PS «хватит срать мне в карму, и так уже минус!», я захожу для проверки в хабрацентр этого пользователя — а там +50 кармы. вот и думай, это ему за пару часов так кармы накидали, или он просто врун-попрошайка). И всё бы хорошо, но вбивать каждый раз вручную (или копипастить) имя этого пользователя в Кармаграфе как-то надоедает. Вспомнив, что есть такая вещь, как [закладурки](http://ru.wikipedia.org/wiki/%D0%91%D1%83%D0%BA%D0%BC%D0%B0%D1%80%D0%BA%D0%BB%D0%B5%D1%82) и потратив 20 минут на освежение памяти о том, как работать со строками в Javascript, родил вот такое:
`javascript:l=window.location.href;i=l.indexOf('.habrahabr.ru');if(i!=-1){window.open('http://karma.goodrone.org.ru/manage/add/'+l.substring(7,i).replace(/-/g,'_'));}void(0);`
Так как javascript в ссылках на хабре рэжэтся, то вместо простого перетаскивания ссылки на панель закладок нужно создать закладку вручную, прописав в качестве ссылки приведённый мной javascript.
##### Как пользоваться
Заимев желание посмотреть кармаисторию какого-нибудь хабрапользователя, идём в его хабрацентр и открываем закладку, сделанную своими руками в предыдущем абзаце. Откроется страница с кармаграфом и вы сможете с полным на то основанием разоблачить кармопопрошайку.
##### Features
1. Можно вызывать кармаграф из любой страницы хабрацентра — лишь бы перед habrahabr.ru шло имя пользователя.
2. Кармаграф открывается в новом окне или табе (не люблю, когда закладурки портят ту страницу, которая у меня сейчас открыта).
3. Если за хабрапользователем раньше не было установлено слежки, то Кармаграф спросит, начинать ли за ним следить.
4. Если попытаться открыть эту закладку не из хабрацентра, а из какого-нибудь другого места, то ничего не произойдёт.
5. Если в имени пользователя есть подчерк (переделываемый в минус в адресе хабрацентра), то он будет корректно обработан. Если подчерков много — тоже всё будет корректно (спасибо [monsterzz](https://habrahabr.ru/users/monsterzz/)).
##### Known bugs
Пока нет. | https://habr.com/ru/post/42835/ | null | ru | null |
# Быстрый старт за 5 минут с Angular 2 beta
*Вашему вниманию предлагается перевод туториала [«5 min quickstart»](https://angular.io/docs/ts/latest/quickstart.html) от команды Angular. Туториал описывает процесс создания «Hello World»-приложения на новом фреймворке Angular 2, который [недавно получил](http://habrahabr.ru/post/273445/) статус «бета».*
Давайте начнём с нуля и построим суперпростое приложение Angular2 на TypeScript.
#### Демо
Запуск [работающего примера](https://angular.io/resources/live-examples/quickstart/ts/plnkr.html) — это самый лучший способ увидеть, как оживает приложение на Angular 2.
Нажатие этой ссылки открывает новую вкладку, загружает пример в [plunker](http://plnkr.co/) и отображает простое сообщение:
```
My First Angular 2 App
```
Вот файловая структура:
```
angular2-quickstart
├── app
│ ├── app.component.ts
│ └── boot.ts
├── index.html
└── license.md
```
Функционально это index.html и два файла TypeScript в папке app/. Давайте сделаем это!
Конечно, мы не будем создавать приложения, которые будут запускаться только в plunker. Давайте сделаем всё как если бы мы делали это в реальной жизни:
1. Обустроим нашу среду разработки.
2. Напишем корневой компонент Angular для нашего приложения.
3. Загрузим его для того, чтобы он принял контроль над главной веб-страницей.
4. Напишем главную страницу (index.html).
> Мы действительно можем собрать QuickStart за пять минут, если будем следовать инструкциям и проигнорируем все комментарии.
>
> Но многие из нас заинтересуются, «почему» и «как» всё это происходит, и ответ на эти вопросы займёт значительно больше времени.
>
>
#### Среда разработки
Нам необходимо место (папка проекта), несколько библиотек, некоторое количество настроек TypeScript и редактор с поддержкой TypeScript на ваш выбор.
##### Создадим новую папку нашего проекта
```
mkdir angular2-quickstart
cd angular2-quickstart
```
##### Добавим нужные нам библиотеки
Мы рекомендуем использовать менеджер пакетов npm для загрузки и управления библиотеками.
> У вас нет npm? [Установите его прямо сейчас](https://docs.npmjs.com/getting-started/installing-node), потому что мы будем использовать несколько раз на протяжении этого туториала.
Добавьте файл **package.json** в папку проекта и скопируйте в него следующий код:
```
// package.json
{
"name": "angular2-quickstart",
"version": "1.0.0",
"scripts": {
"tsc": "tsc",
"tsc:w": "tsc -w",
"lite": "lite-server",
"start": "concurrent \"npm run tsc:w\" \"npm run lite\" "
},
"license": "ISC",
"dependencies": {
"angular2": "2.0.0-beta.0",
"systemjs": "0.19.6",
"es6-promise": "^3.0.2",
"es6-shim": "^0.33.3",
"reflect-metadata": "0.1.2",
"rxjs": "5.0.0-beta.0",
"zone.js": "0.5.10"
},
"devDependencies": {
"concurrently": "^1.0.0",
"lite-server": "^1.3.1",
"typescript": "^1.7.3"
}
}
```
> Не терпится узнать детали? Мы изложили их в [приложении ниже](#package-json).
Установите пакеты. Откройте окно терминала (командную строку в Windows) и запустите эту команду npm:
```
npm install
```
> Жуткие **красные сообщения об ошибках** могут появиться **в течение** установки. Игнорируйте их. Установка будет успешной. Смотрите [приложение ниже](#npm-errors), если хотите узнать больше.
##### Сконфигурируем TypeScript
Нам необходимо довольно специфично настроить компилятор TypeScript.
Добавьте файл **tsconfig.json** в папку проекта и скопируйте в него следующее:
```
// tsconfig.json
{
"compilerOptions": {
"target": "ES5",
"module": "system",
"moduleResolution": "node",
"sourceMap": true,
"emitDecoratorMetadata": true,
"experimentalDecorators": true,
"removeComments": false,
"noImplicitAny": false
},
"exclude": [
"node_modules"
]
}
```
> Мы исследуем tsconfig.json в [приложении ниже](#tsconfig).
**Итак, всё готово.** Давайте напишем немного кода.
#### Наш первый компонент Angular
*Компонент(Component)* — это наиболее фундаментальная концепция Angular. Компонент настраивает отображение(view) — часть веб-страницы, где мы показываем информацию пользователю и реагируем на его действия.
Технически, компонент — это класс, который контролирует шаблон отображения. Мы будем писать много таких классов при создании приложений Angular. Это наша первая попытка, так что мы сделаем всё предельно просто.
##### Создадим подпапку, в которой будут находиться исходники
Мы предпочитаем хранить код нашего приложения в подпапке под названием app/. Выполните следующую команду в консоли:
```
mkdir app
cd app
```
##### Добавим файл компонента
Теперь добавьте файл с именем **app.component.ts** и скопируйте в него следующий код:
```
// app/app.component.ts
import {Component} from 'angular2/core';
@Component({
selector: 'my-app',
template: 'My First Angular 2 App
======================
'
})
export class AppComponent { }
```
Давайте подробно рассмотрим этот файл, начиная с самого конца, где мы определяем класс.
##### Класс Компонента
В самом низу файла располагается пустой и ничем не занятый класс под названием AppComponent. Когда мы будем готовы создать независимое приложение, мы сможем дополнить этот класс свойствами и логикой приложения. Наш класс AppComponent пуст, потому что нам не нужно, чтобы он что-то делал в этом QuickStart.
##### Модули
Приложения на Angular модульны. Они включают в себя множество файлов, каждый из которых имеет определённую цель.
Большинство файлов приложения *экспортируют* что-нибудь вроде компонента. Наш файл app.component экспортирует класс AppComponent.
```
// app/app.component.ts (export)
export class AppComponent { }
```
Факт экспорта превращает обыкновенный файл в модуль. Имя файла (без его расширения), как правило, является именем модуля. Таким образом, *'app.component'* — это имя нашего первого модуля.
Более сложные приложения могут иметь дочерние компоненты, которые наследуют AppComponent в визуальном дереве. Более сложные приложения будут иметь больше файлов и модулей, как минимум столько, сколько у них есть компонентов.
QuickStart не сложен: один компонент — это всё, что нам нужно. Однако модули играют фундаментальную организационную роль даже в таком маленьком приложении.
Модули полагаются на другие модули. В приложениях Angular, написанных на TypeScript, когда нам нужно что-то, предоставляемое иным модулем, мы импортируем его. Когда другому модулю требуется сослаться на AppComponent, он импортирует *символ* AppComponent следующим образом:
```
// app/boot.ts
import {AppComponent} from './app.component'
```
Angular также является коллекцией библиотечных модулей. Каждая библиотека представляет собой модуль, составленный из нескольких связанных общим направлением модулей.
Если нам требуется что-то из Angular, мы импортируем это из его библиотечного модуля. И прямо сейчас нам нужно кое-что, чтобы иметь возможность определить метаданные для нашего компонента.
##### Метаданные компонента
Класс становится компонентом Angular, когда мы привязываем к нему метаданные. Angular нуждается в метаданных для того, чтобы понять, как нужно конструировать отображение, и как компонент взаимодействует с другими частями приложения.
Мы определяем метаданные компонента с помощью функции Component из Angular. Мы получаем доступ к этой функции, импортируя её из основной библиотеки Angular — angular2/core.
```
// app/app.component.ts (import)
import {Component} from 'angular2/core';
```
В TypeScirpt мы можем связать функцию и класс через превращение функции в *декоратор*. Для этого перед её названием нужно добавить символ @, и поместить её прямо перед объявлением класса.
```
// app/app.component.ts (metadata)
@Component({
selector: 'my-app',
template: 'My First Angular 2 App
======================
'
})
```
@Component сообщает Angular, что данный класс *является компонентом Angular*. Объект конфигурации, отправляемый в @Component, имеет два поля: selector и template.
Свойство selector определяет обычный CSS селектор для HTML-элемента my-app, выступающего в качестве хоста. Angular создаёт и отображает экземпляр нашего AppComponent каждый раз, когда он сталкивается с my-app в родительском HTML.
> Запомните селектор my-app! Нам будет нужна эта информация, когда мы будем писать наш index.html.
Свойство template содержит шаблон компонента. Шаблон — это разновидность HTML, которая объясняет Angular, как рендерить отображение. Наш шаблон — это единственная строка HTML, объявляющая: **«My First Angular App»**.
Теперь нам нужно как-то объяснить Angular, что этот компонент необходимо загрузить.
##### Запустим его
Добавьте новый файл, boot.ts, в папку app/, и скопируйте в него следующий код:
```
// app/boot.ts
import {bootstrap} from 'angular2/platform/browser'
import {AppComponent} from './app.component'
bootstrap(AppComponent);
```
Нам требуются две вещи для того, чтобы запустить приложение:
1. Браузерная функция Angular bootstrap.
2. Корневой компонент приложения, который мы только что написали.
Мы импортируем и то, и другое. Потом мы вызываем bootstrap и передаём в неё **тип корневого компонента** AppComponent.
> Изучить, почему мы импортируем bootstrap из angular2/platform/browser и почему мы создаём отдельный файл boot.ts, можно в [приложении ниже](#boot).
Мы попросили Angular запустить приложение в браузере с нашим компонентом в качестве корневого. Однако, где же Angular его запустит?
#### Добавим страницу index.html
Angular отображает наше приложение в специфическом месте на нашей странице index.html. Пришло время создать этот файл.
Мы не будем класть index.html в папку app/. Мы расположим его **на один уровень выше, в корневой папке проекта**.
```
cd ..
```
Теперь создайте файл index.html и скопируйте в него следующее:
```
Angular 2 QuickStart
System.config({
packages: {
app: {
format: 'register',
defaultExtension: 'js'
}
}
});
System.import('app/boot')
.then(null, console.error.bind(console));
Loading...
```
Здесь есть 3 секции HTML, которые необходимо отметить:
1. Мы загружаем библиотеки JavaScript, которые нам требуются. angular2-polyfills.js и Rx.js требуются для работы Angular 2.
2. Мы настраиваем нечто, что называется System, и просим его импортировать файл boot, который мы только что написали.
3. Мы добавляем тэг в . **Это то самое место, где обитает наше приложение!**
Что-то должно найти и загрузить модули нашего приложения. Мы используем для этого **SystemJS**. Есть много вариантов, и нельзя сказать, что SystemJS — лучший выбор, но мы его любим, и он работает.
Специфика настройки SystemJS выходит за пределы данного туториала. Мы кратко опишем часть конфигурации в [приложении ниже](#systemjs).
Когда Angular вызывает функцию bootstrap в boot.js, он читает метаданные AppComponent, находит селектор my-app, обнаруживает тэг с именем my-app и загружает наше приложение в этот тэг.
#### Скомпилируем и запустим!
Откройте окно терминала и введите следующую команду
```
npm start
```
Эта команда запускает два параллельных процесса node.
1. Компилятор TypeScript в режиме наблюдения.
2. Статический сервер **lite-server**, который загружает index.html в браузере и обновляет браузер каждый раз, когда код приложения изменяется.
В течение нескольких мгновений вкладка браузера должна открыться и отобразить:
```
My First Angular 2 App
```
Поздравляем! Вы в деле!
> Если вы видите вместо этого Loading..., прочитайте [приложение «Поддержка ES6 браузерами»](#es6support).
##### Внесём несколько изменений
Попробуйте изменить сообщение на «My SECOND Angular 2 app».
Компилятор TypeScript и lite-server наблюдают за вашими действиями. Они должны засечь изменение, перекомпилировать TypeScript в JavaScript, обновить вкладку браузера и отобразить обновлённое сообщение.
Это изящный способ разработки приложений!
Мы закрываем окно терминала когда мы всё сделали для того, чтобы прервать одновременно компилятор и сервер.
#### Финальная структура
Финальная структура нашей папки проекта должна выглядеть так:
```
angular2-quickstart
├── node_modules
├── app
│ ├── app.component.ts
│ └── boot.ts
├── index.html
├── package.json
└── tsconfig.json
```
И вот наши файлы:
**app/app.component.ts**
```
import {Component} from 'angular2/core';
@Component({
selector: 'my-app',
template: 'My First Angular 2 App
======================
'
})
export class AppComponent { }
```
**app/boot.ts**
```
import {bootstrap} from 'angular2/platform/browser'
import {AppComponent} from './app.component'
bootstrap(AppComponent);
```
**index.html**
```
Angular 2 QuickStart
System.config({
packages: {
app: {
format: 'register',
defaultExtension: 'js'
}
}
});
System.import('app/boot')
.then(null, console.error.bind(console));
Loading...
```
**package.json**
```
{
"name": "angular2-quickstart",
"version": "1.0.0",
"scripts": {
"tsc": "tsc",
"tsc:w": "tsc -w",
"lite": "lite-server",
"start": "concurrent \"npm run tsc:w\" \"npm run lite\" "
},
"license": "ISC",
"dependencies": {
"angular2": "2.0.0-beta.0",
"systemjs": "0.19.6",
"es6-promise": "^3.0.2",
"es6-shim": "^0.33.3",
"reflect-metadata": "0.1.2",
"rxjs": "5.0.0-beta.0",
"zone.js": "0.5.10"
},
"devDependencies": {
"concurrently": "^1.0.0",
"lite-server": "^1.3.1",
"typescript": "^1.7.3"
}
}
```
**tsconfig.json**
```
{
"compileroptions": {
"target": "es5",
"module": "system",
"moduleresolution": "node",
"sourcemap": true,
"emitdecoratormetadata": true,
"experimentaldecorators": true,
"removecomments": false,
"noimplicitany": false
},
"exclude": [
"node_modules"
]
}
```
#### Заключение
Наше первое приложение делает не слишком много. Это, по сути, «Hello World» на Angular 2.
Для первого раза мы сделали всё максимально просто: написали небольшой компонент Angular, добавили немного библиотек JavaScript в index.html и запустили статический файловый сервер. В целом, это всё, что мы ожидали от «Hello World»-приложения.
##### У нас более серьёзные амбиции
Хорошая новость в том, что вся возня с установкой нас не касается. Возможно, мы чуть-чуть коснёмся package.json для обновления библиотек. Мы откроем index.html только если нам нужно будет добавить библиотеку или файл css-стилей.
Мы готовы к следующему шагу, и теперь наша задача — сконструировать приложение, которое демонстрирует, насколько великолепные вещи можно сделать с помощью Angular 2.
Присоединяйтесь к нам в [туториале «Геройский тур»](https://angular.io/docs/ts/latest/tutorial)!
#### Приложения
Остаток данной главы посвящён набору приложений, более подробно излагающих кое-какие моменты, которые мы кратко затронули выше.
Здесь нет никакого критически важного материала. Читайте дальше, если вам интересны детали.
##### [↑](#es6support-back) Приложение: Поддержка ES6 браузерами
Angular 2 полагается на некоторые возможности стандарта ES2015, большая часть из которых уже включена в современные браузеры. Однако некоторым браузерам (таким, как IE11), требуются полифиллы (shim) для поддержки этой функциональности. Попробуйте загрузить следующие полифиллы *перед* другими скриптами в index.html:
```
```
##### [↑](#package-json-back) Приложение: package.json
[npm](https://docs.npmjs.com/) — это популярный менеджер пакетов для node, и многие Angular-разработчики используют его для загрузки и управления библиотеками, которые необходимы их приложениям.
Мы определили пакеты, которые нам необходимы в файле npm [package.json](https://docs.npmjs.com/files/package.json).
Команда Angular предлагает использовать пакеты, указанные в секциях dependencies и devDependencies в этом файле:
```
// package.json (dependencies)
{
"dependencies": {
"angular2": "2.0.0-beta.0",
"systemjs": "0.19.6",
"es6-promise": "^3.0.2",
"es6-shim": "^0.33.3",
"reflect-metadata": "0.1.2",
"rxjs": "5.0.0-beta.0",
"zone.js": "0.5.10"
},
"devDependencies": {
"concurrently": "^1.0.0",
"lite-server": "^1.3.1",
"typescript": "^1.7.3"
}
}
```
> Вы можете выбрать и другие пакеты. Мы рекомендуем именно этот набор потому, что знаем, что все его компоненты хорошо работают вместе. Подыграйте нам сейчас, а позже экспериментируйте в своё удовольствие, подбирая варианты, которые будут соответствовать вашим опыту и вкусу.
В package.json может присутствовать необязательная секция **scripts**, в которой мы можем определить полезные команды для выполнения разработки и построения. Мы включаем несколько таких скриптов в предлагаемом нами package.json:
```
// package.json (scripts)
{
"scripts": {
"tsc": "tsc",
"tsc:w": "tsc -w",
"lite": "lite-server",
"start": "concurrent \"npm run tsc:w\" \"npm run lite\" "
}
}
```
Мы уже видели, как можно запустить компилятор и сервер одновременно с помощью этой команды:
```
npm start
```
Мы исполняем скрипты npm в следующем формате: npm run + *название-скрипта*. Вот описание того, что делают скрипты:
* npm run tsc — запуск компилятора TypeScript на один проход
* npm run tsc:w — запуск компилятора TypeScript в режиме наблюдения; процесс продолжает работу, перекомпилируя проект в тот момент, когда засекает изменения, внесённые в файлы TypeScript.
* npm run lite — запускает [lite-server](https://www.npmjs.com/package/lite-server), легковесный статический файловый сервер, написанный и поддерживаемый [Джоном Папа](http://johnpapa.net/) с великолепной поддержкой приложений Angular, которые используют маршрутизацию.
##### [↑](#npm-errors-back) Приложение: Предупреждения и ошибки npm
Всё хорошо, когда любые консольные сообщения, начинающиеся с npm ERR! отсутствуют *в конце работы* **npm install**. Могут быть несколько сообщений npm WARN в течение работы команды — и это превосходный результат.
Мы часто наблюдаем сообщение npm WARN после серии gyp ERR! Игнорируйте его. Пакет может попытаться перекомпилировать себя с помощью node-gyp. Если эта попытка заканчивается неудачей, пакет восстанавливается (обычно на предыдущую версию), и всё работает.
Всё хорошо до тех пор, пока нет ни одного сообщения npm ERR! в самом конце npm install.
##### [↑](#tsconfig-back) Приложение: Конфигурация TypeScript
Мы добавили конфигурационный файл (tsconfig.json) в наш проект, чтобы объяснить компилятору, как нужно генерировать файлы JavaScript. Подробнее про tsconfig.json вы можете узнать из официальной [TypeScript wiki](https://github.com/Microsoft/TypeScript/wiki/tsconfig.json).
Опции и флаги, которые мы добавили в файл, являются наиболее важными.
Хотелось бы немного подискутировать насчёт флага noImplicitAny. Разработчики TypeScript расходятся во мнении относительно того, должен он быть установлен как true или false. Здесь нет точного ответа, и мы всегда можем изменить флаг позже. Но наш выбор может серьёзно повлиять на крупные проекты, так что он достоин дискуссии.
Когда noImplicitAny установлен в позицию false, компилятор, если он не может вывести тип переменной в зависимости от того, как переменная используется, скрыто устанавливает тип переменной в any. Это и значит «скрытый (implicit) any».
Когда noImplicitAny установлен в позицию true, и компилятор TypeScript не может вывести тип, он всё ещё генерирует файл JavaScript, но также и отчитывается об ошибке.
В этом QuickStart и во многих других примерах этого Developer Guide мы устанавливаем noImplicitAny в позицию false.
Разработчики, которые предпочитают более строгую типизацию, должны устанавливать noImplicitAny в позицию true. Мы всё ещё можем установить тип переменной в позицию any, если это кажется наилучшим выбором, но мы должны сделать это явно после того, как немного поразмыслим над необходимостью этого шага.
Если мы устанавливаем noImplicitAny в true, мы можем также получить скрытые ошибки индексации. Если нам кажется, что это больше раздражает, чем помогает, мы можем выключить их с помощью следующего флага.
```
"suppressImplicitAnyIndexErrors":true
```
##### [↑](#systemjs-back) Приложение: Конфигурация SystemJS
QuickStart использует [SystemJS](https://github.com/systemjs/systemjs) для загрузки приложения и библиотечных модулей. Однако не забывайте, что у него есть рабочие альтернативы, такие как высоко оцениваемый сообществом [webpack](https://webpack.github.io/). SystemJS — это неплохой выбор, но мы хотим дать ясное понимание, что это лишь выбор, а не предпочтение.
Все загрузчики модулей требуют конфигурирования, и любое конфигурирование загрузчика становится тем сложнее, чем более разнообразнее становится файловая структура — вплоть до того, что мы начинаем задумываться об объединении файлов для повышения производительности.
Мы рекомендуем вам хорошо разобраться в загрузчике, который вы выберете.
> Узнать больше о конфигурации SystemJS можно [здесь](https://github.com/systemjs/systemjs/blob/master/docs/config-api.md).
Приняв во внимание эти предостережения, что мы можем сделать?
```
System.config({
packages: {
app: {
format: 'register',
defaultExtension: 'js'
}
}
});
System.import('app/boot')
.then(null, console.error.bind(console));
```
Узел packages указывает SystemJS, что делать, если он видит запрос на модуль из папки app/.
Наш QuickStart создаёт такие запросы каждый раз, когда в любом TypeScript-файле приложения обнаруживается подобный оператор импорта:
```
// boot.ts (часть)
import {AppComponent} from './app.component'
```
Обратите внимание, что наименование модуля (после from) не содержит расширения файла. Конфигурация packages задаёт SystemJS расширение по-умолчанию как 'js', то есть файл JavaScript.
Это разумно, потому что мы компилируем TypeScript в JavaScript *прежде*, чем запускать приложение.
> В демо-примере на plunker мы компилируем в JavaScript прямо в браузере на лету. Это неплохо для демо, но это не может стать нашим выбором для разработки или релиза.
>
>
>
> Мы рекомендуем компилировать в JavaScript в течение фазы построения перед тем, как запускать приложение, по нескольким причинам:
>
> * Мы можем видеть ошибки и предупреждения времени компиляции, которые скрыты от нас в браузере.
> * Прекомпиляция упрощает процесс загрузки модулей, да и намного проще найти проблему, когда компиляция является отдельным внешним процессом.
> * Прекомпиляция даёт большую производительность, потому что браузеру нет нужды тратить время на компиляцию.
> * Наша разработка движется быстрее, потому что мы всего лишь перекомпилируем изменившиеся файлы. Разница станет заметна, когда наше приложение будет содержать множество файлов.
> * Прекомпиляция подходит беспрерывному процессу разработки — построению, тестам, деплою.
>
Вызов System.import заставляет SystemJS импортировать файл boot (boot.js… после компиляции boot.ts, помните?) boot — это файл, где мы просим Angular запустить приложение. Мы также отлавливаем и логируем ошибки запуска в консоль.
Все прочие модули загружаются с помощью запроса, который создаётся оператором импорта или самим Angular.
##### [↑](#boot-back) Приложение: boot.ts
###### **Загрузка платформоспецифична**
Мы импортируем функцию bootstrap из angular2/platform/browser, не из angular2/core. Этому есть причина.
Мы можем назвать «ядром» только те возможности, которые одинаковы для всех целевых платформ. Действительно, многие приложения Angular могут быть запущены только в браузере, и мы будем вызывать функцию bootstrap из этой библиотеки наибольшее количество времени. Вполне «core»-фича — если мы пишем исключительно для браузера.
Но ведь вполне возможно загружать компонент в ином окружении. Мы можем загрузить его на мобильном устройстве с помощью [Apache Cordova](https://cordova.apache.org/). Мы можем захотеть отрендерить начальную страницу нашего приложения на сервере для увеличения производительности или содействия [SEO-продвижению](http://static.googleusercontent.com/media/www.google.com/en//webmasters/docs/search-engine-optimization-starter-guide.pdf).
Эти платформы требуют других вариантов bootstrap-функции, которые мы будем загружать из другой библиотеки
###### **Зачем создавать отдельный файл boot.ts?**
Файл *boot.ts* небольшой. Это всего лишь QuickStart. Мы вполне можем вписать эти несколько строк в файл app.component и избавить себя от излишней сложности.
Но мы так не делаем по причинам, которые, как мы верим, являются весомыми:
1. Сделать всё правильно — это просто.
2. Удобство тестирования.
3. Удобство переиспользования.
4. Разделение обязанностей.
5. Изучение импорта и экспорта.
###### **Это просто**
Да, это дополнительный шаг и дополнительный файл. Насколько это сложно в целом?
Мы увидим, что отдельный файл boot.ts предпочтительней для большинства приложений — даже если это не столь важно для QuickStart. Давайте вырабатывать хорошие привычки сейчас, пока цена этому невысока.
###### **Удобство тестирования**
Мы должны думать об удобстве тестирования с самого начала, даже если мы знаем, что никогда не будем тестировать QuickStart.
Это сложно — тестировать компонент, когда в этом же файле присутствует функция bootstrap. Каждый раз, когда мы загружаем файл компонента для тестирования, функция bootstrap пытается загрузить приложение в браузере. Это вызывает ошибку, потому что мы не ожидали запуска целого приложения — лишь компонента.
Перемещение bootstrap-функции в boot.ts убирает ложную ошибку и оставляет нас с чистым файлом компонента.
###### **Переиспользование**
Мы рефакторим, переименовываем и перемещаем файлы в течение эволюции нашего приложения. Мы не сможем сделать ничего из этого, пока файл вызывает bootstrap. Мы не можем переместить его. Мы не можем переиспользовать компонент в другом приложении. Мы не можем отрендерить компонент на сервере для увеличения производительности.
###### **Разделение обязанностей**
Задача компонента — представлять отображение и управлять им.
Запуск приложения не имеет ничего общего с управлением отображением. Это совершенно другая обязанность. Проблемы, с которыми мы столкнулись при тестировании и переиспользовании, исходят именно из этого ненужного смешения обязанностей.
###### **Импорт/Экспорт**
Когда мы писали отдельный файл boot.ts, то получили важный навык для работы с Angular: как экспортировать что-то из одного модуля и импортировать в другой. Мы будем делать много подобного, когда будем более тесно работать с Angular. | https://habr.com/ru/post/273545/ | null | ru | null |
# Хранение данных в Android
В прошлом своем [посте](http://habrahabr.ru/blogs/android/103582/) я писал о создании всплывающих менюшек, сегодня же мы поговорим о более важной теме такой, как хранение данных. В android есть несколько способов хранения данных: общие настройки, бд и тд. В этом посте я расскажу о том как хранить данные в БД.
В качестве БД android использует встраиваемую SQLite. SQLite очень быстрая база, поэтому ее использование на мобильной платформе не приводит к резкому уменьшению производительности. Перейдем к описанию кода. Гугл позаботился о наших нервах и написал небольшой класс утилиту SQLiteOpenHelper.
> `public class DbOpenHelper extends SQLiteOpenHelper{
>
>
>
> private static final int DB\_VERSION = 1;
>
> private static final String DB\_NAME = "test";
>
>
>
> public static final String TABLE\_NAME = "users";
>
> public static final String LOGIN = "login";
>
> public static final String PASSW = "passw";
>
> private static final String CREATE\_TABLE = "create table " + TABLE\_NAME + " ( \_id integer primary key autoincrement, "
>
> + LOGIN + " TEXT, " + PASSW + " TEXT)";
>
>
>
> public DbOpenHelper(Context context) {
>
> super(context, DB\_NAME, null,DB\_VERSION);
>
> }
>
>
>
> @Override
>
> public void onCreate(SQLiteDatabase sqLiteDatabase) {
>
> sqLiteDatabase.execSQL(CREATE\_TABLE);
>
> }
>
>
>
> @Override
>
> public void onUpgrade(SQLiteDatabase sqLiteDatabase, int i, int i1) {
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
При создании экземпляра класса DbOpenHelper будет проверено, существует ли база с именем test, если существует, то будет вызван метод onUpgrade, если нет то onCreate в котором мы создаем таблицу users(обычно в этом методе создают таблицы и инициализируют их значениями по умолчанию). У класса SQLiteOpenHelper есть методы getReadableDatabase и getWritableDatabase, которые возвращают экземпляр класса SQLiteDatabase. С помощью этого экземпляра мы и будет работать с БД. У него есть все нужные нам методы: insert, update, query, delete и тд.
Напишем небольшое приложение сохраняющее логин и пароль в базу
> `public class TestActivity extends Activity {
>
>
>
> EditText loginEditText = null;
>
> EditText passEditText = null;
>
> Button saveButton = null;
>
>
>
> @Override
>
> public void onCreate(Bundle savedInstanceState) {
>
> super.onCreate(savedInstanceState);
>
> setContentView(R.layout.main);
>
>
>
> loginEditText = (EditText) findViewById(R.id.login);
>
> passEditText = (EditText) findViewById(R.id.passw);
>
> saveButton = (Button) findViewById(R.id.btn1);
>
>
>
> saveButton.setOnClickListener(new View.OnClickListener() {
>
> public void onClick(View view) {
>
> DbOpenHelper dbOpenHelper = new DbOpenHelper(TestActivity.this);
>
> SQLiteDatabase db = dbOpenHelper.getWritableDatabase();
>
> ContentValues cv = new ContentValues();
>
> cv.put(DbOpenHelper.LOGIN,loginEditText.getText().toString());
>
> cv.put(DbOpenHelper.PASSW,passEditText.getText().toString());
>
> db.insert(DbOpenHelper.TABLE\_NAME,null,cv);
>
> db.close();
>
> loginEditText.setText("");
>
> passEditText.setText("");
>
> }
>
> });
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
В примере у нас есть окно в котором два поля ввода и кнопка, а по нажатию кнопки происходит сохранение. Вначале мы создаем экземляр класса DbOpenHelper, который создает саму базу и таблицы. Затем получаем объект SQLiteDatabase, методом insert которого будет происходить запись. ContentValues это некая обертка над данными, которые будут записаны в бд. В методе put первым аргументом является имя столбца, а вторым сами данные которые будут записаны в столбец, на языке SQL это выглядит так:
`INSERT INTO users ( 'login','passw') VALUES ('somelogin','somepass')`
В качестве домашнего задания, попробуйте доставать из бд данные и отображать их на экране.
Исходники проекта можно скачать [тут](http://ifolder.ru/19227075).
Отвечу на вопросы в комментах.
P.S. Оригинал в моем [блоге](http://droidstyle.blogspot.com/2010/09/blog-post_11.html)
P.S.S. Хочу начать большой проект под android, требуется программист и дизайнер. | https://habr.com/ru/post/104038/ | null | ru | null |
# Итак, вы всё ещё не понимаете Хиндли-Милнера? Часть 1
Как-то мы сидели в баре с [Джошем Лонгом](https://twitter.com/starbuxman) и ещё несколькими друзьями с работы, когда он обнаружил, что я на «эй, ты!» с математикой. А он как раз недавно наткнулся на [вот этот вопрос на StackOverflow](http://stackoverflow.com/questions/12532552/what-part-of-milner-hindley-do-you-not-understand) и сейчас спросил меня, что это означает:
Однако, перед выяснением смысла данной китайской грамоты, думаю, стоит в принципе получить представление о том, для чего вообще это нужно. [Пост в блоге Даниэля Спивака](http://www.codecommit.com/blog/scala/what-is-hindley-milner-and-why-is-it-cool) ([перевод](http://habrahabr.ru/post/125250/)) даёт по-настоящему хорошее объяснение конечной цели алгоритма Хиндли-Милнера (в дополнение к углубленному примеру его применения):
> Функционально говоря, Хиндли-Милнер (или Дамас-Милнер) — это алгоритм для вывода типов, основанный на рассмотрении того, как они используются. Он буквально формализует интуитивное знание о том, что тип может быть выведен через функционал, который он поддерживает.
Итак, мы хотим формализовать алгоритм вывода типа для любого заданного выражения. В этом посте я собираюсь остановиться на том, что означает «формализовать что-то», а затем описать «кирпичики» формализации Хиндли-Милнера. Во второй части я дам более конкретное описание этих блоков. Наконец, в третьей части я переведу вопрос со StackOverflow.
#### Что означает «формализовать»?
Итак, мы собираемся говорить о выражениях. Произвольных выражениях. На произвольном языке. А ещё мы хотим поговорить о выводе типов для этих выражений. И мы хотим выяснить правила, по которым мы смогли бы выводить типы. А затем мы хотим создать алгоритм, который использовал бы эти правила для вывода типов. Таким образом, нам нужен некий мета-язык. Такой, чтобы с его помощью можно было говорить о выражении на любом произвольном языке программирования. Этот мета-язык должен:
* Быть абстрактным и общим для того, чтобы позволить нам рассуждать об утверждениях вывода типа, исходя исключительно из их *формы* (отсюда *формализация*), не заботясь о содержании
* Давать точное, однозначное, но интуитивно понятное определение того, чем выражение является
* Давать это определение в терминах малого числа бесспорных примитивных понятий
* Аналогичным образом давать определение для типов, идею того, что выражение имеет тип, и идею, что мы можем вывести положение о том, что данное выражение имеет данный тип
* Поддаваться простому, краткому символическому представлению. Т.е. вместо того, чтобы говорить «выражение, сформированное путём применения первого выражения к второму выражению, имеет тип функции от строки к какому-то типу, который нам нет необходимости специализировать в данном контексте», мы можем просто сказать "`e`1(`e`2):`String`→`t`"
* Легко транслироваться во что-то, что компьютер может понять и реализовать, чтобы могли полностью автоматизировать вывод типов
Чтобы придать вышесказанному больше конкретики, давайте рассмотрим очень короткий пример формализации. Что если вместо того, чтобы формализовать язык для разговора о выводе типов выражений в произвольном языке программирования, мы захотим формализовать язык для разговора об истинности высказывания на произвольном естественном языке? Без формализации мы могли бы сказать что-то вроде:
> Предположим, я знаю, что если идёт дождь, то Боб всегда берёт зонт.
>
> И предположим, что я знаю, что сейчас идёт дождь.
>
> Таким образом, я могу заключить, что Боб взял зонт.
>
>
>
> И любой аргумент, имеющий эту же форму, является допустимым для подобного вывода.
Исчисление высказываний формализует все эти вещи в виде правила, известного как Modus Ponens («правило вывода»):
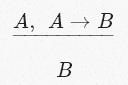
где `А` и `В` — переменные, представляющие утверждения (a.k.a. предложения или положения) в произвольном естественном языке.
А теперь давайте перечислим строительные блоки формализации Хиндли-Милнера:
#### Строительные блоки формализации
Нам потребуются:
1. Формальный способ, чтобы говорить о выражениях. Эта формализация должна соответствовать критериям, перечисленным выше; для этой цели мы используем **лямбда-исчисление**. Я всё объясню буквально через минуту, но тут нет ничего сверхъестественного
2. Формальный способ, чтобы говорить о типах, и формальный способ, чтобы говорить о типах и выражениях вместе. В конце-концов, цель алгоритма Хиндли-Милнера — быть способным вывести заключение вида «выражение `e` имеет тип `t`»
3. Формальный набор правил для получения утверждений о типе выражения через другие утверждения. Эти правила наподобие: «если я уже могу продемонстрировать, что некое выражение имеет один тип, а другое выражение — второй тип, то третье выражение будет иметь третий тип». *Такой набор правил — в точности то, что вы видите в вопросе со StackOverflow*. Я переведу его во всех подробностях
4. Алгоритм должен разумно использовать правила вывода, чтобы из отправной точки вывести требуемое утверждение: «Интересующее меня выражение `e` имеет тип `t`». За это отвечает часть «алгоритм» в словосочетании «алгоритм Хиндли-Милнера», и в этих постах я не планирую обсуждать этот вопрос.
Чтож, поехали!
* [Часть 2](http://habrahabr.ru/post/185686/), в которой мы чётко определимся по пунктам 1 и 2
* [Часть 3](http://habrahabr.ru/post/189446/), в которой мы переведём правила вывода типов из пункта 3
*Примечание переводчика: я буду очень признательна за любые замечания в личку по поводу перевода.* | https://habr.com/ru/post/185362/ | null | ru | null |
# Reverse tethering (получаем интернет на android с ПК linux)
Так как 3g интернет в месте использования телефона у меня медленный, то решено было попытаться использовать интернет от компьютера, на телефоне. Я был удивлен тем, что это стандартными средствами невозможно. Решил сделать нестандартными. Итак, нам понадобятся:
1. busybox
2. root
3. GScript Lite, либо эмуль терминала. GScript лучше, так как позволит сделать ярлычок на раб столе что бы не парится все время с скриптом.
4. Еще может пригодится утилита ifconfig, их много вариантов для андроида, выбрать тот, который похож на линуксовый… то бишь полноценный (но эта утилита только для справки, например если имя сетевого интерфейса, который создали для связи с компом, сменится).
Делать надо так:
1. Сопрягаем телефон с компом… ну тут ясно и инструкций полно.
2. На телефоне лезем в настройки->еще->Режим модема->«Общий интернет по bluetooth» и ставим галку.
2. Лезем в апплет блютуза и выбираем «параметры» (это на компе). Я пользуюсь ubuntu так что там есть апплет, для других дистров есть другие варианты и вы сами знаете куда надо нажать.
3. В параметрах видим свой телефон (мы его сопрягли). Заходим на него и выбираем «Использовать как сетевое устройство (PAN/NAP)». Делать это лучше один раз, NetworkManager, запоминает каждый раз по отдельности и стереть прошлые не дает, так что у меня там список, штук в двадцать пунктов из копий моего телефона. Позже, скрипт накатаю прямой, конечно. Можно посмотреть в сторону blueman он умеет то же.
4. Лезем в NetworkManager и, о чудо, там есть наш телефон, нажали на него.
5. В телефоне, если пункт 2 выполнен, придет оповещение «разрешить ли подключится точке доступа?». Разрешаем.
6. PROFIT1!!! Сеть поднялась. Мне выдает на компе адрес 192.168.44.39, на телефоне 192.168.44.1
7. На компе запускаем такое (у меня давно такое в стартовых скриптах, для домочадцев):
```
#!/bin/sh
modprobe ipt_MASQUERADE
iptables -F; iptables -t nat -F; iptables -t mangle -F
echo 1 > /proc/sys/net/ipv4/ip_forward
iptables -A FORWARD -s ip_адрес_телефона(192.168.44.1) -j ACCEPT
iptables -A FORWARD -d ip_адрес_телефона(192.168.44.1) -j ACCEPT
iptables -t nat -A POSTROUTING -o имя_сетевого_интерфейса_с_интернетом(wlan1 у меня или ppp0 или eth0) -s ip_адрес_телефона(192.168.44.1) -j MASQUERADE
```
Это мы запустили NAT что бы пакеты от телефона, пришедшие нам, отправлять дальше в интернет. То бишь стали шлюзом.
8. Пишем в GSCript или терминале такое (на телефоне):
```
busybox route add -net default gw ip_адрес_компа(192.168.44.39) имя_сетевого_интерфейса_связанного_с_компом(btn0)
```
btn0 — это как раз имя сетевого интерфейса, который с компом связан у телефона.
Эта команда требует права root на телефоне.
9. PROFIT2!!! Имеем работающий интернет на телефоне, через комп, по блютузу.
Сейчас у меня на рабочем столе телефона есть ярлык для настройки шлюза по умолчанию (GSCript-овый). Я создаю сеть с телефоном, а потом запускаю ярлык. Интернет пашет, надо несколько секунд что бы до браузера или еще кого там в потрохах, доперло, что интернет уже есть. Осталось только сделать скриптик на компе, что бы сеть поднимать с такой же кнопочки, или найти софтину для андроида которая это умеет то же кнопочкой со стороны телефона. С телефона оно удобнее будет. Вот собственно и все. | https://habr.com/ru/post/152080/ | null | ru | null |
# Новое в Ext GWT 3.0
JavaScript-библиотеки Ext JS и Ext GWT известны, помимо прочего, одним из лучших наборов визуальных компонентов — как по дизайну, так и по кроссбраузерности, да и по стабильности работы. Потому и руки сами тянутся к любому проекту на GWT добавить Ext и заменить скучные гугловые виджеты на симпатичные формы и окошки.
Однако интеграция Ext GWT и GWT до сих пор оставляла желать лучшего — по сути, вторая версия Ext GWT полностью вытесняет все средства компоновки интерфейса GWT, предлагая собственные API для всего, вплоть до обработки событий. Поэтому для третьей версии библиотеки, доступной сейчас в виде [developer preview](http://www.sencha.com/blog/ext-gwt-3-developer-preview-2/), разработчики из Sencha активно переписывают скриптовое наследие Ext JS, используя паттерны и идиомы, принятые в GWT. Главное ожидаемое преимущество — более корректная интеграция с GWT и, как следствие, более компактный и оптимизированный код интерфейса: генерация и обфускация JavaScript и CSS происходит на этапе GWT-компиляции, с использованием механизма deferred binding, за счёт чего исключаются фрагменты кода, не использующиеся в текущем проекте.
#### Реализация виджетов с использованием Appearance
Одним из паттернов, перенятых у GWT, стал Appearance, позволяющий выделить виджет, его разметку, стиль и связующую логику в независимые и заменяемые части. Такой подход позволяет легко менять стили и темы виджетов, и даже их разметку — например, использовать в качестве DOM-реализации кнопки либо div, либо button. Вот простейший пример применения паттерна Appearance для простой div-кнопки, у которой можно изменять текст и иконку:
```
public interface Appearance {
void render(SafeHtmlBuilder sb);
void onUpdateText(XElement parent, String text);
void onUpdateIcon(XElement parent, Image icon);
}
public static class DefaultAppearance implements Appearance {
public interface Style extends CssResource {
String testButton();
String testButtonText();
String testButtonImage();
}
public interface Resources extends ClientBundle {
@Source("DefaultAppearance.css")
Style style();
}
public interface Template extends XTemplates {
@XTemplate(source = "DefaultAppearance.html")
SafeHtml template(Style style);
}
private final Style style;
private final Template template;
public DefaultAppearance() {
this((Resources) GWT.create(Resources.class));
}
public DefaultAppearance(Resources resources) {
this.style = resources.style();
this.style.ensureInjected();
this.template = GWT.create(Template.class);
}
@Override
public void onUpdateIcon(XElement parent, Image icon) {
XElement element = parent.selectNode("." + style.testButtonImage());
element.removeChildren();
element.appendChild(icon.getElement());
}
@Override
public void onUpdateText(XElement parent, String text) {
parent.selectNode("." + style.testButtonText()).setInnerText(text);
}
@Override
public void render(SafeHtmlBuilder sb) {
sb.append(template.template(style));
}
}
```
Вложенный интерфейс Style представляет стиль отрисовки компонента. По умолчанию он связывается с внешним файлом DefaultAppearance.css — эта связь задаётся в интерфейсе Resources. Наконец, третий вложенный интерфейс, Template, представляет разметку компонента, и связан по умолчанию с внешним файлом DefaultAppearance.html. В конструкторе объекта DefaultAppearance можно переопределить реализацию интерфейса Resources, таким образом заменив стиль или тему компонента. Аналогичным образом можно поменять шаблон Template, или даже весь объект DefaultAppearance целиком — виджету достаточно знать простой интерфейс Appearance, чтобы делегировать ему установку параметров или обработку событий.
В итоге Ext GWT даёт нам три точки расширения, через которые мы можем повлиять на отображение виджета: изменив его CSS-стиль, HTML-разметку, либо полностью переопределив объект Appearance и механизм, с помощью которого он взаимодействует с DOM для отрисовки виджета. Благодаря паттерну Appearance все эти аспекты оказываются аккуратно отделёнными друг от друга.
#### JavaBean-объекты как модели данных
Наконец-то можно будет отказаться от интерфейса ModelData, в который необходимо было раньше оборачивать любые JavaBean-объекты, чтобы они могли служить моделями данных. В Store и Loader возможно станет использовать любые объекты, не связанные какими-либо контрактами интерфейсов и не расширяющие специализированные классы. Всё это достигается за счёт магии deferred binding — код для доступа к конкретным полям объекта генерируется на этапе GWT-компиляции. Пока что примеры нового API для работы с хранилищами и загрузчиками отсутствуют, зато новшество продемонстрировано на примере другого нововведения — переработанного механизма шаблонов XTemplate:
```
interface TemplateTest extends XTemplates {
@XTemplate("{name}")
SafeHtml renderCustomer(Customer customer);
@XTemplate(source="template.html")
SafeHtml renderCustomerExternal(Customer customer);
}
...
TemplateTest template = GWT.create(TemplateTest.class);
SafeHtml html = template.renderCustomer(customer);
```
Поля любого переданного объекта теперь можно использовать непосредственно в теле шаблона — так, в приведённом коде используется поле customer.name. Для тестирования этого кода мне не пришлось даже объявлять каких-либо мета-интерфейсов — всё необходимое генерируется магически на этапе компиляции. Сам шаблон, как видно из примера, может содержаться либо в строке-значении аннотации XTemplate, либо во внешнем файле, имя которого помещается в поле source той же аннотации. Результатом применения шаблона становится безопасный HTML — безопасный в том смысле, что полученный SafeHtml аккуратно обращается с возможными источниками XSS-атак в переданных полях и значениях.
#### UiBinder: декларативная раскладка интерфейса
Ещё одна давно ожидаемая функция — интеграция с существующим ещё с GWT 2.0 механизмом разметки интерфейса в XML — UiBinder. Он позволяет вынести во внешний XML-файл раскладку компонентов, сделав её декларативной и структурированной и отделив от логики интерфейса, прописанной в Java-коде. До сих пор UiBinder был доступен лишь для стандартных виджетов и контейнеров GWT, однако сейчас разработчики Ext GWT активно работают над интеграцией с ним собственных компонентов. Основной проблемой, из-за которой API ещё до конца не зафиксирован и даже вынесен в отдельный jar-файл, является сложность настройки контейнеров с помощью LayoutData — текущая реализация UiBinder не позволяет писать собственные парсеры для атрибутов XML-разметки. Разработчики Ext GWT и GWT сейчас занимаются согласованием изменений в GWT, которые сделают это возможным. Пока что предлагается следующий вариант (корневые теги для удобочитаемости опущены):
```
```
Легко видеть, что предлагаемый синтаксис поля layoutData чем-то напоминает CSS-стили в атрибутах. Для работы этого механизма необходимо подключить к проекту библиотеки gxt-uibinder-3.0.0-SNAPSHOT.jar и uibinder-bridge-2.3.0-SNAPSHOT.jar. Однако надо сказать, что у меня так и не получилось протестировать приведённый пример — GWT упорно отказывался преобразовывать неизвестное ему содержимое layoutData в объект BorderLayoutData.
#### Заключение
К прочим мелким приятностям в новой версии библиотеки можно отнести:
* унифицированный с GWT механизм обработки событий — никаких листенеров, стандартные хендлеры;
* переведённые с Flash на JavaScript графики — примеры из имеющегося в дистрибутиве приложения Ext GWT Explorer, как обычно, впечатляют вылизанностью и быстродействием;
* некоторые упрощения в контейнерах и раскладках — контейнеры LayoutContainer отныне жёстко связаны с раскладками Layout (RowLayoutContainer, BorderLayoutContainer, и т.д.), что несколько облегчает их конфигурацию и обеспечивает при этом типовую безопасность.
В заключение отмечу, что текущая версия Ext GWT 3.0 работает в связке с GWT 2.3.0, и требует как минимум Java 1.6 для успешной компиляции, что обусловлено в том числе и требованиями самого GWT. Поменялся и корневой пакет библиотеки — в духе недавнего ребрендинга компании com.extjs был заменён на com.sencha. Разработчики обещают выпускать новые версии developer preview раз в несколько недель, однако отмечают, что эти версии пока лишь демонстрируют новые функции и ещё не зафиксированный API, а потому не рекомендуются для использования в разработке.
#### Ссылки
* [Ext GWT 3.0 Appearance Design](http://www.sencha.com/blog/ext-gwt-3-appearance-design/)
* [Ext GWT 3.0 XTemplate Redesign](http://www.sencha.com/blog/ext-gwt-3-xtemplate-redesign/)
* [Ext GWT 3.0 Developer Preview 1](http://www.sencha.com/blog/ext-gwt-3-dev-preview-1/)
* [Ext GWT 3.0 Developer Preview 2](http://www.sencha.com/blog/ext-gwt-3-developer-preview-2/) | https://habr.com/ru/post/124384/ | null | ru | null |
# Обращение к Javascript-сообществу: перестаньте писать квадраты
**Disclaimer:** в этой статье будет очень много бредовых примеров и сверх очевидных утверждений. Если для вас предельно очевидно, что `...` внутри `.reduce` даёт вам `O(n^2)`, то можно сразу прыгать к разделу "Критика" или просто проигнорировать статью. Если же нет, милости прошу под cut.
Предисловие
-----------
Все мы знаем про стандартную конструкцию `for (;;)` которая чаще всего, в реальном коде, имеет примерно такой вид:
```
for (let idx = 0; idx < arr.length; ++ idx) {
const item = arr[idx];
// ...
}
```
Далеко не все из нас любят ей пользоваться (*только давайте обойдёмся без холиваров на эту тему, статья не об этом*), особенно в простых сценариях, т.к. когнитивная нагрузка довольно высока ― очень много малозначительных или даже ненужных деталей. Например в таком вот сценарии:
```
const result = [];
for (let idx = 0; idx < arr.length; ++ idx) {
const item = arr[idx];
result.push(something(item));
}
return result;
```
Большинство из нас предпочтёт более компактную и наглядную версию:
```
return arr.map(something);
// или
return arr.map(item => something(item));
```
**note**: *2-й вариант избавит вас от потенциальных проблем в будущем, когда* `something` *может внезапно обзавестись вторым аргументом. Если он будет числовым, то даже Typescript вас не убережёт от такой ошибки.*
Но не будем отвлекаться. О чём собственно речь?
Всё чаще и чаще мы видим в живом коде такие методы как:
* `.forEach`
* `.map`
* `.reduce`
* и другие
В общем и в целом они имеют ту же bigO complexity, что и обыкновенные циклы. Т.е. до тех пор, пока речь не заходит об экономии на спичках, программист волен выбирать ту конструкцию, что ему ближе и понятнее.
Однако всё чаще и чаще вы можете видеть в обучающих статьях, в библиотечном коде, в примерах в документации код вида:
```
return source.reduce(
(accumulator, item) => accumulator.concat(...something(item)),
[]
);
```
или даже:
```
return Object
.entries(object)
.reduce(
(accumulator, value, key) => ({
...accumulator,
[key]: something(value)
}),
{}
);
```
Возможно многие из вас зададутся вопросом: а что собственно не так?
**Ответ**: вычислительная сложность. Вы наблюдаете разницу между `O(n)` и `O(n^2)` .
Давайте разбираться. Можно начать с `...` -синтаксиса. Как эта штука работает внутри? Ответ: она просто итерирует всю коллекцию (будь то элементы массива или ключи-значения в объекте) с 1-го до последнего элемента. Т.е.:
```
const bArray = [...aArray, 42]
```
это примерно тоже самое, что и:
```
const bArray = [];
for (let idx = 0; idx < aArray.length; ++ idx)
bArray.push(aArray[idx]);
```
Как видите, никакой магии. Просто синтаксический сахар. Тоже самое и с объектами. На лицо очевидная сложность `O(n)`.
Но давайте вернёмся к нашему `.reduce`. Что такое `.reduce`? Довольно простая штука. Вот **упрощённый** полифил:
```
Array.prototype.reduce = function(callback, initialValue) {
let result = initialValue;
for (let idx = 0; idx < this.length; ++ idx)
result = callback(result, this[idx], idx);
return result;
}
```
Наблюдаем всё тот же `O(n)`. Уточню почему - мы пробегаем ровно один раз по каждому элементу массива, которых у нас N.
Что же тогда у нас получается вот здесь:
```
return source.reduce(
(accumulator, item) => accumulator.concat(...something(item)),
[]
);
```
Чтобы это понять надо, ещё посмотреть, а что такое `.concat`. В документации вы найдёте, что он возвращает **новый массив**, который состоит из переданных в него массивов. По сути это поэлементное копирование всех элементов. Т.е. снова `O(n)`.
Так чем же плох вышеприведённый код? Тем что на каждой итерации в `.reduce` происходит копирование всего массива `accumulator`. Проведём мысленный эксперимент. Заодно упростим пример (но проигнорируем существование `.map`, так как с ним такой проблемы не будет):
```
return source.reduce(
(accumulator, item) => accumulator.concat(something(item)),
[]
);
```
Допустим наш `source.length` === `3`. Тогда получается, что `.reduce` сделает 3 итерации.
* На 1-й итерации наш `accumulator` пуст, поэтому по сути мы просто создаём новый массив из одного элемента. `// []`
* на 2-й итерации наш `accumulator` уже содержит один элемент. Мы вынуждены скопировать его в новый массив. `// [1]`
* на 3-й итерации уже 2 лишних элемента. `// [1, 2]`
Похоже на то, что мы делаем лишнюю работу. Представьте что `length` === `1000`. Тогда на последней итерации мы будем впустую копировать уже **999 элементов**. Напоминает [алгоритм маляра Шлемиля](https://traditio.wiki/%D0%90%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC_%D0%BC%D0%B0%D0%BB%D1%8F%D1%80%D0%B0_%D0%A8%D0%BB%D0%B5%D0%BC%D0%B8%D1%8D%D0%BB%D1%8F#:~:text=%D0%90%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%CC%81%D1%82%D0%BC%20%D0%BC%D0%B0%D0%BB%D1%8F%D1%80%D0%B0%CC%81%20%D0%A8%D0%BB%D0%B5%D0%BC%D0%B8%D1%8D%CC%81%D0%BB%D1%8F%20%E2%80%94%20%D0%BD%D0%B5%D1%8D%D1%84%D1%84%D0%B5%D0%BA%D1%82%D0%B8%D0%B2%D0%BD%D1%8B%D0%B9%20%D0%B0%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC,%D0%BF%D0%BE%20%D0%BC%D0%B5%D1%80%D0%B5%20%D0%B2%D0%BE%D0%B7%D1%80%D0%B0%D1%81%D1%82%D0%B0%D0%BD%D0%B8%D1%8F%20%D0%BE%D0%B1%D1%8A%D1%91%D0%BC%D0%B0%20%D1%80%D0%B0%D0%B1%D0%BE%D1%82.&text=%D0%9C%D0%B0%D0%BB%D1%8F%D1%80%20%D0%A8%D0%BB%D0%B5%D0%BC%D0%B8%D1%8D%D0%BB%D1%8C%20%D0%BF%D0%BE%D0%B4%D1%80%D1%8F%D0%B4%D0%B8%D0%BB%D1%81%D1%8F%20%D0%BA%D1%80%D0%B0%D1%81%D0%B8%D1%82%D1%8C%20%D0%BF%D1%83%D0%BD%D0%BA%D1%82%D0%B8%D1%80%D0%BD%D1%8B%D0%B5%20%D0%BE%D1%81%D0%B5%D0%B2%D1%8B%D0%B5%20%D0%BB%D0%B8%D0%BD%D0%B8%D0%B8%20%D0%BD%D0%B0%20%D0%B4%D0%BE%D1%80%D0%BE%D0%B3%D0%B0%D1%85.), не так ли?
Как нетрудно догадаться, чем больше `length` , тем больше лишней работы выполняет процессор. А это в свою очередь:
* замедляет программу
* т.к. Javascript однопоточный - препятствует работе пользователя с UI
* тратит батарейку ноутбука или телефона на бесполезную работу
* греет ваше устройство и заставляет работать кулер
В случае объектов ситуация ещё хуже, т.к. там речь идёт не о быстрых массивах, которые имеют многоуровневые оптимизации, а о dictionaries, с которыми, если кратко, всё сложно.
Но что можно с этим поделать? Много чего. Самое главное - переиспользовать тот же самый массив\объект:
```
// вместо
(accumulator, item) => accumulator.concat(...something(item))
// вот так
(accumulator, item) => {
accumulator.push(...something(item));
return accumulator; // это ключевая строка
}
```
```
// вместо
(accumulator, value, key) => ({
...accumulator,
[key]: something(value)
},
// вот так
(accumulator, value, key) => {
accumulator[key] = something(value);
return accumulator;
}
```
Стало чуть менее нагляднее (возможно), но разительно быстрее. Или нет? Давайте разбираться.
Как я уже сказал выше, всё зависит от размера коллекции. Чем больше итераций, тем больше разница. Я провёл пару простых тестов в Chrome и Firefox:
Firefox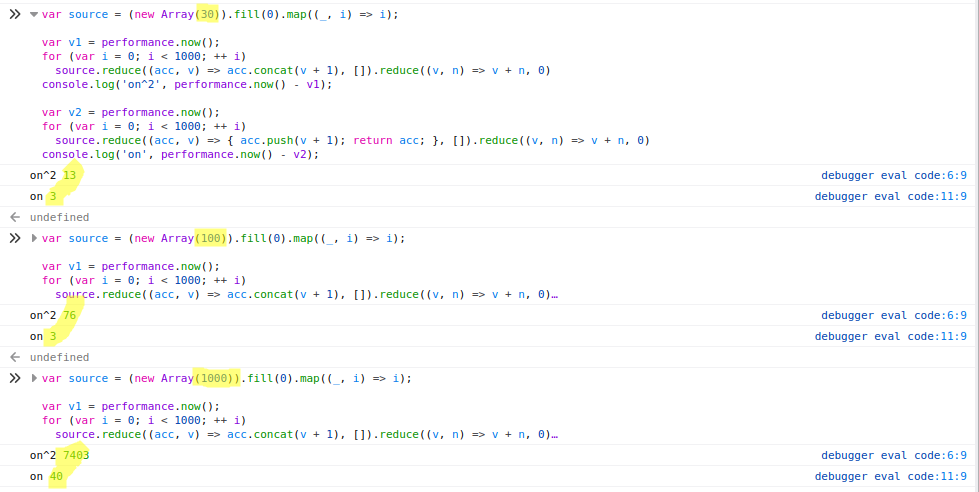ChromeПри length=30 разница не очень убедительная (13 vs 3). При length=1000 уже становится особенно больно (2600 vs 30).
Критика
-------
Я понимаю, что к этому моменту будет уже много недовольных моими обобщениями. Простите, я попытался написать максимально просто. Но давайте пройдёмся по наиболее популярным аргументам против:
1. При малых N вы не заметите разницу
-------------------------------------
Что же, это valid point. Если N=3, то разница столь невелика, что едва ли вы хоть когда-нибудь столкнётесь с её последствиями. ~~Правда ваши друзья из мира C++ перестанут с вами здороваться~~. Особенно в мире Javascript, который как известно скриптовый язык с динамической типизацией, и, поэтому, не предназначен для решения задач, которые требуют настоящей производительности. ~~Что впрочем не мешает ему проникать даже в эти отрасли, вызывая потоки гнева~~
А что если у нас не 3 элемента, а скажем 30. На моих синтетических "наколеночных" тестах получилась разница в 4 раза. Если этот участок кода выполняется единожды, а не, скажем, в цикле, то вы, скорее всего, точно также не сможете ничего заметить. Ещё бы, ведь речь идёт о долях миллисекунды.
Есть ли тут подводные камни? На самом деле да. Я бы сказал, что тут возможны (как минимум) две проблемы.
* **Первая проблема**: сегодня ваш код исполняется единожды. Завтра вы запускаете его для какого-нибудь большого списка. Скорее всего даже не заглянув внутрь (в больших проектах это может быть очень непросто). В итоге та изначально небольшая разница, может начать играть весомую роль. И моя практика показывает, что ~~хочешь рассмешить бога, расскажи ему о своих планах~~ мы слишком часто ошибаемся в своих суждениях относительно того, как наш код будет использоваться в будущем.
* **Вторая проблема**: у вас ваш код запускается для 30 элементов. Okay. Но среди ваших пользователей есть 5% таких, у которых немного нестандартные потребности. И у них уже почему-то не 30, а 300. Кстати, возможно эти 5% пользователей делают 30% вашей выручки.
Приведу пример. На немецком сайте Ikea (надеюсь они это уже исправили) была проблема: при попытке купить больше 10-12 товаров корзина заказа начинала настолько люто тормозить, что почти любая операция с ней сводилась к 40 секундным задержкам. Т.е. до глупого забавная ситуация: человек хочет купить больше, т.е. отдать компании больше денег, но т.к. где-то внутри сокрыты алгоритмы маляра Шлемиля, он не может этого сделать. Полагаю разработчики ничего об этом не знали. И QA отдел тоже (если он у них есть). Не переоценивайте ваших посетителей, далеко не каждый будет готов ждать по 40 секунд на действие. Признаю, что пример экстремальный. Зато показательный.
**Итого**: в принципе всё верно. Для большинства ситуаций вы и правда не заметите разницы. Но стоит ли это того, чтобы экономить **одну единственную строку**? Ведь для того, чтобы избежать этой проблемы, не требуется менять алгоритм, не требуется превращать код в нечитаемый ад. Достаточно просто мутировать итерируемую коллекцию, а не создавать новую.
По сути всё сводится к: каковы мои трудозатраты и каков мой результат. Трудозатраты - одна строка. Результат - гарантия того, что у вас не возникнут "тормоза" на абсолютно ровном месте.
2. Чистые функции в каждый дом
------------------------------
Кто-то может возразить, что пока мы возвращаем в каждой итерации новый массив наша функция чиста, а как только мы начинаем в ней что-нибудь мутировать, мы теряем драгоценную purity. Ребята, любящие FP, у меня для вас замечательная новость: вы можете сколько угодно **мутировать** в своих чистых функциях state. Они от этого не перестают быть чистыми. ~~И тут в меня полетели камни~~.
Да, это не шутка (собственно настоящие FP-ы об этом прекрасно знают). Ваша функция должна удовлетворять всего двум критериям, чтобы оставаться чистой:
* быть детерминированной
* не вызывать **side** effect-ов
И да, мутация это effect. Но обратите внимание на слово "**side**". В нём вся соль. Если вы мутируете то, что было целиком и полностью создано внутри вашей функции, то вы не превращаете её в грязную. Условно:
```
const fn = () => {
let val = 1;
val = 2;
val = 2;
return val;
}
```
Это всё ещё чистая функция. Т.к. `val` существует только в пределах конкретного вызова метода и он для неё локален. А вот так уже нет:
```
let val = 1;
const fn = () => {
val = 2;
return val;
}
```
Т.е. не нужно идти ни на какие сделки с совестью (а лучше вообще избегать всякого догматизма), даже если чистота ваших функций вам важнее чистоты вашего тела.
3. Умный компилятор всё оптимизирует
------------------------------------
Тут я буду краток: нет, не оптимизирует. Попробуйте написать свой, и довольно быстро поймёте, что нет никакой магии. Да внутри v8 есть разные оптимизации, вроде этой ([Fast\_ArrayConcat](https://github.com/v8/v8/blob/bf4b542a1b31bbe8106e394b1dbeff02571dff4b/src/builtins/builtins-array.cc#L1458)). И да, они не бесполезны. Но не рассчитывайте на магию. Увы, но мы не в Хогвартсе. Математические законы превыше наших фантазий.
По сути для того чтобы избежать `O(n^2)` в такой ситуации, компилятору необходимо догадаться, что сия коллекция точно никому не нужна и не будет нужна в текущем виде. Как это гарантировать в языке, в котором почти ничего нельзя гарантировать (из-за гибкости и обилия абстракций)?
Причина
-------
Зачем эта статья? От безысходности и отчаяния. Мне кажется основной причиной этой широко распространённой проблемы является React и Redux, с их любовью к иммутабельности. Причём не сами эти библиотеки, а различные материалы к ним (коих тысячи), где встречается этот "паттерн". Если по началу это можно было объяснить тем, что хочется приводить максимально простые примеры, то сейчас это стало mainstream-ом.
Вот например:
> PS: coming-out - часто делаю concat внутри reduce 🙂 в 99% задач вроде не сильно афектит
>
>
Или [вот](https://engineering.tines.com/blog/understanding-why-our-build-got-15x-slower-with-webpack):
```
getDependencies(nodes) {
this.processQueue();
return nodes.reduce(
(acc, node) => acc.concat(Array.from(this.dependencies.get(node) || [])),
[]
);
}
```
> *I'm pretty surprised that this has any impact, I don't have a good rationale for why but it appears to be dramatically faster to update the array in place.*
>
>
Складывается ощущение, что этот "паттерн" применяется почти в каждой второй статье про Javascript. Я думаю настало время что-то с этим делать. Люди на собеседованиях не видят никакой проблемы в вызове `.includes` внутри `.filter` и подобных штуках. `...`-синтаксис по их мнению работает за `O(1)`. А `v8` переполнен магией. Люди с 7-ю+ годами боевого опыта делают удивлённые глаза и не понимают, что может пойти не так. Впрочем это уже другая история.
**P.S.** по вопросам опечаток и стилистических ошибок просьба обращаться в личку. | https://habr.com/ru/post/590663/ | null | ru | null |
# Создание неблокирующего TCP сервера с использованием принципов OTP
#### Вступление
Предполагается, что читатель этого руководства, уже знаком с *gen\_server* и *gen\_fsm* поведениями, взаимодействиям посредством TCP сокетов с использованием модуля *gen\_tcp*, активным и пассивным режимами сокетов, и принципом «OTP Supervisor».
OTP предоставляет удобный инструментарий для создания надежных приложений. Отчасти, это осуществляется путем абстрагирования общей функциональности в поведения, такие как *gen\_server* и *gen\_fsm*, которые связаны иерархией cупервизоров OTP.
Существует несколько известных шаблонов TCP сервера. Тот, который мы собираемся рассмотреть включает в себя один слушающий процесс и процесс создания нового FSM процесса на каждого подключившегося клиента. Хотя существует поддержка TCP соединений в OTP через *gen\_tcp* модуль, не существует стандартного поведение для создания неблокирующего TCP сервера опираясь на принципы OTP. Под неблокирующим сервером мы подразумеваем, что слушающий процесс и FSM-процесс не должны делать каких-либо блокирующих вызовов и быстро реагировать на входящие сообщения (например, изменения в конфигурации, перезапуск и т.д.), не вызывая таймауты. Обратите внимание, что блокировка в контексте Erlang означает блокировку процесса Erlang, а не процесса операционой системы.
В этом руководстве мы покажем, как создать неблокирующий TCP сервер, используя *gen\_server* и *gen\_fsm*, которые предоставляют контроль над поведением приложения и полностью удовлетворяют принципам OTP.
Читателю, который не знаком с OTP, рекомендуется обратить внимание на руководство Джо Армстронга о том, как построить отказоустойчивые сервера с использованием блокирующих вызовов *gen\_tcp:connect/3* и *gen\_tcp:acceept/1* без использования OTP.
#### Структура сервера
Дизайн нашего сервера будет включать в себя основной процесс-супервизор приложения *tcp\_server\_app* со стратегией перезапуска *one\_for\_one* и два дочерних процесса. Первый из которых является слушающим процессом, реализованным как *gen\_server*, который будет ждать асинхронных уведомлений о клиентских подключениях. Второй является другим супервизором приложения *tcp\_client\_sup* и отвечает за запуск FSM-процесса обработки клиенских запросов и регистрации ненормальных отключений с помощью стандартных отчетов SASL об ошибках.
Для простоты этого материала, обработчик клиенских запросов (tcp\_echo\_fsm) будет предоставлять «Эхо» сервер, который будет возвращать запросы клиента обратно.
#### Поведения приложения и супервизоров
Для того, чтобы создать наше приложение, нам нужно написать модули, реализующие функции обратного вызова поведений «Supervisor» и «Application». Хотя традиционно эти функции реализуются в отдельных модулях, с учетом их краткости мы объединим их в одном.
В качестве дополнительного бонуса мы реализуем *get\_app\_env* функцию, которая показывает, как обрабатывать параметры конфигурации, а также параметры командной строки эмулятора при запуске.
Два экземпляра функции *init/1* нужны для двух уровней иерархии супервизоров. Так как используется две различные стратегии перезапуска, мы реализуем их на различных уровнях.
После запуска приложения функция обратного вызова *tcp\_server\_app:start/2* вызывает функцию *supervisor: start\_link/2*, которая создает главный супервизор приложения вызывая *tcp\_server\_app: init ([Port, Module])*. Это супервизор создает процесс *tcp\_listener* и дочерний супервизор *tcp\_client\_sup* ответственный за обработку клиентских подключений. Аргумент *Module* в функции *init* это имя FSM-обработчика клиентских соединений (в данном случае *tcp\_echo\_fsm*).
TCP Server Application (tcp\_server\_app.erl):
```
-module(tcp_server_app).
-author('[email protected]').
-behaviour(application).
%% Internal API
-export([start_client/0]).
%% Application and Supervisor callbacks
-export([start/2, stop/1, init/1]).
-define(MAX_RESTART, 5).
-define(MAX_TIME, 60).
-define(DEF_PORT, 2222).
%% A startup function for spawning new client connection handling FSM.
%% To be called by the TCP listener process.
start_client() ->
supervisor:start_child(tcp_client_sup, []).
%%----------------------------------------------------------------------
%% Application behaviour callbacks
%%----------------------------------------------------------------------
start(_Type, _Args) ->
ListenPort = get_app_env(listen_port, ?DEF_PORT),
supervisor:start_link({local, ?MODULE}, ?MODULE, [ListenPort, tcp_echo_fsm]).
stop(_S) ->
ok.
%%----------------------------------------------------------------------
%% Supervisor behaviour callbacks
%%----------------------------------------------------------------------
init([Port, Module]) ->
{ok,
{_SupFlags = {one_for_one, ?MAX_RESTART, ?MAX_TIME},
[
% TCP Listener
{ tcp_server_sup, % Id = internal id
{tcp_listener,start_link,[Port,Module]}, % StartFun = {M, F, A}
permanent, % Restart = permanent | transient | temporary
2000, % Shutdown = brutal_kill | int() >= 0 | infinity
worker, % Type = worker | supervisor
[tcp_listener] % Modules = [Module] | dynamic
},
% Client instance supervisor
{ tcp_client_sup,
{supervisor,start_link,[{local, tcp_client_sup}, ?MODULE, [Module]]},
permanent, % Restart = permanent | transient | temporary
infinity, % Shutdown = brutal_kill | int() >= 0 | infinity
supervisor, % Type = worker | supervisor
[] % Modules = [Module] | dynamic
}
]
}
};
init([Module]) ->
{ok,
{_SupFlags = {simple_one_for_one, ?MAX_RESTART, ?MAX_TIME},
[
% TCP Client
{ undefined, % Id = internal id
{Module,start_link,[]}, % StartFun = {M, F, A}
temporary, % Restart = permanent | transient | temporary
2000, % Shutdown = brutal_kill | int() >= 0 | infinity
worker, % Type = worker | supervisor
[] % Modules = [Module] | dynamic
}
]
}
}.
%%----------------------------------------------------------------------
%% Internal functions
%%----------------------------------------------------------------------
get_app_env(Opt, Default) ->
case application:get_env(application:get_application(), Opt) of
{ok, Val} -> Val;
_ ->
case init:get_argument(Opt) of
[[Val | _]] -> Val;
error -> Default
end
end.
```
#### Слушающий процесс
Один из недостатков *gen\_tcp* модуля является то, что он предоставляется интерфейс только для блокирующиего принятия соединений.
Тестирование модуля *prim\_inet* показало интересный факт, что команда сетовому драйверу принять клиентское соединение является асинхронной. Хотя это и не является задокументированным, что означает, что команда OTP может в любой момент изменить это, мы будем использовать эту функциональность в создании нашего сервера.
Слушающий процесс реализуется как *gen\_server*.
TCP Listener Process (tcp\_listener.erl):
```
-module(tcp_listener).
-author('[email protected]').
-behaviour(gen_server).
%% External API
-export([start_link/2]).
%% gen_server callbacks
-export([init/1, handle_call/3, handle_cast/2, handle_info/2, terminate/2,
code_change/3]).
-record(state, {
listener, % Listening socket
acceptor, % Asynchronous acceptor's internal reference
module % FSM handling module
}).
%%--------------------------------------------------------------------
%% @spec (Port::integer(), Module) -> {ok, Pid} | {error, Reason}
%
%% @doc Called by a supervisor to start the listening process.
%% @end
%%----------------------------------------------------------------------
start_link(Port, Module) when is_integer(Port), is_atom(Module) ->
gen_server:start_link({local, ?MODULE}, ?MODULE, [Port, Module], []).
%%%------------------------------------------------------------------------
%%% Callback functions from gen_server
%%%------------------------------------------------------------------------
%%----------------------------------------------------------------------
%% @spec (Port::integer()) -> {ok, State} |
%% {ok, State, Timeout} |
%% ignore |
%% {stop, Reason}
%%
%% @doc Called by gen_server framework at process startup.
%% Create listening socket.
%% @end
%%----------------------------------------------------------------------
init([Port, Module]) ->
process_flag(trap_exit, true),
Opts = [binary, {packet, 2}, {reuseaddr, true},
{keepalive, true}, {backlog, 30}, {active, false}],
case gen_tcp:listen(Port, Opts) of
{ok, Listen_socket} ->
%%Create first accepting process
{ok, Ref} = prim_inet:async_accept(Listen_socket, -1),
{ok, #state{listener = Listen_socket,
acceptor = Ref,
module = Module}};
{error, Reason} ->
{stop, Reason}
end.
%%-------------------------------------------------------------------------
%% @spec (Request, From, State) -> {reply, Reply, State} |
%% {reply, Reply, State, Timeout} |
%% {noreply, State} |
%% {noreply, State, Timeout} |
%% {stop, Reason, Reply, State} |
%% {stop, Reason, State}
%% @doc Callback for synchronous server calls. If `{stop, ...}' tuple
%% is returned, the server is stopped and `terminate/2' is called.
%% @end
%% @private
%%-------------------------------------------------------------------------
handle_call(Request, _From, State) ->
{stop, {unknown_call, Request}, State}.
%%-------------------------------------------------------------------------
%% @spec (Msg, State) ->{noreply, State} |
%% {noreply, State, Timeout} |
%% {stop, Reason, State}
%% @doc Callback for asyncrous server calls. If `{stop, ...}' tuple
%% is returned, the server is stopped and `terminate/2' is called.
%% @end
%% @private
%%-------------------------------------------------------------------------
handle_cast(_Msg, State) ->
{noreply, State}.
%%-------------------------------------------------------------------------
%% @spec (Msg, State) ->{noreply, State} |
%% {noreply, State, Timeout} |
%% {stop, Reason, State}
%% @doc Callback for messages sent directly to server's mailbox.
%% If `{stop, ...}' tuple is returned, the server is stopped and
%% `terminate/2' is called.
%% @end
%% @private
%%-------------------------------------------------------------------------
handle_info({inet_async, ListSock, Ref, {ok, CliSocket}},
#state{listener=ListSock, acceptor=Ref, module=Module} = State) ->
try
case set_sockopt(ListSock, CliSocket) of
ok -> ok;
{error, Reason} -> exit({set_sockopt, Reason})
end,
%% New client connected - spawn a new process using the simple_one_for_one
%% supervisor.
{ok, Pid} = tcp_server_app:start_client(),
gen_tcp:controlling_process(CliSocket, Pid),
%% Instruct the new FSM that it owns the socket.
Module:set_socket(Pid, CliSocket),
%% Signal the network driver that we are ready to accept another connection
case prim_inet:async_accept(ListSock, -1) of
{ok, NewRef} -> ok;
{error, NewRef} -> exit({async_accept, inet:format_error(NewRef)})
end,
{noreply, State#state{acceptor=NewRef}}
catch exit:Why ->
error_logger:error_msg("Error in async accept: ~p.\n", [Why]),
{stop, Why, State}
end;
handle_info({inet_async, ListSock, Ref, Error}, #state{listener=ListSock, acceptor=Ref} = State) ->
error_logger:error_msg("Error in socket acceptor: ~p.\n", [Error]),
{stop, Error, State};
handle_info(_Info, State) ->
{noreply, State}.
%%-------------------------------------------------------------------------
%% @spec (Reason, State) -> any
%% @doc Callback executed on server shutdown. It is only invoked if
%% `process_flag(trap_exit, true)' is set by the server process.
%% The return value is ignored.
%% @end
%% @private
%%-------------------------------------------------------------------------
terminate(_Reason, State) ->
gen_tcp:close(State#state.listener),
ok.
%%-------------------------------------------------------------------------
%% @spec (OldVsn, State, Extra) -> {ok, NewState}
%% @doc Convert process state when code is changed.
%% @end
%% @private
%%-------------------------------------------------------------------------
code_change(_OldVsn, State, _Extra) ->
{ok, State}.
%%%------------------------------------------------------------------------
%%% Internal functions
%%%------------------------------------------------------------------------
%% Taken from prim_inet. We are merely copying some socket options from the
%% listening socket to the new client socket.
set_sockopt(ListSock, CliSocket) ->
true = inet_db:register_socket(CliSocket, inet_tcp),
case prim_inet:getopts(ListSock, [active, nodelay, keepalive, delay_send, priority, tos]) of
{ok, Opts} ->
case prim_inet:setopts(CliSocket, Opts) of
ok -> ok;
Error -> gen_tcp:close(CliSocket), Error
end;
Error ->
gen_tcp:close(CliSocket), Error
end.
```
В этом модуле *init/1* принимает два параметра — номер порта, который слушающий процесс должен открыть и имя обработчика клиентских подключений. Функция инициализации открывает сокет в пассивном режиме. Это делается для того, чтобы у нас был контроль над потоком данных, полученных от клиента.
Самая интересная часть этого кода это вызов *prim\_inet:async\_accept/2*. Для того чтобы заставить это работать нам необходимо скопировать часть внутреннего кода OTP из функции *set\_sockopt/2*, которая обрабатывает регистрацию сокетов и копирование некоторых опций для клиентского сокета.
Как только клиентский сокет будет подключен, сетевой драйвер уведомит об этом слушающий процесс с помощью сообщения *{inet\_async, ListSock, Ref, {OK, CliSocket}}*. На данный момент мы запускаем экземпляр процесса обработки клиентских запросов и передаем ему во владение CliSocket.
#### Процесс обработки клиентских сообщений
В то время как *tcp\_listener* является обобщенной реализацией, *tcp\_echo\_fsm* есть не что иное, как FSM заглушка для описания, как создавать TCP сервера. Из этот модуля необходимо экспортировать две функции — *start\_link/0* для супервизора *tcp\_client\_sup* и *set\_socket/2* для слушающего процесса для того, чтобы последний уведомил процесс обработки клиентских сообщений что то становится владельцем сокета, и может начать получать сообщения, установив *{active, once}* или *{active, true}* опцию.
Мы хотели бы подчеркнуть шаблон синхронизации, используемый между слушающим процессом и клиентскими, для избежания возможных потерь сообщение в связи с передачей их не тому (слушающему) процессу. Процесс, владеющий сокетом, держит его открытым в пассивном режиме. Далее клиентский процесс принимает сокет, который наследует опции(в том числе пассивный режим) от слушающего процесса. Право владения сокетом передается клиентскому процессу с помощью вызовов *gen\_tcp:controlling\_process/2* и *set\_socket/2*, который уведомит клиентский процесс, что он может начать получать сообщения от сокета. До момента, когда сокет будет установлен в активный режим, все принятые данные будут хранится в буфере сокета.
Когда право владения сокетом передается клиентскому FSM-прицессу в состоянии *«WAIT\_FOR\_SOCKET»*, устанавлвается *{active, once}* режим, чтобы позвалить сетевому драйверу передавать одно сообщение за раз. Это принцип OTP применяемый для сохранения контроля над потоком данных и избежания смешивания сообщений и TCP траффика в очереди процесса.
FSM-состояния реализуются с помощью специальных функций в модуле *tcp\_echo\_fsm*, который используют соглашение об именовании. FSM состоит из двух состояний. *WAIT\_FOR\_SOCKET* является начальным состоянием, в котором FSM ждет права владения сокетом, и *WAIT\_FOR\_DATA*, которое является состоянием ожидания TCP сообщения от клиента. В этом состоянии FSM также обрабатывает специальные «timeout» сообщение, что означает отсутствие активности от клиента и вызывает процесс, чтобы закрыть соединение с клиентом.
```
-module(tcp_echo_fsm).
-author('[email protected]').
-behaviour(gen_fsm).
-export([start_link/0, set_socket/2]).
%% gen_fsm callbacks
-export([init/1, handle_event/3,
handle_sync_event/4, handle_info/3, terminate/3, code_change/4]).
%% FSM States
-export([
'WAIT_FOR_SOCKET'/2,
'WAIT_FOR_DATA'/2
]).
-record(state, {
socket, % client socket
addr % client address
}).
-define(TIMEOUT, 120000).
%%%------------------------------------------------------------------------
%%% API
%%%------------------------------------------------------------------------
%%-------------------------------------------------------------------------
%% @spec (Socket) -> {ok,Pid} | ignore | {error,Error}
%% @doc To be called by the supervisor in order to start the server.
%% If init/1 fails with Reason, the function returns {error,Reason}.
%% If init/1 returns {stop,Reason} or ignore, the process is
%% terminated and the function returns {error,Reason} or ignore,
%% respectively.
%% @end
%%-------------------------------------------------------------------------
start_link() ->
gen_fsm:start_link(?MODULE, [], []).
set_socket(Pid, Socket) when is_pid(Pid), is_port(Socket) ->
gen_fsm:send_event(Pid, {socket_ready, Socket}).
%%%------------------------------------------------------------------------
%%% Callback functions from gen_server
%%%------------------------------------------------------------------------
%%-------------------------------------------------------------------------
%% Func: init/1
%% Returns: {ok, StateName, StateData} |
%% {ok, StateName, StateData, Timeout} |
%% ignore |
%% {stop, StopReason}
%% @private
%%-------------------------------------------------------------------------
init([]) ->
process_flag(trap_exit, true),
{ok, 'WAIT_FOR_SOCKET', #state{}}.
%%-------------------------------------------------------------------------
%% Func: StateName/2
%% Returns: {next_state, NextStateName, NextStateData} |
%% {next_state, NextStateName, NextStateData, Timeout} |
%% {stop, Reason, NewStateData}
%% @private
%%-------------------------------------------------------------------------
'WAIT_FOR_SOCKET'({socket_ready, Socket}, State) when is_port(Socket) ->
% Now we own the socket
inet:setopts(Socket, [{active, once}, {packet, 2}, binary]),
{ok, {IP, _Port}} = inet:peername(Socket),
{next_state, 'WAIT_FOR_DATA', State#state{socket=Socket, addr=IP}, ?TIMEOUT};
'WAIT_FOR_SOCKET'(Other, State) ->
error_logger:error_msg("State: 'WAIT_FOR_SOCKET'. Unexpected message: ~p\n", [Other]),
%% Allow to receive async messages
{next_state, 'WAIT_FOR_SOCKET', State}.
%% Notification event coming from client
'WAIT_FOR_DATA'({data, Data}, #state{socket=S} = State) ->
ok = gen_tcp:send(S, Data),
{next_state, 'WAIT_FOR_DATA', State, ?TIMEOUT};
'WAIT_FOR_DATA'(timeout, State) ->
error_logger:error_msg("~p Client connection timeout - closing.\n", [self()]),
{stop, normal, State};
'WAIT_FOR_DATA'(Data, State) ->
io:format("~p Ignoring data: ~p\n", [self(), Data]),
{next_state, 'WAIT_FOR_DATA', State, ?TIMEOUT}.
%%-------------------------------------------------------------------------
%% Func: handle_event/3
%% Returns: {next_state, NextStateName, NextStateData} |
%% {next_state, NextStateName, NextStateData, Timeout} |
%% {stop, Reason, NewStateData}
%% @private
%%-------------------------------------------------------------------------
handle_event(Event, StateName, StateData) ->
{stop, {StateName, undefined_event, Event}, StateData}.
%%-------------------------------------------------------------------------
%% Func: handle_sync_event/4
%% Returns: {next_state, NextStateName, NextStateData} |
%% {next_state, NextStateName, NextStateData, Timeout} |
%% {reply, Reply, NextStateName, NextStateData} |
%% {reply, Reply, NextStateName, NextStateData, Timeout} |
%% {stop, Reason, NewStateData} |
%% {stop, Reason, Reply, NewStateData}
%% @private
%%-------------------------------------------------------------------------
handle_sync_event(Event, _From, StateName, StateData) ->
{stop, {StateName, undefined_event, Event}, StateData}.
%%-------------------------------------------------------------------------
%% Func: handle_info/3
%% Returns: {next_state, NextStateName, NextStateData} |
%% {next_state, NextStateName, NextStateData, Timeout} |
%% {stop, Reason, NewStateData}
%% @private
%%-------------------------------------------------------------------------
handle_info({tcp, Socket, Bin}, StateName, #state{socket=Socket} = StateData) ->
% Flow control: enable forwarding of next TCP message
inet:setopts(Socket, [{active, once}]),
?MODULE:StateName({data, Bin}, StateData);
handle_info({tcp_closed, Socket}, _StateName,
#state{socket=Socket, addr=Addr} = StateData) ->
error_logger:info_msg("~p Client ~p disconnected.\n", [self(), Addr]),
{stop, normal, StateData};
handle_info(_Info, StateName, StateData) ->
{noreply, StateName, StateData}.
%%-------------------------------------------------------------------------
%% Func: terminate/3
%% Purpose: Shutdown the fsm
%% Returns: any
%% @private
%%-------------------------------------------------------------------------
terminate(_Reason, _StateName, #state{socket=Socket}) ->
(catch gen_tcp:close(Socket)),
ok.
%%-------------------------------------------------------------------------
%% Func: code_change/4
%% Purpose: Convert process state when code is changed
%% Returns: {ok, NewState, NewStateData}
%% @private
%%-------------------------------------------------------------------------
code_change(_OldVsn, StateName, StateData, _Extra) ->
{ok, StateName, StateData}.
```
#### Описание приложения
Другая необходимая часть создания приложения OTP является создание конфигурациооного файла, который содержит название приложения, версию, стартовый модуль и переменные окружения.
Application File (tcp\_server.app):
```
{application, tcp_server,
[
{description, "Demo TCP server"},
{vsn, "1.0"},
{id, "tcp_server"},
{modules, [tcp_listener, tcp_echo_fsm]},
{registered, [tcp_server_sup, tcp_listener]},
{applications, [kernel, stdlib]},
%%
%% mod: Specify the module name to start the application, plus args
%%
{mod, {tcp_server_app, []}},
{env, []}
]
}.
```
#### Компиляция
Создайте следующую структуру каталогов для этого приложения:
```
./tcp_server
./tcp_server/ebin/
./tcp_server/ebin/tcp_server.app
./tcp_server/src/tcp_server_app.erl
./tcp_server/src/tcp_listener.erl
./tcp_server/src/tcp_echo_fsm.erl
```
```
$ cd tcp_server/src
$ for f in tcp*.erl ; do erlc +debug_info -o ../ebin $f
```
#### Запуск
Мы собираемся запустить оболочку Erlang с поддержкой SASL, чтобы мы могли видеть состояние процессов и отчеты об ошибках для нашего приложения. Кроме того, мы собираемся запсутить приложение *appmon* в целях визуального изучения иерархии супервизоров.
```
$ cd ../ebin
$ erl -boot start_sasl
...
1> appmon:start().
{ok,<0.44.0>}
2> application:start(tcp_server).
ok
```
Теперь нажмите на кнопку *tcp\_server* в приложении appmon, чтобы отобразить иерархию супервизоров приложения.
```
3> {ok,S} = gen_tcp:connect({127,0,0,1},2222,[{packet,2}]).
{ok,#Port<0.150>}
```
Мы только что инициировали новое соединение клиента Echo Server.
```
4> gen_tcp:send(S,<<"hello">>).
ok
5> f(M), receive M -> M end.
{tcp,#Port<0.150>,"hello"}
```
Мы проверили, что эхо-сервер работает, как ожидалось. Теперь давайте попробуем «положить» соединение клиента на сервере и посмотреть за генерацией сообщения об ошибке.
```
6> [{_,Pid,_,_}] = supervisor:which_children(tcp_client_sup).
[{undefined,<0.64.0>,worker,[]}]
7> exit(Pid,kill).
true
=SUPERVISOR REPORT==== 31-Jul-2007::14:33:49 ===
Supervisor: {local,tcp_client_sup}
Context: child_terminated
Reason: killed
Offender: [{pid,<0.77.0>},
{name,undefined},
{mfa,{tcp_echo_fsm,start_link,[]}},
{restart_type,temporary},
{shutdown,2000},
{child_type,worker}]
```
Заметим, что если вы сервер попадет под нагрузку с помощью большого число соединений, слушающий процесс может не принимать новые подключения после определенного предела, установленного в операционной системе. В этом случае вы увидите сообщение об ошибке:
```
"too many open files"
```
#### Заключение
OTP предоставляет строительные блоки для построения неблокирующих TCP серверов. В этом руководстве показано, как создать простой сервер с использованием стандартного поведения OTP. | https://habr.com/ru/post/111268/ | null | ru | null |
# Юнит-тестирование шаблонов C++ и Mock Injection с помощью трейтов (Traits)
Еще раз здравствуйте! До старта занятий в группе по курсу [«Разработчик С++»](https://otus.pw/sMJb/) остается меньше недели. В связи с этим мы продолжаем делиться полезным материалом переведенным специально для студентов данного курса.

Юнит-тестирование вашего кода с шаблонами время от времени напоминает о себе. (Вы ведь тестируете свои шаблоны, верно?) Некоторые шаблоны легко тестировать. Некоторые — не очень. Иногда не хватает конечной ясности насчет внедрения mock-кода (заглушки) в тестируемый шаблон. Я наблюдал несколько причин, по которым внедрение кода становится сложным.
Ниже я привел несколько примеров с примерно возрастающей сложностью внедрения кода.
1. Шаблон принимает аргумент типа и объект того же типа по ссылке в конструкторе.
2. Шаблон принимает аргумент типа. Делает копию аргумента конструктора или просто не принимает его.
3. Шаблон принимает аргумент типа и создает несколько взаимосвязанных шаблонов без виртуальных функций.
Начнем с простого.
Шаблон принимает аргумент типа и объект того же типа по ссылке в конструкторе
-----------------------------------------------------------------------------
Этот случай кажется простым, потому что юнит-тест просто создает экземпляр тестируемого шаблона с типом заглушки. Некоторое утверждение может быть проверено для mock-класса. И на этом все.
Естественно, тестирование только с одним аргументом типа ничего не говорит об остальном бесконечном количестве типов, которые можно передать шаблону. Элегантный способ сказать то же самое: шаблоны связаны квантором общности, поэтому нам, возможно, придется стать немного проницательнее для более научного тестирования. Подробнее об этом позже.
Например:
```
template
class TemplateUnderTest {
T \*t\_;
public:
TemplateUnderTest(T \*t) : t\_(t) {}
void SomeMethod() {
t->DoSomething();
t->DoSomeOtherThing();
}
};
struct MockT {
void DoSomething() {
// Some assertions here.
}
void DoSomeOtherThing() {
// Some more assertions here.
}
};
class UnitTest {
void Test1() {
MockT mock;
TemplateUnderTest test(&mock);
test.SomeMethod();
assert(DoSomethingWasCalled(mock));
assert(DoSomeOtherThingWasCalled(mock));
}
};
```
Шаблон принимает аргумент типа. Делает копию аргумента конструктора или просто не принимает его
-----------------------------------------------------------------------------------------------
В этом случае доступ к объекту внутри шаблона может быть неосуществим из-за прав доступа. Можно использовать `friend`-классы.
```
template
class TemplateUnderTest {
T t\_;
friend class UnitTest;
public:
void SomeMethod() {
t.DoSomething();
t.DoSomeOtherThing();
}
};
class UnitTest {
void Test2() {
TemplateUnderTest test;
test.SomeMethod();
assert(DoSomethingWasCalled(test.t\_)); // access guts
assert(DoSomeOtherThingWasCalled(test.t\_)); // access guts
}
};
```
`UnitTest :: Test2` имеет доступ к телу TemplateUnderTest и может проверить утверждения на внутренней копии MockT.
Шаблон принимает аргумент типа и создает несколько взаимосвязанных шаблонов без виртуальных функций
---------------------------------------------------------------------------------------------------
Для этого случая я рассмотрю реальный пример: [Asynchronous Google RPC](https://grpc.io/docs/tutorials/async/helloasync-cpp.html).
В C++ async gRPC есть нечто под названием CallData, которая, как следует из названия, хранит *данные, относящиеся к вызову RPC*. Шаблон CallData может обрабатывать несколько RPC разных типов. Так что это закономерно, что она реализована именно шаблоном.
Универсальная CallData принимает два аргумента типов: Request и Response. Выглядеть она может вот так:
```
template
class CallData {
grpc::ServerCompletionQueue \*cq\_;
grpc::ServerContext context\_;
grpc::ServerAsyncResponseWriter responder\_;
// ... some more state
public:
using RequestType = Request;
using ResponseType = Response;
CallData(grpc::ServerCompletionQueue \*q)
: cq\_(q),
responder\_(&context\_)
{}
void HandleRequest(Request \*req); // application-specific code
Response \*GetResponse(); // application-specific code
};
```
Юнит-тест для шаблона CallData должен проверить поведение HandleRequest и HandleResponse. Эти функции вызывают ряд функций членов. Поэтому проверка исправности их вызова имеет первостепенное значение для исправности CallData. Тем не менее, есть подвохи.
1. Некоторые типы из пространства имен grpc создаются внутри и не передаются через конструктор. `ServerAsyncResponseWriter` и `ServerContext`, например.
2. `grpc :: ServerCompletionQueue` передается конструктору в качестве аргумента, но не имеет виртуальных функций. Только виртуальный деструктор.
3. `grpc :: ServerContext` создается внутри и не имеет виртуальных функций.
Вопрос в том, как протестировать CallData без использования полноценного gRPC в тестах? Как сымитировать ServerCompletionQueue? Как сымитировать ServerAsyncResponseWriter, который сам является шаблоном? и так далее…
Без виртуальных функций подстановка пользовательского поведения становится сложной задачей. Захардкоженные типы, такие как grpc::ServerAsyncResponseWriter, невозможно смоделировать, поскольку они, хм, захардкоженны и не внедрены.
В передаче их в качестве аргументов конструктора толку немного. Даже если это сделать, это может оказаться бессмысленно, поскольку они могут быть final-классами или просто не иметь виртуальных функций.
Итак, что же нам делать?
Решение: трейты (Traits)
------------------------
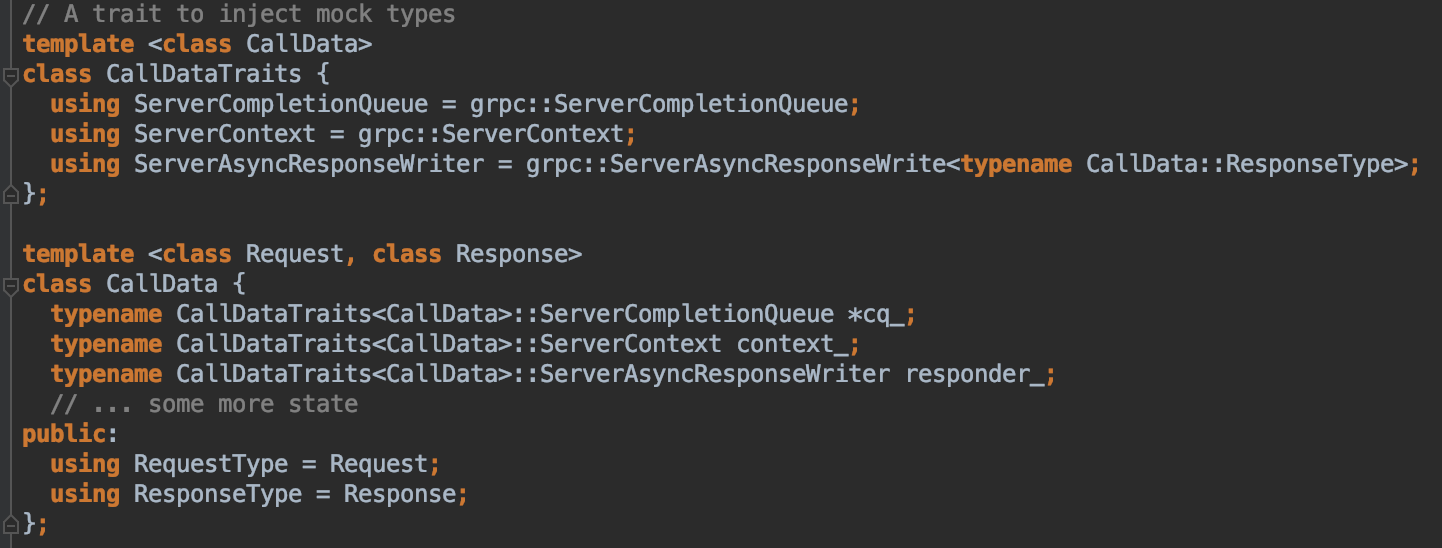
Вместо того, чтобы внедрять пользовательское поведение путем наследования от общего типа (как это делается в объектно-ориентированном программировании), ВНЕДРИТЕ САМ ТИП. Мы используем для этого трейты (traits). Мы специализируем трейты по-разному в зависимости от того, что это за код: продакшн-код или код юнит-тестирования.
Рассмотрим `CallDataTraits`
```
template
class CallDataTraits {
using ServerCompletionQueue = grpc::ServerCompletionQueue;
using ServerContext = grpc::ServerContext;
using ServerAsyncResponseWriter = grpc::ServerAsyncResponseWrite;
};
```
Это основной шаблон для трейта, использующийся для продакшн-кода. Давайте использовать его в CallDatatemplate.
```
/// Unit testable CallData
template
class CallData {
typename CallDataTraits::ServerCompletionQueue \*cq\_;
typename CallDataTraits::ServerContext context\_;
typename CallDataTraits::ServerAsyncResponseWriter responder\_;
// ... some more state
public:
using RequestType = Request;
using ResponseType = Response;
CallData(typename CallDataTraits::ServerCompletionQueue \*q)
: cq\_(q),
responder\_(&context\_)
{}
void HandleRequest(Request \*req); // application-specific code
Response \*GetResponse(); // application-specific code
};
```
Глядя на приведенный выше код, ясно, что код приложения все еще использует типы из пространства имен grpc. Тем не менее, мы можем легко заменить типы grpc на фиктивные типы. Смотрите ниже.
```
/// In unit test code
struct TestRequest{};
struct TestResponse{};
struct MockServerCompletionQueue{};
struct MockServerContext{};
struct MockServerAsyncResponseWriter{};
/// We want to unit test this type.
using CallDataUnderTest = CallData;
/// A specialization of CallDataTraits for unit testing purposes only.
template <>
class CallDataTraits {
using ServerCompletionQueue = MockServerCompletionQueue;
using ServerContext = MockServerContext;
using ServerAsyncResponseWriter = MockServerAsyncResponseWrite;
};
MockServerCompletionQueue mock\_queue;
CallDataUnderTest cdut(&mock\_queue); // Now injected with mock types.
```
Трейты позволили нам выбирать типы, внедренные в CallData, в зависимости от ситуации. Этот метод не требует дополнительной производительности, так как не было создано ненужных виртуальных функций для добавления функциональности. Эта техника может быть использована также и в final-классах.
Как вам материал? Пишите комментарии. И до встречи на дне открытых дверей ;-) | https://habr.com/ru/post/457110/ | null | ru | null |
# Тестирование в Яндексе. Сам себе web-service over SSH, или как сделать заглушку для целого сервиса
Вы практикующий ~~маг~~ менеджер. Или боевой разработчик. Или профессиональный тестировщик. А может быть, просто человек, которому небезразличны разработка и использование систем, включающих в себя клиент-серверные компоненты. Уверен, вы даже знаете, что порт это не только место, куда приходят корабли, а «ssh» это не только звук, издаваемый змеёй. И вы в курсе, что сервисы, расположенные на одной или нескольких машинах, активно между собой общаются. Чаще всего по протоколу HTTP. И от версии к версии формат этого общения нужно контролировать.
[](http://habrahabr.ru/company/yandex/blog/228691/)
Думаю, каждый из вас при очередном релизе задавался вопросами: «Точно ли мы отсылаем верный запрос?» или «Точно ли мы передали все необходимые параметры этому сервису?». Всем должно быть известно и о существовании негативных сценариев развития событий наравне с позитивными. Это знание должно активно порождать вопросы из серии «Что если..?». Что если сервис станет обрабатывать соединения с задержкой в 2 часа? Что если сервис ответит абракадабру вместо данных в формате json?
О таких вещах нередко забывается в процессе разработки. Из-за сложности проверки проблем подобного рода, маловероятности таких ситуаций и еще по тысяче других причин. А ведь странная ошибка или падение приложения в ответственный момент могут навсегда отпугнуть пользователя, и он больше не вернётся к вашему продукту. Мы в Яндексе постоянно держим подобные вопросы в голове и стремимся максимально оптимизировать процесс тестирования, используя полезные идеи. О том, как мы сделали такие проверки легкими, наглядными, *автоматическими* и пойдет речь в этой статье.
#### Соль
Есть ряд давно известных способов узнать, как и что передается от сервиса к сервису — от мобильного приложения к серверу, от одной части к другой.
Первый из наиболее популярных и не требующих серьезной подготовки — подключиться специальной программой к одному из источников передачи или приёма данных. Такие программы называются [анализаторами трафика](http://en.wikipedia.org/wiki/Packet_analyzer) или чаще — снифферами.
Второй — подменить искусственной реализацией целиком одну из сторон. В таком подходе есть возможность определить четкий сценарий поведения в определенных случаях и сохранять всю информацию, которая придет этому сервису. Такой подход называется использованием заглушек ([mock-объектов](http://en.wikipedia.org/wiki/Mock_object)). Мы рассмотрим оба.
##### Использование снифферов
Приходит новый релиз или отладка изменений, затрагивающих межсервисное общение. Мы вооружаемся нужными программами-перехватчиками — [WireShark](http://www.wireshark.org/)'ом или [Tcpdump](http://en.wikipedia.org/wiki/Tcpdump). Запускаем перехват трафика до нужного узла, наложив фильтры хоста, порта и интерфейса. Делаем «темные дела», инициируя нужное нам общение. Останавливаем перехват. Начинаем его разбирать. Процесс разбора у каждого сервиса свой, но обычно всегда напоминает судорожные поиски в куче текста заветных GET, POST, PUT и т.д. Нашли? Тогда повторяем это из релиза в релиз. Это же теперь проверка на регрессию! Не нашли? Повторяем это с разными комбинациями фильтров до понимания причин.
###### Из релиза в релиз?
Вручную такое делать можно раз. Или два. Ну, может быть, три. А потом точно надоест. А на пятый релиз это общение возьмет и сломается. Особенно сложно это заметить косвенно, когда общение представляет из себя вызов колбэка с каким-нибудь уведомлением. Повторяющиеся из релиза в релиз механические действия, отнимающие много времени и сил, стоит автоматизировать. Как это делать в JAVA? Уверен, на других языках это можно сделать похожим образом, но конкретно связка JUnit4 + Maven для автоматизации тестирования в Яндексе прекрасно работает и хорошо себя зарекомендовала.
Предположим, что сервис мы тестируем интеграционно, а значит, скорее всего это похоже на боевой режим, когда он поднят на отдельной машине, а мы подключены к ней по SSH. Берем [библиотечку для работы по SSH](https://code.google.com/p/ganymed-ssh-2/), [подключаемся к серверу](https://code.google.com/p/ganymed-ssh-2/source/browse/trunk/examples/PublicKeyAuthentication.java), запускаем tcpdump и ловим все, что можем, в файлик (все в точности как руками). После теста принудительно завершаем процесс и ищем в файлике то, что нужно, используя grep, awk, sed и т.д. Затем полученное обрабатываем в тесте. Делали так? Нет? И не нужно!
###### Почему не нужно так делать?
> Хочу заметить, что «не нужно» не значит «не можно».
Делать так можно. Просто есть способы проще, потому что:
* Разбор на составляющие больших строк — это всегда много специфического кода, который сложно поддерживать.
* Разбор HTTP сообщений уже давно сделан в сотне библиотек. Зачем делать сто первую?
Пробовали именно такой способ и мы в Яндексе. Сперва это казалось удобным — от нас требовалось только запустить и остановить tcpdump по ssh, а потом найти нужную подстроку в его выдаче. Первые проблемы с поддержкой начались почти сразу: порядок следования query-параметров оказался случайным в искомых запросах. Пришлось разбить эталонную строку на несколько и проверять вхождение каждой. Удручали и сообщения об ошибках в случае, если запроса не находилось, — тонны текста не давали адекватного способа себя структурировать. Головной боли добавили асинхронные запросы, которые могли появиться через несколько минут после активных действий. Приходилось строить головокружительные конструкции по ожиданию нужной подстроки в выдаче с определенной задержкой. Код тестов иногда становился сложнее кода, который мы проверяли. Тогда мы и стали искать другой способ тестировать эту часть.
##### Использование заглушек вместо web-сервисов
Так как речь идет о тестировании, то, скорее всего, у нас есть все возможности не просто поставить сеточку в виде сниффера, но и подменить один из сервисов целиком. При таком подходе до искусственного сервиса дойдут «чистые» запросы, а у нас будет возможность управлять поведением конечного пункта для сообщений. Для таких целей есть замечательная библиотека [WireMock](http://wiremock.org/). Её код можно посмотреть на [GitHub-странице](https://github.com/tomakehurst/wiremock) проекта. Суть в том, что поднимается web-сервис с хорошим REST-api, который можно настроить почти любым образом. Это JAVA-библиотека, но у нее есть возможность запуска как самостоятельного приложения, было бы доступно jre. А дальше простая настройка с подробной документацией.
Тут и произвольные коды ответа, и произвольное содержимое, и прозрачное перенаправление запроса в реальные сервисы с возможностью сохранить ответы и отсылать их затем самостоятельно. Особо стоит отметить возможность воссоздать негативное поведение: таймауты, обрывы связи, невалидные ответы. Красота! Библиотека при этом может работать и как WAR, который можно загрузить в Jetty, Tomcat и т.д. И, самое главное, эту библиотеку можно использовать прямо в тестах как JUnit Rule! Она сама позаботится о разборе запроса, разделив тело, адрес, параметры и заголовки. Нам останется только в нужный момент достать список всех пришедших и удовлетворяющих критериям.
#### Автоматизируем проверки, используя заглушку
Прежде чем продолжать, нужно определиться, какие этапы нужно пройти, чтобы обеспечить легкое, наглядное и автоматическое тестирование, используя второй из рассмотренных вариантов — mock-объект.
> Стоит заметить, что каждый из этапов так же возможно проделать вручную без особых затруднений.
##### Схема
Что проверяем? `{сообщение}` в схеме:
`тестируемый_сервис -> {сообщение} -> сервис_заглушка.`
Более точно, схема будет выглядеть так:
`тестируемый_сервис -> сервис_заглушка :(его лог): {сообщение}.`
Таким образом, нам нужно сделать несколько вещей:
* Поднять сервис-заглушку и заставить его принимать определенные сообщения, отвечая ОК (или неОК — зависит от сценария). Этим займется WireMock.
* Обеспечить доставку сообщений до сервиса-заглушки (в схеме это `->`). Об этом этапе поговорим отдельно.
* Провалидировать то, что пришло. Тут два варианта — используя средства WireMock для валидации, либо получив от нее список запросов, применяя к ним [матчеры](http://habrahabr.ru/company/yandex/blog/184634/).
#### Поднимаем искусственный web-сервис
Как поднять сервис вручную, подробно описано на сайте wiremock в секции [Running standalone](http://wiremock.org/getting-started.html). Как использовать в JUnit тоже впрочем описано. Но это нам понадобится в дальнейшем, поэтому приведу немножко кода.
Создаем JUnit правило, которое будет поднимать сервис на нужном порту при старте теста и завершать после окончания:
```
@Rule
public WireMockRule wiremock = new WireMockRule(LOCAL_MOCKED_PORT);
```
Начало теста будет выглядеть примерно так:
```
@Test
public void shouldSend3Callbacks() throws Exception {
// Пусть наша заглушка принимает любые сообщения
stubFor(any(urlMatching(".*")).willReturn(aResponse()
.withStatus(HttpStatus.OK_200).withBody("OK")));
...
```
Здесь мы настраиваем поднятый web-сервис, чтобы он на любой запрошенный адрес отвечал кодом 200 с телом «ОК». После нехитрых действий по настройке, есть несколько вариантов развития событий. Первый — у нас нет никаких проблем с доступом на любой порт от клиента до той машины, на которой выполняется тест. В этом случае мы просто совершаем нужные действия в рамках тесткейса, после — переходим к валидации. Второй — у нас есть доступ только по ssh. Все же порты прикрыты брэндмауэром. Тут на помощь приходит ssh port forwarding (или ssh-tunneling). Об этом речь ниже.
#### Сокращаем дорогу пакетам
Нам потребуется REMOTE (который с ключом -R) и, соответственно, ssh-доступ к машинке. Это позволит тестовому сервису обращаться на свой локальный порт, а нам — слушать свой. И все будет работать.
> Если в двух словах, то ssh port forwarding (или ssh-tunneling) — это прокидывание трубы через ssh соединение от порта на удаленной машине до порта на локальной. Хорошую инструкцию по применению можно найти на [www.debianadmin.com](http://www.debianadmin.com)
Так как мы занимаемся автоматизацией этого процесса, рассмотрим подробно, как сделать использование этого механизма в тестах удобным. Начнем с самого верхнего уровня — интерфейса junit-правила. Она позволит прокинуть связь `хост_удаленной_машины:порт -> ssh -> хост_машины_где_фейк_сервис:его_порт` до старта теста и закрыть тоннель после его завершения.
#### Делаем junit-правило перенаправления портов
Вспоминаем про библиотеку Ganymed SSH2. Подключаем ее, используя maven:
```
ch.ethz.ganymed
ganymed-ssh2
${last-ganymed-ssh-ver}
```
(Релизную версию всегда можно увидеть в [Maven Central](http://mvnrepository.com/artifact/ch.ethz.ganymed/ganymed-ssh2).)
Открываем [пример](https://code.google.com/p/ganymed-ssh-2/source/browse/trunk/examples/PortForwarding.java?r=2), использующий эту библиотеку для поднятия туннеля через ssh. Понимаем, что нам нужно четыре параметра. Будем считать, что тестируемый «разговаривает» через свой локальный порт, поэтому `хост_удаленной_машины` приравниваем к `127.0.0.1`.
Остаётся три параметра, которые требуется указывать:
```
@Rule
public SshRemotePortForwardingRule forward = onRemoteHost(props().serviceURI())
.whenRemoteUsesPort(BIND_PORT_ON_REMOTE)
.forwardToLocal().withForwardToPort(LOCAL_MOCKED_PORT);
```
Здесь `.forwardToLocal()` это:
```
public SshRemotePortForwardingRule forwardToLocal() {
try {
hostToForward = InetAddress.getLocalHost().getHostAddress();
} catch (UnknownHostException e) {
throw new RuntimeException("Can't get localhost address", e);
}
return this;
}
```
Junit-правило удобно делать как наследника `ExternalResource`, переопределив `before()` для [авторизации](https://code.google.com/p/ganymed-ssh-2/source/browse/trunk/examples/PublicKeyAuthentication.java) и поднятия туннеля, а `after()` для закрытия туннеля и соединения.
Само соединение должно выглядеть примерно так:
```
logger.info(format("Try to create port forwarding: `ssh %s -l %s -f -N -R %s:%s:%s:%s`",
connection.getHostname(), SSH_LOGIN,
hostOnRemote, portOnRemote, hostToForward, portToForward
));
connection.requestRemotePortForwarding(hostOnRemote, portOnRemote, hostToForward, portToForward);
```
#### Валидируем
Успешно поймав запросы заглушенным сервисом, остается только проверить их. Самый простой способ — использовать встроенные средства WireMock:
```
// Обращаясь к логу искусственного сервиса, убеждаемся в наличии нужных сообщений
verify(3, postRequestedFor(urlMatching(".*callback.*"))
.withRequestBody(matching("^status=.*")));
```
Гораздо более гибкий способ — просто получить список нужных запросов, а потом, достав определенные параметры, применить к ним проверки:
```
List all = findAll(allRequests());
assertThat("Должны найти хотя бы 1 запрос в логе", all, hasSize(greaterThan(0)));
assertThat("Тело первого запроса должно содержать определенную строку",
all.get(0).getBodyAsString(), containsString("Wow, it's callback!"));
```
#### Как это сработало в Яндексе
Всё сказанное выше — серьезный общий подход. Его можно использовать во множестве мест как целиком, так и по частям. Сейчас использование заглушек на интеграционном уровне отлично работает в целом ряде больших проектов для подмены различных функций сервисов. Например, у нас в Яндексе есть сервис загрузки файлов, который записывает информацию о файлах не самостоятельно, а еще через один сервис. Начали загружать файл — отослали запрос. Загрузили, посчитали контрольные суммы — еще один запрос. Проверили файл на вирусы, готовы с файлом работать дальше — еще один. Каждая следующая стадия продолжается в зависимости от ответа на предыдущие, при этом количество соединений между сервисами ограничено.
Как проверить, что запросы действительно уходят и содержат всю информацию о файле в нужном формате? Как проверить, что будет, если запрос был принят, но ответа не последовало? Сперва проверяем позитивный сценарий развития событий — заменяем сервис, пишущий в базу данных искусственным, принимаем и анализируем трафик. (Примеры кода выше — копия того, что происходит в тестах.) Туннель через ssh потребовался для того, чтобы автотесты, не обладая правами суперпользователя, могли привязаться к определенному порту на локальной машине, адрес которой всегда произвольный, а в сервисе загрузки можно было указать точкой отправки запросов свой локальный адрес и порт на постоянной основе.
Успешно проверив позитивный сценарий, нам не составило труда добавить проверок и [для негативных](http://wiremock.org/simulating-faults.html). Просто увеличив время задержки ответа в WireMock до величины большей, чем время ожидания в сервисе загрузки файлов, получилось инициировать несколько попыток отправить запрос.
```
//Глушим сервис записи в БД, установив таймаут на ответ в 61 секунду
//(больше чем ожидание ответа на 1с)
stubFor(any(urlMatching(".*")).willReturn(aResponse()
.withFixedDelay((int) SECONDS.toMillis(61))
.withStatus(HttpStatus.OK_200).withBody("ОК")));
```
Проверив, что за 120 секунд при ожидании ответа на сервисе в 60 секунд пришло два запроса, мы точно убедились, что сервис загрузки файлов не зависнет в ответственный момент.
```
waitFor(120, SECONDS);
verify(2, postRequestedFor(urlMatching(".*service/callback.*"))
.withRequestBody(matching("^status_xml.*")));
```
Значит, разработчики предусмотрели такое развитие событий, и в этом месте при такой ситуации информация о загрузке точно не потеряется. Аналогичным образом на одном из сервисов был найден баг. Заключался он в том, что если сервису не ответили сразу, то соединение оставалось открытым на несколько часов, пока его принудительно не закрывали извне контролирующие службы. Это могло привести к тому, что при неполадках в сети за короткое время мог полностью исчерпаться лимит соединений и остальным клиентам пришлось бы ждать в очереди эти несколько часов. Хорошо, что мы проверили такое раньше!
#### О чём еще стоит сказать
Есть и ряд ограничений в таком подходе:
* Потребуется ssh доступ на машину.
* Перенаправление портов должно быть на этой машине включено.
* Потребуется останавливать сервисы, если нужно будет занять их порт и заменить заглушкой. А это значит, что нужны права пользователю на остановку сервисов без пароля. Это так же касается портов с номерами до 1024.
* В некоторых организациях нельзя пробрасывать порт без санкций администраторов.
##### Локальное перенаправление портов
Помимо удаленного, есть также и LOCAL (локальное), с ключом `-L`. Оно позволяет зеркально описанному выше, обращаясь к какому-то порту на своей локальной машине, попадать на внутренний порт удаленной машины, скрытый за брэндмауэром. Такой подход может быть альтернативой в тестах заходу по ssh на тестируемый сервер и вызову curl, wget.
##### Альтернативы
В тестах, помимо WireMock могут быть интересны аналоги: [github.com/jadler-mocking/jadler](https://github.com/jadler-mocking/jadler) или [github.com/robfletcher/betamax](https://github.com/robfletcher/betamax). | https://habr.com/ru/post/228691/ | null | ru | null |
# Функциональные опции на стероидах
Привет, Хабр! Представляю вашему вниманию перевод статьи [Functional options on steroids](https://sagikazarmark.hu/blog/functional-options-on-steroids/) от автора [Márk Sági-Kazár](https://github.com/sagikazarmark).

Функциональные опции — это парадигма в Go для чистых и расширяемых API. Она популяризирована [Дейвом Чейни](https://dave.cheney.net/2014/10/17/functional-options-for-friendly-apis) и [Робом Пайком](https://commandcenter.blogspot.com/2014/01/self-referential-functions-and-design.html). Этот пост о практиках, которые появились вокруг шаблона с тех пор как он был впервые представлен.
Функциональные опции появились как способ создания хороших и чистых API с конфигурацией, включающей необязательные параметры. Есть много очевидных способов сделать это (конструктор, структура конфигурации, сеттеры и т. д.), но когда нужно передавать десятки опций они плохо читаются и не дают на выходе таких хороших API, как функциональные опции.
### Введение — что такое функциональные опции?
Обычно, когда вы создаете «объект», вы вызываете конструктор с передачей ему необходимых аргументов:
```
obj := New(arg1, arg2)
```
*(Давайте на минуту проигнорируем тот факт, что в Go нет традиционных конструкторов.)*
Функциональные опции позволяют расширять API дополнительными параметрами, превращая приведенную выше строку в следующее:
```
// I can still do this...
obj := New(arg1, arg2)
// ...but this works too
obj := New(arg1, arg2, myOption1, myOption2)
```
Функциональные опции — это, в основном, аргументы вариативной функции, которая принимает в качестве параметров составной или промежуточный конфигурационный тип. Благодаря вариативному характеру вполне допустимо вызывать конструктор без каких-либо опций, сохраняя его чистым, даже если вы хотите использовать значения по умолчанию.
Чтобы лучше продемонстрировать шаблон, давайте взглянем на реалистичный пример (без функциональных опций):
```
type Server struct {
addr string
}
// NewServer initializes a new Server listening on addr.
func NewServer(addr string) *Server {
return &Server {
addr: addr,
}
}
```
После добавления опции таймаута код выглядит так:
```
type Server struct {
addr string
// default: no timeout
timeout time.Duration
}
// Timeout configures a maximum length of idle connection in Server.
func Timeout(timeout time.Duration) func(*Server) {
return func(s *Server) {
s.timeout = timeout
}
}
// NewServer initializes a new Server listening on addr with optional configuration.
func NewServer(addr string, opts ...func(*Server)) *Server {
server := &Server {
addr: addr,
}
// apply the list of options to Server
for _, opt := range opts {
opt(server)
}
return server
}
```
Полученный API прост в использовании и легко читается:
```
// no optional paramters, use defaults
server := NewServer(":8080")
// configure a timeout in addition to the address
server := NewServer(":8080", Timeout(10 * time.Second))
// configure a timeout and TLS in addition to the address
server := NewServer(":8080", Timeout(10 * time.Second), TLS(&TLSConfig{}))
```
Для сравнения, вот как выглядят инициализация с использованием конструктора и с использованием конфигурационной структуры config:
```
// constructor variants
server := NewServer(":8080")
server := NewServerWithTimeout(":8080", 10 * time.Second)
server := NewServerWithTimeoutAndTLS(":8080", 10 * time.Second, &TLSConfig{})
// config struct
server := NewServer(":8080", Config{})
server := NewServer(":8080", Config{ Timeout: 10 * time.Second })
server := NewServer(":8080", Config{ Timeout: 10 * time.Second, TLS: &TLSConfig{} })
```
Преимущество использования функциональных опций перед конструктором, наверное, очевидно: их легче поддерживать и читать/писать. Функциональные параметры также превосходят конфигурационную структуру, когда в конструктор не передаются параметры. В следующих разделах я покажу еще больше примеров, когда структура конфигурации может не оправдать ожиданий.
*Прочитайте полную историю функциональных опций перейдя по ссылкам во введении. (примечание переводчика — блог с оригинальной статьей Дейва Чейни не всегда доступен в России и для его просмотра может потребоваться подключение через VPN. Также информация из статьи доступна в [видео его доклада на dotGo 2014](https://www.youtube.com/watch?v=24lFtGHWxAQ))*
### Практики функциональных опций
Сами функциональные опции — это не что иное, как функции, передаваемые конструктору. Простота использования простых функций дает гибкость и имеет большой потенциал. Поэтому неудивительно, что за эти годы вокруг шаблона появилось довольно много практик. Ниже я предоставлю список того, что я считаю наиболее популярными и полезными практиками.
Напишите мне, если вы считате, что чего-то не хватает.
### Тип опций
Первое, что вы можете сделать при применении шаблона функциональных опций, это определить тип для опциональной функции:
```
// Option configures a Server.
type Option func(s *Server)
```
Хотя это может показаться не таким уж большим улучшением, но код становится более читаемым благодаря использованию имени типа вместо определения функции:
```
func Timeout(timeout time.Duration) func(*Server) { /*...*/ }
// reads: a new server accepts an address
// and a set of functions that accepts the server itself
func NewServer(addr string, opts ...func(s *Server)) *Server
// VS
func Timeout(timeout time.Duration) Option { /*...*/ }
// reads: a new server accepts an address and a set of options
func NewServer(addr string, opts ...Option) *Server
```
Еще одним преимуществом наличия типа опции является то, что Godoc помещает функции опции под типом:

### Список типов опций
Обычно функциональные параметры используются для создания одного экземпляра чего-либо, но это не всегда так. Повторное использование списка параметров по умолчанию при создании нескольких экземпляров также не редкость:
```
defaultOptions := []Option{Timeout(5 * time.Second)}
server1 := NewServer(":8080", append(defaultOptions, MaxConnections(10))...)
server2 := NewServer(":8080", append(defaultOptions, RateLimit(10, time.Minute))...)
server3 := NewServer(":8080", append(defaultOptions, Timeout(10 * time.Second))...)
```
Это не очень читаемый код, особенно учитывая, что смысл использования функциональных опций заключается в создании дружелюбных API. К счастью, есть способ упростить это. Нам просто нужно сделать срез []Option непосредственно опцией:
```
// Options turns a list of Option instances into an Option.
func Options(opts ...Option) Option {
return func(s *Server) {
for _, opt := range opts {
opt(s)
}
}
}
```
После замены среза на функцию Options приведенный выше код становится:
```
defaultOptions := Options(Timeout(5 * time.Second))
server1 := NewServer(":8080", defaultOptions, MaxConnections(10))
server2 := NewServer(":8080", defaultOptions, RateLimit(10, time.Minute))
server3 := NewServer(":8080", defaultOptions, Timeout(10 * time.Second))
```
### Префиксы опций With/Set
Опции часто являются сложными типами, в отличие от таймаута или максимального количества соединений. Например, в пакете сервера можно определить интерфейс Logger в качестве опции (и использовать для отсутствия логгера по умолчанию):
```
type Logger interface {
Info(msg string)
Error(msg string)
}
```
Очевидно, что имя Logger не может быть использовано в качестве названия опции, так как оно уже используется интерфейсом. Можно назвать опцию LoggerOption, но это не совсем дружелюбное имя. Если посмотреть на конструктор как на предложение, в нашем случае на ум приходит слово with: WithLogger.
```
func WithLogger(logger Logger) Option {
return func(s *Server) {
s.logger = logger
}
}
// reads: create a new server that listens on :8080 with a logger
NewServer(":8080", WithLogger(logger))
```
Другим распространенным примером опции сложного типа является слайс значений:
```
type Server struct {
// ...
whitelistIPs []string
}
func WithWhitelistedIP(ip string) Option {
return func(s *Server) {
s.whitelistIPs = append(s.whitelistIPs, ip)
}
}
NewServer(":8080", WithWhitelistedIP("10.0.0.0/8"), WithWhitelistedIP("172.16.0.0/12"))
```
В этом случае опция обычно присоединяет значения к уже существующим, а не перезаписывает их. Если вам нужно перезаписать существующий набор значений, вы можете использовать слово set в имени опции:
```
func SetWhitelistedIP(ip string) Option {
return func(s *Server) {
s.whitelistIPs = []string{ip}
}
}
NewServer(
":8080",
WithWhitelistedIP("10.0.0.0/8"),
WithWhitelistedIP("172.16.0.0/12"),
SetWhitelistedIP("192.168.0.0/16"), // overwrites any previous values
)
```
### Шаблон пресетов
Особые случаи использования обычно достаточно универсальны для их поддержки в библиотеке. В случае конфигурации это может означать набор параметров, сгруппированных вместе и используемых в качестве пресета для использования. В нашем примере Сервер может иметь открытый и внутренний сценарии использования, которые по-разному настраивают таймауты, ограничения скорости, количество подключений и т. д.
```
// PublicPreset configures a Server for public usage.
func PublicPreset() Option {
return Options(
WithTimeout(10 * time.Second),
MaxConnections(10),
)
}
// InternalPreset configures a Server for internal usage.
func InternalPreset() Option {
return Options(
WithTimeout(20 * time.Second),
WithWhitelistedIP("10.0.0.0/8"),
)
}
```
Несмотря на то, что пресеты могут быть полезны в некоторых случаях, они, вероятно, имеют большую ценность во внутренних библиотеках, а в публичных библиотеках их ценность меньше.
### Значения типов по умолчанию vs значения пресетов по умолчанию
В Go всегда есть значения по умолчанию. Для чисел это обычно ноль, для булевых типов это false и так далее. В опциональной конфигурации считается хорошей практикой полагаться на значения по умолчанию. Например, нулевое значение должно означать неограниченный timeout вместо его отсутствия (что обычно бессмысленно).
В некоторых случаях дефолтное значение типа не является хорошим значением по умолчанию. Например, значением по умолчанию для Logger является nil, что может привести к панике (если вы не защищаете вызовы логгера с помощью условных проверок).
В этих случаях установка значения в конструкторе (до применения параметров) — хороший способ определить запасной вариант:
```
func NewServer(addr string, opts ...func(*Server)) *Server {
server := &Server {
addr: addr,
logger: noopLogger{},
}
// apply the list of options to Server
for _, opt := range opts {
opt(server)
}
return server
}
```
Я видел примеры с пресетами по умолчанию (при использовании шаблона, описанного в предыдущем разделе). Однако я не считаю это хорошей практикой. Это гораздо менее выразительно, чем просто установка значений по умолчанию в конструкторе:
```
func NewServer(addr string, opts ...func(*Server)) *Server {
server := &Server {
addr: addr,
}
// what are the defaults?
opts = append([]Option{DefaultPreset()}, opts...)
// apply the list of options to Server
for _, opt := range opts {
opt(server)
}
return server
}
```
### Опция структуры конфигурации
Наличие структуры Config в качестве функциональной опции, вероятно, не столь распространено, но это иногда встречается. Идея состоит в том, что функциональные опции ссылаются на структуру конфигурации вместо ссылки на фактический создаваемый объект:
```
type Config struct {
Timeout time.Duration
}
type Option func(c *Config)
type Server struct {
// ...
config Config
}
```
Этот шаблон полезен, когда у вас есть множество опций, и создание структуры конфигурации кажется более чистым, чем перечисление всех опций в вызове функции:
```
config := Config{
Timeout: 10 * time.Second
// ...
// lots of other options
}
NewServer(":8080", WithConfig(config))
```
Другой вариант использования этого шаблона — установка значений по умолчанию:
```
config := Config{
Timeout: 10 * time.Second
// ...
// lots of other options
}
NewServer(":8080", WithConfig(config), WithTimeout(20 * time.Second))
```
### Расширенные шаблоны
После написания десятков функциональных опций вы можете задаться вопросом, есть ли лучший способ сделать это. Не с точки зрения использования, а с точки зрения долговременной поддержки.
Например, что если бы мы могли определить типы и использовать их в качестве параметров:
```
type Timeout time.Duration
NewServer(":8080", Timeout(time.Minute))
```
(Обратите внимание, что использование API остается прежним)
Оказывается, что, изменяя тип Option, мы можем легко сделать это:
```
// Option configures a Server.
type Option interface {
// apply is unexported,
// so only the current package can implement this interface.
apply(s *Server)
}
```
Переопределение опциональной функции в качестве интерфейса открывает двери для ряда новых способов реализации функциональных опций:
Различные встроенные типы могут использоваться в качестве параметров без функции-оболочки:
```
// Timeout configures a maximum length of idle connection in Server.
type Timeout time.Duration
func (t Timeout) apply(s *Server) {
s.timeout = time.Duration(t)
}
```
Списки опций и структуры конфигурации (см. в предыдущих разделах) также могут быть переопределены следующим образом:
```
// Options turns a list of Option instances into an Option.
type Options []Option
func (o Options) apply(s *Server) {
for _, opt := range o {
o.apply(s)
}
}
type Config struct {
Timeout time.Duration
}
func (c Config) apply(s *Server) {
s.config = c
}
```
Мой личный фаворит — возможность повторно использовать опцию в нескольких конструкторах:
```
// ServerOption configures a Server.
type ServerOption interface {
applyServer(s *Server)
}
// ClientOption configures a Client.
type ClientOption interface {
applyClient(c *Client)
}
// Option configures a Server or a Client.
type Option interface {
ServerOption
ClientOption
}
func WithLogger(logger Logger) Option {
return withLogger{logger}
}
type withLogger struct {
logger Logger
}
func (o withLogger) applyServer(s *Server) {
s.logger = o.logger
}
func (o withLogger) applyClient(c *Client) {
c.logger = o.logger
}
NewServer(":8080", WithLogger(logger))
NewClient("http://localhost:8080", WithLogger(logger))
```
### Резюме
Функциональные параметры — это мощный шаблон для создания чистых и расширяемых API с десятками параметров. Хотя это создаёт немного больше работы, чем поддержка простой структуры конфигурации, она обеспечивает гораздо большую гибкость и дает намного более чистые API, чем альтернативы. | https://habr.com/ru/post/489296/ | null | ru | null |
# The Testcontainers’ MongoDB Module and Spring Data MongoDB Reactive in Action
### 1. Introduction
How can I easily test my MongoDB multi-document transaction code without setting up MongoDB on my device? One might argue that they have to set it up first because in order to carry out such a transaction it needs a session which requires a replica set. Thankfully, there is no need to create a 3-node replica set and we can run these transactions only against a single database instance.
To achieve this, we may do the following:
* Run a MongoDB container of version 4 or higher and specify a --replSet command;
* Initialize a single replica set by executing a proper command;
* Wait for the initialization to complete;
* Connect to a standalone without specifying a replica set in order not to worry about modifying our OS host file.
It is worth mentioning that a replica set is not the only option here because MongoDB version 4.2 introduces distributed transactions in sharded clusters, which is beyond the scope of this article.
There are a lot of ways of how to initialize a replica set, including Docker compose, bash scripts, services in a CI/CD etc. However, it takes some extra work in terms of scripting, handling random ports, and making it part of the CI/CD process. Fortunately, starting from Testcontainers’ version 1.14.2 we are able to delegate all the heavy lifting to [the MongoDB Module](https://www.testcontainers.org/modules/databases/mongodb/).
Let us try it out on a small warehouse management system based on Spring Boot 2.3. In the recent past one had to use `ReactiveMongoOperations` and its `inTransaction` method, but since Spring Data MongoDB 2.2 M4 we have been able to leverage the good old `@Transactional` annotation or more advanced `TransactionalOperator`.
Our application should have a REST API to provide the information on successfully processed files including the number of the documents modified. Regarding the files causing errors along the way, we should skip them to process all the files.
It may be noted that even though duplicated articles and their sizes within a single file are a rare case, this possibility is quite realistic, and therefore should be handled as well.
As per business requirements to our system, we already have some products in our database and we upload a bunch of Excel (xlsx) files to update some fields of the matched documents in our storage. Data is supposed to be only at the first sheet of any workbook. Each file is processed in a separate multi-document transaction to prevent simultaneous modifications of the same documents. For example, Figure 1 shows collision cases on how a transaction ends up except for a possible scenario when transactions are executed sequentially (json representation is shortened here for the sake of simplicity). Transactional behavior helps us to avoid clashing the data and guarantees consistency.

*Figure 1 Transaction sequence diagram: collision cases*
As for a product collection, we have an article as a unique index. At the same time, each article is bound to a concrete size. Therefore, it is important for our application to verify that both of them are in the database before updating. Figure 2 gives an insight into this collection.

*Figure 2 Product collection details*
### 2. Business logic implementation
Let us elaborate on the major points of the above-mentioned business logic and start with `ProductController` as an entry point for the processing. You can find a complete project on [GitHub](https://github.com/silaev/wms). Prerequisites are Java8+ and Docker.
```
@PatchMapping(
consumes = MediaType.MULTIPART_FORM_DATA_VALUE,
produces = MediaType.APPLICATION_STREAM_JSON_VALUE
)
public ResponseEntity> patchProductQuantity(
@RequestPart("file") Flux files,
@AuthenticationPrincipal Principal principal
) {
log.debug("shouldPatchProductQuantity");
return ResponseEntity.accepted().body(
uploadProductService.patchProductQuantity(files, principal.getName())
);
}
```
1) Wrap a response in a `ResponseEntity` and return the `flux` of the `FileUploadDto`;
2) Get a current authentication principal, coming in handy later on;
3) Pass the `flux` of the `FilePart` to process.
Here is the `patchProductQuantity` method of the `UploadProductServiceImpl`:
```
public Flux patchProductQuantity(
final Flux files,
final String userName
) {
return Mono.fromRunnable(() -> initRootDirectory(userName))
.publishOn(Schedulers.newBoundedElastic(1, 1, "initRootDirectory"))
.log(String.format("cleaning-up directory: %s", userName))
.thenMany(files.flatMap(f ->
saveFileToDiskAndUpdate(f, userName)
.subscribeOn(Schedulers.boundedElastic())
)
);
}
```
1) Use the name of the user as the root directory name;
2) Do the blocking initialization of the root directory on a separate elastic thread;
3) For each Excel file:
3.1) Save it on a disk;
3.2) Then update the quantity of the products on a separate elastic thread, as blocking processing of the file is ran.
The `saveFileToDiskAndUpdate` method does the following logic:
```
private Mono saveFileToDiskAndUpdate(
final FilePart file,
final String userName
) {
final String fileName = file.filename();
final Path path = Paths.get(pathToStorage, userName, fileName);
return Mono.just(path)
.log(String.format("A file: %s has been uploaded", fileName))
.flatMap(file::transferTo)
.log(String.format("A file: %s has been saved", fileName))
.then(processExcelFile(fileName, userName, path));
}
```
1. Copy the content of the file to the user’s directory;
2. After the copy stage is completed, call the `processExcelFile` method.
At this point, we are going to divide logic in accordance with the size of the file:
```
private Mono processExcelFile(
final String fileName,
final String userName,
final Path path
) {
return Mono.fromCallable(() -> Files.size(path))
.flatMap(size -> {
if (size >= bigFileSizeThreshold) {
return processBigExcelFile(fileName, userName);
} else {
return processSmallExcelFile(fileName, userName);
}
});
}
```
1. Wrap the blocking `Files.size(path)` call in `Mono.fromCallable`;
2. `bigFileSizeThreshold` is injected from a proper application.yml file via `@Value("${upload-file.bigFileSizeThreshold}")`.
Before going into detail on processing Excel files depending on their size, we should take a look at the `getProducts` method of the `ExcelFileDaoImpl`:
```
@Override
public Flux getProducts(
final String pathToStorage,
final String fileName,
final String userName
) {
return Flux.defer(() -> {
FileInputStream is;
Workbook workbook;
try {
final File file = Paths.get(pathToStorage, userName, fileName).toFile();
verifyFileAttributes(file);
is = new FileInputStream(file);
workbook = StreamingReader.builder()
.rowCacheSize(ROW\_CACHE\_SIZE)
.bufferSize(BUFFER\_SIZE)
.open(is);
} catch (IOException e) {
return Mono.error(new UploadProductException(
String.format("An exception has been occurred while parsing a file: %s " +
"has been saved", fileName), e));
}
try {
final Sheet datatypeSheet = workbook.getSheetAt(0);
final Iterator iterator = datatypeSheet.iterator();
final AtomicInteger rowCounter = new AtomicInteger();
if (iterator.hasNext()) {
final Row currentRow = iterator.next();
rowCounter.incrementAndGet();
verifyExcelFileHeader(fileName, currentRow);
}
return Flux.create(fluxSink -> fluxSink.onRequest(value -> {
try {
for (int i = 0; i < value; i++) {
if (!iterator.hasNext()) {
fluxSink.complete();
return;
}
final Row currentRow = iterator.next();
final Product product = Objects.requireNonNull(getProduct(
FileRow.builder()
.fileName(fileName)
.currentRow(currentRow)
.rowCounter(rowCounter.incrementAndGet())
.build()
), "product is not supposed to be null");
fluxSink.next(product);
}
} catch (Exception e1) {
fluxSink.error(e1);
}
})).doFinally(signalType -> {
try {
is.close();
workbook.close();
} catch (IOException e1) {
log.error("Error has occurred while releasing {} resources: {}", fileName, e1);
}
});
} catch (Exception e) {
return Mono.error(e);
}
});
}
```
1. `differ` the whole logic once there is a new subscriber;
2. Verify the excel file header;
3. Create a `flux` to provide the requested number of products;
4. Convert an Excel row into a `Product` domain object;
5. Finally, close all of the opened resources.
Getting back to the processing of the Excel files in the `UploadProductServiceImpl`, we are going to use the MongoDB’s `bulkWrite` method on a collection to update products in bulk, which requires the eagerly evaluated list of the `UpdateOneModel`. In practice, collecting such a list is a memory-consuming operation, especially for big files.
Regarding small Excel files, we provide a more detailed log and do additional validation check:
```
private Mono processSmallExcelFile(
final String fileName,
final String userName
) {
log.debug("processSmallExcelFile: {}", fileName);
return excelFileDao.getProducts(pathToStorage, fileName, userName)
.reduce(new ConcurrentHashMap, BigInteger>>(),
(indexMap, product) -> {
final BigInteger quantity = product.getQuantity();
indexMap.merge(
new ProductArticleSizeDto(product.getArticle(), product.getSize()),
Tuples.of(
updateOneModelConverter.convert(Tuples.of(product, quantity, userName)),
quantity
),
(oldValue, newValue) -> {
final BigInteger mergedQuantity = oldValue.getT2().add(newValue.getT2());
return Tuples.of(
updateOneModelConverter.convert(Tuples.of(product, mergedQuantity, userName)),
mergedQuantity
);
}
);
return indexMap;
})
.filterWhen(productIndexFile ->
productDao.findByArticleIn(extractArticles(productIndexFile.keySet()))
.handle(
(productArticleSizeDto, synchronousSink) -> {
if (productIndexFile.containsKey(productArticleSizeDto)) {
synchronousSink.next(productArticleSizeDto);
} else {
synchronousSink.error(new UploadProductException(
String.format(
"A file %s does not have an article: %d with size: %s",
fileName,
productArticleSizeDto.getArticle(),
productArticleSizeDto.getSize()
)
));
}
})
.count()
.handle((sizeDb, synchronousSink) -> {
final int sizeFile = productIndexFile.size();
if (sizeDb == sizeFile) {
synchronousSink.next(Boolean.TRUE);
} else {
synchronousSink.error(new UploadProductException(
String.format(
"Inconsistency between total element size in MongoDB: %d and a file %s: %d",
sizeDb,
fileName,
sizeFile
)
));
}
})
).onErrorResume(e -> {
log.debug("Exception while processExcelFile fileName: {}: {}", fileName, e);
return Mono.empty();
}).flatMap(productIndexFile ->
productPatcherService.incrementProductQuantity(
fileName,
productIndexFile.values().stream().map(Tuple2::getT1).collect(Collectors.toList()),
userName
)
).map(bulkWriteResult -> FileUploadDto.builder()
.fileName(fileName)
.matchedCount(bulkWriteResult.getMatchedCount())
.modifiedCount(bulkWriteResult.getModifiedCount())
.build()
);
}
```
1. `reduce` helps us handle duplicate products whose quantities should be summed up;
2. Collect a map to get the list of the `ProductArticleSizeDto` against the pair of the list of the `UpdateOneModel` and the total quantity for a product. The former is in use for matching an article and its size in the file with those that are in the database via a projection `ProductArticleSizeDto`;
3. Use the atomic `merge` method of the `ConcurrentMap` to sum up the quantity of the same products and create a new `UpdateOneModel`;
4. Filter out all products in the file by those product’s articles that are in the database;
5. Each `ProductArticleSizeDto` found in the storage matches a `ProductArticleSizeDto` from the file summed up by quantity;
6. Then `count` the result after filtration which should be equal to the distinct number of products in the file;
7. Use the `onErrorResume` method to continue when any error occurs because we need to process all files as mentioned in the requirements;
8. Extract the list of the `UpdateOneModel` from the map collected earlier to be further used in the `incrementProductQuantity` method;
9. Then run the `incrementProductQuantity` method as a sub-process within `flatMap` and `map` its result in `FileUploadDto` that our business users are in need of.
Even though the `filterWhen` and the subsequent `productDao.findByArticleIn` allow us to do some additional validation at an early stage, they come at a price, which is especially noticeable while processing big files in practice. However, the `incrementProductQuantity` method can compare the number of modified documents and match them against the number of the distinct products in the file. Knowing that, we can implement a more light-weight option to process big files:
```
private Mono processBigExcelFile(
final String fileName,
final String userName
) {
log.debug("processBigExcelFile: {}", fileName);
return excelFileDao.getProducts(pathToStorage, fileName, userName)
.reduce(new ConcurrentHashMap, BigInteger>>(),
(indexMap, product) -> {
final BigInteger quantity = product.getQuantity();
indexMap.merge(
product,
Tuples.of(
updateOneModelConverter.convert(Tuples.of(product, quantity, userName)),
quantity
),
(oldValue, newValue) -> {
final BigInteger mergedQuantity = oldValue.getT2().add(newValue.getT2());
return Tuples.of(
updateOneModelConverter.convert(Tuples.of(product, mergedQuantity, userName)),
mergedQuantity
);
}
);
return indexMap;
})
.map(indexMap -> indexMap.values().stream().map(Tuple2::getT1).collect(Collectors.toList()))
.onErrorResume(e -> {
log.debug("Exception while processExcelFile: {}: {}", fileName, e);
return Mono.empty();
}).flatMap(dtoList ->
productPatcherService.incrementProductQuantity(
fileName,
dtoList,
userName
)
).map(bulkWriteResult -> FileUploadDto.builder()
.fileName(fileName)
.matchedCount(bulkWriteResult.getMatchedCount())
.modifiedCount(bulkWriteResult.getModifiedCount())
.build()
);
}
```
Here is the `ProductAndUserNameToUpdateOneModelConverter` that we have used to create an `UpdateOneModel`:
```
@Component
public class ProductAndUserNameToUpdateOneModelConverter implements
Converter, UpdateOneModel> {
@Override
@NonNull
public UpdateOneModel convert(@NonNull Tuple3 source) {
Objects.requireNonNull(source);
final Product product = source.getT1();
final BigInteger quantity = source.getT2();
final String userName = source.getT3();
return new UpdateOneModel<>(
Filters.and(
Filters.eq(Product.SIZE\_DB\_FIELD, product.getSize().name()),
Filters.eq(Product.ARTICLE\_DB\_FIELD, product.getArticle())
),
Document.parse(
String.format(
"{ $inc: { %s: %d } }",
Product.QUANTITY\_DB\_FIELD,
quantity
)
).append(
"$set",
new Document(
Product.LAST\_MODIFIED\_BY\_DB\_FIELD,
userName
)
),
new UpdateOptions().upsert(false)
);
}
}
```
1. Firstly, find a document by article and size. Figure 2 shows that we have a compound index on the size and article fields of the product collection to facilitate such a search;
2. Increment the quantity of the found document and set the name of the user in the `lastModifiedBy` field;
3. It is also possible to `upsert` a document here, but we are interested only in the modification of the existing documents in the storage.
Now we are ready to implement the central part of our processing which is the `incrementProductQuantity` method of the `ProductPatcherDaoImpl`:
```
@Override
public Mono incrementProductQuantity(
final String fileName,
final List> models,
final String userName
) {
return transactionalOperator.execute(
action -> reactiveMongoOperations.getCollection(Product.COLLECTION\_NAME)
.flatMap(collection ->
Mono.from(collection.bulkWrite(models, new BulkWriteOptions().ordered(true)))
).handle((bulkWriteResult, synchronousSink) -> {
final int fileCount = models.size();
if (Objects.equals(bulkWriteResult.getModifiedCount(), fileCount)) {
synchronousSink.next(bulkWriteResult);
} else {
synchronousSink.error(
new IllegalStateException(
String.format(
"Inconsistency between modified doc count: %d and file doc count: %d. Please, check file: %s",
bulkWriteResult.getModifiedCount(), fileCount, fileName
)
)
);
}
}).onErrorResume(
e -> Mono.fromRunnable(action::setRollbackOnly)
.log("Exception while incrementProductQuantity: " + fileName + ": " + e)
.then(Mono.empty())
)
).singleOrEmpty();
}
```
1. Use a `transactionalOperator` to roll back a transaction manually. As has been mentioned before, our goal is to process all files while skipping those causing exceptions;
2. Run a single sub-process to bulk write modifications to the database sequentially for fail-fast and less resource-intensive behavior. The word "single" is of paramount importance here because we avoid the dangerous "N+1 Query Problem" leading to spawning a lot of sub-processes on a `flux` within `flatMap`;
3. `Handle` the situation when the number of the documents processed does not match the one coming from the distinct number of the products in the file;
4. The `onErrorResume` method handles the rollback of the transaction and then returns `Mono.empty()` to skip the current processing;
5. Expect either a single item or an empty Mono as the result of the `transactionalOperator.execute` method.
One would say: "You called `collection.bulkWrite(models, new BulkWriteOptions().ordered(true))`, what about setting a session?". The thing is that the `SessionAwareMethodInterceptor` of the Spring Data MongoDB does it via reflection:
```
ReflectionUtils.invokeMethod(targetMethod.get(), target,
prependSessionToArguments(session, methodInvocation)
```
Here is the `prependSessionToArguments` method:
```
private static Object[] prependSessionToArguments(ClientSession session, MethodInvocation invocation) {
Object[] args = new Object[invocation.getArguments().length + 1];
args[0] = session;
System.arraycopy(invocation.getArguments(), 0, args, 1, invocation.getArguments().length);
return args;
}
```
1) Get the arguments of the `MethodInvocation`;
2) Add `session` as a the first element in the `args` array.
In fact, the following method of the `MongoCollectionImpl` is called:
```
@Override
public Publisher bulkWrite(final ClientSession clientSession,
final List extends WriteModel<? extends TDocument> requests,
final BulkWriteOptions options) {
return Publishers.publish(
callback -> wrapped.bulkWrite(clientSession.getWrapped(), requests, options, callback));
}
```
### 3. Test implementation
So far so good, we can create integration tests to cover our logic.
To begin with, we create `ProductControllerITTest` to test our public API via the Spring’s `WebTestClient` and initialize a MongoDB instance to run tests against:
```
private static final MongoDBContainer MONGO_DB_CONTAINER =
new MongoDBContainer("mongo:4.2.8");
```
1) Use a static field to have single Testcontainers’ `MongoDBContainer` per all test methods in `ProductControllerITTest`;
2) We use 4.2.8 MongoDB container version from Docker Hub as it is the latest stable one, otherwise `MongoDBContainer` defaults to 4.0.10.
Then in static methods `setUpAll` and `tearDownAll` we start and stop the `MongoDBContainer` respectively. Even though we do not use Testcontainers' reusable feature here, we leave open the possibility of setting it. Which is why we call `MONGO_DB_CONTAINER.stop()` only if the reusable feature is turned off.
```
@BeforeAll
static void setUpAll() {
MONGO_DB_CONTAINER.start();
}
@AfterAll
static void tearDownAll() {
if (!MONGO_DB_CONTAINER.isShouldBeReused()) {
MONGO_DB_CONTAINER.stop();
}
}
```
Next we set `spring.data.mongodb.uri` by executing `MONGO_DB_CONTAINER.getReplicaSetUrl()` in `ApplicationContextInitializer`:
```
static class Initializer implements ApplicationContextInitializer {
@Override
public void initialize(@NotNull ConfigurableApplicationContext configurableApplicationContext) {
TestPropertyValues.of(
String.format("spring.data.mongodb.uri: %s", MONGO\_DB\_CONTAINER.getReplicaSetUrl())
).applyTo(configurableApplicationContext);
}
}
```
Now we are ready to write a first test without any transaction collision, because our test files (see Figure 3) have products whose articles do not clash with one another.

*Figure 3 Excel files causing no collision in the articles of the products*
```
@WithMockUser(
username = SecurityConfig.ADMIN_NAME,
password = SecurityConfig.ADMIN_PAS,
authorities = SecurityConfig.WRITE_PRIVILEGE
)
@Test
void shouldPatchProductQuantity() {
//GIVEN
insertMockProductsIntoDb(Flux.just(product1, product2, product3));
final BigInteger expected1 = BigInteger.valueOf(16);
final BigInteger expected2 = BigInteger.valueOf(27);
final BigInteger expected3 = BigInteger.valueOf(88);
final String fileName1 = "products1.xlsx";
final String fileName3 = "products3.xlsx";
final String[] fileNames = {fileName1, fileName3};
final FileUploadDto fileUploadDto1 = ProductTestUtil.mockFileUploadDto(fileName1, 2);
final FileUploadDto fileUploadDto3 = ProductTestUtil.mockFileUploadDto(fileName3, 1);
//WHEN
final WebTestClient.ResponseSpec exchange = webClient
.patch()
.uri(BASE_URL)
.contentType(MediaType.MULTIPART_FORM_DATA)
.body(BodyInserters.fromMultipartData(ProductTestUtil.getMultiPartFormData(fileNames)))
.exchange();
//THEN
exchange.expectStatus().isAccepted();
exchange.expectBodyList(FileUploadDto.class)
.hasSize(2)
.contains(fileUploadDto1, fileUploadDto3);
StepVerifier.create(productDao.findAllByOrderByQuantityAsc())
.assertNext(product -> assertEquals(expected1, product.getQuantity()))
.assertNext(product -> assertEquals(expected2, product.getQuantity()))
.assertNext(product -> assertEquals(expected3, product.getQuantity()))
.verifyComplete();
}
```
Finally, let us test a transaction collision in action, keeping in mind Figure 1 and Figure 4 showing such files:

*Figure 4 Excel files causing a collision in the articles of the products*
```
@WithMockUser(
username = SecurityConfig.ADMIN_NAME,
password = SecurityConfig.ADMIN_PAS,
authorities = SecurityConfig.WRITE_PRIVILEGE
)
@Test
void shouldPatchProductQuantityConcurrently() {
//GIVEN
TransactionUtil.setMaxTransactionLockRequestTimeoutMillis(
20,
MONGO_DB_CONTAINER.getReplicaSetUrl()
);
insertMockProductsIntoDb(Flux.just(product1, product2));
final String fileName1 = "products1.xlsx";
final String fileName2 = "products2.xlsx";
final String[] fileNames = {fileName1, fileName2};
final BigInteger expected120589Sum = BigInteger.valueOf(19);
final BigInteger expected120590Sum = BigInteger.valueOf(32);
final BigInteger expected120589T1 = BigInteger.valueOf(16);
final BigInteger expected120589T2 = BigInteger.valueOf(12);
final BigInteger expected120590T1 = BigInteger.valueOf(27);
final BigInteger expected120590T2 = BigInteger.valueOf(11);
final FileUploadDto fileUploadDto1 = ProductTestUtil.mockFileUploadDto(fileName1, 2);
final FileUploadDto fileUploadDto2 = ProductTestUtil.mockFileUploadDto(fileName2, 2);
//WHEN
final WebTestClient.ResponseSpec exchange = webClient
.patch()
.uri(BASE_URL)
.contentType(MediaType.MULTIPART_FORM_DATA)
.accept(MediaType.APPLICATION_STREAM_JSON)
.body(BodyInserters.fromMultipartData(ProductTestUtil.getMultiPartFormData(fileNames)))
.exchange();
//THEN
exchange.expectStatus().isAccepted();
assertThat(
extractBodyArray(exchange),
either(arrayContaining(fileUploadDto1))
.or(arrayContaining(fileUploadDto2))
.or(arrayContainingInAnyOrder(fileUploadDto1, fileUploadDto2))
);
final List list = productDao.findAll(Sort.by(Sort.Direction.ASC, "article"))
.toStream().collect(Collectors.toList());
assertThat(list.size(), is(2));
assertThat(
list.stream().map(Product::getQuantity).toArray(BigInteger[]::new),
either(arrayContaining(expected120589T1, expected120590T1))
.or(arrayContaining(expected120589T2, expected120590T2))
.or(arrayContaining(expected120589Sum, expected120590Sum))
);
TransactionUtil.setMaxTransactionLockRequestTimeoutMillis(
5,
MONGO\_DB\_CONTAINER.getReplicaSetUrl()
);
}
```
1. We can specify the maximum amount of time in milliseconds that multi-document transactions should wait to acquire locks required by the operations in the transaction (by default, multi-document transactions wait 5 milliseconds);
2. As an example here, we might use a helper method to change 5ms with 20ms (see an implementation details below).
Note that the `maxTransactionLockRequestTimeoutMillis` setting has no sense for this particular test case and serves the purpose of the example. After running this test class 120 times via a script `./load_test.sh 120 ProductControllerITTest.shouldPatchProductQuantityConcurrently` in the tools directory of the project, I got the following figures:
| indicator | 20ms,
times | 5ms(default),
times |
| --- | --- | --- |
| T1 successes | 61 | 56 |
| T2 successes | 57 | 63 |
| T1 and T2 success | 2 | 1 |
*Figure 5 Running the shouldPatchProductQuantityConcurrently test 120 times with 20 and 5 ms maxTransactionLockRequestTimeoutMillis respectively*
While going through logs, we may come across something like:
> Exception while incrementProductQuantity: products1.xlsx: com.mongodb.MongoCommandException: Command failed with error 112 (WriteConflict): 'WriteConflict' on server…
>
> Initiating transaction rollback…
>
> Initiating transaction commit…
>
> About to abort transaction for session…
>
> About to commit transaction for session...
Then, let us test the processing of the big file containing 1 million products in a separate `PatchProductLoadITTest`:
```
@WithMockUser(
username = SecurityConfig.ADMIN_NAME,
password = SecurityConfig.ADMIN_PAS,
authorities = SecurityConfig.WRITE_PRIVILEGE
)
@Test
void shouldPatchProductQuantityBigFile() {
//GIVEN
unzipClassPathFile("products_1M.zip");
final String fileName = "products_1M.xlsx";
final int count = 1000000;
final long totalQuantity = 500472368779L;
final List products = getDocuments(count);
TransactionUtil.setTransactionLifetimeLimitSeconds(
900,
MONGO\_DB\_CONTAINER.getReplicaSetUrl()
);
StepVerifier.create(
reactiveMongoTemplate.remove(new Query(), Product.COLLECTION\_NAME)
.then(reactiveMongoTemplate.getCollection(Product.COLLECTION\_NAME))
.flatMapMany(c -> c.insertMany(products))
.switchIfEmpty(Mono.error(new RuntimeException("Cannot insertMany")))
.then(getTotalQuantity())
).assertNext(t -> assertEquals(totalQuantity, t)).verifyComplete();
//WHEN
final Instant start = Instant.now();
final WebTestClient.ResponseSpec exchange = webClient
.patch()
.uri(BASE\_URL)
.contentType(MediaType.MULTIPART\_FORM\_DATA)
.accept(MediaType.APPLICATION\_STREAM\_JSON)
.body(BodyInserters.fromMultipartData(ProductTestUtil.getMultiPartFormData("products\_1M.xlsx")))
.exchange();
//THEN
exchange
.expectStatus()
.isAccepted()
.expectBodyList(FileUploadDto.class)
.contains(ProductTestUtil.mockFileUploadDto(fileName, count));
StepVerifier.create(getTotalQuantity())
.assertNext(t -> assertEquals(totalQuantity \* 2, t))
.verifyComplete();
log.debug(
"============= shouldPatchProductQuantityBigFile elapsed {}minutes =============",
Duration.between(start, Instant.now()).toMinutes()
);
}
```
1. The general setup is similar to the `ProductControllerITTest`;
2. Unzip a json file containing 1 million products which requires about 254M on a disk;
3. Transactions have a lifetime limit as specified by `transactionLifetimeLimitSeconds` which is 60 seconds by default. We need to increase it here, because generally it takes more than 60 s to process such a file. For this, we use a helper method to change this lifespan to 900 s (see the implementation details below). For your information, the REST call with the file takes GitHub Actions about 9-12 minutes;
4. Before processing, we clean up a product collection, insert 1 million products from the json file and then get the total of the quantity;
5. Given the products in the json file and the big excel file are equal, we assert that the total quantity of the product after processing should double.
Such a test requires a relatively big heap of about 4GB (see Figure 6) and Docker's memory resource of about 6GB (see Figure 7):

*Figure 6 VisualVM Monitor Heap while uploading a 1-million-product file*

*Figure 7 Cadvisor memory total usage while uploading a 1-million-product file*
As we can see, it is sensible to configure the maximum amount of disk space allowed for file parts and the maximum number of parts allowed in a given multipart request. Which is why I added properties to a proper application.yml file and then set them in the `configureHttpMessageCodecs` method of the implemented `WebFluxConfigurer`. However, adding Rate Limiter and configuring `Schedulers` might be a better solution in production environment. Note that we use `Schedulers.boundedElastic()` here having a pool of `10 * Runtime.getRuntime().availableProcessors()` threads by default.
Here is `TransactionUtil`containing the above-mentioned helper methods:
```
public class TransactionUtil {
private TransactionUtil() {
}
public static void setTransactionLifetimeLimitSeconds(
final int duration,
final String replicaSetUrl
) {
setMongoParameter("transactionLifetimeLimitSeconds", duration, replicaSetUrl);
}
public static void setMaxTransactionLockRequestTimeoutMillis(
final int duration,
final String replicaSetUrl
) {
setMongoParameter("maxTransactionLockRequestTimeoutMillis", duration, replicaSetUrl);
}
private static void setMongoParameter(
final String param,
final int duration,
final String replicaSetUrl
) {
try (final MongoClient mongoReactiveClient = MongoClients.create(
ConnectionUtil.getMongoClientSettingsWithTimeout(replicaSetUrl)
)) {
StepVerifier.create(mongoReactiveClient.getDatabase("admin").runCommand(
new Document("setParameter", 1).append(param, duration)
)).expectNextCount(1)
.verifyComplete();
}
}
}
```
### 4. How can I play with the code?
[Small WMS (warehouse management system) on GitHub](https://github.com/silaev/wms).
### 5. What’s in it for me?
1. The `MongoDBContainer` takes care of the complexity in the MongoDB replica set initialization allowing the developer to focus on testing. Now we can simply make MongoDB transaction testing part of our CI/CD process;
2. While processing data, it is sensible to favor MongoDB’s bulk methods, reducing the number of sub-processes within the `flatMap` method of the `Flux` and thus to avoid introducing the "N+1 Query problem". However, it also comes at a price because here we need to collect a list of `UpdateOneModel` and keep it in memory lacking reactive flexibility;
3. When it comes to skipping processing, one might employ `onErrorResume` instead of [`the dangerous onErrorContinue`](https://github.com/reactor/reactor-core/issues/2184)
4. Even though are we allowed to set `maxTransactionLockRequestTimeoutMillis` and `transactionLifetimeLimitSeconds` as parameters during start-up to mongod, we may achieve the effect by calling the MongoDB's `adminCommand` via helper methods;
5. Processing big files is resource-consuming and thus better be limited.
### 6. Want to go deeper?
To construct a multi-node MongoDB replica set for testing complicated failover cases, consider [the mongodb-replica-set project](https://github.com/silaev/mongodb-replica-set).
### 7. Links
1. [Reactive Transactions Masterclass by Michael Simons & Mark Paluch](https://www.youtube.com/watch?v=8TkY_RaoLCQ)
2. [Spring Data MongoDB — Reference Documentation](https://docs.spring.io/spring-data/mongodb/docs/current/reference/html/#reference)
3. [MongoDB Transactions](https://docs.mongodb.com/manual/core/transactions/)
4. [MongoDB Collection Methods](https://docs.mongodb.com/manual/reference/method/js-collection/) | https://habr.com/ru/post/513026/ | null | en | null |
# Выполнение SQL-подобных запросов над данными — как в браузере, так и на сервере
Marak Squires выпустил в свет **JSLINQ** — реализацию [LINQ](http://en.wikipedia.org/wiki/Language_Integrated_Query) для JavaScript, работающую как на стороне браузера, так и на стороне сервера (к примеру, [node.js](http://nodejs.org/)). Поддерживаются такие конструкции, как JOIN, UNION, RANGE, DISTINCT, COUNT etc.
Смотрите:* [Код и примеры на GitHub](http://github.com/marak/JSLINQ);
* [Живая демонстрация на сайте автора](http://maraksquires.com/JSLINQ/).
#### JSLINQ
> `var sample = JSLINQ(sampleData).
>
> Where(function (item) {return item.FirstName == "Chris";}).
>
> Select(function (item) {return item.FirstName;}).
>
> OrderBy(function (item) {return item;});
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Кстати, [XaocCPS](https://habrahabr.ru/users/xaoccps/) когда-то рассказывал о проекте [jLinq](http://www.hugoware.net/Projects/jLinq), а Карл Гертин упомянул о проекте [JSINQ](http://jsinq.codeplex.com/), которые также можно посмотреть.
#### jLinq
> `var results = jLinq.from(data.users)
>
> .startsWith("first", "a")
>
> .orEndsWith("y")
>
> .orderBy("admin", "age")
>
> .select();
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
#### JSINQ
> `var query = new jsinq.Query('\
>
> from order in $1 \
>
> group order by order.customerId into g \
>
> select {customerId: g.getKey(), items: g.sum(function(g) { return g.items; })} \
>
> into h \
>
> join customer in $0 on h.customerId equals customer.id \
>
> where h.items > 10 \
>
> orderby h.items descending \
>
> select {lastname: customer.lastname, items: h.items} \
>
> ');
>
>
>
> query.setValue(0, customers);
>
> query.setValue(1, orders);
>
> var result = query.execute();
>
>
>
> \* This source code was highlighted with Source Code Highlighter.` | https://habr.com/ru/post/92867/ | null | ru | null |
# Джентльменский набор программиста UE4, ч. 3
Данный **вопросник** является дополнением и логическим завершением темы "джентльменского набора", поднятой ранее. Разработка игр — весьма комплексная индустрия, с очень широкими набором технологий и подходов, при этом базис у всех этих вещей на самом деле общий. Этот список создан в первую очередь для тех, кто хочет быть программистом **Unreal Engine**, а также позволяет оценить свой уровень тем, кто уже считает себя продвинутым программером под анрил.
В своей статье я стараюсь затрагивать такие проявления используемой технологии, изучение или исследование которых дает не просто инструкцию "делай так", а формирует рациональные подходы к разработке.
В прошлых сериях
----------------
> 4ертовы хипстеры. Никакой пользы от них
>
>
* Часть 1: [Habr - Джентльменский набор программиста UE4, ч. 1](https://habr.com/ru/company/mailru/blog/427319/)
* Часть 2: [DevGAMM 2019 - Джентльменский набор разработчика Unreal Engine 4](https://www.youtube.com/watch?v=JqZQ7liMff8)
Дисклеймер
----------
Данный список вопросов ни в коем случае **не тест и не экзамен**! Все перечисленные в цитатах термины — это целый комплекс навыков, принципов и технологий. Некоторые вопросы попросту не предполагают единственно верного ответа, но очерчивают поле для дискуссии и поиска всех граней.
Основы архитектуры движка
-------------------------
* Можно ли использовать `STL`? Зачем в Unreal Engine свой набор контейнеров? Зачем движку нужны свои "умные указатели", если есть `UPROPERTY`?
* Как узнать потребление памяти на момент Х и структуру (содержимое) этой памяти? Каким образом можно проверить целостность памяти и найти утечки? Как работает `Garbage Collector` и какие у него боттлнеки?
* Каким образом можно загрузить что-либо (текстуру, блюпринт, эктор, карту) асинхронно, и какие ограничения на этот процесс есть у движка? К чему приведет вызов функции синхронной загрузки ассета или его части в общем процессе асинхронной загрузки?
* Многопоточный ли анриал? Как устроен основной цикл кадра/обновления мира? Какие способы проводить асинхронные вычисления есть на движке, и какие у них особенности?
* Почему `UPROPERTY` — это пустой макрос? Как происходит процесс сборки бинарников проекта? Что такое `unity build`, зачем он нужен и какие плюсы/минусы у него есть?
* Что такое `SlateApplication` и какую роль играет в основном loop'е движка? Какой путь проходит событие ввода от нажатия клавиши до `PlayerInput`?
Blueprints
----------
* Как технически работают блюпринты на уровне виртуальной машины? Как устроен `EventGraph` и что такое `FFrame`? Как происходит вызов функций из БП в нативный код и обратно?
* Как устроены **латентные функции**?
* *(Advanced)* Как можно реализовать `wildcard in/out` параметры и как работают `CustomThunk` функции?
AI
--
* Что такое `Behaviour Tree`? Какие отличия от классического "книжного" BT? Какие есть альтернативы? Как технически (или архитектурно) устроены BT?
* Как выбрать — писать ИИ на BT, или просто запрограммировать логику в блюпринтах или в коде? Либо предпочесть другие (какие?) варианты?
* Каким образом реализуются независимые ветки логики ИИ на BT? (Пример: танк едет и наводится/стреляет одновременно) А если их три или четыре?
* Какие еще модели построения искусственного интеллекта часто используются в геймдеве, в чем их плюсы и минусы?
* Какие алгоритмы `pathfinding`'а и навигации используются на движке? Каким образом происходит ведение персонажа по маршруту?
Rendering
---------
*Означенная глубина погружения не предполагает, что вы* — *рендер-программист. Скорее это взгляд со стороны техарта и "интересующегося" программиста на одни из самых высокоуровневых вопросов.*
* Что такое **draw call**? Какие есть способы батчинга? Инстансинг vs батчинг?
* В чем разница между **Forward** и **Deferred** рендерингом? *(Advanced)* А сколько вообще основных архитектур на текущий момент? Чем принципиально отличается рендеринг на мобилках/консолях от десктопного?
* В чем отличия рендеринга непрозрачных объектов от прозрачных? Что за зверь `Masked`? *(Advanced)* А чем такой подход опасен на мобилках?
* Чем отличается `Shader` от `Material`?
* Какие типы шейдеров существуют и в чем назначение каждого? Как это используется в движке и отражено в материалах?
* Зачем нужны `mipmaps`? В чем сила `power of two` текстур?
* Что такое `texture compression`, как оно работает и используется?
* В чем сила `indirect sampling`? Что означает это на практике в контексте анрила?
* Как устроен цикл рендеринга на движке? Что такое `RHI` и `Proxy`?
* Как работают `Particle Systems`? Где происходит расчет частиц, в каких случаях?
Animation
---------
* В чем отличия рендеринга `skeletal mesh` от `static mesh`? Какие основные параметры и метрики у скелеталки? Какие техники оптимизации скелетной анимации используются на движке? *(Advanced)* По каким причинам `Nanite` не работает для скелетной анимации?
* Какие методы наследования и композиции в `Animation Blueprint` возможны для использования? Плюсы и минусы каждого из них?
* Какие способы анимации вообще могут быть? Какая информация и каким образом хранится в каждом случае?
Прочее
------
Пара дополнительных полезных вопросов вне категорий.
* Что влияет на размер финального билда? Каким образом можно исследовать этот вопрос?
* `Git`, `Perforce`, `Subversion`, `PlasticSCM` и другие — что лучше для работы с Unreal Engine и почему? Какие проблемы могут быть?
---
Кода (3)
--------
Эта статья завершает мини-цикл такого формата — подготовка материала для публикации в виде самостоятельной статьи занимает слишком много времени, многие вещи из которых устаревают либо изменяются по мере написания. Формат следующих публикаций будет переработан и систематизирован несколько иначе.
При этом конечно же два опросника не покрывают все области знания о движке целиком, однако я постарался коснуться тех вещей которые считаю **основными**.
Как и всегда, **призываю к активному обсуждению, комментариям и критике**! =) | https://habr.com/ru/post/564302/ | null | ru | null |
# Ruby: cheatsheet для изучения
Это — статья-roadmap-cheatsheet для изучающих Ruby. Вместо того, чтобы рассказывать очередной how-to я постараюсь расписать все те вещи, которые, на мой взгляд, можно изложить кратко и емко, с упором на то, что программисту пришедшему с других языков и платформ может показаться не очевидным, антипоисковым и просто затратным по времени на изучение без подсказок — на остальное просто дам ссылки. Не смотря на то, что в природе существует множество туториалов/кастов/книг/чего угодно по чему угодно — именно такого формата мне самому всегда не хватает. И по сути, это те вещи, которые чаще всего рассказываю при вопросах «а как оно вообще?», «с чего начать?», «а как делается такая вот штука?», «а какой gem лучше?». Кстати, пока работал над этой статьей [на Хабре появилась похожая про Python](http://habrahabr.ru/post/205944/) — видимо, идея витает в воздухе.
**Около Ruby - слухи, интриги, расследования**Сразу оговорюсь, что текст под этим спойлером отличается от основной «объективной» части статьи, т.к. здесь изложено мое личное мнение и впечатление.
Язык программирования — это не только синтаксис, сборщик мусора, не только парадигма языка, и даже не столько его философия, в первую очередь — это коммьюнити и та кодовая база, которую это коммьюнити создало. Особенно сейчас, в эпоху OpenSource. И тут у Ruby первый жирный плюс в карму. Одна из особенностей — во всем читается прагматичная лень, начиная c опциональности скобок при вызове методов и точек с запятой в конце строки, продолжая емким и выразительным синтаксисом, и заканчивая общим ощущением от проектов — многие из них сделаны работающими из коробки, и требующих минимальных усилий, чтобы сконфигурировать их.
Многие выбирают Ruby, потому что это комфортно и приятно. Удовольствие и радость от программирования можно получить на разных языках — и в Ruby оно похоже на езду на хорошем авто, сидя за рулем которого будешь думать не столько о дороге, сколько о более важных вещах — хотя бы о маршруте и конечной цели поездки.
Также можно сравнить с игрой в Lego (и это во многом благодаря Gems). Хотя кто-то любит сварку арматуры, а кому-то достаточно картона и клея.
Есть несколько утверждений, которые иногда можно встретить о Ruby и Rails — попробую внести в них ясность.
Известно утверждение о том, что Ruby медленный. И поспорить сложно, ведь Ruby интерпретируемый язык. И что характерно, чаще всего я это слышу от тех кто пишет (исключительно) на PHP, который тоже интерпретируем, и по скорости в синтетических тестах находится примерно на том же уровне. Скорее всего, это отголоски дурной славы старых версий. По факту, мне приходилось работать и с Rails и с Symfony — на реальных приложениях Rails быстрее при одинаковом уровне оптимизации (и в обоих правильное кэширование — залог успеха). Если нужна скорость и компактность в памяти — ~~пишите на ассемблере~~ используйте Node.js. Но парадокс в том, что на нем как раз часто пишут рубисты — когда это действительно оправданно. И дело тут вот в чем: важна не только скорость работы, но и скорость написания приложения. И Ruby, и все то, что можно найти на github всячески помогает достичь действительно высокой производительности программиста — в том числе и в возможностях оптимизации приложения. И не нужно забывать, что и главная нагрузка, и бутылочные горлышки, зачастую — это базы данных, а веб-приложения это всего-лишь прослойка бизнес-логики. А такая прослойка неплохо масштабируется.
Есть еще своеобразный миф про высокие зарплаты Ruby-разработчиков с одной стороны, с другой — что работы на Ruby мало. Обычно сравнивают с зарплатами со средней по рынку на PHP, и количеством работы на нем же. Средний уровень зарплат на PHP — это классическая «средняя ~~зарп~~ температура по больнице». Если же сравнить специалистов по Yii/Symfony/Zend и Rails (можно еще добавить Django на Python) — картина выйдет совсем другая, а именно: и зарплаты и объем рынка примерно одинаковы. Действительно, хорошим программистам неплохо платят. И более того, когда берешься за проект с нуля — зачастую выбор платформы за тобой и твоей командой, а не заказчиком/начальством.
Так что, есть множество прекрасных языков и фреймворков для написания веб-приложений, и Ruby с Rails не являются серебряной пулей, которая убьет всех ~~зайцев~~ кроликов-оборотней сразу. Просто, на мой взгляд, если брать совокупность важных критериев, а не пытаться выбрать по одному-двум из них, RoR набирает действительно много очков. В том числе и по зрелости — это уже давно не хипстерская платформа, в которой есть только потенциал, но еще и не старичок (а примеров и тех и других уйма). И старичком, я думаю, еще долго не станет, т.к. потенциал для роста и развития еще есть и у Ruby и у Rails — но это тема для отдельной статьи.
И конечно, несмотря на направленность статьи на Rails, и популярность именно этой платформы — Ruby это далеко не только Rails.
В любом случае, я убежден, что программист не должен сидеть в своем маленьком мирке того, за что ему сегодня платят зарплату. Ruby дает в этом смысле не только +1 язык в резюме, но и, за счет своей ооп-направленности и широким возможностям метапрограммирования, опыт, который пригодится на разных языках и платформах.
[Язык Ruby: история становления и перспективы развития](http://habrahabr.ru/post/131661/)
#### Ruby
**Начало**##### Как установить Ruby на #{ os\_name }?
Сами ссылки:
* [Win](http://www.rubyinstaller.org/downloads/). По той же ссылке можно найти DevKit, которой пригодится для работы с БД и установки Native Extensions
* [Rails Installer](http://railsinstaller.org/) установит сразу Ruby + DevKit, Git, Rails, Bundler и SQLite, на Windows или MacOS. Ruby, правда, 1.9.3, а установщик с 2.0 еще в alpha. (по совету [Jabher](https://habr.com/users/jabher/))
* \*nix — ищите в своих репозиториях, или [legacy](http://www.ruby-lang.org/ru/downloads/)
Кроме того, есть такая штука как [RVM](https://rvm.io/rvm/install). Она позволяет установить несколько версий Ruby на одной ОС и переключаться между ними. На старте в ней потребности нет, но бывает полезна, если уже есть несколько проектов на локальной машине или на сервере — обновляться на всех разом до новой версии сразу не особо здорово. Пока — просто имейте ввиду, что она есть.
[Подробно про RVM](http://habrahabr.ru/post/120504/) на хабре.
Тут же стоит упомянуть про среду разработки. Я приверженец продуктов JetBrains, поэтому рекомендую [RubyMine](http://www.jetbrains.com/ruby/), но ввиду того, что продукт коммерческий кому-то может прийтись по вкусу свободная [Aptana Studio](http://www.aptana.com/). Если же приятнее пользоваться легкими текстовыми редакторами — синтаксис Ruby поддерживается многими.
Прямо в браузере в интерактивном режиме Ruby можно попробовать на [tryruby.org](http://tryruby.org/)
**Все - объект**Включая числа, строки и даже nil — они все наследуются от класса Object. Можно у чего угодно вызывать методы вроде nil?, class, methods и respond\_to?:
```
'Hello world'.class # String
nil.class # NilClass
String.class # Class
String.ancestors # [String, Comparable, Object, Kernel, BasicObject]; массив предков класса
nil.nil? # true
Object.new.methods # вернет методы объекта класса Object; тут же видно как создается новый объект - тоже вызовам метода
nil.respond_to?('nil?') # true
```
По поводу последнего: это важно для [утиной типизации](http://ru.wikipedia.org/wiki/%D0%A3%D1%82%D0%B8%D0%BD%D0%B0%D1%8F_%D1%82%D0%B8%D0%BF%D0%B8%D0%B7%D0%B0%D1%86%D0%B8%D1%8F).
**Синтаксис и пудра**Ruby сильно приправлен «синтаксическим сахаром», благодаря которому зачастую не нужно городить кашу из различных скобок, точек с запятыми и прочего. А под ним — прост и логичен, и сохраняет парадигму «все — объект».
```
a == b # то же, что и
a.==(b) # то есть .==() - это метод
```
В вызовах методов, в if можно не ставить скобки, если нет неоднозначности
```
nil.respond_to?('nil?') # true
nil.respond_to? 'nil?' # true
# все однозначно:
if nil.respond_to? 'nil?'
puts 'ok'
end
# тоже
if 10.between? 1, 5
puts 'ok'
end
# а вот так получится не тот приоритет вызовов, поэтому нужны скобки
if 10.between?(1, 50) && 20.between?(1, 50)
puts 'ok'
end
```
А еще — есть [символы](http://habrahabr.ru/post/48993/). По сути, символы — это неизменяемые строки. Например, они часто используются как ключи в хэшах.
```
a = :nil? # символ
b = 'nil?' # строка
nil.respond_to? a # true
nil.respond_to? b # true
# поиграемся
a == b # false
a.to_s == b && a == b.to_sym # true; символ и строка преобразуются друг в друга
```
С ними связано еще немного пудры:
```
a = {:key1 => 'value1', :key2 => 'value2'} # создаем хэш (ассоциативный массив)
a = {key1: 'value1', key2: 'value2'} # если ключи - символы, то можно так (Ruby >= 1.9.3)
```
Раз уж тема зашла:
```
a = ['value1', 'value2'] # это массив
s = 'String'
s = "Double-quoted #{s}" # "Double-quoted String" - это, думаю, ясно
```
И добьем тему припудривания немного уродливым, но зато удобным способом записи:
```
%w[value1 value2] # ["value1", "value2"] - тот же массив, что и выше
%i[value1 value2] # [:value1, :value2] - массив символов, (Ruby >= 2.0)
s = %q(String)
s = %Q(Double-quoted #{s})
%x('ls') # команда консоли
`ls` # то же самое
%r(.*) == /.*/ # true; два способа создать регулярное выражение
```
Кстати, в Ruby есть многим до боли знакомая точка с запятой — пригодиться она может чтобы записать несколько выражений в одну строку
```
a = 10; puts a # выведет в консоль 10
if nil.respond_to? 'nil?'; puts 'ok'; end # чтобы было понятно - так тоже можно
```
Но однострочные if лучше писать так
```
puts 'ok' if nil.respond_to? 'nil?'
```
**Вводные статьи и доки**Стоит почитать [В Ruby из других языков](http://www.ruby-lang.org/ru/documentation/ruby-from-other-languages/) и [Ruby за двадцать минут](http://www.ruby-lang.org/ru/documentation/quickstart/), ну а главный друг и помощник [ruby-doc.org](http://ruby-doc.org/).
Лучше сразу посмотреть методы базовых классов (во всех — какие бывают each\_ и to\_).
[String](http://ruby-doc.org/core-2.0.0/String.html) (тут — первым делом match, sub)
[Array](http://ruby-doc.org/core-2.0.0/Array.html) (map, join, include?)
[Hash](http://ruby-doc.org/core-2.0.0/Hash.html) (has\_key?, has\_value?, merge)
Достаточно простые примеры разобраны в [Покорим Ruby вместе! Капля первая](http://habrahabr.ru/post/48559/) [Капля вторая](http://habrahabr.ru/post/48607/) [Капля третья](http://habrahabr.ru/post/48667/)
Если хочется продолжения банкета: [Интересный паблик с подборкой магии на Руби](http://vk.com/rgrimoire).
**Классы, модули и метапрограммирование**Классы в Ruby вполне очевидны, но в возможностях работы с ними кроется вся сила и прелесть Ruby.
```
class Foo
def bar
10 # любой метод возвращает значение - результат выполнения последнего выражения
end
def baz(a)
bar + 20
end
end
puts Foo.new.baz(10) # 30
```
Module — к нему можно относиться и как к примеси, и как к пространству имен. Внезапно? По сути — это набор классов, методов и констант, и пользоваться им можно на свое усмотрение.
```
module B # как пространство имен
class Foo
# конструктор
def initialize(k) @k = k end # запишем методы в одну строку
def bar; @k + 20 end
end
end
puts B.Foo.new(3).bar # 23
puts B::Foo.new(3).bar # 23; то же самое, но читается лучше
module C # как примесь
def bar; @k + 25 end
end
class Foo
include C;
def initialize(k) @k = k end
end
puts Foo.new(3).bar # 28
```
В Ruby классы мутабельны, и их можно патчить после их создания. И тут будьте осторожны: здесь начинаются те самые возможности, при помощи которых можно «выстрелить себе в ногу» — так что, делая что-то подобное нужно всегда отдавать отчет: зачем, что получится, ~~кто виноват и что делать~~ и если что — виноваты сами.
```
class Foo
def bar; 20 end
end
class Foo # патчим
def baz; bar + 2 end
end
puts Foo.new.baz # 22
# или лучше - так: сразу понятно что это патч
Foo.class_eval do
def bazz; bar + 3 end
end
puts Foo.new.bazz # 23
# но если нет на то веской причины - используйте примеси или наследование
class Boo < Foo
def boo; bar + 2 end
end
puts Boo.new.boo # 22
# или же - можно пропатчить только объект, а не сам класс
a = Foo.new
a.instance_eval do # патчим объект
def booo; bar + 3 end
end
puts a.booo # 23
puts Foo.new.booo rescue puts 'error' # error; кстати, так перехватываются ошибки
puts a.respond_to? :booo # true
puts Foo.new.respond_to? :booo # false
# или - патчим объект в более легком синтаксисе
def a.booboo
bar + 4
end
puts a.booboo # 24
```
А что если сделать instance\_eval для класса? Конечно же, добавятся статические методы.
```
class Foo
def self.bar; 10 end # обычный статический метод
end
puts Foo.bar # 10
Foo.instance_eval do
def baz; bar + 1 end
end
puts Foo.baz # 11
```
Играться с этим можно вдоволь, главное помните — берегите ноги.
```
class Foo
def self.add_bar # добавим статический метод, который патчит класс
self.class_eval do
def bar; 'bar' end
end
end
end
puts Foo.new.respond_to? :bar # false
class Boo < Foo # отнаследуемся
add_bar # пропатчим
end
puts Boo.new.bar # bar
# а теперь все то же самое, но пропатчим уже существующий класс
Foo.instance_eval do
def add_baz
self.class_eval do
def baz; 'baz' end
end
end
end
class Baz < Foo
add_baz
end
puts Baz.new.baz # baz
```
Как раз такой подход используется на практике — по сути, получается что-то вроде примеси, в которую можно передавать параметры. Это кажется магией, если не знать, как это делается. Патчить можно и базовые классы, особенно любимы Array и String — но всегда стоит подумать трижды, прежде чем начинать их мучить: одно дело методы вроде .blank? (его добавляет Rails: что-то вроде def blank?; nil? || empty? end), другое — когда код метода специфичен для проекта, тогда логично предположить, что он относится к каким-то классам внутри проекта.
По такому принципу работает, например accessor. Что мы сделаем, чтобы добавить публичный параметр в Ruby-класс?
```
class Foo
def bar # геттер
@bar # возвращаем параметр
end
def bar=(val) # сеттер
@bar = val # присваиваем значение параметру
end
end
```
Представляете так писать для десятка-другого параметров? В Ruby много кода по накатанному — смертный грех: [DRY](http://ru.wikipedia.org/wiki/Don%E2%80%99t_repeat_yourself). Так что, можно сделать короче.
```
class Foo
attr_accessor :bar, :baz # добавим сразу парочку атрибутов
attr_reader :boo # только геттер
attr_writer :booo # только сеттер
end
```
Готовы дальше? Тогда:
[Вникаем в метаклассы Ruby](http://habrahabr.ru/post/143990/)
[Metaprogramming patterns — про monkey patching](http://habrahabr.ru/post/50819/), [Reuse в малом — bang!](http://habrahabr.ru/post/50169/), [eval](http://habrahabr.ru/post/49951/)
[Вникаем в include и extend](http://habrahabr.ru/post/143483/)
**Аргументы методов**Ruby 2.0 поддерживает именованные аргументы методов:
```
# bar обязателен
# barr имеет значение по умолчанию 0
# baz - именованный аргумент со значением по умолчанию true
def foo(bar, barr = 0, baz: true)
baz && bar + barr
end
p foo 1 # 1
p foo 1, 2 # 3
p foo 1, baz: false # false
```
В предыдущих версиях добиться такого же поведения можно, разбирая атрибуты:
```
def foo2(bar, *args)
args
end
p foo2 1, 2, :baz => false # [2, {:baz=>false}]
def foo3(bar, *args)
options = args.extract_otions! # именованные аргументы вырезаются из args
p bar
p args
p options
end
foo3 1, 2, 3, :baz => false
# 1
# [2, 3]
# {:baz=>false}
```
Начиная с Ruby 2.1 появилась возможность добавлять обязательные именованные аргументы.
```
def foo4(bar, baz:); bar end
foo4 1 # ошибка
foo4 1, baz: 2 # 1
```
**Замыкания и блоки**Некоторое недоумение поначалу вызывают блоки, замыкания и класс Proc — зачем столько всего? Вкратце — на самом деле, есть только Proc.
Подробно — ссылки внизу, а сейчас — на что стоит обратить внимание.
Первыми рассмотрим блоки. Блок — это просто кусок куда, и даже не объект, просто часть синтаксиса Ruby. Блок используется чтобы передать какой-то код в метод. И уже в методе он оказывается завернут его в класс Proc.
В разделе про классы и методы они уже использовались:
```
Foo.instance_eval do # передаем в метод instance_eval блок с определением метода
def baz; bar + 1 end
end
```
Но возьмем более базовый пример, он же «как сделать foreach в Ruby»:
```
[1,2,3].each do |val|
p val # кстати, p(val) - это shortcut для puts(val.inspect)
end # выводит 1 2 3
# то же, в одну строчку
[1,2,3].each { |val| p val } # выводит 1 2 3
[1,2,3].each_with_index { |val, i| puts val.to_s + ' ' + i.to_s } # на заметку
```
Если же мы хотим передавать блок в собственный метод:
```
def foo
puts yield # выполняем блок
puts yield + yield # и еще, и еще выполняем
end
foo { 2 } # 2 4
def bar(█) # или, если поменьше пудры
puts yield block # выполняем блок
end
bar { 3 } # 3
```
Стоит отметить, что блок идет всегда последним параметром, и если нужно передать несколько блоков — нужно их передавать как обычные параметры, а значит создавать Proc.new, или lambda.
Из блока всегда получается объект класса Proc, но сам блок это часть синтаксиса: мы можем его передать в метод, где он станет Proc, мы можем его передать в конструктор Proc, или использовать lambda, но нельзя просто записать блок в переменную.
```
proc = Proc.new { |a| a - 1 } # через конструктор
p proc.call(10) #9
p proc.class # Proc
l = lambda { |a| a + 1 } # создаем лямбду
p l.call(10) #11
p l.class # Proc
new_l = ->(a) { a + 2 } # тоже лямбда (Ruby >= 2.0)
p new_l.call(10) #12
```
Различия в поведении Proc созданными разными способами есть, [читаем статью](http://habrahabr.ru/post/85578/).
[Здесь замыкания и блоки в Ruby разобраны вдоль и попрек](http://innig.net/software/ruby/closures-in-ruby)
На Хабре [про блоки](http://habrahabr.ru/post/86882/), [про замыкания](http://habrahabr.ru/post/50665/)
**Стиль**По поводу как принято писать в Ruby [есть целый гайд на GitHub](https://github.com/bbatsov/ruby-style-guide)
Вкратце, frequently used:
* Отступы в 2 пробела
* Названия методов строчными буквами через подчеркивание: def method\_name
* Названия классов и модулей с больших букв: class ClassName
* Если метод возвращает true/false, название должно заканчиваться на вопрос (тот же, nil?)
* Если есть два метода, один из которых изменяет объект, а другой возвращает новый — первый оканчивается на '!' (например, методы downcase и downcase! для строки — первый вернет новую, а второй изменит саму строку)
* Вместо if(!value) лучше использовать алиас unless(value)
* Блок однострочный берется в скобки {… }, а многострочный — в do… end
**RubyGems - пакетный менеджер**Мир Ruby, наверное, был бы совсем другим, если бы не RubyGems.
С ними процесс дополнения проекта библиотеками выглядит очень просто:
* выбираем что нам нужно с [rubygems.org](http://rubygems.org/) (или через [ruby-toolbox.com](https://www.ruby-toolbox.com/)), например, json\_pure — JSON парсер на чистом Ruby (без C)
* вводим в консоли gem install json\_pure
* а в нашем rb-файле:
```
require 'json/pure' # какой именно путь должен быть стоит в доках посмотреть, обычно на github
```
Для удобства управления зависимостями есть [bundler](http://bundler.io):
* gem install bundler
* bundler init
* в появившемся Gemfile вписываем зависимости:
```
source 'https://rubygems.org'
gem 'json_pure'
```
* bundler install
* И в своем rb-файле
```
require 'rubygems'
require 'bundler/setup'
```
В реальных проектах список зависимостей может разрастись на несколько экранов, поэтому при переносе проекта на сервер гораздо удобнее выполнять bundle install, чем вручную смотреть что нужно и для каждого гема выполнять gem install. Ну а в Rails bundler используется из коробки.
Сами Gems обязательно рассмотрю в статье про Rails.
[RubyGems — подробно](http://habrahabr.ru/post/120188/)
[Управляем версиями с помощью Bundler](http://habrahabr.ru/post/120259/)
[Знакомство с Gem. Часть первая](http://habrahabr.ru/post/134609/) [Часть вторая](http://habrahabr.ru/post/134878/)
[Пишем свой первый gem](http://habrahabr.ru/post/128378/)
[Делаем gem для RubyGems](http://habrahabr.ru/post/57829/)
[Создание гемов — Руководство](http://habrahabr.ru/post/138582/)
**Ruby и C**Далеко не последняя по важности возможность RubyGems — Native Extensions. Все просто — вместе с гемом может быть скомпилирован прилагающийся код на C и вызван из кода самого гема. Благодаря этому, среди них есть достаточно шустрые парсеры, можно установить JavaScript'овый V8 в виде гема, и много других вкусностей.
А это нужно просто иметь ввиду: [Inline C](https://github.com/seattlerb/rubyinline), может пригодится. Если коротко — в коде Ruby можно исполнять код на C, что полезно, например, при реализации численных алгоритмов.
[Введение в расширения Ruby на C](http://bitsofmind.wordpress.com/2008/07/21/ruby_extensions_in_c/)
[Ruby и C. Часть 1](http://habrahabr.ru/post/48928/), [Часть 2](http://habrahabr.ru/post/49202/), [Часть 3](http://habrahabr.ru/post/50039/).
**Потоки**Простой пример с потоком:
```
thread = Thread.new do # создается отдельный поток
a = 0
1000000.times { a+= 1 } # загружаем процессор на некоторое время
puts a # вывод результата
end
puts 'thread started' # текст выводится сразу после запуска потока
thread.join # ожидание завершения работы потока
```
Код выведет в консоль «thread started 100000».
Более низкоуровневые fibers (волокна) предлагают немного другой синтаксис, позволяющий управлять последовательностью исполнения, а также имеют меньшие издержки по памяти и времени инициализации, чем threads.
```
fiber = Fiber.new do # создание нового волокна
Fiber.yield "fiber 1" # управление возвращается в контекст
'fiber 2' # возвращаемое значение
end
puts fiber.resume # запуск волокна
puts 'context'
puts fiber.resume # возобновление работы волокна
```
Код выведет «fiber 1 context fiber 2».
**Про GIL и настоящую многопоточность**Ruby поддерживает многопоточность, и различные версии интерпретатора отличаются ее реализацией. GIL в основной ветке сводит распараллеливание вычислений на нет, но использование потоков в нем имеет смысл для реализации асинхронности. Самый простой пример: мы можем слушать пользовательский интерфейс, параллельно выполняя какие-то операции. Или можем отправить запрос к БД и ждать ответа в одном потоке, отправлять email в другом, и не дожидаясь завершения отправить ответ пользователю. Но в суммарном времени исполнения выигрыша не будет, т.к. фактически в каждый момент времени будет нагружаться только одно ядро.
Чтобы обойти это ограничение можно использовать версии без GIL — jRuby или Rubinius (и при этом помнить, что потокобезопасность в них существенно ниже — для нее и нужен GIL). Другой вариант — запускать несколько отдельных копий программы, или использовать [UNIX-форки](http://ru.wikipedia.org/wiki/Fork) (естественно, пулом таких воркеров вполне можно управлять Ruby-скриптом).
Узнав все это начинающий рубист может прийти в замешательство (желая использовать всю мощь своего 48-поточного сервера без лишней головной боли). На практике реальная многопоточность не всегда нужна (а иногда — если и нужна, то когда-нибудь потом). Кроме того, для многих задач есть соответствующие gem'ы, реализующие разные подходы, в том числе готовые HTTP-серверы (которые будут рассмотрены в статье про gems) и асинхронные фреймворки.
GIL нужен для этого:
```
a = 0
threads = []
10.times do # создаем 10 потоков
threads << Thread.new do # добавляем объекты потоков в массив
100000.times { a+= 1 } # 100 000
end
end
threads.each(&:join) # ждем завершения всех потоков
puts a # вывод результата
```
Код выведет 1 000 000 в MRI, и черт знает что (от 100 000 до 1 000 000) в jRuby и Rubinius.
[Используем потоки в Ruby](http://habrahabr.ru/post/180741/)
**Зоопарк версий**MRI (Matz's Ruby Interpreter) — основная ветка Ruby от его создателя Yukihiro Matsumoto, или просто, Matz. Реализована на C. Когда просто говорят «Ruby» обычно имеют ввиду ее. Начиная с версии 1.9 объединена с проектом YARV (Yet another Ruby VM). Одна из основных ее особенностей — так называемый GIL (Global Interpreter Lock), на Хабре про нее [писали](http://habrahabr.ru/post/189320/) ([с продолжением](http://habrahabr.ru/post/189486/)). Сейчас актуальная версия ~~Ruby 2.0~~ **UPD:** [вышел Ruby 2.1](http://habrahabr.ru/post/207394/). [Чего нам ждать от Ruby 2.1?](http://habrahabr.ru/post/195844/)
[jRuby](http://jruby.org/), который написан на Java и работает в JVM, и соответственно интегрируется с кодом на Java. К сожалению, версия языка отстает от MRI (сейчас реализован Ruby 1.9.3), но тот же Rails заводится на нем с пол оборота.
[Rubinius](http://rubini.us/), который основан на MRI, но использует потоки операционной системы, а так же по максимуму написан на самом Ruby. По версии обычно up do date.
Скорость всех трех реализаций относительно друг друга разнится от задачи к задаче, а по потреблению памяти из троицы самый прожорливый — jRuby.
MacRuby — работает в связке с Objective-C на LLVM, заменив тем самым более ранний проект RubyCocoa. Для разработки под iOS существует форк MacRuby — [RubyMotion](http://habrahabr.ru/post/143332/).
IronRuby — реализация на платформе .NET. На протяжении своей жизни то забрасывается, то снова возобновляется разработка.
[Opal](http://opalrb.org/) — транслятор Ruby в JavaScript. Но не надо ждать от него чего-то выдающегося, это не jRuby для Node.js — он просто дает возможность писать ваш jQuery-код на Ruby. Или Express-код под Node.js. В общем, вариация на тему CoffeeScript.
[Ruby Enterprise Edition](http://www.rubyenterpriseedition.com/) (REE) — Ruby на стероидах. Проект завершил свое существование, т.к. новые версии и без наркотиков неплохо бегают.
Можно упомянуть [MagLev](http://maglev.github.io/) — специфическая версия, может пригодится для разворачивания облачной инфраструктуры.
Также интересен проект [mruby](https://github.com/mruby/mruby), в котором участвует Matz. Это — встраиваемый Ruby. Проект еще не закончен, но весьма многообещающе выглядит. ~~Так что, ждем ruby на Arduino.~~ [mruby-arduino](https://github.com/kyab/mruby-arduino). На нем же основан [MobiRuby](http://mobiruby.org/), предназначенный для разработки мобильных приложений.
Ну и на закуску, [KidsRuby](http://kidsruby.com/), по смыслу напоминающий старичка Logo.
**upd:**
[learnxinyminutes.com/docs/ruby](https://learnxinyminutes.com/docs/ruby/) — примеры кода на Руби. | https://habr.com/ru/post/206416/ | null | ru | null |
# Создание совершенной печатной машины из Sublime Text
*UPD: Прошло больше месяца с тех пор, как я написал первоначальный черновик этой статьи. С тех пор я опубликовал еще три записи в блоге и более двадцати [на моем канале в Телеграм](https://t.me/nikitonsky_pub). Настройки зарекомендовали себя фантастически, мне он очень нравится, и у меня нет желания искать где-либо еще.*
Я был давним поклонником [iA Writer](https://ia.net/writer) из-за того, что писал. Я купил оригинальную версию для iPad, оригинальную версию macOS (когда она еще называлась MacOS X), версию для Android и даже ту, которую они переиздали как «платное обновление по полной цене». На мой взгляд, в нем есть идеальный баланс между функциями и простотой, дизайном и направленностью.
Вот скриншот первоначальной [версии iA Writer от 2011](https://tonsky.livejournal.com/231968.html) года:
А вот как это выглядит сейчас, в 2021 году:
Дизайн настолько вне времени, что практически не изменился за 10 лет.
И я этим доволен, я не собираюсь жаловаться. Это здорово и для вдохновения, и для нововведений, и для фактического воплощения. Я искренне рекомендую его всем, кто пишет.
### Ограничения iA Writer
Тем не менее, со временем я начал чувствовать, что это не идеально подходит для моего конкретного рабочего процесса:
* iA Writer предназначен для работы с одним документом за раз. Я предпочитаю работать с проектами и папками, переключаясь между файлами.
* Библиотека iA Writer привязана к iCloud, и вы должны хранить там все свои файлы. Недавно [я отказался от iCloud](https://habr.com/ru/company/itelma/blog/550404/) и вообще предпочитаю, когда инструменты не определяют, где мне хранить файлы.
* При наличии собственного блога публикация состоит из периодического редактирования CSS/JS/шаблонов, для чего iA Writer, опять же, не оптимизирован.
* Я привык к таким удобствам Sublime, как несколько курсоров, поиск в файлах, Go Anywhere и интеграция с Git. Чувствуешь себя скованно, не имея этого всего под рукой.
### Оптимизация Sublime Text для письменной работы
Я решил попробовать повторить то, что делает iA Writer, но внутри Sublime Text. Это мои настройки.
### Цветовая схема
К счастью, iA Writer использует абсолютный минимум цветов, поэтому повторить эту часть было проще всего.

[Исходный код](http://github.com/tonsky/sublime-scheme-writer).
В Package Control: Цветовая схема Writer.
P.S. Да, есть и темная версия.
### Шрифт
iA Writer дебютировал с проприетарным шрифтом [Nitti](https://boldmonday.com/typeface/nitti/), но позже переключился на IBM Plex Mono, который выпускается под лицензией Open Font License.
После нескольких попыток и ошибок мне удалось установить размер шрифта, высоту строки и ширину страницы с параметрами, соответствующими тому, что делает iA Writer:

Параметры следующие:
«font\_face»: «IBM Plex Mono»,
«font\_size»: 16,
«line\_padding\_bottom»: 3,
«line\_padding\_top»: 3,
«wrap\_width»: 72
Это уже очень хорошее соответствие, но перфекционист во мне хотел получить точное соответствие. Две вещи требовали корректировки: немного увеличенный вес шрифта (текст вместо обычного) и дополнительные 3,5% ширины символа. Поэтому я взял на себя смелость и модифицировал оригинальный IBM Plex Mono, чтобы он соответствовал этим характеристикам.
Сморите:

Совпадает почти идеально! Вы можете получить мою версию IBM Plex Mono на [github.com/tonsky/font-writer](https://github.com/tonsky/font-writer).
### Смена профиля
Мы настроены на то, чтобы писать, но как нам вернуться к кодированию?
Проблема в том, что режим письма влияет на несколько отдельных настроек (в моем случае 19), а не только на шрифт и цветовую схему.
Встречайте Profile Switcher! Он хранит несколько отдельных файлов Preferences.sublime-settings и мгновенно переключается между ними.


Источники: [github.com/tonsky/sublime-profiles](https://github.com/tonsky/sublime-profiles)
В управлении пакетами: Profile Switcher.
P.S. Альтернативный способ — поместить настройки для записи в файл настроек для синтаксиса Markdown. Мне этот подход нравится меньше, потому что он влияет, например, на Sublime Merge diff view и все файлы разметки, некоторые из которых я не хочу видеть в режиме записи.
Кроме того, Profile Switcher кажется чем-то, что может быть полезно не только для написания/кодирования duo.
### Все вместе (TL;DR)
1. Скачайте и установите [шрифт Writer](https://github.com/tonsky/font-writer).
2. Через Package Control установите цветовую схему Writer
3. Через Package Control установите Profile Switcher.
4. Создайте профиль Writing с помощью команды Profiles: Create profile.
5. Поместите эти настройки сюда (просто замените все, что у вас есть):
```
{
"caret_extra_width": 2,
"draw_centered": true,
"draw_indent_guides": false,
"draw_white_space": ["none"],
"font_face": "Writer",
"font_size": 16,
"gutter": false,
"highlight_line": false,
"line_padding_bottom": 3,
"line_padding_top": 3,
"margin": 10,
"scroll_context_lines": 2,
"scroll_past_end": 0.5,
"word_wrap": true,
"wrap_width": 72,
"color_scheme": "Packages/sublime-scheme-writer/Writer.sublime-color-scheme",
"theme": "Adaptive.sublime-theme",
}
```
Вы должны увидеть что-то вроде этого:

Сравните с тем, с чего мы начали:

Чтобы вернуться, используйте команду «Профили: сменить профиль» и выберите «По умолчанию».
### Отсутствующие функции
К сожалению, мне не удалось воспроизвести все, что в свою очередь является еще одной причиной, по которой вы могли бы подумать о покупке iA Writer вместо того, чтобы следовать этому руководству. В нем гораздо больше, чем просто классный шрифт.
### Дуоширинный шрифт
Чего ждать? Дуоширинный? Это что?
Что ж, это еще одна гениальная идея от iA: сделать W и M 1,5× ширину, оставив остальную часть шрифта моноширинной. Он по-прежнему выглядит и ощущается моноширинным, но Ms и W больше не уродливы без причины. Хотелось бы, чтобы таких шрифтов было больше.

Можем ли мы воспроизвести это в Sublime Text? И да и нет. ST может отображать не моноширинные шрифты, но отключает полужирный/курсивный шрифт, если шрифт не моноширинный.
Похоже на довольно старое ограничение, может быть, при достаточном количестве голосов оно сможет привлечь то внимание, которого заслуживает? [Голосуйте здесь](https://github.com/sublimehq/sublime_text/issues/279), а мы пока будем придерживаться строгой моноширинной версии для написания.
Если вы хотите попробовать дуоширинный шрифт, его можно бесплатно загрузить по ссылке [github.com/iaolo/iA-Fonts](https://github.com/iaolo/iA-Fonts/tree/master/iA%20Writer%20Duo).
### Висячая пунктуация
Функция, которую я люблю с самой первой версии, единственный способ форматировать заголовки Markdown.

Почему это так круто? Если ### выровнено по основному тексту, вам нужно пропустить ### и найти первую значимую букву.
Если он висит снаружи, ничто не сможет помешать вам.
### Динамическая типографика
Еще одна вещь, которую сложно воспроизвести в Sublime Text, — это динамическая типографика. Насколько я понимаю, iA Writer динамически переключается между несколькими версиями с разным интервалом и весом в зависимости от текущего размера шрифта и разрешения экрана. Это сложно реконструировать и еще сложнее повторить в Sublime Text.
Хотя, с профилями…
### Подсветка синтаксиса
Во-первых, да, в iA Writer есть подсветка синтаксиса для простого английского. Выглядит это так:

Предположительно, это помогает писать более сбалансированные предложения. Как вы могли заметить, я этим никогда не пользовался :)
### Режим фокусировки
В режиме фокусировки выделено только текущее предложение, все остальное затенено. Это помогает попасть в зону, хотелось бы, чтобы это можно было сделать и в ST.

### Заключение
Sublime Text можно довольно хорошо настроить и превратить в фантастический инструмент для письменной работы.
Однако специализированное программное обеспечение, такое как iA Writer, может делать больше.
Надеюсь, вы найдете эту информацию полезной или (что еще лучше!) вдохновитесь написать что-нибудь.
*6 апреля 2021 г.*
---
Наши [серверы](https://macloud.ru/?partner=z3sd9322c1) можно использовать для разработки и продакшена на любом языке.
Зарегистрируйтесь по ссылке выше или кликнув на баннер и получите 10% скидку на первый месяц аренды сервера любой конфигурации!
[](https://macloud.ru/?partner=z3sd9322c1&utm_source=habr&utm_medium=perevod&utm_campaign=hytch) | https://habr.com/ru/post/552842/ | null | ru | null |
# Вложенные классы в Java

Добрый день, Хабровчане! Я уже довольно давно программирую на java, и нередко использую вложенные классы, но недавно наткнулся на статический вложенный класс и понял, что я о нем почти ничего не знаю. Поэтому я решил разобраться в этом, систематизировать свои знания, а заодно и поделиться этими знаниями с вами.
### Вложенный класс (InnerClass)
```
public class OuterClass {
public class InnerClass{
}
}
```
**Из него видны:**
— все (даже private) свойства и методы OuterClassа обычные и статические.
— public и protected свойства и методы родителя OuterClassа обычные и статические. То есть те, которые видны в OuterClassе.
**Его видно:**
— согласно модификатору доступа.
**Может наследовать:**
— обычные классы.
— такие же внутренние классы в OuterClassе и его предках.
**Может быть наследован:**
— таким же внутренним классом в OuterClassе и его наследниках.
**Может имплементировать интерфейс**
**Может содержать:**
— только обычные свойства и методы (не статические).
**Экзэмпляр этого класса создаётся так:**
```
OuterClass outerClass = new OuterClass();
OuterClass.InnerClass innerClass = outerClass.new InnerClass();
```
### Статический вложенный класс (StaticInnerClass)
```
public class OuterClass {
public static class StaticInnerClass{
}
}
```
**Из него (самого класса) видны:**
— статические свойства и методы OuterClassа (даже private).
— статические свойства и методы родителя OuterClassа public и protected. То есть те, которые видны в OuterClassе.
**Из его экземпляра видны:**
— все (даже private) свойства и методы OuterClassа обычные и статические.
— public и protected свойства и методы родителя OuterClassа обычные и статические. То есть те, которые видны в OuterClassе.
**Его видно:**
— согласно модификатору доступа.
**Может наследовать:**
— обычные классы.
— такие же статические внутренние классы в OuterClassе и его предках.
**Может быть наследован:**
— любым классом:
— вложенным
— не вложенным
— статическим
— не статическим!
**Может имплементировать интерфейс**
**Может содержать:**
— статические свойства и методы.
— не статические свойства и методы.
**Экзэмпляр этого класса создаётся так:**
```
OuterClass.StaticInnerClass staticInnerClass = new OuterClass.StaticInnerClass();
```
### Локальный класс (LocalClass)
```
public class OuterClass {
public void someMethod(){
class LocalClass{
}
}
}
```
**Из него видны:**
— все (даже private) свойства и методы OuterClassа обычные и статические.
— public и protected свойства и методы родителя OuterClassа обычные и статические. То есть те, которые видны в OuterClassе.
**Его видно:**
— только в том методе где он определён.
**Может наследовать:**
— обычные классы.
— внутренние классы в OuterClassе и его предках.
— такие же локальные классы определённые в том же методе.
**Может быть наследован:**
— таким же локальным классом определённом в том же методе.
**Может имплементировать интерфейс**
**Может содержать:**
— только обычные свойства и методы (не статические).
### Анонимный класс (имени нет)
Локальный класс без имени. Наследует какой-то класс, или имплиментирует какой-то интерфейс.
```
public class OuterClass {
public void someMethod(){
Callable callable = new Callable() {
@Override
public Object call() throws Exception {
return null;
}
};
}
}
```
**Из него видны:**
— все (даже private) свойства и методы OuterClassа обычные и статические.
— public и protected свойства и методы родителя OuterClassа обычные и статические. То есть те, которые видны в OuterClassе.
**Его видно:**
— только в том методе где он определён.
**Не может быть наследован**
**Может содержать:**
— только обычные свойства и методы (не статические).
На этом всё. Жду ваших комментариев: какие есть неточности и ошибки, что я не покрыл и т.п.
Надеюсь, статья будет многим полезна. | https://habr.com/ru/post/342090/ | null | ru | null |
# Оптимизация стоимости при работе с Amazon S3
[Amazon S3](http://aws.amazon.com/ru/s3/) удобно использовать для хранения файлов любых форматов. Кроме удобного API получаем практически безразмерное хранилище. Отличная доступность и невысокая стоимость делают S3 мегапривлекательной для молодых и небольших проектов.
Однако со временем файлов становится все больше. А платить придется не только за новые данные, но за всю историю. Кроме этого, Amazon дерет деньги за GET и POST запросы, а также за трафик.
Несмотря на низкую стоимость на старте, с ростом это решение будет обходиться все дороже.
#### Стоит ли вообще использовать S3?
Безусловно, стоит. Особенно для небольших проектов. Несколько десятков тысяч файлов и несколько тысяч запросов в сутки. Все это обойдется в пару баксов в месяц.
Взамен не нужно будет тратить время и деньги на разные вопросы:
* Доступность. AWS будет работать всегда.
* Масштабирование. Не нужно решать сложные задачи распределения файлов между серверами.
* Нагрузка. Внезапные всплески популярности не приведут к отказу железа.
S3 отлично подойдет для хранения пользовательских файлов любых форматов — [фотографий](http://habrahabr.ru/company/io/blog/257533/), документов и даже видео.
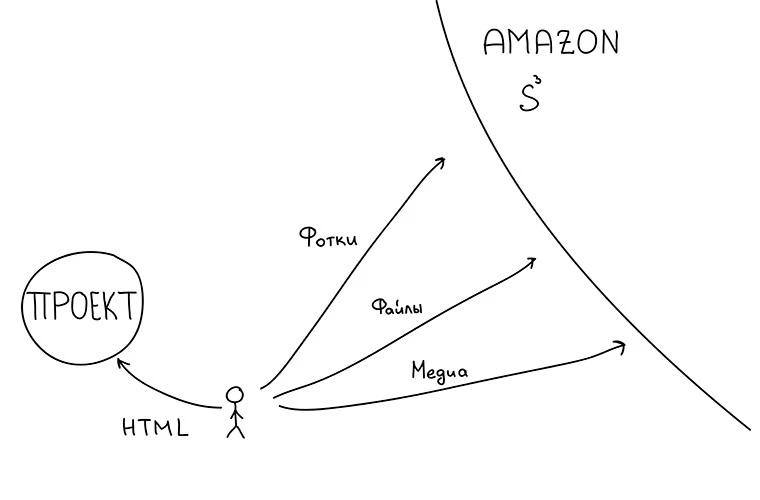
#### Когда использовать не стоит?
Однозначно не следует использовать S3 в качестве CDN. Всю статику (CSS, Javascript и иконки) лучше обслуживать самостоятельно либо использовать подходящего для этого CDN провайдера.
#### Сколько придется платить?
За хранение каждого терабайта файлов нужно платить около 30 баксов в месяц. Кроме этого в 90 баксов обойдется каждый терабайт трафика.
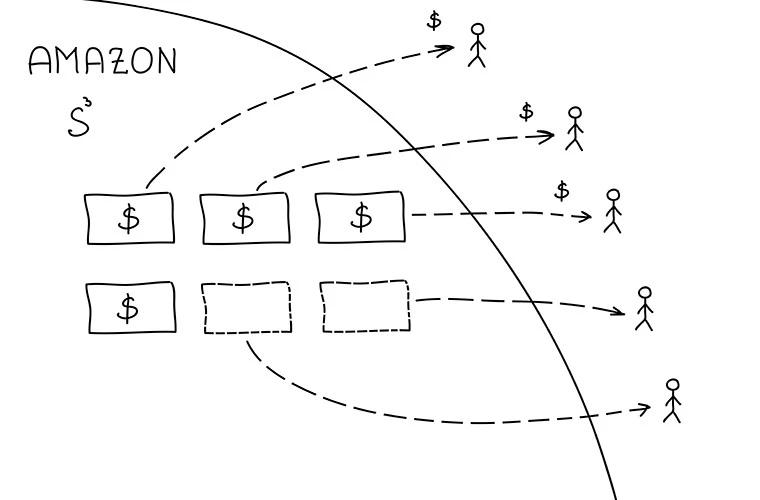
Хранилище в 1 терабайт — это около 5 млн фотографий или 50 тыс. коротких видеороликов.
Сайт со 100 тыс. просмотров в сутки, на каждой странице которого есть 5 фотографий, будет генерировать трафик в 1 терабайт в месяц.
#### Рост стоимости
Однако при росте количества просмотров в 10 раз, S3 трафик обойдется почти в 1 тыс. баксов в месяц.
Альтернативой такого решения станет аренда нескольких серверов с бюджетом в 300 долларов.
#### Гибридное решение
Существенной частью затрат при использовании S3 является именно трафик.
Хранилище и загрузка обходится сравнительно недорого.
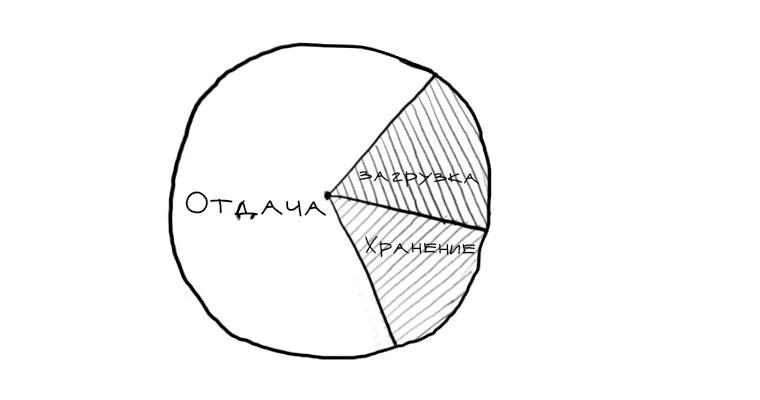
В качестве хорошего решения имеет смысл использовать S3 только как надежное хранилище.
При этом существенное снижение в стоимости трафика можно получить используя простую схему кеширования.
Тогда загрузка файлов происходит непосредственно на Amazon S3, а отдача настраивается через собственные кеширующие сервера.
#### Решение на основе Varnish
Varnish — крутой сервер для HTTP кеширования. С его помощью можно настроить кеширование файлов с Amazon S3. Пример конфигурации:
```
backend s3 {
.host = "s3.amazonaws.com";
.port = "80";
}
sub vcl_recv {
if (req.url ~ "\.(gif|jpg|jpeg|png)$") {
unset req.http.cookie;
unset req.http.cache-control;
unset req.http.pragma;
unset req.http.expires;
unset req.http.etag;
set req.backend = s3;
set req.http.host = "my_bucket.s3.amazonaws.com";
lookup;
}
}
sub vcl_fetch {
set obj.ttl = 3w;
}
```
В примере используется букет my\_bucket. Следует также следить за показателем hit rate. Приемлемое значение — 99%. Это значит, что 99% всех запросов будут попадать в кеш варниша и только 1% будет уходить на S3.
#### Дополнительные меры
Для еще большей оптимизации затрат нужно придерживаться правила — минимизировать размеры файлов. Если сохраняются фотки, можно преобразовать их в [формат Webp](https://onthe.io/learn+%D0%A7%D1%82%D0%BE+%D1%82%D0%B0%D0%BA%D0%BE%D0%B5+WebP) перед сохранением на S3. Они будут занимать значительно меньше места, чем JPG. Даже без этого следует убедиться, что выбран [верный формат изображений](https://onthe.io/learn+%D0%9A%D0%B0%D0%BA+%D0%B2%D1%8B%D0%B1%D1%80%D0%B0%D1%82%D1%8C+%D1%84%D0%BE%D1%80%D0%BC%D0%B0%D1%82+%D0%B8%D0%B7%D0%BE%D0%B1%D1%80%D0%B0%D0%B6%D0%B5%D0%BD%D0%B8%D0%B9) перед сохранением.
Текстовые файлы следует сжимать gzip'ом.
#### Другие облачные хранилища
Альтернатива есть. На S3 мир клином не сошелся, потому стоит попробовать работать и с другими облаками, например Azure или Google Cloud, особенно беря во внимание, что почти все сервисы предлагают [опробовать их бесплатно.](https://onthe.io/learn+5+%D1%81%D0%B5%D1%80%D0%B2%D0%B8%D1%81%D0%BE%D0%B2+%D0%B4%D0%BB%D1%8F+%D1%85%D1%80%D0%B0%D0%BD%D0%B5%D0%BD%D0%B8%D1%8F+%D1%84%D0%BE%D1%82%D0%BE%D0%B3%D1%80%D0%B0%D1%84%D0%B8%D0%B9+%D0%B2+%D0%BE%D0%B1%D0%BB%D0%B0%D0%BA%D0%B5)
#### Конспект
* Amazon S3 очень удобно использовать на старте и для небольших проектов.
* При росте популярности S3 становится дороже, чем собственное железо.
* Чтобы снизить стоимость решения необходимо снизить трафик. Для этого нужно отдавать файлы через кеширующий сервер.
* Для кеширования удобно использовать Varnish. | https://habr.com/ru/post/258029/ | null | ru | null |
# Как мы ржавели. История внедрения и обучения
Все говорили – переходи на rust! Начинай пользоваться самым-самым языком, который самый любимый язык на stackoverflow и всё такое.
Я тяжело вздохнул и огляделся. Ну опять двадцать-пять. Ладно, давайте разбираться, как правильно покрывать всё ржавчиной.
Профессионально я программирую уже 17 лет. В далёкие-предалёкие времена я начал изучать программирование с x86 Assembly. Такой жестокий подход к изучению компьютера дал мне глубокое понимание того как работает процессор и что делают другие языки программирования. Учить новые языки для меня никогда не было проблемой. Я их просто учил. C, C++, шарпы, ГО, тысячи разных скриптов и фреймворков. Чего уж там, ещё один язык, можно и выучить.
Ага. Только вот не с этой ржавой развалюхой. Я просидел две недели над официальным руководством, пялился в VSCode и не мог выдавить из себя больше чем fn main() {}. Ну какого же чёрта?
Я просто закрыл глаза, открыл руководство на рандомной странице и начал его читать. И прикол в том, что я понял о чём там говорится. И тут до меня дошло… Руководство написано наизнанку. Начало и конец ничуть не лучше чем в Мементо Кристофера Нолана. Они как-то умудрились запутать в общем-то нормальное руководство.
После этого всё пошло получше. Ржавые шестерёнки заскрипели и начали крутиться. Программа пошла-поехала. Если хотите знать как я внедрил rust в продакшен, как я ему научился и что из этого вышло – добро пожаловать под кат. Реальные люди, коммиты, примеры и никаких todo-list и хеллоу-ворлдов. Ржаветь так ржаветь.
Для начала – быстро расскажу что я заменил на rust. Жил да был лаборант. Ему сказали, мол, напиши программку – подключается вот к этой системе, сгружает бинарные данные по сети с порта, конвертирует их в удобочитаемый формат и сохраняет всё в базу данных. Лаборант был очень любознательным выскочкой. Почему-бы не показать себя? Он и показал. Написал программу на C# которая подключалась к серверу и тянула данные с компьютера. Преобразовывала их в JSON, который был доступен через POST API. С шарпами он был не очень дружен, посему сохранять в базу данных всё решил на Node.js, который эту программу на шарпах дёргал, получал JSON, делал немного логики и гнал в базу данных (postgres). На всё это дело был прикручен веб интерфейс, который позволял крутить настройки. Всё бы хорошо, но поиска по полученным данным у нас не было. Лаборант сказал: «Да не вопрос! Щас всё сделаю!» и поставил на всё это дело Elasticsearch. Поддерживать всё это дело стало страшно, посему лаборант сказал: «Щас всё починю!» и написал кучу Doсker файлов, положил всё в контейнеры, сделал docker-compose и всё заработало.
Примерно через год я пришёл и посмотрел на всё это дело. Полный дамп базы данных весил 250Мб. Прирост данных составлял 50 метров в год. Чего там, тривиальная задача. Но всё это крутилось на выделенном сервере с 32 гигами оперативки и 24 процессорами. Сервер выл и жужжал потому что приходилось гнать 16 докер-контейнеров с кластером Elasticsearch, который постоянно рушился от перегрузки.
Ай-я-яй. Подумал я. Надо что-то делать. Времени было достаточно, я и решил, почему-бы не попробовать rust?
Акт номер 0: Вступление
-----------------------
Конечно, есть видео на утубиках и всё такое, но я же пришёл из другой эры. Когда мы учили С++ нам в помощь приходила только свежая болванка с дампом MSDN. Мы любим нормальные доки.
Ну и чтобы вы подумали? Доки есть. И они даже в очень приличной форме.
**The Rust Programming Language** – замечательная книга, которая раскрывает все основные аспекты языка и показывает как им пользоваться. Книга примечательна тем, что сначала заводит вас в непроходимый омут с чертями, лешими и пресмыкающимися, а после пытается вас оттуда вытащить. (600 страниц)
**The Rust Reference** – полное, доскональное и дотошное руководство, которое расскажет и покажет что делает каждая закорючка на экране. Хотите знать как rust разложит в памяти ваш замечательный enum? Вам сюда. Абсолютно человеко-нечитабельное руководство, которое рассказывает обо всём. (300 страниц)
**Rust Compiler Error Index** – rust имеет замечательную фитчу. Ихний компилятор настолько разговорчив что вам даже не понадобится резиновая уточка для разговоров. Во время написаниия программы вы будете наслаждаться простынями всяких ошибок компилятора. Просто невероятное количество их. В этом замечательном томике все эти ошибки шибко расписанны и рассказаны. (400 страниц)
**Rustonomicon** – каждый кто более-менее начал работать с rust будет вам рассказывать про «Номикон». Эта книга по чёрной магии, которая позволяет вам убивать ваших врагов и привораживать по кофейной гуще. Все страшные стороны работы rust раскрыты именно здесь. (200 страниц)
В общем-то не хилое количество документации для языка. Всё это добро доступно публично и незаденежку, так что сливайте сколько хотите. Я читал в оригинале, но есть переводы. Ладно, давайте погружаться.
Акт номер 1: О чём вы, Морфеус?
-------------------------------
Каждый раз когда я вижу статью о rust я вижу крабиков, котиков и пушистые замечания о том, как эта ржавчина замечательно смотрится на моём новом сервере.
Но давайте посмотрим на мир более серьёзно, почему же всё-таки rust? Код, генерируемый rust использует LLVM как компилятор. Что это нам даёт? В общем-то неплохую переносимость на разные платформы, при полном отсутствии потребности в разных фреймворках. Программа на rust будет практически такой-же быстрой, как и программа на Си. Конечно куча флейм-троллей сейчас может начать комментить в стиле холивара «Раст против С» и наоборот, но чёрт бы с ними.
Какая разница если rust такой же быстрый как Си или если Си его обгоняет на 5%? Забейте. Не вникайте в это. Момент в том, что rust это системный язык программирования, который позволяет работать с вашим железом на очень низком уровне и не содержит в себе миллионы абстракций, фреймворков и тому подобное.
Давайте посмотрим вот на что:
Проект написанный на .net core 3: Исполняемый файл – 6 Мегабайт.
Проект написанный на rust: Исполняемый файл – 240 Килобайт.
Хаха! Но эти цифры – подстава и обманка! Хреновые маркетологи.
Я беру этот проект, копирую исполняемые файлы на флешку и запускаю их на другом компьютере (Windows 7).
И что бы вы думали? .net core проект не запускается! Почему? Нет фреймворка.
Ладно, давайте перекомпилируем проект так, чтобы включить все библиотеки необходимые для запуска приложения.
Результат? 89 Мегабайт!
Хаха! Вот так тебе и надо, .net! Хитрец! Пытался меня обмануть!
Ладно, теперь запускаем наш проект на rust. Вот, смотрите, просто кликаешь сюда и…
> The program can't start because VCRUNTIME140.dll is missing from your computer. Try reinstalling the program to fix this problem.
>
>
Ладно, пересобираем проект и вшиваем все зависимости в исполняемый файл и… 569 Килобайт.
Хм. Да в общем-то и неплохо. Учитывая то, что эта штука подключается к базе данных и всё такое. Вот такой он, системный язык.
Фреймворка и других финтифлюшек не так-то много. Некоторые вещи будут тривиальными и супер-быстрыми, а некоторые будут сводить с ума. Но то что вы пишете не будет тянуть за собой гигабайты разных библиотек и загружать серверы так что они начинают реветь похлеще голодных котиков. Готовы?
Акт номер 2: Учиться, учиться и ещё раз учиться
-----------------------------------------------
Вот вам пример. На странице 38 официального руководства (600 страниц) показан простой код вот этой замечательной программы:
Программа просто замечательная. Игра «отгадай число». Компьютер загадывает число, а ты его сидишь и отгадываешь. Тривиально, Ватсон, не так ли?
Нет.
Ничегошеньки не тривиально. Эта «простая» программа для «новичков» перегружена подводными камнями, минами и противовертолётными бомбами.
Прикол в том, что несмотря на всю свою сиобразность, rust включает в себя неимоверное количество синтаксического сахара, и всяких плюшек, которые компилируются в приличный и быстрый код. Все эти плюшки запутывают тебя до смерти, если в них не разобраться. И всё это тебе выдаётся на блюдечке с голубой каёмочкой, пока тебе говорят «Вот скушай наш ᾋﯓﻼ҉ᴪᾠﭥ», он вкусный.
Нет, нет, нет и ещё раз нет!
Первая глава этого руководства должна гореть в печи!
Давайте я вам покажу как его читать.
Начинать читать это руководство нужно с главы №4 под названием Understanding Ownership. Разбираемся в правилах владения переменными. Если вы начали работать с rust, то эти правила придётся учить и разбираться в них. Это именно то, почему и как rust такой замечательный.
Управление памятью всегда было узким местом многих программ. Когда вы пишете свои яваскрипты, о памяти вы беспокоитесь редко. Результат? Посмотрите сколько памяти жрёт ваш гуглохром прямо сейчас. Тут памятью занимается так называемый сборщик мусора, который сам знает что и куда чистить.
Но если нужно написать код, который двигается побыстрее, то, пожалуйста, заменяем сборщик мусора на ручное управление памятью. Мы в ассемблере так всегда и делали. Результат?
Результат правильного управления памятью.Накосячить с памятью – это просто святое.
Память надо сначала запросить у операционной системы. После этого её надо получить, потом прочистить как следует, после надо бы её инициализировать, потом только использовать. А после этого надо не забыть её отдать обратно системе. А после того как отдашь её обратно, надо не забыть удалить все ссылки на эту память, чтобы из неё ничего уже не читали.
Что делать? Либо вы отдаёте все в руки вашего фреймворка, который может быть неповоротливым и жрать кучу памяти, либо вы делаете всё в ручную, но это страшно.
В rust всё это было решено следующим образом: Создали ссылку на новый объект – компилятор быстренько встроит туда код, который запросит память у системы, прочистит и инициализирует эту память. А после того, как ваша ссылка уходит за зоны видимости, то компилятор автоматически добавит код, который память по этой ссылке освободит и отдаст обратно системе.
Всё просто и красиво. Чики-пуки! Ага.
Если вы не разберётесь как эти правила работают вы будете сидеть перед монитором часами, рыдая и умоляя компилятор собрать ваш код. Код в котором вы управляете памятью неправильно не будет компилироваться. Вот тебе и всё.
Пример:
`let s1 = String::from("hello");`
`let s2 = s1;`
`println!("{}, world!", s1);`
Простейший код, который понятен каждому программисту. Он нифига в rust не скомпилируется. Почему? Потому что при подобном присвоении существует возможность когда система освободит память дважды, что может привести к ошибке.
Ладно, хватит вас пугать.
Читаем главу Ownership и разбираемся как эта память работает. Благо, глава написана очень толково и рассказывает обо всём по порядку.
Акт номер 3: Все по порядку
---------------------------
После главы №4 надо прочитать главу №3.
Удивительно, но у некоторых людей странное понимание слова «Номер». Они их путают местами.
В главе №3 рассказывается об основных концептах языка. Как и с чем работать, как создавать переменные, ветвить программу и всё такое. Все эти данные на самом деле завязаны на понимание главы 4.
Ладно, разобрались с азами. Теперь пройдитесь по главам 5 (Использование структур), 6 (Enum и паттерны), а затем, понятное дело, прочитайте главу 8 (Коллекции). Это даст вам понимание основных объектов и как с ними работать.
После этого рекомендую перечитать главу №4. Открываются новые горизонты.
Теперь можно смело переходить к главе №9 (Улаживание ошибок).
В rust есть один прикол – в нём нет такого понятия как Null. Если вы погуглите “Null is a mistake” вы поймёте о чём я говорю. Приличное количество разработчиков ещё с 1965 года жалуются на то, что такое понятие как Null в значении переменной было неправильной идеей и не должно было существовать.
Rust избавился от идеи Null и это приводит нас к очень интересной, приятной и понятной системе обработки ошибок. Единственное что – вы такую систему видели не часто, и её надо знать, если хочется работать в rust.
Глава №7 рассказывает о том, как распилить программу на куски, чтобы не нужно было писать весь код в одном файле. Далее можно смело переходить к главе №10, и учить про дженерики, трейты и тому подобные финтифлюшки.
После этого рекомендуется перечитать главу №4. Сознание расширяется.
За главой 10 следуют главы 13 и 17. Они объясняют что rust имеет черты как функциональных так и объектно-ориентированных языков, и рассказывают о том, как пользоваться всеми этими прибамбасами.
После всего этого можно переходить к двум самым зубодробильным главам в этой книге. 15 и 16. При прочтении этих глав рекомендуется перечитывать главу №4 после каждого абзаца. Почему? А всё потому что если вам пришлось долго разбираться в том, как происходит управление памятью в обычной программе, то понять управление памятью в многопоточных программах будет занятием для чемпионов.
Но вы на самом деле не бойтесь. Сами по себе главы в книге написаны дельно, просто порядок неправильный.
Ладно, после этого – вы в доме хозяин. Можно начинать перечитывать книгу с главы №1 и потом переходить к главе №2. Приведённая задачка на нахождение числа покажется вам просто детской игрушкой (коей она и является). После идите по всем остальным главам и вдумчиво читайте. После всего этого вы сможете писать на rust.
И, кстати, это не так-то и сложно и на всё-про всё у меня ушло порядка одной недели, после того как я разобрался в этих главах. Книгу можно найти на русском на гитхабе, но даже на английском она вполне себе простая и читаемая. Плюс в том, что обходя эти подводные камни можно вполне нормально выучить этот язык пользуясь только официальной документацией. После прочтения этой книги вы получите пару специальных скиллов:
1. Вы будете знать что на самом деле написано в Номиконе. (Хотя и лезть туда вы не будете).
2. Вы сможете читать The Rust Reference.
С этими знаниями вы на самом деле можете сесть и начать разрабатывать свой первый проект, который будет посложнее todo-list.
Акт номер 4: Реальности
-----------------------
Реальная разработка принесёт свои определённые знания.
Опыт и мнения которыми я с вами поделюсь, являются чисто моими и у вас может сложиться другая картина восприятия мира.
Первое, что вы поймёте – компилятор не прощает огромного количества ошибок. Да, конечно, это хорошо, ибо потом эти ошибки не пройдут в продакшн. Но и с другой стороны – собрать прототип на rust за пару минут не получится. Если вы где-то сказали «Тут должно быть число, но в 1% случаев его может не быть», то вам придётся писать эту ветку обработки 1% случаев. Код не скомпилируется.
Те кто не освоил главу №4 будут играть в замечательную игру «Уломай компилятор скомпилировать твой код». Все правила управления памятью, которые делают rust таким мягким и пушистым, заставляют вас думать по другому об устройстве вашей программы. Никаких висячих хвостов или незаконченных кусков кода. Если вы просто пытаетесь написать программу от балды, то скорее всего вы потратите часы на то, чтобы привести её в порядок и скомпилировать.
Далее идёт каталог программного обеспечения crates.io.
Это сайт с которого можно слить приличное количество модулей и библиотек для вашего rust приложения. Сайт на самом деле содержит огромное количество программного кода. Но реальность не всегда замечательна.
Например, мне пришлось потратить порядка 2‑х часов, чтобы найти нормальную библиотеку для работы с postgres. Всё было замечательно, и я работал с этой библиотекой порядка десяти часов, пока не наткнулся на очень интересную проблему. В rust нет встроенного типа для валютных операций. Float не подходит, нужно было что-то типа Decimal. Decimal мне удалось найти в виде библиотеки, которую я нехотя скачал и добавил в свой проект. И тут внезапно выясняется, что драйвер для posgresql понятия не имеет, как конвертировать этот Decimal в Postgres Decimal.
Пришлось потратить 4 часа на разбирательства и написание конвертера.
Далее, достаточно скверный момент в rust – документация к пакетам. Да, в rust есть встроенная система документирования кода, и ты всегда можешь слить доки которые авто-генерируются из комментариев к твоему коду. Но вот эти доки зачастую оставляют желать лучшего. Тот же Decimal, из примера чуть повыше, имеет замечательную документацию, в которой сказано следующее – «Это Decimal. Позволяет работать с Decimal. Работайте. Благослови вас Господь!»
Пришлось лезть в исходники и копаться там, пока не разобрался, как же написать этот конвертер.
С другой стороны, развитые проекты имеют хорошие сайты, на которых публикуется тонна дополнительной документации. Например, tokio, actix и rocket.rs. Эти проекты (вы обязательно о них услышите, как только достаточно проржавеете) предоставляют огромное количество дополнительного чтива.
Акт номер 5: Итоги?
-------------------
Старый добрый дымящийся и ревущий сервер успокоился и перестал выходить из себя. 100-мегабайтное приложение на C# было заменено 564 килобайтами кода написанного на rust. 200 мегабайт памяти которые потребляло приложение на шарпах теперь превратились в 1.2 метра RAM для программы на rust. (Заодно избавился от двух докер-контейнеров в которых это приложение работало).
После трёх недель изучения языка, мне потребовалось примерно неделя на то, чтобы переписать приложение. Ну, до кучи, я посмотрел на всё это дело, состоящие из докеров и yaml файлов, и начал его разбирать. Убрал оттуда Elasticsearch. Ко дну пошли семь докер-контейнеров. Как выяснилось, большинство поисков по данным было сделано следующим образом – пользователь выбирает даты в Elastic и после этого скачивает csv. Затем весь поиск происходит в Excel. Elastic был заменён простой командой в cli, которая позволила сливать csv по дате, благо это можно было делать и из postgres.
Далее пришёл черёд web интерфейса для настроек. (Ещё пара контейнеров улетает в океан). Настроек оказалось порядка 12-ти и я их запихнул в TOML файл, который просто читается моим rust приложением. Ушёл ещё один докер-контейнер. Кит остался плавать один, без контейнеров. Он обиделся и уплыл восвояси. Докер можно было сносить.
Я посмотрел на сервер. Остался только postgres и моё замечательное rust приложение. Слил всё это на raspberry Pi и показал всем чудеса оптимизации.
В приведённом выше примере Rust был не единственной причиной почему серверы перестали визжать от перенапряжения. Дизайн приложения отсутствовал как класс. Всё было сделано наспех и безалаберно склеено докером, ибо так всё и должно быть. Я думаю, что если бы я полностью переписал всё на C#, то итоговое приложение получилось бы в 100 мегабайт и сидело бы себе, откушавши 250 мегабайт памяти.
Просто это никак не сравнится с полуметром на диске и полутра-метрами оперативки. Я снова почувствовал себя так же хорошо как в детстве, когда я запускал свои приложения на ассемблере и видел, как какие-то 20 килобайт единичек и ноликов создавали поразительные визуальные эффекты на экране. Rust это весело. После того как прочитаешь их документацию.
Акт номер Last: вывод
---------------------
Rust это годный язык программирования. Он не предназначен для прототипирования приложений. Разработать agile проект на rust за 20 минут не получится. Rust требует хорошего понимания системного программирования. И хотя rust и не такой сложный как Си в управлении памятью и ссылками, он требует очень аккуратного и правильно спланированного дизайна приложения, и, так же как и Си, не прощает ошибки. Но в отличие от Си, очень многие из этих ошибок будут не прощены на этапе компиляции, ещё до того как ваше приложение пойдёт в продакшен.
Использовать rust в изолированных проектах? Да! Если знаете как.
Заменить простую системную утилиту, которую какой-то лаборант написал для вас на node.js за 2 часа и которая перегружает сервер? Да! Вперед!
Добавлять rust в существующие проекты на C и C++? Подумайте ещё раз. Rust заставляет вас думать по-другому. И все те замечательные плюшки управления памятью, которые существуют в rust, есть и для C и С++. Их конечно нужно установить отдельно и настроить как полагается, но если проекту уже много лет, может не стоит. Пусть будет как будет.
Так что давайте, ржавейте. Тут весело.
**P.S.** Хобби – разборка. Разбираю на части перегруженные серверные приложения. Сношу докер. Снижаю счета за AWS. | https://habr.com/ru/post/537790/ | null | ru | null |
# Почему процессоры Intel потребляют больше ожидаемого: требования к теплоотводу и турбо-режим

В последнее время сообщество любителей самостоятельной сборки ПК пронизано темой энергопотребления. У новейших восьмиядерных процессоров от Intel показатель [TDP](https://ru.wikipedia.org/wiki/%D0%A2%D1%80%D0%B5%D0%B1%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F_%D0%BA_%D1%81%D0%B8%D1%81%D1%82%D0%B5%D0%BC%D0%B5_%D0%BE%D1%85%D0%BB%D0%B0%D0%B6%D0%B4%D0%B5%D0%BD%D0%B8%D1%8F_%D0%BF%D1%80%D0%BE%D1%86%D0%B5%D1%81%D1%81%D0%BE%D1%80%D0%B0) заявлен в 95 Вт, однако пользователи наблюдают, как те потребляют 150-180 Вт, что совершенно не имеет смысла. В этой инструкции мы объясним вам, почему это происходит, и почему это доставляет столько проблем авторам обзоров железа.
Что такое TDP (Thermal Design Power, требования к теплоотводу)
--------------------------------------------------------------
Для каждого процессора Intel гарантирует определённую рабочую частоту с определённой мощностью, часто имея в виду определённый кулер. Большая часть людей приравнивает TDP к максимальному энергопотреблению, учитывая, что в расчётах тепловая мощность процессора, которую необходимо рассеять, равна мощности, им потребляемой. И обычно TDP обозначает величину этой мощности.
Но, строго говоря, TDP относится к возможностям кулера по рассеиванию энергии. TDP – это минимальная возможность кулера, гарантирующая указанную эффективность. Часть энергии рассеивается через сокет и материнскую плату, а значит, рейтинг кулера может быть ниже TDP, но в большинстве обсуждений TDP и энергопотребление обычно означали одно и то же: сколько энергии процессор потребляет под нагрузкой.
В рамках системы TDP можно установить в прошивке. Если процессор использовал TDP в качестве максимального ограничения по мощности, то мы бы увидели, как та же измерительная программа выдаёт подобные графики для процессоров высокой мощности с несколькими ядрами.
В последние годы Intel использовала именно такое определение TDP. Для любого заданного процессора Intel гарантировала рабочую частоту (базовую частоту) для конкретной мощности – TDP. Это значит, что процессор типа 65 Вт Core i7-8700, с обычной частотой 3,2 ГГц, и 4,7 ГГц в [турбо-режиме](https://ru.wikipedia.org/wiki/Turbo_Boost), гарантированно будет потреблять до 65 Вт только при работе на частоте в 3,2 ГГц. Intel не гарантирует эффективной работы выше указанных 3,2 ГГц и 65 Вт.
Кроме базовых показателей, Intel также использует турбо-режим. Что-то вроде Core i7-8700 может показывать в турбо-режиме 4,7 ГГц, и потреблять при этом гораздо больше энергии, чем процессор, работающий на 3,2 ГГц. Турбо-режим для всех ядер на процессоре Core i7-8700 работает на частоте 4,3 ГГц – куда как больше гарантированной 3,2 ГГц. Ситуация усложняется, когда турбо-режимы не опускаются до базовой частоты. То есть, если процессор будет работать с постоянным превышением TDP, купленный вами кулер на 65 Вт (или тот, что шёл в комплекте) станет узким местом. Если вам нужно больше быстродействия, такой кулер надо выкинуть и взять что-то получше.
Однако производитель вам этого не сообщает. Если охлаждения для турбо-режимов будет недостаточно, а процессор достигнет температурного потолка, то большая часть современных процов перейдут в режим ограничения мощности, уменьшив быстродействие с тем, чтобы оставаться в рамках заданного энергопотребления. И в результате быстрый процессор не достигает пределов своих возможностей.
Значит, TDP ничего не значит? Почему это стало проблемой только сейчас?
-----------------------------------------------------------------------
За последнее десятилетие методика использования термина TDP не поменялась, а вот процессоры начали по-другому использовать свой энергетический бюджет. Недавнее появление шести- и восьмиядерных потребительских процессоров с частотами за 4 ГГц означает, что новые процессоры с большой загрузкой превышают заявленное TDP. В прошлом мы видели, как четырёхядерные процессоры с обозначенным рейтингом в 95 Вт использовали только 50 Вт даже под полной нагрузкой в турбо-режиме. И если мы добавляем ядра, а обозначение TDP на упаковке не меняем, то что-то должно поменяться.
Тайные цифры, которых нет на упаковке
-------------------------------------
Внутри каждого процессора Intel определяет несколько уровней энергии на основе возможностей и ожидаемых рабочих режимов. Однако все эти уровни энергии и возможности можно подстраивать на уровне прошивки, в результате чего OEM-производители решают, как эти процессоры будут работать в их системе. В итоге значение потребления энергии процессором в системе оказывается весьма размытым показателем.
Для простоты можно следить за тремя важными значениями. Intel называет их PL1 (уровень энергии 1), PL2 (уровень энергии 2) и T (Tau).
PL1 – эффективное равномерное ожидаемое потребление энергии в долгосрочной перспективе. По сути, PL1 обычно определяется, как TDP процессора. То есть, если TDP равно 80 Вт, то PL1 равно 80 Вт.
PL2 – краткосрочное максимальное потребление энергии процессором. Эта величина выше PL1, и в это состояние процессор переходит под нагрузкой, что позволяет ему использовать турбо-режимы вплоть до максимального значения PL2. Это значит, что если Intel определила несколько турбо-режимов у процессора, они будут работать, только когда PL2 доходит до максимального энергопотребления. В режиме PL1 турбо не работает.
Tau – временная переменная. Она определяет, как долго процессор должен оставаться в режиме PL2 перед тем, как откатиться на PL1. Tau не зависит от мощности и температуры процессора (ожидается, что при достижении температурного ограничения будет использоваться другой набор сверхнизких значений напряжения и частоты, а система PL1/PL2 перестаёт работать).
Вот официальные определения от Intel:

Давайте разберём ситуацию большой нагрузки на процессор.
Сначала он начинает работу в режиме PL2. Если нагрузка однопоточная, мы должны достичь верхнего значения турбо, которое обозначено в спецификации. Обычно энергопотребление одного ядра не приблизится к значению PL2 всего чипа. Если мы будем продолжать нагружать ядра, процессор отреагирует, уменьшая частоту турбо-режима в соответствии с по-ядерными значениями, определяемыми Intel. Если энергопотребление процессора достигает значения PL2, то его частота изменяется так, чтобы не выходить за рамки PL2.
Когда система находится под серьёзной нагрузкой долгий промежуток времени, «Tau» секунд, прошивка должна перейти на PL1 как на новое ограничение по мощности. Таблицы турбо перестают применяться – они работают только с режимом PL2.
Если потребление выходит за пределы PL1, тогда частота и напряжение изменяются так, чтобы потребление энергии оставалось в этих пределах. То есть процессор целиком уменьшает частоту от состояния PL2 до состояния PL1 на время работы под нагрузкой. Это значит, что температура процессора должна уменьшиться, и это должно увеличить время жизни процессора.
Режим PL1 работает, пока не исчезнет нагрузка, и ядро не перейдёт в состояние бездействия на определённое количество времени (обычно до 5 секунд). После этого режим PL2 снова может быть включён при появлении другой большой нагрузки.
Приведём примеры некоторых величин – Intel перечисляет несколько вариантов в спецификациях различных процессоров. Для примера я взял Core i7-8700K. Для этого проца верно следующее:
`PL1 = TDP = 95 Вт
PL2 = TDP * 1.25 = 118.75 Вт
Tau = 8 сек`
В данном случае система должна суметь разогнаться до 119 Вт на восемь секунд, а потом снова откатится назад до 95 Вт. Так работает уже несколько поколений процессоров Intel, и по большей части, это не имело особого значения, поскольку энергопотребление процессора целиком часто оказывалось сильно ниже значения PL1 даже под полной нагрузкой.

Однако вся ерунда начинается, когда в игру вступают производители материнских плат, поскольку PL1, PL2 и Tau можно настраивать в прошивке. К примеру, на графике выше можно снять ограничения с PL2, а PL1 назначить 165 Вт и 95 Вт.
Мир случайных чисел
-------------------
В основном я буду говорить о потребительской электронике. Часто PL1, PL2 и Tau тщательно контролируются в таких ограниченных по охлаждению условиях, как ноутбуки или небольшие ПК. Я знаком с несколькими мощными, и в то же время стильными вариантами ПК, у которых PL2 также приравнивали к TDP, чтобы процессор смог немного разогнаться, но не до такой степени, чтобы нагрузка одного-двух ядер выходила за пределы TDP.
Однако в наших обзорах CPU после распространения шестиядерных процессоров мы часто начали видеть цифры гораздо большие, чем PL1 или PL2, и это потребление продолжается сколь угодно долго, если только не выходит за пределы ограничений температуры. Почему это происходит?
В любом современном BIOS, в особенности у основных производителей мат.плат, будут присутствовать настройки по ограничению мощности (краткосрочное и долгосрочное) и длительности. В большинстве случаев по умолчанию пользователю неизвестно, в какое значение они установлены, поскольку там будет написано Auto, что является кодовым обозначением «мы знаем, какое значение им назначить, не волнуйтесь». Производители запишут величины в память и будут их использовать, но пользователь увидит только Auto. В результате можно назначить PL2 в 4096 Вт и сделать Tau очень большим, к примеру, 65535, или -1 (бесконечность – зависит от варианта BIOS). Это означает, что CPU без перерыва будет работать в режиме турбо, пока не превысит температурные ограничения.
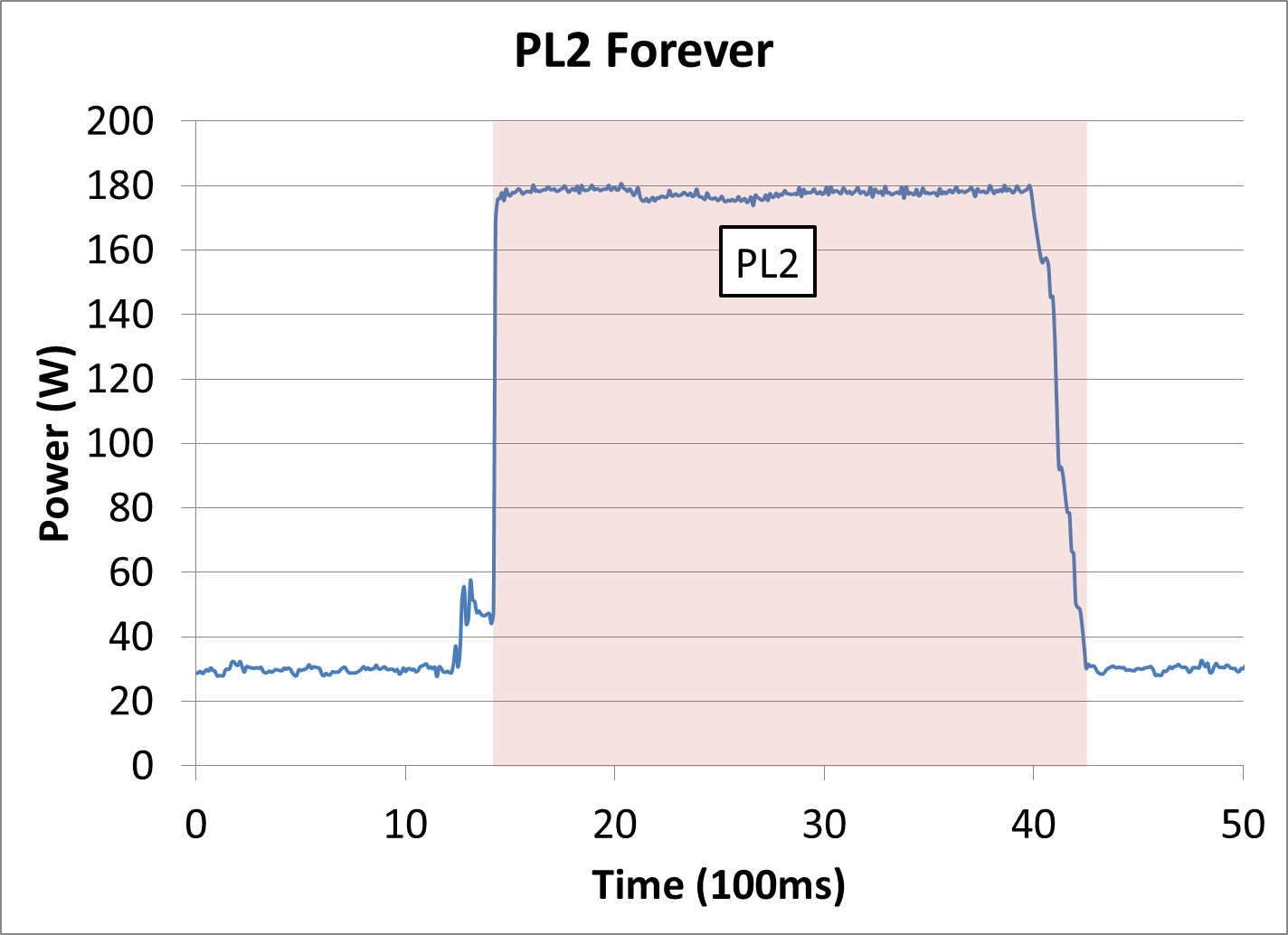
Зачем производители так поступают? Тому может быть много причин, хотя конкретные причины у конкретных производителей могут разниться.
Во-первых, это означает, что пользователь может поддерживать турбо-режим постоянно, и каждое ядро будет работать в режиме турбо каждую секунду. Результаты измерений быстродействия будут доставать до небес, в обзорах или когда пользователя меряются показателями, всё выглядит прекрасно,
Во-вторых, продукты для этого и разрабатываются. Intel часто с каждым запуском определяет спецификацию мат.платы по умолчанию (у них даже были свои материнки, которые они продавали в розницу), с определённым количеством фаз питания и с ожидаемым временем жизни. Производители, очевидно, могут внедрять свои варианты: больше фаз питания, более мощные фазы, особый подвод питания для улучшения эффективности, и т.д. Если их плата может поддерживать турбо-режим всех ядер беспрерывно, то почему бы и нет?
В-третьих, производители более дорогих моделей плат знают, что энтузиасты будут использовать для них улучшенные системы охлаждения. Если процессор потребляет более 160 Вт, а у пользователя есть приличная система охлаждения, тогда турбо-режим на всех ядрах улучшит впечатление от продукта. Стандарты Intel определяются для рекомендованных компанией кулеров.
Так как же правильно, кому доверять, в чём разница?
---------------------------------------------------
Intel назначает стандарты для своих запчастей. PL1, PL2, Tau, схема материнки, настройки прошивки – для всего есть значения по умолчанию, рекомендованные Intel. Некоторые из них публичные, например, те, что Intel указывает в документах, некоторые – конфиденциальные (и Intel нам о них не расскажет, как бы мы ни упрашивали). Однако это всё же рекомендованные значения. А по итогам, производители материнских плат могут делать всё, что им заблагорассудится. И они так и делают.
В результате, к примеру, мне тестировать оборудование из-за этого становится сложнее. Разным пользователям захочется, чтобы наши настройки были:
1. Рекомендованными Intel,
2. Как из коробки,
3. Вывернуты на максимум.
И, естественно, рекомендации Intel дадут куда как меньшие показатели, чем «из коробки», а вариант «вывернуты на максимум» говорит сам за себя.
Стоит отметить, что до сих пор во всех тестах во всех обзорах CPU железо запускалось на настройках «из коробки», а не «рекомендованных Intel».
Чтобы дать некий контекст по значениям измерений, мы использовали мощный CPU и
получили следующие результаты в 25-30 секундном тесте с полной нагрузкой:
| AnandTech | PL2 | Tau | PL1 | Result |
| --- | --- | --- | --- | --- |
| Unlimited | 4096W | 999s | 4096W | 100% |
| Intel Spec, 165W | 207W | 8s | 165W | 98% |
| Constant 165W | 165W | 1s | 165W | 94% |
| Intel Spec, 95W | 118W | 8s | 95W | 84% |
| Constant 95W | 95W | 1s | 95W | 71% |
В последнее время было замечено, что некоторые производители материнских плат меняют свою стратегию по PL1/PL2/Tau, и урезают значение Tau до чего-то разумного, вроде 30 секунд. При запуске измерений скорости на таких материнских платах, пользователи получают результаты меньше, чем обычно, хотя эти результаты оказываются ближе к спецификациям Intel.
Дело в том, что когда на материнских платах стоит значение Auto, производитель обычно не раскрывает точную величину этого значения. В результате описывать работу такого оборудования очень тяжело. А ещё эти значения могут меняться в зависимости от установленного процессора.
Мы обычно проводим тестирования с настройками «из коробки», за исключением памяти, с которой мы используем значения, рекомендованные производителем. Мы считаем, что это наиболее честный способ сообщать читателям о том, на какую скорость они смогут рассчитывать, когда практически никакие настройки не менялись. В реальности это обычно означает, что PL2 установлено в какое-то очень большое значение, а Tau – в очень долгое. Мы постоянно сталкиваемся с режимом турбо, пока температура остаётся в установленных пределах.
Сегодняшняя ситуация, и что мы можем с ней сделать
--------------------------------------------------
Давно хотел написать подобную статью, по меньшей мере, с момента запуска Kaby Lake. Большая часть процессоров в потребительских материнских платах работает с неограниченным PL2, и это считалось нормальным годами. И только по результатам тестирования Core i9-9900K мы начали замечать нечто странное. В нашей статье на прошлой неделе по поводу нового Xeon E написано, что наша материнская плата Supermicro буквально следует рекомендациям от Intel. Может показаться очевидным, что более коммерческая/серверная плата будет следовать спецификациям от Intel, но вживую я лично видел такое впервые. Очевидно, что потребительские платы по таким спецификациям не работают, и не работали. Я бы сказал, что собственные результаты тестирования от Intel (и результаты тестирования процессоров Intel от AMD) на потребительских материнках тоже не соответствуют спецификациям от Intel.
Так что нам с этим делать? Я бы сказал, что Intel надо размещать на коробках два обозначения мощности:
* TDP пиковое для PL2
* TDP долговременное для PL1.
Таким образом Intel и другие смогут объяснить пиковое потребление и базовую частоту.
Если пользователи хотят, чтобы потребительские материнские платы изменились, то это будет сложнее сделать. Все производители хотят опередить друг друга, поэтому мы сталкиваемся с такими вещами, как опция Multi-Core Turbo, включённая по умолчанию. Производители предпочитают путь «неограниченного PL2», поскольку это позволяет им пролезать на вершины чартов быстродействия. А вот в ноутбуках с ограниченными возможностями по охлаждению часто заданы свои варианты PL1, PL2 и Tau, и часто они строго соответствуют этим параметрам.
Вопрос в том, насколько спецификации от Intel важны для настольных процессоров от Intel? Если нам надо следовать этим рекомендациям буквально, может, мы сделаем ещё один шаг, и будем использовать только стоковые кулеры? | https://habr.com/ru/post/431276/ | null | ru | null |
# Прогнозирование обводнённости скважин с помощью методов машинного обучения
Привет Хабр! По основной профессии я инженер по разработке нефтяных и газовых месторождений. Я только погружаюсь в Data Sciense и это мой первый пост, в котором хотел бы поделиться опытом применения машинного обучения в нефтяной сфере.
Предсказание добычи скважинами нефти и газа является одним из самых важных в нефтяной и газовой промышленности. Без обоснованного прогноза добычи невозможно принимать решения о рентабельности проектов, капитальных вложениях, бурении новых и операционном планировании эксплуатации существующих скважин.
В данной статье я хочу поделиться опытом создания модели машинного обучения применительно к нефтегазовой сфере. Цель построения модели была предсказать один из параметров работы скважин и проверить способность модели предсказать обводнённость существующих скважин и скважин, которые планируется пробурить (кандидаты на бурение).
Данные по добыче фактически являются временными рядами, что предполагает построение более сложной модели. С целью упрощения и ускорения было принято решение строить модель на конкретно выбранную дату.
Обзор: как прогнозируют добычу нефти и газа
-------------------------------------------
В настоящий момент кроме классического аналитического способа оценки (эксель + метод матбаланса) общепринятым является построение геологической (статической) и гидродинамической (динамической) моделей, на основе которой принимаются решения.
Геологическая модель строится на основе скважинных данных (обычно с использованием сейсмики). В начале строится трехмерная сетка (каркас) продуктивных пластов. Далее каждой ячейке сетки присваивают такие свойства породы как пористость, проницаемость, водо- нефте- газонасыщенности, давление и прочие.
После этого на основе статической модели рассчитывается динамическая модель, которая отличается от геологической тем, что она рассчитывает как вышеуказанные параметры ячеек меняются во времени в зависимости от того сколько добывают скважины и наоборот. Динамическая модель помогает ответить на вопрос где бурить новые скважины и сколько возможно добыть нефти.
Гидродинамическая модель в 3D представлена на самой первой картинке (выше).
Недостаток подхода с построением полноценной гидродинамической модели в том, что на постройку модели нужно очень много времени (от нескольких месяцев до года и даже больше). Это зависит от количества скважин и имеющихся данных по месторождению. Более того, построенная гидродинамическая модель является сложной системой с высокой чувствительностью к входным данным. Поэтому любая некорректность в данных может привести к неверным результатам. Это не удивительно. Протяжённость месторождений достигает десятков километров. А типичный диаметр скважин находиться в пределах 10 - 15 см. Скважины в свою очередь, пробурены на глубины порядка 3-х километров и на расстояниях 250 - 1000 метров друг от друга. Таким образом, модель строится по крайне ограниченном данным, которые можно охарактеризовать как "точечные уколы".
Обычно скважину представляют себе как дырку в земле. Это не совсем так. Классическое определение скважины звучит так. **Скважина - это цилиндрическая горная выработка, длинной многократно превышающей её диаметр**. Типично - это 3-х километровое (бывает конечно и больше, бывает и меньше) отверстие в которую спущены несколько вложенных друг в друга колонн обсадных труб (для предотвращения обвалов). Пространство между колоннами обсадных труб и горной породой для герметичности цементируется. На поверхности устанавливается фонтанная арматура, которая герметизирует скважину от окружающей среды.
Скважины бурят не только для добычи нефти и газа. Через скважины получают подавляющее большинство данных о недрах.
**Скважинные данные** включают в себя:
* данные полученные при спуске приборов в скважину (например давление, температура, глубина нефте/газо-насыщенного пласта, кажущееся сопротивление породы, радиоактивность и прочие..),
* замеряемые на поверхности - количество добываемых нефти, газа и попутной воды, их состав.
По типу основного добываемого флюида скважины можно разделить на нефтяные и газовые. В данной статье рассматриваются нефтяные скважины. Это значит, что на поверхности мы получаем нефть с растворённым в ней газом и попутную воду. Как правило в начале эксплуатации скважин добывается чистая нефть, но позже скважина обводняется и доля воды увеличивается. Когда доля воды увеличивается, а доля нефти уменьшается до определённого предела - скважина перестаёт быть рентабельной и её останавливают. Обводнённость выражают в процентах и рассчитывают как отношение количества добытой воды к добытой жидкости т.е. Qнефти/(Qнефти + Qводы)\*100%
Типичный профиль добычи нефти во времени (в данном случае по годам) выглядит вот так:
Построение модели
-----------------
Входными данными для обучения модели были выбраны следующие параметры скважин:
* Cum oil: накопленная добыча нефти
* Days: количество дней работы скважины (до момента обводнения (и её остановки по нерентабельности) или до текущего момента в случае если скважина в работе).
* In prod: скважина в работе/остановлена по обводнению
* Q oil: текущий дебит нефти
* wct: текущая обводнённость
* Top perf: глубина верха интервала перфорации - глубина верха и низа
* Bottom perf: глубина низа интервала перфорации
* ST: 0 - основной ствол скважины, 1 - боковой ствол
* x, y: координаты скважины
Импортируем необходимые библиотеки
```
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
%config InlineBackend.figure_format = 'svg'
import pylab
from pylab import rcParams
import plotly.express as px
import plotly.graph_objects as go
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import r2_score as r2, mean_absolute_error as mae, mean_squared_error as mse, accuracy_score
from sklearn.metrics.pairwise import euclidean_distances
```
Загружаем исходные данные на определённую дату из экселя и визуализируем датафрейм.
```
data_path = 'art_df.xlsx'
df = pd.read_excel(data_path, sheet_name='artificial')
df
```
Проверяем местоположение скважин - строим карту местоположений скважин. В данном случае это карта забоев (нижних точек окончаний скважин).
```
ax = df.plot(kind='scatter', x='x', y='y')
df[['x','y','Well']].apply(lambda row: ax.text(*row),axis=1);
rcParams['figure.figsize'] = [11, 8]
```
В процессе построения модели было выявлено, что загрузка координат скважин в модель "как есть" работает неплохо. Но значительное улучшение качества модели происходит если трансформировать координаты в матрицу расстояний между скважинами. Таким образом мы даём возможность алгоритму сразу распознать, что ближайшие скважины имеют больший вес, чем удалённые.
Конструирование признаков
-------------------------
Рассчитываем матрицу евклидовых расстояний между скважинами из их координат.
```
distance = pd.DataFrame(euclidean_distances(df[['x', 'y']]))
distance
```
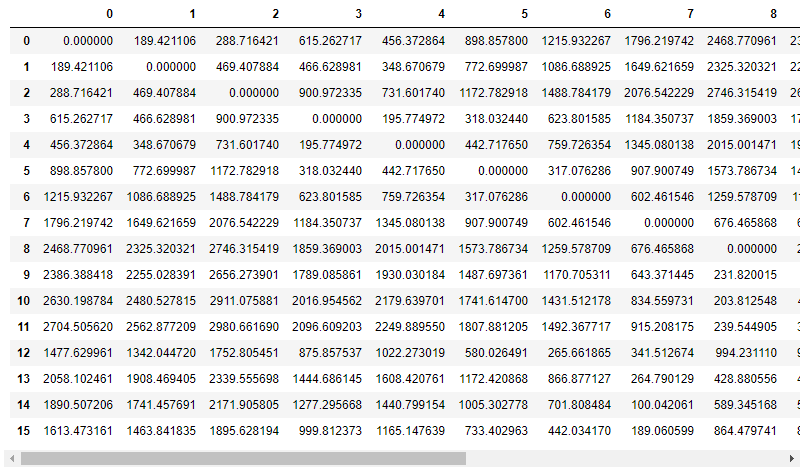Извлекаем список имён скважин. Присваиваем имена скважин колонкам матрицы расстояний.
```
well_names = df['Well']
distance.columns = well_names
```
Объединяем датасет параметров работы скважин с матрицей расстояний между скважинами. Таким образом в датасет добавляем новый признак - удалённость, который является весом скважин друг на друга.
```
df_distance = pd.concat([df.drop(['x', 'y'], axis=1), distance], axis=1)
df_distance
```
Проверка модели
---------------
Ввиду малого количества данных протестируем модель методом слепого тестирования. Создаём тренировочный дата сет, удаляя из него скважины, выбранные для теста и прогноза
```
df_train_1 = df_distance.drop([12, 13, 14, 15], axis=0)
df_train_1
```
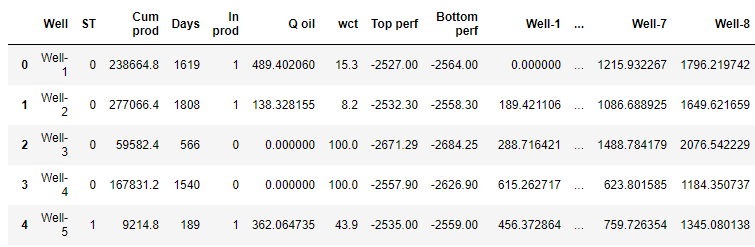Создаём тестовый датасет
```
df_test_1 = df_distance.loc[[12, 13]]
df_test_1
```
Создаём тренировочный DataFrame признаков X\_1. Удаляем категорийный признак (имя скважины) и предсказываемое значение wct.
```
x_1 = df_train_1.drop(['Well', 'wct'], axis=1)
x_1
```
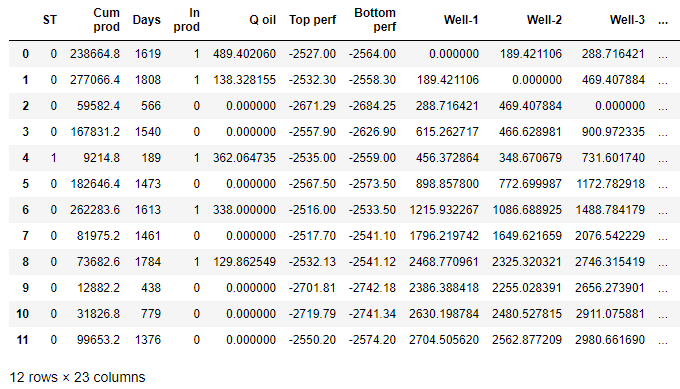Создаём тренировочный вектор целевых значений y\_1
```
y_1 = df_train_1['wct']
```
Создаём тестовый вектор целевых значений y\_*test\_*1
```
y_test_1 = df_test_1['wct']
```
В качестве алгоритма был выбран обычный Random Forest Reggressor, как наиболее универсальный алгоритм, подходящий для большинства типов данных.
```
x_test_1 = df_test_1.drop(['Well', 'wct'], axis=1)
model = RandomForestRegressor(random_state=42, max_depth=14)
model.fit(x_1, y_1)
y_pred_train_1 = model.predict(x_1)
y_pred_1 = model.predict(x_test_1)
print('Predicted values from train data:')
r2_train = r2(y_1, y_pred_train_1)
mae_train = mae(y_1, y_pred_train_1)
mse_train = mse(y_1, y_pred_train_1)
print(f'R2 train: {r2_train.round(4)}')
print(f'MAE train: {mae_train.round(4)}')
print(f'MSE train: {mse_train.round(4)}')
print('Predicted values from test data:')
r2_test = r2(y_test_1, y_pred_1)
mae_test = mae(y_test_1, y_pred_1)
mse_test = mse(y_test_1, y_pred_1)
print(f'R2 test: {r2_test.round(4)}')
print(f'MAE test: {mae_test.round(4)}')
print(f'MSE test: {mse_test.round(4)}')
model
```
```
Predicted values from train data:
R2 train: 0.8832
MAE train: 8.2855
MSE train: 131.1208
Predicted values from test data:
R2 test: 0.8758
MAE test: 3.164
MSE test: 11.4485
RandomForestRegressor(max_depth=14, random_state=42)
```
R2 метрика на тренировочной метрике превышает R2 на тестовой 1%. Это означает, что модель отлично обучилась.
Сравним предсказанную обводнённость с фактической на тестовой выборке, которая не использовалась при обучении модели (blind test)
```
df_y_test = pd.DataFrame({'Well': df_test_1['Well'],
'wct predicted, %': y_pred_1.round(1),
'wct actual, %': y_test_1.round(1),
'difference': (y_pred_1 - y_test_1).round(1)})
df_y_test
```
Сравним предсказанную обводнённость с фактической на тренировочной выборке
```
df_y_train = pd.DataFrame({'Well': df_train_1['Well'],
'wct predicted, %': y_pred_train_1.round(1),
'wct actual, %': y_1.round(1),
'difference': (y_pred_train_1 - y_1).round(1)})
df_y_train
```
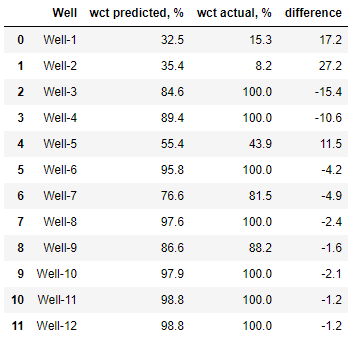Вычислим среднее отклонение обводнённости:
```
round(sum(abs(y_pred_train_1 - y_1)) / len(y_1), 1)
```
8.3
Видим, что среднее отклонение по обводнённости составляет 8%, что является приемлемым результатом.
Создание модели на всех доступных данных
----------------------------------------
Создаём тренировочный дата сет, удаляя из него скважины, выбранные для прогноза
```
df_train_2 = df_distance.drop([14, 15], axis=0)
```
Создаём датасет для прогнозирования из скважин, удалённых на предыдущем шаге.
Предсказываемый параметр WCT (обводнённость) сейчас = NaN.
```
df_fc = df_distance.loc[[14, 15]]
```
Создаём тренировочный DataFrame признаков x\_2. Удаляем категорийный признак (имя скважины) и предсказываемое значение wct.
```
x_2 = df_train_2.drop(['Well', 'wct'], axis=1)
```
Создаём тренировочный вектор целевых значений y\_2 и обучаем модель.
```
y_2 = df_train_2['wct']
x_fc = df_fc.drop(['Well', 'wct'], axis=1)
model = RandomForestRegressor(random_state=42, max_depth=14)
model.fit(x_2, y_2)
y_pred_train_2 = model.predict(x_2)
y_fc = model.predict(x_fc)
print('Predicted values from train data:')
r2_train = r2(y_2, y_pred_train_2)
mae_train = mae(y_2, y_pred_train_2)
mse_train = mse(y_2, y_pred_train_2)
print(f'R2 train: {r2_train.round(4)}')
print(f'MAE train: {mae_train.round(4)}')
print(f'MSE train: {mse_train.round(4)}')
print('Forecasted values could be compared with real data!')
model
```
```
Predicted values from train data:
R2 train: 0.9095
MAE train: 6.5196
MSE train: 89.9625
RandomForestRegressor(max_depth=14, random_state=42)
```
R2 повысилось. Или модель переобучилась или большее количество данных помогло точнее настроить модель
Сравним предсказанную обводнённость с фактической на тренировочной выборке.
```
df_y_train = pd.DataFrame({'Well': df_train_2['Well'],
'wct predicted, %': y_pred_train_2.round(1),
'wct actual, %': y_2.round(1),
'difference': (y_pred_train_2 - y_2).round(1)})
df_y_train
```
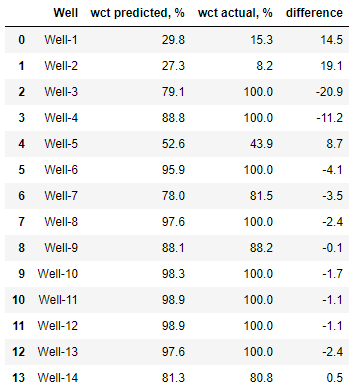
```
round(sum(abs(y_pred_train_2 - y_2)) / len(y_2), 1)
```
6,5
Величина средней ошибки обводнённости снизилась до 6,5. Отлично!
Предсказываем обводнённость по боковым стволам:
```
df_y_test = pd.DataFrame({'Well': df_test_1['Well'],
'wct predicted, %': y_pred_1.round(1),
'wct actual, %': y_test_1.round(1),
'difference': (y_pred_1 - y_test_1).round(1)})
df_y_test
```
Выводим список признаков в порядке убывания их важности и строим диаграмму важности признаков.
```
model.feature_importances_
feature_importances = pd.DataFrame()
feature_importances['feature_name'] = x_2.columns.tolist()
feature_importances['importance'] = model.feature_importances_
feature_importances = feature_importances.sort_values(by='importance', ascending=False)
feature_importances
```
```
fig = px.bar(feature_importances,
x=feature_importances['importance'],
y=feature_importances['feature_name'],
title="Feature importances")
fig.update_layout(yaxis={'categoryorder':'total ascending'})
fig.show()
```
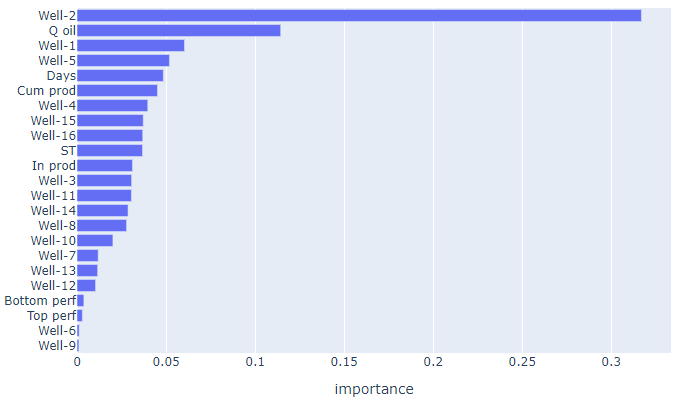Видим, что наиболее важный признак - это расстояние до 2-й скважины. Возможно стоит проанализировать признаки дополнительно и исключить какие то из них из обучения.
Сравнительный график реальных и предсказанных значений. Чем дальше скважина от красной линии - тем хуже она предсказана.
```
fig = px.scatter(x=y_pred_train_2, y=y_2, title="True vs Predicted values",
text=df_train_2['Well'], width=850, height=800)
fig.add_trace(go.Scatter(x=[0,100], y=[0,100], mode='lines', name='True=Predicted',
line = dict(color='red', width=1, dash='dash')))
fig.update_xaxes(title_text='Predicted')
fig.update_yaxes(title_text='True')
fig.show()
```
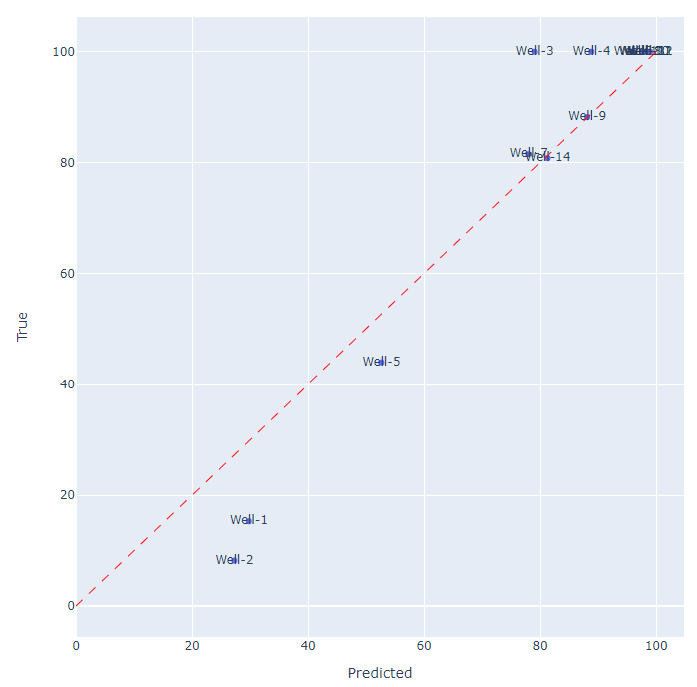Вывод
-----
Предсказание параметров работы скважин возможно различными методами. Одни из них являются очень сложными и трудозатратными (геолого- гидродинамические модели), другие простыми и быстрыми (матбаланс, кривые падения добычи).
Данный пример построения модели и сравнение прогноза с реальными данными позволяет сделать вывод, что даже очень простая модель "без наворотов" хорошо предсказывает параметры работы скважин. Это означает, что что в копилку инженера по разработке месторождений нефти и газа добавляется ещё один метод выполнения рабочих задач, который к тому же позволяет решить поставленную задачу в весьма сжатые сроки.
### Примечания
* Данная модель имеет важное ограничение. У любого месторождения существует контур нефтеносности - та область за пределами которой пробуренная скважина будет "сухой" - там нет нефти.
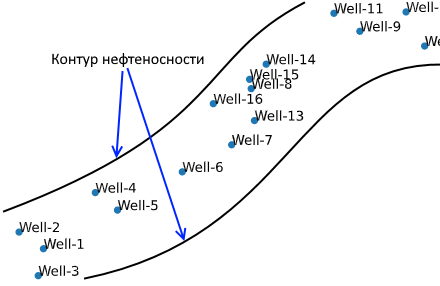Данная модель слабо чувствительна к местоположению. Модель "не знает", что за пределами определённой зоны нефти нет. Для решения этой проблемы можно найти и загрузить данные по "сухим" скважинам которые были пробурены по окружению и не нашли нефть. Также можно создать искусственные данные на контуре нефтеносности с нулевыми дебитами по нефти. В данном примере, я не применял ни одни из способов дабы не усложнять модель.
* Цель исследования была в том, чтобы оценить применимость методов машинного обучения в этой области. Задача выбрать наилучший алгоритм не ставилась, поэтому сравнения разных алгоритмов не проводилось.
* Скважинные данные не являются открытыми данными, а являются собственностью компании, владеющей лицензией на разработку месторождения. Поэтому для иллюстрации выполнной работы были сгенерированы ***искусственные скважинные данные***, которые доступны для данной работы.
* **Исходный код** вместе с текстом статьи доступен здесь: <https://github.com/alex-kalinichenko/re/tree/master/wct_fc> | https://habr.com/ru/post/533470/ | null | ru | null |
# StegoPy — Инструмент LSB-стеганографии на Python
Предисловие
-----------
В последнее время я заметил, что людям на моем форуме стала интересна тема стеганографии различных текстов в изображениях, mp3-файлах и видео. И тут у меня возникла идея написать свой скрипт для стеганографии текста в изображениях. Скажу сразу прежде я ни разу не сталкивался с написанием подобных инструментов для стеганографии.
Прежде, чем познакомиться с LSB-стеганографией я рассматривал другие способы, точнее сказать придумывал свои. Но у меня не хватило сил придумать, что-то свое и я решил загуглить:
**LSB** — метод стеганографии, при котором меняются младшие биты одного из RGB цветов в пикселе на биты кодируемого текста.
Потом я познакомился с библиотекой Pillow для работы с изображениями и Cryptography. Вторая в моем случае была нужна для создания DES-шифрования, которое впоследствии будет закодировано побитно в изображение.
**Кодирование
-----------**
Свое детище я выложил на GitHub, поэтому для дальнейшей работы со StegoPy нам нужно будет просто склонировать проект с GitHub:
```
> git clone https://github.com/securityhigh/StegoPy
> cd StegoPy
> pip3 install -r requirements.txt
> python3 stegopy.py
```
Впрочем все как обычно в плане установки. А сейчас давайте разберем синтаксис команд запуска.
```
> python3 stegopy.py -e in.jpg data.txt
```
Данной командой мы закодируем текст из файла *data.txt* в изображение *in.jpg*
Но перед кодированием у нас запросят баланс, который может быть от 1 до 4. Это как раз одна из самых интересных вещей в программе.
**Файл in.jpg**

**Файл data.txt**
this is private message
**Баланс** — это количество младших битов задействованных в стеганографии. Оно колеблется от 1 до 4.
Соответственно, чем больше баланс, тем:
1. Меньше пикселей будет задействованно в кодировании
2. Заметнее изменения в цветовых каналах
Из этого можно сделать вывод о том, что чем меньше баланс, тем выше надежность стеганографии и она будет незаметна человеческому глазу.
Еще один немаловажный фактор это то, что изменяется лишь синий канал, оттенки которого наименее заметны для нашего глаза.
После того, как мы определились с балансом, наш скрипт создаст два дополнительных файла:
* out.png — изображение с закодированным текстом
* key.dat — файл с ключом, который нужен для расшифровки
**Файл out.png**

**Файл key.dat**
1$960$gxvZH4Q8Gq2qLGeA1aSCXIPRljJlJbihsvSBdzx-wSM=
Декодирование
-------------
Синтаксис команды в нашем случае:
```
> python3 ./stegopy.py -d out.png
```
Затем нас спросят ключ, который мы получили при кодировании. После декодирования расшифрованный текст сохранится в файле *out.txt*
Как вы могли заметить входное изображение имеет формат JPEG, а на выходе PNG. Это является недоработкой программы, которая в скором времени будет пофикшена и у вас будет возможность выбора выходного формата.
На входном изображении тестировались только JPEG и PNG, теоретически должно работать и на менее используемых, таких как bmp и так далее.
К слову pylint оценил StegoPy на 10/10. Приветствуются замечания к коду и функционалу поскольку я планирую развивать приложение.
→ [Проект доступен на GitHub](https://github.com/securityhigh/StegoPy) | https://habr.com/ru/post/497420/ | null | ru | null |
# Google Maps API

Картографический сервис – зачем это? Ну например, я 10 лет жил в нашей маленькой провинции, а потом взял и понаехал в Москву, и всё для меня так ново. А где магазины, боулинг, кафешки, парки отдыха – надо знать же, где тратить московскую зарплату. Но вот беда, как узнать? Раньше был справочник «Желтые страницы» и там была карта и всё по адресам. Чтобы найти что-то уходило масса времени. Сейчас стало всё в разы проще. Вот прекрасный пример: <http://www.pushkino.org/>. Но это далеко не всё.
Я могу отслеживать погоду, пожары, пробки (кстати!) в реальном времени.
Мой заказчик может не вводить свой адрес, а попросту отметить его на карте и я буду знать куда доставить ему товар – какое классное решение, не надо всего этого – «Проспект маршала Блюхера, 43, г. Санкт-Петербург, Россия».
#### Задача для примера
Всё лучше узнавать практически, так что сделаем задачу для примера, чтобы обрести навыки. Вот примерный план работ:
1. Вывести карту (надо же!)
2. Задать город
3. Переместить карту к городу
4. Маркером указать адрес
5. Добавить информации
6. Вывести карту (надо же!)
7. Сохранить маркер с иноформацией (при клике на него вывести ее)
8. Избежать нагромождения (т.е. сделать кластеризацию) маркеров.
#### Как делать?
##### Ключ API
~~Ключ API нужен для использования работы с картой, т.е. при запросе всех их скриптов и сервисов в параметры нужно добавлять &key=[тут наш ключ]. Впрочем для <http://localhost> он не нужен. Получить его надо тут: <http://code.google.com/apis/maps/signup.html>. Кстати, работает и без него на сайте, но может это временно.~~
**Для v.3 не нужен**
##### Map\Marker\InfoWindow
Для работы нам понадобится 3 основных объекта. Первое – это карта.
**Карта создается очень просто.** У нас есть какой-то определенный контейнер:
```
```
Подключаем скрипт:
```
```
Инициализируем карту:
```
function initialize() {
var myLatlng = new google.maps.LatLng(-34.397, 150.644);
var myOptions = {
zoom: 8,
center: myLatlng,
mapTypeId: google.maps.MapTypeId.ROADMAP
}
var map = new google.maps.Map(document.getElementById("map_canvas"), myOptions);
}
```
center: myLatlng – это координаты центра карты
zoom – это увеличение при инициализации
mapTypeId – тип (политическая, физическая, гибрид)
**Карта готова!**
Второе — это **метки**:
```
var marker = new google.maps.Marker({
position: myLatlng,
map: map,
title:"Hello World!"
});
```
position – собственно координаты метки
map – на какую карту метку поместить
title – при наведении мыши будет писать “Hello World!”.
**InfoWindow**
```
var contentString = 'Тут всё то про что должно быть рассказано';
var infowindow = new google.maps.InfoWindow({
content: contentString
});
var marker = new google.maps.Marker({
position: myLatlng,
map: map,
title: 'Uluru (Ayers Rock)'
});
google.maps.event.addListener(marker, 'click', function() {
infowindow.open(map,marker);
});
```
content – содержимое в метке
```
google.maps.event.addListener(marker, 'click', function() { infowindow.open(map,marker); });
```
— при клике на метку, показать окно с информацией, на карте map с привязкой к marker.
##### Geocoding
Geocoding – это просто отличная библиотека, которая позволяет делать всего 2 вещи:
* По наименованию чего-то, найти это на карте и сообщить координаты
* По координатам, сообщить всё что находится на этих координатах.
Запрос выглядит так. Например, мы хотим узнать где находится Иваново. Пишем запрос:
<http://maps.googleapis.com/maps/api/geocode/json?address=Иваново&sensor=false&language=ru>
И в ответе приходит:
```
{
"status": "OK",
"results": [
{
"types": [ "locality", "political" ],
"formatted_address": "город Иваново, Ивановская область, Россия", - полный адрес
"address_components": [
{ - составляющие адреса
"long_name": "город Иваново",
"short_name": "город Иваново",
"types": [ "locality", "political" ]
},
{
"long_name": "Ивановский район",
"short_name": "Ивановский район",
"types": [ "administrative_area_level_2", "political" ]
}, {
"long_name": "Ивановская область",
"short_name": "Ивановская область",
"types": [ "administrative_area_level_1", "political" ]
}, {
"long_name": "Россия",
"short_name": "RU",
"types": [ "country", "political" ]
} ],
"geometry": {
"location": { - местонахождение
"lat": 56.9924086,
"lng": 40.9677888
},
"location_type": "APPROXIMATE", "viewport": { - размеры
"southwest": {
"lat": 56.9699256,
"lng": 40.9265167
},
"northeast": {
"lat": 57.0148916,
"lng": 41.0090609
}
},
"bounds": { - границы
"southwest": {
"lat": 56.9699256,
"lng": 40.9265167
},
"northeast": {
"lat": 57.0148916,
"lng": 41.0090609
}
}
}
}
] }
```
Вся прелесть в том, что можно в address параметре передавать значение на любом языке(Ivanovo, Іваново, <тут была арабская вязь>), еще лучше, что для Санкт-Петербурга прокатывает «Спб» и «Питер». Правда есть и недочеты: мой родной город Ивано-Франковск упорно называет Ивано-Франковс**ь**к, на украинский манер.
Вторая возможность, это по координатам узнать адрес:
<http://maps.googleapis.com/maps/api/geocode/json?latlng=55.75320193022759,37.61922086773683&sensor=false&language=ru>
получаем:
```
{
"status": "OK",
"results": [ {
"types": [ "street_address" ],
"formatted_address": "Красная пл., 3, город Москва, Россия, 109012",
"address_components": [
{
"long_name": "3",
"short_name": "3",
"types": [ "street_address" ]
}, {
"long_name": "Красная пл.",
"short_name": "Красная пл.",
"types": [ "route" ]
}, {
"long_name": "Тверской",
"short_name": "Тверской",
"types": [ "sublocality", "political" ]
}, {
"long_name": "город Москва",
"short_name": "город Москва",
"types": [ "locality", "political" ]
}, {
"long_name": "АО Центральный",
"short_name": "АО Центральный",
"types": [ "administrative_area_level_2", "political" ]
}, {
"long_name": "Москва",
"short_name": "Москва",
"types": [ "administrative_area_level_1", "political" ]
}, {
"long_name": "Россия",
"short_name": "RU",
"types": [ "country", "political" ]
}, {
"long_name": "109012",
"short_name": "109012",
"types": [ "postal_code" ]
} ],
"geometry": {
"location": {
"lat": 55.7546971,
"lng": 37.6215214
},
"location_type": "ROOFTOP",
"viewport": {
"southwest": {
"lat": 55.7515495,
"lng": 37.6183738
},
"northeast": {
"lat": 55.7578447,
"lng": 37.6246690
}
}
}
},
{ ...
```
Супер! Для того чтобы указать свой адрес, можно просто кликнуть на свой дом, добавить квартиру – и всё. Иногда это не срабатывает, например, если дома стоят вплотную друг к другу и считываются как 1 объект, а не 2-3, адрес у них будет один. Особенно плохо, когда они находятся на пересечении улиц, и один дом относится к одной улице, а второй – к перпендикулярной, но думаю по необходимости – можно указать улицу, а дом и квартиру уже вбить. Очень удобное для смартфонов решение.
Кстати, не используйте jquery $.getJSON для получения данных, используйте класс Geocoder (<http://code.google.com/apis/maps/documentation/javascript/reference.html#Geocoder>), он работает лучше (т.е. это означает что getJSON у меня не работает).
А теперь о не очень хорошем. Geocoder – насколько клевая функция, что пользоваться ею можно только 2500 запросов в день. Google предлагает Google API Key Premier от 10000$ в год, и тогда ограничение будет в 100 тыс. запросов в день, причем куча всяких «клевых» дополнений, но я их не могу себе позволить.
##### Markercluster
Когда слишком много маркеров — это выглядит конечно ужасно. Поэтому хорошо бы делать кластеризацию всех этих маркеров. Тут на Хабре я видел уже обсуждение по этому поводу: <http://habrahabr.ru/blogs/google/28621/>
В общем, есть отличный инструмент (а тут их целый набор <http://code.google.com/apis/maps/articles/toomanymarkers.html>) который помогает сделать так, чтобы толпы маркеров не пугали нас.
До:
После:
Это именно то что нам надо.
Эту библиотеку можно скачать тут: <http://google-maps-utility-library-v3.googlecode.com/svn/trunk/>
**Как использовать.**
Добавляем библиотеку
```
```
Составляем массив маркеров, не добавляя в карту:
```
var markers = [];
var marker = new google.maps.Marker({
position: latlng
});
markers.push(marker);
markerClusterer = new MarkerClusterer(_this.map, markers,
{
maxZoom: 13,
gridSize: 50,
styles: null
});
```
maxZoom – максимальный зум при котором мы еще группируем маркеры, дальше – уже нет.
gridSize – размер ячеек сетки, чем меньше значение, тем меньше сетка группировки
styles – дополнительные стили
##### Код из примера
Я не буду тут расписывать что как собрать, собственно все инструменты готовы, дам ссылки на исходники, и прокомментирую некоторые вещи.
Cерверного кода (asp.net mvc) там очень мало, всего 4 запроса:
* собственно страница
* получить все маркеры (в json)
* загрузить файл (через ajaxUploader) и получить ссылку для картинки
* сохранить в базу данных маркер (на выходе json result = ok)
Основной код jquery ( тут полностью: [cocosanka.ru/media/script/map/map.js](http://cocosanka.ru/media/script/map/map.js) ) Там есть комментарии, и всё такое.
Некоторые функции требующие пояснения:
Вычисление значения Zoom по границам
(взято отсюда: <http://groups.google.com/group/google-maps-js-api-v3/browse_thread/thread/43958790eafe037f/66e889029c555bee?fwc=2>)
```
this.getZoom = function (bounds) {
var width = $(".map").width();
var height = $(".map").height();
var dlat = Math.abs(bounds.getNorthEast().lat() - bounds.getSouthWest().lat());
var dlon = Math.abs(bounds.getNorthEast().lng() - bounds.getSouthWest().lng());
var max = 0;
if (dlat > dlon) {
max = dlat;
} else {
max = dlon;
}
var clat = Math.PI * Math.abs(bounds.getSouthWest().lat() + bounds.getNorthEast().lat()) / 360.;
var C = 0.0000107288;
var z0 = Math.ceil(Math.log(dlat / (C * height)) / Math.LN2);
var z1 = Math.ceil(Math.log(dlon / (C * width * Math.cos(clat))) / Math.LN2);
//18 – это максимальный zoom для google.maps
return 18 - ((z1 > z0) ? z1 : z0);
}
```
Функция для «прыжка» маркера:
```
this.toggleBounceMarker = function()
{
if (_this.setMarker.getAnimation() != null) {
_this.setMarker.setAnimation(null);
} else {
_this.setMarker.setAnimation(google.maps.Animation.BOUNCE);
}
}
```
Получение адреса:
```
this.SetAddresses = function (results)
{
$(".address_list").show();
$(".address_list").empty();
var addressText = _this.ComposeAddress(results[0]); ...
}
//Составить строку адреса по первому результату
this.ComposeAddress = function (item) {
retAddress = "";
$.each(item.address_components, function (i, address_item) {
var isOk = false;
$.each(address_item.types, function (j, typeName) {
//не будем брать значения адреса улицы и локали (города) - город потом будет в administrative_level_2
if (typeName != "street_address" && typeName != "locality") {
isOk = true;
}
});
if (isOk) {
if (retAddress == "") {
retAddress = address_item.long_name;
} else {
retAddress = retAddress + ", " + address_item.long_name;
}
}
});
return retAddress;
}
```
#### Итого
Google Maps API – очень классная и удобная штука, которая легка в использовании и понимании. Единственно, что плохо – так это слабое покрытие регионов в России, так что сервисам, которые предполагается использовать в глубинке google.maps пока мало интересен, а вот для больших городов (особенно Москва и Питер), а также для Украины – всё отлично.
Geocoding – очень полезная вещь и при правильном использовании может стоить тех денег, что за нее просят (ну или Microsoft или Яндекс ~~подоспеет с аналогом~~ **уже есть**. Хотя насколько я знаю, картографическая информация стоит бешеных вложений.)
#### Пример\исходники
На живой пример можно глянуть тут: <http://cocosanka.ru/map> (может перестать работать если будет достигнут лимит в Geocoding). Вводите город, потом перетаскиваете маркер, потом загружаете картинку и сохранить. При клике на маркеры выводятся картинки.
Исходники: <https://bitbucket.org/chernikov/citylocator> | https://habr.com/ru/post/110460/ | null | ru | null |
# Toshiba T1100. Культовый ноутбук без жесткого диска
Ноутбук, предназначенный «для мобильных профессионалов», до 8 часов автономной работы, по цене 1899 долларов… в 1985 году. Как такое возможно? Позвольте представить героя нашей истории, Toshiba T1100 Plus:

Давайте выясним, как он работает
Характеристики
--------------
В 80-х компьютеры уже стали важной частью повседневной жизни, и, очевидно, было приятно иметь портативный компьютер, который можно взять с собой, со всеми файлами, документами и личными данными. Что ж, в то время мобильные компьютеры были не «портативными», а «переносными», и причина банальна, первый портативный компьютер, [Osborne I](https://en.wikipedia.org/wiki/Osborne_1), выглядел примерно так:

Источник ©<https://en.wikipedia.org/wiki/Osborne_1>
Эта машина, выпущенная в 1981 году, стала, к слову, первым коммерчески успешным мобильным компьютером, но, конечно, в реальности при весе в 24,5 фунта (11,1 кг) она была далеко не портативной. Но прогресс шел дальше, и уже в 1985 году инженеры Toshiba сделали первый ноутбук, который действительно легко помещался в сумке. Как им это удалось? Решающее значение имели несколько компонентов:
* Дисплей. Тяжелый и громоздкий ЭЛТ был заменен тонким и легким ЖК-дисплеем. Эти дисплеи отличались медленной частотой обновления и низкой контрастностью, но для работы с документами этого было достаточно.
* Подсветка экрана. Какая подсветка? ЖК-дисплей Toshiba T1100 вообще не имеет подсветки — пользователь должен сам позаботиться о достаточном внешнем освещении. В наши дни это решение может показаться странным, но в 80-х и 90-х годах такая практика была довольно распространенной для наручных часов, КПК Psion или Palm. И даже сегодня многим нравится читать книги с экранов e-Ink, так что пассивный экран на самом деле не такая уж плохая идея.
* Накопитель на жестком диске. Жесткий диск? Жесткого диска в Toshiba T1100 нет вообще. Это решение может показаться странным в наши дни (где-то я это уже писал?), но во времена MS-DOS было обычным делом иметь ПК с одним или двумя дисководами для дискет. Жесткие диски были громоздкими и дорогими, а размер программного обеспечения был достаточно мал, чтобы запускать его с дисковода гибких дисков. В настоящее время размер моей папки Windows составляет около 20 ГБ, однако минимальная установка MS-DOS весит всего около 65 КБ — никаких проблем, чтобы поместить системные файлы и необходимое программное обеспечение на одну дискету и запустить ее.
Со всеми этими изменениями Toshiba удалось создать компьютер, который не только обладал достаточно хорошими характеристиками для того времени, но также был портативным и более или менее доступным.

Источник (с) [https://arvutimuuseum.ee](https://arvutimuuseum.ee/)
И получился действительно удачный продукт — Т1100 стал не только «первым в мире массовым портативным компьютером», но и был клонирован в СССР под названием [Электроника МС 1504.](https://en.wikipedia.org/wiki/Elektronika_MS_1504) По сути, это был единственный ноутбук в истории, который производился в Советском Союзе. Экземпляр Toshiba T1100 помещен в лондонском [музее дизайна и искусств Виктории и Альберта](https://collections.vam.ac.uk/item/O1441154/laptop/), и этот компьютер действительно заслуживает этого.
Что касается аппаратной части ноутбука, то сегодня она выглядит не очень впечатляюще, но для 1985 года T1100 был достаточно хорош: процессор 8086 с частотой 4,7 МГц (7,16 МГц для T1100 Plus), 256 КБ ОЗУ (640 КБ для T1100 Plus), ЖК-дисплей 640x200, опциональный модем на 1200 бит/с и два 3,5-дюймовых флоппи-дисковода по 720 Кбайт. T1100 имел сравнительно небольшой вес и потрясающую возможность автономной работы в течение 6–8 часов — даже в наше время не каждый ноутбук на такое способен. Это особенно впечатляет, потому что в ноутбуке установлена NiCd батарея, литиевые батареи еще не получили широкого распространения.
Аппаратное обеспечение
----------------------
Посмотрим, что внутри.

Как мы видим, Toshiba T1100 имеет симпатичную клавиатуру, традиционную для ноутбуков той эпохи — сам ноутбук достаточно толстый, так что разница в толщине клавиатуры ±0,5 см особого смысла не имеет, тренд на использование ультратонких клавиатур еще не «изобрели». Вверху мы видим 4,8 В NiCd аккумулятор ёмкостью 4000 мАч. Интересно, что компонентов на материнской плате не так много — ноутбук сделали максимально дешевым и компактным, нет ни жесткого диска, ни слотов для внешних карт. На материнской плате всего два слота для дисковода гибких дисков и слот расширения памяти:

Карта расширения памяти фирменная, в 80-е модули SIMM или DIMM еще не получили широкого распространения. Модуль оперативной памяти имеет размер 384 КБ:

Оба флоппи-разъема 26-контактные, они имеют как линии данных, так и линии питания в одном плоском кабеле. Этот стандарт не совместим со «стандартными» 34-контактными дисководами IBM PC, но можно использовать специальный переходник с 34 на 26 контактов:

Я купил такой на Aliexpress, но похоже, что этих адаптеров больше нет в наличии, вероятно, маркетинговый спрос действительно низкий. Аналогичный переходник можно сделать и из двух плоских кабелей, используя следующую схему подключения:
`Floppy drive 34 pins connector => 26 pins connector2 | REDWC | Density Select => 6
4 | n/c | Reserved => 9
6 | n/c | Reserved => n/c
8 | INDEX | Index => 2
10 | MOTEA | Motor Enable A => n/c
12 | DRVSB | Drive Sel B => 4
14 | DRVSA | Drive Sel A => n/c
16 | MOTEB | Motor Enable B => 10
18 | DIR | Direction => 12
20 | STEP | Step => 14
22 | WDATE | Write Data => 16
24 | WGATE | Floppy Write Enable => 18
26 | TRK00 | Track 0 => 20
28 | WPT | Write Protect => 22
30 | RDATA | Read Data => 24
32 | SIDE1 | Head Select => 26
34 |DSKCHG | Disk Change/Ready => 8
+5V => 1,3 or 5
GND => 15,17,19,21,23 or 25`
В настоящее время пользоваться дискетами довольно затруднительно, но этот 34-контактный разъем позволяет использовать эмулятор дисковода, что значительно упрощает загрузку различных приложений:

Эмулятор дискет Gotek
Несколько файлов-образов дискет по 720 КБ можно сохранить непосредственно на USB-накопителе (чтобы включить поддержку накопителей объемом 720 КБ, необходимо установить прошивку [FlashFloppy](https://github.com/keirf/FlashFloppy/releases)), для переключения между образами можно использовать кнопки.
Задняя сторона ноутбука более или менее стандартна для того времени:

С левой стороны мы видим порты COM и LPT. Справа мы видим порт CGA RGB (который *не* совместим с современным VGA) и композитный видеопорт. Да, этот ноутбук можно было подключить напрямую к телевизору, что позволяло показывать изображение на большом экране с потрясающим разрешением аналогового телевизора. Проекторы HD и 4K еще не были изобретены, поэтому большой ЭЛТ-экран являлся хорошим способом сделать публичную презентацию в 80-х годах. Телевизора того времени у меня нет, но композитный выход работает и на современном телевизоре, если конечно у этого телевизора есть композитный вход:

Изображение определенно ярче и больше по сравнению со встроенным ЖК-дисплеем ноутбука. Переключение между ЖК-дисплеем и внешним экраном можно выполнить, нажав Ctrl + Alt + End.
Программное обеспечение
-----------------------
Оригинальной ОС для этого ноутбука является OEM-версия DOS 3.20 от Toshiba, образ загрузочного диска можно легко найти в Интернете. Самый простой способ подготовить образы дискет с различными приложениями — это использовать [эмулятор DOSBox](https://github.com/ykhwong/dosbox-svn-daum/releases/) и два одинаковых файла образов дискет по 720 КБ. Я сделал копию исходного образа DOS, смонтировал оба образа в DOSBox и удалил все ненужные файлы со второго образа:
Эти 5 файлов на диске «B» нужны для нормальной загрузки ОС, остальные можно легко удалить, после этого на дискете остается около 650 Кб свободного места.
Найти ПО, которое может работать с диска емкостью 720 КБ, довольно сложно, но, что удивительно, это действительно возможно. Редактор **Word Perfect** был довольно популярным во времена MS-DOS, а версия 4.1 легко работает с дискеты — для этого требуется всего около 250 килобайт места:
Конечно, функции редактирования довольно просты, но Word Perfect достаточно хорош для работы с текстовыми документами, и в любом случае он лучше, чем механическая пишущая машинка «старого образца». Удивительно, но WordPerfect для Windows все еще существует, но он, очевидно, больше не может работать с одной дискеты объемом 720 КБ — даже версия 5.1 для DOS имела размер около 3 МБ.
Следующее интересное приложение — **WordStar 3.30 —** довольно простой текстовый редактор, размер которого не превышает 100 КБ.
Сделать что-то подобное будет непросто даже современным разработчикам, вероятно, что этот редактор был написан на языке ассемблера 8086 — «искусство», которое сегодня почти забыто. WordStar имеет очень долгую историю, первые версии работали даже на операционной системе CP/M, еще до эпохи DOS.
Следующее приложение, **PC Globe**, могло бы пригодиться во времена, когда не было ни Википедии, ни Google Maps:

Это приложение имеет размер 1,3 МБ и может работать с двух дискет по 720 КБ, его размер близок к максимальному, с которым может справиться компьютер без жесткого диска.
В ноутбуке есть последовательный порт и внутренний модем, поэтому также интересно проверить сетевые возможности. **MS-DOS Kermit** (размер приложения 257 КБ) представляет собой коммуникационный программный пакет, позволяющий подключаться через модем к другому компьютеру или к внешней [BBS](https://en.wikipedia.org/wiki/Bulletin_board_system) (Bulletin Board System):

Используя коммутируемое соединение с BBS или удаленным офисным компьютером, можно было получать почту, загружать или скачивать файлы — да, это было возможно даже в «доинтернетовскую» эпоху. Проверить коммутируемое соединение может быть сложно — в большинстве домашних хозяйств больше нет телефонных линий, но модем можно эмулировать с помощью платы Raspberry Pi или ESP8266. И что удивительно, некоторые BBS до сих пор поддерживаются энтузиастами, более подробно об этом я писал [в другой статье.](https://debugger.medium.com/you-can-still-use-an-ms-dos-laptop-in-2021-d43fa10a8211)
С точки зрения программирования **Бейсик** был своего рода стандартом для домашних компьютеров 80-х годов. QBASIC легко запускается с дискеты. Для тестирования я использовал тот [же код](https://medium.com/geekculture/the-luggable-laptop-how-does-it-look-today-part-i-toshiba-t3100-a1d133c32108), что и для Toshiba T3100, он работает и на Toshiba T1100.

Увы, запустить компилятор C/C++ мне не удалось — инсталлятор Turbo C++ требует 4 дискеты, без жесткого диска запустить его не получится.
Что касается игрового опыта, то он оказался на удивление не таким уж плохим, как я ожидал. Игра **Digger** — одна из культовых игр эпохи DOS, а ее исполняемый файл имеет размер всего 57 КБ:

Одна из самых старых игр, которые я пробовал, **Pac-Man,** вышла в 1983 году, размер игры всего 33 КБ:
**Arcanoid** такжеявляется одним из хитов, ставшим классикой, а размер игры составляет всего 226 КБ:

**Prince of Persia** выглядит на удивление хорошо, учитывая, что размер игры всего 500 КБ:

**Blockout** — это своего рода 3D-тетрис, размер игры составляет всего 210 КБ:

И, наконец, **Battle Chess**, которую я уже тестировал на другой DOS-машине, имеет размер 600 КБ, она также может запускаться с дискеты на 720 КБ:

Конечно, эта машина не предназначена для игр, яркость ЖК-экрана и частота обновления не так велики, но провести некоторое время за играми вполне возможно.
Вывод
-----
Тестирование Toshiba T1100 оказалось очень увлекательным, и, как мы видим, для своего времени он был весьма неплох. Запуск программного обеспечения на компьютере без жесткого диска в настоящее время выглядит почти невозможным, но в 1986 году ПО не имело таких больших размеров, и большинство программ могли хорошо работать на дискетах емкостью 720 КБ. По сравнению с другими моделями тех лет Toshiba T1100 был действительно легким и портативным, и я легко могу представить, что для путешественников, журналистов, ученых и других людей, которым приходилось работать «в поле», эта машина стала настоящим шагом вперед. Не в последнюю очередь благодаря цене — Toshiba T1100 действительно опередил свое время, даже спустя 10–20 лет средняя цена ноутбука была намного больше 1899 долларов.
Конечно, такая ситуация длилась недолго — объем ПО рос, и у компьютера с такими характеристиками не было шансов долго оставаться конкурентоспособным. Следующая модель, Toshiba T1200, имела 20-мегабайтный винчестер.
[](https://cloud.timeweb.com/?utm_source=habr&utm_medium=banner&utm_campaign=cloud&utm_content=direct&utm_term=low) | https://habr.com/ru/post/647029/ | null | ru | null |
# Интересные заметки по C# и CLR

Изучая язык программирования C#, я сталкивался с особенностями как самого языка, так и его средой исполнения, \*некоторые из которых, с позволения сказать, «широко известны в узких кругах». Собирая таковые день за днем в своей копилке, что бы когда-нибудь повторить, чего честно сказать еще ни разу не делал до этого момента, пришла идея поделиться ими.
Эти заметки не сделают ваш код красивее, быстрее и надежнее, для этого есть Стив Макконнелл. Но они определенно внесут свой вклад в ваш образ мышления и понимание происходящего.
Что-то из приведенного ниже покажется слишком простым, другое, наоборот, сложным и не нужным, но куда без этого.
Итак, начинаем:
#### 1) Расположение объектов и экземпляров в динамической памяти
Объекты содержат в себе статические поля и все методы. Экземпляры содержат только не статические поля. Это значит, что методы не дублируются в каждом экземпляре, и здесь применяется паттерн Flyweight.
#### 2) Передача параметров в методы
Структура передает свою копию в метод, Класс передает копию своей ссылки. А вот когда мы используем ключевое слово REF — структура передает указатель на себя, а класс передает свою исходную ссылку.
```
Пример REF для ссылочного типа.
1) Работает без ошибок, мы зануляем копию переданной ссылки.
static void Main( string[] args )
{
StringBuilder sb = new StringBuilder();
sb.Append("Hello ");
AppendHello(sb);
Console.WriteLine(sb.ToString());
}
private static void AppendHello(StringBuilder sb)
{
sb.Append(" World!");
sb = null;
}
2) Возникает исключение System.NullReferenceException при попытке обратиться к методу в переменной значение которой null.
static void Main( string[] args )
{
StringBuilder sb = new StringBuilder();
sb.Append("Hello ");
AppendHello(ref sb);
Console.WriteLine(sb.ToString());
}
private static void AppendHello(ref StringBuilder sb)
{
sb.Append(" World!");
sb = null;
}
```
#### 3) Подготовить код до выполнения
В CLR есть блок CER, который говорит JIT — «подготовь код до выполнения, так что когда в нем возникнет необходимость, все будет под рукой». Для этого подключаем пространства имен System.Runtime.CompilerServices и RuntimeHelpers.PrepareConstrainedRegions.
#### 4) Регулярные выражения
Regex можно создать с опцией Compiled — это генерация выражения в IL-код. Он значительно быстрее обычного, но первый запуск будет медленным.
#### 5) Массивы
Одномерные массивы в IL представлены вектором, они работают быстрее многомерных. Массивы одномерных массивов используют векторы.
#### 6) Коллекции
Пользовательские коллекции лучше наследовать от ICollection, реализация IEnumerable получается бесплатно. Но нет индекса (очень индивидуально).
#### 7) Расширяющие методы
Если имя расширяющего метода вступает в конфликт с именем метода типа, то можно использовать полное имя расширяющего метода, и тип передать аргументом.
```
StaticClass.ExtesionMethod( type );
```
#### 8) LINQ
LINQ lazy loading («ленивая» загрузка) — select, where, take, skip etc.
LINQ eager loading (запросы выполняются сразу) — count, average, min, max, ToList etc. (Но если коллекция бесконечна, то запрос ни когда не завершится.)
#### 9) Блок синхронизации
У структурных типов и примитивных (byte,int,long...) нет блока синхронизации, который присутствует у объектов в управляемой куче на ряду с ссылкой. Поэтому не будет работать конструкция Monitor.() или Lock().
#### 10) Интерфейсы
Если в C# перед именем метода указано имя интерфейса, в котором определен этот метод (IDisposable.Dispose), то вы создаете явную реализацию интерфейсного метода (Explicit Interface Method Implementation, EIMI). При явной реализации интерфейсного метода в C# нельзя указывать уровень доступа (открытый или закрытый). Однако когда компилятор создает метаданные для метода, он назначает ему закрытый уровень доступа (private), что запрещает любому коду использовать экземпляр класса простым вызовом интерфейсного метода. Единственный способ вызвать интерфейсный метод — это обратиться через переменную этого интерфейсного типа.
Без EIMI не обойтись (например, при реализации двух интерфейсных методов с одинаковыми именами и сигнатурами).
#### 11) Нет в C#, но поддерживается IL
Статические поля в интерфейсах, методы отличающиеся только возвращаемым значением и многое другое.
#### 12) Сериализация
При сериализации графа объектов некоторые типы могут оказаться сериализуемыми, а некоторые — нет. По причинам, связанным с производительностью, модуль форматирования перед сериализацией не проверяет возможность этой операции для всех объектов. А значит, может возникнуть ситуация, когда некоторые объекты окажутся сериализованными в поток до появления исключения SerializationException. В результате в потоке ввода-вывода оказываются поврежденные данные. Этого можно избежать, например, сериализуя объекты сначала в MemoryStream.
В C# внутри типов, помеченных атрибутом [Serializable], не стоит определять автоматически реализуемые свойства. Дело в том, что имена полей, генерируемые компилятором, могут меняться после каждой следующей компиляции, что сделает невозможной десериализацию экземпляров типа.
#### 13) Константы
Константы помещаются в метаданные сборки, поэтому если были изменения, нужно перекомпилировать все использующие ее сборки. Т.к. DLL с константой может даже не загружаться.
Лучше использовать static readonly задавая значения в конструкторе, она постоянно загружается в использующих ее сборках, и выдает актуальное значение.
#### 14) Делегаты
GetInvocationList — возвращает цепочку делегатов, можно вызывать любые, отлавливать исключения, получать все возвращаемые значения, а не только последнее.
#### 15) Сравнение строк
В Microsoft Windows сравнение строк в верхнем регистре оптимизировано. \*StringComparison.OrdinalIgnoreCase, на самом деле, переводит Char в верхний регистр. ToUpperInvariant. Используем string.compare(). Windows по умолчанию использует UTF-16 кодировку.
#### 16) Оптимизация для множества строк
Если в приложении строки сравниваются часто методом порядкового сравнения с учетом регистра или если в приложении ожидается появление множества одинаковых строковых объектов, то для повышения производительности надо применить поддерживаемый CLR механизм интернирования строк (string interning).
При инициализации CLR создает внутреннюю хеш-таблицу, в которой ключами являются строки, а значениями — ссылки на строковые объекты в управляемой куче.
#### 17) Безопасные строки
При создании объекта SecureString его код выделяет блок неуправляемой памяти, которая содержит массив символов. Уборщику мусора об этой неуправляемой памяти ничего не известно. Очищать эту память нужно вручную.
#### 18) Безопасность
Управляемые сборки всегда используют DEP и ASLR.
#### 19) Проектирование методов
Объявляя тип параметров метода, нужно по возможности указывать «минимальные» типы, предпочитая интерфейсы базовым классам. Например, при написании метода, работающего с набором элементов, лучше всего объявить параметр метода, используя интерфейс IEnumerable.
```
public void ManipulateItems(IEnumerable collection) { ... }
```
В то же время, объявляя тип возвращаемого методом объекта, желательно выбирать самый сильный из доступных вариантов (пытаясь не ограничиваться конкретным типом). Например, лучше объявлять метод, возвращающий объект FileStream, а не Stream.
#### 20) Еще раз про автосвойства
Автоматически реализуемые свойства AIP лучше не использовать (мнение автора, угадай какого).
а) Значение по умолчанию можно задать только в конструкторе. (Изменено в Roslyn C# 6);
б) Проблема при сериализации (пункт 12);
в) Нельзя поставить точку останова.
#### 21) Конфигурационный файл
а) Любому двоичному коду .NET может быть сопоставлен внешний конфигурационный файл XML. Этот файл располагается в том же каталоге, и имеет такое же имя с добавленным в конце словом .CONFIG;
б) Если вы предоставляете решение только в двоичной форме, документирующие комментарии могут быть собраны в XML файл при компиляции, поэтому и в такой ситуации вы можете предоставить пользователям отличный набор подсказок. Для этого нужно только разместить итоговый XML файл в том же каталоге, что и двоичный файл, и Visual Studio .NET будет автоматически отображать комментарии в подсказках IntelliSense.
#### 22) Исключения
CLR обнуляет начальную точку исключения:
```
try {} catch (Exception e) { throw e; }
```
CLR не меняет информацию о начальной точке исключения:
```
try {} catch (Exception e) { throw; }
```
Можно создать событие FirstChanceException класса AppDomain и получать информацию об исключениях еще до того, как CLR начнет искать их обработчики.
Исключения медленно работают, т.к. происходит переход в режим ядра.
#### 23) IS и AS
IS — В этом коде CLR проверяет объект дважды:
```
if ( obj is Person ) { Person p = (Person) obj; }
```
AS — В этом случае CLR проверяет совместимость obj с типом Person только один раз:
```
Person p1 = obj as Person; if ( p1 != null ) { ... }
```
#### 24) Проверяем хватит ли памяти перед выполнением
Создание экземпляра класса MemoryFailPoint проверяет, достаточно ли памяти перед началом действия или вбрасывает исключение. Однако, учтите, что физически память еще не выделялась, и этот класс не может гарантировать, что алгоритм получит необходимую память. Но его использование определенно поможет сделать приложение более надежным.
#### 25) Немного про Null
Чтобы использовать null совместимый Int32 можно написать:
```
Nullable x = null; или Int32? x = null;
```
Оператор объединения null совместимых значений — ?? (если левый операнд равен null, оператор переходит к следующему), рассмотрим два эквивалентных выражения:
1)
```
string temp = GetFileName();
string fileName = ( temp != null ) ? temp : "Untitled";
```
2)
```
string fileName = GetFileName() ?? "Untitled";
```
#### 26) Таймеры
Библиотека FCL содержит различные таймеры:
1) Timer в System.Threading — подходит для выполнения фоновых заданий в потоке пула;
2) Timer в System.Windows.Forms — таймер связан с вызывающим потоком, это предотвращает параллельный вызов;
3) DispatcherTimer в System.Windows.Threading. — эквивалентен второму, но для приложений Silverlight и WPF;
4) Timer в System.Timers. — по сути является оболочкой первого, Джеффри Рихтер не советует его использовать.
#### 27) Type и typeof
Чтобы получить экземпляр Type для типов, вместо метода Type.GetType применяется операция typeof. Если тип известен во время компиляции, то операция typeof сразу осуществляет поиск по методанным вместо того, чтобы делать это во время выполнения.
#### 28) Фишка using
Что бы уменьшить количество кода и сделать его понятнее? можно использовать директиву using следующим образом:
using DateTimeList = System.Collections.Generic.List;
#### 29) Директивы препроцессора
а) #IF DEBUG и #ENDIF — используются для указания блоков кода которые будут компилироваться только в DEBUG режиме.
б) #DEFINE XXX; #IF (DEBUG && XXX) — можно добавить в условие номер сборки «XXX».
в) !DEBUG == RELEASE (на всякий случай).
г) #LINE 111 — в окне ошибок покажет строку 111.
д) #LINE HIDDEN — скрывает строчку от отладчика.
е) #WARNING XXX; #ERROR YYY — означают XXX — предупреждение, YYY — ошибку.
#### 30) Всякая \*антность
Ковариантность — преобразование в прямом порядке, ключевое слово OUT.
```
string[] strings = new string[3];
object[] objects = strings;
interface IMyEnumerator
{
T GetItem( int index );
}
T --> R
IOperation --> IOperation
```
Контравариантность — преобразование в обратном порядке, ключевое слово IN.
```
interface IMyCollection
{
void AddItem( T item );
}
R --> T
IOperation --> IOperation
```
Инвариантность — не разрешено неявное преобразование типов.
По умолчанию обобщенные типы инвариантны. Еще обобщенные классы называют открытыми, в рантайме они закрываются конкретными типами «int», «string», например. И это разные типы, статические поля в них будут тоже разными.
#### 31) Методы расширения
```
public static class StringBuilderExtensions {
public static Int32 IndexOf ( this StringBuilder sb, Char char) { ... }
}
```
Позволяют вам определить статический метод, который вызывается по средством синтаксиса экземплярного метода. Например, можно определить собственный метод IndexOf для StringBuilder. Сначала компилятор проверит класс StringBuilder или все его базовые классы на наличие метода IndexOf с нужными параметрами, если он не найдет такого, то будет искать любой статический класс с определенным методом IndexOf, у которого первый параметр соответствует типу выражения используемого при вызове метода.
А это реализация паттерна Visitor в .Net.
#### 32) Контексты исполнения
С каждым потоком связан определенный контекст исполнения. Он включает в себя параметры безопасности, параметры хоста и контекстные данные логического вызова. По умолчанию CLR автоматически его копирует, с самого первого потока до всех вспомогательных. Это гарантирует одинаковые параметры безопасности, но в ущерб производительности. Чтобы управлять этим процессом, используйте класс ExecutionContext.
#### 33) Volatile
JIT — компилятор гарантирует что доступ к полям помеченным данным ключевым словом будет происходить в режиме волатильного чтения или записи. Оно запрещает компилятору C# и JIT-компилятору кэшировать содержимое поля в регистры процессора, что гарантирует при всех операциях чтения и записи манипуляции будут производиться непосредственно с памятью.
#### 34) Классы коллекций для параллельной обработки потоков
ConcurrentQueue — обработка элементов по алгоритму FIFO;
ConcurrentStack — обработка элементов по алгоритму LIFO;
ConcurrentBag — несортированный набор элементов, допускающий дублирование;
ConcurrentDictionary — несортированный набор пар ключ-значение.
#### 35) Потоки
Конструкции пользовательского режима:
а) Волатильные конструкции — атомарная операция чтения или записи.
VolatileWrite, VolatileRead, MemoryBarrier.
б) Взаимозапирающие конструкции — атомарная операция чтения или записи.
System.Threading.Interlocked (взаимозапирание) и System.Threading.SpinLock (запирание с зацикливанием).
Обе конструкции требуют передачи ссылки (адрес в памяти) на переменную (вспоминаем о структурах).
Конструкции режима ядра:
Примерно в 80 раз медленнее конструкций пользовательского режима, но зато имеют ряд преимуществ описанных в MSDN (много текста).
Иерархия классов:
```
WaitHandle
EventWaitHandle
AutoResetEvent
ManualResetEvent
Semaphore
Mutex
```
#### 36) Поля класса
Не инициализируйте поля явно, делайте это в конструкторе по умолчанию, а уже его с помощью ключевого слова this() используйте для конструкторов принимающих аргументы. Это позволит компилятору генерировать меньше IL кода, т.к. инициализация происходит 1 раз в любом из конструкторов (а не во всех сразу одинаковые значения, копии).
#### 37) Запуск только одной копии программы
```
public static void Main ()
{
bool IsExist;
using ( new Semaphore ( 0, 1, "MyAppUniqueString", out IsExist ) ) {
if ( IsExist ) { /* Этот поток создает ядро, другие копии программы не смогут запуститься. */ }
else { /* Этот поток открывает существующее ядро с тем же именем, ничего не делаем, ждем возвращения управления от метода Main, что бы завершить вторую копию приложения. */ }
}}
```
#### 38) Сборка мусора
В CLR реализовано два режима:
1) Рабочая станция — сборщик предполагает что остальные приложения не используют ресурсы процессора. Режимы — с параллельной сборкой и без нее.
2) Сервер — сборщик предполагает что на машине не запущено никаких сторонних приложений, все ресурсы CPU на сборку! Управляемая куча разбирается на несколько разделов — по одному на процессор (со всеми вытекающими, т.е. один поток на одну кучу).
#### 39) Финализатор
Выполняет функцию последнего желания объекта перед удалением, не может длиться дольше 40 секунд, не стоит с этим играться. Переводит объект минимум в 1 поколение, т.к. удаляется не сразу.
#### 40) Мониторинг и управление сборщиком мусора на объекте
Вызываем статический метод Alloc объекта GCHandle, передаем ссылку на объект и тип GCHandleType в котором:
1) Weak — мониториг, обнаруживаем что объект более не доступен, финализатор мог выполниться.
2) WeakTrackResurrection — мониторинг, обнаруживаем что объект более не доступен, финализатор точно был выполнен (при его наличии).
3) Normal — контроль, заставляет оставить объект в памяти, память занятая этим объектом может быть сжата.
4) Pinned — контроль, заставляет оставить объект в памяти, память занятая этим объектом не может быть сжата (т.е. перемещена).
#### 41) CLR
CLR по сути является процессором для команд MSIL. В то время как традиционные процессоры для выполнения всех команд используют регистры и стеки, CLR использует только стек.
#### 42) Рекурсия
Если вы когда нибудь видели приложение, которое приостанавливается на секунду другую, после чего полностью исчезает безо всякого сообщения об ошибке, почти наверняка это было вызвано бесконечной рекурсией. Переполнение стека, оно как известно, не может быть перехвачено и обработано. Почему? Читаем в книгах или блогах.
#### 43) Windbg и SOS (Son of Strike)
Сколько доменов присутствуют в процессе сразу?
— *3. System Domain, Shared Domain и Domain 1 (домен с кодом текущего приложения).*
Сколько куч (поколений) на самом деле?
— *0, 1, 2 и Large Object Heap.
Large Object Heap — для очень больших объектов, не сжимается по умолчанию, только через настройку в файле XML конфигурации.*
Еще отличие в клиентском и серверном режиме сборки мусора (в книгах не все так подробно, возможно неточность перевода).
— *для каждого ядра создается свой HEAP, в каждом из которых свои 0, 1, 2 поколения и Large Object Heap.*
Создание массива размером больше чем 2 Гб на 64 разрядных платформах.
— gcAllowVeryLargeObjects enabled=«true|false»
Что делать, когда свободная память есть, а выделить большой непрерывный ее участок для нового объекта нельзя?
— *разрешить режим компакт для Large Object Heap. GCSettings.LargeObjectHeapCompactionMode;
Не рекомендуется использовать, очень затратно перемещать большие объекты в памяти.*
Как быстро в рантайме найти петли потоков (dead-locks)?
— !dlk
Источники (не реклама):
1) Джеффри Рихтер, «CLR via C#» 3-е/4-е издание.
2) Трей Нэш, «C# 2010 Ускоренный курс для профессионалов».
3) Джон Роббинс, «Отладка приложений для Microsoft .NET и Microsoft Windows».
4) Александр Шевчук (MCTS, MCPD, MCT) и Олег Кулыгин (MCTS, MCPD, MCT) ресурс ITVDN (https://www.youtube.com/user/CBSystematicsTV/videos?shelf\_id=4&view=0&sort=dd).
5) Сергей Пугачев. Инженер Microsoft (https://www.youtube.com/watch?v=XN8V9GURs6o)
Надеюсь, данный перечень пришелся по вкусу как начинающим, так и бывалым программистам на C#.
Спасибо за внимание!
\*Обновил, исправил ошибки, некоторые моменты дополнил примерами.
*Если вы нашли ошибку, прошу сообщить об этом в личном сообщении.* | https://habr.com/ru/post/256819/ | null | ru | null |
# Консольный cucumber и capybara при помощи Selenium и Hudson
В наши дни разработчики ПО не могут прожить без их любимых тестовых фреймворков. Но вот чего разрабочики не хотят — так это обеспечивать постоянный запуск этих тестов. Также, команды разработчиков не хотят тратить время на доведение результатов теста до всех.
Появляется все больше и больше полезных приложений, библиотек и плагинов, которые частично облегчают головную боль, возникающую в ходе попыток сделать тесты полезными для всей команды. Примерами прекрасных инструментов, которые есть в нашем распоряжении, могут быть [Hudson](http://hudson-ci.org/) для непрерывной интеграции, [Cucumber](http://cukes.info/) для интеграционных тестов и [Selenium](http://seleniumhq.org/) для автоматизированного тестирования веб-приложений в реальном браузере. Но организация совместной работы всего этого требует все больше и больше настроек и конфигураций на сборочном сервере.
Наша цель — задокументировать шаги, требуемые для преодоления встречающихся препятствий на пути к запуску полного набора тестов Cucumber со сценариями на Selenium на сборочном сервере Hudson.
#### Ингридиенты
Мы будем использовать следующие ингридиенты в этом топике:
* 1 инсталляцию Debian 5.0.4 'Lenny'
* 1 инсталляцию [Xvfb](http://en.wikipedia.org/wiki/Xvfb)
* 1 Web-браузер (в нашем случае, [iceweasel](http://www.geticeweasel.org/), Firefox после Debianовского ребрендинга
* 1 приложение для Ruby on Rails 2.3.7 (Не обязательно именно такую версию, с 3.0.0 все ок — прим. переводчика)
* 1 гем Capybara 0.3.8
* cucumber (0.7.3) по вкусу
Мы не будем погружаться в детали создания приложения Rails, установки гемов и разработки сценариев Cucumber. У них есть свои прекрасные мануалы.
#### Установка необходимых пакетов
Начнем с установки пары пакетов, которые позволят нам запускать тесты в браузере без графического режима.
##### Виртуальный фреймбуфер при помощи Xvfb
«В X Window System, Xvfb или виртуальный X фреймбуфер — это сервер X11, который выполняет все операции в памяти, не показывая ничего на экране» — <http://en.wikipedia.org/wiki/Xvfb>
`$ apt-get install xvfb`
##### Web браузер
После установки Xvfb мы можем пойти дальше и установить web браузер.
`$ apt-get install iceweasel`
Прежде, чем мы продолжим, нам нужно сконфигурировать профиль браузера так, чтобы он не ныл по поводу закрытия вкладок или восстановления после сбоя. Если этого не сделать, набор тестов сломается или будет работать вечно.
`$ cd ~/.mozilla/firefox/xxxxxxxx.default/
$ vim user.js`
Теперь впишем две строчки в файл user.js:
`user_pref("browser.sessionstore.enabled", false);
user_pref("browser.sessionstore.resume_from_crash", false);`
##### Проверка дисплея
Прежде чем мы начнем запускать наши тесты мы проверим что все пакеты установлены правильно. Чтобы сделать это запустите виртуальный фреймбуфер (сессию Xvfb) на дисплее 99 с экраном 0:
`$ Xvfb :99 -ac -screen 0 1024x768x16`
В другом окне терминала напишите:
`$ DISPLAY=:99.0 iceweasel example.org`
Это запустит наш веб браузер в виртуальном фреймбуфере и откроет главную страницу example.com в этом браузере. Дальше предстоит сделать «скриншот», чтобы мы могли увидеть что происходит внутри нашего виртуального фреймбуфера.
`$ xwd -root -display :99.0 -out xwdout`
И посмотрим наш скриншот при помощи:
`$ xwud -in xwdout`
(А если вы настраиваете удаленную машину, то можно файл xwdout забрать себе и посмотреть у себя — прим. переводчика)
Видите главную страницу example.org? Значит Xvfb и iceweasel были успешно установлены и мы готовы провести несколько тестов.

#### Запуск cucumber
Прежде чем мы интегрируем эту установку в нашу среду непрерывной интеграции, мы проведем прогон тестов чтобы посмотреть — работает ли cucumber с нашей новой конфигурацией. Мы можем сделать это при помощи следующей команды, держа в уме что необходимо явно указать cucumber использовать дисплей виртуального фреймбуфера:
`$ DISPLAY=:99.0 rake cucumber`
Если все прошло хорошо, тогда мы увидим что все сценарии завершились успешно. Если успешны не все сценарии, проверьте сначала, а все ли хорошо в ситуации с нормальным графическим режимом.
#### Конфигурация Hudson
Теперь мы пришли к тому, чтобы попытаться со всей этой фигней взлететь. Нам нужно добавить новый сборочный шаг к задаче, которая должна запустить наш фоновый cucumber. Но прежде чем добавлять сборочный шаг, мы создадим стартовый скрипт для нашего виртуального фреймбуфера. Этот скрипт можно использовать чтобы запустить буфер перед прогоном сценариев и остановить буфер после завершения сценариев. Вы можете сохранить этот скрипт в /etc/init.d/. Убедитесь, что права установлены таким образом, что пользователь, от которого работает Hudson может выполнить его.
`XVFB=/usr/bin/Xvfb
XVFBARGS="$DISPLAY -ac -screen 0 1024x768x16"
PIDFILE=/var/hudson/xvfb_${DISPLAY:1}.pid
case "$1" in
start)
echo -n "Starting virtual X frame buffer: Xvfb"
/sbin/start-stop-daemon --start --quiet --pidfile $PIDFILE --make-pidfile --background --exec $XVFB -- $XVFBARGS
echo "."
;;
stop)
echo -n "Stopping virtual X frame buffer: Xvfb"
/sbin/start-stop-daemon --stop --quiet --pidfile $PIDFILE
echo "."
;;
restart)
$0 stop
$0 start
;;
*)
echo "Usage: /etc/init.d/xvfb {start|stop|restart}"
exit 1
esac
exit 0`
Финальный шаг — добавить сборочный шаг типа «Execute shell» в задачу Hudson. Вы можете использовать следующий набор команд чтобы запускать Ваш cucumber.
`#!/bin/bash
export DISPLAY=:99
/etc/init.d/xvfb start
rake cucumber
RESULT=$?
/etc/init.d/xvfb stop
exit $RESULT`
После добавления этого сборочного шага сохраним нашу задачу и позволим Hudson собрать ее. Если все идет хорошо, сценарии cucumber теперь будут работать как часть нашего процесса непрерывной интеграции. Вы можете посмотреть страницу «Console output» сборки в Hudson для поиска причин неудачных сборок.
#### Заключение
Если Вы дошли до этого места в этом топике, то сейчас у Вас есть работающая фоновая инсталляция. Преимущество этой инсталляции в том, что она достаточно легковесная и легкая в настройке. Но такая настройка не подойдет Вам, если Вам нужно тестировать с несколькими разными браузерами. Для такой настройки Вам придется посмотреть в сторону виртуальных машин и подчиненных агентов Hudson.
UPD: Перенес в «Тестирование», если проявится интерес хабрасообщества, напишу как оно все у нас сделано. | https://habr.com/ru/post/123565/ | null | ru | null |
# Знакомство с Rock Validate
Валидация данных является одной из множества практик в разработке безопасного web-приложения. Даже совсем «юный» разработчик при первом своём знакомстве с html-формой пытается вывести красивое сообщение об ошибке. Что уж говорить про модель в каком-нибудь навороченном фреймворке. А потому…
Предлагаю вашему вниманию библиотеку для валидации данных с кастомизацией, интернационализацией и иными «плюшками». Используя известный инструмент [Respect/Validation](https://github.com/Respect/Validation) с множеством вбитых по ходу костылей, я в какой-то момент сказал себе: Хватит!
Были поставлены задачи:
* сохранить элегантный синтаксис (сцепной принцип для правил);
* реализовать «лёгкую» и гибкую альтернативу;
* добавить интернационализацию;
* предоставить возможность добавлять свои правила;
* подготовить фундамент для санитизатора — обеспечить единый стиль реализации для обеих библиотек.
#### Всё до безобразия просто
```
$v = Validate::length(10, 20, true)->regex('/^[a-z]+$/i');
$v->validate('O’Reilly'); // output: false
$v->getErrors();
/*
output:
[
'length' => 'value must have a length between 10 and 20',
'regex' => 'value contains invalid characters'
]
*/
$v->getFirstError();
// output: value must have a length between 10 and 20
```
Список ошибок представлен в виде ассоциативного массива.
* getErrors() — вывод всего стека ошибок;
* getFirstError() — возвращает первую ошибку;
* getLastError() — возвращает последнюю ошибку.
#### Правила
Набор правил достаточно широк, ибо с небольшими изменениями перекачивал из стана «конкурента».
Существуют группы правил:
* общего назначения
* строковые
* числовые
* дата и время
* файловой системы
* сетевые
* и др.
[Полный список правил](https://github.com/romeOz/rock-validate/blob/master/docs/rules.md)
Любой дополнительный каприз реализуется кастомизацией, либо pull request-ом.
#### Валидация по атрибутам
Для валидации массива/объекта по атрибутам используется метод attributes().
```
$input = [
'username' => 'O’Reilly',
'email' => 'o-reilly@site'
];
$attributes = [
'username' => Validate::required()
->length(2, 20, true)
->regex('/^[a-z]+$/i'),
'email' => Validate::required()->email()
];
$v = Valiadte::attributes($attributes);
$v->validate($input); // output: false
$v->getErrors();
/*
output:
[
'username' => [
'regex' => 'value contains invalid characters',
],
'email' => [
'email' => 'email must be valid',
],
]
*/
```
Использование одного набора правил для каждого атрибута:
```
Validate::attributes(Validate::required()->string())->validate($input);
```
#### Отрицание правил
Инвертировать поведение правил можно с помощью метода notOf(). В это случае, используется «негативный» шаблон сообщения Locale::MODE\_NEGATIVE.
```
$v = Validate::notOf(Validate::required());
$v->validate(''); // output: true
```
Данный метод применим, как для правил внутреннего атрибута ['email' => Validate::notOf(Validate::email())], так и для всех атрибутов в целом. Пример:
```
$input = [
'email' => 'tom@site',
'username' => ''
];
$attributes = Validate::attributes([
'email' => Validate::email(),
'username' => Validate::required()
]);
$v = Validate::notOf($attributes);
$v->validate($input); // output: true
```
#### Правило oneOf()
Если хотя бы одно правило неверно, то проверка останавливается. Пример:
```
$input = 7;
$v = Validate::oneOf(Validate::string()->email());
$v->validate($input); // output: false
$v->getErrors();
/*
output:
[
'string' => 'value must be string'
]
*/
```
Для валидации по атрибутам сценарий аналогичен отрицанию:
```
$input = [
'email' => 'tom@site',
'username' => ''
];
$attributes = Validate::attributes([
'email' => Validate::email(),
'username' => Validate::required()
]);
$v = Validate::oneOf($attributes);
$v->validate($input); // output: false
$v->getErrors();
/*
output:
[
'email' => [
'email' => 'email must be valid',
]
]
*/
```
#### Правило when()
Необходимо для реализации условия (тернарная условная операция). Общий синтаксис метода выглядит так:
```
v::when(v $if, v $then, v $else = null)
```
Пример:
```
$v = Validate::when(Validate::equals('Tom'), Validate::numeric());
$v->validate('Tom'); // output false
$v->getErrors();
/*
output:
[
'numeric' => 'value must be numeric',
]
*/
```
#### Замена плейсхолдеров, сообщений и шаблонов
Многие сообщения об ошибках содержат плейсхолдеры (к примеру, {{name}}), которые заменяются значениями по умолчанию. Заменить на свои не составит труда:
```
$v = Validate::length(10, 20)
->regex('/^[a-z]+$/i')
->placeholders(['name' => 'username']);
$v->validate('O’Reilly'); // output: false
$v->getErrors();
/*
output:
[
'length' => 'username must have a length between 10 and 20',
'regex' => 'username contains invalid characters',
]
*/
```
Аналогично, такой «горячей» замены подлежит и всё сообщение:
```
$v = Validate::length(10, 20)
->regex('/^[a-z]+$/i')
->messages(['regex' => 'Хьюстон, у нас проблемы!']);
$v->validate('O’Reilly'); // output: false
$v->getErrors();
/*
output:
[
'length' => 'username must have a length between 10 and 20',
'regex' => 'Хьюстон, у нас проблемы!'
]
*/
```
В зависимости от заданных аргументов в методе правила, шаблон сообщения подбирается автоматически, но никто не мешает подставить любой другой, который описан в текущей локали. Пример:
```
$v = Validate::length(10, 20)->templates(['length' => Length::GREATER]);
$v->validate('O’Reilly'); // output: false
$v->getErrors();
/*
output:
[
'length' => 'value must have a length lower than 20',
]
*/
```
#### Интернационализация
На текущий момент времени существуют два словаря сообщений: русский и английский. По умолчанию сообщения об ошибках будут выводится на английском языке. Установить локаль можно через метод locale():
```
$v = Validate::locale('ru')
->length(10, 20)
->regex('/^[a-z]+$/i');
$v->validate('O’Reilly'); // output: false
$v->getErrors();
/*
output:
[
'length' => 'значение должно иметь длину в диапазоне от 10 до 20',
'regex' => 'значение содержит неверные символы',
]
*/
```
#### Кастомизация
Создать свои правила можно в два шага.
**Шаг #1.** Создаём класс с правилом:
```
use rock\validate\rules\Rule
class CSRF extends Rule
{
public function __construct($compareTo, $compareIdentical = false, $config = [])
{
$this->parentConstruct($config);
$this->params['compareTo'] = $compareTo;
$this->params['compareIdentical'] = $compareIdentical;
}
public function validate($input)
{
if ($this->params['compareIdentical']) {
return $input === $this->params['compareTo'];
}
return $input == $this->params['compareTo'];
}
}
```
**Шаг #2.** Создаём класс с сообщениями:
```
use rock\validate\locale\Locale;
class CSRF extends Locale
{
const REQUIRED = 1;
public function defaultTemplates()
{
return [
self::MODE_DEFAULT => [
self::STANDARD => '{{name}} must be valid',
self::REQUIRED => '{{name}} must not be empty'
],
self::MODE_NEGATIVE => [
self::STANDARD => '{{name}} must be invalid',
self::REQUIRED => '{{name}} must be empty'
]
];
}
public function defaultPlaceholders($compareTo)
{
if (empty($compareTo)) {
$this->defaultTemplate = self::REQUIRED;
}
return [
'name' => 'CSRF-token'
];
}
}
```
Как ранее отмечалось, при использовании правила notOf() будет подставлен шаблон сообщения Locale::MODE\_NEGATIVE. Подшаблон же позволяет разнообразить сообщения в зависимости от заданных аргументов в методе правила. По умолчанию Locale::STANDARD.
**Профит:**
```
$config = [
'rules' => [
'csrf' => [
'class' => \namespace\to\CSRF::className(),
'locales' => [
'en' => \namespace\to\en\CSRF::className(),
]
],
]
];
$sessionToken = 'foo';
$requestToken = 'bar';
$v = new Validate($config);
$v->csrf($sessionToken)->validate($requestToken); // output: false
$v->getErrors();
/*
output:
[
'csrf' => 'CSRF-token must be valid',
]
*/
```
Таким образом, можно осуществить подмену [существующих правил](https://github.com/romeOz/rock-validate/blob/master/src/Validate.php#L487).
#### Дополнительные возможности
Существует сценарий, когда необходимо пропустить «пустые» значения. К примеру, для полей формы необязательных к заполнению. Для этих целей существует свойство skipEmpty — задаётся реакция для каждого правила на «пустые» значения. Для некоторых правил это свойство выставлено в false (не пропускать), а именно: Required, Arr, Bool, String, Int, Float, Numeric, Object, NullValue, Closure, всех ctype-правил. Пример:
```
$v = Validate::email();
$v->validate(''); // output: true
```
Данное поведение можно отменить:
```
$v->skipEmpty(false)->validate(''); // output: false
```
По умолчанию пустыми значениями являются $value === null || $value === [] || $value === ''. Для каждого из правил, существует возможность задать свой обработчик isEmpty:
```
$config = [
'rules' => [
'custom' => [
'class' => \namespace\to\CustomRule::className(),
'locales' => [
'en' => \namespace\to\en\Custom::className(),
],
'isEmpty' => function($input){
return $input === '';
}
],
]
];
$v = new Validate($config);
```
#### Установка
```
composer require romeoz/rock-validate:*
```
#### А посмотреть?
* [**Проект на github**](https://github.com/romeOz/rock-validate)
* [**Документация**](https://github.com/romeOz/rock-validate#documentation)
Существует небольшое [демо](https://github.com/romeOz/docker-rock-validate), которое можно запустить с помощью [Docker](https://docs.docker.com/installation/):
```
docker run --name demo -d -p 8080:80 romeoz/docker-rock-validate
```
Демо станет доступно по адресу: <http://localhost:8080/> | https://habr.com/ru/post/253621/ | null | ru | null |
# Как мы внедряли WebAssembly в Яндекс.Картах и почему оставили JavaScript
Меня зовут Валерий Шавель, я из команды разработки векторного движка Яндекс.Карт. Недавно мы внедряли в движок технологию WebAssembly. Ниже я расскажу, почему мы её выбрали, какие результаты получили и как вы можете использовать эту технологию в своём проекте.

В Яндекс.Картах векторная карта состоит из кусочков, называемых тайлами. Фактически тайл — индексированная область карты. Карта векторная, поэтому в каждом тайле содержится немало геометрических примитивов. Тайлы приходят с сервера на клиент закодированными, и перед отображением необходимо обработать все примитивы. Иногда это занимает существенное время. Тайл может содержать больше 2 тысяч ломаных и многоугольников.
При обработке примитивов важнее всего производительность. Если тайл не будет подготовлен достаточно быстро — то и пользователь увидит его поздно, и следующие тайлы задержатся в очереди. Чтобы ускорить обработку, мы решили попробовать относительно новую технологию [WebAssembly (Wasm)](https://ru.wikipedia.org/wiki/WebAssembly).
Использование WebAssembly в картах
----------------------------------
Сейчас бо́льшая часть обработки примитивов происходит в фоновом потоке (Web Worker), который живёт отдельной жизнью. Это сделано для того, чтобы максимально разгрузить главный поток. Таким образом, когда код для показа карты встраивается на страницу сервиса, который может сам добавлять существенную нагрузку, тормозов будет меньше. Минус в том, что нужно правильно настраивать обмен сообщениями между главным потоком и Web Worker’ом.
Часть обработки, происходящая в фоновом потоке, состоит, по сути, из двух шагов:
1. Декодируется формат [protobuf](https://en.wikipedia.org/wiki/Protocol_Buffers), который приходит с сервера.
2. Геометрии генерируются и записываются в буферы.
На втором шаге формируются вершинный и индексный буферы для [WebGL](https://ru.wikipedia.org/wiki/WebGL). Эти буферы применяются при рендеринге следующим образом. Вершинный буфер содержит для каждой вершины её параметры, которые необходимы для определения её положения на экране в конкретный момент. Индексный буфер состоит из троек индексов. Каждая тройка означает, что на экране должен быть отображён треугольник с вершинами из вершинного буфера под указанными индексами. Поэтому примитив необходимо разбить на треугольники, что тоже может быть трудоёмкой задачей:
Очевидно, что во время второго шага происходит немало манипуляций с памятью и математических расчётов, потому что для правильного рендеринга примитивов нужно много информации о каждой вершине примитива:
Нас не устраивала производительность нашего кода на JavaScript’е. В это время все стали писать о WebAssembly, технология постоянно развивалась и улучшалась. Почитав исследования, мы предположили, что Wasm может ускорить наши операции. Хотя мы не были полностью в этом уверены: оказалось сложно найти данные о применении Wasm’а в столь большом проекте.
Также Wasm кое в чём очевидно хуже, чем TypeScript:
1. Нужно инициализировать специальный модуль с необходимыми нам функциями. Это может привести к задержке перед началом работы этой функциональности.
2. Намного больший, чем в TS’е, размер исходного кода при компиляции Wasm’а.
3. Разработчикам приходится поддерживать альтернативный вариант исполнения кода, который к тому же написан на нетипичном для фронтенда языке.
Однако, несмотря на всё это, мы рискнули переписать часть своего кода с использованием Wasm’а.
Общая информация о WebAssembly
------------------------------
Wasm — это бинарный формат; можно скомпилировать в него разные языки, а затем запустить код в браузере. Часто такой заранее скомпилированный код оказывается быстрее классического JavaScript’a. Код в формате WebAssembly не имеет доступа к DOM-элементам страницы и, как правило, применяется для выполнения на клиенте трудоёмких вычислительных задач.
В качестве компилируемого языка мы выбрали C++, поскольку он достаточно удобный и быстрый.
Для компиляции C++ в WebAssembly мы применяли [emscripten](https://emscripten.org/). После его установки и добавления в проект на C++, чтобы получить модуль, нужно написать главный файл проекта определённым образом. Например, он может выглядеть вот так:
```
#include
#include
#include
struct Point {
double x;
double y;
};
double sqr(double x) {
return x \* x;
}
EMSCRIPTEN\_BINDINGS(my\_value\_example) {
emscripten::value\_object("Point")
.field("x", &Point::x)
.field("y", &Point::y)
;
emscripten::register\_vector("vector");
emscripten::function("distance", emscripten::optional\_override(
[](Point point1, Point point2) {
return sqrt(sqr(point1.x - point2.x) + sqr(point1.y - point2.y)) ;
}));
}
```
Далее я опишу, как вы можете использовать этот код в своём проекте на TypeScript.
В коде мы определяем структуру Point и ставим ей в соответствие интерфейс Point в TypeScript, в котором будет два поля — x и y, они соответствуют полям структуры.
Далее, если мы захотим вернуть стандартный контейнер vector из C++ в TypeScript, то понадобится зарегистрировать его для типа Point. Тогда в TypeScript ему будет соответствовать интерфейс с нужными функциями.
И наконец, в коде показано, как зарегистрировать свою функцию, чтобы вызвать её из TypeScript по соответствующему имени.
Скомпилируйте файл с помощью emscripten и добавьте получившийся модуль в свой проект на TypeScript’е. Теперь мы можем для произвольного модуля emscripten написать общий файл d.ts, в котором заранее определены полезные функции и типы:
```
declare module "emscripten_module" {
interface EmscriptenModule {
readonly wasmMemory: WebAssembly.Memory;
readonly HEAPU8: Uint8Array;
readonly HEAPF64: Float64Array;
locateFile: (path: string) => string;
onRuntimeInitialized: () => void;
_malloc: (size: size_t) => uintptr_t;
_free: (addr: size_t) => uintptr_t;
}
export default EmscriptenModule;
export type uintptr_t = number;
export type size_t = number;
}
```
И можем написать файл d.ts для нашего модуля:
```
declare module "emscripten_point" {
import EmscriptenModule, {uintptr_t, size_t} from 'emscripten_module';
interface NativeObject {
delete: () => void;
}
interface Vector extends NativeObject {
get(index: number): T;
size(): number;
}
interface Point {
readonly x: number;
readonly y: number;
}
interface PointModule extends EmscriptenModule {
distance: (point1: Point, point2: Point) => number;
}
type PointModuleUninitialized = Partial;
export default function createModuleApi(Module: Partial): PointModule;
}
```
Теперь мы можем написать функцию, которая создаст Promise на инициализацию модуля, и воспользоваться ей:
```
import EmscriptenModule from 'emscripten_module';
import createPointModuleApi, {PointModule} from 'emscripten_point';
import * as pointModule from 'emscripten_point.wasm';
/**
* Promisifies initialization of emscripten module.
*
* @param moduleUrl URL to wasm file, it could be encoded data URL.
* @param moduleInitializer Escripten module factory,
* see https://emscripten.org/docs/compiling/WebAssembly.html#compiler-output.
*/
export default function initEmscriptenModule(
moduleUrl: string,
moduleInitializer: (module: Partial) => ModuleT
): Promise {
return new Promise((resolve) => {
const module = moduleInitializer({
locateFile: () => moduleUrl,
onRuntimeInitialized: function (): void {
// module itself is thenable, to prevent infinite promise resolution
delete (module).then;
resolve(module);
}
});
});
}
const initialization = initEmscriptenModule(
'data:application/wasm;base64,' + pointModule,
createPointModuleApi
);
```
Теперь по этому Promise мы получаем наш модуль вместе с функцией distance.
К сожалению, отлаживать Wasm-код построчно в браузере нельзя. Поэтому необходимо писать тесты и запускать на них код как обычный C++, тогда у вас будет возможность удобной отладки. Тем не менее даже в браузере у вас есть доступ к стандартному потоку cout, который выведет всё в консоль браузера.
По этой [ссылке](https://github.com/ShavelV/point-sandbox) доступен проект-пример из статьи, там вы можете посмотреть настройку webpack.config и CMakeLists.
Результаты
----------
Итак, мы переписали часть своего кода и запустили эксперимент, чтобы рассмотреть парсинг ломаных и многоугольников. На диаграмме продемонстрированы медианные результаты по одному тайлу для Wasm’а и JavaScript’а:
В итоге мы получили такие относительные коэффициенты по каждой метрике:
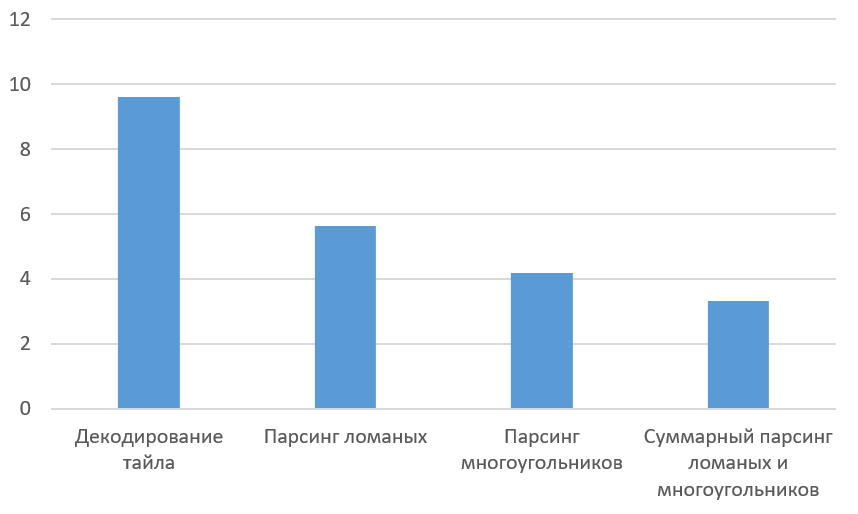
Как видно по чистому времени парсинга примитивов и времени декодирования тайла, Wasm быстрее более чем в четыре раза. Если же смотреть общее время парсинга, то здесь разница тоже значительная, однако она всё-таки немного меньше. Это связано с затратами на то, чтобы передать данные в Wasm и забрать результат. Также стоит отметить, что на первых тайлах общий выигрыш очень высок (на первых десяти — больше чем в пять раз). Однако потом относительный коэффициент уменьшается примерно до трёх.
В итоге всё это вместе помогло на 20–25% снизить время обработки одного тайла в фоновом потоке. Конечно, эта разница не так велика, как предыдущие, однако нужно понимать, что парсинг ломаных и многоугольников — это далеко не вся обработка тайла.
Если говорить о необходимости инициализации модуля, то из-за неё примерно у половины пользователей произошла задержка перед парсингом первого тайла. Медиана задержки — 188 мс. Задержка случается только перед первым тайлом, а выигрыш в парсинге постоянный, так что можно смириться с небольшой паузой на старте и не считать её серьёзной проблемой.
Ещё одна отрицательная сторона — размер файла с исходным кодом. Сжатый gzip’ом минифицированный код всего векторного движка карты без Wasm’а — 85 КБ, с Wasm’ом — 191 КБ. При этом в Wasm’е реализован только парсинг ломаных и прямоугольников, а не всех примитивов, которые могут быть в тайле. Более того, для декодирования protobuf’а пришлось выбрать реализацию библиотеки на чистом C, с реализацией на C++ размер был ещё больше. Эту разницу можно несколько уменьшить, если при компиляции C++ использовать флаг компилятора -Oz вместо -O3, но она по-прежнему существенна. Кроме того, при такой замене мы теряем в производительности.
Тем не менее размер исходника на скорость инициализации карты повлиял незначительно. Wasm хуже только на медленных устройствах, и разница — менее 2%. А вот изначальный видимый набор векторных тайлов в реализации с Wasm’ом был показан пользователям немного быстрее, чем с JS’ной реализацией. Это связано с бо́льшим выигрышем на первых обработанных тайлах, пока JS ещё не оптимизирован.
Таким образом, Wasm сейчас — вполне достойный вариант, если вас не устраивает производительность кода на JavaScript. В то же время вы можете получить меньший выигрыш в производительности, чем мы, либо не получить его вообще. Это связано с тем, что иногда JavaScript сам работает достаточно быстро, а в Wasm требуется передавать данные и забирать результат.
В наших картах сейчас работает обычный JavaScript. Это связано с тем, что выигрыш в парсинге не так велик на общем фоне, и с тем, что в Wasm’е реализован парсинг только некоторых типов примитивов. Если это изменится — возможно, мы станем применять Wasm. Ещё один весомый аргумент против — сложность сборки и отладки: поддерживать проект на двух языках имеет смысл только тогда, когда выигрыш в производительности того стоит. | https://habr.com/ru/post/475382/ | null | ru | null |
# Вёрстка адаптивных email-писем: подробное руководство (часть 2)
[](http://habrahabr.ru/company/pechkin/blog/257397/)
В [прошлом материале](http://habrahabr.ru/company/pechkin/blog/256853/) мы поговорили о том, зачем нужно адаптировать письма [почтовых рассылок](https://pechkin-mail.ru/?utm_source=habr&utm_medium=referral&utm_campaign=adaptive_2) для мобильных устройств, рассмотрели некоторые моменты, которые следует учитывать при создании шаблонов писем, и «поиграли» с кодом вёрстки.
Сегодня речь пойдет о применении media queries для разных устройств, оптимизации изображений для «мобайла» и повышении эффективности форм подписки.
#### Media queries для разных устройств
Возможно, вы заметили, что ранее в этом руководстве мы использовали один стандартный вариант media query: `@media only screen and (max-device-width: 480px) { ... }`. С его помощью можно неплохо работать со старыми iPhone и другими мобильными устройствами того же форм-фактора.
Но если получатели письма могут просматривать его на новых iPhone, планшетах и Android-устройствах с большим экраном различных экзотических разрешений, то необходимо использовать и уникальные media query, и уникальные стили.
Как вы, должно быть, знаете, media query не поддерживаются всеми мобильными почтовыми клиентами без исключения — например, Gmail не покажет адаптивную версию письма ни на одной из платформ.
#### Отладка media queries
Теперь вернемся к уже упомянутой media query и правилу max-device-width: 480px. Оно как бы говорит мобильному почтовому приложению (и браузеру) о том, что максимальная величина для отображения шаблона составляет 480 пикселя. Если экран больше, то следует использовать CSS.
При этом, с помощью media queries можно проводить и более тонкую настройку отображения письма на разных экранах. Например, чтобы нацелиться на дисплеи, ширина которых составляет 320px и выше, но не больше 480px, можно написать так:
`@media only screen and (min-device-width: 320px) and (max-device-width: 480px) { ... }`
Многие не знают, но media queries могут быть [очень фокусированными](http://www.w3.org/TR/css3-mediaqueries/#media1) — с их помощью возможно создание писем не только под диапазоны дисплеев, но также под различные ориентации экранов (ландшафтный, портретный), а также соотношения пикселей (отношение пикселя в изображении к ширине экрана, на котором оно отображается).
В результате возможна работа с ювелирной точностью — нужно создать шаблон «под iPad» — нет проблем, необходимо подстроиться под устройства с Retina — пожалуйста. Добавление новых стилей может занимать время, но media queries позволяют добиться приемлемого отображения писем на многих устройствах с помощью пары строк кода.
Вот здесь представлено [неплохое руководство](http://stuffandnonsense.co.uk/projects/320andup//) по работе с разными экранами для начинающих.
При этом, некоторые дизайнеры и верстальщики выступают против создания шаблонов, ориентированных на фиксированную величину экрана (например, 480px) — эти величины называют еще «точками прерывания» (breakpoints).
> Если вы используете техники адаптивного дизайна (а это определенно стоит делать!), это значит, что применение «дефолтных» media queries с точками прерывания по величинам экрана просто бесполезно.
>
>
>
> — **Марк Драммонд**, «[Адаптивный дизайн с точками прерываний мертв](http://marcdrummond.com/responsive-web-design/2011/12/29/default-breakpoints-are-dead)»
#### Построение «жидких» шаблонов с помощью media queries
С помощью media query, которая вместо использования фиксированной ширины применяет процентную ширину к элементам письма. Это приводит к сжатию и растягиванию контента, ориентированного на большие экраны, при отображении его на небольших дисплеях. С помощью этого метода можно добиться адекватного отображения контента даже на старых Nokia:

Описанный прием в свое время использовали дизайнеры Starbucks — попробуйте открыть [это письмо](http://preview.smartfocusdigital.com/go.asp?/mPJSB64F/bEST001) в браузере и «поиграть» размерами окна.
#### Оптимизация изображений для отображения на мобильных устройствах
Дефицит экранного места на мобильных устройствах требует вдумчивого использования изображений в почтовых рассылках. При этом хорошая поддержка CSS в некоторых мобильных клиентах (вроде Mail для iPhone) предоставляют дизайнерам определенный простор для творчества.
Далее мы рассмотрим несколько методов и техник использования CSS для оптимизации изображений для показа на мобильных устройствах.
##### Фоновые изображения и заголовки
Вообще, использование фоновых изображений — это такая вещь, которую стоит обходить за километр, но в случае «дефолтных» почтовых приложений на iPhone и Android, хорошая поддержка CSS дает некоторую гибкость. Одним из возможных плюсов является возможность замены изображений по-умолчанию на оптимизированные для «мобайла» в том случае, если письмо просматривается на мобильном устройстве.
Как правило, дизайнеры советуют оптимизировать изображения под выбранный массив размеров экрана. Но при ресайзе изображений может возникнуть проблема — иногда какой-то контент (например, текст) становится слишком мелким, и его невозможно разобрать глазом.
В таком случае лучше создавать уникальное изображение для каждого отдельного целевого устройства. Это делается с помощью расположения изображения в ячейке таблице или теге div и использовании media query, которая скрывает оригинальную картинку и выводит вместо нее в заголовок другое фоновое изображение:
CSS:
```
@media only screen and (max-device-width: 480px) {
td[class="headercell"] {
background-image: url(images/header-325.png);
width: 325px !important;
height: 115px !important;
}
td[class="headercell"] img {
display: none;
}
}
```
HTML:
```
| |
| --- |
| |
```
Вот как выглядит письмо в мобильном клиенте до и после этой процедуры:

Плюс этой техники заключается в том, что она позволяет сократить длину письма с помощью использования более «коротких» картинок. Как известно, в «мобайле» [чем короче, тем лучше](http://www.campaignmonitor.com/blog/post/3541/designing-ultra-short-emails-for-mobile-using-progressive-disclosure/).
##### Ресайз изображений для «жидких» шаблонов
Проблема описанного выше способа в том, что он эффективен лишь в том случае, если речь идет о шаблонах с фиксированной шириной. В наши дни существует огромное количество устройств с самыми разными параметрами экрана, так что использование «жидких» шаблонов писем, которые адекватно отображаются на каждом из них — более логичное решение.
Очевидным решением кажется использование в нашей описанной выше media query опции `background-size: 100%`. Но есть и вариант получше — [background-size: cover](http://whereswalden.com/files/mozilla/background-size/page-cover.html):
```
@media only screen and (max-device-width: 480px) {
td[class="headercell"] {
background-image: url(images/header-480.png) !important;
background-size: cover;
}
td[class="headercell"] img {
display: none;
}
}
```
Браузеры на движке Webkit полностью поддерживают `background-size`, так что все будет отлично работать в дефолтных почтовых клиентах iPhone и Android. В остальных случаях можно использовать традиционный подход с применение тега и дальнейшим ресайзом изображения:
```
@media only screen and (max-device-width: 480px) {
td[class=headercell] img {
height:auto !important;
width:100% !important;
}
}
```
##### Отображение high-res изображений для Retina-дисплеев
Здесь весь трюк заключается в создании изображений, которые в два раза больше чем те, что планируется реально использовать — это позволяет добиться кристальной четкости на дисплеях iPhone и iPad. Например, можно создать изображение размером 650px X 230px, а затем урезать его в два раза для мобильных устройств. Сделать это можно с помощью такого кода media query:
```
@media only screen and (max-device-width: 480px) {
td[class="headercell"] {
background-image: url(images/[email protected]) !important;
background-size: 325px 115px;
width: 325px !important;
height: 115px !important;
}
td[class="headercell"] img {
display: none;
}
}
}
```
Для того чтобы работать с дисплеями Retina с помощью конкретной таблицы стилей, можно объявить CSS таким образом:
`@media all and (min-device-pixel-ratio : 1.5) { ... }`
С этим методом тоже не все идеально. Все почтовые клиенты, которые поддерживают media query, будут вынуждены загружать большие hi-res картинки — а значит, в папке «Входящие» письмо тоже будет открываться дольше. Поэтому использовать описанный подход следует с осторожностью и только тогда, когда плюсы от отображения картинок высокой четкости перевешивают сопутствующие минусы.
#### Оптимизация форм подписки
Оптимизация почтовых рассылок для мобильных устройств не ограничивается только лишь работой по повышению читабельности сообщений на маленьких экранах. Помимо всего прочего, какой смысл в том, чтобы тратить столько усилий на эту оптимизацию, если пользователи мобильных устройств не смогут легко подписаться на рассылку?
Смартфоны на iOS и Android позволяют пользователям довольно легко взаимодействовать с формами, но есть несколько способов, которые дизайнеры и разработчики могут использовать, чтобы еще облегчить этот процесс. Оптимизация форм нужна для того, чтобы их было легче заполнять с мобильного устройства. Для бизнеса «легкое заполнение» выливается в повышение конверсии и новых подписчиков.
Приведем несколько советов по работе с формами и рассмотрим небольшой пример, который пригодится начинающим:
* **Выравнивание по верхнему краю**. В случае мобильных устройств часто возникает ситуация, при которой пользователь выбирает поле формы, и не видит его название. К примеру, при первоначальном уровне зума выровненная по левому краю надпись «Введите ваш email» может быть видимой, но после того как пользователь тапнет по полю ввода, произойдет «наезд» на него, в результате чего надпись исчезнет из поля зрения. Выхода из положения может быть два — использовать выравнивание по верхнему краю или добавлять описание формы в качестве ее же текстового значения. В последнем случае потребуется меньше места на экране, но может иногда раздражать пользователей — никому не нравится, когда поле, которое вы только что начали заполнять вдруг скрывается за выехавшей телефонной клавиатурой.
* **Используйте `input type=”email”`**. При использовании параметра `input type=”email”` в формах для ввода почтового адреса, на телефонах под iOS будет появляться специальная клавиатура, включающая символы вроде @.
* **Лучше делать формы более узкими**. Использование media queries и CSS может значительно улучшить юзабилити форм. Однако ничто так не раздражает пользователей, как ситуации, при которых значительная часть полей для ввода на экране загораживается другими элементами или просто в него не влезает после начала набора текста. Если делать длину поля ввода, скажем, не более 80% от ширины экрана, это может значительно улучшить юзабилити форм.
* **Следует делать формы с несколькими вариантов ответа более лаконичными**. Весь контент на мобильном устройстве лучше расположить в один столбец — особенно это касается чекбоксов. Часто выпадающие списки будут удобнее радиокнопок и позволят избавиться от необходимости скроллинга для работы с формой.
* **Практический совет по масштабированию**. Описанное выше больше относится к дизайну в целом, а не только к формам. Теперь один практический совет, относящийся исключительно к формам. Использование viewport-метатега поможет предотвратить непреднамеренный зум формы — и, как следствие, потерю из вида большей части ее содержимого. Вот как такой метатег может выглядеть в заголовке HTML-страницы: `/>` Подробная информация по этой теме представлена, к примеру, в документации Apple.
Для того чтобы лучше разобраться с оптимизацией форм, можно воспользоваться этим примером CSS-шаблона, в котором содержится форма. Скачать пример можно [по ссылке](https://www.campaignmonitor.com/integrations/ajax-subscription-form).
#### Как создать текстовый email для мобильной среды
Во многих случаях возможно эффективное использование текстовых, а не HTML писем. Когда дело доходит до форматирования таких сообщений, то специалисты часто делятся на два лагеря — одни включают разрыв строки после 60-65 символов, и те, кто так не делает. У обоих лагерей свои доводы за и против.
По данным CampaignMonitor лимит в 60-65 символов хорошо работает в случае десктоп- и веб-почтовых клиентов. На десктопе нет особенных границ ширины параграфов текста, поэтому ограничение их на этапе разработки шаблона письма позволяет сделать его более читабельным — прокручивать очень длинную строку не очень-то удобно.
В мобильной среде все не так просто. Иногда в том же iPhone Mail строка в 65 символов выглядит хуже, чем если бы она была гораздо длиннее.
#### Кейс: рассылка Twitter
Рассмотрев немало теории, настало время перейти к практике. И рассмотреть не просто какую-то там рассылку, а такую рассылку, письма которой получают миллионы людей.
Несколько лет назад email-нотификации Twitter были «не очень» при просмотре с мобильных устройств. Проблема заключалась в мелком тексте и широком шаблоне — необходимость постоянного зума и прокрутки убивала все желание читать такое сообщение на маленьком экране. Для улучшения ситуации потребовалось не так уж и много усилий.
##### Разбираемся с маленьким текстом
Прежде всего следовало разобраться с отображением текста. Причина его столь малого размера заключалась в использовании шаблона шириной 710px — для того, чтобы показать его во всей ширине почтовый клиент сильно «отъезжать» при просмотре. Помогло использование специальной media query:
`@media only screen and (max-width: 480px) { ... }`
Подобные объявления располагаются между тегов ``— таблицы стилей внутри них могут быть интерпретированы только HTML-почтовыми клиентами, которые соответствуют критерию @media only screen and (max-width: 480px)`. Вот как выглядят две таблицы, содержащие тело письма:
```
| |
| --- |
|
|
```
Привести их к нормальному размеру можно с помощью введения классов `wrappertable`, `wrappercell` и `structure`:
```
| |
| --- |
|
|
```
Затем эти классы описываются в media query:
```
@media only screen and (max-device-width: 480px) {
body {
width: 320px !important;
}
table[class="wrappertable"] {
width: 320px !important;
}
table[class="structure"] {
width: 300px !important;
}
```
Использованные ширины довольно значительны, поскольку на старых iPhone (*материал впервые опубликован в 2012 году — прим. перев*.) ширина экрана в портретной ориентации составляет 320px. Использование именно этой величины для описания ширины шаблона письма позволит добиться его отображения в режиме 100% зума по умолчанию — это значит, что будет виден не только весь дизайн, но и то, что текст и изображения получатся читабельными.
##### Решаем проблему изображения в заголовке
Для того, чтобы справиться с «ужасно широким» заглавным изображением в письме Twitter, его пришлось разбить на три отдельные картинки. Секции, которые отображать не обязательно, на мобильных устройствах можно просто опустить.
Так выглядел изначальный код:
```

```
Разбиение на три части:
```

```
Нетрудно заметить, что класс logo разбит на три изображения `logo-left.png`, `logo.png` и `logo-right.png`. Скрыть ненужные куски можно довольно простым способом:
```
img[class="logo"] { display: none !important; }
```
В результате письмо стало выглядеть куда лучше:
` | https://habr.com/ru/post/257397/ | null | ru | null |
# Подключение шлюзов Intel для интернета вещей к AWS и обмен данными с облаком при помощи Node-RED или Python
Расскажем о том, как подключить шлюз Intel для интернета вещей к Amazon Web Services (AWS) и приступить к созданию приложений, рассчитанных на работу с этой платформой, с использованием Node-RED и Python. В итоге мы придём к решению, в котором шлюз будет передавать в облако данные, используя протокол MQTT.
[](https://habrahabr.ru/company/intel/blog/314282/)
Для того, чтобы опробовать на практике то, о чём пойдёт речь, вам понадобится шлюз Intel для интернета вещей с IDP 3.1 или выше, подключённый к интернету, и компьютер, с которого можно организовать терминальный доступ к шлюзу.
Если ваш шлюз нуждается в настройке, обратитесь к [этому материалу](https://software.intel.com/en-us/node/633284).
Подготовка шлюза и AWS
----------------------
Начнём с подготовки шлюза и AWS к совместной работе.
### ▍Установка репозитория IoT Cloud на шлюз
Установим на шлюз репозиторий IoT Cloud.
1. Войдите в консоль шлюза, используя либо монитор и клавиатуру, подключённые к нему напрямую, либо, и лучше поступить именно так, по SSH с удалённого компьютера.
2. Добавьте ключ GPG для облачного репозитория, введя следующую команду:
```
rpm --import http://iotdk.intel.com/misc/iot_pub.key
```
3. На компьютере откройте браузер, и, введя IP-адрес шлюза в адресную строку, подключитесь к Intel IoT Gateway Developer Hub. Для того, чтобы выяснить IP-адрес шлюза, можно воспользоваться командой `ifconfig`.
4. Войдите в IoT Gateway Developer Hub, использовав данные вашей учётной записи. Стандартные имя пользователя и пароль – **root**.
*Вход в IoT Gateway Developer Hub*
5. Добавьте в систему репозиторий IoT Cloud.
*Добавление репозитория IoT Cloud*
6. Перейдите в раздел **Packages** и щёлкните по кнопке **Add Repo +**.

*Настройка параметров репозитория*
7. Заполните поля появившегося окна следующим образом:
> **Name**: IoT\_Cloud
>
> **URL**: [iotdk.intel.com/repos/iot-cloud/wrlinux7/rcpl13](http://iotdk.intel.com/repos/iot-cloud/wrlinux7/rcpl13)
Затем щёлкните по кнопке **Add Repository**.
8. И, наконец, щёлкните по кнопке **Update Repositories** для того, чтобы обновить список пакетов.
### ▍Настройка поддержки AWS на шлюзе
Здесь рассмотрим шаги, необходимые для того, чтобы оснастить шлюз поддержкой служб Amazon Web Services.
1. Щёлкните по кнопке **Add Packages +**. Это вызовет список пакетов, которые можно установить.

*Начало процесса установки пакета*
2. Выполните поиск по ключевой фразе **cloud-aws**, введя её в поле, расположенное в верхней части окна добавления нового пакета. Затем, когда нужный пакет будет найден, щёлкните по кнопке **Install**, которая расположена правее записи **packagegroup-cloud-aws**.

*Установка пакета*
### ▍Настройка пользователя в AWS
Настроим параметры учётной записи в Amazon Web Services. Это понадобится для подключения к облаку.
1. В браузере перейдите по адресу [консоли AWS](https://console.aws.amazon.com/) и войдите в свою учётную запись Amazon Web Sevices.
2. Настройте политику **AWSIoTFullAccess**.
*Настройка разрешений для учётной записи AWS*
3. Щёлкните по имени учётной записи в правой верхней части окна и выберите команду **Security Credentials** из выпадающего меню.
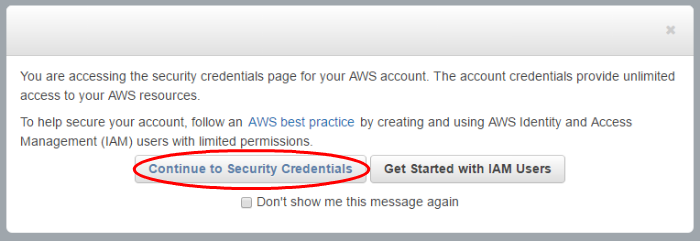
*Предупреждающая надпись о доступе к параметрам безопасности*
Если вы увидите всплывающее сообщение, показанное на рисунке выше, щёлкните по кнопке **Continue to Security Credentials**.
4. В левой части окна щёлкните по ссылке **Users** для того, чтобы вывести список пользователей в вашей учётной записи AWS. Если пользователей в списке нет, щёлкните по кнопке **Create New Users**, введите имя нового пользователя и щёлкните по кнопке **Create**. После этого запись созданного пользователя появится в списке.
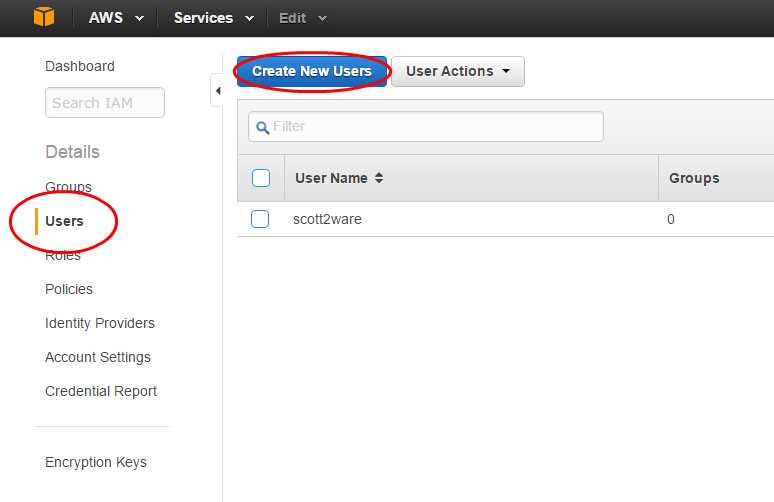
*Добавление нового пользователя к учётной записи AWS*
5. Щёлкните по имени пользователя для вывода страницы со сведениями о нём. Выберите вкладку **Permissions** и щёлкните по кнопке **Attach Policy**.

*Начало назначения политики безопасности для пользователя*
6. Найдите в списке политику **AWSIoTFullAccess**. Поставьте флажок в поле напротив названия политики и щёлкните по кнопке **Attach Policy** для того, чтобы назначить её пользователю.

*Назначение политики безопасности пользователю*
7. Создайте ключ доступа для устройства.
8. Вернитесь на экран сведений о пользователе и щёлкните по кнопке **Create Access Key** на вкладке **Security Credentials**.
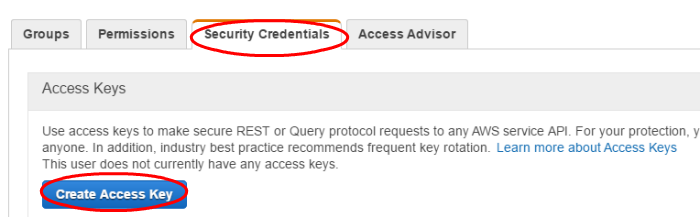
*Создание ключа доступа для устройства*
После этого появится окно, в котором содержится уникальная для каждого пользователя ключевая пара. Ключ, который выводится в поле **Secret Access Key**, показывают лишь один раз, после закрытия окна его больше не увидеть. Это означает, что вам понадобится сгенерировать новый ключ для повторного доступа к системе, если старый, после того, как он был создан, вы нигде не сохранили.
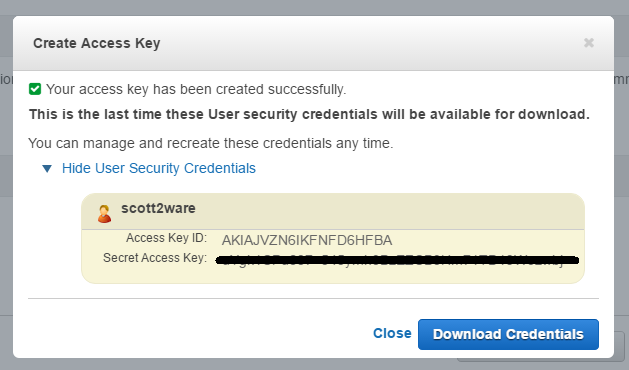
*Создание ключа доступа*
**Внимание!** Не закрывайте это окно до тех пор, пока не выполните действия, описанные в следующем разделе.
### ▍Настройка шлюза
Рекомендовано подключиться к шлюзу по SSH или пользоваться командной строкой с помощью интерфейса IoT Gateway Developer Hub для того, чтобы удобно было копировать команды. Если вы работаете с командной строкой, подключившись к шлюзу напрямую, используя монитор и клавиатуру, вам, в следующем разделе, придётся вручную вводить ключ доступа и секретный ключ.
1. Добавьте учётные данные пользователя на шлюзе. Для этого введите следующую команду:
```
aws configure
```
В ответ на неё система предложит ввести следующее:
* **AWS Access Key ID**: Только что сгенерированный Access Key ID, ключ доступа.
* **AWS Secret Access Key**: Secret Access Key, секретный ключ, который соответствует сгенерированному ключу доступа.
* **Регион по умолчанию**: [здесь](http://docs.aws.amazon.com/general/latest/gr/rande.html#iot_) можно найти список регионов (например, eu-west-1)
* **Формат вывода по умолчанию**: здесь подойдут стандартные настройки, поэтому нажмите **Enter**.
2. Создайте «вещь», привязанную к вашему экземпляру AWS. Для этого введите на шлюзе следующие команды:
```
aws iot create-thing --thing-name gateway-test-01
```
Если добавление «вещи» прошло успешно, в консоль будут выведены сведения, напоминающие те, что показаны на рисунке ниже.

*Успешное создание «вещи»*
3. Задайте разрешения. Для этого введите в консоли следующие команды для того, чтобы создать новую политику разрешений для вашего экземпляра AWS.
```
aws iot create-policy --policy-name gateway-policy --policy-document '{ "Version": "2012-10-17", "Statement": [{ "Effect": "Allow", "Action":["iot:*"], "Resource": ["*"] }] }'
```
Об успешном добавлении политики можно узнать по сообщению в консоли.

*Успешное добавление политики*
4. Создайте ключи и сертификат для «вещи». Для этого нужно ввести следующие команды, которые создадут ключи и сертификаты, необходимые для организации взаимодействия с AWS.
```
wget -O rootCA.pem https://www.symantec.com/content/en/us/enterprise/verisign/roots/VeriSign-Class%203-Public-Primary-Certification-Authority-G5.pem aws iot create-keys-and-certificate --set-as-active --certificate-pem-outfile cert.pem --private-key-outfile privkey.pem
```
Если всё идёт как надо, в консоли появятся сообщения, напоминающие те, что показаны ниже. За ними будет идти большой фрагмент JSON-данных. Для того, чтобы продолжить работу, нам нужен лишь параметр **certificateArn**, который находится в самом начале.

*Успешное добавление ключей и сертификатов*
5. Теперь надо связать политику и сертификат. Для этого воспользуйтесь следующей командой:
```
aws iot attach-principal-policy --policy-name ${POLICY_NAME} –principal ${CERTIFICATE_ARN}
```
Проверьте, верно ли введено имя политики (например, **gateway-policy**) и значение **certificateArn**, полученное на предыдущем шаге. Выглядеть всё это может так:
```
aws iot attach-principal-policy --policy-name gateway-policy --principal arn:aws:iot:eu-west-1:681450608718:cert/122c86b84c6e0b919353882c03ca37385855897e16804438a20d44b3f9934cb3
```
6. Проверьте устройство в консоли AWS IoT. Для этого перейдите к домашнему экрану консоли, щёлкнув по значку **AWS** в левой верхней части страницы. Затем проверьте, чтобы в верхнем правом углу был выбран тот регион, который использован при настройке шлюза (например, Ireland). Теперь щёлкните по значку службы **AWS IoT** в списке.

*Домашний экран AWS, переход к AWS IoT*
Теперь в панели управления AWS IoT должна быть видна только что созданная «вещь», а также политика и сертификат, настройкой которых мы занимались выше.
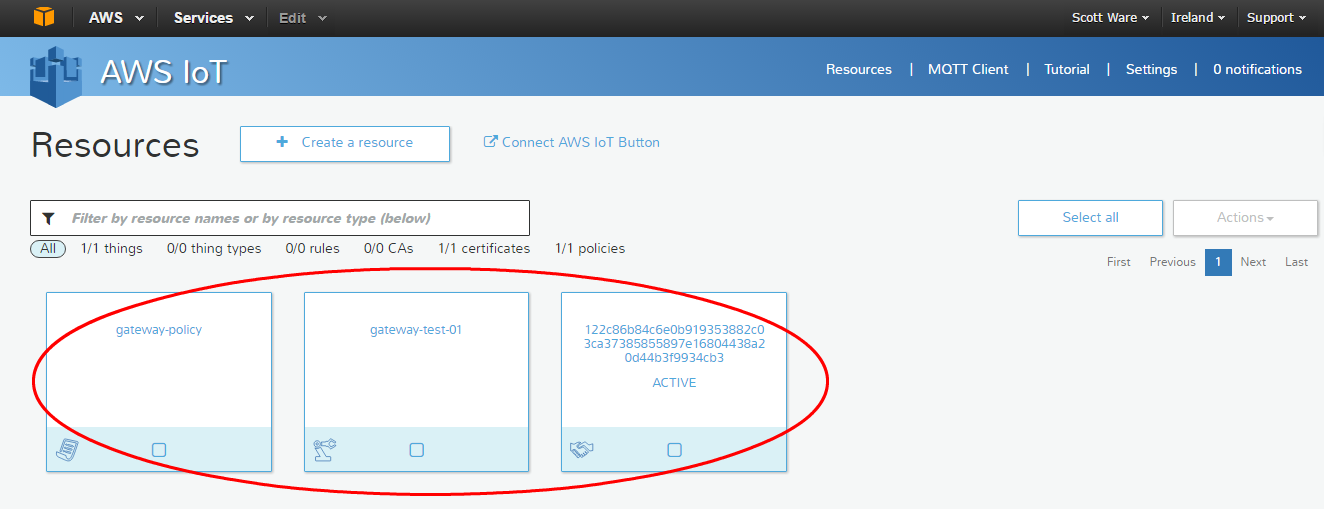
*Панель управления AWS*
На данном этапе, после настройки шлюза, можно заниматься обменом данными с AWS. Сейчас рассмотрим два варианта взаимодействия шлюза и облака: с использованием Node-RED и Python. Если вам интересна лишь одна из вышеупомянутых платформ разработки приложений, вы вполне можете прочесть лишь раздел, посвящённый ей.
Взаимодействие с AWS IoT. Node-RED
----------------------------------
Для того, чтобы приступить к работе в среде Node-RED, нужно убедиться в том, что вы пользуетесь свежей версией ОС. Для работы с AWS требуется Node-RED 0.14.x.
### ▍Настройка AWS
Контролировать взаимодействие AWS и шлюза можно с помощью консоли AWS.
1. В консоли AWS IoT щёлкните по ссылке **MQTT Client**, которая расположена в верхней правой части окна.

*Ссылка MQTT Client*
2. В окне MQTT Client введите имя «вещи», которое назначали ранее (например, **gateway-test-01**) и щёлкните по кнопке **Connect**.
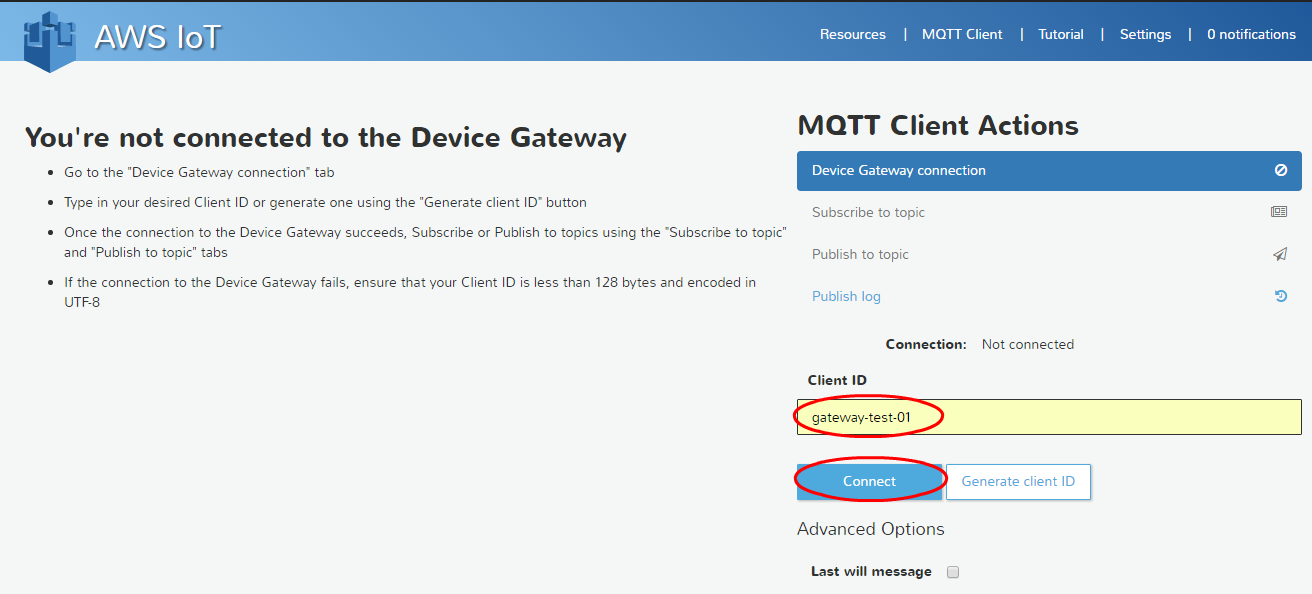
*Подключение к «вещи»*
Если AWS может взаимодействовать со шлюзом, сообщение о состоянии соединения изменится на **Connected** и окрасится в зелёный цвет.
*Состояние подключения шлюза к AWS*
3. Щёлкните по ссылке **Subscribe to topic** в группе **MQTT Client Actions**.
*Начало процесса подписки на MQTT-тему*
4. В поле **Subscription topic** введите `sdk/test/nodered` и щёлкните по кнопке **Subscribe**.

*Подписка на тему*
Теперь сообщения, опубликованные шлюзом в теме **sdk/test/nodered**, будут появляться в окне сообщений.

*Окно просмотра сообщений, полученных от шлюза*
### ▍Загрузка интерфейса Node-RED
Для того, чтобы открыть окно Node-RED, нужно, в **IoT Gateway Developer Hub**, перейти в раздел **Administration**. Здесь, под значком **Node-RED**, надо щёлкнуть по кнопке **Launch**.
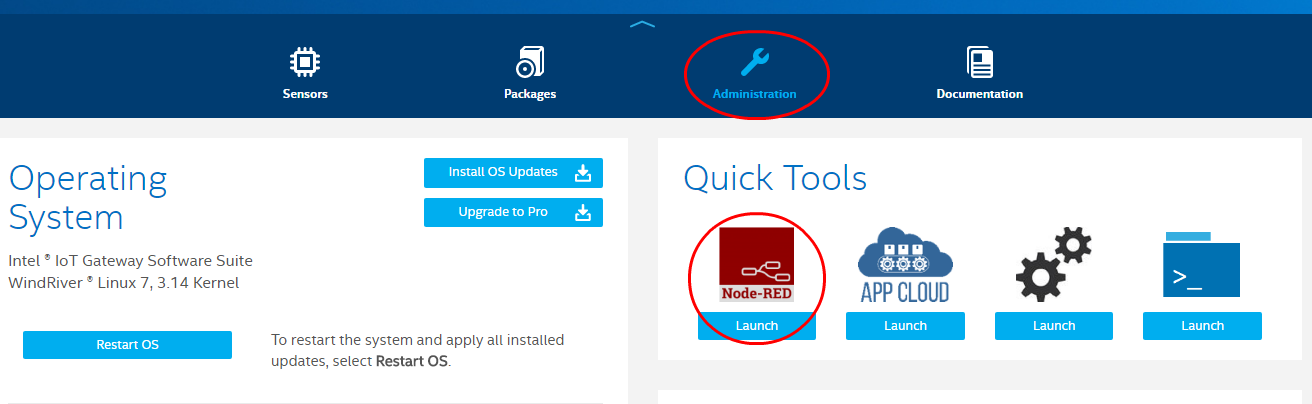
*Запуск Node-RED*
### ▍Настройка блок-схемы приложения
1. Перетащите на текущий лист узлы **mqtt** и **inject** из панели узлов, которая расположена слева. Если нужного узла не видно, прокрутите панель.

*Узлы inject и mqtt*
2. Расположите узлы в окне и соедините их так, как показано на рисунке ниже. Здесь имеется узел **inject**, переименованный в **timestamp**, который будет, с заданным интервалом, отправлять сведения о текущем времени узлу **mqtt**. Узел **mqtt** отвечает за отправку полученных данных MQTT-брокеру. В данном случае это будет **AWS IoT**. После того, как узлы размещены на блок-схеме и связаны, их надо настроить.
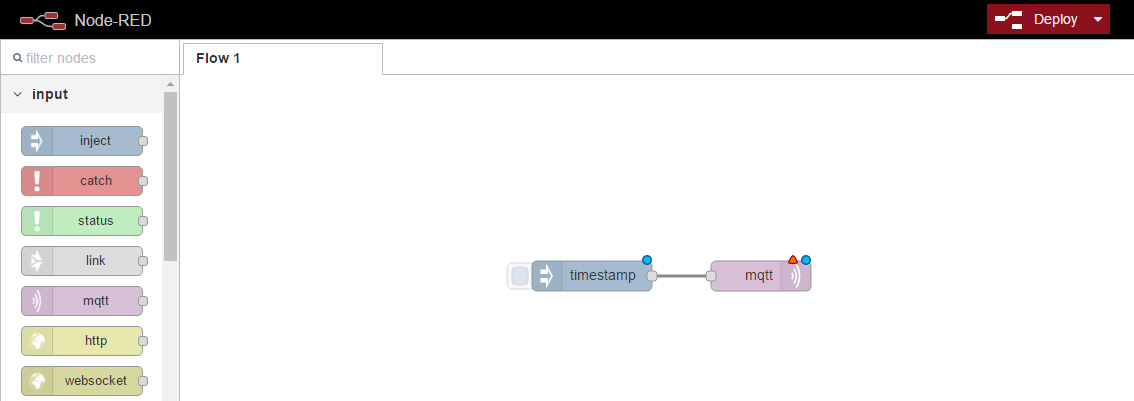
*Схема расположения и связи узлов в Node-RED*
3. Для настройки узла **inject** (который, в итоге, стал узлом **timestamp**), нужно сделать по нему двойной щелчок, который вызовет диалоговое окно. Его надо привести в соответствие рисунку, показанному ниже, и нажать на кнопку **Done**. Благодаря этим настройкам узел будет отправлять данные каждые 5 секунд.
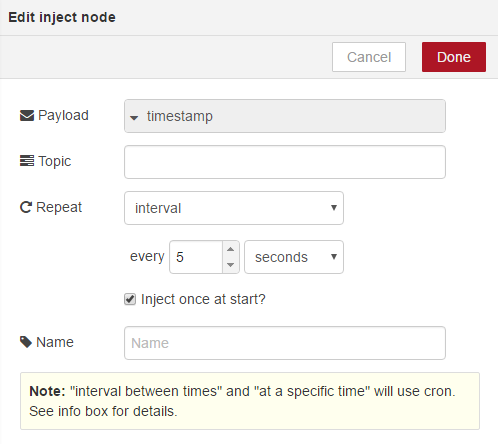
*Настройка узла inject*
4. Для настройки узла **mqtt** выполните по нему двойной щелчок, после чего, в окне настроек, щёлкните по кнопке редактирования у поля **Server**.
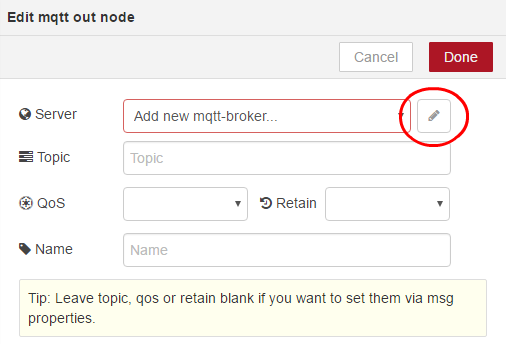
*Начало настройки узла mqtt*
5. Заполните поля настройки MQTT-подключения так, как показано на рисунке ниже. Вам понадобится ввести собственный URL сервера. Сейчас вы узнаете о том, где его взять.

*Настройка узла mqtt, ввод сведений о сервере*
6. Введите следующую команду для того, чтобы получить адрес сервера для передачи сообщений AWS.
```
aws iot describe-endpoint
```
В ответ на неё в консоль будут выведены сведения об адресе. А именно, параметр **endpointAddress** и будет содержать адрес сервера, который нужен нам для настройки MQTT-подключения.

*Адрес сервера в консоли*
Скопируйте URL, размещённый в кавычках, и вставьте его в поле **Server**. Обратите внимание на то, что поле **Port** должно быть пустым.
Теперь надо настроить параметры безопасности соединения. Прежде чем это сделать, нужно установить флаг **Enable secure (SSL/TLS) connection**, после чего щёлкнуть по значку **Edit** в конце раздела **TLS Configuration**.
7. В окне, показанном ниже, надо настроить параметры. А именно, в них нужно указать пути к сгенерированным ранее файлам ключей и сертификатов.
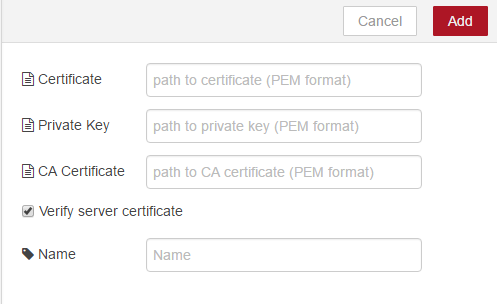
*Настройка путей к файлам ключей и сертификатов*
* В поле **Certificate** нужно ввести путь к файлу `cert.pem`, который был сгенерирован ранее.
* В поле **Private Key** – путь к `privkey.pem`. Этот файл так же был сгенерирован.
* В поле **CA Certificate** – путь к файлу `rootCA.pem`, который должен был быть загружен.
Все сертификаты и ключи должны храниться в одной и той же директории. По умолчанию, если вы ничего не меняли, подключившись к шлюзу, это **/root**.
Вот как выглядят заполненные поля из нашего примера.
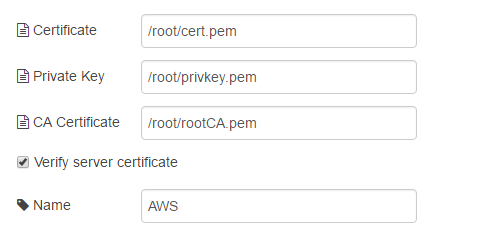
*Заполненные поля путей к файлам ключей и сертификатов*
8. После того, как завершите настройку, щёлкните по кнопке **Add** для того, чтобы сохранить конфигурацию TLS. Экран настройки должен выглядеть примерно так, как показано на рисунке ниже.
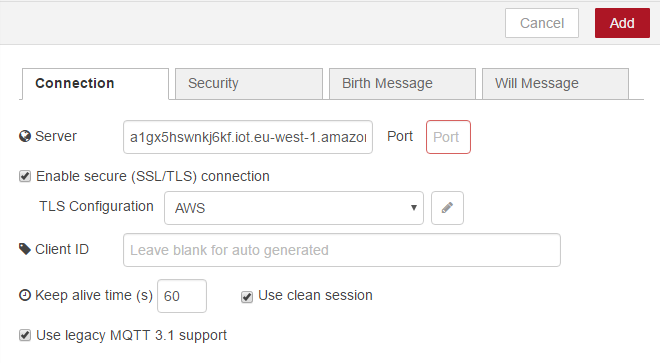
*Завершение настройки*
9. Теперь почти всё готово. Осталось лишь ввести имя темы, в которую планируется отправлять сообщения. Введённая тема должна соответствовать той, на которую мы подписались ранее, настраивая MQTT-клиент в панели управления AWS, поэтому нужно ввести в поле **Topic** строку `sdk/test/nodered` и щёлкнуть по кнопке **Done**.

*Настройка MQTT-темы*
Теперь приложение Node-RED настроено и готово к развёртыванию.
### ▍Развёртывание и проверка приложения
1. Щёлкните по кнопке **Deploy** в правом верхнем углу окна Node-RED. Если появится окно запроса на подтверждение развёртывания, нажмите в нём кнопку **Confirm deploy**.
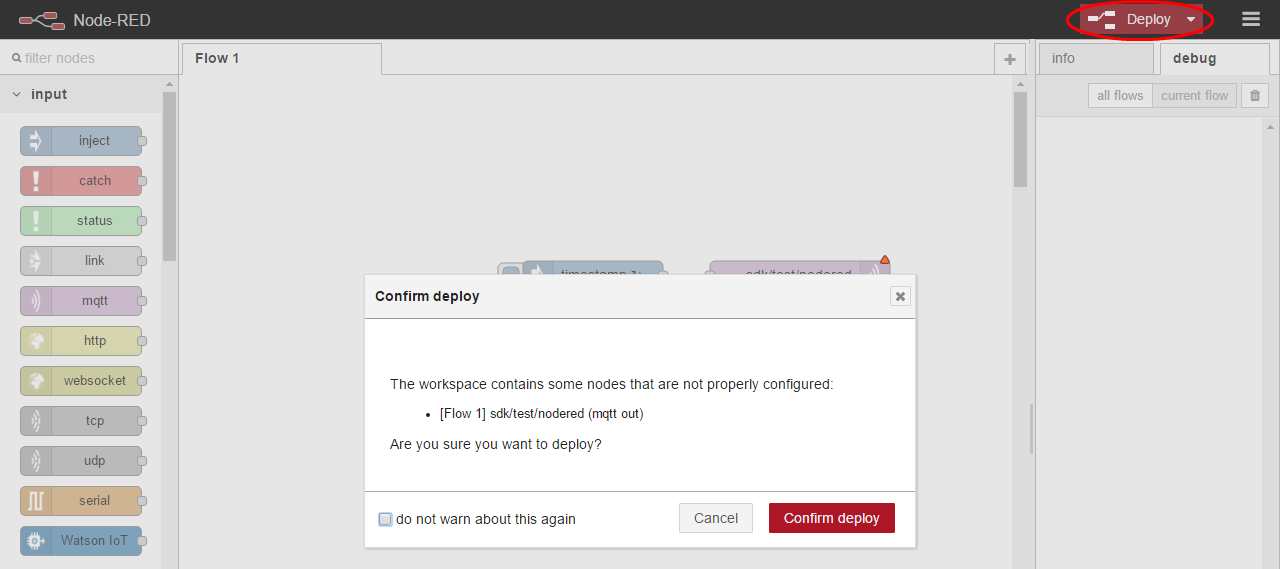
*Развёртывание приложения Node-RED*
Если узел MQTT был успешно сконфигурирован, ниже него можно будет видеть зелёный индикатор с надписью **connected**.

*Состояние узла mqtt*
2. Для того, чтобы окончательно убедиться в том, что всё работает правильно, вернитесь к окну сообщений клиента MQTT в панели управления AWS. Там должны появиться новые сообщения.

*Новые сообщения в окне MQTT-клиента AWS*
Отправку данных в AWS с использованием Node-RED мы наладили. Займёмся теперь организацией того же процесса с использованием Python.
Взаимодействие с AWS IoT. Python
--------------------------------
После того как шлюз настроен на взаимодействие с AWS, можно подготовить его к работе с облаком с использованием Python-скриптов. Существует немало примеров таких скриптов, их можно использовать в учебных целях и для тестирования системы.
### ▍Настройка AWS
1. В консоли AWS IoT щёлкните по ссылке **MQTT Client**, которая расположена в правой верхней части окна программы.

*Ссылка MQTT Client*
2. В окне MQTT Client введите имя «вещи», назначенное шлюзу ранее (например, **gateway-test-01**) и щёлкните по кнопке **Connect**.
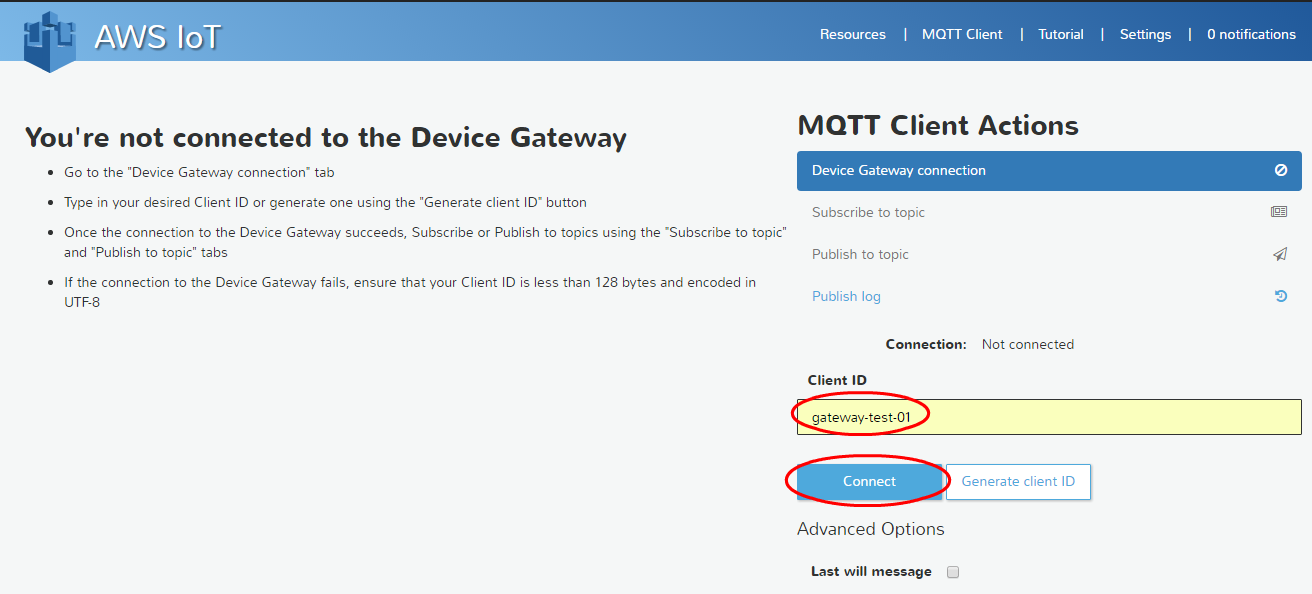
*Подключение к «вещи»*
Если AWS может взаимодействовать со шлюзом, сообщение о состоянии соединения изменится на **Connected** и окрасится в зелёный цвет.

*Состояние подключения шлюза к AWS*
3. В разделе **MQTT Client Actions** щёлкните по пункту **Subscribe to topic**
*Начало подписки на тему MQTT*
4. В поле **Subscription topic** введите `sdk/test/Python` и щёлкните по кнопке **Subscribe**.

*Настройка подписки на тему MQTT*
Сообщения, полученные со шлюза, можно будет просмотреть в окне сообщений.

*Окно сообщений*
### ▍Отправка сообщения со шлюза
1. Для того, чтобы узнать адрес сервера, необходимый для отправки MQTT-сообщений со шлюза, выполните следующую команду:
```
aws iot describe-endpoint
```
В ответ вы получите значение параметра **endpointAddress**, которое и содержит то, что нам нужно. Скопируйте строку адреса, размещённую в кавычках.

*Адрес сервера*
2. Перейдите в папку, которая содержит примеры работы с AWS. Например, в нашем случае для этого потребовалась такая команда:
```
cd /usr/share/awsiotsdk/samples/python/
```
3. Запустите один из примеров кода, воспользовавшись командой такого вида:
```
python basicPubSub.py -e [ENDPOINT] -r [ROOTCA_PATH] -c [CERT_PATH] –k [PRIVATE_KEY_PATH]
```
Вот как задать параметры вызова скрипта:
* **ENDPOINT**: Адрес сервера, который вы выяснили выше.
* **ROOTCA\_PATH**: Путь к загруженному ранее файлу rootCA.pem.
* **CERT\_PATH**: Путь к сгенерированному ранее файлу cert.pem.
* **PRIVATE\_KEY\_PATH**: Путь к сгенерированному ранее файлу privkey.pem.
Файлы сертификатов и ключей должны быть расположены в одной и той же директории. По умолчанию это **/root** или **$HOME**, если вы ничего не меняли, подключившись к шлюзу.
В нашем случае вышеописанная команда выглядела так:
```
python basicPubSub.py -e a1gx5hswnkj6kf.iot.eu-west-1.amazonaws.com -r $HOME/rootCA.pem -c $HOME/cert.pem -k $HOME/privkey.pem
```
Если приложение-пример заработало, в консоль будут выводится данные, вроде тех, что показаны на рисунке ниже. Это указывает на то, что MQTT-сообщения отправляются в тему **sdk/test/Python**.
*Сообщения от Python-скрипта*
4. Для того, чтобы проверить, действительно ли AWS эти сообщения получает, нужно вернуться к окну сообщений на сайте AWS. Там должны появляться новые сообщения.
*Новые сообщения, отправленные со шлюза*
В результате на шлюзе, подключённом к AWS IoT, можно исполнять Python-скрипты, взаимодействующие с облаком.
Выводы
------
Облачная часть играет важнейшую роль во множестве IoT-систем. Теперь, освоив это руководство, вы можете подключать IoT-шлюзы Intel к Amazon Web Services и создавать, в среде Node-RED или на Python, приложения, которые могут работать с облачными службами. | https://habr.com/ru/post/314282/ | null | ru | null |
# ActiveModel: пусть любой Ruby объект почувствует себя ActiveRecord
*Yehuda Katz опубликовал эту запись в своем блоге 10 января 2010 года.*
Огромное количество действительно хорошей функциональности Rails 2.3 скрыты в его монолитных компонентах. Я уже публиковал несколько сообщений о том, как мы упростили код маршрутизатора, диспетчера и некоторых частей ActionController, частично реорганизовав функциональность ActionPack. ActiveModel — еще один модуль, появившийся в Rails 3 после реорганизации полезной функциональности.
#### Для начала — ActiveModel API
ActiveModel имеет два главных элемента. Первый — это API, интерфейс, которому должны соответствовать модели для совместимости с хелперами ActionPack. Дальше я расскажу о нем подробнее, а для начала важная деталь: вашу модель можно сделать подобной ActiveModel без единой строки Rails-кода.
Чтобы убедиться, подходят ли ваши модели для этого, ActiveModel предлагает модуль `ActiveModel::Lint` для тестирования совместимости с API — его нужно просто подключить (заинклудить) в тест:
> `Copy Source | Copy HTML
> class LintTest < ActiveModel::TestCase
> include ActiveModel::Lint::Tests
>
> class CompliantModel
> extend ActiveModel::Naming
>
> def to\_model
> self
> end
>
> def valid?() true end
> def new\_record?() true end
> def destroyed?() true end
>
> def errors
> obj = Object.new
> def obj.[](key) [] end
> def obj.full\_messages() [] end
> obj
> end
> end
>
> def setup
> @model = CompliantModel.new
> end
> end`
Тесты модуля `ActiveModel::Lint::Tests` проверяют совместимость объекта `@model`.
#### Модули ActiveModel
Второй интересной частью ActiveModel является набор модулей для реализации стандартной функциональности в ваших собственных моделях. Код для них был изъят из ActiveRecord, а теперь они отдельно включены в него уже сами по себе.
Поскольку мы сами пользуемся этими модулями, вы можете быть уверены, что функции API, которые вы добавите в свои модели, будут оставаться совместимыми с ActiveRecord, и что они будут поддерживаться в будущих релизах Rails.
Встроенная в ActiveModel интернационализация дает широкие возможности сообществу для работы над переводом сообщений об ошибках и тому подобного.
#### Система валидации
Наверное, валидация была одним из наиболее разочаровывающих мест ActiveRecord, потому что людям, писавшим библиотеки, например, для CouchDB, приходилось выбирать между буквальным переписыванием API с возможностью внести разные несоответствия в процессе переписывания и изобретением полностью нового API.
В валидации присутствуют несколько новых элементов.
Во-первых, объявление самой валидации. Вы помните как это было раньше в ActiveRecord:
> `Copy Source | Copy HTML
> class Person < ActiveRecord::Base
> validates\_presence\_of :first\_name, :last\_name
> end
> Чтобы сделать то же самое на обыкновенном объекте Ruby, просто сделайте следующее:
>
> class Person
> include ActiveModel::Validations
>
> validates\_presence\_of :first\_name, :last\_name
>
> attr\_accessor :first\_name, :last\_name
> def initialize(first\_name, last\_name)
> @first\_name, @last\_name = first\_name, last\_name
> end
> end`
Система валидации вызывает `read_attribute_for_validation` для получения атрибута, но по умолчанию это просто алиас для `send`, который поддерживает стандартную систему атрибутов Ruby через `attr_accessor`.
Для изменения способа поиска атрибута можно переопределить `read_attribute_for_validation`:
> `Copy Source | Copy HTML
> class Person
> include ActiveModel::Validations
>
> validates\_presence\_of :first\_name, :last\_name
>
> def initialize(attributes = {})
> @attributes = attributes
> end
>
> def read\_attribute\_for\_validation(key)
> @attributes[key]
> end
> end`
Давайте посмотрим что такое валидатор по сути. В первую очередь, метод `validates_presence_of`:
> `Copy Source | Copy HTML
> def validates\_presence\_of(\*attr\_names)
> validates\_with PresenceValidator, \_merge\_attributes(attr\_names)
> end`
Как видите, `validates_presence_of` использует более примитивный `validates_with`, передавая ему класс валидатора и добавляя к `attr_names` ключ `{:attributes => attribute_names}`. Дальше сам класс-валидатор:
> `Copy Source | Copy HTML
> class PresenceValidator < EachValidator
> def validate(record)
> record.**errors**.add\_on\_blank(attributes, options[:message])
> end
> end`
Метод `validate` в классе `EachValidator` валидирует каждый атрибут. В данном случае он переопределен и добавляет сообщение об ошибке в объект только в том случае, если атрибут пустой.
Метод `add_on_blank` вызывает `add(attribute, :blank, :default => custom_message)` если `value.blank?` (среди всего прочего), который добавляет локализированное `:blank` сообщение в объект. Встроенный файл локализации для английского языка `locale/en.yml` выглядит следующим образом:
> `Copy Source | Copy HTML
> en:
> errors:
> # Полный формат сообщения об ошибке по умолчанию.
> format: "{{attribute}} {{message}}"
>
> # Значения :model, :attribute и :value всегда доступны для изменения
> # Значение :count доступно если оно применимо. Может быть использовано для множественного числа.
> messages:
> inclusion: "is not included in the list"
> exclusion: "is reserved"
> invalid: "is invalid"
> confirmation: "doesn't match confirmation"
> accepted: "must be accepted"
> empty: "can't be empty"
> blank: "can't be blank"
> too\_long: "is too long (maximum is {{count}} characters)"
> too\_short: "is too short (minimum is {{count}} characters)"
> wrong\_length: "is the wrong length (should be {{count}} characters)"
> not\_a\_number: "is not a number"
> greater\_than: "must be greater than {{count}}"
> greater\_than\_or\_equal\_to: "must be greater than or equal to {{count}}"
> equal\_to: "must be equal to {{count}}"
> less\_than: "must be less than {{count}}"
> less\_than\_or\_equal\_to: "must be less than or equal to {{count}}"
> odd: "must be odd"
> even: "must be even"`
В результате сообщение об ошибке будет выглядеть как `first_name can't be blank`.
Объект Error также является частью ActiveModel.
#### Сериализация
В ActiveRecord также встроена сериализация для JSON и XML, позволяющая делать вещи типа `@person.to_json(:except => :comment)`.
Важнейшая вещь для сериализации — это поддержка общего набора атрибутов, принимаемых всеми сериализаторами. То есть чтобы можно сделать `@person.to_xml(:except => :comment)`.
Чтобы добавить поддержку сериализации в вашу собственную модель, вам нужно добавить (заинклудить) модуль сериализации и реализацию метода `attributes`. Смотрите:
> `Copy Source | Copy HTML
> class Person
> include ActiveModel::Serialization
>
> attr\_accessor :attributes
> def initialize(attributes)
> @attributes = attributes
> end
> end
>
> p = Person.**new**(:first\_name => "Yukihiro", :last\_name => "Matsumoto")
> p.to\_json #=> %|{"first\_name": "Yukihiro", "last\_name": "Matsumoto"}|
> p.to\_json(:only => :first\_name) #=> %|{"first\_name": "Yukihiro"}|`
Для того, чтобы конкретные атрибуты преобразовывались какими-то методами, можно передать опцию `:methods`; эти методы тогда будут вызваны динамически.
Вот модель Person с валидацией и сериализацией:
> `Copy Source | Copy HTML
> class Person
> include ActiveModel::Validations
> include ActiveModel::Serialization
>
> validates\_presence\_of :first\_name, :last\_name
>
> attr\_accessor :attributes
> def initialize(attributes = {})
> @attributes = attributes
> end
>
> def read\_attribute\_for\_validation(key)
> @attributes[key]
> end
> end`
#### Другие модули
Мы познакомились всего с двумя модулями ActiveModel. Коротко об остальных:
`AttributeMethods`: Упрощает добавление методов класса для управления атрибутами типа `table_name :foo`.
`Callbacks`: Колбеки жизненного цикла объекта в стиле ActiveRecord.
`Dirty`: Поддержка «грязных» объектов.
`Naming`: Дефолтные реализации `model.model_name`, которые используются ActionPack (например, при `render :partial => model`).
`Observing`: Обзерверы (наблюдатели) в стиле ActiveRecord.
`StateMachine`: Простая реализация конечного автомата.
`Translation`: Базовая поддержка переводов на другие языки (интеграция с фреймворком интернационализации I18n).
Josh Peek реорганизовал методы из ActiveRecord в отдельные модули в рамках своего проекта для Google Summer of Code прошлым летом, и это только первый шаг всего процесса. Со временем я ожидаю увидеть больше вещей, выделенных из ActiveRecord, и больше абстракций вокруг ActiveModel.
Я также ожидаю от сообщества новых валидаторов, переводов, сериалайзеров и т.д., особенно сейчас, когда их можно использовать не только в ActiveRecord, но и в MongoMapper, Cassandra Object и других ORM, использующих модули ActiveModel. | https://habr.com/ru/post/86938/ | null | ru | null |
# The Little Scrollbar That Could Not

The new Windows Terminal version has been recently released. Everything would be fine, but performance of its scrollbar leaves a great deal to be desired. Time has come to poke it and have some mumbo jumbo dances with it.
What do users usually do with a new version of any application? That's right, exactly what testers haven't done. Therefore, after a brief usage of the terminal for its intended purpose, I began to do terrible things with it. Frankly speaking, I just spilled coffee on the keyboard and accidentally clicked when wiping it. So what happened?

Yes, it doesn't look very impressive, but don't rush to throw stones at me. Pay attention to the right side. First try to figure out what is wrong with it. Here's a screenshot for a hint:

Of course, the article heading was a huge spoiler. :)
So, there is a problem with the scrollbar. Moving to a new line many times, after crossing the lower border, you usually expect a scrollbar to appear and you can scroll up. However, this does not happen until we write a command with the output of something. Let's just say the behavior is strange. However, this might not be so critical if the scrollbar worked…
After testing a bit, I found that switching to a new line doesn't increase the buffer. Only command output does it. So the above *whoami* will increase the buffer by only one line. Because of this, over time we will lose a lot of history, especially after *clear*.
The first thing that came to my mind was to use our analyzer and see what it tells us:

The output is surely impressive, so I will take advantage of the filtration power and omit everything except for the warnings containing *ScrollBar*:
I can't say that there are a lot of messages… Well, maybe then there is something related to the buffer?
The analyzer did not fail and found something interesting. I highlighted this warning above. Let's see what is wrong there:
[**V501**](https://www.viva64.com/en/w/v501/). There are identical sub-expressions to the left and to the right of the '-' operator: bufferHeight — bufferHeight TermControl.cpp 592
```
bool TermControl::_InitializeTerminal()
{
....
auto bottom = _terminal->GetViewport().BottomExclusive();
auto bufferHeight = bottom;
ScrollBar().Maximum(bufferHeight - bufferHeight); // <=Error is here
ScrollBar().Minimum(0);
ScrollBar().Value(0);
ScrollBar().ViewportSize(bufferHeight);
....
}
```
This code is followed by the comment: *«Set up the height of the ScrollViewer and the grid we're using to fake our scrolling height».*
No doubts, simulating the scroll height is great, but why do we set 0 as the maximum? After referring to the [documentation](https://docs.microsoft.com/en-us/uwp/api/Windows.UI.Xaml.Controls.Primitives.ScrollBar), it became clear that the code is not very suspicious. Don't get me wrong: indeed, subtracting a variable from itself is suspicious, but we get zero at the output, which does not do any harm. In any case, I tried to specify the default value (1) in the *Maximum* field:
The scrollbar appeared, but it still does not work:

Just in case, then I was holding for about 30 seconds. Apparently this was not the problem, so I left it as it was, except for replacing *bufferHeight* – *bufferHeight* with 0:
```
bool TermControl::_InitializeTerminal()
{
....
auto bottom = _terminal->GetViewport().BottomExclusive();
auto bufferHeight = bottom;
ScrollBar().Maximum(0); // <= Here is the replacement
ScrollBar().Minimum(0);
ScrollBar().Value(0);
ScrollBar().ViewportSize(bufferHeight);
....
}
```
So, I wasn't actually getting close to solving the problem. In the absence of a better offer, let's move on to the debugging part. First, we could set a breakpoint on the changed line, but I doubt that it will help us somehow. Therefore, we first need to find the fragment that is responsible for the Viewport offset relatively to the buffer.
Let me tell you a bit about the internals of this scrollbar (and most likely about others as well). We have one big buffer that stores all the output. To interact with it, some kind of abstraction is used for printing on the screen, in this case, it's *viewport*.
Using these two primitives, we can become aware of what our problem is. Transition to the new line doesn't increase the buffer, that's why we simply have nowhere to go. Therefore, the problem is right in it.
Armed with this commonplace knowledge, we continue our heroic debugging. After a little walk around the function, this fragment got my attention:
```
// This event is explicitly revoked in the destructor: does not need weak_ref
auto onReceiveOutputFn = [this](const hstring str) {
_terminal->Write(str);
};
_connectionOutputEventToken = _connection.TerminalOutput(onReceiveOutputFn);
```
After we configured the *ScrollBar* above, let's move on to various callback functions and execute *\_\_connection.Start()* for our newly minted window. After which the above lambda is called. Since this is the first time we are writing something to the buffer, I suggest starting our debug from there.
We set a breakpoint inside the lambda and look in *\_terminal*: 
Now we have two variables that are extremely important to us — *\_buffer* and *\_mutableViewport*. Let's set breakpoints on them and find where they change. Well, I'll cheat here with *\_viewport* and set the breakpoint not at the variable itself but at its field *top*, which we actually need.
Now we're pressing , but nothing is happening… Ok, then let's press a couple of dozen times. Nothing happened. Apparently, we set the breakpoint at *\_buffer* too recklessly. *\_viewport* remained at the top of the buffer, which didn't increase in size.
In this case, it makes sense to enter a command to renew the *\_viewport* top. After that we stopped at a very interesting piece of code:
```
void Terminal::_AdjustCursorPosition(const COORD proposedPosition)
{
....
// Move the viewport down if the cursor moved below the viewport.
if (cursorPosAfter.Y > _mutableViewport.BottomInclusive())
{
const auto newViewTop =
std::max(0, cursorPosAfter.Y - (_mutableViewport.Height() - 1));
if (newViewTop != _mutableViewport.Top())
{
_mutableViewport = Viewport::FromDimensions(....); // <=
notifyScroll = true;
}
}
....
}
```
I left a comment where we stopped. If you look at the comment in the fragment, it becomes clear that we are closer to the solution than ever. It's in this place where the visible part is shifted relatively to the buffer, and we can scroll. Having observed this behavior a bit, I noticed one interesting point: when moving to a new line, the value of the *cursorPosAfter.Y* variable is equal to the value of *viewport*; therefore, we don't get it down it and nothing works. In addition, there is a similar problem with the *newViewTop* variable. Therefore, let's increase the value of *cursorPosAfter.Y* by one and see what will happen:
```
void Terminal::_AdjustCursorPosition(const COORD proposedPosition)
{
....
// Move the viewport down if the cursor moved below the viewport.
if (cursorPosAfter.Y + 1 > _mutableViewport.BottomInclusive())
{
const auto newViewTop =
std::max(0, cursorPosAfter.Y + 1 - (_mutableViewport.Height() - 1));
if (newViewTop != _mutableViewport.Top())
{
_mutableViewport = Viewport::FromDimensions(....); // <=
notifyScroll = true;
}
}
....
}
```
The result of this run:

Miracles! I pressed Enter a number of times, and the scrollbar works. Well, until we enter something… To demonstrate this fail, here's a gif file:

It seems that we're doing a few extra jumps to a new line. Let's then try to limit our transitions using the X coordinate. We will only shift the line when *X* is 0:
```
void Terminal::_AdjustCursorPosition(const COORD proposedPosition)
{
....
if ( proposedCursorPosition.X == 0
&& proposedCursorPosition.Y == _mutableViewport.BottomInclusive())
{
proposedCursorPosition.Y++;
}
// Update Cursor Position
cursor.SetPosition(proposedCursorPosition);
const COORD cursorPosAfter = cursor.GetPosition();
// Move the viewport down if the cursor moved below the viewport.
if (cursorPosAfter.Y > _mutableViewport.BottomInclusive())
{
const auto newViewTop =
std::max(0, cursorPosAfter.Y - (_mutableViewport.Height() - 1));
if (newViewTop != _mutableViewport.Top())
{
_mutableViewport = Viewport::FromDimensions(....);
notifyScroll = true;
}
}
....
}
```
The fragment written above will shift the *Y* coordinate for the cursor. Then we update the cursor position. In theory, this should work… What do we get?
Well, that's better. However, there is a problem: we shift the output point, but don't shift the buffer. Therefore, we see two calls of the same command. It may, of course, seem that I know what I am doing, but this is not so. :)
At this point, I decided to check the contents of the buffer, so I returned to the point at which I started the debugging:
```
// This event is explicitly revoked in the destructor: does not need weak_ref
auto onReceiveOutputFn = [this](const hstring str) {
_terminal->Write(str);
};
_connectionOutputEventToken = _connection.TerminalOutput(onReceiveOutputFn);
```
I set a breakpoint in the same place as last time, and started looking at the contents of the *str* variable. Let's start with what I saw on my screen:

What do you think will be in the *str* string when I press ?
1. String *«LONG DESCRIPTION»*.
2. The entire buffer that we now see.
3. The entire buffer, but without the first line.
Fine, enough of dragging it out — the entire buffer, but without the first line. And this is a considerable problem, because it is precisely the reason why we are losing history, moreover, fragmentarily. This is what our *help* output snippet will look like after moving to a new line:
I left an arrow at the place with *«LONG DESCRIPTOIN»*. Maybe then overwrite the buffer with an offset of one line? This would have worked if this callback had not been called every single time.
I have discovered at least three situations when it is called:
* When we enter any character;
* When we scroll through the history;
* When we execute a command.
The problem is that it has to move the buffer only when we execute the command, or press . In other cases, doing this is a bad idea. So we need to somehow determine what needs to be shifted inside.
Conclusion
----------

This article was an attempt to show how skillfully PVS-Studio was able to find defective code leading to the error I noticed. The message on the topic of a variable subtraction from itself strongly encouraged me, and I vigorously proceeded to write the text. However, as you can see, we haven't been out of the woods yet and everything turned out to be much more complicated.
So I decided to stop. I could have spent another couple of evenings, but the deeper I was going, the more problems emerged. All I can do is wish the Windows Terminal developers good luck in fixing this bug. :)
I hope I didn't disappoint the reader that I hadn't finished the research and it was interesting for you to take a walk with me along the insides of the project. As a compensation, I suggest using the #WindowsTerminal promo code, thanks to which you will receive a demo version of PVS-Studio not for a week, but for a month. If you haven't tried the PVS-Studio static analyzer in practice yet, this is a good reason to do it. Just enter "#WindowsTerminal" into the «Message» field on the [download page](https://www.viva64.com/en/pvs-studio-download/).
In addition, taking the opportunity, I'd like to remind you that soon there will be a version of the C# analyzer working under Linux and macOS. Right now you can sign up for beta testing. | https://habr.com/ru/post/493028/ | null | en | null |
# MVCC-7. Автоочистка
Напомню, что мы начали с вопросов, связанных с [изоляцией](https://habr.com/ru/company/postgrespro/blog/442804/), сделали отступление про [организацию данных на низком уровне](https://habr.com/ru/company/postgrespro/blog/444536/), подробно поговорили [о версиях строк](https://habr.com/ru/company/postgrespro/blog/445820/) и о том, как из версий получаются [снимки данных](https://habr.com/ru/company/postgrespro/blog/446652/).
Затем мы рассмотрели [внутристраничную очистку](https://habr.com/ru/company/postgrespro/blog/449704/) (и HOT-обновления), [обычную очистку](https://habr.com/ru/company/postgrespro/blog/452320/), ну а сегодня посмотрим на автоматическую очистку.
Автоочистка (autovacuum)
========================
Мы уже говорили о том, что обычная очистка в нормальных условиях (когда никто не удерживает надолго горизонт транзакций) должна справляться со своей работой. Вопрос в том, как часто ее вызывать.
Если очищать изменяющуюся таблицу слишком редко, она вырастет в размерах больше, чем хотелось бы. Кроме того, для очередной очистки может потребоваться несколько проходов по индексам, если изменений накопилось слишком много.
Если очищать таблицу слишком часто, то вместо полезной работы сервер будет постоянно заниматься обслуживанием — тоже нехорошо.
Заметим, что запуск обычной очистки по расписанию никак не решает проблему, потому что нагрузка может изменяться со временем. Если таблица стала обновляться активней, то и очищать ее надо чаще.
Автоматическая очистка — как раз тот самый механизм, который позволяет запускать очистку в зависимости от активности изменений в таблицах.
При включенной автоочистке (конфигурационный параметр *autovacuum*) в системе всегда присутствует процесс autovacuum launcher, который планирует работу, а реальной очисткой занимаются рабочие процессы autovacuum worker, несколько экземпляров которых могут работать параллельно.
Процесс autovacuum launcher составляет список баз данных, в которых есть какая-либо активность. Активность определяется по статистике, а чтобы она собиралась, должен быть установлен параметр *track\_counts*. Никогда не выключайте *autovacuum* и *track\_counts*, иначе автоочистка не будет работать.
Раз в *autovacuum\_naptime* процесс autovacuum launcher запускает (с помощью процесса postmaster) рабочий процесс для каждой БД из списка. Иными словами, если в базе данных есть какая-то активность, то рабочие процессы будет приходить в нее с интервалом *autovacuum\_naptime*. Для этого, если имеется несколько активных БД (N штук), то рабочие процессы запускаются в N раз чаще, чем *autovacuum\_naptime*. Но при этом общее количество одновременно работающих рабочих процессов ограничено параметром *autovacuum\_max\_workers*.
Запустившись, рабочий процесс подключается к указанной ему базе данных и начинает с того, что строит список:
* всех таблиц, материализованных представлений и toast-таблиц, требующих очистки,
* всех таблиц и материализованных представлений, требующих анализа (toast-таблицы не анализируются, потому что обращение к ним всегда происходит по индексу).
Дальше рабочий процесс по очереди очищает и/или анализирует отобранные объекты и по окончании очистки завершается.
Если процесс не успел выполнить всю намеченную работу за *autovacuum\_naptime*, процесс autovacuum launcher пошлет в ту же базу данных еще один рабочий процесс, и они будут работать вместе. «Вместе» просто означает, что второй процесс построит свой список таблиц и пойдет по нему. Таким образом, параллельно будут обрабатываться разные таблицы, но на уровне одной таблицы параллелизма нет — если один из рабочих процессов уже занимается таблицей, другой пропустит ее и пойдет дальше.
> Обсуждение необходимости параллельной обработки идет уже давно, но [патч](https://commitfest.postgresql.org/23/1774/) пока не принят.
>
>
Теперь разберемся детальнее, что значит «требует очистки» и «требует анализа».
Какие таблицы требуют очистки
=============================
Считается, что очистка необходима, если число «мертвых», то есть неактуальных, версий строк превышает установленное пороговое значение. Число мертвых версий постоянно собирается коллектором статистики и хранится в таблице pg\_stat\_all\_tables. А порог задается двумя параметрами:
* *autovacuum\_vacuum\_threshold* определяет абсолютное значение (в штуках),
* *autovacuum\_vacuum\_scale\_factor* определяет долю строк в таблице.
Итоговая формула такая: очистка требуется, если pg\_stat\_all\_tables.n\_dead\_tup >= *autovacuum\_vacuum\_threshold* + *autovacuum\_vacuum\_scale\_factor* \* pg\_class.reltupes.
Настройки по умолчанию устанавливают *autovacuum\_vacuum\_threshold* = 50 и
*autovacuum\_vacuum\_scale\_factor* = 0.2. Главный параметр здесь, конечно, *autovacuum\_vacuum\_scale\_factor* — именно он важен для больших таблиц (а именно с ними связаны возможные проблемы). Значение 20% представляется сильно завышенным, скорее всего его потребуется существенно уменьшить.
Оптимальные значения параметров могут отличаться для разных таблиц в зависимости от их размера и характера изменений. Имеет смысл установить в целом адекватные значения, и — при необходимости — настроить специальным образом параметры на уровне некоторых таблиц с помощью параметров хранения:
* *autovacuum\_vacuum\_threshold* и *toast.autovacuum\_vacuum\_threshold*,
* *autovacuum\_vacuum\_scale\_factor* и *toast.autovacuum\_vacuum\_scale\_factor*.
Чтобы не запутаться, это стоит делать только для небольшого числа таблиц, которые выделяются среди прочих объемом или интенсивностью изменений, и только в том случае, когда глобально установленные значения не подходят.
Кроме того, автоочистку можно отключать на уровне таблиц (хотя сложно придумать причину, по которой это было бы необходимо):
* *autovacuum\_enabled* и *toast.autovacuum\_enabled*.
Например, в прошлый раз мы создавали таблицу vac с отключенной автоочисткой, чтобы — для целей демонстрации — управлять очисткой вручную. Параметр хранения можно изменить следующим образом:
```
=> ALTER TABLE vac SET (autovacuum_enabled = off);
```
Чтобы формализовать все сказанное выше, создадим представление, показывающее, какие таблицы в данный момент нуждаются в очистке. Оно будет использовать функцию, возвращающую текущее значение параметра с учетом того, что оно может быть переопределено на уровне таблицы:
```
=> CREATE FUNCTION get_value(param text, reloptions text[], relkind "char")
RETURNS float
AS $$
SELECT coalesce(
-- если параметр хранения задан, то берем его
(SELECT option_value
FROM pg_options_to_table(reloptions)
WHERE option_name = CASE
-- для toast-таблиц имя параметра отличается
WHEN relkind = 't' THEN 'toast.' ELSE ''
END || param
),
-- иначе берем значение конфигурационного параметра
current_setting(param)
)::float;
$$ LANGUAGE sql;
```
А вот и представление:
```
=> CREATE VIEW need_vacuum AS
SELECT st.schemaname || '.' || st.relname tablename,
st.n_dead_tup dead_tup,
get_value('autovacuum_vacuum_threshold', c.reloptions, c.relkind) +
get_value('autovacuum_vacuum_scale_factor', c.reloptions, c.relkind) * c.reltuples
max_dead_tup,
st.last_autovacuum
FROM pg_stat_all_tables st,
pg_class c
WHERE c.oid = st.relid
AND c.relkind IN ('r','m','t');
```
Какие таблицы требуют анализа
=============================
С автоанализом дело обстоит примерно так же. Считается, что анализа требуют те таблицы, у которых число измененных (с момента прошлого анализа) версий строк превышает пороговое значение, заданное двумя аналогичными параметрами: pg\_stat\_all\_tables.n\_mod\_since\_analyze >= *autovacuum\_analyze\_threshold* + *autovacuum\_analyze\_scale\_factor* \* pg\_class.reltupes.
Умолчательные настройки автоанализа немного отличаются: *autovacuum\_analyze\_threshold* = 50 и *autovacuum\_analyze\_scale\_factor* = 0.1. Их также можно определить на уровне параметров хранения отдельных таблиц:
* *autovacuum\_analyze\_threshold*,
* *autovacuum\_analyze\_scale\_factor*
Поскольку toast-таблицы не анализируются, соответствующих параметров для них нет.
Создадим представление и для анализа:
```
=> CREATE VIEW need_analyze AS
SELECT st.schemaname || '.' || st.relname tablename,
st.n_mod_since_analyze mod_tup,
get_value('autovacuum_analyze_threshold', c.reloptions, c.relkind) +
get_value('autovacuum_analyze_scale_factor', c.reloptions, c.relkind) * c.reltuples
max_mod_tup,
st.last_autoanalyze
FROM pg_stat_all_tables st,
pg_class c
WHERE c.oid = st.relid
AND c.relkind IN ('r','m');
```
Пример
======
Для экспериментов установим такие значение параметров:
```
=> ALTER SYSTEM SET autovacuum_naptime = ‘1s’; -- чтобы долго не ждать
=> ALTER SYSTEM SET autovacuum_vacuum_scale_factor = 0.03; -- 3%
=> ALTER SYSTEM SET autovacuum_vacuum_threshold = 0;
=> ALTER SYSTEM SET autovacuum_analyze_scale_factor = 0.02; -- 2%
=> ALTER SYSTEM SET autovacuum_analyze_threshold = 0;
```
```
=> SELECT pg_reload_conf();
```
```
pg_reload_conf
----------------
t
(1 row)
```
Теперь создадим таблицу, аналогичную той, что мы использовали в прошлый раз, и вставим в нее тысячу строк. Автоочистка отключена на уровне таблицы, и мы будем сами включать ее. Если этого не сделать, то примеры не будут воспроизводимы, поскольку автоочистка может сработать в неподходящий момент времени.
```
=> CREATE TABLE autovac(
id serial,
s char(100)
) WITH (autovacuum_enabled = off);
=> INSERT INTO autovac SELECT g.id,'A' FROM generate_series(1,1000) g(id);
```
Вот что покажет наше представление для очистки:
```
=> SELECT * FROM need_vacuum WHERE tablename = 'public.autovac';
```
```
tablename | dead_tup | max_dead_tup | last_autovacuum
----------------+----------+--------------+-----------------
public.autovac | 0 | 0 |
(1 row)
```
Тут есть два момента, на которые стоит обратить внимание. Во-первых, max\_dead\_tup = 0, хотя 3% от 1000 строк составляет 30 строк. Дело в том, что у нас еще нет статистики по таблице, поскольку INSERT сам по себе ее не обновляет. Пока наша таблица не будет проанализирована, нули так и останутся, поскольку pg\_class.reltuples = 0. Однако заглянем во второе представление для анализа:
```
=> SELECT * FROM need_analyze WHERE tablename = 'public.autovac';
```
```
tablename | mod_tup | max_mod_tup | last_autoanalyze
----------------+---------+-------------+------------------
public.autovac | 1000 | 0 |
(1 row)
```
Поскольку в таблице изменилось (добавилось) 1000 строк, и это больше нуля, должен сработать автоанализ. Проверим это:
```
=> ALTER TABLE autovac SET (autovacuum_enabled = on);
```
После небольшой паузы видим, что таблица проанализирована и вместо нулей в max\_mod\_tup мы видим корректные 20 строк:
```
=> SELECT * FROM need_analyze WHERE tablename = 'public.autovac';
```
```
tablename | mod_tup | max_mod_tup | last_autoanalyze
----------------+---------+-------------+-------------------------------
public.autovac | 0 | 20 | 2019-05-21 11:59:48.465987+03
(1 row)
```
```
=> SELECT reltuples, relpages FROM pg_class WHERE relname = 'autovac';
```
```
reltuples | relpages
-----------+----------
1000 | 17
(1 row)
```
Вернемся к автоочистке:
```
=> SELECT * FROM need_vacuum WHERE tablename = 'public.autovac';
```
```
tablename | dead_tup | max_dead_tup | last_autovacuum
----------------+----------+--------------+-----------------
public.autovac | 0 | 30 |
(1 row)
```
Max\_dead\_tup, как мы видим, уже исправился. Второй момент, на который надо обратить внимание — dead\_tup = 0. Статистика показывает, что в таблице нет мертвых версий строк… и это правда. Очищать в нашей таблице пока нечего. Так и любая таблица, использующаяся только в режиме добавления данных (append-only), не будет очищаться и, стало быть, для нее не будет обновляться карта видимости. А это делает невозможным использование исключительно индексного сканирования (index-only scan).
(В следующий раз мы увидим, что очистка рано или поздно придет и в append-only-таблицу, но происходить это будет очень редко.)
Практический вывод: если важно использовать исключительно индексное сканирование, может потребоваться вызывать очистку вручную.
Теперь снова отключим автоочистку и обновим 31 строку — на один больше, чем пороговое значение.
```
=> ALTER TABLE autovac SET (autovacuum_enabled = off);
=> UPDATE autovac SET s = 'B' WHERE id <= 31;
=> SELECT * FROM need_vacuum WHERE tablename = 'public.autovac';
```
```
tablename | dead_tup | max_dead_tup | last_autovacuum
----------------+----------+--------------+-----------------
public.autovac | 31 | 30 |
(1 row)
```
Теперь условие срабатывания автоочистки выполняется. Включим автоочистку и после непродолжительной паузы увидим, что таблица обработана:
```
=> ALTER TABLE autovac SET (autovacuum_enabled = on);
=> SELECT * FROM need_vacuum WHERE tablename = 'public.autovac';
```
```
tablename | dead_tup | max_dead_tup | last_autovacuum
----------------+----------+--------------+-------------------------------
public.autovac | 0 | 30 | 2019-05-21 11:59:52.554571+03
(1 row)
```
Регулирование нагрузки
======================
Очистка не блокирует другие процессы, поскольку работает постранично, но тем не менее создает нагрузку на систему и может оказывать заметное влияние на производительность.
Регулирование для обычной очистки
---------------------------------
Чтобы иметь возможность управлять интенсивностью очистки и, следовательно, ее влиянием на систему, процесс чередует работу и ожидание. Очистка выполняет примерно *vacuum\_cost\_limit* условных единиц работы, а затем засыпает на *vacuum\_cost\_delay* мс.
Настройки по умолчанию устанавливают *vacuum\_cost\_limit* = 200, *vacuum\_cost\_delay* = 0. Последний нолик фактически означает, что (обычная) очистка не засыпает, так что конкретное значение *vacuum\_cost\_limit* не играет никакой роли. Это сделано из соображения, что если уж администратору пришлось запускать VACUUM вручную, то он, вероятно, хочет выполнить очистку как можно быстрее.
Тем не менее, если все-таки установить время сна, то указанный в *vacuum\_cost\_limit* объем работы будет складываться из стоимостей работы со страницами в буферном кэше. Каждое обращение к странице оценивается следующим образом:
* если страница нашлась в буферном кэше, то *vacuum\_cost\_page\_hit* = 1;
* если не нашлась, то *vacuum\_cost\_page\_miss* = 10;
* если не нашлась, да еще пришлось вытеснять из буфера грязную страницу, то *vacuum\_cost\_page\_dirty* = 20.
То есть с настройками *vacuum\_cost\_limit* по умолчанию, за один присест могут быть обработаны 200 страниц из кэша, или 20 страниц с диска, или 10 страниц с вытеснением. Понятно, что это довольно условные цифры, но подбирать их точнее нет смысла.
Регулирование для автоочистки
-----------------------------
Регулирование нагрузки при автоматической очистке работает так же, как и для обычной. Но чтобы очистка, запускаемая вручную, и автоочистка могли работать с разной интенсивностью, для автоочистки сделаны собственные параметры: *autovacuum\_vacuum\_cost\_limit* и *autovacuum\_vacuum\_cost\_delay*. Если эти параметры принимают значение -1, то используется значение из *vacuum\_cost\_limit* и/или *vacuum\_cost\_delay*.
По умолчанию *autovacuum\_vacuum\_cost\_limit* = -1 (то есть используется значение *vacuum\_cost\_limit* = 200) и *autovacuum\_vacuum\_cost\_delay* = 20ms. На современной аппаратуре с этими цифрами автоочистка будет работать очень и очень медленно.
В версии 12 значение *autovacuum\_vacuum\_cost\_delay* будет уменьшено до 2ms, что можно считать более подходящим первым приближением.
Кроме того следует учитывать, что предел, устанавливаемый этими параметрами, общий для всех рабочих процессов. Иными словами, при изменении числа одновременно работающих рабочих процессов общая нагрузка будет оставаться постоянной. Поэтому, если стоит задача увеличить производительность автоочистки, то при добавлении рабочих процессов стоит увеличить и *autovacuum\_vacuum\_cost\_limit*.
Использование памяти и мониторинг
---------------------------------
В [прошлый раз](https://habr.com/ru/company/postgrespro/blog/452320/) мы рассматривали, как очистка использует оперативную память размером *maintenance\_work\_mem* для хранения идентификаторов версий строк, подлежащих очистке.
Автоочистка поступает абсолютно так же. Но одновременно работающих процессов может быть много, если установить *autovacuum\_max\_workers* в большое значение. К тому же вся память выделяется сразу и полностью, а не по необходимости. Поэтому для рабочего процесса автоочистки можно установить собственное ограничение с помощью параметра *autovacuum\_work\_mem*. По умолчанию этот параметр равен -1, то есть не используется.
Как уже говорилось, очистка может работать и с минимальным объемом памяти. Но если на таблице созданы индексы, то небольшое значение *maintenance\_work\_mem* может привести к повторным сканированиям индексов. То же самое справедливо и для автоочистки. В идеале следует подобрать такое минимальное значение *autovacuum\_work\_mem*, при котором повторные сканирования не происходят.
Мы видели, что для мониторинга очистки можно использовать параметр VERBOSE (но его нельзя указать для автоочистки) или представление pg\_stat\_progress\_vacuum (но оно показывает только текущую информацию). Поэтому основной способ мониторинга автоочистки — параметр *log\_autovacuum\_min\_duration*, который выводит информацию в журнал сообщений сервера. По умолчанию он выключен (установлен в -1). Есть резон включить этот параметр (при значении 0 будет выводиться информация о всех запусках автоочистки) и наблюдать за цифрами.
Вот как выглядит выводимая информация:
```
=> ALTER SYSTEM SET log_autovacuum_min_duration = 0;
=> SELECT pg_reload_conf();
```
```
pg_reload_conf
----------------
t
(1 row)
```
```
=> UPDATE autovac SET s = 'C' WHERE id <= 31;
```
```
student$ tail -n 7 /var/log/postgresql/postgresql-11-main.log
```
```
2019-05-21 11:59:55.675 MSK [9737] LOG: automatic vacuum of table "test.public.autovac": index scans: 0
pages: 0 removed, 18 remain, 0 skipped due to pins, 0 skipped frozen
tuples: 31 removed, 1000 remain, 0 are dead but not yet removable, oldest xmin: 4040
buffer usage: 78 hits, 0 misses, 0 dirtied
avg read rate: 0.000 MB/s, avg write rate: 0.000 MB/s
system usage: CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s
2019-05-21 11:59:55.676 MSK [9737] LOG: automatic analyze of table "test.public.autovac" system usage: CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s
```
Все необходимые сведения здесь присутствуют.
Напомним, что зачастую следует не увеличивать размер памяти, а уменьшать порог срабатывания очистки, чтобы за один раз обрабатывалось меньше данных.
Также может иметь смысл мониторить длину списка таблиц, требующих очистки, с помощью приведенных выше представлений. Увеличение длины списка будет свидетельствовать о том, что автоочистка не успевает выполнять свою работу и требуется изменение настроек.
[Продолжение](https://habr.com/ru/company/postgrespro/blog/455590/). | https://habr.com/ru/post/452762/ | null | ru | null |
# Создание Aimbot для Half-Life 2
[](https://habr.com/ru/company/ruvds/blog/676270/)
В этом посте мы расскажем о процессе создания aimbot — программы, автоматически прицеливающейся во врагов в игре жанра «шутер от первого лица» (FPS). Создавать будем aimbot для игры [Half-Life 2](https://en.wikipedia.org/wiki/Half-Life_2), работающей на движке [Source](https://en.wikipedia.org/wiki/Source_(game_engine)). Aimbot будет работать внутри процесса игры и использовать для своей работы внутренние функции игры, подвергнутые реверс-инжинирингу (в отличие от других систем, работающих снаружи игры и сканирующих экран).
Для начала изучим [Source SDK](https://github.com/ValveSoftware/source-sdk-2013/tree/master) и используем его как руководство для реверс-инжиниринга исполняемого файла Half-Life 2. Затем мы применим полученные данные, для создания бота. К концу статьи у нас будет написан aimbot, привязывающий прицел игрока к ближайшему врагу.
▍ Реверс-инжиниринг и Source SDK
--------------------------------
Давайте рассмотрим, как выполнить реверс-инжиниринг исполняемого файла, чтобы найти нужную нам информацию. Для создания кода, который будет автоматически прицеливаться в мишень, нужно знать следующее:
* Позицию глаз игрока
* Позицию глаз ближайшего врага
* Вектор от глаза игрока к глазу врага (получаемый по двум предыдущим пунктам)
* Способ изменения положения камеры игрока так, чтобы глаз игрока смотрел по вектору к глазу врага
Для всего, кроме третьего пункта, требуется получать информацию от состояния запущенной игры. Эту информацию получают реверс-инжинирингом игры для поиска классов, содержащих соответствующие поля. Обычно это оказывается чрезвычайно трудоёмкой задачей со множеством проб и ошибок; однако в данном случае у нас есть доступ к [Source SDK](https://github.com/ValveSoftware/source-sdk-2013/tree/master), который мы используем в качестве руководства.
Начнём поиск с нахождения ссылок на позицию глаз в репозитории. Изучив несколько страниц с результатами поиска, мы выйдем на огромный класс [CBaseEntity](https://github.com/ValveSoftware/source-sdk-2013/blob/0d8dceea4310fde5706b3ce1c70609d72a38efdf/mp/src/game/server/baseentity.h#L344). Внутри этого класса есть две функции:
```
virtual Vector EyePosition(void);
virtual const QAngle &EyeAngles(void);
```
Так как *CBaseEntity* является базовым классом, от которого происходят все [сущности](https://developer.valvesoftware.com/wiki/List_of_HL2_entities) (entity) игры, и он содержит члены для позиции глаза и углов камеры, то похоже, именно с ним нам и нужно работать. Дальше нам нужно посмотреть, откуда ссылаются на эти функции. Снова немного поискав на GitHub Source SDK, мы находим интерфейс [IServerTools](https://github.com/ValveSoftware/source-sdk-2013/blob/0d8dceea4310fde5706b3ce1c70609d72a38efdf/mp/src/public/toolframework/itoolentity.h#L173), у которого есть несколько весьма многообещающих функций:
```
virtual IServerEntity *GetIServerEntity(IClientEntity *pClientEntity) = 0;
virtual bool SnapPlayerToPosition(const Vector &org, const QAngle ∠, IClientEntity *pClientPlayer = NULL) = 0;
virtual bool GetPlayerPosition(Vector &org, QAngle ∠, IClientEntity *pClientPlayer = NULL) = 0;
// ...
virtual CBaseEntity *FirstEntity(void) = 0;
virtual CBaseEntity *NextEntity(CBaseEntity *pEntity) = 0;
```
В этом интерфейсе очень удобно то, что он предоставляет доступ к позиции локального игрока, что позволяет привязать игрока к другой позиции и углу обзора, а также обеспечивает возможность итеративно обходить сущности. К тому же его экземпляр создаётся глобально и привязан к жёстко прописанной в коде строке.
```
#define VSERVERTOOLS_INTERFACE_VERSION_1 "VSERVERTOOLS001"
#define VSERVERTOOLS_INTERFACE_VERSION_2 "VSERVERTOOLS002"
#define VSERVERTOOLS_INTERFACE_VERSION "VSERVERTOOLS003"
#define VSERVERTOOLS_INTERFACE_VERSION_INT 3
// ...
EXPOSE_SINGLE_INTERFACE_GLOBALVAR(CServerTools, IServerTools001, VSERVERTOOLS_INTERFACE_VERSION_1, g_ServerTools);
EXPOSE_SINGLE_INTERFACE_GLOBALVAR(CServerTools, IServerTools, VSERVERTOOLS_INTERFACE_VERSION, g_ServerTools);
```
Можем начать разработку aimbot с поиска этого класса в памяти. Запустив Half-Life 2 и подключив к нему [отладчик](https://x64dbg.com/), поищем строковые ссылки на *VSERVERTOOLS*.

Мы видим, откуда на них ссылаются:
```
7BCAB090 | 68 88FA1F7C | push server.7C1FFA88 | 7C1FFA88:"VSERVERTOOLS001"
7BCAB095 | 68 00C4087C | push server.7C08C400 |
7BCAB09A | B9 B02A337C | mov ecx,server.7C332AB0 |
7BCAB09F | E8 8CCA3F00 | call server.7C0A7B30 |
7BCAB0A4 | C3 | ret |
7BCAB0A5 | CC | int3 |
7BCAB0A6 | CC | int3 |
7BCAB0A7 | CC | int3 |
7BCAB0A8 | CC | int3 |
7BCAB0A9 | CC | int3 |
7BCAB0AA | CC | int3 |
7BCAB0AB | CC | int3 |
7BCAB0AC | CC | int3 |
7BCAB0AD | CC | int3 |
7BCAB0AE | CC | int3 |
7BCAB0AF | CC | int3 |
7BCAB0B0 | 68 98FA1F7C | push server.7C1FFA98 | 7C1FFA98:"VSERVERTOOLS002"
7BCAB0B5 | 68 00C4087C | push server.7C08C400 |
7BCAB0BA | B9 BC2A337C | mov ecx,server.7C332ABC |
7BCAB0BF | E8 6CCA3F00 | call server.7C0A7B30 |
7BCAB0C4 | C3 | ret |
```
В ассемблерном листинге видно, что функция-член *server.7C0A7B30* вызывается в *server.7C332AB0* и *server.7C332ABC*. Эта функция получает два аргумента, один из которых — это имя-строка интерфейса. После изучения отладчика становится понятно, что второй параметр — это статический экземпляр чего-то.

Посмотрев на то, что делает в коде макрос *EXPOSE\_SINGLE\_INTERFACE\_GLOBALVAR*, становится понятнее, что это синглтон [CServerTools](https://github.com/ValveSoftware/source-sdk-2013/blob/0d8dceea4310fde5706b3ce1c70609d72a38efdf/sp/src/game/server/entity_tools_server.cpp#L63), предоставленный как глобальный интерфейс. Зная это, мы легко сможем получить указатель на этот синглтон в среде исполнения: мы просто берём адрес этой псевдофункции, перемещающей указатель в *EAX*, и вызываем её напрямую. Чтобы сделать это, можно написать следующий дженерик-код, который мы продолжим применять для нового использования других функций:
```
template
T GetFunctionPointer(const std::string moduleName, const DWORD\_PTR offset) {
auto moduleBaseAddress{ GetModuleHandleA(moduleName.c\_str()) };
if (moduleBaseAddress == nullptr) {
std::cerr << "Could not get base address of " << moduleName
<< std::endl;
std::abort();
}
return reinterpret\_cast(
reinterpret\_cast(moduleBaseAddress) + offset);
}
IServerTools\* GetServerTools() {
constexpr auto globalServerToolsOffset{ 0x3FC400 };
static GetServerToolsFnc getServerToolsFnc{ GetFunctionPointer(
"server.dll", globalServerToolsOffset) };
return getServerToolsFnc();
}
```
Здесь мы берём базовый адрес, в который загружена *server.dll*, добавляем смещение, чтобы попасть туда, откуда можно получить доступ к синглтону *CServerTools*, и возвращаем его как указатель вызывающей функции. Благодаря этому мы сможем вызывать нужные нам функции в интерфейсе и игра будет реагировать соответствующим образом. Нас интересуют две функции: [GetPlayerPosition](https://github.com/ValveSoftware/source-sdk-2013/blob/0d8dceea4310fde5706b3ce1c70609d72a38efdf/sp/src/game/server/entity_tools_server.cpp#L110) и [SnapPlayerToPosition](https://github.com/ValveSoftware/source-sdk-2013/blob/0d8dceea4310fde5706b3ce1c70609d72a38efdf/sp/src/game/server/entity_tools_server.cpp#L122).
Внутри *GetPlayerPosition* при помощи вызова [UTIL\_GetLocalPlayer](https://github.com/ValveSoftware/source-sdk-2013/blob/0d8dceea4310fde5706b3ce1c70609d72a38efdf/mp/src/game/server/util.cpp#L643) получается класс локального игрока, а также вызываются *EyePosition* и *EyeAngles*; внутри *SnapPlayerToPosition* при помощи *SnapEyeAngles* корректируются углы обзора игрока. Всё вместе это даёт нам то, что необходимо для получения позиций и углов обзора сущностей, благодаря чему можно выполнить соответствующие вычисления нового вектора и угла обзора, привязывающихся к глазам врагов.
Давайте разбираться по порядку, начнём с *GetPlayerPosition*. Так как мы можем получить указатель на *IServerTools* и имеем определение интерфейса, можно выполнить явный вызов *GetPlayerPosition* и пошагово пройтись по вызову при помощи отладчика. При этом мы попадём сюда:
```
7C08BEF0 | 55 | push ebp |
7C08BEF1 | 8BEC | mov ebp,esp |
7C08BEF3 | 8B01 | mov eax,dword ptr ds:[ecx] |
7C08BEF5 | 83EC 0C | sub esp,C |
7C08BEF8 | 56 | push esi |
7C08BEF9 | FF75 10 | push dword ptr ss:[ebp+10] |
7C08BEFC | FF50 04 | call dword ptr ds:[eax+4] |
7C08BEFF | 8BF0 | mov esi,eax |
7C08BF01 | 85F6 | test esi,esi |
7C08BF03 | 75 14 | jne server.7C08BF19 |
7C08BF05 | E8 E616E7FF | call server.7BEFD5F0 |
7C08BF0A | 8BF0 | mov esi,eax |
7C08BF0C | 85F6 | test esi,esi |
7C08BF0E | 75 09 | jne server.7C08BF19 |
7C08BF10 | 32C0 | xor al,al |
7C08BF12 | 5E | pop esi |
7C08BF13 | 8BE5 | mov esp,ebp |
7C08BF15 | 5D | pop ebp |
7C08BF16 | C2 0C00 | ret C |
7C08BF19 | 8B06 | mov eax,dword ptr ds:[esi] |
7C08BF1B | 8D4D F4 | lea ecx,dword ptr ss:[ebp-C] |
7C08BF1E | 51 | push ecx |
7C08BF1F | 8BCE | mov ecx,esi |
7C08BF21 | FF90 08020000 | call dword ptr ds:[eax+208] |
7C08BF27 | 8B4D 08 | mov ecx,dword ptr ss:[ebp+8] |
7C08BF2A | D900 | fld st(0),dword ptr ds:[eax] |
7C08BF2C | D919 | fstp dword ptr ds:[ecx],st(0) |
7C08BF2E | D940 04 | fld st(0),dword ptr ds:[eax+4] |
7C08BF31 | D959 04 | fstp dword ptr ds:[ecx+4],st(0) |
7C08BF34 | D940 08 | fld st(0),dword ptr ds:[eax+8] |
7C08BF37 | 8B06 | mov eax,dword ptr ds:[esi] |
7C08BF39 | D959 08 | fstp dword ptr ds:[ecx+8],st(0) |
7C08BF3C | 8BCE | mov ecx,esi |
7C08BF3E | FF90 0C020000 | call dword ptr ds:[eax+20C] |
7C08BF44 | 8B4D 0C | mov ecx,dword ptr ss:[ebp+C] |
7C08BF47 | 5E | pop esi |
7C08BF48 | D900 | fld st(0),dword ptr ds:[eax] |
7C08BF4A | D919 | fstp dword ptr ds:[ecx],st(0) |
7C08BF4C | D940 04 | fld st(0),dword ptr ds:[eax+4] |
7C08BF4F | D959 04 | fstp dword ptr ds:[ecx+4],st(0) |
7C08BF52 | D940 08 | fld st(0),dword ptr ds:[eax+8] |
7C08BF55 | B0 01 | mov al,1 |
7C08BF57 | D959 08 | fstp dword ptr ds:[ecx+8],st(0) |
7C08BF5A | 8BE5 | mov esp,ebp |
7C08BF5C | 5D | pop ebp |
7C08BF5D | C2 0C00 | ret C |
```
Разбираться в этом довольно долго, однако в виде графа потока управления всё выглядит довольно просто:
Если построчно сопоставить дизассемблированную программу с кодом, то мы достаточно быстро найдём необходимое. Код вызывает функцию *UTIL\_GetLocalPlayer* только тогда, когда переданный параметр *pClientEntity* равен `null`. Эта логика проверяется в блоке первой функции графа. Если существует действительная клиентская сущность, код переходит к получению позиции и углов глаза для неё, а в противном случае получает сущность локального игрока. Этот вызов происходит при исполнении команды *call server.7BEFD5F0* по адресу **server.*7C08BF05*. Как и ранее, мы можем создать указатель функции на *UTIL\_GetLocalPlayer* и вызывать её напрямую.
```
CBasePlayer* GetLocalPlayer() {
constexpr auto globalGetLocalPlayerOffset{ 0x26D5F0 };
static GetLocalPlayerFnc getLocalPlayerFnc{ GetFunctionPointer(
"server.dll", globalGetLocalPlayerOffset) };
return getLocalPlayerFnc();
}
```
Следующими в дизассемблированном коде идут вызовы функций *EyePosition* и *EyeAngles*. Нас интересует только получение позиций глаза, поэтому важен только первый вызов. Для получения адреса функции мы можем пошагово пройти по вызову, пока не вызовем адрес, находящийся в [*EAX+0x208*]. После исполнения этой команды мы перейдём на *server.dll+0x119D00*, таким образом узнав, где находится функция.
```
Vector GetEyePosition(CBaseEntity* entity) {
constexpr auto globalGetEyePositionOffset{ 0x119D00 };
static GetEyePositionFnc getEyePositionFnc{ GetFunctionPointer(
"server.dll", globalGetEyePositionOffset) };
return getEyePositionFnc(entity);
}
```
И это всё, что нам нужно от *GetPlayerPosition*; теперь у нас есть возможность получения указателя локальной сущности игрока и получения позиции глаза сущности. Последнее, что нам потребуется — возможность задания угла обзора игрока. Как говорилось выше, это можно сделать, вызвав функцию *SnapPlayerToPosition* и посмотрев, где находится функция *SnapEyeAngles*. Дизассемблированный код *SnapEyeAngles* выглядит следующим образом:
```
7C08C360 | 55 | push ebp |
7C08C361 | 8BEC | mov ebp,esp |
7C08C363 | 8B01 | mov eax,dword ptr ds:[ecx] |
7C08C365 | 83EC 0C | sub esp,C |
7C08C368 | 56 | push esi |
7C08C369 | FF75 10 | push dword ptr ss:[ebp+10] |
7C08C36C | FF50 04 | call dword ptr ds:[eax+4] |
7C08C36F | 8BF0 | mov esi,eax |
7C08C371 | 85F6 | test esi,esi |
7C08C373 | 75 14 | jne server.7C08C389 |
7C08C375 | E8 7612E7FF | call server.7BEFD5F0 |
7C08C37A | 8BF0 | mov esi,eax |
7C08C37C | 85F6 | test esi,esi |
7C08C37E | 75 09 | jne server.7C08C389 |
7C08C380 | 32C0 | xor al,al |
7C08C382 | 5E | pop esi |
7C08C383 | 8BE5 | mov esp,ebp |
7C08C385 | 5D | pop ebp |
7C08C386 | C2 0C00 | ret C |
7C08C389 | 8B06 | mov eax,dword ptr ds:[esi] |
7C08C38B | 8BCE | mov ecx,esi |
7C08C38D | FF90 24020000 | call dword ptr ds:[eax+224] |
7C08C393 | 8B4D 08 | mov ecx,dword ptr ss:[ebp+8] |
7C08C396 | F3:0F1001 | movss xmm0,dword ptr ds:[ecx] |
7C08C39A | F3:0F5C00 | subss xmm0,dword ptr ds:[eax] |
7C08C39E | F3:0F1145 F4 | movss dword ptr ss:[ebp-C],xmm0 |
7C08C3A3 | F3:0F1041 04 | movss xmm0,dword ptr ds:[ecx+4] |
7C08C3A8 | F3:0F5C40 04 | subss xmm0,dword ptr ds:[eax+4] |
7C08C3AD | F3:0F1145 F8 | movss dword ptr ss:[ebp-8],xmm0 |
7C08C3B2 | F3:0F1041 08 | movss xmm0,dword ptr ds:[ecx+8] |
7C08C3B7 | 8BCE | mov ecx,esi |
7C08C3B9 | F3:0F5C40 08 | subss xmm0,dword ptr ds:[eax+8] |
7C08C3BE | 8D45 F4 | lea eax,dword ptr ss:[ebp-C] |
7C08C3C1 | 50 | push eax |
7C08C3C2 | F3:0F1145 FC | movss dword ptr ss:[ebp-4],xmm0 |
7C08C3C7 | E8 14CFD0FF | call server.7BD992E0 |
7C08C3CC | FF75 0C | push dword ptr ss:[ebp+C] |
7C08C3CF | 8BCE | mov ecx,esi |
7C08C3D1 | E8 4A0FE0FF | call server.7BE8D320 |
7C08C3D6 | 8B06 | mov eax,dword ptr ds:[esi] |
7C08C3D8 | 8BCE | mov ecx,esi |
7C08C3DA | 6A FF | push FFFFFFFF |
7C08C3DC | 6A 00 | push 0 |
7C08C3DE | FF90 88000000 | call dword ptr ds:[eax+88] |
7C08C3E4 | B0 01 | mov al,1 |
7C08C3E6 | 5E | pop esi |
7C08C3E7 | 8BE5 | mov esp,ebp |
7C08C3E9 | 5D | pop ebp |
7C08C3EA | C2 0C00 | ret C |
```
Повторив уже описанный выше процесс, мы выясним, что команда *call server.7BE8D320* является вызовом *SnapEyeAngles*. Мы можем определить следующую функцию:
```
void SnapEyeAngles(CBasePlayer* player, const QAngle& angles)
{
constexpr auto globalSnapEyeAnglesOffset{ 0x1FD320 };
static SnapEyeAnglesFnc snapEyeAnglesFnc{ GetFunctionPointer(
"server.dll", globalSnapEyeAnglesOffset) };
return snapEyeAnglesFnc(player, angles);
}
```
Итак, теперь у нас есть всё необходимое.
▍ Создание aimbot
-----------------
Для создания aimbot нам нужно следующее:
* Итеративно обойти сущности
+ Если сущность является врагом, то найти расстояние между сущностью и игроком
+ Отслеживать ближайшую сущность
* Вычислить вектор «глаз-глаз» между игроком и ближайшим врагом
* Корректировать углы глаза игрока так, чтобы он следовал за этим вектором
Ранее мы узнали, что для получения позиции игрока можно вызвать [GetPlayerPosition](https://github.com/ValveSoftware/source-sdk-2013/blob/0d8dceea4310fde5706b3ce1c70609d72a38efdf/sp/src/game/server/entity_tools_server.cpp#L110). Для циклического обхода списка сущностей можно вызвать [FirstEntity](https://github.com/ValveSoftware/source-sdk-2013/blob/0d8dceea4310fde5706b3ce1c70609d72a38efdf/mp/src/game/server/entity_tools_server.cpp#L191) и [NextEntity](https://github.com/ValveSoftware/source-sdk-2013/blob/0d8dceea4310fde5706b3ce1c70609d72a38efdf/mp/src/game/server/entity_tools_server.cpp#L196), которые возвращают указатель на экземпляр [CBaseEntity](https://github.com/ValveSoftware/source-sdk-2013/blob/0d8dceea4310fde5706b3ce1c70609d72a38efdf/mp/src/game/server/baseentity.h#L344). Чтобы понять, является ли сущность врагом, можно сравнить имя сущности со множеством имён враждебных [NPC-сущностей](https://developer.valvesoftware.com/wiki/List_of_HL2_entities). Если мы получили сущность врага, то вычисляем расстояние между игроком и сущностью и сохраняем позицию сущности, если она ближайшая из всех, пока найденных нами.
После итеративного обхода всего списка сущностей мы получаем ближайшего врага, вычисляем вектор «глаз-глаз» и корректируем углы глаза игрока при помощи функции [VectorAngles](https://github.com/ValveSoftware/source-sdk-2013/blob/0d8dceea4310fde5706b3ce1c70609d72a38efdf/mp/src/mathlib/mathlib_base.cpp#L1000).
В виде кода получим следующее:
```
auto* serverEntity{ reinterpret_cast(
GetServerTools()->FirstEntity()) };
if (serverEntity != nullptr) {
do {
if (serverEntity == GetServerTools()->FirstEntity()) {
SetPlayerEyeAnglesToPosition(closestEnemyVector);
closestEnemyDistance = std::numeric\_limits::max();
closestEnemyVector = GetFurthestVector();
}
auto\* modelName{ serverEntity->GetModelName().ToCStr() };
if (modelName != nullptr) {
auto entityName{ std::string{GetEntityName(serverEntity)} };
if (IsEntityEnemy(entityName)) {
Vector eyePosition{};
QAngle eyeAngles{};
GetServerTools()->GetPlayerPosition(eyePosition, eyeAngles);
auto enemyEyePosition{ GetEyePosition(serverEntity) };
auto distance{ VectorDistance(enemyEyePosition, eyePosition) };
if (distance <= closestEnemyDistance) {
closestEnemyDistance = distance;
closestEnemyVector = enemyEyePosition;
}
}
}
serverEntity = reinterpret\_cast(
GetServerTools()->NextEntity(serverEntity));
} while (serverEntity != nullptr);
}
```
В коде есть несколько вспомогательных функций, которые мы ранее не рассматривали: функция *GetFurthestVector* возвращает вектор с максимальными значениями float в полях x, y и z; *GetEntityName* возвращает имя сущности в виде строки, получая член [m\_iName](https://github.com/ValveSoftware/source-sdk-2013/blob/0d8dceea4310fde5706b3ce1c70609d72a38efdf/mp/src/game/server/baseentity.h#L1603) экземпляра *CBaseEntity*; а *IsEntityEnemy* просто сверяет имя сущности со множеством враждебных NPC.
Векторные вычисления и расчёт нового угла обзора происходят в показанной ниже *SetPlayerEyeAnglesToPosition*:
```
void SetPlayerEyeAnglesToPosition(const Vector& enemyEyePosition) {
Vector eyePosition{};
QAngle eyeAngles{};
GetServerTools()->GetPlayerPosition(eyePosition, eyeAngles);
Vector forwardVector{ enemyEyePosition.x - eyePosition.x,
enemyEyePosition.y - eyePosition.y,
enemyEyePosition.z - eyePosition.z
};
VectorNormalize(forwardVector);
QAngle newEyeAngles{};
VectorAngles(forwardVector, newEyeAngles);
SnapEyeAngles(GetLocalPlayer(), newEyeAngles);
}
```
Эта функция вычисляет вектор «глаз-глаз», вычитая из вектора позиции глаза врага вектор позиции глаза игрока. Затем этот новый вектор нормализуется и передаётся функции *VectorAngles* для вычисления новых углов обзора. Затем углы глаза игрока корректируются под эти новые углы, что должно создавать эффект слежения за сущностью.
Как это выглядит в действии?

Вы видите почти прозрачный прицел, следующий за головой идущего по комнате NPC. Когда NPC отходит достаточно далеко, код выполняет привязку к более близкому NPC. Всё работает!
▍ Заключение
------------
Описанные в статье методики в общем случае применимы к любой игре жанра FPS. Способ получения позиций и углов может различаться в разных игровых движках, однако векторные вычисления для создания угла обзора из вектора расстояния применимы в любом случае.
Реверс-инжиниринг Half-Life 2 был сильно упрощён открытостью Source SDK. Возможность сопоставления кода и структур данных с ассемблерным кодом существенно упростила отладку, однако обычно такого везения не бывает! Надеюсь, эта статья помогла вам понять, как работают aimbot и показала, что создавать их не очень сложно.
Полный [исходный код](https://github.com/codereversing/hl2aimbot) aimbot выложен на GitHub, можете свободно с ним экспериментировать.
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=perevod&utm_content=sozdanie_aimbot_dlya_half-life_2) | https://habr.com/ru/post/676270/ | null | ru | null |
# Пишем бота-кликера на Kotlin для Lineage 2
Еще не все новогодние салаты были съедены, “Ирония судьбы” уже просмотрена, а до начала рабочей недели еще целая вечность и нужно было придумать себе развлечение на оставшиеся праздники. Предвкушая ностальгию я открыл Lineage 2, одну из самых популярных MMORPG “нулевых” на СНГ пространстве. Однако, самому играть уже не хотелось и пришла идея автоматизировать это дело. За подробностями под кат!
### Введение
В школьные годы мы с друзьями играли в разные MMORPG игрушки, но самой залипательной для нас была Lineage 2. Суть игры состоит в том, чтобы 80% времени повторять одни и те же действия по убийству монстров и, время от времени, сражаться с другими игроками за этих самых монстров. К сожалению, времени на такие занятия у меня уже нет, поэтому было принято решение заняться автоматизацией! Как раз недавно попалась статья по OpenCV, которая вдохновила меня немного разобраться в этой теме - там автор определял наличие помидора на картинке :)
Сказано - сделано! И вот уже открыт гугл в поисках готовых реализаций и каково же было мое удивление, что я сразу же нашел релазицию хабре. Мои идеи совпали с идеями автора, вот только код написан на Python.. ([Пост](https://habr.com/ru/post/346258/))
Небольшое отступление: я мобильный разработчик, который никогда не трогал этого вашего Питона.. К сожалению, за два вечера у меня не получилось запустить код из репозитория автора. Сначала были конфликты в версии самого питона, потом какие-то непонятные ошибки с библиотеками из либы, в конце тулза AutoHotPy для работы с мышью и клавиатурой вообще отказалась работать. В итоге было принято решение написать свою реализацию на Kotlin с блекджеком и гномками! (Гномы - одна из рас в игре Lienage 2)
### Поехали!
Для работы с окном игры будем использовать опенсорсную либу Java Native Access (JNA). Создаем новый проект в нашей любимой IDE, качаем два джарника с [гитхаба](https://github.com/java-native-access/jna) JNA и JNA Platform, кладем их в наш проект и не забываем подключить их с помощью gradle:
```
implementation(files("lib/jna-5.12.1.jar"))
implementation(files("lib/jna-platform-5.12.1.jar"))
```
### Определяем окно игры
Здесь ничего сложного, в списке окон находим окно с названием Lineage, получаем его координаты и далаем активным:
```
private fun detektWindow(windowName: String): Rectangle {
val user32 = MyUser32.instance
val rect = Rectangle(0, 0, 0, 0)
var windowTitle = ""
val windows = WindowUtils.getAllWindows(true)
windows.forEach {
if (it.title.contains(windowName)) {
rect.setRect(it.locAndSize)
windowTitle = it.title
}
}
val tst: WinDef.HWND = user32.FindWindow(null, windowTitle)
user32.ShowWindow(tst, User32.SW_SHOW)
user32.SetForegroundWindow(tst)
return rect
}
```
### Поиск цели
Моя идея была такая же как и у автора из упомянутой статьи, однако некоторые детали у меня не сработали и пришлось подбирать реализацию под себя. Наш алгоритм действий будет следующими: делаем скриншот игры, с помощью фильтрации OpenCV находим имена монстров, наводимся на них мышкой, атакуем пока у монстра не закончится здоровье, переключаемся на следующего монстра и так до бесконечности! Весело, не правда ли? Погнали!
Устанавливаем OpenCV по гайду с офф сайта, скачиваем и закидываем в проект openCV-...jar и opencv\_java..dll. Не забываем их подключить к проекту через gradle
```
implementation(files("lib/opencv-460.jar"))
```
Делаем скриншот окна игры
Основное окно Lineage 2На скриншоте видно, что помимо имен монстров у нас есть еще другие белые объекты, которые могут помешать: радар, чат, имя нашего персонажа и т.д. Для этого модифицируем наш скриншот и закрашиваем ненужные области в черный цвет:
Закрашены "ненужные" помехиЗдесь уже вступает в игру OpenCV. Чтобы начать [гриндить](https://ru.wikipedia.org/wiki/%D0%93%D1%80%D0%B8%D0%BD%D0%B4_(%D0%BA%D0%BE%D0%BC%D0%BF%D1%8C%D1%8E%D1%82%D0%B5%D1%80%D0%BD%D1%8B%D0%B5_%D0%B8%D0%B3%D1%80%D1%8B)), нам необходимо найти цели. Как работаем - нам нужно провести фильтрацию так, чтобы на экране остались только белые прямоугольные объекты (так выглядят имена монстров). Идея следующая, мы помним что картинка состоит из пикселей, поэтому мы выполняем пороговое преобразование всех пикселей на картинке таким образом, чтобы туда попали только белые пиксели:
```
Imgproc.threshold(source, source, 252.0, 255.0, Imgproc.THRESH_BINARY)
```
далее нужно выполнять несколько формологических преобразований (размытие и растягивание), которые еще раз фильтранут все белые объекты по заданным размерам и преобразуют в белые прямоугольники путем размытия и растягивания (более подробное описание в [офф. доке](https://docs.opencv.org/3.4/d3/dbe/tutorial_opening_closing_hats.html))
Отфильтрованные белые прямоугольники
```
private fun findPossibleTargets(rectangle: Rectangle): List {
val capture: BufferedImage = Robot().createScreenCapture(rectangle)
fillBlackExcess(capture, rectangle)
val source: Mat = img2Mat(capture)
Imgproc.cvtColor(source, source, Imgproc.COLOR\_BGR2GRAY)
Imgproc.threshold(source, source, 252.0, 255.0, Imgproc.THRESH\_BINARY)
val kernel = Imgproc.getStructuringElement(Imgproc.MORPH\_RECT, Size(10.0, 1.0))
Imgproc.morphologyEx(source, source, Imgproc.MORPH\_CLOSE, kernel)
Imgproc.erode(source, source, kernel)
Imgproc.dilate(source, source, kernel)
val points: MutableList = mutableListOf()
Imgproc.findContours(source, points, Mat(), Imgproc.RETR\_TREE, Imgproc.CHAIN\_APPROX\_SIMPLE)
return points
.sortedBy { it.toList().maxBy { it.y }.y }
.filter {
val maxX = it.toList().maxBy { it.x }.x
val minX = it.toList().minBy { it.x }.x
val width = (maxX - minX)
val maxY = it.toList().maxBy { it.y }.y
val minY = it.toList().minBy { it.y }.y
val height = (maxY - minY)
width > 30 && width < 200 && height < 30
}
}
```
### Сравнение объектов
Окей, наводиться мы научились, теперь нам нужно определить находится ли мышь на монстре или же на каком-то объекте флоры.
Т.к. флора и фауна мира Lineage 2 достаточно разнообразна, нам необходимо удостовериться что белый прямоугольник это наша желаемая цель в виде монстра, а не какая-то белая стена или трава. Для этого снова делаем скриншот, достаем наш шаблон, переводим обе картинки в серый и используем метод matchTemplate из OpenCV.
Работает он приблизительно следующим образом: наше шаблонное изображение последовательно накладывается на исходное изображение и между ними вычисляется корреляция, результат мы получаем на выходе в виде значения от 0.0 до 1.0. (Более подробно про метод [в доке](https://docs.opencv.org/4.x/d4/dc6/tutorial_py_template_matching.html)).
P.S. для тех кто будет пробовать реализацию - учтите, что на разных хрониках и серверах будут разные шаблоны у монстров, поэтому придется самостоятельно подготавливать эти изображения.
Сравнение ХП бара
```
private fun isMouseSelectingAMob(rectangle: Rectangle): Boolean {
Thread.sleep(100L)
val minMatchThreshold = 0.8
val capture: BufferedImage = Robot().createScreenCapture(rectangle)
val thresholdScreen: Mat = img2Mat(capture)
Imgproc.cvtColor(thresholdScreen, thresholdScreen, Imgproc.COLOR_BGR2GRAY)
val template: Mat = Imgcodecs.imread("./src/main/resources/$TARGET_TEMPLATE_NAME.png")
Imgproc.cvtColor(template, template, Imgproc.COLOR_BGR2GRAY)
Imgproc.matchTemplate(thresholdScreen, template, thresholdScreen, Imgproc.TM_CCOEFF_NORMED)
val value = Core.minMaxLoc(thresholdScreen).maxVal
return value > minMatchThreshold
}
```
### Эмуляция мыши/клавиатуры
Для начала нам нужно научиться эмулировать движение мыши и нажатие клавиатуры. К сожалению готовой, библиотеки на Java/Kotlin я не нашел, поэтому будем использовать написанную на языке С либу с названием Interception (<https://github.com/oblitum/Interception>). Тут я вспоминаю, что я мобильный разработчик и не умею в С, но быстро преободряюсь потому что написать обертку на Kotlin оказалось достаточно просто. Устанавливаем по гайду, закидываем файлы interception.dll и interception.h в проект. Interception работает в отдельном потоке, полностью перехватывает управление над мышью и клавиатурой, с помощью команд эмулирует движение и нажатие, однако чтобы вернуть управление обратно, нам нужно явно прописать это, задать определенную кнопку, иначе придется перезагружать весь компьютер 🙂
```
override fun run() {
var device: Int
while (Interception.interception_receive(
context,
Interception.interception_wait(context).also { device = it },
emptyStroke,
1
) > 0
) {
val strokeCode = emptyStroke.code
val keyboardEscShort = INTERCEPTION_FILTER_KEYBOARD_ESC.toShort()
if (device == KEYBOARD_DEVICE_ID && strokeCode == keyboardEscShort) {
println("finish program")
exitProcess(0)
}
if (!emptyStroke.isInjected) {
Interception.interception_send(context, device, emptyStroke, 1)
}
}
Interception.interception_destroy_context(context)
}
```
Из интересного - мышь и клавиатура имеют свои ID, по которым принимаются и отправляются команды. Подобрать их можно простым перебором для мыши используется зачение от 11 до 20, а для клавиатуры от 1 до 10. Я заметил, что, время от времени, их ID могут меняться, хотя я физически не переставлял их в другие порты. Если кто-то из читателей знает почему так происходит, то расскажите пожалуйста в комментариях :)
### Движение
Окей, двигать мышь и нажимать клавиши мы научились, но наше движение выглядит как телепортация и может вызывать подозрение у админов сервера. Автор упомянутой статьи верно подметил, что есть так называемый Алгоритм Брезенхэма, который хоть и не полностью, но все же хоть немного напоминает человеческое движение. Берем реализацию с [Вики](https://ru.wikipedia.org/wiki/%D0%90%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC_%D0%91%D1%80%D0%B5%D0%B7%D0%B5%D0%BD%D1%85%D1%8D%D0%BC%D0%B0), переводим на Kotlin, немного модифицируем движение, т.к. Interception двигает мышь не по абсолютным значением, а по относительным текущего расположения мыши.
### Распознание количества здоровья монстра
Находить объекты и атаковать их мы научились, но нам нужно понимать когда мы закончили с текущим монстром и нужно приниматься за следующего. Для этого нам нужно определять оставшееся здоровье монстра. Этот фокус состоит из двух этапов. На первом этапе, после того как мы выбрали нашу цель, мы также по специальному шаблону находим прямоугольинк, который относится к окошку со здоровьем монстра, поэтому подробности опустим.
Окно со здоровьемА вот второй этап рассмотрим немного подробнее. Т.к. окно здоровья монстра содержит полоску из нескольких цветов, где один из них красный (текущее оставшееся здоровье монстра) и бурый (потерянное здоровье монстра), то мы можем найти разницу и понимать жив ли еще монстр или нет. Для этого указываем нижнее и верхнее значение красного цвета, используем фунцию inRange для фильтрации по нужному промежутку цветов и находим все объекты с помощью контурного анализа:
```
private fun checkHpBar(hpBarMat: Mat): Int {
val lower = Scalar(0.0, 150.0, 90.0)
val upper = Scalar(10.0, 255.0, 255.0)
val subImageMat: Mat = hpBarMat.clone()
Imgproc.cvtColor(subImageMat, subImageMat, Imgproc.COLOR_BGR2HSV)
Core.inRange(subImageMat, lower, upper, subImageMat)
val remainingContours: MutableList = mutableListOf()
Imgproc.findContours(subImageMat, remainingContours, subImageMat, Imgproc.RETR\_TREE, Imgproc.CHAIN\_APPROX\_SIMPLE)
val remainingLeftX = remainingContours.firstOrNull()?.toList()?.minBy { it.x }?.x ?: 0.0
val remainingRightX = remainingContours.firstOrNull()?.toList()?.maxBy { it.x }?.x ?: 0.0
val totalHpBarWidth = subImageMat.width()
val remainingHpBarWidth = remainingRightX - remainingLeftX
val percentHpRemaining = remainingHpBarWidth \* 100 / totalHpBarWidth
if (percentHpRemaining < 1) return 0
return percentHpRemaining.toInt()
}
```
Более подробно про [inRange](https://docs.opencv.org/3.4/da/d97/tutorial_threshold_inRange.html) и [findCountours](https://docs.opencv.org/3.4/d4/d73/tutorial_py_contours_begin.html).
Готово! Все необходимые функции у нас есть, осталось закодить алгоритм.
Наши действия:
1. ищем монстра путем поиска всех белых прямоугольников
2. проверяем жив ли он, если нет - возвращаемя на пункт №1
3. начинаем атаковать
4. когда здоровье монстра равняется нулю - возвращаемся на пункт №1
Повторять пока не надоест!
Результат нашей работы на ютубе:
[**Ссылка на исходники**](https://github.com/ivanovd422/KotlinClicker)
### Заключение
Понятное дело, что кликер получился не идеальным и любое внешнее воздействие на персонажа полностью руинит наш код, однако у меня не было цели написать самого оптимального бота. Использование OpenCV позволяет не только определять помидоры и находить монстров в MMORPG, но также открывает огромный простор для применения в различных сферах ограниченный лишь воображением. Моей целью было разобраться в базовых вещах и применить на примере. Следующим этапом хотелось бы попробовать уже современное машинное зрение с использованием нейронок, но это уже когда-то в следующий раз. Делитесь в комментариях в каких еще необычных сферах можно было бы использовать компьютерное зрение 🙂 | https://habr.com/ru/post/711168/ | null | ru | null |
# Liskov Substitution Principle & Contracts
При работе с контрактами существует несколько неприятных вещей, которые приходится обходить. Например, не к ночи помянутый Liskov Substitution Principle, которого придерживаются разработчики Contracts.
Например, у нас есть некий класс, который наследует интерфейс из внешней библиотеки. И мы определяем в классе реализацию метода из этого интерфейса:
```
public class A : Interface1
{
public void MethodInterface1( object sender, Event e) {...}
}
```
Так вот, засада в том, что согласно описанных выше принципов — мы не должны напрямую проверять приходящие значения, т.к. это — ответственность постусловий библиотеки, поставщика интерфейса. Т.е. подобный код — считается некорректным:
```
public void MethodInterface1( object sender, Event e)
{
Contract.Requires(sender != null, "Sender is null");
Contract.Requires(event != null, "Event object is null");
...
}
```
Мало того, даже такая реализация будет выдавать предупреждение (warning CC1033):
```
public void MethodInterface1( object sender, Event e)
{
if (sender == null) throw new ArgumentNullException("sender", "Event sender is null.");
if (evt == null) throw new ArgumentNullException("evt", "Event object is null.");
Contract.EndContractBlock();
...
}
```
Видимо, разработчики надеются, что создатели интерфейсов соображают в правилах наследования и теории построеннии иерархий чуть больше, чем обычно…
PS. Приходится в обработке подобных отнаследованных интерфейсов вместо контрактов использовать старый способ валидации, убрав контрактную спецификацию. | https://habr.com/ru/post/242939/ | null | ru | null |
# Улучшаем формы или Веб-Восемь-Ноль-Сто-Три
Итак, мы выбрали браузер вместо отдельно стоящего толстого клиента. Пользователь очень хочет вводить данные. Однако, обычные формы плохие. Потому, что:
Данные и HTML-код смешаны.
Нет удобного виджета с выпадающим списком и поиском по началу наименования.
Нет удобного встроенного средства грузить данные в формы.
Нет удобной возможности отправлять данные формы через AJAX.
И т.д.
Чего хочется?
Полностью отвязать HTML-код форм от данных.
Иметь возможность предзагрузки форм.
Иметь возможность гибко настраивать форму.
Иметь удобный выпадающий список с поиском по началу имени.
Отвязать контролы формы от ее окружения.
И так далее.
Начнем с конца. Какой должен быть выпадающий список? Уж конечно не как стандартный SELECT!
Во-первых, он должен использовать справочник. То есть набор пар [«ключ», «значение»]. При этом пользователю показывается строка «значение», а на сервер отправляется «ключ».
Во-вторых, он должен подключаться к INPUT вместе со справочником, при вводе символов показывать список, бегать туда-сюда и убираться при уходе фокуса с INPUT.
Для создания выпадающего списка (будем называть его dropdown для краткости) воспользуемся jQuery. Что хорошего в jQuery? Как минимум вот это:
1. удобная функция обратного вызова когда уже загружена DOM-структура документа (и можно его портить), а всякие картинки может еще и не загружены:
`$(document).ready(function(){
// ... здесь можно работать с DOM
});`
2. удобный поиск нужных элементов по ID
`$('#some_id')`
3. удобная обвязка объектом jQuery любого DOM-элемента
`$(some_DOM_element)`
4. удобная привязка всяких событий
`$(li).hover( function() { this.style.fontWeight = 'bold'; }, function() { this.style.fontWeight = 'normal'; } )`
Данный вызов привязывает к DOM-элементу li 2 события: при наезжании курсора на элемент и на отъезжание.
В промежутке между этими событиями DOM-элемент получает bold-шрифт (потому что this как раз на него и указывает в обработчике события)
5. удобные методы jQuery объекта, которые применяются универсально к отдельным DOM-элементам или их наборам
`.show()` показать
`.hide()` спрятать
`.val()` получить значение контрола
`.val(new_value)` задать значение контрола
И так далее.
Мы воспользуемся возможностью jQuery расширяться. За основу нашего dropdown я взял скрипт autocomplete, который при поиске в Гугле показывает похожие запросы. Его легко нагуглить. Готовое решение должно работать примерно так: при настройке формы мы должны иметь возможность привязать dropdown со справочником к контролу вот так:
`$(form.some_element_name).dropdown( some_directory, options ) ;`
some\_directory это и есть справочник (некий JavaScript объект, о котором позже)
Как этого добиться? Создаем свой новый метод jQuery, который вызывается выше:
> `jQuery.fn.dropdown = function(data, options)
>
> {
>
> options = options || {};
>
> options.data = ((typeof data == "object") && (data.constructor == Array)) ? data : null;
>
> options.key = options.key || "key";
>
> options.value = options.value || "value";
>
> options.matchCase = options.matchCase || 0;
>
> options.list\_size = options.list\_size || 11;
>
> options.containerClass = options.containerClass || "\_\_dropdown\_container\_class";
>
> options.selectedItemClass = options.selectedItemClass || "\_\_dropdown\_selected\_item\_class";
>
> options.items = options.data ? clone\_quicksort(options.data, options.value, options.matchCase ? less\_than\_compare : less\_than\_ignore\_case\_compare) : null;
>
> options.items\_hash = options.items ? hash\_array(options.items, options.key) : null;
>
> this.each( function() { var input = this; new jQuery.dropdownConstructor(input, options); } );
>
> return this;
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Я привел его полностью. Нетрудно видеть, что этот скрипт упорно проверяет разные опции (если их вообще нет, то создает). Опции набиваются значениями по умолчанию. Наконец, вот эта строка:
`this.each( function() { var input = this; new jQuery.dropdownConstructor(input, options); } );`
проходится по списку элементов, которые отобрал селектор и для каждого создает новый jQuery объект dropdown с помощью конструктора dropdownConstructor. Который и содержит весь нужный код и выглядит примерно так:
> `jQuery.dropdownConstructor = function(input, options)
>
> {
>
>
>
> var input = input; // это DOM элемент контрола
>
> this.control = input;
>
> var $input = $(input); // это jQuery объект, содержащий DOM элемент контрола (для использования методов jQuery на этом элементе)
>
> var container = document.createElement("div"); // это DIV будет содержать выпадающий список list
>
> var $container = $(container);
>
> var list = document.createElement("ul");
>
> var $list = $(list);
>
> var active = false;
>
> var last\_key\_pressed = null;
>
> var timeout = null;
>
> var value\_of\_key = ""
>
> var prev\_truevalue, next\_truevalue;
>
> var that = this;
>
> input.dropdown = that;
>
> input.truevalue = input.truevalue || null;
>
>
>
> container.appendChild(list); // помещаем список в контейнер
>
> $container.hide().addClass(options.containerClass).css("position", "absolute"); // контейнер в документе пока не виден
>
> if( options.width > 0 ) $container.css("width", options.width);
>
> $("body").append(container); set\_truevalue(input.truevalue);
>
>
>
>
>
> function postpone(func)
>
> {
>
> if (timeout) clearTimeout(timeout);
>
> timeout = setTimeout(function(){ func(); }, 25);
>
> }
>
>
>
> function set\_truevalue(new\_truevalue)
>
> {
>
> if (!options.items\_hash[new\_truevalue])
>
> {
>
> input.truevalue = null;
>
> value\_of\_key = "";
>
> $input.val( "" );
>
> return;
>
> }
>
> input.truevalue = new\_truevalue;
>
> if (input.truevalue) value\_of\_key = options.items\_hash[input.truevalue][options.value]; else value\_of\_key = "";
>
> $input.val( value\_of\_key );
>
> }
>
>
>
> input.update\_control = function() { set\_truevalue(that.control.truevalue); }
>
>
>
> function activate()
>
> {
>
> if (active) return;
>
> var pos = element\_position(input);
>
> var W = (options.width > 0) ? options.width : $input.width();
>
> $container.css( { width: parseInt(W) + "px", left: pos.x + "px", top: (pos.y + input.offsetHeight) + "px" } ).show();
>
> var index = binary\_search(options.items, value\_of\_key, options.value, options.matchCase ? less\_than\_compare : less\_than\_ignore\_case\_compare);
>
> build\_list(index - (options.list\_size >> 1), index);
>
> active = true;
>
> }
>
>
>
> function deactivate()
>
> {
>
> if (!active) return;
>
> $container.hide();
>
> active = false;
>
> }
>
>
>
> function move\_up()
>
> {
>
> ...
>
> }
>
>
>
> function move\_down()
>
> {
>
> ...
>
> }
>
>
>
> function select\_text\_part(start, end)
>
> {
>
> ...
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
И пошло-поехало.
Думаю код достаточно понятен, но все же. truevalue — это ключ. Это аттрибут контрола, который хранит ключевое (не показываемое пользователю) значение. set\_truevalue() задает ключ и синхронизирует отображамое значение. active() показывает выпадающий список, deactive() его прячет. move\_up(), move\_down() — движение по списку вверх и вниз. select\_text\_part() — выделение части текста.
Вот так мы привязываемся к событиями внутри конструктора:
> `$input.keydown(function(e)
>
> {
>
> last\_key\_pressed = e.keyCode;
>
> switch(e.keyCode)
>
> {
>
> case 38: e.preventDefault(); move\_up(); break;
>
> case 40: e.preventDefault(); move\_down(); break;
>
> case 13: case 9: select\_text\_part(); deactivate(); break;
>
> default: postpone(on\_change); break;
>
> }
>
> }).focus(function(){
>
> activate(); select\_text\_part();
>
> }).blur(function(){
>
> deactivate();
>
> }).mousedown( function(e) { if (!active && !input.disabled) { e.preventDefault(); $input.focus(); activate(); } } );
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Теперь поговорим о справочниках. Справочник — это JavaScript массив однотипных объектов (с одинаковым набором полей). Например, "`[ { key:'m', value:'male' }, { key: 'f', value: 'female' } ]`". По умолчанию в поле key находится ключ, а в поле value — значение. Однако, это всегда можно изменить.
Нашему dropdown-у нужен отсортированный по возрастанию value справочник (то есть по возрастанию видимого значения, а не ключевого). Причем обычно с игнорированием регистра букв (когда пользователь вводит начало названия на клавиатуре в большинстве случаев ему все равно зажат CAPS LOCK или нет). Следовательно, этот массив надо сортировать и для этого и пришлось написать быструю сортировку на JavaScript и бинарный поиск. Ведь пользователь может ввести и часть имени. Не буду приводить сортировку, только бинарный поиск для примера:
> `function less\_than\_compare(val1, val2)
>
> {
>
> return val1 < val2;
>
> }
>
>
>
> function binary\_search(items,value,key,compare)
>
> {
>
> key = key || "key";
>
> compare = compare || less\_than\_compare;
>
> var l = -1;
>
> var r = items.length;
>
> while (true)
>
> {
>
> var m = (r - l) >> 1;
>
> if (m == 0) return r;
>
> m += l;
>
> if ( compare(items[m][key],value) )
>
> l = m;
>
> else if ( compare(value, items[m][key]) )
>
> r = m;
>
> else
>
> return m;
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Итак, после упорного кодирования наш замечательный dropdown заработал:
[www.picamatic.com/show/2009/05/12/06/35/3618111\_557x236.png](http://www.picamatic.com/show/2009/05/12/06/35/3618111_557x236.png)
Теперь начнем разбираться с формами. Форма разделяется на три части: HTML-код, JavaScript-код настройки и список справочников, которые требуются форме для работы. Наш серверный скрипт формы будет возвращать все эти части по запросу и кроме того, он должен принимать данные и возвращать ошибки их обработки. Серверный скрипт в файле "/foo.js" выглядит так:
> `function receive\_request()
>
> {
>
> if (request.\_command == "jason") return "/joo.js,/boo.js";
>
>
>
> if (request.\_command == "html") return "\
>
> | Ваше имя \| Ваш пол \| Страна происхождения \| Страна проживания \
> " | |
> | |
> | |
> | |
> ;
>
>
>
> if (request.\_command == "code") return "\
>
> enterAsTab(form, 1);\
>
> $(form.country).dropdown( jason('/boo.js') );\
>
> $(form.birth\_country).dropdown( jason('/boo.js') );\
>
> $(form.sex).dropdown( jason('/joo.js') );\
>
> ";
>
>
>
> if (request.\_command == "post")
>
> {
>
> var error = "";
>
> if (request.user\_name.length == 0) error += "user\_name: Укажите имя пользователя\r";
>
> if (request.user\_name.length < 5) error += "user\_name: В имени должно быть как минимум 5 символов\r";
>
> if (request.birth\_country.length == 0) error += "country: Укажите страну происхождения\r";
>
> if (request.country.length == 0) error += "country: Укажите страну проживания\r";
>
> if (error) return error;
>
>
>
> // .. ура ..
>
>
>
> return "OKAY";
>
> }
>
>
>
>
>
> return "";
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Почему на сервере используется JavaScript объясняется здесь: [habrahabr.ru/blogs/development/48842](http://habrahabr.ru/blogs/development/48842/)
HTML-код это только контролы, без окружающего "". Немного хитрый настроечный код формы требует два параметра: DOM-элемент формы (form) и функцию, которая возвращает загруженный справочник по его url ( jason() ).
Итак, мы хотим все это на страницу асинхронно загружать и использовать. Тут есть два соображения. Во-первых, справочники принадлежат всей странице, а не одной форме. Разные формы могут работать с одними и теми же справочниками. Во-вторых, формой можно пользоваться только после полной и успешной загрузке всех ее составляющих.
Собственно, дальше я написал асинхронный загрузчик, который кеширует загруженные данные и позволяет иерархически вкладывать загрузки друг в друга (чтобы, допустим, полностью удалить все активные загрузки формы). Затем поверх этого — загрузчик форм, который, получив список справочников, просит их загрузить и ждет их появления.
Итак, допустим у нас есть под рукой (загружены на страницу) все необходимые компоненты формы: HTML, javascript и справочники готовы. Следующий шаг — создание \_экземпляра\_ формы, который и есть то, что видит пользователь. Вот код, который создает экземпляр формы формы по имени form\_name в DOM-элементе container. Экземпляр получает имя instance\_name:
> `activate: function(instance\_name, form\_name, container)
>
> {
>
> if (!form\_loader.ready(form\_name)) return false;
>
> var form = document.createElement("form"); \\ для того, чтобы настроечный код формы обращался к ее DOM-элементу через form
>
> var jason = function (url) { return jason\_loader.data(url); } \\ для того, чтобы настроечный код формы обращался к справочнику через функцию jason()
>
> container.innerHTML = '';
>
> container.appendChild(form);
>
> form.innerHTML = "
>
> "
> + form\_loader.html(form\_name) + "";
>
> try
>
> {
>
> eval(form\_loader.code(form\_name));
>
> }
>
> catch (e)
>
> {
>
> form\_loader.forms[form\_name].error = 'Ошибка активации формы *'* + form\_name + '
> ' + e.message;
>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Думаю, идея понятна.
Ну и наконец: десерт. То ради чего весь этот код создавался. Вот как выглядит загрузочный код HTML-страницы, которая использует данный механизм:
> `$(document).ready(function(){
>
>
>
> register\_form("foo", "/foo.js"); // регистрация формы foo по адресу /foo.js
>
> register\_form("voo", "/voo.js"); // и еще другой формы
>
> await(load\_callback); // ждем окончания загрузки всех форм
>
> });
>
>
>
> function load\_callback(form\_name)
>
> {
>
> if (form\_name) // при загрузке этой формы возникла ошибка
>
> $('#report').html( $('#report').html() + '
> ' + form\_loader.error(form\_name) );
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Не правда ли — весьма лаконично? А вот как используется форма.
Создать экземпляр в DOM-элементе с id='foo\_form':
> `director.activate('foo\_instance', "foo", $('#foo\_form')[0]);`
Загрузить данные в экземпляр формы:
> `director.fill("foo\_instance", {user\_name: 'John Smith', country: 'RO' } );`
Ну и наконец ради чего все это нужно — отправка данных:
> `director.submit("foo\_instance", foo\_submit);`
Функция foo\_submit может выглядеть примерно так:
> `function foo\_submit(instance\_name, result, error)
>
> {
>
> if (result)
>
> $('#report').html('Форма ' + instance\_name + ' успешно отправлена');
>
> else if (error)
>
> $('#report').html('При отправке формы ' + instance\_name + ' произошла сетевая ошибка
> ' + error);
>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Метод submit() может получить от серверного скрипта набор ошибок по данным и покажет их автоматически. А при очередной отправке уберет и сделает полный disable формы.

Вообщем, с формой можно сделать практически все что угодно: показать, очистить, загрузить данными, сделать полный disable и обратно enable, отправить на сервер и ждать успешной отправки.
Наконец, убрать экземпляр формы со страницы. Опять-таки, мы можем на странице без труда создать несколько экземпляров одной и той же формы.
К примеру, можно в таких формах показывать неудачные отправки на сервер.
Вот такое вот решение.
Жду замечаний и предложений. Если найду время — сделаю syntax highlight кода на JavaScript (а почему нет под рукой на Хабре??). | https://habr.com/ru/post/59413/ | null | ru | null |
# Отправляем данные с Arduino в Azure IoT Hub
[](http://habrahabr.ru/post/282912/)
Не так давно я стал счастливым обладателем [Genuino MKR1000](https://www.arduino.cc/en/Main/ArduinoMKR1000). Ресурс Hackster.io совместно с Microsoft проводил конкурс на лучшую идею. Пусть я не успел воплотить свою идею в жизнь и принять участие во второй части конкурса, но я могу поделиться с вами информацией, которая поможет вам осуществить свои задумки. Под катом о том, как отправить данные с Arduino в облако и как их считать, если у вас есть WiFi шилд или MKR1000.
#### Настройка Azure
Заходим на portal.azure.com, нажимаем «+», выбираем «Интернет вещей» — «IoT Hub» и придумываем название нашему хабу. Я решил назвать хаб просто и скромно – alexey. Ценовую категорию я выбрал бесплатную S1 (на одно устройство).
Собственно, на этом конфигурация хаба завершена. Необходимо будет еще получить первичный ключ, но это можно сделать позднее.
#### Настройка Arduino
Установим необходимую библиотеку WiFi101:
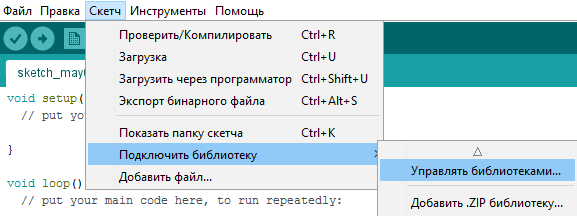
Нам необходима версия выше чем 0.8, так что если у вас уже установлена старая библиотека, то обновите ее.
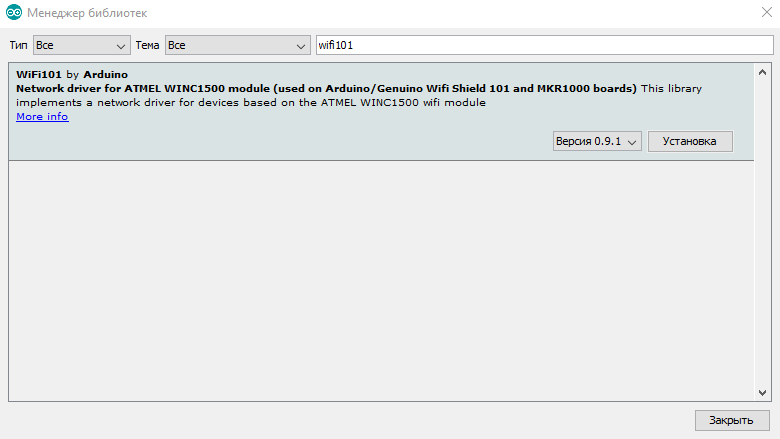
Azure IoT Hub использует SSL для безопасности подключения. Но так как у Arduino недостаточно памяти для того чтобы хранить в ней сертификат SSL, то нам необходимо записать его в чип WiFi. Для этого нужно обновить Firmware версию WiFi101. Скачиваем по [ссылке](https://github.com/arduino-libraries/WiFi101-FirmwareUpdater/releases/tag/0.7.0) файл Wifi101\_FirmwareUpdater\_windows.zip
В Arduino IDE открываем скетч Файл – Примеры – WiFi101 – FirmwareUpdater. Подключаем MRK1000 и загружаем скетч. Теперь плата Arduino готова к получению прошивки с сертификатом.
Распаковываем zip архив Wifi101\_FirmwareUpdater\_windows, который мы недавно скачали и запускаем winc1500-uploader-gui.exe. Вводим адрес узла нашего хаба.
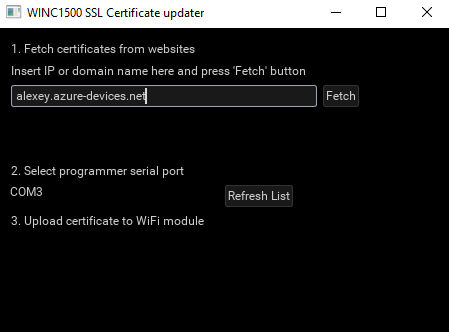
Кликаем и выделяем COM порт, после чего нажимаем «Upload certificate»
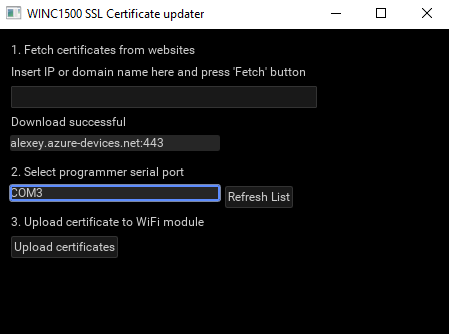
Остается дождаться загрузки сертификата
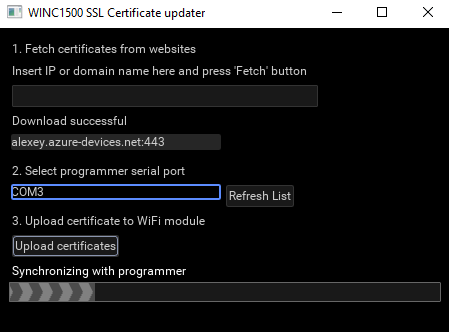
Microsoft Azure IoT Hub использует [Shared Access Signatures](https://azure.microsoft.com/ru-ru/documentation/articles/storage-dotnet-shared-access-signature-part-1/).
Это сигнатуры доступа, которые могут быть использованы для работы с очередью сообщений IoT Hub-а без пароля. Нам необходимо создать SAS token. Для того чтобы не делать это в коде Arduino можно использовать утилиту Device Explorer
Скачиваем по [ссылке](https://github.com/Azure/azure-iot-sdks/releases) файл SetupDeviceExplorer.msi
Устанавливаем и запускаем. Заходим на портал Azure в IoT Hub и нажимаем на ключик в правом верхнем углу:
Выбираем из списка iothubowner и копируем «Строка подключения – первичный ключ»
Эту строку вводим в окно закладки Configuration приложения Device Explorer и нажимаем кнопку Update
Переходим на закладку Management. Здесь мы можем добавить новое устройство. Кнопка Create, придумываем ID нашему девайсу (я назвал свое устройство myDevice) и нажимаем Create.
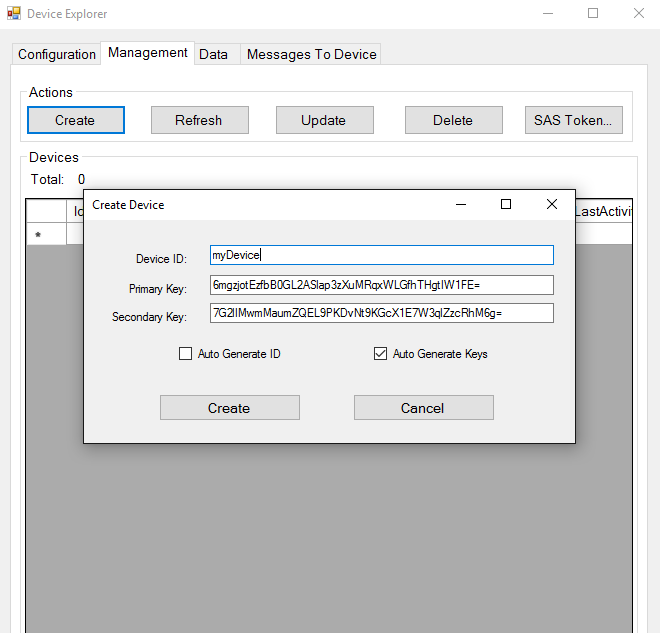
В списке появится наше устройство. Выделяем строку с ним и нажимаем SAS Token…
Вводим промежуток дней и нажимаем Generate. Из получившегося токена нам нужна только часть начинающаяся с «SharedAccessSignature sr=» (копируйте аккуратно, так как текст SharedAccessSignature встречается в строке 2 раза)
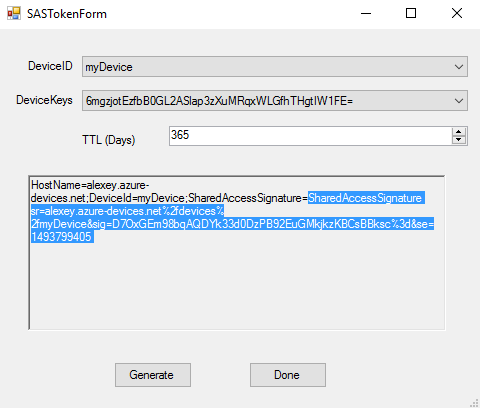
Англоязычный мануал о том как пользоваться Device Explorer находится здесь:
[How to use Device Explorer for IoT Hub devices](https://github.com/Azure/azure-iot-sdks/blob/master/tools/DeviceExplorer/doc/how_to_use_device_explorer.md)
#### Код Arduino
Рассмотрим код Arduino. Заголовок у нас такой:
`#include
#include
char hostname[] = "alexey.azure-devices.net"; // имя узла Azure IoT Hub
char authSAS[] = "SharedAccessSignature sr=alexey.azure-devices.net%2fdevices%2fmyDevice&sig=D7OxGEm98bqAQDYk33d0DzPB92EuGMkjkzKBCsBBksc%3d&se=1493799405"; // SAS token, который был сгенерирован Device Explorer
String deviceName = "myDevice"; // ID нашего девайса
char ssid[] = "myhomenet"; // имя вашей точки доступа wi-fi
char pass[] = "password123"; // пароль от точки доступа
String uri = "/devices/myDevice/messages/events?api-version=2016-02-03";
int status = WL\_IDLE\_STATUS; // статус доступности интернета
WiFiSSLClient client;`
Строка uri будет различна для отправки и для получения данных.
Если бы мы получали данные, то строка была бы
**/devices/myDevice/messages/devicebound?api-version=2016-02-03**
Кроме отправки и получения существует возможность [завершить/отклонить или сбросить](https://msdn.microsoft.com/ru-ru/library/azure/mt590785.aspx) сообщение.
В setup мы только делаем стандартное подключение к сети Wi-Fi
`void setup() {
Serial.begin(9600);
Serial.println("Setup begin");
// check for the presence of the shield:
if (WiFi.status() == WL_NO_SHIELD) {
Serial.println("У Arduino отсутствует WiFi шилд");
while (true); // не продолжаем выполнение кода дальше
}
// пытаемся подключится к сети Wifi:
while ( status != WL_CONNECTED) {
Serial.print("Попытка подключения к точке доступа ");
Serial.println(ssid);
status = WiFi.begin(ssid, pass);
delay(10000); // ждем 10 секунд чтобы подключение завершилось
}
Serial.println("Connected to Wi-Fi");
}`
Нам нужен метод, который будет отправлять строку текста запросом POST по протоколу HTTP на наш узел. Я не заморачиваюсь и отправляю строку текста, хотя обычно в примерах генерируют и отправляют json.
`void httpPost(String content)
{
client.stop(); // закрываем подключение, если вдруг оно открыто
if (client.connectSSL(hostname, 443)) {
client.print("POST ");
client.print(uri);
client.println(" HTTP/1.1");
client.print("Host: ");
client.println(hostname);
client.print("Authorization: ");
client.println(authSAS);
client.println("Connection: close");
client.print("Content-Type: ");
client.println("text/plain");
client.print("Content-Length: ");
client.println(content.length());
client.println();
client.println(content);
delay(200);
} else {
Serial.println("HTTP POST отправка неудачна");
}
}`
Теперь для того чтобы отправить строку текста достаточно вызвать метод
`httpPost("Some message from Arduino");`
Но мы еще и считаем ответ, чтобы убедится в том, что данные благополучно получены
`httpPost("Some message from Arduino");
String response = "";
char c;
while (client.available()) {
c = client.read();
response.concat(c);
}
if (!response.equals(""))
{
if (response.startsWith("HTTP/1.1 204")) {
Serial.println("Строка была отправлена в Azure");
} else {
Serial.println("Ошибка");
Serial.println(response);
}
}`
Весь код вы можете скачать с [github](https://github.com/programmersommer/Arduino_Azure_IoT_Hub)
#### Консольное приложение, считывающее данные с очереди сообщений IoT Hub
Создаем консольное приложение.
Открываем NuGet Package Manager, ищем **WindowsAzure.ServiceBus** и устанавливаем.
Добавляем пару namespace:
```
using Microsoft.ServiceBus.Messaging;
using System.Threading;
```
И объявлений:
```
static string connectionString = "HostName=alexey.azure-devices.net;SharedAccessKeyName=iothubowner;SharedAccessKey=xrzUfBj8gaq2i310MhRCcSEs08t3lk7zbCNI4Tltqp4=";
static string iotHubD2cEndpoint = "messages/events";
static EventHubClient eventHubClient;
```
Здесь вы можете заметить, что значением connectionString я ввел значение, полученное с портала Azure – это «Строка подключения – первичный ключ». Добавляем следующий метод:
```
private static async Task ReceiveMessagesFromDeviceAsync(string partition, CancellationToken ct)
{
var eventHubReceiver = eventHubClient.GetDefaultConsumerGroup().CreateReceiver(partition, DateTime.UtcNow);
while (true)
{
if (ct.IsCancellationRequested) break;
EventData eventData = await eventHubReceiver.ReceiveAsync();
if (eventData == null) continue;
string data = Encoding.UTF8.GetString(eventData.GetBytes());
Console.WriteLine("Message received. Partition: {0} Data: '{1}'", partition, data);
}
}
```
и, наконец, в Main добавляем код:
```
Console.WriteLine("Получение сообщений. Ctrl-C для выхода.\n");
eventHubClient = EventHubClient.CreateFromConnectionString(connectionString, iotHubD2cEndpoint);
var d2cPartitions = eventHubClient.GetRuntimeInformation().PartitionIds;
CancellationTokenSource cts = new CancellationTokenSource();
System.Console.CancelKeyPress += (s, e) =>
{
e.Cancel = true;
cts.Cancel();
Console.WriteLine("Выходим...");
};
var tasks = new List();
foreach (string partition in d2cPartitions)
{
tasks.Add(ReceiveMessagesFromDeviceAsync(partition, cts.Token));
}
Task.WaitAll(tasks.ToArray());
```
Если вы запустите это консольное приложение, то сможете считать сообщения, отправляемые включеной платой Arduino.
ОБНОВЛЕНИЕ: Так как данная отправка с помощью HTTP далека от идеала, то лучше использовать порт Arduino SDK под названием [Azure IoT Hub library for Arduino](https://github.com/Azure/azure-iot-arduino)
#### Полезные ссылки:
[Приступая к работе с центром Azure IoT с использованием .NET](https://azure.microsoft.com/ru-ru/documentation/articles/iot-hub-csharp-csharp-getstarted/)
[MKR1000 Azure IoT Hub Interface Using HTTP](http://mohanp.com/mkr1000-azure-iot-hub-how-to/)
[MKR1000 Temp and Humidity Sensor](https://create.arduino.cc/projecthub/doncoleman/mkr1000-temp-and-humidity-sensor-8f22ed) | https://habr.com/ru/post/282912/ | null | ru | null |
# Трансляция RTSP в WEB. Конвертация в HLS. Коробочное решение
Была задача: собрать все RTSP потоки с видео-регистратора (netsurveillance) и предоставить оперативный доступ к видео-потоку для нескольких человек. Так как ни один браузер не умеет самостоятельно отображать RTSP протокол, то необходимо было найти что угодно, лишь бы могло конвертировать этот поток в пригодный для WEB формат.
Оговорюсь сразу: в процессе эксплуатации данного решения обнаружилась возможность шаринга видео-архива средствами SAMBA. Эта возможность показалась очень удобной лично для меня и я решил реализовать её в данном контексте. Конечно, у кого-то может возникнуть вопрос: «Есть ведь Линия и зачем всё прочее нужно?» — в нашем случае это решение оказалось слишком дорогое. ~~А еще они до сих пор считают в долларах~~. Итак, что имеется:
* Корпоративная сеть на базе Mikrotik средствами обычного VPN
* Несколько ССTV состоящих из самых разных камер и видео-регистратора
* Linux машина с развернутым SAMBA-AD-DC и WEB сервером в центральном офисе
Стоит ли напоминать, что всё это дело у нас конвертируется из RTSP в HLS? Ставлю на Linux хост Shinobi по [этой инструкции](https://shinobi.video/docs/start#content-ubuntu--the-easier-way). В установке нету ничего сложного, требуется только установить git, некоторые зависимости и запустить скрипт установки. Технически та же Линия, только бесплатно. Возможно на первое время хватит. Интерфейс только кажется удобнее, в остальном тоже самое. После установки и запуска открываем [localhost](http://localhost):8080/super логинимся как [email protected] с паролем admin и создаём основную запись для доступа к мониторингу.
Параметры хранения информации, используемые по-умолчанию, мне не подошли. Кроме того, в процессе эксплуатации я долго искал эти настройки, но срочность вынудила попросту отключить cron.js (sudo pm2 stop cron) и средствами уже Linux’a чистить каталоги видео-архива.

**Number of Days to keep Videos** — количество дней на хранение видеозаписей.
**Number of Days to keep Events** — количество дней на хранение событий (входы, смены пароля и прочее).
**Number of Days to keep Logs** — количество дней на хранение системных сообщений: сбои, ошибки, инициализация.
Все эти параметры задаются индивидуально для каждого пользователя, очень удобно. Но кроме этого существует еще и API. Его средствами можно получить все потоки конкретного монитора (монитор — это набор потоков для трансляции) и представить каждый из них по отдельности в виде онлайн трансляции на web-странице. Для начала необходимо добавить в мониторинг информацию о потоках с камер видео-наблюдения.



**Mode** — режим трансляции: **Record** — запись, **Watch only** — только просмотр.
**Name** — название видео-потока
**Storage location** — место хранения архива, если в **Mode** у вас выставлен **Record**
**Full URL Path** — ссылка на сам rtsp поток. Для netsurveillance как правило такая ссылка: *rtsp://IP:554/user=USER&password=PASSWORD&channel=CHANNELNUMBER&stream=1.sdp?real\_stream—rtp-caching=100*
Информация о потреблении ресурсов отображаемая в Shinobi сильно разнится с тем, что показывает **htop**. В web-интерфейсе я постоянно вижу наполовину забитую память, но вот загрузка процессора, кстати, вполне соответствует тому, что видно из консоли.

Насколько было известно, так же есть возможность использовать системный GPU для конвертации потока. Но так как у нас он не установлен, то убедиться в этом не было возможности. Всё происходит средствами CPU. У нас задействована конвертация 17 потоков 3 из которых записываются локально. Приведу здесь информацию о нашем процессоре:
**lscpu**
`Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 36 bits physical, 48 bits virtual
CPU(s): 8
On-line CPU(s) list: 0-7
Thread(s) per core: 2
Core(s) per socket: 4
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 30
Model name: Intel(R) Xeon(R) CPU X3440 @ 2.53GHz
Stepping: 5
CPU MHz: 1210.183
CPU max MHz: 2534,0000
CPU min MHz: 1200,0000
BogoMIPS: 5066.32
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 8192K
NUMA node0 CPU(s): 0-7`
Если нужно только подключить онлайн трансляцию на веб страничке, то необходимо сперва добавить API ключ пользователю, чей монитор нас интересует. Полное руководство по API находится на [официальном сайте](https://shinobi.video/docs/api) приложения. Сверху помещаем курсор на email пользователя, кликаем, выбираем пункт API.

Основной параметр для нас — это **Allowed IPs** (разрешенные IP). У меня доступ открыт только для локальной сети, но если вы планируете стримить свои потоки в глобальный Интеренет, то необходимо указать 0.0.0.0/0 и пробросить порт Shinobi наружу.
> Технически, Shinobi позволяет очень гибко организовать трансляцию RTSP потока, который поддерживается даже самыми простыми видео-регистраторами. Всё зависит от вашей фантазии и потребностей. Что касается технических возможностей: в случае если вы используете аналоговые камеры, вам 100% понадобится какой-никакой, но видео-регистратор с интерфейсом RJ-45. Всё куда проще, если вы используете IP камеры: них уже есть сетевой интерфейс и видео-поток генерируется аппаратными средствами самой камеры. Но стоят они на порядок дороже чем AHD камеры. Зато цифровые камеры выигрывают по таким параметрам как скорость передачи, и, что более значительно (если речь идет о расследовании происшествий) — качество изображения, не говоря уже удобстве развёртывания и реорганизации.
Информацию о веб-потоках можно получиться простым GET запросом, результат получаем в формате JSON, который легко преобразовать в данные. Пример простого скрипта на PHP:
```
php
$url = array(
'host' = '192.168.2.104', # Хост, на котором работает Shinobi
'port' => '8080', # Порт web-сервиса Shinobi
'api' => 'TyIp1yRhqPLnJmlDpMzAenWYqVW8vt', # API ключ
'monitor' => 'f2xnMN0VAv' # ID монитора, которы нужно прогрузить
);
$link = file_get_contents("http://". $url['host'] .":". $url['port'] ."/". $url['api'] ."/monitor/". $url['monitor'] ."/");
foreach(json_decode($link) as $data) {
$source['title'][] = $data->name;
$source['url'][] = "http://". $url['host'] .":". $url['port'] . $data->streams[0];
$source['width'][] = $data->width;
$source['height'][] = $data->height;
$source['status'][] = $data->status;
}
print "
Просмотр видеопотока
";
for($i = 0; $i <= count($source['title']); $i++){
if( $\_POST['streamId'] == $i) {
print "". $source['title'][$i] ."";
} else {
print "". $source['title'][$i] ."";
}
}
if( isset($\_POST['streamId']) ) {
$id = $\_POST['streamId'];
} else {
$id = 0;
}
print "
Режим трансляции потока: ". $source['status'][$id] ."
var player = videojs('hls-example');
player.play();
";
?>
```
Для некоторых камер у меня указан режим Recording. В данном случае, помимо конвертирования потока ведется еще и запись с RTSP на локальный жесткий диск. Если в параметрах Recording указанно Default то запись будет храниться в папке **./Shinobi/videos/[MinitorID]/[CameraID]**. У меня же некоторые папки с основного монитора доступны по сети и монтируются средствами GPO для определенной группы как сетевые диски.

Зачем это сделано? Простая особенность логистики: бывает, что большая машина загружается товаром и уезжает в другой город, там разгружается уже покупателем, который может заявить что чего-то не хватает. А бывает, что и в своих магазинах уже не могут чего-то досчитаться. Поэтому для склада ведется отдельная запись с некоторых камер уже в mp4 формате. Это может сэкономить кучу времени на разборе полётов. | https://habr.com/ru/post/555226/ | null | ru | null |
# Опять про «MikroTik» или долгожданный SOCKS5

Я прекрасно понимаю, что вас достали вездесущие микротики, но это действительно интересно. На самом деле статья написана с задержкой в 4 месяца (поддержка SOCKS5 появилась еще в январе 2020 года), но лучше поздно, чем никогда, тем более что информации об этом не так много и мало кто в курсе.
Итак, давайте начнем!
Предыстория
-----------
Микротик — очень мощный инструмент, который (IMHO) должен быть в хозяйстве любого сетевого инженера. Огромный функционал и набор инструментов, постоянно пополняющийся с каждым релизом. В Changelog к RouterOS 6.47 (beta) был замечена поддержка SOCKS5, которую лично я ждал несколько лет (и много кто еще, судя по многочисленным «Feature Request» на [forum.mikrotik.com](https://forum.mikrotik.com/)):

Судя по одной из веток вышеупомянутого [форума](https://forum.mikrotik.com/viewtopic.php?t=154662#p769703), поддержка встроенного SOCKS5 сервера началась с версии 6.47beta19.
Настройка
---------
Настройка, как всегда с MikroTik, довольно простая и укладывается в четыре строчки.
В качестве испытуемого выступил виртуальный сервер с CHR (Cloud Hosted Router), обновленный до 6.47beta53.
**Префикс «beta» в версии RouterOS означает, что она предназначена исключительно для тестирования и отправки баг-репортов в support[at]mikrotik.com. Я настоятельно рекомендую не торопиться с апгрейдом железок под нагрузкой и дождаться Long-Term или хотя бы Stable релиза. Если же вы решили обновиться, то внимательно читайте Changelog, чтобы быть в курсе всех изменений и возможных проблем.**
Настраиваем SOCKS5-сервер, выбираем авторизацию по паролю (есть возможность сделать открытым), в качестве порта указан 3327 (отличный от стандартного 1080), чтобы не попасть в скан-листы ботнетов:
```
ip socks set enabled=yes version=5 port=3327 auth-method=password
```
Далее добавляем пользователя:
```
ip socks users add name=test_socks5 password=Str0nGP@SSw0RD
```
Создаем правило-исключение в фаерволе:
```
ip firewall filter add chain=input protocol=tcp dst-port=3327 action=accept comment="SOCKS5 TCP"
```
И перемещаем наше правило перед правилом типа «drop»:
```
ip firewall filter move [/ip firewall filter find comment="SOCKS5 TCP"] 0
```
Готово! На нашем микротике поднят SOCKS5 прокси-сервер.
Проверка
--------
Как и любой житель РФ, имея прокси-сервер в Европе, сразу же вспоминаю про телеграм, на нем и была проверена работоспособность свеженастроенного SOCKS5-сервера:

Звонки также прекрасно работают, несмотря на ограничение Free версии CHR в 1Mbps.
Далее стало интересно, как будет выглядеть POF (Passive OS Fingerprint), вносимый Микротиком (проверял на [WhatLeaks](https://whatleaks.com/)):
| С выключенным SOCKS5 | С включенным SOCKS5 |
| --- | --- |
| socks_down | socks_up |
Видно, что система определяется как Linux, что логично (ибо именно его ядро лежит в основе ROS) и не может не радовать. Да, можно было подменить и user-agent, но у нас несколько другая задача.
При этом на самом микротике, как и положено настоящему серверу, выводится статистика по подключениям и трафику:

Заключение
----------
На самом деле многого не хватает (например, поддержки аутентификации по RADIUS), но я искренне верю в то, что и данная опция будет доработана. Важно заметить, что это все таки роутер и основная его задача — форвардинг трафика, а остальные «фичи» это уже скорее просто приятно. В любом случае осознание того, что железка за 50$ столько всего умеет, будоражит воображение.
На этом все, спасибо за внимание :) | https://habr.com/ru/post/502182/ | null | ru | null |
# Как я правил баг в Angular
Всем привет. Сегодня я расскажу, как мой пулл-реквест замерджили в Angular. Вы узнаете про контрибьют в open source проект такого масштаба и как там проходит код ревью. Всем заинтересованным, добро пожаловать под кат.
### Об ошибке
У нас на работе долгоживущее SPA приложение, которое пользователь может не закрывать очень долгое время. И в какой-то момент мы заметили, что некоторые `Observable` HTTP запросы никогда не завершались.
Грустный Observable, который никогда не завершитсяПосле небольшого исследования выяснилось, что Angular никак не реагирует на внешний `XMLHttpRequest.abort()`, если браузер сам отменяет HTTP запросы. Такая ситуация возникает, когда пользователь переводит устройство в спящий режим (конкретно наш случай) или нажимает Ctrl+S с целью сохранить веб-страницу. Мы даже нашли соответствующий [issue](https://github.com/angular/angular/issues/22324). Более того, кто-то уже сделал пулл-реквест (ПР) на фикс этого бага. Мы написали обходное решение с использованием `XhrFactory` внутри нашего проекта, пока этот фикс попадает в какой-то из релизов Angular, и успешно забыли об этом.
Каково же было мое удивление, когда я зашел на страницу issue спустя полгода, а он по-прежнему открыт. Плюс ПР отменили из-за того, что автор не правил ревью комменты. Тогда я решил, что это мой шанс попробовать в open source разработку.
### Контрибьют
Прежде всего я обратился к гайдлайнам для контрибьютеров, которые лежат в [CONTRIBUTING.md](https://github.com/angular/angular/blob/master/CONTRIBUTING.md) файле. Вот список того, что нужно сделать, чтобы ваш ПР приняли в Angular:
1. Убедиться, что на баг или фичу еще нет [ПР на github](https://github.com/angular/angular/pulls).
2. Форкнуть проект.
3. Ответвиться от master ветки.
4. Написать свой код и **написать как минимум один тест** на него, следуя Code Style.
5. Запустить тесты Angular.
6. Сделать коммит с **правильным сообщением**.
7. Запушить свою ветку.
8. Подписать Contributor License Agreement (CLA).
9. Сделать ПР в Angular в master ветку.
Первые три пункта, думаю, можно не комментировать. Интересное начинается с четвертого. Мне было легче, так как уже был отмененный пулл-реквест, который нужно было только улучшить. Но давайте пройдемся по флоу от начала до конца. Как бы я теоретически правил ошибку, не имея никаких наработок.
Проблема возникает в запросах к серверу. Значит, нам нужно в `http` модуль. Быстро пробежав по репозиторию, находим нужный пакет. Знаем, что ошибка связана с `xhr` и его событием `abort`, ищем, где внутри `http` модуля создается `XMLHttpRequest` и как обрабатывается `abort` событие. Находим файл `xhr.ts`, немного изучив, что там происходит, понимаем, что он-то нам и нужен.
Структура http модуляИщем в этом файле слушателя на событие `abort`. Видим, что событие никак не обрабатывается. Бинго!
Получается, что нужно просто назначить обработчик события `abort`, чтобы по нему `Observable` HTTP запроса завершался с ошибкой. И не забыть написать на это дело тест. В `xhr.ts` уже есть функция `onError`, можем использовать ее. Делов на две строчки кода.
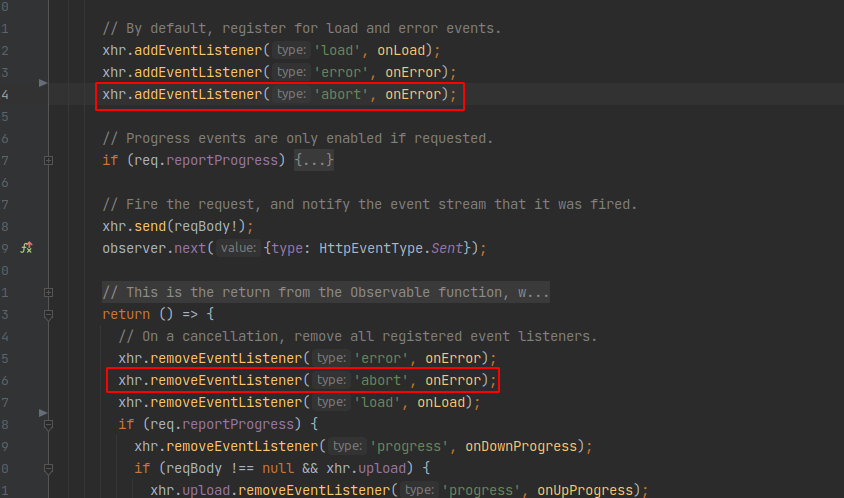Были ещё мысли, что можно обрабатывать внешний аборт, как `HttpEvent` вместо ошибки, тогда все немного сложнее. Но, на мой взгляд, ситуация, когда твой запрос неожиданно прервали внешние силы, является скорее ошибкой.
Код, который правит баг, написан. Дальше необходимо написать юнит-тест на этот код, дабы при изменении функциональности `http` модуля ничего не сломалось. У каждого файла в папке `src` есть свой файл с расширением `.spec.ts` для тестов в папке `test`. Алгоритм очень простой — находим максимально похожий тест и немного изменяем. Мне ещё нужно было расширить один mock.
Тесты написаны. Теперь нужно запустить и прогнать все тесты на проекте. Это может занять много времени. Будьте готовы.
При написании тестов также можно проверять отдельный модуль, это будет намного быстрее. Например так:
```
yarn bazel test packages/common/http/test
```
Все тесты прошли. Пора коммитить наши изменения. Перед этим советую сделать `yarn lint`, если вы до этого не настраивали автоматическое форматирование в виде clang. Code style — наше все.
Переходим к самому коммиту. В Angular строгое отношение к наименованию коммитов. Поэтому внимательно читаем секцию про [commit message](https://github.com/angular/angular/blob/master/CONTRIBUTING.md#commit) в гайдлайнах контрибьютеров и следуем содержимому.
Теперь публикуем нашу ветку. Осталось совсем немного. Необходимо подписать [CLA](https://cla.developers.google.com/about/google-individual) с компанией Google. Это позволяет контрибьютеру сохранить свое право собственности на код, предоставляя Google необходимые юридические права на использование этого кода. CLA нужно подписать только один раз, и он охватывает все проекты Google.
Дальше все легко. Делаем ПР и ждем, когда его посмотрят разработчики Angular.
### Код ревью
После прочтения данной [публикации на Хабре](https://habr.com/ru/post/491788/) я был готов к длительному ожиданию. Но мой пулл-реквест посмотрели спустя 13 минут! Уж не знаю, это мне очень сильно повезло или команда Angular стала уделять больше времени сторонним разработчикам, но было очень круто так быстро получить фидбек по своему коду.
Andrew Kushnir аппрувнул мой ПР и сказал, что мои изменения кажутся ему адекватными. Он также добавил в обсуждение Alex Rickabaugh, который имеет больше контекста по этой ошибке. Alex поставил аппрув спустя 30 минут и написал, что изначально у него были некоторые опасения по поводу моего решения, но немного поразмыслив, он с ним согласился.
Однако на этом все не закончилось. Оказалось, что есть похожий пулл-реквест, который правит [ошибку](https://github.com/angular/angular/issues/26453), связанную с `xhr timeout`, и код там почти идентичен моему, только вместо `abort` события — `timeout`. И у нас возникнут merge конфликты, когда этот ПР вольется. Меня попросили сделать `rebase` и поправить конфликты, когда настанет время. Я вежливо согласился. Спустя 15 минут мне написали о появлении ожидаемых конфликтов. Я разрешил их и сделал `push` с `--force-with-lease` флагом.
На следующий день Andrew Kushnir поставил метку “*merge*” на пулл-реквест и поблагодарил меня за вклад. А буквально через два часа мои изменения влили в проект.
Спустя еще пару дней обновили CHANGE\_LOG.md, что баг поправлен и войдет в 12 версию Angular.
Итоги
-----
Это был очень интересный опыт. Было занимательно посмотреть структуру фреймворка, на котором пишешь долгое время, запустить тесты и узнать какие процессы в Angular команде. Как оказалось, вносить свои изменения в open source фреймворк совсем не сложно.
UPD
---
Про `git push --force-with-lease`. Если еще кто-то коммитил в вашу удаленную ветку и ваша локальная ветка не содержит этих коммитов, вы не сможете сделать `push` с этим флагом, пока не обновите свою локальную ветку. [Данный флаг](https://git-scm.com/docs/git-push#Documentation/git-push.txt---force-with-leaseltrefnamegt) гарантирует, что вы не перепишете чужую историю коммитов. Его рекомендуют использовать в гайдлайнах контрибьютеров, если вам необходимо обновить git историю удаленной ветки. | https://habr.com/ru/post/545388/ | null | ru | null |
# Zend_Mail отправка писем через SMTP с аутентификацией
Переделывал както один сайтик за горе-создателями и потребовалось мне отправлять почту через SMTP c аутентификацией.
Смотрим в руководство на сайте зенда <http://framework.zend.com/manual/ru/zend.mail.smtp-authentication.html>
и видим: *"… на данный момент SMTP-аутентификация не поддерживается"* :(
Что же делать?
Отлично осознавая что документация на сайте устаревает раньше, да и свежая версия фреймворка вышла совсем недавно, смотрим в код.
И что же мы видим? Zend/Mail/Protocol/Smtp/Auth!!! УРА!
итак, результат:
**config.ini** (я храню конфиги в ini файле)
`[mail]
host = mailhost.ru
port = 25
auth = login
username = smtpusername
password = smtppassword`
в соответствии с рекомендацией [мануала](http://framework.zend.com/manual/ru/zend.mail.sending.html)
*«Чтобы отправить сообщение электронной почты через SMTP, нужно создать и зарегистрировать объект Zend\_Mail\_Transport\_Smtp, прежде чем будет вызван метод send(). Для всех последующих вызовов Zend\_Mail::send() в текущем скрипте будет использоваться SMTP»*
**index.php или bootstrap.php**
`$oConfig = new Zend_Config_Ini('config.ini');
/**
* Настройка почты. работаем через SMTP с авторизацией
*/
$tr = new Zend_Mail_Transport_Smtp( $oConfig->mail->host, $oConfig->mail->toArray() );
Zend_Mail::setDefaultTransport($tr);`
здесь следует обратить внимание на второй параметр Zend\_Mail\_Transport\_Smtp в соответствии с кодом это массив
`/**
* Config options for authentication
*
* @var array
*/
protected $_config;`
Zend\_Mail\_Transport\_Smtp не может работать с обьектом конфигурации,
именно поэтому прихотится преобразовывать его toArray()
**и там где нужно отправка** просто шлем почту
`$mail = new Zend_Mail( 'windows-1251' );
$mail->setBodyText('This is the text of the mail.');
$mail->setFrom('[email protected]', 'Some Sender');
$mail->addTo('[email protected]', 'Some Recipient');
$mail->setSubject('TestSubject');
$mail->send();` | https://habr.com/ru/post/41127/ | null | ru | null |
# Бюджетный неттоп в качестве HTPC
У каждого любителя посмотреть хорошее и качественное кино несомненно встает вопрос: как и чем это кино воспроизводить. Сейчас на рынке присутствует огромное количество мультимедийных плееров разной ценовой категории, с разным дизайном, количеством поддерживаемых форматов и других “плюшек” в виде встроенного торрент-клиента и т.д. Но, как правило, достойные плееры выходят за рамки бюджетных устройств и при этом всем они все же не отличаются гибкостью в настройке системы. Но как же тогда поступить? Мы плавно подошли к разговору о HTPC.
HTPC строят уже довольно давно, правда раньше чтобы получить хорошего представителя приходилось выложить довольно кругленькую сумму. Водное охлаждение, красивый корпус, производительный процессор — всё это стоит больших денег. Но всё меняется. Сейчас всё большую популярность набирают платформы с CPU и GPU с аппаратным декодированием Full HD видео на одной плате, что в свою очередь даёт возможность уйти от высокопроизводительных процессоров к менее производительным, с меньшим потреблением электричества и выделением тепла, в следствие чего необходимость в мощной охладительной системе отпадает, и, зачастую она сменяется пассивным охлаждением, что конечно же в разы дешевле.
Выдвигаемые требования
----------------------
* Цена (чем дешевле тем лучше, денег было впритык)
* Поддержка оборудования в Linux ( использование Windows в качестве основы для HTPC не входило в планы)
* Тишина ( я думаю все этого хотят)
* Доступность в магазинах города (хотелось здесь и сейчас, и без проблем с заказами и гарантией)
* Поддержка Full HD видео, всех известных форматов и кодеков
* Наличие HDMI ( ну как без него? это уже стандарт)
* Достаточное современное “железо”
Поиск кандидата
---------------
Я начал искать варианты miniITX платы с Intel Atom и ION2. Пару лет назад я собирал HTPC брату на плате Zotac c Atom N330 и ION, но даже такой платы в прайсах магазинов своего города найти не удалось, не говоря уже о более современных решениях. Решено было брать неттоп, который отвечал бы моим требованиям, благо их в магазинах города оказалось больше. Выбор на брендовый неттоп одного из магазинов под названием [DNS Porto [0131410]](http://voronezh.dns-shop.ru/catalog/176/131410/) О нём собственно я и буду рассказывать дальше.
Технические характеристики
--------------------------
| | |
| --- | --- |
| **Операционная система** | Без ОС |
| **Процессор** | Atom D525 (1.8 ГГц х 2 ядра) |
| **Чипсет** | Intel NM1 |
| **Видео карта** | NVIDIA ION 2 (GT218) |
| **Память** | 320 ГБ (HDD 2.5 Toshiba MK3264GSY, 7200 об/мин) |
| **Оперативная память** | 2 Гб (Nanya DDR3 PC3-8500 1066 МГц) |
| **Проводная связь** | Gigabit Ethernet |
| **Беспроводная связь** | Wi-Fi 802.11b/g/n (Realtek RTL8191SU) |
| **Разъёмы** | 4 x USB, 2 x 3,5-мм, HDMI, VGA, RG-45, разъзём питания |
| **Размеры** | 150 x 170 x 20 мм |
| **Вес** | 900 г |
Комплектация
------------
Неттоп поставляется в картонной коробке с глянцевым покрытием с нанесенным изображением предмета обзора и символикой магазина DNS, наклейкой сверху с информацией о продукте, надписью “Сделано в России”. Что конкретно сделано в России правда непонятно: коробка или наклейка “DNS” на устройстве?
Забегая вперед скажу, что неттоп производит фирма Pegatron, бывшее производственное подразделение ASUS, и в рамках этой фирмы устройство называется **Pegatron AMIS L6 D525.** Далее они отдают их другим фирмам/магазинам на брендирование и те уже продают их под своим названием, поэтому найти устройство в продаже с оригинальным названием практически невозможно.


Внутри упаковочной коробки было
-------------------------------
* Неттоп
* VESA-крепление
* железная подставка для вертикальной установки
* диск с драйверами
* мануал на Английском языке ( особенно актуально для устройства сделанного в России =) )
* Адаптер питания и шнур питания

Внешний вид
-----------

Размеры устройства настолько малы, что кажется можно положить его в карман и пойти к другу/подруге посмотреть фильм или послушать музыку. Устройство собрано в трапециевидном пластиковом корпусе, верхнюю панель прикрывает глянцевая пластина с декоративными полосками и логотипом DNS посередине. Где-то в углу верхней панели есть кнопка питания, которая подсвечивается синим цветом в включенном режиме, лампочка к слову настолько яркая, что в темное время суток озаряет потолок кругом радиусом около метра.

Две боковые стороны отданы прорезям для вентиляции. Они прикрыты сетками: одна для притока, другая для оттока воздуха от встроенного в корпус вентилятора. На переднем торце неттопа есть скрытая панель с двумя портами USB для быстрого подключения флэшки или другой периферии. Отсек прикрыт неудобной пластиковой заглушкой, чтобы открыть и закрыть её без повреждений приходится проявлять чудеса аккуратности.



На заднем торце устройства расположены все интерфейсные разъемы: порт VGA для вывода картинки на обычный монитор, HDMI для ЖК телевизоров и плазменных панелей, а также вывод цифрового звука на ресивер, два USB для периферии, сетевой порт Ethernet, отверстие для адаптера питания и аудиопорты (две штуки – для ввода и вывода).

Нижняя сторона устройства — матовое покрытие пластика и резиновые ободки, а так же наклейки железо производителей, и самую главную “Сделано в России”

Внутренности
------------
Компьютер построен на базе двухъядерного процессора Intel Atom D525 который работает на частоте 1,8 ГГц в паре с чипсетом Intel NM10. За оперативную память отвечает планка с Nanya DDR3 PC3-8500 (1066 МГц с ) 2 Гб памяти на борту, за место для установки ОС и хранения мультимедийных файлов отвечает винчестер Toshiba MK3264GSY емкостью 320 Гб и скоростью вращения шпинделя 7200 оборотов в минуту. Наконец, за графику отвечает дискретный чип NVIDIA ION 2 с 16 шейдерными процессорами и поддержкой ускорения HD-видео. Кажется при разработке этого неттопа оригинальный производитель решил не использовать устаревшие компоненты — придраться к ним не получается при всем желании.
Спасибо Pegatron’у и за встроенный контроллер Wi-Fi (Realtek RTL8191SU 802.11n) — к HTPC не придется вести сетевой кабель, а можно будет воспользоваться возможностью беспроводного доступа к интернету и локальной сети, или же сделать из него точку доступа. Это кстати одна из тех гибкостей, упомянутых в начале статьи, которые недоступны при покупке медиа-плееров.
В работе
--------
Тест производительности системы и сравнение её с AMD Zacate можно почитать [здесь.](http://blog.dns-shop.ru/blog/dev/408.html)
Компьютер можно назвать вполне быстрым для своих размеров — современный Intel Atom с двумя ядрами и поддержкой Hyper-Threading прекрасно справляется с интернетом, стандартными задачами, тогда как NVIDIA ION 2 подхватывает на свои плечи ускорение видео в разрешении Full HD. Проблем с воспроизведением HD контента не наблюдалось, все тяжелые BDRemux, и Blu-Ray воспроизводились без тормозов и каких либо других дефектов.
**Предлагаю ознакомится с результатами qvdpautest:**
```
qvdpautest 0.5.1
Intel(R) Atom(TM) CPU D525 @ 1.80GHz
NVIDIA GPU ION (GT218) at PCI:4:0:0 (GPU-0)
VDPAU API version : 1
VDPAU implementation : NVIDIA VDPAU Driver Shared Library 270.41.06 Mon Apr 18 15:13:22 PDT 2011
SURFACE GET BITS: 193.219 M/s
SURFACE PUT BITS: 162.126 M/s
MPEG DECODING (1920x1080): 65 frames/s
MPEG DECODING (1280x720): 162 frames/s
H264 DECODING (1920x1080): 62 frames/s
H264 DECODING (1280x720): 137 frames/s
VC1 DECODING (1440x1080): 79 frames/s
MPEG4 DECODING (1920x1080): 72 frames/s
MIXER WEAVE (1920x1080): 483 frames/s
MIXER BOB (1920x1080): 675 fields/s
MIXER TEMPORAL (1920x1080): 190 fields/s
MIXER TEMPORAL + IVTC (1920x1080): 122 fields/s
MIXER TEMPORAL + SKIP_CHROMA (1920x1080): 254 fields/s
MIXER TEMPORAL_SPATIAL (1920x1080): 65 fields/s
MIXER TEMPORAL_SPATIAL + IVTC (1920x1080): 53 fields/s
MIXER TEMPORAL_SPATIAL + SKIP_CHROMA (1920x1080): 72 fields/s
MIXER TEMPORAL_SPATIAL (720x576 video to 1920x1080 display): 230 fields/s
MIXER TEMPORAL_SPATIAL + HQSCALING (720x576 video to 1920x1080 display): 121 fields/s
MULTITHREADED MPEG DECODING (1920x1080): 70 frames/s
MULTITHREADED MIXER TEMPORAL (1920x1080): 163 fields/s
```
Некоторые люди жалуются на наличие шумного вентилятора, но у меня это не так: в метре устройство не слышно совсем, при наличии в этой же комнате компрессора для аквариума, от которого шума в разы больше, шум от устройства практически не уловим. Температура компонентов компьютера так же поддерживается на должном уровне. В качестве ОС используется Ubuntu. Изначально же планировался ArchLinux, но с ним не сложилось: не осилил вывод звука через HDMI, в роли медиа центра выступает XBMC.
Плюсы и минусы
--------------
 Компактные размеры
 Малая цена ( от 7000 рублей)
 Хорошая для своего класса производительность
 Wi-Fi 802.11 n
 Поддержка Linux
 Не греется и почти бесшумный
 Довольно стильный дизайн
 Яркая синяя лампочка
 Глянцевая верхняя крышка
 Отсутствие Bluetooth
 Малое количество USB разъёмов | https://habr.com/ru/post/128733/ | null | ru | null |
# Изучаем Adversarial Tactics, Techniques & Common Knowledge (ATT@CK). Enterprise Tactics. Часть 8
[Боковое перемещение (Lateral Movement)](https://attack.mitre.org/tactics/TA0008/)
==================================================================================
**Ссылки на все части:**
[Часть 1. Получение первоначального доступа (Initial Access)](https://habr.com/post/423405/)
[Часть 2. Выполнение (Execution)](https://habr.com/post/424027/)
[Часть 3. Закрепление (Persistence)](https://habr.com/post/425177/)
[Часть 4. Повышение привилегий (Privilege Escalation)](https://habr.com/post/428602/)
[Часть 5. Обход защиты (Defense Evasion)](https://habr.com/post/432624/)
[Часть 6. Получение учетных данных (Credential Access)](https://habr.com/post/433566/)
[Часть 7. Обнаружение (Discovery)](https://habr.com/ru/post/436350/)
[Часть 8. Боковое перемещение (Lateral Movement)](https://habr.com/ru/post/439026/)
[Часть 9. Сбор данных (Collection)](https://habr.com/ru/post/441896/)
[Часть 10 Эксфильтрация или утечка данных (Exfiltration)](https://habr.com/ru/post/447240/)
[Часть 11. Командование и управление (Command and Control)](https://habr.com/ru/post/449654/)
Тактика бокового движения (*англ. «Lateral Movement» — боковое, поперечное, горизонтальное перемещение*) включает методы получения противником доступа и контроля над удаленными системами, подключенными к атакованной сети, а так же, в некоторых случаях, запуска вредоносных инструментов на удаленных системах, подключенных к атакованной сети. Боковое перемещение по сети позволяет злоумышленнику получать информацию из удаленных систем без использования дополнительных инструментов, таких как утилиты удаленного доступа (RAT).
*Автор не несет ответственности за возможные последствия применения изложенной в статье информации, а также просит прощения за возможные неточности, допущенные в некоторых формулировках и терминах. Публикуемая информация является свободным пересказом содержания [MITRE ATT&CK](https://attack.mitre.org/wiki/Main_Page).*
### [AppleScript](https://attack.mitre.org/wiki/Technique/T1155)
*Система:* macOS
*Права:* Пользователь
*Описание:* Язык AppleScript предоставляет возможность работы с Apple Event — сообщениями, которыми обмениваются приложения в рамках межпроцессного взаимодействия (IPC). С помощью Apple Event можно взаимодействовать практически с любым приложением, открытым локально или удаленно, вызывать такие события как открытие окон и нажатие клавиш. Скрипты запускаются с помощью команды: `Osascript -e [скрипт]`.
Злоумышленники могут использовать AppleScript для скрытого открытия SSH-соединений с удаленными хостами, предоставления пользователям поддельных диалоговых окон. AppleScript также может использоваться в более распространенных типах атак, например, организации Reverse Shell.
*Рекомендации по защите:* Обязательная проверка запускаемых сценариев AppleScript на наличие подписи доверенного разработчика.
### [Программное обеспечение для развертывания приложений (Application Deployment Software)](https://attack.mitre.org/wiki/Technique/T1017)
*Система:* Windows, Linux, macOS
*Описание:* Средства развертывания приложений, используемые администраторами сети предприятия, могут применяться злоумышленниками для установки вредоносных приложений. Разрешения, необходимые для совершения этих действий зависят от конфигурации системы: для доступа к серверу установки программного обеспечения могут потребоваться определенные доменные учетные данные, а может быть достаточно и локальных прав, однако для входа в систему установки приложений и запуска процесса развертывания может потребоваться учетная запись администратора системы. Доступ к централизованной корпоративной системе установки приложений позволяет противнику удаленно выполнять код во всех системах атакуемой сети. Такой доступ может использоваться для продвижения по сети, сбора информации или вызова специфического эффекта, например, очистки жестких дисков на всех хостах.
*Рекомендации по защите:* Предоставляйте доступ к системам развертывания приложений только ограниченному числу авторизованных администраторов. Обеспечьте надежную изоляцию и ограничение доступа к критически важным сетевым системам с помощью брандмауэров, ограничьте привилегии учетных записей, настройте групповые политики безопасности и многофакторную аутентификацию. Убедитесь, что данные учетных записей, имеющих доступ к системе развертывания софта, уникальны и не используются во всей сети. Регулярно устанавливайте исправления и обновления систем установки приложений, чтобы предотвратить возможность получения к ним несанкционированного удаленного доступа с помощью эксплуатации уязвимостей. Если система установки приложений настроена на дистрибьюцию только подписанных двоичных файлов, то убедитесь, что доверенные сертификаты подписи размещены не в ней, а хранятся в системе, удаленный доступ к которой невозможен или ограничен и контролируется.
### [DCOM (Distributed Component Object Model)](https://attack.mitre.org/wiki/Technique/T1175)
*Система:* Windows
*Права:* Администратор, System
*Описание:* DCOM — это протокол, который расширяет функциональность Component Object Model (COM), позволяя компонентам программного обеспечения взаимодействовать не только в рамках локальной системы, но и по сети, используя технологию удаленного вызова процедур (RPC), с компонентами приложений других систем. COM является компонентом Windows API. Посредством COM клиентский объект может вызвать метод серверного объекта, обычно это DLL-библиотеки или Exe-файлы. Разрешения на взаимодействие с локальным или удаленным серверным COM-объектом определяются с помощью ACL-листов в реестре. По умолчанию, только администраторы могут удаленно активировать и запускать COM-объекты посредством DCOM.
Противники могут использовать DCOM в целях бокового перемещения по сети. Через DCOM злоумышленник, работающий в контексте пользователя с соответствующими привилегиями может удаленно вызывать выполнение произвольного кода через приложения Office и другие объекты Windows, содержащие небезопасные методы. DCOM также может выполнять макросы в существующих документах, а также вызывать Dynamic Data Exchange (DDE) напрямую через COM-объект, созданный в Microsoft Office, минуя необходимость создания вредоносного документа. DCOM также может предоставлять противнику функциональные возможности, которые можно использовать на других этапах атаки, таких как повышение привилегий или закрепление доступа.
*Рекомендации по защите:* С помощью реестра настройте индивидуальные параметры безопасности COM-приложений: code>HKEY\_LOCAL\_MACHINE\SOFTWARE\Classes\AppID.
Рассмотрите возможность отключения поддержки DCOM с помощью утилиты *dcomcnfg.exe* или в реестре: `HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Ole\EnableDCOM=SZ:N`
Включите брандмауэр Windows, который по умолчанию предотвращает создание экземпляров DCOM. Включите режим защищенного просмотра и оповещения о запуске COM-объектов в документах MS Office.
### [Эксплойты удаленных сервисов (Exploitation of Remote Services)](https://attack.mitre.org/wiki/Technique/T1210)
*Система:* Windows, Linux, macOS
*Права:* Пользователь
*Описание:* Для выполнения произвольного кода злоумышленники могут применять эксплойты, которые используют ошибки в программах, службах, программном обеспечении операционной системы или даже в самом ядре операционной системы. Целью эксплуатации уязвимостей удаленных сервисов после первичной компрометации является обеспечение удаленного доступа к системам для перемещения по сети.
Предварительно противнику необходимо определить системы, имеющие уязвимости. Это может быть выполнено путём сканирования сетевых служб или других методов [обнаружения](https://habr.com/ru/post/436350/), таких как поиск распространенного уязвимого программного обеспечения и отсутствующих исправлений, что служит индикатором наличия уязвимостей, или поиск средств безопасности, которые используется для обнаружения и блокирования удаленной эксплуатации уязвимостей. Серверы, вероятнее всего, будут являться ценной целью для использования при перемещения по сети, но рабочие станции также подвержены риску если они предоставляют противнику какое-либо преимущество или доступ к дополнительным ресурсам.
Известны уязвимости в службах общего доступа, таких как SMB, RDP, а также приложениях, которые могут использоваться во внутренних сетях, таких как MySQL и службы web-серверов. В зависимости от разрешений уязвимой службы, противник, осуществляя боковое перемещение, с помощью эксплойта может дополнительно получить повышение привилегий.
*Рекомендации по защите:* Сегментируйте сети и системы, чтобы уменьшить доступ к критически важным системам и услугам. Минимизируйте доступность сервисов, предоставляя права только тем, кому они необходимы. Регулярно проверяйте внутреннюю сеть на наличие новых и потенциально уязвимых сервисов. Минимизируйте разрешения и доступ для учетных записей служб, чтобы ограничить зону поражения.
Регулярно обновляйте программное обеспечение, внедрите процесс управления установкой исправлений приложений на внутренних хостах и серверах. Разработайте процедуры анализа киберугроз, чтобы определить типы и уровни угроз, в ходе которых против вашей организации могут применяться эксплойты, включая эксплойты уязвимостей нулевого дня. Применяйте песочницы, чтобы усложнить противнику выполнение операций с помощью использования неизвестных вам или неисправленных уязвимостей. Другие типы микросегментации и виртуализации приложений также могут смягчить последствия некоторых типов эксплойтов. Программные средства безопасности, такие как Windows Defender Exploit Guard (WDEG) и Enhanced Mitigation Experience Toolkit (EMET), которые нацелены на поиск поведения, используемого во время эксплуатации уязвимостей, могут использоваться для защиты от эксплойтов. [Проверка целостности потока управления](https://docs.microsoft.com/ru-ru/windows/security/threat-protection/windows-defender-exploit-guard/customize-exploit-protection) — это ещё один способ идентификации и блокирования эксплуатации уязвимостей программного обеспечения. Многие из перечисленных средств защиты могут работать не для всех программ и служб, совместимость зависит от архитектуры и двоичного файла целевого приложения.
В зависимости от имеющегося инструментария обнаружение защищающейся стороной эксплуатации уязвимостей может быть затруднено. Программные эксплойты могут не всегда успешно выполниться или привести к нестабильной работе или аварийному завершению атакуемого процесса. Обращайте внимание на индикаторы компрометации, например, ненормальное поведение процессов, появление на диске подозрительных файлов, необычный сетевой трафик, признаки запуска средств обнаружения, инъекции процессов.
### [Сценарии входа в систему (Logon Scripts)](https://attack.mitre.org/wiki/Technique/T1037)
*Система:* Windows, macOS
*Описание:* Противник может использовать возможность создания новых или изменения существующих logon-скриптов — сценариев которые выполняются всякий раз когда конкретный пользователь или группа пользователей выполняет вход в систему. Если злоумышленник получил доступ к logon-скрипту на контроллере домена, то он может модифицировать его для исполнения кода во всех системах домена в целях бокового перемещения по сети. В зависимости от настроек прав доступа сценариев входа в систему могут потребоваться локальные или административные учетные данные.
В Mac, logon-скрипты ([Login/Logout Hook](https://support.apple.com/de-de/HT2420)), в отличие от Login Item, которые запускаются в контексте пользователя, могут запускаться от имени root.
*Рекомендации по защите:* Ограничение прав администраторов на создание сценариев входа в систему. Идентификация и блокирование потенциально-опасного ПО, которое может использоваться для модификации сценариев входа. AppLocker в Windows может блокировать запуск неизвестных программ.
### [Pass the Hash](https://attack.mitre.org/wiki/Technique/T1075)
*Система:* Windows
*Описание:* Pass the Hash (PtH) — это метод аутентификации пользователя без доступа к его паролю в открытом виде. Метод заключается в обходе стандартных этапов аутентификации на которых требуется ввод пароля и переходе непосредственно к той части аутентификации, которая использует хэш пароля. Хэши действительных паролей захватываются противником с помощью техник доступа к учетным данным (Credential Access), далее хэши используются для PtH-аутентификации, которая может использоваться для выполнения действий в локальных или удаленных системах.
Для осуществления атаки Pass the Hash в Windows 7 и выше с установленным обновлением *[KB2871997](https://support.microsoft.com/ru-ru/help/2871997/microsoft-security-advisory-update-to-improve-credentials-protection-a)* требуются действительные учетные данные пользователя домена или хэши администратора (RID 500).
*Рекомендации по защите:* Проводите мониторинг системных и доменных журналов в целях выявления необычной активности входов учетных записей. Предотвращайте доступ к действующим учетным записям. В системах версии Windows 7 и выше установите исправление KB2871997, чтобы ограничить доступ учетных записей в группах локальных администраторов по умолчанию.
В целях минимизации возможности реализации Pass the Hash отключите удаленный запуск UAC при входе пользователя по сети с помощью редактирования соответствующего ключа в реестре или групповых политик:
`HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\Policies\System\LocalAccountTokenFilterPolice`
`GPO:Computer Configuration > [Policies] > Administrative Templates > SCM: Pass the Hash Mitigation: Apply UAC restriction to local accounts on network logons`
Ограничивайте совпадение учетных записей в различных системах, чтобы помешать их компрометации и снизить способность перемещения противника между системами. Убедитесь, что встроенные и созданные учетные данные локальных администраторов имеют сложные уникальные пароли. Не допускайте, чтобы доменный пользователь входил в группу локальных администраторов на нескольких системах. В целях обнаружения атак Pass the Hash применяется аудит всех событий входа и использования учетных данных с проверкой на расхождение (например, одна учетная запись использовалась одновременно на нескольких системах). Необычные входы в систему, связанные с подозрительными действиями (например, создание и выполнение двоичных файлов) могут также указывать на вредоносную активность. Подозрение также должны вызывать события аутентификации типа NTLM LogonType 3 (сетевой вход), несвязанные с доменными и не анонимными учетными записями (пользователи с SID S-1-5-7).
### [Pass the Ticket](https://attack.mitre.org/wiki/Technique/T1097)
*Система:* Windows
*Описание:* Pass the Ticket (PtT) — это способ аутентификации с помощью билетов Kerberos без доступа к паролю учетной записи. Kerberos-аутентификация может быть использована в качестве первого шага к перемещению противника в удаленную систему.
В ходе PtT, действующие билеты Kerberos для действующих учетных записей фиксируются противником с помощью [техник дампинга учетных данных](https://attack.mitre.org/techniques/T1003/). В зависимости от уровня доступа могут быть получены пользовательские билеты служб (service tickets) или билеты на выдачу билетов (ticket granting ticket (TGT)). Билет службы позволяет получить доступ к конкретному ресурсу, тогда как TGT может быть использован для запроса билетов служб у службы предоставления билетов (TGS) для доступа к любому ресурсу к которому пользователь имеет доступ.
Silver Ticket (поддельный TGS) может быть получен для сервисов, которые используют Kerberos как механизм аутентификации, и использован для генерации билетов для доступа к конкретному ресурсу и системе, в которой размещен ресурс (например, SharePoint).
Golden Ticket (билет Kerberos для неограниченного доступа к ресурсам в контексте любого пользователя, включая несуществующих пользователей) может быть получен путем использования NTLM-хэша учетной записи службы распределения ключей — KRBTGT, который даёт возможность генерировать TGT для любой учетной записи в AD.
*Рекомендации по защите:* Проводите мониторинг наличие в системе необычных учетных данных. Ограничивайте совпадение учетных данных в разных системах тем самым предотвращая повреждения в случае компрометации. Убедитесь, что локальные учетные записи администраторов имеют сложные, уникальные пароли. Не позволяйте пользователю быть локальным администратором нескольких систем. Ограничивайте разрешения учетной записи администратора домена для контроллеров домена и ограниченных серверов. Делегируйте прочие функции администратора отдельным аккаунтам.
Для противодействия ранее сгенерированному Gold Ticket дважды сбросьте пароль встроенной учетной записи KRBTGT, что сделает недействительными все Golden Ticket, созданные с помощью хэша пароля KRBTGT, и другие билеты Kerberos, полученные из Golden Ticket.
С помощью инструментов создания белых списков приложений, таких как Applocker или [Software Restriction Policies](https://docs.microsoft.com/en-us/previous-versions/technet-magazine/cc510322(v=msdn.10)) попытайтесь идентифицировать и заблокировать неизвестное или вредоносное ПО, которое может быть использовано для получения билетов Kerberos и дальнейшей аутентификации.
В целях обнаружения атак PtT рекомендуется аудит всех событий Kerberos-аутентификации и использования учетных данных с анализом расхождений. Необычные события удаленной аутентификации, коррелирующие с другой подозрительной активностью (такой как запись и запуск бинарников) может служить индикатором вредоносной активности.
Событие ID4769 генерируется на контроллере домена при использовании Golden Ticket после двойного сброса пароля KRBTGT. Код состояния 0x1F свидетельствует о неудачной проверке целостности зашифрованного поля и указывает на попытку использования недействительного Golden Ticket.
### [Протокол удаленного рабочего стола (Remote Desktop Protocol)](https://attack.mitre.org/wiki/Technique/T1076)
*Система:* Windows
*Права:* Пользователи удаленного рабочего стола, пользователи
Описание: Удаленный рабочий стол — типовая функция операционных систем, которая позволяет пользователю осуществлять вход в интерактивный сеанс с графическим интерфейсом на удаленном компьютере. Microsoft называет свою реализацию протокола RDP как [Remote Desktop Servoce (RDS)](https://docs.microsoft.com/en-us/windows/desktop/termserv/terminal-services-portal). Есть и другие реализации и сторонние инструменты предоставляющие графический доступ к удаленным сервисам, подобным RDS. Противники могут подключаться к удаленной системе через RDP/RDS для расширения доступа если соответствующая служба включена и разрешает доступ с известными злоумышленнику учетными данными. Предварительно, противник, вероятно, будет использовать [техники доступа к учетным данным](https://habr.com/ru/post/433566/) для получения учетных данных, которые можно использовать с RDP. Противники могут также использовать RDP в сочетании с техникой злоупотребления «специальными возможностями Windows» для закрепления в системе.
Злоумышленник также может пытаться захватить RDP сессии, включающие удаленные сеансы легитимных пользователей. Обычно, при попытке кражи сессии пользователь получает уведомление и запрос на подтверждение, однако имея разрешения уровня System с помощью консоли службы терминалов можно перехватить сеанс без предоставления учетных данных и подтверждения пользователя: `C:\Windows\system32\tscon.exe [номер сеанса, который нужно украсть]`.
Это может быть выполнено удаленно или локально с активными или прерванными сеансами. Это также может привести к повышению привилегий путем захвата сеанса администратора домена или более привилегированного пользователя. Всё вышеописанное может быть сделано с помощью встроенных команд Windows, либо соответствующий функционал может быть добавлен в инструментарий для пентестинга, например [RedSnarf](https://github.com/nccgroup/redsnarf).
*Рекомендации по защите:* Отключите службу RDP если она не нужна, удалите ненужные учетные записи и группы из группы *Remote Desktop Users*, включите правило блокировки трафика RDP между зонами безопасности в брандмауэре. Регулярно проверяйте членов группы *Remote Desktop Users*. Удалите группу администраторов из списка групп, которым разрешен вход через RDP. Если удаленный доступ необходим, то ограничьте права удаленного пользователя. Используйте *[Remote desktop gateways](https://docs.microsoft.com/en-us/windows-server/remote/remote-desktop-services/rds-roles)* и многофакторную аутентификацию для удаленного входа. Не оставляйте RDP доступным из интернета. Измените GPO, определив таймауты и максимальное время, в течение которого может быть активен удаленный сеанс. Измените GPO, указав максимальное время в течение которого отключенный удаленный сеанс остается активным на хост-сервере.
В связи с тем, что использование RDP может быть вполне легитимным процессом индикаторами вредоносной активности могут служить шаблонны доступа и действия, которые происходят после удаленного входа в систему, например, вход пользователей в системы к которым они обычно не обращаются или вход в несколько систем в течение относительно короткого промежутка времени. В целях предотвращения перехвата сеансов RDP рекомендуется мониторинг использования tscon.exe и создания служб, использующих `cmd.exe /k` или `cmd.exe /c` в своих аргументах.
### [Удаленное копирование файлов (Remote File Copy)](https://attack.mitre.org/wiki/Technique/T1105)
*Система:* Windows, Linux, macOS
*Права:* Пользователь
*Описание:* Файлы могут быть скопированы из одной системы в другую для развертывания инструментов противника или других файлов в ходе операции. Файлы могут быть скопированы из внешней системы, контролируемой злоумышленником, через канал C&C или с помощью других инструментов по альтернативным протоколам, например FTP. Файлы также можно копировать на Mac и Linux c помощью встроенных инструментов, таких как scp, rsync, sftp. Противники могут также копировать файлы в боковом направлении между внутренними системами-жертвами для поддержки перемещения по сети и удаленного выполнения команд. Это можно сделать с помощью протоколов предоставления общего доступа к файлам, подключая сетевые ресурсы через SMB или используя аутентифицированные соединения с Windows Admin Shares или RDP.
*Рекомендации по защите:* Применение IDS/IPS-систем, которые используют сигнатуры для идентификации вредоносного трафика или необычной передачи данных посредством известных инструментов и протоколов, подобных FTP, которые могут быть использованы для снижения активности на сетевом уровне. Сигнатуры, как правило, используются для обнаружения уникальных индикаторов протоколов и основаны на конкретной технике обфускации, используемой конкретным злоумышленником или инструментом, и, вероятнее всего, будут отличаться для разных семейств и версий вредоносных программ. Злоумышленники, скорее всего, изменят сигнатуру инструментов C2 или создадут протоколы так, чтобы избежать обнаружения общеизвестными защитными инструментами.
В качестве средств обнаружения рекомендуется мониторинг создания и передачи файлов по сети через SMB. Необычные процессы с внешними сетевыми подключениями, создающие файлы внутри системы могут вызывать подозрения. Нетипичное использование утилит подобных FTP, также может быть подозрительным. Так же рекомендуется анализировать сетевые данные на предмет необычных потоков данных, например клиент отправляет значительно больше данных, чем получает с сервера. Процессы, использующие сеть, которые обычно не имеют сетевого взаимодействия также являются подозрительными. Проанализируйте содержимое пакета с целью обнаружения соединений, которые не соответствуют протоколу и используемому порту.
### [Удаленные сервисы (Remote Services)](https://attack.mitre.org/wiki/Technique/T1021)
*Система:* Windows, Linux, macOS
*Описание:* Злоумышленники могут использовать действительные учетные записи для входа в службу, предназначенную для приема сетевых подключений, например telnet, SSH или VNC. После этого противник сможет выполнять действия от имени вошедшего в систему пользователя.
*Рекомендации по защите:* Ограничьте количество учетных записей, которые могут использовать удаленные службы. По возможности используйте многофакторную аутентификацию. Ограничьте разрешения для учетных записей, которые подвергаются более высокому риску компрометации, например, настройте SSH, чтобы пользователи могли запускать только определенные программы. Предотвращайте использование [техник доступа к учетным данным](https://habr.com/post/433566/), которые могут позволить злоумышленнику приобрести действительные учетные данные. Соотносите активность использования входа в систему, связанную с удаленными службами, с необычным поведением или другой вредоносной или подозрительной активностью. Прежде чем предпринимать продвижение по сети злоумышленнику, скорее всего, потребуется узнать об окружающей среде и взаимосвязях между системами с помощью [техник обнаружения](https://habr.com/ru/post/436350/).
### [Тиражирование через съемные носители (Replication Through Removable Media)](https://attack.mitre.org/wiki/Technique/T1091)
*Система:* Windows
*Описание:* Техника предполагает исполнение вредоносной программы с помощью функции автозапуска в Windows. Чтобы обмануть пользователя «законный» файл может быть предварительно модифицирован или заменён, а затем скопирован на съемное устройство злоумышленником. Так же полезная нагрузка может быть внедрена в прошивку съемного устройства или через программу первоначального форматирования носителя.
*Рекомендации по защите:* Отключение функций автозапуска в Windows. Ограничение использования съемных устройств на уровне политики безопасности организации. Применение антивирусного программного обеспечения.
### [Захват SSH (SSH Hijacking)](https://attack.mitre.org/wiki/Technique/T1184)
*Система:* macOS, Linux
*Описание:* Secure Shell (SSH) — стандартное средство удаленного доступа в Linux и macOS, которое позволяет пользователю подключаться к другой системе через шифрованный туннель, обычно с аутентификацией по паролю, сертификату или пары ключей ассиметричного шифрования. Для продвижения по сети со скомпрометированного хоста противники могут воспользоваться доверительными отношениями, установленными с другими системами посредством аутентификации по открытому ключу в активных SSH-сессиях путем перехвата существующего соединения с другой системой. Это может произойти из-за компрометации самого агента SSH или наличия доступа к сокету агента. Если противник сможет получить root-доступ в системе, то дальнейший захват SSH-сессий будет тривиальной задачей. Компрометация SSH-агента также позволяет перехватить учетные данные SSH. Техника захвата SSH (SSH Hijacking) отличается от использования техники Удаленных сервисов (Remote Services) потому что происходит внедрение в существующий SSH-сеанс, а не создание нового сеанса с использованием действительных учетных записей.
*Рекомендации по защите:* Убедитесь, что пары SSH-ключей имеют надежные пароли и воздержитесь от использования таких технологий хранения ключей как ssh-agent, если они не защищены должным образом. Убедитесь, что все закрытые ключи надежно хранятся в местах, к которым имеет доступ только законный владелец со сложным, часто меняющимся паролем. Убедитесь в правильности файловых разрешений и укрепите систему, чтобы предотвратить возможность повышения привилегий root. Не разрешайте удаленный доступ через SSH с правами root или другими привилегированными учетными записями. Убедитесь, что функция переадресации агента (Agent forwarding) отключена в системах, в которых она явно не требуется. Учитывая, что само по себе использование SSH может быть легитимно, в зависимости от сетевой среды и способа её использования, индикаторами подозрительного или злонамеренного использования SSH могут выступать различные шаблоны получения доступа и последующего поведения. Например, учетных записи, осуществляющие вход в системы, к которым они обычно не обращаются или подключение к нескольким системам в течение короткого промежутка времени. Так же рекомендуется отслеживать файлы сокетов пользовательских SSH-агентов, которые используются разными пользователями.
### [Общедоступный Webroot (Shared Webroot)](https://attack.mitre.org/wiki/Technique/T1051)
*Система:* Windows
*Описание:* Противник может разместить во внутреннем сегменте сети вредоносный контент на веб-сайте, имеющем общедоступный каталог webroot или другой общедоступный каталог подачи веб-контента, а затем перейти к этому контенту с помощью веб-браузера, чтобы заставить сервер выполнить его. Обычно вредоносный контент запускается в контексте процесса веб-сервера, часто, в зависимости от того как настроен веб-сервер, это приводит к получению локальных системных или административных привилегий. Такой механизм общего доступа и удаленного выполнения кода может быть использован для перемещения в систему, на которой работает веб-сервер. Например, веб-сервер под управлением PHP c общедоступным webroot может позволить злоумышленнику загрузить инструменты RAT в ОС веб-сервера при посещении определенной страницы.
*Рекомендации по защите:* Сети, в которых пользователям разрешено вести открытую разработку, тестирование контента и запуск собственных веб-серверов, особенно уязвимы если системы и веб-серверы должным образом не защищены: неограниченно использование привилегированных учетных записей, доступ к сетевым ресурсам возможен без проверки подлинности, а также нет сетевой изоляции сети/системы. Обеспечьте правильность разрешений для каталогов, доступных через веб-сервер. Запретите удаленный доступ к корневой директории сайта (webroot) или другим каталогам, используемым для подачи веб-контента. Отключите выполнение в каталогах webroot. Убедитесь, что разрешения процесса веб-сервера только те что требуются. Не используйте встроенные учетные записи, вместо этого создайте определенные учетные записи для ограничения ненужного доступа или пересечения разрешений в нескольких системах.
Используйте мониторинг процессов, чтобы определить когда когда файлы были записаны на веб-сервер процессом, которые не является обычным для веб-сервера или когда файлы были записаны вне административных периодов времени. Используйте мониторинг процессов, чтобы определить нормальные процессы и в последующем обнаруживать аномальные процессы, которые обычно не выполняются на веб-сервере.
### [Порча общедоступного содержимого (Taint Shared Content)](https://attack.mitre.org/wiki/Technique/T1080)
*Система:* Windows
*Права:* Пользователь
*Описание:* Содержимое общедоступных сетевых дисков и других хранилищ может быть испорчено путем добавления в размещенные файлы вредоносных программ, сценариев или кода эксплойта. Как только пользователь откроет испорченный контент, вредоносная часть может быть выполнена для запуска кода злоумышленника в удаленной системе. Противники могут использовать вышеописанный метод для бокового продвижения.
Есть ещё одна разновидность техники, использующей несколько другие методы распространения вредоносных программ при получении пользователями доступа к общему сетевому каталогу. Суть её заключается в модификации ярлыков ([Shortcut Modification](https://attack.mitre.org/techniques/T1023/)) каталогов (.lnk) с применением маскарадинга таким образом, чтобы ярлыки выглядели как реальные каталоги, которые предварительно были скрыты. Вредоносные .lnk имеют встроенную команду, которая выполняет скрытый вредоносный файл, а затем открывает реальный каталог, ожидаемый пользователем. Реализация этой техники в часто используемых сетевых каталогах может привести к частым повторным заражениям и, как следствие, получению злоумышленником широкого доступа к системам и, возможно, к новым более привилегированным учетным записям.
*Рекомендации по защите:* Защищайте общие папки, сводя к минимум количество пользователей, имеющих права на запись. Используйте утилиты, которые могут обнаруживать или предотвращать эксплойты по первым признакам, например Microsoft Mitigation Experience Toolkit (EMET). Снижайте потенциальный риск бокового продвижения посредством использования веб-служб управления документами и совместной работы, которые не используют обмен файлами и каталогами.
Идентифицируйте и блокируйте потенциально-опасное и вредоносное программное обеспечение, которое может быть использовано для порчи содержимого, с помощью таких инструментов как AppLocker или [Software Restriction Policies](https://docs.microsoft.com/en-us/previous-versions/technet-magazine/cc510322(v=msdn.10)).
Рекомендуется частое сканирование общих сетевых каталогов на наличие вредоносных файлов, скрытых файлов .LNK и других типов файлов, наличие которых не типично для конкретного каталога. Подозрения должны вызывать процессы, записывающие или перезаписывающие множество файлов в общий сетевой каталог, а также процессы выполняемые со съемных носителей.
### [Third-party Software (Стороннее ПО)](https://attack.mitre.org/wiki/Technique/T1072)
*Система:* Windows, Linux, macOS
*Права:* Пользователь, администратор, System
*Описание:* Стороннее ПО и системы развертывания ПО (SCCM, VNC, HBSS, Altris и т.п.), используемые в сети для нужд администрирования, могут использоваться злоумышленником для удаленного запуска кода на всех хостах, подключенных к таким системам. Права, необходимые для реализации данной техники зависят от конкретной конфигурации систем. Локальных учетных данных может быть достаточно для доступа к серверу развертывания ПО, однако для запуска развертывания ПО может потребоваться учетная запись администратора.
*Рекомендации по защите:* Проверяйте уровень безопасности применяемых систем развертывания ПО. Убедитесь, что доступ к системам управления ПО ограничен, контролируется и защищен. Строго используйте политики обязательного предварительного одобрения удаленного развертывания ПО. Предоставляйте доступ к системам развертывания ПО ограниченному числу администраторов, обеспечьте изоляцию системы развертывания ПО. Убедитесь, что учетные данные для доступа к системе развертывания ПО уникальны и не используются в других сервисах корпоративной сети. Если система развертывания ПО настроена на запуск только подписанных двоичных файлов, то проверьте, что доверенные сертификаты не хранятся в самой системе развертывания ПО, а расположены в системе, удаленный доступ к которой невозможен.
### [Windows Admin Shares](https://attack.mitre.org/wiki/Technique/T1077)
*Система:* Windows
*Права:* Пользователь
*Описание:* Системы Windows имеют скрытые сетевые папки, доступные только администраторам и предоставляющие возможность удаленного копирования файлов и другие административные функции. Примеры Windows Admin Shares: C$, ADMIN$, IPC$.
Противники могут использовать эту технику в сочетании с действующими учетными записями уровня администратора для удаленного доступа к системе через server messege block (SMB), взаимодействуя с системами с помощью RPC, передавать файлы и запускать перенесенные двоичные файлы с помощью техник [Выполнения (Execution)](https://habr.com/ru/post/424027/). Примерами методов выполнения, основанных на аутентифицированных сеансах через SMB/RPC являются назначенные задания, запуск служб и WMI. Противники также могут использовать NTLM-хэши для получения доступа к Admin Shares посредством Pass-the-Hash. Команда net use при наличии действующих учетных данных может быть использована для подключения к Windows Admin Shares удаленной системы.
*Рекомендации по защите:* Не используйте одинаковые пароли учетных записей локальных администраторов в разных системах. Обеспечьте сложность и уникальность паролей, чтобы их нельзя было угадать или взломать. Запретите удаленный вход в систему встроенной учетной записи локального администратора. Не допускайте, чтобы учетные записи пользователей входили в локальную группу администраторов нескольких систем.
Идентифицируйте и блокируйте потенциально-опасное и вредоносное программное обеспечение, которое можно использовать для эксплуатации SMB и Admin Shares, с помощью AppLocker или [Software Restriction Policies](https://docs.microsoft.com/en-us/previous-versions/technet-magazine/cc510322(v=msdn.10)).
Обеспечьте централизованный сбор и хранение журналов использования учетных данных для входа в системы. [Windows Event Forwarding](https://docs.microsoft.com/en-us/windows/security/threat-protection/use-windows-event-forwarding-to-assist-in-intrusion-detection) позволяет собирать данные об успешном/неуспешном использовании учетных записей, которые могли быть использованы для перемещения по сети. Отслеживайте действия удаленных пользователей, которые подключаются к Admin Shares. Отслеживайте использование инструментов и команд, которые используются для подключения к общим сетевым ресурсам, таких как утилита Net, или осуществляют поиск систем, доступных удаленно.
### [Windows Remote Management (WinRM)](https://attack.mitre.org/wiki/Technique/T1028)
*Система:* Windows
*Права:* Пользователь, администратор
*Описание:* WinRM — это имя службы и протокола, который позволяет удаленное взаимодействие пользователя с системой (например, запуск файла, изменение реестра, изменение службы. Для запуска используется команда winrm и другие программы, такие как PowerShell.
*Рекомендации по защите:* Отключите службу WinRM, если она необходима, то изолируйте инфраструктуру с WinRM с отдельными учетными записями и разрешениями. Следуйте [рекомендациям WinRM](https://docs.microsoft.com/en-us/windows/desktop/winrm/authentication-for-remote-connections) по настройке методов проверки подлинности и использованию брандмауэров хоста, чтобы ограничить доступ к WinRM и разрешить доступ только с определенных устройств. | https://habr.com/ru/post/439026/ | null | ru | null |
# Полноценное Python приложение на Android

В этой статье я хотел бы рассказать о том, как создать полноценное приложение на Python для Android. Нет, это не очередной мануал для создания скрипта для [sl4a](http://habrahabr.ru/search/?q=%5Bsl4a%5D&target_type=posts), это мануал по созданию полноценного приложения с UI, возможностью собрать apk и выложить на Android Market. Заодно я хотел бы похвалиться своим первым приложением на google.play, это не hello world, а полезное приложение для фотографов, хотя и узко специализированное.
Начну рассказ пожалуй с самого приложения и завершу рассказам о том как оно делалось.
#### isortViewer
Мне как фотографу приходится тратить много времени на сортировку и отбор фотографий. Не всегда хочется сидеть за рабочим компьютером, когда под рукой есть ноутбук, смартфон или планшет, но копировать туда десятки гигабайт raw или jpeg файлов, а потом синхронизировать с рабочим компьютером — сомнительное удовольствие. Именно поэтому я создал программы isortManager и isortViewer, которые значительно облегчили мне работу по сортировке и отбору фотографий. Теперь заниматься отбором и сортировкой фотографий я могу лежа на ~~пляже~~ диване или скучая в пробке :)
Копипаст описания и пара скриншотов:
*isortViewer — программа для фотографов, которая позволяет легко и быстрой отбирать и сортировать тысячи фотографий (raw или jpg) с фотосессий на ваших android смартфонах и планшетах. При этом, нет необходимости копировать десятки гигабайт jpg или raw файлов на устройство. Просто воспользуйтесь бесплатной программой isortManager для компьютера, которая сохранит все в один небольшой файл проекта:
1. Скачайте и запустите isortManager с [официального сайта](http://isort.mobile-master.org);
2. Создайте проект и добавьте папки с фотографиями. Поддерживаются форматы: jpg и raw (cr2, nef, orf и т.д.). В итоге у вас получится небольшой файл проекта (примерно 150 мб на несколько тысяч фотографий, будь то jpg или raw формат);
3. Скопируйте на ваше android устройство файл проекта, откройте в isortViewer. Вы можете помечать фотографии «на удаление», а так же, ставить рейтинги от 1 до 5 звезд;
4. После этого, скопируйте файл проекта обратно и примените изменения в isortManager. Кроме удаления выбранных фотографий, вы можете копировать или перемещать отмеченные фотографии. Например, фотографии с «5 звезд» можно скопировать в папку «шедевры», а «1 звезда» переместить в папку «хлам».*


Приложение абсолютно бесплатно и доступно на [google.play](https://play.google.com/store/apps/details?id=org.mobile_master.isort), однако донейты приветствуются.
Исходники доступны на официальном сайте!
#### Как это делалось
Так как ~~python лучший язык программирования в мире~~ кроме python я ничего не знаю, решено было написать приложение на python.
##### isortManager
С isortManager для PC проблем не возникло, создание GUI сборки под windows уже давно обкатано и работает он очень просто: с помощью dcraw выдирает jpg превьюшки из raw файлов, ресайзит из с помощью PIL и складывает в один файл с достаточно простой структурой. Был изобретен свой весолипед с контейнером для хранения фотографий и метаданных (полный путь к фотографии, отметка «на удаление» и отметка рейтинга), так как, например, zip или tar формат, не могут изменять один файл в архиве (метаданные), требую перепаковки всех файлов. Файлы просто пишутся один за другим подряд и в блоке метаданных (обычный repr питоновского словаря) в конце сохраняется смещения начала файлов, плюс в конце файла пишется размер блока метаданных. GUI написано на Tkinter (люблю я его за быстроту написания и за малый размер итоговой сборки), вот собственно скриншот:
И да, все это работает и на linux, и даже быстрее чем на windows )
##### isortViewer для android
Всего я нашел два способа заставить python приложение работать как полноценное приложение на android, это [pygame for android](http://pygame.renpy.org/) и проект [kivy](http://kivy.org/).
Pygame — более низкоуровневый, все UI пришлось бы рисовать вручную, что отняло бы много времени, поэтому был выбран фреймворк kivy. Итак:
##### Kivy
Это замечательный фрейморк для написания приложение для windows, linux, MacOS, android и iOS. Поддерживается мультитач, UI рисутется через OpenGL, значит должно работать аппаратное ускорение. Увидеть работу виджетов можно установив демонстрационное приложение [Kivy Showcase](https://play.google.com/store/apps/details?id=org.kivy.showcase). Есть возможность использования некоторых платформо специфичных функций, например, вибро или акселерометр, с помощью модуля android.
Для разработки я бы рекомендовал использовать linux, тем более, apk собираются именно в этой OS.
Hello World выглядит так:
```
import kivy
kivy.require('1.0.6') # replace with your current kivy version !
from kivy.app import App
from kivy.uix.button import Button
class MyApp(App):
def build(self):
return Button(text='Hello World')
if __name__ == '__main__':
MyApp().run()
```
Причем этот код будет работать на всех заявленных платформах. Пропадает необходимость в тестировании приложения в эмуляторе. Достаточно запустить скрипт на исполнение в своей любимой IDE и увидеть результат на экране компьютера, без задержек на компиляцию, запуск эмулятора и пр. Если вы все же хотите увидеть как это будет выглядеть непосредственно на устройстве, просто установите [Kivy Launcher](https://play.google.com/store/apps/details?id=org.kivy.pygame), скопируйте файлы проекта на карту памяти и запустите. Дебажить при этом можно при помощи adb logcat.
Если вы используете библиотеку android, которой нет на PC, но хочется запускать приложение не только на android, воспользуйте такой конструкцией:
```
try:
import android
except ImportError:
android=None
...
if android:
android.vibrate(0.05)
```
Сборка apk достаточно проста и описана на [этой](http://kivy.org/docs/guide/packaging-android.html) странице. После сборки релиза, достаточно подписать свое приложение (я использовал [этот](http://www.londatiga.net/it/how-to-sign-apk-zip-files/) мануал) и выложить в google play.
**Плюсы kivy:**
* Быстрая разработка под различные платформы, практически без доработки кода.
* Доступен широкий выбор виджетов
* Высокая скорость работы. Весь ресурсоемкий вынесен в С модули. Сам интерпретатор python на android работает нативно.
* Фремворк включает в себя множество инструментов, например анимация, кеширование и пр.
* **upd:** Доступ к камере, буферу обмена, микрофону. Написать свой видеоплеер можно буквально за [20 строк](https://github.com/kivy/kivy/blob/master/examples/widgets/videoplayer.py).
**Минусы kivy:**
* Большой размер apk файла. Проект с 300 кб ресурсов (скрипты, графика) собирается в 7 мб apk. Хотя, думаю, есть возможность это как то оптимизировать.
* Невозможность (пока), восстанавливать работу после сворачивания — приложение закрывается
В следующей своей статье, я расскажу более подробно о процессе написания приложения «с нуля», расжевывая каждую строчку кода.
Хотелось бы сразу пресечь холивары на тему «для android только java, python не нужен». Я считаю, не важно, какие технологии «под капотом», главное чтоб приложение было качественным.
Сфера применения kivy может быть огромной. Сейчас на моем счету несколько приложений, написанных под заказ, где python с фремворком kivy показал себя с хорошей стороны. Например, ровно за один час, было написано приложение, для сети сервисных центров. Приложение работает в режиме киоска и установлено на дешевые китайские планшеты, которые висят в холле. Клиент набирает номер заказа, далее по WiFi планшет соединяется с сервером и сообщает статус заказа. | https://habr.com/ru/post/149898/ | null | ru | null |
# Тестирование параллельных потоков
В дебагере можно без проблем поймать поток исполнения в правильной точке, а затем, после проведения анализа, перезапустить его. В автоматических тестах эти операции выглядят безумно сложными.
А зачем вообще это нужно?
Построение параллельных систем — дело не самое простое. Необходимо соблюдать баланс между параллельностью и синхронностью. Недосинхронизируешь — потеряешь в стабильности. Пересинхронизируешь — получишь последовательную систему.
Рефакторинг — это вообще прогулка по минному полю.
Если бы не сложность реализации, автоматическое тестирование могло бы здорово помочь. На мой взгляд, в параллельной системе неплохо было бы автоматически проверять одновременную работу отдельных конфликтных участков кода — факт и порядок выполнения.
Вот я наконец и добрался до приостановления и возобновления работы потоков. Как уже говорилось, такой не автоматический механизм существует. Это брейкпоинты. Не будем изобретать новую терминологию — брейкпоинт, значит брейкпоинт.
```
public class Breakpoint
{
[Conditional("DEBUG")]
public static void Define(string name){…}
}
public class BreakCtrl : IDisposable
{
public string Name { get; private set; }
public BreakCtrl(string name) {…}
public BreakCtrl From(params Thread[] threads) {…}
public void Dispose(){…}
public void Run(Thread thread){…}
public void Wait(Thread thread){…}
public bool IsCapture(Thread thread){…}
public Thread AnyCapture(){…}
}
```
Свойства автоматических брейкпоинтов:1. Работают только в режиме отладки (при определенном макросе DEBUG). Мы не должны задумываться, что дополнительный код повлияет на работу системы у конечного пользователя.
2. Брейкпоинт срабатывает только если его контролер определен. Ненужные в конкретном тесте брейкпоинты не должны наводить систему (и усложнять тесты).
3. Контролер знает, в каком состоянии находится брейкпоинт — удерживает ли он поток.
4. Контролер способен заставить брейкпоинт отпустить поток.
5. И необязательная привязка к конкретному потоку. Хотим управляем конкретным потоком, хотим всеми сразу.
```
[TestMethod]
public void StopStartThreadsTest_exemple1()
{
var log = new List();
ThreadStart act1 = () =>
{
Breakpoint.Define("empty");
Breakpoint.Define("start1");
log.Add("after start1");
Breakpoint.Define("step act1");
log.Add("after step act1");
Breakpoint.Define("finish1");
};
ThreadStart act2 = () =>
{
Breakpoint.Define("start2");
log.Add("after start2");
Breakpoint.Define("step act2");
log.Add("after step act2");
Breakpoint.Define("finish2");
};
using (var start1 = new BreakCtrl("start1"))
using (var step\_act1 = new BreakCtrl("step act1"))
using (var finish1 = new BreakCtrl("finish1"))
using (var start2 = new BreakCtrl("start2"))
using (var step\_act2 = new BreakCtrl("step act2"))
using (var finish2 = new BreakCtrl("finish2"))
{
var thr1 = new Thread(act1);
thr1.Start();
var thr2 = new Thread(act2);
thr2.Start();
start1.Wait(thr1);
start2.Wait(thr2);
start1.Run(thr1);
step\_act1.Wait(thr1);
step\_act1.Run(thr1);
finish1.Wait(thr1);
start2.Run(thr2);
step\_act2.Wait(thr2);
step\_act2.Run(thr2);
finish2.Wait(thr2);
finish1.Run(thr1);
finish2.Run(thr2);
thr1.Join();
thr2.Join();
}
Assert.AreEqual(4, log.Count);
Assert.AreEqual("after start1", log[0]);
Assert.AreEqual("after step act1", log[1]);
Assert.AreEqual("after start2", log[2]);
Assert.AreEqual("after step act2", log[3]);
}
```
Правда неудобно? Но надо смириться — ведь без тестирования не возможен рефакторинг. Всегда сначала приходится перебарывать себя… бла-бла-бла. Даже я вскоре понял, что пользоваться этим невозможно. Понял в районе второго десятка написанных тестов. Тесты получаются ненаглядные и сложные. Но…
Сложно — это хорошо. Ведь ничего кроме решения сложности я делать не умею. Немного усилий и получилось такое решение:
```
public class ThreadTestManager
{
public ThreadTestManager(TimeSpan timeout, params Action[] threads){…}
public void Run(params BreakMark[] breaks){…}
}
public class BreakMark
{
public string Name { get; private set; }
public Action ThreadActor { get; private set; }
public bool Timeout { get; set; }
public BreakMark(string breakName){…}
public BreakMark(Action threadActor, string breakName){…}
public static implicit operator BreakMark(string breakName){…}
}
```
При его использовании предыдущий тест выглядеть так:
```
[TestMethod]
public void StopStartThreadsTest_exemple2()
{
var log = new List();
Action act1 = () =>
{
Breakpoint.Define("before start1");
Breakpoint.Define("start1");
log.Add("after start1");
Breakpoint.Define("step act1");
log.Add("after step act1");
Breakpoint.Define("finish1");
};
Action act2 = () =>
{
Breakpoint.Define("before start2");
Breakpoint.Define("start2");
log.Add("after start2");
Breakpoint.Define("step act2");
log.Add("after step act2");
Breakpoint.Define("finish2");
};
new ThreadTestManager(TimeSpan.FromSeconds(1), act1, act2).Run(
"before start1", "before start2",
"start1", "step act1", "finish1",
"start2", "step act2", "finish2");
Assert.AreEqual(4, log.Count);
Assert.AreEqual("after start1", log[0]);
Assert.AreEqual("after step act1", log[1]);
Assert.AreEqual("after start2", log[2]);
Assert.AreEqual("after step act2", log[3]);
}
```
Свойства диспетчера:1. Все делегаты запускаются при старте в своем потоке.
2. Маркеры брейкпоинтов определяют порядок возобновления работы. Не входа, а выхода из брейкпоинтов. Возможно это просто издержки реализации абстракции «брейкпоинт». Но свойство есть и о нем приходится иногда вспомнить.
3. Все контролеры для соответствующих маркеров брейкпоинтов определены на всем протяжении работы диспетчера.
4. С маркером брейкпоинта можно указать потоком (делегат), с которым он будет работать. По умолчанию работает со всеми.
```
[TestMethod]
public void ThreadMarkBreakpointTest_exemple3()
{
var log = new List();
Action act = name =>
{
Breakpoint.Define("start");
log.Add(name);
Breakpoint.Define("finish");
};
Action act0 = () => act("act0");
Action act1 = () => act("act1");
new ThreadTestManager(TimeSpan.FromSeconds(1), act0, act1).Run(
new BreakMark(act0, "finish"),
new BreakMark(act1, "start"),
new BreakMark(act1, "finish"));
Assert.AreEqual(2, log.Count);
Assert.AreEqual("act0", log[0]);
Assert.AreEqual("act1", log[1]);
}
```
5. Определено время, в течении которого должны выполнится все операции — timeout. При превышении — все потоки останавливаются грубо и беспощадно (abort).
6. К маркеру брейкпоинта, можно добавить признак недосягаемости, не добравшись сюда система планово выйдет по timeout-у. Срабатывание брейкпоинта приведет к провалу теста. Этот механизм используется для проверки факта блокировки.
```
[TestMethod]
public void Timeout_exemple4()
{
var log = new List();
Action act = () =>
{
try
{
while (true) ;
}
catch (ThreadAbortException)
{
log.Add("timeout");
}
Breakpoint.Define("don't work");
};
new ThreadTestManager(TimeSpan.FromSeconds(1), act).Run(
new BreakMark("don't work") { Timeout = true });
Assert.AreEqual("timeout", log.Single());
}
```
7. Если хочется остановить выполнение потока и не продолжать его, надо указать соответствующий маркер брейкпоинта после маркера с timeout-ом.
```
[TestMethod]
public void CatchThread_exemple5()
{
var log = new List();
Action act0 = () =>
{
bool a = true;
while (a) ;
Breakpoint.Define("act0");
};
Action act1 = () =>
{
Breakpoint.Define("act1");
log.Add("after act1");
};
new ThreadTestManager(TimeSpan.FromSeconds(1), act0, act1).Run(
new BreakMark("act0") { Timeout = true },
"act1");
Assert.IsFalse(log.Any());
}
```
PS: [Solution](http://files.mail.ru/JE3UNK) | https://habr.com/ru/post/135815/ | null | ru | null |
# ПочемуSQL?
Когда мы давали [общее описание архитектуры нашего сервиса](http://habrahabr.ru/company/evernote/blog/120319/) на нашем англоязычном техноблоге, у читателей, имеющих опыт работы с другими большими сервисами, самыми частыми вопросами были:
1. Почему ваши структурированные данные хранятся в базах данных с SQL вместо того, чтобы использовать NoSQL-решения?
2. Почему вы используете собственное аппаратное обеспечение вместо того, чтобы воспользоваться услугами облачного хостинга?
Оба этих вопроса закономерны и интересны. Сегодня мы ответим на первый, а второй прибережем для отдельного поста.
При правильном применении современный механизм хранения данных в ассоциативных массивах (key-value) может обеспечить значительную производительность и масштабируемость по сравнению с единичным экземпляром SQL-сервера. Однако есть несколько причин, по которым мы все же решили размещать все данные вашего аккаунта в MySQL.
### Преимущества SQL
Для начала, [ACID](http://en.wikipedia.org/wiki/ACID)-свойства транзакционных баз данных, таких как InnoDB с MySQL, имеют важное значение для нашего приложения и [модели синхронизации](http://www.evernote.com/about/developer/api/edam-sync.pdf).
Вот небольшой фрагмент таблиц базы данных для хранения блокнотов и заметок в серверной базе данных:
`CREATE TABLE notebooks (
id int UNSIGNED NOT NULL PRIMARY KEY,
guid binary(16) NOT NULL,
user_id int UNSIGNED NOT NULL,
name varchar(100) COLLATE utf8_bin NOT NULL,
...
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE notes (
id int UNSIGNED NOT NULL PRIMARY KEY,
guid binary(16) NOT NULL,
user_id int UNSIGNED NOT NULL,
notebook_id int UNSIGNED NOT NULL,
title varchar(255) NOT NULL,
...
FOREIGN KEY (notebook_id) REFERENCES notebooks(id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;`
Если вы создаете блокнот под названием “Рецепты” на своем Windows-клиенте Evernote, а затем сразу же копируете в этот блокнот рецепт любимой запеканки, ваш клиент при следующей синхронизации сделает следующее:
* Вызовет [NoteStore.createNotebook()](http://www.evernote.com/about/developer/api/ref/NoteStore.html#Fn_NoteStore_createNotebook), чтобы запросить создание [блокнота](http://www.evernote.com/about/developer/api/ref/Types.html#Struct_Notebook) на сервере. Тот вернет ему идентификатор (GUID) созданного блокнота.
* Вызовет [NoteStore.createNote()](http://www.evernote.com/about/developer/api/ref/NoteStore.html#Fn_NoteStore_createNote), чтобы запросить создание [заметки](http://www.evernote.com/about/developer/api/ref/Types.html#Struct_Note) на сервере с уже заданным GUID блокнота.
Каждый из этих высокоуровневых запросов к API осуществляется посредством единственной SQL-транзакции, которая гарантирует, что клиент может полностью доверять любому ответу сервера.
ACID-совместимая база данных обеспечивает такие преимущества как:
**Атомарность.** Если вызов API проходит успешно, то 100% изменений будут выполнены, а если вызов API не удается, то не будет сделано ни одно из них. Это значит, что если у нас не получается поместить четвертое изображение в вашу заметку, то в вашем аккаунте не останется наполовину сформированная заметка, которая, к тому же, будет высчитана из оставшегося ежемесячного объема для загрузки данных.
**Непротиворечивость.** В конце любого вызова API аккаунт находится в полностью рабочем и внутренне непротиворечивом состоянии. У каждой заметки есть свой блокнот, и ни одна из них не находится в подвешенном состоянии. База данных не даст нам удалить блокнот, в котором еще есть заметки, благодаря ограничению FOREIGN KEY.
**Гарантированность.** Когда сервер сообщает, что блокнот был создан, клиент может считать, что блокнот у него уже есть и учитывать это в дальнейших операциях (таких как вызов на создание заметки). Это изменение гарантированно, и клиент знает, что оно консистентно отражает состояние сервиса в любое время.
Принцип гарантированности играет самую важную роль для нашего протокола синхронизации. Если клиентское приложение не было бы уверено, что изменения, сделанные сервисом, гарантированно произошли, протокол синхронизации стал бы гораздо более сложным и менее эффективным. Каждому синхронизируемому клиенту пришлось бы постоянно проверять соответствие каждого серверного объекта текущей ситуации. Подобная реализация абсолютного контроля над непротиворечивостью для аккаунта с 20 тысячами заметок, 40 тысячами файлов ресурсов и 10 тысячами меток была бы крайне дорогой, если бы изменения не предполагали гарантированность.
### Как насчет большого объема данных?
Преимущества ACID в случае с транзакционной базой данных делают очень сложным масштабирование данных за пределы одного сервера. Кластеризация базы данных и репликация с несколькими мастер-серверами — дело весьма темное, а ассоциативные хранилища данных обеспечивают значительно более простой подход к масштабированию единого хранилища на несколько серверов.
К счастью, в Evernote сейчас нет необходимости решать эту проблему. Хотя у нас на серверах уже около миллиарда заметок и почти 2 миллиарда файлов ресурсов, это, на самом деле, не единый большой набор данных — это 20 миллионов отдельных наборов, по одному на пользователя.
Такая раздробленность означает, что у нас нет проблемы хранения большого единого объема данных, мы имеем дело с хранением множества изолированных наборов данных среднего объема, что аккуратно ложится в нашу серверную архитектуру шардов.
### Возможно, в будущем…
Мы, тем временем, стараемся держать руку на пульсе современных технологий в области хранения данных для будущих проектов, которые не требуют строгой транзакционности ACID и предусматривают горизонтальную масштабируемость. Например, наша система отчетности и аналитики уже переросла возможности MySQL-платформы и требует замены на что-то более большое, быстрое и интересное.
Однако мы вполне удовлетворены имеющимся разбитым на шарды MySQL-хранилищем пользовательских данных, хоть это и не так круто по мнению некоторых ребят. | https://habr.com/ru/post/139021/ | null | ru | null |
# Смелый стайлгайд по AngularJS для командной разработки [1/2]
После прочтения [Google's AngularJS Guidelines](http://google-styleguide.googlecode.com/svn/trunk/angularjs-google-style.html) у меня создалось впечатление о его незавершённости, а ещё в нём часто намекали на профит от использования библиотеки Closure. Ещё [они заявили](http://blog.angularjs.org/2014/02/an-angularjs-style-guide-and-best.html), «Мы не думаем, что эти рекомендации одинаково хорошо применимы для всех проектов, использующих AngularJS. Мы будем рады видеть инициативу от сообщества за более общий стайлгайд, применимый как для небольших так и крупных проектов».
Отталкиваясь от личного опыта работы с Angular, [нескольких выступлений](http://speakerdeck.com/toddmotto), а также имеющемуся опыту командной разработки, представляю Вашему вниманию этот смелый стайлгайд по синтаксису, написанию кода и структуре приложений на AngularJS.
Определение модулей
-------------------
Модули в AngularJS могут быть объявлены различными способами: либо с использованием переменной, либо через getter-синтаксис. Всегда используйте второй способ (более того, [он рекомендован разработчиками фреймворка](http://docs.angularjs.org/guide/module)).
##### Плохо:
```
var app = angular.module('app', []);
app.controller();
app.factory();
```
##### Хорошо:
```
angular
.module('app', [])
.controller()
.factory();
```
Функции и методы модуля
-----------------------
В модулях Angular есть много различных методов, таких как `controller`, `factory`, `directive`, `service` и др. Есть также много различных синтаксисов для модулей, когда речь заходит о DI и форматировании кода. Используйте определение именованных функции, чтобы потом передавать их названия соответствующим методам. Такой способ даёт больше возможности при трассировке стека, так как функции не являются анонимными (конечно, можно просто начать использовать именованные функции вместо анонимных, но такой способ более удобочитаем).
##### Плохо:
```
var app = angular.module('app', []);
app.controller('MyCtrl', function () {
});
```
##### Хорошо:
```
function MainCtrl () {
}
angular
.module('app', [])
.controller('MainCtrl', MainCtrl);
```
Определяйте модуль однажды используя setter-синтаксис так: `angular.module('app', [])`. Затем, если понадобиться обратиться к этому модулю (например, в других файлах), используйте getter-синтаксис: `angular.module('app')`.
А для того, чтобы не загрязнять глобальную область видимости, просто оберните весь свой код в IIFE.
##### Отлично:
```
(function () {
angular.module('app', []);
// MainCtrl.js
function MainCtrl () {
}
angular
.module('app')
.controller('MainCtrl', MainCtrl);
// AnotherCtrl.js
function AnotherCtrl () {
}
angular
.module('app')
.controller('AnotherCtrl', AnotherCtrl);
// и так далее...
})();
```
Контроллеры
-----------
В виду того, что контроллеры – это классы, помимо привычного `controller`-синтаксиса у них есть `controllerAs`-синтаксис. Используйте именно его, так как помимо возможности ссылаться на экземпляр контроллера, такой способ делает скоупы вложенными.
### Привязка к DOM через controllerAs
##### Плохо:
```
{{ someObject }}
```
##### Хорошо:
```
{{ main.someObject }}
```
Стоит также заметить, что способ привязки к DOM через аттрибут `ng-controller` во многом ограничивает применение данного представления (view) только в паре с указанным контроллером. И хотя редко, но всё же бывают ситуации, когда одно и то же представление может быть использовано с разными контроллерами. Для большей гибкости в данном вопросе, используйте роутер для связи view с контроллером.
##### Отлично:
```
{{ main.someObject }}
// ...
function config ($routeProvider) {
$routeProvider
.when('/', {
templateUrl: 'views/main.html',
controller: 'MainCtrl',
controllerAs: 'main'
});
}
angular
.module('app')
.config(config);
//...
```
Чтобы избежать использования `$parent`, когда нужно получить доступ к какому-либо из родительских контроллеров, при таком подходе просто пишем значение `controllerAs` требуемого контроллера, в нашем случае `main`. Понятно, что благодаря такому способу, мы избегаем также вызовов вроде `$parent.$parent`.
### this в controllerAs
Синтаксис `controllerAs` подразумевает использование ключевого слова `this` в коде контроллера вместо `$scope`. При использовании `controllerAs`, контроллер по факту *привязан* к `$scope`, что, собственно, и даёт такую степень разделения.
##### Плохо:
```
function MainCtrl ($scope) {
$scope.someObject = {};
$scope.doSomething = function () {
};
}
angular
.module('app')
.controller('MainCtrl', MainCtrl);
```
Можно также использовать `prototype` для создания классов контроллера, но это быстро загрязнит код, потому что каждому DI-провайдеру необходима соответствующая ссылка в конструкторе.
##### Плохо и хорошо:
Хорошо для наследования, но плохо для общего использования.
```
function MainCtrl ($scope) {
this.someObject = {};
this._$scope = $scope;
}
MainCtrl.prototype.doSomething = function () {
// use this._$scope
};
angular
.module('app')
.controller('MainCtrl', MainCtrl);
```
Если вы используете `prototype` но не знаете зачем, то это плохо. Если вы используете `prototype` для изоляции от других контроллеров – это хорошо. А для общего случая использование `prototype` может быть попросту избыточным.
##### Хорошо:
```
function MainCtrl () {
this.someObject = {};
this.doSomething = function () {
};
}
angular
.module('app')
.controller('MainCtrl', MainCtrl);
```
Выше просто показан пример использования объектов и функций в контроллере. Конечно же, это совсем не значит, что мы собираемся использовать там логику…
### Избегайте использование логики в контроллерах
Делегируйте логику фабрикам и сервисам.
##### Плохо:
```
function MainCtrl () {
this.doSomething = function () {
};
}
angular
.module('app')
.controller('MainCtrl', MainCtrl);
```
##### Хорошо:
```
function MainCtrl (SomeService) {
this.doSomething = SomeService.doSomething;
}
angular
.module('app')
.controller('MainCtrl', MainCtrl);
```
Этот подход максимизирует повторное использование кода, надёжно инкапсулирует его функциональность и делает тестирование более лёгким и точным.
Сервисы
-------
Сервисы инстанцируются, соответственно они должны быть классо-подобными. Именно по этому здесь мы также используем `this`, оформляем код функций в соответствии со всем остальным.
##### Хорошо:
```
function SomeService () {
this.someMethod = function () {
};
}
angular
.module('app')
.service('SomeService', SomeService);
```
Фабрики
-------
Фабрики дают нам синглтон-модуль, для создания сервисных методов (таких, например, как связь приложения с сервером посредством REST). Создание и возврат по запросу цельного объекта поддерживает существующие привязки (binds) в контроллере обновлёнными, а ещё помогают избежать проблем с привязкой примитивов.
Важно: На самом деле «Фабрика» – это шаблон/реализация и не должно отождествляться с провайдером. Правильнее будет называть и фабрики, и сервисы «сервисами».
##### Плохо:
```
function AnotherService () {
var someValue = '';
var someMethod = function () {
};
return {
someValue: someValue,
someMethod: someMethod
};
}
angular
.module('app')
.factory('AnotherService', AnotherService);
```
##### Хорошо:
Сначала мы создаём одноимённый объект внутри функции, а затем наполняем его методами. Это способствует как ручному документированию кода, так и генерации документации автоматическими средствами.
```
function AnotherService () {
var AnotherService = {};
AnotherService.someValue = '';
AnotherService.someMethod = function () {
};
return AnotherService;
}
angular
.module('app')
.factory('AnotherService', AnotherService);
```
Здесь все привязки к примитивам остаются обновлёнными, а ещё это делает внутремодульную организацию пространства имён чуть более простой для понимания – здесь сразу видны приватные методы и переменные.
Продолжение следует...
----------------------
В следующей части перевода:
* Директивы
* Promise в роутере, defer в контроллере
* Избегайте $scope.$watch
* Структура проекта
* Соглашение об именовании и конфликты
* Минификация и аннотация
[Продолжение »](http://habrahabr.ru/post/237279/)
Данный стайлгайд находится в процессе доработки. Всегда актуальные рекомендации Вы найдёте на [Github](https://github.com/toddmotto/angularjs-styleguide). | https://habr.com/ru/post/235873/ | null | ru | null |
# #03 — И целого байта мало… | 2B or not 2B
Итак, друзья, 1-е апреля прошло, пора раскрывать карты, что же такое "**2B or not 2B**" на самом деле. Это совместный текст от автора работы **[jin\_x](https://habr.com/ru/users/jin_x/)** и уже знакомого вам деда **[unbeliever](https://habr.com/ru/users/unbeliever/)**

Обязательно скачайте архив с работой на [**Pouet**](https://www.pouet.net/prod.php?which=85118) и прочитайте [**вводную**](https://habr.com/ru/post/495042/) (первоапрельскую) статью, а так же комментарии к ней. Посмотрите первое видео с практической демонстрацией того, как работает код из «двух байт» на x86. И вот уже потом попробуйте осилить весь текст ниже.
Да, [**2B or not 2B**](https://habr.com/ru/post/495408/) — это действительно среда для запуска различных sizecoding-работ, очень простая и, пожалуй, самая маленькая из существующих. При этом она имеет свои требования и ограничения.
Если кто-то ещё не уловил, тул **2b.com** запускается из-под DOS (DOSBox, FreeDOS, MS-DOS) и осуществляет прыжок в область командной строки (по смещению $82\* сегмента PSP), запуская на исполнение код, который передан в командной строке в двоичном виде. Собственно говоря, код этот вполне может иметь вид строки, которую можно набрать на клавиатуре (т.е. состоять из ASCII-символов с кодами от 33 до 126), но об этом немного позже.
*\* шестнадцатеричные числа мы будем записывать в паскалевской нотации $XX, это удобно, и fasm позволяет это делать.*
Что важно знать?
----------------
В-нулевых, в качестве компилятора мы рекомендуем использовать [fasm](https://flatassembler.net), весь наш инструментарий написан именно под него.
Во-первых, основной код может иметь максимальный размер 125 байт (таковы ограничения длины командной строки) и будет стартовать как обычная COM-программа, только со смещения $82, а не $100, как обычно. Сразу после основного кода будет автоматически добавлен символ возврата каретки (CR) с кодом 13 ($0D), а по адресу $100 будет находиться команда `jmp short $82` ($EB, $80).
Во-вторых, поскольку запуск предполагается из BAT-файла (ну или из интерпретатора командной строки), код не должен содержать некоторые символы. Прежде всего это символы перенаправления ввода-вывода ("<", ">" и "|"), а также символ подстановки параметров и переменных окружения ("%"). В некоторых системах (в том числе Windows, поддерживающих запуск DOS-программ из-под V86) специальное значение имеют ещё и символы "&", "^". Спец-символы с кодами до 32 поддерживаются не всеми DOS, а некоторые не поддерживаются никакими или почти никакими (особенно скудный набор имеет DOSBox), поэтому все эти символы исключаем тоже.
В-третьих, стартовые значения всех регистров и флагов, такие же, как и при запуске COM-программы. В подавляющем большинстве DOS на старте будет: ax=bx=0 (почти всегда это так), cx=$FF, dx=cs=ds=es=ss, si=$100, di=sp=$FFFE (при достаточном количестве оперативной памяти), bp=$9XX (младший байт везде разный, но его старшая тетрада, то есть полубайт, обычно = 1), флаги cf=df=0. Использовать это или нет – дело ваше.
Больше всего здесь смущает пункт «во-вторых», не так ли?
Предположим, нам нужно написать:
```
mov ah,0
int $16
cmp al,27
je x
```
А тут аж сразу 5 запретных символов: 0 в `mov ah,0`, $16 в `int $16`, $3C (символ "<") и 27 ($1B) в `cmp al,27` и некоторое число с кодом < 32 в `je x`, если `x` находится где-то неподалёку дальше по коду.
Что же делать? То, что можно заменить другими командами, заменяем:
* вместо `mov ah,0` пишем `xor ah,ah` или даже `cbw` (когда это возможно);
* вместо `cmp al,27` пишем `not al` + `sub al,not 27` или `xor al,not 27` + `inc al`, а ещё лучше (т.к. здесь нам нужно дождаться нажатия клавиши и сравнить полученный код с кодом клавиши ESC) – `dec ah`.
С `int $16` сложнее, но если подумать, то конструкцию `xor ah,ah` + `int $16` можно заменить, например, на `mov ah,$83` + `ror ah,1` + `int $21`.
Остаётся `je $+10`. Тут есть как минимум 2 пути: либо сделать прыжок назад (на достаточное расстояние), а оттуда – вперёд. Либо произвести замену байта в коде. Например, здесь можно написать `z: je ($*2+3)-x`, а где-то выше: `not byte [si-($100-(z+1))]`.
В итоге получим:
```
not byte [si-($100-(z+1))] ; замена 2-го байта (смещения прыжка) je при si=$100
mov ah,$83
rol ah,1 ; ah=7
int $21 ; ожидаем нажатия клавиши, код будет в al
not al
sub al,not 27 ; cmp al,27
z: je ($*2+3)-x ; прыжок на метку x (после изменения второго байта)
```
Альтернативные решения
----------------------
Конечно, в финальной intro на 100+ байт запретных символов может оказаться довольно много (например, 15-20 и даже больше), и каждый раз производить подобные манипуляции – занятие довольно муторное, к тому же, они нередко приводят к увеличению длины кода.
Поэтому можно прибегнуть к шифрованию. Либо всего кода, либо отдельных мест. В примере **2b\_life.asm** мы шифруем весь код, добавляя к каждому байту значение $AC. После первого шифрования у нас осталось порядка 4-х запретных символов, которые мы смогли проработать заменой на другие команды. Конечно, выбор метода шифрования (add, sub, xor, not и пр.), а также ключа тоже требует времени, но это меньшее из всех зол. Код дешифровщика занимает всего 8 байт – это вполне приемлемо в данной ситуации. Шифрование же происходит автоматически с помощью директив `repeat`, `load` и `store` (т.е. мы получаем уже зашифрованный код).
Отдельные места шифруются в примере **2b\_note.asm**. Здесь, опять же, с помощью `repeat`, `load` и `store` к некоторым байтам добавляется значение $3D, а список адресов этих байтов хранится отдельно (по 1 байту адреса на каждый такой байт). Итого мы шифруем 20 байт + 13 байт занимает дешифровщик. Да, первый способ был более экономичным :)
В начале статьи мы обещали рассказать про код, который может иметь вид строки, состоящий из ASCII-символов с кодами от 33 до 126 (чтобы его можно было, например, без особых трудностей набрать на клавиатуре). Такое возможно, например, если зашифровать код с помощью 16-ричных символов или подобным образом. Да, это расточительно, но если шифровать методом BASE64, расход может оказаться ещё больше, ведь и декодер должен состоять только из таких символов.
Инструменты
-----------
Для удобства написания кода под "**2B or not 2B**" было создано 4 файла:
* **2b.draft.asm** – черновик для создания 128-байтовых интр в BAT-файле, в начало которого добавляются символы запуска программы 2b (однако тут шифрование, подмену или ещё какие-то трюки вам придётся выполнять самим, либо выдергивать из примеров). Читайте комменты, там всё довольно подробно описано.
* **2b.draft44.asm** – черновик для создания 44-байтовых интр, код которых будет полностью состоять из ASCII-символов с кодами от 33 до 126. Здесь каждый байт основного кода шифруется двумя псевдо-шестнадцатеричными символами: сначала младшая тетрада + «A» (диапазон букв «A»...«P»), затем старшая тетрада + «K» (диапазон букв от «K» до «Z»). Размер дешифровщика – 37 байт (+ 2 байта на команды `pusha` + `popa`, если вы хотите сохранить стартовые значения регистров). Итого на код остаётся: (125 — 37) / 2 = 44 байта (или 43, если добавить `pusha` + `popa`). Зато о шифровании можно вообще не париться :). Примеры, основанные на этом черновике – **2b\_snow.asm** и **2b\_hello.asm**
* **2b.check.inc** – include-файл для проверки кода. В случае наличия запретных символов, либо при превышении допустимого размера, при компиляции будет выведено сообщение (с указанием смещения в сегменте кода и смещения от начала BAT-файла).
* **2b.debug.inc** – include-файл для создания отладочных файлов (самостоятельно запускаемого COM-файла и BIN-файла с чистым кодом).
Ну и к чему это всё?
--------------------
Набор существующих платформ, под которые пишутся интры, уже долгие годы практически не меняется, если не брать во внимание категорию Wild (АОН, паяльники, ватные палочки). Мы предлагаем вам… не то чтобы новую платформу, но по крайней мере, некоторое разнообразие, со своими ограничениями. Именно ограничения и их преодоление являются сутью демосцены как процесса. Было бы прикольно на ближайшем демопати узреть оком своим целый конкурс в рамках этой концепции, где разные авторы смогут попробовать свои силы и мастерство в **«2B or not 2B compo»** :)
---EOF---
[#FF — И целого байта мало… | Пилот)](https://habr.com/ru/post/68984/)
[#00 — ИЦБМ… | Приглашение на Revision Online 2020](https://habr.com/ru/post/492984/)
[#01 — ИЦБМ… | Какими бывают intro?](https://habr.com/ru/post/495042/)
[#02 — ИЦБМ… | The Cross of Changes](https://habr.com/ru/post/495408/)
[#03 — ИЦБМ… | 2B or not 2B](https://habr.com/ru/post/495732/)
[#04 — ИЦБМ… | Берем БК за рога](https://habr.com/ru/post/496212/)
[#05 — ИЦБМ… | Анимэ](https://habr.com/ru/post/496512/)
[#06 — ИЦБМ… | Метеоризмы](https://habr.com/ru/post/496692/)
Развлекательный канал деда в Телеграм: [[**teleg.run/bornded**](https://teleg.run/bornded)
Рядом с каналом есть чат. В нем можно попробовать поднять вопросы за демосцену, ассемблер, пиксель-арт, трекерную музыку и другие аспекты процессы. Вам могут ответить либо отправят в другие, более тематические чаты.
ТАК ПОБЕЖДАЛИ — ТАК ПОБЕДИМ!](https://teleg.run/bornded) | https://habr.com/ru/post/495732/ | null | ru | null |
# Spring + Firebird + REST. Часть 1 Конфигурирование проекта
#### Вместо вступления
Если разбираешь что-то, попробуй это описать понятным языком и найти того, кто прочитает и выступит с замечаниями (перефразировал Р.Фейнмана, таки да я это сделал).
Все комментарии, даже злобные в стиле "Да, что этот ~~~белый~~~~чел. себе позволяет" приветствуются.
#### Цели
Приложения — отображение отчетов о ходе продукта (весы) по возможности с раздачей этих данных по сети в пределах предприятия (для функционала);
Личная — немного разобраться в технологии spring
#### Технологии
* Spring Web
* Spring JPA
* Lombok
+ Thymeleaf
* SpringFox Swagger (буду тестить рест на нем)
* jaybird-jdk17, версия 3.0.5
* Maven
#### Мотивация запилить spring+firebird
Недавно было сделано первое клиентское место под ОС Linux Mint для оператора "Овсезавода" и не всегда адекватная работа отображения отчетов из под Wine. (все остальное работает норм — визуализация Qt — SCADA, архивы Java SE).
#### Некоторые грабли на которые пришлось наступить
1. jackson зависимости разных версий (исправлено),
2. firebird не установленный тип кодировки ведет к default (ной) NONE,
Ссылка на [git](#githublink) в конце публикации .
#### Jackson и все все все
Разные компоненты затянули jackson разных версий, как то неприятно, надо исправить.
Выявлено командной
```
mvn dependency:tree -Dincludes=com.fasterxml.jackson.core
+- org.springframework.boot:spring-boot-starter-web:jar:2.1.0.RELEASE:compile
[INFO] | \- org.springframework.boot:spring-boot-starter-json:jar:2.1.0.RELEASE:compile
[INFO] | \- com.fasterxml.jackson.core:jackson-databind:jar:2.9.7:compile
[INFO] \- io.springfox:springfox-swagger2:jar:2.7.0:compile
[INFO] \- io.swagger:swagger-models:jar:1.5.13:compile
[INFO] \- com.fasterxml.jackson.core:jackson-annotations:jar:2.8.5:compile
```
Исправляем в pom.
```
com.fasterxml.jackson.core
jackson-databind
2.9.7
com.fasterxml.jackson.core
jackson-core
com.fasterxml.jackson.core
jackson-annotations
com.fasterxml.jackson.core
jackson-core
2.9.7
com.fasterxml.jackson.core
jackson-annotations
2.9.7
```
Подправил, ок. получилось. Если используете IDEA, то здесь еще проще посмотреть **External Libraries**. Что все зависимости есть и они нужных версий.
#### Общая структура приложения
С послойным тестированием Spring Boot приложения не знаком, поэтому сделаю без тестов
("Да что этот #цвет\_кожи себе позволяет").

#### Конфигурация приложения
Поскольку я seasoned developer, а значит не ознакомлен с устоявшимися методами, то буду делать :
1. в application.yml (пока настраиваю подключение к БД)
```
spring:
datasource:
driver-class-name: org.firebirdsql.jdbc.FBDriver
url: jdbc:firebirdsql://host:3050//work/cmn/db/namedb.fdb?sql_dialect=3&charSet=utf-8
username: ******
password: ******
useUnicode: true
characterEncoding: UTF-8
sql-script-encoding: UTF-8
jpa:
show-sql: true
```
2. используя аннотации непосредственно в классах:
Если не указать **charSet=utf-8, то дефолтная будет NONE** : На случай если в таблицах тоже NONE — получим нечитаемые символы или, согласно firebirdsql.org:
```
3.2.4 How can I solve the error “Connection rejected: No connection character set specified”
If no character set has been set, Jaybird 3.0 will reject the connection with an SQLNonTransientConnectionException with message “Connection rejected: No connection character set specified (property lc_ctype, encoding, charSet or localEncoding). Please specify a connection character set (eg property charSet=utf-8) or consult the Jaybird documentation for more information.”
```
#### Минимальный набор классов и файлов
Для начала index.html содержит пустое body;
Обкатка API — Swagger, package (infra) конфигурации которого поместим на уровне с остальными package проекта.
Добавлю в проект:
* package model
+ clacc CModule — он же [Data](https://habr.com/users/data/)( getter, setter для членов, спасибо Lombok за минимум "code monkey"), он же [Entity](https://habr.com/users/entity/) (сущность таблицы БД);
* package repository
+ interface CModuleRepository extends JpaRepository (он будет выбирать данные из базы), причем пока в него ничего добавлять не надо (типо [Query](https://habr.com/users/query/));
* package services;
+ class CModuleService — он же [Service](https://habr.com/users/service/) и @Transactional(readOnly = true) для работы с репозиторием;
* package resources
+ class CModulesResource — он же @RestController, @RequestMapping("/modules") отвечать будет за обращение по этому адресу. Response body сделает сам (для нас выглядит так)
Будем работать с API RestController по всем путям, укажем это Swagger:
```
@Configuration
@EnableSwagger2
public class SwaggerConfiguration {
@Bean
public Docket documentation(){
return new Docket(DocumentationType.SWAGGER_2)
.select()
.apis(RequestHandlerSelectors.withClassAnnotation(RestController.class))
.paths(PathSelectors.any())
.build();
}
}
```
Создадим класс запускающий Spring Application:
```
@SpringBootApplication
public class App {
public static void main(String[] args) {
SpringApplication.run(App.class,args);
}
}
```
Модели, репозитории, request созданы для нужной таблицы (у меня это modules):
теперь можно браться за @RestController
```
@RestController
@RequestMapping("/modules")
@Api(tags = "Modules", description = "Modules API")
public class CModulesResource {
....
@GetMapping(value = "/{name}")
@ApiOperation(value = "Find module",notes = "Find the module by Name")
@ApiResponses(value = {
@ApiResponse(code = 200,message = "Modules found"),
@ApiResponse(code = 404,message = "Modules not found"),
})
```
[Api](https://habr.com/users/api/) — название класса с описанием;
@ApiOperation название метода с описанием;
@ApiResponses возвращаемые коды API;
@ApiResponse конкретный код с описанием;
Пример (да в нем еще сущность main, которую в статье не описываю)
Теперь можно потестировать выборку данных по REST API.
Список используемой литературы:
```
1. https://www.baeldung.com
2. https://docs.spring.io
3. Spring in Action, 5th Edition
4. https://www.firebirdsql.org/file/documentation/drivers_documentation/java/faq.html#how-can-i-solve-the-error-connection-rejected-no-connection-character-set-specified
```
githublink
==========
[Гитхаб проекта](https://github.com/AlexisVaBel/OutsInfo-backend_spring.git) | https://habr.com/ru/post/432244/ | null | ru | null |
# Руководство по работе с OpenAL на C++. Часть 1: воспроизводим звук
Вашей игре нужен звук! Наверно, вы уже использовали OpenGL для рисования на экране. Вы разобрались с его API, и поэтому обратились к [OpenAL](https://en.wikipedia.org/wiki/OpenAL), потому что название кажется знакомым.
Что же, хорошие новости — OpenAL тоже имеет очень знакомый API. Он изначально задумывался для имитации API спецификации OpenGL. Именно поэтому я выбрал его среди множества звуковых систем для игр; к тому же он кроссплатформенный.
В этой статье я подробно расскажу о том, какой код нужен для использования OpenAL в игре, написанной на C++. Мы обсудим звуки, музыку и позиционирование звука в 3D-пространстве с примерами кода.
История OpenAL
--------------
Постараюсь быть кратким. Как говорилось выше, он намеренно разрабатывался как имитация OpenGL API, и на то есть причина. Это удобный API, который многим известен, и если графика — одна сторона игрового движка, то звук должен быть другой. Изначально OpenAL должен был стать open-source, но потом кое-что произошло…
Людей не так сильно интересует звук, как графика, поэтому в конечном итоге Creative сделала OpenAL своей собственностью, а *эталонная реализация* теперь проприетарна и небесплатна. Но! *Спецификация* OpenAL по-прежнему является «открытым» стандартом, то есть она [публикуется](https://openal.org/documentation/openal-1.1-specification.pdf).
Время от времени в спецификацию вносятся изменения, но их не так много. Звук меняется не так быстро, как графика, ведь особой нужды к этому нет.
Открытая спецификация позволила другим людям создать open-source-реализацию спецификации. Одной из таких реализаций является [OpenAL Soft](https://github.com/kcat/openal-soft), и, честно говоря, нет никакого смысла искать любые другие. Это та реализация, которую буду использовать я, и рекомендую вам использовать её же.
Она кроссплатформенная. Реализована она достаточно любопытно — по сути, внутри библиотека использует другие звуковые API, присутствующие в вашей системе. В Windows она использует [DirectSound](https://en.wikipedia.org/wiki/DirectSound), в Unix — [OSS](https://en.wikipedia.org/wiki/Open_Sound_System). Благодаря этому она и смогла стать кроссплатформенной; в сущности, это громкое название для обёртки API.
Возможно, вас беспокоит скорость этого API. Но не стоит волноваться. Это же звук, а он не создаёт большой нагрузки, поэтому ему не требуется больших оптимизаций, необходимых графическим API.
Но хватит истории, давайте перейдём к технологиям.
Что нужно, чтобы писать код на OpenAL?
--------------------------------------
Нужно собрать OpenAL Soft в выбранном вами тулчейне. Это очень простой процесс, который можно выполнить в соответствии с инструкциями [в разделе Source Install](https://github.com/kcat/openal-soft). У меня никогда не возникало с этим проблем, но если появятся затруднения, то напишите комментарий под оригиналом статьи или [напишите в список рассылки OpenAL Soft](http://openal.org/mailman/listinfo/openal).
Далее вам понадобится несколько звуковых файлов и способ их загрузки. Загрузка аудиоданных в буферы и тонкие подробности различных аудиоформатов находятся за пределами тематики этой статьи, но вы можете почитать о [загрузке и потоковом воспроизведении файлов Ogg/Vorbis](https://indiegamedev.net/2020/01/16/how-to-stream-ogg-files-with-openal-in-c/). Загрузка файлов WAV очень проста, об этом уже есть сотни статей в Интернете.
Задачу поиска аудиофайлов вам придётся решать самим. В Интернете есть множество шумов и взрывов, которые можно скачать. Если у вас есть слух, то можете попробовать [написать собственную чиптюн-музыку](https://indiegamedev.net/2020/01/24/how-to-make-quick-chip-tune-music-for-your-game/) [[перевод](https://habr.com/ru/post/488436/) на Хабре].
Кроме того, держите под рукой [Programmers Guide from OpenALSoft](https://github.com/kcat/openal-soft/wiki/Programmer%27s-Guide). Эта документация гораздо лучше pdf с «официальной» специализацией.
Вот, собственно, и всё. Будем считать, что вы уже знаете, как писать код, использовать IDE и тулчейн.
Обзор OpenAL API
----------------
Как я уже несколько раз говорил, он похож на OpenGL API. Схожесть заключается в том, что он основан на состояниях и вы взаимодействуете с дескрипторами/идентификаторами, а не с самими объектами напрямую.
Существуют расхождения между условными обозначениями API в OpenGL и OpenAL, но они незначительны. В OpenGL для генерации контекста рендеринга нужно выполнять специальные вызовы ОС. Эти вызовы для разных ОС различны и *на самом деле* не являются частью спецификации OpenGL. В OpenAL всё иначе — функции создания контекста являются частью спецификации и одинаковы вне зависимости от операционной системы.
При взаимодействии с API существуют три основных типа объектов, с которыми вы взаимодействуете. **Listeners** («слушатели») — это местонахождение «ушей», расположенных в 3D-пространстве (всегда существует только один listener). **Sources** («источники») — это «динамики», издающие звук, опять-таки в 3D-пространстве. Listener и sources можно перемещать в пространстве и в зависимости от этого изменяется то, что вы слышите через динамики в игре.
Последние объекты — это **buffers** («буферы»). В них хранятся сэмплы звуков, которые sources будут воспроизводить для listeners.
Существуют также **modes** («режимы»), которые игра использует для изменения способа обработки звука через OpenAL.
### Sources
Как говорилось выше, эти объекты являются источниками звуков. Им можно задать положение и направление и они связаны с буфером воспроизводимых аудиоданных.
### Listener
Единственный комплект «ушей» в игре. То, что слышит listener, воспроизводится через динамики компьютера. Он тоже имеет положение.
### Buffers
В OpenGL их аналогом является Texture2D. По сути, это аудиоданные, которые воспроизводит source.
### Типы данных
Чтобы иметь возможность поддержки кроссплатформенного кода, OpenAL выполняет определённую последовательность действий и задаёт некоторые типы данных. На самом деле, он так точно следует OpenGL, что мы даже можем напрямую преобразовывать типы OpenAL в типы OpenGL. В таблице ниже перечислены они и их эквиваленты.
| Тип OpenAL | Тип OpenALC | Тип OpenGL | C++ Typedef | Описание |
| --- | --- | --- | --- | --- |
| `ALboolean` | `ALCboolean` | `GLboolean` | `std::int8_t` | 8-битное булево значение |
| `ALbyte` | `ALCbyte` | `GLbyte` | `std::int8_t` | 8-битное целочисленное значение [дополнительного кода](https://en.wikipedia.org/wiki/Two%27s_complement) со знаком |
| `ALubyte` | `ALCubyte` | `GLubyte` | `std::uint8_t` | 8-битное целочисленное значение без знака |
| `ALchar` | `ALCchar` | `GLchar` | `char` | символ |
| `ALshort` | `ALCshort` | `GLshort` | `std::int16_t` | 16-битное целочисленное значение дополнительного кода со знаком |
| `ALushort` | `ALCushort` | `GLushort` | `std::uint16_t` | 16-битное целочисленное значение без знака |
| `ALint` | `ALCint` | `GLint` | `std::int32_t` | 32-битное целочисленное значение дополнительного кода со знаком |
| `ALuint` | `ALCuint` | `GLuint` | `std::uint32_t` | 32-битное целочисленное значение без знака |
| `ALsizei` | `ALCsizei` | `GLsizei` | `std::int32_t` | неотрицательное 32-битное двоичное целочисленное значение |
| `ALenum` | `ALCenum` | `GLenum` | `std::uint32_t` | перечислимое 32-битное значение |
| `ALfloat` | `ALCfloat` | `GLfloat` | `float` | 32-битное значение с плавающей запятой [IEEE 754](https://en.wikipedia.org/wiki/IEEE_754) |
| `ALdouble` | `ALCdouble` | `GLdouble` | `double` | 64-битное значение с плавающей запятой IEEE 754 |
| `ALvoid` | `ALCvoid` | `GLvoid` | `void` | пустое значение |
Распознавание ошибок OpenAL
---------------------------
Есть статья о том, как [упростить распознавание ошибок OpenAL](https://indiegamedev.net/2020/01/17/c-openal-function-call-wrapping/), но ради полноты руководства я повторю её здесь. Существует два *типа* вызовов OpenAL API: обычные и контекстные.
Контекстные вызовы, начинающиеся с `alc`, похожи на win32-вызовы OpenGL для получения контекста рендеринга или их аналогов в Linux. Звук — достаточно простая вещь, чтобы у всех операционных систем были одинаковые вызовы. Обычные вызовы начинаются с `al`. Для получения ошибок в контекстных вызовах мы вызываем `alcGetError`; в случае обычных вызовов мы вызываем `alGetError`. Они возвращают или значение `ALCenum`, или значение `ALenum`, в которых просто перечисляются возможные ошибки.
Сейчас мы рассмотрим только один случай, но во всём остальном они практически одинаковы. Давайте возьмём обычные вызовы `al`. Сначала создадим макрос препроцессора для выполнения скучной работы по передаче подробностей:
```
#define alCall(function, ...) alCallImpl(__FILE__, __LINE__, function, __VA_ARGS__)
```
Теоретически, ваш компилятор может не поддерживать `__FILE__` или `__LINE__`, но, честно говоря, я был бы удивлён, если бы это оказалось так. `__VA_ARGS__` обозначает переменное количество аргументов, которые могут передаваться этому макросу.
Далее мы реализуем функцию, которая вручную получает последнюю сообщённую ошибку и выводит в стандартный поток ошибок понятное значение.
```
bool check_al_errors(const std::string& filename, const std::uint_fast32_t line)
{
ALenum error = alGetError();
if(error != AL_NO_ERROR)
{
std::cerr << "***ERROR*** (" << filename << ": " << line << ")\n" ;
switch(error)
{
case AL_INVALID_NAME:
std::cerr << "AL_INVALID_NAME: a bad name (ID) was passed to an OpenAL function";
break;
case AL_INVALID_ENUM:
std::cerr << "AL_INVALID_ENUM: an invalid enum value was passed to an OpenAL function";
break;
case AL_INVALID_VALUE:
std::cerr << "AL_INVALID_VALUE: an invalid value was passed to an OpenAL function";
break;
case AL_INVALID_OPERATION:
std::cerr << "AL_INVALID_OPERATION: the requested operation is not valid";
break;
case AL_OUT_OF_MEMORY:
std::cerr << "AL_OUT_OF_MEMORY: the requested operation resulted in OpenAL running out of memory";
break;
default:
std::cerr << "UNKNOWN AL ERROR: " << error;
}
std::cerr << std::endl;
return false;
}
return true;
}
```
Возможных ошибок не так много. Объяснения, которые я написал в коде — это единственная информация, которую вы будете получать об этих ошибках, но в спецификации объяснено, почему конкретная функция может возвращать конкретную ошибку.
Затем мы реализуем две разные шаблонные функции, которые будут «оборачивать» все наши вызовы OpenGL.
```
template
auto alCallImpl(const char\* filename,
const std::uint\_fast32\_t line,
alFunction function,
Params... params)
->typename std::enable\_if\_t,decltype(function(params...))>
{
auto ret = function(std::forward(params)...);
check\_al\_errors(filename,line);
return ret;
}
template
auto alcCallImpl(const char\* filename,
const std::uint\_fast32\_t line,
alcFunction function,
ALCdevice\* device,
Params... params)
->typename std::enable\_if\_t,bool>
{
function(std::forward(params)...);
return check\_alc\_errors(filename,line,device);
}
```
Их две, потому что первая используется для функций OpenAL, возвращающих `void`, а вторая используется, когда функция возвращает непустое значение. Если вы не очень знакомы с метапрограммированием шаблонов в C++, то взгляните на части кода с `std::enable_if`. Они определяют то, какие из этих шаблонных функций реализуются компилятором для каждого вызова функции.
А теперь то же самое для вызовов `alc`:
```
#define alcCall(function, device, ...) alcCallImpl(__FILE__, __LINE__, function, device, __VA_ARGS__)
bool check_alc_errors(const std::string& filename, const std::uint_fast32_t line, ALCdevice* device)
{
ALCenum error = alcGetError(device);
if(error != ALC_NO_ERROR)
{
std::cerr << "***ERROR*** (" << filename << ": " << line << ")\n" ;
switch(error)
{
case ALC_INVALID_VALUE:
std::cerr << "ALC_INVALID_VALUE: an invalid value was passed to an OpenAL function";
break;
case ALC_INVALID_DEVICE:
std::cerr << "ALC_INVALID_DEVICE: a bad device was passed to an OpenAL function";
break;
case ALC_INVALID_CONTEXT:
std::cerr << "ALC_INVALID_CONTEXT: a bad context was passed to an OpenAL function";
break;
case ALC_INVALID_ENUM:
std::cerr << "ALC_INVALID_ENUM: an unknown enum value was passed to an OpenAL function";
break;
case ALC_OUT_OF_MEMORY:
std::cerr << "ALC_OUT_OF_MEMORY: an unknown enum value was passed to an OpenAL function";
break;
default:
std::cerr << "UNKNOWN ALC ERROR: " << error;
}
std::cerr << std::endl;
return false;
}
return true;
}
template
auto alcCallImpl(const char\* filename,
const std::uint\_fast32\_t line,
alcFunction function,
ALCdevice\* device,
Params... params)
->typename std::enable\_if\_t,bool>
{
function(std::forward(params)...);
return check\_alc\_errors(filename,line,device);
}
template
auto alcCallImpl(const char\* filename,
const std::uint\_fast32\_t line,
alcFunction function,
ReturnType& returnValue,
ALCdevice\* device,
Params... params)
->typename std::enable\_if\_t,bool>
{
returnValue = function(std::forward(params)...);
return check\_alc\_errors(filename,line,device);
}
```
Самое большое изменение — это включение `device`, которое используют все вызовы `alc`, а также соответствующее использование ошибок стиля `ALCenum` и `ALC_`. Они выглядят очень похожими, и очень долго небольшие изменения с `al` на `alc` сильно вредили моему коду и пониманию, поэтому я просто продолжал чтение прямо поверх этого `c`.
Вот и всё. Обычно вызов OpenAL на C++ выглядит как один из следующих вариантов:
```
/* example #1 */
alGenSources(1, &source);
ALenum error = alGetError();
if(error != AL_NO_ERROR)
{
/* handle different possibilities */
}
/* example #2 */
alcCaptureStart(&device);
ALCenum error = alcGetError();
if(error != ALC_NO_ERROR)
{
/* handle different possibilities */
}
/* example #3 */
const ALchar* sz = alGetString(param);
ALenum error = alGetError();
if(error != AL_NO_ERROR)
{
/* handle different possibilities */
}
/* example #4 */
const ALCchar* sz = alcGetString(&device, param);
ALCenum error = alcGetError();
if(error != ALC_NO_ERROR)
{
/* handle different possibilities */
}
```
Но теперь мы можем делать это вот так:
```
/* example #1 */
if(!alCall(alGenSources, 1, &source))
{
/* error occurred */
}
/* example #2 */
if(!alcCall(alcCaptureStart, &device))
{
/* error occurred */
}
/* example #3 */
const ALchar* sz;
if(!alCall(alGetString, sz, param))
{
/* error occurred */
}
/* example #4 */
const ALCchar* sz;
if(!alcCall(alcGetString, sz, &device, param))
{
/* error occurred */
}
```
Возможно, это выглядит для вас странно, но мне так удобнее. Разумеется, вы можете выбрать другую структуру.
Загрузка файлов .wav
--------------------
Вы можете или загружать их самостоятельно, или использовать библиотеку. Вот [open-source-реализация загрузки файлов .wav](https://github.com/adamstark/AudioFile). Я сумасшедший, поэтому делаю это сам:
```
std::int32_t convert_to_int(char* buffer, std::size_t len)
{
std::int32_t a = 0;
if(std::endian::native == std::endian::little)
std::memcpy(&a, buffer, len);
else
for(std::size_t i = 0; i < len; ++i)
reinterpret_cast(&a)[3 - i] = buffer[i];
return a;
}
bool load\_wav\_file\_header(std::ifstream& file,
std::uint8\_t& channels,
std::int32\_t& sampleRate,
std::uint8\_t& bitsPerSample,
ALsizei& size)
{
char buffer[4];
if(!file.is\_open())
return false;
// the RIFF
if(!file.read(buffer, 4))
{
std::cerr << "ERROR: could not read RIFF" << std::endl;
return false;
}
if(std::strncmp(buffer, "RIFF", 4) != 0)
{
std::cerr << "ERROR: file is not a valid WAVE file (header doesn't begin with RIFF)" << std::endl;
return false;
}
// the size of the file
if(!file.read(buffer, 4))
{
std::cerr << "ERROR: could not read size of file" << std::endl;
return false;
}
// the WAVE
if(!file.read(buffer, 4))
{
std::cerr << "ERROR: could not read WAVE" << std::endl;
return false;
}
if(std::strncmp(buffer, "WAVE", 4) != 0)
{
std::cerr << "ERROR: file is not a valid WAVE file (header doesn't contain WAVE)" << std::endl;
return false;
}
// "fmt/0"
if(!file.read(buffer, 4))
{
std::cerr << "ERROR: could not read fmt/0" << std::endl;
return false;
}
// this is always 16, the size of the fmt data chunk
if(!file.read(buffer, 4))
{
std::cerr << "ERROR: could not read the 16" << std::endl;
return false;
}
// PCM should be 1?
if(!file.read(buffer, 2))
{
std::cerr << "ERROR: could not read PCM" << std::endl;
return false;
}
// the number of channels
if(!file.read(buffer, 2))
{
std::cerr << "ERROR: could not read number of channels" << std::endl;
return false;
}
channels = convert\_to\_int(buffer, 2);
// sample rate
if(!file.read(buffer, 4))
{
std::cerr << "ERROR: could not read sample rate" << std::endl;
return false;
}
sampleRate = convert\_to\_int(buffer, 4);
// (sampleRate \* bitsPerSample \* channels) / 8
if(!file.read(buffer, 4))
{
std::cerr << "ERROR: could not read (sampleRate \* bitsPerSample \* channels) / 8" << std::endl;
return false;
}
// ?? dafaq
if(!file.read(buffer, 2))
{
std::cerr << "ERROR: could not read dafaq" << std::endl;
return false;
}
// bitsPerSample
if(!file.read(buffer, 2))
{
std::cerr << "ERROR: could not read bits per sample" << std::endl;
return false;
}
bitsPerSample = convert\_to\_int(buffer, 2);
// data chunk header "data"
if(!file.read(buffer, 4))
{
std::cerr << "ERROR: could not read data chunk header" << std::endl;
return false;
}
if(std::strncmp(buffer, "data", 4) != 0)
{
std::cerr << "ERROR: file is not a valid WAVE file (doesn't have 'data' tag)" << std::endl;
return false;
}
// size of data
if(!file.read(buffer, 4))
{
std::cerr << "ERROR: could not read data size" << std::endl;
return false;
}
size = convert\_to\_int(buffer, 4);
/\* cannot be at the end of file \*/
if(file.eof())
{
std::cerr << "ERROR: reached EOF on the file" << std::endl;
return false;
}
if(file.fail())
{
std::cerr << "ERROR: fail state set on the file" << std::endl;
return false;
}
return true;
}
char\* load\_wav(const std::string& filename,
std::uint8\_t& channels,
std::int32\_t& sampleRate,
std::uint8\_t& bitsPerSample,
ALsizei& size)
{
std::ifstream in(filename, std::ios::binary);
if(!in.is\_open())
{
std::cerr << "ERROR: Could not open \"" << filename << "\"" << std::endl;
return nullptr;
}
if(!load\_wav\_file\_header(in, channels, sampleRate, bitsPerSample, size))
{
std::cerr << "ERROR: Could not load wav header of \"" << filename << "\"" << std::endl;
return nullptr;
}
char\* data = new char[size];
in.read(data, size);
return data;
}
```
Я не буду объяснять код, потому что это не совсем в тематике нашей статьи; но он очень очевиден, если читать его параллельно со [спецификацией файла WAV](http://soundfile.sapp.org/doc/WaveFormat/).
Инициализация и уничтожение
---------------------------
Сначала нам нужно инициализировать OpenAL, а потом, как любому хорошему программисту, завершить его, когда мы закончим с ним работу. При инициализации используется `ALCdevice` (заметьте, что это `ALC`, а *не* `AL`), которое по сути представляет нечто на вашем компьютере для воспроизведения фоновой музыки и использует `ALCcontext`.
`ALCdevice` аналогично выбору графической карты. на которой ваша OpenGL-игра будет выполнять рендеринг. `ALCcontext` аналогичен контексту рендеринга, который нужно создать (уникальным для операционной системы образом) для OpenGL.
### ALCdevice
OpenAL Device — это то, через что выполняется вывод звука, будь то звуковая карта или чип, но теоретически это может быть и множеством различных вещей. Аналогично тому, как стандартный вывод `iostream` может быть вместо экрана принтером, устройство может быть файлом или даже потоком данных.
Тем не менее, для программирования игр это будет звуковое устройство, и обычно мы хотим, чтобы это было стандартное устройство вывода звука в системе.
Для получения списка доступных в системе устройств можно запросить их такой функцией:
```
bool get_available_devices(std::vector& devicesVec, ALCdevice\* device)
{
const ALCchar\* devices;
if(!alcCall(alcGetString, devices, device, nullptr, ALC\_DEVICE\_SPECIFIER))
return false;
const char\* ptr = devices;
devicesVec.clear();
do
{
devicesVec.push\_back(std::string(ptr));
ptr += devicesVec.back().size() + 1;
}
while(\*(ptr + 1) != '\0');
return true;
}
```
На самом деле это просто обёртка вокруг обёртки вокруг вызова `alcGetString`. Возвращаемое значение — это указатель на список строк, разделённых значением `null` и заканчивающийся двумя значениями `null`. Здесь обёртка просто превращает его в удобный для нас вектор.
К счастью, нам не нужно этого делать! В общем случае, как я подозреваю, большинство игр может просто выводить звук на устройство по умолчанию, каким бы оно ни было. Я нечасто вижу опции изменения аудиоустройства, через которое нужно выводить звук. Поэтому для инициализации OpenAL Device мы используем вызов `alcOpenDevice`. Этот вызов немного отличается от всего остального, поскольку он не задаёт состояния ошибки, которое можно получить через `alcGetError`, поэтому мы вызываем его, как обычную функцию:
```
ALCdevice* openALDevice = alcOpenDevice(nullptr);
if(!openALDevice)
{
/* fail */
}
```
Если вы перечислили устройства показанным выше образом, и хотите, чтобы пользователь выбрал одно из них, то нужно передать его название в `alcOpenDevice` вместо `nullptr`. Отправка `nullptr` приказывает *открыть устройство по умолчанию*. Возвращаемое значение — это или соответствующее устройство, или `nullptr`, если произошла ошибка.
В зависимости от того, выполнили ли вы перечисление или нет, ошибка может остановить выполнение программы на дорожках. Нет устройства = нет OpenAL; нет OpenAL = нет звука; нет звука = нет игры.
Последнее, что мы делаем при закрытии программы — правильно её завершаем.
```
ALCboolean closed;
if(!alcCall(alcCloseDevice, closed, openALDevice, openALDevice))
{
/* do we care? */
}
```
На этом этапе, если выполнить завершение не удалось, то нам это уже не важно. Перед закрытием устройства мы должны закрыть все созданные контексты, однако по моему опыту, этот вызов тоже завершает контекст. Но мы сделаем это правильно. Если вы всё завершаете перед совершением вызова `alcCloseDevice`, то ошибок быть не должно, и если они по каким-то причинам возникли, то вы ничего не сможете с этим сделать.
Возможно, вы заметили, что вызовы с `alcCall` отправляют две копии устройства. Так получилось из-за того, как работает шаблонная функция — одна ей нужна для проверки ошибок, а вторая используется как параметр функции.
Теоретически, я могу улучшить шаблонную функцию так, чтобы она передавала первый параметр на проверку ошибок и всё равно пересылала его функции; но мне лениво это делать. Оставлю это вам в качестве домашнего задания.
### Наш ALCcontext
Вторая часть инициализации — это контекст. Как и ранее, он аналогичен контексту рендеринга из OpenGL. В одной программе может быть несколько контекстов и мы можем переключаться между ними, но нам это не понадобится. Каждый контекст имеет собственные **listener** и **sources**, и их нельзя передавать между контекстами.
Возможно, это полезно в ПО обработки звука. Однако для игр в 99.9% случаев достаточно только одного контекста.
Создать новый контекст очень просто:
```
ALCcontext* openALContext;
if(!alcCall(alcCreateContext, openALContext, openALDevice, openALDevice, nullptr) || !openALContext)
{
std::cerr << "ERROR: Could not create audio context" << std::endl;
/* probably exit program */
}
```
Нам нужно сообщить, для какого `ALCdevice` мы хотим создать контекст; также мы можем передать необязательный завершающийся нулём список ключей и значений `ALCint`, которые являются атрибутами, с которыми должен быть создан контекст.
Честно говоря, я даже не знаю, в какой ситуации пригождается передача атрибутов. Ваша игра будет работать на обычном компьютере с обычными звуковыми функциями. Атрибуты имеют значения по умолчанию, зависящие от компьютера, поэтому это не особо важно. Но на случай, если вам это всё-таки важно:
| Название атрибута | Описание |
| --- | --- |
| `ALC_FREQUENCY` | Частота микширования в буфер вывода, измеряемая в Гц |
| `ALC_REFRESH` | Интервалы обновления, измеряемые в Гц |
| `ALC_SYNC` | `0` или `1` обозначают, должен ли это быть синхронный или асинхронный контекст |
| `ALC_MONO_SOURCES` | Значение, помогающее сообщить, сколько источников вы будете использовать, которым потребуется возможность обработки монофонических звуковых данных. Оно не ограничивает максимально допустимое количество, просто позволяет быть более эффективным, когда знаешь это заранее. |
| `ALC_STEREO_SOURCES` | То же самое, но для стереоданных. |
Если вы получаете ошибки, то скорее всего это из-за того, что желаемые вами атрибуты невозможны или вы не можете создать ещё один контекст для поддерживаемого устройства; при этом будет получена ошибка `ALC_INVALID_VALUE`. Если вы передадите недопустимое устройство, то получите ошибку `ALC_INVALID_DEVICE`, но, разумеется, эту ошибку мы уже проверяем.
Создания контекста недостаточно. Нам ещё нужно сделать его текущим — выглядит похоже на Windows OpenGL Rendering Context, правда? Это то же самое.
```
ALCboolean contextMadeCurrent = false;
if(!alcCall(alcMakeContextCurrent, contextMadeCurrent, openALDevice, openALContext)
|| contextMadeCurrent != ALC_TRUE)
{
std::cerr << "ERROR: Could not make audio context current" << std::endl;
/* probably exit or give up on having sound */
}
```
Делать контекст текущим необходимо для совершения любых дальнейших операций с контекстом (или с sources и listeners в нём). Операция вернёт `true` или `false`, единственное возможное значение ошибки, передаваемое `alcGetError` — это `ALC_INVALID_CONTEXT`, которое понятно из названия.
Завершив с контекстом, т.е. при выходе из программы, нужно, чтобы контекст больше не был текущим, а затем уничтожить его.
```
if(!alcCall(alcMakeContextCurrent, contextMadeCurrent, openALDevice, nullptr))
{
/* what can you do? */
}
if(!alcCall(alcDestroyContext, openALDevice, openALContext))
{
/* not much you can do */
}
```
Единственная возможная ошибка от `alcDestroyContext` такая же, как и у `alcMakeContextCurrent` — `ALC_INVALID_CONTEXT`; если вы всё делаете правильно, то не получите её, а если получаете, то с этим ничего нельзя поделать.
> **Зачем проверять наличие ошибок, с которыми ничего нельзя сделать?**
>
>
>
> Потому что мне хочется, чтобы сообщения о них хотя бы появлялись в потоке ошибок, что для нас делает `alcCall`.Допустим, он никогда не выдаёт нам ошибки, но будет полезно знать, что подобная ошибка возникает на чьём-то чужом компьютере. Благодаря этому мы можем изучить проблему, а возможно и [сообщить о баге разработчикам OpenAL Soft](https://github.com/kcat/openal-soft/issues).
Воспроизводим наш первый звук
-----------------------------
Ну, хватит всего этого, давайте проиграем звук. Для начала нам очевидно понадобится звуковой файл. Например, этот, из [игры, которую я когда-нибудь закончу](https://deckhead.itch.io/the-last-boundary).
<https://indiegamedev.net/wp-content/uploads/2020/02/iamtheprotectorofthissystem.wav>
*I am the protector of this system!*
Итак, откроем IDE и используем следующий код. Не забудьте подключить OpenAL Soft и добавить показанный выше код загрузки файла и код проверки ошибок.
```
int main()
{
ALCdevice* openALDevice = alcOpenDevice(nullptr);
if(!openALDevice)
return 0;
ALCcontext* openALContext;
if(!alcCall(alcCreateContext, openALContext, openALDevice, openALDevice, nullptr) || !openALContext)
{
std::cerr << "ERROR: Could not create audio context" << std::endl;
return 0;
}
ALCboolean contextMadeCurrent = false;
if(!alcCall(alcMakeContextCurrent, contextMadeCurrent, openALDevice, openALContext)
|| contextMadeCurrent != ALC_TRUE)
{
std::cerr << "ERROR: Could not make audio context current" << std::endl;
return 0;
}
std::uint8_t channels;
std::int32_t sampleRate;
std::uint8_t bitsPerSample;
std::vector soundData;
if(!load\_wav("iamtheprotectorofthissystem.wav", channels, sampleRate, bitsPerSample, soundData))
{
std::cerr << "ERROR: Could not load wav" << std::endl;
return 0;
}
ALuint buffer;
alCall(alGenBuffers, 1, &buffer);
ALenum format;
if(channels == 1 && bitsPerSample == 8)
format = AL\_FORMAT\_MONO8;
else if(channels == 1 && bitsPerSample == 16)
format = AL\_FORMAT\_MONO16;
else if(channels == 2 && bitsPerSample == 8)
format = AL\_FORMAT\_STEREO8;
else if(channels == 2 && bitsPerSample == 16)
format = AL\_FORMAT\_STEREO16;
else
{
std::cerr
<< "ERROR: unrecognised wave format: "
<< channels << " channels, "
<< bitsPerSample << " bps" << std::endl;
return 0;
}
alCall(alBufferData, buffer, format, soundData.data(), soundData.size(), sampleRate);
soundData.clear(); // erase the sound in RAM
ALuint source;
alCall(alGenSources, 1, &source);
alCall(alSourcef, source, AL\_PITCH, 1);
alCall(alSourcef, source, AL\_GAIN, 1.0f);
alCall(alSource3f, source, AL\_POSITION, 0, 0, 0);
alCall(alSource3f, source, AL\_VELOCITY, 0, 0, 0);
alCall(alSourcei, source, AL\_LOOPING, AL\_FALSE);
alCall(alSourcei, source, AL\_BUFFER, buffer);
alCall(alSourcePlay, source);
ALint state = AL\_PLAYING;
while(state == AL\_PLAYING)
{
alCall(alGetSourcei, source, AL\_SOURCE\_STATE, &state);
}
alCall(alDeleteSources, 1, &source);
alCall(alDeleteBuffers, 1, &buffer);
alcCall(alcMakeContextCurrent, contextMadeCurrent, openALDevice, nullptr);
alcCall(alcDestroyContext, openALDevice, openALContext);
ALCboolean closed;
alcCall(alcCloseDevice, closed, openALDevice, openALDevice);
return 0;
}
```
Компилируем! Компонуем! Запускаем! ***I am the prrrootector of this system***. Если вы не слышите звука, то снова всё проверьте. Если в окне консоли что-то написано, то это должен быть стандартный вывод потока ошибок, и он важен. Наши функции сообщений об ошибках должны подсказать нам строку исходного кода, сгенерировавшую ошибку.
Найдя ошибку, изучите [Programmers Guide](https://github.com/kcat/openal-soft/wiki/Programmer%27s-Guide) и в [спецификацию](https://openal.org/documentation/openal-1.1-specification.pdf), чтобы понять, при каких условиях эта ошибка может быть сгенерирована функцией. Это поможет вам разобраться. Если не удастся, то оставьте комментарий под оригиналом статьи, и я попробую помочь.
### Загрузка данных RIFF WAVE
```
std::uint8_t channels;
std::int32_t sampleRate;
std::uint8_t bitsPerSample;
std::vector soundData;
if(!load\_wav("iamtheprotectorofthissystem.wav", channels, sampleRate, bitsPerSample, soundData))
{
std::cerr << "ERROR: Could not load wav" << std::endl;
return 0;
}
```
Это относится к коду загрузки wave. Важно то, что мы получаем данные, или как указатель, или собранные в вектор: количество каналов, частота дискретизации и количество битов на сэмпл.
### Генерация буфера
```
ALuint buffer;
alCall(alGenBuffers, 1, &buffer);
```
Вероятно, это выглядит для вас знакомым, если вы когда-нибудь генерировали буферы текстурных данных в OpenGL. По сути, мы генерируем буфер и притворяемся, что он будет существовать только в звуковой карте. На самом же деле он скорее всего будет храниться в обычной ОЗУ, но спецификация OpenAL абстрагирует все эти операции.
Итак, значение `ALuint` является *дескриптором* нашего буфера. Помните, что **buffer** в сущности является звуковыми данными в памяти звуковой карты. У нас больше нет *прямого доступа* к этим данным, поскольку мы забрали их из программы (из обычной ОЗУ) и переместили в звуковую карту/чип и т.п. Аналогичным образом работает OpenGL, перемещая текстурные данные из ОЗУ во VRAM.
Этот *дескриптор* генерирует `alGenBuffers`. Он имеет пару возможных значений ошибок, самым важным из которых является `AL_OUT_OF_MEMORY`, которое означает, что мы больше не может добавлять звуковые данные в звуковую карту. Вы не получите *этой* ошибки, если, например, используете единственный буфер, однако это нужно учитывать, если вы [создаёте движок](https://indiegamedev.net/2020/01/23/game-engine-development-for-the-hobby-developer-part-3-audio/).
### Определяем формат звуковых данных
```
ALenum format;
if(channels == 1 && bitsPerSample == 8)
format = AL_FORMAT_MONO8;
else if(channels == 1 && bitsPerSample == 16)
format = AL_FORMAT_MONO16;
else if(channels == 2 && bitsPerSample == 8)
format = AL_FORMAT_STEREO8;
else if(channels == 2 && bitsPerSample == 16)
format = AL_FORMAT_STEREO16;
else
{
std::cerr
<< "ERROR: unrecognised wave format: "
<< channels << " channels, "
<< bitsPerSample << " bps" << std::endl;
return 0;
}
```
Звуковые данные работают так: существует несколько *каналов* и есть величина *битов на сэмпл*. Данные состоят из множества *сэмплов*.
Для определения количества *сэмплов* в аудиоданных мы делаем следующее:
```
std::int_fast32_t numberOfSamples = dataSize / (numberOfChannels * (bitsPerSample / 8));
```
Что удобным образом можно преобразовать в вычисление *длительности* звуковых данных:
```
std::size_t duration = numberOfSamples / sampleRate;
```
Но пока нам не нужно знать ни `numberOfSamples`, ни `duration`, однако важно знать, как используются все эти фрагменты информации.
Вернёмся к `format` — нам нужно сообщить OpenAL формат звуковых данных. Это кажется очевидным, правда? Аналогично тому, как мы заполняет буфер текстур OpenGL, сообщая, что данные находятся в последовательности BGRA и составлены из 8-битных значений, нам нужно сделать подобное и в OpenAL.
Чтобы сообщить OpenAL о том, как интерпретировать данные, на которые указывает тот указатель, который мы передадим позже, нам нужно определить формат данных. Под *форматом* подразумевается то, как его понимает OpenAL. Существует всего четыре возможных значения. Есть два возможных значения для количества каналов: один для моно, два для стерео.
Кроме количества каналов, у нас есть количество битов на сэмпл. Оно равно или `8`, или `16`, и по сути является качеством звука.
Так что с помощью значений каналов и битов на сэмпл, о которых нам сообщила функция загрузки wave, мы можем определить, какой `ALenum` использовать для будущего параметра `format`.
### Заполнение буфера
```
alCall(alBufferData, buffer, format, soundData.data(), soundData.size(), sampleRate);
soundData.clear(); // erase the sound in RAM
```
С этим всё должно быть просто. Мы загрузим в OpenAL Buffer, на который указывает *дескриптор* `buffer`; данные, на которые указывает ptr `soundData.data()`, в размере `size` с указанной `sampleRate`. Также мы сообщим OpenAL формат этих данных через параметр `format`.
В конце мы просто удаляем данные, которые получил загрузчик wave. Зачем же? Потому что мы уже скопировали их в звуковую карту. Нам нет необходимости хранить их в двух местах и расходовать драгоценные ресурсы. Если звуковая карта потеряет данные, то мы просто снова загрузим их с диска и нам не нужно будет копировать их для ЦП или ещё кого-то.
### Настройка Source
Вспомним, что OpenAL по сути является **listener**, слушающим звуки, издаваемые одним или несколькими **sources**. Ну, теперь настало время создать источник звука.
```
ALuint source;
alCall(alGenSources, 1, &source);
alCall(alSourcef, source, AL_PITCH, 1);
alCall(alSourcef, source, AL_GAIN, 1.0f);
alCall(alSource3f, source, AL_POSITION, 0, 0, 0);
alCall(alSource3f, source, AL_VELOCITY, 0, 0, 0);
alCall(alSourcei, source, AL_LOOPING, AL_FALSE);
alCall(alSourcei, source, AL_BUFFER, buffer);
```
Честно говоря, некоторые из этих параметров задавать необязательно, потому что из значения по умолчанию вполне нам подходят. Но это показывает нам некоторые аспекты, с которыми можно поэкспериментировать и посмотреть, что они делают (можно даже поступить хитро и изменять их со временем).
Сначала мы генерируем source — помните, это снова *дескриптор* чего-то внутри OpenAL API. Мы задаём pitch (тон) так, чтобы он не изменился, gain (громкость) делаем равным исходному значению звуковых данных, позицию и скорость обнуляем; мы *не зацикливаем* звук, потому что в противном случае наша программа никогда не завершится, и указываем буфер.
Помните, что разные источники могут использовать один буфер. Например, враги, стреляющие в игрока из разных мест, могут воспроизводить одинаковый звук выстрела, поэтому нам не нужно множество копий звуковых данных, а только несколько мест в 3D-пространстве, из которых издаётся звук.
### Воспроизведение звука
```
alCall(alSourcePlay, source);
ALint state = AL_PLAYING;
while(state == AL_PLAYING)
{
alCall(alGetSourcei, source, AL_SOURCE_STATE, &state);
}
```
Сначала нам нужно запустить воспроизведение source. Достаточно просто вызвать `alSourcePlay`.
Затем мы создаём значение для хранения текущего состояния `AL_SOURCE_STATE` источника и бесконечно его обновляем. Когда оно больше не равно `AL_PLAYING` мы можем продолжить. Можно изменить состояние на `AL_STOPPED`, когда он завершит издавать звук из буфера (или когда возникнет ошибка). Если задать для looping значение `true`, то звук будет воспроизводиться вечно.
Затем мы можем изменить буфер источника и воспроизвести другой звук. Или заново проиграть тот же звук, и т.д. Просто задаём буфер, используем `alSourcePlay` и, может быть, `alSourceStop`, если нужно. В следующих статьях мы рассмотрим это более подробно.
### Очистка
```
alCall(alDeleteSources, 1, &source);
alCall(alDeleteBuffers, 1, &buffer);
```
Так как мы просто воспроизводим звуковые данные один раз и выполняем выход, то удалим ранее созданные source и buffer.
Остальная часть кода понятна без объяснений.
Куда двигаться дальше?
----------------------
Зная всё описанное в данной статье, уже можно создать небольшую игру! [Попробуйте создать Pong](https://indiegamedev.net/2020/02/09/making-your-first-game-pong-the-architecture/) или [какую-нибудь другую классическую игру](https://indiegamedev.net/2020/01/21/5-games-for-hobby-developers-to-make/), для них большего и не требуется.
Но помните! Эти буферы подходят только для коротких звуков, скорее всего, длительностью несколько секунд. Если вам нужна музыка или озвучка, то потребуется потоковая передача аудиоданных в OpenAL. Об этом мы расскажем в одной из следующих частей серии туториалов. | https://habr.com/ru/post/488744/ | null | ru | null |
# Подключение phpStorm tasks к Битрикс24
 Добрый день.
Хочу поделится опытом подключения phpStorm к Битрикс24 для быстрого доступа к задачам и учета времени на их выполнение.
К сожалению Битрикс24 не входит в список поддерживаемых багтрекеров, а необходимость у меня появилась.
Давайте приступим.
Первым делом нужно пройти в Битрикс24 и создать вебхук.
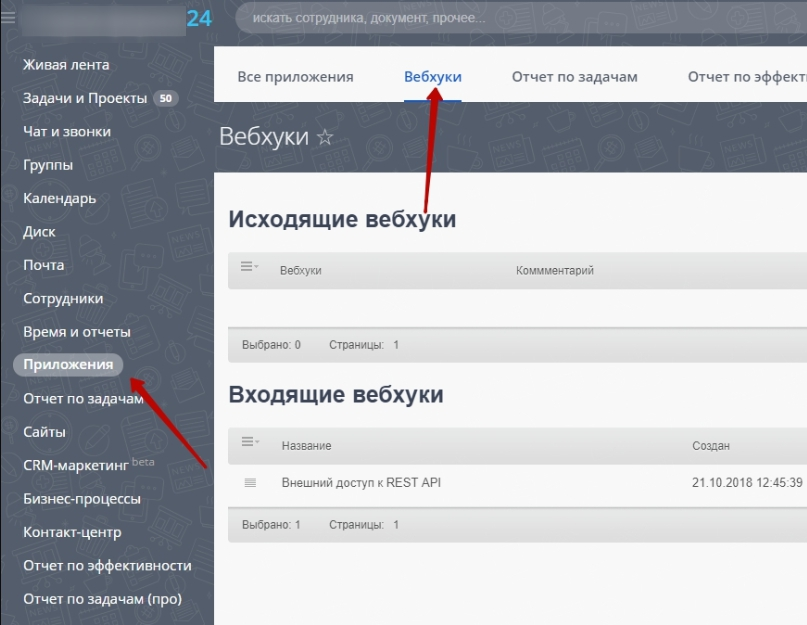
И нажимаем "**добавить вебхук**" > "**входящий вебхук**"
Не забудьте в правах указать доступ к данным "**Задачи (task)**".
В результате вы должны получить код, он понадобится для авторизации.
Открываем **настройки phpStorm > Tool > Tasks > Servers**
Добавляем новый сервер типа **Generic**
Переходим на вкладку **Server Configuration** и нажимаем на кнопку **Manage Template Variables...**
Нам нужно добавить два поля **userId** и **secretKey**, сделайте их видимыми на первой вкладке.
Нажимаем **OK** и переходим на вкладку **General**.
Заполняем поля:
**Server Url**: https://\*\*\*.bitrix24.ru/rest
Поставьте галочку **Login Anonymously**
**UserId**: ваш пользовательский id в Битрикс24, можно посмотреть в урле любой задачи в системе (https://\*\*\*.bitrix24.ru/company/personal/user/**14**/tasks/task/view/6223/)
**SecretKey**: Полученный нами ранее ключ от вебхука Битрикс24.
Выглядеть это все должно примерно так:
Переходим во вкладку **Server Configuration**
Заполняем поля:
**Tasks List URL**: {serverUrl}/{userId}/{secretKey}/task.item.list.json?ORDER%5B%5D=&FILTER%5BRESPONSIBLE\_ID%5D={userId}&FILTER%5B%3CREAL\_STATUS%5D=4&PARAMS%5B%5D=&SELECT%5B%5D=\*
**Single Task URL**: {serverUrl}/{userId}/{secretKey}/task.item.getdata.json?TASKID={id}
**Response type**: JSON
Соотносим поля:
```
tasks | result[*]
id | ID
summary | TITLE
description | DESCRIPTION
updated | CHANGED_DATE
created | CREATED_DATE
singleTask-id | result.ID
singleTask-summary | result.TITLE
singleTask-description | result.DESCRIPTION
singleTask-updated | result.CHANGED_DATE
singleTask-created | result.CREATED_DATE
```
Получится должно примерно так:

Жмем на **Test** для проверки.
Отлично:
Жаль не получилось сформировать issueUrl, какие бы варианты JSON конкатинации я не пробовал.
Ну и о Post work item to bugtracker, конечно, стоит забыть.
Приятного дня. | https://habr.com/ru/post/427451/ | null | ru | null |
# Kibana-мать или Зачем вам вообще нужны логи?
Вы можете сказать, что “иногда бывает нужно...” **Но на самом деле, вы хотите всегда** видеть, что у вас в логах, через графический интерфейс. Это позволяет:
* Облегчить жизнь разработчикам и сисадминам, время которых просто жалко и дорого тратить на написание grep-конвейеров и парсеров под каждый отдельный случай.
* Предоставить доступ к информации, содержащейся в логах, умеренно-продвинутым пользователям — менеджерам и техподдержке.
* И видеть динамику и тенденции появления залогированых событий (например, ошибок).
Так что сегодня вновь поговорим о стэке ELK (Elasticsearch+Logstash+Kibana).
**Но на этот раз — в условиях json-логов**!
Такой use case обещает наполнить вашу жизнь совершенно новыми красками и заставит испытать полную гамму чувств.

##### Пролог:
> *«Пойми, на Хабрахабре только и разговоров, что о Kibana и Elasticsearch. О том, как это чертовски здорово — наблюдать, как огромный текстовый лог превращается в красивые графики, а еле видимая нагрузка на CPU горит где-то в глубине top-а. А ты?.. Что ты им скажешь?»*
#### **Матчасть**
В жизни каждого нормального пацана возникает момент, когда он решил-таки поставить на своем проекте связку ELK.
Схема среднестатистического пайплайна выглядит примерно так:
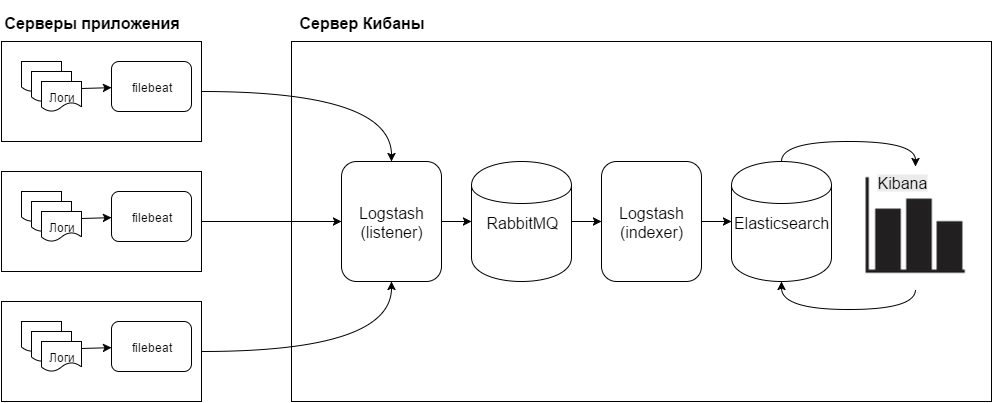
Мы шлём в Kibana 2 вида логов:
1. **“Почти обычный” лог nginx.** Единственная его изюминка – request-id. Их мы будем генерировать, как сейчас модно, с помощью Lua-в-конфиге™ .
2. **“Необычные” логи самого приложения на node.js.** То есть лог ошибок и “продлог”, куда летят “нормальные” события — например, “пользователь создал новый сайт”.
Необычность этого типа логов в том, что он:
* Сериализованный json (логирует события npm-модуль bunyan)
* Бесформенный. Набор полей у сообщений разный, кроме того, в одних и тех же полях у разных сообщений могут быть разные типы данных (это важно!).
* Очень жирный. Длина некоторых сообщений превышает 3Мб.
Это, соответственно, front- и back-end-ы всей нашей системы… Приступим!
**filebeat**
**filebeat.yml:**Описываем пути к файлам и добавляем к сообщениям поля, которые нам понадобятся для определения типов логов на этапе фильтрации и при отправке в ES.
```
filebeat:
prospectors:
-
paths:
- /home/appuser/app/production.log.json
input_type: log
document_type: production
fields:
format: json
es_index_name: production
es_document_type: production.log
-
paths:
- /home/appuser/app/error.log.json
input_type: log
document_type: production
fields:
format: json
es_index_name: production
es_document_type: production.log
-
paths:
- /home/appuser/app/log/nginx.log
input_type: log
document_type: nginx
fields:
format: nginx
es_index_name: nginx
es_document_type: nginx.log
registry_file: /var/lib/filebeat/registry
output:
logstash:
hosts: ["kibana-server:5044"]
shipper:
name: ukit
tags: ["prod"]
logging:
files:
rotateeverybytes: 10485760 # = 10MB
```
**logstash**
**logstash-listener/01-beats-input.conf:**
```
input {
beats {
port => 5044
}
}
```
**logstash-listener/30-rabbit-output.conf:**
```
output {
rabbitmq {
exchange => "logstash-rabbitmq"
exchange_type => "direct"
key => "logstash-key"
host => "localhost"
port => 5672
workers => 4
durable => true
persistent => true
}
}
```
**logstash-indexer/01-rabbit-input.conf:**
```
input {
rabbitmq {
host => "localhost"
queue => "logstash-queue"
durable => true
key => "logstash-key"
exchange => "logstash-rabbitmq"
threads => 4
prefetch_count => 50
port => 5672
}
}
```
**logstash-indexer/09-filter.conf:**В зависимости от формата, прогоняем его через соответствующий кодек.
В случае с nginx, это будут вот такие “необычные” регулярки-полуфабрикаты, предлагаемые фильтрующим модулем “grok” (слева), и названия полей, в которые попадут заматченые данные (справа). Для пущей красоты у нас есть еще фильтр geoip, который определяет локацию клиента. В Кибане можно будет сделать “географию” клиентов. Базу качаем отсюда [dev.maxmind.com/geoip/legacy/geolite](http://dev.maxmind.com/geoip/legacy/geolite).
А в случае с json, как видите, ничего делать вообще не надо, что не может не радовать.
```
filter {
if [fields][format] == "nginx" {
grok {
match => [
"message", "%{IPORHOST:clientip} - \[%{HTTPDATE:timestamp}\] %{IPORHOST:domain} \"(?:%{WORD:verb} %{NOTSPACE:request}(?: HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})\" %{NUMBER:status:int} (?:%{NUMBER:bytes:int}|-) %{QS:referrer} %{QS:agent} %{NUMBER:request_time:float} (?:%{NUMBER:upstream_time:float}|-)( %{UUID:request_id})?"
]
}
date {
locale => "en"
match => [ "timestamp" , "dd/MMM/YYYY:HH:mm:ss Z" ]
}
geoip {
source => "clientip"
database => "/opt/logstash/geoip/GeoLiteCity.dat"
}
}
if [fields][format] == "json" {
json {
source => "message"
}
}
}
```
**logstash-indexer/30-elasticsearch-output.conf:**Имя индекса и document\_type для ES берем из полей, которые в самом начале пути приклеили к сообщениям в filebeat-е.
```
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "logstash-%{[fields][es_index_name]}-%{+YYYY.MM.dd}"
document_type => "%{[fields][es_document_type]}"
}
}
```
#### **Связывание событий в логах фронта и бэка**
##### Завязка:
> *“У нас было 2 типа логов, 5 сервисов в стэке, полтерабайта данных в ES, а также несчетное множество полей в логах приложений. Не то чтобы это был необходимый набор для риалтайм-анализа состояния сервиса, но когда начинаешь задумываться еще и о связывании событий nginx-а и приложения, становится сложно остановиться.
>
>
>
> Единственное, что вызывало у меня опасения — Lua. Нет ничего более беспомощного, безответственного и порочного, чем Lua в конфигах Nginx. Я знал, что рано или поздно мы перейдем и на эту дрянь”.*

Для генерации request-id на Nginx-е будем использовать Lua-библиотеку, которая генерирует uuid-ы. Она, в целом, справляется со своей задачей, но пришлось немного доработать ее напильником — ибо в первозданном виде она (та-дам!) дуплит uuid-ы.
```
http {
...
# Либа для генерации идентификаторов запросов
lua_package_path '/etc/nginx/lua/uuid4.lua';
init_worker_by_lua '
uuid4 = require "uuid4"
math = require "math"
';
...
# Объявляем переменную request_id,
# обычный способ (set $var) не будет работать в контексте http
map $host $request_uuid { default ''; }
# Описываем формат лога
log_format ukit '$remote_addr - [$time_local] $host "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" $request_time '
'$upstream_response_time $request_uuid';
# Путь к файлу и формат лога
access_log /home/appuser/app/log/nginx.log ukit;
}
server {
...
# Генерируем id запроса
set_by_lua $request_uuid '
if ngx.var.http_x_request_id == nil then
return uuid4.getUUID()
else
return ngx.var.http_x_request_id
end
';
# Отправляем его в бекэнд в виде заголовка, чтобы он у себя тоже его залогировал.
location @backend {
proxy_pass http://127.0.0.1:$app_port;
proxy_redirect http://127.0.0.1:$app_port http://$host;
proxy_http_version 1.1;
proxy_set_header Connection "";
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Nginx-Request-ID $request_uuid; #id запроса
proxy_set_header Host $host;
...
}
...
}
```
На выходе получаем возможность по событию в логе приложения найти повлекший его запрос, прилетевший на Nginx. И наоборот.
Довольно быстро обнаружилось, что наши [“вселенски-уникальные”](https://ru.wikipedia.org/wiki/UUID) айдишники не такие уж уникальные. Дело в том, что randomseed библиотека берет из таймстампа на момент запуска nginx-воркера. А воркеров у нас столько, сколько ядер у процессора, и запускаются они одновременно… Не беда! Подмешаем туда pid воркера и будет нам счастье:
```
...
local M = {}
local pid = ngx.worker.pid()
-----
math.randomseed( pid + os.time() )
math.random()
...
```
P.S. В репозитарии Debian-а есть готовый пакет nginx-extras. Там сразу есть Lua и еще куча полезных модулей. Рекомендую, вместо того чтобы вкомпиливать модуль Lua руками (еще бывает openresty, но я не пробовал).
#### **Группировка ошибок по частоте возникновения.**
Kibana позволяет группировать (строить рейтинги) событий на основе одинаковых значений полей.
В логе ошибок у нас есть стэктрейсы, они почти идеально подходят в качестве ключа группировки, но загвоздка в том, что в Кибане нельзя группировать по ключам длиннее 256 символов, а стэки конечно длиннее. Поэтому мы делаем md5-хэши стэктрейсов в bunyan и группируем уже по ним. Красота!
Так выглядит топ 20 ошибок:
И отдельно взятый тип ошибки на графике и списком эпизодов:
Теперь мы знаем, какой баг в системе можно пофиксить когда-нибудь потом, т.к. он слишком редкий. Согласитесь, такой подход куда научнее, чем “за эту неделю было много подобных тикетов в саппорт”.
#### **А теперь — срыв покровов: оно работает, но плохо**
##### Кульминация:
> *«Я понимаю. Ты нашёл в NoSQL рай: у тебя быстро шла разработка, ведь ты хранил все в MongoDB, и тебе не нужны были такие друзья, как я. А теперь, ты приходишь и говоришь: мне нужен поиск. Но ты не просишь с уважением, ты даже не называешь меня Лучшим Поисковым Движком. Нет, ты приходишь ко мне в дом в день рождения [Lucene](https://en.wikipedia.org/wiki/Elasticsearch) и просишь меня индексировать неструктурированные логи бесплатно»*

##### **Неожиданности**
###### **Все ли сообщения из лога попадают в Кибану?**
Нет. Не все попадают.
Маппинг запоминает название поля и его тип (число, строка, массив, объект и т.д.). Если мы посылаем в ES сообщение, в котором есть поле, уже существующее в маппинге, но тип не совпадает с тем, что было в этом поле раньше (например, в маппинге — массив, а пришел объект), то такое сообщение не попадет в ES, а в его логе будет не слишком очевидное сообщение:
{«error»:«MapperParsingException[object mapping for [something] tried to parse as object, but got EOF, has a concrete value been provided to it?]»
[Источник](http://blog.endpoint.com/2013/04/elasticsearch-object-mapping-eof-400.html)
###### **Имена полей в json-логах**
Elasticsearch v2.x не принимает сообщения, в которых есть поля, имена которых содержат точки. В v1.x этого ограничения не было, и мы не можем перейти на новую версию, не переделав все логи, т.к. у нас такие поля уже “исторически сложились”.
[Источник](https://discuss.elastic.co/t/field-name-cannot-contain/33251)
Кроме того, в Kibana не поддерживаются поля имена которых начинаются с подчеркивания ‘\_’.

[Комментарий разработчика](https://github.com/elastic/kibana/issues/2551#issuecomment-69045927)
###### **Автоматическое уползание данных в соседние инстансы ES**
По-умолчанию в ES включена опция Zen Discovery. Благодаря ей, если вы запустите несколько инстансов ES в одной сети (например, несколько докер-контейнеров на одном хосте), то они друг друга найдут и поделят данные между собой. Очень удобный способ смешать продуктивные и тестовые данные и долго с этим разбираться.
###### **Оно падает и потом долго поднимается. Это еще больнее, когда docker**
Стэк вовлеченных в нашу преступную схему демонов достаточно многочисленен. Кроме того, некоторые из них любят непонятно падать и очень долго подниматься (да, те, что на Java). Чаще всех зависает logstash-indexer, в логах при этом тишина или неудачные попытки послать данные в ES (видно, что они были давно, а не вот только что). Процесс жив, если послать ему kill — он очень долго умирает. Приходится слать kill -9, если некогда ждать.
Реже, но тоже бывает, что падает Elasticsearch. Делает он это “по-английски” (т.е. молча).
Чтобы понять, кто из них двоих упал, делаем http-запрос в ES — если ответил, значит лежит не он. Кроме того, когда у вас относительно много данных (скажем, 500G), то ваш Elasticsearch после запуска будет еще около получаса просасывать эти данные, и в это время они будут недоступны. Данные самой Kibana хранятся там же, поэтому она тоже не работает, пока ее индекс не подхватится. По закону подлости, до нее обычно очередь доходит в самом конце.
Приходится мониторить мониторингом длину очереди в rabbitmq, чтобы оперативно реагировать на инциденты. Раз в неделю они стабильно случаются.
А когда у вас всё в docker-е, и контейнеры слинкованы между собой, то вам нужно перезапустить еще и все контейнеры которые были слинкованы с контейнером ES, кроме него самого.
###### **Большие дампы памяти при OOM**
По-умолчанию в ES включена опция HeapDumpOnOutOfMemoryError. Это может привести к тому, что у вас неожиданно закончилось место на диске из-за одного или нескольких дампов размером ~30GB. Сбрасываются они, разумеется, в директорию, где лежат бинарники (а не туда, где данные). Происходит это быстро, мониторинг даже не успевает прислать смс-ку. Отключить это поведение можно в bin/elasticsearch.in.sh.
#### **Производительность**
В Elasticsearch существует т.н. “маппинг” индексов. По-сути, это схема таблицы, в которой хранятся данные в формате “поле — тип”. Создается она автоматически на основе поступающих данных. Это значит, что ES запомнит имя и тип данных поля, исходя из того, данные какого типа пришли в этом поле в первый раз.
Например, у нас есть 2 очень разных лога: access-log nginx и production-log nodejs-приложения. В одном стандартный набор полей, он короткий, типы данных никогда не меняются. В другом же, напротив, полей много, они nested, они свои у каждой строчки лога, названия могут пересекаться, данные внутри полей могут быть разных типов, длина строки доходит до 3 и более Mб. В итоге автомаппинг ES делает так:
**Маппинг ~~здорового~~ “прямоугольного” лога nginx:**
root@localhost:/ > du -h ./nginx.mapping
16K ./nginx.mapping
**Маппинг ~~курильщика~~ “бесформенного” json-лога нашего приложения:**
root@localhost:/ > du -h ./prodlog.mapping
2,1M ./prodlog.mapping
В общем, оно сильно тормозит как при индексации данных, так и при поиске через Kibana. При этом, чем больше накопилось данных, тем хуже.
Мы пытались бороться с этим закрытием старых индексов c помощью [curator](https://github.com/elastic/curator). Положительный эффект безусловно есть, но все-таки это анестезия, а не лечение.
**Поэтому мы придумали более радикальное решение.** Весь тяжелый nested-json в production-логе отныне будет логироваться в виде строки в специально-отведенном одном поле сообщения. Т.е. вот прямо JSON.stringify(). За счет этого набор полей в сообщениях становится фиксированным и коротким, мы приходим к “легкому” маппингу как у nginx-лога.
Конечно, это своего рода “ампутация с дальнейшим протезированием”, но вариант рабочий. Будет интересно увидеть в комментариях, как еще можно было сделать.
#### **Промежуточный итог**
Стэк ELK — классный инструмент. Для нас он стал просто незаменимым. Менеджеры следят за всплесками ошибок на фронтэнде после очередного релиза и приходят жаловаться к разработчикам уже “не с пустыми руками”. Те, в свою очередь, находят корреляции с ошибками в приложении, сразу видят их стэки и прочие важнейшие данные, необходимые для дебага. Есть возможность моментально строить различные отчеты из серии “хиты по доменам сайтов” и т.п. Словом, непонятно как мы жили раньше. Но с другой стороны…
“Robust, Reliable, Predictable” — все это не про ELK. Cистема очень капризная и богатая на неприятные сюрпризы. Очень уж часто приходится копаться во всем этом шатком, извините, Jav-не. Лично я не могу припомнить технологию, которая бы так плохо следовала принципу “настроил и забыл”.
**Поэтому за последние 2 месяца** мы полностью переделали логи приложения. Как в плане формата (избавляемся от точек в именах, чтобы перейти на ES v.2), так и в плане подхода к тому, что вообще логировать а что нет. Сам по себе этот процесс, имхо, абсолютно нормальный и логичный для такого проекта, как наш — недавно [uKit](https://ukit.com) отпраздновал свой первый день рождения.
«В начале пути вы сваливаете в логи как можно больше инфы, т.к. заранее неизвестно, что понадобится, а потом, начав „взрослеть“, постепенно убираете лишнее». (c. [pavel\_kudinov](https://habrahabr.ru/users/pavel_kudinov/)) | https://habr.com/ru/post/278729/ | null | ru | null |
# Houdini: один из самых впечатляющих проектов в CSS, о котором вы никогда не слышали

Бывало ли у вас так, что хотелось использовать какую-нибудь фичу из стандарта CSS, но вы этого не делали, потому что она **поддерживается не всеми браузерами**? Или ещё хуже: её поддерживают все браузеры, но поддержка глючная, противоречивая или вообще несовместимая? Наверняка вы с таким сталкивались, и поэтому рекомендую вам присмотреться к [Houdini](https://wiki.css-houdini.org/).
Это новая рабочая группа W3C, которой поставлена амбициозная задача — навсегда решить описанную выше проблему. Сделать это планируется с помощью нового набора API, который впервые даст разработчикам возможность самостоятельно расширять CSS, а также предоставит инструменты для **подключения к процессу создания макета и применения стилей в ходе работы браузерного движка**.
Но что конкретно кроется за этими обещаниями? Это хотя бы хорошая затея? И как всё вышесказанное поможет нам, разработчикам, создавать сайты сегодня и завтра?
На все эти вопросы я постараюсь дать ответы. Но сначала внесу ясность относительно актуальных сегодняшних проблем и необходимости их решения. А затем уже мы поговорим о том, как Houdini может нам с ними помочь, и рассмотрим ряд его наиболее впечатляющих возможностей, находящихся в процессе разработки. И в завершение я внесу ряд предложений, как сообщество разработчиков может помочь реализоваться проекту Houdini.
Какие проблемы пытается решить Houdini?
=======================================
Каждый раз, когда я пишу статью или создаю демоприложение для популяризации какой-то новой CSS-фичи, неизбежно получаю комментарии вроде: «Это замечательно! Как жаль, что мы не сможем это использовать ещё лет десять». Хотя такие комментарии неконструктивны и весьма раздражают, я могу понять настроение разработчиков. Так сложилось, что широкое распространение нововведений занимает годы. И главной причиной тому, как учит нас история веба, является получение новых возможностей CSS исключительно через процесс стандартизации.
*Этапы процесса стандартизации*
Я ничего не имею против стандартизации, но это занимает слишком много времени! К примеру, [flexbox](https://drafts.csswg.org/css-flexbox/) был предложен в 2009 году, а разработчики всё ещё объясняют, что они до сих пор не могут его использовать из-за недостаточной поддержки браузерами. К счастью, эта проблема постепенно сходит на нет, поскольку почти все современные браузеры обновляются автоматически. Но даже в этом случае всегда имеется задержка между предложением функциональности и общей готовностью к её использованию. Любопытно, что такая ситуация наблюдается не во всех сферах в Сети. Сравните, например, с JavaScript:
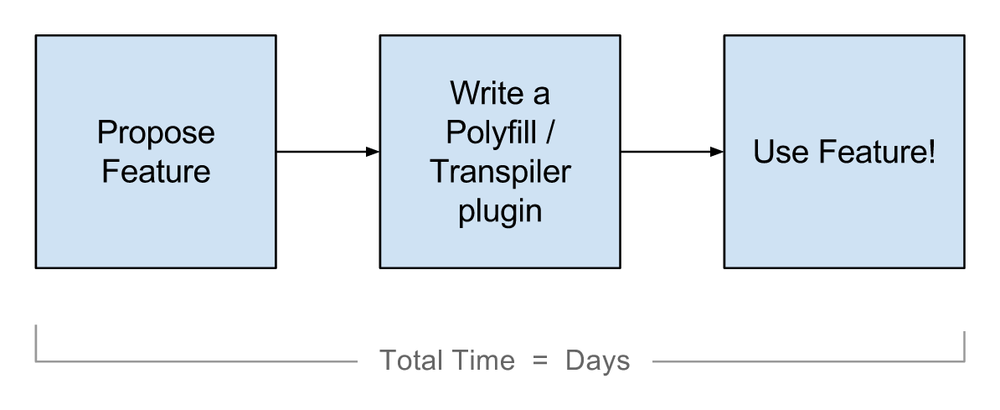
*Этапы внедрения полифиллов*
В данном случае с момента возникновения идеи до её использования в работе могут проходить дни. Например, я уже использую функции `async/await` в продакшене, а ведь эта функциональность ещё не реализована ни в одном браузере!
Наверняка вы замечали огромную разницу в настроениях обоих сообществ. В JS-комьюнити вы читаете статью, в которой кто-то сетует на то, что всё меняется слишком быстро. А в CSS все стенают о тщетности изучения новинок, поскольку пройдёт ещё куча времени, пока их можно будет использовать.
### *Так почему нам просто не написать побольше CSS-полифиллов?*
На первый взгляд, это вполне очевидное решение. Благодаря хорошим полифиллам CSS мог бы cтать таким же быстроразвивающимся, как и JavaScript, верно? Увы, не всё так просто. Внедрять полифиллы в CSS невероятно трудно, а во многих случаях это невозможно сделать, не обрушив производительность полностью.
JavaScript — динамический язык, поэтому можно на JS создавать полифиллы для JS. Его невероятная расширяемость является следствием его динамической природы. А CSS редко можно использовать для создания собственных полифиллов. Иногда на этапе сборки можно компилировать код CSS в код CSS (transpile) (это делает [PostCSS](https://github.com/postcss/postcss)). Но если вы хотите использовать полифиллы для чего-либо, зависящего от DOM-структуры, либо для позиции или раскладки (layout) элемента, то логику полифилла придётся исполнять на клиентской стороне. К сожалению, браузеры эту задачу не облегчают.
Ниже представлена базовая схема процесса работы браузера, от получения HTML-документа до вывода пикселей на экран. Синим выделены этапы, на которых JavaScript может влиять на результат:

*Доступ JavaScript к конвейеру визуализации браузера*
Довольно мрачная картина. Вы как разработчик не контролируете процесс парсинга HTML и CSS с последующим превращением в [DOM](https://dom.spec.whatwg.org/) и [объектную модель CSS](https://drafts.csswg.org/cssom/) (CSSOM). Вы не управляете каскадом (cascade). Вы не управляете процессом выбора схемы размещения (layout) элементов в DOM, не управляете их окраской (paint) при выводе на экран. Наконец, вы никак не влияете на работу компоновщика (composite). Только DOM полностью вам подвластен. Какое-то влияние вы имеете на CSSOM, но, согласно сайту Houdini, этот этап «недостаточно определён, различается в зависимости от браузера, а также лишён ряда критически важных возможностей». К примеру, сегодня CSSOM не покажет вам правила из cross-origin таблиц стилей, при этом он просто их отбросит, если не поймёт. А это означает, что если вы хотите написать полифилл, добавляющий функциональности, то будете вынуждены идти в обход CSSOM. Вам придётся через DOM найти теги | https://habr.com/ru/post/282027/ | null | ru | null |
# Кто такой Thread Pool и как его написать своими руками на С++
### Для кого статья?
Статья для тех, кто хочет разобраться в работе Thread Pool и написать наивную реализацию с использованием `С++ 14` и `С++ 17`. Стоит упомянуть, что представленные реализации будут представлять решение учебной задачи и не подойдут для коммерческого использования.
### Что нового я могу узнать из статьи?
* Кто такой Thread Pool?
* Зачем использовать Thread Pool?
* Логика работы Thread Pool
* [Реализация](https://github.com/skprpi/Habr/blob/main/thread_pool/basic_version.cpp) (С++ 14)
* [Реализация](https://github.com/skprpi/Habr/blob/main/thread_pool/best_version.cpp) (С++ 17)
* Сравнение реализаций
### Кто такой Thread Pool?
Это удобный в использовании `паттерн`, позволяющий выполнять множество задач используя ресурсы множества потоков. Thread Pool состоит обычно из *очереди задач* и нескольких потоков, которые достают задачи из очереди и выполняют их параллельно. Есть и реализации с отдельной очередью на каждый поток, но мы их рассматривать не будем.
### Зачем использовать Thread Pool?
* Помогает увеличить производительность программы благодаря созданию потоков один раз (создание потока считается достаточно тяжёлой операцией).
* Предоставляет удобный интерфейс для работы с многопоточностью.
### Немного цифр
Протестировав 3 случая: запуск без дополнительных потоков, с созданием потоков через `std::thread` и с использованием `thread_pool`. На программе:
```
void test_func(int& res, const std::vector& arr) {
res = 0;
for (int i = arr.size() - 1; i >= 0; --i) {
for (int j = 0; j < arr.size(); ++j) {
res += arr[i] + arr[j];
}
}
}
```
Получились следующие результаты:
| | | |
| --- | --- | --- |
| Способ запуска | Время (миллисекунды) | Кол-во потоков |
| Без дополнительных потоков | 83954 | 1 |
| `std::thread` | 62386 | 6 |
| `thread_pool` | 52474 | 6 |
У меня на компьютере можно создать максимум 8 потоков и запускался тестовый пример в Visual Studio на платформе Windows. Это значит, что фоновая работа сторонних приложений может создавать флуктуации и при каждом запуске мы будем получать разные времена. Код примеров можно посмотреть [ТУТ](https://github.com/skprpi/Habr/blob/main/thread_pool/basic_version.cpp) функция `run_test` .
### Почему 6 потоков не ускорили код в 6 раз?
Дело в том, что Thread Pool в моей реализации сделан не оптимально т.к. использует `condition_variable`, что сильно замедляет работу, так же присутствуют средства синхронизации (нужно помнить про закон Амдала). По мимо вышеперечисленных фактов тестирование проводилось на Windows, что не исключает разделение общих ресурсов ПК с другими приложениями.
### Хорошо, но тогда как Thread Pool работает?
Thread Pool имеет *очередь задач*, из которой каждый поток достаёт новую задачу при условии, что *очередь не пуста и поток свободен*. Для более детального описания давайте рассмотрим работу Thread Pool на примере:
**Начальная стадия:** все потоки свободны, а в очереди присутствует 5 задач.
**Стадия 1:** Каждый из потоков взял задачу на исполнение, при этом на практике первый поток не обязательно берёт первую задачу, это зависит от того, кто первый получит доступ к *общему ресурсу* - очереди. В очереди остались только 4 и 5 задача (чёрным цветом обозначены задачи, которые остались в очереди).
**Стадия 2:** На 3 секунде второй поток завершает выполнение 2 задачи и берёт первую свободную задачу из очереди (4 задачу). В очереди остаётся только 5 задача.
**Стадия 3:** Третий поток завершил задачу 3 и взял последнюю задачу из очереди (5 задачу). Очередь стала пустой, но наша программа не должна завершать работу, сначала следует дождаться выполнения всех задач.
**Стадия 4:** Первый поток завершил выполнение своей задачи и не берёт новых задач (т. к. очередь пуста). Может показаться, что если у нас нет задач в очереди, то следующие задачи поток уже не выполняет. На самом деле это не так и как только придёт новая задача, свободный поток (но мы не знаем какой именно) сразу начнёт её исполнение.
**Стадия 5:** Третий поток закончил выполнять задачу 5.
**Стадия 6:** Второй поток закончил исполнение 4 задачи.
**Итог:** Thread Pool выполнил 5 задач за 11 секунд.
### Что будет уметь делать наш Thread Pool?
Мы уже разобрались с общим механизмом работы Thread Pool, теперь подумаем о его функциональности.
В нашем Thread Pool будет 2 типа задач: `блокирующие` (будут тормозить основной поток до тех пор, пока команда не будет исполнена) и `не блокирующие` (гарантированно исполняются очень быстро и не тормозят основной поток).
Thread Pool будет иметь следующий *интерфейс*:
* `init(num_threads)` - метод, создающий массив из `num_threads` потоков. В нашей реализации в качестве данного метода будет выступать *конструктор*.
* `add_task(task_func, args)` - *не блокирующий* метод добавления новой задачи. Принимает функцию `task_func` и аргументы данной функции `args` и возвращает `task_id` (уникальный номер задачи).
* `wait(task_id)` - *блокирующий метод*, ожидающий выполнения задачи с указанным `task_id`. В данной реализации мы не будем сохранять *результат работы функции* (мы исправим данный недостаток чуть позже), при этом функция обязательно должна возвращать `void`.
* `wait_all()` - *блокирующий метод*, дожидающийся завершения всех задач.
* `calculated(task_id)` - *не блокирующий метод*, проверяющий была ли выполнена задача с номером `task_id`.
* `shutdown()` - *блокирующий метод*, дожидающийся завершения всех задач и завершающий работу Thread Pool. Для корректного завершения работы программы будем использовать *деструктор* (хотя можно дополнительно добавить и метод).
### Реализация базовой версии (C++ 14)
Рассмотрим *переменные*, которые будут использоваться в нашем классе:
```
// очередь задач - хранит функцию(задачу), которую нужно исполнить и номер задачи
std::queue, int64\_t>> q;
std::mutex q\_mtx;
std::condition\_variable q\_cv;
// помещаем в данный контейнер исполненные задачи
std::unordered\_set completed\_task\_ids;
std::condition\_variable completed\_task\_ids\_cv;
std::mutex completed\_task\_ids\_mtx;
std::vector threads;
// флаг завершения работы thread\_pool
std::atomic quite{ false };
// переменная хранящая id который будет выдан следующей задаче
std::atomic last\_idx = 0;
```
Очередь хранит `std::future` - объект, который в будущем вернёт тип void, использование `std::future` позволяет не сразу вычислять функцию, а отложить вызов до нужного нам момента, также можно использовать и `std::function` (такой способ тоже допустим).
```
thread_pool(uint32_t num_threads) {
threads.reserve(num_threads);
for (uint32_t i = 0; i < num_threads; ++i) {
threads.emplace_back(&thread_pool::run, this);
}
}
```
В конструкторе мы создаём указанное число потоков и каждый из потоков запускает единственный приватный метод `run`.
```
void run() {
while (!quite) {
std::unique_lock lock(q\_mtx);
// если есть задачи, то берём задачу, иначе - засыпаем
// если мы зашли в деструктор, то quite будет true и мы не будем
// ждать завершения всех задач и выйдем из цикла
q\_cv.wait(lock, [this]()->bool { return !q.empty() || quite; });
if (!q.empty()) {
auto elem = std::move(q.front());
q.pop();
lock.unlock();
// вычисляем объект типа std::future (вычисляем функцию)
elem.first.get();
std::lock\_guard lock(completed\_task\_ids\_mtx);
// добавляем номер выполненой задачи в список завершённых
completed\_task\_ids.insert(elem.second);
// делаем notify, чтобы разбудить потоки
completed\_task\_ids\_cv.notify\_all();
}
}
}
```
`condition_variable` на методе `wait` (q\_cv) захватывает мьютекс, проверяет условие, если условие верно, то мы идём дальше по коду, иначе - засыпаем, отпускаем мьютекс и ждём вызов `notify` из метода добавления задач (когда приходит `notify` процедура повторяется - захватываем мьютекс и проверяем условие). Таким образом мы берём задачи до тех пор, пока они не кончатся, а когда кончатся и придёт новая задача мы разбудим поток.
```
template
int64\_t add\_task(const Func& task\_func, Args&&... args) {
// получаем значение индекса для новой задачи
int64\_t task\_idx = last\_idx++;
std::lock\_guard q\_lock(q\_mtx);
q.emplace(std::async(std::launch::deferred, task\_func, args...), task\_idx);
// делаем notify\_one, чтобы проснулся один спящий поток (если такой есть)
// в методе run
q\_cv.notify\_one();
return task\_idx;
}
```
`std::async(std::launch::deferred, task_func, args...)` данная функция не смотря на название `async` ничего не делает асинхронно благодаря параметру `std::launch::deferred`. Мы просто запоминаем аргументы функции, как в случае с `std::bind` . Отличаем является лишь то, `bind` не требует заполнять все аргументы функции, в отличает от `std::async`.
```
void wait(int64_t task_id) {
std::unique_lock lock(completed\_task\_ids\_mtx);
// ожидаем вызова notify в функции run (сработает после завершения задачи)
completed\_task\_ids\_cv.wait(lock, [this, task\_id]()->bool {
return completed\_task\_ids.find(task\_id) != completed\_task\_ids.end();
});
}
void wait\_all() {
std::unique\_lock lock(q\_mtx);
// ожидаем вызова notify в функции run (сработает после завершения задачи)
completed\_task\_ids\_cv.wait(lock, [this]()->bool {
std::lock\_guard task\_lock(completed\_task\_ids\_mtx);
return q.empty() && last\_idx == completed\_task\_ids.size();
});
}
```
Обратите внимание, что `wait_all` внутри `wait` использует ещё одну блокировку для очереди для проверки на пустоту (мы должны блокировать каждый разделяемый ресурс, чтобы избежать `data race`).
Так же обратите внимание, что `std::lock_guard` стоит там, где нет `wait` для мьютекса и не нужно делать `unlock` (`std::unique_lock` в остальных случаях). Если вы будите придерживаться данного правила, то программисты, смотрящие ваш код скажут вам спасибо.
```
bool calculated(int64_t task_id) {
std::lock_guard lock(completed\_task\_ids\_mtx);
if (completed\_task\_ids.find(task\_id) != completed\_task\_ids.end()) {
return true;
}
return false;
}
```
*Неблокирующий метод* проверки задачи на завершённость возвращает `true` если задача с данным `task_id` уже посчитана, иначе - `false`.
```
~thread_pool() {
// можно добавить wait_all() если нужно дождаться всех задачь перед удалением
quite = true;
for (uint32_t i = 0; i < threads.size(); ++i) {
q_cv.notify_all();
threads[i].join();
}
}
```
Если экземпляр класса `thread_pool` удаляется, то мы дожидаемся завершения всех потоков в деструкторе. При этом, если в очереди есть ещё задачи, то каждый поток выполнит ещё одну задачу и завершит работу (это поведение можно поменять и, например, дожидаться выполнения всех задач перед завершением).
Полный код данной реализации можно посмотреть [ТУТ](https://github.com/skprpi/Habr/blob/main/thread_pool/basic_version.cpp).
Пример работы с Thread Pool
---------------------------
```
void sum(int& ans, std::vector& arr) {
for (int i = 0; i < arr.size(); ++i) {
ans += arr[i];
}
}
int main() {
thread\_pool tp(3);
std::vector s1 = { 1, 2, 3 };
int ans1 = 0;
std::vector s2 = { 4, 5 };
int ans2 = 0;
std::vector s3 = { 8, 9, 10 };
int ans3 = 0;
// добавляем в thread\_pool выполняться 3 задачи
auto id1 = tp.add\_task(sum, std::ref(ans1), std::ref(s1));
auto id2 = tp.add\_task(sum, std::ref(ans2), std::ref(s2));
auto id3 = tp.add\_task(sum, std::ref(ans3), std::ref(s3));
if (tp.calculated(id1)) {
// если результат уже посчитан, то просто выводим ответ
std::cout << ans1 << std::endl;
}
else {
// если результат ещё не готов, то ждём его
tp.wait(id1);
std::cout << ans1 << std::endl;
}
tp.wait\_all();
std::cout << ans2 << std::endl;
std::cout << ans3 << std::endl;
return 0;
}
```
Стоит обратить внимание на `std::ref` благодаря ему будет передана ссылка, а не копия объекта (это особенность передачи аргумента в `std::future`).
Тут приведён достаточно простой пример работы с Thread Pool. Давайте посмотрим на этот небольшой фрагмент кода и подумаем что можно улучшить.
| | | |
| --- | --- | --- |
| № | Недостаток | Последствия |
| 1 | Функция обязательно должна быть void | Придётся менять сигнатуру функции, если она возвращала какое-то значение |
| 2 | Приходится хранить дополнительно переменную для ответа | Если нам понадобиться несколько значений из thread\_pool, то придётся с собой таскать все эти переменные. А если нам нужно 100 значений и больше ... ? |
К сожалению, у меня не получилось решить эти проблемы средствами `C++ 14`, но зато `C++ 17` позволил избавиться от приведённых выше недостатков.
### Улучшаем Thread Pool с помощью C++ 17
Чтобы улучшить нашу версию нужно сначала понять в чём была основная проблема, а проблема была в том, чтобы узнать тип возвращаемого значения функции и при этом суметь положить результат вычислений (может быть разный возвращаемый тип) в 1 объект и тут на помощь приходит `std::any`.
Теперь мы можем хранить в нашей очереди `std::function` (запись `std::future`не валидна) . Именно так я и сделал в своей первой попытке и получил очень [красивый код](https://github.com/skprpi/Habr/blob/main/thread_pool/void_func_problem.cpp), который не сильно отличался от изначальной реализации, но тут я столкнулся с проблемой, что `std::any` не может быть типа `void` . Тогда я решил создать класс `Task`, который бы смог хранить в одном случае `std::function` а в другом `std::function`. Рассмотрим его конструктор:
```
template
Task(FuncRetType(\*func)(FuncTypes...), Args&&... args) :
is\_void{ std::is\_void\_v } {
if constexpr (std::is\_void\_v) {
void\_func = std::bind(func, args...);
any\_func = []()->int { return 0; };
}
else {
void\_func = []()->void {};
any\_func = std::bind(func, args...);
}
}
```
Мы используем `if constexpr` для компиляции только одной ветки условия. Если мы будем использовать обычный `if`, то при получении функции возвращающей `void` компилятор попробует преобразовать `void` в `std::any` и таким образом мы получим ошибку преобразования типа, не смотря на то, что этот каст будет происходить в другой ветке условия.
Используем `typename ...Args` и `typename ...FuncTypes`, чтобы был возможен неявный каст между `std::referense_wrapper` и ссылочным типом, тогда нам в функциях не придётся в сигнатуре явно прописывать `std::referense_wrapper`.
`any_func = []()->int { return 0; };` и `void_func = []()->void {};` функции-заглушки. Они позволяют избавиться от лишнего условия при вычислении значения:
```
void operator() () {
void_func();
any_func_result = any_func();
}
```
`has_result` проверяет вернёт ли функция значение или нет, а `get_result` получит его.
```
bool has_result() {
return !is_void;
}
std::any get_result() const {
assert(!is_void);
assert(any_func_result.has_value());
return any_func_result;
}
```
Ещё один вспомогательный класс: `TaskInfo`:
```
enum class TaskStatus {
in_q,
completed
};
struct TaskInfo {
TaskStatus status = TaskStatus::in_q;
std::any result;
};
```
Данная структура хранит информацию о задаче: статус и возможный результат. Если структура будет возвращать `void`, то поле `result` останется незаполненным.
Рассмотрим приватные поля класса `thread_pool`
```
std::vector threads;
// очередь с парой задача, номер задачи
std::queue> q;
std::mutex q\_mtx;
std::condition\_variable q\_cv;
// Будем создавать ключ как только пришла новая задача и изменять её статус
// при завершении
std::unordered\_map tasks\_info;
std::condition\_variable tasks\_info\_cv;
std::mutex tasks\_info\_mtx;
std::condition\_variable wait\_all\_cv;
std::atomic quite{ false };
std::atomic last\_idx{ 0 };
// переменная считающая кол-во выполненых задач
std::atomic cnt\_completed\_tasks{ 0 };
```
В отличие от прошлой реализации нам понадобиться переменная `cnt_completed_tasks` (в прошлой реализации у нас был отдельный контейнер для завершённых задач и кол-во завершённых задач мы получали по размеру этого контейнера), для подсчёта кол-ва завершённых задач. Эта переменная будет использоваться в функции `wait_all` для определения того, что все задачи завершились.
Так же отдельно рассмотрим 3 разных функции ожидания результата:
```
void wait(const uint64_t task_id) {
std::unique_lock lock(tasks\_info\_mtx);
tasks\_info\_cv.wait(lock, [this, task\_id]()->bool {
return task\_id < last\_idx && tasks\_info[task\_id].status == TaskStatus::completed;
});
}
std::any wait\_result(const uint64\_t task\_id) {
wait(task\_id);
return tasks\_info[task\_id].result;
}
template
void wait\_result(const uint64\_t task\_id, T& value) {
wait(task\_id);
value = std::any\_cast(tasks\_info[task\_id].result);
}
```
* `void wait(const uint64_t task_id)` - используется для ожидании задачи, которая возвращает `void`.
* `std::any wait_result(const uint64_t task_id)` и `void wait_result(const uint64_t task_id, T& value)` разными способами возвращают результат.
`std::any wait_result(const uint64_t task_id)` вернёт `std::any` и пользователь сам должен будет сделать `cast` к нужному типу. Шаблонная функция `void wait_result(const uint64_t task_id, T& value)` принимает вторым аргументом ссылку на переменную, куда и будет положено новое значение и явный `cast` пользователь не должен будет делать.
В остальном код очень похож на предыдущую версию и код новой версии вы можете найти [ТУТ](https://github.com/skprpi/Habr/blob/main/thread_pool/best_version.cpp).
### Использование Thread Pool (С++ 17)
```
int int_sum(int a, int b) {
return a + b;
}
void void_sum(int& c, int a, int b) {
c = a + b;
}
void void_without_argument() {
std::cout << "It's OK!" << std::endl;
}
int main() {
thread_pool t(3);
int c;
t.add_task(int_sum, 2, 3); // id = 0
t.add_task(void_sum, std::ref(c), 4, 6); // id = 1
t.add_task(void_without_argument); // id = 2
{
// variant 1
int res;
t.wait_result(0, res);
std::cout << res << std::endl;
// variant 2
std::cout << std::any_cast(t.wait\_result(0)) << std::endl;
}
t.wait(1);
std::cout << c << std::endl;
t.wait\_all(); // waiting for task with id 2
return 0;
}
```
В данном примере рассмотрены 2 способа получения значения через функцию `wait_result`. Мне лично больше нравится 2 вариант. Не смотря на то, что нужно делать каст, получается компактное решение, а так же можно поймать и отработать исключение в случае ошибки.
### У нас действительно получилась версия лучше предыдущей?
И да, и нет. После анализа я получил следующие результаты:
| | | |
| --- | --- | --- |
| Тип передаваемого аргумента при создании новой задачи | `thread_pool` c++ 14 | `thread_pool` c++ 17 |
| функция возвращающая `void` | + | + |
| функция возвращающая всё *кроме* `void` | + | - |
| `std::bind` | - | + |
| функтор | - | + |
Пример с функтором и `std::bind`:
```
class Test {
public:
void operator() () {
std::cout << "Working with functors!\n";
}
};
void sum(int a, int b) {
std::cout << a + b << std::endl;
}
int main() {
Test test;
auto res = std::bind(sum, 2, 3);
thread_pool t(3); // C++ 14
t.add_task(test);
t.add_task(res);
t.wait_all();
return 0;
}
```
### А почему не получилось сделать лучше?
Изначально задумывалось реализовать Thread Pool, который сам сможет определять тип возвращаемого значения и исходя из этого типа формировать объект `Task`, но тип возвращаемого значения `std::bind` нельзя явно получить через `std::invoke_result`, поэтому пришлось пойти на некоторые уступки.
### Итог
Мы получили 2 разные версии `thread_pool`. Сложно сказать какая из них лучше. Мне лично больше нравится версия с `C++ 17`. Она позволяет не таскать за собой много переменных как ссылки на результат, а хранит всё внутри себя. Да, эта версия уступает по функциональности, но использование функторов и `std::bind` не частая практика, поэтому именно это вариант я и считаю лучшим. | https://habr.com/ru/post/656515/ | null | ru | null |
# Unix-пароль Кена Томпсона
Где-то в 2014 году в дампах исходного дерева BSD 3 я нашла файл [/etc/passwd](https://github.com/dspinellis/unix-history-repo/blob/BSD-3-Snapshot-Development/etc/passwd) с паролями всех ветеранов, таких как Деннис Ричи, Кен Томпсон, Брайан В. Керниган, Стив Борн и Билл Джой.
Для этих хэшей использовался алгоритм [crypt(3)](https://minnie.tuhs.org/cgi-bin/utree.pl?file=V7/usr/man/man3/crypt.3) на основе DES — известный своей слабостью (и с длиной пароля максимум 8 символов). Поэтому я подумала, что будет легко взломать эти пароли ради удовольствия.
Берём стандартные брутеры [john](https://www.openwall.com/john/) и [hashcat](https://hashcat.net/wiki/).
Довольно быстро я взломала много паролей, большинство из которых были очень слабыми (любопытно, что bwk использовал пароль `/.,/.,,` — его легко набрать на клавиатуре QWERTY).
Но пароль Кена не поддавался взлому. Даже полный перебор всех строчных букв и цифр (несколько дней в 2014 году) не дал результата. Поскольку алгоритм разработан Кеном Томпсоном и Робертом Моррисом, мне было интересно, в чём тут дело. Я также поняла, что, по сравнению с другими схемами хэширования паролей типа NTLM, crypt(3) довольно медленно брутится (возможно, и менее оптимизирован).
Неужели он использовал прописные буквы или даже специальные символы? (7-битный полный брутфорс займёт более двух лет на современном GPU).
В начале октября эту тему [снова подняли](https://inbox.vuxu.org/tuhs/tqkjt9nn7p9zgkk9cm9d@localhost/T/#m160f0016894ea471ae02ee9de9a872f2c5f8ee93) в списке рассылки [The Unix Heritage Society](https://www.tuhs.org/), и я [поделилась своими результатами](https://inbox.vuxu.org/tuhs/[email protected]/) и разочарованием, что не смогла взломать пароль Кена.
Наконец, сегодня Найджел Уильямс раскрыл эту тайну:
> *От: Найджел Уильямс
>
> Тема: Re: [TUHS] Восстановление файлов /etc/passwd
>
>
>
> Кен готов:
>
>
>
> ZghOT0eRm4U9s:p/q2-q4!
>
>
>
> Потребовалось более четырёх дней на AMD Radeon Vega64 в hashcat примерно на 930MH/с (знающие в курсе, что хэшрейт колеблется и снижается к концу).*
Это первый ход пешкой на две клетки в [описательной нотации](https://en.wikipedia.org/wiki/Descriptive_notation) и начало [многих типичных дебютов](https://en.wikibooks.org/wiki/Chess_Opening_Theory/1._d4), что очень хорошо вписывается в [бэкграунд Кена Томпсона по компьютерным шахматам](https://www.chessprogramming.org/index.php?title=Ken_Thompson).
Очень рада, что тайна разрешилась, а результат такой приятный. | https://habr.com/ru/post/470966/ | null | ru | null |
# Riding the Web 3.0 wave
Developer Christophe Verdot shares his experiences of recently taking the online course [‘Mastering Web 3.0 with Waves’](https://stepik.org/course/54415).

**What is your background? What motivated you to take the course?**
I’ve been a web developer for about 15 years, working mostly as a freelancer.
Working on the development of sustainable registry web application for emerging countries, financed by a bank group, I was once asked about the possibility of implementing blockchain certification into the registry. At that time, I didn’t know much about blockchain certification even though I had been into crypto for a while, mostly on the investor side.
We didn’t push through with the implementation of that feature on that specific application but the idea that institutions and banks were asking about implementing such technologies in their applications made me do a lot of study and research into the topic and then start the [Signature Chain](https://www.signature-chain.com/) project.
I developed a beta version that is already live on Mainnet. At that time [Waves programming language] Ride wasn’t ready yet, so I developed it in the simplest way, using transfer transactions with attached JSON. But the main goal has always been to deliver more advanced features once Ride was available. And this was the main reason for me to take the course, since the next planned step for the project is turning it into a decentralised application (dApp).
**What aspects of the course did you find the easiest and most difficult?**
The easiest aspect was that we had plenty of time to do it, that it was about just learning rather than competing to be the best. It was also well explained, with simple but explicit illustrations which helped a lot to visualise and understand different topics.
In the challenges, we were pushed to think on our own and sometimes do some research, which is the best way to learn and get a stronger understanding of concepts from a lesson.
Several times, I didn’t have a clear understanding from the lecture part until I got into the code and went through the challenge. No ‘copy/paste’ was allowed, which forced us to write all the challenge code, and that was another important point in reinforcing understanding.
The most difficult part was that sometimes multiple-choice questions in the challenge part were not that clear. I mean, my English isn’t excellent, and the questions were written by a non-native English speaker, so there was a gap in understanding sometimes.
Probably, I would have liked to learn more from the oracle and NFT sections. But, in any case, this course mainly aims to hook developers in, and you definitely need to spend time playing around with it and practising later to really get a full understanding of every aspect and detail.
**Could you discuss in detail the solution you worked on during the course – ‘Coupon Bazaar’? Could you also provide examples of code?**
We worked on ‘Coupon Bazaar’, which is basically a marketplace where people buy and sell discount coupons for goods and services at a low price. Each coupon was represented by a digital asset, which also represented a special discount offered by suppliers.

Work was required on several components of the application. First, it had to allow suppliers to register and manage their items (coupons). Then, a purchase confirmation feature needed to be created, as well as a feature enabling customers to search for and purchase coupons.
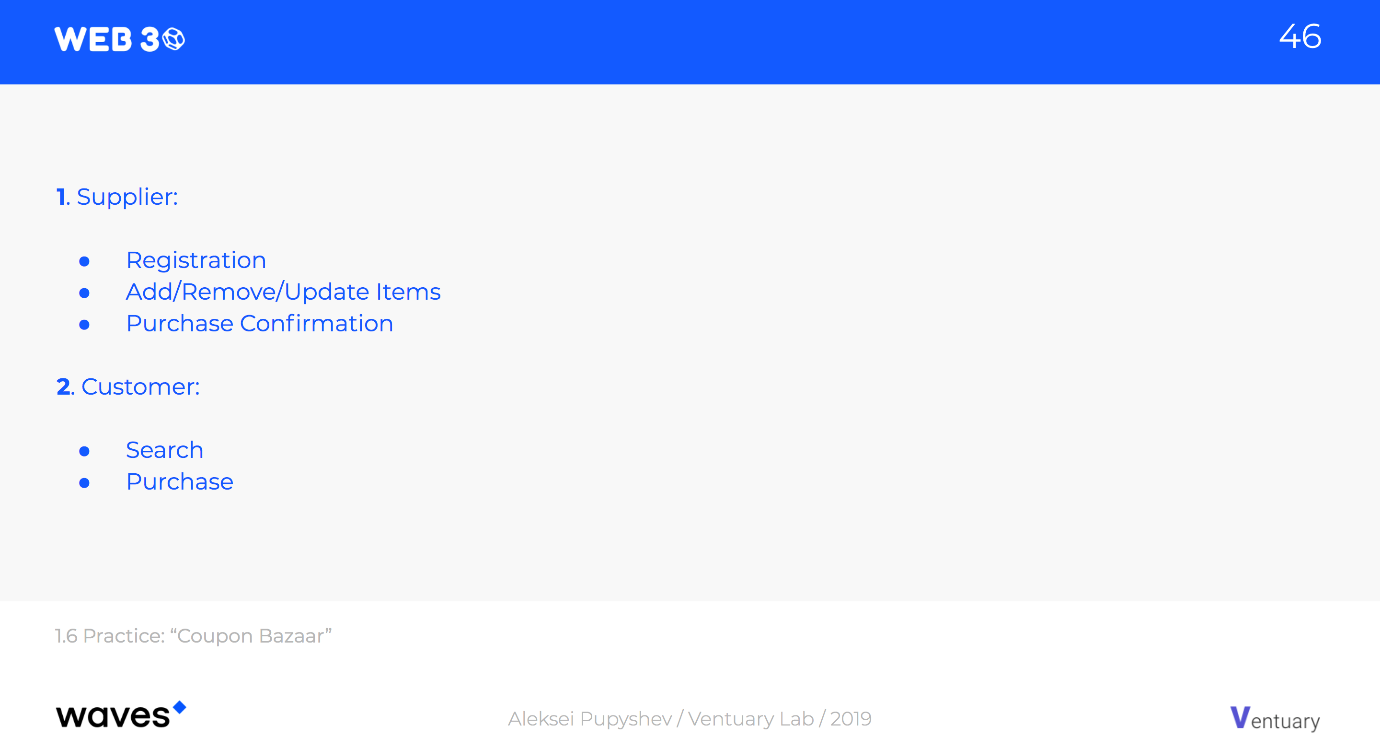
Several extra features were also added during the course, including a voting system and a feature for verification and blacklisting of suppliers.
We first went through differences between Smart Assets, Smart Accounts and dApp accounts, and the fundamentals of working with verifier functions. Verifier functions allow changing the default behavior of an account. By default, they check signatures of transactions, but the verifier function allows you to set another ‘rule’.
```
{-# STDLIB_VERSION 3 #-}
{-# CONTENT_TYPE DAPP #-}
{-# SCRIPT_TYPE ACCOUNT #-}
letownerPublicKey = base58'H8ndsHjBha6oJBQQx33zqbP5wi8sQP7hwgjzWUv3q95M'
@Verifier(tx)
funcverify() = {
matchtx {
cases: SetScriptTransaction=>sigVerify(tx.bodyBytes, tx.proofs[0], ownerPublicKey)
cased: DataTransaction=>true
case_ =>false
}
}
```
Then we started adding items. We used one of the most important features for dApp development that allows any type of data to be recorded onto the blockchain as key-value pairs, the data transaction. We combined it with a new transaction, invokeScript, used to call a callable function into a dApp from the outside.
One type of data transaction we used in the course was for suppliers to add items to the marketplace:
```
letdatajson = {
"title": "t-shirt with , vote 1",
"coupon_price": 10000000,
"old_price": 1000000000,
"new_price": 100000000,
"address": "Universe",
"description": "I want you to make love, not war, i know you've heard it before",
"image": "https://bit.ly/2EXTghg"
}
it('add item', asyncfunction(){
letts = invokeScript({
dApp: dappAddress,
call:{
function:"addItem",
args:[
{ type:"string", value: datajson.title },
{ type:"integer", value: datajson.coupon_price },
{ type:"string", value: JSON.stringify(datajson) }
]},
payment: []
}, accountSupplierSeed)
lettx = awaitbroadcast(ts)
awaitwaitForTx(tx.id)
})
```
To process that data transaction through the addItem function and later develop a purchase and other options, we went through the callable function, able to be called by users from the outside. As a result, it can perform various tasks, such as initiating transfer of funds, writing or updating data in the dApp’s data storage, etc.
Here is an example of a callable function. It is used for the addItem function:
```
@Callable(i)
funcaddItem(title: String, price: Int, data: String) = {
letsupplierAddress = toBase58String(i.caller.bytes)
letitem = getKeyItem(supplierAddress, title)
if( price <= 0) thenthrow("purchase amount cannot be less than item price")
elseif( getValueItemSupplier(item) !=NONE ) thenthrow("an item is already exist")
else{
WriteSet([
DataEntry(getKeyItemSupplier(item), supplierAddress),
DataEntry(getKeyItemPrice(item), price),
DataEntry(getKeyItemData(item), data)
])
}
}
```
We later worked on a voting system to allow users to vote for promotion or removal of certain products. It used a ‘Commit-Reveal’ scheme to avoid outside influence during the voting process.
The commit step was used to collect encrypted votes with a hash function and salt.
The reveal step is for collecting decrypted votes and comparing their hashes.
Here is an example of a callable function used for this feature:
```
@Callable(i)
funcvoteCommit(item: String, hash: String) = {
letuser = toBase58String(i.caller.bytes)
letcommits = getValueCommitsCount(item)
letstatus = getValueItemStatus(item)
if( commits >=VOTERS) thenthrow("reached max num of voters")
elseif(getValueCommit(item, user) !=NONE) thenthrow("user has already participated")
elseif(getKeyItemSupplier(item) ==NONE) thenthrow("item does not exist")
elseif(status !=NONE && status !=VOTING) thenthrow("voting is not possible")
else{
WriteSet([
DataEntry(getKeyCommit(item, user), hash),
DataEntry(getKeyCommitsCount(item), commits +1),
DataEntry(getKeyItemStatus(item),if(commits ==VOTERS) thenREVEAL elseVOTING)
])
}
}
```
**What else did you learn from the course?**
The course also touched upon tokenisation and non-fungible tokens (NFTs) – tokens that represent something unique and are therefore not interchangeable.
The last class focused on the use of oracles. Since a blockchain cannot access data from the outside world, we need to use oracles that send real-world data to the blockchain.
In the scope of our marketplace, we used an oracle to verify and, if necessary, blacklist a supplier that, for instance, didn't accept a previously sold coupon.
Here is a code example:
```
funcgetExtValueItemWhiteListStatus(item:String) = {
item +"_verifier_status"
}
letverifier = "3Mx9qgMyMhHt7WUZr6PsaXNfmydxMG7YMxv"
letVERIFIED = "verified"
letBLACKLISTED = "blacklist"
@Callable(i)
funcsetstatus(supplier: String, status: String) = {
letaccount = toBase58String(i.caller.bytes)
if( account !=verifier ) thenthrow("only oracle verifier are able to manage whitelist")
elseif( status !=VERIFIED && status !=BLACKLISTED) thenthrow("wrong status")
else{
WriteSet([
DataEntry(getExtValueItemWhiteListStatus(supplier), status)
])
}
}
```
**What part(s) of the course did you find most useful?**
The most useful part was the challenges. They made the lectures clearer and solidified my newly-acquired knowledge by trial and error. Practising with the [IDE](https://ide.wavesplatform.com/), [explorer](https://wavesexplorer.com/) and [oracles](https://oracles.wavesexplorer.com/) was really useful.
**How do you plan to use what you learned from the course?**
From the beginning, this course was supposed to help bring my project to the next level. So, the idea is now to rewrite [sign-web.app](https://www.sign-web.app/) on Ride. The current version already offers working features for document certification, but it will definitely be enhanced with a future Ride version. It will allow more flexibility and clarity and more features, including email certification, multi-party agreement, etc.
The course was also very mind-opening, and many ideas started to pop up in my head. I'm sure that more will come out of it in the future. | https://habr.com/ru/post/462991/ | null | en | null |
# Неблокирующий повтор (retry) в Java и проект Loom
Неблокирующий повтор (retry) в Java и проект Loom
=================================================
Введение
--------
Повтор (retry) операции является старейшим механизмом обеспечения надежности программного обеспечения. Мы используем повторы при выполнении HTTP запросов, запросов к базам данных, отсылке электронной почты и проч. и проч.
Наивный повтор
--------------
Если Вы программировали, то наверняка писали процедуру какого либо повтора. Простейший повтор использует цикл с некоторым ожиданием после неудачной попытки. Примерно вот так.
```
static T retry(long maxTries, Duration delay, CheckedSupplier supp) {
for (int i = 0; i < maxTries; i++) {
try {
return supp.get();
} catch (Exception e) {
if (i < maxTries - 1) { //not last attempt
try {
Thread.sleep(delay.toMillis());
} catch (InterruptedException ie) {
Thread.currentThread().interrupt(); //Propagate interruption
break;
}
}
}
}
throw new RuntimeException("Retry failed after %d retries".formatted(maxTries));
}
```
Вот пример использования повтора для получения соединения к базе данных. Мы делаем 10 попыток с задержкой 100 msec.
```
Connection retryConnection() {
return retry(10, Duration.ofMillis(100), () -> DriverManager.getConnection("jdbc:foo"));
}
```
Этот код блокирует Ваш поток на одну секунду (точнее 900 milliseconds, мы не ждем после последней попытки) потому что `Thread.sleep()` является блокирующей операцией. Попробуем оценить производительность метода в терминах количества потоков (threads) и времени. Предположим нам нужно сделать 12 операций повтора. Нам потребуется 12 потоков чтобы выполнить задуманное за минимальное время 1 сек, 6 потоков выполнят повторы на 2 сек, 4 — за три секунды, один поток — за 12 секунд. А что если нам потребуется выполнить 1000 операций повтора? Для быстрого выполнения потребуется 1000 потоков (нет, только не это) или 16 минут в одном потоке. Как мы видим этот метод плохо масштабируется.
Давайте проверим это на тесте
```
public void testNaiveRetry() throws Exception {
ExecutorService ex = Executors.newFixedThreadPool(4); //4 threads
Duration dur = TryUtils.measure(() -> {
IntStream.range(0, 12) //12 retries
.mapToObj(i -> ex.submit(() -> this.retryConnection())) //submit retry
.toList() //collect all
.forEach(f -> Try.of(()->f.get())); //wait all finished
});
System.out.println(dur);
}
Output: PT2.723379388S
```
Теоретически: 900 ms \* 3 = 2.7 sec, хорошее совпадение
Неблокирующий повтор
--------------------
А можно ли делать повторы не блокируя потоки? Можно, если вместо `Thread.sleep()` использовать перепланирование потока на некоторый момент в будущем при помощи `CompletableFuture.delayedExecutor()`. Как это сделать можно посмотреть в моем классе `Retry.java`. Кстати подобный подход используется в неблокирующем методе `delay()` в Kotlin.
Retry.java — компактный класс без внешних зависимостей который может делать неблокирующий асинхронный повтор операции ( [исходный код](https://github.com/skopylov58/java-functional-addons/blob/master/function/src/main/java/com/github/skopylov58/retry/Retry.java), [Javadoc](https://skopylov58.github.io/java-functional-addons/com/github/skopylov58/retry/package-summary.html) ).
Полное описание возможностей `Retry` [с примерами можно посмотреть тут](https://github.com/skopylov58/java-functional-addons#retryt---non-blocking-asynchronous-functional-retry-procedure)
Так можно сделать повтор, который мы уже делали выше.
```
CompletableFuture retryConnection(Executor ex) {
return Retry.of(() -> DriverManager.getConnection("jdbc:foo"))
.withFixedDelay(Duration.ofMillis(100))
.withExecutor(ex)
.retry(10);
}
```
Мы видим что здесь возвращается не `Connection`, а `CompletableFuture`, что говорит об асинхронной природе этого вызова. Давайте попробуем выполнить 1000 повторов в одном потоке при помощи `Retry`.
```
public void testRetry() throws Exception {
Executor ex = Executors.newSingleThreadExecutor(); //Один поток
Duration dur = TryUtils.measure(() -> { //Это удобная утилита для измерения времен
IntStream.range(0, 1_000) //1000 раз
.mapToObj(i -> this.retryConnection(ex)) //запускаем операцию повтора
.toList() //собираем future в список
.forEach(f -> Try.of(()->f.get())); //дожидаемся всех результатов
});
System.out.println(dur); //печатаем прошедшее время
}
Output: PT1.065544748S
```
Как мы видим, `Retry` не блокируется и выполняет 1000 повторов в одном потоке чуть-чуть более одной секунды. Ура, мы можем эффективно делать повторы.
Причем здесь проект Loom?
-------------------------
Проект Loom добавляет в JDK 19 виртуальные потоки (пока в стадии preview). Цель введения виртуальных потоков лучше всего описана в [JEP 425](https://openjdk.org/jeps/425) и я рекомендую это к прочтению.
Возвращаясь к нашей теме повтора операций, коротко скажу что `Thread.sleep()` более не является блокирующей операцией будучи выполняемой в виртуальном потоке. Точнее говоря, `sleep()` приостановит (suspend) виртуальный поток, давая возможность системному потоку (carrier thread) переключиться на выполнение других виртуальных потоков. После истечения срока сна, виртуальный поток возобновит (resume) свою работу. Давайте запустим наивный алгоритм повтора в виртуальных потоках.
```
var dur =TryUtils.measure(() -> {
ExecutorService executor = Executors.newVirtualThreadPerTaskExecutor();
IntStream.range(0, 1_000)
.mapToObj(i -> executor.submit(() -> retryConnection()))
.toList()
.forEach(f -> Try.of(() -> f.get()));
});
System.out.println(dur);
Output: PT1.010342284S
```
Поразительно, имеем чуть более одной секунды на 1000 повторов, как и при использовании `Retry`.
Проект Loom принесет кардинальные изменения в экосистему Java.
* Стиль виртуальный поток на запрос (thread per request) масштабируется с почти оптимальным использованием процессорных ядер. Этот стиль становится рекомендуемым.
* Виртуальные потоки не усложняют модель программирования и не требуют изучения новых концепций, автор JEP 425 говорит что скорее нужно будет забыть старые привычки ("it may require unlearning habits developed to cope with today's high cost of threads.")
* Многие стандартные библиотеки модифицированы для совместной работы с виртуальными потоками.Так например, блокирующие операции чтения из сокета станут неблокирующими в виртуальном потоке.
* Реактивный/асинхронный стиль программирования становится практически не нужным.
Нас ждут интересные времена в ближайшем будущем. Я очень надеюсь что виртуальные потоки станут стандартной частью JDK в очередной LTS версии Java.
Сергей Копылов
[email protected]
[Резюме](https://github.com/skopylov58/cv)
[Смотреть код на Github](https://github.com/skopylov58/) | https://habr.com/ru/post/702628/ | null | ru | null |
# FAQ по программированию под Android от новичка, и для новичков
Предисловие к FAQ.
Программирование является моим хобби уже давно (правда на других языках и платформах), но до андроида руки дотянулись совсем недавно. Прошло несколько этапов, прежде чем я добрался до написания программ.
Сначала была пара месяцев посвященных Java, на сайте с «Сгибателем».
После, долгие попытки подружится с Eclipse, закончившиеся побегом на Android Studio.
На данный момент выпущено 7 программ и две находятся в разработке.
Данная подборка возникла как попытка структурирования и оптимизации полученной в процессе информации.
Заранее извиняюсь за возможно некорректную терминологию – так как практикую обучение через создание, и в теоретической части есть пробелы.
Надеюсь, что приведенные примеры окажутся полезными.
**Как явно программно закрыть приложение при нажатии по кнопке:**
```
finish();
```
Выход с большей вероятностью (api 15+)
```
Intent intent = new Intent(Activity.this, Activity.class);
intent.setFlags(Intent.FLAG_ACTIVITY_NEW_TASK | Intent.FLAG_ACTIVITY_CLEAR_TASK);
finish();
```
Либо прописываем в AndroidManifest.xml — android:noHistory=«true»
Данные настройки позволяют избежать гуляния по предыдущим активностям вместо выхода.
**Жизненный цикл:**[stackoverflow.com/questions/8515936/android-activity-life-cycle-what-are-all-these-methods-for](http://stackoverflow.com/questions/8515936/android-activity-life-cycle-what-are-all-these-methods-for)
**Сохранение настроек:**[developer.alexanderklimov.ru/android/theory/sharedpreferences.php](http://developer.alexanderklimov.ru/android/theory/sharedpreferences.php)
**Конвертация string to float**[www.velocityreviews.com/forums/t128798-convert-string-to-float-not-so-trivial.html](http://www.velocityreviews.com/forums/t128798-convert-string-to-float-not-so-trivial.html)
**Как использовать мелодии и вибрацию:**Пример кода:
```
Uri alert = RingtoneManager.getDefaultUri(RingtoneManager.TYPE_NOTIFICATION);
try {
MediaPlayer mp = MediaPlayer.create(context.getApplicationContext(), alert);
mp.setVolume(100, 100);
mp.start();
mp.setOnCompletionListener(new MediaPlayer.OnCompletionListener() {
@Override
public void onCompletion(MediaPlayer mp) {
mp.release();
}
});
} catch (Exception e) {
Toast.makeText(context, "Error default media ", Toast.LENGTH_LONG).show();
}
```
Что бы звук не был тихим: [stackoverflow.com/questions/8278939/android-mediaplayer-volume-is-very-low-already-adjusted-volume](http://stackoverflow.com/questions/8278939/android-mediaplayer-volume-is-very-low-already-adjusted-volume)
Для вибрации необходимо прописать в манифесте
```
```
Сам код:
```
vibrator = (Vibrator) getSystemService (VIBRATOR_SERVICE);
vibrator.vibrate(400);
```
**Выбор рингтона через диалог:**[stackoverflow.com/questions/7671637/how-to-set-ringtone-with-ringtonemanager-action-ringtone-picker](http://stackoverflow.com/questions/7671637/how-to-set-ringtone-with-ringtonemanager-action-ringtone-picker)
[learn-it-stuff.blogspot.ru/2011/12/how-to-use-androids-ringtonemanager-to.html](http://learn-it-stuff.blogspot.ru/2011/12/how-to-use-androids-ringtonemanager-to.html)
[developer.android.com/reference/android/media/RingtoneManager.html](http://developer.android.com/reference/android/media/RingtoneManager.html)
[stackoverflow.com/questions/9021846/is-there-a-way-to-customize-the-android-ringtone-picker-dialog](http://stackoverflow.com/questions/9021846/is-there-a-way-to-customize-the-android-ringtone-picker-dialog)
**Работа с текстом:**Цвет:
```
builder.setMessage(Html.fromHtml("**John:**"+"How are you?"))
```
Выравнивание текста диалога:
[stackoverflow.com/questions/3965122/android-how-to-align-message-in-alertdialog](http://stackoverflow.com/questions/3965122/android-how-to-align-message-in-alertdialog)
Форматирование текста:
[stackoverflow.com/questions/3235131/set-textview-text-from-html-formatted-string-resource-in-xml](http://stackoverflow.com/questions/3235131/set-textview-text-from-html-formatted-string-resource-in-xml)
Тень на тексте:
```
textv.setShadowLayer(1, 0, 0, Color.BLACK);
```
**Как сменить активити:**
```
Intent intent = new Intent(MainActivity.this, Level002Activity.class);
intent.setFlags(Intent.FLAG_ACTIVITY_NEW_TASK | Intent.FLAG_ACTIVITY_CLEAR_TASK); // Если не хотим сохранять историю
startActivity(intent);
```
**Простой шаблон обработки нажатий:**1. В строчку public class MyActivity extends Activity дописываем implements View.OnClickListener, получается следующее:
```
public class MyActivity extends Activity implements View.OnClickListener {
```
2. Объявляем переменную Button btn;
3. В onCreate прописываем
```
btn =(Button) findViewById(R.id.btn);
btn.setOnClickListener(this);
```
4. Создаем процедуру:
```
public void onClick(View v) {
// по id определеяем кнопку, вызвавшую этот обработчик
switch (v.getId()) {
case R.id.btn:
//Прописываем действие по нажатию
break;
}
}
```
**Вывод всплывающего сообщения:**
```
Toast.makeText(this, "Текст сообщения", Toast.LENGTH_SHORT).show();
```
**Установка прозрачности на Активити:**[stackoverflow.com/questions/2176922/how-to-create-transparent-activity-in-android](http://stackoverflow.com/questions/2176922/how-to-create-transparent-activity-in-android)
```
android:theme="@android:style/Theme.Translucent.NoTitleBar"
```
**Вызов диалога:**[startandroid.ru/ru/uroki/vse-uroki-spiskom/119-urok-60-dialogi-alertdialog-title-message-icon-buttons.html](http://startandroid.ru/ru/uroki/vse-uroki-spiskom/119-urok-60-dialogi-alertdialog-title-message-icon-buttons.html)
Пример кода:
```
protected Dialog onCreateDialog(int id) {
if (id == DIALOG_EXIT) {
AlertDialog.Builder adb = new AlertDialog.Builder(this);
// заголовок
adb.setTitle(R.string.Help);
// сообщение
// adb.setMessage(R.string.HelperD);
adb.setMessage(this.getResources().getText(R.string.helpMain));
// иконка
adb.setIcon(R.drawable.ic_launcher);
// кнопка положительного ответа
adb.setPositiveButton( getResources().getString(R.string.close),myClickListener);
// кнопка отрицательного ответа
return adb.create();
}
return super.onCreateDialog(id);
}
DialogInterface.OnClickListener myClickListener = new DialogInterface.OnClickListener() {
public void onClick(DialogInterface dialog, int which) {
switch (which) {
// положительная кнопка
case Dialog.BUTTON_POSITIVE:
// saveData();
// Intent intent = new Intent(MyActivity.this, MyActivity.class);
// startActivity(intent);
// finish();
break;
}
}
};
```
Вызов: showDialog(DIALOG\_EXIT);
**Получить строку из ресурсов:**
```
String mess = getResources().getString(R.string.mess_1);
```
**Ловля исключений:**[stackoverflow.com/questions/5984507/sharedpreferences-getintcumulative-0-catch-22-how-to-resolve](http://stackoverflow.com/questions/5984507/sharedpreferences-getintcumulative-0-catch-22-how-to-resolve)
[habrahabr.ru/post/129582](http://habrahabr.ru/post/129582/)
Код выглядит так:
```
try {
// Выполняется
}
catch (Exception e) {
// исключение
}
```
**Получение формата времени на устройстве 24/12:**
```
android.text.format.DateFormat.is24HourFormat(context)
```
[muratonnet.blogspot.ru/2013/08/when-i-was-developing-date-time-picker.html](http://muratonnet.blogspot.ru/2013/08/when-i-was-developing-date-time-picker.html)
**Обращение к ресурсам:**
```
getResources().getColor(R.color.errorColor)
```
**Округление Float:**[stackoverflow.com/questions/8911356/whats-the-best-practice-to-round-a-float-to-2-decimals](http://stackoverflow.com/questions/8911356/whats-the-best-practice-to-round-a-float-to-2-decimals)
```
String.format("%.2f%n1 paramFloat);
```
**Кнопки в title bar:**[stackoverflow.com/questions/14545139/android-back-button-in-the-title-bar](http://stackoverflow.com/questions/14545139/android-back-button-in-the-title-bar)
[www.londatiga.net/it/how-to-create-custom-window-title-in-android](http://www.londatiga.net/it/how-to-create-custom-window-title-in-android/)
[stackoverflow.com/questions/5681081/android-adding-button-to-custom-title-bar](http://stackoverflow.com/questions/5681081/android-adding-button-to-custom-title-bar)
**Очистка стэка:**[stackoverflow.com/questions/7075349/android-clear-activity-stack](http://stackoverflow.com/questions/7075349/android-clear-activity-stack)
Пример Кода:
```
intent.setFlags(Intent.FLAG_ACTIVITY_NEW_TASK | Intent.FLAG_ACTIVITY_CLEAR_TASK);
```
**Работа с хронометром:**[developer.alexanderklimov.ru/android/views/chronometer.php](http://developer.alexanderklimov.ru/android/views/chronometer.php)
[stackoverflow.com/questions/5594877/android-chronometer-pause](http://stackoverflow.com/questions/5594877/android-chronometer-pause)
**Работа с уведомлениями:**[startandroid.ru/ru/uroki/vse-uroki-spiskom/164-urok-99-service-uvedomlenija-notifications.html](http://startandroid.ru/ru/uroki/vse-uroki-spiskom/164-urok-99-service-uvedomlenija-notifications.html)
[developer.android.com/design/patterns/notifications.html](http://developer.android.com/design/patterns/notifications.html)
[developer.android.com/guide/topics/ui/notifiers/notifications.html](http://developer.android.com/guide/topics/ui/notifiers/notifications.html)
Для api<16
```
void sendNotif(Context context) {
nm = (NotificationManager) context.getSystemService(context.NOTIFICATION_SERVICE);
String msgText = "Текст Сообщения";
Notification notif = new Notification(R.drawable.ic_launcher, "Статус строка сообщения",
System.currentTimeMillis());
Intent intent = new Intent(context, options.class);
intent.putExtra(MyActivity.FILE_NAME, "somefile");
PendingIntent pIntent = PendingIntent.getActivity(context, 0, intent, 0);
notif.setLatestEventInfo(context, "Статус строка сообщения", msgText, pIntent);
// ставим флаг, чтобы уведомление пропало после нажатия
notif.flags |= Notification.FLAG_AUTO_CANCEL;
// отправляем, цифра ID сообщения.
nm.notify(1, notif);
}
//Для api>15
void sendNotif16(Context context) {
String msgText = "Текст Сообщения";
NotificationManager notificationManager =getNotificationManager(context);
PendingIntent pi = getPendingIntent(context);
Notification.Builder builder = new Notification.Builder(context);
builder.setContentTitle("NotificationTitle")
.setContentText("Текст отображаемый в свернутом виде")
.setSmallIcon(R.drawable.ic_launcher)
.setAutoCancel(true)
.setPriority(Notification.PRIORITY_HIGH)
.addAction(R.drawable.ic_launcher,context.getResources().getString(R.string.NotificationButton), pi);
Notification notification = new Notification.BigTextStyle(builder)
.bigText(msgText).build();
notificationManager.notify(1, notification);
}
public NotificationManager getNotificationManager(Context context) {
return (NotificationManager) context.getSystemService(context.NOTIFICATION_SERVICE);
}
//Вызов:
if (Build.VERSION.SDK_INT < 16) {
sendNotif(context);
} else {
sendNotif16(context);
}
//Отмена
public static void CancelNotification(Context ctx, int notifyId) {
String ns = Context.NOTIFICATION_SERVICE;
NotificationManager nMgr = (NotificationManager) ctx.getSystemService(ns);
nMgr.cancel(notifyId);
}
```
**Держать экран включенным**[stackoverflow.com/questions/5331152/correct-method-for-setkeepscreenon-flag-keep-screen-on](http://stackoverflow.com/questions/5331152/correct-method-for-setkeepscreenon-flag-keep-screen-on)
Пример кода:
В XML android:keepScreenOn=«true» или в программе:
```
getWindow().addFlags(WindowManager.LayoutParams.FLAG_KEEP_SCREEN_ON);
```
**Android эмулятор:**[www.genymotion.com](http://www.genymotion.com/)
Лучшее из того что встречал, не всегда стабильно, но быстро.
**Создаем таблицу:**[stackoverflow.com/questions/13189790/how-to-draw-horizontal-and-vertical-line-in-table-layout](http://stackoverflow.com/questions/13189790/how-to-draw-horizontal-and-vertical-line-in-table-layout)
Пример кода:
```
TableLayout table = (TableLayout) findViewById(R.id.score_table);
// create a new TableRow
TableRow row = new TableRow(this);
// create a new TextView
TextView t = new TextView(this);
t.setBackgroundResource(R.drawable.cell_shape);
t.setPadding(5,5,5,5);
View view_instance = (View)findViewById(R.id.txt1);
ViewGroup.LayoutParams params=view_instance.getLayoutParams();
t.setLayoutParams(params);
t.setText(data) ;
t.setTextColor(getResources().getColor(R.color.windowBackground));
row.addView(t);
table.addView(row,new TableLayout.LayoutParams(TableLayout.LayoutParams.FILL_PARENT, TableLayout.LayoutParams.FILL_PARENT));
```
**Обработка нажатия кнопки назад (Back Pressed):**[stackoverflow.com/questions/3141996/android-how-to-override-the-back-button-so-it-doesnt-finish-my-activity](http://stackoverflow.com/questions/3141996/android-how-to-override-the-back-button-so-it-doesnt-finish-my-activity)
Пример кода:
```
public void onBackPressed() {
Intent intent = new Intent(Activity1.this, Activity2.class);
startActivity(intent);
super.onBackPressed();
}
```
**Кнопка произвольной формы:**[www.cyberforum.ru/android-dev/thread431958.html](http://www.cyberforum.ru/android-dev/thread431958.html)
[developer.android.com/guide/topics/ui/controls/button.html](http://developer.android.com/guide/topics/ui/controls/button.html)
[stackoverflow.com/questions/18507351/how-to-create-custom-button-in-android-using-xml-styles](http://stackoverflow.com/questions/18507351/how-to-create-custom-button-in-android-using-xml-styles)
**Отображаем спец. символы:**[stackoverflow.com/questions/3053062/how-can-i-write-character-in-android-strings-xml](http://stackoverflow.com/questions/3053062/how-can-i-write-character-in-android-strings-xml)
**Сдвигаем Активность при вводе текста**[stackoverflow.com/questions/9771746/admob-ad-disappears-after-soft-keyboard-pops-up](http://stackoverflow.com/questions/9771746/admob-ad-disappears-after-soft-keyboard-pops-up)
[stackoverflow.com/questions/7417123/android-how-to-adjust-layout-in-full-screen-mode-when-softkeyboard-is-visible](http://stackoverflow.com/questions/7417123/android-how-to-adjust-layout-in-full-screen-mode-when-softkeyboard-is-visible)
[stackoverflow.com/questions/9003166/android-keyboard-next-button-issue-on-edittext](http://stackoverflow.com/questions/9003166/android-keyboard-next-button-issue-on-edittext)
Пример кода:
Прописываем в манифесте
```
android:windowSoftInputMode="stateAlwaysHidden|adjustResize|adjustPan"
```
**Перемещение фокуса с EditText:**[stackoverflow.com/questions/17989733/move-to-another-edittext-when-soft-keyboard-next-is-clicked-on-android](http://stackoverflow.com/questions/17989733/move-to-another-edittext-when-soft-keyboard-next-is-clicked-on-android)
Используем в XML
```
android:imeOptions="actionNext"
```
для завершения
```
android:imeOptions="actionDone"
```
**Как мигрировать на gradle:**[stackoverflow.com/questions/19573043/android-studio-how-to-migrate-project-to-gradle](http://stackoverflow.com/questions/19573043/android-studio-how-to-migrate-project-to-gradle)
**Временный запрет смены ориентации активити:**[stackoverflow.com/questions/3611457/android-temporarily-disable-orientation-changes-in-an-activity](http://stackoverflow.com/questions/3611457/android-temporarily-disable-orientation-changes-in-an-activity)
[stackoverflow.com/questions/2795833/check-orientation-on-android-phone/10453034#10453034](http://stackoverflow.com/questions/2795833/check-orientation-on-android-phone/10453034#10453034)
[stackoverflow.com/questions/3611457/android-temporarily-disable-orientation-changes-in-an-activity](http://stackoverflow.com/questions/3611457/android-temporarily-disable-orientation-changes-in-an-activity)
Такое использовать не рекомендуется, но если надо.
Вот пример относительно стабильной реализации:
```
private static void disableRotation(Activity activity)
{
WindowManager windowManager = (WindowManager) activity.getSystemService(Context.WINDOW_SERVICE);
Configuration configuration = activity.getResources().getConfiguration();
int rotation = windowManager.getDefaultDisplay().getRotation();
// Search for the natural position of the device
if(configuration.orientation == Configuration.ORIENTATION_LANDSCAPE &&
(rotation == Surface.ROTATION_0 || rotation == Surface.ROTATION_180) ||
configuration.orientation == Configuration.ORIENTATION_PORTRAIT &&
(rotation == Surface.ROTATION_90 || rotation == Surface.ROTATION_270))
{
// Natural position is Landscape
switch (rotation)
{
case Surface.ROTATION_0:
activity.setRequestedOrientation(ActivityInfo.SCREEN_ORIENTATION_LANDSCAPE);
break;
case Surface.ROTATION_90:
activity.setRequestedOrientation(ActivityInfo.SCREEN_ORIENTATION_REVERSE_PORTRAIT);
break;
case Surface.ROTATION_180:
activity.setRequestedOrientation(ActivityInfo.SCREEN_ORIENTATION_REVERSE_LANDSCAPE);
break;
case Surface.ROTATION_270:
activity.setRequestedOrientation(ActivityInfo.SCREEN_ORIENTATION_PORTRAIT);
break;
}
}
else
{
// Natural position is Portrait
switch (rotation)
{
case Surface.ROTATION_0:
activity.setRequestedOrientation(ActivityInfo.SCREEN_ORIENTATION_PORTRAIT);
break;
case Surface.ROTATION_90:
activity.setRequestedOrientation(ActivityInfo.SCREEN_ORIENTATION_LANDSCAPE);
break;
case Surface.ROTATION_180:
activity.setRequestedOrientation(ActivityInfo.SCREEN_ORIENTATION_REVERSE_PORTRAIT);
break;
case Surface.ROTATION_270:
activity.setRequestedOrientation(ActivityInfo.SCREEN_ORIENTATION_REVERSE_LANDSCAPE);
break;
}
}
}
private static void enableRotation(Activity activity)
{
activity.setRequestedOrientation(ActivityInfo.SCREEN_ORIENTATION_UNSPECIFIED);
}
```
**Использование AlarmManager для напоминаний:**[www.mobilab.ru/androiddev/androidalarmmanagertutorial.html](http://www.mobilab.ru/androiddev/androidalarmmanagertutorial.html)
[stackoverflow.com/questions/3052149/using-alarmmanager-to-start-a-service-at-specific-time](http://stackoverflow.com/questions/3052149/using-alarmmanager-to-start-a-service-at-specific-time)
[developer.android.com/reference/android/app/AlarmManager.html](http://developer.android.com/reference/android/app/AlarmManager.html)
[stackoverflow.com/questions/2844274/multiple-calls-to-alarmmanager-setrepeating-deliver-the-same-intent-pendinginten](http://stackoverflow.com/questions/2844274/multiple-calls-to-alarmmanager-setrepeating-deliver-the-same-intent-pendinginten)
Возобновление после перезагрузки:
[stackoverflow.com/questions/12512717/android-alarmmanager-after-reboot](http://stackoverflow.com/questions/12512717/android-alarmmanager-after-reboot)
[github.com/commonsguy/cw-omnibus/blob/master/AlarmManager/Scheduled/src/com/commonsware/android/schedsvc/PollReceiver.java](https://github.com/commonsguy/cw-omnibus/blob/master/AlarmManager/Scheduled/src/com/commonsware/android/schedsvc/PollReceiver.java)
[stackoverflow.com/questions/4315611/android-get-all-pendingintents-set-with-alarmmanager](http://stackoverflow.com/questions/4315611/android-get-all-pendingintents-set-with-alarmmanager)
Пример кода с вызовом после перезагрузки (не оптимальный нужно дорабатывать):
В манифесте прописываем:
```
```
```
BootReceiver.java
public class BootReceiver extends BroadcastReceiver
{
@Override
public void onReceive(Context context, Intent intent) {
AlarmManagerBroadcastReceiver.setTime=3;
PowerManager pm = (PowerManager) context.getSystemService(Context.POWER_SERVICE);
PowerManager.WakeLock wl = pm.newWakeLock(PowerManager.PARTIAL_WAKE_LOCK, "EyeGuard");
SetAlarm(context);
}
}
public void SetAlarm(Context context)
{
//Toast.makeText(context, "SetAlarm", 10).show();
AlarmManager am=(AlarmManager)context.getSystemService(Context.ALARM_SERVICE);
Intent intent = new Intent(context, AlarmManagerBroadcastReceiver.class);
intent.putExtra(AlarmManagerBroadcastReceiver.ONE_TIME, Boolean.FALSE);
PendingIntent pi = PendingIntent.getBroadcast(context, 0, intent, 0);
//After after 30 seconds
am.setRepeating(AlarmManager.RTC_WAKEUP, System.currentTimeMillis(), 1000 * AlarmManagerBroadcastReceiver.setTime *60 , pi); /// 1000
}
public void CancelAlarm(Context context)
{
// Toast.makeText(context, "CancelAlarm", Toast.LENGTH_LONG).show();
Intent intent = new Intent(context, AlarmManagerBroadcastReceiver.class);
PendingIntent sender = PendingIntent.getBroadcast(context, 0, intent, 0);
AlarmManager alarmManager = (AlarmManager) context.getSystemService(Context.ALARM_SERVICE);
alarmManager.cancel(sender);
}
}
AlarmManagerBroadcastReceiver.java
public class AlarmManagerBroadcastReceiver extends BroadcastReceiver {
@Override
public void onReceive(Context context, Intent intent) {
AlarmManagerBroadcastReceiver.setTime=3;
PowerManager pm = (PowerManager) context.getSystemService(Context.POWER_SERVICE);
PowerManager.WakeLock wl = pm.newWakeLock((PowerManager.SCREEN_BRIGHT_WAKE_LOCK | PowerManager.FULL_WAKE_LOCK | PowerManager.ACQUIRE_CAUSES_WAKEUP), "EyeGuard");
wl.acquire(10000); //Засыпает через 10 секунд
//Здесь свой код
//
}
public void SetAlarm(Context context)
{
AlarmManager am=(AlarmManager)context.getSystemService(Context.ALARM_SERVICE);
Intent intent = new Intent(context, AlarmManagerBroadcastReceiver.class);
intent.putExtra(ONE_TIME, Boolean.FALSE);
PendingIntent pi = PendingIntent.getBroadcast(context, 0, intent, 0);
am.setRepeating(AlarmManager.RTC_WAKEUP, System.currentTimeMillis(), 1000 *setTime *setTime2 , pi); /// 1000 *25 *60
}
public void CancelAlarm(Context context)
{
Intent intent = new Intent(context, AlarmManagerBroadcastReceiver.class);
PendingIntent sender = PendingIntent.getBroadcast(context, 0, intent, 0);
AlarmManager alarmManager = (AlarmManager) context.getSystemService(Context.ALARM_SERVICE);
alarmManager.cancel(sender);
}
public void setOnetimeTimer(Context context){
AlarmManager am=(AlarmManager)context.getSystemService(Context.ALARM_SERVICE);
Intent intent = new Intent(context, AlarmManagerBroadcastReceiver.class);
intent.putExtra(ONE_TIME, Boolean.TRUE);
PendingIntent pi = PendingIntent.getBroadcast(context, 0, intent, 0);
am.set(AlarmManager.RTC_WAKEUP, System.currentTimeMillis(), pi);
}
}
```
В активити из которой вызываем
Прописываем private AlarmManagerBroadcastReceiver alarm;
В onCreate:
```
alarm = new AlarmManagerBroadcastReceiver();
```
Добавляем процедуры:
```
public void startRepeatingTimer(View view) {
// Toast.makeText(this, "startRepeatingTimer", 30).show();
Context context = this.getApplicationContext();
if(alarm != null){
alarm.SetAlarm(context);
}else{
//Toast.makeText(context, "Alarm is null", Toast.LENGTH_SHORT).show();
}
}
public void cancelRepeatingTimer(View view){
// Toast.makeText(this, "cancelRepeatingTimer", 30).show();
Context context = this.getApplicationContext();
if(alarm != null){
alarm.CancelAlarm(context);
}else{
// Toast.makeText(context, "Alarm is null", Toast.LENGTH_SHORT).show();
}
}
```
Вызов осуществляем:
startRepeatingTimer(v);
Отменяем:
cancelRepeatingTimer(v);
**Включение экрана из программы:**[developer.android.com/reference/android/os/PowerManager.html](http://developer.android.com/reference/android/os/PowerManager.html)
[stackoverflow.com/questions/18679455/in-android-how-can-i-turn-off-the-screen-programatically](http://stackoverflow.com/questions/18679455/in-android-how-can-i-turn-off-the-screen-programatically)
[pastebin.com/RyjTF08K](http://pastebin.com/RyjTF08K)
[stackoverflow.com/questions/13696891/programmatically-set-screen-to-off-in-android](http://stackoverflow.com/questions/13696891/programmatically-set-screen-to-off-in-android)
[forum.xda-developers.com/showthread.php?t=1210421](http://forum.xda-developers.com/showthread.php?t=1210421)
[developer.android.com/reference/android/os/PowerManager.html#goToSleep%28long](http://developer.android.com/reference/android/os/PowerManager.html#goToSleep%28long)
В Манифест добавляем:
```
< uses-permission android:name="android.permission.WAKE_LOCK" />
```
Сам код:
```
PowerManager pm = (PowerManager) getApplicationContext().getSystemService(Context.POWER_SERVICE);
WakeLock wakeLock = pm.newWakeLock((PowerManager.SCREEN_BRIGHT_WAKE_LOCK | PowerManager.FULL_WAKE_LOCK | PowerManager.ACQUIRE_CAUSES_WAKEUP), "TAG");
wakeLock.acquire();
```
**Немного про Admob:**[forum.hellroom.ru/index.php?PHPSESSID=6ef77d2e403cac8c366ce8f5a9e3f9fa&topic=16515.0](http://forum.hellroom.ru/index.php?PHPSESSID=6ef77d2e403cac8c366ce8f5a9e3f9fa&topic=16515.0)
[habrahabr.ru/post/133858](http://habrahabr.ru/post/133858/)
[habrahabr.ru/post/203368](http://habrahabr.ru/post/203368/)
Пример кода:
В Манифест добавляем:
```
```
Прописываем в активити import com.google.android.gms.ads.\*;
В onCreate:
```
adView = new AdView(this);
adView.setAdUnitId("код баннера");
adView.setAdSize(AdSize.SMART_BANNER);
// Поиск разметки LinearLayout (предполагается, что ей был присвоен
// атрибут android:id="@+id/mainLayout").
RelativeLayout layout = (RelativeLayout)findViewById(R.id.RLMain);
// Добавление в разметку экземпляра adView.
layout.addView(adView);
// Инициирование общего запроса.
// AdRequest adRequest = new AdRequest.Builder().build();
AdRequest adRequest = new AdRequest.Builder().build();
//Для теста разкомментируем строчки и подставляем ID тестового девайса
/* AdRequest adRequest = new AdRequest.Builder()
.addTestDevice(AdRequest.DEVICE_ID_EMULATOR) // Эмулятор
.addTestDevice("B6F0A0DED6232ADEA16984CB963C6552") // Тестовый телефон Galaxy Nexus
.build();*/
// Загрузка adView с объявлением.
adView.loadAd(adRequest);
@Override
public void onPause() {
adView.pause();
super.onPause();
}
@Override
public void onResume() {
super.onResume();
adView.resume();
}
@Override
public void onDestroy() {
adView.destroy();
super.onDestroy();
}
```
**Продвижение приложения:**[habrahabr.ru/post/147243](http://habrahabr.ru/post/147243/)
[habrahabr.ru/post/133858](http://habrahabr.ru/post/133858/)
[habrahabr.ru/post/203368](http://habrahabr.ru/post/203368/)
[habrahabr.ru/post/188374](http://habrahabr.ru/post/188374/)
[bestreviewapp.com/indexs.php](http://bestreviewapp.com/indexs.php)
**Создание галереи:**[megadarja.blogspot.ru/2011/05/gallery.html](http://megadarja.blogspot.ru/2011/05/gallery.html)
[stackoverflow.com/questions/13796382/android-viewpager-as-image-slide-gallery](http://stackoverflow.com/questions/13796382/android-viewpager-as-image-slide-gallery)
[stackoverflow.com/questions/7818753/alternative-to-gallery-widget](http://stackoverflow.com/questions/7818753/alternative-to-gallery-widget)
[startandroid.ru/ru/uroki/vse-uroki-spiskom/228-urok-125-viewpager.html](http://startandroid.ru/ru/uroki/vse-uroki-spiskom/228-urok-125-viewpager.html)
[habrahabr.ru/post/131889/#comment\_4379987](http://habrahabr.ru/post/131889/#comment_4379987)
**Загрузка и просмотр больших изображений и связанные с этим проблемы:**[stackoverflow.com/questions/10200256/out-of-memory-error-imageview-issue](http://stackoverflow.com/questions/10200256/out-of-memory-error-imageview-issue)
[developer.android.com/training/displaying-bitmaps/index.html](http://developer.android.com/training/displaying-bitmaps/index.html)
[stackoverflow.com/questions/14359024/out-of-memory-error-while-loading-bitmaps](http://stackoverflow.com/questions/14359024/out-of-memory-error-while-loading-bitmaps)
[stackoverflow.com/questions/477572/strange-out-of-memory-issue-while-loading-an-image-to-a-bitmap-object](http://stackoverflow.com/questions/477572/strange-out-of-memory-issue-while-loading-an-image-to-a-bitmap-object)
[hashcode.ru/questions/310542/java-android-%D0%BF%D0%B0%D0%B4%D0%B0%D0%B5%D1%82-%D0%BF%D1%80%D0%B8%D0%BB%D0%BE%D0%B6%D0%B5%D0%BD%D0%B8%D0%B5-%D0%BF%D1%80%D0%B8-%D0%B7%D0%B0%D0%B3%D1%80%D1%83%D0%B7%D0%BA%D0%B5-%D0%B8%D0%B7%D0%BE%D0%B1%D1%80%D0%B0%D0%B6%D0%B5%D0%BD%D0%B8%D0%B9](http://hashcode.ru/questions/310542/java-android-%D0%BF%D0%B0%D0%B4%D0%B0%D0%B5%D1%82-%D0%BF%D1%80%D0%B8%D0%BB%D0%BE%D0%B6%D0%B5%D0%BD%D0%B8%D0%B5-%D0%BF%D1%80%D0%B8-%D0%B7%D0%B0%D0%B3%D1%80%D1%83%D0%B7%D0%BA%D0%B5-%D0%B8%D0%B7%D0%BE%D0%B1%D1%80%D0%B0%D0%B6%D0%B5%D0%BD%D0%B8%D0%B9)
[hashcode.ru/questions/305592/java-%D0%B2%D1%8B%D0%B2%D0%BE%D0%B4-%D0%B8%D0%B7%D0%BE%D0%B1%D1%80%D0%B0%D0%B6%D0%B5%D0%BD%D0%B8%D1%8F-android](http://hashcode.ru/questions/305592/java-%D0%B2%D1%8B%D0%B2%D0%BE%D0%B4-%D0%B8%D0%B7%D0%BE%D0%B1%D1%80%D0%B0%D0%B6%D0%B5%D0%BD%D0%B8%D1%8F-android)
**Работа с камерой**[developer.alexanderklimov.ru/android/photocamera.php](http://developer.alexanderklimov.ru/android/photocamera.php)
[developer.android.com/training/camera/photobasics.html](http://developer.android.com/training/camera/photobasics.html)
[stackoverflow.com/questions/2386025/android-camera-without-preview/5384913#5384913](http://stackoverflow.com/questions/2386025/android-camera-without-preview/5384913#5384913)
[stackoverflow.com/questions/7398897/how-to-use-camera-to-take-picture-in-a-background-service-on-android](http://stackoverflow.com/questions/7398897/how-to-use-camera-to-take-picture-in-a-background-service-on-android)
[stackoverflow.com/questions/9976817/take-picture-with-camera-intent-and-save-to-file](http://stackoverflow.com/questions/9976817/take-picture-with-camera-intent-and-save-to-file)
[stackoverflow.com/questions/15214321/saving-pictures-taken-by-camera-in-android-app](http://stackoverflow.com/questions/15214321/saving-pictures-taken-by-camera-in-android-app)
[developer.android.com/guide/topics/media/camera.html](http://developer.android.com/guide/topics/media/camera.html)
**Локализация**[developer.alexanderklimov.ru/android/locale.php](http://developer.alexanderklimov.ru/android/locale.php)
**Как дать возможность оставить отзыв из программы:**[stackoverflow.com/questions/2893350/how-to-launch-the-google-play-intent-in-give-feedback-mode-on-android](http://stackoverflow.com/questions/2893350/how-to-launch-the-google-play-intent-in-give-feedback-mode-on-android)
[stackoverflow.com/questions/8031276/prompt-user-to-rate-an-android-app-inside-the-app](http://stackoverflow.com/questions/8031276/prompt-user-to-rate-an-android-app-inside-the-app)
Пример кода:
```
String appPackageName= getPackageName();
Intent marketIntent = new Intent(Intent.ACTION_VIEW, Uri.parse("market://details?id="+appPackageName));
marketIntent.addFlags(Intent.FLAG_ACTIVITY_NO_HISTORY|Intent.FLAG_ACTIVITY_CLEAR_WHEN_TASK_RESET|Intent.FLAG_ACTIVITY_MULTIPLE_TASK);
startActivity(marketIntent);
```
**Публикация приложения:**[developer.alexanderklimov.ru/android/publish.php](http://developer.alexanderklimov.ru/android/publish.php)
[dolbodub.blogspot.ru/2014/04/android-studio-apk.html](http://dolbodub.blogspot.ru/2014/04/android-studio-apk.html)
[developer.android.com/tools/help/proguard.html](http://developer.android.com/tools/help/proguard.html)
[forum.hellroom.ru/index.php?topic=14805](http://forum.hellroom.ru/index.php?topic=14805) | https://habr.com/ru/post/232885/ | null | ru | null |
# Туториал из руководства по Ember.js. Приложение Super Rentals. Часть 1.1
После довольно удачной [пробы пера с Ember Octane](https://habr.com/ru/post/482158/) я решил (точнее мы с гуглотранслейтом решили) замахнутся на ~~святое~~ перевод туториала из официального руководства Ember.js
Как вы увидите из текста, данный туториал рассчитан на ~~самых маленьких~~ начинающих программистов. Что не мешает ему служить опытным бойцам прекрасной отправной точкой для знакомства фреймворком. Для полного прохождения ~~этой игры~~ туториала вам понадобится 1-2 часа времени. После этого вы сможете оценить Ember.js в его последней редакции Octane без необходимости читать [обзоры позапрошлогодней свежести](https://habr.com/ru/company/ruvds/blog/476288/)
Список тем, которые покрывает туториал внушает:
* Использование Ember CLI
* Навигация по структуре файлов и папок приложения Ember
* Создание и связь между страницами
* Шаблоны (templates) и компоненты
* Автоматизированное тестирование
* Работа с данными сервера
* Динамические сегменты в маршрутах
* Сервисы в Ember
* Библиотека Ember Data
* Адаптеры и сериализаторы
* Паттерн компонента-провайдера
Если вы согласны, что это вкуснота стоит траты 1-2 часов, добро пожаловать под кат!
> От переводчика:
>
> Так как Хабр не может корректно отобразить `hbs` я вставлял картинки. Воспользуйтесь текстом оригинала, чтобы копировать кодовые вставки. Сорри за неудобства.
>
>
>
> Также оригинальный туториал состоит из двух частей, но из-за объема я разбил первую часть на две: часть 1.1 и [часть 1.2](https://habr.com/ru/post/482390/). Надеюсь, что вторая часть будет переводиться целиком и тогда я дам ей нумерацию часть 2. Также надеюсь, что это не приведет к путанице)
>
>
>
> На русском про Ember можно спрашивать в телеграмм канале [ember\_js](https://t.me/ember_js)
Вступление
==========
Добро пожаловать в мир Ember!
В этом туториале мы будем использовать Ember для создания приложения Super Rentals. Это будет веб-сайт для просмотра интересных мест, где можно остановиться во время вашего следующего отпуска. Проверьте [готовое приложение](https://super-rentals-tutorial--ember-super-rentals.netlify.com/), чтобы получить представление о масштабах проекта.
Попутно вы узнаете все, что вам нужно знать для создания базового приложения Ember. Если вы застряли в какой-то момент во время урока, не стесняйтесь скачать [исходники](https://github.com/ember-learn/super-rentals/tree/super-rentals-tutorial-output) для полного рабочего примера.
Этот урок состоит из двух частей. Первая часть охватывает следующие основные понятия:
* Использование Ember CLI
* Навигация по структуре файлов и папок приложения Ember
* Создание и связь между страницами
* Шаблоны и компоненты
* Автоматизированное тестирование
* Работа с данными сервера
Во [второй части](https://habr.com/ru/post/482390/) урока мы перейдем на следующий уровень, используя уже изученные концепции.
Генерация нового проекта
========================
В этой части вы будете устанавливать Ember CLI, использовать его для создания нового проекта Ember и добавлять базовые шаблоны и стили в свое новое приложение. К концу части у вас должна появиться целевая страница с изображением милого профессора Томстера:

Создавая эту страницу, вы научитесь:
* Устанавливать Ember CLI
* Создавать новое приложение Ember с Ember CLI
* Запускать и останавливать сервер разработки
* Редактировать файлы и видеть сразу видеть результат (live reload)
* Работать с HTML, CSS и ресурсами в приложении Ember
Установка Ember CLI
-------------------
Вы можете установить последнюю версию Ember CLI, выполнив следующую команду:
```
$ npm install -g ember-cli
```
Чтобы убедиться, что ваша установка прошла успешно, запустите:
```
$ ember --version
ember-cli: 3.15.0
node: 12.8.1
os: linux x64
```
Если отображается номер версии, вы готовы к работе.
Создание нового приложения Ember с помощью Ember CLI
----------------------------------------------------
Мы можем создать новый проект, используя команду Ember CLI `new`. Используйте паттерн `ember new` . В нашем случае название проекта будет `super-rentals`:
```
$ ember new super-rentals
installing app
Ember CLI v3.15.0
Creating a new Ember app in /home/runner/work/super-rentals-tutorial/super-rentals-tutorial/dist/code/super-rentals:
create .editorconfig
create .ember-cli
create .eslintignore
create .eslintrc.js
create .template-lintrc.js
create .travis.yml
create .watchmanconfig
create README.md
create app/app.js
create app/components/.gitkeep
create app/controllers/.gitkeep
create app/helpers/.gitkeep
create app/index.html
create app/models/.gitkeep
create app/router.js
create app/routes/.gitkeep
create app/styles/app.css
create app/templates/application.hbs
create config/environment.js
create config/optional-features.json
create config/targets.js
create ember-cli-build.js
create .gitignore
create package.json
create public/robots.txt
create testem.js
create tests/helpers/.gitkeep
create tests/index.html
create tests/integration/.gitkeep
create tests/test-helper.js
create tests/unit/.gitkeep
create vendor/.gitkeep
Installing packages... This might take a couple of minutes.
npm: Installing dependencies ...
npm: Installed dependencies
Initializing git repository.
Git: successfully initialized.
Successfully created project super-rentals.
Get started by typing:
$ cd super-rentals
$ npm start
Happy coding!
```
Эта команда создаст для нас новую папку под названием `super-rentals`. Мы можем перейти к ней с помощью команды `cd`.
```
$ cd super-rentals
```
В оставшейся части туториала все команды должны выполняться в папке `super-rentals`. Эта папка имеет следующую структуру:
```
super-rentals
├── app
│ ├── components
│ │ └── .gitkeep
│ ├── controllers
│ │ └── .gitkeep
│ ├── helpers
│ │ └── .gitkeep
│ ├── models
│ │ └── .gitkeep
│ ├── routes
│ │ └── .gitkeep
│ ├── styles
│ │ └── app.css
│ ├── templates
│ │ └── application.hbs
│ ├── app.js
│ ├── index.html
│ └── router.js
├── config
│ ├── environment.js
│ ├── optional-features.json
│ └── targets.js
├── public
│ └── robots.txt
├── tests
│ ├── helpers
│ │ └── .gitkeep
│ ├── integration
│ │ └── .gitkeep
│ ├── unit
│ │ └── .gitkeep
│ ├── index.html
│ └── test-helper.js
├── vendor
│ └── .gitkeep
├── .editorconfig
├── .ember-cli
├── .eslintignore
├── .eslintrc.js
├── .gitignore
├── .template-lintrc.js
├── .travis.yml
├── .watchmanconfig
├── README.md
├── ember-cli-build.js
├── package.json
├── package-lock.json
└── testem.js
15 directories, 32 files
```
По мере продвижения по уроку мы узнаем о предназначении этих файлов и папок. А пока, просто знайте, что большую часть времени мы будем работать в папке `app`.
Запуск и остановка сервера разработки
-------------------------------------
Ember CLI поставляется с множеством различных команд для различных задач разработки, таких как команда `ember new` которую мы видели ранее. Он также поставляется с сервером разработки, который мы можем запустить с помощью команды `ember server` :
```
$ ember server
building...
Build successful (9761ms) – Serving on http://localhost:4200/
```
Сервер разработки отвечает за компиляцию нашего приложения. Также в него встроен веб-сервер, поставляющий файлы браузеру. Загрузка может занять некоторое время. Как только он заработает, откройте ваш любимый браузер и перейдите по адресу `http://localhost:4200`. Вы должны увидеть следующую страницу приветствия:

> ### Зои поясняет:
>
>
>
>
>
> Адрес `localhost` в URL означает, что вы можете получить доступ к серверу разработки только с вашего локального компьютера. Если вы хотите поделиться своей работой со всем миром, вам придется *развернуть* свое приложение в общедоступном Интернете. Мы расскажем, как это сделать, во второй части урока.
Вы можете выйти из сервера разработки в любое время, набрав `Ctrl + C` (для MacOS `Cmd + C`) в окне терминала, где работает `ember server`. То есть, нажимая клавишу «C» на клавиатуре, одновременно удерживая клавишу «Ctrl». Как только он остановился, вы можете запустить его снова с помощью той же команды `ember server`. Мы рекомендуем открыть два окна терминала: одно для запуска сервера в фоновом режиме, другое для ввода других команд консоли Ember.
Редактирование файлов и живая перезагрузка (live reload)
--------------------------------------------------------
Сервер разработки имеет функцию под названием live reload, которая отслеживает изменения файлов в вашем приложении, автоматически перекомпилирует все и обновляет все открытые страницы браузера. Это очень удобно при разработке, поэтому давайте попробуем!
Как указывалось в тексте на странице приветствия, исходный код страницы находится в `app/templates/application.hbs`. Давайте попробуем отредактировать этот файл и заменить его собственным контентом:
Вскоре после сохранения файла ваш браузер должен автоматически обновиться и передать наши поздравления всему миру. Супер!

Когда вы закончите экспериментировать, удалите файл `app/templates/application.hbs`. Он нам не понадобится еще какое-то время. Мы добавим его позже.
Опять же, если у вас по-прежнему открыта вкладка браузера, ваша вкладка автоматически повторно отобразит пустую страницу, как только вы удалите файл. Это отражает тот факт, что у нас больше нет шаблона приложения в нашем приложении.
Работа с HTML, CSS и активами в приложении Ember
------------------------------------------------
Создайте файл `app/templates/index.hbs` и вставьте следующую разметку.
Если вы думаете: «Эй, это похоже на HTML!», То вы абсолютно правы! В своей простейшей форме шаблоны Ember — это просто HTML. Если вы уже знакомы с HTML, вы должны чувствовать себя здесь как дома.
Конечно, в отличие от HTML, шаблоны Ember могут сделать гораздо больше, чем просто отображать статический контент. Мы скоро увидим это в действии.
После сохранения файла ваша вкладка браузера должна автоматически обновиться, показывая нам приветственное сообщение, над которым мы только что работали.
Прежде чем делать что-то еще, давайте добавим немного стиля в наше приложение. Мы тратим достаточно времени, глядя на экран компьютера, поэтому мы должны защитить свое зрение от голой HTML разметки!
К счастью, наш дизайнер прислал нам немного CSS для использования, поэтому мы можем [загрузить файл таблицы стилей](https://guides.emberjs.com/downloads/style.css) и скопировать его в `app/styles/app.css`. В этом файле есть все стили, которые нам нужны для создания остальной части приложения.
```
@import url(https://fonts.googleapis.com/css?family=Lato:300,300italic,400,700,700italic);
/**
* Base Elements
*/
* {
margin: 0;
padding: 0;
}
body,
h1,
h2,
h3,
h4,
h5,
h6,
p,
div,
span,
a,
button {
font-family: 'Lato', 'Open Sans', 'Helvetica Neue', 'Segoe UI', Helvetica, Arial, sans-serif;
line-height: 1.5;
}
body {
background: #f3f3f3;
}
/* ...snip... */
```
Если вы знакомы с CSS, не стесняйтесь настраивать эти стили по своему вкусу! Просто имейте в виду, что вы можете увидеть некоторые визуальные различия в будущем, если вы решите это сделать.
Когда вы будете готовы, сохраните файл CSS; наш надежный сервер разработки должен сразу же его заберет и обновить нашу страницу. Нет больше голого HTML контента!

Чтобы соответствовать макету от нашего дизайнера, нам также нужно скачать изображение `teaching-tomster.png`, на которое ссылается наш CSS-файл:
```
.tomster {
background: url(../assets/images/teaching-tomster.png);
/* ...snip... */
}
```
Как мы узнали ранее, конвенция Ember заключается в размещении вашего исходного кода в папке `app`. Для других ресурсов, таких как изображения и шрифты, существует папка `public`. Мы будем следовать этому соглашению, [загрузив файл изображения](https://guides.emberjs.com/downloads/teaching-tomster.png) и сохранив его в `public/assets/images/teaching-tomster.png` .
И Ember CLI, и сервер разработки понимают эти соглашения о папках и автоматически делают эти файлы доступными для браузера.
Вы можете подтвердить это, перейдя по `http://localhost:4200/assets/images/teaching-tomster.png`. Изображение также должно отображаться на странице приветствия, над которой мы работаем. Если при обновлении изображение все-таки не появилось, попробуйте выполнить обновление вручную, чтобы браузер подобрал новый файл.

Создание страниц приложения
===========================
В этой части вы создадите первые несколько страниц вашего приложения Ember и установите ссылки между ними. К концу этой главы у вас должны появиться две новые страницы — страница "O нас" и страница "Контакты". Эти страницы будут связаны с вашей стартовой страницей:


Создавая эти страницы, вы узнаете об:
* Определении маршрутов (route)
* Использовании шаблонов маршрутов
* Настройке URL
* Связывании страниц с компонентом
* Передаче аргументов и атрибутов компонентам
Определение маршрутов
---------------------
После создания нашей первой страницы, давайте добавим еще одну!
На этот раз мы хотели бы, чтобы страница размещалась по URL-адресу `/about`. Для этого нам нужно сообщить Ember о нашем плане добавить страницу в этом месте. В противном случае Ember будет считать, что мы посетили неверный URL!
Местом для управления доступными страницами является маршрутизатор. Откройте `app/router.js` и внесите следующие изменения:
Это добавляет маршрут с именем «about», который по умолчанию обслуживается в URL-адресе `/about`.
Использование шаблонов маршрутов (route templates)
--------------------------------------------------
Теперь мы можем создать новый файл `app/templates/about.hbs` со следующим содержимым:
Чтобы увидеть это в действии, перейдите по `http://localhost:4200/about`.

Вот и готова наша вторая страница!
Определение маршрутов с помощью пользовательских путей
------------------------------------------------------
Продолжаем! Давайте добавим нашу третью страницу. На этот раз все немного по-другому. Все в компании называют это страницей «контактов». Тем не менее, старый веб-сайт, который мы заменяем, уже имеет аналогичную страницу, которая обслуживается по устаревшему URL-адресу `/getting-in-touch`.
Мы хотим сохранить существующие URL-адреса для нового веб-сайта, но нам не нужно вводить `getting-in-touch` всему новому коду! К счастью, мы можем поступить лучше:
Здесь мы добавили маршрут `contact`, но явно указали путь для маршрута. Это позволяет нам сохранить устаревший URL, но использовать новое, более короткое имя для маршрута, а также имя файла шаблона.
Говоря о шаблоне, давайте создадим и его. Мы добавим файл `app/templates/contact.hbs` с содержимым:
Ember придерживается жестких соглашений и разумных настроек по умолчанию — если бы мы начинали с нуля, мы бы не возражали против дефолтного URL `/contact`. Однако, если настройки по умолчанию не работают для нас, это не проблема. Мы можем настроить Ember для наших нужд!
После того как вы добавили маршрут и шаблон выше, у нас должна появиться новая страница по адресу `http://localhost:4200/getting-in-touch`.

Создаем перекрестную навигацию на страницах используя компонент
---------------------------------------------------------------
Мы приложили столько усилий, чтобы сделать эти страницы, но нам нужно, чтобы люди могли их найти! В Интернете для этого используют гиперссылки или для краткости просто ссылки.
Ember предлагает отличную поддержку для URL-адресов «из коробки». Мы можем просто связать наши страницы вместе, используя тег с соответствующим `href`. Однако щелчок по этим ссылкам потребует от браузера полного обновления страницы, а это значит, что ему придется вернуться на сервер, чтобы получить страницу, а затем снова загрузить все с нуля.
С Ember мы можем добиться большего! Вместо простого старого тега Ember предлагает альтернативу . Например, вот как вы могли бы использовать его на страницах, которые мы только что создали:
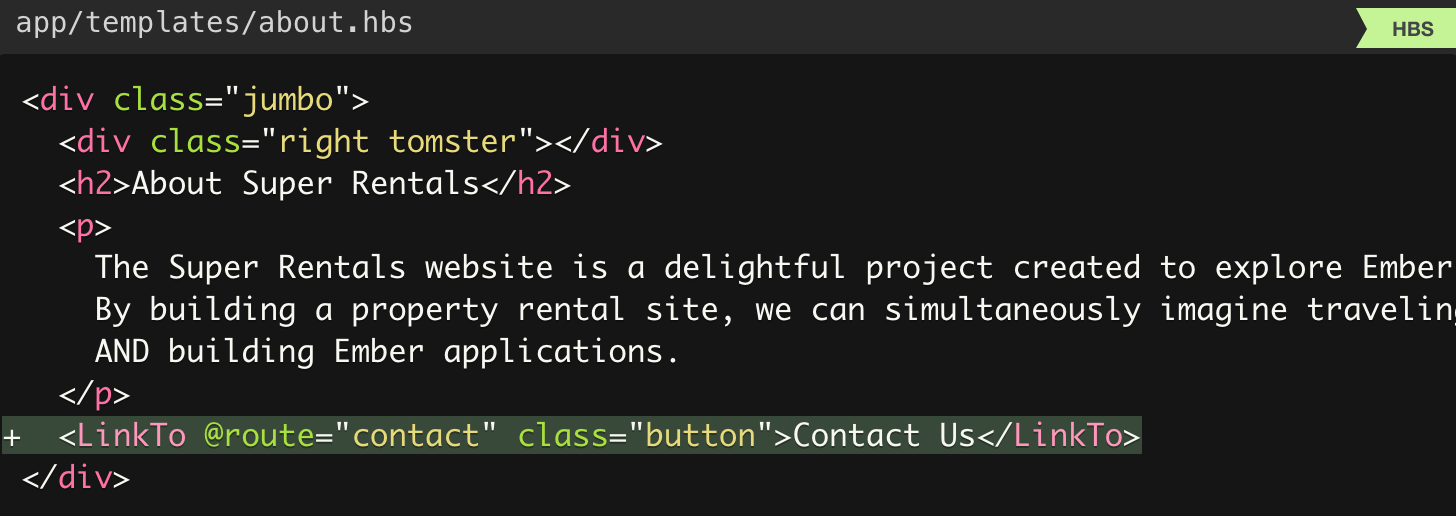
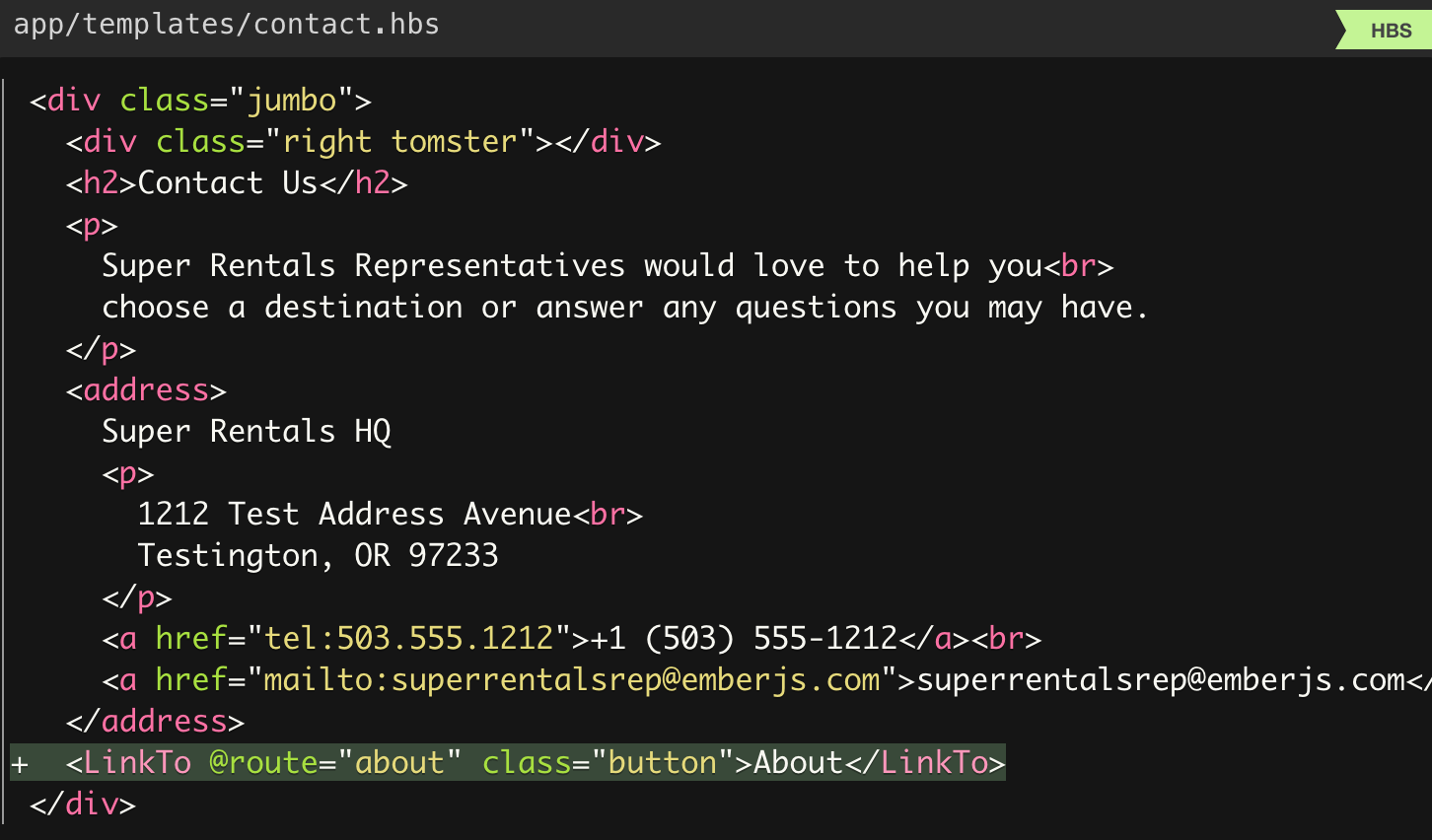
Давайте разберем подробнее, что мы сейчас добавили.
является примером компонента в Ember — вы можете отличить его от обычных тегов HTML, поскольку они начинаются с заглавной буквы. Наряду с обычными тегами HTML, компоненты являются теми кирпичиками, которые мы можем использовать для создания пользовательского интерфейса приложения.
Позже у нас будет гораздо больше информации о компонентах, но сейчас вы можете думать о них как о способе предоставления пользовательских тегов, дополняющих встроенные в браузеры теги.
Часть `@route=...` — это то, как мы передаем аргументы в компонент. Здесь мы используем этот аргумент, чтобы указать, какой маршрут мы хотим связать. (Обратите внимание, что это должно быть имя маршрута, а не путь, поэтому мы указали `"about"` вместо `"/about"` и `"contact"` вместо `"/getting-in-touch"` .)
В дополнение к аргументам компоненты также могут принимать обычные атрибуты HTML. В нашем примере мы добавили класс `"button"` для стилизации, но мы могли бы также указать другие атрибуты, которые мы посчитаем нужными, такие как атрибут `role ARIA`. Они передаются без символа `@` ( `class=...` в отличие от `@class=...`), поэтому Ember будет знать, что они являются обычными HTML-атрибутами.
Под капотом компонент генерирует для нас обычный тег с соответствующей `href` для конкретного маршрута. Этот тег прекрасно работает с программами чтения с экрана, а также позволяет нашим пользователям добавить ссылку в закладки или открыть ее в новой вкладке.
Однако при нажатии на одну из этих специальных ссылок Ember будет перехватывать клик мышки, отображать содержимое для новой страницы и обновлять URL-адрес — все это выполняется локально, без ожидания сервера. Это позволяет избежать полного обновления страницы.
Мы узнаем больше о том, как все это работает в ближайшее время. А пока идем дальше и нажимаем на ссылку в браузере. Вы заметили, как это быстро происходят переходы?
Поздравляем, вы уже на полпути к тому, чтобы стать мастером по созданию страниц!
Автоматизированное тестирование
===============================
В этой части вы будете использовать встроенную среду тестирования Ember, чтобы написать несколько автоматических тестов для вашего приложения. В результате у нас будет автоматизированный набор тестов, который мы сможем запустить, чтобы убедиться, что наше приложение работает правильно:
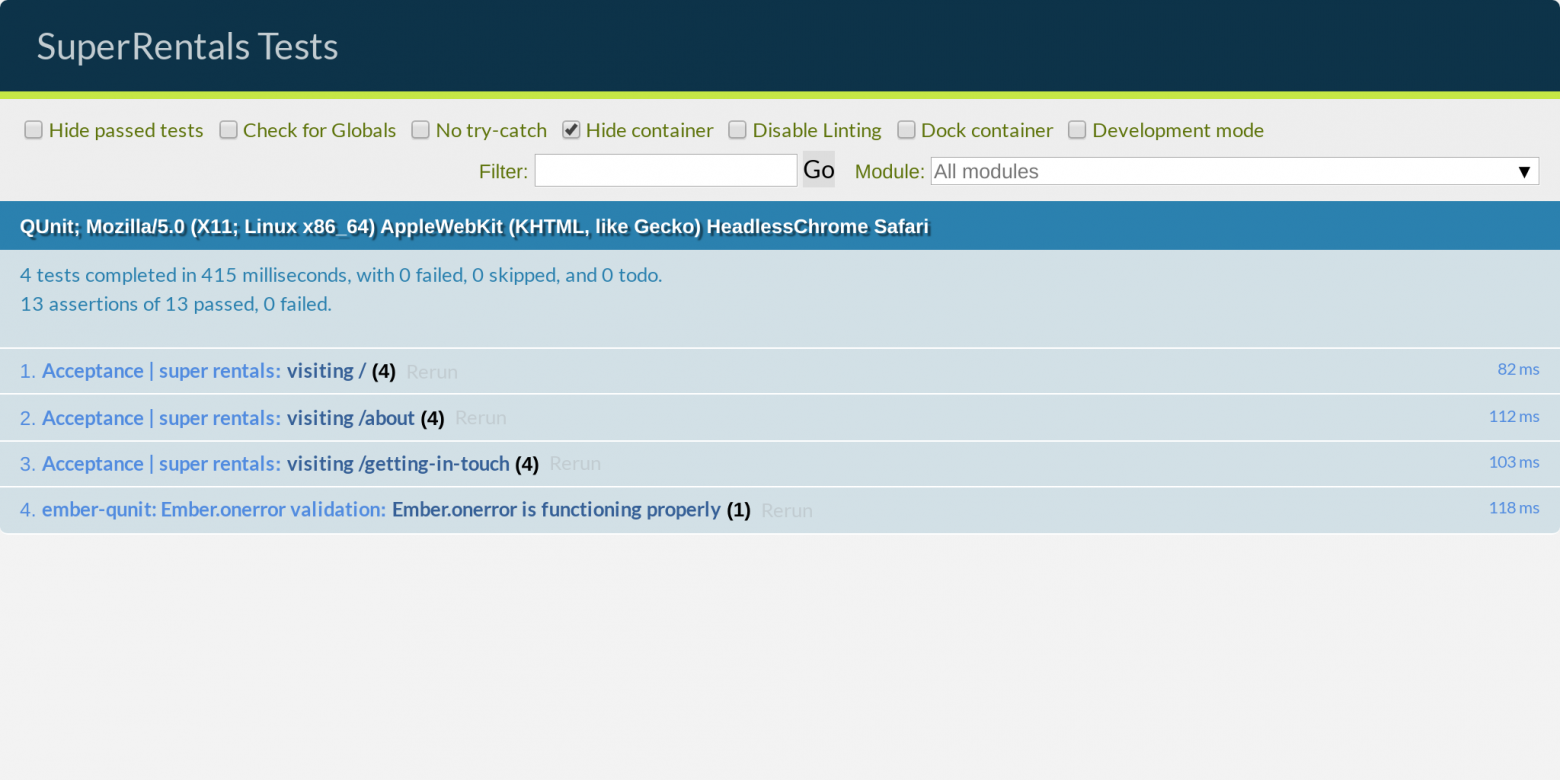
В процессе вы узнаете о:
* Цели автоматизированного тестирования
* Написании приемочных тестов (acceptance tests)
* Использовании генераторов в Ember CLI
* Тестировании с помощью тестовой библиотеке QUnit
* Работе с тестовыми помощниками (test helpers) Ember
* Практике рабочего процесса тестирования
Цель автоматизированного тестирования
-------------------------------------
Мы уже достигли многого! Подведем итоги — мы начали с чистого листа, добавили несколько страниц контента, стилизовали все, чтобы выглядело красиво, добавили изображение Томстера, добавили ссылки между нашими страницами и, что удивительно, все заработало!
Но *действительно ли* мы уверены, что все на самом деле работает? Конечно, мы немного покликали, чтобы убедиться, что все выглядит так, как ожидалось. Но уверены ли мы, что проверили *каждую страницу* после самого последнего внесенного нами изменения?
В конце концов, большинство из нас имеют опыт (или услышали ужасные истории), когда маленькое изменение в одной области приложения непреднамеренно ломало что-то *в другой* части. Даже если мы ничего там не меняли (и соответственно, не проверяли потом).
Допустим, мы можем написать список проверок и проверить его после внесения изменений на нашем сайте. Но, конечно, это выйдет из-под контроля, когда мы добавим больше функций в наше приложение. Он также очень быстро устареет. Поэтому такие повторяющиеся задачи лучше оставить роботам.
Хм, роботы. Это идея! Что если мы сможем написать этот контрольный список и просто заставить компьютер проверить все за нас? Я думаю, что мы только что изобрели идею автоматизированного тестирования! Ладно, может быть, мы не были первыми, кто придумал эту концепцию, но мы независимо ее обнаружили, поэтому мы все еще заслуживаем небольшой похвалы)
Использование генераторов для создания приемочных тестов (acceptance tests)
---------------------------------------------------------------------------
Как только мы закончим поглаживать себя по голове или доедим пирожок с полки, выполним следующую команду в терминале:
```
$ ember generate acceptance-test super-rentals
installing acceptance-test
create tests/acceptance/super-rentals-test.js
```
В Ember CLI это называется командой *генератора*. Генераторы автоматически создают файлы для нас на основе соглашений Ember и заполняют их соответствующим стандартным содержимым, подобно тому, как `ember new` изначально создала для нас скелетное приложение. Обычно он следует шаблону `ember generate` , где — это то, что мы генерируем, а — то, как мы хотим это назвать.
В данном случае мы сгенерировали приемочный тест, расположенный по адресу `tests/acceptance/super-rentals-test.js`.
Конечно, использовать генераторы не обязательно; мы могли бы сами создать файл, который бы сделал то же самое. Но генераторы, безусловно, избавляют нас от ненужной умственной нагрузки на поиск правильной папки и имени, а также времени на набор содержимого. Взгляните на файл приемочного теста и убедитесь сами.
> ### Зои поясняет ...
>
>
>
>
>
> Хотите сэкономить еще больше при печатании? `ember generate ...` может быть сокращено до `ember g ...` Это на 7 символов меньше! Другие команды следуют похожей логике
Пишем приемочные тесты
----------------------
Приемочные тесты, являются одним из видов автоматизированного тестирования, который находится в нашем распоряжении в Ember. Позже мы узнаем о других типах, но что делает приемочные тесты уникальными, так это то, что они тестируют наше приложение как бы с точки зрения пользователя — это автоматизированная версия тестирования «нажми и посмотри, работает ли», которое мы делали ранее самостоятельно.
Давайте откроем сгенерированный тестовый файл и заменим шаблонный тест нашим собственным:
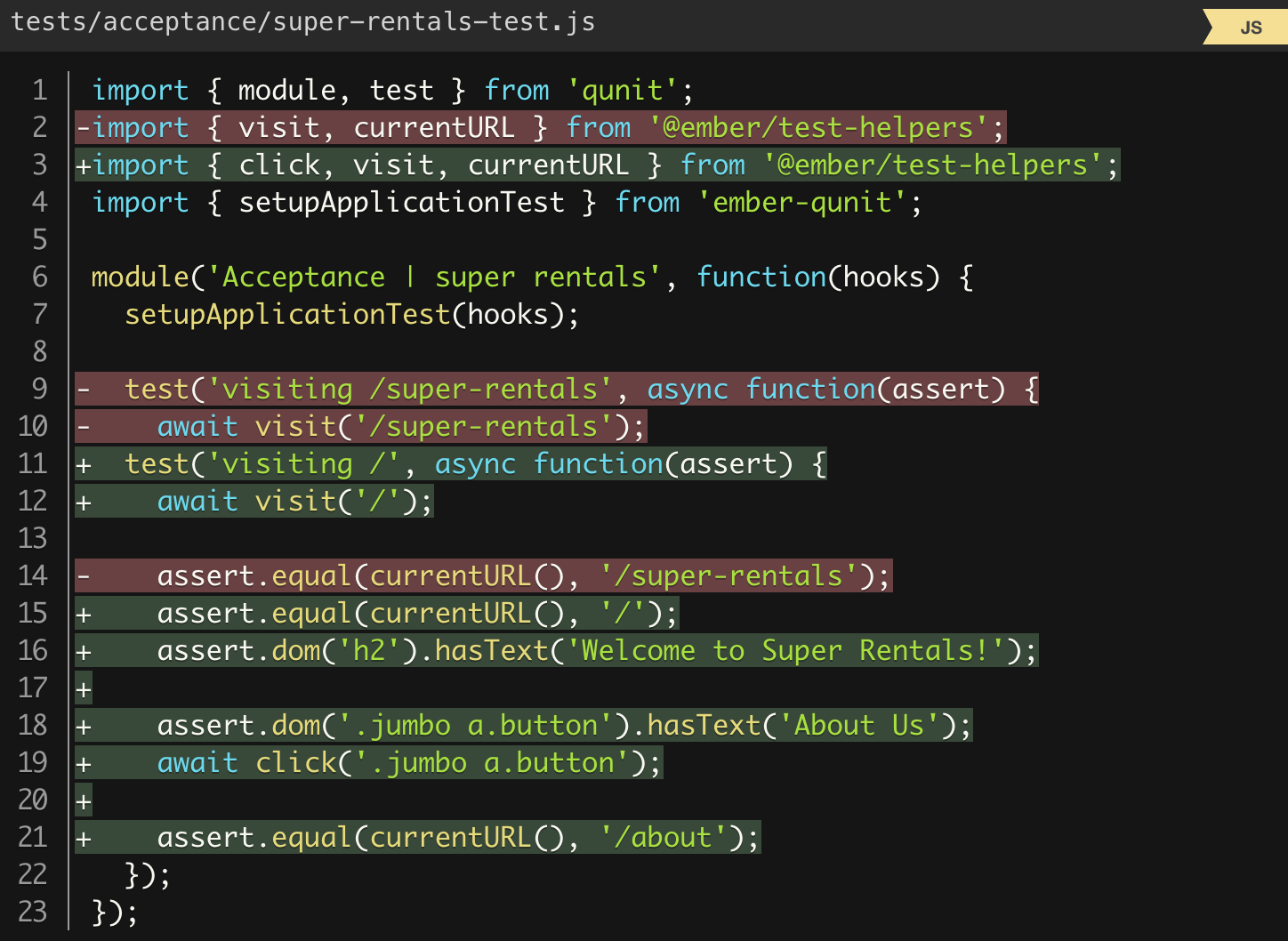
Сначала мы проинструктировали тестового робота перейти к корневому URL `/` нашего приложения с помощью тестового помощника (test helper) `visit` предоставленного Ember. Это сродни тому, что мы набрав `http://localhost:4200/` в адресной строке браузера нажали клавишу `enter`.
Поскольку загрузка страницы займет некоторое время, это называется асинхронным шагом, поэтому нам нужно будет сказать тестовому роботу ждать, используя ключевое слово JavaScript `await`. Таким образом, он будет ждать, пока страница полностью не загрузится, прежде чем перейти к следующему шагу.
Это почти всегда то поведение, которое мы хотим получить, поэтому мы почти всегда будем использовать `await` и `visit` как пару. Это относится и к другим видам симулированного взаимодействия, например, к нажатию на кнопку или ссылку, поскольку все они требуют времени для завершения. Хотя иногда эти действия могут показаться нам незаметно быстрыми, мы должны помнить, что у нашего тестового робота действительно, очень быстрые руки, в чем мы убедимся через мгновение.
После перехода к URL `/` и ожидания решения проблемы мы проверяем, соответствует ли текущий URL ожидаемому URL ( `/` ). Мы можем использовать `currentURL` тест-помощник `currentURL`, а также `equal` утверждение. Вот как мы кодируем наш «контрольный список» в код. Указав или заявив, как все должно себя вести, мы будем предупреждены, если наше приложение не будет вести себя так, как мы ожидаем.
Затем мы подтвердили, что на странице есть тег , содержащий текст `«Добро пожаловать в Super Rentals!»`. Проверка этого, означает, что мы можем быть совершенно уверены, что шаблон был отображен без ошибок.
Затем мы искали ссылку с текстом `«About Us»`, расположенную с помощью *селектора CSS* `.jumbo a.button`. Это тот же синтаксис, который мы использовали в нашей таблице стилей, что означает *«заглянуть внутрь тега с классом `jumbo` для тега с классом button»*. Это соответствует структуре HTML в нашем шаблоне.
Как только существование этого элемента на странице подтвердилось, мы попросили тестового робота нажать на эту ссылку. Как упоминалось выше, это взаимодействие с пользователем, поэтому к нему необходимо добавить ключевое слово `await`.
Наконец, мы убеждаемся, что нажатие на ссылку должно привести нас к URL-адресу `/about`.
> ### Зои поясняет ...
>
>
>
>
>
> Здесь мы пишем тесты в среде, называемой `QUnit`, откуда берутся функции `module`, `test` и `assert`. У нас также есть дополнительные помощники, такие как `click`, `visit` и `currentURL` предоставляемые пакетом `@ember/test-helpers`. Вы можете судить, из какого пакета берется та или иная функция исходя из пути `import` в верхней части файла. Знание этого будет полезно, когда вам нужно искать документацию в Интернете или обратиться за помощью.
Мы можем запустить наш автоматический тест, запустив тестовый сервер с помощью команды `ember test --server` или `ember t -s` для краткости. Этот сервер ведет себя во многом как сервер разработки, но он запущен для наших тестов. Он может автоматически открыть окно браузера и перейти к тестовому интерфейсу. Или вы можете открыть `http://localhost:7357/` самостоятельно.
Если вы посмотрите очень внимательно, вы увидите, как наш тестовый робот бродит по нашему приложению и нажимает на ссылки (это происходит очень быстро):
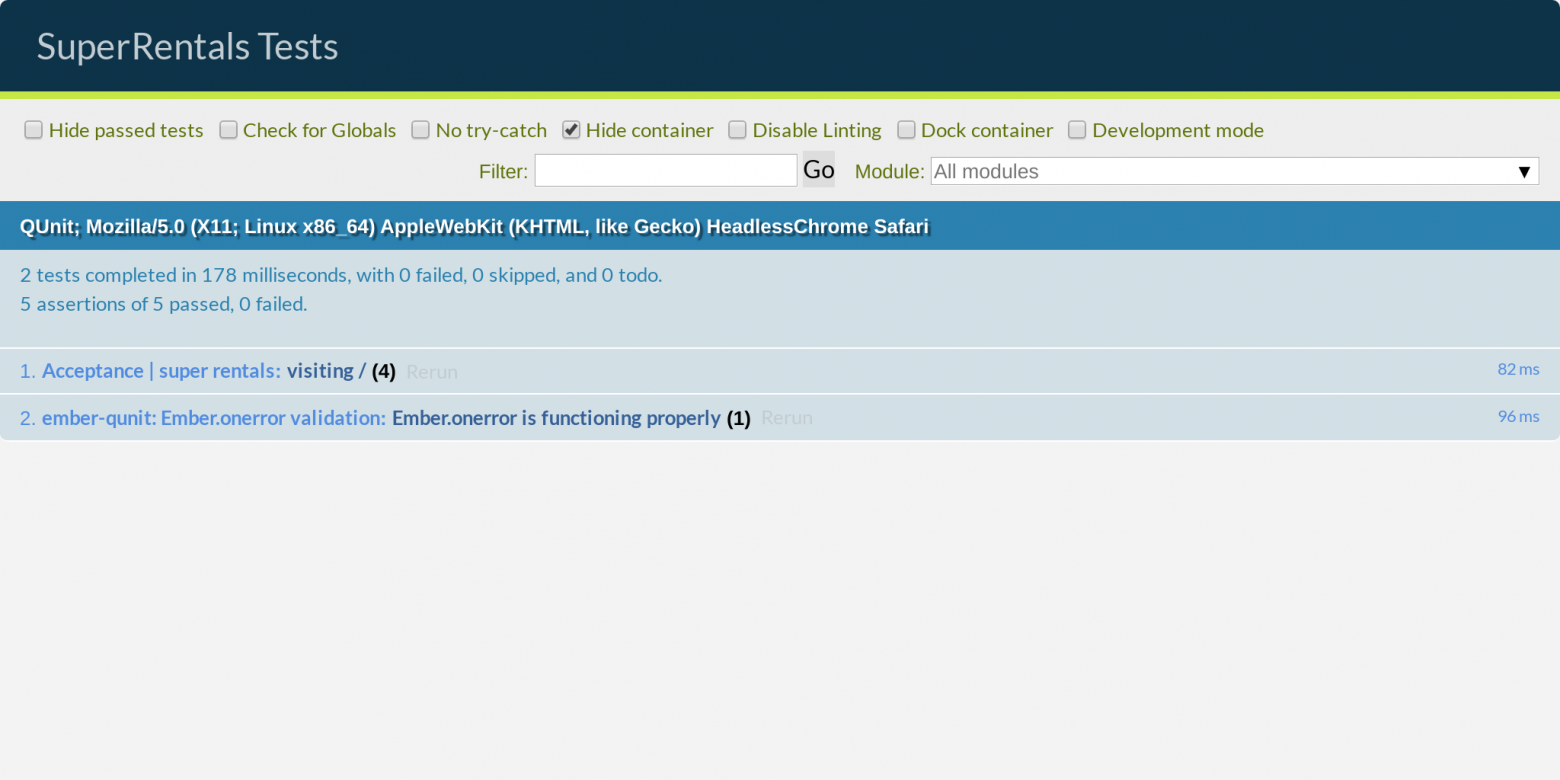
Здесь важно то, что тест, который мы написали, прошел, а это означает, что все работает именно так, как мы ожидаем, и в пользовательском интерфейсе теста все зеленое и счастливое. Если вы хотите, вы можете перейти к `index.hbs`, удалить компонент и посмотреть, как все будет выглядеть, когда у нас будет неудачный (failing) тест:
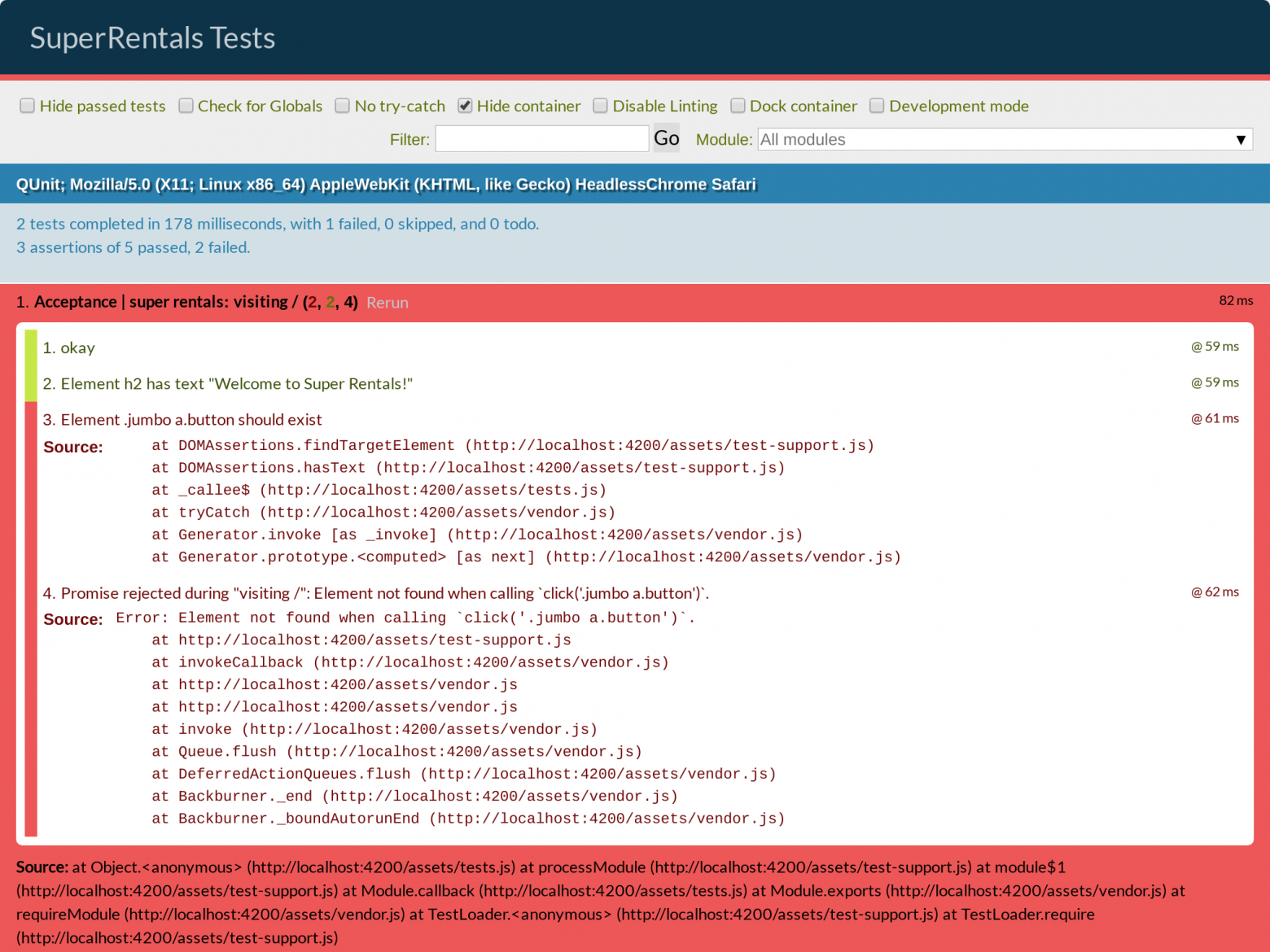
Не забудьте вернуть эту строку обратно!
Практикуя рабочий процесс тестирования
--------------------------------------
Давайте попрактикуемся в том, что мы узнали, добавив тесты для оставшихся страниц:
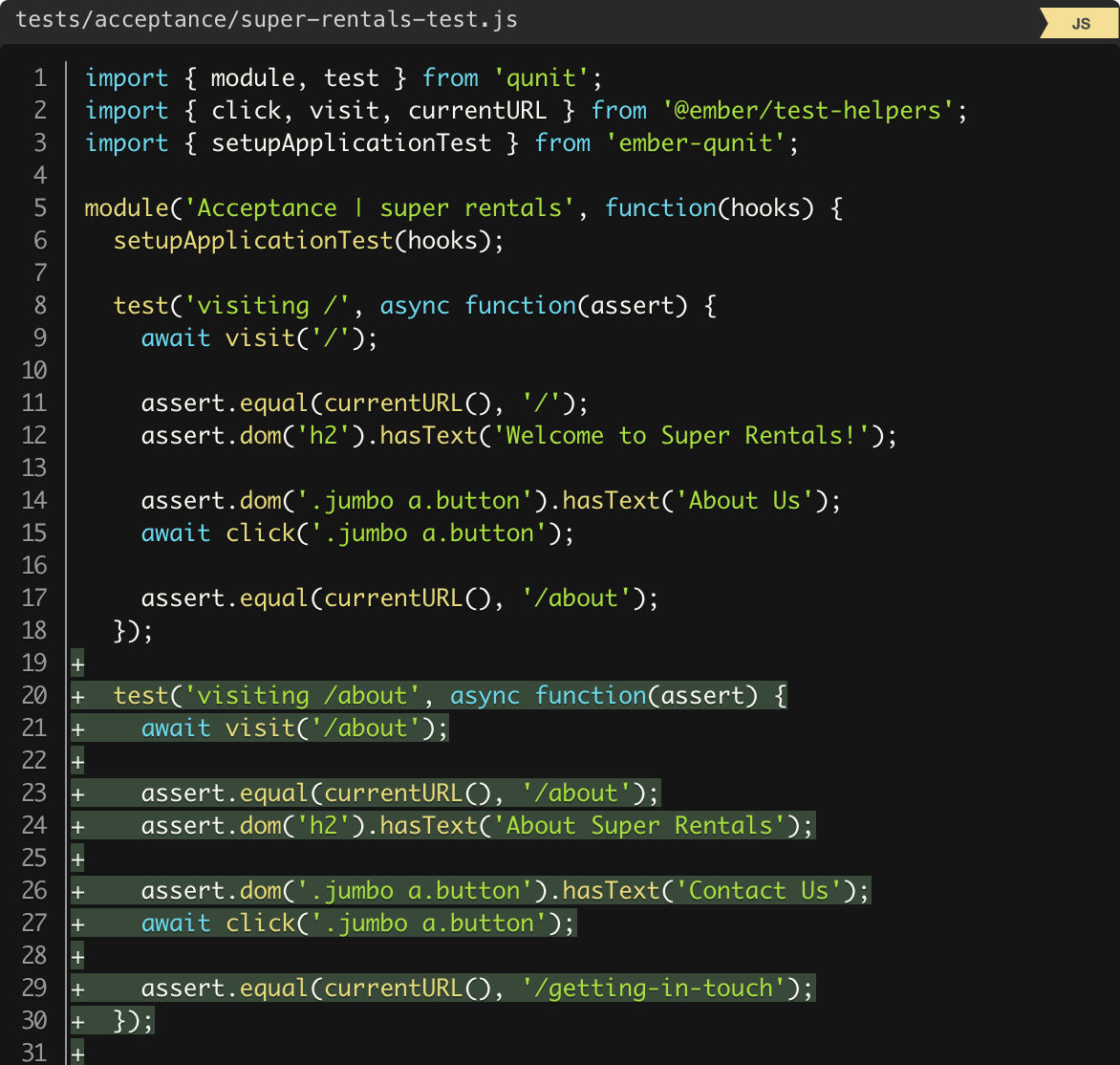
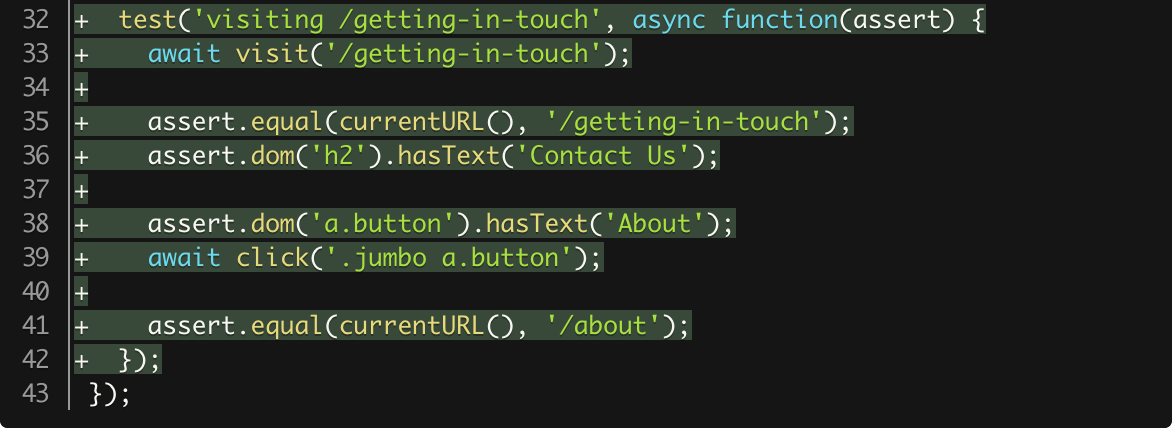
Как и на сервере разработки, пользовательский интерфейс теста должен автоматически перезагружаться и повторно запускать весь набор тестов при сохранении файлов. Рекомендуется держать эту страницу открытой при разработке приложения. Таким образом, вы получите немедленную обратную связь, если случайно что-то сломаете.

В оставшейся части руководства мы продолжим добавлять дополнительные автоматизированные тесты по мере разработки новых функций. Тестирование не является обязательным, но настоятельно рекомендуется (*от переводчика: особенно, когда вы дописываете или переписываете ваше приложение*) Тесты не влияют на функциональность вашего приложения, они просто защищают его от регрессий, что просто является способом заметить «случайные поломки».
Если вы спешите, вы можете пропустить разделы тестирования в этом учебном пособии и при этом продолжать следить за всем остальным. Но разве вы не находите супер удовлетворяющим — странно удовлетворяющим — наблюдать, как робот шустро бегает по страницам и выдает в конце зеленую полосочку?
Основы компонентов
==================
В этой части вы проведете *рефакторинг* существующих шаблонов для использования компонентов. Мы также добавим панель навигации для всего сайта:
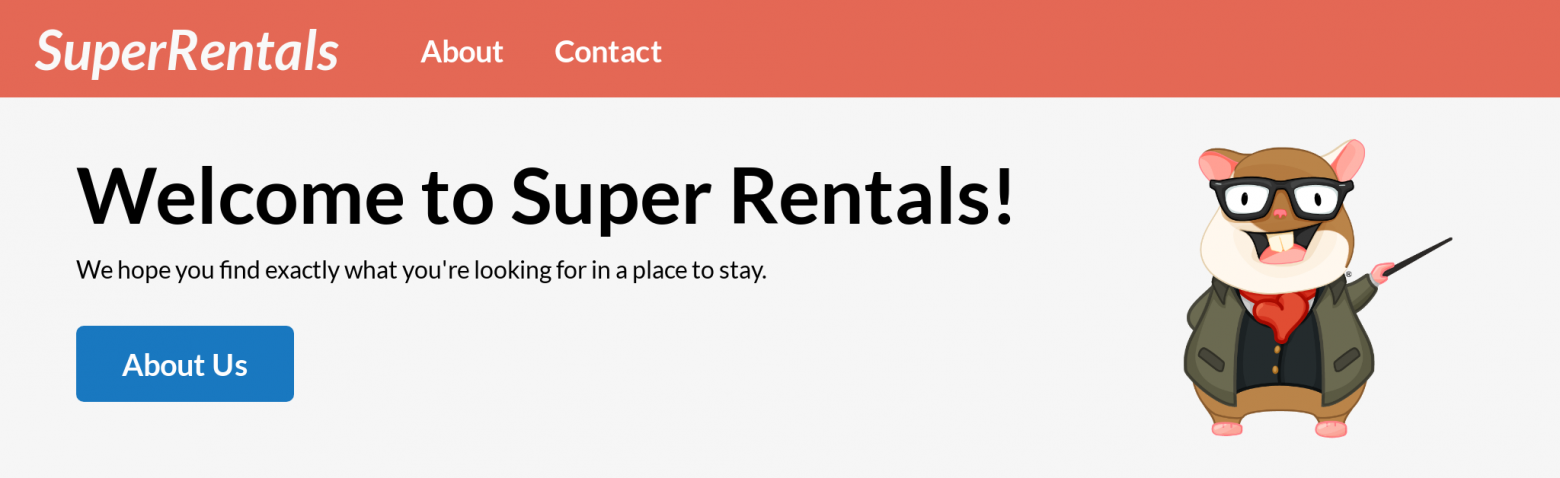
При этом вы узнаете об:
* Извлечении разметки в компоненты
* Вызове компонентов
* Передаче контента в компоненты
* Выводе контента с ключевым словом `{{yield}}`
* Рефакторинге существующего кода
* Написании компонентных тестов
* Использовании шаблона приложения и `{{outlet}}`
Извлечение разметки в компоненты
--------------------------------
В предыдущей части мы получили небольшое представление о компонентах при использовании для соединения наших страниц. Напомним, что мы говорили, что компоненты — это способ создания пользовательских тегов Ember в дополнение к встроенным тегам HTML из браузера. Теперь мы собираемся создать наши собственные компоненты!
В ходе разработки приложения довольно часто используется один и тот же элемент пользовательского интерфейса в разных частях приложения. Например, мы использовали один и тот же заголовок `"jumbo"` на всех трех страницах. На каждой странице мы работали, следуя одной и той же базовой структуре:
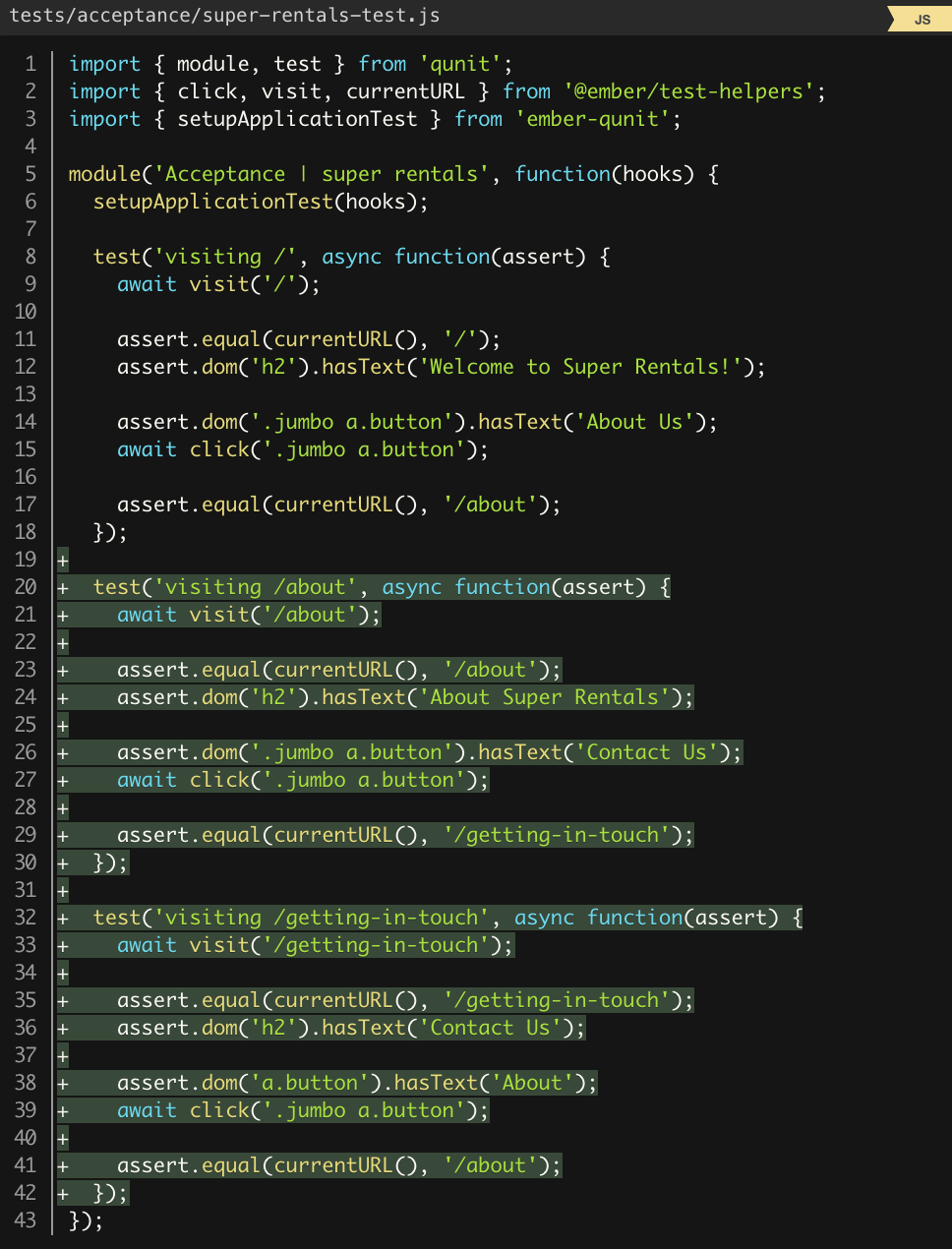
Поскольку кода не так много, может показаться, что дублировать эту структуру на каждой странице не составляет большого труда. Однако, если бы наш дизайнер захотел, чтобы мы внесли изменения в заголовок, мы должны были бы найти и обновить каждую копию этого кода. Когда наше приложение станет больше, это станет еще более серьезной проблемой.
Компоненты являются идеальным решением для этого. В своей основной форме компонент — это просто часть шаблона, на которую можно ссылаться по имени. Давайте начнем с создания нового файла в `app/components/jumbo.hbs` с разметкой для заголовка `«jumbo»`:

Вот и все, мы создали наш первый компонент! Теперь мы можем вызвать этот компонент в любом месте нашего приложения, используя качестве имени тега.
> ### Зои поясняет ...
>
>
>
>
>
> Помните, что при вызове компонентов нам нужно использовать заглавные буквы их имен, чтобы Ember мог отличить их от обычных элементов HTML. Шаблон `jumbo.hbs` соответствует тегу , так же, как `super-awesome.hbs` соответствует .
Передача содержимого в компоненты с помощью`{{yield}}`
------------------------------------------------------
При вызове компонента Ember заменяет тег компонента содержимым, найденным в шаблоне компонента. Как и в случае с обычными HTML-теги, распространено передавать контент компонентам, например, `some content`. Мы можем обработать это с помощью ключевого слова `{{yield}}`, которое будет заменено содержимым, которое было передано компоненту.
Давайте попробуем это, отредактировав шаблон индекса:
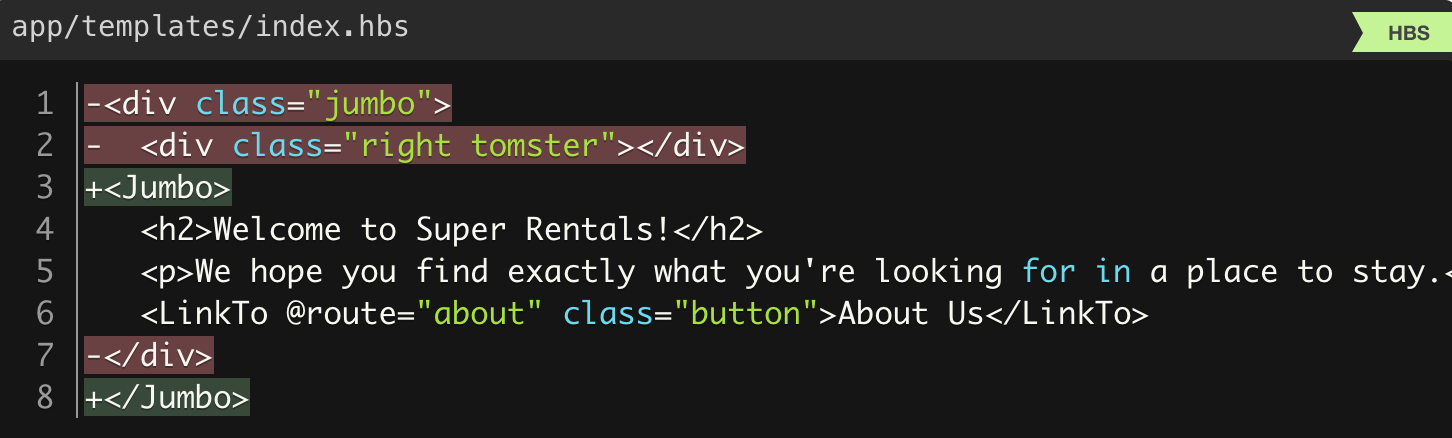
Рефакторинг существующего кода
------------------------------
После сохранения изменений ваша страница должна автоматически перезагрузиться, и, вуаля… ничего не изменилось! Ну, это именно то, что мы хотели! Мы успешно реорганизовали наш индексный шаблон для использования компонента , и все по-прежнему работает, как и ожидалось.

И тесты проходят!

Давайте сделаем то же самое для двух других наших страниц.
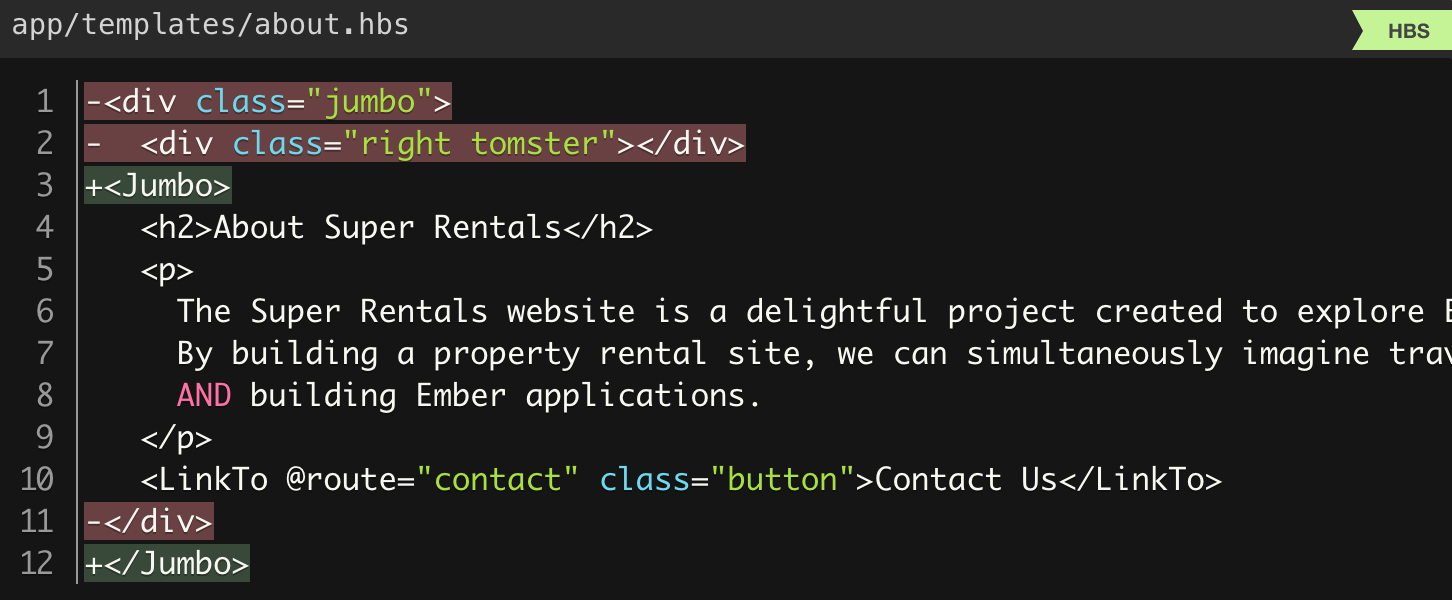
После сохранения все должно выглядеть точно так же, как и раньше, и все тесты должны пройти.
Хотя в этом случае это может не сэкономить много символов, инкапсуляция реализации заголовка `«jumbo»` в его собственный компонент делает шаблон более читаемым, поскольку позволяет читателю сосредоточиться на вещах, которые уникальны для данной страницы. Кроме того, если нам нужно внести изменения в заголовок, мы можем сделать это в одном месте. Не стесняйтесь попробовать!
Написание тестов компонентов
----------------------------
Прежде чем мы перейдем к следующему аспекту, давайте напишем автоматический тест для нашего компонента . Запустите эту команду в своем терминале:
```
$ ember generate component-test jumbo
installing component-test
create tests/integration/components/jumbo-test.js
```
Здесь мы использовали генератор для генерации теста компонента (component test), также известного как тест рендеринга (rendering test). Они используются для визуализации и тестирования одного компонента за раз. Это в отличие от приемочных тестов, которые мы написали ранее, которые должны отображать целые страницы контента.
Давайте заменим шаблон кода, который был сгенерирован для нас, нашим собственным тестом:
Вместо перехода по URL-адресу мы начинаем тестирование с отображения нашего компонента на тестовой странице. Это полезно, потому что в противном случае может потребоваться много настройки и взаимодействия, чтобы просто попасть на страницу, где используется ваш компонент. Тестирование компонентов позволяет нам пропустить все это и сосредоточиться исключительно на тестировании компонента в отдельности.
Как и при посещении и клике, который мы использовали ранее, рендеринг также является асинхронным шагом, поэтому нам нужно связать его с ключевым словом `await`. Кроме этого, остальная часть теста очень похожа на приемочные тесты, которые мы написали в предыдущей главе. Убедитесь, что тест проходит, проверив пользовательский интерфейс тестов в браузере.
Мы уже некоторое время проводим рефакторинг нашего существующего кода, поэтому давайте сменим род деятельности и добавим новую фичу: панель навигации для всего сайта.
Создадим компонент в `app/components/nav-bar.hbs`:
Далее добавим наш компонент вверху каждой страницы:
Вуаля, мы сделали еще один компонент!

> ### Зои поясняет ...
>
>
>
>
>
> является сокращением для . Теги компонентов всегда должны быть закрыты должным образом, даже если вы не передаете им какой-либо контент, как в этом случае. Поскольку это довольно распространенное явление, Ember предлагает альтернативную самозакрывающуюся нотацию!
В браузере все выглядит отлично, но, как мы знаем, мы никогда не можем быть слишком уверены. Итак, давайте напишем несколько тестов!
Но каких? Мы могли бы написать тест компонента для сам по себе, как мы только что сделали для компонента . Однако, поскольку задача состоит в том, чтобы ориентировать нас по приложению, нет особого смысла тестировать этот конкретный компонент изолированно. Вернемся же к написанию приемочных тестов!
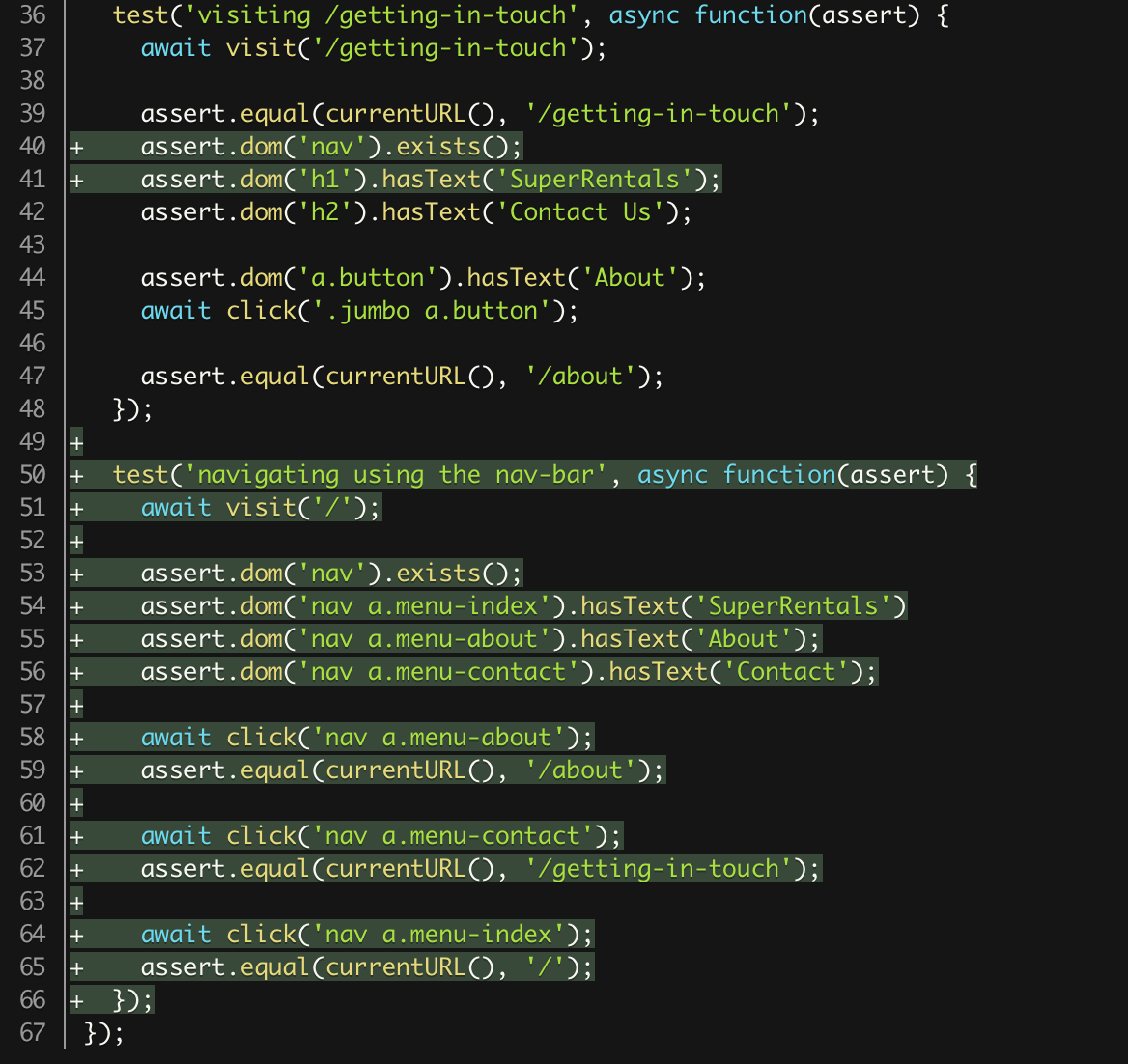
Мы обновили существующие тесты, чтобы утверждать, что на каждой странице существует элемент . Это важно для доступности (accessibility), так как программы чтения с экрана будут использовать этот элемент для обеспечения навигации. Также мы добавили новый тест, который проверяет поведение ссылок .
Все тесты должны пройти в этот момент!
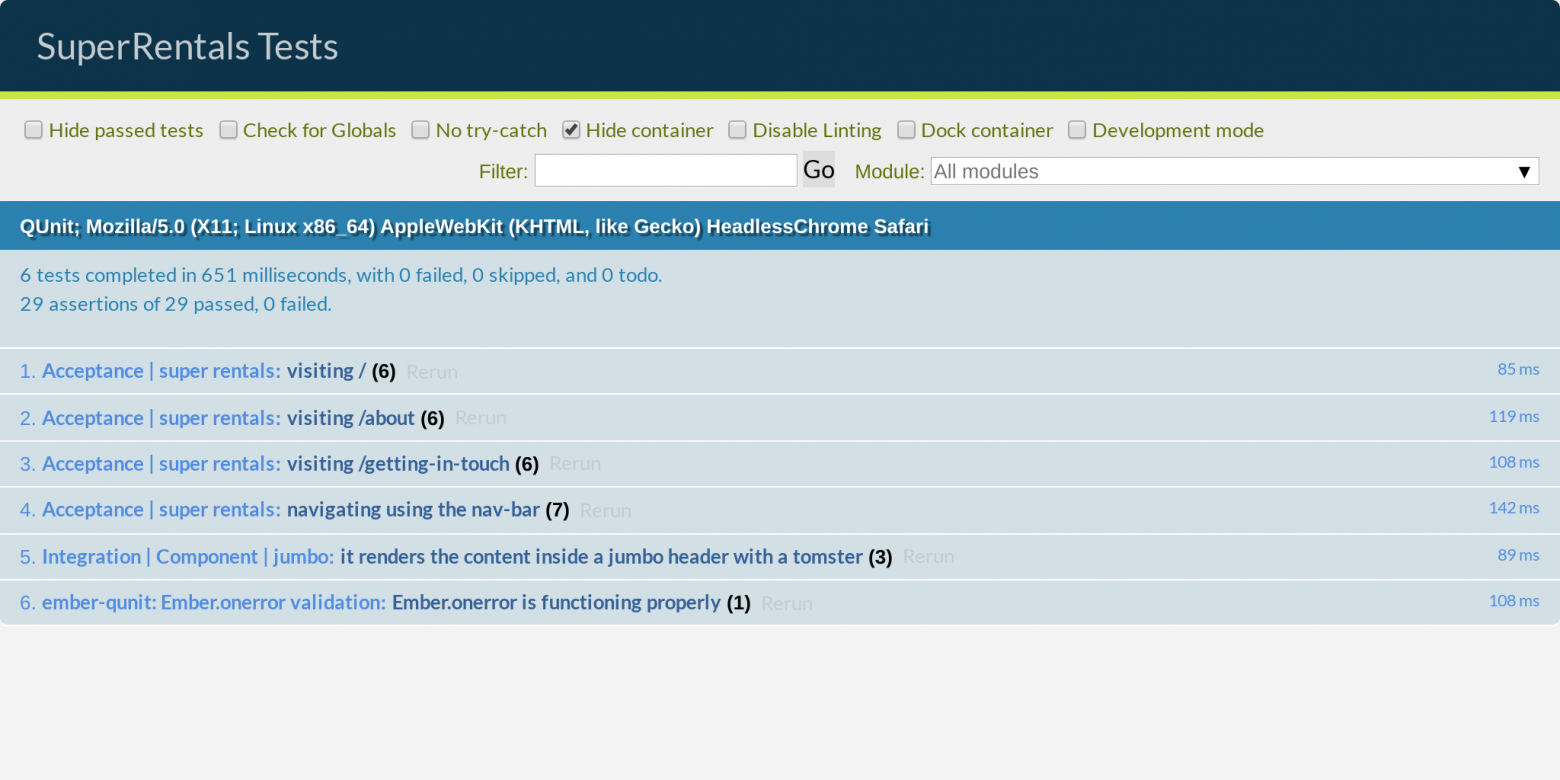
Использование глобального шаблона приложения и `{{outlet}}`
===========================================================
Прежде чем мы перейдем к следующей функции, есть еще одна вещь, которую мы могли бы улучшить. Поскольку используется для навигации по всему сайту, его действительно необходимо отображать на каждой странице приложения. До сих пор мы добавляли компонент на каждую страницу вручную. Это подвержено ошибкам, так как мы можем легко забыть сделать это при следующем добавлении новой страницы.
Мы можем решить эту проблему, переместив панель навигации в специальный шаблон под названием `application.hbs`. Возможно, вы помните, что он был сгенерирован для нас, когда мы впервые создали приложение, но тогда мы его удалили. Теперь пришло время вернуть!
Этот шаблон отличается тем, что у него нет собственного URL-адреса, и на него нельзя перейти самостоятельно. Скорее, он используется для указания общего макета, который используется всеми страницами вашего приложения. Это отличное место для размещения элементов пользовательского интерфейса, таких как навигационная панель и нижний колонтитул (footer) сайта.
Пока мы это делаем, мы также добавим элемент контейнера, который будет охватывать всю страницу, как того требует наш дизайнер для стилизации.

Ключевое слово `{{outlet}}` обозначает место, где должны отображаться страницы нашего сайта, аналогично ключевому слову `{{yield}}`, которое мы использовали ранее.
Так намного приятнее! Мы можем запустить наш набор тестов, который подтверждает, что все работает после нашего рефакторинга. И мы готовы перейти к следующей фиче!

На этом часть 1.1 заканчивается. ~~Как посадить самолет~~ Продолжение мы с гуглотранслейтом расскажем в [следующей серии](https://habr.com/ru/post/482390/).
UPDATE: Благодарю пользователя [MK1301](https://habr.com/ru/users/mk1301/) за легкую редактуру. | https://habr.com/ru/post/482296/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.